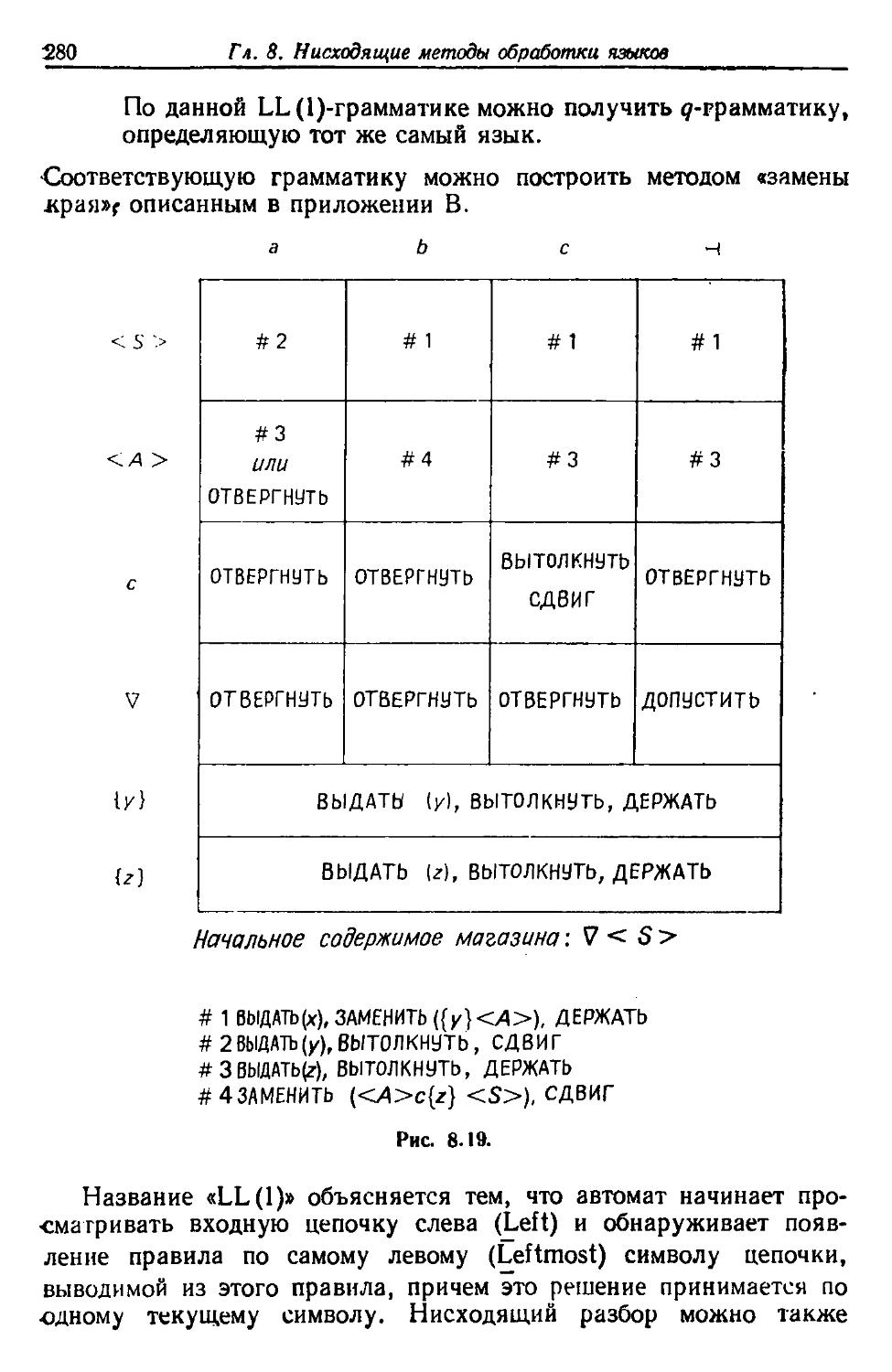
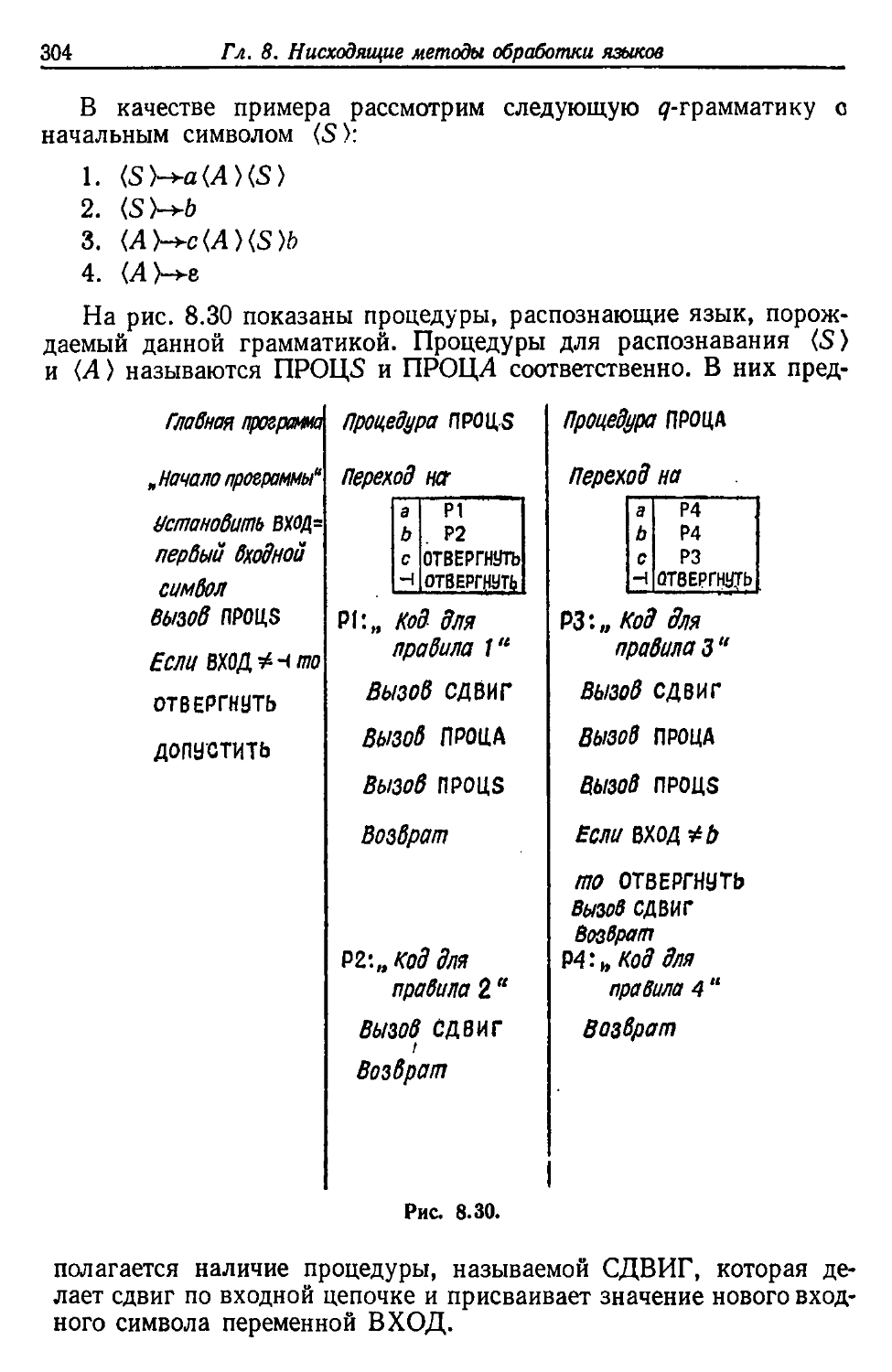
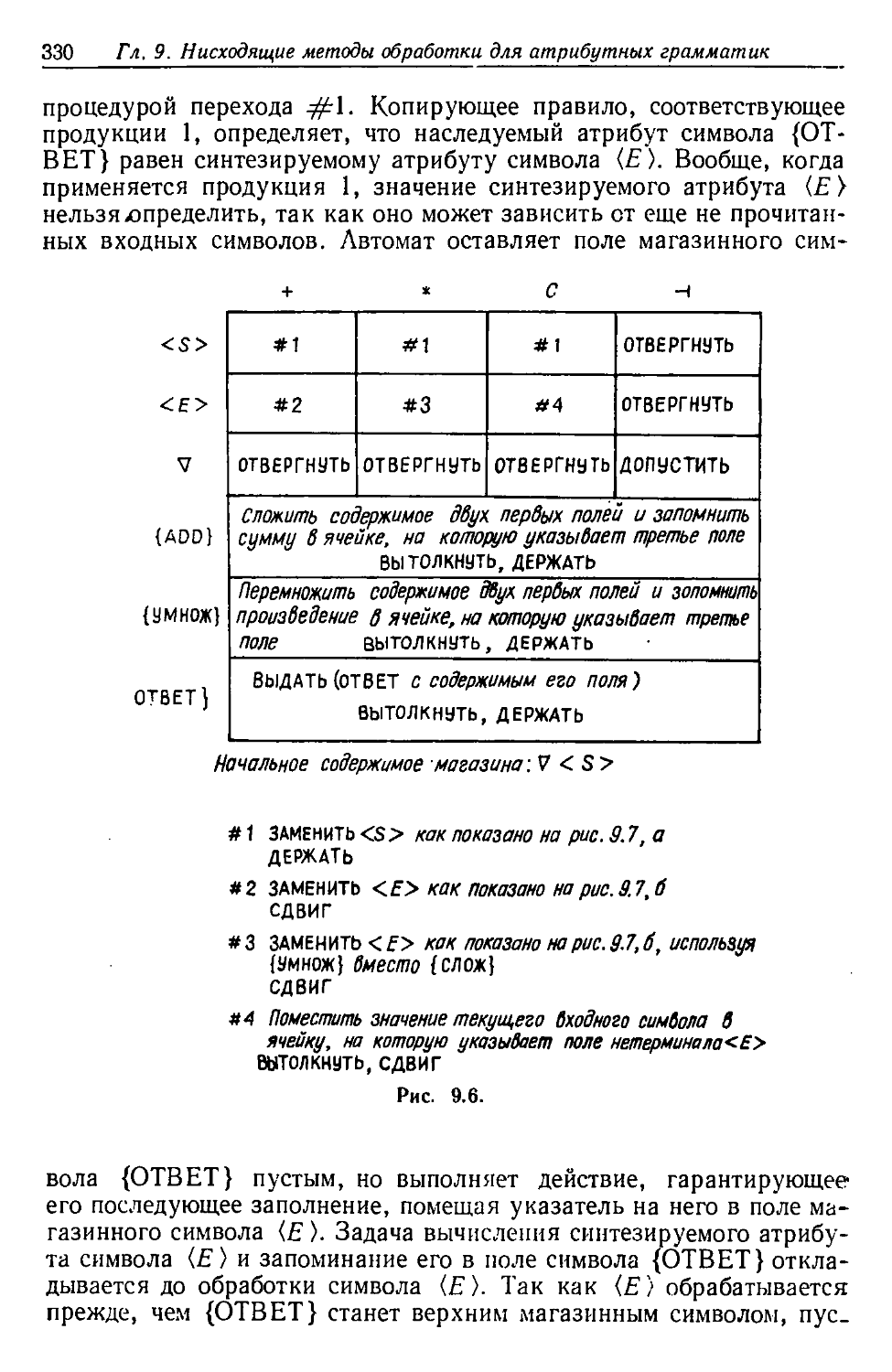
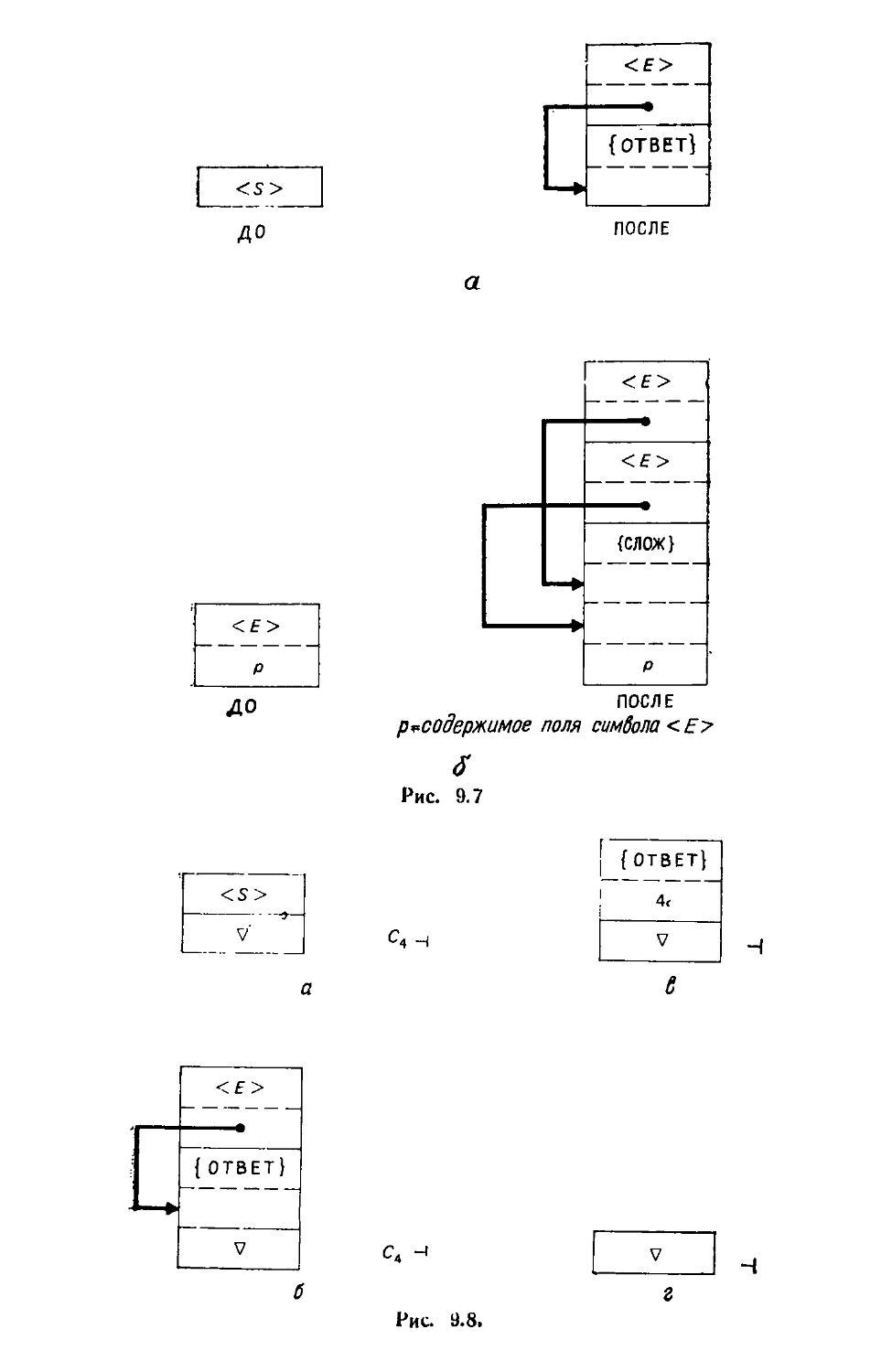
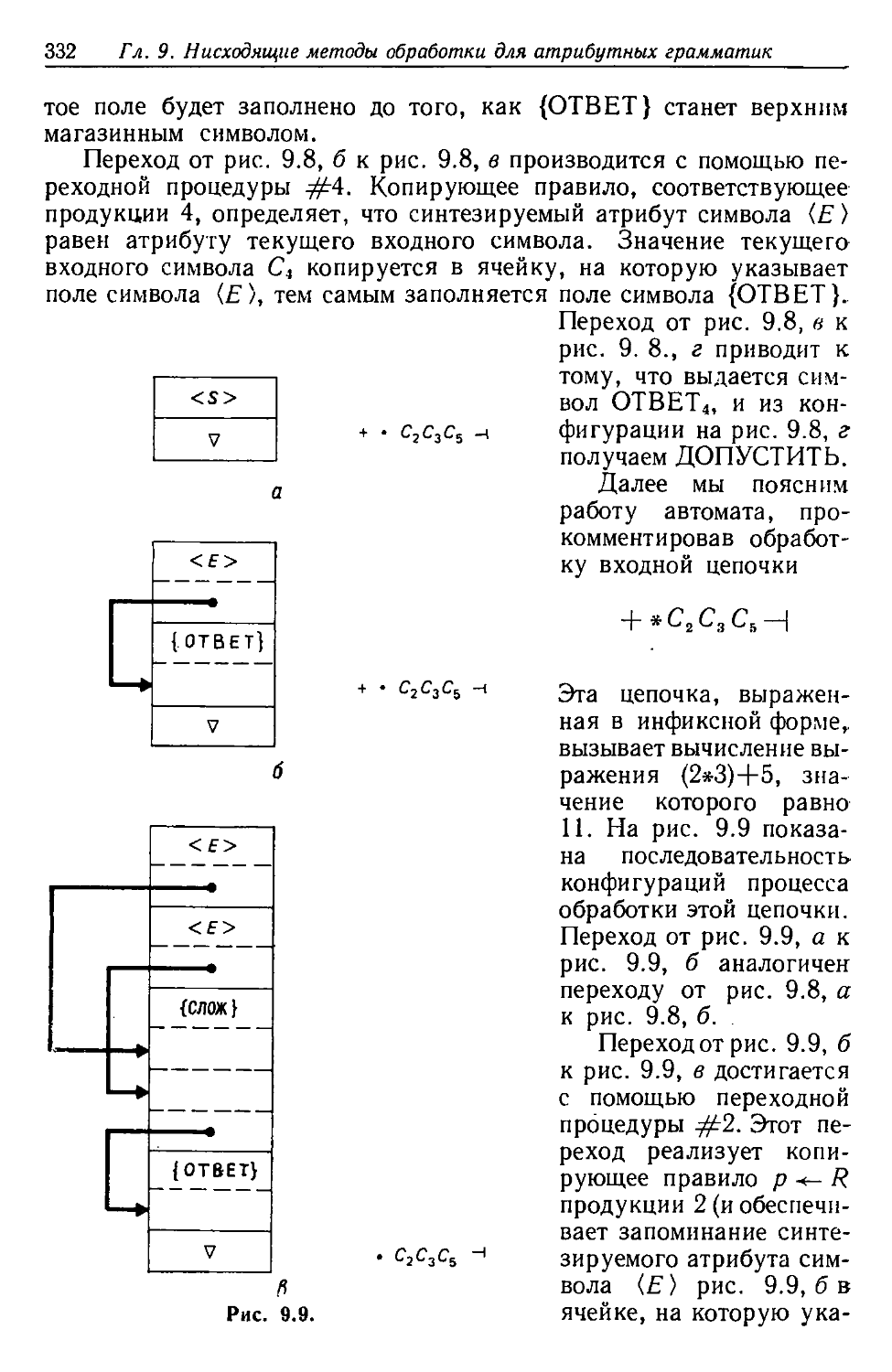
/






























































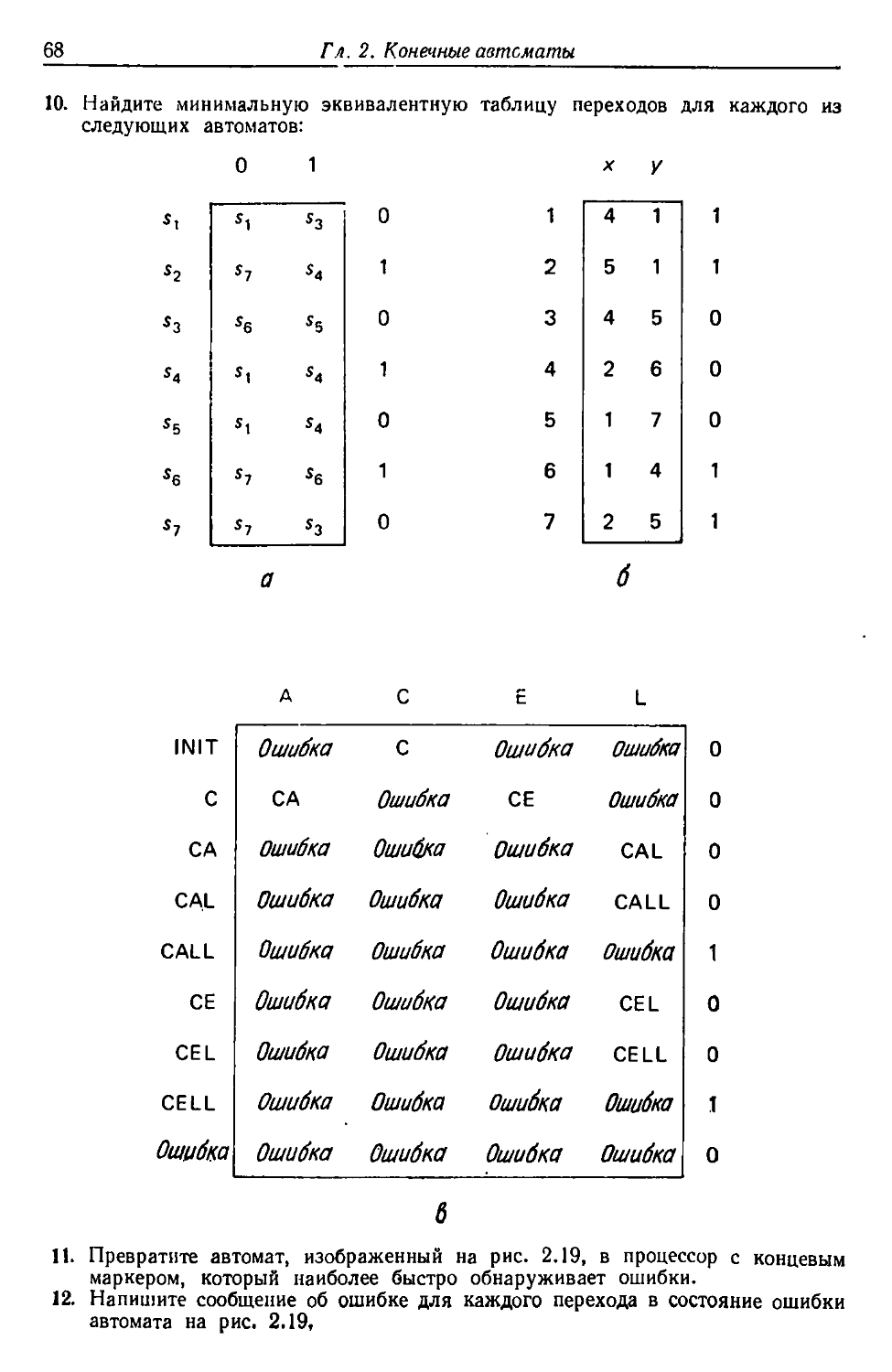
















































































































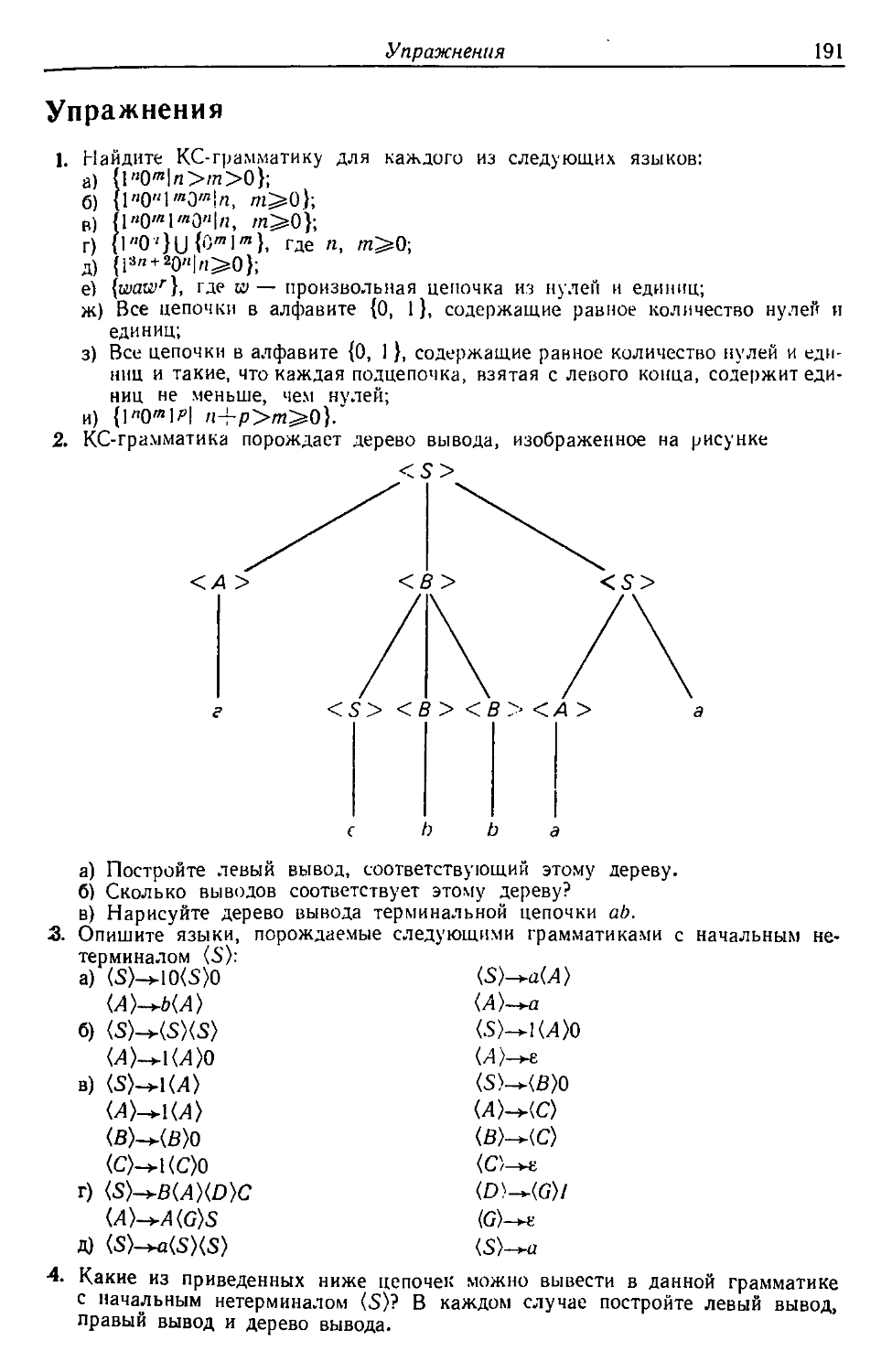






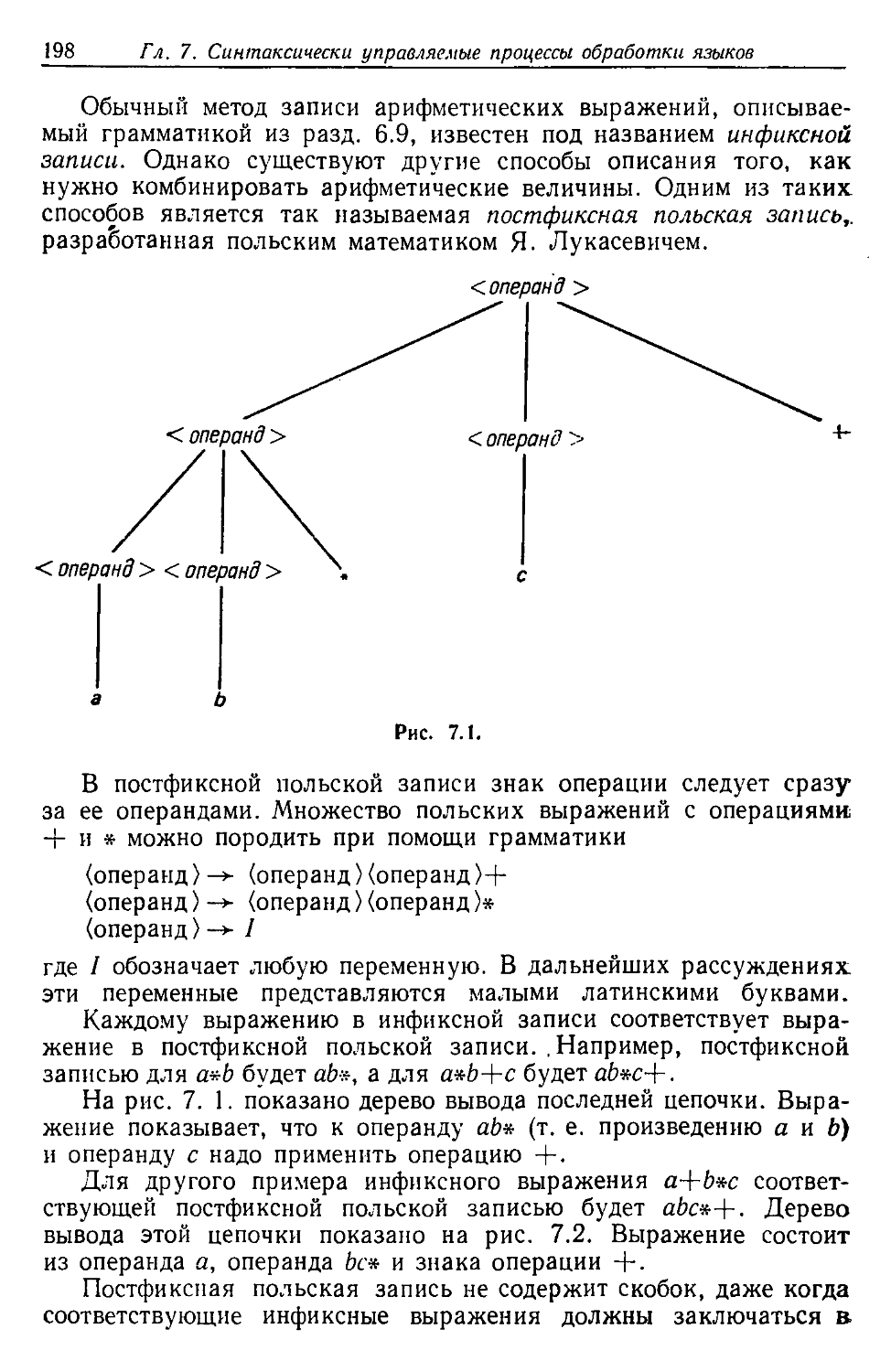
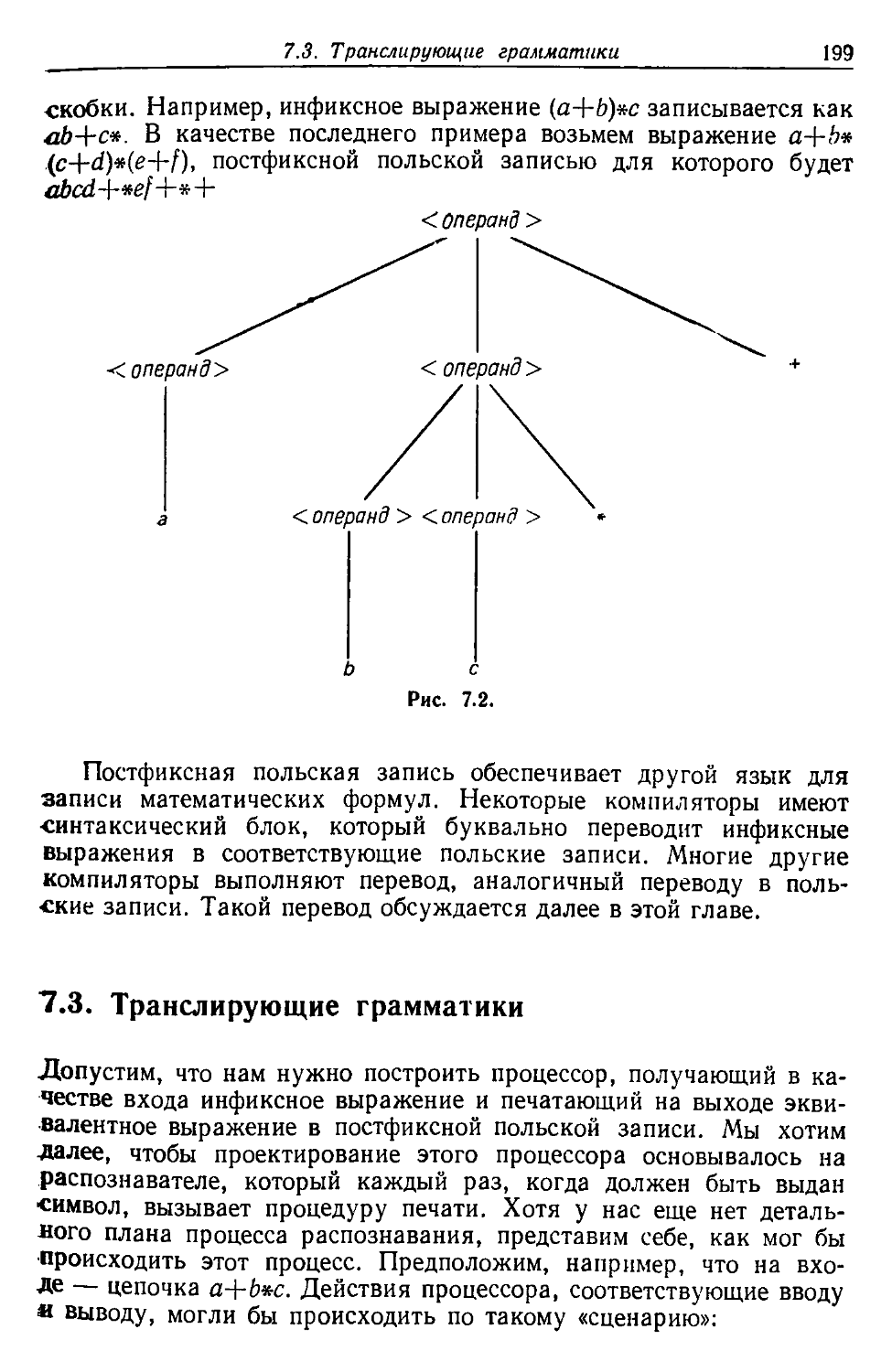



































































































































































































































































































































































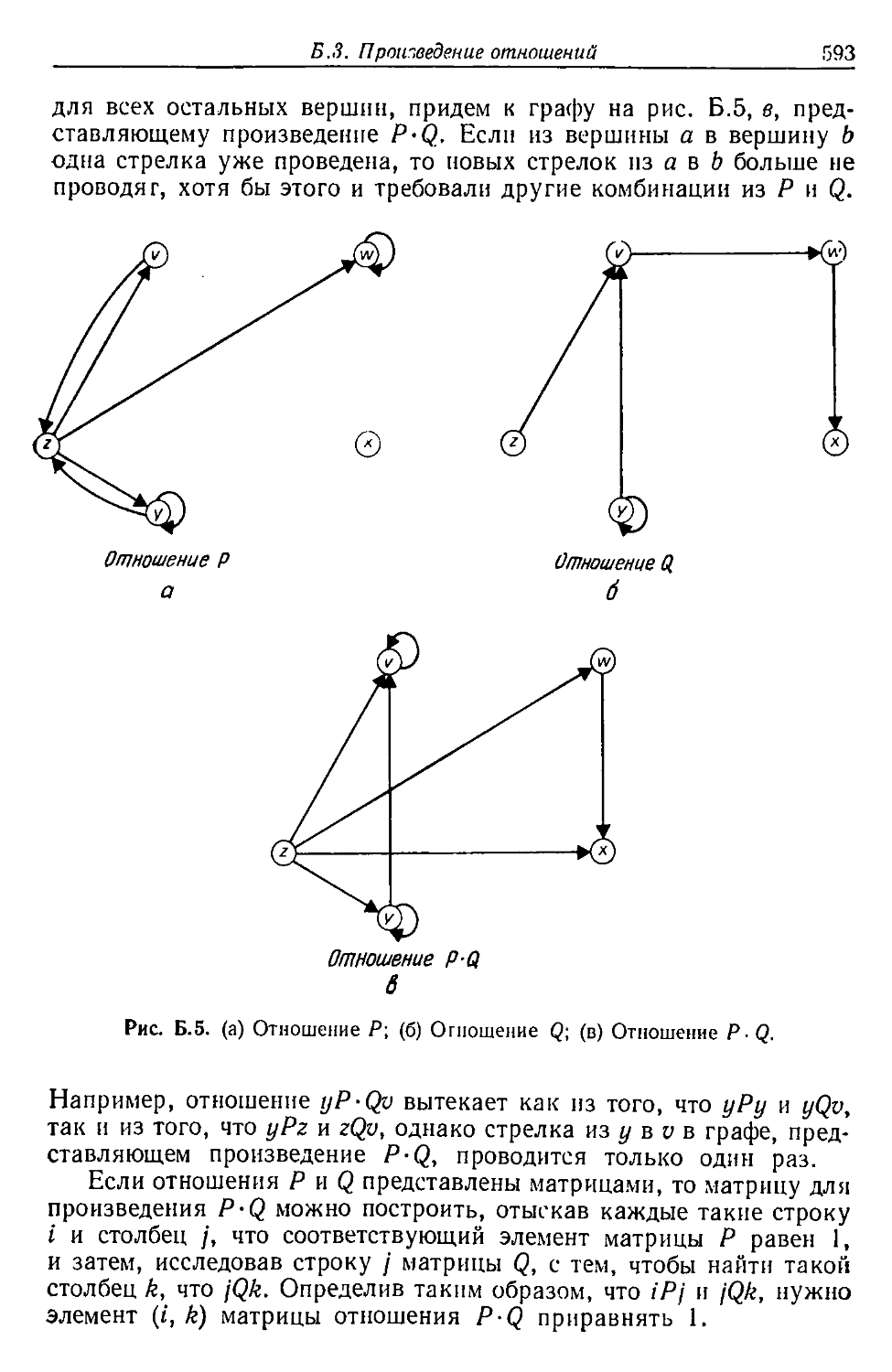


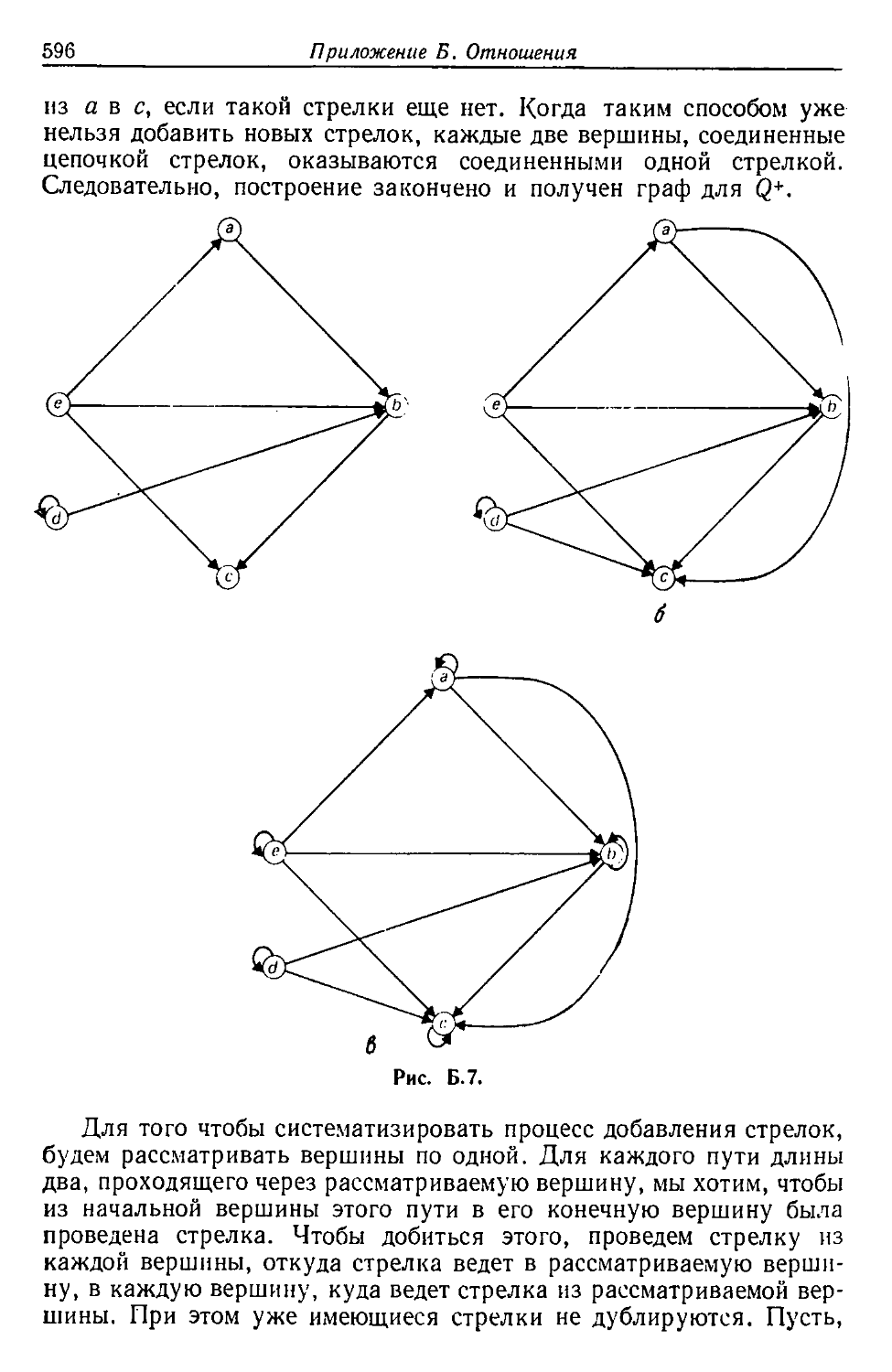





















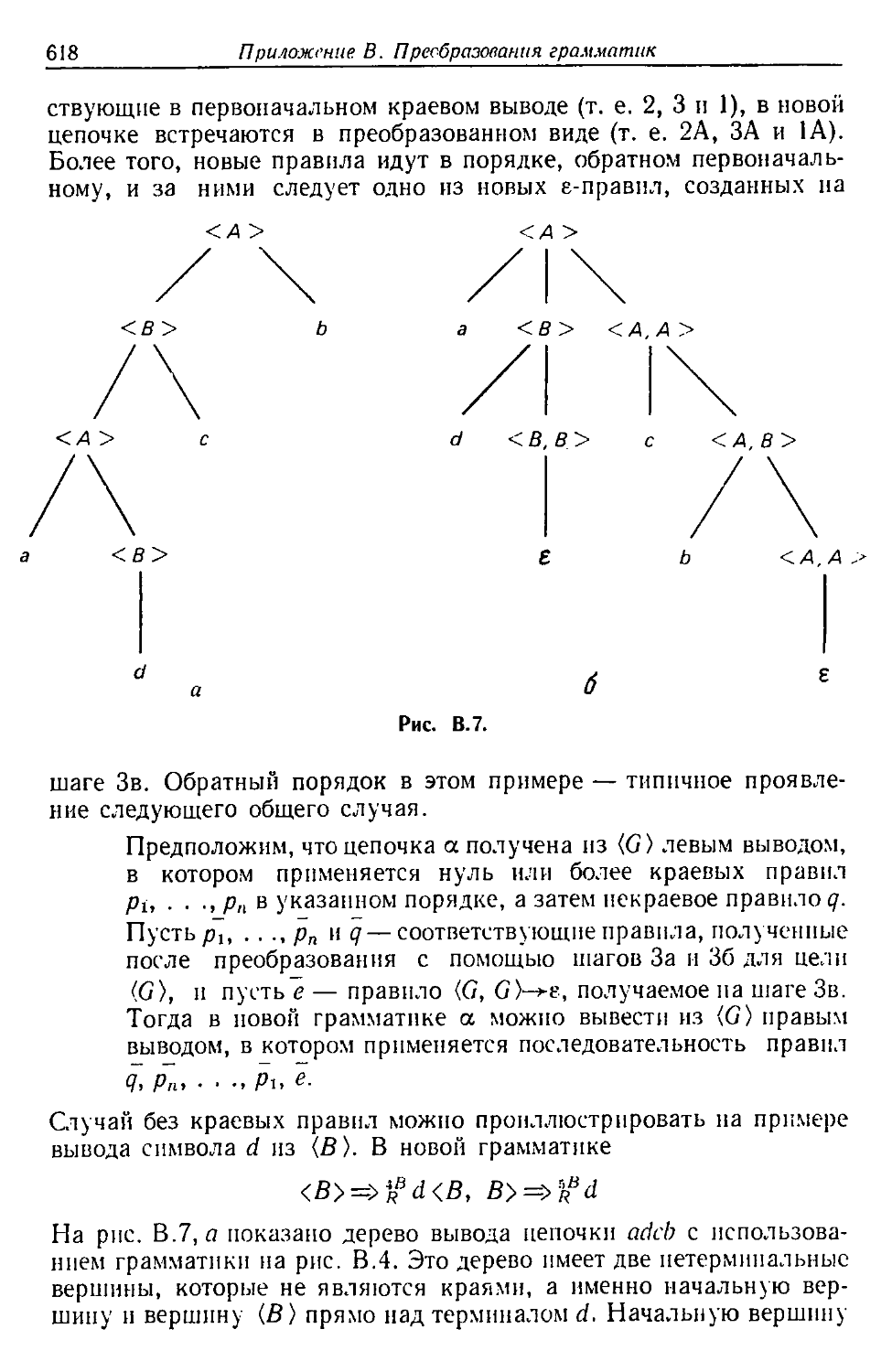






































Автор: Льюис Ф. Розенкранц Д. Стирнз Р.
Теги: вычислительная математика численный анализ математика проектирование
Год: 1979




Текст
THE SYSTEMS PROGRAMMING SERIES
СомрИег Design Theory
PHILIP M. LEWIS II
DANIEL J. ROSENKRANTZ
RICHARD E. STEARNS
General Electric Company
k ADDISON-WESLEY PUBLISHING COMPANY
* Reading, Massachusetts • Menlo Park, California
London • Amsterdam • Don Mills, Ontario • Sydney
1976
Ф. ЛЬЮИС,
Д. РОЗЕНКРАНЦ,
Р. СТИРНЗ
Теоретические
основы проектирования
компиляторов
Перевод с английского
В. А. Исаева
В. С. Нумерова
Н. П. Терновой
Под редакцией
В. Н. Агафонова
ИЗДАТЕЛЬСТВО «МИР»
Москва 1979
УДК 519.685.1
В книге ичг-естных американских специалистов излагаются
математические понятия и методы теории автоматов и формальных
грамматик, лежащие в основе проектирования компиляторов,
и показывается, как их применять на практике. Применение
теории детально продемонстрировано на примере компилятора для
учебного языка программирования. Разработанный авторами метод
позволил им включить в синтаксический блок значительную часть
того, что обычно относится к семантике (генерации кода).
Изложение строгое, но не формальное, доступное читателю, не
имеющему специальной математической подготовки.
Книга рекомендуется широкому кругу системных
программисте!1 и студентов соответствующего профиля (особенно
инженерных вузов).
Редакция литературы по математическим наукам
2405000000
20205-027 © 1976by Addison-Wesley Publishing Company, In
041 (01)-79 © Перевод на русский язык, «Мир», 1979 •
От редактора перевода
Приятно рекомендовать читателю хорошую книгу о том, как математическая
теория может служить основой практических разработок (в данном случае
связанных с проектированием трансляторов). Ее авторы одновременно и теоретики,
известные первоклассными работами по теории формальных языков, и практики,
построившие не один компилятор. Таким образом, читатель получает «из первых
рук» и теоретическую модель, и рекомендации, как ее воплотить в программу.
Этим книга отличается от всех других, посвященных проблемам трансляции.
Она написана как учебник для студентов, обладающих скромными
математическими навыками. Начиная всегда с примеров и содержательных пояснений,
авторы очень заботливо подводят читателя к математически точным понятиям,
не пугая его изощренным формализмом. С методической точки зрения книга
поучительна и для преподавателей вузов, особенно технических.
Что касается специалистов-практиков, им будет интересно прочесть о
разработанном авторами нисходящем методе обработки языков на основе L-атрибутной
грамматики, о восходящих методах, основанных на понятиях простой ССП-грам-
матики и SLR (1)-грамматики. Каждому методу сопутствует обсуждение техники
обработки ошибок, которая до сих пор остается скорее искусством, чем наукой.
Специалисту-теоретику будет интересно посмотреть, как теоретический «костяк»
обрастает программной «плотью», в которой постепенно проявляются контуры
работающей системы.
Несколько слов о терминологии. Во-первых, мы решили переводить на русский
названия процедур, переменных и т. п., что, возможно, облегчит работу с ними.
Насколько удачно это сделано, можно судить по предметному указателю.
Во-вторых, говоря об автоматах и грамматиках, мы следовали терминологии, принятой п
теории формальных языков. Поэтому, в частности, популярный у программистов
стек в большей части книги называется магазином. Мотивировка некоторых
терминов дана в примечаниях.
Работа над переводом была распределена так: Н. П. Терновая перевела гл. 1 —
6 и приложение А, В. А. Исаев —гл. 7—10 и разделы В.1—В.7, В. С.
Нумеров— гл. 11—15, приложение Б и разделы В.8—В.11.
В. Н. Агафонов
От редакционного бюро IBM1'
Область системного программирования возникла как результат усилий
многих программистов и менеджеров, чья творческая энергия воплотилась в
практически полезных системных программах, потребность в которых остро ощущалась в
быстро развивающейся вычислительной индустрии. Программирование было
искусством — каждый программист решал стоящие перед ним задачи по-своему,
влияние со стороны других специалистов, занимавшихся аналогичными
вопросами, было незначительным. В 1968 г. покойный Эшер Оплер, работавший тогда в
IBM, высказал мнение, что знания, накопленные в программировании,
необходимо объединить в форме, приемлемой для всех системных программистов. Изучив
состояние дел в этой области, он пришел к выводу, что попытка систематического
обобщения материала будет вполне оправданна. По его рекомендации фирма IBM
приняла решение финансировать издание «Серии системного программирования».
Цель этого долгосрочного проекта — собрать, систематизировать и опубликовать
те принципы и методы, которые надолго сохранят свою актуальность в
вычислительной технике.
Серия будет состоять из взаимосвязанных книг учебно-справочного характера.
Содержание каждой книги должно отражать точку зрения индивидуального
автора, которая не обязательно совпадает с точкой зрения корпорации IBM. Каждая
книга организуется как учебный курс, однако материал описывается достаточно
подробно, чтобы ей можно было пользоваться как справочником. Серия имеет три
уровня: нижний составляют тома, содержащие вводный материал, средний — тома,
посвященные математическому обеспечению и содержащие материал более узкого
профиля, и, наконец, верхний уровень — специальные теоретические работы.
Организованная таким образом Серия будет полезна и новичкам, и опытным
программистам, и теоретикам.
В целом Серия отражает положение дел в области системного
программирования и может послужить хорошей базой для этой дисциплины.
]) Состав редакционного бюро IBM:
Joel D. Агоп, Chairman Paul S. Herwitz
Richard P. Case James P. Morrissey
Gerhart Chroust Asher Opler
Edgar F. Codd George Radin
Robert H. Glaser David Sayre
Charles L. Gold Norman A. Stanton (Addison-Wesley)
James Greismer Heinz Zemanek
7
Серия включает следующие книги:
Уровень 1: Агоп Joel D., The Program Development Process. Part 1 — The
Individual Programmer.
Агоп Joel D., The Program Development Process. Part II — The Programming Team.
Nichols John E., The Design and Structure of Programming Languages.
Beckman Frank, Mathematical Background of Programming.
Mills Harlan D., Linger Richard C, Structured Programming.
Withington Frederic G., Gardner George, The Environment for Systems Programs,
Уровень 2: Date С J., An Introduction to Database Systems.
Van Dam Andries, Interactive Computer Graphics.
Lorin Harold, Sorting and Sort Systems.
Lewis Philip P>\., Rozenkrantz Daniel J., Stearns Richard E., Compiler Design
Theory-
Уровень 3: Burge William, Recursive Programming Techniques.
Sowa John F,, Conceptual Structures: Information Processing in Mind and Machines,
Нашим женам —
Предисловие
Эта книга задумана как учебное пособие для полугодового или
годового курса по проблемам построения компиляторов. В ней
излагается математическая теория, лежащая в основе построения
компиляторов и других процессоров, предназначенных для
обработки языков, и показывается, как применять эту теорию на
практике.
Применяемые математические понятия взяты из теории
автоматов и формальных грамматик. Эти понятия излагаются строго,
но неформально, чтобы сделать их доступными широкому кругу,
читателей, включая тех, кто не привык к математическому стилю
изложения. Мы считаем, что идеи теории автоматов и формальных
языков служат прекрасной основой как для обучения построению
компиляторов, так и для реальной их разработки. Мы сами
построили два компилятора, основываясь на этой теории.
При отборе и изложении материала большое внимание было
уделено именно «переводу», а не просто «разбору». Для описания
того, как при обработке языков различными процессорами вход
преобразуется в выход, используется формальное понятие
синтаксически управляемого атрибутного перевода.
Другое понятие, на котором мы заостряем внимание,— это
понятие «автомата». Такие автоматы, как конечный автомат или
автомат с магазинной памятью, служат основными строительными
блоками при создании компилятора. Мы описываем процедуры
синтеза автомата, который должен выполнять требуемый перевод
(трансляцию).
Материал данной книги содержит достаточно полную теорию,
необходимую для построения лексического и синтаксического
блоков компилятора. Применение атрибутной трансляции позволило
нам включить в построение синтаксического блока значительную
часть того, что часто называют «генерацией кода» или «семантикой».
В книгу включен также дополнительный материал по генерации
кода и краткий обзор по оптимизации кода.
Хотя проблемы организации рабочей программы очень важны
при решении вопроса о том, каким должен быть код,
генерируемый компилятором, мы не рассматриваем их в нашей книге, так
Предисловие
9
как считаем, что они не относятся к «теории построения
компиляторов», а являются, скорее, темой отдельного курса, в котором
специально рассматриваются структуры языков
программирования.
В этой книге излагаются лишь те аспекты теории автоматов,
которые имеют отношение к построению компиляторов, поэтому
некоторые из ее основных понятий опущены, и, следовательно,
книгу нельзя использовать как исчерпывающий курс по теории
автоматов. Однако студенты, прослушавшие курс по этой книге,
впоследствии гораздо легче воспримут курс теории автоматов.
И наоборот, знание основ теории автоматов поможет студентам
быстрее освоить материал, изложенный в этой книге; таким
образом, данный учебник можно использовать как до, так и после того,
как прослушан вводный курс по теории автоматов.
Для понимания книги требуется лишь знакомство с языками
программирования и математические навыки, какими обычно
владеют студенты технических вузов.
После вводной главы в гл. 2—4 рассматриваются конечные
автоматы, а также другие вопросы, имеющие отношение к лексической
обработке языков. В гл. 5 и 6 вводятся автоматы с магазинной
памятью и контекстно-свободные грамматики.
Если студенты уже прослушали вводный курс по теории
автоматов, большую часть материала, содержащегося в гл. 2—6, можно
опустить, а остальную часть изложить очень быстро, акцентируя
внимание на применении теории к построению компиляторов.
В любом случае можно опустить разд. 2.7—2.11.
В гл. 7 вводятся понятия перевода (трансляции) и атрибутного
перевода; этим материалом нужно овладеть, прежде чем двигаться
дальше.
В гл. 8—10 рассматриваются нисходящие методы обработки
языков (сверху вниз по дереву разбора), а гл. 11—13 посвящены
восходящим методам (снизу вверх). Эти части книги независимы, и
можно ограничиться изучением лишь одной из них. В любом
случае можно опустить разд. 8.7, 10.5, 12.6 и 13.6.
Чтобы продемонстрировать применение теории в «реальной»
ситуации, в книге проводится построение компилятора для
подмножества языка BASIC'). С одной стороны, избранный нами язык
достаточно сложен, чтобы проиллюстрировать на нем приведенные
в книге понятия, с другой стороны, можно обойтись при этом
тривиальной организацией рабочей программы (поскольку
эффективная реализация всех свойств языка, как уже отмечалось, яв-
1) Язык BASIC был создан специально для обучения студентов
программированию и получил широкое распространение в вузах США. Изучить его можно
по книге: Кет ков Ю. Л. Программирование на БЭЙСИКе, Практическое пособие.—
М.: Статистика, 1978,— Прим. ред.
10
Предисловие
ляется предметом отдельного разговора). Этот язык обладает
разнообразными синтаксическими и семантическими свойствами,
включая синтаксически рекурсивную структуру управления (цикл).
В гл. 4 мы строим лексический блок компилятора, а в гл. 10 и 12 —
синтаксические блоки, осуществляющие обработку нисходящим и
восходящим методами соответственно. В гл. 14 разрабатывается
генератор кода. На практических занятиях можно построить
компилятор в данном или расширенном виде.
В гл. 15 приведен краткий обзор по оптимизации кода.
В книге имеется также три приложения: приложение А — это
руководство по языку MINI-BASIC; в приложении Б
рассматриваются некоторые математические отношения, необходимые для
различных процедур проверки и построения; в приложении В
содержатся несколько методов приведения грамматики данного языка
программирования к одной из указанных в книге специальных
форм.
Материал, изложенный з данной книге, в течение нескольких
лет использовался при чтении полугодового курса в Ренсселеров-
ском политехническом институте (г. Трои, штат Нью-Йорк) и в
Университете штата Нью-Йорк (г. Олбани). Он читался также как
полугодовой спецкурс учащимся Объединенного колледжа в
Скенектади (штат Нью-Йорк). Нам хочется поблагодарить слушателей,
чьи недоумевающие взгляды заставили нас несколько раз
переделывать курс.
Хочется также выразить признательность тем, кто читал
первоначальные варианты рукописи и сделал полезные замечания:
Джону Хатчисону, Майклу Хэммеру, Стефену Моурзу, Джону
Джонстону, Донне Филипс, Даниэлю Берри, Алисе Орн, Гэри
Фишеру, Уолтеру Стоуну, Джеймсу Робертсу и Роберту Блину.
Мы благодарны руководству Исследовательского центра
компании Дженерал электрик, и в особенности Ричарду Л. Шайе и
Джеймсу Л. Лоусону, которые создали прекрасные условия для
нашей работы и предоставили нам время и возможность для
написания этой книги.
Скенектади
Декабрь 1975 г.
Авторы
1
Введение
1.1. Программы для обработки языков
В общении человека и машины существуют естественные
трудности. Машины на атомарном уровне оперируют битами и
регистрами, а люди изъясняются на естественных языках (например,
русском или английском) или пользуются математическими
обозначениями. Обычно этот разрыв преодолевается с помощью
искусственного языка, позволяющего употреблять строго определенное
множество слов, предложений и формул, которые машина может
«понять». Чтобы общение с машиной стало возможным, человек
получает руководство для пользователя, в котором объясняются
допустимые в языке конструкции и значения, а для вычислительной
машины создается программное обеспечение, с помощью которого
она может воспринимать последовательности битов,
представляющие команды или программы, написанные человеком на
искусственном языке, и переводить их во внутренние битовые структуры,
необходимые для исполнения того, что было задумано человеком.,
Существующие языки для общения с вычислительными
машинами очень различны по сложности, например:
машинный язык — набор команд конкретной
вычислительной машины, который интерпретируется на аппаратном
уровне или с помощью микропрограмм самой машины;
языки ассемблера, или языки «низкого уровня», которые в
значительной мере отражают набор команд некоторой
конкретной машины;
языки управляющих карт и директивные языки, которые
используются для связи с операционной системой;
языки «высокого уровня», такие, как Фортран, Алгол, ПЛ/1,
Лисп и т. д., которые имеют сложную структуру и не зависят
ни от набора команд, ни от операционной системы
конкретной машины.
Программу для вычислительной машины, позволяющую ей
«понимать» директивы и предложения входного языка, используемого
программистом, мы будем называть «языковым процессором».
12
Гл. 1. Введение
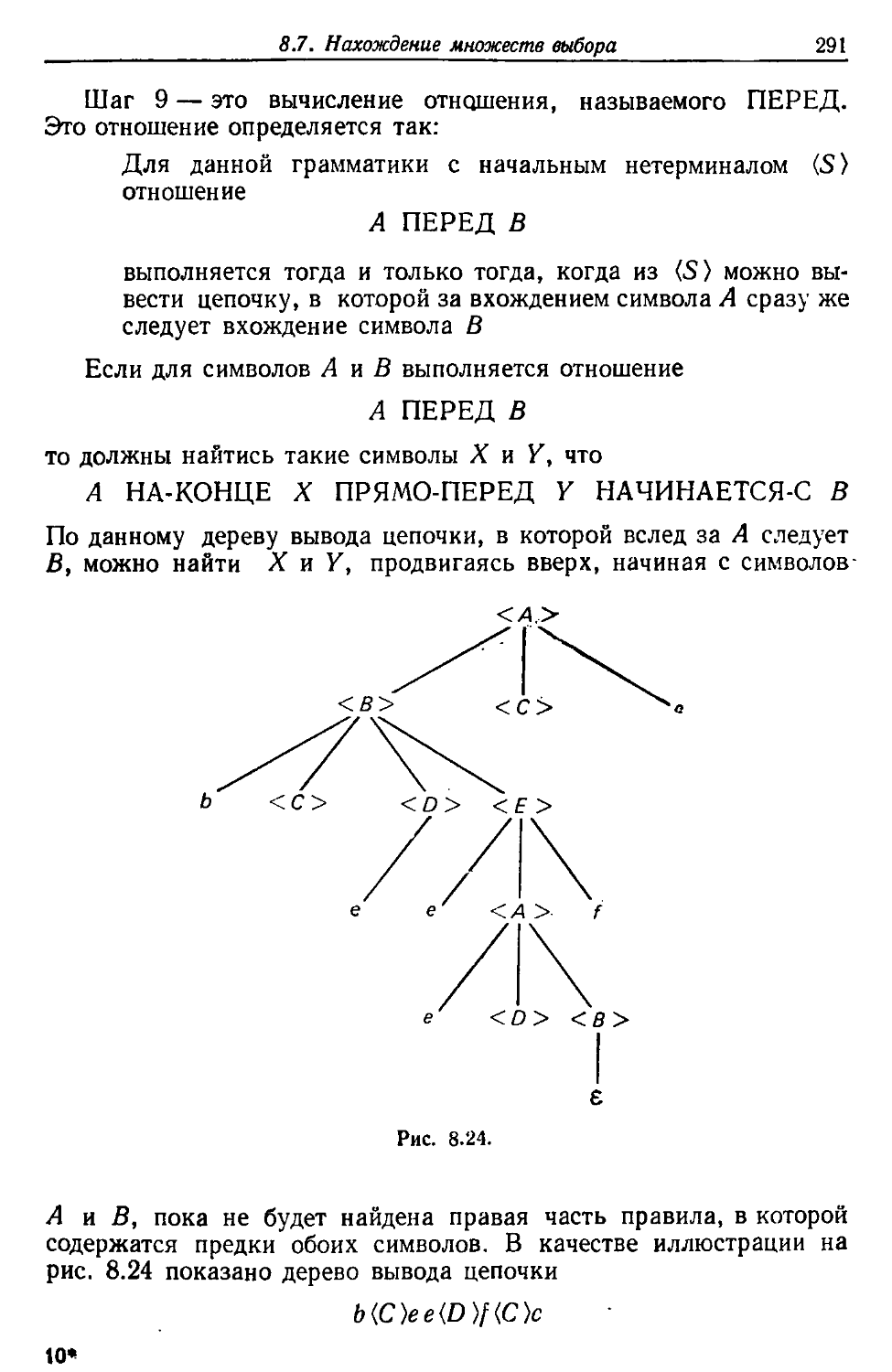
Вообще говоря, существует два типа таких программ для обработки
языков: интерпретаторы и трансляторы.
Интерпретатор — это программа, которая допускает в
качестве входа исходную программу, записанную на языке,
называемом исходным языком, и производит вычисления,
предписываемые этбй программой.
Транслятор — это программа, которая допускает в качестве
входа программу на исходном языке, а в качестве выхода выдает
другую версию этой программы, написанную на другом языке,
который называется объектным языком. Объектный язык обычно
является машинным языком некоторой вычислительной машины,
причем в этом случае программу можно сразу же выполнять.
Существует довольно условное деление трансляторов на ассемблеры
и компиляторы, которые транслируют соответственно языки
низкого и высокого уровней.
В основе всех процессов обработки языков лежит теория
автоматов и формальных языков. Поскольку в этой книге обсуждаются
в основном проблемы построения компиляторов, мы изложим те
разделы теории, которые имеют к этому наиболее прямое
отношение, и опишем практические методы, посредством которых можно
применять эти математические построения. Хотя теория излагается
здесь в контексте компиляторов, ее можно применять при
построении любого языкового процессора.
1.2. Упрощенная модель компилятора
Работа компилятора состоит в том, чтобы перевести наборы битов,
представляющие программу, написанную на некотором исходном
языке программирования, в последовательность машинных команд,
которые выполняют то, что задумал программист. Это настолько
сложная задача, что понимание или построение компилятора как
единого целого является нелегким и трудоемким занятием. Поэтому
лучше рассматривать процесс компиляции как взаимодействие
небольших процессов, задачи которых описать гораздо легче.
Выбор таких подпроцессов для каждого конкретного
компилятора может зависеть от особенностей обрабатываемого языка, но
в любом случае его лучше сделать с учетом соответствующей теории
построения компиляторов. Поэтому мы не предлагаем никакого
конкретного множества подпроцессов. С другой стороны, нельзя
говорить о теории построения компиляторов, не имея некоторого
представления о возможной внутренней организации компилятора.
Поэтому в качестве основы дальнейшего изложения мы введем
очень упрощенную, но характерную модель компилятора.
Согласно этой модели, компиляция осуществляется тремя
последовательно соединенными блоками, которые мы будем назы-
1.2. Упрощенная модель компилятора
13
вать лексическим блоком, синтаксическим блоком и генератором кода.
Эти три блока имеют доступ к общему набору таблиц, куда можно
помещать долговременную или глобальную информацию о
программе. Одна из них, например,— это таблица имен (называемая
также таблицей идентификаторов или таблицей символов), в ко-
Пексический
блок
i
i
-
Синтаксичес
кий блок
11
,, ■ i ■
'
Таблицы
Рис.
1
1.
н
Генератор
кода
и
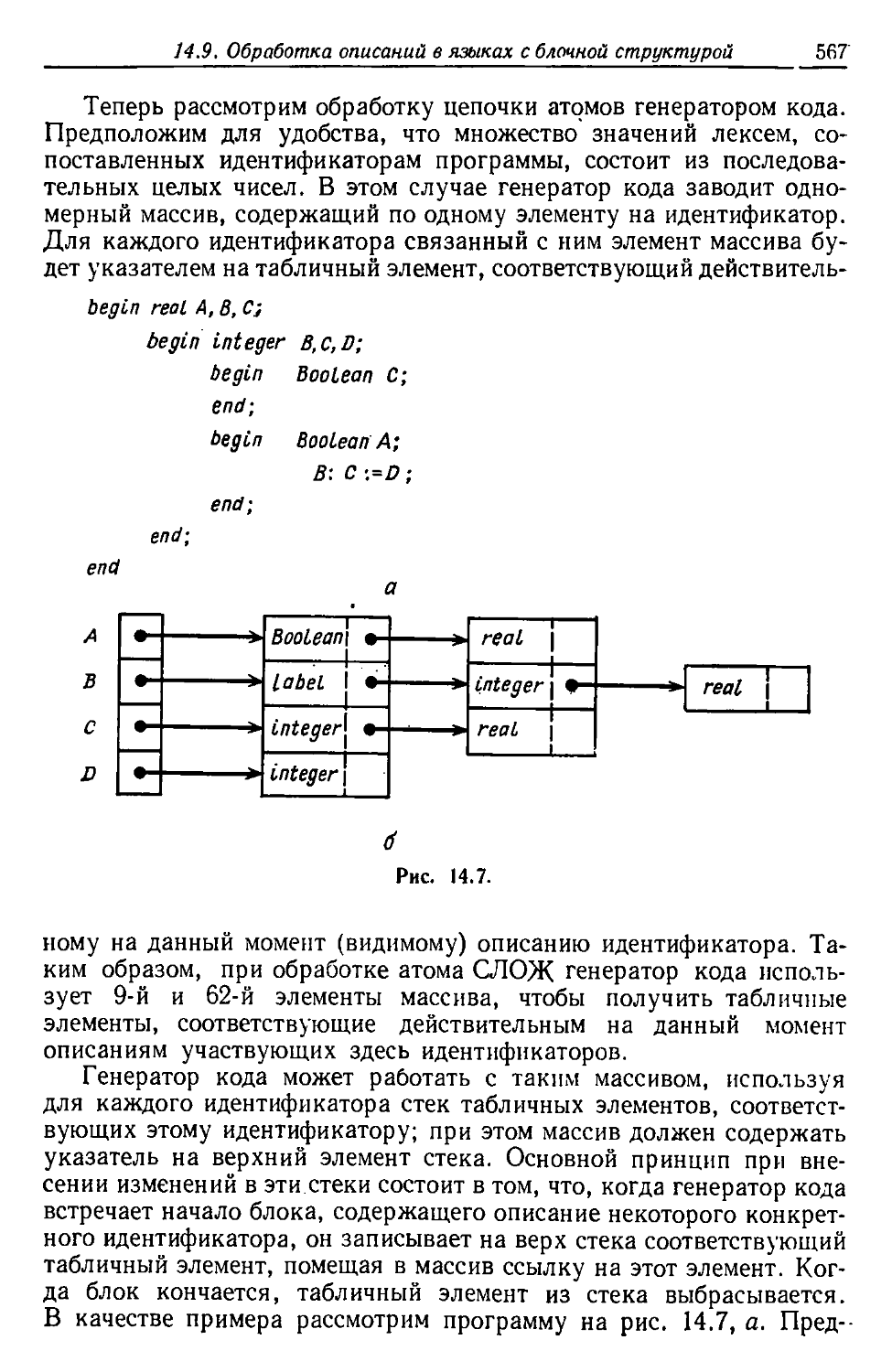
торой накапливается информация о каждой переменной или.
идентификаторе. Связи между этими блоками и таблицами показаны на
рис. 1.1. Теперь опишем блоки более детально.
Лексический блок. Входом компилятора служит набор битов,
представляющий цепочку символов (литер). Лексический блок
предназначен для того, чтобы разбивать цепочку символов на слова,
..из которых она состоит. Например, цепочка символов может быть
такой:
IFB1 = 13G0T04
Лексический блок устанавливает, что цепочка символов
представляет слово IF, за которым следуют переменная В1, знак равенства,
число 13, слово GOTO и метка 4. Таким образом, двенадцать
входных символов преобразуются в шесть новых единиц. Эти единицы
часто называют лексемами, и мы тоже будем пользоваться этим
термином.
Каждая лексема состоит из двух частей: класса и значения.
Первая часть означает, что лексема принадлежит одному из
конечного множества классов, и указывает характер информации,
включенной в значение лексемы. Возвращаясь к нашему примеру,
заметим, чго переменная В1 может принадлежать классу «переменная»
и иметь значение, которое служит указателем на элемент таблицы
имен для В1. Этот указатель на таблицу имен фактически является
внутренним именем переменной В1. Лексема 13 может принадлежать
классу «константа» и иметь в качестве значения набор битов,
изображающий число 13. Знак равенства может относиться к классу
«знак отношения», а его значение может указывать на то, какого
именно. Лексема IF может принадлежать классу «IF», и
информация о ее значении не требуется.
14
Гл. 1. Введение
Если рассматривать таблицу имен как словарь, то
лексическая обработка в какой-то степени аналогична группировке букв
в слова и нахождению этих слов в словаре. Таким образом, слово
«лексический» в названии этого блока вполне оправдано.
Синтаксический блок. Этот блок переводит последовательность
лексем, построенную лексическим блоком, в другую
последовательность, которая более непосредственно отражает порядок, в
котором, по замыслу программиста, должны выполняться операции в
программе. Например, если программирующий на Фортране пишет
А+В*С
он подразумевает, что числа, представленные идентификаторами
В к С, будут перемножены, и к результату будет прибавлено число,
представленное идентификатором А. Указанное выражение можно
перевести так:
УМНОЖ (S, С, R\) СЛОЖ(Л, Я1, /?2)
где УМНОЖ (£, С, R\) интерпретируется как «умножить В на С
и заслать результат в RI», а СЛОЖИ, RI, R2) интерпретируется
как «сложить А и RI и заслать результат в R2». Таким образом,
пять лексем, выданных лексическим блоком, преобразуются в
две новые единицы, которые описывают то же действие. Эти новые
единицы называются атомами и образуют выход синтаксического
блока. Преимуществом здесь является то, что последовательность
атомов отражает порядок, в котором должны выполняться
действия. Программист поставил знак умножения после знака
сложения, но синтаксический блок должен сначала поместить умножение.
Предположим, как и раньше, что каждый атом состоит из класса
и значения. Тогда атом УМНОЖ(В, С, RI) может принадлежать
классу «УМНОЖ» и иметь значение, состоящее из трех указателей
на элементы таблицы: для В, С и RI соответственно. Внутри
компилятора атом будет представлен целым числом, обозначающим
«УМНОЖ», и тремя указателями, обозначающими его значение.
Выполняя необходимые преобразования, синтаксический блок
должен учитывать структуру языка, так же, как при переводе с
естественного языка учитываются его грамматические особенности.
Трансляцию рассмотренного выше выражения можно сравнить
с переводом с английского языка (где глаголы стоят обычно в
середине предложения) на немецкий (где глаголы часто стоят в конце).
Таким образом, название «синтаксический блок» является здесь
вполне подходящим.
Генератор кода. Этот блок «развертывает» атомы, построенные
синтаксическим блоком, в последовательность команд
вычислительной машины, которые выполняют соответствующие действия.
Точный характер этого развертывания может зависеть от
элементов таблицы, на которые ссылаются атомы, и от ожидаемого состоя-
1.2. Упрощенная модель компилятора
15
ния вычислительной машины в момент фактического выполнения
команд. В случае таких атомов, как УМНОЖ(В, С, R\), развертка
может зависеть от типа операндов В и С, места, где хранятся
операнды, и содержимого регистров машины. Целочисленные
операнды требуют умножения с фиксированной точкой, операнды с
плавающей точкой — умножения с плавающей точкой, а смешанные
операнды требуют дополнительных команд преобразования типа.
В некоторых машинах для вычисления произведения должен
использоваться регистр.
Чтобы порождаемый код был эффективным, часто требуется,
чтобы генератор кода основательно анализировал содержимое
различных регистров машины в период выполнения программы,—
это позволяет избежать повторной загрузки уже доступной
информации и выбрать наиболее подходящие регистры для хранения
переменных, промежуточных результатов и разнообразной
изменяемой информации. Выбор конкретной схемы работы с
регистрами в большей степени должен зависеть от машины, для которой
порождается код, так как в разных машинах число регистров и
возможности, предоставляемые ими, могут существенно
различаться.
Та часть работы компилятора, которая связана со смыслом
лексем, иногда называется семантической обработкой. Семантика
идентификатора, например, может включать его тип, а в случае,
если это массив,— его размерность. Один из видов семантической
обработки включает занесение в таблицу имен свойств отдельных
идентификаторов по мере их выявления. Другой вид включает
действия, зависящие от типа данных. Например, мы предполагали,
что при развертывании атома УМНОЖ(В, С, R\) генератор кода
порождает команды либо с фиксированной, либо с плавающей
точкой. Поскольку выбор зависит от типа операндов, его можно
назвать семантическим. В некоторых компиляторах определенные
семантические действия выполняются отдельным семантическим
блоком, который помещается между синтаксическим блоком и
генератором кода.
Та часть работы компилятора, которая, строго говоря, не
является необходимой, но позволяет получать более эффективные
объектные программы, часто называется оптимизацией. В
некоторых компиляторах роль оптимизации так велика, что между
синтаксическим (или семантическим, если он есть) блоком и
генератором кода помещают специальный блок оптимизации.
Например, присутствие такого блока может быть желательным, если
нужно выделять расположенные внутри цикла вычисления,
результаты которых в ходе выполнения цикла не меняются, и выполнять
эти вычисления один раз до входа в цикл. Эффект блока
оптимизации часто состоит в переупорядочении атомов.
Всего мы обсудим пять видов действий, выполняемых компиля-
16
Гл. 1. Введение
тором, а именно: лексическую обработку, синтаксическую
обработку, семантическую обработку, оптимизацию и генерацию кода.
Пять этих эвристических понятий полезны и, возможно,
обязательны для понимания и организации построения компилятора.
Тем не менее эту классификацию не надо воспринимать слишком
серьезно, так как:
1) выделение некоторых этапов работы компилятора можно
подвергнуть сомнению;
2) необходимые действия должны выполняться там, где это
наиболее удобно, а не в «блоке», выделенном на основе топ
или иной классификации;
3) соглашения относительно лексики и синтаксиса, принятые
внутри компилятора, могут в какой-то степени отличаться от
того, что написано в руководстве по языку для пользователя,
хотя общий результат, разумеется, должен быть таким,
какого ожидает программист.
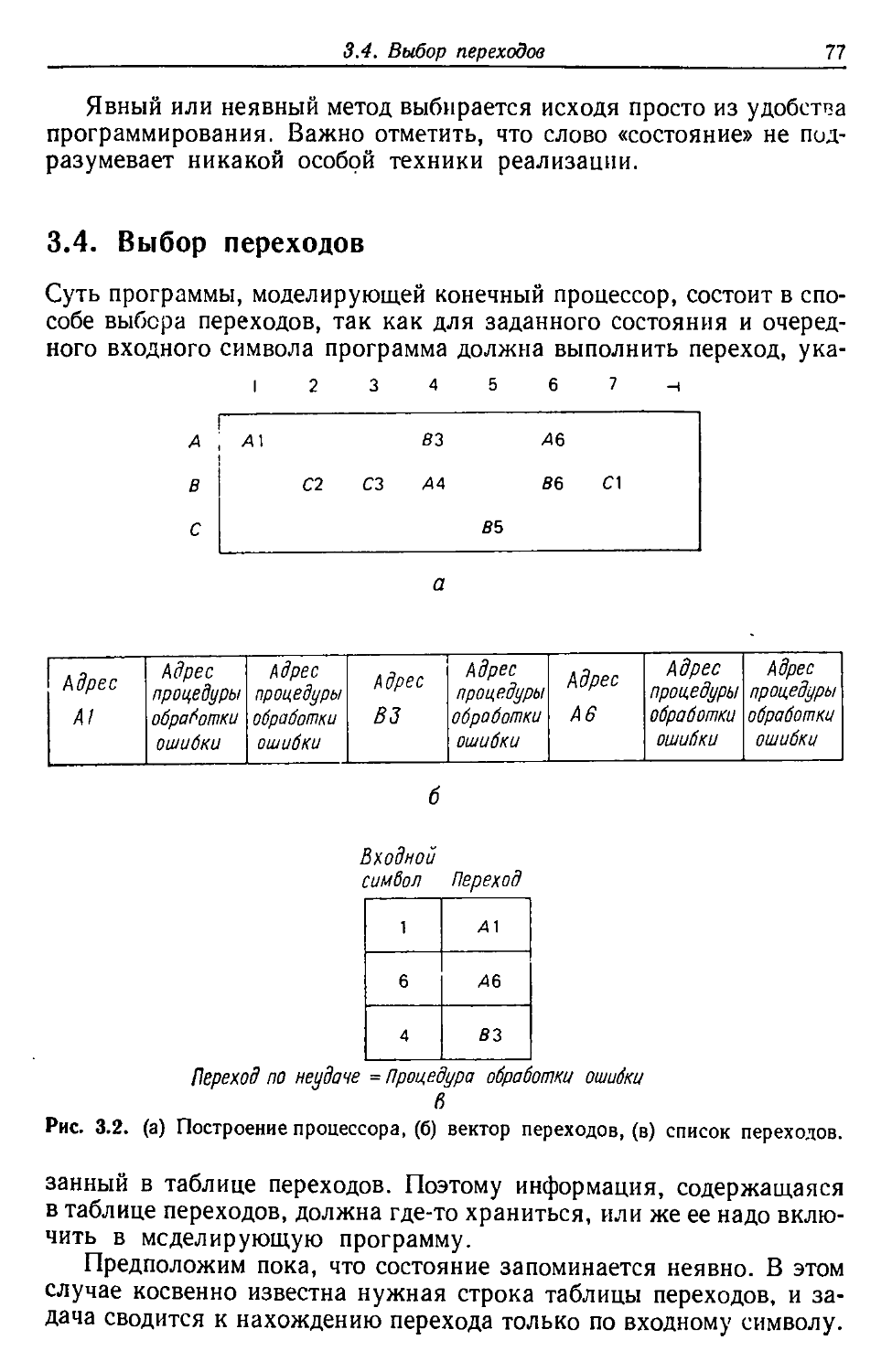
1.3. Блоки и проходы компилятора
Обсуждая упрощенную модель компилятора, изображенную на'
рис. 1.1, мы не касались того, как управление передается от одного
блока к другому. Рассмотрим, например, взаимодействие между
лексическим и синтаксическим блоками Здесь возможен выбор по
крайней мере из двух типов взаимодействия.
Один тип предполагает, что каждый раз, когда лексический
блок выдает лексему, управление передается синтаксическому
блоку для обработки этой лексемы. Когда возникает необходимость
е следующей лексеме, управление возвращается в лексический
блок.
При другом типе взаимодействия лексический блок выдает всю
цепочку лексем до того, как управление передается
синтаксическому блоку. В этом случае говорят, что работа лексического блока
образует отдельный проход.
В упрощенной модели компилятора проходы можно
организовать четырьмя разными способами. Если модель организована как
однопроходный компилятор, управление передается из блока в блок
всякий раз, когда требуется или когда производится лексема или
атом. Если она организована, как трехпроходный компилятор, то
лексический блок подготавливает всю последовательность лексем,
которая затем используется синтаксическим блоком при
порождении всей последовательности атомов, которая в свою очередь
используется генератором кода при порождении машинного кода,
возможны также два типа двухпроходной организации. В одном
случае лексический и синтаксический блоки работают одновременно
в течение одного прохода, заготавливая полную последовательность
1.3. Блоки и проходы компилятора
17
атомов для генератора кода. В другом случае в один проход
организуются синтаксический блок и генератор кода.
Вообще чем больше блоков в компиляторе, тем больше
существует возможностей для его многопроходной реализации. Разбиение
на проходы может привести к дополнительным затратам памяти,
так как каждое взаимодействие между проходами требует, чтобы
сохранялась вся цепочка выходных символов. Однако разбиение
на проходы часто мотивируется убедительными доводами. Среди
них можно привести следующие:
Логика языка
Иногда сам исходный язык наводит на мысль о том, что компилятор
должен иметь не менее двух проходов. Такая потребность
возникает, если в какой-то момент компилятору нужна информация из
еще не просмотренной части программы. Например, если описание
идентификатора или переменной может появляться в тексте
программы после их использования, то может случиться, что код нельзя
выдать до тех пор, пока не будет частично обработана вся исходная
программа. В этом случае для генерации кода требуется отдельный
проход.
Оптимизация кода
Иногда объектный код получается более эффективным, если
генератору кода доступна информация обо всей программе. Например,
согласно некоторым методам оптимизации, нужно знать все те места
программы, где используются переменные и где могут изменяться
их значения. Поэтому, прежде чем начать оптимизацию,
необходимо просмотреть всю программу до конца.
Экономия памяти
Обычно многопроходные компиляторы занимают в памяти меньше
места, чем компиляторы с одним проходом, так как код каждого
прохода может вновь использовать память, занимаемую кодом
предыдущего прохода.
Каждый проход компилятора можно организовать в виде
одного блока или комбинации нескольких блоков. С точки зрения
теории построения компиляторов блок — это просто часть
компилятора, которая мыслится и строится как одно целое.
Так как блоки играют основную роль при конструировании
компиляторов, мы будем заниматься главным образом описанием
и построением блоков. С точки зрения теории построения
компиляторов не имеет значения, будет ли блок реализован как отдельный
проход ил«-как частв'тгекото^ого прохода. Так, работу лексического
18
Гл. 1. Введение
блока, состоящую в порождении лексем, можно обсуждать вне
зависимости от того, помещаются ли эти лексемы в промежуточный
файл или направляются сразу в синтаксический блок.
1.4. Организация рабочей программы
Обычно задача построения компилятора ставится перед
разработчиком не вполне определенно. Сам исходный язык часто задается
весьма точно, но то, что компилятор должен выдавать в качестве
выхода, зачастую не определяется вовсе. Разработчику известно
лишь, что выход должен соответствовать «семантике» языка и
удовлетворять определенным требованиям, касающимся, например,
скорости выполнения или затрат памяти.
Поэтому на первом этапе построения нужно решить, что должно
быть на выходе компилятора. Сюда входит определение того, какие
структуры данных и механизмы управления будут необходимы во
время выполнения программы для реализации различных свойств
языка; как, например, будут размещены в памяти массивы и
организован доступ к ним, как будет реализован вызов процедур и как
будет обрабатываться рекурсия, если в языке допустимы рекур-'
сивные процедуры. Выбор этих структур данных и механизмов
управления относится к организации рабочей программы при
реализации языка.
Решения по организации рабочей программы служат важной
частью всей работы по построению компилятора. Однако они не
являются предметом изучения в данной книге, поскольку здесь
делается акцент на самой проблеме перевода. Мы предполагаем,
что нам известны как вход, так и желаемый выход, и будем
заниматься осуществлением самого перевода.
1.5. Математические модели перевода
Теория построения компиляторов, излагаемая в этой книге,
основана на математической теории переводов и трансляторов
(устройств, выполняющих перевод). Сам компилятор, а также каждый
из трех блоков упрощенной модели компилятора являются
трансляторами. Однако рассматриваемые в теории трансляторы — это
не обязательно блоки упрощенной модели, а скорее «машины» или
«автоматы», которые выполняют основные действия, связанные с
переводом, но достаточно просты, что позволяет весьма подробно
изучить их теоретически. Эти автоматы служат «строительными
блоками» нашей теории в том смысле, что мы хотим строить
компиляторы в виде систем таких взаимосвязанных автоматов.
Теория построения компиляторов состоит из двух частей:
1.6. Компилятор для языка MINI-BASIG
19
1. Математическое изучение этих автоматов, включая
а) их возможности в качестве трансляторов языков,
б) их синтез по заданному переводу, который они должны
осуществлять.
2. Применение теории к построению компиляторов, включая:
а) представление компилятора (или некоторого блока
компилятора) в виде системы взаимосвязанных моделей
автоматов,
б) реализацию или моделирование этих автоматов в виде
программ для вычислительной машины.
Математическая дисциплина, имеющая дело с автоматными
моделями такого типа, называется теорией автоматов. На самом
деле существует целая иерархия моделей теории автоматов,
применимых при построении компиляторов. Обычно оказывается, что
с возрастанием мощности этих моделей, выступающих в роли
трансляторов, возрастают затраты как времени, так и памяти при их
реализации в виде программ для вычислительных машин. Таким
образом, разработчику следует выбирать наиболее простой автомат,
который может выполнить поставленную задачу.
Материал в книге организован так, что сначала описываются
более простые модели автоматов. Даже эти очень простые модели
применимы на практике при решении многих проблем, связанных
с обработкой языков.
1.6. Компилятор для языка MINI-BASIC
В первую очередь в этой книге рассматриваются те аспекты теории
автоматов, которые полезны при построении компиляторов. Чтобы
продемонстрировать их полезность и показать, как теорию можно
применять в практических ситуациях, мы будем по мере
продвижения по книге строить некоторый компилятор.
В качестве языка, для которого будет строиться компилятор,
мы выбрали подмножество языка BASIC, названное MINI-BASIC
(Manifestly-Imaginatively-Named-Illustrative-BASIC). Описание
этого языка приведено в приложении А. Хотя язык, по-видимому,
слишком прост, чтобы получить широкое распространение,
построение компилятора для него иллюстрирует многие проблемы и
решения, которые действительно возникают при построении
компиляторов на практике.
Компилятор для MINI-BASIC'a это — однопроходный
компилятор, в основе которого лежит упрощенная модель из трех блоков,
приведенная в разд. 1.2. Он состоит из лексического блока,
синтаксического блока и генератора кода. Предполагается, что каждый
блок — это независимая часть компилятора. Сначала лексический
блок обрабатывает символ из входной цепочки. Когда это сделано,
20
Гл. 1. Введение
он либо переходит к другому входному символу, либо выдает
некоторые выходные символы, инициируя тем самым работу
синтаксического блока. Аналогичным образом, когда синтаксический блок
заканчивает обработку полученных символов, он может либо
обратиться к' лексическому блоку за новым входным символом, либо
выдать некоторые выходные символы для генератора кода.
Генератор кода в свою очередь обрабатывает эти символы, образуя
окончательный выход компилятора, а затем может обратиться к
синтаксическому блоку за новыми входными символами.
Построение лексического блока описано в гл. 4, а
синтаксические блоки строятся в гл. 10 и 12. Построение генератора кода
описано в гл. 14.
2
Конечные автоматы
2.1. Введение
В основе излагаемой в этой книге теории построения компиляторов
лежит теория автоматов. Поэтому мы начнем с конечного автомата,
одного из основных ее понятий. Под автоматом мы, конечно,
подразумеваем не реально существующее устройство, а некоторую
математическую модель, свойства и поведение которой можно
изучать и которую можно имитировать с помощью программы на
реальной вычислительной машине. Конечный автомат является
простейшей из моделей теории автоматов и служит управляющим
устройством для всех остальных изучаемых в ней автоматов.
Помимо того что они служат основой теории автоматов,
конечные автоматы находят непосредственное применение в ряде
ситуаций, возникающих при построении компиляторов, благодаря
следующим их свойствам:
1. Конечный автомат может решать (по крайней мере в первом
приближении) ряд легких задач компиляции. В частности,
лексический блок почти всегда строится на основе конечного
автомата.
2. Поскольку при моделировании конечного автомата на
вычислительной машине обработка одного входного символа
требует небольшого количества операции, программа работает
быстро.
3. Моделирование конечного автомата требует фиксированного
объема памяти, что упрощает проблемы, связанные с
управлением памятью.
4. Существует ряд теорем и алгоритмов, позволяющих
конструировать и упрощать конечные автоматы,
предназначенные для тех или иных целен.
Термин «конечный автомат» в действительности употребляется
в разных смыслах — в зависимости от подразумеваемых
приложений. В литературе по теории автоматов существует несколько
различных формальных определений. Общим в этих определениях
является то, что они моделируют вычислительные устройства с
фиксированным и конечным объемом памяти, которые читают
последовательности входных символов, принадлежащих некоторому
конечному множеству. Принципиальные различия в определениях
22
Гл. 2. Конечные автоматы
связаны с тем, что автоматы делают на выходе. Следующий раздел
начинается с рассмотрения конечного автомата, единственным
«выходом» которого является указание на то, «допустима» или нет
данная входная цепочка (последовательность символов). «Допустимой»
мы называем «правильно построенную» или «синтаксически
правильную» цепочку; например, цепочка, которая должна изображать
числовую константу, построена не правильно, если содержит две
десятичные точки.
2.2. Конечные распознаватели
Конечный распознаватель — это модель устройства с конечным
числом состояний, которое отличает правильно образованные или
«допустимые» цепочки от недопустимых. Хотя это понятие чисто
математическое, определяемое в терминах множеств,
последовательностей (цепочек) и функций, лучше представлять его себе в виде
вычислительной машины.
Примером задачи распознавания может служить проверка
нечетности числа единиц в произвольной цепочке, состоящей из
нулей и единиц. Соответствующий конечный автомат будет
«допускать» все цепочки, содержащие нечетное число единиц, и
«отвергать» цепочки с четным их числом. Назовем этот автомат
«контролёром нечетности». Мы будем строить его по мере введения
терминологии, связанной с конечными распознавателями.
На вход конечного автомата подается цепочка символов из
конечного множества, называемого входным алфавитом автомата
и представляющего собой совокупность символов, для работы с
которыми он предназначен. Как допускаемые, так и отвергаемые
автоматом цепочки состоят только из символов входного алфавита.
Символы, не принадлежащие входному алфавиту, нельзя подавать
на вход автомата. Входной алфавит контролера нечетности состоит
из двух символов: 0 и 1.
Представим себе, что в каждый момент времени конечный
автомат имеет дело лишь с одним входным символом, а информацию
о предыдущих символах входной цепочки сохраняет с помощью
конечного множества состояний. Согласно этому представлению,
автомат помнит о прочитанных ранее символах только то, что при
их обработке он перешел в некоторое состояние, которое и является
памятью автомата о прошлом.
Контролер нечетности будет построен так, чтобы он умел
запоминать, четное или нечетное число единиц встретилось ему при
чтении отрезка входной цепочки. Поэтому множество состояний
нашего автомата содержит два состояния, которые мы будем
называть ЧЕТ и НЕЧЕТ.
2.2. Конечные распознаватели
23
Одно из этих состояний должно быть выбрано в качестве
начального. Предполагается, что автомат начинает работу в этом
состоянии. Начальным состоянием контролера нечетности будет
ЧЕТ, так как на первом шаге число прочитанных единиц равно
нулю и нуль — четное число.
При чтении очередного входного символа состояние автомата
меняется, причем новое его состояние зависит только от входного
символа и текущего состояния. Такое изменение состояния
называется переходом. Может оказаться, что новое состояние совпадает
со старым.
Работу автомата можно описать математически с помощью
функции б, называемой функцией переходов. По текущему состоянию
sren и текущему входному символу х она дает новое состояние
автомата sH0B. Символически эта зависимость описывается так:
Учитывая, что состояния ЧЕТ и НЕЧЕТ означают
соответственно четное и нечетное число прочитанных единиц, определим
функцию переходов контролера нечетности следующим образом:
б (ЧЕТ, 0)=ЧЕТ
б(ЧЕТ, 1) = НЕЧЕТ
S (НЕЧЕТ, 0)=НЕЧЕТ
б(НЕЧЕТ, 1)=ЧЕТ
Эта функция переходов отражает тот факт, что четность меняется
тогда и только тогда, когда на входе читается единица.
Некоторые состояния автомата выбираются в качестве
допускающих или заключительных. Если автомат, начав работу в
начальном состоянии, при прочтении всей цепочки переходит в одно
из допускающих состояний, говорят, что эта входная цепочка
допускается автоматом. Если последнее состояние автомата не
является допускающим, говорят, что автомат отвергает цепочку.
Контролер нечетности имеет единственное допускающее
состояние — НЕЧЕТ.
Суммируя все сказанное, можно дать следующее определение
конечного расюзнавателя.
Конечный автомат задается:
1) конечным множеством входных символов,
2) конечным множеством состояний,
3) функцией переходов 6\ которая каждой паре, состоящей из
входного символа и текущего состояния, приписывает
некоторое новое состояние,
4) состоянием, выделенным в качестве начального, и
5) подмножеством состояний, выделенных в качестве
допускающих или заключительных.
24
Гл. 2. Конечные автоматы
Переход автомата из состояния sieK в состояние sH0B при чтении
входного символа х будем наглядно изображать так:
х
"тек лнов
Для контролера нечетности, например, можно написать
НЕЧЕТ Л ЧЕТ
Аналогичным образом можно изобразить последовательность
переходов. Например, запись
ЧЕТ Л НЕЧЕТ Л ЧЕТ Л ЧЕТ Л НЕЧЕТ
показывает, как автомат в состоянии ЧЕТ применяется к цепочке
1101. Первый символ 1 меняет состояние ЧЕТ на НЕЧЕТ, так как
б (ЧЕТ, 1) = НЕЧЕТ. Следующая единица меняет НЕЧЕТ на ЧЕТ.
Нуль оставляет автомат в состоянии ЧЕТ. Последняя единица
изменяет состояние на НЕЧЕТ. Так как ЧЕТ — начальное, а
НЕЧЕТ— допускающее состояние, цепочка 1101 допускается нашим
автоматом.
Входную цепочку 101 автомат отвергает, так как она переводит
его из начального состояния в состояние, не являющееся
допускающим. Символически это изображается так:
ЧЕТ Л НЕЧЕТ Л НЕЧЕТ Л. ЧЕТ
Иногда мы хотим говорить о множестве всех цепочек,
распознаваемых некоторым конечным автоматом. Например, контролер
нечетности распознает множество цепочек, состоящих из нулей и
единиц и содержащих нечетное число единиц. Такие множества
обычно называют «регулярными».
Регулярным множеством называется множество цепочек, которое
распознается некоторым конечным распознавателем.
Таким образом, множество цепочек из нулей и единиц с
нечетным числом единиц может служить примером регулярного
множества.
2.3. Таблица переходов
Один из удобных способов представления конечных автоматов —
таблица переходов. Для контролера нечетности такая таблица
изображена на рис. 2.1. Информация размещается в таблице переходов
в соответствии со следующими соглашениями:
1. Столбцы помечены входными символами.
3. Строки помечены символами состояний.
2.3. Таблица переходов
25
3. Элементами таблицы являются символы новых состояний,
соответствующих входным символам столбцов и состояниям
строк.
4. Первая строка помечена символом начального состояния.
5. Строки, соответствующие допускающим (заключительным)
состояниям, помечены справа единицами, а строки,
соответствующие отвергающим состояниям, помечены справа нулями.
О 1
I——■«--■ -
ЧЕТ НЕЧЕТ 0 '
НЕЧЕТ ' ЧЕТ j
Рис. 2.1.
Таким образом, таблица переходов, изображенная на рис. 2.1,
задает конечный автомат, у которого:
входное множество={0, 1},
множество состояний = {ЧЕТ, НЕЧЕТ},
переходы S (ЧЕТ, 0)=ЧЕТ и т. д.,
начальное состояние=ЧЕТ,
допускающие состояния = {НЕЧЕТ}.
х у г
1 входное множество ={х, у,г]
о множество состояний={1,2,3,4}
переходы 8 (/, х) = 1,8(l,y)=3 и т.д.
начальное состояние = /
допускающие состояния =[1,3]
Рис. 2.2.
Еще один автомат изображен на рис. 2.2. Входная цепочка
хугг допускается этим автоматом, так как
1Д|Л3^4^3
и 3 является допускающим состоянием, тогда как цепочка гух
отвергается, потому что
1Д4ЛЗЛ2
ЧЕТ
НЕЧЕТ
1 13 4
2 2 13
3 2 4 4
4 3 3 3
и 2 — отвергающее состояние.
26
Гл. 2. Конечные автоматы
2.4. Концевые маркеры и выходы из распознавания
Конечный распознаватель лежит в основе процессов распознавания
цепочек,в компиляторе. Один из способов использования такого
распознавателя — поставить его под контроль некоторой
управляющей программы, которая определяет момент, когда входная
цепочка прочитана, и по состоянию распознавателя выясняет,
допустима она или нет. Однако во многих
приложениях, связанных с разработкой
компиляторов, желательно, чтобы
распознаватель играл более активную роль и в большей
степени выполнял функции управляющей
программы. Требуется, чтобы он сам узнавал
момент, когда задание выполнено, и
соответствующим образом выходил из процесса
распознавания. Поэтому таблицы переходов в
том виде, в каком они были рассмотрены
выше, требуют небольших, но существенных
изменений.
Рассмотрим автомат, изображенный на
рис. 2.3. Он допускает множество цепочек в
алфавите {а, Ь}, таких, что символы Ь в них
либо не встречаются, либо встречаются парами. Например, этот
автомат допускает цепочки abb, abba, aaa, abbbbabb, bba, но
отвергает baa, abbb и abbab. Состояние 1 «помнит», что обработанная
часть цепочки допустима. Если после допустимой части цепочки
следует символ Ь, автомат переходит в состояние 2. В состояние Е
он переходит, когда входная цепочка окончательно испорчена
вхождением символа а вслед за «неспаренным» Ь. Таким образом,
состояние Е можно назвать «состоянием ошибки», которое запоминает,
что обнаружена ошибка.
Пусть теперь нам нужно построить программу или «компилятор»,
который, прочитав цепочку или «программу» в алфавите {а, Ь),
вызывает процедуру «ДА», если цепочка принадлежит множеству,
распознаваемому автоматом рис. 2.3, и процедуру «НЕТ» в случае,
когда цепочка не принадлежит этому множеству. Хотелось бы,
конечно, чтобы наш компилятор имитировал работу автомата
простым и естественным способом, поскольку именно это мы имели
в виду, когда утверждали, что конечный автомат лежит в основе
теории построения компиляторов. Однако очевидно, что в модели
автомата, изображенного на рис. 2.3, не отражена идея «окончания»
входной цепочки. Например, должен ли компилятор после
прочтения символов abb выйти из процесса распознавания и перейти
на процедуру «ДА», поскольку обработанная часть цепочки
принадлежит заданному множеству, или он должен ждать появления
дальнейших символов? Если за abb следуют символы Ьа, то, обра-
1
2
В
1
Е
Е
2
1
Е
2.4. Концевые маркеры и выходы из распознавания
27
ботав всю цепочку abbba, автомат должен выйти на процедуру
«НЕТ».
На практике компилятор справляется с этой проблемой,
используя информацию о конце файла, предоставляемую
вычислительной системой, на которой он реализован. Так, в пакетном режиме
программа abb может быть отперфорирована на картах и подана
на вход компилятора между управляющими картами, причем
листинг выглядит так:
$BEGIN
а
b
b
$END
Если работа идет в режиме разделения времени, то маркер конца
файла устанавливается операционной системой. Если весь вход
задается на одной перфокарте, то конец файла можно обнаружить,
используя тот факт, что число символов на карте не больше 80.
а ь и а b -н
1
2
Е
1
Е
Е
,2
1
Е
ДА
НЕТ
НЕТ
1 2 ДА
НЕТ 1 НЕТ
Рис. 2.4.
В описанных выше ситуациях будем считать, что цепочка,
подаваемая на вход автомата, имеет концевой маркер. Пусть это
будет символ —|. Тогда цепочка abb поступит на вход автомата в виде
abb-\
Автомат, изображенный на рис. 2.3, нужно изменить так, чтобы
он умел обрабатывать дополнительный символ —|. Преобразованный
автомат изображен на рис. 2.4, а. Символ «ДА» — это сокращенное
указание на то, что работа закончена и автомат должен выйти на
процедуру «ДА». Новое состояние не наступает, так как на этом
автомат свою работу заканчивает.
С введением концевого маркера необходимо заметить, что
следует различать алфавит обрабатываемого языка и входной алфавит
автомата, осуществляющего обработку. В рассматриваемом примере
28
Гл. 2. Конечные автоматы
алфавит языка по-прежнему {а, Ь) и концевой маркер в описании
языка не участвует. Входным алфавитом автомата, распознающего
этот язык (рис. 2.3), также остается {а, Ь), тогда как входным
алфавитом автомата, обрабатывающего тот же язык (рис. 2.4, а), будет
{а, Ь, н \
Метод, с помощью которого мы получили обрабатывающий
автомат из распознающего, очень прост. Мы добавили столбец,
помеченный концевым маркером, и поместили «ДА» в строки,
соответствующие допускающим состояниям, и «НЕТ» — в строки,
соответствующие отвергающим состояниям. Ясно, что этим же
способом каждый распознаватель может быть преобразован в
обрабатывающий автомат. Поэтому очевидно, что любая техника
построения конечных распознавателей потенциально применима
и при построении обрабатывающих автоматов (процессоров).
До сих пор мы имели дело с автоматами, которые были обязаны
просматривать всю входную цепочку до конца. На практике многие
конечные процессоры, применяемые в компиляторах, выполняют
свою работу раньше, чем прочитана вся цепочка, и прекращают
свою деятельность, не доходя до концевого маркера. В
программистских терминах это означает, что в компиляторе могут быть
процедуры, которые заканчивают работу, не дочитав до конца своей
входной цепочки.
Допустим, нам хочется построить автомат, который при
обнаружении первой же ошибки передает управление некоторой
внешней процедуре, обрабатывающей ошибки. Эта процедура либо
прерывает процесс обработки цепочки, либо восстанавливает нужное
состояние и возобновляет обработку с целью обнаружения
дальнейших ошибок. Возвращаясь к рис. 2.4, а, напомним, что если
автомат попал в состояние Е, то входная цепочка будет отвергнута.
Поэтому первый же переход в это состояние означает, что
обнаружена ошибка. Если мы решили прерывать процесс, как только
обнаружена ошибка, то все переходы в состояние Е в таблице
переходов нужно заменить вызовами процедуры «НЕТ». Результат
замены изображен на рис. 2.4, б. Состояние Е удалено из автомата,
так как отсутствие переходов в него означает, что автомат никогда
не достигнет этого состояния, исходя из начального. Первоначально
состояние Е было введено, чтобы обеспечить дочитывание входной
цепочки после того, как обнаружена ошибка. Теперь в нем нет
надобности, так как мы решили, что при обнаружении ошибки
автомат должен выходить из процесса распознавания.
Мы допускаем теперь, что любой элемент таблицы переходов
конечного процессора может быть не переходом, а выходом из
распознавания. Этот аспект процесса обработки входных цепочек
назовем обнаружением (или детекцией). Автомат обнаруживает
некоторую ситуацию до того, как прочитана вся цепочка, и
прекращает свою работу.
2.5. Пример построения автомата
29
Детекция может встречаться при обработке как допустимых,
так и ошибочных цепочек. Рассмотрим, например, задачу
распознавания цепочек из нулей и единиц, содержащих хотя бы одну пару
стоящих рядом единиц. Соответствующий распознаватель показан
на рис. 2.5, а. Он переходит в состояние С при обнаружении пары 11.
0 1 0 1 н
А
В
С
А В
А С
С С
а
0
0
1
А
В
Рис. 2.5.
А
А
В
ДА
6
НЕТ
НЕТ
Если мы хотим получить распознаватель, который выходит на «ДА»,
как только обнаружена пара единиц, то переходы в состояние С
нужно заменить на «ДА». Распознаватель рис. 2.5, а превратится,
таким образом, в процессор, изображенный на рис. 2.5, б. В нем
нет состояния С, так как переходы в него отсутствуют.
2.5. Пример построения автомата
Чтобы продемонстрировать автоматную технику на конкретном
примере, построим автомат для распознавания цепочек, которые
могут следовать за словом INTEGER в операторах спецификации
Фортрана. Примеры таких операторов:
INTEGER A
INTEGER X, 1(3)
INTEGER С (3, J, 4), В
Будем считать, что массивы могут иметь любую размерность,
хотя в большинстве стандартов и компиляторов с Фортрана она
ограничена. Входной алфавит будет состоять из пяти символов:
v с, ( )
где v — лексема, означающая произвольную неременную, с —
лексема, соответствующая целочисленной константе (см. разд. 1.2).
Будем считать, что эти лексемы порождаются каким-то другим
автоматом.
Построение автомата будем осуществлять, используя
эвристический прием, который мы назовем «разметкой символов». На
первом шаге построения из определяемого множества надо выбрать
30
Гл. 2. Конечные автоматы
одну или более типичных цепочек и пометить входящие в них
символы. Если на интуитивном уровне ясно, что множество цепочек,
которые могут следовать за некоторым символом, совпадает с
множеством цепочек, следующих за другим символом, то этим
символам приписываются одинаковые метки. Эти метки отражают одно
эвристическое понятие, которое мы будем называть «ролью».
Впоследствии «роли» станут состояниями нашего конечного
распознавателя.
В нашем примере на первом шаге мы выписали цепочку,
изображенную на рис. 2.6, и пометили ее символы номерами от 2 до 8.
Номер 1 зарезервирован для начального состояния автомата и
помещен перед началом цепочки, чтобы мы нагляднее представляли
переходы автомата при построении таблицы.
INTEGER А ( 3 , J , 4 ) , В
12345654782
Рис. 2.6.
Заметим, что две запятые помечены номером 5. Действительно,
цепочка
4), В
которая следует за второй запятой, могла встретиться и после
первой запятой, образуя допустимую цепочку
INTEGER A(3, 4), В
И вообще после этих запятых могут следовать одни и те же цепочки,
т. е. две запятые выполняют одну и ту же роль. С другой стороны,
запятая, помеченная номером 8, играет другую роль. Так, если
цепочку, идущую за этой запятой, поместить после запятой,
играющей роль 5, то мы получим недопустимую цепочку
INTEGER A(3, В
Аналогичным образом оба целых числа помечены номером 4,
поскольку они допускают одинаковые продолжения.
Роли, встречающиеся в нашем примере, словами могут быть
описаны так:
2 — имя переменной, описываемой как INTEGER;
3 — левая скобка;
4 — целое число, задающее размерность;
5 — запятая, разделяющая размерности;
6 — переменная, задающая переменную размерность;
7 — правая скобка;
8 — запятая, разделяющая объекты, описываемые как целые.
Так как мы уверены, что каждому символу, встречающемуся в
любой другой допустимой цепочке, подходит одна из указанных
2.5. Пример построения автомата
31
ролей, то мы не будем рассматривать другие цепочки в поисках
новых ролей.
После того как все роли опознаны, дальше автомат можно
строить по следующему алгоритму:
1. Ввести начальное состояние и состояние ошибки
2. Ввести состояние для каждой роли.
3. Поместить в таблицу
переходы из одного состояния в
другое, если
соответствующие роли могут следовать
одна за другой.
4. Пополнить таблицу
переходами в состояние ошибки.
5. Выбрать в качестве
допускающих те состояния, роли
которых появляются в конце
допустимой цепочки.
В нашем примере на первом шаге
вводится начальное состояние 1 и
состояние ошибки Е. На втором
шаге мы вводим состояния 2—8,
соответствующие ролям,
выявленным при интуитивном анализе.
Затем на шаге 3 получаем все
нужные переходы. Заметим, что
первым символом каждой
допустимой цепочки должна быть
переменная в роли 2, поэтому заносим
в таблицу переход от начального
состояния 1 в состояние 2 при
чтении входного символа v. Этот
элемент мы видим в таблице, изображенной на рис. 2.7, где показан
конечный результат нашего построения. За вхождением символа
с ролью 2 может следовать либо вхождение с ролью 3 (как в
цепочке на рис. 2.6), либо с ролью 8 (как в цепочке INTEGER А, В).
Поэтому для соответствующих входных символов помещаем в
таблицу переходы из 2 в 3 и из 2 в 8. Завершая этот анализ, во все
остальные ячейки таблицы заносим переходы в состояние Е.
И наконец, выполняем шаг 5. Заметим, что символы, стоящие
в конце допустимых цепочек, могут иметь роль 2 или 7, поэтому
объявляем состояния 2 и 7 допускающими и на этом завершаем
построение таблицы.
Одно из возражений против предложенного метода состоит в
том, что построенный автомат не обязательно будет наилучшим
2
Е
6
Е
6
Е
Е
2
Е
Е
Е
4
Е
4
Е
Е
Е
Е
Е
8
Е
5
Е
5
8
Е
Е
Е
<з"~
Е
Е
Е
Е
Е
Е
Е
Е
Е
Е
7
Е
7
Е
Е
Е
0
1
0
0
0
0
1
0
0
32
Гл. 2. Конечные автоматы
в том смысле, что может найтись другой автомат с меньшим числом
состояний, который определяет то же множество цепочек. Позднее
мы убедимся в том, что автомат, изображенный на рис. 2.7,
действительно не является наилучшим. Это возражение будет
устранено в разд. 2.11, где будет дан алгоритм приведения
произвольного конечного автомата к оптимальному виду.
Более серьезное возражение заключается в том, что описанный
метод явно не применим в случаях, когда за символом в некоторой
роли может следовать один и тот же символ в двух разных ролях.
Это возражение будет снято в разд. 2.13, где мы покажем, что в
одну ячейку таблицы можно помещать два или более переходов,
а затем преобразовывать полученную таблицу в новую, каждый
элемент которой содержит один переход.
Таким образом, творческая часть построения автомата
заключается в определении ролей и переходов. Затем с помощью
указанного метода и описанных далее процедур можно автоматически
перейти к наилучшему конечному распознавателю. В гл. 6 будет
дано другое определение регулярного множества цепочек и
показано, как с его помощью можно автоматически построить
соответствующий конечный автомат, не прибегая к выявлению ролей.
2.6. Пустая цепочка
До сих пор мы молчаливо предполагали, что читатель имеет
интуитивное представление о том, что такое цепочка. В большинстве
случаев это предположение оправдано, и дать простое объяснение
этого понятия нелегко. Можно сказать, например, что цепочка
1) состоит из следующих друг за другом символов,
2) образуется сцеплением символов.
Однако все это в сущности сводится к определению: «цепочка —
это последовательность символов». Поэтому будем считать, что
читатель не раз имел дело с цепочками и знает, что это такое.
Возможное упущение в таком предположении заключается в
том, что многие не осознают важности понятия пустой (или
нулевой) цепочки. Цепочка нулевой длины, называемая пустой цепочкой,
часто встречается в теоретико-автоматных рассуждениях и
действительно имеет большое практическое значение. Чтобы лучше
познакомиться с этим понятием, установим его связь с введенными
ранее понятиями.
Во-первых, рассмотрим пустую цепочку как программу
вычислительной машины. Если заключить ее в управляющие карты и
ввести в вычислительную машину для компиляции, то листинг
будет выглядеть так:
$BEGIN
$END
2.6. Пустая цепочка
33
Если мы хотим, чтобы пустую цепочку обработал один из
автоматов разд. 2.4, необходимо добавить к ней справа концевой маркер,
т. е. на вход автомата поступит цепочка
н
Автомат допустит эту цепочку, если элемент таблицы переходов,
соответствующий начальному состоянию и концевому маркеру,
содержит «ДА», и отвергнет ее, если этот элемент содержит «НЕТ».
Если рассмотреть конечные распознаватели разд. 2.2, то станет
ясно, что
Конечный распознаватель допускает пустую цепочку тогда
и только тогда, когда его начальное состояние является
допускающим.
В терминах переходов это означает, что пустая цепочка,
примененная к начальному (или к любому другому состоянию), не
вызывает никаких переходов, т. е. оставляет состояние неизменным.
Таким образом, под действием пустой цепочки, примененной к
начальному состоянию, распознаватель заканчивает работу в
начальном состоянии, которое и определяет допустимость цепочки.
Последовательность переходов для пустой цепочки, примененной
к произвольному состоянию s, выглядит так:
s
Следовательно, если первое состояние в этой последовательности
(s) является начальным, а последнее (тоже s) — допускающим,
то пустая цепочка допускается.
Пустая цепочка часто встречается в описаниях языков
программирования. Так, в Алголе 60 допустим пустой оператор, т. е.
пустая цепочка.
Одно из неудобств, связанных с пустой цепочкой, заключается
в том, что ее очень трудно изобразить графически в печатном
тексте. Мы изображали пустую цепочку, помещая ее между
управляющими картами или снабжая концевым маркером, но изобразить
ее непосредственно невозможно, так как она присутствует в
предложении незримо. Решим эту проблему, обозначая пустую цепочку
через е. Символически е определяется следующим равенством:
е=
Это обозначение настолько полезно, что мы сохраним е в этой
роли до конца книги. Оно широко используется в литературе по
теории автоматов, хотя иногда пустую цепочку обозначают еще
символами Я, или е.
Пустую цепочку путают иногда с пустым множеством, хотя
цепочка и множество совершенно разные понятия. Пустым (или
нулевым) называют множество, не содержащее ни одного элемента;
Ф. Льюис и др.
34
Гл. 2, Конечные автоматы
его часто обозначают через <р или Ф. Чтобы пояснить это различие,
сравним пустое множество { } и множество {е}. Пустое
множество, понятно, не содержит элементов, тогда как множество {е}
содержит один элемент, а именно пустую цепочку е. На рис. 2.8, а
изображен автомат с алфавитом {а, Ь), распознающий множество
{ }. Рис. 2.8, б изображает автомат с тем же входным алфавитом,
допускающий множество {е}. Ясно, что эти автоматы различны.
Заметим, что е не является входом автомата, распознающего {е}.
а
S
ь
S
0
S
Т
т
т
т
т
1
0
а б
Рис. 2.8. (а) Распознаватель множества { };
(б) Распознаватель множества {е}.
Символ е используется в описаниях и сам по себе не является
входным символом автомата. Если мы говорим «пусть у—abba», то это
не означает, что мы добавим у к входному алфавиту автомата.
Аналогично не надо думать, что е принадлежит входному множеству
только потому, что мы сказали «пусть е=».
Другое заблуждение связано с отождествлением пустой цепочки
и знака пробела. Однако выражение 1е0 обозначает цепочку 10,
а не 1 0. Поскольку пустая цепочка не содержит ни одного символа,
ее длина равна 0. Длина же цепочки, состоящей из одного символа
пробела, равна 1.
2.7. Эквивалентность состояний
Для каждого конечного автомата существует бесконечное число
других конечных автоматов, которые распознают то же множество
цепочек. При конструировании распознавателя для данной
проблемы естественно учитывать возможность существования какого-
то другого распознавателя для того же множества, который
определяется проще, и при реализации в качестве программы для
вычислительной машины требует меньших затрат памяти. В этом и в
последующих четырех разделах мы развиваем некоторую теорию,
касающуюся этого вопроса. Один из ее результатов заключается
в том, что для каждой задачи распознавания существует
единственный автомат, свойства которого полностью соответствуют нашим
представлениям об автомате, «имеющем простейшее определение»
и «требующем минимальных затрат памяти при реализации». Кроме
2.7. Эквивалентность состояний
35
того, мы покажем, как можно получить такой автомат по
произвольному исходному автомату. В частности, в разд. 2.7—2.11
устанавливается следующий факт:
Для каждого конечного распознавателя существует
единственный конечный автомат, распознающий то же самое
множество цепочек, при этом число его состояний не больше числа
состояний любого другого конечного распознавателя для
этого множества.
Употребление в предыдущем утверждении слова «единственный»
требует некоторого пояснения. Для любого автомата можно
получить новый автомат с таким же числом состояний, просто
переименовав его состояния. Однако имена состояний не имеют никакого
значения для распознавания цепочек или для реализации автомата
как программы вычислительной машины. Поэтому на практике
автоматы, которые различаются лишь именами состояний, можно
считать «одинаковыми». В данном контексте слово «единственный»
следует понимать как «единственный с точностью до имен
состояний». Этот единственный автомат будем называть минимальным
автоматом.
При изложении теории станет очевидным, что минимальный
автомат для заданной проблемы распознавания является на самом
деле результатом приведения (или редукции) более громоздких
автоматов, решающих ту же задачу. Точное описание характера
приведения будет дано ниже. Суть в том, что минимальный
автомат — это компактный вариант автоматов большего объема, а не
просто еще один автомат, у которого случайно оказалось меньше
состояний. Этот факт усиливает довод в пользу выбора
минимального автомата в качестве главного кандидата на реализацию.
В гл. 3, где детально рассматриваются несколько методов
реализации конечных автоматов как программ для вычислительных
машин, значение минимального автомата станет еще более
очевидным.
Первым шагом в нашем изложении теории минимизации и
приведения автоматов будет введение понятия эквивалентности
состояний. Неформально два состояния эквивалентны, если они одинаково
реагируют на все возможные продолжения входной цепочки. Это
понятие применимо и к состояниям одного и того же автомата, и к
состояниям разных автоматов.
Применительно к конечным распознавателям, назначение
которых — допускать цепочки, эквивалентность состояний можно
определить так:
Состояние s конечного распознавателя М эквиваленте
состоянию t конечного распознавателя N тогда и только тогда,
когда автомат М, начав работу в состоянии s, будет допу-
36
Гл. 2. Конечные автоматы
екать в точности те же цепочки, что и автомат N, начавший
работу в состоянии t.
Если два состояния s и t одного автомата эквивалентны, то
автомат можно упростить, заменив в таблице переходов все
вхождения имен этих состояний каким-нибудь новым именем, а затем
удалив одну из двух строк, соответствующих $и/. Например,
состояния 4 и 5 автомата, изображенного на рис. 2.9, а, явно имеют
одинаковые функции, так как оба они являются допускающими,
1
2
3
4
5
1 4
3 5
5 1
2 3
2 3
а
0
1
0
1
1
1
2
3
X
X
, X
3 X
X 1
2 3
2 3
.6
Рис. 2.9.
0
1
0
1
1
1
2
3
X
\ 1 X
I
3 X
\
X 1
2 3
I
в
0
1.
0
1
оба переходят в состояние 2 при чтении входного символа а и оба
переходят в состояние 3 при чтении Ь. Поэтому мы объединяем со
стояния 4 и 5 в одно состояние, для которого выбираем имя X
Заменяя в таблице состояний каждое вхождение имен 4 и 5 именем
X, мы получаем тем самым таблицу, изображенную на рис. 2.9, б
Две ее строки помечены X; удалив одну из них, получаем упрощен
ную таблицу состояний на рис. 2.9, в.
Обычно эквивалентность менее очевидна, чем в данном примере
поэтому нам придется обращаться к тесту на эквивалентность
излагаемому в следующем разделе.
Вторая цель проверки состояний на эквивалентность состоит
в выяснении того, делают ли два автомата одно и то же, т. е.
совпадают ли множества допускаемых ими цепочек. Это достигается
просто проверкой эквивалентности начальных состояний
автоматов. Если они эквивалентны, то по определению эквивалентности
состояний оба автомата допускают и отвергают одни и те же цепочки.
Таким образом, понятие эквивалентности состояний приводит нас
к понятию эквивалентности автоматов, а именно:
Автоматы М и N эквивалентны тогда и только тогда, когда
эквивалентны их начальные состояния.
2.8. Проверка эквивалентности двух состояний
37
Если два состояния не эквивалентны, то любая цепочка, под
действием которой одно из них переходит в допускающее
состояние, а другое — в отвергающее состояние, называется цепочкой,
различающей эти два состояния. Состояния а и х на рис. 2.10 не
эквивалентны, так как их различает цепочка 101. Символически
1 0 1
а—*с—*о—*с
1 0 1
х—уу—<• г—>г
причем состояние с — допускающее, а состояние z — нет.
Поскольку а и х — начальные состояния соответствующих автоматов,
0 1 0 1
0
0
1
Рис.
X
У
Z
2.10.
мы показали также, что автоматы, изображенные на рис. 2.10, не
эквивалентны. Мы видим, что
Два состояния эквивалентны тогда и только тогда, когда не
существует различающей их цепочки.
Заметим, что понятие эквивалентности состояний является
отношением эквивалентности в математическом смысле; это
отношение рефлексивно (каждое состояние эквивалентно себе),
симметрично (из того, что s эквивалентно /, следует, что / эквивалентно
s) и транзитивно (если s эквивалентно /, а / эквивалентно и, то s
эквивалентно и).
2.8. Проверка эквивалентности двух состояний
Договоримся, что в этом разделе будут рассматриваться автоматы
с одним и тем же входным множеством. Построим метод проверки
эквивалентности состояний, основанный на следующем факте:
Состояния s и / эквивалентны тогда и только тогда, когда
выполняются следующие два условия:
1) условие подобия — состояния s и t должны быть либо оба
допускающими, либо оба отвергающими,
2) условие преемственности — для всех входных символов
состояния s и t должны переходить в эквивалентные
состояния, т. е. их преемники эквивалентны.
38
Гл. 2. Конечные автоматы
Теперь покажем, что эти два условия выполняются тогда и
только тогда, когда s и / не имеют различающей цепочки.
Сначала заметим, что если нарушено хотя ,бы одно из них, то
существует цепочка, различающая эти два состояния. Если не
выполняется условие подобия, то различающей цепочкой является
пустая цепочка. Если нарушено условие преемственности, то
некоторый входной символ х переводит
состояния s и t в неэквивалентные состояния.
Поэтому х с приписанной к нему цепочкой,
различающей эти новые состояния, образует
цепочку, различающую sat.
Теперь убедимся, что если состояния s и
t различаются некоторой цепочкой, то хотя
бы одно из этих условий должно быть
нарушено. Если их различает пустая
цепочка (нулевой длины), то не выполняется
условие подобия. Если длина различающей
цепочки больше нуля, то ее первый символ
переводит s и / в пару состояний, которые не
эквивалентны, так как различаются
оставшейся частью цепочки, различающей s и /.
Таким образом, мы видим, что оба
условия выполняются, если два состояния
эквивалентны, и что хотя бы одно из них
нарушается в случае неэквивалентности состояний.
Условия 1 и 2 можно использовать в
общем методе проверки на эквивалентность
произвольной пары состояний. Этот метод,
вероятно, лучше понимать как проверку на
неэквивалентность и рассматривать его как
метод поиска различающей цепочки.
Проиллюстрируем его на примере автомата, изображенного на рис. 2.11,
прежде чем формулировать правила проверки в общем виде. Для
записи необходимых данных мы будем строить таблицы нового
типа, которые назовем таблицами эквивалентности состояний.
Сначала мы проверяем на эквивалентность состояния 0 и 7
рис. 2.11. Таблица эквивалентности состояний для этой проверки
содержит по одному столбцу для каждого входного символа, а
именно столбец для у и столбец для г. Строки будут добавляться
в ходе проверки. Первоначально имеется одна строка, которая
помечена парой состояний, подвергаемых проверке, а именно парой
0,7. Результат изображен на рис. 2.12, а.
Сначала мы надеемся продемонстрировать неэквивалентность
состояний 0 и 7, показав, что нарушается условие подобия. К
сожалению, это условие выполняется, так как оба состояния являются
отвергающими.
О
1
2
3
4
5
6
7
0
2
2
6
1
6
6
6
3
5
7
7
6
5
3
3
2.8. Проверка эквивалентности двух состояний
39
Теперь нам остается надеяться на то, что будет нарушено
условие преемственности. Чтобы исследовать эту возможность,
рассмотрим, как действует на данную пару состояний каждый входной
символ, и запишем результат в соответствующую ячейку таблицы.
Так как состояния 0 и 7 под действием входного символа у перехо-
б
Рис. 2.12.
дят в состояния 0 и 6 соответственно, мы записываем 0,6 в столбец
таблицы, соответствующий символу у. Так как оба состояния 0 и 7
переводятся символом г в состояние 3, запишем 3 в столбец для г.
Теперь мы получили рис. 2.12, б. Чтобы нарушалось условие
преемственности, должны быть неэквивалентными либо состояния
О и 6, либо состояния 3 и 3. Так как каждое состояние эквивалентно
самому себе, состояния 3 и 3 автоматически эквивалентны.
Чтобы исследовать на неэквивалентность состояния 0 и 6,
добавляем к таблице эквивалентности состояний новую строку и
помечаем ее этой парой. Результат показан на рис. 2.12, в.
Процесс теперь повторяется с этой новой строкой. Сначала мы
проверяем условие подобия для состояний 0 и 6. Обнаруживаем, что 0 и 6
неэквивалентны, так как 6 — допускающее, а 0 — отвергающее
состояние. Проверка закончена, и мы убедились, что исходные
состояния 0 и 7 неэквивалентны. Таблицу эквивалентности
состояний можно использовать для построения различающей цепочки.
Строка 0,6 появилась как результат применения входного символа у
к паре 0,7, поэтому у является различающей цепочкой.
Теперь проверим, эквивалентны ли состояния 0 и 1. Начнем
построение таблицы эквивалентности состояний с пары 0,1. Эти
состояния подобны, поэтому мы вычисляем результат применения
к ним каждого входного символа и помещаем полученные состояния
в таблицу. Получаем рис. 2.13, а. Наши надежды на
неэквивалентность состояний 0 и 1 оправдаются, если будет установлена
неэквивалентность состояний 0,2 или 3,5. Поэтому мы добавляем в
таблицу строку для каждой из этих пар. Результат изображен на
рис. 2.13, б.
Обратившись к строке 0,2, мы замечаем, что эти состояния
подобны, и поэтому надо вычислить следующие пары состояний,
чтобы проверить условие преемственности. Результат показан на
40
Гл. 2. Конечные автоматы
рис. 2.13, в. Из двух новых элементов таблицы лишь один дает новую
строку, а именно пара 3,7. Другой элемент, пара 0,2, уже имеется
в таблице, и нет надобности его повторять. Тот факт, что пара 0,2
порождается алгоритмом дважды, означает, что имеются две вход-
0,1
0,2
3,5
0,1
0,2
3,5
0,2
3,5
_^
0,1
0,2
3,5
0,2
0,2
3,5
3,7
0,1
0,2
3,5
3.7
5,7
0,2
0,2
6
3,5
3,7
5,7
0,1
0,2
3,5
3,7
5,7
0,2
0,2
6
6
6
3.5
3,7
5,7
3,7
3,5
Рис. 2.13.
ные цепочки, которые ведут из исходной пары 0,1 в пару состояний
0,2. Любая из этих цепочек с приписанной к ней цепочкой,
различающей состояния 0 и 2, образует различающую цепочку для
состояний 0 и 1. Однако, поскольку для доказательства
неэквивалентности состояний 0 и 1 достаточно одной различающей их
цепочки, достаточно одного вхождения в таблицу пары 0,2.
Следовательно, единственной новой строкой в таблице будет строка 3,7.
Идя вниз по списку строк, рассмотрим теперь строку 3,5.
Устанавливаем, что состояния 3 и 5 подобны. Вычисляем следующие
пары, а именно 6,6 и 5,7. Так как состояние 6 эквивалентно самому
себе, единственной новой строкой будет 5,7. В этот момент наша
таблица выглядит так, как изображено на рис. 2.13, г. Продолжая
процедуру, мы не обнаруживаем ни одной пары неподобных
состояний и ни одной новой пары, которую надо проверять на подобие.
2.8. Проверка эквивалентности двух состояний
41
Таблица заполнена, как показано на рис. 2.13, д, и поиск
различающей цепочки окончился неудачей. Поэтому состояния 0 и 1
должны быть эквивалентными.
Общую процедуру можно описать следующим образом:
1. Начать построение таблицы эквивалентности состояний с
отведения столбца для каждого входного символа. Пометить
первую строку парой состояний, подвергаемых
проверке.
2. Выбрать в таблице эквивалентности
состояний строку, ячейки которой еще не
заполнены, и проверить, подобны ли
состояния, которыми она помечена. Если они не
подобны, то два исходных состояния
неэквивалентны, и процедура оканчивается. Если
они подобны, вычислить результат
применения каждого входного символа к этой паре
состояний и записать полученные пары
состояний в соответствующие ячейки
рассматриваемой строки.
3. Для каждого элемента таблицы,
полученного на шаге 2, существует три
возможности. Если элементом таблицы является
пара одинаковых состояний, то для этой пары не требуется никаких
действий. Если элементом таблицы является пара состояний,
которые уже использовались как метки строк, то для нее также
не требуется никаких действий. Если элемент таблицы — это пара
разных состояний, которая еще не использовалась как метка, то
для этой пары состояний нужно добавить новую строку. В данном
случае порядок состояний в паре не важен, и пары s, t и t, s
считаются одинаковыми. После того как произведены необходимые
действия для каждой пары состояний в данной строке, перейти к
шагу 4.
4. Если все строки таблицы эквивалентности состояний
заполнены, исходная пара состояний и все пары состояний, порожденные
в ходе проверки, эквивалентны, и проверка закончена. Если
таблица не заполнена, нужно обработать еще по крайней мере одну ее
строку, и применяется шаг 2.
Так как каждая пара, появившаяся в заполненной таблице
эквивалентности состояний, содержит эквивалентные состояния,
эт-iT метод проверки часто дает больше информации, чем
предполагалось вначале. Возвращаясь к нашему последнему примеру,
на рис. 2.13, д мы видим, что кроме эквивалентности пары (0, 1),
которая подвергалась проверке, мы попутно доказали
эквивалентность пар (0,2), (3,5), (3,7) и (5,7). По свойству транзитивности из
эквивалентности пар состояний 0,2 и 0,1 следует эквивалентность
А
6
А
6
В
В
6
В
42
Гл. 2. Конечные автоматы
пары 1, 2. Таким образом, состояния 0, 1 и 2 эквивалентны друг
другу. Аналогично эквивалентны друг другу состояния 3, 5 и 7.
Информацию об эквивалентности состояний можно
использовать для упрощения автомата. Мы объединяем состояния 0, 1 и 2
в одно Состояние, которое называем А, а состояния 3, 5 и 7 — в
состояние, которое называем В. Подставляя эти новые имена в
рис. 2.11 и удаляя лишние строки, мы получаем более простой
эквивалентный автомат, изображенный на рис. 2.14.
2.9. Недостижимые состояния
Среди состояний автомата могут быть такие, которые не достижимы
из начального состояния ни для какой входной цепочки. На рис.
2.15, а таким состоянием является s4, так как в таблице нет
переходов в s4.
Такие состояния, как s4, называются недостижимыми. Строки,
соответствующие этим состояниям, можно удалить из таблицы
*0
*1
*2
h
и
h
*б
h
s8
*i
Н
*z
%
*5
*3
s8
*0
*3
а
%
*7
*S
h
s6
«1
s0
s1
0
1
1
0
0
0
1
1
0
so
*i
s2
h
H
J6
«7
*8
*1 %
h h
h h
S5 S-,
h *\
ss *o
s0 «1
h *e
6
Рис. 2.15.
0
1
1
0
0
1
1
0
so
*i
h
h
%
J7
*t
h
s2
S5
S3
s0
в
h
sl
S5
h
*,
*1
0
1
1
0
0
1
переходов, получив тем самым таблицу переходов автомата, который
эквивалентен исходному, но имеет меньшее число состояний. Это
сделано на рис. 2.15, б.
Для любого заданного автомата довольно просто составить
список достижимых состояний.
1. Начать список начальным состоянием.
2. Для каждого состояния, уже внесенного в список, добавить
2.10. Приведенные автоматы
43
все еще не занесенные в него состояния, которые могут быть
достигнуты из этого нового состояния под действием одного
входного символа.
Если эта процедура перестает давать новые состояния, то все
достижимые состояния получены, а все остальные состояния можно
удалить из автомата. Так как на каждом шаге процедуры к списку
достижимых состояний добавляется хотя бы одно новое состояние,
число шагов процедуры ограничено числом состояний данного
автомата.
В качестве примера рассмотрим автомат на рис. 2.15, а. Начав
с состояния So, мы видим, что состояния Si и s6 наступают под
действием одного входного символа. Из состояния st есть переход в
Sj и s7; из состояния s5 — в ss и st. Таким образом, нам известно,
что s0, Si, s5, s2, s, и ss достижимы, и нужно посмотреть, есть ли
переходы в какие-нибудь новые состояния из s2, s, и s3. Проверка
этих состояний показывает, что никакие новые состояния не
достигаются, и, следовательно, оставшиеся состояния s4, se и s8
недостижимы. Таким образом, эти три состояния можно удалить,
получив тем самым эквивалентный автомат, изображенный на рис. 2.15, в.
2.10. Приведенные автоматы
Мы говорим, что автомат приведенный, если он не содержит
недостижимых состояний и никакие два его состояния не эквивалентны
друг другу. Если автомат не приведенный, то можно получить
эквивалентный ему автомат с меньшим числом состояний, либо
путем выбрасывания недостижимых состояний, либо путем
объединения двух эквивалентных состояний в одно, как было показано
в двух предыдущих разделах. Процесс приведения можно повторять
до тех пор, пока не получится приведенный автомат. Таким образом,
для каждого конечного автомата существует эквивалентный ему
приведенный автомат. Приведенный автомат, полученный таким
способом, имеет меньшее число состояний, чем исходный (если
исходный не был уже приведенным), и может быть более компактно
реализован на вычислительной машине.
Осуществляя приведение различными способами или начиная с
разных эквивалентных автоматов, можно предположить, что
полученные приведенные автоматы окажутся разными. Однако эти
автоматы будут фактически одинаковыми во всех отношениях, за
исключением имен, которыми названы их состояния.
Чтобы проиллюстрировать это на примере, мы изобразили на
рис. 2.16, а и 2.16, б два приведенных автомата. Применяя тест
из разд. 2.8 к паре начальных состояний (Л, 1), строим таблицу
44
Гл. 2. Конечные автоматы
эквивалентности состояний на рис. 2.17 и устанавливаем, что
следующие пары эквивалентны:
(А, 1), (В, 3), (С, 4), (D, 2).
Это значит, что автоматы эквивалентны, и по парам можно
установить, какие имена обозначают эквивалентные состояния. Подстав-
0 1
о
о
А
k
С
D
В С
0 А
В В
С 0
а
1
0
1
0
1
2
3
4
3 4
4 2
2 1
3 3
6
Рис. 2.1
1
0
0
1
6.
(А)
(В)
(С)
(D)
1
3
4
2
3
2
3
4
Я
4
1
3
2
1
0
1
0
АЛ
6,3
С.4
0,2
О
ляя в рис. 2.16, а новые имена, мы получаем рис. 2.16, в, который
совпадает с рис. 2.16, б во всем, кроме порядка строк.
Таким образом, эти два автомата идентичны с точностью до имен
состояний. Чтобы убедиться, что это справедливо для любой пары
эквивалентных приведенных автоматов
М и N, посмотрим, что происходит
при применении к М и /V метода
проверки эквивалентности из разд. 2.8.
Сначала в таблицу эквивалентности
состояний включается пара, состоящая из
начального состояния автомата М и
начального состояния автомата N.
Последующие пары, порождаемые при
проверке, будут обязательно содержать одно
состояние из М и одно состояние из N.
Каждое состояние автомата М может
входить в пару не более чем с одним
состоянием автомата N, и, наоборот,
так как если бы состояниет автоматам
было эквивалентно двум состояниям tii
и п2 автомата N, то состояния пх и п2
были бы эквивалентны друг другу, что противоречит нашему
предположению о том, что N — приведенный автомат. Кроме того,
каждое состояние т автомата М образует пару хотя бы с одним
состоянием автомата N, и, наоборот, так как входная цепочка,
6,3
0,2
6,3
С, 4
С А
А,1
6,3
0,2
Рис. 2.17.
2.11. Получение минимального автомата
45
которая переводит автомат М в состояние т, переведет также пару
начальных состояний из таблицы эквивалентности в пару,
содержащую состояние т. Отсюда мы заключаем, что каждое состояние
автомата М эквивалентно в точности одному состоянию /V, и
наоборот. Это означает, что автоматы М и N одинаковы go всем, кроме
имен состояний.
Мы показали, что если не придавать значения именам
состояний, то для каждой проблемы распознавания можно найти только
один приведенный автомат. Это означает, что, какой бы
распознаватель мы ни выбрали для некоторой проблемы распознавания и
каким бы образом ни происходило приведение его состояний, мы
можем построить только один приведенный автомат. Этот автомат
является минимальным автоматом, о существовании которого
говорилось в начале разд. 2.7.
2.11. Получение минимального автомата
Произвольный конечный автомат можно превратить в
эквивалентный ему минимальный, выбрасывая недостижимые состояния и
объединяя эквивалентные состояния. В разд. 2.9 дан эффективный
метод нахождения недостижимых состояний. Однако метод
проверки эквивалентности состояний, описанный в разд. 2.8,
использовать для приведения автоматов неудобно, так как он позволяет
обрабатывать одновременно только два состояния. Здесь мы
приводим более эффективный метод нахождения и объединения
эквивалентных состояний. Он имеет большое практическое значение,
так как минимальные конечные автоматы используются в
большинстве приложений с целью минимизации затрат памяти.
Этот новый способ будем называть «методсм разбиения», так как
он заключается в разбиении множества состояний на
непересекающиеся подмножества или блоки, такие, что неэквивалентные
состояния попадают в разные блоки. Применение этого способа
продемонстрируем на автомате рис. 2.18, а.
Сначала состояния разбиваются на два блока; один содержит
допускающие состояния, а другой — отвергающие состояния. В
нашем примере это начальное разбиение Р0 выглядит следующим
образом:
Я.= ({1, 2, 3, 4}, {5, 6, 7}),
так как 1, 2, 3 и 4 — отвергающие состояния, а 5, 6 и 7 —
допускающие состояния. Ни одно из состояний первого блока не
эквивалентно ни одному состоянию второго блока, поскольку такие
пары состояний нарушают условие подобия (см. разд. 2.8).
Теперь посмотрим, что происходит с состояниями блока {1,2,
3, 4} под действием входного символа а. Состояния 3 и 4 переходят
46
Гл. 2. Конечные автоматы
в состояния, принадлежащие первому блоку (а именно в состояния
1 и 4 соответственно), тогда как состояния 1 и 2 переходят в
состояния, принадлежащие второму блоку (а именно в состояния 6 и 7
соответственно). Это означает, что для любого состояния из
множества {1„2} и любого состояния из {3, 4} соответствующие состоя-
a b a b
1
2
3
4
5
6
7
& 3
7 3
t 5
4 6
7 3
4 1
4 2
a
0
0
0
0
1
1
1
(1,2)
{3}
(4)
{5}
{6,7} .
Рис. 2.18.
{6,7}
{1.2}
{4}
{6,7}
{4}
6
{3}
{5}
{6,7}
{3}
{1,2}
0
0
0
1
1
ния-преемники по входу а будут неэквивалентны. Это нарушает
условие преемственности, и потому мы можем заключить, что ни
одно состояние из множества {1, 2} не эквивалентно ни одному
состоянию из множества {3, 4}. Это позволяет произвести новое
разбиение:
Л=({1, 2}, {3,4}, {5,6,7}),
причем состояния из разных блоков всегда не эквивалентны. Мы
говорим, что получили Рх из Ре, разбивая блок {1, 2, 3, 4}
относительно входа а.
Теперь попытаемся найти такой входной символ и такой блок
в Ри чтобы его можно было разбить относительно этого входного
символа и получить тем самым новое разбиение. Для этого
разбиения также будет выполняться свойство неэквивалентности
состояний, принадлежащих разным блокам. Повторяем процесс до того
момента, когда дальнейшее разбиение становится невозможным.
Так как мы не устанавливаем порядок, в котором входные символы
и блоки проверяются на возможность разбиения,
последовательность разбиений можно порождать многими способами. Последнее
разбиение, однако, будет одним и тем же во всех случаях. В нашем
примере после Pi можно продолжать процесс следующим образом:
2.11. Получение минимального автомата
47
Разбивая блок {3, 4} из Pi относительно а, получаем
/\=({1, 2}, {3}, {4}, {5, 6, 7}).
Разбивая {5, 6, 7} из Р2 относительно а или Ь, получаем
Я.= ({1, 2}, {3}, {4}, {5}, {6, 7}).
Р3 не допускает дальнейшего разбиения. Чтобы убедиться в
этом, заметим, что все состояния блока {1,2} переходят
относительно а в состояния блока {6, 7}, а относительно Ь — в состояния
блока {3}. Аналогично блок {6, 7} переходит в блоки {4} и {1, 2}
относительно а и Ъ соответственно. Оставшиеся блоки имеют по
одному элементу и поэтому автоматически исключают дальнейшее
разбиение.
Когда процедура закончена, состояния внутри каждого блока
эквивалентны. В нашем примере эквивалентны состояния 1 и 2,
6 и 7. Чтобы понять, почему эти состояния должны быть
эквивалентными, можно рассуждать следующим образом. Поскольку
дальнейшее разбиение невозможно, входные символы, примененные
к состояниям одного блока, переводят их в состояния, которые
снова принадлежат одному блоку. Так как это положение
справедливо для всех блоков и всех входных символов, оно должно
выполняться и тогда, когда входные символы образуют входные цепочки.
Вследствие того, что Рй было разбиением на допускающие и
отвергающие состояния, каждый блок любого последующего разбиения
содержит либо только допускающие, либо только отвергающие
состояния. Таким образом, если для пары состояний существует
различающая цепочка, то она переводит их в разные блоки. Отсюда
мы заключаем, что состояния, принадлежащие одному блоку в
последнем разбиении, не могут иметь различающих цепочек и
должны быть эквивалентными.
Блоки последнего разбиения можно использовать для построения
нового автомата, который эквивалентен исходному и не содержит
эквивалентных состояний. Такой автомат для нашего примера
изображен на рис. 2.18, б. Множество состояний нового автомата —
это множество блоков последнего разбиения. Переходы нового
автомата мы получили из старого, прослеживая переходы из блока
в блок для каждого входного символа. Так, на рис. 2.18, б
элементом таблицы для состояния {1, 2} и входа а является состояние
{6, 7}, потому что состояния блока {1, 2} последнего разбиения Р3
переходят в состояния блока {6, 7} при входе а. Начальным
состоянием нового автомата будет просто блок, содержащий начальное
состояние исходного автомата, а допускающими состояниями будут
те блоки, которые содержат допускающие состояния исходного
автомата.
Автомат, изображенный на рис. 2.18,6, не имеет недостижимых
состояний и является поэтому минимальным для автомата рис. 2.18, а.
48
Гл. 2. Конечные автоматы
В общем случае процедура разбиения должна сопровождаться
выбрасыванием недостижимых состояний в целях получения
минимального автомата. Не имеет значения, которая из двух процедур
выполняется первой.
Теперь попытаемся привести автомат, изображенный на рис. 2.7
и предназначенный для распознавания цепочек, которые могут
следовать за словом INTEGER в операторе Фортрана. Прежде
всего замечаем, что автомат не имеет недостижимых состояний.
Затем применяем процедуру разбиения. Сначала строим разбиение
Р0, разделяя допускающие и отвергающие состояния:
Ро=({1, 3, 4, 5, 6, 8, Е), {2, 7}).
Разбивая {1, 3, 4, 5, 6, 8, Е} относительно входа v получаем
Р,= ({1, 8}, {3, 4,5, 6, Е}, {2,7})
Разбивая {3, 4, 5, 6, Е) относительно входа ) получаем
/V=({1,8}, {3, 5, Е), {4, 6}, {2,7}).
Разбивая {3, 5, Е) относительно входа v получаем
Р3=({1,8},{3, 5}, {Е}, {4, 6}, {2, 7}).
Разбивая {2, 7} относительно входа ( получаем
Я«=({1,8}, {3,5}, {Е}, {4,6}, {2}, {7}).
Никакое дальнейшее разбиение невозможно, поэтому Р4 —
последнее разбиение, которое выявляет эквивалентные состояния.
v с , ( )
{1,8} А
2
(3,5) В
{4,6} С
7
Е
2
Е
С
Е
Е
Е
Е
Е
С
Е
Е
Е
Е
А
Е
В
А
Е
Е
В
Е
Е
Е
Е
Е
Е
Е
7
Е
Е
Рис. 2.19.
О
1
О
О
1
О
Обозначая символами А, В и С блоки {1, 8}, {3, 5} и {4, 6}
соответственно, а символом Е — соответствующий одноэлементный
блок, мы получаем на рис. 2.19 таблицу переходов, которая
изображает минимальный автомат для автомата рис. 2.7. Таким образом
2.12. Недетерминированные автоматы
49
получен автомат с шестью состояниями, который выполняет ту же
работу, что и построенный нами сначала автомат с девятью
состояниями.
Вспомнив толкование состояний, данное в разд. 2.5, можно
следующим образом интерпретировать полученные классы
эквивалентности :
{1, 8}—должен начаться непустой список объектов,
{3, 5} — должна появиться размерность,
{4, 6} — только что задана размерность.
Попрактиковавшись, можно научиться опознавать роли,
которые приводят к одной и той же ситуации, и получать тем самым
исходные автоматы меньшего объема. Однако, каким бы ни было
число включенных в исходный автомат ненужных состояний, с
помощью описанного алгоритма его можно привести к
минимальному конечному автомату.
2.12. Недетерминированные автоматы
Теперь мы введем принадлежащее теории автоматов понятие не-
детерминированного автомата. Этот термин может привести в
недоумение, так как в русском и других языках понятие автомата, в
сущности, не позволяет применять к нему прилагательное
«недетерминированный». Поэтому в первую очередь надо иметь в виду,
что недетерминированный автомат неудобно интерпретировать как
модель поведения некоторого физического устройства. Еще одним
поводом для недоразумений является то, что термин
«недетерминированный» наводит на мысль о чем-то случайном, однако в
недетерминированном автомате ничего случайного нет. Таким образом,
второе, что нужно иметь в виду,— это то, что никакие вероятности
здесь ни при чем.
Недетерминированный автомат — это просто формализм для
определения множеств цепочек. Слово «автомат» присутствует в
его названии потому, что этот формализм является обобщением
формализма, используемого для определения обычного
детерминированного автомата. Недетерминированные конечные
распознаватели важны, поскольку:
1) для заданного множества иногда легче найти
недетерминированное описание;
2) существует процедура для превращения произвольного не.
детерминированного конечного распознавателя в обычный
конечный распознаватель.
Недетерминированный конечный распознаватель представляет
собой обычный распознаватель с той разницей, что значениями его
50
Гл. 2. Конечные автоматы
функции переходов являются множества состояний, а не отдельные
состояния, и вместо одного начального состояния задается
множество начальных состояний. Таким образом, можно дать
следующее определение:
Недетерминированный конечный распознаватель задается:
1) конечным множеством входных символов,
2) конечным множеством состояний,
3) функцией переходов 6, которая каждой паре, состоящей из
состояния и входного символа, ставит в соответствие
множество новых состояний,
4) подмножеством состояний, выделенных в качестве начальных,
5) подмножеством состояний, выделенных в качестве
допускающих.
Если состояние sH0B принадлежит множеству новых состояний,
приписанному функцией переходов «текущему» состоянию sTeK и
входному символу х, то мы пишем
х
с .. о
•'тек °нов
Этим обозначением можно, конечно, пользоваться и в том
случае, когда мы предпочитаем не интерпретировать его как переход
некоторого реального автомата. Говорят, что автомат допускает
входную цепочку, если она позволяет связать одно из его начальных
состояний с одним из допускающих. Так, если для некоторого
автомата справедливо
*, *8 *3
s0 >• s1 »■ s2 »■ s3
где So — начальное, a s3 — допускающее состояние, то мы будем
говорить, что входная цепочка XiX2x3 допускается этим автоматом.
Перефразировав последний абзац несколько более формально,
мы получаем следующее определение:
Входная цепочка длины п допускается
недетерминированным конечным распознавателем тогда и только тогда, когда
можно найти последовательность состояний s0 ... sn, такую,
что So —«начальное состояние, sn — допускающее состояние,
и для всех i, таких, что 0<t^n, состояние st принадлежит
множеству новых состояний, приписанных функцией
переходов состоянию Si-! для i-ro элемента входной цепочки.
Способ представления конечных распознавателей с помощью
таблицы переходов легко распространяется и на представление
недетерминированных конечных распознавателей. Необходимо
сделать лишь два изменения. Во-первых, каждый элемент таблицы
должен содержать множество состояний. Мы указываем это множе-
2.12. Недетерминированные автоматы 51
ство, просто перечисляя его элементы и не заключая их в скобки.
Второе изменение состоит в том, что начальные состояния
указываются с помощью стрелок, расположенных перед метками
соответствующих строк. Если таких стрелок нет, подразумевается,
что есть только одно начальное состояние, а именно состояние,
соответствующее первой строке.
На рис. 2.20 изображена таблица переходов, представляющая
недетерминированный конечный распознаватель. Множество
состояний— {Л, В, С}, входное множество— {0, 1}, допускающие
состояния — {В, С} и начальные
состояния — {А, В). Переходы такие:
б(Л, 0) = {Л, В},
б (В, О) = {0},
б (С, 0)={ },
б (Л, 1)={С},
Ь(В, 1)={С},
б(С, 1) = {Л, С}.
Цепочка 11 — одна из
допускаемых автоматом цепочек, так как
B-Lc\c,
причем В — начальное состояние, а С — допускающее.
Существования одной этой последовательности переходов достаточно для
того, чтобы показать допустимость входной цепочки 11, и
существование другой последовательности переходов из начального
состояния в отвергающее, например
вХс-^А
на это не влияет.
Один из переходов недетерминированного распознавателя, а
именно б (С, 0) является переходом в пустое множество. Это попросту
означает, что для состояния С и входа 0 дальнейшие переходы не'
возможны. Такой элемент таблицы переходов может препятствовать
существованию последовательности переходов для некоторой
входной цепочки. В данном примере такой цепочкой является 10; так
как 1 переводит оба начальных состояния в состояние С,
множество преемников которого пусто. Такие входные цепочки просто
отвергаются наряду со всеми прочими цепочками, которые не могут
перевести начальное состояние в заключительное.
«Работу» недетерминированного автомата можно
интерпретировать двояким образом. Покажем это на примере автомата,
приведенного на рис. 2.20. Пусть автомат находится в состоянии Л, и к
нему применяется входная цепочка, начинающаяся с 0. Тогда
. можно представить себе один из следующих вариантов:
А
В
С
А.В С
В С
А,С
Рис. 2.20.
0
1
1
52
Гл. 2. Конечные автоматы
1. Автомат осуществляет выбор, переходя либо в А, либо в В,
т. е. в одно из новых состояний, соответствующих старому
состоянию А и входу 0. Автомат продолжает работать подобным образом,
и при этом возможно много выборов. Если имеется какая-нибудь
последовательность выборов, при которой автомат под действием
входной цепочки заканчивает работу в допускающем состоянии, то
говорят, что эта входная цепочка допускается автоматом.
Подчеркнем, что достаточно только одной последовательности выборов,
приводящей к допускающему состоянию, и автомат допускает данный
вход, даже если имеется много других последовательностей выборов,
которые не ведут к допускающему состоянию.
2. Автомат распадается на два автомата, один — в состоянии Л,
а другой — в состоянии В. При продолжении обработки входа
происходит дальнейшее деление каждого автомата в соответствии с
возможностями, содержащимися в таблице переходов. Когда вход
обработан, цепочка допускается, если один из результирующих
автоматов находится в допускающем состоянии.
Эти две интерпретации эквивалентны, и обе полезны для
понимания недетерминированного автомата. Однако автомат служит не
для моделирования этих ситуаций. Его назначение состоит в
определении допустимого множества входных цепочек.
Пример
Построим недетерминированный автомат с входным алфавитом
{А, Л, Н, О, С, Ь}
который допускает только две цепочки ЛАССО и ЛАНЬ.
Применяя технику пометки символов, находим следующие
очевидные роли:
Со —
Лг-
Аг-
Сг-
с2-
0-
л2-
л2-
н-
ь —
начальное состояние
Л в ЛАССО
• А в ЛАССО
- первое С в ЛАССО
- второе С в ЛАССО
- О в ЛАССО
- Л в ЛАНЬ
- А в ЛАНЬ
-Н в ЛАНЬ
Ь в ЛАНЬ
Затем эти роли преобразуются в таблицу переходов,
изображенную на рис. 2.21. Недетерминированность проявляется двояким
образом. Во-первых, поскольку оба Л — из ЛАССО и из ЛАНЬ —
2.13. Эквивалентность конечных распознавателей
53
могут встречаться сразу после начального состояния, мы просто
помещаем как Ль так и Л2 в этот элемент таблицы. Во-вторых, во-
многих местах встречается буква, которая не может быть
правильным продолжением слова, и эти места просто оставляются незапол-
Н С Л О A b
"о
А,
С,
С2
О
Л2
А2
н
Ь
л„л2
И
о
О
О
О
о
1
о
! о
! О
!
I
! 1
Рис. 2.21.
ненными или пустыми как указание на то, что продолжение
невозможно. Это освобождает нас от введения состояния ошибки, что мы
делали в разд. 2.5, когда пытались непосредственно по ролям
строить детерминированную таблицу.
2.13. Эквивалентность недетерминированных
и детерминированных конечных распознавателей
Понятие недетерминированного конечного распознавателя
приобретает практическое значение благодаря следующему факту:
Для каждого недетерминированного конечного
распознавателя существует детерминированный конечный
распознаватель, который допускает в точности те же входные цепочки,
что и недетерминированный.
В данном разделе мы покажем, как можно найти этот
эквивалентный детерминированный автомат.
54
Гл. 2. Конечные автоматы
Основная идея построения заключается в том, что после
обработки отдельной входной цепочки состояние детерминированного
автомата будет представлять собой множество всех состояний
недетерминированного автомата, которые он может достичь из начальных
состояний после применения данной цепочки. Переходы
детерминированного автомата можно получить из недетерминированных
переходов, вычисляя множество состояний, которые могут следовать
после данного множества при различных входных символах.
Допустимость цепочки определяется по тому, является ли последнее
детерминированное состояние, которого он достиг, множеством
недетерминированных состояний, включающим хотя бы одно
допускающее состояние. Результирующий детерминированный автомат
является конечным, так как существует лишь конечное число
подмножеств недетерминированных состояний.
Если недетерминированный автомат имеет п состояний, то
эквивалентный детерминированный автомат, который мы только что
описали, может, вообще говоря, иметь 2" состояний, по числу
подмножеств исходного множества состояний. На практике многие из
этих подмножеств представляют собой недостижимые состояния.
В приводимой ниже процедуре переходы строятся только для тех
подмножеств, которые действительно необходимы.
Процедура задается следующими пятью шагами. Пусть Мв —
недетерминированный автомат, а МЛ — эквивалентный ему
детерминированный автомат, который нужно построить.
1. Пометить первую строку таблицы переходов для Ма
множеством начальных состояний автомата Мя. Применить к этому
множеству шаг 2.
2. По данному множеству состояний S, помечающему строку
таблицы переходов автомата Мл, для которой переходы еще не
вычислены, вычислить те состояния М„, которые могут быть
достигнуты из S с помощью каждого входного символа х, и поместить
множества последующих состояний в соответствующие ячейки
таблицы для Мд. Символически это выражается так. Если б —
функция недетерминированных переходов, то функция
детерминированных переходов б' задается формулой
6'(S, *)={s|s принадлежит 8(t, х) для некоторого t из S}
3. Для каждого нового множества, порожденного переходами
на шаге 2, посмотреть, имеется ли уже в Мд строка, помеченная
этим множеством. Если нет, то создать новую строку и пометить ее
этим множеством. Если множество уже использовалось как метка,
никаких действий не требуется.
4. Если в таблице автомата Мл есть строка, для которой еще не
вычислены переходы, вернуться назад и применить к этой строке
шаг 2. Если все переходы вычислены, перейти к шагу 5.
2.13. Эквивалентность конечных распознавателей
55
5. Пометить строку как допускающее состояние автомата МЛ
тогда и только тогда, когда она содержит допускающее состояние
недетерминированного автомата. В противном случае пометить как
отвергающее состояние.
Проиллюстрируем эту процедуру на примере
недетерминированного автомата рис. 2.20. Результат применения шага 1 изображен
на рис. 2.22, а. Применяя шаг 2 к {А, В}, обнаруживаем, что б'({Л,
В}, 0)={Л, В} и 8'({А, В}, 1)={С}. См. рис. 2.22, б.
Применяя шаг 3, мы видим, что уже имеется строка для {А, В},
но не для {С}. Поэтому создаем новую строку для {С}, получая тем
самым конфигурацию на рис. 2.22, в.
Переходя к шагу 4, обнаруживаем, что надо применить шаг 2
к {С}. После того как это сделано, на шаге 3 выясняется, что нужны
еще две строки (рис. 2.22, г). Применение шага 2 к {А, С} и к
пустому множеству { }дает нам переходы в множества, которые уже
являются именами состояний. Этот результат изображен на рис. 2.22, д.
Теперь шаг 4 предписывает нам перейти к шагу 5. Состояние
{А, В} отмечается как допускающее, поскольку оно содержит
допускающее состояние В; состояния {С} и {Л, С} отмечаются как
допускающие, так как содержат допускающее состояние С. Пустое
множество, разумеется, не содержит допускающего состояния и поэтому
помечается как отвергающее.
Результат приведен на рис. 2.22, е, где изображен
окончательный вариант детерминированного автомата, эквивалентного
исходному недетерминированному. Чтобы напомнить, что множества на
рис. 2.22, е — это просто имена состояний нового автомата, мы
подставляем новый набор имен, получая на рис. 2.22, ж таблицу
состояний, которая задает тот же самый автомат, но в более простых
обозначениях.
В качестве еще одного примера применим процедуру к автомату
на рис. 2.21. Результат изображен на рис. 2.23. Так как
большинство переходов приводят к пустому множеству, мы обозначаем это
состояние в таблице пробелом, чтобы не загромождать ее
символами { }. Состояние, соответствующее пустому множеству, на самом
деле является состоянием ошибки, введенным в разд. 2.5; это
отвергающее состояние, которое переходит само в себя для всех входов
и имеет место только тогда, когда для данной входной цепочки нет
допустимых продолжений.
Теоретически недетерминированный автомат с десятью
состояниями, изображенный на рис. 2.21, может иметь
детерминированный вариант с 1024 состояниями, в соответствии с числом
подмножеств множества, содержащего десять состояний, но на самом
деле потребовалось только девять состояний. Это меньше исходного
числа. Таким образом, мы видим, что порождение только
необходимых подмножеств — чрезвычайно полезный прием.
56
Гл. 2. Конечные автоматы
{А,В},
{А,В\
0
;,Г
0
{А,В}
6
1
1
{С}
{А.В)
{С}
{}
{А.С}
0
{А,В}
О
{)
{А,В}
д
1
{С)
{А.С}
{}
И,с}
{А,В}
{С}
{А.В}
б
{С}
{А,В)
{С}
{)
{А.С)
{А,В) {С}
{ ) {А,С}.
{) (}
{А.В) {А.С}
е
1
1
0
1
{AS}
{С}
{}
{Л,С}
{AS}
U
{С}
{АС}
1
2
3
4
1
3
3
1
2
4
3
4
1
1
0
1
2
Рис. 2.22.
2.14. Пример: константы языка MINI-BASIC
57
Глядя на таблицу переходов, изображенную на рис. 2.23, мы
замечаем, что не надо делать различия между ролями Лг и Л2, а
также Л, и А2. Алгоритм позволяет нам не заботиться об этом при
создании исходного распознавателя.
Н
Л
{с0}
{лм
{АиА2)
{С,}
{С2)
W)
{Н}
{Ь}
{}
<«}
{ДМ
{А„Аг)
{С,}
{С2}
{0}
Ь]
о
о
о
о
о
1
о
1
о
предполагается, что незаполненные элементы содержат {}
Рис. 2.23.
Хотя процедура гарантирует, что детерминированный автомат
не содержит недостижимых состояний, детерминированный автомат
может оказаться не минимальным. В последнем примере состояния
{О} и {Ь} явно эквивалентны и могут быть объединены.
2.14. Пример: константы языка MINI-BASIC
Мы уже знаем, как использовать конечные автоматы для
определения множеств цепочек и как превращать эти автоматы в процессоры,
которые могут выдавать «ДА», когда входная цепочка допускается,
или «НЕТ», когда цепочка отвергается. На практике конечные
процессоры должны делать нечто большее, чем просто выдавать
положительный или отрицательный ответ. Теория автоматов не может
сказать нам, как расширять конечные распознаватели до
процессоров специального назначения, поскольку требования,
предъявляемые к таким процессорам, меняются от приложения к приложению.
Таким образом, мы достигли того момента, когда разработчик ком-
58
Гл. 2. Конечные автоматы
пиляторов должен применить свои творческие способности, чтобы
довести дело до конца. Этот последний шаг — от распознавателя
к практическому процессору — состоит обычно в дополнении
переходов короткими процедурами.
Чтобы посмотреть, как можно расширить распознаватель до
практического процессора, мы построим процессор, распознающий
константы языка MINI-BASIC и превращающий их в
последовательности битов, которые являются их внутренним представлением
в виде чисел с плавающей точкой. В гл. 4 эта конструкция включена
в лексический блок компилятора для языка MINI-BASIC.
На первом шаге вычисления последовательности битов число
представляется в виде двух целых чисел, которые мы будем
называть значащей частью и порядком *).
Порядок — это степень десяти, на которую нужно умножить
значащую часть, чтобы получить фактическое число. Так, число
12.35Е14 будет представлено значащей частью 1235 и порядком 12.
Затем мы преобразуем эту пару целых чисел в соответствующую
последовательность битов. Так как детали этого шага существенно
зависят от особенностей конкретной машины, мы просто
предположим, что такая процедура у нас имеется, и больше не будем о ней
говорить. Мы предполагаем также, что разработчик может видоиз:
менять наши процедуры с учетом разного рода переполнений,
которые могут иметь место при построении целых чисел.
Так как лексический анализатор для языка MINI-BASIC будет
трактовать знак унарной операции + или — как отдельный символ,
то в данном примере мы полагаем, что такой знак не может
встретиться перед константой. Мы строим автомат для обработки
констант без знака.
В этом примере входное множество распознавателя не совпадает
с множеством символов языка MINI-BASIC и состоит лишь из
четырех символов, а именно
ЦИФРА • Е ЗНАК
Мы предполагаем, что имеется препроцессор, переводящий
символы MINI-BASIC'a в эти четыре входные символа, играющие роль
лексем. Конкретно имеется в виду такой перевод символов языка
MINI-BASIC:
1. Каждая из цифр 0, 1,2, 3, 4, 5, 6, 7, 8 и 9 переводится в пару,
состоящую из символа ЦИФРА и значения этой цифры.
2. Каждый знак + или — переводится в пару, состоящую из
символа ЗНАК и указания на то, какой это знак.
3. Буква Е переводится в символ Е; точка переводится в точку,
причем обе эти лексемы не имеют значений.
1) В оригинале integer part и exponent part,— Прим. ред.
2.14. Пример: константы языка MINI-BASIC
59
Лексический блок MINI-BASlC'a, построенный в гл. 4,
включает аналогичную предварительную обработку множества
символов.
Выписав несколько^цепочек, мы можем, выделить семь ролей:
3 8 • 7 Е —' 3 • 9 Е 2 1
11234 56 73466
Эти роли можно описать так:
2 1) цифра перед возможно присутствующей десятичной точкой,
=. 2) необязательно присутствующая десятичная точка,
■-, 3) цифра после десятичной точки,
^ 4) буква Е,
5) знак порядка,
1 6) цифра порядка,
^ 7) десятичная точка, требующая десятичных цифр.
' Одна из особенностей этого списка ролей состоит в
необходимости различать роли 2 и 7, что может показаться неочевидным.
Отличие заключается в том, что после вхождения символа в роли 2
может следовать не только цифра, но и Е, а также может не
следовать ничего, как в цепочках 38.Е — 21 и 38. После вхождения
символа в роли 7 должна следовать цифра, так как цепочки, вроде.Е—
21, или одна десятичная точка не считаются правильно
построенными константами.
Затем мы вводим начальное состояние 0 и используем это
состояние вместе с ролями для построения таблицы переходов. Как
обычно, переходы заполняются в соответствии с тем, какие роли могут
следовать одна за другой, а в случае переходов из начального
состояния — с учетом того, какие роли могут встречаться в
начале цепочек. Роли, которые могут завершать цепочку, отмечаются
как допускающие состояния. Результат показан на рис. 2.24, а.
Полученный автомат фактически детерминированный, если пробелы
в таблице интерпретировать как переходы в состояние ошибки,
не включенное в список.
Очевидно, этот автомат не является приведенным, так как
состояния 2 и 3 эквивалентны, поэтому следует объединить их в одно
состояние, назовем его 23. Результат показан на рис. 2.24, б.
Просмотр этой таблицы переходов показывает, что она приведенная.
Следующий шаг построения процессора состоит в добавлении к
входному множеству концевого маркера и присвоении каждому
переходу отдельного имени. Результат показан на рис. 2.25. Так как в
исходной таблице переходов было два перехода в состояние 1, мы
назвали эти переходы 1а и lb, чтобы различать их в процедурах
обработки, описываемых ниже. Аналогично различаются переходы
в 23, 4 и 6. Допускающим состояниям, в которые автомат переходит
при чтении концевого маркера, также даны разные имена.
60
Гл. 2. Конечные автоматы
ЛУеханическая часть построения процедуры завершена, и
начинается специальная часть. Переходы автомата интерпретируются
как вызовы процедур или частей объектного кода, которые должны
выполняться при переходах. Задача разработчика — описать эти
Цифра Е
Знак
Цисрра £
Знак
0
1
2
3
4
5
6
1
1
1
3
3
6
6
6
3
4
4
4
а
7
2
5
0
1
Т
1
0
0
1
0
Рис.
0
1
23
4
5
6
7
2.24.
1
1
23
6
6
6
23
4
4
7
23
5
6
0
1
1
0
0
1
0
процедуры так, чтобы получить желаемый результат, который
заключается в данном случае в переводе входной цепочки в пару,
состоящую из значащей части и порядка.
Цифра
Знак
0
1
23
4
5
6
7
1а
1/;
23а
6э
6Ь
6с
23Ь
4а
4Ь
7
23с
5
ДА 1
ДА2
ДАЗ
Рис. 2.25.
Чтобы выполнить это преобразование, заведем четыре
переменные: РЕГИСТР ЧИСЛА, РЕГИСТР ПОРЯДКА, РЕГИСТР
СЧЕТЧИКА и РЕГИСТР ЗНАКА. Назначение этих переменных таково:
2.14. Пример: константы языка MINI-BASIC
61
РЕГИСТР ЧИСЛА — для накопления значащей части,
РЕГИСТР ПОРЯДКА — для накопления порядка,
РЕГИСТР СЧЕТЧИКА — для подсчета разрядов, следующих
за десятичной точкой,
РЕГИСТР ЗНАКА — для запоминания знака порядка.
Теперь обеспечим каждый переход процедурой. Здесь мы
ограничимся словесным описанием процедур. Разработчик может
превратить их в программу для своей конкретной машины. Для
понимания этих процедур нужно помнить интерпретацию состояний и
расположение переходов в таблице. Например, \а — это действие,
предпринимаемое, когда встречается первая цифра, alb — когда
встречается следующая цифра. Процедуры переходов таковы:
1а: Поместить значение цифры в РЕГИСТР ЧИСЛА.
Для очередного входного символа сделать переход из
состояния 1.
lb: Умножить содержимое РЕГИСТРА ЧИСЛА на 10.
Прибавить значение цифры и запомнить результат в
РЕГИСТРЕ ЧИСЛА.
Для очередного входного символа сделать переход из
состояния 1.
23а: Увеличить РЕГИСТР СЧЕТЧИКА на 1.
Умножить содержимое РЕГИСТРА ЧИСЛА на 10.
Прибавить значение цифры и запомнить результат в
РЕГИСТРЕ ЧИСЛА.
Для очередного входного символа сделать переход из
состояния 23.
236: Инициализировать РЕГИСТР СЧЕТЧИКА единицей ').
Поместить значение цифры в РЕГИСТР ЧИСЛА.
Для очередного входного символа сделать переход из
состояния 23.
23с: Инициализировать РЕГИСТР СЧЕТЧИКА нулем.
Для очередного входного символа сделать переход из
состояния 23.
4а: Инициализировать РЕГИСТР СЧЕТЧИКА нулем.
Для очередного входного символа сделать переход из
состояния 4.
4Ь: Для очередного входного символа сделать переход из
состояния 4.
*) «Инициализировать икс игреком» на программистском жаргоне означает
«дать иксу начальное значение игрек» или «установить икс в начальное состояние
игрек»,— Прим, ред.
62
Гл. 2. Конечные автоматы
5: Если знак +, заслать +1 в РЕГИСТР ЗНАКА.
Если знак —, заслать —1 в РЕГИСТР ЗНАКА.
Для очередного входного символа сделать переход из
, состояния 5.
6а: Поместить +1 в РЕГИСТР ЗНАКА.
Поместить значение цифры в РЕГИСТР ПОРЯДКА.
Для очередного входного символа сделать переход из
состояния 6.
&>: Поместить значение цифры в РЕГИСТР ПОРЯДКА.
Для очередного входного символа сделать переход из
состояния 6.
6с: Умножить содержимое РЕГИСТРА ПОРЯДКА на 10.
Прибавить значение цифры и запомнить результат в
РЕГИСТРЕ ПОРЯДКА.
Для очередного входного символа сделать переход из
состояния 6.
7: Для очередного входного символа сделать переход из
состояния 7.
ДА1: Заслать 0 в РЕГИСТР ПОРЯДКА.
Прекратить работу автомата.
ДА2: Заслать в РЕГИСТР ПОРЯДКА значение РЕГИСТРА
СЧЕТЧИКА с минусом.
Прекратить работу автомата.
ДАЗ: Если РЕГИСТР ЗНАКА равен —1, сделать
отрицательным РЕГИСТР ПОРЯДКА.
Вычесть РЕГИСТР СЧЕТЧИКА из РЕГИСТРА
ПОРЯДКА.
Прекратить работу автомата.
Следует заметить, что, говоря «Для очередного входного
символа сделать переход из состояния s», мы не подразумеваем, что это
надо реализовать каким-то особым способом. Мы просто имеем
в виду, что состояние s и очередной входной символ используются
для выбора следующего перехода.
Заметим также, что при записи процедур мы не воспользовались
тем, что некоторые из них имеют общую часть, как, например,
процедуры 6а и 6Ь. Это было сделано для ясности. На практике мы
написали бы что-нибудь вроде:
6а: Заслать +1 в РЕГИСТР ЗНАКА.
6Ь: Поместить значение цифры в РЕГИСТР ПОРЯДКА.
Для очередного входного символа сделать переход из
состояния 6.
2.14. Пример: константы языка MINI-BASIC
63
Чтобы завершить построение процессора, нужно поместить в
пустые ячейки таблицы переходов вызовы процедур, обрабатывающих
ошибки. Мы не будем здесь обсуждать, какими должны быть эти
процедуры.
Новые значения регистров
Входной i Л ^
символ Переход Число Порядок Счетчик Знак
4
7
•
2
Е
-
1
3
н
1а
■\ь
53с
53а
АЬ
5
6Ь
6с
ДАЗ
А
47
47
472
472
472
472
472
472
—
-
-
-
-
-
1
13
-14
—
-
0
—
-
-
-
-
-1
-1
-1
-1
4
Е
6
Ч
1а
4а
6а
ЛАЗ
4
4
4
4
-
-
6
б
—
0
0
0
-
-
+1
+1
•
8
н
7
23Ь
ДА 2
_
8
8
—
-
-1
—
1
1
—
-
-
3
н
1э
ДА1
3
3
-
0
-
-
-
-
Рис. 2.26.
Чтобы посмотреть, как работает автомат, и приобрести
некоторую уверенность в том, что он действительно работает, мы сейчас
построим несколько проверочных «программ». Как минимум, под
действием этих программ каждый переход будет сделан хотя бы
64
Гл. 2. Конечные автоматы
один раз. Один набор программ, вызывающий все переходы, состоит
из следующих четырех программ:
47. 2Е-13 4Е6 .8 3
Действие этих программ на процессор показано на рис. 2.26.
Каждая строка рисунка изображает конфигурацию, состоящую из
введенного символа, перехода, который он вызвал, и новых
значений переменных, присвоенных процедурами переходов.
Заметим, что если процессор реализован как программа для
вычислительной машины, эти тестовые программы можно использовать
в целях отладки. На самом деле отладочные программы и их
результаты может задавать сам разработчик; при этом, если программы
проходят правильно, то возрастает уверенность в том, что
процессор также работает правильно.
Чтобы проверить процедуры, обрабатывающие ошибки, которые,
как мы договорились, печатают сообщения об ошибках для
программирующего на языке MINI-BASIC, необходимо придумать входную
цепочку для каждого из переходов, приводящих к состоянию
ошибки Например, переход из состояния 4 для входа Е можно проверить
с помощью входной цепочки
ЦИФРА Е Е
Идея этого примера состоит в том, что теория позволила нам
разбить большую задачу (как обрабатывать цепочки) на ряд
небольших задач (как дополнить переходы). Решение каждой из этих
маленьких задач можно записать в несколько строчек.
2.15. Замечания по литературе
Модель конечного автомата была введена Хафменом [1954], Муром
[1956] и Мили [1955], каждый из которых занимался вопросами
приведения автоматов. Весьма абстрактная точка зрения на автоматы
представлена в работе Рабина и Скотта [1959], в ней содержатся
обсуждавшиеся здесь результаты о недетерминированных автоматах.
Многие из первоначальных работ по конечным автоматам были
переизданы в сборнике под ред. Мура [1964]. В книгах Гинзбурга [1962],
Хартманиса и Стирнза [1966] дано детальное математическое
изложение некоторых аспектов теории конечных автоматов. Другие
книги, содержащие много материала по конечным автоматам,
написаны Хенни [1968], Минским [1967], Бутом [1967], Харрисоном
11965] и Гиллом [1962].
Упражнения
65
Упражнения
t. Постройте конечный автомат, который будет распознавать слова
GO TO
причем между ними может быть произвольное (включая нулевое) число
пробелов.
2. а) Найдите самую короткую цепочку, распознаваемую автоматом,
изображенным на рисунке.
б) Найдите четыре других цепочки, распознаваемых этим автоматом.
в) Найдите четыре цепочки, которые отвергаются этим автоматом.
А
В
С
D
Е
F
0
D
А
А
В
В
Е
1
А
С
F
С
С
А
0
0
0
0
1
1
3. Сначала постройте конечные распознаватели для описанных ниже множеств
цепочек из нулей и единиц. Затем превратите каждый распознаватель в
процессор с концевым маркером. Наконец сделайте так, чтобы процессор
обнаруживал допустимость и недопустимость цепочек как можно скорее.
а) Число единиц четное, а число нулей — нечетное.
б) Между вхождениями единиц четное число нулей.
в) Число вхождений пары 00 нечетное, причем допускаются наложения пар
друг на друга.
г) За каждым вхождением пары 11 следует 0.
д) Каждый третий символ — единица.
е) Имеется по крайней мере одна единица.
4. Постройте конечный автомат с входным алфавитом {0, 1}, который допускает
в точности такое множество цепочек:
а) Все входные цепочки.
б) Ни одной входной цепочки.
в) Входную цепочку 101.
г) Две входные цепочки: 01 и 0100.
д) Все входные цепочки, кончающиеся на 1 и начинающиеся с 0.
е) Все цепочки, не содержащие ни одной единицы.
ж) Все цепочки, содержащие в точности три единицы.
з) Все цепочки, в которых перед и после каждой единицы стоит 0.
и) Пустую цепочку и 011.
к) Все входные цепочки, кроме пустой.
5. а) Постройте конечный автомат, который будет распознавать следующие
зарезервированные слова Алгола 60:
STEP, STRING, SWITCH
б) Оцените, сколько состояний понадобится для распознавания всех
зарезервированных слов Алгола 60.
3 Ф. Льюис и др.
66
Гл. 2. Конечные автомоты
6. Опишите словами множества цепочек, распознаваемых каждым из следующих
автоматов:
А
В
С
В
в
с
А
С
С
0
0
1
А
В
С
В
С
С
С
В
С
0
1
0
О 1
А
В
С
D
В
/
D
С
D
С
В
D
D
0
1
1
0
А
В
С
D
В
D
С
D
А
С
D
D
0
0
1
0
А
В
С
D
Е
F
в
F
С
Е
F
F
F
С
D
С
F
F
F
F
С
С
F
F
0
0
0
0
(1
0
7. Для каждого из автоматов найдите входную цепочку или цепочки с
минимальной суммарной длиной, такие, что под нх действием
а) каждое состояние имеет место хотя бы раз,
б) каждый переход происходит хотя бы раз.
Упражнения
67
О 1
А
В
С
D
Е
F
С
D
А
А
F
Е
В
В
Е
А
Е
А
О
1
О
О
1
1
А
В
С
D
Е
F
А
В
С
D
В
F
Е
а
F
в
F
с
О
0
1
1
1
О
8. Найдите различающую цепочку (если она существует) для такой пары
автоматов:
0 1 0 1
А
В
С
D
А
С
в
А
В
D
А
В
0
0
1
0
А
В
с
D
А
А
В
С
D
D
А
В
i
0
1
0
9. Найдите недостижимые состояния автомата
О 1 2
А
В
С
D
Е
F
G
Н
1
J
С
J
J
F
Е
D
Н
G
D
В
E
E
A
A
J
1
A
J
F
H
G
G
H
G
H
A
J
В
G
G
0
1
0
1
0
1
0
1
0
1
68
Гл. 2. Конечные автоматы
10. Найдите минимальную эквивалентную
следующих автоматов:
О 1
*1
s2
S3
SA
S5
S6
S7
*1
h
S6
*1
*1
h
h
S3
*4
S5
S4
SA
S6
h
0
1
0
1
0
1
0
a
А С
INIT
С
CA
CAL
CALL
CE
CEL
CELL
Ошибка
Ошибка
CA
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
С
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
б
11. Превратите автомат, изображенный i
маркером, который наиболее быстро
12. Напишите сообщение об ошибке для
автомата на рис. 2.19,
таблицу переходов для каждого из
х у
4
5
4
2
1
1
2
1
1
5
6
7
4
5
6
Е L
Ошибка
СЕ
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
Ошибка
CAL
CALL
Ошибка
CEL
CELL
Ошибка
Ошибка
0
0
0
0
1
0
0
I
0
ia рис. 2.19, в процессор с концевым
обнаруживает ошибки,
каждого перехода в состояние ошибки
Упражнения
69
13. Многие компиляторы с Алгола 60 содержат ограничение, состоящее в том, что
в описаниях собственных массивов границы массива должны быть
целочисленными константами. Типичны описания такого вида:
OWN REAL ARRAY Al[4:6j
OWN INTEGER ARRAY A2[—1 : 3,12 : +4, 171 : 173]
а) Постройте конечный автомат, который распознает часть описания,
следующую за идентификатором. Пусть входной алфавит будет
[ ]: ,- + ц
где ц — лексема цифра.
б) Превратите этот автомат в процессор с концевым маркером, который
наиболее быстро обнаруживает ошибки.
в) Найдите множества цепочек, под действием которых каждый переход
автомата происходит хотя бы один раз.
14. Опишите словами множества цепочек, распознаваемые каждым из
недетерминированных автоматов, изображенных на рисунке.
0
0
1
А
В
С
В
С,А
6
0
0
1
А
В
С
D
В
С,О
В
В
0
0
0
1
в
15. Найдите детерминированный автомат, эквивалентный такому
недетерминированному автомату:
а Ь
1
2
3
2,3
1
2
1
3
0
0
1
16. Постройте конечный автомат, который будет допускать только те цепочки,
которые можно построить из подцепочек
GO, GOTO, TOO, ON
Возможны повторения, но не пересечения. Так, одна из допустимых цепочек
GOONGOTOONGOTOOON
Можно построить сначала недетерминированный автомат, а затем сделать его
детерминированным.
17. Рассмотрим язык, состоящий из арифметических выражений, в которых
используются операции + и — (как унарные, так и бинарные), * и /, но нет
скобок. Пусть операнды — либо целочисленные константы (например, 314),
либо идентификаторы, являющиеся цепочками из букв и цифр, начинающихся
с буквы (например, D12).
70
Гл. 2. Конечные автоматы
а) Пользуясь методом ролей, постройте минимальный конечный
распознаватель для этих выражений. Пусть входной алфавит будет
+ — * / б ц,
где б — обозначает букву, а ц — цифру.
б) Пусть арифметические операции выполняются строго слева направо, так
что, например, значение выражения
3+5*2
равно 16. Разработайте специальные процедуры, которые нужно добавить
к распознавателю, чтобы порождать машинные команды для этих
выражений. Адреса идентификаторов в рабочей программе считаются известными.
18. а) Постройте конечный автомат, который будет распознавать изображенные
римскими цифрами числа, меньшие 2000.
б) Превратите этот автомат в процессор, который распознает римские цифры
и переводит их в соответствующие последовательности битов.
в) Найдите множество цепочек, под действием которых осуществляются все
переходы этого процессора, и опишите работу автомата применительно
к этим цепочкам.
г) Введите в процессор сообщения об ошибках, желательно на латыни.
19. а) Найдите множество входных цепочек, не совпадающее с приведенным
ранее в тексте, под действием которых осуществляются все переходы
автомата, изображенного на рис. 2.25.
б) Для указанных выше цепочек составьте таблицу, аналогичную
изображенной на рис. 2.26.
20. а) Напишите сообщение об ошибке для каждого перехода в состояние ошибки
автомата на рис. 2.25.
б) Найдите множество входных цепочек, которые приводят в действие все
переходы в состояние ошибки автомата рис. 2.25.
21. Напишите программу на любом языке, реализующую автомат, изображенный
на рис. 2.25, и все процедуры, необходимые для его переходов.
22. Постройте таблицу переходов конечного автомата, входной алфавит которого
состоит из тридцати одного символа: ОДИН, ДВА, ТРИ, . . ., ДЕВЯТЬ,
ДЕСЯТЬ, ОДИННАДЦАТЬ ВОСЕМНАДЦАТЬ, ДЕВЯТНАДЦАТЬ,
ДВАДЦАТЬ, ТРИДЦАТЬ ДЕВЯНОСТО, СТО, ДВЕСТИ, СТА, СОТ;
пусть выходной алфавит состоит из десяти символов 0, 1, 2, ... 9, и пусть он
допускает в качестве входа словесную запись любого числа от 1 до 999
(например, ВОСЕМЬСОТ ТРИДЦАТЬ ПЯТЬ) и переводит вход в эквивалентную
цифровую запись (835).
23. Два автомата на рис. 2.35 допускают множества St и S2 соответственно.
а) Постройте недетерминированные автоматы для
i) SiUS2 (объединения множеств St и S2),
ii) Sif|S2 (пересечения множеств Sj и S2).
б) Найдите минимальные детерминированные автоматы, эквивалентные
указанным недетерминированным автоматам.
0 1 0 1
С
в
с
в
с
с
Абтомат для множества S,
Автомат для множества s2
D
С
D
D
В
С
D
D
Упражнения
71
24. Рассмотрим множество всех распознавателей с двумя состояниями и входным
алфавитом {0, 1 \.
а) Сколько автоматов а этом множестве?
б) Сколько в нем неэквивалентных автоматов?
в) Опишите словами множество цепочек, распознаваемое каждым из этих
неэквивалентных автоматов.
25. В некоторых приложениях начальное состояние конечного автомата не
указывается. Он может начать работу в любом состоянии благодаря какому-либо
внешнему воздействию. Два таких автомата эквивалентны, если каждому
состоянию одного автомата эквивалентно некоторое состояние другого, и
наоборот. Опишите процедуру, которая по такому автомату строит
минимальный эквивалентный ему автомат.
26. а) Пусть k — длина наименьшей различающей цепочки для некоторой пары
состояний конечного автомата. Покажите, что если k^\, то автомат
содержит два других состояния, наименьшая' различающая цепочка которых
имеет длину k— 1.
б) Покажите, что если два состояния автомата, имеющего п состояний,
неэквивалентны, то для них существует различающая цепочка длины п—2
или меньше.
в) Постройте таблицу переходов для автомата с шестью состояниями, такого,
что длина наименьшей цепочки, различающей два состояния, равна 4.
27. Рассмотрим два конечных автомата Мг и М.г с числом состояний /Vj и /V2
соответственно. Покажите, что недетерминированному конечному автомату,
который распознает объединение множеств, распознаваемых автоматами /И]
и /W2, требуется не более Л/,-г-Л/2 состояний.
28. Конечный автомат называется сильно связным тогда и только тогда, когда
для любых двух его состоянии s, и s2 существует входная цепочка, которая
переводит автомат из s, в s2. Покажите, что для автомата с N состояниями эту
цепочку всегда можно выбрать такой, что ее длина не превышает N—1.
29. Входная цепочка называется отладочной для некоторого конечного
автомата, если она вызывает каждый переход этого автомата хотя бы один раз.
Покажите, что для сильно связного (см. упр. 28) автомата с N состояниями и
/ входными символами длина отладочной цепочки может не превышать
/V2/.
30. Покажите, что конечный автомат не может распознавать все цепочки вида
1"0"
(т. е. после некоторого числа единиц следует такое же число нулей). Эти
цепочки аналогичны левым и правым скобкам в выражениях. Указание:
Предположите, что автомат имеет всего г состояний. Заметьте, что если п>г, то
при чтении подцепочки из единиц автомат по крайней мере дважды переходит
в одно и то же состояние.
31. а) Приведите такой пример эквивалентных автоматов М и /V, чтобы некоторое
состояние автомата М было эквивалентно более чем одному состоянию
автомата /V.
б) Приведите такой пример эквивалентных автоматов М и /V, чтобы для
некоторого состояния автомата М в /V не было эквивалентных ему состояний.
32. Как проверить на эквивалентность два состояния недетерминированного
автомата?
33. а) Постройте конечный автомат, который распознает химические формулы,
составленные из восьми элементов: Н, С, N, О, SI, S, CL и SN. Элементы
в формулах разделяются запятыми. Они могут появляться в любом порядке
и в любых сочетаниях. Формулы не обязательно представляют реально
2
Гл. 2. Конечные автоматы
существующие соединения. Вот несколько образцов формул:
Н2, О
О, Н7
SN, S, СМ
CL
N, Н4, С7, Н5, 02
02
Имеется девять входных символов:
С Н I L N О S, ц
где ц — обозначение цифры,
б) Постройте конечный процессор, вычисляющий молекулярный ве
нения, представленного входной цепочкой.
3
Реализация конечных автоматов
3.1. Введение
В предыдущей главе мы обсуждали конечные автоматы с чисто
теоретической точки зрения, лишь слегка касаясь их предполагаемого
применения в качестве одного из основных составных блоков
компилятора. В этой главе мы рассмотрим некоторые проблемы,
связанные с реализацией конечного автомата или процессора как
программы или подпрограммы для вычислительной машины. Этот
материал относится также к реализации более общих моделей
автоматов, обсуждаемых в последующих главах, так как конечный автомат
используется в этих моделях как центральное управляющее
устройство.
На протяжении этой главы рассматриваются три
взаимосвязанных вопроса:
1) как представлять входы, состояния и переходы конечного
автомата, чтобы удовлетворить зачастую противоречивые
требования, предъявляемые к реализации: быстродействие и
небольшие затраты памяти,
2) как справиться с некоторыми специфическими проблемами,
постоянно возникающими при компиляции,
3) как расчленить задачу построения компилятора, чтобы
получить автоматы, допускающие простую реализацию.
Некоторые задачи, решаемые с помощью конечных автоматов,
заключаются всего лишь в распознавании конечного множества слов.
Суть этих проблем в том, что компилятор должен обнаружить
появление некоторого слова из такого множества и затем действовать
в зависимости от того, какое это слово. Операторы MINI-BASIC'a,
например, могут начинаться с одного из девяти слов (LET, IF,
GOTO и т. д.), и для компилятора важно установить, с какого из
них (если оно есть) начинается строка, и предпринять действия,
соответствующие данному типу оператора. Задачу такого характера
мы называем проблемой «идентификации», так как действия компи-
74
Гл. 3. Реализация конечных автоматов
лятора зависят от идентичности некоторому известному слову
данного слова, включенного в входную цепочку автомата. Так как для
решения задач идентификации может потребоваться огромное число
состояний, в подобных случаях часто приходится пользоваться
специальными методами реализации. По этой причине нередко
рекомендуется строить компилятор так, чтобы проблема идентификации
решалась отдельным подпроцессором, специально предназначенным
для этого.
Существуют проблемы идентификации, которые, строго говоря,
не могут быть решены с помощью конечного автомата. Обратимся
к часто встречающейся проблеме распознавания переменных или
идентификаторов некоторого языка и соотнесения их с
соответствующими элементами таблицы имен. Решение этой проблемы обычным
методом с помощью конечного автомата потребует нескольких
состояний и элемента таблицы имен для каждого допустимого
идентификатора. Однако множество допустимых идентификаторов в
большинстве языков бесконечно или так велико, что его вполне можно
считать бесконечным. В Алголе, например, где идентификатор может
состоять из произвольного числа символов, множество допустимых
идентификаторов бесконечно, тогда как в Фортране, где длина
идентификатора не больше шести, число допустимых идентификаторов
конгчно, но астрономически велико, так что на практике считается
бесконечным. (В противоположность этому идентификаторы MINI-
BASIC'a могут состоять не более чем из двух символов, поэтому
число допустимых идентификаторов конечно и поддается
обработке.)
Понятно, что для языков, где число допустимых
идентификаторов бесконечно или практически бесконечно, невозможно отвести
место в памяти или элемент таблицы имен для каждого возможного
идентификатора. Это затруднение преодолевается с помощью
понятия расширяющегося конечного автомата. При считывании своей
входной цепочки этот автомат отводит для идентификатора
необходимое место в памяти и элемент в таблице, как только тот впервые
встречается в программе. Если этот идентификатор встречается в
программе снова, то, чтобы идентифицировать его, автомат
использует технику идентификации слов с помощью конечного автомата.
Когда появляется какой-то новый идентификатор, автомат снова
расширяется и так далее. Хотя этот автомат не является, строго
говоря, конечным, к нему применимы многие принципы построения
и анализа конечных автоматов.
Большинство методов идентификации потенциально полезны при
идентификации как фиксированных множеств, для которых память
отводится заранее, так и расширяющихся множеств. Поэтому при
обсуждении этих специальных методов идентификации, помимо
обычных требований, предъявляемых к времени и объему памяти,
мы должны учитывать относительную легкость расширения.
3.2. Представление входных символов
75
3.2. Представление входных символов
Чтобы смоделировать конечный автомат, мы должны каким-нибудь
подходящим способом закодировать его входное множество.
Наиболее гибкое решение состоит в представлении входного
множества с помощью набора последовательных целых чисел, начиная с О
или 1. Это кодирование хорошо работает во всех рассматриваемых
Входное
множество
Конечный
Транслитератор автомат
а
Символ
a
z
0
9
+
и т.д.
Перевод
(БУКВА,а)
(БУКВА,z)
(ЦИФРА.О)
(ЦИФРА, 9)
(ОПЕРАЦИЯ, +)
И Т.д.
Типичная таблица тоанслитеэсции
6
Рис. 3.1.
далее способах реализации переходов автомата. Однако некоторые
из этих способов работают также и при произвольном кодировании
входного множества.
Если входом конечного автомата является выход какого-то
другого блока компилятора, то обычно нетрудно построить этот блок
так, чтобы он подавал на вход конечного автомата цепочки в
наиболее удобном для него виде. Единственное место при построении
компилятора, где может возникнуть проблема кодировки,— это
процедура чтения символов исходной программы. В оставшейся части
данного раздела мы займемся этим вопросом.
76
Гл. 3. Реализация конечных автоматов
Если бы множество символов исходной программы
непосредственно служило входом для некоторого конечного процессора,
содержащего много состояний, то автомат имел бы большую таблицу
переходов, так как одни только цифры и латинские буквы образуют
множество из 36 символов, обычно же множество символов в не-
сколько'раз больше. Удобный способ уменьшения размера таблицы
переходов заключается в обработке исходных символов двумя
последовательно соединенными автоматами: первый автомат — это
транслитератор, единственная задача которого — сократить
входное множество до приемлемых размеров; второй автомат выполняет
остальную часть работы. Этот вид взаимодействия показан на
рис. 3.1, а.
Зависимость между входом и выходом транслитератора можно
выразить с помощью таблицы, например, такой, как на рис. 3.1, б,
которая содержит перевод каждого символа исходного языка.
Выход этого транслитератора будем называть символьной лексемой.
Такая лексема обычно состоит из двух частей: класса и значения.
Так, буква а будет иметь класс БУКВА и значение а, тогда как знак
операции + имеет класс ОПЕРАЦИЯ и значение +. Класс лексемы
должен служить входом для второго автомата, а ее значение
доступно процедурам переходов этого автомата. Потребность в такой пред-'
варительной обработке упоминалась в гл. 2.
(Вспомним, например, обработку констант).
Транлитератор — это просто процессор с одним состоянием, хотя
вряд ли имеет смысл рассматривать его именно в этом качестве.
Разумеется, он реализуется как процедура, которая находит в
таблице перевод для каждого входного символа. На многих машинах
это можно сделать одной или двумя командами. Множество классов
символьных лексем обычно представляется с помощью
последовательных натуральных чисел, так как они являются возможными
входными символами для второго автомата.
3.3. Представление состояний
Есть два основных способа, с помощью которых программа,
моделирующая конечный автомат, может запоминать состояние
моделируемого автомата. Первый заключается в запоминании номера,
соответствующего текущему состоянию, в некотором регистре или
ячейке памяти вычислительной машины. Этот способ мы называем явным,
так как состояние явно задается некоторой переменной. Второй
основной метод заключается в том, что для каждого состояния имеется
отдельная часть программы. Поэтому тот факт, что моделируемый
автомат находится в заданном состоянии, «запоминается» тем, что
моделирующая программа исполняет часть кода, которая
«принадлежит» этому состоянию. Такой метод называется неявным.
3.4. Выбор переходов
77
Явный или неявный метод выбирается исходя просто из удобства
программирования. Важно отметить, что слово «состояние» не
подразумевает никакой особой техники реализации.
3.4. Выбор переходов
Суть программы, моделирующей конечный процессор, состоит в
способе выбора переходов, так как для заданного состояния и
очередного входного символа программа должна выполнить переход, ука-
12 3 4 5 6 7-1
А
В
С
А)
С2
СЗ
S3
АЛ
въ
-46
S6
С\
Адрес
М
кдрес
процедуры
обработки
ошибки
кдрес
процедуры
обработки
ошибки
кдрес
ВЗ
кдрес
процедуры
обработки
ошибки
кдрес
А6
Адрес
процедуры
обработки
ошибки
кдрес
процедуры
обработки
ошибки
Входной
символ Переход
1
6
4
А\
А6
S3
Переход по неудаче = Процедура обработки ошибки
В
Рис. 3.2. (а) Построение процессора, (б) вектор переходов, (в) список переходов.
занный в таблице переходов. Поэтому информация, содержащаяся
в таблице переходов, должна где-то храниться, или же ее надо
включить в моделирующую программу.
Предположим пока, что состояние запоминается неявно. В этом
случае косвенно известна нужная строка таблицы переходов, и
задача сводится к нахождению перехода только по входному символу.
78
Гл. 3. Реализация конечных автоматов
Зта задача должна, разумеется, решаться для каждого состояния в
отдельности.
Рассмотрим два метода решения задачи выбора перехода для
заданного входного символа. Мы называем их методом «вектора
переходов» н методом «списка переходов».
Согласно методу вектора переходов, адреса или метки тех
процедур переходов, на которые должно передаваться управление,
хранятся в виде вектора в последовательных ячейках памяти, по
одной ячейке для каждого входного символа. Очередной входной
символ служит индексом, по которому выбирается элемент вектора,
дающий нужный переход. Чтобы этот метод работал, входное
множество должно быть представлено каким-нибудь подходящим образом,
например в виде множества последовательных целых чисел. Пример
такого вектора приведен на рис. 3.2, б, где изображен вектор
переходов для состояния А на рис. 3.2, а. Достоинство метода в том, что
нужную процедуру перехода можно выбрать очень быстро. Затраты
памяти — по ячейке на каждый элемент строки. В большинстве
языков программирования высокого уровня этот метод можно
реализовать, используя переключатель или вычисляемый переход.
Согласно методу списка переходов, входные символы делятся на
два класса: каждому входному символу первого класса
приписывается индивидуальный переход, а все символы второго класса
имеют общий переход (обычно процедуру, обрабатывающую ошибку).
Для первого класса соответствие между входным символом и
адресом процедуры перехода задается в виде списка упорядоченных пар.
Общий переход для символов из второго класса запоминается
отдельно и называется переходом по неудаче.
При поступлении нового входного символа происходит поиск в
списке этого символа и соответствующего ему перехода. Если поиск
заканчивается неудачей, делается переход на процедуру,
соответствующую неудаче. Этот метод можно применять, даже если входной
символ не является индексом.
На рис. 3.2, в показан список переходов для состояния А
процессора, изображенного на рис. 3.2, а. Переход по неудаче вызывают
входные индексы 2, 3, 5, 7 и концевой маркер, тем самым пять
элементов таблицы объединяются в один переход.
Среднее время, необходимое для выбора перехода методом
списка переходов, зависит от длины списка и относительной частоты, с
которой входные символы встречаются в исходной программе.
Естественно, более выгодно помещать пары, содержащие наиболее
часто встречающиеся входные символы, в начале списка. Тем не
менее этот метод всегда работает медленнее, чем метод вектора
переходов, а при увеличении длины списка становится еще медленнее.
Метод списка требует совсем незначительных затрат памяти, когда
список короткий, однако при длинном списке затраты памяти для
этого метода больше, чем для метода вектора, так как память отво-
3.5. Идентификация слов: метод автомата
79
дится и для метки процедуры перехода, и для символа,
вызывающего этот переход. Таким образом, этим методом лучше всего
пользоваться, когда память дорога, а таблица переходов содержит много
стандартных переходов, связанных с ошибкой.
Разумеется, при моделировании автомата можно пользоваться
смешанным методом. В примере на рис. 3.2, а при выборе переходов
из состояния В был бы предпочтителен метод вектора переходов,
тогда как для состояния С метод списка переходов сэкономил бы
много места.
Если состояние моделируемого автомата хранится в явном виде,
то в этом случае принципы указанных методов векторов и списков
по-прежнему применимы, но возможны многочисленные варианты.
Одна из возможностей состоит в том, чтобы пользоваться состоянием
как индексом для передачи управления одной из уже описанных
процедур. Другая заключается в том, чтобы хранить таблицу
переходов как единый двумерный массив, индексы которого — это
состояния и входные символы. Можно также использовать метод
списка для выбора элементов из столбцов, а не из строк таблицы
переходов. Мы не будем говорить о преимуществах того или иного
метода, разработчику рекомендуется самому выбирать метод в
соответствии со своей конкретной задачей и особенностями
вычислительной машины.
3.5. Идентификация слов: метод автомата
Это первый из шести разделов, в которых пойдет речь об
идентификации. Мы начнем с проблемы идентификации слов. Предположим,
что заданы конечное множество слов в некотором входном алфавите
и некоторое входное слово и нужно установить, какой элемент
заданного множества (если такой существует) совпадает с входным
словом. В данном разделе мы решаем эту проблему путем построения
конечного процессора, который по предъявленному входному слову
с концевым маркером устанавливает его идентичность некоторому
элементу множества. В последующих разделах рассматриваются
другие методы.
Наиболее широкое применение автомат, идентифицирующий
слова, находит в лексическом блоке компиляторов. Один из способов
использования такого автомата в гипотетическом лексическом блоке
показан на рис. 3.3. Управляющая программа знает, что некоторая
цепочка букв, появившаяся в некотором месте программы, должна
быть словом, и подает эти буквы по одной на вход автомата,
идентифицирующего слова, для анализа. Когда управляющий автомат
обнаруживает, что слово кончилось, он посылает на вход
идентифицирующего автомата концевой маркер. Предположим, что буквы уже
80
Гл. 3. Реализация конечных автоматов
§■
6
о
8-
1
Й-
Упрадляющий
автомат
>
•
1
Идентифицирующий
автомат
Рис. 3.3. Возможная организация
лексического блока.
переведены транслитератором в символьные лексемы типа БУКВА
с соответствующими значениями. Под действием входного символа
БУКВА управляющий автомат подает значение этой буквы на вход
идентифицирующего автомата и сам совершает определенный
переход.
Если идентифицирующий автомат использовать таким образом,
то язык должен быть таким, чтобы управляющий автомат узнавал,
какие входные символы, следуя друг за другом, образуют слово.
Некоторые проблемы идентификации не так просты, как эта.
В разд. 3.10 мы обсудим
применение техники
идентификации слов к
некоторым задачам, решение
которых менее очевидно.
Автомат,
идентифицирующий некоторое
множество слов, можно построить
путем введения в него
состояния для каждой
подцепочки, которая может быть
префиксом какого-либо
слова из этого множества.
Множество префиксов
включает в себя пустую
цепочку, которая служит
префиксом любого слова, а также сами заданные слова, так как
каждое слово является своим префиксом. Так как эту процедуру
легче проделать, чем описать ее словами, продемонстрируем ее на
следующем примере.
Рассмотрим задачу построения конечного процессора, имеющего
входной алфавит {О, Б, С, К, А} плюс концевой маркер и
предназначенного для идентификации множества {ОСА, БОК, БОКА, БАК}.
Процессор для этого множества изображен на рис. 3.4. Имена
состояний автомата соответствуют цепочкам входных символов,
просмотренных к этому моменту. Так, начальное состояние названо
е, что соответствует пустой цепочке, которая считается
просмотренной до того, как используется первый входной символ, а цепочка
БО переведет автомат в состояние БО. Такие элементы таблицы, как
«ОСА», означают, что автомат идентифицировал соответствующее
слово. Пустые ячейки указывают выходы, означающие, что
встретилась ошибка, при этом печатается что-нибудь вроде ВХОДНОЕ
СЛОВО НЕ ПРИНАДЛЕЖИТ МНОЖЕСТВУ. Автомат может
также переходить в состояние ошибки, которое откладывает сообщение
об ошибке до тех пор, пока ошибочное слово не будет просмотрено
полностью. При этом переходы не сопровождаются никакими
действиями, кроме изменения состояния.
3.5. Идентификация слов: метод автомата
81
Так как эта конкретная проблема идентификации слов
включает всего пять букв и десять состояний, процессор можно легко
реализовать, пользуясь либо методом вектора переходов, либо методом
списка переходов. Однако на практике часто возникают проблемы
идентификации слов гораздо большего объема. Входное множество,
к примеру, обычно включает все буквы латинского алфавита или все
буквы и цифры. Число идентифицируемых слов также может быть
Рис. 3.4.
большим. Поэтому таблица переходов содержит тысячи элементов,
и от реализации с помощью метода вектора переходов приходится
отказаться из-за недостатка места.
Обратившись к методу списка переходов, мы замечаем, что
подавляющее большинство элементов таблицы являются переходами
в состояние ошибки. Это характерно для большинства задач
идентификации слов, встречающихся на практике, и объясняется тем
фактом, что каждое состояние представляет собой префикс слова и
поэтому может быть достигнуто только одним путем. Состояние
БОК, например, может быть достигнуто только из состояния БО
и только для входного символа К. Число переходов из некоторого
состояния равно или меньше числа слов множества, имеющих
префикс, соответствующий этому состоянию. Так, есть два перехода из
состояния БОК, один — в состояние БОКА, а другой — в состоя-
82
Гл. 3. Реализация конечных автоматов
ние «БОК», тогда как из состояния
БО — только один переход, в
состояние БОК, хотя имеется два слова с
префиксом БО. Таким образом, метод
списка переходов можно эффективно
применять для решения довольно
больших задач идентификации слов
независимо от объема входного
алфавита.
Так как рассматриваемые
процедуры переходов просты, автомат
можно реализовать еще проще, чем
предлагалось ранее при обсуждении
метода списка переходов. В случаях,
подобных нашему, где переходы — это
не процедуры переходов, а просто
изменения состояния, удобно
представлять состояние в виде указателя
на его список переходов. Так как
здесь нет процедур переходов, то нет
и необходимости снабжать каждый
переход меткой процедуры перехода.
Вместо этого, используя списки
переходов, свяжем с каждым неошибочным
входным символом указатель на
список переходов для следующего
состояния. Переход состоит в простой
замене указателя списка переходов для
текущего состояния на полученный
по таблице указатель списка
переходов для следующего состояния.
Элементы списков переходов,
соответствующие концевому маркеру,
должны содержать индекс или указатель
таблицы имен, который указывает,
какое слово найдено.
Применяя эту технику к нашему
примеру, мы получаем списочную
структуру, изображенную на рис. 3.5.
Начальное состояние представляет
собой указатель на список 1. Процессор
считывает очередной входной символ
и просматривает список для текущего
состояния, пока не найдет этот входной символ или не натолкнется
на символ ОШИБКА. Например, если первый символ — С,
процессор сначала сравнивает его с символами О и Б из списка 1. Затем
о
ь
©
©
ОШИБКА
С
©
"0ШИ.БКА
О
А
©
©
ОШИБКА
А
©
ОШИБКА
К
©
ОШИБКА
К
©
ОШИБКА
—1
ОШ
А
-4
ОСА
ИБКА
©
БОК
ОШИБКА
—i
БАК
ОШИБКА
н
БОКА
ОШИБКА
Рис. 3.5.
3.5. Идентификация слов: метод автомата
83
он встречает символ ОШИБКА и выполняет процедуру по обработке
ошибки. Если же первый символ — Б, то процессор идентифицирует
его с символом Б из списка I и устанавливает указатель состояния
на список 3 (соответствующий состоянию Б). Затем, если
следующий входной символ — А, процессор устанавливает указатель
состояния на список 6 (список для состояния БА). В случае если
следующий входной символ — К, указатель состояния
устанавливается на список 9 (список для состояния БАК). Наконец, если
очередной входной символ — концевой маркер, процессор идентифицирует
его с концевым маркером из списка 9, а затем находит указатель
таблицы имен или какой-нибудь другой указатель на слово «БАК»
в соответствующей таблице. Заметим, что в этой списочной
структуре имеется по одному элементу для каждого перехода, отличного
от перехода в состояние ошибки, и по одному переходу на ошибку
для каждого состояния, из которого есть хотя бы один переход в
состояние ошибки.
Предположим теперь, что мы хотим расширить таблицу на
рис. 3.5 так, чтобы соответствующий ей автомат распознавал также
слово ОКО. Пришлось бы добавить еще два списка переходов —
для состояния ОК и для состояния ОКО. Кроме того, список 2
увеличился бы за счет внесения в него перехода из состояния О в
состояние ОК. Такое расширение легко произвести при построении, но
очень трудно — во время компиляции. Поэтому такой способ
реализации применим лишь к распознаванию фиксированного
множества слов и не может быть эффективно использован для
распознавания расширяющегося множества. Имеется, однако, разновидность
реализации метода списков, которая идеально подходит для таких
расширений во время компиляции.
Чтобы реализовать расширяющиеся списки, заметим, что
каждому символу в прежних списках на самом деле соответствуют два
списка. Один из них — это список переходов, который
используется, если этот символ совпадает с входным символом, а другой —
список дополнительных символов, которые надо проверять, если
входной символ не совпал с рассматриваемым символом таблицы.
Адрес первого списка задается соответствующим указателем, а
второй список считается начинающимся со следующей ячейки. Чтобы
добиться расширяемости, нужно поменять эти соглашения. Будем
считать, что список переходов для следующего состояния
начинается в следующей ячейке, а начало списка дополнительных
символов, которые надо проверять, будет запоминаться указателем.
Набор новых списков для нашего примера показан на рис. 3.6, а.
В этой новой реализации каждому символу соответствует либо
указатель на следующую проверку, либо пустой элемент. Этот
пустой элемент указывает, что больше нет символов, с которыми нужно
производить сравнение, и что произошла ошибка. Например, если
первый символ С, то процессор сравнивает С с О в списке 1. Так как
Гл. 3. Реализация конечных автоматов
С не совпадает с О и символу О соответствует указатель на список 2,
процессор затем сравнивает С с Б из списка 2. Символы опять не
совпадают, но на сей раз символу таблицы соответствует пустой
©
©
©
©
0
с
А
н
Б
0
К
н
А
н
А
К
н
©
'ОСА"
©
©
'БОК"
"БОКА "
"БАК"
©
©
©
©
0
с
А
н
Б
Q
К
н
А
н
А
К
н
К
0
н
©
©
"ОСА"
©
©
"£0K "
"БОКА "
"ВАК"
"ОКО"
Рис. 3.6.
элемент. Процессор заключает, что нет слова, начинающегося с С,
и выполняет процедуру обработки ошибки. В отличие от рис. 3.5
концевому маркеру также может соответствовать указатель списка
(как, например, в списке 2) или пустой элемент (как, например,
в списке 1). Когда обнаруживается совпадение с концевым
маркером, то входное слово идентифицируется со следующим словом спи-
3.6. Идентификация слов: метод индексов
85
ска. Заметим, что эта списочная структура содержит по одному
элементу для каждого перехода, отличного от перехода в состояние
ошибки, и по одному элементу для каждого слова из
распознаваемого множества.
Теперь посмотрим, что происходит, когда мы хотим расширить
наш автомат, чтобы он мог обрабатывать слово ОКО. Это значит,
что после входного символа О допускается не только символ С, но и
символ К- Для запоминания того, что должно следовать после К,
добавляется новый список, а символ пробела, соответствующий в
исходной структуре символу С, заменяется на указатель этого
списка. Результат показан на рис. 3.6, б. Заметим, что для того, чтобы
расширить список, дополнительную память можно добавить к
концу уже использованной области памяти, т. е. это изменение не
повлечет за собой перестройку всей исходной структуры. Поэтому
такая реализация допускает расширение во время компиляции.
3.6. Идентификация слов: метод индексов
В предыдущем разделе мы обсуждали решение проблемы
идентификации слов с помощью конечного автомата. Теперь мы рассмотрим
ряд методов решения этой проблемы без моделирования автомата.
Все эти методы основаны на том, что распознаваемое множество слов
хранится в виде некоторого списка или таблицы, а затем, когда на
вход поступает какое-то слово, выясняется, есть ли данное слово
в списке. В этом разделе мы рассмотрим возможность вычисления
по входной цепочке индекса, который обеспечивает прямой доступ
к таблице.
В качестве примера рассмотрим проблему идентификации
переменных языка MINI-BASIC. В данном случае переменная — это
либо одна английская буква, либо буква, за которой следует цифра.
Всего имеется точно 286 допустимых в MINI-BASIC'e
переменных. Так как это число невелико, можно позволить себе завести по
одному элементу таблицы для каждой допустимой переменной.
Тогда проблема идентификации переменных сводится к
преобразованию переменной в индекс, который указывает ее место в таблице.
Один из способов заключается в присваивании индексу значения
от 1 до 26 для каждой входной буквы английского алфавита. Далее,
если следующий входной символ — произвольная цифра d, то к
индексу прибавляется число 26*(d+l). Это значит, например, что
переменная Z получит номер 26, переменная АО — номер 27, а
Z9 — номер 286.
Предположим в общем случае, что распознаватель может иметь
дело лишь с конечным числом допустимых входных слов.
Предположим также, что нам хочется выделить память для каждого
допустимого слова. И наконец, предположим, что для каждого
86
Гл. 3. Реализация конечных автоматов
из допустимых слов мы можем быстро вычислять однозначно
соответствующее ему число, скажем от 1 до М. Это число называется
индексом слова. Тогда таблицу можно хранить в последовательных
ячейках памяти так, чтобы /-и элемент таблицы отводился для
слова» с индексом /. Такую таблицу называют иногда
индексированной таблицей, она аналогична одномерному массиву, причем
индекс слова служит индексом компоненты массива. Обработка
входного слова состоит в вычислении его индекса и нахождении
элемента таблицы, соответствующего этому индексу.
Этот индексный метод можно применять, если выполнены три
условия. Во-первых, число слов не должно быть слишком большим.
Это условие исключает, например, множество переменных
Фортрана, так как последнее содержит более миллиарда элементов. Во-
вторых, индекс должен легко вычисляться. Это условие может
исключить даже небольшие множества зарезервированных слов, для
которых нет хорошего способа построения индекса. В-третьих,
объем множества слов фиксируется при построении, так как метод
вычисления индекса неудобно изменять во время компиляции. Если
учесть эти три условия, становится очевидным, что
рассматриваемым методом можно воспользоваться нечасто. Однако, когда он
применим, идентификация осуществляется с минимальными
затратами времени.
Если цель идентификации — связать слово с элементом таблицы
имен, то соответствия между индексами и элементами таблицы имен
можно достичь по крайней мере двумя способами:
1. Индекс можно использовать для непосредственного доступа
к таблице имен. В этом случае слово с индексом i
соответствует i-му элементу таблицы имен.
2. Индекс может указывать на таблицу указателей, содержащую
указатели на таблицу имен. Чтобы найти элемент таблицы
имен для слова с индексом i, нужно взять указатель из 1-го
элемента таблицы указателей.
Второй метод позволяет заводить элементы таблицы имен только
для тех слов, которые действительно имеются в данной программе.
Чтобы достичь этого, таблицу указателей инициализируют нулями,
которые означают, что ни один элемент в таблице имен еще не
отведен. Когда слово встречается впервые, об этом свидетельствует
нуль в соответствующей ячейке таблицы указателей. Для этого
слова заводится элемент таблицы имен, а указатель на него
помещается в таблицу указателей.
Исходя из обычно правдоподобных предположений о том, что
элементы таблицы имен занимают больше места, чем элементы
таблицы указателей, а слова, используемые в конкретной
компилируемой программе, составляют лишь небольшую часть всех
допустимых слов, можно заключить, что второй метод требует меньше
3.7. Идентификация слов: метод линейного списка
87
памяти. С другой стороны, он может увеличить время доступа к
таблице имен. Этот метод позволяет также заводить элементы таблиц
переменного размера.
3.7. Идентификация слов: метод линейного списка
Вероятно, наиболее прямой метод идентификации слов заключается
в том, чтобы, построив копию входного слова, сравнивать ее с
каждым элементом хранимого в памяти списка до тех пор, пока не
произойдет совпадение (если оно возможно). Этот метод легко
приспособить к случаю расширяющихся множеств, так как все, что нужно
сделать в подобных случаях,— это добавить в список еще одно
слово. Требование, предъявляемое к памяти, состоит только в том,
чтобы хватило места для размещения списка слов. У этого метода есть
лишь один недостаток: поиск по длинному списку занимает много
времени. Предполагая, что слова из списка появляются с примерно
одинаковыми вероятностями, можно ожидать, что для обнаружения
заданного слова потребуется просмотреть в среднем половину
списка. Точнее, если имеется М слов, то ожидаемое число
сопоставлений, необходимых для нахождения одного случайно выбранного
слова, равно (УИ + 1)/2.
Есть два основных способа хранения списков слов —
последовательное хранение и связанное хранение. В первом случае, чтобы
найти следующий элемент списка, нужно перейти к следующей ячейке
памяти. Свободное место для расширения резервируется в конце
списка. Во втором случае, согласно методу связанного списка,
каждое слово снабжается указателем на следующее слово. Для
расширения списка отводится некоторая свободная область, но она не
обязана физически располагаться в конце имеющегося списка. Одна
и та же свободная область может одновременно обслуживать
несколько связанных списков.
3.8. Идентификация слов: метод
упорядоченного списка
Время поиска по длинному списку значительно уменьшается, если
элементы списка упорядочены — например, лексикографически,
т. е. по алфавиту. Пусть у нас имеется список из М слов,
расположенных в алфавитном порядке и хранящихся в последовательных
ячейках памяти, и пусть мы хотим по некоторому входному слову
найти ячейку списка (если таковая существует), в которой
содержится это слово. Согласно методу, описанному в предыдущем разделе„
для нахождения слова потребуется в среднем (М + \)/2 сравнений,
а для слова, которого нет в списке,— М сравнений. Воспользовав-
88
Гл. 3. Реализация конечных автоматов
шись упорядоченностью списка, мы можем уменьшить число
сравнений примерно до log M. Это делается следующим образом:
1. Поиск начинается сравнением входного слова со словом,
расположенным в середине списка. Если число слов списка четно, то
сравнение делается с любым из двух элементов списка,
расположенных посредине. Если входное слово и элемент списка совпадают,
поиск окончен. В противном случае вследствие упорядоченности
списка сравнение показывает, где следует искать входное слово —
до или после середины списка.
2. Если, согласно заданному порядку, входное слово
предшествует середине списка, то имеются две возможности. Если среднее
слово является также и первым словом, что может случиться в
списках длины 1 или 2, то мы заключаем, что входного слова в списке
нет. Если среднее слово не первое в списке, то поиск должен
продолжаться в новом списке, а именно в списке, начинающемся с
первого слова и кончающемся словом, расположенным непосредственно
перед серединой исходного списка. Длина этого нового списка не
превышает половины длины исходного списка, таким образом,
сделав всего одно сравнение, мы сократили задачу вдвое. Теперь мы
снова применяем шаг 1, осуществляя поиск в этом новом списке.
3. Если, согласно данному порядку, входное слово расположено
после середины, то список слов, стоящих после середины,
подвергается такому же анализу, что и на шаге 2. К этому подсписку снова
применяется шаг 1.
В качестве примера на рис. 3.7 показан поиск слова STEP в
списке из 18 идентификаторов, который успешно завершается на пятом
сравнении. Так как в списке 18 элементов, серединой можно
считать девятое или десятое слово. Мы произвольно выбираем девятое
слово INTEGER и сравниваем его с входным словом. Поскольку
входное слово «больше» среднего слова в смысле алфавитного
порядка, мы переходим к анализу нового списка — с девятого по
восемнадцатое слово. Теперь мы сравниваем входное слово со словом
STRING, серединой нового списка. Так как входное слово «меньше»,
мы переходим к новому списку, состоящему из слов с десятого по
тринадцатое. Таким образом, каждое последующее сравнение
уменьшает список в два раза, и поиск продолжается до тех пор, пока после
пятого сравнения не обнаруживается слово STEP.
Если вместо этого входного слова взять слово STOP, процедура
будет работать таким же образом с той лишь разницей, что, когда мы
переходим к последнему списку длины I (состоящему из слова
STEP), входное слово оказывается «больше» среднего слова этого
списка. Так как среднее слово является также и последним, нового
списка не будет. Отсюда мы заключаем, что этого входного слова нет
в исходном списке.
3.8. Идентификация слов: метод упорядоченного списка 89
Разумеется, некоторые слова могут быть найдены в списке менее
чем за пять сравнений. Слово INTEGER, например, будет найдено
при первом же сравнении.
Вообще на шаге 1 либо обнаруживается совпадение, либо
список, в котором надо продолжать поиск, сокращается вдвое. Пусть
Весь список
Первое
сровнение
Третье сравнение
Четвертое сравнение
Пятое сравнение
Второе сравнение
>-
У.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
IS.
16.
17.
18.
ARRAY
BEGIN
BOOLEAN
DO
ELSE
END
FOR
GOTO
INTEGER
OWN
PROCEDURE
REAL
STEP
STRING
THEN
UNTIL
VALUE
WHILE
Рис. З.7.
исходный список состоит из М слов, тогда можно уменьшать его
вдвое не более чем \og2M раз, при этом получится список, состоящий
из одного элемента. Понятно, что к этому моменту либо слово будет
найдено, либо выяснится, что его нет в списке.
Точная граница числа сравнений равна
1 + наибольшее целое число, которое меньше или равно log2^W.
Эту процедуру называют методом логарифмического поиска. Ее
часто называют также методом бинарного поиска.
При реализации этой процедуры требуются некоторые действия
для вычисления середины списка. Поэтому на каждом шаге уходит
несколько больше времени, чем в случае непосредственного доступа
к списку. Однако благодаря тому, что вместо М или М/2 шагов надо
выполнить лишь \ogzM шагов, логарифмический метод работает
быстрее даже при не очень большом М.
Основной недостаток логарифмической процедуры состоит в том,
что неудобно расширять список. Дело в том, что новые слова нужно
90
Гл. 3. Реализация конечных автоматов
не просто добавлять к концу списка, а вставлять их туда, где они
обязаны находиться в соответствии с выбранным порядком.
Эту процедуру легко применить к связным спискам, если
снабдить каждое слово двумя указателями. Один из них указывает на
середину списка слов, которые идут после данного слова, а другой —
на середину списка слов, которые предшествуют ему. Такое пред-
DO
/
ч
BEGIN
Ч
ARRAY
BOOLEAN
END
Ч
ELSE
INTEGER
FOR
GOTO
STRING
4
PROCEDURE
4
OWN
REAL
STEP
UNTIL
4
THEN
VALUE
WHILE
Рис З.8.
ставление списка рис. 3.7 показано на рис. 3.8. Заметим, что этот
список размещается в памяти в виде дерева. При поиске слова
FOR оно сравнивается со словами INTEGER, DO, END и FOR
именно в этом порядке.
Разместив список в памяти в виде дерева, можно добавлять
к нему слова, не нарушая этого размещения. Слово ASK, например*-
присоединяется к ARRAY, а слово FOX, присоединяется к GOTO.
К сожалению, результирующее время поиска может превышать
логарифмическую границу. Для слова FOX, например, потребуется
6 сравнений. Если желательно расширить множество слов,
сохранив логарифмическое время поиска, нужно провести реорганизацию
всей структуры дерева, так как в середине помещаются другие ело-
3.9. Идентификация слов: метод расстановки
91
ва. Таким образом, такой метод использования связанных
упорядоченных списков допускает расширение только в некотором
ограниченном смысле.
3.9. Идентификация слов: метод расстановки
Идеальным методом решения проблем идентификации больших и
расширяющихся множеств слов был бы такой, который позволял
легко расширять множества, требовал умеренных затрат памяти и
гарантировал обнаружение заданного слова (в среднем) при
небольшом числе сравнений. Каждый из методов, описанных в трех
предыдущих разделах, не удовлетворяет хотя бы одному из этих
требований. Сейчас будет рассмотрен некоторый гибридный метод,
обладающий всеми указанными достоинствами. Из множества методов,
называемых методами расстановки (хеширования) или
перемешанных таблиц, мы рекомендуем именно этот.
Идентификация осуществляется за два шага следующим
образом:
1. По входному слову вычисляется индекс, как в разд. 3.6, где
описан индексный метод. Однако в данном случае многие слова
могут иметь один и тот же индекс. Этот индекс затем используется для
нахождения указателя списка в таблице указателей списков. Если
этот указатель равен нулю, т. е. указывает на нулевой список, то
входное слово не принадлежит множеству. В противном случае
применяется шаг 2.
2. Найденный элемент таблицы указателей списков указывает
на некоторый связанный список слов, а именно тех слов, индекс
которых совпадает с вычисленным индексом. Поиск в этом списке
происходит до тех пор, пока не произойдет совпадение входного слова
с элементом списка или будет достигнут конец списка. В последнем
случае множество не содержит входного слова, и это слово можно
добавить, просто связав его с последним элементом списка.
В литературе метод расстановки (хеширования) иногда
описывается в терминах «гроздей» (buckets). Говорят, что каждый индекс
указывает на некоторую гроздь, и все слова, имеющие этот индекс,
принадлежат одной грозди.
Для примера мы взяли слова из списка на рис. 3.7 и изобразили
возможную реализацию методом расстановки на рис. 3.9. Для того
чтобы вычислить индекс, в этом примере нужно сложить номера (в
алфавитном порядке) двух первых букв и взять остаток от деления
результата на 7. Например, индекс слова ARRAY получается
сложением \(=А) и 18 ( = Я) и последующим делением результата (19)
на 7, остаток равен 5. Это значит, что указатель списка,
содержащего слово ARRAY (если такой список существует), находится в
ячейке 5 таблицы указателей списков.
92
Гл. 3. Реализация конечных автоматов
Вообще реализация этой процедуры расстановки зависит от:
1) метода вычисления индекса,
2) объема таблицы указателей списков.
Таблица
указателей списка
FOR
GOTO
*■ INTEGER
* WHILE
¥ STEP
* DO
* PROCEDURE
BEGIN
VALUE
BOOLEAN
STRING
ARRAY
Рис. З.9.
THEN
REAL
ELSE
END
UNTIL
OWN
Поскольку эти факторы могут оказать существенное влияние
на скорость и затраты памяти процедуры (а фактически и всего
компилятора), мы остановимся на этих вопросах подробнее.
Единственная цель вычисления индекса — это уменьшение
длины списков, в которых должен производиться поиск. В идеале нам
3.9. Идентификация слов: метод расстановки
93
хотелось бы, чтобы списки были одинаковой длины. К сожалению,
разработчик должен выбрать метод вычисления индекса до того,
как он узнает, какие слова появятся в списке в ходе данной
компиляции. Поэтому единственное, на что можно рассчитывать,— это
что новые слова будут попадать в заданные списки с одинаковой
вероятностью, и выбор списков не зависит от каких бы то ни было
соглашений, использованных при написании исходной программы.
Перед разработчиком стоит задача найти метод выбора индекса,
удовлетворяющий этим свойствам псевдослучайности.
В качестве примера процедуры не такого уж случайного выбора
индекса посмотрим, что происходит, если при обработке
идентификаторов мы относим каждое слово к одному из 26 списков по первой
букве слова. Так как в английском языке гораздо больше слов,
которые начинаются с буквы R, чем слов, начинающихся с буквы О,
следует ожидать, что ^-список будет содержать гораздо больше
элементов, чем О-список. Такая неравномерность еще более усилится,
если программирующий на Фортране решит, что в его программе
все идентификаторы целых переменных будут начинаться'с буквы /.
Хотя с точки зрения разбиения по спискам этот метод получения
индекса не является идеальным, в некоторых приложениях им можно
пользоваться, так как индекс легко вычислять.
Метод индексации по двум буквам, примененный в примере на
рис. 3.9, лучше, чем метод индексации по одной букве, так как он
ведет к более равномерному заполнению списков. Однако
программист может употреблять имена с одинаковым началом (например,
ALPHA 1, ALPHA 2, ALPHA 3 и т. д.), что отрицательно влияет
на работу компилятора. Можно добиться более быстрого поиска,
если вычислять индекс по сумме всех букв. Однако затраты при
вычислении индекса могут перекрыть выигрыш во времени поиска.
Таким образом, нужно найти компромисс между временем поиска и
временем вычисления индекса.
На практике процедуры наиболее случайного выбора индекса
получают, интерпретируя двоичный код входного слова как одно
число или (для длинных слов) как ряд чисел, которые каким-нибудь
образом комбинируются (например, складываются), чтобы
получилось одно число. Затем это число каким-нибудь способом
уменьшают, чтобы получить индекс желаемого размера. Один из способов
состоит в использовании остатка от деления числа на некоторую
константу. Так как деление на небольшие числа может давать в какой-
то степени предсказуемые остатки (например, все они могут быть
четными), важно, чтобы делитель, с помощью которого
осуществляется рандомизация, не был кратным какому-нибудь маленькому
числу. Поэтому в качестве рандомизирующего делителя обычно
выбирают простое число. Другой метод получения индекса состоит в
возведении числа в квадрат и выделении средних двоичных
разрядов. Средние разряды используются для того, чтобы гарантировать
94
Гл. 3. Реализация конечных автоматов
участие в вычислении всех разрядов исходного числа. Методы
вычисления индекса, подобные указанным и обладающие свойствами
псевдослучайности, называются иногда методами функции
расстановки.
Теперь мы переходим к вопросу о том, насколько большой н\жно
делать таблицу указателей списков. Считая, что слова на самом деле
помещаются в списки некоторым случайным образом, можно изучить
вопрос об объеме таблицы чисто количественными методами. Пусть
в таблице указателей есть место для С указателей, и пусть
случайным образом введены М слов. Если входное слово случайно выбргп о
из М слов, то ожидаемое число сравнений, необходимых для
нахождения входного слова, равно
1+(УИ—1)/2С
(Чтобы установить, что некоторого нового слова в множестве нет,
нужно произвести М/С сравнений.) Если нам известно число слов,
с которыми придется иметь дело, эта формула говорит нам, как
^_-
*
бпш
to
е
с-
10
50
ЮО
200
500
ЮОО
20
1.95
1.19
1,10
1,05
1,02
1.01
Число
100
5,95
1,99
1,50
1.25
1.Ю
1.05
слов,
500
25,95
5,99
3,50
2,25
1,50
1,25
М
1000
50,95
10.99
5,60
3,50
2,00
1,50
5000
250,95
50,99
26,00
13,50
6,00
3,50
Рис. 3.10. Значения функции 1+(УИ—1)/2С.
именно число сравнений зависит от объема таблицы. На рис. 3.10
помещены результаты вычисления формулы для некоторых
значений М и С.
Пусть нас интересует эффективность обработки 500 разных слов,
и мы хотим узнать, сколько списков выгоднее завести: 500 или 100.
Преимуществом 100 списков является то, что экономится место,
необходимое для хранения еще 400 указателей, а недостатком — то,
что для идентификации слова необходимо (в среднем) большее число
сравнений. На рис. 3.10 можно видеть, что эта разница равна точно
2 сравнениям (т. е. 3.50 минус 1.50). Решение сводится к выбору
между 400 дополнительными указателями или 2 дополнительными
сравнениями, необходимыми для идентификации каждого слова.
Дополнительные сравнения должны, разумеется, оцениваться
временем, необходимым для их выполнения на вычислительной ма-
3.10. Обнаружение прификсов
95
шине, на которой будет реализован компилятор. Выигрыш во
времени будет иметь место при каждом поиске в ходе компиляции,
который осуществляется зачастую по нескольку раз для каждой
строки программы. Сэкономленное время вполне может составлять
значительную часть всего времени компиляции. Выигрыш будет,
конечно, меньше, когда число слов меньше 500, и больше для
большего множества слов. Поэтому рекомендуется проделывать
указанный анализ для нескольких разных чисел слов, чтобы посмотреть,
какой выигрыш во времени можно получить в разных случаях.
Вообще говоря, неизбежно напрашивается вывод, что на размере
таблицы экономить не нужно.
3.10. Обнаружение префиксов
Как отмечалось в разд. 3.5, процедуры идентификации слов удобно
применять вместе с управляющим автоматом, который знает, какие
символы могут принадлежать распознаваемому слову и когда это
слово заканчивается. Другими словами, их можно применять, когда
границы предполагаемого слова могут быть установлены
управляющим автоматом. Четкие границы слов имеются, например, в
естественных языках, где в каждом предложении слова отделяются друг
от друга пробелами или другими средствами пунктуации. Четкие
границы слов есть также во многих языках программирования, где
последовательности букв и цифр отделяются пробелами. Если слова
разграничены подобным образом, то идентифицирующий их под-
процессор играет в общем процессе ту же роль, что и словарь при
чтении текста на естественном языке.
Примером проблемы идентификации слов с нечеткими
границами является проблема идентификации зарезервированных слов
языка MINI-BASIC. Эта проблема возникает в связи с соглашением о
том, что пробелы в MINI-BASIC'e ничего не значат. Рассмотрим
оператор MINI-BASIC'a
10 FORK = STOP
Границы слов здесь можно установить, только зная множество
зарезервированных слов: по тому факту, например, что есть
зарезервированное слово FOR и нет зарезервированного слова FORK- На
самом деле эта же цепочка символов является правильным
оператором Фортрана, но с другими границами слов. Если бы пробелы были
средствами пунктуации, этот оператор был бы записан так:
10 FOR К = S ТО Р
Чтобы справиться с проблемами идентификации такого рода, мы
приступим теперь к изучению специфической задачи
идентификации, которую будем называть задачей обнаружения префиксов. Пусть
96
Гл. 3. Реализация конечных автоматов
€
д
л
до
ло
д
л
0
до
ло
л
л
"ДОЛ"
М -ч
"ДОМ"
"ЛОМ"
задано конечное множество слов в некотором входном алфавите, и
нам дают входную цепочку, которая, возможно, начинается с
некоторого слова, принадлежащего этому множеству. Требуется найти
элемент цепочки (если таковой существует), на котором это слово
кончается, и выйти на
процедуру,
соответствующую найденному слову.
Заданное множество слов
можно понимать как
множество допустимых
префиксов, с которых
может начинаться
правильная входная
цепочка. Мы хотим
обнаружить конец префикса и
установить, какой это
префикс. Чтобы задача
была корректной,
предположим, что ни одно
слово заданного
множества не является
префиксом другого слова этого
множества.
Сначала рассмотрим
возможность
обнаружения префиксов с
помощью конечного
процессора. Как и для задачи
идентификации слов,
такой процессор можно
построить путем
введения состояния для
каждой подцепочки,
являющейся префиксом
некоторого слова множества.
Однако в данном случае
нет необходимости
вводить состояния,
соответствующие самим словам.
Лучше
продемонстрировать этот способ на примере.
Рассмотрим задачу обнаружения префиксов из множества
{ДОЛ, ДОМ, ЛОМ} в цепочках, образованных буквами алфавита
{Д, Л, М, О}. Соответствующий конечный процессор,
обнаруживающий префиксы, изображен на рис. 3.11, а. В нем имеется три вида
переходов: переходы в новые состояния, выходы для слов, принад-
е
д
л
DP
ЛО
дол
ЛОМ
ЛОМ
д
д
О
До
ЛО
Л
Л
ДОЛ
м ч
дом
ЛОМ
■дол-
"ДОМ"
"ЛОМ"
Рис. 3.11. (а) Процессор, обнаруживающий
префиксы; (б) Процессор,
идентифицирующий слова.
3.10. Обнаружение префиксов
97
лежащих заданному множеству, такие, как «ДОМ», и выходы на
процедуру обработки ошибок, обозначенные в таблице пробелами.
Если автомат, обнаруживающий префиксы, управляется некоторым
другим процессором, то он не обязан обрабатывать концевой
маркер, и этот столбец можно выкинуть из таблицы. Для сопоставления
задач обнаружения префиксов и идентификации слов, на рис. 3.11, б
показан соответствующий процессор, идентифицирующий слова.
При реализации автомата, обнаруживающего префиксы,
остается в силе почти все, о чем говорилось в разд. 3.5 по поводу
реализации автомата, идентифицирующего слова.
Различие между этими двумя задачами становится более
очевидным, если рассмотреть решение задачи обнаружения префиксов
методом списка. Основная идея этого метода заключается в том,
чтобы, прочитав вход, строить потенциальное слово и затем
осуществлять его поиск в списке, чтобы узнать, есть ли оно в списке
идентифицируемых слов. В случае префиксов это невозможно, так как
конец префикса нельзя обнаружить, не зная, какой именно это
префикс. Поэтому необходима некоторая модификация метода,
и очевидное изменение состоит в том, чтобы производить поиск
после каждого входного символа. В этом случае каждый входной сим'
вол рассматривается как возможный конец префикса, и как только
это подтверждается, префикс обнаружен. Чтобы не просматривать
длинный список снова и снова, можно завести отдельные списки
префиксов каждой возможной длины. Так, получив первый входной
символ, компилятор осуществляет поиск в списке префиксов длины
один. Когда получен второй символ, компилятор просматривает
список префиксов длины два, и т. д. В этом случае нужно будет
выполнить не более одного сравнения с каждым из возможных
префиксов. Как и раньше, для ускорения поиска можно также применять
расстановку и упорядочение.
При попытке применения метода индексов для решения
проблемы обнаружения префиксов возникают трудности такого же
характера, Трудно решить, когда нужно вычислять и использовать
индекс. Можно вычислять индекс после каждого входного символа,
однако трудно представить, чтобы на практике встретилось
множество цепочек, для которого такая процедура была бы оправдана.
Мы убедились в том, что задача обнаружения префиксов по
существу является разновидностью проблемы идентификации слов, для
которой начало слова известно, но конец можно определить лишь
путем сравнения его с отдельными словами из множества
префиксов. Этой проблемы и ее решения достаточно для описания
лексического блока компилятора языка MINI-BASIC. Однако в других
языках встречаются проблемы идентификации слов с еще менее четкими
границами.
4 Ф Льюис и др.
98
Гл. 3. Реализация конечных автоматов
3.11. Замечания по литературе
Многие методы, приведенные в этой главе, относятся к
программистскому «фольклору» и использовались еще до их появления в
литературе. Хорошее изложение способов расстановки, применявшихся
до 1968 года, дано в работе Морриса [1968]. Метод связывания в
цепочки для преодоления коллизий, возникающих при использовании
расстановки, дается в работе Джонсона [19611. Обзор методов
решения проблемы идентификации слов, главным образом для
нерасширяющихся множеств, дан в работе Прайса [1971]. Решение проблемы
идентификации методами, аналогичными методу списка переходов,
описано у Фрэдкина [1960], Скидмора и Вайнберга [19631, а также
у Сассенгута [1963]. Метод бинарного поиска для расширяющегося
множества слов обсуждается в работах Хиббарда [1962], Фостера
[1965], Мартина и Несса [1972]. Очень глубоко методы поиска
обсуждаются Кнутом [1973]. Смотрите также работы Северанса [1974)
и Нивергельта [1974].
Упражнения
1. Опишите, как бы вы реализовали транслитерацию, используя следующие
языки:
а) Фортран,
б) АПЛ,
в) язык ассемблера машины, которая вам больше нравится.
2. Постройте списки переходов для автомата рис. 2.19.
3. Опишите, как бы вы реализовали метод вектора переходов, используя
следующие языки:
а) Фортран,
б) Алгол 60,
в) ПЛ/1,
г) АПЛ,
д) язык ассемблера машины, которая вам больше нравится.
4. Можно строить векторы и списки переходов не для состояний, а для входных
символов. Найдите такой автомат, чтобы затраты памяти при его реализации
были различными в зависимости от того, для состояний или для входных
символов построены списки переходов.
{Указание. Переход по Неудаче для списка не обязан быть переходом в
состояние ошибки).
.5. а) Измените автомат на рис. 3.5 и рис. 3.6, а так, чтобы распознаваемое им
множество пключало еще слова КАССА, БО и ОСАКА,
б) Добавьте к этим словам слово е.
6. Почему способ реализации, показанный на рис. 3.6, применим лишь к
задачам идентификации слов, а не к произвольному конечному автомату?
.7. Оцените объем памяти, затрачиваемой при распознавании зарезервированных
слов Алгола 60 методами:
а) списка переходов,
б) линейного списка,
в) вектора переходов.
•8. Нужно распознать следующее множество: МАССИВ, МАТРОС, ГЦ, П2, ПЗ,
ДОМ, СОН, ДОМАШНИЙ.
Упражнения
99
Нарисуйте в виде диаграммы структуру распознавателя этого множества,
построенного
а) методом списка переходов,
б) методом списка переходов для расширяющихся множеств,
в) методом упорядоченного списка.
• 9. Расширение языка BASIC включает следующие типы переменных:
Л) простые переменные — одна буква или буква, за которой следует цифра;
2) переменные с индексами — буква, за которой следуют левая скобка,
выражение и правая скобка;
3) переменные для строк — одна буква, за которой следует знак $.
Заметьте, что одна и та же буква может использоваться r именах переменных
всех трех типов (например, А, А1, AS и А(1)). Составьте схему индексации,
которая позволяла бы по символам имени г временной строить индекс,
однозначно соответствующий каждой допустимой переменной.
10. Видоизмените рис. 3.9 так, чтобы можно было осуществлять логарифмический
поиск в каждом списке.
П. Для каждого из следующих методов опишите, что нужно сделать, чтобы
удалить некоторое слово из распознаваемого множества слов:
а) метод списка переходов,
б) метод списка переходов для расширяющихся множеств,
в) метод индексов,
г) метод линейного списка,
д) метод упорядоченного списка.
е) метод расстановки.
12. Рассмотрим схему расстановки дли дешификаторов, поступающих в
следующем порядке:
АБВГ, АБГВ, ГВБА, ЕЛЬ, СОН, ДЕЛО,
ДУБ, КОНЬ, ОКНО, ЛОЖЬ, ГРОМ, 0\-а.
Мы хотим применить функцию расстановки
R mod 13
где R — число, шестнадцатеричной записью которого янляется код ASCII
данного слева1'. Нарисуйте таблицу расстановки после введения всех
двенадцати слов.
13. Постройте эффективную схему идентификации для зарезервированных слов
ягыка Кобол.
14. В некоторой гипотетической автоматизированной системе управления таблица
имен содержит элемент для каждого предприятия. Разработайте процедуру
поиска, которая по двух- или трехбуквенному коду, такому, как ЗИЛ или
БАМ, находит элемент таблицы имен для соответствующего предприятия.
Оцените среднее время поиска для вашей процедуры.
15. .Предположим, что в данном языке допустимы п идентификаторов, но в
некоторой конкретной программе используются только к. Предположим, что
элемент таблицы имен, отведенный для каждого из k идентификаторов,
занимает Ь ячеек памяти. Предположим также, что каждый указатель занимает
одну ячейку памяти. Подсчитайте, какой объем памяти потребуется для
идентификации с помощью индексированных таблиц, описанных в разд. 3.6, если
она осуществляется:
а) прямым методом, по которому для каждого индекса в индексированной
таблице отводится место соответствующему элементу таблицы имен;
б) непрямым методом, в соответствии с которым в индексированной таблице
содержится указатель на элемент таблицы имен.
1J См. Джермейн К. Программирование на IBM/360. M.: Мир, 1973,— с. 55.—
Прим. ред.
100
Гл. 3. Реализация конечных автоматов
Покажите, что при
ft/n> 1—1/6
метод (а) требует меньших затрат памяти, чем метод (б).
16. Пусть имеется такая схема расстановки, что как только таблица
расстановки заполняется на 80%, мы удваиваем ее объем, применяем к новой
таблице новую функцию расстановки и заново расставляем все старые элементы
в новой таблице. Покажите, что для программы с т идентификаторами
(каждый из которых встречается в программе один раз) среднее число сравнений,
производимых в соответствии с этой схемой (включая время, затрачиваемое
на расстановку), пропорционально т.
17. Если объем таблицы указателей списков Сив связанные списки включены k
разных слов, то при использовании метода расстановки среднее количество
слов, находящихся в связанном списке, равно kIC. Используя этот результат,
выведите формулу
1+(УИ—1)/2С
приведенную в разд. 3.9.
18. Рассмотрим разновидность метода логарифмического поиска, в которой
оставшаяся часть списка на каждом этапе делится на три равные части; входное
слово сравнивается со словами, стоящими в конце первой и второй трети,
и та треть списка, в которой находится входное слово, используется на
следующем этапе. Найдите максимальное число сравнений при поиске одного
слова, использующем этот метод, и сравните его с бинарным
логарифмическим методом, описанным в разд. 3.8.
Лексический блок для языка
MINI-BASIC
4.1. Множество лексем
В этой главе мы проведем довольно детальное построение
лексического блока для языка MINI-BASIC на основе конечного автомата.
На первом шаге определяется взаимодействие между лексическим
ЛЕКСЕМА
г
КЛАСС
СТРОКА
ОПЕРАНД
АРИФМЕТ. ОПЕРАЦИЯ
ОТНОШЕНИЕ
КОНЕЦ ЦИКЛА
ПРИСВОИТЬ
для
ПЕРЕХОД НА
ПОДПР
ЛЕВАЯ СКОБКА
ПРАВАЯ' СКОБКА
ЕСЛИ
ВОЗВРАТ
КОНЕЦ
до
ШАГ
КОММЕНТАРИЙ
ОШИБКА
КОНЦМАРКЕР
ЗНАЧЕНИЕ
Указатель на таблицу имен
Указатель на таблицу имен
Номер операции
Номер отношения
Указатель на таблицу имен
Указатель на таблицу имен
Указатель на таблицу имен
Указатель на таблицу имен
Указатель на таблицу имен
Нет
Нет
Нет
Нет
Нет
Нет
Нет
Нет
Нет
Нет
Рис. 4.1.
120
X, РЗ, 10ЕЗ, 2.6, 2
+ , *, /Л,-
= ,>=,<>
NEXT J
LET X =, LET A7 -
FOR I =, FOR N9 =
GOTO 17
GOSUB 130
(
)
IF
RETURN
ENB
TO
STEP
REM ЭТО КОММЕНТАРИЙ
10.6.3, LOT X =
конец файла
и синтаксическим блоками. Множество лексем, обеспечивающих
это взаимодействие, изображено на рис. 4.1. Таблица содержит и
класс лексемы, и соответствующее значение. Справа от каждого
элемента таблицы приведены примеры цепочек символов, образую-
102
Гл. 4. Лексический блок для языка MINI-BASIC
щих данную лексему. Классам лексем даны значимые имена, но
внутри компилятора они будут представлены числами.
Мы предполагаем, что имеется некоторая процедура СОЗДАТЬ
ЛЕКСЕМУ, с помощью которой осуществляется взаимодействие
с синтаксическим блоком. По отношению к лексическому блоку
СОЗДАТЬ ЛЕКСЕМУ может быть процедурой записи лексемы
в промежуточный файл или процедурой, которая сообщает
синтаксическому блоку о готовности очередного выхода. Так как мы
планируем однопроходную компиляцию языка MINI-BASIC, здесь
используется только последняя интерпретация, хотя общее
построение годится как для одного, так и для нескольких проходов
компилятора.
Мы предполагаем, что, когда вызывается процедура СОЗДАТЬ
ЛЕКСЕМУ, переменной РЕГИСТР КЛАССА уже присвоено
некоторое число, представляющее класс создаваемой лексемы, а
значение этой лексемы находится в некоторой переменной, зависящей
от класса лексемы. Чтобы задать эти переменные и объяснить
выбор лексем, обсудим каждую лексему в отдельности.
Лексема СТРОКА служит для указания номера строки,
стоящего перед оператором. Ее значение — указатель на элемент
таблицы имен для этого номера строки. Этот указатель будет
засылаться в переменную РЕГИСТР УКАЗАТЕЛЯ ".
Лексема ОПЕРАНД служит для указания вхождения
константы или переменной в выражение. Она не используется для тех
вхождений переменных, которые следуют непосредственно после
слов NEXT, FOR и LET. Эти исключения рассматриваются
отдельно в описании лексем КОНЕЦ ЦИКЛА, ДЛЯ, ПРИСВОИТЬ.
Значением лексемы ОПЕРАНД является указатель на элемент
таблицы имен, содержащий переменную или константу. Этот
указатель будет храниться в РЕГИСТРЕ УКАЗАТЕЛЯ.
Лексема АРИФМЕТ ОПЕРАЦИЯ 2) указывает вхождения
символов + , —, *, / и |. Эти знаки операций будут пронумерованы
числами от 1 до 5 соответственно. Номер операции служит
значением лексемы и будет находиться в переменной РЕГИСТР
ЗНАЧЕНИЯ. На самом деле этот номер будет засылаться туда
непосредственно процедурой транслитерации.
Лексема ОТНОШЕНИЕ указывает вхождения знаков
отношений = , >, <, ">—-, <.=- и < >, которым присваиваются номера
5) Выражения «заслать в переменную Хъ, «хранить в переменной X» и т. п.
надо понимать как сокращения более правильных, но более длинных выражений
«заслать в ячейку, соответствующую переменной X», и т. д.— Прим. ред.
2) Словом «операция» (в оригинале operator) здесь для краткости назван
собственно знак операции. Так же употребляется ниже слово «отношение» (в
оригинале relational operator). В дальнейшем тот или иной смысл этих слов будет ясен
из контекста,— Прим. ред.
4.1. Множество лексем
103
от 1 до 6 соответственно. Номер данного отношения будет
засылаться в переменную РЕГИСТР ОТНОШЕНИЯ.
Лексема КОНЕЦ ЦИКЛА представляет слово NEXT и идущую
за ним переменную. Ее значение, указатель на элемент таблицы
имен, соответствующий этой переменной, засылается в РЕГИСТР
УКАЗАТЕЛЯ так же, как значение лексемы ОПЕРАНД. Можно
было бы определить взаимодействие так, чтобы последовательность
символов NEXT КЗ представлялась двумя лексемами — для NEXT
и для КЗ. Однако мы решили представлять эту информацию одной
лексемой. Такое решение принято для того, чтобы уменьшить
количество вызовов процедуры СОЗДАТЬ ЛЕКСЕМУ, а также для
того, чтобы читатель лучше усвоил тот факт, что лексемы,
используемые внутри компилятора, не совпадают с лексемами, которые
фигурируют в руководстве по этому языку. На самом деле в
лексическом блоке мы производим мало синтаксических действий,
чтобы добиться большей эффективности. Принимая решения такого
рода, мы полагаемся на понимание возможностей конечных
автоматов, а не на эвристическое истолкование слов «лексический» и
«синтаксический».
Лексема ПРИСВОИТЬ представляет слово LET, за которым
следуют переменная и знак равенства. Ее значение — указатель
на элемент таблицы имен, соответствующий этой переменной,—
засылается в РЕГИСТР УКАЗАТЕЛЯ. Мы снова используем
лексический блок для сжатия информации, содержащейся в исходном
операторе. Для представления того, что в руководстве по языку
выражалось бы тремя словами, здесь используется одна лексема.
Лексема ДЛЯ представляет слово FOR, за которым следуют
переменная и знак равенства. Ее значение — указатель на элемент
таблицы имен, соответствующий этой переменной,— засылается
в РЕГИСТР УКАЗАТЕЛЯ. Эта лексема —вариант лексемы
ПРИСВОИТЬ.
Лексема ПЕРЕХОД НА представляет слово GOTO, за
которым следует номер строки. Мы вновь объединяем два понятия в одну
лексему. Значение лексемы — указатель на элемент таблицы имен,
содержащий этот номер строки,— помещается в РЕГИСТР
УКАЗАТЕЛЯ.
Лексема ПЕРЕХОД НА ПОДПР представляет слово GOSUB,
за которым следует номер строки. Как и для лексем СТРОКА и
ПЕРЕХОД НА, ее значением служит указатель на элемент
таблицы имен, содержащий этот номер строки. Значение лексемы
засылается в РЕГИСТР УКАЗАТЕЛЯ.
Лексемы ЛЕВАЯ СКОБКА и ПРАВАЯ СКОБКА представляют
левую и правую скобки соответственно. У них нет значений.
Лексемы ЕСЛИ, ВОЗВРАТ, КОНЕЦ, ДО и ШАГ представляют
соответствующие зарезервированные слова IF, RETURN, END,
ТО и STEP. У этих лексем нет значений.
104 Гл. 4. Лексический блок для языка MINI-BASIC
Лексема КОММЕНТАРИЙ представляет слово REM и все
остальные символы данной строки 1]. У нее нет значения. С помощью
этой лексемы синтаксический блок обнаруживает комментарии,
вставленные в неподходящем месте, как, например, в операторе
13 IF Al REM ЭТО НЕЛЕПО
Лексический блок порождает лексему КОММЕНТАРИЙ, чтобы
синтаксический блок мог проверить правильность расположения
комментария.
Лексема ОШИБКА используется в лексическом блоке для
передачи в синтаксический блок сообщения о том, что обнаружена
ошибка. Это освобождает синтаксический блок от необходимости
выдавать еще одно сообщение об ошибке. Эта лексема будет
порождаться каждый раз, когда лексический блок окажется не в
состоянии разбить исходный оператор на значимую последовательность
лексем. Такая ситуация может возникнуть, когда неправильно
написаны зарезервированные слова (например, RETARN), когда
неверно сформированы константы (например, 3.6Е.З) или когда
перемешиваются между собой переменные и константы (например,
АЗ.Е2). У лексемы ОШИБКА значения нет.
Лексема КОНЦ МАРКЕР выдается, когда встречается конец
файла. У нее нет значения. Информация, необходимая для
процедуры СОЗДАТЬ ЛЕКСЕМУ, представлена на рис. 4.2, где даны
переменные, о которых шла речь при обсуждении множества
лексем, и описано их использование.
РЕГИСТР' КЛАССА —Для номера класса лексемы
РЕГИСТР УКАЗАТЕЛЯ —Для указателя на элемент таблицы
имен
РЕГИСТР ЗНАЧЕНИЯ —Для номера арифметической операции
РЕГИСТР ОТНОШЕНИЯ —Для номера отношения
Рис. 4.2. Информация, используемая процедурой СОЗДАТЬ ЛЕКСЕМУ.
4.2. Проблемы идентификации
Установив взаимодействие между лексическим и синтаксическим
блоками, мы займемся теперь проблемами построения собственно
лексического блока. Начнем построение с описания схемы решения
следующих четырех проблем идентификации:
1) обнаружение зарезервированных слов,
2) идентификация переменных,
3) идентификация номеров строк,
4) идентификация знаков отношений.
') Далее в примерах программ комментарии пишутся по-русски, что не
противоречит определению языка (см. разд. А.5), так как компилятор игнорирует текст
комментария,— Прим, ред, •-...■■
4.2. Проблемы идентификации
105
Мы обсудим все эти задачи по очереди.
Обнаружение зарезервированных слов — это по сути задача
обнаружения префиксов, обсуждавшаяся в разд. 3.10. Конечное
множество слов таково: {END, FOR, GOSUB, GOTO, IF, LET,
NEXT, REM, RETURN-, STEP, TO}. Мы можем обнаружить, где
А
В
С
D
Е
F
G
Н
J
К
L
М
N
О
Р
Q
R
S
Т
и
V
W
X
Y
Z
Начальный
©
©
©
rtTi
lil)
©
©
©
©
©
вектор
©
©
©
©
©
©
©
©
©
©
©
©
©
©
©
©
©
©
©
©
©
©
©
©
©
Буква
N
D
О
R
О
- Т
О
S
и
В
F
Е
Переход
file/
A2q
aic/
F16
Sid
S1c/
f1a
S1c/
Sic/
F16
/»2r
Sic/
кпьтериатЬа
©
T
E
X
T
E
T
и
R
N
M
T
E
P
О
F\a
B\d
S1c/
Cla
Sic/
S1c/
Sic/
S1c/
,42*
G\a
B\d
file/
/»2f
V»2u
Таблица обнаружения
Рис. 4.3. Обнаружение зарезервированных слов.
106
Гл. 4. Лексический блок для языка MINI-BASIC
эти слова начинаются, но не можем обнаружить, где они кончаются,
если не рассматривать все заданное множество. Выбранное нами
решение основывается на моделировании соответствующего
автомата, обнаруживающего префиксы. В основных чертах схема,
изображена на рис. 4.3. Для переходов, происходящих под
действием первой буквы, используется вектор переходов, а для
последующих переходов используются списки переходов (подобно тому,
как на рис. 3.6). Когда начинается зарезервированное слово, его
первая буква служит для указания на элемент начального вектора.
Это действие соответствует первому переходу автомата,
обнаруживающего префиксы. Каждый элемент вектора содержит
указатель на таблицу обнаружения. В таблице обнаружения
содержатся списки переходов для обработки дальнейших букв.
Например, по начальной букве G из начального вектора выбирается
указатель 5, по которому в таблице обнаружения разыскивается
информация для обнаружения слов GOTO и GOSUB. Для букв, с
которых зарезервированные слова начинаться не могут (таких, как
А), начальный вектор содержит нулевые элементы. Если по первой
букве слова выбирается нулевой элемент вектора, происходит
вызов соответствующей процедуры обработки ошибок.
Каждый элемент таблицы обнаружения состоит из трех частей.
Первая часть содержит представление буквы, вторая — метку
процедуры перехода, а третья — указатель или нуль, означающий
отсутствие указателя. Очередная входная буква сравнивается
с буквой из текущего элемента таблицы. Если они совпадают,
управление передается процедуре перехода, метка которой
содержится в этом элементе. Если они не совпадают, то по указателю,
содержащемуся в данном элементе, находится новый элемент
таблицы, для которого повторяется весь процесс сравнения. Элементы
таблицы, связанные друг с другом таким образом, соответствуют
списку переходов автомата, обнаруживающего префиксы, который
решает эту же задачу. Процедуры переходов, метки которых
встречаются в таблице, описываются с помощью основных процедур
лексического анализа, перечисленных ниже. Процедура Bid
увеличивает указатель на текущий элемент таблицы так, что он будет
указывать на следующий элемент. Так, если после G следует О,
то под действием О указатель изменится с 5 на 6. 6 — это первый
элемент списка переходов для состояния, соответствующего
префиксу GO. Другие процедуры переходов, перечисленные в
таблице, соответствуют выходам из процедуры обнаружения
префиксов. Каждый из этих выходов представляется меткой процедуры
перехода, соответствующей конкретному зарезервированному слову,
которое удалось обнаружить Система выбора имен для этих
меток то же, что и в основном лексическом анализаторе, и
описывается ниже.
Идентификация переменных будет осуществляться методом ин-
4.2. Проблемы идентификации
107
дексов, задающих их места в таблице имен. Предположим, что
первые 286 ячеек таблицы-отведены для 286 возможных переменных.
Остальная часть таблицы имен отводится для констант, меток и т. д.
Как только прочитана буква, с которой начинается переменная,
соответствующее число в интервале от 1 до 26 прибавляется к
базовому адресу таблицы имен и результат засылается в РЕГИСТР
УКАЗАТЕЛЯ.
Если за буквой следует цифра й, то к РЕГИСТРУ УКАЗАТЕЛЯ
прибавляется число 26*(d+l). Этот метод индексирования
переменных MINI-BASIC'a обсуждался в разд. 3.6.
Значение
1
2
3
4
5
6
Отношение
=
<
>
<=
>=
о
а
1W
РЕГИСТР
2 (О
ОТНОШЕНИЯ
3(»
РЕГИСТР ЗНАЧЕНИЯ
1 (=) 2 К) 3 (»
0
4К=)
5(>=)
0
0
0
0
6 К»
0
Рис. 4.4. <а) Значения лексемы ОТНОШЕНИЕ;
(б) Таблица отношений.
Идентификация номеров строк достигается построением числового
значения номера строки при обработке автоматом цифр этого номера.
Вспомним, что значением лексемы СТРОКА является указатель на
элемент таблицы имен для данного номера строки. Значит, каждому
появлению данного номера строки нужно поставить в соответствие
один и тот же элемент таблицы имен. Это будет сделано путем
поиска в списке элементов таблицы имен, соответствующих номерам
строк. При поиске в списке мы используем метод расстановки.
108
Гл. 4. Лексический блок для языка MINI-BASIC
Функцией расстановки будет остаток от деления числового
значения номера строки на простое число, скажем Р. Число Р —
параметр построения, его можно легко изменить в зависимости от
таких факторов, как объем доступной компилятору памяти и
ожидаемый объем исходной программы, поступающей на вход
компилятора. Первоначально мы выбираем Р равным 101.
Идентификация знаков отношения — это задача идентификации
элементов множества {=, <С, >, <=, >=, < >}. Наш процесс
идентификации будет основываться на методе индексов, в котором
используется тот факт, что каждое слово состоит либо из одного,
либо из двух символов. Когда встречается первый символ, в
РЕГИСТР ОТНОШЕНИЯ загружается соответствующее число от 1
до 3. Если встречается еще и второй символ, соответствующее ему
число помещается в РЕГИСТР ЗНАЧЕНИЯ. Затем номер
соответствующего двухсимвольного знака отношения ищется в таблице,
называемой таблицей отношений. Этот метод детализирован
на рис. 4.4. На рис. 4.4, а показана выбранная нами нумерация
знаков отношения; на рис. 4.4, б изображена сама таблица
отношений. Нулевые элементы соответствуют ситуациям, подобным = =,
когда комбинация символов ошибочна. Заметим, что для того,
чтобы придать недозволенным сочетаниям =>, =< и X их
естественный смысл, достаточно изменить лишь несколько
элементов таблицы. В конкретных ситуациях некоторые расширения
языка часто реализуются тривиальным образом.
4.3. Транслитератор
При определении транслитератора мы постараемся помнить об
экономии, стремясь получить небольшое множество символьных
(или литерных) лексем. Спецификация транслитератора
приведена на рис. 4.5. Взаимодействие транслитератора с операционной
системой вычислительной машины и с остальной частью
лексического блока не описывается здесь детально, но оно подразумевается,
когда мы говорим «для очередного входного символа сделать
переход из состояния Л». Предположим, что транслитератор будет
помещать значения символьных лексем в переменную РЕГИСТР
ЗНАЧЕНИЯ. Чтобы выбрать множество символьных лексем,
обсудим каждую из них в отдельности.
Символьная лексема БУКВА используется для представления
всех букв, а ее значение указывает конкретную букву. Буквы
объединены в один класс, поскольку все они, за единственным
исключением, более или менее взаимозаменяемы. Единственное
исключение составляет буква Е, которая может использоваться
для записи порядка константы. Таким образом, встретив символы
10Е, мы ожидаем, что после Е будет следовать число, задающее
N
СЛ
<£
X
со
>
СП
-<
Ч
(Г
X
ш
>
14}
<Л
X
СП
1С
7s
CD
>
S
Щ
1С
А
Ш
>
со
<
щ
1С
х
ш
>
гч)
С
43
(С
х
со
>
1ч>
ч
13
и;
тс
го
>
1ч>
О
СО
СП
1С
т:
со
>
(О
33
m
(С
7ч
Ш
>
00
D
m
(Г
т;
го
>
~j
-а
СП
(С
X
го
>
СП
О
03
1С
х
ш
J>
«л
Z
гл
и*
7ч
го
>
А
2
m
и:
тс
го
>
со
г-
m
1С
т;
го
>
14}
7?
СП
(С
7ч
го
>
-
<_
m
ir
7ч
ГО
>
О
-
OJ
(Г
7ч
го
>
(О
X
СП
1Г
X
го
>
со
о
m
1С
X
го
J>
>4
-п
m
tt.
7ч
ГО
>
СП
m
гп
1С
7ч
го
3>
«л
о
m
иг
7ч
ГО
>
■и
о
m
(Г
7ч
ГО
J>
СО
OS
m
IT
7ч
ГО
>
14}
>
сп
ее
т;
ш
>
-
1
Ci
_ «о
о>
I
2
$
лек
семы
X
кон
1
■А-
>
1'
®
кон-
п
ч
РОК
1
©d)
ПРОБ
ПРОБ
m m
ь ^
=1
■о
О
сп
гп
ь
1
•
ч
о
JZ
ж
>
1
—
ПРА
го
i
о
КОБ
1
—
m
Ш
-СКОБ
1
V
О
н
X
о
h
со
Л
О
ч
X
о
Ь
NJ
И
О
ч
О
Ь
-
>
-о
X
■&
1
о
=1
ел
-
>
"0
■ч
в
о
Л
*
>
"0
■с
ۥ
О
со
1
>
"0
т
е
о
3
I4J
+
>
-о
X
■в
1
О
(О
Я
тг
-ft
Т1
>
СО
09
J=
f
т»
>
00
~J
р
.т
в
Т1
>
~J
СП
J=
S
-{*
Т1
>
СП
«л
с;
з:
■В-
тт
j>
ел
■и
р
i
■в-
Т»
>'
■и
со
с
S
е
■о
>
со
м
р;
S
#
Т)
>
м
-
с;
з:
«
■о
>
о
с
X
4*
и
J>
о
>5
^
й
f^
i§%?
I
S
№
•лексемы
S
по
Гл. 4. Лексический блок для языка MINI-BASIC
порядок, а встретив 10S, мы ожидаем, что S — первая буква
зарезервированного слова (по всей вероятности, слова STEP). Одно
вполне разумное решение заключается в юм, чтобы выделить
букву Е в специальный класс символьных лексем, оставив ее
значение фавным 5. Однако мы выбрали для буквы Е другую схему
проверки, она осуществляется при тех особых переходах автомата,
где это важно. Получившийся выигрыш в числе столбцов таблицы
переходов не имеет реального значения для нашего довольно
маленького автомата, но мы хотим продемонстрировать читателю
эту технику. Значения лексем становятся внутренним
представлением букв, и именно они па самом деле используются в таблице
обнаружения на рис. 4.3.
Символьная лексема ЦИФРА используется для представления
всех цифр. Им приписываются их естественные значения, так как
нам нужно будет производить арифметические действия над этими
значениями при обработке констант и номеров строк.
Символьная лексема АРИФ-ОПЕР представляет
арифметические операции. Значение каждой арифметической операции
такое же, как у соответствующей лексемы АРИФМЕТ ОПЕРАЦИЯ.
Символьные лексемы ЛЕВ-СКОБ, ПРАВ-СКОБ и ТОЧКА
представляют соответственно левую скобку, правую скобку и
десятичную точку. Значений у них нет.
Символьная лексема ПРОБЕЛ представляет символ пробела,
символ вычеркивания RO и символ перевода строки LF. Такая
кодировка символа вычеркивания и символа перевода строки требует
некоторого объяснения. Мы предполагаем, что исходная программа
должна подготавливаться на некотором устройстве типа телетайпа,
где конец строки представляется некоторой комбинацией символов
вычеркивания и символов возврата каретки CR и перевода строки.
Наш принцип работы с такой системой заключается в том, чтобы
интерпретировать символы вычеркивания и перевода строки как
пробелы, а возврат каретки — как символ конца строки. Читатель,
которому эти символы незнакомы, может просто забыть об их
существовании, так как они нигде в построении не участвуют.
Символьная лексема КОН-СТРОК представляет символ
возврата каретки и свидетельствует о том, что строка окончена.
Символьная лексема КОН-ФАЙЛ служит для лексического
блока сигналом о том, что на входе больше нет символов. Метод
получения этой лексемы зависит от конкретных особенностей
операционной системы машины и не влияет на построение.
Предполагается, что у нас есть средства для генерации этой лексемы в
нужный момент, и к этому вопросу мы больше не будем возвращаться.
Мы игнорируем возможность существования других символов,
допускаемых операционной системой, но не используемых в языке
MINI-BASIC. Входная цепочка могла бы, например, включать
запятую. Такие символы можно было бы переводить в новую лексему,
4.4. Лексический блок
111
появление которой означает ошибку в любом месте, кроме
комментария. Однако для простоты будем считать, что мы имеем дело лишь
с символами, приведенными на рис. 4.5.
4.4. Лексический блок
Конечный автомат, заключающий в себе основную часть
лексического блока, изображен на рис. 4.6. Имена состояний, имеющих
одинаковое назначение, начинаются с одной и той же буквы, а сами
эти состояния сгруппированы в одном месте таблицы переходов.
Рассмотрим эти группы состояний, чтобы читатель мог понять,
как работает автомат.
Состояния Al, А2 и A3 можно считать управляющими. Они
используются для представления таких ситуаций, когда только
что прочитана одна лексема и должна начаться другая. Состояние
А1 — начальное и используется в начале строки, первой лексемой
которой должен быть номер строки. Чтобы убедиться в
необходимости двух других управляющих состояний, рассмотрим оператор
MINI-BASIC'a " •
30 IF G < G1*(G+1) GOTO 10
Буква G встречается в этом операторе четыре раза. В первых трех
случаях (после зарезервированного слова IF, после знака
отношения и после левой скобки) буква G является началом переменной
MINI-BASIC'a. Последнее вхождение G (после правой скобки) —
не начало переменной, а первая буква зарезервированного слова.
Состояние А2 используется в тех случаях, когда буква
рассматривается как первая буква переменной, а состояние A3, когда буква
должна быть первой буквой зарезервированного слова. Какое
состояние должно быть использовано, можно определить по
предыдущей лексеме. Не будь такого различия между состояниями,
лексический блок мог бы пытаться переводить GOTO в
последовательность ОПЕРАНД G ОПЕРАНД О ОПЕРАНД Т
ОПЕРАНД О.
Приводимое нами в конце этого раздела описание процедур
перехода организовано так, чтобы процедуры, соответствующие
переходам в одно и то же состояние, были расположены рядом.
В случае управляющих состояний многие переходы, которые ведут
в эти состояния, сопровождаются действиями, необходимыми для
завершения предыдущей лексемы. Чтобы понять назначение этих
особых процедур, следует обращать внимание на то состояние, из
которого происходит тот или иной переход.
Состояние В1 предназначено для обнаружения
зарезервированных слов. Оно использует переменную РЕГИСТР
ОБНАРУЖЕНИЯ для хранения указателя на таблицу обнаружения рис. 4.3
112
Гл. 4. Лексический блок для языка MINI-BASIC
1ГИУФ-Н0Я
MOdiO- НОИ
U390dli
VMhOl
домо-flwu
йОЮ-8Эи~
тоню
йШ-ФШ
Vd^Htl
vgxfig
Начало строки
Искать пер., конст., оп., отн., CR,),(
Искать зарезерВ. слабо, оп„ отн., cr,).
EXITl
EXIT1
EXITl
5 5 5
«- гм о
ч ч ч
со со
Ч Ч
■с -с
гм гм
ч ч
1 1
(0 fQ
СМ СМ
Ф Ф (В
гм »- ■-
Ш Q Q
(0 £13
ГМ *-
О QQ
<- ем го
Ч Ч Ч
Обнаружить зарезербиробаиное слово
00
i
QQ
Искать переменную
Завершить обработку переменной
гм
н
X
LU
со
5
•- гм
оо
•4:
гм
Ч
1
СП
ГМ
ч
со
Ч
■о -о
ем •-
(J QQ
— ем
Завершить обработку целой части
Забершить офаботку десятичной часп
После букбы Е
После буквы Е и знака
Забершить обработку порядка
После первой десятичной точки
EXIT3
EXIT4
EXIT5
5 5 5
<- rj п ^ ю о
Q Q Q Q Q Q
гм
Q
го Л го
ч ч ч
гм гм гм
ч ч ч
11 1
О "S3 (0 Q»
гм гм <т гм
Ч Ч Q Ч
•О пз <5 -О о -О
*- гм in in m гм
Q Q Q Q Q Q
ем ool £
5 5 оо
*- гм со *r in to
Q Q Q Q Q Q
Искать номер строки
Оставшаяся часть номера строки
со
н
X
LU
5
*- гм
Uj 1JJ
Ч
гм
Ч
ч*
1
ч.
ГМ
Ч
гм см
00
г- CM
Uj Uj
Искать переменную и =
Оставшаяся часть переменной
Искать =
>- гм со
п. п. п.
0 0
см ем
Ч Ч
со
п.
го
СМ
п.
— ем оо
U. U. П.
Найти cr
г-
X
ш
5
О
5
о
о
5
5
5
5
5
Завершить обработку отношение
гм
н
X
LU
го
5
5
Q
го
Ч
см
Ч
«N1
ч
см1
Ч
о
Q
О
*
4.4. Лексический блок
113
(описанную выше). Когда входом служит буква, следующее
состояние определяется переходом ЛИ, при котором из таблицы обнару^
жения выбирается новое состояние. Описание Ml приведено после
других процедур переходов.
Состояния С1 и С2 предназначены для обнаружения переменных^.
Они используются для вычисления значений лексем ОПЕРАНД
и КОНЕЦ ЦИКЛА. Состояние С1 обнаруживает букву, а
состояние С2 — возможную цифру, которая может следовать за буквой.
Во многих случаях определить, что началась переменная, можно
только после того, как прочитана ее первая буква. В таких
случаях сразу наступает состояние С2 и процедура перехода должна
включать все те действия, которые обычно выполняются в
состоянии С1. К ним относится загрузка в РЕГИСТР КЛАССА имени
обрабатываемой лексемы, так как иначе эта информация будет
быстро потеряна. Состояние С1 используется только после
появления слова NEXT.
Состояния DI, ..., D6 используются для вычисления значений
констант MINI-BASIC'a. Эти состояния соответствуют состояниям
1, 23, 4, 5, 6 и 7 процессора, рассмотренного в разд. 2.14. Как и
в том разделе, для промежуточных вычислений мы пользуемся
переменными РЕГИСТР ЧИСЛА, РЕГИСТР ПОРЯДКА, РЕГИСТР
СЧЕТЧИКА и РЕГИСТР ЗНАКА. Предполагается, что
существует процедура ВЫЧИСЛИТЬ КОНСТАНТУ, которая получает
новый элемент таблицы имен, строит внутреннее представление
константы с помощью РЕГИСТРА ЧИСЛА и РЕГИСТРА
ПОРЯДКА, запоминает это представление в новом элементе таблицы
и засылает указатель на этот элемент в РЕГИСТР УКАЗАТЕЛЯ.
Процедуры переходов по существу те же, что и в разд. 2.14. Три
процедуры выхода ДА1, ДА2 и ДАЗ из разд. 2.14 используются
и здесь, но с той разницей, что они не служат больше процедурами
выхода. Они переименованы в.ДАШ, ДА20 и ДАЗО, что
указывает на их связь с состояниями DI, ..., £)6, обрабатывающими
константы. Они вызываются в тех ситуациях, когда ясно, что
константа кончилась и начинается следующая лексема. Например,
в операторе MINI-BASIC'a
512 IF 3>(X + 10.3)/2E3 GOTO 10
имеются три константы, и лексический блок не может определить
последний символ константы, пока не будет прочитан следующий
символ, а именно—>,) или G. Другими словами, 3 может оказаться
началом 37; 10.3 может оказаться префиксом 10.31, а 2ЕЗ можно
продолжить до 2Е30. В каждом из трех случаев процедуры
переходов должны заканчивать обработку константы и начинать
обработку следующей лексемы. Таким образом, соответствующие
процедуры переходов (т. е. Hlc, АЗе и Blc) сначала вызывают подхо-
114
Гл. 4. Лексический блок для языка MINI-BASIC
дящую ДА-процедуру для завершения константы, а затем
процедуры переходов начинают действия по обработке следующей
лексемы.
Состояния £1 и £2 служат для обработки номеров строк. Они
используются для вычисления значений лексем СТРОКА,
ПЕРЕХОД НА и ПЕРЕХОД НЛ ПОДПР. Состояние £1 обнаруживает
первую цифру номера строки, а Е2 обрабатывает остальную часть
номера строки. Пока идут цифры, в переменной РЕГИСТР СТРОКИ
накапливается соответствующее целое число. Когда номер строки
завершен, вызывается процедура ДА1Е, которая находит
соответствующий элемент в таблице имен и помещает указатель на него
в РЕГИСТР УКАЗАТЕЛЯ. Эта процедура вызывается после того,
как встретился символ, следующий за номером строки, т. е.
аналогично другим ДА-процедурам.
Состояния Fl, F2 и F3 служат для обнаружения переменной,,
за которой следует знак равенства, и используются для вычисления
значений лексем ПРИСВОИТЬ и ДЛЯ. Состояние F\ находит букву
переменной, F2 ищет возможную цифру, a F3 — знак равенства
после цифры. Они используют РЕГИСТР УКАЗАТЕЛЯ так же,
как состояния С\ и С2.
Состояние G\ служит для того, чтобы найти КОН-СТРОК после
того, как обнаружено слово REM. В результате выбрасывается
комментарий. Переход в G\ может произойти также после
обнаружения лексической ошибки, чтобы возобновить нормальную
лексическую обработку на следующей строке.
Состояние Н\ используется, когда встречается символьная
лексема ОТНОШ, и служит для того, чтобы узнать, следует ли далее
еще одна лексема ОТНОШ. Идентификация знаков отношения уже
обсуждалась выше.
В таблице переходов лексического анализатора есть несколько
дополнительных элементов, где могут быть использованы
процедуры, обрабатывающие ошибки. Примером может служить
элемент таблицы, соответствующий ПРАВ-СКОБ и состоянию Л2.
Так как состояние Л2 наступает только после обработки знака
арифметической операции, отношения, левой скобки или слов
END, IF, RETURN, STEP и ТО, мы знаем, что правая скобка не
может следовать далее ни в одном правильном операторе. Однако
мы решили, что лексический блок сформирует лексему ПРАВ-
СКОБ и будет продолжать работу, как будто ничего не случилось.
Синтаксический блок, разумеется, обнаружит ошибку и выдаст
сообщение. Как правило, лексема создается всякий раз; когда ее
границы четко определены, и обнаружение ошибок предоставляется
синтаксическому блоку. Мы поступаем так, считая, что
синтаксический блок располагает большей информацией о том, что делает
пользователь, и может выдавать более осмысленные сообщения об
ошибках.
4.4. Лексический блок
115
Есть три процедуры переходов, в которых следующее состояние
определяется иначе, чем по информации о том, что автомат
находится в данном состоянии. Это процедуры Ml, M2 и МЗ. Следующее
состояние для перехода Ml определяется по таблице обнаружения
с тем, чтобы после завершения зарезервированного слова можно
было выполнять разные действия. Переходы М2 и МЗ определяют
следующее состояние в зависимости от того, является ли Е
следующей буквой. Оба эти действия обсуждались раньше.
Способ определения процедур переходов ориентирован на
кодировку переходов с неявным представлением состояний. Переход
А\Ь, например, задается тремя операторами, последний из которых
«Для очередного входного символа сделать переход из
состояния Ah. Второй оператор помечен как А]а, потому что
последние операторы, оказывается, задают переход А\а, и две процедуры
переходов могут иметь в этом месте общий код. Процедуры,
ориентированные на явное представление состояний, могут начинаться
с такого оператора, как «Установить состояние /41», а затем
передавать управление операторам, общим для переходов в другие
состояния. Последним оператором может быть оператор «Для
очередного входного символа сделать переход».
Спецификация элементов таблицы переходов приводится ниже.
Пустые элементы соответствуют процедурам, обрабатывающим
ошибки. Эти процедуры детально не описаны. Предполагается
лишь, что они вызывают создание лексемы ОШИБКА и переводят
автомат в состояние G\ для продолжения лексического анализа
Если на входе находится КОН-ФАЙЛ, будем считать, что выходом
является процедура обработки ошибки.
Alb:
Ala:
Al:
Ale:
Aid:
Ale:
Л 2c:
A2g:
A2a:
A2b:
Выполнить процедуру ДА1 D
СОЗДАТЬ ЛЕКСЕМУ
Для очередного входного символа сделать переход
из состояния Л1
Выполнить процедуру ДА20
Перейти на Ala
Выполнить процедуру ДАЗЭ
Перейти на А 1а
Выполнить процедуру ДА IE
Перейти на Ala
Выполнить процедуру ДАШ
СОЗДАТЬ ЛЕКСЕМУ
Загрузить АРИФМЕТ ОПЕРАЦИЮ в РЕГИСТР
КЛАССА
СОЗДАТЬ ЛЕКСЕМУ
116
Гл. 4. Лексический блок для языка MINI-BASIC
Л2: Для очередного входного символа сделать
переход из состояния Л2
Л 2d: Выполнить процедуру ДА20
Перейти на A2g
А2е: Выполнить процедуру ДАЗО
Перейти на A2g
Л2/: Выполнить процедуру ДАШ
Перейти на A2g
/42/: Выполнить процедуру ДА1Е
A2k: СОЗДАТЬ ЛЕКСЕМУ
A2h: Загрузить ЛЕВУЮ СКОБКУ в РЕГИСТР
КЛАССА
СОЗДАТЬ ЛЕКСЕМУ
Для очередного входного символа сделать
переход из состояния Л2
Л2/: Выполнить процедуру ДАШ
Перейти на A2k
/42m: Выполнить процедуру ДА20
Перейти на A2k
А2п: Выполнить процедуру ДАЗО
Перейти на A2k
А2о: Если в РЕГИСТРЕ ЗНАЧЕНИЯ не 1 (т. е. знак
операции отличен от =), то перейти на процедуру
обработки ошибки
Если РЕГИСТР ЗНАЧЕНИЯ содержит 1, то
перейти на А2Ь
А2р: Используя РЕГИСТР ОТНОШЕНИЯ и РЕГИСТР
ЗНАЧЕНИЯ, получить число из таблицы
отношений (рис. 4.4, 6)
Если это число равно нулю, то перейти на
процедуру, обрабатывающую ошибку
Заслать полученное число в РЕГИСТР
ОТНОШЕНИЯ
Перейти на А2Ь
A2q: Загрузить КОНЕЦ в РЕГИСТР КЛАССА
Перейти на А2Ь
А2г. Загрузить ЕСЛИ в РЕГИСТР КЛАССА
Перейти на А2Ь
A2s: Загрузить ВОЗВРАТ в РЕГИСТР КЛАССА
Перейти на А2Ь
4.4. Лексический блок
117
Alt: Загрузить ШАГ в РЕГИСТР КЛАССА
Перейти на Alb
А2и: Загрузить ДО в РЕГИСТР КЛАССА
Перейти на Alb
АЪа: Содержимое РЕГИСТРА ЗНАЧЕНИЯ увеличить
на 1 и умножить на 26
Сложить результат с содержимым РЕГИСТРА
УКАЗАТЕЛЯ
СОЗДАТЬ ЛЕКСЕМУ
A3: Для очередного входного символа сделать
переход из состояния ЛЗ
AM: Выполнить процедуру Да ID
АЗс: СОЗДАТЬ ЛЕКСЕМУ
АЗЬ: Загрузить ПРАВУЮ СКОБКУ в РЕГИСТР
КЛАССА
СОЗДАТЬ ЛЕКСЕМУ
Для очередного входного символа сделать
переход из состояния ЛЗ
АЗе: Выполнить процедуру ДА2Э
Перейти на АЗс
ЛЗ/: Выполнить процедуру ДАЗЭ
Перейти на АЗс
A3g: Выполнить процедуру ДАШ
Перейти на АЗс
В\с: Выполнить процедуру ДАЗО
Bib: СОЗДАТЬ ЛЕКСЕМУ
Qla: Пользуясь РЕГИСТРОМ ЗНАЧЕНИЯ как
индексом, получить из начального вектора
указатель и загрузить его в РЕГИСТР
ОБНАРУЖЕНИЯ
Если в РЕГИСТРЕ ОБНАРУЖЕНИЯ нуль,
перейти на процедуру, обрабатывающую ошибку
fll: Для очередного входного символа сделать
переход из состояния В\
ВЫ: Увеличить РЕГИСТР ОБНАРУЖЕНИЯ на 1
Для очередного входного символа сделать
переход из состояния В\
В\е: Выполнить процедуру ДАШ
Перейти на Bib
С\а- Загрузить КОНЕЦ ЦИКЛА в РЕГИСТР КЛАССА
118 Гл. 4. Лексический блок для языка MINI-BASIC
CI: Для очередного входного символа сделать
переход из состояния С1
С2Ь: СОЗДАТЬ ЛЕКСЕМУ
£2а: Загрузить ОПЕРАНД в РЕГИСТР КЛАССА
С2± Загрузить в РЕГИСТР УКАЗАТЕЛЯ базовый
адрес таблицы имен плюс содержимое РЕГИСТРА
ЗНАЧЕНИЯ
С2: Для очередного входного символа сделать
переход из состояния С2
Die: СОЗДАТЬ ЛЕКСЕМУ
D\a: Заслать ОПЕРАНД в РЕГИСТР КЛАССА
Переслать число из РЕГИСТРА ЗНАЧЕНИЯ
в РЕГИСТР ЧИСЛА
Для очередного входного символа сделать
переход из состояния D\
D\b: Умножить содержимое РЕГИСТРА ЧИСЛА на 10
Прибавить к РЕГИСТРУ ЧИСЛА число из
РЕГИСТРА ЗНАЧЕНИЯ
D\: Для очередного входного символа сделать переход
из состояния D\
D2a: Увеличить РЕГИСТР СЧЕТЧИКА на 1
Умножить на 10 содержимое РЕГИСТРА ЧИСЛА
Прибавить к РЕГИСТРУ ЧИСЛА число из
РЕГИСТРА ЗНАЧЕНИЯ
D2: Для очередного входного символа сделать
переход из состояния D2
D2b: Инициализировать РЕГИСТР СЧЕТЧИКА
единицей
Переслать число из РЕГИСТРА ЗНАЧЕНИЯ
в РЕГИСТР ЧИСЛА
Для очередного входного символа сделать
переход из состояния D2
D2c: Инициализировать РЕГИСТР СЧЕТЧИКА нулем
Для очередного входного символа сделать
переход из состояния D2
D3a: Инициализировать РЕГИСТР СЧЕТЧИКА нулем
D3: Для очередного входного символа сделать переход
из состояния D3
D4a: Если РЕГИСТР ЗНАЧЕНИЯ содержит 1 (т. е.
знаком операции оказался +), загрузить +1
в РЕГИСТР ЗНАКА
4.4. Лексический блок
\\9
Если РЕГИСТР ЗНАЧЕНИЯ содержит 2 (т. е.
знаком операции оказался —), загрузить —1
в РЕГИСТР ЗНАКА
Если РЕГИСТР ЗНАЧЕНИЯ содержит число
больше 2, перейти на процедуру,
обрабатывающую ошибку
D4: Для очередного входного символа сделать
переход из состояния D4
D5a: Загрузить +1 в РЕГИСТР ЗНАКА
Dbb: Переслать число из РЕГИСТРА ЗНАЧЕНИЯ
в РЕГИСТР ПОРЯДКА
D5: Для очередного входного символа сделать
переход из состояния D5
Dbc: Умножить содержимое РЕГИСТРА ПОРЯДКА
на 10
Прибавить к РЕГИСТРУ ПОРЯДКА число из
РЕГИСТРА ЗНАЧЕНИЯ
Для очередного входного символа сделать переход,
из состояния D5
D6a: СОЗДАТЬ ЛЕКСЕМУ
D6: Загрузить ОПЕРАНД в РЕГИСТР КЛАССА
Для очередного входного символа сделать
переход из состояния D6
Е\а: Загрузить ПЕРЕХОД НА в РЕГИСТР КЛАССА
El: Для очередного входного символа сделать
переход из состояния Е\
Elb: Загрузить ПЕРЕХОД НА ПОДПР в РЕГИСТР
КЛАССА
Для очередного входного символа сделать
переход из состояния Е\
ЕЧа: Загрузить СТРОКУ в РЕГИСТР КЛАССА
Е2Ь: Загрузить в РЕГИСТР СТРОКИ содержимое
РЕГИСТРА ЗНАЧЕНИЯ
£2: Для очередного входного символа сделать
переход из состояния Е2
Е2с: Умножить на 10 содержимое РЕГИСТРА СТРОКИ
Прибавить к РЕГИСТРУ СТРОКИ содержимое
РЕГИСТРА ЗНАЧЕНИЯ
Для очередного входного символа сделать
переход из состояния £2
120 Гл. 4. Лексический блок для языка MINI-BASIC
Fla: Загрузить ПРИСВОИТЬ в РЕГИСТР КЛАССА
F\: Для очередного входного символа сделать
переход из состояния F\
Fib: Загрузить ДЛЯ в РЕГИСТР КЛАССА
Для очередного входного символа сделать
переход из состояния F\
F2a: Загрузить в РЕГИСТР УКАЗАТЕЛЯ базовый
адрес таблицы имен плюс содержимое РЕГИСТРА
ЗНАЧЕНИЯ
F2: Для очередного входного символа сделать
переход из состояния F2
F3a: К содержимому РЕГИСТРА ЗНАЧЕНИЯ
прибавить 1 и умножить на 26
Прибавить результат к содержимому РЕГИСТРА
УКАЗАТЕЛЯ
F3: Для очередного входного символа сделать
переход из состояния F2
Gla: Загрузить КОММЕНТАРИЙ в РЕГИСТР
КЛАССА
СОЗДАТЬ ЛЕКСЕМУ
01: Для очередного входного символа сделать
переход из состояния G1
Н\с: Выполнить процедуру ДАЮ
Hlb: СОЗДАТЬ ЛЕКСЕМУ
Hla: Загрузить содержимое РЕГИСТРА ЗНАЧЕНИЯ
в РЕГИСТР ОТНОШЕНИЯ
Загрузить ОТНОШЕНИЕ в РЕГИСТР КЛАССА
HI: Для очередного входного символа сделать
переход из состояния Н\
Hid: Выполнить процедуру ДА20
Перейти на Hlb
Hie: Выполнить процедуру ДАЗО
Перейти на Hlb
Hlf: Выполнить процедуру ДАШ
Перейти на Hlb
Ml: Сравнить значение символа, на которое указывает
РЕГИСТР ОБНАРУЖЕНИЯ, с РЕГИСТРОМ
ЗНАЧЕНИЯ
Если значения равны, перейти к процедуре
4.4. Лексический блок
121
перехода, на которую указывает РЕГИСТР ОБ'
НАРУЖЕНИЯ
В противном случае заслать несовпадающее
значение, на которое указывает РЕГИСТР
ОБНАРУЖЕНИЯ, в РЕГИСТР ОБНАРУЖЕНИЯ
Если РЕГИСТР ОБНАРУЖЕНИЯ содержит О,
перейти на процедуру, обрабатывающую ошибку
Перейти на All
М2: Если РЕГИСТР ЗНАЧЕНИЯ содержит число,
не равное 5 (т. е. буква оказалась не Е), то
выполнить процедуру ДАШ и перейти на Bib
Если число равно 5, перейти на D3a
МЗ: Если РЕГИСТР ЗНАЧЕНИЯ содержит число,
не равное 5 (т. е. оказалось, что это не буква Е),
то выполнить процедуру ДА20 и перейти на
Bib
Если число равно 5, перейти на D3
ВЫХОДЗ: Выполнить процедуру ДАШ
ВЫХОД2: СОЗДАТЬ ЛЕКСЕМУ
ВЫ ХОД 1: Загрузить КОНЦ МАРКЕР в РЕГИСТР КЛАССА
СОЗДАТЬ ЛЕКСЕМУ
Выйти из лексического блока
ВЫХОД4: Выполнить процедуру ДА20
Перейти на ВЫХОД2
ВЫХОД5: Выполнить процедуру ДАЗО
Перейти на ВЫХОД2
ВЫХОД6: Выполнить процедуру ДАШ
Перейти на ВЫХОД2
Процедуры, связанные с обработкой констант
ДАШ: Загрузить 0 в РЕГИСТР ПОРЯДКА
ВЫЧИСЛИТЬ КОНСТАНТУ
Возврат
DA2D: Присвоить РЕГИСТРУ ПОРЯДКА значение РЕ-
ГИСТРА СЧЕТЧИКА с минусом
ВЫЧИСЛИТЬ КОНСТАНТУ
Возврат
ДАЗЭ: Если РЕГИСТР ЗНАКА содержит —1, сделать
РЕГИСТР ПОРЯДКА отрицательным
Вычесть РЕГИСТР СЧЕТЧИКА из РЕГИСТРА
ПОРЯДКА
ВЫЧИСЛИТЬ КОНСТАНТУ
Возврат
122 Гл. 4. Лексический блок для языка MINI-BASIC
Процедура для поиска номеров строк
ДАШ: (Используется метод расстановки. Индекс
расстановки вычисляется путем деления номера
строки на константу Р. На начальных стадиях
построения мы полагаем Р равным 101. По
индексу из таблицы указателей списков (см. разд. 3.9)
выбирается указатель на таблицу номеров строк,
имеющих этот индекс, организованную в виде
связного списка элементов. В этих элементах
нас интересуют только две их части: НОМЕР
СТРОКИ и СЛЕД ЭЛЕМЕНТ, содержащий
указатель на следующий элемент списка. Если
в списке, соответствующем индексу номера строки,
нет элемента, содержащего номер, который мы
ищем (возможно, из-за того, что список пуст),
создается новый элемент, он заполняется и
помещается в начало этого списка.)
Вычислить остаток от деления РЕГИСТРА
СТРОКИ на Р
Загрузить в РЕГИСТР УКАЗАТЕЛЯ содержимое
элемента таблицы указателей списков,
выбранного по индексу, равному только что
вычисленному остатку.
ДА1ЕЦИКЛ: Если в РЕГИСТРЕ УКАЗАТЕЛЯ нуль, то
Начало
(в списке больше нет элементов)
Создать новый табличный элемент
Загрузить в РЕГИСТР УКАЗАТЕЛЯ указатель
на новый элемент
Заслать в НОМЕР СТРОКИ нового элемента
содержимое РЕГИСТРА СТРОКИ
Заслать в СЛЕД ЭЛЕМЕНТ нового элемента
содержимое выбранного элемента таблицы
указателей списков
Заслать в выбранный элемент таблицы
указателей списков указатель на новый элемент таблицы
имен
Возврат
Конец
4.4. Лексический блок
123
Если НОМЕР СТРОКИ элемента списка, на
который указывает РЕГИСТР УКАЗАТЕЛЯ, равен
содержимому РЕГИСТРА СТРОКИ, то (номер
строки найден) выполнить возврат
В противном случае (номер строки не найден, и
нужно перейти к следующему элементу списка)
загрузить в РЕГИСТР УКАЗАТЕЛЯ то, что
содержится в СЛЕД ЭЛЕМЕНТЕ элемента списка,
на который указывает РЕГИСТР УКАЗАТЕЛЯ,
и перейти на ДА1ЕЦИКЛ
Построение любого значительного блока программного
обеспечения должно включать средства для его проверки и отладки.
В связи с этим мы включили в текст следующую «программу»,
которая вызывает каждый переход, не являющийся переходом
в состояние ошибки, и приводит в действие все части лексического
блока. Заметим, что она не является правильной программой
MINI-BASIC'a, но лексический блок не обнаруживает в ней ошибки.
Правильную последовательность лексем, которая должна
появиться на выходе при обработке этой программы, можно получить
путем моделирования лексического блока вручную (см. упр. 4.9).
Если эта последовательность лексем действительно является
выходом при некоторой реализации построенного лексического блока,
то разработчик может быть в значительной степени уверен в том,
что при программировании не сделано ошибок. Если эта
последовательность не получается, то обнаружена ошибка. Для отладки
разработчик может заготовить таблицу правильных значений
различных внутренних переменных лексического блока. В разд. 2.14
мы сделали это для процессора, обрабатывающего константы, но
здесь мы этого делать не будем.
1 REM ПРОГРАММА ОТЛАДКИ ЛЕКСИЧЕСКОГО БЛОКА
5 REM А1 + ='( ).
13 LET F 1 = ■? / - (ЬЗ < > Ч)) = * < (
W LET G = - 3 TO .fe.5 + .01 = .1) + .fl( .fe.
50 F OR I = .} E Ь fl STEP . ЭЕ + t> = 1.3E - 1) (1.ЭЕЧ
53 IF 10 Eb +'3E1 (1ELGQTO 1 5 = H I >
<0 NEXT ЕЭ
<5 + A T В ( С ) 5 ( D
<5 GOSUB 1)G0T0 fe.
so ( q
• 55 ) . Ь RETURN )END >=<=<)
Ь0 7
54 =J0+Kl+L5+M3+»K+O5+Pb+Q7+Ra+Sq+T+U+V+H+X+Y+Z
124
Гл. 4. Лексический блок для языка MINI-BASIC
Упражнения
1. Определите содержимое каждой переменной лексического блока при
обработке каждого символа данного оператора.
010 IF X>Y1+2E3 GOTO 20
2. Составьте сообщения об ошибках для каждого пустого элемента лексического
блока.
3. Укажите, какие изменения нужно внести в лексический блок, если таблицу
транслитерации на рис. 4.5 изменить так, как показано на рисунке
Е
Е
5
+
+
1
-
-
2
=
=
1
Укажите изменения, которые нужно внести в лексический блок, если
множество выходных лексем изменить так, чтобы различались унарное и
бинарное употребление знаков + и —. На рис. 4.1 лексема АРИФМЕТ ОПЕРАЦИЯ
будет по-прежнему указывать на бинарные операции +, —, *, /, f
(например, 1+1), а новая лексема УНАРНАЯ ОПЕРАЦИЯ будет использована для
унарных операций + и — (например, —1). Значения лексем + и —
останутся прежними.
Напишите на MINI-BASIC'e программу, вызывающую все переходы на
рис. 4.6, которые может вызывать правильная программа, написанная на
этом языке.
Лексический блок допускает все правильные, а также многие неправильные
программы на MINI-BASIC'e. Найдите на рис. 4.6 веете переходы, прн замене
которых переходами в состояние ошибки новый блок будет тем не менее
допускать все правильные программы на MINI-BASIC'e.
Лексический блок допускает такой неправильный оператор
IF X1=X2 GOSUB 10
Однако этот оператор «не лишен смысла» и мог бы быть включен в
потенциальное расширение языка MINI-BASIC. Найдите еще три неправильных, но
имеющих смысл оператора.
8. Укажите, как бы изменились процедуры из разд. 4.4, если бы для
запоминания состояний использовался явный метод.
Какое множество лексем порождает лексический блок для отладочной
цепочки, приведенной в конце разд. 4.4?
Постройте лексический блок для языка MINI-BASIC при условии, что
используются пробелы, т. е. зарезервированные слова, переменные и константы
должны разделяться пробелами.
11. Запрограммируйте лексический блок для языка MINI-BASIC на любом языке.
9.
10.
Упражнения
125
12. Постройте лексический блок для автомата, решающего задачу 2.22. Входом
для лексического блока служат символы а, б, в, . . ., я. Выходами являются
лексемы ОДИН, ДВА ДЕСЯТЬ, ОДИННАДЦАТЬ
ДВАДЦАТЬ ДЕВЯНОСТО, СТО, ДВЕСТИ, СТА, СОТ.
13. Постройте лексический блок для языка Снобол.
14. Постройте лексический блок для языка ассемблера, которым вы пользуетесь.
15. Постройте лексический блок для кода Морзе. Входами служат «точка», «тире»
и «пауза». Выходами являются лексемы, соответствующие всем буквам,
цифрам, а также знакам пунктуации, которые представляются этим кодом.
5
Автоматы с магазинной памятью
5.1. Определение автомата с магазинной памятью
Конечный автомат может решать лишь такие вычислительные
задачи, которые требуют фиксированного и конечного объема памяти.
В компиляторе, однако, возникает много задач, которые не могут
быть решены при таком ограничении, и поэтому нам нужна модель
более сложного автомата. Рассмотрим, например, задачу обработки
скобок в арифметических выражениях. Арифметическое выражение
может начинаться с любого количества левых скобок, и компилятор
должен проверять, имеется ли в выражении точно такое же число
соответствующих правых скобок. Каждый раз самая левая из
скобок в выражении будет иметь особую «роль», так как каждая из
таких ролей требует разного числа соответствующих правых
скобок для завершения выражения. Другими словами, компилятор
должен эффективно подсчитывать левые скобки, чтобы
сбалансировать их. Разумеется, конечное множество состояний не годится
для запоминания числа необходимых правых скобок, так как
множество этих чисел бесконечно. Для систематического решения этой
проблемы, связанной с выражениями, а также для решения
многих других проблем компиляции необходимо использовать в
компиляторе модели более мощных автоматов.
Чтобы получить более мощный автомат, память конечного
автомата расширяется за счет дополнительного механизма хранения
информации. Один из методов хранения информации, который
оказался весьма полезным в компиляции и просто реализуется,— это
использование магазина или стека1). Основная особенность
магазинной памяти с точки зрения работы с нею состоит в том, что
символы можно помещать в магазин и удалять из него по одному,
причем удаляемый символ — это всегда тот, который был помещен
в магазин последним. Последовательность символов в магазинной
памяти можно сравнить со стопкой тарелок в кафетерии. Служащие
кафетерия ставят чистые тарелки на верх стопки, и посетители
затем берут их тоже сверху. Таким образом, посетитель всегда берет
*) В данной книге и очень часто вообще в программировании эти термины
считаются синонимами, хотя в литературе по теории автоматов они различаются,
причем стек имеет более широкий смысл. Мы пошли на компромисс, в более
«автоматных» разделах употребляя термин магазин, а в более «программистских»
переходя на стек.— Прим. ред.
5.1. Определение автомата с магазинной памятью
127
из стопки тарелку, поставленную туда последней. В подобных же
терминах можно описать и функционирование магазинной памяти.
Когда информация помещается в магазин, мы говорим, что она
«вталкивается» в магазин. Когда информация удаляется из
магазина, мы говорим, что она «выталкивается» из него 1>. Говорят, что
С
А
В
А
V
а
информация, только что поступившая в магазин, находится в его
верхушке или наверху. Хотя такое представление о работе с
магазином полезно, оно мало что говорит 6 том, как реализовать
магазин в компиляторе.
Мы изобразили магазин на рис. 5.1, а. На дне магазина
находится символ V, а на верху — символ С. Символы расположены
в том порядке, в каком они поступали в магазин. Сначала поступил
символ V, затем нижнее А, затем В, затем верхнее А и наконец
символ С. Если втолкнуть в магазин символ D, то магазин будет
выглядеть так, как показано на рис. 5.1, б, где D — верхний
символ магазина. Если же, наоборот, вытолкнуть из магазина верхний
символ С, то верхним символом окажется А, и магазин будет
выглядеть, как показано на рис. 5.1, Ь. В обоих случаях изменениям
подвергается только верх магазина, а остальные символы остаются
неизменными. Символ у — это специальный символ, который
помечает начало или «дно» магазина и называется маркером дна.
Он используется только как метка дна и никогда не выталкивается
из магазина. Так, если X — верхний символ магазина, как на
рис. 5.1, г, то мы знаем, что других символов в магазине нет. В этом
') Эти термины, как, собственно, и магазин, навеяны аналогией с магазином
■автоматического оружия и патронами, которые вталкиваются в него или
выталкиваются. Стек надо бы по-русски назвать стопкой, да, наверное, поздно,— Прим.
В
с
А
В
А
7
6
А
В
А
V
в
И
Рис. 5.1.
128
Гл. 5. Автоматы с магазинной памятью
случае говорят, что магазин пуст. Магазин на рис. 5.1, а можно
также изобразить в виде цепочки одним из следующих способов:
1. С А В А V
2. К А В А С
Представление магазина в первой строке соответствует соглашению
о том, что его «верхний символ находится слева», а во второй
строке — что «верхний символ справа». Которое из двух
соглашений использовано, можно определить по маркеру дна.
И)
Состояние
1
Входная цепочка
Рис. 5.2.
С
А
В
А
V
> Магазин
1
0
0
1
1
1
0
н
1 1
Одной из моделей автомата, в которых используется магазинный
принцип организации памяти, является автомат с магазинной
памятью (или сокращенно МП-автомат). В нем очень просто
комбинируется память конечного автомата и магазинная память.
МП-автомат может находиться в одном из конечного числа
состояний и имеет магазин, куда он может помещать и откуда может
извлекать информацию.
Как и в случае конечного автомата, обработка входной цепочки
осуществляется за ряд мелких шагов. На каждом шаге действия
автомата конфигурация его памяти может измениться за счет
перехода в новое состояние, а также вталкивания символа в магазин
или выталкивания из него. Однако в отличие от конечного автомата.
МП-автомат может обрабатывать один входной символ в течение
нескольких шагов. На каждом шаге управляющее устройство
автомата решает, пора ли закончить обработку текущего входного
символа и получить, если это так, новый входной символ или
продолжить обработку текущего символа на следующем шаге. На
рис. 5.2 изображена одна из конфигураций, которая может возник-
5.1. Определение автомата с магазинной памятью 129
нуть при обработке некоторым гипотетическим МП-автоматом
входной цепочки 100110. Для большей наглядности входная
цепочка изображена записанной в ячейках файла или ленты с
указателем на входной символ, подвергающийся в данный момент
обработке.
Каждый шаг процесса обработки задается множеством правил,
использующих информацию трех видов:
1) состояние,
2) верхний символ магазина,
3) текущий входной символ.
Это множество правил называется управляющим устройством или
механизмом управления. На рис. 5.2 информация, поступающая
в управляющее устройство, такова: состояние 6, верхний симеол
магазина С, текущий входной символ 0.
В зависимости от получаемой информации, управляющее
устройство выбирает либо выход из процесса (т. е. прекращает
обработку), либо переход в новое состояние. Переход состоит из трех
операций: над магазином, над состоянием и над входом.
Возможные операции таковы:
Операции над магазином
1. Втолкнуть в магазин определенный магазинный символ.
2. Вытолкнуть верхний символ магазина.
3. Оставить магазин без изменений.
Операция над состоянием
1. Перейти в заданное новое состояние.
Операции над входом
1. Перейти к следующему входному символу и сделать его
текущим входным символом.
2. Оставить данный входной символ текущим, иначе говоря,
держать его до следующего шага.
Обработку входной цепочки МП-автомат начинает в некотором
выделенном состоянии при определенном содержимом магазина,
а текущим входным символом является первый символ входной
цепочки. Затем автомат выполняет операции, задаваемые его
управляющим устройством. Если происходит выход из процесса,
обработка прекращается. Если происходит переход, то он дает
новый верхний магазинный символ, новый текущий символ, автомат
переходит в новое состояние и управляющее устройство определяет
новое действие, которое нужно произвести.
' Ф. Льюнс и др.
130
Гл. 5. Автоматы с магазинной памятью
Чтобы управляющие правила имели смысл, автомат не должен
требовать следующего входного символа, если текущим символом
является концевой маркер, и не должен выталкивать символ из
магазина, если это маркер дна. Поскольку маркер дна может
находиться исключительно на дне магазина, автомат не должен также
вталкивать его в магазин.
Теперь подытожим, как задается МП-автомат1). Он определяется
следующими пятью объектами:
1) конечным множеством входных символов, в которое входит
и концевой маркер;
2) конечным множеством магазинных символов, включающим
маркер дна;
3) конечным множеством состояний, включающим начальное
состояние;
4) управляющим устройством, которое каждой комбинации
входного символа, магазинного символа и состояния ставит
в соответствие выход или переход. Переход в отличие от
выхода заключается в выполнении операций над магазином,
состоянием и входом, как было описано выше. Операции,
которые запрашивали бы входной символ после концевогЪ
маркера или выталкивали из магазина, а также вталкивали
в него маркер дна, исключаются;
5) начальным содержимым магазина, которое представляет собой
(при условии, что верхний символ считается расположенным
справа) маркер дна, за которым следует (возможно, пустая)
цепочка других магазинных символов.
МП-автомат называется МП-распознавателем, если у него два
выхода — ДОПУСТИТЬ и ОТВЕРГНУТЬ. Говорят, что цепочка
символов входного алфавита (исключая концевой маркер)
допускается распознавателем, если под действием этой цепочки с
концевым маркером автомат, начавший работу в своем начальном
состоянии и с начальным содержимым магазина, делает ряд
переходов, приводящих к выходу ДОПУСТИТЬ. В противном случае
цепочка отвергается.
При описании переходов МП-автомата будем обозначать
действия автомата словами ВЫТОЛКНУТЬ (или для краткости ВЫ-
ТОЛК), ВТОЛКНУТЬ (или ВТОЛК), СОСТОЯНИЕ, СДВИГ и
ДЕРЖАТЬ, причем:
ВЫТОЛКНУТЬ означает вытолкнуть верхний символ магазина,
ВТОЛКНУТЬ (Л), где А —магазинный символ, означает
втолкнуть символ А в магазин,
г) Заметим, что описываемая здесь и используемая до конца этой книги модель
в теории автоматов называется детерминированным МП-автоматом, тогда как
МП-автомат в общем случае может быть недетерминированным (ср. с
недетерминированным конечным автоматом в разд. 2.12).— Прим. ред.
5.1. Определение автомата с магазинной памятью
131
СОСТОЯНИЕ (s), где s — состояние, означает, что следующим
состоянием становится s,
СДВИГ означает, что текущим входным символом становится
следующий входной символ. В некоторых реализациях это
может означать сдвиг указателя на входе,
ДЕРЖАТЬ означает, что текущий входной символ надо держать
. до следующего шага, т. е. оставить его текущим (в некоторых
реализациях — оставить указатель на прежнем месте).
Когда нам нужно определить переход, который оставляет
содержимое магазина неизменным, это выражается в том, что мы
опускаем слова ВЫТОЛКНУТЬ и ВТОЛКНУТЬ. Хотя ДЕРЖАТЬ
по существу означает, что СДВИГ отсутствует, мы всегда будем
записывать операции над входом в явном виде, чтобы читателю
было понятнее, что происходит. Если автомат содержит в точности
одно состояние, мы будем опускать слово СОСТОЯНИЕ.
Сейчас мы опишем, как применить МП-распознаватель к
проблеме скобок. Каждый раз, когда встречается левая скобка, в
магазине будет вталкиваться символ А. Когда будет обнаружена
соответствующая правая скобка, символ А будет выталкиваться из
магазина. Цепочка отвергается, если на входе остаются правые
скобки, а магазин пуст (т. е. во входной цепочке есть лишние
правые скобки) или если цепочка прочитана до конца, а в магазине
остаются символы А (т. е. входная цепочка содержит лишние левые
скобки). Цепочка допускается, если к моменту прочтения входной
цепочки до конца магазин опустошается. Полное определение
таково:
1. Входное множество {(,), —|}.
2. Множество магазинных символов {А, у}.
3. Множество состояний {s}, где s — начальное состояние.
4. Переходы:
(, A, s= ВТОЛКНУТЬ (А), СОСТОЯНИЕ (s), СДВИГ
(, V, 8 = ВТОЛКНУТЬ (А), СОСТОЯНИЕ (s), СДВИГ
), A, s = ВЫТОЛКНУТЬ, СОСТОЯНИЕ (s), СДВИГ
), V, sОДЕРЖАТЬ
Н, A, s = ДЕРЖАТЬ
•Ч, V, s = ДОПУСТИТЬ
Здесь комбинации входного символа, магазинного символа
и состояния расположены слева от знака равенства, а
переходы — справа от него.
5. Начальное содержимое магазина V.
•Чтобы продемонстрировать работу автомата, мы изобразили
на рис. 5.3, как он обрабатывает цепочку
(()())
5*
132
Гл. 5. Автоматы с магазинной памятью
¥ V
(
(
(
(
(
(
)
f
i
(
)
)
а
н
А
А
V
'
)
\
(
)
)
б
\
)
S
(
)
)
д
н
А
А
V
н
V
/
S » 4
V
1 ( ) ( ) ) н
d
( 1 ) ( ) j ~>
г
(
(
)
(
)
)
н
пи*
1/7V
ЛОПУСТИТЬ
Рис. 5.3.
5.1. Определение автомата с магазинной памятью 133
На рисунке показан каждый шаг процесса обработки, начиная
с начальной конфигурации на рис. 5.3, а и кончая допускающей
конфигурацией на рис. 5.3, з. Такое изображение
последовательности конфигураций МП-автомата требует много места, поэтому
представим ее в таком более компактном виде:
а:
б\
6:
г '.
д:
е :
ж:
з :
V
VA
VAA
VA
VAA
VA
V
ДОПУСТИТЬ
м
[s]
W
M
w
И
Is]
(OO)H
()())H
)())4
0)4
))H
)4
4
В этом линейном представлении конфигураций МП-автомата
магазин изображен слева, состояние — в середине, а необработанная
часть входной цепочки — справа. Эта часть входной цепочки
включает текущий входной символ и символы, которые следуют после
( ) н
втолкнуть (л)
сдвиг
ВТОЛКНУТЬ^)
сдвиг
ВЫТОЛКНУТЬ
сдвиг
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
Рис 5.4.
него. Чтобы восстановить всю входную цепочку, нужно вернуться
назад, к исходной конфигурации. Информацию, поступающую
в управляющее устройство, выделить очень легко, так как символ,
расположенный на верху магазина, находится непосредственно
■слева от состояния, а текущий входной символ — справа от него.
Многие из МП-автоматов, применяемых на практике, имеют лишь
одно состояние (как в этом примере), и в подобных случаях мы, как
правило, опускаем информацию, касающуюся состояний.
Управляющее устройство этого автомата с одним состоянием
можно представить в виде управляющей таблицы, как на рис. 5.4,
где показаны действия автомата для каждого сочетания входного
символа и верхнего символа магазина. Столбцы таблицы
обозначены входными символами, а на пересечении строк и столбцов
134
Гл. 5. Автоматы с магазинной памятью
обозначены соответствующие им действия. Так как этот
конкретный автомат имеет лишь одно состояние, информация о состоянии
опущена.
Мы будем пользоваться таблицами такого вида (т. е. со
столбцами для входных символов и строками для символов магазина)
как стандартным представлением МП-автоматов с одним
состоянием.
5.2. Некоторые обозначения для множеств цепочек
Чтобы привести несколько примеров обработки множеств цепочек
МП-автоматом, мы введем некоторые обозначения. Начнем с
определения трех операций над множествами цепочек. Применяя эти
операции к множествам цепочек, мы получаем другие множества
цепочек. Эти три операции — объединение, конкатенация и
итерация Клини (или просто итерация).
Объединение. Если Р и Q — множества цепочек, то объединение Р
и Q — это множество цепочек, которые принадлежат Р или Q или
обоим множествам одновременно. Хотя обычное
теоретико-множественное обозначение для объединения — это Р U Q, в теории
автоматов объединение множеств часто обозначается как P+Q.
Некоторые примеры объединения:
{FOR, IF, THEN} + {DO, IF} = {FOR, IF, THEN, DO};
{AB, X3} + {Y, e} = {AB, X3, Y, e};
{все цепочки из нулей и единиц, начинающиеся с 0 и
заканчивающиеся 1}
+ {все цепочки из нулей и единиц, начинающиеся с 0 и
заканчивающиеся 0}
= {все цепочки из нулей и единиц, начинающиеся с 0};
{простые переменные Алгола}
+ {переменные с индексами Алгола}
= {переменные Алгола}.
Конкатенация. Конкатенация, или сцепление двух цепочек,
определяется как цепочка, получаемая их соединением, или
«приписыванием», друг к другу. Конкатенацией цепочек ОКРЕСТ и НОСТЬ,.
например, является цепочка ОКРЕСТНОСТЬ. Длина получившейся
цепочки равна сумме длин цепочек, участвующих в конкатенации.
Так как длина пустой цепочки равна нулю, то в результате ее
конкатенации с любой цепочкой последняя не изменится. Например,,
конкатенацией цепочек ОКРЕСТ и е остается цепочка ОКРЕСТ
длины шесть.
5.2. Некоторые обозначения для множеств цепочек
135
Конкатенацию как операцию над цепочками можно расширить
до операции над множествами цепочек. Если Р и Q — множества
.цепочек, то конкатенацией Р и Q называется множество, состоящее
яз всевозможных конкатенации цепочек из f с цепочками из Q.
Конкатенация множеств Р и Q обозначается P-Q. Точку можно,
однако, опускать и писать PQ. Некоторые примеры конкатенации:
{10} {1, 00}={101, 1000};
\аВ, X, ABY}{e, Y}={AB, X, ABY, XY, ABYY};
{все буквы} {все цепочки из букв и цифр}—
= {все цепочки, начинающиеся с буквы, за которой следует
цепочка из букв и цифр}.
Конкатенация множества R с самим собой, т. е. RR или R-R,
обозначается также R*. Например {0, 11}*= {00, 011, ПО, 1111}.
Аналогично R1, где i — целое положительное число, обозначает
множество R-R'...-R. Удобно считать, что
Я°={е}.
Это определение согласуется с правилом умножения степеней,
-а именно
так что нетрудно заметить, что обозначения, связанные с
конкатенацией, во многом те же, что и для умножения.
Итерация Клини. Полезно иметь обозначение для множества всех
щепочек, состоящих из символов данного алфавита. Если А —
множество символов алфавита, то будем говорить, что А*— множество
всех цепочек, составленных из символов множества А.
Предполагается, в частности, что А* всегда содержит пустую цепочку е.
Так, {0, 1}* обозначает множество всех цепочек в алфавите
40, П.
Описанная операция называется итерацией Клини или просто
итерацией.
Итерацию Клини как операцию над алфавитами можно
расширить до операции над другими множествами цепочек. Например,
{IF, THEN} * обозначает бесконечное множество цепочек, которое
«ключает е, IF, THEN, IFIF, THENIFTHEN, IF THENIFIF.
Если R — множество цепочек, то мы определим множество R*
«бесконечным рядом
В этом выражении + обозначает, разумеется, рассмотренную
*ыше операцию объединения.
Часто используется вариант итерации Клини, обозначаемый А+
я называемый позитивной итерацией. Если А — некоторое мно-
136
Гл. 5. Автоматы с магазинной памятью
жество цепочек, то множество Л+ определяется равенством
А+=АА*.
Такии образом, А+ можно выразить как
Л+=Л1+Л2+Л3+... .
Множество Л+ в точности совпадает с множеством Л*, за
исключением того, что Л+ содержит пустую цепочку е лишь тогда, когда ее
содержит А.
Эти три операции обладают тем свойством, что при их
применении к регулярным множествам получается регулярное множество.
(Регулярным называется множество, которое можно распознать
конечным автоматом.) На самом деле любое регулярное множества
цепочек в данном алфавите можно получить путем применения этих
трех операций к символам алфавита. В оставшейся части данного'
раздела мы дополним эти операции некоторыми способами задания
множеств, позволяющими получать нерегулярные множества.
Первый способ заключается в использовании переменных как
показателей при обозначении множеств в виде степеней. Простым
примером может служить
{1"0п|я>0}.
Так обозначается множество цепочек, состоящих из некоторого
количества единиц, за которыми следует такое же количество
нулей. Вот некоторые цепочки принадлежащие множеству:
10
111000
11111110000000
Вообще говоря, этот способ обозначения заключается в том, что
в качестве показателей степени используются буквы и указываются
отношения между ними, а также границы их значений.
Еще один пример:
{1п0т\п^т>0}.
Эта формула обозначает множество цепочек, состоящих из
некоторого числа единиц, за которыми следует такое же или меньшее
число нулей; сюда входят, например, цепочки
111000
1110
Аналогичным образом множество
{a"bmcmd" |л>0, т>0}
состоит из цепочек, в которых после некоторого числа символов а
следует некоторое число символов Ь, затем — некоторое число сим-
5.3. Пример распознавания множества МП-автоматом 137
волов с и некоторое число символов d, причем число символов а
равно числу символов d, а число Ь совпадает с числом с. Этому
множеству принадлежат такие, например, цепочки:
abbccd
aaabbbbccccddd
Второй способ — это обозначение операции обращения цепочки
•с помощью верхнего индекса г. Так, например
(abc)r—cba.
Используя операцию обращения, мы можем писать формулы вроде
{до, дог|до принадлежит множеству (0+1)*},
которая обозначает множество цепочек, состоящих из
произвольных цепочек из нулей и единиц, за которыми следуют их
обращения. Это в точности множество цепочек четной длины, которые
читаются слева направо так же, как и справа налево. Вот образцы
таких цепочек:
1110110111
0000
Хотя эти новые способы обозначения позволяют задавать
нерегулярные множества и описывать работу некоторых МП-автоматов,
они не достаточно общие, чтобы описывать реальные языки
программирования. Поэтому примерам и упражнениям этой главы не
достает непосредственной практической мотивировки с точки
зрения языков программирования. Тем не менее их достаточно для
выработки правильного интуитивного понимания процессов
обработки цепочек с помощью МП-автоматов.
5.3. Пример распознавания множества МП-автоматом
Чтобы привести еще один пример распознавания МП-автоматом,
использующим более чем одно состояние, рассмотрим задачу
распознавания множества
{0п1"|м>0}.
В качестве первого шага построения МП-распознавателя опишем
словами схему распознавания:
Начальный отрезок цепочки, состоящий из нулей, вталкивается
в магазин. Затем каждый раз, когда встречается единица, один
нуль выталкивается из магазина. Цепочка допускается тогда и
только тогда, когда в момент завершения считывания цепочки
магазин пуст. Если после первого вхождения единицы
встречается нуль, цепочка сразу отвергается.
1
2
3
4
5
6
7
8
1
2
3
4:
5:
V
[*,]
0 0
0 1 1 1 н
V Z [s, ] 001 IH
V Z Z [s, ] 01 IH
V Z Z Z [s, ] 1 1 1 H
VZZ [*j] 1 1 -,
VZ [*2] H
V Is21 -4
ДОПУСТИТЬ
tx
V [s, ] 0 0 1 0 1 1 4
V Z [s, ] 0 1 0 1 H
v2г [s,] ioi и
VZ [s2] 01H
ОТВЕРГНУТЬ
6
Рис 5.5.
Z
Состояние 1
\sv\tHIV/iiM4& 1
V
z
Состояние 2
V
0 1 H
СОСТОЯ HME(S,)
втолкнуть (z)
СДВИГ
СОСТОЯНИЕ ($j)
втолкнутьсг,
СДВИГ
СОСТОЯНИЕ^)
ВЫТОЛКНУТЬ
СДВИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
0 1 Н
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
СОСТОЯНИЕ (S2)
вытолкнуть
СДВИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
Начальное содержимое магазина; V
Рис. 5.6.
5.4. Расширенные операции над магазином
139
Чтобы реализовать эту схему, нужно завести магазинный символ,
представляющий входной символ 0. Хотя в качестве магазинного
символа можно использовать сам нуль, во избежание путаницы мы
предпочитаем пользоваться символом Z. Процесс обработки
распадается на две фазы. Первая из них — фаза «вталкивания»; в этой
.фазе нули, начинающие цепочку, помещаются в магазин. Эти нули
представляются магазинными символами Z. Вторая фаза — фаза
«выталкивания»; здесь при появлении единицы из магазина
удаляется Z, а при появлении нуля, цепочка немедленно отвергается.
Чтобы автомат «помнил», в какой фазе он находится, мы введем
два состояния S* и s2, соответствующие этим фазам.
Прежде чем детально определить управление МП-автоматом,
посмотрим, как он работает, на примере последовательности
конфигураций, возникающей при обработке цепочки 0 00 1 1 1, которую
юн допускает. Эта последовательность конфигураций показана на
рис. 5.5, а. Мы изобразили также на рис. 5.5, б последовательность
конфигураций автомата, отвергающую цепочку 0 0 10 1 1. После
конфигурации 3 на рис. 5.5, б автомат переходит в состояние s2,
запоминая, что началась фаза выталкивания. Затем, встретив на
входе нуль, он отвергает цепочку.
Один из удобных способов описания механизма управления
заключается в том, чтобы задавать множество управляющих
таблиц, по одной для каждого состояния, причем каждая таблица
имеет стандартный вид с одним состоянием. Две управляющие
таблицы для нашего примера изображены на рис. 5.6. Чтобы уста-
«овить, какое действие должно выполняться для данной
комбинации состояния, входа и магазинного символа, нужно сначала
найти управляющую таблицу для данного состояния, а затем по
•входному и магазинному символам определить нужное действие
в выбранной управляющей таблице. На рис. 5.6 комбинация s2, 1,
Z вызывает выполнение операций СОСТОЯНИЕ (s2),
ВЫТОЛКНУТЬ, СДВИГ.
В итоге полное определение МП-автомата, распознающего
множество {0"l"|n>0}, таково:
1) входное множество {0, 1, —|},
2) множество магазинных символов {Z, V).
3) множество состояний {sj, s2}, где St — начальное состояние,
4) переходы, изображенные на рис. 5.6,
5) начальное содержимое магазина V-
5.4. Расширенные операции над магазином
На самом деле имеется много разных способов определения класса
моделей автоматов, переходы которых выбираются в зависимости от
входа, состояния и верхних магазинных символов, а операции
140
Гл.5. Автоматы с магазинной памятью
затрагивают только верхнюю часть магазина. Каждую из этих
моделей принято называть автоматом с магазинной памятью.
Таким образом, модель автомата, описанная в разд. 5.1,— это
как раз пример модели МП-автомата.
В тех случаях, когда может возникнуть недоразумение, мы будем
называть МП-автоматы такого типа примитивными
МП-автоматами.
Есть несколько причин для того, чтобы начать изучение МП-
автоматов с примитивной модели. Одна из них в том, что принципы
МП-обработки проявляются в этой модели в простейшей форме.
Вторая причина заключается в том.что эта модель — математически
определенное понятие, которое можно применять при доказательстве
теорем или при решении задач, приведенных в конце этой главы.
Она служит стандартной моделью в том смысле, что термин «МП-
автомат» сохраняется для всех автоматов, которые используют
магазин аналогичным образом и обладают той же способностью
распознавания (например, могут распознавать те же множества), что
и примитивные МП-автоматы.
Мы называем примитивные автоматы «примитивными» по той
причине, что их переходы включают не более одной операции втал-i
кивания или выталкивания. Эти операции можно было бы
использовать при аппаратной реализации МП-автомата в некоторой
реальной машине. Однако, если МП-автомат взять за основу при
разработке программной реализации алгоритмов, эти операции
оказываются неестественно ограниченными. В данном разделе мы
будем рассматривать операции над магазином с точки зрения их
программирования.
Как только по состоянию, магазинному символу и входу
выбран переход, с точки зрения программирования разумно сделать
как можно больше, прежде чем вновь обращаться к управляющей
информации и выбирать новый переход. Другими словами,
разработчик может захотеть связать с переходами более общие процедуры
и не ограничивать работу с магазином операциями вталкивания и
выталкивания одного символа. Предположим, например, что надо
поместить в магазин два символа. При желании можно втолкнуть
в магазин первый символ и перейти в состояние, единственное
назначение которого — поместить в магазин второй символ при
следующем переходе. Однако этот метод с двумя переходами является
неэффективным и неестественным по сравнению с другим очевидным
методом, когда оба вталкивания выполняются одной процедурой
перехода. Так как переход с двумя вталкиваниями можно
промоделировать с помощью двух переходов примитивного МП-автомата,
мы можем назвать такое вталкивание двух символов «расширенной
операцией над магазином», а термин МП-автомат распространим
на устройства, которые могут вталкивать в магазин по два символа
сразу.
5.4 Расширенные операции над магазином
141
Методы, описанные в этой книге, включают процедуры
переходов многих типов. В принципе результат каждой из этих
процедур можно получить, комбинируя примитивные переходы; поэтому
мы по-прежнему называем автоматы, в которых они используются,
МП-автоматами.
В этом разделе мы введем расширенную операцию над
магазином, назовем ее ЗАМЕНИТЬ и проиллюстрируем ее
использование. Другие расширенные операции будут вводиться в
последующих главах по мере надобности.
Операция ЗАМЕНИТЬ состоит в выталкивании верхнего
символа магазина и последующем выполнении нескольких
вталкиваний. Последовательность символов, которые операция ЗАМЕНИТЬ
должна помещать в магазин, указывается в качестве ее аргумента.
Так, мы пишем
ЗАМЕНИТЬ (ABC)
если в магазин нужно поместить ABC. Это эквивалентно
последовательности операций
ВЫТОЛКНУТЬ
ВТОЛКНУТЬ(Л)
ВТОЛКНУТЬ(В)
ВТОЛКНУТЬ(С)
Таким образом, левый символ последовательности помещается
в магазин первым и оказывается ниже остальных символов этой
последовательности. Если операция ЗАМЕНИТЬ (ABC)
применяется к магазину
V X У Z
то новый магазин выглядит так:
V X У А В С
Операция ЗАМЕНИТЬ широко и систематически используется
в последующих главах. В данный момент мы рассматриваем ее
просто как сокращение для последовательности примитивных
операций над магазином, которую программист может включить как
часть одной процедуры перехода.
Чтобы проиллюстрировать использование операции
ЗАМЕНИТЬ, вернемся к задаче распознавания множества {0"1"|«>0}.
В разд. 5.3 мы видели, что можно построить распознаватель,
который работает в двух фазах — «вталкивания» и «выталкивания».
Мы строили такой автомат, пользуясь для запоминания фазы
управляющим состоянием. Теперь для этой же задачи построим
другой МП-автомат.
Новый МП-автомат использует тот же метод счета, что и
предыдущий автомат. Z вталкивается в магазин при каждом появлении
142
Гл. 5. Автоматы с магазинной памятью
на входе символа 0 и выталкивается из него при каждом появлении
на входе символа 1. Однако для различения фаз вталкивания и
выталкивания используется иная стратегия. Во время фазы втал-
0 1 ч
X
ЗАМЕНИТЬ (ZX)
СДВИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
вытолкнуть
дер; (ать
вытолкнуть
сдвиг
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
Начальное содержимое магазина ■ V X
Рис 5.7.
кивания в верхней ячейке магазина хранится новый магазинный
символ X. Единственное его назначение—напоминать
управляющему устройству, что автомат находится в фазе вталкивания. Когда
впервые встречается единица^ X выталкивается из магазина и
автомат начинает
сопоставлять символы Z и
единицы. Наличие процедуры
ЗАМЕНИТЬ позволяет нам
реализовать этот алгоритм
с помощью единственного
состояния, как показано
на рис. 5.7.
Последовательность конфигураций
при распознавании*
цепочки 0 0 0 1 1 1 показана на
рис. 5.8. Эту
последовательность конфигураций
можно сравнить с рис.
5.5, а, где изображена
обработка этой же цепочки
предыдущим автоматом.
Операция ЗАМЕНИТЬ
используется, когда на
верху магазина X, а на входе 0. За один шаг эта операция выталкивает
из магазина ненужный верхний символ X, помещает на его место
символ для запоминания вхождения 0, а затем помещает на верх
магазина другой X, чтобы указать, что автомат по-прежнему в
«фазе вталкивания».
1
2
3
4
5:
6:
7:
8:
9:
V X
V Z X
V Z Z X
V Z Z Z X
V Z Z Z
V Z Z
V Z
V
ДОПУСТИТЬ
Рис
5.8.
00011 t н
0 0
0
1 1 1 н
11 И
111-1
1 1 И
1 1 н
1 н
н
5.5. Перевод с помощью МП-автоматов
143
В этом примере впервые используется операция ДЕРЖАТЬ.
Она появляется при переходе, на котором X выталкивается из
магазина и начинается «фаза выталкивания». Входной символ 1
удерживается, т. е. сдвига на входе не происходит, и эту единицу
можно сопоставить с соответствующим магазинным символом.
Сравнивая рис. 5.7 с предыдущим автоматом, изображенным
на рис. 5.6, мы видим, что новый автомат использует только два
вида информации: входной символ и магазинный символ, тогда как
предыдущему автомату был необходим обычный набор из трех
видов информации. С другой стороны, в новом автомате операции
с магазином сложнее.
В отличие от конечных автоматов здесь нет понятия
единственного «приведенного МП-автомата» и соответственно труднее сделать
выбор между конкурирующими МП-автоматами. Во время
написания этой книги не было даже известно, существует ли алгоритм,
который решает проблему, допускают ли два МП-распознавателя
одно и то же множество1). Во всяком случае на этом примере видно,
что для одной и той же задачи можно построить несколько
хороших МП-автоматов и даже есть возможность выбирать, какую
информацию запоминать с помощью состояния, а какую хранить
в магазине.
5.5. Перевод с помощью МП-автоматов
МП-автомат называется МП-транслятором, если при
распознавании он порождает выходную цепочку. Чтобы автомат выдавал
выходную цепочку, управляющее устройство может наряду с обычными
операциями над состоянием, входом и магазином производить
операцию на выходе. При отсутствии выходной операции
предполагается, что на выход ничего не выдается. Если надо выдать цепочку
АВ, то в определении соответствующего МП-перехода мы пишем
ВЫДАТЬ (А В)
Чтобы посмотреть, как можно пользоваться операцией ВЫДАТЬ,
рассмотрим задачу перевода произвольной цепочки из нулей и
единиц в цепочку вида \nQm, где пит соответственно число
единиц и нулей в данной цепочке. Например, цепочка 0 110 11 будет
переведена в 1 1 1 1 0 0, так как в цепочке четыре единицы и два
нуля.
Один из способов такого перевода заключается в том, чтобы
выдавать единицы сразу при их появлении на входе, а при
появлении на ^входе нулей помещать их в магазин. Когда встречается
концевой маркер, автомат выталкивает из магазина нули и выдает
) К моменту перевода это по-прежнему неизвестно.— Прим. рео\
144
Гл. 5. Автоматы с магазинной памятью
их на выход. Управляющая таблица для автомата с одним
состоянием, реализующего этот способ, изображена на рис. 5.9.
О * , н
ВТОЛКНУТЬ(А)
СДВИГ
L
ВТОЛКНУТЬ (А)
СДВИГ
выхоШЮтЬ I выттктуъ ,\ ,*
сдвиг
у ■уК.'.'.Г
держа-
(tb^
ДОПУСТИТЬ
Начальное содержите магазина: V
Рис. 5.9.
Последовательность конфигураций этого автомата при
обработке цепочки 0 10 11 показана на рис. 5.10. Если переход
вызывает операцию с выходом, мы помещаем эту операцию между
конфигурацией, вызывающей
переход, и конфигурацией,
наступающей после
перехода.
Множество,
распознаваемое в нашем примере,—
1:
2:
3:
4:
8:
9:
V
V О
ВЫДАТЬ(1)
V О
V 0 0
ВЫДАТЬ (1/
V О О
ВЫДАТЬ (1)
V О О
ВЫДАТЬ (0)
V О
ВЫДАТЬ (0)
V
ДОПУСТИТЬ
Рис. 5.10
1 О
I 0
1 1 ч
1 1 ч
1 1 ч
1 1 ч
! Ч
Ч
это просто (0+1)*, т. е.
множество всех цепочек.
В данном случае магазин
служит не для
распознавания, а только для
перевода. Нули вталкиваются в
магазин только для того,
чтобы позже автомат выдал
их на выходе. В следующем
примере магазин будет
использован как для
распознавания, так и для
перевода.
Рассмотрим проблему
распознавания множества
{w2wr} до принадлежит
(0+1)*
и перевода каждой цепочки
до2дог в цепочку l"0m, где п
и m соответственно число единиц и нулей в цепочке до. Так,
цепочка
0 10 112 110 10
5.5. Перевод с помощью МП-автоматов 145
должна быть переведена в
1110 0
Чтобы выполнить этот перевод, построим МП-автомат,
работающий в двух фазах. Первая из них — фаза вталкивания — длится
О 1 2 ч
СОСТОЯНИЕ (ФАЗА 1)
ВТОЛКНУТЬ (0)
СДВИГ
С0СТ0ЯНИЕ(ФАЗА1)
ВТОЛКНУТЬ (0)
СДВИГ
СОСТОЯНИЕ (ФАЗА 1)
ВТОЛКНУТЬ (0)
СД6ИГ
—
СОСТОЯ НИ Е (ФАЗ А 1)
ВТОЛКНУТЬ (1)
ВЫДАТЬ (1)
СДВИГ
СОСТОЯНИЕ (ФАЗА 1)
ВТОЛКНУТЬ (1)
ВЫДАТЬ (1)
СДВИГ
СОСТОЯНИЕ(ФАЗА1)
ВТОЛКНУТЬ С V)
ВЫДАТЬ (1)
СДВИГ
■
СОСТОЯНИЕ (ФАЗАф
СДВИГ
СОСТОЯНИЕ (ФАЗА 2)
СДВИГ
СОСТОЯН.ИЕ(ФАЗА2)
СДВИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
а
0 1 2 ч
СОСТОЯНИЕ (ФАЗА2)
вытолкнуть
ВЬ|ДАТЬ ( 0)
СДВИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
СОСТОЯНИЕ (ФАЗА2)
вытолкнуть
СДВИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
6
Начальное содержимое магазина : v
Рис 5.11. (а) Таблица для начального состояния ФАЗА 1;
(б) Таблица для состояния ФАЗА 2.
146
Гл. 5. Автоматы с магазинной памятью
до тех пор, пока на входе не встретится 2. Во время этой фазы при
появлении на входе символов 0 и 1 они помещаются в магазин.
Кроме того, при появлении на входе единицы она выдается на
выход. Вторая фаза — фаза выталкивания — наступает после того,
как встретился входной символ 2. Во время этой фазы входные
символьТ сравниваются в магазинными символами, чтобы
проверить, совпадают ли они. В результате мы убедимся, что цепочка
1: V ФАЗА1 0 0 12 10 1Н
2: V 0 ФАЗА1 0 1 2 1 0 1 Н
3: V 0 0 ФАЗА1 1 2 1 0 1 Н
ВЫДАТЬ (1)
4: V 0 0 1 ФАЗА1 2101 Н
5: V 0 0 1 ФАЗА2 1 0 1 -»
6: V 0 0 ФАЗА2 0 1 -I
ВЫДАТЬ (0)
7: V 0 ФАЗА2 1 н
8: ОТВЕРГНУТЬ
Рис. 5.12.
после 2 действительно является обращением цепочки,
предшествующей символу 2. При совпадении символов каждый
встреченный нуль выдается на выход. Фаза МП-автомата запоминается
с помощью состояния. Две управляющие таблицы, реализующие
эту схему, изображены на рис. 5.11, где используются состояния
ФАЗА1 и ФАЗА2.
На рис. 5.12 показана работа автомата, отвергающего входную
цепочку 0 0 12 10 1. Так как эта цепочка отвергается, мы говорим,
что у нее нет перевода, даже если МП-автомат выдает что-то на
выход до того, как обнаруживает входной символ 1, который не
совпадает с соответствующим символом цепочки, предшествующей
символу 2.
5.6. Зацикливание
Одна из опасностей, связанных с использованием МП-автомата,
заключается в том, что он может работать бесконечно, никогда не
выходя из процесса обработки. Рассмотрим, например, автомат
с одним состоянием, изображенный на рис. 5.13.
Последовательность конфигураций этого автомата при обработке цепочки 0 0 1
показана на рис. 5.14. Когда на верху магазина находится символ А,
а на входе — символ 0, автомат вталкивает в магазин символ В,
5.6. Зацикливание
147
причем входной символ остается прежним. Однако В тотчас же
выталкивается, причем автомат удерживает все тот же входной
символ. Поэтому автомат зацикливается, т. е. бесконечно повторяет
цикл, никогда не выходя из обработки и не сдвигаясь по входу.
Аналогичная ситуация возникает при обработке входной
цепочки 1 1 0, как показано на рис. 5.15. Когда на верху магазина
символ В, а на входе 1,
автомат вталкивает в
магазин еще один В,
удерживая тот же
входной символ. Таким
образом, автомат
зацикливается,
продолжая помещать в
магазин символы В, не
выходя из обработки и
не сдвигая входной
указатель.
При построении
МП-автомата,
предназначенного для
использования в
компиляторе, нужно быть
уверенным, что автомат
никогда не
зациклится — даже при
обработке недопустимой
цепочки. Если он зацикливается, компилятор тоже зациклится и
не выполнит своей задачи.
Тем не менее проблема зацикливания не является одной из
основных при построении компиляторов. Все обычные процедуры
1:
2:
3:
4:
5:
б:
7:
V
VA
VAB
VA
VAB
VA
VAB
ООН
он
он
он
он
он
он
1:
2:
3:
4:
5:
V
VB
VBB
VBBB
VBBBB
Рис. 5.14. Рис. 5.15.
построения, включая те, которые приводятся в данной книге,
фактически дают автоматы, которые никогда не зацикливаются. Более
того, даже если автомат строится некоторым специальным образом,
О 1
втолкнуться
ДЕРЖАТЬ
ВЫТОЛКНУТЬ
ДЕРЖАТЬ
ВЫТОЛКНУТЬ
сдвиг
втолкнуть^
ДЕРЖАТЬ
ВТОЛКНУТЬА ВТОЛКНУТЬ(А)
СДВИГ СДВИГ
вытолкнуть
ДЕРЖАТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
Начальное содержимое магазию-я
Рис. 5.13.
1 юн
i.o Н
юн
юч
148
Гл. 5, Автоматы с магазинной памятью
эвристических соображений обычно достаточно, чтобы убедиться
в том, что автомат не может зацикливаться.
Хотя, как правило, они не требуются, существуют методы,
позволяющие по каждой комбинации состояния, входного и
магазинного символов определять, не начинается ли с этой комбинации-
цикл. Полное исследование этого вопроса дано в книге Хопкрофтэ
и Ульмана [1969] 1).
5.7. Замечания по литературе
Организация памяти в виде магазина (или, как часто говорят, стека)
используется в программировании давно и принадлежит
«фольклору» этой области. Использование автоматов с магазинной
памятью в компиляторах описано у Ершова [1959], у Бауэра и За-
мельзона [1959, I960]. Детерминированные МП-автоматы,
рассматриваемые в этой главе, изучались в работах Шютценберже [1963],
Фишера [1963], Гинзбурга и Грейбах [1966]. Они обсуждаются
также в книге Хопкрофтэ и Ульмана [1969].
Упражнения
1. а) Напишите три цепочки, принадлежащие множеству, распознаваемому
МП-автоматом с одним состоянием, изображенным на рисунке,
б) Для каждой из этих цепочек укажите соответствующие
последовательности конфигураций, допускающие эти цепочки.
a b с -i
втолкнуть(а)
сдвиг
ВТОЛКНУТЬ (С)
сдвиг
ВТОЛКНУТЬ (15)
ДЕРЖАТЬ
ВТОЛКНУТЬ (А)
СДВИГ
ОТВЕРГНУТЬ
ВЫТОЛКНУТЬ
ДЕРЖАТЬ
ВТОЛКНУТЬ (С)
сдвиг
ВТОЛКНУТЬСЯ)
сдвиг
ВЫТОЛКНУТЬ
сдвиг
ВТОЛКНУТЬ(А)
сдвиг
вытолкнуть
СДВИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
Начальное содержимое магазина : V
2. Опишите словами множество цепочек, распознаваемое МП-автоматом с одним
состоянием, изображенным на рисунке. (Сравните с рис. 5.4.)
*) См. также книгу Ахо и Ульмана [1972а, стр. 213—215].— Прим, ред.
Упражнения
149
ВТОЛКНУТЬ(О)
сдвиг
ВТОЛКНУТЬ(О)
сдвиг
ВЫДАТЬ (1)
СДВИГ
ВЫДАТЬ (1)
сдвиг
ВЫДАТЬ (0)
ВЫТОЛКНУТЬ
ДЕРЖАТЬ
ДОПУСТИТЬ
Начальное содержание магазина: V
3. Постройте (примитивный) МП-распознаватель для каждого из следующих
множеств цепочек:.
а) {l"Om|«>m>0};
б) {l"Om|n>m>0};
в) \\»От\т>п>0};
г) {1"0п|я>0}+{0'я!2'я|л, т>0);
д) \\пОп\тОт\п, т>0};
е) {1"0'в1'я0л|л> m>\);
ж) множество цепочек из нулей и единиц, где число единиц равно числу нулей;
з) {bi2(bi+l)r}, где Ь; — цепочка из нулей и единиц, являющаяся двоичным
представлением числа i (например, для (=48 цепочка, принадлежащая
данному языку такова: 1100002100011).
4. а) Для каждого из множеств задачи 3 укажите цепочку длины, большей 3.
б) Покажите последовательность конфигураций соответствующих автоматов,
построенных в упр. 3, при распознавании каждой из этих цепочек.
6. Постройте (примитивный) МП-автомат, распознающий дополнение множества,
распознаваемого автоматом на рис. 5.6.
в. На каждом из следующих языков напишите программу для вычислительной
машины, реализующую МП-автомат на рис. 5.7:
а) Фортран. Напишите подпрограммы, выполняющие операции ВТОЛКНУТЬ
и ВЫТОЛКНУТЬ.
б) Лисп.
в) Язык ассемблера некоторой вычислительной машины. Один регистр
используйте как указатель верхнего символа магазина. Составьте
макрокоманды, выполняющие операции ВТОЛКНУТЬ и ВЫТОЛКНУТЬ.
7. Решите задачи 3 и 4, пользуясь операцией ЗАМЕНИТЬ. Постарайтесь найти
автомат с одним состоянием.
8. Составьте три допускаемые цепочки и соответствующие последовательности
конфигураций для следующего МП-автомата с одним состоянием,
изображенного на рисунке.
0 1 н
"ЗАМЕНИТЬ (АА)
СДВИГ
ОТВЕРГНУТЬ
ВЫТОЛКНУТЬ
СДВИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
Начальное содержимое магазина: VA
150
Гл. 5. Автоматы с магазинной памятью
9. Рассмотрим новую расширенную операцию над магазином:
ВЫТОЛКНУТЬ («), где п — произвольное целое положительное число. Эта операция
выталкивает из магазина л верхних символов. Если в магазине меньше п
символов, включая концевой маркер, то автомат отвергает входную цепочку.
а) Докажите, что ВЫТОЛКНУТЬ {п) можно промоделировать на
примитивном МП-автомяте.
б) Пользуясь этой новой операцией, постройте автоматы, распознающие
каждое из следующих множеств:
i) {l**0«|m>0}
ii) {12<»0'в}и{1л2л} m>0, «>0.
10. Покажите последовательности конфигураций каждого из МП-автоматов на
рис. 5.6, 5.7, 5.9 и 5.11 при обработке пустой цепочки.
11. Найдите множество входных цепочек, под действием которых происходят
все переходы автоматов на рис. 5.6 и 5.7.
12. Используя операцию ЗАМЕНИТЬ, постройте транслятор с одним состоянием,
который выполняет тот же перевод, что и автомат на рис. 5.11.
13. Постройте не примитивные МП-автоматы, которые будут выполнять
следующие переводы:
а) l"*)»1 в 1л22л, где «>0, /и>0;
б) l«o»l*On в l'«0',+m, где тХ), л>0;
в) Ь{ в (bi+i)r,
где Ь{ — цепочка из нулей и единиц, являющаяся бинарным
представлением числа i;
г) \т0п в \т~п, если т>п,
0 "-«, если т<п,
е, если т=п
(задача (г) аналогична выдаче сообщений об ошибке для неправильных
скобочных выражений).
14. Покажите, что любой конечный распознаватель можно промоделировать МП-
распознавателем с одним состоянием.
15. Покажите, что каждый из МП-автоматов, изображенных на рисунке, никогда
не зацикливается при обработке любой входной цепочки.
0 1 2 3 Н
ВЫТОЛКНУТЬ
сдвиг
ВТОЛКНУТЬ(В)
сдвиг
ВТОЛКНУТЬ (4)
сдвиг
ВТОЛКНУТЬ(4.)
сдвиг
ДОПУСТИТЬ
втолкнуть(а)
сдвиг
ОТВЕРГНУТЬ
ВЫТОЛКНУТЬ
СДВИГ
ОТВЕРГНУТЬ
ВЫТОЛКНУТЬ
СДВИГ
допустить
ВТ0ЛКНУТЬ(4)
сдвиг
ДОПУСТИТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
Начальное содержимое магазина: v
Упражнения
151
н
ВТОЛКНУТЬСЯ
сдвиг
ВЫТОЛКНУТЬ
сдвиг
ВТОЛКНУТЬСС)
ДЕРЖАТЬ
ДОПУСТИТЬ
ВТОЛКНУТЬСС)
ДЕРЖАТЬ
ОТВЕРГНУТЬ
ВТОЛКНУТЬСЯ)
сдвиг
ВЫТОЛКНУТЬ
ДЕРЖАТЬ
ВТОЛКНУТЬСЯ)
СДВИГ
ДОПУСТИТЬ
вытолкнуть
ДЕРЖАТЬ
ДОПУСТИТЬ
Начальное содержимое магазинам
16. Для каждого из следующих случаев покажите, что МП-автомат с заданным
свойством никогда не "зацикливается ни на какой входной цепочке.
а) Каждый переход, не являющийся выходом из процесса обработки,
содержит операцию СДВИГ.
б) Операция ДЕРЖАТЬ встречается только в переходе ВЫТОЛКНУТЬ.
17. Найдите две входные цепочки, одна из которых начинается нулем, а другая —
единицей, при обработке которых следующий автомат зацикливается.
О 1 2 3 ■ н
ДОПУСТИТЬ
ВЫТОЛКНУТЬ
сдвиг
ВТОЛКНУТЬ(Е)
ДЕРЖАТЬ
ДОПУСТИТЬ
ВТОЛКНУТЬ (С)
ДЕРЖАТЬ
ВТОЛКНУТЬ^)
сдвиг
ВТОЛКНУТЬ (А)
ДЕРЖАТЬ
ДОПУСТИТЬ
ВТОЛКНУТЬЦ
сдвиг
ВТОЛКНУТЬСД)
сдвиг
ОТВЕРГНУТЬ
ВТОЛКНУТЬСЯ)
СДВИГ
втолкнытьсе)
СДВИГ
ОТВЕРГНУТЬ
втолкнуться)
ДЕРЖАТЬ
ВТОЛКНУТЬ(£)
СДВИГ
ДОПУСТИТЬ
ВТОЛКНУТЬСИ)
СДВИГ
втолкнуть 04)
СДВИГ
ВТОЛКНУТЬСС)
ДЕРЖАТЬ
ВЫТОЛКНУТЬ
ДЕРЖАТЬ
допустить
ВТОЛКНУТЬЙ
СДВИГ
ВТОЛКНУТЬ(Я)
СДВИГ
ОТВЕРГНУТЬ
ВЫТОЛКНУТЬ
сдвиг
ОТВЕРГНУТЬ
ДОПУСТИТЬ
ВТОЛКНУТЬ (Я)
сдвиг
ДОПУСТИТЬ
Начальное содержимое магазина; V
18. Перестройте автомат рис. 5.13 таким образом, чтобы новый автомат допускал
тот же язык, но никогда не зацикливался.
19. Поясните, почему МП-автомат не может распознать ни одно из следующих.
множеств:
а) jlWI/tX)};
б) «о wr}, где w — цепочка из нулей и единиц;
в) {1по»Н-{1лОгл} п>0.
152
Гл. 5. Автоматы с магазинной памятью
20. Постройте МП-автомат, допускающий S-выражения Лиспа. Входной алфавит
автомата таков:
{АТОМ, (,), -, 4}
21. Предположим, МП-автомат таков, что при обработке любой входной цепочки
число символов, записанных в его магазине, не превышает некоторой
константы. Покажите, что такой МП-автомат можно промоделировать конечным
автоматом.
22. Приведите пример такого множества цепочек, что его можно распознать
МП-автоматом, в переходах которого используются обе операции — СДВИГ
и ДЕРЖАТЬ, но нельзя распознать МП-автоматом, в котором используется
только операция СДВИГ.
23. Покажите, что МП-автомат, который вталкивает в магазин маркер дна,
можно смоделировать МП-автоматом, который этого не делает.
24. Покажите, что любой МП-автомат можно промоделировать на МП-автомате,
магазинный алфавит которого состоит из маркера дна и еще двух символов.
25. Покажите, что для любого k>\ существует множество цепочек, которое можно
распознать примитивным МП-автоматом с k состояниями, но нельзя
распознать никаким примитивным МП-автоматом с k—1 состояниями.
26. Один из способов расширения возможностей конечного автомата состоит
в том, что в его переходы добавляется операция ДЕРЖАТЬ. Покажите, что
конечный распознаватель, в котором используется операция ДЕРЖАТЬ,
может распознавать только регулярные множества.
27. Покажите, что если множество цепочек допускается МП-автоматом, то его
дополнение также допускается некоторым МП-автоматом.
28. Пусть даиы МП-автомат и конечный распознаватель. Покажите, что можно
построить МП-автомат, который распознавал бы пересечение множеств,
допускаемых этими двумя автоматами.
29. Приведите пример такого множества цепочек, которое может распознать
МП-автомат с магазинным алфавитом, содержащим маркер дна и еще два
символа, но не может распознать никакой МП-автомат, чей магазинный
алфавит состоит из маркера дна и еще одного символа.
30. Как по данному МП-автомату проверить, заканчивается ли выходом
обработка каждой из его входных цепочек?
-31 Постройте МП-автомат, допускающий множество истинных логических
выражений Фортрана, (т. е. принимающих значение .TRUE.), в которых
используются операции .AND., .OR. и .NOT., а операндами являются логические
константы .TRUE, и .FALSE. .
Вот, например, одно из таких выражений:
.TRUE. .AND. .NOT. ( .FALSE. .OR. ( .FALSE. .AND. .TRUE. ))
Входным алфавитом («словарем») автомата является
{.TRUE., .FALSE., .NOT., .AND., .OR.,), (, 4}
6
Контекстно-свободные грамматики
6.1. Введение
В этой главе мы изложим метод определения множеств цепочек,,
основанный на понятии контекстно-свободной грамматики
(сокращенно — КС-грамматики). В отличие от предыдущих методов
описания таких множеств мощность метода контекстно-свободных
грамматик достаточна, чтобы описывать почти все так называемые
синтаксические свойства языков программирования.
КС-грамматики на самом деле часто используются в руководствах по языкам
программирования.
Применение того или иного метода задания множества при
описании языка программирования может оказаться важным
шагом в построении компилятора для этого языка, если имеются
систематические методы преобразования описания множества в
программу, которая это множество обрабатывает. В последующих
главах будут разработаны методы преобразования некоторых
контекстно-свободных грамматик в МП-автоматы, которые распознают
и даже транслируют множества, задаваемые этими грамматиками.
Прежде чем вникать в эти методы, мы должны понять, как
контекстно-свободные грамматики определяют множества (гл. 6) и.
как можно определить перевод в терминах этих грамматик (гл. 7).
6.2. Формальные языки и формальные грамматики
Многие понятия этой главы аналогичны понятиям, которые
используются при изучении естественных языков, например английского
или русского. На самом деле некоторые определения,
появляющиеся в этой главе, первоначально были введены с целью описания
естественных языков.
Наиболее фундаментальным является понятие языка. С
теоретической точки зрения слово «язык» — синоним термина «множество
цепочек». Так, язык Фортран IV можно понимать как множество
цепочек, задаваемое некоторым множеством правил. Наиболее
интересные языки, такие, как Фортран IV, состоят из бесконечного
множества цепочек.
Чтобы отличать употребление слова «язык» в значении точно
определенного множества цепочек от употребления этого слова
154
Гл. 6. Контекстно-свободные грамматики
в повседневной речи, множество цепочек называют иногда
формальным языком.
Чтобы применить математический подход к проблемам,
связанным с языками и их обработкой, мы должны ограничиться
множествами цепочек, которые можно определить некоторым точным
образом. Есть много способов точного задания таких множеств.
Один способ, например, заключается в задании языка как
множества, допускаемого каким-нибудь распознавателем цепочек вроде
конечного автомата или автомата с магазинной памятью. Другой
подход состоит в использовании методов, которые можно считать
грамматическими.
Термин «формальная грамматика» применим к любому
определению формального языка, основанному на «грамматических
правилах», с помощью которых можно порождать и анализировать
цепочки аналогично тому, как грамматики используются при
изучении естественных языков. В этой главе мы займемся особым видом
формальных грамматик, называемых контекстно-свободными
грамматиками.
6.3. Формальные грамматики: пример
В этом разделе приводится формальная грамматика, которая в
какой-то степени напоминает фрагмент грамматики русского
языка,1) и задает формальный язык, состоящий из четырех русских
предложений.
В этой формальной грамматике используются элементы,
играющие роль членов предложения или частей речи:
(предложение >
(подлежащее >
(сказуемое >
(дополнение >
(прилагательное >
(существительное >
Мы заключаем их в угловые скобки, чтобы отличать их от слов из
фактического словаря, составляющих предложения языка. В
нашем примере словарь состоит из следующих пяти слов, или
«символов»:
ДОМ
ДУБ
ЗАСЛОНЯЕТ
СТАРЫЙ
(точка)
1) В оригинале пример из английского языка.— Прим, перев.
6.3. Формальные грамматики: пример
155
В грамматике имеются определенные правила, содержащие
информацию о том, как из этих символов можно строить предложения
языка. Одно из этих правил таково:
1. (предложение)-> (подлежащее) (сказуемое) (дополнение).
Это правило интерпретируется следующим образом: «Предложение
может состоять из подлежащего, за которым следуют сказуемое,
затем дополнение и точка». В грамматике вполне могут быть и
другие правила, задающие предложения другой структуры. Однако
в данной грамматике таких правил нет.
Остальные правила таковы:
2. (подлежащее) -*- (прилагательное) (существительное)
3. (дополнение) -> (прилагательное) (существительное)
4. (сказуемое) -^ЗАСЛОНЯЕТ
5. (прилагательное) -> СТАРЫЙ
6. (существительное )-> ДОМ
7. (существительное )-> ДУБ
Применим эту грамматику для порождения (или вывода)
предложения. По правилу 1 предложение имеет вид
(подлежащее) (сказуемое) (дополнение).
Так как, согласно правилу 2, подлежащим может быть
комбинация
(прилагательное) (существительное)
ее можно подставить вместо подлежащего и получить предложение,
которое имеет вид
(прилагательное) (существительное) (сказуемое) (дополнение).
Аналогичным образом можно применить правило 3, чтобы заменить
(дополнение) и получить
(прилагательное) (существительное) (сказуемое)
(прилагательное ) (существительное).
Теперь можно дважды применить правило^, чтобы, заменив
(прилагательное), получить
СТАРЫЙ (существительное) (сказуемое) СТАРЫЙ
(существительное ).
Применяя правила 6 и 7, заменяющие первое и второе
(существительное), и правило 4, заменяющее (сказуемое), получаем готовое
предложение:
СТАРЫЙ ДОМ ЗАСЛОНЯЕТ СТАРЫЙ ДУБ.
156
Гл. 6. Контекстно-свободные грамматики
Этот вывод можно наглядно изобразить в виде дерева (см.
рис. 6. 1). Дерево показывает, какие правила применялись к
различным промежуточным элементам, но скрывает порядок их
применения. Таким образом, можно видеть, что результирующая цеппн-
<предложейие>
<подлежащее> <сказуе~мое> <доп'олнение>
Л
< прилагательное^ <суш.ествит>
<ррилагательноё> <суш,естбит2>
СТАРЫЙ ЛОМ ЗАСЛОНЯЕТ СТАРЫЙ
Рис. 6.1,
лав
ка не зависит от порядка, в котором делались замены
промежуточных элементов. Иногда говорят, что дерево представляет собой
•«синтаксическую структуру» предложения.
Идея вывода подсказывает другие интерпретации правил,
подобных правилу
(подлежащее>->- (прилагательное) (существительное)
Вместо того чтобы говорить «(подлежащее) — это
(прилагательное), за которым следует (существительное)», можно сказать, что
(подлежащее) «порождает» (или «из него выводится», или «его
можно заменить на») (прилагательное) (существительное).
С помощью этой грамматики можно вывести также три других
предложения, а именно:
СТАРЫЙ ДУБ ЗАСЛОНЯЕТ СТАРЫЙ ДОМ.
СТАРЫЙ ДОМ ЗАСЛОНЯЕТ СТАРЫЙ ДОМ.
СТАРЫЙ ДУБ ЗАСЛОНЯЕТ СТАРЫЙ ДУБ.
Эти три предложения и предложение, выведенное раньше, и есть
все предложения, порождаемые данной грамматикой. Множество,
состоящее из этих четырех предложений, называется языком,
который определяется грамматикой (порождается ею или выводится
в ней).
€.4. Контекстно-свободные грамматики
Грамматика, приведенная в предыдущем разделе,— это простой
пример грамматики, принадлежащей интересующему нас классу
контекстно-свободных грамматик. В данном разделе мы определим
6.4. Контекстно-свободные грамматики
157
этот тип грамматик и введем обозначения, принятые при их
описании.
Такие элементы, как (подлежащее) или (существительное),
играющие роль членов предложения или частей речи, называются
нетерминальными (вспомогательными) символами или просто
нетерминалами. В контекстно-свободной грамматике может быть
любое конечное число нетерминалов. При определении языков
программирования нетерминалами служат такие элементы, как
(оператор), (арифметическое выражение) и т.д.
Такие элементы, как ДУБ, ЗАСЛОНЯЕТ, играющие роль слов из
словаря языка, называются терминальными (основными)
символами или просто терминалами. КС-грамматика может содержать
любое конечное число терминалов. В языках программирования
терминалами являются фактически используемые в них слова и
символы, такие, как DO, -f и т. д.
Правила грамматики иногда называются продукциями 1) и в
общем виде выглядят так:
Один нетерминал -> любая конечная цепочка из терминалов и
нетерминалов
Цепочка справа от стрелки может быть пустой. Пример такого
правила:
Иногда правило с пустой правой частью мы будем называть
эпсилон-правилом. КС-грамматика может содержать любое конечное
множество продукций. Пример продукции языка
программирования:
(оператор)-)- IF (логическое выражение) THEN (оператор)
Один из нетерминалов выделен как начальный нетерминал или
начальный символ (или аксиома), с которого должны начинаться
выводы цепочек языка. Для естественных языков таким
нетерминалом может быть (предложение), для языков программирования —
(программа). Начальный символ мы будем часто обозначать
через (S).
Суммируя все сказанное, будем задавать КС-грамматику
а) конечным множеством нетерминалов;
б) конечным множеством терминалов, которое не пересекается
с множеством нетерминалов;
в) конечным множеством правил вида
(Л ) -> а
*) Обычно предпочитают термин «правило». Второй термин чаще используют,
когда в грамматике встречаются правила разных типов (например, в атрибутных
грамматиках, помимо продукций, есть правила вычисления атрибутов).— Прим.
ред.
158
Гл. 6. Контекстно-свободные грамматики
где С4 ) — нетерминал, а а — цепочка терминалов и
нетерминалов (возможно, пустая); нетерминал (А > называется
левой частью правила, а а — правой частью;
г) одним нетерминальным символом, выделенным в качестве
начального.
Если множество правил приводится без специального
указания множества нетерминалов и терминалов, то предполагается,
что грамматика содержит в точности те нетерминалы и терминалы,
которые встречаются в правилах. Пусть, например, даны четыре
таких правила:
1. S-^aAbS
2. S-+b
3. А-у S Ac
4. Л->- е
Если больше ничего не определено, предполагается, что множество
нетерминалов — {S, А}, так как это те нетерминалы, которые
встречаются в левых частях правил. Предполагается также, что
множество терминалов — {а, Ь, с), так как это остальные символы,
используемые в правилах. Понятно, что символ е в правиле 4
представляет пустую цепочку и не является символом грамматики.
Правило 4 можно записать без е в таком виде:
4. А-+
Как было сказано в предыдущем абзаце, можно определять
грамматику, задавая ее правила и начальный нетерминал.
Нетерминальное и терминальное множества нужно задавать в явном виде лишь
тогда, когда они не совпадают с
множествами, которые получаются описанным спосо-
1. <s> —> а<А> b <S> б°м- Так, если бы мы хотели, чтобы
терминальным множеством в последнем примере
2. <S>—*b было множество {а, Ь, с, d), то нам при-
3. <л> —>■ <s> <A> с шлось бы задать его в явном виде. В этом
4 <А._+ случае автомат, распознающий язык, вос-
"8 принимал бы d как вход, хотя этот символ
рис_ 6-2> не входит ни в одну допустимую цепочку.
Чтобы легче было различать
нетерминальные и терминальные символы, примем
соглашение заключать нетерминалы в угловые
скобки при их определении. В соответствии с этим соглашением
правила из последнего примера записываются, как показано на
рис. 6.2. Благодаря этому достаточно посмотреть на какую-нибудь
цепочку вроде а{А)Ь{В), чтобы понять, какие символы
нетерминальные, а какие терминальные.
Хотя обозначения, используемые нами для описания
грамматик, довольно широко распространены в соответствующей лите-
6.5. Выводы
159
ратуре, часто используется еще один способ записи, называемой
формой Бэкуса — Наура или БНФ. В этих обозначениях -*-
заменяется символом ::=, за которым может следовать любое число
правых частей, разделенных вертикальной чертой |. Здесь также
нетерминалы заключаются в угловые скобки. Пользуясь БНФ, мы
запишем грамматику, приведенную на рис. 6.2, так:
{S):=a(A)b{S)\b
(Л>:= (S)(A)c\&
Идею совмещения правых частей можно применять, разумеется, и
при записи со стрелкой ->-, но для ясности мы предпочитаем
писать каждое правило в отдельной строке, так, чтобы можно было
нумеровать строки, как на рис. 6.2., и затем ссылаться на них по
номерам.
6.5. Выводы
В этом разделе мы более подробно обсудим, как грамматики
используются для порождения цепочек языка.
Правила грамматики используются для того, чтобы задавать
способы подстановки или замены цепочек. Подстановка
осуществляется путем замены некоторого нетерминала в какой-нибудь
заданной цепочке терминалов и нетерминалов на правую часть правила,
левой частью которого является этот нетерминал. Иногда мы будем
говорить, что правило применяется к нетерминалу цепочки.
Рассмотрим, например, такую грамматику с начальным
нетерминалом (S):
1. (S)^a(A)(B)c
2. (S)->e
3. (A)^c(S){B)
4. Ш-»- {A)b
5. {B)^b(B)
6. (B)->a
Если дана цепочка
а<Л><В>с
t
и мы хотим применить правило 5 к нетерминалу (В), на который
указывает стрелка, то результат соответствующей подстановки
таков:
а(А)Ь(В)с
160 Гл. 6. Контекстно-свободные грамматики
Эту подстановку мы записываем так:
а <Л> <В> с=ьа < Л> Ь <В> с
t
5
Вертикальная стрелка указывает здесь на заменяемый
нетерминал, число под стрелкой указывает номер применяемого правила,
а символ =Ф отделяет цепочку до подстановки от цепочки,
получающейся после подстановки.
Иногда это обозначение будет использоваться без вертикальной
стрелки, при этом указываются только цепочки до и после
подстановки. Можно, например, писать
а<А><В>с=ьа<А>Ь<В->с
что является сокращенной записью утверждения «цепочка
а(А)Ь(В)с может быть получена из цепочки а(А){В)с в
результате одной подстановки».
Однако такого сокращенного обозначения не всегда достаточно
для описания выполняемых подстановок. Например, ту же.
цепочку можно также получить путем следующей подстановки:
а<Л><5>с=>а<Л>6<В>с
t
4
Последовательность подстановок называется выводом. Цепочка
acabac, например, может иметь следующий вывод, начинающийся с
начального нетерминала:
<S> => а < Л> <5> с =ф а <Л> Ъ <В> с=>ас <S> <B> b <В> с
t t t t
14 3 6
=Ф ас <S> ab <5> с =t> acab <£> с =t> acabac
t t
2 6
Каждая цепочка терминалов и нетерминалов, встречающаяся в
выводе, называется промежуточной цепочкой этого вывода. Так,
в описанном выше выводе семь промежуточных цепочек, включая
начальную и заключительную цепочку (промежуточную цепочку,
выводимую из начального символа, в литературе иногда называют
сентенциальной формой или выводимой цепочкой).
Мы часто будем употреблять слово «вывод», не указывая
начальной цепочки вывода. В таких случаях предполагается, что
начальной цепочкой является начальный нетерминал. Если
имеется в виду другая начальная цепочка, это указывается явно.
6.6. Деревья
16!
Существование вывода одной цепочки из другой обозначается
с помощью символа
Так, имея в виду, что «существует вывод цепочки acabac из
цепочки (S)» или, что эквивалентно, «из цепочки (S) можно вывести
цепочку acabac», мы будем писать
<S> =t>* acabac
Для единообразия допускается нулевое число подстановок в
выводе. Например,
Ь(А)с
можно рассматривать как вывод нулевой длины, в котором b (А )с
является одновременно начальной и заключительной цепочкой.
Таким образом, для любой цепочки а мы можем написать
так как а можно получить из себя самой с помощью
последовательности подстановок длины нуль.
Звездочка «*» здесь играет ту же роль, что и в итерации Клини,
так как означает нуль или более применений отношения =*>. Если
необходимо исключить слишком тривиальный вывод нулевой
длины и указать, что «цепочку acabac можно получить из цепочки (5) с
помощью вывода, длина которого больше нуля», то символ *
заменяют на + и пишут
<S> =t>+ acabac
Язык, задаваемый грамматикой, мы определим как множество
терминальных цепочек, которые можно вывести из начального
символа грамматики. Иногда говорят, что язык «определяется»
грамматикой, «порождается» ею или «выводится» в ней. Любой язык,
который можно задать контекстно-свободной грамматикой,
называется контекстно-свободным языком (или, кратко, КС-языком).
В приведенном выше примере цепочку acabac можно вывести из
начального символа грамматики, и поэтому acabac принадлежит
языку, задаваемому грамматикой. С другой стороны, изучение этой
грамматики показывает, что цепочка bb, например, не выводится из
(S); таким образом, bb не принадлежит языку, задаваемому этой
грамматикой.
6.6. Деревья
Мы определили КС-язык, задаваемый некоторой грамматикой, как
множество терминальных цепочек, которые можно вывести из
начального символа. Можно построить дерево вывода цепочки КС-
Ф. Льюис и др.
162
Гл. 6. Контекстно-свободные грамматики
a <A> < В> с <5>
a < A> <B>с
Г
а
a <A> b <В> с <S>
t /V V\
3 a <A> <В> с
/ \
<A> b
t
6
a с <$>ab <6>с <S>
2 a <A> <B>с
/ \
<A> b
с <5> <B>
t 1
a
д
a c a b a c <S>
a <A> <B> с
/\ 1
<A> b a
<r <S> <B>
1 i
OK
6
a c. <S > < В ■ h <B ■ с ^ s-~.
I ^/w
6 а <Д > <6 > с
/ \
с < 5 > < В >
t
г
a с a b <B> с <S>
t >^\\
6 а<л><е>с
/\ t
<Л > b
с <S> <B>
1 i
e
Рис. 6.З.
6.6. Деревья
163
языка. Это легко сделать, интерпретируя подстановки как шаги
построения дерева. Так как построение дерева легче
продемонстрировать, чем описать, мы покажем это на примере.
В предыдущем разделе была приведена грамматика и вывод в
ней терминальной цепочки acabac. Этот вывод можно использовать
для построения соответствующего дерева вывода, изображенного
на рис. 6.3, где показан каждый шаг вывода и соответствующее ему
дерево. На рис. 6.3, а начальному символу (S) соответствует
дерево с одной вершиной (S). Когда к символу (S) применяется
правило 1, он заменяется правой частью этого правила, а именно
а(А)(В)с. Соответствующий шаг построения дерева состоит в том,
что добавляются вершины, помеченные символами а, (А), (В) и с,
к которым ведут дуги, исходящие из вершины, помеченной
заменяемым символом. Результат — на рис. 6.3, б. Вывод и
соответствующее ему построение дерева продолжается вплоть до рис. 6.3, ж.
Окончательный вариант дерева называется деревом вывода
терминальной цепочки acabac.
В дереве вывода отражено, какие правила были применены во
время вывода и к каким вхождениям нетерминалов они
применялись. Однако дерево не несет никакой информации о порядке
применения правил, кроме одного очевидного соображения, что
правила должны применяться к каждой вершине дерева раньше, чем к
нетерминальным вершинам, расположенным ниже ее. Так,
рассматривая дерево на рис. 6.3, ж, можно заметить, что правило 4
применялось раньше правила 3, но невозможно сказать, в каком
порядке применялись правило 2 и дважды правило 6.
Поскольку порядок подстановок в дереве скрыт, может быть
много выводов, соответствующих одному и тому же дереву вывода.
Дерево на рис. 6.3, ж, например, соответствует также выводу
<S> => а <Л> <Б> c=s>a <Л> b <B> с=$>ас <S> <fi> b <B> с
t ! T t
14 3 2
=> ас<В> b <В> с => acab <B> с =ф acabac
1 t
6 , 6
Такой вывод называется левым (или левосторонним) выводом, так
как на каждом шаге заменяется самый левый нетерминальный
символ. Для каждого дерева существует единственный левый вывод,
так как благодаря условию выбора самого левого нетерминала
место каждой подстановки устанавливается единственным образом, а
по дереву можно определить то единственное правило, которое
должно применяться при этой подстановке.
Для каждого дерева существует также единственный правый
(или правосторонний) вывод, который получается, если всегда
заменять самый правый нетерминал. Правый вывод, соответствую-
6*
1G4
Гл. 6. Контекстно-свободные грамматики
щий дереву на рис. 6.3, ж, таков:
<.S>=$>a<,A><,B>c=$>a<A>ac=s>a<.A'>bac
t t t t
1 6 4 3
=Ф ас <S> <Б> bac =Ф ас <S> о&ас =ф acabac
t t
6 2
Многие методы обработки языков рассчитаны исключительно на
левые или правые выводы, так как они очень удобны для
систематической обработки. В подобных случаях пишем
подразумевая, что «цепочка Р может быть получена из цепочки a
в результате одной самой левой подстановки», а для обозначения
того, что «цепочка Р может быть получена из цепочки а применением
одной самой правой подстановки», мы пишем
а=Фдр
В таких случаях подстановку можно восстановить по двум
промежуточным цепочкам. Понятно, например, что
а < Л> <Б> с=>£ а < Л> b <Б> с
может быть только результатом подстановки
а<Л><Б>с =ф а<Л>b<Б>с
t
4
и что
a<,Ay<,B>c=^Ra<Ayb<B>c
может быть результатом только такой подстановки:
а<Л><Б>с =ф а<Л>6<В>с
t
5
Кроме того, мы будем писать
а=Ф1Р
если существует левый вывод Р из а, и
а=Ф«Р
если существует правый вывод.
Цепочке языка может соответствовать более, чем одно дерево,
так '/ак она может иметь разные выводы, порождающие разные
деревья. На самом деле это имеет место и для нашей цепочки acabac.
Кроме дерева на рис. 6.3, ж, которое еще раз изображено на рис.
6.6. Деревья
165
€.4, а, ей соответствует также дерево, изображенное на рис. 6.4, б,
которое построено по такому выводу:
<S> =s>a<A> <B> c=pa<Ayb <Б> с =ф ас <S> <Б> 6 <5> с
t t t t
15 3 6
=Ф ас <S> а& <Б> с =ф acab <Б> с =ф acabac
t t
2 6
В этом выводе даже промежуточные цепочки совпадают с
промежуточными цепочками первого вывода. Однако в данном случае
правило 5 применяется там, где в первом выводе используется правило 4
и соответствующие деревья явно различны.
<s> <s>
<в>
Рис 6.4.
1
Когда одна цепочка может иметь несколько деревьев вывода,
говорят, что соответствующая грамматика неоднозначна.
Все сказанное можно резюмировать следующим образом:
1. Каждой цепочке, выводимой в данной КС-грамматике,
соответствует одно или несколько деревьев вывода.
2. Каждому дереву соответствует один или более выводов.
3. Каждому дереву соответствует единственный правый и
единственный левый выводы.
4. Если каждой цепочке, выводимой в данной КС-грамматике,
соответствует единственное дерево вывода, эта грамматика
называется бднозначной; в противном случае ее называют
неоднозначной.
166
Гл. 6. Контекстно-свободные грамматики
6.7. Грамматика для констант языка MINI-BASIC
Нередко бывает необходимо найти контекстно-свободную
грамматику дл^я какого-нибудь языка, который задан неформально. Мы
продемонстрируем, как это делается, строя грамматику для
констант MIM-BASIC'a.
Присвоим нетерминалам имена, соответствующие цепочкам,
которые могут быть из них выведены. Начальный нетерминал —
(константа >.
В руководстве по MINI-BASIC'y описаны два вида констант: с
символом Е, служащим для представления степени числа 10, и без
этого символа. Константы без Е выводятся с помощью правила
1. (константа)-»- (десятичное число)
где (десятичное число > порождает последовательность цифр с
возможной десятичной точкой. Константы с Е выводятся по правилу
2. (константа>-v (десятичное число) Е (целое)
где (десятичное число) — тот же нетерминал, что и в предыдущем:
правиле, а (целое) — нетерминал, порождающий
последовательность цифр, перед которой может стоять знак -f или —.
Чтобы завершить построение грамматики, нам нужно добавить
правила для (десятичного числа) и (целого). Начнем с (целого).
3. (целое) ->- -f (целое без знака )
4. (целое )-*-— (целое без знака)
5. (целое)-»- (целое без знака)
где (целое без знака) — нетерминал, порождающий
последовательность цифр.
Для (целого без знака) в грамматику вводятся следующие
правила:
6. (целое без знака)-»- d(целое без знака)
7. (целое без знака )-*-d
где d представляет любую цифру. Эти два правила порождают, как
легко видеть, последовательности цифр.
Правила для (десятичного числа) можно выразить с помощыа
нетерминала (целое без знака).
8. (десятичное число) -*• (целое без знака )
9. (десятичное число)-»- (целое без знака).
10. (десятичное число)-»- .(целое без знака)
11. (десятичное число )->- (целое без знака). (целое без знака V
Правило 8 — для чисел без десятичной точки; правило 9 —
для чисел с десятичной точкой после последней цифры, правило
10 — для чисел с десятичной точкой в начале, а правило 11 — для
6.8. Грамматика для S-выражений Лиспа
167
чисел, в которых цифры стоят по обе стороны от десятичной точки.
В правых частях этих правил используется только нетерминал
(целое без знака), правила для которого уже приведены выше.
<-.константи ^>
■< целое без знака >
:целое >
'целое без знака >
< целое без знака>
2 < целое без знака >
Рис. 6.5.
Таким образом, все нетерминалы описаны, и грамматика построе-
яа.
Например, константу
3.1 Е — 21
можно вывести с помощью следующего левого вывода:
<константа)=><десятичное число) Е<целое>=>
<иелое без знака> . <целое без знака> Е <целое>=4>
3. <целое без знака) Е <целое>=>
3.1 Е<иелое>=>
3.1 Е — <иелое без знака) =£
3.1 Е—2<целое без знака) =^>
3.1 Е —21
Соответствующее дерево вывода показано на рис. 6.5.
6.8. Грамматика для S-выражений Лиспа
В качестве еще одного примера построим грамматику для
S-выражений языка Лисп. В руководстве по Лиспу S-выражения
определяются рекурсивно в терминах других S-выражений и атомов,
которые являются аналогами идентификаторов:
«S-выражение — это либо атом, либо левая скобка, за которой
168
Гл. 6. Контекстно-свободные грамматики
следуют S-выражение, точка, S-выражение и правая скобка».
Если АТОМ считать терминальным символом, то грамматика для
S-выражений выглядит так:
<S>- ATOM
Эта грамматика демонстрирует два привлекательных свойства КС-
грамматик: они позволяют обрабатывать вложенные скобки и
<5>
АТОМ
АТОМ
АТОМ
Рис. в. в.
АТОМ
могут определять множества цепочек рекурсивным образом.
Вот пример вывода в этой грамматике:
<S> =ф «S> • <S» =>(«S> • <S» • <S» =ф ((ATOM • <S» • <S» =>
((ATOM-«S>-<S»)-<S»=>
((ATOM • (ATOM • <S») • <S» =Ф
((ATOM • (ATOM • ATOM)) • <S» =>
((ATOM • (ATOM • ATOM)) • ATOM)
Соответствующее дерево вывода показано на рис. 6.6.
6.9. Грамматика для арифметических выражений
Иногда грамматика не только определяет, какие цепочки
принадлежат языку, но и отражает некоторую «структуру» языка.
Рассмотрим, например, такую грамматику:
6.9. Грамматика для арифметических выражений
169
1. <£>-* <£>+ (Т)
2. <£>-»- <Г>
3. (Г)-»- <Л * (F)
4. (Г)-*- <F>
5. {F)-+ (F)\ (P)
6. (F)-+ (P)
7. </>>->(<£»
8. (/>>->/
где (£> — начальный символ, а / представляет произвольное целое
число. Эта грамматика, в основе которой лежит грамматика для
арифметических выражений, приведенная в официальном сообще-
<Е> + <Т>
<Е> + <Т><Т>
<F>
/\\\> \
<Т> * <F> <Р> <1
/ / //\\ !
F> <F> <P> ( <F> )
/ / / /к
<р> </■"
/ /
<F>
<Р>
<F> + <Г>
<Т> <F>
<F> <P>
<Р> 6
Рис 6.7.
170
Гл. 6. Контекстно-свободные грамматики
нии об Алголе 60, порождает все арифметические выражения
Алгола 60, в которых используются целые числа и операции +, * и f.
На рис. 6.7 показано дерево вывода в этой грамматике выражения
1 + 2*3+(5+6)*7
где целые числа рассматриваются как вхождения терминального
символа /.
В описании языка программирования должно быть указано не
только то, какие цепочки принадлежат языку, но также и то, как
они должны выполняться. Поэтому описание арифметических
выражений включает правила для определения операндов каждой
операции в выражении. Например, операндами первой операции
сложения + в приведенном выше выражении являются целое число 1
и результат вычисления подвыражения 2*3. Заметим, что на рис. 6.7
подвыражение 1+2*3 выводится из одной вершины, помеченной
символом (£), эта вершина имеет три потомка: (Е), порождающий
операнд 1, + и (Т), порождающий подвыражение 2*3. Аналогично
каждая из трех остальных операций является потомком вершины,,
два других потомка которой порождают операнды этой операции.
Таким образом, в дереве отражено, какие части входной цепочк»
образуют подвыражения, которые нужно вычислять, и каковы
операнды каждой операции. В этом смысле дерево представляет собой.
«структуру» выражения.
6.10. Разные грамматики для одного
и того же языка
Для любого КС-языка существует бесконечное число грамматик,,
порождающих этот язык. Хотя большинство из этих грамматик
чересчур сложны, часто оказывается, что для описания некоторого*
языка полезно иметь несколько разных грамматик.
Например, грамматика с начальным символом (£),
приведенная ниже, порождает тот же язык арифметических выражений, что>
и грамматика, приведенная в разд. 6.9.
1. {Е)-+ (Т) (£-список>
2. (£-список>-*-+ (ГХ-Е-список)
3. (Е-список) -*- е
4. <7>-* (F)<7-список)
5. (Г-список)-*- *(Р)(Г-список)
6. (Г-список > >- е
7. (F)-+ (P)(F-cmcoK)
8. (F-список)-»- f (PXF-список)
9. (F-список > ->- е
10. </>>+((£»
11. (P)-+l
6.11. Регулярные множества как контекстно-свободные языки 171
На самом деле нетерминалы (£), (Т), (F) и (Р) порождают в
•обеих грамматиках одни и те же цепочки.
Во-первых, заметим, что обе грамматики содержат одинаковые
.правила для нетерминала (Р). Теперь рассмотрим нетерминал
(F). В обеих грамматиках (F) трактуется как {Р), за которым
следует нуль или более f (P). В грамматике разд. 6.9 л применений
правила 5 и последующее применение правила 6 порождают список
из (п+1) нетерминалов (Р), разделенных символами f. Например,
<f > => <F> f <P> =» <F> f <P> t <P> =»
<P>t<P>t<P>
В новой грамматике эта же цепочка порождается применением
правила 7 с последующими п применениями правила 8 и
применением правила 9. Например,
<F> => </>> <f-список> => <Ру | <Р> </7-список> =j>
<Ру t <Р> t <Р> <F-cnHCOK> —> <Р> | <Р> | <Р>
Нетерминал (F-список) предназначен для порождения списка,
я который входят нуль или более f {P). Правило 8 порождает \{Р),
за которым следует нетерминал (F-список), порождающий
остальные |(Р). Правило 9 порождает пустой список.
«Структура» выражения отражена в грамматике. Правый
операнд каждой операции f порождается нетерминалом (Р >,
непосредственно следующим за f в правиле 8. Левый операнд каждой f
выводится из цепочки символов (Р) и f, предшествующей
вхождению (F-списка >, к которому применяется правило 8.
Рассмотрим теперь нетерминал (Г). В обоих множествах
правил (Т) трактуется как (F), за которым следует список, состоящий
из нуля или более «(F). Нетерминал (Г-список) предназначен для
лорождения списка, состоящего из нуля или более элементов.
Правила 4, 5 и 6 порождают первый элемент списка, продолжение
списка и его окончание.
Нетерминал (Е) интерпретируется аналогичным образом в
соответствии с правилами 1, 2 и 3.
6.11. Регулярные множества
жак контекстно-свободные языки
В нашей книге введены два класса языков: регулярные множества
« контекстно-свободные языки. В этом разделе будет показано, что
класс КС-языков мощнее. В частности, мы докажем следующий
«факт:
Любое регулярное множество можно описать с помощью
КС-грамматики.
172
Гл. б. Контекстно-свободные грамматики
Другими словами, это означает, что регулярные множества
являются КС-языками.
Пусть задан конечный распознаватель для некоторого
регулярного^ множества. КС-грамматику, порождающую это
регулярное множество, можно получить следующим образом:
1. Терминальным множеством грамматики сделать входное
множество автомата.
2. Нетерминальным множеством сделать множество состояний
автомата, а начальным символом — его начальное состояние.
3. Если в автомате есть переход из состояния А в состояние В
по входу х, то в грамматику надо ввести правило
А->хВ
4. Если А — некоторое допускающее состояние автомата, то
в грамматику надо ввести правило
А^е
Чтобы убедиться, что действительно построена грамматика для
множества цепочек, определяемого автоматом, дадим
нетерминалу, который соответствует состоянию Z, такую интерпретацию:
(цепочка, допускаемая автоматом, начавшим работу в
состоянии Z)
Тогда правило А -»- хВ, построенное на шаге 3, интерпретируется
следующим образом:
цепочка, допускаемая автоматом, начавшим работу в
состоянии А, может представлять собой символ х с приписанной
к нему цепочкой, которая допускается автоматом,
начавшим работу в состоянии В.
Правило А -*- е, построенное на шаге 4, интерпретируется так:
цепочка, допускаемая автоматом, начавшим работу в
(допускающем) состоянии А, может быть пустой.
Таким образом, правила грамматики отражают процесс работы
конечного автомата.
Благодаря такой интерпретации, можно установить
однозначное соответствие между выводами и действиями конечного
автомата. В качестве примера на рис. 6.8, а показан автомат, а на
рис. 6.8,6 — построенная по нему грамматика, Цепочка aba
допускается автоматом, так как она вызывает такую
последовательность переходов:
S-+A-+A-+B
6.12. Праволинейные грамматики
173
где S — начальное, а В — допускающее состояние автомата.
Соответствующий вывод получается путем применения правила,
соответствующего данному переходу и последующего удаления
оставшегося нетерминала применением к нему эпсилон-правила. Так,
цепочке aba соответствует такой вывод:
S =» а А =» аЪА =» abaB =t> aba
Если, наоборот, по данному выводу нужно найти соответствующую
ему последовательность переходов, то по нетерминалу и самому
a b
А
В
S
В
А
А
a
S - Ь В S - е
А - Ь А
В -» b А В -* е
6
Рис. 6.8.
правому терминалу на каждом шаге можно установить новое
состояние и вход, использованный при переходе в это состояние. Так,
по выводу
S=$>bB=>baS=S>ba
получается такая последовательность переходов:
S^B^S
и применение заключительного эпсилон-правила показывает, чта
состояние 5 является допускающим.
6.12. Праволинейные грамматики
Рассмотрим грамматику специального вида, которая содержит
правила двух типов:
04>-> х(В) или (Л)->б
S -» а а
А -» а В
В -> а S
174
Гл. 6. Контекстно-свободные грамматики
где х — некоторый терминальный символ. Процедуру
предыдущего раздела можно обратить, чтобы строить конечный автомат,
который распознает язык, порождаемый грамматикой такого вида.
А именно обратная процедура выглядит так:
1) входным множеством автомата сделать терминальное
множество грамматики;
2) в качестве множества состояний автомата использовать
нетерминальное множество грамматики, а в качестве
начального состояния — ее начальный нетерминал;
3) если в грамматике имеется правило
(А)-+х{В)
то ввести в автомат переход из состояния (А ) в состояние
(В) по входу х\
4) если в грамматике есть правило
(А)-+е
то сделать состояние (А ) допускающим.
Результатом этого построения является недетерминированный
автомат с одним начальным состоянием. Процедура построения из
предыдущего раздела применима к недетерминированным
автоматам такого типа, хотя она была описана как процедура, применяемая
к детерминированным автоматам. Применив новую процедуру к
грамматике на рис. 6.8, б, получаем рис. 6.8, а. Шаги вывода, как
и прежде, соответствуют переходам автомата.
Знание того, что грамматики указанного специального вида
порождают регулярные множества, помогает нам описать задачи,
решаемые конечными автоматами, а потом по грамматикам
получить автоматы о помощью данной процедуры. Например,
идентификаторы Алгола 60 можно задавать следующей грамматикой с
начальным нетерминалом (идентификатор):
(идентификатор >-► /(буквы и цифры)
(буквы и цифры>-»■ /(буквы и цифры)
(буквы и цифры) ->- d(буквы и цифры)
(буквы и цифры)-»-к
где / и d представляют соответственно букву и цифру. Так как
грамматика имеет указанный специальный вид, ясно, что порождаемый
ею язык можно распознавать конечным автоматом. Применив
процедуру, получаем недетерминированный автомат, изображенный
на рис. 6.9. Грамматики описанного выше специального вида,
конечно, не единственный класс грамматик, порождающих
регулярные множества. Еще один легко определяемый класс грамматик,
обладающих свойством порождать регулярные множества,— это
класс так называемых «праволинейных» грамматик. Грамматика
6.12. Праволинейные грамматики
175
называется праволинейной, если правая часть каждого ее правила
содержит не более одного нетерминала, причем этот нетерминал
является самым правым символом правой части. Другими
словами, правила праволинейной грамматики могут иметь вид
{А ) ->- w (В > либо (A)-+w
где (А ) и (R) — нетерминалы, а а» — терминальная цепочка.
г d
Идентификатор
< буквы и цисрры>
< буквы и цифры >
< буквы и цифры >
< буквы и цирры>
Рис. 6.9
Примером праволинейной грамматики может служить такая
грамматика с начальным символом (5):
1.
2.
3.
4.
5.
6.
(S)^a(A)
{S)^bc
(S)^ (A)
(A)-+abb(S)
{А)^с(А)
(А)-* г
Правила 1, 3, 4 имеют вид А -»■ w(B), а правила 2 и 6 имеют вид
А -*■ w. В правилах 3 и 6 цепочка w пуста.
Праволинейные грамматики легко преобразуются в грамматики
специального вида, которые обсуждались выше. Продемонстрируем
это на нашем последнем примере. Правило 4 не имеет надлежащего
вида, так как в нем перед нетерминалом стоят три терминальных
символа вместо одного. Чтобы это исправить, заменим правило 4
следующими тремя правилами:
(A)-*a{bbS)
(bbS)^ b(bS)
(bS)-+ b(S)
каждое из которых имеет нужный вид. В результате вместо одного
правила
(A)-*abb{S)
мы будем применять три:
< Л> =» a <bbS> =» ab <bS> =Ф abb <5>
Правило 2 не имеет надлежащего вида прежде всего потому,
что в его правой части после терминальных символов нет. нетер-
176
Гл. 6. Контекстно-свободные грамматики
минала. Чтобы исправить это, заменим его двумя правилами:
(5> -*- fee (эпсилон)
(эпсилон) -> б
Первое правило, содержащее (S) в левой части, нужно
преобразовать Так же, как было преобразовано правило 4.
Наконец, осталось правило 3, которое не имеет нужного вида,
так как в его правой части стоит один нетерминал. Чтобы
исправить это, заменим это правило на правила вида
(5)->- правая часть правил для (А)
для всех правил, содержащих (А) в левой части.
В результате получилась такая новая грамматика:
1. (S)-vaM)
2а. (5 > -v b (с эпсилон)
26. (с эпсилон > -*- с (эпсилон)
2в. (эпсилон) -»- е
За. (S)-a(bbS)
36. (5>->с(Л>
Зв. (S)-ve
4а. (A)-*-a(bbS)
46. (bbS)^b(bS)
4в. (bS)-+b(S)
5. (А)^с(А)
6. (А ) -> е
Преобразованную грамматику теперь можно использовать для
построения конечного распознавателя, изображенного на рис. 6.10.
a be
<S>
<сэпсилон>
< эпсилон>.
<А>
<bbS>
<bS>
<A>,<bbS>
<bbS>
Рис.
<c эпсиш>
<bS>
<S>
6.10.
<A>
<эпсилон>
<A>
1
0
1
1
0
0
Хотя преобразованная праволинейная грамматика идеально
подходит для построения конечного распознавателя, исходная
непреобразованная грамматика, по всей видимости, дает более
6.12. П'раволииейные грамматики
177
естественное описание множества цепочек, так как в ней меньше
правил и нетерминалов.
Иногда, особенно после применения к грамматике
преобразований, грамматика содержит правила вида
(А > -> (А >
Они означают, что нетерминал переводится сам в себя. Эти
правила бесполезны, и их можно удалить из грамматики, не изменяя
порождаемого ею языка.
Приемы преобразования грамматик, излагаемые в этом
разделе, можно объединить в единую процедуру, которая преобразует
праволинейную грамматику в грамматику специального вида,
описанного в начале раздела.
1. Если имеются правила вида
где w — непустая терминальная цепочка, ввести новый
нетерминал, например (эпсилон >, и добавить правило
(эпсилон > -*■ е
Затем заменить каждое из правил вида (А > -> w правилом
{А > -*- w(эпсилон)
2. Заменить каждое правило вида
(А)^(ц...ап{В)
для п>\ на правила
^Ау-^а^а, ... апВ>
<я, ... а„В> —> a,- <ai+i ... а„В> для 1 < i < п
<апВ>-+а„<В>
где {а{.. .апВ) для Ki'^n — это новые нетерминалы.
3. Если в грамматике есть нетерминал (В), такой, что имеются
правила вида
<Л>-> (В)
то, во-первых, удалить правило
(В)-у (В)
если таковое имеется, и, во-вторых, заменить их правилами вида
(А)-* у
Для всех (А > и у, таких, что существуют правила
<Л>^ <В> и (В)-+у
178
Гл. 6. Контекстно-свободные грамматики
Если останутся правила, правая часть которых состоит из
одного нетерминала, повторить шаг 3.
В результате выполнения шага 3 полностью удаляются
правила, содержащие в правой части один нетерминал (В). Если после
шага 3 из грамматики уже удалены правила, правая часть которых
состоит из одного данного нетерминала, то при последующих
применениях шага 3 к другим нетерминалам этот нетерминал не может
снова появиться в качестве правой части правила. Поэтому
достаточно один раз применить шаг 3 к каждому нетерминалу,
являющемуся правой частью какого-нибудь правила.
Иногда в результате применения этой процедуры правила
дублируются. Рассмотрим, например, так>ю грамматику с начальным
символом (5):
1. (S)-+ab(A)
2. (А)^ ЬЬ(А)
3. (A)-+b(S)
4. (S)^e
Шаг 1 процедуры не применяется, так как в грамматике нет
правил подходящего вида. Шаг 2 применяется к правилам 1 и 2, в
результате получается грамматика
la. (S)-*a{bA)
16. (ЬА)-+Ь(А)
2а. (А)-+Ь(ЬА)
26. (ЬА)-+Ь(А)
3. (A)-*b<S)
4. (5)->е
Однако правила 16 и 26 одинаковы, и одно из них нужно выкинуть.
Шаг 3 не применяется к этой грамматике, так как она уже приняла
нужную форму
В качестве еще одной иллюстрации применим нашу процедуру
к такой грамматике с начальным символом (S):
1. (S)-*a(A)
2. (S)-+ (A)
3. <Л>— (5)
4. (А > -»■ е
Шаги процедуры 1 и 2 не применяются. Применение шага 3 к не-
терминалу (А > дает правила
1. (S)^a(A)
2а. (5>-* (5)
26. (S)-ve
3. Ш-+ (S)
4. (А)-* в
6.13. Еще одна грамматика для констант языка MINI-BASIC 179
Применяя шаг 3 к нетерминалу (S), мы сначала удаляем правило
2а, а затем заменяем правило 3 двумя новыми правилами. Новая
грамматика такова:
1. (S)-^a(A)
26. <S>-»-e
За. (А)-у а (А)
36. (А ) -»■ е
4. (А ) -* г
Правила 36 и 4 совпадают, поэтому одно из них нужно удалить, в
результате чего будет получена грамматика требуемого вида,
состоящая из четырех правил.
В силу того, что существует процедура, преобразующая праволи-
нейные грамматики в грамматики указанного специального вида,
мы можем утверждать следующее:
Язык, порождаемый праволинейной грамматикой, является
регулярным.
Чтобы посмотреть, как праволинейные грамматики возникают
на практике, обратимся к описаниям переменных Алгола 60,
которые имеют такой вид:
ТИП ИДЕНТ, ИДЕНТ, ..., ИДЕНТ
где ТИП и ИДЕНТ — лексемы. Эти описания довольно компактно
задаются праволинейной грамматикой:
(описание) ->- ТИП ИДЕНТ (список описанных переменных)
(список описанных переменных > -»- , ИДЕНТ (список
описанных переменных)
(список описанных переменных > -*■ г
6.13. Еще одна грамматика для констант
языка MINI-BASIC
Грамматика, задающая константы языка MINI-BASIC, была
приведена в разд. 6.7. Сейчас мы получим еще одну грамматику путем
применения процедуры из разд. 6.11 к конечному распознавателю
для констант MINI-BASIC'a.
Распознаватель для констант MINI-BASIC'a без знака был
построен в разд. 2.14 и изображен на рис. 2.24, б. В
рассматриваемом примере мы просто добавим состояние ошибки ОШ и получим
тем самым распознаватель на рис. 6.11. Имена входных символов
были изменены, чтобы привести их в соответствие с именами из
разд. 6.7.
Применение процедуры из разд. 6.11 к этой таблице переходов
дает грамматику с 40 правилами вида {А )-»- х(В) и тремя
правилами вида (А ) -у е. Однако более глубокий анализ показывает, что
объем грамматики несколько завышен Рассмотрим правила для
180
Гл. 6. Контекстно-свободные грамматики
нетерминала (ОШ). Их можно найти по строке, соответствующей
состоянию (ОШ), таблицы переходов, и выглядят они так:
<OIH>->d(OIII>
(ОШ > -v E (ОШ >
(OIII>-v . (ОШ>
<ОШ>-> +(ОШ>
(ОШ > -* — (ОШ >
Из этих правил ясно, что нетерминал (ОШ > не может участвовать
в выводе ни одной терминальной цепочки, так как любая замена
нетерминала (ОШ) дает новую цепочку, содержащую этот
нетерминал. На самом деле,
если (ОШ) интерпрети-
d ё . + - руется как
(цепочка,
допускаемая автоматом,
начавшим работу в состоянии
ОШ)
то понятно, что этот
нетерминал вообще не
порождает ни одной
терминальной цепочки, так
как ОШ — это
состояние ошибки,
обладающее тем свойством, что,
перейдя в него, автомат
не допускает
впоследствии ни одной цепочки.
Таким образом,если
нетерминал (ОШ) хоть
раз появится в выводе,
все последующие промежуточные цепочки должны содержать (0111)
и не могут быть терминальными.
Так как нетерминал (ОШ) не порождает ни одной терминальной
цепочки, мы можем исключить из грамматики все правила,
содержащие (ОШ) в левой или правой части. Поскольку (ОШ) не
участвует в порождении цепочек языка, удаление из грамматики этого
нетерминала и всех его правил никак не повлияет на язык,
порождаемый грамматикой.
После выбрасывания всех правил, содержащих (ОШ), число
правил исходной грамматики уменьшается с 43 до 16, и грамматика
принимает такой вид:
<0>^d<l>
<0>^.<7>
<l>-*d<l>
0
1
23
4
5
6
7
ОЩ
1
1
23
6
6
6
23
ОШ
ОШ
4
4
ОШ
ОЩ
оЩ
ОШ
оШ
7
23
ОШ
ОШ
ОШ
ОШ
ош
ОШ
ОШ
ОШ
ОШ
5
ош
ОШ'
ОШ
ОШ
ОШ
ОШ
ОШ
5
ОШ
ОШ
ОШ
ош
о
1
1
о
о
1
о
о
Рис. 6.11.
6.14. Лишние нетерминалы
181
<1>—
<1>->
<1>—
<23> —
<23>->
<23> —
<4> —
<4> —
<4>-
<5>^
<6>-
<6> —
<7>-н
Е<4>
. <23>
■е
d<23>
Е<4>
е
►d<6>
► + <5>
— <5>
►d<6>
►d<6>
е
.d<23>
Чтобы грамматика более наглядно передавала вид констант язы
ка MINI-BASIC, дадим нетерминалам значащие имена. Например
такие:
<0> = <константа>
<1> = <цифры возможно с десятичной точкой и порядком)
<23> = <десятичные цифры и, возможно, порядок>
<4> = <целое>
<5> = <целое без знака>
<6> = <цифры>
<7> = <десятичное целое и, возможно, порядок>
6.14. Лишние нетерминалы
В предыдущем разделе мы столкнулись с примером нетерминала,
который не участвует в выводе терминальных цепочек и поэтому
может быть исключен из грамматики вместе со всеми правилами,
в которые он входит. Нетерминалы, которые не порождают ни одной
терминальной цепочки, называются бесплодными или мертвыми.
В предыдущем разделе бесплодным был нетерминал (ОШ >, так
как все правила с (ОШ > в левой части содержали (ОШ > и в правой
части. Нетерминалы могут оказаться бесплодными и вследствие
других, более тонких причин. Рассмотрим, например, такую
грамматику с начальным символом (S):
1. (S)-+a(S)a
2. (S)-+b(A)d
3. (S)-+c
182
Гл. 6. Контекстно-свободные грамматики
4. (A)^c(B)d
5. (A)^a{A)d
6. (B) — d(A)f
Бесплодными здесь являются нетерминалы (А) и (В). Применив
правило 4 к цепочке с символом {А ), можно получить цепочку,
содержащую (В), а применив к этой цепочке правило 6, можно
снова получить цепочку, содержащую (А ). Но независимо от того, в
каком порядке делаются подстановки, цепочка, содержащая (А >
или (В), всегда переводится в цепочку, которая также содержит
(А ) или (В). Поэтому правила, в которые входят (А > или (В),
можно исключить из грамматики, оставив в ней лишь правила 1 и 3.
Грамматика, состоящая из правил 1 и 3, порождает те же
терминальные цепочки, что и грамматика с правилами 1—6.
Аналогичная ситуация имеет место и в случае, когда в
грамматике есть нетерминалы, которых невозможно достичь из начального
нетерминала. Рассмотрим, например, такую грамматику с
начальным символом (S):
1. (S)-+a{S)b
2. (S)-+c
3. (A)—b(S)
4. (А)-+а
Ни одно из двух правил с начальным символом (5) в левой части
правила 1 и 2 не содержит в правой части символа {А). Ни одна
цепочка, выводимая из (S), не может содержать (А). Поэтому (А)
не может участвовать в выводе цепочки из (S), хотя сам по себе
этот нетерминал не является бесплодным. Нетерминал (А > можно
удалить из грамматики, оставив лишь правила 1 и 2. Нетерминалы,
которые не появляются ни в одной цепочке, выводимой из
начального символа, называются недостижимыми нетерминалами.
Нетерминалы, которые бесплодны или недостижимы,
называются лишними (бесполезными). Если грамматика получена путем
применения какого-нибудь механического способа типа процедуры из
разд. 6.11, то в ней часто появляются лишние нетерминалы. Обычно
надо проверять, нельзя ли упростить такую грамматику,
выбросив лишние нетерминалы. Даже в грамматиках, составленных
вручную, лишние нетерминалы могут возникнуть вследствие ошибок
разработчика. Поэтому поиск лишних нетерминалов часто может
оказаться полезным при отладке грамматики, составленной
вручную. Опишем процедуру обнаружения лишних нетерминалов.
Процедура состоит из двух частей: одна — для обнаружения
бесплодных нетерминалов, другая — для обнаружения
недостижимых нетерминалов. Сначала нужно выполнить процедуру для
бесплодных нетерминалов, так как при их удалении из
грамматики другие нетерминалы могут стать недостижимыми.
6.14. Лишние нетерминалы
183
Мы называем терминальный или нетерминальный символ
продуктивным (живым), если из него выводится какая-нибудь
терминальная цепочка (т. е. если он не является бесплодным
нетерминалом). Процедура обнаружения бесплодных нетерминалов
основана на следующем свойстве продуктивных символов:
Свойство А: Если все символы правой части правила
продуктивны, то продуктивен и символ, стоящий в ее левой части.
Чтобы убедиться в правильности этого утверждения, заметим, что
терминальную цепочку можно получить из символа, стоящего
в левой части такого правила, применив к нему сначала это
правило, а затем заменив каждый нетерминал правой части на одну
из цепочек, благодаря которым он является продуктивным.
Основная идея процедуры состоит в том, что список начинается
нетерминалами, которые являются «заведомо продуктивными»,
а затем для обнаружения других продуктивных нетерминалов
используется свойство А, и список пополняется. Шаги процедуры
таковы:
1. Составить список нетерминалов, для которых найдется хотя
бы одно правило, правая часть которого не содержит
нетерминальных символов.
2. Если найдено такое правило, что все нетерминалы, стоящие
в его правой части, уже занесены в список, то добавить в список
нетерминал, стоящий в его левой части.
3. Если на шаге 2 список больше не пополняется новыми
нетерминалами, то получен список всех продуктивных нетерминалов
грамматики, а все нетерминалы, не попавшие в него, являются
бесплодными.
То, что список, полученный на шаге 3, содержит только
продуктивные нетерминалы, объясняется тем фактом, что в него
заносились только нетерминалы, продуктивные по свойству Д. Чтобы
убедиться, что список содержит все продуктивные нетерминалы,
заметим, что если дана последовательность правил, используемых
в выводе терминальной цепочки из данного нетерминала, можно
рассмотреть эту последовательность в обратном порядке и показать
таким образом, что все нетерминалы, участвующие в выводе,
продуктивны по свойству А.
. Чтобы продемонстрировать эту процедуру в действии,
рассмотрим грамматику с начальным символом (5), изображенную на
рис. 6.12, а. Благодаря правилу 9 на шаге 1 в список можно
поместить нетерминал (С). Затем на шаге 2 можно добавить
нетерминал (Л >, воспользовавшись правилом 5. Наконец, благодаря
правилу 2 в список можно добавить (S). Дальнейшие попытки
применить шаг 2 оказываются безуспешными, и это говорит о том, что
продуктивными нетерминалами являются (С), (А) и <S>, а ос-
184
Гл. 6. Контекстно-свободные грамматики
Рис
4.
5.
ра
9.
6.12.
(A)^c(S)(A)
(А}-*с(С)(С)
<о-
<с>-
^с<5>
6
тавшийся нетерминал (В > — бесплодный. Удалив все правила,
связанные с (В), получаем грамматику, изображенную на рис. 6.12, б.
Символ называется достижимым в грамматике, если он может
появиться в какой-нибудь цепочке, выводимой из начального не-
1. (S)^a(A)(B)(S)
2. (S) ~+ Ь (С) (А) (С) d 2. <5> - Ь (С) (А) <С> d
3. {А)^Ъ{А)(В) '
4. (A)^c(S)(A)
5. (А)-+с{С){С)
6. (В)-*Ь(А){В}
7. (B)^c(S)(B)
8. (C)-c(Sy
9. <С>-с '
а
терминала (т. е. если он не является недостижимым). Процедура
обнаружения недостижимых символов грамматики основана на
следующем свойстве достижимых символов:
Свойство Б: Если нетерминал в левой части правила
является достижимым, то достижимы и все символы правой части
этого правила.
Это свойство выполняется, так как можно сначала вывести
цепочку, содержащую символ, который является левой частью
правила, и потом применить к ней это правило. Основная идея
процедуры заключается в том, что список начинается нетерминалами,
которые «заведомо достижимы», а затем для обнаружения других
достижимых нетерминалов используется свойство Б, и список
пополняется. Шаги процедуры таковы:
1. Образовать одноэлементный список, состоящий из
начального нетерминала.
2. Если найдено правило, левая часть которого уже имеется
в списке, то включить в список все нетерминалы, содержащиеся в
правой его части.
3. Если на шаге 2 новые нетерминалы в список больше не
поступают, то получен список всех достижимых нетерминалов, а
нетерминалы, не попавшие в него, являются недостижимыми.
Список, полученный на шаге 3, содержит только достижимые
летерминалы, так как в него вносились только нетерминалы, до-
6.14. Лишние нетерминалы
185
стижимые по свойству Б. В окончательном списке должны
оказаться все достижимые нетерминалы, так как, используя свойство
Б и последовательность правил, благодаря которой достижим дан-
1. <5>- а (А) (В)
2. (S) - (Е)
3. (А)^ d (D)(A)
А. (А)-* е
5. (В) - Ъ (Е)
6. (В) - f
7. <С>- с (А) (В)
8. <С>- d(S) <Л>
9. (С)- а
10. (D)-^ e (А)
11. <£>- f(A)
12. <£)-. g
(7
Рис.
1.' <5> - я (А) (В)
2. <5> - <£>
3. (А)^ d(D)(A)
4. {А)-* е
5. <В> - *"■<£>
6. <В>- /
10. <Z>>- e (А)
11. <£>^ / (А)
12. <£>- ^
6
6.13.
ный нетерминал, можно показать, что все нетерминалы,
участвующие в выводе, попадают в список.
Чтобы продемонстрировать процедуру в действии, рассмотрим
грамматику с начальным символом (S), изображенную на рис.
1. (S)-+ac
2. (S)^b(A)
3. (А)-*С(В)(С);
4. (B)-*a(S)(A)
5. (С)-Ь(С)
6. <С>-</
а
Рис. 6.14
1. <S> —ас
5. (С)-^Ь(С)
6. <С> —</
6
1. <S> — а с
в
6.13, а. На шаге 1 мы начинаем список, помещая в него начальный
символ (S). Применяя шаг 2 к правилам, содержащим (5) в левой
части, а именно к правилам 1 и 2, обнаруживаем, что надо добавить
в список нетерминалы (Л >, (В) и (Е>. Применяя шаг 2 к правилу 3,
выясняем, что нужно добавить также нетерминал (D). При
проверке остальных правил новые нетерминалы в список не заносятся,
186
Гл. 6. Контекстно-г.ппбодные грамматики
и мы заключаем, что достижимыми являются нетерминалы (Ь >, {А ),
(В), (D) и (Е), а оставшийся нетерминал (С) — недостижимый.
Удалив правила, содержащие (С), получаем грамматику,
изображенную на рис. 6.13,6
Проиллюстрируем, наконец, применение обеих процедур на
примере грамматики с начальным символом (S), изображенной на
ри.-. 6.14, а. Применив процедуру для бесплодных символов, мы
обнаруживаем, что символы {А) и (В) являются бесплодными.
Удалив правила, содержащие эти символы, получаем грамматик\ на
рис. 6.14, б. Теперь, осуществив проверку на недостижимость,
выясняем, что символ (С) недостижим. Удалив правила с этим
символом, получаем грамматику, изображенную на рис. 6.14, «.
Теперь понятно, что язык, порождаемый грамматикой на рис. 6.14, а
содержит одну цепочку ас. Заметим, что нетерминал (С) стал
недостижимым лишь после удаления правила 3. Таким образом, если
бы мы устраняли сначала недостижимые нетерминалы, а затем
бесплодные, то нам не удалось бы до конца упростить грамматику.
6.15. Грамматика MINl-BASIC'a для руководства
по этому языку
Руководство по языку MINI-BASIC, приведенное в приложении А,
предназначено для объяснения языка тем, кто не имеет опыта
работы с формальными языками. Структуры языка обьясняются в
руководстве на примерах. Мы надеемся, что, рассмотрев несколько
примеров, читатель сможет самостоятельно составлять
конструкции того или иного вида. Слабость такого подхода в том, что
читатель тем не менее не сможет составить точного представления о том,
что в языке допустимо, а что нет. В помощь более опытном)
пользователю полезно дополнить элементарное описание языка
контекстно-свободной грамматикой, чтобы читатель, знакомый с
формальными языками, мог более точно определить, какие
конструкции разрешены в языке. В этом разделе мы приводим грамматику
MINI-BASIC'a, которая могла бы в свою очередь послужить в
качестве приложения к руководству по языку.
Терминалами грамматики являются символы, которые обычно
входят в программу на MINI-BASIC'e. Символ пробела не входит
в терминальное множество, так как правило «пробелы
игнорируются» прекрасно понимается и не будучи встроенным в
грамматику.
Начальный нетерминал
Для начального нетерминала, называемого (список операторов),
есть два правила:
в.15. Грамматика MINI-BASIC'a для руководства по этому языку 187
1. (список операторов>-> (число) (оператор) CR (список
операторов )
2. (список операторов)->- (число) END CR
Символ CR означает «возврат каретки». Эти правила задают
программу как список операторов, перед которыми стоят номера строк,
причем последним оператором является оператор END.
Рассмотрим теперь каждый из операторов.
Пустой оператор
Строка, которая вообще не содержит оператора.
3. (оператор) -> е
Оператор присваивания
4. (оператор) -»- LET (переменная )= (выражение)
GOTO-onepamop (оператор перехода)
5. (оператор) -»- GOTO (число)
IF-onepamop (условный оператор)
6. (оператор) -> ^(выражение) (знак отношения)
(выражение) GOTO (число)
GOSUВ-оператор (оператор перехода на подпрограмму)
7. (оператор) -*- GOSUB (число)
RETURN-оператор (оператор возврата)
8. (оператор)-> RETURN
FOR-onepamop (заголовок цикла)
9. (оператор) -»- FOR (переменная )= (выражение) ТО
(выражение)
10. (оператор) -> FOR (переменная )= (выражение) ТО
(выражение) STEP (выражение)
NEXT-onepamop (конец цикла)
11. (оператор)-»-NEXT (переменная )
REM-onepamop (комментарий)
12. (оператор) -> REM (литеры)
Так как «литер» можно использовать очень много1), мы не будем
выписывать правила для нетерминала (литеры), а заметим лишь,
что он порождает произвольные цепочки, составленные из любых
символов, кроме символа CR.
*) Можно считать, что среди них и все русские буквы.— Прим. ред.
188 Гл. 6. Контекстно-свободные грамматики
Выражения
Грамматика для выражений — расширенный вариант грамматики,
приведенной в разд. 6.9. Правила 13 и 14 порождают унарные
операции + и —.
13. (выражение)-> + (терм)
14. (выражение)-*-— (терм)
15. (выражение)-»- (выражение) + (терм)
16. (выражение)-»- (выражение)— (терм)
17. (выражение)-*■ (терм)
18. (терм) -*■ (терм)*(множитель)
19. (терм )-> (терм)/(множитель)
20. (терм)-»- (множитель)
21. (множитель)-»- (множитель) f (первичное)
22. (множитель)-»- (первичное)
23. (первичное) -*• ((выражение >)
24. (первичное)-»- (переменная)
25. (первичное)-»- (константа без знака)
Числа и константы
26. (число)-*- (цифра)(цифры)
27. (цифры) -*■ (цифра) (цифры)
28. (цифры) -*■ е
Правила для нетерминала (цифра) будут приведены позже.
29. (константа без знака)-»- (число)(порядок >
30. (константа без знака)-*- (число). (цифры)(порядок)
31. (константа без знака)-»-. (число)(порядок)
32. (порядок >-»-Е + (число)
33. (порядок ) -*■ Е— (число)
34. (порядок) -*■ Е (число)
35. (порядок )-> е
Переменные
36. (переменная ) -»- (буква)
37. (переменная)-»- (буква) (цифра)
Другие правила
Для экономии места мы будем писать несколько правил в одной
строчке
38—43. (знак отношения) -»- = | О I < I <= I > | >=
44—53. (цифра)-* 0|1|2|3|4|5|6|7|8|9
54-79. (буква) -»- A|B|C|D|E|F|G|H|I|JIKIL|
MINIOIPIQIRISITIUIVIWI
X I Y I Z
в.15. Грамматика MINI-BASIC'a для руководства по этому языку 189
Некоторые аспекты языка MINI-BASIC не определяются этой
грамматикой, например:
а) никакие две строки программы на MINI-BASIC'e не могут
начинаться с одного и того же номера строки;
б) номера строк, используемые в операторах GOTO, GOSUB и
IF, должны действительно встречаться в начале каких-
нибудь строк программы;
в) каждому FOR-оператору должен соответствовать NEXT-
оператор с той же переменной, и эти операторы должны
быть правильно вложены (если внутри циклов встречаются
другие циклы).
Опубликованные КС-грамматики для таких известных языков
программирования, как Алгол и ПЛ/I, также дают неполное
определение этих языков. Обычно язык программирования задается с
помощью КС-грамматики плюс некоторые неформальные описания.
Таким образом, язык программирования должен состоять из
цепочек, которые порождаются этой грамматикой, и удовлетворяют
дополнительным ограничениям, содержащимся в неформальном
описании. Грамматика порождает все программы, принадлежащие
языку, плюс некоторые дополнительные программы, которые
языку не принадлежат; грамматика MINI-BASIC'a, например,
порождает некоторые программы, в которых две строки имеют один и
тот же номер.
Свойства языка, которые в руководстве описываются
грамматикой, принято называть синтаксическими или грамматическими
свойствами, а свойства, которые грамматикой не описываются —
семантическими свойствами. В руководстве по языку семантические
свойства описываются обычно на естественном языке.
Слова «синтаксический», и «семантический» не следует
воспринимать здесь слишком серьезно. Если при описании какого-нибудь
языка программирования используются разные грамматики, то
некоторые свойства языка, которые не описываются одной
грамматикой (и, следовательно, называются семантическими), могут быть
описаны с помощью другой грамматики (и, следовательно, для этой
грамматики будут синтаксическими)1). Примером такой
ситуации может служить то, что грамматика, которая фактически
используется в синтаксическом блоке нашего компилятора с языка MINI-
BASIC (см. разд. 10.1 и 12.8), именно грамматически описывает
требование, чтобы каждому FOR-оператору соответствовал
некоторый NEXT-оператор.
*) «Синтаксический» отнюдь не означает «описываемый КС-грамматикой».
Так называемые контекстные условия языков программирования не описываются,
как отмечено далее, никакой КС-грамматикой, но тоже являются
синтаксическими.— Прим. ред.
190
Гл. 6. Контекстно-свободные грамматики
Однако имеются такие аспекты языков программирования,
которые в принципе не могут быть описаны контекстно-свободными
грамматиками. Например, если допускаются сколь угодно длинные
номера строк, то можно доказать, что ни одна КС-грамматика не
порождает в точности те программы на MINI-BASIC'e, которые
удовлетворяют ограничению, что никакие две строки программы
не имеют одинаковых номеров. Еще одним примером является то,
что КС-грамматика не может гарантировать, что порождаемые ею
программы на Алголе удовлетворяют требованию, чтобы
идентификаторы не описывались в одном блоке дважды.
Есть еще и такие аспекты языков программирования, которые
можно описать контекстно-свободной грамматикой, но при этом
грамматика будет чрезмерно громоздкой. Так, можно найти
грамматику, порождающую такие программы на MINI-BASIC'e, для
которых выполняется требование, что каждый FOR-оператор и
соответствующий ему NEXT-оператор на самом деле используют
одну и ту же переменную Однако эта грамматика будет слишком
громоздкой; поэтому мы решили задать это ограничение
неграмматическими средствами.
На практике КС-грамматики используются для описания языка
программирования лишь в той степени, в какой это можно сделать
компактно. При описании остальных аспектов языка обычно
используются неформальные методы ').
6.16. Замечания по литературе
Контекстно-свободные грамматики были впервые формализованы
Хомским [1956, 1957, 1959]. Многие свойства КС-языков впервые
рассмотрены в работе Бар-Хиллела, Перлеса и Шамира [1961].
Связь между регулярными множествами и праволинейными
грамматиками была установлена Хомским и Миллером [1958]. Обзор
КС-грамматик дан в работе Хомского [1963]. Формы Бэкуса —
Наура были впервые применены для описания языка
программирования в сообщении об Алголе 60 [Наур и др. 1960, 1962].
Контекстно-свободным языкам полностью посвящена математическая книга
Гинзбурга [1966]. В книге Ахо и Ульмана [1972а] обсуждаются
методы получения распознавателей для произвольных
КС-грамматик.
') В последние годы достигнут немалый прогресс в разработке методов
формального описания контекстно-зависимого синтаксиса и особенно семантики.—
Прим. ред.
Упражнения
191
Упражнения
1. Найдите КС-грамматику для каждого из следующих языков:
а) {1'Ю"'|я>т>0};
б) {1"0"1"10'л!п, т>0};
в) {1»0"Ч"»0"|п, т>0};
г) {l"0'}U{0",lm}. где л, m>0;
д) {13п + 20"Ю0};
е) {wawr}, где ш— произвольная цепочка из нулей и единиц;
ж) Все цепочки в алфавите {0, 1}, содержащие равное количество нулей и
единиц;
з) Все цепочки в алфавите {0, 1 }, содержащие равное количество нулей и
единиц и такие, что каждая подцепочка, взятая с левого конца, содержит
единиц не меньше, чем нулей;
и) {1"0гаИ '!+Р>т>0}."
2. КС-грамматика порождает дерево вывода, изображенное на рисунке
<S>
<А >
<S><B><BXA>
b
b
а) Постройте левый вывод, соответствующий этому дереву.
б) Сколько выводов соответствует этому дереву?
в) Нарисуйте дерево вывода терминальной цепочки ab.
3. Опишите языки, порождаемые следующими грамматиками с начальным
нетерминалом (S):
а) (S)-*10<S>0 (S)^a(A)
(А)-+ЫА) {А)-*а
б) (S)-+(S)(S) <S>-*lC4>0
(А)-+\(А)0 (Л>-*е
в) {S)-+\(A) <S>-*<B>0
С4>—1С4> МЫО
(вМвЮ (в)—(О
<С)-*1(С>0 <С>-*е
г) {S)-+B(A)(D)C (D)-+(G)l
{A)-+A(G)S (G)-+e
Д) {S)-+a(S)(S) <S>—a
•4. Какие из приведенных ниже цепочек можно вывести в данной грамматике
с начальным нетерминалом (S)? В каждом случае постройте левый вывод,
правый вывод и дерево вывода.
192
Гл. б. Контекстно-свободные грамматики
(S)-+a(A)c(B) (А)-+(В)а(В)
(S)^(B)d{S) <А)^а(В)с
(B)-+a(S)c(A) (A)->a
(В)-+с{А)(В) (Л)->6
а) аасЪ
б) aababcbadcd
в) aacbccb
г) aacabcbcccaacdca
д) aacabcbcccaacbca
5. Найдите КС-грамматику для выражений в лямбда-исчислении, описываемых
следующим образом:
Выражение в лямбда-исчислении — это переменная или символ К, за которым*
следует переменная, а далее либо выражение, либо левая скобка, выражение,
еще одно выражение и правая скобка.
6. Может ли цепочка иметь два левых вывода и лишь один правый?
7. Покажите, что если некоторый язык является контекстно-свободным, то
контекстно-свободным будет и язык, который получается, если в конце каждой
цепочки исходного языка приписать маркер конца, считающийся в новом
языке терминальным символом.
8. Найдите КС-грамматику для двух типов условных операторов Фортрана.
9. Найдите КС-грамматику для условных операторов Кобола.
10. Нарисуйте дерево вывода следующей программы на Алголе, пользуясь
стандартной грамматикой из Сообщения об Алголе (Наур и др. [1963]):
begin integer Al;
Al := 12; end
11. Найдите КС-грамматику для операторов Снобола.
12. Найдите КС-грамматику для регулярных выражений (Хенни [1968]), в
которых используются операции +, * и конкатенация, изображаемая просто
приписыванием аргументов друг к другу.
13. Опишите язык, порождаемый следующей грамматикой, и нарисуйте деревья
вывода для трех цепочек этого языка.
Ш)-++(р№
(r)^*{P)(R)
(R)^i(p)(R)
<Я)->е
14. Найдите грамматику, порождающую то же множество арифметических
выражений, что и грамматика из разд. 6.9, но имеющую всего лишь один
нетерминал.
15. а) Найдите КС-грамматику для логических выражений, составленных из
логических переменных, констант, скобок и знаков операций отрицания
(—i) дизъюнкции (v) и конъюнкции (л). Приоритеты обычные: ~1
выполняется перед л, а л — перед V.
б) Добавьте к указанному языку первичные логические выражения, каждое
из которых представляет собой арифметическое выражение, за которым
следует знак отношения (>, ^, =, ф, <, <) и еще одно арифметическое
выражение, и постройте соответствующую грамматику.
16. Найдите праволинейную грамматику для языка, распознаваемого
лексическим блоком компилятора с MINI-BASIC'a.
17. Обозначим буквой L язык, распознаваемый автоматом, который изображен
на рисунке
Упражнения
193
А
В
С
В
С
В
А
В
А
0
1
0
Найдите праволинейные грамматики для языков;
а) L+e в) L*
б) L-L г) L +
18. Рассмотрим грамматику
S^Sa
S^Sb
S-wi
а) Найдите праволинейную грамматику, которая порождает этот же язык,
б) Нарисуйте дерево вывода цепочки ababb в каждой из этих грамматик.
19. Найдите праволинейные грамматики для языков и/или автоматов, описанных
в следующих упр. из гл. 2.
а) 1 д) 13 и) 17
б) 3 е) 14 к) 18
в) 4 ж) 15 л) 22
г) 6 з) 16 м) 23
20. Покажите, что следующие две праволинейные грамматики порождают один
и тот же язык:
а) (начальный нетерминал — (X))
W—0 <У)->1(К>
U)-*0<V) (Y)-*l
(X)-+\(Z) <Z>-*0<Z)
(Y)-+Q{X) (Z)-+\{X)
б) (начальный нетерминал — (А))
C4)-*0(B> (D)^O(A)
C4>-*1<£> <D)->1(D>
<B>-*0<i4> <D>-H3
<B)^l{F) (E)^0(C)
(B)-^ (E)-yl(A)
<СЫ)<0 (F)^O(A)
<O-*l04> (F)-+\(B)
(F)^e
21. Найдите лишние нетерминалы в следующей грамматике с начальным
нетерминалом (S):
(S)^a{A){B)(C) (S)^b(C){E)(S)
(S)-+a{E) (A)^b{E)
(A)-+(S)(C)(D) (A)^d
(B)-+d(F){S) <fl>-m<fl><0
{C)-+a(E){S) (C)^b(E)
(D)-+a(A)(C) <D>—d
(E)-+a{C){E) <£)-^e
(F)-*(A){B) (F)^a(F)
Ф. Льюио и др.
194
Гл. 6. Контекстно-свободные грамматики
22. Найдите праволинейную грамматику без лишних нетерминалов для каждого
из автоматов на рис. 6.15.
А
В
С
D
А,В
С
С В.С
C.D
а
А
1 В
С
1 D
Е
F
С
Н
1
В
1
А
F
С
И
А
D
D
G
F
В
D
Н
F
В
F
А
0
1
0
0
0
0
1
0
0
Рис. 6.15.
23.
24.
25.
Каково значение каждого из следующих выражений MINI-BASIC'a? Каковы
их значения в Фортране (предполагается, что символ f заменен на **)?
а) -2*2
б) 2+2/2+2
в) —2*2
г) 2f2/2t2
д) 2f2f2t2
Опишите словами язык, порождаемый этой грамматикой, где роль
начального символа играет (£}:
(Е)МТ)
(T)MT){F)*
(F)^(P)
Найдите грамматику для арифметических выражений, аналогичную
грамматике, описанной в разд. 6.9, с той лишь разницей, что знаки унарных
операций плюс и минус могут стоять перед каждым числом или переменной
(например, допустима цепочка 3*—4) и интерпретируются согласно одному из
следующих соглашений:
а) унарные операции имеют такой же приоритет, что и бинарное сложение и
вычитание
(например, — 2|2=—(2;2)=— 4);
Упражнения
195
г) унарные операции всегда выполняются первыми
(например, — 2f2=(—2)f2=4).
26. Нарисуйте деревья выводов, соответствующие грамматике из разд. 6.15,
для таких программ на языке MINI-BASIC:
a) 05 LET XI = -С * 3 * (+1 - 7)
10 END
b) 15 JOB XI = 1 ТО 12
52P0RX2= 1TO10
г< let xi = хг +1
55 NEXT X?
5Ь NEXT XI
57 END
27. Используя терминальный алфавит грамматики из разд. 6.9, напишите
грамматику, которая порождала бы все составленные из этих терминалов цепочки,
не являющиеся арифметическими выражениями (в смысле грамматики из
разд. 6.9).
28. В обычной алгебре переменные обозначаются одной буквой, и поэтому знак
операции умножения часто опускается (так, 2z означает удвоение г). Найдите
КС-грамматику для многочленов, составленных из чисел, однобуквенных
переменных, и операций -f-, — и t, причем операция умножения
подразумевается между соседними переменными, а также между стоящими рядом
переменной и целым числом.
29. Опишите общие процедуры, которые по данным КС-грамматикам Gt и G2,
порождающим языки L, и L2, строят КС-грамматику для:
а) ицЦ
б) LVL„
в) L\
30. Найдите КС-грамматику, которая порождала бы операторы FORMAT в
Фортране (за исключением холлеритовых, т. е. типа Н).
31. Найдите КС-грамматику для языка BASIC в том виде, как он описан в каком-
нибудь подходящем руководстве '). Какие свойства языка не описываются
вашей грамматикой?
32. Найдите КС-грамматику, порождающую S-выражения Лиспа, для
представления которых используется
а) точечная запись,
б) списочная запись,
в) Лисп — метаязык.
33. Пусть в программе на MIXI-BASIC'e можно использовать только три номера
строки: 1, 2 и 3. Напишите КС-грамматику, которая порождала бы все
программы на MINI-BASIC'e, удовлетворяющие требованию, что все строки
начинаются с разных номеров и все номера строк, используемые в операторах
GOTO, IF и QOSUB, действительно встречаются в начале каких-нибудь строк
программы.
34. Как определить, содержит ли язык, порождаемый грамматикой, бесконечное
число цепочек?
') См. примечание во введении на стр. 9.— Прим. ред.
196
Гл. 6. Контекстно-свободные грамматики
35. Как определить, порождает ли грамматика хоть одну терминальную
цепочку?
36. Покажите, что если контекстно-свободный язык не содержит пустой цепочки,
то для этого языка существует КС-грамматика, в которой нет эпсилон-правил.
37. Приведите пример грамматики, в которой нет терминальных символов, но
определяемый ею язык содержит по крайней мере одну цепочку.
38. Приведите пример грамматики, такой, что каждая цепочка порождаемого ею
языка имеет бесконечное число деревьев вывода.
39. Каким свойством должна обладать грамматика, чтобы каждому дереву
соответствовал лишь один вывод?
40. а) Будем писать х&у, если либо х=&у, либо у=$>х. Предположим также, что
*
ФФ означает нуль или более применений отношения ФФ. Приведите пример
КС-грамматики с начальным нетерминалом (S), для которой множество
терминальных цепочек до, таких, что {S)=$>*w, не совпадает с множеством
*
терминальных цепочек до, таких, что (S)G$w.
б) Как выглядело бы «дерево вывода», в котором используется отношение ФФ ?
41. Покажите, что язык а*-\-Ь* нельзя породить никакой КС-грамматикой с
одним нетерминалом.
42. Покажите, что для любой грамматики существует константа, такая, что для
каждой цепочки порождаемого грамматикой языка существует вывод, число
шагов которого меньше, чем длина цепочки, умноженная на эту константу.
43. Найдите КС-грамматику, порождающую все правильно построенные формулы
исчисления высказываний.
44. Постройте процедуру, с помощью которой можно определить, порождают ли
две праволинейные грамматики один и тот же язык.
45. Для каждого из следующих выражений нарисуйте их деревья вывода в
грамматиках из разд. 6.9 и 6.10:
а) /*/+/
б) /•(/+/)
7
Синтаксически управляемые процессы
обработки языков
7.1. Введение
Изучая конечные автоматы, мы развили теорию, охватывающую
проблемы распознавания. Причем когда конечные автоматы
использовались в практических задачах, такие аспекты обработки цепочек,
как выходы из распознавания и вычисление значений, решались
нами с помощью переходных процедур, задаваемых в зависимости
от конкретного случая. Так как почти всегда оказывалось, что
нужные процедуры могут быть описаны кратко и построены просто,
мы решили, что теория конечных распознавателей является
адекватной теоретической базой для разработки конечных процессоров.
В последующих главах мы займемся распознаванием контекстно-
свободных языков автоматами с магазинной памятью. В отличие от
конечного распознавателя для МП-распознавателя строить
соответствующие расширения достаточно трудно, поэтому теория
распознавания контекстно-свободных языков сама по себе не
обеспечивает адекватной теоретической базы для построения
компиляторов. Цель данной главы — заложить выходящий за границы
теории распознавания теоретический фундамент обработки
контекстно-свободных языков, на основе которого легко обеспечить
необходимые расширения.
Все методы проектирования, рассматриваемые в последующих
главах, основываются на технике, в которой процесс обработки
контекстно-свободного языка определяется в терминах обработки
каждого отдельного правила соответствующей грамматики. Для
описания процесса обработки, основанного на этой технике,
обычно используется прилагательное «синтаксически управляемый».
Синтаксически управляемые методы в данной книге основываются
на математическом понятии «транслирующей грамматики»,
которое вводится в разд. 7.3, и понятии «атрибутной транслирующей
грамматики», которое будет рассмотрено в разд. 7.7.
7.2. Польская запись
На протяжении всей данной главы в качестве иллюстрирующего
примера используется задача трансляции арифметических
выражений. В этом разделе мы дадим один конкретный пример того,
во что можно переводить такие выражения.
198 Гл. 7. Синтаксически управляемые процессы обработки языков
Обычный метод записи арифметических выражений,
описываемый грамматикой из разд. 6.9, известен под названием инфиксной
записи. Однако существуют другие способы описания того, как
нужно комбинировать арифметические величины. Одним из таких
способов является так называемая постфиксная польская запись,.
разработанная польским математиком Я. Лукасевичем.
< операнд >
< операнд > < операнд >
< операнд > < операнд >
а Ь
Рис. 7.1.
В постфиксной польской записи знак операции следует сразу
за ее операндами. Множество польских выражений с операциями
+ и * можно породить при помощи грамматики
(операнд)->- (операнд) (операнд)+
(операнд) -> (операнд)(операнд)*
(операнд >-> /
где / обозначает любую переменную. В дальнейших рассуждениях
эти переменные представляются малыми латинскими буквами.
Каждому выражению в инфиксной записи соответствует
выражение в постфиксной польской записи. .Например, постфиксной
записью для а*Ъ будет аЫ, а для а*Ь+с будет аЬ*с+.
На рис. 7. 1. показано дерево вывода последней цепочки.
Выражение показывает, что к операнду аЬ* (т. е. произведению а и Ь)
и операнду с надо применить операцию +•
Для другого примера инфиксного выражения а+Ь*с
соответствующей постфиксной польской записью будет аЬс*+. Дерево
вывода этой цепочки показано на рис. 7.2. Выражение состоит
из операнда а, операнда be* и знака операции +.
Постфиксная польская запись не содержит скобок, даже когда
соответствующие инфиксные выражения должны заключаться в
7.3. Транслирующие грамматики
199
скобки. Например, инфиксное выражение (а+Ь)*с записывается как
dQ-\-c*. В качестве последнего примера возьмем выражение а+Ь*
(c+d)*{e+f), постфиксной польской записью для которого будет
abcd+*ef+*+
<Операнд>
< операнд>
< операнд > < операнд >
Ь с
Рис. 7.2.
Постфиксная польская запись обеспечивает другой язык для
записи математических формул. Некоторые компиляторы имеют
синтаксический блок, который буквально переводит инфиксные
выражения в соответствующие польские записи. Многие другие
компиляторы выполняют перевод, аналогичный переводу в
польские записи. Такой перевод обсуждается далее в этой главе.
7.3. Транслирующие грамматики
Допустим, что нам нужно построить процессор, получающий в
качестве входа инфиксное выражение и печатающий на выходе
эквивалентное выражение в постфиксной польской записи. Мы хотим
далее, чтобы проектирование этого процессора основывалось на
распознавателе, который каждый раз, когда должен быть выдан
■символ, вызывает процедуру печати. Хотя у нас еще нет
детального плана процесса распознавания, представим себе, как мог бы
■происходить этот процесс. Предположим, например, что на
входе — цепочка а+Ь*с. Действия процессора, соответствующие вводу
« выводу, могли бы происходить по такому «сценарию»:
: операнду
200 Гл. 7. Синтаксически управляемые процессы обработки языков
ЧИТАТЬ(а) ПЕЧАТАТЬ(а) ЧИТАТЬ (+) ЧИТАТЬ(Ь)
ПЕЧАТАТЬ^) ЧИТАТЬ(*) ЧИТАТЬ(с) ПЕЧАТАТЬ(с) ПЕЧАТАТЬ(*>
ПЕЧАТАТЬ(Ч-).
Этот сценарий правдоподобен, поскольку символы, а, Ь и с
печатаются, как только они поступают на вход, а операторы
печатаются сразу после того, как напечатаны оба операнда.
Слово ЧИТАТЬ не должно восприниматься слишком буквально,
поскольку многие автоматы не содержат операции ЧИТАТЬ.
Например, примитивный МП-автомат сдвигается на входной символ,
держится на нем в течение неопределенного числа переходов, а
затем сдвигается с этого символа.
Последовательность действий ввода и вывода можно описать,
не используя слов ЧИТАТЬ и ПЕЧАТАТЬ, следующим образом:
a{a}+b{b}*c{c}{*}{+).
Операции ввода представлены самими входными символами, а
операции вывода — символами, заключенными в скобки. Эта
последовательность представляет собой пример того, что мы называем
последовательностью актов х). Результатом указанных в ней
операций ПЕЧАТАТЬ будет выходная цепочка, состоящая из
символов, заключенных в скобки, а именно abc*+. С целью создания
математической модели перевода пару скобок и заключенный в них
выход будем рассматривать как единый символ, называемый
символом действия. Так, приведенная выше последовательность актов
содержит пять символов действия, а именно {а}, {Ь}, {с}, {*} и {+}.
В этом примере символы действия рассматриваются как имена
процедур, которые печатают выходные символы, заключенные в
скобки. В других приложениях символы действия используются для
представления более общих процедур.
Приведенная выше последовательность актов просто говорит нам
о том, как можно обработать одно конкретное инфиксное
выражение. Для того чтобы показать, как обрабатывать все инфиксные
выражения, можно описать множество или язык последовательностей
актов. Наша цель — описание таких языков с помощью
контекстно-свободных грамматик. Сейчас мы разработаем такое описание
для рассматриваемого примера. В данном случае мы построим КС-
грамматику, описывающую множество последовательностей актов
для перевода инфиксной записи в постфиксную польскую запись.
Обычно исходным пунктом при разработке
контекстно-свободного описания языка последовательностей актов служит
грамматика для входного языка, так как она описывает входную часть
последовательности актов. Грамматика для инфиксных выражений
(с начальным нетерминалом (£)) такова:
*) Авторы различают последовательность актов (activity sequence) и
последовательность действий (action sequence), в последнюю не входят входные символы,
рассматриваемые как акты чтения,— Прим. ред,
7.3. Транслирующие грамматики
201
1. (£>^ Ш)+(Т)
2. (£>-> <7>
3. (Г)-»- (Т)*(Р)
4. <7>-*- (Р)
5. </»>-*-(<£»
6. (Р>->я
7. <Р>^6
8. </>>-* с
Для удобства изложения грамматика содержит три конкретных
имени переменных а, Ь, и с. Чтобы построить грамматику для
последовательностей актов, мы просто опишем действия,
соответствующие каждой правой части правил грамматики.
Например, чтобы напечатать а после того, как а прочитано,
лравило 6 изменится следующим образом: (Р) -> а{а). Чтобы
напечатать знак сложения после того, как напечатаны оба его
операнда, правило 1 заменяется на (£)-> {Е)+(Т){+}.
Это новое правило можно выразить словами «обработка (£)
состоит из обработки (Е), чтения +, обработки (7") и печатания
+». После аналогичных изменений в других правилах новая
грамматика будет такой:
1. <£>-> (Е)+(Т){ + )
2. <£>-^ (Т)
3. <Г>-»- <Г>*<Р>{*}
4. <Т>-> (Р)
5. </>>-*«£»
6. (Р)-+а{а)
7. (P)-+b{b)
• 8. (Р)-+с{с}
Эта новая грамматика представляет собой то, что мы называем
транслирующей грамматикой или грамматикой перевода.
В силу соответствия между правилами инфиксной грамматики
и правилами транслирующей грамматики вывод входной
последовательности в инфиксной грамматике можно использовать для того,
чтобы получить последовательность актов для этой входной
последовательности с помощью транслирующей грамматики. Это
делается просто путем применения соответствующих правил в
соответствующих местах. Например, рассмотрим инфиксное
выражение (а+Ь)*с. Левый вывод этой цепочки получается
применением последовательности правил 2, 3, 4,5, 1, 2, 4, 6, 4, 7, 8. Эта же
последовательность правил транслирующей грамматики,
примененная к соответствующим нетерминалам (в данном случае к
самым левым нетерминалам), дает вывод последовательности актов
202 Гл. 7, Синтаксически управляемые процессы обработки языков
для этой входной последовательности. Соответствующие выводы
имеют вид
<£> => <Г> => <Г> * </>> => </>> * </>>
=> «£» * </>> => «£> + <Г» * <Р> =>* (а + Ь) * с
<£> => <Г> => <Г> * </>> •{*} => </>> * </>> {*}
=$«Е»*<Р>{*\=>«Е> + <Т>{ + })*<Р>\*\
=>*(а{а}+Ь{Ь}{ + })*с{с}{*}
Некоторые более тривиальные шаги в выводе здесь не приведены-
Они имеют место там, где появляется символ => *.
Приведенные выше идеи мы сформулируем в виде
математической модели с помощью следующих определений.
Транслирующей грамматикой или грамматикой перевода
называется контекстно-свободная грамматика, множество'
терминальных символов которой разбито на множество
входных символов и множество символов действия.
Цепочки языка, определяемого транслирующей
грамматикой, называются последовательностями актов.
Пример транслирующей грамматики:
входные символы = {а, Ь, с}
символы действия = {х, у, г}
нетерминальные символы = {(А), (В)}
начальный нетерминал = (А >
правила = {А > -> а (А )х{В)
(A)-+z
(В)^ (В)с
(В)^Ьу
Для того чтобы символы действия при чтении отличались от
нетерминальных и входных символов, мы примем соглашение заключать
их в фигурные скобки. При таком соглашении, взглянув на
любую цепочку символов, можно сразу увидеть, какие из символов
являются нетерминалами, какие — входными символами и какие —
символами действий. Например, если только что приведенная
грамматика была бы построена с символами действий {х}, {у} и {г}
вместо х, у и г, то множество правил имело бы вид
(А)^а{А){х}(В)
(А)^ {г}
(В>-> {В)с
{В)^Ь{у}
и можно легко различить вхождения терминалов, нетерминалов к
символов действия.
7.4. Синтаксически управляемый перевод
203
В многих применениях, например при переводе из инфиксной
записи в польскую, подразумевается, что каждый символ действия
представляет процедуру, которая осуществляет выдачу символа,
заключенного в скобки. Когда надо подчеркнуть, что
подразумевается именно такая интерпретация, будем называть
соответствующую грамматику грамматикой, транслирующей в цепочки, или
грамматикой цепочечного перевода. Таким образом, термин
«грамматика, транслирующая в цепочки» указывает на то, что данная тран-
•слирующая грамматика предназначена для описания перевода вход-
яых цепочек в выходные цепочки. В этом заключается отличие от
общей интерпретации символов действия, как представляющих
произвольные процедуры.
7.4. Синтаксически управляемый перевод
.Математически мы рассматриваем перевод как множество пар, где
первый элемент принадлежит множеству объектов, которые надо
перевести, а второй элемент — множеству объектов, которые
являются результатами перевода. В переводах, обсуждаемых в
данной книге, первый элемент пары — это цепочка входного языка,
а второй элемент — последовательность, представляющая
результат перевода входной цепочки. Когда эти пары получаются с
помощью некоторой грамматики, перевод иногда называют
синтаксически управляемым переводом.
В этом разделе мы используем понятие последовательности
актов как основу одного класса синтаксически управляемых
переводов. Вначале мы установим, как последовательность действий можно
использовать для задания пары.
Пусть дана последовательность актов, состоящая из
входных символов и символов действия, мы будем
использовать термин входная последовательность или входная
цепочка для обозначения последовательности входных
символов, полученной из последовательности актоз путем
вычеркивания всех символов действия, и термин
подпоследовательность действий для обозначения
последовательности символов действия, полученной из последовательности
актов путем вычеркивания всех входных символов. Мы
говорим, что входная подпоследовательность образует пару с
подпоследовательностью действий.
При этом определении для последовательности актов а{а}+
+Ь{Ь}*с{с}{*}{ + }, обсуждавшейся в прошлом разделе, входная
цепочка а-\-Ь*с образует пару с подпоследовательностью действий
1*){Ь){с}{»){+}.
204 Гл. 7. Синтаксически управляемые процессы обработки языков
Для данной транслирующей грамматики множество пар можно
получить, образуя пары из входной подпоследовательности каждой
последовательности актов и подпоследовательности действий. Это
множество пар называется переводом, определяемым данной
транслирующей грамматикой.
При таком определении перевод, определяемый грамматикой
предшествующего раздела, транслирующей инфиксную запись в
польскую,— это множество пар, в которых первый элемент — это
инфиксное выражение, а второй — последовательность символов
действия, говорящих о том, как напечатать эквивалентное
выражение в польской записи.
Некоторые транслирующие грамматики обладают тем свойством,,
что одна и та же входная цепочка может встретиться более чем в
одной последовательности актов или образовывать пары с более
чем одной подпоследовательностью действий. Эта ситуация более
полно обсуждается в разд. 7.11. Здесь же мы лишь отметим, что-
нас интересуют в основном только те случаи, когда каждая
входная подпоследовательность является частью одной
последовательности актов и, следовательно, имеет только один перевод.
Говоря о переводах, мы часто используем понятие входной
грамматики:
Если дана транслирующая грамматика, то грамматика,
полученная путем вычеркивания всех символов действия из
правил этой грамматики, называется входной грамматикой для
этой транслирующей грамматики. Язык, определяемый
входной грамматикой, называется входным языком.
В примере перевода инфиксной записи в польскую входная
грамматика — это просто грамматика, определяющая инфиксные
выражения. Для грамматики, иллюстрировавшей определение
транслирующей грамматики, входной грамматикой будет
(А)^а(А)(В)
(А)-* г
(В)^ {В)с
{В)^Ь
Для любой транслирующей грамматики входной язык является
не чем иным, как множеством входных цепочек. Таким образом,
входная грамматика, описывает множество цепочек, для которых
транслирующая грамматика определяет переводы.
Хотя мы определили входную грамматику, исходя из
транслирующей грамматики, обычно ход событий при разработке
компилятора несколько иной. Вначале обрабатываемый язык описывается
входной грамматикой, а затем в правила этой грамматики
вставляются символы действия для описания требуемого процесса
обработки.
7.4. Синтаксически управляемый перевод
205
Для данной транслирующей грамматики выходную грамматику,
или грамматику действий, можно получить вычеркиванием
входных символов. Таким образом, транслирующую грамматику можно
рассматривать как переводящую с одного КС-языка, входного
языка, на другой КС-язык, выходной язык, или язык действий.
Однако понятие грамматики действий далее в книге никакой роли
не играет.
В случае грамматики цепочечного перевода мы считаем
последовательность символов действия синонимом соответствующей
выходной цепочки. В примере перевода инфиксной записи в польскую
мы рассматриваем последовательность действий {а}{Ь}{с}{*}{-г}
как синоним выходной последовательности abc*+, и любую из
этих последовательностей символов можно назвать переводом
входной цепочки а-\-Ь*с. Таким образом, грамматику, транслирующую в
цепочки можно интерпретировать как способ определения перевода
со входного языка на выходной язык.
Перевод можно определить многими различными
транслирующими грамматиками. Например, перевод инфиксных выражений в
польскую запись, рассмотренный в разд. 7.3, можно также описать
при помощи следующей транслирующей грамматики, основанной на
входной грамматике из разд. 6.10:
1. <£>-> <П<£-список>
2. <£-список>-> +(Г){+}(£-список>
3. (f-список) -*■ е
4. (Г)-> <Р)(Г-список)
5. СГ-список)->- *(Р){*}(7'-список>
6. (Г-список) -> е
7. (Р>^(<£>)
8. (Р)-+а{а}
9. {Р)-*Ь{Ь}
10. (Р)->ф}
Как было описано в разд. 6.10, (Г) в правиле 2 порождает правый
операнд оператора +. Значит, подходящее место для + будет
непосредственно за (Т). Аналогичные соображения применимы к *
в правиле 5. Левый вывод последовательности актов для входной
последовательности (а+Ь)*с, согласно этой грамматике, будет
таким:
<£> =о<Г><£ -список)
=> <Р> <Г-список> <£-список>
=Ф «£■>) <7'-список> <£-список>
=> (<Т> <£-список» <Г-список> <£-список>
=5> (<Р> <Г-список> <£-список>) <Г-список> <£-список>
206 Гл. 7. Синтаксически управляемые процессы обработки языков
—> (а {а} <Г-списбк> <£-список» <Г-список> <£-список>
=> (а \а} <£-список» <Т-список> <£-список>
=> (а \а\ + <Т> \ + } <£-список» <Г-список> <£-список>
—)■ (а {а\ + </>> <Г-список> { + } <£-список>)
<Г-список> <£-список>
=> (а {а} +Ь {Ь} <Г-список> { + } <£-сиисок»
<Г-список> <£-список>
=> {a \a}+b{b\ { +} <£-список» <Г-список> <£-список>
=> (a \a\+b \b\ { +}) <Г-список> <£-список>
=> (а \а\ + Ь \Ь) { +}) * <Р> {*} <Г-список> <£-список>
—> (а \а\ -\-Ь \Ь\ { + })*с {с} •[*} <Г-список> <£-слисок>
=> (а {а\ +Ь \Ь\ { +}) *с {с} {*} <£-список>
=*{а\а}+Ь{Ь\{ + \)*с{с}{*\
7.5. Пример: синтезируемые атрибуты
В предыдущих разделах мы рассматривали переводы цепочек
символов в цепочки символов. Используемые символы принадлежали
некоторым конечным множествам, и в понятие символа не
включалось представление о том, что он должен состоять из двух частей:
значения и класса. В действительности грамматики, транслирующие
цепочки, способны описывать перевод только той компоненты
символа, которая указывает его класс. Сейчас мы расширим понятие
транслирующей грамматики, чтобы включить в перевод и значение
символа. Расширенное понятие называется «атрибутной
грамматикой», и полное его описание дается в разд. 7.7. Здесь мы приводим
конкретную атрибутную грамматику, чтобы проиллюстрировать
понятие «синтезируемого атрибута».
Глазная идея, лежащая в основе понятия атрибутной
грамматики, состоит в том, что значения символов сопоставляются всем
вершинам дерева вывода, как терминальным так и нетерминальным.
Отношения между входными и выходными значениями выражаются
по принципу «от правила к правилу»; при этом значения находятся в
вершинах дерева. Чтобы проиллюстрировать, как можно было бы
выразить такие отношения, рассмотрим простои пример.
Предположим, что существует лексический блок, задающий
входное множество.
{(,), + . *■ с}
где с — лексема, представляющая константу; ее значением
является значение константы, построенное лексическим блоком.
Рассмотрим теперь проблему проектирования синтаксического
блока, который допускает арифметические выражения, построенные
7.5. Пример: синтезируемые атрибуты
207
из символов данного входного множества, и выдает численные
значения этих выражений. Соответствие между компонентами входов
и выходов, представляющих их классы, можно выразить следующей
грамматикой, транслирующей в цепочки ((S) — ее начальный
символ):
1. (S)^ (Е) {ОТВЕТ}
2. <£>+ (Е)+(Т)
3. <£>-* (Т)
4. (Т)-+ {Т)*(Р)
5. <Г>+ </>>
6. (Р)-+((Е))
7. (P)-vc
Значение выходного символа ОТВЕТ должно быть числом.
Требуемое отношение между значениями входных лексем и значением
выходной лексемы ОТВЕТ можно выразить словами «значение лексемы
ОТВЕТ — это числовое значение входного выражения».
Назначение данного примера состоит в том, чтобы найти математический
способ выражения отношения, описанного этой фразой.
Рассмотрим теперь конкретную входную цепочку (с3+си)«(Со-г
+Сц), где значения входных лексем, выданных лексическим
блоком, указаны индексами. Этой входной цепочке должна, конечно,
соответствовать выходная цепочка OTBET5Ui. На рис. 7.3, а
показано дерево вывода, соответствующее этой входной цепочке. Мы
ищем метод, посредством которого входную цепочку и дерево
вывода можно использовать для определения значений выходных
символов.
Самый естественный способ определения значения данного
входного выражения состоит в определении значения каждой его части.
Так как каждое вхождение нетерминалов (Е), (Г) и (Р) в дереве
вывода представляет некоторое подвыражение входного выражения,
естественно приписать данному вхождению нетерминала числовое
значение порождаемого им подвыражения. На рис. 7.3, б показано
дерево, изображенное на рис. 7.3, а, на котором каждый
нетерминал {Е), (Т) и (Р) помечен значением соответствующего
подвыражения, а выходной символ — требуемым выходным значением.
Чтобы определить, как расставлять значения на дереве вывода,
полученном по данной грамматике, вначале определим, как
получить значение любой нетерминальной вершины, если даны значения
ее прямых потомков. С этой целью сопоставим каждому правилу
грамматики для (Е), (Т) и (Р) правило вычисления значения
вершины, соответствующей нетерминалу левой части продукции,
по данным значениям ее прямых потомков, соответствующих
символам правой части правил грамматики. (Для краткости там, где
речь идет одновременно о правилах вычисления значений и прави-
208 Гл. 7. Синтаксически управляемые процессы обработки языков
<S>.
<Е> + <Г>
<т:
<р:
<р>
<Е> + <7">
<Г>
<Р>
<Р>
{ ОТВЕТ 616}
<г>
<р^
<т>
<р>
<р>
<р>
Рис. 7.3.
7.5. Пример: синтезируемые атрибуты
209
лах грамматики, мы будем называть первые просто правилами, а
вторые — продукциями.) Например, правило вычисления значений
для продукции
(Е)^(Е)+(Т)
состоит в том, что значения нетерминала (Е) в левой части равно
сумме значения нетерминала (Е) в правой части и значения
нетерминала (Г>. Чтобы применить это правило к левому, заключенному
в скобки вхождению (Е), в дереве вывода нашего примера,
заметим, что значение (Е) в правой части равно 3, а значение (Т)
равно 9. Отсюда следует, что значение (Е) в левой части равно 12, и
можно приписать значение 12 соответствующей вершине дерева.
Правило для продукции (Е)-*-(Т) состоит в том, что значение
(Е) равно значению (Т). Правило для продукции (Г)-»- (Т)*(Р)
состоит в том, что значение (Т) в левой части равно произведению
значения (Т) в правой части и значения {Р). Правило для (Г}->-
->{Р) состоит в том, что значение (Т) равно значению (Р).
Правило для (Р)-*- ((E)) состоит в том, что значение (Р) равно
значению (Е >. Правило для (Р > ->■ с состоит в том, что значение (Р>
равно значению с.
И наконец, продукцию (S)-»-(£) {ОТВЕТ} мы снабдим
правилом, что значение символа ОТВЕТ равно значению (Е >.
В рассматриваемом примере правила, сопоставляемые
продукциям, определяют как вычислять численные значения выражений.
В этом смысле они отражают «значение» или «смысл» продукции.
Однако технику сопоставления правил продукциям можно
использовать для определения значений, которые не обязательно отражают
явное значение входной цепочки. Например, с помощью правил для
продукций можно с каждой вершиной дерева связать элемент
некоторой таблицы.
Продолжим рассмотрение нашего примера. Для того чтобы
выразить приведенные выше правила математически более строго,
можно в каждой продукции дать разные имена разным
встречающимся в ней значениям, а затем сформулировать соответствующие
■ей правила при помощи этих имен. Например, продукцию 2 и
правило вычисления значения (Е) можно записать так:
2. (E)p^(E)Q+(T)r
p+-q+r
где символ присваивания -<- указывает, что атрибут р получает
значение выражения в правой части (т. е. q-t-r).
Остальные продукции и соответствующие им правила можно
зависать так:
3. <£>„-+ (Т\
Р+-Я
210 Гл.7. Синтаксически управляемые процессы обработки языков
4. (T)p^(T)q*{P)r
р ч- q*r
5. <ПР-*</>>,
6. '</>>р- ((£)„)
p<-q
7. </>>„-с,
1. (S) -> <£>,{ОТВЕТ,}
/-Ч-9
Использование имен переменных локально для каждой
продукции, и, если одна и та же буква р встречается в двух разных
продукциях, это не имеет значения. Мы могли бы с таким же успехом
продукцию 4 записать как
'' 'Зевс * ' ' 'Матвей * ''/Харальд
Зевс <— Д\атвей * Харальд
Приведенные выше продукции вместе с соответствующими
правилами вычисления значений являются примерами «атрибутных
правил» или «атрибутных продукций» и, взятые вместе с начальным
нетерминалом (S), образуют «атрибутную грамматику». В этой
терминологии значения вышеприведенных символов называются
«атрибутами». Далее мы увидим, что значение на самом деле может
быть вектором атрибутов.
В нашем примере значение атрибута каждого нетерминала
определяется символами, расположенными в дереве вывода под этим
нетерминалом. Такое «восходящее» вычисление выражается в том,
что правила вычисления атрибутов нетерминалов, ассоциированные"
с продукциями, указывают, как вычислять атрибуты в левой части
продукции по данным атрибутам символов правой части. Атрибуты,
значения которых получаются таким восходящим способом, т. е.
снизу вверх, традиционно называются «синтезируемыми»
атрибутами. В следующем разделе приводится пример атрибутов
нетерминалов, которые передаются и вычисляются по дереву вывода сверху
вниз.
Одно заключительное замечание по поводу обозначений. Обычно
мы записываем символ действия с атрибутом вне скобок и
стандартная запись будет {ОТВЕТ}5, а не {ОТВЕТ.,}. Однако в случаях
подобных рассматриваемому, когда символ действия образуется путем
заключения в скобки выходного символа, можно заключить атрибут
в скобки, давая этим понять, что он должен быть выдан как часть
заключенного в скобки выходного символа.
7.6. Пример: наследуемые атрибуты
211
7.6. Пример: наследуемые атрибуты
Теперь мы приведем пример, показывающий, каким образом можно
определить атрибутную информацию, так чтобы она
распространялась вниз по дереву вывода. Рассмотрим следующую грамматику
с начальным символом (описание):
1. (описание) -> ТИП V (список переменных)
2. (список переменных) ->, V (список переменных)
3. (список переменных) -> е
Эта грамматика порождает описания, подобные тем, что
встречаются во многих языках программирования.
Предположим, что существует лексический блок, задающий три
лексемы:
V ТИП,
где лексема V обозначает переменную и ее значение является
указателем на соответствующий этой переменной элемент таблицы имен;
ТИП — лексема со значением, определяющим, какой из типов,
ВЕЩЕСТВЕННЫЙ, ЦЕЛЫЙ или ЛОГИЧЕСКИЙ, должен быть
поставлен в соответствие переменным из данного списка.
При обработке описания каждой переменной синтаксический
блок вызывает процедуру УСТАНОВИТЬ-ТИП, которая помещает
один из типов, ВЕЩЕСТВЕННЫЙ, ЦЕЛЫЙ или ЛОГИЧЕСКИЙ,
в надлежащее поле элемента таблицы имен, соответствующего
данной переменной. Вызов УСТАНОВИТЬ-ТИП лучше всего
осуществить сразу после того, как переменная поступила на вход
синтаксического блока. Такая синхронизация описывается следующей
грамматикой, транслирующей в цепочки, где для обозначения вызова
процедуры УСТАНОВИТЬ-ТИП используется символ действия
{УСТАНОВИТЬ-ТИП}:
1. (описание)-- ТИП V {УСТАНОВИТЬ-ТИП} (список
переменных >
2. (список переменных)^-, V {УСТАНОВИТЬ-ТИП} (список
переменных )
3. (список переменных ) -> е
Предположим, что процедура УСТАНОВИТЬ-ТИП имеет два
аргумента: указатель на элемент таблицы имен, соответствующий
переменной, и тип переменной. Тогда вызов процедуры
УСТАНОВИТЬ-ТИП можно записать так:
УСТАНОВИТЬ-ТИП (указатель, тип)
Мы хотим ввести в вышеприведенную грамматику атрибуты и
правила их вычисления, чтобы в последовательностях актов входные
символы были представлены вместе с их значениями, играющими
роль атрибутов, а вхождения символов действия {УСТАНОВИТЬ-
212 Гл. 7. Синтаксически управляемые процессы обработки языков
ТИП} имели по два атрибута, представляющих аргументы
соответствующего вызова процедуры УСТАНОВИТЬ-ТИП. Тогда
вхождения УСТАНОВИТЬ-ТИП будут иметь такой вид:
{УСТАНОВИТЬ-ТИП}указагель, тип
Символ действия {УСТАНОВИТЬ-ТИП} с его атрибутами
хорошо иллюстрирует разницу между атрибутом и значением. У этого-
символа имеется два атрибута — указатель и тип, но только одно'
значение, которым является пара (указатель, тип). Таким образом,
понятие атрибута —это уточнение понятия значения. Так как мы
переходим к особенностям модели атрибутной грамматики, теперь,
мы имеем дело исключительно с атрибутами.
Возвращаясь к задаче порождения требуемой атрибутной
последовательности актов, рассмотрим как вхождения {УСТАНОВИТЬ-
ТИП} получают свои атрибуты. В правиле 1 это делается просто,,
так как атрибуты символа действия {УСТАНОВИТЬ-ТИП} можно*
получить, используя входные символы ТИП и V, входящие в это
правило. В правиле 2 ТИП не доступен, и его нужно как-то
передать, используя атрибуты нетерминала. Для этой цели мы снабдим
нетерминал (список переменных) атрибутом, который будет пред:
ставлять тип. Требуемая последовательность актов будет
порождаться следующими правилами с атрибутами:
1. <описание> —ТИП(Ур {УСТАНОВИТЬ ТИП}Я,,Х <список.
переменных>(2
(t2, t\)*-t pi — р
2. <список переменных>(—, Vp {УСТАНОВИТЬ-ТИП}р,, ,t
<список переменных>/2
(/2, t\)^~t p\ +-р
3. <список переменных>4—<-е
Запись (12, tl) *~ t означает, что t присваивается одновременно /L
и 12. На рис. 7.4 показано атрибутное дерево вывода
последовательности
ТИПвещественный V и V2, V3
определяемое данной грамматикой.
Заметим, что на рис. 7.4, чтобы получить значения атрибутов,,
соответствующие вхождениям нетерминала (список переменных),,
используются символы, расположенные выше в дереве вывода, ил»
символы, входящие в ту же правую часть правила. Входной символ
ТИП определяет значение ВЕЩЕСТВЕННЫЙ, которое передается
самому верхнему вхождению нетерминала (список переменных),,
а затем передается вниз по дереву другим вхождениям. Такой
нисходящий характер вычисления значений атрибутов отражается
в том, что каждое правило вычисления атрибутов нетерминалов..
7.7. Атрибутные транслирующие грамматики 213
сопоставленное продукциям, указывает, как вычислять атрибуты
нетерминала, входящего в правую часть продукции. Атрибуты,
значения которых задаются таким нисходящим способом, принято
называть «наследуемыми» атрибутами.
Сравнивая примеры этого и предыдущего разделов, мы видим,
что информация о синтезируемых атрибутах распространяется вверх
по дереву, тогда как информация о наследуемых атрибутах — вниз
Рис. 1Л.
по дереву. Синтезируемые атрибуты вычисляются по правилам,
связанным с нетерминалами, входящими в левую часть продукции,
тогда как наследуемые атрибуты— по правилам, связанным с
нетерминалами, входящими в правую часть.
Одно заключительное замечание по поводу обозначений. В
отличие от символа {ОТВЕТ} из разд. 7.5 символ действия {УСТАНО-
ВИТЬ-ТИП} не является заключенным в скобки выходным
символом. Поэтому мы использовали стандартное обозначение, поместив
атрибуты символа действия вне скобок.
7.7. Атрибутные транслирующие грамматики
После того как в разд. 7.5 и 7.6 были рассмотрены две атрибутные
транслирующие грамматики, мы можем теперь точно определить,
что понимается под «атрибутной транслирующей грамматикой».
Определение атрибутных грамматик включает как синтезируемые, так
и наследуемые атрибуты нетерминалов, проиллюстрированные на
предыдущих примерах. В одной и той же грамматике допускаются
оба типа атрибутов. Кроме того, в определении проводится различие
214 Гл.7. Синтаксически управляемые процессы обработки языков
между синтезируемыми и наследуемыми атрибутами символов
действия. Все атрибуты символов действия в предыдущих примерах
были наследуемыми и получали свои значения сверху по правилам,
связанным с вхождением символа действия в правую часть
продукции. Пр*и определение переводов в синтезируемых атрибутах
символов действия нет серьез.юй необходимости, но они играют важную
роль в гл. 9.
Атрибутная транслирующая грамматика — это
транслирующая грамматика, к которой добавляются следующие определения:
1. Каждый входной символ, символ действия или
нетерминальный символ имеет конечное множество атрибутов, и каждый
атрибут имеет (возможно, бесконечное) множество
допустимых значений.
2. Все атрибуты нетерминальных символов и символов действия
делятся на наследуемые и синтезируемые х).
3. Правила вычисления наследуемых атрибутов определяются
следующим образом:
а) каждому вхождению наследуемого атрибута в правую часть
данной продукции сопоставляется правило вычисления
значения этого атрибута как функции некоторых других'
атрибутов символов, входящих в правую или левую часть
данной продукции;
б) задается начальное значение каждого наследуемого
атрибута начального символа.
4. Правила вычисления синтезируемых атрибутов определяются
так:
а) каждому вхождению синтезируемого нетерминального
атрибута в левую часть данной продукции сопоставляется
правило вычисления значения этого атрибута как функции
некоторых других атрибутов символов, входящих в левую
или правую часть данной продукции;
б) каждому синтезируемому атрибуту символа действия
сопоставляется правило вычисления значения этого атрибута
как функции некоторых других атрибутов этого символа
действия.
В пункте 1 данного определения говорится о том, что входные
символы, символы действия и нетерминальные символы должны
быть атрибутными. Описывая грамматику, мы обычно записываем
атрибуты в виде индексов. В описаниях каждое вхождение символа
имеет по одному индексу для каждого своего атрибута.
Пункт 2 требует, чтобы каждый атрибут нетерминального
символа или символа действия был задан либо как синтезируемый,
') Зги не очень удачные термины, к сожалению, уже укоренились в
литературе.— Прим. ред.
7.7. Атрибутные транслирующие грамматики
215
либо как наследуемый. Это нужно для того, чтобы указать, по каким
правилам вычислять значение атрибута — из пункта 3 или из
пункта 4. В обозначениях мы изображаем символы вместе с их
атрибутами и говорим, к какому классу относится каждый атрибут.
Например, можно записать
<Х>Й,Ь,С СИНТЕЗИРУЕМЫЕ а, с НАСЛЕДУЕМЫЙ b
или
{УДВОЕНИЕ},,, НАСЛЕДУЕМЫЙ £ СИНТЕЗИРУЕМЫЙ р.
Для синтезируемых атрибутов символов действия утверждение, что
атрибут является синтезируемым, должно сопровождаться
правилом, соответствующим подпункту (б) пункта 4. Например, в
определение атрибутов приведенного выше символа действия
{УДВОЕНИЕ} можно включить правило вычисления синтезируемого
атрибута р
р ч-2*г
Подпункт (а) пункта 3 и подпункт (а) пункта 4 описывают
правила вычисления атрибутов, которые должны сопоставляться
правилам грамматики. Подпункт (а) пункта 3 относится к наследуемым
атрибутам как нетерминальных символов, так и символов действия,
поскольку и те, и другие могут встречаться в правой части правила.
Для того чтобы определить правила, связанные с данной
продукцией, присвоим имя каждому атрибуту каждого символа продукции
и включим эти имена в запись продукции. После этого имена
атрибутов используются в качестве переменных, при помощи которых
описываются правила.
Например, если (X) имеет три атрибута, (Y) и (Z) — по два
атрибута каждый, a b — один атрибут, то правило
(X)^b(Y)(Z)
может быть записано в виде
<*>„.,.«■ — bs<Y\hU<Z>r,w
Если в левой части продукции синтезируемыми являются только
атрибуты q и г, которые должны, следовательно, вычисляться по
правилам подпункта (а) пункта 4, а в правой части наследуемыми
являются только атрибуты у и у, вычисляемые соответственно по
правилам подпункта (а) пункта 3, то вышеуказанную продукцию
можно дополнить такими правилами:
q -«- SIN (и+а.')
(г, v) ч- s*«
У+-Р
'216 Гл. 7. Синтаксически управляемые процессы обработки языков
По традиции мы будем записывать правила в виде операторов
присваивания. Левая часть каждого присваивания — это либо один
атрибут, либо список атрибутов, заключенных в скобки. Правая
часть всегда будет некоторым выражением. Эта запись означает,
что значение выражения правой части нужно присвоить каждому
атрибуту, входящему в левую часть. Так, второе из вышеуказанных
правил присваивает произведение s*u обоим атрибутам г к v.
Атрибутные транслирующие грамматики используются для
определения атрибутных деревьев вывода, а затем — атрибутных
последовательностей актов и атрибутных переводов. Деревья
определяются следующими процедурами построения:
1. По соответствующей неатрибутной грамматике построить
дерево вывода последовательности актов, состоящей из входных
символов и символов действия без атрибутов.
2. Присвоить значения атрибутам входных символов, входящих
в дерево вывода.
3. Присвоить начальные значения наследуемым атрибутам
начального символа дерева вывода.
4. Вычислить значения атрибутов символов, входящих в дерево
вывода, повторяя следующее действие до тех пор, пока оно станет
невозможным: найти атрибут, которого еще нет в дереве, но
аргументы правила его вычисления уже имеются, вычислить значение
этого атрибута и добавить его к дереву.
5. Если выполнение шага 4 приведет к тому, что значения всех
атрибутов всех символов дерева окажутся вычисленными, то будем
называть полученное дерево завершенным. В противном случае мы
называем дерево незавершенным.
Для того чтобы проиллюстрировать описанные шаги, вернемся
к рис. 7.3 и грамматике из разд. 7.5. На рис. 7.3, а показано дерево
вывода, построенное на шаге 1, на котором четырем вхождениям
лексемы с присвоены значения атрибутов, как того требует шаг 2.
Шаг 3 выполняется впустую, так как начальный символ не имеет
атрибутов; таким образом, на рис. 7.3, а показан результат
применения первых трех шагов. Выполнение шага 4 изменяет дерево
рис. 7.3, а на дерево рис. 7.3, б. Результирующее дерево является
завершенным, так как все атрибуты входящих в него символов
получили значения.
Заметим, что пункты 3 и 4 определения атрибутной грамматики
гарантируют, что для каждого атрибута нетерминального символа
или символа действия имеется соответствующее правило
вычисления. Так как каждый символ дерева вывода либо входит в правую
часть некоторой продукции (т. е. продукции, соединяющей этот
символ с его предком в дереве), либо является вершиной дерева (в
таком случае это начальный символ); каждый наследуемый атрибут
данного символа должен иметь правило согласно одному из под-
7.7. Атрибутные транслирующие грамматики 217
пунктов пункта 3. Поскольку каждый нетерминальный символ
дерева вывода входит в левую часть некоторой продукции, подпункт
(а) пункта 4 гарантирует наличие правила вычисления для каждого
синтезируемого нетерминального атрибута. Наконец, подпункт (б)
пункта 4 гарантирует наличие правила для каждого синтезируемого
атрибута символа действия.
Важно осознавать, что, хотя для каждого атрибута, входящего
в дерево вывода, существует правило его вычисления, нет никакой
гарантии, что его значение действительно можно вычислить и таким
образом получить завершенное дерево. Поскольку правило можно
применять только после того, как получены все его аргументы,
между атрибутами иногда может возникнуть круговая зависимость.
Если атрибутная грамматика такова, что шаги 1—5 процедуры
построения дерева всегда дают в итоге завершенное дерево, то она
называется вполне определенной или корректной. При проектировании
компиляторов мы будем иметь дело только с вполне определенными
грамматиками.
Кнут [1968а] предложил тест, позволяющий определить,
является ли грамматика вполне определенной. Однако мы не будем
пользоваться этим тестом в данной книге, так как излагаемые далее методы
построения включают другие ограничения на грамматику, из
которых следует, что она вполне определенная. Не вполне определенные
грамматики мы использовать не будем.
Пусть даны атрибутная транслирующая грамматика и дерево
вывода, полученное с помощью этой грамматики.
Последовательность атрибутных символов действия и атрибутных входных
символов, полученная по этому дереву вывода, называется атрибутной
последовательностью актов. Атрибутная подпоследовательность
действий данной атрибутной последовательности актов называется
переводом атрибутной входной цепочки. Множество пар, состоящих
из атрибутной входной цепочки и атрибутной последовательности
действий, которые получаются по данной атрибутной грамматике,
называется атрибутным переводом, определяемым этой
грамматикой. Если атрибутной транслирующей грамматике соответствует
однозначная входная грамматика, то для каждой атрибутной
входной цепочки существует не более одного дерева вывода и не более
одного атрибутного перевода.
Во многих применениях символы действия записываются путем
заключения в скобки выходных символов. Это означает, что каждый
символ действия представляет процедуру, которая выдает символ,
содержащийся внутри скобок, используя при этом атрибуты символа
действия в качестве атрибутов этого выходного символа. Когда
подразумевается такая интерпретация, мы будем называть
грамматику атрибутной грамматикой цепочечного перевода или
атрибутной грамматикой, транслирующей в цепочки, чтобы
подчеркнуть отличие от более общей интерпретации атрибутных символов
218 Гл. 7. Синтаксически управляемые процессы обработки языков
действия как представляющих произвольные процедуры, которые
используют атрибуты в качестве аргументов.
В случае атрибутной грамматики цепочечного перевода мы
представляем себе последовательность атрибутных символов действия
как синоним соответствующей цепочки выходных символов с
атрибутами. Таким образом, атрибутную грамматику цепочечного
перевода можно интерпретировать как способ определения перевода
атрибутного входного языка на атрибутный выходной язык. При
использовании атрибутных грамматик цепочечного перевода мы
предпочитаем записывать атрибутные символы действия, изображая
атрибуты внутри скобок в виде индексов содержащегося там
выходного символа. Так, если выходной символ СЛОЖИТЬ имеет три
атрибута р, q иг, мы будем писать {СЛОЖИТЬ?1 q> r} вместо
{СЛОЖИТЬ }Ptqir. Такой способ записи выбран исключительно из
эстетических' соображений и не имеет принципиального значения.
7.8. Перевод арифметических выражений
В этом разделе мы построим атрибутную транслирующую
грамматику, которая описывает обработку арифметических выражений
синтаксическим блоком компилятора, организованного согласно
упрощенной модели из разд. 1.2. В этой модели выходом
синтаксического блока является цепочка атомов и некоторые таблицы.
В разд. 1.2 предполагалось, что атомы, соответствующие бинарным
операциям, могут иметь значение, состоящее из трех указателей на
элементы таблиц. Эти элементы должны содержать информацию об
обоих операндах и результате операции. Будем следовать здесь
этому предположению, тогда ожидаемым переводом цепочки
а+Ь
будет
СЛОЖИТЬ (ра, рь, рг)
где ра и рь — указатели на элементы таблицы, представляющие а
и b соответственно, ар,— указатель на элемент таблицы,
представляющий результат операции сложения.
На рис. 7.5 показан полный перевод выражения
{а+Ь)*{а+с)
включая цепочку атомов и элементы таблицы. На вход
синтаксического блока поступает не буквально данное выражение, а цепочка
лексем — результат работы лексического блока. Предположим, что
каждая переменная представлена лексемой класса / (класс
идентификаторов), значением которой является указатель на
соответствующий элемент таблицы. На рисунке эти значения указаны
индексами.
7.8. Перевод арифметических выражений
210
На рис. 7.5 показано, что табличные элементы принадлежат
одной таблице, но в некоторых реализациях идентификаторы и
промежуточные результаты заносятся в разные таблицы, в особенности
если элементы таблицы, соответствующие идентификаторам,
создаются лексическим блоком, а элементы, соответствующие
промежуточным результатам, формируются синтаксическим блоком. Кроме
Выражение:
Вход:
Выход:
Элементы
таблицы :
(а + Ь) • (а + с)
(/, +/2) • (/,
СЛОЖИ, 2, 3) СЛ0Ж(1, 4. 5)УМН0Ж(3, 5, 6)
Л>
©
©
©
©
©
©
Идентификатор a
Идентификатор ь
Промежуточный результат
Идентификатор с
Промежуточный результат
Промежуточный результат
Рис. 7.5.
того, фактические значения указателей на элементы таблицы могут
отличаться от тех, что показаны на рис. 7.5, так как они зависят от
порядка, в котором создаются элементы. Например, вполне
возможно, что для b будет указана первая позиция таблицы, а для а —
вторая.
Вообще нам нужно, чтобы цепочки атомов, выдаваемые
синтаксическим блоком, обладали следующими свойствами:
1. Каждой бинарной операции во входной строке соответствует
атом.
3. Атомы в цепочке расположены в том же порядке, что и
операции, которые должны быть выполнены во время выполнения
рабочей программы.
3. Каждый атом имеет три указателя на элементы таблицы:
а) левый операнд,
б) правый операнд,
в) результат операции.
Чтобы убедиться, что предлагаемый выход синтаксического
блока содержит достаточно информации для того, чтобы генератор кода
сделал свое дело, рассмотрим кратко, как генератор кода может вое-
220 Гл.7. Синтаксически управляемые процессы обработки языков
пользоваться этим выходом для генерации соответствующей
последовательности машинных команд.
Атомы играют роль инструкций генератору кода относительно
того, какие операции должны выполняться во время выполнения
рабочей программы. Элементы таблицы могут быть использованы
генератором кода для запоминания и получения информации о
размещении переменных и промежуточных результатов в рабочей
программе. Например, когда генератор кода обрабатывает в цепочке
атомов, изображенной на рис. 7.5, атом СЛОЖИТЬ (1, 2, 3), он
может использовать третий элемент таблицы для запоминания ячейки,
в которой находится промежуточный результат. Эту информацию
можно извлечь, когда генератор приступит к обработке атома
УМНОЖИТЬ (3, 5, 6), так что код, генерируемый для выполнения
умножения, извлечет левый операнд из надлежащей ячейки рабочей
памяти.
Вернемся к проблеме проектирования синтаксического блока.
Мы хотим определить перевод в указанное множество цепочек
атомов. Вначале построим транслирующую грамматику, которая
указывает, когда нужно выдавать атомы. Введем символы действия
{СЛОЖИТЬ} и {УМНОЖИТЬ}, соответствующие атомам СЛО-
СЛОЖИТЬ и УМНОЖИТЬ.
Пусть синтаксический блок выдает каждый атом сразу, как это
становится возможным. Атом СЛОЖИТЬ лучше создать сразу, как
только обработаны оба операнда операции +, поскольку обработка
этих операндов может потребовать выдачи атомов, которые должны
предшествовать в цепочке атомов атому СЛОЖИТЬ. Аналогично
атом УМНОЖИТЬ нужно выдать сразу после того, как будут
обработаны оба операнда операции *. Эта согласованность во времени
будет достигнута, если символы действия {СЛОЖИТЬ} и
{УМНОЖИТЬ} поместить в соответствующие правила в крайнее правое
положение. В результате чего получаем следующую
транслирующую грамматику ((E)— ее начальный символ):
(£>-+ (Е)+ (Т) {СЛОЖИТЬ}
(£>-> (Т)
<Г>-> (Т)*</>>{УМНОЖИТЬ}
(Т)-+ (Р)
(Р)^((Е))
<Р)-+1
Символы {СЛОЖИТЬ} и {УМНОЖИТЬ} расположены здесь так
же, как {+} и {*} в правилах перевода в польскую запись,
приведенных в рэзд. 7.3.
Для входной цепочки
(а+Ь)*(а+с)
л
V--"
>/
N
r
VU
1
/7
л/ л /
a.— \м{—
/V\V\
/ \
/
/
/ „
Л
/v-
+
V
NUj_
V
.•t
Л
-0
Л"
-k.
V
i *-
Л"
—о
V
-C
g
C0
<i
222 Гл. 7. Синтаксически управляемые процессы обработки языков
перевод которой показан на рис. 7.5, эта грамматика определяет
последовательность актов
(а+6{СЛОЖИТЬ})»(а+с{СТОЖИТЬ}){УМНОЖИТЬ}
Соответствующая выходная последовательность
сложить сложить умножить
указывает порядок, в котором должны выдаваться атомы.
Зададим теперь атрибуты и правила их вычисления, чтобы эта
грамматика стала атрибутной грамматикой цепочечного перевода,
позволяющей вычислять для выходных символов нужные значения.
Основная идея состоит в том, что каждый нетерминал снабжается
единственным синтезируемым атрибутом, который является
указателем на элемент таблицы, соответствующий выражению,
порождаемому этим нетерминалом. Входная лексема / имеет
единственный атрибут, который является указателем на соответствующий
элемент таблицы, задаваемым лексическим блоком. Каждый
выходной символ, СЛОЖИТЬ или УМНОЖИТЬ, имеет три
(наследуемых) атрибута-указателя на левый операнд, правый операнд и
результат. Чтобы проиллюстрировать, как атрибуты входят в
конкретное дерево, на рис. 7.6 показано дерево вывода и атрибуты для
входной цепочки
{а+Ь)*(а+с)
приведенной на рис. 7.5 для иллюстрации перевода.
Транслирующая грамматика, реализующая эту идею, такова:
<Е>Х СИНТЕЗИРУЕМЫЙ х
<Тух СИНТЕЗИРУЕМЫЙ х
<Р>Х СИНТЕЗИРУЕМЫЙ х
{СЛОЖИТЬ,,,,, р) НАСЛЕДУЕМЫЕ у, г, р
{УМНОЖИТЬ,, z,p\ НАСЛЕДУЕМЫЕ у, г, р
Начальный символ: <£>
1. <£>, — <£>,+ <Г>, {СЛОЖИТЬ,, „„}
{х, р)^-НОВТ y*—q г<— г
2. <Е>х-*<Т>р
х*-р
3. <Т>, —<7->,*<Я>, {УМНОЖИТЬ,,, ,,„}
(х, р)^-НОВТ y+-q г*—г
4. <Т>Х-+ <Р>р
х<—р
5. </>>, — «£>,)
х<— р
6. <Р>х-*/р
х*—р
7.9. Трансляция некоторых операторов языка MINI-BASIC 223
Выражение
(х, р)*— НОВТ
в правиле 1 означает, что значения р и х должны вычисляться с
помощью вызова системной процедуры НОВТ, задающей указатель
на некоторый неиспользованный элемент таблицы. Этот указатель
используется как третий атрибут выходного символа СЛОЖИТЬ
и как атрибут левого вхождения (£).
7.9. Трансляция некоторых операторов
языка MINI-BASIC
В предыдущем разделе атрибутная грамматика использовалась для
определения перевода арифметических выражений в цепочки
атомов. Чтобы показать, как правила этой грамматики можно
использовать как часть более широкого перевода, мы зададим сейчас
атрибутные правила для двух операторов MINI-BASIC'a, включающих
выражения.
Сначала рассмотрим оператор присваивания, который, по
нашему предположению, описывается следующим правилом:
(оператор)->- LET ПЕРЕМЕННАЯ = (выражение)
Также как и в предыдущем разделе, мы считаем, что лексема
ПЕРЕМЕННАЯ имеет один атрибут — указатель на элемент таблицы,
соответствующий этой переменной, а нетерминал (выражение)
имеет один синтезируемый атрибут — указатель на элемент таблицы,
соответствующий данному выражению. Введем новый атом,
соответствующий присваиванию
ПРИСВОИТЬ (jc, у)
в котором х — указатель на элемент таблицы, соответствующий
переменной, а у — указатель на элемент таблицы, соответствующий
выражению. На рис. 7.7 приведен пример перевода цепочки
LET A=B+C
Считая два указателя атома ПРИСВОИТЬ наследуемыми
атрибутами, опишем перевод оператора присваивания следующим
атрибутным правилом:
<оператор> —► LET ПЕРЕМЕННАЯ,^ = <выраженне>выр1
{ПРИСВОИТЬпер2,выр2}
ПЕР2<— ПЕР1 ВЫР2^-ВЫР1
Теперь рассмотрим оператор IF, который как мы предполагаем,
можно описать следующим правилом:
(оператор) -*- IF (выражение) ОТНОШЕНИЕ (выражение)
GOTO ЧИСЛО
224 Гл. 7. Синтаксически управляемые процессы обработки языков
Лексема ОТНОШЕНИЕ имеет единственный атрибут, который
обозначает представляемый ею знак отношения. Лексема ЧИСЛО имеет
один атрибут — указатель на элемент таблицы, в котором содержит-
Оператор: let а = в + с
Вход: LET ПЕРЕМЕННАЯ
Выход:
Элементы
таблицы: (ул
ПЕРЕМЕННАЯ , + ПЕРЕМЕННАЯ .
СЛ0Ж23.4 лрисв т.-,
®
®
®
Идентификатор а
Идентификатор в
Идентисрикатор с
Промежуточный
результат
Рис. 7.7.
ся номер строки программы. Нетерминал (выражение) имееттот же
синтезируемый атрибут, что и прежде. Определим новый атом
УСЛПЕРЕХОД (я, Ь, с, d)
(условный переход), в котором а — указатель на элемент таблицы,
соответствующий первому выражению, b — указатель на элемент
Оператор:
Вход:
Выход:
Элементы
таблицы
IF A7 » В < 32 GOTO 360
IF ПЕРЕМЕННАЯ, * ПЕРЕМЕННАЯ., ОТНОШЕНИЕ <
КОНСТАНТА 4 GOTO 5
УМНОЖ, 2 з УСЛПЕРЕХОДз 4< 5
®
®
®
Рис. 7.8.
таблицы, соответствующий второму выражению, с обозначает
используемый знак отношения и d — указатель на элемент таблицы,
содержащий номер строки программы. На рис. 7.8 показан пример
Идентификатор
Идентификатор
А7
в
Промежуточный результю
Константа
Номер строки
32
360
7.10. Еще одна атрибутная транслирующая грамматика для выражений 225
перевода цепочки
IF A7*B<32 GOTO 360
Атом УСЛПЕРЕХОД сообщает генератору кода, что тот должен
выдать код, который проверяет, выполняется ли отношение,
обозначенное с, для выражений, обозначенных а и Ь, и, если оно
выполняется, передает управление строке программы, обозначенной d.
Перевод можно определить атрибутным правилом
<оператор>—> IF <выражение>в1 ОТНОШЕНИЕси
<выражение>В2 GOT0 4HCJI04i {УСЛПЕРЕХОДвз,в4,02,42}
ВЗ — В1 В4+-В2 02^-01 42^-41
где все атрибуты символа УСЛПЕРЕХОД — наследуемые.
7.10. Еще одна атрибутная транслирующая
грамматика для выражений
Любой данный атрибутный перевод можно описать многими
атрибутными грамматиками. В этом разделе мы рассмотрим
атрибутную транслирующую грамматику, описывающую тот же перевод
арифметических выражений в цепочки атомов СЛОЖ и УМНОЖ,
что в разд. 7.8, но ее входной грамматикой будет другая грамматика
для арифметических выражений, приведенная в разд. 6.10. Этот
пример продемонстрирует ряд новых способов использования
атрибутов.
Рассмотрим сначала несколько более простой пример,
основанный на следующей входной грамматике с начальным символом (£):
1. (E)^l(R)
2. (R)->+I(R)
3. (R)->-I(R)
4. (J?)-ve
Мы предполагаем, что / представляет идентификатор, значением
которого является указатель на элемент таблицы, соответствующий
данному идентификатору.
Такая грамматика порождает список идентификаторов,
разделенных знаками + и —. Порождаемый ею язык фактически
является множеством бесскобочных выражений, состоящих из
идентификаторов, к которым применяются только две бинарные операции
+ и —.
Пусть нам нужно перевести входные цепочки в цепочки атомов,
аналогично тому как описывалось в разд. 1.2 и 7.8. В данном случае
мы хотим использовать атомы СЛОЖ и ВЫЧИТ. Значение каждого
из этих атомов должно состоять из трех указателей на левый опе-
Ф. Льюис и др.
226 Гл. 7. Синтаксически управляемые процессы обработки языков
ранд, правый операнд и результат. Пусть, далее, каждый атом
выдается сразу после того, как обработаны оба его операнда. В
правиле 2 правым операндом операции + является /, потому нужно
выдать соответствующий данной операции атом СЛОЖ сразу
после обработки /. Аналогично в правиле 3 нужно выдать атом ВЫ-
ЧИТ, соответствующий операции, сразу после того, как будет
обработан операнд /. Согласованность во времени выходных
символов определяется следующей грамматикой цепочечного перевода:
1. (E)->I(R)
2. <#>-►+/{СЛОЖ}О? >
3. <#>->— /{ВЫЧИТ}<#>
4. Ш)->е
Теперь, чтобы задать три указателя для каждого атома, введем
в грамматику атрибуты. Нетерминалу (R) придается наследуемый
атрибут, который является указателем на элемент таблицы,
соответствующий промежуточному результату, предшествующему (/?>.
Получаем следующую атрибутную транслирующую грамматику:
(R >РНАСЛЕДУЕМЫЙР
Атрибуты символов действия — НАСЛЕДУЕМЫЕ.
1. <E>-+Ipi<R>p2
p2+-pl
2. <#V — + /„ {СЛОЖя2
(г2, г1) — НОВТ р2ч_р1 q2*-ql
3. </?>p(^_/(7i {ВЫЧИТЯ2,„2,Г1} <R>r2
(г2, rl)+-HOBT p2*-pl q2+-ql
4. <R>r — s
На рис. 7.9, а показан пример атрибутного дерева вывода для
входной цепочки
/!-/.+ /•
Здесь предполагается, что системная процедура НОВТ задает
значения 4 и 5 для элементов таблицы, соответствующих промежуточным
результатам.
Обратите внимание на то, что атрибут нетерминала {R > является
указателем на элемент таблицы, соответствующий промежуточному
результату подвыражения, предшествующего (R). Этот
промежуточный результат является также левым операндом первой
операции, порождаемой нетерминалом (R), если таковая вообще
имеется.
7.10. Еще одна атрибутная транслирующая грамматика для выражений 227
Предположим теперь, что оператор присваивания порождается
следующим правилом:
<S)-v/=<£>
вместе с описанными выше правилами для (Е >; предположим далее,
что мы хотим перевести оператор присваивания в цепочку атомов,
5-4 >
+ /3 {шж435}<я>5
<s>
+ '3 {СЛ0Жо.5)<Я>5.,
Рис. 7.9.
оканчивающуюся атомом ПРИСВ так, как это было описано в
разд. 7.9. Пусть (Е > имеет синтезируемый атрибут — указатель на
элемент таблицы, соответствующий выражению, порождаемому
посредством (£>. Заменим нашу грамматику на следующую ((S) —
228 Гл. 7. Синтаксически управляемые процессы обработки языков
начальный символ):
<£>, СИНТЕЗИРУЕМЫЙ t
<R>D t НАСЛЕДУЕМЫЙ р СИНТЕЗИРУЕМЫЙ t
Атрибуты символов действия — наследуемые.
5. <S>-*Ipl = <E>qi {ПРИСВОИТЬ,,, „}
р2+— р\ q2*—q\
1. <E>u-*Ipi </?>„,„
р2*—р\ t2*-t\
2. <R>Puu-* + I„x {СЛОЖя2 \ <R>n,U
(г2, rl)*-HOBT p2*-p\ q2+-q\
3. <R>pi {ВЫЧИТ,2 } <R>n.u
(r2, rl)+-HOBT p2+-p] q2*-ql
Р2 —pi
На рис. 7.9, б показан пример атрибутного дерева вывода для
входной цепочки
/•=/i-/t+/.
Обратите внимание на то, что при применении правила 4
синтезируемому атрибуту нетерминала (R > присваивается значение его
наследуемого атрибута. Затем это значение передается вверх по
дереву как синтезируемый атрибут левого нетерминала правил 2,
3 и 1 и используется как атрибут атома ПРИСВ.
Теперь обратимся к грамматике из разд. 6.10, используя только
бинарные операции + и *.
1. <£>->- <Г>(£-список>
2. Ш-список) ->- + (Т > (£-список >
3. (£-список > -v e
4. (Т)-> (Р>(Г-список>
5. (Г-список > -*■ * (Р > (Г-список >
6. (Г-список >->- е
7. </>>->(<£»
8. (Р)->1
Допустим, что мы хотим перевести выражения этой грамматики
в цепочки атомов СЛОЖ и УМНОЖ так же, как в разд. 7.8. Пусть
как и прежде атом, соответствующий операции, будет выдан сразу
после того, как обработан ее правый операнд. Однако в данном
случае правый операнд — это не просто /, а целое подвыражение. Так,
в правиле 2 правый операнд операции + порождается нетермина-
/2 —/1
t2*-t\
7.10. Еще одна атрибутная транслирующая грамматика для выражений 229
лом (Г), который следует за символом +. Такая согласованная
выдача символов действия задается следующей грамматикой,
транслирующей в цепочки:
1. <£>-> <Г>(£-список>
2. (£-список)->+(Г){СЛОЖ} <£-список>
3. (£-список >->- е
4. (D-v (РХГ-список>
5. (Г-список > ->- * (Р > {УМНОЖ} (ТЧписок)
6. (Г-список) -*- г
7. </>>->((£»
8. (Р)->1
Атрибуты этой грамматики можно определить так же, как и в
аналогичных примерах. Каждый из нетерминалов (£>, (Т) и (Р) будет
иметь синтезируемый атрибут, указывающий элемент таблицы с
соответствующим результатом. Окончательная грамматика показана
да рис. 7.10.
<Е>р СИНТЕЗИРУЕМЫЙ р
<Т>р СИНТЕЗИРУЕМЫЙ р
<Р>р СИНТЕЗИРУЕМЫЙ р
<£-список>^, q НАСЛЕДУЕМЫЙ р СИНТЕЗИРУЕМЫЙ q
<Г-список>/,'19 НАСЛЕДУЕМЫЙ р СИНТЕЗИРУЕМЫЙ q
Рис 7.10.
Атрибуты символов действия НАСЛЕДУЕМЫЕ
1, <E>i2—>-<T>pi <E-cnmoK>p2iti
р2-н-р1 12*— /1
2, <E-cnncoK>pi,H—* + <T>gi {СЛОЖЯ2, ?2, ri} <£-список>га, «
(г2, rl)+— HOBT р2*— p\ q2*—q\ t2*—t\
3, <£-список>Я1, pi —► 8
р2*—р\
4, <Т>и —* <P>pi <T-ciwcOK>p2. a
p2*—pl t2*—tl
5, <Г-список>/,1 и—** <P>gi {УМНОЖ^2, ?2, п} <Г-список>г2, ц
(г2) r\)*— HOBT р2*—р\ q2*—q\ t2*—t\
6, ^Г-список;^, рг—»-е
р2+- р\
7, <Р>Р2-+«Е>р1)
р2*—р\
-8. <Р>рг —+ lpi
Р2*-р\
На рис. 7.11 показано дерево вывода выражения
/i+/a*/s
230 Гл. 7. Синтаксически управляемые процессы обработки языков
<Р>
<Т-слисок>4
Рис. 7.11.
7.11. Неоднозначные грамматики и многозначные
переводы
Как уже говорилось в разд. 6.6, грамматика называется
неоднозначной, если в определяемом ею языке существует цепочка, для которойг
имеется более одного дерева вывода. Например, используя
грамматику
<£>-> (E)t(E)
<£>->*
для цепочки xtxtx, получим два дерева соответствующих левым
выводам
<£> => <£> t <£> =Ф <£> / <£> t <£> =Ф xt <£> t <£>
=> xtxt <£> =Ф xtxtx
<£> => <£> t <£> =Ф xt <£> =ф xt <£> t <£>
=> xtxt <£> =$ xtxtx
На рис. 7.12 показаны оба дерева вывода. Когда неоднозначная
грамматика превращается в транслирующую грамматику путем
добавления в нее символов действия, некоторые входные цепочки
могут иметь более чем один перевод. В данном примере это произойдет,,
если мы добавим выходные символы Т и X для получения
грамматики цепочечного перевода:
<£>-> <£>/<£>{Г}
(Е)-+х{Х}
7.11. Неоднозначные грамматики и многозначные переводы 231
Два приведенных выше вывода порождают разные
последовательности актов, соответствующие входной цепочке xtxtx, а именно:
x{X}tx{X}{T}tx{X}{T} и x{X}tx{X)tx{X}{T}{T}
Выходными подпоследовательностями этих последовательностей
актов будут соответственно ХХТХТ и ХХХТТ. Если
интерпретировать t как бинарную операцию, ад: — как операнд, то эти выходные
<£> <£>
■ Е>
<Е>
<Е>
<Е>
<Е>
Рис. 7.Т2. Два дерева вывода для xtxtx.
подпоследовательности представляют собой два выражения в
польской записи, вычисляемые по-разному. Первый перевод вызывает
вначале выполнение левой операции, как в выражении (xtx)tx, а
второй — правой операции, как в выражении xt(xtx).
С точки зрения проектирования компиляторов, неоднозначные
переводы имеют сомнительную ценность, так как для данной
входной цепочки компилятор может сделать только один перевод. Одна
из возможных интерпретаций состоит в том, что человек, задающий
неоднозначную грамматику, хочет, чтобы компилятор выдал любой
перевод. В нашем примере такая ситуация возникает, если операция
t является операцией сложения, так как справедливо следующее
математическое соотношение:
(Х!+Х2)+Xa=Xi+(Х2+Х3)
Если в качестве t взять операцию вычитания, то такого уже не
будет, так как
\Х\—Хъ)—Хз^фХх—(Х,2—Хз)
В любом случае наиболее полезная техника синтаксической
обработки цепочек основывается на использовании однозначных
грамматик, так что мы рассматриваем неоднозначность как зло, которого
нужно избегать.
По данной неоднозначной грамматике для контекстно-свободного
языка иногда (но не всегда) можно найти однозначную грамматику
для того же языка. Для языка из текущего примера существует
.много однозначных грамматик, в том числе две такие:
232 Гл. 7. Синтаксически управляемые процессы обработки языков
(£>-> (E)t(T)
(Е)^ (Т)
<£>■
<£>■
(T)t(E)
(Т)
Первая грамматика подходит для определения переводов, в которых
вначале выполняется самая левая операция, вторая —для
определения переводов, в которых раньше выполняется самая правая
операция.
С математической точки зрения транслирующая грамматика
может задавать много переводов данной входной цепочки, и любую
выходную последовательность следует считать переводом соответст-
<s>
<s
<s>
if <В > then <S>
6
Рис. 7.13.
вующей входной цепочки. В случае однозначной грамматики,
перевод понимается однозначно. Так как большинство грамматик, с
которыми мы будем иметь дело, однозначны, иногда мы не будем
специально указывать, что перевод однозначен,
7.12. Замечания по литературе
233
Чтобы показать, как неоднозначность может появиться при
неосмотрительном определении языка, предположим, что была
определена грамматика, включающая следующие два правила:
(S > ->- if(5>then(S) else (S)
<S)->if(5>then(S>
где нетерминал (S) порождает операторы, а (В) — логические
выражения. Первоначальная версия языка Алгол 60 на самом деле
допускала такие конструкции, но нынешняя грамматика Алгола
ограничивает виды выражений, которые могут следовать за словом
then. Подразумеваемая интерпретация каждого из этих правил
очевидна, однако в языке возникает двусмысленность, поскольку
существует два дерева, соответствующие выводу
<5> =»* if <5> then if <B> then <S> else <S>
которые показаны на рис. 7.13. Если интерпретировать оператор
if true then if false then ПЕЧАТАТЬ («X») else ПЕЧАТАТЬ («Г»)
согласно рис. 7.13, а, то в качестве выхода будет напечатано «F»,
тогда как вычисление этого оператора, согласно рис. 7.13, б, не
дает на выходе никакого результата. Отсюда следует, что
грамматику нужно переопределить так, чтобы одну из этих интерпретаций
исключить.
7.12. Замечания по литературе
Синтаксически управляемые переводы впервые были использованы
Айронсом [1961, 1963а] и далее развиты Читэмом и Сэтли [1964].
Процедуры действия использовались также в работах Брукера и
Морриса [1960, 1962]. Математические модели синтаксически
управляемых переводов были изучены в работах Петроне [1965], Чулика
[1966], Пола [1967], Янгера [1967], Льюиса и Стирнза [1968], Ахо
и Ульмана [1969а, 19696], и Вера [1970]. Атрибутные грамматики
с синтезируемыми и наследуемыми атрибутами были введены и
изучены Кнутом [1968а]. Описанная в данной главе конкретная модель
атрибутных транслирующих грамматик введена Льюисом, Розен-
кранцем и Стирнзом [1974].
Упражнения
1. Чему равно значение следующих постфиксных польских выражений.
а) 3 7 11 + * 4 —
б) 16 9 5 2 * + *
в) 123 — 45*67+*-)
■2. Найдите перевод выражения
а+Ь*с*(Ь-\-а)*(с-\-а)
234 Гл. 7. Синтаксически управляемые процессы обработки языков
в постфиксную польскую запись согласно транслирующей грамматике из-
разд. 7.3.
3. Предположим, что в постфиксной польской записи символ — используется
для обозначения как унарной, так и бинарной операции вычитания.
Покажите, что в этом случае для выражения
7 5
возможны две разные интерпретации, дающие разные значения.
4. Постройте транслирующую грамматику, которая будет переводить
определяемые грамматикой разд. 6.15 арифметические выражения языка MINI-BASIC
в постфиксную польскую запись. В польской записи выражений должны
использоваться разные символы для унарных и бинарных операций.
6. Постройте транслирующую грамматику, которая переводит арифметические
выражения, использующие сложение (унарное и бинарное), умножение и
возведение в степень, из инфиксной записи в постфиксную польскую запись.
ft В префиксной польской записи операции предшествуют своим операндам,
так, например, инфиксному выражению а-\-Ь*с соответствует выражение
-\-а*Ьс в префиксной польской записи. Постройте для выражений,
включающих переменные и операции + и *, транслирующую грамматику, которая
задавала бы перевод этих выражений:
а) из инфиксной записи в префиксную польскую запись,
б) из префиксной польской записи в постфиксную польскую запись,
в) из постфиксной польской записи в префиксную польскую запись,
г) из префиксной польской записи в инфиксную запись.
7. Найдите перевод цепочки POLISH согласно следующей транслирующей
грамматике с начальным символом (S):
' (S)-+P{LU}(S)(H) • {S)-y{K)0{D)L
(S)^{W}IS{E) <S)^e
(D)^{T){AS}(K) (K)-»(T){IE)
WMTHIC) (H)-y(S)(U){Z)(Y)
WU*
8. Постройте транслирующую грамматику, допускающую в качестве вход&
произвольную цепочку, состоящую из нулей и единиц, и порождающую в
качестве выхода:
а) обращение входной цепочки,
б) пустую цепочку е,
в) саму входную цепочку,
г) цепочку 0п\т, где п — число нулей, am — число единиц во входной
цепочке.
9. Постройте транслирующие грамматики для переводов, описанных в упр. 13,
гл. 5.
10. Постройте транслирующую грамматику, переводящую арифметические
выражения из инфиксной записи в функциональную запись, так что, например,
выражение а+6 перейдет в /+(о, о), и выражение а-{-Ь*с перейдет в.
f+(a, /*(6, с)), где /+ и f* — отдельные символы.
11. Определите, что делает следующая транслирующая грамматика
(S)-+{C)EN{HI}GL{N)I[E)S{SE}H
12. Некоторая транслирующая грамматика порождает следующие две
последовательности актов:
{х){у)Ь{г}
Шх}{у}Ь{г}{х){х}{у}Ь{г}{у}
Упражнения
235
Входная грамматика, получаемая вычеркиванием символов действия из этой
транслирующей грамматики, такова:
<S)-wz(S)(S>
Какова сама транслирующая грамматика?
13. Выпишите все пары, принадлежащие синтаксически управляемому
переводу, определяемому следующей транслирующей грамматикой с начальным
символом (S):
(S)^{A){x}c(B){y}
(S)^{y}d{x}c{z)b
{А)МВ)а{у}
{A)-+d
(B)^b{x}
14. Постройте транслирующую грамматику, допускающую в качестве входных
цепочки, допускаемые конечным автоматом, изображенным на рисунке, и
порождающую в качестве выхода последовательность состояний автомата,
которые он проходит в процессе обработки этой входной цепочки. Например,
входная цепочка 1010 должна переводиться в ABBCD.
О 1
А
В
D
А
В
С
А
D
15. Постройте транслирующую грамматику, которая переводит логические IF-
операторы Фортрана на Алгол.
16. Постройте транслирующую грамматику, переводящую логические выражения
Фортрана в логические выражения Алгола, имеющие те же значения.
17. Постройте транслирующую грамматику, переводящую if-операторы Алгола
(операторы «если») в IF-операторы языка ПЛ/1.
18. Постройте транслирующие грамматики, которые переводят операторы Кобола
ADD, SUBTRACT, MULTIPLY и DIVIDE в соответствующие операторы
языка MINI-BASIC.
■19. Найдите цепочку атомов и таблицу, получаемые в результате перевода
цепочки
a+b*c*(b-{-a)*(c-{-a)
согласно транслирующей грамматике разд. 7.8.
20. Рассмотрим входную цепочку
и следующую атрибутную грамматику с начальным символом (S),
наследуемый атрибут которого имеет начальное значение, равное 1:
<SyPi4 СИНТЕЗИРУЕМЫЙ р НАСЛЕДУЕМЫЙ q
<A>Pig СИНТЕЗИРУЕМЫЙ р НАСЛЕДУЕМЫЙ q
236 Гл. 7. Синтаксически управляемые процессы обработки языков
Атрибуты символов действия — НАСЛЕДУЕМЫЕ. •
!• <5>Я4,91 *" <*pl <S>(1;;2 bsi {Сд2>р3} <A>ritg3 {drilS2,u}
(р2, рЗ, р4)«— р\ (92, g3)-<—gl s2«— si *2«— t\ r2+—r\
2. (S}pi< pi he
p2+-p\
3. <Л>/,з, д —► <5>я1_ <2 69i <i4>,j, ?2 <Л>,1, ?s {/r2i i2i p2)
(p2, p3) «—pi (g2, g3)«—gl /-2«— rl s2«—sl <2«—/1
4- <-4>p2,91 —*■ {едг} Cpi
p2«—-pi q2+—q\
а) Нарисуйте дерево вывода данной входной цепочки вместе с атрибутами
всех используемых символов.
б) Какова соответствующая последовательность действий?
21. Найдите атрибутное дерево и последовательность актов для входной цепочки
порождаемые следующей атрибутной транслирующей грамматикой с
начальным нетерминалом (S):
<T>a,v,w,x НАСЛЕДУЕМЫЕ и, v СИНТЕЗИРУЕМЫЕ w, х
Все атрибуты символов действия — НАСЛЕДУЕМЫЕ.
<S>-+d<T>Pig,r,s
р-^—т
q*-s
<T>a,v,w,x—*ay {gz} <ХУР,д, г,s {ht}
z«—т
р+—и + у
q*—v+3*y
t+—v
w*—/■+1
х+—s+5
М/а,да, «>,х *■ "у \fzl
z-<— v
w*—у
x*— и
22. Рассмотрим следующую атрибутную транслирующую грамматику
<S>,iiS НАСЛЕДУЕМЫЙ i СИНТЕЗИРУЕМЫЙ s
Начальное значение (=3.
Атрибуты символов действия — НАСЛЕДУЕМЫЕ,
<s>/.#—-MMte*}
y—x+i
г+-у-\-х
s-<— z
<S>;,s-^bx{fy}{gz}
у*—г
г«— s
s«—у
Упражнения
237
<S>i.s-+cx{fu){g,}
y^-z+l
z+—s+l
s+-y+l
<S>i,s-*dx{hy}<S>jtt
y<—i+t
/«-*
s<— t
<S>i., — ex<S>/ti{fy}
y*—x
i*-t
s<—t
Найдите атрибутное дерево вывода и последовательность актов (если они
существуют) для каждой из следующих входных цепочек:
а) яв б) ахаг в) dsat
г) ЬА д) с„ е) djdsdsdids
ж) е^хё2ё^аь
23. Постройте атрибутную транслирующую грамматику цепочечного перевода,
допускающую в качестве входа списки, записанные с помощью списочной
нотации языка Лисп и переводящую их в S-выражения Лиспа (в точечной
записи), представляющие те же самые списки. Например, список
(AB(CD))
переводится в
(А -(В.((С-(D -NIL))-NIL)))
24. Рассмотрим следующую грамматику для условных операторов, взятую .из
сообщения об Алголе 60:
1. (условный оператор)-*-ОГ-оператор)
2. (условный onepaTOp)-»-(if-onepaTop)eIse(onepaTOp)
3. (if-оператор)—>-Ш-предложение) (безусловный оператор)
4. (if-предложение)—^(логическое выражение) then
Предположим, что нетерминал (логическое выражение) имеет один
синтезируемый атрибут — указатель на элемент таблицы, соответствующий его
результату. Предположим, что существуют следующие три атома:
МЕТКА (р), где р — указатель на элемент таблицы, соответствующий
метке. Этот атом помещается в те места программы, куда атомы переходов
передают управление.
ПЕРЕХОД (р), где р — указатель на элемент таблицы, соответствующий
метке. Этот атом приводит к порождению команды, передающей управление
на указанную метку.
ПЕРЕХОДПОЛЖИ (q, p), где q — указатель на элемент таблицы,
соответствующий результату логического выражения, ар — указатель на
элемент таблицы, соответствующий метке. Этот атом вызывает условную передачу
управления. ПЕРЕХОДПОЛЖИ приводит к созданию команд, которые
проверяют значения логического выражения, и в случае, если оно — ложь,
передают управление на указанную метку.
Используя эти атомы, добавьте к приведенной выше грамматике
атрибуты, чтобы получалась атрибутная грамматика, задающая перевод условных
операторов в последовательности атомов.
25. Предположим, что в языке имеется WHILE-оператор такого вида:
(оператор)-»ЛУН11,Е(логическсе выражение)ОО(оператор)
который интерпретируется следующим образом:
238 Гл. 7. Синтаксически управляемые процессы обработки языков
Вычисляется логическое выражение. Если оно истинно, выполняется
оператор (записанный после DO), иначе он пропускается. После выполнения
оператора, если при этом не произошло передачи управления за пределы WHILE-
оператора, вновь вычисляется логическое выражение, и весь процесс
повторяется.
а) Используя атомы, определенные в упр. 24, постройте атрибутную грам-
'матику, задающую перевод в цепочки атомов.
б) С помощью построенной атрибутной грамматики, найдите перевод цепочки
WHILE х>у DO WHILE z>x DO *=*+4
Определите соответствующие атомы для логических выражений и
оператора присваивания.
26. Подвыпивший программист написал приведенную ниже атрибутную
грамматику. Найдите в ней ошибки и противоречия.
<В>Х НАСЛЕДУЕМЫЙ х
<С>Х СИНТЕЗИРУЕМЫЙ х
ф>а;ь НАСЛЕДУЕМЫЕ a, b
Атрибуты символов действия — НАСЛЕДУЕМЫЕ.
1. <А>-^-ахЬу
У+—х
2. <Л> —► cyl <£>>„4, 3,3
((/2, уЗ) *- у\
3. <Л> —► ах <D>yU у2
у2*—у\
4. <В>-*■**! {FLOP,,}
х2*—х\
5. <Ож -> е
6. <C>pi—^dgl<A>g2{NlPpUgS}
{q2,q3) — ql р2+—р\
ч <D>pi, qs ■—► <в>д <с> <d>92, р2
(q2,q3)*—ql р2*~ р\
8. <Р>,,Л-+ал<р>п<В>%
(s2, s3)*—s\
9. <D>-+ax_v<C>zi<C>2i
г2*—г\
27. а) Определите атрибуты для следующей грамматики:
(целое)-»-цифра (цифры)
(цифры)-»-цифра (цифры)
(цифры)-»-е
так, чтобы нетерминал (целое) имел один синтезируемый атрибут, равный
значению порождаемого им числа. Считайте, что входной символ «цифра»
имеет один атрибут — число между 0 и 9.
б) Для констант языка MINI-BASIC (они порождаются грамматикой из разд.
G.7) постройте атрибутную грамматику, начальный символ которой имеет
один синтезируемый атрибут, равный значению константы.
28. Рассмотрим следующую транслирующую грамматику, где с — лексема,
представляющая константу и имеющая значение, равное значению этой константы-
Упражнения
239
Начальный символ — (S).
(S)ME) {ОТВЕТ}
(E)^(P)(R)
{R)^+(P)(R)
(R)^-(P)(R)
<РЫ<£»
Определите атрибуты этой грамматики так, чтобы {ОТВЕТ} имел один
атрибут, равный числовому значению выражения.
29. Постройте атрибутную грамматику для выражений, в которых используются
бинарные операции +, —, *, / над константами и скобки. Операции должны
выполняться строго слева направо, но для выражений, заключенных в скобки,
действуют обычные правила. Например, выражение 3+4*5 эквивалентно
выражению (3+4) * 5 и его значение равно 35. Грамматика должна иметь
один символ действия {ОТВЕТ}, входящий в правило для начального
символа и имеющий один атрибут, который равен числовому значению
выражения.
30. Предположим, что в описанных в разд. 7.9 операторах присваивания
операция + и — ассоциируются справа налево, а не слева направо, как обычно.
Так, входной цепочке
LET /2=/i_/2+/3
должна соответствовать цепочка атомов
СЛОЖИТЬ^ з, 4 ВЫЧЕСТЬ1>4,5 ПРИСВОИТЬ^ 5
Введите выходные символы и символы действия в каждую из следующих
грамматик, чтобы задать нужный атрибутный перевод
а) (S)-^LET /=(£) <£)-»-/+(£)
(E)^I-(E) <£)+/
б) <S)->-LET /= Е) (E)^I(R)
(R)^+I(R) {R)^-I(R)
(R)-*e
31. Введите атрибуты в следующую грамматику так, чтобы нетерминал
(описание) имел один синтезируемый атрибут, равный числу идентификаторов,
следующих за словом ВЕЩЕСТВЕННЫЕ.
(описание)->- ВЕЩЕСТВЕННЫЕ / (список идентификаторов)
(список идентификаторов)-»-, / (список идентификаторов)
(список идентификаторов) —»- е
32. Атрибут может быть цепочкой, а правило, определяющее атрибут, может
содержать операцию конкатенации цепочек.
а) Покажите, что для любой данной контекстно-свободной грамматики можно
так определить атрибуты, чтобы начальный символ имел синтезируемый
атрибут, равный генерируемой цепочке.
б) Для некоторых вычислительных машин выражения желательно
переводить в цепочки, состоящие из атомов СЛОЖИТЬ, ВЫЧЕСТЬ,
УМНОЖИТЬ и ДЕЛИТЬ так, чтобы перевод правого операнда операций — и /
предшествовал переводу левого операнда. Введите атрибуты в следующую
грамматику.
240 Гл. 7. Синтаксически управляемые процессы обработки языков
(S>->-<£> {ВЫХОДНАЯ ЦЕПОЧКА}
(Е)МЕ)+(Т) (Е)МЕ)-(Т)
(Е)^{Т) (Т)-+{Т)*{Р)
(Т)^{Т)/{Р) (Т)^(Р)
ЧР>^«£» (Р)^1
так, чтобы выходной символ ВЫХОДНАЯ ЦЕПОЧКА имел один атрибут
равный требуемой цепочке атомов. Например, для входной цепочки
выход должен быть таким:
ВЫХОДНАЯ ЦЕПОЧКАделить, умножить, вычесть
в) Введите атрибуты в грамматику из пункта (б) так, чтобы атрибутом
символа действия ВЫХОДНАЯ ЦЕПОЧКА была надлежащая атрибутная
цепочка. Например, для входной цепочки
I1*I2—I3Hi
выход должен быть таким
ВЫХОДНАЯ ЦЕПОЧКАДЕЛИТЬ (3> 4, 5> умножить (1, 2, 6) вычесть (6,5, 7)
Считайте, что необходимые указатели на таблицу создаются с помощью
вызова процедуры НОВТ.
33. Нарисуйте дерево вывода цепочки
согласно грамматике, приведенной на рис. 7.10.
34. В Алголе 60 арифметическое выражение
if х>у then 1 else 2+3
могло бы иметь два смысловых значения, которые с помощью скобок можно
выразить таким образом:
if x>y then 1 else (2+3)
(if x>y then 1 else 2)+3
Покажите, что грамматика в сообщении об Алголе GO однозначна и найдите
значение, которое имеется в виду.
35. Дана транслирующая грамматика
<£> + <£>_<£){-}
<£>+/(/},
где / представляет любую переменную. Какие выходные последовательности
возможны для входной цепочки
a—b—c—d
36. Дайте пример грамматики цепочечного перевода, в которой входная цепочка
может иметь бесконечное число возможных выходных последовательностей.
37. Пусть дана произвольная грамматика. Покажите как построить грамматику
цепочечного перевода, чтобы входные последовательности всех ее
последовательностей актов состояли из цепочек, порождаемых данной грамматикой,
а выходные последовательности — из цепочек имен продукций,
использованных в левом выводе входной цепочки согласно данной грамматике.
38. а) Постройте атрибутную транслирующую грамматику, которая будет
переводить бесскобочные выражения, состоящие из идентификаторов и
операций + и *, на язык ассемблера некоторой вычислительной машины.
Считайте, что имеется ячейка памяти 77 для промежуточных результатов.
Упражнения
241
Например, выражение
Ia*!b+iC*iD
можно перевести в:
ЗАГРУЗИТЬл
УМНОЖИТЬв
ЗАПОМНИТЬ п
ЗАГРУЗИТЬС
УМНОЖИТЬд
СЛОЖИТЬ Т1
Атрибут терминала / — имя идентификатора.
б) Сделайте то же, что в пункте (а) для выражений, содержащих скобки.
Считайте, что имеется неограниченное число ячеек памяти Т\, Т2, ТЗ, . ..
для промежуточных результатов.
39. а) Покажите, что если транслирующая грамматика имеет однозначную
входную грамматику, то длина последовательности действий любой
последовательности актов ограничена длиной входной последовательности,
умноженной на константу,
б) Покажите на примере, что данная оценка не обязательно выполняется, если
входная грамматика неоднозначна.
40. Приведенная ниже транслирующая грамматика ((S) — ее начальный символ)
имеет только одну последовательность актов, в которой входная цепочка
совпадает с выходной. Найдите эту последовательность актов.
(S)-y(S)(Y)
(S)-»(X)(S){X){e}
(S)^{a}(Z)(Z){a)
(Y)--a
(Y)-+e
(X)^g(Y){g)
(Z)-yb{rb)
(Z)^r
41. Некоторая грамматика содержит нетерминал (описание), порождающий слово
ВЕЩЕСТВЕННЫЕ, за которым следует список идентификаторов,
разделенных запятыми. Значением каждого идентификатора является указатель на
элемент таблицы, соответствующий данному идентификатору. Нетерминал
(описание) имеет наследуемый атрибут, равный следующей доступной ячейке
рабочей памяти, которая используется для описанных в списке переменных.
Для каждой переменной из этого списка синтаксический блок должен
вызывать процедуру действия, название которой — ЗАПОЛНЕНИЕ
ЭЛЕМЕНТА. У этой процедуры есть два параметра: указатель на элемент
таблицы, соответствующий идентификатору, и рабочая ячейка для этого
идентификатора. Адрес ячейки для каждой переменной на единицу больше адреса
ячейки ранее описанной переменной.
Постройте атрибутную грамматику, задающую вызовы процедуры
действия с надлежащими параметрами.
8
Нисходящие методы обработки языков
8.1. Введение
В предыдущих главах мы рассматривали контекстно-свободные
грамматики и транслирующие грамматики как способ задания
языков и переводов. Теперь мы приступаем к изучению того, как и при
каких условиях заданные таким образом распознавание и перевод
может выполнить автомат с магазинной памятью. При
проектировании компиляторов эта проблема фактического выполнения перевода
имеет, конечно, первостепенное значение.
Фактически все методы построения компиляторов, основанные
на использовании контекстно-свободных грамматик, приводят к
созданию процессоров, которые как-то «используют» грамматику, в том
смысле, что действия процессора можно интерпретировать как
распознавание отдельных правил в дереве вывода. Любой процессор,
работа которого включает распознавание правил, называется
синтаксическим анализатором. Термин «синтаксический анализ» (или
«разбор») заимствован у лингвистов, которые называют им анализ
предложений естественного языка или построение для них
синтаксических диаграмм.
Методы анализа можно разделить на две категории: нисходящие
и восходящие («сверху вниз» и «снизу вверх»). Каждая категория
характеризуется порядком, в котором распознаются правила в
дереве вывода. Грубо говоря, нисходящие процессоры распознают
правила сверху вниз, верхние правила раньше нижних, в то время
как восходящие процессоры распознают нижние правила раньше
тех, что расположены выше. Это различие станет понятнее при более
детальном рассмотрении этих методов.
При построении МП-автоматов можно использовать как
восходящий, так и нисходящий подходы. Однако при каждом из этих
подходов можно распознать нелюбой контекстно-свободный язык х)
и не любой синтаксически управляемый перевод можно выполнить
с помощью МП-автомата. Каждый из методов налагает ограничения
на вид входной и транслирующей грамматик, к которым он
применим, и на характер допустимых связей между действующими
процедурами.
1) Напомним, что в этой книге рассматриваются только детерминированные
МП-автоматы. Недетерминированные МП-автоматы распознают (в специальном
смысле) все КС-языки,— Прим. рад.
8.2. Пример
243
Вначале мы изучим нисходящий подход к процессам обработки
языков с помощью МП-автоматов. Нисходящий разбор g помощью
МП-автомата иногда называют детерминированным нисходящим
анализом в отличие от некоторых других методов, называемых
«недетерминированным нисходящим анализом» или «нисходящим
анализом с возвратами».
На протяжении всей данной главы предполагается, что
используемые грамматики не содержат лишних нетерминалов. Таким
образом, мы считаем, что каждые правило и нетерминал могут быть
использованы в выводе какого-либо предложения языка. Это
предположение не является существенным ограничением, поскольку
удаление из грамматики лишних нетерминалов и правил не изменит
ни распознаваемого языка, ни выполняемого перевода.
8.2. Пример
В этом разделе мы проиллюстрируем некоторые принципы
нисходящей обработки цепочек МП-автоматами на примере
распознавателя для следующей грамматики ((S) — ее начальный нетерминал):
1. <S>->d(S>04>
2. (S)-+b{A)c
3. (A)^d(A)
4. (А)^с
Магазинными символами МП-автомата являются нетерминалы,
некоторые терминалы грамматики и маркер дна. В нашем примере
множеством магазинных символов будет
{<S>, <Л>, с, V}
На каждом шаге процесса обработки магазин представляет
некоторое утверждение о цепочке входных символов, оставшихся
необработанными. А именно он представляет утверждение о том, что вся
входная цепочка допустима тогда и только тогда, когда цепочка
оставшихся входных символов (включая текущий входной символ, если
он не является концевым маркером) выводима из цепочки символов,
находящейся в магазине. Например, если в процессе обработки
входной цепочки в магазине оказалось
<5><Л>с<Л>У
то данный магазин представляет утверждение, что вся входная
цепочка допустима тогда и только тогда, когда цепочка входных
символов, которую предстоит еще обработать, состоит из цепочки,
порождаемой нетерминалом (S), за которой следует цепочка, порож-
244
Гл. 8. Нисходящие методы обработки языков
даемая (А >, потом терминал с, потом еще цепочка, порождаемая
(А >, и наконец концевой маркер.
Прежде чем привести управляющую таблицу, покажем как МП-
автомат использует магазин при распознавании цепочки
dbccdc
То, что данная цепочка принадлежит языку, определяемому
указанной грамматикой, видно из следующего левого вывода
<S>=s>d<S></4>=s>d&<,4>c04>=s>
db се <Л> =s>db се d<.4>=2> dbccdc
или из показанного на рис. 8.1 дерева вывода.
Для того чтобы начать обработку цепочки, поместим в магазин
(5)V- Такая инициализация — это просто утверждение, что вход-
<S>
d <S> <A>
b
с с
Рис. 8.1.
ная цепочка (если она допустима) должна порождаться начальным
нетерминалом (S), за которым следует концевой маркер. Это
начальное содержимое магазина вместе с исходной входной цепочкой
является начальной конфигурацией, показанной в первой строке
последовательности конфигураций на рис. 8.2. Дополнительный
столбец справа на этом рисунке мы пока не будем рассматривать.
На рисунке не указаны состояния, так как автомат имеет только
одно состояние.
Из начальной конфигурации автомат должен сделать переход
на основании того факта, что верхним символом магазина является
<А>
А>
8.2. Пример
245
(S >, а текущий входной символ — d. Верхний символ магазина
говорит о том, что оставшаяся цепочка входных символов (при
условии, что она допустима) должна начинаться с цепочки, порождаемой
(S), а текущий входной символ говорит о том, что эта цепочка
начинается с d. Мы заключаем, что цепочка, порождаемая начальным
нетерминалом (S >, должна начинаться с d. Для вывода цепочки из
нетерминала (S) к нему можно применить два правила, а именно
1: V (S)
2: V (A) (S)
3: v (А) с (А)
4: v (А) с
5: V (А)
6: V (А)
7: V
8: ДОПУСТИТЬ
d Ь с с d с —|
Ъ с с d с —j
cede —|
с d с —|
dc-\
сЧ
И
Рис. 8.2.
1
2
4
с
3
4
правило 1 и правило 2. Однако цепочку, начинающуюся с d, нельзя
получить, применив сразу же правило 2, так как правая часть
правила 2 начинается с Ь, а это значит, что все выводимые из правой
части правила 2 цепочки должны начинаться с Ь. Отсюда неизбежно
заключение, что требуемая цепочка получается из (S >, если к этому
нетерминалу вначале применить правило 1. Так как правая часть
этого правила равна d(S)(A), порождаемая (S) цепочка должна
состоять из d (текущий входной символ), за которым следуют
цепочки, порождаемые (S) и (А). Для того чтобы зарегистрировать
этот факт, МП-автомат переходит к следующему входному символу
и заменяет верхний символ магазина (5) на символы (S) и (А),
причем (5) помещается выше (А). Делая такой переход, автомат
фактически утверждает, что цепочка символов, следующая за d,
состоит из цепочки, порождаемой (5), за которой следует цепочка,
порождаемая (А >, а потом цепочки, порождаемые символами,
оказавшимися в магазине ниже заменяемого (5). В нашем примере ниже
заменяемого (S) нет никаких символов грамматики, магазин
содержит
<5> <Л> V
утверждая таким образом, что оставшаяся цепочка входных
символов (если она допустима) должна состоять из цепочки, порождаемой
(S), за которой следует цепочка, порождаемая (А). Новая
конфигурация автомата показана во второй строке рис. 8.2.
246
Гл. 8. Нисходящие методы обработки языков
Теперь автомат имеет верхний магазинный символ (5) и
текущий входной символ Ь. В данной ситуации единственная
возможность порождения требуемой цепочки нетерминалом (S > — это
сразу применить к нему правило 2, так как для порождения цепоч-
ки.'Начинающейся с Ь, к (S) можно применить только это правило.
Таким образом оставшаяся необработанной цепочка терминалов
должна состоять из символа Ь, за которым следует цепочка,
порождаемая {А >, символ с и цепочка, выводимая из символов
грамматики, расположенных ниже верхнего магазинного символа (S). МП-
автомат регистрирует этот факт, сдвигаясь вперед по входу, чтобы
учесть, что символ Ь обработан, и заменяя (S > на верху магазина
на (А )с, после чего содержимое магазина становится таким:
<Л>с<Л>у
Новая конфигурация показана в строке 3 рио. 8.2.
Теперь автомат по верхнему магазинному символу {А > видит,
что необработанная часть входа начинается в цепочки, порождаемой
(А), и по входному символу с определяет, что эта цепочка начинается
с с. Поскольку правая часть правила 3 начинается символом d,
вывод нужной цепочки из {А > начинается применением правила 4.
Так как правая часть правила 4 — это просто с, то текущий
входной символ сам порождается нетерминалом {А). Цепочка
терминалов, следующих за с, должна описываться магазинными символами,
расположенными ниже верхнего (А >. Этот факт регистрируется
посредством выталкивания (А > из магазина и сдвига к следующему
входному символу. Описанные действия приводят к результату,
показанному в четвертой строке рис. 8.2.
Верхний магазинный символ с указывает на то, что цепочка
необработанных входных символов должна начинаться с с. Текущим
входным символом на самом деле является требуемый с. Автомат
отмечает этот факт, выталкивая символ с из магазина и сдвигаясь
к следующему входному символу. Результат показан в строке 5
рис. 8.2.
Теперь на верху магазина символ (А), и текущий входной
символ — d. Единственным правилом, которое можно применить, чтобы
начать вывод из (А ) цепочки символов, начинающейся с d, является
правило 3. Таким образом, мы заключаем, что оставшаяся цепочка
состоит из символа d, за которым следует цепочка, выводимая из
(А), и далее все то, что выводится из символов магазина,
расположенных ниже (А ). Автомат регистрирует этот факт, сдвигаясь по
входу и заменяя (А) на верху магазина на (А>. Результат показан
в строке 6 рис. 8.2.
Теперь на верху магазина — символ (А >, а текущий входной
символ — с. Эта ситуация уже была рассмотрена выше и, так же
как и раньше, автомат продвигается по входной цепочке на один
8.2. Пример
247
символ и удаляет из магазина {А >. Полученный результат показан
в строке 7 рис. 8.2.
Теперь символ V на верху магазина свидетельствует о том, что
исходная входная цепочка допустима в том и только в том случае,
Обработанные и Промежуточная стро-
сймволы магазин ка В ле5ом Выводе
1:
2: d
3: db
4: dbc
5: db с с
6: db cc d
7: dbc с dc
<s>v
(S)(A) V
<A)
с (A) V
c(A)v)
(A) V /
(A)V
V
Рис. 8.З.
<s>
d(S)(A)
db{A)c (A)
dbcc(A)
dbccd{A)
db с с dc
если оставшаяся необработанной часть входной цепочки пуста.
Текущим вводным символом является концевой маркер, а это
значит, что оставшаяся входная цепочка на самом деле пуста. Поэтому
автомат выдает выход ДОПУСТИТЬ, и процесс обработки окончен.
Каждый раз, когда на верху магазина оказывался нетерминал,
МП-автомат делал переход, регистрирующий то обстоятельство,
что только одно конкретное правило можно применить к верхнему
символу магазина с целью порождения цепочки терминалов,
начинающейся текущим входным символом. Крайний правый столбец
на рис. 8.2 показывает номер применяемого правила. В строке 4
использовалась запись с=$с, когда на вершине магазина находился
терминал с, а переход был основан на том, что с тривиально
выводится из с.
Порядок, в котором правила использовались в процессе
обработки, а именно 1, 2, 4, 3, 4, совпадает с порядком применения
правил в левом выводе входной терминальной цепочки. На рис. 8.3
показана связь между конфигурациями МП-автомата и левым
выводом. Для каждого показанного на рис. 8.2 шага распознавания,
на рис. 8.3 показаны цепочка обработанных входных символов,
магазин, изображенный с учетом соглашения «верхний символ
слева», и промежуточная цепочка, соответствующая данному шагу
левого вывода.
Связь между шагом распознавания и промежуточной
цепочкой заключается в том, что промежуточная цепочка — это
просто конкатенация, т. е. соединение в одну цепочку,
обработанной части входной цепочки и содержимого магазина.
248
Гл. 8. Нисходящие методы обработки языков
Шаги 4 и 5 соответствуют одному и тому же шагу вывода,
потому что, делая соответствующие переходы, автомат сравнивает два
терминала, а не применяет правила.
Поскольку между шагами вывода и конфигурациями автомата
имеется указанная связь, можно считать, что верхний символ
магазина в каждой конфигурации соответствует опредьленному символу
1
2
3
4
5
6
7
V <S>,,
V <A>5<S>2
V <А >5 сА
V <А >5 с4
V <А>5
V<A>io
V
<А >3
d Ь
Ь
с
с
с
с d с ч
с d с Ч
с d с Ч
с с/ с ч
с/ с ч
с Ч
Ч
<s>,
\
<s>,
<4>к
Ь <Л>3 с4 с/ <Л>6
6
Рис. 8.4.
дерева вывода. На рис. 8.4 показано это соответствие. На рис. 8.4, а
повторяется последовательность конфигураций, изображенная на
рис. 8.2, с тем отличием, что каждому магазинному символу
приписан индекс. Индекс указывает конфигурацию, в которой данный
магазинный символ оказывается на верху магазина.
Воспользовавшись показанным на рис. 8.3 соответствием между
последовательностью конфигураций и левым выводом, припишем те же самые
индексы нетерминалам, входящим в левый вывод, получая таким об-
8.2. Пример
249
разом
<S>l^d<S>,<A\=^db<A,>ct<A\=^
d b сс4 <Л >5 => d b с с4 d <Л >„ =ф d Ъ с с4 d с
Приписав индексы этого вывода вершинам дерева, изображенного
на рис. 8.1, получим дерево на рис. 8.4, б. Соответствие между
индексами на рис. 8.4 означает больше, чем просто соответствие между
символами. Это также соответствие между правилами, которые
применяет автомат, и правилами, используемыми при построении
дерева. Например, автомат применяет правило 1, когда на верху
магазина символ (S)i, и это же правило применяется к (S)i при
построении дерева. Указанное соответствие имеет место также и для
правых частей правил. Так, автомат использует символы (S>2 и
(А >5 для замены в магазине символа (S >ь и эти же символы
расположены в дереве непосредственно ниже <S>i. Таким образом, можно
представлять себе, что МП-автомат «обходит» нетерминалы по
дереву или «анализирует» входную цепочку, если даже в процессе
обработки никакого представления дерева не строится.
Цифры, используемые на рис. 8.4, б в качестве индексов,
указывают порядок, в котором МП-автомат обрабатывает
соответствующие символы дерева. Каждый символ дерева всегда обрабатывается
прежде, чем символы, находящиеся ниже его. Отсюда название —
нисходящий анализ. Когда о двух символах нельзя сказать, который
из них выше другого (например, {А >3 и (Л>5), раньше
обрабатывается тот, что расположен левее.
Так как магазин содержит описание необработанной части
входной цепочки (если вся входная цепочка допустима), содержимое
магазина иногда называют «предсказанием» необработанной части
входной цепочки. Аналогично разбор такого типа иногда называют
«предсказывающим разбором», а не нисходящим разбором. В
процессе разбора верхний символ магазина иногда называют «целью» и
работу автомата представляют как поиск подцепочки входных
символов, порождаемой предсказываемой целью.
На каждом шаге анализа входной цепочки мы исследуем
грамматику и решаем, какие операции нужно выполнить над магазином
и входной цепочкой, чтобы не нарушить интерпретации, согласно
которой магазин представляет утверждение о том, какой должна
быть необработанная часть входной цепочки. Опишем теперь МП-
автомат с одним состоянием, который выполняет такие операции над
магазином и входной цепочкой. Этот автомат в дополнение к
примитивным операциям автоматов с магазинной памятью использует
расширенную магазинную операцию ЗАМЕНИТЬ. Напомним, что при
записи операции ЗАМЕНИТЬ используется соглашение «верхний
символ справа».
На рис. 8.5 показана управляющая таблица МП-автомата.
Входные цепочки образуются из терминалов грамматики и концевого
250
Гл. 8. Нисходящие методы обработки языков
маркера. Множество магазинных символов состоит из маркера дна
и терминальных и нетерминальных символов, которые нужны для
того, чтобы делать утверждения о необработанной части входной
цепочки. Элементы таблицы, не являющиеся выходами,— это
операций над магазином и входной цепочкой, которые мы считаем
подходящими при анализе входной цепочки. Например, если (S) —
верхний символ магазина, ad — входной символ, мы решаем в на-
d b с -и
ЗАМЕНИТЬ KAXS»
СДВИГ
ЗАМЕНИТЬ [<А>)
СДВИГ
ЗАМЕНИТЬ (с <А»
сдвиг
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ ОТВЕРГНУТЬ
i
ОТВЕРГНУТЬ ! ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
вытолкнуть
сдвиг
ВЫТОЛКНУТЬ
сдвиг
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
Начальное содержимое магазина •. V<S>
Рис. 8.5.
шем примере, что подходящую цепочку можно вывести из (S),
только применив правило 1, и, следовательно, верхний магазинный
символ (S > нужно заменить на {А) и (S) и продвинуться на один
входной символ. Поэтому мы записали ЗАМЕНИТЬ (C4>(S>),
СДВИГ в качестве элемента таблицы, соответствующего (S) и d.
Элементы ОТВЕРГНУТЬ отмечают те ситуации, когда текущий
входной символ и верхний символ магазина несовместимы. Так,
элемент, соответствующий магазинному символу (S) и входному
символу с, помечен словом ОТВЕРГНУТЬ, потому что цепочка,
порождаемая нетерминалом (S >, не может начинаться с терминала с,
и потому такая цепочка не может быть допустимой.
8.3. S-грамматики
В данной главе мы рассматриваем главным образом проблему
построения нисходящих распознавателей по заданным грамматикам.
В частности, нас интересуют МП-автоматы, действия которых
основываются на том принципе, что магазин всегда содержит цепочку
терминалов и нетерминалов, из которой выводимо множество
допустимых продолжений обработанной части входной цепочки.
Автоматы такого типа имеют большое практическое значение, так как они
8.3. S-грамматики
251
отличаются простотой реализации, быстродействием и не требуют
больших затрат памяти. Кроме того, как будет показано дальше,
автоматы такого типа легко расширять так, чтобы приспособить их
для выполнения разнообразных синтаксических управляемых
переводов.
К сожалению, не все КС-грамматики пригодны для нисходящего
анализа МП-автоматом, так как для многих грамматик множество
всех допустимых продолжений обработанной части входной цепочки
не всегда можно представить единственной цепочкой терминальных
и нетерминальных символов. В этой главе мы будем рассматривать
такие классы грамматик, для которых нисходящие
МП-распознаватели можно построить. В данном разделе описывается один из таких
классов, так называемые s-грамматики.
Контекстно-свободная грамматика называется s-грамматикой
(а также разделенной или простой) тогда и только тогда, когда
выполняются следующие два условия:
1. Правая часть каждого правила начинается терминалом.
2. Если два правила имеют совпадающие левые части, то правые
части этих правил должны начинаться различными
терминальными символами.
Проверить является ли данная грамматика s-грамматикой очень
просто. Например, грамматика
1. {S)^a(T)
2. <S>-> (T)b(S)
3. (Т)-+Ь(Т)
4. (T)-*ba
очевидно, не s-грамматика, так как правая часть правила 2 не
начинается терминалом и, следовательно, не удовлетворяет условию 1,
кроме того, правила 3 и 4 нарушают условие 2. С другой стороны,
грамматика
1. (S)-*ab(R)
2. (S)^b(R)b(S)
3. </?>-> а
4. (R)^b(R)
очевидно, является s-грамматикой, так как каждое правило имеет
вид, удовлетворяющий условию 1, а правые части двух правил,
имеющих в левой части нетерминал (S), начинаются с различных
терминальных символов, как и требуется в условии 2, кроме того,
оба правила, в левой части которых стоит нетерминал (R), также
удовлетворяют условию 2.
Контекстно-свободный язык можно задать многими
грамматиками, причем некоторые из них, возможно, являются s-граммати-
252
Гл. 8. Нисходящие методы обработки языков
ками, а другие нет. Например, оба приведенные выше множества
правил (с начальным символом (S)), задают один и тот же язык,
хотя одно из них является s-грамматикой, а другое нет. С другой
стороны, существует много КС-языков, которые не могут быть
описаны никакой s-грамматикой.
Грамматика из предыдущего раздела является s-грамматикой,
и соответствующая таблица управления МП-автоматом строилась
так, что для каждого правила грамматики вводилась операция
ЗАМЕНИТЬ или ВЫТОЛКНУТЬ, а остальные элементы таблицы
заполнялись той из операций ДОПУСТИТЬ, ОТВЕРГНУТЬ или
ВЫТОЛКНУТЬ, которая там подходила. Эту технику построения
управляющей таблицы можно применить ко всем s-грамматикам с
помощью следующих правил:
Для данной s-грамматики МП-распознаватель с одним
состоянием задается следующим образом:
1. Множество входных символов — это множество
терминальных символов грамматики, расширенное концевым маркером.
2. Множество магазинных символов состоит из маркера дна,
нетерминальных символов грамматики и терминалов, которые входят
в правые части правил, за исключением тех, что занимают крайнюю
левую позицию.
3. Вначале магазин состоит из маркера дна и начального
нетерминала.
4. Управление работой МП-автомата с одним состоянием
описывается управляющей таблицей, строки которой помечены
магазинными символами, столбцы — входными символами, а элементы
описываются ниже.
5. Каждому правилу грамматики сопоставляется элемент
таблицы. Правило имеет вид
(А) -> Ьа
где (А ) — нетерминал, Ъ — терминал, а а — цепочка, состоящая
из терминалов и нетерминалов. Этому правилу будет
соответствовать элемент в строке {А > и столбце Ь
ЗАМЕНИТЬ (а'), СДВИГ
где аг — цепочка а, записанная в обратном порядке для того, чтобы
удовлетворить соглашению «верхний символ справа». Если правило
имеет вид (А > -*- Ь, то вместо ЗАМЕНИТЬ (е) используется
ВЫТОЛКНУТЬ.
6. Если магазинным символом является терминал Ь, то
элементом таблицы в строке b и столбце Ь будет
ВЫТОЛКНУТЬ, СДВИГ
8.3. S-грамматики
253
7. Элементом таблицы, который находится в строке маркера дна
и столбце концевого маркера, является
ДОПУСТИТЬ
8. Элементы таблицы, не описанные ни в одном из пунктов 5,
6 и 7, заполняются операцией
ОТВЕРГНУТЬ
Два условия определения s-грамматик гарантируют, что эти
правила построения МП-автомата всегда будут работать. Условие 1
говорит, что продукции грамматики имеют требуемую форму, а
условие 2 нужно для того, чтобы при применении правила 5 элемент
таблицы содержал только одну продукцию. Таким образом, мы
приходим к заключению, что:
Если язык определяется s-грамматикой, то его можно
распознать с помощью МП-автомата с одним состоянием,
использующим расширенную магазинную операцию ЗАМЕНИТЬ.
Применяя эти правила к s-грамматике данного раздела,
получим управляющую таблицу, показанную на рис. 8.6, а.
МП-автомат, построенный согласно приведенным выше
правилам, может рассматриваться как «использующий» s-грамматику, по
которой он был построен. Когда выполняется переход,
определенный по правилу 5, можно сказать, что автомат «использует»
соответствующее правило или что автомат «применяет» правило к
символу, находящемуся на верху магазина. Интуитивный смысл слов
«использует» и «применяет» зависит от того, как представлять себе
работу автомата.
Если предположить, что автомат строит левый вывод (как на
рис. 8.3), то можно считать, что он применяет правило к самому
левому нетерминальному символу промежуточной цепочки. Этот
самый левый нетерминал соответствует верхнему магазинному символу,
и результатом является цепочка, полученная заменой этого символа
на правую часть «используемого» правила.
Если предположить, что автомат строит дерево вывода, то можно
считать, что он применяет правило к самому левому
нетерминальному символу, к которому еще предстоит пририсовать ветви в
частично построенном дереве. Этот нетерминал соответствует верхнему
магазинному символу, и к дереву добавляется правая часть правила.
Если предположить, что автомат предсказывает последующие
входные символы, то можно считать, что он использует правило,
*Юбы сделать предсказание о последующих входных символах.
Если предположить, что автомат делает утверждение о
требуемой форме необработанной части входной цепочки, то можно счи-
t*fb> что он использует правила для уточнения своих утверждений
254
Гл. 8. Нисходящие методы обработки языков
Специальные условия, налагаемые на грамматику, гарантируют
правильность уточненных утверждений.
Эти представления о том, как автомат применяет правила,
подкрепляются видом управляющей таблицы, если изобразить ее так,
<s>
<й>
ЗАМЕНИТЬ
К/?>6)
сдвиг
ВЫТОЛКНУТЬ
СДВИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ЗАМЕНИТЬ
KS>b<R»
СДВИГ
ЗАМЕНИТЬ
сдвиг
ВЫТОЛКНУТЬ
сдвиг
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
допустить
Начальное содержимое магазина: V<S>
а
<s>
ь
# 1
#3
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#2
#4
ВЫТОЛКНУТЬ
СДВИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
Начальное содержимое магазина: V<S>
#1 ЗАМЕНИТЬ (</?>й), СДВИГ
#2 ЗАМЕНИТЬ KS>b<R», СДВИГ
#3 вытолкнуть, сдвиг
#4 ЗАМЕНИТЬ (</?», СДВИГ
6
Рис. 8.6.
как на рис. 8.6, б. В ней указываются только номера правил, а
описание соответствующих переходов этого правила приводятся ниже,
под таблицей. Например, магазинному символу (S) и входному
символу а соответствует элемент таблицы #1, который указывает, что
8.4. Нисходящая обработка для транслирующих грамматик 255
должно применяться правило 1. Переходом для данного правила
будет
ЗАМЕНИТЬ (<Д)Ь), СДВИГ
как показано на рисунке в объяснениях под таблицей.
Незаключительные переходы МП-автомата можно представлять
себе не как применение правила, а как «сопоставление» текущему
входному символу вхождения этого символа в правую часть правила.
Переходы, описанные в пункте 5, представляют собой
сопоставление входному символу самого левого символа в правой части
соответствующего правила. Переходы, описанные в пункте 6,
представляют собой сопоставление входному символу терминального
символа на верху магазина; этот магазинный символ представляет
символ в правой части правила, использованного тем переходом,
который записал этот символ в магазин.
При реализации переходов, приведенных на рис. 8.6, б, их
можно несколько оптимизировать. Например, переход #2 приводит к
замене (S) на (S)b{R). Эффективнее будет просто поместить b{R)
в магазин, на верху которого уже находится символ (S). Таким
образом, можно записать
#2 ВТОЛКНУТЬ (b(R)) СДВИГ
Аналогично переход #4 приводит к замене (R) на (R >, и его можно
заменить на
#4 СДВИГ
В дальнейшем мы будем применять подобную простейшую технику
оптимизации, но не во всех случаях это будет особо оговариваться.
8.4. Нисходящая обработка для транслирующих
грамматик
Теперь мы рассмотрим проблему выполнения синтаксически-
управляемых цепочечных переводов, определяемых грамматиками,
транслирующими в цепочки. В частности, рассмотрим те
транслирующие грамматики, входные грамматики которых являются s-грам-
матиками. Мы покажем, что такие цепочечные переводы можно
выполнить с помощью МП-автомата, который представляет собой
непосредственное расширение стандартного МП-распознавателя s-грам-
матики, построенного по правилам, приведенным в предыдущем
разделе. Техника преобразования МП-распознавателя в транслятор
является достаточно мощной для того, чтобы ее можно было
применить к другим классам грамматик, допускающих нисходящий
анализ, которые будут описаны позже в данной главе.
256
Гл. 8. Нисходящие методы обработки языков
Метод преобразования стандартного МП-автомата заключается
в следующем. Берется каждый переход, в котором используется
правило данной входной грамматики (т. е. те переходы, которые
был,и построены в силу пункта 5), и изменяется так, чтобы в нем
учитывалось соответствующее правило транслирующей грамматики.
Вначале проиллюстрируем, как это делается на конкретном
примере.
Предположим, что была задана транслирующая грамматика
цепочечного перевода и в ней имеется такое правило:
(Л)-* {v}a{w)(B){x}c{y}(D){z}
соответствующее следующему правилу входной грамматики:
(A)-+a(B)c(D)
Предположим далее, что входная грамматика является s-граммати-
кой. Стандартный МП-распознаватель для s-грамматики использует
данное правило при переходе, когда верхним магазинным символом
является (А >, а текущим входным символом — а. Правило перехода
определяется так:
ЗАМЕНИТЬ ((D)c(B)), СДВИГ
Наша цель — так изменить этот переход, чтобы в соответствующие
моменты времени происходила выдача символов v, w, х, у и г. При
этом изменении используются две разные стратегии, одна — для
выходных символов v и w и другая — для выходных символов х,
У Ч 2-
Выдачу символов v и до зададим, добавив выходную операцию
ВЫДАТЬ (vw) в определение данного перехода. Этот переход —
подходящий момент времени для выдачи данных символов, так как
символы действия {v} и {до} примыкают к терминалу а в правой
части правила транслирующей грамматики, а данный переход как
раз устанавливает соответствие между этим терминалом и текущим
входным символом а.
Выдачу символов х, у и z, вообще говоря, нельзя осуществить
как часть данного перехода, поскольку транслирующая грамматика
указывает, что выходные символы доил; отделены в выходной
подпоследовательности переводом цепочки, выводимой из
нетерминала (В).
Для того чтобы обеспечить выдачу этих символов в надлежащие
моменты времени, операция ЗАМЕНИТЬ модифицируется так, что
она помещает в магазин добавочные символы вместе с символами
(D), см (В), которые нужны для распознавания. Содержимое
магазина до и после выполнения операции ЗАМЕНИТЬ показано на
рис. 8.7. Новые магазинные символы — это символы действия,
соответствующие выходным символам х, у и г, операции выдачи
которых должны быть отложены на некоторое время. Когда на верху
8.4. Нисходящая обработка для транслирующих грамматик 257
магазина оказывается символ действия, пусть автомат поступает
следующим образом: выдает соответствующий выходной символ,
удаляет символ действия из магазина и удерживает входной символ
(сдвига нет).
Магазин «после» на рио. 8.7 можно интерпретировать как
следующее предсказание: вначале встретится и будет переведена
некоторая цепочка, порожденная нетерминалом (В); затем будет вы-
<в>
'.У;
<D>
После
Рис 8.7.
дан х; затем будет проверено, является ли текущий входной символ
символом с, и произойдет сдвиг по входной цепочке; затем будет
выдан у; затем будет переведена цепочка, порожденная
нетерминалом (D >, и наконец будет выдан г. Предполагая, что входная
цепочка допуетима и наши предсказания подтвердятся, х и у будут
выданы в надлежащем месте, между переводом цепочки, порожденной
(В >, и переводом цепочки, порожденной {D >. После этого
требуемый перевод правила будет завершен.
Переход измененного таким образом МП-автомата можно
записать так:
ВЫДАТЬ (ив), ЗАМЕНИТЬ ({z}(D){y}c{x}(B)), СДВИГ
цепочка символов, которая помещается в магазин,— это просто
копия правой части правила без некоторых начальных символов,
которые обрабатываются во время самого перехода.
" Ф. Льюис н др.
258
Гл. 8. Нисходящие методы обработки языков
Чтобы лучше понять, как происходит перевод, предположим, что
полная транслирующая грамматика о начальным символом (А >
имеет следующие правила:
1.*{А)-+ {v}a{w}(B){x}c{y}(D){z}
2. (А > -> Ъ
3. (В)-+с{г)
4. {В)-+а{т)<А)
5. ф)-+сф){п)
6. <D>-*- {s}b
Задачи, возникающие при построении надлежащих переходных
процедур, являются частными случаями задач, обсуждавшихся при
рассмотрении примера правила, которое вошло в данную
грамматику (правило 1). На рис. 8.8 показана управляющая таблица
соответствующего автомата с магазинной памятью.
в 6 С -I
<а >
<в>
<D>
# 1
= л
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#2
ОТВЕРГНУТЬ
*6
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#3
*5
вытолкнуть
сдвиг
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
ВЫДАТЬ U), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
ВЫДАТЬ (к). ВЫТОЛКНУТЬ, ДЕРЖАТЬ
ВЫДАТЬ (г), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
ВЫДАТЬ (1), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
{*}
{/}
и>
{«}
Начальное содержимое магазина-.ч <а>
* 1 ВЫДАТЬ (Vh/), ЗАМЕНИТЬ (Ы <D >{/} с{х} <В», СДВИГ
в 2 ВЫТОЛКНУТЬ , СДВИГ
«3 ВЫДАТЬСЯ, ВЫТОЛКНУТЬ, СДВИГ
#4 ВЫДАТЬ (т), ЗАМЕНИТЬ (<А>), СДВИГ
* 5 ЗАМЕНИТЬ Цл}< D>), СДВИГ
#6 ВЫДАТЬ (S), ВЫТОЛКНУТЬ, СДВИГ
Рис. «.8.
8.4. Нисходящая обработка для транслирующих грамматик 259
Заметим, что в таблицу рис. 8.8 включены строки,
показывающие, что происходит, когда верхним магазинным символом является
один из символов {*}, {у}, {г} и {п}. Действия, выполняемые для
каждой из этих строк, не зависят от входного символа; поэтому эле-
1: V<^>.
ВЫДАТЬ (vw)
2: V{z)(D){y)c{x}(B)
3: V{z}(D)(y)c{x)
4: v{z)(D){y)c
5: V{z)(D){y)
6: V{z}<Z>>
7: V{z}
8: v
9:
ВЫДАТЬ (г)
ВЫДАТЬ (x)
ВЫДАТЬ (у)
ВЫДАТЬ (s)
ВЫДАТЬ (г)
ДОПУСТИТЬ
Рис. 8.9.
асе Ь—j
ccb—\
cb-\
cb-\
ь-{
M
Н
Н
менты строк для всех столбцов одинаковы. Эта независимость
подчеркивается на рисунке тем, что действия, предписываемые данными
строками, изображены как один элемент.
Рис. 8.9 показывает последовательность конфигураций при
переводе МП-автоматом цепочки
ас с Ь в цепочку v w г х у s г.
Между смежными конфигурациями магазина приведены выходные
операции (если таковые вообще имеются), которые осуществляются
в данном переходе.
Теперь мы сформулируем общие правила определения
нисходящего транслятора с магазинной памятью, выполняющего перевод,
заданный транслирующей грамматикой, входная грамматика
которой является s-грамматикой.
1. Множеством входных символов является множество входных
(терминальных) символов грамматики, дополненное
концевым маркером.
260 Гл. 8. Нисходящие методы обработки языков
2. Множество магазинных символов состоит из маркера дна,
нетерминальных символов грамматики, тех входных
символов, которые входят в правые части правил входной
грамматики и занимают в них любое положение, кроме самого левого,
и некоторых символов действия, упоминаемых в пункте 5.
3. В самом начале магазин состоит из маркера дна и начального
нетерминала.
4. Управление описывается управляющей таблицей с одним
состоянием, строки которой помечены магазинными
символами, столбцы — входными символами, а элементы описаны
ниже.
5. Для каждого правила грамматики создается элемент таблицы.
Правила имеют вид
(А> -> £Ца
где (А > — нетерминал, b — терминал, £ и г|> — цепочки
символов действия (возможно, пустые), а а — цепочка,
состоящая из терминальных символов, нетерминальных символов
и символов действия, не начинающаяся с символа действия.
В соответствии с этим правилом на пересечении строки (А)
и столбца Ь будет элемент
ВЫДАТЬ (|^), ЗАМЕНИТЬ (а'), СДВИГ
Запись £г|> обозначает цепочку выходных символов,
соответствующую цепочке символов действия £г|> (т. е. £\|э — это
цепочка £\|э, из которой удалены фигурные скобки). Если
цепочка £\|э пуста, то ВЫДАТЬ опускается, и если цепочка а
пуста, то ЗАМЕНИТЬ превращается в ВЫТОЛКНУТЬ.
6. Если терминал b является магазинным символом, то
элементом таблицы, соответствующим строке b и столбцу Ь, будет
ВЫТОЛКНУТЬ, СДВИГ
7. Элементом таблицы, который соответствует строке,
помеченной маркером дна, и столбцу, помеченному концевым
маркером, будет
ДОПУСТИТЬ
S. Если символ действия {jc} является магазинным символом, то
элементом таблицы, соответствующим строке {х}, будет
ВЫДАТЬ (jc), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
S. Все элементы таблицы, не описанные ни в одном из пунктов
5, 6, 7 и 8, будут
ОТВЕРГНУТЬ
8.5. д-грамматшси
261
Приведенные выше правила — это просто указанное ранее
расширение правил построения нисходящего распознавателя,
описанных в предыдущем разделе.
Условие, что входная грамматика является s-грамматикой, это
гарантия того, что в пункте 5 не будет дано два разных определения
одного и того же перехода. Из данного построения вытекает
справедливость следующего утверждения:
Если дана транслирующая грамматика цепочечного перевода,
входная грамматика которой является s-грамматикой, то
соответствующий перевод может быть осуществлен
МП-автоматом с одним состоянием, который использует расширенную
магазинную операцию ЗАМЕНИТЬ.
МП-автомат, который был построен выше для цепочечных
переводов, может служить базовым автоматом при рассмотрении
некоторых других видов синтаксически управляемой обработки.
Операции выдачи символов можно легко заменить на операции вызова
процедур. Так, если дана транслирующая грамматика, символы
действия которой представляют собой имена процедур действия,
подлежащих вызову, а входная грамматика является s-грамматикой,
то МП-автомат, вызывающий эти процедуры в порядке, заданном
грамматикой, можно легко получить из стандартного автомата,
печатающего имена этих процедур. Таким образом, проблема
определения моментов вызова процедур решается автоматически, и
программист может сосредоточить свои усилия непосредственно на
написании самих процедур. В гл. 9 мы обсудим проблему написания
этих процедур вместе с проблемами передачи информации между
ними.
8.5. q-грамматики
Рассмотрим следующую грамматику ((S > — ее начальный
нетерминал):
1. (S)^a(A)(S)
2. (S)^b
3. 04>-*cG4><S>
4. (А)^г
Эта грамматика не принадлежит классу s-грамматик, потому что
правая часть правила 4 не начинается с терминального символа.
Несмотря на это, МП-автомат все еще может «использовать» данную
грамматику для того, чтобы управлять магазином, который
содержит утверждение о форме необработанной части входной цепочки
(если она допустима). Для того чтобы проиллюстрировать процесс
262
Гл. 8. Нисходящие методы обработки языков
управления магазином, мы покажем, как автомат мог бы
обрабатывать цепочку
аасЬЬ
которая 'принадлежит языку, определяемому данной грамматикой
(см. дерево вывода на рис. 8.10).
Когда МП-автомат начинает работу, начальным содержимым
магазина является V '(S), так как вся входная цепочка должна по-
<s>
<s>
<А>
<S>
Рис. 8.10.
рождаться нетерминалом (S >. Поскольку верхним магазинным
символом является (S), а текущим входным символом — а, автомат
применяет правило 1, потому что оно начинается с а; другое
правило для (S), правило 2, начинается с символа Ь. Полученный
результат изображен во второй строке последовательности конфигураций,
показанной на рис. 8.11.
До настоящего момента поведение автомата и мотивировка этого
поведения были те же, что и в случае s-грамматики. Это сходство
объясняется тем, что правила с нетерминальным символом (S > в
левой части удовлетворяют требованиям, которые предъявляются к
s-грамматике.
В конфигурации, находящейся во второй строке, впервые
необходимо применить е-правило. Верхний магазинный символ (А >
говорит о том, что оставшаяся входная цепочка должна начинаться
8.5. ({-грамматики
263
цепочкой, порождаемой нетерминалом (А ), а текущий входной
символ а — о том, что она начинается с а. Требуемую цепочку нельзя
получить из (А >, применяя к нему правило 3, так как это правило
начинается с символа с, а текущий входной символ не с. Объяснить
это можно только тем, что требуемая цепочка получается из {А >
с помощью правила 4 (т. е. она пуста), а текущий символ а является
началом цепочки, порождаемой символами магазина, которые
расположены ниже (А >.
1: V <5>
2: V(S)(A)
3: v <5>
4: V'(S)(A)
5: V (S) (S) (А)
6: V <5) <5>
7: V <5>
8: v
9: допустить
aacbb —|
ас ЬЬ —|
а с ЬЬ —|
сЬЬ-\
ЬЬ-{
ЬЬ-{
М
Ч
Рис. 8. П.
Применение правила 4 заключается в том, что из стека
удаляется верхний символ {А >, поскольку цепочка, порождаемая (Л > (т. е.
в), уже обработана. Текущий входной символ остается тем же
самым, так как он начинает цепочку, которая еще только будет
порождена символами, оставшимися в магазине. Результат приведен в
третьей строке рис. 8.11.
Переход от строки 3 к строке 4 такой же, как от строки 1 к
строке 2 и не требует дальнейших пояснений.
В строке 4 верхним магазинным символом является (А); а
текущим входным символом — с. На первый взгляд кажется, что
появление текущего входного символа в данной ситуации можно
объяснить двумя разными способами. Одно объяснение состоит в том, что
нужная цепочка получается из (А), если сначала применить
правило 3, а текущий входной символ с соответствует символу с в
правой части правила 3. Второе объяснение состоит в том, что на самом
деле эта цепочка пустая и получается по правилу 4, а текущий
входной символ с порождается каким-либо из символов, расположенных
в магазине ниже {А >. Однако более тщательный анализ этой
ситуации показывает, что в языке не существует промежуточных цепочек,
в которых цепочка, порожденная (А >, стояла бы непосредственно
перед символом с, и поэтому второе объяснение отпадает.
Следовательно, для вывода допустимой цепочки, состоящей из еще не
обработанных входных символов, можно применить только правило 3.
264
Гл. 8. Нисходящие метобы обработки языков
Чтобы показать, что символ о не может следовать за цепочкой,
порожденной (А >, заметим, что за любым вхождением нетерминала
{А ) в правую часть какого-либо правила следует нетерминал (S).
Следовательно, за вхождением нетерминала (А > могут идти в
точности те'символы, которые могут начинать цепочки, порожденные
<S>, а именно а (по правилу 1), или Ь (по правилу 2), но не с.
Чтобы убедиться в том, что применение правила 4 в конкретной
ситуации нашего примера оказывается безрезультатным, посмотрим,
что бы случилось, если бы мы применили правило 4 в четвертой
строке последовательности конфигураций. В этом случае строка 5 этой
последовательности примет вид
5: ^<Syccb-\
и обработка прекратится, так как цепочка, порождаемая <S>, не
может начинаться с символа о. Вновь мы убеждаемся, что в строке 4
нужно применить правило 3, а не правило 4.
Переход от строки 4 к строке 5 на рис 8.11 показывает результат
применения правила 3. В строке 5 применяется правило 4, потому
что появление на входе символа b можно объяснить только тем, что
а Ь с -\
#1
#4
ОТВЕРГНУТЬ
#2
#4
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#3
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
*4
ДОПУСТИТЬ
Начальное содержимое магазина :V < S>
# 1 ЗАМЕНИТЬ «S > <А >), СДВИГ
#2 ВЫТОЛКНУТЬ, СДВИГ
#3 ЗАМЕНИТЬ^><Д», СДВИГ
#4 ВЫТОЛКНУТЬ, ДЕРЖАТЬ
Рис. 8.12.
из (А) требуется получить е, и Ь — часть цепочки, порождаемой
символами, расположенными в магазине ниже (А >. Остальные шаги
в последовательности конфигураций осуществляются по правилам
s-грамматики.
Ня рис. 8.12 показана управляющая таблица, выполняющая
описанную процедуру. Элемент 1аблнцы, соответствующий магазин-
8.5. ц-грамматики
265
ному символу {А ) и входу, —\ представляет вобой ситуацию, ранее не
встречавшуюся. Те же самые причины, что привели к применению
правила 4 в строке 2 последовательности конфигураций, побуждают
нао сделать этот элемент таблицы применением правила 4. Однако
из цепочки (S > —| нельзя вывести промежуточную цепочку, в
которой за вхождением (А > немедленно следует символ —)• Таким
образом, применение правила 4 не может привести к тому, что входная
цепочка будет допущена. Точнее говоря, так как за каждым
вхождением нетерминала (А > в правую часть правила следует
нетерминал (S >, символ, находящийся под (А >, всегда будет символ (S).
Если при переходе, который соответствует символам {А > и —|,
применяется правило 4, то следующим шагом автомата будет переход,
соответствующий символам (S) и —|, т. е. ОТВЕРГНУТЬ. Поэтому
элемент, соответствующий символам (А > и —|, с таким же успехом
можно заменить на ОТВЕРГНУТЬ. Фактически применение
правила 4 оказывается бесполезным, но безвредным шагом, и элемент,
соответствующий символам (А) и —|, может быть либо
ОТВЕРГНУТЬ, либо ВЫТОЛКНУТЬ, ДЕРЖАТЬ. Так как нет
никаких теоретических оснований для того, чтобы предпочесть одну
альтернативу другой, на практике выбор осуществляется на основе
того, какую из них легче реализовать или какая обеспечивает
лучшую информацию об ошибке.
Для того чтобы упростить дальнейшие рассуждения, введем
понятие множества терминалов, «следующих за» данным
нетерминалом.
Для данной контекстно-свободной грамматики с начальным
символом {S) и нетерминала {X) мы определим
СЛЕДАХ»
как множество терминальных символов, которые могут
следовать непосредственно за (X> в какой-либо промежуточной
цепочке, выводимой из (S) —|. Это множество называется
множеством следующих за (X) терминалов.
СЛЕД ((X >) — это просто множество входных символов, которые
могут следовать за цепочкой, порожденной нетерминалом (X),
в какой-либо допустимой входной цепочке.
Анализируя предыдущий пример, мы установили, что после
нетерминала (А > могут идти только терминальные символы а и Ь.
Теперь мы можем выразить этот факт с помощью равенства
СЛЕД (С4 »={<*, Ь)
Отсюда мы заключаем, что бесполезно применять е-правило к
магазинному символу {А >, если текущий входной символ не
принадлежит этому множеству (т. е. если на входе <; или —О- С другой
стороны, существуют входные цепочки, в которых содержится цепочка,
266
Гл. 8. Нисходящие методы обработки языков
порожденная нетерминалом {А >, за которой следует символ а или
символ Ъ. Следовательно, МП-автомат обязательно должен
применить е-правило к нетерминалу (А >, если текущий входной символ а
или Ь, но^в этом нет необходимости в случае с или —|.
Мы выделили две ситуации, в которых данное правило должно
быть применено к данным магазинному символу (А> и входному
символу Ь. Первый случай — когда правило имеет вид
{А)-+Ьа
а второй случай — когда это правило
a b принадлежит множеству терминалов, следующих за (А >. Для
того чтобы рассматривать обе эти ситуации одновременно, введем,
понятие множества выбора для данного правила:
Если правило грамматики имеет вид
(А) ->- Ьа
где Ь — терминальный символ, а а — цепочка, состоящая из
терминальных и нетерминальных символов, то определим
ВЫБОР (04 >-*Ьа)={&}
Если правило имеет вид
(А)-+г
то определим
ВЫБОР ((А > -> е)=СЛЕД ((А »
Если р — номер правила
(А)-+а
то иногда будем писать
ВЫБОР 0?)
вместо
ВЫБОР(С4>->а)
Множество ВЫБОР (р) называется множеством выбора
правила р.
Множество выбора правила просто содержит те входные
символы, для которых соответствующий МП-автомат должен применить
это правило. Например:
ВЫБОР (1)=ВЫБОР ((S > -> а (А > (S »= {а}
ВЫБОР (2)=BbIBOP((S>-> Ь)={Ь)
BbIBOP(3)=BbIBOP(C4)-^cC4)<S»={c}
ВЫБОР (4)=ВЫБОР( 04 >-* е)=СЛЕД( 04 »={<*, Ь)
8.5. ^-грамматики
267
Мы смогли построить МП-распознаватель потому, что для каждой
комбинации нетерминала и входного символа оказывалось, что этот
входной символ принадлежал множеству выбора не более чем одного
правила, содержащего этот нетерминал в левой части.
Теперь мы хотим определить особый класс грамматик, более
общий, чем класс s-грамматик, в котором содержится грамматика
рассмотренного примера и все грамматики которого можно
распознавать с помощью нисходящих МП-распознавателей.
Представителей этого класса мы называем ^-грамматиками.
Контекстно-свободная грамматика называется q-граммати-
кой тогда и только тогда, когда выполняются следующие два
условия:
1. Правая часть каждого правила либо представляет собой
е, либо начинается с терминального символа.
2. Множества выбора правил с одной и той же левой частью
не пересекаются.
Условие 1 просто утверждает, что все правила ограничиваются
двумя видами, для которых мы определили понятие множества выбора.
Условие 2 указывает, что при построении управляющей таблицы
соответствующего МП-автомата конфликтных ситуаций не
возникает. Наш пример удовлетворяет обоим условиям, потому что
правила имеют надлежащий вид, и, кроме того, справедливы равенства
ВЫБОР(1) П ВЫ БОР (2)= МП {*>}={ }
ВЫБОР(3) Л ВЫБОР(4)= {с}Г) {а, Ь}={ }
Приведенные в разд. 8.3 правила построения МП-распознавателя
по s-грамматике легко расширить так, чтобы они оказались
применимыми к ^-грамматикам. Правило 5 нужно заменить на следующие
два правила:
5'. Правило грамматики «применяется» всякий раз, когда
магазинный символ является его левой частью, а входной символ
принадлежит его множеству выбора. Для того чтобы применить правило вида
(А > ->- Ьа
где Ъ — терминальный символ, а а — цепочка, состоящая из
терминальных и нетерминальных символов, используется переход
ЗАМЕНИТЬ (оО, СДВИГ
Если правило имеет вид
то вместо ЗАМЕНИТЬ (е) можно воспользоваться операцией
ВЫТОЛКНУТЬ. Для того чтобы применить правило вида
268
Гл. 8. Нисходящие методы обработки языков
используется переход
ВЫТОЛКНУТЬ.^СДВИГ^ ЩиЛиоХЬ Q
5*. Если- имеется е-правило с нетерминалом (А) в левой части и
элемент, соответствующий магазинному символу (А > и входному
символу Ь, не был создан по правилу 5', то таким элементом может
быть либо «применение» этого е-правила, либо операция
ОТВЕРГНУТЬ.
В качестве другого примера рассмотрим следующую грамматику
с начальным нетерминалом (с^-
1. (S)^a(A)
2. (S)->b
3. {А)^с (S)a
4. Ц)^е
В этой грамматике за нетерминалом {а ) могут следовать л'.(.о а,
либо —|, как показывают следующие промежуточные цепочки:
аса<.А>а—\ и а<-<4> —|
Множества выбора таковы:
ВЫБОР (1) = {а} ВЫБОР (2) = {Ь\
ВЫБОР (3) = {с} ВЫБОР (4) = {а, Н}
Так как ВЫБОР(1) и ВЫБОР(2) не пересекаются, ВЫБОР(3)
и ВЫБОР(4) также не пересекаются, данная грамматика является
^-грамматикой. На рис. 8.13 показана управляющая таблица,
полученная по приведенным выше правилам. Согласно правилу 5",
элемент таблицы, соответствующий магазинному символу J^Jl/Ujujo}
и входному символу Ь, будет либо ВЫТОЛКНУТЬ, <Щ^(1Г£г^
#4), либо ОТВЕРГНУТЬ. На рис. 8.13 указаны обе эти
альтернативы.
^, Элемент таблицы, соответствующий магазинному символу (А >
' и входному символу Hi по правилу 5' будет ВЫТОЛКНУТЬ,
СДВИГ^Автомат использует этот элемент таблицы при распозна-
"вЪнтпГцепочки а.
Правила построения распознавателя для ^-грамматики
позволяют установить следующий факт:
Если язык определяется ^-грамматикой, то его можно
распознать с помощью МП-автомата с одним состоянием,
использующим расширенную магазинную операцию
ЗАМЕНИТЬ.
Примененные в разд. 8.4 принципы легко расширить так, чтобы
получить нисходящий МП-транслятор для транслирующей грам-
8.5. q-грамматики
269
матики цепочечного перевода, входная грамматика которой
является <7-грамматикой. Расширение касается правил вида
где | — цепочка символов действия, которым соответствуют
правила входной грамматики вида
(А)-+г
Чтобы охватить этот случай, переход МП-распознавателя, в
котором применяется указанное правило, должен быть таким:
ВЫДАТЬ (f), ВЫТОЛКНУТЬ, чСДВИГ^ ^илМ^И
где £ — выходная цепочка для цепочки действий £. С учетом этого
добавления в ходе построения устанавливается следующий факт:
а ь с н
<S>
<А>
#1
#4
ВЫТОЛКНУТЬ
сдвиг
ОТВЕРГНУТЬ
#2
#4
или
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#3
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#4
ОТВЕРГНУТЬ
ДОПУСТИТЬ
Начальное содержимое магазина: V < S >
#1 ЗАМЕНИТЬ «А», СДВИГ
# 2 ВЫТОЛКНУТЬ, СДВИГ
#3 ЗАМЕНИТЬСЯ <S», СДВИГ
#4 ВЫТОЛКНУТЬ, ДЕРЖАТЬ
Рис. 8.13.
Для данной транслирующей грамматики цепочечного
перевода, входная грамматика которой является ^-грамматикой,
определяемый ею цепочечный перевод можно выполнить с
помощью МП-автомата с одним состоянием, использующим
расширенную магазинную операцию ЗАМЕНИТЬ.
В качестве примера рассмотрим транслирующую грамматику с
начальным символом (S):
1. (S)-+a{x)(A){y}
2. {S)-+b{z}
270
Гл. 8. Нисходящие методы обработки языков
3. (A)-+c(S){v)a
4. (A)-+{w}
Входной грамматикой для этой транслирующей грамматики
является ^-грамматика, распознаватель которой показан на рис.
8.13. На рис. 8.14 показана управляющая таблица МП-автомата,
выполняющего задаваемый ею перевод.
<s:
<А
#1
#4
ВЫТОЛКНУТЬ
СДВИГ
ОТВЕРГНУТЬ
#2
#4
или
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#3
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#4
ОТВЕРГНУТЬ
ДОПУСТИТЬ
ВЫДАТЬ (у), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
ВЫДАТЬ (V), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
Ы
{v)
Начальное содержимое магазина-.ч <s>
* 1 ВЫДАТЬ (x),3AMEHUTb({y) < А>), СДВИГ
*2 ВЫДАТЬ (Z), ВЫТОЛКНУТЬ, СДВИГ
*3 ЗАМЕНИТЬ (a{v}<S>), СДВИГ
#4,ВЫДАТЬ {w), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
Рис. 8.14.
8.6. ЬЬ(1)-грамматики
В предыдущем разделе мы ввели понятие множества выбора для
грамматик, в которых правые части правил либо пусты, либо
начинаются с терминального символа. Множество выбора какого-
либо правила задает входные символы, которые требуют
применения этого правила, когда его левая часть является верхним
символом магазина. В случае если не существует комбинаций
входного и магазинного символов, для которых требуется применение
двух различных правил, то мы называем данную грамматику q-
грамматикой и используем множество выбора для построения
управляющей таблицы МП-автомата. В этом разделе мы обобщим
понятие множества выбора таким образом, что его можно будет
применить к КС-правилам произвольного вида.
8.6. LL(1 )-грамматики
271
В предыдущем разделе мы нашли два условия, согласно которым
входной символ Ь принадлежит множеству выбора правила, левой,
частью которого является (А >:
1. Правая часть правила начинается с Ь.
2. Правая часть правила представляет собой е, а Ъ принадлежит
множеству СЛЕД(<Л>).
В данном разделе мы обобщим оба условия, обобщив понятия
«правая часть начинается с Ы и «правая часть — е». Эти обобщения
позволяют определить множество выбора для правил, правые
части которых начинаются нетерминальным символом.
Грамматика, для которой обобщенные множества выбора подразумевают
применение не более одного правила для каждой комбинации
магазинного и входного символов, называется LL(1) грамматикой.
Предположим, что нам нужно построить нисходящий МП-
распознаватель для некоторой грамматики, содержащей правило
C4>->bC4><S>
Мы заключаем, что любая цепочка, в выводе которой из {А > сразу
применяется это правило, начинается терминальным символом Ь.
Отсюда следует, что данное правило должно применяться тогда,
когда {А) — верхний символ магазина, а текущий входной
символ — Ь. В отношении данного правила существенно не то, что его
правая часть начинается с символа Ь, а то, что любая цепочка,
выводимая из этой правой части, начинается с Ь. Если мы
рассмотрим правила с точки зрения порождаемых ими цепочек, то
оказывается, что мы можем говорить о правых частях правил, не
начинающихся с терминального символа.
Предположим, например, что нам нужно построить нисходящий
МП-распознаватель для грамматики, которая содержит правило
(S)-+{A)b{B)
Предположим далее, что анализ грамматики показал, что любая
терминальная цепочка, выводимая из (А)Ь(В), правой части
данного правила, начинается с одного из четырех терминальных
символов множества
{а, Ь, с, е)
Мы можем заключить, что правило должно применяться, если
верхним магазинным символом является (S> и текущим входным
символом — один из четырех символов а, Ь, с или е. Слово
«применить» в данном случае означает: заменить в магазине верхний
символ (S) правой частью правила и держать текущий входной символ
до следующего шага. Переход будет таким:
ЗАМЕНИТЬ ({В )Ь (А )), ДЕРЖАТЬ
272
Гл. 8. Нисходящие методы обработки языков
Операция ЗАМЕНИТЬ представляет собой утверждение, что
требуемая цепочка, порождаемая (S), должна начинаться цепочкой,
порождаемой (А >, за которой следует Ь, а потом цепочка,
порождаемая (В). Текущий входной символ нужно оставить прежним,
потому 'что он является частью цепочки, выводимой из символов,
находящихся в магазине.
Для обеспечения дальнейших рассмотрений введем следующее
понятие:
По данным контекстно-свободной грамматике и
промежуточной цепочке а, состоящей из символов этой грамматики,
определим
ПЕРВ (а)
как множество терминальных символов, которые стоят в
начале промежуточных цепочек, выводимых из а, т. е.
являются их первыми символами.
Процедура вычисления ПЕРВ будет дана в следующем разделе,
но часто оказывается, что множество ПЕРВ для данной
промежуточной цепочки можно найти путем непосредственного
рассмотрения.
[а, Ь, с, е]
1.
2.
3.
4.
5.
6.
7.
8.
<S> -* <A> b <В>
<S> -*d
<А > -» <С> <А> Ь
<А>-><В>
<В> ->c,<S> d
<В> -$
<С> -а
<С> -«■ е d
ПЕРВ «А > Ь <В» =
ПЕРВ (сО = {d}
ПЕРВ «О <А > Ь) =
ПЕРВКй» = {с}
ПЕРВ (с <S> d) = {с}
ПЕРВ(е) = { }
ПЕРВ(э) = {а}
ПЕРВ(е d) = {e.
Начальный нетерминал: <s>
Рис. 8.15.
Для того чтобы проиллюстрировать ПЕРВ на конкретной КС-
грамматике, на рис. 8.15 показана грамматика вместе со
значениями ПЕРВ, вычисленными для правых частей всех правил.
Вычисление множеств ПЕРВ для правил 2, 5, 7 и 8 тривиально,
поскольку их правые части начинаются с терминальных символов.
Эти множества ПЕРВ содержат по одному элементу — первому
терминальному символу правила.
8.6. LL(\)-epaMMamuKU
273
Вычисление ПЕРВ для правила 6 также тривиально. Так как
из е нельзя вывести никакой цепочки, кроме самой е, ПЕРВ(е)
не содержит ни одного символа.
Для правила 3 ПЕРВ((С)(Л)Ь) состоит из терминалов,
начинающих правила для нетерминала (С), а именно из а (правило 7)
и е (правило 8).
Для правила 4 множество ПЕРВ((B)) состоит только из одного
символа с (по правилу 5), так как, применяя правило 6, получим в.
Вычисление множества ПЕРВ ((Л )Ь(В)) для правила 1 гораздо
сложнее. Первый нетерминал (А > может порождать цепочки,
начинающиеся (О или (В) (правила 3 и 4), которые в свою очередь
начинаются с терминальных символов с, а и е, и эти терминалы
должны быть включены в ПЕРВ ((Л )Ь(В)). Поскольку цепочкой,
порождаемой первым нетерминалом (А >, может быть е, следующий
за (А) терминал b может стать первым символом в порождаемой
цепочке, и, следовательно, Ь тоже нужно включить в ПЕРВ((Д )Ь{В)).
Точнее, b принадлежит множеству ПЕРВ, потому что цепочка
(А )Ь (В > порождает цепочку b (В) следующим образом:
<Л>Ь<5>=»<В>6<В>=4>&<5>
Для данного правила р с левой частью (А > и правой частью ос
мы знаем, что если Ь принадлежит ПЕРВ (а), то цепочку,
начинающуюся с Ь, можно вывести из (А), применив сначала правило р.
Следовательно, b нужно включить в множество выбора правила р.
И наоборот, если b не принадлежит ПЕРВ (а), то из (А) нельзя
вывести цепочку, начинающуюся с Ь, применив сначала правило р.
Таким образом, понятие «Ь принадлежит ПЕРВ (правая часть
правила)» играет ту же роль в построении множества выбора, что
и понятие «правая часть правила начинается с Ь» в предыдущем
разделе. Это понятие характеризует те ситуации, когда правило
должно применяться для вывода цепочек, начинающихся с
текущего входного символа.
Теперь перейдем к вопросу о том, как охарактеризовать
ситуации, в которых правило должно применяться для порождения е
из верхнего магазинного символа. Этот вопрос мы уже обсуждали
в связи с е-правилами. В рассматриваемом примере на рис. 8.15
е-правило 6 должно применяться к (В), когда текущий входной
символ принадлежит множеству
СЛЕД «В» = {&, d, -\\
Принадлежность символов b, d и —| данному множеству
демонстрируется следующими выводами:
S -| =» <Л> b <В> Ч =5> <В> b <В> Н
<S> -| =» <Л> b <В> Ч =Ф <А> Ь с <S> d Ч => <. А > b с < А у b<B>d-\
274
Гл. 8. Нисходящие методы обработки языков
Первый вывод показывает, что за (В) следуют b и —|, а второй
вывод — что за (В > следует d.
В грамматике имеется еще одно правило, с помощью которого-
можно породить е, а именно правило 4. Хотя оно само не является
е-правялом, его можно использовать для порождения е:
<Л>=»<В>=Фе
Таким образом, применение правила 4 должно приниматься в
рассмотрение, когда на вершине магазина находится нетерминальный
символ (А >, а текущий входной символ принадлежит множеству
СЛЕД((Л>). Можно найти, что
СЛЕД(<Л»={&}
Для упрощения дальнейших рассуждений о правых частях
правил, приводящих к е, введем понятие аннулирующих цепочек
и правил.
Цепочка а, состоящая из символов грамматики, называется
аннулирующей тогда и только тогда, когда
а=£* в
Правило грамматики называется аннулирующим тогда и
только тогда, когда его правая часть является аннулирующей.
В рассматриваемом примере имеется два правила, а именно
правила 4 и 6. Понятие «правая часть — аннулирующая» обобщает,
как и планировалось, понятие «правая часть — пустая».
Аннулирующие правила играют ту же роль, что е-правила в изучении
^-грамматик.
Объединяя случаи, когда правило применяется для порождения
цепочки, начинающейся текущим входным символом, и когда оно
применяется для порождения е, определим множество выбора для
правил произвольного вида следующим образом:
Для данного правила
где а — цепочка, состоящая из терминалов и нетерминалов,
определим
ВЫБОР(С4)->а)=ПЕРВ(а)
если а не аннулирующая, и
ВЫБОР (С4 )->а)=ПЕРВ(а) и СЛЕД ((Л))
если а — аннулирующая. Если р — номер правила, то мы иногда
пишем
ВЫБОР(р)
8.6. 1Л.(1)-грамматики 275
вместо
ВЫБОР(<Л)-их)
Это определение согласуется с предыдущим определением
множества ВЫБОР. Если правая часть начинается с терминала
(А >-»£> а
то правило не является аннулирующим и
ВЫБОР({А)^Ь ос)=ПЕРВ(&<*)={&}
что совпадает с множеством выбора, описанным в определении
предыдущего раздела. Если у нас есть е-правило
то это правило аннулирующее и
ВЫБОР (04 >^е)=ПЕРВ(е) и СЛЕД ((Л »=СЛЕД((Л »
так как множество ПЕРВ(е) пусто; опять мы видим, что новое
определение согласуется со старым.
В рассматриваемом примере множества выбора двух
аннулирующих правил вычисляются так:
ВЫБОР (4) = ПЕРВ «В» и СЛЕД «А» = \с\ и \Ь\ = {с, Ь) -
ВЫБОР (6) = ПЕРВ (е) и СЛЕД «В» = < \ U {Ь. d, Ч} =
= {Ь, d, -\\
Для других правил множества выбора совпадают с множествами
ПЕРВ, которые показаны на рис. 8.15, т. е.
ВЫБОР(1)=ПЕРВ((Л>Ь(5>)={а, Ь, с, е)
После того как мы для всех правил вычислили множества
выбора, мы можем задать управляющую таблицу нисходящего МП-
распознавателя. Зададим эту таблицу так, чтобы каждое правило
«применялось» в тех элементах управляющей таблицы, чей
магазинный символ является левой частью данного правила, а входной
символ принадлежит множеству выбора. В нашем примере в
таблице нет таких элементов, в которых должны применяться два
различных правила, и на рис. 8.16 показана полученная
управляющая таблица. Из предыдущих рассуждений ясно, что этот
автомат распознает данный язык.
Теперь мы хотим определить 1Х(1)-грамматику как грамматику,
для которой такой способ задания таблицы переходов всегда
оказывается успешным.
КС-грамматика называется Ы.(1)-грамматикой тогда и
только тогда, когда множества выбора правил с одинаковой
левой частью не пересекаются.
276
Гл. 8. Нисходящие методы обработки языков
Данные в разд. 8.3 правила построения распознавателя с
магазинной памятью теперь можно расширить так, чтобы они стали
применимыми к ЬЬ(1)-грамматикам. Правило 5 должно быть
заменено на следующие два правила:
<S>
^А >
<В>
<С>
b
* 1
#3
ОТВЕРГНУТЬ
*7
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
* 1
*4
*6
ОТВЕРГНУТЬ
вытолкнуть
СДВИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
# 1
*4
#5
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#2
ОТВЕРГНУТЬ
V 6
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ВЫТОЛКНУТЬ
СДВИГ
ОТВЕРГНУТЬ
#1
#3
ОТВЕРГНУТЬ
= 8
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
*6
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
допустить
Начальное содержимое магазина
V <s>
Н 1 ЗАМЕНИТЬ (<£> b <A >), ДЕРЖАТЬ
#2 ВЫТОЛКНУТЬ, СДВИГ
# 3 ЗАМЕТИТЬ ( Ь < А > < О), ДЕРЖАТЬ
#4 ЗАМЕНИТЬ ( <В>), ДЕРЖАТЬ
# 5 ЗАМЕНИТЬ (d<S>), СДВИГ
#6 ВЫТОЛКНУТЬ, ДЕРЖАТЬ
#7 ВЫТОЛКНУТЬ, СДВИГ
#8 ЗАМЕНИТЬСЯ, СДВИГ
Рис 8.10.
5'. Любое из правил применяется каждый раз когда магазинный
символ является левой частью правила, а входной символ
принадлежит его множеству выбора. Для того чтобы применить правило
вида
(А)-+Ьа
где Ь — терминальный символ, а а — цепочка, состоящая из
терминальных и нетерминальных символов, используется переход
ЗАМЕНИТЬ (а'), СДВИГ
8.6. ЪЪ(1)-грамматики
27Т
Для того чтобы применить правило вида
(А)-+а
где а — цепочка, которая состоит из терминальных и
нетерминальных символов и не начинается с терминала, используется переход.
ЗАМЕНИТЬ (а'), ДЕРЖАТЬ
Когда цепочка ос равна е, вместо операции ЗАМЕНИТЬ (е) можно
применить операцию ВЫТОЛКНУТЬ.
5". Если для нетерминала (А) имеется аннулирующее правило
и по правилу 5' не было создано элемента таблицы,
соответствующего магазинному символу {А > и входному символу Ь, то можно
или применить аннулирующее правило, или отвергнуть входную-
цепочку.
Совокупность правил построения распознавателя
устанавливает следующий факт:
Если язык определяется 1Х(1)-грамматикой, то его можно
распознать с помощью МП-автомата с одним состоянием,
использующего расширенную магазинную операцию
ЗАМЕНИТЬ.
В качестве другого примера построим распознаватель для
описанных грамматикой из разд. 6.10 арифметических выражений, а
которых используются операции + и *.
1. <£)-><7)<£-список)
2. <£-список)->+<7)(£-список)
3. (£-список)->е
4. <7>-><ЯИГ-список>
5. <7-список)-»-*(Я>(Т-список>
6. (7-список)->-е
7. <Я >-►(<£»
8. (РУ+1
Эта грамматика является ЬЬ(1)-грамматикой со следующими
множествами выбора:
ВЫБОР (1) = ПЕРВ(<7><£-список» = {/, ( }
ВЫБОР (2) = ПЕРВ (+ <7> <£-список» = { + }
ВЫБОР (3) = СЛЕД «£-список» = {), -]}
ВЫБОР (4) = ПЕРВ (</>> <7-список» = {/, (}
ВЫБОР (5) = ПЕРВ (* </>> <7-список» = {*}
ВЫБОР (6) = СЛЕД«7-список» = 4 + , ), -|}
ВЫБОР (7) = ПЕРВ («£») = {(}
ВЫБОР (8) = ПЕРВ (/) = {/}
.278
Гл. 8. Нисходящие методы обработки языков
На рис. 8.17 показан процессор, обрабатывающий данный язык.
Рисунок 8.18 показывает последовательность конфигураций при
проверке данным процессором, является ли допустимым выражение
Принципы разд. 8.4 легко расширить так, чтобы можно было
осуществить цепочечные переводы, заданные транслирующими
грамматиками цепочечного перевода, входные грамматики которых
являются 1Х(1)-грамматиками. Расширения касаются правил вида
(Л >->£<*
где | — цепочка, состоящая из символов действия, а а — либо е,
либо цепочка, начинающаяся с нетерминала. Во втором случае
переход, применяющий это правило, должен быть таким:
ВЫДАТЬ (I), ЗАМЕНИТЬ (а'), ДЕРЖАТЬ
где 5 — выходная цепочка, которая имеется в виду цепочкой
символов действия £. С учетом этого добавления, в процессе построения
устанавливается следующий факт:
Для данной транслирующей грамматики цепочечного перевода,
входная грамматика которой является 1Х(1)-грамматикой,
определяемый ею перевод можно осуществить МП-автоматом
с одним состоянием, использующим расширенную магазинную
операцию ЗАМЕНИТЬ.
Для того чтобы проиллюстрировать этот процесс построения,
рассмотрим следующую грамматику с начальным символом (5):
1. {S)^{x}(A){y}
2. (S)^a{y}
3. <Л>->{2}
4. (A)-+b{S){z}c(A)
Множества выбора входной грамматики таковы:
ВЫБОР (1) = ПЕРВ «А» и СЛЕД «S» = \Ь) U {с, -\}
= {6, с, 4}
ВЫБОР (2) = ПЕРВ(а) = {а}
ВЫБОР (3) = ПЕРВ (е) и СЛЕД «Л» = { ) и {с, -|/
ВЫБОР (4) = ПЕРВ ф <5> с < Л» = {Ь}
Полученный МП-автомат показан на рис. 8.19.
Следующий факт выражает отношение между LL
(^-грамматиками и ^-грамматиками:
8.6. Ы.(\)-грамматики
279
<5>
<7">
<Р>
< Еспиаж)
<Т-ашсек>
)
#1
#4
#8
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#2
#6
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#5
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
/И
#4
#7
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#3
#6
вытолкнуть
СД8ИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#3
#6
ОТВЕРГНУТЬ
ДОПУСТИТЬ :
Начальное содержимое магазина: 57<£>
# 1 ЗАМЕНИТЬ «Е-ашО < Т », ДЕРЖАТЬ
#2 ЗАМЕНИТЬ «Е-спиажХТ», СДВИГ
#3 ВЫТОЛКНУТЬ, ДЕРЖАТЬ
#4 ЗАМЕНИТЬ «Т-шсаХР», ДЕРЖАТЬ
#5 ЗАМЕНИТЬ КТгСПШЖХР», СДВИГ
#6 ВЫТОЛКНУТЬ, ДЕРЖАТЬ
#7 ЗАМЕНИТЬ! )<£»", СДВИГ
#8 ВЫТОЛКНУТЬ. СДВИГ
Рис
v<£>
V (E-cnucafy(T)
V (Е-елиаж)(Т-С1шаж}(Р)
V (Е-ак/со$(Т-спиа>к)
V (Е-слисок)
V (E-cnucoit){T)
V (Е-спиеок){Т-Сйисш){Р)
V (E-cnucty)(T-cmcoi<)
V {Е-С1шк)(Т-аш£){Р)
V {Е-ша»)(Т-список)
V (Е-сюш)
V
8.17.
ДОПУСТИТЬ
Рис
8.18.
1 + 1*1- ~|
/ + / * / —|
/ + /*/-)
+ /*/-|
+ /*/Н
/*/-)
/*/-1
•ч
'Ч
н
ч
и
280
Гл. 8. Нисходящие методы обработки языков
По данной ЬЬ(1)-грамматике можно получить ^-грамматику,
определяющую тот же самый язык.
•Соответствующую грамматику можно построить методом «замены
края»; описанным в приложении В.
< s >
<А >
V
{у}
{г)
#2
#3
или
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
# 1
#4
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#1
#3
ВЫТОЛКНУТЬ
сдвиг
ОТВЕРГНУТЬ
#1
#3
ОТВЕРГНУТЬ
ДОПУСТИТЬ
ВЫДАТЬ (у), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
ВЫДАТЬ (г), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
Начальное содержимое магазина: V < S>
# 1 ВЫДАТЬ(х), ЗАМЕНИТЬ {{у} <А>), ДЕРЖАТЬ
#2 ВЫДАТЬ (у), ВЫТОЛКНУТЬ, СДВИГ
#3ВЫДАТЬ^), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
#43АМЕНИТЬ {<A>c{z} <S>), СДВИГ
Рис 8.19.
Название «LL(1)» объясняется тем, что автомат начинает
просматривать входную цепочку слева (Left) и обнаруживает
появление правила по самому левому (Leftmost) символу цепочки,
выводимой из этого правила, причем это решение принимается по
•одному текущему символу. Нисходящий разбор можно также
8.7. Нахождение множеств выбора
281
рассматривать в терминах «множеств выбора», состоящих из
входных цепочек длины k. В таком случае мы говорим о LL
(^-грамматиках. Грамматики в k большим 1 на практике применяются
довольно редко и этот случай далее не рассматривается.
8.7. Нахождение множеств выбора
В этом разделе мы опишем процедуру нахождения множеств выбора
для правил данной грамматики. Процедура позволяет определить,
является ли данная грамматика ЬЬ(1)-грамматикой, и, если это
так, построить для нее нисходящий МП-распознаватель. При этом
предполагается понимание приложения об отношениях
(Приложение Б). Это приложение можно читать независимо от остального
материала книги.
Как и раньше, предполагается, что в рассматриваемых
грамматиках нет лишних нетерминалов. В действительности мы
предполагаем, что предварительно данная грамматика проверяется в
помощью процедуры из разд. 6.14 и лишние нетерминалы
удаляются, либо в противном случае грамматика переписывается.
Процедура нахождения множеств выбора резюмирована на
рис. 8.20. Этот рисунок можно рассматривать как оглавление
данного раздела. В оставшихся частях этого раздела определяются
приведенные на рисунке отношения и объясняется каждый шар
процедуры.
С помощью да пной грамматики:
1. Найти аннулирующие нетерминалы и правила.
2. Построить отношение НАЧИНАЕТСЯ-ПРЯМО-С.
3. Вычислить отношение НАЧИНАЕТСЯ-С.
4. Вычислить множество ПЕРВ для каждого нетерминала.
5. Вычислить множество ПЕРВ для каждого правила.
6. Построить отношение ПРЯМО-ПЕРЕД.
7. Вычислить отношение ПРЯМО-НА-КОНЦЕ.
8. Вычислить отношение НА-КОНЦЕ.
9. Вычислить отношение ПЕРЕД.
10. Расширить отношение ПЕРЕД, включив концевой
маркер.
11. Вычислить множество СЛЕД для каждого аннулирующего
нетерминала.
12. Вычислить множества выбора.
Рис. 8.20. Процедура для нахождения множеств выбора.
Шаг 1 процедуры нахождения множеств выбора делается для
того, чтобы определить аннулирующие нетерминалы и правила.
Это легко осуществить следующим образом:
1. Из данной грамматики вычеркпррюия все правила, правые
части которых содержат хо!я бы один к. ^.иналььын символ. (По-
282
Гл. 8. Нисходящие методы обработки языков
скольку е не является терминальным символом, на этом шаге
е-правила не вычеркиваются.)
2. По грамматике, полученной на предыдущем шаге, с помощью
процедуры, описанной в разд. 6.14, определяется, какой из
нетерминалов живой, а какой мертвый.
3. Аннулирующие нетерминалы — это те, что на шаге 2
оказались живыми, аннулирующие правила — это те, правые части
которых состоят сплошь из аннулирующих нетерминалов.
Зта процедура работает правильно, потому что она определяет те
нетерминальные символы, из которых можно вывести терминальные
цепочки, используя правила, не содержащие терминальные
символы. Единственной цепочкой, которую можно породить таким
•способом, является пустая цепочка.
Для того чтобы проиллюстрировать данную процедуру,
рассмотрим следующую грамматику с начальным нетерминалом (S):
1.
3.
5.
7.
9.
<S>-»-04><B>
(А)-+е
(ВЬ-е
(С)-+(А)ф)
(D)-+a(S)
2.
4.
6.
8.
10.
(S)-+b{C)
(А)-+Ь
(B)-+a(D)
(C)^b
Ф)-+с
Вычеркивая все правила, содержащие терминальные символы,
получим следующую грамматику:
1. (S)-+{A)(B)
2. <Л>-М5
3. (В)-+г
4. <С>-><Л><£>>
Применяя шаг 2, получим, что (S), {А >, (В) — живые и,
следовательно, аннулирующие, а (С) и ф)— нет. Таким образом,
аннулирующими будут правила 1, 3 и 5.
Шаг 2 процедуры нахождения множества выбора состоит в
построении отношения, называемого НАЧИНАЕТСЯ-ПРЯМО-С.
Это отношение определяется на множестве символов грамматики,
для которых мы хотим найти множества выбора. Интуитивно
А НАЧИНАЕТСЯ-ПРЯМО-С В
означает: если, применив к нетерминалу А точно одно правило и,
возможно, заменив в нем некоторые аннулирующие нетерминалы
на е, можно получить цепочку, начинающуюся с В. Это отношение
можно выразить следующим образом:
Если А и В — символы данной грамматики, то мы пишем
А НАЧИНАЕТСЯ-ПРЯМО-С В
8.7. Нахождение множеств выбора
283-
тогда и только тогда, когда существует правило вида
А-+аВр
где а — аннулирующая, ар — произвольная цепочка.
Важно осознавать, что правило можно представить в виде
А-+аВ?>
где a — аннулирующая цепочка, более чем одним способом.
Предположим, что у нас есть правило
(A)-*(V){X)(Y)<Z)
Оно имеет вид (Л )-*-аВр, если взять А = (А), a=e, B=(V), f}=
= (X) (Y) (Z), и, таким образом,
<Л> НАЧИНАЕТСЯ-ПРЯМО-С (V)
Однако если (V) — аннулирующий нетерминал, то требуемый,
вид получится также при
А = (А), a=(V), В=(Х), $={Y)(Z)
и, следовательно, выполняется отношение
(А) НАЧИНАЕТСЯ-ПРЯМО-С <Я>
Если нетерминал {X > также является аннулирующим, то требуемый
вид получится при
А = (А), a=(V){X), В=(У), р=Ш
и, значит,
(А) НАЧИНАЕТСЯ-ПРЯМО-С (У)
Наконец, если окажется, что {Y > тоже аннулирующий нетерминал,
то отношение
(Л) НАЧИНАЕТСЯ-ПРЯМО-С <Z>
будет выполнено, хотя нетерминал (Z) и является самым правым
символом в правой части правила.
Описанный подход можно выразить с помощью очень простой
процедуры, которая строит матрицу или граф отношения
НАЧИНАЕТСЯ-ПРЯМО-С:
Для каждого правила
А-+а
и каждого символа В в правой части а определяем, являются
ли аннулирующими символы (если они вообще существуют)
находящиеся в цепочке а левее В. Если да, сделаем в матрице
или графе пометку, указывающую, что
Л НАЧИНАЕТСЯ-ПРЯМО-С В
284
Гл. 8. Нисходящие методы обработки языков
Теперь проиллюстрируем приведенную выше процедуру, построив
матрицу, представляющую отношение НАЧИНАЕТСЯ-ПРЯМО-С
для следующей грамматики с начальным нетерминалом (А). Эту
грамматику мы будем рассматривать в качестве примера до конца
данного раздела.
1. (А)-+(В)(С)с 2. (A)-+e{D)(B)
3. (В>->е 4. (B)-+b(C)(D)(E)
5. (С)-+Ф)а(В) 6. (С)-+са
7. (£>>->е 8. (D)-+d(D)
9. {Ey+e{A)f 10. (Е)-+с
Тривиальные вычисления показывают, что аннулирующими
нетерминалами будут (В) и (D), а аннулирующими правилами —
правила 3 и 7.
Исследуя правило 1, приходим к выводу, что
(А) НАЧИНАЕТСЯ-ПРЯМО-С (В)
и, так как (В) — аннулирующий нетерминал, то
(A) НАЧИНАЕТСЯ-ПРЯМО-С (С)
Поскольку нетерминал (О не является аннулирующим, мл
правила 1 больше ничего нельзя заключить. Анализируя остальные
правила, получим следующие отношения:
(А > НАЧИНАЕТСЯ-ПРЯМО-С е
(B) НАЧИНАЕТСЯ-ПРЯМО-С Ъ
(C) НАЧИНАЕТСЯ-ПРЯМО-С (D) и а
(C) НАЧИНАЕТСЯ-ПРЯМО-С с
(D) НАЧИНАЕТСЯ-ПРЯМО-С d
(£) НАЧИНАЕТСЯ-ПРЯМО-С е
(E) НАЧИНАЕТСЯ-ПРЯМО-С с
Для того чтобы записать эти отношения с помощью матрицы,
приготовим таблицу, ряды и столбцы которой помечены символами
грамматики. Затем занесем 1 в те элементы таблицы, которые
соответствуют каждому из приведенных отношений. Так, по правилу
1 те элементы строки (А ), которые находятся в столбцах (fl> а (С),
будут равны 1. На рис. 8.21, а показано расположение всех
элементов, заполненных единицей.
Шаг 3 процедуры — это вычисление отношения НАЧИНАЕТСЯ-
С, определяемого следующим образом:
Если А и В — символы данной грамматики, то мы пишем,
что
А НАЧИНАЕТСЯ-С В
по
по
по
по
по
по
по
правилу
правилу
правилу
правилу
правилу
правилу
правилу
2
4
5
6
8
9
10
<A> <B> <C> <D> <E> a b с d e f
1
1
1
1,
1
1
1
1
1
1
<A > <B> <C> <0> <£> a
*
1
с
1
•
*
1
*
*
*
1
•
*
1
*
*
1
1
«
«
1»
1
"
1
1
*
*
Рис. 8.21. (а) Отношение НАЧИНАЕТСЯ-ПРЯМО-С; (б) Отношение
- НАЧИНАЕТСЯ-С
286
Гл. 8. Нисходящие методы обработки языков
тогда и только тогда, когда существует цепочка,
начинающаяся с В, которую можно вывести из Л.
Так как в любом выводе, начинающемся нетерминалом (Л > и
заканчивающемся цепочкой с нетерминалом Б в ее начале, для
первых символов каждой пары последовательных цепочек
выполнено отношение НАЧИНАЕТСЯ-ПРЯМО-С, то отношение
НАЧИНАЕТСЯ-С является рефлексивно-транзитивным замыканием
отношения НАЧИНАЕТСЯ-ПРЯМО-С. Следовательно, шаг 3
процедуры вычисляет рефлексивно-транзитивное замыкание по методу,
описанному в приложении Б. На рис. 8.21, б в качестве примера
приведена матрица отношения НАЧИНАЕТСЯ-С, в которой
символ # обозначает те пары, которые добавлены с помощью
процедуры замыкания к таблице, представляющей отношение
НАЧИНАЕТСЯ-ПРЯМО-С.
Шаг 4 вычисляет множество ПЕРВ ((А )) для каждого
нетерминала (А). Множество ПЕРВ ((Л)) — это просто множество таких
терминалов Ь, для которых выполняется отношение
<Л > НАЧИНАЕТСЯ-С Ь
Для каждой строки матрицы отношения НАЧИНАЕТСЯ-С
отмеченные столбцы, соответствующие терминальным символам,
указывают терминалы, составляющие множество ПЕРВ для
символа, которым помечена данная строка. Так, в нашем примерз
ПЕРВ(<Л>)={а, Ь, с, d, е)
ПЕРВ(<В»={М
ПЕРВ(<С»={а, с, d)
nEPB((D))={d}
ПЕРВ(<£>)={с, е)
Шаг 5 — вычисление множества ПЕРВ для г.раьои части
каждого правила. Имея информацию, полученную на шаге 4, эти
вычисления проделать очень просто.
Начав с правила 1 и учитывая, что (В)— аннулирующий
нетерминал, а (С) — нет, получим:
1.ПЕРВ((БХС)с)=ПЕРВ((Б» U ПЕРВ ((C))={а, Ь, с, d)
Аналогично для остальных правил грамматики проделаем
следующие вычисления:
2. ПЕРВ(еф)<Я>)=ПЕРВ(е)={е}
3. ПЕРВ(С)={ }
4. ПЕРВ(ИСХОХ£>)=ПЕРВ(Ь) = {М
5. ПЕРВ(ФЫВ))=ПЕРВ((D)) и ПЕРВ(а)={а, d)
6. ПЕРВ(са)=ПЕРВ(с)={с}
8.7. Нахождение множеств выбора
287
7. ПЕРВ(е)={ }
8. nEPB(d(D>)=nEPB(d)={d}
9. ПЕРВ(еС4)/)=ПЕРВ(е)={е}
10. ПЕРВ(с)={с}
Единственным символом, который может быть в начале цепочки,
выводимой из нетерминала t, является сам терминал t. Поэтому
нет никакой необходимости в строках матрицы НАЧИНАЕТСЯ-С,
помеченных терминальными символами; мы можем запомнить
отношение
t НАЧИНАЕТСЯ-С t
не отражая этот факт в матрице. На рис. 8.21 двойной линией
разделяется фактически необходимая информация и информация,
нужная только для объяснения введенного понятия.
Шаг 6 — это построение отношения, называемого ПРЯМО-
ПЕРЕД. Это отношение определяется следующим образом:
Мы пишем
А ПРЯМО-ПЕРЕД В
тогда и только тогда, когда существует правило вида
D-+aAf>By
где А и В — символы, |J — аннулирующая цепочка, а а и
Y — произвольные цепочки символов.
По данной правой части правила можно получить надлежащие
комбинации символов А и В многими различными способами.
В нашем примере, по правилу 4 получаем четыре пары, а именно:
Ь ПРЯМО-ПЕРЕД (С)
(C) ПРЯМО-ПЕРЕД (D)
(D) ПРЯМО-ПЕРЕД (£>
(С) ПРЯМО-ПЕРЕД (Е)
Последнее отношение справедливо, потому что указанное в
определении условие будет выполнено при
а=Ь, Л = (С>, p=(D>, fi=<£> и v=e
Матрицу или граф отношения ПРЯМО-ПЕРЕД можно построить,
систематически применяя следующую процедуру:
Для каждого правила
D-wx
и каждой пары символов Л и В из правой части правила а
определяем, является ли цепочка, разделяющая эти сим-
288
Гл. 8. Нисходящие методы обработки языков
волы в а, аннулирующей, Если да и А находится левее В,
то сделаем в матрице или графе отметку, обозначающую, что
А ПРЯМО-ПЕРЕД В
Возвращаясь к нашему примеру, отметим, что мы уже
обработали с помощью данной процедуры правило 4. Отношения ПРЯМО-
ПЕРЕД для других правил можно вычислить так же просто, и в
<А> <В> <С> <D> <E> a Ь с d e f
<А >
<В>
<с>
<D>
<Е>
a
b
с
с/
е
f
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
Рис 8.22. Отношение ПРЯМО-ПЕРЕД.
результате, пометив соответствующие элементы, получим матрицу,
показанную на рис. 8.22.
Шаг 7 — это построение отношения ПРЯМО-НА-КОНЦЕ,
определяемого следующим образом:
Если А и В — символы данной грамматики, то мы пишем
А ПРЯМО-НА-КОНЦЕ В
тогда и только тогда, когда есть правило Рида
где Р — аннулирующая цепочка, а а — произвольная
цепочка символов.
8.7. Нахождение множеств выбора
289
Отношение ПРЯМО-НА-КОНЦЕ — это просто разновидность
отношения НАЧИНАЕТСЯ-ПРЯМО-С, если правую часть правила
рассматривать справа налево, и потому его легко построить,
систематически применяя следующую процедуру:
Для каждого правила
и каждого символа А в правой части правила — а
определяем, являются ли символы справа от А аннулирующими.
Если да, то сделаем соответствующую отметку в матрице
или графе, обозначающую отношение
А ПРЯМО-НА-КОНЦЕ В
Вычислим теперь это отношение для нашего примера. По
правилу 2:
(В) ПРЯМО-НА-КОНЦЕ (А-)
так как {В > — аннулирующий нетерминал, то
<D> ПРЯМО-НА-КОНЦЕ (А)
а так как (D) — тоже аннулирующий нетерминал, то
е ПРЯМО-НА-КОНЦЕ (А >
По правилу 4 получаем только отношение
(Е) ПРЯМО-НА-КОНЦЕ <В>
поскольку нетерминал (Е) в правой части правила не является
аннулирующим. После рассмотрения всех правил все полученные
пары будут помечены единицей в матрице, показанной на рис.
8.23, а.
Шаг 8 — построение отношения НА-КОНЦЕ, определяемого
следующим образом:
Если А к В — символы данной грамматики, то мы пишем
А НА-КОНЦЕ В
тогда и только тогда, когда из В можно вывести цепочку,
заканчивающуюся символом А.
Отношение НА-КОНЦЕ — это рефлексивно-транзитивное
замыкание отношения ПРЯМО-НА-КОНЦЕ по тем же причинам, что
и отношение НАЧИНАЕТСЯ-С является
рефлексивно-транзитивным замыканием отношения НАЧИНАЕТСЯ-ПРЯМО-С.
Применение процедуры, осуществляющей рефлексивно-транзитивное
замыкание, к матрице отношения ПРЯМО-НА-КОНЦЕ приводит к
добавлению в таблице на рис. 8.23, б пар, помеченных *.
Ю Ф. Льюис и др.
<A> <B> <C> <D> <E> abode f
<A>
<B>
<C>
<D>
<E>
a
b
с
d
1
1
1
1
1
1
I 1
1
1
!
i
1
1
L
i
i
!
|
1
1
1
j
i
1
j |
1
■
i
1
|
i .
i
1
1
а
<A> <B> <C> <D> <E> abode
<A>
<B>
<C>
KD>
■',E >
-
1
1
■
I
1
'
1
■
~
■
1
,
•
i
1 i
1
1
' i
1 1
■
■
1
j
j
i i
!
i
1
1
i
..
■
i
1
1
1
I
|
I
!
i
1
!
i
'
Рис. 8.23. (а) Отношение ПРЯМО-НА-КОНЦЕ; (б) НА-КОНЦЕ.
8.7. Нахождение множеств выбора
291
Шаг 9 — это вычисление отношения, называемого ПЕРЕД.
Это отношение определяется так:
Для данной грамматики с начальным нетерминалом (S)
отношение
А ПЕРЕД В
выполняется тогда и только тогда, когда из (S) можно
вывести цепочку, в которой за вхождением символа А сразу же
следует вхождение символа В
Если для символов А к В выполняется отношение
А ПЕРЕД В
то должны найтись такие символы X и Y, что
А НА-КОНЦЕ X ПРЯМО-ПЕРЕД Y НАЧИНАЕТСЯ-С В
По данному дереву вывода цепочки, в которой вслед за А следует
В, можно найти X и Y, продвигаясь вверх, начиная с символов-
<А>
Рис. 8.24.
А а В, пока не будет найдена правая часть правила, в которой
содержатся предки обоих символов. В качестве иллюстрации на
рис. 8.24 показано дерево вывода цепочки
b(C)ee(D)f(C)c
to»
292
Гл. 8. Нисходящие методы обработки языков
построенного с помощью грамматики нашего примера. Для того
чтобы найти такие X и Y, которые объясняют отношение
(D) ПЕРЕД /
проследим пути из (D > и / до надлежащей правой части правила,
а именно е(А>/. Поскольку (D> выводится из (А), а/ из /, возьмем
Х=(А) и У=/ и запишем
(D) НА-КОНЦЕ {А > ПРЯМО-ПЕРЕД / НАЧИНАЕТСЯ-С /
Аналогичный анализ отношения
(С) ПЕРЕД е
дает
(С) НА-КОНЦЕ (С) ПРЯМО-ПЕРЕД (Е) НАЧИНАЕТСЯ-С б
Теперь мы видим, что отношение ПЕРЕД является произведением
отношений
НА-КОНЦЕ • ПРЯМО-ПЕРЕД-НАЧИНАЕТСЯ-С
Это произведение можно вычислить с помощью процедуры из
приложения Б. Вычисление для нашего примера даст матрицу,
показанную на рис. 8.25 (без столбца, помеченного символом —|).
Для того чтобы определить те множества выбора, в которых
содержится концевой маркер, мы должны выявить все символы,
которые могут предшествовать символу —| в цепочке, выводимой
из (S > —1, где (S) — начальный символ. Очевидно, что это в
точности те символы, которыми может заканчиваться нетерминальный
символ (S), потому мы расширим отношение ПЕРЕД так, чтобы
в него включался концевой маркер, определив
А ПЕРЕД -|
тогда и только тогда, когда
А НА-КОНЦЕ (S)
где (S) — начальный символ.
Такая информация уже содержится в столбце вычисленной на
шаге 8 матрицы отношения НА-КОНЦЕ, соответствующем
начальному символу. Таким образом, шаг 10 заключается в том, что к
матрице отношения ПЕРЕД, вычисленной на шаге 9, добавляется
указанный столбец, который метится как столбец, соответствующий
концевому маркеру. Для рассматриваемого примера на рис. 8.25
показана вычисленная на шаге 9 матрица, к которой добавлен
столбец, соответствующий начальному символу ((A)).
Добавленный столбец расположен правее всех и отделен от первоначальной
матрицы двойной чертой.
8.7. Нахождение множеств выбора
293
Шаг 11 — это вычисление множества СЛЕД для каждого
аннулирующего нетерминала, что очень легко сделать после того, как
была вычислена матрица отношения ПЕРЕД. В нашем примере
аннулирующими нетерминалами являются (В) и (D >. На рис. 8.25
строки, соответствующие (В) и (D), показывают, что
СЛЕД«Б»={а, с, d, e, f, -\\
СЛЕД«0» = {а, Ь, с, е, /, -\\
Отношение ПЕРЕД нужно только для построения этих двух строк,
и рис. 8.25 фактически содержит много ненужной информации.
<АХВХС> <D><£> а Ь с d e f H
<А>
<В>
<С>
<D>
<£>
a
b
*
d
JS
1
1
1
r
1
1
S
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1-
1
1
1
1
1
1
1
1
1
1 ,
1
1
1
1
1
1
Рис 8.25. Отношение ПЕРЕД.
Фактически, так как мы вычисляем множество СЛЕД только для
нетерминалов, то нам нужны только те части рисунков 8.22 и 8.23,
что выделены жирными линиями.
Шаг 12 — вычисление множеств выбора, которые теперь можно
получить из уже вычисленных значений множеств ПЕРВ и СЛЕД.
В нашем примере множества выбора будут такими:
ВЫБОР (1) = ПЕРВ«В><С>с) = {а, Ь, с, d)
ВЫБОР (2) = ПЕРВ(е<Д><В» = \е\
ВЫБОР (3) = ПЕРВ(е)иСЛЕД«Б» = {а, с, d, e, f, -\\
ВЫБОР (4) = nEPB(6<C><D><£» = {6}
294 Гл. 8. Нисходящие методы обработки языков
ВЫБОР (5) = ПЕРВ«£>а<Я» = {а, d)
ВЫБОР (6) = ПЕРВ(са) = {с}
ВЫБОР (7) = ПЕРВ(е)иСЛЕД«£»На, Ь, с, е, f, -\\
ВЫБОР (8) = nEPB(d<D» = {d|
ВЫБОР (9) = ПЕРВ(е<Л>/) = {4
ВЫБОР(Ш) = ПЕРВ(с) = \с\
Отсюда видно, что множества выбора правил, имеющих в левой
части один и тот же нетерминал, не пересекаются. Следовательно,,
грамматика, порождающая рассматриваемый язык, является LL (1)-
грамматикой и для нее можно построить нисходящий
МП-распознаватель.
8.8. Обработка ошибок при нисходящем разборе
Цепочки, поступающие на вход компилятора, часто не
принадлежат распознаваемому языку. Такие цепочки мы называем
неправильными.
Когда компилятору встречается неправильная цепочка, он
должен обнаружить, что в ней имеется ошибка (т. е. что входная
цепочка является неправильной). Более того, желательно, чтобы
компилятор выдавал сообщения об ошибках, указывая те ошибки,
которые мог допустить программист.
Вопрос о том, сколько и какие сообщения об ошибках для
данной неправильной цепочки выдать, зависит от разработчика и часто
является спорным. На самом деле различные компиляторы для
одного и того же языка программирования часто выдают разные
сообщения об ошибках для одной и. той же неправильной цепочки.
МП-распознаватель обнаруживает, что входная цепочка
является неправильной, как только он в первый раз встречает
элемент ОТВЕРГНУТЬ в управляющей таблице. Желательно, чтобы
в этот момент компилятор сделал сообщение об ошибке,
описывающее ту ошибку, которую программист, возможно, совершил. Далее,
нам нужно, чтобы компилятор изменил конфигурацию
МП-автомата таким образом, чтобы процесс обработки входной цепочки
можно было продолжить и получить, если это целесообразно,
дополнительные сообщения об ошибках. Процесс изменения
конфигурации называется нейтрализацией ошибок. Обычно в
управляющей таблице элементы ОТВЕРГНУТЬ — это не просто выходы,
они содержат вызовы процедур, которые выдают сообщения об
ошибках и осуществляют их нейтрализацию. Изученные нами
нисходящие распознаватели обычно могут делать полезные сосбщения
об ошибках благодаря тому, что обладают особым свойством,
которое мы называем «префиксным свойством». Для данных МП-
распознавателя и неправильной цепочки мы называем символ этой.
8.8. Обработка ошибок при нисходящем разборе
295
цепочки нарушающим символом, если он является текущим входным
символом в тот момент, когда автомат отвергает входную цепочку.
Говорят, что МП-автомат обладает префиксным свойством, если
для любой недопустимой цепочки цепочка символов, расположенных
слева от нарушающего символа, является префиксом какой-нибудь
допустимой входной цепочки. Другими словами, распознаватель
имеет префиксное свойство, если нарушающий символ является
первым символом, противоречащим гипотезе о том, что входная
цепочка является допустимой. Таким образом, нисходящий
распознаватель с префиксным свойством обнаруживает «самую левую»
ошибку во входной цепочке.
Все определенные в данной главе автоматы обладают
префиксным свойством, так как цепочку символов, расположенных слева
от нарушающего символа, можно «дополнить» до допустимой
цепочки, приписав к ней любую терминальную цепочку, выводимую
из промежуточной цепочки, находящейся в магазине в тот момент,
когда обнаруживается, что входная цепочка недопустима.
Если распознаватель обладает префиксным свойством, то часто
можно получить хорошее сообщение об ошибке, предположив, что
она произошла в самом нарушающем символе или где-то
поблизости. Для того чтобы сделать подходящее сообщение об ошибке,
компилятор может проанализировать входную цепочку и
содержимое магазина в тот момент, когда автомат отверг входную цепочку.
Однако часто глубокого анализа не проводится, и сообщение об
ошибке основывается только на верхнем магазинном символе и
текущем входном символе. Верхний символ магазина указывает
на то, что компилятор ожидает обнаружить на входе, а текущий
входной символ говорит, что он обнаруживает на самом деле. Таким
образом, формат сообщения может быть таким:
«ОЖИДАЛОСЬ (НАЧАЛО) , НО ВМЕСТО
ЭТОГО ОБНАРУЖЕНО .»
где первый прочерк заменяет имя верхнего магазинного символа
(подходящим образом перефразированное, чтобы оно было
понятным пользователю) и второй — входной символ. Сообщение об
ошибке может быть выражено и другими словами, но в приведенной
форме по существу суммирована вся информация, на которой
основывается сообщение об ошибке.
В типичном случае сообщение об ошибке содержит еще номер
строки или перфокарты, а также позицию нарушающего символа.
В качестве примера рассмотрим проектирование сообщений
об ошибках для следующей s-грамматики:
1. (Sh+a
2. (S)-+((S)(R))
296 Гл. 8. Нисходящие методы обработки языков
3. <ЛЬ-, (S)(R)
4. «Н
с начальным символом (S). Эта грамматика порождает цепочки,
подобнее выражениям языка Лисп, таким, как
а
(а, (а, а))
((а, (а, а), (а, а)), а)
Предположим, что в руководстве, по языку эти выражения на-
вваны «S-выражениями» и программист знаком с этим термином,
когда он встречается в сообщении об ошибке.
a , ( ) Н
#1
ОТВЕРГНУТЬ
d
ОТВЕРГНУТЬ
9
ОТВЕРГНУТЬ
a
#3
ОТВЕРГНУТЬ
h .
#2
ОТВЕРГНУТЬ
е
ОТВЕРГНУТЬ
/'
ОТВЕРГНУТЬ
ь
#4
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
с
ОТВЕРГНУТЬ
f.
ДОПУСТИТЬ
Начальное содержимое магазина : V <5>
#1 ВЫТОЛКНУТЬ, СДВИГ
#2 ЗАМЕНИТЬ «Я><5», СДВИГ
#3 ЗАМЕНИТЬ «Д><5», СДВИГ
#4 ВЫТОЛКНУТЬ, СДВИГ
Рис. 8.26.
На рис. 8.26 показана управляющая таблица, построенная по
данной грамматике с помощью процедуры разд. 8.3. Для удобства
элементы ОТВЕРГНУТЬ на рис. 8.26 помечены буквами от а до /'.
Теперь попробуем выбрать сообщение об ошибке для каждого
элемента ОТВЕРГНУТЬ, начав тем самым конструирование процесса
обработки ошибок.
Опыт показывает, что часто для нескольких элементов данной
строки таблицы можно выбрать одно и то же сообщение об ошибке.
Рассмотрим поэтому каждую строку отдельно. В строке (S)
содержатся три элемента ОТВЕРГНУТЬ: а, Ь и с. Так как цепочки,
порождаемые нетерминалом (S), называются S-выражениями, та
сообщения для элементов а и b могут быть такими:
СТОИТ ТАМ, ГДЕ ОЖИДАЕТСЯ S-ВЫРАЖЕНИЕ
8.8. Обработка ошибок при нисходящем раэборе 297
где на месте черты должен стоять входной символ. Такое
сообщение не подходит для элемента с, так как замена прочерка на
КОНЦЕВОЙ МАРКЕР или КОНЕЦ ВЫРАЖЕНИЯ мало что говорит
среднему пользователю. Посмотрев на некоторые типичные
входные цепочки, где требуется задать сообщение об ошибке для
элемента с, например,
ч
(Ч
(а, Ч
мы решаем, что сообщение должно быть таким:
S-ВЫРАЖЕНИЕ НЕ ЗАКОНЧЕНО
Теперь рассмотрим строку, соответствующую нетерминалу (R).
Так как средний пользователь, вероятно, ничего не знает о
нетерминале (R), нет смысла упоминать о нем в сообщении об ошибке.
Вместо этого можно перечислить те входные символы, которые
могут стоять в начале допустимого продолжения обработанной
части входной цепочки. В данном случае допустимые продолжения
начинаются с запятой или закрывающей скобки, потому сообщение
может быть таким:
СТОИТ ТАМ, ГДЕ ОЖИДАЕТСЯ ЗАПЯТАЯ ИЛИ ПРАВАЯ
СКОБКА
Однако если быть менее консервативными, то можно дать более
подробное сообщение, указывающее возможную причину
возникновения ошибки. Это приводит к риску сделать неверное сообщение.
Во всех тех цепочках, которые заставляют автомат использовать
элементы due, содержится цепочка, порожденная нетерминалом
(S), за которой следует а или (.Некоторые типичные цепочки,
приводящие к тому, что автомат использует элементы d и е, таковы
(нарушающие символы подчеркнуты):
(а а) -\
(( а) а) Ч
(а(а))-\
((а)(а))-\
Если в каждую из этих цепочек вставить запятую перед
нарушающим символом, то это позволит автомату продолжить обработку
входной цепочки, а если вставить правую скобку (второй входной
символ, соответствующий нетерминалу (R)),— то нет.
Следовательно, для элементов d и е мы выбираем сообщение:
ПРОПУЩЕНА ЗАПЯТАЯ
298
Гл. 8. Нисходящие методы обработки языков
Это сообщение должно указать пользователю, в чем состоит его
ошибка, даже если она описана не точно. Например, если вместо
правой скобки ошибочно напечатана левая скобка, то могла
получиться,такая цепочка:
(И , а)
Даже для такой цепочки программист скорее всего правильно
поймет сообщение, содержащее номер строки и позицию, занимаемую
в ней закрывающей скобкой, а также слова ПРОПУЩЕНА
ЗАПЯТАЯ.
Для элемента / выберем сообщение
ПРОПУЩЕНА ПРАВАЯ СКОБКА
поскольку ясно, что в этой ситуации пропущена правая скобка;
это можно проиллюстрировать таким характерным примером:
(а, а —|
Ошибочные элементы g, h, i и / в строке, помеченной маркером
дна, соответствуют ситуации, в которых распознаватель считает,
что S-выражение закончилось, но входная цепочка содержит еще
какие-то символы. Надлежащим сообщением будет
ВСТРЕЧАЕТСЯ ПОСЛЕ КОНЦА S-ВЫРАЖЕНИЯ
На рис. 8.27 приведены все выбранные нами, сообщения об
ошибках.
а, Ь: ВСТРЕТИЛОСЬ КОГДА ОЖИДАЛОСЬ S-ВЫРАЖЕНИЕ
с: S-ВЫРАЖЕНИЕ НЕ ЗАВЕРШЕНО
d, e: ПРОПУЩЕНА ЗАПЯТАЯ
/: ПРОПУЩЕНА ПРАВАЯ СКОБКА
gi h, i, j: ВСТРЕТИЛОСЬ ПОСЛЕ КОНЦА S-ВЫРАЖЕНИЯ
Рис. 8.27.
Теперь рассмотрим проблему нейтрализации ошибок. Наш
подход к этой проблеме состоит в разработке процедур, которые
приводят в надлежащее состояние магазин и входную цепочку и
затем продолжают процесс обработки, как будто никакой ошибки
не было. Если МП-автомат в очередной раз обнаруживает элемент
ОТВЕРГНУТЬ, то он добавляет сообщение об ошибке, которое
дается в этом элементе, к списку сообщений об ошибках,
созданному до сих пор, и выполняет процедуру нейтрализации ошибок,
соответствующую данному элементу. Мы надеемся, что после
обнаружения первой ошибки восстановленная конфигурация является
«правильной» в том смысле, что она соответствует конфигурации,
которая имела бы место, если бы программист не сделал первой
ошибки, и поэтому, если после нейтрализации ошибки будут
получены еще какие-то сообщения, то они соответствуют уже другим
ошибкам, о которых программисту тоже хотелось бы знать. Риск
состоит в том, что конфигурация может быть восстановлена неверно
8.8. Обработка ошибок при нисходящем разборе
299
и компилятор может в дальнейшем сделать сообщения о фиктивных
ошибках, которые будут раздражать программиста, поскольку они
яе представляют новых ошибок в программе. Таким образом,
a , ( ) -ч
<я>
V
#1
d
9
a
#3
h .
#•2
е
i
b
#4
/'
с
f
допустить
Начальное содержимое магазина: v <s>
#1
#2
#3
.#4
«/'•
вытолкнуть, сдвиг
ЗАМЕНИТЬ KRXS», СДВИГ
ЗАМЕНИТЬ «RXS», СДВИГ
ВЫТОЛКНУТЬ, СДВИГ
Г ПЕЧАТАТЬ (_ ВСТРЕТИЛОСЬ,КОГДА ОЖИДАЛОСЬ
S- ВЫРАЖЕНИЕ), ВЫТОЛКНУТЬ , ДЕРЖАТЬ
ПЕЧАТАТЬ ($-ВЫРАЖЕНИ£ НЕ ЗАВЕРШЕНО)
ВЫХОД
ПЕЧАТАТЬ (ПРОПУЩЕНА ЗАПЯТАЯ)
ЗАМЕНИТЬ (<RXS>), ДЕРЖАТЬ
ПЕЧАТАТЬ ( ПРОПУЩЕНА^ ПРАВАЯ СКОБКА)
ВЫХОД
: ПЕЧАТАТЬ (_ ВСТРЕТИЛОСЬ ПОСЛЕ КОНЦА
S-ВЫРАЖЕНИЯ)
ВТОЛКНУТЬ «RXS», ДЕРЖАТЬ
ПЕЧАТАТЬ (_ ВСТРЕТИЛОСЬ ПОСЛЕ КОНЦА
S-ВЫРАЖЕНИЯ)
ВТОЛКНУТЬ (<R>), ДЕРЖАТЬ
ПЕЧАТАТЬ (_ ВСТРЕТИЛОСЬ ПОСЛЕ КОНЦА
S-ВЫРАЖЕНИЯ)
СДВИГ
Рис. 8.28.
любая попытка нейтрализации ошибок представляет собой
компромисс между желанием обнаружить как можно больше ошибок,
и желанием избежать сообщений о несуществующих ошибках.
300
Гл. 8. Нисходящие методы обработки языков
Вначале рассмотрим подход к проблеме нейтрализации ошибок,,
который можно охарактеризовать, как «локальный». Идея этого
подхода состоит в том, что каждый элемент ОТВЕРГНУТЬ в
управляющей таблице заполняется обычными операциями над
магазином и входом. Если обнаруживается какая-то конкретная ошибка,
то автомат вначале выдает сообщение об ошибке, затем
выполняются указанные операции над магазином и входом и наконец
возобновляется обычный процесс обработки. Разработчик выбирает
операции отдельно для каждого элемента таблицы,
соответствующего ошибке, на основе интуитивного предположения о том, какая
ошибка могла произойти и какие изменения магазина и входной
цепочки позволят возобновить процесс обработки наилучшим
образом.
На рис. 8.28 показан окончательный вид управляющей таблицы,
в которой для каждого ошибочного элемента задана подходящая
процедура нейтрализации. Заметим, что мы использовали
обозначение ВТОЛКНУТЬ ( ) для вталкивания цепочки символов,
которое рассматривается как одна операция.
Иногда оказывается, что один нарушающий символ может
привести к двум сообщениям об ошибках. В нашем примере первый
символ входной цепочки
, а) Ч
вначале приведет к тому, что будет использован элемент а, а после
выполнения процедуры нейтрализации элемента а нужно будет
использовать элемент h. Однако ясно, что мы не хотим печатать
сообщение элемента h. Потому примем такое соглашение: если один
входной символ порождает несколько сообщений, то только первое
из них будет напечатано.
В качестве примера того, как происходит нейтрализация
ошибок, на рис. 8.29, а показана последовательность конфигураций
процесса обработки автоматом, показанным на рис. 8.28, входной
цепочки
(а„а
В этой последовательности предполагается, что сообщения
заготавливаются с помощью процедуры ПЕЧАТАТЬ с двумя
параметрами: позиция нарушающего символа и текст сообщения.
Сообщения могут быть представлены и так, как показано на рис. 8.29, б,
где входная цепочка печатается вместе со стрелкой, указывающей
на нарушающий символ.
Многие компиляторы делят все ошибки на «фатальные» и
«нефатальные». Для фотальных ошибок процедура, обрабатывающая
ошибку, прекращает компиляцию программы и предотвращает ее
выполнение. Для нефатальных ошибок процедура не предпринимает
подобных действий, и если далее не обнаруживается фатальных
8.8. Обработка ошибок при нисходящем разборе 301
ошибок, то производятся компиляция и полное выполнение
программы. Обычно нефатальные ошибки — это те, которые по мнению
разработчика компилятора могут быть с большой вероятностью
устранены процедурой нейтрализации. В тексте сообщений для
V <5> (а,,а-]
V <Л><5> а,,а-\
V.<*> »>«Н
V <*><£> ,а-\
ПЕЧАТАТЬ (4, ВСТРЕТИЛАСЬ ЗАПЯТАЯ, КОГДА ОЖИДАЛОСЬ
V{R) ' S- ВЫРАЖЕНИЕ) f.e_j
V{R)\S) a-\
V<*> Н
ПЕЧАТАТЬ (6, . ПРОПУЩЕНА ПРАВАЯ СКОБКА)
ВЫХОД
(а,, а
t
ЗАПЯТАЯ ВСТРЕТИЛАСЬ, КОРДА ОЖИДАЛОСЬ S -ВЫРАЖЕНИЕ
(а,, а
t
ПРОПУЩЕНА .ПРАВАЯ СКОБКА
в
Рис. 8.29.
нефатальных ошибок обычно указывается, что это только
предупреждение.
В предыдущем примере такой тип ошибок, по-видимому,
соответствует элементам d и е. Сообщение об ошибке можно заменить
на предупреждение
«ПРЕДПОЛАГАЕТСЯ, ЧТО ПРОПУЩЕНА ЗАПЯТАЯ»
Теперь обсудим подход к нейтрализации ошибок, который
можно охарактеризовать, как «глобальный». Этот второй подход
можно использовать, когда разработчик недостаточно уверен в
точности какой-либо из локальных процедур нейтрализации или
когда ограничения на память не позволяют иметь для каждого
элемента свою нейтрализующую процедуру.
Основная идея заключается в следующем: входная цепочка
считывается до тех пор, пока не будет обнаружен символ из
множества «надежных» входных символов. Нейтрализация tзависит от
этого символа и верхнего символа магазина. Можно выделить два
типа надежных символов.
302
Гл. 8. Нисходящие методы обработки языков
Синхронизирующие символы
Синхронизирующий символ — это такой символ, относительно
которого разработчик по разумным причинам уверен, что он знает,
как возобновить процесс обработки. Множество синхронизирующих
символов для данного языка может включать некоторые символы
пунктуации, такие, как запятая, точка с запятой, и некоторые
зарезервированные слова, такие, как END и THEN.
В ходе процесса нейтрализации ошибок, когда процедура
считывания находит один из синхронизирующих символов, из
магазина выталкиваются символы до тех пор, пока не будет найден
магазинный символ, к которому можно применить данный
синхронизирующий символ для правильного продолжения процесса
обработки. С этого момента процесс обработки продолжается.
Один простой пример нейтрализации, основанный на
использовании синхронизирующих символов, встречается в тех
компиляторах, в которых после обнаружения ошибки игнорируются все
символы вплоть до следующей строки или следующего оператора.
Синхронизирующими символами в этом случае являются
разделители операторов и символы «новая строка». Нейтрализующие
процедуры для MINI-BASIC'a (разд. 10.4) и для многих компиляторов
с Фортрана принадлежат указанному типу.
Начинающие символы
Начинающий символ — это такой символ, который позволяет
разработчику предсказать несколько следующих терминальных и
нетерминальных символов, даже если он не в состоянии возобновить
процесс обработки.
Например, предположим, что грамматика для 5-выражений
является частью какой-то большей грамматики, которая не
использует скобки ни в каком другом контексте. Следовательно, когда во
входной строке встречается левая скобка, разработчик уверен, что
началось S-выражение, даже если невозможно полностью
согласовать содержимое магазина и входную цепочку.
Если в ходе процесса нейтрализации ошибок считывающая
процедура встречает левую скобку, то мы можем предсказать, что
она начинает цепочку, порожденную (S). Процедура
нейтрализации выполняет операцию
ВТОЛКНУТЬ ({ОШИБКА} (5 »
а затем продолжается обычный процесс обработки, в котором левая
скобка применяется к (S). Символ {ОШИБКА} — это новый
символ действия, который действует как мнимый маркер дна. Когда
{ОШИБКА} оказывается на верху магазина, мы знаем, что
предсказание проверено. Теперь предпринимается действие, выталки-
8.9. Метод рекурсивного спуска
303
вающее символ {ОШИБКА} из магазина и возобновляющее поиск
другого синхронизирующего или начинающего символа.
Вообще, обнаружив начинающий символ, процедура
нейтрализации вталкивает в магазин символ {ОШИБКА} и символы,
предсказываемые данным начинающим символом. Другие примеры
начинающих символов встречаются в тех языках, в которых всегда
операторы начинаются некоторыми зарезервированными словами.
Следует подчеркнуть, что в глобальных процедурах
нейтрализации множества синхронизирующих и начинающих символов нужно
рассматривать вместе. Например, некоторый символ часто можно
использовать как синхронизирующий, только если какой-то другой
особый символ используется в качестве начинающего символа.
Например, в грамматике для 5-выражений схема нейтрализации
ошибок, основанная только на использовании запятой и правой
скобки в качестве синхронизирующих символов, работать не будет,
так как, если считывающая процедура встретит левую скобку в
то время, когда она ищет запятую, то подсчет скобок будет
неверным. Однако если левую скобку рассматривать как начинающий
символ, то такая комбинация начинающих и синхронизирующих
символов будет удовлетворительной.
Указанные выше способы нейтрализации никоим образом не
являются единственно возможными способами, которые можно
использовать. Можно придумать другие процедуры, особенно
глобального типа, для того чтобы учесть особенности данного языка.
Нейтрализация ошибок — это скорее искусство, чем наука, и
указанные в этом разделе способы нужно рассматривать как примеры,
а не как универсальные процедуры.
8.9. Метод рекурсивного спуска
Мы показали, как некоторые типы языков можно распознавать и
переводить нисходящим методом с помощью МП-автомата. В этом
разделе приводится другой, но тесно связанный с ним метод
распознавания и перевода языков. Этот другой метод называется
рекурсивным спуском и ориентирован на те случаи, когда компилятор
программируется на одном из языков высокого уровня (таком как
Алгол или ПЛ/1), когда допускается использование рекурсивных
процедур. (Процедура называется рекурсивной, если она может
вызывать саму себя либо непосредственно, либо через цепь вызовов
других процедур.)
Основная идея рекурсивного спуска состоит в том, что каждому
нетерминалу грамматики соответствует процедура, которая
распознает любую цепочку, порождаемую этим нетерминалом. Эти
процедуры вызывают друг друга, когда это требуется. Таким
образом, магазинный механизм МП-автомата заменяется
механизмом вызова процедур, присущим языкам высокого уровня.
304
Гл. 8. Нисходящие методы обработки языков
В качестве примера рассмотрим следующую <7"гРамматикУ о
начальным символом (S):
1. (S)-+a{A){S)
2. (S)-+b
3. {A)-+c{A){S)b
4. {А)-+г
На рис. 8.30 показаны процедуры, распознающие язык,
порождаемый данной грамматикой. Процедуры для распознавания (S)
и (Л > называются ПРОЦ5 и ПРОЦЛ соответственно. В них пред-
Главная программа
н Начало программы"
Установить ВЩ=
первый входной
символ
вызов npous
Если ВХОД*нто
отвергнуть
допустить
Процедура ПРОЦЭ
Переход нее
а
Ь
с
ч
Р1
. Р2
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
а
Ь
с
-\
Р4
Р4
РЗ
ОТВЕРГНУТЬ
Pf:„ Код- для
правила 1"
Вызов сдвиг
Вызов Прона
Вызов ПРОЦЭ
Возврат
Р2:„ Код для
правила 2 "
вызов сдвиг
Возврат
Процедура ПРОЦЛ
Переход на
Р3:„ Код для
правила 3 "
Вызов сдвиг
Вызов проца
Вызов npous
вели вход *ь
то отвергнуть
Вызов сдвиг
Возврат
№. у, Код для
правила 4 "
Возврат
Рис. 8.30.
полагается наличие процедуры, называемой СДВИГ, которая
делает сдвиг по входной цепочке и присваивает значение нового
входного символа переменной ВХОД.
8.9. Метод рекурсивного спуска
305
Процедура ПРОЦ5, соответствующая (S), начинает работу,
принимая то же решение, что и МП-автомат, когда он
обнаруживает на верху магазина символ (S). Процедура рассматривает
текущий входной символ и выбирает то правило, которое нужно
применить. На рис. 8.30 показано, что этот выбор производится
с помощью некоторого переключателя или оператора перехода
на вычисляемую метку. В следующей за словом goto таблице для
каждого значения переменной ВХОД указана метка, на которую
происходит переход. Считается, что у нас есть процедура обработки
ошибки, помеченная меткой ОТВЕРГНУТЬ.
Меткой Р\ помечен код, соответствующий правилу 1. Вначале
этот код вызывает процедуру СДВИГ. Это делается по той же
причине, по которой МП-распознаватель делает СДВИГ, применяя
правило 1. Текущий входной символ был сопоставлен с самым
левым символом правой части правила, и нужно сделать сдвиг по
входу, чтобы можно было обработать остальные входные символы.
МП-автомат должен, кроме того, втолкнуть (S > и (Л > в магазин,
потому что очередные цепочки, которые нужно найти во входной
цепочке, должны порождаться этими символами. Процедура ПРОЦ5
отыскивает эти цепочки, просто вызывая процедуру ПРОЦЛ для
того, чтобы найти цепочку, порожденную <Л >, а затем — nPOUS
для того, чтобы найти цепочку, порожденную (5). Так как правая
часть правила 1 будет исчерпана, после того как эти вызовы
завершатся, далее происходит возврат из процедуры.
Код, помеченный Р2 и соответствующий правилу 2, очень прост.
Известно, что входной символ является желаемым порождением
(5 >, и потому производится сдвиг по входу и возврат из процедуры.
Соответствующая (Л > процедура, ПРОЦЛ, начинает работу
с выбора правила, которое нужно применить. Решение принимается
на основе следующих равенств:
ВЫБОР (3) = {с}
ВЫБОР(4)=СЛЕД((Л» = {а, Ь)
Код, соответствующий правилу 3, помечен РЗ. Вначале вызывается
СДВИГ, затем ПРОЦЛ и затем ПРОЦЯ. После вызова ПРОЦЯ
код достигает точки, в которой текущий входной символ должен
совпадать с символом Ь из правой части третьего правила. Чтобы
убедиться, что текущим входным символом на самом деле является
Ь, проверяется значение переменной ВХОД. Если это не так, то
управление передается отвергающей процедуре. Если текущим
входным символом является Ь, то программа продолжает работу,
сдвигаясь по входной цепочке, поскольку Ь—это часть цепочки,
порождаемой (Л >, которую процедура ПРОЦЛ обнаружила. Так
как теперь правая часть правила полностью обработана, делается
возврат из этой процедуры. Соответствующий правилу 4 код с
меткой Р4 тривиален. Над входной цепочкой не выполняется ни-
306
Гл. 8. Нисходящие методы обработки языков
каких операций, так как текущий входной символ должен
обрабатываться дальше, и никакая процедура не вызывается, так как
правая часть правила пуста. Таким образом, единственное
действие — это возврат.
На, рис. 8.30 показана также главная программа, которая
инициирует вызовы процедур. Эта программа должна гарантировать,,
что входная цепочка состоит из цепочки, порожденной (5), за
которой следует концевой маркер. Она начинается с того, что входной
символ присваивается переменной ВХОД. Затем следует вызов
riPOUS, а затем проверка, является ли текущий входной символ
концевым маркером.
Процедуры можно легко расширить так, чтобы они выполняли
перевод, описываемый грамматикой цепочечного перевода, входной
грамматикой которой является данная грамматика. Например,
предположим, что к грамматике добавлены действия, в результате
чего правила стали такими:
1. (S)^a(A){x}(S)
2. {S)^b{z}
3. (A)^c{y}(A){S){v}b
4. (A)^{w)
Процедуры рис. 8.30 изменяются так, что в точках,
соответствующих действиям, добавленным к грамматике, вставляются
выходные действия. В результате получаем множество процедур»
показанных на рис. 8.31.
Рекурсивный спуск можно использовать для любой LL (1)-
грамматики. Каждому нетерминалу грамматики соответствует
процедура, которая начинается с перехода на вычисляемую метку и
содержит код, соответствующий каждому правилу для данного
нетерминала. Для тех входных символов, которые принадлежат
множеству выбора данного правила, вычисляемый переход
передает управление коду, соответствующему этому правилу. Для
остальных входных символов управление передается процедуре
ОТВЕРГНУТЬ, или если нетерминал имеет аннулирующее
правило, то коду этого правила.
Код любого правила содержит операции для каждого символа,
входящего в правую часть правила. Операции расположены в
том порядке, в каком символы расположены в правиле. За
последней операцией код содержит возврат из процедуры.
Различным типам символов, которые могут встретиться в
правой части правила грамматики цепочечного перевода,
соответствуют такие операции:
1) символу действия — операция ВЫДАТЬ этот символ;
2) терминалу, который в данном правиле является первым
символом, отличным от символа действия,— операция СДВИГ;
8.9. Метод рекурсивного спуска
307
3) другим терминалам — проверка и СДВИГ;
4) нетерминалам — вызов соответствующей процедуры.
Заметим, что рекурсивная процедура для нетерминала очень
похожа на строку, соответствующую этому нетерминалу в
управляющей таблице нисходящего МП-распознавателя.
Главная .программа
/ и
начало программы
Установить 8Х0Д =
первый, входной символ
Вызов npoixs
если ВХОД * н то
ОТВЕРГНУТЬ
допустить
Процедура ЛРОЦЭ
Переход на
a
h
с
ч
Р1
Р2
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
Р1: „Код для
правила 1 "
Вызов сдвиг
Вызов ПРОЦА
Вызов ВЫДАТЬ (я)
вызов лроцб
Возврат
Р2: „ код для
правила 2"
Вызов сдвиг
Вызов выдать (z)
Возврат
Рис.
8.31.
Процедура: worn
Переход на
a
Ь
с
ч
Р4
Р4
РЗ
ОТВЕРГНЭТЬ
РЗ: „код для
правила 3 "
Вызов сдвиг
ВЫЗов ВЫДАТЬ (у)
Вызов проца
вызов npous
Вызов выдать Си)
Если ВХОД ФЬ то
ОТВЕРГНУТЬ
Вызов сдвиг
Возврат
Р4: „ Код .дЛЯ
правила 4."
Вызов выдать (w)
Возврат
Реализация рекурсивного спуска на языке высокого уровня
облегчает программирование и отладку. В частности, программисту
не нужно создавать магазин и обеспечивать управление им.
Тем не менее наличие магазина является существенной
особенностью рекурсивного спуска, так как сама реализация языка вы-
308
Гл. 8. Нисходящие методы обработки языков
сокого уровня должна включать использование магазина или его
эквивалента во время выполнения программы. В частности, в ходе
выполнения программы нужно использовать стек адресов возврата,
так чтобы каждый вызов данной рекурсивной процедуры мог
передать-управление туда, откуда он был сделан. На самом деле многие
языки высокого уровня имеют более сложные стековые механизмы
чем те, что требуются для реализации МП-автомата. Следовательно,
прямая реализация МП-автомата по затратам времени и памяти
будет, вероятно, эффективнее, чем рекурсивный спуск.
8.10. Замечания по литературе
Вначале работы по нисходящим процессам обработки были
связаны в «недетерминированными нисходящими» процессами.
Поэтому слово «нисходящий», применяемое в литературе без
пояснения, часто относится к недетерминированному случаю.
5-грамматики были формализованы и изучены Кореньяком и
Хопкрофтом [1966]. LL-грамматики были формализованы Льюисом
и Стирнзом [1968] и изучались также в работах Курки-Суонио
[1969], Вуда [1969а, 19696], Розенкранца и Стирнза [1970]. Гро
[1961] описал использование рекурсивных процедур в компиляторе.
Некоторая изощренная техника нейтрализации ошибок описана
у Айронса [19636] и Фримэна [1964].
Упражнения
1. s-грамматика порождает следующее дерево вывода:
<s> <s>
я <fi> <А> b <A> <A> с <А>
/I /
b с с с
Выпишите последовательности конфигураций соответствующего этой
грамматике нисходящего МП-распознавателя, возникающие при обработке
следующих входных цепочек:
Упражнения
30»
а) aababbccccaa
б) cb
в) ссса
г) teac
2. Для каждого из следующих языков постройте s-грамматику и
соответствующий нисходящий МП-распознаватель:
а) {1"т0п|п>0}
б) {w m wr\w из (0+1)*}
в) {lnmOn}U{ml"m02n}, где я>0
г) {\пт0"\Рт0Р\п>0, р>0}
д) {1"0"|и>0}
Изобразите в виде последовательности конфигураций, как автомат,
построенный для (г), распознает цепочку HmOOlmO.
3. Нисходящий процессор для следующей грамматики
1. (S)-ya(S)(S)
2. (S)-у b{S)
3. (S)-+c(S)(S){S)
4. {S)->d
при обработке некоторой цепочки распознает правила в таком порядке:
1, 4, 3, 2, 4, 2, 1, 4, 2, 4, 4.
Найдите эту цепочку.
4. Следующая последовательность конфигураций получается при обработке
входной цепочки adbabab нисходящим МП-распознавателем для какой-то
s-грамматики. Постройте дерево вывода этой входной цепочки,
V<S> adbabab-\
V &<£>> dbabab-\
V b <D> a <S> 6 a 6 a b -j
V 6 <£>>a ab ab—\
Vb<D> bab-\
V ba ab—\
Vb b-\
V H
ДОПУСТИТЬ
5. Покажите, что никакая цепочка языка, порождаемого s-грамматикой, не
может быть префиксом какой-либо другой цепочки этого языка.
6. Для каждого из следующих языков постройте ^-грамматику и
соответствующий нисходящий МП-распознаватель.
а) {1»|л>0}
б) {1"0"|п>0}
в) {1"0»»|0<п<т}
Укажите без строгого доказательства, почему для этих языков не существует
s-грамматик.
7. Следующий автомат построен с помощью методов этой главы:
310
Гл. 8. Нисходящие методы обработки языков
<s>
<А>
0
<В>
V
а
#1
#2
#4
#4
Ь
#2
#3
#4
#4
с
#2
#2
#5
#4
d
#2
#2
#6
#4
н
#2
#2
#4
#7
#1 ЗАМЕНИТЬ (<8> <А>), СДВИГ
#2 ВЫТОЛКНУТЬ, ДЕРЖАТЬ
#3 ЗАМЕНИТЬ(<Я> <Л> <S>), СДВИГ
#4 ОТВЕРГНУТЬ
#5 ЗАМЕНИТЬ (<Я>), СДВИГ
#6 ВЫТОЛКНУТЬ, СДВИГ
#7 ДОПУСТИТЬ
Начальное содержимое магазина :V<S >
а) Найдите грамматику, использованную при построении автомата.
б) Какие элементы таблицы можно заменить на ОТВЕРГНУТЬ так, чтобы
это не повлияло на распознаваемый язык.
8. Для переводов, описанных в упр. 5.13, (а) и (б):
а) постройте грамматику цепочечного перевода, входная грамматика которой
является «^-грамматикой;
б) с помощью этой грамматики постройте управляющую таблицу МП-автомата
с одним состоянием, выполняющего этот перевод.
9. Для каждой из следующих грамматик (с начальным символом {S)) постройте
управляющую таблицу МП-автомата, который распознает сверху вниз
порождаемый грамматикой язык.
а) (S)-+a(A)(B)
(S)-+b{B)(S)
(S)-^e
(A)-+c(B)(S)
<Л>-*е
(B)^d(B)
{B)-+e
б) {S)-+a(A)b{B)b(S)
<S)-*e
{A)^a{B){C)
iA)-+b(A)
(B)^a(B)
(C) + c(C)
в) Изобразите в виде последовательности конфигураций, как автомат,
соответствующий грамматике (б), распознает цепочки:
aaabab
aabbaabb
10. Некоторая ^-грамматика порождает две цепочки: BABY и ВВВВ. Когда
цепочка BABY применяется в качестве входа МП-автомата с одним состоянием,
который распознает нисходящим методом язык, порождаемый этой
грамматикой, получается последовательность конфигураций, приведенная ниже.
(Заметьте, что в последовательности не показаны входные символы, которые
применяются в конфигурациях.)
V<S>
v<s><c>
Упражнения
311
V<S> Y <S><C>
V<S> Y <S>
V<S> К
V<S>
V
Постройте последовательность конфигураций, которая была бы получена,
если бы на вход автомата поступила цепочка ВВВВ.
П. Напишите программу на любом языке, которая реализует МП-автомат,
показанный на:
а) рис. 8.6,
б) рис. 8.8,
в) рис. 8.12,
г) рис. 8.16.
Для реализации управляющей таблицы используйте один из методов,
приведенных в гл. 3, а для реализации магазина используйте массив с указателем
произвольного типа.
12. Покажите, как для произвольной грамматики построить грамматику
цепочечного перевода, описывающую перевод левых выводов (представленных
цепочками, состоящими из имен правил) в цепочки, порождаемые этими
выводами.
13. Покажите, как для произвольной КС-грамматики можно построить МП-
автомат, который бы допускал в качестве входной цепочку, состоящую из
правил, используемых в левом выводе некоторой цепочки определяемого
грамматикой языка, и выдавал в качестве выхода:
а) обращение последовательности правил, используемых в правом выводе
той же цепочки;
б) цепочку, порождаемую при выводе;
в) перевод, определяемый для данной грамматики произвольной
транслирующей грамматикой.
14. Для следующей грамматики с начальным символом (S):
(S)-+a(A)(B)
(S) - Ь(А)
(S)-ye
{А)-+а{А)Ь
(А)^г
{В)^Ь{В)
(В)^с
а) найдите множество СЛЕД для каждого нетерминала;
б) найдите множество ВЫБОР для каждого правила;
в) определите, является ли эта грамматика (/-грамматикой.
15. Постройте МП-автомат для каждой из следующих грамматик цепочечного
перевода (с начальным символом (S)):
{S)->a{x}(B){h}{a}c
<S)-+{a}b{a}
(В)^с{х}{у}(В)(В){е)
(B)-+a{b){c}d{e)f{y)
<S>-*-3{THREE}(erp)<S){V01D}
{S)-+{y}{z}4
(a)
312
Гл. 8. Нисходящие методы обработки языков
(егр) -»- 8
<erp>->2{TWOK5><erp>
(S) -+ {A){noon){Y)Y
(5>->X{0RB}
(hoon>-> {NIB}Q<noon>
<noon>->{BLAZB}
(6)
(в)
16. Покажите, как можно для данной И-(1)-грамматики построить
транслирующую грамматику, которая бы переводила любую цепочку определяемого ею
языка в цепочку, состоящую из имен правил, используемых в левом еа
выводе, в том порядке, в котором правила распознаются нисходящим
распознавателем.
17. ЬЦ1)-грамматика порождает следующее дерево вывода:
<S>
<в>
18.
10.
.20.
Выпишите последовательности конфигураций нисходящего
МП-распознавателя для этой грамматики, возникающие при обработке следующих входных
цепочек:
а) abcccdaa
б) 8
в) ассо
г) adab
Предположим, что грамматика содержит правило {А)-*-а (где а — цепочка
терминалов и нетерминалов), и это правило является аннулирующим.
Покажите, что если множество ПЕРВ(а) и СЛЕД((Л>) пересекаются, то данная
грамматика не может быть 1Х(1)-грамматикой.
Покажите, что данная LL(1) -грамматика с начальным символом (5) (в
которой нет лишних нетерминалов) останется ЬЦ1)-грамматикой, если в качестве
начального символа будет взят любой другой нетерминал.
Установите, могут ли следующие последовательности конфигураций
принадлежать нисходящему МП-распознавателю,
Упражнения
313
V<5>
V с <5> (В)
VC(S)
V с
V
ДОПУСТИТЬ
а
v<s>
V <Я> <5>
V <Я> <Я> <5>
V (В) (В) (В) (S)
V (В) (В) (В)
V (В) (В)
V(B)
V
ДОПУСТИТЬ
-0
V<5>
v<s>
V<5>
v<s>
V<5>
V
ДОПУСТИТЬ
ab ac —|
ftoc —|
ac —|
c-\
4
aaa b —\
a a b —\
ab-\
ь-\
H
H
4
4
a b с d—\
bcd-\
cd-\
d-\
H
H
V<5>
V (B) (S) (B)
V <Д> <5>
V(B)
V С
V
ДОПУСТИТЬ
6
v(S)
V
ОТВЕРГНУТЬ
г
V<5>
V
V
ДОПУСТИТЬ
e
21. Найдите все аннулирующие нетерминалы в следующей
(S)^a(B)(D) (S)^{A){B)
(S)_>(Z»M>(C> {S)-+b
{A) -> (S)(C){B) (A) -> (S){A){B)(C)
{A)-+{C)b(D) {А)-*-с
{A) -+ e (B) -* c{£>>
<B> -► d <fl> ->- e
<D)^<S)a{0 {D)^{S){0
0)^fg
abас —f
йа с —)
6ac —)
« c—|
M
H
H
-4
<v6-{
a-h
H
грамматике:
314
Гл. 8. Нисходящие методы обработки языков
22. Могут ли два аннулирующих правила ЬЦ1)-грамматики иметь одинаковые
левые части?
23. Покажите, как в случае <7-грамматик можно упростить процедуру нахождения
множеств выбора, приведенную в разд. 8.7.
24. Для следующей грамматики с начальным символом (S):
{S)^a{A)(B)b(C){D) <S)->-e
(A)^{A)(S)d <Л> —е
(B)-+{S)(A)c (В)^е(С)
(5> — е (С) — (S)/
<C>^<C)g (С>->8
(D) -+ a{B){D) (D) -+ 8
а) найдите СЛЕД для каждого нетерминала;
б) найдите ВЫБОР для каждого правила;
в) определите, является ли данная грамматика ЬЦ1)-грамматикой.
25. Напишите программу на Алголе или ПЛ/I, которая бы реализовала
процедуру рекурсивного спуска для МП-автоматов, показанных на
а) рис. 8.6,
б) рис. 8.8,
в) рис. 8.12,
г) рис. 8.16.
26. Покажите, как можно реализовать процедуру, аналогичную рекурсивному
спуску, с помощью такого языка, как Фортран, который не допускает
рекурсивных вызовов процедур. Используйте стек для запоминания точек возврата.
Продемонстрируйте полученную процедуру в применении к МП-автомату
на рис. 8.12.
27. Покажите, как можно обобщить идеи, изложенные в разд. 8.9, для того, чтобы
разработать метод рекурсивной обработки для реализации любого
примитивного МП-автомата (т. е. автомата не с одним, а несколькими состояниями и
с магазинными операциями ВТОЛКНУТЬ и ВЫТОЛКНУТЬ).
28. Для каждого элемента ОТВЕРГНУТЬ на рис. 8.26:
а) найдите самую короткую входную цепочку, для которой этот элемент будет
достигнут.
б) Из каждой цепочки, найденной в пункте (а), вычеркните нарушающий
символ и найдите самую короткую цепочку, конкатенация которой с
префиксом исходной цепочки даст правильную цепочку языка.
29. а) Найдите множество цепочек, под действием которых автомат посетит все
элементы управляющей таблицы рис. 8.28, включая элемент ОТВЕРГНУТЬ,
б) Выпишите все сообщения об ошибках, которые будут сделаны для этих
цепочек.
30. Выпишите последовательность конфигураций и список всех сообщений об
ошибках, которые будут сделаны автоматом рис. 8.28, если дана входная
цепочка
,а,аа(а, ,( )а, , ,
31. Как вы думаете, целесообразно ли заменить процедуру нейтрализации
ошибок для элемента а рис. 8.28 на:
а) ЗАМЕНИТЬ ((R){S)), СДВИГ
б) ВЫТОЛКНУТЬ, СДВИГ
в) СДВИГ
32. Найдите три цепочки, для которых локальная процедура нейтрализации
ошибок, показанная на рис. 8.28, работает плохо. Объясните, почему это так.
33. Постройте КС-грамматику для множества цепочек, под действием которых
автомат, найденный на рис. 8.28, достигает элемента ДОПУСТИТЬ.
Упражнения
315
34. В следующей грамматике с начальным символом (Е) знак f обозначает
операцию возведения в степень. В выражениях, порождаемых этой
грамматикой, возведение в степень должно выполняться слева направо, за
исключением операций внутри скобок, которые выполняются раньше.
1. (E)-+a(R)
2. (Е)~+ ((£))</?)
3. (R)^ia(R)
4. (/?>-* 8
а) Покажите, что это <7-грамматика.
б) Спроектируйте для нее распознаватель.
в) Для этого процессора разработайте полностью действия, касающиеся
обработки ошибок, включая сообщения об ошибках и локальные процедуры
нейтрализации ошибок.
35. Для следующей алголоподобной грамматики с начальным символом
{оператор):
1. (оператор)-v begin (описания), (список операторов)епс1
2. (описания) ->■ d; (описания)
3. (описания) -»• е
4. (список операторов)-> «(остальные операторы)
5. (список операторов) ->• e
6. (остальные операторы) -»-; (список операторов)
7. (остальные операторы) ->• г
а) покажите, что это (^-грамматика,
б) постройте для нее распознаватель,
в) разработайте подходящее множество сообщений об ошибках,
г) разработайте локальные процедуры нейтрализации ошибок,
д) разработайте глобальные процедуры нейтрализации ошибок.
36. а) Постройте ^-грамматику для S-выражений из языка Лисп.
б) Постройте управляющую таблицу нисходящего МП-распознавателя,
соответствующего вашей грамматике.
в) Разработайте сообщения об ошибках, для всех отвергающих элементов
таблицы.
г) Разработайте локальные процедуры нейтрализации ошибок.
37. а) Покажите, что каждое регулярное множество определяется (у-граммати кой.
б) Найдите такое регулярное множество, для которого не существует s-
грамматики.
в) Покажите, что для любого регулярного множества /?, язык R—|, где —|
рассматривается как терминальный символ, имеет s-грамматику.
38. Конечный транслятор — это конечный распознаватель, расширенный таким
образом, что каждый переход может сопровождаться определенным выходом.
Покажите, что отношение между входами и выходами такого устройства всегда
можно описать грамматикой цепочечного перевода, входной грамматикой
которой является ^-грамматика.
39. Постройте (^-грамматику для следующих конструкций языка Алгол. Считайте
терминалами (логическое выражение) и (арифметическое выражение), а в
случае оператора цикла — (оператор), т. е., дойдя до них, вывод прекращается.
а) Описания массивов.
б) Описания переключателей.
в) Операторы цикла.
40. а) Поясните, почему не существует LL-грамматики для следующего языка:
{1"0"}U{1"2"} л>0
б) Постройте для этого языка МП-распознаватель с одним состоянием
(использующий операцию ЗАМЕНИТЬ).
41. Покажите, что МП-автоматы, построенные согласно процедурам разд. 8.4,
8.5 и 8.6, никогда не зацикливаются,
316
Гл. 8. Нисходящие методы обработки языков
42. Покажите, что все s-грамматики, ^-грамматики и ЬЦ1)-грамматики
однозначны.
43. а) Преобразуйте ЬЦ1)-грамматику рис. 8.15 вд-грамматикудлятогожеязыка.
б) Опишите процедуру, которая будет преобразовывать любую LL(l)-rpaw-
матику в (^-грамматику для того же языка.
44. Следующие две грамматики с начальным символом (5) порождают один и
тбт же язык:
Грамматика 1:
1. <5>->(5>(Л>
2. {А) -+ {B){S)
3. (A)-+d
4. {В)-+а{А)
5. {fi>->6(S>
6. {В)-+с
Грамматика 2;
1. {S)^a{A)(A)
2. (S)->6(5)U)
3. (5>->с(Л)
4. {А)-+а{А№
5. {A)-+b{S){S)
6. {A)-+c{S)
7. (A)-+d
Грамматика 2 была получена из грамматики 1 подстановкой вместо {В) в
правила 1 и 2 правых частей правил для {В). После этого {В) становится
недостижимым и удаляется.
1. Покажите, что грамматика 1 является И-(1)-грамматикой, а грамматика
2 — д-грамматикой.
2. Для каждой грамматики постройте соответствующий МП-автомат.
3. Сравните последовательности конфигураций каждого автомата,
возникающие при распознавании цепочки
abcdbcdccdd
4. Сравните, сколько времени и памяти требует каждый из автоматов.
45. Предположим, что (Л) является аннулирующим нетерминалом, который можно
использовать для порождения по крайней мере двух терминальных цепочек.
Покажите, что в ЬЦ1)-грамматике не может быть правила, в правой части
которого имеется два смежных вхождения (Л). Другими словами, не может
быть правил вида
(В)^а(А)(А)£
где а и Р — произвольные цепочки, состоящие из терминалов и нетерминалов.
46. Покажите, что число операций, выполняемых нисходящим
МП-распознавателем для ЬЦ1)-грамматики, при распознавании ограничено числом входных
символов, умноженным на константу.
47. а) Покажите, что следующая грамматика не является ЬЦ1)-грамматикой:
(S)-+(S)a
{S)-+b
б) Говорят, что нетерминал {X) леворекурсивный, если:
<Х> =>+ <Х> w
Покажите, что если грамматика содержит леворекурсивный нетерминал, то
она не ЬЦ1)-грамматика,
Упражнения
317
48. Выпишите последовательности конфигураций процессора на рис. 8.17,
возникающие при обработке следующих цепочек:
а) /*(/+/+/)*/+/
б) /+(/•/)/
49. а) Покажите, что элемент ОТВЕРГНУТЬ, который стоит в строке (£-список)
и столбце ♦ управляющей таблицы рис. 8.17, никогда не достигается даже
при обработке неправильных входных цепочек,
б) Разработайте сообщения об ошибках для достижимых элементов
ОТВЕРГНУТЬ таблицы на рис. 8.17.
60. а) Постройте ЬЦ1)-грамматику для арифметических выражений, в которых
используются операции +, —, *, /, \.
б) К построенной грамматике добавьте правила, чтобы включить унарные
операции + и —.
в) Постройте процессоры для грамматик, найденных вами в пунктах (а) и (б).
61. Для следующей грамматики с начальным символом (логическое выражение):
(логическое выражение) ->• (логическое выражение) л (логический
множитель)
(логическое выражение) -*■ (логический множитель)
(логический множитель)-v (логический множитель) л (логическое вторичное)
(логический множитель)-v (логическое вторичное)
(логическое вторичное) -у-1 (логическое первичное)
(логическое вторичное) ->- (логическое первичное)
(логическое первичное) ->• ((логическое выражение))
(логическое первичное) -у /
а) постройте ЬЦ1)-грамматику, порождающую тот же язык;
б) для каждого оператора введите подходящий символ действия;
в) постройте МП-процессор;
г) выпишите последовательность конфигураций автомата, возникающую
при обработке цепочки
-1/V/Л/
62. Используя метод рекурсивного спуска, постройте анализатор,
соответствующий распознавателю арифметических выражений рис. 8.17.
53. Постройте процессор, выполняющий перевод арифметических выражений из
инфиксной в польскую запись (см. разд. 7.3).
64. Рассмотрите следующие две транслирующие грамматики (каждая с начальным
символом (F)):
(F) -+ <F)t<P){BbIP} (F) -+ (Р)№{ВЫР}
{F)^(P) (F)-+(P)
<P)->-((F)) <P)->«F))
(P) -+I (P) -+ /
а) Выпишите последовательности актов и деревья выводов, соответствующие
обеим грамматикам, для входной цепочки:
/f/f/
(Операция f в первой грамматике называется «левоассоциативной», во
второй грамматике — «правоассоциативной»).
б) Найдите ЬЬ(1)-грамматики, порождающие те же последовательности
актов, что и приведенные выше грамматики.
65. Напишите 1Х(1)-грамматику, порождающую тот же язык, что и каждая из
следующих грамматик:
318
Гл. 8. Нисходящие методы обработки языков
а) 1. (программа)-> begin (список операторов) end
2. (список операторов) -> (список операторов); (оператор)
3. (список операторов) -»- (оператор)
4. (оператор) -»- s
Начальный символ: (программа)
б)'1. (идентификатор) -»- (буква)
2. (идентификатор) -»- (идентификатор) (буква)
3. (идентификатор)-»-(идентификатор) (цифра)
4. (буква)-»-А
5. (буква)-»- В
6. (цифра) -»■ 3
7. (цифра)-»-4
Начальный символ: (идентификатор)
56. Постройте И,(1)-грамматику для выражений языка MINI-BASIC,
предполагая, что в языке сделаны следующие изменения:
а) Там, где допустимы унарные операции, их можно использовать сколько
угодно раз. Так выражение 2+( 4 +5) допустимо и равно П.
б) Все операции выполняются слева направо, но операции, которые находятся
внутри скобок, выполняются прежде, чем операции вне скобок. Так,
3+2*7 равно 35.
в) Все операции выполняются справа налево, но операции внутри скобок
выполняются раньше, чем операции вне скобок.
г) Унарные операции + и — разрешены перед любым операндом и
выполняются раньше других операций. Так, выражение 3*—4f2 допустимо и
равно 48.
57. Рассмотрим следующую грамматику с начальным символом (Л):
(А)-+{А)с(В)
(Л)-^с(С)
(Л)^(С)
(B) -> Ь(В)
(flU/
(с) -► <сЫв)
(C) ->- (ВЖВ)
(С) -*• (В)
а) Покажите, что эта грамматика однозначна.
б) Постройте ЬЬ(1)-грамматику для того же языка.
58. Постройте процедуру нисходящего анализа для каждой из следующих LL(2)-
грамматик с начальным символом (S):
а) (5) -»- ab(S)a
{S)^>.aa(A)b
<S)-+b
(A)-*-ba(A)b
(A)^b
б) (S)-*a{S)(A)
<S) + e
(A) -> b(B)
(A) -»■ cc
(B) ->- bd
(B) ->- e
59. Опишите процедуру нейтрализации ошибок для метода рекурсивного спуска
из разд. 8.9.
60. Покажите, что если язык и его дополнение порождаются ^-грамматиками, то
они оба являются конечными языками.
9
Нисходящие методы обработки
для атрибутных грамматик
9.1. Введение
В этой главе мы покажем, как строить устройства, которые с
помощью магазинной памяти делают переводы, описываемые
некоторым классом атрибутных грамматик. О грамматиках, к которым
применяются рассматриваемые методы, можно неформально
сказать, ,что у них анализируемая сверху вниз входная грамматика и
вычисляемые сверху вниз правила для атрибутов. Под
«анализируемой сверху вниз грамматикой» мы имеем в виду такую
грамматику, что определяемый ею язык можно распознать одним из
автоматов, описанных в предыдущей главе,— например, LL (1)-
грамматику. Под «вычисляемыми сверху вниз правилами для
атрибутов» имеется в виду то, что значения атрибутов можно вычислять
по этим правилам в ходе нисходящего разбора,— например, «L-
атрибутные» правила, рассматриваемые в разд. 9.2.
Процедура построения представлена в виде алгоритма,
применяемого к атрибутным грамматикам цепочечного перевода.
Получаемые в результате ее применения устройства с магазинной памятью
являются автоматами, которые обрабатывают цепочки входных
символов с атрибутами и для каждой входной цепочки либо выдают
выходную цепочку в качестве ее перевода, либо отвергают ее как
не принадлежащую данному входному языку. Однако эту технику
легко расширить на более общие ситуации, так как действие,
производящее выход с атрибутами, можно заменить на действие,
вызывающее процедуру, которая использует эти атрибуты в качестве
своих аргументов.
9.2. L-атрибутные грамматики
В этом разделе мы определим класс грамматик, называемых L-ат-
рибутными грамматиками. Свойство L-атрибутности предназначено
для того, чтобы можно было вычислять атрибуты в порядке,
пригодном для нисходящих процессов обработки. В разд. 9.5 мы
покажем как можно получить расширенный атрибутный автомат с
магазинной памятью, который выполняет перевод, задаваемый
L-атрибутной грамматикой, имеющей анализируемую сверху вниз
(LL(1)) входную грамматику.
320 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
Атрибутная транслирующая грамматика называется L-ampu-
бутной тогда и только тогда, когда выполняются следующие три
условия:
1. Для каждого правила вычисления атрибута,
соответствующего'наследуемому атрибуту данного символа из правой части
данной продукции, каждый аргумент этого правила — это или
наследуемый атрибут левой части, или произвольный атрибут
символа из правой части, находящегося левее данного.
2. Для каждого правила вычисления атрибута,
соответствующего синтезируемому атрибуту левой части данной продукции,
любой аргумент этого правила — это или наследуемый атрибут
левой части, или произвольный атрибут символа правой части этой
продукции.
3. Для каждого правила вычисления атрибута,
соответствующего синтезируемому атрибуту символа действия, любой аргумент
этого правила — наследуемый атрибут данного символа действия.
Вспомним определение атрибутных транслирующих грамматик,
данное в разд. 7.7. Это определение содержало четыре пункта,
причем пункты 3 и 4 имели разделы а) и б). Приведенные выше
условия 1, 2 и 3 являются ограничениями на разделы За, 4а и 46
соответственно. Правила вычисления атрибутов, которые не
ограничиваются тремя приведенными выше условиями,— это только
правила инициализации из разд. 36.
Обладает ли данная грамматика свойством L-атрибутности,
можно проверить, независимо исследуя каждую продукцию (для
проверки условий 1 и 2) и каждое определение атрибутов символа
действия (для проверки условия 3). Эти исследования в свою
очередь состоят из независимых исследований, выполняемых для
различных правил вычисления атрибутов.
Чтобы проиллюстрировать подобную проверку, предположим,
что грамматика содержит продукцию
, 52, 5з ./7, /8
где /1, /4, II, /8 и /9 — наследуемые атрибуты, S2, S3, S5 и S6—
синтезируемые атрибуты; пусть правила вычисления атрибутов
S2, S3, 14, II, /8 и /9 заданы. Процедура исследования для этой
продукции состоит в проверке того, что правила для /4, II, /8 и /9
удовлетворяют условию 1, а правила для S2 и S3 удовлетворяют
условию 2.
Согласно условию 1, правило вычисления атрибута /4 может
использовать в качестве аргумента только /1. Таким образом,
правила могут быть такими:
/4ч-/(/1) или /4ч-328 или (/4, /7)ч-/1
9.3. Форма простого присваивания
321
но не могут быть такими:
/4ч-52 или /44-g(S6, /4)
Аналогично аргументы правил для /7 и /8 должны принадлежать
множеству {/1, /4, S5}, и аргументы правила для /9 должны быть
из множества {/1, /4, S5, S6, /7, /8}. По условию 2 правила
вычисления атрибутов S2 и S3 могут использовать любые атрибуты,
кроме самих S2 и S3.
Условие 3 используется для проверки правил вычисления
атрибутов символов действия. Чтобы убедиться в его выполнении, надо
просмотреть список аргументов правила и установить, что среди
них нет синтезируемых атрибутов.
«L-атрибутным» мы иногда будем называть также правило
вычисления атрибута, продукцию или символ действия. Мы называем
правило L-атрибутным, если оно удовлетворяет тому из указанных
трех условий, которое к нему относится. Мы называем продукцию
или символ действия L-атрибутным, если все соответствующие ему
правила вычисления атрибутов являются L-атрибутными. Таким
образом, атрибутная грамматика является L-атрибутной, если все
ее продукции и символы действия являются L-атрибутными.
Значение условия 1 состоит в том, что при его выполнении
наследуемые атрибуты данного символа зависят только от
информации, которая находится слева от него. («L» в слове «L-атрибутный» —
это сокращение, Left — левый.) Условие 1 полезно для обработки
атрибутов сверху вниз, потому что каждый символ обрабатывается
до того, как прочитаны входные символы, расположенные справа
от него. Условия 2 и 3 введены, чтобы исключить круговую
зависимость атрибутов, т. е. порочные круги в их определениях. Все
три условия, взятые вместе, приводят к тому, что если дана
продукция С4)->(В> (О, то атрибуты символов (А), (В) и (О можно
вычислить в следующем порядке:
1. наследуемые атрибуты (А );
2. наследуемые атрибуты (В);
3. синтезируемые атрибуты (В);
4. наследуемые атрибуты (О;
5. синтезируемые атрибуты (С);
6. синтезируемые атрибуты (А >.
9.3. Форма простого присваивания
Обычно мы записываем правила вычисления атрибутов как
операторы присваивания, в которых вычисляется функция,
использующая в качестве аргументов значения некоторых атрибутов, и ее
результат присваивается одному или нескольким другим атрибутам.
11 Ф. Льюис и др.
322 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
Например, в операторе присваивания
x+-f(y, г)
нужно вычислить /, которая использует значения атрибутов у и г
в качестве аргументов, и присвоить ее значение атрибуту х. Однако
в некоторых простых случаях (а именно в случае тождественной
или константной функции), правые части операторов присваивания
не содержат вычислений каких-либо функций. Вместо этого они
просто показывают, что значение одного из атрибутов или константа
присваиваются другим атрибутам. Вот два таких примера:
Хч-г/ и (х, у, г)ч-17
Правило вычисления атрибутов называется копирующим
правилом тогда и только тогда, когда оно имеет один из
следующих видов:
лгч-г/ или (*, хп)<-у
где левая часть — это атрибут или список атрибутов, а
правая часть у — либо атрибут, либо константа. Правая часть
называется источником копирующего правила, а каждый
атрибут в левой части называется приемником или
получателем копирующего правила.
Иногда можно объединить два копирующих правила в одно.
Например,
(х, y)<-z и (а, Ь)<-у
можно записать, как одно правило
(а, Ь, х, у)+-г
потому что источнику у второго правила, согласно первому
правилу, присваивается значение г. Аналогично
х ч- 2 и (а, Ь) ч- 2
можно записать, как
(х, а, Ь) ч- г
потому что источники правил полностью совпадают. Заметим, что
в обоих случаях получатели объединяются в общую левую часть.
Множество копирующих правил называется независимым
тогда и только тогда, когда источник каждого правила из
этого множества не входит ни в одно из других правил
множества.
Если два копирующих правила независимы, то их нельзя
объединить.
Понятие независимых копирующих правил приводит нас к
основному понятию данного раздела:
9.3. Форма простого присваивания
323
Атрибутная грамматика имеет форму простого присваивания
тогда и только тогда, когда
а) не копирующими могут быть только правила вычисления
синтезируемых атрибутов символов действия;
б) для каждой продукции соответствующее множество
копирующих правил независимо.
В разд. 9.5 мы покажем, как можно по данной L-атрибутной
грамматике в форме простого присваивания построить МП-автомат,
который выполняет соответствующий атрибутный перевод. В этом
разделе мы займемся следующей проблемой: «По данной
L-атрибутной грамматике найти «эквивалентную» L-атрибутную грамматику
в форме простого присваивания». Смысл используемого здесь
понятия эквивалентности обсуждается дальше.
Для данной продукции, у которой одно из правил вычисления
атрибутов не является копирующим, можно легко построить
продукцию, содержащую только копирующие правила и достигающую
такого же эффекта, что и данная. Для того чтобы
проиллюстрировать, как это делается, рассмотрим атрибутное правило
lA)-+aR(B)s{C),
l*-f(R, S)
где / — наследуемый, a S — синтезируемый атрибуты. Указанное
правило вычисления атрибута, конечно, не является копирующим,
так как оно требует вычисления функции /.
На первом шаге вводится новый символ действия,
представляющий вычисление функции /. Этот символ действия естественно
изобразить в виде {/}. Снабдим символ {/} двумя наследуемыми
атрибутами, по одному для каждого аргумента функции /, и одним
синтезируемым атрибутом.
Значение синтезируемого атрибута можно получить путем
применения / к наследуемым атрибутам. Полное определение {/} таково:
W/i./t.s* НАСЛЕДУЕМЫЕ II, 12 СИНТЕЗИРУЕМЫЙ S1
S1«-•/(/!. 12)
Второй шаг — изменение самой продукции с помощью:
1) включения в правую часть нового символа действия {/};
2) введения нового копирующего правила, которое
устанавливает требуемое соответствие между аргументами функции / (т. е.
R и S) и наследуемыми атрибутами символа {/};
3) введения нового копирующего правила, устанавливающего
соответствие между синтезируемым атрибутом символа {/} и
атрибутом, которому присваивается значение, вычисляемое функцией /
(т.е. /);
4) удаления правила, содержащего /.
324 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
Продукция, получаемая в результате выполнения этого шага,
не определяется однозначно, потому что возможен произвол в выборе
имен переменных, а также позиции вставляемого символа в правой
части продукции. В результате этого шага может получиться
такая продукция:
<Л> —a*<B>5W/i./..si<C>/
l\*-R /2 —S I*-S\
Заметим, что первоначальное правило, использующее /, заменено
на три копирующих правила, два из которых копируют аргументы
и одно — результат. Некопирующие правила исключены, и в
результате получена форма простого присваивания. Эта новая
продукция дает тот же эффект, что и старая в том смысле, что оба
правила порождают одинаковые входные цепочки с атрибутами и
задают одно и то же значение атрибута /. В этом смысле оба правила
приводят к одной и той же компиляции.
Формально новое правило не порождает того же перевода, так
как новое правило включает в последовательность актов символ
{/}. Новую последовательность актов можно рассматривать как
удлиненную таким образом, чтобы показать «действия»,
образующие вычисление функции /.
Проиллюстрировав технику получения формы простого
присваивания, рассмотрим теперь, каким образом ее применять, чтобы
сохранить свойство L-атрибутности. В рассмотренном примере мы
выбрали как будто произвольное решение — поместить {/} между
(В) и (С). Однако на самом деле это единственная позиция,
сохраняющая свойство L-атрибутности первоначальной продукции.
Предположим, например, что символ {/}был вставлен перед (В),
как в продукции
<Л> —а* {/}„.„. Sl<fi>s<C>,
II+-R /2 —S / —SI
Это форма простого присваивания, но наследуемый атрибут /2
оказался функцией атрибута, расположенного правее него, что
нарушает свойство L-атрибутности. Необходимо, чтобы вставляемый
символ был правее всех символов правой части, которые дают
значения, используемые для вычисления его наследуемых атрибутов.
Теперь предположим, что {/} был вставлен справа от (С), так что:
, /2, Si
/1—/? /2 — 5 / — SI
Теперь наследуемый атрибут / является функцией атрибута,
расположенного правее него, и вновь нарушается свойство
L-атрибутности. Необходимо, чтобы новый символ располагался левее
любого символа правой части, атрибуту которого присваивается
значение функции, соответствующей новому символу.
9.3. Форма простого присваивания
325
В этом примере два необходимых требования определяют
единственную позицию для вставки символа действия в правую часть
продукции. Если предъявляемые требования позволяют как-то
выбирать позицию, то самая левая из возможных позиций часто
оказывается наиболее эффективной, так как некоторые крайне
левые символы действия не нужно делать магазинными символами
МП-автомата, производящего
обработку. Если требования не
оставляют никакого
приемлемого выбора, то грамматика, следо- </г><. синтезируемый р
вательно, не может быть L-ат- { ОТВЕТ г} НАСЛЕДУЕМЫЙ,-
рибутной.
Для того чтобы проиллюстри- ' (S) — (£>р { ОТВЕТ,}
ровать эту технику на полной г~-р
грамматике, рассмотрим L-ат- _
рибутную грамматику, приведен- ' '* +\e)<,\f-)t
ную на рис. 9.1. Входной символ p — q + r
С этой грамматики представляет 3 (£\ _ * /f\ /f\
константу и его значение — это '" ^ '" ' ' ■"
арифметическое значение кон- Р — q* r
станты. Грамматика порождает 4. (Е) —■ С
префиксные польские выраже- " ''
ния над константами. Перевод Р*~Ч
аналогичен переводу инфиксных Чачальный симбол:($)
выражений над константами,
приведенному в разд. 7.5. ис" 9|-
Для того чтобы представить
эту грамматику в форме простого
присваивания, мы должны избавиться от двух некопирующих
правил рч-(/4-г и p+-q*r. В данном случае «функциями» являются
•сложение и умножение. Для их представления используются
символы действия {СЛОЖ} и {УМН}. Для сохранения свойства L-
атрибутности символ действия {СЛОЖ} нужно поместить правее
всех символов правой части, так как одним из аргументов
сложения является атрибут г самого правого символа (£).
Атрибут, получающий в качестве своего значения результат
сложения, при определении места расположения {СЛОЖ} не
рассматривается, так как он не приписан ни одному из
символов правой части. На рис. 9.2 показана полученная в
результате преобразования L-атрибутная грамматика в форме простого
присваивания.
После того как мы получили множество копирующих правил
для какой-то продукции, нетрудно объединить их в независимое
множество правил. Если источник какого-нибудь копирующего
правила входит еще и в другое правило, то эти правила просто
соединяются в одно так, как было показано в начале этого раздела.
326 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
Теперь представим приведенные выше идеи в виде отдельной
процедуры, преобразующей L-атрибутную грамматику в L-атри-
бутную грамматику в форме простого присваивания, пригодную
для методов построения автоматов разд. 9.5.
<£>р СИНТЕЗИРУЕМЫЙ/?
{ОТВЕТ г1 НАСЛЕДУЕМЫЙ г
{СЛ0Ж}^М2,я НАСЛЕДУЕМЫЙ А1,А2 СИНТЕЗИРУЕМЫЙ)?
R*- А\ + А2
{УМН0Ж}ЛЫ2,я НАСЛЕДУЕМЫЙ А\, А2 СИНТЕЗИРУЕМЫЙ К
R*-Al *A2
1. <5> -<£>„{ ОТВЕТ.,}
г^р
2. <£>„-* + (Е)я(Е)г{СЛОЩЛУА2Л
A\*-q A2+-r p^R
3. (Е)Р~**{Е)Я{Е)Г{ВМНЩЛ,Я2Я
A\^q Л2«-г p^R
p+-q
Начальный сшбол: <S>
Рис. 9.2.
1. Для каждой функции /(**, ...,хп), входящей в правило
вычисления атрибутов, связанное с некоторой продукцией
грамматики, создать соответствующий ей символ действия {/}, задаваемый
следующим образом:
\f\Xt Хп,Р НАСЛЕДУЕМЫЕ хх, ...,ха СИНТЕЗИРУЕМЫЙ р
Р*— f(*i, ■•■, ха)
2. Для каждого некопирующего правила
(2i 2m) 4-/(^1 Уп)
связанного с некоторой продукцией грамматики, найти символы
аи ..., ап, г, которые не содержатся в данной продукции, и
вставить в ее правую часть символ
Vfoi ап, г
9.3. Форма простого присваивания
327
в соответствии с приведенными ниже условиями. Заменить неко-
пирующее правило на следующие (п+1) копирующих правила:
o-i-ь-Уi Для каждого аргумента /;
При вставлении символа действия нужно соблюдать следующие
ограничения:
а) Символ действия должен располагаться правее каждого
символа правой части продукции, атрибутом которого
служит один из аргументов уи ..., уп.
б) Символ действия должен располагаться левее каждого символа
правой части продукции, атрибутом которого служит один
из атрибутов zu ..., zm.
в) С учетом ограничений а) и б) можно предоставить выбор
точек вставления разработчику. Предпочтение следует
отдать самой левой из возможных позиций, так как это
позволит в некоторых случаях избежать использования
соответствующего магазинного символа в МП-автомате,
реализующем перевод.
3. Два копирующие правила одной и той же продукции нужно
объединить в одно, если источник одного из них входит в другое.
Это объединение осуществляется путем удаления правила с лишним
источником и объединения его получателей с получателями
оставшегося правила.
Одно заключительное замечание относительно формы простого
присваивания: в последних примерах мы трактовали процедуры —
функции без параметров — как константы и разрешали
использовать их в качестве источников атрибутных правил в форме простого
присваивания. Например, разрешается использовать правило
Ш-* (В)х(С)у
(х, у) ч- НОВ
Однако этой свободы следует остерегаться, так как два разных
вызова процедуры-функции без параметров могут давать разные
значения, и, значит, два разных вхождения имени этой функции
считаются разными константами и их атрибутные правила нельзя
объединять. Например, в правиле
04 > + (B)x(Oy{dz}
х ч- НОВ (у, г) ч- НОВ
мы не можем объединить два присваивания в одно такое:
(*, у, г) ч- НОВ
328 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
9.4. Пример атрибутного автомата
В этом разделе мы приведем пример атрибутного автомата. Во
всех атрибутных автоматах мы используем магазинные символы,
которые состоят из имени и соответствующего множества полей.
Поля каждого символа, находящегося в магазине,— это ячейки
памяти, доступные для записи и извлечения информации в течение
времени существования этого символа (т. е. от момента вталкивания
до момента выталкивания). Для удобства изложения предположим,
что магазинный символ с п полями представляется в магазине
(п+1) ячейками, верхняя из которых содержит имя символа, а
нижние — поля. Рис. 9.3 показывает магазин V С А В А, в
котором А имеет два поля, В — одно и С не имеет полей.
Теперь рассмотрим грамматику на рис. 9.2. Если из нее удалить
все атрибуты и трактовать ее, как обычную грамматику цепочечного
перевода, то метод построения нисходящего процессора для
ЬЦ1)-грамматик даст нам МП-автомат на рис. 9.4. Теперь мы
расширим этот автомат так, чтобы получить атрибутный МП-автомат,,
обрабатывающий атрибуты заданным образом.
В атрибутном процессоре магазинные символы имеют по одному
полю для каждого атрибута соответствующего символа грамматики.
Таким образом, {СЛОЖ} и {УМНОЖ} имеют по три поля, (Е) и
{ОТВЕТ} имеют по одному полю, a (S) и V полей не имеют.
Расположение полей показано на рис. 9.5. Важно понимать, что поле
символа в магазине не обязательно должно содержать значение
соответствующего атрибута. На самом деле поля синтезируемых
атрибутов никогда не содержат соответствующих значений атрибутов.
Они используются для хранения указателей. Поля наследуемых
атрибутов вначале пусты, но иногда они получают значения
соответствующих атрибутов до того как их магазинный символ становится
верхним символом магазина. Автомат работает таким образом, что
каждое поле верхнего магазинного символа, соответствующее
наследуемому атрибуту, содержит значение этого атрибута, а поле,
соответствующее синтезируемому атрибуту, содержит указатель
на то место, где должно храниться значение атрибута.
На рис. 9.6 показана управляющая таблица атрибутного
автомата. На рис. 9.7 для двух атрибутных подстановок изображен
магазин до и после каждой подстановки.
Для того чтобы разобраться в автомате, вначале рассмотрим
последовательность конфигурации на рис. 9.8, соответствующую
обработке входной цепочки
Конфигурация на рис. 9.8, а показывает магазин в начальный
момент и входную цепочку. Переход от рис. 9.8, а к рис. 9.8, б
представляет собой применение продукции 1 (рис. 9.2), осуществляемое
9.4. Пример атрибутного автомата
329
А
Поле 1
Поле 2
в
Поле 1
А
Поле j
Поле 2
с
7
<S>
<Е>
V
{СЛОЖ}
{умнаж}
{ОТВЕТ }
#i
#2
ОТВЕРГНУТЬ
#1
#3
ОТВЕРГНУТЬ
#1
#4
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
допустить
ВЫДАТЬ({СЛОЖ}), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
ВЫДАТЬ ({УМНОЖ}), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
ВЫДАТЬ ([ОТВЕТ}), ВЫТОЛКНУТЬ, ДЕРЖАТЬ
Начальное содержимое магазина : V < S >
*1 ЗАМЕНИТЬ({0ТВЕТ }<£», ДЕРЖАТЬ
#2 ЗАМЕНИТЬ.({СЛОЖ}<£><£», СДВИГ
#3 ЗАМЕНИТЬ ({УМН0Ж}<£Х£»,СД8ИГ
#4 ВЫТОЛКНУТЬ, СДВИГ
Рис. 9.4.
<S >
<£>
Указатель на
место, где должен
запоминаться
синтезируемый
атрибут
нетерминала < Е >
{ ответ}
Место для
запоминания
наследуемого атрибута сим
бола дейстбия(ответ)
{СЛОЖ.}
или
{УМНОЖ}
Место для
запоминания первого
наследуемого
атрибута
Место для
запоминания второго
наследуемого ат-
рибута
Указатель на
место, где должен за
поминаться
синтезируемый атрибут
Рис. 9.5.
330 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
процедурой перехода #1. Копирующее правило, соответствующее
продукции 1, определяет, что наследуемый атрибут символа
{ОТВЕТ} равен синтезируемому атрибуту символа (£). Вообще, когда
применяется продукция 1, значение синтезируемого атрибута {£>
нельзя определить, так как оно может зависить от еще не
прочитанных входных символов. Автомат оставляет поле магазинного сим-
<s>
<Е>
V
{ADD}
{УМНОЖ}
ОТВЕТ)
+
#1
#2
ОТВЕРГНУТЬ
*
#1
#3
ОТВЕРГНУТЬ
С
#1
#4
ОТВЕРГНУТЬ
-1
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
Сложить содержимое двух первых полей и запомнить
сумму в ячейке, на которую указывает третье поле
ВЫТОЛКНУТЬ, ДЕРЖАТЬ
Перемножить содержимое двух первых полей и зопомшть
произведение в ячейке, на которую указывает третье
поле вытолкнуть, лержать
Выдать (ответ с содержимым его поля)
ВЫТОЛКНУТЬ, ДЕРЖАТЬ
Начальное содержимое магазина: V < S >
# 1 заменить <s> как показано на рис. 9.7, а
ДЕРЖАТЬ
# 2 ЗАМЕНИТЬ <5> как Показано на рис. 9.7,6
СДВИГ
#3 ЗАМЕНИТЬ <f> как показано на рис. 9.7,6, используя
{Умнож} вместо (слож)
сдвиг
#4 Поместить значение текущего входного символа в
ячейку, на которую указывает поле нетерминала<£>
ВЫТОЛКНУТЬ, СДВИГ
Рис. 9.6.
вола {ОТВЕТ} пустым, но выполняет действие, гарантирующее
его последующее заполнение, помещая указатель на него в поле
магазинного символа (£). Задача вычисления синтезируемого
атрибута символа (£) и запоминание его в поле символа {ОТВЕТ}
откладывается до обработки символа (Е). Так как (£) обрабатывается
прежде, чем {ОТВЕТ} станет верхним магазинным символом, пус_
<s>
ДО
a
<E>
*
{ОТВЕТ}
ПОСЛЕ
<£>
P
ДО
<s>
V'
<£>
^
<£>
{СЛ0Ж}
p
ПОСЛЕ
ртсодержимое поля символа <£>
s
Рис. 9.7
-4 Н
{ОТВЕТ}
Н
—♦
<£>
{ ОТВЕТ)
V
С, -)
Рис. 9.8.
332 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
тое поле будет заполнено до того, как {ОТВЕТ} станет верхним
магазинным символом.
Переход от рис. 9.8, б к рис. 9.8, в производится с помощью
переходной процедуры #4. Копирующее правило, соответствующее
продукции 4, определяет, что синтезируемый атрибут символа (£ >
равен атрибуту текущего входного символа. Значение текущего
входного символа С, копируется в ячейку, на которую указывает
поле символа (£), тем самым заполняется поле символа {ОТВЕТ}.
Переход от рис. 9.8, в к
рис. 9. 8., г приводит к
тому, что выдается
символ ОТВЕТ,,, и из кон-
+ • с7с2съ -л фигурации на рис. 9.8, г
получаем ДОПУСТИТЬ.
Далее мы поясним
работу автомата,
прокомментировав
обработку входной цепочки
<s>
<£ >
^
{ОТВЕТ}
V
С 2 Сз Cg
<£ >
<£ >
{СЛОЖ }
*
{ОТВЕТ}
V
Рис. 9.9.
+ *С2С3 С5 —|
Эта цепочка,
выраженная в инфиксной форме,
вызывает вычисление
выражения (2*3)+5,
значение которого равно
11. На рис. 9.9
показана последовательность
конфигураций процесса
обработки этой цепочки.
Переход от рис. 9.9, а к
рис. 9.9, б аналогичен
переходу от рис. 9.8, а
к рис. 9.8, б.
Переход от рис. 9.9, б
к рис. 9.9, в достигается
с помощью переходной
процедуры #2. Этот
переход реализует
копирующее правило р ч- R
продукции 2 (и
обеспечивает запоминание
синтезируемого атрибута
символа (£> рис. 9.9, б в
ячейке, на которую ука-
9.4. Пример атрибутного автомата
333
1—►
<£>
<£ >
{УМНОЖ}
"™^
<£>
{СЛОЖ}
( ОТВЕТ }
V
С2 С3 С5
L
<£>
^^^^^
{УМНОЖ}
2.
^^""^^
<f >
^^^^^
{СЛОЖ}
,
{ ОТВЕТ}
V
С, С* -\
—¥
{УМНОЖ}
2
3
"
<£ >
{СЛОЖ}
"
{ОТВЕТ)
V
—¥
»
<£>
{СЛОЖ}
6
{■ ОТВЕТ}
V
да
Рис. 9.9. (продолжение)
334 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
—►
{СЛОЖ}
6
5
*
{ОТВЕТ}}
V
{ОТВЕТ}
11
Рис. 9.9 (продолжение).
зывает поле символа (Е > рис. 9.9, б, переписав указатель из поля
старого (Е) в третье поле символа {СЛОЖ}). После того как
сложение будет выполнено (при переходе от рис. 9.9, з к рис. 9.9, и).
полученная сумма будет скопирована в поле символа {ОТВЕТ}
Магазин на рис. 9.9, в содержит также два символа (Е), как этого
требует соответствующая продукция,— по одному для каждого
операнда операции сложения. В поля символов (Е) вначале
записываются указатели так, чтобы значения операндов можно было
переписать в поля символа {СЛОЖ} и в нужное время выполнить
сложение. При обработке каждого символа (Е) его атрибут будет
помещен в соответствующее поле символа {СЛОЖ}, следовательно,
все три поля символа {СЛОЖ} будут заполнены надлежащим
образом к тому моменту, когда он достигнет верха магазина.
Переход от рис. 9.9, в к рис. 9.9, г осуществляется переходной
процедурой #3, применяющей продукцию 3. {УМНОЖ} возникает
так же, как раньше {СЛОЖ}. Указатель символа {УМНОЖ}
получает значение от верхнего символа (Е) конфигурации рис. 9.9, в
и обеспечивает передачу результата умножения символу {СЛОЖ}.
Переход от рис. 9.9, г к рис. 9.9, д достигается с помощью
переходной процедуры #4, применяющей продукцию 4. Значение
текущего входного символа Сг копируется в то поле, на которое
указывает верхний символ (Е). Таким образом, первый операнд
операции {УМНОЖ} получен.
В результате перехода от рис. 9.9, д к рис. 9.9, е определяется
второй операнд {УМНОЖ} и впервые на верху магазина
оказывается символ действия.
Переход от рис. 9.9, е к рис. 9.9, ж осуществляется процедурой
символа действия. Эта процедура приводит к перемножению
значений полей, соответствующих наследуемым атрибутам (т. е. one-
9.5. Атрибутный автомат с магазинной памятью 335
рандов), и запоминанию полученного результата в том поле, на
которое указывает поле, соответствующее синтезируемому
атрибуту. Заметим, что на выходе ничего не выдается, хотя некоторый
выход и был определен автоматом без атрибутов (рис. 9.4).
Причина этого заключается в том, что символ {УМНОЖ} был введен
искусственно в разд. 9.3 для получения формы простого
присваивания. Поскольку на самом деле такой выход не нужен, мы его не
выдаем. Наш атрибутный автомат фактически выполняет цепочечный
перевод, задаваемый грамматикой, приведенной на рис. 9.7, из
которой затем была получена грамматика на рис. 9.2. Переход от
рис. 9.9, ж к рис. 9.9, з достигается просто определением второго
операнда символа {СЛОЖ}, а переход от рис. 9.9, з к рис. 9.9, и
состоит в выполнении сложения. Теперь атрибут символа {ОТВЕТ}
получает свое значение. Переход от рис. 9.9, и к рис. 9.9, к
приводит к тому, что выдается ОТВЕТц и конфигурация 9.9, к дает
ДОПУСТИТЬ.
9.5. Атрибутный автомат с магазинной памятью
Теперь обратимся к следующей проблеме:
Для данной L-атрибутной грамматики в форме простого
присваивания с входной LL (1)-грамматикой построить
устройство с магазинной памятью, выполняющее описываемый
ею перевод.
Сначала воспользуемся методами гл. 8, чтобы построить МП-
процессор для грамматики цепочечного перевода без атрибутов,
которая получается из заданной атрибутной транслирующей
грамматики вычеркиванием всех атрибутов. Этот автомат, называемый
«автоматом без атрибутов», нужно преобразовать в процессор для
атрибутной грамматики, введя поля магазинных символов и
расширив переходы так, чтобы они вычисляли атрибуты и записывали
их в соответствующие поля.
Согласно процедуре построения, описанной в гл. 8, магазинные
символы автомата без атрибутов соответствуют символам данной
грамматики. В атрибутном автомате к каждому магазинному символу
добавляются поля для каждого атрибута соответствующего символа
грамматики.
Схема использования атрибутных магазинных символов следует
соображениям, проиллюстрированным в разд. 9.4. К тому моменту,
когда магазинный символ оказывается на верху магазина, его поля
будут заполнены следующим образом:
1. Если соответствующий атрибут наследуемый, то поле будет
содержать значение этого атрибута.
336 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
2. Если соответствующий атрибут синтезируемый, то поле будет
содержать указатель на связанный список полей, соответствующих
наследуемым атрибутам, где этот атрибут должен быть запомнен.
3. Атрибуты входного символа трактуются
так же, как и синтезируемые атрибуты.
<А >
I
<0>
<с>
<D>
В поле для синтезируемого атрибута и
атрибута входного символа заносится указатель в
тот момент, когда он вталкивается в
магазин; содержимое поля не изменяется в
течение времени существования
соответствующего магазинного символа.
Поле для наследуемого атрибута
заполняется либо значением этого атрибута, либо
указателем на список (или маркером конца
списка). В последнем случае поле является
элементом списка, на который указывает
поле какого-нибудь синтезируемого атрибута
или атрибута входного символа, и будет
заполнено каким-то значением перед тем, как
соответствующий символ окажется на верху
магазина.
Как обычно, на рисунках используем
пустые поля, которые называем пустыми
указателями, и которые служат в качестве
маркеров конца списка. Таким образом,
конфигурация «после» на рис. 9.7, а
показывает поле синтезируемого атрибута символа
(Е), которое указывает на список, состоящий
из одного элемента. Список состоит только
из одного элемента, так как атрибут
символа (£) копируется только в один
наследуемый атрибут. Если в данной грамматике
содержится какой-то символ (А > с одним
синтезируемым атрибутом и в процессе
обработки возникла ситуация, когда синтезируемое
значение верхнего магазинного символа (А >
должно быть присвоено трем другим полям,
то магазин может быть таким, как на рис.
9.10. На рисунке показано поле символа (А >,
указывающее на список из трех элементов:
второе поле символа (С), поле символа (D>
и поле символа (F). В случаях, подобных описанным в разд. 9.4,
когда указатель всегда указывает на список из одного элемента,
можно достичь некоторого увеличения эффективности, если автомат
строить так, чтобы он не искал в списке маркер конца списка.
<Е >
<F>
I
Рис. 9.10.
9.5. Атрибутный автомат с магазинной паиятью 3.37
Начальная конфигурация. Процесс обработки начинается, когда в
магазине находятся начальный символ и маркер дна.
Инициализация полей начального символа является частью общей
инициализации магазина. Поля, соответствующие наследуемым
атрибутам, заполняются начальными значениями, которые задаются
атрибутной грамматикой. Поля, соответствующие синтезируемым
атрибутам, заполняются пустыми указателями. В результате
такой инициализации поля наследуемых атрибутов
первоначального верхнего символа магазина заполняются значениями
атрибутов, а поля синтезируемых атрибутов заполняются указателями
на связанные списки; таким образом достигается согласованность
с запланированным использованием атрибутных полей.
Когда автомат проектируется не для простого цепочечного
перевода, разработчик может пожелать, чтобы процедура
ДОПУСТИТЬ использовала синтезируемые атрибуты начального
нетерминала. В таких случаях каждое поле начального магазинного
символа, соответствующее синтезируемому атрибуту, можно заполнить
указателем на связанный список ячеек (обычно это одна ячейка),
в котором должен запоминаться атрибут для процедуры
ДОПУСТИТЬ.
На верху магазина входной символ. Когда верхним магазинным
символом является входной символ, и магазинный символ
совпадает с текущим входным символом (случай, когда нет ошибки),
атрибуты текущего входного символа отображаются на
соответствующие поля верхнего магазинного символа. Каждое из этих
атрибутных полей содержит указатель на список полей магазина, в которых
требуется значение этого атрибута. Обычное в таких случаях
действие автомата (а именно ВЫТОЛКНУТЬ, СДВИГ) расширяется
так, что каждый атрибут текущего входного символа копируется во
все поля списка полей, на который указывает соответствующее
поле верхнего магазинного символа.
На верху магазина символ действия. Когда на верху магазина
оказывается символ действия, переход МП-автомата дополняется
процессами обработки атрибутов следующим образом:
1) значения наследуемых атрибутов извлекаются из
соответствующих полей верхнего магазинного символа;
2) значения синтезируемых атрибутов вычисляются по
наследуемым атрибутам с помощью правил вычисления атрибутов,
связанных с символом действия;
3) значение каждого синтезируемого атрибута помещается во
все поля списка полей, на который указывает соответствующее
поле верхнего магазинного символа.
В том случае, когда производится цепочечный перевод,
атрибуты также используются для того, чтобы выдать соответствующий
338 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
выходной символ. Вообще разработчик может использовать
атрибуты произвольным образом.
Особого упоминания заслуживает ситуация, когда
первоначально был задуман именно цепочечный перевод, но для того, чтобы
привести грамматику к форме простого присваивания, оказалось
необходимым ввести в нее добавочные символы действия. В этом
случае первоначально задуманный перевод можно осуществить,
если просто выдавать только первоначальные выходные символы и
не производить никаких выходных действий, когда встречаются
добавочные символы.
Кроме описанных выше процессов обработки атрибутов и
выходных действий, переходная процедура для символа действия
также выполняет обычные действия автомата без атрибутов —
ВЫТОЛКНУТЬ, .СДВИГ.
На верху магазина нетерминал. Когда верхний магазинный симеол
является нетерминалом, автомат без атрибутов производит переход,
основанный на использовании распознаваемого правила. Этот
переход заменяет магазинный символ на некоторую цепочку символов
и, возможно, производит выдачу (или другие действия), связанную
с символами действия, которые входят в применяемое правило, но
не вталкиваются в магазин (например, £ и \р правила 5 в процедуре
из разд. 8.4 и |, используемая в разд. 8.6 при обсуждении
переводов).
Атрибутный автомат вталкивает в магазин ту же цепочку
символов и выдает те же выходные символы. Однако атрибутный
переход может потребовать некоторых вычислений атрибутов,
связанных с входными символами, которые не вталкиваются в магазин,
некоторых действий по заполнению полей помещенных в магазин
символов и действий, заносящих значение атрибутов в некоторые
поля символов, хранящихся в магазине.
Источниками атрибутных правил, связанных с продукциями
грамматики в форме простого присваивания, могут быть только
константы, наследуемые атрибуты левой части, атрибуты входных
символов или синтезируемые атрибуты символов правой части. Все
источники можно разделить на шесть категорий, как это показано в
табл. 9.1.
Таблица показывает в зависимости от категории источника,
является ли значение источника доступным во время работы
переходной процедуры для соответствующей продукции, и если это так, то
как переходная процедура может получить это значение. Источники,
принадлежащие второй категории таблицы, доступны, так как
переходная процедура, применяющая данную продукцию, вычислит
все атрибуты символов действия, которые не вталкиваются в
магазин (так, как это описано ниже в правиле 1).
Получателями могут быть только синтезируемые атрибуты ле-
9.5. Атрибутный автомат с магазинной памятью 339
Таблица 9.1
Доступ к источникам
Источник
Доступ
Наследуемый атрибут левой части
Синтезируемый атрибут невталки-
ваемого символа действия
Атрибут нсвталкиваемого входного
символа
Константа
Синтезируемый атрибут
вталкиваемого символа
Атрибут вталкиваемого входного
символа
Значение находится в
соответствующем поле верхнего магазинного
символа
Значение вычисляется посредств; м
расширенного перехода в
соответствии с правилом 1
Значение — часть входного символа
Всегда доступна
Недоступен
Недоступен
вой части продукции и наследуемые атрибуты символов правой
части. Получатели можно разделить на три категории, как это
показано в табл. 9.2. Таблица показывает в зависимости от
категории получателя, какие поля в магазине, соответствующие
атрибутам, нужно заполнить, если данный получатель встретился в
одном из конкретных копирующих правил.
Поля получателей
Таблица 9.2
Получатель
Поле
Наследуемый атрибут
вталкиваемого символа
Синтезируемый атрибут левой части
продукции
Наследуемый атрибут невтллкивае-
мого символа действия
Соответствующее поле вталкиваемого
символа
Все поля в списке полей, па который
указывает соответствующее поле
магазинного символа
Нет полей
Атрибутные действия, связанные с данной продукцией грамма
тики, описываются следующим образом:
340 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
Правило 1. Для каждого символа действия данного правила,
который не вталкивается в магазин, вычисляются его синтезируемые
атрибуты по связанным с ними правилам вычисления атрибутов
и выдаются соответствующие выходные символы (или выполняются
другие соответствующие действия).
Атрибутный автомат обрабатывает невталкиваемые символы
действия слева направо. Таким образом, действие, связанное с
данным невталкиваемым символом, выполняется после действий,
связанных с символами действия левее него, и раньше действий,
связанных с невталкиваемыми символами действия правее него.
Правило 2. Если источник копирующего правила «доступен» (т. е.
попадает в одну из первых четырех категорий перечисленных в
табл. 9.1), то атрибутный автомат помещает его значение в
определенные поля символов магазина. Эти поля для каждого получателя
показаны в табл. 9.2. В табл. 9.1 подробно описано, где атрибутный
автомат получает доступные значения для запоминания в полях
получателя.
Правило 3. Если источник копирующего правила «недоступен» (т. е.
попадает в одну из последних двух категорий табл. 9.1), го
источник является атрибутом символа, который еще-предстоит поместить
в магазин, и атрибутный автомат заполняет соответствующее поле
вталкиваемого символа, помещая в него указатель на список полей.
Атрибутный автомат создает этот список, связывая все поля,
указанные для каждого получателя в табл. 9.2.
Для того чтобы проиллюстрировать правило 1, предположим,
что верхним магазинным символом является {А ), текущим входным
символом — а и что атрибутный автомат должен применить
следующее правило:
{ВЫДАТЬ/5, ,,\ <другие>
(/5, /4)<~-/1 /2^-Sl /3-Х /6^-S2
где SI и S2 — синтезируемые, /1, /2, /3, /4, /5 и /6 —
наследуемые. Мы предполагаем, что {НОВ} и {/} были введены с помощью
методов, описанных в разд. 9.3, для того, чтобы привести
грамматику к форме простого присваивания. Таким образом, {НОВ}
вычисляет свой синтезируемый атрибут, применяя процедуру без
параметров НОВ, и {/} вычисляет свой синтезируемый атрибут
применяя / к своим наследуемым атрибутам. Мы применяем
обозначение {ВЫДАТЬ}, представляющее выходной символ ВЫДАТЬ,
взятый в скобки, и считаем, что цель символа действия {ВЫДАТЬ}—
выдать символ ВЫДАТЬ с надлежащими выходными значениями.
(Эта интерпретация символа {ВЫДАТЬ} подчеркивается
помещением атрибутов в скобки.)
9.5. Атрибутный автомат с магазинной памятью 341
Автомат без атрибутов для данного правила втолкнет в магазин
только (другие), что приводит к тому, что к символам {НОВ},
{/} и {ВЫДАТЬ}, как к символам действия, которые не
вталкиваются в магазин, применяется правило 1. Рассматривая эти
символы слева направо, атрибутный автомат должен проделать
следующие шаги:
1) вычислить S1 с помощью вызова процедуры без параметров
НОВ;
2) вычислить S2, вызвав /(/2, 13,14), где /2 равно значению S1,
вычисленному на шаге 1, /3 равно значению текущего входного
символа и /4 равно значению, запомненному в поле верхнего
магазинного символа (А );
3) выдать атрибутный символ ВЫДАТЬ ,ь ;й, где /5 равно
значению, запомненному в поле верхнего магазинного символа {А >,
и /6 равно значению S2, вычисленному на шаге 2.
Заметим, что любой порядок вычисления, отличный от порядка
слева направо, здесь неприменим. Вычисление / требует, чтобы
вначале вызвалась НОВ для вычисления S1. Выдача символа
ВЫДАТЬ требует, чтобы прежде вычислялась / для того, чтобы
получить значение второго атрибута этого символа. Свойство L-атри-
бутности гарантирует, что для любого L-атрибутного правила не-
вталкиваемые действия могут быть успешно выполнены слева
направо.
Проиллюстрируем правило 2, считая, что применяется правило
<А>п, 51. 52 — ах {g\!u 53 <fi>/3 {ВЫДАТЬ,,, 1ъ\ <С>/6, „
(/4, /2)^-/1 (51, /6, /3) —S3
(S2, /7)«-Х /5+-36
где /1, /2, /3, /4, /5, /6 и 11 — наследуемые, SI, S2 и 53 —
синтезируемые. Согласно построению устройства, не
затрагивающего атрибуты, символы (В), {ВЫДАТЬ} и (С) вталкиваются в
магазин, а и {g} — не вталкиваются. Источник каждого
копирующего правила «доступен». Действия, требуемые правилом 2, таковы:
1. Для присваивания (/4, /2)ч-/1 берется значение из поля
наследуемого атрибута верхнего магазинного символа (Л ) и
помещается в первое поле (поле /4) вталкиваемого в магазин символа
{ВЫДАТЬ}. Для поля /2 невталкиваемого символа {g} никаких
действий не требуется. Этот атрибут был учтен правилом 1.
2. Для присваивания (S2, /7) ч- X берем значение текущей
входной лексемы и запоминаем его во втором поле вталкиваемого
символа (С), а также во всех полях списка, на который указывает
третье поле верхнего магазинного символа {А >.
3. Для присваивания (S1, /6, /3) ч- S3 берется значение S3,
которое предварительно вычисляется автоматом (действие, выполня-
342 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
емое для невталкиваемого символа {g} согласно правилу 1), и
помещается в поле вталкиваемого символа (В >, в первое поле
вталкиваемого символа (С) и во все поля списка, на который
указывает второе поле верхнего магазинного символа (А >.
4. Для присваивания /5-*- 36 значение, равное 36, помещается
во второе поле вталкиваемого в магазин символа {ВЫДАТЬ}.
Для того чтобы проиллюстрировать правило 3, предположим,
что мы распознали правило
<A>su st — а <B>s* гх \g)lu St <C>/2, „
S2 —S3 (/2, /1) — X (SI, /3)<-S4
где SI, S2, S3 и S4 — синтезируемые и /1, /2 и /3 — наследуемые.
Заметим, что {В), z, {g} и (С) должны вталкиваться в магазин,
тогда как а — не должен. Источник каждого присваивания
«недоступен». По правилу 3 требуются следующие действия:
1. Для присваивания S2 ч- S3 указатель из второго поля
верхнего магазинного символа (А) помещается в поле вталкиваемого
символа (В). Это приводит к тому, что связанное с S3 поле символа
{В) указывает на список полей, на который «показывает» S2.
2. Для присваивания (/2, /1) ч- X первые поля вталкиваемых
символов {g} и (С) связываются в один список (это два поля,
которые обозначаются /1 и /2) и указатель на этот список помещается
в поле вталкиваемого символа z (т. е. поле, соответствующее
атрибуту X).
3. Для присваивания (S1, /3) ч-S4 список предписываемых
элементов состоит из второго поля вталкиваемого символа (С) и
всех полей списка, на который указывает первое поле верхнего
магазинного символа (А). С точки зрения реализации этот список
удобно получить, прикрепив поле символа (С) к взятому из (А)
началу списка (т. е. передвинув указатель от (А) к полю символа
(С>). Независимо от того, как этот список был получен, указатель
на этот новый список нужно поместить во второе поле
вталкиваемого символа {g}, которое соответствует источнику S4.
Заметим, что все поля списка полей расположены в магазине
ниже символа, имеющего указатель на этот список. Важно, что
каждый указатель на список встречается раньше, чем элементы
этого списка, так как в противном случае на вершине магазина
мог бы оказаться символ, не имеющий значения своего наследуемого
атрибута, запоминаемого в поле наследуемого атрибута.
Условие L-атрибутности гарантирует, что для любого L-атрибутного
правила указатель на список, созданный по правилу 3, всегда
расположен выше элементов списка. Важно, чтобы сами элементы
списка встречались в том порядке, в котором они расположены в
магазине, хотя обычно мы сами задаем такой порядок.
9.6. Пример: условный оператор
3431
Возможно, что правило 3 потребует соединения двух списков,
так, как в примере
<Л>51,52 — a<B>S3
(SI, S2)+-S3
где SI, S2 и S3 — синтезируемые. На практике такие случаи
встречаются, по-видимому, редко.
Возможно также, что атрибут вталкиваемого входного символа
или синтезируемый атрибут вталкиваемого символа не является
источником никакого атрибутного правила вообще. Например,
(A)-+a(B)sbz
где S—синтезируемый атрибут. Для этого правила переходная
процедура должна поместить пустые указатели в поля
вталкиваемых магазинных символов {В) и Ь.
Резюме. Приведенный выше процесс построения можно применить
к любой L-атрибутной грамматике в форме простого присваивания
со входной ЬЬ(1)-грамматикой. Если мы берем L-атрибутную
грамматику со входной ЬЦ1)-грамматикой и приводим ее к форме
простого присваивания (методом разд. 9.3), включая в нее добавочные
символы действия, то атрибутный автомат для новой грамматики
может произвести первоначально заданный перевод с помощью
простого приема, состоящего в том, что для добавочных символов
действия выдача не производится. Это позволяет сделать
следующий вывод:
Для заданной L-атрибутной грамматики цепочечного перс-
вода с входной ЬЦ1)-грамматикой можно построить
нисходящий процессор с магазинной памятью, который
выполняет перевод, определяемый этой грамматикой.
9.6. Пример: условный оператор
Предположим, что мы хотим построить синтаксический блок для
языка, грамматика которого содержит три правила:
1. <S>-^ IF У У (S) (конец)
2. (конец >-^ENDIF
3. (конец>-► ELSE(S)ENDIF
где символ V представляет переменную, и его значением является
указатель на таблицу символов. IF, ENDIF к ELSE — лексемы,
не имеющие значений. Мы полагаем, что грамматика языка
содержит больше правил, чем приведено, но мы хотим рассмотреть
проблемы, связанные с переводом цепочек, порожденных этими тремя
344 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
правилами. Нетерминал (S) предназначен для порождения
операторов данного языка, и правило 1 порождает IF-операторы.
Так как (конец) определяется двумя правилами, то по существу
IF-операторы могут быть двух типов, а именло
IF VV (S) ENDIF
IF VV <S> ELSE <S> ENDIF
В IF-операторе первого типа, если две переменные равны, то
выполняется (S) и затем управление передается оператору,
следующему за ENDIF. Если переменные не равны, то управление
передается прямо оператору, следующему за ENDIF без выполнения
Оператор: if а ь . . . endif
Вход: if v, v2 . . . endif
Выход: ПЕРЕХОДЕ, 2,3) . МЕТКА(З)
Элементы таблицы: \
1 Идентификатор а
2 идентификатор b
3 Метка
а
Оператор: if а ь . . . . else .... endif
Вход: IF V, V, . . . ELSE .... ENDIF
Выход: ПЕРЕХОДЕ. 2,3).. .ПЕРЕХОД (4) МЕТКА (3) . . МЕТКАМ)
Элементы таблицы: . ,
1 Идентификатор а
2 Идентификатор b
3 Метка
4 Метка
б
Рис. 9.11.
оператора (S). В случае IF-оператора второго типа нужно
выполнить один из двух операторов (S >, и затем управление передается
оператору, следующему за ENDIF. Если две переменные равны,
то нужно выполнить первый оператор (S ), а если переменные не
равны, то — второй оператор (S >.
Будем считать, что для описания надлежащей передачи
управления генератору кода доступны три атома. Это атомы МЕТКА,
ПЕРЕХОД ч ПЕРЕХОДН. На рис. 9.11, а и 9.11,6 показано
9.6. Пример: условный оператор
345>
использование этих атомов для перевода IF-операторов обоих
типов.
Атом МЕТКА используется в тех точках программы, где с
помощью некоторых управляющих атомов нужно передавать
управление. Этот атом появляется так же и там, где программист
использует метки; но в случае трех рассматриваемых правил атом МЕТКА
используется для того, чтобы пометить управляющие точки,
естественно подразумеваемые в IF-операторах. Значением атома А1ЕТ-
КА служит указатель на элемент таблицы, который генератор кода
использует для передачи информации между атомами,
ссылающимися на данную метку.
Атом ПЕРЕХОД помечает места, в которых нужно
сгенерировать код, вызывающий безусловный переход. Значение атома
ПЕРЕХОД — это указатель на элемент таблицы для метки, на
которую должно передаваться управление. Каждый атом ПЕРЕХОД
имеет, таким образом, тот же указатель, что и соответствующий ему
атом МЕТКА.
Атом ПЕРЕХОДЫ (переход по неравенству) помечает точки,
где нужно сгенерировать код для сравнения двух переменных и
передачи управления в том случае, когда эти переменные не
равны. Значение ПЕРЕХОДИ состоит из трех указателей, первые два
из которых указывают на элементы таблицы для сравнения
переменных, а третий — на элемент для МЕТКИ, на которую должно
передаваться управление, если переменные не равны.
В качестве первого шага в построении синтаксического блока
мы дополним правила 1, 2 и 3 до правил цепочечного перевода,
выражающих надлежащее размещение атомов. Так как атом
ПЕРЕХОДЫ использует значения двух переменных и должен
предшествовать переводу первого символа (S), совершенно ясно, что
{ПЕРЕХОДЫ} нужно поместить между V и (S) в правило 1. Так как
оператору, расположенному после ELSE, должны предшествовать
ПЕРЕХОД и МЕТКА, символы {ПЕРЕХОД} и {МЕТКА} hjjkho
вставить в правило 3 между ELSE и (S).
Единственным атомом, расположение которого не так
очевидно, является МЕТКА для конца IF-оператора. Возможны два
естественных размещения. Первая возможность — поместить символ
{МЕТКА} на конце правила 1, так как эта позиция означает
конец IF-оператора. Другая возможность — поместить символ
{МЕТКА} после каждого вхождения терминала ENDIF в правилах 2 и 3,
так как ENDIF также означает конец IF-оператора. Оба варианта
работают, но мы рассмотрим только второй, так как оказывается,
что он дает правила, более удобные для введения
атрибутов.
Суммируя содержание двух предыдущих абзацев, получаем.
что перевод для правил 1, 2 и 3 должен основываться на
следующих продукциях грамматики цепочечного перевода:
346 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
1. (S)^IF ^{ПЕРЕХОД} <S>(конец)
2. (конец)-»- ENDIF {МЕТКА}
3. (конец)-> ELSE {ПЕРЕХОД} {МЕТКА} (S) ENDIF {МЕТКА}
Следующий шаг в построении синтаксического блока состоит в
том, чтобы дополнить эти продукции атрибутами и атрибутными
правилами, чтобы получить L-атрибутные правила в форме
простого присваивания. Мы предполагаем, что имеется процедура-
функция НОВТАМ, распределяющая память для элементов
таблицы. Результатом действия этой процедуры является указатель на
вновь созданный элемент таблицы, представляющий метку.
Входной символ V имеет один синтезируемый атрибут —
указатель на соответствующий ему элемент таблицы. Дадим атому
ПЕРЕХОДЫ три наследуемых атрибута, по одному для каждого из
его указателей. Аналогично дадим атомам ПЕРЕХОД и А^ЕТКА по
одному наследуемому атрибуту. Указатель на метку, который
является третьим атрибутом символа ПЕРЕХОДЫ в правиле 1,
должен использоваться в качестве атрибута подходящего атома
МЕТКА либо в правиле 2, либо в правиле 3. Символу (конец) дадим
наследуемый атрибут, значение которого должно быть этим
указателем.
Выбрав атрибуты для каждого символа, построим следующие
атрибутные продукции:
1. <S>^ IFVXV„ {ПЕРЕХОДИ,,,^г1}<5><конец>г2
(zl, г2) —НОВТАМ xl«— х у\*-у
2. <конец>г-* ENDIF {МЕТКА,,}
г\ «—г
3.<конец>,—ELSE{nEPEXOHw}{METKA„}(S>ENDIF{METKAeI}
(wl, ш)«—НОВТАМ г\*—г
Эти правила — просто описания требуемых отношений между
указателями. Легко проверить, что данная грамматика является
L-атрибутной. Строго говоря, грамматика не имеет формы простого
присваивания, так как атрибутные правила содержат вызов
процедуры-функции без параметров НОВТАМ. Однако можно
рассматривать НОВТАМ как константу и использовать метод
построения процессора из разд. 9.5.
В качестве последнего шага построим для каждого правила
атрибутные процедуры переходов. Для правила 1 атрибутной
процедурой перехода будет:
1. Вызвать НОВТАМ.
2. ЗАМЕНИТЬ, как на рис. 9.12.
3. СДВИГ.
9.6. Пример: условный оператор
347
Для правила 2 переход будет таким:
1. Выдать символ МЕТКА, используя содержимое поля верхнего
магазинного символа (конец) в качестве его атрибута.
2. ВЫТОЛКНУТЬ.
3. СДВИГ.
Для правила 3 процедурой перехода будет:
1. Вызвать НОВТАМ.
2. Выдать ПЕРЕХОД с результатом вызова НОВТАМ в качестве
атрибута.
3. Выдать символ МЕТКА, используя содержимое поле верхнего
магазинного символа (конец) в качестве его атрибута.
<s>
> V -
V
1 ПЕРЕХОДИ}
г
<S>
< конецусл>
г
АО ПОСЛЕ
г=Указатель на элемент таблицы, поставляемый процедурой новтам
Рис. 9.12.
348 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
4. ЗАМЕНИТЬ ({МЕТКА} ENDIF (S» и результат НОВТАМ
поместить в поле символа {МЕТКА}.
5. СДВИГ.
Когда на верху магазина оказывается входной символ V и
текущим входным символом также является V, значение текущего
входного символа помещается в каждое поле связанного списка
полей, на который указывает поле верхнего магазинного символа.
Фактически этот список состоит в точности из одного элемента, и
поэтому нет необходимости просматривать список.
9.7. Пример: арифметические выражения
/ + * ( ) и
■ - 1 [ j
<£>
<Т>
<Р>
<Е-яшсок>
<т-спиж>
)
V
{слож!
{умнож)
Начальное содержимое магазина : рис. 9.14, а
■
#1
#4
#8
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#2
#6
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#5
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#1
#4
#7
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#3
#6
ВЫТОЛКНУТЬ
СДВИГ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#3
#6
ОТВЕРГНУТЬ
ДОПУСТИТЬ
ВЫДАТЬ (СЛож о о г)> используя содержимое трех полей.
ВЫТОЛКНУТЬ. ДЕРЖАТЬ
ВЫДАТЬ (УМНОЖ0^Г), используя содержимое трех полей.
ВЫТОЛКНУТЬ, ДЕРЖАТЬ
# 1 ЗАМЕНИТЬ как на рис. 9.14,6, ДЕРЖАТЬ
#2 Вызвать новт, заменить как на рис. 9.14, в, сдвиг
#з Поместить содержимое первого поля магазинного символа В поле,
на которое указывает второе поле магазинного символа, вытолкнуть,
ДЕРЖАТЬ
#4 ЗАМЕНИТЬ как на рис. 9.14, г , ДЕРЖАТЬ
#5 Вызвать новт, заменить как на рис. 9.14, д, сдвиг
#6 Поместить содержимое первого магазинного символа в поле, на которое
указывает второе поле магазинного символа, вытолкнуть, ДЕРЖАТЬ
#7 заменить как на рис. 9.14, е, сдвиг
#8 Поместить значение входа в поле, на которое указывает поле
магазинного символа, вытолкнуть, держать
Рис. 9.13.
9.7. Пример: арифметические выражения
349
<£>
Начальное содержимое
магазина
а
<Е>
L !_
ДО
До
ПОСЛЕ
Г = значение, поставляемое процедурой HOST
в
ДО
<Т>
< Е-Список^
ПОСЛЕ
*
< Е список >
р
t
<т>
"
{СЛОЖ;
Р
Г
<Е-СписОК>
г
t
<Т>
t
*■
<Р>
*
<т список >
t
ПОСЛЕ
<т- списокУ
р
t
*
<р>
\ умнод(
р
г
< Т-список >
г
f
<р>
р
АО ПОСЛЕ.
Г» значение, поставляемое процедурой" НОВТ
д
ДО
<Е>
р
)
ЛОСЯЕ
Рис. 9.14.
<f >
/, + 12 ' '.I -•
<T>
< Е-список>
/,+/,»/, H
< Т-список>
< Е-список>
<E~список>
1
+ /,-/, -*
+ /2 • /J -»
♦
+
</>>
<T-список >
< Е-список >
V
/.+/,•/, -и
♦
<7">
{СЛОЖ }
1
100
<Е-списокУ
100
V
«овг= юо
Рис. 9.15.
*•
#.
<p>
< Т-список>
{СЛОЖ}
1
100
< Е-список?
100
V
»
< Т с/шсок>
2
{СЛОЖ}
1
.100
< ЕсписокУ
100
V
*
*■
<Р>
{УМШ}
2
101
< Т-списокУ
101
{СЛОЖ}
1
100
<Е-список>
100
V
н
'э *
овт =101
Рис. 9.15 (продолжение),
{УМНОЖ}
2
3
*
i
•
-►
"
+
-__
101
< T-список >
101
{СЛОЖ)
1
100
< £СПиСОК>
100
V
вьш
тз(умнож\,3101)
< 7 сдадаг >
101
{сюж}
1
100
< Е-список>
100
V
н
{СЛОЖ}
1
'101
100
<£ список > .
100
V
--
выд/
<£cnUCOK>
100
V
_
/У
V
0
ВЫДАТЬ(СЛОКМ0,.100>
Рис. 9.15 (продолжение).
9.8. Метод рекурсивного спуска для атрибутных грамматик 353
В этом разделе мы построим процессор для атрибутной грамматики
рис. 7.10, транслирующей арифметические выражения. В разд. 8.6
было показано, что ее входная грамматика является 1_Ц1)-грамма-
тикой, и на рис. 8.17 показан МП-распознаватель для этой
входной грамматики.
Атрибутная грамматика рис. 7.10 — это уже L-атрибутная
грамматика в форме простого присваивания, и, значит, к ней можно
непосредственно применить методы из разд. 9.5. На рис. 9.13 и
9.14 показан полученный в результате процессор.
На рис. 9.15 показана обработка этим процессором цепочки
9.8. Метод рекурсивного спуска
для атрибутных грамматик
В этом разд. мы покажем, как можно расширить метод рекурсив
ного спуска, описанный в разд. 8.9, применительно к
синтаксическому анализу, чтобы выполнять L-атрибутные цепочечные
переводы. В этом расширенном методе процедура для нетерминала имеет
параметр для каждого атрибута этого нетерминала. Для
наследуемого атрибута соответствующий фактический параметр вызова
процедуры является значением этого атрибута. Для синтезируемого
атрибута соответствующий фактический параметр — это
переменная, которой мы хотим присвоить значение этого синтезируемого
атрибута. К тому моменту, когда происходит возврат из
процедуры, этому параметру будет присвоено значение данного
синтезируемого атрибута.
Предполагается, что эти процедуры написаны на языке, в
котором есть такой механизм передачи параметров, что в тот момент,
когда формальному параметру присваивается значение, это
значение хранится в соответствующем фактическом параметре.
Таким свойством обладают такие механизмы передачи параметров,
как «вызов по имени» в Алголе 60 и «вызов по ссылке» в Фортране.
При расширении метода, описанного в разд. 8.9, используются
имена атрибутов из атрибутных правил грамматики в качестве
имен переменных и параметров. Таким образом, названия
атрибутов связаны с реализацией процедур рекурсивного спуска, и при
именовании атрибутов должны выполняться некоторые условия в
дополнение к обычным соглашениям об обозначениях, принятым
для атрибутных переводов.
Одно из дополнительных соглашений, касающихся именования
атрибутов, заключается в том, что все вхождения данного
нетерминала в левые части правил имеют один и тот же список имен
атрибутов. Например, в грамматике не можеч быть двух таких пра-
2 Ф. Льюис и др.
354 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
вил:
потому что одно вхождение нетерминала (L) имеет атрибуты а, Ь,
а другое — х, у. В этом случае разработчик должен выбрать какой-
то список имен атрибутов нетерминала (L) и переименовать его
атрибуты соответствующим образом. Например, можно выбрать
список a, b в качестве «официального» списка имен атрибутов
нетерминала (L > и, подставляя а вместо х и Ь вместо у, записать
второе правило так:
<£>,.»—•<#>„„ {ZAPA,,>
Такая замена приводит к тому, что левой частью обоих правил
для нетерминала (L) становится (L)a,b- Этот список имен мы
используем и при описании того, какие атрибуты являются
синтезируемыми, а какие наследуемыми. В рассматриваемом примере,
если a, b выбраны в качестве «официального» списка для
нетерминала (L) и а — синтезируемый атрибут, a b — наследуемый, то
описание должно быть таким:
<L>aib СИНТЕЗИРУЕМЫЙ а НАСЛЕДУЕМЫЙ b
Заметим, что официальный список имен атрибутов не относится к
вхождениям данного нетерминала в правые части правил.
После того как атрибуты в левых частях и в описании типа
переименованы так, чтобы они соответствовали друг другу, новое
соглашение об обозначениях можно использовать для упрощения или
устранения некоторых правил вычисления атрибутов.
Новое соглашение об обозначениях таково:
Если два атрибута получают одно и то же значение, то им
можно дать одно и то же имя, при условии что для этого
не нужно изменять имена атрибутов нетерминала в левой
части.
Проиллюстрируем это соглашение несколькими примерами.
Вначале рассмотрим правило грамматики, записанное в соответствии со
старым соглашением:
{S)-+ 1а(В\(С)с
(Ь, с)+-а
Копирующее правило присваивает атрибутам a, b и с одно и то же
значение, и им можно дать общее имя. Используя имя х и новое
соглашение, правило можно переписать таким образом:
{S)-+1S(B)X{C)X
9.8. Метод рекурсивного спуска для атрибутных грамматик 355
Это новое атрибутное правило вообще не имеет правил вычисления
атрибутов. В старой форме записи требовалось явное правило
вычисления атрибутов, показывающее, что три атрибута имеют
одно и то же значение. Теперь это отражено в том, что все атрибуты
имеют одно общее имя.
Теперь рассмотрим правило
а>,-> (A)s{f}T
(S, Т) +- I
Здесь атрибутам можно дать одно и то же имя, но оно должно быть /,
для того чтобы не изменилась левая часть. С этим именем правило
становится таким:
и отпадает необходимость в копирующем правиле. Иногда можно
сделать лишь частичные упрощения, как в правиле
<L>,,s-xi<B>x<C>y
(S, X, К) — /
Здесь S, X, Y и / имеют одно и то же значение, но им нельзя дать
одно и то же имя, так как S и / входят в левую часть. Тем не менее
можно сделать некоторые упрощения, а именно:
<L>,,S-+ a<B>s<C>s
S«-/
Практическим примером такой ситуации является правило
<£-список>Л s—>-к
S«-/
которое мы использовали в некоторых грамматиках,
порождающих выражения.
Упрощение допускают даже не копирующие правила. Например,
<L>/iS — ax<R>Y
(S, Y)^f(l, X)
можно упростить следующим образом:
<L>,,s —a*<#>s
так как S и Y присваивается одно и то же значение.
В качестве последнего примера рассмотрим
(XI, Х2)«-НОВТ (К1.К2) —74 S<-g(Xl, Y2, I) R+-V
12*
356 Гл. 9. Нисходящие методы обработки для атрибутных грамматик'
Дав атрибутам XI и Х2 имя X, атрибутам VI и V2 — имя V, и
атрибутам R и V — имя V, мы получим
<^>/, 5 —* aV <^>Х, У (B>V, X, Y
X —НОВТ S*-g(X, Y, I) V —74
Введение нового способа записи связано с тем, что мы хотим
превращать списки атрибутов непосредственно в списки
аргументов. Такая запись имеет определенный недостаток, состоящий в
том, что из нее не видно, каким образом распространяется
информация. Например, если мы видим
а>-> (С)АХ(В)Х
то не ясно с первого взгляда, присваивается ли атрибут
нетерминала (А) атрибуту нетерминала (В) или наоборот. Если атрибут
нетерминала {А) присваивается атрибуту нетерминала {В >, то
правило является L-атрибутным и к нему применим описываемый
метод построения. Если, с другой стороны, атрибут нетерминала
(В) присваивается атрибуту нетерминала {А >, то данное правило не
яьляется L-атрибутным и к нему этот метод неприменим. Можно
определить, какой атрибут какому атрибуту присваивается, так как
нам известно, что синтезируемый атрибут должен присваиваться
наследуемому атрибуту, однако при этом мы должны обратиться к
описанию типов атрибутов. Так как в новом способе записи
направление передачи информации скрыто, в большинстве случаев мы
пользуемся старой записью и переходим к новой записи только после
того, как мы имеем L-атрибутную грамматику и хотим применить
именно данный конкретный способ построения.
Теперь опишем детально, в чем состоит расширение метода
разд. 8.9. Для иллюстрации применим этот метод к следующей
L-атрибутной версии грамматики цепочечного перевода из разд. 8.9:
(S)R НАСЛЕДУЕМЫЙ R
(А)р СИНТЕЗИРУЕМЫЙ Р
Все атрибуты символов действия — НАСЛЕДУЕМЫЕ.
1. <S>ff — aT<A>0{xT<R\<S>Q
2. <S>R-+ b{zR\
3. <A>p-*cu{yu\<A>Q<S>z{vP\b
P^Q+U
4. <A>p-+{w\
P^8
Начальный нетерминал —(S) и начальное значение его
наследуемого атрибута — 7.
9.8. Метод рекурсивного спуска для атрибутных грамматик 357
Процедуры рекурсивного спуска для грамматики без атрибутов
приведены на рис. 8.31, а на рис. 9.16 показан расширенный
вариант, к которому нам нужно прийти. Рис. 9.16 предполагает
наличие двух глобальных переменных ВКЛАСС и ВАТР и
прожигая программа
„ начало программы"
Установить ВКЛАСС =
масс пербого бходного
симЬола
Установить ВАТР =
значение пербого
бходного симбола
Вызоб nP0U,S(7)
Если ВКЛАСС* н,
то ОТВЕРГНУТЬ
ДОПУСТИТЬ
Процедура nPO\i,s(R)
Наследуемый атрибут
Переход на
а
Ь
с
н
Р1
Р2
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
?\."Код для
правила 1"
вокальные перемен
ные Т, Q
Установить Г=ВАТР
Вызов СДВИГ
Вызов nPOUA(Q)
Вызов ВЫДАТЬ (Хг^
Вызов riP0U,S(Q)
Возврат
Р2: -Код для
правила 2"
Вызов сдвиг
ВЫЗОв ВЫДАТЬ^)
Возврат
Процедура ПРОЦД(Р)
Синтезируемый атри-
переходна 6Утр
а
Ь
с
н
Р4
Р4
РЗ
ОТВЕРГНУТЬ
РЗ: "Код для
правила 3"
Локальные
переменные U, Q, Z
Установить У=ВАТР
Вызов СДВИГ
Установить Z=U-3
Вызов ВЫДАТЬ {уи)
Вызов ПРОЦА (в)
Установить Р=в+и
Вызов nPOUSCZ)
ВЫЗОв ВЫДАТЬ (VP)
Если вклассфь то
ОТВЕРГНУТЬ
вызов сдвиг
Возврат
Р4: "Код для
правила 4"
Установить Р=8
ВЫЗОв ВЫДАТЬ (ш)
Возврат
Рис. 9.16.
цедуры СДВИГ. Процедура СДВИГ производит сдвиг по входной
цепочке и присваивает класс текущего входного символа
переменной ВКЛАСС, а его значение (если оно вообще есть)—
переменной ВАТР.
Добавления к методам разд. 8.9 описываются восемью правилами,
которые приводятся ниже. Эти правила предполагают, что
грамматика является L-атрибутной, левые части правил и описания
нетерминалов используют одни и те же имена атрибутов и для
атрибутов, имеющих одно и то же значение, можно использовать
одинаковые имена.
358 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
Правило 1. Формальные параметры. Список имен атрибутов,
соответствующий вхождениям нетерминала в левые части, становится
списком формальных параметров соответствующей процедуры.
Правило 2. Спецификации параметров. Спецификации атрибутов
(НАСЛЕДУЕМЫЙ или СИНТЕЗИРУЕМЫЙ) становятся
спецификациями формальных параметров, в которых тип НАСЛЕДУЕ-
Л1ЫЙ означает «вызываемый по значению», а СИНТЕЗИРУЕМЫЙ—
«вызываемый по ссылке» или «вызываемый по имени»
Правило 3. Локальные переменные. Все имена атрибутов данного
правила грамматики, кроме тех, что связаны с левой частью,
становятся локальными переменными соответствующей процедуры.
Правило 4. Код для нетерминала. Для каждого вызова процедуры,
соответствующего вхождению нетерминала в правую часть правила,
список атрибутов этого вхождения используется в качестве списка
фактических параметров.
Правило 5. Код для входного символа. Для каждого вхождения в
грамматику входного символа перед соответствующим СДВИГОМ
в процедуру вставляется код, который каждой переменной из
списка атрибутов входного символа присваивает соответствующий
входной атрибут, находящийся в некоторой глобальной
переменной, используемой в процедуре СДВИГ.
Правило 6. Код для символа действия. Для каждого вхождения
символа действия вводится соответствующий код, который по
соответствующим правилам вычисляет значения синтезируемых
атрибутов символа действия и присваивает полученные результаты
переменным, соответствующим синтезируемым атрибутам. Затем
выдается выходной символ с атрибутами.
Правило 7. Код для правила вычисления атрибутов. Для каждого
правила вычисления атрибутов, сопоставленного продукции,
вводится соответствующий код, который вычисляет правую часть
этого правила и присваивает полученный результат каждой
переменной из левой части правила. (Если соглашение об «одном и
том же имени» полностью выполнено, то левая часть обычно
будет одной переменной.) Код можно поместить в любом месте,
которое находится А) после точки, где используемые в правиле атрибуты
уже вычислены и В) перед точкой, где вычисленное значение
впервые используется.
Правило 8. Главная программа. Все имена синтезируемых
атрибутов начального нетерминала становятся локальными переменными
главной программы. Список фактических параметров вызова
процедуры, соответствующей начальному нетерминалу, содержит для
9.8. Метод рекурсивного спуска для атрибутных грамматик 359
каждого наследуемого атрибута начальное значение этого атрибута
и для каждого синтезируемого атрибута — имя этого атрибута.
Применение правила 1 к рис. 8.31 приводит к тому, что для
процедуры ПРОЦЭ задается параметр R, являющийся индексом
символа (S) в левых частях продукций 1 и 2, а для ПРОЦА
задается параметр Р. В результате применения правила 2 параметр R
описывается как наследуемый, а Р — как синтезируемый.
Понятия «наследуемый» и «синтезируемый» должны быть, конечно,
переведены в соответствующие понятия фактически используемого
языка программирования, например «вызываемый по значению» и
«вызываемый по имени», если используется Алгол.
В результате применения правила 3 процедура ПРОЦЭ имеет
локальные переменные Т и Q, а ПРОЦА — U, Q и Z. Способ
описания этих переменных, конечно, зависит от используемого
языка программирования.
Действие правила 4 видно на рис. 9.16 там, где вызывается
процедура, соответствующая какому-нибудь нетерминалу. Там, где
происходит вызов, соответствующий вхождению {А > в продукцию 1,
ПРОЦА вызывается с параметром Q, так как Q — имя атрибута,
сопоставленного вхождению (А) в продукцию 1.
Действие правила 5 иллюстрируется присваиванием Т — ВАТР
в коде для продукции 1. Это присваивание происходит как раз
перед вызовом процедуры СДВИГ, соответствующим вхождению
ат в правую часть продукции 1. Входному символу Ъ не
сопоставляется никакого присваивания, так как у Ь нет атрибутов.
Применение правила 6 ко всем символам действия приводит
к тому, что атрибуты выдаются вместе с соответствующими
выходными символами.
В соответствии с правилом 7 правило вычисления атрибута
Z ч- U — 3 нужно вставить после того, как вычислено U и до того,
как используется Z. Правило вычисления атрибута Р -<- Q-\-U
нужно вставить после того, как вычислены Q и U, и перед тем, как
используется Р. Свойство L-атрибутности данной грамматики
гарантирует, что такие места можно найти.
Правило 7 аналогично правилу 2 процедуры, приведенной з
конце разд. 9.3 и применяемой для преобразования к форме
простого присваивания. Оба правила описывают вставливание
правил вычисления атрибутов в правую часть продукции. Разница
между ними заключается в том, что правило 7 использует
копирующие правила, если они не уничтожаются в результате применения
соглашения об «одном и том же имени».
Действие правила 8 состоит в том, что в главной программе
фактический параметр в вызове ПРОЦЭ равен константе 7.
Как было отмечено в разд. 8.9, при реализации рекурсивного
спуска в языке высокого уровня его легко программировать и от-
360 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
лаживать. Механизм вызова процедур в этих языках
обеспечивает запоминание необходимой информации в магазине.
Использование рекурсивного спуска для атрибутных грамматик еще
характерно тем, что механизм передачи параметров в языках высокого
уровня обеспечивает передачу атрибутов между символами.
9.9. Замечания по литературе
Выполнение атрибутных переводов с помощью МП-автоматов
рассматривается в работе Льюиса, Розенкранца и Стирнза [1974].
Упражнения
1. Следующие продукции являются частью некоторой атрибутной грамматики.
Атрибуты р, q и г — наследуемые, a s и I — синтезируемые. Для каждой
продукции определите, от каких атрибутов могут зависеть правила вычисления
риг, чтобы данная продукция была L-атрибутной.
а) <S>S, q —»• au<S>Up<A>r
б) <S>S, q —> {cp} bu <S>t r
в) <S>s.q —• cu<A>r<S>t,P
2. Покажите в виде последовательности конфигураций, как цепочка
-\- * + С1С2-^С^*СЯС2С^
обрабатывается автоматом рис. 9.6.
3. Перепишите каждую из следующих продукций в форме простого
присваивания. Те атрибуты, имена которых начинаются с /, — наследуемые, а те, чьи
имена начинаются с S, — синтезируемые.
а) <S>si./i —* <M>S2<S>S3./2<C>s.i,/.')<'D>S5, /4
/2 «— S2*/l
/3 <— /l2
/4 <— /2*/3
SI «— S22
б) <S>S1, „ — e
SI <— SIN(/!)
в) <S>Si,S2 —- <Л>5з<Я>/1{ДЖОН}/2,/3<С>/4
/1 *— 3*S3
/2 <— /l2
(S2, /3) <— /2
/4 <— /3
SI ^- /4+2
4. Постройте процессор для следующей грамматики с начальным символом (S);
<£),, СИНТЕЗИРУЕМЫЙ р"
Все атрибуты символов действия — 11АСЛЕДУЕМЫЕ
I. <S> — V=<£>M {ПРИСВ,,2, п)
р2 ч— р\ г2 <— г\
Упражнения
361
2. <Е>п — +<£>я<£>?1{СЛОЖр2,?2,г1}
(/•2, /-1) ч— НОВТ pi ч— pi 92 ч— 91
3. <£>г2 -+ * <£>р1 <£>?1 {УМНОЖра, ?2, „}
(л2, л1) *— НОВТ р2 ч— р\ q2 ч— q\
4. <£>« -* Ум
/•2 ч— г\
5. Постройте процессор для следующей грамматики и сравните его с
процессором из предыдущего упр.
(Е)р СИНТЕЗИРУЕМЫЙ р
{СЛОЖл q, r) СИНТЕЗИРУЕМЫЙ г НАСЛЕДУЕМЫЕ р, q
г *- НОВТ
{УМНОЖя, д, г) СИНТЕЗИРУЕМЫЙ г НАСЛЕДУЕМЫЕ р, q
г -*- НОВТ
{ПРИСВЛ q) НАСЛЕДУЕМЫЕ р, q
1. <S> — /Я1=<£>Г1{ПРИСВЯ2,Г2}
pi «— р\ г2 ч— г\
2. <£>,2 — +<£>,п <£>«/! {СЛОЖ//2,?2,л1}
рЧ ■*— р\ ql ч— <?1 '2 ч— /-1
3. <£>,2 — *<£>>, <£>,,, {УМНОЖ/,2,?2,г1}
р2 ч— pi 92 ч— 91 /-2 ч— /-1
4. <£>л2 — 1«
/•2 ч— /-I
6. Нарисуйте состояния магазина «до» и «после», соответствующие двум
атрибутным продукциям для нетерминала (оператор), которые были даны в
разд. 7.9.
7. Рассмотрим следующую L-атрибутную грамматику цепочечного перевода с
начальным символом (S):
<Sya,b СИНТЕЗИРУЕМЫЙ а НАСЛЕДУЕМЫЙЬ
начальное значение 6 = 1
<А>р,9 СИНТЕЗИРУЕМЫЙ р НАСЛЕДУЕМЫЙ q
{gt} СИНТЕЗИРУЕМЫЙ t t ч— НОВТ
атрибуты символов {с}, {d} и {/} — НАСЛЕДУЕМЫЕ
1- <S>a,b — 4c<S>d,el>f{Cg,h}<A>ij{dm, п,р}
е ч— с g ч— 6 h <— / / ч—- 6—с
т <— i h ч— /+3 р ч— d а ч— с-\-п
2. <S>P. q —■ е
Р ♦— 9
3- <5>а, ь — с, К, „} <S>,,, ? {cd, е} 6, {df< gl й}
ы ч— b v ч— s ? ч— 6—о е ч— ^
(а, /,*)•—* (d, h)*-p
4. <Л>р, ? — d <S>a> ь й„ <Л>,, , <Л>С, d {gt} {/„. „. а}
6 ч ^ /Я ч Г (S, d, р) ч и
ге ч— с ы ч— t
5. <Л>Я>? —>• {сг,,}с,
Г ч— ^ Р * S < <— 9 + 3
362 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
а) Покажите, что входная грамматика является (/-грамматикой.
б) Приведите грамматику к форме простого присваивания.
в) Для каждого правила грамматики нарисуйте магазин МП-процессора «до»
и «после» соответствующего шага.
г) Завершите построение процессора.
8. Сделайте то же, что в предыдущей задаче для следующей L-атрибутной
грамматики цепочечного перевода с начальным символом (S):
(А)р СИНТЕЗИРУЕМЫЙ р
(В)р НАСЛЕДУЕМЫЙ р
{Ь,} НАСЛЕДУЕМЫЙ t
1. {S)-+ap{A)q{B)r{A)s{bt)
г -<- p+2q
t+-r+s
2. (A)p^aq(A)r{B)s(B)t(B)a(S)
s+-q+r
t **- q*s—7
(и, p)^r+(
3. (A)p^b
P+-13
4. (B)p^aq{A)r{bt}
1+-Р + Я
9. Постройте атрибутный МП-автомат для следующей L-атрибутной грамматики
цепочечного перевода с начальным символом (S):
(А)а СИНТЕЗИРУЕМЫЙ А
(В)в НАСЛЕДУЕМЫЙ В
Все атрибуты выходных символов — НАСЛЕДУЕМЫЕ.
<S> —>■ aMl <A>Nl {dM2, N2} <B>N3
- /VI
<s> -
<A>Q4
<A>R2
<B>T-
<B>T
M2 <— Ml
- bK<B>Rl{gRi}
(R2, R\) «—
—► "p<A>qi {dQ2,
(Q4, Q3, Q2)
—► hi {Яп} ori
T2 «— 74
— °z<B>y
Y <— Z+T
—> {dn.L)
T2 <— T\
(N3, N
52
<?з} <AyN
«- Q\
R2 <—
L <— T
Rl
Г1—5
10. а) Установите, является ли грамматика из упр. 7.21 L-атрибутной.
б) Если она L-атрибутная, то для каждой продукции нарисуйте магазин «до»
и «после» соответствующего шага процессора.
11. Введите атрибуты и правила их вычисления в следующий продукции так,
чтобы получить L-атрибутные правила для перевода, описанного в разд. 9.6.
1. <S)-*IF VV {ПЕРЕХОДИ} (S) (конец) {МЕТКА}
2. (конец)-vENDIF
3. (конец) ->- ELSE {ПЕРЕХОД} {МЕТКА }<S)ENDIF
12. а) Для условных операторов из упр. 7.24 постройте L-атрибутиую
транслирующую грамматику, входная грамматика которой является (/-грамматикой;
б) Постройте процессор для этой грамматики.
13. а) Найдите L-атрибутиую транслирующую грамматику с входной
(/-грамматикой для WHILE-оператора из упр. 7.25.
б) Постройте процессор для этой грамматики.
Упражнения
363
14. Постройте процессор, интерпретирующий выражения, описанные п упр. 7.28.
15. Рассмотрим следующую грамматику, описывающую оператор присваивания:
1. (оператор присваивания) -»- ИДЕНТИФИКАТОР = (конец оператора)
2. (конец оператора)->■ ИДЕНТИФИКАТОР = (конец оператора)
3. (конец оператора) -»- (выражение)
4. (выражение)-v+(выражение) (выражение)
5. (выражение) -»- «(выражение) (выражение)
6. (выражение) -*■ ИДЕНТИФИКАТОР
Типичным примером оператора присваивания будет
/£=/»=++* V3*Wi
При выполнении таких операторов вначале вычисляется выражение и затем
присваивание выполняется справа налево (в данном примере вначале делается
присваивание /5, затем 1{).
а) Найдите L-атрибутную транслирующую грамматику со входной д-грамма-
тикой, которая переводит эти операторы в подходящее множество цепочек
атомов, содержащих указатели на таблицу.
б) На основе этой грамматики постройте нисходящий процессор.
в) Покажите в виде последовательности конфигураций, как построенный
процессор обрабатывает приведенный выше оператор.
16. Рассмотрим грамматику для операторов присваивания из предыдущего упр.,
к которой добавлено еще одно правило:
7. (выражение)->-((оператора присваивания))
Типичным примером оператора присваивания в новой грамматике будет
Выполнение этих операторов происходит так же, как раньше, кроме тех
случаев, когда оператор присваивания, заключенный в скобки, встречается в ходе
вычисления выражения. В этом случае выполняется оператор присваивания
в скобках и затем значение выражения из этого оператора используется в
качестве значения выражения в скобках. В нашем примере значение выражения
в скобках равно -\-12*IJt
а) Постройте L-атрибутную транслирующую грамматику с (/-грамматикой в
качестве входной грамматики, переводящую эти операторы в надлежащее
множество цепочек атомов, имеющих указатели на некоторую таблицу.
б) На основе этой грамматики постройте нисходящий процессор.
в) Покажите в виде последовательности конфигураций, как построенный
процессор обрабатывает приведенный выше оператор.
17. а) Найдите L-атрибутную транслирующую грамматику с (/-грамматикой в
качестве входной грамматики, которая описывает отношение между входом
и выходом процессора из разд. 2.14, обрабатывающего константы,
б) Постройте атрибутный МП-автомат для этой грамматики.
18. Приведите последовательность конфигураций, получающуюся при обработке
процессором на рис. 9.13 выражения
/i*(/2+/3)
19. Постройте обрабатывающий арифметические выражения процессор, аналс
гичпый приведенному на рис. 9.13, за исключением того, что:
а) разрешена унарная операция — (минус);
б) возведения в степень разрешены и выполняются справа налево.
20. Постройте МП-автомат, действующий как интерпретатор арифметических
выражений (с операциями + и *), использующих константы и записанных в
инфиксной форме. Интерпретатор должен строиться на основе L-атрибутной
грамматики с входной ЬЬ(1)-грамматикой.
21. Постройте методом рекурсивного спуска интерпретатор арифметических вы<
ражений (с операциями + и *), записанных в инфиксной форме,
364 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
22. Постройте методом рекурсивного спуска процессор для следующей
L-атрибутной грамматики цепочечного перевода с начальным символом (S):
<SL СИНТЕЗИРУЕМЫЙ а
Wx.y.z НАСЛЕДУЕМЫЙ х СИНТЕЗИРУЕМЫЙ у, г
Все атрибуты символов действия — НАСЛЕДУЕМЫЕ.
<Syq -4 ахХ <А>Х, у. г <5>?! {bw)
w *— y*z-\-q\ x <— х\ q *— q\
<S>n —* ь<*у {cw) <A>a. r. x {bv)
w <— J/+3 r\ <— r
v <— r*x—w и <— w-\-2
<A>x.y,zi —* aq{cv)<.A>xl,z,a<A>aitiUi
v <— x — q x\ <— x у <— y\ г\ *— г и «— 3
<A>i,s,n —* baq{bn)as2
t\ <— t (s, si) <— s2
23. Постройте по методу рекурсивного спуска процессоры для грамматик из упр.:
9.4, 9.5, 9.8, 9.1I, 9.12, 9.13, 9.16.
24. а) Найдите L-атрибутиую грамматику, для которой число операций
МП-процессора, построенного в соответствии с методами данного раздела, при
обработке входной цепочки пропорционально квадрату числа символов в этой
цепочке,
б) Измените метод проектирования таким образом, чтобы число выполняемых
процессором операций стало пропорциональным числу символов во
входной цепочке. Указание. Пусть каждый синтезируемый атрибут состоит из
двух полей, указывающих на оба конца его связанного списка.
25. Рассмотрим следующую атрибутную грамматику
<L>p.s СИНТЕЗИРУЕМЫЕ р, s
<E>P.s — +<E>g.t<E>r.u
р +— НОВТ
s «_ t"u" СЛОЖ° q°r°p
<E>„.s —• -<E>4.t<E>r,u
p <— НОВТ
s — u°t" ВЫЧЕСТЬ0 q°r°p
<Or> s —* 'pi
p2 «— pi
s <— e (пустая цепочка)
где первый атрибут нетерминала (Е) — это указатель на некоторый элемент
таблицы, второй атрибут — некоторая цепочка, с обозначает операцию
конкатенации, и процедура НОВТ дает указатель на какой-то новый элемент
таблицы.
а) Объясните, что эта грамматика делает.
б) Каким будет перевод входной цепочки
-+iJb-le+UI,
в) Постройте МП-процессор для этой атрибутной грамматики.
26. Покажите, что для данных L-атрибутной транслирующей грамматики и дерева
вывода, в котором указаны значения атрибутов входных символов, можно
вычислить все значения атрибутов этого дерева с помощью шагов 3 и 4 процедуры
построения последовательности актов из разд. 7.7.
27. Рассмотрим следующую грамматику с начальным символом (GO ТО-оператор):
Упражнения
365
1. (GO ТО-оператор)-)-GO TO (меточное выражение)1)
2. (меточное выражение) -»- ИДЕНТИФИКАТОР
3. (меточное выражение)-»-IF ПЕРЕМЕННАЯ THEN (меточное
выражение) ELSE (меточное выражение)
Предположим, что ИДЕНТИФИКАТОР — это лексема, значением которой
является указатель на элемент таблицы, соответствующий некоторой метке,
а ПЕРЕМЕННАЯ — это лексема, значением которой является указатель на
элемент таблицы, соответствующий некоторой переменной.
Во время исполнения оператор GO TO приводит к передаче управления иа
некоторую метку. Меточное выражение в правиле 1 вычисляется во время
исполнения, и его значением является метка, на которую передается управление.
Для меточных выражений, описываемых правилом 2, значение выражения,
получаемое во время исполнения,— это та метка, которую именует данный
идентификатор.
Для меточных выражений, описываемых правилом 3, значением выражения,
вычисляемого во время исполнения, является значение первого меточного
выражения в правой части, если ПЕРЕМЕННАЯ равна 0, и в противном
случае значение второго выражения. Предположим, что в нашем
распоряжении имеются следующие атомы:
а) МЕТКА (р), где р — указатель на элемент таблицы, соответствующий
некоторой метке. МЕТКА играет двоякую роль. Этот атом отмечает место,
где программист определил некоторую метку, а также отмечает место, где
компилятор определил метку в своих собственных целях. Элемент таблицы,
на который указывает р, в обоих случаях одного и того же типа.
б) ПЕРЕХОД(р), где р — указатель на элемент таблицы, соответствующий
некоторой метке. ПЕРЕХОД порождает код, вызывающий безусловную
передачу управления иа метку, определяемую р.
в) ПЕРЕХОДНЕН (</, р), где р — указатель па элемент таблицы, соответст-
иующий метке, и q — указатель на элемент таблицы, соответствующий
переменной. ПЕРЕХОДНЕН порождает код для передачи управления на
метку, определяемую р, если переменная, определяемая q, не равна нулю.
i) Найдите L-атрибутную грамматику цепочечного перевода, задающую
некоторый перевод цепочек этого языка в надлежащие цепочки атомов.
В качестве примера переводом GO TO ИДЕНТИФИКАТОР7
будет ПЕРЕХОД(7) и переводом цепочки
GO TO IF ПЕРЕМЕННАЯ5 THEN ИДЕНТИФИКАТОР,, ELSE
ИДЕНТИФИКАТОР,,
может быть
ПЕРЕХОДНЕН (5, 31) ПЕРЕХОД (17) МЕТКА (31) ПЕРЕХОД (II)
где 31 — указатель иа элемент таблицы, соответствующий некоторой
метке, определенной компилятором.
ii) На основе этой грамматики постройте процессор.
Ш) Предположим, что в нашем распоряжении есть такой атом:
ПЕРЕХОДИ ((/, р), где q указывает на элемент таблицы, соответствующий
переменной, и р указывает на элемент таблицы, соответствующий метке.
ПЕРЕХОДИ порождает код для передачи управления па метку,
определяемую р, если переменная, определяемая q, равна нулю.
Найдите L-атрибутную грамматику (возможно, изменив входную
грамматику), которая задает перевод н цепочку атомов, такой, что, если меточное
выражение после THEN является идентификатором, то используется атом
ПЕРЕХОДИ, второй атрибут которого является указателем иа элемент
таблицы, соответствующий этому идентификатору. Например, переводом
цепочки
') Меточное выражение (label expression) называю! 1акже именующим вы
ражением.— Прим. ред.
36П Гл. 9. Нисходящие методы обработки для атрибутных грамматик
GO TO IF ПЕРЕМЕННАЯ5 THEN ИДЕНТИФИКАТОР!, ELSE
ИДЕНТИФИКАТОРи
будет
ПЕРЕХОДИ (5, 17) ПЕРЕХОД (11)
(iv) Предположим, что кроме атома ПЕРЕХОДИ у нас есть еще атом
УРАВН-МЕТОК(р, а)
где р — указатель на элемент таблицы, соответствующий метке,
определенной программистом, и q — указатель на элемент таблицы, соответствующий
метке, определенной компилятором. Этот атом указывает генератору кода,
что обе метки помечают одно и то же место в программе.
Найдите L-атрибутную грамматику (возможно, изменив входную
грамматику), задающую перевод в цепочку атомов так, что, если меточное
выражение после THEN начинается с IF и меточное выражение после ELSE
является идентификатором, то используется атом ПЕРЕХОДНЕН с
некоторой меткой, определенной компилятором, которая в свою очередь равна
метке, стоящей после ELSE, определенной программистом. Например,
перевод выражения GO TO IF ПЕРЕМЕННАЯ, THEN IF ПЕРЕМЕН-
НАЯ5 THEN ИДЕНТИФИКАТОР!, ELSE ИДЕНТИФИКАТОРц ELSE
ИДЕНТИФИКАТОР.^!
может быть таким:
ПЕРЕХОДНЕН (7, 31) ПЕРЕХОДИ (5, 17) ПЕРЕХОД (II) УРАВН-
МЕТОК(21, 31)
где 31 — указатель на элемент таблицы, содержащий метку, определенную
компилятором.
28. а) При разработке процессора для L-атрибутной грамматики некоторые поля
магазинных символов можно иногда заменить глобальными переменными,
которые используются для того, чтобы «следить» за значениями атрибутов.
Постройте атрибутный МП-процессор для грамматики на рис. 9.2, в
котором только магазинные символы {СЛОЖ} и {УМНОЖ} имеют поля.
У этих магазинных символов должно быть одно поле, которое используется
для запоминания значения левого операнда. Процессор должен иметь также
одну глобальную переменную для хранения значения подвыражения,
полученного последним,
б) Выполните пункт а) для грамматики на рис. 7.10.
29. Рассмотрим следующую атрибутную грамматику:
(Е>, СИНТЕЗИРУЕМЫЙ г
Все атрибуты символов действия — НАСЛЕДУЕМЫЕ.
1. <S> — 1р1 = <Е>п{ПРИСВр2>г2}
р2 <— р\ Г2 «— г\
2. <£>, — +<£>„ <£>?i {СЛОЖ^, 92}
р2 +— р\ </2 <— q\
г <— адрес атома СЛОЖ
3. <£>, -+ * <E>pl <E>gl {УМНОЖ^, ?2}
р2 *— р\ ?2 <— q\
г <— адрес атома УМНОЖ
4. <£>г2 -^ /,,
/■2 <— г\
Цепочка атомов начинается в ячейке 400, и адрес каждого атома в этой цепочке
равен адресу предыдущего атома, увеличенному на три.
Упражнения
367
а) Найдите атрибутный перевод цепочки
/,= + /2*+/3/1*V5
б) Пусть (Е) имеет еще два атрибута, один из которых наследуемый, а другой
синтезируемый. Наследуемый атрибут равен адресу первого атома в
цепочке атомов, который может появиться при переводе (Е). Синтезируемый
атрибут равен адресу первого атома в цепочке атомов, который появляется
сразу после перевода цепочки, порожденной нетерминалом (Е).
Введите в данную грамматику правила, определяющие значения этих
атрибутов. Кроме того, измените правила для г в продукциях 2 и Зтак,
чтобы извлечь выгоду из этих новых атрибутов.
в) Постройте процессор для приведенной выше грамматики.
30. Предположим, что какое-то поле некоторого магазинного символа в
атрибутном МП-автомате может содержать указатель на произвольную ячейку в уже
полученной цепочке атомов.
а) Используйте эту возможность при построении процессора для следующей
не L-атрибутной грамматики:
(S)-+a{c}y(S)dx
(S)-+b
б) Покажите, что, если L-атрибутная грамматика изменена путем включения
в ее продукции выходных символов с наследуемыми атрибутами, что не
удовлетворяет пункту 1 определения L-атрибутных грамматик, то
надлежащий перевод можно выполнить помощью атрибутного МП-автомата,
использующего в указанную выше возможность.
31. Некоторые компиляторы устроены так, что их синтаксический блок дает в
качестве выхода некоторое представление дерева вывода входной цепочки.
Одним из возможных представлений является структура данных, содержащая
отдельный атом для каждой вершины дерева. В качестве примера дерево,
приведенное ниже на рисунке, имеет представление, показанное на втором
рисунке. Каждый атом структуры данных состоит из класса и двух атрибутов.
Класс — это имя терминала или нетерминала. Первый атрибут — указатель
на самого левого прямого потомка, если он вообще существует. Если потомков
нет, как у любого терминала или нетерминала, к которому применено е-пра-
вило, то первый атрибут равен нулю. Второй атрибут атома — это указатель
на вершину, ближайшую справа к данной вершине и являющуюся потомком
той же вершины, что и данная. Если таких вершии нет, как например, в
случае самого последнего символа в правиле или начального нетерминала, то
второй атрибут равен нулю.
<S>
а <А>
<В> <С>
Ь S
<А> <В> е
/\
с d Ь
368 Гл. 9. Нисходящие методы обработки для атрибутных грамматик
<s>
0
Г Л И | I 1 1 |
кя> > » i »i < о I о J » i т<А>
Найдите L-атрибутную грамматику, задающую перевод каждой цепочки,
порождаемой следующей грамматикой, с начальным символом (S) в
цепочку атомов, представляющую ее дерево.
{S)^a{A)(S}
(S) - (В)е
(А) _* (B)(C){A)
{А) -* cd
<С) + е
<С> — а(В){В)
Атомы можно порождать в любом желаемом порядке.
Указание. Для приведенного выше примера дерева может порождаться
следующая выходная цепочка:
1. 6(0, 0) 10. (S>(9, 0)
2. d(0, 0) 11. U>(6, 10)
3. с(0, 2) 12. а(0, 11)
4. (А)(3, 0) 13. (S>(12, 0)
5. <С>(0, 4)
6. (В>(1, 5)
7. &(0, 0)
8. е(0, 0)
9. (Д>(7 8)
Для удобства атомы пронумерованы.
10
Синтаксический блок для языка
MINI-BASIC
10.1. LL(1)-грамматика языка
В этой главе мы построим синтаксический блок для языка
MINI-BASIC на основе L-атрибутной транслирующей грамматики
с входной ЬЬ(1)-грамматикой. Работа синтаксического блока
состоит в том, что он получает в качестве входа цепочку лексем,
которую поставляет лексический блок, описанный в гл. 4, и выдает
в качестве выхода цепочку атомов, которые будут использоваться
в качестве входной цепочки генератора кода, описанного в гл. 14.
Вначале рассмотрим ЬЬ(1)-грамматику, которая лежит в
основе перевода. Эта грамматика показана на рис. 10.1, и ее можно
сравнить с грамматикой языка MINI-BASIC, приведенной в
разд. 6.15.
Множество терминалов грамматики на рис. 10.1 — это
множество лексем, перечисленных на рис. 4.1, за исключением того, что
пять знаков арифметических операций представлены не одной, а
различными лексемами. Изучая грамматики, полезно иметь в
виду те фактические цепочки символов, которые соответствуют
каждой лексеме. Например, лексема ПРИСВ соответствует слову LET,
за которым следуют переменная и символ-, а лексема СТРОКА
соответствует номеру, стоящему в начале строки.
Отметим, что правило 9 порождает как FOR-оператор, так и
соответствующий ему NEXT-оператор. Отметим также, что правило 9
порождет FOR-операторы обоих типов, тогда как нетерминал (шаг)
порождает либо пустую цепочку, либо лексему ШАГ, за которой
следует некоторое выражение.
Можно легко убедиться, что грамматика на рис. 10.1 является
ЬЦ1)-грамматикой.
10.2. Множество атомов и транслирующая
грамматика
Теперь мы можем задать множество атомов и транслирующую
грамматику. Рис. 10.2 показывает полное множество атомов вместе с
описаниями всех атрибутов.
ОКОНЧАНИЕ, первый атом на рисунке, служит концевым
маркером цепочки атпмов. Он используется в качестве сообщения
370 Гл. 10. Синтаксический, блок для язика MINI-BASIC
Начальный символ: <программа>
Структура программы
1. <программа>—»■ СТРОКА <тело программы> КОНЕЦ
2. село программы> —► е
Пустой оператор
3. <тело программы> —► СТРОКА <тело программы>
Оператор присваивания
4. <тело программы> —► ПРИСВОИТЬ <выражение> <другие строки>
GOTO-onepamop
5. <тело программы>—>• ПЕРЕХОД НА <другие строки>
IF-оператор
6. <тело программы>—► ЕСЛИ <выражение> ОТНОШЕНИЕ
<выражение> ПЕРЕХОД НА <другие
строки>
GOSU В-оператор
7. <тело программы>—»• ПЕРЕХОД НА ПОДПР <другие строки>
RETURN-onepamop
8. <тело программы> —»■ ВОЗВРАТ <другие строки>
FOR-onepamop
9. <тело программы> —> ДЛЯ <выражение> ДО <выражение>
<шаг> <другие строки> КОНЕЦ ЦИКЛА
<другие строки>
10. <шаг>—>-ШАГ <выражение>
11. <шаг> —>- е
RE М-оператор
12. <тело программы>—»-КОММЕНТАРИЙ <другие строки>
Номер строки
13. <другие строки>—«-СТРОКА <тело программы>
Выражения
14. <выражение>—>- <терм> <£-список>
15. <выражеиие>—>- + <терм> <£-список>
16. <выражение>—► — <терм> <£-список>
17. <£-список>—>- + <терм> <£-список>
18. <£-список>—>• — <терм> <£-список>
19. <£-список>—»-е
20. <терм>—>■ <множитель> <7"-cnncoK>
21. <7'-список>—* * <множитель> <7"-список>
22. <7'-список>—>/<множитель> <7"-список>
23. <Г-список>—>-е
24. <множитель> —>• <первичное> <У7-сиисок>
25. ^-списо^ —>■ t <первичное> <У7-список>
26. ^-списо^ —»- е
27. <первичное> —>■ (<выражеиие>)
28. <первичное> —> ОПЕРАНД
Рис. 10.1. LL (1)-грамматика для синтаксического блока компилятора
MINI-BASIC.
10.2. Множество атомов и транслирующая грамматика 371
множество атомов
Название
ОКОНЧАНИЕ
НОМСТРОК
ПРИСВ
ПЕРЕХОД
ХРАН ПЕРЕХОД
ВОЗВПЕРЕХОД
УСЛПЕРЕХОД
ХРАНЕНИЕ
МЕТКА
ПРОВЕРКА
УВЕЛИЧ
слож
вычит
А три дут ы
Указатель на
номер
строки
Указатель на
переменную
Указатель на
номер
строки
Указатель на
номер строки
Указатель на
результат
выражения
Указатель на
результат
выражения
Указатель
на метку
Указатель
на ДЛЯ -
переменную
Указатель
на
Непеременную
Указатель
на левый
операнд
Указатель
на левый
операнд
Указатель
на результат
выражения
Указатель на
результат
выражения
Указатель на
результат
атомо
ХРАНЕНИЕ
Указатель
на результат
атома
ХРАНЕНИЕ для
до-
выражения
Указатель
на результат
атома
ХРАНЕНИЕ для ШАГ-
выражения
Указатель
на правый
операнд
Указатель
на правый
операнд
Имя
отношения
Указатель
на результат
атома
ХРАНЕНИЕ для
ШАГ -
выражения
Указатель
на
результат
Указатель
на результат
Указатель
на номер
строки
Указатель
на МЕТКУ
Рис. 10.2. Множество атомов.
372 Гл. 10. Синтаксический блок для ятыка MINI-BASIC
Множество атомов
Название
УМНОЖ
ДЕЛЕН
ЭКСП
плюс
минус
Атрибуты
Указатель на
левый
операнд
Указатель
на левый
операнд
Указатель
на левый
операнд
Указатель
на операнд
Указатель
на операнд
Указатель
на правый
операнд
Указатель
на прабый
операнд
Указатель
на правый
операнд
Указатель на
результат
Указатель на
результат
Указатель
на результат
Указатель на
результат
Указатель на
результат
Рис. 10.2 (продолжение).
синтаксического блока генератору кода о том, что процесс
синтаксической обработки закончен, и текущим входным символом
синтаксического блока является концевой маркер. Получив атом
ОКОНЧАНИЕ, генератор кода порождает код окончания
исполнения программы. Атом ОКОНЧАНИЕ производится выходной
процедурой синтаксического блока и как элемент транслирующей
грамматики не определяется. То, что ОКОНЧАНИЕ выдается выходной
процедурой, гарантирует, что он всегда будет последним
выдаваемым атомом, даже если синтаксический блок получил на вход
синтаксически неправильную цепочку, и была вызвана процедура
нейтрализации ошибок.
Следующий атом НОМСТРОК(р) должен выдаваться, когда
встречается лексема СТРОКА. Атрибут р равен значению лексемы
СТРОКА, а именно указателю на элемент таблицы, содержащий
номер строки. Появление этого атома в цепочке атомов приведет к
тому, что генератор кода запишет адрес объектного кода,
соответствующий данному номеру строки. Моменты времени, подходящие
для создания атома НОМСТРОК, можно определить такими
правилами:
1. (программа>-> СТРОКА {НОМСТРОК} (тело программы)
КОНЕЦ
3. (тело программы)-> СТРОКА {НОМСТРОК} (тело
программы)
13. (остальные строки)-> СТРОКА {НОМСТРОК} (тело
программы)
Когда синтаксический блок встречает лексему СТРОКА,
хотелось бы также, чтобы он запоминал значение этой лексемы, так
10.2. Множество атомов и транслирующая грамматика 373
что в случае обнаружения ошибки во время обработки этой строки
ее номер можно было напечатать в качестве части сообщения об
ошибке. Предположим, что для запоминания текущего номера
строки синтаксический блок использует переменную НОМЕР
СТРОКИ. Введем новый символ действия {УСТАН НОМЕР
СТРОКИ}, которому будет соответствовать процедура действия,
присваивающая значение лексемы СТРОКА неременной НОМЕР
СТРОКИ. Моменты вызова этой процедуры действия можно определить
так:
1. (программа )-> СТРОКА {НОМ СТРОК} {УСТАН НОМЕР
СТРОКИ} (тело программы) КОНЕЦ
3. (тело программы)-> СТРОКА {НОМ СТРОК} {УСТАН
НОМЕР СТРОКИ} (тело программы)
13. (остальные строки) -+ СТРОКА {НОМ СТРОК} {УСТАН
НОМЕР СТРОКИ} (тело
программы)
Для выражений мы используем перевод, аналогичный
переводу из разд. 7.4.
14. (выражение)-> (терм)(£-список)
15. (выражение)-»- + (терм) {ПЛЮС} (£-список)
16. (выражение)-»-— (терм) {МИНУС} (£-список)
17. (£-список)-> + (терм) {СЛОЖ} (£-список)
18. (£-список)-v — (терм) {ВЫЧИТ} (£-список)
19. (£-список) -v е
20. (терм)-* (множитель) (Т-список)
21. (Г-список)-> * (множитель) {УМНОЖ} (Т-список)
22. (Г-список) -v / (множитель) {ДЕЛЕН} (7-список '
23. (Г-список) -> е
24. (множитель)-> (первичное)(£-список)
25. (£-список)-> f (первичное) {ЭКСП} (F-список)
26. (/^-список) -v е
27. (первичное)-> ((выражение))
28. (первичное )-> ОПЕРАНД
Назначение остальных атомов выявляется при отдельном
рассмотрении каждого типа операторов. В разд. 7.9 мы построили
перевод оператора присваивания и IF-оператора с помощью
соответствующих атомов ПРИСВ и УСЛПЕРЕХОД. Здесь мы
используем те же атомы с теми же атрибутами. Соответствующие правила
транслирующей грамматики таковы:
374 Гл. 10. Синтаксический блок для языка MINI-BASIC
4. (тело программы>-> ПРИСВ (выражение) {ПРИСВ}
(остальные строки)
6. (тело программы)-> ЕСЛИ (выражение) ОТНОШЕНИЕ
(выражение) ПЕРЕХОД НА {УСЛ
ПЕРЕХОД} (другие строки)
Для пустого оператора и REM-оператора никакие атомы в
качестве выхода не требуются.
Для GOTO-оператора мы используем атом
ПЕРЕХОД(р)
где р — указатель на элемент таблицы, содержащий номер
строки, на которую передается управление (то есть р равен значению
лексемы ПЕРЕХОД). Момент создания этого атома задается так:
5. (тело программы) -> ПЕРЕХОД НА {ПЕРЕХОД} (другие
строки)
Теперь рассмотрим GOSUB-оператор и RETURN-оператор. Наш
план реализации вызовов подпрограмм во время исполнения
предполагает использование рабочего магазина, в котором
запоминается адрес возврата. Всякий раз, когда выполняется GOSUB-оператор,
управление передается на заданную строку и адрес возврата
вталкивается в рабочий магазин. Затем, когда выполняется RETURN-
оператор, управление передается по адресу, находящемуся на
верху рабочего магазина,и этот адрес удаляется из
магазина.Маркер дна магазина является адресом процедуры обработки ошибок
во время исполнения программы, так что, если RETURN-оператор
выполняется большее число раз, чем GOSUB-оператор, то
управление будет передано этой процедуре обработки ошибок. Последняя
напечатает надлежащее сообщение об ошибке и остановит
программу.
Для того чтобы выполнить этот план, мы используем два
атома: атом ПЕРЕХОД ХРАН(р), который появляется сразу, как
только встретилась лексема ПЕРЕХОД НА ПОДПР, и атом
ВОЗВРАТ-ПЕРЕХОД, который появляется сразу, как только
встретилась лексема ВОЗВРАТ. ПЕРЕХОД ХРАН имеет один атрибут —
указатель на элемент таблицы, содержащий номер строки, на
которую должно быть передано управление (т. е., атрибут равен
значению лексемы ПЕРЕХОД НА ПОДПР). ПЕРЕХОД ХРАН
приводит к порождению кода, выполняющего переход и вталкивающего
адрес возврата в рабочий магазин. Атом ВОЗВРАТ-ПЕРЕХОД
атрибутов не имеет и приводит к порождению кода, который
выталкивает адрес возврата из рабочего магазина и передает
управление по этому адресу.
Моменты выдачи этих атомов можно задать правилами:
10.2. Множество атомов и транслирующая грамматика
1. Вычислить
значение первого выражение
1
2. Присвоить по/ц/ченное
значение для-переменной
1
3. Вычислить
ДО-выражение
'
1
4. Запомнить значение
ДО-выражение •
1
S. Вычислить
ШАГ-Выражение.
1
6. Запомнить значение
ШАГ -выражения
У7 Прс
А
верит*^
>S. WKJI s^
Нет\
8. Выполнить
операторы в цикле
1
9. Увеличить -значение
ДЛЯ - переменной
1
10. Переход на начало
цикла
1
"\
Да
1
1.
2.
3.
4.
5.
6.
А.
7.
8.
9.
10.
В.
<8ыражение>
{ПРИСВОИТЬ}
< выражение>
{ХРАНИТЬ}
<выражение>или1
{ХРАНИТЬ}
{МЕТКА}
{ПРОВЕРИТЬ}
< другие строки>
{УВЕЛИЧ}
{ПЕРЕХОД}
{МЕТКА)
6
Рис. 10.3.
376 Гл. 10. Синтаксический блок для языка MINI-BASIC
7. (тело подпрограммы)-> ПЕРЕХОД НА ПОДПР
{ПЕРЕХОД ХРАН} (остальные
строки)
8. (те^о подпрограммы)-> ВОЗВРАТ {ВОЗВРАТ-ПЕРЕХОД}
(остальные строки)
Теперь рассмотрим FOR-оператор. Чтобы объяснить схему
перевода FOR-оператора в цепочку атомов, вначале опишем схему
реализации FOR-оператора во время исполнения. Она приведена
на рис. 10.3, а в виде блок-схемы. Объектный код для блоков этой
схемы нужно генерировать в том порядке, в котором эти блоки
расположены на рис. 10.3, а. Во время исполнения программы мы
прежде всего вычисляем значение начального выражения и
присваиваем его ДЛЯ-переменной (т. е. переменной, на которую
указывает значение лексемы ДЛЯ, она следует за FOR в исходной
программе). Затем мы вычисляем значение ДО-выражения (т. е.
выражения, следующего за словом ДО в программе, поступающей
на вход синтаксического блока) и запоминаем его для
дальнейшего использования. Затем вычисляем значение ШАГ-выражения
и запоминаем его. Теперь проверяем условие выполнения
операторов цикла. Если операторы выполняются, то после их
выполнения мы увеличиваем значение ДЛЯ-переменной и возобновляем
проверку. Заметим, что вычисление и запоминание ДО-выражения
и ШАГ-выражения перед циклом блок-схемы гарантирует, что
для этих выражений будут использоваться те же самые значения,
даже если какая-нибудь переменная, используемая при их
вычислении, изменяется одним из операторов цикла.
Наш план обработки синтаксическим блоком конструкции ДЛЯ-
КОНЕЦ ЦИКЛА состоит в выдаче одного или нескольких атомов
для каждого блока и каждой помеченной вершины блок-схемы на
рис. 10.3, а. Теперь рассмотрим каждый блок и каждую помеченную
вершину и опишем требуемый перевод в атомы. Результаты этого
рассмотрения суммированы на рис. 10.3, б. Атомы для блоков 1 и 3
порождаются двумя вхождениями нетерминала (выражение) в
правиле 9.
Если к нетерминалу (шаг) применяется правило 10, то атомы
для блока 5 порождаются нетерминалом (выражение), входящим
в правило 10. Если к (шаг) применяется правило 11, то
выражение для блока 5 равно константе 1.
Код для блока 2 получается с помощью атома ПРИСВ, который
мы уже рассмотрели. Для блоков 4 и 6 введем атом ХРАНЕНИЕ
{р, q), где р — указатель на элемент таблицы, в котором хранится
значение выражения, и q — указатель на элемент таблицы,
связанный с рабочей ячейкой, в которой должно запоминаться это
значение. Элемент таблицы, на который указывает q, мы называем
результатом атома ХРАНЕНИЕ. Генератор кода обращается с
10.2. Множество атомов и транслирующая грамматика 377
атомом ХРАНЕНИЕ иначе, чем с атомом ПРИСВ. Когда первый
атрибут атома ХРАНЕНИЕ указывает на элемент таблицы,
содержащий константу, генератор не порождает никакого кода, а
использует саму эту константу в коде, порождаемом для других
атомов, связанных с ШАГ-выражением. Когда элемент таблицы
соответствует переменной или выражению, содержащему какую-нибудь
операцию, атом ХРАНЕНИЕ порождает код для запоминания
значения ШАГ-выражения в некоторой ячейке. Эта ячейка
используется в коде, порождаемом для других атомов, связанных с
ШАГ-выражением.
Вершины Л и В в блок-схеме представляют точки, куда
должно передаваться управление. Мы рассматриваем каждую из этих
точек как некоторую метку и сопоставляем ей элемент в таблице.
Чтобы генератор кода мог вырабатывать адрес в объектом коде,
соответствующий каждой из этих меток, вершины А и В
представляются атомом LABEL(p), где р — указатель на элемент таблицы,
содержащий метку. Отметим, что метка — это объект, создаваемый
компилятором, и этим она отличается от номера строки.
Для блока 7 используем атом ПРОВЕРКА(р, q, r, s), где р —
указатель на элемент таблицы, содержащий ДЛЯ-переменную,
q — указатель на элемент таблицы, используемый для атома
ХРАНЕНИЕ, соответствующего ДО-выражению, г — указатель на
элемент таблицы, используемый для атома ХРАНЕНИЕ,
соответствующего ШАГ-выражению, s — указатель на элемент таблицы
для метки, соответствующей вершине В на рис. 10.3, а. Код,
получаемый из атома ПРОВЕРКА, реализует следующий алгоритм, в
котором имена атрибутов используются для представления
соответствующих значений во время исполнения программы:
ЕСЛИ (г>0 и p>q) или (л<0 и p<q) TO
ПЕРЕХОД НА s
Атомы для блока 8 должны получаться при обработке первого
вхождения нетерминала (остальные строки) в правую часть
правила 9.
Для блока 9 мы используем атом УВЕЛИЧ(р, q), где р —
указатель на элемент таблицы, содержащий ДЛЯ-переменную, и q —
указатель на результат атома ХРАНЕНИЕ, связанного с ШАГ-
выражением. Код, получаемый из атома УВЕЛИЧ, прибавляет к
ДЛЯ-переменной значение ШАГ-выражения.
Для блока 10 мы используем атом ПЕРЕХОД(р), где р —
указатель на элемент таблицы, содержащий метку, которая
соответствует точке А в блок-схеме.
Блок-схема конструкции ДЛЯ-КОНЕЦ ЦИКЛА описывает,
что происходит во время исполнения и показывает, какие атомы
должны порождаться во время компиляции. Однако кроме
порождения указанных атомов во время компиляции можно выполнить
378 Гл. 10. Синтаксический блок для языка MINI-BASIC
еще одно действие, а именно проверить, совпадает ли ДЛЯ-пере-
менная с переменной из лексемы КОНЕЦ ЦИКЛА. Для
выполнения этой проверки вводим процедуру действия, {КОНТРОЛЬ }Pi ?i n
где р и q — равны значениям лексем ДЛЯ и КОНЕЦ ЦИКЛА
соответственно, иг — указатель на элемент таблицы, содержащий
номер строки FOR-оператора. Действие процедуры {КОНТРОЛЬ}
заключается в проверке равенства р н q. Если они не равны, то
выдается предупреждение, указывающее номер строки
FOR-оператора. Однако это не рассматривается как фатальная ошибка, и
компиляция продолжается. Моменты выдачи атомов и вызова
процедуры {КОНТРОЛЬ} определяются правилами:
9. (тело программы) -> ДЛЯ (выражение) {ПРИСВ} ДО
(выражение) {ХРАНИТЬ} (шаг)
{ХРАНИТЬ} {МЕТКА} {ПРОВЕРКА}
(остальные строки) КОНЕЦ ЦИКЛА
{КОНТРОЛЬ} {УВЕЛИЧ}
{ПЕРЕХОД} {МЕТКА} (остальные строки)
10. (шаг)->ШАГ (выражение)
11. (шаг) ->- ё
10.3. L-атрибутная грамматика
L-атрибутная грамматика показана на рис. 10.4. Мы
предполагаем существование трех процедур распределения элементов
таблиц: НОВТ, НОВТХ и НОВТАМ. НОВТ выдает указатель на
новый элемент таблицы, который отводится под промежуточный
результат, НОВТХ выдает указатель на новый элемент таблицы,
используемый для результата атома ХРАНЕНИЕ, и НОВТАМ выдаст
указатель на новый элемент таблицы, который отводится под
метку. Как будет показано в гл. 14, каждый из этих типов элементов
имеет несколько полей, которые нужны генератору кода.
Заполнение некоторых полей начинают процедуры НОВТ, НОВТХ и
НОВТАМ во время распределения элементов таблицы, но это мы
обсудим в гл. 14. Здесь нам надо знать только то, что НОВТ, НОВТХ
и НОВТАМ выдают надлежащие указатели.
В правиле 11 мы предполагаем, что можно получить указатель
на ранее заготовленный элемент таблицы для константы 1.
10.4. Синтаксический блок
Оставшееся построение можно выполнить, используя либо МП-
автоматы, либо метод рекурсивного спуска, рассмотренные в гл. 9.
В нашем примере мы проиллюстрируем технику построения МП-
автомата.
10.4. Синтаксический блок
379
Все атрибуты нетерминалов СИНТЕЗИРУЕМЫЕ, кроме следующих:
<£-список>,,, 1 НАСЛЕДУЕМЫЙ р СИНТЕЗИРУЕМЫЙ t
<7-список>я,, НАСЛЕДУЕМЫЙ р СИНТЕЗИРУЕМЫЙ t
</г-сиисок>/,, , НАСЛЕДУЕМЫЙ р СИНТЕЗИРУЕМЫЙ t
Все атрибуты символов действия НАСЛЕДУЕМЫЕ.
Описание процедуры действия {УСТАНОВИТЬ НОМЕР СТРОКИ},,
НОМЕР СТРОКИ ^р
Описание процедуры действия {КОНТРОЛЬ}^ Wi y
ЕСЛИ р Ф w ТО печатать предупреждение
Начальный символ: <программа>
Структура программы
1. <программа>—>-СТРОКАг, {НОМСТРОКр2} {УСТАНОВИТЬ НОМЕР
СТРОКИ},,, <тело програ.ммы> КОНЕЦ
(рЗ, р2)«—pi
2. <тело программы> —>■ е
Пустой оператор
3. <тело программы> —- СТРОКА,,, {НОМСТРОКр2} {УСТАНОВИТЬ НОМЕР
СТРОКИ}^ <тело программы>
(рЗ,р2)+-р\
Оператор присваивания
4. <тело программы^ —► ПРИСВОИТЬ^ <выражение>(?1
{ПРИСВ„2 „„} <другие строки>
р2+— р\ q2*—q\
GOTC-onepamop
5. <тело программы>—> ПЕРЕХОД HA^i {ПЕРЕХОД^2} <другие строки>
р2 — р\
lF-onepamop
6. <тело программы> —>• ЕСЛИ <выражение>^1 ОТНОШЕНИЕ,!
<выражение>?1 ПЕРЕХОД HAit
{УСЛПЕРЕХОД,,, „,„,„}
<другие строки>
р2«—pi <72«—<?1 /-2<— r\ s2 <— si
GOSU B-onepamop
7. сгело программы>—> ПЕРЕХОД НА ПОДПРр1 {ХРАНПЕРЕХОД,,,}
<другие строки>
р2<-Р1
RETURN-оператор
8. <тело программы> —>• ВОЗВРАТ {ВОЗВПЕРЕХОД} <другие строки>
FOR-onepamop
9. <тело программы> —»• ДЛЯ,,] <выражение>?1 {ПРИСВ^21 qi)
ДО <выражение>г1 {ХРАНИТЬ,.,, sl}
<шаг>л1 {ХРАНИТЬ*.,, п} {МЕТКАИ,}
{UPOBEPKAf,3,s2,t2.vi} <другие строки>
КОНЕЦ ЦИКЛАт {КОНТРОЛЬ}^, w,.,,
Рис. 10.4. L-атрибутная грамматика для синтаксического блока компилятора
MINI-BASIC.
380 Гл. 10. Синтаксический блок для языка MINI-BASIC
{УВЕЛИЧЯ5,,8| {ПЕРЕХОД,,}
{МЕТКАС2} <другие строки>
(s2, si) —HOBTX (/3, t2, tl)*— HOBTX
(и2, и\)*— НОВТАМ (v2, v\) *— НОВТАМ
(р€, р4, рЗ, р2) —pi </«— НОМЕР СТРОКИ
<?2<—gl a2<- /-1 х2*—х\ w2*—w\
10. <шаг>/,2—>• ШАГ <выражение>р]-
Р'2 ■>— р\
11. <шаг>р—>-е
р—указатель на элемент таблицы для константы 1.
REM-onepamop
12. <тело программы> —► КОММЕНТАРИЙ <другие строки>
Номер строки
13. аругие строки> —.-СТРОКА,,, {НОМСТРОК^} {УСТАНОВИТЬ НОМЕР
СТРОКИ},,,, <тело программы>
(рЗ, р2) *- pi
Выражения
14. <выражение>/2—>• <терм>р] <£-список>р2, и
р2<— р! /2-— /1
15. <выражение><2—»-+<терм>?, {ПЛЮС?2 г1} <£-список>г2, п
q2*—q\ t2*—t\
(r2, r\)*— HOBT
16. <выражение>(.,—<• — <терм>?] {МИНУС?.2 г,} <£-список>г2, а
q2*—q\ (2*—(\
(г2, Н)— НОВТ
17. <£-список>р1,/2—>+<TepM>9] {СЛОЖрг, 9г п} <£-список>г2, п
р2«—pi ' q2*—q\ >2 *— 1\'
(/■2, г1)^-НОВТ
18. <£-список>/,,1,2—<■ —<терм>?1 {ВЫЧИТрг, д2, п) <£ -список>л2. п
р2*—pi q2*—q\ 12*—11
(r2, Н)«—НОВТ
19. <£-cnHCOKN?I дг —► е
q2*-q\
20. <терм>(2—► <множитель>/,1- <7,-список>р2, и
р2*—р\ 12*— П
21. <7'-список>р1> (2—>• * <множитель>?1 {УМНОЖ^г, чъ, п) <Т-списокуrit /j
р2*-р\ ' q2*-qi (2*-tl
(/■2, r\)*- HOBT
22. <Г-список>/)1,/г—<-/<множитель>9, {ДЕЛЕНя8> ?2, ri} <T-a\ucoK.>r2iti
p2*-p\ q2*-q\ t2*—t\
(r2, M)—HOBT
23. <Г-список>91 ?2 —>8
q2*-q\
24. <множитель>^2—>• <первичное>,,1 <F-cnHC0K>p2> a
p2*—p\ t2*—t\
25. <f-список>я1, (2 —»■ | <первичное>?1 {ЭКСП^ 92, n} <£-список>Г2_ ц
10.4. Синтаксический блок
381
р2<—pl q2-*—q\ 12-
(г2, /■!)•>— НОВТ
26. <^-список>91, а2—► е
<?2 — <?1
'27, <"первичное>р2 —>■ (<выражение>/,1)
28. <первичное>р2—«-ОПЕРАНД,,,
р2— р!
На рис. 10.5 показана управляющая таблица автомата.
Занумерованные элементы соответствуют переходам, в которых
применяются правила грамматики. Элементы, помеченные латинскими
буквами, соответствуют неошибочным переходам (т. е. не
указывающим на ошибку), для которых верхним магазинным символом
является маркер дна или терминальный символ транслирующей
5 I
§
2 I
1 Ш
< программа >
«пело программы?
<шаг >
кдрцгие строки >
(биражение >
<терм>
ешюжитель>
<первичное >
<£-списак >
<Г- список >
<Г-список>
ОТНОШЕНИЕ
КОНЕЦ ЦИКЛА
ПЕРЕХОД
ПРАВАЯ СКОБКА
КОНЕЦ
ДО
V
(Присвоить)
(асл. переход!
(ХРАНИТЬ!
{ МЕТКА 1
(ПРОВЕРИТЬ!
(КОНТРОЛЬ)
{УВЕЛИЧИТЬ!
(ПЕРЕХОД)
(СЛОЖ 1
JBH4NTI
(КМНОЖ)
iделен|
Тэксп )
1плюс|
1 минусI
1
3
11
13
{2
42
Г2
1Г2
,9J
23
26
02
U
р2
12
w
п2
Р
о
(S
11
ъ
а
в
7'
Л
м ! [1
20 : ч\
24 ' (1
28 1 Г1
41
с
J7-1
01н
19
23
26
ь
и) ■ ш
Л<
el
to
тг1
о
рЗ
el
и
«1
о
а
2
11
ft
Я
и
и
и
OJ
„
и
01
„
4
71*'
»
И.
!4
S4
J-
01
„ ч
,1
и
1
гМ
р
pl
v\
W
ТГ1
р
а
9
71
6
Г4
Г4
«;
ш
Г4
fll
ы
*1
о
5
71
А
(1
fl
(1
ft
19
23
26
«1
И И
а) и
я1 : in
р i р
—
а
7
71
6
t4
С
И
И
и
и
Lll.
ei
.
pl
^7Г
w
ii
р
а
0
71
S
14
20
24
27
57
01
u)
pi
и
u
JTl
p
а
в
72
6
(3
i3
(3
;з
19
23
26
03
cp
p4
a
и
гЗ
P
а
6
71
6
!*
f4
t"
Г4
(O
<P
H
51
Ul
Ml
f]
и
rl
p
— -
—
а
в
7l
6
И
f4
?4
UJ
GJ
f4
01
а
7
Tl
Й
or
i
71
Л
Г-* i fi
И
Ш
UJ
f4
01
pi
rl ■ «1
U) Я
ffl : rl
f\P
ft
ft
0
19
23
26
01
~*r
vl
^
a
p
а
в
10
19
23
26
91
ы
pt
pi
ы
p
d
e
f
9
.".
,
k
V
m
n
о
P
а
12
,1
f,
f4
it
<4
t«
CJ
'И"
«1
0)
pl
el
и
i:l
- —
а
С
71
6
15
t6
{6
(6
17
23
26
1)1
u;
pl
И
и
nl
0
а
^
71
«
16
?6
(6
f6
18
23
26
01
tp
pl
«1
u;
Jil
p
...
--
1
4
71
Л
f5
{6
>6
Г6
OJ
21
26
J1
Ml
TTl
—
i
11
«,
3
11
6 ft
Г5 15
(6 1 (6
0
0
0
0
f]
"
f6 ! ?6 I n
Г6 (6-
w ' ^
22
26
01
OJ
25
"1
pl "~
el
el
u;
П in
P | p
—
0
w
Ы
"V
u
"
•
Tl
t2
r2
r2
гЗ
;3
гЗ
73
IP
т2
гЗ
тЗ
гЗ
ы
:3
с
Я
'
Рис. 10.5
3«2 Гл. 10. Синтаксический блок для языка MINI-BASIC
грамматики. Элементы, помеченные греческими буквами,
соответствуют ошибкам. Все элементы, которые могут либо применить
какое-нибудь правило, либо сообщить об ошибке, рассматриваются
как ошибочные.
На'рис. 10.6 показано состояние магазина «до» и «после»
применения каждого из правил, для которых соответствующий переход
использует операцию ЗАМЕНИТЬ. На рис. 10.7 показаны
управляющие процедуры, на которые ссылается управляющая таблица.
Автомат использует обычные операции ЗАМЕНИТЬ,
ВЫТОЛКНУТЬ, СДВИГ и ДЕРЖАТЬ.
Процедура ВЫДАТЬ АТОМ взаимодействует с генератором
кода, выдавая свой параметр в качестве атома. Что касается
проектирования синтаксического блока, эта процедура может либо
записать данный атом в промежуточный файл, либо сообщить
генератору кода, что очередной атом уже готов. Поскольку мы планируем
компилировать MINI-BASIC за один проход, примем последнюю
интерпретацию.
Процедура ОШИБКА, описанная на рис. 10.7, вызывается
в момент обнаружения ошибки. Эта процедура имеет в качестве
параметра некоторую последовательность букв, которую она
печатает в качестве сообщения об ошибке для программиста,
написавшего программу на языке MINI-BASIC. Например, процедура
перехода а такова:
ОШИБКА «ПРОГРАММА НАЧИНАЕТСЯ НЕПРАВИЛЬНО»
Процедура ОШИБКА выдает это сообщение и приписывает к нему
номер строки, полученный из переменной НОМЕР СТРОКИ.
Так, если ошибка произошла в строке 10, то пользователю может
быть выдано такое сообщение:
10: ПРОГРАММА НАЧИНАЕТСЯ НЕПРАВИЛЬНО
Мы предусматриваем возможность вставки в сообщения об
ошибках дополнительной информации. Например, нам часто
хочется вставить в сообщение входной символ, нарушающий
правильность программы, что можно проиллюстрировать на процедуре
перехода б:
ОШИБКА («НЕПРАВИЛЬНЫЙ $ (вход) ПОСЛЕ ОКОНЧАНИЯ
ОПЕРАТОРА»)
Когда печатается это сообщение, $ (вход) заменяется на
представление соответствующей входной лексемы. Если лексемой
является ОПЕРАЦИЯ ОТНОШЕНИЯ, то $ (вход) заменяется
используемым в данном случае отношением (например, =). Если
лексема — это ОПЕРАНД, то $ (вход) заменяется либо на слово
«КОНСТАНТА», либо на имя фактически используемой перемен-
<программа>
до
<_тело программьА
КОНЕЦ
Правило 1
ПОСЛЕ
<щело программы^
ДО
<тело программы^
ПОСЛЕ
Пробило 3
<тело программы>
ДО
<выражение>
{присв!
р
< другие стропи >
р рабно значению входа
Правило 4
ПОСЛЕ
<тело ррограммыу
Кдругие строки >
АО
Прадило 5,7,8, \г
ПОСЛЕ
\<тело программы >
*■
< выражение >
Г"
ОТНОШЕНИЕ
<выражение >
ПЕРЕХОД НА
*
(услпереход)
<другие строки^.
до
ПОСЛЕ
Правило 6
Рис. 10.6.
р равно значению входа
S равно значению,
поставляемому вызовом процедуры
НОВТХ
t равно значению,
поставляемому другим вызовом
процедуры НОВТХ
и равно значению,
поставляемому вызовом процедуры
НОВТАМ
v равно значению,
поставляемому другим вызовом
процедуры НОВТАМ
у равно номер строки
<тело программы >
< выражение>
^^^^^^
{ПРИСВ}
р
U
ДО
< выражение >
Г ™ *
1 (ХРАНЕНИЕ}
1
s
< шаг >
1 '
1 {ХРАНЕНИЕ}
U
г
{МЕТКА}
и
{ПРОВЕРКА}
Р
s
t
V
< другие строки >
КОНЕЦ ЦИКЛА
{КОНТРОЛЬ}
р
У
{ИВЕЛИЧ}
р
г
{ПЕРЕХОЛ}
и
{МЕТКА}
V
кдругие строки >
йО
Правило 9
ПОСЛЕ
Рис. 10.6 (продолжение).
< шаг >
До
Правило 10
< выражение>
ПОСЛЕ
< другие строки >
ДО
Правило 13
<тело программы >
ПОСЛЕ
<выражение >
t
*
<терм >
<'£-список>
t
ДО
Правило 14
ПОСЛЕ
< выражение>
■*
<терм >
*
(ПЛЮС)
г
<Е - список>
Г
t
ДО ПОСЛЕ
г равно значению, поставляемому
вызовом процедуры НОВТ
Правило 15
" Ф. Льюис и др.
Рис. 10.6 (продолжение).
Гл. 10. Синтаксический блек Оля языка MINI-BASIC
< выражение > j
<терм>
{минус}
<.£- список>
йо
ПОСЛЕ
г равно значению, поставляемому вызовом
процедуры новт
Правило 16
< Е-список >
р
t
♦
<терм>
{СЛОЖ}
р
г
<£- список >
г
t
ДО ПОСЛЕ
г равно значению, поставляемому вызовом
процедуры новт
Правило 17
Рис. 10,6 (продолжение).
10.4. Синтаксический блок
< Е-список >
<терм>
{вычит)
р
<Е-список>
ДО ПОСЛЕ
г равно значению, поставляемому вызовом
процедуры Новт
Правило 18
<терм>
'
йО
<Т - список >
р
t
Правило 20
*
< множитель >
<Т-список >
t
ПОСЛЕ
<множитель >
{УМНОЖ}
р
»
г
<Т~ список >
г
t
ДО ПОСЛЕ
г равно значению, поставляемому вызовом процедуры Н08Т
Правило 21
Рис. 10.6 (продолжение)
<7 -список >
*
< множитель >
(ДЕЛЕН)
р
г
<Т- список >
г
1
до после
г равно значению, поставляемому вызовом процедуры НОВТ
Правило 22
<множитель >
i
АО
<F-CPUCOK >
р
t
Правило
»
24
+
< первичное >
*
<F-список >
1
ПОСЛЕ
<первичное>
'
(эксп)
р
1
< F- список >
Т
ДО ПОСЛЕ
Г равно значению, поставляемому вызовом процедуры НОВТ
Правило 25
< первичное >
р
< выражение >
р
)
ДО
Правило 27
Рис. 10.6 (продолжение)
ПОСЛЕ
10.4. Синтаксический блок
389
ной. Для других лексем $ (вход) заменяется на имя лексемы или
некоторое зарезервированное слово.
В переходе i для магазинного символа (КОНТРОЛЬ) мы также
предполагаем, что в предупреждающее сообщение можно вставить
номер строки.
1: ЗАМЕНИТЬ как на рис. 10.6 для правила 1.
ВЫДАТЬАТОМ (НОМСТРОК^), где р — значение входа.
НОМЕР СТРОКИ <— значение входа.
СДВИГ.
2: ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
3: ЗАМЕНИТЬ как на рис. 10.6 для правила 3.
ВЫДАТЬАТОМ (НОМСТРОКр), где р— значение входа.
НОМЕР СТРОКИ — значение входа.
СДВИГ.
4: ЗАМЕНИТЬ как на рис. 10.6 для правила 4.
СДВИГ.
5: ЗАМЕНИТЬ как на рис. 10.6 для правила 5.
ВЫДАТЬАТОМ (ПЕРЕХОД,), где р — значение входа.
СДВИГ.
6: ЗАМЕНИТЬ как на рис. 10.6 для правила 6.
СДВИГ.
7: ЗАМЕНИТЬ как на рис. 10.6 для правила 7.
ВЫДАТЬАТОМ (ХРАНПЕРЕХОД,,), где р — значение входа.
СДВИГ.
8: ЗАМЕНИТЬ как на рис. 10.6 для правила 8.
ВЫДАТЬАТОМ (ВОЗВПЕРЕХОД).
СДВИГ.
9: ЗАМЕНИТЬ как на рис. 10.6 для правила 9.
СДВИГ.
10: ЗАМЕНИТЬ как на рис. 10.6 для правила 10.
СДВИГ.
И: Поместить указатель на элемент таблицы для константы 1 в поле, на ко.
торое указывает поле верхнего магазинного символа <шаг>,
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
12: ЗАМЕНИТЬ как на рис. 10.6 для правила 12.
СДВИГ.
13: ЗАМЕНИТЬ как на рис. 10.6 для правила 13.
.ВЫДАТЬАТОМ (НОМСТРОК,), где р — значение входа.
НОМЕР СТРОКИ <— значение входа.
СДВИГ.
14: ЗАМЕНИТЬ как на рис. 10.6 для правила 14,
ДЕРЖАТЬ.
Рис. 10.7.
390 Гл. 10. Синтаксический блок для языка MINI-BASIC
15: ЗАМЕНИТЬ как на рис. 10.6 для правила 15.
СДВИГ.
16: ЗАМЕНИТЬ как на рис. 10.6 для правила 16.
СДВИГ.
17. ЗАМЕНИТЬ как на рис. 10.6 для правила 17.
СДВИГ.
18: ЗАМЕНИТЬ как на рис. 10.6 для правила 18.
СДВИГ.
19: Поместить содержимое первого поля верхнего магазинного символа <£-
список> в ячейку, на которую указывает второе поле.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
20: ЗАМЕНИТЬ как на рис. 10.6 для правила 20.
ДЕРЖАТЬ.
21: ЗАМЕНИТЬ как на рис. 10.6 для правила 21.
СДВИГ.
22: ЗАМЕНИТЬ как на рис. 10.6 для правила 22.
СДВИГ.
23: Поместить содержимое первого поля верхнего магазинного символа
<Г-список> в ячейку, на которую указывает второе поле,
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
24: ЗАМЕНИТЬ как на рис. 10.6 для правила 24.
ДЕРЖАТЬ.
25: ЗАМЕНИТЬ как на рис. 10.6 для правила 25.
СДВИГ.
26: Поместить содержимое первого поля верхнего магазинного символа
<^-список> в ячейку, на которую указывает второе поле.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
27: ЗАМЕНИТЬ как на рис. 10.6 для правила 27.
СДВИГ.
28: Поместить значение входного символа в ячейку, на которую указывает
поле верхнего магазинного символа <первичное>.
ВЫТОЛКНУТЬ.
СДВИГ,
а: ВЫТОЛКНУТЬ.
СДВИГ.
Ь: Поместить значение входа в ячейку, на которую указывает поле верхнего
магазинного символа.
ВЫТОЛКНУТЬ.
СДВИГ,
с: ВЫДАТЬАТОМ (ОКОНЧАНИЕ),
d: ВЫДАТЬАТОМ (ПРИСВ^^), где р и q — содержимое первых двух полей
магазина.
ВЫТОЛКНУТЬ.
10.4. Синтаксический блок
391
ДЕРЖАТЬ,
е: ВЫДАТЬАТОМ (УСЛПЕРЕХОДл ?, r, s), где р, q, r и s —содержимое
первых четырех полей магазина.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
f: ВЫДАТЬАТОМ (ХРАНЕНИЕ^ q), где р и q — содержимое первых двух
полей магазина.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
g: ВЫДАТЬАТОМ (МЕТКА»), где р — содержимое первого поля магазина.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
h: ВЫДАТЬАТОМ (ПРОВЕРКА^, ?, г, s), где р, q, r и s—содержимое
первых четырех полей магазина.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
i: ЕСЛИ содержи.мое первого поля магазинного символа не равно
содержимому второго поля
ТО ПЕЧАТАТЬ («ПЕРЕМЕННАЯ NEXT-ОПЕРАТОРА ОТЛИЧНА ОТ
ПЕРЕМЕННОЙ FOR-ОПЕРАТОРА В СТРОКЕ $ (номер строки в
элементе таблицы, на который указывает третье поле) — ПРЕДПОЛАГАЕМАЯ
ПЕРЕМЕННАЯ»),
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
j: ВЫДАТЬАТОМ (УВЕЛИЧЛ q), где р и q — содержимое первых двух
полей магазина.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
к: ВЫДАТЬАТОМ (ПЕРЕХОД,,), где р — содержимое первого поля магазина.
ВЫТОЛКНУТЬ,
ДЕРЖАТЬ.
1: ВЫДАТЬАТОМ (СЛОЖр, ?, г). где р, q, а —содержимое первых трех
полей магазина.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ,
т: ВЫДАТЬАТОМ (ВЫЧИТр q г), где р, q и г —содержимое первых трех
полей магазина.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
п: ВЫДАТЬАТОМ (УМНОЖр. q, г), где р, q и г —содержимое первых трех
полей магазина,
ВЫТОЛКНУТЬ,
ДЕРЖАТЬ,
о: ВЫДАТЬАТОМ (ДЕЛЕНр, я, г), где р, q и а —содержимое первых трех
полей магазина.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
392
Гл. 10. Синтаксический блок для языка MINI-BASIC
р: ВЫДАТЬАТОМ (ЭКСПР| q, r), где р, q и г — содержимое первых трех
полей магазина.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ,
q: ВЫДАТЬАТОМ (ПЛЮС?1 г), где q и /- — содержимое первых двух полей
магазина.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ.
г: ВЫДАТЬАТОМ (МИНУС^,.), где q и /- — содержимое первых двух полей
магазина.
ВЫТОЛКНУТЬ.
ДЕРЖАТЬ,
а: ОШИБКА («ПРОГРАММА НАЧИНАЕТСЯ НЕВЕРНО»)
Р: ОШИБКА («ОПЕРАТОР НАЧИНАЕТСЯ НЕВЕРНО»)
У1: ОШИБКА («НЕОЖИДАННЫЙ $ (вход) В КОНЦЕ FOR-ОПЕРАТОРА»)
у2: ОШИБКА («ЛИШНЯЯ ПРАВАЯ СКОБКА В ВЫРАЖЕНИИ ПОСЛЕ ТО»)
6: ОШИБКА («НЕОЖИДАННЫЙ $ (вход) ПОСЛЕ ОКОНЧАНИЯ
ОПЕРАТОРА»)
£/: ОШИБКА («ВЫРАЖЕНИЕ НЕЗАКОНЧЕНО —НЕТ ОПЕРАНДА»)
12: ОШИБКА («ОПЕРАТОР НЕЗАКОНЧЕН»)
ЪЗ: ОШИБКА («В ВЫРАЖЕНИИ ПРОПУЩЕН ОПЕРАНД»)
14: ОШИБКА («НЕОЖИДАННЫЙ S (вход) ПОСЛЕ ВЫРАЖЕНИЯ»)
15: ОШИБКА («ВЫРАЖЕНИЕ НАЧИНАЕТСЯ С § (вход)»)
1б: ОШИБКА («ДВА ЗНАКА ОПЕРАЦИИ ПОДРЯД В ВЫРАЖЕНИИ»)
17: ОШИБКА («В ВЫРАЖЕНИИ ПРОПУЩЕН ЗНАК ОПЕРАЦИИ»)
01: ОШИБКА («НЕОЖИДАННЫЙ S (вход) В IF-ОПЕРАТОРЕ»)
92: ОШИБКА («IF-ОПЕРАТОР НЕЗАКОНЧЕН»)
9-3: ОШИБКА («ЛИШНЯЯ ПРАВАЯ СКОБКА В ВЫРАЖЕНИИ ПОСЛЕ IF»)
\: ОШИБКА («FOR-ОПЕРАТОРЫ ВЛОЖЕНЫ НЕПРАВИЛЬНО
ПРОПУЩЕНО NEXT»)
ц1: ОШИБКА («НЕОЖИДАННЫЙ $ (вход) в IF-ОПЕРАТОРЕ»)
ц2: ОШИБКА («IF-ОПЕРАТОР НЕЗАКОНЧЕН»)
цЗ: ОШИБКА («ДВА ЗНАКА ОТНОШЕНИЯ В IF-ОПЕРАТОРЕ»)
ц4: ОШИБКА («ЛИШНЯЯ ПРАВАЯ СКОБКА В ВЫРАЖЕНИИ ПОСЛЕ
ЗНАКА ОТНОШЕНИЯ»)
v/: ОШИБКА («ПРОПУЩЕНА ПРАВАЯ СКОБКА ПЕРЕД $ (вход)»)
v2: ОШИБКА («ПРОПУЩЕНА ПРАВАЯ СКОБКА В КОНЦЕ СТРОКИ»)
Ь ОШИБКА («FOR-ОПЕРАТОРЫ ВЛОЖЕНЫ НЕПРАВИЛЬНО -
ЛИШНЕЕ NEXT»),
я/: ОШИБКА («НЕОЖИДАННЫЙ S (вход) в FOR-ОПЕРАТОРЕ»)
д2: ОШИБКА («FOR-ОПЕРАТОР НЕЗАКОНЧЕН»)
пЗ: ОШИБКА («ЛИШНЯЯ ПРАВАЯ СКОБКА В ВЫРАЖЕНИИ ПОСЛЕ»)
п4: ОШИБКА («ТО ПРОПУЩЕНО ИЛИ НЕ НА СВОЕМ МЕСТЕ В FOR-
ОПЕРАТОРЕ»)
р: ОШИБКА («ПРОГРАММА ПРОДОЛЖАЕТСЯ ПОСЛЕ END-ОПЕРАТОРА»)
а: ОШИБКА (« »)
10.4. Синтаксический блок
393
тУ: ОШИБКА («НЕТ ПРОГРАММЫ»)
%2: ОШИБКА («ПРОПУЩЕН END-ОПЕРАТОР»)
хЗ: ОШИБКА («ПРОГРАММА КОНЧАЕТСЯ ПОСРЕДИ ОПЕРАТОРА»)
ш: ОШИБКА («ОШИБКА КОМПИЛЯТОРА»)
Описание процедуры ОШИБКА
Напечатать сообщение об ошибке.
Установить флажок ошибки для указания того, что произошла ошибка.
Считывать цепочку лексем, включая текущую лексему, пока не будет найдена
лексема СТРОКА, или если текущая лексема есть —), то окончить
компиляцию. В противном случае выполнить магазинную операцию, зависящую от
верхнего магазинного символа, как указано ниже.
Магазинный символ Операция
<программа> Никакой
<тело программы> Никакой
<другие строки> Никакой
КОНЕЦ ВТОЛКНУТЬ (<тело программы»
у ВТОЛКНУТЬ (<тело программы»
Любой другой ВЫТОЛКНУТЬ, пока на верху мага-
*' зина не окажется нетерминал <другие
строки>. (Не выполнять процедур,
соответствующих символам действия.)
ДЕРЖАТЬ
Рис. 10.7.
Заметим, что в переходе о параметром вызова процедуры
ОШИБКА является пустая цепочка. В этом случае никакого
сообщения не печатается: надлежащее сообщение об ошибке уже было
сделано лексическим блоком.
Выдав сообщение об ошибке, процедура ОШИБКА
устанавливает «флажок ошибки» для того, чтобы указать, что встретилась
ошибка. Все ошибки, для которых вызывается процедура
ОШИБКА, являются фатальными, и после установления флажка
ошибки генерация объектного кода прекращается.
Процедура ОШИБКА несет также ответственность за
нейтрализацию ошибки. Метод нейтрализации ошибок основывается на
идеях, изложенных в разд. 8.8, и использует лексемы СТРОКА
и в качестве синхронизирующих символов.
Элементы, помеченные ш, соответствуют конфигурациям,
которые не могут встретиться даже при обработке неправильных
цепочек. Рассмотрим, например, элемент таблицы для магазинного
символа (Г-список) и входного символа f. Из правил 20, 21, 22
мы видим, что всякий раз, когда (Г-список> вталкивается в
магазин, (множитель) вталкивается над ним. К нетерминалу
(множитель) затем применяется правило 24, и (F-список) оказывается
в магазине прямо над нетерминалом (Г-список). Поскольку к
нетерминалу (F-список) применяется правило 25, магазинным сим-
Г-Р4 Гл. 10. Синтаксический блок для языка MINI-BASIC
гг.-см, расположенным прямо над символом (Т-список), останется
(/•"• список). Символ (Г-список) может оказаться на верху
магазина только в единственном случае, когда для того, чтобы
вытолкнуть (r-список) из магазина, используется правило 26. Поскольку
правило 26 является е-правилом, текущий входной символ в момент
его применения так и остается текущим в тот момент, когда (Г-
список) еггшовится верхним магазинным символом. Следовательно,
10 ОТЛА;; ЧНАЯ ПРОГРАММА ДЛЯ СИНТАКСИЧЕСКОГО БЛОКА
50
30 LET X = II * 5
40 GOSUB ЬО
50 GOTO 70
ЬО RETURN
70 IF X = 0 GOTO йЗ
АО TOR X = 0 ТО 10
qo for y = x то го sn:.? г
100 NEXT Y
110 NEXT X
150LETA = XT2t3*Y*5 + Y*(-ZT2 + 3)
130 LET В = A T 5 / X / ?.l - ((3 + X + A))
W0LETC = B-C-(+Y/5T 3 + 5) Г 5 - < * X t S-l
150LETD = 3*A + BT (CTB-1)*X/Y + 1
1Ь0 LET E = A / В Т С / 2 - A T ЗГ < / Y * В - Ь
17D LET F = 37 T (A T В - С * A t A T 5 * D) + 3
IflO END
Рис. 10.8.
всякий раз, когда на вершине магазина находится (Г-список),
текущий входной символ —• это один из символов,
обусловливающий применение правила 26 к символу (/-"-список), т. е. текущий
входной символ принадлежит множеству выбора правила 26. Так
как символа f нет в этом множестве, он никогда не будет текущим
входным символом в момент, когда (Г-список) является верхним
магазинным символом. Кроме того, процедура нейтрализации
ошибки никогда не работает в ситуации, когда (Г-список) является
верхним магазинным символом, at — текущим входным символом.
10.5. Компактный процессор для выражений языка MINI-BASIC 395
Таким образом, элемент таблицы для символов (Г-список) и f
никогда не достигается даже для неправильной цепочки. Однако
мы заполняем этот элемент символом ш, так что, если этот элемент
каким-либо образом был достигнут, то будет напечатано сообщение
ОШИБКА КОМПИЛЯТОРА
обозначающее, что ошибка допущена при проектировании или
программировании самого компилятора.
На рис. 10.8 показана программа на языке MINI-BASIC,
которая вызывает все неошибочные переходы синтаксического блока.
Правильную цепочку атомов для этой программы можно получить,
если промоделировать вручную описанное построение
синтаксического блока. Если эта цепочка атомов будет на самом деле
выдана при некоторой реализации указанного построения, то
разработчик с высокой степенью уверенности может считать, что
программирование выполнено правильно.
10.5. Компактный процессор для выражений
языка MINI-BASIC
Рассмотренные до сих пор нисходящие процессоры характерны
тем, что каждый магазинный символ представляет единственный
символ грамматики. Для некоторых грамматик выгодно строить
процессоры, в которых один магазинный символ представляет
несколько символов грамматики, а поля магазинного символа
задают в точности тот символ грамматики, который представляется
данным вхождением магазинного символа. В частности, техника
«уплотнения» символов очень полезна для некоторых грамматик,
описывающих выражения. Сейчас мы проиллюстрируем некоторые
приемы на грамматике для выражений языка MINI-BASIC.
В качестве предварительного шага наших построений
продемонстрируем на рис. 10.9 грамматику, транслирующую
выражения языка MINI-BASIC, входная грамматика которой такая же,
как в синтаксическом блоке, за исключением того, что к ней
добавляется нетерминал (Р-список), порождающий только пустую
цепочку. Причина введения новой грамматики заключается в том,
что все правила с левой частью (Е), (Г>, (У7) и (Р) имеют правые
части, которые оканчиваются «списковым» нетерминалом (т. е.
(£-список>, (Г-список>, (Р-список) или (Р-список)). Для удобства
ссылок грамматика поделена на четыре раздела.
На рис. 10.10 показана транслирующая грамматика MINI-
BASIC'a, входная грамматика которой является ^-грамматикой.
Эта грамматика порождает те же последовательности актов, что и
грамматика на рис. 10.9. В новой грамматике нетерминалы (£),
(Г), (У7) и (Р) порождают те же цепочки терминалов. Эта грам-
396
Гл. 10. Синтаксический блок для языка MINI-BASIC
матика также содержит десять нетерминалов вида (X, Y). Каждый
из этих нетерминалов порождает то же множество терминальных
цепочек, что и некоторая цепочка, состоящая из списковых
нетерминалов грамматики на рис. 10.9. Цепочки списковых нетерми-
Раздел: (Е):
AI. (£> — <Г> (Е-список)
А2. <£> -. + (Т) {ПЛЮС} (Е-список)
A3. <£> -> - (Т) {МИНУС} (Е-список)
А4. (Е-список)-* + (Т) {СПОЖ.} (Е-сшажУ
А5. (Е-список)-* - (Т) {ВЫЧИТ} (Е-список)
А6. (Е-список)-* £
Раздел:( Т):
А7. (Т) ^ (F) (Т-Спиж)
А8. (Т-спижУ* * (F) {УМНОЖ} (Т-спиж)
А9. (Тсписок)-* I (F) Щ£Щ (Т-список)
А10. (Т-списокУ* е
Раздел:^):
All. (F)^(P) (F-список)
А12. (F-список)-^ Т (Р) {ЭКСП} (F-список)
А13. (F-список)^ г
Раздел:(Р):
А14. (Р)^((Е) )(Р-список)
А15. (Р) — / (Р-список)
А16. (Р-список)^ е
Начальный символ: < е>
Рис. 10.9.
налов, соответствующие каждому из десяти новых нетерминалов,
показаны на рис. 10.11. Заметим, что для каждого нового
нетерминала вида (X, Y) последним нетерминалом в соответствующей
цепочке является (Х-список), а первым— (У-список). Символ X
из пары (X, У) не только определяет последний списковый
нетерминал соответствующей цепочки, он еще указывает раздел
грамматики, в который входит нетерминал (X, Y). Например, все вхож-
Компактный процессор для выражений языка MINI-BASIC 397
Раздел<Е>:
81. <£>->(<F>)<F,F)
82. <£> -» / (Е, Р)
83. <£>-> + (Т) {ПЛЮС} <£, Е)
84. <£> — - (Т) {МИНУС <£, £)
85. (Е, Р)-+ + (Т) {СЛОЖ} (Е, Е)
86. <£, F>-« - (Т) {ВЫЧИТ} <£, £)
87. <£, F) — * (F) {УМНОЖ} (Е, Т)
88. (Е, Р) — I (F) {ДЕЛЕН}<£, Т)
89. <£, F) — T <F> {ЭКСП} <£, F)
810. <£, F>^e
811. (Е, F>^ + <7*> {СЛОЖ} <£, Е)
812. <£, F>^ - <Г> {ВЫЧИТ} (Е, Е)
813. <£, F>-* * <F> {УМНОЖ } {Е, Т)
814. <£, F>— / <F> {ДЕЛЕН}<£, Т)
815. <£, F> — t </>> {ЭКСП} <£, F>
816. <F, F> —e
817. <£, Т)^ + <7> {СЛОЖ} <£, £)
818. <£, Г> — - (Т) {ВЫЧИТ} <£, £>
819. (Е, Т) — * <F> (УМНОЖ } (Е, Т)
820. (Е, Г> — / <F> (ДЕЛЕН}(£, Т)
821. <£, Г> —е
822. <£, £>-> + (Г) {СЛОЖ} <£, Е)
823. <£, £>— - <7> {ВЫЧИТ} (Е, Е)
824. <£, Е)-*е
Раздел (Т):
825. <Г>-*(<£> )<7, Р)
826. (Г) — /<Т, F)
827. <7; F>— * <F> {УМНОЖ} (Т, Т)
828. (Т,Р)^/ <F> {ДЕЛЕН} (Г, Т)
829. <7, F>-> T {Р) {ЭКСП} (Г, F>
830. (Т,Р)^е
831. <Г. F>^ * <F> {УМНОЖ]} (Т, Т)
832. (Т, F)-*/ (F) {ДЕЛЕН}<Т, Т\
833. <Г, F> — Т <F> {ЭКСП} <Г, F)
834. <Г, F)^e
835. (Г, Г)-. * <F> {УМНОЖ} <Г, Г)
836. (Т, Г)-. / <F> {ДЕЛЕН}(7; П
837. (Г, Г>-*е
Рис. 10.10.
398
Гл. 10. Синтаксический блок для языка MINI-B ASIC
Раздел: (F):
838. (F)^((E))(F,P)
839. <F> — / <F, Р)
840. <F, Р) — Т <F> {ЭКСП} <F, F)
841. <F,F> —£
842. <F, F>— T <P> {ЭКСП} <F, F)
B43. <F, F> — £
A73ob:<F>:
B44. </>> -(<£>) (P, P)
B45. (P)-*I(P, P)
B46. <P, P> — 6
Начальный символ: (E)
Рис. 10.10 (продолжение).
дения {Т, Р) в правую или левую часть правила содержатся в
разделе <Г>.
Раздел (Р) новой грамматики понять легко. Согласно
интерпретации имен на рис. 10.11, (Р, Р) следует понимать как (Р-список),
и разделы (Р) в обеих грамматиках оказываются идентичными.
Нетерминал
<Е,Р)
{EfF)
(Е,Т)
(Е,Е)
(Т,Р)
(TF)
(Т, Т)
(F.P)
<KF>
(РР)
Цепочка
{Р-сжок)(Р-список){Т-список)(Е-список}
< Fcnum){ T- список){ Е-список)
{ Т-список){Е-список)
{Е-список)
{ Р-еписак){ F-crucok){ Т-список)
(F-списокХ. Т-список)
{Т-список)
(Р-список)(Е-соисок)
(F-CWC0K)
(Р-список)
Рис. 10.11.
Чтобы понять раздел (F) новой грамматики, надо иметь в виду,
что
(F, F) представляет (F-список)
(F, Р) представляет (Я-список) (F-список)
В нашей интерпретации каждое правило представляет несколько
шагов левого вывода в грамматике на рис. 10.9. Например, исполь-
10.5. Компактный процессор для выражений языка MINI-BASIC 399
зование правил All и А14 дает
<F> => L <P> <F-cnHCOK> =Ф L «£» <Я-список> </?-список>
Этот двухшаговый вывод представляется правилом В38, в котором
(F, Р) используется как сокращение для (Я-список> (^-список).
Правило В39 аналогично представляет вывод, в котором
применяются правила АН и А15. Правило В40 интерпретируется как
представляющее двухшаговый вывод.
<Р-список> <^-список>=>д<^-список>=>д t <P>{3KCn}<F-cnncoK>
который получается применением правил А16 и А12. Правило В41
интерпретируется как двухшаговый вывод.
<Я-спнсок> <^-список> => L </г-список> =5> Lt>
в котором используются правила А16 и А13. Правило В42
представляет одношаговый вывод, задаваемый правилом А12. Правило
В43 — это одношаговый вывод, задаваемый правилом А13.
Чтобы понять раздел (Г), следует помнить об интерпретации
новых нетерминалов. Правило В25 интерпретируется как вывод
<Т> => I «/:>) <Р-список> </г-список> <Г-спнсок>
который получается за три шага с помощью правил А7, АН и А14.
Правило В31 интерпретируется как вывод
<F-cnncoK> <Г-спнсок> =>[ * <F> {УМНОЖ} <Г-список>
который получается применением правил А13 и А8. Правило В2Э
гласит, что
<Я-список> <F-cnHCOK> <Г-список> => "L \
t <Я> {ЭКСП} </7-список> <Г-список>
а это ясно из правил А16 и А12. Правило В34 гласит, что
</?-список> <Т-список> => I e
а это получается по правилам А13 и А10. Аналогичный анализ
показывает, как интерпретировать другие правила раздела (Е)
и раздела (Г).
Процедура вычисления множеств выбора показывает, что новая
грамматика является ^-грамматикой. Для удобства ссылок
множества выбора для е-правил показаны на рис. 10.12. Множество
выбора каждого неспискового правила — это, конечно,
терминальный символ, с которого начинается правая часть.
Грамматика на рис. 10.10 сложнее грамматики на рис. 10.9
в том смысле, что в ней 14 нетерминалов и 46 правил против
прежних 8 нетерминалов и 16 правил. Однако новая грамматика выгоднее
в том отношении, что деревья вывода в ней значительно короче.
400 Гл. 10. Синтаксический блок для языка MINI-BASIC
В качестве следующего подготовительного этапа при
объяснении компактного процессора мы покажем в несколько шагов,
как грамматику на рис. 10.10 можно представить в компактной
форме. Первый шаг представлен грамматикой на рис. 10.13. Это
просто рис. 10.10 с переименованными символами и записанными
ВЫБОР(Ю) =
ВЫ50Р (16) =
ВЫБОР (21) =
ВЫБОР (24) =
ВЫ БОР (30) =
ВЫБОР (34) =
ВЫБОР (37) =
ВЫБОР (41) =
ВЫБОР (43) =
ВЫБОР (46) =
СЛЕД
СЛЕД
СЛЕД
СЛЕД
СЛЕД
СЛЕД
СЛЕД
СЛЕД
СЛЕД
СЛЕД
«£, Р))
«£, F))
((Е,Т))
((Е, £»
(<Т,Р))
((T,F)) :
«г. г»
«F, Р)) ■■
«F, О) =
«Л Р)) ■
Рис. 10.12.
= 0-4}
= 0. Н)
= 0.4)
= 0. И}
= о. ч +,
= {).Ч+,
- 0.Н+,
= 0.4.+,
= {).Н.+,
= {).Н.+.
-}
-}
-}
-.*./}
-.*./}
-.*•■/,
в другом порядке правилами. Каждое правило на рис. 10.13
получено из правила на рис. 10.10, имеющего тот же номер, с помощью
замены букв Е, Т, F и Р на Еи Ег, Е3 и Ех соответственно.
Правила на рис. 10.13 разбиты на десять групп, помеченных
буквами от а до /. Внутри каждой группы правила совпадают
с точностью до индексов. На рис. 10.14 мы изобразили каждую
группу правил в виде одной строки. Каждая строка состоит из
схемы правила, содержащей в качестве переменных индекс i или
индексы / и /', и числовых ограничений на эти индексы. Каждая
строка означает, что правило грамматики можно получить, заменив
в схеме переменные i и / на любые значения, удовлетворяющие
числовым ограничениям. Так, например, строка а представляет четыре
правила, по одному для каждого значения i, удовлетворяющего
неравенствам l^i^4, а строка g представляет шесть правил.
Грамматику можно сделать еще более компактной, чем на
рис. 10.14, если представить входные символы и символы действия
как символы с индексами. Для того чтобы это сделать, заменим
знаки операций +, —, *, / и f на ОП+, ОП_, ОП*, ОП/ и ОП»;
заменим символы действия {СЛОЖ}, {ВЫЧИТ}, {УМНОЖ},
{ДЕЛЕН} и {ЭКСП} на {БИНАР+} {БИНАР.}, {БИНАР,},
{БИНАР,} и {BHHAPt}; символы {ПЛЮС} и {МИНУС} заменим
на {УНАР+} и {УНАР_}. После того как это сделано, каждая
группа схем правил, помеченная на рис. 10.14 цифрой от I до V,
объединяется в одну схему, показанную на рис. 10.15.
10.5. Компактный процессор для выражений языка MINI-BASIC 401
Каждая схема на рис. 10.15 имеет некоторые из переменных (',
/ и х в качестве параметров. Самая сложная схема IV имеет все эти
три параметра. Для того чтобы выяснить, получается ли правило
из схемы IV при данных значениях /, / и х, необходимо отыскать
значение т(х) в таблице на рисунке и проверить отношения
l^.i^.m(x)^.j^4. Если эти отношения выполняются, то данное
правило грамматики получается подстановкой в схему значений
а <
Ь<
1.
25.
38.
44.
2.
26.
39.
.45.
с{г
d{ 4.
€ '
f ,
J
£<
6
'22.
17.
11.
5.
'23.
18.
12.
. 6.
' 19.
13.
7.
35.
31.
,27.
(£.>-(<£i>)<£i>£4>
(£,>-(<£!>)<£,,£«>
(£3>-*( <£,>)<£,,£,>
(£,>-(<£,>)<£,,£,>
(£,>- /<£„£«>
(E2)-~I(E2,E<)
(£3>-/<£3,£4>
(£4>-/<£4,£4>
{£,>.-+ <£2> {ПЛЮС} <£,,£,>
(£,>--<£2> {МИНУС}(Е^Е,)
(£p £,> - + <£2> {СЛ0Ж} <£„ £x)
(£lf £2>- + <£2>{СЛОЖ} <£„£,>
(£„ £3>- + <£2> {СЛОЖ} <£lt £,>
(£lt £4> — + <£2> {СЛОЖ} <£1; £,)
(£,.£,>-- <£2>{ВЫЧИТ} <£,,£,>
(£1( £2>— - <£2> {ВЫЧИТ} (Ev £,>
(£1>£3>--<£2>{ВЫЧИТ} (f,,^)
(£„ £4>- - <£2> {ВЫЧИТ} <£„ £x)
(£p £2>^ * <£3> {УМН0Ж} <£1( £2>
(£,, £3)^ * <£3> {УМНОЖ} <£!, £2>
(£lt £4> — * <£3> {УМН0Ж} (Ely £2>
(£2, £2>— * <£3) {УМНОЖ} <£2, £2)
(£2> £3>- * <£3> {УМНОЖ} <£2, £2>
[E2, £4>^ * <£3> {УМНОЖ} <£2, £2>
Рис. 10.13.
402 Гл. 10. Синтаксический блок для языка MINI-BASIC
I,
fl
j •
i <
J
'20.
1.4.
8.
36.
32.
28.
V
' 15.
9.
33.
29.
42.
40.
'24. <
21.
16. <
10. <
37. <
34. <
30. <
43. <
41. <
.46. <
j, x и т{х). Ее
ли, н
(£,, E2) - / (E3) {ДЕЛЕН} <£x, £2>
(*i
(*i
(E2
<*2
(£2
(*i
<*i
(£2
[E2
[E3
1^3
:*!
(*i
[E,
[Ex
[E2
[E2
'&•
'E3
[E3,
[E4,
Яз>-*/<£з>{ДЕЛЕН}<£>,£2>
£4>-/<£3> {ЛЕЛЕНК^, £-2>
£2W<£3> {ДЕЛЕН}<£2, £2>
Е3)^/(Е3){Ц,ЕПЫ}(Е2,Е2)
Е4)^/<Е3) {ДЕЛЕН} <£2,£2>
^з>^Ч^4>{ЭКСП}<£1,£3>
^>-*Т(£4>{ЭКСП}<£1)£3>
^з>-Ч^>{ЗКСП}<£2,£3>
£4>-»Т<£4> {ЭКСП} <£2>£3>
^з>-*Ч^>{эксп}<£3,£3>
^4>-*Ч^4>{ЭКСП}<£3,£з>
£t>-e
£2>-е
£3>-е
£4>-е
£2>-*е
£3>-е
£4>-е
£3>^s
£4>-е
£4>-~е
Начальный символ: <£,}
Рис. 10.13 (продолжение).
аир
имер, /=2, /=3 и х—», то таблица
пока-
зывает, что /л(*) = 2, отношение 1^2^2^3^4 выполняется
и результат подстановки в схему будет таким:
{Е,,Еа)^ОП„{Еа){ЪИНАРш}{Ег, Ег)
что является правилом 31 на рис. 10.13 либо на рис. 10.10 с учетом
новых соглашений об обозначениях.
На рис. 10.16 и 10.17 показан процессор, в основе которого
лежит схема грамматики на рис. 10.15. Каждый из магазинных
символов (£)и (Е, Е) представляет некоторое множество
нетерминалов. (Е) представляет символы (£,•), и (Е, Е) представляет
символы <£,-, Ej). Символы (Е) и (Е, Е) имеют одно и два поля соот-
10.5. Компактный процессор для выражений языка MINI-BASIC 403
III
\i
I {a. <£,>-(<£!>)<£„£,>
II {b. <£(>^/<£(,£4>
(Е,)^+(Е2){ПЛЮС}(ЕиЕ1)
<£,>--<£8>1МИНИС}<ВД>
e. <£„ £,->-* + <£2> {СЛОЖ} <£4, £,>
f. <£„£,>-- <£2> {ВЫЧИТ} <£0£х>
g. <£„.£,>- * <£3>{УМНОЖ}<£4(£2>
h. <£„£,>- / <£3> {ДЕЛЕН}<£;,£2>
i/<£„£,>- t <£4> {ЭКСП} <£„ £3>
Начальный символ : <£t>
Рис. 10.14.
IV
v{
1 < / < 4
1 < / < 4
/= 1
/= 1
< / < 1 \ <j
< / < 1 \<j
</<2 2<у
< * < 2 2 <у
</<3 3<у
1 < / <j < 4
<4
<4
<4
<4
<4
I. <£,>-( <£г>)<£«.£4> 1</<4
II. <£,>-/<£„ £4> 1</<4
III. <£,) -> ОПя<£2> { УНАР х) <£„ ЕЛ i = 1
х = +или-
IV. <£„ £,>- ОП, <£m(r)+1> { БИНАР х} <£„ £m(J)>
1 < / < т(х) < у s^ 4
х = +,-,*,/,илаГ
х т(х)
+ 1
1
* 2
/ 2
Т 3
V (Е- £>—>•£ 1</<у<4
N *' " Начальный символ: <£/>
Рис. 10.15.
OP, I ( ) н
<£>
<£,£>.
{ УНАР }
У
! { БИНАР}
I У
#111
*IV
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#11
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#1
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#v
ВЫТОЛКНУТЬ
сдвиг
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
#v
ОТВЕРГНУТЬ
ДОПУСТИТЬ
ВЫДАТЬ (УНАР^)
ВЫТОЛКНУТЬ, ДЕРЖАТЬ
ВЫДАТЬ (БИНАРу)
ВЫТОЛКНУТЬ, ДЕРЖАТЬ
Начальное содержимое магазина:
<Е>
#1 ЗАМЕнть как на рис. 10.17, а, сдвиг
# 11 заменить как на рис. ю.П,б, сд ви г,
#ш если i=l ц(х = + или х=-)
то заменить как на рис. 10.17, в, сдвиг
иначе отвергнуть
#iv Используя значение т, заданное следующей таблицей
+
*
/
t
1
2
2
3
если L^m и m^j
то заменить как на рис. 10.17, г, сдвиг
иначе выполнить * IV
#V ВЫТОЛКНУТЬ, ДЕРЖАТЬ
Рис. 10.16.
10.5. Компактный процессор для выражений языка MINI-BASIC 405
ветственно для запоминания значений i или i и /'. Значения этих
полей показывают, какой из символов, (£,•) или <£,-, Ef), на
самом деле представляется данным вхождением магазинного символа.
Магазинные символы {УНАР} и {БИНАР} имеют по одному полю
для запоминания имени операции.
<Е>
i
<Е>
1
)
<Е,Е>
i
4
<Е>
i
<Е,Е>
i
4
ДО
ПОСЛЕ
ДО
ПОСЛЕ
<£>
ао
<Е>
2
{ УНАй}
X
<Е,Е>
i
1
<Е,Е>
i
/
<Е>
т(х) + 1
{БИНАР.}
X
<Е,Е>
i
т(х)
ПОСЛЕ. ДО
Рис. 10.17.
ПОСЛЕ
МП-распознаватель на рис. 10.16 построен так, что он
моделирует МП-распознаватель, основанный на грамматике рис. 10 13.
Если входной символ принадлежит множеству выбора какого-
нибудь правила для нетерминала, представляемого магазинный
символом, то это правило применяется. Его применение
заключается в замене верхнего магазинного Символа на магазинные
символы, представляющие надлежащие символы правой части
выбранного правила.
Вначале рассмотрим переход # I для магазинного символа (Е)
и текущего входного символа. Каждый из четырех нетерминалов,
которые может представлять верхний магазинный символ, имеет
одно правило схемы I, и МП-распознаватель, основанный на грам-
406 Гл. 10. Синтаксический блок для языка MINI-BASIC
матике рис. 10.13, должен применить надлежащее правило схемы I
к каждому из этих четырех нетерминалов. Как показано на
рис. 10.17, компактный процессор заполняет поля новых
магазинных символов, так что они представляют символы правой части
соответствующего правила.
Далее рассмотрим переход # III, выполняемый для
магазинного символа {Е) и текущего входного символа ОП со значением х.
Для нетерминалов вида (Et > только множества выбора для правил
схемы III содержат терминальный символ вида ОП.,.. Однако
данная грамматика содержит правило схемы III только тогда, когда
i=I и л:= + или —. Автомат, основанный на грамматике рис. 10.13,
применяет правило схемы III только тогда, когда у нетерминала,
представляемого верхним магазинным символом, имеется правило
схемы III, которое начинается с терминала, представляемого
входным символом; в противном случае входная цепочка отвергается.
Таким образом, переходная процедура # III вначале
'проверяет наличие правила схемы III для данных конкретных (Е) и ОП.
Если такое правило есть, то поле символа (Е) и значение символа
ОП используются для того, чтобы выполнить надлежащим образом
инициализированную операцию замены. Если правила схемы III
нет, то переход отвергает входную цепочку.
Теперь рассмотрим случай, когда на верху магазина символ
{Е, Е), а текущий входной символ — правая скобка. Ни в одной
из схем правая часть не начинается с правой скобки. Поэтому
применить можно только е-правила, задаваемые схемой V. Правая
скобка содержится в множествах выбора всех правил схемы V
(рис. 10.12), следовательно, если для представляемого нетерминала
имеется правило схемы V, то его нужно применить. Ограничение
1=0^/^4, связанное со схемой V, удовлетворяется для всех
индексов i и / всех символов (£,-, Ej) грамматики. Поэтому для
представляемого нетерминала имеется правило схемы V, и автомату
не нужно проверять выполнение этого ограничения. Таким
образом, переходная процедура # V просто выполняет операции
ВЫТОЛКНУТЬ, ДЕРЖАТЬ.
В том случае, когда на верху магазина находится символ {Е, Е),
а текущий входной символ — / или левая скобка, эти входные
символы не содержатся в множествах выбора е-правил схемы V
и не являются первыми символами никакой другой схемы. Таким
образом, автомат может либо отвергнуть входную цепочку, либо
применить правило схемы V. Автомат на рис. 10.6 построен так,
что он отвергает входную цепочку.
Наиболее сложная переходная процедура — это процедура
Ф IV, которая применяется, когда {Е, Е) — верхний магазинный
символ, и ОП — текущий входной символ. В этом случае можно
применить две схемы: IV и V. Схема IV применима, потому что ее
правая часть начинается с ОП, а схема V применима, так как для
Упражнения
407
некоторых i, /их символ ОПж содержится в множестве СЛЕД
нетерминала (£,-, £у> (например, для i—3, /=4, х=*).
Переходная процедура # IV вначале проверяет поля верхнего магазинного
символа и значение входного символа для того, чтобы выяснить,
есть ли правило схемы IV для данных конкретных (£b Ej) и ОПх.
Если такое правило находится, то верхний магазинный символ
заменяется на {Е, Е) {БИНАР}(£> и значения полей этих
символов заполняются так, чтобы они соответствовали правой части
найденного правила схемы IV для нетерминала (Eh Ej),
начинающегося с символа ОПл-. Если для данных (£,-, £,-> и ОПл- нет
правила схемы IV, переходная процедура применяет е-правило схемы
V. В некоторых случаях (например, i=3, /=4, х=*) ОПх
содержится в множестве выбора правила схемы V. В других случаях
(например, t = l, /=2, х=|) ОП,. не содержится в множествах
выбора ни правил схемы IV, ни правил схемы V для (Eit Ej) и
автомат может либо отвергнуть входную цепочку, либо применить
правило схемы V.
Грамматику на рис. 10.14 или схемы грамматики на рис. 10.15
можно переделать в атрибутную грамматику и автомат, построение
которого показано на рис. 10.16 и 10.17 и который будет
компактным транслятором, выполняющим перевод выражений с
атрибутами по грамматике рис. 10.4.
Упражнения
1. Рассмотрим следующую программу на языке .MINI-BASIC:
10 FOR X = 1 ТО 100
50 LET Y = Y + X
30 NEXT X
40 END
а) Постройте дерево вывода этой программы а грамматике из разд. 6.15.
б) Постройте соответствующее дерево в грамматике из разд. 10.1.
в) Используя атрибутную грамматику па рис. 10.4. найдите цепочку атомов
и таблицу, выдаваемые для данной программы.
г) Покажите в виде последовательности конфигураций, как МП-автомат на
рис. 10.5 обрабатывает эту программу.
2. Найдите цепочку атомов, выдаваемую синтаксическим блоком языка MINI-
BASIC из разд. 10.4 для отладочной программы, изображенной на рис. 10.8.
3. а) Используя метод рекурсивного спуска, постройте синтаксический блок
языка MINI-BASIC, основанный на атрибутной грамматике рис. 10.4.
б) Напишите на любом языке высокого уровня программу, реализующую
построенный блок.
в) Отладьте полученную программу с помощью программы па языке .MINI-
BASIC, приведенной на рис. 10.8; проверьте правильность выдачи для этой
программы.
403 Гл. 10. Синтаксический блок для языка MINI-BASIC
4. Объясните, почему в проекте синтаксического блока для языка MINI-BASIC
и разд. 10.4 использовано указанное там сообщение об ошибке для элемента,
помеченного буквой £ в управляющей таблице на рис. 10.5.
5. Объясните, почему каждый элемент, помеченный ш на рис. 10.5, недостижим,
даже если на вход поступила неправильная цепочка.
■6. ВыпииЛгге все сообщения об ошибках, которые сделает синтаксический блок
для языка MINI-BASIC, построенный в разд. 10.4 для следующей входной
цепочки:
10
30
за
40
50
ьо
END
FOR A = 1 STEP 1 ТО 5
TOR В = 5
LET Y = (В
NEXT A
IF A > В>
70 GOSDB Ь5
АО GOTO flO
во
+ (C * D)
С LET X = Ь
IF A = В GOSDB flO
7. Постройте более тонкую процедуру нейтрализации ошибок, чем та, что
используется в разд. 10.4.
8. Напишите неправильную программу на языке MINI-BASIC, для которой
синтаксический блок, построенный в разд. 10.4, сделает сообщение об ошибках,
не соответствующее фактическим ошибкам.
9. а) Предполагая, что лексический блок для языка MINI-BASIC в разд. 4
работает правильно, определите, какие соответствующие ошибкам элементы
в управляющей таблице на рис. 10.5 никогда не достигаются.
б) Найдите минимальный набор программ на языке MINI-BASIC, которые
вызывают все достижимые переходы, связанные с ошибками.
в) Основываясь на результатах пункта а) постройте улучшенное множество
сообщений об ошибках.
10 а) Реализуйте на любо.и языке синтаксический блок для языка MINI-BASIC,
построенный в разд. 10.4.
б) Отладьте полученную программу, используя программу на рис. 10.8, и
проверьте правильность выдачи для этой программы.
11. Покажите, что грамматика языка MINI-BASIC, приведенная на рис. 10.1,
является LL(l)-rpaMMaTHKoft.
12. Рассмотрим следующие правила для FOR-оператора вместо правил 9, 10 и 11
в грамматике языка MINI-BASIC на рис. 10.1.
9'. (тело программы) -*■ ДЛЯ (выражение) ДО (выражениеХостаток шага)
10'. (остаток шага) ->• ШАГ (выражение) (остальные строки) КОНЕЦ
ЦИКЛА (остальные строки)
1Г. (остаток шага)-»-(остальные строки) КОНЕЦ ЦИКЛА (остальные
строки).
а) Введите в эти правила атомы и атрибуты так, чтобы полученные таким
образом правила описывали тот же атрибутный перевод, что и правила 9,
10 и И на рис. 10.4.
б) Опишите преимущества и недостатки использования 9', 10' и 1Г вместо
9, 10 и 11.
Упражнения
409-
13. а) Переделайте правило 9 на рис.
10.4 так, чтобы конструкции
ДЛЯ/КОНЕЦ ЦИКЛА
порождали атомы, пригодные для
генерации кода, реализующего
рабочую блок-схему на рис.
10.18 (вместо рис. 10.3а).
б) Нарисуйте магазин «до» и «после»
того, как автомат применяет
правила.
в) Опишите относительные
преимущества двух приведенных
рабочих блок-схем.
14. Предположим, что при ввелении
атрибутов в правило 9 на рис. 10.4
атрибуты символа ХРАНИТЬ
определены так:
{ХРАНИТЬ., „}
НАСЛЕДУЕМЫЙ а
СИНТЕЗИРУЕМЫЙ Ъ
Ь «- НОВТ
Задайте каждую из следующих
частей проектируемого процессора:
а) правило 9 на рис. 10.4;
б) магазин до и после применения
автоматом правила 9;
в) процедуру перехода для
правила 9;
г) процедуру /, которая
вызывается, когда символ {ХРАНИТЬ}
находится на верху магазина.
15. а) Найдите атрибутную
транслирующую грамматику, задающую
процесс обработки, который
выполняет лексический блок для
языка MINI-BASIC,
построенный в гл. 4.
б) Используя построенную
грамматику, реализуйте лексический
блок методом рекурсивного
спуска.
16. Иногда, когда нетерминал имеет
один синтезируемый и один
наследуемый атрибут, наследуемый
атрибут можно запомнить в той же
ячейке, в которой запоминается
синтезируемый атрибут.
Магазинный символ для такого
нетерминала может иметь только одно
поле, содержащее указатель на эту
ячейку.
Покажите, что два атрибута
нетерминалов (Я-список), (7'-спи-
сок) и (Я-список) в проекте синтак-
Вычислить значение первого
Выражения
Присвоить полученное
значение^для - переменной
Вычислить ДО - Выражение
Запомнить значение ДО ■
выражения
Вычислить ШАГ- Выражение
Запомнить значение ШАГ-
выражения
Переход на проверку
Увеличить значение
ДЛЯ-переменной
Выполнить операторы 3
цикле
Переход на приращение
Рас. 10.18.
410
Гл. 10. Синтаксический блок для языка MINI-BASIC
сического блока для языка MINI-BASIC в разд. 10.4 можно реализовать этим
способом. Укажите все требуемые изменения, включая новые изображения
магазина «до» и «после» применения правил и новые процедуры перехода.
17. Если правило задано так, что в нем содержится несколько идущих друг за
другом символов действия, то часто можно повысить эффективность,
объединяя ИЛ в один символ действия. В проекте синтаксического блока для языка
MINI-BASIC в разд. 10.4 таким является правило 9, в котором
последовательно идут символы действия {ХРАНИТЬ}, {МЕТКА} и {ПРОВЕРИТЬ}, а
также символы действия {КОНТРОЛЬ}, {УВЕЛИЧ}, {ПЕРЕХОД} и
{МЕТКА}. Эти символы действия можно объединить в два символа действия,
скажем {ХРАНИТЬ-МЕТКА-ПРОВЕРИТЬ} и {КОНТРОЛЬ-УВЕЛИЧ-ПЕРЕ-
ХОД-МЕТКА}, и правило 9 грамматики цепочечного перевода можно
записать так:
9. (тело программы) -»- ДЛЯ (выражение) {ПРИСВ} ДО
(выражение) {ХРАНИТЬ} (шаг)
{ХРАНИТЬ-МЕТКА-ПРОВЕРИТЬ }
(остальные строки) КОНЕЦ ЦИКЛА
{КОНТРОЛЬ-УВЕЛИЧ-ПЕРЕХОД-МЕТКА}
(остальные строки)
Покажите, как нужно изменять проект, если использовать это новое правило.
18. Рассмотрим язык, порождаемый следующей грамматикой с начальным
символом {В):
<В> — <В> V <#> {ИЛИ}
<В> .— </?>
</?>-* <£>=<£> {РАВН}
<£>— -1<Я> {НЕ}
<£> — <£>+<Г>{СЛОЖ}
<£> — <Г>
<Г> — <Г> * <F> {УМНОЖ}
<Г> — - <Г> {МИНУС}
<Г> — <F>
<F> — </>> f <F> {ЭКСП}
<F> — </>>
<P> — «Л»
</>> — /
а) Найдите ЬЬ(1)-грамматику, описывающую этот язык.
б) Найдите ^-грамматику, описывающую этот язык.
в) Найдите для этого языка грамматику, имеющую компактное
представление.
г) Постройте компактный процессор для этого языка.
19. В некоторых однопроходных компиляторах элементы, содержащие
промежуточные результаты, хранятся в полях магазинных символов. Такой подход
отличается от используемого в проекте для языка MINI-BASIC (разд. 10.4),
в котором поля содержат указатели на элементы для частичных результатов.
Единственная возможная трудность, связанная с использованием полей для
элементов, которые содержат промежуточные результаты, состоит в том, что
магазинные символы, содержащие элементы с промежуточными результатами,
должны находиться в магазине все время, пока генератору кода нужен
доступ к этим элементам. Предположим, что в компиляторе для языка MINI-
BASIC ячейки, содержащие результат, доступны генератору кода только в
течение обработки атомов, для которых эти ячейки являются атрибутами.
Упражнения
411
Предположим также, что при обработке атомов для бинарных операций
генератор кода может использовать одну из ячеек какого-нибудь операнда в
качестве ячейки для результата. Переделайте синтаксический блок так, чтобы поля
магазинных символов использовались для ячеек, содержащих результат
вызова процедур НОВТМ, НОВТ и НОВТХ.
20. Покажите, что каждый раз, когда используется переходная процедура 4£IV
автомата на рис. 10.16, условие /л-</ выполнено, а следовательно, его не
нужно проверять, и поле / магазинного символа (£, Е) можно исключить из
процессора.
21. а) Введите атрибуты в грамматику на рис. 10.15 для того, чтобы получить
атрибутный перевод выражений, определенный на рис. 10.4.
б) Постройте соответствующий атрибутный вариант процессора на рис. 10.16.
в) Постройте соответствующий процессор методом рекурсивного спуска.
г) Покажите в виде последовательности конфигураций, как процессор пунк«
та б) обрабатывает входную цепочку
/4ОП f (ОП _ /8ОП „, /вОП + /4)ОП/ Л
и
Восходящие методы обработки языков
11.1. Введение
В гл. 6 и 7 мы рассмотрели контекстно-свободные и транслирующие
грамматики как способ задания языков и переводов. Теперь нас
интересует, как и в каких случаях задаваемые таким образом
распознавание и перевод может выполнять автомат с магазинной
памятью. Соответствующий процесс обработки цепочек можно
проводить или «сверху вниз» или «снизу вверх». В гл. 8—10 мы
излагали нисходящие методы, а в гл. 11—13 дадим описание
восходящих методов. Для удобства читателей мы попытались сделать
изложение каждого из этих подходов независимым. Чтобы достичь
такой независимости, потребовались некоторые повторения.
Например, значительная доля материала оставшейся части данного
раздела является повторением материала, изложенного в разд. 8.1.
В сущности, все методы построения, основанные на контекстно-
свободных грамматиках, приводят к процессорам, которые так или
иначе «используют» грамматику, в том смысле, что действия
процессора можно трактовать как распознавание отдельных правил
в дереве вывода. Всякий процессор, работа которого включает
в себя распознавание правил, называется синтаксическим
анализатором. Термины «синтаксический анализ» или «разбор»
заимствованы у лингвистов, которые пользуются ими, говоря об анализе
предложений естественного языка или построения для них
соответствующих диаграмм разбора.
«Сверху вниз» и «снизу вверх» — это две категории методов
анализа. Каждую категорию характеризует порядок, в котором
распознаются правила в дереве вывода. Грубо говоря, нисходящие
процессоры сначала распознают правила, расположенные в дереве
вывода выше, а потом правила, расположенные ниже, в то время
как восходящие процессоры распознают нижние правила раньше
верхних. Это различие станет яснее при более детальном
рассмотрении обоих методов.
МП-автоматы можно строить, используя или нисходящий или
восходящий подход. Однако при каждом из этих подходов могут
быть распознаны не все контекстно-свободные языки ') и не все
') Напомним, что в этой книге рассматриваются только детерминированные
МП-аьтоматы. Недетерминированные МП-автоматы распознают (в специальном
смысле) все КС-языки.— Прим. ред,
11.2. Понятие основы
413
синтаксически управляемые трансляции можно выполнить с
помощью МП-автомата. Каждый метод накладывает ограничения на
форму входной и транслирующей грамматик, которые можно
обрабатывать этим методом, а также на характер допускаемых
связей между процедурами, выполняющими нужные действия.
Продолжим изучение обработки цепочек МП-автоматами,
используя теперь восходящий подход. Восходящий разбор с помощью
МП-автомата иногда называют детерминированным восходящим
анализом в противоположность некоторым другим методам,
называемым «недетерминированным восходящим анализом» или
«восходящим анализом с возвратами».
В этой главе мы предполагаем, что рассматриваемые грамматики
не содержат бесполезных нетерминалов. Тем самым мы
предполагаем, что каждое правило и каждый нетерминал можно
использовать при выводе некоторого предложения соответствующего языка.
Это ограничение несущественно, так как удаление из грамматики
бесполезных нетерминалов и содержащих их правил не изменяет
ни распознаваемого языка, ни выполняемого перевода.
11.2. Понятие основы
В этом разделе мы введем понятие, на котором базируется
восходящий анализ. Сначала рассмотрим грамматику на рис. 11.1. Эта
грамматика однозначна, так что каждая цепочка порождаемого ею
языка имеет единственное дерево
вывода и единственный правый вывод.
Теперь рассмотрим цепочку [ <s>—+(<A><S»
(((b)a(a))(b)) 2.<S>^(b)
Дерево вывода этой цепочки показа- 3- <А> *(<5>а<л>)
но на рис. 11.2, а ее правый вывод— 4. <л>—► (а)
на рис. 11.3, а. На каждом шаге вы- Начальный символ: <S>
вода на рис. 11.3, а нетерминал,
отмеченный стрелкой, заменяется на ис-
правую часть правила, номер
которого указан под стрелкой.
При восходящем анализе мы имеем дело с обращением правого
вывода. Для выбранной цепочки обращение правого вывода
показано на рис. 11.3, б. На каждом шаге на рис. 11.3, б вхождение
правой части некоторого правила заменяется нетерминалом из
левой части этого правила. Каждое вхождение заменяемой правой
части подчеркнуто, и под ним указан номер соответствующего
правила. Мы называем каждую подчеркнутую подцепочку на
рис. 11.3, б «основой» цепочки, в которой она встречается, а
соответствующее правило — «основывающим правилом» этой цепочки.
414
Гл. 11. Восходящие метсды обработки языков
Например, (а) ■
цепочки
это основа, а правило 4
(((S)a(a))(b))
основывающее правило
в общем случае
Основа цепочки (состоящей из терминалов и нетерминалов) —
это вхождение правой части последнего правила,
примененного в правом выводе этой цепочки. Основывающее правило
цепочки — это последнее правило, примененное в правом
выводе этой цепочки.
Если грамматика однозначна, у цепочки может быть не более
одного правого вывода, а значит, не более одной основы и одного
основывающего правила.
Рис. 11.2.
Цепочка может и не иметь основы. Например, цепочка (а))
вообще иевыводима, согласно грамматике на рис. 11.1, и,
следовательно, не имеет основы. Цепочка
имеет вывод
((a)(5))
<S> => (04><S>) =Ф ((a)<S>)
t t
1 4
но у нее нет правого вывода и, значит, нет основы.
Правый вывод на рис. 11.3, а можно интерпретировать как
построение дерева вывода, показанного на рис. 11.2. Замена
нетерминала правой частью одного из его правил соответствует
добавлению символов правой части в качестве вершин дерева,
«подвешенных» снизу к вершине, соответствующей заменяемому
нетерминалу
11.2. Понятие основы
415
Аналогично рис. 11.3, б можно понимать как подрезку дерева
вывода на рис. 11.2. На рис. 11.4 изображены деревья вывода для
шести цепочек из рис. 11.3,6. Рис. 11.4, а — это дерево вывода
первой, начальной терминальной цепочки. Рис. 11.4,6 — это
дерево вывода второй цепочки.
(({S)a(a))(b))
и т. д.
Мы используем слово лист для обозначения вершины дерева,
не имеющей потомков. Цепочку, соответствующую каждому из
деревьев на рис. 11.4, можно получить путем конкатенации всех
листьев дерева.
<5> =>
Т
1
(<Л><5>) => (((b)a{a))(b))
Т 2
2 (( (S)a(a))(b))
3 (((S)a(A))(b))
(((S)a(A))(b)) => 3
I ((А)(Ь))
4 2
(((S)a(a))(b)) =* ((A)(S))
2 !
ШЬ)а(а))(Ь)) (S)
а 6
Рис. 11.3.
Каждый шаг на рис. 11.3, б представляет собой замену правой
части основывающего правила его левой частью. Соответствующая
операция подрезки дерева на рис. 11.4 состоит в удалении листьев
дерева, составляющих правую часть правила. Так как эти листья
суть непосредственные потомки вершины дерева, соответствующей
нетерминалу в левой части, то эта вершина становится листом
нового дерева и представляет вхождение нетерминала из левой части,
который заменяет правую часть в цепочке. Например, рис. 11.4, б
получается на рис. 11.4, а подрезкой, соответствующей правилу 2,
при которой листья, представляющие цепочку (Ь) — правую часть
правила 2, удаляются. Это удаление превращаете лист их общего
предка, вершину, помеченную (S) (левую часть правила 2).
Аналогично каждый шаг на рис. 11.3,6 соответствует удалению из
416
Гл. //. Восходящие методы обработки языков
дерева правой части, в результате чего левая часть остается без
потомков.
В общем случае дерево вывода может содержать несколько
вершинъ допускающих «подрезку» в том смысле, что все их потомки
<s> <s>
( 5Д? <s> ' (<а> <s>)
' <,£> э <£> ' ( &^ ( <S> a <A?) ( ^й
/1\. /К /Г\
Ь ) ( а )
{ a )
а 6
<s> <s>
( <А> <S> ) { <А> <S> )
/f\\^ ^. /l\
( <S> a <A>) ( ^Л^^- ) ( b )
в г
<J> <s>
( <А> <S>
д
Рис. 11.4.
являются листьями. Однако при обращении правого вывода мы
всегда подрезаем самую левую из допускающих подрезку вершин.
Удаляемые при этом листья представляют основу промежуточной
цепочки, получаемой конкатенацией листьев дерева.
11.3. Пример
В этом разделе мы проиллюстрируем некоторые принципы
обработки цепочек снизу вверх на примере МП-автомата, который
распознаёт язык, задаваемый грамматикой на рис. 11.1. Входной
алфавит автомата состоит из множества терминалов грамматики и
концевого маркера. Магазинный алфавит состоит из маркера дна,
терминалов и нетерминалов грамматики.
Автомат построен так, что если входная цепочка допустима, то
на каждом шаге обработки конкатенация терминалов и нетерми-
П.3. Пример
417
налов в магазине (причем действует соглашение, что верхний
символ расположен справа) и цепочки еще не обработанных терминалов
(включая текущий входной символ, если это не концевой маркер)
дает промежуточную цепочку в правом выводе всей входной
цепочки.
Наш МП-автомат использует пять операций для
манипулирования с магазином и входной цепочкой. Эти операции называются
ПЕРЕНОС, CBEPTKA(l), СВЕРТКА(2), СВЕРТКА(З) и СВЕРТ-
КА(4). Операция ПЕРЕНОС переносит текущий входной символ
на верх магазина и сдвигает вход. На каждом шаге выбирается
и выполняется одна из операций, причем автомат построен так,
что ПЕРЕНОС не выбирается, если текущий входной символ —
это концевой маркер. После операции ПЕРЕНОС цепочка,
получаемая конкатенацией содержимого магазина с необработанной
частью входной цепочки, остается той же, что была до нее,
ПЕРЕНОС просто превращает входной символ из не обработанной еще
части входной цепочки в магазинный символ.
Что касается операций типа СВЕРТКА, то автомат устроен
таким образом, что операция СВЕРТКА(р) для р=\, 2, 3 или 4
выбирается только в тех случаях, когда верхние символы магазина
совпадают с правой частью правила под номером р. Например,
операция CBEPTKA(l) выбирается только тогда, когда верхние
символы магазина образуют правую часть правила 1, а именно
(04 XS)). Таким образом, CBEPTKA(l) может быть выбрана при
любом из следующих трех вариантов содержимого магазина:
S7(«S>a(«A><S»
S/«S><S>«A><S»
Операция СВЕРТКА(р) выталкивает из магазина все символы
правой части правила под номером р, а затем вталкивает в него левую
часть. Таким образом, операция CBEPTKA(l) делает следующее:
ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВТОЛК (<S>)
Результаты применения операции CBEPTKA(l) в трех вышeпpивe^
денных случаях будут соответственно
v<s>
S7(«S>a«S>
V«s><s><s>
СВЕРТКА(р) изменяет цепочку, получаемую конкатенацией
содержимого магазина и необработанной части входной цепочки,
заменяя вхождение правой части правила под номером р на его левую
часть.
** Ф. Льюис и др.
418
Гл. П. Восходящие методы обработки языков
Операции свертки не принадлежат к числу примитивных
магазинных операций; следовательно, наш автомат не примитивен.
Другой непримитивной чертой этого автомата является то, что
в некоторых случаях при выборе операции используются несколько
1. V
2. V(
3. V((
4. V(((
5. V(((ft
6. V(((ft)
7 V((<5>
8. V{((S)a
9. v (( <S> a (
10. v((<5>a(fl
11. v((<5>a(a)
12. v({(S)a(A)
13. v(((S)a(A))
14. V((A)
15. V ((A)(
16. V (<Л>( 6
17. v(</f>(M
18. V((A) (S)
.19. V(</() <5>
20. V <S>
(((*)
((*)
(ft)
ft)
)
Рис.
a(a))
a(a))
a(a))
a(a)}
a{a))
a(a)
a(a)
(«Г
a)'
)
11.5.
(ft))H
(MM
(MM
(MM
(MM
(MM
(ft))4
>(ft)M
(MM
>(ft)M
)(ft)M
)(MM
(MM
(ft))4
ft))4
>M
M
)4
4
H
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА (2)
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС .
СВЕРТКА (4)
ПЕРЕНОС
СВЕРТКА (3)
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА (2)
ПЕРЕНОС
СВЕРТКА (1)
ДОПУСТИТЬ
верхних символов магазина. Однако, прежде чем говорить о том,
каким образом автомат выбирает операции, мы покажем, как он
использует свой магазин при распознавании цепочки
(((b)a(a))(b))
Напомним, что эта цепочка рассматривалась в предыдущем разделе
и что на рис. 11.3, б показано обращение в ее правого вывода.
На рис. 11.5 приведена последовательность конфигураций
автомата для этой входной цепочки. В самой правой колонке каждой
строки рисунка указана операция, выбранная для получения
следующей конфигурации. Так, в строке 1 используется ПЕРЕНОС
U.S. Пример
419
для получения строки 2, а для перехода от строки 6 к строке 7
применяется СВЕРТКА(2).
Как показано в строке 1, в магазин вначале помещается
символ V- Строка терминалов и нетерминалов, представленная
конкатенацией содержимого магазина и необработанных входных
символов,— это сама входная цепочка:
(i(b)a{a))(b))
Основой этой цепочки является первое вхождение подцепочке (Ь).
Чтобы преобразовать представленную таким образом цепочку
в другую цепочку правого вывода, автомат пытается заменить
основу цепочки на соответствующий нетерминал из левой части.
Автомат переносит входные символы в магазин до тех пор, пока
в верхней части магазина не окажется основа. На рис. 11.5
операция переноса выбирается в строках 1—5. Наконец, в строке 6 основа
оказывается в верхней части магазина. Автомат выбирает операцию
СВЕРТКА(2), которая заменяет основу на нетерминал из левой
части правила 2, а именно на (S). В результате получается
представление цепочки:
(((S)a(a))(b))
Эта новая цепочка совпадает со второй цепочкой на рис. 11.3, б.
Основой этой новой цепочки является подцепочка (а). В
строках 7-10 на рис. 11.5 автомат переносит входные символы до тех
пор, пока основа не окажется в верхней части магазина. Далее
в строке 11 автомат выбирает операцию СВЕРТКА(4), которая
заменяет основу на нетерминал из левой части основывающего
правила. Полученная в результате цепочка, представленная
в строке 12, совпадает с третьей цепочкой на рис. 11.3, б.
Автомат продолжает работать таким образом до тех пор, пока
(строка 20 па рис. 11.5) на входе не появляется концевой маркер;
при этом магазин содержит только начальный символ грамматики
и маркер дна. В этой конфигурации автомат допускает входную
цепочку, так как он убедился, что входная цепочка выводима из
(S). На каждом шаге процесса обработки старая, представленная
в автомате цепочка или совпадала с новой представленной
цепочкой, или могла быть выведена из нее применением одного правила.
Последовательность промежуточных цепочек, представленных
магазином и входом, описывает метод вывода входной цепочки из (S)
при помощи правых подстановок. В самом деле, порядок правил,
использованных операциями СВЕРТКА,— обратный порядку
правил, использованных в правом выводе.
Описанный МП-автомат показан на рис. 11.6. По верхнему
символу магазина и текущему входному символу управляющая
таблица выбирает одну из трех переходных процедур ОПОЗНАТЫ,
ОПОЗНАТЬ2 или СВЕРТКА. Заметим, что ОПОЗНАТЫ выби-
14*
420 Гл. И'. Восходящие методы обработки языков
рается во всех тех случях, когда верхний символ
магазина—закрывающая скобка.
Переходная процедура ОПОЗНАТЫ исследует несколько
символов в верхней части магазина и выбирает одну из операций
( * Ь ) н
<s>
<А>
(
)
Ь
a
7
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ОПОЗНАТЫ
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ОПОЗНАТЫ
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС-
ПЕРЕНОС
ОПОЗНАТЬ 1
ПЕРЕНОС
. ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ОПОЗНАТЬ 1
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ОПОЗНАТЬ 2
ОПОЗНАТЬ 2
ОПОЗНАТЬ2
ОПОЗНАТЬ 1
ОПОЗНАТЬ 2
ОПОЗНАТЬ 2
ОПОЗНАТЬ2
Начальное содержимое магазина: 7
ОПОЗНАТЬ!: если на верху магазина (<AXS»,mo СВЕРТКА (/)
иначе если на верху магазина Ш, то свертка (2)
иначе если на верху магазина (<s>a <A»;mo свёртка(З)
иначе если на верху магазина (а), то свертка (4)
иначе отвергнуть
опознать 2: если на верху магазина v<s>,mo допустить
иначе отвергнуть
перенос : втолк (текущий входной символ), сдвиг
свертка(/): вытолк.вытолк.вытолк,вытолк, втолк«$»
сверткаС?): вытолк, вытолк, вытолк, втолк«s»
свертка(З): вытолк.вытолк.вытолк, вытолк, вытолк, втолк «а»
свертка (4): вытолк,Вытолк, вытолк, втолк «а»
Рис. 11.6.
СВЕРТКА(р) или операцию ОТВЕРГНУТЬ. СВЕРТКА(р)
выбирается, если несколько верхних символов магазина совпадают
с правой частью правила р, а если верхняя часть магазина не
совпадает с правой частью какого-либо правила, то выбирается
операция ОТВЕРГНУТЬ. На рис. 11.6 выбор осуществляется при
помощи конструкции если-то-иначе, однако по существу это
проблема идентификации, подобная тем, которые обсуждались в гл. 3;
методы, описанные там, можно применить и здесь.
Процедура ОПОЗНАТЬ2 проверяет, совпадает ли содержимое
магазина с цепочкой SJ{S). Если да, то входная цепочка
допускается, в противном случае она отвергается.
Работа автомата основана на том, что если вся входная цепочка
допустима, то цепочка, представленная магазином и
необработанной частью входа, является промежуточной цепочкой в правом
выводе входной цепочки. Автомат переносит'входные символы в ма*
11.3. Пример
421
газин до тех пор, пока в его верхней части не окажется основа
представленной им цепочки. Затем автомат выполняет операцию
СВЕРТКА, соответствующую основывающему правилу. Эта
операция заменяет основу левой частью основывающего правила.
В терминах подрезки дерева вывода СВЕРТКА соответствует
удалению листьев, представляющих правую часть; при этом вершина,
представляющая левую часть, становится листом. Таким образом,
имеется соответствие между вершиной дерева и вталкиваемым в
магазин символом, представляющими левую часть одного и того же
правила. Для характеристики этого метода распознавания
используют термин восходящий, потому что правила для потомков любого
нетерминала в дереве распознаются раньше, чем правило для него
самого.
Построить автомат для данной грамматики достаточно просто.
Глядя на рис. 11.3, б, можно заметить, что основа каждой
промежуточной цепочки включает в себя самую левую из закрывающих
скобок цепочки. И вообще, так как каждое правило оканчивается
закрывающей скобкой, основа может находиться на верху
магазина только в том случае, когда верхний символ в
магазине—закрывающая скобка. С другой стороны, закрывающие скобки
появляются только на концах правил; следовательно, закрывающая
скобка в верхушке магазина должна быть концом основы. В связи
с этим автомат выполняет процедуру ОПОЗНАТЫ тогда и только
тогда, когда верхний символ магазина — закрывающая скобка.
Далее, так как правая часть каждого правила начинается
открывающей скобкой, каждая основа должна тякже начинаться
открывающей скобкой. С другой стороны, открывающие скобки
появляются только в начале правых частей правил, значит, самая
верхняя открывающая скобка в магазине начинает ту основу, которая
оканчивается закрывающей скобкой на самом верху магазина.
Таким образом, если только правый вывод вообще существует
(т. е. если входная цепочка является допустимой), то эти две скобки
и заключенные между ними символы магазина должны составить
правую часть основывающего правила. И наконец, так как никакие
два правила не имеют одинаковых правых частей, опознание правой
части однозначно определяет правило.
Для иллюстрации того, как отвергается недопустимая входная
цепочка, на рис. 11.7 показана последовательность конфигураций
автомата, изображенного на рис. 11.6, в процессе обработки
терминальной цепочки
(((b)a(aa))(b))
Содержимое магазина, входной символ и операция в первых девяти
конфигурациях такие же, как на рис. 11.5, потому что обе входные
.цепочки начинаются одними и теми же восемью входными
символами.
422
Гл. 11. Восходящие методы обработки языков
Рассмотрим строку б в этих двух последовательностях
конфигураций. На рис. 11.5 подцепочка (Ь) в верхней части магазина
представляет собой основу цепочки, полученной путем конкатенации
символов магазина и необработанной части входных символов.
На рис.'11.7 подцепочка (Ь) в верхней части магазина не является
основой, потому что цепочка, получаемая конкатенацией символов
I. V
2. V(
з. v((
4. V((
5. V((
6. v((
7- V((
8- V((
9- V((
10. V ((
11. v((
12. v((
(b
(b)
(S)
(S)a
(S)a(
(S)a(a
<S> a(aa
<S> a(aa)
(((b)a
i(b)a(
(b)a
b)a{
)a{
a
a
,a a)
[aa)
[a a)
[a a)
aa)
[a a)
a a)
[a a)
a a)
a)
)(b))-\
)(b))-\
)(b))-{
)(b))-\
)(b))-\
)(b))-{
)<*))H
)(b))-\
)(b))-{
)(*))H
)(*)M
)(b))-\
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА(2)
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ОТВЕРГНУТЬ
Рис. 11.7.
магазина и оставшейся части входной цепочки, вообще не выводима-
из (S > и, следовательно, не имеет основы. Интуитивное
представление о работе автомата как о замене основ применимо только
в случае обработки допустимой цепочки. При работе с
недопустимыми цепочками цепочка, получаемая конкатенацией символов
магазина и оставшихся входных символов, не содержит основы,
и действия автомата можно понимать как замену некоторых
вхождений правых частей правил их левыми частями. В строке б, где
в магазине находится S/(((b) на — текущий входной символ,
естественно выполнить операцию СВЕРТКА(2), так как если
представленная в автомате цепочка имеет основу, то эта основа есть (Ь).
Автомату не известно, какова оставшаяся часть цепочки — (а))(Ь)),
как на рис. 11.5, (аа))(Ь)), как на рис. 11.7, или какая-либо другая
цепочка,— поэтому было бы неточно сказать, что автомат «знает»,
что (Ь) — основа.
Вернемся к рис. 11.7. Автомат продолжает работу, пока не
достигает конфигурации, изображенной в строке 12. В этот момент
выполняется процедура ОПОЗНАТЫ. Подцепочка (а а) в верхней
части магазина не совпадает с правой частью никакого правила,
поэтому ОПОЗНАТЫ отвергает входную цепочку.
11.4. Второй пример
423
На каждом шаге обработки любой входной цепочки, допустимой
или недопустимой, первоначальная входная цепочка выводима из
цепочки, получаемой конкатенацией содержимого магазина и
оставшейся части входных символов, потому что в процессе работы
к магазину и входу применяются только операции ПЕРЕНОС и
СВЕРТКА(р). Ввиду того что автомат допускает цепочку только
в том случае, когда представленная в нем цепочка — это (S >, а
из (S) нельзя вывести цепочку, не принадлежащую языку,
допускаются только правильные цепочки. Автомат не может зациклиться,
так как число выполненных в процессе работы операций ПЕРЕНОС
и СВЕРТКА не превышает удвоенной длины входной цепочки.
Следовательно, все цепочки, не принадлежащие языку, автоматом
отвергаются.
11.4. Второй пример
В предыдущем разделе мы описали МП-автомат, распознающий
язык, заданный грамматикой на рис. 11.1. В этом разделе мы
рассмотрим другой МП-автомат, распознающий тот же язык. Так же,
как и в предыдущем разделе, описываемый здесь автомат пытается
отыскать правый вывод для данной входной цепочки. Оба эти
автомата используют магазин и необработанную часть входной
цепочки для представления промежуточных цепочек правого вывода.
Они оба манипулируют с магазином и входными символами при
помощи операций переноса и свертки (хотя в новом автомате эти
операции требуют некоторого дополнительного шага). Однако
автоматы существенно различаются с точки зрения механизмов
выбора операций переноса или свертки, которые должны
применяться на том или ином шаге.
Автомат из предыдущего раздела исследует несколько верхних
символов магазина, чтобы решить, какую из операций СВЕРТКА(р)
нужно выполнить. Присутствие закрывающей скобки в верхушке
магазина говорит о том, что в верхней части магазина должна
находиться основа, но не указывает, какая именно. Автомат,
описываемый в данном разделе, использует расширенный магазинный
алфавит для кодирования дополнительной информации о
магазине. Закодированной информации достаточно, чтобы по верхнему
символу магазина и текущему входному символу выяснить,
находится ли основа в верхней части магазина, и если да, то определить
основывающее правило, не просматривая других символов
магазина. Однако для каждого правила соответствующая ему операция
СВЕРТКА просматривает символ магазина, расположенный под
основой.
Магазинный алфавит нового автомата состоит из четырнадцати
магазинных символов, изображенных во втором столбце на рис. 11.8.
424
Гл. П. Восходящие методы обработки языков
Для удобства записываем эти символы как грамматические
символы с нижними индексами, а при реализации автомата их можно
представить четырнадцатью последовательными целыми числами.
Каждый магазинный символ понимается одновременно как
представление грамматического символа и кода цепочки, как по-
Представляе-
мыи символ Магазинный Кодируемая
грамматики симбол цепочка
a
b
(
I
<S>
< A >
Hem
a1
a7
*x
M
M
'3
M
<s>,
<s>7
<S>3
< A >,
<A >2
V
{<S>a
[a
(b
(
«A ><S»
(b)
(<S>a <A »
(a).
{<A ><S>
«s>
v<s>
\<A >
«S>a<A>
V
Рис. 11.8.
казано на рис. 11.8. Каждый символ магазина представляет
грамматический символ, получаемый из него отбрасыванием индекса.
Таким образом, все три магазинных символа (S)lt (S)2 и (S)3,
представляют нетерминал (S), а магазинный символ Ь^
представляет терминал Ь. При таком неоднозначном представлении
символов можно считать, что магазин представляет цепочку из
терминалов и нетерминалов по существу так же, как в предыдущем разделе.
Например, магазин, содержащий S/diS)^ представляет цепочку
((S)a, полученную отбрасыванием символа V и индексов.
Наряду с этим каждый грамматический символ
рассматривается как код некоторой цепочки. Например, (S)i рассматри-
И .4. Второй пример
425
вается как код цепочки (<Л>(5>. Самым правым символом каждой
кодируемой цепочки является грамматический символ,
представляемый магазинным символом.
Исключение составляет маркер дна. Он не представляет
никакого грамматического символа, но рассматривается как код
цепочки, состоящей из него самого.
Новый МП-автомат построен так, что магазинный символ
вталкивается в магазин только тогда, когда кодируемая этим символом
цепочка совместима с цепочкой, которую будет представлять
магазин после вталкивания.
Мы будем говорить, что цепочка, кодируемая данным
символом магазина, совместима с цепочкой, представляемой
символами магазина, расположенными ниже данного
символа и включая его самого, если выполнено одно из
следующих условий:
а) кодируемая цепочка является суффиксом цепочки,
представляемой магазином;
б) кодируемая цепочка является конкатенацией V и
цепочки, представляемой магазином.
Например, если магазин содержит
автомат мог бы втолкнуть символ {А >2, получив новое содержимое
магазина
Vd(i<S>.fli04>t
Символ, который втолкнул автомат, совместим с новым
содержимым магазина, так как четыре верхних символа магазина
представляют цепочку, закодированную символом (А >2. Магазинный
символ (А >! оказался бы несовместимым, потому что после его
вталкивания магазин содержит
и цепочка ((А), закодированная верхним символом магазина, не
является суффиксом представляемой магазином цепочки
(((S)a{A)
и не получается конкатенацией V и представляемой цепочки.
Магазинный алфавит построен так, что для каждого
магазинного символа, за исключением (S)3 и V, кодируемая цепочка
является префиксом правой части некоторого правила. И наоборот,
каждый непустой префикс правой части кодируется магазинным
426
Гл. П. Восходящие методы обработки языков
символом. Например, правая часть правила 1 — это цепочка
(C4HS)), которая имеет четыре непустых префикса, а именно
(,((Л>, ((A)(S) и (ШШ).
Заметим, что вся правая часть также рассматривается как префикс.
Эти четыре префикса кодируются четырьмя магазинными
символами:
(It04>b<S>,H ),.
Аналогично правая часть правила 2 имеет три префикса,
кодируемые символами (,, bi и )2. Отметим, что префикс (, кодируемый
магазинным символом d, является общим для всех правых частей.
Г )
<S>
<А>
а2
а1
Ь,
>4
>2
>1
>3
<S>2
<s>.
<5>3
<А>2
</»>,
<s>,
<s>2
<S>3
Рис. 11.9.
Последствия такого кодирования префиксов станут видны, когда
этот МП-автомат будет описан более детально.
Управление МП-автоматом осуществляется при помощи двух
таблиц. Во-первых, обычная управляющая таблица, которая будет
обсуждаться позднее, используется для выбора между переносом
и сверткой. Если принятое решение включает вталкивание, то оно
определяет только, какой грамматический символ должен быть
представлен новым символом магазина. Для определения того,
какой из магазинных символов, представляющих данный
грамматический символ, нужно втолкнуть, используется «таблица вталки-
11.4. Второй пример
427
ваннй», показанная на рис. 11.9. Этот выбор делается исходя из
символа, находящегося на верху магазина перед вталкиванием,
и грамматического символа, представляемого новым символом
магазина. Таблица на рис. 11.9 содержит строку для каждого
магазинного символа, поверх которого можно втолкнуть новый
магазинный символ и столбец для каждого символа грамматики.
Каждый непустой элемент таблицы указывает символ, который нужно
втолкнуть для данной комбинации символа магазина и символа
грамматики. Пустые элементы в таблице относятся к комбинациям,
при которых автомат отвергает входную цепочку. Таблица не
содержит строк для магазинных символов ),, )2, )., и )4, потому что
в данной схеме управления никогда не делается попыток втолкнуть
символ, если верхушка магазина представляет правую скобку.
Чтобы убедиться в том, что вталкивания, соответствующие
таблице на рис. 11.9, сохраняют совместимость верхнего символа
магазина со всей магазинной цепочкой, рассмотрим столбец,
задающий вталкивание символов, представляющих правую скобку.
Согласно таблице, )г вталкивается в том случае, когда на верху
магазина находится {S)u )г вталкивается тогда, когда наверху
Ьй )3 вталкивается тогда, когда наверху (А >2, и )4 вталкивается,
если наверху находится аг. Для остальных верхних символов
магазина автомат отвергает входную цепочку.
Сначала рассмотрим решение втолкнуть )!( если на верху
магазина находится (S>i. Согласно информации, закодированной в
символе (S)u три верхних символа магазина представляют цепочку
(C4XS). Ввиду того что вталкиваемый символ )| представляет ),
новые четыре верхних символа магазина представляют
конкатенацию цепочки ((/4>(S> с символом ), т.е. цепочку (C4)(S>), a
это — цепочка, кодируемая символом К. Другими словами,
совместимость вталкиваемого символа )t с цепочкой, представляемой
магазином, очевидна, если рассмотреть цепочку, кодируемую
предыдущим символом магазина, и учесть тот факт, что )i
представляет ). Мы не можем втолкнуть какой-либо из символов )4,
)з или )4 сразу над (SK, потому что цепочка, кодируемая каждым
из этих символов, несовместима с цепочкой, которую будет
представлять содержимое магазина.
Аналогичные рассуждения показывают, что символы )2, )3 и )4
вталкиваются в ситуациях, когда совместимость при вталкивании
символа может быть установлена по предыдущему символу
магазина. Более того, в каждой из этих ситуаций цепочка,
закодированная последним, исключает возможность использования любого
другого символа, представляющего ).
Теперь рассмотрим решение отвергнуть входную цепочку в
случае, если верхним символом магазина является (А >(, а входной
символ — правая скобка. В соответствии с цепочкой, кодируемой
символом (A )i, два верхних символа магазина представляют це-
428
Гл. 11. Восходящие методы обработки языков
почку ((А). Втолкнув символ, представляющий правую скобку,
мы получим магазин, в котором три верхних символа представляют
цепочку ((A)). Автомат построен так, что на каждом шаге
обработки допустимой входной цепочки конкатенация цепочки,
представляемой магазином, и необработанной части входа может быть
получена из (S) путем правого вывода. Однако, так как цепочка
({А)) не может встретиться внутри цепочки, выводимой из (S),
входная цепочка не может быть допустимой, и, отвергая ее, автомат
несомненно прав. Аналогичный анализ применим и к другим
магазинным символам, для которых автомат отвергает вход.
Мы видели, что для каждого возможного верхнего символа
магазина оказывается, что существует не более одного магазинного
символа (из тех, что представляют правую скобку), кодирующего
цепочку, совместимую с цепочкой, полученной добавлением правой
скобки к цепочке, закодированной данным верхним символом
магазина. В тех случаях, когда такого магазинного символа нет,
оказывается, что решение отвергнуть вход можно оправдать тем,
что цепочка, представляемая предполагаемым новым содержимым
магазина и необработанными входными символами, не выводима
из (S). Чтобы понять, как это получается, вспомним, что
магазинные символы по построению кодируют префиксы правых частей
правил. Если конкатенация префикса, закодированного верхним
символом магазина, с правой скобкой дает новый префикс, то
таблица вталкиваний задает магазинный символ, кодирующий новый,
более длинный префикс. Если же эта конкатенация не дает нового
префикса, значит, обнаружена недопустимая комбинация входных
символов между двумя парными скобками, и автомат благополучно
отвергает вход.
Элементы таблицы вталкиваний для других грамматических
символов построены на основе аналогичных соображений. Если
конкатенация грамматического символа и префикса,
закодированного магазинным символом, дает новый префикс, то вталкивается
тот магазинный символ, который кодирует этот новый префикс.
В том случае, когда грамматический символ — левая скобка,
предполагается, что она начинает новую правую часть, и автомат
вталкивает в магазин символ (ь который кодирует односимвольную
цепочку (. Если грамматический символ нельзя использовать для
продолжения префикса, закодированного верхним символом
магазина, или в качестве начала нового префикса, то автомат отвергает
вход на том основании, что оставшиеся символы не могут завершать
правую часть правила и, следовательно, не могут завершать
допустимую цепочку. Исключение представляет случай магазинного
символа V и грамматического символа (S), потому что из
единственного символа (S) можно породить допустимую цепочку (и лаже
все допустимые цепочки). В этом случае таблица вталкиваний дает
символ (S>3, который кодирует цепочку S?{S).
11.4. Второй пример '
429
На рис. 11.10 показана управляющая таблица МП-автомата.
По этой таблице для каждой комбинации входного символа и
верхнего символа магазина выбирается переходная процедура.' (Мы
опустили слово ДЕРЖАТЬ для процедур, которые не сдвигают
вход.)
ь,
<s>,
<s>,
<s>.
<А >,
</* >,
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
CBEPTKA(f)
СВЕРТКА(2)
СВЕРТКА (3)
СВЕРТКА(4)
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА CD
СВЕРТКА (2)
СВЕРТКА(З)
СВЕРТКА (4)
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
CBEPTKA(I)
СВЕРТКА (2)
СВЕРТКА(3)
СВЕРТКА(4)
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКАО)
СВЕРТКА (2)
СВЕРТКА(3)
СВЕРТКА (4)
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
СВЕРТКАО)
СВЕРТКА(2)
СВЕРТКА(З)
СВЕРТКАМ)
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ДОПУСТИТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
Начальное содержимое магазина: v
перенос: тьъшМтекущий входной символ ), СДВИГ
СВЕРТКАО): ВЫТОЛК, ВЫТОЛК, ВЫТОЛК,ВЫТОЛК,ТАВТ0ЛК(<5>)
СВЕРТКА(2): ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ТАВТОЛК (<S>)
СВЕРТКАО): ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ТА ВТ0ЛК(<<4>)
СВЕРТКА(4): ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ТА вТОЛК(<А>)
Операция ТА ВТОЛК испольгует таблицу на рис, 11.9
Рис. 11.10.
430
Гл. П. Восходящие методы обработки языков
Слово ТАВТОЛК, встречающееся в процедурах переноса и
свертки,— это имя операции, которая использует таблицу
вталкиваний на рис. 11.9 для определения того, какой магазинный символ
втолкнуть, если это необходимо, в магазин. Аргументом этой
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
16.
17.
18.
19.
V
v(,
v(,
v(,
v(,
v(,
v(,
v(,
v(,
v(,
v(,
v(,
v(,
vd
v(,
v(,
vd
v(,
v(t
d
(id
dd*l
d d h )2
d (S>2
<1<S>2«1
<1<S>2«1
d<S>2«,
d<S>2«l
(l<S>2«l
d<S>2«l
<^>!
<^)ld
<^>ld*l
<^>ld'*l
<^>i <S>i
<^>i<5>1
d
d«2
d «2 h
(A>2
<A)2)3
)2
)l
(Ub)a(a)
((*)«(«)
(b)a(a)
b)a(a)
)a(a)
a(a)
a{a)
(a)
a)
)
(b)
(b)
(b)
(b)
(b)
(*)
(b).
(b)
(b)
(b)
(b)
(b)
(b)
(b)
b)
)
20. v <5>3
H
H
H
H
H
H
4
4
H
4
H
H
H
H
H
H
H
H
H
H
(2)
ПЕРЕНОС
перенос
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА (4)
ПЕРЕНОС
СВЕРТКА (3)
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА (2)
ПЕРЕНОС
СВЕРТКА (1)
ДОПУСТИТЬ
Рис. 11.11.
операции является грамматический символ, по нему и верхнему
символу магазина в таблице ищется вталкиваемый магазинный
символ. Процедуры ПЕРЕНОС, CBEPTKA(l), СВЕРТКА(2), СВЕРТ-
КА(3) и СВЕРТКА(4) отличаются от одноименных процедур
предыдущего раздела только использованием ТАВТОЛК вместо ВТОЛК.
Действие ТАВТОЛК отличается от действия ВТОЛК одним
дополнительным шагом, состоящим в использовании таблицы
вталкиваний для определения символа, который следует втолкнуть в
магазин.
Рассмотрим табличные элементы строки )i на рис. 11.10.
Согласно этим элементам, во всех случаях, когда верхним символом
11.4. Второй пример
431
в магазине является )i, независимо от входного символа выбирается
CBEPTKA(l). Процедура CBEPTKA(l) построена специально
для правила 1. Она убирает из магазина по одному символу для
каждого из четырех символов правой части правила 1 и после этого
выполняет ТАВТОЛК, используя в качестве аргумента левую часть
I. V
2. V(
3. V((
4. V(.(6
5. V((Z>)
6. V(<S>
7. V{(S)b
.8. V((S)b(
9. v((S)b(a
10. v((S)b(a)
11. V(<S> b(A)
12. V((S)b(A))
{(b)b(a))-\
(b)b(a))-\
Ь)Ь(а))-]
)Ь(а))-]
b(a))-\
b{a))-\
(a))-]
«))H
))H
)4
)H
H
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА (2)
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА (4)
ПЕРЕНОС
ОТВЕРГНУТЬ
а
1.
2.
3.
4.
5.
6.
V
V(i
v(,d
v d d ьх
v d d ьх )2
V (t <5>2
{(b)b(a))-\
(b)b{a))-\
b)b{a))-\
)b(a))-\
b(a))-\
b(a))-{
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА (2)
ОТВЕРГНУТЬ
Рис. 11.12. Последовательности конфигураций: (а) автомата рис. 11.6,
(б) автомата рис. 11.10.
правила 1,т. е. (S). В правильности выбора операции CBEPTKA(l)
можно убедиться по информации, закодированной символом )1г
так как это в точности правая часть правила 1. Аналогично
магазинные символы )2, )3 и )4 кодируют цепочки, в точности
совпадающие с правыми частями правил 2, 3 и 4, и по управляющей таблице
в каждом из этих случаев выбирается соответствующая процедура
432
Гл. 11. Восходящие методы обработки языков
свертки. Таким образом всегда, когда на верху магазина находится
символ, представляющий правую скобку, происходит вызов
процедуры свертки, соответствующей закодированной цепочке.
Решение вызвать нужную процедуру свертки принимается здесь
сразу в'отличие от ситуации, описанной в предыдущем разделе,
когда верхний символ магазина, соответствующий правой скобке,
требовал обращения к процедуре ОПОЗНАТЫ для того, чтобы
решить, какую из процедур свертки следует вызвать.
Если посмотреть на столбец на рис. 11.10, соответствующий
концевому маркеру, то видно, что автомат допускает вход тогда и
только тогда, когда символы магазина представляют особую
цепочку \/(S), которая кодируется символом (S>3. Здесь автомат
за один шаг выполняет то, что в предыдущем разделе делала
процедура ОПОЗНАТЬ2.
На рис. 11.11 показана последовательность конфигураций МП-
автомата, допускающая цепочку
((ф)а{а)){Ь))
При сравнении рис. 11.11 с рис. 11.5 обнаруживается сходство
методов данного и предыдущего разделов. Рис. 11.11 отличается
от рис. 11.5 только индексами, добавленными к магазинным
символам.
На рис. 11.12, а и б показано, как каждый из описанных
автоматов отвергает цепочку:
№Ь(а))
Автоматы отвергают эту входную цепочку, находясь в различных
ее точках. Автомат на рис. 11.6 отвергает вход при обработке
концевого маркера, когда процедура опознания не обнаруживает
правила с правой частью ({S) b (А)). Автомату на рис. 11.10
удается сделать это на пять входных символов раньше, при
обработке второго вхождения Ь, когда с помощью таблицы вталкиваний
выясняется, что b нельзя втолкнуть в магазин над (S)2.
11.5. Грамматические основы восходящих методов
Все рассматриваемые в этой книге восходящие методы включают
в себя построение МП-автомата по подходящей исходной
грамматике. При этом всегда получаются автоматы, о которых можно
сказать, что они «используют» исходную грамматику и способы
«использования» грамматик имеют много общего. В частности, все
автоматы по существу одинаково пользуются магазином. В этом
разделе мы изложим грамматические принципы, лежащие в основе
использования магазина, и рассмотрим два возможных способа
управления автоматом. Эти принципы и методы управления уже
П. 5. Грамматические основы восходящих методов 433
были проиллюстрированы в двух предыдущих разделах, но здесь
мы отделяем черты, присущие всем восходящим процессорам, от
особенностей, характерных для процессоров, описанных в
упомянутых разделах.
Одной из общих черт восходящих процессоров,
рассматриваемых в этой книге, является то, что магазиьиые. символы и
содержимое магазина имеют грамматическую интерпретацию. А именно:
Каждый магазинный символ, кроме маркера дна,
связывается с некоторым терминальным или нетерминальным
символом исходной грамматики. На каждом шаге работы
магазин представляет цепочку, которая получается из
цепочки символов магазина, удовлетворяющей соглашению
«верхний символ спраЕа>;, если' отбросить символ V и
заменить каждый из оставшихся символов связанным с ним
грамматическим символом.
Простейший способ установления соответствия между
магазинными и грамматическими символами состоит в том, что магазинный
алфавит строится из терминалов и нетерминалов грамматики.
Именно так это соответствие было получено в разд. 11.3. Однако
в общем случае одному грамматическому символу может
соответствовать несколько магазинных символов, как в разд. 11.4.
В разд. 11.4 построение было основано на кодировании префиксов,
но есть и другие способы установления такого неоднозначного
соответствия.
Восходящие МП-автоматы в этой книге манипулируют своими
магазинами и текущими входными символами с помощью
операций переноса и свертки. Под «операцией переноса» и «операцией
свертки» мы имеем в виду следующее:
Операция переноса — это операция, которая вталкивает
в магазин символ, соответствующий текущему входному
символу, и сдвигает вход, т. е. переносит со входа в
магазин текущий символ и, возможно, помещает туда
дополнительную информацию, закодированную в соответствующем
магазинном символе.
Операция свертки для правила per символами в правой
части — это операция, которая выбирается только тогда,
когда г верхних символов магазина представляют правую
часть правила р. Операция свертки выталкивает из
магазина верхние г символов и вталкивает туда символ,
соответствующий левой части правила р.
Обычно мы используем одну операцию переноса с именем ПЕРЕНОС
и для каждого правила р — операцию СВЕРТКА(р). В тех
случаях, когда автомат построен так, что некоторым грамматическим
434
Гл. П. Восходящие, методы обрабг.тки языков
символам соответствует по нескольку магазинных символов,
операции переноса и свертки выбирают для вталкивания в магазин
некоторый специально определенный магазинный символ.
В разд. J 1.4 для осуществления такого выбора использовалась
таблица вталкиваний.
Ввиду того что все грамматики, изучаемые в гл. 12 и 13,
однозначные, мы в дальнейшем будем без дополнительных оговорок
предполагать существование единственного правого вывода у любой
допустимой цепочки.
Каждая конфигурация, которая встречается в процессе
восходящего анализа допустимой входной цепочки, соответствует
некоторой промежуточной цепочке в правом выводе этой входной
цепочки. Это соответствие таково:
Цепочка, представляемая конкатенацией символов магазина
и еще необработанных терминалов (включая текущий
входной символ, если это не концевой маркер), является
промежуточной цепочкой в правом выводе первоначальной
входной цепочки из начального символа грамматики.
Восходящий автомат пытается заменить основу представленной
в нем цепочки нетерминалом из левой части основывающего
правила. На каждом (кроме последнего) шаге обработки допустимой
цепочки автомат выбирает операцию переноса или одну из
операций свертки. Если основа представленной в автомате
промежуточной цепочки соответствует верхним символам магазина, то автомат
выполняет свертку, которая соответствует основывающему
правилу. Если в верхней части магазина нет основы, автомат
выполняет перенос. На последнем шаге, когда представленная в автомате
цепочка состоит из начального символа грамматики, автомат
допускает вход.
Для грамматики на рис. 11.1 присутствие основы в верхней
части магазина обнаруживается тривиальным образом, так как
правая часть каждого правила оканчивается правой скобкой.
Сама основа начинается с предшествующей левой скобки.
Определение основывающего правила также тривиально, поскольку
каждая из заключенных в скобки правых частей отличается от всех
остальных.
Для других грамматик решение этих вопросов менее очевидно,
и разработчик должен использовать более тонкие свойства
грамматики. Гл. 12 и 13 посвящены рассмотрению таких свойств. Для
некоторых грамматик отыскание и идентификация основы не могут
быть выполнены МП-автоматом; в этих случаях разработчик
должен обратиться к другой грамматике или другому методу анализа.
Для любого восходящего автомата, построенного в этой книге,
последовательность операций переноса и свертки, выполненных
при обработке допустимых входных цепочек, можно описать с по-
11.5. Грамматически'' основы восходящих методов
435
мощью транслирующей грамматики. Входной грамматикой для
этой транслирующей грамматики является грамматика, на основе
которой построен автомат. Для каждого правила р транслирующая
грамматика содержит символ действия {СВЕРТКА(р)}. Этот
символ действия вставляется в конец правой части правила р. Для
грамматики на рис. 11.1 такой транслирующей грамматикой
является грамматика, показанная на рис. 11.13.
Если каждый входной символ в последовательности актов
понимать как представление операции ПЕРЕНОС, выполняемой
в случае, когда этот символ является текущим входным символом,
то последовательность актов в точности описывает
последовательность операций переноса и свертки, выполняемых при обработке
входной цепочки. Например, для входной цепочки
(((b)a(a))(b))
анализ которой показан на рис. 11.5 и 11.11, последовательность
актов, получаемая с помощью грамматики на рис. 11.13, такова:
(((6){СВЕРТКА(2)}а(а) {СВЕРТКА(4)})
{СВЕРТКА(3)}(6) {СВЕРТКА{2)}) {CBEPTKA(l)}
Можно видеть, что 19 символов этой последовательности актов
соответствуют 19 операциям переноса и свертки, показанным на
упомянутых рисунках. Например, шестым символом в
последовательности является {СВЕРТ-
КА(2)}, т. е. операция,
связанная со строкой 6. Седь- l. <S>^M><S» {СВЕРТКА (1)}
мым символом является а, и <s>^(6) {СВЕРТКА (2)}
операция, связанная со стро- 1 '
кой 7,- это ПЕРЕНОС, вы- 3- <А> — «s> а <А> (СВЕРТКА (3)}
полняемый в тот момент, ког- 4- <А>—>(а) {СВЕРТКА (4)}
да соответствующий а ока- Начальный символ: <S>
зывается текущим входным
символом. Последовательно- Рис- 1|13-
сти актов описывают
последовательности операций
переноса и свертки потому, что каждая операция свертки
выполняется сразу же после того, как соответствующая основа помещена
в магазин, т. е. тогда, когда завершается обработка последнего
символа в правой части правила.
В этой книге мы сосредоточим внимание на автоматах, которые
выбирают операции переноса и свертки при помощи одного из двух
методов. Иллюстрацией первого метода, который мы называем
методом «перенос — опознание», является автомат из разд. 11.3.
Второй метод называется методом «перенос — свертка», примером
его применения является автомат из разд. 11.4.
436
Гл. 11. Восходящие методы обработки языков
Метод «перенос — опознание» в качестве магазинных символов
использует символы грамматики. На каждом шаге анализа по
верхнему символу магазина и текущему входному символу автомат
выбирает либо операцию ПЕРЕНОС, либо операцию
ОТВЕРГНУТЬ* или процедуру опознания. Каждая из процедур опознания
может просмотреть несколько верхних символов магазина и на
основе полученной информации выполнить операцию свертки,
операцию ДОПУСТИТЬ или ОТВЕРГНУТЬ. Эти процедуры
называются процедурами опознания, потому что они используются
для определения основывающего правила в тех случаях, когда
основа находится в верхней части магазина. Заметим, однако, что
на рис. 11.6 процедура ОПОЗНАТЬ2 выбирает только между
операциями ДОПУСТИТЬ И ОТВЕРГНУТЬ.
Метод «перенос — свертка» использует несколько магазинных
символов для каждого символа грамматики. На каждом шаге
анализа автомат по верхнему символу магазина и текущему входному
символу выбирает одну из операций ПЕРЕНОС, ДОПУСТИТЬ,
ОТВЕРГНУТЬ или СВЕРТКА(р) для каждого правила. Этот
выбор требует такого построения, при котором магазинные символы
заключали бы в себе достаточно информации, чтобы основы и
основывающие правила могли быть определены без заглядывания «под»
верхний символ магазина. Однако закодированная информация
не обязательно должна выражаться в форме «префикса», как это
имело место в разд. 11.4. При анализе методом «перенос — свертка»
операции переноса и свертки должны определять, какой из
магазинных символов, соответствующих данному грамматическому
символу, нужно втолкнуть в магазин; такое решение принимается
с помощью таблицы вталкиваний, которая в тех случаях, когда
требуется вталкивание, позволяет по комбинации входного символа
и верхнего символа магазина определить новый вталкиваемый
символ. Для некоторых комбинаций верхнего символа магазина и
символа грамматики таблица вталкиваний может указывать на то,
что входная цепочка должна быть отвергнута. Таким образом,
операции переноса и свертки для метода «перенос — свертка»
отличаются от одноименных операций для метода «перенос —
опознание» тем, что первые используют информацию из таблицы
вталкиваний и могут отвергнуть входную цепочку.
11.6. Польский перевод
Теперь покажем, как можно расширить магазинные
распознаватели, о которых говорилось в предыдущем разделе, чтобы они
могли выполнять перевод. Наши рассуждения будут основаны на
понятии грамматики польского перевода.
11.6. Польский перевод 437
Транслирующая грамматика называется грамматикой
польского перевода тогда и только тогда, когда все символы
действия в правых частях расположены правее всех входных
и нетерминальных символов.
Например, на рис. 11.14 показана грамматика польского перевода
в цепочки, использующая в качестве входной грамматику
из рис. 11.1. Термин «польский» применен здесь по аналогии
с разд. 7.3, где описана транслирующая грамматика для перевода
арифметических выражений из
инфиксной формы в польскую запись.
Если задана грамматика польско- ] <^> ►«4><S»{;t}
го перевода и имеется восходящий
магазинный распознаватель, исполь- 2- <s> *(b)iz}
зующий входную грамматику так, з. <Л>—->■ «S> а <А» {х} {у}
как это описано в предыдущем разде- . . >
ле, то такой распознаватель легко
МОЖНО модифицировать так, чтобы ОН Начальный символ: <S>
выполнял перевод. После этой моди-
. Риг 11 Ы
фикации каждая операция свертки *"-• '•'*•
должна выполнять действия,
описываемые символами действия в
соответствующем правиле. Для транслирующей грамматики на рис. 11.14
модификация распознавателей, описанных в разд. 11.3 и 11.4,
сводится к изменению операций свертки таким образом, чтобы
CBEPTKA(l) выполняла выдачу х, СВЕРТКА(2) — выдачу z и
СВЕРТКА(З) — выдачу ху. Операция СВЕРТКА(4) не изменяется,
так как с правилом 4 не связано каких-либо символов действия.
Объяснение работы модифицированных таким образом автоматов
состоит в том, что, как показано в предыдущем разделе, вызов
каждой из операций СВЕРТКД(р) можно описать добавлением символа
действия {СВЕРТКА(р)} в правый конец правила р, т. е. в ту
позицию, где встречаются символы действия в грамматике польского
перевода. Сравнивая, например, рис. 11.13 и рис. 11.14, мы видим,
что {CBEPTKA(l)} занимает ту же позицию, что {х}, {СВЕРТ-
КА(2)} — ту же позицию, что {г}, а {СВЕРТКА(З)} — ту же
позицию, что {х} {у}. Ввиду того что при обработке входной цепочки
каждая из операций СВЕРТКА(р) выполняется в тот момент, когда
нужно выполнить действия для правила р, эти действия можно
включить в операцию СВЕРТКА(р).
Резюме
Если дана грамматика польского перевода, входная грамматика
которой может использоваться магазинным распознавателем, как
это описано в разд. 11.5, то можно построить процессор с магазин-
438
Гл. 11. Восходящие методы обработки языков
ной памятью, который выполнит соответствующий перевод. Такой
транслятор получается из распознавателя внесением некоторых
добавлений в операции свертки.
11.7. S-атрибутные грамматики
Теперь мы покажем, как можно расширить обсуждавшиеся в
предыдущем разделе магазинные распознаватели, чтобы они
выполняли атрибутный перевод. Основную роль при этом будет играть
понятие S-атрибутной грамматики.
Атрибутная транслирующая грамматика называется
S-атрибутной тогда и только тогда, когда выполнены три следующих
условия:
1. Все атрибуты нетерминалов — синтезируемые.
2. Каждое правило для синтезируемого атрибута не зависит
от синтезируемых атрибутов того символа, чей атрибут задается
этим правилом.
3. Каждое правило для наследуемого атрибута зависит только
от атрибутов тех символов в правой части продукции, которые
встречаются слева от символа, чей атрибут задается данным
правилом. (В терминах разд. 9.2 атрибутная грамматика является
S-атрибутной тогда и только тогда, когда она является L-атрибут-
ной, а все атрибуты нетерминалов — синтезируемые.) Буква S
в слове «S-атрибутная» призвана напоминать о том, что атрибуты
нетерминалов — синтезируемые.
Когда мы говорим, что атрибут «зависит только» от некоторого
набора атрибутов, мы имеем в виду, что правило для вычисления
указанного атрибута можно представить как функцию атрибутов
из этого набора. Эта функция не обязательно должна включать
все атрибуты набора и даже может на самом деле не зависеть ни
от одного из них. В качестве примера на рис. 11.15 показана S-
атрибутная версия транслирующей грамматики на рис. 11.14.
В продукции 1 правило для атрибута г2 «зависит только» от
атрибутов q, r\ и s, но выражается, как функция одного г\. Атрибут
р «зависит только» от атрибутов q, r\, s и г2, но выражается
функцией г\ и s. В продукции 3 атрибут v «зависит только» от атрибутов
р, П, q3, r, s, tw «2, но выражается функцией, не содержащей
атрибутов. В продукции 4 атрибут q зависит только от атрибута г\,
а выражается через функцию без параметров НОВ.
Если дана S-атрибутная грамматика польского перевода и
имеется восходящий магазинный распознаватель, использующий
входную грамматику, как это описано в разд. 11.5, то этот МП-
авгомат нетрудно расширить так, чтобы он мог выполнять
атрибутный перевод. В расширенном автомате каждый магазинный символ
11.7. ^-атрибутные грамматики
439
состоит из имени и связанного с ним набора полей. Поля каждого
символа магазина — это ячейки памяти, которые доступны для
запоминания и получения информации в период существования этого
символа (т. е. от его вталкивания до выталкивания). Для нагляд-
Все атрибуты нетерминалов—СИНТЕЗИРУЕМЫЕ
Все атрибуты символов действия — НАСЛЕДУЕМЫЕ
1. <S>p —-«A>t,n<S>t){xn)
r2*—r\ p*—r\—s
2. <S>p3 — (bpi) {zpi}
(/73, p2)^p\
3- <A>tt, v — «S>pan <A>q3, r) {xs} {y,, h)
s*—p*r ?<—s+?3 i'2-e— (1 u«— /-+10 wt— 13
4- <A>g, rt —► fan)
<?<— HOB rt<—r\
Начальный символ: <S>
Рис. 11.15.
ности будем представлять себе, что магазинный символ с п полями
занимает в магазине п+1 ячеек, верхняя из которых содержит имя
символа, а остальные соответствуют
полям. На рис. 11.16 такое представление
изображено для магазина, содержащего
VCABA
в
Поле 1
где А имеет два поля, В — одно, а С не
имеет полей.
В расширенном процессоре каждый
магазинный символ имеет по одному полю
для каждого атрибута соответствующего
грамматического символа. Эти поля
заполняются значениями атрибутов в момент
вталкивания символа в магазин и не
изменяются до его выталкивания.
Операция переноса расширяется таким
образом, что атрибуты переносимого
входного символа помещаются в
соответствующие поля вталкиваемого при переносе
магазинного символа.
Когда выбирается операция свертки для
продукции р, верхние символы магазина
представляют правую часть продукции р
входной грамматики и поля содержат
атрибуты соответствующих грамматических
символов. Расширенная операция свертки использует эти
атрибуты для вычисления всех атрибутов символов действия,
связанных с продукцией и всех атрибутов нетерминала в левой части
Поле 1
Поле 2
Поле 1'
Поле 2
Рис. 11.16.
440 Гл. 11. Восходящие методы обработки языков
продукции. Атрибуты символов действия используются для выдачи
результатов или выполнения соответствующих действий.
Атрибутами нетерминала в левой части продукции заполняются поля
символа, представляющего этот нетерминал и вталкиваемого в магазин
операцией свертки.
h
<А>2
2
5
ai
3
<S>2
7
_d
V
АО
Рис. 11.17.
На рис. 11.17 дан пример того, как расширенная версия
автомата из разд. 11.4 выполнила бы переход от строки 13 к строке 14
на рис. 11.11. Рисунок сделан в предположении, что используется
атрибутная транслирующая грамматика на рис. 11.15 и что
предыдущие операции дали значения атрибутов, равные 2, 5, 3 и 7; они
показаны на изображении магазина до перехода, который
выполняется с помощью расширенной операции СВЕРТКА(З). Операция
заменяет правую часть продукции 3 на ее левую часть и вычисляет
значения атрибутов, равные 15 и 13 для левой части и 35, 37 и 3
для выдаваемых символов. Происходит выдача символов с
атрибутами, и атрибуты левой части помещаются в соответствующие поля
нового символа магазина, т. е. (A )lt
Резюме
Если дана S-атрибутная грамматика польского перевода, входная
грамматика которой может использоваться магазинным
распознавателем, как это описано в разд. 11.5, то можно построить процес-
<Л>,
15
13
d
7
-
выход: x3Sy37i3
ПОСЛЕ
Упражнения
441
сор с магазинной памятью, выполняющий атрибутный перевод.
Транслятор получается из распознавателя добавлением полей для
магазинных символов и расширением операций переноса и свертки.
Упражнения
1. В соответствии с грамматикой на рис. 11.1 для каждой из следующих цепочек
найдите основу, если она существует.
а) (MXS»
б) (А)
в) (а)
г) <S>
д) (UX((S)a(A))(b)))
е) «i4)((o)(S»)
ж) (a)(6)
2. а) Покажите, что грамматика на рис. 11.1 не принадлежит классу LL(1)-
грамматик.
б) Изобразите последовательность конфигураций автомата из разд. 11.3 для
входной цепочки:
((((в)(6))в(0))(6))
в) Изобразите последовательность конфигурации автомата из разд. 11.4 для
входной цепочки, приведенной в пункте б).
3. Восходящий процессор для следующей грамматики
1. {S)-+(S)(S)a
2. (S)-*-(,S)b
3. (S) ^ (S)(S){S)c
4. <S)-d
при обработке некоторой входной цепочки распознает правила в следующем
порядке:
4,4. 4, 1, 4, 4, 1,3, 2
а) Какова эта входная цепочка?
б) В каком порядке будут распознаваться правила при обработке этой
цепочки нисходящим процессором?
4. Следующая последовательность конфигураций соответствует анализу
некоторой цепочки восходящим магазинным распознавателем. Изобразите дерево
вывода этой цепочки.
V t с da е а сЪЬ -~\
V в edaeaebb —|
V (А) с dа е и с \> b -• J
V (А) С dа е а с b b - \
V <Л> <5> da с a ebb -\
V{A)(S)d aeaebb--]
yf(A) aeacbb-\
V (A) a e а с b b - |
V (А) а с а с b b —{
V(A)a{A) &Qbb-\
442
Гл. 11. Восходящие методы обработки языков
V (А) а (А) а
V (А) а (А) ас
V (A)a(A)a(S)
V (A)a(AJa(S) b
V(A)a(S)
V (A)a(S)b
V<S>
cbb-{
b'b~\
bb-\
H
b-\
4
4
5. Предложение, порождаемое деревом, показанным на рисунке, распознается
снизу вверх магазинным автоматом. Изобразите подрезанное дерево, которое
получится после того, как автомат выполнит шесть сверток.
<S>
<S> <A> с <S> <A> ^-d
а Ь
а <S> <A> d
Правомаркированной грамматикой называется контекстно-свободная
грамматика, в которой правая часть каждого правила оканчивается особым
терминалом, причем каждый из этих терминалов нигде больше в грамматике не
встречается.
Покажите, что язык, порождаемый правомаркированной грамматикой,
можно распознавать с помощью анализатора типа «перенос — опознание».
Содержимое каких элементов управляющей таблицы на рис. 11.6 можно
заменить на операцию ОТВЕРГНУТЬ, не изменив при этом языка,
распознаваемого соответствующим автоматом?
Ниже приведено несколько вариантов содержимого магазина, алфавит
которого показан на рис. 11.8. В каких из этих вариантов цепочка,
закодированная каждым из магазинных символов, совместима с цепочкой, представляемой
магазином?
Упражнения
44"*
а) V
б) V (i <S>i ai <А>г
в) V d (i (i d d
г) VG04>i<S>i)i
9. а) Содержимое каких элементов таблицы вталкиваний на рис. 11.9 можно
заменить на операцию ОТВЕРГНУТЬ, не изменив при этом языка,
распознаваемого автоматом?
б) Содержимое каких элементов управляющей таблицы на рис. 11.10 можио
заменить на операцию ОТВЕРГНУТЬ, не изменив при этом языка,
распознаваемого автоматом?
10. Скобочная грамматика — это контекстно-свободная грамматика, в которой
правая часть каждого правила начинается левой скобкой и оканчивается
правой скобкой, причем эти скобки нигде больше в грамматике не встречаются.
Обратимая грамматика — это такая грамматика, в которой никакие два
правила не имеют одинаковых правых частей.
а) Покажите, что всякий язык, который порождается обратимой скобочной
грамматикой, можно распознать с помощью анализатора типа «перенос —
опознание».
б) Покажите, что всякий язык, который порождается скобочной грамматикой,
можно распознать МП-автоматом.
11. Показанная на рисунке таблица вталкиваний была построена для
распознавателя типа «перенос — свертка» и некоторой скобочной грамматики (см.
предыдущую задачу). Найдите эту грамматику.
♦1
d
<S>3
V
a
a\
*
'1
)
)з
).
(S)
<S>2
<S>3
12. Постройте анализатор типа «перенос — опознание» и анализатор типа
«мереное — свертка» для следующей грамматики с начальным символом (S):
(S)^a(S)(A)\
(S)^a{A)\
(S) -+■ a{S)0
{A)^b(A)(S)0
(A)-+Ь(А)(А)1
(A)^ab0
13. Постройте анализатор типа «перенос -
свертка» для следующей грамматики!
444
Гл. 11. Восходящие методы обработки языков
14. Некоторая грамматика содержит правила:
а) Pi. Рг н Рз. с правыми частями, состоящими из одного терминала и двух
нетерминалов;
б) Pi, Ръ ч Рп. с правыми частями, состоящими из одного терминала.
Согласно этой грамматике, при нисходящем разборе некоторого предложения
из соответствующего языка правила распознаются в следующем порядке:
PiP2PiP3PbPe,P2PiPiPbPe
В каком порядке будут распознаваться правила при восходящем разборе
этого предложения, согласно той же грамматике?
15. Покажите, что если грамматика принадлежит классу LL (1)-грамматик, то
некоторый МП-автомат, обрабатывающий «сверху вниз» входную цепочку,
порождаемую этой грамматикой, может выдать последовательность номеров
правил в том порядке, в каком они были бы распознаны некоторым
МП-автоматом, обрабатывающим цепочку «снизу вверх».
16. Покажите, как по данной однозначной грамматике найти транслирующую
грамматику, которая задает перевод каждого предложения языка,
порождаемого данной грамматикой, в цепочку из имен правил, использованных при
выводе этого предложения, в том порядке, в каком они были бы распознаны:
а) нисходящим анализатором,
б) восходящим анализатором.
17. Рассмотрим следующую грамматику, порождающую S-выраження языка Лисп
в точечной нотации:
1. (S)-*((S)-(S))
2. (S)-+a
а) Постройте для этой грамматики анализатор типа «перенос — опознание».
б) Постройте для этой грамматики анализатор типа «перенос — свертка».
в) Для анализатора из пункта а) составьте набор сообщений об ошибках,
которые должны выдаваться процедурами опознания при обнаружении
ошибок.
г) Для анализатора из пункта б) составьте сообщения об ошибках,
соответствующие элементам таблицы вталкиваний, содержащим операцию
ОТВЕРГНУТЬ.
18. Предположим, что помимо вталкивания и выталкивания операция свертки
может выполнять сдвиг.
а) Измените автомат на рис. 11.6 так, чтобы он никогда не вталкивал в
магазин закрывающие скобки.
б) Изобразите в виде последовательности конфигураций, как измененный
автомат обрабатывает входную цепочку:
(((6)о (о)) (6))
19. Изобразите последовательность конфигураций, соответствующую обработке
цепочки
Ша)(Ь))а(а))(Ь))
процессором типа «перенос — свертка»:
а) построенным методами разд. 11.6 для грамматики польского перевода на
рис. 11.14;
б) построенным методами разд. 11.7 для атрибутной грамматики польского
перевода на рис. 11.15. Значения атрибутов для входных символов
придумайте сами.
20. Рассмотрим следующую S-атрибутную транслирующую грамматику с
начальным символом (S). Нетерминал (S) имеет один атрибут, а нетерминал (А) —
два.
1. <S>X — «A>„,vau){dz}
г <— и *v-\-y х <— 3
Упражнения
445
2. <S>X — (by <S>„) {/„} {d,}
;i t— у г <— v—2 x *— и-\-г
3. <Л>л-,у — (flA<S>„)
х <— г+u—у i/ <— и
4. <Л>л,у -* ( )
х <— 1 у <— 2
а) Постройте для этой 1рамматики процессор типа «перенос — опознание».
б) Постройте для этой грамматики процессор типа «перенос — свертка».
21. Рассмотрим следующую грамматику для арифметических выражений:
<£>-*«£>+<£))
<£) -»■ ((£)*(£))
<£>->/
Пусть / — лексема, значением которой является указатель на элемент
таблицы для идентификатора. Нам нужно транслировать цепочки этого языка
и цепочки, составленные из атомов СЛОЖ^, Чь г и УМНОЖр. 9, г, где р, q,
г — указатели на табличные элементы, соответствующие левому операнду,
правому операнду и результату.
а) Постройте S-атрибутную грамматику польского перевода, задающую
указанный перевод.
б) Постройте восходящий процессор, выполняющий этот перевод.
22. Рассмотрим следующую транслирующую грамматику с начальным
символом (S):
1. (S)->-(£){ОТВЕТ}
2. (£> — (Р)
3. (£> -+■ (Е)+{Р)
4. <£)_><£>-</>>
5. (P)-vc
6. (Р) -* ((£»
а) Пусть с — лексема, представляющая константу, и ее значением является
значение этой константы.
Введите в грамматику атрибуты, так чтобы символ {ОТВЕТ} имел атрибут,
равный численному значению выражения.
б) Постройте расширенный восходящий процессор для грамматики из
пункта а).
23. Покажите, что для всякой транслирующей грамматики существует грамматика
польского перевода, определяющая тот же самый перевод.
24. Предположим, что входная грамматика из упр. 7.24 заменена следующей:
1. (условный оператор) —>- (условие) (безусловный оператор)
2. (условный оператор)-»- (полное условное) (оператор)
3. (полное условное) -*■ (условие) (безусловный оператор) else
4. (условие) -> ^(логическое выражение) then
а) Постройте восходящий распознаватель, основанный на этой грамматике.
б) Введите в грамматику символы действия и атрибуты, чтобы получилась
S-атрибутная грамматика польского перевода, задающая перевод,
описанный в упр. 7.24.
с) Постройте расширенный процессор по грамматике из пункта б).
25. Для грамматики на рис. 11.1 постройте восходящий магазинный анализатор,
обладающий префиксным свойством с точки зрения обнаружения ошибок (см.
разд. 8.8). Используйте магазинный алфавит, кодирующий больше
информации, чем алфавит на рис. 11.8.
26. а) Приведите пример неоднозначной грамматики, согласно которой любая
цепочка имела бы не более одной основы.
44G
Гл. И. Восходящие, методы обработки языков
б) Приведите пример неоднозначной грамматики, согласно которой лют"гя
цепочка имела бы не более одного основывающего правила.
в) Покажите, что грамматика однозначна тогда и только тогда, когда любья
цепочка имеет, согласно этой грамматике, не более одной основы и не более
одного основывающего правила.
27. Дл£ каждой из нижеперечисленных задач постройте S-атрибутную грамматику
польского перевода, задающую перевод, описанный в соответствующем
упражнении. В каждом случае нужно построить свою входную грамматику.
а) Упр. 7.25
б) Упр. 9.11
в) Упр. 9.27
12
Обработка методами типа
„перенос—опознание"
12.1. Введение
В предыдущей главе мы обсуждали два метода восходящего анализа:
метод «перенос — опознание» и метод «перенос — свертка». В этой
главе мы рассмотрим особый тип процессоров с магазинной
памятью, использующих метод «перенос — опознание».
Соответствующие автоматы мы будем называть автоматами типа «перенос —
опознание». Точнее, когда мы говорим об автомате типа «перенос —
опознание» для данной грамматики, мы имеем в виду автомат
с такими свойствами:
1. Магазинные символы автомата — это все символы данной
грамматики и маркер дна.
2. Входные символы автомата — это терминальные символы
данной грамматики и концевой маркер.
3. Управление автоматом задается управляющей таблицей типа
«перенос — опознание», которая задает операцию ПЕРЕНОС,
ОТВЕРГНУТЬ или процедуру опознания для каждой комбинации
магазинного и входного символов.
4. Каждая из процедур опознания просматривает несколько
верхних символов магазина и либо выбирает одну из операций
СВЕРТКА для некоторого правила, либо ДОПУСТИТЬ или
ОТВЕРГНУТЬ.
5. В любой момент в процессе анализа допустимой входной
цепочки цепочка, представляемая содержимым магазина и
необработанными входными символами, является промежуточной
цепочкой в правом Еьшоде начальной входной цепочки. Управляющий
механизм выбирает процедуру опознания каждый раз, когда основа
представленной в автомате цепочки находится на верху магазина,
в остальных случаях выбирается операция ПЕРЕНОС.
Далее в этой главе мы предполагаем, что имеем дело с
однозначной грамматикой, не содержащей е-правил. Таким образом, мы
вправе говорить о единственном правом выводе цепочки. Мы
предполагаем также, что мертвые и недостижимые нетерминалы удалены
из грамматики.
448 Гл. 12. Обработка методами типа «перенос— опознание*
12.2. Управление автоматом типа
«перенос — опознание»
Нас интересуют методы построения автомата типа «перенос —
опознание» 'по данной грамматике. Оказывается удобным разделить
задачу построения автомата на две части. Первая из них
(рассматриваемая в этом разделе) состоит в том, чтобы решить, какие
элементы таблицы управления должны содержать операции ПЕРЕНОС,
какие — процедуры опознания и какие — операции
ОТВЕРГНУТЬ. Вторая часть задачи, а именно отыскание подходящих
процедур опознания, обсуждается в последующих разделах.
Теперь предположим, что у нас есть автомат типа «перенос —
опознание» для данной грамматики с начальным символом (S).
На каждом шаге обработки этим автоматом некоторой входной
цепочки справедливо в точности одно из следующих утверждений:
1. Входная цепочка допустима, и верхняя часть магазина
представляет основу цепочки, представляемой магазином и еще не
обработанными входными символами.
2. Входная цепочка допустима, содержимое магазина—V(S>,
и текущий входной символ — концевой маркер.
3. Входная цепочка допустима, текущий входной символ —
не концевой маркер, и верхняя часть магазина не представляет
основу представленной в автомате цепочки.
4. Входная цепочка недопустима.
Каждый раз, когда автомат достигает конфигурации,
описываемой одним из первых двух утверждений, он должен выбрать
процедуру опознания. Выбор осуществляется с помощью управляющей
таблицы, исходя из верхнего символа магазина и текущего входного
символа. Итак, предположим, что при данной комбинации
магазинного и входного символов возникает ситуация,
соответствующая утверждению 1 или утверждению 2. Так как в этой ситуации
автомат должен выбрать процедуру опознания, то элемент
управляющей таблицы для данной комбинации входного и магазинного
символов должен содержать процедуру опознания. И вообще
управляющая таблица должна быть построена так, чтобы для каждой
комбинации входного и магазинного символов в ситуациях,
описываемых утверждениями 1 и 2, обеспечить выбор процедуры
опознания.
Каждый раз при достижении автоматом конфигурации,
описываемой утверждением 3, он должен выбрать операцию ПЕРЕНОС.
Следовательно, элементы управляющей таблицы для комбинаций
входных и магазинных символов, встречающихся в конфигурациях,
описываемых утверждением 3, должны содержать ПЕРЕНОС.
Может показаться, что из наличия конфигураций, описываемых
утверждением 4, следует, что некоторые элементы управляющей
12.2. Управление автоматом типа «перенос — опознание!) 449
таблицы должны содержать операцию ОТВЕРГНУТЬ, но это не
так. На самом деле эти конфигурации не влияют на управление,
потому что если входная цепочка не выводима из (S), то никакая
комбинация операций переноса и свертки не может превратить
цепочку, первоначально представленную в автомате (т. е. исходную
входную цепочку), в представление цепочки (S). Поэтому
независимо от того, каким образом элементы управляющей таблицы
заполнены операциями ПЕРЕНОС, ОТВЕРГНУТЬ и процедурами
опознания, все недопустимые входные цепочки будут отвергнуты.
Для того чтобы решить, какие элементы управляющей таблицы
должны содержать ПЕРЕНОС, а какие — процедуры опознания,
разработчик должен проанализировать грамматику и предвидеть,
какие элементы таблицы могут встретиться в конфигурациях,
описываемых утверждениями 1 или 2, и какие — в конфигурациях,
соответствующих утверждению 3. Для некоторых грамматик такой
анализ показывает, что некоторые элементы таблицы могут
встретиться как в ситуации, описываемой утверждением 1 или 2, так и
в ситуации, описываемой утверждением 3. В этом случае из
приведенных выше аргументов следует, что табличный элемент должен
содержать и ПЕРЕНОС, и процедуру опознания. Это означает, что
управляющий механизм типа «перенос — опознание» не подходит
для данной грамматики, и разработчик должен обратиться к какой-
либо другой грамматике или другому типу автомата.
Как средство анализа грамматик мы используем понятия
множеств первых и следующих символов.
По данной контекстно-свободной грамматике с начальным
символом <5> и по символу грамматики х мы определим два
множества:
1. СЛЕД (jc)
—множество входных символов (возможно, включающее—]), которые
могут непосредственно следовать за л; в некоторой промежуточной
цепочке, выводимой из (5) —\,
2. ПЕРВ (х)
— множество тех символов грамматики, которые встречаются в
начале промежуточных цепочек, выводимых из х. За исключением
тривиальных различий, эти определения совпадают с
определениями множеств СЛЕД и ПЕРВ, данными в гл. 8, и при желании
эти множества могут быть получены методами разд. 8.7.
Вычисления упрощаются в связи с отсутствием е-правил. В разд. 8.6
множество ПЕРВ определялось для цепочек, в то время как здесь нас
интересуют лишь множества ПЕРВ для отдельных символов.
Кроме того, мы включаем в множества ПЕРВ нетерминалы, тогда
как в гл. 8 нас интересовали только терминалы.
15 Ф. Льюис и др.
450 Гл. 12. Обработка методами типа «.перенос— опознание*
Множества ПЕРВ и СЛЕД для символов грамматики,
изображенной на рис. 12.1, приведены на рис. 12.2. Вычисление множеств
первых символов тривиально, так как каждое правило начинается
терминалом. Заметим, что каждый символ грамматики
принадлежит своему собственному множеству ПЕРВ.
Множество СЛЕД ((S)) содержит концевой маркер, так как он
следует за (S) в цепочке (S) —|. Это множество содержит также
символ с, так как с следует за вхождением (S) в правой части
правила 3. Из того, что (S) входит в правую часть правила 1,
вытекает принадлежность множеству СЛЕД ((S)) всех терминалов
множества ПЕРВ((Б>), последнее,
однако, состоит из единственного
символа с.
Чтобы вычислить СЛЕД ((Л >),
заметим, что {А > встречается в правых
частях правил 1, 2 и 5. Благодаря
вхождению его в правило 1, в СЛЕД
((А >) включаются терминалы из
множества ПЕРВ ((S)), а именно символ
Ь. Вхождение в правило 2 добавляет
входные символы из СЛЕД(<5>), а
именно с и —). А вхождение в правило
5 добавляет символ а.
Остальные множества СЛЕД
можно вычислить аналогичным
образом.
Возвращаясь к вопросу о том, каким образом требования к
управляющей таблице могут быть выведены из грамматики,
рассмотрим задачу разработки управляющего механизма типа
«перенос— опознание»для грамматики на рис. 12.1.
Многие элементы управляющей таблицы можно заполнить на
основе простого наблюдения, какие из символов в правых частях
правил встречаются только в самой правой позиции, а какие —
только в других позициях. Например, символы b, d w (S) ни в
одной правой части не встречаются в качестве самых правых
символов, и поэтому b, d, {S) или V на верху магазина не могут быть
крайними правыми символами основы. Следовательно, если один
из этих символов находится на верху магазина, автомат
благополучно может выполнить перенос любого входного символа
(отличного от концевого маркера), и, значит, можно соответствующим
образом заполнить элементы управляющей таблицы.
Символы а, ей (В> встречаются только в крайних правых
позициях правил, следовательно, появление а, е или (В) на верху
магазина может соответствовать лишь самому правому символу
основы. Значит, если один из этих символов находится на верху
магазина, автомат может благополучно вызвать процедуру опозна-
1
2.
3
4
5.
6.
<S)
(S)
(А)
(А)-
(В)-
(В)-
-b(A)(S)(B)
-*Ь{Л)
-^d(S)ca
—► е
-~с (А)а
-* с
Начальный символ: <S>
Рис. 12.1.
12.2. Управление автоматом типа «.перенос — опознание» 451
ния и вызовы этих процедур можно включить в управляющую
таблицу.
Подобные простые соображения относительно заполнения
управляющей таблицы неприменимы лишь в тех случаях, когда на
верху магазина находится (Л) или с. Нетерминал (А)
встречается один раз в крайней правой позиции (правило 2) и дважды
в других позициях (правила 1 и 5). То же относится и к символу с.
ПЕРВ «S» = {Ь, (S)} СЛЕД «S» = {с, 4}
ПЕРВ ((A)) = {d, е, (А)) СЛЕД «Л» = {а, Ь, с, Н}
ПЕРВ ((B)) = {с, (В)} СЛЕД «5» = {с, -|}
ПЕРВ (а) = {а} СЛЕД (а) = {а, Ь, с, -{}
ПЕРВ (Ь) = {Ь} СЛЕД (b) = {d, e)
ПЕРВ (с) = {с} СЛЕД (с) = {а, с, d,e,-\)
ПЕРВ(йО={<*} СЛЕД (d) = {Ь}
ПЕРВ (в) = {е} СЛЕД (е) = {а, Ь, с, Н}
Рис. 12.2.
Для заполнения строк управляющей таблицы, соответствующих
этим двум символам, необходим более глубокий анализ
конфигураций, которые могут появиться.
На рис. 12.3 показаны три различные конфигурации и
соответствующие им подрезанные деревья вывода для случаев, когда
(Л > находится на верху магазина. В ситуации, изображенной
на рис. 12.3, в, справедливо утверждение 1, а в остальных двух
случаях на рис. 12.3 истинно утверждение 3. Рис. 12.3, в
показывает, что элемент строки управляющей таблицы, соответствующей
символу (Л >, для входного символа с должен содержать
процедуру опознания, а из рис. 12.3, а к б следует, что элементы этой
строки для входных символов а и Ъ должны содержать ПЕРЕНОС.
Как разработчикам, нам нужно знать, возможны ли другие
ситуации, противоречащие нашему выбору элементов управляющей
таблицы для входных символов а, Ь и с. Нам также надо знать,
какой выбор можно сделать для входных символов d и с.
Сначала попытаемся найти все входные символы х, такие, что
элемент управляющей таблицы в строке (Л > и столбце х должен
содержать процедуру опознания. Это означает, что нам нужно
найти все входные символы х, для которых может возникнуть
ситуация, соответствующая утверждению 1 с символом (Л > на
верху магазина и х в качестве текущего входного символа. Ввиду
того что единственным вхождением (А > в правую часть, которое
может заканчивать основу, является вхождение в правило 2, мы
15*
452 Гл. 12. Обработка методами типа «.перенос— опознание»
должны найти входные символы, которые могут следовать за <Л >из
правила 2 в выводе, начинающемся с (S) —|- Поскольку левой
частью правила 2 является (S),3Ta задача эквивалентна отысканию
множества таких х, что х может следовать в некотором выводе за
любым вхождением (S >. Это следует из того, что если х следует за (S),
<s>
<s>
<А >
<S> <в>
<А>
<S> <В>
с <А> a
Vb<A><S>c<A>
а
V Ь<А>
<А> с
е
Ь е с ■
<S>
<А >
<S> <В>
/I
<А >
Vb<A>b<A>
в
с-\
Рнс. 12.3.
то после применения правила 2 х будет следовать за (А >, и,
наоборот, если х следует за (А >, то соответствующая СВЕРТКА(2)
помещает (S > из левой части правила перед х. Таким образом,
искомое множество входных символов — это СЛЕД(<5>). Согласно
рис. 12.2,
СЛЕД «S» He, -tt
Итак, все входные символы, для которых требуется процедура
опознания,— это с и —|.
Теперь попытаемся найти все входные символы у, такие, при
которых управляющая таблица в строке {А > и столбце у содержит
ПЕРЕНОС. Это те входные символы, которые могут следовать за
вхождениями (А) в правилах 1 и 5. За вхождением в правило 5
может следовать только а, что вытекает непосредственно из вида
правой части правила 5. За вхождением {А) в правило 1 следует
12.2. Управление автоматом типа мереное — опознание» 453
вхождение {S >, поэтому за (А) могут следовать входные символы
из множества nEPB((S>), а именно Ь. Объединяя эти два случая,
мы заключаем, что ПЕРЕНОС требуется только для символов
а и Ь. Теперь мы убедились в том, что требования переноса и
опознания не противоречат друг другу. Можно также заключить, что
при обработке допустимой входной цепочки элементы строки (А >
для входных символов d и е не будут использоваться и каждый из
этих элементов может содержать либо ОТВЕРГНУТЬ, либо
ПЕРЕНОС, либо процедуру опознания.
Приведенные рассуждения иллюстрируют два принципа,
которые мы назовем «принципом свертывания» и «принципом переноса».
Принцип свертывания можно сформулировать следующим образом:
Для данной грамматики управляющую таблицу типа
«перенос — опознание» нужно строить так, чтобы она
обеспечивала выбор процедуры опознания для магазинного
символа А и входного символа х в тех случаях, когда
выполняется одно из следующих условий:
а) существует нетерминал (L) и цепочка а, такие, что
(L)^aA
— правило грамматики и х принадлежит СЛЕД( (/.));
б) Л — начальный символ грамматики, а х — концевой
маркер.
Более того, управление можно построить так, что процедуры
опознания выбираются только в указанных выше случаях.
Часто бывает удобно рассматривать принцип свертывания в
терминах отношения СВЕРТЫВАЕТСЯ-ПО, определяемого
следующим образом:
Если А — символ грамматики, ах — входной символ, то мы
пишем
А СВЕРТЫВАЕТСЯ-ПО х
тогда и только тогда, когда выполнено одно из условий в
формулировке принципа свертывания.
Определение дает метод вычисления этого отношения по
грамматике, использующий вычисление множеств СЛЕД в качестве
промежуточного этапа. Ниже этот метод применяется к
рассматриваемому примеру. Более прямой метод описан в разд. 12.6.
Принцип свертывания можно сформулировать теперь проще:
Управляющий механизм типа ПЕРЕНОС — ОПОЗНАНИЕ
нужно строить так, чтобы он содержал процедуру опознания
для всех комбинаций магазинного символа А и входного
символа х, таких, что
А СВЕРТЫВАЕТСЯ-ПО х
454 Гл. 12. Обработка методами типа «перенос— опознание»
Остальные элементы управляющей таблицы не обязаны
содержать процедур опознания.
Принцип переноса можно сформулировать следующим образом:
Для данной грамматики управляющую таблицу типа
«перенос — опознание» нужно строить так, чтобы она содержала
ПЕРЕНОС для магазинного символа А и входного символа х
в тех случаях, когда выполнено одно из следующих
условий:
а) имеется символ грамматики В, такой, что в правую часть
некоторого правила входит цепочка А В, и х принадлежит
ПЕРВ(В);
б) Л — маркер дна магазина, и х принадлежит ПЕРВ( (S)),
где (S)—начальный символ грамматики. Более того,
управляющий механизм можно построить так, чтобы ПЕРЕНОС
выбирался только в указанных выше случаях.
Часто бывает удобно рассматривать принцип переноса в терминах
отношения ПОД, определяемого следующим образом:
Если А — магазинный символ, ах — входной символ, мы
пишем:
А ПОД х
тогда и только тогда, когда выполняется одно из условий
в формулировке принципа переноса.
Из определения вытекает метод вычисления этого отношения по
грамматике, использующий вычисление множеств ПЕРВ в
качестве промежуточного этапа. Ниже этот метод применяется к
рассматриваемому примеру. Более прямой метод описан в разд. 12.6.
Принцип переноса теперь можно сформулировать проще:
Управляющую таблицу типа «перенос — опознание» нужно
строить так, чтобы она содержала ПЕРЕНОС для всех
комбинаций магазинного символа А и входного символа х,
таких, что
А ПОД х
Остальные элементы управляющей таблицы не обязаны
содержать ПЕРЕНОС.
Мы говорим, что грамматика содержит конфликты переноса —
опознания тогда и только тогда, когда существуют грамматический
символ А и терминальный символ х, такие, что одновременно
А СВЕРТЫВАЕТСЯ-ПО х и А ПОД х.
Грамматика с конфликтами переноса — опознания не может
служить основой автомата типа «перенос — опознание», потому что
12.2. Управление автоматом типа «.перенос — опознание* 455
принцип свертывания и принцип переноса требуют, чтобы элемент
управляющей таблицы для магазинного символа Л и входного
символа х содержал как процедуру опознания, так и ПЕРЕНОС.
Это противоречит требованию, что таблица должна указывать
единственную процедуру. Для грамматики без конфликтов
переноса — опознания принципы свертывания и переноса определяют
следующие требования к построению управляющей таблицы:
1) элементы для магазинного символа А и входного символа х,
таких, что А СВЕРТЫВАЕТСЯ-ПО х, должны содержать
процедуры опознания,
2) элементы для магазинного символа А и входного символа х,
таких, что А ПОД х должны содержать ПЕРЕНОС,
3) остальные элементы могут содержать операции
ОТВЕРГНУТЬ, ПЕРЕНОС или процедуры опознания. Требуется
лишь, чтобы ПЕРЕНОС никогда не применялся к концевому
маркеру.
Возвращаясь к нашему примеру, рассмотрим строку
управляющей таблицы для магазинного символа с. Этот символ является
самым правым в правиле 6. Значит, в этой строке управляющей
а ь с d e н
ОТВЕРГНУТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ПЕРЕНОС
ОПОЗНАТЬ
ПЕРЕНОС
ПЕРЕНОС
ОПОЗНАТЬ
ОПОЗНАТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ПЕРЕНОС
ПЕРЕНОС
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ПЕРЕНОС
ПЕРЕНОС
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОПОЗНАТЬ
ОПОЗНАТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
Рис. 12.4.
таблицы должны содержаться процедуры опознания для входных
символов из множества СЛЕД((В)), а именно для с и -\. В
правиле 3 за вхождением с следует а, поэтому для входных символов
из ПЕРВ(а), т. е. для самого а, требуется ПЕРЕНОС. В правиле 5
за с следует (Л), значит, ПЕРЕНОС нужен также для входных
символов из ПЕРВ((Л», а именно для due. Заметим, что все
входные символы, для которых нужен ПЕРЕНОС, отличны от
символов, для которых требуются процедуры опознания, и, значит,
456 Гл. 12. Обработка методами типа «.перенос — опознание»
при построении строки для магазинного символа с конфликтов не
возникает.
Теперь мы можем проделать полный анализ для всех строк
управляющей таблицы. Например, ранее мы отметили, что все
элементы в строке для символа (В) могут быть заполнены
процедурами опознания, однако теперь мы можем отделить элементы,
которые обязательно должны содержать процедуры опознания, от
элементов, которые могли бы вместо этого содержать операции
ПЕРЕНОС или ОТВЕРГНУТЬ. Имеется лишь два входных
символа х, таких, что
(В) СВЕРТЫВАЕТСЯ-ПО х
а именно с и —-1; поэтому только два соответствующих им элемента
этой строки обязаны содержать процедуры опознания.
На рис. 12.4 показана управляющая таблица для данного
примера, построенная с учетом всех приведенных соображений. Она
содержит ПЕРЕНОС и ОПОЗНАНИЕ там, где это необходимо, а
всюду, где есть возможность выбора, используется операция
ОТВЕРГНУТЬ. Чтобы завершить построение, осталось разработать
процедуры опознания, выполняющие операцию ОПОЗНАТЬ,
указанную в таблице.
12.3. Бессуффиксные ПО-грамматики
Теперь приступим к изучению процедур опознания. Предположим>
что у нас есть грамматика без конфликтов переноса — опознания
(в противном случае для нее не существовало бы автомата типа
«перенос — опознание»). Методы предыдущего раздела указывают,
когда (т. е. для каких комбинаций входного и магазинного символов)
нужно вызывать процедуры опознания; целью этого и двух
следующих разделов является детальное выяснение того, какими должны
быть сами процедуры опознания. Из предыдущего раздела нам
известно, что обращение к процедуре опознания при обработке
допустимой цепочки происходит тогда и только тогда, когда
несколько верхних символов магазина представляют основу или (на
заключительном шаге) если содержимым магазина является
выделенная цепочка \/{S).
Теперь рассмотрим автомат типа «перенос — опознание» для
грамматики на рис. 12.1. Правые части правил этой грамматики
обладают следующим свойством: никакая правая часть не является
суффиксом какой-либо другой правой части или цепочки \/{S).
Поэтому всякая цепочка магазинных символов может оканчиваться
не более чем одной основой или подцепочкой \/(S). Например, если
цепочка символов магазина оканчивается символом с, то правило 6
является единственным правилом, чья правая часть совпадает с.
12.3. Бессуффиксные ПО-грамматики
457
окончанием этой цепочки независимо от того, какие магазинные
символы находятся ниже с. Если цепочка символов магазина
оканчивается подцепочкой с(А)а, то независимо от остальных символов
магазина единственным правилом, чья правая часть совпадает с
окончанием этой цепочки, является правило 5. Если же цепочка
символов магазина оканчивается подцепочкой V(S), то ни одна
правая часть не совпадает с окончанием этой цепочки.
Когда в процессе обработки допустимой входной цепочки
выбирается процедура опознания, верхняя часть магазина
представляет основу или цепочку V(S). Следовательно, верхняя часть
магазина должна совпадать с правой частью основывающего
правила или с цепочкой \/(S). А так как на верху магазина может
находиться лишь одна правая часть или цепочка \/(S), само
присутствие некоторой правой части на верху магазина указывает
на то, что эта правая часть в действительности является основой.
Таким образом, когда процедура опознания обнаруживает в
верхней части магазина правую часть правила р, она должна выбрать
операцию СВЕРТКА (р). Аналогично присутствие на верху
магазина цепочки V(S) несовместимо с наличием в магазине какой-
либо основы, и в этом случае правильным действием для процедуры
опознания будет выбор операции ДОПУСТИТЬ, при условии что
текущим входным символом является концевой маркер —|. Короче
говоря, процедура опознания должна только выяснить, какая
правая часть (или цепочка V(S>) совпадает с верхней частью
магазина, и выбрать соответствующую операцию свертки (или операцию
ДОПУСТИТЬ).
Таким образом, для грамматики на рис. 12.1 можно построить
распознаватель типа «перенос — опознание» с одной-единственной
процедурой опознания. Эта процедура используется во всех
элементах управляющей таблицы, для которых этого требует анализ
управляющей таблицы, описанный в предыдущем разделе.
Процедура просто проверяет несколько верхних символов магазина на
совпадение с правой частью какого-либо правила или с цепочкой
V(S). Если обнаружено совпадение с правой частью правила р,
процедура выполняет операцию СВЕРТКА (р). Если два верхних
символа магазина образуют цепочку V(S), процедура проверяет,
является ли текущий входной символ концевым маркером, и если
это так, то допускает входную цепочку. Если ни одна из
вышеперечисленных ситуаций не имеет места, процедура отвергает
вход. Таким образом, построение управляющей таблицы на рис. 12.4
можно дополнить следующей единственной процедурой опознания:
если на верху магазина b{A)(S)(B) то СВЕРТКА (1)
иначе если на верху магазина Ь(А) то СВЕРТКА (2)
иначе если на верху магазина d{S)ca то СВЕРТКА (3)
иначе если на верху магазина е то СВЕРТКА (4)
458 Гл. 12. Обработка методами типа «перенос— опознание»
иначе если на верху магазина с (А) а то СВЕРТКА (5)
иначе если на верху магазина с то СВЕРТКА (6)
иначе если на верху магазина S/ (S)
и текущий входной символ —| то ДОПУСТИТЬ
иначе ОТВЕРГНУТЬ
Этот «метод одной процедуры» — не единственный способ
завершить построение управляющей таблицы, и в определенном
смысле он неэффективен. Более эффективное построение показано на
<s>
<А >
<8>
a
b
с
6 .
е
V
а
ОТВЕРГНУТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ОПОЗНАТЬ 4
ОТВЕРГНУТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ОПОЗНАТЬ 6
ОТВЕРГНУТЬ
b
ОТВЕРГНУТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ОПОЗНАТЬ 4
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ПЕРЕНОС
ОПОЗНАТЬ 6
ПЕРЕНОС
с
ПЕРЕНОС
ОПОЗНАТЬ2
ОПОЗНАТЬ 3
ОПОЗНАТЬ 4
ОТВЕРГНУТЬ
ОПОЗНАТЬ5
ОТВЕРГНУТЬ
ОПОЗНАТЬ 6
ОТВЕРГНУТЬ
d
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ПЕРЕНОС
ПЕРЕНОС
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
е
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ПЕРЕНОС
ПЕРЕНОС
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
—
ОПОЗНАТЬ 1
ОПОЗНАТЬ 2
ОПОЗНАТЬЗ
ОПОЗНАТЬ4
ОТВЕРГНУТЬ
.ОПОЗНАТЬ 5
ОТВЕРГНУТЬ
ОПОЗНАТЬ 6 !
ОТВЕРГНУТЬ]
Начальное содержимое магазина: v
ПЕРЕНОС: ВТОЛКНУТЬ (текущий входной символ), СДВИГ
опознать!: если на верху магазина у@Уто допустить
иначе отвергнуть
опознать 2: если на верху магазина Ь<АУ то С8ЕРТКА(2)
иначе отвергнуть
опознатьЗ: если на верхи магазина b<A><s><3> то CBEPtka(I)
иначе отвергнуть
опознать4: если на Верху магазина d<S>ca то СВЕртка(з')
иначе если на верху магазина с<А>а та СВЕРтка(5)
иначе отвергнуть
опознать 5: свертка(6)
ОПОЗНАТЬ б: СВЕРТКА (4)
Рис. 12.5.
рис. 12.5, где для каждой строки, содержащей на рис. 12.4 элементы
с процедурами опознания, дается отдельная процедура.
Например, процедура ОПОЗНАТЬ2 вызывается только тогда,
когда верхним символом в магазине является (А), а сама про-
12.3. Бессуффиксные ПО-грамматики
459
цедура построена с учетом того обстоятельства, что только правая
часть правила 2 имеет символ (А) в качестве самого правого
символа. Процедура просто выясняет, присутствует, ли в верхней части
магазина правая часть правила 2, и в зависимости от результатов
проверки либо выполняет свертку, либо отвергает вход.
Процедура ОПОЗНАТБ5 вызывается только тогда, когда верхним
символом магазина является с; эта процедура просто выполняет
операцию СВЕРТКА (6), так как символ с наверху магазина образует
правую часть правила 6. Процедура ОПОЗНАТБ4 — единственная,
которой приходится выбирать между двумя правилами, правые
части которых оканчиваются символом а. Использование на рис. 12.5
условных операторов объясняется удобством описания и не
означает предпочтительности такой реализации.
Описанные методы построения применимы к классу грамматик,
которые мы назовем «бессуффиксными». Цепочка а называется
суффиксом цепочки р, если Р оканчивается цепочкой а. Заметим,
в частности, что всякая цепочка является своим собственным
суффиксом и е является суффиксом любой цепочки.
Мы называем грамматику бессуффиксной, если правая часть
любого ее правила не является суффиксом правой части
какого-либо другого правила или суффиксом цепочки SJ(S).
Мы называем бессуффиксную грамматику, не имеющую
конфликтов переноса — опознания бессуффиксной ПО-грам-
матикой.
В частности, грамматика на рис. 12.1—бессуффиксная ПО-
грамматика.
Важность понятия бессуффиксной грамматики заключается
в том, что для автомата типа «перенос — опознание» верхняя часть
магазина совпадает с правой частью не более чем одного правила
грамматики (или с цепочкой V(S>) тогда и только тогда, когда
грамматика бессуффиксная.
При разработке автомата типа «перенос — опознание» для
бессуффиксной ПО-грамматики управляющую таблицу можно
построить с помощью методов предыдущего раздела. Затем можно
построить процедуры опознания, которые:
1) выполняют операцию СВЕРТКА(р) в тех случаях, когда
на верху магазина находится правая часть правила р\
2) допускают вход тогда и только тогда, когда магазин
содержит цепочку V(S> (где (S) — начальный символ
грамматики) и текущим входным символом является концевой
маркер.
При построении управляющей таблицы типа «перенос —
опознание» всегда можно обойтись одной-единственной процедурой
опознания. Однако разработчик может предпочесть, чтобы для каждой
460 Гл. 12. Обработка методами типа теренос— опознание»
строки таблицы была отдельная процедура опознания, как на рис.
12.5. Метод, приводящий к такому построению, описан ниже.
Хотя мы называем этот метод методом «одной процедуры опознания
на стрдку», он может дать две процедуры для строки,
соответствующей начальному символу грамматики: одну для концевого
маркера и одну для остальных элементов, требующих вызова
процедуры опознания.
Для данной бессуффиксной ПО-грамматики распознаватель
типа «перенос — опознание» можно получить следующим образом.
1. Провести анализ, описанный в разд. 12.2, и определить,
какие элементы управляющей таблицы должны содержать
процедуры опознания.
2. Для каждой строки управляющей таблицы ввести имя
процедуры опознания и поместить его в каждый элемент этой строки,
требующий вызова процедуры опознания (за исключением элемента,
соответствующего концевому маркеру в строке для начального
символа; он рассматривается на шаге 3). Эта процедура опознания
рассматривает те правые части правил, которые оканчиваются
символом, соответствующим заполняемой строке таблицы, и проверяет
эти правые части на совпадение с верхней частью магазина. Если
обнаружено такое совпадение, то выполняется соответствующая
операция свертки. В противном случае процедура отвергает
входную цепочку.
3. Ввести имя процедуры опознания и поместить его в строку,
соответствующую начальному символу и в столбец для концевого
маркера. Эта процедура допускает вход, если непосредственно под
начальным символом в магазине находится маркер дна. В
противном случае процедура действует так, как указано в описании шага 2
(и, следовательно, отвергает вход, если ни одна из правых частей
не оканчивается начальным символом).
В заключение сформулируем основной результат этого раздела:
Каждую бессуффиксную ПО-грамматику можно положить
в основу распознавателя типа «перенос — опознание» для
языка, задаваемого этой грамматикой.
12.4. Грамматики слабого предшествования
Если данная грамматика без конфликтов «переноса — опознания»
не является бессуффиксной, то управляющий механизм типа
«перенос — опознание» для этой грамматики будет в некоторых
случаях выбирать процедуру опознания, когда на верху магазина
находятся несколько правых частей правил. Пусть, например, нам
дана грамматика, изображенная на рис. 12.6, и мы хотим построить
процедуру опознания, которая должна вызываться в тех случаях,
1.
2.
3.
4.
5.
6.
<£> —
<£> —
<Т>—>
<7"> —
<Я>^
<^> —
<£> + <Г>
<г>
<Т> * <Р>
<я>
«Е»
а
Начальный символ: <£>
Рис.
12.6.
12.4. Грамматики слабого предшествования 461
когда верхним символом магазина является (Г). Эта процедура
опознания должна выбирать одну из операций СВЕРТКА(1),
СВЕРТКА (2) и ОТВЕРГНУТЬ.
Правая часть правила 2 является суффиксом правой части
правила 1. Если три верхних символа магазина составляют цепочку
(Е)+{Т), то правая часть каждого из
этих правил совпадает с верхней
частью магазина. Ясно, что при этом в
одних случаях основывающим
правилом является правило 1, в других —
правило 2. Предположим, однако, что в
ситуации, когда на верху магазина
(Е)+(Т), выполняется СВЕРТКА(2).
При выполнении этой операции (Т)
выталкивается из магазина (так что
верхним символом становится +), а
затем на его место вталкивается левая
часть правила 2 — нетерминал (Е >.
В грамматике на рис. 12.6 символ + входит только в правило 1,
и за ним следует символ (Т). Поэтому все символы, которые при
обработке допустимой входной цепочки могут оказаться в
магазине непосредственно над символом +, принадлежат множеству
ПЕРВ ((Г». Просмотрев грамматику, можно вычислить
ПЕР«û={(Г>, <Р>, (, а}
Ввиду того что символ (Е) не принадлежит этому множеству, он
не может оказаться в магазине непосредственно над символом -f-
при обработке допустимой цепочки, и, значит, если в верхней части
магазина находится цепочка (Е)-{-(Т), то правило 2 не является
основывающим. Поэтому процедуру опознания нужно строить
таким образом, чтобы в этом случае она выбирала операцию СВЕРТ-
КА(1).
Для описания принципа, иллюстрируемого приведенным
примером, расширим отношение ПОД следующим образом:
Если А и х — символы некоторой заданной грамматики, мы
пишем
А ПОД х
тогда и только тогда, когда существует грамматический
символ В, такой, что цепочка А В содержится в правой
части некоторого правила грамматики, и х принадлежит
множеству ПЕРВ (В). Если х — символ грамматики, мы
пишем
V ПОД х
тогда и только тогда, когда х принадлежит множеству ПЕРВ
((S>), где (5) — начальный символ грамматики.
462 Гл. 12. Обработка методами типа «перенос — опознание»
Это определение отличается от определения в разд. 12.2 лишь тем,
что теперь допускается появление нетерминальных символов справа
от ПОД. «Принцип переноса» из разд. 12.2 теперь можно обобщить
до следующего принципа вталкивания:
Если для данной грамматики имеется распознаватель
типа «перенос — опознание» и заданы два магазинных
символа А и х, то допустимая цепочка, при обработке которой
символ х вталкивается непосредственно над А, существует
тогда и только тогда, когда
А ПОД х
Как было показано при обсуждении приведенного выше
примера, при выборе одной из двух правых частей в качестве основы
предпочтение может быть отдано более длинной правой части, если
с помощью отношения ПОД удается установить, что более короткая
правая часть не может быть основой. Общий принцип можно
сформулировать следующим образом:
Если данная грамматика содержит два правила вида
(Л)-их у у
где а и у — цепочки, ay — символ грамматики, и если
отношение у ПОД (В) не имеет места, то второе правило
не может быть основывающим, если на верху магазина
находится правая часть первого правила. Таким образом,
процедуры опознания для автомата типа «перенос —
опознание», основанного на данной грамматике, можно построить
так, что, если на верху магазина находятся обе правые части,
операция свертки, соответствующая второму правилу,
выполняться не будет.
Грамматики без конфликтов переноса — опознания, для
которых проблемы опознания, возникающие из-за нарушения свойства
бессуффиксности, можно разрешить при помощи описанного
принципа построения, известны под названием «грамматик слабого
предшествования». Точнее,
Грамматика называется грамматикой слабого
предшествования тогда и только тогда, когда справедливы четыре
следующих условия:
1. В грамматике нет конфликтов переноса — опознания.
2. Правые части любых двух правил не совпадают.
3. Для любых двух правил вида
{А )-^ауу
(ВУ>у
12.4. Грамматики слабого предшествования
463
где а и у — цепочки, а у — символ, отношение
у ПОД (В)
не имеет места.
4. Неверно, что (S)=s>+(S), где (S) — начальный символ.
(Это условие введено для того, чтобы исключить особый вид
грамматической неоднозначности, который не всегда
исключается остальными условиями. В разд. 12.1 мы сказали,
что все грамматики, рассматриваемые в этой главе,
предполагаются однозначными. Включая в определение
грамматик слабого предшествования условие 4, мы тем самым
гарантируем, что любая грамматика, удовлетворяющая этому
определению, однозначна.)
По данной грамматике слабого предшествования можно построить
автомат типа «перенос — опознание» примерно так же, как по
бессуффиксной ПО-грамматике. Отличие состоит в том, что
процедуры опознания должны выполнять операцию свертки,
соответствующую самой длинной из правых частей, находящихся в верхней
части магазина. Процедуры опознания могут сначала делать
проверку совпадения с верхней частью магазина для более длинной
правой части, так что можно написать:
если наверху магазина (Е)+(Т) то СВЕРТКА(1)
иначе если наверху магазина <Т> то СВЕРТКА (2)
но было бы неправильно писать:
если наверху магазина (Т> то СВЕРТКА (2)
иначе если наверху магазина (Е)+(Т) то СВЕРТКА (1).
Вернемся к нашему примеру. На рис. 12.7 изображены
множества ПЕРВ и СЛЕД для всех нетерминалов грамматики,
приведенной на рис. 12.6.
Отношение ПОД для этой
грамматики показано в виде ПЕРВ (<£» = {(, а, <£>, (Ту, <Я>}
матрицы на рис. 12.8. Как ПЕрв {<г>) = {( а> <г>> <я>}
было показано выше, отно- 1
шение +ПОД<£> не вы- ПЕРВ «Я» = {(, а, <Р>}
полняется, поэтому кон- СЛЕД (<£» = {+,), 4}
фликт суффиксов между СЛЕД «Г» = {+,*,), —|}
правилами 1 и 2 можно СЛЕД «Я» = {+,*,),-|}
разрешить в пользу более
длинного правила. Точно ис'
так же не имеет места отно-
шение*ПОД(Т>, и, значит,
конфликт суффиксов между правилами 3 и 4 разрешается в пользу
более длинного правила. Так как других конфликтов суффиксов,
а также конфликтов переноса — опознания в грамматике нет, то
( ) <f> <Т> <P>
)
<e>
<r>
<p>
v
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
X ПОД Y
Рис. 12.8.
(
)
<£> \ ПЕРЕНОС
<T> ОПОЗНАТЬ 2
<P> ОПОЗНАТЬ 3
+ ОТВЕРГНУТЬ
" [ОТВЕРГНУТЬ
a !ОПОЗНАТЬ 4
( ОТВЕРГНУТЬ
) ОПОЗНАТЬ 5
V. ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ПЕРЕНОС
ОПОЗНАТЬ 3
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОПОЗНАТЬ 4
ОТВЕРГНУТЬ
ОПОЗНАТЬ 5
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ ОТВЕРГНУТЬ
ОТВЕРГНУТЬ ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ОТВЕРГНУТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ПЕРЕНОС
ПЕРЕНОС
ОТВЕРГНУТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ПЕРЕНОС
ПЕРЕНОС
ОПОЗНАТЬ 2
ОПОЗНАТЬ 3
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОПОЗНАТЬ 4
ОТВЕРГНУТЬ
ОПОЗНАТЬ 5
ОТВЕРГНУТЬ
ОПОЗНАТЬ 1
ОПОЗНАТЬ 2
ОПОЗНАТЬ 3
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОПОЗНАТЬ 4
ОТВЕРГНУТЬ
ОПОЗНАТЬ 5
ОТВЕРГНУТЬ
Начальное содержимое магазина: V
ОПОЗНАТЬ 1: если на верху магазина 7<ЕУ то ДОПУСТИТЬ иначе ОТВЕРГНУТЬ
опознать 2: если на верху магазина <еу+<т> то СВЕРТКА (1)
иначе СВЕРТКА(2)
опознать 3: если наверху магазина <Т>*<Р> то свертм(З)
иначе СВЕРТКА (4)
опознать 4: свертка(6)
опознать 5: если на берху магазина (<£> то свертка (5)
иначе отвергнуть
ПЕРЕНОС; втолкнуть {/пекущий входной ствол), сдвиг
Рис. 12.9.
12.5. Простые грамматики смешанной стратегии предшествования 465
она является грамматикой слабого предшествования. На рис. 12.9
изображен автомат типа «перенос — опознание» для данной
грамматики. Автомат построен методом «одной процедуры опознания
на строку», который был описан в предыдущем разделе. Отметим,
что процедуры ОПОЗНАТЬ2 и ОПОЗНАТЬЗ сначала выполняют
проверку для более длинных правых частей.
Итак, методы построения для бессуффиксных ПО-грамматик
обобщаются на случай грамматик слабого предшествования,
поэтому мы заключаем раздел так:
Каждую грамматику слабого предшествования можно
использовать в качестве основы распознавателя типа
«перенос — опознание» для языка, задаваемого этой грамматикой.
12.5. Простые грамматики смешанной
стратегии предшествования
Если данная грамматика удовлетворяет всем условиям в
определении грамматики слабого предшествования, кроме условия 2 (т. е.
содержит несколько правил с одинаковыми правыми частями),
то в некоторых случаях все же можно построить для этой
грамматики автомат типа «перенос —
опознание». В этом разделе мы познакомимся
со стратегией, позволяющей автомату
рассматривать символ магазина,
расположенный под правой частью, общей
для нескольких правил. Пусть,
например, нам дана грамматика, как на рис.
12.10. Множества ПЕРВ и СЛЕД для
символов этой грамматики показаны на
рис. 12.11. Отношение ПОД изображено
на рис. 12.12, а на рис. 12.13 показана
управляющая таблица, построенная
согласно этим отношениям. Конфликты
переноса — опознания отсутствуют. Эта
грамматика не является грамматикой
слабого предшествования, так как
правила 1 и 7 имеют одну и ту же правую
часть {В )v, а правила 3 и 5 одну и ту же
правую часть и. Чтобы построить
процедуры опознания для этой грамматики,
нужны какие-то средства для определения основывающего правила
в тех случаях, когда в верхней части магазина находится (B)v
или и.
Сначала рассмотрим ситуацию, в которой на верху магазина
находится (B)v, а управляющий механизм вызывает процедуру
1.
2.
3.
4.
5.
6.
7.
8.
<s>-
<s> -
(Л)-
{А)-
{В)-
{В)-
<с>-
(Q-
Начальный
Рис.
(B)v
v<C>
и
v (В) (S)
и
■yw
■(B)v
■у {A) w
символ: (S)
12.10.
466 Гл. 12. Обработка методами типа «перенос — опознание»
ПЕРВ «.V» = {<5>,<В>,и,
ПЕРВ «.4» = {</4>.и. v}
ПЕРВ ((B)) = {(В), и, у}
ПЕРВ «С» - {<«>, <С>, 1/,
ПЕРВ (и) = {м}
ЛЕРВ(г) ---■ [v]
ПЕРВ (и) = {и-}
ПЕРВ(>) - {.)•}
v.v)
У)
Рис. 12.11.
СЛЕД «5» = {w,-\}
СЛЕД «Л» = {*•}
СЛЕД «Л)) = {и. v.j/}
СЛЕД«С>) = {нч-]}
СЛЕД (и) = [и. v, и-.j/}
СЛЕД (у) = {и. и\>>,-{)
СЛЕД (и-) -= {н, v, vv.j/, —|
СЛЕД О) = {(/: v, iv}
<S> <4> <S> <С>
<s>
<А>
<В>
<С>
и
У
1
1
1
1
1
1
1 1
1
1
1
1
1
1
1
1
1
1
у под у
Рис. 12.12.
<s>
ОТВЕРГНУТЬ
<А > рТВЕРГНУТЬ
<В> | ПЕРЕНОС
<С> IОТВЕРГНУТЬ
и ОПОЗНАТЬ
v ! ПЕРЕНОС
VV
У
V
ОПОЗНАТЬ
ПЕРЕНОС
ПЕРЕНОС
ОТВЕРГНУТЬ
ОТВЕРЗНУТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ПЕРЕНОС
ПЕРЕНОС
ОПОЗНАТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОПОЗНАТЬ
ОПОЗНАТЬ
ОПОЗНАТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ПЕРЕНОС
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ПЕРЕНОС
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
Рис. 12.13.
12.5. Простые грамматики смешанной стратегии предшествования 467
опознания. Процедура опознания должна выбрать операцию
СВЕРТКА (1), если основывающим является правило 1, или операцию
СВЕРТКА (7), если основывающим является правило 7. Сейчас
мы покажем, каким образом процедура опознания может сделать
такой выбор, используя символ, находящийся в магазине под {B)v.
В частности, покажем, что правило 1 может быть основывающим
только тогда, когда под (B)v в магазине находится (В) или V.
а правило 7 — только тогда, когда под (B)v находится v. Поэтому
процедура опознания, способная определить символ под правой
частью (В )v, может сделать удовлетворительный выбор между
операциями СВЕРТКА (1) и СВЕРТКА (7).
Чтобы показать, что правило 1 может быть основывающим
только тогда, когда под (B)v в магазине находится (В) или V»
рассмотрим действие операции СВЕРТКА (1). Это действие состоит
в замене {B)v левой частью (5), после чего (S) оказывается в
магазине над тем символом, который раньше находился под (B)v.
Согласно принципу вталкивания, при обработке допустимой
входной цепочки под символом (5) в магазине могут появиться только
такие магазинные символы X, для которых X ПОД (5). Все такие
символы приведены на рис. 12.12, это (В) и V- Чтобы показать,
что правило 7 может быть основывающим только тогда, когда под
(B)v находится символ v, заметим, что действие операции
СВЕРТКА (7) состоит в замене (B)v на (О и что v — единственный
магазинный символ X, для которого X ПОД (О.
Теперь рассмотрим тот случай, когда на верху магазина
находится и и выбирается процедура опознания. Левыми частями
правил 3 и 5 являются соответственно символы (А ) и (В). На рис. 12.12
видно, что при обработке допустимой входной цепочки под этими
нетерминалами в магазине могут оказаться следующие символы:
у ПОД <Л>
<Б> ПОД <В>
v ПОД <В>
V ПОД <Б>
Поэтому, если поды находится у, то основывающим правилом может
быть только правило 3, а если под и находится (В), v или V. то
основывающим может быть только правило 5.
Автомат типа «перенос — опознание» для этого примера показан
на рис. 12.14. Обратите внимание на то, как в процедурах
ОПОЗНАТЬ и ОПОЗНАТЬб символ, расположенный в магазине под
правой частью правила, участвует в проверках.
В этом примере мы использовали рассуждения, основанные
на «принципе вталкивания», сформулированном в предыдущем
разделе. Этот принцип гласит, что для любого магазинного
символа А и нетерминала (В) допустимая входная цепочка, при ана-
468 Гл. 12. Обработка методами типа «.перенос — опознание»
лизе которой (В) оказывается в магазине над А, существует тогда
и только тогда, когда
А ПОД (В)
w
<s>
<А>
<В>
<С>
и
V
w
У
V
ПЕРЕНОС
опознать-*
ПЕРЕНОС
ОПОЗНАТЬ6
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
0П03НАТЬ4
ОПОЗНАТЬ 6
ПЕРЕНОС
ПЕРЕНОС
ОПОЗНАТЫ
ПЕРЕНОС
ОПОЗНАТЬЗ
ОПОЗНАТЬ 4
ОПОЗНАТЬ5
ОПОЗНАТЬ 6
ПЕРЕНОС
ПЕРЕНОС
ОПОЗНАТЬ 4
ПЕРЕНОС
ОПОЗНАТЬ 6
ПЕРЕНОС
ОПОЗНАТЬ Z
ОПОЗНАТЬЗ
ОПОЗНАТЬ 5
ОПОЗНАТЬ 6
Начальное содержимое магазина: 7
ОПОЗНАТЫ: если на верху магазина tr<BXS> то свертка (4>
иначе отвергнуть
опознать 2: если на верху магазина V<S> то допустить
иначе опознать 1
опознатьз: если на Верху магазина и<с> то свертки (г)
иначе отвергнуть
опознать4: если наверху магазина уи, то сВЕРтка(3)
иначе, если на верху маеазна<В>и или ии
или Vu то СВЕРТКА (5) иначе ОТВЕРГНУТЬ
опознать 5: если на верху магазина <вхв>а или v<b>v
то свертка (/) иначе если на верху магазина
и*-в>0 то свертка(7) иначе отвергать
опознать 6: если на верху магазина уи/, то сВЕРТКАСв)
иначе.если на верху магазина у<ь>иг то
свертка (8) иначе отвергнуть
перенос: втолкнуть {текущий входной символ), сдвиг
Рис. 12.14.
Следовательно, если автомат достигает конфигурации, в которой
на верху магазина находится цепочка Лр\ а в грамматике есть
правило
(В)^р
то это правило не может быть основывающим, если А не
удовлетворяет отношению
А ПОД (В)
12.5. Простые грамматики смешанной стратегии предшествования 46£
Общий принцип построения можно сформулировать следующим
образом:
Если данная грамматика содержит два правила вида
и если для данного магазинного символа А выполняется
отношение
А ПОД (В)
и не выполняется
А ПОД (С)
то второе из этих правил не может быть основывающим, если
на верху магазина находится Ар. Следовательно, процедуры
опознания для автомата типа «перенос — опознание»,
основанного на данной грамматике, можно построить так, что
операция свертки, соответствующая второму правилу, не
будет выполняться, если на верху магазина находится
цепочка Ар.
Грамматики без конфликтов переноса — опознания, для
которых все проблемы опознания можно разрешить методами этого и
предыдущего раздела, известны под названием простые грамматики
смешанной стратегии предшествования. Более точно, грамматика
называется простой грамматикой смешанной стратегии
предшествования (простой ССП-грамматикой) тогда и только тогда, когда
выполняются четыре следующих условия:
1. В грамматике нет конфликтов переноса — опознания.
2. Для любых двух правил с одной и той же правой частью:
С4)->а
не существует такого символа X, что одновременно X ПОД (А }
и X ПОД (В)
3. Для любых двух правил вида
(А >->-ш/7
(В)^у
где а и у — цепочки, а у — символ грамматики, отношение
У ПОД (В) не имеет места.
4. Неверно, что (S)=>+(S>, где (S) — начальный символ.
Условия 1, 3 и 4 — те же, что и для грамматик слабого
предшествования; условие 2 новое, оно должно выполняться для правил с
одинаковыми правыми частями.
470 Гл. 12. Обработка методами типа «перенос— опознание»
Для данной простой грамматики смешанной стратегии
предшествования автомат типа «перенос — опознание» строится так же,
как для грамматики слабого предшествования, только в тех случаях,
когда имеется несколько правил с одной и той же правой частью,
процедуры опознания должны исследовать символ, расположенный
в магазине непосредственно под этой правой частью, и выбирать
соответствующие операции свертки. Таким образом,
каждая простая грамматика смешанной стратегии
предшествования может быть положена в основу распознавателя типа
«перенос — опознание» для языка, задаваемого этой
грамматикой.
Важнейшим свойством простых ССП-грамматик является то,
что они характеризуют класс языков, которые можно распознавать
автоматом с магазинной памятью. (Под автоматом с магазинной
памятью мы здесь имеем в виду как примитивный автомат,
введенный в гл. 5, так и все «расширенные» автоматы, обсуждаемые в
других главах.)
Язык можно распознать автоматом с магазинной памятью
тогда и только тогда, когда он порождается некоторой
простой грамматикой смешанной стратегии предшествования.
Один из способов доказать это утверждение состоит в том, чтобы
обеспечить процедуры для:
1) построения по данной простой ССП-грамматике автомата типа
«перенос — опознание», распознающего порождаемый этой
грамматикой язык;
2) построения по данному МП-автомату простой ССП-грамма-
тики, порождающей язык, который распознается этим автоматом.
Первая из этих процедур была указана в этом разделе. Вторая
процедура приведена в работе Ахо, Деннинга и Ульмана [1972]
и в книге Ахо и Ульмана [1973а]; здесь мы эту процедуру не
рассматриваем, так как при построении компиляторов она не нужна.
Из приведенного выше утверждения не следует, что
грамматика, используемая при построении МП-автомата, обязательно
должна быть простой ССП-грамматикой. Утверждается лишь, что
если для данного языка существует распознающий его МП-
автомат, то этот язык порождается некоторой простой
ССП-грамматикой. Это утверждение можно расширить и на переводы.
Перевод может быть выполнен автоматом с магазинной
памятью тогда и только тогда, когда этот перевод можно
задать грамматикой польского перевода, входная грамматика
которой является простой грамматикой смешанной стратегии
предшествования.
12.6. Вычисление отношений ПОД и СВЕРТЫВАЕТСЯ-ПО 471
Методы этой главы и гл. 11 дают метод построения автомата по
данной грамматике. Доказательство обратного утверждения мы
опускаем.
S-атрибутные переводы, введенные в гл. 11, не характеризуют
класс атрибутных переводов, которые могут выполнять
МП-автоматы, расширенные так, как показано в гл. 9 и 11. Класс,
характеризующий атрибутные переводы, приводится в работе Льюиса,
Розенкранца и Стирнза [19741. Однако на практике S-атрибутные
переводы, входные грамматики которых являются грамматиками
слабого предшествования или простыми ССП-грамматиками, почти
всегда адекватны реальным задачам проектирования.
12.6. Вычисление отношений ПОД
и СВЕРТЫВАЕТСЯ-ПО
Цель этого раздела — построить процедуру вычисления отношений
ПОД и СВЕРТЫВАЕТСЯ-ПО. Этой процедурой можно
пользоваться для выявления конфликтов переноса — опознания, для
построения управляющего механизма, для проверки принадлеж-
1. Построить стношение НАЧИНАЕТСЯ-ПРЯМО-С.
2. Построить отношение ПРЯМО-НА-КОНЦЕ.
3. Построить отношение ПРЯМО-ПЕРЕД.
4. Вычислить отношение ^., определяемое как
ПРЯМО-ПЕРЕД НАЧИНАЕТСЯ-ПРЯМО-С*
5. Вычислить отношение • > , определяемое как
ПРЯМО-НА-КОНЦЕ+ •«£•
6. Расширить «s- до отношения ПОД, добавив все пары (V. -Ю,
такие, что
<S> НАЧИНАЕТСЯ-ПРЯМО-С* Л
где <S>—начальный символ.
7. Расширить •> до отношения СВЕРТЫВАЕТСЯ-ПО, добавив
все пары (Л, —1)> такие, что
X ПРЯМО-НА-КОНЦЕ* <S>
где <S> —начальный символ.
Рис. 12.15. Процедура вычисления отношении ПОД и СВЕРТЫВАЕТСЯ-ПО.
ности грамматики к классу грамматик слабого предшествования и к
классу простых ССП-грамматик, а также для построения процедур
опознания по простым ССП-грамматикам. Общая схема процедуры
вычисления ПОД и СВЕРТЫВАЕТСЯ-ПО изображена на рис. 12". 15.
Процедура использует три примитивных отношения, которые
вычисляются непосредственно по грамматике (шаги 1, 2 и 3), и
операции над отношениями, описанные в приложении Б.
472 Гл. 12. Обработка методами типа «.перенос-опознание»
Шаг 1 состоит в построении отношения НАЧИНАЕТСЯ-ПРЯМО-
С, описанного в разд. 8.7. Если в данной грамматике нете-правил, то
для символов А и В мы пишем
А НАЧИНАЕТСЯ-ПРЯМО-С В
тогда и только тогда, когда грамматика содержит правило
вида
A^Bf>
где Р — произвольная цепочка.
Отношение НАЧИНАЕТСЯ-ПРЯМО-С для грамматики рис. 12.16
показано на рис. 12.17, а.
Оно получается по грамматике путем перебора всех правил и
заполнения соответствующих элементов матрицы. Например, левая
часть правила 1 — это символ {S >, а
правая часть этого правила начинается
1 <S>—>-<л>г с №)> поэтому элемент строки (S) и
о' •$>—* столбца {А > помечается единицей. Стро-
> >-уг ки матрицы, соответствующие терми-
3- *-А> '•<B><B><S> нальным символам, не могут содержать
4. <<4>—*d единиц, так как терминал не может
5. <б>—>(д<Л> быть левой частью правила, но для пол-
6 (В) е*</4> ноты эти строки на рисунке показаны.
„„„„,„. , „„ ~. Шаг 2 процедуры состоит в по-
НаЧЭЛЬНЫИ СИМВОЛ: <S> r г-тпчлттл lrr^n
строении отношения ПРЯМО-НА-КОН-
Рис. 12.16. це, описанного в разд. 8.7. Если
в данной грамматике нет е-правил,
то
для символов грамматики А и В мы пишем
А ПРЯМО-НА-КОНЦЕ В
тогда и только тогда, когда грамматика содержит правило
вида
В^аА
где а — произвольная цепочка.
Отношение ПРЯМО-НА-КОНЦЕ для рассматриваемой грамматики
показано на рис. 12.17, б. Оно получается по грамматике путем
перебора всех правил и заполнения соответствующих элементов
матрицы. Например, левая часть правила 1 — это символ (S),
а правая часть оканчивается символом г. Поэтому элемент строки z
и столбца (S) помечается единицей. Столбцы матрицы,
соответствующие терминальным символам, не могут содержать
помеченных элементов, но для полноты они также показаны на рисунке.
<S> <A> <8>
<S> <A> <B>
НАЧИНАЕТСЯ-ПРЯМО
a
<S> <A> <B>
ПРЯМО-ПЕРЕД
в
>
д
<s>
<А>
<В>
d
1
1
1
1
ПРЯМО-НА-КОНЦЕ
6
<S> <A> <B> d х
1 1
<S>
<А>
<В>
d
1 1 1
1 1
1 1 1
1 1 1
1 ч
1
1
г
<S><A>
1 1
1 1
1 1
1 1
<В>
1
1
1
1
d
1
1
1
1
X
1
1
1
1
У
1
1
1
1
г
1
1
1
<S> <A> <В>
<S>
<А>
<В>
d
х
У
1 1 1
1 1
1 1 1
1
1
I1
1
1
1
1
1
1
1
1
1
под
е
<s>
<А>
<В>
d
X
У
г
<s>
1
1
1
1
<А><В>
1 1
1 1
1 1
1 1
d
1
1
1
1
X
1
1
1
1
У
1
1
1
1
г
1
1
1
-1
1
1
СВЕРТЫВАЕТСЯ-ПО
Ж
Рис. 12.17.
474 Гл. 12. Обработка методами типа «перенос—опознание»
Шаг 3 описываемой процедуры состоит в построении отношения
ПРЯМО-ПЕРЕД, описанного в разд. 8.7. Если в данной грамматике
нет е-правил, то
для ее символов А и В мы пишем:
А ПРЯМО-ПЕРЕД В
тогда и только тогда, когда грамматика содержит правило
вида
D-yaABy
где а и у — произвольные цепочки.
Отношение ПРЯМО-ПЕРЕД для грамматик без е-правил
исторически получило обозначение _l, которое иногда читают как «равно
по предшествованию», хотя оно и не является отношением
эквивалентности. На рис. 12.17, в показано это отношение для
рассматриваемой грамматики. Оно получается по грамматике путем
перебора всех правых частей правил и заполнения элементов матрицы,
соответствующих парам соседних символов. Так, посмотрев на
правую часть правила 1, получаем
(А) ПРЯМО-ПЕРЕД г
Правило 3 дает
(В) ПРЯМО-ПЕРЕД {В)
и
(В) ПРЯМО-ПЕРЕД (S)
Шаг 4 нашей процедуры состоит в вычислении отношения ^.
определяемого как произведение отношений:
ПРЯМО-ПЕРЕД- НАЧИНАЕТСЯ-ПРЯМО-С *
Мы используем обозначение ^-, так как это отношение является
объединением отношения J_ и еще одного отношения, обычно
обозначаемого <• и определяемого как
ПРЯМО-ПЕРЕД- НАЧИНАЕТСЯ-ПРЯМО-С +
(обратите внимание на + вместо *). Знак <• иногда читают как
«меньше по предшествованию», хотя обозначаемое им отношение
и не является транзитивным, как арифметическое отношение
«меньше». Чтобы вычислить :£С- нужно взять рефлексивно-транзитивное
замыкание отношения НАЧИНАЕТСЯ-ПРЯМО-С, а затем
вычислить указанное выше произведение. Для рассматриваемой
грамматики результат показан на рис. 12.17, г. Заметим, что
рефлексивно-транзитивное замыкание отношения НАЧИНАЕТСЯ-
ПРЯМО-С описывает множества ПЕРВ; т. е. символ В принадлежит
ПЕРВ(С) тогда и только тогда, когда
С НАЧИНАЕТСЯ-ПРЯМО-С * В
12.6. Вычисление отношений ПОД и СВЕРТЫВАЕТСЯ-ПО 475
Таким образом, указанное выше произведение связывает каждый
грамматический символ А с символами множества ПЕРВ(С) для
каждого С, непосредственно следующего за Л в правой части
правила. Другими словами, ^- — это отношение ПОД, без маркера
дна.
Шаг 5 процедуры состоит в вычислении отношения •> как
произведения
ПРЯМО-НА-КОНЦЕ +•<•
Отношение •> называют «больше по предшествованию», хотя в
отличие от арифметического отношения «больше» оно не транзи-
тивно. Результат указанного вычисления для рассматриваемой
грамматики показан на рис. 12.17, д. Заметим, что отношение •>
можно выразить как
ПРЯМО-НА-КОНЦЕ- (ПРЯМО-НА-КОНЦЕ *•<■)
Отношение, заключенное в скобки, описывает множества СЛЕД
без концевого маркера, т. е. символ грамматики В принадлежит
СЛЕД (С) тогда и только тогда, когда
С (ПРЯМО-НА-КОНЦЕ *•<•)#
Таким образом, отношение •> связывает каждый символ
грамматики А с символами множества СЛЕД (С) для каждого
нетерминала С, который является левой частью правила, оканчивающегося
символом А. Поэтому для любого символа грамматики А и
терминала х А СВЕРТЫВАЕТСЯ-ПО х тогда и только тогда, когда А •>*.
Теперь можно сравнить отношения ^- и •> чтобы посмотреть,
нет ли конфликтов переноса — опознания. Доопределение этих
отношений до отношений ПОД и СВЕРТЫВАЕТСЯ-ПО путем
включения маркера дна и концевого маркера не влияет на резуль-
. таты этой проверки.
Шаг 6 состоит в расширении ^- до ПОД путем отыскания таких
X, что
(5) НАЧИНАЕТСЯ-ПРЯМО-С * X
(где (S) — начальный символ) и заполнения единицами элементов,
соответствующих таким X в добавленной к матрице строке для
маркера дна. Если в процессе вычисления на шаге 4 была получена
. матрица для отношения НАЧИНАЕТСЯ-ПРЯМО-С *, то строку
(S) этой матрицы можно добавить к матрице для ^- в качестве
строки маркера дна. Для нашего примера результат показан на
рис. 12.17, е. Столбцы, представляющие нетерминалы, не
используются при построении управляющей таблицы, но применяются
, при проверке грамматики на слабое предшествование и при
построений процедур опознания для простых ССП-грамматик.
476 Гл. 12. Обработка методами типа «перенос — опознание»
Шаг 7 состоит в расширении ->до отношения СВЕРТЫВАЕТ-
СЯ-ПО путем отыскания таких X, что
А" ПРЯМО-НА-КОНЦЕ * (5)
(где, (S) — начальный символ) и заполнения единицами элементов,
соответствующих этим X, в добавленном к матрице столбце для
концевого маркера. Для нашего примера результат показан на
рис. 12.17, ж. При этом столбцы для нетерминалов не включаются
в матрицу отношения СВЕРТЫВАЕТСЯ-ПО, так как второй
компонентой пары, входящей в это отношение, является по
предположению входной символ. Шаг 7 завершает процедуру.
12.7. Обработка ошибок при разборе типа
«перенос — опознание»
Компиляторам часто приходится иметь дело с входными цепочками;
не принадлежащими распознаваемому языку. Мы будем называть
такие цепочки неправильными.
При обработке неправильной цепочки компилятор должен
обнаружить, что произошла ошибка, т. е. что входная цепочка
неправильная. Более того, предполагается, что компилятор выдает
ряд сообщений об ошибках; указывающих, какие именно ошибки
мог допустить программист.
Число и содержание сообщений об ошибках, выдаваемых для
данного неправильного предложения, обычно определяются
субъективно, и решения, принятые по этому вопросу, нередко являются
спорными. На практике различные компиляторы для одного и
того же языка программирования часто выдают различные
сообщения об ошибках для одной и той же неправильной программы.
Распознаватель с магазинной памятью обнаруживает, что
входная цепочка неправильная, когда он в первый раз приходит к
конфигурации, в которой данный вход должен быть отвергнут. В этот
момент от компилятора требуется сообщение об ошибке, которую
мог допустить программист. Более того, компилятор должен
каким-то образом модифицировать конфигурацию МП-автомата так,
чтобы можно было продолжить обработку входной цепочки и в
случае необходимости выдать дополнительные сообщения об
ошибках. Такой процесс изменения конфигураций называется
нейтрализацией ошибок.
Существуют два типа ситуаций, в которых автомат типа
«перенос — опознание» отвергает вход: а) при обращении к элементу
управляющей таблицы, содержащему операцию ОТВЕРГНУТЬ,
или б) при вызове процедуры опознания, которая выбирает эту
операцию. Для ситуаций первого типа сообщение об ошибке обычно
основывается на верхнем символе магазина и текущем входном
12.7. Обработка ошибок при раэборе типа «.перенос — опознание» 477
символе. Ключевое замечание относительно элементов управляющей
таблицы, содержащих ОТВЕРГНУТЬ, состоит в том, что обращение
к ним происходит в таких ситуациях, когда в правом выводе не
существует промежуточной цепочки, в которой текущий входной
символ следует за символом грамматики, представленным верхним
символом магазина. Поэтому подходящим форматом для сообщения
об ошибке является
СЛЕДУЕТ ЗА
на месте первого прочерка указывается имя входного символа, а
на месте второго — имя верхнего символа магазина (в форме,
понятной для пользователя).
Для тех ситуаций, когда операция ОТВЕРГНУТЬ выбирается
процедурой опознания, формат сообщения об ошибке не очевиден.
Ключевым фактом здесь является то, что эта ситуация встречается,
когда верхний символ магазина и текущий входной символ
указывают, что на верху магазина должна быть основа, однако эта основа
не обнаружена. Для бессуффиксной ПО-грамматики и для
грамматики слабого предшествования это означает, что на верху магазина
нет правой части правила. Для простой грамматики смешанной
стратегии предшествования это означает, что либо никакой правой
части на верху магазина нет, либо такая правая часть имеется, но
символ, находящийся под ней в магазине, не связан отношением
ПОД ни с одним из соответствующих ей нетерминалов, образующих
левые части правил
Один из подходов к составлению сообщения об ошибке
заключается в том, чтобы исследовать магазин и определить самую
короткую цепочку его верхних символов, которая не является
суффиксом правой части какого-либо правила и не состоит из правой
части некоторого правила и предшествующего ей символа,
находящегося в отношении ПОД с левой частью этого правила.
Сообщение об ошибке в этом случае может иметь форму утверждения о
том, что такая цепочка и следующий за ней такущий входной
символ образуют недопустимую комбинацию.
Пусть, например, грамматика содержит правило
(S >^IF(B>THEN (SI >ELSE (SI )
Предположим также, что за операторами такого типа всегда должна
следовать точка с запятой и что указанное правило —
единственное, оканчивающееся символами
ELSE (SI)
Пусть теперь в некоторый момент обработки неправильной входной
цепочки верхняя часть магазина выглядит так:
IF(S>THEN(S1 )ELSE(S1 >ELSE(S1)
478 Гл. 12. Обработка методами типа «перенос — опознание»
а текущим входным символом является точка с запятой. В этой
ситуации управляющий механизм выберет процедуру опознания.
Процедура опознания выяснит, что наверху магазина основы нет
и что четыре верхних символа магазина
ELSE(S1)ELSE<51>
образуют наименьшую цепочку, которая не является суффиксом
правой части какого-либо правила. Процессор может теперь
вставить эти четыре символа и текущий входной символ в стандартное
сообщение об ошибке:
КОНСТРУКЦИЯ НЕДОПУСТИМА
В результате получится
КОНСТРУКЦИЯ ELSE ОПЕРАТОР ELSE ОПЕРАТОР;
НЕДОПУСТИМА
Если считается, что эта ошибка очень распространена, то
обнаружение конструкции можно рассматривать как особый случай и
сообщение об ошибке сделать более специальным:
ДВА ПОСЛЕДОВАТЕЛЬНЫХ ELSE-ПРЕДЛОЖЕНИЯ
В качестве более полного примера рассмотрим следующую
грамматику с начальным символом <S> (она использовалась в
примере обработки ошибок в разд. 8.8.У
1. (S)^a
2. (S)^((S)(R)
3. (R)^,(S)(R)
4. (R)-+)
Эта грамматика порождает цепочки, подобные выражениям Лиспа,
например:
а
(а, (а, а))
((а, (а, а), (а, а)), а)
Грамматика является бессуффиксной ПО-грамматикой. На рис.
12.18 изображен соответствующий автомат типа «перенос —
опознание», причем все ситуации, в которых выбирается операция
ОТВЕРГНУТЬ, помечены различными буквами. Ситуации,
помеченные буквами от а до q, соответствуют элементам управляющей
таблицы, содержащим ОТВЕРГНУТЬ, а ситуации г и s
соответствуют процедурам опознания, выбирающим эту операцию.
На рис. 12.19 показан подходящий набор сообщений об ошибках.
В ситуациях е, f, h, i, /', k, m и п магазинный и входной символы —
терминалы, и сообщения имеют предложенный ранее формат. Этот
12.7. Обработка ошибок при разборе типа «перенос— опознание» 479
формат только слегка изменен для конфигураций g и /, где входным
символом является концевой маркер, и для конфигураций о и р,
где магазинный символ — это маркер дна.
<s>
<R>
( '
)
ОТВЕРГНУТЬ
а
ОТВЕРГНУТЬ
с
ПЕРЕНОС
отвергнуть
h
ПЕРЕНОС
ОТВЕРГНУТЬ
m
ПЕРЕНОС
отвергнуть
ь
ОТВЕРГНУТЬ
d
ПЕРЕНОС
ОПОЗНАТЬ 2
ПЕРЕНОС 1 ОТВЕРГНУТЬ
! е
ОТВЕРГНУТЬ i ОПОЗНАТЬ 3
i I
пеРЕнос
ОТВЕРГНУТЬ
п.
ПЕРЕНОС
ОТВЕРГНУТЬ
i
ОПОЗНАТЬ 4
ОТВЕРГНУТЬ
0
ПЕРЕНОС
ОПОЗНАТЬ 2
ОТВЕРГНУТЬ
f
ОПОЗНАТЬ 3
ОТВЕРГНУТЬ
к
ОПОЗНАТЬ 4
ОТВЕРГНУТЬ
Р
ОПОЗНАТЬ 1
ОПОЗНАТЬ2
ОТВЕРГНУТЬ
9
ОПОЗНАТЬ 3
ОТВЕРГНУТЬ
С
0П03НАТЬ4
ОТВЕРГНУТЬ
q
ОПОЗНАТЬ 1: если на верху магазина 7<S> то ДОПУСТИТЬ
иначе отвергнуть Г
опознать 2: если на верку магазине (<s><R>mo СВЕРТКА(2),
иначе если наверху магазина, <$><r>
то свертка (3)
иначе ОТВЕРГНУТЬ ^
ОПОЗНАТЬ 3: СВЕРТКА (4)
ОПОЗНАТЬ*»*. СВЕРТКА (1)
свертка(П: вытолк, emnK(<s»
СВЕРТКА (2): ВЫТОЛК, 8ЫТ0ЛК, ВЫТОЛК, ВТОЛК(<$>)
сверткасз): вытолк, вытолк, вытолк,втолкиr>)
сверткам): вытолк, втолк (<"/?>)
Рис. 12.18.
Конфигурация q, соответствующая случаю пустой входной цепочки,
требует специального сообщения.
Для ситуаций а, Ь, с и d сообщения об ошибках не задаются,
так как обращения к соответствующим элементам таблицы
невозможны даже при анализе неправильных цепочек. Рассмотрим,
480 Гл. 12. Обработка методами типа теренос — опознание»
например, ситуацию а, когда на верху магазина находится (S).
а текущий входной символ — а. Так как (S > — нетерминал, он не
может попасть в магазин в результате операции ПЕРЕНОС. Его
вталкивание в магазин может произойти только при выполнении
операций СВЕРТКА (1) или СВЕРТКА (2), которые обе выбираются
только в процедурах опознания. Ввиду того, что столбец а управ-
а, Ь, с, d: He требуется (см. текст)
е, /, Л, I, j, k, m, n: «(входной символ)
ПОСЛЕ (магазинный символ)»
g, I: «S-ВЫРАЖЕНИЕ НЕ ОКОНЧЕНО»
О, р: «(входной символ) В НАЧАЛЕ
S-ВЫРАЖЕНИЯ»
<?: «S-ВЫРАЖЕНИЕ ОТСУТСТВУЕТ»
г. «ПРОПУЩЕНА ПРАВАЯ СКОБКА»
s: «НЕПАРНАЯ СКОБКА»
Рис. 12.19.
ляющей таблицы не содержит процедур опознания, символ (S)
никак нельзя поместить в магазин при текущем входном символе а.
Следовательно, ситуация а недостижима. Аналогичные соображения
применимы к ситуациям Ь, с и d.
Сообщения для ошибочных ситуаций в процедурах опознания
часто бывают более осмысленными, если они построены на основе
индивидуального рассмотрения, а не с помощью стандартного
формата. Ситуация г возникает, когда текущий входной символ —
концевой маркер, верхним символом магазина является (S), но
содержимое магазина отлично orSJiS). Сначала заметим, что
символ, находящийся в магазине под (S), должен обладать тем
свойством, что в результате переноса над ним может оказаться
некоторый символ из ПЕРВ((5>). Множество I1EPB((S)) состоит из
символа а и левой скобки. Из управляющей таблицы видно, что эти
входные символы в результате переноса в магазин могут оказаться
только над запятой, левой скобкой и маркером дна. Отсюда мы
заключаем, что в ситуации г под символом (S) в магазине может быть
запятая или левая скобка. В любом из этих случаев видно, что
пропущена правая скобка, поэтому мы выбираем соответствующее
сообщение, приведенное на рис. 12.19.
Аналогичный анализ можно провести для ситуации s. Так как
ПЕРВ ((/?>) состоит из запятой и правой скобки, а эти символы
можно перенести в магазин только так, что они окажутся над (S >,
мы заключаем, что в момент вызова процедуры ОПОЗНАТЬ2 два
верхних символа в магазине — это (S)(R). Как показано ранее,
под (S) в магазине могут находиться лишь запятая, левая скобка
и маркер дна. Поскольку запятая и левая скобка не вызывают
12.7. Обработка ошибок при разборе типа «перенос — опознание» 481
выбора процедурой ОПОЗНАТЬ2 операции ОТВЕРГНУТЬ, мы
заключаем, что в ситуации s содержимым магазина является
V <£></?>
Так как всякая цепочка, выводимая из (/?), содержит правых
скобок на одну больше, чем левых, скобка, оканчивающая цепочку,
выводимую из верхнего символа, не имеет парной левой скобки;
поэтому мы выбираем сообщение, приведенное на рис. 12.19.
В данный момент сообщения об ошибках, перечисленные на
рис. 12.19, представляют собой лишь пробный вариант, пока не
будут построены процедуры нейтрализации ошибок, которые могут
изменить приведенный выше анализ ошибочных ситуаций.
Теперь рассмотрим проблему нейтрализации ошибок. Наш
подход состоит в построении процедур нейтрализации, которые
приводят в порядок вход и магазин и затем продолжают анализ так,
как будто ошибки не было. Если после этого автомат снова
обращается к элементу управляющей таблицы, содержащему
ОТВЕРГНУТЬ, он добавляет сообщение об ошибке, соответствующее этому
элементу, к списку выданных на данный момент сообщений об
ошибках, а затем использует связанную с этим элементом
процедуру нейтрализации. Мы надеемся, что в любом сообщении об
ошибке, выданном после нейтрализации, отражаются
дополнительные ошибки, на которые было бы желательно обратить внимание
программисту. Существует опасность, что впоследствии компилятор
мог бы породить фиктивные сообщения об ошибках, раздражающие
программиста, так как они, по-видимому, не соответствуют никаким
дополнительным ошибкам в программе. Таким образом, всякая
попытка нейтрализации ошибок представляет собой компромисс
между желанием обнаружить как можно больше ошибок и
желанием избежать фиктивных сообщений.
Сначала рассмотрим подход к нейтрализации ошибок, который
можно охарактеризовать как «локальный». Идея его состоит в
том, чтобы в каждый элемент таблицы, содержащий операцию
ОТВЕРГНУТЬ, включить последовательность операций над
магазином и входом. Если обнаружена какая-то ошибка, то сначала
выдается сообщение, затем выполняется указанная
последовательность операций и после этого возобновляется обычный процесс
обработки. Разработчик выбирает операции для каждого
отвергающего элемента отдельно, основываясь на своем интуитивном
представлении о том, какая ошибка могла быть допущена и как
лучше всего привести в порядок вход и магазин, чтобы можно было
возобновить анализ.
На рис. 12.20 показан один из возможных наборов процедур
локальной нейтрализации ошибок для автомата на рис. 12.18.
Заметим, что на рисунке указаны процедуры для ситуаций о, ft, с и d,
которые теперь становятся достижимыми в процессе нейтрализации
Ф. Льюис и др.
482 Гл. 12. Обработка методами типа «перенос—опознание»
из ситуаций т, п, h и i. Заметим также, что анализ, лежащий в
основе сообщений об ошибках, приведенных на рис. 12.19, остается
справедливым.
На рис. 12.21 показана последовательность конфигураций
указанного автомата, возникающая при обработке цепочки
(а, , а
Этот рисунок можно сравнить с рис. 8.29, а, где показано, как эта
же цепочка обрабатывается автоматом на рис. 8.28.
а, Ь: ВТОЛКНУТЬ (,) ДЕРЖАТЬ
с, d: ОПОЗНАТЬ2
е, /, /, k: ПЕЧАТАТЬ (Сообщение на рис. 12.19)
ВТОЛКНУТЬ (а)
ДЕРЖАТЬ
g, I, q: ПЕЧАТАТЬ (Сообщение на рис. 12.19)
ВЫХОД
Л, i: ПЕЧАТАТЬ (Сообщение на рис. 12.19)
ОПОЗНАТЬЗ
т, п: ПЕЧАТАТЬ (Сообщение на рис. 12.19)
ОПОЗНАТЬ4
о, р: ПЕЧАТАТЬ (Сообщение на рис. 12.19)
СДВИГ
г: ПЕЧАТАТЬ (Сообщение на рис. 12.19)
ВТОЛКНУТЬ ( ) )
ДЕРЖАТЬ
s: ПЕЧАТАТЬ (Сообщение на рис. 12.19)
ВЫТОЛКНУТЬ
ДЕРЖАТЬ
Рис. 12.20.
Теперь рассмотрим подход к нейтрализации ошибок, который
можно охарактеризовать как «глобальный». Этот подход можно
использовать в тех случаях, когда разработчик не чувствует
достаточной уверенности в правильности процедур локальной
нейтрализации или когда ограниченный объем памяти не позволяет иметь
отдельные процедуры нейтрализации для всех ошибочных ситуаций.
Основная идея состоит в том, чтобы продолжать считывание
входных символов до тех пор, пока не встретится один из
«надежных» символов. После этого нейтрализация ошибки происходит в
зависимости от этого и верхнего символов магазина. Можно
выделить два типа «надежных» символов.
1. Оканчивающие символы. Оканчивающий символ — это такой,
относительно которого разработчик имеет разумные основания
считать, что этот символ указывает на конец правой части
некоторого правила, такого, что первый символ его правой части содер-
12.7. Обработка ошибок при разборе типа «перенос — опознание» 483
жится в магазине. Оканчивающим символом может быть либо
последний терминал, порождаемый правой частью, либо первый
символ, следующий за этой правой частью. Типичными оканчива-
V (а ,,а—{
V ( а ,,а—\
V (а ,,а—\
V(<5> ,,H
V(<5>, ,a-\
ПЕЧАТАТЬ („ДВЕ ЗАПЯТЫЕ ПОДРЯД")
V ( <5> , а ,а-\
V(<5>,<5) ,H
V(<5),<5>, aH
V((S),(S),a H
V ( (S) , (S) , <5> Н
ПЕЧАТАТЬ („ПРОПУЩЕНА ПрАВАЯ СКОБКА")
V(<5),<5),<5>) H
V ( (S) , (S) , (S) (R) Н
V((S),(S)(R) -\
V ( (S) (R) Н
ВЫХОД
Рис. 12.21.
ющими символами в языке с блочной структурой являются END
и точка с запятой.
В процессе нейтрализации ошибки входная цепочка считывается
до тех пор, пока не встретится оканчивающий символ. Затем из
магазина выталкиваются символы до тех пор, пока не встретится
символ, начинающий, как кажется разработчику, правую часть,
конец которой отмечен найденным оканчивающим символом. Этот
магазинный символ заменяется нетерминалом, который, по мнению
разработчика, представляет собой левую часть правила, начало
и конец которого только что найдены. Далее возобновляется
нормальный процесс обработки, причем в качестве текущего входного
символа используется первый символ, следующий за правой частью
указанного правила.
2. Первые символы. Первый символ — это такой, относительно
которого разработчик имеет разумные основания предполагать,
16*
484 Гл.12. Обработка методами типа «перенос—опознание»
что с этого символа начинается правая часть правила, которую
разработчик считает нужным проверить на наличие дополнительных
ошибок. Во многих языках с блочной структурой в качестве первого
символа можно использовать символ BEGIN.
В процессе нейтрализации ошибок, когда при считывании
входной цепочки обнаружен первый символ, выполняются следующие
магазинные операции
ВТОЛК({ОШИБКА}), ПЕРЕНОС
и затем возобновляется нормальный процесс обработки. Позднее,
когда символ {ОШИБКА} окажется на верху магазина, этот
символ выталкивается и процедура нейтрализации возобновляет
считывание в поисках другого оканчивающего или первого символа.
Следует подчеркнуть, что множества оканчивающих и первых
символов нужно рассматривать вместе. Пусть, например, для
некоторого языка с блочной структурой разработчик хочет
использовать в качестве оканчивающих символов END и точку с запятой.
Было бы неверно при поиске этих символов пропустить символ
BEGIN, так как это привело бы к неправильному анализу
компилятором блочной структуры. Поэтому BEGIN нужно использовать
в качестве первого символа.
12.8. Синтаксический блок для языка
MINI-BASIC
В этом разделе мы построим синтаксический блок для языка MINI-
BASIC на основе S-атрибутной грамматики польского перевода,
входная грамматика которой является простой грамматикой
смешанной стратегии предшествования. Работа синтаксического блока
состоит в том, что, получив цепочку лексем, созданную лексическим
блоком (гл. 4), он выдает в качестве выхода цепочку атомов, которая
затем будет использована генератором кода, описанным в гл. 14.
Другой синтаксический блок, задающий то же отношение между
входом и выходом, был разработан в гл. 10 с использованием
нисходящих методов.
Начнем с рассмотрения простой ССП-грамматики, лежащей в
основе перевода. Эта грамматика приведена на рис. 12.22, и ее можно
сравнить с грамматикой языка MINI-BASIC, данной в разд. 6.15.
Множество терминалов грамматики состоит из лексем,
перечисленных на рис. 4.1, с тем отличием, что здесь пять арифметических
операций представлены пятью лексемами, тогда как на рис. 4.1
использовалась одна лексема с пятью возможными значениями.
Полезно было бы вспомнить исходные цепочки символов,
соответствующие лексемам. Например, лексема ПРИСВ соответствует
12.8. Синтаксический блок для языка MINI-BASIC 485
Структура программы
1. <программа> —► <список операторов> КОНЕЦ
2. <список операторов) —>■ <список операторов) <оператор> СТРОКА
3. <список операторов) —► СТРОКА
Пустой оператор
4. <список операторов) —► <список операторов) СТРОКА
Оператор присваивания
5. <оператор) —► ПРИСВОИТЬ <выражение>
GOTO-onepamop
6. <оператор>—►ПЕРЕХОД НА
IF-onepamop
7. <оператор> — ЕСЛИ <выражение> ОТНОШЕНИЕ
<пыражение> <если-переход>
8. <есл и-переход)—* ПЕРЕХОД НА
GOSU В-оператор
9. Оператор)— ПЕРЕХОД НА ПОДПР
RET URN-оператор
10. <оператор> — ВОЗВРАТ
FOR-onepamop
11. <оператор)—► <для-оператор) <список операторов) КОНЕЦ ЦИКЛА
12. <для-операгор> —► <для-предложение> <до-предложение> ШАГ <выражение)
13. <для-оператор> —► <для-предложение> <до-предложение>
14. <для-предложеш1е> —► ДЛЯ <выражение>
15. <до-предложенне> —► ДО <выражение>
REM-onepamop
16. <оператор> —► КОММЕНТАРИИ
Выражения
17. <выражеиие> —► <выражеш!е)+<терм>
18. <выраженне) —► <выражение> — <терм>
19. <выражение>—> + <герм>
20. (выражение)—► — <терм>
21. (выражение)—► <терм>
22. <терм> —>• <терм> » <множитель>
23. <терм> —» <терм)/<множитель>
24. <терм> —► <множитель)
25. <множитель> —► <множитель> f <первичное>
26. <множитель> —► <первичиое>
27. <первичное> —► «выражение»
28. <первичное> —► ОПЕРАНД
Начальный символ: <программа>
Рис. 12.22. Простая ССП-грамматика для синтаксического блока
M1N I-BASIC-компилятора,
486 Гл. 12. Обработка методами типа «перенос—опознание»
слову LET, за которым следует знак =, а лексема СТРОКА
соответствует номеру строки, с которого она начинается.
Заметим, что правило 11 порождает как FOR-оператор, так и
соответствующий ему NEXT-оператор. Правила для FOR-оператора
построены таким образом, чтобы последующее введение символов
действия привело к грамматике польского перевода.
Можно легко убедиться в том, что грамматика на рис. 12.22
является простой ССП-грамматикой.
Теперь можно задать множество атомов и транслирующую
грамматику. Полное множество атомов с описанием всех атрибутов
было приведено на рис. 10.2 как часть синтаксического блока,
построенного в гл. 10. Текст, сопровождающий этот рисунок,
поясняет предполагаемое использование каждого атома. Хотя
моменты выдачи атома указаны в соответствии с грамматикой из
гл. 10, мы уверены, что читатель разберется в этом описании.
На рис. 12.23 приведена грамматика польского перевода, а на
рис. 12.24 — S-атрибутная транслирующая грамматика. Смысл
большинства атрибутов нетерминалов очевиден. Единственный
нетерминал, имеющий более одного атрибута,— это FOR-оператор.
Первым его атрибутом является указатель на табличный элемент
для переменной цикла; второй атрибут — это указатель на
табличный элемент для значения шага цикла; третий и четвертый
атрибуты — это указатели на табличные элементы для двух меток,
участвующих в цикле, а пятый атрибут содержит номер строки, в
которой появляется FOR-оператор. Этот пятый атрибут
используется процедурой действия {КОНТРОЛЬ} как часть
предупредительного сообщения в том случае, если соответствующий NEXT-
оператор ссылается на переменную, отличную от переменной цикла.
При построении атрибутной грамматики предполагалось, что
существуют три процедуры для отведения табличных элементов:
НОВТ, НОВТХ и НОВТАМ. НОВТ дает указатель на новый
табличный элемент для промежуточного результата; НОВТХ
дает указатель на новый табличный элемент для результата атома
ХРАНЕНИЕ; а НОВТАМ дает указатель на новый табличный
элемент для метки. Как мы увидим в гл. 14, каждый из этих типов
табличных элементов содержит определенные поля, нужные
генератору кода. В некоторые из этих полей процедуры НОВТ,
НОВТХ и НОВТАМ должны при отведении элемента помещать
начальные значения, однако отложим разговор об этой инициализации
до гл. 14. Здесь нам нужно лишь знать, что НОВТ, НОВТХ
и НОВТАМ дают соответствующие указатели.
В правиле 13 предполагается возможность получить указатель
на заранее заготовленный табличный элемент для константы 1.
Теперь можно описать процессор с магазинной памятью. На
рис. 12.25 приведен магазинный алфавит с указанием полей всех
символов.
Структура программы
1. <программа>—» <сгшсок операторов) КОНЕЦ
2. <список операторов) —► <список операторов) <оператор> СТРОКА
{НОМСТРОК} {УСТАНОВИТЬ НОМЕР СТРОКИ}
3. <список операторов) —>■ СТРОКА {НОМСТРОК} {УСТАНОВИТЬ НОМЕР
СТРОКИ}
Пустой оператор
4. <список операторов) —► <список операторов) СТРОКА {НОМСТРОК}
{УСТАНОВИТЬ НОМЕР СТРОКИ}
Оператор присваивания
5. <оператор> — ПРИСВОИТЬ <выражение> {ПРИСВ}
GOTO-oncpamop
6. ^оператор) — ПЕРЕХОД НА {ПЕРЕХОД}
IF-onepamop
7. <оператор> —>-ЕСЛИ <выражение> ОТНОШЕНИЕ
<выражение> <если-переход> {УСЛПЕРЕХОД}
8. <если-переход> —* ПЕРЕХОД НА
GOSU В-оператор
9. <оператор> —>■ ПЕРЕХОД НА ПОДПР {ХРАНПЕРЕХОД}
RET U RN-оператор
10. <оператор> —* ВОЗВРАТ {ВОЗВПЕРЕХОД}
FOR-onepamop
11. <оператор>—>• <для-операгор> <список операторов) КОНЕЦ ЦИКЛА
{КОНТРОЛЬ} {УВЕЛИЧ} {ПЕРЕХОД} {МЕТКА}
12. <для-оператор>—► <для-предложение> <до-предложение> ШАГ
<выражение> {ХРАНЕНИЕ} {МЕТКА} {ПРОВЕРКА}
13. <для-оператор>—>• <для-предложение> <до-предложение) {ХРАНЕНИЕ}
{МЕТКА}{ПРОВЕРКА}
14. <для-предложение>—► ДЛЯ <выражение> {ПРИСВ}
15. <до-предложение> —► ДО {ХРАНЕНИЕ}
REM-оператор
16. <оператор> — КОММЕНТАРИЙ
Выражения
17. <выражение>—> <выражение)+<терм> {СЛОЖ}
18. <выражение>—<■ <выражение> — <терм> {ВЫЧИТ}
19. <выражение>—>-+<терм) {ПЛЮС}
20. <выражение>—* —<терм> {МИНУС}
21. <выражение>—>■ <терм>
22. <терм>—* <терм> * <множитель> {УМНОЖ}
23. <терм>—* <терм>/<множитель> {ДЕЛЕН}
24. <терм> —<■ <множитель>
25. <множитель> —> <миожитель> \ <первичное> {ЭКСП}
26. <множитель>—* <первичное>
27. <первичное> —> «выражение»
28. <первичное> —►ОПЕРАНД
Начальный символ: <программа>.
Рис. 12.23. Грамматика польского перевода для синтаксического блока
MINI-BASIC-компилятора.
Все атрибуты символов действия НАСЛЕДУЕМЫЕ.
Списание процедуры действия {УСТАНОВИТЬ НОМЕР СТРОКИ},,
НОМЕР СТРОКИ *— р
Описание процедуры действия {КОНТРОЛЬ},, wy
IF р Ф w THEN печатать предупреждающее сообщение
Структура программы
1. <пр*ограмма>—* <список операторов) КОНЕЦ
2. <список операторов)—► <список операторов) <оператор) СТРОКА,,,
{НОМ СТРОК,,..} {УСТАНОВИТЬ НОМЕР СТРОКИ}^
(р2, рЗ) — р\
3. <список операторов) —* СТРОКА,,, {НОМСТРОКр2} {УСТАНОВИТЬ
НОМЕР СТРОКИ},,.,
(р2, рЗ) — р\
Пустой оператор
4. <список операторов) —>• <список операторов) СТРОКА,,, {НОМ СТРОК^2}
{УСТАНОВИТЬ НОМЕР СТРОКИ}^
(р2, рЗ) — р\
Оператор присваивания
5. <оператор>—• ПРИСВОИТЬр1 <выражение>(?1 {ПРИСВр2,?2}
р2«—pi q2*—q\
GOTO-onepamop
6. <оператор>—* ПЕРЕХОД НА,,, {ПЕРЕХОД р2)
р2 — р\
IF-onepamop
7. <оператор>—>■ ЕСЛИ выражение),,, ОТНОШЕНИЕ,-, <выражение>?1
<если-переход>^, {УСЛПЕРЕХОДя2, ?2, гг, s2}
•р2+—р) q2<—q\ г2<^-г\ s2<— si
8. <если-переход>,52 —>• ПЕРЕХОД HAi:
s2<— si
GOSUB-onepamop
9. <оператор> -* ПЕРЕХОД НА ПОДПР,,, {ХРАНПЕРЕХОД}я2
Р2+-р\
RET URN-оператор
10. <оператор> — ВОЗВРАТ {ВОЗВПЕРЕХОД}
FOR-onepamop
11. <оператор>—► ^гля-оператор),,,,;, и1 vi,yi <список операторов) КОНЕЦ
ЦИКЛАШ1 {КОНТРОЛЬ}^, то2" r/j {УВЕЛИЧрз./2} {ПЕРЕХОД^}
{МЕТКА„2}
(р2, рЗ)<— pi w2*—w\ y2*—y\
tt*—t\ м2<—i/l v2*—v\
12. <для-оператор)р31<я,„., „2,1/—* Сгля-предложение),,, <до-предложеиие>^1
ШАГ <выражение)х, {ХРАНЕНИЕ*,,,,,} {МЕТКА,,,}
{ПРОВЕРКА^, 52i/2i„,}
(М, t2, /3) —НОВТХ
(н1, н2)ч—НОВТАМ S2-.— si
Р*с. 12.24. S-атрибутная грамматика для синтаксического блока
MINI-BASIC-компилятора.
12.8. Синтаксический блок для языка MINI-BASIC
489
(в1, с-2) *— НОВТАМ у *— НОМЕР СТРОКИ
(р2, рЗ)*—р\ *2<—xl
13. ^ля-оператор),,:, /я а2.г»2,!/—>• <ДЛя-предложение>р, <до-предложение>п
{ХРАНЕНИЕ*,,,} {МЕТКА,,,} {ПРОВЕРКА,, i2 t2iVl}
(И, /2, *3)«— НОВТХ
(«I, и2)«— НОВТАМ s2<— si
(i/l, у2) *— НОВТАМ </«— НОМЕР СТРОКИ
(р2, p3)«-pl
* <— указатель на табличный элемент для константы 1
14. <для-предложение>^:)—«-ДЛЯ^, <выражение>^, {ПРИСВр2 fl2}
(р2, рЗ)<—pi <?2ч—<?1
15. <до-предложение>52—► ДО <выражение>Г1 {XPAHEHHEr2|ii}
л2+— r\ (si, s2)4_ НОВТХ
REM-onepamop
16. <оператор> — КОММЕНТАРИЙ
Выражения
17. <выражение>г.> —► <выражение>/,1 Н-<терм>9, {СЛОЖ,,2| q2, n)
(/-1, /-2)*—НОВТ р2<—р\ q2+—q\
18. <выражение>г2 —> <выражение>^1 —<тер.м>?1 {ВЫЧИТ?2 ?2] л1}
(/•1, г2)*— НОВТ р2*—pi 92ч—gl
19. <выражение>г2—' + <терм>;,1 {ПЛЮСр2, г1}
(/■1, л2) — НОВТ р2ч—pi
20. <выражение>Г2—^ —<терм>р1 {МИНУС,,.,, м}
(Н, л2)<— НОВТ р2*—р\
21. <выраженне>г2—<■ <терм>г1
г 2 — г\
22. <терм>г2 —' <терм>/)1 * <множитель>(?1 {УМНОЖ^2, ^г, п}
(г\, л2)<— НОВТ р2ч— pi a4+—q\
23. <терм>г2—►<терм>А,1/<множитель>9, {ДЕЛЕНр2, ?2,п}
(л1, л2)«—НОВТ р2*— р\ q2*—q\
24. <терм>л2—► <множитель>л1
л2ч—rl
25. <множитель>г2—*- <множитель>^t f <первичное>91 {ЭКСП^2) q2, n]
(rl, г2)<— НОВТ р2<—pi 92ч— 91
26. <множитель>г2—► <первичное>г1
л2*— г\
27. <первичное>г2 —>■ «выражение),-,)
л2<—л1
28. <первичное>г2—►ОПЕРАНДг1
г2+—г1
Начальный символ: <программа>
Рис. 12.24 (продолжение),
490 Гл. 12. Обработка методами типа «перенос—опознание*
СТРОКА
Значение лексемы строка
ОПЕРАНД
Значение лексемы операнд
Г ОТНОШЕНИЕ
[Значениелексемы отношение
КОНЕЦ ЦИКЛА
Значение лексемы конец цикла
ПРИСВОИТЬ
Значение лексемы присвоить
Am
Значение лексемы для
ПЕРЕХОД НА
Значение лексемы переход на
ПЕРЕХОД НД ПОДПР
Значение лексемы переход нд подпр
(
ЕСЛИ
ВОЗВРАТ
КОНЕЦ
ДО
ШАГ
КОММЕНТАРИИ
t
< программа >
<список операторов>
<оператор >
<для -оператору
#1
#2
#3
#4
#5
<для - предложение >
#1
< до - предложение >
#1
<выражение>
#1
<терм>
#1
< множительу
#1
< первичное >
#1
< если- переходу
#1
Рис. 12.25.
12.8. Синтаксический блок для языка MINI-BASIC
491
На рис. 12.26 показана управляющая таблица. Элементы,
помеченные буквой П, соответствуют операции ПЕРЕНОС. Для
каждой строки задана отдельная процедура опознания. Элементы,
if Ы
Ш Н
9: =f
х
ы
S
£
о
ж:
s
Э
_ о
5
СТРОКА
ОПЕРАНД
ОТНОШЕНИЕ
КОНЕЦ ЦИКЛА
ПРИСВ
ДЛЯ
ПЕРЕХОД НА
ПЕРЕЩйДОДЛР
ЛЕВАЯ ШБКА
ПРАВАЯ СКОПИ
ЕСЛИ ВОЗВРАТ
ВОЗВРАТ
КОНЕЦ
'ДО
ШАГ
КОММЕНТАРИЙ
+
-
;
/ .
t
< программа >|
< список.операторов
<оператор >
<8пя- оператору
<Вт-предложение)
<во-преЗлтение>
<быражение >
< терм >
<мнотитель>
< первичноеу
к если-пере%од>
7
1
2
а
3
а
а
4
5
а
6
Of
7
а
"
а
9
а
а
а
а
а
Р
Л
п
п
V
11
12
13
14
15
16
а
о
а
П
а
Л
Л
а
■ а
Л
а
П
а
а
Л
Л
а
Л
П
Л
Л
Л
р
р
р
р
р
р
р
р
р
р
р
ь
а
.2-
а
а
а
а
а
а
а
6
or
а
0
о
а
а.
а
а
а
а
а
Р
Р
Р
Р
Р
Р
П
13
-14
15
Р
Ъ
1
а
or
а
а
а
а
or
а
а
а
or
а
а
а
о
а
'or
а
а
а
Р
П
Р
Р
Р
Р
Р
Р.
Р
Р
Р
Ъ
1
ОТ
. ОГ
а
Or
а
or
а
or
а
а
ОТ
а
о
or
Of
а
а
а
а
а
Р
П
Р
р'
Р
Р
Р
Р
Р
Р
Р
Ь
1
а
' а
or
or
Of
ст
or
а
а
а
а
а
а
ст
а
а
а
а
а
а
Р
П
Р
р
Р
Р
Р
Р
Р
Р
Р
Ь
1
2
ст
а
а
а
а
а
а
6
■or
or
а
or
а
or
а
.а
or
а
ст
Р
П
Р
Р
Р
Р
Л
13
14
15
Р
5
1
а
а
or
а
а
а
а
ст
а
а
а
а
а
а
or
or
о
or.
а
or
Р
П
Р
Р
Р
Р
Р
Р
Р
Р
р
6
а
а
Л
а
П
П
а
а
Л
а
П
а
а
Л
Л
а
Л
Л
Л
п
л
р
р
р
р
р
р
р
р
р
р
р
ь
Or
2
or
Of
or
a
a
or
0/
6-
or
or
a
a
a
a
or
а
or
or
or
p
p
p
p
p
p
л
13
14-
15
P
6
1
Of
Or
а
a
a
о
a
a
a
or
«
or
a
a
a
a
a
a
or
or
P
П
P
P
P
P
P
P
P
p
P
ь
1
a
a
a
a
a
a
a
a
a
a
a
a
a
a
«
or
i/
or
a
a
P
Л
P
P
P
P
P
P
P
P
p
ь
1
or
а
a
Of
a.
a
a'
ct
a
or
a
a
a
a
a
a
a
ft
a
'or
P
П
P
P
P
P
P
P
p
P
ь
a
2
or
a
■ or
or
or
«
ct
6
ГУ
a
a
Or
г*
or
or
or
Or
Or
or
p
p
0
л
IT
12
13
14
15
P
6
Or
2
or**
or
a
a
a
a
0/
6
CT
or
a
a
or
or
or
cr
Or
o:
or
p
p
0
p
I
n
12
13
14
15
Р
Ь
1
or
or
CT
а
a
a
a
or
a
a
a
a
a
a
a
Or
or
or
Or
ft
p
Л
P
P
p
P
p
0
p
p
p
b
a
2
Л
a
Л
Л
or
CT
Л
'6
Л
CT
CT
/7
Л
or
or
or
a
a
a
P
P
P
P
P
P
Л
13
14
'15
P
Ь
or'
2
Л
a
n
П
a
a
Л
6
Л
a
cr-
П
Л
ct
ct
о
or
or
a
P
P
P
P
P
P
Л
13
14
15
P
6
cr
2
CT
а
or
or
a
.a'
а
6
а
д
or
a
a
"
a
or
cr
or
a
P
P
P
P
P
P
P
Л
14
15
P
6
or
2
cr
• or
CT
or
CT
or
CT
6
Or
or
or
ft
or
CT
or
а
or
Or
or
p
p
p
p .
h
p
p
л
14
15
P
Ь
or
2
or
■or
or
CT
or
a
a
6
a
о
a
a
CT
a
'a
«
or
or
CT
p
p
r
p
p
p
p
p
П
15
P
b
1
7
1
7
7
7
7
7
7
7'
7
7
7
7
7
*7
7
7
7
7
7
P
P
p
Р
P
P
P'
P
P
P
7
a
a
a •
a
»
;
a
rf
$
a ■
(j
0
8
»J ,
a
i
3
0
3
v
V
10
p
p
p .
p
p
p (
p ■
1
p
p
?
Рис. 12.26.
помеченные греческими буквами, соответствуют ошибочным
ситуациям.
Процедуры опознания и элементы, соответствующие ошибкам,
описаны на рис. 12.27. На рис. 12.28 показаны процедуры свертки,
492 Гл. 12. Обработка методами типа «перенос—опознание»
1: если на верху магазина <список операторов><оиератор> СТРОКА то
СВЕРТКА(2)
иначе если на верху магазина <список операторов} СТРОКА то
,СВЕРТКА(4) иначе СВЕРТКА(З)
2: СВЕРТКА(28)
3: если на верху магазина <для-оператор> <список операторов} КОНЕЦ
ЦИКЛА то СВЕРТКА(П)
иначе ОШИБКА (NEXT-ОПЕРАТОР не СООТВЕТСТВУЕТ
FOR-ОПЕРАТОРУ)
4: если на верху магазина <список операторов> ПЕРЕХОД НА то
СВЕРТКА(б)
иначе если на верху магазина <выражение> ПЕРЕХОД НА то
CBEPTKAfR)
иначе ОШИБКА (ОШИБКА КОМПИЛЯТОРА)
5: СВЕРТКА(9)
6: если на верху магазина «выражение» то СВЕРТКА(27)
иначе ОШИБКА (НЕПАРНАЯ ПРАВАЯ СКОБКА)
7: СВЕРТКА(Ю)
8: если на верху магазина <список операторов> КОНЕЦ то CBEPTKA(l)
иначе ОШИБКА (ОШИБКА КОМПИЛЯТОРА)
9: СВЕРТКА(16)
10: если на верху магазина V <программа> то ВЫДАТЬ
АТОМ (ОКОНЧАНИЕ)
иначе ОШИБКА (НЕПРАВИЛЬНАЯ ВЛОЖЕННОСТЬ ЦИКЛОВ —
ПРОПУЩЕН NEXT-ОПЕРАТОР)
11: если на верху магазина <для-предложепие> <до-предложение> то
СВЕРТКА(13)
иначе ОШИБКА (ОШИБКА КОМПИЛЯТОРА)
12: если на верху магазина ПРИСВ <выражение> то СВЕРТКА(5)
иначе если на верху магазина <для-предложение> <до-предложение>
ШАГ <выражение> то СВЕРТКА(12)
иначе если на верху магазина ДЛЯ <выражение> то СВЕРТКА(14)
иначе если на верху магазина ДО <выражение> то СВЕРТКА(15)
иначе если на верху магазина «выражение) то ОШИБКА (НЕПАРНАЯ
ЛЕВАЯ СКОБКА)
иначе ОШИБКА (КОНСТРУКЦИЯ $ (второй сверху символ магазина)
$ (верхний символ магазина) $ (входной символ) НЕ РАЗРЕШЕНА)
13: если на верху магазина <выражение>+<терм> то СВЕРТКА(17)
иначе если па верху магазина <выражение> — <терм>, тоСВЕРТКА(18)
иначе если на верху магазина+<терм> то СВЕРТКА(19)
иначе если на верху магазина —<терм> то СВЕРТКА(20)
иначе СВЕРТКА(21)
14: если на верху магазина <терм>*<множитель> то СВЕРТКА(22)
иначе если на верху магазина <терм>/<множитель> то СВЕРТКА(23)
иначе СВЕРТКА(24)
15: если на верху магазина <множитель> f <первичное> то СВЕРТКА(25)
иначе СВЕРТКА(26)
16: если на верху магазина ЕСЛИ <выражение> ОТНОШЕНИЕ <выражение>
<если-переход> го СВЕРТКА(7)
Рис. 12.27.
12.8. Синтаксический блок для языка MINI-BASIC
493
иначе если на верху магазина ОТНОШЕНИЕ <ныражение> <если-
переход> то ОШИБКА (ЗНАК ОТНОШЕНИЯ НЕ НА МЕСТЕ)
иначе ОШИБКА (КОНСТРУКЦИЯ $(три верхних символа магазина)
НЕ РАЗРЕШЕНА)
а: ОШИБКА ($ (входной символ) ПОСЛЕ £ (иерхний символ магазина)
{S: ОШИБКА (ПРОПУЩЕН END-ОПЕРАТОР)
у: ОШИБКА ( )
б: ОШИБКА (ПРОПУЩЕН НОМЕР НАЧАЛЬНОЙ СТРОКИ)
С: ОШИБКА (ПРОГРАММА ОТСУТСТВУЕТ)
8: ОШИБКА ($ (входной символ) В ОПЕРАТОРЕ ПРИСВАИВАНИЯ)
К: ОШИБКА (ДВА ТО-ПРЕДЛОЖЕНИЯ В FOR-ОПЕРАТОРЕ)
а: ОШИБКА (ДВА STEP-ПРЕДЛОЖЕНИЯ В FOR-ОПЕРАТОРЕ)
v: ОШИБКА (НЕЗАКОНЧЕННЫЙ FOR-ОПЕРАТОР)
Е: ОШИБКА (В FOR-ОПЕРАТОРЕ ОТСУТСТВУЕТ ИЛИ НЕ НА МЕСТЕ
ТО-ПРЕДЛОЖЕНИЕ)
л: ОШИБКА (ДВА ТО-ПРЕДЛОЖЕНИЯ ПОДРЯД)
р: ОШИБКА (ОШИБКА КОМПИЛЯТОРА)
Рис. 12.27 (продолжение).
СВЕРТКА (1): ВЫТОЛК, ВЫТОЛК, ВТОЛК«программа»
СВЕРТКА(2): р<—поле магазинного символа СТРОКА
ВЫДАТЬ АТОМ (НОМСТРОКр)
НОМЕР СТРОКИ *—р
ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВТОЛК«список операторов»
СВЕРТКА(З): р <— поле магазинного символа СТРОКА
ВЫДАТЬ АТОМ(НОМ СТРОК»)
НОМЕР СТРОКИ <—р
ВЫТОЛК, ВТОЛК«список операторов»
СВЕРТКА(4): р -—поле магазинного символа СТРОКА
ВЫДАТЬ АТОМ (НОМ СТРОК»)
НОМЕР СТРОКИ— р
ВЫТОЛК, ВЫТОЛК, ВТОЛК«список операторов»
СВЕРТКА(5): р «— поле магазинного символа ПРИСВОИТЬ
q -<— поле магазинного символа <выражение>
ВЫДАТЬ АТОМ(ПРИСВл q)
ВЫТОЛК, ВЫТОЛК, ВТОЛК«оператор»
СВЕРТКА(б): р *— поле магазинного символа ПЕРЕХОД НА
ВЫДАТЬ АТОМ(ПЕРЕХОДр)
ВЫТОЛК, ВТОЛК«оператор»
СВЕРТКА(7): р *— поле нижнего магазинного символа <выражение>
q <— поле верхнего магазинного символа <выражение>
г ч поле магазинного символа ОТНОШЕНИЕ
s <— поле магазинного символа <если-переход>
ВЫДАТЬ АТОМ(УСЛПЕРЕХОД „, q, r, s)
ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВЫТОЛК,
ВТОЛК«оператор»
СВЕРТКА(8): s-<—поле магазинного символа ПЕРЕХОД НА
ВЫТОЛК, ВТОЛК«если-переход>^)
СВЕРТКА(9): р^-поле магазинного символа ПЕРЕХОД НА ПОДПР
ВЫДАТЬ АТОМ (ХРАНПЕРЕХОД „)
ВЫТОЛК, ВТОЛК«оператор»
СВЕРТКА(Ю): ВЫДАТЬ АТОМ (ВОЗВПЕРЕХОД)
ВЫТОЛК, ВТОЛК «оператор»
Рис. 12.28.
CBEPTKA(ll): p*—первое поле магазинного символа <для-оператор>
t ■*— второе поле магазинного символа <для-оператор>
и ■<—третье поле магазинного символа <для-оператор>
v *—-четвертое поле магазинного символа <для-оператор>
у «—■ пятое поле магазинного символа <для-оператор>
км—• поле магазинного символа КОНЕЦ ЦИКЛА
если (р Ф да) то ПЕЧАТАТЬ (NEXT-ПЕРЕМЕННАЯ ОТЛИЧЛЕТСЯ
ОТ FOR -ПЕРЕМЕННОЙ В СТРОКЕ % (у) -ПРЕДПОЛАГАЕТСЯ
ЧТО ЗДЕСЬ ПОДРАЗУМЕВАЛАСЬ FOR-ПЕРЕМЕННЛЯ)
ВЫДАТЬ АТОМ (УВЕЛИЧ _ Л
ВЫДАТЬ АТОМ (ПЕРЕХОД,,)'
ВЫДАТЬ АТОМ (МЕТКА*)
ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВТОЛК «оператор»
СВЕРТКА(12): р*—поле магазинного символа <для-предложение>
s -<— поле магазинного символа <до-предложение>
х *—поле магазинного символа <выражение>
t <— НОВТХ
и —НОВТАМ
v <—НОВТАМ
а <— НОМЕР СТРОКИ
ВЫДАТЬ АТОМ(ХРАНЕНИЕ х ,)
ВЫДАТЬ АТОМ(МЕТКА „)
ВЫДАТЬ АТОМ(ПРОВЕРКА р, s. t v)
ЯЫТОЛК, ВЫТОЛК, ВЫТОЛК', ВЫТОЛК, ВТОЛК«ДЛЯ-опера-
т°Р>я, /, в, v, у)
СВЕ1'ТКА(13): р <— поле магазинного символа <для-предложение>
s*—поле магазинного символа <до-предложение>
t*—НОВТХ
и <-- НОВТАМ
v <— НОВТАМ
у^- НОМЕР СТРОКИ
х *— указатель на табличный элемент для константы 1
ВЫДАТЬ АТОМ(ХРАНЕНИЕ.,. ,)
ВЫДАТЬ АТОМ(МЕТКА „) '
ВЫДАТЬ ЛТОМ(ПРОВЕРКАр, Si ,, „)
ВЫТОЛК, ВЫТОЛК, ВТОЛК ('(для-оперетор) PJ,r,v,y)
СВЕРТКА(Н): р <—поле магазинного символа ДЛЯ
q •<— поле магазинного символа <выражение>
ВЫДАТЬ АТОМСПРИСВ,,, q)
ВЫТОЛК, ВЫТОЛК, ВтЬлК«Для-предложение>/7
СВЕРТКА(15): г <—поле магазинного символа <выражение>
s<~-НОВТХ
ВЫДАТЬ АТОМ(ХРАНЕНИЕг, s)
ВЫТОЛК, ВЫТОЛК, ВТОЛК«До-предложение>5)
СВЕРТКА(!6): ВЫТОЛК, ВТОЛК«оператор»
СВЕРТКА(17): р ■>—поле магазинного символа <выражение>
q -— поле магазинного символа <терм>
s *—НОВТ
ВЫДАТЬ АТОМ(СЛОЖ^, д, г)
ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВТОЛК«выражение>г)
СВЕРТКА(18): р -<—поле магазинного символа <выражение>
q •<— поле магазинного символа <терм>
г +— НОВТ
ВЫДАТЬ АТОМ(ВЫЧПТ„, „ г)
ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВТОЛК«выражение>г)
СВЕРТКЛ(19): р*—поле магазинного символа <терм>
г *— НОВТ
Рис. 12.28 (продолжение).
12.8. Синтаксический блок для языка MINI-BASIC 495
ВЫДАТЬ АТОМ(ПЛЮС^. ,)
ВЫТОЛК, ВЫТОЛК, ВТОЛК «выражение),.)
СВЕРТКА(20): р*—поле магазинного символа <терм>
г<_ НОВТ
ВЫДАТЬ АТОМ(МИНУСг г)
ВЫТОЛК, ВЫТОЛК, ВТОЛК«выражение>г)
СВЕРТКА(21): г <—ноле магазинного символа <терм>
ВЫТОЛК, ВТОЛК«выражение>г)
СВЕРТКА(22): р <—поле магазинного символа <терм>
q <— поле магазинного символа <множитель>
г +— НОВТ
ВЫДАТЬ АТОМСУМНОЖ^, ,, г)
ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВТОЛК«терм>г)
СВЕРТКА(23): р *—поле магазинного символа <терм>
q *— поле магазинного символа <множитель>
,- «_ НОВТ
ВЫДАТЬ АТОМ(ДЕЛЕНя> q_ r)
ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВТОЛК«терм>г)
СВЕРТКА(24): г <— поле магазинного символа <ыножитель>
ВЫТОЛК, ВТОЛК «терм),)
СВЕРТКА (25): р<—поле магазинного символа (множитель)
q <— поле магазинного символа <первичное>
г*— НОВТ
ВЫДАТЬ АТОМ(ЭКСПр, q_ ,)
ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВТОЛК«множитель>г)
CBEPTKA(2G): г -<— поле магазинного символа <первичное>
ВЫТОЛК, ВТОЛК«множитель>,)
СВЕРТ1<А(27) г 1— поле магазинного символа <выражение>
ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ВТОЛК «первичное),-)
СВПРТКА(28): г -<—поле магазинного символа ОПЕРАНД
ВЫТОЛК, ВТОЛК«первичное>А)
Рис. 12.28 (продолжение).
Напечатать сообщение об ошибке.
Установить флажок ошибки, указывающий на то, что встречена ошибка.
Просматривать входную цепочку, начиная с текущей лексемы, до тех пор
пока не встретится СТРОКА или —|.
Если встретился концевой маркер —|, прекратить компиляцию.
В противном случае выталкивать из магазина символы до тех пор, пока
не попадется один из символов, указанных в приведенной ниже таблице, посла
чего выполнить задаваемые таблицей действия.
Магазинный символ Действие
ДЛЯ или <для-предложение) ВЫТОЛК
ВТОЛК (Саля-оператор)^ ( „ Vi y)
р<— поле символа ДЛЯ или
<для-предложение>
t<—НОВТХ
и*— НОВТAM
уч—НОВТAM
у<—НОМЕР СТРОКИ
<для-оператор> НИКАКОГО
<список операторов) НИКАКОГО
V ВТОЛК«список операторо.ч»
Рис. 12.29. Описание процедуры ОШИБКА.
496 Гл. 12. Обработка методами типа «.перенос—опознание»
а на рис. 12.29 описана процедура ОШИБКА. Процедуры опознания
порождают нужные атомы, используя процедуру ВЫДАТЬАТОМ,
которая выдает в качестве атома свой параметр.
Процедура ОШИБКА, описанная на рис. 12.29, вызывается в
случае обнаружения ошибки. Процедура имеет своим параметром
строку, печатаемую в качестве сообщения об ошибке вместе
с номером строки, получаемым из переменной НОМЕР СТРОКИ.
Таким образом, если в строке 100 встретилась ошибочная ситуация,
сообщение будет следующим:
100: ПРОПУЩЕН END-ОПЕРАТОР
Предполагается, что можно вносить в сообщение об ошибке
некоторую специальную информацию. Например, если в
сообщении появляются конструкции $ (входной символ), $ (верхний
символ магазина), $ (второй сверху символ магазина), или s (три
верхних символа магазина), то они заменяются соответствующим
символом или группой символов. Так, если в строке 20 встретилась
ошибочная ситуация а и при этом текущий входной символ — IF,
а на верху магазина — ТО, то сообщение об ошибке будет
следующим:
20: ТО ПОСЛЕ IF
Вместо символа ОТНОШЕНИЕ при этом используется имя
операции, а вместо символа ОПЕРАНД используется или слово
КОНСТАНТА, или имя конкретной переменной. Кроме того,
предупредительное сообщение^ выдаваемое процедурой
СВЕРТКА (11), предполагает возможность внесения в сообщение номера
строки.
Сообщение
ОШИБКА КОМПИЛЯТОРА
выдается в тех ситуациях, которые, согласно детальному изучению
грамматики, не могут возникнуть даже при анализе неправильной
входной цепочки. Например, рассмотрим работу процедуры
опознания 8 в случае, когда верхним символом магазина является
END. По управляющей таблице мы видим, что END может попасть
в магазин только путем переноса над символом (список операторов >.
Поэтому под END в магазине должен быть (список операторов).
Следовательно, при работе процедуры опознания 8 два верхних
символа магазина — это всегда (список операторов > END, и
процедура ОШИБКИ никогда не должна вызываться.
Процедура нейтрализации ошибок использует стратегию
пропуска символов до следующей строки. Причина выделения FOR-
операторов в специальный случай объясняется попыткой избежать
фиктивных сообщений о непарных FOR и NEXT. Заметим, что в
rex случаях, когда нейтрализация включает в себя вталкивание в
Упражнения
497
магазин символа (for-оператор), в пятое поле заносится номер
текущей строки для возможного использования в последующем
сообщении об ошибке.
Отладочную программу, приведенную на рис. 10.8 для
синтаксического блока из гл. 10, можно использовать и в
рассматриваемом случае. Она проверяет все неошибочные элементы
управляющей таблицы и работу всех ветвей в процедурах опознания и
свертки.
12.9. Замечания по литературе
Исторически синтаксический анализ типа «перенос — опознание»
получил развитие на основе понятия «предшествование».
Первоначальная формулировка методов предшествования и определение
некоторых классов грамматик, анализируемых этими методами,
содержится в работах Флойда [1963], Пэра [1964], а также Вирта
и Вебера [1966]. Грамматики слабого предшествования
определяются в работе Ихбиа и Морзе [1970]. Простые грамматики
смешанной стратегии предшествования вводятся в работе Ахо, Ден-
нинга и Ульмана [1972] и представляют собой частный случай
грамматик смешанной стратегии предшествования Маккимана,
Хорнинга и Уортмэна [1970]. Свойства различных классов
грамматик предшествования изучены в работах Фишера [1969], Грэхем
[1970], Лернера и Лима [1970], Макафи и Прессера [1972], Грэя
и Харрисона [1972, 1973]. Различные классы грамматик
предшествования широко изучены в книге Ахо и Ульмана [1972а, 1973а].
Нейтрализация ошибок для разбора типа «перенос —
опознание» рассматривается в работе Вирта [1968].
Упражнения
1. Найдите две грамматики, порождающие различные языки, но имеющие одну
и ту же управляющую таблицу типа «перенос — опознание» (без конфликтов).
2. Найдите грамматику с начальным символом (S) и следующей управляющей
таблицей типа «перенос — опознание».
о 1 н
ОТВЕРГНУТЬ
ПЕРЕНОС
ОПОЗНАТЬ
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ОПОЗНАТЬ
ОПОЗНАТЬ
ПЕРЕНОС
ОТВЕРГНУТЬ
ОПОЗНАТЬ
ОПОЗНАТЬ
ОПОЗНАТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
498 Гл. 12. Обработка методами типа «.перенос—опознание»
3. Для каждого из следующих утверждений выясните, истинно оно или ложно;
для ложных утверждений приведите контрпримеры.
а) Пусть А — магазинный символ, а X — входной символ. Тогда
А ПОД X
тогда и только тогда, когда
X принадлежит СЛЕД (Л)
б) Всякий язык, порождаемый грамматикой без конфликтов переноса —
опознания, порождается также и некоторой грамматикой с конфликтами.
в) Пусть имеется правило
</.) -* аА
для цепочки а и символа А. Тогда если (L) СВЕРТЫВАЕТСЯ-ПО X, то
А СВЕРТЫВАЕТСЯ-ПО А'.
г) Если А ПОД В и В ПОД С, то А ПОД С.
4. Для следующей грамматики с начальным символом (S) постройте процессор
на основе слабого предшествования:
(S)-+(S)(A)
(S)-+(A)
{A)-+\(S)0
(/О-* 10
5. Для каждого из следующих языков найдите грамматику слабого
предшествования и постройте соответствующий магазинный распознаватель:
а) {1»0"} л>0
б) {vj m wr] к' из (0+1)*
в) {1»оС»}и(1" Ь0*п\ п>0
6. Покажите, что всякое регулярное множество, не содержащее е, порождается
некоторой грамматикой слабого предшествования.
7. Найдите грамматику слабого предшествования для логических выражений
Алгола. При этом не опускайтесь ниже уровня конструкций (число без знака),
(переменная) и (указатель функции).
8. Почему не имеет смысла определять класс грамматик, аналогичных
грамматикам слабого предшествования, таких, что при наличии в магазине двух сенов,
правильной всегда является более короткая из них?
9. Напишите на любом языке программу, реализующую процессор на рис. 12.5.
10. Покажите, что следующая грамматика не является простой грамматикой
смешанной стратегии предшествования:
<S)-*1(S)0
(S) -* 0(S)1
(5)->10
11. Постройте для следующей грамматики (Ахо, Дениипг, Ульман [1972а])
процессор на основе простого метода смешанной стратегии предшествования.
(S)-+a(A)
(S)-+b(B)
(A)^{C)(A)l
<Л)-*(С)1
<B)-v(D)(/?)(£)l
<B)-+(D)(F.)l
<С)-*0
(D) -+ 0
<£> -* I
Упражнения 499
12. Постройте простую грамматику смешанной стратегии предшествования и
соответствующий ей процессор для языка:
{аО"1в}и{&Ои12»} п>0
13. Для следующей алголоподобной грамматики с начальным символом
(программа):
1. (программа)—»-(блок)
2. (программа) ->- (составной оператор)
3. (блок) -> (начало блока); (конец составного)
4. (начало блока) -*■ begin d
5. (начало блока) -»- (начало блока); d
6. (конец составного) ->- s end
7. (конец составного) -»- s; (конец составного)
8. (составной оператор) —>■ begin (конец составного)
а) Покажите, что это грамматика слабого предшествования.
б) Постройте анализатор на основе слабого предшествования.
в) Постройте соответствующий !мбэр сообщений об ошибках.
г) Постройте процедуры локальной нейтрализации ошибок.
д) Постройте процедуры глобальной нейтрализации ошибок.
14. а) Постройте грамматику слабого предшествования для 5-выражснип Лиспа.
б) Постройте соответствующий процессор.
в) Постройте сообщения об ошибках и процедуры нейтрализации.
15. Организуйте работу с ошибками для анализатора арифметических
выражений на рис. 12.9, построенного на основе слабого предшествования.
16. Для каждого из следующих автоматов разработайте отладочную цепочку (или
цепочки), при анализе которой (которых) возникали бы все неошибочные
конфигурации.
а) Рис. 12.5.
б) Рис. 12.9.
в) Рис. 12.14.
17. Для каждой отвергающей ситуации на рис. 12.18 найдите кратчайшую
входную цепочку, анализ которой приводит к этой ситуации.
18. Найдите три ошибочных цепочки, для которых неудовлетворительно
работают процедуры локальной нейтрализации на рис. 12.20. Объясните, что именно
плохо.
19. Переформулируйте определение грамматик слабого предшествования в
терминах отношений <-, <;•, =, ■ >, определенных в разд. 12.6.
20. а) Для языка
{wwr} w из (0+1) +
найдите грамматику без конфликтов переноса — опознания,
б) Покажите, почему этот язык нельзя распознать МП-автоматом.
21. На любом языке напишите программу, которая проверяет, является ли данная
грамматика грамматикой слабого предшествования и, если это так, строит
соответствующую программу-анализатор.
22. Напишите па любом языке программу, которая по данной грамматике
строит либо управляющую таблицу типа «перенос — опознание», либо список
конфликтов переноса — опознания.
23. Для некоторых грамматик, которые не содержат конфликтов переноса —
опознания, но не являются простыми ССП-грамматиками, можно построить
процедуры опознания, использующие при выборе основывающего правила
текущий входной символ.
а) Для следующей грамматики постройте автомат типа «перенос —
опознание», использующий такую возможность:
500 Гл. 12. Обработка методами типа «перенос—опознание»
(S)^{B)d
(А)^а
(В)-+а
Начальный символ: (S)
б) Сформулируйте принцип построения автомата, основанный на указанной
возможности.
24. Покажите, что для каждого контекстно-свободного языка существует
порождающая его грамматика без конфликтов переноса — опознания. (Ответ
см. в приложении В.)
25. Постройте цепочку атомов, являющуюся выходом синтаксического блока из
разд. 12.8 для отладочной программы на рис. 10.8.
26. Объясните, почему каждый из элементов, таблицы на рис. 12.26, помеченных
буквой Р, не может быть достигнут даже при обработке неправильных цепочек.
27. Перечислите сообщения об ошибках, которые выдает синтаксический блок,
построенный в разд. 12.8, при обработке следующей входной цепочки:
ID END
20 FOR Л = 1 STEP I TO S
за for в = г
АО LET Y = (В + (С * D)
50 NEXT A
b0lFA>B>CLETX = E,
70 GOSDB Ь5
АО GO TO 60
60 IF Л = В GOSDB вО
28. а) Покажите, что если в грамматике языка MINI-BASIC, приведенной на
рис. 12.22, правило 7 заменить на
7'(оператор) ->- ЕСЛИ (выражение) ОТНОШЕНИЕ
(выражение) ПЕРЕХОД НА
и удалить правило 8, то получится грамматика слабого предшествования.
б) Постройте соответствующий этой грамматике анализатор.
в) Пусть этот процессор обрабатывает программу на языке MINI-BASIC,
и пусть программа содержит единственный неправильный оператор
100 IF 1<X<2 GOTO 10
Покажите, что независимо от того, в каком месте программы встречается
этот неправильный оператор, процессор не обнаружит ошибку до тех пор,
пока не доберется до последнего END-оператора.
29. Постройте более тонкую, чем использованная в разд. 12.8, процедуру
нейтрализации ошибок.
30. Составьте неправильную программу на языке MINI-BASIC, для которой
синтаксический блок из разд. 12.8 выдает неприемлемые, вводящие в
заблуждение, сообщения об ошибках.
31. а) Предполагая, что лексический блок, описанный в гл. 4, работает
правильно, определите, какие из элементов таблицы переходов на рис. 12.26
соответствующих ошибкам, недостижимы,
б) Составьте небольшой набор программ на языке MINI-BASIC, вызывающий
все достижимые переходы, соответствующие ошибкам.
Упражнения
501
в) На основе результатов пункта а) постройте улучшенный набор сообщений
об ошибках.
32. а) Используя любой язык программирования, реализуйте синтаксический
блок, описанный в разд. 12.8.
б) Проведите отладку полученного блока с помощью программы на рис. 10.8.
Убедитесь, что для этой программы получается правильный выход.
33. Покажите, что грамматика языка MINI-BASIC, приведенная на рис. 12.22,
является простой ССП-грамматикоп.
34. Переделайте правила 11 —15 па рис. 12.24 гак, чтобы для FOR/NEXT-kohct-
рукций порождались атомы, позволяющие генерировать объектный код,
реализующий блок-схему на рис. 10.18 (вместо блок-схемы на рис. 10.3, а).
35. Покажите, что каждый раз, когда выбирается процедура опознания 12 на
рис. 12.27 и когда двумя верхними символами магазина являются ШАГ
(выражение), два предшествующих символа магазина — это (для-предложение)
(до-предложение).
36. Перепишите процедуры опознания па рис. 12.27, используя тот факт, что не
все цепочки магазинных символов могут оказаться в магазине. Например,
процедуру опознания 8 можно заменить на СВЕРТКА (1), а первую строку
процедуры 14 можно заменить на
если на верху магазина «(множитель) то СВЕРТКА (22)
37. Найдите S-атрибутную грамматику польского перевода с входной
грамматикой слабого предшествования, описывающую перевод языка MINI-BASIC,
выполняемый лексическим блоком из гл. 4.
38. Составьте неправильную программу на языке MINI-BASIC, в которой
процессор из гл. 10 обнаруживает ошибку раньше, чем процессор из разд. 12.8.
39. Рассмотрим следующую грамматику с начальным символом (тело) (Морзе
и Харрис, не опубликовано):
1. (тело) -»- ОПИСАНИЕ; (тело)
2. (тело) -»- (список операторов)
3. (список операторов) ->- (список операторов); ОПЕРАТОР
А. (список операторов) -> ОПЕРАТОР
а) Покажите, что это — не грамматика слабого предшествования.
б) Покажите, что для этой грамматики все-таки можно построить процессер
типа «перенос — опознание», так как во всех случаях, когда на верху
магазина одновременно находятся правые части правил 3 и 4, основывающим
является правило 3.
40. Грамматика называется грамматикой простого предшествования (Вирт и Ве-
бер [1966]), если не существует двух таких символов грамматики А а В, для
которых справедливы два или более из следующих отношений (определенных
в разд. 12.6):
А<- В
А---В
А >В
Грамматика называется однозначно обратимой или просто обратимой, если
она не содержит двух правил с одной и той же правой частью.
а) Покажите, что всякая обратимая грамматика простого предшествования
является грамматикой слабого предшествования.
б) Покажите, что язык порождается обратимой грамматикой простого
предшествования тогда и только тогда, когда он порождается некоторой
грамматикой слабого предшествования (Ахо, Деннинг и Ульман [1972]).
41. Объем автомата типа «перенос — опознание» иногда можно уменьшить с
помощью функций предшествования (Ахо и Ульман [1973а]). С каждым магазин-
502 Гл. 12. Обработка методами типа «.перенос—опознание»
ным символом к свяжем некоторое целое число /(.*) и с каждым входным
символом у свяжем целое число g(y). Заметим, что каждый терминал г является
как магазинным символом, так и входным, поэтому с г связываются два целых
числа /(г) и g(z). Предположим, что для магазинного символа х и входного
символа у, если х ПОД у, то /(x)<g(y), а если х СВЕРТЫВАЕТСЯ-ПО у, то
f(x)>g(y). Тогда управляющую таблицу автомата можно заменить таблицами
функций предшествования / и g.
а) Найдите функции предшествования для управляющей таблицы на рис. 12.9.
б) Найдите функции предшествования для управляющей таблицы на рис. 12.4.
в) Найдите функции предшествования для управляющей таблицы па
рис. 12.13.
г) Покажите, что следующая грамматика является бессуффнкенон ПО-грам-
матикой, но описать управляющую таблицу функциями предшествования
невозможно.
<S>->C4>a
(S) -> {В)Ь
(A) -> Ьа
(B) -+ аЬ
Начальный символ: (61)
д) Найдите функции предшествования для управляющей таблицы на
рис. 12.26. Для полученного процессора составьте сообщения об ошибках.
е) Опишите общую процедуру, которая выясняет, существуют ли функции
предшествования для данной управляющей таблицы типа «перенос —
опознание», и если да, то находит эти функции.
42. а) Операторная грамматика — это грамматика без «-правил, в которой
никакая правая часть правила не содержит двух рядом стоящих
нетерминалов. Покажите, что промежуточная цепочка, выведенная из начального
символа операторной грамматики, не может содержать двух рядом стоящих
нетерминалов.
б) Для данной операторной грамматики с начальным символом (S), определим
ТСЛЕД(Х), как множество входных символов, которые в промежуточных
цепочках, выводимых из (S) —| следуют непосредственно за X или за
нетерминалом, непосредственно следующим за X. Определим ТПЕРВ(Х)
как множество терминальных символов, которые встречаются в качестве
первых терминалов в промежуточных цепочках, выводимых из X.
Вычислите множества ТСЛЕД и ТПЕРВ для следующей грамматики:
(S)^a
(S) -> «S»
<S>-*(M»
M)-(S>, (S)
<A)-+(S), (A)
Начальный символ: (S)
в) Для некоторых операторных грамматик можно использовать метод разбора,
в котором выбор между переносом и опознанием делается на основе самого
верхнего символа магазина, не являющегося нетерминалом, и текущего
входного символа. Сформулируйте для управляющей таблицы такого
анализатора принципы свертывания и переноса, подобные тем, которые
приведены в разд. 12.2. Этот метод представляет собой вариант метода
операторного предшествования (Флойд [1963]).
г) С помощью принципов, сформулированных в пункте в), постройте автомат
для грамматики из пункта б).
д) С помощью указанных принципов постройте автомат для грамматики на
рис. 12.6. Предположите, что этот распознаватель должен выполнять
Упражнения
503
лишь «остовный» разбор (Грей и Харрисон [1972, 1973]), при котором один
магазинный символ представляет нетерминалы (Е), (Т) и (F), и правила
2 и 4 не распознаются ').
43. Пусть в управляющей таблице для простой ССП-грамматики операции
ПЕРЕНОС и ОПОЗНАТЬ содержатся только в тех элементах, для которых этого
требуют принципы переноса и свертывания.
а) Укажите способ, позволяющий по этой грамматике определить, какие из
отвергающих элементов управляющей таблицы не используются даже при
обработке неправильных цепочек.
б) Укажите способ, позволяющий по этой грамматике определить, в каких
процедурах опознания не требуется проверок, выявляющих ошибки.
') Об остовном разборе см. разд. 5.4,3 книги Ахо и Ульмана [1972а].—
Прим. ред.
13
Обработка методами типа
„перенос—свертка"
13.1. Введение
В этой главе мы рассмотрим методы обработки типа «перенос —
свертка». Возвращаясь к гл. 11, вспомним, что в процессе такой
обработки магазинные символы не просто представляют символы
грамматики, а еще и кодируют некоторую дополнительную
информацию, позволяющую автомату выполнять свертки только на
основе информации., содержащейся в верхнем символе магазина и
текущем входном символе, минуя этап опознания. По этой причине
в сравнении с процессорами типа «перенос — опознание» для
обработки данной входной цепочки обычно требуется меньше времени,
но больше памяти. Кроме того, процессоры типа «перенос —
свертка», описанные в этой главе, обладают некоторым специальным
свойством (которое мы обсудим в разд. 13.7), позволяющим, как
правило, добиться лучшей (по сравнению с процессорами типа
«перенос — опознание») диагностики и нейтрализации ошибок.
Методы типа «перенос — опознание» и типа «перенос — свертка»
применимы в точности к одному и тому же классу языков; т. е.
если некоторый язык можно распознавать автоматом одного из
этих двух типов, то его можно распознавать и автоматом другого
типа. Однако множество грамматик, для которых работают методы
типа «перенос — опознание», описанные в этой книге, является
собственным подмножеством множества грамматик, к которым
применимы описанные здесь методы типа «перенос — свертка».
13.2. Пример
Сначала рассмотрим задачу восходящего разбора для грамматики
на рис. 13.1. Эта грамматика не является простой ССП-граммати-
кой, так как имеет место конфликт переноса — опознания для
магазинного символа (А > и входного символа Ь.
Глубже вникнув в существо конфликта, мы видим, что
правильный выбор между переносом и опознанием (и даже между
переносом и сверткой) возможен, если можно установить,
соответствует ли символ (А > в магазине символу (А > в правой части
правила 1, или же он представляет символ (А) из правой части
правила 5. В первом случае основы на верху магазина нет, и автомат
13.2. Пример
505
должен втолкнуть в магазин символ Ь. Во втором случае на верху
магазина находится основа, и основывающим является правило 5.
Следовательно, нужно выполнить операцию СВЕРТКА(5).
В этой главе мы собираемся строить автоматы типа «перенос —
свертка», магазинные символы которых представляют вхождения
символов в грамматику, т. е. такие объекты, как «символ (А) в
правой части правила 1» и «символ (А ) из правила 5». Для удобства
рассуждений мы будем называть такие объекты «грамматическими
вхождениями». Точнее:
грамматическое вхождение (кроме определяемого ниже
начального вхождения) задается именем правила и номером
позиции. Позиция указывает место символа в правой части
данного правила, причем самый левый символ считается
первым.
Вхождение (А) в правую часть правила 1 задается правилом 1
и позицией 2, или, короче, парой (1,2), а с из правила 6 определяется
парой (6, 1).
В восходящем процессоре для грамматики на рис. 13.1 символ
магазина, представляющий нетерминал {S >, может соответствовать
вхождению (5) в правило 3, при этом следует выполнить операцию
СВЕРТКА (3). Однако этот символ магазина может соответствовать
и тому (5), с которого начинается вывод входной цепочки, и в
этом случае автомат должен допустить ее, если текущим входным
символом является концевой маркер.
Для того чтобы с этим вторым случаем
связать также грамматическое вхож- ) <5ч >а<л>б
дение, примем соглашение о том, что „ с
каждая грамматика содержит 3. <Л> ►6<S>
грамматическое вхождение, на- ' „
зываемое начальным вхождени-
ем и задаваемое начальным сим- 5- <в> *а <A">
волом грамматики. 6. <В>—>-с
,. , , Начальный символ: <5>
Часто бывает удобно
пользоваться таким обозначением вхождения Рис- 131-
символа, в котором явно указан
Этот символ. Одно из таких
обозначений — это запись грамматического вхождения в виде
символа грамматики с двумя индексами, дающими соответственно
имя правила и номер позиции. При этом вхождение (1, 2) в
грамматику на рис. 13.1 получит обозначение С4),, 2, так как второй
символ правой части правила 1 — это (А >. Аналогично вместо
(4, 1) будем писать (В)4, :. Преимущество обозначения (А >,, 2
по сравнению с (1, 2) заключается в том, что в первом случае видно,
506 13. Обработка методами типа «перенос—св?ртка»
что обозначаемое грамматическое вхождение — это вхождение
символа {А ).
Часто для определения грамматического вхождения бывает
достаточно знать грамматический символ и имя правила. Это имеет
место в тех случаях, когда правая часть данного правила содержит
лишь одно вхождение данного символа. В таких случаях
обозначение можно сократить, опустив индекс позиции. В рассматриваемом
<S>{<S>0)
<А >{<А >,ГЛ(й,
a(aj
Ь(ЬЛ)
Ь(Ь.)
<s>«s>,r
с{с7)
Рис. 13.2.
а,
а,
а,
а,
а,
<S>o
<А >, Ь,
<S>4646,
э5 <Л >5Ь4Ь,
а5 й3 <S >3 Ь4 Ь
а5 Ь3 с2 Ь4 Ь,
=»
=»
=>
=»
=>
=>
примере (Л >,, 2 можно сократить до {А >ь так как правая часть
правила 1 содержит единственное вхождение символа {А >, а именно
во второй позиции. Кроме того, мы используем один индекс 0 для
обозначения начального вхождения.
Если задано дерево вывода, можно очевидным образом
установить соответствие между его вершинами и грамматическими
вхождениями. Корню дерева ставится в соответствие начальное
вхождение, а каждой из вершин сопоставляется вхождение
соответствующего символа грамматики в правую часть того правила,
применение которого привело к появлению этой вершины в дереве
вывода. Например, на рис. 13.2, а изображено дерево вывода цепочки
ааЬсЪЪ в грамматике рис. 13.1. Около каждой вершины в скобках
указано соответствующее грамматическое вхождение.
Аналогично, если задан некоторый вывод, каждому символу
в любой промежуточной цепочке этого вывода можно сопоставить
грамматическое вхождение. На рис. 13.2, б показан правый вывод
цепочки aabcbb, причем для удобства вместо имен символов
используются имена грамматических вхождений.
13.2. Пример
507
Теперь мы покажем, как понятие грамматического вхождения
можно использовать в процессоре типа «перенос — свертка». На
рис. 13.3 изображен распознаватель типа «перенос — свертка»
для грамматики на рис. 13.1. На рис. 13.3, а изображена таблица
вталкиваний (предполагается, что незаполненные элементы
содержат операцию ОТВЕРГНУТЬ), а на рис. 13.3, б показана
управляющая таблица. В качестве магазинных символов автомат
использует грамматические вхождения. На рисунке вхождения
изображены с одним индексом, означающим номер правила.
Предполагается, что каждая процедура свертки состоит из определенного
числа операций ВЫТОЛК, равного длине правой части
соответствующего правила, за которым следует операция ТАВТОЛК,
выполняемая над нетерминалом из левой части правила так, как
это описано в гл. 11. Например, СВЕРТКА (1) эквивалентна
следующему:
ВЫТОЛК, ВЫТОЛК, ВЫТОЛК, ТАВТОЛК ((5))
Магазинный символ представляет тот символ грамматики,
вхождение которого в грамматику он обозначает, например
грамматический символ, представляемый магазинным символом {А)и—
это просто (А >. Информация, закодированная в магазинном
символе,— это описание некоторого конкретного вхождения
представляемого им грамматического символа. Так как автомат является
восходящим распознавателем, в процессе обработки допустимой
входной цепочки конкатенация цепочки, представляемой
магазином, и необработанных входных символов является промежуточной
цепочкой в выводе исходной цепочки. Автомат построен таким
образом, что
для каждой допустимой входной цепочки символы в
магазине— это грамматические вхождения соответствующих
символов представленной в автомате промежуточной цепочки.
Для иллюстрации этого свойства на рис. 13.4 изображена
последовательность конфигураций автомата, допускающего цепочку
aabcbb, ту же, что на рис. 13.2. Можно сравнить эти два рисунка
и убедиться в наличии соответствия. Например, видно, что ах
в магазине на рис. 13.4 соответствует вершине, помеченной
грамматическим вхождением а, на рис. 13.2, а, а также вхождениям aL
в промежуточных цепочках на рис. 13.2, б.
Рассмотрим строку 1 на рис. 13.4. На верху магазина
находится символ V. а текущим входным символом является а. Так
как верхний символ магазина— V. первый входной символ должен
начинать некоторую цепочку, выводимую из (S). Рассмотрев оба
правила для (S), мы видим, что первый входной символ должен
соответствовать одному из двух вхождений: ах или сг.
Следовательно, входной символ а должен соответствовать вхождению аи а не
a b c <S> <A> <B>
V
<s>0
*\
<A >,
ь,
c2
*3
<5>3
<Я>4
ь*
as
<A>5
c6
a,
35
a,
аь
b2
ь,
b.
ft,
C2
C6
C2
<s>0
<S>3
!
c6
<-4 >,
<^>6
<fl>4
<S>4
Таблица вталкиваний
v
<s>0
a1
<A >,
ft,
<s>3
<S>4
b4
</4 >.
ПЕРЕНОС
ОТВЕРГНУТЬ
ПЕРЕНОС
ПЕРЕНОС
СВЕРШИ)
СВЕРТКА! 2)
ПЕРЕНОС
СВЕРТКА(З)
ПЕРЕНОС
СВЕРШИ)
ПЕРЕНОС
СВЕРТКА(5)
СВЕРТКА(б)
ПЕРЕНОС
ОТВЕРГНУТЬ
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКАШ
СВЕРТКА (2)
ПЕРЕНОС
СВЕРТКА (3)
ПЕРЕНОС
СВЕРТКА (4)
ПЕРЕНОС
CBEPTKAI5)
СВЕРТКА (6)
ПЕРЕНОС
ОТВЕРГНУТЬ
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКАШ
СВЕРТКА (2)
ПЕРЕНОС
СВЕРТКА (3)
ПЕРЕНОС
СВЕРТКА (4)
ПЕРЕНОС
СВЕРТКА (5)
СВЕРТКА(б)
ОТВЕРГНУТЬ
ДОПУСТИТЬ
отверзнуть
ОТВЕРГНУТЬ
СВЕРТКАШ
СВЕРТКА (2)
ОТВЕРГНУТЬ
СВЕРТКА (3)
ОТВЕРГНУТЬ
СВЕРТКА (4)
ОТВЕРГНУТЬ
CBEPTKAI5)
СВЕРТКА (6)
Управляющая таблица
б
Рис 13.3.
13.2. Пример
509
аъ. И в самом деле, элемент таблицы вталкиваний в строке V и
столбце а указывает, что нужно втолкнуть в магазин символ а,.
Теперь рассмотрим строку 2 на рис. 13.4, где на верху магазина
находится а,, а входным символом является а. Так как а, — не
самое правое вхождение в правило 1, верхняя часть магазина
основу не представляет. По грамматике мы видим, что за вхождением
1.
2.
3.
4.
5.
6.
7.
8.
9.
10.
П.
12.
V
V я,
V я, а г,
V а1 я.- ft.,
V я, я- ft., с2
V я, «г, ft-, {5)3
V я, я- </«)-
V я, <«>.,
V я, (й>4 Ь4
va, <Л>,
Va, </!>, *,
^ <*>о
я я ft
a h
ft
ebb—,
ebb —'
С h Ь —;
r ft ft—:
ft ft-.
ft ft —
bb-\
b ft—|
ftH
ft^
4
H
ПЕРЕНОС
flFPEHOC
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА С2)
CBEPTKAG)
СВЕРТКАМ)
ПЕРЕНОС
С ВЕРТКА (4}
ПЕРЕНОС
CBEPTKA(l)
ДОПУСТИТЬ
а! должна следовать часть входной цепочки, порождаемая
вхождением {A >t. Цепочка, порождаемая С4 )ь может начинаться либо
вхождением Ь3, либо вхождением (В),. Цепочка, порождаемая (В)4,
может начинаться с аъ или с«. Следовательно, входной символ а
соответствует вхождению а5. а не аг. И действительно, элемент
таблицы вталкиваний в строке а, и столбце а указывает, что нужно
втолкнуть символ аъ.
В строке 3 на рис. 13.4 верхним символом магазина является
а6, а входным символом — Ь. По грамматке мы видим, что за
вхождением аь должно следовать вхождение {А )г„ которое может
порождать цепочку, начинающуюся с Ь3 либо с (б)4, которое в свою
очередь может порождать цепочку, начинающуюся с а-0 или св. Из
этого мы заключаем, что входной символ b соответствует вхождению
Ь3, а не bi или ft4-
В строке 4 на верху магазина находится Ь3, а входной символ —
с. Согласно грамматике, за вхождением Ь3 должно следовать
вхождение (S>3, которое может порождать цепочку, начинающуюся
с а, или с2. Значит, входной символ с соответствует вхождению сг.
В строке 5 на верху магазина находится с2, а входной символ —
Ь. Так как с2 — самое правое вхождение в своем правиле, присут-
510 13. Обработка метоОамч типа «перенос—свертка»
ствие сг на верху магазина говорит о наличии там основы, причем
основывающим является правило 2. Автомат выполняет операцию
СВЕРТКА (2), которая выталкивает с, из магазина и заменяет его
магазинным символом, представляющим грамматический символ
(S) — девую часть правила 2. Под основой в магазине находится
символ Ь3. Согласно грамматике, за вхождением Ь3 должно следовать
вхождение (S>3 и не может следовать вхождение (S>0. Поэтом"
вталкиваемым в магазин символом, представляющим
грамматический символ (S), должен быть символ {S)3. И действительно,
элемент таблицы вталкиваний в строке Ь3 и столбце (S) указывает,
что нужно втолкнуть символ (S)3.
В строке 6 на верху магазина находится (S)s, а на входе —
символ Ь. Так как (S)3 — самое правое вхождение в своем правиле.
на верху магазина находится основа и основывающим является
правило 3. Автомат выполняет операцию СВЕРТКА (3), которая
выталкивает из магазина два верхних символа и заменяет их
магазинным символом, представляющим (А >. Под основой в магазине
находится символ а5. Анализ показывает, что единственное
вхождение (А), которое может следовать за аъ,— это {А )5, а не (Л),.
Поэтому в магазин над аь помещается {А >5.
В дальнейшем переход от одной конфигурации к другой
происходит аналогичным образом. Наконец, в строке 12 на Еерху
магазина оказывается (S)0, а на входе появляется коннеиой маркер
—\. Символ (S>o на верху магазина представляет символ грамматики
(S), поэтому в данной конфигурации автомат допускает входную
цепочку.
Продемонстрировав распознавание автоматом конкретной
входной цепочки, займемся теперь вопросами построения таких
автоматов. Методы гл. 12 были основаны на отношении ПОД,
описывающем пары грамматических символов/которые могут быть
представлены соседними магазинными символами в процессе обработки
допустимой входной цепочки. В этой главе процедуры построения
основываются на рассмотрении того, какие пары (грамматических
вхождений^логут быть представлены соседними магазинными
символами в процессе обработки допустимой входной цепочки. Новые
методы построения мы будем выражать в соответствии с отношением
ВПОД, аналогичного отношению ПОД, но определяемого для
вхождений.
Прежде чем определить ВПОД, мы введем множества ВПЕРВ
по аналогии с множествами ПЕРВ.
Если Xt — грамматическое вхождение символа X, a Y} —
грамматическое вхождение символа Y, мы пишем
Xt принадлежит ВПЕРВ (Yj)
тогда и только тогда, когда
a) Xt — это само Yj, или
13.2. Пример
511
б) Xt начинает промежуточную цепочку, выводимую из Y
без применения е-правил.
Когда в условии б) мы говорим, что «Xt начинает промежуточную
цепочку, выводимую из У», формально это означает, что
К=>*</:>р=ФХа(3
для некоторых (L), а и р\ таких, что Xt — самое левое вхождение
в правой части правила:
(L)^Xa
Так как грамматика на рис. 13.1 не содержит е-правил, вторая
фраза в условии б) для нашего примера несущественна. Она
включена в определение для использования в последующих разделах,
где будут рассматриваться е-правила.
Обобщив определение множества ПЕРВ, мы теперь обобщим
отношение ПОД (определенное в разд. 12.4) до отношения ВПОД
следующим образом:
Если А — грамматическое вхождение или маркер дна, а
Yj — грамматическое вхождение, мы пишем
А ВПОД Yj
тогда и только тогда, когда выполнено одно из следующих
условий:
а) существует грамматическое вхождение Zh непосредственно
следующее за вхождением А в правой части некоторого
правила, и
Yj принадлежит BnEPB(Z,)
б) А—это маркер дна и Yj принадлежит ВПЕРВ ((S>0),
где (S)0 — начальное вхождение.
Возвращаясь к примеру на рис. 13.1, можно вычислить
ВПЕРВ(04>x)= К Ь„ с„ (А)и (В),}
и, следовательно,
fl! ВПОД а,, а, ВПОД Ь„ а, ВПОД с„
а, ВПОД <Л>Ь а, ВПОД <Я>4.
Матрица отношения ВПОД для данной грамматики приведена на'
рис. 13.5.
Таблица вталкиваний на рис. 13.3, а построена таким образом,
что символ вталкивается в магазин тогда и только тогда, когда
верхний символ магазина и вталкиваемый символ удовлетворяют
отношению ВПОД. Поэтому можно считать, что таблица вталкива-
512
13. Обработка методами типа мереное—свертка»
ний и указанная матрица представляют одну и ту же информацию.
Например, матрица показывает, что
а, ВПОД (А)и
а из таблицы вталкиваний мы видим, что (A )i — это то вхождение
символа (А >, которое следует втолкнуть в магазин над ах. Вообще
каждая строка таблицы вталкиваний содержит один непустой эле-
<s>n
<д>, 6,
< S >, < В >,
<А >.
V
s>0
в1
л>,
ь,
с2
из
5>з
S>4
Ь4
а5
*>Ь
Сб
1
1
1
^
J
1
1
I
|
1
1
1
1
i
!
1
i j i iii
. .4 . ... * : . .
1
I'll
j : . I i
1
I
1
_ _. _
1
1 i ! 1
; i
!
1
!
I
i
i
,
1 1
1 -J
Рис. 13.5. Отношение ВПОД.
мент для каждого непустого элемента матрицы отношения. Имена
вхождений в таблице вталкиваний — это имена столбцов матрицы,
содержащих 1 в соответствующих строках. Таким образом, таблицу
вталкиваний можно считать представлением отношения ВПОД.
Таблицу вталкиваний на рис. 13.3, а можно также
интерпретировать как определение некоторого конечного автомата,
обнаруживающего основы,— «детектора основ». Этот детектор основ
изображен на рис. 13.6. Состояния детектора основ — это магазинные
символы рис. 13.3, а, т. е. грамматические вхождения и маркер
13.2. Пример
513
дна. Входной алфавит состоит из грамматических символов и нового
символа ВЕРХ. Символ ВЕРХ служит для детектора основ
концевым маркером. Мы используем ВЕРХ вместо —| для того, чтобы
не путать входные цепочки детектора основ с входными цепочками
МП-автомата.
Переходы в столбцах, соответствующих символам грамматики,
совпадают с элементами таблицы вталкиваний на рис. 13.3, а.
Переходы в столбце, соответствующем символу ВЕРХ,— это вы-
V
<5>0
а,
<А >,
Ь,
из
<S>3
<В>,
а5
</1Х
а
в1
Э5
в1
в5
Ь
с
с2
ьз ] с6
ь,
t>4
"з
С2
С6
<s>
<s>0
<s>3
<А >
<А >,
<А >5
<В>
<в>„
<В>А
ВЕРХ
ПОКА НЕТ
НАЧАЛО
ПОКА НЕТ
ПОКА НЕТ .
ПРАВИЛО (1)
ПРАВИЛОМ)
ПОКА НЕТ
ПРАВИЛО(З)
ПОКА НЕТ
ПРАВИЛО^
ПОКА НЕТ
ПРАВИЛО®
ПРАВИЛО (6)
Рис. 13.6.
ходы. Для каждого состояния, соответствующего самому правому
грамматическому вхождению некоторого правила, выход в столбце
ВЕРХ обозначен именем этого правила; для состояния,
соответствующего начальному вхождению, выход называется «НАЧАЛО»;
для всех остальных состояний указан выход «ПОКА НЕТ».
Мы говорим, что цепочка грамматических символов а
оканчивается основой тогда и только тогда, когда существует терминальная
Цепочка В, такая, что ар\ является промежуточной цепочкой в
" Ф. Льюис и др.
514 13. Обработка методами типа «.перенос—свертка»
правом выводе из начального нетерминала и у этой промежуточной
цепочки есть основа, расположенная на конце а.
Мы называем автомат на рис. 13.6 «детектором основ», так как,
если на его вход подать цепочку а ВЕРХ, он определяет,
оканчивается ли а основой, и если да, то какое правило является
основывающим. Например, для цепочки
aab (S) ВЕРХ
детектор основы выполняет следующие переходы
уЛЙ1Ла5Лбэ^ <S3> ~ ПРАВИЛО (3)
Выход ПРАВИЛО (3) указывает на то, что цепочка
aab (S)
оканчивается основой, и основывающим является правило 3.
Кроме обнаружения основ, детектор основ распознает особую
цепочку
(S) ВЕРХ
В этом случае входная промежуточная цепочка — это начало
вывода, и детектор основ отмечает этот факт специальным выходом
«НАЧАЛО».
Чтобы проиллюстрировать использование выхода ПОКА НЕТ,
рассмотрим входную цепочку
а (В) ВЕРХ
Получив такую входную цепочку, детектор основ выполнит
следующие переходы:
у Л а, 52 <Д>4 ™ ПОКА НЕТ
Цепочка а (В) не оканчивается основой, но если мы присоединим
к ней терминальную цепочку Ь, то получится цепочка
а (В) Ь
у которой есть основа (В) Ь.
Вообще, если для входной цепочки
а ВЕРХ
детектор основ дает ПОКА НЕТ, это означает, что существует
терминальная цепочка р\ такая, что цепочка ар содержит основу,
часть символов которой принадлежит р.
Чтобы проиллюстрировать использование выхода
ОТВЕРГНУТЬ, рассмотрим входную цепочку
a (S) с ВЕРХ
13.2. Пример
515
Имея на входе такую цепочку, детектор основы выполняет
следующие переходы:
у Л a, i5 ОТВЕРГНУТЬ
Исследование грамматики показывает, что за вхождением ах не
может следовать вхождение (S), и поэтому цепочка a (S) с не
может быть началом никакой промежуточной цепочки в правом
выводе.
Вообще, когда детектор основ отвергает входную цепочку
а ВЕРХ
это означает, что а не оканчивается основой, и не существует такой
терминальной цепочки р\ что оф содержит основу, включающую
символы из р\
Теперь мы проиллюстрируем тесную связь между детектором
основ и МП-автоматом. Пусть нам известно, что в процессе
обработки некоторой входной цепочки МП-автомат приходит к
конфигурации, в которой магазин представляет цепочку
а а Ь (S)
но мы не знаем, какие именно грамматические вхождения
находятся в магазине. Ввиду того что накопление символов в магазине
и переходы детектора основ управляются одной и той же таблицей,
можно использовать детектор основ для восстановления
содержимого магазина. Для этого мы добавляем к цепочке, представляемой
магазином, символ ВЕРХ и подаем ее на вход детектора основ,
получая следующую последовательность переходов:
у Л fll Л а, Л 6, 15 <S>3 -™ ПРАВИЛО (3)
Последовательность состояний
V afibb3 <S>3
образует содержимое магазина в рассматриваемой конфигурации
МП-автомата, а выход ПРАВИЛО (3) указывает на то, что на верху
магазина находится основа, и основывающим является правило 3.
Этот выход подтверждает, что к магазину, содержимое которого
мы восстановили, нужно применить операцию СВЕРТКА (3).
Вообще, если a—цепочка, представляемая магазином в
некоторый момент обработки входной цепочки, то обработка детектором
основ цепочки
а ВЕРХ
приведет к последовательности состояний, совпадающей с
содержимым магазина, из которого была получена цепочка а, а
заключительный выход подтверждает правильность выбора следующей
516 13. Обработка методами типа «.перенос—свертка»
операции МП-автомата. Выход ПРАВИЛО (i) соответствует
операции СВЕРТКА (0; ПОКА НЕТ соответствует операции ПЕРЕНОС
(если очередной входной символ не —|); а выход НАЧАЛО
соответствует операции ДОПУСТИТЬ (если очередной входной символ
—!)• Выход ОТВЕРГНУТЬ выдается тогда и только тогда, когда
цепочку а вообще нельзя получить из содержимого магазина (она
не может быть представлена магазином, так как не начинает
никакой промежуточной цепочки в правом выводе).
Итак, у нас есть три интерпретации рис. 13.3, а: таблица
вталкиваний, отношение ВПОД и детектор основ как конечный автомат.
13.3. Еще один пример
Допустим, что мы должны найти процессор типа «перенос —
опознание» для грамматики на рис. 13.7. Рассмотрения из предыдущего
раздела подсказывают нам, что следует начать с построения
отношения ВПОД для грамматических вхождений. Это отношение
изображено на рис. 13.8. Заметим, что,
так как правая часть правила 1 содер-
! sSy >/A>(A>d жит Два вхождения (А), мы исполь-
<"?•> <A^d 3Уем для этих ВХ0ЖДений обозначения
* с двумя индексами: (А)^ j и (Л)^ 2.
3- <s> "b Все остальные вхождения записаны,
4. <Ау—></!><S>c как обычно, с одним индексом, указы-
5. <л> —, ей вающим номер правила.
б уду „ а Как и в предыдущем разделе, мы
• s^fe представим теперь отношение ВПОД таб-
' " лицей, столбцы которой помечены симво-
Начальныи символ: <S> лаш, Грамматики а элемент столбца,
Риг 14 7
ГИ1" помеченного данным символом,
содержит грамматические вхождения этого
символа, для которых в
соответствующей строке матрицы на рис. 13.8 есть единица. Полученная
таблица изображена на рис. 13.9, а. Она оказывается сложнее, чем в
примере из предыдущего раздела. Некоторые из элементов таблицы
содержат более одного грамматического вхождения. Одним из них
является элемент в строке (А )4 и столбце с, который содержит
два грамматических вхождения: с2 и с5. Это означает, что
справедливы два отношения:
{А >4 ВПОД с2 и {А >4 ВПОД съ
Наличие элементов, содержащих более одного грамматического
вхождения, делает невозможным использование таблицы на рис.
13.9, а в качестве таблицы вталкиваний для МП-автомата,
магазинными символами которого являются грамматические вхождения.
V
<S>o
<*>,.,
<A>,3
d,
c2
<A >2
*3
*3
<A >4
<S>,
<=A
>5
•ds
*6
<S>7
*7
<s>0
1
<А>,Л
1
1
1
1
<A>,,
1
Чу
1
Cj
1
.1
1
2
1
| |
1
L. -
d,
*3
I 1
i
1
1
1
<А>Л
1
1
1
<S>„
■'
i
|
1
._.
1
1
c.
1
c5
1
1
1
1
<v
1
1
1
1
1
<s>7
1
1
1
1
»1
1
Рис. 13.8. Отношение ВПОД для грамматики на рис. 13.7.
518 13. Обработка методами типа ^перенос—свертка»
Элемент таблицы вталкиваний должен указывать единственный
магазинный символ или операцию ОТВЕРГНУТЬ.
В предыдущем разделе предлагалась также возможность
интерпретации таблицы на рис. 13.9, а, полученной по отношению
V
<S>o
<*>,.,
<">,.,
"i
с2
<А >2
d7
Ьг
<Л >4
<S>4
с«
с5
"»
«G
<S>7
ь7
<s>
<s>0, <s>7
<s>7
<s>7
<s>4, <s>,
<A>
<А>,,.<А>Л
</»>,,. <A>,2,<A >4
</»>,,. </»>j,</»>4
</l >,,,,</» >4
3
*6
a6
a6
«6
b
*3
*3
*3
*J
by
С
c2, c6
c2-c5
c2,cs
C2-CS
c4
rf
<Л
«*2
*5
Рис. 13.9.
ВПОД как таблицы переходов конечного автомата — «детектора
основы» (с добавлением столбца для символа ВЕРХ), состояниями
которого являются грамматические вхождения, соответствующие
строкам таблицы. Ввиду того что некоторые из элементов на рис.
13.9, а содержат более одного грамматического вхождения, рис.
13.9, а следует интерпретировать как таблицу
недетерминированных переходов. Рис. 13.9, б отличается от рис. 13.9, а столбцом
для символа ВЕРХ, добавленным согласно правилам, описанным
13.3. Еще один пример
519
в предыдущем разделе. Строки, представляющие самые правые
вхождения, содержат имена соответствующих правил, строка для
начального вхождения содержит выход НАЧАЛО, остальные
строки содержат выход ПОКА НЕТ. Недетерминированный автомат
<s>„
<А>,
<А>,
<А>2
*г
<S>4
с*
я,
6
•5>7
*7
<S>
<А>
ВЕРХ
<s>0,<s>,
<s>7
<s>7
<s>4,<s>7
<A>, ,,,</»>„
<*>,„ <d>, 2, <d>„
<Д>, ,,<Д>2,<4>«
</>>,, ,</»>4
*6
Э6
Э6
aG
*3
*3
"з.
*з
*7
с2.с5
с2.съ
с2.съ
С2.С5
с4
rf,
^
rf5
ПОКА НЕТ
НАЧАЛО
ПОКА НЕТ
ПОКА НЕТ
ПРАВИЛОМ)
ПОКА НЕТ
ПОКА НЕТ ■
ПРАВИЛОМ)
ПРАВИЛОМ)
ПОКА НЕТ
ПОКА НЕТ
ПРАВИЛО (4)
ПОКА НЕТ
ПРАВИЛО(5)
ПРАВИЛО (6)
ПОКА НЕТ
ПРАВИЛО(7)
Рис. 13.9 (продолжение).
на рис. 13.9, б обладает следующим свойством: для входной цепочки
а ВЕРХ
где а — цепочка грамматических символов, последовательность
переходов, приводящая к выходу ПРАВИЛО (0, существует тогда
и только тогда, когда а оканчивается основой, и основывающим
является правило i.
На рис. 13.10, а показан детерминированный детектор основы,
полученный путем детерминизации автомата рис. 13.9, б. Пустые
0Г£! -эи<1
о
a)oimavdu
13 Н VMOU
Cg)0l/M8tfdU
(S)01/M9VdU
(HOI/MflVdU
X3H VMOU
(£) Ol/M9VdU
(Z)0l/M9VdU
1ЭН VMOU
1ЭН VMOU
(|)0l/M9VdU
i3H VMOU
J.3H VMOU
J.3HVMOU 'Ol/VbVH
13H VMOU
{ZP}
igp}
f'p}
{'0}
{5Э'гЭ}
(9э'гд}
(5э'гэ}
(5э'гэ)
{=э'гэ}
{'<?}
{'<?}
{Е<7}
{Е<?}
{Е<7}
<Е<7}
{'<?}
(Е<7)
{9Р}
{9Р}
{9Р}
{Эр}
{Эр}
{»<V>'ri< v>'li< v>]
{t<V>'z<V>'ll<V>}
{*< V>'li< V>'il< V>)
{"< У>'1Л< V>'Vi< V>)
{"< V>'il<V>.}
{L<S>'*<S>>
{L<S>}
C<s>',<s»
l'<s>"<s>!
{'<5>'°<5>}
{'«7}
{SP}
^<S>'"<S>}
{E<7}
{ZP)
{*<v>'z<v>'li<v>}
{lP}
{*< v>'z'l< v>'li< v>
{*< f>"'l< V>
{L<S>,0<S»
Ш
Xd39
< v>
<s>
13.3. Еще один пример
521
V
<s>„
<А>,
<А>Г
Чу
сх
<А>,
d2
63
<s>y
С4
^5
э6
<s>7
bi
<s>
<s>.
<s>y
<s>„
<s>7
<s>,
<A >
<A>,
<A >y
<A>y
<A>,
<A>y
a
a6
*6
4
a6
a6
b
b,
bj
b3
b3
b3
*3
*7
i
bj
с
с.
Сч
с*
Сх
с.
<М
d
Чу
Чь
ч2
ВЕРХ
ПОКА НЕТ
НАЧАЛО, ПОКА НЕТ
ПОКА НЕТ
ПОКА НЕТ
ПРАВИЛО(О
ПОКА НЕТ
ПОКА НЕТ
ПРАВИЛО (2;
ПРАВИЛО (3)
ПОКА НЕТ
ПРАВИЛО (4)
ПРАВИЛО (5)
ПРАВИЛО (6)
ПОКА НЕТ
ПРАВИЛО (7) '
i
Рис. 13.10 (продолжение).
элементы на рис. 13.10, а следует понимать как отвергающие
выходы, а не как переходы в состояние, представляющее пустое
множество.
На рис. 13.10, а имеется шесть строк, представляющих по
нескольку грамматических вхождений. Пять из них (все, за
исключением строки {(S)0, (S>7}) таковы, что элементы столбца ВЕРХ на
рис. 13.9, б для каждого из грамматических вхождений,
соответствующих этим строкам, содержат выход ПОКА НЕТ. Таким
образом, это подходящий выход независимо от того, какое
грамматическое вхождение было фактически представлено символом,
вызвавши.м переход детектора основ в состояние, соответствующее
строке.
Что касается строки {{S)0, (S),}, то элементы столбца ВЕРХ
для (S)o и (S)7 на рис. 13.9, б содержат соответственно выходы
522 13. Обработка методами типа мереное—свертка»
НАЧАЛО и ПОКА НЕТ. Можно считать, что у детектора основ на
рис. 13.10, а есть специальный выход, обозначаемый
НАЧАЛО, ПОКА НЕТ
Допустим, что автомат выдает этот выход, получив входную цепочку
а ВЕРХ
Тогда, ввиду того что для этой цепочки существует
последовательность состояний недетерминированного детектора основ рис. 13.9, б,
приводящая к выходу НАЧАЛО, цепочка а должна состоять из
единственного символа (S). Далее, так как для цепочки ВЕРХ
существует (другая) последовательность состояний автомата на
рис. 13.9, б, приводящая к выходу ПОКА НЕТ, существует
некоторая терминальная цепочка, присоединение которой к (S) дает
цепочку, имеющую основу. Таким образом, выход НАЧАЛО,
ПОКА НЕТ указывает на то, что автомат пришел к промежуточной
цепочке, состоящей из начального символа (S), что эта
промежуточная цепочка не оканчивается основой, но существует некоторое
терминальное продолжение, оканчивающееся основой.
Заметим, что для каждого состояния на рис. 13.10, а все
содержащиеся в нем грамматические вхождения — это вхождения одного
и того же символа. Например, все грамматические вхождения в
состоянии {(Л)! 1, {А), г, (А )4} являются вхождениями символа
{А). Это не удивительно, так как метод детерминизации автоматов
может поместить два состояния в одно и то же множество лишь в
том случае, когда существует столбец, соответствующий некоторому
входному символу и содержащий переходы к обоим состояниям.
Каждый столбец на рис. 13.9 содержит переходы только к
грамматическим вхождениям (входного) символа, расположенного над
этим столбцом. Тот факт, что каждое состояние детерминированного
автомата содержит грамматические вхождения только одного
символа, позволяет переименовать состояния таким образом, что
каждое имя будет состоять из грамматического символа, общего для
всех вхождений, содержащихся в состоянии, и индекса. На рис.
13.10, б показан детектор основ, полученный путем такого
переименования.
Каждое состояние, содержащее единственное грамматическое
вхождение, получает имя этого вхождения. Так, {d,}
переименовывается в d, и т. д. Состояния, содержащие по нескольку
вхождений, аименно{(5„>, (S>7}, {(5>4, (S>7), {(А)к ,, (А),}, {(Л),, „
<Л>12, (Л>4}, {(А)ки С4>2, {А)А} и {с2, с5} переименовываются
соответственно в (S)'x, (S)y, (А)х, {А)у, (А )2 и сх.
На рис. 13.11 изображен распознаватель типа «перенос —
свертка» для данной грамматики. Можно представлять себе, что он
получен из детектора основ рис. 13.10,6. Магазинными символами
автомата типа «перенос — свертка» являются состояния детерминн-
13.3. Еще один пример
523
рованного детектора основ, таблица вталкиваний — это
управляющая таблица детектора основ без столбца ВЕРХ, а элементы
управляющей таблицы типа «перенос — свертка» определяются
столбцом ВЕРХ детектора основ.
7
<S>K
<А>„
<А>у
Чу
с*
<А>,
ь3
<S>„
аб
<s>7
<s>
<А>
<s>.
<S>K
<s>K
<s>7
<s>K
<A>„
<A>Y
<A>y
<А>г
<A>y
a6
as
a6
a6
a6
b3
by
ь3
b3
b3
h
by
by
c.
c.
c,
c*
c„
c4
Чу
*ь
ч2
Рис. 13.11. (а) Таблица вталкиваний;
Элементы управляющей таблицы типа «перенос — свертка» —
это действия, определяемые столбцом ВЕРХ детектора основы.
Каждый раз, когда автомат на рис. 13.11 вталкивает символ в
магазин, этот символ совпадает с тем состоянием, в котором оказался бы
детектор основ на рис. 13.10, б, получив цепочку символов
грамматики, представляемую магазином. Если верхний символ в
магазине совпадает с состоянием, для которого на рис. 13.10, б элемент
524 13. Обработка методами типа «перенос—свертка»
в столбце ВЕРХ содержит ПРАВИЛО (i), то представляемая
магазином цепочка оканчивается основой и основывающим является
правило i. Поэтому строка управляющей таблицы для этого
магазинного символа заполняется операциями СВЕРТКА (г). Для ма-
v
<s>,
<А>„
<А>у
<л
с,
<А >,
<S>„
<s>,
ь7
a
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА! 1>
ПЕРЕНОС
ПЕРЕНОС
C6EPTKAI2)
СВЕРТКА(З)
ПЕРЕНОС
СВЕРГКА14)
СВЕРТКА (5)
СВЕРТКА(б)
ПЕРЕНОС
СВЕРТКА (7)
Ь
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА! 1)
ПЕРЕНОС
ПЕРЕНОС
CBEPTKAI2)
свертка о)
ПЕРЕНОС
СВЕРТКА(4)
СВЕРТКА (5)
CBEPTKAI6I
ПЕРЕНОС
CBEPTKAI7)
с
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА! 1)
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА (2)
СВЕРТКА (3)
ПЕРЕНОС
СВЕРТКА (4)
СВЕРТКА (5)
СВЕРТКА (6)
ПЕРЕНОС
СВЕРТКА (7)
d
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
перЕнос
СВЕРТКА (1)
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА (2)
СВЕРТКА (3)
ПЕРЕНОС
СВЕРТКА (4)
СВЕРТКА (5)
СВЕРТКА i6)
ПЕРЕНОС
CBEPTKAI7)
-(
ОТВЕРГНУТЬ
ДОПУСТИТЬ
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
C8EPTKAU)
ОТВЕРГНУТЬ
ОТВЕРГНУТЬ
СВЕРТКА (2)
СВЕРТКА (3)
ОТВЕРГНУТЬ
СВЕРТКАМ)
СВЕРТКА (5)
СВЕРТКА (6)
ОТВЕРГНУТЬ
СВЕРТКА (7)
Рис. 13.11 (б) Управляющая таблица.
газинных символов, которым в столбце ВЕРХ детектора основ
соответствует выход ПОКА НЕТ, управляющая таблица типа
«перенос — опознание» содержит ПЕРЕНОС во всех столбцах,
кроме столбца концевого маркера, где указана операция
ОТВЕРГНУТЬ. ПЕРЕНОС в данном случае является правильным решением,
так как тот факт, что столбец ВЕРХ содержит выход ПОКА НЕТ,
означает, что представляемая магазином цепочка не оканчивается
основой,однако некоторое продолжение ее подходящими терминалами
13.4. ЪЩО)-грамматики 525
f
может дать цепочку, оканчивающуюся основой. Элемент,
содержащий операцию ОТВЕРГНУТЬ, необходим для соблюдения
общего правила: наши автоматы не продвигаются далее концевого
маркера.
Для магазинного символа (S)x, имеющего в столбце ВЕРХ
детектора основ выход НАЧАЛО, ПОКА НЕТ, управляющая
таблица содержит ПЕРЕНОС во всех столбцах, кроме столбца
концевого маркера, где указана операция ДОПУСТИТЬ. Выбор
операции ДОПУСТИТЬ в данном случае верен, так как представляемая
магазином цепочка — это начальная промежуточная цепочка (S >,
порождающая всю входную цепочку. В остальных столбцах такой
выбор был бы неправильным, так как в этих случаях
представленная в магазине промежуточная цепочка (S) порождает лишь часть
входной терминальной цепочки. Для этих столбцов подходит
операция ПЕРЕНОС, так как представляемая магазином
промежуточная цепочка не оканчивается основой (хотя некоторое
продолжение ее подходящими терминалами может оканчиваться основой).
Поскольку мы показали, что все возможные шаги автомата
правильны, становится очевидным, что этот автомат является
распознавателем типа «перенос — свертка» для данной грамматики.
В предыдущем разделе мы рассмотрели МП-автомат, магазинные
символы которого интерпретировались как грамматические
вхождения или как состояния детектора основ. Это было возможно, так
как множество вхождений и множество состояний совпадают. В
примере из данного раздела мы обнаруживаем, что состояния
детектора основ соответствуют множествам грамматических вхождений и
что распознаватель использует в качестве магазинных символов
эти состояния, а не грамматические вхождения. Причина выбора
состояний детектора основ в качестве главной интерпретации
магазинных символов состоит в том, что именно детерминированный
детектор основ позволяет сделать выбор между операциями
переноса и свертки.
13.4. LR(0) -грамматики
В предыдущем разделе мы взяли грамматику на рис. 13.7, и ряд
неформальных шагов (рис. 13.8—13.10) привел нас к распознавателю
на рис. 13.11, магазинные символы которого можно было
рассматривать как состояния «детектора основ». В этом разделе мы
определим формальную процедуру, описывающую такое построение в
общем случае. Эта процедура применима только для грамматик
без е-правил, а класс грамматик, для которых она успешно
работает, известен под названием «LR(0)-rpaMMaTiiKn без е-правил».
Для любой данной грамматики без е-правил следующая
процедура либо строит распознаватель типа «перенос — свертка»,
526 13. Обработка методами типа ^перенос—свертка»
либо указывает, что данная грамматика не принадлежит классу
LR(0):
1. Вычислить для данной грамматики отношение ВПОД.
2. Построить недетерминированную таблицу, имеющую по
одной строке для каждогочграмматического вхождениями маркера дна,
а также по одному столбцу для каждого^рамматического символа.
Элемент в строке At и столбце В содержит все грамматические
вхождения Bj символа В, такие, что
At ВПОД Вj
3. Переделать таблицу, полученную на шаге 2, в
детерминированную, рассматривая ее как таблицу переходов
недетерминированного конечного автомата с начальным состоянием,
соответствующим маркеру дна.
4. Состояния, полученные на шаге 3 (кроме состояния,
соответствующего пустому множеству), нужно использовать в качестве
магазинных символов. Таблица переходов используется в качестве
таблицы вталкиваний (причем переходы к состоянию,
соответствующему пустому множеству, понимаются как элементы, содержащие
операцию ОТВЕРГНУТЬ).
5. Управляющая таблица типа «перенос — свертка»
заполняется строка за строкой согласнофножествам грамматических
вхождении^ соответствующим магазинным символам (состояниям),
помечающим строки.
а) Если единственным элементом множества является
начальное вхождение, то в элемент строки, соответствующий
концевому маркеру, заносится операция ДОПУСТИТЬ,
а во все остальные элементы строки — операция
ОТВЕРГНУТЬ.
б) Если единственным элементом множества является
грамматическое вхождение, самое правое в правиле р, то во все
элементы строки помещается СВЕРТКА(р).
в) Если магазинным символом, помечающим строку,
является •маркер дна" или если все грамматические вхождения
из множества, представляемого этим магазинным
символом, не являются самыми правыми в своих правилах, то
в элемент для концевого маркергЬзаносится операция
ОТВЕРГНУТЬ, а во все остальные элементы строки —
ПЕРЕНОС.
г) Если множество содержит начальное вхождение и хотя бы
одно вхождение, отличное от начального, но не содержит
ни одного самого правого вхождения, то в элемент для
маркера'/дна, помещается операция ДОПУСТИТЬ, а во
все остальные элементы строки — ПЕРЕНОС.
13.4. ЪЩО)-грамматики
527
Если обнаружено множество грамматических вхождений, не
учтенное пунктами а), б), в) и г), то грамматика не принадлежит
классу LR(0) и процедура не приводит к построению автомата.
Процедура не может построить распознаватель типа «перенос — свертка»
только в том случае, когда в детерминированной таблице,
полученной на шаге 3, есть состояние, которое одновременно содержит
некоторое самое правое вхождение и еще какое-нибудь вхождение.
Название «LR(0)-rpaMMaTHKa» указывает на то, что для нее
существует МП-автомат, который начинает просмотр слева
(Left), распознает правило, когда добирается до самого правого
(Rightmost) символа, выводимого из этого правила, и может
обнаружить любую основу без просмотра входных символов (т. е.
просмотром нулевого количества символов), расположенных правее
последнего входного символа, выводимого из основы. Всякая
грамматика, для которой описанная выше процедура успешно строит
автомат, этим свойством обладает, так как, когда на верху
магазина оказывается основа, автомат выполняет свертку независимо
от текущего входного символа. Таким образом, автомат «не
заглядывает» за основу. И наоборот, имеет место такой факт: для
всякой грамматики без е-правил, обладающей указанным свойством,
применение описанной процедуры заканчивается построением
автомата. Мы не будем заниматься здесь довольно сложным
доказательством этого факта.
Таблицы вталкиваний, получаемые с помощью описанной выше
процедуры, обычно содержат строки, целиком заполненные
операцией ОТВЕРГНУТЬ. На рис. 13.3, а семь таких строк, включая
строки (S)o и Ь\. На рис. 13.11. а также семь таких строк. Пустая
строка таблицы вталкиваний означает, что автомату запрещается
вталкивать какие-либо символы в магазин после данного
магазинного символа. Согласно построению, пустые строки соответствуют
магазинным символам, представляющим самые правые вхождения
или начальное вхождение, а механизм управления даже не пытается
вталкивать символы в магазин после какого-либо из таких
символов. Таким образом, автомату ни при каких обстоятельствах не
потребуется информация, содержащаяся в этих строках, и их
незачем включать в таблицу вталкиваний. Поэтому можно дополнить
нашу процедуру следующим шагом:
6. Удалить из таблицы вталкиваний все строки, содержащие
только элементы с операцией ОТВЕРГНУТЬ.
В последующих разделах мы опишем методы
усовершенствования шага 5 описанной процедуры, так чтобы с ее помощью можно
было строить МП-автоматы для некоторых грамматик, не
принадлежащих классу LR(0). Кроме того, мы рассмотрим
усовершенствования, позволяющие работать с е-правилами.
528 13. Обработка методами типа «перенос—свертка»
13.5. SLR(l)-грамматики
В этом разделе мы пересмотрим шаг 5 процедуры, описанной в
предыдущем разделе, чтобы получить анализаторы для некоторых
грамматик, не принадлежащих классу LR(0). В качестве примера возьмем
уже знакомую нам грамматику на рис. 13.12.
Шаг 1 процедуры, описанной в разд. 13.4, дает нам таблицу
отношения ВПОД, изображенную на рис. 13.13, а. После шага 2
получаем недетерминированную таблицу, показанную на рис. 13.13,6.
После шага 3 получается детерминированная таблица на рис. 13.14,й.
Для удобства переименуем состояния и придем к рис. 13.14, б.
В случае когда имеется лишь одно
грамматическое вхождение символа (напри-
j ^£ч /£ч , /^ мер, +i единственное вхождение
символа +), его индекс на рис. 13.14, б опу-
2-<Е>—><Т> щен, а состояния {(Е)0, (£)i}, {<£>,,
3. <7'> — <7><Я> <£>„}, {(Г>2, (Г),} и {(Т\, (Г)я}
/р\ переименованы соответственно в (£}д.,
4. </> — <f> {Е)^ {т)х и {т)^ Таблица на рис
5. <Р>—»■ а 13.14, б будет использоваться в качестве
6 /ру *■«£» таблицы вталкиваний в соответствии с
шагом 4.
Начальный символ: <£> j_ja шаге 5 мы обнаруживаем, что на-
р ]3 (2 ша грамматика не принадлежит классу
LR(0), так как магазинные символы (Т )х
и {Т)у не удовлетворяют условиям
пунктов а), б), в) и г), применяемых на
этом шаге (множества вхождений, соответствующие этим символам,
содержат самые правые вхождения символа (Г) и не являются
одноэлементными). Поэтому на шаге 5 не удается построить элементы
управляющей таблицы для строк (Т)х и (Т)у. Однако мы покажем,
что, сделав некоторый дополнительный анализ, можно заполнить
эти строки надлежащим образом. Этот анализ проводится для
каждого элемента строки отдельно и использует информацию о том,
как текущий входной символ связан с данным элементом. Таким
образом, получающийся автомат «смотрит» на этот входной символ,
чтобы выбрать между переносом и сверткой.
Рассмотрим, например, элемент управляющей таблицы для
магазинного символа {Т)х и входного символа +. Тот факт, что
множество вхождений, представляемое (Т)х, содержит самое правое
вхождение (Г>.2, наводит на мысль, что в этой ситуации можно
выполнить операцию СВЕРТКА(2), а наличие в этом множестве
вхождения (Т)3 свидетельствует в пользу операции ПЕРЕНОС.
Однако после переноса входного символа + вход неминуемо будет
отвергнут, так как таблица вталкиваний требует вызова процедуры
ОТВЕРГНУТЬ при попытке вталкивания символа + над символом
<£>„ <£>, +, <Г>, <Г>2 <7">з 'з <Р>, <Р>Л аъ (6 <£>6 )6
( I <£>
<Т> <Р-
V
<£>0
<£>,
+ i
<Г>,
<т>,
<т>,
з
<Р>,
<P>t
*5
<6
+ ,
—
1
■—•
3
а5
*5
(б
(.
аЪ , <6
!
i
i
—
<£>„,<£>,
<7->2,<7->з j <Р>Л
\
'. < т >,. < г >3 ! < р >< ;
1
■ !
Г._ .._i J
ч
i ._ ..
:
1
<р>2
:
а5:;(6! ! <£>,.<£>6 <Г>2.<Г>3 </>>„
'! ' ' :
1 )6 !
i i i ;
6
Рис. 13.13.
■we i эи<1
P
z<d>
"<</>
><</>
*<d>
"<1>
*<!>
"<!>
л<з>
*<3>
•
(
)
)
)
)
в
e
e
e
*
«
+
+
<d>
<1>
o>
D
( )
z<d>
A<1>
(
"<3>
*<_£>
"<3>
)
iz<d»
{*<</■>)
{*<</>}
{"<</>}
{E<J>"<i>}
{*<±>'1<1>}
{E<JL>'3<-£»
{9< J >'*<*>}
C<3>'°<3»
{90
<9)}
<9)}
{9)}
{9)}
iqe)
{s»>
{S*}
{••}
{E.)
{M
{'+}
('+}
P<</>)
(E<i>'
{9D
Iе.)
{4}
l9o>-
{*<</>}
{E<i>'
{l<3>'
(9)}'
{9e}
l<i>}
l<5>}
г<1>}
°<3>]
<d>
<1>
<3>
I )
13.5. SLR([)-epaMMamuKu
531
{T)x. Поэтому для допустимых входных цепочек приемлемой будет
лишь операция СВЕРТКА(2), и ее можно поместить в
рассматриваемый элемент управляющей таблицы.
Снова рассмотрим магазинный символ {Т)х, но в качестве
входного возьмем на этот раз символ *. Теперь таблица вталкиваний
указывает, что при обработке допустимых входных цепочек перенос
символа * может быть правильным действием. Более того, мы можем
показать, что в этом случае применение операции СВЕРТКА(2)
было бы ошибкой. Если входная цепочка допустима, то выбор
операции СВЕРТКА(2) приведет к тому, что некоторый магазинный
символ, представляющий нетерминал (Е), левую часть правила 2,
будет помещен в магазин. Текущим входным символом при этом
остается *, поэтому конкатенация содержимого магазина и
необработанных входных символов должна представлять некоторую
промежуточную цепочку, в которой за вхождением (£>
непосредственно следует *. Однако нетрудно установить, что * не принадлежит
множеству СЛЕД((£>), и, значит, такой промежуточной цепочки
не существует. Таким образом, операция СВЕРТКА(2)
исключается, и в соответствующий элемент управляющей таблицы можно
поместить ПЕРЕНОС.
Принципы, проиллюстрированные приведенными выше
рассуждениями, позволяют пересмотреть шаг 5, описанной в
предыдущем разделе процедуры проверки ЬН(0)-свойства и построения
анализатора. Грамматики, для которых этот пересмотренный шаг
выполним, обычно называют «5ЬН(1)-грамматиками без е-правил».
В следующем разделе мы рассмотрим работу с е-правилами. Новый
шаг 5 выглядит так:
5. Для данных магазинного символа, представляющего маркер
дна или^шожество грамматических вхождений^, и входного
символа z соответствующий элемент управляющей таблицы типа
«перенос — свертка» определяется следующим образом:
а) Если Q содержит начальное вхождение, а г — концевой
маркер, то элементом таблицы будет операция
ДОПУСТИТЬ.
б) Если входной символ г — не концевой маркер и в таблице
вталкиваний для данных входного и магазинного символа
содержится операция ОТВЕРГНУТЬ, то элементом будет
ПЕРЕНОС.
в) Если Q содержит самое правое вхождение в правиле риг
принадлежит СЛЕД((1>), где (L) — левая часть
правила р, то элементом будет СВЕРТКА(р). Если при
построении управляющей таблицы в соответствии с пунктами
а), б) и в) возникают противоречащие друг другу
требования, то грамматика не принадлежит классу SLR(l).
532 13. Обработка методами типа «перенос—свертке»
Элементом, на который не распространяются требования
а), б), в), может быть операция ОТВЕРГНУТЬ.
Единица в обозначении SLR(l) отражает тот факт, что при
разборе просматривается один символ после основы, а буква S взята
<т>.
<Р>Л
СВЕРТКА !51
ПЕРЕНОС
СВЕРТКА'2)
СВЕРТКАМ)
ПЕРЕНОС
СВЕРТКА'6)
СВЕРТКАМ)
СВЕРТКА (3)
СВЕРТКА. 5)
ПЕРЕНОС
СВЕРТКАИ)
СВЕРТКА (6)
ПЕРЕНОС
СВЕРТКА'З)
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
пеРЕНос
СВЕРТКА (5)
СВЕРТКА! 2)
CBEPTKAI4)
ПЕРЕНОС
СВЕРТКА(б)
СВЕРТКА (1)
СВЕРТКА (3)
СВЕРТКА (5)
ДОПУСТИТЬ
СВЕРТКА(2)
СВЕРТКА (4)
СВЕРТКА(б)
CBEPTKAd)
СВЕРТКА(З)
<г>„
<Р>з , L
в незаполненных элементах предполагается ОТВЕРГНУТЬ
Рис. 13.15.
из слова «simple» (простой), чтобы подчеркнуть отличие от более
сложного класса ЁЙ(1)-грамматик.
Множества СЛЕД для рассматриваемой грамматики таковы:
СЛЕД«£»Н + , )• -1}
СЛЕДКГ» = {», +, ), 4}
СЛЕД«Р» = {*, +, ), 4}
Управляющая таблица, полученная согласно пересмотренной
процедуре, показана на рис. 13.15. Этот рисунок вместе с
таблицей вталкиваний на рис. 13.14, б представляет собой полностью
построенный автомат.
Как и в случае 1Л?(0)-грамматик, процедура построения такова,
что полученный автомат никогда не обращается к элементам строк
13.6. Эпсилон-правила
533
таблицы вталкиваний, которые содержат только операцию
ОТВЕРГНУТЬ. Поэтому предложенный в предыдущем разделе шаг 6,
состоящий в исключении пустых строк таблицы вталкиваний,
применим и здесь. Таким образом, из рис. 13.14, б можно удалить
строки а, <Р>4 и (Р)3.
13.6. Эпсилон-правила
Рассмотрим теперь задачу построения автомата типа «перенос —
свертка» для случая, когда данная грамматика содержит е-пра-
вила. Сначала возьмем грамматику, изображенную на рис. 13.16,
с е-правилами 2 и 6. Одной из цепочек, порождаемых этой грамма-
1. (S)-^d(A)a
2. (S)-*e
3. (A)-*a(S)(B)
4. (A)-+d(S)c
5. </?>-» 6
6. (B)-*e
Начальный символ v (S)
Рис. 13.16.
тикой, является daa, и на рис. 13.17 показано дерево вывода этой
цепочки.
Задача построения автоматов для грамматик с е-правилами в
сущности не отличается от задачи, рассмотренной нами ранее в
этой главе, и осложняется только тем, что надо решать, когда на
верху магазина находится основа, соответствующая е-правилу. На
каждом шаге работы автомата верхняя часть магазина совпадает с
правой частью любого е-правила р, и поэтому имеются основания
для того, чтобы каждый элемент управляющей таблицы сделать
операцией СВЕРТКА(/?), если только разработчику не удастся
найти доводы в пользу какого-либо другого решения.
Для иллюстрации работы автомата типа «перенос — свертка» в
случае грамматики с е-правилами на рис. 13.18, а показана
последовательность конфигураций автомата, получаемая при обработке
входной цепочки daa. Рисунок не совсем точен, так как в качестве
магазинных символов показаны символы грамматики, а не символы
магазинного алфавита окончательно построенного автомата. Од-
<S:
d <A > а
a <S> <B
е г
Рис. 13.17.
534 IS. Обработка методами типа «.перенос—свертка»
нако степень детализации достаточна для того, чтобы увидеть
результаты применения операций СВЕРТКА(2) и СВЕРТКА(б) на
шагах 3 и 4. В каждой из восьми конфигураций верхние нулевые
символы магазина совпадают с правыми частями правил 2 и 6,
однако управление должно быть организовано таким образом, чтобы
пустая цепочка на верху магазина признавалась за основу лишь
в строках 3 и 4.
1.
2.
3.
4.
5.
5.
7.
8.
V
Ч d
V d a
V d a <S>
V d a <SXB>
V d <A>
V d <A> a
V <S>
d a a н
a a -H
a ч
a н
a -\
a H
-i
ч
ПЕРЕНОС
ПЕРЕНОС
CBEPTKA(2)
СВЕРТКА®
CBEPTKA(3)
ПЕРЕНОС
CBEPTKA(I)
ДОПУСТИТЬ
а
8. <S> =>
6,7. d <А> а =>
5. d a <SXB> a =r>
4. c/ a <S> _ a =^>
1,2,3. d a _ a
Рис 13.18.
На рис. 13.18, б изображен правый вывод, соответструющий
рассматриваемой последовательности конфигураций. Каждая
конфигурация на рис. J 3.18, а соответствует представляемой ею
промежуточной цепочке вывода, и для указания этого соответствия
каждая промежуточная цепочка на рис. 13.18, б помечена номерами
соответствующих конфигураций. Основа каждой промежуточной
цепочки подчеркнута. Заметим, что в двух последних
промежуточных цепочках основами являются пустые подцепочки. В данной
последовательности конфигураций операция СВЕРТКА(2) или
СВЕРТКА(б) выполняется только тогда, когда основой
представленной в автомате промежуточной цепочки является пустая цепочка,
13.6. Эпсилон-правила
535
а магазин содержит часть этой промежуточной цепочки,
оканчивающуюся основой.
Процедура построения автомата для 5Ы?(1)-грамматики с е-
правилами начинается теми же четырьмя шагами, что и раньше. На
этих шагах к-правила полностью игнорируются и результаты
получаются такие же, как если бы мы удалили из грамматики все е-пра-
вила. Это происходит оттого, что добавление к грамматике или
удаление из нее е-правил не изменяет множества грамматических
вхождений и никак не влияет на отношение ВПОД. Все модификации
процедуры построения относятся к шагу 5 и имеют вид
дополнений.
Чтобы приблизиться в нашем примере к критической точке,
выполним первые четыре шага процедуры. На рис. 13.19 показано
отношение ВПОД, получаемое на шаге 1. На рис. 13.20 изображена
таблица, получаемая на шаге 2. Эта таблица оказывается
детерминированной, не изменяется на шаге 3 и используется в качестве
таблицы вталкиваний.
Построение управляющей таблицы основано на расширенной
версии шага 5, описанной в предыдущем разделе. Эта расширенная
версия включает в себя пункты а), б), в) из предыдущего раздела и
позволяет установить, какие элементы управляющей таблицы
должны содержать операции ДОПУСТИТЬ, ПЕРЕНОС и СВЕРТКА^)
для правил с непустыми правыми частями. К этому нужно добавить
новый пункт, определяющий элементы управляющей таблицы,
которые должны содержать операции СВЕРТКА(/?) для е-правил.
Грамматика принадлежит классу SLR(l), если при работе процедуры
указанные четыре пункта не предъявляют противоречивых требований
к данному элементу управляющей таблицы.
Добавляемый четвертый пункт основан на идее, подобной тем,
которые были использованы в остальных пунктах. С помощью
различных отношений мы пытаемся показать, что некоторые элементы
управляющей таблицы не могут содержать операцию СВЕРТКА(/>)
для е-правила р и надеемся, что этого будет достаточно, чтобы
избежать конфликтов при определении элемента.
Сначала рассмотрим правило 6. Операция СВЕРТКА(б) не.
удаляет из магазина ни одного символа, так как длина правой части
правила 6 равна нулю. Единственным результатом этой операции
является вталкивание в магазин некоторого магазинного символа,
представляющего символ (В >, левую часть правила 6. Вталкиваемый
символ определяется элементом столбца (В) таблицы вталкиваний
в строке, соответствующей тому самому магазинному символу,
который, согласно управляющей таблице, был использован при выборе
операции СВЕРТКА(б). Так как единственным неотвертающим
элементом столбца {В) таблицы вталкиваний является элемент в
строке <S>3, мы заключаем, что магазинный символ,
представляющий (В), можно поместить в магазин только над символом (S )3. По-
<S>0 r/, <A >, a, a3 <S>3 <8>3 rf4 <S>4 cA b.
V
<S>o
"i
<A >, '
'<i
<S>3
<в>3
<s>A
1
1
1
1
1
1
1
1
1
1
i
1 1
1
1
1
V
<s>0
c>
<л>,
a,
a2
<S>3
<s>,
<>4
Отношение 6 ПОД
Рис. 13.19.
S> <A> <B>
г, ■
^ - п I
Ь С
I ^
- s>.
<s>,
1
I
1 н
.;. —
i
1
! rf.
--
<м
-
—
d.
__
i
Таблица бталкибаний
Рис. 13.20.
13.6. Эпсилон-правила
537
этому операция СВЕРТКА(б) может быть уместна лишь в строке
(S>3 управляющей таблицы.
Теперь рассмотрим элемент в строке{S)s и столбце/?. При
выполнении операции СВЕРТКА(б) некоторый магазинный символ,
представляющий (В), помещается в магазин. Текущим входным
символом при этом останется Ь, поэтому конкатенация содержимого
магазина и оставшихся входных символов должна представлять
некоторую промежуточную цепочку, в которой за вхождением (В)
непосредственно следует Ь. Однако нетрудно установить, что Ъ
не принадлежит СЛЕД((В)); поэтому в выводе допустимой
входной цепочки не может быть такой промежуточной цепочки. Это
означает, что рассматриваемый элемент управляющей таблицы не
должен содержать операцию СВЕРТКА(б).
Для наглядности мы приводим множества СЛЕД на рис. 13.21.
При наличии е-правил вычисление этих множеств иногда
оказывается непростым, и поэтому в тех случаях, когда их трудно вычислить
просто глядя на грамматику, мы рекомендуем использовать
процедуру из разд. 8.7.
Согласно рис. 13.21, СЛЕД((В)) состоит из единственного
элемента а. Поэтому СВЕРТКА(б) может быть уместной лишь в
столбце а управляющей таблицы.
СЛЕД«5» = {а, Ъ, с, -\)
СЛЕД «Л» = {а}
СЛЕД «Я» = {а}
Рис. 13.21.
Итак, мы заключаем, что операция СВЕРТКА(б) может
содержаться только в строке <S>3 и столбце а. Проверки, выполняемые
на шаге 5 в пунктах а), б), и в), указывают, что никакое другое
действие для этого элемента не подходит. Таким образом, грамматика
не содержит конфликтов, касающихся операции СВЕРТКА(б).
Рассмотрим теперь проблему, связанную с операцией СВЕРТ-
КА(2). Как и раньше, сначала выделяем строки таблицы
вталкиваний, которые содержат неотвергающий элемент, соответствующий
верхнему символу магазина и левой части правила (в данном
случае— (S)). Таким образом, мы устанавливаем, что СВЕРТКА(2)
уместна лишь в строках V. аз и dx. Затем выделяем столбцы, для
которых входной символ принадлежит множеству СЛЕД для
рассматриваемой левой части (т. е. СЛЕД((5>)). Это позволяет нам
установить, что СВЕРТКА(2) уместна лишь в столбцах а, Ь, с и —|.
Окончательно получаем, что операцию СВЕРТКА(2) нужно
поместить на пересечениях строк V. а.9, dt и столбцов а, Ь, с и —|.
Вместе с элементами, полученными в пунктах а), б), в) шага 5,
это дает нам управляющую таблицу, показанную на рис. 13.22.
538 13. Обработка методами типа «перенос—свертка»
Так как полученная таблица не содержит конфликтов, данная
грамматика принадлежит классу SLR(l).
Проиллюстрированные выше соображения можно
сформулировать в виде общего принципа:
Для данных магазинного и входного символов и е-правила р
с левой частью (L) соответствующий элемент управляющей
таблицы типа «перенос —свертка» будет операцией
СВЕРТКА^) только в том случае, если данный входной символ
принадлежит СЛЕД((£>), а элемент таблицы вталкиваний
в строке, соответствующей данному магазинному символу,
и столбце (L) отличен от ОТВЕРГНУТЬ.
Действие операции СВЕРТКА(р) на цепочку, представляемую
конкатенацией содержимого магазина и необработанной части
входной цепочки, заключается в том, что символ (L) вставляется
v
<s>0
Чу
<А >,
э!
аз
<S>3
<S>3
<S>„
с4
СВЕРТКА |2)
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА (1)
CBEPTKAI2)
СВЕРТКА'6)
СВЕРТКА(З)
СВЕРТКА!2)
СВЕРТКА(4)
СВЕРТКА (5)
СВЕРТКА! 2)
СВЕРТКА (1)
СВЕРТКА (2)
ПЕРЕНОС
CBEPTKAI2)
СВЕРТКА (2)
СВЕРТКАШ
СВЕРТКА (2)
СВЕРТКА (2)
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
ПЕРЕНОС
СВЕРТКА (2)
ДОПУСТИТЬ
СВЕРТКА (1)
СВЕРТКА (2)
СВЕРТКА.(2)
Рис 13.22.
в нее непосредственно после подцепочки, представляемой
магазином. Первое условие в сформулированном выше принципе
означает, что текущий входной символ может следовать за (L > в
некоторой промежуточной цепочке, порождаемой грамматикой.
Второе условие означает, что конкатенация цепочки, представляемой
магазином, и цепочки, состоящей из символа (L), должна либо
13.6. Эпсилон-правила
53fr
оканчиваться основой, либо иметь некоторое продолжение,
оканчивающееся основой.
Теперь объединим все полученные результаты в полную
процедуру проверки принадлежности грамматики классу SLR(l) и
построения для нее автомата:
1. Вычислить для данной грамматики отношение ВПОД (е-пра-
вила в этом вычислении не участвуют).
2. Построить недетерминированную таблицу, в которой имеется
строка для каждого грамматического вхождения и маркера дна, а
также столбец для каждого символа грамматики. Элемент в строке
Ai и столбце В содержит все грамматические вхождения Bj
символа В, такие, что
А, ВПОД Bj
3. Сделать таблицу, полученную на шаге 2 детерминированной,
рассматривая ее как управляющую таблицу недетерминированнога
конечного автомата с маркером дна в качестве начального символа.
4. Состояния, полученные на шаге 3, будут использоваться в.
качестве магазинных символов (за исключением состояния,
соответствующего пустому множеству). Таблица переходов служит
таблицей вталкиваний (причем переходы в состояние, соответствую-
щее пустому множеству, трактуются как элементы, содержащие
операцию ОТВЕРГНУТЬ).
5. Для данных магазинного символа, представляющего маркер-
дна или множество грамматических вхождений Q, и входного
символа 2 соответствующий элемент управляющей таблицы типа
«перенос — опознание» определяется следующим образом:
а) Если Q содержит начальное вхождение, а г — концевой
маркер, то элементом будет операция ДОПУСТИТЬ.
б) Если входной символ г — не концевой маркер и элемент
таблицы вталкиваний для данных магазинного и входного
символа отличен от ОТВЕРГНУТЬ, то элементом будет
ПЕРЕНОС.
в) Если Q содержит самое правое вхождение в правило р и
2 принадлежит СЛЕД((1,)), где (L) — левая часть
правила р, то элементом будет СВЕРТКА(р). (Множества
СЛЕД(<Х>) можно вычислить методами разд. 8.7.)
г) Если правило р — это е-правило с левой частью (L),
г принадлежит СЛЕД((.М) и элемент таблицы
вталкиваний в строке, соответствующей данному магазинному
символу, и столбце (L> отличен от ОТВЕРГНУТЬ, то
элементом будет СВЕРТКА(р).
Если в пунктах а), б), в) и г) обнаруживаются
противоречивые требования к элементам управляющей таблицы,
то данная грамматика не принадлежит классу SLR(l).
540 13. Обработка методами типа «.перенос—свертка»
В качестве элементов, которые не определяются
указанными пунктами, принять операцию ОТВЕРГНУТЬ.
6. Удалить из таблицы вталкиваний все строки, содержащие
только операцию ОТВЕРГНУТЬ.
Возможность оптимизации, выполняемой на шаге 6, объясняется
тем, что в соответствии с пересмотренным шагом 5 и
предшествующими ему шагами автомат никогда не пользуется строками
таблицы вталкиваний, содержащими лишь операцию ОТВЕРГНУТЬ.
13.7. Обработка ошибок при разборе
типа «перенос — свертка»
Обработка ошибок при синтаксическом анализе типа «перенос —
свертка» происходит примерно так же, как при анализе типа
«перенос — опознание», описанном в разд. 12.7. Однако анализаторы
типа «перенос — свертка», обсуждаемые в данной главе, обладают
некоторым специальным свойством, отсутствующим у
анализаторов типа «перенос — опознание», которое позволяет выдавать более
осмысленные сообщения об ошибках и строить более эффективные
процедуры нейтрализации. Если заданы МП-распознаватель и
неправильная цепочка, мы будем называть нарушающим тот символ
этой цепочки, который является текущим в момент, когда
распознаватель отвергает вход. О МП-распознавателе говорят, что он
обладает префиксным свойством, если для любой неправильной цепочки
подцепочка слева от нарушающего символа является префиксом
некоторой допустимой цепочки. Другими словами, распознаватель
обладает префиксным свойством, если нарушающий символ •— это
первый входной символ, появление которого несовместимо с
гипотезой о допустимости входной цепочки. МП-распознаватель с
префиксным свойством обнаруживает ошибку на самом первом из
входных символов, для которых это возможно. Все автоматы,
определяемые в этой главе, обладают префиксным свойством, так как каждой
таблице вталкиваний соответствует построенный по грамматике
детектор основ, и на каждом шаге обработки до того, как входная
цепочка будет отвергнута, цепочка, представленная магазином,
оканчивается основой или имеет некоторое продолжение,
оканчивающееся основой. При попытке поместить в магазин символ, такой,
что после его вталкивания представляемая цепочка не будет
обладать этим свойством, автомат согласно таблице вталкиваний
отвергает входную цепочку.
Автомат типа «перенос — свертка» может отвергнуть входную
цепочку при обращении к отвергающему элементу, либо в управляю-
13.7. Обработка ошибок при разборе типа «перенос—свертка» 541
щей таблице, либо в таблице вталкиваний. В обоих случаях
подходящей формой сообщения об ошибке может быть
« СЛЕДУЕТ ЗА »
где справа и слева на месте прочерка вставляются словесные
описания символов, помечающих соответственно столбец и строку, где
находится элемент, благодаря которому автомат отвергает
входную цепочку.
Поскольку магазинные символы представляют "вхождения, а не
просто символы грамматики, возможно, будет трудно подобрать
подходящие словесные описания, понятные программисту. Тем не
менее аккуратное описание вхождений может иметь большое
значение, так как появление данного входного символа может быть
допустимо после одного вхождения данного символа грамматики и
недопустимо после другого вхождения того же самого символа.
Если в сообщении об ошибке нет точного описания этого второго
вхождения, то сообщение может оказаться для программиста
непонятным.
Можно показать, что распознаватели, построенные SLR(l)-
методами из разд. 13.5 и 13.6, обладают следующим свойством:
обращений к отвергающим элементам таблицы вталкиваний не
происходит даже при обработке неправильных цепочек. Из этого
факта следует, что для автоматов, построенных с помощью SLR(l)-
методов, не нужны сообщения об ошибках, соответствующие
указанным элементам таблицы вталкиваний.
Чтобы дать пример, как составляются сообщения об ошибках,
вернемся к грамматике S-выражений, которая уже встречалась
в разд. 12.7 и 8.8.
1. (S)-+a
2. (S)-+((S)(R)
3. (R)-+,(S)(R)
4. (R)-+)
На рис. 13.23 показаны управляющая таблица и таблица
вталкиваний 5Ы?(1)-распознавателя для этой грамматики. Отвергающие
элементы управляющей таблицы на этом рисунке помечены, а на
рис. 13.24 приведен подходящий набор сообщений об ошибках.
Все сообщения для элементов строк, соответствующих
терминалам, имеют стандартный формат, за исключением сообщений для
столбца концевого маркера, которые слегка отличаются по
формату. Формат сообщений для строки маркера дна также близок к
стандартному.
В строках, соответствующих нетерминалам, элементы столбцов
а и ( недостижимы даже при обработке неправильных цепочек,
Например, элемент
ОТВЕРГНУТЬ г
<s>„
<s>,
<s>.
<я>,
<я>,
a
ОТВЕРГНУТЬ
a
ПЕРЕНОС
ПЕРЕНОС
ОТВЕРГНУТЬ
i
ОТВЕРГНУТЬ
к
ОТВЕРГНУТЬ
о
ОТВЕРГНУТЬ
г
ОТВЕРГНУТЬ
и
ОТВЕРГНУТЬ
w
ПЕРЕНОС
1
СВЕРТКА (1)
ОТВЕРГНУТЬ
с
ОТВЕРГНУТЬ
(
.СВЕРШИ)
ОТВЕРГНУТЬ
ПЕРЕНОС
ПЕРЕНОС
CBEPTKAI2)
СВЕРТКА(З)
ОТВЕРГНУТЬ
У
(
ОТВЕРГНУТЬ
Ь
ПЕРЕНОС
ПЕРЕНОС
ОТВЕРГНУТЬ
i
ОТВЕРГНУТЬ
m
ОТВЕРГНУТЬ
Р
ОТВЕРГНУТЬ
s
ОТВЕРГНУТЬ
V
ОТВЕРГНУТЬ
X
ПЕРЕНОС
1
СВЕРТКА.(1)
ОТВЕРГНУТЬ
d
ОТВЕРГНУТЬ
g
СВЕРТКА-(4)
ОТВЕРГНУТЬ
п
ПЕРЕНОС
■ПЕРЕНОС
CBEPTKAI2)
СВЕРТКА(З)
ОТВЕРГНУТЬ
z
-1
СВЕРТКА! 1)
ОТВЕРГНУТЬ
е
ОТВЕРГНУТЬ
h
СВЕРТКА (4)
ДОПУСТИТЬ
ОТВЕРГНУТЬ
q
ОТВЕРГНУТЬ
t
CBEPTKAI2)
СВЕРТКА(З)
ОТВЕРГНУТЬ
2Z
Управляющая таблица
а
I ) <S> <Я>
<s>n
<s>.
<s>.
<я>,
■<Я>1
3
a
a
•
.
(
(
(
)
)
<S>3
<S>2
<s>0
<R>2
<R>3
Таблица вталкиваний
б
Рис 13.23.
13.8. Замечания по литературе
543
в строке (5 >а и столбце а недостижим, так как (5 )э может
находиться на верху магазина только после выполнения операции
CBEPTKA(l) или СВЕРТКА(2), но ни одна из этих сверток не
выполняется в случае, когда текущим входным символом является а.
Остальные сообщения для строк, соответствующих нетерминалам,
т. е. сообщения для элементов /, п, q и t, построены индивидуально,
на основе интерпретации вхождений, метящих эти строки.
Например, сообщение для элемента / основано на том факте, что верхний
символ магазина в рассматриваемом случае представляет
начальное вхождение.
а, Ь, с, d, /, g, (', /: „(входной символ) ПОСЛЕ (магазинный символ)"
е, h: „S-ВЫРАЖЕНИЕ НЕ ОКОНЧЕНО
/: „ЗАПЯТАЯ ПОСЛЕ ОКОНЧАНИЯ S-ВЫРА-
ЖЕНИЯ"
п: „ЛИШНЯЯ ПРАВАЯ СКОБКА"
q, t: „ПРОПУЩЕНА ПРАВАЯ СКОБКА"
у, г: „(входной символ) ВНАЧАЛЕ S-ВЫРАЖЕНИЯ"
гг. „S-ВЫРАЖЕНИЕ ОТСУТСТВУЕТ"
к, т, о, р, г, s, и, v, а, х: Не требуется (см. текст).
Рис. 13.24.
Методы нейтрализации ошибок при разборе типа «перенос —
свертка» аналогичны применяемым при разборе типа «перенос —
опознание». На рис. 13.25 показан возможный набор процедур
локальной нейтрализации ошибок для автомата на рис. 13.23.
Заметим, что процедура нейтрализации для элементов а и b делает
элементы k, m, о, р, г и s достижимыми в процессе разбора. Аналогично
процедура нейтрализации для элементов i и / делает достижимыми
элементы и, v, w и х. Однако новые сообщения об ошибках в этих
ситуациях не нужны. На рис. 13.26 изображена последовательность
конфигураций автомата, обрабатывающего цепочку
(а , , а
Этот рисунок можно сравнить с рис. 8.29, а и рис. 12.21, где
показана обработка этой же цепочки другими автоматами.
13.8. Замечания по литературе
Класс SLR(l)-rpaMMaTHK является собственным подклассом
класса грамматик, называемых Ы?(1)-грамматиками, которые
допускают распознавание методами «перенос — свертка» с заглядыванием
вперед на один символ. В действительности для каждого целого k^O
существует класс грамматик, называемых Ы?(£)-грамматиками,
которые можно распознавать методами «перенос—свертка» с
заглядыванием вперед на k символов.
544 13. Обработка методами типа «.перенос—свертка»
а, Ь: ПЕЧАТАТЬ(Сообщение с рис. 13.24)
CBEPTKA(l)
ДЕРЖАТЬ
с, d, f, g: ПЕЧАТАТЬ(Сообщепие с рис. 13.24)
ВТОЛКНУТЬ(о)
ДЕРЖАТЬ
е, h, k, I, m, n, q, t, гг: ПЕЧАТАТЬ(Сообщение с рис. 13.24)
ВЫХОД
i, /: ПЕЧАТАТЬ(Сообщение с рис. 13.24)
СВЕРТКА(4)
ДЕРЖАТЬ
о, р, г, s: ВТОДКНУТЬ(,)
ДЕРЖАТЬ
и, v. СВЕРТКА(2)
ДЕРЖАТЬ
w, х: СВЕРТКА(З)
ДЕРЖАТЬ
у, г: ПЕЧАТАТЬ(Сообщение с рис. 13.24)
СДВИГ
Рис. 13.25.
V (а,,а-\
V( я,,Н
V (а , ,в_|
V(<5>2 ,,a-\
V(<S>2) ,a-\
ПЕЧАТАТЬ(, ДВЕ ЗАПЯТЫЕ ПОДРЯД ")
V(<5>2,a , д_|
V(<5>2,<5>3 ,a-\
V(<5>2)<5>3) a-\
V((S)2,(S)3,a _|
V(<5>2)<S>3,<5>3 H
ПЕЧАТАТЬ („ПРОПУЩЕНА ПРАВАЯ СКОБКА'^
ВЫХОД
Рис. 13.26.
Упражнения
545
Ь1?(&)-грамматики были введены Кнутом [1965]. Многие
варианты их определения обсуждались в статье Геллера и Харрисона
(1973]. Основной способ определения ЬК(0)-грамматик
(используемый в книге Ахо и Ульмана [1972а]) требует, чтобы никакое
состояние детерминированного детектора основ не содержало
вместе с начальным вхождением какого-либо другого вхождения.
Ахо и Ульман [1972а, 1973а] обсуждают большинство
аспектов ЬК(&)-грамматик, включая их собственную более раннюю
работу об уменьшении объема и увеличении быстродействия
LR(^-анализаторов (например, Ахо и Ульман [19726]). Деремер [19711 ввел
SLR-грамматики. Другие работы по этой тематике — это статьи
Кореньяка [1969], Деремера [1969], Пэйджера [1970, 1973], Ахо
и Джонсона [1974], Хаяши [1971] и Кемпа [1973]. Альтернативный
подход к разбору типа «перенос — свертка», основанный на
понятии строго детерминированных грамматик, вводится в работах
Харрисона и Хавела [1972, 1973, 1974].
Упражнения
1. Изобразите в виде последовательности конфигураций, как автомат рис. 13.3
обрабатывает цепочку
abacbbb
2. Найдите все элементы таблицы вталкиваний и управляющей таблицы на.
рис. 13.3, которые достижимы при обработке:
а) допустимых цепочек
б) недопустимых цепочек
3. Для следующей грамматики с начальным символом (S):
1. (S)^a
2. (S)-+({S){R)
3. (R) —, (S){R)
4. </?)-►)
а) вычислите множества ВПЕРВ для каждого вхождении,
б) вычислите отношение ВПОД;
в) постройте Ы?(0)-распознаватель.
4. Постройте ЬН(0)-распознаватель для каждой из следующих грамматик:
а) 1. (S)^-a{S)b
2. {S)^a(S)c
3. (S)->-ab
б) 1. (S)^c(A)
2. (S)^.cc(B)
3. (A)^c(A)
4. (A)^a
5. {B)-*cc(B)
6. (B>->-£>
в) 1. (S)^a{S)(S)b
2. <S> -> a(S)(S)(S)
3. (S)^-c
18 ф. Льюис и др.
546 13. Обработка методами типа «.перенос—свертка»
5. На рис. 13.27 показан детерминированный детектор основ для некоторой
грамматики. Каждое состояние детектора основ состоит из множества
вхождений, а каждое вхождение обозначено символом грамматики, который помечен
номером правила, где встречается данное вхождение. Найдите грамматику,
для которой построена таблица.
V
<М
{Ь2}
ib3)
{с4}
{<S>01
{</>>,}
{<А>2)
{<А>3}
<S>
<А>
{a7,a3}
{з2<аз>
{*2'аз)
{Ь,}
{Ь2}
{Ь3)
{с,}
<с4)
{сА}
{<s>0]
{<А>3}
{</*>,}
{<А>2)
Рис. 13.27.
6. Для каждого из следующих языков найдите одну LR(0)-rpaMMaTHKy и
соответствующий МП-распознаватель:
а) {1"а0"}и {1л&02"} л>0
б) {al"0"}U {*l"02"} л>0
в) {I"0m} 0<
0<л<т
г) {wnwr}, где w принадлежит (0+1)*.
7. Постройте SLR(l)-npou.eccop для каждого из языков в предыдущей задаче.
8. Покажите, что следующая грамматика не принадлежит классу SLR(l):
<S>-*KS>0
<S>->-0(S>l
(S>^10
9. Определите, какие из следующих грамматик принадлежат классу SLR (1).
В каждом случае начальный символ — (S):
а) (S)-+(L)={R)
<D -* *</?>
<L)-*a
</?>-* а>
б) {S)^a(A)d
(S)-+b(A)o
{S)-+aec
(S) -»- bed
U)->e
Упражнения
547
10. Постройте SLR (1)-процессор для каждой из следующих грамматик:
а) Рис. 12.1.
б) Рис. 12.10.
11. Постройте SLR (1)-анализатор для грамматики на рис. 13.7. Сравните его с
LR (О)-анализатором для этой грамматики, показанным на рис. 13.11,6.
12. Опишите, каким образом можно реализовать SLR (1)-анализатор из разд. 13.5,
используя для управления им лишь одну таблицу. Столбцы таблицы
соответствуют символам грамматики и концевому маркеру, строки соответствуют
магазинным символам. Продемонстрируйте свой метод на примере грамматики
арифметических выражений на рис. 13.12.
13. Покажите, что SLR (1)-автоматы, построенные в соответствии с разд. 13.5,
никогда не зацикливаются.
14. Изобразите последовательность конфигураций и перечислите все сообщения
об ошибках, получающихся в результате обработки автоматом на рис. 13.23
входной цепочки
, а , а а(а , , ( ) а, , ,
15. Найдите три цепочки, для которых процедура локальной нейтрализации
ошибок автомата на рис. 13.23 работает плохо. Объясните почему.
16. Измените процедуру нейтрализации ошибок на рис. 13.25 для элементов k, I,
т, п так, чтобы полученный распознаватель в указанных случаях пытался
обнаружить ошибки в оставшейся необработанной части входной цепочки.
17. Для каждого из следующих автоматов постройте отладочную цепочку (или
цепочки), при обработке которой происходит обращение ко всем элементам
управляющей таблицы и таблицы вталкиваний, кроме тех, которые
соответствуют ошибкам:
а) Рис. 13.14 и 13.15.
б) Рис. 13.20 и 13.22.
в) Рис. 13.23.
г) Рис. 13.11. Как задать отладочную цепочку для LR (О)-автомата?
18. Постройте схему обработки ошибок для SLR (1)-процессора арифметических
выражений на рис. 13.14 и 13.15. Приведите тексты сообщений об ошибках
и укажите методы нейтрализации ошибок.
19. Для следующей алголоподобной грамматики с начальным символом
(программа):
1. (программа) ->- (блок)
2. (программа) ->- (составной оператор)
3. (блок) ->- (начало блока); (конец составного)
4. (начало блока) ->- begin d
5. (начало блока) ->- (начало блока); d
6. (кон ц составного) ->- S end
7. (конец составного) ->- S; (конец составного)
8. (составной оператор)->-begin (конец составного)
а) Покажите, что эта грамматика принадлежит классу SLR(l).
б) Постройте соответствующий SLR (^-распознаватель.
в) Постройте подходящий набор сообщений об ошибках.
г) Разработайте процедуры локальной нейтрализации ошибок.
д) Разработайте процедуры глобальной нейтрализации ошибок.
20. Покажите, что каждая простая ССП-грамматика является SLR
(^-грамматикой.
21. Для каждого из переводов, описанных в упр. 5.13, а) и б):
а) постройте грамматику цепочечного перевода, входная грамматика которой
была бы SLR (1)-грамматикой;
б) постройте соответствующий процессор.
18*
548 13. Обработка методами типа «перенос — свертка»
22. Разработайте SLR (1)-процессор для синтаксического блока MINI-BASIC-
компилятора с использованием грамматики слабого предшествования на
рис. 12.22.
23. Покажите, что для каждого примитивного МП-автомата цепочки, которые
могут находиться в магазине в различные моменты обработки всевозможных
входных цепочек, образуют регулярный язык.
24. а) Постройте SLR (1)-грамматику для S-выражений языка ЛИСП.
б) Постройте соответствующий процессор.
в) Разработайте сообщения об ошибках и процедуры нейтрализации ошибок.
25. Для каждого отвергающего элемента на рис. 13.23, а:
а) найдите самую короткую из цепочек, при обработке которых происходит
обращение к этому элементу (если такие цепочки для данного элемента
существуют).
б) из каждой цепочки, полученной в пункте а), удалите нарушающий символ
и символы правее него и найдите кратчайшую цепочку, конкатенация
которой с оставшимся префиксом дает допустимую цепочку.
26. Для каждой из перечисленных ниже конструкций Алгола найдите SLR (1)-
грамматику, выводы в которой доходят только до уровня понятий (целое без
знака), (переменная), (указатель функции) и (оператор).
а) Арифметические выражения.
б) Логические выражения.
в) Описания массивов.
г) Описания переключателей.
д) for-операторы.
27. Постройте SLR (1)-процессор для следующей грамматики с начальным
символом (S):
(S) -> а(А)
{S)-+b(B)
(А)^1{А)0
{А)^г
(В)-* 1(В)00
<б) + е
28. Постройте SLR (1)-процессор для следующей грамматики с начальным
символом (программа):
(программа)-»-begin (список описаний) (список операторов) end
(список описаний) ->- (список описаний)^;
(список описаний) ->- е
(список операторов) -»• (список операторов); (оператор)
(список операторов) -»■ (оператор)
(оператор) -»- s
(оператор) -»- г
.26. Рассмотрим следующую неоднозначную транслирующую грамматику для
арифметических выражений:
<£>-*<£>+<£){+}
<£>-* <£)*(£){*}
<£) -*а[а)
Попробуйте построить для этой грамматики SLR (1)-процессор. В тех случаях,
когда в таблицах возникают конфликты, m нескольких противоречивых
элементов выбирайте один правильный ihk, 'тобы получался требчемьш перевод.
Сравните окончательный процессор с процессором рис. 13.14 и 13.15. (Об-
Упражнения
549
суждение этого подхода можно найти в работе Ахо, Джонсона и Ульмана
[1973].)
30 Покажите, что если для LR (0)-языка существуют терминальные цепочки х,
у, г, такие, что х, хг, у принадлежат этому языку, то уг также принадлежит
этому языку. (Геллер и Харрисон [1973].)
31. Покажите, что грамматика без е-правил принадлежит классу LL (1)-грамматик
тогда и только тогда, когда детектор основ, полученный непосредственно по
отношению ВПОД, оказывается детерминированным конечным автоматом.
32. Найдите:
а) грамматику слабого предшествования, не являющуюся LR (0)-грамматикой.
б) LR (О)-грамматику, не являющуюся простой ССП-грамматикой.
в) LR (О)-грамматнку, не являющуюся ЬЬ(1)-грамматикой.
33. Докажите, что SLR (^-распознаватели обладают следующим свойством:
отвергающие элементы таблицы вталкиваний недостижимы даже при
обработке неправильных цепочек.
14
Генератор кода
для MINI-BASIC-компилятора
14.1. Введение
В этой главе мы опишем построение генератора кода для языка
MINI-BASIC. Он завершает MINI-BASIC-компилятор и дает
представление о том, какую структуру мог бы иметь более сложный
генератор кода. Кроме того, в разд. 14.9 мы дадим решение одной
важной проблемы, которая для языка MINI-BASIC не возникает,—
проблемы обработки описаний в языках с блочной структурой.
14.2. Окружение компилятора и объектная
машина
Многие детали генератора кода зависят от окружения, в котором
работает компилятор, а также от машины, для которой он
порождает объектный код. Мы делаем следующие предположения
(большинство из которых упрощают построение генератора):
1. Компиляция целиком происходит в оперативной памяти.
По мере того как генератор кода порождает команды и константы,
они помещаются в ячейки оперативной памяти, где и будут
находиться в период исполнения; они остаются в этих ячейках до
конца компиляции. (В качестве альтернативы этому предположению
можно указать буферизацию команд и использование загрузчика.)
2. Все арифметические операции в период исполнения — с
плавающей точкой, причем машина имеет лишь один арифметический
регистр для операций с плавающей точкой, в дальнейшем
называемый сумматором.
3. Машина обладает обычным набором команд для загрузки
регистров и записи в ячейки памяти, выполнения арифметических
операций (включая «обратное вычитание» и «обратное деление»),
а также для выполнения сравнений и передач управления.
Возведение в степень осуществляется подпрограммой. Конкретные
команды будут обсуждаться по мере возникновения потребности е
них.
4. Мы предполагаем, что имеется четыре индексных регистра
для косвенной адресации или для передачи параметров
процедурам в период исполнения.
14.3. Моделирование исполнения
551
14.3. Моделирование исполнения
Рассмотрим выражение
(A+B)+(X+Y)
Очевидный способ его вычисления в терминах машинного языка
таков:
1. загрузить А в сумматор;
2. прибавить В к сумматору;
3. записать результат А+В во временную рабочую ячейку;
4. загрузить X в сумматор;
5. прибавить Y к сумматору;
6. прибавить временный результат А+В к X+Y в сумматоре.
Каждому из трех сложений предшествует своя последовательность
команд загрузки и записи.
1. Первому сложению предшествует команда загрузки,
помещающая один из операндов в сумматор.
2. Перед вторым сложением производится загрузка в сумматор
и запись в ячейку памяти. Запись в память требуется для того,
чтобы сохранить содержимое сумматора, которое в противном случае
будет уничтожено при вычислении X+Y. Загрузка в сумматор
необходима для того, чтобы операнд оказался на месте.
3. Перед третьим сложением нет ни записи, ни загрузки.
Загрузка не требуется, так как один операнд, X+Y, уже находится в
сумматоре. Запись в ячейку не нужна, ввиду того что содержимое
сумматора в дальнейшем не потребуется.
Чтобы построить код, подобный вышеописанному, генератор
хранит некоторую информацию о том, что будет происходить в период
исполнения генерируемого им кода. Например, при генерации кода
для каждого атома сохраняется информация о том, где будут
найдены операнды и куда будут помещены результаты, когда этот код
будет исполняться. При этом возможна генерация команд загрузки
и записи в память в соответствии с ситуацией, которая создастся в
период исполнения. Работа по хранению этой информации
называется «моделированием исполнения». Детально подобное
моделирование обсуждается в последующих разделах.
Наши усилия, направленные на исключение лишних команд
загрузки и записи, можно рассматривать как элементарную форму
оптимизации. Моделирование исполнения — метод оптимизации,
используемый во многих оптимизирующих компиляторах, хотя и в
значительно более развитых вариантах. В несложном генераторе
кода для языка MINI-BASIC можно было бы обойтись без
моделирования исполнения и генерировать для каждого сложения все три
команды: загрузить в сумматор, сложить, записать в ячейку.
552 14. Генератор кода для MINI-BASIC-компилятора
14.4. Распределение памяти
Наш первый шаг при разработке генератора кода заключается в
том, чтобы определить, как будет организована память машины в
период исполнения скомпилированной программы. Предлагаемое
распределение памяти показано на рис. 14.1. Область ПРОГРАММА
содержит команды объектной программы. ПОДПРОГРАММНЫЙ
СТЕК используется для хранения адресов возврата вызовов
подпрограмм (начальная ячейка
этого стека инициализируется
адресом процедуры обработки
ошибок в период исполнения).
Область ХРАНИМЫЕ
РЕЗУЛЬТАТЫ используется для
хранения результатов атома
ХРАНЕНИЕ в FOR-операторах. В
областях КОНСТАНТЫ и
ПЕРЕМЕННЫЕ хранятся
соответственно значения констант и
переменных.
Область ВРЕМЕННЫЕ
РЕЗУЛЬТАТЫ используется для
хранения промежуточных
результатов. Как уже говорилось
в разд. 14.3, только некоторые
промежуточные результаты
нуждаются в сохранении, остальные
жизнь в сумматоре. Для
каждого промежуточного результата, требующего временной
ячейки, генератор кода выделяет ее. В целях экономии памяти
генератор выделяет ячейки таким образом, что, если два
промежуточных результата не требуется хранить в один и тот же момент
периода исполнения программы, для них может быть отведена одна
общая ячейка.
Фактически временные ячейки для промежуточных
результатов отводятся таким образом, что в период исполнения эти
результаты хранятся как бы в стеке, причем наверху хранятся значения,
записанные последними. Такое отведение памяти возможно, так
как результат, записанный последним, всегда требуется раньше.
Подчеркнем, что работа со стеком осуществляется не через
стековые операции периода исполнения, а посредством команд загрузки
и записи, работающих со специальными «стековыми» ячейками,
отведенными под соответствующие данные. Единственным
напоминанием о моделировании магазинной памяти является
переменная периода компиляции, указывающая местонахождение
последнего записанного результата. Эта переменная ведет себя подобно
Программа
Константы
Подпрограммный
стек
Промежуточные
результаты
Хранимые
результаты
Переменные
Рис. 14.
*
Области
' данных
.
могут провести свою недолгую
14.5. Элементы таблиц
553
указателю верхушки стека, хотя фактическая работа со стеком
откладывается до периода исполнения.
На рис. 14.2 показаны различные переменные и константы
периода компиляции, отражающие схему распределения памяти в г,е-
Имя
Переменные периода компиляции
Начальное значение
СЧЕТКОМ
СЧЕТВРЕМ
СЧЕТКОНСТ
СЧЕТХРАН
Имя
ГРАНКОМ
ГРАНВРЕМ
НАЧВРЕМ
ГРАНКОНСТ
ГРАНХРАН
ГРАНСТЕКА
Адрес первой команды в рабочей программе
Адрес первой ячейки под промежуточный
результат в рабочей программе
Адрес первой константы в рабочей программе
Адрес первой хранимой переменной в
рабочей программе
Константы периода компиляции
Значение
Максимальный адрес команды -|- 1
Максимальный адрес промежуточного
результата + 1
Адрес первой ячейки под промежуточный
результат в рабочей программе
Максимальный адрес константы + 1
Максимальный адрес хранимой
переменной +1
Максимальный адрес ячейки подпрограм-
много стека + 1
Рис. 14.2.
риод исполнения. Каждая из этих переменных периода компиляции
используется для того, чтобы следить за очередной свободной
ячейкой из соответствующей области памяти в период исполнения.
14.5. Элементы таблиц
Генератор кода использует табличные элементы для хранения
информации о параметрах атомов. Каждый табличный элемент имеет
поле ВИД, указывающее вид объекта, описываемого этим
элементом, а также одно или два других поля. Поле ВИД содержит одно из
следующих пяти значений: КОНСТАНТА, ПЕРЕМЕННАЯ,
ПРОМЕЖУТОЧНЫЙ РЕЗУЛЬТАТ, ХРАНИМЫЙ РЕЗУЛЬТАТ или
МЕТКА. Ниже описываются все виды элементов:
1. КОНСТАНТА. Этот элемент состоит из поля ВИД и поля
ЗНАЧЕНИЕ. Поле ЗНАЧЕНИЕ заполняется лексическим блоком
и содержит значение константы.
2. ПЕРЕМЕННАЯ. Этот элемент состоит из поля ВИД и поля
АДРЕС. Поле АДРЕС содержит приписанный (разработчиком
компилятора) переменной адрес в период исполнения.
554 14. Генератор кода для ШН\-ЪР&\СгКомпилятора
3. ПРОМЕЖУТОЧНЫЙ РЕЗУЛЬТАТ. Этот элемент состоит
из поля ВИД и поля АДРЕС. Поле АДРЕС содержит информацию,
необходимую для моделирования исполнения, и может изменяться
в процессе компиляции. В каждый момент компиляции между
получением промежуточного результата и его использованием иоле
АДРЕС указывает, где этот результат будет находиться в
соответствующий момент периода исполнения программы. Нуль в поле АДРЕС
означает, что в период исполнения промежуточный результат
находится в сумматоре. Ненулевое значение поля АДРЕС
указывает, что в период исполнения промежуточный результат находится
в оперативной памяти по адресу, содержащемуся в поле АДРЕС.
Табличный элемент, соответствующий промежуточному результату,
впервые используется генератором кода в тот момент компиляции,
когда генерируется код для вычисления этого результата. Так как
результат вычисляется в сумматоре, в поле АДРЕС табличного
элемента в этот момент записывается нуль. Если в дальнейшем нужно
сгенерировать команду записи промежуточного результата в
оперативную память, содержимое поля АДРЕС заменяется на адрес
соответствующей ячейки памяти. Еще позднее, когда генерируется
код, использующий промежуточный результат, поле АДРЕС
указывает на место нахождения этого результата. После того как
промежуточный результат использован, табличный элемент больше
никогда не потребуется и содержимое поля АДРЕС теряет смысл.
Подпрограммы, модифицирующие поле АДРЕС для промежуточных
результатов, описаны в двух следующих разделах.
4. ХРАНИМЫЙ РЕЗУЛЬТАТ. Этот элемент состоит из поля
ВИД и поля АДРЕС. Он используется для хранения информации о
результате атома ХРАНЕНИЕ. Поле АДРЕС содержит адрес, пс
которому в период исполнения должен быть размещен сохраняемый
результат. Оно заполняется генератором кода путем обращения к
функции НОВХРАН. Эта функция возвращает текущее значение
переменной СЧЕТХРАН. Она также увеличивает СЧЕТХРАН и
сравнивает новое значение с ГРАНХРАН.
5. МЕТКА. Этот элемент состоит из поля ВИД, поля СТАТУС и
поля АДРЕС. Такой элемент имеется для каждого номера строки и
для каждой метки, созданной синтаксическим блоком для FOR-
оператора. Поле СТАТУС может содержать одно из двух значений:
ВИСЯЧАЯ или ПРИПИСАННАЯ. Поле АДРЕС может содержать
нуль или адрес периода исполнения в области ПРОГРАММА. Оба
эти поля могут быть модифицированы в процесс компиляции и
обсуждаются в следующем разделе.
Поле ВИД заполняется при создании табличного элемента, но
в некоторых случаях изменяется генератором кода. Для удобства
таких изменений элементы вида ПРОМЕЖУТОЧНЫЙ РЕЗУЛЬТАТ
14.6. Процедура ГЕН
555
и ХРАНИМЫЙ РЕЗУЛЬТАТ структурированы таким образом, что
их легко можно преобразовать в элемент с полем ЗНАЧЕНИЕ.
Для этого каждый элемент делается достаточно большим, чтобы он
мог содержать поля ВИД, АДРЕС и ЗНАЧЕНИЕ, или
используется такой формат элементов, в котором одно и то же поле может
служить как полем АДРЕС, так и полем ЗНАЧЕНИЕ.
14.6. Процедура ГЕН
Мы предполагаем, что генератор кода содержит процедуру,
называемую ГЕН, которая строит двоичное представление генерируемой
команды. ГЕН вызывается с двумя параметрами: кодом операции
(например, СЛОЖ) генерируемой команды и указателем на
табличный элемент, соответствующий полю адреса генерируемой
команды.
Например, если нам нужно сгенерировать команду вычитания
значения переменной А из сумматора, следует написать
ГЕН (ВЫЧИТ, р)
где р — указатель на табличный элемент для переменной А.
Для удобства в случаях, когда в генерируемой команде
участвует индексный регистр или специальный вид адресации (такой,
как «косвенно»), эта информация включается в первый параметр
процедуры ГЕН. В более сложных генераторах кода эта
информация обычно передается процедурам типа ГЕН через
дополнительные параметры. Процедура ГЕН выполняет следующие действия:
1. Формируется двоичный код (последовательность битов),
соответствующий первому параметру процедуры ГЕН.
2. Формируется (как описано ниже) двоичный код,
соответствующий второму параметру процедуры ГЕН.
3. Двоичный код, образующий сгенерированную команду,
помещается в ячейку, соответствующую текущему значению СЧЕТКОМ.
4. СЧЕТКОМ увеличивается и сравнивается с ГРАНКОМ.
Действия, выполняемые процедурой ГЕН при формировании
двоичного кода, соответствующего второму параметру, зависят от
вида указываемого им табличного элемента следующим образом:
ПЕРЕМЕННАЯ, ХРАНИМЫЙ РЕЗУЛЬТАТ. Используется
двоичный код, содержащийся в поле АДРЕС табличного элемента.
КОНСТАНТА. ГЕН записывает значение константы (полученное
из поля ЗНАЧЕНИЕ табличного элемента) в ячейку памяти с
адресом, равным текущему значению переменной периода компиляции
СЧЕТКОНСТ. Кроме того, этот адрес используется в генерируемой
команде. ГЕН также увеличивает СЧЕТКОНСТ и сравнивает
.новое значение с ГРАНКОНСТ.
556 14. Генератор кода для М1Ш-В ASIC-компилятора
ПРОМЕЖУТОЧНЫЙ РЕЗУЛЬТАТ. ГЕН вызывается с табличным
элементом этого вида в качестве параметра в случаях, когда нужно
сгенерировать команду ЗАП (которая переносит промежуточный
результат из сумматора в стек ВРЕМЕННЫЕ РЕЗУЛЬТАТЫ) или
команду, которая использует промежуточный результат,
находящийся в стеке ВРЕМЕННЫЕ РЕЗУЛЬТАТЫ.
ГЕН проверяет содержимое поля АДРЕС. Нулевое значение в
этом поле указывает на то, что в период исполнения данный
промежуточный результат находится в сумматоре. В этом случае может
быть сгенерирована только команда записи во временную память.
ГЕН отводит очередную доступную ячейку из области
ВРЕМЕННЫЕ РЕЗУЛЬТАТЫ, записывая текущее значение СЧЕТВРЕМ в
поле АДРЕС табличного элемента и используя это значение как
часть сгенерированной команды записи. ГЕН также увеличивает
СЧЕТВРЕМ и сравнивает новое значение с ГРАНВРЕМ.
Если поле АДРЕС имеет ненулевое содержимое, это означаетг
что генерируемая команда использует временный результат,
находящийся в верхней ячейке стека ВРЕМЕННЫЕ РЕЗУЛЬТАТЫ.
ГЕН освобождает эту ячейку, используя в сгенерированной
команде содержимое поля АДРЕС и уменьшая СЧЕТВРЕМ.
МЕТКА. При создании лексическим или синтаксическим блоком
табличного элемента типа МЕТКА поле СТАТУС инициализируется
значением ВИСЯЧАЯ, а поле АДРЕС — нулем. Когда генератор
кода встречает атом вида НОМСТРОК или МЕТКА, значением
которого является указатель на этот табличный элемент, в поле
СТАТУС записывается значение ПРИПИСАННАЯ, а в поле АДРЕС
помещается текущее значение СЧЕТКОМ.
Вызов процедуры ГЕН с табличным элементом вида МЕТКА
в качестве параметра происходит тогда, когда нужно сгенерировать
ту или иную команду перехода к этой метке. Прежде всего ГЕН
проверяет значение поля СТАТУС. Если оно равно
ПРИПИСАННАЯ, значит, метка встречается в программе раньше команды
перехода и ГЕН использует для формирования этой команды поле
АДРЕС табличного элемента.
В случае когда поле СТАТУС содержит значение ВИСЯЧАЯ,
нужно сгенерировать команду перехода к метке, которой еще не
приписан адрес. Это явление называется ссылкой вперед и
представляет собой проблему, возникающую при разработке любого
компилятора.
Мы разрешаем эту проблему, составляя связанный список всех
сгенерированных команд, содержащих ссылку вперед на одну и
ту же метку, и записывая в поле АДРЕС табличного элемента для
этой метки указатель на первый элемент списка. Точнее, если в
поле СТАТУС элемента, соответствующего метке, содержится
значение ВИСЯЧАЯ, ГЕН помещает содержимое поля АДРЕС этого-
14.7. Блок управления сумматором
557
элемента в генерируемую команду, а затем адрес этой команды в
поле АДРЕС элемента. Таким образом, новая ссылка вперед
добавляется в начало списка, а в поле АДРЕС заносится указатель на,
расширенный список. Впоследствии, когда встречается атом вида
НОМСТРОК или МЕТКА, адрес метки (полученный из СЧЕТКОМ)
помещается в каждую из сгенерированных команд, содержащих
ссылку вперед на эту метку. Мы предполагаем, что процедура,
называемая ЗАПОЛН(р), заносит адрес метки в каждую из команд
списка.
Возможно, что имеется обращение к какому-то номеру строки,
например
GOTO 390
но нигде в начале строки этот номер не появляется. Чтобы учесть
такой случай, по завершении компиляции проверяется, содержит
ли поле СТАТУС каждого табличного элемента, соответствующего
номеру строки, значение ПРИПИСАННАЯ. Для каждого номера
строки, для которого это поле содержит значение ВИСЯЧАЯ,
печатается сообщение об ошибке.
14.7. Блок управления сумматором
Говоря о моделировании исполнения, мы, в частности, требуем,
чтобы во время компиляции генератору кода было постоянно
известно содержимое сумматора в соответствующий момент
исполнения. Блок управления сумматором — это часть генератора кода,
ответственная за работу с информацией о содержимом сумматора.
Блок управления сумматором используется также для генерации
команд запоминания содержимого сумматора (при этом
обновляется информация в соответствующем табличном элементе), когда это
содержимое соответствует промежуточному результату, который
нужно сохранить.
Блок управления сумматором использует переменную периода
компиляции СУМ, которая содержит информацию о текущем
состоянии сумматора. Если сумматор не занят, значение СУМ равно
нулю. Если сумматор занят, то СУМ содержит указатель на
табличный элемент, соответствующий промежуточному результату,
занимающему сумматор. Генератор кода взаимодействует с блоком
управления сумматором, используя следующие процедуры:
ИСПОЛЬЗОВАН. Эта подпрограмма сообщает блоку управления
сумматором о том, что содержимое сумматора используется в
последний раз, и таким образом сумматор освобождается от какой-
либо полезной информации. Процедура отмечает этот факт,
присваивая переменной СУМ нулевое значение. Так как каждый
промежуточный результат используется только один раз, то каждое
использование является «последним» и требует вызова процедуры
558 14. Генератор кода для MMl-BASlC-компилятора
ИСПОЛЬЗОВАН. Если использование включает арифметическую
операцию, то нужен вызов некоторой другой процедуры, которая
проинформирует блок управления сумматором о новом содержимом
сумматора.
ОЧИСТИТЬ. Эта процедура сообщает блоку управления
сумматором о том, что сумматор требуется для некоторой операции, но эта
операция не использует текущее содержимое сумматора. Таким
образом, если в сумматоре находится какой-либо промежуточный
результат, требуются команды записи этого результата во временную
ячейку. Если СУМ содержит нуль, то ОЧИСТИТЬ не делает
ничего. Если значение СУМ ненулевое, то ОЧИСТИТЬ обращается к
ГЕН:
ГЕН(ЗАП.СУМ)
и заносит нуль в СУМ.
СВЯЗАТЬ(Р). Эта процедура сообщает блоку управления
сумматором о том, что промежуточный результат, соответствующий
табличному элементу Р, только что вычислен в сумматоре. Процедура
присваивает СУМ значение Р и инициализирует нулем поле АДРЕС
элемента Р.
14.8. Процедуры для атомов
Множество атомов было перечислено на рис. 10.2. В генераторе
кода есть вектор начального перехода, использующий имя
входного атома для перехода к процедуре, которая обрабатывает этот
атом и генерирует все необходимые команды. Если установлен
флажок ошибки, то генератор кода прекращает компиляцию в
случае атома ОКОНЧАНИЕ, а для всех остальных атомов
возвращает управление синтаксическому блоку. Процедуры для
различных атомов в случае, когда флажок ошибки не установлен,
перечислены ниже.
ОКОНЧАНИЕ
Для каждого табличного элемента, соответствующего номеру
строки, поле СТАТУС которого содержит значение
ВИСЯЧАЯ: call ОШИБКА («НЕ ОПРЕДЕЛЕН НОМЕР
СТРОКИ»);
сгенерировать весь код, необходимый для завершения
объектной программы; закончить компиляцию и, если флажок
ошибки не установлен, инициировать исполнение
скомпилированной программы.
14.8. Процедуры для атомов
559
НОМСТРОК Р\ МЕТКА Р
if СТАТУС (Р) = ВИСЯЧАЯ then call ЗАПОЛН (Р)
let СТАТУС (/>) = ПРИПИСАННАЯ
let АДРЕС (Р) = СЧЕТКОМ
ПРИСВ Р, Q
if АДРЕС(С>) = 0 then
begin
comment Q В СУММАТОРЕ
call ИСПОЛЬЗОВАН
call ГЕН (ЗАП.Р)
end
else begin
comment Q В ПАМЯТИ
call ГЕН(ЗАГР,ф
call ГЕН(ЗАП.Р)
end
ПЕРЕХОД Р
call ГЕН(ПЕРЕЙТИ.Р)
ХРАНПЕРЕХОД P
Предполагается, что есть стек периода исполнения, в котором
мы храним адреса возврата из вызываемых процедур, а также
индексный регистр ИРСТЕКА, указывающий на верх этого стека.
Нам нужно сгенерировать команду записи нового адреса возврата
в стек. Однако прежде генерируются команды для проверки стека
подпрограмм на переполнение.
Мы предполагаем, что объектная машина имеет команду СРАВН,
которая сравнивает содержимое сумматора с содержимым ячейки
по адресу, указанному в этой команде, устанавливая определенные
индикаторы в соответствии с результатом проверки
Предположим, кроме того, что имеется команда условного перехода для
каждого возможного результата выполнения команды СРАВН.
И наконец, предположим, что второй параметр в первых трех
вызовах процедуры ГЕН находится в подходящей для ГЕН форме.
call ГЕН(СРАВН.ИРСТЕКА, ГРАНСТЕКА)
call ГЕЩПЕРЕЙТИ.ПО.БОЛЬШЕ.ИЛИ.РАВНО, МЕТКА.
ПЕРЕПОЛНЕНИЯ)
call ГЕЩЗАП.В.ЯЧЕЙКУ.УКАЗАННУЮ.ИРСТЕКА,
СЧЕТ КОМ + 3)
call ГЕН(УВЕЛИЧИТЬ.ИРСТЕКА.НА.1, —)
call ГЕН(ПЕРЕЙТИ.Р)
560 14. Генератор кода для MlNl-BASlC-компилятора
Часть этих команд на некоторых объектных машинах можно
реализовать единственной командой.
ВОЗВПЕРЕХОД
call СЕН(УМЕНЫ11ИТЬ.ИРСТЕКА.НА.1, — )
call ГЕЩПЕРЕИТИ.ПО.АДРЕСУ.УКАЗАННОМУ.
ИРСТЕКА, —)
УСЛПЕРЕХОД Р, Q, N, L
На рис. 14.3 даны таблицы КОПОТН и КОПОБРОТН для кодов
операций команд условного перехода, соответствующих каждому
из отношений. Для выполнения условного перехода один из операн-
ОТНОШЕНИЕ КОПОТН КОПОБРОТН
= ПЕРЕХОД.ПО.НУЛЮ ПЕРЕХОД.ПО.НУЛЮ
Ф ПЕРЕХОД.ПО.НЕ.НУЛЮ ПЕРЕХОД.ПО.НЕ.НУЛЮ
< ПЕРЕХОД.ПО.МЕНЬШЕ ПЕРЕХОД.ПО.БОЛЬШЕ
«s; ПЕРЕХОД.ПО.МЕНЬШЕ, ПЕРЕХОД.ПО.БОЛЬШЕ.
ИЛИ. РАВНО ИЛИ. РАВНО
> ПЕРЕХОД.ПО.БОЛЬШЕ ПЕРЕХОД.ПО.МЕНЬШЕ.
S* ПЕРЕХОД.ПО.БОЛЬШЕ. ПЕРЕХОД.ПО.МЕНЬШЕ.
ИЛИ.РАВНО ИЛИ.РАВНО
Рис. 14.3. Таблицы КОПОТН и КОПОБРОТН.
дов должен находиться в сумматоре. Если в сумматоре левый
операнд, то код операции для генерируемой команды получается по
знаку отношения с помощью таблицы КОПОТН. Если в
сумматоре — правый операнд, то используется таблица КОПОБРОТН.
it АДРЕС(Р) = 0 then
begin
comment P В СУММАТОРЕ
call ИСПОЛЬЗОВАН
call ГЕН(СРАВН, Q)
call ГЕН(КОПОТН(Л0, L)
end
else if АДРЕС(<2) --= 0 then
begin
comment Q В СУММАТОРЕ
call ИСПОЛЬЗОВАН
call ГЕН(СРАВН, Р)
call ГЕН(КОПОБРОТН(Л0, L)
end
14.8. Процедуры для атомов
5G1
else begin
comment P и Q В ПАМЯТИ
call ГЕН(ЗАГР, Р)
call ГЕН(СРАВН, Q)
call ГЕН(КОПОТН(Л0, L)
end
ХРАНЕНИЕ/», Я
it ВИД(Р) ■= КОНСТАНТА then
begin
comment КОМАНД СОХРАНЕНИЯ НЕ
ТРЕБУЕТСЯ
let ВИД (/?) = КОНСТАНТА
let ЗНАЧЕНИЕ (/?) = ЗНАЧЕНИЕ (Р)
end
else begin
let АДРЕС (/?) = НОВХРАН
if АДРЕС (Р) = 0 then call ИСПОЛЬЗОВАН
else call ГЕН (ЗАГР, P)
call ГЕН(ЗАП, R)
end
ПРОВЕРКА P, Q, R, L.
Генератор кода проверяет, является ли шаг константой. Если да,
то ее знак можно определить в период компиляции и генерировать
команды динамической проверки знака не надо. В противном
случае такие команды генерируются и генерируемый код соответствует
блок-схеме на рис. 14.4. Мы предполагаем, что объектная машина
имеет команду УСТ.ИНДИКАТОРЫ, которая устанавливает
индикаторы в соответствии с результатами сравнения с нулем
содержимого адресуемой в команде ячейки.
if ВИД (R) = КОНСТАНТА then
begin
call ГЕН (ЗАГР, Р)
call rEH(CPABH.Q)
if значение константы^ О
then call ГЕН (ПЕРЕЙТИ. ПО. БОЛЬШЕ,
L)
else call ГЕН (ПЕРЕЙТИ. ПО. МЕНЬШЕ,
L)
end
562 14. Генератор кода для MINI-BASIC-компилятора
ЗагрузитьР
СраВнить
регистр с
Q (границей)
Сравнить
регистр с
Q (границей)
Регистр <
ячейки
Регистр ?
ячейки
Продолжать
Переход на I
Регистр >
ячейки
Регистр 4
ячейки
Продолжать
Переход на L
Рис. 14.4.
else begin
call ГЕН (ЗАГР, Р)
call ГЕН (УСТ.ИНДИКАТОРЫ, R)
call ГЕН (ПЕРЕЙТИ.ПО.БОЛЬШЕ.СЧЕТ-
КОМ + 4)
call rEH(CPABH.Q)
call ГЕН (ПЕРЕЙТИ. ПО. МЕНЬШЕ, L)
call ГЕН(ПЕРЕЙТИ,СЧЕТКОМ + 3)
call ГЕН(СРАВН,<?)
call ГЕН (ПЕРЕЙТИ.ПО.БОЛЬШЕ, L)
end
УВЕЛИЧ Р, Q
Нужно сгенерировать команды для увеличения Р на Q. Известно,.
что оба операнда — в памяти, но сложение требует использования;
сумматора.
call ГЕН (ЗАГР, Q)
call ГЕН(СЛОЖ, Р)
call ГЕН(ЗАП, Р)
14.8. Процедуры для атомов
563
СЛОЖ Р, Q, R; ВЫЧИТ Р, Q, R; УМНОЖ Р, Q, R; ДЕЛЕН Р,
Q,R
Эти атомы обрабатываются таким же образом. Для выполнения
операции, соответствующей любому из этих атомов, один из операндов
должен находиться в сумматоре. Если оба операнда — в памяти,
то генерируются команды для загрузки левого операнда в сумматор.
Когда один операнд в сумматоре, а другой — в памяти,
генерируется команда арифметической операции, соответствующей атому.
Если в сумматоре находится левый операнд, то код операции для
этой команды получается по имени атома с помощью таблицы КОП
на рис. 14.5. Если в сумматоре правый операнд, то используется
таблица КОПОБРОП, изображенная на том же рисунке. Таким
образом, для атома ВЫЧИТ выбирается операция ВЫЧ или ОБР.
ВЫЧ в зависимости от того, какой из операндов находится в
сумматоре. Команда ОБР.ВЫЧ вычитает содержимое сумматора из
содержимого ячейки памяти, помещая результат в сумматор.
ОПЕРАЦИЯ КОПОП КОПОБРОП
СЛОЖ СЛОЖ СЛОЖ
ВЫЧ ВЫЧ ОБР.ВЫЧ
УМНОЖ УМНОЖ УМНОЖ
ДЕЛЕН ДЕЛЕН ОБР.ДЕЛЕН
Рис. 14.5. Таблицы КОПОП и КОПОБРОП для арифметических
операций.
if АДРЕС(Р)=0 then
begin
comment P В СУММАТОРЕ
call ИСПОЛЬЗОВАН
call ГЕН (КОПОП (ATOM), Q)
end
-else if АДРЕС(<3) = 0 then
begin
comment Q В СУММАТОРЕ
call ИСПОЛЬЗОВАН
call ГЕН (КОПОБРОП (ATOM), P)
end
else begin
comment P И Q В ПАМЯТИ
call ОЧИСТИТЬ
call ГЕН (ЗАГР, Р)
564 14. Генератор кода для M1NI-BASIC-компилятора
call ГЕН (КОПОЩАТОЛЧ О*
end
call СВЯЗАТЬ (R)
ЭКСП Р; Q, R
Генерируется код вызова процедуры возведения в степень. В два
индексных регистра ИР1 и ИР2 загружаются адреса двух операндов
и выполняется переход с возвратом (при этом адрес возврата
помещается в индексным регистр ИРВОЗВР) на процедуру. Процедура
возведения в степень помещает результат в сумматор.
call ОЧИСТИТЬ
call ГЕН(ЗАГР.АДРЕС.В.ИР2, Q)
call ГЕН(ЗАГР.АДРЕС.В.ИР1, Р)
call ГЕР(ПЕРЕЙТИ.С.ВОЗВР.ЧЕРЕЗ.ИРВОЗВР, ПРОЦЕД.
ВОЗВЕД.В.СТЕП)
call СВЯЗАТЬ(Я)
ПЛЮС Р, Q
Для этого атома не нужно генерировать никакого кола. Однако
табличный элемент для Q должен быть соответствующим образом
заполнен и, если нужно, связан с блоком сумматора.
let ВИД (0) = ВИД (Р)
if ВИД(Р)= КОНСТАНТА then let ЗНАЧЕНИЕ (Q) =
-ЗНАЧЕНИЕ (Р)
else begin
let АДРЕС (Q) = АДРЕС (Р)
if АДРЕС (Q) = 0 then call СВЯЗАТЬ (Q)
end
МИНУС Р, Q
Предполагается наличие команды МИНУС, которая меняет знак
содержимого сумматора, а также команды ЗАГРМИНУС, которая
загружает в сумматор значение, полученное за счет изменения знака
содержимого ячейки памяти.
if АДРЕС(Р) = 0 then
begin
comment P В СУММАТОРЕ
call ИСПОДЬЗС ВЛН
call СВЯЗАТЬ (Q)
0«J REM ПРОГРАММА ДЛЯ ОТЛАДКИ ГЕНЕРАТОРА
OS0LETAl = 3*4*a
030 LET В = + Д1 * Ь/?
QCQ LET С = А1 + В * Я.Ь
D50LETD = A1-7.2*C
ObOLETE = Al*(C + D)
070 LET F = (С * A)/(E - С)
06QLETG=-E*F
0Я0 LET H = -<F Г G) + Al
100LETJ = A1*B*(CT D * (E - F) + G/H)
110 IF Al = В GOTO 500
150 IF H + В <> С GOTO 100
130 IF D + E < G GOTO 500
WO IF H <= E GOTO 150
150 IF Al * В > 10 GOTO 500
IbO IF Ч.Ь >= 35 GOTO 300
170 IF Al = 3 + В GOTO 500
160 IF В + 5 <> G - 1 GOTO 500
1Я0 IF С < 5 * J GOTO 170
500IFD-E<=B*C + D GOTO 540
510 IF H + J > B/C GOTO 150
550 IF F >= Al T 3 GOTO 150
530 GOSOB 550
540 GOTO 400
550 TOR H = 1 TO 100 STEP 10
5b0FORI = AlT0CfD STEP В
570 LET Al = 10 + H + I
560 NEXT I
5Я0 NEXT H
300 FOR K' = 100 TO 0 STEP - 1
31QLETW = A1*B + C + K
350 NEXT К
330 LET V = + (С + D) - E
340 FOR К = Al + В ТО Ю00 + В
350 FOR Z = 1 TO 10 STEP С + D
3bOLETJ = K + Z + J
370 NEXT Z
360 NEXT К
340 RETURN
400 END
Рис 14.6.
565 14. Генератор кода для ММ1-В ASIC-компилятора
call ГЕН (МИНУС, —)
end
else begin
comment P В ПАМЯТИ
call ОЧИСТИТЬ
call СВЯЗАТЬ (Q)
call ГЕЩЗАГРМИНУС, Р>
end
Этим завершается набор процедур. На рис. 14.6 показана
отладочная программа, которая вызывает работу всех частей генератора
кода.
14.9. Обработка описаний в языках
с блочной структурой
В языках с блочной структурой, таких, как Алгол и ПЛ/1,
программа может содержать несколько описаний одного и того же
идентификатора. Каждый раз, когда этот идентификатор встречается в
программе, компилятор должен определить, какое из описаний
связать с данным вхождением (если это вообще возможно). В этом
разделе мы описываем один способ установления таких связей.
Будем считать, что компилятор двухпроходный. При первом
проходе работают лексический и синтаксический блоки, при
втором — генератор кода.
Лексический блок заменяет все вхождения в программу любого
идентификатора лексемой, значением которой является число,
связываемое с идентификатором. Заметим, что все вхождения одного
и того же идентификатора представляются лексемой с одним и тем
же значением.
Когда синтаксический блок встречает описание, он создает в
таблице элемент, соответствующий этому описанию, и помещает в
него информацию, содержащуюся в описании (такую, как тип,
размерность массива и т. п.). Когда синтаксический блок встречает
вхождение идентификатора не в описании, он выполняет
трансляцию в атомы, используя для него то же значение, что и в
соответствующей лексеме. Например, переводом оператора присваивания
КОРДЕЛИЯ := ГОНЕРИЛЬЯ + РЕГАНА
может быть цепочка лексем
ИДЕНТИФИКАТОР,,.^ ИДЕНТИФИКАТОР,+
+ИДЕНТИФИКАТОР62
и, далее, цепочка атомов
СЛОЖв.в2.М0 ПРИСВв,500
14.9. Обработка описаний в языках с блочной структурой 567
Теперь рассмотрим обработку цепочки атомов генератором кода.
Предположим для удобства, что множество значений лексем,
сопоставленных идентификаторам программы, состоит из
последовательных целых чисел. В этом случае генератор кода заводит
одномерный массив, содержащий по одному элементу на идентификатор.
Для каждого идентификатора связанный с ним элемент массива
будет указателем на табличный элемент, соответствующий действитель-
begin real А, В, С;
begin integer B,C,D;
begin Boolean С;
end;
begin
Boolean A;
В: С :=D ;
end;
end;
end
A
В
С
D
j
integer \
real |
. i
real |
i
real |
d
Рис. 14.7.
ному на данный момент (видимому) описанию идентификатора.
Таким образом, при обработке атома СЛОЖ генератор кода
использует 9-й и 62-й элементы массива, чтобы получить табличные
элементы, соответствующие действительным на данный момент
описаниям участвующих здесь идентификаторов.
Генератор кода может работать с таким массивом, используя
для каждого идентификатора стек табличных элементов,
соответствующих этому идентификатору; при этом массив должен содержать
указатель на верхний элемент стека. Основной принцип при
внесении изменений в эти стеки состоит в том, что, когда генератор кода
встречает начало блока, содержащего описание некоторого
конкретного идентификатора, он записывает на верх стека соответствующий
табличный элемент, помещая в массив ссылку на этот элемент.
Когда блок кончается, табличный элемент из стека выбрасывается.
В качестве примера рассмотрим программу на рис. 14.7, а. Пред--
3568 14. Генератор кода для MINI-BASIC-компилятора
.положим, что каждый табличный элемент в стеке содержит
указатель на элемент, находящийся в стеке непосредственно под ним.
Тогда при обработке генератором кода оператора присваивания на
рис. 14.7, а, массив и стеки будут иметь вид, показанный на
рис. 14.7, б.
Описываемый метод работы со стеками включает в себя
составление связанного списка всех табличных элементов,
соответствующих отдельному блоку. Атрибутное правило для блока
(оператор )-*■ begin {НАЧБЛОКАр} (тело блока >р
end {КОНБЛОКАр}
р «- НОВТАБЛЭЛЕМДЛЯ БЛОКА
Табличный элемент р, соответствующий блоку, будет содержать
указатель на список табличных элементов для описаний,
встречающихся в блоке. Как только синтаксический блок создает табличный
элемент для очередного описания, этот новый элемент добавляется
в список текущего блока.
При втором проходе, когда генератор кода встречает атом НАЧ-
БЛОКА, он помещает каждый из табличных элементов,
соответствующих описаниям, имеющимся в этом блоке, на ве^х нужною
стека. Когда генератор кода встречает атом КОНБЛОКА, все
табличные элементы, содержащиеся в списке для этого блока,
выбрасываются из соответствующих стеков.
На этом мы завершаем описание метода. Общее время,
затрачиваемое при его использовании, пропорционально числу вхождений
идентификаторов в программу. В заключение заметим, что элементы
массива, соответствующие встроенным процедурам, таким, как
SIN, можно инициализовать указателями на зарезервированные
табличные элементы, описывающие эти процедуры, а остальные
элементы массива — указателями на специальный табличный элемент,
сообщающий, что «ВИДИМЫХ ОПИСАНИЙ НЕТ».
14.10. Замечания по литературе
Обсуждение нескольких полезных методов из области итерации
кода см. в книге Гриса [1971]. Метод из разд. 14.9 в принципе
аналогичен методу, описанному Науром [1964]. Некоторые другие
аспекты генератора кода для языка MINI-BASIC промоделированы
.в генераторе кода, разработанном В. В. Стоуном.
Упражнения
569-
Упражнения
1. Какой код будет генерироваться для каждой из следующих программ на языке
MINI-BASIC?
a) ID
ED
3D
5D
С>) ID
2D
3D
АО
ЬО
70
LETT. = (Ь + 7) *5 + 7
IF I > 15 + У GOTO SO
LETX= (7 + 1) * (1 + 5
END
FOR XI = 1 ТО - 5 + ID
FOR X5 = 1 TO 15
LET ХЭ = XI + X5
NEXT X5
NEXT XI
END
2. Опишите, каким образом можно расширить генератор кода, чтобы допустить.
использование операндов различных типов (целых и с плавающей точкой).
Считайте, что каждый элемент таблицы имен содержит поле ТИП, в котором
указывается его тип.
3. а) Разработайте улучшенную реализацию FOR-операторов, при котг рой знак
шага цикла вычисляется только один раз, а не при каждом повторении
цикла,
б) Пусть имеется машинная команда УВЕЛИЧИТЬ.ЯЧЕЙКУ.НАЛ.
Используйте эту команду в объектном коде, там где это возможно.
4. Покажите, как можно оптимизировать объектный код для атома УСЛПЕРЕ-
ХОД, проверяя при компиляции, является ли один из операндов константой 0.
5. Опишите метод оптимизации объектного кода для бинарных и унарных
операций, состоящий в проверке вида операндов и выполнении во время
компиляции тех операций, операнды которых являются константами.
6. Пусть в языке MINI-BASIC имеется следующее ограничение (как в
Фортране): переменную цикла нельзя изменять внутри цикла. Разработайте
реализацию FOR-оператора, улучшенную за счет использования этого
ограничения. Предположите, что в объектной машине есть индекс-регистры.
7. Переделайте процедуры генерации для атомов ВЫЧИТ и ДЕЛЕН,
предполагая, что система команд машины не содержит команд обратного вычитания и
обратного деления.
8 Опишите словесно возможное расширение генератора кода для работы с
индексированными переменными.
9. Опишите модификацию MINI-BASIC-компилятора, которая для каждой
константы, встречающейся в программе более одного раза, отводит лишь одну
ячейку на весь период исполнения.
10. Покажите, что в случае языка ПЛ/I использовать стек для хранения
промежуточных результатов было бы неадекватным решением. (Указание. Обратите
внимание на операторы агрегатного присваивания для работы с
индексированными переменными.)
11. а) Пусть объектная машина MINI-BASIC-компилятсра имеет деэ
арифметических регистра с плавающей точкой (т. е. два сумматора). Опишите
модификацию табличных элементов и блока управго ия с\ммагора (ь этом слу-
570 14. Генератор кода для MINI-BASIC-колпилятора
чае уместнее называть его блоком управления регистрами), которая
позволила бы генерировать код, использующий оба регистра. Опишите детально
генерацию кода для атомов ПРИСВ и СЛОЖ.
б) Выполните пункт а) для случая, когда объектная машина имеет N
регистров, где N — параметр генератора кода.
12. Измените метод разд. 14.9 так, чтобы он позволял обнаруживать ошибку,
состоящую* в повторном описании некоторого идентификатора внутри данного
блока.
13. В следующей программе на языке Алгол 60:
begin integer procedure F; /г:=1;
F:=2
end
первый оператор присваивания правильный, а второй содержит ошибку.
Опишите, как можно расширить методы разд. 14.9, чтобы обнаруживать
ошибки такого типа.
14. В языке Алгол 60 (см. Наур и др. [1963], разд. 5.2.4.2) идентификатор,
который входит в выражение, задающее границу индекса в описании некоторого
массива, нельзя описывать в том же блоке, что и указанный массив. Таким
образом, вхождение идентификатора в выражение для границы индекса
является не только использованием этого идентификатора, но еще и его
«антиописанием» для того блока, в котором описан массив. Опишите расширение метода
разд. 14.9, позволяющее обнаруживать ошибки такого типа.
15. Разработайте метод, который для данного вхождения составного имени в
программу на Коболе позволяет проверить однозначность этого составного
имени и найти определяемый именем элемент структуры. (Такой метод описан
у Кнута [19686].)
15
Обзор методов оптимизации
объектного кода
15.1. Введение
В этой главе мы кратко обсудим ряд преобразований, которые
можно выполнять над программами с целью повышения эффективности
объектного кода. Обычно эти преобразования называют
«оптимизацией», хотя более подходящим было бы слово «улучшение». Такие
преобразования можно выполнять в различных блоках
компилятора, но наиболее сложные из них обычно выполняются отдельным
блоком оптимизации, работа которого происходит в период между
синтаксическим анализом и генерацией кода. Мы рассмотрим только
сами преобразования, не останавливаясь на методах, которые
нужны для выяснения применимости преобразований и их фактического
выполнения.
Мы будем иллюстрировать описываемые преобразования
примерами на языке MINI-BASIC, который будет расширен путем
введения одномерных и двумерных массивов.
15.2. Распределение регистров
Одной из особенностей традиционной архитектуры вычислительных
машин, имеющей большое значение для генерации эффективного
объектного кода, является наличие лишь ограниченного числа
быстрых регистров наряду с существенно большим объемом оперативной
памяти. Команды, работающие с оперативной памятью, могут быть
более медленными и требовать для своего задания большего объема
памяти, чем команды, работающие с регистрами. Поэтому
желательно использовать регистры как можно более эффективно.
Распределение регистров означает принятие решения относительно того,
каким должно быть содержимое каждого регистра в каждый момент
исполнения программы. Регистры можно использовать для хранения
переменных, промежуточных результатов и информации,
необходимой для функционирования рабочей программы (такой, как адреса
возвратов и указатели на различные области оперативной памяти).
Один часто используемый метод состоит в том, что во всей
программе или на некотором ее участке данной переменной отводится
регистр, а не ячейка оперативной памяти. Даже если переменной
отведена ячейка оперативной памяти, компилятор может в момект
572 15. Обзор методов оптимизации объектного кода
присваивания ей нового значения, вычисленного в регистре,
отложить генерацию команды записи этого значения в соответствующую
ячейку. Компилятор временно использует регистр вместо ячейки
в качестве носителя значения переменной.
Аналогичные методы применяются при распределении регистров
под промежуточные результаты, индексы массивов, адреса
возвратов из процедур и т. д. Для каждого из этих объектов регистр или
ячейка оперативной памяти отводятся либо на все время его
существования, либо на некоторую его часть. Использование регистров
.для хранения промежуточных результатов кратко обсуждалось f
гл. 14 и будет рассматриваться снова в разд. 15.5.
15.3. Оптимизация одного атома
Некоторые простые виды оптимизации можно осуществить, выясняя
для каждого атома, образуют ли значения его параметров один из
выделенных частных случаев, позволяющих генерировать более
эффективный код. Например, можно посмотреть, не окажется ли
-один из операндов атома СЛОЖ константой, равной нулю. В этом
случае генерировать код не нужно. Может также оказаться, что оба
операнда — константы; тогда сложение можно выполнить в период
компиляции, и генерировать код также не требуется.
Другим примером специального случая является возведение в
•степень, равную некоторой небольшой константе. Например, для
А\2 компилятор может сгенерировать код, соответствующий А*А,
вместо того чтобы генерировать вызов общей процедуры возведения
в степень.
Иногда система команд объектной машины содержит такие
команды, которые можно использовать только в специальных
случаях. Пусть, например, имеется команда ЗАПНУЛЬ, которая
записывает в ячейку памяти константу, равную нулю. Тогда, хотя для
атома ПРИСВ/>1 q в общем случае следует генерировать команды,
позволяющие записать значение, соответствующее второму
параметру, компилятор может сгенерировать ЗАПНУЛЬ, если второй
параметр — это константа, равная нулю.
15.4. Оптимизация фиксированной цепочки
атомов
В некоторых случаях возможности для оптимизации можно
выявить, исследуя некоторое фиксированное число последовательных
атомов (так называемое «окно»). Пусть, например, грамматика
содержит правило:
<оператор)-*- IF (логическое выражение) THEN (оператор)
15.5. Оптимизация одного оператора
573
Соответствующее правило атрибутной транслирующей грамматики,
используемой в синтаксическом блоке, может иметь вид
^пепатор) —► 1Р<логическое выражение;^, THEN
{ПЕРЕХОДПОЛЖИ,?, п}<оператор>
{МЕТКА,,}
(LI, L2) *- НОВТАМ R2 *~- R\
где HI —синтезируемый атрибут, а НОВТАМ дает указатель на
новый табличный элемент для метки. Если за THEN следует
оператор перехода, то такому условному оператору может
соответствовать следующая типичная цепочка атомов:
ПЕРЕХОДПОЛЖИ (39, 62) ПЕРЕХОД(92) МЕТКА (62)
Эту цепочку атомов можно заменить более эффективной цепочкой:
ПЕРЕХОДПОИСТИНЕ(39, 92)
Компилятор может обнаруживать такие ситуации, отыскивая
вхождения цепочек атомов вида
ПЕРЕХОДПОЛЖИ ПЕРЕХОД МЕТКА
где второй параметр атома ПЕРЕХОДПОЛЖИ совпадает с
параметром атома МЕТКА.
15.5. Оптимизация одного оператора
Теперь рассмотрим некоторые преобразования, охватывающие
неограниченное число последовательных атомов, но обязательно в
пределах одного оператора.
Переупорядочение выражений
Часто оказывается возможным генерировать более эффективный
объектный код для вычисления выражений, если использовать
порядок вычислений, отличный от порядка атомов в цепочке,
соответствующей польскому переводу исходного выражения.
Предположим, например, что в системе команд объектной машины нет
команды обратного вычитания и что имеется лишь один регистр для
вычисления выражения
A*B—C*D
Если выполнять команды в соответствии с порядком польской
записи, то объектный код будет состоять из восьми команд
574 15. Обзор методов оптимизации объектного кода
ЗАГР
УМНОЖ
ЗАП
ЗАГР
УМНОЖ
ЗАП
ЗАГР
ВЫЧИТ
А
В
ВРЕМ1
С
D
ВРЕМ2
ВРЕМ1
ВРЕМ2
Однако, если выражение можно переупорядочить таким образом,
чтобы C*D вычислялось раньше, чем А#В, то удается сгенерировать
объектный код, состоящий всего из шести команд:
ЗАГР С
УМНО>Г D
ЗАП ВРЕМ1
ЗАГР А
УМНОЖ В
ВЫЧИТ ВРЕМ1
Для машины с фиксированным числом регистров перестройка
выражения иногда позволяет вычислить его без запоминания
промежуточных результатов в оперативной памяти. Пусть, например,
имеются два регистра и нужно вычислить выражение
A»B+(C+D)»(E+F)
Вычисление этого выражения в соответствии с польской записью
требует следующих девяти команд (обозначение каждой команды
содержит номер используемого регистра):
ЗАГР1
умнож 1
ЗАГР2
СЛ0Ж2
ЗАП1
ЗАГР1
СЛОЖ1
УМНОЖ 1
СЛОЖ1
А
В
с
D
ВРЕМ
Е
F
РЕГИСТР2
ВРЕМ
Однако это же выражение можно перестроить так, что объектный
код будет состоять из следующих восьми команд:
ЗАГР1 С
СЛОЖ1 D
15.6. Оптимизация нескольких операторов
575
ЗАГР2
СЛ0Ж2
УМН0Ж1
ЗАГР2
УМН0Ж2
СЛ0Ж1
Е
F
РЕГИСТР2
А
В
РЕГИСТР2
Вызовы процедур
Часто оказывается возможным сократить время выполнения
процедур и функций, вызываемых внутри оператора. Компилятор
может исследовать параметры и в тех случаях, когда они относятся
к некоторым специальным классам, сгенерировать код вызова
соответствующей частной версии процедуры, работающей быстрее,
чем общая версия, которая допускает любые возможные параметры.
В некоторых случаях код процедуры вставляется
непосредственно в код вызывающего оператора; время исполнения процедуры при
этом уменьшается за счет исключения команд вызова.
Комбинирование переходов
Иногда программа может содержать условный или безусловный
переход на метку, а первый после нее атом — это переход на
некоторую другую метку. В этом случае первый переход можно
заменить переходом непосредственно на эту вторую метку. В качестве
примера такой ситуации можно привести следующий оператор
Алгола:
if X>Y then Z:=Q else go to L
Условный переход в случае Х^У можно адресовать
непосредственно метке L, а код для оператора go to L генерировать не нужно.
15.6. Оптимизация нескольких операторов
Теперь обсудим некоторые преобразования программ, которые
можно выполнять в пределах одного оператора, но применяемые
обычно для нескольких операторов. Проведение такой оптимизации
может потребовать сложного анализа программы.
Общие подвыражения
«Общим подвыражением» называют такое подвыражение, которое
встречается в программе более одного раза, но можно сгенерировать
код, вычисляющий его только один раз. Например, в выражении
(A+B)*C+D/(A+B)
сложение А-\-В достаточно выполнить только один раз.
576 15. Обзср методов оптимизации объектного кеда
Общие подвыражения очень часто встречаются при вычислении
адресов индексированных переменных. Например, в операторе
LET A(I, J)=A(l, J)+B(l, J)
адрес переменной А (/, J) достаточно вычислить один раз. Более
того, если А и В имеют одинаковую размерность, то при вычислении
адресов переменных А (/, J) и B(I, J) может встретиться общее
подвыражение.
Для каждого конкретного вхождения подвыражения повторного
вычисления не требуется, если на всех ведущих к нему
траекториях исполнения программы это подвыражение уже было вычислено.
Например, рассмотрим программу, содержащую следующие
операторы:
40 LETX = A*£ + C
50 GOTO 100
40 LETW = A*B-E
100 LETZ = 3-A*B
Если в программе нет других переходов к строке 100, то при
каждом выполнении этой строки значение подвыражения А*В
оказывается предварительно вычисленным (в строке 40 или в строке 90)
и повторного вычисления А*В не требуется.
Выполнение константных действий')
Операции над константами можно выполнять во время компиляции,
не откладывая их до периода исполнения. Иногда результаты таких
операций можно «распространить» по нескольким операторам.
Например, в последовательности операторов
10 LET A = 1
го LETB = a
30 LETC = A + B
сложение в третьем операторе можно выполнить во время
компиляции, а сам оператор можно заменить более эффективным
30 LETC = 3
1) В оригинале constant propagation.— Прим. ред.
15.7. Оптимизация циклов
577
Распространение констант можно использовать, например, при
вычислении адресов индексированных переменных, в тех случаях,
когда значения индексов можно определить во время компиляции.
15.7. Оптимизация циклов
Существует ряд приемов, специально направленных на повышение
эффективности циклов.
Вынесение кода или чистка цикла
Иногда часть сгенерированного кода можно вынести из цикла так,
чтобы она исполнялась перед выполнением цикла. Таким образом,
вынесенный код исполняется лишь один раз за все время
выполнения цикла, вместо того чтобы исполняться при каждом его
повторении. Например, если некоторый оператор внутри цикла использует
подвыражение А*В, причем Л и В не изменяют своих значений в
процессе выполнения цикла, то это произведение можно вычислить
один раз перед входом в цикл и внутри цикла использовать
полученный результат.
Улучшения такого типа часто оказываются возможными при
вычислении адресов индексированных переменных. Если, например,
индексированная переменная А (/, J) встречается в цикле, для
которого переменной цикла является /, то в вычислении адресов
может участвовать подвыражение, включающее J и некоторую
константу, и это выражение можно вычислить за пределами цикла.
В литературе по оптимизации код, который можно вынести из
цикла, часто называется «инвариантным» в этом цикле.
Слияние циклов
Иногда два цикла можно объединить в один, уменьшив таким
образом число команд проверки и приращения значения переменной
цикла. Например, следующие операторы на языке MINI-BASIC
iaa for i = i то iaa
110 LETA(I)=0
iaa next i
130 FOR J = 1 TO 10D
WO LETB(J) =3*C(J)
150 NEXT J
можно объединить в один цикл:
iaa for к = i то юо
110 LETA(K)=0
iaa letb(k) = э*с(К)
130 NEXT К
19 Ф. Льюис и др.
578 15. Обзор методов оптимизации объектного кода
Расчленение циклов
В некоторых случаях один цикл можно разбить на два цикла, из
которых выполняться должен только один. Например, цикл
300 FOR I = 1 ТО 100
310 IF X > Y GOTO 3<0
350 LETA(I) =B(I)+X
330 GOTO 350
340 LETA(I) =B(I)-Y
350 NEXT I
можно превратить в
300
310
зго
330
140
350
эьо
370
ЗАО
IFX>Y GOTO 350
FOR I = 1 ТО 100
LETA(I) =B(I) + X
NEXT I
GOTO ЗАО
FOR I = 1 TO 100
LETA(I) =B(I)-Y
NEXT I
В преобразованной программе условный оператор выполняется
лишь один раз, в то время как в исходной программе его нужно
было исполнять 100 раз.
Уменьшение силы операций
Эти преобразования содержат замену одной операции некоторой
другой операцией, выполняемой быстрее. Например, цикл:
100 FOR I = 1 ТО 100
110 LETQ(I) =1*5
150 NEXT I
15.7. Оптимизация циклов
579
можно заменить на
10Q
110
150
130
КО
LETJ = 5
FOR I = 1 ТО 100
LETQ(I) =J
LET J = J + S
NEXT I
Умножение 1*5 в исходном цикле заменено более быстрым
сложением: J+5.
Развертывание циклов
Развертывание циклов означает уменьшение числа повторений
цикла за счет выполнения вычислений, соответствующих двум (или
более) повторениям старого цикла в течение одного повторения
нового цикла. Например, цикл
100 FOR I = 1 ТО 100 STEP 1
110 LETA(I)=B(I)*C(I)
130 NEXT I
можно преобразовать в другой цикл:
100 FOR I = 1 ТО ЧЯ STEP S
110 LETA(I) =B(I) *C(I)
120 LETA(I + 1) =B(I + 1) *C(I + 1)
130 NEXT I
Это преобразование уменьшает число проверок переменной
цикла (выполняемых с целью выяснить, окончился ли цикл) от ста до
пятидесяти. Более того, на машине, допускающей параллелизм,
два оператора присваивания, имеющихся в новом варианте цикла,
можно выполнить за то же самое время, которое требовалось для
выполнения одного оператора присваивания в первоначальном
цикле.
Линеаризация массивов
Линеаризация л-мерного массива означает, что компилятор
генерирует код так, как если бы массив был одномерным. Например,
двойной цикл:
19*
580 15. Обзор методов оптимизации объектного кода
100 FOR I = 1 ТО SO
110 FOR J = 1 ТО 30
ISO LETft(I,J)=0
130 NEXT J
КО NEXT I
обращает в нуль значения четырехсот элементов двумерного
массива А. Того же эффекта можно достигнуть при помощи следующего
цикла, в котором А трактуется как одномерный массив из
четырехсот элементов:
100 FOR I = 1 ТО 400
110 LETA(I)=0
iao нвхт i
15.8. Прочие приемы оптимизации
Существует много других приемов, которые на первый взгляд
направлены на исправление лишь очевидных несообразностей в
исходной программе, но могут оказаться очень важными после того, как
программа преобразована с помощью других методов.
Удаление бесполезных операторов
Оператор называется бесполезным или несущественным, если в
программе на него ни при каких обстоятельствах не происходит
передачи управления. Кроме того, присваивание называется
бесполезным, если присваиваемое переменной значение не используется
до следующего присваивания этой же переменной. Бесполезные
операторы и присваивания можно удалить из программы.
Оптимизация «через щель»')
Иногда просмотр сгенерированных команд как бы через «щель»,
в которую видно только небольшое число команд, позволяет
обнаружить команду, которую можно удалить. Если, например,
имеются две последовательных команды
ЗАП А
ЗАГР А
и в программе нет передачи управления на команду загрузки, то
эту команду можно опустить.
-1) В оригинале peephole optimization,— Прим. ред.
15.9. Замечания по литературе
581
15.9. Замечания по литературе
Значительная часть этой главы основана на работе Аллена и Кока
11972]. Дальнейшее обсуждение оптимизации объектного кода,
включающее методы выполнения различных оптимизирующих
преобразований, можно найти в книгах Ахо и Ульмана [1973а], Аллена
119691, Кока и Шварца [1970].
Приложение А
Руководство по языку MINI-BASIC
А.1. Общий вид программы на MINI-BASIC'e
Программа ка языке MINI-BASIC представляет собой
последовательность строк, каждая из которых начинается с номера. Эти
номера называются номерами строк и используются для их
идентификации. Вся остальная часть строки называется оператором. Номера
строк служат также для определения порядка, в котором
выполняются операторы. Очередность выполнения операторов, как
правило, соответствует номерам строк, за исключением тех случаев,
когда управление передается операторами GOTO (безусловный
переход), IF (условный переход), NEXT (конец цикла), FOR
(заголовок цикла), GOSUB (переход на подпрограмму) или RETURN
(возврат).
Пробелы ничего не значат и компилятор их игнорирует. Тем не
менее иногда их можно вставлять для наглядности.
Пример:
10 LETX = 1S
20 IF X> 10 GOTO 30
30 END
А.2. Числа
Число может быть записано одним из двух способов:
а) в виде цепочки десятичных цифр (содержащей или не
содержащее! точку), перед которой может стоять знак, например:
Э.471Э
-1535
Е.
б) с 1;пдс цепочки десятичных цифр (содержащей или не
содержащей точку), которой может предшествовать знак и за
которой следуют символ Е и еще одна цепочка десятичных цифр,
A.4. Арифметические выражения
583
которой также может предшествовать некоторый знак,
например:
15Э4Е-11
1S.34E-R
.oaooaaoi23<Ea
причем три этих цепочки изображают одно и то же число.
А.З. Переменные
Переменная обозначается одной буквой (английского алфавита)
или буквой, за котоиой следует цифра.
Примеры:
X
Y1
zq
Q0
А.4. Арифметические выражения
Арифметические выражения — это формулы, по которым
вычисляются значения. Они образуются из чисел, переменных, пяти знаков
арифметических операций:
+ Сложение
— Вычитание
«Умножение
/ Деление
f Возведение в степень
а также левых и правых скобок.
Допустима любая осмысленная формула, составленная из этих
символов, с одним лишь условием — символы унарных операций
+ и — могут появляться только в начале выражения или
непосредственно после левой скобки, т. е. символы операций не могут стоять
рядом.
Примеры с унарными операциями:
-А*В
-(А*В)
С*(-А*В)
584 Приложение А. Руководство по языку MINI-BASIC
Примеры общих выражений:
ftl + B* (C + Dt (C + E))
Al + 3.W15q/<*(C + 15)
Обычный порядок выполнения операций — слева направо, за
исключением того, что
1) операции внутри скобок выполняются перед тем как
заключенная в скобки величина используется в дальнейших вычислениях;
2) возведение в степень выполняется перед умножением и
делением, которые в свою очередь выполняются перед сложением и
вычитанием.
Пример
Порядок выполнения операций обозначен цифрами под
выражением:
А + (В/(С + D)) * F T G Т (Н + В) + С
7 2 1 6 3 5 4 8
А.5. Операторы
В языке допускаются следующие типы операторов:
а) Оператор присваивания.
В общем виде оператор присваивания выглядит так:
LET (переменная) = (арифметическое выражение)
Значение арифметического выражения вычисляется и
присваивается переменной.
Пример
LETXl = Yl + lE.b*Z +X1
б) GOTO-оператор (безусловный переход).
В общем виде GOTO-оператор выглядит так:
GOTO (номер строки)
Управление передается оператору с указанным номером
строки.
Пример
GOTO 75
в) IF-оператор (условный оператор).
A.5. Операторы
585
В общем виде условный оператор выглядит так:
IF (арифметическое выражение) (знак отношения)
(арифметическое выражение) GOTO (номер строки)
где знаками отношений являются следующие:
= равно
< > не равно
< меньше
< = меньше или равно
> больше
> = больше или равно
Если между значениями двух арифметических выражений
выполняется данное отношение, управление передается на
строку с указанным номером. В противном случае управление
переходит на следующий оператор программы.
Примеры
IF X > Y GOTO 15
IF Z + (X * Y) = X1 + 15 GOTO 75
r) FOR-оператор (заголовок цикла) и NEXT-оператор (конец
цикла).
Эти операторы используются для записи циклов.
Существуют две формы FOR-оператора:
FOR (переменная ) = (арифметическое выражение 1) ТО
(арифметическое выражение 2) STEP (арифметическое
выражение 3)
FOR (переменная ) = (арифметическое выражение 1) ТО
(арифметическое выражение 2)
Вторая форма интерпретируется так же, как и первая, с той
лишь разницей, что величина шага (значение
арифметического выражения 3) предполагается здесь равной 1. FOR-
оператор представляет собой вход в цикл, тело которого
состоит из некоторого числа операторов, расположенных перед
NEXT-оператором. Общий вид NEXT-оператора такой:
NEXT (переменная)
где переменная должна быть той же, что в FOR-операторе.
586 Приложение А. Руководство по языку MINI-BASIC
Пример
TOR X = 1 ТО 1DD STEP 5
LETW=X+Y+Z
LET Z = X * Y
NEXT X
Неформально операторы цикла, расположенные между FOR-
оператором и NEXT-оператором, выполняются снова и снова
столько раз, сколько указано в FOR-операторе. Каждый раз
при выполнении цикла значение переменной цикла
увеличивается на величину шага и сравнивается с конечным
значением, результат сравнения показывает, следует ли войти
в тело цикла снова или прекратить повторение цикла. Точнее,
выполнение FOR-NEXT-конструкции заключается в
следующем:
i) Вычисляется арифметическое выражение 1 (начальное
значение), арифметическое выражение 2 (конечное значение)
и арифметическое выражение 3 (величина шага).
и) Переменной цикла присваивается начальное значение.
iii) В зависимости от значения величины шага выполняется
следующая проверка.
Если величина шага больше или равна нулю, а значение
переменной цикла меньше или равно конечному значению,
управление переходит к оператору, следующему за FOR-
оператором (т. е. происходит вход в тело цикла). В противном
случае управление передается оператору, следующему за
соответствующим NEXT-оператором (т. е. входа в тело
цикла не происходит, и выполнение FOR-NEXT-конструкции
завершается).
Если величина шага отрицательна, а значение переменной
цикла больше или равно конечному значению, управление
переходит к оператору, следующему за FOR-оператором (т. е.
происходит вход в тело цикла). В противном случае
управление переходит к оператору, следующему за соответствующим
NEXT-оператором (т. е. входа в тело цикла не происходит,
и исполнение FOR-NEXT-конструкции заканчивается).
iv) Если произошел вход в тело цикла, выполняются
операторы, расположенные между FOR и NEXT.
v) Когда достигается NEXT, к текущему значению
переменной прибавляется величина шага и результат присваивает-
/4.5. Операторы
587
ся переменной. Повторяется шаг iii). Заметим, что начальное
значение, конечное значение и величина шага вычисляются
только один раз, в начале а не каждый раз при повторении
цикла. Значение же переменной цикла может изменяться
операторами внутри тела цикла, и при увеличении значения
переменной, а также при прооерках вгегда используется
последнее значение.
Разрешены циклы внутри циклов, однако они должны
иметь правильную вложенность.
Пример
Г КЖ X = 1 ТО N
ГГОЙ Y = 1 ТО N
LNEXT Y
L NEXT X
Л) GOSUB-оператор (переход на подпрограмму) и RETURN-
оператор (возврат).
Определять и вызывать подпрограммы можно с помощью
GOSUB-оператора и RETURN-оператора. Общий вид
GOSUB-оператора такой:
GOSUB (номер строки)
Управление передается на строку с указанным номером, и
затем выполняются последующие операторы, пока не будет
достигнут RETURN-оператор.
Общий вид RETURN-оператора таков:
RETURN
Управление передается на строку, следующую
непосредственно за последним выполненным GOSUB-оператором.
В одной подпрограмме может быть несколько RETURN-
операторов. Однако из подпрограммы можно выйти только с
помощью этого оператора. Нельзя использовать с этой целью
GOTO-оператор или IF-оператор.
GOSUB-оператор можно использовать внутри подпрограммы
для вызова какой-нибудь другой подпрограммы. Однако этот
оператор не должен в таких случаях обращаться к подпро-
588 Приложение А. Руководство по языку MINI-BASIC
граммам, вход в которые уже осуществлен. (Рекурсия
запрещена.)
е) END-оператор (конец).
В каждой программе должен быть один END-оператор —
последний ее оператор (с самым большим номером). Общий вид
END-оператора:
END
ж) REM-оператор (комментарий)
С помощью REM-оператора в программу вставляются
комментарии, его общий вид:
REM (произвольная цепочка символов)
В этом случае компилятор пропускает все, что стоит в данной
строке после ее номера. Тем не менее номер строки REM-
оператора можно использовать в операторах GOTO, IF и
GOSUB.
Приложение Б
Отношения
Б.1. Введение
Пусть задано множество целых чисел, например {1, 2, 3, 4}, и нам
нужно описать отношение порядка < применительно к этому
множеству. Один из способов состоит в указании множества всех
упорядоченных пар (т, п), таких, что т<Ог. В нашем случае отношение
описывается множеством
{(1, 2), (1, 3), (1, 4), (2, 3), (2, 4), (3, 4)}
По этому описанию мы можем установить, что отношение 1<4
справедливо, так как пара (1, 4) принадлежит указанному
множеству, а отношение 3<2 не выполняется, так как пара (3, 2) ему не
Рис. Б.1.
принадлежит. С математической точки зрения удобно говорить, что
указанное множество упорядоченных пар и есть отношение < на
множестве {1, 2, 3, 4}.
В качестве второго примера понятия отношения рассмотрим
граф, изображенный на рис. Б.1. На этом рисунке показано
множество из пяти вершин, причем некоторые пары вершин соединены
690
Приложение Б. Отношения
стрелками. Мы хотим описать отношение, называемое УКАЗЫ ВА-
ЕТ-НА, такое, что для двух вершин х и у
х УКАЗЫВАЕТ-НА у
тогда и только тогда, когда в графе есть стрелка от вершины х к
вершине у.'Это отношение УКАЗЫВАЕТ-НА описывается
следующим множеством упорядоченных пар:
{(а, Ь), (Ь, с), (d, b), (d, d), (e, a), (e, c)}
Таким образом, мы можем сказать, что отношения
а УКАЗЫВАЕТ-НА bud УКАЗЫВАЕТ-НА d
выполняются, в то время как отношения
с УКАЗЫВАЕТ-НА а к с УКАЗЫВАЕТ-НА b
не выполняются. И опять с математической точки зрения можно
сказать, что отношение УКАЗЫВАЕТ-НА — это указанное
множество упорядоченных пар.
Общее математическое понятие отношения определяется
следующим образом:
Для данного множества S отношением R на множестве S
называется множество упорядоченных пар элементов S.
Если s и t принадлежат S, мы говорим, что отношение sRt
выполняется тогда и только тогда, когда пара (s, t)
принадлежит множеству R.
Б.2. Представление отношений, определенных
на конечных множествах
Один из способов представления отношения, заданного на конечном
множестве, заключается просто в перечислении всех пар, входящих
в это отношение. Этот способ мы уже использовали в двух примерах
предыдущего раздела. В данном разделе мы введем два других
метода, которые будем называть «методом графов» и «методом матриц».
Метод графов. Отношение на множестве S представляется графом,
который содержит по одной вершине для каждого элемента S,
и из вершины s в вершину t ведет стрелка тогда и только тогда,
когда пара (s, t) принадлежит множеству упорядоченных пар,
определяющему данное отношение. Фактически мы уже
проиллюстрировали метод графов в предыдущем разделе, где отношение
УКАЗЫВАЕТ-НА было .-начала описано с помощью графа на рис. Б.1.
Теперь мы можем заметить, что граф является представлением
множества упорядоченных пар, и наоборот. Применив метод графов к
отношению < на множестве {1, 2, 3, 4}, получим граф на рис. Б.2,
Б.2. Представление отношений, определенных на конечных множествах 591
где из вершины т в вершину п проведена стрелка тогда и только
тогда, когда т<.п.
Метод матриц. Отношение на множестве S представляется матрицей,
в которой каждому элементу из 5 соответствуют одна строка и один
Рис. Б.2.
столбец. Если s и t принадлежат множеству S, то элемент матрицы
в строке s и столбце t получает значение 1, когда упорядоченная
пара (s, t) принадлежит данному множеству пар, и значение 0 в
abode
12 3 4
1
2
3
4
Mai
0
.0
0
0
урица
1
0
0
0
■1 1
1 1
0 1
0 0
отношения <
Рис.
Б.З.
Матрица отношения эклзывдет-на
Рис. Б.4.
противном случае. Матрица отношения < на множестве {1, 2, 3, 4}
изображена на рис. Б.З. Матрица — это просто таблица, в которой
для каждой комбинации строки и столбца указано, выполняется
592
Приложение Б. Отношения
данное отношение для соответствующей пары или нет. Так, 1 в
строке 2 и столбце 3 указывает, что справедливо отношение 2<3,
а 0 в строке 4 и столбце 3 означает, что отношение 4<3 не
выполняется. На рис. Б.4 изображена матрица отношения УКАЗЫВА-
ЕТ-НА.
Б.З. Произведение отношений
Иногда оказывается, что одно интересное отношение можно
определить в терминах двух других отношений. Если, например, S —
это множество людей, на котором определены отношения ЖЕНА
и МАТЬ, то можно определить отношение ТЕЩА следующим
образом:
Отношение
а ТЕЩА b
справедливо тогда и только тогда, когда существует элемент
с множества S, такой, что
а МАТЬ с \\ с ЖЕНА Ь.
В этом случае мы говорим, что отношение ТЕЩА является
произведением отношений МАТЬ и ЖЕНА. Понятие произведения
отношений определяется следующим образом:
Произведением двух данных отношений Р и Q называется
отношение, состоящее из всех таких пар (а, Ь), для каждой
из которых существует некоторый элемент с, такой, что
аРс и cQb.
Для обозначения произведения двух отношений мы будем
использовать знак •; таким образом, произведение
отношений Р и Q обозначается P-Q.
Понятие произведения отношений находит основное применение
в тех вычислительных задачах, где нам нужно построить некоторое
отношение R = P-Q, построив сначала отношения Р и Q, а затем
вычислив их произведение.
Пусть даны графы, представляющие отношения Р и Q на
некотором множестве S, и нам нужно построить граф, представляющий
произведение P-Q. Начнем с построения множества вершин S без
каких-либо стрелок. Затем будем исследовать вершины графов Р
и Q и добавлять в новый граф стрелки в соответствии с
определением. Пусть, например, даны графы, показанные на рис. Б.5, а
и рис. Б.5, б. Начав с вершины v, мы видим, что zPv и vQw. Поэтому
мы проводим в новом графе стрелку из г в до. Повторив этот процесс
Б.З. Произведение отношений
593
для всех остальных вершин, придем к графу на рис. Б.5, в,
представляющему произведение P'Q. Если из вершины а в вершину b
одна стрелка уже проведена, то новых стрелок из а в Ь больше не
проводят, хотя бы этого и требовали другие комбинации из Р и Q.
+®
S
Отношение Р
а
Отношение Q.
6
Отношение P-Q
в
Рис. Б.5. (а) Отношение Р; (б) Отношение Q; (в) Отношение Р ■ Q.
Например, отношение yP-Qv вытекает как из того, что уРу и yQv,
так и из того, что yPz и zQv, однако стрелка из у в v в графе,
представляющем произведение P-Q, проводится только один раз.
Если отношения Р и Q представлены матрицами, то матрицу для
произведения P-Q можно построить, отыскав каждые такие строку
i и столбец /, что соответствующий элемент матрицы Р равен 1,
и затем, исследовав строку / матрицы Q, с тем, чтобы найти такой
столбец k, что jQk. Определив таким образом, что iPj и jQk, нужно
элемент (i, k) матрицы отношения PQ приравнять 1.
594
Приложение Б. Отношения
На рис. Б.6 показана программа на языке BASIC, вычисляющая
произведение двух отношений. В ней предполагается, что матрицы
для Р и Q хранятся соответственно в массивах А и В, а матрица
для произведения P-Q строится в массиве С, все элементы которого
первоначально равны нулю.
10 REM ВЫЧИСЛЯЕТ ПРОИЗВЕДЕНИЕ ОТНОШЕНИЙ
15 REM ЗАДАВАЕМЫХ МАТРИЦАМИ А И В ПОРЯДКА N
20 REM ПРЕДПОЛАГАЕТСЯ ЧТО ВНАЧАЛЕ ВСЕ ЭЛЕМЕНТЫ
25 REM МАТРИЦЫ С РАВНЫ НУЛЮ
30 TOR J = 1 ТО N STEP I
АО TOR I = 1 ТО N STEP 1
50 IF A(I,J) = 0 GOTO 120
ЬО REM ЦИКЛ ИССЛЕДОВАНИЯ СТРОКИ J МАТРИЦЫ В
Ь5 REM ВЫПОЛНЯТЬ ТОГДА И ТОЛЬКО ТОГДА КОГДА A(I, J) =1
70 TOR К = 1 ТО N STEP 1
АО IF B(J,K) = 0 GOTO 110
Я0 REM ПРИСВАИВАТЬ ТОГДА И ТОЛЬКО ТОГДА КОГДА A(I,J)=B(J,K) = 1
100 LET C(I,K) = Ъ
110 NEXT К
1Е0 NEXT I
130 NEXT J
КО END
Рис. Б.6. Программа на языке BASIC для вычисления произведения отношений.
Б.4. Транзитивное замыкание
Иногда оказывается, что какое-то интересное отношение можно
определить в терминах повторного применения некоторого другого
отношения. Если, например, S — множество, на котором определено
отношение РОДИТЕЛЬ, то отношение ПРЕДОК можно определить
следующим образом:
Отношение
а ПРЕДОК Ь
Б.4. Транзитивное замыкание
595
выполняется тогда и только тогда, когда существует
последовательность с,, ..., сп, такая, что
а—си Ь = сп и С( РОДИТЕЛЬ с,+1
для всех i, таких, что 1^/<п.
Если, например, ct = Авраам, с2 = Исаак, с3 = Иаков
и с4 = Иосиф, то мы имеем
Авраам РОДИТЕЛЬ Исаак
Исаак РОДИТЕЛЬ Иаков
Иаков РОДИТЕЛЬ Иосиф
откуда заключаем, что
Авраам ПРЕДОК Иосиф
Отношение ПРЕДОК называется транзитивным замыканием
отношения РОДИТЕЛЬ. Понятие транзитивного замыкания можно
определить следующим образом.
Транзитивным замыканием данного отношения Q называется
отношение, состоящее из всех таких пар (а, Ь), для каждой
из которых существует последовательность
си • • •, сп
при некотором п>1, такая, что
а = си Ь = сп и сДс1+1
для всех i, удовлетворяющих условию l^.i<n. Для
обозначения транзитивного замыкания мы используем верхний
индекс"1". Таким образом, транзитивное замыкание отношения
Q обозначается Q+.
Понятие транзитивного замыкания находит основное применение
в тех вычислительных задачах, когда нам нужно построить
некоторое отношение R=Q+, построив сначала отношение Q, а затем его
транзитивное замыкание.
Существует наглядная интерпретация понятия транзитивного
замыкания в терминах представления отношений в виде графов.
Пусть дан граф, представляющий отношение Q. Тогда отношение
aQ+b
справедливо тогда и только тогда, когда в графе для Q есть цепочка
стрелок, ведущая из а в Ь.
Пусть нам нужно построить граф, представляющий Q+. Мы
начнем с изготовления копии графа отношения Q. Затем будем
отыскивать такие тройки вершин а, Ь, с, для которых в графе есть стрелки
из а в b и из Ь в с. Для каждой такой тройки добавим в граф стрелку
596 Приложение Б. Отношения
из а в с, если такой стрелки еще нет. Когда таким способом уже
нельзя добавить новых стрелок, каждые две вершины, соединенные
цепочкой стрелок, оказываются соединенными одной стрелкой.
Следовательно, построение закончено и получен граф для Q+.
Для того чтобы систематизировать процесс добавления стрелок,
будем рассматривать вершины по одной. Для каждого пути длины
два, проходящего через рассматриваемую вершину, мы хотим, чтобы
из начальной вершины этого пути в его конечную вершину была
проведена стрелка. Чтобы добиться этого, проведем стрелку из
каждой вершины, откуда стрелка ведет в рассматриваемую
вершину, в каждую вершину, куда ведет стрелка из рассматриваемой
вершины. При этом уже имеющиеся стрелки не дублируются. Пусть,
Б А. Транзитивное замыкание
597
например, нам нужно вычислить отношение УКАЗЫВАЕТ-НА4-,
где УКАЗЫВАЕТ-НА — это отношение, определяемое графом на
рис. Б.1. Начиная с графа на рис. Б.1 и исследуя вершину а, мы
видим стрелку из е в а и стрелку из а в Ъ. Добавляем стрелку из е в b
и получаем рис. Б.7, а. В вершину Ь входят три стрелки — из
вершин a, d и е, а выходит из нее одна стрелка в вершину с. Поэтому
мы должны провести стрелки из а в с, из d в с, а также из е в с, но,
так как стрелка из е в с в графе уже есть, мы проводим только
первые две из трех указанных стрелок и приходим к графу на
рис. Б.7, б. Из вершины с стрелок не выходит, поэтому здесь новые
стрелки не требуются. В вершину d стрелки не входят, за
исключением стрелки, выходящей из самой этой вершины, и в этом случае
новые стрелки также не нужны. Из вершины е стрелки тоже не
выходят, и, значит, новых стрелок эта вершина не добавляет. На
рис. Б.7, б показан граф, получившийся после того, как все
вершины были исследованы по одному разу.
Может показаться, что множество вершин теперь следует
исследовать снова, на тот случай, если стрелки, проведенные после
исследования какой-либо вершины, сделают необходимым
добавление новых стрелок, не проведенных при первом исследовании
этой вершины. Однако теорема, доказанная Уоршоллом [1962],
утверждает, что это не так, и, даже если после исследования какой-
либо вершины в нее или из нее проведены стрелки, повторное
исследование этой вершины не может добавить к графу каких-либо
новых стрелок. Таким образом, достаточно одного исследования
каждой вершины, и, следовательно, граф на рис. Б.7, б
представляет отношение УКАЗЫВАЕТ-НА+.
Когда отношение Q представлено матрицей, то матрица для
Q+ получается из матрицы для Q путем замены в последней
некоторых нулей единицами. Общий принцип здесь состоит в
повторении описанного выше метода рассмотрения вершин графа по одной.
Пусть мы имеем дело с вершиной /. В терминах графа мы должны
добиться того, чтобы для стрелки из i в / и стрелки из / в k в графе
была бы и стрелка из i в k. Стрелка из вершины i в вершину /'
соответствует единице на пересечении строки i и столбца / матрицы.
Стрелка из вершины / в вершину k соответствует единице на
пересечении строки / и столбца k. Добиться, чтобы в графе была стрелка из
вершины i в вершину k, означает сделать элемент на пересечении
строки / и столбца k матрицы равным единице. Таким образом,
если на пересечении строки i и столбца /' находится единица (что
соответствует стрелке из i в /), то для каждого k, такого, что на
пересечении строки / и столбца k находится единица (соответствующая
стрелке из / в k), мы сделаем элемент на пересечении строки i и
столбца k равным единице (что будет соответствовать стрелке
из i в k). После рассмотрения всех возможных значений /
получается матрица для Q+.
698
Приложение Б. Отношения
На рис. Б.8 приведена программа на языке BASIC,
вычисляющая транзитивное замыкание отношения, представленного
матрицей. Предполагается, что матрица отношения задана массивом А
и этот же массив используется для хранения результата.
Описанный алгоритм известен, как алгоритм Уоршолла (Уоршолл [1962]).
ID REM ВЫЧИСЛЯЕТ ТИАНЗИТИВНОЕ ЗАМЫКАНИЕ ОТНОШЕНИЯ
15 REM ЗАДАННОГО МАТРИЦЕЙ А ПОРЯДКА N
30 REM РЕЗУЛЬТАТ ПОЛУЧАЕТСЯ В" МАТРИЦЕ А
3D TOR J = 1 ТО N STEP I
АО TOR I = 1 TO N STEP 1
5D IF A(I,J) = D GOTO 1ED
fc.0 REM ЦИКЛ ИССЛЕДОВАНИЯ СТРОКИ J ВЫПОЛНЯТЬ
Ь5 REM ТОГДА И ТОЛЬКО КОГДА A(I,J) = 1
7D TOR К = 1 ТО N STEP 1
ВО IF A(J,K) = D GOTO 110
ЯО REM ПРИСВАИВАТЬ ТОГДА И ТОЛЬКО ТОГДА КОГДА
45 REM A(I,J) = A(J,K) = l
LOO IET l.'T,K) = 1
L10 NEXT К
150 NEXT I
130 NEXT J
КО END
Рис. Б.8. Программа на языке BASIC для вычисления транзитивного замыкания
отношения.
В математике отношение R называют транзитивным, если
из aRb и bRc следует aRc, т. е. если принадлежность отношению
пар (я, Ь) и (Ь, с) влечет принадлежность ему пары (а, с).
Отношение < транзитивно, в то время как отношение УКАЗЫВАЕТ-НА не
транзитивно.
Для любого заданного отношения Q отношение Q+ транзитивно.
Q4 называется «транзитивным замыканием», потому что его можно
понимать как множество пар, полученное из Q добавлением
минимального количества пар, необходимого для того, чтобы новое
отношение было транзитивным.
Упражнения
599
Б.5. Рефлексивно-транзитивное замыкание
Транзитивное замыкание отношения R, определенное в
предыдущем разделе,— это, попросту говоря, отношение, связывающее
такие элементы, которые связаны или непосредственно, или через
цепочки других элементов отношением R. Часто бывает удобно
считать, что каждый элемент «связан» с самим собой. В таких
случаях мы можем добавить к транзитивному замыканию все пары вида
(а, а) и получить множество пар, называемое
«рефлексивно-транзитивным замыканием». Это понятие можно определить следующим
образом:
Рефлексивно-транзитивным замыканием данного отношения
Q называется отношение, состоящее из всех пар (а, Ь), таких,
что
aQ+b или а=Ь
Рефлексивно-транзитивное замыкание множества Q мы
обозначаем через Q*.
Граф, представляющий отношение Q+, можно превратить в
граф, представляющий Q*, проводя из каждой вершины стрелку
в самое себя. Например, показанный на рис. Б.7, б граф
отношения УКАЗЫВАЕТ-НА+ превращается, таким образом, в
изображенный на рис. Б.7, в граф для УКАЗЫВАЕТ-НА*.
Матрицу для Q* можно получить из матрицы для Q+, заполнив
единицами ее главную диагональ.
Программу на рис. Б.8 для вычисления транзитивного
замыкания отношения можно преобразовать в программу, вычисляющую
рефлексивно-тразитивное замыкание, добавив только один новый
оператор
125 LET A(J, J) = l
В математике отношение R на множестве S называют
рефлексивным, если aRa для всех а, принадлежащих S. Отношение R*
называется рефлексивно-транзитивным замыканием отношения R,
потому что его можно получить из R добавлением минимального
количества пар, необходимого для того, чтобы новое отношение
было рефлексивным и транзитивным.
Упражнения
1. В бар входят двое программистов. Один из них — отец сына другого. Кем-
приходятся друг другу эти программисты?
2. Как назвать следующие произведения отношений, определенных на множестве
всех мужчин.
а) (ДВОЮРОДНЫЙ-БРАТ-ПО-ОТЦУ) -(СЫН)
coo
Приложение Б. Отношения
б) (ОТЕЦ) -(ДВОЮРОДНЫЙ-БРАТ-ПО-ОТЦУ)
и) (СЫН)-(БРАТ)-(ОТЕЦ)
3. Отношение R на множестве {1, 2, 3, 4} состоит из следующих пар:
(12), (2,3), (3,4), (4, 1)
а) Изобразите графы отношений R, R-R, R-R>R и R-R-R-R.
б) Какие'из этих четырех графов представляют транзитивные отношения?
в) Какие из этих четырех графов представляют рефлексивно-транзитивные
отношения?
4. Какие из следующих отношении, определенных на множестве всех женщин,
являются транзитивными?
а) СЕСТРА
б) МАТЬ
в) ДВОЮРОДНЛЯ-СЕСТРА
г) СТАРШЕ
д) РОВЕСНИЦА
е) НЕ-МЛАДШЕ
ж) ИМЕЕТ-ТУ-ЖЕ-СВОДНУЮ-СЕСТРУ-ЧТО-И
5. Отношения Р и Q на множестве {1, 2, 3, 4} представляются следующими
двумя м.:т'|Ииами:
"1 0 0 Г
10 11
0 10 0
0 0 1 0_
>
"0 1 0 П
10 0 0
0 0 0 1
_0 1 0 0j
а) Перечислите пары, составляющие отношения Р и Q.
б) Нарисуйте графы для Р и Q.
в) По матрицам для Р и Q найдите матрицу для Р-Q.
г) По графам для Р и Q постройте граф для Р-Q.
д) По матрице для Р найдите матрицу для Р + .
е) По графу для Q найдите граф для Q*.
ж) Постройте граф для (Q-P)*- (P-Q) + .
6. а) Покажите, что операция умножения отношений ассоциативна, т. е. что
P.(Q.R) = (P .Q).R
где Р, Q и R — отношения.
б) Покажите, что операция умножения не коммутативна, т. е.
P-Q^Q-P
в) Дайте пример таких отношений Р и Q, для которых P-Q=Q-P.
7. а) Дайте определение рефлексивного замыкания отношения.
б) Напишите на языке BASIC программу, вычисляющую рефлексивное
замыкание отношения, заданного матрицей.
8. Опишите тест, позволяющий выяснить, транзитивно ли некоторое отношение
R.
9. а) Покажите, что отношение R транзитивно тогда и только тогда, когда все
пары из R-R принадлежат также и R.
б) Приведите пример транзитивного отношения R, содержащего хотя бы одну
пару, не принадлежащую R-R.
.10, Рассмотрите следующее отношение R между состояниями конечного автомата:
sRt тогда и только тогда, когда существует входной символ, вызывающий
переход из состояния s в состояние t.
а) Представьте отношение R для автомата на рис 2.15, а в виде матрицы.
Упражнения
601
б) Используя транзитивное замыкание отношения R, опишите процедуру,
определяющую недостижимые состояния конечного автомата.
в) Продемонстрируйте работу своей процедуры на примере автомата на
рис. 2.15, а.
11. Определим степени отношений следующим образом:
R2=R-R
R3=R.R-R и т.д.
при этом R" определяется, как отношение тождества (aR°a для всех а). Далее
определим объединение двух отношений как множество упорядоченных пар,
каждая из которых принадлежит хотя бы одному из этих отношений.
Объединение отношений Р и Q будем обозначать P-\-Q. Покажите, что
а) R + = R+R2+R3-I . . .
б) R'=R4-R+R2+R3+- ■ •
в) Если R — отношение на множестве из п элементов, то
R+=R+Ri+R3+. . .+R"
г) Если R — отношение на множестве из п элементов, то
12. Пусть Р и Q — два отношения, представленные соответственно матрицами
МР и Mq. Покажите, что
P-Q=MP-MQ
где MP'Mq — обычное произведение матриц, в котором используются
логические операции И (конъюнкция) и ИЛИ (дизъюнкция) вместо арифметических
операций умножения и сложения.
13. Некоторое отношение на множестве из п объектов можно представить в виде
матрицы, в которой все элементы, расположенные выше главной диагонали,—
единицы, а остальные элементы — нули. Покажите, что такое отношение
транзитивно при любом п.
14. Сформулируйте и докажите теорему Уоршолла, описанную неформально
в разд. Б.4.
Приложение В
Преобразования грамматик
В.1. Введение
Многие рассматриваемые в этой книге процедуры построения
синтаксического блока требуют, чтобы данная КС-грамматика обладала
определенными свойствами (например, чтобы она была LL
(^-грамматикой или не содержала конфликтов переноса — опознания).
Грамматика, взятая из руководства по языку или полученная
каким-нибудь другим способом, часто не обладает требуемыми
свойствами. В этом приложении мы приведем несколько методов
преобразования грамматик, с помощью которых данную грамматику
можно переделать так, чтобы новая грамматика порождала тот
же язык и имела некоторые из желательных свойств. Разд. В2—В7
содержат преобразования, позволяющие получать грамматики, к
которым применимы нисходящие методы синтаксического анализа,
а разд. В.8—В. 10 — преобразования, связанные с восходящими
методами разбора. Ниже мы будем всюду предполагать, что все
правила грамматики, содержащие лишние нетерминалы, уже
исключены.
Описываемые преобразования не гарантируют, что
произвольную грамматику можно переделать так, чтобы ее можно было
анализировать нисходящим или восходящим методом, так как
для некоторых КС-языков не существует КС-грамматик, для
которых возможен восходящий или нисходящий разбор
МП-автоматом. Однако наш опыт показывает, что для большинства реальных
языков программирования синтаксический блок можно построить
на основе грамматики одного из следующих типов: ^-грамматика,
ЬЦ1)-грамматика, грамматика слабого предшествования или
смешанной стратегии предшествования, SLR(l)-rpa.MMaTHKa. Более
того, наш опыт показывает, что преобразований, указанных в
данном приложении, обычно достаточно для переделки грамматики
языка программирования в один из нужных типов.
В.2. Нисходящая обработка списков
Многие языки программирования содержат конструкции, которые
включают в себя списки таких элементов, как переменные,
параметры, индексы и операторы. Эти конструкции встречаются так
В.2. Нисходящая обработка списков
603
часто, что разработчик, желая описать язык с помощью
LL(^-грамматики, обычно должен включить в нее надлежащие правила
порождения списков. Для того чтобы помочь в построении правил
порождения списков, на рис. В.1 приведены пять LL
(^-грамматик для списков. Этот рисунок можно использовать как таблицу
стандартных грамматик для списков.
Пустой
список не
допускает
Пустой
список
допустим
без пунктуации
1.
<L> -» a<R>
<R> ■* a<R>
<R> -* £
III.
<L> -* £
<L> -* a <R>
<R> -» a<R>
<R> -* £
или
in'. <L> -* e
<L > -> a<L>
Разделены запятой
ii.
<L > -
<R> ->
• <R> -
IV.
<*.>-»
<L > -
<R> -
<R> ~
a<R>
, a <R>
e
e
a<R>
. a<R>
£
Рис. В. 1. Грамматики, порождающие списки из нетерминала (L).
Грамматика I порождает списки, состоящие из одного или
нескольких символов а. Нетерминал (L) порождает сам список, а
(R > можно рассматривать как нетерминал, порождающий
«остаток» списка, после первого символа а.
Грамматика II порождает списки, состоящие из одного или
нескольких символов а, разделенных запятыми.
Грамматика III порождает списки из нуля или более символов а.
Грамматика III'—это другая грамматика для того же языка, она
проще, но иногда оказывается непригодной для перевода.
Грамматика IV порождает списки, состоящие из нуля или более
символов а, разделенных запятыми. Эту грамматику можно
считать основным прототипом всех приведенных грамматик, так как
грамматика без запятых (т. е. III) получается из IV вычерчиванием
запятой; грамматика, запрещающая список длины ноль (т. е. II),
получается вычеркиванием е-правила для нетерминала (L);
грамматика I получается, если выполнить оба эти преобразования.
604
Приложение В. Преобразования грамматик
В каждой из этих грамматик «остаток» списка, порождаемый
нетерминалом (R), сам является списком, состоящим из нуля или
более элементов. В грамматике II, например, (R) порождает список
из нуля или более вхождений пары символов , а. В каждой
грамматике пра§ила для (R) образованы по образцу грамматики ИГ—
это простейший способ порождения списка, состоящего из нуля или
Атрибуты символов действия — НАСЛЕДУЕМЫЕ
1. <L> —► {ПУСТО}
2. <L> — an {ПЕРВ/2} </?>
/2—/1
3. </?>—, в/, {СЛЕД,,} </?>
/2— /1
4. </?> —<■ {КОНЧИТЬ}
(а)
1. <L>—►{ПУСТО}
2. <L> — {ИНИЦИАЛ} а </?>
3. </?> — {СЛЕД}, я </?>
4. </?> — {ПОСЛЕДИ}
(б)
Атрибуты симнолов действия — НАСЛЕДУЕМЫЕ
1. <L>— {ПУСТО}
2. <L> — ал </?> {КОНЧИТЬ/2}
/2*—/I
3. <Я> -* , ал </?> {СЛЕД/2}
/2«—/1
4. </?>—* {НАЧАТЬ}
(в)
Рис. В.2.
более элементов. Таким образом, грамматика ИГ — это в некотором
смысле основная грамматика для списков, а другие грамматики —
это просто более изощренные способы порождения списков из нуля
и более элементов. С этой точки зрения грамматика II описана, как
порождающая символ а, за которым следует список из нуля или
более цепочек , а.
Существует несколько способов введения символов действия и
атрибутов в грамматику на рис. В.1. Мы продолжим наши
рассуждения, дополняя грамматику IV, так как она служит в качестве
«основного прототипа». На рис. В.2 показаны три способа
введения в эту грамматику символов действия и атрибутов.
В.З. Левая факторизация
605
Грамматика на рис. В.2, а порождает, в частности, такую
последовательность актов:
а, {ПЕРВ^ , аг {СЛЕД2} , а3 {СЛЕД3} {КОНЧИТЬ}
В последовательности символов действия символы а представлены
в том же порядке, в каком они встречаются во входном списке
символов.
Одна из последовательностей актов, порождаемая
грамматикой на рис. В.2, б, такова:
{ИНИЦИАЛ} а {СЛЕД} , а {СЛЕД} , а {ПОСЛЕДИ}
Действие {СЛЕД} следует за каждым вхождением символа а, кроме
последнего, за которым следует {ПОСЛЕДИ}.
Грамматика на рис. В.2, б имеет то преимущество, что символы
действия расположены на левых концах правил, и для них не
нужно создавать магазинных символов. Недостатком этой
грамматики является то, что атрибут символа а нельзя передать
следующему за ним символу действия, не вводя наследуемого атрибута для
(R).
Одна из последовательностей актов, порождаемых грамматикой
на рис. В.2, в, такова:
а, , а2 , а3 {НАЧАТЬ} {СЛЕД3} {СЛЕДг} {КОНЧИТЬ,}
В последовательности символов действия символы а
представлены в порядке, обратном порядку их следования в списке входных
символов.
В.З. Левая факторизация
Предположим, что некоторая грамматика содержит такие два
правила:
(Sb-IF (В) THEN (SI)
(S>^IF (В) THEN <S1> ELSE (S)
Эта грамматика не может быть ЬЬ(1)-грамматикой, так как IF
содержится в множествах выбора обоих правил. Всякий раз, когда
у двух правил с одинаковой левой частью правые части начинаются
одним или несколькими одинаковыми символами и эти
совпадающие символы порождают хотя бы одну непустую терминальную
цепочку, множества выбора этих правил содержат общие символы
и грамматика не принадлежит классу LL (1).
При построении ЬЬ(1)-грамматики важно, чтобы конструкции
языка, начинающиеся с одинаковых символов, порождались одним
общим для них правилом. Для рассматриваемого примера общее
606
Приложение В. Преобразования грамматик
начало можно получить, заменив приведенные выше два правила на
следующие три:
<S>->IF (В) THEN <S1> (нечто)
(нечто >->ELSE <S>
(нечто >->е
где (нечто) — это новый нетерминал, который в грамматике больше
нигде не встречается. Про такие три правила говорят, что они
получены из первоначальных двух методом «левой факторизации» или
«вынесения левого множителя», а про общий левый участок правых
частей, что он «вынесен» в одно правило.
Принцип левой факторизации можно выразить в символической
форме следующим образом:
Если грамматика содержит п правил
<А> — ар,
<Л> -* арп
где (Л) — нетерминал, а а и Pi для 1<л<;п — цепочки
нетерминалов и терминалов, то эти правила можно заменить
на следующие п+l правила:
<Л> —► ос<новый>
<новый> —► jix
<новый> —► р\,
где (новый) — нетерминальный символ, не входящий в
исходную грамматику. Грамматика, полученная такой
заменой, порождает тот же язык, что и исходная грамматика,
и о ней говорят, что она получена левой факторизацией.
Левую факторизацию можно также применять к грамматикам
цепочечного перевода. Например, два правила
<Sb-IF (В) {ПЕРЕХОД ПО ЛЖИ} THEN (SI) {МЕТКА}
(S)->IF (В) {ПЕРЕХОД ПО ЛЖИ} THEN (SI) {ПЕРЕХОД}
{МЕТКА} ELSE (S) {МЕТКА}
после левой факторизации становятся такими:
(S)->IF (В) {ПЕРЕХОД ПО ЛЖИ} THEN (SI) (конец предл)
(конец предл )->{МЕТКА}
(конец предл)-> {ПЕРЕХОД} {МЕТКА} ELSE(S) {МЕТКА}
В А. Замена кра«
ВД7
В.4. Замена края
Рассмотрим заданное грамматическое вхождение какого-нибудь
нетерминала в правую часть правила. Каждый раз, когда данное
правило используется в выводе, это вхождение должно
соответственно заменяться правой частью какого-нибудь правила для
данного нетерминала.
Данную грамматику можно изменить так. чтобы исключить
шаги, состоящие в замене этого вхождения. Такое изменение
называется «заменой» и символически описывается следующим образом:
Если грамматика содержит п правил
<А> — ап
с левой частью (А) (и других таких правил нет) и если в
грамматике есть правило вида
{В)^(А)у
для какого-то нетерминала (В)и цепочек р и y из
нетерминалов и терминалов, то это правило можно заменить на п
правил
<В> — p4v
<В> — Росл
Грамматика, полученная этой подстановкой, порождает
тот же язык, что и первоначальная грамматика и говорят,
что она получается заменой вхождения {А > в заданное
правило.
В любом правиле грамматики мы называем самое левое
вхождение символа (если они вообще есть) в его правую часть краем
правила, е-правило края не имеет. Если заменяемое вхождение
является краем данного правила, то такая замена называется заменой
края. Замена края лежит в основе методов получения и улучшения
ЬЬ(1)-грамматик.
Для иллюстрации того, как замену края можно использовать
для получения ЬЬ(1)-грамматик. рассмотрим следующую
грамматику с начальным символом {А ):
G08
Приложение В. Преобразования грамматик
1. (А >-> а
2. <Л>-> (В) с
3. (В)^а(А)
4. <В>-> b (В)
Это не £Ь(1)-грамматика, так как множества выбора правил 1 и 2
оба содержат а. Заменяя край правила 2 (т. е. вхождения {В} в
правую часть правила 2), мы получим грамматику
1. (А > -> а
2а. (Л > -> а (Л > с
26. <Л>^ b (В) с
3. <#>->а(Л>
4. (В)->Ь{В)
где правило 2 заменено на два правила, по одному для каждого
правила с нетерминалом (В) в левой части.
Новая грамматика по-прежнему не принадлежит классу
LL(1), так как множества выбора правил 1 и 2а содержат символ а.
Конечно ожидалось, что одно из полученных после замены правил
будет порождать цепочку, начинающуюся с а, так как
первоначальное правило порождает такую цепочку. Важной особенностью
новой грамматики является то, что конфликтующие правила оба
начинаются с а и к ним можно применять левую факторизацию,
после чего грамматика становится ЬЬ(1)-грамматикой.
Замена края полезна также при преобразовании LL
(^-грамматик в ^-грамматики. Рассмотрим, например, следующую LL (1)-
грамматику с начальным символом (S):
1. {S)->c (S)
2. (S> -> {А ) с
3. (А)-+а (S)
4. Ш-> Ь
Это не ^-грамматика, так как край правила 2 не является
нетерминалом. Замена этого края дает грамматику
1. (S)->c{S)
2а. (S)^-a (S)c
26. (S)-> be
Так как эта замена исключила из грамматики вхождение (А ) в
правило 2, правила 3 и 4 становятся недостижимыми и
выбрасываются. Полученная грамматика является <7_грамматикой.
Замена края сохраняет ЬЬ(1)-свойство, и ее всегда можно
использовать для преобразования ЬЬ(1)-грамматики в ^-грамматику.
Общий принцип такой:
B.5. Одиночная замена
609
Если в LL(l)-rpaMMaTHKe делается замена края, то в
результате снова получается 1Х(1)-грамматика.
Если в LL(l)-rpaMM3THKe замена края повторяется до тех
пор, пока все ее края не станут терминалами, то в результате
получается ^-грамматика.
Преимущество преобразования 1Х(1)-грамматикн заменой края
состоит в том, что АШ-автомат, соответствующий новой грамматике,
выполняет синтаксический анализ за меньшее число шагов.
Недостаток в том, что полученная грамматика обычно имеет больше
правил, и потому соответствующий автомат тоже больше.
В.5. Одиночная замена
Когда мы пытаемся получить ЬЬ(1)-грамматику, замена
вхождений, которые не являются краями, обычно не дает нужного
результата. Это происходит по той причине, что при таких заменах обычно
вместо одного правила появляется несколько правил с одним и
тем же краем, а общий край приводит к конфликтам множеств
выбора. Одно важное исключение представляет случай, когда
существует только одно правило с данной левой частью. Правило,
являющееся единственным правилом с данной левой частью,
называется одиночным.
Важное свойство одиночного правила состоит в том, что если
его левая часть входит в правую часть правила р, то замена данного
вхождения приведет просто к замене правила р одним другим
правилом. Таким образом, вхождения левой части можно
повторно заменять без увеличения числа правил.
Рассмотрим, например, следующую грамматику с начальным
символом (SУ
1. (S)->a (А) (А)
2. (S > -> Ь (А >
3. (S)-yc
4. (А)->а (S)b
В этом примере правило 4 — это единственное правило с левой
частью (А ). Замена вхождения {А ) в правиле 2 приведет к замене
правила 2 одним правилом
{S)^ba (S)b
Дальнейшие замены вхождений (А > в правило 1 приводят к
грамматике
1. {S)->aa (S)ba (S) b
2. (S)->ba (S)b
3. (S)->c
20 Ф, Льюис и др.
610
Приложение В. Преобразования грамматик
из которой исключено правило 4, поскольку оно стало
недостижимым. Эта грамматика проще, чем старая в том отношении, что
в ней меньше правил и меньше нетерминалов; она сложнее в том
смысле, что для представления правых частей правил требуется
больше вхождений символов. Обе грамматики являются
^-грамматиками.
Л\ы называем одиночной заменой замену вхождений
нетерминалов, являющихся левыми частями одиночных правил.
Важное свойство одиночной замены заключается в том, что для
каждого нового правила множество выбора остается тем же, что и
для заменяемого им правила, и потому одиночная подстановка
сохраняет LL(l)-CBoftcTBO. Как в приведенном выше примере,
одиночная подстановка может повторяться до тех пор, пока не
исчезнут все вхождения некоторой левой части в правые части правил.
Одиночное правило затем можно выбросить из грамматики, если
только его левая часть не является начальным символом. Говорят,
что выбрасываемое правило исключено одиночной подстановкой.
Полученная грамматика является 1.Ь(1)-грамматикой, если
первоначальная грамматика была таковой, и соответствующий ей
автомат имеет меньше магазинных символов.
Одно незначительное исключение к вышеизложенному
представляет случай, когда правая часть одиночного правила содержит
его левую часть, как в правиле
<L> -> a (L)b
В этом случае символ левой части непродуктивен, и такое правило
исчезает при исключении лишних символов.
В.6. Левая рекурсия
Нетерминал называется леворекурсивным, если, применяя к нему
одно или более правил, можно вывести цепочку, начинающуюся
этим же нетерминалом. Правило называется леворекурсивным, если
оно используется на первом шаге такого вывода. Формально
нетерминал {А > является леворекурсивным тогда и только тогда, когда
существует такая цепочка р\ что
<Л>=>^ <Л>р
а правило
<Л>=>а
является леворекурсивным тогда и только тогда, когда существует
такая цепочка р\ что
а=>*<Л>Р
B.6. Левая рекурсия
611
Правило называется самолеворекурсивным, если его край и
левая часть — это один и тот же символ. Такое правило должно
быть также и леворекурсивным, так как его правая часть сама
является цепочкой, начинающейся g левой части, и требуемый вывод
1. <5> — <S> a
2. <S> — Ь
. Начальный символ: <S>
Рис. В.З.
состоит из нуля шагов. Самолеворекурсивность иллюстрируется
правилом 1 на рис. В.З, где (S) является краем и левой частью.
Остальные правила этой грамматики не являются
леворекурсивными.
1. <Л> — а<В>
2. <Л>—><В>Ь
3. <В>—+<А>с
4. <В> —► d
Начальный символ: <Л>
Рис. В.4.
Пример леворекурснвности, но не самолеворекурсивности
показан на рис. В.4. Нетерминалы (А) и (В) — леворекурсивны,
как показывают следующие выводы:
<Л>=ф<В>&=><Л>сЬ
<В>=><Л>с=><В>Ьс
Эти выводы начинаются с правил 2 и 3 соответственно, которые,
таким образом, также леворекурсивны. Левая рекурснвность в
этом примере демонстрируется отношениями
<B>b=>*<A>cb и <А>с=>*<В>Ьс
Правила 1 и 4 не леворекурсивны.
Грамматика с леворекурсивным нетерминалом не может быть
ЬЬ(1)-грамматикой. Идея доказательства этого утверждения
состоит в том, что множество выбора любого леворекурсивного
правила с левой частью (X> должно содержать ПЕРВ {(X)), и
поэтому оно конфликтует с множествами выбора всех других правил с
левой частью (X >. Для грамматики на рис. В.4, конфликт множеств
выбора правила 1 и леворекурсивного правила 2 демонстрируется
отношениями
ВЫБОР (1) = ПЕРВ (а(В)) = {а)
ВЫБОР (2) = ПЕРВ ((В) b)^{a, d)
20*
612
Приложение 8. Преобразования грамматик
Грамматику с левой рекурсивностью всегда можно переделать
в грамматику без левой рекурсивности. Общий способ выполнения
этого преобразования достаточно сложен, но в одном особом случае
это делается очень просто. К счастью, этот случай применим в
большинстве практических ситуаций, связанных с языками
программирования.
При разборе этого случая основная идея состоит в том, чтобы
смотреть на рекурсивный нетерминал как на порождающий
некоторую цепочку, за которой следует список из одного или более
элементов. Например, на рис. В.З, мы трактуем нетерминал
(S) как порождающий символ Ь, за которым следует список из
нуля или более символов а. Естественный нисходящий метод
выражения этой идеи дают правила
(Л >-> b (список)
(список >-> а (список)
(список) -> е
где правила с левой частью (список) построены по образцу
грамматики ИГ на рис. В.1.
Указанная идея обобщается на другие грамматики с помощью
следующего преобразования, предназначенного для исключения
самолеворекурсивности:
Предположим, что нетерминал (Л ) имеет т саморекурсивных
правил
(Л)-> (Л) а,- для 1</<т
и п правил
(Л )-»- Р; для 1</<я
которые не являются леворекурсивными. Заменим эти
правила на следующие:
(Л ) ->- Ру (список Л ) для 1^/^п
(список Л ) -> а,- (список Л ) для 1^л^/п
(список Л ) -> е
где (список Л ) — новый нетерминал.
Новые правила можно интерпретировать, сказав, что (А ) порождает
одну из цепочек р1;, за которой следует список из нуля или более
цепочек а,-.
За исключением некоторых неоднозначных грамматик,
справедливо следующее утверждение:
Если данная грамматика такова, что все леворекурсивные
правила саморекурсивны, то эквивалентную грамматику
без левой рекурсивности можно получить, применяя ко всем
леворекурсивным нетерминалам приведенное выше
преобразование.
B.7. Преобразование <щель-край»
613
Если приведенное выше правило преобразования объединить
с заменой края, то его можно использовать для исключения
леворекурсивное™, даже когда некоторые леворекурсивные правила не
являются самолеворекурсивными. Взяв в качестве примера рис. В.4,
получаем, что левую рекурсию можно исключить, вначале сделав
замену края правила 2 и затем применив указанное
преобразование к нетерминалу (А >.
1. <Л> —а<б> I. <Л> — а<£><список>
2.4. <Л> —» db 2.4. <Л> —► db <спигок>
2,3. <Л>—><.А>сЬ 2.3. <список>—► cb <список>
3. <б>—><.А>с х. <список>—>• е
4. <S> — d 3. <S>—»<Л>с
4. <B>—*d
(а) (б)
Рис. В.5.
Замена края правила 2 дает грамматику на рис. В.5, а, где
правило 2.4 — результат замены края правила 2 правилом 4 и
правило 2.3 — результат аналогичной замены правилом 3.
Исключение самолеворекурсивности нетерминала (А > приводит к
грамматике на рис. В.5, б. В этой грамматике нет левой рекурсивности.
В.7. Преобразование «цель-край»
Если дана некоторая не LL(l)-rpaMMaTHKa реального языка
программирования, то методов, изложенных в разд. В.2 — В.6, обычно
достаточно для того, чтобы переделать ее в LL(l)-rpa.\iMaTHKy.
Однако иногда возникают ситуации, требующие более мощных методов.
В этом разделе мы приведем один такой полезный, с нашей точки
зрения, метод — преобразование «цель край».
Почти во всех случаях, представляющих практический интерес,
это преобразование исключает любую леворекурсивность, даже
когда эта рекурсивность не является самолеворекурсивностью.
Кроме того, это преобразование можно легко реализовать в виде
программы для вычислительной машины, используемой при
преобразовании грамматик.
Вначале рассмотрим следующую иллюстративную грамматику с
начальным символом (D >:
1. (D)-* (Е)с
2. <£>-* (Е)а
3. (£>-+ Ь
В этой грамматике есть такой вывод:
<D> =j> <£> с =$•<£> а с =Ф <£> аас=>Еааас=$Ьааас
614
Приложение В. Преобразования грамматик
Так как терминальная цепочка, выводимая из (D), всегда
начинается с Ь, мы введем новый нетерминал, порождающий то, что в
цепочках, порождаемых символом (D >, остается после Ь. Мы
назовем этот новый нетерминал (D, Е), чтобы указать, что он
порождает цепочки, которые можно приписать к цепочке,
порождаемой нетерминалом (Е) (например, Ъ — цепочка, порождаемая
нетерминалом (£>), чтобы получить цепочку, порождаемую
нетерминалом (D). Создадим новое правило
Ф)^Ь (D, Е)
чтобы указать, что цепочка, порождаемая нетерминалом (D),
состоит из символа Ь, за которым следует цепочка (порожденная
нетерминалом (D, Е)), которая, если приписать ее к цепочке,
порождаемой нетерминалом (£), даст цепочку, порождаемую нетерминалом
(D).
По правилу 2 мы знаем, что, прибавляя а к любой цепочке,
порожденной нетерминалом (Е), мы получим более длинную
цепочку, порожденную нетерминалом (Е). Предположим, что
некоторая цепочка а порождается нетерминалом (D, Е). Тогда а,
приписанная к более длинной цепочке, порожденной нетерминалом (Е),
дает цепочку, порождаемую {D}. Но тогда аа — это цепочка,
приписывая которую к данной цепочке, порожденной нетерминалом
(£■>, получаем цепочку, порождаемую нетерминалом (D). Таким
образом, аа должна принадлежать языку, порождаемому
нетерминалом {D, Е). Вывод: цепочка, которую можно приписать к
цепочке, порождаемой нетерминалом (Е), чтобы получить цепочку,
порождаемую нетерминалом (D >, может состоять из символа а, за
которым следует некоторая цепочка, порождаемая нетерминалом
{D, Е). Таким образом, мы создаем новое правило:
(D, £>->а (D, Е)
По правилу 1 к цепочке, порожденной нетерминалом (Е), можно
приписать с для получения цепочки, порождаемой нетерминалом
(D >. Поэтому можно записать новое правило:
(D, £>->с
Вся новая грамматика такова:
(D)^b(D,E)
(D, E)-+a (D, Е)
(D, £)->с
Эта грамматика не леворекурсивна и на самом деле является LL (1)-
грамматикой. Эта грамматика — несколько упрощенная версия
грамматики, которая получилась бы с помощью преобразования
«цель-край», но иллюстрирует основные используемые принципы.
B.7. Преобразование щель-край»
615
Чтобы выполнять преобразования «цель-край», мы делаем
различие между «краевым» правилом и «некраевым» правилом.
Правило, правая часть которого начинается нетерминалом,
называется краевым правилом, а все остальные правила
называются некраевыми.
В грамматике на рис. В.4, правила 2 и 3 — краевые правила, а
правила 1 и 4 — некраевые.
Ключевое понятие, лежащее в основе преобразования «цель-
край»,— это понятие «краевого вывода».
Левый вывод (G)=5>"La называется краевым выводом тогда
и только тогда, когда последним применялось некраевое
правило, а все остальные правила — краевые.
Для грамматики на рис. В.4 левый вывод (где над стрелками
надписаны номера применяемых правил)
<Л > => I <5> b => I <А> cb => I a <B>cb
является краевым выводом, так как последним применялось
некраевое правило 1, а все остальные применяемые правила —
краевые. Другой пример краевого вывода —
<B>=>id
так как последним применялось некраевое правило 4, а
остальные правила (числом ноль) — краевые.
В формулировке преобразования «цель-край» делается
следующее различие, основанное на краевых выводах:
Правило р называется существенным для нетерминала (G)
тогда и только тогда, когда его можно использовать в
некотором краевом выводе, начинающемся с (G). Все
остальные правила называются несущественными для (G).
Нетерминал (А) называется расширенным краем нетерминала
(G), если (.4) — левая часть какого-нибудь правила,
существенного для (G).
В грамматике на рис. В.4 все правила существенны для
нетерминалов (А) и (В). Несущественный случай будет проиллюстрирован
позднее. Термин «расширенный край нетерминала (G)»
используется потому, что (.4) является расширенным краем (G) тогда и
только тогда, когда существует такая цепочка символов
грамматики ее, что (.4 )а можно получить из (G) левым выводом, используя
нуль пли более краевых правил.
Основная идея преобразования «цель-край» состоит в том, чтобы
обеспечить другой метод выполнения краевых выводов. Мы
опишем преобразование, дадим интерпретацию его шагов, а затем
покажем на примере другой способ краевого вывода.
616
Приложение В. Преобразования грамматик
Поданной КС-грамматике данного языка можно получить новую
грамматику этого языка с помощью следующей процедуры,
которую мы называем преобразованием «цель-край»:
1. Выберем в данной грамматике нетерминал (С). Он называется
целью данного повторения шагов 2 и 3.
2. Для каждого нетерминала (О, который является
расширенным краем нетерминала (G), добавим к множеству нетерминалов
новый нетерминал (G, С).
3. Построим пидапанозочног множеспию для (G) следующим
образом:
а) Для каждого существенного краевого правила исходной
грамматики
(С)^ {D)a
поместить в подстановочное множество для нетерминала (G)
правило
{G,D)->a (G, О
б) Для каждого существенного некраевого правила исходной
грамматики
(С>->р
поместить в это множество правило
<G>-*p (G,C)
в) Поместить в это множество правило
{G,G)^e
4. Повторить шаги 1—3 для каждой возможной цели (G) из
исходной грамматики. Удалить старые правила и обьединить
подстановочные множества в новое множество правил.
Интерпретация нового нетерминала (G, С), введенного на шаге 2,
такова, что он порождает цепочку, приписав которую к цепочке,
порожденной нетерминалом (С), получаем цепочку, порождаемую
нетерминалом (G). Более формально, (G, С) порождает множество
терминальных цепочек х, таких, что
<G> =>), <С> х
Согласно такой интерпретации, правило подстановочного
множества, получаемое на шаге 36, говорит о том, что цепочка,
порождаемая нетерминалом <G>, может состоять из цепочки, порождаемой
цепочкой р (т. е. цепочки, порождаемой нетерминалом (О), за
которой следует цепочка, порождаемая нетерминалом (G, С) (т. е.
цепочка, которую можно приписать к цепочке, порождаемой
нетерминалом (О, для того, чтобы получить цепочку, порождаемую не-
В.7. Преобразование щель-кряй»
617
терминалом (О). Новое правило, получаемое на шаге За, говорит
о том, что цепочка, которую можно приписать к цепочке,
порожденной нетерминалом (D), для получения цепочки, порожденной
нетерминалом (G), сама может состоять из цепочки, порожденной
цепочкой а (т. е. цепочки, приписываемой к цепочке, порождаемой
нетерминалом (D >, для получения цепочки, порождаемой
нетерминалом (О), за которой следует цепочка, приписываемая к цепочке,
порождаемой нетерминалом (С), для получения цепочки,
порождаемой нетерминалом (О. Новое правило, получаемое на шагеЗв,
говорит о том, что к цепочке, порождаемой нетерминалом (О, можно
приписать пустую цепочку, чтобы получилась цепочка,
порождаемая нетерминалом (G).
На рис. В.6 мы показали новую версию грамматики рис. В.4,
полученную в результате преобразования. Номера правил на
рис. В.6 скомбинированы из номеров правил и названий целей.
Так, правило 2А получено преобразованием правила 2 для цели
(А >, как того требует шаг За нашей процедуры. Правила 5А и
5В — это е-правила, которые получены на шаге Зв и не
соответствуют правилам исходной грамматики. Новая грамматика
принадлежит классу LL (1), и ее можно сделать компактнее с помощью
одиночной подстановки.
1Л. <Л> —а<б><Л, Л>
2А. <Л, 5>—-6<Л, А>
ЗА. <Л, А>—>с<А, В>
4А. <Л>—+ d<A, S>
5А. <Л, Л>—► е
1В. <Я> — a <Ву<В, Л>
2В. <Я, В> —&<Я, Л>
ЗВ. <В, А>—»с<.В, By
4В. <S>—>-d<B, By
5В. <5, By—-г
Начальный символ: <Л>
Рис В. 6.
Ранее мы показали, что а (В) сЬ можно получить из (А > в
старой грамматике с помощью краевого вывода. В новой грамматике
цепочка а{В) сЪ получается последовательностью правых
подстановок, а именно
<A>=$lRAa<B><A, Л>=>#а<В>с<Л, В>=^%А
a<B>cb<A, А>=>%Аа<В>сЬ
Теперь рассмотрим последоватетьность правил, использованных
в старом и новом выводах цепочки а (В) cb из {А). Правила, уча-
618
Приложение В. Преобразования грамматик
ствующие в первоначальном краевом выводе (т. е. 2, 3 и 1), в новой
цепочке встречаются в преобразованном виде (т. е. 2А, ЗА и 1А).
Более того, новые правила идут в порядке, обратном
первоначальному, и за ними следует одно из новых е-правил, созданных на
<А >
<в>
<А >
<В> <А,А>
В,В>
<В>
<А,А
Рис. В. 7.
шаге Зв. Обратный порядок в этом примере — типичное
проявление следующего общего случая.
Предположим, что цепочка а получена из (G) левым выводом,
в котором применяется нуль или более краевых правил
ри . . ., рп в указанном порядке, а затем некраевое правило q.
Пусть рь . . ., рп и q— соответствующие правила, полученные
после преобразования с помощью шагов За и 36 для цели
(G), и пусть е — правило (6, G)-+e, получаемое на шаге Зв.
Тогда в новой грамматике а можно вывести из (G) правым
выводом, в котором применяется последовательность правил
Я, Рп Ри ё.
Случай без краевых правил можно проиллюстрировать на примере
вывода символа d из (В). В новой грамматике
<B>=>tfd<B, B>=yfd
На рис. В.7, а показано дерево вывода цепочки adeb с
использованием грамматики на рис. В.4. Это дерево имеет две нетерминальные
вершины, которые не являются краями, а именно начальную
вершину и вершину (В) прямо над терминалом d. Начальную вершину
B.7. Преобразование щель-край*
619
можно считать корнем краевого вывода цепочки а (В) cb из (А ),
а вершину (В) можно рассматривать как корень краевого вывода
терминала d. На рис. В.7, б показан вывод той же терминальной
цепочки в преобразованной грамматике. Это дерево тоже
представляет вывод цепочки а (В) cb из (А) и вывод d из (В), но эти
выводы выполняются в обратном порядке.
1. <Л> — <В>а
2. <А>^а
3. <В>-^<5>6
4. <В> -^ <С>
5. <В>—>Ьс
G.
7.
8.
9.
<С>—>ас<А>
<С> —* Ь <£>>
<D>—>d<B>a
<D> —>■ г
Начальный символ: <Л>
(а)
1А. <Л, В>—>-а<Л, Л> ЗВ. <В, B>-^ft<B, В>
2А. <Л>--*а<Л, Л> 4В. <В, С> — <В, В>
ЗА. <Л, В>—>fc</1, В> 5В. <В>—*ftc<B, B>
4А. <Л,С>-^<Л,В> 6В. <В>—*а<:<^><В, О
5А. <Л>— >bc<A, By 7B. <В>—>&<0><В, С>
6А. <Л> — пс <Л> <Л, С> 10В. <fl, B> — 8
7Л. <Л>—>-6<0><Л,С> GC. <С> —яс<Л><С, С>
10А. <Л,Л>^е 7С. <С>-^ * <0><С, С>
8D. <D> —► d <B> й <D, D> IOC. <C, C> —» t
9D. ф>—+ф, D>
10D. <D, D>—к
Начальный символ: <Л>
(б)
Рис. В.8.
На рис. В.8 приведен другой иллюстративный пример.
Расширенными краями для нетерминала (А) являются (Л), (В) н (С).
Все правила, кроме 8 и 9, существенны для {А ). Для нетерминал»
(В) расширенными краями являются (В) и (О, а существенными
правилами — 3, 4, 5, 6 и 7. Для нетерминала (С) в качестве
расширенного края выступает только он сам, и только правила 6 и 7
существенны для него. Аналогично для (D > расширенным краем
служит только он сам, и только правила 8 и 9 для него существенны.
Расширенные края легко вычисляются методом транзитивного
замыкания, обсуждавшимся в приложении Б. Отношение РАСШИ-
G20
Приложение В. Преобразования грамматик
РЕННЫЙ-КРАИ — рефлексивно-транзитивное замыкание
отношения КРАЙ, где
Ш КРАЙ (Y)
тогда и только тогда, когда
(У> -> (X) а
является правилом грамматики для некоторой цепочки а.
На рис. В.8, б мы показали грамматику, полученную
преобразованием грамматики на рис. В.8, а. Три е-правила, полученные
на шаге Зв нашей процедуры, являются одиночными правилами,
а именно 10А, ЮС и 10D.
После исключения одиночных правил 10А, ЮС и 10D в
результате замены правила 2А, 6С, 7С, 8D н 9D восстанавливаются в их
первоначальном виде. Кроме того, нетерминалы (С) и (С, О
недостижимы, и поэтому правила 6С, 7С и ЮС можно исключить.
Грамматика па рис. В.8, б не принадлежит классу LL (1), но
•ее можно сделать таковой с помощью левой факторизации правил
-2А и 6А, 5А и 7А, 5В и 7В.
В.8. Исключение е-правил
Методы типа «перенос — опознание», описанные в гл.12, применимы
только к грамматикам без е-правил. Это ограничение, однако, не
является критическим в том смысле, что, имея грамматику с е-пра-
вилами, всегда можно преобразовать ее в грамматику без е-правил.
Полученная грамматика будет порождать тот же язык, что и
исходная грамматика, за одним исключением: если исходный язык
содержал пустую цепочку, то новый язык ее содержать не будет.
Грамматика без е-правил не может порождать пустых цепочек.
Чтобы проиллюстрировать этот метод в его простейшем виде,
мы покажем, как исключить из грамматики на рис. В.9, а е-пра-
вило для нетерминала (А >. Представим себе, что на самом деле
есть две разновидности нетерминала (А): нетерминал (/4ДА>, к
которому в выводе всегда применяется е-правило, и нетерминал
</4НЕ1), к которому е-правило не применяется никогда. Заменив
нетерминал (А > этими двумя его разновидностями, получим
грамматику на рис. В.9, б. Заметим, что правило 1 превратилось в два
правила, одно из которых содержит в правой части символ (А нет). а
другое — символ С4ДА). В левой части правила 4 оказался символ
Мда ). так как это к нему всегда применяется е-правило, а в
левую часть правила 3 мы поместили символ (АНЕТ), потому что
именно этот символ нужно использовать в тех случаях, когда
.применяется не е-правило.
B.8. Исключение е-праяил
621
Эпсилон-правило на рис. В.9, б представляет собой одиночное
правило, так как по построению это единственное правило с левой
частью С4дд). (Все правила для (А ) с непустыми правыми частями
в качестве левых частей имеют нетерминал (ЛНЕТ).) Это правила
можно исключить методом, обсуждавшимся в разд. В.5, получив
1. <5> — а<Л><5> 1-НЕТ. <5> — а<ЛНЕТ><5>
2. <S> — b 1-ДА. <5> — а <Лдл> <5>
3. <.4>—-c<S> 2. <S> — Ъ
4. <А>->е 3. <Лцет> —с<5>
4. <Лдд> —♦?
Начальный символ: <5> Начальный символ: <5>
(а) (б)
1-НЕТ. <S>--а<Лцпт><5;
1-ДА. <5>-*а<5>
2. <5>-^6
3. <Лнет> —c<S>
Начальный символ: <S>
(в)
Рис.
В. 9.
1-НЕТ. <S> — о<Л><5>
1-ДА. <5> — а<5>
2. <5> —* 6
3. <л>-^с<5>
Начальный символ: <5>
(г)
при этом рис. В.9, в. Поскольку имя (ЛдА) из грамматики исчезло,
можно заменить (ЛНЕТ ) прежним именем (А ) и получить рис. В.9, г.
Грамматика на рис. В.9, г порождает тот же язык, что и грамматика
на рис. В.9, а, но нетерминалы (А > этих двух грамматик порождают
разные множества цепочек. Из нетерминала (А) на рис. В.9, а
выводима пустая цепочка, а из (А) на рис. В.9, г она не выводима.
Теперь забудем об (ЛДА) и {АНЕ1) и рассмотрим
преобразование грамматики на рис. В.9, а в грамматику на рис. В.9, г как
один шаг. Мы разбили правило 1 на два правила, в одном случае
применив правило (А )->е к вхождению (А) в правую часть
правила 1, а в другом случае не применяя к-правнла. В результате
е-правило удалось исключить из грамматики.
Ситуация несколько усложняется в тех случаях, когда в
правой части какого-нибудь правила имеется несколько вхождений
нетерминала, вместо которого нам нужно подставлять или не
подставлять пустую цепочку. Пусть, например, грамматика на
рис. В.9, а вместо правила 1 содержит следующее правило:
(S)-+a (A) (S) (А)
622
Приложение В. Преобразования грамматик
.Для этого правила мы должны выделить четыре случая. В терминах
<ЛдА> и (Л нЕТ) получаем:
(S)-»a (ЛНЕт> (S) (ЛНЕТ>
(S)-+a (ЛДА> (S) (А
НЕ! /
<S>->'fl (ЛнЕТ> (S) (Лдд)
(S)-+u{AaA) (S) (ЛДА>
Окончательный вид преобразованных правил будет таким:
(S)-+a (A) (S) (А)
(S)-+a (S) (А)
(S)-+a (A) (S)
(S)-+a (S)
Мы приходим к преобразованным правилам, применяя или не
применяя правило (Л ) -+ е. во всех возможных комбинациях.
Далее, предположим, что грамматика содержит два нетерминала,
(Л ) и (В), каждый из которых может порождать пустую цепочку.
Пусть мы имеем дело с правилом
(S)-+a (A) (S) (В)
Подставляя пустую цепочку вместо (Л) и (В) во всех возможных
комбинациях, получим следующие четыре правила:
(S)-»a (A) (S) (В)
(S)-+a (S) (В)
(S > -> о (Л ) (S)
{S)-+a (S)
Теперь мы сформулируем рассмотренную здесь методику в
виде общей процедуры исключения е-правил.
1. Определить, какие нетерминалы грамматики могут
порождать пустую цепочку. Такие нетерминалы называются
аннулирующими; процедура их отыскания описана в разд. 8.7.
2. Заменить каждое из правил, правые части которых содержат
хотя бы по одному аннулирующему нетерминалу, множеством новых
правил. Если правая часть правила содержит /г вхождений
аннулирующих нетерминалов (/г^1), то множество, заменяющее это
правило, состоит из 2* правил, соответствующих всем возможным
способам удаления некоторых (или всех) из этих вхождений.
3. Исключить из грамматики все е-правила (включая те, которые
могли появиться на шаге 2).
Заметим, что в случаях неоднозначности на шаге 2 может
получиться меньше чем 2* различных правил. Например, правило
(S)-*a (А) (А)
B.9. Получение польского перевода
623
заменяется не четырьмя, а тремя правилами:
(S > -* а {А > (А > (S > -> а {А > (S > -> о
Правило (S)->-a (/1) получается как удалением первого
вхождения нетерминала (А ), так и удалением второго его вхождения.
В заключение заметим, что если начальный символ грамматики
аннулирующий, то язык, порождаемый преобразованной
грамматикой, будет отличаться от исходного языка тем, что он не будет
содержать пустой цепочки.
В.9. Получение польского перевода
Пусть нам нужно реализовать перевод, задаваемый правилом
{оператор >-> IF (логическое выражение) {ПЕРЕХОД ПО ЛЖИ}
THEN (оператор) {МЕТКА}
с использованием восходящего метода, допускающего только
польский перевод. Мы решаем эту задачу, заменяя имеющееся
правило двумя новыми правилами, так что {ПЕРЕХОД ПО ЛЖИ)
оказывается на правом конце первого из них, а {МЕТКА} — на
правом конце второго. Эти новые правила мы получаем, вводя
новый нетерминал (ее л и-предложение), порождающий цепочку IF
(логическое выражение) {ПЕРЕХОД ПО ЛЖИ} и заменяя
вхождение этой цепочки в исходное правило новым нетерминалом. Таким
образом, получаются два правила:
(оператор)-*- (если-предложение) THEN (оператор) {МЕТКА}
(еели-предложение) -> IF (логическое выражение) {ПЕРЕХОД
ПО ЛЖИ}
В общем случае, если имеется правило вида
(L)-+a{A\ p
где аир" — цепочки грамматических символов, то можно ввести
новый нетерминал (новый) и заменить исходное правило двумя
следующими:
(L) -> (новый) р
(новый) -+■ а {А}
В результате символ действия {А} оказывается в крайней правей
позиции правила, и число символов действия, нарушающих условие,
налагаемое на польский перевод, уменьшается.
Последовательное применение этого метода ко всем правилам,
для которых это нужно, всегда позволяет переписать данную
транслирующую грамматику в виде грамматики польского перевода.
Более того, если данная транслирующая грамматика не содержит
624
Приложение В. Преобразования грамматик
символов действия в крайних левых позициях правых частей
правил, то указанное преобразование не добавляет к грамматике е-пра-
вил.
В.10. Устранение конфликтов переноса — опознания
Здесь мы опишем метод, позволяющий преобразовать любую
контекстно-свободную грамматику в грамматику без конфликтов
переноса — опознания. В качестве примера рассмотрим следующую
грамматику с начальным символом (S >:
1. <S)->c (А)а
2. {А)-+с (В)
3. (A)-+d (В) а
4. (B)-+d{S)e{B)f
5. {B)-+g
Грамматика содержит конфликт переноса — опознания для
магазинного символа {В) и входного символа а, так как, имея на верху
магазина (В), а на входе а, мы не знаем, что нужно делать: перенос
в соответствии с правилом 3 или опознание (с последующей
сверткой) в соответствии с правилом 2. Идея состоит в том, чтобы ввести
новый нетерминал (В) и новое одиночное правило
<В> — <й>
а затем заменить все вхождения (В) в правые части правил, кроме
самых правых вхождений, вхождениями нового символа (В).
Преобразованная грамматика выглядит следующим образом:
1. <S> —* с<А}а
2. <Л> — с<В>
3. <Ау —> d(B>a
4. <В> — d<S>e<B>f
5. <В> — g
6. <fi> — <fi>
В полученной грамматике (В) встречается только в самых
правых позициях и, следовательно, не может быть в отношении ПОД
с каким-либо нетерминалом. Аналогично символ (В) никогда не
встречается в самой правой позиции и, следовательно, не может
быть в отношении СВЕРТЫВАЕТСЯ-ПО ни с каким терминалом.
Легко видеть, что преобразованная грамматика не содержит
конфликтов переноса — опознания.
В.П. Замечания по литературе
625
Описанный метод является достаточно общим, и его повторное
применение позволяет по очереди устранить все конфликты.
Общую процедуру можно сформулировать следующим образом:
Для каждого символа грамматики А (нетерминального
или терминального), для которого в грамматике есть
конфликт переноса— опознания, т. е. существует терминал Z,
такой, что
А СВЕРТЫВАЕТСЯ-nOZ
и
А ПОД Z
ввести новый нетерминал (А > и одиночное правило
<А>-+ А
и заменить все вхождения А, кроме самых правых,
вхождениями (А ).
' Если дана грамматика, для которой нужно построить процессор
типа «перенос — опознание», мы рекомендуем применять методы
разд. В.8—В. 10 в следующем порядке:
1. Исключить имеющиеся е-правила методом разд. В.8.
2. Ввести символы действия так, чтобы ни один из них не
оказался в крайней левой позиции какой-либо правой части.
3. Преобразовать полученную транслирующую грамматику в
грамматику польского перевода в соответствии с разд. В.9.
4. Устранить все конфликты переноса — опознания методом,
описанным в разд. В. 10.
Отметим, что после устранения на шаге 4 конфликтов переноса —
опознания грамматика остается грамматикой польского перевода,
так как применяемый метод не затрагивает самых правых позиций
правил.
С помощью описанных методов можно преобразовать любую
контекстно-свободную грамматику в грамматику без е-правил и
конфликтов переноса — опознания. Однако нет никакой гарантии,
что полученная грамматика будет обладать свойствами,
необходимыми для разбора типа «перенос — опознание» (т. е. что она будет
грамматикой слабого предшествования или простой ССП-грамма-
тикой).
В.П. Замечания по литературе
Преобразование грамматики к ЬЬ(1)-форме рассматривается Фос-
тером [19681 и Стирнзом [19711. Возможность исключения левой
рекурсии следует из результата Грейбах [19651 о том, что всякую
21 Ф. Льюис и др.
620
Приложение В. Преобразования грамматик
грамматику, которая порождает язык, не содержащий пустой
цепочки, можно преобразовать так, чтобы правые части всех правил
начинались терминальными символами. Метод разд. В.6
обсуждается в работе Курки-Суонио [1966]. Преобразования «цель-
край» и подобные им методы рассматриваются в работах Розен-
кранца [19,67], Фостера [1968], Гриффитса и Петрика [1968] и Вуда
[1969в]. Класс грамматик, которые можно преобразовать к
ЬЬ(1)-форме, обсуждается Розенкранцем и Льюисом [1970]. Более
общий метод преобразования грамматик к ЬЬ(1)-форме описан
Хаммером [1974].
Метод исключения е-правил ввели Бар-Хиллел, Перлис и
Шамир [1961]. Методы устранения конфликтов переноса — опознания
описаны в работах Фишера [1969], Лернера и Лима [1970], Грэхем
[1971], Макафи и Прессера [1972]. Ломет [1973] описывает метод
исключения левой рекурсии из LR-грамматик. Много различных
методов преобразований грамматик описано в работе Грэхем [1974].
Упражнения
1. Введите атрибуты в грамматику на рис. В.2, б так, чтобы получилась L-атри-
бутная грамматика, порождающая последовательность актов:
{ИНИЦИАЛК{СЛЕДД я2{СЛЕД2}, а3{ПОСЛЕДИ8}
2. а) Введите атрибуты в грамматику на рис. В.2, а так, чтобы в результате
получилась L-атрибутная грамматика и символ {КОНЧИТЬ} имел один
атрибут, значение которого — число символов а в списке.
б) Введите атрибуты в грамматику на рис. В.2, в так, чтобы получилась
L-атрибутная грамматика и {НАЧАТЬ} имел атрибут, значение которого —
число символов а в списке.
в) Введите атрибуты в грамматику на рис. В.2, в так, чтобы получилась
L-атрибутная грамматика и {КОНЧИТЬ} имел один атрибут, значение
которого — число символов а в списке.
3. Если в грамматике нет лишних символов, то может ли одиночное правило быть
леворекурсивным?
4. Докажите, что грамматика с леворекурсивным нетерминалом ие может быть
LL(l)-rpaMMaTHKOfl (считая, что в ней нет лишних символов).
5. Используя методы разд. В.2 — В.6, переделайте следующую грамматику с
начальным символом (£) так, чтобы она стала LL (1)-грамматикой.
(£>->(£>+' Т)
<£>-*<Г>
(Т)-у(Т)*(Р)
(Т)^(Р)
<Р>->«£))
(Р)^а
8. Переделайте следующий фрагмент грамматики Алгола 60 с начальным
символом (идентификатор) в LL(l)-rpaMMaTHKy:
(идентификатор) -»- (буква)
(идентификатор) ->■ (идентификатор) (буква)
(идгнтификатор)-»- (идентификатор) (цифра)
Упражнения
627
(цифра) -у 0| 1|2|. . .|9
(буква) -у а\Ь\с\. . .|г
7. Переделайте следующий фрагмент грамматики Алгола 60 с начальным
символом <программа> в ЬЬ(1)-грамматику. Для нетерминалов (оператор),
(описание) или (метка) правила строить не нужно.
(программа) -> (блок)
(программа) -»• (составной оператор)
(блок) ->- (непомеченный блок)
(блок) —>- (метка) : (блок)
(составной оператор) -»• (непомеченный составной оператор)
(составной оператор) -»- (метка) : (составной оператор)
(непомеченный блок) -> (заголовок блока) ; (конец составного оператора)
(непомеченный составной оператор) -»- begin (конец составного оператора)
(заголовок блока) ->- begin (описание)
(заголовок блока) -> (заголовок блока) ; (описание)
(конец составного оператора) -»- (оператор) end
(конец составного оператора) ->• (оператор) ; (конец составного оператора)
8. Примените преобразование «цель-край» к грамматикам из перечисленных
ниже упражнений. В каждом случае определите, принадлежит ли полученная
грамматика классу LL(1).
а) Упр. В.5.
б) Упр. В.6.
в) Упр. В.7.
9. Найдите леворекурсивную грамматику, применение к которой преобразования
«цель-край» оставляет ее леворекурсивной.
10. Покажите, что применение преобразования «цель-край» к ЬЦ1)-грамматике
дает в результате ЬЬ(1)-грамматику.
11. Переделайте следующую грамматику та , чтобы в ней не было е-правил:
С4)-><Л)С4)<Л)
(А)^а
<Л)-*е
12. Переделайте следующую грамматику так, чтобы s hc:"i не было е-правил:
(S) -* a(D)(D)
(S)-+(A)(B)
(S)-+(D)(A)(C)
(S)-+b
(A) -* (S)(C)(B)
(A) -> (S)(A)(B)(C)
(A)^{C)b{D)
(A)-+c
(A)-+s
(B) -* c(D)
(B)^d
(B)^e
(C)-* (A)(D)(C)
(C)-+c
(D) -* (S)a(C)
628
Приложение В, Преобразования грамматик
(О)-* <S)(C>
13. Переделайте следующие правила с атрибутами в S-атрибутную грамматику
польского перевода:
(логическое выражение),, СИНТЕЗИРУЕМЫЙ р
Все атрибуты символов действия — НАСЛЕДУЕМЫЕ.
<S> — if <ВУр1 {ПЕРЕХОД ПО ЛЖИ}- ,1then<SI>
{ПЕРЕХОД},, {МЕТКА}„2 else <S> {МЕТКА},,
Р2 *~ р\
(q2, ql) «- НОВТ
(г2, rl) — НОВТ
<S> — if <B>p1 {ПЕРЕХОД ПО ЛЖИ}р2 „ then<Sl> {METKA}„2
р2+- р\
(q2, q\) — НОВТ
И. а) Перепишите следующую грамматику так, чтобы исчезли конфликты
переноса — опознания:
<s>-i<s>i
<S> — 0<S)0
(S> -* О О
<S>-*1 1
б) Можно ли язык, описываемый полученной грамматикой, анализировать
МП-автоматом?
15. Переделайте следующую грамматику с начальным символом (список
операторов) так, чтобы она не содержала конфликтов переноса — опознания.
Новая грамматика не должна порождать к.
1. (список операторов) -»- (список операторов) ; (оператор)
2. (список операторов) -»■ е
3. (оператор) -+• ЕСЛИ (логическое выражение) ТО (оператор)
4. (оператор)-»-ДЕЛАЙ (otiepaTOp) ПОКА (логическое выражение)
5. (оператор) -* ДЛЯ ПЕРЕМЕННАЯ = (выражение) ДЕЛАЙ (оператор)
ЗАТЕМ ШАГ (выражение) ПОКА (выражение)
6. (оператор) -* ДЛЯ ПЕРЕМЕННАЯ = (выражение) ДЕЛАЙ (оператор)
7. (оператор) -»■ s
8. (логическое выражение) -v b
9. (выражение) -*■ е
16. Опишите, как упростить общую процедуру из разд. В.10 для устранения
конфликтов переноса — опознания так, чтобы нетерминал {А) заменялся на
(А) только тогда, когда это абсолютно необходимо.
17. Ниже перечислены некоторые формы правил грамматик. Покажите, что .-/ю-
бую грамматику, порождающую язык, не содержащий пустой цепочки,
'ложно преобразовать в эквивалентную так, что правая часть каждого правила
а) состоит либо из одного терминала, либо двух нетерминалов (Хамский
11959]);
б) начинается терминалом (Грейбах [1965]);
в) начинается и кончается нетерминальным символом (Розенкранц [1967]);
г) не длиннее трех символов и начинается терминалом (Грейбах f 1965]);
д) не содержит двух стоящих рядом нетерминалов (Грейбах fi965]).
Список литературы1'
Абрамсон (Abramson H.)
[1973] Theory and Application of a Bottom-up Syntax-directed Translator,
New York: Academic Press.
Айронс (Irons E. T.)
[1961] «A syntax directed compiler for AIGOL 60», Comm. ACM, 4, 1, 51—55.
[1963a] «The structure and use of syntax-directed compiler», Annual Review
in Automatic Programming», 1963, 3, 207—227, (ed.) R. Goodman, New York
[andLondon: Pergamon Press. Переиздано в сб. под ред. Поллака [1972].
196 36] «An error-correcting parse algorithm», Comm. ACM, 6, 11, 669—673,
Пере]идано в сб. под ред. Поллака [1972].
[1964 3«Structural connections in formal languages», Comm. ACM, 7, 2,
67—71.
Аллен (Allen F. E.)
[1969] «Program optimization», Annual Review in Automatic Programming, 5,
239—307, Elmsford, N. Y.: Pergamon Press.
Аллен и Кок (Allen F. E., Cocke J.)
[1972] «A catalogue of optimizing transformations», Design and Optimization
of Compilers, 1—30, (ed.), Rustin R., Englewood Cliffs, N. J.: Prentice-Hall.
Альпиар (Alpiar R.)
[1971] «Double syntax oriented processing», Computer J., 14, 1, 25—37.
Ангер (linger S. H.)
[1968] «A global parser for context-free phrase structure grammars», Comm.
ACM, 11, 4, 240—247.
Андерсон и др. (Anderson Т., Eve J., Horning J. J.)
[1973] «Efficient LR(1) parsers», Acta Informatica, 2, 12—39.
Арбиб (Arbib M. A.)
[1970] Theories of Abstract Automata, Englewood Cliffs, N. J.: Prentice-Hall.
Арден и др. (Arden В. W., Galler В. A., Graham R. M.)
[1962] «An algorithm for translating Boolean expressions», J. ACM, 9, 2,
222—239.
Axo (Aho A. V.)
[1968] «Indexed grammars — an extension of context-free grammars», J. ACM,
15, 4, 647—671. (Русский перевод: Axo А. Индексные грамматики —
расширение контекстно-свободных грамматик.— В сб. «Языки и автоматы».—»
М.: Мир, 1975, с. 130—165).
Ахо и Джонсон (Aho A. V., Johnson S. С.)
[1974] «LR parsing», Computing Surveys, 6, 2, 99—124.
Ахо и Петерсон (Aho A. V., Peterson T. G.)
[1972] «A minimum distance error-correcting parser for context-free languages»,
SIAM J. Computing, 1, 4, 305—312.
Axo и Ульман (Aho A. V., Ullman J. D.)
[1969a] «Syntax directed translations and the pushdown assembler», J.
Computer and System Sciences, 3, 1, 37—56.
[19696] «Properties of syntax directed translations», J. Computer and System
Sciences, 3, 3, 319—334.
'* Дополнительную литературу, в частности работы советских авторов, см,
в русском переводе книги Ахо и Ульмана [1972а, 1973а].— Прим. ред.
630
Список литературы
[1971] «Translations on a context-free grammar», Information and Control,
19, 5, 439—475.
[1972a, 1973a] The Theory of Parsing, Translation and Compiling, Englewood"
Cliffs, N. .1.: Prentice-Hall, 1972, 1, 1973, 2. (Русский перевод: Ахо А.,
Ульман Дж. Теория синтаксического анализа, перевода и компиляции, т. 1,
т. 2.—М.: Мир, 1978.)
[19726] «©ptimizafion of LR(£) parsers», J. Computer and System Sciences, 6,
6, 573—602.
[1972b] «Linear precedence functions for weak precedence grammars»,
International J. Computer Mathematics, 3, 4, 149—155.
[19736] «A technique for speeding up LR(£) parsers», SI AM J. Computing, 2,
2, 106—127.
[1973b] «Error detection in precedence parsers», Mathematical Systems Theory,
7, 2, 97—113.
Ахо и др. (Aho A. V., Hopcroft J. E., Ullman J. D.)
[1968] «Time and tape complexity of pushdown automaton languages»,
Information and Control, 13, 3, 186—206. (Русский перевод: АхоА., Хопкрофт
Дж., Ульман Дж. Временная и ленточная сложности языков, допускаемых
магазинными автоматами.— В сб. «Языки и автоматы»,— М.: Мир, 1977,.
185—197.)
Ахо и др. (Aho A. V., Denning P. J., Ullman J. D.)
[1972] «Weak and mixed strategy precedence parsing», J. ACM, 19, 2, 225—
243.
Ахо и др. (Aho A. V.-, Johnson S. C, Ullman J. D.)
[1973] «Deterministic parsing of ambiguous grammars», Conf. Rec. ACM
Symposium on Principles of Programming Languages, Boston, Mass., 1—2K
См. также Сотт. ACM, 1975, 18, 8, 441—453.
Барнет и Футрель (Barnett M. P., Futrelle R. P.)
[1962] «Syntactic analysis by digital computer», Comm. ACM, 5, 10, 515—526.
Батсон (Batson A.)
[1965] «The organization of symbol tables», Comm. ACM, 8, 2, 111—112.
Бар-Хиллел и др. (Bar-Hillel Y., Perles M., Shamir E.)
[1961] «On formal properties of simple phrase structure grammars», Zeits-
chrift fiir Phonetik, Sprachwissenschafi und Kommunikationsforschung, 14, 2,
143—172. См. также Bar-Hillel Y., Language and Information, Reading,
Mass.: Addison-Wesley, 1964, 116—150.
Бауэр и Замельзон (Bauer F. L., Samelson K.)
[1959] «Sequentialle formeliibersetzung», Elektronische Rechenanlagen, 176—
182. -
[1960] «Sequential formula translation», Comm. ACM, 3, 2, 76—83.
Переиздано в сб. под ред. Розена [1967] и Поллака [1972].
Белл (Bell J. R.)
[1969] «A new method for determining linear precedence functions for
precedence grammars», Comm. ACM, 12, 10, 567—569.
[1970] «The quadratic quotient method: a hash coding eliminating secondary
clustering», Comm. ACM, 13, 2, 107—109.
Белл и Каман (Bell J. R., Kaman С. Н.)
[1970] «The linear quotient hash code», Comm. ACM, 13, 11, 675—677.
Берж (Burge W. H.)
[1964] «The evaluation, classification and interpretation of expressions», Proc.
19th National ACM Conf., New York.
Брент (Brent R. P.)
[1973] «Reducing the retrieval time of scatter storage techniques», Comm. ACM,
16, 2, 105—109.
Список литературы
631
Брукер и Моррис (Brooker R. A., Morris D.)
[1960] «An assembly program for a phrase structure language», Computer J.,
3, 168—174.
[1962] «A general translation program for phrase structure languages», J. ACM,
9, 1, 1—10.
Брукер и др. (Brooker R. A., MacCallum I. R„ Morris D,, Rohl J. S.)
[1963] «The compiler compiler», Annual Review in Automatic Programming,
(ed.) Goodman R., N. Y., and London: Pergamon Press, 229—271.
Брукер и др. (Brooker R. A., Morris D., Rohl J. S.)
[1967] «Experience with the compiler-compiler», Computer J., 9, 4, 345—349,
Бут (Booth T. L.)
[1967] Sequential Machines and Automata Theory, New York: John Wiley
and Sons.
Бэйз (Bays C.)
[1973] «The reallocation of hash-coded tables», Comm. ACM, 16, 1, 11—14.
[1973] «A note on when to chain overflow items within a direct access table»,
Comm. ACM, 16, 1, 46—47.
Бэкс (Backes S.)
[1971] «Top-down syntax analysis and Floyd-Evans production language»,
Proc. of Hie IFIP Congress.
Бэкус (Backus J. W.)
[1959] «The syntax and semantics of the proposed international algebraic
language of the Zurich ACM-GAMM Conference», Proc. Internal. Conf. on
Information Processing, UNESCO, 125—132.
Бэкус и др. (Backus J. W. et al.)
[1957] «The FORTRAN automatic coding system», Proc. Western Joint
Computer Conf., Los Angeles, 11, 188—198. Переиздано в сб. под ред. Розена
[1967].
Вайз (Wise D. S.)
[1972] «Generalized overlap resolvable grammars and their parsers», J. Сотри.
ter and System Sciences, 6, 538—572.
Вайнгартен (Weingarten F. W.)
[1973] Translation of a Computer Languages, San Francisco, Holden-Day.
(Русский перевод: Вайнгартен Ф. Трансляция языков программирования.—
М.: Мир, 1977.)
Вегнер (Wegner P.)
[1968] Programming Languages, Information Structures and Machine
Organization, New York: McGraw-Hill.
Вер (Vere S.)
[1970] «Translation equation», Comm. ACM, 13, 2, 83—89.
Вирт (Wirth N.)
[1968] «PL360, a programming language for the 360 computers», J. ACM, 15,
1, 37—74.
Вирт и Вебер (Wirth N., Weber H.)
[1966] «EULER: a generalization of ALGOL, and its formal definition: Part 1:
Comm. ACM, 9, 1, 13—23.
Вуд (Wood D.)
[1969a] «A note on top-down deterministic languages», BIT, 9, 4, 387—399.
[19696] «The theory of left factored languages: Part I», Computer J., 12, 4,
349—356.
[1969b] «The normal form theorem — another proof», Computer J., 12, 2,
139—147.
Геллер и Харрисон (Geller M. M., Harrison M. A.)
[1973] «Characterizations of LR(0) languages», IEEE Conference Record of
14th Annual Symposium on Switching and Automata Theory, 103—108.
Гилберт (Gilbert P.)
[1966] «On the syntax of algorithmic languages», J, ACM, 13, 1, 90—107,
632
Список литературы
Гилл (Gill A.)
[1962] Introduction to the Theory of Finite-state Machines, New York,
McGraw-Hill. (Русский перевод: Гилл А. Введение в теорию конечных
автоматов.— М.: Наука, 1966.)
Гинзбург (Ginsburg S.)
[1962] An Introduction to Mathematical Machine Theory, Reading, Mass.*.
Addison-Wesley.
[1966] The Mathematical Theory of Context-Free Languages, New York,
McGraw-Hill. (Русский перевод: Гинзбург С. Математическая теория
контекстно-свободных языков.— М.: Мир, 1977.)
Гинзбург и Грейбах (Ginsburg S., Greibach S. A.)
[1966] «Deterministic context-free languages», Information and Control, 9,
6, 620—648.
Гинзбург и Роуз (Ginsburg S., Rose G. F.)
[1966] «Preservation of languages by transducers», Information and Control,
9, 2, 153—176. (Русский перевод: Гинзбург С, Роуз Дж. Об инвариантности
классов языков относительно некоторых преобразований.—
Кибернетический сборник, Новая серия, вып. 5.— М.: Мир, 1968, с. 138—166.)
[1968] «A note on preservation of languages by transducers», Information
and Control, 12, 5—6, 549—552.
Гинзбург и Уллиан (Ginsburg S., Ullian J.)
[1966] «Ambiguity in context free languages», J. ACM, 13, 1, 62—89.
Гласе (Glass R. J.)
[1969] «An elementary discussion of compiler/interpreter writing», Computing
Surveys, 1, 1, 55—77.
Готье и Понто (Gauthier R., Ponto S.)
[1970] Designing Systems Programs, Englewood Cliffs, N. J.: Prentice-Hall.
Грау (Grau A. A.)
[1961] «Recursive processes and ALGOL translation», Comm. ACM, 4, 1, 10—
15.
Гро и др. (Grau A. A., Hill A. U., Lungmaack H.)
[1967] Translation of ALGOL 60, New York: Springer Verlag.
Грейбах (Greibach S. A.)
[1965] «A new normal-form theorem for context-free phrase structure
grammars», J. ACM, 12, 1, 42—52.
Грис (Gries D.)
[1968] «Use of transition matrices in compiling», Comm. ACM, 11,1, 26—34.
Переиздано в сб. под ред. Поллака [1972].
[1971] Compiler Construction for Digital Computers, New York: Wiley.
(Русский перевод: Грис Д. Конструирование компиляторов для цифровых
вычислительных машин.— М.: Мир, 1975.)
Грис и др. (Gries D., Paul M., Wiehle H. R.)
[1965] «Some techniques used in the ALCOR ILLINOIS 7090», Comm. ACM, 8,
8, 496—500. Переиздано в сб. под ред. Поллака [1972].
Гриффите и Петрик (Griffiths Т. V., Petrick S. R.)
[1965] «On the relative efficiences of context-free grammar recognizers»,
Comm. ACM, 8, 5, 289—300.
[1968] «Top-down versus bottom-up analysis», IFIP Congress, Software I,
Booklet B. 80—85.
Гросс и Лантен (Gross M., Lentin A.)
[1970] «Introduction to Formal Grammars, New York: Springer-Verlag.
(Русский перевод: Гросс М., Лантен А. Теория формальных грамматик.—
М.: Мир, 1971.)
Грэй и Харрисон (Cray J. N.. Harrison M. A.)
[1972] «On the covering and reduction problems for context-free grammars»,
J. ACM, 19, 4, 675—698.
[1973] «Canonical precedence schemes», J, ACM, 20, 2, 214—234,
Список литературы 633
Грэхем (Graham R. М.)
[1964] «Bounded context translation», Proc. AFIPS 1964 Spring Joint
Computer Conf., Baltimore. Md: Spartan Books, 25, 17—29. Переиздано в сб. под
ред. Розена [1967].
Грэхем (Graham S. L.)
[1970] «Extended precedence languages, bounded right context languages
and deterministic languages», IEEE Conf. Record of 1970 11th Annual
Symposium on Switching and Automata Theory, 175—180.
[1971] «Precedence languages and bounded right context languages», Ph. D.
Thesis, Stanford Univ.
[1974] On bounded right context languages and grammars», S1AM J.
Computing, 3, 3, 224—254.
Грэхем и Роудз (Graham S. L., Rhodes S. P.)
11973] «Practical syntactic error recovery in compilers», Conf. Rec. ACM
Symposium on Principles of Programming Languages, Boston, Mass., 52—58.
См. также Сотт ACM, 1975, 18, 11, 639—649.
Делабрианде (de la Briandais R.)
[1959] «File searching using variable length keys», Proc. Western Joint
Computer Conference, 295—298.
Деремер (De Remer F. L.)
[1969] «Generating parsers for BNF grammars», Proc. AFIPS 1969 Spring
Joint Computer Conf., Montvale, N. J., AFIPS Press, 34, 793—799.
[1971] «Simple LR(ft) grammars», Comm. ACM, 14, 7, 453—460.
Джеймс и Патриж (James E. В., Partridge D. P.)
[1973] «Adaptive correction of program statements», Comm. ACM, 16, 1, 27—
37.
Джонсон (Johnson L. R.)
[1961] «Indirect chaining method tor addressing on secondary keys», Comm.
ACM, 4, 5, 218—222.
Джонсон и др. (Johnson W. L., et al.)
[1968] «Automatic generation of efficient lexical processers using finite state
techniques», Comm. ACM, 11, 12, 805—813.
Домёлки (Domolki B.)
[1964] «An algorithm for syntactic analysis», Computational Linguistics, 3,
29—46.
[1965] Алгоритмы для распознавания свойств последовательностей
символов.— Ж. вычисл. матем. и мат. физики, 5, 1, 77—97.
[1968] «A universal compiler system based on production rules», BIT, 8, 4,
262—275.
Донован и Ледгард (Lonovan J. J., Ledgatd H. F.)
11967] «A formal system for the specification of the syntax and translation of
computer languages», Proc. AFIPS 1967 Fall Joint Computer Conf.,
Washington, D. C: Thompson Books, 21, 553—569.
Дэвис (Davis M.)
[1958] Computability and Unsolvability, New York: McGraw-Hill.
Дэй (Day A. C.)
[1970] «The use of symbol-state tables», Computer J., 13, 4, 332—339.
Ершов А. П.
[1958] Программирующая программа для быстродействующей электронной
счетной машины,— М.: Изд. АН СССР.
Ингерман (Ingerman P. Z.)
[1966] A Syntax Oriented Translator, New York: Academic Press. (Русский
перевод: Ингерман П. Синтаксически ориентированный транслятор.— М,:
Мир. 1969.)
Ихбиа и Морзе (Ichbiah J. D., Morse S. P.)
[1970] «A technique for generating almost optimal Floyd-Evans productions
for precedence grammars», Comm. ACM, 13, 8, 501—508.
634
Список литературы
Камингер (Kaminger F. Р.)
[1973] «Generation, recognition, and parsing of context-free languages by-
means of recursive graphs», Computing, 11, 1, 87—96.
Каннер и др. (Kanner H., Kosinski P., Robinson C. L.)
[1965] «The structure of yet another ALGOL compiler», Comm. ACM, 8, 7,
427—438. Переиздано в сб. под ред. Розена [1967].
Кантор (Cantor* D. G.)
[1962] «On the ambiguity problem of Backus Systems», J. ACM, 9, 10, 447—
479.
Касами и Тории (Kasami Т., Torii К.)
[1969] «A syntax-analysis procedure for unambigous context-free grammars»,
J. ACM, 16, 3, 423—431.
Кемп (Kemp R.)
[1973] «An estimation of the set of states of the minimal LR(0)-acceptor»,
Automata, Languages, and Programming, (ed.) N'ivat M., Amsterdam: North
Holland, 563—574.
Кнут (Knuth D. E.)
[1962] «A history of writing compilers», Computers and Automation,
11, 12, 8—14. Переиздано в сб. под ред. Поллака [1972].
[1965] «On the translation of languages from left to right». Information and
Control, 8, 6, 607—639. (Русский перевод: Кнут Д. О переводе (трансляции)
языков слева направо. В сб. «Языки и автоматы.»— М.: Мир, 1975, 9—42.)
[1968а] «Semantics of context-free languages», Math. Systems Theory. 2,
2, 127—145.
[19686] The Art of Computer Programming, Volume I: Fundamental
Algorithms, Reading Mass.: Addison-Wesley. (Русский перевод: Кнут Д.
Искусство программирования для ЭВМ. т. I.— М.: Мир, 1975.)
[1971] «Top-down syntax analysis», Acta Informatica I, 2, 79—110.
[1973] The Art of Computer Programming, Volume HI, Sorting and
Searching, Reading, Mass.: Addison-Wesley. (Русский перевод: Кнут Д.
Искусство программирования для ЭВМ. Т. III.— М.: Мир, 1978.)
Кок и Шварц (Соске J., Schwartz J. T.)
[1970] Programming Languages and Their Compilers: Preliminary Notes,
New York: Courant Institute of Mathematical Sciences.
Колмерауэр (Colmerauer A.)
[1970] «Total precedence relations», J. ACM, 17, 1, 14—30.
Конвэй (Conway M. E.)
[1963] «Design of a separable transition-diagram compiler», Comm. ACM,
6, 7, 396—408. (Русский перевод: Конвэй М. Проект делимого компилятора,
основанного на диаграммах перехода.— В сб. «Современное
программирование».— М.: «Сов. радио», 1967, 206—246.)
Конвэй и Уилкокс (Conway R. W., Wilcox T. R.)
[1973] «Design and implementation of a diagnostic compiler for PL/I», Comm.
ACM, 16, 3, 169—179.
Кореньяк (Korenjak A. J.)
[1969] «A practical method for constructing LR (k) processors», Comm. ACM,
12, 11, 613—623. Переиздано в сб. под ред. Поллака [1972].
Кореньяк и Хопкрофт (Korenjak A. J., Hopcroft J. E.)
[1966] «Simple-deterministic languages», IEEE, Conference Record of Seventh
Annual Symposium on Switching and Automata Theory, Berkeley, Calif,
36—46. (Русский перевод: Кореньяк А., Хопкрофт Дж. Простые
детерминированные языки.— В сб. «Языки и автоматы».— М.: Мир, 1975, 71—96.)
Кохен и Готлиб (Cohen D. J., Gotlieb С. С.)
[1970] «A list structure form of grammars for syntactic analysis», Computing
Surveys, 2, 1, 65—82.
Кроув (Crowe D.)
[1972] «Generating parsers for affix grammars», Comm. ACM, 15, 8, 728—734.
Список литературы
635
Куно (Kuno S.)
[1966] «The augmented predictive analyzer for context-free languages —
its relative efficiency», Comm. ACM, 9, 11, 810—823.
Куно и Эгтингер (Kuno S., Oettinger A. Q.)
[1963] «Multiple-path syntactic analyzer», Information Processing 62, (ed.),
Popplewell С M.r Amsterdam: North-Holland, 306—311,
Курки-Суонио (Kurki-Suonio R.)
[1966] «On top-to-bottom recognition and left recursion», Comm, ACM, 9,
1 527 529
[1969] «Notes on top down languages», BIT, 9, 3, 225—238.
Лалонд и др.
(LaLonde W. R., Lee E. S., Horning J. J.)
[1971] «An LALR(ft) parser generator», Proc. IFIP Congress, Ta-3, Amsterdam:
North Holland, 153—157.
Ламдвебер (Landweber P. S.)
[1964] «Decision problems of phrase structure grammars», IEEE Trans, on
Electronic Computers, EC-13, 4, 354—362.
Ледли и Уилсон (Ledley R. S., Wilson J. B.)
[1962] «Language translation through syntactic analysis», Comm. ACM, 5,
3, 145—155.
Лерпер и Лим (Learner A., Lim A. L.)
[1970] «A note on transforming context-free grammars to Wirth-Weber
precedence form», Computer J., 13, 2, 142—144.
Ли (Lee J. A. N.)
[1974] Anatomy of a Compiler, 2nd edition, New York: Van Nostrand.
Лион (Lyon G.)
[1974] «Syntax-directed least-errors analysis for context-free languages: a
practical approach», Comm. ACM, 17, 1, 3—14.
Локс (Loeckx J.)
[1970] «An algorithm for construction of bounded-context parsers», Comm,
ACM, 13, 5, 297—307.
Ломег (Lomet D. B.)
[1973] «A formalization of transition diagram system» J. ACM, 20, 2, 235—257.
Л ум (Lum V. Y.)
11973] «General performance analysis of key-to-address transformation
methods using an abstract file system», Comm. ACM, 16, 10, 603—612.
Лум и др. (Lum V. Y., Yuen P. S. Т., Dodd M.)
[1971] «Key-to-address transform techniques: a fundamental performance
study on large existing formatted files», Comm. ACM, 14, 4, 228—239.
Льецке (Lietzke M. P.)
[1964] «A method of syntax-checking ALGOL 60», Comm. ACM, 7, 8, 475—478
Лью и др. (Liu С. L., Chang G. D., Marks R. E.)
[1967] «The design and implementation of a table driven compiler system»,
Proc. AFIPS 1967 Spring Joint Computer Conf., Washington, D. C:
Thompson Books, 30, 691—697.
Льюис и Розенкранц (Lewis P. M. II, Rosenkrantz D. J.)
[1971] «An ALGOL compiler designed using automata theory», Proc.
Symposium on Computers and Automata, Microwave Research Institute Symposia
Series, Polytechnic Institute of Brooklyn, N. Y., 21, 75—88.
Льюис и Стирнз (Lewis P. M. II, Stearns R. E.)
[1968] «Syntax-directed transduction», J. ACM, 15, 3, 465—488.
Льюис и др. (Lewis P. M. II, Rosenkrantz D. J., Stearns R. E.)
[1974] «Attributed translations», J. Computer and System Sciences, 9, 3, 279—
307.
Льюис и др. (Lewis P. M., II, Stearns R. E., Hartmanis J.)
[1965J «Memory bounds for recognition of contex-free and context-sensitive
languages», IEEE Conference Record on Switching Circuit Tlieory and Logical
636
Список литературы
Design, 191—202, Ann Arbor, Mich., (Русский перевод: Льюис П. М.,
Стирнз Р. Е., Хартманис Ю. Границы памяти для разрешения контекстно-
свободных и контекстных языков.— В сб. «Проблемы математической
логики»: Сложность алгоритмов и классы вычислимых функций.— М.:
Мир, 1970, с. 320—338.)
Лючио (Luccio F.)
[1972] «Weighted increment linear search for scatter tables», Comm. ACM, 15,
12, 1045—1047.
Макафи и Прессер (McAfee J., Presser L.)
[1972] «An algorithm for the design for simple precedence grammars», Comm.
ACM, 19, 3, 385—395.
Макилрой (Mcllroy M. D.)
[1963] «A variant method of file searching», Comm. ACM, 6, 3, 101.
Маккиман и др. (McKeeman W. M., Horning J. J., Wortman D. B.)
[1970] A Compiler Generator. Englewood Cliffs, N. J.: Prentice-Hall.
Макклюр (McClure R. M.)
[1965] «TMQ — a syntax directed compiler», Proc. 20th Natl. ACM Conf.,
New York, 262—274.
Макнотон (McNaughton R.)
[1967] «Parenthesis grammars», J. ACM, 14, 3, 490—500.
Мартин (Martin D. F.)
[1968] «Boolean matrix methods for detection of simple precedence grammars»,
Comm. ACM, II, 10, 685—687.
[1972] «A Boolean matrix method for the computation of linear precedence
functions», Comm. ACM, 15, 6, 448—454.
Мартин и Hecc (Martin W. A., Ness D. N.)
[1972] «Optimizing binary trees grown with a sorting algorithm», Comm. ACM,
15, 2, 88—93.
Maypep (Maurer W. D.)
[1968] «An improved hash code for scatter storage», Comm. ACM, II, 1,35—38.
Микунас и Шнейдер (Mickunas M. D., Schneider V. В.)
[1973] «A parser-generating system for constructing compressed compilers»,
Comm. ACM, 16, 11, 669—676.
Мили (Mealy G. H.)
[1955] «A method for synthesizing sequential circuits», Belt Syst. Tech.. J.,
34, 5, 1045—1079.
Минский (Minsky M.)
[1967] Computation: Finite and Infinite Machines, Englewood Cliffs, N. J.:
Prentice-Hall. (Русский перевод: Минский М. Вычисления и автоматы.—
М.: Мир, 1971.)
Морган (Morgan H. L.)
[1970] «Spelling correction in systems programs», Comm. ACM, 13, 2, 90—94.
Моррис (Morris R.)
[1968] «Scatter storage techniques:,, Comm. ACM, 11, 1, 38—43.
Моултон и Мюллер (Moulton P. G., Muller M. E.)
[1967] «DITRAN— a compiler emphasizing diagnostics», Comm. ACM. 10,
1,45—52.
Myp (Moore E. F.)
[1956] «Gedanken-experiments on sequential machines», Automata Studies,
Princeton, N. J.: Princeton University Press, 129—153. (Русский перевод:
Myp Э. Умозрительные эксперименты с последовательностными
машинами.— Сб. «Автоматы».— М.: ИЛ, 1956, с. 179—210.)
Мур ред. (Moore E. F. (ed.))
[1964] Sequential Machines: Selected Papers, Reading, Mass.: Addison-Wesley.
Наката (Nakata I.)
[1967] «On compiling algorithms for arithmetic expressions», Comm. ACM, 10,
8, 492-494,
Список литературы
637
Наур (Naur P.)
[1964] «The design of the GIER ALGOL compiler», (in) (ed.) Goodman R.t
Annual Review in Automatic Programming, New York and London: Perga-
mon Press, 4, 49—85.
Наур и др. (Naur P. et al.)
[I960] «Report on the algorithmic language ALGOL 60» Comm. ACM, 3, 5,
299—314; см. также Numerische Mathematik, 1960, 2, 106—136. (Русский
перевод: Бэкус Дж. В. и др. Сообщение об алгоритмическом языке АЛГОЛ-
60.— Под ред. П. Наура.- ЖВМ и МФ, 1961, 1, № 2, 308—342.)
[1963] «Revised repoit on the algorithmic language ALGOL 60», Comm. ACM,
6, 1, 1—17; см. также Computer J., 1963. 5, 4, 349—367 и Numerische
Mathematik, 1963,4, 5. 420—452. (Русский перевод: Алгоритмический язык
АЛГОЛ 60.- М.: Мир. 1965.)
Нивергельт (Nievergelt J.)
[1974] «Binary search trees and file organizations», Computing Susveys, 6,
3, 195—207.
Парик (Parikh R. J.)
[1966] «On context-free languages», J. ACM, 13, 4, 570—581.
Петерсон (Peterson W. W.)
[1957] «Addressing for random access storage», IBM J. Res. Develop., I. 2,
2, 130—146.
Петроне (Petrone L.)
[1965] «Syntactic mappings of context-free languages», Proc. IFIP Congress,
2, 590—591.
Пол (Paull M.)
[1967] «Bilateral descriptions of syntactic mappings», First Annual Princeton
Conference on Information Sciences and Systems, 76—81.
Пол и Ангер (Paull M. С, Unger S. H.)
[1968] «Structural equivalence of context-lree grammars», J. Computer and
System Sciences, 2, 4, 427—468.
Поллак ред. (Pollack В. W. (ed.))
[1972] Compiler Techniques, Philadelphia: Auerbach Publishers.
Прайс (Price С. Е.)
[1971] «Table lookup techniques», Computing Surveys, 3, 2, 49—65.
Пэйджер (Pagei D.)
[19701 «A solution to an open problem by Knuth», Information and Control,
17, 5, 462—473.
[1973] «The lane tracing algorithm for constructing LR(ft) parsers», Conf. Rec.
ACM Symposium on Theory of Computing, Austin, Texas, 172—181.
Пэр (Pair C.)
[1964] «Trees, pushdown stores and compilation», RFTl-Chiffres, 7, 3, 199—
216.
Рабин и Скотт (Rabin M., Scott D.)
Ц959] «Finite automata and their decision problems», IBM J. Res. Develop.
3, 2, 114—125. См. также Мур [1964] (Русский перевод: Рабин М., Скотт Д.
Конечные автоматы и задачи их разрешения.— Кибернетический сборник,
вып. 4.—М.: ИЛ, 1962, 56—91.)
Радке (Radke С. Е.)
[I970J «The use of quadratic residue research», Comm. ACM, 13, 2, 103—105.
Реджеёвский (Redziejowski R. R.)
[1969] «On arithmetic expression and trees», Comm. ACM, 12, 2, 81—84.
Рейнолдс (Reynolds J. C.)
[1965] «An introduction to the COGENT programming language , Proc. 20th
Natl. ACM Conf., New York, 422—436.
Ренделл и Рассел (Randell В., Russell L. J.)
[1964] ALGOL 60 Implementation, London: Academic Press. (Русский пере.
вод: Ренделл Б., Рассел Л. Реализация АЛГОЛа 60.— М.: Мир, 1967.)
C3S
Список литературы
Розен ред. (Rosen S. (ed.))
[1967] Programming Systems and Languages, New York: McGraw-Hill.
[1964] «A compiler-building system developed by Brooker and Morris», Comm.
ACM, 7, 7, 403—414. Переиздано в сб. под ред. Розена [1967] и Поллака
[1972].
Розенкранц (Rosenkrantz D. J.)
[1967jr «Matrix equations and normal forms for context-free grammars», J.
ACM, 14, 3, 501—507.
[1969] «Programmed grammars and classes of formal languages», J. ACM, 16,
1, 107—131. (Русский перевод: Розенкранц Д. Программные грамматики и
классы формальных языков.— Сб. Сборник переводов по вопросам
информационной теории и практики.—М.: ВИНИТИ, 1970, 16, 117—146.)
Розенкранц и Лыоис (Rosenkrantz D. J., Lewis P. M. II)
[1970] «Deterministic left corner parsing», IEEE Conf. Record of 1970 Eleventh
Annual Symposium Switching and Automata Theory, 139—152.
Розенкранц и Стирнз (Rosenkrantz D. J., Stearns R. E.)
[1970] «Properties of deterministic top-down grammars», Information and
Control, 17, 3, 226—256.
Росс (Ross D. T.)
[1964] «On context and ambiguity in parsing», Comm. ACM, 7, 2, 131 — 133.
Росс и Родригес (Ross D. Т., Rodriguez J. E.)
[1963] «Theoretical foundations of the computer aided design system», Proc.
AF1PS 1963 Spring Joint Computer Conf., Baltimore, Md.: Spartan Books,
23, 305—322.
Саломаа (Salomaa A.)
[1969] Theory of Automata, Elmsford, N. Y.: Pergamon.
Сассенгут (Sussenguth E. H., Jr.)
11963] «Use of tree structures for processing files», Comm. ACM, 6, 5, 272—279.
Северанс (Severance D. Q.)
[1974] «Identifier search: a survey and generalized model», Computing
Surveys, 6, 3, 175—194.
Сети и Ульман (Sethi R., Ullman J. D.)
[1970] «The generation of optimal code for arithmetic expressions», J. ACM,
17, 4, 715—728. Переиздано в сб. под ред. Поллака [1972].
Симпсон (Simpson H. R.)
[1969] «A compact form of one-track syntax analyzer», Computer J. 12, 1,
233—243.
Скидмор и Вейнберг (Scidmore А. К., Weinberg В. L.)
[1963] «Storage and search properties of a tree-organized memory system»,
Comm. ACM, 6, 1, 28—31.
Стирнз (Stearns R. E.)
[1967] «A regularity test for pushdown machines», Information and Control,
11, 3, 323—340. (Русский перевод: Стирнз Р. Проверка регулярности для
магазинных автоматов.— Кибернетический сборник, новая серия, вып. 8.—
М.: Мир, 1971, 117—139.)
[1971] «Deterministic top-down parsing», Proc. Fifth Annual Princeton Conf.
on Information Sciences and Systems, 182—188.
Стирнз и Льюис (Stearns R. E., Lewis P. M. II)
[1969] «Property grammars and table machines», Information and Control, 14,
6, 524—549.
Террин (Terrine Q.)
[1973] «Coordinate grammars and parsers», Computer J., 16, 3, 232—244.
Томпсон (Thompson Ц.)
[1968] «Regular expression search algorithm», Comm. ACM, 11, 6, 419—422.
Тэйпитер (Tainiter M.)
[1963] «Addressing for random-access storage with multiple bucket capacities»,
J. ACM, 10, 3, 307-315,
Список литературы
639
Ульман (Ullman J. D.)
[1972] «A note on hashing functions», J. ACM, 19, 3, 569—575.
Уоршелл (Warshall S.)
11962] «A theorem on Boolean matrices», J. ACM, 9, 1, 11—12.
Уоршелл и Шапиро (Warschall S. Shapiro R. M.)
[1964] «A general purpose table-driven compiler», Proc. AFIPS 1964 Spring
Joint Computer Conf., Balti more, Md.: Spartan Books, 25, 59—65. Переиздано
в сб. под ред. Розена [1967].
Фельдман (Feldman J. A.)
[1966] «A formal semantics for computer languages and its application in a
compiler-compiler», Comm. ACM, 9, 1, 3—9. Переиздано в сб. под ред.
Поллака [1972].
Фельдман и Грис (Feldman J. A., Gries D.)
[1968] «Translator writing systems», Comm. ACM, 11,2, 77—113. (Русский
перевод: Фельдман Дж., Грис Д. Системы построения трансляторов В сб.
«Алгоритмы и алгоритмические языки», вып. 5.— М.: ВЦ АН СССР, 1971.)
Фишер (Fischer M. J.)
[1969] «Some properties of precedence languages», Conference Record of ACM
Symposium on Theory of Computing, Marina del Rey, Calif., 181—190.
Фишер (Fischer P. C.)
[1963] «On computability by certain classes of restricted Turing machines»,
IEEE Proceedings Fourth Annual Symposium on Switching Circuit Theory and
Logical Design, Chicago, 23—32.
Флойд (Floyd R. W.)
[1961] «A descriptive language for symbol manipulation», J. ACM, 8, 4,
579—584.
[1963] «Syntactic analysis and operator precedence J. ACM, 10, 3, 316—333.
Переиздано в сб. под р:д. Поллака [1972].
[1964а] «Bounded context syntactic analysis». Comm. ACM, 7, 2, 62—G7.
[19646] «The syntax of programming languages — a survey-), IEEE Trans.
on Electronic Computers, EC-13, 4, 346—353. Переиздано в сб. под ред.
Розена [1967] и Поллака [1972].
[1967] «Nondeterministic algorithms», J. ACM, 14, 4, 636—644.
Фостер (Foster С. С.)
[1965] «Information storage and retrieval using AVL trees», Proc. 20th Xati.
ACM Conf., 192—205.
[1973] «A generalization of AVL trees», Comm. ACM, 16, 8, 513—517.
Фостер (Foster J. M.)
[1968] «A syntax improving program», Computer J., 11, 1 31—34.
[1970] Automatic Syntactic Analysis, New York: American Elsevier Publ. Co.
(Русский перевод: Фостер Дж. Автоматический синтаксический анализ.—
М.: Мир, 1975.)
Фредкин (Fredkin E.)
[1960] «Trie memory», Comm. ACM, 3, 9, 490—499.
Фримэн (Freeman D. N.)
[1964] «Error correction in CORC— the Cornell computing language», Proc.
AFIPS 1964 Fall Joint Computer Conf., Spartan, New York, 26, 15—34.
Переиздано в сб. под ред. Поллака [1972].
Халстед (Halstead М. Н.)
[1962] Machine-independent Computer Programming, New York: Spartan
Books.
Хаммер (Hammer M. H.)
[1974] «A new grammatical transformation into LL(ft) form», Proc. Sixth
Annual ACM Symp. on Theory of Computing, 266—275.
Хант и др. (Hunt H. В., III, Szymanski T. G., Ullman J. D.)
[1974] «Operations on sparse relations and efficient algorithms for grammar
640
Список литературы
problems», IEEE Conference Record of Fifteenth Annual Symposium on
Switching and Automata Theory, 127—132.
Харрисон (Harrison M. A.)
[1965] Introduction to Switching and Automata Theory, New York: McGraw-
Hill.
Харрисон и Хавел (Harrison M. A., Havel I. M.)
[1972] «Real-time strict deterministic languages», S/AM J. Computing, 1, 4,
333—349.
[1973] «Strict deterministic grammars», J. Computer and System Sciences, 7,
3, 237—277.
[1974] «On the parsing of deterministic languages», J. ACM, 21,4, 525—548.
Хартманис и Стирнз (Hartmanis J., Stearns R. E.)
[1966] Algebraic Structure Theory of Sequential Machines, Englewood Cliffs,
N. J.: Prentice-Hall.
Хафмен (Huffman D. A.)
[1964] «The synthesis of sequential switching circuits», J. Franklin Inst., 257,
N3—4, 161—190, 275—303. Переиздано в сб. под ред. Мура [1964].
Хаяши (Hayashi К.)
[1971] «On the construction of LR(ft) parsers», Proc. ACM Annual Conf.,
N. Y., 538—553.
Хейс (Hays D.)
[1962] «Automatic language — data processing», Computer Applications in
the Behavioral Sciences, (ed.) Borko H., Englewood Cliffs, N. J.: Prentice-Hall,
394 421,
Хекст и Роберте (Hext J. В., Roberts P. S.)
[1970] «Syntax analysis by Domolki's algorithm», Computer J., 13, .3, 263—
271.
Хенни (Hennie F. C.)
[1968] Finite-state Models for Logical Machines, New York: Wiley.
Хиббард (Hibbard T. N.)
[1962] «Some combinatorial properties of certain trees with applications to
searching and sorting», J. ACM, 9, 1, 13—28.
Хомский (Chomsky N.)
[1956] «Three models for the description of language», IRE Trans, on
Information Theory, IT-2, 3, 113—124. (Русский перевод: Хомский Н. Три модели
для описания языка.— Кибернетический сборник, вып. 2.— М.: ИЛ, 1961,
237—266.)
[1957] Syntactic Structures, The Hague, Netherlands: Мои ton & Co. (Русский
перевод: Хомский Н. Синтаксические структуры.— Сб. «Новое в
лингвистике», вып. П.—М.: ИЛ, 1962, 412—527.)
[1959] «On certain lormal properties of grammars», Information and Control,
2, 2, 137—167. (Русский перевод: Хомский Н. О некоторых формальных
свойствах грамматик.— Кибернетический сборник, вып. 5.— М.: ИЛ, 1962,
279—311.)
[1962] «Context-free grammars and pushdown storage», M. I. T. Res. Lab.
Electron. Quart. Prog. Rept. 65, 187—194.
[1963] «Formal properties of grammars», Handbook of Mathematical
Psychology, II, 323—418 (eds.) Luce R. D., Bush R. R., Qalanter E., New York:
Wiley. (Русский перевод: Хомский Н. Формальные свойства грамматик.—
Кибернетический сборник, новая серия, вып. 2.— М.: Мир, 1966, с. 121 —
230.)
Хомский и Миллер (Chomsky N. Miller Q. A.)
[1958] «Finite state languages», Information and Control, 1, 2, 91—112.
(Русский перевод: Хомский Н., Миллер Дж. Языки с конечным числом
состояний.— Кибернетический сборник, вып. 4.— М.: ИЛ, 1962, с. 233—255.)
Хомский и Шютценберже (Chomsky N., Schiitzenberger M. Р.)
[1963] «The algebraic theory of context-free languages», Braffert P„ Hirschberg
Список литературы
641
D. (eds.), Computer Programming and Formal Systems, Amsterdam: North
Holland, 1963, 118—161. (Русский перевод: Хомский Н., Шютценберже М.
Алгебраическая теория контекстно-свободных языков.— Кибернетический
сборник, новая серия, вып. 3.— М.: Мир, 1966, с. 195—242.)
Хопгуд (Hopgood F. R. А.)
[1968] «A solution to the table overflow problem for hash tables», Computer
Bulletin, 11, 1, 297—300.
[1969] Compiling Techniques, New York: American Elsevier. (Русский
перевод: Хопгуд Ф. Методы компиляции.— М.: Мир, 1972.)
Хопкрофт (Hopcroft J. E.)
11972] «An n log n algorithm for minimizing states in я finite automaton»,
Theory of Machines and Computations, (eds.) Kohavi, Paz A., New York:
Academic Press, 189—196. (Русский перевод: Хопкрофт Дж. Алгоритм для
минимизации конечного автомата.— Кибернетический сборник, новая
серия, вып. П.—М.: Мир, 1974, с. 177—184.)
Хопкрофт и Ульман (Hopcroft J. E., Ullman J. D.)
[1969] Formal Languages and their Relation to Automata, Reading, Mass,:
Addison-Wesley.
Хорвиц и др. (Horwitz L. P., Karp R. M., Miller R. E., Winograd S.)
[1966] «Index register allocation», J, ACM, 13, 1, 43—61.
Чартрес и Флорентин (Chartres В. A., Florentin J. J.)
11968] «A universal syntax-directed top-down analyzer», J. ACM, 15, 3, 447—
463.
Читэм (Cheatham Т. Е., Jr)
[1967! The Theory and Construction of Compilers, Wakefield, Mass.: Computer
Assoc 13 tes
Читэм и Сэтли (Cheatham Т., Sattley К.)
[1964] «Syntax directed compiling», Proc. AFIPS 1964 Spring Joint Computer
Conf. Baltimore, Md.: Spartan Books, 25, 31—57. Переиздано в сб. под ред.
Розена [1967].
Чулик (Culik К.)
[1966] «Well-translatable grammars and ALGOL-like languages», Steel Т. В.,
Jr. (ed.), Formal Language Description Languages for Computer Programming,
Amsterdam: North Holland 76—85. (Русский перевод: Чулик К. Хорошо
переводимые языки и языки типа АЛГОЛ.— Научно-техн. информ., сер. 2,
ном. 3, с. 21—23.)
Чулик (Culik К. П)
[1968] «Contribution to deterministic top-down analysis of context-free
languages», Kybernetika, 5, 4, 422—431.
[1970] «n-ary grammars and the description of mapping of languages»,
Kybernetika, 6, 99—117.
Чулик и Кохен (Culik К. II, Cohen R.)
11973] «LR-regular grammars — an extension ot LR(ft) grammars», J.
Computer and System Sciences, 7, 1, 66—69.
Чулик и Морей (Culik К. II, Morey С. J. W.)
[1971) «Formal schemes for language translations», Intern. J. Computer Math.,
Section A., 3, 17—48.
Шей и Спрут (Schay Q. Spruth W. Q.)
[1961] «Analysis of a file addressing method», Comm. ACM, 4, 5, 218—222.
Шефер (Schaefer M.)
[1973] A Mathematical Theory of Global Program Optimization, Englewood
Cliffs, N. J.: Prentice-Hall.
Школьник (Schkolnick M.)
[1974] «The equivalence of reducing transition languages and deterministic
languages», Comm. ACM, 17, 9, 517—519.
Шнейдер (Schneider V.)
[1967] «Syntax-checking and parsing of context-free languages by pushdown.
642
Список литературы
store automata», Proc. AFIPS 1967 Spring Joint Computer Conf.,
Washington, D. C: (Thompson Books, 685—690).
11969] «A system for designing fast programming language translators», Prog.
AFIPS 1969 Spring Joint Computer Conf., 34, Montvale, N. J.: AFIPS Press,
777—792.
Шнейдер и Джонсон (Schneider F. W., Johnson G. D.)
|1964]»«META-3; a syntax directed compiler writing compiler to generate
efficient code», Proc. 19//t National ACM Conf., New York.
LUoppe (Schorre D. V.)
[1964] «META-II: a syntax-oriented compiler writing language», Proc. 19th
Natl. ACM Conf., New York.
Шютценберже (Schutzenberger M. P.)
[1963] «On context-free languages and pushdown automata»,
Information and Control, 6, 3, 246—264.
Эванс (Evans A.)
[1964] «An ALGOL 60 compiler», Proc. 18th Natl. ACM Conf., Denver, см.
также Goodman R. (ed.), Annual Review in Automatic Programming, New
York and London: Pergamon Press, 1964, 4, 87—124. Переиздано в сб. мод
ред. Поллака [1972].
Эви (Evey R. J.)
[1963а] «Application of pushdown-store machines», Proc. AFIPS 1963 Fall
Joint Computer Conf., 24, New York: Spartan Books, 215—227.
[19636] «The theory and application of pushdown store machines»,
Mathematical Linguistics and Automatic Translation, Harvard Univ. Computation Lab.
Rept. NSF-10.
Энкель и др. (Eickel J., Paul M., Bauer F. L., Samelson K.)
[1963] «A syntax controlled generator of formal language processors», Cornm,
ACM, 6, 8, 451—455.
Эрли (Earley J.)
[1970] «An efficient context-free parsing algorithm», Comm. ACM, 13, 2,
94—102. (Русский перевод: Эрли Дж. Эффективный алгоритм анализа
контекстно-свободных языков. Сб. «Языки и автоматы».— М.: Мир, 1975,
с. 47—70.)
Янгер (Younger D. Н.)
|1967] «Recognition and parsing of context-free languages in time n3»,
Information and Contro', io. 2, 189—208. (Русский перевод: Янгер Д.
Распознавание и анализ контекстно-свободных языков за время л3.— Сб, «Проблемы
математической логики».— М,: Мир, 1970, с, 344—362.)
Именной указатель
Айронс (Irons E. Т.) 233, 308
Аллен (Allen F. Е.) 581
Ахо (Aho A. V.) 190, 233, 470, 497,
498, 501, 545, 549, 581
Бар-Хиллел (Bar-Hillel Y.) 190, 626
Бауэр (Bauer F. L.) 148
Брукер (Brooker R. А.) 233
Бут (Booth Т. L.) 64
Вайнберг (Weinberg B. L.) 98
Вебер (Weber H.) 497, 501
Вер (Vere S.) 233
Вирт (Wirth N.) 497, 501
Вуд (Wood D.) 308, 626
Геллер (Geller M. М.) 545, 549
Гил л (Gill A.) 64
Гинзбург (Ginsburg S.) 64, 148, 190
Гро (Grau А. А.) 308
Греибах (Greibach S. А.) 148, 625, 628
Грис (Gries D.) 568
Гриффите (Griffiths Т. V.) 626
Грэй (Gray J. N.) 497
Грэхем (Graham S. L.) 497, 626
Делабрианде (de la Briandais R.) 98
Деннинг (Denning P. J.) 470, 497, 498,
501
Деремер (DeRemer F. L.) 545
Джонсон Л. (Johnson L. R.) 98
Джонсон С. (Johnson S. C.) 545, 549
Ершов А. П. 148
Замельзои (Samelson K) 148
Ихбиа (Ichbiah J, D.) 497
Кемп (Kemp R.) 545
Кнут (Knuth D. E.) 98, 217, 233, 545
Кок (Cocke J.) 581
Кореньяк (Korenjak A. J.) 308, 545
Курки-Суонио (Kurki-Suonio R.)
308, 626
Лернер (Learner A.) 497, 626
Лим (Lim A. L.) 497, 626
Ломег (Lomet D. B.) 626
Лукасевич (Lukasiewicz J.) 198
Льюис (Lewis P. M.) 233, 308, 360, 471,
626
Макафи (McAfee J.) 497, 626
Маккиман (McKeeman W. M.) 497
Мартин (Martin W. A.) 98
Мили (Mealy G. H.) 64
Миллер (Miller G. A.) 190
Минский (Minsky M.) 64
Морзе (Morse S. P.) 497
Моррис (Morris R.) 98, 233
Myp (Moore E. F.) 64
Hayp (Naur P.) 190, 568
Нивергельт (Nievergelt J.) 98
Hecc (Ness D. N.) 98
Перлис (Perles M.) 190, 626
Петрик (Petrick S. R.) 626
Петроне (Petrone L.) 233
Пол (Paull M.) 233
Прайс (Price С. Е.) 98
Прессер (Presser L.) 497, 626
Пэйджер (Pager D.) 545
Пэр (Pair C.) 497
Рабин (Rabin M.) 64
Розенкранц (Rozenkrantz D. J.) 233,
308, 360, 470, 026, 628
€44
Именной указатель
Сассенгут (Sussenguth Е. Н„ Jr.) 98
Северанс (Severance D. G) 98
Скидмор (Sckidmore А. К.) 98
Скотт (Scott D.) 64
Стирнз (Stearns R. Е.) 64, 233, 308, 360,
470, 625
Стоун (Stofie W. W.) 568
Сэтли (Sattley К.) 233
Ульман (Ullman J. D.) 148, 190, 233,
471, 497, 498, 501, 545, 549, 581
Уортман (Wortman D. В.) 497
Уоршолл (Warshall S.) 597
Фишер М. (Fischer M. J.) 497, 626
Фишер П. (Fischer P. S) 148
Флойд (Floyd R. W.) 497, 502
Фостер (Foster С. С.) 98, 625
Фредкин (Fredkin E.) 98
Фримэн (Freeman D. N.) 308
Харрисон (Harrison M. A.) 64, 497, 545,
549
Хартманис (Hartmanis J.) 64
Хафмен (Huffman D. A.) 64
Хаяши (Hayashi K.) 545
Хенни (Hennie F. C.) 64
Хиббард (Hibbard T. N.) 98
Хомский (Chomsky N.) 190, 628
Хопкрофт (Hopcroft J. E.) 148, 308.
Хорнинг (Horning J.J.) 497
Читэм (Cheatham Т. Е.) 233
Чулик (Culik K.) 233
Шамир (Shamir E.) 190, 626
Шварц (Schwartz J. T.) 581
Шютценберже (Schutzenberger M. P.).
148
Эттингер (Oettinger A. G.) 148
Хавел (Havel J. M.) 545
Хаммер (Hammer M, H,) 625
Янгер (Younger D, H.) 233
Предметный указатель
Автомат (automation, machine)
— конечный (finite-state) 21
— — расширяющийся (expanding) 74
— минимальный (minimal) 35
— недетерминированный (nondetermi-
nistic) 49—50
— приведенный (reduced) 43
— с магазинной памятью
(МП-автомат) (pushdown) 128
— — атрибутный (attributed) 335
— типа «перенос — опознание»
(SHIFT-IDENTIFY) 448
примитивный (primitive) 140
Аксиома грамматики [см. символ
начальный]
Алфавит (alphabet)
— входной (input) 22, 130
— магазинный (stack) 130
Анализ (analysis)
— лексический (lexical) 13, 79
— синтаксический (syntactical, parse)
14, 242, 412
— — восходящий (bottom-up) 412, 421
— — — детерминированный
(deterministic) 413
— — нисходящий (top-down) 242
— — —детерминированный
(deterministic) 243
остовный (sparse) 503
предсказывающий (predictive)
249
типа «перенос — опознание»
(SHIFT-IDENTIFY) 436
— — типа «перенос — свертка»
(SHIFT-REDUCE) 436
Анализатор синтаксический (parser)
242, 412
Ассемблер (assembler) 12
Атом (atom) 14
— ВОЗВПЕРЕХОД (RETURNJUMP)
371
— ВЫЧИТ (SUBT) 371
— ДЕЛЕН (DIV) 372
— МЕТКА (LABEL) 371
— МИНУС (NEG) 372
— НОМСТРОК (LINEW) 371
— ОКОНЧАНИЕ (FINIS) 371
_ ПЕРЕХОД (JUMP) 371
— ПЛЮС (PLUS) 372
— ПРИСВ (ASSIGN) 37!
— ПРОВЕРКА (TEST) 371
— СЛОЖ (ADD) 371
— УВЕЛИЧ (INCR) 371
— УМНОЖ (MULT) 372
— УСЛПЕРЕХОД (CONDJUMP) 371
— ХРАНЕНИЕ (SAVE) 371
— XPAHnEPEX0.1(SAVEJUMP)371
— ЭКСП (EXP) 372
Атрибут (attribute)
— наследуемый (inherited) 206, 214
— синтезируемый (synthesised) 211,
214
Блок (компилятора) (block) 12, 16
— лексический (lexical) 13
— семантический (semantic) 15
— синтаксический (syntax) 13, 369, 484
Блок состояний (block) 45
БНФ (BNF) 159
Вид (mode) табличного элемента
— КОНСТАНТА (CONSTANT) 553
— МЕТКА (LABEL) 554
— ПЕРЕМЕННАЯ (VARIABLE) 553
— ПРОМЕЖУТОЧНЫЙ РЕЗУЛЬТАТ
(PARTIAL RESULT) 554
— ХРАНИМЫЙ РЕЗУЛЬТАТ
(SAVED RESULT) 554
Вхождение (occurence)
— грамматическое (grammatical) 505
— начальное (starting) 505
Вывод (derivation)
— краевой (corner) 615
— левый (leftmost) 163
— правый (rightmost) 163
Вызов (параметра) (call)
— по значению (by value) 358
— по имени (by name) 353, 358
— по ссылке (by reference) 353, 358
Выражения (expressions)
— арифметические (arithmetic) 168—
171, 188,218—230,583
— языка Лисп (S-выражения) 167,
296, 418
Выход (exit) 28
— ДОПУСТИТЬ (ACCEPT) 130
■64G
Предметный указатель
— НАЧАЛО (STARTING) 513
— ОТВЕРГНУТЬ (REJECT) 130
— ПОКА НЕТ (NOT YET) 613
— ПРАВИЛО (PROD) 514
Генератор кода (code generator) 13—
15, 550-£-570
Грамматика (grammar)
— атрибутная (attributed) 206
— —вполне определенная [см.
корректная]
— — корректная (well formed) 217
транслирующая (translation) 214
— — цепочечного перевода (string
translation) 217
— бессуффиксная (suffix-free) 459
ПО (SI-) 459
— входная (input) 204
— выходная транслирующей
грамматики [см. грамматика действий]
— действии (action) 204
— контекстно-свободная (context-free)
153
— неоднозначная (ambiguous) 165
— обратимая (invertible) 443, 501
— однозначная (nonambiguous) 165
— операторная (operator) 502
— перевода [см. транслирующая]
— польского перевода (Polish
translation) 437
— праволинейная (right linear) 175
— право маркированная (marked right-
parenthesis) 442
— простая [см. S-грамматика]
— простая смешанной стратегии
предшествования (simple mixed stra-
togy precedence) 469
— простого предшествования (simple
precedence) 501
— разделенная [см. S-грамматика]
— скобочная (parenthesis) 443
— слабого предшествования (weak
precedence) 462
— транслирующая (translation) 201
— транслирующая в цепочки [см.
грамматика цепочечного перевода]
— формальная (formal) 154
— цепочечного перевода (string
translation) 203
— L-атрибутиая 320
— LL(1) 275
— LL(k) 281
— LR(0) 525
— LR(k) 526
— q267
— S-атрибутная (S-attributed) 438
— S 251
— SLR(l) 531
Гроздь (bucket) 91
Дерево (tree)
— вывода (derivation) 161
— завершенное (complete) 216
— незавершенное (incomplete) 216
Детектор основ (handle detector) 512
Детекция [см. обнаружение]
Дно магазина (bottom) 127
Допускать цепочку (accept) 23, 130
Замена (substitution)
— вхождения 607
— края (corner) 607
— одиночная (singleton) 610
Замыкание (отношения) (closure)
— рефлексивное (reflexive) 558
— рефлексивно-транзитивное
(reflexive-transitive) 599
— транзитивное (transitive) 595
Запись (notation)
— инфиксная (infix) 198
— польская (Polish) [см. польская
запись]
Зацикливание (cycling) МП-автомата
146
Интерпретатор (interpreter) 12
Итерация
— Клинн (Kleene star) 135
— — позитивная (Kleene plus) 135
Класс лексемы 13
Код (code)
— объектный (object) [см. язык
объектный]
— цепочки 424
Компилятор (compiler) 12
Конкатенация (concatenation) 134
Константы 57
— ГРАНВРЕМ (TEMPLIM) 553
— ГРАНКОМ (INSTLIM) 553
— ГРАНКОНСТ (CONSTLIM) 553
— ГРАНСТЕКА (SUBSKTLIM) 553
— ГРАНХРАН (SAVELIM) 553
— НАЧВРЕМ (TEMPSTART) 553
Конфигурация (configuration)
МП-автомата 128—133
— начальная (starting) 130
Конфликт (conflict)
— переноса — опознания
(shift-identify) 454, 624
Край (corner)
— расширенный (extended) 615
КС-грамматика [см. грамматика
контекстно-свободна я ]
Предметный указатель
647
КС-язык [см. язык
контекстно-свободный]
Лексема (token) 13, 101—104
- АРИФМЕТ ОПЕРАЦИЯ
(ARITHMETIC OPERATOR) 101—102
- ВОЗВРАТ (RETURN) 101, 103
- ДЛЯ (FOR) 101—102
- ДО (ТО) 101, 103
- ЕСЛИ (IF) 101, 103
- КОММЕНТАРИЙ (COMMENT) 101,
104
- КОНЕЦ (END) 101
- КОНЕЦ ЦИКЛА (NEXT) 101-102
- КОНЦМАРКЕР (ENDMARKER)
101, 108
- ЛЕВАЯ СКОБКА (LEFT PAREN)
101, 103
- литерная [см. символьная]
- ОПЕРАНД (OPERAND) 101-102
- ОТНОШЕНИЕ (RELATIONAL
OPERATOR) 101, 102
- ОШИБКА (ERROR) 101, 104
- ПЕРЕХОД НА (GOTO) 101, 103
-ПЕРЕХОД НА ПОДПР (COSUB)
101, 103
- ПРАВАЯ СКОБКА (RIGHT
PAREN) 101, 103
- ПРИСВОИТЬ (ASSIGN) 101-102
- символьная (character) 76, 108—ПО
- СТРОКА (LINE) 101 — 102
- ШАГ (STEP) 101 — 102
Лист (дерена) (leal) 415
Магазин (pushdown stack) 126
Маркер (marker)
— дна (bottom) 127
— концевой (end) 27, 130
Метод (method, approach)
— бинарного (двоичного) поиска
(binary search) 89
— вектора переходов (transition
vector) 78
— индексный (index) 85
— линейного списка (linear-list) 87
— логарифмического поиска
(logarithmic search) 89
— разбиения (separation) 45
— расстановки (hash coding) 91
— рекурсивного спуска (recursive
descent) 303
— связанного списка (linked list) 87
— списка переходов (transition-list) 78
Множество (set)
— ВПЕРВ (OFIRST) 510
— ВЫБОР (SELECT) 266
— ПЕРВ (FIRST) 272, 449
— подстановочное (для цели)
(replacement production) 616
— регулярное (regular) 24
— СЛЕД (FOLLOW) 265, 449
МП-автомат [см. автомат с магазинной
памятью]
Нейтрализация ошибок (error recovery)
294, 476
— глобальная (global) 301, 482
— локальная (local) 300, 481
Нетерминал (nonterminal) 157
— аннулирующий (nullable) 281, G22
— бесплодный [см. мертвый]
— бесполезный [см. лишний]
— достижимый (reachable) 184
— живой (alive) 183, 282
— леворекурсивный (left recursive) 316,
610
— лишний (extraneous) 182
— мертвый (dead) 181 — 182
— начальный (starting) 157
— недостижимый (unreachable) 182
— продуктивный [см. живой]
Обнаружение (detection) 28
Обработка (processing)
— ошибок 294—303, 476—484
— семантическая 15, 189
— списков (list) G02
— языков 197, 242, 412
методом «перенос — опознание»
(SHIFT-IDENTIFY) 435, 447-503
методом «перенос — свертка»
(SHIFT-REDUCE) 435, 504-519
Объединение (union) множеств цепочек
134
Оператор (statement) 582, 584
— присваивания (assignment) 584
— условный (conditional) 584
— цикла [см. циклы]
— языка MINI-BASIC 582—588
Операции (operations, operators)
— магазинные (stack) 129
— на выходе (output) 143
— переноса (shifting) 433
— расширенные (extended) 140
— свертки (reducing) 433
Операция
— ВТОЛКНУТЬ (PUSH) 130
— ВЫДАТЬ (OUT) 143
— ВЫТОЛКНУТЬ (POP) 130
— ДЕРЖАТЬ (RETAIN) 130
— ДОПУСТИТЬ (ACCEPT) 130
— ЗАМЕНИТЬ (REPLACE) 141
— ОТВЕРГНУТЬ (REJECT) 130
— ПЕРЕНОС (SHIFT) 417
— СВЕРТКА (REDUCE) 417
648
Предметный указатель
— СДВИГ (ADVANCE) 130
— СОСТОЯНИЕ (STATE) 130
— Т АВТОЛ К (PUSHT) 430
Опознание (identification) 421, 436
Оптимизация (optimization) 15, 571 —
581
Организация рабочей программы (run
time implementation) 18, 552
Основа (handle) 414
Отвергать (цепочку) (reject) 23, 130
Отладка (debugging) 123, 395, 497
Отношение (relation) 590
— ВПОД (OB E LOW) 511
— КРАЙ (IS-CORNER-OF) 620
— НА-КОНЦЕ (1S-END-OF) 289
— НАЧИНАЕТСЯ-ПРЯМО-С (ВЕ-
GINS-DIRECTLY-WITH)282, 472
— НАЧИНАЕТСЯ-С (BEGINS-WITN)
289
— ПЕРЕД (IS-FOLLOWED-BY) 292
— ПОД (BELOW) 454, 471
— ПРЯМО-НА-КОНЦЕ (IS-DIRECT-
END-OF) 288, 472
— ПРЯМО-ПЕРЕД (IS-FOLLOWED-
DIRECTLY-BY) 287, 474
— РАСШИРЕННЫЙ-КРАЙ (IS-
EXTENDED-CORNER-OF) 620
— рефлексивное (reflexive) 37, 599
— СВЕРТЫВАЕТСЯ-ПО (REDUCED.
BY) 453, 471
— симметричное (symmetric) 37
— транзитивное (transitive) 37, 598
— yKA3bIBAET-HA(POINTS-AT)590
— эквивалентности (equivalence) 37
Ошибки
— нефатальные (nonfatal) 300
— фатальные (fatal) 300
Перевод (translation) 203
— атрибутный (attributed) 217
— многозначный (multiple) 230—231
— польский (Polish) 437
Переменная (variable)
— НОМЕРСТРОКИ (LINE NUMBER)
373
— СУМ (REG) 557
— СЧЕТВРЕМ (TEMPCOUNTER)
553
— СЧЕТКОМ (INSTCOUNTER) 553
— СЧЕТКОНСТ (CONSTCOUNTER)
553
— СЧЕТХРАН (SAVECOUNTER) 553
Перенос (shifting) 433
Переход (transition) 23
— по неудаче (default) 78
Подрезка (дерева) (pruning) 415
Подстановка (substitution) [см. замена]
Польская запись (Polish notation) 198
— инфиксная (infix) 198
— постфиксная (postfix) 198
Последовательность (sequence)
— актов (activity) 202
атрибутная (attributed) 217
— действий (action) 204
— конфигураций МП-автомата (stack
movie) 133, 244, 418
Правило (production, rule) 157
— аннулирующее (nullable) 274
— краевое (corner) 615
— копирующее (copy) 322
— леворекурсивное (left recursive)
610
— некраевое (noncomer) 615
— одиночное (singleton) 609
— основывающее (handle) 414
— самолеворекурсивное (self left
recursive) 611
— эпсилон (espsilon) 157, 533, 620
— L-атрибутное (L-attributed) 321
Представление (representation)
— отношения 590—592
методом графов (graph method)
590
методом матриц (matrix method)
591
Предшествование (precedence)
— простое (simple) 501
— простое смешанной стратегии
(simple mixed-strategy) 469
— слабое (weak) 462
Преобразования грамматик
(transformation) 602—628
— «цель — край» (goal-corner) 616
Префикс (prefix) 80
Префиксное свойство (prefix property)
295, 540
Применение правила 159
Принцип (principle)
— вталкивания (pushing) 462
— левой факторизации (left factoring)
606
— переноса (shifting) 454
— свертывания (reducing) 453
Проблема (problem)
— идентификации (indentification) 73
слов (word identification) 79
— обнаружения префиксов (prefix
detection) 95
Продукция [см. правило]
Произведение отношений (product of
relations) 592
Проход компилятора (pass) 16
Процедура (procedure, routine)
— ВЫЧИСЛИТЬ КОНСТАНТУ
(COMPUTE CONSTANT) 113
— ГЕН (GEN) 555
Предметный указатель
649
— ДА ID (YES1D) 113
— ДА 2D (YES2D) 113
— ДА 3D (YES3D) 113
— ДА IE (YES1E) 114
— ЗАПОЛН (FLUSH) 557
— ИСПОЛЬЗОВАН (USED) 557
— НОВТ (NEWTR) 378, 486
— НОВТАМ (NEWTL) 378, 486
— НОВТХ (NEWTSR) 378, 486
— HOBXPAH (NEWSAVED) 554
— ОЧИСТИТЬ (CLEAR) 558
— СВЯЗАТЬ (LINK) 558
— СОЗДАТЬ ЛЕКСЕМУ (CREATE
TOKEN) 102
Процедуры (routines)
— нейтрализации ошибок [см.
нейтрализация ошибок]
— опознания (identification) 436
Процессор (processor)
— языковый (language) 11, 242, 412
Рабочая программа 18
Разбор [см. анализ синтаксический]
Распознаватель (recognizer)
— конечный (finite-state) 22
— с магазинной памятью (pushdown)
130
Расстановка (хеширование) (hash
coding) 91
Регистр (register)
— арифметический (arithmetic) 550
— индексный (index) 550
РЕГИСТР ЗНАКА (SIGN REGISTER)
60
РЕГИСТР ЗНАЧЕНИЯ (VALUE
REGISTER) 102
РЕГИСТР КЛАССА (CLASS
REGISTER) 102
РЕГИСТР ОБНАРУЖЕНИЯ
(DETECTION REGISTER) 111
РЕГИСТР ОТНОШЕНИЯ
(RELATIONAL REGISTER) 103
РЕГИСТР ПОРЯДКА (EXPONENT
REGISTER) 103
РЕГИСТР СЧЕТЧИКА
(COUNT REGISTER) 60
РЕГИСТР УКАЗАТЕЛЯ
(POINTER REGISTER) 102
РЕГИСТР ЧИСЛА (NUMBER
REGISTER) 60
Рекурсия (recursion)
— левая (left) 610
Свертка (reduction) 433
Семантика (semantics) 15, 189
Символ (symbol)
— входной (inputs 22, 202
МП-автомата 130
текущий (current) 23
— выходной (output) 200, 210, 218
— грамматики (grammatical) [см.
нетерминалы и терминалы]
— действия (action) 202
ЗАПОМ НОМЕР СТРОКИ
({SET LINE NUMBER}) 373
— — КОНТРОЛЬ ({CHECK}) 378
ОШИБКА ({ERROR}), 302, 484
L-атрибутный (L-attributed) 321
— достижимьгй (reachable) 184
— магазинный (stack) 130
— нарушающий (offending) 295, 540
— начальный (starting) 157
— начинающий (beginning) 302
— нетерминальный (nonterminal) [см.
нетерминал]
— оканчивающий (ending) 482
— первый (first) 483
— терминальный (terminal) [см.
терминал]
Сообщения об ошибках (error
messages) [см. обработка ошибок]
Состояние (state) 22
— допускающее (accepting) 23
— заключительное [см.
допускающее]
— МП-автомата 130
— недостижимое (unreachable,
extraneous) 42
— отвергающее (rejecting) 25
— ошибки (error) 31
Список (list) 602
Ссылка вперед (forward reference) 556
Статус (метки) (status) 554
— ВИСЯЧАЯ (OWED) 554, 556—557
— ПРИПИСАННАЯ (ASSIGNED)
554, 556—557
Стек [см. магазин]
Сумматор [см. регистр арифметический]
Суффикс (suffix) 459
Таблица (table)
— вталкиваний (push) 426
— имен (symbol) 13
— недетерминированных переходов
(indeterministic transition) 518
— переходов (transition) 24
— указателей списков (list-pointer)
91
— управляющая (control) 133, 139
— эквивалентности состояний (state
equivalence) 38
Терминал (terminal) 157
Транслитератор (transl iterator) 108
Транслятор (translator) 12
Трансляция (см. перевод]
650
Предметный указатель
Управляющее устройство (механизм)
(control) 130
— типа «перенос — опознание»
(SHIFT-IDENTIFY) 448
— типа «перенос — свертка»
(SHIFT-REDUCE) 526
Условие,(condition)
— подобия (compatibility) 37
— преемственности (propagation) 37
Факторизация (factoring)
— левая 606
Форма Бэкуса — Наура (Backus-
Naur Form) [см. БНФ]
Функция (function)
— предшествования (precedence) 501
— расстановки (hash) 94
Хранение (storage)
— последовательное (consecutive) 87
— связанное (linked) 87
Цель (goal) 616
Цепочка (sequence, string) 32
— аннулирующая (nullable) 274
— входная (input) 22
— допустимая (accepted) 22
— неправильная (nonsentence) 294,
476
Цепочка
— отвергаемая (rejected) 23
— промежуточная (intermediate) 160
— пустая (null) 32
— различающая (distinguishing) 37
Циклы (loops) 376—378, 408—409,
585—586
Эквивалентность (equivalence)
— автоматов (machine) 36
— состояний (state) 35
Эпсилон-правила (epsilon productions)
157, 533, 620
Язык (language) 153
— ассемблера (assembly) 11
— входной (транслирующей
грамматики) (input) 204
— высокого уровня (high level) 11
— директивный (command) 11
— исходный (source) 12
— контекстно-свободный (context-
free) 161
— машинный (machine) 11
— объектный (object) 12
— управляющих карт (control-card) 11
— формальный (formal) 154
ОГЛАВЛЕНИЕ
От редактора перевода 5
От редакционного бюро IBM ... 6
Предисловие * 8
Глава I. Введение 11
1.1. Программы для обработки языков И
1.2. Упрощенная модель компилятора . i ; 12
1.3. Блоки и проходы компилятора 16
1.4. Организация рабочей программы 18
1.5. Математические модели перевода 18
1.6. Компилятор для языка MINI-BASIC 19
Глава 2. Конечные автоматы 21
2.1. Введение ..■.;< 21
2.2. Конечные распознаватели ■ * 22
2.3. Таблица переходов 24
2.4. Концевые маркеры и выходы из распознавания 26
2.5. Пример построения автомата 29
2.6. Пустая цепочка 32
2.7. Эквивалентность состояний 34
2.8. Проверка эквивалентности двух состояний ....;.... 37
2.9. Недостижимые состояния ■ 42
.2.10. Приведенные автоматы . . . , 43
(.2.11. Получение минимального автомата 45
2.12. Недетерминированные автоматы 49
2.13. Эквивалентность недетерминированных и детерминированных
конечных распознавателей 53
2.14. Пример: константы языка MINI-BASIC 57
2.15. Замечания по литературе 64
Упражнения 65
Глава 3. Реализация конечных автоматов 73
3.1. Введение 73
3.2. Представление входных символов 75
3.3. Представление состояний 76
3.4. Выбор переходов 77
3.5. Идентификация слов: метод автомата 79
3.6. Идентификация слов: метод индексов 85
3.7. Идентификация слов: метод линейного списка 87
3.8. Идентификация слов: метод упорядоченного списка 87
3.9. Идентификация слов: метод расстановки , , ■ 91
3.10. Обнаружение префиксов 95
3.11. Замечания по литературе 98
Упражнения , 98
Глава 4. Лексический блок для языка MINI-BASIC 101
4.1. Множество лексем > 101
652 Оглавление
4.2. Проблемы идентификации 104
4.3. Транслитератор 108
4.4. Лексический блок 111
Упражнения 124
Глава 5. Автоматы с магазинной памятью 126
5.1. Определение автомата с магазинной памятью 126
*5.2. Некоторые обозначения для множеств цепочек 134
5.3. Пример распознавания множества МП-автоматом 137
5.4. Расширенные операции над магазином 139
5.5. Перевод с помощью МП-автоматов 143
5.6. Зацикливание 146
5.7. Замечания по литературе 148
Упражнения 148
Глава 6. Контекстно-свободные грамматики 153
6.1. Введение 153
6.2. Формальные языки и формальные грамматики 153
6.3. Формальные грамматики: пример 154
6.4. Контекстно-свободные грамматики 156
6.5. Выводы 159
6.6. Деревья 161
6.7. Грамматика для констант языка MINI-BASIC 166
6.8. Грамматика для S-выражений Лиспа 167
6.9. Грамматика для арифметических выражений 168
6.10. Разные грамматики для одного и того же языка 170
6.11. Регулярные множества как контекстно-свободные языки . , . . 171
6.12. Праволинейные грамматики 173
6.13. Еще одна грамматика для констант языка MINI-BASIC 179
6.14. Лишние нетерминалы 181
6.15. Грамматика MINI-BASIC'a для руководства по этому языку 186
6.16. Замечания по литературе 190
Упражнения 191
Глава 7. Синтаксически управляемые процессы обработки языков .... 197
7.1. Введение 197
7.2. Польская запись 197
7.3. Транслирующие грамматики 199
7.4. Синтаксически управляемый перевод . . . , 203
7.5. Пример: синтезируемые атрибуты 206
7.6. Пример: наследуемые атрибуты 211
7.7. Атрибутные транслирующие грамматики 213
7.8. Перевод арифметических выражений 218
7.9. Трансляция некоторых операторов языка MINI-BASIC .... 223
7.10. Еще одна атрибутная транслирующая грамматика для выр -
жений 225
7.11. Неоднозначные грамматики и многозначные переводы .... 230
7.12. Замечания по литературе 233
Упражнения 233
Глава 8. Нисходящие методы обработки языков 242
8.1. Введение 242
8.2. Пример 243
8.3. 5-грамматики 250
8.4. Нисходящая обработка для транслирующих грамматик .... 255
8.5. д-грамматики 261
8.6. ЬЬ(1)-грамматики 270
8.7. Нахождение множеств выбора 281
Оглавление 653
8.8. Обработка ошибок при нисходящем разборе 294
8.9. Метод рекурсивного спуска 303
8.10. Замечания по литературе 308
Упражнения 308
Глава 9. Нисходящие методы обработки для атрибутных грамматик . . . 319
9.1. Введение 319
9.2. L-атрибутные грамматики 319
9.3. Форма простого присваивания 321
9.4. Пример атрибутного автомата 328
9.5. Атрибутный автомат с магазинной памятью 335
9.6. Пример: условный оператор 343
9.7. Пример: арифметические выражения 348
9.8. Метод рекурсивного спуска для атрибутных грамматик .... 353
9.9. Замечания по литературе 360
Упражнения 360
Глава 10. Синтаксический блок для языка MINI-BASIC 369
10.1. ЬЦ1)-грамматика языка 369
10.2. Множество атомов и транслирующая грамматика , 369
10.3. L-атрибутная грамматика 378
10.4. Синтаксический блок 378
10.5. Компактный процессор для выражений языка MINI-BASIC 395
Упражнения 407
Глава 11. Восходящие методы обработки языков 412
I1.I Введение 412
11.2. Понятие основы 413
11.3. Пример 416
11.4. Второй пример 423
11.5. Грамматические основы восходящих методов 432
11.6. Польский перевод 436
11.7. S-атрибутные грамматики 438
Упражнения 441
Глава 12. Обработка методами типа «перенос — опознание» 447
12.1. Введение 447
12.2. Управление автоматом типа «перенос — опознание» 448
12.3. Бессуффиксные ПО-грамматики ; 456
12.4. Грамматики слабого предшествования 460
12.5. Простые грамматики смешанной стратегии предшествования . . 465
12.6. Вычисление отношений ПОД и СВЕРТЫВЛЕТСЯ-ПО .... 471
12.7. Обработка ошибок при разборе типа «перенос — опознание» 476
12.8. Синтаксический блок для языка MINI-BASIC 484
12.9. Замечания по литературе 497
Упражнения 497
Глава 13. Обработка методами типа «перенос — свертка» 504
13.1. Введение 504
13.2. Пример 504
13.3. Еще один пример 5!6
13.4. LR(0)-rpaMMaTHKH 525
13.5. SLR(l)-rpaMMaTHKH 528
13.6. Эпсилон-правила 533
13.7. Обработка ошибок при разборе типа «перенос — свертка» 540
13.8. Замечания по литературе 543
Упражнения . . .' 545
654 Оглавление
Глава 14. Генератор кода для MINI-BASIC-компилятора 550
14.1, Введение 550
14.2. Окружение компилятора и объектная машина 550
14.3, Моделирование исполнения 551
14.4. Распределение памяти 552
14.5. Элементы таблиц 553
14.6. Процедура ГЕН 555
14.7, Блок управления сумматором , , , , 557
14.8. Процедуры для атомов 558
14.9, Обработке описаний в языках с блочной структурой 566
14.10, Замечания по литературе 568
Упражнения 569
Глава 15. Обзор методов оптимизации объектного кода 571
15.1. Введение . , . . , 571
15.2. Распределение регистров 571
15.3. Оптимизация одного атома ■ , , 572
15.4. Оптимизация фиксированной цепочки атомов 572
15.5. Оптимизация одного оператора 573
15.6. Оптимизация нескольких операторов 575
15.7. Оптимизация циклов . . , . , 577
15.8. Прочие приемы оптимизации 580
15.9. Замечания по литературе 581
•' Приложение А. Руководство по языку MINI-BASIC 582
АЛ. Общий вид программы на MINl-BASIC'e 582
А.2. Числа 582
А.З. Переменные 583
А.4. Арифметические выражения 583
А.5. Операторы 584
Приложение Б. Отношения 589
Б.1. Введение 589
Б.2. Представление отношений, определенных на конечных
множествах 590
Б.З. Произведение отношений 592
Б.4. Транзитивное замыкание 594
Б.5. Рефлексивно-транзитивное замыкание 599
Упражнения 599
Приложение В. Преобразования грамматик 602
8.1. Введение 602
8.2. Нисходящая обработка списков 602
8.3. Левая факторизация 605
8.4. Замена края 607
8.5. Одиночная замена 609
8.6. Левая рекурсия 610
8.7. Преобразование «цель-край» 613
8.8. Исключение е-правил 620
8.9. Получение польского перевода , , , , 623
В.10. Устранение конфликтов переноса — опознания 624
В. 11. Замечания по литературе . . , ; 625
Упражнения 626
Список литературы 629
Именной указатель 643
Предметный указатель 645
УВАЖАЕМЫЙ ЧИТАТЕЛЬ!
Ваши замечания о содержании книги, се
оформлении, качестве перевода и другие просим присылать
по адресу: 129820, Москва, И-110, ГСП, 1-й Рижский
пер., д. 2, издательство «Мир»,
Ф. Льюис. Л. Розенкранн. Р. Стирнз
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ ПРОЕКТИРОВАНИЯ
КОМПИЛЯТОРОВ
Научный редактор К. Г. Батаев
Мл научный редактор Л. С. Суркова
Художник И. Р. Алиев
Художественный редактор В. И. Шаповалов
Технический редактор Г. Б. Алюлина
Корректор Е. Г. Литвак
ИБ У? 1ВД8
Сдано в набор 12.04.79. Подписано к печати 23.08.79.
Формат 60X907,6. Бумага типографская № 1. Гарнитура
латниская. Печать высокая. Обьем 20,50 бум. л. Усл. печ.
л. 41.00. Уч.-изд. л. 41,17. Изд. Ха 1/9801. Тираж/14 000 экз.
Заказ № 373. Цена 3 р. 20 к.
ИЗДАТЕЛЬСТВО «МИР»
Москва. 1-й Рижский пер.. .'
Набрано и сматрицировано в ордена Октябрьской Революции
и ордена Трудового Красного Знамени Первой Образцовой
типографии имени А А. Жданова Союзполнграфпрома при
Государственном комитете СССР по делам издательств,
полиграфии и книжной торговли. Москва. М-54. Валовая, 28
Отпечатано в ордена Трудового Красного Знамени
Ленинградской типографии vNs 2 имени Евгении Соколовой
«Союзполнграфпрома» при Государственном комитете СССР по
делам издательств, полиграфин и книжной торговли. 198052,
Ленинград, Л-52, Измайловский проспект, 29