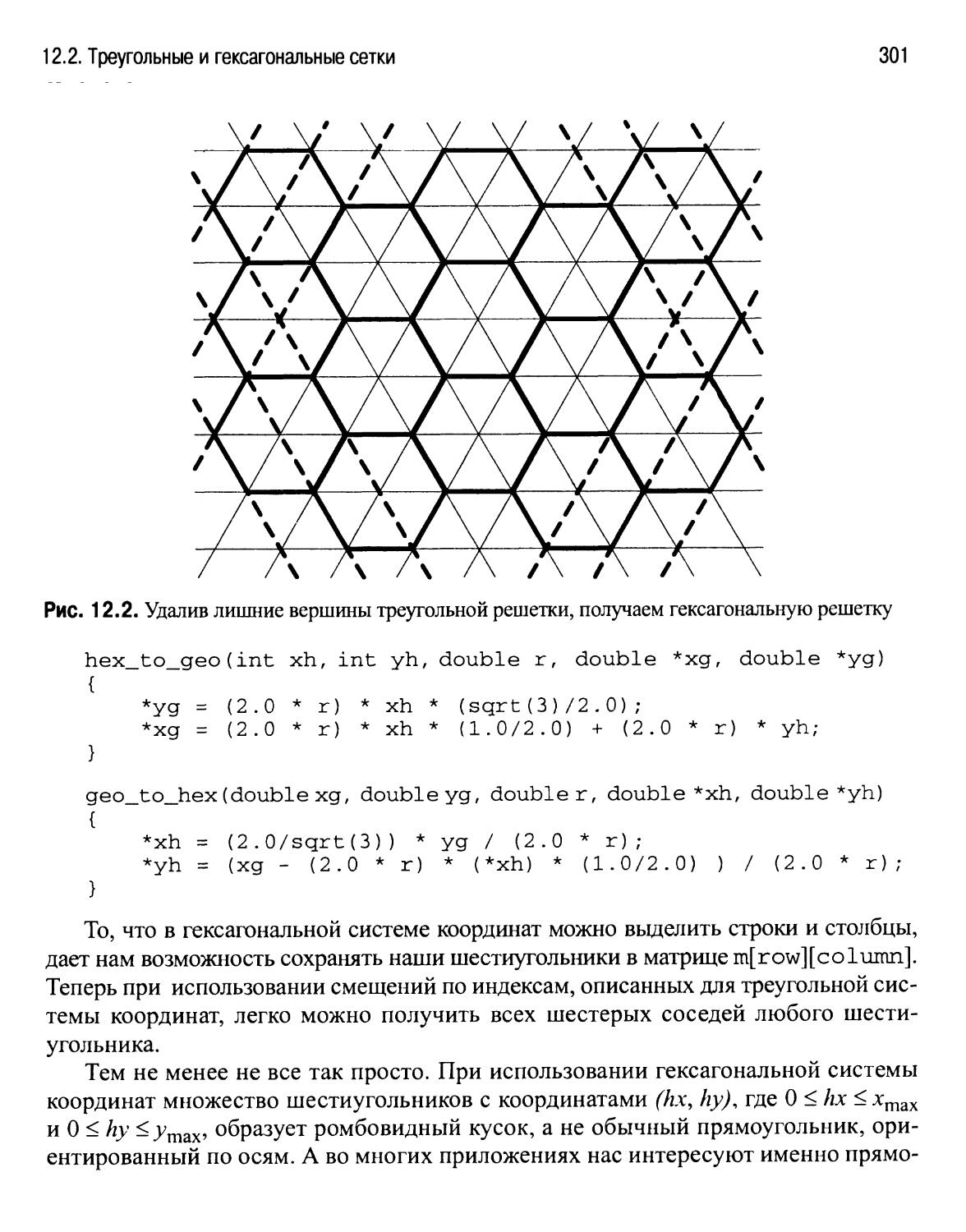
/






























































































































































































































































































































































































































Автор: Стивен С. Скиена Мигель А. Ревилла
Теги: кибернетика программирование задачи по программированию
ISBN: 0-387-00163-8
Год: 2005




Текст
ОЛИМПИАДНЫЕ
ЗАДАЧИ
по программированию
Руководство
по подготовке
к соревнованиям
т
Стивен С. Скиена
Мигель А. Ревилла
КУДИЦ-ОБРАЗ
Steven S. Skiena Miguel A. Revilla
PROGRAMMING CHALLENGES
The Programming Contest Training Manual
With 65 Illustrations
Springer
Стивен С. Скиена, Мигель А. Ревилла
ОЛИМПИАДНЫЕ
ЗАДАЧИ
по программированию
Руководство по подготовке к соревнованиям
Перевод с английского
Послесловие В. М. Кирюхина
КУДИЦ-ОБРАЗ
Москва • 2005
ББК- 32.81
Скиена С. С, Ревилла М. А.
Олимпиадные задачи по программированию. Руководство по подготовке к соревнованиям/
Пер. с англ. - М: КУДИЦ-ОБРАЗ, 2005. - 416 с.
Книга представляет собой перевод учебника по подготовке к международным соревнованиям
по программированию, написанный по материалам АСМ - олимпиад.
Бестселлер, признанный Journal of Object Technology как «Лучшая книга 2003г.», в своих 14
главах книга охватывает все основные категории задач международных соревнований. Каждая
глава содержит необходимое теоретико-алгоритмическое введение, разбор типовых задач и серию
тренировочных заданий уровня АСМ.
Поддержка книги осуществляется сайтом: http://www.programming-challenges.com, а также по-
популярным тренировочным сайтом http://online-judge.uva.es.
«Эта книга вызывает восхищение любого, кто способен оценить красивую программу или кто
имеет интерес к решению задач, структурам данных или алгоритмам...» - таков отзыв о книге
известного теоретика и практика программирования, тренера сборной АСМ А. М.Тененбаума,
опубликованный в АСМ Computing Reviews вскоре после ее выхода в свет. Так ли это - предостав-
предоставляется судить читателю.
Книга предназначена для учащихся, их преподавателей и тренеров, а также других специали-
специалистов, интересующихся олимпиадным программированием и алгоритмами.
Стивен С. Скиена, Мигель А. Ревилла
Олимпиадные задачи по программированию.
Руководство по подготовке к соревнованиям
Учебно-справочное издание
Перевод с англ. Б. В. Кучин Корректор В. Клименко
Научный редактор О. А. Левченко Макет С. Красильникова
.«ИД КУДИЦ-ОБРАЗ»
119049, Москва, Ленинский пр-т., д. 4, стр. 1 А. Тел.: 333-82-11, ok@kudits.ru
Подписано в печать 20.04.05. Отпечатано с готовых диапозитивов
Формат 70x90/16. в ОАО «Щербинская типография»
Печать офсетная. Бумага офс. 117623, Москва, ул. Типографская, д. 10
Усл. печ. л. 30,4. Тираж 2000. Закач 972
ISBN 0-387-00163-8
ISBN 5-9579-0082-6 (рус.) © Перевод, макет и обложка «ИД КУДИЦ-ОБРАЗ», 2005
Translation from English language edition: Programming Challenges by Steven S. Skiena and Miguel A. Revilla
Copyright © 2003 Springer-Verlag New Yourk, Inc. All Rights Reserved
Все права защищены. Русское издание опубликовано издательством КУДИЦ-ОБРАЗ, © 2005.
Информация, содержащаяся в данной книге, получена из источников, рассматриваемых издательством как
надежные. Тем не менее, имея в виду возможные человеческие или технические ошибки, издательство
не может гарантировать абсолютную точность и полноту приводимых сведений и не несет ответственности за
возможные ошибки, связанные с использованием книги.
Введение
С программированием связано много приятного. Мастерство приносит свои ма-
маленькие радости - удовлетворение от того, что ты сделал что-то полезное и оно ра-
работает. Возбуждение, приходящее от внезапного озарения, позволившего решить
упрямую задачу. Стремление к элегантности, которое превращает хакера в художни-
художника. Приятно выжимать последние капли производительности из умных алгоритмов
и экономичного кода.
Решение задач с международных состязаний по программированию - замеча-
замечательный способ испытать все это, параллельно изучая новые алгоритмы и шлифуя
свое умение писать программы. Эта книга содержит свыше 100 задач, взятых с
олимпиад прошлых лет, а также обсуждение теории и идей, необходимых для их ре-
решения. Моментальная проверка решений обеспечивается двумя сайтами, поддержи-
поддерживающими автоматические тестирующие системы. Использование такой системы
вместе с этой книгой позволит вам значительно улучшить свои навыки програм-
программирования.
Эту книгу можно рекомендовать для самостоятельного изучения, для проведе-
проведения занятий по алгоритмам и программированию и для подготовки к международ-
международным соревнованиям.
Читателю
Задачи для этой книги были выбраны из более чем 1000 задач по программирова-
программированию, представленных на сайте автоматической тестирующей системы Universidad de
Valladolid, доступной по адресу http://online-judge.uva.es. На сегодняшний день эта
система обработала более одного миллиона запросов от 27 000 зарегистрированных
пользователей со всего мира. Мы выбрали только лучшие - самые забавные, увлека-
увлекательные и интересные задачи.
Мы разделили эти задачи по темам и привели достаточное количество спра-
справочного материала (в основном по математике и теории алгоритмов), чтобы дать вам
хороший шанс решить их. Для иллюстрации большинства важных.концепций приве-
приведены примеры программ. Прочитав эту книгу и попробовав решить приведенные за-
задачи, вы обретете четкое понимание таких алгоритмических методов, как перебор с
возвратами или динамическое программирование, и разберетесь с продвинутыми те-
темами, такими, как теория чисел и вычислительная геометрия. Эти предметы стоят
вашего внимания даже в том случае, если вы никогда не соби-раетесь принимать уча-
участие в соревнованиях по программированию.
6 Введение
Все задачи по-настоящему интересны. Они связаны с увлекательными темами
из теории вычислительных систем и математики, что нередко скрыто за забавной
историей. Порой возникает интерес к более глубокому изучению предмета, поэтому,
где это возможно, мы приводим ссылки на литературу для дальнейшего чтения.
Мы обнаружили, что люди, практика которых состоит в прикладном програм-
программировании и разработке программного обеспечения, часто недооценивают мощь,
предоставляемую алгоритмами. Аналогично теоретики обычно не понимают, что
нужно для того, чтобы алгоритм стал программой, и насколько сильно грамотное
программирование может облегчить решение сложной задачи.
По этой причине первая часть книги в основном делает акцент на технике про-
программирования, такой, как, к примеру, правильный подбор структур данных и работа
с библиотеками. Эти главы ложатся в основу второй части книги, более ориентиро-
ориентированной на алгоритмы. Чтобы успешно решать задачи, вам потребуется и уметь про-
программировать, и владеть необходимыми алгоритмами.
Преподавателю
Эта книга разрабатывалась как учебник для трех типов курсов:
• курсы по алгоритмам, ориентированные на программирование;
• курсы по программированию, ориентированные на изучение алгоритмов;
• факультативные курсы для подготовки студентов к участию в таких соревно-
соревнованиях, как Association for Computing Machinery (ACM) International Collegiate
Programming Contest и International Olympiad in Informatics.
Такие курсы могут быть приятным времяпровождением для всех занятых на
них. Учащиеся легко поддаются ощущению соревнования и получают положи-
положительные эмоции всякий раз, когда тестирующая система принимает их решение.
Самый очевидный алгоритм может вызвать сообщение «Превышен лимит време-
времени» от тестирующей системы, что подталкивает студентов к поиску более эффек-
эффективных алгоритмов. Внезапное озарение может привести к программе из несколь-
нескольких десятков строк, вместо огромного массива кода. Лучшие учащиеся будут
решать дополнительные задачи просто ради удовольствия.
Преподавать на таких курсах не менее приятно. Многие задачи не так просты,
как кажутся, что позволит посмотреть на стандартные темы в программировании
и теории алгоритмов под новым углом. Поиск лучшего возможного решения тре-
требует сосредоточенности и вдохновения. Приятно понять, как правильно решается
каждая задача, и еще более приятно видеть, как это понимают учащиеся.
Введение
Возможности этой книги в качестве учебного пособия:
Дополняет стандартные учебники по алгоритмам. Хотя эта книга самодоста-
самодостаточна, она писалась в предположении, что большинство студентов уже получили
некоторое представление о разработке алгоритмов. Эта книга разрабатывалась
так, чтобы она могла служить в качестве дополнительного учебника для тради-
традиционных курсов по алгоритмам, дополняя абстрактные описания конкретными
реализациями, а теоретический анализ опытом практического применения.
Более того, в книге затрагиваются некоторые интересные темы, которые не все-
всегда включаются в обычные учебники по программированию.
Предоставляет завершенные реализации классических алгоритмов. Многим
студентам тяжело дается переход от абстрактного алгоритма к работающей
программе. Чтобы помочь им, мы приводим аккуратные реализации всех важ-
важных алгоритмов, обсуждаемых в книге. Для этого мы используем такое подмно-
подмножество языка С, которое легко читается и C++- и Java-программистами. Неко-
Некоторые из приведенных в книге задач можно решить, немного модифицировав
приведенные подпрограммы, что дает студентам отправную точку, с которой
можно начать.
Комплексная среда управления курсом. Мы разработали специальную среду
управления курсом, позволяющую легко с ним работать, так как все пробле-
проблемы с проверкой и определением результатов она берет на себя! Наш сайт
http://www.programming-challenges.com позволяет вам назначить задачи сту-
студентам, поддерживать списки, просматривать результаты и программы каж-
каждого студента и даже обнаруживать подозрительно похожие решения.
Предоставляет помощь студентам любого уровня. Задачи, включенные в эту
книгу, выбирались так, чтобы охватить большой диапазон сложностей. Многие
подходят для начинающих студентов, но некоторые способны бросить вызов
и тем, кто готов к международным соревнованиям. Большинство задач снабже-
снабжены подсказками.
Чтобы помочь подобрать задачу для каждого конкретного студента, каждой
из них мы поставили в соответствие три различных показателя сложности.
Популярность задачи (А, В или С) показывает, насколько много студентов
пытались ее решить, а частота успехов (от низкой до высокой) - сколько из
них в этом преуспело. Наконец, уровень задачи (от 1-го до 4-го, что грубо
соответствует новичку и старшекурснику) показывает, насколько должен
быть образован студент для того, чтобы иметь реальный шанс решить задачу.
8 Введение
Тренеру или участнику соревнований
Эта книга разрабатывалась, в частности, как руководство по подготовке
к соревнованиям школьного и студенческого уровней. Мы предлагаем удобный
конспект/справочник по важным темам математики и теории алгоритмов, а также
соответствующие задачи, которые помогут вам освоить материал.
Автоматическая тестирующая система проверяет присланные программы точно
так же, как и судьи на ACM International Collegiate Programming Contest. Как только
вы настроили личную учетную запись на сайте автоматической тестирующей систе-
системы, можете присылать решения, написанные на C/C++, Pascal или Java, и ждать
ответа об успехе или неудаче. Система ведет статистику ваших успехов, поэтому вы
можете сравнить себя с тысячами других участников.
Чтобы помочь участникам соревнований, мы включили приложение,
содержащее советы финалистов трех важнейших состязаний по программиро-
программированию: ACM International Collegiate Programming Contest (ICPC), International
Olympiads in Informatics (IOI) и TopCoder Programmer Challenge. В нем мы рас-
рассматриваем историю этих соревнований, объясняем, что нужно, чтобы на них
попасть, и пытаемся помочь вам выступить как можно лучше.
Примерно 80% всех финалистов АСМ прошлого года тренировались, используя
автоматическую тестирующую систему Universidad de Valladolid. To, что финал
обычно проводится в экзотических местах, например на Гавайях, это еще один
стимул для тренировок. Удачи!
Связанные сайты
Эта книга создавалась для взаимодействия с двумя сайтами. Сетевая проверка
всех задач доступна по адресу http://www.programming-challenges.com вместе
с большим количеством сопутствующих материалов. В частности, мы предостав-
предоставляем полный код всех программ, встречающихся в книге, а также лекционные
записи, позволяющие проще добавлять материал в курсы.
Все задачи из этой книги (а также многие другие) могут быть проверены автома-
автоматической тестирующей системой Universidad de Valladolid, http://online-judge.uva.es.
В частности, для каждой из задач этой книги приведены идентификационные
номера на обоих сайтах, так что вы можете пользоваться преимуществами и того
и другого.
Введение 9
Благодарности
Существование этой книги стало возможным в большой степени благодаря
щедрости людей, позволивших включить свои задачи в автоматические тес-
тестирующие системы и в книгу. Не менее 17 представителей четырех разных кон-
континентов пожертвовали задачи для этой книги. Мы находимся в неоплатном долгу
перед Гордоном Кормаком (Gordon Cormack) и Шахрияром Манзуром (Shahriar
Manzoor), составителями задач, сравнимыми с Сэмом Лойдом и Ш. Е. Дьюдни
(Sam Loyd, H. E. Dudeney).
Полная информация по задачам и их авторам приведена в приложении, но
особую благодарность за их вклад мы хотим выразить следующим организаторам
соревнований: Гордон Кормак C8 задач), Шахрияр Манзур B8), Мигель Ревилла
(Miguel Revilla) A0), Педро Демаси (Pedro Demasi) A0), Мануэль Карро (Manuel
Cairo) D), Руя Лю (Rujia Liu) D), Петко Минков (Petko Minkov) D), Оуэн Астракан
(Owen Astrakan) C), Александр Денисюк (Alexander Denisjuk) C), Лон Чон (Long
Chong) B), Ральф Энгельс (Ralf Engels) B), Алекс Жевак (Alex Gevak) A), Уолтер
Гуттман (Walter Guttmann) A), Арун Кишо (Arun Kishore) A), Эрик Морено (Erick
Moreno) A), Удвранто Патик (Udvranto Patik) A) и Марчин Войцичовски (Marcin
Wojciechowski) A). Некоторые из этих задач разрабатывались и другими людьми,
благодарности которым можно найти в дополнении.
Определить истинных авторов некоторых задач было не проще, чем определить
автора Библии. Мы изо всех сил пытались найти автора каждой задачи, но разрешение
каждый раз получали от кого-то, кто, по его словам, говорил с автором. Заранее при-
приносим извинения за возможные ошибки. Если таковые будут найдены, пожалуйста,
уведомите нас, чтобы мы могли выказать должную благодарность.
Автоматическая тестирующая система - это проект многих людей. Основной
автор программного обеспечения проекта - Сириако Гарсия (Ciriaco Garcia).
Фернандо П. Найера (Fernando P. Najera) создал многие инструменты, позволяющие
системе быть дружественной клиентам. Карлос М. Касас (Carlos M. Casas) отвечает
за тестовые файлы, обеспечивая их честность и полную проверку всех случаев. Хосе
А. Каминеро (Jose A. Caminero) и Иисус Пауль (Jesus Paul) отвечают за четкость задач
и целостность решений. Мы особенно благодарим Мигеля Ревиллу за помощь в соз-
создании и поддержании сайта http://www.programming-challenges.com.
Эта книга была частично исправлена в течение курса, читавшегося в Стоуни Брук
(Stony Brook) Винцуй Фаном (Vinhthuy Phan) и Павлом Сумазиным (Pavel Sumazin)
весной 2002 года. Студенты наших замечательных команд по программированию этого
года (Ларри Мак (Larry Мак), Дэн Порте (Dan Ports), Том Ротамел (Tom Rothamel),
Алексей Смирнов (Alexey Smirnov), Джеффри Версоза (Jeffrey Versoza) и Чарльз Райт
10 Введение
(Charles Wright) помогали проверять рукописную копию, и мы хотим поблагодарить их
за интерес и отдачу. Хаовен Жан (Haowen Zhang) внес значительный вклад, тщательно
читая рукопись, проверяя программы и улучшая код.
Мы благодарим Уэйна Юхаза (Wayne Yuhasz), Уэйна Вилера (Wayne Wheeler),
Франка Ганса (Frank Ganz), Лесли Полинера (Lesley Poliner) и Рича Путтера (Rich
Putter) из Springer-Verlag за их помощь в превращении рукописи в опубликованную
книгу. Хотим сказать спасибо Гордону Кормаку, Лорену Коулзу (Lauren Cowles),
Давиду Гризу (David Gries), Джо О'Рурку (Joe O'Rourke), Сорабх Сетиа (Saurabh
Sethia), Тому Верхоффу (Tom Verhoeff), Даниелю Райту (Daniel Wright) и Стэну
Вагону (Stan Wagon) за вдумчивые рецензии на рукопись, которые значительно
улучшили конечный продукт. Fulbright Foundation и Факультет прикладной матема-
математики и вычислений Universidad de Valladolid обеспечили необходимую поддержку,
позволившую двум авторам работать вместе. Citigroup CIB, усилиями Петера Ремха
(Peter Remch) и Дебби 3. Бекмена (Debby Z. Beckman), внесли значительный вклад
в успех ACM ICPC в Стоуни Брук. Их участие стало толчком к написанию этой книги.
Стивен С. Скина (Steven S. Skiena)
Стоуни Брук, штат Нью-Йорк
Мигель А. Ревилла (Miguel A. Revilla)
Валладолид, Испания
Февраль, 2003 год
Глава 1
Начало работы
Мы начнем эту книгу с набора относительно элементарных задач по програм-
программированию, ни одна из которых не требует знаний больших, чем знание массивов
и циклов.
Тем не менее элементарный не всегда значит простой! Эти задачи дадут пред-
представление о требованиях автоматической тестирующей системы (автоматическо-
(автоматического судьи) и необходимости аккуратно читать и понимать спецификации. Также
они дают возможность обсудить стили программирования, которые наилучшим
образом подходят для решения поставленных задач.
Чтобы вам легче было начать, мы начнем с описания автоматических судей
и их особенностей. Далее, прежде чем представить вам первый набор задач, мы
обсудим основы стиля программирования и структур данных. Как и во всех
главах этой книги, мы предоставим некоторые советы по задачам и некоторые
заметки для дальнейшего изучения.
1.1. Начало работы с автоматической
тестирующей системой () (robot judge)
Эта книга написана для совместного использования с одним или обоими сайта-
сайтами автоматического оценивания. Тестирующая система (Судья) Programming Chal-
Challenges (http://www.programming-challenges.com) была настроена специально таким
образом, чтобы помочь вам извлечь максимум из задач, приведенных в этой книге.
Судья Universidad de Valladolid (http://online-judge.uva.es) имеет другой интерфейс,
а также сотни дополнительных доступных для решения задач.
Все задачи, приведенные в книге, могут оцениваться тем или другим сайтом,
они оба администрируются Мигелем Ревиллой (Miguel Revilla). В этом разделе
мы опишем, как использовать их и в чем состоят различия между ними. Не забы-
забывайте, что эти сайты являются развивающимися и активно живущими, так что
процедуры могут меняться со временем. Проверьте текущие правила на каждом
из сайтов, чтобы уточнить этот вопрос.
12 Глава 1. Начало работы
Вашим первым заданием будет получить учетную запись (account) на сайте
тестирующей системы, которую вы выбрали. Вас попросят задать пароль,
который позволяет получать доступ к вашим персональным данным, точнее,
к вашему имени и адресу электронной почты.
Обратите внимание, что списки участников на этих сайтах различны, но это
совсем не значит, что вы не можете зарегистрироваться на обоих из них
и пользоваться достоинствами и того и другого.
1.1.1. Автоматический судья Programming Challenges
Сайт Programming Challenges (http://www.programming-challenges.com) обес-
обеспечивает специальные возможности, связанные с каждой из задач, представленных
в этой книге. Например, описание каждой задачи, приведенной в этой книге, имеет-
имеется на сайте, так же как и файлы входных и выходных данных, которые можно
скачать, чтобы вам не пришлось вводить все эти тестовые данные.
Сайт Programming Challenges использует web-интерфейс для представления
к рассмотрению задач вместо E-Mail-интерфейса судьи UV . Это делает пред-
представления к рассмотрению (submission) намного легче и надежнее и обеспечивает
более быструю ответную реакцию.
Каждая задача в книге имеет два связанных с ней ID-номера, один для каждого
судьи. Одним из преимуществ web-интерфейса является то, что идентификатор
для сайта Programming Challenges (PC ID) не нужен для большинства представле-
представлений к рассмотрению. Описания задач, приведенных в книге, были переписаны для
большей ясности, поэтому они часто отличаются от описаний на сайте судьи UV
в непринципиальных вещах. Тем не менее задачи, которые они описывают, иден-
идентичны. Поэтому любое решение, засчитанное как верное на одном из сайтов,
должно быть засчитано как верное на другом.
Сайт Programming Challenges имеет специальный интерфейс управления
курсом, который позволяет преподавателю поддерживать список студентов
в каждом классе и следить за представлениями к рассмотрению их задач и резуль-
результатами. Также он содержит тестер идентичности программ, так что преподава-
преподаватель может проверять самостоятельность решений, которые представили студен-
студенты. Это делает поиск решений в web или в директориях ваших одноклассников
«плохой кармой».
Сокращение от Universidad de Valladolid. - Примеч. науч. ред.
1.1. Начало работы с автоматической тестирующей системой () (robot judge) 13
1.1.2 Автоматический судья Universidad de Valladolid
Все задачи этой книги наравне со многими другими находятся на сайте тес-
тестирующей системы Universidad de Valladolid (http://online-judge.uva.es), самой
большой коллекции задач по программированию в мире. Мы призываем всех, чей
аппетит только разгорелся от предложенных нами задач, продолжить свое обуче-
обучение там.
После регистрации на сайте UV вы получите E-Mail, содержащий ID-номер,
который будет идентифицировать ваши программы для судьи. Вам потребуется
этот ID-номер для любого решения, которое вы отправите.
Судья UV постепенно переходит на web-интерфейс, но пока пользуется отправкой
решений через E-Mail. Решения отправляются непосредственно на judge@uva.es
после того, как вы зададите достаточное количество информации, необходимой для
того, чтобы автоматический судья понял, какую задачу вы пробуете решить, кто явля-
является автором решения и какой язык программирования используется.
Говоря точнее, каждая программа должна содержать строку (в любом месте)
с полем @ JUDGE_ID:. Обычно эта. строка помещается внутрь комментария.
Например,
/* @JUDGE_ID: 1000AA 100 С *Dynamic Programming" */
Аргумент, который следует за @JUDGE_ID:, - это ваш пользовательский
ID-номер A000АА в этом примере). Далее следует номер задачи (в данном
случае 100), и далее следует используемый язык программирования. Не забы-
забывайте использовать ID-номер UV для всех отправок этому судье! Верхний
и нижний регистр не различаются. Если вы забудете указать язык программиро-
программирования, судья автоматически попробует определить его - но зачем вам это
нужно? И наконец, если вы использовали какой-то интересный алгоритм или
метод, можете указать название того эффекта, к которому приводит его приме-
применение, заключенное в кавычки; в нашем примере это Dynamic Programming.
Заключение вашей программы в своеобразные скобки из комментариев
начала/окончания исходного кода программы - это хороший способ застрахо-
застраховаться от того, что судья запутается во всем том мусоре, который добавит ваша
почтовая программа.
/* @BEGIN_OF_SOURCE_CODE*/
your program here
/* @END_OF_SOURCE_CODE*/
После того как вы это сделаете, часть таинственных ошибок исчезнет.
14 Глава 1. Начало работы
1.1.3. Ответы тестирующих систем (судей)
Студенты должны знать, что обе тестирующие системы (автоматические судьи)
часто очень требовательны к тому, что можно назвать правильным решением.
Очень важно правильно понять спецификацию задачи. Никогда не делайте предпо-
предположения, которые точно не описаны в спецификации. Нет абсолютно никакой
причины, чтобы верить в то, что входные данные отсортированы, графы соединены
или что целые числа, рассматриваемые в задаче, положительны и достаточно малы,
если это не указано в спецификации.
Точно так же как и человеческие судьи ACM International Collegiate
Programming Contest, автоматические сетевые судьи дают вам очень мало
информации насчет того, что неправильно в вашей программе. Вероятнее всего,
будет дан один из следующих ответов.
• Accepted (AC). Наши поздравления! Ваша программа работает верно
и укладывается во временные рамки и необходимый объем памяти.
• Ошибки представления (Presentation Error (РЕ). Выходные данные вашей
программы верны, но они не представлены в необходимом формате.
Проверьте пробелы, правое/левое выравнивание, переводы строк и т. д.
• Accepted (РЕ). Ваша программа имеет небольшую ошибку представления, но
судья простил вам ее и засчитал программу с предупреждением. Не беспокой-
беспокойтесь об этом, потому что многие задачи имеют в некоторой степени запутан-
запутанные указания насчет вывода. Обычно ваша ошибка тривиальна (к примеру,
лишний пробел в конце строки), так что успокойтесь и празднуйте победу.
• Wrong Answer (WA). Это должно вас обеспокоить, потому что ваша
программа вывела неверный ответ на один из секретных тестов судьи. Вам
нужно заняться дальнейшей отладкой.
Compile Error (СЕ). Компилятор не смог понять, как скомпилировать вашу
программу. Итоговое сообщение компилятора будет вам отправлено. Преду-
Предупреждения, которые не пересекаются с компиляцией, будут проигнорированы
судьей.
• Runtime Error (RE). Ваша программа прекратила работу во время запуска из-
за ошибки сегментации, исключения, связанного с плавающей точкой, или
похожей проблемы. Последнее сообщение программы будет вам отправлено.
Проверьте работу с указателями и возможные деления на ноль.
• Time Limit Exceeded (TL). Работа вашей программы заняла слишком много
времени на, как минимум, одном тесте, так что, вероятнее всего, у вас пробле-
проблема с эффективностью. Тем не менее, если ваша программа превысила лимит
времени на одном из тестов, это не значит, что она сработала верно во всех
остальных случаях!
1.2. Выбор оружия 15
• Memory Limit Exceeded (ML). Ваша программа потребовала больше памяти,
чем доступно по умолчанию у судьи.
• Output Limit Exceeded (OL). Ваша программа попробовала вывести слишком
много данных. Обычно это значит, что программа попала в бесконечный
цикл.
• Restricted Function (RF). Ваша программа попробовала использовать
запрещенную системную функцию, такую, как fork() или fopen(). Ведите себя
хорошо.
• Submission Error (SE). Вы некорректно указали одно или несколько
информационных полей, возможно, указали неправильный ID пользователя
или задачи.
Повторюсь еще раз: если оказалось, что ваша программа выдает неправиль-
неправильный ответ, судья не покажет вам, на каком тесте это произошло, и не даст вам
никаких дополнительных подсказок по поводу того, почему она выдала неверный
результат. Именно поэтому очень важно аккуратно просматривать спецификации.
Даже тогда, когда вы можете быть уверены, что ваша программа работает верно,
судья все равно может говорить, что это не так. Вероятно, вы проглядели какой-то
из граничных случаев или предположили то, что на самом деле неверно.
Повторная отправка программы без всяких изменений не принесет вам абсолютно
никакой пользы. Перечитайте задачу заново, чтобы убедиться, что ваши мысли
совпадают с тем, что написано в спецификации.
Иногда судья выносит более экзотичный вердикт, который по существу не
зависит от вашего решения. Смотрите соответствующие сайты для более
подробных разъяснений.
1.2. Выбор оружия
Какой язык программирования вам следует использовать в ваших сражениях
с автоматическим судьей? Вероятнее всего, тот язык, который вы лучше всего знае-
знаете. На данный момент судья принимает программы, написанные на Pascal, С, С++
и Java, так что, вероятнее всего, ваш любимый язык доступен. Один язык програм-
программирования может быть существенно лучше другого для решения какой-то конкрет-
конкретной задачи. Тем не менее эти задачи в гораздо большей степени проверяют способ-
способности к решению, чем переносимость, модульность или эффективность, являющие-
являющиеся стандартными параметрами, по которым сравниваются языки.
16
Глава 1. Начало работы
Обращения в месяц по языкам программирования
8
1997
1998
1999 2000
Год
2001
2002
Рис. 1.1. Зависимость обращений к автоматическому судье от языка программирования
(на декабрь 2002)
1.2.1. Языки программирования
Четыре языка, понимаемые автоматическим судьей, создавались в разное
время с разными целями.
• Pascal - наиболее популярный язык для обучения в 1980-х годах. Pascal был
создан для поощрения развития навыков структурного программирования.
Его популярность упала практически до нуля, но он все еще используется
в средних школах и в Восточной Европе.
• С - оригинальный язык операционной системы UNIX. С был создан для того,
чтобы дать опытным программистам возможность делать все, что они хотят.
Это включает в себя возможность все испортить неправильной ссылкой на
указатель и неправильным преобразованием типов. Исследования в объектно-
ориентированном программировании, проводившиеся в 1990-х годах, приве-
привели к новому и улучшенному...
C++ - первый коммерчески успешный язык программирования, сумевший
провернуть ловкий трюк, состоявший в том, что язык был совместим с С и при
этом привносил новый уровень абстракции данных и механизмы наследования.
1.2. Выбор оружия 17
C++ стал основным языком программирования для обучения и разработок
программного обеспечения в средних и поздних 1990-х годах, но сейчас ему
наступает на пятки ...
• Java - разработанный как язык для поддержки мобильных программ, Java имеет
специальные механизмы защиты, которые позволяют избежать стандартных
ошибок программистов, таких, как нарушение границ массивов и нелегальный
доступ к указателям. Это полнофункциональный язык программирования,
который может все, что могут остальные, и много больше.
Таблица 1.1.
Решения автоматического судьи по языкам программированияна декабрь 2002 года)
Язык
С
C++
Java
Pascal
Итого
Всего
451447
6396565
16373
149408
1256793
АС
31.9%
28.9%
17.9%
27.8%
29.7%
РЕ
6.7%
6.3%
3.6%
5.5%
6.3%
WA
35.4%
36.8%
36.2%
41.8%
36.9%
СЕ
8.6%
9.6%
29.8%
10.1%
9.6%
RE
9.1%
9.0%
0.5%
6.2%
8.6%
TL
6.2%
7.1%
8.5%
7.2%
6.8%
ML
0.4%
0.6%
1.0%
0.4%
0.5%
0L
1.1%
1.0%
0.5%л
0.4%
1.0%
RF
0.6%
0.7%
2%
0.5%
0.6%
Обратите внимание, что каждый язык имеет особенности, связанные с компи-
компилятором и с операционной системой. Так что программа, которая идет на вашей
машине, может не заработать у судьи. Внимательно просмотрите записи, связан-
связанные с языками, на сайте вашего судьи, особенно если вы используете Java.
Интересно посмотреть на те языки, которые люди используют. На декабрь
2002 года 1 250 000 программ были отправлены автоматическому судье. Прак-
Практически половина из них была написана на C++ и еще треть на С. Совсем неболь-
небольшая часть программ была написана на Java, но это ни о чем не говорит, так как
судья стал принимать программы, написанные на Java, только с ноября 2001 года.
На рис. 1.1 эти отправки разбиты по месяцам. Язык С был самым популярным
до 1999 года, когда C++ вырвался вперед. Интересно отметить, что годовой пик
популярности совпадает со временем подготовки студентов к региональным
этапам ACM International Collegiate Programming Contest. С каждым годом судья
становится все более и более занят, так как все больше и больше студентов
жаждут рассмотрения своего дела в его суде.
Также интересно посмотреть на решения судьи по языкам программирования.
Они отражены в таблице 1.1, следуя тем буквенным обозначениям, которые мы ввели
в разделе 1.1.3. В решениях нет ничего особенно непонятного. Тем не менее кажется,
что частота определенных типов ошибок зависит от языка. С++-программы чаще
18 Глава 1. Начало работы
превышают лимиты времени и памяти, чем программы, написанные на С. Это знак
того, что C++ относительно жаден до ресурсов. Язык С имеет слегка больший про-
процент принятий, чем C++, вероятно, из-за его популярности на ранней стадии развития
судьи. Pascal имеет наименьший процент ошибок, связанных с использованием запре-
запрещенных функций, это является следствием того, что он был создан как приятный
и безопасный язык, с которым студенты могут позабавиться. Java имеет гораздо
больше ошибок компиляции, но, с другой стороны, гораздо реже, чем в других языках,
вызываются ошибки во время работы. Безопасность требует своих жертв.
Но основной вывод состоит в том, что не инструмент делает человека. Язык
программирования не решает задачи - их решаете вы.
1.2.2. Чтение наших программ
В этой книге вы встретите несколько примеров программ, которые
иллюстрируют методики программирования и обеспечивают полную реализацию
фундаментальных алгоритмов. Весь этот код доступен для использования и экс-
экспериментов на http://www.programming-challenges.com. Нет лучшего пути для
отладки программ, чем их прочтение несколькими тысячами одаренных студен-
студентов, так что не пропустите список опечаток и исправленные решения.
Наши примеры программ реализованы на простом подмножестве языка С, что
будет понятно, как мы надеемся, всем нашим читателям без большого труда. С в свою
очередь является подмножеством C++, и его синтаксис достаточно схож с синтакси-
синтаксисом Java. Мы позаботились о том, чтобы на протяжении книги избежать диких С-спе-
цифических выражений, структур указателей и динамического вьщеления памяти, так
что оставшееся должно быть понятно пользователям всех четырех языков автома-
автоматического суцьи.
Вот некоторые замечания по языку С, которые могут оказаться полезными при
чтении наших программ.
Передача параметров. Все параметры в С передаются при вызове по
значению; это значит, что при вызове функции делаются копии всех аргумен-
аргументов. Но тогда кажется, что нельзя писать функции, которые будут влиять на
передаваемые переменные. Для решения этой проблемы С предлагает вам
передавать указатель на любой аргумент, который вы собираетесь изменять
внутри тела функции.
Единственно, где мы будем использовать указатели, это в передаче
параметров. Указатель на х обозначается &х, тогда как то, на что указывает р,
обозначается *р. Не путайте умножение и раскрытие указателей!
1.2. Выбор оружия 19
• Типы данных. С поддерживает несколько базовых типов данных, включая
int, float и char, которые не требуют разъяснений. Более точные int
и float обозначаются long и double соответственно. Если не указано
иначе, все функции возвращают int.
• Массивы. Индексы в массивах С всегда имеют значения от 0 до п - 1, где п -
число элементов в массиве. Таким образом, если для удобства мы хотим
начать с индекса 1, то мы должны не забыть выделить место для п + 1
элемента в массиве. Никакой проверки на соблюдение границ массива не
производится, так что такие ошибки являются обычными причинами
программных сбоев.
Мы не будем жестко определять, где расположен первый элемент массива.
Начинать с 0 - это традиционный стиль написания программ на С. Тем не
менее иногда понятнее или удобнее начать с 1, и мы готовы заплатить памя-
памятью, необходимой для размещения одного дополнительного элемента за это
удобство. Постарайтесь не запутаться при чтении нашего кода.
• Операторы. С содержит несколько важных операторов, которые могут быть
незнакомы некоторым читателям. Целочисленный остаток, или операция
mod, обозначается %. Операции логического «и» и логического «или», появ-
появляющиеся в условных выражениях, обозначаются && и | | соответственно.
1.2.3. Стандартный ввод/вывод
Программисты, работавшие в UNIX, знакомы с понятием фильтров
и программ-каналов, которые получают один входной поток и производят один
выходной поток. Вывод таких программ может быть вводом для других. Принцип
состоит в том, чтобы составить цепочку из множества небольших программ,
вместо того чтобы создавать большие и сложные системы программного обес-
обеспечения, которые пытаются делать все сразу.
Эта философия организации программного обеспечения несколько сдала свои
позиции в последние годы из-за популярности пользовательских графических ин-
интерфейсов (GUI). Многие программисты на подсознательном уровне создают
point-and-click-интерфейс для каждой программы. Но такие интерфейсы могут
сильно затруднить передачу данных от одной программы к другой. Совсем
несложно работать с текстовым выводом другой программы, но что можно сде-
сделать с картинкой, кроме как посмотреть на нее?
Стандарты судьи ввода/вывода отражают официальные правила АСМ-соревно-
ваний по программированию. Каждая программа должна считьшать входные данные
из стандартного ввода и вьшодить результаты в стандартный вьгоод. Программам не
разрешается открывать файлы или выполнять некоторые системные вызовы.
20
Глава 1. Начало работы
Стандартный ввод/вывод достаточно прост в С, C++ и Pascal. Рис. 1.2 показы-
показывает простой пример для каждого языка, который читает два числа в строке и со-
сообщает абсолютную величину их разности. Обратите внимание на то, как ваш
любимый язык проводит проверку на условие завершения (end-of-file). В боль-
большинстве задач обработка входных данных облегчена еще больше либо заданием
числа примеров, либо описанием специальной завершающей строки.
#include<stdio.h>
int main() {
long p,q,r;
while (scanf(M%ld %ld/&p/&q
!=EOF) {
if (q>p) r=q-p;
else r=p-q;
printf("%ld\n",r)
#include<iostream.h>
void main()
long long a,b,c;
while (cin»a»b) {
if (b>a)
c=b-a;
else
c=a-b;
cout « с « endl;
{$N+}
program a cm;
var
a, b/ с : integer;
begin
while not eof do
begin
readln(a, b)
if b > a then
begin
с := b;
b := a;
a : = с ;
end ;
; } writeln(a - b);
end
end.
Рис. 1.2. Стандартные примеры ввода/вывода в С (слева), C++ (по центру) и в Pascal
(справа)
Большинство языков предоставляют мощные функции для работы с вводом/выво-
вводом/выводом. При правильном использовании команда в одну строку длиной может заменить
некоторые необязательные и достаточно неприятные подпрограммы синтаксического
разбора и форматирования, которые пишут те, кто не читал руководство.
Тем не менее стандартный ввод/вывод не прост в Java. Электронный шаблон для
Java I/O C5 строк длиной) доступен на http://www.programming-challenges.com.
Настройте его один раз, а потом используйте для всех необходимых случаев.
Java-программы, подаваемые судье, должны состоять из одного файла исходно-
исходного кода. На данный момент они компилируются и запускаются как собственные при-
приложения с использованием компилятора gc j, хотя это и может измениться в буду-
будущем. Обратите внимание, что использование Java: :io ограничено; это ведет
к тому, что некоторые возможности недоступны. Сетевые функции и потоки также
недоступны. Тем не менее методы из math, util и других стандартных пакетов
разрешены. Все программы должны начинаться в статическом основном методе
класса Main. He используйте публичные классы: даже Main должен быть непуб-
непубличным, чтобы избежать ошибок компиляции. Тем не менее вы можете добавлять
и создавать экземпляры такого количества классов, которое вам требуется.
1.3. Советы по программированию 21
Если вы обнаружите, что используете операционную систему/компилятор,
который затрудняет использование стандартного ввода/вывода, обратите внима-
внимание, что судья во время компиляции всегда определяет символ. Таким образом, вы
можете проводить тесты с его использованием и перенаправлять ввод/вывод
в файл, когда запускаете программу на вашей системе.
1.3. Советы по программированию
Цель этой книги не научить вас тому, как программировать, а научить тому, как
программировать лучше. Мы полагаем, что вы знакомы с такими фундаментальны-
фундаментальными понятиями, как переменные, условные выражения (к примеру, if-then-else,
case), а также с основами итерации (например, f or-do, while-do, repeat-
until), подпрограммами и функциями. Если вы незнакомы с этими понятиями, то,
возможно, взяли в руки не ту книгу, но ее все равно стоит купить для дальнейшего
использования.
Очень важно понять, насколько мощным является то, что вы знаете. В принципе
любой интересный алгоритм/программу можно написать, основываясь на тех зна-
знаниях, которые вы получили в самом начале обучения программированию. Все
мощные способности современных языков не обязательны для построения интерес-
интересных вещей - они нужны только для того, чтобы построить их более четко и удобно.
Говоря другими словами, хорошим писателем становится не тот, кто выучил
много слов из словаря, а тот, кто нашел, о чем рассказать. После одного-двух курсов
программирования вы знаете все необходимые слова, чтобы вас понимали. Задачи
в этой книге постараются дать вам что-нибудь интересное, что можно рассказать.
Мы предлагаем несколько несложных советов по программированию, которые
помогут вам в написании качественных программ. Все примеры с ошибками
взяты из того, что присылали автоматическому судье.
• Пишите сначала комментарии. Начинайте ваши программы и процедуры
с нескольких предложений, которые объясняют то, что они должны делать. Это
важно, потому что если вы не можете с легкостью написать эти комментарии,
то, вероятнее всего, вы не понимаете, что делает программа, Редактировать наши
комментарии гораздо проще, чем редактировать наши программы, и мы считаем,
что время, потраченное на дополнительное печатание, потрачено с большой
выгодой. Конечно, из-за того, что на соревнованиях обычно поджимает время,
появляется привычка быть небрежным, но в этом нет ничего хорошего.
• Документируйте каждую переменную. Напишите одну строку комментария
для каждой переменной, чтобы вы знали, что она делает. И снова, если вы не
можете четко это написать, то вы не понимаете, что она тут делает. Вы будете
22 Глава 1. Начало работы
общаться с программой, по крайней мере, несколько циклов отладки, и вы
оцените это скромное вложение в ее читабельность.
Используйте символьные константы. Когда бы вам ни потребовалась констан-
константа в вашей программе (размер входных данных, математическая константа,
размер структуры данных и т. д.), объявляйте ее в начале программы. Использо-
Использование противоречивых констант может привести к очень сложным и труднооб-
наруживаемым ошибкам. Конечно, символьное имя нужно только тогда, когда
вы собираетесь его использовать в том месте, где должна быть константа...
Используйте перечислимые типы (enumerated types) там, где это необходимо.
Перечислимые типы (то есть символьные переменные, такие, как булевы
переменные (true, false) могут сильно облегчить понимание программы.
Тем не менее они часто бывают ненужными в небольших программах. Обрати-
Обратите внимание на этот пример, представляющий масть (трефы, бубны, червы,
пики) колоды карт.
switch (cursuit){
case *С :
newcard.suit = С;
break;
case *D':
newcard.suit = D;
break;
case *H':
newcard.suit = H;
break;
case XS': .
newcard.suit = S;
break;
Из использования перечислимых переменных (С, D, Н, S) вместо первоначального
символьного представления (*C',*D',*H',%S')He возникает никакой допол-
дополнительной ясности, появляется только дополнительная возможность ошибиться.
Используйте подпрограммы, чтобы избежать излишнего кода. Просмотрите
следующий фрагмент программы, который управляет состоянием прямо-
прямоугольной доски, и подумайте, как бы вы могли его упростить и укоротить.
while (с != ч0'){
scanf(w%c", &c);
if (с == *А'){
if (row-1 >= 0){
temp = b[row-l][col];
1.3. Советы по программированию 23
b[row-l][col] = * х;
b[row][col] = temp;
row = row-I;
}
}
else if (c == 4B'){
if (row+1 <= BOARDSIZE - 1){
temp = b[row+l][col];
b[row+l][col] = x л;
b[row][col] = temp;
row = row+1;
В полном тексте программы было четыре блока по три строки каждый, каж-
каждый из которых перемещал значение в соседнюю ячейку. Ошибка в написании
одного + или - приведет к фатальным последствиям. Гораздо безопаснее было
бы написать одну подпрограмму для перемещения и вызывать ее с соответст-
соответствующими параметрами.
• Делайте ваши отладочные инструкции понятными. Учитесь использовать
средства отладки вашей системы. Это позволит вам останавливать выполне-
выполнение программы на заданном выражении или условии, так что вы сможете
посмотреть, чему равны все интересующие вас переменные. Обычно это
проще и быстрее, чем писать кучу сообщений вывода. Но если вы все-таки
собираетесь использовать отладочные сообщения вывода, то пусть они что-
нибудь сообщают. Выведите все необходимые переменные и укажите для
каждого выведенного значения имя переменной. Иначе очень легко потерять-
потеряться в собственном отладочном выводе.
Большинство студентов, изучающих вычислительную технику, хорошо знакомы
с объектно-ориентированным программированием, принципом разработки про-
программного обеспечения, разработанным для создания и использования компонент
программного обеспечения многократного использования. Объектно-ориентирован-
Объектно-ориентированное программирование полезно при создании больших программ многократного
использования. Тем не менее большинство задач по программированию, приведен-
приведенных в этой книге, решаются с помощью коротких, умных программ. Основная идея
объектно-ориентированного программирования не находит применения в этой
области, так что определение сложных новых объектов (вместо использования предо-
предопределенных объектов), вероятнее всего, будет пустой тратой времени.
Ключ к успешному программированию не в том, чтобы не использовать ника-
никакого определенного стиля, а в том, что нужно использовать стиль, соответст-
соответствующий поставленной задаче.
24 Глава 1. Начало работы
1.4. Элементарные типы данных
Простые структуры данных, такие, как массивы, имеют важное преимущество
перед более сложными структурами данных, такими, как связанные списки: они
простые. Многие ошибки в структурах, основанных на указателях, просто не могут
случиться в статических массивах.
Верный признак хорошего профессионала - не усложнять простую работу.
Это достаточно сложно для тех, кто только приступил к изучению нового предме-
предмета. Студенты-медики являются обычным примером этой проблемы. После посе-
посещения нескольких лекций по запутанным тропическим болезням молодой доктор
беспокоится, что каждый пациент с насморком и сыпью может быть болен бубон-
бубонной чумой или вирусом Эбола, тогда как более опытный врач просто отправляет
пациента домой с пузырьком аспирина.
Аналогично вы могли недавно узнать про сбалансированные поисковые бинарные
деревья, обработку исключений, параллельную обработку данных и о различных
моделях наследования объектов. Все это важные и полезные предметы. Но они совсем
необязательно являются лучшим решением для простой задачи.
Да, структуры, основанные на указателях, являются очень мощным инстру-
инструментом, если вы не знаете максимальный размер данных загодя или если вам
нужны быстрые операции поиска и обновления. Тем не менее для многих задач,
которые вы будете здесь решать, максимальный размер указан. Более того, авто-
автоматический судья обычно позволит вашей программе проработать несколько
секунд, что является весьма большим количеством счетного времени, если не
сильно задумываться по этому поводу. Вам не начисляются дополнительные
баллы за более быструю работу.
Итак, что же нужно знать про структуры данных? Во-первых, нужно быть знако-
знакомым с основными примитивными типами данных, встроенными в ваш язык програм-
программирования. В принципе вы можете построить практически все, что хотите, основыва-
основываясь на следующем.
• Массивы. Этот основополагающий тип данных позволяет обращаться
к данным по положению, а не по содержанию, точно так же как номера домов
на улице позволяют получить доступ по адресу, а не по имени. Они исполь-
используются для хранения последовательностей элементов одного типа, таких, как
целые числа, вещественные числа или составные объекты (к примеру, записи).
Массивы символов могут быть использованы для представления строк текста,
тогда как массивы строк текста могут быть использованы для представления
практически чего угодно.
1.4. Элементарные типы данных 25
Сигнальные метки могут быть удобны для упрощения программирования мас-
массивов. Сигнальная метка - это сторожевой элемент, который неявно, без прове-
проведения явных проверок, смотрит, чтобы программа не вышла за пределы массива.
Рассмотрим случай вставки элемента х в заданную позицию среди п элементов
отсортированного массива а. Мы можем явно проверять на каждом шаге, достиг-
достигли ли мы дна массива:
i = п;
while ((a[i]>=x) && (i>=l)) {
a[i] = a[i-l];
i = i - 1;
}
a[i+l] = x;
или мы можем удостовериться в том, что неиспользуемый элемент а [ 0 ]
меньше любого элемента, находящегося справа от него:
i = п;
а[0] = - MAXINT;
while (a[i]>=x) {
a[i] = a[i-l];
i = i - 1;
}
a[i+l] = x;
Грамотное использование сигнальных меток и создание вашего массива
немного большим, чем он предположительно должен быть, может помочь
избежать множества граничных ошибок.
Многомерные массивы. Прямоугольные сеточные структуры, такие, как шах-
шахматные доски и изображения первыми приходят в голову, когда разговор идет
о двумерных массивах, но, обобщая, можно сказать, что они могут быть
использованы для группировки гомогенных записей данных. Например, мас-
массив из п точек на плоскости х-у можно рассматривать как я х 2 массив, где
второй аргумент @ или 1) массива А[/][/] говорит о том, ссылаемся мы на
координату х или у.
Записи. Они используются для группировки гетерогенных данных. Например,
массив записей людей может объединить имена людей, идентификационные
номера, высоты роста и веса в один пакет. Записи важны для четкости понима-
понимания в больших программах, но их поля часто без ущерба могут быть представ-
представлены различными массивами в программах среднего размера.
26 Глава 1. Начало работы
Не всегда четко понятно, что лучше использовать в задаче - записи или мно-
многомерные массивы. Рассмотрим проблему представления точек на плоскости х-у,
рассмотренную выше. Очевидным представлением будет примерно такая струк-
структура или запись:
struct point {
int x, у;
};
вместо двумерного массива. Большим плюсом записей является то, что обозначе-
обозначения р. х и р. у похожи на те обозначения, которые мы используем при работе
с точками. Тем не менее недостатком представления в виде записи является то,
что вы не можете пройти циклом по индивидуальным переменным, как вы можете
сделать это с массивом.
Представьте, что вы хотите изменить геометрическую программу для работы
с трехмерными точками вместо точек на плоскости или даже для работы с произ-
произвольным числом измерений. Конечно, вам будет совсем несложно добавить новые
поля в запись, но теперь везде, где вы проводили какие-то вычисления над х и у,
вы должны будете повторить их для z. Но при использовании представления
в виде массива изменение расчета расстояния при переходе от двух измерений
к трем сводится к изменению константы:
typedef int point [DIMENSION];
double distance(point a, point b)
{
int i ;
double d = 0.0;
for (i=0; i<DIMENSION;
d=d+ (a[i]-
return( sqrt(d) );
}
В главе 2 мы рассмотрим более продвинутые структуры данных, которые могут
быть построены на базе этих основных примитивов. Они позволят нам работать
с более высоким уровнем абстракции, но не бойтесь использовать простые техноло-
технологии, когда этого достаточно для задачи.
1.5.0 задачах 27
1.5. О задачах
Каждая глава этой книги заканчивается соответствующим набором задач по
программированию. Эти задачи были аккуратно выбраны из более чем 1000 таких
задач, собранных на сайте Universidad de Valladolid. Мы выбирали понятные,
интересные задачи с различными уровнями сложности. Особенно мы искали ту
вспышку интуиции, которая превращает простую задачу в вызов.
Описание каждой выбранной проблемы было отредактировано для корректно-
корректности и читабельности. Мы пытались сохранить собственный вкус и цвет каждой
оригинальной задачи, делая при этом ее понятной в разумных пределах. Предос-
Предоставляются идентификационные номера для каждой задачи для обоих сайтов. Эти
номера необходимы для успешной отправки. Первый номер в каждой паре отно-
относится к http://www.programming-challenges.com; второй к http://online-judge.uva.es.
Чтобы дать какое-то представление об относительной сложности задач, для
каждой предоставляются три дополнительные метки. Во-первых, каждой задаче
был присвоен уровень А, В или С, отражающий то, сколько правильных решений
было прислано судье. Проблемы уровня А предположительно легче или чем-то
привлекательнее, чем проблемы уровня В. Во-вторых, частота, с которой прислан-
присланные решения принимаются судьей, обозначается как высокая, средняя или низкая.
Низкая частота может означать излишне придирчивых судей, или, возможно,
задача оказалась более хитрой, чем казалась поначалу. Или они просто отражают
ошибки в тестах, которые позже были исправлены. Таким образом, не сильно
обращайте внимание на частоту успеха. И наконец, мы присвоили субъективный
рейтинг (от 1 до 4) уровня знаний, который необходим для решения задачи. Более
высокие значения означают более сложные задачи.
Удачи и счастливого программирования!
1.6. Задачи
1.6.1. Задача Зп + 1
PC/UVaIDs: 110101/100,
Популярность: А
Частота успехов: низкая
Уровень: 1
Рассмотрим следующий алгоритм генерации последовательности чисел.
Начнем с целого числа п. Если п четно, то поделим на 2. Если п нечетно, то умно-
умножим на 3 и добавим 1. Будем повторять этот процесс с новым полученным л, пока
28 Глава 1. Начало работы
п не станет равным 1. Например, для я = 22 будет сгенерирована следующая
последовательность чисел:
22 11 34 17 52 26 13 40 20 10 5 16 8 4 2 1
Полагают (но это еще не доказано), что этот алгоритм сведется к п = 1 для
любого целого п. По крайней мере, это предположение верно для всех целых
чисел до 1 000 000.
Для данного п длиной цикла п будем называть число сгенерированных чисел
до и включая 1. В примере, приведенном выше, длина цикла 22 равна 16. Для двух
заданных чисел i и у вы должны определить максимальную длину цикла для всех
чисел между / и у, включая обе конечные точки.
Входные данные
Входные данные будут состоять из серии пар целых чисел / и у, одна пара
чисел в строке. Все целые числа будут меньше 1 000 000 и больше 0.
Выходные данные
Для каждой пары чисел i и у выведите i, j в том порядке, в каком они были вве-
введены, и после этого выведите максимальную длину цикла для всех целых чисел
между / иу, включая сами i иу. Эти три числа должны быть разделены одним про-
пробелом, все три числа в одной строке, и для каждой строки входных данных должна
быть одна строка выходных данных.
Пример входных данных Соответствующие выходные данные
1 10 1 10 20
100 200 100 200 125
201 210 201 210 89
900 1000 900 1000 174
1.6,2. Сапер
РС/UVaIDs: 1I0102/10189
Популярностью А
Частота успехов: высокая
Уровень: 1
Играли ли вы когда-нибудь в Сапера (Minesweeper)? Эта приятная маленькая игра
поставляется вместе с операционной системой, имя которой мы не помним. Цель
ифы состоит в том, чтобы найти расположение всех мин на поле размером Мх N.
1.6. Задачи 29
Игра показывает вам число в клеточке, которое говорит вам, сколько мин нахо-
находится в соседних с этой клеточках. Каждая клеточка имеет максимум восемь со-
соседних. Поле 4x4 слева содержит две мины, каждая из которых представлена
символом «*». Если мы добавим к этому полю числа-подсказки по принципу, опи-
описанному выше, то получим поле, изображенное справа:
*... *100
2210
.*.. 1*10
1110
Входные данные
Входные данные будут состоять из произвольного числа полей. Первая строка
каждого поля содержит два целых числа пит@<п, т < 100), которые соответст-
соответствуют числу строк и столбцов поля соответственно. Каждая из последующих п строк
содержит ровно т символов, представляя собой поле.
Безопасные клеточки обозначаются «.» , мины обозначаются «*», и то и другое
без кавычек. Первая строка поля, где п = т = 0, представляет собой окончание вход-
входных данных и обрабатываться не должна.
Выходные данные
Для каждого поля выведите сообщение Field #*:, единственное на строке,
где х обозначает номер текущего поля, начиная с 1. Следующие п строк должны
содержать поле с символами «.», замененными на число мин в соседних кле-
клеточках. Между выводами полей должна быть пустая строка.
Пример входных данных Соответствующие выходные данные
4 4 Field #1:
*... *100
2210
.*.. 1*10
1110
3 5
Field #2:
**100
•*..¦ 33200
0 0 1*100
30 Глава 1. Начало работы
1.6.3. Путешествие
PC/UVaIDs: 110103/10137
Популярность: В
Частота успехов: средняя
Уровень:1
Группа студентов является членами клуба, который ежегодно путешествует
в различные места. Предыдущие места их поездок включают Индианаполис,
Финикс, Нашвилл, Филадельфию, Сан-Хосе и Атланту. Этой весной они планируют
съездить в Айндховен.
Группа заранее договорилась делить расходы поровну, но неудобно делить рас-
расходы по мере их поступления. Поэтому каждый студент в отдельности платит за
определенные вещи, такие, как еда, проживание, поездки на такси и билеты на само-
самолет. После путешествия расходы каждого студента суммируются, и происходит
обмен деньгами так, что итоговая стоимость для всех оказывается равной с точно-
точностью до одного цента. В прошлом этот обмен деньгами был скучным и долгим.
Ваша задача состоит в том, чтобы, основываясь на списке расходов, определить ми-
минимальную сумму денег, которая должна поменять хозяина, для того чтобы уравнять
(с точностью до цента) расходы всех студентов.
Входные данные
Стандартные входные данные будут содержать данные для нескольких путе-
путешествий. Каждое путешествие состоит из строки, содержащей положительное
•целое число п, обозначающее число путешествовавших студентов. Далее следуют
п строк входных данных, каждая из которых содержит расходы одного студента
в долларах и центах. Студентов не более 1000, и ни один из них не истратил более
$10000.00. Единственная строка, содержащая 0, следует за информацией о по-
последнем путешествии.
Выходные данные
Для каждого путешествия выведите строку, содержащую минимальную сумму
денег, в долларах и центах, которая должна быть передана, чтобы уравнять траты
студентов.
1.6. Задачи 31
Пример входных данных Соответствующие выходные данные
3 $10.00
10.00 $11.99
20.00
30.00
4
15.00
15.01
3.00
3.01
0
1.6.4. LCD-дисплей
PC/UVaIDs: 110104/706
Популярность: А
Частота успехов: средняя
Уровень:1
Ваш друг только недавно купил себе новый компьютер. До этого самой
мощной машиной, которую он когда-либо использовал, был карманный калькуля-
калькулятор. Он немного расстроен, потому что LCD-дисплей его калькулятора ему нра-
нравился больше, чем экран его компьютера! Чтобы обрадовать его, напишите про
грамму, которая отображает числа в стиле LCD-дисплея.
Входные данные
Входные данные содержат несколько строк, по строке для каждого числа, ко-
которое нужно отобразить. Каждая строка содержит целые числа s и я, где п - это
число, которое нужно отобразить @ < п < 99 999 999) и s, это размер, в котором
оно должно быть изображено @ <.? < 10). Входные данные заканчиваются стро-
строкой, состоящей из двух нулей, которую не нужно обрабатывать.
Выходные данные
Выведите числа указанные во входных данных в стиле LCD-дисплея, используя
s «-» символов для горизонтальных сегментов и s «|» символов для вертикальных.
Каждая цифра занимает ровно s + 2 колонок и 2 s + 3 строк. Не забудьте заполнить
все белое пространство, занимаемое цифрами, пробелами, включая последнюю
цифру. Между двумя цифрами должна быть точно одна колонка пробелов.
Выводите пустую строку после каждого числа. Вы найдете пример вывода
каждой цифры ниже.
32 Глава 1. Начало работы
Пример входных данных
2 12345
3 67890
0 0
Соответствующие выходные данные
1.6. Задачи 33
1.6.5. Графический редактор
PC/UVaIDs: 110105/10267
Популярность: В
Частота успехов: низкая
Уровень: 1
Графические редакторы, такие, как Photoshop, позволяют нам изменять растро-
растровые изображения таким же образом, каким мы изменяем документы. Изображения
представляются в виде массива пикселов размеромМх N, где каждый пиксел имеет
свой цвет.
Вашей задачей является написать программу, симулирующую простой интерак-
интерактивный графический редактор.
Входные данные
Входные данные состоят из последовательности команд редактора, одна на
строку. Каждая команда представляется одной заглавной буквой, стоящей в каче-
качестве первого символа строки. Если команде требуются параметры, то они будут
переданы в той же строке, разделенные пробелами.
Координаты пиксела представляются двумя целыми числами: номер столбца,
лежащий в пределах 1 ... А/, и номер строки, лежащий в пределах 1..jV, где 1 <М,
N<250. Начало координат расположено в верхнем левом углу таблицы. Цвета
обозначаются заглавными буквами.
Редактор понимает следующие команды.
IМ N Создать новый рисунок размером Мх N, со всеми пикселами белого
цвета (о)
С Очистить таблицу, сделав все пикселы белыми (о). Размер не меняется
L X Y С Покрасить пиксел (X У) в цвет (с)
V X Y1 Y2 С Нарисовать вертикальную линию цвета (с) в столбце X между
строками К1 и К2 включительно
Н Х1 Х2 Y С Нарисовать горизонтальную линию цвета (с) в строке У} между
столбцами Х\ и Х2 включительно
К Х1 Х2 Y1 Y2 С Нарисовать закрашенный прямоугольник цвета (с), где (Х\, К1) -
координаты верхнего левого угла и (Х2, Y2) - координаты правого
нижнего угла прямоугольника
2-972
34 Глава 1. Начало работы
F X Y С Закрасить область R цветом (с), где R определяется следующим
образом. Пиксел (X У) принадлежит /?. Любой другой пиксел того же
цвета, что и (XJ), и имеющий общую сторону с любым пикселом из
R также принадлежит этой области
S Name Вывести имя файла в формате MSDOS 8.3 с последующим выводом
текущего изображения
X Закрыть сессию
Выходные данные
На каждой команде S NAME выводите имя файла NAME и содержание текущего
изображения. Каждая строка представлена цветом каждого пиксела. Смотрите
пример выходных данных.
Игнорируйте всю строку команд, определенных символом, отличным от I, С,
L, V, Н, К, F, S и X, и переходите к следующей команде. В случае других ошибок
поведение программы не определено.
Пример входных данных Соответствующие выходные данные
15 6 one.bmp
L 2 3 А ООООО
S one.bmp 00000
G 2 3 J OAOOO
F 3 3 J 00000
V 2 3 4 W 00000
H 3 4 2 Z 00000
S two.bmp - two.bmp
X JJJJJ
JJZZJ
JWJJJ
JWJJJ
JJJJJ
JJJJJ
1.6. Задачи 35
1.6.6. Интерпретатор
PC/UVaIDs: 110106/10033
Популярность: В
Частота успехов: низкая
Уровень:2
Некий компьютер имеет десять регистров и 1000 слов (word) ОЗУ. Каждый ре-
регистр или ячейка ОЗУ содержит трехзначное целое число от 0 до 999. Инструкции
кодируются как трехзначные целые числа и сохраняются в ОЗУ. Кодировки имеют
следующий вид:
100 означает останов,
2dn означает установить регистр dравным п (между 0и9),
Zdn означает добавить п к регистру d>
Adn означает умножить регистр d на п%
bds означает установить значение регистра dравным значению регистра $
6ds означает добавить значение регистра s крегистру dt
Ids означает умножить значение регистра с/на значение регистра s;
Sc/a означает установить регистр dравным значению ячейки ОЗУ, чейадреснаходится
в регистре а,
9sa означает установить значение ячейки ОЗУ, чей адрес находится в регистре а,
равным значению регистра s,
Ods означает перейти к ячейке, чей адрес находится в регистре d, если регистре
не содержите.
Изначально все регистры содержат 000. Начальное значение RAM считывается
со стандартного ввода. Первая инструкция, подлежащая выполнению, находится
в ячейке ОЗУ с адресом 000. Все результаты приводятся по модулю 1000.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное
целое число, которое означает количество тестируемых блоков, описываемых
ниже, за которой следует пустая строка. Между двумя последовательными тесто-
тестовыми блоками также находится пустая строка.
Каждый блок входных данных состоит из трехзначных целых чисел без знака
количеством не более 1000, представляющих собой последовательные ячейки ОЗУ,
начинающиеся с 0. Явно не установленные ячейки ОЗУ инициализируются как 000.
2*
36 Глава 1. Начало работы
Выходные данные
Выходными данными для каждого тестового блока является одно целое число:
число инструкций, исполненных до инструкции останов, включая саму инструк-
инструкцию. Вы можете считать, что программа обязательно заканчивается этой командой.
Выходные данные для двух последовательных блоков должны быть разделены
пустой строкой.
Пример входных данных Соответствующие выходные данные
1 16
299
492
495
399
492
495
399
283
279
689
078
100
000
000
000
1.6.7. Проверка на шах
PC/UVaIDs: 110107/10196
Популярность: В
Частота успехов: средняя
Уровень:1
Вашей задачей является написание программы, которая считывает положение на
шахматной доске и определяет, атакован ли король (находится ли он под шахом).
Король находится под шахом, если он может быть взят следующим ходом противника.
Белые фигуры будут представлены прописными буквами, черные фигуры -
строчными буквами. Белая сторона доски всегда находится снизу, черная сверху.
Для тех, кто не знаком с шахматами, вот как ходит каждая фигура.
Пешка (Pawn - р или Р): может ходить только прямо вперед по одной клетке
за ход. Тем не менее фигуры она берет по диагонали, а в этой задаче вас интересу-
интересует именно это.
1.6. Задачи 37
Конь (Knight - п или N): ходит буквой «Г», как показано ниже. Это единст-
единственная фигура, которая может перепрыгивать через другие.
Слон (Bishop - b или В): может ходить на любое число клеток по диагонали
вперед и назад.
Ладья (Rook - г или R): может ходить на любое число клеток по вертикали
или горизонтали вперед и назад.
Ферзь (Queen - q или Q): может ходить на любое число клеток в любом направ-
направлении (по диагонали, вертикали или горизонтали) вперед и назад.
Король (King - k или К): может ходить на одну клетку в любом направлении
(по диагонали, вертикали или горизонтали) вперед и назад.
Примеры того, как ходят фигуры, показаны ниже, где «*» означает клетку, на
которой фигура может взять другую.
Пешка Ладья Слон Ферзь Король Конь
• * * * * *
• ** *** **
• ** *** *** *...*.
...p.... ***r**** ...b.... ***q**** . . *k* п....
• • * * * *** *** * *
• * * *** •*
• • * ***
Не забывайте, что конь - это единственная фигура, которая может перепрыгивать
через другие. Направление движения пешки зависит от ее цвета. Если пешка черная,
то она может двигаться на одну клетку по диагонали в направлении низа доски. Если
это белая пешка, то она может двигаться на одну клетку по диагонали в направлении
верха доски. Сверху показан пример с черной пешкой, обозначенной строчной «р».
Мы используем слово «двигаться» для обозначения клеток, на которых пешка может
взять фигуру
Входные данные
На вход будет подано произвольное количество позиций на шахматной доске,
каждая состоит из восьми строк по восемь символов каждая. Символ «.» обозначает
пустую клетку, тогда как прописные и строчные буквы обозначают фигуры, как
было описано выше. Некорректные символы вводиться не будут, и позиции, при
которых оба короля под шахом, вводиться также не будут. Вы должны считывать
входные данные до тех пор, пока не обнаружите пустую доску, состоящую из одних
символов «.», которую обрабатывать не нужно. Между двумя позициями будет
пустая строка. Все позиции, за исключением пустой, будут содержать ровно одного
белого и одного черного короля.
38 Глава 1. Начало работы
Выходные данные
Для каждой считанной позиции вы должны вьшести один из следующих ответов:
Game #d: white king is in check.
Game #d: black king is in check.
Game #d: no king is in check.
d означает номер игры, начиная с 1.
Пример входных данных Соответствующие выходные данные
. .k Game #1 black is in check.
ppp.pppp Game #2 white king is in check.
.R...B..
PPPPPPPP
К
rnbqk.nr
PPP••PPP
p. . .
. ..p.. . .
.bPP....
N. .
PP..PPPP
RNBQKB.R
1.6. Задачи 39
1.6.8. Австралийское голосование
PC/UVaIDs: 110108/10142
Популярность: В
Частота успехов: низкая
Уровень: 1
Австралийские бюллетени требуют, чтобы избиратели расположили всех канди-
кандидатов в порядке предпочтения. Первоначально учитывается только первый кандидат
из получившегося списка, и если один из кандидатов набрал более 50% голосов, то
он считается избранным. Тем не менее, если ни один из кандидатов не набрал более
50% голосов, все кандидаты с наименьшим числом голосов выбывают. Бюллетени,
засчитанные в пользу этих кандидатов, засчитываются в пользу не выбывшего кан-
кандидата, который следующим идет по порядку предпочтения. Этот процесс исключе-
исключения самых слабых кандидатов и пересчет их бюллетеней в пользу следующего по
порядку предпочтения, не выбывшего кандидата продолжается до тех пор, пока
один из кандидатов не наберет более 50% голосов или пока у всех кандидатов не
окажется одинаковое число голосов.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное
целое число, которое означает количество тестовых блоков, за которой следует
пустая строка. Между двумя последовательными тестовыми блоками также нахо-
находится пустая строка.
Первая строка каждого блока - это целое число п < 20, означающее число канди-
кандидатов. Следующие п строк содержат имена кандидатов, каждое до 80 символов
длиной и содержащее любые печатаемые символы. Далее следуют до 1000 строк,
каждая включает содержимое бюллетеня. Каждый бюллетень содержит числа от 1 до
п в каком-либо порядке. Первое число обозначает наиболее предпочтительного канди-
кандидата; второе - второго по предпочтимости и т. д.
Выходные данные
Выходные данные для каждого тестового блока содержат одну строку,
содержащую имя победителя, или несколько строк, содержащих имена всех кан-
кандидатов, которые набрали одинаковое число голосов. Выходные данные для
каждых двух последовательных блоков должны разделяться пустой строкой.
40 Глава 1. Начало работы
Пример входных данных Соответствующие выходные данные
1 John Doe
3
John Doe
Jane Smith
Jane Austen
12 3
2 13
2 3 1
12 3
3 12
1.7. Подсказки
1.1. Кто должен получать лишние деньги, если все сумма не делится нацело?
1.2. Как лучше всего обработать команду заполнения? Проще ли сохранять раз-
раздельные копии старого и нового изображения?
1.8. Замечания
1.1. . Задача Ъп + 1 (или задача Коллаца (Collatz) остается не решенной по ны-
нынешний день. Смотрите [Lag85] для замечательного математического обзора.
Международная конференция по задаче Коллаца проводилась в 1999 году;
смотрите http://www.math.grinnell.edu/-chamber/conf.html на предмет прото-
протоколов конференции.
1.2. . Задача непротиворечивости для Сапера формулируется так: «Требуется
определить, существует ли такое расположение мин для квадратного поля
п х п с клеточками, заполненными числами от 0 до 8, минами и оставленны-
оставленными пустыми, что оно приведет к заданной картине поля при использовании
стандартных правил Сапера?» Clay Institute of Mathematics (http://www.clay-
math.org) установил приз $1 000 000 долларов для эффективного алгоритма,
который решает эту задачу.
Но не спешите радоваться! Было доказано, что задача непротиворечивости
для Сапера является NP-полной [КауОО], что значит, что для нее не может су-
существовать эффективного алгоритма решения, если мы не пересмотрим
коренным образом наши представления о вычислениях. Более подробно об
обсуждении NP-полноты смотрите [GJ79].
1.8. Замечания 41
1.3. Программно реализованные виртуальные компьютеры являются ключом
к переносимости языков, таких, как Java. Интересным проектом является на-
написание эмулятора машинного языка старого, вышедшего из употребления,
но простого компьютера, такого, как PDP-8. Сегодняшнее аппаратное обес-
обеспечение обладает настолько высоким быстродействием, что ваш виртуаль-
виртуальный PDP-8 будет работать намного быстрее оригинала!
1.4. Как только вы написали генератор легальности ходов (сердце этой задачи),
вы подошли достаточно близко к написанию собственной программы,
играющей в шахматы! Смотрите [New96, Sch97] на предмет историй о том,
как работают шахматные и шашечные программы и как они обыгрывают
чемпионов мира в своей игре.
1.5. Математика системы голосования - это увлекательный предмет. Теорема не-
невозможности Арроу (Arrow) утверждает, что ни одна система голосования не
может удовлетворять всем пяти очевидным желаемым свойствам. Интересное
обсуждение математики общественного выбора можно найти в [СОМ94].
Глава 2
Структуры данных
Структуры данных - это сердце любой сложной программы. Выбор правиль-
правильной структуры данных может очень сильно повлиять на сложность итоговой реа-
реализации. Выберете правильное представление данных, и вашу задачу будет легко
запрограммировать. Выберете неверное представление данных, и вы можете по-
потратить огромное количество времени и кода, чтобы компенсировать оши-
ошибочность вашего первоначального решения.
В этой главе мы рассмотрим фундаментальные структуры данных, с которыми
должен быть хорошо знаком любой программист. Мы будем проводить рассуждение
на примере программы, основанной на детской карточной игре. Множество классиче-
классических задач по программированию основано на играх. Как-никак, кто в начале изуче-
изучения программирования не передвигал ханойские башни, не обходил конем доску или
не решал задачу про восемь ферзей?
2.1. Элементарные структуры данных
Здесь мы приведем краткий обзор наиболее важных структур данных: стеков,
очередей, словарей, очередей по приоритету и множеств. Также мы опишем про-
простейший способ реализации этих структур с нуля.
Тем не менее не стоит забывать, что современные объектно-ориентированные
языки программирования, такие, как C++ или Java, поставляются со стандартны-
стандартными библиотеками фундаментальных структур данных. Они будут кратко описаны
в разделе 2.2. Изучение собственных библиотек вместо постоянного изобретения
колеса будет удачным вложением времени для любого программиста. После того
как вы это сделали, можете читать этот раздел, для того чтобы понять, для чего
хороша каждая конкретная структура, вместо описания того, как ее реализовы-
вать.
2.1. Элементарные структуры данных 43
2.1.1. Стеки (Stacks)
Стеки и очереди - это контейнеры, из которых вещи извлекаются в зависимости
от порядка их поступления и вне зависимости от их содержимого. Стеки поддержи-
поддерживают порядок последний вошел, первый вышел (last-in, first-out - LIFО). Очевидные
операции со стеком включают в себя:
• Push(x,s) - вставить объект jc на вершину стека s;
• Pop(s) - получить (и удалить из стека) верхний объект стека s;
• Initialize(s) - создать пустой стек;
• Full(s), Empty(s) - проверить, возможны ли еще операции добавления и извле-
извлечения элемента из стека соответственно.
Обратите внимание, что для стандартных стеков и очередей не определена
никакая операция поиска элементов.
Определение этих абстрактных операций позволяет создать нам стековый
модуль для использования без знания деталей реализации. Самая простая реализа-
реализация использует массив с переменной, являющейся индексом, которая обозначает
вершину стека. Альтернативный вариант реализации с использованием связанных
списков лучше, так как там отсутствует возможность переполнения.
Стеки хорошо моделируют стопки объектов, таких, как обеденные тарелки.
Когда тарелка моется, она помещается на вершину стопки. Когда кто-то проголо-
проголодался, то тарелка берется с вершины. Стек является подходящей структурой
данных для решения этой задачи, так как все равно, какая тарелка будет использо-
использована следующей. Таким образом, одним важным приложением стеков являются те
случаи, когда порядок не важен, потому что стеки достаточно просто реализовать.
Порядок в стеке важен при обработке любой вложенной структуры. Это включает
в себя формулы со скобками (помещаем при «(», извлекаем при «)»), рекурсивный
вызов программ (помещаем при входе в процедуру, извлекаем при выходе из проце-
процедуры) и обход графов в глубину (помещаем при обнаружении вершины, извлекаем
при оставлении ее в последний раз).
2.1.2. Очереди (Queues)
Очереди поддерживают порядок первый вошел, первый вышел (first-in, first-out-
FIFO). Это кажется более честным, чем последний вошел, первый вышел, и именно
поэтому очереди в магазинах реализованы как очереди, а не как стеки. Колоды
игральных карт могут быть смоделированы очередями, так как мы сдаем карты
с верха колоды, а после помещаем их под низ. Очереди FIFO будут использованы
при реализации поиска в ширину в графах в главе 9.
44 Глава 2. Структуры данных
Очевидные операции с очередью включают в себя:
• Enqueue(x,q) - вставить объект х в хвост очереди q\
Dequeue(q) - получить (и удалить из очереди) первый объект очереди q;
• Initialize(q), Full(q), Empty(q) - аналогичны соответствующим операциям со
стеком.
Очереди реализуются сложнее, чем стеки, потому что действие происходит на
обоих концах. Простейшая реализация использует массив, вставляя новые эле-
элементы на одном конце и перемещая все оставшиеся элементы, чтобы заполнить
пустое место, возникающее после каждой операции извлечения.
Тем не менее чересчур затратно перемещать все элементы при каждой операции
извлечения. Как можно реализовать лучше? Мы можем использовать индексы для
первого (голова) и последнего (хвост) элемента массива/очереди и проводить все
операции локально. Нет никакой причины, по которой мы должны явно очищать
предварительно использованные ячейки, хотя так мы буцем оставлять след из мусора
позади ранее извлеченных объектов.
Кольцевые списки позволяют нам повторно использовать это пустое про-
пространство. Обратите внимание, что указатель на голову очереди всегда позади
указателя на хвост! Когда очередь полна, эти два индъекса будут указывать на
соседние или совпадающие элементы. Существует несколько различных способов
работы с индексами для кольцевых очередей. Все хитрые! Самое простое реше-
решение отличает заполненное пространство от пустого, ведя подсчет количества эле-
элементов в очереди:
typedef struct {
int q[QUEUESIZE+l]; /* body of queue */
int first; /* position of first element */
int last; /* position of last element */
int count; /* number of queue elements */
} queue;
init_queue(queue *q)
{
q->first = 0;
q->last = QUEUESIZE-1;
q->count = 0;
}
enqueue(queue *q, int x)
{
if (q->count >= QUEUESIZE)
printf("Warning: queue overflow enqueue x=%d\n",x);
else {
2.1. Элементарные структуры данных 45
q->last = (q->last+l) % QUEUESIZE;
q->q[ q->last ] = x;
q->count = q->count + 1;
int dequeue(queue *q)
{
int x;
if (q->count <= 0) printf ("Warning: empty queue dequeue\n");
else {
x = q->q[ q->first ] ;
q->first = (q->first+l) %QUEUESIZE;
q->count = q->count - 1;
}
return(x) ;
}
int empty(queue *q)
{
if (q->count <= 0) return (TRUE);
else return (FALSE);
}
Очереди являются одной из немногих структур данных, которые легче програм-
программировать, используя связанные списки, так как в этом случае исчезает необходи-
необходимость проверки условий цикличности.
2.1.3. Словари (Dictionaries)
Словари поддерживают извлечение по содержанию, а не по положению, что
делают стеки и очереди. Словари поддерживают три основные операции:
• Insert(x,d) - вставить объект х в словарь d\
• Delete(x,d) - удалить объект х (или объект, на который указывает х) из словаря d;
• Search(k,d) - вернуть объект с ключом к, если таковой имеется в словаре d.
В направленных структурах данных можно предложить десятки способов
реализации словарей, включая отсортированные/несортированные связанные
списки, отсортированные/несортированные массивы, и целый лес, полный
случайных, однонаправленных (AVL) и черно-красных деревьев; не говоря обо
всех вариациях хеширования.
46 Глава 2. Структуры данных
Основным объектом анализа алгоритмов является производительность,
точнее, достижение лучшего возможного компромисса между этими тремя опера-
операциями. Но на практике мы обычно хотим получить простейший путь решения
проблемы, удовлетворяющий ограничениям по времени. Корректный выбор реа-
реализации зависит от того, насколько сильно меняется содержимое вашего словаря
в процессе выполнения.
• Статические словари. Эти структуры строятся один раз и никогда не меняются.
Таким образом, они должны поддерживать поиск, но не вставку и удаление.
Правильным выбором для статического словаря обычно является массив.
Единственным важным вопросом будет вопрос о том, нужно ли держать его
отсортированным, чтобы использовать бинарный поиск для быстрой обработ-
обработки запросов. Если у вас нет жестких временных ограничений, то, вероятнее
всего, не имеет смысла использовать бинарный поиск до тех пор, пока п не
превысит 100 или около того. Возможно, вы сумеете обойтись последователь-
последовательным поиском до п = 1000 или более при условии, что вам не нужно будет
проводить слишком много поисков.
Алгоритмы сортировки и бинарного поиска оказались сложнее для отладки,
чем должны были быть. Библиотечные подпрограммы сортировки/поиска
доступны для С, C++, Java и будут представлены в главе 4.
• Полудинамические словари. Эти структуры поддерживают поиск и вставку, но
не удаление. Если мы знаем верхний предел числа элементов, которые могут
быть вставлены, мы можем использовать массив, иначе мы должны использо-
использовать связанные структуры.
Хеш-таблицы являются превосходными структурами данных для словарей,
в особенности если не требуется поддерживать удаление. Идея состоит в приме-
применении функции к поисковому ключу, так что мы можем определить, где объект
появится в массиве, не просматривая остальные объекты. Чтобы создать таблицу
разумного размера, мы должны учесть коллизии, когда два различных ключа
привязаны к одной ячейке.
Два компонента хеширования - это A) определение хеш-функции, которая
привяжет ключи к целым числам в определенном диапазоне, и B) создание
массива, чей размер соответствует этому диапазону, так чтобы значение хеш-
функции означало индекс.
Простая хеш-функция превращает ключ в целое число и берет значение, равное
целочисленному остатку от деления этого числа на размер хеш-таблицы. Выбор
простого числа в качестве размера таблицы (или, по крайней мере, отказ от
выбора очевидных составных чисел, таких, как 1000) помогает избежать
проблем. Строки могут быть переведены в целые числа, если использовать буквы
2.1. Элементарные структуры данных 47
алфавита в качестве цифр системы счисления с основанием, равным длине алфа-
алфавита. Чтобы перевести слово «steve» в число, заметим, что е - это 5-я буква алфа-
алфавита, s - это 19-я буква, / - это 20-я буква и v - это 22-я буква. Таким образом,
«steve» =>264х19 + 263х20 + 262х5 + 26]х22 + 26°х5 = 9 038 021. Первые,
последние или средние 10 символов или около того, вероятно, подойдут для
хорошего индекса. Советы по поводу того, как проводить арифметические
операции над абсолютными значениями чисел, эффективно буцут обсуждаться
в главе 7.
Отсутствие необходимости удаления делает открытую адресацию простым,
удобным способом для разрешения конфликтов. При открытой адресации мы
используем простое правило для решения того, куда положить новый объект,
если желаемое место уже занято. Пусть мы всегда кладем его в следующую
незанятую ячейку. При поиске данного объекта мы идем в предназначенное
место и начинаем последовательный поиск. Если мы обнаруживаем пустую
ячейку до того, как обнаруживаем объект, то он не существует в таблице.
Удаление в схеме с открытой адресацией неприемлемо, поскольку удаление
одного элемента может сломать цепочку вставок, сделав некоторые элементы
недоступными. Ключ к эффективности лежит в выборе достаточно большой
таблицы, в которой будет много свободного места. Не жадничайте, когда
выбираете размер таблицы, иначе потом придется платить дороже.
• Полностью динамические словари. Хеш-таблицы также удобны для реализа-
реализации полностью динамических словарей при условии, что мы используем
формирование цепочки данных при разрешении конфликтов. В данном случае
с каждой позицией в хеш-таблице мы связываем связанный список, так что
задачи вставки, удаления и запросов сводятся к аналогичным задачам для свя-
связанных списков. Если хеш-функция работает хорошо, то т ключей будут
равномерно распределены по таблице размера п, так что каждый список
окажется достаточно коротким и поиск будет быстрым.
2.1.4. Очереди по приоритету (Priority queues)
Очереди по приоритету - это структуры данных на множествах объектов,
поддерживающие три операции:
• Insert(x,p) - вставить объект х в очередь по приоритету р\
• Maximum(p) - получить объект с максимальным ключом в очереди по
приоритету/?;
• ExtractMax(p) - получить и удалить из очереди объект с максимальным
ключом в р.
48 Глава 2. Структуры данных
Очереди по приоритету используются для работы с расписаниями и кален-
календарями. Они решают, чья очередь следующая при моделировании аэропортов,
автостоянок и схожих вещей, всех, где нам требуется распланировать события по
часам. При моделировании человеческой жизни они будут наиболее удобны для
определения того, когда кто-либо умрет сразу после того, как родился. Тогда мы
можем поместить эту дату в очередь по приоритетам, так чтобы нам напомнили,
когда похороны.
Очереди по приоритету используются при планировании событий в алгорит-
алгоритмах с линейным проецированием (sweep-line), обычных в вычислительной гео-
геометрии. Чаще всего, мы используем очереди по приоритету для хранения точек,
которых мы еще не встретили, упорядоченных по х-координате, и продвигаем
линию вперед по одному шагу.
Самая знаменитая реализация очередей с приоритетом это частично упоря-
упорядоченное бинарное дерево - бинарная куча (binary heap), с которым можно эффек-
эффективно работать как сверху вниз, так и снизу вверх. Эти деревья очень удобны
и эффективны, но с ними, возможно, будет немного сложно уложиться во времен-
временные рамки. Гораздо проще работать с отсортированным массивом, особенно если
вы не предполагаете слишком много вставок.
2.1.5. Множества (Sets)
Множества (или, говоря точнее, подмножества) - это неупорядоченные наборы
элементов, набранные из данного универсального множества U. Структуры данных
множества отличаются от словарей, потому что существует, как минимум, неявная
необходимость задать, какие элементы из U не входят в данное подмножество.
Базовые операции над подмножествами:
• Member(x,S) - является ли объект х элементом подмножества S1
• Union(A,B) - построить множество Аи В из всех элементов, которые принад-
принадлежат А или В;
• Intersection(A,B) - построить множество А п В из всех элементов, которые
принадлежат и А и В;
• Insert(x,S), Delete(x,S) - вставить/удалить элемент х в/из множества S.
Для множеств большого или неограниченного универсума, очевидным реше-
решением будет представление множества словарем. Использование отсортированных
словарей делает реализацию операции объединения и пересечения намного легче,
по существу сводя задачу к слиянию двух отсортированных массивов. Элемент
лежит в объединении, если он появился хотя бы раз в объединенном списке,
и лежит в пересечении, если он появился там ровно два раза.
2.2. Объектные библиотеки 49
Для множеств, набранных из небольших, неизменных универсумов, удобным
представлением будут битовые векторы, «-битный вектор или массив может пред-
представлять собой любое подмножество из «-элементного универсума. Бит / будет
выставлен в 1, если i принадлежит S. Вставка и удаление элементов просто изме-
изменяют значение соответствующего бита на противоположный. Пересечение и объ-
объединение делаются с помощью операций логического «и» и логического «или»
соответственно. Так как на один элемент тратится только один бит, то битовые
векторы могут иметь небольшой размер для удивительно больших значений \Ц.
Например, массив из 1000 стандартных четырехбайтовых целых чисел (integer)
может представлять собой любое подмножество 32 000 элементов.
2.2. Объектные библиотеки
Пользователи современных объектно-ориентированных языков, таких, как C++
и Java, имеют доступ к реализациям этих базовых структур данных, используя стан-
стандартные библиотечные классы.
2.2.1. Стандартная библиотека шаблонов C++ (C++ Standard
Template Library)
В языке С библиотека универсальных структур данных, таких, как стеки
и очереди, не может существовать, потому что функции в С не могут указывать
тип их аргументов. Таким образом, нам потребовалось бы определять различные
подпрограммы, такие, как push_init () и push_char (), для всех возможных
типов данных. Более того, такой подход нельзя обобщить для создания стеков
с типами данных, определенными пользователем.
Шаблоны - это механизм C++ для определения абстрактных объектов, ко-
которые могут быть параметризованы по типу. Стандартная библиотека шаблонов
(STL) C++ обеспечивает реализацию всех структур данных, описанных выше,
и многих дополнительных. Каждый объект данных должен иметь фиксированный
тип его элементов на момент компиляции, так что
#include <stl.h>
stack<int> S;
stack<char> T;
объявляет два стека с различными типами элементов.
Хорошими справками по STL являются [MDS01] и http://ww.sgi.com/tech/stl/.
Краткие описания упомянутых нами структур данных следуют далее.
50 Глава 2. Структуры данных
Стек. Методы включают S . push (), S . top (), S . pop () и S . empty (). Top
получает значение, но не удаляет его из стека, a pop удаляет значение из стека,
но не возвращает его. Таким образом, всегда после top идет pop[Seu63]. Связан-
Связанная реализация гарантирует, что стек никогда не заполнится.
• Очередь. Методы включают Q. front (), Q . back (), Q. push (), Q. pop ()
и Q. empty () и имеют те же свойства, что и для стека.
• Словари. STL содержит множество контейнеров, включающих hash_map,
хешированный ассоциативный контейнер, привязывающий ключи к объектам
данных. Методы включают Н. erase (), Н. find и Н. insert ().
• Очереди по приоритету. Объявление priority_queue<int> Q;, методы
включают Q. top (), Q. push (), О . pop () и Q. empty ().
• Множества. Множества представлены как отсортированные ассоциативные кон-
контейнеры; объявление set<key, comparison> S;. Алгоритмы для множеств
включают в себя set_union и set_intersection, так же как и другие стан-
стандартные операции над множествами.
2.2.2. Пакет java. util для Java
Полезные стандартные объекты Java можно обнаружить в пакете java.util.
Почти все из java.util доступно автоматическому судье, за исключением
нескольких библиотек, которые представляют чрезмерную мощь участнику состя-
состязания. Подробнее смотрите сайт Sun http://java.sun.com/products/jdk.
Объединение всех классов Java определяет иерархию наследования, что значит,
что подклассы надстраиваются в надклассы путем добавления методов и перемен-
переменных. По мере продвижения вверх по иерархии наследования классы становятся более
общими и абстрактными. Единственная цель абстрактного класса - обеспечить
подходящий надкласс, из которого другие классы могут наследовать его интерфейс
и/или реализацию. Абстрактные классы могут только объявлять объекты, но не при-
присваивать им значения. Классы, объектам которых может быть присвоено значение,
называются конкретными.
Если вы хотите объявить общий объект структуры данных, объявите его
с интерфейсом абстрактного класса и присвойте ему значение с помощью кон-
конкретного класса. Например:
Map myMap = new HashMapO ;
В этом случае туМар считается объектом класса Map. Иначе вы можете объя-
объявить и присвоить значение объекту с помощью конкретного класса, так:
HashMap myMap = new HashMap();
2.3. Пример разработки программы: сборы на войну
51
Здесь шуМар - это просто объект класса HashMap.
Для использования java.util вставьте import java.util. * ; в начале
вашей программы для импортирования всего пакета или замените звездочку - для
импортирования специального класса, например import j ava. util. HashMap;.
Соответствующие реализации базовых структур данных включают в себя:
Структура
данных
Стек
Очередь
Словари
Очередь по
приоритету
Множества
Абстрактный
класс
Нет интерфейса
List
Map
SortedMap
Set
Конкретный класс
Stack
ArrayList,
LinkedList
HasMap, Hashtable
TreeMap
HashSet
Методы
pop, push, empty, peek
add, remove, clear
put, get, contains
f irstKey, lastKey,
headMap
add, remove, contains
2.3. Пример разработки программы: сборы
на войну
В детской карточной игре «Война», стандартная 52-карточная колода делится на
двоих игроков A и 2) так, чтобы у каждого игрока оказалось по 26 карт. Игроки не
смотрят на свои карты, но держат их стопкой рубашкой вверх. Цель игры - выиграть
все карты.
Оба игрока играют, переворачивая их верхние карты рубашкой вниз и выкла-
выкладывая их на стол. Кто открыл старшую карту, тот забирает обе карты и добавляет
их (рубашкой вверх) снизу своей стопки. Старшинство карт обычное, от старшей
к младшей: A, Kf Q, J, T, 9, 8, 7, 6, 5, 4, 3, 2. Масти игнорируются. Далее оба игрока
переворачивают следующую карту и повторяют. Игра продолжается до тех пор,
пока один из игроков не выиграет все карты.
Когда вскрытые карты оказываются равными по старшинству, происходит
война. Эти карты остаются на столе, а игроки снимают со стопки следующую
карту и кладут ее на стол рубашкой вверх, а затем еще одну, рубашкой вниз. Чья
карта, вскрытая второй, оказалась старше, тот и выигрывает войну и добавляет
все шесть карт снизу своей стопки. Если новые вскрытые карты также оказались
равны по старшинству, то война продолжается: каждый игрок кладет еще одну
карту рубашкой вверх и одну рубашкой вниз. Война продолжается тем же
52 Глава 2. Структуры данных
манером до тех пор, пока вскрытые карты оказываются равными по старшинству.
Как только вскрыты различные карты, игрок, который вскрыл старшую карту,
выигрывает все карты на столе.
Если у одного из игроков заканчиваются карты в середине войны, то другой
игрок автоматически выигрывает. Карты добавляются снизу стопки точно в том
порядке, в котором они сдавались, точнее, первая карта игрока 1, первая карта
игрока 2, вторая карта игрока 1 и т. д.
Как знает любой человек, у которого есть пятилетний племянник, игра в войну
может затянуться надолго. Но насколько долго? Вашей задачей будет написать
программу, которая будет симулировать игру и сообщать число ходов.
Решение начинается ниже
Как мы читаем описание задачи? Когда вы разрабатываете, кодируете, тес-
тестируете и отлаживаете свои решения, имейте в виду следующее.
• Внимательно читайте задачу. Внимательно читайте каждую строку
формулировки задачи и перечитывайте ее, когда судья сообщает об ошибке.
Просмотрите вступление, не прилагая большого внимания, поскольку большая
часть описания может быть фоном/предысторией, которая никак не влияет на
решение. Обратите особенное внимание на описание входных и выходных дан-
данных, а также на примеры входных и выходных данных, но...
• Не предполагайте. Чтение и понимание спецификаций - это важная часть
соревновательного (и реального) программирования. Спецификации часто
оставляют неописанные ловушки, в которые можно попасть.
Из того, что определенные примеры показывают какое-либо приятное свойство,
еще не следует, что все тестовые данные будут этим свойством обладать. Будьте
внимательны на предмет неописанных входных команд, неограниченных вход-
входных чисел, больших длин строк, отрицательных чисел и т. п. Любые данные,
которые явно не запрещены, должны считаться разрешенными!
• Не так быстро, Луи. Если мы не используем экспоненциальные алгоритмы
в задаче, где хватило бы полиномиальных, то эффективность часто не является
важным вопросом. Не беспокойтесь сильно насчет эффективности, если вы не
столкнулись с проблемой или не можете ее предсказать. Узнайте максимальный
размер входных данных из спецификации и решите, подходит ли наиболее
прямолинейный алгоритм для таких входных данных.
И хотя, когда вы играете с племянником в войну, вам может казаться, что игра
бесконечна (фактически она может продолжаться вечно), мы не видим никакой
причины, чтобы беспокоиться об эффективности при таком описании задачи.
2.4. Что касается колоды 53
2.4. Что касается колоды
Какая структура лучше всего подходит для представления колоды карт? Ответ
на этот вопрос зависит от того, что вы собираетесь с ними делать. Собираетесь ли
вы тасовать их? Сравнивать их значения? Собираетесь ли вы искать определен-
определенное расположение карт в колоде? Действия, которые вам нужны, определяют
операции структуры данных.
Основное действие, которое нам требуется от нашей колоды, - это сдавать карты
сверху и добавлять их снизу колоды. Таким образом, естественно представить руку
каждого игрока с использованием очереди FIFO, которую мы описали ранее.
Но есть еще и более фундаментальная проблема. Как мы будем представлять
каждую карту? Карты имеют и масть (трефы, бубны, червы и пики) и значения
(туз, 2-10, валет, дама и король). У нас есть возможность выбрать один из несколь-
нескольких вариантов. Мы можем представлять каждую карту двумя символами или чис-
числами, которые будут означать масть и достоинство карты. В задаче про войну мы
можем даже вообще не обращать внимания на масть, но такая реализация может
вызвать проблемы. Что, если нам будет необходимо вывести выигравшую карту
или потребуется непосредственное доказательство того, что наша реализация
очереди работает правильно? Альтернативный вариант состоит в представлении
каждой карты числом от 0 до 51 и задании соответствия между таким представле-
представлением и реальными картами.
Основная операция в игре «Война» - это сравнение карт по их значениям. Это
сложнее сделать, используя первый вариант представления карт, потому что мы
должны сравнивать по исторически сложившемуся, но случайному порядку карт.
Вероятно, для этой задачи пришлось бы использовать специальную логику.
Вместо этого мы продемонстрируем подход с преобразованием данных (mapping)
в качестве распространенной полезной методики программирования. Для любого
случая, когда мы можем создать числовую ранжирующую функцию и обратную
к ней деранжирующую функцию, которые применяются к определенному множеству
объектов s e S, мы можем представить каждый объект целочисленным значением.
Основное свойство состоит в том, что s = unrank(rank(s). Таким образом, можно счи-
считать, что ранжирующая функция - это хеш-функция без конфликтов.
Как мы можем ранжировать и деранжировать игральные карты? Мы упоря-
упорядочиваем карты в порядке от младшей к старшей и отмечаем, что существуют
четыре карты с одинаковым значением. Умножение и деление являются ключевы-
ключевыми действиями при отображении карт на диапазон от 0 до 51.
54 Глава 2. Структуры данных
#define NCARDS 52 /* число карт */
#define NSUITS 4 /* число мастей */
charvalues[] = 3456789TJQKA11 ;
char suits[] = "cdhs";
int rank_card(char value, char suit)
{
int i/j; /* счетчики */
for (i=0; i<(NCARDS/NSUITS); i
if (values[i]==value)
for (j=0; j<NSUITS; j++)
if (suits[j]==suit)
return( i*NSUITS + j );
printf ("Warning: bad input value=%d, suit=%d\n",value, suit) ;
}
char suit(int card)
{
return! suits[card % NSUITS] );
}
char value(int card)
{
return( values[card/NSUITS] );
}
Ранжирующие и деранжирующие функции легко написать для перестановок, под-
подмножеств и большинства комбинаторных объектов. Это является распространенной
методикой программирования, которая может упростить операции на многих типах
данных.
2.5. Строковый ввод/вывод
Для нашей программы входные данные состоят из двух строк для каждой вво-
вводимой колоды, первая строка соответствует картам игрока 1, вторая строка соот-
соответствует картам игрока 2. Вот пример карт для трех игр:
4dKsAs 4hJh6hJdQsQh6s 6с 2с Кс 4s Ah 3hQd 2h 7s 9s 3c 8hKd7hThTd
8d8c 9c 7c 5d4c JsQc 5s Ts Jc Ad 7dKhTc 3s 8s 2d2s 5h6dAc 5c 9h3d9d
6d9d8c 4s Kc 7c4dTcKd3s 5h2hKs 5c 2s Qh 8d 7d 3d Ah Js Jd 4c Jh 6c Qc
9hQdQs 9s Ac 8h Td Jc 7s 2d 6s As 4hTs 6h2cKhTh7h5s 9c 5dAd3h8s 3c
Ah As 4c 3s7dJc 5h 8s Qc Kh Td 3h 5c 9h 8c Qs 3dKs 4dKd 6c 6s7hQh3c Jd
2h8h7s 2c 5d7c 2dTc JhAc 9s 9c 5sQd4s Js 6dKc 2s Th 8d 9d 4h Ad 6hTs
2.5. Строковый ввод/вывод 55
Во многих задачах требуется считывать нечисловые данные. Текстовые
строки будут обсуждаться подробнее в главе 3, сейчас только отметим, что у вас
есть несколько способов считывания текстовых данных.
• Вы можете циклически считывать по одному символу из входного потока (то есть
getchar () в С) и обрабатывать их по одному.
• Вы можете циклически скачивать форматированные лексемы (то есть scanf ()
в С) и обрабатывать их по необходимости.
• Вы можете считать всю строку как строковую переменную (то есть gets () в С)
и после этого обработать ее путем доступа к символам или подстрокам.
• Вы можете использовать современные примитивы ввода/вывода, такие, как
строковые переменные, если ваш язык их поддерживает. Конечно, вам все равно
придется решить, нужны ли вам символы, строки или что-либо еще в качестве
базовой единицы входных данных.
В нашей реализации войны мы воспользуемся первой возможностью из пред-
предложенных, то есть будем последовательно считывать символы и обрабатывать их
один за другим. Чтобы сделать пример более иллюстративным, мы делаем явную
проверку на конец строки (Л \п' в С):
main()
{
queue decks[2]; /* колоды игроков */
char value,suit,с; /* вводимые символы */
int i; /* счетчик колоды */
while (TRUE) {
for (i=0; i<=l; i++) {
init_queue(&decks[i]);
while ((c = getchar()) != '\n') {
if (c == EOF) return;
if (c !=••){
value = c;
suit = getchar();
enqueue(&decks[i], rank_card(value, suit);
war(&decks[0],&decks[1]);
}
}
Обратите внимание на то, что мы представляем две колоды массивом очередей
вместо двух разных переменных типа «очередь». Таким образом, мы избавляемся от
необходимости повторять весь код обработки входных данных для каждой колоды.
56 Глава 2. Структуры данных
2.6. Победа на войне
После того как мы получили соответствующий «фундамент», разработав
наши структуры данных, основная подпрограмма становится достаточно прямо-
прямолинейной. Обратите внимание, что порядок, в котором выигранные карты поме-
помещаются в выигравшую их колоду, также может быть смоделирован в виде очере-
очереди, так что мы снова можем использовать наш абстрактный тип данных:
war(queue *a, queue *b)
{
int steps=0; /* счетчик ходов */
int x,y; /* верхние карты */
queue с; /* карты, вовлеченные в войну */
bool inwar; /* вовлечены ли мы в войну? */
inwar = FALSE;
init_queue(&c);
while ( ( ! empty (a) ) && ( ! empty (b) && (steps <MAXSTEPS) ) ) {
steps = steps + 1;
x = dequeue(a);
у = dequeue(b);
enqueue(&c,x);
enqueue(&c,y);
if (inwar) {
inwar = FALSE;
} else {
if (value(x) > value(y))
• clear_queue(&c,a);
else if (value(x) < value(y))
clear_queue(&c,b);
else if (value(x) == value(y))
inwar = TRUE;
if ('empty(a) && empty(b))
printf("a wins in %d steps\n",steps);
else if (empty(a) && !empty(b))
printf("b wins in %d steps\n",steps);
else if (!empty(a) && !empty(b))
printf("game tied after %d steps, |a|=%d |b|=%d \n"
steps,a->count,b->count);
else
printf("a and и tied in %d steps \n", steps);
}
clear_queue(queue *a, queue *b)
{
while (!empty(a)) enqueue(b,dequeue(a));
}
2.7. Тестирование и отладка 57
2.7. Тестирование и отладка
Отладка с программным судьей может быть весьма раздражительной, по-
поскольку у вас никогда не будет возможности увидеть тестовый случай, на котором
ошиблась ваша программа. Таким образом, у вас нет возможности решить задачу
случайно - вам нужно решить ее полностью правильно.
В этом случае очень важным становится систематическое тестирование про-
программы перед отправкой ее судье. Отлавливание глупых ошибок сэкономит вам
время при длительной работе, что особенно важно на соревнованиях, где отправка
неверных решений штрафуется. Несколько идей по созданию грамотных тестов:
• Проверяйте заданные входные данные. Большинство спецификаций задач
включают пример входных и выходных данных. Часто (но не всегда) они сов-
совпадают друг с другом. Правильная обработка тестовых данных является необ-
необходимым, но не достаточным условием.
• Проверяйте некорректные входные данные. Если в описании задачи
говорится, что ваша программа должна предпринимать определенные дейст-
действия при нелегальных входных данных, обязательно протестируйте такие
проблематичные случаи.
• Проверяйте граничные случаи. Многие дефекты в программах связаны
с ошибками завышения или занижения на единицу. Четко проверяйте свои
программы на такие условия, как пустой ввод, один объект, два объекта
и значения, равные нулю.
• Проверяйте те случаи, для которых вы знаете ответ. Важным условием
разработки грамотного тестового случая является знание правильного ответа.
Ваши тесты должны работать с достаточно простыми примерами, которые вы
можете решить без помощи программы. Без полного анализа желаемого пове-
поведения программы легко быть обманутым нормально выглядящими выходны-
выходными данными.
• Проверяйте большие случаи, где вы не знаете правильного ответа. Обычно
вручную можно решить только небольшие примеры. Это делает сложным оцен-
оценку работы программы для большего количества входных данных. Проверьте
несколько легко конструируемых случаев входных данных, таких, как
случайные данные или числа от 1 до п включительно, просто для того чтобы
убедиться, что программа не завершается с ошибкой и не делает ничего глупого.
58 Глава 2. Структуры данных
Тестирование - это искусство отлавливания ошибок. Отладка - это искусство их
уничтожения. Мы разработали эту задачу по программированию и в целях иллюстра-
иллюстрации примера написали для него программу самостоятельно. Однако нам потребова-
потребовалось значительно больше времени, чем предполагалось, чтобы заставить ее работать
без ошибок. В этом нет ничего удивительного, так как все программисты - прирож-
прирожденные оптимисты. Но как можно не попасть в такие ловушки?
• Разберитесь со своим отладчиком. Любая нормальная среда программирования
поставляется с отладчиком уровня входного языка, который позволяет вам оста-
останавливать выполнение на заданной позиции или по заданному логическому
условию, посмотреть содержимое переменной и изменить его значение, чтобы
увидеть, что случится. Отладчики уровня входного языка являются достойной
заменой выражениям отладочного вывода; учитесь их использовать. Чем раньше
вы начнете, тем больше времени и нервов вы сбережете.
• Отображайте ваши структуры данных. В определенный момент отладки
нашей программы войны у нас наблюдалась ошибка завышения/занижения на
единицу в нашей очереди по приоритету. Непосредственно проверку можно было
провести, лишь отобразив содержимое очереди по приоритету, чтобы увидеть,
чего же не хватает. Пишите специальные процедуры вывода для всех нетривиаль-
нетривиальных структур данных, так как у отладчика нередко возникают проблемы с пони-
пониманием их смысла.
• Строго проверяйте инвариантность. Функции ранжирования и деран-
жирования карт окажутся потенциальными источниками ошибок, если они не
являются обратными по отношению друг к другу. Инвариантом называется
параметр программы, который постоянен независимо от входных данных.
Простой тест на инвариантность:
for (i=0; i<NCARDS;
if (i != rank_card(value(i), suit(i)))
printf("Error: rank_card(%c,%c)=%dnot %d\n", value(i),
suit(i), rank_card(value(i), suit(i)), i);
полностью проверяет корректность функции ранжирования и деранжирования.
Внимательно читайте ваш код. Возможно, самым мощным средством отладки
программы является ее внимательное прочтение. Ошибки с большей вероятно-
вероятностью появляются в коде, который чересчур неаккуратно оформлен для прочтения
или чересчур сложен для понимания.
Пусть ваши выражения отладочного вывода что-нибудь значат. Встраива-
Встраивание выражений отладочного вывода непосредственно внутрь вашей нерабо-
неработающей программы - это неизбежное зло, которое можно свести к минимуму
2.8. Задачи 59
эффективным использованием отладчика уровня входного языка. Но если вы
все-таки собираетесь использовать выражения отладочного вывода, сделайте
их максимально полезными. Не забывайте выводить имена переменных, их
положение в программе и их значения. В большом количестве выводимой
информации легко запутаться, но важные строчки легко отыскать, просмотрев
выходной файл.
После того как вы исправили часть программы, закомментируйте связанный с ней
отладочный вывод, но не торопитесь удалять его. Если вы похожи на нас, то он
вам еще понадобится.
• Делайте ваши массивы чуть больше, чем это необходимо. Ошибки завышения
или занижения на единицу особенно незаметны и хитры. Ясное мышление
и определенная дисциплина помогут вам избежать этих ошибок. Но думать
тяжело, а память дешевая. Нам кажется, что удобно определять массивы на
один или два элемента больше, чем они должны быть, чтобы минимизировать
последствия возможной ошибки завышения/занижения.
• Удостоверьтесь, что ваши ошибки - это на самом деле ошибки. Мы потратили
некоторое время, вьшскивая бесконечный цикл в нашей программе, прежде чем
поняли, что случайные раздачи карт имеют удивительно высокую вероятность
вхождения игры в цикл, когда игроки вечно забирают карты друг у друга. Вино-
Виновен был детерминированный порядок карт, при котором «добыча войны» доста-
доставалась по очереди то игроку 1, то игроку 2. Фактически никакой ошибки в про-
программе не было!
Пожалуйста, не повторяйте наших ошибок. Всегда перемешивайте
выигранные карты случайным образом, чтобы не пришлось играть с племян-
племянником в войну бесконечно.
2.8. Задачи
2.8.1. Jolly Jumpers
PC/UVaIDs: 110201/10038
Популярность: А
Частота успехов: средняя
Уровень:1
Последовательность п > 0 целых чисел называется jolly jumper, если абсолют-
абсолютные значения разностей последовательных элементов принимают все возможные
значения от 1 до п - 1. К примеру,
14 2 3
60 Глава 2. Структуры данных
это jolly jumper, потому что абсолютные разности равны 3, 2 и 1 соответственно.
Определение подразумевает, что любая последовательность из одного числа - это
jolly jumper. Напишите программу, которая определяет, является ли каждая из вве-
введенных последовательностей jolly jumper.
Входные данные
Каждая строка входных данных содержит число п < 3000, за которым следуют
п целых чисел, представляющих собой последовательность.
Выходные данные
Для каждой строки входных данных выведите строку, говорящую "Jolly"
или "Not jolly".
Пример входных данных Соответствующие выходные данные
4 14 2 3 Jolly
5 14 2-16 Not jolly
2.8.2. Руки в покере
PC/UVaIDs: 110202/10315
Популярность: С
Частота успехов: средняя
Уровень:2
Колода для покера состоит из 52 карт. Каждая карта имеет масть: кресты,
бубны, червы и пики (во входных данных обозначаются С, D, H, S). Каждая карта
также имеет значение от 2 до 10, валет, дама, король или туз (обозначаются 2, 3,4,
5, 6, 7, 8, 9, Т, J, Q, К, А). Для целей подсчета значение (старшинство) карт идет
в указанном порядке, то есть 2 - это самая младшая карта, а туз самая старшая.
Масть на старшинство никак не влияет.
Рука в покере состоит из пяти карт, сдаваемых с колоды. Руки в покере ран-
ранжируются в следующем порядке от самой слабой к самой сильной.
Старшая карта. Руки, которые не попадают ни в одну из старших категорий,
ранжируются по их старшей карте. Если старшие карты имеют одинаковое
старшинство, то руки ранжируются по следующей старшей карте, и т. д.
Пара. Две из пяти карт в руке имеют одинаковое старшинство. Если обе руки со-
содержат пару, то они ранжируются по значению карты, формирующей пару. Если эти
значения совпадают, то руки ранжируются по значению карт, не формирующих
пару, в порядке старшинства.
2.8. Задачи 61
Две пары. Рука содержит две различные пары. Если обе руки содержат две
пары, то они ранжируются по значению их старшей пары. Если значение старших
пар совпадает, то руки ранжируются по значению младшей пары. Если и эти
значения совпадают, то руки ранжируются по оставшейся карте.
Тройка. Рука содержит три одинаковые по старшинству карты. Если обе руки
содержат тройку, то они ранжируются по старшинству карты, формирующей тройку.
Стрит. Рука содержит пять карт с последовательными значениями. Если обе
руки содержат стрит, то они ранжируются по старшей карте.
Флеш. Рука содержит пять карт одной масти. Если обе руки содержат флеш,
то они ранжируются по правилам старшей карты.
Фулл-хаус. Рука содержит тройку и пару. Ранжируются по значению тройки.
Каре. Четыре равные по старшинству карты. Ранжируются по старшинству
карты, формирующей каре.
Стрит флеш. Пять карт одной масти с последовательными значениями.
Ранжи-яруются по старшей карте в руке.
Вам нужно сравнить несколько пар рук и выявить старшую, если таковая имеется.
Входные данные
Входные данные состоят из нескольких строк, каждая из которых содержит
обозначения десяти карт: первые пять карт - это рука игрока по имени «Black»,
а следующие пять карт - это рука игрока по имени «White».
Выходные данные
Для каждой строки входных данных напечатайте строку, содержащую один из
следующих результатов:
Black wins.
White wins.
Tie.
Пример входных данных Соответствующие выходные
данные
2Н 3D 5S 9С KD 2С ЗН 4S 8С АН White wins.
2Н 4S 4С 2D 4Н 2S 8S AS QS 3S Black wins.
2Н 3D 5S 9С KD 2С ЗН 4S 8С КН Black wins.
2Н 3D 5S 9С KD 2D ЗН 5С 9S КН Tie.
62 Глава 2. Структуры данных
2.8.3. Харталы (Hartals)
PC/UVaIDs: 110203/10050
Популярность: В
Частота успехов: высокая
Уровень:2
Политические партии в Республике Бангладеш показывают свою силу, объявляя
регулярные харталы (забастовки), которые наносят значительный ущерб экономике.
Для наших целей каждую партию можно охарактеризовать положительным целым
числом Л, называемым параметром харталов, которое означает среднее количество
дней между двумя успешными забастовками, объявленными данной партией.
Рассмотрим три политические партии. Положим hj = 3, /*2 = 4 и h$ = 8, где А,- -
это параметр харталов для партии /. Мы можем смоделировать поведение этих трех
партий для N = 14 дней. Моделирование всегда начинается с воскресенья. По пят-
пятницам и субботам харталы не объявляются.
Дни
Парт.
Парт.
Парт.
1
2
3
Харталы
1
Вс
2
Пн
3
Вт
X
1
4
Ср
X
2
5
Чт
6
Пт
X
7
Сб
8
Вс
X
X
3
9
Пн
X
4
10
Вт
11
Ср
12
Чт
X
X
5
13
Пт
14
Сб
За 14 дней будет ровно пять харталов (дни 3, 4, 8, 9 и 12-й). На шестой день
хартала не будет, потому что это пятница. Отсюда мы теряем пять рабочих дней за
две недели.
Получив параметры харталов для нескольких политических партий, а также значе-
значение N, определите количество рабочих дней, которое будет потеряно за эти Ладней.
Входные данные
Первая строка входных данных состоит из одного целого числа Г, задающего
число тестовых блоков, следующих далее. Первая строка каждого блока содержит
число N G<N<3650), задающее число дней для моделирования. Следующая
строка содержит другое целое число Р A < Р < 100), представляющее собой число
политических партий, /-я из следующих Р строк содержит положительное целое
число ht (которое никогда не кратно семи), задающее параметр харталов для
партии / A < / <Р).
2.8. Задачи 63
Выходные данные
Для каждого тестового блока выведите отдельной строкой количество потерянных
рабочих дней.
Пример входных данных Соответствующие выходные данные
2 5
14 15
3
3
4
8
100
4
12
15
25
40
2.8.4. Дешифратор
PC/UVaIDs: 110204/843
Популярность: В
Частота успехов: низкая
Уровень: 2
Распространенный, но ненадежный метод шифровки текста состоит в перемене
букв алфавита. Другими словами, каждая буква алфавита последовательно заменя-
заменяется в тексте какой-то другой буквой. Чтобы шифровка была обратимой, никакие
две буквы не заменяются одной и той же буквой.
Ваша задача - расшифровать несколько закодированных строк текста, полагая,
что все строки содержат различные наборы замещений и что все слова в расшифро-
расшифрованном тексте из словаря известных слов.
Входные данные
Входные данные состоят из строки, содержащей целое число и, далее следуют
п слов, записанных строчными буквами, одно на строку, в алфавитном порядке.
Эти п слов составляют словарь тех слов, которые могут появиться в расшифрован-
расшифрованном тексте. За словарем следуют несколько строк входных данных. Каждая строка
зашифрована, как описано выше.
В словаре не более 1000 слов. Длина каждого не превышает 16 букв. Зашифро-
Зашифрованные строки содержат только строчные буквы и пробелы, и их длина не превы-
превышает 80 символов.
64 Глава 2. Структуры данных
Выходные данные
Расшифруйте каждую строку и выведите ее в стандартный вывод. Если возможны
несколько вариантов решения, подойдет любое. Если решений не существует, замени-
замените каждую букву алфавита звездочкой.
Пример входных данных
б
and
dick
jane
puff
spot
yertle
bjvg xsb hxsn xsb qymm xsb rqat xsb pnetfn
xxxx yyy zzzz www yyyy aaa bbbb ccc dddddd
Соответствующие выходные данные
dick and jane and puff and spot and yertle
2.8.5. Расположить по порядку
PC/UVaIDs: 110205/10205
Популярность: В
Частота успехов: средняя
Уровень:1
В Большом городе много казино. В одном из них дилер жульничает. Она
довела до совершенства несколько перетасовочных трюков; каждый трюк меняет
порядок карт одним и тем же образом, когда бы он ни был использован. Простой
пример - это трюк «нижней карты», при котором нижняя карта переносится на
верх колоды. Используя различные комбинации известных ей трюков, нечестный
дилер может расположить карты практически в любом желаемом порядке.
Вы были наняты менеджером службы безопасности, чтобы поймать этого дилера.
Вам дали список всех трюков, используемых дилером, а также список визуальных
подсказок, благодаря которым вы можете определить, какой трюк она использует
в любой данный момент времени. Ваша задача состоит в том, чтобы предсказать
порядок карт после последовательности трюков.
2.8. Задачи 65
Стандартная игральная колода состоит из 52 карт, четыре масти по 13 значе-
значений каждая. Значения карт: 2, 3, 4, 5, 6, 7, 8, 9, 10, Валет (Jack), Дама (Queen),
Король (King), Туз (Асе). Названия мастей: Трефы (Clubs), Бубны (Diamonds),
Червы (Hearts), Пики (Spades). Определенная карта в колоде может быть одно-
однозначно определена по ее значению и масти и обычно обозначается <значение>
of <масть>. Например, «9 of Hearts» или «King of Spades». По традиции карты
в новой колоде идут по мастям в алфавитном порядке, а потом по значению
в порядке, описанном выше.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное
целое число, которое означает количество тестовых блоков, за которой следует
пустая строка. Между двумя последовательными тестовыми блоками также нахо-
находится пустая строка.
Каждый блок состоит из целого числа лг < 100 — числа трюков, которые знает
дилер. Далее следуют п наборов по 52 целых числа, каждый из которых содержит все
числа от 1 до 52 в определением порядке. Внутри каждого набора из 52 чисел, если i
стоит/'-м по счету, то это значит, что трюк перемещает i-ю карту в колоде нау'-е место.
Далее следуют несколько строк, каждая из которых содержит целое число к от
1 до п. Оно означает, что вы увидели, как дилер делает к-й трюк, заданный во
входных данных.
Выходные данные
Для каждого тестового блока считайте, что дилер начинает с новой колоды,
карты в которой расположены в порядке, описанном выше. Выведите новый поря-
порядок карт в колоде, после того как все трюки были проделаны. Выходные данные
для двух последовательных блоков должны быть разделены пустой строкой.
Пример входных данных
1
2
2 1 3 4 5 б 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
27 28 29 30 3132 33 34 35 36 37 3 8 39 40 4142 43 44 45 46 47 48 49 50 52 51
52 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
27 28293031323334353637383940 4142 43 44 45 46 47 48 49 50 511
1
2
3-972
66 Глава 2. Структуры данных
Соответствующие выходные данные
King
2
4
5
6
7
8
9
10
of
of
of
of
of
of
of
of
Jack
Queen
King
of Spades
Clubs
Clubs
Clubs
Clubs
Clubs
Clubs
Clubs
Clubs
of Clubs
of Clubs
of Clubs
Ace of Clubs
2
3
4
5
6
7
8
9
10
of
of
of
of
of
of
of
of
of
Jack
Queen
King
Diamonds
Diamonds
Diamonds
Diamonds
Diamonds
Diamonds
Diamonds
Diamonds
Diamonds
of Diamonds
. of Diamonds
of Diamonds
Ace of Diamonds
2
3
4
5
6
7
8
9
10
of
of
of
of
of
of
of
of
I Of
Jack
Queen
King
Hearts
Hearts
Hearts
Hearts
Hearts
Hearts
Hearts
Hearts
: Hearts
of Hearts
l of Hearts
of Hearts
Ace of Hearts
2
3
4
5
6
7
8
of
of
of
of
of
of
of
Spades
Spades
Spades
Spades
Spades
Spades
Spades
2.8. Задачи 67
9 of Spades
10 of Spades
Jack of Spades
Queen of Spades
Ace of Spades
3 of Clubs
2.8.6. Числа Эрдеша
PC/UVaIDs: 110206/10044
Популярность: В
Частота успехов: низкая
Уровень:2
Венгерский ученый Пауль Эрдеш (Paul Erdus, 1913-1966) был одним из
самых известных математиков XX века. Любой математик, имевший честь быть
соавтором Эрдеша, глубоко уважаем.
К сожалению, не у всех была возможность написать статью совместно
с Эрдешем, лучшее, что они могли сделать, - это опубликовать статью с кем-либо,
кто опубликовал научную статью в соавторстве с Эрдешем. Это дало начало так
называемым числам Эрдеша. Автор, публиковавшийся совместно с Эрдешем, имеет
число Эрдеша 1. Автор, не публиковавшийся с Эрдешем, но публиковавшийся
совместно с кем-либо, кто имеет число Эрдеша 1, получал число Эрдеша 2 и т. д.
Ваша задача - написать программу, которая рассчитывает числа Эрдеша для
данного множества статей и ученых.
Входные данные
Первая строка входных данных содержит число сценариев. Каждый сценарий
состоит из базы данных статей и из списка имен. Он начинается со строки вида Р
N, где Р и N - натуральные числа. За этой строкой следует база данных статей из
Р строк, каждая из которых содержит описание одной статьи, выглядящее так:
Smith, M.N. , Martin, G. , Erdos, P. : Newtonian forms of prime factors
Обратите внимание, что умляуты, такие, как "о", пишутся просто как "о".
После Р статей идут N строк с именами. Такая строка с именем имеет следующий
формат:
Martin, G.
68 Глава 2. Структуры данных
Выходные данные
Для каждого сценария вы должны вывести строку, содержащую w Scenario i"
(где / - это номер сценария), и имена авторов вместе с их числами Эрдеша для всех
авторов из списка имен. Авторы должны выводиться в том же порядке, в котором
они были в списке имен. Число Эрдеша основано на статьях из базы данных статей
этого сценария. Авторы, которые не имеют никакого отношения к Эрдешу, суця по
статьям данной базы данных, имеют число Эрдеша "infinity".
Пример входных данных
1
4 3
Smith, M.N., Martin, G., Erdos, P.: Newtonian forms of prime
factors
Erdos, P., Reisig, W.: Stuttering in petri nets
Smith, M.N., Chen, X.: First order derivates in structured
programming
Jablonski, Т., Hsueh, Z.: Selfstabilizing data structures
Smith, M.N.
Hsueh, Z.
Chen, X.
Соответствующие выходные данные
Scenario 1
Smith, M.N. 1
Hsueh, Z. infinity
Chen, X. 2
2.8.7. Табло соревнований
PC/UVaIDs: 110207/10258
Популярность: В
Частота успехов: средняя
Уровень:1
Хотите посоревноваться в ACM ICPC? Тогда вам нужно знать, как вести счет!
Участники соревнований ранжируются сначала по числу решенных задач (чем
больше, тем лучше), а потом по уменьшению величины штрафного времени. Если
у двух и более участников совпадает и количество решенных задач, и величина
штрафного времени, то они отображаются в порядке увеличения номеров команд.
2.8. Задачи 69
Задача засчитывается решенной участником соревнований, если любая из
попыток отправки этой задачи была признана верной. Штрафное время рассчиты-
рассчитывается как число минут, прошедших до того, как было отправлено правильное
решение, плюс 20 минут за каждую некорректную отправку, имевшую место до
верного решения. За нерешенные задачи штрафное время не начисляется.
Входные данные
Входные данные начинаются со строки, содержащей одно целое положительное
число, задающее число блоков, которые описаны ниже. За этой строкой следует пус-
пустая. Также пустая строка находится между двумя последовательными блоками.
Входные данные состоят из судейского списка очередности, содержащего вхожде-
вхождения по нескольким или по всем участникам соревнований с 1-го по 100-й, решающим
задачи с 1-й по 9-ю. Каждая строка входных данных состоит из трех чисел и буквы
в формате участник задача время L, где L может быть С, I, R, U или Е. Это означа-
означает: Correct (верно), Incorrect (неверно), Clarification Request (уточняющий запрос),
Unjudged (необработан) и Erroneous submission (отправка с ошибкой). Последние три
случая не влияют на счет.
Строки входных данных идут в том порядке, в котором получались посылки.
Выходные данные
Выходные данные для каждого блока должны представлять собой табло,
отсортированное по критериям, описанным выше. Каждая строка выходных данных
должна содержать номер участника, количество задач, решенных участником,
и полное штрафное время, полученное участником. Так как не все участники в дейст-
действительности соревнуются, отображайте только тех участников, кто посылал решения.
Между выходными данными для двух последовательных блоков должна быть
пустая строка.
Пример входных данных Соответствующие выходные данные
1 1 2 66
3 1 11
1 2 10 I
3 1 11 С
1 2 19 R
1 2 21 С
1 1 25 С
70 Глава 2. Структуры данных
2.8.8. Yahtzee
PC/UVaIDs: 110208/10149
Популярность: С
Частота успехов: средняя
Уровень:3
В игре Yahtzee используются пять игральных костей, которые бросаются в 13 раун-
раундах. Протокол результатов содержит 13 категорий. Счет за каждый раунд может быть
записан в категорию по выбору игрока, но в каждую категорию счет можно записы-
записывать только один раз. Счет в эти 13 категорий записывается следующим образом:
• единицы - сумма всех выброшенных единиц;
• двойки - сумма всех выброшенных двоек;
• тройки - сумма всех выброшенных троек;
• четверки - сумма всех выброшенных четверок;
• пятерки - сумма всех выброшенных пятерок;
• шестерки - сумма всех выброшенных шестерок;
• шанс - сумма чисел на всех костях;
• три одинаковые - сумма чисел на всех костях, при условии, что как минимум
три из них имеют одно и то же значение;
• четыре одинаковые - сумма чисел на всех костях, при условии, что как
минимум четыре из них имеют одно и то же значение;
• пять одинаковых - 50 очков, при условии, что на всех костях выпало одина-
одинаковое число;
• короткий стрит - 25 очков, при условии, что четыре кости образуют последо-
последовательность (то есть 1, 2, 3,4, или 2, 3, 4, 5, или 3, 4, 5, 6);
короткий стрит - 35 очков, при условии, что все кости образуют последова-
последовательность (то есть 1, 2, 3, 4, 5 или 2, 3, 4, 5, 6);
• фулл-хаус - 40 очков, при условии, что на трех костях выпало одно и то же
число и на оставшихся двух костях также выпало одно и то же число.
Каждая из последних шести категорий может быть засчитана за 0 очков, если
необходимые условия не выполняются.
Счетом игры является сумма всех 13 категорий плюс дополнительные 35 очков,
если сумма первых шести категорий 63 или больше.
Ваша задача - рассчитать максимальный счет для последовательности раундов.
2.8. Задачи 71
Входные данные
Каждая строка входных данных содержит пять целых чисел от 1 до 6, представ-
представляющих собой пять костей, брошенных в каждом раунде. Для каждой игры 13 таких
строк, и во входных данных может быть любое количество игр.
Выходные данные
Ваши выходные данные должны состоять из одной строки для каждой игры,
содержащей 15 чисел: счет в каждой категории (в заданном порядке), дополни-
дополнительные очки @ или 35) и суммарный счет. Если существует несколько распреде-
распределений, приводящих к одному и тому же максимальному счету, то подойдет любое.
Пример входных данных
12 3 4 5
12 3 4 5
12 3 4 5
12 3 4 5
12 3 4 5
12 3 4 5
12 3 4 5
12 3 4 5
12 3 4 5
12 3 4 5
12 3 4 5
12 3 4 5
12 3 4 5
11111
6 6 6 6 6
6 6 6 11
1112 2
1112 3
12 3 4 5
12 3 4 6
6 12 6 6
14 5 5 5
5 5 5 5 6
4 4 4 5 6
3 13 6 3
2 2 2 4 6
Соответствующие выходные данные
123450 15 000 25 35 00 90
3 6 9 12 15 30 21 20 26 50 25 35 40 35 327
72 Глава 2. Структуры данных
2.9. Подсказки
2.1. Можем ли мы свести значение покерной руки к одному числовому значению,
чтобы сделать сравнение проще?
2.2. Нужно ли нам строить реальную таблицу, чтобы рассчитать число харталов?
2.3. Окупается ли разбиение слов по классам эквивалентности, основываясь на
повторяющихся буквах и на длине?
2.4. Какой самый простой способ сортировки по нескольким критериям?
2.5. Нужно ли нам проверять все возможные отображения раундов на категории,
или мы можем сделать определенные присвоения более прямолинейным
способом?
2.10. Замечания
2.1. Jolly number - это особый случай нумерации изящного графа. Граф называ-
называется изящным, если существует способ пронумеровать п вершин целыми
числами так, чтобы абсолютные значения разностей конечных точек всех т
ребер пробегали все значения от 1 до w. Jolly jumper представляет собой
изящную нумерацию пути из п вершин. Знаменитая гипотеза изящного дере-
дерева спрашивает, для любого ли дерева существует изящная нумерация. Изящ-
Изящные графы - это широкое поле для студенческих исследований. Смотрите ди-
динамический обзор Галлиана (Gallian) [GalOl] на предмет списка доступных
нерешенных задач.
2.2. Математика тасовки карт - это увлекательная тема. Идеальная тасовка раз-
разбивает колоду на две стопки А и В и после этого перемешивает карты по
очереди: верхняя А, верхняя 5, верхняя А... Удивительно, но восемь идеаль-
идеальных тасовок возвращают колоду к ее первоначальному состоянию! Это мож-
можно доказать, используя либо арифметические операции над абсолютными
значениями чисел, либо теорию циклов в перестановках. Смотрите [DGK83,
Мог98] для более подробного разбора идеальных тасовок.
2.3. Первый автор этой книги имеет число Эрдеша 2, давая второму число < 3.
Эрдеш был известен за постановки красивых, легких для понимания, но
трудно решаемых задач по комбинаторике, теории графов и теории чисел.
Больше об этом удивительном человеке можно узнать, прочитав одну из по-
популярных биографий его жизни [Hof99, SchOO].
Глава 3
Строки
Текстовые строки - это фундаментальная структура данных, чья важность по-
постоянно возрастает. Поисковики в Интернете, такие, как Google, находят милли-
миллиарды документов практически мгновенно. Расшифровка человеческого генома
дала нам три миллиарда символов текста, описывающих все протеины, из ко-
которых мы созданы. Разыскивая необычные схемы в строке, мы буквально ищем
секрет жизни.
Ставки при решении задач по программированию этой главы значительно
ниже, чем эти. Тем не менее они обеспечивают понимание того, как символы
и текстовые строки представляются в современных компьютерах, и описывают
умные алгоритмы поиска и управления этими данными. Мы отсылаем заинтере-
заинтересовавшегося читателя к [Gus97] для более продвинутого обсуждения алгоритмов
работы со строками.
3.1. Коды символов
Коды символов - это отображение символов, составляющих определенный ал-
алфавит, на пространство чисел. В основе компьютеры созданы для работы
с числовыми данными. Все, что они знают про данный алфавит, - это какой
символ присвоен каждому возможному числу. Когда вы меняете шрифт в тексто-
текстовом редакторе, на самом деле меняется только изображение, связанное с каждым
символом. Когда вы меняете язык операционной системы с английского на рус-
русский, меняется лишь привязка изображений к кодам символов.
При работе с текстовыми строками полезно немного разбираться в идейной
основе кодов символов. Американский стандартный код обмена информацией
(American Standard Code for Information Interchange - ASCII) - это однобайтовый
код символов, для которого заданы 27 = 128 символов. Байты состоят из восьми
бит; это значит, что старший бит всегда выставляется равным нулю.
4
0
8
16
24
32
40
48
56
64
72
80
88
96
104
112
120
NUL
BS
DLE
CAN
SP
(
0
8
@
H
P
X
«
h
P
X
1
9
17
25
33
41
49
57
65
73
81
89
97
105
113
121
SOH
HT
DC1
EM
j
)
1
9
A
I
Q
Y
a
j
q
У
2
10
18
26
34
42
50
58
66
74
82
90
98
106
114
122
STX
NL
DC2
SUB
2
В
J
R
Z
b
j
r
z
3
11
19
27
35
43
51
59
67
75
83
91
99
107
115
123
ETX
vr
DC3
ESC
#
+
3
;
С
К
s
[
с
к
s
{
4
12
20
28
36
44
52
60
68
76
84
92
100
108
116
124
EOT
NP
DC4
FS
$
,
4
<
D
L
T
/
d
1
t
—
5
13
21
29
37
45
53
61
69
77
85
93
101
109
117
125
ENQ
CR
NAK
GS
%
-
5
=
E
M
U
]
e
m
u
}
6
14
22
30
38
46
54
62
70
78
86
94
102
110
118
126
Глава 3.
ACK
SO
SYN
RS
&
6
>
F
N
V
л
f
n
V
7
15
23
31
39
47
55
63
71
79
87
95
103
111
119
127
Строки
BEL
SI
ETB
US
/
7
?
G
0
W
g
0
w
DEL
Рис. 3.1. ASCII-коды символов
Рассмотрим таблицу ASCII-кодов символов, представленную на рис. 3.1, где
в каждой паре левый элемент- это десятичный (основание системы счисления -десять)
номер в спецификации, а правый элемент - это привязанный к этому номеру символ.
Привязка символов производилась не случайным образом. Несколько интересных
свойств разработки таблицы облегчают программирование.
• У всех непечатаемых символов либо старшие три бита равны нулю, либо все
семь младших битов равны единице. Из-за этого их очень легко отсеивать,
прежде чем выводить мусор на дисплей, хотя почему-то очень немногие
программы так делают.
И прописные, и строчные буквы, а также цифры идут последовательно. Таким
образом, мы можем проходить по всем буквам/цифрам, просто проходя от
значения первого символа (скажем, "а") до значения последнего символа
(скажем, "z").
• Другим следствием последовательного расположения является то, что мы
можем преобразовать символ (скажем, "I") в его порядковый номер
в упорядоченной последовательности (восьмой, если считать, что "А" - это
нулевой символ), просто вычтя первый символ ("А").
3.2. Представление строк 75
• Мы можем преобразовать символ (скажем, "С") из верхнего в нижний регистр,
добавив разницу между начальными символами верхнего и нижнего регистра
("C"-UA" + Ua"). Аналогично символ jc является прописной буквой, только
если он лежит между "А" и " Z ".
• При заданных кодах символов, мы можем предсказать, что произойдет при
простой сортировке текстовых файлов. Что из "х ", " 3 ", " С " считается первым
в алфавитном порядке? Сортировка по алфавиту означает просто сортировку по
кодам символов. Использование другой упорядоченной последовательности
требует более сложных функций сравнения, что будет обсуждаться в главе 4.
Непечатаемые коды символов для новой строки A0) и возврата каретки A3)
созданы для задания конца текстовых строк. Непоследовательное использова-
использование этих кодов является проблемой при переносе текстовых файлов между
UNIX- и Windows-системами.
Более современные международные модели кодов символов, такие, как
Уникод (Unicode), используют два или даже три байта на знак и теоретически
могут представить любой символ любого языка на Земле. Тем не менее старый
добрый ASCII остается в живых, будучи встроенным в Уникод. Когда все биты
старшего порядка выставлены в 0, текст интерпретируется как последователь-
последовательность однобайтовых, а не двухбайтовых символов. Таким образом, мы все еще
можем применять более простую, более эффективную в смысле памяти кодиров-
кодировку и при этом иметь возможность использовать тысячи новых символов.
Все это привносит множество различий в управление текстом в различных
языках программирования. Старые языки, такие, как Pascal, С, C++, считают, что
тип char в сущности 8-битный. Таким образом, символьный тип данных выбира-
выбирается для работы с любыми файлами, даже с теми, которые не считаются печатае-
печатаемыми. С другой стороны, Java разрабатывался с поддержкой Уникода, так что
символы являются 16-битными. Старший байт тождественно равен нулю при
работе с ASCII/ISO Latin 1 текстом. Не забывайте об этой разнице, когда вы пере-
переключаетесь между языками программирования.
3.2. Представление строк
Строки это последовательности символов, причем порядок, очевидно, имеет
значение. Важно знать, как ваш любимый язык программирования представляет
строки, потому что существует несколько различных возможностей.
• Массивы, оканчивающиеся нуль-символом. C/C++ считает строки массивами.
Строка заканчивается, как только она доходит до нулевого символа " \ 0 ", то есть
нулевой символ - ASCII. Если явно не заканчивать строку этим символом,
76 Глава 3. Строки
то обычно она расширяется кучей непечатаемых символов. Если вы определяете
строку и не хотите, чтобы возникла ошибка, то должен быть выделен массив дос-
достаточно большого размера, способный вместить строку максимально возможной
длины (плюс нулевой символ). Преимуществом представления в виде массива,
является то что отдельные символы доступны по индексу как элементы массива.
• Массив плюс длина. При другом подходе первая ячейка массива используется
для сохранения длины строки, таким образом устраняя необходимость добав-
добавления символа конца строки. По-видимому, такая реализация используется
внутри Java, хотя пользователь рассматривает строки как объекты с набором
операторов и методов, действующих на них.
• Связанные списки символов. Текстовые строки могут быть представлены
с использованием связанных списков, но обычно этого избегают из-за высоких
издержек памяти, связанных с использованием указателя длиной несколько байт
для каждого однобайтового символа. Все же такое представление может быть
полезно, если вам необходимо часто добавлять/удалять подстроки из тела строки.
Используемое представление имеет большое влияние на то, какие операции
могут легко и эффективно производиться. Сравните эти три структуры данных по
отношению к следующим свойствам.
• Какая использует наименьшее количество памяти? Для строк какого размера?
• Какая ограничивает содержимое строк, которое возможно представить?
Какая обеспечивает постоянный доступ к i-uy символу?
• Какая предоставляет удобный способ проверки, что /-й символ действительно
лежит внутри строки, помогая тем самым избежать ошибок нарушения
границ?
• Какая предоставляет удобный способ вставки/удаления /-го символа?
• Какое представление используется, когда пользователи ограничены макси-
максимальной длиной строк 255 (например, имена файлов в Windows)?
3.3. Пример разработки программы: корпоративные
переименования
Корпоративная смена имен происходит все чаще, так как компании объеди-
объединяются, покупают друг друга, пытаются скрыться от дурной славы или даже под-
поднимают курс акций - вспомните то время, когда секретом успеха было добавить
.com к имени компании.
3.3. Пример разработки программы: корпоративные переименования 77
Из-за этих изменений при прочтении старых документов сложно установить
текущее имя компании. Ваша компания, Digiscam (ранее Algorist Technologies),
предложила вам разработать программу, которая обслуживает базу данных
корпоративных смен имен и производит необходимые замены в старых докумен-
документах, чтобы поддерживать их на уровне современных требований.
Входными данными для вашей программы является файл с заданным числом смен
имен, за которым следует заданное число строк текста для исправления. Только
точные совпадения строк должны заменяться. Смен имен будет не более 100, и длина
каждой строки текста не превышает 1000 символов. Пример входных данных:
4
wAnderson Consulting" to "Accenture"
"Enron" to wDynegy"
"DEC" to "Compaq"
"TWA" to "American"
5
Anderson Accounting begat Anderson Consulting, which
offered advice to Enron before it DECLARED bankruptcy,
which made Anderson
Consulting quite happy it changed its name
in the first place!
Что должно быть преобразовано в -
Anderson Accounting begat Accenture, which
offered advice to Dynegy before it CompaqLARED bankruptcy,
which made Anderson
Consulting quite happy it changed its name
in the first place!
В спецификации не указано, что вы должны соблюдать разделители между
словами (такие как пробел), так что преобразование DECLARED в CompaqLARED
это именно то, что нужно было сделать.
Решение начинается ниже
Какие типы операций со строками нам необходимы для решения этой задачи?
Нам нужно уметь читать строки и сохранять их, искать необходимые вхождения
в строках, изменять их и, наконец, выводить их.
Обратите внимание на то, что файл входных данных разбит на две части.
Первая часть, словарь смены имен, должна быть полностью считана и обработана
до начала преобразования текста. Объявление важных структур данных:
78 Глава 3. Строки
#include <string.h>
#define MAXLEN 1001 /* максимально возможная
длина строки */
#define MAXCHANGES 101 /* максимальное число смен
имен */
typedef char string[MAXLEN];
string mergers [MAXCHANGES] [2] /* сохраняем корпоративные
имена до/после смены */
int nmergers; /* число различных смен
имен */
Мы представляем словарь двумерным массивом строк. У нас нет необходимости
сортгировать ключи в каком-то определенном порядке, так как мы будем просматри-
просматривать все для каждой строки текста.
Чтение списка имен компаний в какой-то степени осложнено тем фактом, что нам
нужно анализировать строку, чтобы извлечь данные между кавычками. Хитрость
состоит в том, что нужно игнорировать текст до первой кавычки и забирать его до
второй кавычки.
read_changes()
{
int i; /* счетчик */
scanf("%d\n",&nmergers);
for (i=0; i<nmergers; i++) {
read_quoted_string(&(mergers[i][0]));
read_quoted_string(&(mergers[i] [1])) ;
read_quoted_string(char *s)
{
int i=0; /* счетчик */
char с; /* последний считанный символ */
while ((c=getchar()) != ' \ " ' ) ;
while ((c=getchar()) != ' \ '" ) {
s [ i ] = с ;
i = i+1;
}
s[i] = 'XO1;
}
Более продвинутые операции, которые нам требуются, представлены в сле-
следующих разделах.
3.4. Поиск шаблонов 79
3.4. Поиск шаблонов
Простейший алгоритм определения присутствия шаблонной строки р в тексте t
совмещает начало шаблонной строки с каждым символом текста и проверяет, совпа-
совпадает ли каждый символ шаблонной строки с соответствующим ему символом текста.
/*
Возвращает позицию первого совпадения шаблона р и текста t,
если совпадений нет, то возвращается -1
*/
int findmatch(char *р, char *t)
{
int i/j; /* счетчики */
int plen, tlen; /* длины строк */
plen = strlen(p);
tlen = strlen(t);
for (i=0; i<=(tlen-plen); i=i+l) {
J=0;
while ((j<plen) && (t[i+j]==p[j]))
j = j+1;
if (j == plen) return(i);
}
return(-1);
}
Обратите внимание, что эта подпрограмма ищет только точные совпадения с шаб-
шаблоном. Если буква является прописной в шаблоне, а в тексте она таковой не является,
то совпадения нет. Что более важно: если имя компании разбито между строками
(смотрите пример входных данных), то никакого совпадения обнаружено не будет.
Такие поиски можно проводить, изменив сравнение текста/шаблона t [ i + j ] ==р [ j ]
на что-либо более интересное. Подобная методика может применяться с использова-
использованием джокеров, символов, которые совпадают с любым. Более общий подход к при-
приближенному совпадению строк будет обсуждаться в главе 11.
Этот простейший алгоритм может в худшем случае потребовать 0(|/?|И) вре-
времени. Можете ли вы придумать пример шаблона и текста произвольной длины,
который на самом деле потребовал бы столько времени, без единого совпадения
с шаблоном? Обычный прямолинейный поиск будет много более эффективен, так
как мы продвигаемся дальше по тексту сразу же после того, как обнаружили
первое несовпадение. Существуют более сложные алгоритмы с линейной зависи-
зависимостью времени работы от длины входных данных: смотрите [Gus97] для подроб-
подробного рассмотрения. Вероятнее всего, эти алгоритмы реализованы в библиотеке
для работы со строками вашего языка программирования.
80 Глава 3. Строки
3.5. Управление строками
Для управления строками требуется точно знать, какое представление строк вы
или ваш язык программирования использует. Здесь мы полагаем, что строки пред-
представляются последовательностью однобайтовых символов в массиве, заканчи-
заканчивающемся нуль-символом окончания, как принято в С.
Рассмотрение строк как массивов делает многие операции сравнительно легкими.
• Вычисление длины строки. Просматриваем символы, входящие в строку, и добав-
добавляем к счетчику по единичке за каждый, пока не дойдем до нуль-символа.
• Копирование строки. Если ваш язык программирования не поддерживает
копирование массивов за одну операцию, вы должны явно пройти циклом по сво-
своей строке и скопировать символы по одному. Не забывайте зарезервировать дос-
достаточно места для новой копии и не теряйте нуль-символ!
• Запись строки в обратном порядке. Простейшей реализацией этого будет ско-
скопировать строку справа налево во второй массив. Правая конечная точка опреде-
определяется исходя из длины строки. Не забудьте завершить новую строку символом
конца строки! Запись строки в обратном порядке может делаться путем переста-
перестановки символов, если вы хотите уничтожить первоначальную строку.
В качестве примера мы реализовали подпрограмму, заменяющую подстроку
в заданной позиции другой строкой. Она нам потребуется для нашей программы
корпоративного слияния. Нетривиальной частью является перестановка остальных
символов строки так, чтобы поместилась новая строка. Если замещающая подстро-
подстрока длиннее оригинальной, нам нужно отодвинуть оставшиеся символы так, чтобы
не произошло наложения. Если замещающая подстрока короче, нам нужно подви-
подвинуть оставшиеся символы так, чтобы закрыть образовавшееся пустое место.
/*
Заменяет подстроку длины xlen, начинающуюся с
позиции pos строки s, на содержимое строки у
*/
replace_x_with_y(char *s, int pos, int xlen, char*y)
{
int i; /* счетчик */
int slen, ylen; /* длины важных строк */
slen = strlen(s);
ylen = strlen(y);
if (xlen >= ylen)
for (i=(pos+xlen); i<=slen; i++) s[i+(ylen-xlen)] =s[i];
else
3.6. Завершение программы 81
for (i=slen; i>=(pos+xlen); i--) s[i+(ylen-xlen)] =s[i];
for (i = 0; i<ylen; i + +) s[pos+i] = y[i];
Альтернативный вариант реализации состоит в компоновке новой строки во
временном буфере и последующей перезаписи всех символов строки s содержи-
содержимым буфера.
3.6. Завершение программы
После того как созданы все необходимые подпрограммы, оставшаяся часть
программы становится довольно простой:
main()
{
string s; /* строка входных данных */
char с; /* входной символ */
int nlines; /* количество строк в тексте */
int i/j; /* счетчики */
int pos; /* положение шаблона в строке */
read_changes();
scanf("%d\n",&nlines);
for (i=l; l<=nlines; i = i+l) { /* чтение строки текста */
j=0;
while ((c=getchar()) != '\n() {
s[j] = c;
j = j+1;
}
s[j] = 'NO1;
for (j=0; j<nmergers; j=j+l)
while ((pos=findmatch(mergers[j][0],s)) != -1) {
replace_x_with_y(s, pos
strlen(mergers[j][0]), mergers[j][1]);
}
printf("%s\n", s) ;
82 Глава 3. Строки
3.7. Функции библиотеки для работы со строками
Работаете ли вы в С, C++ или в Java, вам нужно знать о возможностях, предостав-
предоставляемых для работы с символами и строками через библиотеки и классы. Нет никакого
смысла снова изобретать колесо.
В стандартном Pascal строки не являются поддерживаемым типом данных,
а потому детали зависят от конкретной реализации.
Функции библиотеки языка С для работы со строками
Язык С содержит библиотеки как для работы с символами, так и для работы со
строками. Символьная библиотека языка С ctype.h содержит несколько простых
проверок и функций изменения кодов символов. Как и со всеми логическими
утверждениями в С, истина определена как любое ненулевое значение, а ложь как
нулевое.
#include <ctype.h> /* включаем символьную библиотеку */
int isalpha(int с); /* истина, если с — прописная или строчная
буква */
int isupper(int с); /* истина, если с - прописная буква */
int islower(int с); /* истина, если с - строчная буква */
int isdigit(int с); /* истина, если с 0 цифра @-9) */
int ispunct(int с); /* истина, если с - знак пунктуации */
int isxdigit(int с); /* истина, если с - шестнадцатеричная
цифра @-9,A-F) */
int isprint(int с); /* истина, если с - любой печатаемый
символ */
int toupper(int с); /* преобразует с в верхний регистр - нет
проверки ошибок */
int tolower(int с); /* преобразует с в нижний регистр - нет
проверки ошибок */
Прежде чем считать, что функция делает именно то, что вы хотите, внимательно
ознакомьтесь с ее описанием.
Следующие функции взяты из строковой библиотеки языка С string. h. Здесь
приведены не все функции и возможности полной библиотеки, так что ознакомьтесь
с ее описанием.
#include <string.h> /* включаем строковую библиотеку */
char *streat (char *dst, const char *src) ; /* объединение */
int stremp (const char *sl, const char *s2) ; /* si == s2? */
3.7. Функции библиотеки для работы со строками
83
char *strcpy (char *dst, const char*src) ; /* копирует src в dst */
size t strlen(const char *s) ; /* длина строки */
char *strstr (const char *sl, const char *s2) ; /* ищет s2 в si */
char *strtok(char *sl, const char *s2) ; /* итерирует слова в
si */
Функции библиотеки языка C++для работы со строками
В добавление к поддержке строк языка С в языке C++ имеется строковый
класс, который содержит методы для этих и других операций.
string::size() /* длина строки */
string: .-empty() /* пуста ли строка */
string: :c_str() /* возвращает указатель на строку языка С */
string::operator [](size_type i)
/* доступ к i-му символу */
string:
string:
string:
string:
string:
:append(s) /* прицепляет к строке */
:erase(n,m) /* удаляет серию символов */
: insert (size_type n, const string &s) /* вставляет строку s
вп */
:find(s)
:rfind(s)
/* левый и правый поиск заданной строки */
string::first()
string::last()
/* возвращает символы, также есть итераторы */
Существуют подгружаемые операторы для слияния и сравнения строк.
Строковые объекты Java
Строки Java - это first-class objects, получаемые либо из класса String, либо
из класса StringBuf f er. Класс String предназначен для статических строк,
которые не меняются, тогда как класс StringBuf fer разработан для динамиче-
динамических строк. Вспомните, что Java был создан с поддержкой Уникода, так что сим-
символы там 16-битные.
Пакет java. text содержит более продвинутые операции над строками,
включая подпрограммы для анализа дат и другого структурированного текста.
84
Глава 3. Строки
3.8. Задачи
3.8.1. WERTYU
PC/UVaIDs: 110301/10082
Популярность: А
Частота успехов: высокая
Уровень: 1
•|1|2|3
Tab[Qjw
|A|S
4I5I6I7I8I9I°II= fcckSp
eIrItIyIuIiIoIpIii]I \
DIFIGIHIJIKILII'IEnter
[Control JAItJ
|zIx|c|v|b|n|m|7TT7T
jAltJcontrol]
Обычная ошибка при наборе состоит в том, что вы помещаете ваши руки на
клавиатуру на один ряд правее верной позиции. Тогда "Q" печатается как "W",
" J" печатается как UK", и т. д. Ваша задача состоит в расшифровке сообщения,
набранного таким образом.
Входные данные
Входные данные состоят из нескольких строк текста. Каждая строка может со-
содержать цифры, пробелы, прописные буквы (кроме UQ", "A", "Z") и знаки препи-
препинания, показанные выше [кроме обратной кавычки (')]. Клавиши, обозначенные
словами [Tab, BackSp, Control и т. д.], не представлены во входных данных.
Выходные данные
Вы должны заменить каждую букву и знак пунктуации тем, который находит-
находится непосредственно слева от него на клавиатуре QWERTY, изображенной выше.
Пробелы во входных данных должны повторяться в выходных.
Пример входных данных
0 S, GOMR YPSFU/
Соответствующие выходные данные
1 AM FINE TODAY.
3.8. Задачи 85
3.8.2. Где Waldorf?
PC/UVaIDs: 110302/10010
Популярность: В
Частота успехов: средняя
Уровень:2
По заданной сетке букв размером т х п и списку слов определить позицию
в сетке, в которой находится это слово.
Слово в сетке может располагаться только по прямой непрерывной линии
букв. Регистр букв значения для совпадения не имеет (то есть строчные и пропис-
прописные буквы считаются одинаковыми). Слово может располагаться в любом из
восьми диагональных, горизонтальных и вертикальных направлений.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное
целое число, которое означает количество тестовых блоков, за которой следует
пустая строка. Между двумя последовательными тестовыми блоками также нахо-
находится пустая строка.
Каждый блок начинается со строки, содержащей два целых числа тип, причем
1 < т,п < 50 в десятичной системе счисления. Следующие т строк содержат ровно
по п букв каждая, они представляют собой сетку букв, в которой необходимо искать
слова. Буквы в сетке могут быть как прописными, так и строчными. Далее за сеткой
следует строка, содержащая одно целое число к A < А: < 20). Следующие к строк
входных данных содержат список слов для поиска, одно слово в строке. Эти слова
состоят только из прописных и строчных букв - никаких пробелов, дефисов или
других символов, не принадлежащих стандартному алфавиту.
Выходные данные
Для каждого слова в тестовом блоке выведите два целых числа, представ-
представляющих собой его положение в сетке. Эти числа должны быть разделены одним
пробелом. Первое число в паре - это строка, где расположена первая буква данно-
данного слова A соответствует самой верхней строке, т соответствует самой нижней
строке). Второе число в паре представляет собой столбец, где расположена первая
буква данного слова A соответствует самому левому столбцу, п самому правому).
Если в сетке данное слово встречается более одного раза, выведите расположение
самого верхнего варианта (то есть тот случай, в котором первая буква расположе-
расположена максимально близко к верху сетки). Если под это условие подходит два и более
слова, выведите самый левый из этих случаев. Все слова встречаются в сетке по
крайней мере один раз.
Выходные данные для двух последовательных блоков должны быть разделены
пустой строкой.
86 Глава 3. Строки
Пример входных данных
8 11
abcDEFGhigg
hEbkWalDork
FtyAwaldORm
FtsimrLqsrc
byoArBeDeyv
Klcbqwikomk
strEBGadhrb
yUiqlxcnBj f
4
Waldorf
Bambi
Betty
Dagbert
Соответствующие выходные данные
2 5
2 3
1 2
7 8
3.8.3. Обычная перестановка
PC/UVaIDs: 110303/10252 #
Популярность: А
Частота успехов: средняя
Уровень: 1
Даны две строки а и 6, вывести строку х максимальной длины, состоящую из,
букв, таких, что существует перестановка х, являющаяся подстрокой перестанов-|
ки а и одновременно являющаяся подстрокой перестановки Ъ.
Входные данные
Файл входных данных содержит несколько блоков, причем каждый блок состоит
из двух последовательных строк. Это значит, что строки 1 и 2 - это тестовый блок,;
строки 3 и 4 - другой тестовый блок, и т. д. Каждая строка состоит из символов нияс^1
него регистра, причем первая строка в паре обозначает я, а вторая строка - Ъ. Максин
мальная длина каждой строки - 1000 символов.
3.8. Задачи 87
Выходные данные
Для каждого набора входных данных выведите строку, содержащую х. Если
несколько х подходит под вышеописанные критерии, выберите первую в алфавит-
алфавитном порядке.
Пример входных данных
pretty
women
walking
down
the
street
Соответствующие выходные данные
e
nw
et
3.8.4. Дешифратор II
PC/UVaIDs: 110304/850
Популярность: А
Частота успехов: средняя
Уровень:2
Распространенный, но ненадежный метод шифровки текста состоит
в перемене букв алфавита. Другими словами, каждая буква алфавита последова-
последовательно заменяется в тексте какой-то другой буквой. Чтобы шифровка была обра-
обратимой, никакие две буквы не заменяются одной и той же буквой.
Мощным методом криптоанализа является атака с известным открытым тек-
текстом (known plain text attack). При атаке с известным открытым текстом
дешифровщик знает фразу или предложение, зашифрованное противником,
и путем изучения зашифрованного текста выясняет метод кодировки.
Ваша задача - расшифровать несколько зашифрованных строк текста, полагая,
что каждая строка использует один и тот же набор замещений и что одна из зако-
закодированных строк является шифровкой открытого текста the quick brown fox
jumps over the lazy dog.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное
Целое число, которое означает количество тестовых блоков, за которой следует
пустая строка. Между двумя последовательными тестовыми блоками также нахо-
находится пустая строка.
Глава 3. Строки
Каждый блок состоит из нескольких строк входных данных, зашифрованных
способом, описанным выше. Зашифрованные строки содержат только строчные
буквы и пробелы, и их длина не превышает 80 символов. Число строк входных
данных не превышает 100.
Выходные данные
Для каждого тестового блока расшифруйте каждую строку и напечатайте их
в стандартный вывод. Если существует несколько различных вариантов дешифровки,
то подойдет любой. Если расшифровка невозможна, выведите
No solution.
Выходные данные для двух последовательных блоков должны быть разделены
пустой строкой.
Пример входных данных
vtz ud xnm xugm itr pyy j ttk gmv xt otgm xt xnm puk ti xnm f prxq
xnm ceoub lrtzv ita hegfd tsmr xnm ypwq ktj
frtjrpgguvj otvxmdxd prm iev prmvx xnmq
Соответствующие выходные данные
now is the time for all good men to come to the aid of the party
the quick brown fox jumps over the lazy dog
programming contests are fun arent they
3.8.5. Автоматизированное судейство
PC/UVaIDs: 110305/10188
Популярность: В
Частота успехов: средняя
Уровень:1
Известно, что люди, являющиеся судьями на состязаниях по программированию,
очень придирчивы. Чтобы устранить необходимость в них, напишите сценарий авто-
автоматизированного судейства (automated judge script), который будет суцить прислан-
присланные решения.
3.8. Задачи 89
Ваша программа должна принимать в качестве входных данных файл, содержа-
содержащий верные выходные данные, а также выходные данные присланной программы;
результатом работы программы должен быть ответ Accepted, Presentation
Error или Wrong Answer, определяемый следующим образом.
Accepted. Вы должны ответить "Accepted", если выходные данные коман-
команды полностью совпадают со стандартным решением. Все символы должны совпа-
совпадать и идти в том же порядке.
Presentation Error. Выводите "Presentation Error", если все цифровые
символы совпали в том же порядке, но при этом есть как минимум один несовпа-
несовпадающий нецифровой символ. Например, 5 0" и 50" вызовут "Presentation
Error", тогда как 5 0" и 0" вызовут "Wrong Answer", что описано ниже.
Wrong Answer. Если выходные данные команды не подходят ни под один из выше-
вышеописанных случаев, то у вас нет иного выбора, кроме как засчитать "Wrong Answer ".
Входные данные
Входные данные состоят из произвольного числа наборов. Каждый набор вход-
входных данных начинается со строки, содержащей положительное целое число п < 100,
описывающее число строк правильного решения. Следующие п строк содержат пра-
правильное решение. Далее следует строка, содержащая одно положительное целое
число т < 100, описывающее число строк в присланных командой выходных дан-
данных. Следующие т строк содержат эти выходные данные. Входные данные
завершаются значением п = 0, которое обрабатывать не нужно.
Длина любой строки не превышает 1000 символов.
Выходные данные
Для каждого набора выведите один из следующих вариантов:
Run #x: Accepted
Run #x: Presentation Error
Run #x: Wrong Answer
x обозначает номер набора входных данных (начиная с 1).
Пример входных данных
2
The
The
2
The
The
2
The
answer
answer
answer
answer
answer
is :
is :
is :
is :
is :
10
5
10
5
10
90
Глава 3. Строки
The answer
2
The answer
The answer
2
The answer
The answer
2
The answer
The answer
3
Input Set
Input Set
Input Set
3
Input Set
Input Set
Input Set
1
10 10
1
10101
1
The judges
1
The judges
0
is
is
is
is
is
is
is
#1
#2
#3
#0
#1
#2
10
15
10
5
10
YES
NO
NO
YES
NO
NO
are mean!
are good!
Соответствующие выходные данные
Run #1: Accepted
Run #2: Wrong Answer
Run #3: Presentation Error
Run #4: Wrong Answer
Run #5: Presentation Error
Run #6: Presentation Error
3.8.6. Осколки файлов
PC/UVaIDs: 110306/10132
Популярность: С
Частота успехов: средняя
Уровень:2
Ваш друг, специалист в области биохимии, споткнулся, когда вез тележку
с компьютерными файлами по лаборатории. Все файлы упали на землю и разбились.
Ваш друг собрал все осколки и обратился к вам с просьбой снова собрать их вместе.
3.8. Задачи 91
К счастью, все файлы на тележке были одинаковы, каждый разбился ровно на
два осколка, и все осколки были найдены. К сожалению, не все файлы сломались
в одном и том же месте, и осколки полностью смешались во время падения на пол.
Оригинальные бинарные осколки были транслированы в строки ASCII из единиц
и нулей. Вашей задачей является написание программы, которая определяет битовую
схему, содержавшуюся в файлах.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное
целое число, которое означает количество тестовых блоков, за которой следует
пустая строка. Между двумя последовательными тестовыми блоками также нахо-
находится пустая строка.
Каждый блок состоит из последовательности «файловых осколков», по
одному на строку, завершающейся меткой конца файла или пустой строкой.
Каждый осколок состоит из ASCII нулей и единиц.
Выходные данные
Для каждого тестового блока выведите единственную строку, состоящую из
ASCII нулей и единиц и задающую битовую схему оригинальных файлов. Если во
входных данных содержится 2N осколков, должна существовать возможность
объединить эти осколки в пары так, чтобы получилось N копий выходной строки.
Если существующее решение не единственно, то в качестве выходных данных по-
подойдет любое из возможных решений.
Ваш друг уверен, что на тележке было не более 144 файлов и что файлы были
не длиннее 256 байт.
Выходные данные для двух последовательных блоков должны быть разделены
пустой строкой.
Пример входных данных Соответствующие выходные данные
1 01110111
011
0111
01110
111
0111
10111
92 Глава 3. Строки
3.8.7. Дублеты
PC/UValDs: 110307/10150
Популярность: С
Частота успехов: средняя
Уровень:3
Дублетом называются два слова, которые отличаются ровно в одной букве
(например, «booster» и «rooster», или «rooster» и «roaster», или «roaster» и «roasted»).
Вам задается словарь длиной не более 25 143 слов, состоящих из строчных букв,
причем длина каждого слова не превышает 16 букв. Далее вам задается некоторое
число пар слов. Для каждой пары слов найдите последовательность слов, имеющую
наименьшую длину, причем первое слово последовательности должно совпадать
с первым словом из заданной пары, а последнее слово последовательности - со
вторым словом из пары. Каждая пара соседних слов последовательности должна
быть дублетом. Например, если вам задана пара «booster» и «roasted», возможным
решением является «booster», «rooster», «roaster», «roasted», при условии, что все
эти слова присутствуют в словаре.
Входные данные
Файл входных данных содержит словарь, за которым следует некоторое число пар
слов. Словарь состоит из произвольного числа слов, по одному на строку, и заверша-
завершается пустой строкой. Далее идут пары слов; каждая строка содержит пару слов, разде-
разделенных пробелом.
Выходные данные
Для каждой введенной пары напечатайте набор строк, начинающийся
с первого слова и заканчивающийся последним. Каждая пара соседних строк
должна быть дублетом.
Если существует несколько вариантов минимальных решений, то подойдет
любое. Если решения не существует, выведите строку "No solut ion. ". Между
блоками должна быть пустая строка.
3.8. Задачи 93
Пример входных данных Соответствующие выходные данные
Booster booster
rooster rooster
roaster roaster
coasted roasted
roasted
coastal No solution.
postal
booster roasted
coastal postal
3.8.8. Fmt
PC/UVaIDs: 110308/848
Популярность: С
Частота успехов: низкая
Уровень:2
UNIX - программа ym/ читает строки текста, комбинируя и разбивая их так,
чтобы создать выходной файл со строками, максимально приближающимися по
длине к 72 символам, не превышая этого лимита. Правила объединения и разбие-
разбиения следующие.
• Новая строка может начинаться с любого пробела во входных данных. Когда
начинается новая строка, пробелы в конце предыдущей и начале новой строки
удаляются.
• Конец строки во входных данных может быть удален в выходных данных,
если A) он не находится в конце пустой строки или строки, состоящей из
пробелов, и B) за ним не следует пробел или другой конец строки. Когда
конец строки удаляется, он заменяется пробелом.
• В конце каждой строки выходных данных пробелы должны удаляться.
• Любое слово во входных данных, которое содержит более 72 символов, долж-
должно выводиться одно на строку.
Вы можете считать, что входной текст не содержит символов табуляции.
Пример входных данных
Unix fmt
The unix fmt program reads line of text, combining
and breaking lines so as to create an
output file with lines as close to without exceeding
72 characters long as possible. The rules for combining and breaking
lines are as follows.
94 Глава 3. Строки
1. A new line may be started anywhere there is a space in the input.
If a new line is started, there will be no trailing blanks at the
end of the previous line or at the beginning of the new line.
2 . A line break in the input may be eliminated in the output, provided
it is not followed by a space or another line break. If a line
break is eliminated, it is replaced by a space.
Соответствующие выходные данные
Unix fmt
The unix fmt program reads line of text, combining and break-
breaking lines so as to create an output file with lines as close
to without exceeding 72 characters long as possible. The
rules for combining and breaking lines are as follows.
1. A new line may be started anywhere there is a space in the
input. If a new line is started, there will be no trailing
blanks at the end of the previous line or at the beginning of
the new line.
2. A line break in the input may be eliminated in the output,
provided it is not followed by a space or another line break.
If a line break is eliminated, it is replaced by a space.
3.9. Подсказки
3.1. Нужно ли вам жестко кодировать логику, чтобы произвести замещение симво-
символов, или проще будет использовать стратегию инициализированных таблиц
замещения?
3.2. Можете ли вы написать одну-единственную подпрограмму сравнения с аргу-
аргументами, которые могут поддерживать сравнение во всех восьми направле-
направлениях, при вызове с соответствующими аргументами? Имеет ли смысл зада-
задавать направления как пару чисел E^, 5^) вместо имени?
3.3. Можете ли вы переставить буквы в каждом слове так, чтобы обычная переста-
перестановка стала более очевидной?
3.4. Как проще всего сравнивать только цифровые символы, что требуется для
определения ошибок представления?
3.5. Можете ли вы просто выяснить, какие пары осколков идут вместе, если не учи-
учитывать их порядок?
3.6. Можем ли мы смоделировать эту задачу как задачу пути в графах? Возможно,
стоит заглянуть вперед, в главу 9, где мы введем структуры данных для графов
и алгоритмы обхода.
3.10. Замечания 95
3.10. Замечания
3.1. Хотя история криптографии насчитывает тысячи лет, коренной прорыв был
произведен улучшениями численных методов и новыми алгоритмами. Читайте
книги Шнейера (Shneier) [Sch94] и/или Стинсона (Stinson) [StiO2], чтобы
узнать больше об этой интересной области науки.
3.2. Золотым стандартом среди программ текстового форматирования является
Latex, система, которую мы использовали для набора этой книги. Она осно-
основана на системе ТеХ, которую разработал ведущий компьютерный ученый
Доналд Кнут (Don Knuth). Он является автором известных книг Искусство
программирования (Art of Computer Programming) [Knu73a, Knu81, Knu73b],
остающихся актуальными и непревзойденными спустя более 30 лет после их
первого издания.
Глава 4
Сортировка
Сортировка является наиболее фундаментальной алгоритмической задачей
в теории вычислительных машин и систем по двум различным причинам. Во-
первых, сортировка - это полезная операция, которая эффективно решает многие
задачи, с которыми встречается каждый программист. Как только вы поймете, что
ваша задача - это определенный случай сортировки, надлежащее использование
библиотечных функций быстро решит проблему.
Во-вторых, были разработаны буквально десятки различных алгоритмов
сортировки, каждый из которых основывается на определенной хитрой идее или на-
наблюдении. Большинство примеров разработки алгоритмов ведет к интересным ал-
алгоритмам, включающим «разделяй и властвуй», рандомизацию, инкрементную
вставку и продвинутые струюуры данных. Из свойств этих алгоритмов следует
множество интересных задач по программированию/математике.
В этой главе мы рассмотрим основные приложения сортировки, так же как и
теорию, на которой основаны наиболее важные алгоритмы. Наконец, мы опишем,
как использовать подпрограммы библиотек сортировки, которые предоставляют-
предоставляются всеми современными языками программирования, и покажем, как применять
их для решения нетривиальной задачи.
4.1. Приложения сортировки
Ключом к пониманию сортировки является понимание того, как она может
быть использована для решения многих важных задач программирования.
• Проверка уникальности. Как мы можем проверить, все ли элементы данного
набора объектов S являются различными? Отсортируем их либо
в возрастающем, либо в убывающем порядке, так что любые повторяющиеся
объекты будут следовать друг за другом. После этого один проход по всем
элементам с проверкой равенства 5[/] = 5[/+ 1] для любого 1 <i<n решает
поставленную задачу.
• Удаление повторяющихся элементов. Как мы можем удалить все копии, кроме
одной, любого из повторяющихся элементов в 5? Сортировка и чистка снова
4.1. Приложения сортировки 97
решают задачу. Обратите внимание, что чистку проще всего производить, исполь-
используя два индекса - back, указывающий на последний элемент в очищенной части
массива, и /, указывающий на следующий элемент, который нужно рассмотреть.
Если S[back] < > S[i], увеличиваем back и копируем S[i] в S[back].
• Распределение приоритетов событий. Предположим, что у нас имеется список
работ, которые необходимо сделать, и для каждой определен свой собственный
срок сдачи. Сортировка объектов по времени сдачи (или по аналогичному
критерию) расположит работы в том порядке, в котором их необходимо делать.
Очереди по приоритетам удобны для работы с календарями и расписаниями,
когда имеются операции вставки и удаления, но сортировка удобна в том
случае, когда набор событий не меняется в процессе выполнения.
• Медиана/Выбор. Предположим, что мы хотим найти к-и по величине объект в S.
После сортировки объектов в порядке возрастания нужный нам будет находиться
в ячейке S[k]. В определенных случаях этот подход может быть использован для
нахождения (слегка неэффективным образом) наименьшего, наибольшего и меди-
медианного элемента.
• Расчет частоты. Какой элемент чаще всего встречается в S, то есть является
модой? После сортировки линейный проход позволяет нам посчитать число
раз, которое встречается каждый элемент.
• Восстановление первоначального порядка. Как мы можем восстановить
первоначальное расположение набора объектов, после того как мы перестави-
переставили их для некоторых целей? Добавим дополнительное поле к записи данных
объекта, такое что для /-й записи это поле равняется /. Сохранив это поле во
время всех перестановок, мы сможем отсортировать по нему тогда, когда нам
потребуется восстановить первоначальный порядок.
• Создание пересечения/объединения. Как мы можем рассчитать пересечение
или объединение двух контейнеров? Если они оба отсортированы, мы можем
объединить их, если будем выбирать наименьший из двух ведущих элемен-
элементов, помещать его в новое множество, если хотим, а затем удалять из соответ-
соответствующего списка.
• Поиск необходимой пары. Как мы можем проверить, существуют ли два целых
числа x,yeS таких, что х + у = z для какого-то заданного z? Вместо того чтобы
перебирать все возможные пары, отсортируем числа в порядке возрастания
и sweep. С ростом S[i], при увеличении /, его возможный партнеру, такой что
S\j] = z ~ $[i]> уменьшается. Таким образом, уменьшая j соответствующим
образом при увеличении /, мы получаем изящное решение.
4-972
Глава 4. Сортировка
Эффективный поиск. Как мы можем эффективно проверить, принадлежит ли
элемент s множеству 5? Конечно, упорядочивание множества с целью приме-
применения эффективного бинарного поиска - это, наверное, наиболее стандартное
приложение сортировки. Просто не забывайте остальные!
4.2. Алгоритмы сортировки
Вполне возможно, что вы видели десяток или даже больше алгоритмов сортиров-
сортировки данных. Вы помните пузырьковую сортировку, сортировку методом вставок,
сортировку методом выбора, пирамидальную сортировку , сортировку слиянием,
быструю сортировку, поразрядную сортировку, распределяющую сортировку,
сортировку Шелла, симметричный обход деревьев и сортировочные сети? Вероятнее
всего, вам надоело читать уже на середине списка. Кому нужно столько способов сде-
сделать одно и то же, особенно при условии, что существует библиотека функций
сортировки, поставляемая вместе с вашим любимым языком программирования?
Настоящей причиной для изучения алгоритмов является то, что идеи, стоящие
за ними, стоят за алгоритмами для многих других задач. Если вы поймете, что пира-
пирамидальная сортировка на самом деле основана на структурах данных, быстрая
сортировка на самом деле основана на рандомизации, сортировка слиянием на
самом деле основана на принципе «разделяй и властвуй», то у вас появится большой
диапазон алгоритмических инструментов для последующего использования.
Ниже мы рассмотрим несколько достаточно поучительных алгоритмов. Не забудьте
познакомиться с полезными свойствами (такими, как минимизация перемещения дан-
данных), приведенными для каждого алгоритма.
Сортировка методом выбора. Этот алгоритм разбивает входной массив на
отсортированную и несортированную части, на каждой итерации находит
наименьший элемент, имеющийся в несортированной части, и перемещает
его в конец отсортированной области.
selection_sort(int s[], int n)
{
*/
индекс минимального элемента */
min=j
'Пирамидальную сортировку часто называют сортировкой с помощью кучи. - Примеч. науч. ред.
int
int
for
} }
i/ j;
min;
(i = 0
min=
for
swap
;
i;
(j
if
i<n
;
= i + l;
(s
(&s[i
[j
],
/* счетчр'
/* индекс
i + + ) (
j<n; j++)
] < s[min]
&s[min]);
4.2. Алгоритмы сортировки 99
Сортировка методом выбора производит множество сравнений, но доста-
достаточно эффективна, если все, что нас интересует, - это число перемещений
данных. Алгоритмом производится всего п - 1 перестановок в наихудшем
случае; считайте сортировку «обратной перестановкой цепочки минимумов»
reversed permutation. Также на ее примере можно пронаблюдать эффектив-
эффективность продвинутых структур данных. Использование очереди по приорите-
приоритетам для несортированной части массива неожиданно превращает О(п2)
сортировку методом выбора в О(п ^)-пирамидальную сортировку!
• Сортировка методом вставки. Этот алгоритм также использует отсортирован-
отсортированную и несортированную части массива. На каждой итерации очередной
несортированный элемент помещается на соответствующую позицию в отсор-
отсортированной области.
insertion_sort(int s[], int n)
{
int i,j; /* счетчики */
for (i=l; i<n;
while ((j>0) ScSc (s[j] < s[j-l])) {
swap(&s[j] ,&s[j-l] ) ;
j = j-l;
Сортировка методом выбора достаточно важна как алгоритм, сводящий
к минимуму количество перемещаемых данных. Инверсией в перестановке р
называется пара элементов, стоящих не по порядку, то есть i,j такие, что / <j,
хотя p[i] >/?[/]. Каждая перестановка в методе вставки удаляет только одну
инверсию, в противном случае ни один элемент не перемещается, так что
число перестановок равняется числу инверсий. Так как в почти упоря-
упорядоченной перестановке содержится очень мало инверсий, сортировка мето-
методом вставки может быть весьма эффективной для таких данных.
Быстрая сортировка. Этот алгоритм сводит задачу сортировки одного большого
массива к задаче сортировки двух меньших массивов, добавляя шаг разбиения.
Разбиение делит массив на элементы меньшие центрального/делящего элемента
и на элементы строго большие центрального/делящего элемента. Так как никако-
никакому элементу больше не понадобится покидать свою область, каждый подмассив
может сортироваться отдельно. Для облегчения сортировки подмассивов в аргу-
аргументы quicksort включены индексы первого A) и последнего (h) элемента
подмассива.
100 Глава 4. Сортировка
quicksort(int s[], int 1, int h)
int p; /* индекс разбиения */
if ((h-l)>0) {
p = partition(s,1,h);
quicksort(s, 1, p-1);
quicksort(s,p+l,h);
int partition(int s[], int 1, int h)
{
int i; /* счетчик */
int p; /* индекс центрального элемента */
int firsthigh; /* расположение делителя для централь-
центрального элемента */
Р = h;
firsthigh = 1;
for (i=l; i<h; i++)
if (s[i] < s[p]) {
swap(&s [i] , &s [firsthigh] ) ;
firsthigh + +;
}
swap(&s[p], &s[firsthigh]);
return(firsthigh);
}
Быстрая сортировка интересна по нескольким причинам. При правильной реа-
реализации это самый быстрый алгоритм сортировки «в памяти». Алгоритм является
прекрасной иллюстрацией возможностей рекурсии. Алгоритм partition удобен
для многих задач сам по себе. Например, как вы разделите массив, содержащий
только 0 и 1, на две части, каждая из которых состоит только из одного символа?
4.3. Пример разработки программы: рейтинг
ухажеров
У красотки Полли нет недостатка в прекрасно воспитанных ухажерах. Напротив,
самой большой ее проблемой является отслеживание самых лучших из них. Она дос-
достаточно умна, чтобы понять, что программа, ранжирующая мужчин от наиболее
к наименее желаемому, упростит ее жизнь. Также она достаточно настойчива, чтобы
упросить вас написать эту программу.
4.3. Пример разработки программы: рейтинг ухажеров 101
Полли очень любит танцевать, и она считает, что оптимальный рост ее партнера
составляет 180 сантиметров. Поэтому первое ее требование состоит в том, чтобы
найти кого-либо, чей рост близок, насколько это возможно, к этой величине; будут
они чуть выше или чуть ниже, не имеет значения. Среди всех кандидатов одного
роста ей нужен кто-либо, чей вес близок, насколько это возможно, к 75 килограммам,
но не превышает этой величины. Если все кандидаты одного роста весят больше, то
она выберет самого легкого. Если у двух или более людей все эти характеристики
совпадают, то отсортируйте их по фамилии, а после, если это необходимо, по имени.
Полли нужно видеть только имена отсортированных кандидатов, так что вход-
входной файл:
George Bush
Harry Truman
Bill Clinton
John Kennedy
Ronald Reagan
Richard Nixon
Jimmy Carter
195
180
180
180
165
170
180
110
75
75
65
110
70
77
приведет к следующим выходным данным:
Clinton, Bill
Truman, Harry
Kennedy, John
Carter, Jimmy
Nixon, Richard
Bush, George
Reagan, Ronald
Решение начинается ниже
Суть этой проблемы состоит в достаточно сложной сортировке по критериям,
заданным для нескольких полей. Существует как минимум два различных способа,
которыми мы можем это сделать. В первом способе мы производим несколько про-
проходов сортировки, сортируя сначала по наименее важному ключу, затем по сле-
следующему по важности ключу и т. д., пока мы не проведем последнюю сортировку
по самому важному ключу.
Почему нужно сортировать именно в таком порядке? Второстепенные ключи ис-
используются только для того, чтобы разрешить равенство в сортировке по главному
ключу. При условии, что наш алгоритм устойчив, то есть сохраняет относительный
порядок равных ключей, наша обработка второстепенных ключей остается незатро-
незатронутой, если это важно для конечного ответа.
102 Глава 4. Сортировка
Не все алгоритмы сортировки устойчивы; более того, самые быстрые неустойчи-
неустойчивы! Функции insertion_sort и selection_sort из раздела 4.2 устойчивы,
тогда как quicksort неустойчива. Внимательно ознакомьтесь с документацией,
прежде чем предполагать устойчивость любой функции сортировки.
При другом подходе, который предпочли мы, все ключи свертываются в одну
сложную функцию сравнения. При выборе такого способа проще всего восполь-
воспользоваться преимуществами библиотечной подпрограммы сортировки, описанной
в следующем разделе.
4.4. Функции библиотеки сортировки
Когда есть возможность, используйте встроенные в ваш любимый язык про-
программирования библиотеки сортировки/поиска:
Сортировка и поиск в С
В stdlib.h содержатся библиотечные функции для сортировки и поиска.
Для сортировки присутствует функция qsort.
#include <stdlib.h>
void qsort(void *base, size_t nel, size_t width,
int (*compare) (const void *, const void *));
Ключ к использованию qsort лежит в понимании, для чего нужны его аргумен-
аргументы. Функция сортирует первые nel элементов массива (на который указывает base),
причем размер каждого элемента составляет width байт. Таким образом, мы можем
сортировать массивы 1-байтовых символов, 4-байтовых целых чисел или 100-байто-
100-байтовых записей, меняя значение width.
Общий желаемый порядок определяется функцией compare. В качестве
аргументов она принимает два элемента длиной width байт и возвращает отри-
отрицательное число, если в порядке сортировки первый лежит перед вторым; поло-
положительное число, если в порядке сортировки второй лежит перед первым; нуль,
если они равны.
Вот функция сравнения для сортировки целых чисел в порядке возрастания:
int intcompare(int *i, int *j)
if
if
(
(
*i
*i
return
>
<
@)
*D
*j
•
)
)
return
return
A)
(-1
;
);
4.4. Функции библиотеки сортировки 103
Эта функция сравнения может быть использована для сортировки массива а,
в котором заняты первые cnt элементов:
qsort((char *) a, cnt, sizeof(int), intcompare);
Более сложный пример использования qsort будет показан в разделе 4.5. Имя
qsort предполагает, что алгоритм, реализованный в библиотечной функции, это
быстрая сортировка, хотя пользователю обычно это безразлично.
Обратите внимание, что qsort уничтожает содержимое первоначального
массива, так что если вам необходимо восстановить первоначальный порядок,
создайте копию или добавьте новое поле к записи, как описано в разделе 4.1.
Бинарный поиск весьма непросто правильно реализовать при недостатке времени.
Лучшим решением будет даже не пробовать, потому что библиотека stdlib.h
содержит вариант реализации, называющийся bsearch(). Все аргументы, кроме
ключа поиска, аналогичны аргументам qsort. Чтобы провести поиск в предыдущем
отсортированном массиве, используйте
bsearch(key/ (char *) a, cnt, sizeof(int), intcompare);
Сортировка и поиск в C++
C++ Standard Template Library (STL), которая обсуждалась в разделе 2.2.1,
включает методы для сортировки, поиска и других задач. Пользователи,
собирающиеся серьезно работать с C++, должны хорошо знать STL.
Чтобы провести сортировку с помощью STL, мы можем или использовать
функцию сравнения по умолчанию (например, <), определенную для класса, или
подменить ее специализированной функцией сравнения ор:
void sort(RandomAccessIterator bg, RandomAccessIterator end)
void sort(RandomAccessIterator bg, RandomAccessIterator end,
BinaryPredicate op)
STL также предоставляет устойчивую подпрограмму сортировки, в которой
ключи с равными значениями гарантированно останутся в том же относительном
порядке. Это может пригодиться для сортировки по нескольким критериям:
void stable_sort (RandomAccessIterator bg, RandomAccessIterator end)
void stable_sort (RandomAccessIterator bg, RandomAccessIterator end,
BinaryPredicate op)
В других функциях STL реализованы некоторые приложения сортировки,
описанные в разделе 4.1, включающие в себя:
• nth_element — возвращает n-й по величине элемент в контейнере.
104
Глава 4. Сортировка
• set_union, set_intersection, set_dif f erence - задают объеди-
объединение, пересечение и разность множеств для двух контейнеров.
• unique - удаляет все последовательные дубликаты.
Сортировка и поиск в Java
Класс java.util .Arrays содержит различные методы для сортировки
и поиска. В частности,
static void sort(Object[] a)
static void sort(Object[] a, Comparator c)
сортируют заданный массив объектов в порядке возрастания, используя либо
естественное упорядочивание его элементов, либо специальный компаратор с.
Также доступны устойчивые сортировки.
Методы для поиска заданного объекта в отсортированном массиве с использо-
использованием либо натуральной функции сравнения, либо нового компаратора с:
binarySearch(Object[] a, Object key)
binarySearch(Object[] a, Object key, Comparator c)
4.5. Рейтинг ухажеров
Для решения проблемы Полли со свиданиями мы хотели сделать шаг
сортировки по нескольким критериям настолько простым, насколько это возмож-
возможно. Сначала мы должны разобраться с базовыми структурами данных.
#include <stdio.h>
tinclude <string.h>
#def ine NAMELENGTH 3 0
#def ine NSUITORS 100
#def ine BESTHEIGHT 180
#def ine BESTWEIGHT 75
typedef struct {
char first [NAMELENGTH] ;
char last [NAMELENGTH] ;
int height;
int weight;
} suitor;
suitor suitors[NSUITORS];
int nsuitors;
/* максимальная длина имени */
/* максимальное число ухажеров */
/* лучший рост в сантиметрах */
/* лучший вес в килограммах */
/* фамилия ухажера */
/* имя ухажера */
/* высота ухажера */
/* вес ухажера */
/* база данных ухажеров */
/* число ухажеров */
4.5. Рейтинг ухажеров 105
Далее нам нужно считать входные данные. Обратите внимание, что мы не
сохраняем действительный рост и вес ухажера! Критерии ранжирования Полли
для роста и веса достаточно неудобны и основываются на том, как эти величины
соотносятся с эталонным ростом/весом вместо обычного линейного упорядочива-
упорядочивания (то есть в порядке убывания или возрастания). Вместо простого сохранения
мы изменяем каждый рост и вес так, чтобы величины были линейно упорядочены
по привлекательности:
read_suitors()
{
char first[NAMELENGTH], last[NAMELENGTH];
int height, weight;
nsuitors = 0;
while (scanf("%s %s %d %d\n", suitors[nsuitors].first,
suitors [nsuitors] .last, Scheight, &weight) != EOF) {
suitors[nsuitors].height = abs(height - BESTHEIGHT);
if (weight > BESTWEIGHT)
suitors[nsuitors].weight = weight - BESTWEIGHT;
else
suitors[nsuitors].weight = - weight;
nsuitors++;
Наконец, обратите внимание, что мы прочитали имя и фамилию как лексемы,
вместо того чтобы считывать их посимвольно.
Центральная функция сравнения принимает в качестве входных данных двух
ухажеров аиЬи решает, а лучше, Ъ лучше или они одинаковы по привлекательности.
Чтобы удовлетворить требованиям qsort, мы должны возвращать -1, 1 и 0 в этих
трех случаях соответственно. Это реализовано в следующей функции сравнения:
int suitor_compare(suitor *а, suitor *b)
{
int result; /* результат сравнения */
if (a->height < b->height) return(-1);
if (a->height > b->height) returnA);
if (a->weight < b->weight) return(-1);
if (a->weight > b->weight) returnA);
if ((result=strcmp(a->last,b->last)) != 0) return result;
return(strcmp(a->first,b->first));
106 Глава 4. Сортировка
После того как мы разобрались с подпрограммами сравнения и считывания
входных данных, все, что остается, - это основная программа, которая на самом
деле просто вызывает qsort и формирует выходные данные.
main()
{
int i; /* счетчик */
int suitor_compare();
read_suitors();
qsort(suitors, nsuitors, sizeof(suitor), suitor_compare);
for (i=0; i<nsuitors; i
printf("%s, %s\n",suitors[i] .last, suitors[i] .first);
4.6. Задачи
4.6.1. Семья Вито
PC/UVaIDs: 110401/10041
Популярность: А
Частота успехов: высокая
Уровень:1
Знаменитый гангстер Вито Дедстоун переезжает в Нью-Йорк. У него там очень
большая семья, и все живут на Лямафия-авеню. Так как он собирается навещать
всех своих родственников очень часто, он хочет найти дом рядом с ними.
На самом деле Вито хочет свести к минимуму совокупное расстояние до всех
своих родственников, и он шантажирует вас с целью заставить написать програм-
программу, которая решит его проблему.
Входные данные
Входные данные состоят из нескольких тестовых блоков. Первая строка содержит
число тестовых блоков.
В каждом тестовом блоке вам будет задано целое число родственников г
@ < г < 500) и номера домов (также целые числа) sj, s2, ..., sif ..., sn в которых они
проживают. Несколько родственников могут жить в одном доме.
4.6. Задачи 107
Выходные данные
Для каждого тестового блока ваша программа должна вывести минимальную сумму
расстояний от оптимального дома Вито до домов всех его родственников. Расстояние
между двумя домами с номерами st и s.- вычисляется по формуле йц — \ sx¦- S: |.
Пример входных данных
2
2 2 4
3 2 4 6
Соответствующие выходные данные
2
4
4.6.2. Стопки оладий
PC/UValDs: 110402/120
Популярность: В
Частота успехов: высокая
Уровень: 2
Приготовить идеальную стопку оладий на гриле - это хитрое дело, потому
что, как вы ни старайтесь, все оладьи в стопке имеют разные диаметры. Тем не
менее для аккуратности вы можете упорядочить стопку по размеру так, чтобы
каждая оладья была меньше всех оладий, находящихся под ней. Размер оладьи
определяется ее диаметром.
Сортировка стопки производится серией «переворотов» оладий. Переворот состоит
в том, что вы помещаете лопатку между двумя оладьями в стопке и переворачиваете
(меняете порядок на обратный) все оладьи на лопатке (реверсируете подстопку). Пере-
Переворот задается позицией оладьи, находящейся внизу подстопки, которую нужно пере-
перевернуть по отношению ко всей стопке. Позиция нижней оладьи 1, тогда как для
стопки из п оладий позиция верхней оладьи п.
Стопка определяется заданием диаметра каждой оладьи в стопке в порядке
следования. Например, рассмотрим три стопки оладий, причем в левой стопке
оладья 8 является самой верхней:
8 7 2
4 6 5
6 4 8
7 8 4
5 5 6
2 2 7
От левой стопки к средней можно перейти путем flipC). От средней стопки
к правой можно перейти путем команды flip(l).
108 Глава 4. Сортировка
Входные данные
Входные данные состоят из последовательности стопок оладий. Число оладий
в каждой стопке лежит между 1 и 30, и каждая оладья имеет целочисленный диа-
диаметр, лежащий в пределах от 1 до 100. Входные данные завершаются символом
конца файла. Каждая стопка задается одной строкой входных данных, при этом
верхняя оладья в стопке идет первой, нижняя последней и все оладьи разделены
пробелами.
Выходные данные
Для каждой стопки оладий ваша программа должна повторять оригинальную
стопку одной строкой, за которой должна следовать последовательность пере-
переворотов, упорядочивающая стопку оладий так, что самая большая оладья нахо-
находится внизу стопки, а самая маленькая наверху. Последовательность переворотов
для каждой стопки должна завершаться 0, указывающим на то, что больше пере-
переворотов не нужно.
Пример входных данных Соответствующие выходные данные
12345 12345
5 4 3 2 1 0
51234 54321
1 0
5 12 3 4
12 0
4.6.3. Мост
PC/UValDs: 110403/10037
Популярность: В
Частота успехов: низкая
Уровень: 3
Группа из п людей хочет ночью пересечь мост. Одновременно по мосту могут
идти максимум два человека, и у каждой группы должен быть фонарик. Фонарик
у этих п людей только один, так что кто-то должен приносить фонарик назад, чтобы
все люди смогли перейти.
Каждый человек переходит мост со своей скоростью; скорость пары определя-
определяется скоростью более медленного ее члена. Ваша задача состоит в определении
стратегии, при которой все п людей пересекут мост за минимальное время.
4.6. Задачи 109
Входные данные
Входные данные начинаются со строки, содержащей одно положительное
целое число, которое означает количество тестовых блоков, за которой следует
пустая строка. Между двумя последовательными тестовыми блоками также нахо-
находится пустая строка.
Первая строка каждого блока содержит и, далее следуют п строк, задающие
скорости каждого человека. Всего людей не более 1000, и каждому требуется не
более 100 секунд, чтобы пересечь мост.
Выходные данные
Для каждого тестового блока первая строка выходных данных должна сооб-
сообщать суммарное число секунд, которое потребуется на то, чтобы все п людей
пересекли мост. Последующие строки содержат стратегию, ведущую к получе-
получению такого времени. Каждая строка содержит одно или два целых числа, показы-
показывающих, какой человек или люди образуют следующую группу, пересекающую
мост. Каждый человек обозначается временем пересечения моста, заданным во
входных данных. Хотя у многих людей скорости могут совпадать, эта неопреде-
неопределенность не имеет никакого значения.
Обратите внимание, что переходы меняют направление, так как необходимо
возвращать фонарик, чтобы остальные могли перейти. Если к минимальному вре-
времени ведет более чем одна стратегия, то подойдет любая.
Выходные данные для двух последовательных блоков должны быть разделены
пустой строкой.
Пример входных данных Соответствующие выходные данные
1 17
1 2
4 1
1 5 10
2 2
5 12
10
110 Глава 4. Сортировка
4.6.4. Подремать подольше
PC/UVaIDs: 110404/10191
Популярность: В
Частота успехов: средняя
Уровень:1
Профессора ведут очень активный образ жизни, и их расписания наполнены
работой и встречами. Профессор Р. любит подремать днем, но его расписание
заполнено настолько плотно, что у него почти нет возможности это сделать.
Тем не менее он очень хочет подремать днем хотя бы один раз. На самом деле,
он хочет подремать за один раз как можно дольше при его расписании. Напишите
программу, чтобы помочь ему с этой задачей.
Входные данные
Входные данные состоят из произвольного числа тестовых блоков, причем
каждый тестовый блок представляет собой один день.
Первая строка каждого блока содержит положительное число s < 100, представ-
представляющее собой число запланированных на этот день событий. Далее следуют s строк,
содержащие события в формате timel time2 appointment, где timel - это время начала
события, a time2 - время его окончания. Все времена задаются в формате hh: mm;
время окончания всегда будет строго позже времени начала и отделено от него одним
пробелом.
Все времена будут больше либо равны 10:00 и меньше либо равны 18:00.
Таким образом, ваш ответ также должен попадать в этот интервал; то есть профес-
профессор не может начать дремать раньше 10:00 и закончить позже 18:00.
Событие может быть любой последовательностью символов, но всегда будет
находиться на той же строке. Вы можете считать, что длина каждой строки не пре-
превышает 255 символов, что 10 < hh < 18 и что 0 < mm < 60. Но тем не менее вы не
можете считать, что входные данные будут в каком-либо определенном порядке,
и должны считывать их, пока не достигнете конца файла.
Выходные данные
Для каждого тестового блока вы должны вывести следующую строку:
Day #d: the longest nap starts at hh:mm and will last for [H hours and]
M minutes.
Здесь d обозначает номер тестового блока (начиная с 1) и hh:mm - это время,
когда профессор начинает дремать. Чтобы отобразить время, которое профессор
будет дремать, используйте следующие правила.
4.6. Задачи 111
1. Если общее время Xменьше чем 60 минут, выведите просто "X minutes . ".
2. Если общая длительность X как минимум 60 минут, напечатайте "Я hours
andMminutes", где
Н = Х + 60 (деление, естественно, целочисленное) иМ = Xmod 60.
Вам не нужно заботиться о правильном отображении множественного
и единственного числа; то есть вы должны в соответствующем случае выводить
minutes"или hours".
Продолжительность времени, в течение которого профессор дремлет, определя-
определяется как разность конечного и начального времени. Например, если одно событие
заканчивается в 14:00 и следующее начинается в 14:47, то у профессора есть воз-
возможность подремать 14:47 - 14:00 = 47 минут.
Если профессор может подремать максимальное количество времени два раза
за день (длительности перерывов совпадают), выведите более ранний вариант.
Вы можете считать, что у профессора не будет занят весь день, так что время для
того, чтобы подремать хотя бы один раз, у него обязательно найдется.
Пример входных данных
4
10:00 12:00 Lectures
12:00 13:00 Lunch, like always.
13:00 15:00 Boring lectures...
15:30 17:45 Reading
4
10:00 12:00 Lectures
12:00 13:00 Lunch, just lunch.
13:00 15:00 Lectures, lectures... oh, no!
16:45 17:45 Reading (to be or not to be?)
4
10:00 12:00 Lectures, as everyday.
12:00 13:00 Lunch, again!!!
13:00 15:00 Lectures, more lectures!
15:30 17:45 Reading (I love reading, but should I schedule it?)
1
12:00 13:00 I love lunch! Have you ever noticed it? :)
Соответствующие выходные данные
Day #1: the longest nap starts at 15:00 and will last for 3 0 minutes .
Day #2 : the longest nap starts at 15 : 00 and will last for 1 hours
45 minutes.
Day #3 : the longest nap starts at 17 :15 and will last for 45 minutes .
Day #4 : the longest nap starts at 13 : 00 and will last for 5 hours and
0 minutes.
112 Глава 4. Сортировка
4.6.5. Задача сапожника
PC/UVaIDs: 110405/10026
Популярность: С
Частота успехов: средняя
Уровень:2
У сапожника имеется N заказов от покупателей, которые он должен выпол-
выполнить. Сапожник может заниматься в день только одним заказом, и заказы обычно
требуют на выполнение несколько дней. Для /-го заказа целое число 7} A < 7} < 1000)
означает число дней, необходимых сапожнику для завершения заказа.
Но за популярность нужно платить. За каждый день задержки перед тем, как он
приступит к работе над i-м заказом, сапожник согласился платить штраф в размере
5/ A ^Sj< 1000) центов в день. Помогите сапожнику, написав программу, находя-
находящую последовательность работ, ведущую к минимальному штрафу.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное целое
число, которое означает количество тестовых блоков, за которой следует пустая строка.
Между двумя последовательными тестовыми блоками также находится пустая строка.
Первая строка каждого блока содержит целое число, задающее число заказов N9
причем 1 < N< 1000. /-я последующая строка содержит время завершения 7} и еже-
ежедневный штраф Si для /-го заказа.
Выходные данные
Для каждого тестового блока ваша программа должна вывести последователь-
последовательность заказов, ведущую к минимальному штрафу. Каждый заказ представляется сроей
позицией во входных данных. Все целые числа должны находиться на одной строке
выходных данных и каждая пара чисел должна быть разделена одним пробелом. Если
возможны несколько решений, выведите первое в лексикографическом порядке.
Выходные данные для двух последовательных блоков должны быть разделены
пустой строкой.
Пример входных данных
1
4
3 4
1 1000
2 2
5 5
Соответствующие выходные данные
2 13 4
4.6. Задачи 113
4.6.6. CDVII
PC/UVaIDs: 110406/10138
Популярность: С
Частота успехов: низкая
Уровень:2
Римские дороги известны их безупречной конструкцией. К сожалению, безу-
безупречная конструкция стоит недешево, и некоторые современные нео-Цезари
решили сэкономить на автоматическом взимании дорожной пошлины.
У конкретного платного шоссе CDVII структура оплаты проезда работает сле-
следующим образом: проезд по дороге стоит определенную сумму за каждый кило-
километр проезда в зависимости от времени суток, в котором началась поездка.
Камеры на каждом въезде и выезде фиксируют номера всех въезжающих и выез-
выезжающих машин. Каждый календарный месяц зарегистрированному владельцу
машины отправляется счет за каждый километр проезда (по таксе, определяемой
временем суток), плюс один доллар за поездку, плюс два доллара за предоставле-
предоставление счета. Ваша работа состоит в том, чтобы подготовить счет за один месяц по
данным фотографиям номерных знаков автомобилей.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное
целое число, которое означает количество тестовых блоков, за которой следует
пустая строка. Между двумя последовательными тестовыми блоками также нахо-
находится пустая строка.
Каждый тестовый блок делится на две части: структура оплаты и фотографии
номерных знаков. Структура оплаты состоит из строки, содержащей
24 неотрицательных целых числа, обозначающих плату (центов/км) с 00:00 до
00:59, плату с 1:00 до 01:59 и т. д. для каждого часа в сутках. Каждая запись для
фотографии включает номер автомобиля (до 20 буквенно-цифровых символов),
время и дату (mm: dd: hh: mm), слово enter или exi t и расположение входа или
выхода (в км, считая от одного конца шоссе). Все даты будут принадлежать
одному месяцу. Каждой записи типа «enter» соответствует следующая (хроноло-
(хронологически) запись для этого же автомобиля, при условии, что это запись типа «exit».
Не имеющие пары записи типа «enter» или «exit» игнорируются. Вы можете счи-
считать, что для одного автомобиля никакие две записи не имеют одно и то же время.
Время записывается в 24-часовом формате. Записей не более 1000.
114 Глава 4. Сортировка
Выходные данные
Для каждого тестового блока выведите строку для каждого автомобиля, содержа-
содержащую номер автомобиля и общую сумму счета, в алфавитном порядке по номеру авто-
автомобиля. Выходные данные для двух последовательных блоков должны быть разделе-
разделены пустой строкой.
Пример входных данных
1
10 10 10 10 10 10 20 20 20 15 15 15 15 15 15 15 20 30 20 15 15 10 10 10
ABCD123 01:01:06:01 enter 17
765DEF 01:01:07:00 exit 95
ABCD123 01:01:08:03 exit 95
765DEF 01:01:05:59 enter 17
Соответствующие выходные данные
765DEF $10.80
ABCD123 $18.60
4.6.7. Сортировка Шелла
PC/UVaIDs: 110407/10152
Популярность: В
Частота успехов: средняя
Уровень:2
Kopojfb Йертл (Yertle) хочет перегруппировать свой трон из черепах так, чтобы
его самые знатные дворяне и ближайшие советники оказались ближе к вершине.
Для изменения порядка черепах в груде доступна лишь одна операция: черепаха
может уползти со своего места в груде и заползти по остальным черепахам наверх.
Вам задается начальный порядок груды черепах и желаемый порядок той же
груды, ваша задача состоит в том, чтобы найти минимальную последовательность
операций, которые преобразуют заданную груду в желаемую.
Входные данные
Первая строка входных данных состоит из одного целого числа К, задающего
количество тестовых блоков. Каждый тестовый блок состоит из целого числа п,
задающего число черепах в груде. Следующие п строк содержат начальный поря-
порядок груды черепах. Каждая строка содержит имя черепахи, начиная с черепахи,
4.6. Задачи 115
находящейся на верху груды, и заканчивая черепахой, находящейся в самом низу
груды. Имя каждой черепахи уникально, причем каждое имя состоит не более чем
из 80 символов, которые выбираются из символьного множества, состоящего из
буквенно-цифровых символов, символа пробела и точки («.»). Следующие п строк
входных данных задают желаемый порядок груды, снова перечисляя имена чере-
черепах сверху вниз. Каждый тестовый блок состоит ровно из 2л + 1 строк. Число
черепах (п) не превышает 200.
Выходные данные
Для каждого тестового блока выходные данные состоят из последовательности
имен черепах - по одному на строку, означающих порядок, в котором черепахи
должны уползать со своего места и заползать наверх. Эта последовательность опера-
операций должна преобразовывать начальный порядок в желаемый и иметь минимальную
длину. Если подходят несколько различных решений, вы можете привести любое.
После каждого тестового блока должна быть пустая строка.
Пример входных данных
2
3
Yertle
Duke of Earl
Sir Lancelot
Duke of Earl
Yertle
Sir Lancelot
9
Yertle
Duke of Earl
Sir Lancelot
Elizabeth Windsor
Michael Eisner
Richard M. Nixon
Mr. Rogers
Ford Perfect
Mack
Yertle
Richard M. Nixon
Sir Lancelot
Duke of Earl
Elizabeth Windsor
Michael Eisner
Mr. Rogers
Ford Perfect
Mack
116 Глава 4. Сортировка
Соответствующие выходные данные
Duke of Earl
Sir Lancelot
Richard M. Nixon
Yertle
4.6.8. Футбол
PC/UVaIDs: 110408/10194
Популярность: В
Частота успехов: средняя
Уровень: 1
Футбол - это самая популярная игра в мире, даже несмотря на то, что американцы
называют его «soccer». В такой стране, как пятикратный чемпион мира Бразилия, так
много национальных и региональных турниров, что их очень тяжело отслеживать.
Ваша задача состоит в написании программы, получающей на вход название чемпио-
чемпионата, названия команд и проведенные встречи и выводящей текущее положение
команд в турнирной таблице.
Команда выигрывает встречу, если она забивает больше голов, чем ее противник,
и проигрывает, если она забивает меньше голов. Обеим командам засчитывается
ничья, если они забивают одинаковое число голов. За каждую победу команда полу-
получает 3 очка, за ничью 1 очко и 0 очков за каждое поражение.
Команды упорядочиваются согласно следующим правилам (в порядке умень-
уменьшения важности критерия).
1. Максимум набранных очков.
2. Максимум побед.
3. Максимальная разница забитых и пропущенных мячей.
4. Максимальное число забитых мячей.
5. Минимальное число проведенных встреч.
6. Лексикографический порядок, не зависящий от регистра.
Входные данные
Первая строка входных данных содержит одно целое число N@ <N< 1000).
За ним следуют N описаний чемпионатов, каждое из которых начинается с имени
чемпионата. Эти имена могут быть комбинацией максимум 100 букв, цифр, про-
пробелов и т. д. на одной строке. Следующая строка содержит число Т A < Т< 30),
4.6. Задачи 117
задающее число команд, участвующих в чемпионате. Далее следуют Т строк,
каждая из которых содержит название одной команды. Название команды состоит
максимум из 30 символов и может содержать любые символы с ASCII-кодом
большим или равным 32 (пробел), кроме символов «#» и «@».
После названий команд идет строка, содержащая одно неотрицательное целое
число G, которое задает число игр в чемпионате, сыгранных на данный момент.
G не превышает 1000. Далее следуют G строк с результатами проведенных встреч
в формате:
team_name_l#goalsl@goals2#team_name_2
Например, Team A#3@l#Team В означает, что в игре между Team А и Team В,
Team А забила три гола, a Team В забила 1 гол. Все голы являются неотрицательными
целыми числами, не превышающими 20. Вы можете считать, что все команды, для
которых приведены результаты, взяты из команд, участвующих в чемпионате, и что
ни одна команда не будет играть сама с собой.
Выходные данные
Для каждого чемпионата вы должны вывести название чемпионата одной
строкой. Следующие Т строк должны содержать текущее положение команд
в турнирной таблице, определенное по правилам, приведенным выше. Если для
упорядочивания команд придется использовать лексикографический порядок на-
названий, то это должно делаться без учета регистра. Формат вывода для каждой
строки показан ниже.
[a]) Teamjiame [6]p, [c]g ([d]-[e]-[f]), fe]gd ([/*]-[/]),
где [a] - это положение команды в турнирной таблице, [Ь] - количество набран-
набранных очков, [с] - число проведенных встреч, [d] - число побед, [е] - число ничьих,
[/] - поражений, [g] - разница забитых и пропущенных мячей, [h] - забитые мячи
и [i] - пропущенные мячи.
Между полями вывода должен быть ровно один пробел и между выведенными
таблицами должна быть ровно одна пустая строка. Смотрите пример выходных
данных.
118
Глава 4. Сортировка
Пример входных данных Соответствующие выходные данные
World Cup 1998 - Group A
4
Brazil
Norway
Morocco
Scotland
6
Brazil#2@l#Scotland
Norway#2@2#Morocco
Scotland#l@l#Norway
Brazil#3@0#Morocco
Morocco#3@0#Scotland
Brazil#l@2#Norway
Some strange tournament
5
Team A
Team В
Team С
Team D
Team E
5
Team A#l@l#Team В
Team A#2@2#Team С
Team A#0@0#Team D
Team E#2@l#Team С
Team E#l@2#Team D
World Cup 1998 - Group A
1) Brazil 6p, 3g, B-0-1), 3gd F-3)
2) Norway 5p, 3g, A-2-0), lgd E-4)
3) Morocco 4p, 3g A-1-1), Ogd E-5)
4) Scotland lp, 3g @-1-2), -4gd B-6)
Some strange tournament
1) Team D 4p, 2g(l-l-0), lgd B-1)
2) Team E 3p, 2g(l-0-l), Ogd C-3)
3) Team A 3p, 3g@-3-0), Ogd C-3)
4) Team В lp, lg(O-l-O), Ogd A-1)
5) Team С lp, 2g@-l-l)f -lgd C-4)
4.7. Подсказки
4.1. Что правильнее взять в качестве среднего для решения проблемы Вито: среднее
по координатам, среднее по пути mean, median или что-либо другое?
4.2. Поможет ли сортировка людей по скорости определить, кого с кем нужно
ставить в пару?
4.3. Как может помочь сортировка?
4.4. Помогает ли сортировка работ по их длительности, размеру штрафа или по тому
и другому?
4.5. Можем ли мы преобразовать дату/время в одно целое число, чтобы облегчить
работу с ними?
4.8. Замечания 119
4.6. При каких условиях нам не нужно перемещать черепах?
4.7. Как мы можем упростить нашу задачу написания функции сравнения для такой
сложной системы ранжирования?
4.8. Замечания
4.1. Задачу сортировки оладий, используя минимальное число переворотов, стоит
отметить хотя бы потому, что это тема единственного исследования, опублико-
опубликованного Биллом Гейтсом (Bill Gates) [GP79]! Кроме чисто математического
интереса эта задача имеет интересное приложение в реконструкции истории эво-
эволюции между особями, такими, как мышь и человек. Инверсия генома меняет
порядок генов в ДНК организма на обратный. Эти редкие события могут сущест-
существенно влиять на эволюцию в течение больших периодов времени, так что рекон-
реконструкция порядка инверсий становится важной задачей. Смотрите [BerOl, Gus97]
для более подробного обзора инверсий генома.
Глава 5
Арифметика и алгебра
Связь между умением программировать и математическими способностями
хорошо известна. Более того, первые компьютеры были созданы программистами
для ускорения вычислений. Паскаль (который был математиком задолго до того, как
стал язьжом программирования) построил шестереночную машину для сложения
в 1645 году. Такие ученые, стоявшие у истоков вычислительной техники, как
Тьюринг и фон Нейман, сделали столько же, если не больше, для чистой математики.
В этой главе мы рассмотрим задачи по программированию, связанные с арифме-
арифметикой и алгеброй, по-видимому, самыми простыми разделами математики. Но то,
что определенные алгоритмы связаны с продвинутыми темами, такими, как теория
чисел, показывает, что они не настолько просты, как кажутся.
5.1. Машинная арифметика
В любом языке программирования есть целочисленный тип данных, под-
поддерживающий четыре основных арифметических действия: сложение, вычита-
вычитание, умножение и деление. Эти действия обычно привязаны практически напря-
напрямую к аппаратным арифметическим инструкциям, так что диапазон целых чисел
зависит от процессора.
На сегодняшний день большинство PC являются 32-битными, то есть стандарт-
стандартный целочисленный тип данных поддерживает целые числа примерно в диапазоне
± 231 = ± 2 147 483 648. Таким образом, на обычных машинах, используя стандарт-
стандартные целые числа, мы може'м спокойно считать до миллиарда или около того.
Большинство языков программирования поддерживают long- или даже
long long-целочисленный тип данных, которые часто задают 64-битные или
даже 128-битные целые числа. Так как 263 = 9 223 372 036 854 775 808, то мы го-
говорим о числах, на несколько порядков превышающих триллион. Это очень
много, настолько много, что просто сосчитать до него со скоростью современного
компьютера потребует времени намного больше, чем вам захочется ждать. Это
больше, чем число центов в дефиците бюджета Соединенных Штатов, так что
обычно его оказывается более чем достаточно, если речь не идет о математиче-
математических исследованиях или о задачах соревнований по программированию.
5.2. Высокоточные целые числа 121
Стандартные 32-битные целые числа обычно представляются четырьмя после-
последовательными байтами, а 64-битные целые числа - массивом из восьми байт. Это
неэффективно при сохранении большого числа не таких уж больших чисел. Напри-
Например, компьютерные изображения часто представляются матрицей однобайтовых
цветов (то есть 256 градаций серого) в целях эффективного использования места.
Положительные целые числа представляются в положительном двоичном
виде. Для отрицательных чисел обычно используется более сложное представле-
представление, такое, как двоично-дополняемое, которое облегчает вычисления на аппарат-
аппаратном уровне ценой большей запутанности.
Числа с плавающей запятой будут обсуждаться в разделе 5.5. Величина чисел,
представляемых числами с плавающей запятой, может быть невероятно большой, осо-
особенно при использовании чисел с плавающей запятой с удвоенной точностью. Но тем
не менее не забывайте, что эта величина является следствием представления числа
в экспоненциальной форме записи, то есть в виде а х 2е. Так как и на а и на с отведено
конечное число битов, точность ограничена. Не думайте, что float позволяет вам
считать до очень больших чисел. В этих целях лучше использовать целые и длинные
целые числа.
5.2. Высокоточные целые числа
Для представления действительно огромных целых чисел требуется «сшивать»
цифры вместе. Двумя возможными представлениями являются:
• Массивы цифр. Самым простым представлением для длинных целых чисел
является массив цифр, в котором начальный элемент массива соответствует
наименее значащей цифре. Использование счетчика, содержащего количество
цифр в числе, может увеличить эффективность путем упрощения операций,
не влияющих на выход.
• Связанные списки цифр. Динамические структуры необходимы в том случае,
если мы действительно собираемся использовать вычисления с произвольной
точностью, то есть если нет верхнего предела длины чисел. Все же обратите
внимание, что целые числа длиной 100 000 цифр являются достаточно длинны-
длинными по любым меркам и могут быть представлены с использованием массивов
длиной всего 100 000 байт каждый. На современных машинах такой размер -
это копейки.
В этом разделе мы реализуем основные арифметические действия для пред-
представления массивом цифр. Динамическое выделение памяти может дать иллюзию
способности получить неограниченное количество памяти по необходимости.
Тем не менее связанные структуры могут очень неэкономно расходовать память,
так как часть каждого узла состоит из ссылок на другие узды.
122 Глава 5. Арифметика и алгебра
Что динамическое выделение памяти на самом деле дает, так это свободу ис-
использовать память там, где это нужно. Если вы хотите создать большой массив
высокоточных целых чисел, несколько из которых будут большими, а остальные
маленькими, тогда вам будет гораздо удобнее использовать представление в виде
списка цифр, так как вы не можете себе позволить выделить огромное количество
памяти для всех элементов.
Наша структура данных для сверхчисел выглядит так:
#define MAXDIGITS 100 /* максимальная длина
сверхчисел */
#define PLUS I /* положительный знаковый
разряд */
#define MINUS -I /* отрицательный знаковый
разряд */
typedef struct {
char digits [MAXDIGITS] ; /* представление числа */
int signbit; /* PLUS или MINUS */
int lastdigit; /* индекс цифры самого
старшего порядка */
} bignum
Обратите внимание, что каждая цифра @-9) представляется однобайтовым сим-
символом. Хотя работать с такими числами немного сложнее, экономия памяти позволяет
нам уменьшить чувство вины за то, что мы не используем связанные структуры.
Использование 1 и -1 в качестве возможных значений signbit окажется удобным,
так как мы сможем перемножить знаковые разряды и получить правильный ответ.
Обратите внимание, что нет никакой причины, по которой мы должны прово-
проводить наши вычисления в десятичной системе счисления. На самом деле, исполь-
использование большего основания системы счисления позволяет увеличить эффектив-
эффективность, уменьшая число цифр, необходимых для представления каждого числа.
Все же десятичная система счисления облегчает преобразование из/в представле-
представление, которое удобно выводить1:
print_bignum(bignum *n) /
{
int i ;
if (n->signbit == MINUS) printf(n- ");
for (i=n->lastdigit; i>=0; i--)
printf("%c", '0'+ n->digits[i]);
printf("\n");
}
Для простоты наши функции будут игнорировать возможность переполнения.
1 Не менее удобна система счисления с основанием, например, 10 000. - Примеч. науч. ред.
5.3. Высокоточная арифметика 123
5.3. Высокоточная арифметика
Первые алгоритмы, узнанные нами в школе, были связаны с четырьмя стандарт-
стандартными арифметическими действиями: сложением, вычитанием, умножением и деле-
делением. Мы учились с ними работать, не всегда понимая теорию, лежащую в их основе.
Сейчас мы рассмотрим эти действия из курса начальной школы, делая акцент
на понимании того, как они работают, и на том, как можно объяснить их ком-
компьютеру. Для всех четырех действий примем следующие обозначения для аргу-
аргументов с = a*b, где * - это +, -, * или /.
• Сложение. Сложение двух целых чисел производится справа налево, при
этом любой остаток переносится в следующий разряд. Возможность отрица-
отрицательных чисел все усложняет, превращая сложение в вычитание. Проще всего
это обработать, выделив в специальный случай.
add_bignum(bignum*a, bignum *b, bignum *c)
{
int carry; /* перенос в следующий разряд */
int i; /* счетчик */
initialize_bignum(c);
if (a->signbit == b->signbit) c->signbit = a->signbit;
else {
if (a->signbit == MINUS) {
a->signbit = PLUS;
subtract_bignum(b,a,c);
a->signbit = MINUS;
} else {
b->signbit = PLUS;
subtract_bignum(a,b, c) ;
b->signbit = MINUS;
}
return;
}
c->lastdigit = max(a->lastdigit,b->lastdigit)+ 1;
carry = 0;
for (i=0; i<=(c->lastdigit);
c->digits[i] = (char)
(carry+a->digits[i]+b->digits[i]) % 10;
carry = (carry + a->digits[i] + b->digits[i]) / 10;
}
zero_justify(c);
124 Глава 5. Арифметика и алгебра
Код содержит в себе ряд интересных вещей. Работа со знаковым разрядом не
относится к разряду тривиальных. Мы сводим определенные случаи к вычита-
вычитанию, меняя знак чисел на минус и/или переставляя порядок операций, но при этом
изменение знаков происходит первым.
Собственно сложение реализуется достаточно просто и упрощено инициализа-
инициализацией всех цифр старших порядков в 0 и тем, что мы рассматриваем последний пере-
перенос как специальный случай сложения цифр. Операция zero_justify изменяет
lastdigit так, чтобы не считались лишние нули, стоящие впереди. Эту функцию
можно спокойно вызывать после каждого действия, в особенности из-за того, что
в ней поправляется случай -0.
zero_justify(bignum *n)
{
while ( (n->lastdigit > 0) && (n->digits [ n-> lastdigit] ==0) )
n->lastdigit --;
if ((n->lastdigit == 0) && (n->digits[0]==0))
n->signbit = PLUS; /* избегаем -0 */
}
• Вычитание. Вычитание сложнее, чем сложение, потому, что при вычитании
требуется занимать из соседних разрядов. Чтобы занятие не привело к ошибке,
проще всего сделать так, чтобы уменьшаемое было всегда больше вычитаемого.
subtract_bignum(bignum*a, bignum *b, bignum*с)
{
int borrow; /* занимаем? */
int v; /* цифра - «заполнитель» */
int i; /* */
if ((a->signbit ==MINUS) |j (a->signbit ==MINUS)) {
b->signbit = -1 * b->signbit;
add_bignum(a,b,с);
b->signbit = -1 * b->signbit;
return; -^
}
if (compare_bignum(a,b) == PLUS) {
subtract_bignum(b,a,c);
c->signbit = MINUS;
return;
}
c->lastdigit = max(a->lastdigit,b->lastdigit);
borrow = 0;
5.3. Высокоточная арифметика 125
for (i=0; i<=(c->lastdigit); i + +) {
v = (a->digits[i] - borrow - b->digits[i]);
if (a->digits[i] > 0)
borrow = 0;
if (v < 0) {
v = v + 10;
borrow = 1;
}
c->digits[i] = (char) v % 10;
}
zero_justify(c);
}
Сравнение. Чтобы решить, какое из двух чисел больше, требуется операция
сравнения. Сравнение идет от старшего разряда к младшему, начиная со знако-
знакового разряда.
compare_bignum(bignum *а, bignum *b)
{
int i; /* счетчик */
if ((a->signbit==MINUS) && (b->signbit==PLUS)) return(PLUS);
if ((a->signbit==PLUS) && (b->signbit==MINUS)) return(MINUS);
if (b->lasdigit > a->lasdigit) return (PLUS * a->signbit);
if (a->lasdigit >b->lasdigit) return (MINUS * a->signbit);
for (i = a->lasdigit; i>=0; i--) {
if (a->digits[i] > b->digits[i])
return (MINUS * a->signbit);
if (b->digits[i] > a->digits[i])
return (PLUS * a->signbit);
}
return@);
}
Умножение. Умножение кажется более продвинутым действием, чем сложе-
сложение и вычитание. Такая развитая цивилизация, как римляне, имела проблемы
с умножением, хотя числа римлян и выглядят впечатляюще на угловых кам-
камнях зданий и суперкубках.
Проблема римлян была в том, что они не использовали основание системы
счисления. Конечно, мы можем рассматривать умножение как многократное
сложение и решить задачу так, но получится очень и очень медленно. Возве-
Возведение в квадрат 999 999 требует около миллиона операций, но при этом легко
делается вручную, используя метод умножения строки на строку («столби-
(«столбиком»), который мы знаем со школы.
126 Глава 5. Арифметика и алгебра
multiply_bignum(bignum *а, bignum *b)
{
bignum row; /* сдвинутая строка */
bignum tmp; /* «заполнитель» сверхчисла */
int i/j; /* счетчики */
initialize_bignum(c);
row = *a;
for (i=0; i<=b->lastdigit; i++) {
for (j=l; j<=b->digits[i];
add_bignum(c,&row,&tmp);
*c = tmp;
}
digit_shift(&row,l);
c->signbit = a->signbit * b->signbit;
zero_justify(c);
Каждое действие требует сдвига первого числа на один разряд вправо
и последующего прибавления сдвинутого первого числа к сумме d раз, где d- это
соответствующая цифра второго числа. Мы могли сделать что-то более хитрое,
чем повторяющееся прибавление, но так как цикл не может быть пройден более
девяти раз на цифру, то любая экономия времени будет незначительной. Сдвиг
числа на один разряд вправо эквивалентен умножению его на основание системы
счисления, равной 10 для десятичных чисел.
digit_shift(bignum*n, int d) /* умножаем п на lO^d */
int i; /* счетчик */
if ((n->lastdigit == 0) && (n->digits[0] == 0)) return;
for (i=n->lastdigit; i>=0; i--)
n->digits[i+d] = n->digits[i];
for (i=0; i<d; i++) n->digits[i] = 0;
n->lastdigit = n->lastdigit + d/
Деление. Хотя длинное деление - это действие, которого боятся школьники
и разработчики компьютеров, оно тоже может быть обработано более
простым основным циклом, чем кажется поначалу. Деление повторяющимися
5.3. Высокоточная арифметика 127
вычитаниями опять работает чересчур медленно с длинными числами, но
простой цикл сдвига остатка влево, включая следующую цифру, и вычитания
нужное число раз делителя намного проще, чем «угадывание» каждой цифры,
как нас учили в школе.
divide_bignum(bignum *a, bignum *b, bignum *c)
bignum row; /* сдвинутая строка */
bignum tmp; /* «заполнитель» сверхчисла */
int asign, bsign; /* временно сохраняем знаки */
int i,j; /* счетчики */
initialize_bignum(с);
c->signbit = a->signbit * b->signbit;
asign = a->signbit;
bsign = b->signbit;
a->signbit = PLUS;
b->signbit = PLUS;
initialize_bignum(&row);
initialize_bignum(&tmp);
c->lastdigit = a->lastdigit;
for (i=a->lastdigit; i>=0; i--) {
digit_shift(&row; 1) ;
row.digits[0] = a->digits[i];
c->digits[i] = 0;
while (compare_bignum(&row,b) != PLUS) {
c->digits[i] + +;
subtract_bignum(&row,b,&tmp);
row = tmp;
zero_justify(c);
a->signbit = asign;
b->signbit = bsign;
}
Эта подпрограмма производит целочисленное деление и отбрасывает остаток.
Если вы хотите посчитать остаток от деления а на Ь, то вы всегда можете
посчитать а - b(a+b). Более хитрые методы будут описаны в разделе 7.3 при
обсуждении арифметических операций над абсолютными значениями чисел.
128 Глава 5. Арифметика и алгебра
Знак частного и остатка в случае, когда делимое и делитель имеют разные зна-
знаки, не определен, так что не удивляйтесь, если ответ будет зависеть от языка
программирования.
Возведение в степень. Возведение в степень - это повторяемое умножение, так
что тут возникают те же проблемы с производительностью, что и при много-
многократном сложении длинных чисел. Хитрость состоит в том, чтобы заметить, что
an=andiv2xandiv2xan mod 2^
так что можно обойтись, используя только логарифмическое число умножений.
5.4. Системы счисления и соответствующие переходы
При цифровом представлении числа в заданной системе счисления использу-
используется основание системы счисления. Особенно важными являются следующие сис-
системы счисления.
• Двоичная. Числа в системе счисления с основанием 2 состоят из цифр 0 и 1.
Целые числа представляются внутри компьютера, используя эти цифры, так
как они напрямую отражают состояния включено/выключено или высокое/
низкое напряжение.
• Восьмеричная. Числа в этой системе счисления удобны для более короткой
записи двоичных чисел, так как три бита соответствуют одной цифре в вось-
восьмеричной системе счисления. Таким образом, 101110012 = 3718 = 24910. Также
восьмеричные числа используются в единственной шутке про переходы между
системами счисления. Почему программисты думают, что Рождество - это
Хэллоуин? Потому что 31 Oct = 25 Dec!
• Десятичная. Мы используем десятичную систему счисления, потому что
учились считать по пальцам на руках. Древние люди майя использовали сис-
систему счисления с основанием 20, возможно, потому что они считали пальцы
и на руках и на ногах
• Шестнадцатеричная. Шестнадцатеричная система позволяет записывать дво-
двоичные числа еще короче, как только вы свыкнетесь с тем, что цифры от 10 до 15
обозначаются буквами отх<А» до «F».
• Буквенно-цифровая. Иногда встречаются системы счисления с основанием
большим 16. 36 - это максимальное основание, которое вы можете получить,
используя 10 цифр и 26 букв латинского алфавита. Любое целое число можно
представить в системе счисления с основанием^при условии, что вы сумеете
отобразить Xразличных символов.
5.4. Системы счисления и соответствующие переходы 129
Существует два различных алгоритма, с помощью которых вы можете перевести
число х, записанное в системе счисления с основанием я, в число у, записанное
в системе счисления с основанием Ъ.
• Слева направо. Сначала мы находим значение старшего разряда числа у. Это
целое число dj такое, что
причем \<di<b -1. В принципе это можно проделать методом проб
и ошибок, хотя для этого вы должны уметь сравнивать два числа, записанные
в различных системах счисления. Это аналогично алгоритму длинного деле-
деления, описанному выше.
• Справа налево. Сначала мы находим значение самого младшего разряда числа у.
Это остаток от деления х на Ъ. Вычисление остатков обсуждается в разделе 7.3.
Преобразование справа налево аналогично тому, как преобразовываем обычные
целые числа в наше представление длинных чисел. Операция вычисления остатка при
целочисленном делении нашего целого числа на 10 позволяет получить нам младший
разряд числа.
int_to_bignum(int s, bignum *n)
{
int i; /* счетчик */
int t; /* целое число для перехода */
if (s >= 0) n->signbit = PLUS;
else n->signbit = MINUS;
for (i=0; i<MAXDIGITS; i++) n->digits[i] = (char) 0;
n->lastdigit = -1;
t = abs(s);
while (t > 0) {
n->lastdigit ++;
n->digits[ n->lastdigit ] = (t % 10);
t = t / 10;
}
if (S == 0) n->lastdigit = 0;
}
Использование целочисленного деления на число отличное от 10 позволяет
преобразовывать числа в другие системы счисления.
5-972
130 Глава 5. Арифметика и алгебра
5.5. Вещественные числа
Области математики, созданные для работы с вещественными числами, дейст-
действительно важны для понимания окружающего мира. Ньютону пришлось разрабо-
разработать исчисление для того, чтобы он смог сформулировать основные законы дви-
движения. Необходимость интегрировать или решать системы уравнений возникает
в любой области науки. Первые компьютеры были разработаны как машины для
обработки чисел, и они обрабатывали именно вещественные числа.
Работа с вещественными числами на компьютере достаточно сложна из-за того,
что арифметика с плавающей точкой имеет ограниченную точность. Главное, что
нужно помнить при работе с вещественными числами, что они не настоящие веще-
вещественные числа.
В математике многое основано на непрерывности вещественных чисел, то
есть на том факте, что для любых а и Ь, если а < Ъ, то существует число с.
а < с < Ъ. Для представления вещественных чисел в компьютере это неверно.
• Многие алгоритмы опираются на точные вычисления. Для представления
вещественных чисел в компьютере это неверно. Ассоциативность сложения
обеспечивает, что
К сожалению, из-за ошибок округления это не обязательно выполняется при
вычислениях на компьютере.
Существует несколько типов чисел, с которыми, возможно, потребуется работать.
Целые числа. Это счетные числа - оо,..., -2, -1, 0,1,2,..., + оо. Важными подмно-
подмножествами целых чисел являются натуральные числа (целые числа, начиная с 0)
и положительные числа (большие 0), хотя эти обозначения могут не совпадать
с другими. Ограничивающее свойство целых чисел - это их дискретность. Одна-
Однажды, на 1 апреля, одна из газет поместила заголовок «Ученые открыли новое
число между 6 и 7». Это забавно, потому что, хотя всегда найдется вещественное
число между любыми вещественными числами (например, их полусумма), будет
действительно интересно, если ученые найдут целое число между 6 и 7.
Рациональные числа. К этим числам относятся те, которые могут быть представ-
представлены как отношение двух целых чисел, то есть с является рациональным, если
с = а/b, где а и b целые. Любое целое число является рациональным, так как
с = с/1. Рациональные^числа синонимичны дробям при условии, что мы
рассматриваем и неправильные дроби а/Ь, где а > Ъ.
2 Принимать 0 за начало натурального ряда чисел принято в компьютсристикс. - Примеч. науч. ред.
5.5. Вещественные числа 131
• Иррациональные числа. Существует много интересных чисел, которые не
являются рациональными. Примерами являются п = 3.1415926..., л/2 = 1.41421...
и е = 2.71828... . Для любого из этих чисел можно доказать, что не существует
пары таких целых чисел х и у, что х/у равняется этому числу.
Но как тогда представлять их на компьютере? Если вам действительно нужны
их значения с произвольной точностью, то вы можете использовать ряды Тейлора.
Но для всех практических нужд хватает их приближенного значения с точностью
около 10 цифр.
5.5.1. Работа с вещественными числами
Внутреннее представление чисел с плавающей запятой меняется в зависимости
от компьютера, языка программирования и компилятора. Из-за этого работа с ними
является большой проблемой.
Существует IEEE-стандарт для работы с числами с плавающей запятой,
причем число компаний, следующих ему, постоянно увеличивается, но в любом
случае могут появиться проблемы при вычислениях с очень высокой точностью.
Числа с плавающей запятой представляются в экспоненциальной записи, то есть
а х 2е, причем и на мантиссу а, и на порядок степени с выделено ограниченное
число битов. Действия над двумя числами, у которых показатель степени сильно
различается, часто приводят к ошибкам переполнения или обнуления, так как
битов, отведенных на мантиссу, недостаточно для сохранения результата.
Эти проблемы являются источниками многих ошибок округления. Самая
важная проблема связана с проверкой на эквивалентность двух вещественных
чисел, так как младшие биты мантиссы содержат достаточное количество мусора,
чтобы сделать эту проверку бессмысленной. Поэтому никогда не проверяйте, яв-
является ли число с плавающей запятой равным нулю или другому вещественному
числу. Вместо этого проверяйте, лежит ли ваше число в диапазоне ± г от того
числа, с которым хотите сравнивать.
Во многих задачах вам потребуется вывести ответ с определенным количест-
количеством цифр после запятой. Тут мы должны разобраться с разницей между округле-
округлением (rounding) и усечением (truncating). Примером усечения является функция
floor, преобразующая вещественное число в целое путем отбрасывания дроб-
дробной части. Округление используется для более точного расчета последнего разря-
разряда числа. Для округления числа X до А: десятичных цифр используйте формулу
round(X, k) = floorA0*Ar+ A/2))/10*.
Для отображения определенного числа цифр, когда это требуется, используйте
функцию форматного вывода.
132 Глава 5. Арифметика и алгебра
5.5.2. Простые дроби
Точные рациональные числа х/у проще всего представить парой целых чисел
х, у} где х - это числитель, ау- это знаменатель дроби.
Базовые арифметические действия для рациональных чисел с = xj/yj wd = х2/у2
программируются легко.
• Сложение. Перед сложением мы должны привести дроби к общему знамена-
знаменателю, так что
УхУг
• Вычитание. Аналогично вычитанию, так как c-d = с + -\ х d, получаем
УхУг
Умножение. Так как умножение - это повторяющееся сложение, то легко
показать, что
сха = .
УхУг
• Целение. Деление дробей эквивалентно умножению делимого на
перевернутый делитель, так что
с/ = *i х У2
/d Ух *г
Но почему это именно так? Потому что по определению d(c/d) = с, то есть
именно то, что должно делать деление.
Прямая реализация этих операций ведет к значительной опасности переполне-
переполнения. Важно сокращать дроби до их простейшей формы, то есть заменять 2/4 на 1/2.
Ключ к этому лежит в нахождении наибольшего общего делителя числителя и знаме-
знаменателя, то есть наибольшего целого числа, на которое делится без остатка и числи-
числитель и знаменатель.
Нахождение наибольшего общего делителя методом подбора или полным пере-
перебором может затребовать очень много ресурсов. Тем не менее алгоритм Евклида для
нахождения НОД эффективен и прост для реализации, он будет обсуждаться
в разделе 7.2.1.
5.5. Вещественные числа 133
5.5.3. Десятичные дроби
Десятичное представление вещественных чисел - это особый случай рацио-
рациональных чисел. Десятичное число представляет сумму двух чисел: целой части,
находящейся слева от запятой, и дробной части, находящейся справа от запятой.
Таким образом, десятичное представление первых пяти десятичных цифр числа я:
3.1415 = C/1) + A415 /10000) = 6283 /2000
Знаменатель дробной части равен 10/+/, где / - это номер последней ненулевой
цифры после запятой.
В принципе преобразовать рациональное число в десятичное несложно;
нужно просто поделить числитель на знаменатель. Ловушка в том, что для многих
дробей нет конечного десятичного представления. Например, 1/3 = 0/3333333...
и 1/7 = 0.14285714285714285714... . Обычно хватает десятичного представления
с точностью до 10 цифр, но иногда нам необходимо знать точное представление,
то есть 1/30 = 0.03 и 1/7 = 0.142587 .
Какая простая дробь соответствует заданной периодической десятичной
дроби? Мы можем найти ее, явно моделируя деление. Десятичное представление
простой дроби 1/7 получается при делении 7 на 1.000000... . Следующая цифра
дроби определяется умножением остатка на десять, добавлением последней
цифры (всегда нуль) и определением того, сколько раз знаменатель укладывается
в эту величину. Обратите внимание, что мы входим в бесконечный цикл, когда эта
величина повторяется. Соответственно десятичные цифры между этими позиция-
позициями повторяются бесконечно.
Более простой метод возникает, если мы знаем (или предполагаем) длину по-
повторяющейся последовательности. Пусть у простой дроби а/Ъ повторяющаяся по-
последовательность R имеет длину /. Тогда 10'(a/b)-(a/b) = Л, и отсюда
а IЪ - R /A0 -1). Проиллюстрируем это. Пусть мы хотим найти простую дробь, со-
соответствующую alb = 0.0123123.... Длина повторяющейся последовательности равна
трем, и согласно приведенной формуле R = 12.3. Отсюда alb = 12.3/999 = 123/9990.
134 Глава 5. Арифметика и алгебра
5.6. Алгебра
Главная идея алгебры состоит в изучении групп и числовых колец. Универси-
Университетская алгебра в основном ограничена изучением уравнений, заданных с помо-
помощью операций сложения и умножения. Самым важным классом формул являются
полиномы вида Р{х) = с0 + с1х + с2х2 +..., где х - это переменная, а с,- - это коэф-
коэффициент перед /-М одночленом х1. Степень полинома - это максимальное / такое,
что С( не равно нулю.
5.6.1. Работа с полиномами
Наиболее естественным представлением одномерного (зависящего от одной
переменной) полинома п-й степени является массив п + 1 коэффициентов от с0 до
сп. Такое представление сильно облегчает основные арифметические действия
над полиномами.
• Вычисление. Вычисление Р(х) для определенного х можно провести «в лоб»,
вычислив каждый одночлен сУ по отдельности и сложив их потом все вместе.
Проблема в том, что на это потребуется О(п ) умножение, хотя достаточно О(п).
Нужно заметить, что х* = xl~ х, так что если мы буцем вычислять одночлены от
наименьшей степени к наибольшей, то можем следить за текущей степенью х и
обходиться двумя умножениями на одночлен (х1 ~ * х х, а затем с1 х х1).
С другой стороны, можно реализовать схему Горнера, которая является еще
более экономным вариантом решения этой проблемы:
апх" + я„-1*Л~1 + - + ао = (К* + ап-х )х + •••)* + «о.
• Сложение/Вычитание. Сложение и вычитание для полиномов даже проще,
чем для длинных целых чисел, так как нет необходимости переносить и зани-
занимать. Мы просто складываем или вычитаем коэффициенты при /-м одночлене
для всех / от нуля до максимальной степени.
• Умножение. Произведение полиномов Р(х) и Q(x) - это сумма произведений
всех пар одночленов, берущихся из разных полиномов:
de$ree(P)degree(Q)
P(x)xQ(x)= X 2>/Cy)*'+y.
/=0 У=0
Такая операция умнЪжения всех на все называется сверткой. Другими
примерами сверток в этой книге является умножение целых чисел (все цифры
5.6. Алгебра 135
на все цифры) и поиск совпадения строки (все возможные положения шаб-
шаблонной строки на все возможные положения текста). Существует поразитель-
поразительный алгоритм (быстрое преобразование Фурье - fast Fourier transform - FFT),
который вычисляет свертку за время О(п\пп) вместо О(п2), но его описание
лежит далеко за пределами этой книги. Все же, проводя свертку, приятно
осознавать, что такие инструменты есть.
• Деление. Деление полиномов - это непростое дело, так как оно для мно-
многочленов не определено. Обратите внимание, что Мх можно считать, а можно
и не считать полиномом, так как это х~\ но 2х/(х + 1) определенно не являет-
является полиномом. Это рациональная функция.
Иногда полиномы являются разреженными, что значит, что многие коэффи-
коэффициенты равны нулю. Достаточно разреженные полиномы могут быть
представлены связанным списком пар коэффициент/степень. Многомерные
полиномы зависят более чем от одной переменной. Двумерный полином f(x, у)
может быть представлен матрицей коэффициентов С такой, что C[i][j] - это
коэффициент перед х1у1.
5.6.2. Нахождение корней
При заданном полиноме Р(х) и числе t задача нахождения корней состоит
в отыскании всех х таких, что Р(х) = t.
Если Р(х) является полиномом первой степени, то корень равен просто х = (t- a^/aj,
где at - это коэффициент перед х1 в Р(х). Если Р(х) является полиномом второй степе-
степени, то решения квадратного уравнения:
Существуют более сложные формулы для конечного решения полиномов
третьей и четвертой степени. Для уравнения пятой степени и выше никаких
формул не существует.
Для уравнений порядков третьего и выше применяют численные методы.
В любой книге по вычислительной математике вы найдете описание ряда раз-
различных методов отыскания корней, включая методы Ньютона и Ньютона-Рапсо-
на (Raphson), а также множество потенциальных ловушек, таких, как численная
устойчивость. Но основной идеей является идея бинарного поиска. Пусть функ-
функция/^ монотонно возрастает на отрезке от / до и, что значит, что f(i) <f(l) для
любых I < i < j <и. Теперь пусть мы хотим найти х такое, что/fxj = /. Мы можем
136 Глава 5. Арифметика и алгебра
сравнить f((l+u)/2) и /. Если / <f((l + иI2), то корень лежит между / и (I + и)/2;
если же нет, то корень лежит между (I + иI2 и и. Мы можем продолжать умень-
уменьшать этот отрезок до тех пор, пока точность не станет достаточной.
Этот метод можно использовать для нахождения квадратных корней, так как
это эквивалентно решению уравнения х2 = t на отрезке от 1 до t для любого / > 1.
Но все же проще вычислить корень /-й степени из /, используя степенные функции
и логарифмы для вычисления t .
5.7. Логарифмы
Возможно, вы замечали клавиши log и ехр на вашем калькуляторе, но, веро-
вероятнее всего, никогда ими не пользовались. Возможно, вы даже забыли, для чего
они там нужны. Логарифм - это просто функция, обратная степенной. Утвержде-
Утверждение, что Ьх = у9 аналогично утверждению х = log^y.
Параметр Ъ называется основанием логарифма. Два основания являются осо-
особенно важными по математическим и историческим причинам. Натуральный ло-
логарифм, обозначаемый обычно lruc, - это логарифм с основанием е = 2.71828... .
Обратной lnx является экспоненциальная функция ехр х = е*. Таким образом, со-
собирая эти функции вместе:
exp(lruc) = х.
Менее распространенным на сегодня является логарифм с основанием 10 или
десятичный логарифм, обозначаемый обычно log*. Десятичные логарифмы
широко использовались в те дни, когда еще не было карманных калькуляторов3.
С помощью логарифмов было проще всего перемножать большие числа вручную,
используя логарифмическую линейку или напрямую таблицу логарифмов.
И сегодня с помощью логарифмов удобно умножать, особенно возводить
в степень. Вспомним, что log^xy = log^x + log^y; то есть логарифм произведения
равен сумме логарифмов. Прямым следствием этого является то, что:
\oga пь = blogan
Тогда как мы можем вычислить а для любых а и 6, используя функции ехр(х)
и ln(x)? Мы знаем, что
ah = exp(ln( ah)) = ехр(Ъ In a),
так что наша задача свелась к одному умножению плюс по одному вызову этих
функций.
3Авторы этой книги достаточно взрослые, чтобы помнить время до 1972 года.
5.8. Математические библиотеки 137
Мы можем использовать этот метод для вычисления квадратных корней, так
как л/х = х1/2, а также для любых других дробных степеней. Такое приложение -
это одна из причин, по которой математическая библиотека любого современного
языка включает функции In и ехр. Не забывайте, что они являются сложными чис-
численными функциями (вычисляемыми с помощью рядов Тейлора), так что им при-
присущи некоторые вычислительные неточности, поэтому не стоит ожидать, что
ехр@.5 In 4) будет точно равняться 2.
Другим важным свойством логарифма, которое стоит помнить, является то,
что логарифм легко преобразуется от одного основания к другому, что является
следствием формулы.
logflZ>
logca
Таким образом, изменение основания log Ь с с на а сводится к простому делению
. Значит, несложно написать функцию десятичного логарифма на основании
функции натурального логарифма и наоборот.
5.8. Математические библиотеки
Математические библиотеки в C/C++
В стандартной математической библиотеке C/C++ есть несколько полезных
функций для работы с вещественными числами:
#include <math.h> /* включаем математическую библио-
библиотеку */
double floor(double x); /* отбрасывает дробную часть х */
double ceil (double x); /* округляет х до ближайшего боль-
большего целого числа */
double fabs(double x); /* вычисляет абсолютное значение
х */
double sqrt (double x) ; /* вычисляет квадратные корни */
double ехр(double х) ; /* вычисляет еЛх */
double log (double x) ; /* вычисляет натуральный логарифм */
double loglO(double x); /* вычисляет десятичный логарифм
*/
double pow(double х,double у); /* вычисляет хЛу */
138 Глава 5. Арифметика и алгебра
Математические библиотеки в Java
В Java кпассе-java.lang.Math имеются все эти функции и некоторые дополни-
дополнительные; самой очевидной является функция round, округляющая вещественное
число до ближайшего целого.
5.9. Задачи
5.9.1. Начала арифметики
PC/UVaIDs: 110501/10035
Популярность: В
Частота успехов: средняя
Уровень: 1
Детей учат складывать многоразрядные числа справа налево, по одной цифре за
один раз. Многие из детей считают операцию «переноса», когда 1 переносится в сле-
следующий разряд, достаточно сложной. Ваша работа состоит в том, чтобы сосчитать
число операций переноса для каждого набора задач на сложение, чтобы учителя
могли оценить их сложность.
Входные данные
Каждая строка входных данных содержит два беззнаковых целых числа, каждое
длиной не более 10 цифр. Последняя строка входных данных содержит 0 ".
Выходные данные
Для каждой строки входных данных, за исключением последней, рассчитайте
число операций переноса, возникающих при сложении двух чисел, и выведите его
в формате, показанном ниже.
Пример входных данных
123 456
555 555
123 594
0 0
Соответствующие выходные данные
No carry operation.
3 carry operations.
1 carry operation.
5.9. Задачи 139
5.9.2. Изменение порядка и сложение
PC/UVaIDs: 110502/10018,
Популярность: А
Частота успехов: низкая
Уровень:1
Функция изменения порядка и сложения начинает с числа, меняет порядок его
цифр на противоположный и складывает получившееся число с начальным. Если
сумма не является палиндромом (то есть не дает одно и то же число прочитанная
слева направо и справа налево), мы повторяем эту процедуру до тех пор, пока она
им не станет.
Например, если мы начнем с числа 195, то получим 9339 в качестве итогового
палиндрома после четвертого сложения:
195 786 1473 5 214
591 687 3 714 4 125
786 1473 5 214 9 339
Этот метод сходится к палиндрому за несколько итераций практически для
всех целых чисел. Но существуют интересные исключения. 196 является первым
числом, для которого не было обнаружено палиндрома. Но тем не менее не было
доказано, что такого палиндрома не существует.
Вы должны написать программу, которая для заданного числа выдает итого-
итоговый палиндром (если он существует) и число итераций/сложений, которые потре-
потребовались, чтобы его найти.
Вы можете считать, что все числа, задаваемые в качестве тестовых данных,
сойдутся к ответу за менее чем 1000 итераций (сложений) и приведут к итоговому
палиндрому, не превышающему 4 294 967 295.
Входные данные
Первая строка содержит целое число N @ <N< 100), задающее число тесто-
тестовых случаев, а каждая из следующих N строк содержит одно целое число Р, чей
палиндром вы должны найти.
Выходные данные
Для каждого из N целых чисел выведите строку, содержащую минимальное
число итераций, необходимых для нахождения палиндрома, один пробел и затем
собственно итоговый палиндром.
140 Глава 5. Арифметика и алгебра
Пример входных данных Соответствующие выходные данные
3 4 9339
195 5 45254
265 3 6666
750
5.9.3. Дилемма археолога
PC/UValDs: 110503/701
Популярность: А
Частота успехов: низкая
Уровень:1
Археолог, ищущий доказательства того, что инопланетяне в прошлом приле-
прилетали на Землю, наткнулся на частично уничтоженную стену, содержащую стран-
странные последовательности чисел. Левая .часть строк, содержащих эти цифры, всегда
не повреждена, а правая, к сожалению, часто отсутствует из-за эрозии камня. Тем
не менее она заметила, что все числа, у которых сохранились все цифры, являются
степенями 2, так что у нее появилась очевидная гипотеза, что все числа являются
степенями 2. Чтобы удостовериться в этом, она выбрала несколько чисел, для ко-
которых очевидно, что число разборчивых цифр строго меньше, чем число потерян-
потерянных, и попросила вас найти минимальную степень 2 (если такая вообще сущест-
существует), чьи первые цифры совпадают с теми, которые она выбрала.
Таким образом, вы должны написать программу, которая для заданного числа
определяет минимальную степень Е (если она существует) такую, что первые
цифры 2е совпадают с заданным числом (не забывайте, что потеряно более поло-
половины цифр).
Входные данные
Каждая строка входных данных содержит положительное число N, не превы-
превышающее 2 147 483 648.
Выходные данные
Для каждого из этих целых чисел выведите наименьшее положительное целое
число Е такое, что первые цифры 2Е в точности совпадают с цифрами N, или, если
таковой степени не существует, предложение "no power of 2".
5.9. Задачи 141
Пример входных данных
1
2
10
Соответствующие выходные данные
7
8
20
5.9.4. Единицы
PC/UVaIDs: 110504/10127
Популярность: А
Частота успехов: высокая
Уровень:2
Для любого заданного целого числа 0 < п < 10 000, не кратного 2 и 5, сущест-
существует число, кратное и, такое, что в десятичной записи оно является последователь-
последовательностью единиц. Сколько цифр в наименьшем таком числе?
Входные данные
Файл целых чисел, по одному числу на строке.
Выходные данные
Каждая строка выходных данных должна содержать наименьшее целое х > 0
такое, что р = Х/=о^х Юг, где л - это соответствующее входное число, р = axb
иЬ- это целое число, большее нуля.
Пример входных данных
3
7
9901
Соответствующие выходные данные
з
б
12
142 Глава 5. Арифметика и алгебра
5.9.5. Игра в умножения
PC/UVaIDs: 110505/847
Популярность: А
Частота успехов: высокая
Уровень:3
Стэн (Stan) и Олли (ОШе) играют в умножения, умножая целое число р на
одно из чисел от 2 до 9. Стэн всегда начинает ср = 1, умножает, затем Олли умно-
умножает получившееся число, затем Стэн и т. д. До начала игры они выбирают целое
число 1 < п < 4 294 967 295, и выигрывает тот, кто первым достигнет/? > п.
Входные данные
Каждая строка входных данных содержит одно целое число п.
Выходные данные
Для каждой строки входных данных выведите одну из строк - или
Stan wins.
или
Ollie wins.
считая, что они оба играют идеально.
Пример входных данных
162
17
34012226
Соответствующие выходные данные
Stan wins.
Ollie wins.
Stan wins.
,5.9. Задачи 143
5.9.6 Коэффициенты полинома
PC/UVaIDs: 110506/10105
Популярность: В
Частота успехов: высокая
Уровень:1
В задаче требуется определить коэффициенты, получающиеся при возведении
в степень полинома:
Входные данные
Входные данные состоят из набора пар строк. Первая строка каждой пары состо-
состоит из двух целых чисел пик, разделенных пробелом @ < п, к < 13). Эти целые числа
задают степень полинома и число переменных. Вторая строка каждой пары состоит
из к неотрицательных целых чисел пх,..., пк, где пх +... + пк = п.
Выходные данные
Для каждой пары строк входных данных выходная строка должна содержать
одно целое число - коэффициент перед одночленом х"х хп22 ...хпкк в возведенном
в степень полиноме {хх+ х2+... + хк)п.
Пример входных данных
2 2
1 1
2 12
100000000010
Соответствующие выходные данные
2
144 Глава 5. Арифметика и алгебра
5.9.7. Числовая система Штерна-Броко (Stern-Brocot)
РС/UVaIDs: 110507/10077
Популярность: С
Частота успехов: высокая
Уровень:1
Дерево Штерна-Броко - это изящный способ построения множества всех не-
т
отрицательных дробей ~~~, где тип- взаимно простые. Идея состоит в том, чтобы
0 1
начать с двух дробей (т; ~) и затем повторить нижеследующую операцию столь-
столько раз, сколько это нужно.
т + т щ ni
Вставить п + п' между двумя соседними дробями и ~.
0 1.
Например, первый шаг дает нам одно новое вхождение между 7 и - *
0 1 I
J 9 ?
1 1 0
следующий шаг дает еще два:
9. 1 I 1 1
Г 2'? ГО
Следующий дает еще четыре:
1'з'г'з' I'2'Т' Т'о
6.9. Задачи
145
Весь массив можно рассматривать, как бесконечное бинарное дерево, чьи
верхние уровни выглядят так :
О 1
1
Г
1
'3\
2
/Г
/4^
Эта конструкция сохраняет порядок, так что мы не можем получить одну и ту
же дробь в различных местах.
Фактически мы можем рассматривать дерево Штерна-Броко как систему счисле-
счисления для представления рациональных чисел, потому что каждая положительная,
сокращенная дробь встречается в дереве только один раз. Будем использовать буквы
"L" и "R" для обозначения того, двигаемся мы по левой или по правой ветви дерева,
когда спускаемся от корня дерева к определенной дроби; тогда строка, состоящая из
определенной последовательности этих L и R, уникальным образом определяет поло-
1 1
жение в дереве. Например, LRRL означает, что мы идем по левой ветви от г~ к ~ затем
2
S
по правой к т~, затем по правой к ~~, затем по левой к —. Мы можем рассматривать
5
LRRL как представление т~. Любая положительная дробь представляется таким
путем уникальной строкой, состоящей из L и R.
1
Ну, скажем, почти любая дробь. Дроби г~ соответствует пустая строка. Мы
будем обозначать ее /, так как это похоже на 1 и является первой буквой слова
«identity» («единица»).
В этой задаче вы должны представить данную положительную рациональную
дробь в системе счисления Штерна-Броко.
146 Глава 5. Арифметика и алгебра
Входные данные
Входной файл содержит несколько тестовых блоков. Каждый тестовый блок
состоит из строки, содержащей два положительных целых числа тип, причем т
и п взаимно простые. Входные данные заканчиваются тестовым блоком, содержа-
содержащим две 1 для тип, причем этот блок обрабатывать не нужно.
Выходные данные
Для каждого тестового блока во входном файле выведите строку, содержащую
представление заданной дроби в системе счисления Штерна-Броко.
Пример входных данных
5 7
878 323
1 1
Соответствующие выходные данные
LRRL
RRLRRLRLLLLRLRRR
5.9.8. Попарно суммируемые числа
PC/UValDs: 110508/10202
Популярность: В
Частота успехов: высокая
Уровень:4
Любой набор из п целых чисел образует п(п - 1)/2 сумм, если сложить все воз-
возможные пары. Ваша задача состоит в том, чтобы найти п целых чисел по заданному
набору сумм.
Входные данные
Каждая строка входных данных содержит п, за которым следуют п(п - 1)/2
целых чисел, разделенных пробелами, причем 2 < п < 10.
Выходные данные
Для каждой строки входных данных выведите одну строку, содержащую п целых
чисел в неубывающем порядке таких, что входные числа - это попарные суммы этих
п чисел. Если существует более одного решения, то подойдет любое. Если решения
не существует, выведите "Impossible"...
5.10. Подсказки 147
Пример входных данных
3 1269 1160 1663
3 111
5 226 223 225 224 227 229 228 226 225 227
5 216 210 204 212 220 214 222 208 216 210
5-10-1-210-110-1
5 79950 79936 79942 79962 79954 79972 79960 79968 79924 79932
Соответствующие выходные данные
383 777 886
Impossible
111 112 113 114 115
101 103 107 109 113
-1-10 0 1
39953 39971 39979 39983 39989
5.10. Подсказки
5.1. Нужно ли нам реализовывать высокоточное сложение для этой задачи, или мы
можем получить число операций переноса, используя более простой метод?
5.2. Нужно ли нам реализовывать высокоточное умножение для этой задачи, или
тот факт, что мы ищем степени 2, как-то упрощает дело?
5.3. Нужно ли нам вычислять число, для того чтобы определить число цифр, из
которых оно состоит?
5.4. Возможно, будет проще решить более общую задачу - кто выигрывает, если
они начинают с числа х и заканчивают на числе nl
5.5. Нужно ли нам вычислять итоговый полином, или существует более простой
способ для вычисления искомого коэффициента? Может ли нам помочь би-
бином Ньютона?
5.6. Является ли полный перебор возможностей необходимым? Если да, то обра-
обратитесь к главе 8 на предмет поиска с возвратом.
5.11. Замечания
5.1. Трехлетний компьютерный поиск палиндрома для 196 дошел до 2 миллионов
цифр, но палиндром так и не был найден. Чем дольше мы ищем, тем меньше
вероятность того, что такой палиндром существует. Подробнее смотрите ht-
tp://www.fourmilab.ch/documents/threeyears/threey ears.html.
Глава 6
Комбинаторика
Комбинаторика - это математика счета. Существует несколько основных счет-
счетных задач, которые регулярно появляются в вычислительной технике
и программировании.
Задачи по комбинаторике замечательны тем, что они опираются на смекалку
и проницательность. Как только вы посмотрите на задачу под правильным углом,
ответ неожиданно становится очевидным. Явление ага! делает их идеальными для
соревнований по программированию, потому что удачно подмеченный факт может
устранить необходимость написания сложной программы, генерирующей и счи-
считающей все решения, и заменить это все одним вызовом простой формулы. Иногда
это ведет к решениям «с отключенным компьютером». Если итоговые вычисления
рассматриваются только для небольших целых чисел или фактически идентичны дня
всех входных данных, то можно рассчитать все возможные решения, используя, ска-
скажем, карманный калькулятор, и потом написать программу, выдающую ответы по
требованию. Не забывайте, что судья не может заглянуть в ваше сердце или вашу
программу - он только проверяет ответы.
6.1. Базовые методики счета
Здесь мы рассмотрим определенные основные правила счета и формулы,
которые вы, возможно, видели, но уже забыли. В частности, существует три основ-
основных правила счета, из которых получаются многие формулы. Важно понять, какое
конкретное правило нужно применять в вашей задаче.
• Правило умножения. Правило умножения утверждает, что если существует \А\
вариантов из множества А и \В\ вариантов из множества 5, то тогда существует
\А\ х \В\ комбинаций одного варианта из множества А и одного из множества В.
Например, пусть у вас есть 5 рубашек и 4 брюк. Тогда у вас есть 5 х 4 = 20
различных вариантов костюмов на завтра.
6.1. Базовые методики счета 149
• Правило сложения. Правило сложения утверждает, что если существует \А\ вари-
вариантов из множества^, и \В\ вариантов из множества В, то тогда существует \А\ + \В\
вариантов, что случится А или В при условии, что элементы А и В различны.
Например, если у вас есть 5 рубашек и 4 штанов и в прачечной повредили одну из
вещей, то тогда существует 9 возможно поврежденных вещей1.
• Формула включений-исключений. Правило сложения является специальным
случаем более общей формулы, когда два множества могут пересекаться, точнее:
Например, пусть А - это набор расцветок моих рубашек, а В - это расцветки
моих штанов. Используя формулу включений-исключений, я могу посчитать
общее чис-ло расцветок, если я знаю, какая одежда совпадает по цвету
и наоборот. Причина, по которой это срабатывает, состоит в том, что при сло-
сложении множеств мы два раза считаем определенные варианты, а конкретнее
те, которые входят и в то и в другое множество. Формула включений-исклю-
включений-исключений обобщается на три множества и более естественным образом:
\А u В u С\ = \А\ + \В\ + \С\ - \А п В\ - \А п С\ - \В п С\ + |А п В п С\ •
Проблема двойного счета - это скользкий аспект комбинаторики, который
может затруднить решение задач через включение-исключение. Другой мощ-
мощной методикой является установление биекции. Биекция - это взаимно-одно-
взаимно-однозначное соответствие между элементами одного множества и другого. Если
у вас есть такое соответствие, то при подсчете размера одного множества вы
автоматически получаете размер другого.
Например, если мы подсчитаем количество брюк, которые надеты на
студентах в аудитории, и будем считать, что на всех студентах надеты
брюки, то мы получим число людей в аудитории. Это работает, потому что
существует однозначное соответствие между брюками и людьми, которое
исчезнет, если мы будем рассматривать носки или разрешим студентам
носить вместо брюк юбки.
Для использования биекций нам нужен набор множеств, которые мы умеем
считать, тогда мы сможем привязывать к ним другие объекты. Основные ком-
комбинаторные объекты, которые вы должны знать, перечислены ниже. Полезно
примерно понимать, с какой скоростью растет число объектов, чтобы знать,
когда полный перебор перестает подходить нам в качестве алгоритма.
!На самом деле, это неправда, потому что из всех вещей наверняка повредили вашу любимую.
150 Глава 6. Комбинаторика
• Перестановки. Набор п упорядоченных объектов, в котором каждый объект
встречается ровно один раз, называется перестановкой. Всего существует
п\- ГТ" / различных перестановок. Например, 3! = 6 перестановок трех объ-
объектов: 123, 132, 213, 231, 312 и 321. Для п = 10 имеем п\ = 3 628 800, так что
мы начинаем приближаться к пределу возможностей полного перебора.
• Подмножества. Произвольная выборка элементов из п возможных объектов
называется подмножеством. Для п объектов существует 2п различных подмно-
подмножеств. Таким образом, существует 2=8 подмножеств трех объектов, а кон-
конкретно: 1, 2, 3, 12, 13, 23, 123 и пустое множество; никогда не забывайте про
пустое множество. Для п = 20 имеем 2п = 1 048 576, так что мы начинаем
приближаться к пределу возможностей полного перебора.
• Размещения с повторениями (Strings). Последовательность символов, наби-
набираемая с возможностью повторения, называется размещением с повторениями.
Существует тп различных последовательностей из п объектов т различных видов.
27 размещений длиной 3 для набора 123: 111, 112, 113, 121, 122, 123, 131, 132,
133, 211, 212, 213, 221, 222, 223, 231, 232, 233, 311, 312, 313, 321, 322, 323, 331,
332 и 333. Число двоичных размещений длины п равняется числу подмножеств п
объектов (почему?), и число возможных вариантов растет еще быстрее с уве-
увеличением т.
6.2. Рекуррентные соотношения
Рекуррентные соотношения значительно облегчают подсчет ряда рекурсивно
заданных структур. К рекурсивно заданным структурам относятся деревья, спи-
списки, правильно построенные формулы и алгоритмы «разделяй и властвуй», так
что они часто встречаются на пути ученых, занимающихся алгоритмами.
Что есть рекуррентное соотношение? Это равенство, которое определено
само через себя. Почему они удобны? Потому что многие натуральные функции
легко выражаются рекуррентно! Рекуррентно можно представить любой поли-
полином, включая линейную функцию:
Любая степенная функция может быть задана рекуррентно:
ая=2ая_19ах=2->аИ=2*.
И наконец, некоторые необычные, но интересные функции, которые не так-то
просто представить в обычной записи, могут быть заданы рекуррентно:
а„ =пап_19а{ = 1-» ая = п\.
6.3. Биномиальные коэффициенты . 151
Таким образом, рекуррентные соотношения являются весьма универсальным спо-
способом представления функций. Часто в качестве решения счетной задачи мы получа-
получаем именно рекуррентные соотношения. Разрешение такого соотношения и получение
краткой аналитической формулы нередко относится к области искусства, но, как мы
увидим, компьютерные программы могут легко вычислять значение заданного рекур-
рекуррентного соотношения, даже если аналитической формы не существует.
6.3. Биномиальные коэффициенты
Одним из самых важных понятий в комбинаторике является понятие биномиаль-
биномиальных коэффициентов, чисел, обозначаемых | и задающих число способов, которыми
k)
можно выбрать к предметов из п возможных. Что можно рассчитать с их помощью?
• Комиссии. Сколькими способами можно сформировать комиссию, состоящую
из к членов, из п человек? По определению, | .
• Пути через сетку. Сколькими способами можно пройти из верхнего левого
угла сетки размером п х т до правого нижнего, если идти можно только вниз
или вправо? Каждый путь должен содержать т + п шагов, п вниз и т вправо.
Каждый путь с различным набором шагов вниз является уникальным, так что
( п + т Л
всего существует п I таких наборов/путей.
• Коэффициенты (а + Ь)п. Заметим, что
(а + ЪK = la3 + 3a2b + ЪаЪ2 - \ЪЪ.
Какой коэффициент стоит перед akbn~kl Очевидно, что п , так как он равен
* )
числу возможных способов получения к я-одночленов из п возможных.
• Треугольник Паскаля. Наверняка вы встречались с таким расположением
чисел в старших классах средней школы. Каждое число является суммой двух
чисел, стоящих прямо над ним:
1
1 1
12 1
13 3 1
14 6 4 1
1 5 10 10 5 1
152 Глава 6. Комбинаторика
Но почему это заинтересовало Паскаля и должно заинтересовать вас? Дело
в том, что, пользуясь таким построением, можно найти биномиальные
коэффициенты! (п + 1)-й ряд треугольника задает значения п для 0 < / <п.
U )
Изящество треугольника состоит в том, что благодаря ему можно заметить
некоторые интересные соотношения, например, что сумма всех коэффициен-
коэффициентов (п+1) ряда равняется 2я.
Как можно рассчитать биномиальные коэффициенты?
Во-первых, = я!/(( п - к )! к!), так что теоретически вы можете посчитать
ук)
их напрямую через факториалы. Тем не менее у этого метода есть серьезный недос-
недостаток. Промежуточные вычисления легко могут вызвать арифметическое перепол-
переполнение, тогда как итоговый коэффициент не выходит за пределы целочисленного
типа данных.
Более надежный путь вычисления биномиальных коэффициентов состоит
в использовании рекуррентного соотношения, неявно заложенного в треугольни-
треугольнике Паскаля, а именно
(:)¦(::;)¦(•;'
Почему это верно? Предположим, что я-й элемент присутствует в одном из
подмножеств к элементов. Если это так, то мы можем дополнить подмножество,
к)
выбрав недостающие к- 1 объектов из п -1 оставшихся. Если нет, то мы должны вы-
выбрать все к объектов из п - 1 оставшихся. Эти случаи не перекрываются, все возмож-
возможности включены, так что их сумма подсчитывает все подмножества размера к.
Но мы не можем построить рекуррентную последовательность без задания
начальных случаев. Какие биномиальные коэффициенты мы знаем без вычисле-
[п - к Л
. Скольки-
Сколькими способами можно выбрать 0 объектов из множества? Ровно одним, взяв пустое
множество. Если это выглядит неубедительно, то можно принять, что
( кЛ
Правое слагаемое в сумме приводит нас к . Сколькими способами можно вы-
\к )
брать к объектов из ?-элементного множества? Ровно одним, взяв полное множе-
множество. Вместе с рекуррентными формулами эти начальные случаи определяют
биномиальные коэффициенты для всех интересных значений.
6.4. Другие счетные последовательности
153
Лучше всего рассчитать такую рекуррентную последовательность, построив
таблицу всех возможных величин необходимого размера. Ознакомьтесь с функци-
функцией, приведенной ниже, чтобы понять, как мы это сделали.
#define MAXN
100
/* максимальное п или m */
long binomial_coef f icient A1,111)
int m,n;
int i,j;
long be [MAXN] [MAXN]
for (i=0; i<=n;
for (j=0; j<=n;
for (i=l; i<=n;
for (j=l;
/* сочетания из m no n */
/* счетчики */
/* таблица биномиальных коэффициентов */
bc[i][0] = 1;
bc[j][j] = 1;
return( be[n][m] );
Такие программы, вычисляющие рекуррентные последовательности, являются
основой динамического программирования алгоритмической методики, которую мы
изучим в главе 11.
6.4. Другие счетные последовательности
Существует несколько других счетных последовательностей, периодически
появляющихся в приложениях и легко вычисляемых с использованием ре-
рекуррентных соотношений. Мудрый комбинаторщик никогда о них не забывает.
Числа Фибоначчи. Задаваемые рекуррентным соотношением Fn = Fn_j + Fn_2
и начальными значениями Fq = 0 и Fj=1, они периодически встречаются,
вероятно, потому что это простейшее интересное рекуррентное соотношение.
Первые несколько значений: 0, 1, 1, 2, 3, 5, 8, 13, 21, 34, 55... . Для чисел
Фибоначчи существует поразительное число математических тождеств и их
весьма интересно изучать. Для них существует следующая трудноугадывае-
мая, но легковыводимая аналитическая форма:
i-VsY
154 Глава 6. Комбинаторика
Из этой аналитической формы можно получить несколько важных следствий.
Так как абсолютное значение A - у[Е) 12 лежит между 0 и 1, то возведение его
в любую степень оставляет число в этом интервале. Таким образом, первое
слагаемое' фп, где ф - A + V 5) / 2, - величина значительно большая и может
быть использована для оценки Fn с точностью до плюс или минус 1.
• Числа Каталана. Рекуррентная формула и соответствующая ей анали-
аналитическая форма
п-\ j Bп\
определяют числа Каталана, которые возникают в удивительном числе комби-
комбинаторных задач. Несколько первых: 2, 5,14,42,132,429,1430,..., причем Со = 1.
Сколькими способами можно построить правильную формулу из п наборов
левых и правых скобок? Например, для п = 3 это можно сделать пятью способами:
(@))> 0@)> (ОХХ @0) и 000- Самой левой открывающей скобке / соответствует
определенная закрывающая скобка г, которая должна разбивать формулу на две
правильные части, часть между / и г и часть справа от г. Если левая часть содержит
к пар, то правая должна содержать п~к-\ пар, так как /, г представляют собой
одну пару. Обе эти подформулы должны быть правильными, что ведет к рекур-
рекуррентной формуле
п / j к п-1-к '
к=0
и мы получаем числа Каталана.
Те же самые рассуждения подходят при подсчете числа триангуляции выпук-
выпуклого многоугольника, подсчете числа корневых бинарных деревьев с п+1
листьями и при подсчете числа путей через решетку, не поднимающихся над
главной диагональю. Аналитическая форма чисел Каталана весьма удобна:
С —
п + 1
Числа Эйлера. Числа Эйлера ( ) задают число перестановок длины п ровно с к
\к1
возрастающими последовательностями или сериями (run). Рекуррентное соот-
соотношение можно найти, рассмотрев все перестановки/? чисел 1, ..., и - 1. Суще-
Существует п позиций, куда мы можем вставить элемент и, и каждая из них либо
6.4. Другие счетные последовательности 155
разбивает существующую серию в р, либо попадает точно после последнего
элемента существующей серии, тем самым не меняя количество серий. Таким
образом, ( ) = к(п ~ )+ (п - к + 1)( ~ ). Можете ли вы предложить И пере-
\к/ \к I \*-1/
становок длины четыре ровно с двумя сериями?
Числа Стирлинга (Stirling). Существует два различных вида чисел Стерлинга.
Первый вид, , задает число перестановок п элементов ровно к циклами.
Чтобы сформулировать рекуррентное соотношение, заметим, что либо п-й
элемент формирует одноэлементный цикл, либо нет. Если формирует, то тогда
существует L / способов упорядочить оставшиеся п - 1 элементов так, чтобы
|_A:-1J
они формировали к- 1 цикл. Если нет, то тогда я-й элемент может быть вставлен
в любую возможную позицию любого цикла
к циклов из п - 1 элементов. Таким образом,
ствует 11 перестановок четырех элементов ровно с двумя циклами.
способами, чтобы составить
;- :::¦<-" г ¦!•<*»
Разбиения множеств. Второй вид чисел Стирлинга < > задает число способов,
[к)
которыми можно разбить п объектов на к непустых множеств. Например, 4 объ-
объекта на два подмножества можно разбить семью способами: A)B34), A2)C4),
A3)B4), A4)B3), A23)D), A24)C) и A34)B). Элемент п может быть вставлен
в любое из к подмножеств разбиения п - 1 элемента или сформировать
одноэлементное множество. Таким образом, рассуждениями, аналогичными
тем, которые применялись к другому виду чисел Стирлинга, получаем, что
\п\ Гя-11 {«-11 хл
рекуррентное соотношение имеет вид \,\ = к\, \+)к if- Можно
выде-
лить особый случаи: < > = 2 - 1; равенство верно, так как любое корректное
подмножество элементов 2 ... п можно объединить с A) и задать таким образом
разбиение множества. Вторая часть разбиения состоит из всех элементов, не
вошедших в первую часть.
156 Глава 6. Комбинаторика
• Разбиения целых чисел. Целочисленное разбиение п - это неупорядоченный
набор положительных целых чисел, которые в сумме дают п. Например, для
числа 5 существует семь целочисленных разбиений, а именно E), D,1), C,2),
C,1,1), B,2,1), B,1,1,1) и A,1,1,1,1). Проще всего подсчитать их число, задав
функцию/^, к), определяющую число таких целочисленных разбиений п, что
самая большая часть любого разбиения не превышает к. В любом приемле-
приемлемом разбиении наибольшая часть либо превышает установленный предел,
либо нет, так что f(n, к) =f(n -к, к) +f(n, к- \). Базовые случаи - f(l,l) = 1
иДи, к) = О для любых к > п.
За более подробным описанием этих и других числовых последовательностей
отсылаем заинтересованных читателей к [GKP89] . Если вам нужно распознать
интересную числовую последовательность, то стоит посетить Sloane's Handbook
of Integer Sequences по адресу http://www.research.att.com/-njas/sequences/.
6.5. Рекурсия и индукция
Одним из удобных инструментов для решения рекуррентных соотношений
является математическая индукция. Когда мы впервые узнали о математической
индукции в средней школе, она казалась полным шаманством. Вы проверяете
формулу для некоторых базовых случаев, обычно 1 или 2, затем полагаете, что
она верна для всех чисел вплоть до п - 1, и затем доказываете, что она верна для
произвольного л, используя предположение. И это доказательство? Чепуха!
Когда мы впервые узнали в университете о такой методике программирования,
как рекурсия, она тоже казалась полным шаманством. Ваша программа проверяет,
является ли входной аргумент одним из базовых вариантов, к примеру, 1 или 2. Если
нет, то вы решаете более общий случай, разбивая его на части и вызывая для каждой
ту же подпрограмму. И это программа? Чепуха!
Причина, по которой и то и другое кажется шаманством, в том, что рекурсия - это
математическая индукция! И там и там у нас имеются общие и граничные условия,
причем общее условие разбивает задачу на все более и более мелкие куски. Рекурсия
завершается на начальном или граничном условии. После того как вы поймете что-
нибудь одно, рекурсию или индукцию, вы должны суметь разобраться и в другом.
Можно угадать решение и затем доказать, что оно верно, используя индукцию.
Это является мощным способом решения рекуррентных соотношений. При по-
попытке угадать решение имеет смысл составить таблицу небольших значений
функций и попытаться найти закономерность, глядя на них.
2См. также: Грэхем Р.. Кнут Д., Паташник О. Конкретная математика. Основание информатики: Пер. с англ. -
М.: Мир, 1998. -Примеч. науч. ред.
6.6. Задачи 157
Например, рассмотрим следующее рекуррентное соотношение:
Гя = 27^ + 1,70 = 0.
Построение таблицы значений дает нам следующее:
/701234567
Тп О 1 3 7 15 31 63 127
Можете ли вы угадать решение? Вы должны заметить, что кажется, что ре-
результат удваивается, впрочем, судя по формуле, в этом нет ничего удивительного.
Но полного совпадения с 2п нет. Рассматривая вариации этой функции, вы
должны прийти к гипотезе, что Тп = 2п - 1. Чтобы довести работу до конца, мы
должны доказать это предположение, используя три шага индукции.
1. Доказываем, что это верно для базиса: Го = 2 - 1 = 0.
2. Теперь полагаем, что это верно для Тп_\.
3. Используем предположение, чтобы завершить доказательство:
тп = 2Г„Ч +1 = 2{2п-х -1) +1 =2п -1
Угадывание решения - это обычно самая сложная часть работы, здесь вам могут
помочь лишь смекалка и опыт. Общая идея состоит в том, что нужно рассматривать
небольшие значения и пытаться догадаться, также неплохо иметь некоторое пред-
представление о том, какого рода должна быть итоговая аналитическая формула.
б.б. Задачи
6.6.1. Сколько чисел?
PC/UVaIDs: 110601/10183
Популярность: В
Частота успехов: средняя
Уровень:1
Напомним определение чисел Фибоначчи:
/г =2
Для двух заданных чисел а и Ъ определите, сколько чисел Фибоначчи лежит
в диапазоне [а, Ь].
158 Глава 6. Комбинаторика
Входные данные
Входные данные содержат несколько тестовых блоков. Каждый тестовый блок
состоит из двух неотрицательных целых чисел а и Ъ. Входные данные завершаются
блоком a = b = 0. В других случаях a<b< 10100. Числа а и Ъ вводятся без лишних
нулей, стоящих перед числом.
Выходные данные
Для каждого тестового блока выведите одну строку, содержащую количество
чисел Фибоначчи/J таких, что a <ft < b.
Пример входных данных
10 100
1234567890 9876543210
0 0
Соответствующие выходные данные
5
4
6.6.2. Сколько частей земли?
PC/UVaIDs: 110602/10213
Популярность: В
Частота успехов: средняя
Уровень: 2
Вам дается кусок земли в виде эллипса и предлагается выбрать п произволь-
произвольных точек на ее границе. После этого вы соединяете прямыми линиями каждую
точку со всеми остальными, образуя п(п - 1)/2 соединений. Какое максимальное
число кусков земли вы можете получить, аккуратно выбирая точки?
. "Входные данные
Первая строка входного файла содержит одно целое число s @ < s < 3500), за-
задающее число экземпляров входных данных. Следующие s строк задают s экзем-
экземпляров входных данных, причем каждая строка содержит только одно целое число
л@<и<231).
Выходные данные
Для каждого экземпляра входных данных выведите на отдельной строке мак-
максимально возможное число кусков земли, задаваемых п точками.
6.6. Задачи
159
Деление земли для п = 6
Пример входных данных
4
1
2
3
4
Соответствующие выходные данные
1
2
4
6.6.3. Счет
PC/UVaIDs: 110603/10198
Популярность: В
Частота успехов: высокая
Уровень: 2
Густаво знает, как считать, но он еще только учится писать числа. Он уже
научился писать цифры 1, 2, 3 и 4. Правда, он еще не знает, что 4 отличается от 1,
так что он думает, что 4 - это просто другой способ написания 1.
160 Глава 6. Комбинаторика
Ему нравится простая игра, которую он придумал: он пишет числа из тех четырех
известных ему цифр и складывает их значения. Например:
132 = 1 + 3 + 2 = 6
112314 = 1 + 1 + 2 + 3 + 1 + 1 = 9 (не забывайте, что Густаво считает, что 4 = 1)
Густаво интересно, сколько таких чисел с суммой равной числу п он может соста-
составить. Для п - 2 он может составить 5 чисел: 11,14,41,44 и2. (Он знает, как считать до
пяти и дальше, просто не знает, как это записать.) Тем не менее он не может найти это
количество для п больших 2 и поэтому просит вас помочь ему.
Входные данные
Входные данные состоят из произвольного числа целых чисел п таких, что
1 < п < 1000. Вы должны считывать данные до тех пор, пока не достигнете символа
конца файла.
Выходные данные
Для каждого считанного целого числа выведите строку, содержащую одно
целое число, показывающее, сколько чисел с суммой цифр равной п может соста-
составить Густаво.
Пример входных данных
2
3
Соответствующие выходные данные
5
13
6.6.4. Выражения
PC/UValDs: 110604/10157
Популярность: С
Частота успехов: средняя
Уровень:2
Пусть Х- это множество правильно построенных скобочных выражений. Эле-
Элементами Хявляются строки, состоящие только из символов « (» и «) », причем они
определяются следующим образом.
Пустая строка принадлежит X.
• Если А принадлежит X, то (А) также принадлежит X.
6.6. Задачи 161
• Если А и В принадлежат X, то их конкатенация АВ также принадлежит X.
Например, строки ()(())() и (()(())) это правильно построенные ско-
скобочные выражения и поэтому они принадлежат множеству X. Выражения ( () ) ) ( ()
и ())(() построены неправильно и не принадлежат множеству X.
Длиной правильно построенного скобочного выражения Е называется число
одиночных скобок (символов) в Е. Вложенность D(E) множества Е определяется
следующим образом:
{О, если Е пустое',
D( А) +1, если Е-(А)иА принадлежит Х\
max(D(A),D(B)), еслиЕ- АВ и Аи В принадлежат X.
Например, длина ()(())() равна 8, а вложенность 2. Напишите программу,
которая считывает nndn рассчитывает число правильно построенных скобочных
выражений длины п и вложенности d.
Входные данные
Входные данные состоят из пар целых чисел rind, причем на одной строке на-
находится максимум одна пара чисел и 2 < п < 300, 1 <d< 150. Входные данные
могут содержать пустые строки, которые не нужно рассматривать.
Выходные данные
Для каждой пары чисел во входных данных выведите строку, содержащую одно
целое число - число правильно построенных скобочных выражений длины п и вло-
вложенности d.
Пример входных данных Соответствующие выходные данные
6 2 3
300 150 1
Замечание. Для длины 6 и вложенности 2 три правильно построенных ско-
скобочных выражения: (())(),()( О ) и (()()).
6-972
162 Глава 6. Комбинаторика
6.6.5. Нумерация полного дерева
PC/UValDs: 110605/10247
Популярность: С
Частота успехов: средняя
Уровень:2
Полным Парным деревом называется &-арное дерево, у которого глубина всех
листьев одинакова и степень ветвления всех внутренних узлов равна к. Найти
число узлов такого дерева совсем несложно.
Для заданных глубины и степени ветвления такого дерева вы должны подсчи-
подсчитать число таких способов нумерации узлов дерева, что метка каждого узла меньше,
чем метки всех его потомков. При к = 2 это свойство задает структуру данных, пред-
представляющую собой бинарную кучу очереди с приоритетом. При нумерации дерева
с N узлами считайте, что вы можете использовать метки A,2,3,...,jV-1,7V).
Входные данные
Входной файл содержит несколько строк входных данных. Каждая строка со-
содержит два целых числа к и d. Число к > 0 задает степень ветвления полного Уг-
Угарного дерева, a d > 0 задает глубину полного Парного дерева. Ваша программа
должна работать со всеми парами, для которых к х d < 21.
Выходные данные
Для каждой строки входных данных выведите одну строку, содержащую
целое число, равное числу способов нумерации ^-арного дерева, подходящих под
условия, приведенные выше.
Пример входных данных
2 2
10 1
Соответствующие выходные данные
80
3628800
6.6. Задачи
163
6.6.6. Монах-математик
PC/UVaIDs: 110606/10254
Популярность: С
Частота успехов: высокая
Уровень:2
Древнюю историю, связанную с задачей о ханойских башнях, знают все. Более
поздняя легенда рассказывает о том, что когда брамины узнали, сколько времени
у них займет перемещение 64 дисков с одного колышка на другой, они решили
найти более быстрое решение и воспользоваться им.
Ханойские башни с четырьмя колышками
Один из монахов сказал своим товарищам, что они могут произвести это пере-
перемещение за день, если будут работать со скоростью один диск в секунду и будут
использовать дополнительный колышек. Он предложил следующее решение.
• Сначала перемещаем верхние диски (скажем, к верхних дисков) на один из
свободных колышков.
• Далее перемещаем оставшиеся п - к дисков (в общем случае п дисков),
используя стандартное решение с тремя колышками.
• И наконец, перемещаем верхние к дисков на нужное место, используя четыре
колышка.
Он вычислил значение к, сводящее к минимуму количество перемещений,
и обнаружил, что хватит 18 433 перемещения. Таким образом, они могут потра-
потратить всего 5 часов 7 минут и 13 секунд, используя эту схему, вместо 500 000 мил-
миллионов лет, которые потребовались бы без дополнительного колышка!
Попробуйте повторить рассуждения мудрого монаха и вычислить число пере-
перемещений при использовании четырех колышков при условии, что за раз можно
перемещать только один диск и на колышек диск можно класть только так, чтобы
под ним не было дисков меньшего размера. Вычислите к, сводящее к минимуму
число перемещений при таком способе решения.
164 Глава 6. Комбинаторика
Входные данные
Входной файл содержит несколько строк входных данных. Каждая строка со-
содержит одно целое число О <N< 10 000, задающее число переносимых дисков.
Входные данные заканчиваются символом конца файла.
Выходные данные
Для каждой строки входных данных выведите одну строку, содержащую
целое число, равное числу перемещений, необходимых для переноса N дисков на
конечный колышек.
Пример входных данных
1
2
28
64
Соответствующие выходные данные
1
з
769
18433
6.6.7. Самоописывающая последовательность
PC/UVaIDs: 110607/10049
Популярность: С
Частота успехов: высокая
Уровень:2
Самоописывающая последовательность Соломона Голомба (/A), /B), /C),...) -
это единственная неубывающая последовательность положительных целых чисел,
обладающая тем свойством, что она содержит ровно/(?) экземпляров к для каждого к.
Немного поразмыслив, можно прийти к выводу, что последовательность должна
начинаться так:
п 1
f(n) 1
2
2
3
2
4
3
5
3
6
4
7
4
8
4
9
5
10
5
11
5
12
6
6.6. Задачи 165
В этой задаче от вас требуется написать программу, которая будет рассчиты-
рассчитывать значение/^ по заданному п.
Входные данные
Входные данные могут содержать несколько тестовых блоков. Каждый тесто-
тестовый блок занимает отдельную строку и состоит из одного целого числа п
A < л < 2 000 000 000). Входные данные завершаются тестовым блоком, содержа-
содержащим 0 в качестве п. Этот блок обрабатывать не нужно.
Выходные данные
Для каждого тестового блока входных данных выведите строку, содержащуюся/
Пример входных данных
100
9999
123456
1000000000
0
Соответствующие выходные данные
21
356
1684
438744
6.6.8. Шаги
PC/UVaIDs: 110608/846
Популярность: А
Частота успехов: высокая
Уровень:2
Рассмотрим процесс пошагового перехода от целого числах к целому числу;; по
целочисленным точкам числовой прямой. Длина каждого шага должна быть неотри-
неотрицательной и может быть на единицу больше, равной или на единицу меньшей, чем
длина предыдущего шага.
Каково минимальное число шагов, необходимое, чтобы добраться из х в yl
Длина и первого и последнего шага должна быть 1.
166 Глава 6. Комбинаторика
Входные данные
Входные данные начинаются со строки, содержащей число тестовых блоков п.
Каждый из последующих тестовых блоков состоит из строки, содержащей два
целых числа: 0 < х < у < 231.
Выходные данные
Для каждого тестового блока выведите строку, содержащую минимальное
число шагов, которые необходимы, чтобы добраться из х в у.
Пример входных данных
3
45 48
45 49
45 50
Соответствующие выходные данные
з
3
4
6.7. Подсказки
6.1. Можно ли использовать аналитическую форму Fn для сведения к минимуму
необходимости в арифметике с произвольной точностью?
6.2. Можно ли получить рекуррентное соотношение для искомой величины?
6.3. Можно ли получить рекуррентное соотношение для искомой суммы?
6.4. Можно ли сформулировать рекуррентное соотношение? Возможно, подой-
подойдет двухпараметрическая версия чисел Каталана?
6.5. Можно ли получить рекуррентное соотношение для искомой величины?
6.6. Нужно ли вам явно строить последовательность, или вы должны изобрести
что-либо более изящное из-за ограничений по памяти?
6.7. Какого типа будут последовательности шагов при оптимальном решении?
6.8. Замечания
6.1. Хотя в задаче предлагается быстрый способ решения задачи о ханойских баш-
башнях с четырьмя колышками, неизвестно, является ли он оптимальным. Для бо-
более подробного рассмотрения см. [GKP89].
Глава 7
Теория чисел
Теория чисел является, возможно, самым интересным и красивым разделом ма-
математики. Доказательство Евклидом существования бесконечного количества про-
простых чисел остается таким же четким и ясным сегодня, каким оно было более двух
тысяч лет назад. Такие невинные вопросы, как существуют ли решения уравнения
ап + Ъп = сп для целых а, Ъ, с и п > 2, часто оказываются совсем не такими невинны-
невинными. Более того, это формулировка великой теоремы Ферма!
Теория чисел является отличным способом потренироваться в формальных, стро-
строгих рассуждениях, так как все доказательства должны быть ясными и четкими. Изуче-
Изучение целых чисел интересно тем, что они такие понятные и вместе с тем важные объ-
объекты. Открывая какие-либо новые свойства целых чисел, открываешь что-то удиви-
удивительное про окружающий мир.
Компьютеры уже долгое время используются в исследованиях теории чисел. Про-
Проведение необходимых вычислений, связанных с теорией, для больших чисел требует
значительной эффективности. К счастью, существует множество алгоритмов, которые
могут нам в этом помочь.
7.1. Простые числа
Целое число р > 1 называется простым, если оно делится только на 1 и само на
себя. Говоря другими словами, еслир - простое число, то равенствор = ах Ъ для
целых а < Ъ эквивалентно тому, что а = 1 и Ъ =р. Первые десять простых чисел: 2, 3,
5,7,11,13, 17, 19, 23 и 29.
Важность простых чисел отражена в основной теореме арифметики. Несмотря
на впечатляющее название, все, что она утверждает, это то, что любое целое число
представляется в виде произведения простых сомножителей, причем единственным
образом. Например, 105 уникально представляется как 3 х 5 х 7, а 32 уникально пред-
представляется как 2x2x2x2x2. Этот уникальный набор сомножителей, образующих я,
168 Глава 7. Теория чисел
называется разложением числа п на простые множители. В разложении на простые
множители порядок не имеет значения, так что мы можем перечислять числа в от-
отсортированном порядке. Но количество вхождений одного сомножителя значение
имеет; именно поэтому различаются разложения на простые множители для 4 и для 8.
Мы говорим, что число р является множителем числа х, если оно входит в его
разложение на простые множители. Любое число не являющееся простым, называ-
называется составным.
7.1.1. Поиск простых чисел
Самым простым способом определения того, простое ли число х, является мно-
многократное деление. Деление проводится на все необходимые числа, начиная с наи-
наименьшего возможного делителя. Так как 2 - это единственное четное простое число,
то, убедившись в том, что х не четно, мы можем проверять в качестве возможных
множителей только нечетные числа. Более того, мы можем утверждать, что х - про-
простое число, как только мы проверим все возможные простые множители, не превы-
превышающие yjx. Почему? Предположим, что это неверно, то есть х является составным,
но при этом его наименьший нетривиальный простой множитель/? превышает
Тогдах также должно делиться на число х/р, и при этом х/р должно быть больше/?,
так как иначе мы бы встретили его раньше. Но произведение двух чисел больших
V х должно быть больше х; получили противоречие.
При нахождении разложения на простые множители нам требуется не только
найти первый простой множитель, но еще и удалить все его вхождения в число и про-
продолжить обработку того, что осталось.
prime_factorization(long x)
{
long i; /* счетчик */
long с; /* оставшееся произведение */
С = X *
while'((с % 2) == 0) {
printf("%ld\n"f2);
с = с / 2;
}
i = 3;
while (i <= (sqrt(с)+1)) {
if ((с % i) == 0) {
printf("%ld\n",i) ;
с = с / i ;
7.1. Простые числа 169
else
i = i + 2;
}
if (с > 1) printf ("%ld\n"',c) ;
}
Проверка условия остановки i > y/x может привести к некоторым проблемам,
так как sqr t () - это численная функция с ограниченной точностью. Чтобы избе-
избежать возможных неприятностей, мы позволяем / проделать лишнюю итерацию.
Другой подход, позволяющий вообще избежать операций с плавающей точкой,
предполагает остановку при выполнении условия i*i > с. Тем не менее при
работе с очень большими числами операция произведения может вызвать пере-
переполнение. Умножения можно избежать, если заметить, что G +1J = /2 + 2/ +1, так
что, добавив / + / + 1 к /2, мы получим (/ + IJ.
Для увеличения производительности мы можем вынести функцию sqrt () за
пределы основного цикла и обновлять ее, только когда с меняет значение. Тем не
менее эта программа работает мгновенно на моем компьютере для простого числа
2 147 483 647. Существуют удивительные алгоритмы, основанные на рандомиза-
рандомизации, которые являются более эффективными для проверки, является ли число
простым для очень больших чисел, но нам не стоит об этом беспокоиться в наших
масштабах - разве что только в олимпиадных задачах.
7.1.2. Подсчет простых чисел
Сколько всего простых чисел? Кажется разумным, что простые числа
встречаются все реже и реже по мере рассмотрения все больших и больших чисел,
но исчезают ли они совсем? На самом деле они не исчезают, что следует из дока-
доказательства Евклида о бесконечности числа простых чисел. В нем используется
изящное доказательство от противного. Знание этого доказательства необяза-
необязательно для участия в соревнованиях по программированию, но оно является при-
признаком эрудированности человека. Так что не случится ничего плохого, если мы
его здесь рассмотрим.
Предположим обратное, то есть что существует только конечное число простых
чисел Р],Р2, ~',Рп- Пусть т - 1 + Y\_ Pr т0 есть произведение всех этих простых
чисел плюс один. Так как это число больше, чем любое из наших простых чисел, то
оно должно быть составным. Таким образом, оно должно делиться на какое-то про-
простое число.
170 Глава 7. Теория чисел
Но на какое? Мы знаем, что т не делится на/?/, потому что получается остаток 1.
Также т не делится нар2, потому что также получается остаток 1. На самом деле,
остаток 1 получается при делении т на любое из простых чисел pi для 1 < / = п.
Таким образом,/?у,/?2, —>рп не могут быть всеми простыми числами, потому что из
наших рассуждений следует, что т тогда также должно быть простым.
Так как это противоречит сделанному предположению, то, значит, не существует
полного списка всех простых чисел; таким образом, число простых чисел должно
быть бесконечно! ЧТД!1
Помимо того что количество простых чисел бесконечно, они еще и достаточно
часто встречаются. Существует примерно х/\пх простых чисел меньших или
равных х, или, говоря другими словами, примерно одно число из lnx является
простым.
7.2. Делимость
Теория чисел - это учение о делимости чисел. Мы говорим, что а делится на Ъ
(обозначается Ь\а), если для какого-то целого к верно а = Ък. Аналогично, если Ь\а,
мы говорим, что Ь - это делитель а или а кратно Ъ.
Следствием этого определения является то, что наименьшим натуральным дели-
делителем любого ненулевого целого числа является 1. Почему? Очевидно, что в общем
случае не существует такого целого к, что а - 0 х к.
Как можно найти все делители данного целого числа? Из теоремы о разложе-
разложении на простые множители мы знаем, что х уникальным образом представляется
произведением его простых множителей. Любой делитель является произведе-
произведением некоторого подмножества этих простых множителей. Такие подмножества
могут быть построены с использованием перебора с возвратом, который будет
обсуждаться в главе 8, правда, при этом нам нужно аккуратно рассматривать
случаи повторяющихся простых множителей. Например, разложение на простые
множители числа 12 содержит три элемента B, 2 и 3), но у 12 только 6 делителей
A,2,3,4,6, 12).
!А теперь небольшая проверка на то, как вы поняли доказательство. Предположим, мы взяли первые п простых
чисел, перемножили их и добавили единицу. Является ли получившееся число простым? Приведите
доказательство или контрпример.
7.2. Делимость 171
7.2.1. Наибольший общий делитель
Так как на 1 делится любое целое число, то наименьшим общим делителем
любой пары целых чисел а, Ъ является 1. Интереснее рассматривать наибольший
общий делитель, или НОД, самый большой делитель, общий для двух заданных
целых чисел. Рассмотрим дробь х/у, скажем, 24/36. Мы можем получить приве-
приведенную форму этой дроби, если разделим числитель и знаменатель на НОД(Зс, у),
равный в этом случае 12. Мы говорим, что два числа взаимно простые, если их
НОД равен 1.
Алгоритм Евклида для нахождения наибольшего общего делителя считается
первым интересным алгоритмом, который донесла до нас история. Чтобы найти
НОД «в лоб», мы должны перебрать все делители первого числа и явно проверить,
являются ли они делителями второго, или, как вариант, найти разложение на про-
простые множители обоих чисел и взять произведение всех их общих множителей.
Но и тот, и другой подход требует значительных вычислительных затрат.
Алгоритм Евклида основывается на двух наблюдениях.
1. Если Ь\а, то НОД^я, Ъ) = Ь.
Это очевидно. Если а делится на Ъ, то а = Ь х к для какого-то целого к, но тогда
НОД(Ъ хк,Ь) = Ъ.
2. Если а = b х t + г для целых / и г, то НОД(а, Ъ) = НОД^я, г).
Почему? По определению НОД fa, Ъ) = ЯОД(Ь х t + г, Ъ). Любой общий дели-
делитель а и b должен делить г без остатка, так как очевидно, что b x t делится на
любой делитель Ь.
Алгоритм Евклида - это рекурсивное, повторяющееся замещение большего из
двух чисел на остаток от целочисленного деления большего числа на меньшее.
Обычно при этом один из аргументов уменьшается примерно вдвое, так что после
логарифмического числа операций мы приходим к базовому случаю. Рассмотрим
следующий пример. Пусть а = 34 398 и Ъ = 2132.
НОД C4398,2132) = НОД C4398 тос!2132,2132) = ЯОД B132,286),
#0Д B132,286) = #<9Д B132 mod 286,286) = НОД B86,130),
НОД B86,130) = НОД B86 тосПЗОДЗО) = НОД A30,26),
ЯОДA30,26) = ЯОДA30тоA26,26) = НОД B6,0).
Таким образом, НОДC4398,2132) = 26 .
Тем не менее из алгоритма Евклида мы можем найти не только НОД fa, b). С его
помощью мы можем также найти целые х и у такие, что
ахх + Ьху= НОД(а, Ь),
172 Глава 7. Теория чисел
что окажется весьма полезно при решении линейных сравнимостеи. Мы знаем, что
НОД(а, Ъ) = НОД(Ь, а!), где а'= a- t\_a/b]. Более того, предположим, что из рекурсии
мы знаем целые х' и/ такие, что
Ьхх' + а'ху'=НОД(а,Ь).
Подставив наше выражение для а' в это выражение, получим:
Ь х х1 +( а - lia/bj) х / = НОД(а, Ь),
тогда, приведя подобные, мы найдем искомые хиу. Чтобы наш алгоритм был пол-
полным, нам нужен базисный случай, он выбирается просто: а х 1 + 0 х 0 = НОД(а, 0).
Для предыдущего примера мы получаем: 34 398 х 15 + 2132 х (-242) = 26. Вот
реализация этого алгоритма :
/* Вычисляет gcd(p,q) и х и у такие, что р*х +q*y = gcd(p,q) */
long gcd(long p, long q, long*x/ long *y)
{
long xl,yl; /* предыдущие коэффициенты */
long g; /* значение gcd(p/q) */
if (q > p) return(gcd(q>p/y/x));
if (q == 0) {
*x = 1;
*y = 0;
return(p);
}
g = gcd(q, p%q, &xl, &yl);
*x = yl;
*y = (xl - floor(p/q)*yl);
return(g);
2gcd - сокращение от greatest common divisor, аналогичное НОД. - [JpwueH. науч. ред.
7.3. Арифметика остатков 173
7.2.2. Наименьшее общее кратное
Еще одной важной функцией от двух целых чисел является наименьшее общее
кратное (НОК), самое маленькое целое число, которое делится на оба заданных
целых числа. Например, наименьшее общее кратное 24 и 36 - это 72.
Наименьшее общее кратное появляется в тех задачах, где требуется посчитать
периодичность совпадения двух различных периодических событий. Когда в сле-
следующий раз (после 2000-го) год президентских выборов (которые проводятся каждые
4 года) совпадет с годом переписи населения (которая проводится раз в 10 лет)? Эти
события совпадают каждые двадцать лет, так как НОКD,\0) = 20.
Очевидно, что НОК(х, у) > max(x, у). Аналогично, так как х х у кратно и х и у,
то НОК{х, у) = х х у. Меньшее общее кратное может существовать только в том
случае, если существует нетривиальный множитель, общий для х и у.
Это наблюдение вместе с алгоритмом Евклида дает нам эффективный алгоритм
вычисления наименьшего общего кратного, а именно НОК(х, у) = х х у/НОД(х, у).
Более хитрый алгоритм, в котором нет необходимости в умножении и, как следст-
следствие, исчезает возможность переполнения, можно найти в [Dij76].
7.3. Арифметика остатков
В главе 5 мы рассмотрели простейшие арифметические операции, такие, как
сложение и умножение, для целых чисел. Но нам не всегда нужен полный ответ.
Иногда нам вполне хватает остатка. Например, предположим, что в этом году ваш
день рождения попал на среду. На какой день недели он попадет в следующем
году? Вам нужно знать только остаток от деления на 7 количества дней между
днем рождения в этом году и в следующем (или 365 или 366). Таким образом, он
попадает на среду плюс один C65 mod 7) или два C66 mod 7) дня, то есть на чет-
четверг или на пятницу в зависимости от того, високосный год или нет.
Арифметика остатков позволяет нам эффективно проводить такие вычисления.
Конечно, теоретически мы можем явно посчитать полное число и после этого найти
остаток. Но для достаточно больших чисел будет куца проще работать исключительно
с остатками, используя модулярную арифметику (modular arithmetic).
Число, на которое мы делим, называется модулем (modulus), а то, что оста-
осталось, называется остатком (residue). Чтобы эффективно использовать арифмети-
арифметику остатков, нужно понять, как для заданного модуля работают операции сложе-
сложения, вычитания и умножения.
174 Глава 7. Теория чисел
• Сложение. Как посчитать (х +у) mod nl Чтобы не складывать большие числа,
мы можем упростить до
{{х mod п) + (у mod n)) mod п.
Сколько у меня будет мелочи, если мама мне дала $123.45, а папа дал $94.67?
A2345 mod 100) + (9467 mod 100) = D5 + 67) mod 100 = 12 mod 100.
• Вычитание. Вычитание - это просто сложение с отрицательной величиной.
Сколько у меня останется мелочи после того, как я потрачу $52.53?
A2 mod 100) - E3 mod 100) = -41 mod 100 = 59 mod 100
Обратите внимание, что мы можем преобразовать отрицательное число mod n
к положительному, добавив число, кратное п. Более того, это преобразование
имеет смысл в нашем примере. Лучше всего, чтобы остаток был между 0 и п - 1,
так как в этом случае мы будем работать с числами минимальной возможной
величины.
• Умножение. Так как произведение - это просто повторяющееся сложение,
ху mod п = (х mod n)(y mod n) mod п.
Сколько у вас будет мелочи, если вы зарабатывали $17.28 в час в течение 2143
часов?
A728 х 2143) mod 100 = B8 mod 100) х D3 mod 100) = 4 mod 100.
Кроме того, так как возведение в степень - это просто повторяющееся умножение,
ху mod п = (х mod пУ mod п.
Так как возведение в степень - это наиболее быстро растущая функция, то
именно здесь арифметика остатков проявляет себя лучше всего.
• Деление. С делением работать намного сложнее. Его мы обсудим в разделе 7.4.
У арифметики остатков есть множество интересных приложений, например:
• Нахождение последней цифры. Чему равна последняя цифра числа 2100?
Конечно, мы можем использовать сверхточную арифметику и посмотреть на
последнюю цифру, но зачем? Это вычисление несложно провести вручную.
На самом деле нам нужно узнать, чему равняется 2100 mod 10. Если мы будем
циклически возводить в квадрат и на каждом шаге брать остаток от mod 10, то
получим ответ очень быстро.
7.4. Сравнимости 175
23mod 10 = 8,
26 mod 10 = 8x8 mod 10 -> 4,
212 mod 10 = 4x4 mod 10 -> 6,
224 mod 10 = 6x6 mod 10 -> 6,
248 mod 10 = 6x6 mod 10 -> 6,
296 mod 10 = 6x6 mod 10 -* 6,
2100 mod 10 = 296 x 23 x 21 mod 10 -> 6.
RSA-кодирование. Классическим приложением арифметики остатков для боль-
больших чисел является кодирование с открытым ключом, а именно RSA-алгоритм.
Сообщение преобразуется к целому числу т, которое возводится в степень к,
называемую открытым ключом или ключом шифрования, после чего берется
результат по mod п. Так как т,пи к- это все большие числа, то для эффектив-
эффективного вычисления т mod n требуются методы, описанные нами выше.
Календарные расчеты. Как было показано на примере с днем рождения,
арифметику остатков удобно применять Для расчета дня недели по количеству
дней, считая от сегодняшнего, или времени через определенное число секунд.
7.4. Сравнимости
Сравнимости - это альтернативный вариант представления модулярной
арифметики. Мы говорим, что а = b(mod m), если т\(а - Ь). По определению, если
a mod b = т, то а = b(mod m).
Сравнимости - это альтернативный вариант записи, а не что-то идейно новое.
Но этот вариант записи важен. Он наводит нас на мысль о множествах целых чисел
с данным остатком п и позволяет нам записывать уравнения, задающие эти множест-
множества. Пусть х - это переменная. Какие целые х удовлетворяют сравнимости х = 3(mod 9)?
Для такой простой сравнимости ответ найти несложно. Очевидно, что х = 3 явля-
является решением. Далее, добавляя или вычитая модуль (в данном случае 9), мы получа-
получаем другое решение. Таким образом, множеством решения данной сравнимости явля-
является 9у + 3, щеу целое.
А как насчет более сложных сравнимостей, таких, как 2х = 3(mod 9)
и 2х = 3(mod 4)? Методом подбора вы можете найти, что решением первого при-
примера являются целые числа вида 9у + 6, а второй пример не имеет решений.
Нам нужно разобраться, как проводить арифметические действия со сравнимо-
стями и как их решать. И то и другое обсуждается в следующих разделах.
176 Глава 7. Теория чисел
7.4.1. Операции со сравнимостями
Для сравнимостей определены следующие операции: сложение, вычитание, умно-
умножение и урезанная форма деления - при условии, что они имеют одинаковый модуль.
• Сложение и вычитание. Пусть а = fe(mod ri) и с = d(mod ri). Тогда а + с =
= Ъ + d(mod т). Например, пусть я знаю, что 4х = 7(mod 9) и Ъх = 3(mod 9).
Тогда
4х - Зх = 7 - 3(mod 9) -» я: = 4(mod 9).
• Умножение. Очевидно, что из того, что а = b(mod ?i), следует, что а х d =
= Ъ х d(mod л) (добавляем сравнимость саму к себе d раз). На самом деле,
верно даже более общее утверждение: из того, что а = b(mod ri) и с = J(mod л),
следует, что ас = 6d(mod и).
• Деление. Тем не менее мы не можем просто сокращать общие множители
в сравнимостях. Например, 6 х 2 = 6 х l(mod w), но очевидно, что 2 * l(mod 3).
Чтобы понять, в чем дело, заметим, что деление можно определить, как умноже-
умножение на обратную величину, то есть alb эквивалентно ab~\ Таким образом, мы смо-
сможем найти a/b(mod я), если сможем найти обратное Ь~х такое, что bb~l = l(mod ri).
Обратная величина существует не всегда - попробуйте найти решение
2x=l(mod4).
Мы можем упростить сравнимость ad = bd{mod dri) до а = 6(mod ri), так что
мы можем делить все три числа на общий делитель, если таковой существует.
Таким образом, из того, что 170 = 30(mod 140), следует, что 17 = 3(mod 14).
Нужно заметить, что если b не делится на НОД(я, ri), то сравнимость
а = 6(mod ri) не имеет решений.
7.4.2. Решение линейных сравнимостей
Линейная сравнимость - это уравнение в форме ах = 6(mod ri). Решить это
уравнение - значит найти все значения х, удовлетворяющие ему.
Не все такие уравнения имеют решения. Мы видели, что не для всех целых чисел
можно найти мультипликативные инверсии по заданному модулю, что значит, что
ах = l(mod ri) в этих случаях не имеет решений. На самом деле, ах = l(mod ri) имеет
решение тогда и только тогда, когда модуль и множитель являются взаимно просты-
простыми, то есть НОД(а, п)= \. Мы можем использовать алгоритм Евклида для нахождения
обратной величины путем решения ах х' + п ху' = НОД(а, п) = \. Таким образом,
ах = l(mod ri) -» ах = а х хг + п х /(mod ri).
Очевидно, что nx/ = 0(mod и), так что фактически обратная величина - это х'
из алгоритма Евклида.
7.4. Сравнимости 177
Вообще, в зависимости от a, b ип могут реализоваться три случая.
• НОД(а, Ь,п)> 1. В этом случае мы можем поделить все три члена на этот
делитель и получить эквивалентную сравнимость. Это дает нам одно решение
mod новое основание или, что одно и то же, НОД(а, Ь, п) решений (mod n).
• Ъ не делится на НОД(а, п). Тогда, как уже было сказано, сравнимость реше-
решений не имеет.
• НОД(а, п)=\. Тогда существует одно решение (mod ri). Подходитx = a~lb, так как
аа b = b(mod n). Как показано выше, эта обратная величина существует и может
быть найдена с помощью алгоритма Евклида.
Китайская теорема об остатках дает нам возможность работать с системами
сравнимостей по разному модулю. Пусть существует целое х такое, что х = я/(mod nij)
их = a2(modmi)- Тогдах единственным образом определяется (mod mjm2) при усло-
условии, что т;ит2 взаимно простые.
Чтобы найти х и решить, таким образом, систему двух сравнимостей, мы
сначала решаем линейные сравнимости m2bj = l(mod т}) и га/й2 - l(niod и^),
чтобы найти Ь] и Ь2 соответственно. После этого легко показать, что
х = ajbjm2 + a2b2mj
является решением обеих заданных сравнимостей. Более того, теорема просто
расширяется на систему произвольного числа сравнимостей, чьи модули попарно
взаимно простые.
7.4.3. Диофантовы уравнения
Диофантовыми называются уравнения, решения которых должны быть це-
целочисленными. Примером может служить великая теорема Ферма ап + Ьп = сп.
Решить такое уравнение для вещественных чисел несложно. Задача становится
сложной только в том случае, если все переменные должны быть целыми.
С диофантовыми уравнениями тяжело работать из-за нестандартной операции
деления для целых чисел. Тем не менее существуют классы решаемых диофанто-
вых уравнений, которые могут нередко встречаться.
Наиболее важный класс линейных диофантовых уравнений имеет вид ах —
пу = Ь, где х и у - это целочисленные переменные, а, Ъ и п - это целочисленные
константы. Несложно показать, что решение этого уравнения эквивалентно реше-
решению сравнимости вида ах = 6(mod и), и, как следствие, мы можем использовать
методы, описанные в предыдущем разделе.
Более сложный диофантов анализ выходит за пределы этой книги, но мы отсылаем
читателя к стандартным источникам по теории чисел, таким, как Нивен и Цукерман
(Niven, Zuckerman) [ZMNN91] и Харди и Райт (Hardy, Wright) [HW79], для более
подробного обсуждения этой интереснейшей области математики.
178 Глава 7. Теория чисел
7.5. Библиотеки по теории чисел
Java-класс Biglnteger (Java.math.Biglnteger) содержит ряд полез-
полезных функций, основанных на теории чисел. Конечно, самыми важными являются
функции арифметических операций с произвольной точностью, обсуждавшихся
в главе 5. Но кроме них есть несколько функций, представляющих интерес с точки
зрения теории чисел.
• Наибольший общий делител. Biglnteger gcd (Biglnteger val) возвращает
Biglnteger, чье значение является НОД abs(this) и abs(val).
• Возведение в степень по модулю. Biglnteger modPow( Biglnteger exp,
Biglnteger m) возвращает thisexp mod m.
• Обратная величина по модулю. Biglnteger modlnverse (Biglnteger m)
возвращает this (mod m), то есть решает сравнимость у х this = l(mod m), воз-
возвращая соответствующее целое число, если оно существует.
• Является ли число простым, public Boolean isProbablePrime (int
certainty) использует проверку на простоту, основанную на рандомизации,
чтобы вернуть истину, если есть вероятность, что это число простое, и ложь, если
это число составное. Если при вызове функция вернула истину, то вероятность
того, что число простое, > 1 - тсегШп*У.
7.6. Задачи
7.6.1,. Света, больше света
PC/UVaIDs: 110701/10110
Популярность: А
Частота успехов: средняя
Уровень:1
В нашем институте есть человек по имени Мабу, который включает/выключает
лампы вдоль коридора. Для каждой лампы есть свой выключатель, отвечающий за
то, светит лампа или нет. Если лампа выключена, то нажатие на выключатель ее
включает. Повторное нажатие выключает лампу. В начальном состоянии все лампы
выключены.
Включает лампы он весьма экстравагантным способом. Если в коридоре име-
имеется п ламп, то проходит по коридору туда и обратно п раз. Когда он проводит /-й
обход, то нажимает выключатели только тех ламп, чья позиция делится на L Когда
он возвращается на свою начальную позицию, то выключатели он не трогает. Для
Мабу i-й обход определяется как проход вдоль коридора (во время которого ведет
себя странно) и последующее возвращение. Определите конечное состояние
последней лампы. Светит она или нет?
7.6. Задачи 179
Входные данные
На вход подается целое число, задающее п-ю лампу в коридоре, причем оно
меньше либо равно 232 - 1. Нуль задает конец входных данных и обрабатываться
не должен.
Выходные данные
Выведите "yes " или "по" на отдельной строке для каждого тестового блока,
чтобы указать, светится лампа или нет.
Пример входных данных
3
6241
8191
О
Соответствующие выходные данные
по
yes
по
7.6.2. Числа Кармайкла
PC/UValDs: 110702/10006
Популярность: А
Частота успехов: средняя
Уровень: 2
В определенных криптографических алгоритмах используются большие про-стые
числа. Но проверить, является ли большое число простым, не так-то просто.
Существуют проверки на простоту, основанные на рандомизации, обла-
обладающие высокой степенью точности и не требующие больших затрат. Примером
таких проверок может служить тест Ферма. Пусть a - это случайное число между
2ип-\, где п - это число, чью простоту мы проверяем. Тогда п вероятно простое,
если выполняется следующее условие:
an mod п = а
Если число проходит тест Ферма несколько раз, то оно является простым
с большой вероятностью.
180 Глава 7. Теория чисел
К сожалению, у этого метода §сть и минусы. Определенные составные числа
(не простые) проходят тест Ферма для любых чисел меньших их. Такие числа
называются числами Кармайкла (Carmichael).
Напишите программу, которая будет проверять, является ли заданное целое
число числом Кармайкла.
Входные данные
Входные данные состоят из последовательности строк, каждая из которых
содержит небольшое положительное число п B < п < 65 000). Число п = 0 означает
конец входных данных, и его обрабатывать не нужно.
Выходные данные
Для каждого введенного числа выведите, является ли оно числом Кармайкла,
как показано в примере выходных данных.
Пример входных данных Соответствующие выходные данные
172 9 The number 1729 is a Carmichael number.
17 17 is normal.
561 The number 561 is a Carmichael number.
1109 1109 is normal.
431 431 is normal.
0
7.6.3. Задача Евклида
PC/UVaIDs: 110703/10104
Популярность: А
Частота успехов: средняя
Уровень: 1
Со времен Евклида известно, что для любых положительных целых чисел А и В
существуют такие целые X и Y, что АХ+ BY= Д где D - это наибольший общий
делитель чисел Аи В. Задача состоит в том, чтобы найти соответствующие X, Y и D
для заданных А и В.
Входные данные
Входные данные состоят из последовательности строк, каждая из которых
содержит целые числа А и В, разделенные пробелом (А, В < 1 000 000 001).
7.6. Задачи 181
Выходные данные
Для каждой строки входных данных выходная строка должна содержать три
целых числам, Yw Д разделенные пробелами. Если существует несколько различных
парХн Y, то вы должны вывести такую, чтоХ< Yu\X\ + \Y\ минимально.
Пример входных данных
4 б
17 17
Соответствующие выходные данные
-112
О 1 17
7.6.4. Делители факториалов
PC/UVaIDs: 110704/10139
Популярность: А
Частота успехов: средняя
Уровень:2
Для всех неотрицательных чисел п функция факториала, я!, определяется сле-
следующим образом:
0! = 1,
я! = лх (л-1)! (w>0).
Мы говорим, что а делит Ь, если существует такое целое к, что
к х a = 6.
Входные данные
Входные данные состоят из нескольких строк, каждая из которых содержит
два неотрицательных числа тип меньших 231.
Выходные данные
Для каждой строки входных данных выведите в формате, показанном ниже,
строку, говорящую, делится п\ на т или нет.
182 Глава 7. Теория чисел
Пример входных данных
6 9
6 27
20 10000
20 100000
1000 1009
Соответствующие выходные данные
9 divides 6!
27 does not divide б!
10000 divides 20!
100000 does not divide 20!
1009 does not divide 1000!
7.6.5. Сумма четырех простых чисел
PC/UVaIDs: 110705/10168
Популярность: А
Частота успехов: средняя
Уровень:2
Гипотеза простых чисел Варинга (Waring) утверждает, что любое нечетное
число можно представить в виде суммы трех простых чисел. Гипотеза Гольдбаха
(Goldbach) утверждает, что любое четное число можно представить в виде суммы
двух простых. Обе задачи остаются открытыми уже на протяжении 200 лет.
В этой задаче от вас требуется чуть меньше. Найдите способ представить задан-
заданное целое число как сумму ровно четырех простых чисел.
Входные данные
Каждый тестовый блок состоит из строки, содержащей одно целое число п
(п = 10 000 000). Входные данные завершаются символом конца файла.
Выходные данные
Для каждого тестового блока выведите одну строку выходных данных, содержа-
содержащую четыре простых числа, в сумме дающих п. Если число невозможно представить
в виде суммы четырех простых чисел, то выведите строку "Impossible. ". Для
одного числа может существовать несколько решений. Любое верное решение
будет принято.
7.6. Задачи 183
Пример входных данных
24
36
46
Соответствующие выходные данные
3 11 3 7
3 7 13 13
11 11 17 7
7.6.6. Числа Смита
PC/UVaIDs: 110706/10042
Популярность: В
Частота успехов: средняя
Уровень: 1
Просматривая свою телефонную книжку в 1982 году, математик Альберт Вилански
(Albert Wilansky) обратил внимание, что телефонный номер его зятя Г. Смита (Н. Smith)
обладает следующим забавным свойством: сумма цифр этого номера была равна
сумме цифр разложения этого номера на простые множители. Понятно? Номер теле-
телефона Смита был 493-7775. Это число раскладывается на простые множители сле-
следующим образом:
4 937 775 = 3 х 5 х 5 х 65 837.
Сумма цифр телефонного номера равна 4 + 9 + 3 + 7 + 7 + 7 + 5 = 42, и сумма цифр
его разложения на простые множители также равна 3 + 5 + 5 + 6 + 5 + 8 + 3 + 7 = 42.
Вилански назвал такой тип чисел по имени своего зятя: числа Смита.
Так как этим свойством обладают все простые числа, Вилански не включил их
в определение. Примерами других чисел Смита являются 6036 и 9985.
Вилански не сумел найти число Смита большее, чем телефонный номер его
зятя. Сможете ли вы ему помочь?
Входные данные
Входные данные состоят из нескольких тестовых блоков, причем число тестовых
блоков задается в первой строке входных данных. Каждый тестовый блок состоит из
строки, содержащей одно положительное целое число меньшее 10 .
184 Глава 7. Теория чисел
Выходные данные
Для каждой введенной величины п выведите строку, содержащую наименьшее
число Смита большее п. Вы можете считать, что такое число обязательно существует.
Пример входных данных
1
4937774
Соответствующие выходные данные
4937775
7.6.7. Шарики
PC/UVaIDs: 110707/10090
Популярность: В
Частота успехов: низкая
Уровень:1
Я коллекционирую шарики (маленькие, цветные, стеклянные шарики) и хочу
купить коробки для их хранения. Коробки бывают двух типов.
Тип 1: каждая такая коробка стоит Cj долларов и в ней может храниться ровно
П] шариков.
Тип 2: каждая такая коробка стоит с2 долларов и в ней может храниться ровно
п2 шариков.
Я хочу, чтобы коробки были заполнены полностью и при этом свести к минимуму
суммарную стоимость покупки. Помогите мне найти наилучший способ распределе-
распределения шариков по коробкам.
Входные данные
Входной файл может содержать несколько тестовых блоков. Каждый тестовый
блок начинается со строки, содержащей целое число п A < п < 2 000 000 000) - задан-
заданное число шариков. Вторая строка содержит Cj и л/, и третья строка содержит с2 и п2.
Целые числа cj, nj, c2 и п2 положительны и меньше 2 000 000 000.
Входные данные завершаются тестовым блоком, в котором в качестве количества
шариков задается нуль.
7.6. Задачи 185
Выходные данные
Для каждого тестового блока входных данных выведите строку, содержащую
решение с минимальной стоимостью (два неотрицательных числа mj\\ m2, где тг -
требуемое число коробок типа *), если таковое существует. Иначе выведите
"failed".
Если решение существует, можете считать, что оно единственно.
Пример входных данных
43
1 3
2 4
40
5 9
5 12
0
Соответствующие выходные данные
13 1
failed
7.6.8. Переупаковка
PC/UVaIDs: 110708/10089
Популярность: С
Частота успехов: низкая
Уровень:2
Association of Cup Makers (ACM) производит кофейные чашки трех размеров
(размера 1, размера 2 и размера 3) и продает их в различных упаковках. Каждый
тип упаковок описывается тремя положительными целыми числами (Sj, S2, Sj),
где St: A <i< 3) обозначает число чашек размера /, находящихся в упаковке. К со-
сожалению, не существует таких упаковок, что Sj = S2 = S3.
Маркетинговые исследования показали, что существует большой спрос на упа-
упаковки, содержащие одинаковое количество чашек каждого размера. Чтобы восполь-
воспользоваться этой возможностью, АСМ решила распаковывать некоторые упаковки на
своем безразмерном складе непроданной продукции и переупаковывать их в упаков-
упаковки, содержащие одинаковое число чашек каждого размера. Например, пусть у АСМ
на складе имеются следующие упаковки: A,2,3), A,11,5), (9,4,3) и B,3,2). Тогда мы
можем распаковать три A,2,3) упаковки, одну (9,4,3) упаковку и две B,3,2) упаковки
186 Глава 7. Теория чисел
и переупаковать чашки так, чтобы получить шестнадцать A,1,1) упаковок. Можно
также собрать восемь B,2,2) упаковок или четыре D,4,4) упаковки или две (8,8,8)
упаковки или одну A6,16,16) упаковку и т. д. Обратите внимание, что для новых
упаковок должны использоваться все распакованные чашки; то есть ни одна из рас-
распакованных чашек остаться не должна.
АСМ наняла вас, чтобы вы написали программу, которая будет решать, воз-
возможно ли собрать упаковки, содержащие одинаковое число чашек каждого типа,
используя все чашки, полученные при распаковке любой комбинации упаковок,
имеющихся на складе.
Входные данные
Входные данные могут содержать несколько тестовых блоков. Каждый тесто-
тестовый блок начинается со строки, содержащей целое число N C<jV<1OOO),
задающее число различных типов упаковок, находящихся на складе. Каждая из
следующих N строк содержит три положительных целых числа, представляющих
собой, соответственно, число чашек размера 1, размера 2 и размера 3 в упаковке.
Никакие два описания упаковок в тестовом блоке совпадать не будут.
Входные данные завершаются тестовым блоком, содержащим нуль в качестве
N в первой строке.
Выходные данные
Для каждого тестового блока выведите строку, содержащую " Yes ", если желае-
желаемая переупаковка достижима. В ином случае выведите "No ".
Пример входных данных
4
12 3
1 11 5
9 4 3
2 3 2
4
13 3
1 11 5
9 4 3
2 3 2
О
Соответствующие выходные данные
Yes
No
7.7. Подсказки 187
7.7. Подсказки
7.1. Можем ли мы выяснить состояние я-й лампы, не проверяя все числа от 1 до л?
7.2. Как можно эффективно вычислить an(mod n)l
7.3. Верно ли, что метод, приведенный в тексте, дает минимальную такую пару?
7.4. Можем ли мы проверить делимость без непосредственного вычисления п\1
7.5. Можете ли вы найти возможные точные решения, не обращая внимания на
стоимость? Какое из них будет самым дешевым?
7.6. Можем ли мы решить эти диофантовы уравнения, используя методики, описан-
описанные в главе?
7.8. Замечания
7.1. Предположения Гольдбаха и Варинга почти наверняка верны, но эта уверен-
уверенность основана на грубом переборе, а не на каких-то свойствах простых чисел.
Проведите небольшой расчет предполагаемого числа решений для каждой
задачи, полагая, что существует п1Щп) простых чисел меньших п. Имеет ли
смысл искать контрпример дальше, если его не было найдено для п = 1 000 000?
7.2. Подробнее о свойствах чисел Смита [Wil82, McD87].
Глава 8
Поиск с возвратом
Современные компьютеры обладают настолько высоким быстродействием,
что подчас решение задачи полным перебором становится эффективным и дос-
достойным уважения способом. Например, временами, чтобы посчитать число объек-
объектов множества, проще напрямую сконструировать его и не использовать сложные
комбинаторные формулы. Конечно, для такого расчета требуется, чтобы число
объектов было небольшим.
Тактовая частота современного процессора в среднем равна 1 гигагерцу, что эк-
эквивалентно миллиарду операций в секунду. Чтобы сделать что-то интересное, по-
потребуется несколько сотен инструкций и более. Таким образом, вы можете считать,
что за одну секунду на современной машине вы успеете перебрать несколько мил-
миллионов объектов.
Важно понимать, как это много (или мало) - миллион. Один миллион перестано-
перестановок соответствует всем перестановкам 10 или 11 объектов, но не более. Один милли-
миллион подмножеств соответствует всем комбинациям примерно 20 объектов и не более.
Для решения задач значительно большего размера требуется аккуратно отсекать все
ненужные ветви поиска и внимательно следить за тем, чтобы мы перебирали только
необходимые объекты.
В этой главе мы рассмотрим алгоритмы поиска с возвратом для полного пере-
перебора, а также различные методики его сокращения, позволяющие использовать
эти алгоритмы по максимуму.
8.1. Поиск с возвратом
Поиск с возвратом - это метод систематического перебора всех возможных конфи-
конфигураций поискового пространства. Это алгоритм/методика общего характера, которая
требует подстройки для каждого конкретного случая.
В общем случае мы будем формулировать решение в виде вектора а =
= (aj, a2, ..., afl), где каждый элемент at выбирается из конечного упорядоченного
множества 5,-. Такой вектор может задавать перестановку, при этом а{ задает i-Pi
элемент перестановки. Или такой вектор может задавать заданное подмножество
8.1. Поиск с возвратом 189
множества S, причем в этом случае а{ - это истина в том и только в том случае,
если i-й элемент универсума принадлежит S. Такой вектор может даже задавать
последовательность ходов в игре или путь по графу, и в этом случае at содержит /-е
событие последовательности.
На каждом шаге алгоритма перебора с возвратом мы начинаем с заданного час-
частичного решения, скажем, а = (ah a2, ..^а^п пытаемся расширить его, добавляя еще
один элемент в конец вектора. После этого мы должны проверить, является ли то, что
мы имеем на данный момент, решением; если так, то мы должны вывести его, сосчи-
сосчитать, или сделать с ним все, что мы хотим. Если же нет, то нужно проверить, можем
ли мы расширить получившееся частное решение до полного. Если да, то повторяем
все вышеописанное и продолжаем. Если нет, то удаляем последний элемент а и под-
подставляем на это место следующий возможный вариант, если он существует.
Простой вариант кода приведен ниже. Мы добавили глобальный флаг finished
для возможности досрочного завершения, которая может быть использована по необ-
необходимости в любой конкретной задаче.
bool finished = FALSE; /* нашли все решения? */
backtrack(int а[], int k, data input)
{
int с [MAXCANDIDATES] ; /* кандидаты на следующее место */
int ncandidates; /* счетчик кандидатов на последнее
место */
int i; /* счетчик */
if ( is_a_solution (a, k, input) )
process_solution(a,k,input);
else {
k = k+1;
construet_candidates(a,k,input,c,&ncandidates);
for (i=0; i<ncandidates; i++) {
a[k] = c[i];
backtrack(a,k,input);
if (finished) return; /* досрочное завершение */
В этом алгоритме три подпрограммы зависят от конкретного применения.
is_a_solution (a, k, input). Эта булева функция проверяет, являются ли
первые к элементов вектора а полным решением данной задачи. Последний
аргумент, input, позволяет нам передавать в подпрограмму информацию обще-
общего характера. Мы будем использовать его для передачи п, размера искомого
190 Глава 8. Поиск с возвратом
решения. Это имеет смысл при построении всех перестановок размера п или
подмножеств п элементов, но при построении объектов переменного размера,
таких, как последовательности ходов игры, может стать ненужным. При таком
использовании алгоритма последний аргумент можно игнорировать.
• cons true t_candidates (a,k, input, с,ncandidates). Эта подпрограмма
заполняет массив с полным набором всех возможных кандидатов на к-е место
в массиве а при условии, что заданы первые к-\ элементов. Число кандида-
кандидатов возвращается с помощью ncandidates. И снова input может исполь-
использоваться для передачи вспомогательной информации, такой, как желаемый
размер решения.
• process_solution(a/ k, input). Эта подпрограмма учитывает, выводит
или еще как-то обрабатывает полное решение после того, как оно построено.
Обратите внимание, что вспомогательный аргумент input здесь не нужен,
так как к задает число элементов в решении.
При поиске с возвратом полнота решения гарантируется полным перебором
вариантов. Эффективность гарантируется тем, что ни одно возможное решение не
проверяется дважды.
Обратите внимание на то, как легко и изящно реализуется поиск с возвратом
с помощью рекурсии. Так как память под массив новых кандидатов с выделяется
заново при каждом рекурсивном вызове функции, то подмножества еще не рас-
рассмотренных кандидатов на каждое место не будут пересекаться друг с другом.
Мы увидим, что в графах (глава 9) при поиске в глубину используется практиче-
практически тот же самый рекурсивный алгоритм, что и в backtrack. Перебор с возвра-
возвратом можно рассматривать как поиск в глубину в неявном графе.
Рассмотрим два примера применения перебора с возвратом (все подмножества
и перестановки п элементов), для которых определены конкретные реализации этих
трех функций.
8.2. Построение всех подмножеств
Как было отмечено выше, мы можем построить 2п подмножеств п элементов, рас-
рассмотрев все 2п возможных векторов длины п, состоящих из элементов истина иложь,
что дает возможность i-му элементу задавать, входит или нет объект / в подмножество.
Если использовать обозначения для общего алгоритма перебора с возвратом, то
Sk = (true, false) на-решение при к>п. Теперь мы можем построить все подмноже-
подмножества, используя простые реализации для is_a_solution (a, k, input), const-
ruct_candidates(а,к,input,с,ncandidates) и process_-solution
(а, к, input). На самом деле, сложнее всего вывести подмножество после того, как
оно построено!
8.2. Построение всех подмножеств 191
is_a__solution (int а[], int к, int n)
{
return (к == n); /* верно ли, что к == п? */
}
cons true t_candidates (int a [] , int к, int n, intc[], int *ncandidates)
{
C[O] = TRUE;
C[l] = FALSE;
*ncandidates = 2;
}
process_solution(int a[], int k)
{
int i; /* счетчик */
printf(»{");
for (i=l; i<=k; i++)
if (a[i] == TRUE) printf (" %d",i);
printf("}\n");
}
И наконец, мы должны вызвать backtrack с правильными аргументами.
Говоря точнее, мы должны передать указатель на пустой вектор решений, устано-
установить к = 0, чтобы показать, что он пустой, и указать число элементов в универсуме.
generate_subsets(int n)
{
int a[NMAX]; /* вектор решений */
backtrack(a,0,n);
}
В каком порядке мы будем получать подмножества множества {1, 2, 3}? Это
зависит от порядка в construct_candidates. Так как истина всегда стоит
впереди лжи, то подмножество, состоящее только из истин, будет построено
первым, а подмножество, целиком состоящее из лжи, будет построено последним:
{12 3}
{12}
{13}
{ 1 }
{23}
{ 2 }
{ 3 }
192 Глава 8. Поиск с возвратом
8.3. Построение всех перестановок
Задача построения всех перестановок аналогична задаче построения всех под-
подмножеств с тем отличием, что кандидаты на следующее место теперь зависят от
значений, содержащихся в частном решении. Чтобы при построении мы не ис-
использовали один элемент несколько раз, мы должны проверять, что /-и элемент
перестановки отличен от всех предыдущих.
Если пользоваться обозначениями для общего алгоритма перебора с возвратом,
то Sk = {1, ..., п} - а и а - решение при к = п.
construct_candidatee (int а[], intk, int n, intc[], int *ncandidates)
{
int i; /* счетчик */
bool in_perm[NMAX]; /* кто уже в перестановке? */
for (i=l; i<NMAX; i++) in_perm[i] = FALSE;
for (i=0; i<k; i++) in_perm[ [a[i] ] = TRUE;
*ncandidates = 0;
for (i=l; i<= n;
if (in_perrn[i] == FALSE) {
c[ *ncandidates] = i;
*ncandidates = *ncandidates
Проверку на то, является ли / кандидатом на к-ъ место в перестановке, можно
сделать, пройдя по всем к-\ элементам а и удостоверившись, что ни с одним из
них нет совпадения, но мы предпочли завести дополнительный битовый вектор
(см. главу 2), чтобы знать, какие элементы находятся в перестановке. Он дает нам
возможность проводить моментальные проверки на легальность.
Чтобы закончить работу по построению перестановок, нам нужно задать
process_solution и is_a_solution, а также установить соответствующие
аргументы при вызове backtrack. Все это аналогично построению подмножеств:
process_solution(int a[], int k)
{
int i; /* счетчик */
for (i = l; i<=k; i + +) printf (" %d'\a[i]);
printf("\n");
}
is_a_solution(int a[], int k, int n)
8.4. Пример разработки программы: задача восьми ферзей
193
return (к == n);
generate_permutations(int n)
int a[NMAX]; /* вектор решений */
backtrack(a,0,n);
Обратите внимание, что эти подпрограммы строят перестановки в лексикогра-
лексикографическом или отсортированном порядке, то есть 123, 132, 213, 231, 312 и 321.
8.4. Пример разработки программы: задача
восьми ферзей
Задача восьми ферзей - это классическая головоломка, в которой требуется рас-
расставить восемь ферзей на шахматной доске размером 8x8 так, чтобы они не били
друг друга. Это значит, что ни на одной вертикали, горизонтали или диагонали не
могут находиться два ферзя одновременно, что показано на рис. 8.1. В течение мно-
многих лет эта задача изучалась многими известными математиками, включая Гаусса,
а также огромным числом не таких уж известных людей, изучавших основы про-
программирования.
Ml
т
Рис. 8.1. Решение задачи восьми ферзей
7-972
194 Глава 8. Поиск с возвратом
В задаче нет ничего, что запрещало бы рассмотрение чисел больших восьми.
В задаче «п ферзей» спрашивается, сколькими способами можно разместить п
ферзей на шахматной доске размером п х п так, чтобы ни один из них не атаковал
другого. Даже для среднего п количество решений настолько велико, что их стано-
становится неинтересно выводить. Но для каких значений п мы можем найти их число
за умеренное количество времени?
Решение начинается ниже
Чтобы понять суть задачи такого типа, обычно требуется построить решения
для небольших случаев вручную. Очевидно, что для п = 2 решений не существует,
так как второй ферзь будет атаковать первого по вертикали, горизонтали или диа-
диагонали. Для п = 3 вариантов уже больше, но методом проб и ошибок вы должны
понять, что и в этом случае решений не существует. Мы предлагаем вам постро-
построить решение для п = 4 - нетривиального случая наименьшего размера.
Для использования backtrack-поиска нам нужно аккуратно выбрать самый
краткий и эффективный способ представления наших решений в виде вектора.
Как можно представить решение задачи «п ферзей» и насколько большим может
быть это представление?
Наиболее прямолинейным представлением было бы эмулировать наш генератор
подмножеств и использовать вектор решений, в котором at принимало бы значение
истина в том и только в том случае, если на /-й клетке стоит ферзь. Для этого каждой
клетке требуется присвоить уникальное имя от 1 до п . Набор возможных решений
содержит для z-й клетки истину, если ни один из ранее поставленных ферзей не бьет
эту клетку, и лоэюь - в противном случае. Мы получим решение после того, как будут
заполнены все п клеток, причем ровно п из них буцут иметь значение истина.
Подойдет ли нам это представление? Не похоже, что оно будет кратким, так
как почти все элементы в найденном решении будут иметь значение лоэюь. Также
из этого следует его высокая стоимость. Для доски размером 8x8 существует
264 « 1.84 х 1019 различных векторов, и, хотя не все из них будут полностью
построены, на это число даже страшно смотреть.
А что, если /-й элемент решения будет в явном виде содержать клетку, на
которой располагается /-й ферзь? В этом представлении at будет целым числом,
имеющим значение от 1 до п , причем решение мы получим в том случае, если
заполним первые п элементов а. Кандидатами на /-е место будут все клетки,
которые не бьются первыми / - 1 ферзями.
8.5. Поиск с отсечением вариантов 195
Лучше ли это представление предыдущего? При использовании этого представле-
представления для доски размером 8x8 существует «всего» 648 «2.81 х 1014 векторов. Да, мы
сильно продвинулись, но нам еще далеко до поискового пространства порядка 106, на
котором наши возможности уже подходят к своему пределу. Чтобы поиск с возвратом
заработал, нам придется отбрасьшать или отсекать большую часть вариантов еще до
того, как они построены.
8.5. Поиск с отсечением вариантов
Экспоненциальный рост поисковых пространств с увеличением числа вариантов
носит название комбинаторного взрыва. Таким образом, даже задачи среднего раз-
размера быстро переходят ту грань, за которой они уже не могут быть решены за разум-
разумное количество времени. Чтобы использовать алгоритм поиска с возвратом для реше-
решения интересных задач, мы должны сужать поисковое пространство, отсекая каждую
ветвь поиска в тот момент, когда мы понимаем, что она не может привести к правиль-
правильному решению.
Термин отсекать в данном случае подходит как нельзя больше. Садовник отсе-
отсекает мертвые и корявые ветки у деревьев так, чтобы они могли не тратить на них
лишнюю энергию. Аналогично рекурсивные вызовы backtrack определяют
дерево. Когда мы отсекаем лишние ветви, понимая, что на самом деле множество
кандидатов на место является пустым, мы уходим от неконтролируемого роста.
Так как же мы можем использовать поиск с отсечением вариантов для представ-
представления позиции приведенного выше? Во-первых, мы можем избавиться от сим-
симметричных случаев. В случаях, рассматриваемых нами ранее, нет никакой разницы
между ферзем, находящимся на первом месте вектора (я/), и ферзем, находящимся
во второй позиции (aj). Если все так и оставить, то каждое решение будет построено
8! = 40 320 раз! Это можно легко исправить, если рассматривать только те случаи,
в которых ферзь в а( находится на клетке с большим номером, чем ферзь в a(_j.
f 64 о
Это простое изменение уменьшит количество вариантов до = 4.426 х 10 .
V8 ,
Если еще поразмышлять над задачей, то можно прийти и к лучшему представле-
представлению. Обратите внимание, что в решении задачи п ферзей на одну горизонталь должен
приходиться ровно один ферзь. Почему? Если бы на какой-то горизонтали не было
ферзей, тогда на какой-то другой обязательно должно было бы быть два ферзя, чтобы
в сумме у нас получилось п ферзей. Но на одной горизонтали не может быть два
ферзя, потому что в этом случае они бьют друг друга. Ограничение кандидатов для /-го
ферзя до 8 клеток /-й горизонтали приводит нас к поисковому пространству размером
Я8 « 1.677 х 107, что является хоть и большой, но уже доступной величиной.
196 Глава 8. Поиск с возвратом
Но мы можем еще улучшить наше достижение! Так как никакие два ферзя не
могут находиться на одной вертикали, то мы получаем, что п вертикалей конечно-
конечного решения должны образовывать перестановку п. Избегая повторяющихся эле-
элементов, мы уменьшаем наше поисковое пространство до 8! =40 320, что пред-
представляет совсем небольшую работу для любой более-менее быстрой машины.
Вот теперь мы можем начать писать код нашего решения. Самой важной подпро-
подпрограммой является построение кандидатов. Мы повторно проверяем, бьется ли к-я
клетка данной горизонтали одним из ранее поставленных ферзей. Если да, то идем
дальше, но если же нет, то мы включаем ее в качестве возможного кандидата.
construct_candidates (int а[], intk, intn, intc[], int *ncandidates)
{
int i/j; /* счетчики */
bool legal_move; /* легальность хода */
*ncandidates = 0;
for (i=l; i<=n; i++) {
legal_move = TRUE;
for (j=l; j<k; j++) {
if (abs((k)-j) == abs(i-a[j])) /* угроза по диа-
диагонали */
legal_move = FALSE;
if (i == a[j]) /* угроза по
вертикали */
legal_move = FALSE;
}
if (legal_move == TRUE) {
с[*ncandidates] = i;
*ncandidates = *ncandidates + 1;
Оставшиеся подпрограммы достаточно просты, так как нам нужно только посчи-
посчитать решения, а не выводить их.
process_solution(int a[], int k)
{
int i; /* счетчик */
SOlution_COUnt ++;
}
is_a_solution(int a[], int k, unt n)
{
return (k == n);
8.5. Поиск с отсечением вариантов 197
nqueens(int n)
{
int a[NMAX]; /* вектор решений */
solution_count = 0;
backtrack(a, 0,n);
printf("n=%d solution_count=%d\n",n,solution_count);
}
Средний портативный компьютер, на котором была написана эта программа,
решил задачу для п = 9 мгновенно. Вентилятор компьютера включился при п = 10,
так как вычисления стали производить достаточно тепла, чтобы потребовалось
охлаждение. Для п = 14 потребовалось несколько минут, чего нам было вполне
достаточно, чтобы не интересоваться результатами для больших п. Кроме того, от
вентилятора у нас разболелась голова. Итоги наших вычислений:
n=l solution_count=l
n=2 solution_count=0
n=3 solution_count=0
n=4 solution_count=2
n=5 solution_count=10
n=6 solution_count=4
n=7 solution_count=40
n=8 solution_count=92
n=9 solution_count=352
n=10 solution_count=724
n=ll solution_count=2680
n=12 solution_count=14200
n=13 solution_count=73712
n=14 solution_count=3 65596
Более эффективные программы могли бы продвинуться чуть дальше. Можно
увеличить быстродействие при построении кандидатов, если обрывать внутрен-
внутренний цикл for сразу же, как булевская переменная примет значение «ложь». Еще
больше времени можно сэкономить, если использовать дальнейшее отсечение
вариантов. К текущей реализации мы возвращаемся, как только на к-и горизонта-
горизонтали нет легальных ходов. Но если на какой-то последующей горизонтали (скажем,
(к + 2)-й) нет легальных ходов, то все, что мы делаем на А>й, лишено смысла. Чем
раньше мы это поймем, тем лучше.
Мы могли бы попробовать извлечь больше выгоды из симметрии. Поворот
любого решения на 90° дает нам другое решение, так же как и симметрия относительно
центра доски. Рассматривая только одно решение из каждого класса эквивалентности,
мы могли бы в значительной степени понизить вычислительную нагрузку.
198
Глава 8. Поиск с возвратом
Забавно пытаться сделать программу поиска настолько эффективной, насколько
это возможно. Почему бы вам не попробовать свои силы в этой задаче и не посмотреть,
до какого максимального п вы сможете дойти при условии, что вычисления должны
идти не более минуты? Не думайте, что вы сможете продвинуться намного дальше нас,
потому что в этом диапазоне размеров решение для п + 1 требует примерно в 10 раз
больше вычислений, чем решение для п. Таким образом, даже совсем небольшое
увеличение размера решаемой задачи становится значительным достижением.
8.6. Задачи
8.6.1. Слоны
PC/UVaIDs: 110801/861
Популярность: С
Частота успехов: высокая
Уровень:2
Слон - это шахматная фигура, которая из текущей позиции может ходить
только по диагонали. Два слона атакуют друг друга, если один из них находится
на пути другого. На рисунке внизу темными клетками обозначены поля, доступ-
доступные для слона Bj из его текущей позиции. Слоны Bj и В2 атакуют друг друга,
а слоны В] иВ] нет. Слоны В2 и В$ также не атакуют друг друга.
Для заданных чисел пик определите число способов, которыми можно рас-
расставить к слонов на доске размером п х п так, чтобы никакие два из них не атако-
атаковали друг друга.
8.6. Задачи 199
Входные данные
Входной файл может содержать несколько тестовых блоков. Каждый тестовый
блок состоит из одной строки входного файла, содержащей два целых числа
лA <п<Ъ)ик@<к<п2).
Входные данные завершаются тестовым блоком, содержащим два нуля.
Выходные данные
Для каждого тестового блока выведите строку, содержащую полное число
способов, которыми можно расставить заданное число слонов на доске заданного
размера так, чтобы ни один из них не атаковал другого. Вы можете считать, что
это число будет меньше, чем 1015.
Пример входных данных
8 б
4 4
О О
Соответствующие выходные данные
5599888
260
8.6.2. Задача про пятнашки
PC/UValDs: 110802/10181
Популярность: В
Частота успехов: средняя
Уровень:3
Пятнашки - это очень популярная головоломка, и вы наверняка видели ее,
хотя, быть может, и не под таким именем. Она состоит из 15 квадратиков,
которые могут скользить вдоль стороны и на каждом из которых написан свой
номер от 1 до 15, причем все эти квадратики помещены в рамку размером 4x4
и в результате одно место остается незанятым (мы будем называть его пустышкой).
Цель головоломки - упорядочить квадратики так, чтобы они шли в порядке,
изображенном ниже.
200
Глава 8. Поиск с возвратом
1
5
9
13
2
6
10
14
3
7
11
15
4
8
12
Единственное, что можно делать, это менять местами пустышку и один из 2, 3
или 4 квадратиков, имеющих с ей общую сторону. Рассмотрим следующую после-
последовательность ходов:
2
6
3
8
12
15
7
11
10
9
1
14
5
13
4
2
6
3
8
12
15
9
7
11
10
1
14
5.
13
4
2
6
3
8
12
15
9
7
11
10
1
14
5
13
4
2
6
3
8
12
9
7
11
15
10
1
14
5
13
4
Случайное состояние Пустышка движется Пустышка движется Пустышка движется
вправо (R) вверх (U) влево (L)
головоломки
Мы обозначаем ходы исходя из соседа пустышки, с которым она меняется
местами. Разрешенными являются значения "R", "L", "U", "D" для перемещений
пустышки вправо, влево, вверх и вниз.
Вы должны по начальному состоянию головоломки определить последова-
последовательность шагов, ведущую к итоговому состоянию. Для каждого решаемого
начального расположения судейскому решению требуется максимум 45 ходов; вы
ограничены 50 ходами для решения головоломки.
Входные данные
Первая строка входных данных содержит целое число и, задающее количество
начальных позиций головоломки. Следующие Лп строк содержат п начальных
позиций, причем на каждую позицию приходится 4 строки. Пустышка обознача-
обозначается нулем.
8.6. Задачи 201
Выходные данные
Для каждого введенного начального состояния головоломки вы должны вывести
одну строку выходных данных. Если для заданной конфигурации не существует
решения, то выведите строку "This puzzle is not solvable . ". Если же
головоломка имеет решение, то выведите последовательность ходов, решающих
головоломку в формате, описанном выше.
Пример входных данных
2
2 3 4 0
15 7 8
9 б 10 12
13 14 11 15
13 1 2 4
5 0 3 7
9 б 10 12
15 8 11 14
Соответствующие выходные данные
LLLDRDRDR
This puzzle is not solvable.
8.6.3. Шеренга
PC/UVaIDs: 110803/10128
Популярность: В
Частота успехов: высокая
Уровень:2
Рассмотрим шеренгу из N людей разного роста. Каждый из них видит все
слева, если он или она выше всех людей, стоящих слева; иначе поле зрения пере-
перекрыто. Аналогично каждый из них видит все справа, если он или она выше всех
людей, стоящих справа.
Было совершено преступление - человек, стоящий слева от шеренги, убил буме-
бумерангом человека, стоящего справа от шеренги. Ровно Р человек в шеренге видели
все слева и ровно R человек видели все справа, и, таким образом, они могут служить
свидетелями.
Защита наняла вас, чтобы определить, сколько перестановок N людей обладают
таким свойством для заданных PuR.
202 Глава 8. Поиск с возвратом
Входные данные
Входные данные состоят из Г тестовых блоков, причем Т{\ < Т< 10 000) задается
первой строкой входного файла.
Каждый тестовый блок представляет собой строку, содержащую три целых
числа. Первое число Nзадает число людей в шеренге A <N< 13). Второе число
соответствует количеству людей, которые видят все слева (Р). Третье число соот-
соответствует количеству людей, видящих все справа (R).
Выходные данные
Для каждого тестового блока выведите число перестановок N людей таких,
что Р людей видят все слева и R людей видят все справа.
Пример входных данных
3
10 4 4
11 3 1
3 12
Соответствующие выходные данные
90720
1026576
1
8.6.4. Станции техобслуживания
PC/UVaIDs: 110804/10160
Популярность: В
Частота успехов: низкая
Уровень:3
Компания занимается продажей персональных компьютеров в N городах
C <N< 35), обозначаемых 1, 2, ..., N. М пар этих городов соединены прямыми
дорогами. Компания решила построить несколько станций техобслуживания так,
чтобы для любого города X станция находилась либо непосредственно в X, либо
в каком-то городе, напрямую соединенном с X.
Напишите программу, определяющую минимальное число станций, необходимых
компании.
8.6. Задачи 203
Входные данные
Входные данные состоят из нескольких вариантов условия. Каждый вариант
начинается с числа городов N и числа пар М, разделенных пробелом. Каждая из
следующих М строк содержит пару целых чисел, определяющих соединенные
города, причем на одну строку приходится ровно одна пара чисел, разделенных
пробелом. Входные данные завершаются при N = 0 и М = 0.
Выходные данные
Для каждого блока тестовых данных выведите строку, содержащую число необхо-
необходимых станций техобслуживания.
Пример входных данных
8
1
1
1
2
2
3
3
4
4
5
6
б
0
12
2
б
8
3
б
4
5
5
7
6
7
8
0
Соответствующие выходные данные
2
8.6.5. Перетягивание каната
PC/UVaIDs: 110805/10032
Популярность: В
Частота успехов: низкая
Уровень:2
Перетягивание каната - это состязание в грубой силе, когда две группы людей
тянут канат в противоположные стороны. Та команда, которая сумела утянуть
канат в свою сторону, объявляется победителем.
204 Глава 8. Поиск с возвратом
На корпоративном пикнике решили посостязаться в перетягивании каната.
Участников пикника нужно честно разбить на две команды. Каждый человек
должен попасть в одну или другую команду, число человек в одной команде не
должно превышать число человек в другой более чем на одного, и суммарные веса
людей каждой команды должны быть близки, насколько это возможно.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное
целое число, которое означает количество тестовых блоков, за которой следует
пустая строка.
Первая строка каждого блока содержит п, число участников пикника. Каждая из
следующих п строк содержит вес одного из участников пикника, причем вес задается
целым числом между 1 и 450. Число участников пикника не превышает 100.
Между двумя последовательными тестовыми блоками также находится пустая
строка.
Выходные данные
Для каждого тестового блока вы должны вывести строку, содержащую два
числа: суммарный вес людей в одной команде и суммарный вес людей в другой
команде. Если эти числа отличны, выведите сначала меньшее.
Выходные данные для двух последовательных блоков должны быть разделены
пустой строкой.
Пример входных данных
1
3
100
90
200
Соответствующие выходные данные
190 200
8.6. Задачи 205
8.6.6. Эдемский сад
PC/UVaIDs: 110806/10001
Популярность: В
Частота успехов: средняя
Уровень:2
Клеточные автоматы - это математические идеализации физических систем,
в которых время и пространство дискретны и физические величины рассматри-
рассматриваются на конечном множестве дискретных значений. Клеточный автомат состоит
из решетки (или массива) переменных, принимающих дискретные значения.
Состояние такого автомата полностью определяется значением всех переменных
решетки. Клеточные автоматы развиваются дискретными временными шагами,
причем на значение каждой позиции (ячейки) влияют значения переменных в сосед-
соседних клетках в предыдущий квант времени. Для каждого автомата определен набор
правил, задающий его развитие.
Для большинства клеточных автоматов существуют недостижимые конфигура-
конфигурации (состояния): не существует такого состояния, из которого к ним можно прийти,
пользуясь заданными правилами развития. Такие состояния принято называть
Эдемскими садами, так как автомат может их принимать только в начальный
момент времени. В качестве примера рассмотрим тривиальный набор правил, пере-
переводящий все ячейки в 0. Для такого автомата любое состояние с ненулевыми ячей-
ячейками - это Эдемский сад.
В общем случае нахождение прообраза заданного состояния (или доказательство
того, что прообраза не существует) является очень сложной задачей, требующей
большого количества вычислений. В целях упрощения задачи мы ограничимся рас-
рассмотрением конечных одномерных бинарных клеточных автоматов. Другими словами,
число ячеек конечно, ячейки выстроены в одну линию, и они могут находиться в двух
состояниях: " 0 " и м 1". Чтобы упростить задачу еще больше, буцем считать, что
состояние каждой ячейки зависит только от предыдущих состояний самой ячейки
и ее непосредственных (правого и левого) соседей.
Ячейки расположены по кругу, то есть последняя ячейка является соседом первой.
Условие задачи
Для заданного кругового бинарного клеточного автомата вы должны определить,
является данное состояние Эдемским садом или достижимым состоянием. Клеточный
автомат задается через правила развития. Например, следующая таблица задает пра-
правила развития автомата: Cell = XOR(Left, Right).
206 Глава 8. Поиск с возвратом
Left
[/-1]
0
0
0
0
1
1
1
1
Cell
И
0
0
1
1
0
0
1
1
Right
[/+1]
0
1
0
1
0
1
0
1
Новое
состояние
0
1
0
1
1
0
1
0
0*2°
1*21
0*22
1*23
1*24
0*25
1*26
0*27
90 = Идентификатор автомата
С учетом всех наложенных ограничений существует только 256 различных
автоматов. Мы можем получить идентификатор каждого автомата, взяв вектор
новых состояний и рассмотрев его как двоичное число, как показано в таблице.
Идентификатор автомата, взятого в качестве примера, равен 90, тогда как иденти-
идентификатор тоэюдественного автомата (в котором каждое состояние переходит само
в себя) равен 204.
Входные данные
Входные данные состоят из нескольких тестовых блоков. Каждый тестовый блок
задает одной строкой клеточный автомат и состояние. Первым на строке идет иден-
идентификатор автомата, с которым вы будете работать. Вторым на строке идет положи-
положительное целое число N D<N< 32), задающее число ячеек в этом тестовом блоке.
И наконец, третьим на строке идет состояние, которое представляется строкой
ровно из N нулей и единиц. Ваша программа должна считывать входные данные,
пока она не достигнет символа конца файла.
Выходные данные
Если тестовый блок задает Эдемский сад, выведите строку GARDEN OF EDEN.
Если же нет (заданное состояние достижимо), то выведите строку REACHABLE.
Выходные данные для каждого тестового блока должны идти отдельной строкой.
8.6. Задачи 207
Пример входных данных
О 4 1111
204 5 10101
255 б 000000
154 16 1000000000000000
Соответствующие выходные данные
GARDEN OF EDEN
REACHABLE
GARDEN OF EDEN
GARDEN OF EDEN
8.6.7. Color hash
PC/UVaIDs: 110807/704
Популярность: В
Частота успехов: средняя
Уровень:3
Эта головоломка состоит из двух колес. Оба колеса могут вращаться по
и против часовой стрелки. Они содержат 21 цветной фрагмент, 10 из которых -
это скругленные треугольники и 11 - это разделители. Слева на рис. 8.2 показано
конечное состояние головоломки. Обратите внимание, что, для того чтобы пере-
перевести колесо в следующее состояние, вы должны вращать колесо, пока не продви-
продвинетесь на один треугольник и один разделитель.
Рис. 8.2. Конечное состояние головоломки (слева) и головоломка после того, как левое
колесо повернуто по часовой стрелке на один шаг (справа)
208 Глава 8. Поиск с возвратом
Ваша задача состоит в том, чтобы написать программу, которая считывает
начальное состояние головоломки и определяет кратчайшую последовательность
ходов, ведущую к конечному состоянию. Для обозначения частей мы будем исполь-
использовать следующие значения:
0 - серый разделитель;
1 - желтый треугольник;
2 - желтый разделитель;
3 - голубой треугольник;
4 - голубой разделитель;
5 - фиолетовый треугольник;
6 - фиолетовый разделитель;
7 - зеленый треугольник;
8 - зеленый разделитель;
9 - красный треугольник;
10 - красный разделитель.
Состояние головоломки описывается 24 целыми числами; первые 12 задают
состояние левого колеса; следующие 12 задают состояние правого колеса. Первое
число задает нижний правый разделитель левого колеса, а следующие 11 чисел
задают части левого колеса по часовой стрелке. 13-е число задает нижний левый
разделитель правого колеса, а следующие 11 чисел задают части правого колеса
против часовой стрелки.
Тогда конечное состояние описывается так:
034305650121078709 10 90121
Если мы повернем левое колесо на одну позицию по часовой стрелке (как показано
справа на рисунке), то состояние головоломки будет описываться так:
210343056501078709 10 90501
Входные данные
Входные данные состоят из нескольких начальных состояний головоломки.
Первая строка входных данных содержит целое число п, задающее количество
начальных состояний. Далее следуют п строк, каждая из которых содержит 24 целых
числа, разделенных одним пробелом, и задает начальное состояние головоломки, как
описано выше.
J.6. Задачи 209
Выходные данные
Для каждого начального состояния ваша программа должна вывести одну
строку, содержащую одно число, определяющее решение. Каждое изменение го-
головоломки задается одной цифрой от 1 до 4:
1 - поворот левого колеса по часовой стрелке;
2 - поворот правого колеса по часовой стрелке;
3 - поворот левого колеса против часовой стрелки;
4 - поворот правого колеса против часовой стрелки.
Между цифрами не должно быть пробелов. Так как может существовать несколько
решений, вы должны вывести такое решение, которое задается минимальным числом.
Для решения никогда не потребуется более 16 поворотов.
Если вы не нашли решения, вы должны вывести "NO SOLUTION WAS FOUND
IN 16 STEPS". Если вам задана конечная позиция, вы должны вывести " PUZZLE
ALREADY SOLVED".
Пример входных данных
3
034305650121
034503650121
094305650121
Соответствующие выходные данные
PUZZLE ALREADY SOLVED
1434332334332323
NO SOLUTION WAS FOUND IN 16 STEPS
8.6.8. Больший квадрат
PC/UVaIDs: 110808/10270
Популярность: С
Частота успехов: высокая
Уровень:3
У Томи есть много бумажных квадратиков. Длина их стороны (размер) изменяется
от 1 до N- 1, и у него есть неограниченное число квадратов любого размера. Но ему
очень хочется получить больший квадрат - квадрат размера N.
Он может получить такой квадрат, построив его из уже имеющихся квадратов.
Например, квадрат размера 7 может быть построен из 9 меньших квадратов.
0
0
0
7 1
1 i
7 i
г 7
3 7
В 7
0
0
0
9
9
9
10
10
10
9
9
3
0
0
0
1
1
1
2
2
2
1
1
1
210
Глава 8. Поиск с возвратом
Внутри квадрата не должно быть пустого места, меньшие квадраты не
должны выходить за пределы большего и не должны перекрываться. Кроме того,
Томи хочет истратить минимально возможное число квадратов. Поможете?
Входные данные
Первая строка входных данных содержит одно целое число Г, задающее число
тестовых блоков. Каждый тестовый блок состоит из одного целого числа N,
причем 2 <N< 50.
Выходные данные
Для каждого тестового блока выведите строку, содержащую одно число К,
задающее минимальное количество квадратов, из которых можно построить
квадрат заданного размера. Далее должны идти К строк, каждая из которых
должна содержать три целых числа х,уи1, задающие координаты левого верхнего
угла A <х,у <N)n длину стороны соответствующего квадрата.
Пример входных данных
3
4
3
8.7. Подсказки 211
Соответствующие выходные данные
4
112
13 2
3 12
3 3 2
6
112
13 1
2 3 1
3 11
3 2 1
3 3 1
9
112
13 2
3 11
4 11
3 2 2
5 13
4 4 4
15 3
3 4 1
8.7. Подсказки
8.1. Как мы можем изменить наше решение задачи п ферзей для решения задачи
о слонах? Может ли помочь разбиение задачи на отдельные задачи по разме-
размещению белопольных и чернопольных слонов?
8.2. Как мы можем избежать повторяющихся состояний головоломки, ведущих
и к уменьшению эффективности, и к получению чрезмерно длинных после-
последовательностей ходов?
8.3. Как мы можем представить решение для эффективного поиска? Что лучше,
составлять перестановки или распознавать подмножества людей с непере-
крытым полем зрения?
8.4. Возможный размер этой задачи делает ее сложной и, пожалуй, слишком боль-
большой даже для качественного отсечения вариантов. Можем ли мы отслеживать
все командные веса, реализуемые некоторым подмножеством, состоящим из
первых / людей, без явного рассмотрения всех 21 подмножеств? Обратите вни-
внимание, что число различных командных весов гораздо меньше, чем 21.
8.5. Какое представление лучше всего подходит для состояния решения?
8.6. Окупится ли попытка разместить большие квадраты первыми?
212 Глава 8. Поиск с возвратом
8.8. Замечания
8.1. Существует красивое комбинаторное решение задачи о слонах, позволяющее
подсчитать число ответов, избежав полного перебора. Это позволяет нам опре-
определить число размещений для гораздо больших шахматных досок. Постановка
задачи 10 237 судьи UVa предполагает достаточно большие входные данные,
чтобы сделать использование такого решения необходимостью.
8.2. Множество вершин S графа G, такое что любая вершина либо принадлежит
ему, либо соединена с вершиной из этого множества, называется доми-
доминирующим множеством графа. Задача нахождения минимального доми-
доминирующего множества относится к разряду NP-полных, так что единствен-
единственным возможным алгоритмом является полный перебор.
8.3. Клеточные автоматы разрабатывались для моделирования различных природ-
природных явлений. Чтобы понять, что это такое, смотрите книгу Wolfram A New Kind
of Science [Wol02].
8.4. У Binary Arts Corp., создателя Color Hash и многих других головоломок,
представляющих комбинаторный интерес, существует сайт www.puzzles.com.
Если есть желание, то можете с ним ознакомиться.
Глава 9
Обходы графов
В теории алгоритмов графы - это одна из универсальных тем, абстрактное пред-
представление, которым описывается организация транспортных систем, электри-ческих
цепей, взаимодействий людей и сетей телекоммуникации. То, что столь многие раз-
различные структуры могут быть смоделированы с использованием одного формализма,
дает образованному программисту большое преимущество.
В этой главе мы будем рассматривать только те задачи, которые требуют элемен-
элементарного знания графовых алгоритмов, точнее, соответствующего использования гра-
графовых структур данных и алгоритмов обхода. В главе 10 мы рассмотрим задачи,
опирающиеся на более продвинутые графовые алгоритмы, которые ищут остовные
деревья, кратчайшие пути и потоки в сети.
9.1. Особенности графов
Граф G = (V,E) определяется множеством вершин Уи множеством ребер Е, со-
состоящим из упорядоченных или неупорядоченных пар из V. При моделировании
дорожной сети вершины могут представлять города или перекрестки, некоторые
из которых соединены дорогами/ребрами. При анализе исходного кода ком-
компьютерной программы вершины могут представлять строки кода, и если строка^
может быть выполнена после строки jc, to строки хну соединяются ребром. При
анализе человеческих отношений вершины обычно обозначают людей, а ребра
соединяют пары связанных личностей.
Графы обладают несколькими фундаментальными свойствами, влияющими
на выбор структуры для представления графа и на алгоритмы, которые могут
быть применены к графу. Первым шагом в каждой задаче на графы является опре-
определение особенностей графа, с которым вам предстоит работать.
• Ориентированный или неориентированный. Граф G = (V9 Е) называется
неориентированным, если из того, что ребро (х9 у) е Е9 следует, что (у9 х) также
принадлежит Е. Если это не так, то граф называется ориентированным.
Дорожная сеть между городами обычно неориентированная, так как по любой
214 Глава 9. Обходы графов
большой дороге можно ездить в обе стороны. Уличная сеть внутри городов
практически всегда ориентированная, так как существуют хотя бы несколько
улиц с односторонним движением. Графы программ обычно ориентированные,
так как выполнение идет построчно и его направление меняется только в местах
ветвления. Большинство графов, представляющих теоретиче-ский интерес,
неориентированные.
• Взвешенный или невзвешенный. Граф называется взвешенным, если каждому
ребру (или вершине) G присвоено численное значение или вес. Обычными
весами ребер графа дорожной сети, в зависимости от приложения, могут быть
расстояние, время поездки или максимальная пропускная способность дороги
между х и у. В невзвешенных графах между различными ребрами и вершина-
вершинами нет никакой разницы в стоимости.
Разница между взвешенными и невзвешенными графами становится особенно
очевидной при поиске кратчайшего пути между двумя вершинами. В невзве-
шенном графе кратчайший путь должен состоять из минимального числа ребер,
и он может быть найден путем поиска в ширину, обсуждаемого в этой главе.
Поиск кратчайшего пути во взвешенном графе требует использования более
сложных алгоритмов, обсуждаемых в главе 10.
• Циклический или ациклический. Граф, не содержащий циклов, называется
ациклическим. Связные неориентированные ациклические графы называются
деревьями. Деревья - это простейшие интересные графы, причем они
являются внутренне рекурсивными структурами, так как рассечение любого
ребра приводит к появлению двух меньших деревьев.
Ориентированные ациклические графы называются DAG (Directed Acyclic
Graph). Они естественным образом возникают в задачах планирования, где
ребро (х,у) означает, что событие у должно произойти позже события х.
Операция, называемая топологической сортировкой, упорядочивает вершины
DAG с учетом этих ограничений предшествования. Обычно топологическая
сортировка - это первый шаг в любом алгоритме, связанном с DAG. Она будет
обсуждаться в разделе 9.5.
• Простой или непростой. Определенные типы ребер усложняют работу
с графами. Петлей называется ребро (х9 х), для которого используется только
одна вершина. Ребро (х9 у) называется мультиребром, если оно встречается
в графе несколько раз.
При реализации графовых алгоритмов обеим этим структурам требуется уде-
уделять особое внимание. Поэтому граф, в котором таких структур нет, называется
простым.
9.1. Особенности графов 215
• Привязанный или топологический. Граф называется привязанным (embedded),
если его вершинам и ребрам было присвоено определенное геометрическое
положение. Таким образом, любое изображение графа - это привязка, которая
может влиять, а может и не влиять на алгоритм.
Иногда структура графа полностью определяется геометрией его привязки.
Например, если нам задан набор точек на плоскости и нам нужно найти обход
минимальной стоимости, при котором мы посещаем все вершины графа
(задача о коммивояжере), то топологией, лежащей в основе, будет полный
граф, в котором каждая вершина соединена со всеми остальными. Веса
обычно определяются евклидовым расстоянием между двумя точками.
Другой пример топологии на основе геометрии проявляется в сетках точек.
Во многих задачах, определенных на сетке размером п х т, требуется переме-
перемещаться между соседними точками, так что ребра неявным образом появ-
появляются из геометрии.
• Явный или неявный. Графы не обязательно строятся явным образом, а потом
обходятся, нередко они строятся в процессе использования. Хорошим
примером будет перебор с возвратом. Вершинами неявного поискового графа
являются состояния поискового вектора, а ребра соединяют пары состояний,
которые могут быть получены непосредственно друг из друга. Нередко проще
работать с неявным графом, чем строить его явно для последующего анализа.
• Помеченный или непомеченный. В помеченном графе каждой вершине
присвоено уникальное имя или идентификатор, который отличает ее от
остальных вершин. В непомеченных графах никаких различий такого рода не
делается.
В большинстве графов, возникающих при решении конкретных задач, метки
возникают естественным образом (например, имена городов в транспортной
сети). Обычной задачей, возникающей в графах, является проверка на изо-
изоморфизм, определяющая, совпадают ли топологические структуры двух
графов, если отбросить все метки. Такие задачи обычно решаются поиском
с возвратом, когда мы присваиваем каждой вершине каждого графа опреде-
определенные метки так, чтобы итоговые структуры получились идентичными.
216 Глава 9. Обходы графов
9.2. Структуры данных для графов
Графы можно представить несколькими способами. Ниже мы обсудим четыре
полезных варианта. Мы полагаем, что граф G = (V,E) содержит п вершин и т ребер.
Матрица смежности. Мы можем представить G, используя матрицу М
размером п х я, в которой элемент M[i9j] равен, скажем, 1, если (ij) является
ребром G, и 0 иначе. Это позволяет быстро отвечать на такие вопросы, как:
«Принадлежит ли (ij) G?» - и позволяет быстро обновлять граф в случае
вставки и удаления. Тем не менее для графов со многими вершинами
и небольшим количеством ребер мы займем чересчур много лишнего места.
Рассмотрим граф, представляющий уличную карту Манхэттена в Нью-Йорке.
Каждое пересечение двух улиц будет вершиной графа, и соседние перекрестки
будут соединяться ребрами. Насколько велик такой график? В основе Манхэттен
состоит из 15 авеню, каждое из которых пересекает примерно 200 улиц. Это дает
нам примерно 3000 вершин и 6000 ребер, так как каждая вершина соседствует
еще с четырьмя вершинами и каждое ребро является общим для двух вершин.
Такое небольшое количество данных можно легко и удобно хранить, но у матрицы
смежности будет 3000 х 3000 = 9 000 000 ячеек, и почти все они будут пустыми!
• Списки смежных вершин через списки. Более эффективным способом представ-
представления разреженных графов являются связанные списки, в которых хранятся
инцидентные соседи каждой вершины. Для работы со списками смежных
вершин требуются указатели, но в этом нет ничего страшного, если вы уже рабо-
работали со связанными структурами.
При работе со списками смежности становится сложнее ответить на вопрос
о принадлежности данного ребра (ij) графу, так как нам нужно просматривать
соответствующий список, чтобы найти подходящее ребро. Тем не менее нередко
совсем несложно построить алгоритмы работы с графами, не прибегающие к таким
запросам. Обычно мы проходим по всем ребрам графа за один заход, используя
обход в ширину или в глубину, и обновляем ребро в момент его посещения.
• Списки смежных вершин через матрицы. Списки смежности также можно
реализовать через матрицы, избегая, таким образом, работы с указателями.
Мы можем представить список массивом (или, что эквивалентно, строкой
в матрице), введя счетчик к числа элементов и помещая их в первые к элементов
массива. Теперь мы можем последовательно обойти элементы от первого
к последнему, просто увеличивая счетчик цикла, а не путешествуя по указателям.
На первый взгляд кажется, что эта структура данных объединила в себе худшие
черты матриц смежности (большой размер) и списков смежности (необходимость
поиска ребер). Тем не менее существуют и плюсы. Во-первых, эту структуру
9.2. Структуры данных для графов 217
данных проще всего запрограммировать, особенно, если речь идет о статичных
графах, неизменных после построения. Во-вторых, проблему с размером можно
решить, если выделять строки для каждой вершины динамически и делать их
соответствующего размера.
Чтобы доказать нашу точку зрения, мы будем использовать эту структуру
данных во всех наших последующих примерах.
• Таблица ребер. Еще более простой структурой данных будет массив или свя-
связанный список ребер. Работая с ней, сложнее отвечать на такие вопросы, как:
«Какие вершины являются соседними для х?» - но она прекрасно подходит
для определенных простых процедур, таких, как алгоритм Крускала (Kruskal)
остовного дерева минимального веса.
Как было сказано выше, мы будем использовать списки смежности через матрицы
в качестве наших основных графовых структур. Совсем несложно преобразовать эти
подпрограммы для работы с честными, реализованными через указатели списками
смежности. Пример кода для списков и матриц смежностей можно найти во многих
книгах, например [SedOl].
Графы будут представляться следующим типом данных. Для каждого графа
мы храним счетчик числа вершин и присваиваем каждой вершине номер от 1 до
nvertices. Мы храним ребра в массиве размером MAXV x MAXDEGREE, так что
каждая вершина может быть соседней для MAXDEGREE других. Установив
MAXDEGREE равной MAXV, мы сможем описать любой простой граф, но для
графов низкого порядка это трата места.
#defineMAXV 100 /* максимальное число вершин */
#define MAXDEGREE 50 /* максимальная степень вершины
*/
typedef struct {
int edges [MAXV+1] [MAXDEGREE] ; /* информация о смежности */
int degree [MAXV+1] ; /* степень каждой вершины */
int nvertices; /* число вершин графа */
intnedges; /* число ребер графа */
} graph;
Ориентированное ребро (х, у) мы задаем целым числом у в списке смежности х,
который расположен в подмассиве graph->edges [x]. Поле degree хранит количе-
количество входов для данной вершины. Неориентированное ребро (х, у) отмечается дважды
в любой графовой структуре, основанной на смежности, - один раз как у в списке х
и второй раз как х в списке у.
218 Глава 9. Обходы графов
Чтобы продемонстрировать использование этой структуры данных, мы покажем,
как граф считывается из файла. Обычное представление графа состоит из первой
строки, задающей число вершин и ребер графа, за которой следует список ребер -
по две вершины на строку.
read_graph(graph *g, bool directed)
{
int i; /* счетчик */
int m; /* число ребер */
int x,y; /* вершины ребра (x,y) */
initialize_graph(g);
scanf("%d %d",&(g->nvertices),&m);
for (i = l, i<=m;
scanf("%d %d"/ &x, &y);
insert_edge(g,x,y,directed);
initialize_graph(graph *g)
{
int i; /* счетчик */
g -> nvertices = 0;
g -> nedges = 0;
for (i=l; i<=MAXV; i++) g->degree[i] = 0;
}
Самой важной подпрограммой является insert_edge. Мы передаем в нее
булевский параметр directed, определяющий, нужно ли нам вставлять две
копии ребра или только одну. Обратите внимание на использование рекурсии для
решения поставленной задачи:
insert_edge(graph *g, int x, int y, bool directed);
{
if (g->degree[x] > MAXDEGREE)
printf ("Warning: insertion (%d,%d) exceeds max degree \n" , x, у) ;
g->edges[x][g->degree[x]] = y;
g->degrее[x] + +;
if (directed == FALSE)
insert_edge(g/y/x,TRUE);
else
g->nedges ++;
9.3. Обход графа: в ширину 219
Теперь вывод соответствующего графа свелся к вложенным циклам:
print_graph(graph *g)
{
int i,j; /* счетчики */
for (i=l; i<=g->nvertices;
printf("%d: ", i);
for (j=0; j<g->degree[i];
printf(" %d", g->edges[i][j]);
printf("\n");
9.3. Обход графа: в ширину
Базовой операцией в любом графовом алгоритме является полный и систематиче-
систематический обход графа. Мы хотим посетить каждую вершину и каждое ребро ровно один
раз в строго определенном порядке. Существует два основных алгоритма обхода:
поиск в ширину (breadth-first search - BFS) и поиск в глубину (depth-first search - DFS).
Для определенных задач нет никакой разницы, какой из них вы будете использовать,
но в некоторых случаях выбор становится жизненно важным.
Обе процедуры обхода графа используют одну фундаментальную идею, а именно:
мы должны помечать вершины, которые уже видели, чтобы не пытаться посетить их
снова. Иначе мы можем потеряться в лабиринте и не суметь из него выбраться. BFS
и DFS различаются только порядком, в котором они рассматривают вершины.
Поиск в ширину следует использовать в том случае, если A) нам не важен
порядок, в котором мы обходим вершины и ребра графа, то есть нас устроит
любой, или если B) нам нужно найти кратчайший путь в невзвешенном графе.
9.3.1. Поиск в ширину
В нашей реализации поиска в ширину, bf s, мы используем два булевских мас-
массива, чтобы хранить информацию о каждой вершине графа. Мы говорим, что
вершина открыта (discovered), когда первый раз ее посещаем. Вершина счита-
считается обработанной (processed) после того, как мы обошли все ребра,
опирающиеся на эту вершину. Таким образом, статус каждой вершины изменяет-
изменяется от неоткрытой к открытой, а затем к обработанной. Эту информацию можно
хранить с помощью одной переменной перечислимого типа данных, но вместо
этого мы решили использовать две булевские переменные.
220
Глава 9. Обходы графов
Как только вершина открыта, она помещается в очередь, реализованную, как
в разделе 2.1.2. Так как мы обрабатываем вершины в порядке «первый вошел,
первый ушел», то старшие вершины обрабатываются первыми, то есть именно те,
кто ближе всего к корневому узлу.
обработанные вершины */
открытые вершины */
порядок нахождения */
/* очередь вершин, необходимых
для посещения */
/* текущая вершина */
/* счетчик */
bool processed[MAXV}; /<
bool discovered[MAXV]; /i
int parent[MAXV]; Г
bfs(graph *g, int start)
queue q;
int v;
int i ;
init_queue(&q);
enqueue(&q,start);
discovered[start] = TRUE;
while (empty(&q) == FALSE) {
v = dequeue(&q);
process_vertex(v);
processed[v] = TRUE;
for (i=0; i<g->degree[v].
if (valid_edge(g->edges[v][i]) == TRUE) {
if (discovered[g->edges[v][i]] == FALSE)
enqueue(&q,g->edges[v][i]);
discovered[g->edges[v][i]] = TRUE;
parent[g->edges[v][i]] = v;
if (processed[g->edges[v][i]] == FALSE)
process_edge(v,g->edges[v][i]);
}
}
/* счетчик */
initialize__search(graph *g)
{
int i;
for (i=l; i<=g->nvertices; {
processed[i] = discovered[i] = FALSE;
parent[i] = -1;
9.3. Обход графа: в ширину 221
9.3.2. Использование обхода
Точное поведение bfs зависит от функций process_vertex ()
Hprocess_edge (). Путем задания этих функций мы можем легко
определить, что должно происходить при единственном посещении каждого
ребра и каждой вершины. Задав эти функции так:
process_vertex(int v)
{
printf("processed vertex%d\n",v);
}
process_edge(int x, int y)
{
printf("processed edge (%d,%d)\n",x,y);
}
мы напечатаем каждую вершину и каждое ребро ровно один раз. А задав их так:
process_vertex(int v)
{
}
process_edge(int x, int y)
{
nedges = nedges + 1;
}
мы найдем точное число ребер. Во многих задачах требуется предпринимать раз-
различные действия при нахождении ребер и вершин. Эти функции позволяют нам
легко подстраиваться под требования конкретной задачи.
Еще одна возможность подстройки содержится в булевском предикате
valid__edge, позволяющем нам игнорировать существование определенных
ребер во время нашего обхода графа.
9.3.3. Нахождение путей
Массив parent, заполняемый внутри bf s(), может оказаться весьма полезным
при поиске интересующих нас путей по графу. Вершина, являющаяся предком
вершины /, задается как parent[i]. Так как во время обхода мы открываем все
вершины, то, за исключением корня, все узлы имеют предка. Предковое отношение
задает открываемое дерево, причем начальный поисковой узел является корнем
этого дерева.
222
Глава 9. Обходы графов
Так как вершины открываются в порядке увеличения расстояния от корня, это
дерево обладает очень важным свойством. Уникальный путь по дереву от корня
к любому узлу х е V содержит минимально возможное число ребер (или, что то же
самое, промежуточных вершин) для любого пути от корневого узла до х в графе G.
Мы можем воспроизвести этот путь по цепи предков, начиная с х и заканчивая
корнем. Обратите внимание, что нам нужно работать в обратном направлении. Мы
не можем найти путь от корня до х, так как такое направление не совпадает с направ-
направлением указателей на предков. Вместо этого мы должны искать путь от х к корню.
13
14
9
5
1
10
6
2
11
7
3
15
16
12
8
13
14
10
15
11
16
12
8
Рис. 9.1. Неориентированный граф-сетка размера 4x4 (слева) и DAG, ребра которого
идут по направлению к вершинам с большим номером (справа)
Так как в этом случае мы получаем путь, обратный желаемому, мы можем или
A) сохранить его, а затем, используя стек, явно поменять направление на противо-
противоположное, или B) позволить рекурсии сделать все без нашего участия, как показано
в следующей подпрограмме.
f ind_path (int st.art, int end, int parents [])
{
if ((start == end) || (end == -1))
printf("\n%d",start);
else {
find_path(start,parents[end],parents);
printf(" %d",end);
9.4. Обход графа: в глубину 223
Для примера нашего сетчатого графа (рис. 9.1) алгоритм выдал следующую
последовательность родительских отношений.
Вершина 1 2 3 4 5 б 7 8 9 10 11 12 13 14 15 16
Предок -11 23 123456789 10 11 12
Исходя из родительских отношений, самым коротким путем из левого нижнего
угла в правый верхний является {1, 2, 3,4, 8, 12, 16}. Конечно, кратчайший путь не
единствен; число таких путей в таком графе подсчитывалось в разделе 6.3.
При использовании поиска в ширину для нахождения кратчайшего пути от х до у
следует помнить две вещи: во-первых, дерево кратчайших путей можно использо-
использовать только в том случае, если корневым узлом BFS был задан*. Во-вторых, BFS дает
кратчайший путь только для невзвешенного графа. Алгоритмы поиска кратчайшего
пути во взвешенных графах будут описаны в разделе 10.3.1.
9.4. Обход графа: в глубину
В основе поиска в глубину лежит та же идея, что и в переборе с возвратом. Оба
алгоритма производят полный перебор всех возможностей, продвигаясь, пока это воз-
возможно, и возвращаясь, когда не остается неисследованных вариантов дальнейшего
продвижения. Оба алгоритма проще рассматривать как рекурсивные алгоритмы.
Поиск в глубину можно рассматривать как поиск в ширину с очередью, заменен-
замененной стеком. Изящность реализации df s через рекурсию состоит в том, что исчезает
необходимость явной реализации стека.
dfs(graph *g, int v)
{
int i ; /* счетчик */
int у; /* вершина-преемник */
if (finished) return; /* возможность прекращения поиска */
discovered[v] = TRUE;
process_vertex(v);
for (i=0; i<g->degree[v]; i++) {
у = g->edges[v][i];
if (valid_edge(g->edges[v][i]) ==TRUE) {
if (discovered[y] == FALSE)
parent[y] = v;
dfs(g,y);
} else
if (processed[y] == FALSE)
224 Глава 9. Обходы графов
process_edge(v,y);
}
if (finished) return;
}
processed[v] = TRUE;
}
Корневые деревья - это особые случаи графов (ориентированные, ациклические,
степень по входу не превышает 1, причем порядок определяется по исходящим ребрам
каждого узла). Левое поддерево-корень-правое поддерево (in-order), корень-левое под-
поддерево-правое поддерево (pre-order) и левое поддерево-правое поддерево-корень
(post-order) - обходы, по сути, являются DFS, различающимися только в том, как они
используют порядок исходящих ребер, и в том, когда они обрабатывают вершины.
9.4.1. Обнаружение циклов
Поиск в глубину разбивает все ребра неориентированного графа на две группы,
ребра дерева (tree edge) к ребра возврата (back edge). К ребрам дерева относятся те
ребра, которые сохраняются в массиве parent, то есть ребра, открывающие новые
вершины. Ребрами возврата называются ребра, указывающие «обратно в дерево», то
есть их конец является предком ранее обнаруженной вершины.
То, что все ребра попадают в одну из этих двух категорий, является удивитель-
удивительным свойством поиска в глубину. Почему ребро обязательно должно идти к предку?
В DFS все узлы, достижимые из данной вершины v, исследуются прежде чем мы
закончим обход из v, так что иные топологии невозможны для неориентированных
графов. В случае ориентированных графов итоговая картина получается в чем-то
более сложной, но все равно высокоструктурированной.
Ребра возврата играют решающую роль в обнаружении циклов в неориентирован-
неориентированных графах. Если ребер возврата не существует, то все ребра являются ребрами дерева
и никаких циклов нет. Но любое ребро возврата, идущее от* к предку>>, создает цикл
из пути в дереве отукх. Такой цикл легко обнаружить, используя df s.
process_edge(int x, int y);
{
if (parent[x] != y) { /* нашли ребро возврата! */
printf("Cycle from %d to %d:",y,x);
find_path(y,x,parent);
finished = TRUE;
process_vertex(int v)
9.4. Обход графа: в глубину 225
Мы используем флаг finished для прекращения работы после обнаружения
первого цикла в нашем сеточном графе 4x4, а именно 3 4 8 7, причем ребром
возврата является G,3).
9.4.2. Связные компоненты
Связным компонентом неориентированного графа называется максимальное
множество вершин таких, что существует путь между любой парой вершин. Они
являются различными, не соединенными «кусками» графа.
Большое количество с виду сложных задач сводится к нахождению или подсчету
связных компонент. Например, проверка разрешимости таких головоломок, как
кубик Рубика или «пятнашки», на самом деле является проверкой связности графа
разрешенных конфигураций.
Связные компоненты легко могут быть найдены с помощью поиска в глубину
или поиска в ширину, так как порядок вершин не важен. Обычно мы начинаем
с первой вершины. Все, что мы откроем во время этого поиска, должно являться
частью одного и того же связного компонента. Далее мы повторяем поиск, начиная
с одной из неоткрытых вершин (если таковые существуют), чтобы обнаружить сле-
следующий компонент, и так далее до тех пор, пока не будут обнаружены все вершины.
connected_components(graph *g)
{
int с; /* номер компонента */
int i; /* счетчик */
initialize_search(g);
с = 0;
for (i=l; i<=g->nvertices; i++)
if (discovered[i] == FALSE) {
с = c+1;
printf("Component %d:",c);
dfs(g,i);
printf("\n");
process_vertex(int v)
{
printf(" %d",v);
}
process_edge(int x, int y)
Разновидности связных компонентов обсуждаются в разделе 10.1.2.
8-972
226 Глава 9. Обходы графов
9.5. Топологическая сортировка
Топологическая сортировка - это фундаментальная операция на ориентирован-
ориентированных ациклических графах (DAG). С ее помощью вершины располагаются в таком
порядке, что все направленные ребра идут «слева направо» (от вершины с меньшим
порядковым номером к вершине с большим). Очевидно, что такой расстановки не
существует, если граф содержит ориентированные циклы, так как нельзя идти по
прямой вправо и вернуться туда, откуда вы начали!
Важность топологической сортировки состоит в том, что благодаря ей вы
можете обрабатывать каждую вершину до обработки ее наследников. Пусть ребра
представляют собой ограничения предшествования так, что ребро (х,у) означает,
что работа х должна быть выполнена до работы у. Тогда топологическая сортировка
определяет правильное расписание. Кроме того, для заданного DAG может сущест-
существовать множество таких расстановок.
Но существуют и другие приложения. Пусть мы ищем самый короткий (или самый
длинный) путь из х в у в DAG. Определенно, никакая вершина, идущая послед в топо-
топологическом порядке, не может принадлежать такому пути, потому что не существует
способа вернуться обратно к у. Мы можем обрабатывать соответствующим образом
все вершины слева направо в топологическом порядке, рассматривая влияние исходя-
исходящих из них ребер, и знать, что мы рассмотрим все, что нам нужно, и ничего лишнего.
Топологическая сортировка эффективно реализуется с использованием варианта
поиска в глубину. Тем не менее более прямолинейный алгоритм основан на анализе
входящих ребер всех вершин DAG. Если в вершину не заходит ни одно ребро, то
есть ее степень по входу равна 0, то мы можем спокойно ставить ее первой в топо-
топологическом порядке. Удаление опирающихся на нее ребер может привести к появле-
появлению новых вершин со степенью по входу равной 0. Этот процесс можно продолжать
до тех пор, пока все вершины не будут расставлены по порядку; если такого не
случится, то граф содержал цикл и не являлся DAG.
Рассмотрим следующую реализацию.
topsort(graph *g, int sorted[])
{
int indegree[MAXV]; /* степень по входу каждой
вершины */
queue zeroin; /* вершины со степенью по
входу 0 */
int х, у; /* текущая и следующая
вершины */
int i, j; /* счетчики */
compute__indegrees (g, indegree) ;
init_queue(&zeroin);
for (i=l; i<=g->nvertices; i++)
if (indegree[i] == 0) enqueue(&zегоin,i);
9.5. Топологическая сортировка 227
j = 0;
while (empty(&zeroin) == FALSE) {
j = j + 1;
x = dequeue(&zeroin);
sorted[j] = x;
for (i=0; i<g->degree[x]; i++) {
у = g->edges[x][i] ;
indegree[y] --;
if (indegree[y] == 0) enqueue(&zeroin,у);
if (j != g->nvertices)
printf("Not a DAG -- only %d vertices found\n",j);
}
compute_indegrees(graph *g, int in[])
{
int i,j; /* счетчики */
for (i=l; i<=g->nvertices; i++) in[i] = 0;
for (i=l; i<=g->nvertices; )
for (j = 0; j<g->degree[i] ; j++) in [ g->edges [i] [ j ] ] ++;
Нужно отметить несколько вещей. Поскольку поле degree записей графовой
структуры данных содержит степень по выходу вершин, то сначала мы вычисля-
вычисляем степени по входу каждой вершины DAG. Эти величины совпадают для неори-
неориентированных графов, но могут различаться для ориентированных.
Далее, обратите внимание, что мы используем очередь для хранения вершин
со степенью по входу 0, но только по той причине, что у нас уже есть описанная
очередь в разделе 2.1.2. Подойдет любой контейнер, так как порядок никоим обра-
образом не влияет на корректность решения. Обрабатывая вершины в разном порядке,
можно получить разные топологические сортировки.
Влияние порядка обработки хорошо заметно при топологической сортировке
ориентированной сетки, показанной на рис. 9.1, в которой все ребра идут от
вершин с меньшими номерами к вершинам с большими. Отсортированная пере-
перестановка {1, 2,..., 15, 16} является топологически упорядоченной, но наша про-
программа упорно «прыгала», пробегая по диагоналям, к результату:
1 2 5 3 6 9 4 7 10 13 8 11 14 12 15 16
Также возможно множество других вариантов упорядочивания.
И наконец обратите внимание, что эта реализация не удаляет ребра из графа на
самом деле! Вполне достаточно рассмотреть их влияние на степень по входу и обойти
их, а не удалять.
8*
228 Глава 9. Обходы графов
9.6. Задачи
9.6.1. Раскраска двумя цветами
PC/UVaIDs: 110901/10004
Популярность: А
Частота успехов: высокая
Уровень:1
Теорема четырех красок утверждает, что любую плоскую карту можно рас-
раскрасить, используя только четыре цвета, таким образом, что никакие две соседние
области не будут покрашены в один цвет. Эту теорему не могли доказать более
100 лет, после чего, в 1976 году, она была доказана с помощью компьютера.
Сейчас вам нужно решить более простую задачу. Вам нужно узнать, может ли
данный связный граф быть раскрашен двумя цветами, то есть могут ли вершины
быть покрашены красным и черным так, чтобы никакие две смежные вершины не
были одного цвета.
Чтобы упростить задачу, вы можете считать, что граф связный, неориентиро-
неориентированный и не содержит петель (то есть ребер, идущих из вершины в нее же).
Входные данные
Входные данные состоят из нескольких тестовых блоков. Каждый тестовый
блок начинается со строки, содержащей число вершин п, причем 1 < п < 200.
Каждая вершина обозначается числом от 0 до п-\. Вторая строка содержит
число ребер /. Далее следуют / строк, каждая из которых содержит два номера
вершин, задающих ребро.
Входной блок с« = 0 обозначает конец входных данных и обрабатываться не
должен.
Выходные данные
Решите, можно ли покрасить введенный граф двумя цветами, и выведите резуль-
результаты, как показано ниже.
Пример входных данных
3
3
0 1
1 2
2 0
9
9.6. Задачи
229
О 1
О 2
О 3
О 4
О 5
О б
О 7
О 8
О
Соответствующие выходные данные
NOT BICOLORABLE.
BICOLORABLE.
9.6.2. Колеса
PC/UValDs: 110902/10067
Популярность: С
Частота успехов: средняя
Уровень:2
Рассмотрим следующую математическую машину. Цифры от 0 до 9 последова-
последовательно (по часовой стрелке) напечатаны по краю каждого колеса. Самые верхние
цифры колес образуют четырехзначное целое число. Например, на рисунке колеса
образуют число 8056. У каждого колеса есть две кнопки. Нажатие кнопки с левой
стрелкой поворачивает колесо на одну цифру по часовой стрелке, а нажатие кнопки
с правой стрелкой поворачивает на одну цифру в противоположном направлении.
230 Глава 9. Обходы графов
Начальное положение колес формирует целое число Sj S2 S$ S4. Вам задается
набор из п запрещенных состояний F^ Fi2Fi3Fi4 A <i<ri) к конечное состояние
Tj T2 Tj T4. Ваша задача состоит в написании программы, которая считает мини-
минимальное число нажатий кнопок, необходимое для преобразования начального
состояния в конечное, не принимая при этом запрещенных состояний.
Входные данные
Первая строка входных данных содержит целое число N, задающее число тесто-
тестовых блоков. За ней следует пустая строка.
Первая строка каждого тестового блока содержит начальное состояние колес,
задаваемое четырьмя цифрами. Следующая строка содержит конечное состояние.
Третья строка содержит целое число п, задающее количество запрещенных
состояний. Каждая из следующих п строк содержит запрещенное состояние.
Между двумя последовательными тестовыми блоками находится пустая строка.
Выходные данные
Для каждого введенного тестового блока выведите строку, содержащую мини-
минимальное необходимое количество нажатий кнопок. Если конечное состояние недос-
недостижимо, выведите " -1".
Пример входных данных
2
8
6
5
8
8
5
7
6
0
5
8
0
0
0
0
0
0
0
5
0
0
5
5
4
0
3
0
0
0
0
1
9
5
0
5
4
0
0
0
0
1
0
0
1
9
0
0
6
8
7
7
8
8
8
0
7
1
9
0
0
0
0
10 0 0
9 0 0 0
9.6. Задачи
231
Соответствующие выходные данные
14
-1
9.6.3. Экскурсовод
PC/UVaIDs: 110903/10099
Популярность: В
Частота успехов: средняя
Уровень:3
М-р Ж. работает экскурсоводом в Республике Бангладеш. Его текущее зада-
задание состоит в том, чтобы показать группе туристов удаленный город. Как и во всех
странах, определенные пары городов соединены дорогами с двусторонним дви-
движением. В каждой паре между соединенными городами и только между ними дей-
действует междугороднее автобусное сообщение, использующее дорогу, соеди-
соединяющую их напрямую. В каждой автобусной службе есть определенный предел
количества перевозимых пассажиров. У м-ра Ж. есть карта, на которой показаны
города и соединяющие их дороги, а также пассажирские лимиты соответст-
соответствующих автобусных служб.
Но он не всегда может перевезти всех туристов в место назначения за одну
поездку. Например, рассмотрим следующую карту дорог для семи городов, где
дороги представляются ребрами, а число, написанное на каждом ребре, задает
пассажирский лимит соответствующей автобусной службы.
20
232 Глава 9. Обходы графов
М-ру Ж. потребуется, как минимум, пять поездок, чтобы перевезти 99 туристов
из города 1 в город 7, так как ему нужно сопровождать автобус с каждой группой.
Наилучшим маршрутом будет 1-2-4-7.
Помогите м-ру Ж. найти маршрут, чтобы перевезти всех туристов в требуемый
город за минимальное число поездок.
Входные данные
Входные данные будут состоять из одного и более тестовых блоков. Первая
строка каждого блока содержит два целых числа: N(N< 100) и 7?, задающие соответ-
соответственно число городов и число дорожных сегментов. Каждая из следующих R строк
содержит три целых числа (С/ С2 и Р), где С/ и С2 - это номера городов и Р (Р > 1) -
это максимальное число пассажиров, которые могут перевозиться между двумя горо-
городами. Номера городов - это положительные целые числа от 1 до N. (R + 1)-я строка
содержит три целых числа (S, D и 7), задающих, соответственно начальный город,
конечный город и число туристов, которых необходимо перевезти.
Входные данные завершаются при Nn R равных нулю.
Выходные данные
Для каждого введенного тестового блока сначала выведите номер сценария,
а затем, на отдельной строке, минимальное число необходимых поездок. После
каждого тестового блока выведите пустую строку.
Пример входных данных
7 10
1 2 30
1 3 15
1 4 10
2 4 25
2 5 60
3 4 40
3 б 20
4 7 35
5 7 20
6 7 30
1 7 99
0 0
Соответствующие выходные данные
Scenario #1
Minimum Number of Trips = 5
9.6. Задачи 233
9.6.4. Лабиринт из косых
PC/UValDs: 110904/705
Популярность: В
Частота успехов: средняя
Уровень:2
Заполняя прямоугольник левыми (/) и правыми (\) косыми чертами (слешами),
можно строить симпатичные небольшие лабиринты. Вот пример.
Как можно заметить, пути в лабиринте не могут разветвляться, так что во всем
лабиринте могут содержаться только A) циклические пути и B) пути, которые
где-то заходят и где-то выходят. Нас интересуют только циклы. В нашем примере
их ровно два.
Ваша задача состоит в написании программы, которая подсчитывает число
циклов и находит длину самого длинного. Длина определяется как количество
маленьких квадратов, из которых состоит цикл (те, границы которых на картинке
нарисованы серым цветом). В нашем примере протяженность длинного цикла
равна 16, а короткого 4.
Входные данные
Входные данные состоят из нескольких описаний лабиринтов. Каждое описание
начинается со строки, содержащей два целых числа w и h (\ <w,h< 75), задающих
ширину и высоту лабиринта. Следующие h строк задают лабиринт, каждая из них
содержит по w символов; причем все эти символы являются или «/» или «\».
Входные данные завершаются тестовым блоком, начинающимся с w = h = 0.
Этот блок обрабатывать не нужно.
234 Глава 9. Обходы графов
Выходные данные
Для каждого лабиринта выведите строку "Maze #n: ", где п - это номер
лабиринта. Далее выведите строку "A: Cycles; the longest has length /. ",
где к - это число циклов в лабиринте, а / - это протяженность самого длинного из
них. Если лабиринт является ациклическим, выведите "There are no cycles . ".
После каждого тестового блока выведите пустую строку.
Пример входных данных Соответствующие выходные данные
б 4 Maze #1:
\//\\/ 2 Cycles; the longest has length 16.
/A\/\ Maze #2:
\/\/// There are no cycles.
3 3
\\\
0 0
9.6.5. Лесенки ступенек редактирования
PC/UVaIDs: 110905/10029
Популярность: В
Частота успехов: низкая
Уровень:3
Назовем ступенькой редактирования (edit step) такое преобразование слова х
в слово у, что слова х и у принадлежат словарю и слово х может быть преобразо-
преобразовано в слово;/ путем добавления, удаления или изменения одной буквы. Преобра-
Преобразования dig в dog и dog в do являются ступеньками редактирования. Лесенка сту-
ступенек редактирования (edit step ladder) - это отсортированная в лексикографиче-
лексикографическом порядке последовательность слов w/, w2,..., wn такая, что преобразование w,-
в wi+j является ступенькой преобразования для любого / от 1 до п - 1.
Для заданного словаря вы должны найти самую большую лесенку ступенек
редактирования.
Входные данные
Входные данные состоят из словаря: набора слов в нижнем регистре в лексико-
лексикографическом порядке по одному слову на строку. Длина каждого слова не превышает
16 букв, и в словаре не более 25 000 слов.
9.6. Задачи 235
Выходные данные
Выходные данные состоят из одного целого числа, количества слов в самой
большой лесенке ступенек редактирования.
Пример входных данных
cat
dig
dog
fig
fin
fine
fog
log
wine
Соответствующие выходные данные
5
9.6.6. Башни из кубиков
PC/UValDs: 110906/10051
Популярность: С
Частота успехов: высокая
Уровень: 3
У вас есть N цветных кубиков разного веса. Кубики не одноцветные - напротив,
каждая грань кубика покрашена в свой цвет. Вам нужно построить максимально
высокую башню, подчиняющуюся тем ограничениям, что A) мы не можем класть
тяжелый кубик на легкий и B) цвет нижней грани каждого кубика (за исключением
самого нижнего) должен совпадать с цветом верхней грани кубика под ним.
Входные данные
Входные данные могут содержать несколько тестовых блоков. Первая строка
каждого тестового блока содержит целое число N(\ <N<500), задающее число
данных вам кубиков, /-я строка из следующих N содержит описание /-го кубика.
Кубик описывается цветами его граней в следующем порядке: передняя, задняя,
левая, правая, верхняя и нижняя. Для вашего удобства цвета описываются целыми
числами от 1 до 100. Вы можете считать, что кубики вводятся в порядке их утяже-
утяжеления, то есть кубик 1 самый легкий, а кубик N самый тяжелый.
Входные данные завершаются при N равном 0.
236 Глава 9. Обходы графов
Выходные данные
Для каждого блока начните с вывода строки, содержащей номер тестового
блока, как показано в примере выходных данных. На следующей строке выведите
число кубиков в самой высокой возможной башне. Далее выведите описания куби-
кубиков в башне, по одному описанию на строку. Каждое описание содержит порядко-
порядковый номер этого кубика во входных данных, один пробел, а затем строку-идентифи-
строку-идентификатор (front, back, left, right, top, bottom) верхней грани кубика в башне.
Может существовать несколько решений, подойдет любое.
Выходные данные для двух последовательных блоков должны быть разделены
пустой строкой.
Пример входных данных
3
12 2 2 12
3 3 3 3 3 3
3 2 1111
10
1 5 10 3 б 5
2 6 7 3 6 9
5 7 3 2 19
1 3 3 5 8 10
6 6 2 2 4 4
12 3 4 5 6
10 9 8 7 6 5
6 12 3 4 7
12 3 3 2 1
3 2 112 3
0
Соответствующие выходные данные
Case #1
2
2 front
3 front
Case #2
8
1 bottom
2 back
3 right
4 left
6 top
8 front
9 front
10 top
9.6. Задачи 237
9.6.7. От заката до рассвета
PC/UValDs: 110907/10187
Популярность: В
Частота успехов: средняя
Уровень:3
У Владимира бледная кожа, очень длинные зубы, и ему уже 600 лет, но в этом
нет ничего особенного, потому что Владимир - вампир. Ему всегда нравилось быть
вампиром. На самом деле, он весьма успешный доктор, никогда не отказывающийся
от ночного дежурства, и, как следствие, у него много друзей среди коллег. Он знает
впечатляющий трюк, который любит показывать на званых обедах: он может опре-
определять группу крови по вкусу. Владимир любит путешествовать, но так как он вам-
вампир, это вызывает определенные трудности.
1. Он может путешествовать только поездом, потому что ему нужно брать с собой
свой гроб. К счастью, он всегда может путешествовать первым классом, потому
что он сделал много денег на долгосрочных инвестициях.
2. Путешествовать он может только от заката до рассвета, а именно с 6 P.M. до 6 A.M.
В течение дня он должен оставаться внутри железнодорожной станции.
3. Ему нужно брать с собой что-нибудь поесть. На день ему требуется литр крови,
который он выпивает в полдень A2:00) в своем гробу.
Помогите Владимиру найти кратчайший маршрут между двумя заданными
городами, чтобы он мог путешествовать, взяв с собой минимальное количество
крови. Если он возьмет с собой слишком много, то люди начнут приставать к нему
с глупыми вопросами типа «А что вы собираетесь делать со всей этой кровью?».
Входные данные
Первая строка входных данных содержит одно целое число, задающее число
тестовых блоков.
Описание каждого тестового блока начинается с одного числа, задающего число
описаний маршрутов, следующих ниже. Каждое описание маршрута состоит из имен
двух городов, времени отправления из первого города и общего времени путешествия,
причем все время измеряется в часах. Не забывайте, что Владимир не может путеше-
путешествовать маршрутами, отправляющимися до 18:00 и прибывающими после 6:00.
Общее число городов не превышает 100, а соединений 1000. Длительность любого
маршрута не менее 1 и не более 24 часов, но Владимир может пользоваться только
маршрутами, чье время путешествия не превышает 12 часов от заката до рассвета.
Длина имен всех городов не превышает 32 символов. Последняя строка содержит
имена двух городов. Первый - это отправной пункт Владимира; второй - это место
назначения.
238 Глава 9. Обходы графов
Выходные данные
Для каждого тестового блока вы должны вывести номер тестового блока, за
которым должно следовать " Vladimir needs # litre (s) of blood."
или "There is no route Vladimir can take.".
Пример входных данных
2
3
Ulm Muenchen 17 2
Ulm Muenchen 19 12
Ulm Muenchen 5 2
Ulm Muenchen
10
Lugoj Sibiu 12 6
Lugoj Sibiu 18 6
Lugoj Sibiu 24 5
Lugoj Medias 22 8
Lugoj Medias 18 8
Lugoj Reghin 17 4
Sibiu Reghin 19 9
Sibiu Medias 20 3
Reghin Medias 20 4
Reghin Bacau 24 6
Lugoj Bacau
Соответствующие выходные данные
Test Case 1.
There is no route Vladimir can take.
Test Case 2.
Vladimir needs 2 litre(s) of blood.
9.6.8 И снова ханойские башни!
РС/UVaIDs: 110908/10276
Популярность: В
Частота успехов: высокая
Уровень:3
Существует много интересных вариаций задачи о Ханойских башнях. В этой
версии у нас имеется п колышков и шарики, содержащие все числа от 1, 2, 3,..., оо.
Если сумма чисел на двух шариках не является полным квадратом (то есть с* для
некоторого целого с), то они будут отталкивать друг друга с такой силой, что никогда
не смогут соприкоснуться.
9.6. Задачи
239
О
Игрок помещает шарики на колышки по одному, в порядке увеличения
номеров (то есть сначала шарик 1, затем шарик 2, затем шарик 3 и т. д.). Игра
заканчивается, когда у игрока нет хода, не приводящего к отталкиванию шариков.
Цель игры - поместить как можно больше шариков на колышки. На рисунке
выше приведен наилучший возможный результат для четырех колышков.
Входные данные
Первая строка содержит одно целое число Г, задающее число тестовых блоков
A < Г<50). Каждый тестовый блок содержит одно целое число N(\ <N<50),
задающее число доступных колышков.
Выходные данные
Для каждого тестового блока выведите строку, содержащую целое число,
равное максимальному количеству шаров, которые возможно поместить. Если
поместить можно бесконечное количество шаров, то выведите " -1".
Пример входных данных
Соответствующие выходные данные
2
4
25
11
337
240 Глава 9. Обходы графов
9.7. Подсказки
9.1. Можем ли мы покрасить граф за один обход?
9.2. Что за граф лежит в основе этой задачи?
9.3. Можем ли мы свести эту задачу к проверке на связность?
9.4. Имеет ли смысл представлять граф явно или можно работать с матрицей косых
черт?
9.5. Что за граф лежит в основе этой задачи?
9.6. Можем ли мы задать ориентированный граф на кубиках так, чтобы искомая
башня задавалась путем по этому графу?
9.7. Можем ли мы представить эту задачу как задачу с невзвешенным графом для BFS?
9.8. Можем ли мы эффективно смоделировать ограничения, используя DAG?
Глава 10
Графовые алгоритмы
Различные варианты представления графов и алгоритмы обхода из главы 9 яв-
являются «кирпичиками» для любого вычисления, основанного на графах. В этой
главе мы рассмотрим более продвинутую теорию графов и более продвинутые ал-
алгоритмы.
Теория графов - это раздел математики, изучающий свойства графов. Благодаря
ему у нас есть язык для описания графов. Многие задачи легко решаются, если
суметь распознать лежащее в их основе понятие теории графов, а затем использо-
использовать классические алгоритмы для решения переформулированной задачи.
Мы начнем с обзора основ теории графов, а затем рассмотрим важные
алгоритмы поиска таких вещей, как минимальные остовные деревья, кратчайшие
пути и максимальные потоки.
10.1. Теория графов
В этом разделе мы кратко рассмотрим основы теории графов. Для более подроб-
подробного изучения можно использовать [PS03, WesOO]. Мы наметим в общих чертах
важные алгоритмы, которые относительно несложно запрограммировать, используя
инструменты, разработанные в предыдущей главе.
10.1.1. Свойства степеней
Графы состоят из вершин и ребер. Простейшим свойством вершины является
ее степень, то есть число инцидентных ей ребер1.
Степени вершин обладают несколькими важными свойствами. Сумма степеней
всех вершин любого неориентированного графа в два раза больше числа его ребер,
так как любое ребро дает вклад в степень каждой из смежных вершин. Следствием
этого является то, что любой граф содержит четное число вершин нечетной степени.
Для ориентированных графов аналогичное утверждение состоит в том, что сумма
1На самом деле степень вершины определяется количеством соединений в ней, иначе при добавлении
к вершине петли степень увеличивалась бы на 1, а не на 2. - Примеч. науч. ред.
242 Глава 10. Графовые алгоритмы
всех степеней по входу равняется сумме всех степеней по исходу. Четность степеней
вершин играет важную роль в обнаружении эйлеровых циклов, что обсуждается в
разделе 10.1.3.
Деревьями называются неориентированные графы, не содержащие циклов.
Степени вершин важны для анализа деревьев. Листом дерева называется вершина
степени 1. Любое дерево, содержащее п вершин, содержит п -1 ребро, так что
любое нетривиальное дерево содержит, как минимум, два листа. Если удалить
лист, то останется одно меньшее, «подстриженное» дерево, вместо двух несоеди-
несоединенных кусков.
Корневым деревом называется ориентированный граф, в котором степень по
входу каждого узла, за исключением корневого, равна 1. Степень по выходу листьев
равна 0. Бинарным деревом называется корневое дерево, степень по выходу каждой
вершины которого равна либо 0, либо 2. Как минимум половина вершин бинарного
дерева должна быть листьями.
Остовным деревом графа G = (V,E) называется подмножество ребер Е а Е
такое, что Е является деревом на К Для любого связного графа остовные деревья
существуют; родительское отношение, получаемое нами при открытии вершин
в процессе поиска в глубину или поиска в ширину, вполне подойдет для создания
одного из них. Остовное дерево минимального веса является весьма важным для
взвешенных графов и более подробно обсуждается в разделе 10.2.
10.1.2. Связность
Граф называется связным, если существует неориентированный путь между
любой парой его вершин. Существование остовного дерева доказывает связность
графа. Алгоритм поиска связных компонентов, основанный на поиске в глубину,
обсуждался в разделе 9.4.2.
Тем не менее нужно знать и о других видах связности. Вершинной (реберной)
связностью называют минимальное число вершин (ребер), которое нужно удалить,
чтобы граф стал несвязным. Наиболее интересным частным случаем является
наличие единственного слабого звена. Единственная вершина, чье удаление ведет
к несвязности графа, называется точкой сочленения; если в графе таких точек нет, то
граф называется двусвязным. Единственное ребро, чье удаление ведет к несвязности
графа, называется перешейком (bridge); если в графе таких ребер нет, то он называ-
называется двусвязным в смысле ребер (edge-biconnected).
Достаточно просто «в лоб» проверить граф на наличие точек сочленения
и перешейков. Для каждой вершины/ребра удаляем ее/его из графа и проверяем,
остался ли граф связным. Не забудьте вернуть на место вершину/ребро перед сле-
следующим удалением!
10.1. Теория графов 243
При работе с ориентированными графами мы нередко сталкиваемся с сильно свя-
связанными компонентами, то есть с такими частями графа, что в каждой существует
ориентированный путь между любой парой вершин. Дорожные сети должны быть
сильно связаны, иначе будут существовать места, куца вы сможете приехать, но не
сможете оттуда вернуться домой, не нарушив знаки одностороннего движения.
Мы можем распознать сильно связанные компоненты в графе, основываясь на
следующей идее. С помощью поиска в глубину несложно найти ориентированный
цикл, так любое ребро возврата и путь к нему в DFS-дереве задает такой цикл. Все
вершины этого цикла должны принадлежать одному и тому же сильно связанному
компоненту. Таким образом, мы можем стянуть (сжать) вершины этого цикла в одну
точку, представляющую компонент, и затем повторить этот процесс. Эта последова-
последовательность сжатий заканчивается тогда, когда не остается ни одного ориентированного
цикла и каждая вершина представляет собой один сильно связанный компонент.
10.1.3. Циклы в графах
Все связанные графы, не являющиеся деревьями, содержат циклы. Особенно
интересными являются циклы, включающие в себя все вершины или ребра графа.
Эйлеровым циклом называется такое путешествие по графу, при котором каждое
ребро посещается ровно один раз. Детская задача об изображении геометрической
фигуры, не отрывая карандаша от бумаги, является примером нахождения эйлерова
цикла (или пути), вершины которого являются пересечениями линий рисунка,
а ребра линиями, которые нужно изобразить. В идеале маршрут почтальона должен
являться эйлеровым циклом, чтобы он мог посетить каждую улицу (ребро) едино-
единожды до того, как вернуться домой. Строго говоря, эйлеровы циклы - это цепи, а не
циклы, так как они могут посещать каждую вершину более одного раза.
Если неориентированный граф является связным и все его вершины имеют
четную степень, то он содержит эйлеров цикл. Почему? Цепь должна заходить
и исходить из каждой вершины на ее пути, из чего следует, что степени всех вершин
должны быть четными. В этой идее содержится также способ нахождения эйлерова
цикла. Мы можем найти простой цикл в графе используя, алгоритм, основанный на
DFS, который обсуждался в разделе 9.4.1. Удалив ребра этого цикла, получим вершины
с четной степенью. После того как мы разбили все ребра на несовместные по ребрам
циклы, мы можем их объединять по общим вершинам, чтобы построить эйлеров цикл.
В случае ориентированных графов важным условием является то, что все
вершины должны иметь степень по выходу равную степени по входу. Удаление
любого цикла сохраняет это свойство, так что в ориентированных графах эйлеровы
циклы можно строить аналогичным способом. Эйлеровой цепью называется такое
путешествие по графу, при котором каждое ребро посещается ровно один раз и которое
может заканчиваться не там, где оно начиналось. При таком определении условие чет-
244 Глава 10. Графовые алгоритмы
ности может быть нарушено ровно для двух вершин, одна из которых должна быть
начальной вершиной, а вторая конечной.
Гамилыпоновым называется цикл, проходящий по каждой вершине графа
ровно один раз. В задаче о коммивояжере требуется на взвешенном графе найти
кратчайшее такое путешествие. Задача на эйлеров цикл в G = (V, Е) может быть
сведена к задаче на гамильтонов граф построением графа G' = (V, Е) такого, что
каждая вершина из V соответствует ребру из Е и Е содержит ребра, соединяющие
все соседние пары ребер из G.
К сожалению, для решения задач на гамильтоновы графы не существует
эффективного алгоритма. Таким образом, при необходимости решения у вас есть
две возможности. Если граф достаточно маленький, то можно использовать поиск
с возвратом. Каждый гамильтонов цикл описывается перестановкой вершин.
Мы возвращаемся, когда не существует ребра, соединяющего последнюю рас-
рассмотренную вершину с непосещенной. Если граф слишком велик для такого под-
подхода, мы должны попробовать переформулировать задачу, возможно, как задачу
на эйлеров цикл на другом графе.
10.1.4. Пленарные графы
Планарным (плоским) называется граф, который можно изобразить на плоскости
так, чтобы никакие два его ребра не пересекались. Планарными являются многие
графы, с которыми мы встречаемся. Любое дерево планарно: можете ли вы объяснить,
как построить изображение заданного дерева без самопересечений? Любая дорожная
сеть, не содержащая бетонных/стальных мостов, должна быть планарной. Структура
смежности выпуклого многогранника также должна являться планарным графом.
Планарные графы обладают- несколькими важными свойствами. Во-первых,
существует тесная взаимосвязь между числом вершин и, ребер т и граней/любого
планарного графа. Теорема Эйлера утверждает, что п-т +/= 2. Дерево содержитп - 1
ребро, так что любое планарное изображение дерева содержит ровно одну грань,
а именно лицевую грань. Любая привязка куба (8 вершин и 12 ребер) должна содер-
содержать 6 граней, это может подтвердить любой человек, игравший в кости.
Для проверки на планарность и нахождения привязки без самопересечений суще-
существуют эффективные алгоритмы, но они все труднореализуемы. Тем не менее теорема
Эйлера позволяет достаточно просто определить, что определенный граф не является
планарным. Любой планарный граф содержит не более 3/7-6 ребер для п > 2.
Из этого ограничения следует, что максимальная степень вершины, которую может
содержать планарный граф, равняется 5 и удаление этой вершины оставляет меньший
планарный граф, обладающий тем же свойством. Проверка того, является ли данный
рисунок планарной привязкой, аналогична проверке того, пересекаются ли отрезки из
заданного набора, что будет обсуждаться при разборе геометрических алгоритмов.
10.2. Минимальные остовные деревья 245
10.2. Минимальные остовные деревья
Остовным деревом графа G- (V,E) называется подмножество ребер из Е, обра-
образующее дерево и соединяющее все вершины из К Для реберно-взвешенных графов
нас особенно интересует остовное дерево минимального веса, то есть остовное
дерево, сумма весов ребер которого минимальна.
Остовные деревья минимального веса решают задачи по соединению множества
точек (представляющих города, перекрестки или что-либо другое) минимальным
количеством дорожного полотна, кабеля или труб. Любое дерево - это связный граф
с минимальным числом ребер, а остовное дерево минимального веса - это связный
граф с минимальным реберным весом.
Двумя основными алгоритмами для вычисления остовного дерева минимального
веса являются алгоритм Крускала (Kruskal) и алгоритм Прима (Prim). Здесь мы рас-
рассмотрим алгоритм Прима, потому что, как нам кажется, его проще запрограммиро-
запрограммировать, а также, потому что из него можно получить алгоритм Дейкстры (Dijkstra)
поиска кратчайшего пути, внеся минимальные изменения.
Сначала нам нужно обобщить графовую структуру данных из главы 9 так,
чтобы она поддерживала реберно-взвешенные графы. Ранее реберная состав-
составляющая содержала только вторую точку заданного ребра. Теперь нам нужно заме-
заменить ее структурой, позволяющей сохранять взвешенные ребра.
typedef struct {
int v; /* смежная вершина */
int weight; /* вес ребра */
} edge;
typedef struct {
edge edges [MAXV+1] [MAXDEGREE] ; /* информация о смежности */
int degree[MAXV+1]; /* степень по выходу каждой
вершины */
int nvertices; /* число вершин графа */
int nedges; /* число ребер графа */
} graph;
Также нам нужно соответствующим образом обновить различные алгоритмы
обхода и инициализации. Это несложное задание.
В алгоритме Прима остовное дерево минимального веса наращивается ступенчато,
начиная с заданной вершины. Жадный алгоритм обеспечивает корректность: мы
всегда добавляем ребро минимального веса, соединяющее вершину, принадлежащую
дереву, и вершину, лежащую вне него.
При простейшей реализации этого алгоритма каждой вершине присваивается
булевская переменная, обозначающая принадлежность этой вершины к дереву
(массив intree в нижеследующем коде), а затем на каждом шаге ищется ребро
с минимальным весом и ровно одной intree-вершиной.
246 Глава 10. Графовые алгоритмы
Наша реализация немного умнее. Для каждой вершины дерева она ищет свое
ребро минимальной стоимости, соединяющее ее с вершиной, еще не принадлежащей
дереву, и добавляет его. После каждой вставки мы должны обновлять минимальные
стоимости для всех вершин. Тем не менее, так как новая вершина - это единственное
изменение в дереве, все возможные изменения в весах происходят за счет исходящих
из нее ребер.
prim(graph *g, int start)
{
inti,j; /* счетчики */
bool intree [MAXV] ; /* принадлежит ли вершина дереву? */
int distance [MAXV] ; /* расстояние вершины от начала */
int v; /* текущая вершина */
intw; /* вершина-кандидат */
int weight; /* вес ребра */
int dist; /* кратчайшая текущая дистанция */
for (i=l; i<=g->nvertices;
intree[i] = FALSE;
distance[i] = MAXINT;
parent[i] = -1;
}
distance[start] = 0;
v = start;
while (intree[v] == FALSE) {
intree[v] = TRUE;
for (i=0; i<g->degree[v];
w = g->edges[v][i].v;
weight = g->edges[v][i].weight;
if ((distance[w] > weight) && (intree[w]==FALSE))
{
distance[w] = weight;
parent[w] = v;
v = 1;
dist = MAXINT;
for (i=2; i<=g->nvertices;
if ((intree[i]==FALSE) && (dist>distance[i])) {
dist = distance[i];
v = i;
10.2. Минимальные остовные деревья 247
Остовное дерево минимальной стоимости или его стоимость можно воспроиз-
воспроизвести двумя различными способами. Проще всего было бы добавить в эту проце-
процедуру выражения для вывода ребер по мере нахождения или суммирования их
весов в специальной переменной для последующего использования. С другой
стороны, так как топология дерева сохраняется в массиве parent, то он, в сумме
с оригинальным графом, выдаст вам все про остовное дерево минимального веса.
Этот алгоритм нахождения минимального остовного дерева обладает несколь-
несколькими интересными свойствами, помогающими решить множество связанных задач.
• Остовное дерево с максимальным весом. Пусть мы наняли зловредную теле-
телефонную компанию соединить группу домов вместе и оплата услуг компании
пропорциональна количеству израсходованного кабеля. Естественно, что они
захотят построить остовное дерево настолько дорогое, насколько это возмож-
возможно. Остовное дерево максимального веса для любого графа можно найти,
просто поменяв знаки весов всех его ребер и запустив после этого алгоритм
Прима. Самое «отрицательное» дерево в «отрицательном» графе является
остовным деревом максимального веса в оригинале.
Большинство графовых алгоритмов совсем не так легко приспосабливается
к отрицательным числам. Более того, алгоритмы поиска кратчайшего пути
плохо работают с отрицательными числами, и они определенно не найдут
путь максимальной длины, если использовать эту методику.
• Остовное дерево с минимальным произведением весов. Пусть мы хотим
построить остовное дерево с минимальным произведением весов ребер. При
этом мы считаем, что все веса положительны. Так как lg(a х Ь) = lg(tf) + lgF),
то минимальное остовное дерево графа, в котором вес каждого ребра заменен
его логарифмом, - это остовное дерево с минимальным произведением весов.
• Наименее критичное остовное дерево. Иногда нам нужно найти остовное
дерево с наименьшим возможным весом самого тяжелого ребра. На самом
деле, остовное дерево минимального веса обладает таким свойством. Это сле-
следует из справедливости алгоритма Крускала.
Такие деревья могут оказаться полезными, если реберный вес задает стоимость,
пропускную способность или мощность. Менее эффективный, но более
простой способ состоит в удалении всех «тяжелых» ребер из графа и проверки
получившегося графа на связность. Проверки такого рода можно проводить,
используя BFS/DFS.
Остовное дерево минимального веса уникально, если все т реберных весов
отличны друг от друга. Если нет, то остовное дерево минимального веса, получаемое
нами, зависит от порядка, в котором алгоритм Прима выбирает один из двух рав-
равнозначных случаев.
248
Глава 10. Графовые алгоритмы
10.3. Кратчайшие пути
Задача нахождения кратчайшего пути в невзвешенном графе обсуждалась
в разделе 9.3.1 - для нее вполне достаточно поиска в ширину. Но BFS не подходит
для поиска кратчайшего пути во взвешенном графе, потому что кратчайший взве-
взвешенный путь между а и Ъ необязательно содержит минимальное число ребер. У всех
нас есть свои маршруты для поездок/прогулок, содержащие больше поворотов, чем
самая простая дорога, но на которые, как по волшебству, тратится меньше времени,
из-за того что мы не попадаем в пробки, не стоим на светофорах и т. д.
В этом разделе мы реализуем два различных алгоритма для поиска кратчайших
путей во взвешенных графах.
10.3.1. Алгоритм Дейкстры (Dijkstra)
Для поиска кратчайшего пути в реберно-взвешенных графах или графах
со взвешенными вершинами предпочтительно использовать алгоритм Дейкстры.
Для заданной вершины s он находит кратчайший путь от s до всех остальных
вершин, включая желаемую вершину t.
Основная идея весьма схожа с алгоритмом Прима. На каждой итерации мы
собираемся добавлять ровно одну вершину к дереву вершин, для которых мы
знаем кратчайший путь до s. Точно так же как и в алгоритме Прима, мы будем
отслеживать для всех вершин лучший путь, известный на данный момент, и добав-
добавлять их в порядке увеличения стоимости.
Разница между алгоритмами Прима и Дейкстры в том, как они оценивают жела-
желательность каждой вершины, не входящей в дерево. В задаче нахождения минималь-
минимального остовного дерева все, что нас интересует, - это вес следующего потенциально-
потенциального ребра дерева. Для нахождения кратчайшего пути нам нужно выбрать вершину,
ближайшую (в смысле наименьшего путевого расстояния) к началу. Получаем
функцию от веса нового ребра и от расстояния от начала смежной вершины дерева.
На самом деле, - это не повлечет практически никаких изменений. Реализация
алгоритма Дейкстры получается из реализации алгоритма Прима изменением
трех строчек, одна из которых это просто название функции!
dijkstra(graph *g, int start) /* БЫЛО prim(g/ start) */
inti,j;
bool in tree [MAXV]
int distance[MAXV]
intv;
intw;
int weight;
/* счетчики */
/* принадлежит ли вершина дереву? */
/* расстояние вершины от начала */
/* текущая вершина */
/* вершина-кандидат */
/* вес ребра */
10.3. Кратчайшие пути 249
intdist; /* кратчайшая текущая дистанция */
for (i=l; i<=g->nvertices;
intree[i] = FALSE;
distance[i] = MAXINT;
parent[i] = -1;
distance[start] = 0;
v = start;
while (intree[v] == FALSE) {
intree[v] = TRUE;
for (i=0; i<g->degree[v];
w = g->edges[v][i].v;
weight = g->edges[v][i].weight;
if ((distance[w] > (distance[v]+weight)) {
/*ИЗМЕНЕНО*/
distance[w] =distance[v]+weight; /*ИЗМЕНЕН0*/
parent[w] = v;
v = 1;
dist = MAXINT;
for (i=2; i<=g->nvertices; i++)
if ((intree[i]==FALSE) && (dist > distance[i])) {
dist = distance[i];
v = i;
Как с помощью di j kstra найти длину кратчайшего пути от start до заданной
вершины t? Она в точности равна значению distanceft]. Как мы можем восстано-
восстановить собственно путь? Следуя указателям parent, начиная с / и до тех пор, пока не
дойдем до start (или до -1, если пути не существует), аналогично тому, как было
в подпрограмме f ind_path () раздела 9.3.3.
В отличие от алгоритма Прима алгоритм Дейкстры работает только на графах
с неотрицательными значениями реберных весов. Причина в том, что иначе мы
можем посреди алгоритма обнаружить настолько отрицательный вес, что он изме-
изменит кратчайший путь от s до какой-то вершины, которая уже находится в дереве.
Более того, наиболее выгодным путем от двери вашего дома до двери соседнего
может стать путь через представительство какого-либо банка, предлагающего
достаточно денег, чтобы поездка окупилась.
250 Глава 10. Графовые алгоритмы
В большинстве прикладных задач отрицательные ребра не возникают, что
делает наши рассуждения чистой теорией. Алгоритм Флойда (Floyd), обсуждаемый
ниже, работает верно для всех графов, не содержащих циклов отрицательной стои-
стоимости, полностью искажающих понятие кратчайшего пути. Если рассмотренный
банк не сделает вознаграждение единовременным, то вы можете получить такую
выгоду, зайдя в представительство бесконечное число раз, что поездка к вашему
месту назначения никогда не окупится!
10.3.2. Кратчайшие пути между всеми парами вершин
Многим приложениям требуется знать длины кратчайших путей между всеми
парами вершин заданного графа. Например, пусть вы хотите найти «центральную»
вершину, сводящую к минимуму наибольшее или среднее расстояние до всех осталь-
остальных вершин. Или пусть вам нужно найти диаметр графа - кратчайший путь между
всеми парами вершин наибольшей длины. Он может соответствовать максимальному
времени, которое требуется письму или сетевому пакету для доставки между двумя
произвольными пунктами.
Мы могли бы решить эту задачу, вызвав алгоритм Дейкстры для каждой из
п возможных начальных вершин. Но алгоритм Флойда для построения кратчай-
кратчайших путей между всеми парами вершин предлагает гораздо более изящный
способ построения матрицы расстояний на основании начальной матрицы весов.
Алгоритм Флойда проще всего реализовать для матрицы смежности, которая
в данном случае не является расточительством, так как нам все равно нужно сохра-
сохранять все п расстояний. Наш тип adj acency_matr ix выделяет место для матрицы
максимально возможного размера.и следит за количеством вершин в графе.
typedef struct {
int weight [MAXV+1] [MAXV+1] ; /* информация о смежно-
смежности/весе */
int nvertices; /* число вершин графа */
} adjacency_matrix;
Для нашей реализации матрицы смежности очень важно определить, как мы
будем обозначать ребра, которых в графе нет. Для невзвешенных графов обычно ис-
используют следующее соглашение: ребра графа обозначаются 1, а отсутствие ребра - 0.
Но тогда для взвешенных графов мы получаем совершенно неверное представление,
так как отсутствие ребра дает бесплатный переход от одной вершины к другой.
Вместо этого для отсутствующего ребра нам нужно использовать значение MAXINT.
Таким образом, мы можем и проверить наличие ребра в графе, и игнорировать отсут-
отсутствующие ребра при поиске кратчайших путей при условии, что диаметр графа
меньше MAXINT.
10.3. Кратчайшие пути 251
initialize_adjacency_matrix(adjacency_matrix *g)
int i, j ; /* счетчики */
g -> nvertices = 0;
for (i=l; i<=MAXV; j++)
for (j=l; j<=MAXV; j++)
g->weight[i][j] = MAXINT;
read_adjacency_matrix(adjacency_matrix *g# bool directed)
int i; /* счетчик */
int m; /* число ребер */
int x,y,w; /* для хранения ребра/веса */
initialize_adjacency_matrix(g);
scanf("%d %d\n",&(g->nvertices),&m);
for (i=l; i<=m; i
scanf("%d %d %d\n",&x,&y/&w);
g->weight[x][y] = w;
if (directed==FALSE) g->weight[y][x] = w;
Все это достаточно просто. Как мы можем найти кратчайшие пути в такой
матрице? Алгоритм Флойда начинает с нумерации вершин от 1 до л, но эти числа
используются для упорядочивания вершин, а не их маркировки.
Алгоритм состоит из п итераций, где на к-й итерации в качестве промежу-
промежуточных шагов при составлении пути между х и у могут использоваться только
к первых вершин. При к = 0 промежуточные вершины использоваться не могут,
так что все возможные кратчайшие пути состоят из начальных ребер графа. Таким
образом, начальная матрица кратчайших путей между всеми парами вершин экви-
эквивалентна начальной матрице смежности. На каждой итерации нам становится
доступно все большее число возможных кратчайших путей. Добавление вершины
к в качестве промежуточной влияет только на те кратчайшие пути, которые прохо-
проходят через к, так что
J9 ЩЩ^1 + W[kJ\k'!).
Справедливость этого утверждения не очевидна, так что мы предлагаем чита-
читателю самостоятельно в ней убедиться. Впрочем, справедливость и изящность реа-
реализации очевидны и без этого.
252 Глава 10. Графовые алгоритмы
floyd(adjacency_matrix *g)
{
inti,j; /* счетчики */
int k; /* счетчик промежуточной вершины */
int through_k; /^расстояние через вершину к */
for (k=l; k<=g->nvertices;
for (i-1; i<=g->nvertices;
for (j=l; j<=g->nvertices;
through_k = g->weight[i][k]+g->weight[k][j];
if (through_k < g->weight[i][j])
g->weight[i][j] = through_k;
Результат работы алгоритма Флойда в его текущей реализации не позволяет
воссоздавать собственно кратчайший путь между любой парой вершин. Если вам
нужен сам путь, используйте алгоритм Дейкстры. Тем не менее стоит отметить,
что большинству задач на все пары вершин требуется именно итоговая матрица
расстояний. Именно для таких задач и был разработан алгоритм Флойда.
Другое важное приложение алгоритма Флойда - это нахождение транзитив-
транзитивного замыкания ориентированного графа. При анализе ориентированного графа
нас часто интересует, какие вершины достижимы из заданного узла.
Например, рассмотрим граф шантажа, определенный на множестве из п людей,
в котором ребро (i,j) существует, если у / имеется достаточно значимая информация,
чтобы заставить j сделать то, что необходимо /. Вы хотите нанять одного из этих
п людей в качестве вашего личного представителя. Кто из них обладает большей вла-
властью в смысле возможностей шантажа?
Простейшим ответом была бы вершина максимальной степени, но на самом
деле лучший представитель - это тот, у кого есть цепочки шантажа к максималь-
максимальному количеству людей. Возможно, Стив может шантажировать только Мигеля,
но если Мигель может шантажировать всех остальных, то Стив - это тот человек,
который вам нужен.
Вершины, достижимые из любого заданного узла, можно найти с помощью
поиска в ширину или в глубину. Но полную картину можно получить при реше-
решении задачи на кратчайшие пути между всеми парами вершин. Если в результате
работы алгоритма Флойда кратчайший путь из / в j остался равным MAXINT, то
можно считать, что ориентированного пути из / в у не существует. Любая вершина,
такая что длина кратчайшего пути до нее меньше MAXINT, должна быть доступна
как в смысле теории графов, так и в смысле шантажа.
10.4. Потоки в сети и паросочетания в двудольных графах 253
10.4. Потоки в сети и паросочетания в двудольных
графах
Любой реберно-взвешенный граф можно рассматривать как сеть труб, причем
вес ребра (i,j) задает пропускную способность трубы. Пропускную способность
можно рассматривать как функцию площади поперечного сечения трубы - широкая
труба может пропустить 10 единиц потока за определенное количество времени,
тогда как труба с меньшей площадью поперечного сечения - всего 5 единиц. Для за-
заданного взвешенного графа G и двух вершин 5и/в задаче потока в сети спрашива-
спрашивается, какой максимальный поток может быть отправлен из s в / с учетом максималь-
максимальной пропускной способности каждой трубы.
Хотя задача потока в сети представляет интерес сама по себе, она важна прежде
всего как средство для решения других важных задач на графы. Паросочетанием
в графе G = (V,E) называется такое подмножество ребер Е с Е, что никакие два
ребра не опираются на одну и ту же вершину. Таким образом, паросочетания строят
такие пары вершин, что каждая вершина принадлежит максимум одной паре.
Граф G называется двудольным, если его вершины можно разделить на два
множества, назовем их L и R, таких, что для любого ребра одна его вершина при-
принадлежит Z, а другая R. Многие естественные графы являются двудольными.
Например, пусть некоторые вершины обозначают работы, которые необходимо
выполнить, а оставшиеся вершины - людей, которые могут их сделать. Существо-
Существование ребра (/, р) обозначает, что человек р может сделать работу у. Или пусть
часть вершин обозначает юношей и часть девушек, а ребра задают совместимые
пары. Естественным толкованием паросочетаний в таких графах будет назначение
на работу или женитьба.
Максимальное паросочетание в двудольном графе можно найти, используя
поток в сети. Создаем исток s, который соединен со всеми вершинами в L ребрами
веса 1. Создаем сток t, который соединен со всеми вершинами в R ребрами веса 1.
Присваиваем каждому ребру двудольного графа G вес 1. Теперь максимальный
поток из s в / определяет максимальное паросочетание в G. Мы всегда можем найти
поток равный паросочетанию, взяв ребра паросочетания и ребра, соединяющие их
со стоком и истоком. Кроме того, большего потока существовать не может. Каким
образом мы сможем пропустить более одной единицы потока через какую-либо
вершину?
Для расчета потока в сети проще всего реализовать алгоритм дополняющего
пути Форда - Фалкерсона (Ford - Fulkerson). Для каждого ребра нам нужно отсле-
отслеживать поток через него, а также остаточную пропускную способность. Тогда мы
должны изменить нашу структуру edge, добавив новые ноля.
254 Глава 10. Графовые алгоритмы
typedef struct {
int v; /* смежная вершина */
int capacity; /* пропускная способность ребра */
int flow; /* поток через ребро */
int residual; /* остаточная пропускная способность
ребра */
} edge;
Мы ищем любой путь от истока до стока, который увеличивает общий поток,
и прибавляем его к сумме. Мы достигнем оптимального потока, когда не будет
существовать ни одного такого дополняющего пути.
netflow(flow_graph *g, int source, int sink)
{
int volume; /* вес дополняющего пути */
add__residual_edges (g) ;
initialize_search(g);
bfs(g,source);
volume = path_volume(g/ source, sink, parent);
while (volume > 0) {
augment_path(g,source,sink,parent,volume);
initialize_search(g);
bfs(g,source);
volume = path_volume(g, source, sink, parent);
Любой дополнительный путь от истока до стока увеличивает поток, так что
мы можем использовать bf s для поиска такого пути в соответствующем графе.
Мы можем идти вдоль тех ребер сети, чья пропускная способность использована
не полностью, или, говоря другими словами, остаточный поток этих ребер должен
быть положительным. На основании этого утверждения bf s будет различать насы-
насыщаемые и ненасыщаемые ребра.
bool valid_edge(edge e)
{
if (e.residual > 0) return (TRUE);
else return (FALSE);
10.4. Потоки в сети и паросочетания в двудольных графах 255
Дополнение пути переносит максимальный возможный поток из остаточной
пропускной способности в положительный поток. Объем, который мы можем
передать, ограничивается ребром пути с наименьшим значением остаточной про-
пропускной способности, так же как и движение по улицам города ограничивается
наиболее загруженной точкой.
int path_volume (f low_graph *g, int start, int end, int parents [])
{
edge *e; /* рассматриваемое ребро */
edge *find_edge();
if (parents[end] == -1) return(O);
e = find_edge(g,parents[end],end);
if (start == parents[end])
return(e->residual);
else
return ( min(path_volume(g,start,parents[end],parents),
e->residual) );
}
edge *find_edge(flow_graph *g, int x, int y)
{
int i; /* счетчик */
for (i=0; i<g->degree[x];
if (g->edges[x][i].v == y)
return( &g->edges[x][i] );
return(NULL);
}
Отправка дополнительной единицы потока по ориентированному ребру (i, j)
уменьшает остаточную пропускную способность ребра (i,j), но увеличивает оста-
остаточную пропускную способность ребра (j, i). Таким образом, при дополнении
пути требуется смотреть и прямые и обратные ребра для каждого звена пути.
augment_path(flow_graph *g, int start, intend, int parents!],
int volume)
{
edge *e; /* рассматриваемое ребро */
edge *find_edge();
if (start == end) return;
e = find_edge(g,parents[end],end);
e->flow += volume;
256 Глава 10. Графовые алгоритмы
e->residual -= volume;
e = find_edge(g,end,parents[end]);
e->residual += volume;
augment_path(g,start,parents[end],parents,volume);
Для инициализации потокового графа требуется создать ориентированные потоко-
потоковые ребра (i, j) и (j, i) для каждого ребра сети е = (i, j). Все начальные потоки считаются
равными 0. Начальный остаточный поток (i,j) выставляется равным пропускной спо-
способности е, а начальный остаточный поток (j, i) выставляется равным 0.
Сетевые потоки - это продвинутая методика программирования, и для того,
чтобы определить, можно ли решить конкретную задачу сетевыми потоками, тре-
требуется некоторый опыт. Мы отправляем читателя к книгам Кука и Канингема
(Cook, Canningham) [CC97] и Ахуджи, Магнати и Орлина (Ahuji, Magnati, Orlin)
[АМО93] для более подробного рассмотрения предмета.
10.5. Задачи
10.5.1. Веснушки
PC/UVaIDs: 111001/10034
Популярность: В
Частота успехов: средняя
Уровень:1
В одной из серий шоу Дика ван Дайка (Dick van Dyke) маленький Ричи соединяет
веснушки на спине своего отца так, чтобы они образовали изображение колокола
Свободы. Увы, одна из веснушек оказалась шрамом, и свидание с Рипли сорвалось.
Рассмотрим спину папы как плоскость с веснушками в различных точках (х,у).
Ваша задача состоит в том, чтобы объяснить маленькому Ричи, как нужно соединить
веснушки, израсходовав наименьшее количество чернил из ручки. Он соединяет две
точки, рисуя прямую линию между ними. Также между двумя линиями Ричи может
отрывать ручку от спины папы. После того как Ричи закончит, любые две веснушки
должны быть соединены последовательностью связанных линий.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное
целое число, означающее количество тестовых блоков. За ней следует пустая
строка.
10.5. Задачи
257
Первая строка тестового блока содержит количество веснушек на спине Дика
(О < п < 100). Далее для каждой веснушки следует строка, содержащая два веще-
вещественных числа, задающих координаты (х, у) веснушки.
Между двумя последовательными тестовыми блоками находится пустая строка.
Выходные данные
Для каждого тестового блока ваша программа должна вывести одно вещест-
вещественное число с точностью до двух десятичных цифр: минимальную суммарную
длину линий, соединяющих все веснушки. Выходные данные для двух последова-
последовательных блоков должны быть разделены пустой строкой.
Пример входных данных
1.0 1.0
2.0 2.0
2.0 4.0
Соответствующие выходные данные
3.41
10.5.2. Ожерелье
PC/UVaIDs: 111002/10054
Популярность: В
Частота успехов: низкая
Уровень:3
У моей маленькой сестры есть красивое ожерелье, сделанное из цветных бусин.
Любые две соседние бусины в ожерелье имеют один и тот же цвет в точке касания,
как показано ниже.
3
5
s.
.Уч.
9-972
258 Глава 10. Графовые алгоритмы
Но, ах! Однажды ожерелье порвалось, и бусины разлетелись по всему полу.
Моя сестра постаралась собрать их все, но она не уверена, что у нее это получи-
получилось. Тогда она попросила меня помочь. Она хочет знать, можно ли собрать
ожерелье по тому же принципу, что и старое, из тех бусин, что у нее есть. И если
можно, то как?
Напишите программу, чтобы ей помочь.
Входные данные
Первая строка входных данных содержит целое число Г, задающее число тес-
тестовых блоков. Первая строка каждого тестового блока содержит целое число
NE <N< 1000), задающее количество бусин, найденных моей сестрой. Каждая
из следующих N строк содержит два целых числа, задающих цвета бусины. Цвета
задаются целыми числами от 1 до 50.
Выходные данные
Для каждого тестового блока выведите его номер, как показано в примере выход-
выходных данных. Если восстановить ожерелье невозможно, выведите строку, содержа-
содержащую " some beads may be lost". В противном случае выведите TV строк, каждая
из которых содержит описание одной бусины. Для любого /A < i<N- 1) второе
число строки / должно совпадать с первым числом строки / + 1. Кроме того, второе
число строки N должно равняться первому числу строки 1. Если возможны несколько
решений, то подойдет любое.
Выходные данные для двух последовательных блоков должны быть разделены
пустой строкой.
Пример входных данных
2
5
1 2
2 3
3 4
4 5
5 б
5
2 1
2 2
3 4
3 1
2 4
10.5. Задачи 259
Соответствующие выходные данные
Case #1
some beads may be lost
Case #2
2 1
1 3
3 4
4 2
2 2
10.5.3. Пожарное депо
РС/UVaIDs: 111003/10278
Популярность: В
Частота успехов: низкая
Уровень:2
Город обслуживается несколькими пожарными депо. От жителей стали поступать
жалобы, что расстояние между некоторыми домами и ближайшим пожарным депо
чересчур велико, так что придется построить новое. Вам нужно выбрать местополо-
местоположение нового депо так, чтобы уменьшить расстояние от домов жалующихся жителей
до ближайшего депо.
В городе не более 500 перекрестков, соединенных отрезками дорог различной
длины. Любой перекресток является пересечением не более 20 отрезков дорог.
Мы полагаем, что и дома и пожарные депо располагаются на перекрестках. Более
того, мы считаем, что на каждом перекрестке есть хотя бы один дом. Также на
одном перекрестке могут находиться несколько пожарных депо.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное целое
число, которое означает количество тестовых блоков. За ней следует пустая строка.
Между двумя последовательными тестовыми блоками также находится пустая строка.
Первая строка каждого тестового блока содержит два положительных целых
числа: количество существующих пожарных депо/(/*< 100) и количество перекрест-
перекрестков / (/ < 500). Перекрестки пронумерованы последовательно от 1 до /. Далее следуют
/строк, каждая из которых содержит номер перекрестка, на котором расположено
пожарное депо. Затем следуют строки, каждая из которых содержит три положитель-
положительных целых числа: номер перекрестка, номер другого перекрестка и длину соеди-
соединяющего их отрезка дороги. Движение по всем отрезкам двустороннее (по крайней
мере, для пожарных машин), между любой парой перекрестков существует маршрут.
260 Глава 10. Графовые алгоритмы
Выходные данные
Для каждого тестового блока выведите наименьший номер перекрестка, на
котором нужно построить пожарное депо так, чтобы свести к минимуму макси-
максимальное расстояние от каждого перекрестка до ближайшего к нему пожарного
депо. Выходные данные для двух последовательных блоков должны быть разделены
пустой строкой.
Пример входных данных Соответствующие выходные данные
1 б
2
1 2 10
2 3 10
3 4 10
4 5 10
5 б 10
6 1 10
10.5.4. Железные дороги
PC/UVaIDs: 111004/10039
Популярность: С
Частота успехов: средняя
Уровень:3
Завтрашним утром Джилл должна поехать из Гамбурга в Дармштадт, чтобы
принять участие в региональной олимпиаде по программированию. Так как она
боится опоздать на олимпиаду, ей нужен поезд, который прибывает в Дармштадт
как можно раньше. Тем не менее она не хочет приходить на станцию слишком
рано, так что если имеется несколько вариантов с одинаковым временем прибы-
прибытия, она предпочтет отправиться как можно позже.
Джилл попросила вас помочь ей. По заданному железнодорожному расписанию
вы должны найти вариант поездки, при котором она приедет раньше всего и при
этом потратит наименьшее количество времени на поездку. К счастью, у Джилл
имеется большой опыт пересадок с одного поезда на другой, поэтому она может
делать это мгновенно, то есть за нулевое время!
Входные данные
Первая строка входных данных задает количество сценариев. Каждый сценарий
состоит из трех частей. Первая часть содержит все города, соединенные между
собой железными дорогами. Она начинается с числа 1 < С < 100, за которым сле-
следуют С строк, содержащие названия городов. Все имена состоят только из букв.
10.5. Задачи 261
Вторая часть описывает все поезда, отправляющиеся в течение дня. Она начина-
начинается с числа Т< 1000, за которым следуют Г описаний поездов. Каждое состоит из
строки, содержащей число ti < 100. За ней следуют еще tt строк, каждая из которых
состоит из времени и названия города. Пассажиры могут сходить с поезда и садить-
садиться на него в это время и в этом городе.
Последняя часть состоит из трех строк: первая содержит самое раннее воз-
возможное время отправления, вторая - город, из которого отправляется Джилл,
а третья - город, в который ей нужно попасть. Начальный город никогда не совпа-
совпадает с местом назначения.
Выходные данные
Для каждого сценария выведите строку, содержащую " S с enar i о /", где / - это
номер сценария, начиная с 1.
Если подходящие пересадки существуют, то выведите, как показано
в примере, две строки, содержащие временные метки без пробелов и названия
городов. Для отступов используйте пробелы. Если подходящих пересадок в этот
день (то есть прибытие до полуночи) не нашлось, выведите строку, содержащую
"No connection".
Выходные данные для двух последовательных сценариев должны быть разде-
разделены пустой строкой.
Пример входных данных
2
3
Hamburg
Frankfurt
Darmstadt
3
2
0949 Hamburg
1006 Frankfurt
2
1325 Hamburg
1550 Darmstadt
2
1205 Frankfurt
1411 Darmstadt
0800
Hamburg
Darmstadt
2
Paris
Tokyo
262 Глава 10. Графовые алгоритмы
1
2
0100 Paris
23 00 Tokyo
0800
Paris
Tokyo
Соответствующие выходные данные
Scenario I
Departure 0949 Hamburg
Arrival 1411 Darmstadt
Scenario 2
No connection
10.5.5. Война
PC/UVaIDs: 111005/10158
Популярность: В
Частота успехов: средняя
Уровень:3
Воюют две страны, Аи В. Как верный гражданин страны С, вы решили помочь
своей стране, секретно посетив мирные переговоры между А и В. На переговорах при-
присутствуют еще п людей, но вы не знаете, кто из какой страны. Вы можете наблюдать за
переговаривающимися людьми и по их поведению определять, друзья они или враги.
Вам необходимо знать про определенные пары людей, из одной они страны
или нет. Во время мирных переговоров ваше правительство может задавать вам
вопросы такого рода, и вам будет нужно отвечать на них на основе ваших
наблюдений.
Если подходить более формально, то у вас есть черный ящик со следующими
операциями:
setFr iends (x, у) - показывает, что х и у из одной страны;
setEnemies (х, у) - показывает, что х иу из разных стран;
areFr iends (x, у) - возвращает истину, если вы уверены в том, что х и у друзья;
ar eEnemi e s (х, у) - возвращает истину, если вы уверены в том, что х и у враги.
Для первых двух операций следует подать сигнал об ошибке, если они проти-
противоречат вашим предыдущим наблюдениям. Отношения «друзья» (обозначим ~)
и «враги» (обозначим *) имеют следующие свойства.
10.5. Задачи 263
— это отношение эквивалентности.
1. Если х -у и у ~ z, то х ~ z. (Друзья моих друзей - мои друзья.)
2. Если х ~ д;, то у ~ jc. (Дружба взаимна.)
3. х ~ х. (Каждый человек сам себе друг.)
* - это симметричное и антирефлексивное отношение.
1. Если х * у, то у * х. (Ненависть взаимна.)
2. Не * * х. (Никто не враг самому себе.)
3. Если х * у и у * z, то х - z. (Общий враг делает людей друзьями.)
4. Если х ~ у и >> * z, то х * z. (Враг друга - твой враг.)
Операции setFriends (x,y) и setEnemies (х,у) должны следовать
этим свойствам.
Входные данные
Первая строка содержит одно целое число п, задающее количество людей.
Каждая последующая строка содержит тройку чисел с х у, где с - это код операции:
с = 1, setFriends,
с = 2, setEnemies,
с = 3, areFriends,
с = 4, areEnemies,
ах и у - ее параметры. Это целые числа в диапазоне [0, и), задающие двух различных
людей. Последняя строка содержит 0 0 0.
Все целые числа во входном файле разделены как минимум одним пробелом
или концом строки. Количество людей не превышает 10 000, но количество опера-
операций не ограничено.
Выходные данные
Для каждой операции areFriends или areEnemies выведите " 0 " (нет) или
" (да). Для каждой операции setFriends или setEneinies, противоречащей
предыдущей информации, выведите «-1»; такая операция не производит никакого
эффекта, и выполнение должно продолжаться. Если setFriends и setEnemies
не противоречат имеющимся данным, выводить ничего не нужно.
Все целые числа в выходном файле должны разделяться одним обрывом строки.
264 Глава 10. Графовые алгоритмы
Пример входных данных
10
10 1
112
2 0 5
3 0 2
3 8 9
4 15
4 12
4 8 9
18 9
15 2
3 5 2
0 0 0
Соответствующие выходные данные
1
о
1
о
о
-1
о
10.5.6. Экскурсовод
PC/UVaIDs: 111006/10199
Популярность: В
Частота успехов: средняя
Уровень: 1
Рио-де-Жанейро очень красивый город, но там столько мест, куда можно по-
поехать, что временами вы просто теряетесь. К счастью, ваш друг Бруно пообещал
быть вашим экскурсоводом.
К сожалению, Бруно отвратительно водит машину. Ему уже нужно оплатить
много штрафов, и он вовсе не хочет получить еще один. Поэтому он хочет знать, где
расположены все полицейские камеры наблюдения, чтобы вести машину аккуратнее,
проезжая мимо них. Из стратегических соображений камеры расположены в таких
местах, мимо которых водитель обязан проехать, если он хочет попасть из одной
части города в другую. Таким образом, в точке С будет расположена камера в том
и только в том случае, если существуют две точки в городе, А и В, такие, что все пути
из А в В проходят через С.
10.5. Задачи 265
К примеру, пусть у нас есть шесть точек (А, В, С, Д Е и F) и семь двунаправ-
двунаправленных маршрутов :B-C,A-B,C-A,D-C,D-E,E-FhF-C. Тогда в С должна
быть камера, потому что из А в Е можно попасть только через С. При таком усло-
условии камера будет только в точке С.
Чтобы помочь Бруно, напишите программу, которая для заданной карты
города определяет, где расположены все камеры.
Входные данные
Входные данные состоят из произвольного числа карт города. Каждая карта
города начинается с целого числа N B < N < 100), задающего общее число частей
города. За этим числом следуют N строк, каждая из которых содержит название
одной из частей города. Все названия отличны друг от друга и состоят минимум
из одной и максимум из 30 букв нижнего регистра. Затем идет неотрицательное
число /?, обозначающее число маршрутов. За ним следуют R строк, описывающие
двунаправленные маршруты. Каждый маршрут задается названиями двух частей
города, которые он соединяет.
Названия частей всегда задаются корректно. Маршрутов, ведущих из определен-
определенной части города в эту же часть, не будет. Вы должны считывать входные данные до
карты города с N = 0. Ее обрабатывать не нужно.
Выходные данные
Для каждой карты города вы должны вывести следующую строку:
City map #d: с camera (s) found,
где d обозначает номер карты (начиная с 1), а с равняется числу обнаруженных
камер. Затем вы должны вывести с строк с названиями частей города, в которых рас-
расположены камеры. Названия частей должны идти в алфавитном порядке. Выходные
данные для двух последовательных карт должны быть разделены пустой строкой.
Пример входных данных
б
sugarloaf
maracana
copacabana
ipanema
corcovado
lapa
7
ipanema copacabana
266 Глава 10. Графовые алгоритмы
copacabana sugarloaf
ipanema sugarloaf
maracana lapa
sugarloaf maracana
corcovado sugarloaf
lapa corcovado
5
guanabarabay
downtown
botanicgarden
Colombo
sambodromo
4
guanabarabay sambodromo
downtown sambodromo
sambodromo botanicgarden
Colombo sambodromo
0
Соответствующие выходные данные
City map #1: 1 camera(s) found
sugarloaf
City map #2: 1 camera(s) found
sambodromo
10.5.7. Большой обед
PC/UVaIDs: 111007/10249
Популярность: С
Частота успехов: высокая
Уровень:4
Все команды, участвовавшие в ACM World Finals, приглашаются на большой
банкет, который устраивается после церемонии награждения. Чтобы члены
разных команд общались как можно больше, за одним столом не разрешается
сидеть двум членам одной и той же команды.
Определите по заданному числу членов каждой команды (включая участников,
тренеров, запасных и гостей) и числу мест за каждым столом, можно ли рассадить
команды так, как описано выше. Если это возможно, то выведите один из возмож-
возможных вариантов рассадки. Если существует несколько вариантов решения, то подой-
подойдет любой.
10.5. Задачи 267
Входные данные
Входной файл может состоять из нескольких тестовых блоков. Первая строка каж-
каждого тестового блока содержит два целых числа, 1 <М< 70 и 1 <7V< 50, задающих
число команд и столов соответственно. Вторая строка каждого тестового блока
содержит М чисел; /-е число mt показывает количество членов команды номер L Число
членов любой команды не превышает 100 человек. Третья строка содержит N чисел,
причему'-е число Пр 2 < л,- < 100, означает число мест зау-м столом.
Входные данные заканчиваются тестовым блоком, содержащим нули в каче-
качестве MwN.
Выходные данные
Для каждого тестового блока выведите строку, содержащую 1 или 0, указы-
указывающую на то, существует ли корректная рассадка членов команд. В случае поло-
положительного ответа выведите еще М строк, /-я из которых содержит номера столов
(от 1 до N) для членов команды номер /.
Пример входных данных Соответствующие выходные данные
4 5 1
4535 1245
35264 12345
4 5 2 4 5
4535 12345
3 5 2 6 3 0
0 0
10.5.8. Задача про постановщика задач
PC/UVaIDs: 111008/10092
Популярность: С
Частота успехов: средняя
Уровень:3
В этом году так много студентов решили принять участие в региональных этапах
олимпиад по программированию, что мы решили составить отбраковочные тесты, для
того чтобы выявить наиболее многообещающих студентов. В этот тест могут входить
до 100 задач из 20 категорий. Мне предложили набрать задачи для этого теста.
Поначалу работа казалась легкой, так как мне сказали, что дадут набор при-
примерно из 1000 задач, поделенный на соответствующие категории. После того как
я получил задачи, оказалось, что их авторы нередко относили одну задачу к не-
нескольким категориям. Так как ни одну из задач нельзя использовать в тесте более
одного раза и число задач каждой категории установлено заранее, то выбрать
задачи для теста - не такая уж и легкая работа.
268 Глава 10. Графовые алгоритмы
Входные данные
Входной файл может содержать несколько тестовых блоков, каждый из которых
начинается со строки, содержащей два целых числа, пк и пр, где пк - это количество
категорий, а пр - число задач в данном наборе. Число категорий лежит в диапазоне
от 2 до 20, а число задач в наборе не превышает 1000.
Вторая строка содержит п^ положительных целых чисел, причем /-е число
задает количество задач, которые должны быть отнесены к категории / A <i< rijj.
Вы можете считать, что сумма этих чисел не превышает ЮО.у'-я из следующих пр
строк содержит информацию о категорияху-й задачи набора. Каждое такое описа-
описание категорий задачи начинается с положительного целого числа, задающего
количество категорий, к которым может быть отнесена задача. За этим числом
следуют сами номера категорий.
Входные данные завершаются тестовым блоком, который содержит нули
в качестве п^ и пр.
Выходные данные
Для каждого тестового блока выведите строку, сообщающую, можно ли на-
набрать задачи из набора, следуя заданным ограничениям. Для положительного
ответа используйте 1, для отрицательного - 0.
Если задачи набрать можно, выведите еще пк строк так, чтобы /-я строка
содержала номера задач, которые могут быть включены в категорию /. Номера
задач должны быть положительными целыми числами, не превышающими пр,
и два последовательных номера должны быть разделены одним пробелом. Подой-
Подойдет любая правильная выборка задач.
Пример входных данных
3 15
3 3 4
2 12
1 3
1 3
1 3
1 3
3 12 3
2 2 3
2 13
1 2
1 2
2 12
2 13
2 12
10.6. Подсказки 269
1 l
3 12 3
3 15
7 3 4
2 12
1 1
1 2
1 2
1 3
3 12 3 2 2 3
2 2 3
1 2
1 2
2 2 3
2 2 3
2 12
1 1
3 12 3
О О
Соответствующие выходные данные
1
8 11 12
16 7
2 3 4 5
О
10.6. Подсказки
10.1. Какую задачу из этой главы пытается решить Ричи?
10.2. Можно ли свести эту задачу к задаче на эйлеров или гамильтонов цикл?
10.3. Как нам может помочь информация о кратчайшем пути?
10.4. Как мы можем свести эту задачу к задаче на кратчайший путь? Что мы
должны взять в качестве начального узла нашего графа? Как из двух одина-
одинаковых по времени прибытия маршрутов выбрать нужный?
10.5. Можем ли мы расширить некоторые следствия наших наблюдений через
транзитивное замыкание?
10.6. С каким понятием теории графов связано расположение камер?
10.7. Подойдет ли нам жадный алгоритм, или нам нужно использовать что-то вроде
потока в сети?
10.8. Можем ли мы свести эту задачу к задаче на поток в сети? Может быть, есть
более простой подход?
Глава 11
Динамическое программирование
Как разработчикам алгоритмов и программистам нам нередко требуется напи-
написать программу, которая находит лучшее решение. Обычно несложно написать про-
программу, которая найдет подходящее решение, но, чтобы программа всегда возвра-
возвращала самое лучшее решение, вам нужно глубоко понимать задачу.
Динамическое программирование - это очень мощный и широко распространен-
распространенный инструмент для решения задач по оптимизации структур, упорядоченных слева
направо, таких как символьные строки. Он несложно реализуется, если в нем разо-
разобраться, но для многих это тяжело.
Чтобы динамическое программирование не казалось шаманством нужно рас-
рассмотреть достаточное количество примеров. Начать можно с функции вычисления
биномиальных коэффициентов, рассмотренной в главе 6. Обратите внимание на то,
что мы сохраняем промежуточные результаты, чтобы потом нам было легче считать.
Затем имеет смысл рассмотреть алгоритм Флойда для вычисления кратчайших путей
между всеми парами вершин из раздела 10.3.2. И только потом вам следует перехо-
переходить к рассмотрению двух задач, описанных ниже. Первая - это классический
пример динамического программирования, который можно найти в любом учебнике.
Вторая демонстрирует более специфическое применение динамического програм-
программирования - разработку алгоритмов.
11.1. Не нужно жадничать
Во многих задачах требуется найти лучшее решение при заданных ограничениях.
Мы уже сталкивались с подобным. Например, в задачах на перебор с возвратом главы
8 часто требуется найти наибольшую, наименьшую или наиболее выигрышную кон-
конфигурацию. При переборе с возвратом перебираются все возможные решения и из
них выбирается наилучшее, поэтому итоговое решение должно быть правильным. Но
такой подход возможен лишь для задач небольшого размера.
Для многих важных задач на графы известны корректные и эффективные реше-
решения. К таким задачам относятся: поиск кратчайшего пути, минимальные остовные
деревья и паросочетания, рассмотренные в главе 10. В каждом конкретном случае
11.2. Стоимость редактирования 271
нужно смотреть, нельзя ли свести задачу к одной из перечисленных, чтобы восполь-
воспользоваться уже готовым решением.
Алгоритм называется жадным, если в каждой точке принятия решения он
выбирает наилучший локальный вариант. Например, естественно было бы
пытаться найти кратчайший путь из х в у, выйдя из х и в каждой точке ветвления
выбирая ребро минимальной стоимости. Естественно, но неверно! Более того,
если корректность жадного алгоритма не доказана, то с большой вероятностью он
приведет к неверному результату.
Как же быть? Динамическое программирование дает нам возможность разрабаты-
разрабатывать собственные алгоритмы, систематически перебирающие все возможные варианты
(что обеспечивает правомерность), но сохраняющие при этом промежуточные резуль-
результаты, чтобы избежать повторения одних и тех же вычислений (что обеспечивает
эффективность).
Алгоритмы динамического программирования определяются рекурсивными
алгоритмами/функциями, решающими целую проблему через решения более
мелких проблем. Примеры таких рекурсивных процедур - это перебор с возвратом
и поиск в глубину в графах.
Чтобы обеспечить эффективность такого алгоритма, нам требуется сохранять
достаточно информации, позволяющей избежать повторения уже сделанных
вычислений. Почему поиск в глубину эффективен? Потому что мы маркируем
найденные вершины, чтобы не посещать их снова. Почему грубый перебор с воз-
возвратом требует больших вычислительных мощностей? Потому что он перебирает
все возможные пути/решения, вместо того чтобы рассматривать только те вариан-
варианты, которые мы не видели раньше.
Динамическое программирование - это методика эффективной реализации
рекурсивных алгоритмов через сохранение промежуточных результатов. Хитрость
в том, чтобы понять, что простой рекурсивный алгоритм рассчитывает одни и те же
подзадачи снова, снова и снова. Но если так, то, чтобы повысить эффективность
алгоритма, мы можем сохранять полученные результаты в таблице, а не считать все
заново. Чтобы понять примеры, которые приведены ниже, лучше всего найти какой-
нибудь рекурсивный алгоритм. Только после того как у вас есть правильно рабо-
работающий алгоритм, имеет смысл пытаться его ускорить через матрицу решений.
11.2. Стоимость редактирования
Задача нахождения шаблонов в строках текста имеет очень большое значение,
и в главе 3 мы рассматривали соответствующие алгоритмы. Но там мы ограничи-
ограничились исследованием точного совпадения строк, то есть поиском позиций, где
шаблонная строка s в точности содержится в тестовой строке Л На практике все
часто совсем не так просто. Возможность ошибок при написании теста или
272 Глава 11. Динамическое программирование
шаблона лишает нас возможности проверки на идентичность. Эволюционные из-
изменения геномных последовательностей или структур языка приводят к тому, что
мы часто ищем устаревшие шаблоны: «Thou shalt not kill» преобразуется в «You
should not murder».
Если нам предстоит работать с неточным совпадением, то первым делом нам
нужно задать функцию стоимости, определяющую, насколько различаются две
строки. При измерении расстояния сводится к минимуму стоимость изменений,
которые необходимо сделать, чтобы преобразовать одну строку к другой. Сущест-
Существует три естественных типа изменений.
• Замещение. Замена одного символа шаблона s на отличный от него символ
текста t, к примеру, переход от «shot» к «spot».
• Вставка. Вставка одного символа в шаблон s так, чтобы он совпал с текстом,
к примеру, переход от «ago» к «agog».
• Удаление. Удаление одного символа из шаблона s так, чтобы он совпадал
с текстом /, к примеру, переход от «hour» к «our».
Чтобы мы могли говорить об идентичности строк, мы должны задать стои-
стоимость каждой операции преобразования строк. Если считать стоимость каждой
операции равной единице, мы опишем стоимость редактирования (edit distance)
между двумя строками. Как будет показано в разделе 11.4, другие варианты стои-
стоимости также могут привести к интересным результатам.
Но как мы можем найти стоимость редактирования? Мы можем разработать
рекурсивный алгоритм на основании того наблюдения, что последний символ
строки при последней операции редактирования должен быть либо вставлен, либо
заменен, либо удален. Отбрасывая символы, использованные в последней операции,
мы приходим к паре меньших строк. Пусть / и у - это последние символы значащих
префиксов s и t соответственно. После последней операции могут получиться три
пары меньших строк, соответствующие замене, вставке и удалению. Если бы мы
знали стоимость редактирования трех пар меньших строк, мы могли бы выбрать
вариант, ведущий к решению наименьшей стоимости. Мы можем найти их стоимо-
стоимости, используя волшебство рекурсии:
#define MATCH 0 /* обозначение перечислимого типа
для совпадения */
#define INSERT I /* обозначение перечислимого типа
для вставки */
#define DELETE 2 /* обозначение перечислимого типа
для удаления */
int string_compare(char *s, char *t, int i, int j)
{
int k; /* счетчик */
11.2. Стоимость редактирования 273
int opt[3]; /* стоимость трех вариантов */
int lowest__cost; /* минимальная стоимость */
if (i == 0) return(j * indel(' '));
if (j == 0) return(i * indel(' '));
opt[MATCH] = string_compare(s,t,i-1,j-1) + match (s[i],t [j] ) ;
opt[INSERT] = string_compare(s/t,i,j-1) + indel(t[j]);
opt[DELETE] = string_compare(s,t,i-1,j) + indel(s[i]);
lowest_cost = opt[MATCH];
for (k=INSERT; k<=DELETE; k++)
if (opt[k] < lowest_cost) lowest_cost = opt[k];
return( lowest_cost );
}
Программа работает абсолютно верно - убедитесь сами. Кроме того, она рабо-
работает невообразимо медленно. При проверке на нашем компьютере ей потребова-
потребовалось несколько секунд, чтобы сравнить две строки по И символов каждая. При
попытке сравнить строки большей длины ждать можно бесконечно.
Почему же алгоритм работает так медленно? Ему требуется экспоненциальное
время, потому что он вычисляет одни и те же величины снова, снова и снова.
На каждом символе строки рекурсия разделяется на три ветви, что значит, что скорость
разрастания, по меньшей мере, Зп. На самом деле, скорость еще больше, так как боль-
большинство вызовов уменьшает только один из двух индексов, а не оба одновременно.
Как нам сделать этот алгоритм пригодным для практического использования?
Важно заметить, что большинство рекурсивных вызовов заново считают то, что уже
было вычислено ранее. Откуда это можно понять? Число возможных уникальных
рекурсивных вызовов - |s| x \t\, так как именно столько различных пар (i, j) могут
передаваться в качестве параметров вызова. Сохранив в таблице значения для каждой
такой пары, мы сможем избежать повторного вычисления уже известных величин.
Ниже приводится реализация этого алгоритма на основе динамического про-
программирования (с использованием таблиц). Таблица реализуется двумерной
матрицей т, в которой каждая из \s\ x |/| ячеек содержит стоимость соответст-
соответствующей подоперации и указатель на родительский элемент, с помощью которого
можно понять, как мы пришли к этой ячейке.
typedef struct {
int cost; /* стоимость достижения этого
элемента */
int parent; /* родительский элемент */
} cell;
cell m[MAXLEN+l][MAXLEN+1]; /* таблица динамического
программирования */
274 Глава 11. Динамическое программирование
Между версией, основанной на динамическом программировании, и версией,
основанной на рекурсии, существуют три отличия. Во-первых, промежуточные
значения получаются через обращение к таблице, а не через рекурсивные вызовы.
Во-вторых, поле parent обновляется для каждой ячейки, что позволит нам
позже восстановить последовательность редактирования. В-третьих, благодаря
функции goal_cell() мы можем сделать больше, чем просто вывести
m[|s|][|t|].cost. Это позволит нам применять подпрограмму для более
широкого класса задач.
Обратите внимание, что в дальнейших подпрограммах мы придерживаемся
определенных нестандартных соглашений по строкам и индексам. В частности,
мы полагаем, что каждая строка начинается с дополнительного пробела, так что
первый значимый символ строки s находится в s [ 1 ]. Это было реализовано так:
s[0] = t[0] = ' ¦;
scanf ("%s";Sc(s[l] ) ) ;
scanf (ll%s",&(t [1] ) ) ;
Зачем мы это сделали? Так мы сможем использовать одинаковые индексы
и для строк, и для матрицы т. Не забывайте, что в крайнем ряду и крайней строке
матрицы т мы должны хранить граничные значения, соответствующие пустому
префиксу. С другой стороны, мы могли не трогать входные строки, а просто соот-
соответствующим образом подправить индексы.
int string_compare(char *s, char *t)
{
int i,j,k; /*счетчики */
int opt[3]; * /^стоимости трех вариантов */
for (i=0; i<MAXLEN;
row_init(i);
column_init(i);
}
for (i=l; i<strlen(s);
for (j=l; j<strlen(t); j) {
opt [MATCH] =m[i-l] [j-1] .cost + match(s[i] , t[j] )
opt[INSERT] = m[i][j-1].cost + indel(t[j]);
opt[DELETE] = m[i-l] [j] .cost + indel(s[i]);
m[i] [j] .cost = opt[MATCH];
m[i][j].parent = MATCH;
for (k=INSERT; k<=DELETE; k++)
if (opt[k] < m[i][j].cost) {
m[i][j].cost = opt[k];
m[i] [j] .parent = k;
11.3. Восстановление пути 275
goal_cell(s,t,&i,&j);
return( m[i][j].cost );
}
Обратите внимание на порядок, в котором заполняются элементы матрицы.
Чтобы определить значение элемента (ij), нам требуется знать значения трех эле-
элементов, а именно G-1,у-1), (/,/-1) и (i-\J). В принципе подойдет любой порядок
заполнения, обладающий этим свойством, например использованный нами поря-
порядок заполнения по строкам.
Ниже приводится пример работы программы, в котором за пять шагов «thou
shalt not» преобразуется в «you should not» (показаны значения стоимости и роди-
родительские элементы).
you- should- not you-shoul d-not
: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 : -111111111111111
t: 11 23456789 10 11 12 13 13 t: 200000000000000
h: 2 2234556789 10 11 12 13 h: 200000011111111
o: 3 32345656789 10 11 12 o: 200000001111101
u: 4432345656789 10 11 u: 20 2011110111111
-: 55432345667789 10 -: 202201111000111
s: 66543234567889 10 s: 202220111100000
h: 77654323456789 10 h: 202222011111100
a: 8 87654334567 89 10 a: 202222200000000
I: 998765444456789 I: 202222200011111
t: 10 10 9876555556 78 8 t: 202222200000000
-: 11 11 10 98766666567 8 -: 202202200000111
n: 12 12 11 10 98777776 56 7 n: 202222200002011
o: 13 13 12 1110 9878887 65 6 o: 200222200002201
t: 14 14 13 12 1110 988998 76 5 t: 202222220002220
11.3. Восстановление пути
Реализация на основе динамического программирования, приведенная выше,
возвращает стоимость оптимального решения, но не само решение. Замечательно,
когда ты знаешь, что от «thou shalt not» к «you should not» можно перейти за пять
шагов, но как именно выглядят эти шаги?
276 Глава 11. Динамическое программирование
Возможные решения данной задачи на динамическое программирование опи-
описываются путями через матрицу динамического программирования. Путь начина-
начинается исходной конфигурацией (пара пустых строк @,0)) и заканчивается итоговым
конечным состоянием (пара полных строк (И,|ф). Ключ к построению решения
лежит в восстановлении операций, использованных на каждом шаге пути, привед-
приведшего к оптимальному решению. Эти операции сохранялись в поле parent каж-
каждого элемента массива.
Восстановление проводится на основании указателя parent. Мы начинаем
с итогового элемента и идем назад, пока не дойдем до начальной конфигурации.
Поле parent элемента m [ i, j ] позволяет нам узнать тип преобразования для (i,j)
- MATCH, INSERT или DELETE. Последовательность преобразований перехода от
«thou shalt not» к «you should not»: DSMMMMMISMSMMMM, то есть мы удаляем первую
«t», заменяем «h» на «у», следующие пять символов совпадают, поэтому мы их не
трогаем, затем мы вставляем «о», заменяем «а» на «и» и заменяем «t» на «d».
Если начинать с итогового элемента, то последовательность операций будет
восстановлена в обратном порядке. Правда, умное использование рекурсии может
сделать все за нас.
reconstruct_j?ath(char *s, char *t, int i, int j)
{
if (m[i][j].parent == -1) return;
if (m[i][j].parent == MATCH) {
reconstruct_path(s,t,i-1,j-1);
match_out(s, t, i, j);
return;
}
if (m[i][j].parent == INSERT) {
reconstruct_path(s,t,i,j-1);
insert_out(t, j );
return;
}
if (m[i][j].parent == DELETE) {
reconstruct_path(s,t,i-1,j);
delete_out(s,i);
return;
Во многих задачах, включая поиск стоимости редактирования, переход можно
восстановить без явного использования массива последних преобразований.
Можно просто идти назад и смотреть, какое из преобразований могло привести
к текущему элементу так, чтобы в итоге получилась заданная стоимость.
11.4. Варианты стоимости редактирования 277
11.4. Варианты стоимости редактирования
В процедурах оптимизации и восстановления пути использовались некоторые
функции, которые мы пока не определили. Их можно разбить по четырем категориям.
• Инициализация таблиц. Функции row_init () и column_init () инициа-
инициализируют нулевую строку и столбец таблицы динамического программирова-
программирования соответственно. В задаче о расстоянии редактирования ячейки (i, 0) и @, i)
соответствуют сравнению строк длины / со строками нулевой длины. Для
преобразования требуется ровно / вставок/удалений, так что определение этих
функций очевидно.
row_init(int i) column_init(int i)
{ {
m[0][i].cost = i; m[i][0].cost = i;
if (i > 0) if (i > 0)
m [ 0 ] [ i ] . parent = INSERT; m [ i ] [ 0 ] . parent. = DELETE ;
else else
m[0][i].parent = -1; m[i][0].parent = -1;
Расчет стоимости. Функции match(с,d) и indel (с) определяют стои-
стоимость для преобразования символа с в символ d и для вставки/удаления сим-
символа с. Для простейшего варианта стоимость редактирования match должна
возвращать 0, если символы идентичны, и 1 иначе, тогда как indel должна
возвращать 1 вне зависимости от аргумента. Но, безусловно, можно использо-
использовать и более точные функции стоимости, которые, например, будут более мяг-
мягко относиться к заменам, расположенным рядом для стандартных раскладок
клавиатуры, или к таким, которые звучат или выглядят похоже.
int match (char с, char d) int indel (char c)
{ {
if (c == d) return(O); return(l);
else return(l); }
Обнаружение конечной ячейки. Функция goal__cell возвращает индексы
ячейки, задающей конечную точку решения. Для стоимости редактирования
она определяется исходя из длины двух входных строк. Тем не менее другие
приложения, как мы увидим ниже, могут не иметь строго определенной
конечной точки.
278 Глава 11. Динамическое программирование
goal_cell(char *s, char *t, int *i, int *j)
{
*i = strlen(s) - 1;
*j = strlen(t) - 1;
}
Возвращение назад. Функции match_out, insert__out и delete__out
отвечают за определенные действия для каждой операции редактирования
при восстановлении пути. Для алгоритма стоимости редактирования такими
действиями могут быть (в зависимости от требований к приложению) выведе-
выведение совершенной на этом шаге операции редактирования или символа, задей-
задействованного на этом шаге.
insert_out(char*t, intj ) match_out(char *s, char*t, inti, int j)
{ {
printf ("I") ; if (s[i]==t[j]) printf("M");
} else printf("S");
}
delete_out (char *s, inti)
{
printf("D");
Для нашего случая вычисления стоимости редактирования все эти функции дос-
достаточно просты. Тем не менее мы должны признать, что корректная работа
с граничными условиями и индексами ячеек весьма сложна. Хотя алгоритмы дина-
динамического программирования достаточно просто разрабатываются, как только вы
поняли методику, понимание всех тонкостей требует аккуратных расчетов и полной
проверки.
Как видно, для такой простой программы приходится разрабатывать достаточно
сложную инфраструктуру. Тем не менее, внеся минимальные изменения в те функ-
функции, которые мы получили, можно решить несколько важных задач.
• Совпадение подстрок. Предположим, мы хотим найти позицию, где короткая
строка s лучше всего совпадает с длинным текстом t. Скажем, мы ищем слово
«Skiena» с учетом всех его неправильных написаний (Skienna, Skena, Skina и т. д.).
Такой поиск с помощью наших обычных функций будет обладать малой чувстви-
чувствительностью, так как в каждой стоимости редактирования решающую роль будет
играть стоимость удаления основной части текста.
Нам нужен такой вариант поиска расстояния редактирования, в котором стоимость
совпадения не зависит от того, где это совпадение начинается, так чтобы совпаде-
совпадение в центре текста ничем не отличалось от совпадения в начале. Аналогично
11.4. Варианты стоимости редактирования 279
конечным состоянием не обязательно является конец обеих строк, это просто
самое дешевое место, в котором достигается совпадение подстроки. Изменив две
соответствующие функции, получим подходящее решение.
row_init(int i)
{
m[0][i].cost = 0; /^изменение*/
m[0][i].parent = -1; /^изменение*/
}
goal_cell(char *s, char *t, int *i, int *j)
{
int k; /*счетчик*/
*i = strlen(s) - 1;
*j = 0;
for (k=l; k<strlen(t); k++)
if (m[*i][k].cost < m[*i][*j].cost) *j = k;
}
• Наибольшая общая подпоследовательность. Часто нам нужно найти наиболь-
наибольшую разрозненную строку символов, которая включается в каждое из двух
слов. Наибольшая общая подпоследовательность (НОП) для слов «democrat»
и «republican» - это еса.
Обычная подпоследовательность задается всеми совпадениями символов по
прямой редактирования. Чтобы число таких совпадений было максимальным,
мы должны отказаться от замены несовпадающих символов. Это достигается
путем изменения функции расчета стоимости для совпадения:
int match(char с, char d)
{
if (с == d) return(O);
else return(MAXLEN);
}
На самом деле, вполне достаточно сделать стоимость замены большей, чем
суммарная стоимость удаления и вставки, чтобы замена потеряла всякий
смысл как операция редактирования.
• Наибольшая монотонная подпоследовательность. Числовая последовательность
называется монотонно возрастающей, если /-й элемент, не меньше (i-l)-ro.
В задаче о наибольшей монотонной подпоследовательности требуется удалить
минимальное число символов из входной строки S так, чтобы оставшаяся строка
представляла собой монотонно возрастающую подпоследовательность.
К примеру, наибольшая возрастающая подпоследовательность для «243517698»
это «23568».
280 Глава 11. Динамическое программирование
Фактически эта задача сводится к задаче о наибольшей общей подпоследо-
подпоследовательности, если составить вторую строку из элементов S, отсортирован-
отсортированных в порядке возрастания. Любая общая подпоследовательность этих двух
строк будет A) представлять символы в таком порядке, в каком они идут
в S, и B) использовать только символы, идущие в порядке возрастания
в упорядоченной строке, значит, нам нужна просто самая длинная такая
подпоследовательность. Конечно, такой подход можно легко модифи-
модифицировать для случая убывающей подпоследовательности, просто изменив
направление сортировки.
Как вы могли заметить, наша простая функция для расстояния редактирования
легко позволяет проделывать множество удивительных вещей. Трудность лишь в том,
чтобы заметить, что ваша задача - это частный случай неточного совпадения строк.
11.5. Пример разработки программы:
оптимизация лифта
Я работаю в очень высоком здании с очень медленным лифтом. Особенно меня
раздражает, когда люди нажимают кнопки нескольких соседних этажей (скажем, 13,
14 и 15-го), а я еду с нижнего этажа на верхний. Моя поездка наверх прерывается
трижды, по разу на каждом из этажей. Было бы гораздо вежливее со стороны этих
людей, если бы они нажали только 14-й, а люди с 13-го и 15-го этажей прошли бы по
одному этажу пешком. В любом случае кто-то из них мог бы пройтись.
Ваша задача состоит в написании программы оптимизации лифта. Желаемый
этаж каждого из пассажиров задается в начале поездки. Далее лифт должен решить,
на каких этажах он будет останавливаться. Число остановок лифта не должно пре-
превышать &, при этом этажи нужно выбрать так, чтобы свести к минимуму полное
число этажей, которое нужно пройти людям вверх или вниз. Можно считать, что
лифт знает, сколько человек выходит на каждом этаже.
Мы полагаем, что стоимость подъема на один лестничный пролет равняется
стоимости спуска; не забывайте, что у этих людей есть возможность поупражнять-
поупражняться. Если однозначного решения не существует, руководство предлагает отдавать
предпочтение тем случаям, когда лифт останавливается на минимально возможном
этаже, так как на это требуется меньше электричества. Обратите внимание, что лифт
вовсе не обязан останавливаться на этажах, указанных пассажирами. Если пасса-
пассажиры указали 27 и 29 этажи, то лифт вместо этого может остановиться на 28.
11.5. Пример разработки программы: оптимизация лифта 281
Решение начинается ниже
Это пример обычной задачи на программирование/алгоритмы, которая пре-
прекрасно решается с помощью динамического программирования. Как мы до этого
додумались и что делать дальше?
Вспомните, что алгоритмы динамического программирования основываются
на рекурсивных алгоритмах. Решение о том, где лучшего всего сделать к-ю оста-
остановку, зависит от стоимости всех возможных решений для к-\ остановки. Если
вы сможете сказать мне стоимость лучшего из частных решений, то я смогу при-
принять верное решение насчет последней остановки.
Эффективные алгоритмы динамического программирования нередко требуют
упорядоченных входных данных. Нам важен тот факт, что требования пассажиров
можно упорядочить от наименьшего этажа к наибольшему. К примеру, пусть лифт
сначала остановился на этаже/у, а затем на этаже У}. Вторая остановка может не
иметь никакого значения для пассажира, который хочет попасть на этаж/у или ниже.
Это значит, что задачу можно разбить на части. Если мне нужно добавить третью
остановку f3 выше f2, то для выбора ее позиции мне не нужно ничего знать о/у.
Мы почувствовали, что задача имеет отношение к динамическому програм-
программированию. Как выглядит алгоритм? Для начала нам нужно определить функцию
стоимости для частных решений, которая позволит нам принимать более важные
решения. Что вы скажете о такой:
Пусть m [ i ] [ j ] задает минимальную стоимость обслуживания всех пассажиров,
если делается ровноу остановок, последняя из которых делается на этаже /.
Может ли эта функция помочь нам разместить (/ + 1)-ю остановку так, чтобы
общая стоимость уменьшилась? Да. (/ + 1)-я остановка по определению должна
располагаться выше (/-й) остановки на этаже /. Значит, новая остановка будет ин-
интересовать только тех пассажиров, которые хотят выйти выше /-го этажа. Чтобы
понять, как это может нам помочь, мы должны правильно разделить пассажиров
между новой остановкой и / на основании того, к какой остановке ближе они на-
находятся. Эта идея приводит к заданию следующей рекуррентной последователь-
последовательности:
mi у+1 = ГПШ (mk j ~ floors _ walked (к, oo) + floors _ walked (kj) + floors _ walked (/, oo)) •
Что она значит? Если последняя остановка совершается на этаже /, то предыду-
предыдущая должна быть на этаже к < i. Какова стоимость решения в таком случае? Мы
должны вычесть из пгк .• стоимость обслуживания всех пассажиров выше к (то есть
floors_walked(&, oo)) и заменить ее (предположительно) уменьшенной стоимостью
добавления остановки на этаже / (то есть floors_walked(&, /) + floors_walked(z, oo)).
282 Глава 11. Динамическое программирование
Основной здесь является функция f loors_walked (а, b). Она подсчитывает
полное число этажей, проходимых пассажирами, которые направляются на этажи,
лежащие между двумя последовательными остановками а и Ь. Каждый такой пасса-
пассажир идет к своему этажу кратчайшим путем:
floors_walked(int previous, int current)
int nsteps=0; /* общее пройденное расстояние */
inti; /* счетчик */
for(i=l; i<=nriders;
if ((stops[i] > previous) && (stops[i] <= current))
nsteps += min(stops[i]-previous, current-
stops [i] ) ;
return(nsteps);
Как только вы ухватили основную идею, реализация алгоритма становится
очевидной. Мы создаем глобальные матрицы для хранения таблиц динамического
программирования. В одной из таблиц хранятся стоимости, в другой - родитель-
родительские элементы:
#define NFLOORS 110 /* высота здания в этажах */
#define MAX_RIDERS 50 /* вместимость лифта */
int stops [MAX_RIDERS] ; /* кто на каком этаже выходит */
int nriders; /* количество пассажиров */
int nstops; /* число разрешенных остановок */
int m[NFLOORS+l][MAX_RIDERS]; /* таблица стоимости */
int p[NFLOORS+l][MAX_RIDERS]; /* таблица родительских
элементов */
Функция оптимизации - это непосредственная реализация рекуррентного соот-
соотношения. Особое внимание уделяется такому расположению циклов, чтобы все
величины были подсчитаны к тому моменту, когда они могут понадобиться.
int optimize_floor()
int i,j,k; /* счетчики */
int cost; /* стоимость */
int laststop; /* последняя остановка лифта */
for (i=0; i<=NFLOORS;
m[i][0] = floors_walked@,MAXINT);
p[i] [0] = -1;
11.5. Пример разработки программы: оптимизация лифта 283
for (j=l; j<=nstops;
for (i=0; i<=NFLOORS;
m[i][j] = MAXINT;
for (k=0; k< = i; k++) {
cost = m[k][j-1] - floors_walked(k,MAXINT) +
floors_walked(k,i) + floors_.walked(i,MAXINT) ;
if (cost < m[i][j]) {
m[i] [j] = cost;
p[i] [j] = k;
laststop = 0;
for (i=l; i<=NFLOORS;
if (m[i][nstops] < m[laststop][nstops])
laststop = i;
return(laststop);
}
Наконец, нам нужно восстановить решение. Идея та же, что и в предыдущих
примерах: нужно идти по указателям на родительские элементы в обратную
сторону.
reconstruct_path(int lastfloor, int stops_to_go)
{
if (stops_to_go > 1)
reconstruct_path(p[lastfloor][stops_to__go], stops_to_go-l);
printf("%d\n",lastfloor);
}
Запустим программу для 10-этажного здания европейского типа (нижний этаж
считается нулевым). Для случая, когда по одному пассажиру хочет выйти на
каждом этаже от 1-го до 10-го, и разрешена всего одна остановка, получаем, что
лучше всего остановиться на 7-м этаже, суммарная стоимость - 18 лестничных
пролетов (пассажиры, направляющиеся на этажи 1, 2 и 3-й, должны с нулевого
этажа идти пешком). Если разрешено две остановки, то лучше всего остановиться
на этажах 3-м и 8-м, стоимость - 11, а лучшие три остановки - это 3, 6 и 9-й этажи,
приводящие к суммарной стоимости в 7 пролетов.
284 Глава 11. Динамическое программирование
11.6. Задачи
11.6.1. Умнее ли больший?
PC/UVaIDs: 111101/10131
Популярность: В
Частота успехов: высокая
Уровень:2
Некоторые люди считают, что чем слон больше, тем он умнее. Чтобы опро-
опровергнуть это утверждение, вы хотите проанализировать набор слонов
и расположить наибольшее из возможных подмножеств этого набора в последо-
последовательность слонов с увеличивающимся весом, но уменьшающимся IQ.
Входные данные
Входные данные состоят из данных о наборе слонов, по одному слону на строку,
и завершаются меткой конца файла. Данные о каждом конкретном слоне состоят из
двух целых чисел: первое - это вес слона в килограммах, второе - его IQ. Оба числа
лежат в пределах от 1 до 10 000. Во входных данных содержится информация не
более чем о 1000 слонах. У двух слонов могут быть одинаковыми: вес, IQ или даже
и вес, и IQ.
Выходные данные
Первая строка выходных данных должна содержать целое число п - длину
найденной последовательности слонов. Каждая из оставшихся п строк должна
содержать единственное целое число, задающее слона. Обозначим числа на /-й строке
входных данных как W[i] и S[i]. Если ваша последовательность состоит из п слонов
я[1], #[2],..., а[п], то должны выполняться условия:
W[a[l]] < W[a[2]] < ... < W[a[n]] и S[a[l]] < S[a[2]] < ... < S[a[n]]i.
Чтобы ответ был засчитан как верный, п должно быть настолько большим,
насколько это возможно. Все неравенства строгие: веса должны строго возрас-
возрастать, a IQ должны строго уменьшаться.
Ваша программа может вывести любой верный ответ из возможных для задан-
заданных входных данных.
11.6. Задачи 285
Пример входных данных Соответствующие выходные данные
6008 1300 4
6000 2100 4
500 2000 5
1000 4000 9
1100 3000 7
6000 2000
8000 1400
6000 1200
2000 1900
11.6.2. Различные подпоследовательности
PC/UVaIDs: 111102/10069
Популярность: В
Частота успехов: средняя
Уровень:3
Подпоследовательность заданной последовательности S составляется из S путем
удаления некоторого числа элементов (возможно, нуля). Формально последователь-
последовательность Z = Z]Z2... zk является подпоследовательностьюX=xjx2... xm, если существует
строго возрастающая последовательность <//,/2, •••? ^> индексов X такая, что для
всеху = 1,2, ..., к выполняется jc =z • Например, Z = bcdb - это подпоследователь-
подпоследовательность Х= abcbdab с соответствующей последовательностью индексов < 2, 3, 5, 7 >.
Ваша задача состоит в написании программы, которая будет подсчитывать
число таких вхождений Z в X в качестве подпоследовательности, что каждому
вхождению соответствует своя последовательность индексов.
Входные данные
Входные данные начинаются со строки, содержащей целое число N, которое
задает количество тестовых блоков. Первая строка каждого тестового блока содержит
строку X, целиком состоящую из строчных букв, причем ее длина не превышает
10 000 символов. Вторая строка содержит строку Z, также состоящую только из
строчных букв и имеющую длину не более 100 символов. Можете считать, что и Z,
и любой префикс или суффикс Z имеют не более 10 различных вхождений в Хв каче-
качестве подпоследовательности.
Выходные данные
Для каждого тестового блока выведите число различных вхождений Z в Хв каче-
качестве подпоследовательности. Выходные данные для каждого блока должны быть
расположены на отдельной строке.
286 Глава 11. Динамическое программирование
Пример входных данных
2
babgbag
bag
rabbbit
rabbit
Соответствующие выходные данные
5
3
11.6.3. Веса и меры
PC/UValDs: 111103/10154
Популярность: С
Частота успехов: средняя
Уровень:3
Черепашка по имени Мак очень боится, что его панцирь может сломаться.
Поэтому он попросил вас дать совет, как поставить черепашек друг на друга, чтобы
построить трон Йертла Черепахи (Yertle the Turtle). Каждая из 5607 черепах, при-
призванных Йертлом, обладает своей силой и весом. Ваша задача состоит в том, чтобы
составить из них стопку максимальной высоты.
Входные данные
Входные данные состоят из нескольких строк, каждая из которых содержит два
целых числа, разделенные одним и более пробелом. Эти числа задают вес и силу
черепахи. Вес черепахи измеряется в граммах. Сила, которая также измеряется
в граммах, - это максимальный вес, который способна выдержать черепаха (включая
свой собственный). Таким образом, черепаха, весящая 300 грамм и имеющая силу
1000 грамм, может держать 700 грамм на спине. Число черепах не превышает 5607.
Выходные данные
Выходные данные должны состоять из одного целого числа, равного макси-
максимальному числу черепах, которые можно поставить стопкой так, чтобы сила ни
одной из них не была превышена.
11.6. Задачи
287
Пример входных данных
300 1000
1000 1200
200 600
100 101
Соответствующие выходные данные
11.6.4 Однонаправленная задача коммивояжера
PC/UVaIDs: 111104/116
Популярность: А
Частота успехов: низкая
Уровень:3
Для заданной матрицы размером m x n вы должны написать программу, которая
вычисляет путь с минимальным весом с левого края матрицы до правого. Путь начи-
начинается в любой строке первого столбца и состоит из последовательности шагов,
обрывающихся в столбце п. Каждый шаг состоит в переходе из столбца / в столбец
/ + 1 в соседнюю (по горизонтали или диагонали) ячейку. Первая и последняя строки
(строки \ к т) матрицы считаются соседними; то есть матрица «сворачивается»,
образуя горизонтальный цилиндр. Разрешенные шаги показаны ниже.
<
Весом пути называется сумма целых чисел, записанных в каждой из п посе-
посещенных ячеек.
Пути с минимальным весом через две немного отличные матрицы размером 5x6
показаны ниже. Значения матриц отличаются только в нижнем ряду. Путь, показан-
показанный для правой матрицы, использует соседство первого и последнего рядов.
288
Глава 11. Динамическое программирование
6
5
8
3
4
\
9
4
7
1
8
X
1
2
2
2
9
8
8
7
9
л
6
6
4
5
6
6
5
8
3
4
Y
9
4
7
/
8
3
1
2
2
2
9
3
/
8
7
9
Л
2
6
4
5
6
Входные данные
Входные данные состоят из последовательности описаний матриц. Каждая матрица
задается строкой с количеством строк и столбцов, которые обозначаются тип соответ-
соответственно. Далее следуют тхп целых чисел, идущих по строкам; то есть первые п целых
чисел составляют первую строку матрицы, следующие п целых чисел составляют
вторую строку и т. д. Целые числа, стоящие на одной строке, будут отделены друг от
друга одним или более пробелами. Обратите внимание: целые числа не обязаны быть
положительными. Во входном файле могут быть заданы одна или более матриц. Вход-
Входные данные завершаются маркером конца файла.
Для каждого описания число рядов будет лежать от 1 до 10 включительно;
число столбцов - от 1 до 100 включительно. Вес любого пути не будет превышать
целого числа, для хранения которого потребуется больше 30 бит.
Выходные данные
Для каждого описания матрицы требуется вывести две строки. Первая строка
задает путь минимальной стоимости, а вторая - собственно стоимость этого пути.
Путь состоит из последовательности п целых чисел (разделенных одним или более
пробелами), задающих ряды, из которых состоит путь минимальной стоимости.
Если путей минимальной стоимости больше одного, то должен быть выведен лекси-
лексикографически меньший путь.
Пример входных данных
5 6
3 4 12 8 6
6 18 2 7 4
5 9 3 9 9 5
8 4 13 2 6
3 7 2 8 6 4
11.6. Задачи 289
5 6
3 4 12 8 6
6 18 2 7 4
5 9 3 9 9 5
8 4 13 2 6
3 7 2 12 3
2 2
9 10 9 10
Соответствующие выходные данные
12 3 4 4 5
16
12 15 4 5
11
1 1
19
11.6.5. Распил брусьев
PC/UVaIDs: 111105/10003
Популярность: В
Частота успехов: средняя
Уровень:2
Вам нужно распилить деревянный брус на несколько кусков. Самая удобная
компания Analog Cutting Machinery (ACM) берет плату за пилку в зависимости от
размера бруса, который нужно распилить.
Легко понять, что различные заказы приводят к различным ценам. Например, рас-
рассмотрим брус длиной 10 м, который необходимо распилить на расстоянии 2,4 и 7 м,
считая от одного конца. Это можно сделать несколькими способами. Можно распи-
распилить сначала на отметке 2 м, потом 4 и потом 7 м. Это приведет к стоимости:
10 + 8 + 6 = 24, потому что сначала длина бруса, который пилили, была 10 м, затем
она стала 8м и, наконец, 6 м. А можно распилить иначе: сначала на отметке 4 м, затем
2 и затем 7 м. Это приведет к стоимости: 10 + 4 + 6 = 20, что для нас лучше.
Ваш начальник требует, чтобы вы написали программу, которая находит мини-
минимальную стоимость распила для любого бруса заданного размера.
Входные данные
Входные данные состоят из нескольких тестовых блоков. Первая строка каждого
тестового блока содержит положительное число /, задающее длину бруса, который
нужно распилить. Вы можете считать, что /< 1000. Следующая строка содержит
число п (п < 50) распилов, которые нужно сделать.
10-972
290 Глава 11. Динамическое программирование
Следующая строка содержит п положительных чисел ct @ < ct < /), задающих
места, в которых необходимо сделать распилы, в строго возрастающем порядке.
Входной блок с / = 0 задает окончание входных данных.
Выходные данные
Выведите стоимость пилки минимальной цены в формате, приведенном ниже.
Пример входных данных
100
3
25 50 75
10
4
4 5 7 8
0
Соответствующие выходные данные
The minimum cutting is 200.
The minimum cutting is 22.
11.6.6. Заполнение парома
PC/UVaIDs: 111106/10261
Популярность: В
Частота успехов: низкая
Уровень:3
Паромы используются для перевозки машин через реки или другие водные препят-
препятствия. Обычно паромы имеют достаточно большую ширину, поэтому машины выстраи-
выстраиваются в две линии вдоль парома. Машины заезжают в две линии с одного конца паро-
парома, затем паром пересекает реку, и машины выезжают с другого конца парома.
Имеется одна очередь из машин, заезжающих на паром, и оператор направля-
направляет машины из очереди на правый или левый борт парома так, чтобы нагрузка была
сбалансирована. Все машины в очереди имеют разную длину, которую оператор
узнает, осматривая очередь. На основании своих наблюдений и длины парома
оператор решает, на какую сторону должны заезжать машины, чтобы загрузить
паром максимальным числом машин из очереди. Напишите программу, которая
будет указывать оператору, какую машину на какую сторону отправлять так,
чтобы поместилось максимальное число машин.
11.6. Задачи 291
Входные данные
Входные данные начинаются со строки, содержащей одно положительное целое
число, которое означает количество тестовых блоков, за которой следует пустая строка.
Первая строка каждого тестового блока содержит одно целое число от 1 до 100 -
длину парома (в метрах). Для каждой машины в очереди имеется своя строка во
входных данных, задающая длину машины в сантиметрах., целое число (от 100 до
3000 включительно). Последняя строка входных данных содержит 0. Машины
должны загружаться по порядку, а также с учетом того факта, что суммарная длина
машин по каждому борту не должна превышать длину парома. Должно быть загру-
загружено как можно больше машин, начиная с первой и далее по порядку до тех пор,
пока вы не сможете загрузить очередную машину.
Между двумя последовательными блоками входных данных находится пустая
строка.
Выходные данные
Для каждого тестового блока первая строка выходных данных должна содержать
число машин, которые могут быть загружены на паром. Для каждой машины, которая
может быть загружена на паром, в порядке их следования во входных данных выведи-
выведите строку, содержащую "port", если машина должна быть направлена на левую
сторону и "starboard", если машина должна быть отправлена на правую сторону.
Если под приведенные условия подходит более одного варианта расположения
машин, подойдет любой.
Выходные данные для двух последовательных тестовых блоков должны быть
разделены пустой строкой.
Пример входных данных
50
2500
3000
1000
1000
1500
700
800
0
Соответствующие выходные данные
б
port
starboard
10*
292 Глава 11. Динамическое программирование
starboard
starboard
port
port
11.6.7. Палочки для еды
PC/UVaIDs: 111107/10271
Популярность: В
Частота успехов: средняя
Уровень:3
В Китае для еды люди используют две палочки, но мистер Л. не обычный чело-
человек. Он использует набор из трех палочек, двух обычных и еще одной дополнитель-
дополнительной; это длинная палочка, на которую он насаживает большие куски еды. Длины
двух коротких палочек должны совпадать как можно с большей точностью, а длина
дополнительной неважна до тех пор, пока она самая длинная. Для набора палочек
с длинами А, В, С(А<В < С) функция (А - ВJ определяет «ошибку» набора.
Мистер Л. пригласил К гостей на вечеринку по случаю своего дня рождения,
и на ней он хочет представить свой способ использования палочек. Ему нужно
приготовить К + 8 наборов палочек (для себя, своей жены, сына, дочери, мамы,
папы, зятя, тещи и К других гостей). Но все палочки, которые у него есть, имеют
разную длину! Зная эти длины, он должен суметь составить К+ 8 наборов так,
чтобы суммарная «ошибка» всех наборов была минимальна.
Входные данные
Первая строка входных данных содержит одно целое число Г, задающее число
тестовых блоков A < Т <20). Каждый тестовый блок начинается с двух целых
чисел К и N @<К< 1000, ЪК + 24 <N< 5000), задающих число гостей и число
палочек. Далее в неубывающем порядке идут TV положительных целых чисел Li9
которые задают длину палочек A < Z, < 32 000).
Выходные данные
Для каждого тестового блока входных данных выведите строку, содержащую
минимальную суммарную «ошибку» всех наборов.
Пример входных данных
1
1 40
1 8 10 16 19 22 27 33 3 6 40 47 52 56 61 63 71 72 75 81 81 84 88 96 98
103 110 113 118 124 128 129 134 134 139 148 157 157 160 162 164
11.6. Задачи 293
Соответствующие выходные данные
23
Замечание. Возможный вариант составления девяти наборов для этого примера:
(8,10,16), A9,22,27), F1,63, 75), G1,72, 88), (81,81,84), (96,98,103), A28,129,148),
A34, 134, 139) и A57, 157, 160).
11.6.8. Приключения в дороге: часть IV
PC/UVaIDs: 111108/10201
Популярность: А
Частота успехов: низкая
Уровень:3
Вы собираетесь арендовать грузовик, чтобы вернуться из Ватерлоо в большой
город. Но цены на бензин в последние дни были так высоки, что вы решили узнать,
сколько топлива потребуется скормить по дороге этому прожорливому зверю.
Грузовику требуется один литр бензина на каждый пройденный километр. Он
оснащен 200-литровым баком. Когда вы арендуете грузовик в Ватерлоо, бак запол-
заполнен наполовину. Когда вы будете его возвращать в городе, бак также должен быть
заполнен, по крайней мере наполовину, или компания, которая сдала вам автомо-
автомобиль в аренду, сдерет с вас еще больше денег. Ваша цель - потратить на горючее как
можно меньше денег, но при этом не оказаться посреди дороги без бензина.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное целое
число, которое означает количество тестовых блоков, за которой следует пустая строка.
Каждый тестовый блок содержит только целые числа. Первое число - это рас-
расстояние от Ватерлоо до города, не превышающее 10 000. Далее идет набор макси-
максимум из 100 описаний заправочных станций, задающих все заправки вдоль вашего
пути в неубывающем по расстоянию порядке. Каждое описание состоит из расстоя-
расстояния в километрах от Ватерлоо до заправочной станции и цены одного литра горюче-
горючего на этой заправочной станции, в десятках центов. Цена не превышает 2000.
Между двумя последовательными блоками входных данных находится пустая
строка.
Выходные данные
Для каждого тестового блока выведите минимальное количество денег, которое
вы должны истратить на горючее в дороге от Ватерлоо до города. Если не сущест-
существует возможности добраться до Ватерлоо, удовлетворив условиям, приведенным
выше, то выведите " Imp о s s i b 1 e ".
Выходные данные для двух последовательных тестовых блоков должны быть
разделены пустой строкой.
294 Глава 11. Динамическое программирование
Пример входных данных
1
500
100
150
200
300
400
450
500
999
888
777
999
1009
1019
1399
Соответствующие выходные данные
450550
11.7. Подсказки
11.1. Можно ли это свести к какой-либо задаче на совпадение строк?
11.2. Имеет ли начальный порядок входных данных какое-либо значение, или мы
можем свободно их переупорядочить по своему желанию? Если так, то какой
йорядок следует выбрать?
11.3. Что нам необходимо знать о более коротких путешествиях, чтобы мы смогли
выбрать последний ход оптимальным образом?
11.4. Можем ли мы использовать тот факт, что каждый распил делает из одной пал-
палки две, чтобы разработать рекурсивный алгоритм?
11.5. Всегда ли нужно ставить машину на ту сторону, где осталось больше свобод-
свободного места? Почему? Можем ли мы как-то использовать тот факт, что сум-
суммарная длина машин на каждой стороне парома - это всегда целое число?
11.6. Как мы могли бы решить задачу, если бы нас не интересовала длина третьей
палочки?
11.7. Какую информацию о стоимости достижения определенных мест с опреде-
определенным количеством горючего в запасе можно считать достаточной, чтобы
верно выбрать последнее передвижение?
11.8. Замечания
11.1. Подробнее о Йертле Черепахе можно прочитать в [Seu58].
Глава 12
Сетки
Дело не в том, что полярные координаты чересчур сложны, а в том, что пря-
прямоугольные координаты проще, чем они имеют право быть. - Клеппнер и Ко-
ленхау. «Введение в механику».
Сетки (grids) лежат в основе многих естественных структур. Шахматные
доски - это сетки. Городские кварталы обычно расположены по сетке; более того,
при измерении большинства расстояний в естественных сетках используется так
называемое манхэттенское расстояние («Manhattan» distance). Система широты
и долготы задает сетку для поверхности планеты, хотя и делается это на поверх-
поверхности сферы, а не на плоскости.
Сетки нашли такое широкое применение, потому что они предоставляют наи-
наиболее простой и естественный способ разбиения пространства на области, ко-
которые можно различить. В пределе такими ячейками могут являться отдельные
точки, но мы будем рассматривать более грубые сетки, ячейки которых имеют
определенную форму. Для регулярных сеток все ячейки имеют одинаковую форму
и расположены периодически. Прямоугольные или прямолинейные сетки наибо-
наиболее широко распространены из-за их простоты, но также важны и основанные на
треугольниках гексагональные сетки. К примеру, в производстве меда их преиму-
преимущества используются уже буквально миллионы лет.
12.1. Прямолинейные сетки
Прямолинейные сетки знакомы всем, кто хоть раз держал в руках кусок милли-
миллиметровки. В таких сетках ячейки обычно задаются вертикальными и горизонтальными
линиями, расположенными на равных расстояниях. Неравные расстояния все равно
приводят к регулярной топологии, хотя размеры клеток могут различаться. Трех-
Трехмерные сетки формируются из плоских сеток с перпендикулярами, проходящими
через слои. Для трехмерных сеток все равно определены плоские грани, задаваемые
двумя соседними кубиками.
296 Глава 12. Сетки
У плоских сеток выделяют три важных компонента: вершины, ребра и содержи-
содержимое ячеек. Временами нас интересует то, что находится внутри ячейки (например,
в геометрических приложениях, где каждая ячейка описывает область в пространст-
пространстве). Временами нас интересуют вершины (например, если нам нужно работать
с шахматной доской). Временами нас интересуют ребра (например, если мы ищем
определенный маршрут по городу, где здания составляют содержимое ячеек).
Вершины плоской сетки, кроме тех, что находятся на границе, соседствуют
с четырьмя ребрами и содержимым четырех ячеек. Вершины в ЗБ-сетках соседст-
соседствуют с шестью ребрами и содержимым восьми ячеек. В J-мерном пространстве
каждая вершина соседствует с 2d ребрами и 2d ячейками. В плоской сетке каждая
ячейка соседствует с восемью другими, из них с четырьмя по диагонали и с четырьмя
через ребра. В ЗБ-сетке каждая ячейка касается 26 других, из них с шестью она
имеет общую грань, с 12 - общее ребро и с восемью - общую вершину.
12.1.1. Обход
Часто бывает необходимым обойти все ячейки прямолинейной сетки пх т.
Каждый такой обход можно рассматривать как установление соответствия между
каждой из пт упорядоченных пар и одного целого числа от 1 до пт.
В определенных приложениях порядок важен, как, например, в задачах на дина-
динамическое программирование. Самые важные методы обхода следующие.
• По строкам. Мы разбиваем матрицу на строки так, что первые т элементов
принадлежат первой строке, вторые т элементов - второй строке и т. д. Такой
порядок используется в компиляторах большинства современных языков
программирования для представления двумерных матриц одним линейным
массивом.
A.1) row_major(int n, int m)
A.2) {
A.3) int i,j; /* счетчики */
B,1)
B.2) for (i=l; i<=n; i++)
B.3) for (j=l; j<=m; j++)
C.1) process(i,j);
C.2) }
C,3)
• По столбцам. Мы разбиваем матрицу на столбцы так, что первые п элементов
принадлежат первому столбцу, вторые п элементов - второму столбцу и т. д.
Этого можно добиться, поменяв порядок вложенных циклов в реализации
12.1. Прямолинейные сетки 297
обхода по строкам. Для оптимизации использования кеша и определенных
арифметических операций с указателями нужно знать, какой порядок для
матриц использует компилятор - по строкам или по столбцам.
A,1) column_major(int n, int m)
B,1) {
C.1) int i, j ; /*счетчики*/
A,2)
B.2) for (j=l; j<=m; j++)
C.2) for (i=l; i<=n; i++)
A.3) process(i,j);
B,3) }
C,3)
«Змейкой». Вместо того чтобы начинать обход каждой строки с первого
элемента, мы меняем направление обхода при переходе на новую строку. Мы
как будто используем пишущую машинку, которая может печатать слева
направо и справа налево, чтобы уменьшить общее время набора.
A.1) snake_order(int n, int m)
A.2) {
A.3) int i,j; /* счетчики */
B,3)
B,2) for (i=l; i<=n; i++)
B,1) for (j=l; j<=m;
C.1) process(i,j
C.2) }
C,3)
По диагоналям. Идем вниз и вверх по диагоналям. Обратите внимание, что
у сетки размером п х т имеется т + п-1 диагоналей, каждая со своим числом
элементов. Этот алгоритм хитрее, чем кажется с первого взгляда.
A,1) diagonal_order(int n, int m)
B.1) {
A.2) int d,j; /* счетчики */
C.1) int pcount; /* ячейки на диагонали */
B.2) int height; /* строка нижней ячейки */
A,3)
D.1) for (d=l; d<=(m+n-l); d++) {
C.2) height = 1 + max@, d-m) ;
B.3) pcount = min(d, (n-height+1));
D.2) for (j=0; j<pcount; j++)
C.3) process(min(m,d)-j, height+j);
D,3) }
298 Глава 12. Сетки
12.1.2. Двойственные графы и представления
Естественный выбор для представления плоских прямолинейных сеток - это
двумерные массивы. Ячейка m[i][j] может задавать или (/,/) вершину, или (/,у)
грань в зависимости от того, что нас интересует. Четыре соседние ячейки
получаются просто добавлением ±1 к одной из координат.
Достаточно удобным при рассмотрении задач о плоских подразделениях являет-
является понятие двойственного графа - каждой области подразделения ставится
в соответствие вершина, ребрами соединяются те вершины, которые соответствуют
соседним областям.
Теорема четырех красок утверждает, что любую плоскую карту можно раскра-
раскрасить, используя не более четырех цветов так, чтобы любые две соседние области
были раскрашены в разные цвета. Но на самом деле это утверждение о числе
цветов вершин, необходимых для раскраски двойственного графа карты. Фак-
Фактически двойственный граф любого плоского подразделения должен быть пло-
плоским графом. Можете ли вы объяснить почему?
Обратите внимание, что двойственные графы прямоугольной и гексагональ-
гексагональной решеток - это чуть меньшие прямоугольная и гексагональная решетки.
Именно поэтому любая структура, которая может быть использована для пред-
представления соединений вершин, может применяться для представления соедине-
соединений граней.
Реберно-взвешенную прямолинейную сетку естественно представить через
смежные элементы. Проще всего это сделать, создав трехмерный массив
m[i][j][d], где d принимает четыре значения (север, восток, юг и запад)
и определяет направление ребра, выходящего из точки (/,/).
12.2. Треугольные и гексагональные сетки
Существует еще две важные разновидности сеток - треугольные и гексаго-
гексагональные. Они тесно связаны друг с другом - гексагональная решетка получается
из треугольной удалением определенных вершин.
12.2.1. Треугольные решетки
Треугольные решетки строятся из трех наборов равноудаленных линий: гори-
горизонтальных «строчных», «столбцовых», расположенных под углом 60° к горизон-
горизонтальным, и «диагональных», расположенных под углом 120° к горизонтальным
(см. рис. 12.1). Вершины решетки образуются пересечением трех осевых линий,
поэтому каждая грань решетки - это равносторонний треугольник. Каждая
вершина v соединена с шестью другими, по две соседних v на каждой из осей.
12.2. Треугольные и гексагональные сетки 299
Чтобы работать с треугольными решетками, нам нужно уметь различать соот-
соответствующих соседей каждой из этих вершин, а также их местоположение. Для
этого нам потребуется работать с двумя типами координатных систем.
• Треугольные/гексагональные координаты. Одну из вершин мы считаем началом
координат - точкой @, 0). Мы должны присвоить координаты так, чтобы
логических соседей каждой из вершин можно было легко получить. В обычной
прямолинейной системе координат четыре соседние ячейки для (х, у) полу-
получаются добавлением ±1 к горизонтальной или вертикальной координате.
Хотя каждая из вершин определяется пересечением трех линий, для задания ее
положения фактически достаточно двух. Для определения нашей координатной
системы мы будем использовать «строковые» и «столбцовые» линии. Чтобы
разобраться, см. рис. 12.1. Вершина (х,у) лежит на х «строк» выше начала
координат и на у F0°)-столбцов правее. Чтобы получить координаты соседей
вершины к нужно прибавить к ее координатам следующие пары, против часо-
часовой стрелки: @, 1), A, 0), A,-1), @, -1), (-1, 0) и (-1, 1).
Аналогичные координаты можно использовать и для граней треугольной сетки,
так как двойственный граф граней будет также треугольной сеткой. В принципе
можно использовать и другие варианты координат; смотрите [LR76].
с = -1 с=0 с=1
г= 1
г = 0
г = -1
Рис. 12.1. Координатная система для треугольных сеток
300 Глава 12. Сетки
• Геометрические координаты. Вершины треугольной решетки также соответ-
соответствуют геометрическим точкам на плоскости. Обратите внимание, что на
рис. 12.1 ряды вершин наполовину прореженные из-за того, что оси идут под
углом 60°, а не 90°, как в прямолинейных решетках.
Пусть d- это расстояние от вершины до ее шести ближайших соседей и точка
@, 0) в треугольных координатах совпадает с точкой @, 0) в геометрических
координатах. Тогда точка с треугольными координатами (xt, yt) должна лежать
в геометрической точке:
(xg, yg) = (d(xt +(v,cosF0°))), dy,smFO0)),
что находится из простой тригонометрии. Так как cosF0°) = 1/2
и sinF0°) = л/з^/2, нам даже не нужно использовать тригонометрические
функции для вычислений.
Код для аналогичных манипуляций с гексагональными решетками мы приве-
приведем в следующей секции.
12.2.2. Гексагональные решетки
Удалив определенные вершины в треугольной решетке, мы получим гексагональ-
гексагональную решетку, изображенную на рис. 12.2. Теперь грани решетки - это правильные
шестиугольники, и каждый из них соседствует с шестью другими. Степень вершин
сетки теперь стала равна 3, так как эта сетка - двойственный граф треугольной
решетки.
Гексагональные решетки обладают многими интересными и полезными свой-
свойствами, в основном из-за того, что шестиугольники «круглее» квадратов. Круги
обладают наибольшей площадью среди всех фигур заданного периметра, в этом
смысле они самые эффективные фигуры для построения. Гексагональные решет-
решетки прочнее прямоугольных, это еще одна причина, по которой пчелы делают соты
именно шестиугольной формы. Уменьшение количества границ на единицу
поверхности для шестиугольников уменьшает визуальные артефакты в графике,
ввиду чего изображения из гексагональных замощений используются в ком-
компьютерных играх чаще, чем из прямоугольных.
В предыдущем разделе мы обсуждали переход между треугольными/гексаго-
треугольными/гексагональными координатами и геометрическими. Мы полагаем, что начало обеих
систем координат находится в центре диска в @, 0). Гексагональная координата
(xh, yh) соответствует центру диска, находящемуся в горизонтальной строке xh
и диагональном столбце yh. Геометрическая координата такой точки — это функция
радиуса диска г, равного половине диаметра d, заданного в предыдущем разделе.
12.2. Треугольные и гексагональные сетки
301
\/ \/ V У У
/A A A A /W\ A \
Рис. 12.2. Удалив лишние вершины треугольной решетки, получаем гексагональную решетку
hex_to_geo(int xh, int yh, double r, double *xg, double *yg)
{
*yg = B.0 * r) * xh * (sqrtC)/2.0);
*xg = B.0 * r) * xh * A.0/2.0) + B.0 * r) * yh;
}
geo_to_hex (double xg, double yg, double r, double *xh, double *yh)
{
*xh = B.0/sqrtC)) * yg / B.0 * r);
*yh = (xg - B.0 * r) * (*xh) * A.0/2.0) ) / B.0 * r);
}
To, что в гексагональной системе координат можно выделить строки и столбцы,
дает нам возможность сохранять наши шестиугольники в матрице m[row][column].
Теперь при использовании смещений по индексам, описанных для треугольной сис-
системы координат, легко можно получить всех шестерых соседей любого шести-
шестиугольника.
Тем не менее не все так просто. При использовании гексагональной системы
координат множество шестиугольников с координатами (hx9 hy), где 0 < fix <xmax
и 0 < hy ^.ymax, образует ромбовидный кусок, а не обычный прямоугольник, ори-
ориентированный по осям. А во многих приложениях нас интересуют именно прямо-
302
Глава 12. Сетки
угольники, а не ромбы. Чтобы решить эту проблему, введем матричные координа-
координаты так, что (ах, ау) соответствует положению шестиугольника в прямоугольни-
прямоугольнике, ориентированном по осям, причем точка @, 0) является левым нижним углом.
array_to_hex(int xa, int уа, int *xh, int*yh)
{
*xh = xa;
*yh = ya - xa + ceil(xa/2.0);
hex_to_array(int xh, int yh, int *xa, int *ya)
}
*xa = xh;
*ya = yh + xh - ceil(xh/2.0);
На рис. 12.3 показана гексагональная решетка с нанесенными для каждого
шестиугольника гексагональными координатами и, ниже, наклонным шрифтом,
его матричные координаты, если они отличны от гексагональных.
Рис. 12.3. Упаковка дисков с приведенными гексагональными и матричными (наклонный
шрифт) координатами
12.3. Пример разработки программы: Вес тарелки
303
12.3. Пример разработки программы: Вес тарелки
Производитель обеденных тарелок желает выйти на рынок поставщиков
посуды для столовых кампуса. Столовые покупают тарелки одного стандартного
размера, чтобы их было удобно составлять вместе. Студенты во время боев за
едой разбивают немало посуды, поэтому поставка новой может быть очень при-
прибыльным бизнесом. Тем не менее этот рынок очень чувствителен к изменениям
цен, так как администрация устает покупать все новые и новые тарелки.
Наша компания хочет занять свой сектор рынка, используя уникальную техно-
технологию упаковки тарелок. Она основывается на факте, что гексагональные решет-
решетки плотнее прямоугольных, из-за чего тарелки укладываются в коробки размером
Ixw так, как показано на рис. 12.4 (слева). Каждая тарелка имеет радиус, равный
г единиц, и нижний ряд содержит ровно р = \wlBr)\ тарелок. Все остальные
ряды либо содержатр тарелок каждый, либо/? up - 1 поочередно, в зависимости
от соотношения между w и г. Каждой тарелке присваивается уникальный иденти-
идентификационный номер, как показано на рис. 12.4 (слева). В коробку укладывается
максимально возможное количество рядов, которое ограничивается ее длиной /.
23
ч
X
12
\
X
1
X
18
X
7
X
24
X
13
X
2
4— ^s
X
19
X
8
X
25
X
14
X
3
X
20
X
9
X
26
X
15
X
4
v_ ¦
I
21
X
10
X
27
X
16
X
5
I
22
X
11
I
28
I
—^
\
17
/
I
—^
\
6
Рис. 12.4. Упаковка тарелок в коробки (слева). Гексагональная решетка как упаковка
дисков (справа)
Руководство хочет знать, сколько тарелок помещается в коробку заданного
размера. Также оно хочет знать максимальное число тарелок, лежащих на любой
заданной, чтобы быть уверенными, что упаковка достаточно крепка и тарелки не
разобьются (если посуду разобьют на почте, то зачем нужны студенты?). Ваша
задача состоит в том, чтобы определить, какая тарелка испытывает наибольшее
напряжение и сколько на ней лежит тарелок, а также подсчитать полное число
тарелок и слоев в коробке заданного размера.
304 Глава 12. Сетки
Решение начинается ниже
В первую очередь нужно найти, сколько рядов тарелок входит в коробку при
использовании гексагональной раскладки. Наверное, это одна из причин, по ко-
которой Всемогущий придумал тригонометрию. Нижний ряд тарелок находится на
дне коробки, так что самые нижние центры дисков находятся на высоте г единиц
над полом, где г- это радиус тарелки. Расстояние между двумя соседними рядами
тарелок равняется 2rsinF0°) = 2 г 4b 12. Мы могли бы просто сократить двойки,
но тогда происхождение формулы сложнее понять.
int dense_layers(double w, double h, double r)
{
double gap; /* расстояние между слоями * /
if (B*r) > h) return(O);
gap = 2.0 * r * (sqrtC)/2.0);
return( 1 + floor((h-2.0*r)/gap) ) ;
}
Число тарелок, помещающихся в коробку, зависит и от числа рядов тарелок,
и от того, сколько тарелок входит в каждый ряд. Мы всегда начинаем заполнять
нижний (или нулевой) ряд, начиная с левой стороны коробки, поэтому он
содержит максимально возможное число тарелок для данной ширины. Тарелки
в рядах с нечетными номерами смещены на г, и, возможно, нам придется убирать
последнюю тарелку в ряду, если для нее не найдется достаточно места (> г).
int plates_per_row(int row, double w, double r)
{
int plates_per_full__row; /* тарелок в полном/четном
ряду */
plates_per_full_row = floor(w/B*r));
if ((row % 2) == 0) return(plates_per_full_row);
if (((w/B*r))-plates_per_full_row) >= 0.5) /* нечетный
ряд полон */
return(plates_per_full_row);
else
return (plates_j?er_full_row-l) ;
}
Процедуру определения количества тарелок, лежащих поверх данной, можно
упростить при грамотном использовании нашей координатной системы. В неогра-
неограниченной решетке на шестиугольнике (г, с) давят две тарелки из г + 1 ряда,
а именно (г + 1, с - 1) и (г + 1, с). В общем случае в г + i ряде должно быть i + 1
12.4. Упаковка кругов 305
такая тарелка. Но мы должны отбрасывать часть из них из-за ограничений, нало-
наложенных на нашу область. Это отбрасывание проще производить в матричных коорди-
координатах, так что мы перейдем к ним, чтобы определить число тарелок в нашем усечен-
усеченном конусе.
int plates_on_top (int xh, int yh, double w, double 1, doubler)
{
int number_on_top = 0; /* число тарелок сверху */
int layers; /* число рядов в сетке */
int rowlength; /* число тарелок в ряде */
int row; /* счетчик */
int xla,yla, xra,yra; /* матричные координаты */
layers = dense_layers(w,l,r);
for (row=xh+l; row<layers; row++) {
rowlength = plates__per_row(row/ w, r) - 1;
hex_to_array (row,yh-row, &xla, &yla) ;
if (yla < 0) yla = 0; /* левая граница
*/
hex_to_array(row,yh,&xra,&yra);
if (yra > rowlength)yra = rowlength; /* правая
граница */
number_on_top + = yra-yla+1;
}
return(number_on_top);
12.4. Упаковка кругов
Существует важная и интересная взаимосвязь между гексагональными решет-
решетками и упаковкой круглых дисков. Шесть соседей каждой вершины v сетки равно-
равноудалены от v, а значит, мы можем провести через них окружность с центром
в точке v, как показано на рис. 12.4 (справа). Каждый такой диск будет касаться
шести дисков, относящихся к соседним вершинам, как показано на рис. 12.3.
Задача об упаковке тарелок предлагает нам поместить набор круглых дисков
одного размера двумя различными способами: так, чтобы центры пластинок лежали
в вершинах прямолинейной решетки, и так, чтобы их центры лежали в вершинах
гексагональной решетки. Какой способ ведет к более плотной упаковке? С помо-
помощью уже разработанных функций несложно рассчитать оба варианта.
306 Глава 12. Сетки
/* сколько тарелок радиусом г поместится в коробку размером
w*h, если использовать гексагональную решетку? */
int dense_plates(double w, double 1, double r)
{
int layers; /* число слоев тарелок */
layers = dense_layers(w,1,r);
return (ceil(layers/2.0) * plates_per_row@/w,r) +
floor(layers/2.0) * plates_per_row(l,w,r) );
}
/* сколько тарелок радиусом г поместится в коробку размером
w*h, если использовать прямолинейную решетку? */
int grid_plates(double w, double h, double r)
{
int layers; /* число слоев тарелок */
layers = floor(h/B*r));
return (layers * plates_per_row@,w,r));
}
Для достаточно больших коробок гексагональная упаковка определенно позво-
позволит нам разместить больше тарелок, чем упаковка по прямолинейной решетке.
Более того, гексагональная упаковка - это асимптотически оптимальный способ
упаковки дисков, а ее трехмерный аналог - это оптимальный способ упаковки сфер.
В коробку размером 4x4 мы можем уложить 16 тарелок единичного диа-
диаметра, тогда как для гексагональной упаковки мы получаем всего 14 тарелок из-за
граничных эффектов. Но для коробки размером 10 х 10 при гексагональной упа-
упаковке получаем 105 тарелок, что на пять больше, чем при стандартной. Далее гек-
гексагональная упаковка всегда оказывается эффективнее. Коробка 100 х 100 вмеща-
вмещает в себя 11 443 тарелки при гексагональной упаковке против 10 000 при упаковке
по прямолинейной сетке. Таким образом, мы можем получить значительную вы-
выгоду, используя предложенную технологию упаковки.
12.5. Широта и долгота
Еще одна достаточно важная система координат - это система широты и долготы,
позволяющая однозначно задать любую точку на поверхности Земли.
Линии, идущие с востока на запад параллельно экватору, называются линиями
широты. Экватор имеет широту 0°, тогда как Северный и Южный полюс имеют
широту 90° северной и 90° южной широты соответственно.
Линии, идущие с севера на юг, называются линиями долготы или меридианами.
Нулевой меридиан проходит через Гринвич (Англия) и имеет долготу 0°, а полный
диапазон изменения - от 180° восточной до 180° западной долготы.
12.6. Задачи
307
Каждая точка на поверхности Земли описывается пересечением линий широты
и долготы. Например, центр вселенной (Манхэттен) лежит на 40°47' северной
широты и 73°58' западной долготы.
Обычная задача - найти кратчайшую дистанцию полета между двумя точками на
поверхности Земли. Большим кругом называется сечение сферы плоскостью, проходя-
проходящей через ее центр. Оказывается, что кратчайшее расстояние между точками хиу-
это дуга единственного большого круга, проходящего через точки хм у.
Мы не будем проводить все выкладки сферической геометрии, а приведем
лишь окончательный результат. Будем задавать положение точки р ее широтой
и долготой (Piat^iong)' считая, что все углы измеряются в радианах. Тогда расстоя-
расстояние по дуге большого круга между точками р и q можно найти по формуле/
g -qlong)(r).
12.6. Задачи
12.6.1. Муравей на доске
PC/UVaIDs: 111201/10161
Популярность: В
Частота успехов: высокая
Уровень: 1
Однажды муравей по имени Алиса пришла на шахматную доску размером
Мх М. Ей хотелось исследовать все клетки доски. И она начала идти по доске,
начав с угла.
Алиса начала идти из клетки A, 1). Сначала она прошла на клетку вверх, потом
клетку направо и клетку вниз. После этого она прошла клетку вправо, две клетки
вверх и две клетки налево. Каждый раз к тому углу, что она уже успела исследовать,
она добавляла один новый ряд и один новый столбец.
Например, первые ее 25 шагов выглядели так (номер в каждой клетке показывает,
на каком шаге Алиса ее посетила):
25
10
9
2
1
24
11
8
3
4
23
12
7
6
5
22
13
14
15
16
21
20
19
18
17
308 Глава 12. Сетки
Ее 8-й шаг привел Алису на клетку B, 3), а ее 20-й шаг привел на клетку E, 4).
Ваша задача найти, где она находилась в любой заданный момент времени, считая,
что шахматная доска достаточно большая, чтобы Алиса не выползла за ее пределы.
Входные данные
Входной файл содержит несколько строк, каждая из которых содержит целое
число N, задающее номер шага, причем 1 < N< 2 х 109. Файл оканчивается строкой,
содержащей число 0.
Выходные данные
Для каждой строки входных данных выведите строку, содержащую два числа
(х, у), означающие номер столбца и ряда соответственно. Между ними должен
быть один пробел.
Пример входных данных
8
20
25
0
Соответствующие выходные данные
2 3
5 4
1 5
12.6.2. Моноцикл
PC/UVaIDs: 111202/10047
Популярность: С
Частота успехов: средняя
Уровень: 3
Моноциклом называется одноколесный велосипед. Мы будем рассматривать
особенный экземпляр - со сплошным колесом, которое раскрашено в пять цветов,
как показано на рисунке.
12.6. Задачи
309
Квадрат 1
Квадрат 2
; |;г Квадрат 3
Цветные сегменты занимают равные центральные углы G2°) колеса. Велоси-
Велосипедист ездит на моноцикле по полю, состоящему из Мх N квадратов. Размер
квадратов подобран так, что при перемещении от центра одного квадрата до центра
другого колесо поворачивается вокруг центра ровно на 72°. Это показано на рисунке,
приведенном выше. Когда колесо находится в центре квадрата 1, средняя точка
синего сегмента соприкасается с землей. Но когда колесо перемещается до центра
следующего квадрата (квадрат 2), земли касается средняя точка белого сегмента.
N
t
м
1
л
S
т
Некоторые квадраты сетки перекрыты, и поэтому велосипедист не может заез-
заезжать на них. Он начинает ехать с какого-то из квадратов и пытается добраться до
целевого квадрата за минимальное время. Из любой клетки он может либо пере-
переместиться вперед, либо повернуться на 90° направо или налево. На каждое из этих
310 Глава 12. Сетки
действий ему требуется ровно одна секунда. Он всегда начинает свою поездку
лицом на север и в начале, земли касается средняя точка зеленого сегмента колеса.
В целевом квадрате ему также нужно оказаться так, чтобы земли касался именно
зеленый сегмент, но куда он будет смотреть, уже неважно.
Помогите велосипедисту понять, можно ли добраться до цели, и, если возмож-
возможно, найдите минимально необходимое для этого время.
Входные данные
Входные данные могут содержать несколько тестовых блоков.
Первая строка каждого тестового блока содержит два целых числа М и N
A <M,N< 25), задающие размер сетки. Далее идет описание сетки, состоящее из
М строк, каждая по N символов. Символ * # " обозначает блокированный квадрат,
все остальные клетки свободны. Начальная позиция велосипедиста задается сим-
символом " S ", а целевой квадрат - * Т ".
Входные данные завершаются двумя нулями для MnN.
Выходные данные
Для каждого тестового блока сначала на отдельной строке выведите номер
тестового блока, как показано в примере выходных данных. Если велосипедист
может достичь целевого квадрата, выведите минимальное количество времени
(в секундах), необходимое ему, чтобы туда добраться, в формате, показанном
ниже. Иначе выведите "destination not reachable".
Между выводом для двух последовательных тестовых блоков должна быть
пустая строка.
Пример входных данных Соответствующие выходные данные
1 3 Case #1
S#T destination not reachable
10 10
#S # Case #2
#..#.##.## minimum time = 49 sec
.# ##.#
#. .#.##...
# ##.
. .##.##...
#.###...#.
# ###T
0 0
12.6. Задачи 311
12.6.3. Звезда
PC/UVaIDs: 111203/10159
Популярность: С
Частота успехов: средняя
Уровень:2
Поле содержит 48 треугольных клеток. В каждой ячейке написана цифра от 0 до 9.
Каждая ячейка принадлежит двум или трем линиям. Эти линии обозначены буквами
от А до L. На рисунке, изображенном ниже, клетка, содержащая цифру 9, принадле-
принадлежит линиям D, G и /, а клетка с цифрой 7 - линиям В и /.
Для каждой линии мы можем найти максимальную цифру на ней. В нашем
примере наибольшее число для линии А - это 5, В - 7, Е - 6, Н- 0 и для /это 8.
Напишите программу, которая по заданным максимальным числам для
каждой из 12 линий будет определять минимальную и максимальную возможную
сумму всех чисел на поле.
Входные данные
Каждая строка входных данных содержит 12 цифр, которые разделены пробе-
пробелами. Первое из этих чисел - это максимальное число линии А, второе - В и так
далее до L.
312 Глава 12. Сетки
Выходные данные
Для каждой входной строки выведите значения минимальной и максимальной
возможной суммы цифр для данного поля. Эти две величины должны быть на одной
строке, и между ними должен быть ровно один пробел. Если решения не существует,
то ваша программа должна вывести " NO S OLUTI ON ".
Пример входных данных
578961909846
Соответствующие выходные данные
40 172
12.6.4. Пчела Майя
PC/UVaIDs: 111204/10182
Популярность: В
Частота успехов: высокая
Уровень: 2
Майя - пчела. Она живет в улье с шестиугольными сотами, а вместе с ней
и тысячи других пчел. Но у Майи приключилась беда. Ее друг Вилли сказал ей,
где она может его найти, но у Вилли (трутня) и у Майи (рабочей пчелы) разные
системы координат.
• Система координат Майи. Майя (слева) летит напрямую к необходимой
соте, используя продвинутую двумерную систему координат для всего улья.
• Система координат Вилли. Вили (справа) не такой умный и поэтому просто
обходит ячейки против часовой стрелки, начиная с 1 в центре улья.
Помогите Майе преобразовать систему координат Вилли в свою. Напишите
программу, которая для любого заданного номера соты определит координаты
в системе Майи.
Входные данные
Входной файл содержит одно или несколько простых чисел, каждое на своей
строке. Номер соты не превышает 100 000.
Выходные данные
Выведите координаты в системе Майи, которые соответствуют числам Вилли.
Каждая пара координат должна быть на отдельной строке.
12.6. Задачи
313
Система Майи
Система Вилли
Пример входных данных Соответствующие выходные данные
1
2
3
4
5
О О
О 1
-1 1
-1 О
О -1
12.6.5. Ограбление
PC/UValDs: 111205/707
Популярность: В
Частота успехов: средняя
Уровень:3
Инспектор Робостоп очень зол. Прошлой ночью был ограблен банк
и преступник сумел скрыться с места преступления. Настолько быстро, насколько
это было возможно, все дороги из города были перекрыты, что сделало невозмож-
невозможным для преступника бежать из города. После этого инспектор попросил всех
быть осторожными и высматривать преступника, но все, чего он добился - это
слов «Мы его не видели».
314 Глава 12. Сетки
Робостопу приказали точно узнать, как сбежал преступник. Он попросил вас
написать программу, которая будет анализировать всю имеющуюся у него информа-
информацию, чтобы выяснить, где был грабитель в каждый момент времени.
Город, в котором был ограблен банк, имеет форму прямоугольника. Все дороги,
ведущие из города, были перекрыты на некий период времени t, в течение которого
было сделано несколько докладов вида «В момент времени tf грабителя в прямо-
прямоугольнике R; не было». Полагая, что скорость преступника не превышает одну еди-
единицу за квант времени, определите его положение в каждый момент времени.
Входные данные
Входной файл описывает несколько ограблений. Первая строка каждого опи-
описания состоит из трех чисел W, Н и / A < W,H,t< 100), где W- это ширина города,
Н - высота, a t - промежуток времени, за который выезд из города был закрыт.
Следующая строка содержит одно целое число п A < п < 100), задающее число
сообщений, которое получил инспектор. Каждая из следующих п строк содержит
пять целых чисел /,, Lz-, 7}, /?,-, В;, где tt - это время, когда было проведено наблюдение
A < ti < /), и Ьь 7}, Л,-, Bt - это соответственно левая, верхняя, правая и нижняя сторо-
сторона прямоугольной области, за которой наблюдали. Точка A, 1) - это верхний левый
угол, a (W, Н) - это нижний правый угол города. Смысл сообщения в том, что граби-
грабителя не было в данном прямоугольнике в момент времени tt.
Входные данные завершаются тестовым блоком, который начинается
с W = Н = t = 0. Этот случай обрабатывать не нужно.
Выходные данные
Для каждого ограбления выведите строку мRobbery #k: ", где к- это номер
ограбления. Далее существуют три возможности.
Если преступник не может все еще находиться в городе, выведите "The robber
has escaped".
Во всех остальных случаях полагайте, что преступник все еще в городе. Выве-
Выведите строку вида "Time step т: The robber has been at x,y" для каж-
каждого момента времени, в который можно точно определить позицию; здесь х и у -
это соответственно столбец и строка координаты преступника в момент времени т.
Выведите эти строки в порядке времени т.
Если ничего нельзя установить, выведите строку "Nothing known."
и надейтесь, что инспектор не разозлится еще сильнее.
После каждого обработанного блока выведите пустую строку.
12.6. Задачи 315
Пример входных данных
4 4 5
4
1114 3
1113 4
4 113 4
4 4 2 4 4
10 10 3
1
2 1 1 10 10
0 0 0
Соответствующие выходные данные
Robbery #1:
Time step 1: The robber has been at 4,4.
Time step 2: The robber has been at 4#3.
Time step 3: The robber has been at 4,2.
Time step 4: The robber has been at 4,1.
Robbery #2:
The robber has escaped.
12.6.6. B/3/4)-ОКвад/Прям/Ку6...?
PC/UValDs: 111206/10177
Популярность: В
Частота успехов: высокая
Уровень:2
Сколько всего квадратов и прямоугольников спрятано в сетке размером 4x4,
изображенной ниже? Может, вы и сможете подсчитать их количество в уме для
такой небольшой сетки, но что для сетки 100 х 100 или больше?
А что, если увеличить количество измерений? Сможете ли вы подсчитать,
сколько кубов и параллелепипедов различных размеров в кубе 10х 10х 10 или
сколько гиперкубов и гиперпараллелепипедов содержится в четырехмерном
гиперкубе 5x5x5x5?
Ваша программа должна быть эффективной, то есть быть умной. Вам придется
считать, что квадраты - это не прямоугольники, кубы не параллелепипеды и гиперкубы
не гиперпараллелепипеды.
316
Глава 12. Сетки
/ / / /
/
/ /
Сетка 4x4
Куб 4 х 4 х 4
Входные данные
Входные данные в каждой строке содержат по одному целому числу N
@<N< 100), которое задает длину одной стороны сетки, куба или гиперкуба.
В примере выше N = 4. Число входных строк может доходить до 100.
Выходные данные
Для каждой строки входных данных выведите шесть целых чисел S2, R2, S3,
R3, S4, R4 на одной строке, где S2 означает число квадратов, a R2 - число прямо-
прямоугольников, спрятанных в двумерной (Nx N) сетке. Целые числа S3, R3, S4, R4
означают аналогичные величины для пространств более высокой мерности.
Пример входных данных
1
2
3
Соответствующие выходные данные
10 10 10
5 4 9 18 17 64
14 22 36 180 98 1198
12.6. Задачи
317
12.6.7. Дермубский треугольник
PC/UVaIDs: 111207/10233
Популярность: С
Частота успехов: высокая
Уровень:2
Дермубский треугольник - это известная на всю вселенную плоская и тре-
треугольная область на планете L-PAX в галактике Геометрии. Люди Дермубы живут
в полях, имеющих вид равносторонних треугольников со стороной ровно 1 км.
Дома строятся всегда в центрах окружностей, описанных вокруг треугольных
полей. Их дома нумеруются так, как показано на рисунке ниже.
Когда Дермубианцы навещают друг друга, они всегда идут кратчайшей доро-
дорогой от своего дома к тому дому, который им нужен. Очевидно, что кратчайшей
дорогой будет прямая, соединяющая два дома. Вот мы и подошли к вашей задаче.
Вы должны написать программу, которая будет по номерам двух заданных домов
рассчитывать длину кратчайшего пути между ними.
Входные данные
Входные данные состоят из нескольких строк с двумя неотрицательными
целыми числами пит, которые задают начало и конец пути, причем 0 < я,
т < 2 147 483 647.
Выходные данные
Для каждой строки входных данных выведите кратчайшее расстояние между
заданными домами в километрах, округленное до трех знаков после запятой.
318 Глава 12. Сетки
Пример входных данных Соответствующие выходные данные
О 7 1.528
2 8 1.528
9 10 0.577
10 11 0.577
12.6.8. Авиалинии
PC/UValDs: 111208/10075
Популярность: С
Частота успехов: высокая
Уровень:3
Ведущая авиакомпания наняла вас для написания программы, от которой тре-
требуется следующим образом обрабатывать запросы: для данного списка городов
и прямых перелетов между ними программа должна найти минимальное расстоя-
расстояние, которое нужно пролететь пассажиру, чтобы попасть из одного заданного
города в другой. Координаты городов задаются с помощью долготы и широты.
Чтобы попасть из одного города в другой, пассажир может воспользоваться
прямым перелетом, если он существует; иначе он должен предпринять серию пере-
пересадок и последовательно перебираться из одного города в другой, пока не доберется
до желаемого.
Считайте, что если пассажиру нужно совершить прямой перелет изЛГ в Y, то рас-
расстояние перелета никогда не превышает географическое расстояние между ними.
Географическое расстояние между двумя точками Хи Y- это длина сегмента геоде-
геодезической линии, соединяющего X и Y. Сегмент геодезической линии на сфере - это
кратчайшая соединительная кривая, полностью лежащая на сфере. Считайте, что
Земля представляет собой идеальный шар радиусом примерно 6378 км и что значе-
значение числа к примерно 3.141592653589793. Округляйте географическое расстояние
между любыми двумя городами до ближайшего целого числа.
Входные данные
Входные данные могут содержать несколько тестовых блоков. Первая строка
каждого тестового блока содержит три целых числа N < 100, М < 300 и Q < 10 000,
где TV задает число городов, М- число прямых перелетов, a Q - число запросов.
Следующие N строк содержат список городов; /-я из этих строк включает в себя
строку cz, за которой следуют два вещественных числа lti и lni9 задающих соответст-
соответственно имя города и его широту и долготу. Длина имени города не превышает 20 сим-
символов и не содержит разделителей. Широта может меняться в пределах от -90°
12.6. Задачи 319
(Южный полюс) до +90° (Северный полюс). Долгота может меняться в пределах от
-180° до +180°, причем отрицательные (положительные) значения задают места,
лежащие западнее (восточнее) меридиана, проходящего через Гринвич (Англия).
Следующие М строк содержат список прямых перелетов; /-я из этих строк
содержит имена двух городов at и bt, что означает, что существует прямой перелет
из города а{ в город bt. Имена и первого и второго города будут взяты из списка,
который вводился ранее.
Следующие Q строк содержат список запросов; /-я из этих строк содержит
имена двух городов а{ и Ъь запрашивая минимальное расстояние, которое пасса-
пассажиру нужно пролететь, чтобы добраться из at в Ъ{. Можете быть уверены, что оба
названия городов взяты из списка и начальный и конечный пункты не совпадают.
Входные данные завершаются тремя нулями для N,M nQ.
Выходные данные
Для каждого тестового блока сначала выведите его номер (начиная с 1), как
показано в примере выходных данных. Затем для каждого введенного запроса выве-
выведите строку, содержащую минимальное расстояние (в километрах), которое нужно
пролететь пассажиру, чтобы добраться из первого города (at) во второй F/). Если не
существует маршрута, ведущего из а{ в bi9 то просто выведите строку wno route
exists".
Между выводами для двух последовательных тестовых блоков выведите
пустую строку.
Пример входных данных
3 4 2
Dhaka 23.8500 90.4000
Chittagong 22.2500 91.8333
Calcutta 22.5333 88.3667
Dhaka Calcutta
Calcutta Dhaka
Dhaka Chittagong
Chittagong Dhaka
Chittagong Calcutta
Dhaka Chittagong
5 6 3
Baghdad 33.2333 44.3667
Dhaka 23.8500 90.4000
Frankfurt 50.0330 8.5670
Hong_Kong 21.7500 115.0000
Tokyo 35.6833 139.7333
Baghdad Dhaka
320 Глава 12. Сетки
Dhaka Frankfurt
Tokyo Hong_Kong
Hong_Kong Dhaka
Baghdad Tokyo
Frankfurt Tokyo
Dhaka Hong_Kong
Frankfurt Baghdad
Baghdad Frankfurt
0 0 0
Соответствующие выходные данные
Case #1
485 km
231 km
Case #2
19654 km
no route exists
12023 km
12.7. Подсказки
12.1. Нужно ли нам явно проходить весь путь, или мы можем найти нужную клетку
с помощью какой-то формулы?
12.2. Какой нужно выбрать граф, чтобы верно отразить цветовую структуру?
12.3. Можем ли мы найти верхний и нижний предел для каждой цифры в отдель-
отдельности?
12.4. Если мы не можем подобрать формулу для вычисления позиции в системе
Вилли, как мы можем наилучшим образом симулировать его обход, используя
явную структуру данных?
12.5. Какой нужно выбрать граф, чтобы верно отразить и пространство и время?
12.6. Как формулы для 2-D и 3-D обобщаются на 4-D? Любой ли гиперкуб всегда
можно задать двумя угловыми точками?
12.7. Как мы можем перейти от нашей предыдущей треугольной системы коорди-
координат к необходимой в этой задаче?
12.8. Имеют ли смысл расстояния, высчитанные на основании долготы/широты,
или здесь есть какая-то хитрость? Что за задача на графы лежит в основе этой?
Глава 13
Геометрия
Над воротами в академию Платона была надпись «Да не войдет сюда несведу-
несведущий в геометрии». Организаторы соревнований по программированию считают
примерно так же, поэтому вы можете рассчитывать, что как минимум одна гео-
геометрическая задача будет на каждой олимпиаде.
Геометрия по сути своей дисциплина наглядная - нужно рисовать картинки
и внимательно их изучать. Одна из проблем при программировании геометрии на
компьютере состоит в том, что некоторые «очевидные» операции, которые вы
легко производите карандашом, например нахождение пересечения двух линий,
требуют совсем не тривиального программирования, чтобы компьютер рассчитал
их правильно.
Геометрия - это такой предмет, который все изучают в средней школе и ко-
который со временем легко забывается. В этой главе мы освежим ваши знания, ис-
используя задачи по программированию, связанные с «настоящей» геометрией - прямы-
прямыми, точками, окружностями и т. д. После их изучения вы снова почувствуете себя дос-
достаточно уверенно, чтобы пройти через ворота академии Платона.
Но это еще не все. Задачи, связанные с отрезками и многоугольниками, мы от-
отложим до главы 14.
13.1. Прямые
Отрезки прямых - это кратчайшее расстояние между любыми двумя точками.
Прямые идут бесконечно в обе стороны, в противоположность конечным отрез-
отрезкам. Здесь мы ограничимся рассмотрением прямых на плоскости.
• Представление. Прямые можно представить одним из двух способов - парами
точек или уравнениями. Любая прямая / однозначно задается любыми двумя
точками (x],yj) и (х2,У2), лежащими на ней. Также прямые однозначно задаются
уравнениями вида у = тх + 6, где т задает наклон прямой, а Ъ - отрезок, отсе-
отсекаемый на оси у от начала координат (у - intercept), то есть единственную точку
11-972
322 Глава 13. Геометрия
(О, Ь), где прямая пересекает ось х. Прямая 1 имеет наклон рав]ный
т = Ау/ Ах = (ух - у2)/(х] -х2) nb^yj-mxj.
Но вертикальные прямые уравнениями такого вида не описываются, так как
для них Ах равняется 0. Равенство х = с задает вертикальную прямую, которая
пересекает ось х в точке (с, 0). Такой случай называется вырождением и
требует к себе особого внимания при программировании геометрии. В качест-
качестве основы для нашей прямой мы используем формулу более общего вида:
ах + by + с = 0, поскольку она позволяет задавать все возможные типы
прямых на плоскости.
typedef struct {
double a
double b
double с
/* коэффициент при х */
/* коэффициент при у */
/* свободный член */
} line;
Умножив все три коэффициента на ненулевую константу, получим еще одно
представление этой же прямой. Мы введем каноническое представление
прямой - коэффициент при у должен быть равен 1, если он ненулевой. Иначе
коэффициент при х должен быть равен 1.
points_to_line(point pi, point p2, line *1)
{
if (pl[X] == p2[X]) {
l->a = 1;
l->b = 0;
l->c = -pl[X];
} else {
l->b = 1;
l->a = -(pl[Y]-p2[Y])/(pl[X]-p2[X]);
l (l * l[X]) (lb * l[])
point_and_slope_to_line(point p, double m, line *1)
{
l->a = -m;
l->b = 1;
l->c = -((l->a*p[X]) + (l->b*p[Y]));
}
Пересечение. У двух различных непараллельных прямых имеется единственная
точка пересечения. У параллельных прямых точек пересечения нет, они имеют
одинаковый наклон, но отсекают различные отрезки на оси у и по определению
не пересекаются.
13.1. Прямые 323
bool parallelQdine 11, line 12)
{
return ( (fabsA1.a-12.a) <= EPSILON) &&
(fabsA1.b-12.b) <= EPSILON) );
}
bool same_lineQ(line 11, line 12)
{
return ( parallelQ(ll,12) && (fabs(ll.c-12.c) <= EPSILON) );
}
Точка (x\ yf) лежит на прямой I :y = mx, если при подстановке х' в уравнение
получим у'. Точкой пересечения прямых l\iy = mxj + bj и 12-У = т*2 + ^2
называется точка, где они совпадают, а именно:
Ъ2-Ъх Ъ2-Ъх ,
х = — -, у = тх — - + Ъх
intersection_jpoint(line 11, line 12, point p)
{
if (same_lineQ(ll,12)) {
printf ("Warning: Identical lines, all points intersect. \n") ;
p[X] = p[Y] = 0.0;
return;
}
if (parallelQ(ll,12) == TRUE) {
printf ("Error: Distinct parallel lines do not intersect. \n") ;
return;
}
p[X] = A2.b*ll.c - ll.b*12.c) / A2.a*ll.b - ll.a*12.b);
if (fabs A1.b) > EPSILON) /* проверка на
вертикальную линию */
p[Y] = - A1.а * (р[Х]) л 11.с) / 11.Ь;
else
p[Y] = - A2.а * (р[Х]) + 12.с) / 12.Ь;
}
Углы. Любые две непараллельные прямые пересекаются под определенным
углом. Прямые 1\ : ахх + Ъ\у + с\ = 0 и 12 : а^х + Ъу + с2 = 0, записанные в общей
форме, пересекаются под углом в, который находится по формуле
324 Глава 13. Геометрия
Для прямых, записанных через наклон и отсекаемый отрезок, эта формула
сводится к tan в = — .
тхт2 + 1
Две прямые называются перпендикулярными, если они пересекаются под
прямым углом. Например, оси х и у декартовой системы координат взаимно
перпендикулярны, так же как и прямыеу = хиу = -1/х. Прямая, перпендику-
перпендикулярная l:y = mx + b, находится по формуле у = (-\/т)х + Ь\ здесь V может
принимать любые значения.
Ближайшая точка. Очень полезной подзадачей оказывается нахождение на
прямой / точки, ближайшей к точке/?. Такая точка лежит на прямой, проходя-
проходящей через точку р и перпендикулярной прямой /, поэтому мы можем ее найти,
использовав те функции, которые мы уже написали:
closest__point (point p_in, line 1, point p_c)
lineperp; /* перпендикуляр к 1 через (х,у) */
if (fabs(l.b) <= EPSILON) { /* вертикальная прямая */
P_c[X] = -(l.c);
p_c[Y] = p_in[Y];
return;
if (fabs(l.a) <= EPSILON) { /* горизонтальная прямая */
P_c[X] = p_in[X];
p_c[Y] = -(l.c);
return;
point_and_slope_to_line(p_in,1/1.a,&perp); /* общий
случай */
intersection_point(l/perp/p_c);
Лучи. Лучами называются полупрямые, начинающиеся из некоторой точки v,
называемой началом луча. Любой луч однозначно задается уравнением прямой,
началом и направлением или началом и другой точкой, лежащей на луче.
13.2. Треугольники и тригонометрия 325
13.2. Треугольники и тригонометрия
Углом называется совокупность двух лучей, имеющих общее начало. Тригоно-
Тригонометрией называется раздел математики, который занимается углами и их измерением.
Для измерения углов существуют две общепринятые единицы измерения: гра-
градусы и радианы. Полный диапазон измерения углов изменяется от 0 до 2к радиан
и, что аналогично, от 0 до 360°. Использование радианов предпочтительнее с
вычислительной точки зрения, поскольку, как мы увидим в разделе 13.5, матема-
математические библиотеки считают, что углы измеряются в радианах. Тем не менее
стоит признать, что нам привычнее думать в градусах. Исторически дробные
части градусов измеряются в минутах, причем одна минута равна 1/60 градуса.
Счет с такими величинами чересчур неудобен, поэтому радианы (или хотя бы де-
десятичные градусы) предпочтительнее для работы.
Геометрия треугольников («три угла») тесно связана с тригонометрией, поэто-
поэтому ниже мы будем обсуждать их вместе.
13.2.1. Прямоугольные треугольники и теорема Пифагора
Прямой угол равен 90°, или я 12 радиан. Прямые углы образуются при пере-
пересечении перпендикулярных прямых, таких, как оси в прямоугольной системе ко-
координат. Такие прямые делят 360° = 2я* радиан на четыре равные части.
Любые два луча с общим началом на самом деле задают два угла: внутренний
угол, равный а радиан, и внешний угол, равный 2п — а радиан. Обычно нас будут
интересовать внутренние углы. Три внутренних (меньших) угла любого треуголь-
треугольника в сумме равны 180°, или п радиан, а значит, в среднем внутренний угол
равен 60° = п73 радиан. Треугольники с тремя равными углами называются рав-
равносторонними и уже обсуждались в разделе 12.2.
Треугольник называется прямоугольным, если один из его внутренних углов -
прямой. С прямоугольными треугольниками достаточно работать с помощью
теоремы Пифагора, которая позволит нямтм гтгтмну третьей стороны на основа-
основании длин двух других. Конкретно \а\ + |й|" = \с\ , где а и Ъ - это две меньшие
стороны, а с - самая длинная сторона, называемая гипотенузой.
Можно достаточно долго исследовать треугольники с помощью теоремы
Пифагора. Но мы можем пойти еще дальше с помощью тригонометрии.
13.2.2. Тригонометрические функции
Тригонометрические функции синус и косинус определяются как х- и ^-координа-
^-координата точек на единичной окружности с центром в точке @, 0), как показано на рис. 13.1
(слева). Таким образом, синус и косинус могут принимать значения от -1 до 1. Более
того, эти две функции на самом деле одно и то же, так как cos(#) = sin(# -f к 12).
326
Глава 13. Геометрия
Противолежащий катет
Гипотенуза
Прилежащий катет
Рис. 13.1. Определение синуса и косинуса (слева). Обозначения сторон прямоугольного
треугольника (справа)
Третья важная тригонометрическая функция - это тангенс, определяемый как
отношение синуса и косинуса. Таким образом, tan(#) = sin(#)/cos(#) и все
в порядке, за исключением случаев, когда cos(#) = 0 при 6= nil и в - Ъп 12.
Эти функции позволяют нам связать длины любых двух сторон прямоугольного
треугольника Тс его непрямыми углами. Вспомните, что гипотенуза прямоугольно-
прямоугольного треугольника Т - это его самая длинная сторона, и она лежит напротив прямого
угла. Другие две стороны Т могут быть обозначены как прилежащая и противоле-
противолежащая по отношению к данному ушу а, как показано на рис. 13.1 (справа). Тогда
cos(a) =
\прилежащая\
\гипотенуза\
\противолежащая\
\гипотенуза\
\прилежащая\
\противолежащая\
Эти соотношения стоят того, чтобы их запомнить. Хотя в них не было бы
особой пользы, если для синуса, косинуса и тангенса не существовало бы обрат-
обратных функций для нахождения углов. Обратные функции носят название арксинус,
арккосинус и арктангенс соответственно. С их помощью мы можем рассчитать
все углы прямоугольного треугольника по длинам двух его сторон.
Эти тригонометрические функции корректно рассчитываются с помощью рядов
Тейлора, но не беспокойтесь - математическая библиотека вашего любимого языка
программирования уже содержит их. Тригонометрические функции могут быть
численно неустойчивы, так что arccos(cos (в)) не всегда строго равняется в, осо-
особенно для больших и для малых углов.
13.2. Треугольники и тригонометрия
327
Рис. 13.2. Обозначения для решения треугольников (слева) и нахождения их площади
(справа)
13.2.3. Решение треугольников
Две тригонометрические теоремы позволяют нам рассчитывать важные свой-
свойства треугольников. Теорема синусов формулирует соотношения между сторона-
сторонами и углами в любом треугольнике. Для углов А, В, С и противоположных сторон
а, 6, с (см. рис. 13.2 (слева):
а Ъ с
sin A sin В sin С
Теорема косинусов - это обобщение теоремы Пифагора для непрямых углов.
Для любого треугольника с углами А, В, Си противоположными сторонами а, Ь, с
a2 =b2 +c2 -2bccosA.
Решением треугольника называется нахождение всех его углов и сторон, если
известны значения некоторых из них. Такие задачи подразделяются на две категории.
• По двум углам и стороне найти все остальное. Третий угол находится
просто, так как три угла в сумме должны давать 180° — п радиан. Затем
недостающие стороны можно найти из теоремы синусов.
• По двум сторонам и углу найти все остальное. Если заданный угол находится
между заданными сторонами, то мы можем найти длину неизвестной стороны
из теоремы косинусов. Затем из теоремы синусов найдем недостающие углы.
Иначе, мы можем воспользоваться теоремой синусов и свойством суммы углов,
чтобы найти все углы в треугольнике, а затем найти недостающую сторону по
теореме синусов.
328 Глава 13. Геометрия
к
с.
av 1
У
= ахЪу - (
'Л -
Площадь А(Т) треугольника Гнаходится по формуле А(Т) = (l/2)ab, где а - это
высота, а Ъ - основание треугольника. Основанием может быть любая из сторон,
тогда как высота - это расстояние от третьей вершины до этого основания, как по-
показано на рис. 13.2 (справа). Эта высота легко находится из соображений тригоно-
тригонометрии или теоремы Пифагора в зависимости от известных величин.
Другим подходом будет найти площадь треугольника на основании его ко-
координатного представления. Используя линейную алгебру и определители, можно
показать, что площадь со знаком А(Т) треугольника Т= (а, Ь, с):
2А(Т) =
Эта формула просто обобщается для подсчета d! раз объема симплекса в d из-
измерениях.
Обратите внимание, что площадь со знаком может принимать отрицательные
значения, так что мы должны взять модуль этой величины, если хотим найти на-
настоящую площадь. Так и должно быть, это не ошибка. Мы увидим, для чего может
пригодиться знак площади при построении важных примитивов для вычисли-
вычислительной геометрии, в разделе 14.1.
double signed_triangle_area(point a, point b, point с)
{
return! (a[X]*b[Y] - a[Y]*b[X] + a[Y]*c[X]
- a[X]*c[Y] + b[X]*c[Y] - c[X]*b[Y]) / 2.0 );
}
double triangle_area(point a, point b, point c)
{
return( fabs(signed_triangle_area(a,b,c)) );
13.3. Окружности
Окружность - это геометрическое место точек, находящихся на заданном
расстоянии (называемом радиусом) от ее центра (хс, ус). Круг - это окружность
и все, что находится внутри нее, иначе говоря, геометрическое место точек, нахо-
находящихся от центра на расстоянии, не превосходящем г.
13.3. Окружности 329
• Представление. Окружность можно представить двумя простыми способами:
либо тремя точками, лежащими на ней, либо центром/радиусом. Для боль-
большинства приложений представление через центр/радиус самое удобное:
typedef struct {
point с; /* центр окружности */
double г; /* радиус окружности */
} circle;
Уравнение окружности можно получить прямиком из этого представления.
Так как расстояние между двумя точками на плоскости равняется
+(у]-у2) , уравнение окружности радиусом г имеет вид
г = лД* ~ хс) + (У ~ Ус) , или, что то же самое, г2 = (х - хсJ + (у - усJ,
чтобы избавиться от корня.
Длина окружности и площадь. Многие важные величины, связанные
с окружностями, вычисляются очень просто. И площадь А, и длина окружно-
окружности С зависят от магической постоянной п- 3.1415926. Формулы выглядят
так: А = л -г1 и С -2п г. Запоминать числор с большим числом знаков не
имеет смысла. Диаметр или отрезок максимальной длины, помещающийся
в окружности, равен просто 2г.
Касательные. Чаще всего прямая / пересекает окружность либо в двух
точках, либо ни в одной; в первом случае прямая пересекает внутренность
окружности, во втором проходит мимо совсем. Единственный оставшийся
случай - когда прямая пересекает окружность с, но не имеет общих точек
с областью, находящейся внутри окружности. Такие прямые называются
касательными.
Построение касательной / к окружности с, проходящей через точку О, показано
на рис. 13.3. Точка касания лежит на прямой, перпендикулярной / и проходящей
через центр окружности с. Так как треугольник со сторонами r,d,x- прямоуголь-
прямоугольный, мы можем найти неизвестную величину х из теоремы Пифагора. Зная х, мы
можем найти точку касания и угол а. Расстояние d от точки О до центра находится
по формуле расстояния между двумя точками.
Пересекающиеся окружности. Две окружности Cj и с^ с различными радиусами
rj и г2 могут взаимодействовать несколькими способами. Окружности будут
пересекаться тогда и только тогда, когда расстояние между их центрами не
превышает суммы радиусов1. Меньшая окружность (скажем, Cj) будет лежать
не меньше | rj-r2 |. - Примеч. науч. ред.
330
Глава 13. Геометрия
внутри большей тогда и только тогда, когда расстояние между их центрами
плюс г/ не превышает г2. Оставшийся случай - если с у и с2 пересекаются в двух
точках. Как показано на рис. 13.4,точки пересечения и центры окружностей
образуют треугольники с полностью заданными сторонами (т*у, г2 - расстояние
между центрами окружностей), так что при необходимости все углы и коор-
координаты могут быть найдены2.
Рис. 13.3. Построение касательной к окружности, проходящей через точку О
Рис. 13.4. Точки пересечения двух окружностей
2Часто в задачах необходимо рассматривать два случая пересечения: когда центр одной окружности находится
внутри другой и когда вне. - Примеч. науч. ред.
13.4. Пример разработки программы: быстрее пули 331
13.4. Пример разработки программы: быстрее пули
Супермен обладает по крайней мере двумя возможностями, недоступными
обычным смертным: рентгеновское зрение и возможность летать быстрее пули.
Некоторые из его оставшихся возможностей не столь впечатляющи: вы или я тоже
могли бы переодеваться в телефонной будке, если бы в этом была необходимость.
Супермен жаждет продемонстрировать свои способности между его текущим
положением s = (xs,ys) и желаемым t = (xt,yt). Все вокруг заполнено препятствиями
в форме круга (цилиндра). Рентгеновское зрение Супермена имеет ограниченную
дальность действия, которая зависит от количества вещества, сквозь которое он
должен посмотреть. Он хочет вычислить общую длину пересечений с препятствиями
между двумя точками, чтобы понять, демонстрировать ему свой трюк или нет.
Рис. 13.5. План полета Супермена и связанная с ним толщина препятствий
После этого Стальной человек хочет пролететь от его текущего положения до
желаемой точки. Он может видеть сквозь объекты, но не пролетать сквозь них.
Его путь (рис. 13.5) идет по прямой к цели до тех пор, пока он не наталкивается на
препятствие. Далее он облетает препятствие по его границе, пока не вернется на
прямую линию, соединяющую начальную точку и конечную. Это, конечно, не
кратчайший, свободный от препятствий путь, но Супермен не совсем дурак - он
всегда выбирает кратчайшую из двух возможных дуг.
Вы можете считать, что препятствия не пересекаются и начальная и конечная
точки не находятся внутри препятствий. Окружности задаются через координаты
центра и радиус.
332
Глава 13. Геометрия
Решение начинается ниже
Для решения этой задачи нам требуются три основные геометрические операции.
Мы должны уметь A) проверять, пересекает ли данная окружность прямую /, прохо-
проходящую через начальную и конечную точки, B) вычислять длину хорды, получившейся
в результате пересечения, и C) вычислять длину меньшей дуги, получившейся в ре-
результате пересечения окружности прямой /.
Первая задача относительно проста. Найдем длину кратчайшего пути от центра
окружности до прямой /. Если она меньше радиуса, то они пересекаются; если боль-
больше, то нет. Чтобы понять, лежит ли это пересечение между s и /, достаточно
посмотреть, лежит ли ближайшая к центру окружности, принадлежащая / точка
внутри прямоугольника, задаваемого s и /.
Измерение того, что получилось в результате пересечения, кажется более слож-
сложным. Мы могли бы найти координаты точек пересечения прямой и окружности.
Хотя это и можно сделать, приравняв уравнения окружности и прямой и решив
получившееся квадратное уравнение, но это ведет к излишним сложностям. Обычно
геометрический способ решения задачи проще, чем напрямую, найдя координаты
всех точек.
Такой простой способ для нашей задачи показан на рис. 13.6. Длина хорды,
получившейся в результате пересечения, на чертеже равна 2х. Мы знаем, что d -
кратчайшее расстояние от центра окружности до / - лежит на прямой, перпендику-
перпендикулярной /. Таким образом, все четыре угла, получившиеся в результате пересечения, -
прямые, включая два угла, принадлежащие треугольникам со сторонами г, d и х.
Значит, х мы можем найти из теоремы Пифагора.
Рис. 13.6. Вычисление длин хорды и дуги, получившихся в результате пересечения
Искомую длину дуги можно найти из угла а этого треугольника. Дуга, которая нас
интересует, определяется углом 2а (в радианах), значит, ее длина равняется Bа)/Bя)
частей от полной длины окружности, которая равна 2пг. Угол легко находится из
сторон треугольника с помощью обратных тригонометрических функций.
13.4. Пример разработки программы: быстрее пули
333
Если подойти к задаче так, то с использованием функций, созданных ранее,
решение становится очень простым:
point s;
point t;
int ncircles;
circle c[MAXN]
/* начальное положение Супермена */
/* желаемое положение */
/* число окружностей */
/* структура данных для хранения
окружностей */
/* прямая от начальной позиции до
конечной */
/* ближайшая точка */
/* расстояние от центра окружности */
/* длина пересечений с окружностями */
/* длина Дуг окружностей */
/* угол, стягивающий дугу */
/* общая длина полета */
/* счетчик */
superman()
line 1;
point close;
double d;
double xray = 0.0;
double around = 0.0;
double angle;
doub1e travel;
int i ;
double asin(), sqrt();
double distance();
points_to_line(s,t,&1)
for (i=l; i<=ncircles;
closest_point(c[i].c,1,close);
d = distance(c[i].c,close);
if ((d>=0) ScSc (d < c[i].r) && point_in_box (close, s, t) ) {
xray += 2*sqrt(c[ij.r*c[i].r - d*d);
angle = acos(d/c[i].r);
around += (B*angle)/B*PI)) * B*PI*c[i].r);
travel = distance(s,t) - xray + around;
printf ("Superman sees thru %7 .3If units, and flies %7 .31f units\n"
xray, travel);
334 Глава 13. Геометрия
13.5. Библиотеки тригонометрических функций
Тригонометрические библиотеки всех языков программирования очень близ-
близки. Вам необходимо знать, с градусами или с радианами работают функции вашей
библиотеки и в каком диапазоне лежат значения углов, возвращаемые обратными
тригонометрическими функциями.
Тригонометрические функции в C/C++
Стандартная математическая библиотека C/C++ math. h включает все необхо-
необходимые функции. Не забывайте включать ее в свои программы, чтобы все работало
корректно.
#include <math.h>
double cos(double x); /* вычисляет косинус х радиан */
double acos(double x); /* вычисляет арккосинус [-1;1] */
double sin(double x); /* вычисляет синус х радиан */
double asin(double x); /* вычисляет арксинус [-1;1] */
double tan(double x); /* вычисляет тангенс х радиан */
double atan(double x) ; /* вычисляет основной арктангенс х */
double atan2 (double y, double x) ; /* вычисляет арктангенс у/х */
Основная причина для введения двух разных функций арктангенса - это коррект-
корректное определения четверти, в которой лежит угол. Она зависит от знаков х и у.
Тригонометрические функции в Java
Тригонометрические функций Java находятся в Java. lang.Math, причем
считается, что углы задаются в радианах. Также имеются библиотечные функции
для перевода градусов в радианы и наоборот. Все функции статические и делают
примерно то же, что и функции библиотеки C/C++.
double cos (double а) Возвращает тригонометрический косинус угла а.
double acos(double а) Возвращает арккосинус а, [0,pi].
double sin (double а) Возвращает тригонометрический синус угла а.
double asin(double а) Возвращает арксинус a, [-pi/2 , pi/2] .
double tan (double а) Возвращает тригонометрический тангенс
угла а.
double atan (double а) Возвращает арктангенс a, [-pi/2 ,pi/2] .
double atan2(double a, double b) Аналогично С.
double toDegrees (double angrad) Переводит радианы в градусы,
double toRadians (double angdeg) Переводит градусы в радианы.
13.6. Задачи 335
13.6. Задачи
13.6.1. Суслик и собака
PC/UVaIDs: 111301/10310
Популярность: А
Частота успехов: средняя
Уровень: 1
На большом поле находятся суслик и собака. Собака хочет суслика съесть, а суслик
хочет оказаться в безопасности, добежав до одной из норок, выкопанных в поле.
Ни собака, ни суслик в математике не сильны; но, с другой стороны, они и не
беспросветно глупы. Суслик выбирает определенную норку и бежит к ней по
прямой с определенной скоростью. Собака, которая очень хорошо понимает язык
телодвижений, угадывает, к какой норке бежит суслик, и устремляется к ней со
скоростью вдвое большей скорости суслика. Если собака добегает до норки
первой, то она съедает суслика; иначе суслик спасается.
Суслик вас нанял, чтобы вы выбрали норку, в которой он может спастись, если
таковая существует.
Входные данные
Входной файл содержит несколько наборов входных данных. Первая строка
каждого набора содержит одно целое число и четыре числа с плавающей запятой.
Целое число п задает количество норок. Четыре числа с плавающей запятой
задают (х, у) координаты суслика, за которыми следуют (х, у) координаты собаки.
Каждая из п следующих строк входных данных содержит два числа с плавающей
запятой: (х, у) координаты норки. Все расстояния измеряются в метрах с точно-
точностью до миллиметра. Входные данные завершаются концом файла, и между двумя
наборами входных данных расположена пустая строка.
Выходные данные
Для каждого набора входных данных выведите одну строку. Если у суслика
имеется возможность спастись, строка должна выглядеть так: "The gopher
can escape through hole at (x,y) . ", причем должна быть указана бли-
ближайшая норка с точностью до миллиметра. Иначе выведите строку "The
gopher cannot escape. ". Если у суслика есть возможность спрятаться
в нескольких норках, выведите ту, которая первая шла во входных данных. Набор
входных данных содержит не более 1000 норок, и все координаты могут изме-
изменяться в диапазоне от -10 000 до +10 000.
336
Глава 13. Геометрия
Пример входных данных
1 1.000 1.000 2.000 2.000
1.500 1.500
2 2.000 2.000 1.000 1.000
1.500 1.500
2.500 2.500
Соответствующие выходные данные
The gopher cannot escape.
The gopher can escape through
the hole at B.500,2.500).
13.6.2. Проблема с канатами в Канатово
PC/UVaIDs: 111302/10180
Популярность: В
Частота успехов: средняя
Уровень:2
Перетягивание каната - это очень популярная игра в Канатово, почти как крикет
в Бангладеш. Две команды игроков тянут канат за разные концы. Та группа, которая
сумеет вырвать канат из рук противников, объявляется победителем.
Из-за дефицита канатов сельский староста объявил, что командам не позволя-
позволяется покупать канат большей длины, чем им это необходимо.
Перетягивание каната проводится в большой комнате, в которой стоит большая
круглая колонна заданного радиуса. Если две команды находятся с разных сторон
колонны, то канат не может иметь форму прямой линии. По заданным позициям
двух команд определите минимальную длину каната, необходимую, чтобы начать
соревнования по перетягиванию. Вы можете считать, что позиция каждой команды
задается точкой.
(X1.Y1)
(X1.Y1)
(X2.Y2)
(X2.Y2)
Две команды, отделенные
друг от друга колонной
Две команды, которым
колонна не мешает
13.6. Задачи 337
Входные данные
Первая строка входного файла содержит целое число N, задающее количество
блоков входных данных. Далее следуют N строк, каждая из которых содержит пять
чисел Xj, Yj, Х2, Y2 и R, где (Xj, Yj) и (Х2, Y2) задают позиции команд, a R > 0 - это
радиус колонны.
Центр колонны всегда находится в начале координат, и начальная позиция ни
одной из команд никогда не лежит внутри круга колонны. Все входные данные, за
исключением N, - это числа с плавающей запятой, и модуль каждого < 10 000.
Выходные данные
Для каждого блока входных данных выведите строку, содержащую число
с плавающей запятой, округленное до третьего знака после запятой и задающее
минимальную необходимую длину веревки.
Пример входных данных Соответствующие выходные данные
2 3.571
11-1-11 2.000
11-111
13.6.3. Рыцари Круглого стола
PC/UVaIDs: 111303/10195
Популярность: А
Частота успехов: средняя
Уровень: 2
Король Артур собирается поставить круглый стол в комнате с треугольным
окном в потолке. Он хочет, чтобы солнце попадало на его круглый стол. В частно-
частности, он хочет, чтобы, когда солнце в полдень находилось прямо над окном, стол
был освещен полностью.
Таким образом, стол необходимо поставить в определенной треугольной части
комнаты. Конечно, король хочет, чтобы его стол был максимально возможного размера.
Так как Мерлин отошел пообедать, напишите программу, которая находит радиус
наибольшего круглого стола, входящего по размерам в освещенную солнцем область.
Входные данные
Входные данные содержат произвольное число тестовых блоков, каждый из
которых состоит из трех вещественных чисел (я, Ъ и с), задающих длины сторон
треугольной области. Длина ни одной из сторон не превышает 1 000 000, и вы
можете считать, что тах( я, Ь, с) < (а + Ъ + с) 12.
Вы должны считывать входные данные пока не дойдете до конца файла.
338 Глава 13. Геометрия
Выходные данные
Для каждой считанной конфигурации комнаты вы должны вывести строку
следующего содержания:
The radius of the round table is: r,
где г - это радиус наибольшего круглого стола, который помещается в освещен-
освещенную солнцем область, округленный до трех десятичных цифр.
Пример входных данных Соответствующие выходные данные
12.0 12.0 8.0 The radius of the round table is: 2.82 8
13.6.4. Шоколадное печенье
PC/UVaIDs: 111304/10136
Популярность: С
Частота успехов: средняя
Уровень: 3
Чтобы приготовить шоколадное печенье, замешивают тесто из муки, соли,
масла, пищевой соды и маленьких кусочков шоколада, которое затем раскатывают
в плоский квадрат со стороной примерно 50 см. Затем из этого квадрата выре-
вырезаются круглые печенья, которые помещаются на противень и запекаются
в духовке примерно 20 мин. Когда печенья готовы, их достают и дают им остыть.
Из всего этого нас интересует процесс вырезания первого печенья, после того
как тесто было раскатано. На плоском тесте видно все кусочки шоколада, так что
нам нужно просто поместить нож в виде окружности так, чтобы количество
кусочков шоколада в первом печенье было максимальным.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное
целое число, которое означает количество тестовых блоков, за которой следует
пустая строка. Между двумя последовательными блоками входных данных также
находится пустая строка.
Каждый тестовый блок состоит из некоторого числа строк, каждая из которых
содержит два числа с плавающей запятой, задающих (х,у) координаты кусочка шоко-
шоколада в плоскости теста. Каждая координата лежит в диапазоне от 0.0 до 50.0 (см).
Каждый кусочек шоколада можно считать точкой; то есть это не то печенье, которое
будет подаваться к столу президента. Всего таких кусочков шоколада не более 200.
13.6. Задачи
339
Выходные данные
Для каждого тестового блока выходные данные состоят из одного целого числа:
максимального количества кусочков шоколада, которое может содержаться в круглом
печенье диаметром 5 см. Печенье не обязательно должно целиком находиться в квад-
квадрате теста со стороной 50 см (то есть у него могут быть плоские стороны).
Выходные данные для двух последовательных тестовых блоков должны быть
разделены пустой строкой.
Пример входных данных
Соответствующие выходные данные
4.0
4.0
5.0
1.0
1.0
1.0
1.0
1.0
4.0
5.0
6.0
20.0
21.0
22.0
25.0
26.0
13.6.5. Именинный пирог
PC/UVaIDs: 111305/10167
Популярность: С
Частота успехов: средняя
Уровень:2
Люси и Лили - близнецы. Сегодня у них день рождения, поэтому мама покупает
им именинный пирог. На пироге расположено 2N вишенок, причем 1 < N < 50. Мама
хочет поделить пирог на две части одним прямым разрезом, проходящим через
центр пирога, так, чтобы каждой девочке досталось одинаковое количество пирога
и одинаковое количество вишенок. Вы не могли бы ей помочь?
4 Y
340
Глава 13. Геометрия
Радиус пирога равен 100, а его центр расположен в точке @, 0). Координаты
каждой вишенки задаются двумя целыми числами (х,у). Вы должны найти
прямую вида Ах + By = 0, где и А и В - целые числа из диапазона [-500, 500].
Вишенки не могут лежать на разрезе. Для каждого тестового блока имеется, по
крайней мере, одно решение.
Входные данные
Входной файл содержит несколько тестовых блоков. Первая строка каждого
блока содержит целое число N. Далее следуют 2N строк, каждая из которых содержит
(х, у) координаты одной вишенки, разделенные одним пробелом. Входные данные
завершаются блоком cN=0.
Выходные данные
Для каждого тестового блока выведите строку, содержащую А и В, разделен-
разделенные пробелом. Если существует несколько решений, то подойдет любое.
Пример входных данных
Соответствующие выходные данные
0 1
2
-20 20
-30 20
-10 -50
10 -5
0
13.6.6. Самая большая/маленькая коробка...
PC/UValDs: 111306/10215
Популярность: А
Частота успехов: средняя
Уровень: 2
На рисунке показан прямоугольный кусок картона шириной W, длиной L и толщи-
толщиной 0. Из четырех углов по пунктирным линиям вырезаются квадраты размером х х х.
Затем картон сгибается по штриховым линиям, чтобы получилась открытая коробка.
13.6. Задачи 341
По заданным высоте и ширине куска определите значения х, при которых
коробка имеет максимальный и минимальный объем.
Входные данные
Входной файл содержит несколько строк входных данных. Каждая строка
содержит два положительных числа с плавающей запятой L @<Z<10 000)
и W @ < W < 10000), которые задают длину и ширину куска соответственно.
Выходные данные
Для каждой строки входных данных выведите одну строку, содержащую два
или более чисел с плавающей запятой, отделенных друг от друга одним пробелом.
Каждое число с плавающей запятой должно содержать три цифры после деся-
десятичной точки. Первое число задает величину, которая позволяет добиться макси-
максимального объема коробки, а следующие числа (отсортированные в порядке
возрастания) задают величины разрезов, которые позволяют получить коробку
минимального объема.
Пример входных данных Соответствующие выходные данные
1 1 0.167 0.000 0.500
2 2 0.333 0.000 1.000
3 3 0.500 0.000 1.500
13.6.7. Это интегрирование?
PC/UVaIDs: 111301/10310
Популярность: А
Частота успехов: высокая
Уровень:3
На рисунке ниже показан квадрат ABCD, у которого АВ = ВС = CD = DA = a.
Рисуются четыре дуги: точки А, В, С, D берутся в качестве центров, а а в качестве
радиуса. Дуга, центром которой является точка А, начинается в соседней вершине
В и заканчивается в соседней вершине D. Оставшиеся дуги рисуются таким же
образом. При этом получаются области трех разных форм. Вам нужно подсчитать
полную площадь областей разной формы.
Входные данные
Каждая строка входного файла содержит число с плавающей точкой я, задающее
длину стороны квадрата, причем 0<а< 10000.0. Входные данные завершаются
концом файла.
342
Глава 13. Геометрия
Выходные данные
Для каждого тестового блока выведите на одной строке площади областей разной
формы, показанных на рисунке, приведенном выше. Каждое число с плавающей
запятой должно выводиться с тремя знаками после десятичной точки. Первое число
для каждого тестового блока должно обозначать площадь «полосатой» области,
второе - общую площадь областей, заполненных точками, а третье число - остав-
оставшуюся площадь.
Пример входных данных
Соответствующие выходные данные
0.1
0.2
0.3
0.003 0.005 0.002
0.013 0.020 0.007
0.028 0.046 0.016
13.6.8. Насколько она большая?
PC/UVaIDs: 111308/10012
Популярность: В
Частота успехов: низкая
Уровень:3
Ян собирается в Калифорнию, и ему нужно собрать свои вещи, включая его
коллекцию кругов. Для заданного набора кругов ваша программа должна найти
наименьшую прямоугольную коробку, в которую она поместится.
Все круги должны касаться дна коробки. Рисунок ниже показывает приемле-
приемлемый способ упаковки для набора кругов, хотя, возможно, для данных конкретных
кругов это не оптимальный способ. При идеальной упаковке каждый круг должен
касаться, по меньшей мере, одного другого, впрочем, наверное, это вы уже поняли
из рисунка.
13.6. Задачи
343
Входные данные
Первая строка входных данных содержит одно положительное десятичное
целое число п, п < 50. Оно задает количество тестовых блоков, следующих далее.
Каждая из следующих п строк содержит набор чисел, разделенных пробелами.
Первое число в каждой из этих строк - это положительное целое число т, т < 8,
которое задает, сколько еще чисел будет в этой строке. Следующие т чисел в этой
строке задают радиусы кругов, которые нужно упаковать в одну коробку. Эти
числа не обязаны быть целыми.
Выходные данные
Для каждого тестового блока ваша программа должна вывести размер минималь-
минимального прямоугольника, в который поместятся круги. Вьшод для каждого блока должен
находиться на отдельной строке и содержать три знака после десятичной точки.
Не выводите начальные нули, если только число не меньше 1, например 0.543.
Пример входных данных
3
3 2.0 1.0 2.0
4 2.0 2.0 2.0 2.0
3 2.0 1.0 4.0
Соответствующие выходные данные
9.657
16.000
12.657
344 Глава 13. Геометрия
13.7. Подсказки
13.1. Верно ли, что ближайшая норка на самом деле самая безопасная?
13.2. Поможет ли нахождение прямых, касающихся колонны?
13.3. Сколько сторон треугольника должны касаться стола?
13.4. Всегда ли мы можем поместить режущий круг так, чтобы некоторые кусочки
находились на его границе? Если да, то сколько будет таких кусочков? Описы-
Описывает ли это плюс радиус все «интересные» положения резальной машины?
13.5. Решение этой задачи существует всегда, если снять ограничение на целость
Aw В,- можете ли вы это доказать? Существует ли более эффективное решение,
чем просто перебор всех возможных пар АкВ1
13.6. Чему равны значения х, при которых достигается минимальный объем
коробки? Нужны ли вычисления для получения максимального объема?
13.7. Можем ли мы использовать включение-исключение для получения площа-
площадей сложных областей из частей, площадь которых просто найти?
13.8. Что лучше - размещать круги от большего к меньшему или чередовать их?
Существуют ли случаи, когда порядок не важен? Поможет ли перебор с воз-
возвратом в решении этой задачи?
Глава 14
Вычислительная геометрия
В последнее время геометрические расчеты становятся все более и более важ-
важными в таких приложениях, как компьютерная графика, робототехника
и автоматизированная разработка, потому что форма объекта - это одно из его ос-
основных свойств. Но большинство реальных объектов в нашем мире составлены не
из прямых, идущих в бесконечность. Вместо этого большинство компьютерных
программ работают с графикой, как с набором отрезков. Произвольные замкнутые
кривые или формы могут быть представлены упорядоченным набором отрезков
прямых или многоугольником.
Вычислительную геометрию можно определить (для наших целей) как гео-
геометрию отдельных отрезков и многоугольников. Это забавный и интересный
предмет, но ему обычно не уделяют много внимания в стандартных курсах. То,
что мы изучим, позволит заинтересованному студенту чувствовать себя уверен-
увереннее на олимпиадах по программированию и откроет ему окно в увлекательную
область алгоритмов, которые до сих пор находятся в стадии активного изучения.
Существуют прекрасные книги по вычислительной геометрии [O'ROO,
dBvKOSOO], но для начала вам должно хватить этой главы.
14.1. Отрезки и пересечения
Отрезок - это часть прямой /, заключенная между двумя точками и включающая
эти точки. Таким образом, естественно определить отрезок через его концы:
typedef struct {
point pl,p2; /* концы отрезка */
} segment;
Самое простое геометрическое действие над отрезками - проверка того, пере-
пересекаются ли два данных отрезка, - оказывается неожиданно сложным из-за множе-
множества особых случаев. Два отрезка могут лежать на параллельных прямых; что
значит, что они не пересекаются вовсе. Один отрезок может пересекать другой в ко-
конечной точке, или два отрезка могут лежать поверх друг друга так, это они пересе-
пересекаются не в одной точке, а на отрезке.
346 Глава 14. Вычислительная геометрия
Проблема особых геометрических случаев, или вырожденности, серьезно ослож-
осложняет задачу построения эффективных алгоритмов вычислительной геометрии. Выро-
Вырожденность может сильно увеличить количество работы, которую необходимо проде-
проделать. Внимательно читайте условия задач на предмет гарантий, что прямые не будут
параллельны и что отрезки не будут перекрываться. Если это не оговорено в условии,
лучше всего перестраховаться и заставить программу обрабатывать такие случаи.
Лучше всего разбираться с вырожденными случаями, построив все свои вычис-
вычисления на небольшом числе тщательно разработанных геометрических примитивов.
В главе 13 мы реализовали общий тип данных для прямых, который позволял нам
работать с вертикальными прямыми (имеющими бесконечный наклон). Мы можем
воспользоваться полученными результатами и обобщить наши функции для пересе-
пересекающихся прямых на случай отрезков:
bool segments_intersect(segment si, segment s2)
{
line 11,12; /* прямые, содержащие заданные
отрезки */
point p; /* точка пересечения */
points_to_line(si.pi,si.p2,&11);
points_to_line(s2.pi,s2.p2,&12);
if (same_lineQA1,12)) /* перекрывающиеся или
непересекающиеся отрезки */
return( point_in_box(si.pi,s2.pi,s2.p2)
point_in_box(si.p2,s2.pi,s2.p2)
point_in_box(s2.pi,si.pi,si.p2)
point_in_box(s2.pl,sl.pl,si.p2) );
if (parallelQdl, 12) ) return (FALSE) ;
intersection_pointA1,12,p);
return(point_in_box(p,si.pi,si.p2) &&
point_in_box(p,s2.pi,s2.p2));
}
Мы используем наши функции для прямых, чтобы найти точку пересечения, если
таковая существует. Если она существует, то остается выяснить, лежит ли эта точка
в области, задаваемой нашими отрезками. Проще всего в этом убедиться, проверив, что
для каждого отрезка точка лежит в прямоугольной области, задаваемой его концами:
bool point_in_box(point p, point bl, point Ь2)
{
return( (p[X] >=min(bl[X] ,b2[X] ) ) && (p[X] <=max(bl[X] ,b2[X] ) )
ScSc (p[Y] >=min(bl[Y] ,b2[Y]) ) && (p[Y] <=max(bl[Y] ,b2[Y]) ) ) ;
14.2. Многоугольники и вычисления углов 347
Проверить отрезки на пересечение можно с помощью примитива, проверяющего,
что три упорядоченные точки идут против часовой стрелки. Такой примитив описы-
описывается в следующем разделе. Тем не менее нам кажется, что проще воспринять метод
point__in_box.
14.2. Многоугольники и вычисления углов
Многоугольником (полигоном) называется замкнутая цепочка непересекающихся
отрезков. Под замкнутостью подразумевается, что первая вершина цепочки одно-
одновременно является и последней. Под тем, что отрезки не пересекаются, подразуме-
подразумевается, что два отрезка могут иметь только общую конечную точку.
Многоугольники - это базовые структуры для описания плоских форм.
Вместо явного перечисления отрезков (или сторон) многоугольника мы можем
задать их неявно, перечислив по порядку п вершин, составляющих границу много-
многоугольника. Таким образом, отрезок существует между /-й и (/ + 1)-й точкой цепочки
для 0 < / < п - 1. Эти индексы берутся по модулю п, чтобы первая и последняя
точка многоугольника обязательно были соединены:
typedef struct {
int n; /* число вершин многоугольника */
point p [MAXPOLY] ; / * массив вершин многоугольника * /
} polygon;
Многоугольник Р называется выпуклым, если отрезок, соединяющий любые
две точки внутри многоугольника, целиком лежит внутри него, то есть не сущест-
существует никаких выемок и выпуклостей таких, что отрезок может выйти из Р, а потом
снова попасть в него. Из этого следует, что все внутренние углы выпуклого мно-
многоугольника не должны превышать 180°, или л-радиан.
Прямое вычисление угла, образованного тремя упорядоченными точками. -
непростая задача. Мы можем избежать необходимости вычисления значений
углов в большинстве задач по вычислительной геометрии, используя предикат
«против часовой стрелки» (counterclockwisepredicate) ccw(a, b, с). Эта функция
проверяет, лежит ли точка с справа от ориентированной линии, идущей от а к Ь.
Если да, то угол, образованный переходом от а к с против часовой стрелки через Ь,
меньше 180°, отсюда и название предиката. Если нет, то точка с либо лежит слева
от ab , либо все три точки лежат на одной прямой.
Эти предикаты можно вычислить, используя формулу signed_tri~
angle_area (), введенную в разделе 13.2.3. Если площадь получилась отрица-
отрицательной, точка с лежит слева от ab . Если площадь получилась нулевой, значит,
все три точки лежат на одной прямой. Для устойчивости к ошибкам при работе
348 Глава 14. Вычислительная геометрия
с числами с плавающей запятой сравнения проводятся не с нулем, а с маленькой
константой е. Это неидеальное решение; построение доказуемо устойчивого кода
для геометрических приложений с использованием арифметики с плавающей
точкой - задача, по уровню сложности находящаяся где-то между сложной и невы-
невыполнимой. Тем не менее это все же лучше, чем ничего.
bool ccw(point a, point b, point с)
{
double signed_triangle__area () ;
return (signed_triangle_area(a,b,c) > EPSILON);
}
bool cw(point a, point b, point c)
{
double signed_triangle_area();
return (signed_triangle_area(a,b,c) < EPSILON);
}
bool collinear(point a, point b, point c)
{
double signed__triangle_area () ;
return (fabs(signed_triangle_area(a,b,c)) <= EPSILON);
14.3. Выпуклые оболочки
Построение выпуклой оболочки для вычислительной геометрии - это как
сортировка для других алгоритмических задач - первый шаг, применяемый к неструк-
неструктурированным данным, позволяющий совершать более сложные операции. Выпуклая
оболочка C(S) множества точек S- это наименьший выпуклый многоугольник, содер-
содержащий 5, см. рис. 14.1 (слева).
Различных алгоритмов для построения выпуклой оболочки существует не мень-
меньше, чем сортировок. Алгоритм просмотра Грэхема (Graham's scan) построения вы-
выпуклой оболочки сначала сортирует все точки в угловом порядке или слева направо,
а затем по очереди добавляет их в оболочку в получившемся порядке. Предыдущие
точки оболочки, ставшие ненужными в результате последней вставки, удаляются.
Наша реализация основана на версии просмотра Грэхема, созданной Грайзом
и Стойменовичем (Gries, Stojmenovic) [GS87], в которой вершины сортируются по
углу относительно самой левой из нижних точки. Обратите внимание, что и самая
левая и самая нижняя точки должны лежать на оболочке, потому что они не могут
14.3. Выпуклые оболочки
349
Рис. 14.1. Выпуклая оболочка множества точек (слева), изменение оболочки из-за
добавления самой правой точки (справа)
лежать внутри какого-то другого треугольника, образованного точками. Мы исполь-
используем второй критерий, чтобы разрешать противоречия первого: несколько точек
могут оказаться самыми левыми. Такие рассуждения необходимы для устойчивости
в случае вырожденных входных данных.
Основной цикл алгоритма вставляет точки в порядке возрастания угла против
хода стрелки часов относительно начальной точки. Из-за такого порядка добавленная
точка должна находиться на оболочке тех точек, которые уже были вставлены. Новая
вставка может образовать треугольник, содержащий предыдущие точки оболочки,
которые теперь нужно удалить. Эти точки-для-удаления будут находиться на самом
конце цепочки, как последние принятые вставки. Критерий удаления: новая вставка
образует угол больше 180° с последними двумя точками цепочки - вспомните, что
в выпуклом многоугольнике все углы должны быть меньше 180°. Если угол слишком
большой, последнюю точку цепочки нужно отбрасывать. Мы будем повторять этот,
процесс пока не найдем угол меньший 180° или пока не кончатся точки. Для опреде-
определения того, больше угол 180° или нет, можно использовать предикат ccw ().
point first_point; /* первая точка оболочки */
convex_hull(point in[], int n, polygon *hull)
4
эазмер оболочки */
if (n <= 3) { /* все точки на оболочке! */
for (i=0; i<n; i++)
copy_point(in[i],hull->p[i]);
hull->n = n;
return;
int
int
bool
l ;
top;
smaller_angle();
/*
/*
счетчик
текущий
sort_and_remove_duplicates(in,&n);
copy_point(in[0],&first_point);
350 Глава 14. Вычислительная геометрия
qsort(&in[1], n-1, sizeof(point), smaller_angle);
copy_point(first_point,hull->p[0] ) ;
copy_point(in[1],hull->p[1]);
copy_jpoint ( f irst_point, in [n] ) ; /* замыкаем */
top = 1;
i = 2;
while (i <= n) {
if (!ccw(hull->p[top-l], hull->p[top], in[i]))
top = top - 1; /* убираем последнюю точку */
else {
top = top + 1;
copy_point(in[i],hull->p[top]);
i = i+1;
hull->n = top;
Красота этой реализации в том, насколько естественно она обходит большин-
большинство проблем, связанных с вырождением. Один из хитрых случаев - когда три
и более точки лежат на одной прямой, особенно если одна из этих точек - самая
левая из нижних точка оболочки, с которой мы начинали. Если мы будем невни-
невнимательны, то мы можем включить три вершины, лежащие на одной прямой,
в оболочку, хотя на самом деле должны быть включены только концы отрезка.
Мы обходим эту проблему, введя дополнительную сортировку для одинако-
одинаковых углов по расстоянию до начальной точки оболочки. Если самая дальняя из
этих точек, лежащих на одной прямой, вставляется последней, то в оболочке оста-
останется она, а не ее «собратья по углу»:
bool smaller_angle(point *pl, point *p2)
if (collinear(first_point,*pl,*p2)) {
if (distance(first_point/*pl) <= distance(first_point,*p2))
return(-1);
else
returnA);
if (ccw(first_point,*pl,*p2))
return(-1);
else
returnA);
}
14.3. Выпуклые оболочки 351
Оставшиеся вырожденные случаи связаны с повторяющимися точками. Что
делать с тремя вхождениями одной и той же точки? Чтобы избавиться от этой про-
проблемы, мы удаляем повторяющиеся копии точек, когда сортируем множество
точек для определения самой левой нижней точки оболочки.
sort_and_remove_duplicates(point in[], int *n)
{
int i; /* счетчик */
int oldn; /* число точек до удаления */
int hole; /* индекс, намеченный для возмож-
возможного удаления */
bool leftlower();
qsort(in, *n, sizeof(point), leftlower);
oldn = *n;
hole = 1;
for (i=l; i<(oldn-l); i++) {
if ((in[hole-l][X]==in[i][X]) && (in[hole-l][Y]==in[i][Y]))
(*n)~;
else {
copy_point(in[i], in[hole]);
hole = hole + 1;
copy_point(in[oldn-1],in[hole]);
}
bool leftlower(point *pl, point *p2)
{
if ((*pl)[X] < (*p2)[X]) return(-1);
if ((*pl)[X] > (*p2)[X]) return(l);
if ((*pl)[Y] < (*p2)[Y]) return(-1);
if ((*pl)[Y] > (*p2)[Y]) return(l);
return@);
}
В заключение стоит сделать еще несколько замечаний о convex_hull. Обратите
внимание на изящное использование сигнальных меток (sentinels), позволяющих
упростить код. Мы копируем начальную точку в конец цепочки, чтобы избежать
явной проверки условия замыкания. Затем мы неявно удаляем эту продублированную
точку, возвращая правильное количество точек.
И наконец, обратите внимание, что мы сортируем точки по углам, не подсчи-
подсчитывая их значения. Предиката ccw вполне достаточно для этой работы.
352 Глава 14. Вычислительная геометрия
14.4. Триангуляция: алгоритмы и смежные задачи
Найти периметр многоугольника просто: достаточно найти длину каждой
стороны, используя формулу евклидова расстояния, и сложить все получившиеся
значения. Найти площадь фигуры сложной формы несколько сложнее. Самый
прямолинейный подход в данном случае - разбить многоугольник на неперекры-
неперекрывающиеся треугольники и затем просуммировать их площади. Операция разбие-
разбиения многоугольника на треугольники носит название триангуляции.
Триангулировать выпуклый многоугольник несложно, мы можем просто соеди-
соединить заданную вершину v с остальными п - 1 вершинами, чтобы получился «веер».
В общем случае такой способ не работает, так как соединяющие отрезки могут
выходить за пределы многоугольника. Мы должны разделить многоугольник Р на
треугольники, используя непересекающиеся хорды, целиком лежащие внутри Р.
Мы можем представить триангуляцию или набором хорд, или, как мы предлагаем
сделать здесь, явным списком индексов вершин каждого треугольника.
typedef struct {
int n; /* количество треугольников в триангуляции */
int t[MAXPOLY][3]; /* индексы вершин в триангуляции */
} triangulation;
14.4.1. Алгоритм Ван Гога
Существует несколько алгоритмов триангуляции многоугольников, самый
быстрый из которых выполняется за линейное от числа вершин время. Но, пожалуй,
самый простой для реализации алгоритм основан на отсекании «ушей». «Ухом» мно-
многоугольника Р называется такой треугольник, задаваемый вершиной v и ее соседними
вершинами - левой и правой (/ и г), что треугольник (v, /, г) целиком лежит внутри Р.
Так как /v и vr - это стороны Р, треугольник определяется хордой d . Какие
условия должны быть выполнены, чтобы эта хорда участвовала в триангуляции?
Во-первых, rl должна целиком лежать внутри Р. Чтобы это выполнялось, угол /vr не
должен превышать 180°. Во-вторых, хорда не должна пересекать никакой другой
отрезок или многоугольник, так как иначе от треугольника будет отрезан кусок.
Важно то, что у любого многоугольника есть «ухо»; на самом деле, не менее
двух для любого п > 3. Это приводит к следующему алгоритму. Проверяем все
вершины, пока не найдем «ухо». Добавив соответствующую хорду, отсечем «ухо»
и уменьшим число вершин на одну. У оставшегося многоугольника также должно
быть «ухо», так что мы можем продолжать процедуру отсекания до тех пор, пока
у нас не останется только три вершины, которые составят последний треугольник.
14.4. Триангуляция: алгоритмы и смежные задачи 353
Рис. 14.2. Триангуляция многоугольника с помощью алгоритма Ван Гога. Треугольники
обозначены в порядке вставки (А - Г)
Проверка вершины на то, определяет она «ухо» или нет, состоит из двух частей.
Для проверки угла мы опять можем воспользоваться нашими предикатами ccw/cw.
Мы должны позаботиться о том, чтобы наши предположения не шли вразрез
с порядком вершин многоугольника. Мы полагаем, что вершины многоугольника
пронумерованы против часовой стрелки, если смотреть относительно некоего
виртуального центра, как показано на рис. 14.2. Изменение порядка вершин много-
многоугольника потребует изменения знака нашей проверки угла.
bool ear_Q(int i, int j , int k, polygon *p)
{
triangle t; /* координаты точек i, j , k */
int m; /* счетчик */
bool cw();
copy_point(p->p[i],t[0])
copy_point(p->p[j],t[1])
copy_point(p->p[k],t[2])
if (cw(t[0]/t[l]/t[2])) return(FALSE);
for (m=0, m<p->n;
if ((m!=i) ScSc (m!=j) && (m!=k))
if (point_in_triangle(p->p[m], t) ) return(FALSE);
return(TRUE);
}
12-972
354
Глава 14. Вычислительная геометрия
Для проверки пересечения с другими отрезками достаточно проверить, суще-
существуют ли вершины, лежащие внутри рассматриваемого треугольника. Если точек
нет, то пересечения с отрезками быть не должно, так как Р не пересекает сам себя.
Проверка того, лежит ли данная точка внутри данного треугольника, будет рас-
рассмотрена в разделе 14.3.3.
Наша основная подпрограмма триангуляции свелась к проверке вершин на
«ушастость» и к отсечению найденных таким образом «ушей». Удобным свойст-
свойством нашего представления многоугольника в виде массива точек является то, что
соседи вершины с номером / очень просто находятся, а именно, это вершины с но-
номерами / - 1 и / + 1. С другой стороны, эта структура данных явным образом не
поддерживает удаления вершин. Чтобы решить эту проблему, мы вводим два до-
дополнительных массива /иг, которые указывают на текущего правого и левого
соседа каждой точки, оставшейся в многоугольнике.
triangulate(polygon *p, triangulation *t)
int 1[MAXPOLY], r[MAXPOLY];
int i ;
for (i=0; i
/* индексы левого/правого
соседа */
/* счетчик */
p->n) % p->n;
p->n) % p->n;
/* инициализация */
t->n = 0;
i = p->n-l;
while(t->n < (p->n-2)) {
i = r [ i ] ;
if (ear_Q(l[i],i,r[i
add_triangle(t,l
1[ r[i] ] = l[i]
r[ l[i] ] = r[i]
i], p)
14.4.2 Подсчет площади
Мы можем найти площадь любого триангулированного многоугольника, про-
просуммировав площади всех треугольников. Это легко реализовать, используя уже
созданные функции.
Тем не менее, существует еще более изящный алгоритм, основанный на пред-
представлении о площади со знаком, которое использовалось в функции ccw. Просум-
Просуммировав соответствующим образом площади со знаком треугольников, образованных
14.4. Триангуляция: алгоритмы и смежные задачи 355
произвольной точкой р и сторонами многоугольника Р, мы получим площадь Р, так
как треугольники с отрицательной площадью нейтрализуют площадь снаружи мно-
многоугольника. Вычисления сводятся к равенству1:
где все индексы берутся по модулю числа вершин. Таким образом, нам даже не
нужно использовать нашу функцию signed__routine! Чтобы понять, почему это
работает, см. [O'ROO], но в любом случае мы получаем очень простое решение:
double area(polygon *p)
{
double total =0.0; /* полная площадь */
int i,j; /* счетчики */
for (i=0; i<p->n; i
j = (i+1) % p->n;
total+= (p->p[i] [X]*p->p[j] [Y]) - (p->p[j] [X]*p->p[i] [Y]);
}
return(total / 2.0);
}
14.4.3. Относительное положение точки
Наш алгоритм триангуляции определяет, что точка задает «ухо» только если
получившийся треугольник не содержит других точек. Таким образом, мы
должны уметь определять, лежит ли данная точка/? внутри треугольника t.
Рис. 14.3. Четность/нечетность числа пересечений с границами определяет, лежит ли
данная точка внутри или снаружи данного многоугольника
'Следует, например, из формулы для площади трапеции. - Примеч. науч. ред.
12*
356 Глава 14. Вычислительная геометрия
Треугольники - всегда выпуклые многоугольники, так как трех точек недоста-
недостаточно для создания выпуклостей и впадин. Точка лежит внутри выпуклого много-
многоугольника, если она лежит слева от всех ориентированных прямых ptpM, где
вершины многоугольника нумеруются против часовой стрелки. Предикат ccw
позволяет нам с легкостью проводить такие проверки:
bool point_in_triangle(point р, triangle t)
{
int i; /* счетчик */
bool cw() ;
for (i=0; i<3;
if (cw(t[i],t[(i+l)%3],p)) return(FALSE);
return(TRUE);
}
Этот алгоритм определяет относительное положение точки (внутри Р или вне?)
для выпуклых многоугольников. Но он приводит к неверному ответу для невы-
невыпуклых полигонов. Пусть нам нужно решить, лежит ли данная точка в центре
сложного невыпуклого многоугольника спиралевидной формы. Существует пря-
прямолинейное решение данной задачи, использующее уже разработанные подпро-
подпрограммы. Для отсечения «ушей» нам требовалось проверять, лежит ли данная
точка внутри данного треугольника. Таким образом, мы можем разбить много-
многоугольник на треугольники с помощью функции triangulate, а затем проверить
каждый из них, содержит он эту точку или нет. Если один из них содержит, то
содержит и многоугольник.
Тем не менее для такой задачи, как и для подсчета площади, триангуляция -
это чересчур сложное решение. Существует гораздо более простой алгоритм, ос-
основанный на теореме Жордана о кривой, которая утверждает, что для многоуголь-
многоугольника или другой замкнутой фигуры невозможно перейти из внутренней области
во внешнюю (или обратно), не пересекая границы.
Это приводит к следующему алгоритму, проиллюстрированному на рис. 14.3.
Предположим, мы строим прямую, которая начинается вне многоугольника Р и про-
проходит через точку q. Если эта прямая пересекает стороны многоугольника четное
число раз, прежде чем достичь точки q, то точка лежит вне многоугольника Р. Поче-
Почему? Если мы начинаем снаружи многоугольника, то после двух пересечений снова
оказываемся снаружи. А нечетное число пересечений оставляет нас в Р.
В вырожденных случаях появляются важные тонкости. Прохождение через
вершину Р считается пересечением границы, только если после этого мы попада-
попадаем внутрь многоугольника, а не просто «срезаем» вершину. Мы пересекаем грани-
14.5. Алгоритмы для сеток 357
цу тогда и только тогда, когда вершины, соседние данной, остаются по разные
стороны от прямой /. Прохождение по стороне Р не меняет количества пересечен-
пересеченных сторон, хотя в этом случае поднимается вопрос, считать ли лежащую на гра-
границе точку находящейся внутри многоугольника или снаружи.
14.5. Алгоритмы для сеток
Так как многоугольники, построенные на вершинах прямоугольной и шести-
шестиугольной сеток, могут быть естественным образом разбиты на отдельные ячейки,
имеет смысл знать, как решать определенные вычислительные задачи для этих ячеек.
• Площадь. Формула длина х ширину позволяет найти площадь прямоугольника.
Для треугольника можно использовать формулу S х высоту х основание.
Равносторонний треугольник с длиной стороны г имеет площадь V3r2/4;
поэтому правильный шестиугольник радиусом г имеет площадь Зл/Зг2 / 2.
• Периметр. Для прямоугольников - 2 х {длина + ширина). Для треугольников мы
складываем длины сторон а + Ъ + с, что сводится к Ъг для равностороннего
треугольника. Периметр правильного шестиугольника радиусом г равен 6г;
обратите внимание, как эта формула приближает длину окружности 2лг > 6.28г.
• Выпуклые оболочки. Прямоугольники, равносторонние треугольники и правиль-
правильные шестиугольники по определению выпуклы, поэтому они - выпуклые обо-
оболочки самих себя.
Триангуляция. Добавление одной диагонали в прямоугольник или трех, исходя-
исходящих из одной вершины в шестиугольник, позволяет триангулировать эти фигуры.
Мы можем так поступить, так как фигуры выпуклые; выпуклости и провалы
делают этот процесс сложнее.
• Положение точки. Как мы видели, точка лежит внутри прямоугольника со
сторонами, параллельными осям, тогда и только тогда, когда хтах > х > xmin
И Утах > У > Утт- Такие проверки чуть более сложны для треугольников
и шестиугольников, но для них обычно хватает просто ограничивающего
прямоугольника.
В завершение раздела мы хотим продемонстрировать два интересных алгоритма
для вычислительной геометрии на сетках. В основном они используются для пря-
прямолинейных решеток, но при необходимости могут быть перенесены и на другие
типы сеток.
355Г Глава 14. Вычислительная геометрия
14.5.1. Запросы на значение области
Запрос на значение прямоугольной области — это обычная операция при
работе с прямоугольными сетками п х т. Мы хотим построить структуру данных,
которая могла бы быстро реагировать на запросы вида: «Чему равна сумма чисел
в заданном прямоугольнике, входящем в матрицу?»
Любой прямоугольник, чьи стороны параллельны осям, можно задать двумя
точками - верхним левым углом (х/, у}) и нижним правым(хл уг). Проще всего было
бы использовать вложенные циклы, чтобы просуммировать все элементы m[i][j]
для xi<i< хгиуг <j <yj. Но это неэффективно, особенно если вам нужно делать это
постоянно при поиске прямоугольника с наибольшей или наименьшей суммой.
Вместо этого мы можем построить альтернативную матрицу, такую что элемент
ml[x][y] - это сумма всех элементов m[i][ j ], таких, что / < х и у <у. Эта доминаци-
онная матрица ml позволяет легко находить сумму элементов в любом прямоуголь-
прямоугольнике, потому что сумма его элементов S(x[, y^ хп уг) задается формулой
S(xl9yI,xr9yr) = ml[xr,y/]-ml[x, -\yl]-mx[xr,yr -Y\ + mx[Xj -\,yr -1].
Естественно, это намного быстрее, так как все подсчеты сводятся к подстановке
четырех элементов матрицы. Почему эта формула верна? Элемент mj[xryi] содержит
сумму всех элементов заданного прямоугольника плюс сумму всех остальных доми-
нированных элементов. Следующие два элемента убирают все лишнее, но при этом
нижний левый угол вычитается два раза и его нужно прибавить. Это похоже на
обычную формулу включений-исключений в комбинаторике. Массив mj может быть
заполнен за время О(тп), используя заполнения ячеек по рядам и аналогичные идеи.
14.5.2. Решетчатые многоугольники и теорема Пика
Прямоугольные сетки с единичным расстоянием между точками (называемы-
(называемыми также узлами решетки) лежат в основе любой координатной системы, осно-
основанной на решетке. В общем случае на единицу площади будет приходиться при-
примерно один узел решетки, так как каждый узел это верхний правый угол своего
пустого квадрата размером 1x1. Таким образом, число узлов решетки, лежащих
внутри данной фигуры - должно давать хорошую аппроксимацию ее площади.
Теорема Пика (Picks theorem) дает точное соотношение между площадью
решетчатого многоугольника Р (это такой многоугольник без самопересечений, что
все его вершины лежат в узлах решетки) и числом вершин на/внутри многоугольника.
Пусть внутри многоугольника Р лежит 1{Р) узлов, а на сторонах Р лежит В(Р) узлов.
Тогда площадь А{Р) задается формулой
А(Р) =
как показано на рис. 14.4.
14.5. Алгоритмы для сеток
359
Например, рассмотрим треугольник с координатами вершин (х, 1), (у, 2), (у + к, 2).
Вне зависимости от того, чему равны х, у и к, внутри треугольника узлов решетки нет,
потому что три точки лежат на последовательных рядах сетки. Узел решетки (дс, 1)
служит вершиной треугольника, плюс на основании треугольника находится к + 1
узлов. Значит, 1(Р) = О, В(Р) = к + 2, и, как следствие, площадь равна к/2 в точности то
же самое можно получить с помощью формулы площади треугольника.
В качестве другого примера рассмотрим прямоугольник, заданный углами (xj, yf)
и (х2,У2)- Число точек на границе определяется формулой
Четверка здесь нужна, чтобы не подсчитывать угловые вершины дважды.
Чтобы найти число точек внутри прямоугольника, вычтем из полного числа точек
внутри прямоугольника и на его границе число граничных точек:
7(P) = (At+l)(Av+l)-2(Av-A.t).
И в этом случае теорема Пика дает верное значение площади прямоугольника -
Д.А-
Применение этой теоремы на практике требует аккуратного подсчета узлов
решетки. Теоретически это можно реализовать полным перебором для многоуголь-
многоугольников маленькой площади, используя функции, которые будут A) проверять, при-
принадлежит ли заданная точка заданному отрезку, и B) проверять, лежит ли точка
внутри многоугольника. Более умные и эффективные алгоритмы проверяют не все
точки, а только граничные. Смотрите [GS93] на предмет интересного обсуждения
теоремы Пика и связанных с ней задач.
Рис. 14.4. Решетчатый многоугольник: число узлов решетки на сторонах - десять,
внутри многоугольника - девять, значит, площадь равна 13
360 Глава 14. Вычислительная геометрия
14.6. Геометрические библиотеки
Пакет java.awt.geom в Java предоставляет классы и методы для работы
с объектами, связанными с геометрией на плоскости. Класс Polygon обеспечивает
большую часть возможностей, разработанных нами, включая метод contains для
определения положения точки относительно многоугольника. Более широкий класс
Area позволяет нам объединять и пересекать многоугольники с другими кривыми.
Класс Line2D обеспечивает большую часть возможностей, разработанных нами
для отрезков, включая проверку на пересечение и предикат ccw.
14.7. Задачи
14.7.1. Пасем первокурсников
PC/UVaIDs: 111401/10135
Популярность: С
Частота успехов: средняя
Уровень:2
Однажды наша лужайка в центре кампуса оказалась заполнена новоприбыв-
новоприбывшими студентами. Чтобы кампус не выглядел так дико, один из наших старше-
старшекурсников-отличников решил окружить их куском шелковой нити. Ваша задача
состоит в том, чтобы подсчитать, сколько шелка потребовалось для выполнения
этой задачи.
Старшекурсник привязал шелк к телеграфному столбу и пошел по периметру
области, содержащей новичков, держа нить таким образом, чтобы все они попали
в область, ограниченную шелком. Затем он вернулся к телеграфному столбу.
Отличник использовал минимальное количество шелка, необходимое для заключе-
заключения всех первокурсников в круг, плюс по дополнительному метру с каждой сторо-
стороны для закрепления шелка.
Вы можете считать, что телеграфный столб имеет координаты @, 0), где
первая координата - это север/юг, а вторая - запад/восток. Координаты новопри-
новоприбывших задаются в метрах относительно столба. Количество первокурсников не
превышает 1000.
Входные данные
Входные данные начинаются со строки, содержащей одно положительное
целое число, которое означает количество тестовых блоков, за которой следует
пустая строка.
14.7. Задачи 361
Каждый тестовый блок состоит из строки, задающей число первогодков, за ко-
которой следуют строки, по одной на студента, содержащие два вещественных
числа, задающих его или ее позиции.
Между двумя последовательными блоками входных данных находится пустая
строка.
Выходные данные
Для каждого тестового блока выходные данные должны состоять из одного
числа: длины шелка в метрах с точностью до двух знаков после запятой. Выход-
Выходные данные для двух последовательных тестовых блоков должны быть разделены
пустой строкой.
Пример входных данных Соответствующие выходные данные
1 10.83
4
1.0 1.0
-1.0 1.0
-1.0 -1.0
1.0 -1.0
14.7.2. Задача о ближайших точках
PC/UVaIDs: 111402/10245
Популярность: А
Частота успехов: низкая
Уровень: 2
Малоизвестная телефонная компания хочет показать, что она в состоянии пре-
предоставить клиентам высокоскоростную широкополосную сеть. Для маркетинго-
маркетинговых целей им вполне достаточно создать только одну такую линию, соеди-
соединяющую напрямую двух абонентов. Так как стоимость установки такой сети про-
пропорциональна расстоянию между абонентами, им необходимо узнать, какие два
абонента находятся на минимальном расстоянии, чтобы на эту маркетинговую
стратегию понадобилось меньше денег.
Говоря конкретнее, для заданного множества точек на плоскости найдите рас-
расстояние между двумя ближайшими при условии, что это расстояние должно быть
меньше некого порогового значения. Если ближайшие точки находятся на слиш-
слишком большом расстоянии, отделу маркетинга придется выбирать менее накладную
рекламную стратегию.
362 Глава 14. Вычислительная геометрия
Входные данные
Входной файл содержит несколько наборов входных данных. Каждый набор
входных данных начинается с целого числа N @ < N< \0 000), которое задает
число точек в этом наборе. Следующие N строк содержат координаты N точек на
плоскости. Два числа задают х- и ^-координату соответственно. Входные данные
завершаются набором с N=0, который обрабатывать не нужно. Все координаты
неотрицательны и не превышают 40 000.
Выходные данные
Для каждого набора входных данных выведите одну строку, содержащую
число с плавающей запятой (с четырьмя цифрами после десятичной точки),
равное расстоянию между двумя ближайшими точками. Если расстояние между
всеми точками больше или равно 10000 выведите строку "INFINITY".
Пример входных данных Соответствующие выходные данные
3 INFINITY
0 0 36.2215
10000 10000
20000 20000
5
0 2
б 67
43 71
39 107
189 140
0
14.7.3. Резня бензопилой
PC/UVaIDs: 111403/10043
Популярность: В
Частота успехов: низкая
Уровень: 3
Канадское сообщество лесорубов только что провело свои ежегодные состяза-
состязания по валке леса, и лесные заповедники между Монреалем и Ванкувером разорены.
Теперь переходим к общественной части! Чтобы подготовить соответствующую
танцплощадку, организационный комитет ищет большую прямоугольную область
без деревьев. Всем лесорубам уже порядком хорошо, и никто не хочет пробовать,
что получится, если им дать в руки бензопилу.
14.7. Задачи 363
Организационный комитет попросил вас найти самую большую пустую прямо-
прямоугольную площадку для танцпола. Область, которая выделена вам для поисков, также
имеет форму прямоугольника, и танцплощадка должна целиком в ней помещаться.
Ее стороны должны быть параллельны сторонам области. Танцплощадка может рас-
располагаться на границе области, и на границе танцплощадки могут расти деревья.
Входные данные
Первая строка входных данных задает число тестовых блоков. В каждом тестовом
блоке первая строка содержит длину / и ширину w области в метрах @ < /, w < 10 000,
оба целые). Каждая из следующих строк описывает или одно дерево, или ряд деревьев
в одном из следующих форматов:
• 1 х у, где w 1" описывает одно дерево, а х и у задают его координаты в метрах
относительно левого верхнего угла;
• кху dx dy, где к > 1 задает ряд деревьев с координатами
(х,у),(х + dx,y + dy),..., (* + (*- l)dx,y + (к - \)dy);
• 0 - это окончание блока.
Все координаты х, у, dx, dy - целочисленные. Все деревья расположены в этой
области, то есть имеют координаты из [0, /] х [0, w]. Число деревьев не превышает 1000.
Выходные данные
Для каждого тестового блока выведите строку, содержащую максимальный
размер танцплощадки в квадратных метрах.
Пример входных данных Соответствующие выходные данные
2 6
2 3 80
0
10 10
2 118 0
2 19 8 0
0
364 Глава 14. Вычислительная геометрия
14.7.4. Теплее - холоднее
PC/UVaIDs: 111404/10084
Популярность: С
Частота успехов: низкая
Уровень:3
Детская игра теплее - холоднее выглядит следующим образом. Игрок А выходит
из комнаты, а игрок В в это время прячет там какой-то предмет. Игрок А снова входит
в комнату в точке @, 0) и затем ходит по комнате, останавливаясь в некоторых мес-
местах. Когда игрок А останавливается в новой точке, игрок В говорит «теплее», если
новая позиция игрока находится к предмету ближе предыдущей; «холоднее», если
дальше, и «также», если расстояние не изменилось.
Входные данные
Входные данные состоят из строк количеством не более 50, каждая из которых
содержит (х, ^-координатную пару, за которой следует "Hotter", "Colder"
или "Same". Каждая пара задает точку в комнате, которую можно считать квадра-
квадратом с противоположными углами, имеющими координаты @, 0) и A0, 10).
Выходные данные
Для каждой строки входных данных выведите полную площадь области,
в которой может находиться предмет, с точностью до двух знаков после запятой.
Пример входных данных Соответствующие выходные данные
10.0 10.0 Colder 50.00
10.0 0.0 Hotter 37.50
0.0 0.0 Colder 12.50
10.0 10.0 Hotter 0.00
14.7.5. Useless Tile Packers
PC/UValDs: 111405/10065
Популярность: С
Частота успехов: средняя
Уровень: 3
Useless Tile Packer, Inc., гордится своей эффективностью. Как видно из их назва-
названия, их цель - использовать меньше пространства (use less), чем остальные компа-
компании. Отдел маркетинга пытался убедить управление, что нужно сменить название,
потому что слово «useless» имеет другие значения, но пока это ни к чему не привело.
14.7. Задачи
365
Объекты, которые нужно упаковывать, имеют одинаковую толщину и форму
простого многоугольника. Для каждого объекта подбирается своя коробка. Пол
коробки - это выпуклый многоугольник, имеющий минимально возможный раз-
размер, подходящий объекту, для которого предназначена коробка.
Container
Wasted
Space
При таком подходе внутри коробки остается неиспользованное место. Ваша
задача - вычислить процент такого места для заданного объекта.
Входные данные
Входной файл содержит несколько блоков входных данных. Каждый блок
данных описывает один объект. Первая строка блока данных содержит целое
число N C <N< 100), задающее количество угловых точек объекта. Каждая из
следующих N строк содержит два целых числа, задающих (х, у) координаты угло-
угловой точки (определенных для соответствующего начала координат и направления
осей), причем 0 < х, у < 1000. Угловые точки на границе объекта идут в том же
порядке, в котором они указаны во входных данных. Никакие три последователь-
последовательные точки не лежат на одной прямой.
Входной файл заканчивается блоком с N равным 0.
Выходные данные
Для каждого заданного объекта выведите процент неиспользуемого простран-
пространства, округленный до двух цифр после запятой. Вывод должен быть на отдельной
строке.
После каждого выходного блока выведите пустую строку.
366 Глава 14. Вычислительная геометрия
Пример входных данных Соответствующие выходные данные
5 Tile #1
0 0 Wasted Space = 25.00 %
2 О
2 2 Tile #2
1 1 Wasted Space = 0.00 %
О 2
5
О О
0 2
1 3
2 2
2 О
О
14.7.6. Радиолокация
PC/UVaIDs: 111406/849
Популярность: С
Частота успехов: низкая
Уровень: 2
В системе слежения типа земля-воздух используется антенна, которая вращается
в горизонтальной плоскости по часовой стрелке с периодом в две секунды. Когда
антенна наводится на объект, расстояние от него до антенны измеряется и он отобра-
отображается на круглом экране в виде белой точки. Расстояние от точки до центра экрана
пропорционально расстоянию по горизонтали от антенны до объекта, а угол, обра-
образуемый прямой, проходящей через центр экрана и точку, показывает направление
объекта относительно антенны. Точка, находящаяся прямо над центром экрана, соот-
соответствует объекту, который находится к северу от антенны; находящаяся справа от
центра - объекту, находящемуся на востоке, и т. д.
В небе находится несколько объектов. Каждый из них движется с постоянной
скоростью, и соответствующая ему точка отображается на экране в разных местах
каждый раз, когда антенна находит этот объект. Ваша задача состоит в том, чтобы
определить, где точка появится на экране, когда антенна в следующий раз заметит
объект, если у вас есть результаты двух предыдущих наблюдений. Если существу-
существует несколько вариантов, вы должны найти их все.
14.7. Задачи 367
Входные данные
Входные данные состоят из некоторого числа строк, каждая из которых
содержит четыре вещественных числа: я у, d/, a2, d2. Первая пара я/, dj - это угол
(в градусах) и расстояние (в произвольных единицах измерения расстояния), по-
получившиеся в результате первого наблюдения, а вторая пара a2, d2 - это угол
и расстояние второго наблюдения.
Обратите внимание, что антенна вращается по часовой стрелке; то есть если она
направлена на север в момент времени t = 0.0, то она указывает на восток при t = 0.5,
на юг при t = 1.0, на запад при /=1.5, снова на север при t = 2.0 и т. д. Если объект на-
находится прямо над антенной, его нельзя заметить. Углы задаются аналогично компа-
компасу, то есть север - это 0° или 360°, восток - это 90, юг - 180 и запад 270°.
Выходные данные
Выходные данные должны состоять из одной строки, содержащей все решения
для каждого входного блока. Каждое решение состоит из двух вещественных чисел
(с двумя цифрами после десятичной точки), задающих угол а$ и расстояние d$ для
следующего наблюдения.
Пример входных данных Соответствующие выходные данные
90.0 100.0 90.0 110.0 90.00 120.00
90.0 100.0 270.0 10.0 270.00 230.00
90.0 100.0 180.0 50.0 199.93 64.96 223.39 130.49
14.7.7. Деревья моего острова
PC/UVaIDs: 111407/10088
Популярность: С
Частота успехов: средняя
Уровень:3
Я купил остров, на котором хочу посадить деревья рядами и столбцами. Дере-
Деревья будут формировать прямоугольную сетку, так что можно считать, что каждое
из них имеет целочисленные координаты, если выбрать подходящую точку сетки
в качестве начала координат.
Но мой остров не прямоугольный. Я нашел простую многоугольную область
внутри острова с вершинами, лежащими в узлах сетки, и решил, что деревья
будут высаживаться только в узлах сетки, находящихся внутри многоугольника.
Мне нужна ваша помощь, чтобы подсчитать, сколько деревьев я могу посадить.
368
Глава 14. Вычислительная геометрия
1 1 1 1
-Г-М--1
-1-4-44
_ULJ.J!
-LL1J
¦НЙ-44
i Г?ч
n
3
П
I
1С
^4
1
Щ
1 1 Д/
1
1 1 1
Пример моего острова
Входные данные
Входной файл может содержать несколько тестовых блоков. Каждый тестовый
блок начинается со строки, содержащей целое число N C <N< 1000), задающее
число вершин многоугольника. Следующие 7V строк содержат вершины многоуголь-
многоугольника, перечисляемые по или против часовой стрелки. Каждая из этих N строк
содержит два целых числа, задающих х- и ^-координаты вершины. Абсолютное
значение ни одной из координат не превышает 1 000 000.
Тестовый блок, содержащий в первой строке 0 в качестве N, завершает вход-
входные данные.
Выходные данные
Для каждого тестового блока выведите строку, содержащую число деревьев,
помещающихся внутри многоугольника.
14.7. Задачи
369
Пример входных данных
Соответствующие выходные данные
12
3 1
6 3
9 2
8 4
9 б
9 9
8 9
б 5
5 8
4 4
3 5
1 3
12
1000
2000
4000
6000
8000
8000
7000
5000
4000
3000
3000
1000
0
1000
1000
2000
1000
3000
8000
8000
4000
5000
4000
5000
3000
21
25990001
14.7.8. Вкусное молоко
PC/UVaIDs: 111408/10117
Популярность: С
Частота успехов: низкая
Уровень:4
Маленький Томми любит смачивать хлеб молоком. Он делает это, погружая
его так, чтобы нижняя сторона куска касалась дна чашки, как показано на рисунке
ниже.
370
Глава 14. Вычислительная геометрия
Действие 1
Действие 2
Результат
Так как количество молока в чашке ограничено, смачивается только область
между поверхностью молока и нижней стороной хлеба. Глубина молока в чашке
всегда h и не меняется вне зависимости от того, сколько раз туда погружали хлеб.
Томми хочет, чтобы как можно большая часть куска хлеба была покрыта моло-
молоком, но при этом не хочет макать хлеб больше чем к раз. Можете ли вы ему по-
помочь? Чашка с молоком шире любой стороны куска хлеба, так что любую сторону
можно смочить целиком.
Входные данные
Каждый тестовый блок начинается со строки, содержащей три целых числа n,knh
C < п < 20,0 < к < 8, 0 < h < 10). Кусок хлеба - это выпуклый многоугольник с п верши-
вершинами. Каждая из следующих п строк содержит два целых числа х( и yt @ < xh yt < 1000),
задающие декартовы координаты /-й вершины. Вершины пронумерованы против
часовой стрелки. Тестовый блок cn=k=:h = 0 завершает входные данные.
Выходные данные
Выведите (с точностью до двух знаков после запятой) площадь максимальной
части куска хлеба, которую можно покрыть молоком, макая не более к раз. Ответ
для каждого тестового блока должен идти отдельной строкой.
Пример входных данных
4 2 1
Соответствующие выходные данные
7.46
0 0 0
14.8. Подсказки 371
14.8. Подсказки
14.1. Как проще всего разобраться с ограничением, которое налагается телеграфным
столбом?
14.2. Сравнение каждой точки со всеми остальными может работать очень медленно.
Можем ли мы использовать тот факт, что нас интересуют только близлежащие
точки, чтобы уменьшить число сравнений?
14.3. Удобнее ли представить данные в виде явной матрицы / х w или оставить в сжа-
сжатом виде, как во входных данных?
14.4. Как нам лучше всего представить область возможных положений предмета?
Всегда ли это выпуклый многоугольник?
14.5. Что проще посчитать: разницу двух площадей или отдельно площадь каждой
внешней полости?
14.6. Откуда могут взяться несколько решений?
14.7. Нужно ли здесь применять теорему Пика, или есть лучший вариант?
14.8. Существует ли какая-то форма жадного алгоритма, которая доказуемо получает
максимальную площадь, покрытую молоком, или нам нужно использовать пол-
полный перебор?
Приложение А
Высокие достижения в соревнованиях по программированию или в любых
других спортивных состязаниях зависят не только от таланта. Чтобы хорошо вы-
выступить, важно знать состязание, правильно тренироваться и разрабатывать соот-
соответствующую стратегию и тактику.
В этой главе мы расскажем о трех самых важных соревнованиях по программиро-
программированию: ACM International Collegiate Programming Competition для студентов, Interna-
International Olympiad in Informatics для школьников и TopCoder Challenge для всех практи-
практикующих программистов. Мы обсудим историю, формат и требования к участникам
каждой олимпиады. Более того, мы пообщались с лучшими участниками и судьями,
так что мы можем поделиться с вами их секретами стратегий и тренировок.
А.1. ACM International Collegiate Programming
Contest
ACM International Collegiate Programming Competition (ACM ICPC) - это меро-
мероприятие, где студенты, интересующиеся программированием, показывают, на что
они способны. Число участников, интересность и престижность ICPC постоянно
возрастали со времени его основания в 1976 году. Соревнование 2002 года собрало
3082 команды (из трех человек), представляющие более 1300 учебных заведений из
67 стран, плюс огромное число студентов, участвующих в аналогичных местных со-
состязаниях и сетевых олимпиадах по программированию.
Формат состязания выглядит так. Каждая команда состоит из трех человек,
которым предлагается решить от пяти до десяти задач по программированию.
Команде предоставляется только один компьютер, так что координация и работа
в команде жизненно важны.
Победителем считается команда, правильно решившая большинство задач,
уложившись в отведенное время - порядка пяти часов. Частичное решение никак
не оценивается, то есть зачитываются только полностью решенные задачи. Если
команды набрали равное количество очков, то они сравниваются по времени, ко-
которое им потребовалось, чтобы задачи приняли. Таким образом, побеждают
*По крайней мере, по мнению судей. Нередко это несоответствие вызывает ожесточенные споры.
А. 1. ACM International Collegiate Programming Contest 373
самые быстрые программисты (а не самые быстрые программы). За стиль про-
программирования и эффективность дополнительные очки не начисляются, главное,
чтобы программа уложилась в несколько секунд, которые обычно отводятся судь-
судьями на проверку. Временное наказание в 20 минут накладывается за каждую не-
неверную программу, присланную судьям, что дает студентам хороший стимул к
усиленной проверке своей работы.
Мы попытались расспросить лучшие команды и судей 2002 ACM ICPC о секретах
тренировки и участия в соревнованиях. Вот что мы смогли узнать...
А. 1.1. Подготовка
Выбор команды и тренера
Набор команды из студентов своего учебного заведения - это работа тренера.
В некоторых учебных заведениях тренерами могут быть выпускники, как, напри-
например, в институтах Cornell и Tsinghua. В остальных случаях команды тренируют
опытные преподаватели, как, например, в Duke и Waterloo. Неизменным для хоро-
хорошей команды является тщательный отбор студентов и эффективное руководство.
И те и другие тренеры могут хорошо готовить студентов, что демонстрируют их
подопечные из вышеперечисленных учебных заведений.
Многие серьезные команды проводят местные соревнования, чтобы подобрать
команды для выступления на соревнованиях более высокого уровня. Тренер Waterloo
Гордон Кормак (Gordon Cormack) предпочитает командным соревнованиям оди-
одиночные, в которых одиночкам легче пробиться. Уже после них он набирает в команду
наиболее подходящих друг к другу студентов. Такие соревнования относительно
несложно проводить, если использовать возможности автоматической тестирующей
системы Universidad de Valladolid.
Лучшие команды усердно тренируются. Например, команда Waterloo собира-
собирается вместе два-три раза в неделю и тренируется в условиях аналогичных
финальной стадии соревнований.
Ресурсы
Правила ACM ICPC разрешают студентам пользоваться любым печатным
материалом, но запрещают использовать любые сетевые ресурсы. Книги тщательно
проверяются на наличие CD-ROM-дисков, а сеть или отключается, или просматри-
просматривается анализаторами пакетов (sniffer programs).
Какие книги стоит изучить, кроме той, которую вы сейчас держите у себя в руках?
В качестве общего пособия по алгоритмам мы порекомендуем Skiena's
Algorithm Design Manual, и многие судьи и участники, не так лично заинтересованные,
как мы, с нами согласятся. Особенно популярными являются книги, содержащие pea-
374 Приложение А
лизации алгоритмов на настоящем языке программирования, такие, как Sedgewick
[SedOl] для графовых алгоритмов и O'Rourke [O'ROO] для вычислительной геометрии.
Правда, если вы не понимаете, как работает алгоритм, подготовьтесь к длительной
отладке того, что вы спишете с книги. Кормак предупреждает: «Код гораздо менее по-
полезен, чем вы думаете, если вы не составили и/или не написали его собственноручно».
Также необходимо иметь руководство по вашему языку программирования и сопутст-
сопутствующим библиотекам.
Хорошо подготовленные команды приносят с собой распечатки решений для
старых задач на тот случай, если им попадется что-то аналогичное. Кристиан Олер
(Christian Ohler) из University of Oldenburg (Германия) подчеркивает важность зара-
заранее приготовленных геометрических функций. «Вы обречены, если их нет в готовом
и отлаженном варианте».
Такие заготовки особенно полезны, если вы собираетесь пользоваться Java.
Подпрограммы правильной работы с вводом/выводом и основными типами
данных сложны, но без них ничего не будет работать. Возможно, имеет смысл
заставить одного из членов команды набрать их в начале соревнования, пока его
товарищи читают условия задач.
Тренировка
Лучший ресурс для тренировки - это автоматическая тестирующая система
Universidad de Valladolid. По меньшей мере 80% финалистов прошлого года тре-
тренировалось с использованием этой тестирующей системы. Периодические сете-
сетевые соревнования проводятся по адресу http://acm.uva.es/contest/, причем они
устраиваются чаще перед региональными и международными олимпиадами.
Уральский государственный университет (http://acm.timus.ru/contest/) и Internet
Problem Solving Contest (ISPC) (http://iscp.ksp.sk) также поддерживают автоматиче-
автоматические тестирующие системы и проводят аналогичные соревнования. Сайт команды
США http://wnvw.usaco.org содержит множество интересного материала, в том числе
и задач.
Многие студенты предпочитают изучать решения к задачам прошлогодних
олимпиад, даже если они и не решали их самостоятельно. Такие задачи можно
найти на официальном сайте ACM ICPC http://www.acmicpc.org. Руя Лю из Tsinghua
University обращает внимание на то, что в разных странах даются задачи разных
типов. Например, по его мнению, в странах Азии задачи «очень странные и слож-
сложные», поэтому решения задач прошлых лет имеет смысл изучать и анализировать.
Задачи в странах Северной Америки хорошо подходят для практики программиро-
программирования в условиях соревнований, но не требуют глубокого изучения алгоритмов.
А. 1. ACM International Collegiate Programming Contest 375
A.1.2. Стратегия и тактика
Работа в команде
По правилам ICPC команды состоят из трех человек. Так как доступен всего
один компьютер, командная работа играет основную роль. Команды, которые
спорят из-за того, кто будет сидеть за машиной, никогда не выигрывают. Жу Ян из
Shanghai Jiaotong University (чемпион мира 2002 года) формулирует это так: «Все, что
вы делаете, должно быть подчинено одной цели - принести больше пользы команде,
а не себе одному».
Большинство успешных команд разделяют работу между членами команды
в зависимости от их способностей. Обычно один из студентов - это кодера чело-
человек, который большую часть состязания общается с клавиатурой по причине вели-
великолепного знания языка программирования и очень быстрого набора. Другой сту-
студент - это алгоритмер; у него лучше остальных получается разбираться с задача-
задачами, и он способен быстро обрисовать решение в общих чертах. Третий студент -
отладчик; он работает с распечатками программ и их выходными данными,
устраняя ошибки и освобождая компьютер и кодера для других задач.
Конечно, по ходу соревнования студенты могут меняться ролями, да и сами
роли от команды к команде могут сильно изменяться. Некоторые команды
выбирают капитана, который решает, кто какой задачей занимается и кто в какое
время работает с компьютером.
Определенные команды применяют специальные стратегии для чтения задач.
На данный момент самым эффективным кажется разделение задач по студентам
и их параллельное чтение, так как самые легкие задачи могут оказаться в самом
конце. Как только кто-то находит простую задачу, он начинает ею заниматься или
передает ее наиболее подходящему члену команды. В некоторых международных
командах человек, лучше всех знающий английский, бегло просматривает усло-
условия и разъясняет их остальным членам команды.
Тактика на соревнованиях
• Представляйте свои возможности.Тж как очки даются только за полностью
верные решения, выбирайте самые легкие задачи и решайте сначала их. Часто
задача, которая звучит просто, требует чего-нибудь сложного или имеет двусмыс-
двусмысленное описание, что ведет к повторяющимся и раздражающим неверным отве-
ответам. Шахрияр Манзур из Bangladesh University of Engineering and Technology
советует: «Если ваше решение простейшей задачи на соревновании отклоняется
по непонятным причинам, попросите товарища по команде сделать ее заново,
чтобы он избежал тех логических ловушек, в которые попали вы».
376 Приложение А
• Следите за ходом соревнования. Если это возможно, следите за текущим
состоянием соревнования и выясняйте, какие задачи решаются чаще других.
Если ваша команда еще не занималась ими - попробуйте! Чаще всего они ока-
оказываются сравнительно простыми.
• Избегайте неверных ответов. Руя Лю из Tsinghua считает, что правильность
гораздо важнее скорости. «Мы не закончили соревнования в числе первых
трех команд в этом году из-за наказаний по времени за неправильные отве-
ответы». Чтобы уменьшить количество наказаний, все задачи требуют тщатель-
тщательной проверки и тестирования, а также обсуждения командой, чтобы убедить-
убедиться, что задача правильно понята.
• Будьте внимательны. Сообщение time limit exceeded (превышен лимит време-
времени) не всегда является следствием проблем алгоритма. Вы можете войти в бес-
бесконечный цикл из-за проблем с получением входных данных [ManOl]. Возмож-
Возможно, ваша программа хочет получить входные данные из стандартного ввода/
вывода, а судья ждет, пока она считает их из файла. Или, может быть, вы
неправильно поняли формат входных данных; например, вы думаете, что вход-
входные данные заканчиваются 0, а судья заканчивает их маркером конца файла.
• Знайте свой компилятор. Некоторые среды программирования обладают воз-
возможностями, которые могут облегчить вам жизнь. Флаги, ограничивающие
доступный объем памяти, могут помочь на соревнованиях, где есть опреде-
определенные ограничения на используемую память. «Избавляйтесь от ненужных
сюрпризов, готовясь заранее», - говорит Гордон Кормак.
• Держите машину занятой. Кормак побуждает свою команду «всегда исполь-
использовать клавиатуру, даже если вы просто вводите входные данные для
программы».
• Отлаживайте аккуратно. Как можно отлаживать при таком малом количестве
информации? Все, что вам говорит судья, - это то, что программа работает
неправильно. Вы не можете посмотреть на образец входных данных, на котором
валится ваша программа. Проблемы с судейством временами случаются, но
обычно, если программа не принимается, это значит, что где-то у вас ошибка.
В этом случае ваши лучшие друзья - распечатка программы и рассудительность.
Аккуратно проверьте тестовые данные, которые вы используете для проверки
программы. Одна из наших команд два часа отлаживала правильную
программу, потому что они вводили неверные тестовые данные. Но не откла-
откладывайте в сторону неверные решения слишком быстро. Дженс Цумбругель из
University of Oldenburg предупреждает никогда не «начинать новую задачу,
когда осталось 90 минут и у вас еще есть программы, требующие отладки».
А.2. International Olympiad in Informatics (Международная олимпиада по информатике) 377
• «Грязная» отладка. Существует хитрость, которая может вам помочь, если вы на
самом деле застряли. Добавьте бесконечный цикл или деление на 0 в том месте,
где, по вашему мнению, ошибается программа. Тогда в обмен на 20-минутное
наказание вы можете получить немного информации. Не пользуйтесь этим слиш-
слишком часто, иначе вы наверняка навлечете на себя гнев своих товарищей по команде
к тому моменту, когда программа будет принята.
• Пользуйтесь исключительными ситуациями. Даниель Райт из Stanford University
рекомендует следующий трюк. Если ваш язык программирования поддерживает
обработку исключительных ситуаций, то используйте ее, чтобы программа не
падала, а что-то выдавала в ответ. Например, отлавливайте все исключительные
ситуации и выводите, что решения не существует или что входные данные заданы
неверно.
• Не волнуйтесь. Попытайтесь не расстраиваться и не ссориться с вашими кол-
коллегами по команде. «Радуйтесь и не теряйте настрой», - советует Гордон
Кормак своим студентам.
А.2. International Olympiad in Informatics
(Международная олимпиада по информатике)
International Olympiad in Informatics (IOI) - это ежегодное соревнование по
информатике для школьников среднего/старшего звена. С момента своего основания
в 1989 году, оно выросло до второй по величине из пяти международных олимпиад
по научным дисциплинам, уступая только математике. В 2002 году 78 стран отправи-
отправили 276 участников на финал, проходивший в Корее, но эти финалисты выбирались
буквально из сотен тысяч учеников, желающих попасть в команду своей страны.
Цели IOI немного отличаются от целей ACM ICPC. Участники еще не выбрали
свою карьеру; цель 101 - повысить их интерес к информатике (компьютеристике).
На 101 собираются вместе талантливые школьники из разных стран, и там они могут
поделиться культурным и научным опытом друг с другом.
А.2.1. Участие
IOI каждый год проводится в разных странах: Висконсин, США, в 2003 году;
Греция в 2004 году и Польша в 2005 году. Каждая страна, принимающая участие,
отправляет команду, состоящую из четырех учеников и двух тренеров. Школьники
соревнуются по отдельности и пытаются набрать максимальное число очков,
решая некоторое число задач по программированию на протяжении двух дней.
Обычно им дается пять часов на три задания в каждый из двух дней.
378 Приложение А
В каждой стране существует своя процедура отбора участников национальной
команды. Некоторые страны, такие, например, как Китай и Иран, проводят
отборочные экзамены буквально для сотен тысяч школьников, чтобы найти наи-
наиболее многообещающих кандидатов. Большинство стран практикуют более
скромные отборочные олимпиады, чтобы сократить число претендентов при-
примерно до 20 человек. Затем эти школьники усиленно тренируются под руково-
руководством национального тренера, который в итоге выбирает четырех наиболее мно-
многообещающих учеников, чтобы они представляли страну на олимпиаде.
USA Computing Olympiad поддерживает замечательную программу тренировки
по адресу http://train.usaco.org и проводит соревнования по программированию
через Интернет, в которых может принимать участие любой. Чтобы у вас была воз-
возможность попасть в команду США, вы должны принять участие в U.S. Open National
Championship. Для этого требуется разрешение учителя в вашей школе. Участники,
показавшие лучшие результаты, приглашаются на сборы для дополнительной тре-
тренировки и формирования команды. В Канаде примерно из 1000 кандидатов с помо-
помощью отборочных экзаменов выбираются 22 для дополнительной недельной тре-
тренировки на сборах.
А.2.2. Формат
В отличие от ACM ICPC на олимпиаде принимаются не полностью решенные
задачи. Для каждой задачи обычно имеется десять наборов входных данных, и за
каждый решенный верно вы получаете 10 очков. Если каждый день дается по три
задачи, то максимальное количество очков равно 600.
Все задачи (называемые заданиями (tasks) на жаргоне IOI) предполагают
вычисления алгоритмического плана. Даже в том случае, когда требуется алгорит-
алгоритмическая эффективность, организаторы стараются подобрать хотя бы один набор
входных данных, на котором неэффективные программы смогли бы получить
очки. Но член IOI Scientific Member Ян Манро (Ian Munro) говорит: «Тяжело при-
придумывать такие задания, чтобы они оказались несложными для большинства уча-
участников, но при этом позволяли бы нам четко понимать, кто же все-таки победил».
Класс задач, присущий только IOI, - это «реактивные задачи» (reactive tasks),
требующие живого ввода [HV02]. В них общение с вашей программой обеспечи-
обеспечивается посредством вызова функций, а не файлов с данными. Например, вас могут
попросить обследовать лабиринт так, что вызываемая функция будет вам сооб-
сообщать, утыкаетесь вы вашим следующим ходом в стену или нет. Или вас могут
попросить написать игровую программу, которая должна будет противостоять
живому оппоненту.
А.2. International Olympiad in Informatics (Международная олимпиада по информатике) 379
На соревнованиях 2002 года участникам предлагалось выбрать Linux или Windows
в качестве среды программирования. Из языков программирования можно было
использовать Pascal или C/C++. Участникам не разрешается пользоваться
любыми печатными или сетевыми материалами.
Результаты решений сообщаются после того, как закончилось время, отведен-
отведенное на решение заданий, а не «в оперативном режиме», как принято на АСМ
ICPC. Как и в обычном школьном экзамене, участники не знают количество
набранных ими очков до момента объявления оценок.
Из трех главных состязаний по программированию IOI наименее спонсируемое.
Из-за этого оно носит учебный характер, как говорит Даниель Райт, который дохо-
доходил до финала всех трех соревнований, обсуждаемых в этой книге. Разницу можно
заметить по тому, как размещают участников. На 101 они живут в университетских
общежитиях, а финалисты ICPC/TopCoder поселяются в роскошные гостиницы.
А.2.3. Подготовка
Тренер США по подготовке к 101 Роб Колстад рекомендует всем заинтересован-
заинтересованным школьникам много работать на тренировочном сайте и участвовать во всех
предварительных соревнованиях, проводящихся до U. S. Open. Он пытается научить
своих подопечных грамотно распоряжаться временем на соревнованиях. Гордон
Кормак, по совместительству являющийся тренером Канады по подготовке к IOI,
рекомендует своим ученикам отказаться от привычки «отлаживать до тех пор, пока
как-нибудь не заработает» и стараться создавать решения, которые рассматривают
все возможные случаи за отведенное время. Чтобы помочь школьникам сконцен-
сконцентрироваться, он доходит до того, что запрещает им использовать отладчик.
Бытует мнение, что задачи 101 не похожи на задачи ACM ICPC. По Колстаду,
задачи 101 «полностью алгоритмические» и их условия прописаны более четко,
чтобы не было «хитрых или слишком умных вариантов входных данных». Задачи
ACM ICPC более подвержены спорным вопросам с проверкой входных данных
и форматированием выходных.
По Кормаку, задачи 101 «примерно такого же уровня, как и задачи АСМ
ICPC». Временами их решения короче, чем решения АСМ ICPC, но все же они
рассчитаны на усилия одного человека, а не целой команды. Они создаются таким
образом, что простое и относительно неэффективное решение сможет получить
очки лишь за небольшое число вариантов входных данных. А для получения пол-
полного балла требуется подойти к задаче с умом. Задачи прошлых лет можно по-
посмотреть на официальном сайте IOI: http://olympiads.win.tue.nl/ioi/. Там же нахо-
находятся ссылки на две рекомендуемые студентам книги: Практика программирова-
программирования Кернигана и Пайка [КР99] и, говорим это с гордостью, Skiena's The Algorithm
Design Manual [Ski97].
380 Приложение А
Чтобы удачно выступить на соревновании, требуется хорошая подготовка по
математике. Чемпион IOI2001 года, Рейд Бартон из США, также выиграл Между-
Международную олимпиаду по математике, и, вероятнее всего, проблем с поступлением
в университет у него не было.
Участие в IOI - это хорошая подготовка перед участием в ACM ICPC. Очень
большое число участников IOI этого года становятся в следующем году финали-
финалистами ACM ICPC. Например, все три члена команды Tsinghua 2002 ACM ICPC
(занявшей 4-е место) были в числе 20 кандидатов в команду Китая на IOI. Анало-
Аналогично примерно половина «звезд» TopCoder были лучшими на IOI и ACM ICPC.
А.З. Topcoder.com
Существует множество причин, по которым имеет смысл участвовать в олим-
олимпиадах по программированию. Вы получаете удовольствие и одновременно
улучшаете навыки программирования и послужной список для будущих работо-
работодателей. Задачи по программированию, описанные в этой книге, похожи на «голо-
«головоломные» задачи, которые многие продвинутые компании предлагают всем пре-
претендентам на рабочее место.
Примерно так появилась TopCoder - компания, использующая соревнования
по программированию для поиска многообещающих работников и предостав-
предоставляющая эту информацию своим клиентам. Главная приманка соревнования -
деньги. Состязание 2002 года TopCoder Collegiate Challenge спонсировалось Sun
Microsystems, и призовой фонд был порядка 150 000$. Даниель Райт из Stanford
University легко выиграл главный приз в 100 000$ и согласился поделиться с нами
своими секретами.
TopCoder поддерживает отличный сайт (www.topcoder.com), на котором разме-
размещаются новости о последних соревнованиях, что делает его похожим на ленты
спортивных новостей. Также на сайте проводятся тренировочные соревнования, по-
помогающие готовиться к еженедельным турнирам, каждый из которых состоит из трех
задач по программированию. Такие турниры начали проводиться с 2001 года,
и с этого времени более 20 000 программистов зарегистрировалось в качестве их уча-
участников. На сегодняшний день TopCoder выплатил порядка 1 000 000$ призовых денег.
Формат соревнований TopCoder быстро меняется, так как они подбирают наи-
наиболее подходящую деловую модель. Предварительные раунды проводятся по
сети, а финальные этапы больших соревнований проходят вживую.
В основе каждого из таких этапов лежит схожая структура. Программисты де-
делятся на «комнаты», где они соревнуются с другими участниками. Каждый раунд
начинается с фазы программирования (coding phase), длящейся 75-80 минут,
в течение которых участники решают задачи. Количество очков за каждую задачу
А.4. Аспирантура 381
обратно пропорционально отрезку времени между получением задачей и ее
отправкой. Далее следует 15-минутная фаза проверки (challengephase), в течение
которой программисты могут просматривать решения других участников и искать
в них ошибки. За отправку варианта входных данных, на которых валится чужая
программа, участник получает дополнительные очки. Частично решенные задачи
не засчитываются.
Большинство участников обычно решают задачи в порядке возрастания слож-
сложности, хотя Райт предпочитает делать сначала те задачи, за которые дают больше
очков, если, по его мнению, времени на все три ему не хватит. На TopCoder разре-
разрешается повторная отправка, ценой временного наказания, так что есть определен-
определенная стратегия при принятии решений, когда отправлять задачу и когда тестиро-
тестировать. Временной фактор - самый важный на соревнованиях TopCoder. Чтобы
работать быстрее, Райт рекомендует участникам изучать и эффективнее использо-
использовать стандартные библиотеки.
Фаза программирования обычно более важна, чем фаза проверки, потому что
число очков, набираемых на чужих ошибках, недостаточно велико, чтобы компен-
компенсировать разницу в задачах. Чтобы спланировать свою работу в эту фазу, Райт
бегло просматривает решения, чтобы понять, как работает предложенный
алгоритм. Если он находит вариант, который он рассматривал, но отбросил, как
неверный, то имеет смысл попробовать уронить эту программу. Чаще он находит
опечатки и ошибки занижения/завышения на единицу.
А.4. Аспирантура
Если задачи, приведенные в этой книге, показались вам интересными, то, воз-
возможно, вам стоит подумать о более глубоком изучении предмета. Аспирантура по
компьютеристике включает в себя курсы по продвинутым темам, которые осно-
основываются на том, что вы изучили, будучи студентами; но, что гораздо более
важно, вы будете заниматься новыми интересными исследованиями в области по
вашему выбору. Все разумные докторские программы будут оплачивать обучение
всех своих студентов плюс платить стипендию, достаточную, чтобы жить
нормально, если не расточительно.
Добраться до финала ACM International Collegiate Programming Contest или
International Olympiad on Informatics или выиграть региональные соревнования -
это значительное достижение. Это ясно говорит о том, что у вас есть достаточно
знаний для дальнейшей работы. Я, конечно, рекомендую вам продолжить вашу
учебу. Было бы замечательно, если бы вы решили обучаться, работая у меня,
Стивена Скиена (Steven Skiena), в Стоуни Брук (Stony Brook)!
382
Приложение А
Моя группа занимается исследованием ряда интересных тем теории
алгоритмов и дискретной математики. Вы можете подробнее об этом узнать на
http://www. algolist. com/gradstudy/.
Так что я надеюсь, что мы с вами встретимся. Кстати, официальными прави-
правилами ACM ICPC разрешается, чтобы одним из членов команды был аспирант
первого года обучения. Может быть, именно вы сможете привести нас в финал
в следующем году!
А.5. Благодарности за задачи
Первое из приведенных имен - это человек, который разрабатывал, изучал или
заведовал задачей и разрешил нам использовать ее в этой книге. Последующие
имена (если таковые имеются) - это имена людей, также работавших над задачами.
Мы приносим всем благодарности за тот вклад, который они внесли в проект.
1.1
1.2
1.3
1.4
1.5
1.6
1.7
1.8
2.1
2.2
2.3
2.4
2.5
2.6
2.7
2.8
3.1
PC ID
110101
110102
110103
110104
110105
110106
110107
110108
110201
110202
110203
110204
110205
110206
110207
110208
110301
UVa
100
10189
10137
706
10267
10033
10196
10142
10038
10315
10050
843
10205
10044
10258
10149
10082
Название
Задача Зп +1
Сапер
Путешествие
LCD-дисплей
Графический редактор
Интерпретатор
Проверка на шах
Австралийское голосование
Jolly Jumpers
Руки в покере
Харталы (Hartals)
Дешифратор
Расположить по порядку
Числа Эрдеша
Табло соревнований
Yahtzee
WER1YU
Автор
Оуэн Астракан
Педро Демаси
Гордон Кормак
Мигель Ревилла, Эммануэль Херрман
Александр Денисюк
Гордон Кормак
Педро Демаси
Гордон Кормак
Гордон Кормак, Вим Нуи
Гордон Кормак
Шахрияр Манзур, Резол Алам Чоудхари
Гордон Кормак
Гордон Кормак
Мигель Ревилла, Феликс Гартнер
Гордон Кормак, Майкл Ван Бисбрук
Гордон Кормак
Гордон Кормак
А.5. Благодарности за задачи
383
3.2
3.3
3.4
3.5
3.6
3.7
3.8
4.1
4.2
4.3
4.4
4.5
4.6
4.7
4.8
5.1
5.2
5.3
5.4
5.5
5.6
5.7
5.8
6.1
6.2
6.3
6.4
6.5
6.6
PC ID
110302
110303
110304
110305
110306
110307
110308
110401
110402
110403
110404
110405
110406
110407
110408
110501
110502
110503
110504
110505
110506
110507
110508
110601
110602
110603
110604
110605
110606
UVa
10010
10252
850
10188
10132
10150
848
10041
120
10037
10191
10026
10138
10152
10194
10035
10018
701
10127
847
10105
10077
10202
10183
10213
10198
10157
10247
10254
Название
Где Waldorf?
Обычная перестановка
Дешифратор II
Автоматизированное судейство
Осколки файлов
Дублеты
Fmt
Семья Вито
Стопки оладий
Мост
Подремать подольше
Задача сапожника
CDVII
Сортировка Шелла
Футбол
Начала арифметики
Изменение порядка и сложение
Дилемма археолога
Единицы
Игра в умножения
Коэффициенты полинома
Числовая система Штерна-Броко
Попарно суммируемые числа
Сколько чисел?
Сколько частей земли?
Счет
Выражения
Нумерация полного дерева
Монах-математик
Автор
Гордон Кормак
Шахрияр Манзур
Гордон Кормак
ПедроДемаси
Гордон Кормак, Чарльз Кларк
Гордон Кормак
Гордон Кормак
Мигель Ревилла, Пабло Пуенте
Оуэн Астракан
Гордон Кормак
Педро Демаси
Алекс Жевак, Антонио Санчес
Гордон Кормак
Гордон Кормак, Чарльз Кларк
Педро Демаси
Гордон Кормак
Ерик Морено
Мигель Ревилла
Гордон Кормак, Петр Рудницки
Гордон Кормак, Петр Рудницки
Александр Денисюк
Шахрияр Манзур, Резол Алам Чоудхари
Гордон Кормак, Петр Рудницки
Руя Лю, Уолтер Гутман
Шахрияр Манзур
ПедроДемаси
Петко Минков
Шахрияр Манзур
Шахрияр Манзур, Мигель Ревилла
384
Приложение А
6.7
6.8
7.1
7.2
7.3
7.4
7.5
7.6
7.7
7.8
8.1
8.2
8.3
8.4
8.5
8.6
8.7
8.8
9.1
9.2
9.3
9.4
9.5
9.6
9.7
9.8
10.1
PC ID
110607
110608
110701
110702
110703
110704
110705
110706
110707
110708
110801
110802
110803
110804
110805
110806
110807
110808
110901
110902
110903
110904
110905
110906
110907
110908
111001
UVa
10049
846
10110
10006
10104
10139
10168
10042
10090
10089
861
10181
10128
10260
10032
10001
704
10270
10004
10067
10099
705
10029
10051
10187
10276
10034
Название
Самоописывающая
последовательность
Шаги
Света, больше света
Числа Кармайкла
Задача Евклида
Делители факториалов
Сумма четырех простых чисел
Числа Смита
Шарики
Переупаковка
Слоны
Задача про пятнашки
Шеренга
Станции техобслуживания
Перетягивание каната
Эдемский сад
Цветные кусояки
Больший квадрат. Пожалуйста...
Раскраска двумя цветами
Игра с колесами
Экскурсовод
Лабиринт из слешей
Лесенки ступенек редактирования
Башни из кубиков
От заката до рассвета
И снова ханойские башни!
Веснушки
Автор
Шахрияр Манзур, Резол Алам Чоудхари
Гордон Кормак, Петр Рудницки
Удвранто Патик, Сади Канн, Суман Мабуб
Мануель Карро, Цезарь Санчес
Александр Денисюк
Гордон Кормак
Шахрияр Манзур
Мигель Ревилла, Феликс Гартнер
Шахрияр Манзур, Резол Алам Чоудхари
Шахрияр Манзур, Резол Алам Чоудхари
Шахрияр Манзур, Резол Алам Чоудхари
Шахрияр Манзур, Резол Алам Чоудхари
Марчин Войцичовски
Петко Минков
Гордон Кормак
Мануель Карро,
Мануель Ж. Пети де Габриэль
Мигель Ревилла, Пабло Пуенте
РуяЛю
Мануель Карро, Альваро Мартинез
Эшеварья
Шахрияр Манзур, Резол Алам Чоудхари
Шахрияр Манзур, Резол Алам Чоудхари
Мигель Ревилла, Эммануэль Херрман
Гордон Кормак, Резол Алам Чоудхари
Шахрияр Манзур
Руя Лю, Ральф Энгельс
РуяЛю
Гордон Кормак
А.5. Благодарности за задачи
385
10.2
10.3
10.4
10.5
10.6
10.7
10.8
11.1
11.2
11.3
11.4
11.5
11.6
11.7
11.8
12.1
12.2
12.3
12.4
12.5
12.6
12.7
12.8
13.1
13.2
13.3
13.4
PC ID
111002
111003
111004
111005
111006
111007
111008
111101
111102
111103
111104
111105
111106
111107
111108
111201
111202
111203
111204
111205
111206
111207
111208
111301
111302
111303
111304
UVa
10054
10278
10039
10158
10199
10249
10092
10131
10069
10154
116
10003
10261
10271
10201
10161
10047
10159
10182
707
10177
10233
10075
10310
10180
10195
10136
Название
Ожерелье
Пожарное депо
Железные дороги
Война
Экскурсовод
Большой обед
Задача про постановщика задач
Умнее ли больший?
Различные
подпоследовательности
Веса и меры
Однонаправленная задача
коммивояжера
Распил брусьев
Заполнение парома
Палочки для еды
Приключения в дороге: часть IV
Муравей на доске
Моноцикл
Звезда
Пчела Майя
Ограбление
B/3/4)-D Квадраты/Прям./
Кубы/Ящики?
Дермубский треугольник
Авиалинии
Суслик и собака
Проблема с канатами в Канатово
Рыцари Круглого стола
Шоколадное печенье
Автор
Шахрияр Манзур, Резол Алам Чоудхари
Гордон Кормак
Мигель Ревилла, Филипп Хан
Петко Минков
ПедроДемаси
Шахрияр Манзур, Резол Алам Чоудхари
Шахрияр Манзур, Резол Алам Чоудхари
Гордон Кормак, Чарльз Ракофф
Шахрияр Манзур, Резол Алам Чоудхари
Гордон Кормак
Оуэн Астракан
Мануель Карро, Хулио Марио
Гордон Кормак
РуяЛю
Гордон Кормак, Ондрей Лотак
Лон Чон
Шахрияр Манзур, Резол Алам Чоудхари
Петко Минков
Руя Лю, Ральф Энгельс
Мигель Ревилла, Эммануэль Херрман
Шахрияр Манзур
Арун Кишо
Шахрияр Манзур, Резол Алам Чоудхари
Гордон Кормак
Шахрияр Манзур, Резол Алам Чоудхари
Педро Демаси
Гордон Кормак
13 - 972
386
Приложение А
13.5
13.6
13.7
13.8
14.1
14.2
14.3
14.4
14.5
14.6
14.7
14.8
PC ID
111305
111306
111307
111308
111401
111402
111403
111404
111405
111406
111407
111408
UVa
10167
10215
10209
10012
10135
10245
10043
10084
10065
849
10088
10117
Название
Именинный пирог
Самая большая/маленькая
коробка...
Это интегрирование?
Насколько он большой?
Пасем первокурсников
Задача о ближайших точках
Резня бензопилой
Теплее - холоднее
Useless Tile Packers
Радиолокация
Деревья моего острова
Вкусное молоко
Автор
Лон Чон
Шахрияр Манзур
Шахрияр Манзур
Гордон Кормак
Гордон Кормак
Шахрияр Манзур
Мигель Ревилла, Кристоф Мюллер
Гордон Кормак
Шахрияр Манзур, Резол Алам Чоудхари
Гордон Кормак
Шахрияр Манзур, Резол Алам Чоудхари
РуяЛю
Послесловие
Олимпиадное движение по информатике, в отличие от таких предметов, как
математика, физика и химия, имеет относительно недавнюю историю. Это и по-
понятно, так как первый компьютер появился в 1949 году, а понимание того, что
с развитием компьютерной техники наступает эра новых информационных техно-
технологий, возникло только в конце 70-х годов.
Сейчас олимпиады по информатике и программированию очень популярны
среди школьников и студентов, а начиналось все в нашей стране в 1988 году, когда
в г. Свердловске через три года после начала преподавания во всех школах школь-
школьного курса «Основы информатики и вычислительной техники», прошла первая
Всесоюзная олимпиада школьников по информатике. Инициаторами проведения
олимпиад по информатике были академики Н. Н. Красовский и А. П. Ершов.
В мае следующего 1989 года в болгарском городе Правец уже была проведена
первая Международная олимпиада школьников по информатике. Идея проведе-
проведения подобных международных соревнований была высказана на 24-й конферен-
конференции ЮНЕСКО болгарским делегатом профессором Сендовым в октябре 1987 года
в Париже. Олимпиада сразу привлекла к себе внимание международной общест-
общественности. Уже тогда в ней приняли участие 13 стран, что гораздо больше, чем
число стран-участниц первых международных олимпиад по математике, физике
и другим предметам. С тех пор олимпиады по информатике проводятся ежегодно,
и число участвующих стран год от года растет. В 2004 году в Афинах участвовало
около 300 школьников из 81 стран мира.
В то время всероссийские и международные олимпиады школьников по ин-
информатике носили чисто индивидуальный характер. Олимпиады такого рода про-
проводились в два тура, каждый участник в течение пяти часов, отводимых на
каждый тур, должен был решить предложенные ему задачи. В распоряжение каж-
каждого участника предоставлялось рабочее место, оборудованное персональным
компьютером с соответствующим программным обеспечением. Результатом ре-
решения олимпиадной задачи была готовая к исполнению программа, написанная
на одном из допустимых на олимпиаде языков программирования. Победитель
олимпиады определялся по результатам тестирования программ участников с по-
помощью специальной системы тестов.
13*
388 Послесловие
С интенсивным развитием и широким распространением компьютерной тех-
техники и информационных технологий появились новые по форме и содержанию
школьные олимпиады по информатике. Так автору этих строк на международной
олимпиаде по информатике удалось узнать у коллег из Сингапура о проведении
в странах азиатского региона командных олимпиад по программированию для
школьников. Воспользовавшись их приглашением, в 1991 году команда советских
школьников впервые приняла участие в таких соревнованиях. Соревнования им
очень понравились, особенно своей динамикой. Поделившись своими впечатле-
впечатлениями об этой олимпиаде с коллегами из Санкт-Петербурга, мы решили провести
нечто подобное в рамках очередной национальной олимпиады по информатике,
а затем в 1993 году в Санкт-Петербурге состоялась первая городская командная
олимпиада школьников по программированию. С этого началось у нас в стране
проведение командных олимпиад школьников по программированию.
В отличие от личных олимпиад по информатике на командной олимпиаде по
программированию команде из трех человек предоставляется для решения задач
один компьютер. Они вместе организуют совместную работу, выполняют предло-
предложенные задания. Как оказалось, по этой же формуле, начиная с 1977 года прово-
проводится командный чемпионат мира по программированию среди сборных команд
высших учебных заведений (ACM International Collegiate Programming Contest),
но так получилось, что впервые такого рода соревнования были проведены
в нашей стране именно для школьников.
Увлекательные интеллектуальные состязания молодых программистов не за-
заканчиваются с их поступлением в высшие учебные заведения, поскольку начиная
с 1993 г., вузы России также стали принимать участие в студенческих командных
чемпионатах мира по программированию. Более того, в 1996 г. наша страна по-
получила право на создание собственной полуфинальной Северо-Восточной Евро-
Европейской региональной группы, победители которой сразу выходят в финал чем-
чемпионата мира.
За время проведения международных и всероссийских олимпиад по информа-
информатике и программированию для школьников и студентов накоплен огромный орга-
организационный опыт, налажено взаимодействие различных звеньев в системе под-
подготовки одаренных молодых программистов, которые вносят существенный
вклад в развитие современных компьютерных технологий. С ребятами работают
высококлассные специалисты и педагоги, ориентированные не только на непо-
непосредственный результат, то есть, на призовые места для своих подопечных, но
и на долгосрочную перспективу - воспитание будущей смены специалистов в об-
области информационных технологий и программирования. По сути дела, олимпиа-
Послесловие 389
ды, как сами турниры, так и их материальная и кадровая база, это дополнительная
образовательная структура, в институциональных рамках которой идет селекция,
развитие и образование одаренных детей в области информатики и программиро-
программирования, а таких у нас много.
Благодаря этому, российские школьники и студенты добились впечатляющих
результатов на международных олимпиадах по информатике и программированию
и обеспечили России одно из первых мест среди стран, ведущих в области подго-
подготовки молодых одаренных программистов. Начиная с 1993 года, когда
в российских школах в заметном количестве появились персональные ком-
компьютеры, сборная команда России неизменно входила в число призеров в неофи-
неофициальном командном зачете Международной олимпиады школьников по информа-
информатике, трижды, в 1994, 1997 и 2000 гг. занимая первые места. Пять раз, больше чем
любая другая страна, российские школьники: петербуржец Виктор Баргачев в 1994
- 1995 гг, нижегородцы Владимир Мартьянов в 1997 и 1998 гг. и Михаил Баутин
в 2000 г. завоевывали звания абсолютных чемпионов мира по информатике.
В общей сложности российские школьники по числу завоеванных на этих олим-
олимпиадах медалей (общее количество - 59, из них золотых 28, серебряных 20, брон-
бронзовых 11) лишь немного уступают китайским школьникам, у которых общее ко-
количество медалей 62, из них золотых 31, серебряных 17 и бронзовых 11. По этому
показателю школьники этих двух стран намного превосходят другие страны.
Не отстают от наших школьников и российские студенты, постоянно зани-
занимающие высокие места на командных чемпионатах мира по программированию
среди сборных команд высших учебных заведений. Только за последние два года
команда студентов Санкт-Петербургского государственного университета ин-
информационных технологий, механики и оптики стала чемпионами мира и Европы
в сезоне 2003/2004 г.г, а команда Московского государственного университета им.
М.В. Ломоносова завоевала в упорной борьбе с китайскими студентами второе
место в мире в сезоне 2004/2005 гг, став при этом чемпионами Европы. Дважды
становилась чемпионами мира и Европы команды Санкт-Петербургского госу-
государственного университета в сезонах 1999/2000 г.г. и 2000/2001 г.г.
Отрадно отметить, что многие победители Всероссийских и Международных
олимпиад по информатике, став студентами, принимают участие в организации
этих олимпиад и в подготовке своих младших товарищей, привлекают кандидатов
в сборные регионов и сборную команду России. В жюри, организационные и тех-
технические комитеты Всероссийской командной олимпиады школьников по ин-
информатике и полуфинальных соревнований Северо-Восточного Европейского ре-
региона командного студенческого чемпионата мира по программированию входят
многие победители и призеры соревнований самого высокого ранга.
390 Послесловие
Российская система образования в области точных наук по праву считается
одной из лучших в мире. За многие десятилетия в стране сложилась уникальная
система поиска и подготовки молодых талантливых программистов. Основой этой
системы является неформальное сообщество российских педагогов высочайшей
квалификации, которых традиционно отличает подвижнический труд и предан-
преданность своему делу. Не даром, за разработку концепции и создание организационной
структуры учебно-методического и программного обеспечения инновационной
системы подготовки высококвалифицированных кадров в области информацион-
информационных технологий большая группа российских ученых, среди которых ректор СПбГУ
ИТМО В. Н. Васильев, декан СПбГУ ИТМО В. Г. Парфенов, ассистенты СПбГУ
ИТМО Р. А. Елизаров, А. С. Станкевич, декан Уральского государственного уни-
университета М. О. Асанов, старший преподаватель Санкт-Петербургского государст-
государственного университета Н. Н. Вояковская, ректор Алтайского государственного тех-
технического университета В. В. Евстигнеев, доцент Московского инженерно-физиче-
инженерно-физического института (государственного университета) В. М. Кирюхин, проректор Мос-
Московского государственного университета А.В. Михалев, доцент Саратовского госу-
государственного университета А. Г. Федорова, награждена Премией Президента РФ
в области образования за 2003 год.
Чтобы успешно выступать на всероссийских и международных соревновани-
соревнованиях по информатике, школьникам и студентам необходимо постоянно совершенст-
совершенствовать свои знания и практические навыки. Какие бы высококлассные педагоги
и специалисты с ними не занимались бы, без самостоятельной работы и упорного
труда здесь не обойтись.
В настоящее время много различных и полезных для тренингов материалов со-
содержится на образовательных порталах и сайтах университетов страны, активно
участвующих в командных чемпионатах мира по программированию. Представляе-
Представляемая вашему вниманию книга является удачным дополнением к ним, и, несмотря на
отличительные особенности школьных олимпиад по информатике и командных
чемпионатов мира по программированию, среди сборных команд высших учебных
заведений, будет полезна как школьникам, так и студентам, готовящимся к успеш-
успешному выступлению на соревнованиях по информатике и программированию.
Дерзайте, уважаемые читатели, и успехи не заставят себя ждать.
Председатель методической комиссии
по информатике Центрального оргкомитета
всероссийских олимпиад школьников В. М. Кирюхин
Список рекомендуемой литературы
[АМО93] R. Ahuja, T. Magnanti, J.Orlin. Сетевые потоки. Prentice Hall, Englewood Cliffs NJ, 1993.
[BerO1 ] A. Beregeron. Введение в элементарную теорию Ганненгалли-Певзнера (Hannenhalli-
Pevzner). Proc. 12thSymp. Combinatorial Pattern Matching (CPM), том 2089, страницы
106-117. Springer-Verlag Lecture Notes in Computer Science, 2001.
[CC97] W. Cook, W. Cunningham. Комбинаторная оптимизация. Wiley, 1997.
[COM94] COMAP. Практически значимые случаи. W. H. Freeman, New York, третье издание, 1994.
[dBvKOSOO] M de Berg, M. van Kreveld, M. Overmars, 0. Schwarzkopf. Вычислительная геометрия:
Алгоритмы и приложения. Springer-Verlag, Berlin, второе издание, 2000.
[DGK83] P. Diaconis, R. L Graham, W. M. Kantor. Математика идеальных перетасовок. Advanced
in Applied Mathematics, 4:175,1983.
[Dij76] E. W. Dijkstra. Дисциплина программирования. 1976.
[Gal01] J. Gallian. Обход графов: краткий обзор. Bectronic Journal in Combinatorics, DS6,
www.combinatorics.org, 2001.
[GJ79] M. R. Garey, D. S. Johnson. Компьютеры и неразрешимость: Руководство к теории
NP-полноты. W. H. Freeman, San Francisco, 1979.
[GKP89] R. Graham, D. Knuth, 0. Patashnik. Конкретная математика. Addison-Wesley, Reading MA, 1989.
[GP79] B. Gates, С Papadimitriou. Граничные значения для сортировки изменением порядка
префиксов. Discrete Mathematics, 27:47-57,1979.
[GS87] D. Gries, I. Stojmenovic. Замечания по алгоритму Грэхема построения выпуклой
оболочки. Information Processing Letters, 25E):323-327,10 июля 1987.
[GS93] В. Granbaum, G. Shephard. Теорема Пика. Amer. Math. Monthly, 100:150-161,1993.
[Gus97] D. Gusfield. Алгоритмы на строках, деревья и последовательности: Информатика
и вычислительная биология. Cambridge University Press, 1997.
[Hof99] P. Hoffman. Человек, который любил только числа: История Пауля Эрдеша и поиск
математической истины. Little Brown, 1999.
[HV02] Q. Horvath, T. Verhoeff. Поиск оптимума в условиях IOI1. Informatics in Education, 1:73-92,
также по адресу http://www.vtex.lt/informatics_in_education/2002.
[HW79] G. H. Hardy, E. M. Wright. Введение в теорию чисел. Oxford University Press, пятое
издание, 1979.
ЧО1 - Международная олимпиада по информатике. - Примеч. науч. ред.
392 Список рекомендуемой литературы
[KayOO] R. Кауе. Сапер - NP-полон. Mathematical Intelligencer, 22B):9-15, 2000.
[Knu73a] D. E. Knuth. Искусство программирования. Том 1: Основные алгоритмы.
Addison-Wesley, Reading MA, второе издание, 1973.
[Knu73b] D. E. Knuth. Искусство программирования, Том 3: Сортировка и поиск. Addison-Wesley,
Reading MA, 1973.
[Knu81 ] D. E Knuth. Искусство программирования. Том 2: Получисленные алгоритмы. Addison-Wesley,
Reading MA, второе издание, 1981.
[КР99] В. Keringhan, R. Pike. Практическое программирование. Addison-Wesley, Reading MA, 1999.
[Lag85] J. Lagarias. Задача Зх+1 иее обобщения. American Mathematical Monthly, 92:3-23,1985.
[LR76] E. Luzack, A. Rosenfeld. Расстояния на шестиугольной сетке. IEEE Transactions on
Computers, 25E):532-533,1976.
[Man01 ] S. Manzoor. Стандартные ошибки в обычных и сетевых соревнованиях. ACM Crossroads
Student Magazine, http://mm.acm.org/crossroads/xrds7-5/contests.html, 2001.
[McD87] W. McDaniel. Существование бесконечного количества k-x чисел Смита. Fibonacci
OZy, 25:76-80,1987.
[MDS01 ] D. Musser, G. Derge, A. Saini. STL Tutorial and Reference Guide: C++ Programming with
Standard Template Library. Addison-Wesley, Boston MA, второе издание, 2001.
[Mor98] S. Morris. Магические уловки, перетасовка карт и динамика компьютерной памяти: Математика
идеальной перестановки. Mathematical Association of America, Washington, D. C, 1998.
[New96] M. Newborn. Каспаров против Deep Blue: Компьютерные шахматы достигают
совершеннолетия. Springer- Verlag, 1996.
[O'ROO] J. O'Rourke. Вычислительная геометрия на С. Cambridge University Press, New York,
второе издание, 2000.
[PS03] S. Pemmaraju, S. Skiena. Вычислительная дискретная математика: Комбинаторика
и теория графов с математикой. Cambridge University Press, New York, 2003.
[Sch94] B. Schneier. Прикладная криптография. Wiley, New York, 1994.
[Sch97] J. Schaeffer. Шаг вперед: Оспаривание человеческого превосходства в проверяющих
системах. Springer-Verlag, 1997.
[SchOO] В. Schechter. Мой мозг открыт: Математические полеты Пауля Эрдеша. Touchstone
Books, 2000.
[Sed01 ] R. Sedgewick. Алгоритмы C++: Алгоритмы на графах. Addison-Wesley, третье издание, 2001.
[Seu58] Dr. Seuss. Yertle the Turtle. Random House, 1958.
[Seu63] Dr. Seuss. Вылет при выталкивании. Random House, 1963.
[Ski97] S. Skiena. Пособие по разработке алгоритма. Springer-Verlag, New York, 1997.
Список рекомендуемой литературы 393
[StiO2] D. Stinson, Криптография: Теория и практика. Chapman and Hall, второе издание, 2002.
[WesOO] D. West. Введение в теорию графов. Prentice-Hall, Englewood Cliffs NJ, второе издание, 2000.
[WH82] A. Wilansky. Числа Смита. Two- Year College Math. J., 13:21,1982.
[Wol02] S. Wolfram. Новый вид науки. Wolfram Media, 2002.
[ZMNN91] H. Zuckerman, H. Montgomery, I. Niven, A. Niven. Введение в теорию чисел. Wiley, New
York, пятое издание, 1991.
Предметный указатель
#
Зп + 1 задача, 23
8 ферзей задача, 193
А
Accepted (РЕ): заключение
«принято с ошибками
представления», 14
Accepted: заключение
«принято», 14
American Standard Code
for Information Interchange, 73
В
BFS (поиск в ширину), 219
bsearchO, ЮЗ
С
C++, 16,49
D
DAG, 214, 226
DFS, 223
Dr. Seuss, 50
G
Google, 73
IEEE стандарт для работы с
числами с плавающей запятой, 131
in-order обход, 224
Java строки, 83
Java, 17, 50
Java, библиотека сортировок, 104
Java, библиотеки, 178
Java, советы по языку, 20
java.util, 50
java.util.arrays, 104
jolly jumper, 59
L
LCD дисплей, 31
qsortO, 102
R
RSA-кодирование, 175
S
Seuss, Dr., 50
Standard Template Library, 49,103
и
Unicode, 75
Предметный указатель
395
Y
Yahtzee, 70
А
автоматизированное судейство, 88
автоматическая тестирующая сис-
система Universidad de Valladolid, 11
автоматическая тестирующая
система, 11
академия Платона, 321
алгебра, 134
арифметика остатков, 173
арккосинус/синус/тангенс, 326
ациклический граф, 214
Б
безразличный символ (джокер), 79
бесконечность простых чисел, 169
библиотека сортировок C++, 103
библиотека сортировок языка С, 102
библиотеки, 42
библиотеки, тригонометрические
функции, 334
биекция, 149
бинарное дерево, 46
бинарные деревья, исчисление , 154
бинарный поиск, 98,103,104
биномиальные
коэффициенты, 151, 271
битовый вектор, 49
ближайшая пара, 361
ближайшая точка, 324
ближайший сосед, 335
большой круг, 307
быстрая сортировка, 99
в
Ван Гога алгоритм, 352
ввод строк, 54
Великая теорема Ферма, 167
величина чисел, 121
вершина, 213
вершинная связность, 242
вещественные числа, 130
взвешенный граф, 214
вирус Эбола, 24
возведение в степень, 128
возрастающая
подпоследовательность, 279
Война, карточная игра, 51
восстановление пути, 275
восьмеричное число, 128
восьми ферзей задача, 193
вписанный круг, максимального
радиуса, 337
выбор, 97
вызов по ссылке/значению, 18
выпуклая оболочка, 348
выпуклый многоугольник, 347
вырожденность, 322, 346
высокоточные целые числа, 121
вычисление квадратного корня, 135
вычисление многочленов, 134
вычислительная геометрия, 345
вычитание многочленов, 134
вычитание, 124
396
Предметный указатель
вычитание, арифметика
остатков, 174
вычитание, рациональные
числа, 132
вычитание, сравнимости, 176
г
Гамильтонов цикл, 244
гексагональные координаты, 299
геометрическая
библиотека, Java, 360
геометрия сеток, 357
геометрия, 321
гипотенуза, 325
Голомба последовательность, 164
Гольдбаха гипотеза, 182
Горнера схема, 134
градусы, 325
граничные условия, динамическое
программирование, 278
граф программы, 214
граф шантажа, 252
граф, 213
графа обход, 190
графические интерфейсы
пользователя, 19
графов теория, 241
Грэхема просмотр, 348
д
движение денег, 30
двоичное дополнение чисел 121
двоичное число,128
двойной счет, 149
двойственный граф, 298
двудольный граф, 228, 253
двусвязный граф, 242
Дейкстры алгоритм, 248
деление полиномов, 135
деление чисел большой длины, 126
деление, 126
деление, арифметика остатков, 174
деление, рациональные числа, 132
деление, сравнимости, 176
делимость, 166
деранжирования функция, 53, 75
дерево, 242
десятичная дробь, 128,133
дешифровка, 63, 87
динамическое выделение
памяти, 121
динамическое
программирование, 153, 270
динамическое программирование,
обратная трассировка, 276
динамическое программирование,
ощущение необходимости, 281
диофантово уравнение, 177,184
длина окружности, 329
длинное целое, 120
добавление в очередь, 44
добавление палиндрома, 139
доказательство от противного, 169
долгота, 306
доминирующее множество, 202
дорожная сеть, 213
древовидная сортировка,98
дробь, 132
Предметный указатель
397
Е
Евклида алгоритм, 171,180
ж
жадный алгоритм, 271
з
забастовки, 62
зависимость результата оценки задач
от языка программирования, 17
задача Варинга, 182
замещение подстроки, 80
записи, 25
заполнение парома, 290
запрещенная функция, ответ
тестирующей системы, 15
запрос на диапазон, 358
запросы на прямоугольной
области, 358
знак нижнего регистра, 75
И
игры в кости, 70
игры, 70
извлечение из очереди, 44
изменение направления строки
на обратное, 80
изменение основания логарифма, 137
изменение системы счисления, 129
инвариант, 58
инверсия, 99
индукция и рекурсия, 156
иррациональное число, 131
исчисление бинарной кучи , 162
К
календарные расчеты, 175
календарь, 48
карточные игры, 51, 60, 64
карты игральные, 53
касательная,329
Каталонские числа, 154
квадратное уравнение, 135
Китайская теорема об остатках, 177
клавиатура, компьютер, 84
клеточный автомат, 205
код символа, 73
кодирование, 63, 87
кодировка ASCII, 73
кольцевые списки, 44
комбинаторика, 148
комбинаторный взрыв, 201
комментарии, 21
коммивояжера задача, 287
конкатенация строк, 90
копирование строки, 80
корневое дерево, 224, 242
корней нахождения алгоритм, 135
косинус, 325
кратчайшие пути между всеми
парами вершин, 250
кратчайший путь, алгоритмы
поиска, 248
кратчайший путь, невзвешенный
граф, 222
кроссворд, задача, 85
Крускала алгоритм, 245
куча, 48
398
Предметный указатель
Л
лесенка ступенек
редактирования,234
линейная сравнимость, 176
линейного проецирования
алгоритм, 48
лишний код, 22
логарифм, 136
луч,324
м
мантисса, 131
Манхэттен, 307
массивы в С, 19
массивы, 24
математическая библиотека
языка С, 137
матрица смежности, 216
машинная арифметика, 120
медианный элемент, 97
минимаксное игровое дерево, 142
минимальное остовное
дерево, 245, 256
минимальное покрывающее
дерево, 248
многомерные массивы, 25
многоугольник, 345, 347
многочлены, 134
множество, структура данных, 48
модуль, 173
мозаичного размещения задача, 209
монотонная
подпоследовательность, 279
мультипликативная инверсия, 176
мультиребро, 214
н
наибольшая общая
подпоследовательность, 284, 286
наибольший общий делитель, 171
наименьшее общее кратное, 173
натуральное число, 130
натуральный логарифм, 136
нахождение повторяющихся
элементов, 96
неверный ответ, заключение
тестирующей системы, 14
невзвешенный граф, 214
необходимая пара, 97
неориентированный граф, 213
непечатаемый символ, 75
непрерывность вещественных
чисел,130
неразмеченный граф, 215
неточное совпадение строк, 271
неявный граф, 215
НОД, 171,178
Ньютона бином, 151
О
обеденные тарелки, 303
обратные тригонометрические
функции, 326
обход "змейкой", 297
обход по диагоналям, 297
обход по столбцам, 296
обход по строкам, 296
Предметный указатель
399
объединение, 48, 97,104
объектно-ориентированное
программирование, 23
один миллион, 188
округление чисел, 131
окружность, 328
операции перестановки, 64
операция переноса, сложение, 138
опечатка, 84
описание задачи, 52
описание переменной, 21
определение последней цифры, 174
оптимизация лифта, 280
ориентированный ациклический
граф, 214
ориентированный граф, 213
основание системы счисления, 128
основная теорема арифметики, 167
остовное дерево
максимального веса, 247
остовное дерево с минимальным
произведением весов, 247
остовное дерево, 242
острый угол, 347
ответы тестирующей системы, 14
открытая адресация, 47
отладка, методы, 23, 57
отладчик,уровень
исходных кодов, 58
относительное положение точки, 355
отправка программ, 13
отрезок, 321,345
отсекание "ушей", 352
отслеживание снизу вверх,
динамическое
программирование, 276
охватывающий круг, 338
очередь FIFO, 43, 50, 220
очередь по приоритету, 47, 50, 97
очередь, 43, 50
ошибка во время работы,
заключение тестирующей
системы, 14
ошибка компиляции (СЕ),
заключение тестирующей
системы, 14
ошибка округления, 131
ошибка отправки,
ответ автоматической системы, 14
ошибка представления, ответ
тестирующей системы, 14
ошибки завышения или занижения
на единицу, 59
ошибки почтовой программы, 13
п
параллельные прямые, 322
паросочетания
в двудольных графах, 253, 267
паросочетания, 253
Паскаль, 16, 82
передача параметра, 18
перемещение данных, 98, 99
перемещенная
подпоследовательность, 86
пересечение многоугольников, 364
400
Предметный указатель
пересечение прямых, 346
пересечение, 48, 97,104
перестановка, 150
перестановки, максимумы
и минимумы, 201
перестановки, составление, 192
перетягивание каната, 203
переход от десятичной к дробной
записи,133
переход от рациональной записи
к десятичной, 133
перечислимые типы данных, 22
перешеек, 242
периодические
десятичные дроби, 133
перпендикулярные прямые, 324
печатаемый знак, 74
платный проезд, 113
плоский граф, 245, 298
площадь круга, 329
площадь со знаком, 328, 347, 354
площадь треугольника, 328
подмножества, 150
подмножества, построение, 190
подсчет площади, 354, 364
подсчет частоты, 97
подсчет числа комиссий, 151
поиск в глубину, 219
поиск в глубину, 223
поиск в тексте, 79
поиск с возвратами, 188
поиск с отсечением вариантов, 168
поиск циклов, 224
поиск шаблонов, 79
поиск, 45
покер, 60
получение верхнего элемента
стека, 43
помеченный граф, 215
помещение элемента
на вершину стека, 43
последовательность разностей, 59
поток в сети, 253
потоки,55
превышен лимит времени,
заключение тестирующей
системы, 14
превышен лимит вывода, ответ
тестирующей системы, 15
превышен лимит памяти, ответ
тестирующей системы, 15
Предикат ccw_, 347
Предметный указатель
представление символов, 75
представление строк, 75
привязанный граф, 215
Прима алгоритм, 245, 248
примерное совпадение строк, 271
примеры программ, 18
проверка на простоту, 168
проверка на простоту, основанная
на рандомизации, 169, 178,179
проверка на уникальность, 96
проверка программ, 57
произведение многочленов, 143
простое число, 167
Предметный указатель
401
простой граф, 214
прямая, 321
прямая, уравнение, 321
прямой порядок
(pre-order) обхода, 224
прямой угол, 325
прямоугольная сетка, 295
пути в графах, 221
пути через сетку, подсчет, 151
«Пятнашки», 195
Р
работа с индексами, 278
радианная мера, 325
радиус, 328
разбиение множеств, 156
разделение, приложения, 100
разложение на простые
сомножители, 168
разреженный многочлен, 135
разрешение рекуррентных
соотношений, 156
ранжирования функция, 53, 75
расположение здания, 259
распределения ошибок по языкам
программирования, 17
расстояние редактирования, 271
растровые изображения, 33
рациональное число, 130
рациональные функции, 135
реберная связность, 242
реберно-взвешенная
прямоугольная сетка, 298
ребро возврата, 224
ребро дерева, 224
ребро отрицательной стоимости, 249
ребро,213
редактор изображений, 33
рейтинг ухажеров, 100
рекуррентное соотношение, 152
рекуррентное соотношение,
базовый случай, 150
рекурсивные программные
вызовы, 43
рекурсия и индукция, 156
рекурсия,222, 223
рекурсия, возврат с переборами, 190
рекурсия, ускорение, 271
решение сравнимостей, 176
решение треугольников, 327
решето Эратосфена, 62
решетчатый многоугольник, 358
римские цифры, 125
С
самоописывающая
последовательность, 164
самый длинный путь, DAG, 226,
234, 235
Сапер, 28
сбалансированность скобок, 154
связанные структуры,
преимущества, 121
связанный список, 76
связный компонент, 225, 242
сетка из слов, 85
402
Предметный указатель
сетка, 295
сигнальные метки, 25
сильно связанный компонент, 243
символ верхнего регистра, 75
символьные константы, 22
симметрия, 197
симулятор компьютера, 35
синус, 325
система счисления
Броко-Штерна, 144
системы счисления, 144
словарь, 45, 50
сложение многочленов, 134
сложение, 123
сложение, арифметика остатков, 174
сложение, действительных
чисел, 132
сложение, сравнимости, 176
сложность задач, 27
советы по проверке программ, 57
советы по программированию, 21
совпадение подстрок, 278
соединение точек, 256
сокращение дробей, 132
сортировка методом вставки, 99
сортировка методом выбора, 98
сортировка оладий, 107
сортировка с минимумом
перемещения, 114
сортировка, 46
сортировки алгоритмы, 98
сортировки порядок, 75
сортировки приложения, 96
составление расписания, 226
составление расписания, задача, 112
соты, 300
список смежных вершин
в матрице, 216
список смежных вершин, 216
сравнение строк, 79
сравнение, 125
сравнимость, 175
среднее, 106
стандартный ввод/вывод, 19
стек, 43, 50
степени двойки, 140
степень вершины, 241
стоимость наказаний, 277
сторона-угол-сторона, 327
строка, комбинаторная, 150
строки в C++, 83
строки в языке С, 82
строки, 73
структура данных для графа, 245
структура данных для карты, 53
структура данных
для расписания, 48
структуры данных, 42
Супермен, 331
схема из слов лестничного типа, 92
счет соревнований, ACM ICPC, 68
считывание графов, 218
т
таблица ребер, 217
табло с футбольным счетом, 116
Предметный указатель
403
тасовка карт, 64
текстовая строка, 73
теорема Жордана о кривой, 356
теорема косинусов, 327
теорема о бутерброде с ветчиной
и сыром, 339
теорема Пика, 358
теорема Пифагора, 325
теорема синусов, 327
теорема сложения,
комбинаторика, 149
теорема умножения, комби-
комбинаторика, 148
теорема четырех красок, 298
теория вычислений, 148
теория чисел, 167
тест Ферма, 179
типы данных, 24
топологическая сортировка, 226
топологический граф, 215
точка пересечения, 322
точка сочленения, 242
точки, трехмерные, 26
точность, 121
транзитивное замыкание, 252
треугольная решетка, 298
треугольник Паскаля, 151
треугольники, решение, 327
триангуляции, подсчет
количества, 154
триангуляция, 352
тригонометрия, 325
убывающая
подпоследовательность, 279
угол,323
угол-сторона-угол, 327
указатели, 18
умножение многочленов, 134
умножение, 125
умножение, арифметика
остатков, 174
умножение,
рациональные числа, 132
умножение, сравнимости, 176
упаковка кругов, 305
упаковка сфер, 306
упорядоченная
последовательность, 74
уравнения, 134
уровни сложности, 27
устойчивые алгоритмы
сортировки, 101
учетная запись
для автоматической тестирующей
системы, 12
учетная запись, тестирующая
система, 12
ф
философия организации
программного обеспечения, 19
Флойда алгоритм, 250
Форда - Фалкерсона алгоритм, 253
форматирование текста, 93
404 Предметный указатель
форматированный ввод, 55 функция факториала, 181
формирование цепочки данных, 47 y
формула
включений-исключений, 149 Ханойские башни, 163
формула расстояний, 26 хеш-таблица, 46
формулы, содержащие скобки, 43 хеш-функция, 53
функции строковых библиотек, 82 Ц
функции форматированного . „
™ -г г г целое число, 130
ввода/вывода, 19
функция сравнения, 102
Содержание
Введение 5
Глава 1. Начало работы 11
1.1. Начало работы с автоматической тестирующей системой
(robot judge) 11
1.1.1. Автоматический судья Programming Challenges 12
1.1.2 Автоматический судья Universidad de Valladolid 13
1.1.3. Ответы тестирующих систем (судей) 14
1.2. Выбор оружия 15
1.2.1. Языки программирования 16
1.2.2. Чтение наших программ 18
1.2.3. Стандартный ввод/вывод 19
1.3. Советы по программированию 21
1.4. Элементарные типы данных 24
1.5. О задачах 27
1.6. Задачи 27
1.6.1. Задача Зп + 1 27
1.6.2. Сапер 28
1.6.3. Путешествие 30
1.6.4. LCD-дисплей 31
1.6.5. Графический редактор 33
1.6.6. Интерпретатор 35
1.6.7. Проверка на шах 36
1.6.8. Австралийское голосование 39
1.7. Подсказки 40
1.8. Замечания 40
406 Содержание
Глава 2. Структуры данных 42
2.1. Элементарные структуры данных 42
2.1.1. Стеки (Stacks) 43
2.1.2. Очереди (Queues) 43
2.1.3. Словари (Dictionaries) 45
2.1.4. Очереди по приоритету (Priority queues) 47
2.1.5. Множества (Sets) 48
2.2. Объектные библиотеки 49
2.2.1. Стандартная библиотека шаблонов C++
(C++ Standard Template Library) 49
2.2.2. Пакет java.util для Java 50
2.3. Пример разработки программы: сборы на войну 51
2.4. Что касается колоды 53
2.5. Строковый ввод/вывод 54
2.6. Победа на войне 56
2.7. Тестирование и отладка 57
2.8. Задачи 59
2.8.1. Jolly Jumpers 59
2.8.2. Руки в покере 60
2.8.3. Харталы (Hartals) 62
2.8.4. Дешифратор 63
2.8.5. Расположить по порядку 64
2.8.6. Числа Эрдеша 67
2.8.7. Табло соревнований 68
2.8.8. Yahtzee 70
2.9. Подсказки 72
2.10. Замечания 72
Глава 3. Строки 73
3.1. Коды символов 73
3.2. Представление строк 75
Содержание 407
3.3. Пример разработки программы: корпоративные переименования 76
3.4. Поиск шаблонов 79
3.5. Управление строками 80
3.6. Завершение программы 81
3.7. Функции библиотеки для работы со строками 82
3.8. Задачи 84
3.8.1. WERTYU 84
3.8.2. Где Waldorf? 85
3.8.3. Обычная перестановка 86
3.8.4. Дешифратор II 87
3.8.5. Автоматизированное судейство 88
3.8.6. Осколки файлов 90
3.8.7. Дублеты 92
3.8.8. Fmt 93
3.9. Подсказки 94
3.10. Замечания 95
Глава 4. Сортировка 96
4.1. Приложения сортировки -96
4.2. Алгоритмы сортировки 98
4.3. Пример разработки программы: рейтинг ухажеров 100
4.4. Функции библиотеки сортировки 102
4.5. Рейтинг ухажеров 104
4.6. Задачи 106
4.6.1. Семья Вито 106
4.6.2. Стопки оладий 107
4.6.3. Мост 108
4.6.4. Подремать подольше 110
4.6.5. Задача сапожника 112
4.6.6. CDVII ИЗ
4.6.7. Сортировка Шелла 114
4.6.8. Футбол 116
408 Содержание
4.7. Подсказки 118
4.8. Замечания 119
Глава 5. Арифметика и алгебра 120
5.1. Машинная арифметика 120
5.2. Высокоточные целые числа 121
5.3. Высокоточная арифметика 123
5.4. Системы счисления и соответствующие переходы 128
5.5. Вещественные числа 130
5.5.1. Работа с вещественными числами 131
5.5.2. Простые дроби 132
5.5.3. Десятичные дроби 133
5.6. Алгебра 134
5.6.1. Работа с полиномами 134
5.6.2. Нахождение корней 135
5.7. Логарифмы 136
5.8. Математические библиотеки 137
5.9. Задачи 138
5.9.1. Начала арифметики 138
5.9.2. Изменение порядка и сложение 139
5.9.3. Дилемма археолога 140
5.9.4. Единицы 141
5.9.5. Игра в умножения 142
5.9.6 Коэффициенты полинома 143
5.9.7. Числовая система Штерна-Броко (Stern-Brocot) 144
5.9.8. Попарно суммируемые числа 146
5.10. Подсказки 147
5.11. Замечания 147
Содержание 409
Глава 6. Комбинаторика 148
6.1. Базовые методики счета 148
6.2. Рекуррентные соотношения 150
6.3. Биномиальные коэффициенты 151
6.4. Другие счетные последовательности 153
6.5. Рекурсия и индукция 156
6.6. Задачи 157
6.6.1. Сколько чисел? 157
6.6.2. Сколько частей земли? 158
6.6.3. Счет 159
6.6.4. Выражения 160
6.6.5. Нумерация полного дерева 162
6.6.6. Монах-математик 163
6.6.7. Самоописывающая последовательность 164
6.6.8. Шаги 165
6.7. Подсказки 166
6.8. Замечания 166
Глава 7. Теория чисел 167
7.1. Простые числа 167
7.1.1. Поиск простых чисел 168
7.1.2. Подсчет простых чисел 169
7.2. Делимость 170
7.2.1. Наибольший общий делитель 171
7.2.2. Наименьшее общее кратное 173
7.3. Арифметика остатков 173
7.4. Сравнимости 175
7.4.1. Операции со сравнимостями 176
7.4.2. Решение линейных сравнимостей 176
7.4.3. Диофантовы уравнения 177
7.5. Библиотеки по теории чисел 178
7.6. Задачи 178
410 Содержание
7.6.1. Света, больше света 178
7.6.2. Числа Кармайкла 179
7.6.3. Задача Евклида 180
7.6.4. Делители факториалов 181
7.6.5. Сумма четырех простых чисел 182
7.6.6. Числа Смита 183
7.6.7. Шарики 184
7.6.8. Переупаковка 185
7.7. Подсказки 187
7.8. Замечания 187
Глава 8. Поиск с возвратом 188
8.1. Поиск с возвратом 188
8.2. Построение всех подмножеств 190
8.3. Построение всех перестановок 192
8.4. Пример разработки программы: задача восьми ферзей 193
8.5. Поиск с отсечением вариантов 195
8.6. Задачи 198
8.6.1. Слоны 198
8.6.2. Задача про пятнашки 199
8.6.3. Шеренга 201
8.6.4. Станции техобслуживания 202
8.6.5. Перетягивание каната 203
8.6.6. Эдемский сад 205
8.6.7. Color hash 207
8.6.8. Больший квадрат 209
8.7. Подсказки 211
8.8. Замечания 212
Содержание 411
Глава 9. Обходы графов 213
9.1. Особенности графов 213
9.2. Структуры данных для графов 216
9.3. Обход графа: в ширину 219
9.3.1. Поиск в ширину 219
9.3.2. Использование обхода 221
9.3.3. Нахождение путей 221
9.4. Обход графа: в глубину 223
9.4.1. Обнаружение циклов 224
9.4.2. Связные компоненты 225
9.5. Топологическая сортировка 226
9.6. Задачи 228
9.6.1. Раскраска двумя цветами 228
9.6.2. Колеса 229
9.6.3. Экскурсовод 231
9.6.4. Лабиринт из косых 233
9.6.5. Лесенки ступенек редактирования 234
9.6.6. Башни из кубиков 235
9.6.7. От заката до рассвета 237
9.6.8 И снова ханойские башни! 238
9.7. Подсказки 240
Глава 10. Графовые алгоритмы 241
10.1. Теория графов 241
10.1.1. Свойства степеней 241
10.1.2. Связность 242
10.1.3. Циклы в графах 243
10.1.4. Планарные графы 244
10.2. Минимальные остовные деревья 245
10.3. Кратчайшие пути 248
10.3.1. Алгоритм Дейкстры (Dijkstra) 248
412 Содержание
10.3.2. Кратчайшие пути между всеми парами вершин 250
10.4. Потоки в сети и паросочетания в двудольных графах 253
10.5. Задачи 256
10.5.1. Веснушки 256
10.5.2. Ожерелье 257
10.5.3. Пожарное депо 259
10.5.4. Железные дороги 260
10.5.5. Война 262
10.5.6. Экскурсовод 264
10.5.7. Большой обед 266
10.5.8. Задача про постановщика задач 267
10.6. Подсказки 269
Глава 11. Динамическое программирование 270
11.1. Не нужно жадничать 270
11.2. Стоимость редактирования 271
11.3. Восстановление пути 275
11.4. Варианты стоимости редактирования 277
11.5. Пример разработки программы: оптимизация лифта 280
11.6. Задачи 284
11.6.1. Умнее ли больший? 284
11.6.2. Различные подпоследовательности 285
11.6.3. Веса и меры 286
11.6.4 Однонаправленная задача коммивояжера 287
11.6.5. Распил брусьев 289
11.6.6. Заполнение парома 290
11.6.7. Палочки для еды 292
11.6.8. Приключения в дороге: часть IV 293
11.7. Подсказки 294
11.8. Замечания 294
Содержание 413
Глава 12. Сетки 295
12.1. Прямолинейные сетки 295
12.1.1. Обход 296
12.1.2. Двойственные графы и представления 298
12.2. Треугольные и гексагональные сетки 298
12.2.1. Треугольные решетки 298
12.2.2. Гексагональные решетки 300
12.3. Пример разработки программы: Вес тарелки 303
12.4. Упаковка кругов 305
12.5. Широта и долгота 306
12.6. Задачи 307
12.6.1. Муравей на доске 307
12.6.2. Моноцикл 308
12.6.3. Звезда 311
12.6.4. Пчела Майя 312
12.6.5. Ограбление 313
12.6.6. B/3/4)ЛЭКвад/Прям/Куб...? 315
12.6.7. Дермубский треугольник 317
12.6.8. Авиалинии 318
12.7. Подсказки 320
Глава 13. Геометрия 321
13.1. Прямые 321
13.2. Треугольники и тригонометрия 325
13.2.1. Прямоугольные треугольники и теорема Пифагора 325
13.2.2. Тригонометрические функции 325
13.2.3. Решение треугольников 327
13.3. Окружности 328
13.4. Пример разработки программы: быстрее пули 331
13.5. Библиотеки тригонометрических функций 334
13.6. Задачи 335
414 Содержание
13.6.1. Суслик и собака 335
13.6.2. Проблема с канатами в Канатово 336
13.6.3. Рыцари Круглого стола 337
13.6.4. Шоколадное печенье 338
13.6.5. Именинный пирог 339
13.6.6. Самая большая/маленькая коробка 340
13.6.7. Это интегрирование? 341
13.6.8. Насколько она большая? 342
13.7. Подсказки 344
Глава 14. Вычислительная геометрия 345
14.1. Отрезки и пересечения 345
14.2. Многоугольники и вычисления углов 347
14.3. Выпуклые оболочки 348
14.4. Триангуляция: алгоритмы и смежные задачи 352
14.4.1. Алгоритм Ван Гога 352
14.4.2 Подсчет площади 354
14.4.3. Относительное положение точки 355
14.5. Алгоритмы для сеток 357
14.5.1. Запросы на значение области 358
14.5.2. Решетчатые многоугольники и теорема Пика 358
14.6. Геометрические библиотеки 360
14.7. Задачи 360
14.7.1. Пасем первокурсников 360
14.7.2. Задача о ближайших точках 361
14.7.3. Резня бензопилой 362
14.7.4. Теплее - холоднее , 364
14.7.5. Useless Tile Packers 364
14.7.6. Радиолокация 366
14.7.7. Деревья моего острова 367
14.7.8. Вкусное молоко 369
14.8. Подсказки 371
Содержание 415
Приложение А 372
АЛ. ACM International Collegiate Programming Contest 372
A. 1.1. Подготовка 373
A.I.2. Стратегия и тактика 375
А.2. International Olympiad in Informatics
(Международная олимпиада по информатике) 377
A.2.1. Участие 377
A.2.2. Формат 378
A.2.3. Подготовка 379
А.З. Topcoder.com 380
A.4. Аспирантура 381
А.5. Благодарности за задачи 382
Послесловие В. М. Кирюхина 387
Список рекомендуемой литературы 391
Предметный указатель 394
Электронный задачник по программированию
В СУНЦ МГУ им. М. В. Ломоносова - школе им. А. Н. Колмогорова - разра-
разработан и успешно используется в учебном процессе электронный задачник по про-
программированию. В нем реализованы технологии, аналогичные интернет-сервисам
проверки решений задач по программированию.
Задачник предоставляет каждому учащемуся возможность работать в индиви-
индивидуальном темпе и по индивидуальной программе. Выполненные задания автома-
автоматически проверяются оперативно и качественно. В результате использования за-
задачника в учебном процессе повышаются интенсивность и эффективность заня-
занятий, развиваются навыки самостоятельной работы учащихся.
Задачник имеет открытую архитектуру, т. е. он может быть дополнен любыми
компиляторами, а база задач может пополняться преподавателями в любое время.
Схема добавления нового задания достаточно проста. Открытость архитектуры
позволяет при планировании учебного процесса не ограничиваться в выборе зада-
заданий. Тем не менее, в задачник уже включено более 200 учебных задач по програм-
программированию. В частности, по таким темам, как:
Целочисленная арифметика.
Условный оператор.
Порядковые типы данных.
Сортировка.
Задачи на обработку текстовой информации.
Задачи на алгоритмы работы в различных системах счисления.
Комбинаторные алгоритмы.
Задачник поддерживает сетевую базу данных учащихся, которая позволяет
учителю отслеживать текущую успеваемость, осуществлять назначение опреде-
определенных задач тем или иным пользователям, анализировать коды программ учащих-
учащихся и получать полную информацию о тестах, на которых та или иная программа ра-
работает неверно. Последняя информация может также пересылаться и учащимся.
В настоящее время для задачника разрабатывается web-интерфейс. Не позднее ав-
августа 2005г. на сайте http://books.kudits.ru/taskbook задачник будет работать в тестовом
демонстрационном режиме. Все желающие смогут работать с данным программным
средством в качестве учеников, а также зарегистрироваться на серевере в качестве
учителя и получить возможность администрировать работу своих учащихся.
Более подробную информацию о задачнике можно получить по электронной
почте opt@okc.ru или на сайте проекта http://books.kudits.ru/taskbook.