/





















































































































































































































































































































































































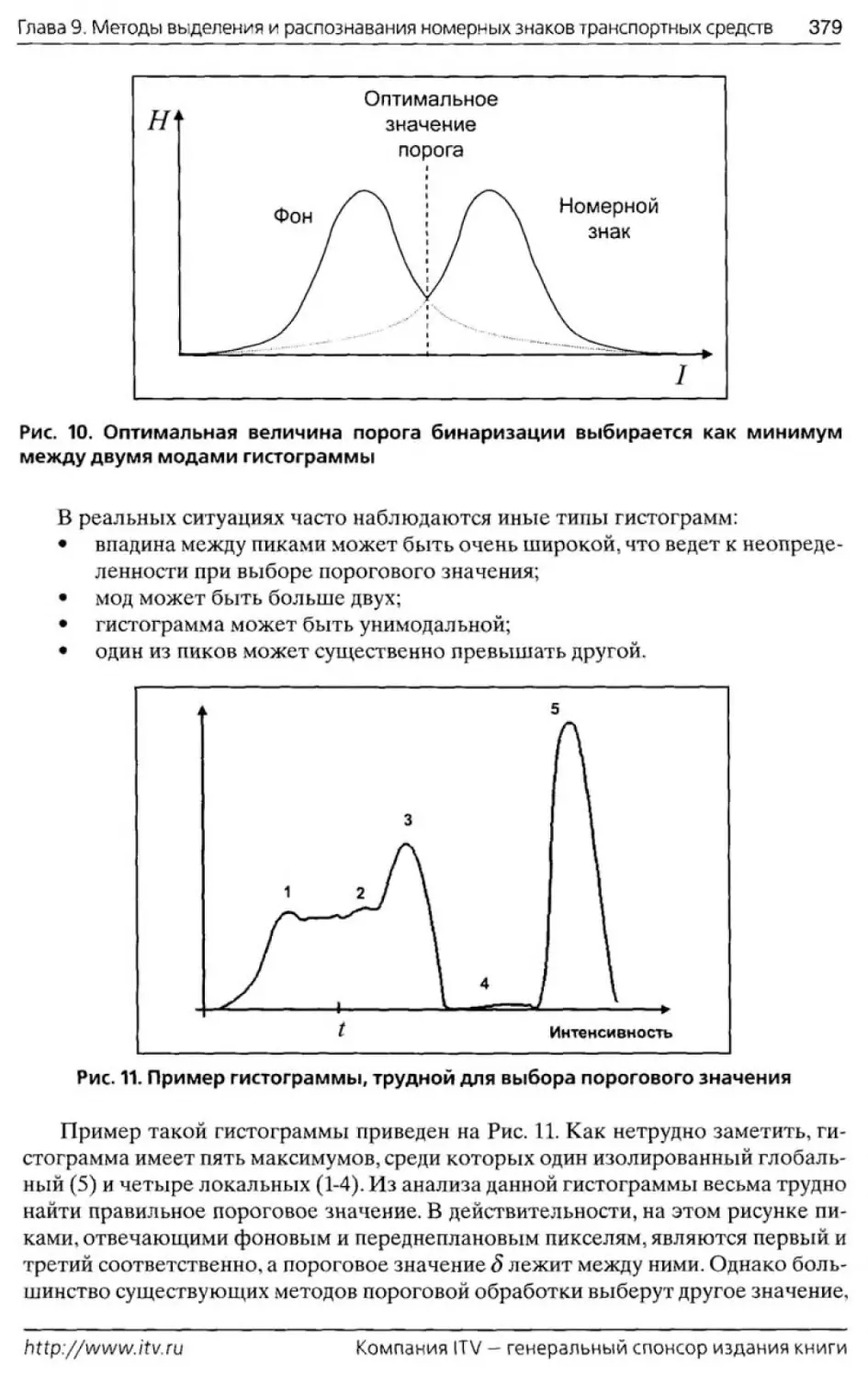








































































































































Автор: Лукьяница А.А. Шишкин А.Г.
Теги: компьютерные науки изобразительное искусство издательство москва цифровая обработка изображений цифровая обработка видео
ISBN: 978-5-9901899-1-1
Год: 2009




Текст
lalTV ОХХ^П
i*<TtnrwKT пхюлггии видео i.... .... »<.< ><.. ..
А. А. Лукьяница, А. Г. Шишкин
Цифровая обработка
видеоизображений
А. А. ЛУКЬЯНИЦА, А. Г. ШИШКИН
ЦИФРОВАЯ ОБРАБОТКА
ВИДЕОИЗОБРАЖЕНИЙ
Издательство «Ай-Эс-Эс Пресс»
Москва 2009
Научный рецензент: доктор физико-математических наук, профессор
МГУ имени М. В. Ломоносова. В. Е. Бенинг
Лукьяница Андрей Александрович, Алексей Геннадиевич Шишкин
Цифровая обработка видеоизображений / А. А. Лукьяница,
А. Г. Шишкин. — М.: «Ай-Эс-Эс Пресс», 2009. — 518 с.
ISBN 978-5-9901899-1-1
В настоящее время в нашу жизнь все больше проникает видеоин-
формация, требующая применения специальных методов обработки
и анализа. В книге рассмотрен широкий круг алгоритмов, применяе-
мых для решения важных практических задач: детектирование дви-
жения, отслеживание траекторий, поиск и распознавание объектов
заданных классов, таких как человеческие лица, транспортные сред-
ства, автомобильные номера, дым и огонь. Большое внимание уделено
проблеме поиска разноплановой информации в цифровых видеоархи-
вах. Книга может быть полезна научным сотрудникам, аспирантам и
студентам старших курсов технических ВУЗов, а также всем специ-
алистам в области обработки изображений и распознавания образов.
Редактор Поздняков С. А.
Технический редактор Позднякова М. Е.
Корректор Дикова Е. В.
Компьютерная верстка Малышев А Ю.
Дизайн обложки Лукьяница А. А.
Подписано в печать 29.09.2009. Формат 70x100/16. Тираж 1 000 экз. Отпечатано
в типографии ООО «Ама-Пресс».
ООО «Ай-Эс-Эс Пресс». Москва, ул. Б. Семеновская, 40.
ISBN 978-5-9901899-1-1 © Лукьяница А. А., Шишкин А. Г., 2009
© Оформление. ООО «Ай-Эс-Эс Пресс», 2009
ОТ СПОНСОРА
Современный мир демонстрирует конвергенцию различных сфер де-
ятельности человека. Эта тенденция очень отчетливо прослеживается и
в области видеонаблюдения, куда все более интенсивно проникают ин-
формационные технологии. Видеонаблюдение и охранное телевидение
заимствуют различные компьютерные и сетевые технологии, на осно-
ве которых разрабатываются уже совершенно новые интеллектуаль-
ные алгоритмы, позволяющие расширить функциональность и повы-
сить эффективность систем видеонаблюдения. Эта книга именно о та-
ких алгоритмах.
Конечно, компания ITV, будучи разработчиком программного обе-
спечения для систем безопасности и видсонаблюдения, не могла прой-
ти мимо такого серьезного проекта, каким является издание книги
«Цифровая обработка видеоизображений»... не могла пройти хотя бы
уже в силу специфики своей деятельности. Дело в том, что инновации -
это один из краеугольных камней, на которых выстроено здание на-
шей компании: ITV всегда, с самого основания, была нацелена на вне-
дрение самых передовых технологий. Интеллектуальные алгоритмы
обработки видеоизображений, которые рассматриваются в этой книге,
являются именно такими передовыми технологиями, авангардом раз-
вития современного охранного телевидения и видеонаблюдения. И это
очень важная, хотя и не единственная, причина нашего спонсорства.
Хотелось бы отметить, что материал, изложенный в этой работе,
не ограничивается исключительно сферой охранного телевидения и
видеонаблюдения, как это может показаться на первый взгляд. Дей-
ствительно, видеодетекторы движения, автоматическое распознава-
ние автомобильных номеров, видеодетскторы оставленных и унесен-
ных предметов в первую очередь находят применение в системах ви-
деонаблюдения. Тем не менее, в книге есть главы, которые затрагива-
ют темы, не имеющие непосредственного отношения к сфере видеона-
блюдения. Например, в главе, посвященной автоматическому обнару-
жению дыма и пламени по видеоизображению, разбираются очень пер-
спективные алгоритмы, причем они ближе уже к другим технологиям
безопасности - к пожарной безопасности. А рассматриваемые в послед-
ней главе вопросы индексации видеоизображений и поиска в видеоар-
хивах и цифровых библиотеках выходят далеко за рамки прикладных
задач систем видеонаблюдения.
Конечно, эта книга в первую очередь написана для специалистов в
области распознавания образов и цифровой обработки изображений, а
также для студентов соответствующих кафедр технических институтов.
И все же она не только для них. Уверен, что книга окажется полезна и
многим специалистам индустрии безопасности. Инсталляторы, проекти-
ровщики. консультанты смогут почерпнуть много новой и актуальной с
практической точки зрения информации, необходимой для понимания
принципов, лежащих в основе интеллектуальных алгоритмов современ-
ных систем видеонаблюдения. А это позволит более корректно настра-
ивать и тем самым более эффективно применять на практике интеллек-
туальные функции таких систем.
Эту книгу .можно рассматривать как своего рода учебник по видео-
анализу и в то же время важный фактор, который будет способствовать
повышению уровня знаний и привлечению новых специалистов в отече-
ственную индустрии безопасности. И компания ITV, оказывая спонсор-
скую поддержку изданию самой первой российской книги, посвященной
видеоанализу, преследует именно эти цели.
ПРЕДИСЛОВИЕ
За последние годы в нашей стране был выпущен целый ряд прекрас-
ных книг, посвященных цифровой обработке изображений. Среди таких
работ следует упомянуть Р. Гонсалес, Р. Вудс «Цифровая обработка изо-
бражений», Л. Шапиро, Дж. Стокман «Компьютерное зрение». В. А. Сой-
фер и др. «Методы компьютерной обработки изображений». Д. Форсайт,
Ж. Понс «Компьютерное зрение. Современный подход». Читатель, озна-
комившийся с этими трудами, может получить достаточно полное пред-
ставление обо всех тонкостях цифровой обработки статических изо-
бражений. В последнее время в нашу жизнь отовсюду проникает виде-
оинформация, требующая использования специальных методов анали-
за. Однако до сих пор не существует книг, посвященных обработке ви-
деоизображений. Настоящая монография призвана восполнить образо-
вавшийся пробел. В ней детально рассмотрены все основные этапы тех-
нологии обработки видеоизображений: разнообразные методы постро-
ения модели фона и выделения движущихся объектов, их сегментации и
распознавания, а также отслеживания траекторий. В книге рассматри-
вается широкий круг алгоритмов, применяемых для решения важных
практических задач: детектирование оставленных предметов, выделе-
ние на изображениях объектов заданных классов, таких как человече-
ские лица, транспортные средства, автомобильные номера, очаги дыма
и огня. Большое внимание уделено проблеме осуществления поиска раз-
ноплановой информации в цифровых видеоархивах. Все разделы книги
сопровождаются соответствующими иллюстрациями. В конце приведен
глоссарий для основных использованных понятий.
Предполагается, что читатель знаком с основами цифровой обра-
ботки отдельных изображений. Книга будет полезна научным сотруд-
никам, аспирантам и студентам старших курсов технических ВУЗов, а
также всем специалистам в области обработки изображений и распо-
знавания образов.
А. А. Лукьяница
А. Г. Шишкин
ГЛАВА 1.
ВВЕДЕНИЕ
6
Цифвая обработка видеоизображений
В последние годы существешю возрос интерес к цифровой обработке видеоизобра-
жений, что связано с резким снижением цен на цифровые телекамеры, благодаря чему
они стали доступными широкому’ классу пользователей и начали внедряться во многих
сферах человеческой деятельности для решения задач автоматического контроля и ви-
дсонаблюдсния. И если сначала телекамеры (в дальнейшем мы часто будем называть
их просто камерами) нашли применение в системах охранного телевидения, то вскоре
их стали использовать для решения самых разнообразных задач, таких как:
• наблюдение за шоссейными и железными дорогами для предотвращения
аварий,
• измерение скорости автомобилей,
• фиксирование проезда автомобилями перекрестка на запрещающий сигнал
светофора, неправильных перестроений, а также остановки в неположенном
месте,
• автоматическое определение числа занятых и свободных мест на парковках,
• мониторинг банков, гипермаркетов, аэропортов, музеев, вокзалов, парковок
автомобилей,
• осуществление автоматического контроля воздушной обстановки,
• мониторинг урбанизированных территорий, лесных массивов и дачных участ-
ков с целью раннего обнаружения пожаров,
• контроль доступа на охраняемые объекты.
• измерение интенсивности дорожного движения и подсчет числа проехавших
транспортных средств различного класса (легковые автомобили, грузовики,
фуры и т. п.),
• проведение статистических исследований в торговых и развлекательных цен-
трах, а также в музеях,
• бесконтактное наблюдение за животными,
• обнаружение препятствий, возникающих по ходу движения автомобиля,
• подсчет числа изделий на конвейере и первичный контроль качества.
Конечно же, это далеко не полный перечень проблем, которые могут быть
решены путем применения телекамер; мы выделили эти задачи лишь потому, что
авторам в той или иной степени пришлось с ними столкнуться в своей практиче-
ской деятельности.
Одной из наиболее сложных и актуальных задач обработки видеоизображе-
ния является проблема выделения и распознавания движущихся объектов при
наличии различного рода помех и создание на этой основе системы мониторин-
га. Главная задача таких систем - информировать человека о ситуации, сложив-
шейся в поле зрения камеры, и по возможности предпринять какие-либо заранее
предусмотренные и программно заложенные действия.
На первых порах задача сводилась к простому детектированию движущихся
объектов. Уже в таком виде это важно для многих систем безопасности, когда в
охраняемой зоне исключено какое бы то ни было движение. Более совершенные
системы подразумевают наличие в своем составе интеллектуальных видеодетск-
торов движения (которые для краткости мы в дальнейшем будем также назы-
вать прост о детекторами движения), способных отличить движущегося человека
от собаки, машины или дерева, раскачивающегося на ветру. На данный момент
лишь немногие системы безопасности могут похвастаться такими возможно-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 1. Введение 7
стями, существенно их удорожающими. Привлекая внимание к определенному
монитору и автоматически регистрируя произошедшее событие, такие системы
значительно повышают уровень безопасности охраняемого объекта. Кроме того,
видеодстекторы движения часто используются для интеллектуальной компрес-
сии, что позволяет значительно экономить дисковое пространство при архивиро-
вании видеоизображений.
Процесс построения указанных систем представляет собой сложную техно-
логическую цепочку, включающую получение цифрового изображения, его об-
работку с целью выделения значимой информации и анализ этой информации
для решения определенной задачи. Конечно, идеальным представляется создание
универсальной самообучающейся системы, которая в условиях возможных огра-
ничений обеспечивала бы эффективный мониторинг объекта.
Несмотря на то. что в мире создается большое число систем, имеющих различ-
ное предназначение, последовательность обработки видеосигнала в них прибли-
зительно одинакова. Более того, анализ различных систем показал, что в основе
каждой из них лежат практически одни и те же модули. Условно обработку ви-
деоизображений в таких системах можно разделить на следующие этапы:
• выделение переднего плана.
• выделение и классификация движущихся объектов.
• отслеживание траектории движения найденных объектов.
• распознавание и описание действий объектов, представляющих интерес.
Процесс выделения переднего плана заключается в отделении движущихся
фрагментов изображения от неподвижных, которые называют фоновыми или при-
надлежащими заднему плану От того, насколько аккуратно и корректно решена
эта задача, зависят все последующие этапы обработки информации, а также тре-
буемые вычислительные ресурсы. Именно поэтому этапу выделения переднепла-
нового изображения и применяемым для этого методам уделено особое внимание
разработчиков. Сложность этой задачи обуславливается большим количеством
разнообразных факторов, таких как собственные шумы камеры, внезапное измене-
ние освещенности сцены, падающие тени, движение ветвей деревьев на ветру и др.
На втором этапе выделения и классификации сначала производится сегмен-
тация изображения переднего плана, т. е. находятся компактные области, дви-
жущиеся с одинаковой скоростью, которые считаются движущимися объектами.
Далее они соотносятся с заранее определенными классами: автомобили, люди,
животные и т. п.
После этого можно переходить к следующему этапу - отслеживанию траекто-
рии каждого движущегося объекта (этот процесс называется трекингом - от англ,
tracking). Для осуществления трекинга нужно установить взаимно-однозначное
соответствие между обнаруженными объектами на последовательных кадрах.
При этом обеспечивается временная идентификация выделенных областей изо-
бражения и выдается соответствующая информация об объектах в наблюдаемой
зоне, а именно: траектория, скорость и направление движения.
На заключительном этапе обработки проводится распознавание и описание
действий выделенных объектов. В идеальном случае система должна выдавать
сообщения типа: «автомобиль выехал с парковочного места и подъехал к воро-
там», «на перекрестке образовался затор» и т. п.
h 11р. //www. 11 v. г и
Компания ITV - генеральный спонсор издания книги
8
Цифвая обработка видеоизображений
Методам построения переднего плана посвящена Глава 2. Этот этап обработки
видеоряда является наиболее важным, поскольку именно он определяет дальней-
шее качество системы в целом и позволяет значительно сократить объем вы-
числений путем обработки только тех пикселей, которые относятся к переднему
плану. В принятой терминологии считается, что движущиеся объекты принад-
лежат «переднему плану», а стационарные - к «заднему плану», который также
называют фоном. Для построения переднего плана наиболее часто используются
методы, основанные на вычитании фона, вероятностные методы, методы вре-
менной разности и оптического потока.
Методы вычитания фона являются самыми простыми и наиболее часто при-
меняемыми для детектирования движущихся объектов. Суть их заключается в на-
хождении попиксельной разности между* текущим кадром и некой моделью фона.
В принципе, такая модель должна представлять собой сцену без движущихся объ-
ектов. При этом необходимо се регулярное обновление, для того чтобы учитывать
изменение условий освещенности и настроек камеры, таких как поворот, наклон и
изменение фокусного расстояния. Главным недостатком методов вычитания фона
является возможная классификация фоновых пикселей как переднеплановых. Это
может происходить, например, для листьев деревьев, колышущихся на ветру, падаю-
щих снега и дождя, теней, отбрасываемых движущимися объектами и др. Кроме
того, методам данного класса присуща латентность в обновлении модели фона:
должно пройти некоторое время, прежде чем в модели будут учтены изменения,
связанные с началом движения или остановкой объекта. Наконец, методы вычита-
ния фона в своей простейшей реализации предъявляют достаточно высокие требо-
вания к ресурсам вычислительной системы.
В вероятностных методах задний план формируется в результате моделиро-
вания стохастического «пиксельного процесса», т. е. для каждого пикселя изме-
нение его интенсивности от кадра к кадру рассматривается как временной ряд,
состоящий из скалярных величин для полутоновых изображений, и векторов -
для цветных. В результате фон представляет собой гауссову смесь, т. е. линей-
ную комбинацию одномерных, нормально распределенных случайных величин.
Более совершенными являются алгоритмы, создающие поликссльную модель
всей сцены, в которой используются отдельно гауссовы смеси для фона, передне-
го плана и теней. Основываясь на времени существования и дисперсии каждого
гауссиана в смеси, можно определить, какие из них относятся к фону. Пиксели,
значения которых не укладываются в фоновые распределения, считаются перед-
неплановыми до тех пор, пока не появится гауссиан, позволяющий с достаточной
точностью отнести их к фону. Такой подход позволяет учитывать медленные из-
менения освещенности путем подстройки параметров гауссианов. Кроме того, в
рамках вероятностных методов возможен адекватный анализ распределений с
несколькими максимумами, что является типичным для ситуаций с падающими
тенями, отражениями, качающимися ветвями и др. Однако быстрые изменения
фона и освещенности сцены данные алгоритмы описать не могут.
Методы временной разности отделяют передний план от фона при помощи
попиксельного вычитания двух или более последовательных кадров. Очевид-
но, что методы временной разности хорошо определяют динамические измене-
ния сцены, но обычно не могут выделить целиком все однородные пиксели одно-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www. procctv.ru
Глава 1. Введение
Рис. 1. Пример построения модели заднего плана (фона): 1 - методом вычитания
фона, 2 - методом временной разности. 3 - вероятностным методом, 4 - методом,
основанным на нейросети
го объекта, что приводит к фрагментированности выделенных объектов (часто
внутри них образуются пустоты). Кроме того, этим методам не удается обнару-
живать остановившиеся объекты. Поэтому чаще всего методы временной раз-
ности используются совместно с другими методами (например, вероятностными
или вычитания фона), что позволяет им достаточно устойчиво отделять перед-
ний план от фона за небольшое время.
Для выделения переднего плана из видеопоследовательности весьма перспек-
тивным является метод оптического потока. Понятие потока обычно исполь-
зуется для описания когерентного движения точек или характерных признаков
между последовательными кадрами. Выделение фона, основывающееся на вы-
числении оптического потока, использует характеристики вектора потока дви-
жущихся объектов для нахождения тех областей видеопоследовательности, в
которых происходят изменения. Также с помощью оптического потока можно
получить информацию о расположении, размерах и некоторых других параме-
трах таких областей. В принципе, с помощью методов оптического потока может
быть проведено наиболее аккуратное выделение движущихся объектов, даже в
случае перемещения камеры. Однако алгоритмы данного класса являются слиш-
ком ресурсоемкими и. кроме того, чрезвычайно чувствительны к шуму. Вслед-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
10
Цифвая обработка видеоизображений
Рис. 2. Результаты обнаружения движущихся объектов для различных моделей
заднего плана (фона): 1 - методом вычитания фона, 2 - методом временной
разности, 3 - вероятностным методом, 4 - методом, основанным на нейросети
ствие этого они на данный момент не могут быть применены к видеопотокам в
реальном времени без дорогих специализированных процессоров.
В настоящее время развиваются методы построения заднего плана, осно-
ванные на применении искусственных нейронных сетей. Эти методы использу-
ют свойство нейронной сети адаптироваться к входным данным за счет введе-
ния настраиваемых обратных связей. Каждый пиксель фона управляется своей
нейронной сетью, в результате чего через некоторое время, требуемое для на-
стройки (обучения) нейронной сети, формируется модель фона, способная за-
данным образом подстраиваться к изменениям входного изображения.
На Рис. I приведен пример выделения фона для одного и того же видеоряда раз-
личными методами. На Рис. 2 представлены результаты выделения движущихся
объектов для тех же самых способов построения модели заднего плана. Видно, что
от качества формирования фона существенно зависит количество найденных дви-
жущихся объектов.
Глава 3 посвящена описанию методов, применяемых для выделения и клас-
сификации движущихся объектов. На видеоизображении могут присутство-
вать различные движущиеся объекты: автомобили, автобусы, мотоциклы, люди,
группы людей, животные и г. п. Основной интерес для систем мониторинга пред-
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp:// w w w. procc t v. ru
Глава 1. Введение
11
Рис. 3. Результаты оконтуривания блобов для различных способов формирования
заднего плана: 1 - методом вычитания фона. 2 - методом временной разности,
3 - вероятностным методом, 4 - методом, основанным на нейросети
ставляют транспортные средства и люди. В большинстве случаев конечной це-
лью видеонаблюдения является выявление нештатных ситуаций, поэтому край-
не важно правильно классифицировать обнаруженные объекты. Так как видео-
наблюдение и анализ ведутся в масштабе реального времени, алгоритмы клас-
сификации должны быть относительно быстрыми, эффективными и инвариант-
ными к изменяющимся условиям освещения.
Методы классификации объектов условно можно разделить на три большие
группы: геометрические методы, методы, основанные на динамических харак-
теристиках движения, и методы, использующие динамические текстуры. Пер-
вые основаны на выделении ряда признаков, характеризующих геометриче-
скую форму объекта, накоплении такой информации за определенный пери-
од времени, создании базы данных многочисленных шаблонов (во время пери-
ода обучения) и сравнении интересующего объекта с шаблонами. К геометри-
ческим методам относятся методы, основанные на сегментировании объектов,
и различные контурные методы. Методы, основанные на динамических харак-
теристиках. используют периодичность процессов, присутствующую практиче-
ски во всех движущихся объектах. Методы, использующие динамические тек-
стуры, являются расширением алгоритмов, основанных на обычных текстурах.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
12
Цифвая обработка видеоизображений
и представляют собой одно из наиболее многообещающих направлений в обла-
сти классификации объектов в настоящее время.
Интересующие нас объекты находятся на переднем плане, причем априорно
неизвестно, сколько их, какого они размера, какое имеют взаимное расположе-
ние. Для того чтобы провести классификацию таких объектов, нужно сначала
отделить каждый объект от других, т. е. провести сегментацию изображения.
Результатом этого является либо помеченный набор пикселей переднего плана,
либо указание вершин прямоугольника, внутри которого находится выделенный
объект. В первом случае говорят о выделении так называемого «блоба» (blob -
англ, капля), который задастся набором координат составляющих его пикселей.
Для обработки блобов удобны контурные методы. Выделение описанного пря-
моугольника дает более грубое описание объекта, хотя требует значительно
меньшего времени обработки. На Рис. 3 приведены результаты оконтуривания
блобов для найденных движущихся объектов при различных способах формиро-
вания заднего плана. Из рисунков видно, что огрехи при выделении фона приво-
дят к значительным деформациям контуров и. как следствие, к ошибкам в опре-
делении типа транспортного средства.
Когда объекты хорошо отделимы друг от друга, то даже на основе такой про-
стой характеристики, как отношение высоты к ширине прямоугольника, можно
предварительно определить тип объекта. После проведения сегментирования пе-
реднего плана в большинстве случаев невозможно приступать непосредственно
к классификации объектов. Дело в том, что выделенные блобы обычно имеют
фрагменты, состоящие из отдельных, не связанных пикселей. Кроме того, изо-
бражение часто имеет ряд недостатков в виде мелких областей, линий и отдель-
ных пикселей, не отнесенных ни к какой области.
Существует много различных факторов, которые приводят к таким недостат-
кам в сегментированном изображении. Такие изъяны можно устранить путем
выполнения подходящих морфологических операций дилатации (расширения)
и эрозии. После проведения соответствующей обработки контуры выделенных
сегментов становятся более плавными и содержат минимальное число пустот
внутри объекта.
Однако такая обработка изображения существенно осложняется необходи-
мостью правильного задания конфигурации структурирующего элемента и его
размера. Выбор конфигурации является, в какой-то мере.эмпирическим и интуи-
тивным процессом, а корректный выбор размера структурирующего элемента
для конкретного изображения или его отдельных частей является сложной опти-
мизационной задачей.
Геометрические методы классификации основаны на двух ключевых поняти-
ях: классификационной метрике, позволяющей определить меру близости рас-
сматриваемого объекта и шаблона из имеющейся базы данных, и временной со-
гласованности (классифицируются только те объекты, которые присутствуют в
видеопотоке в течение ряда последовательных кадров, в противном случае они
считаются фоновым шумом). Особую трудность этому придает тот факт, что в
текущем кадре истинная природа объекта может быть искажена вследствие на-
ложения нескольких объектов. Например, группа идущих рядом людей в отдель-
ных кадрах может выглядеть как едущий автомобиль.
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://w w w. procc t v. ru
Глава 1. Введение
13
Динамические методы основаны на анализе периодичных движений. Свойство
периодичности является весьма распространенным среди движущихся объектов.
Например, у человека во время ходьбы довольно легко можно выделить повто-
ряющиеся через определенное время позы.То же самое относится и к животным.
Поэтому периодичность движения можно использовать для классификации дви-
жущихся объектов.
Особый интерес представляет использование для поставленной задачи динами-
ческих текстур (ДТ). которые являются расширением понятия обычных текстур с
учетом их повторяемости стечением времени.Типичными примерами ДТ служат
видеопоследовательности, изображающие дым.огонь, волны, листву колышущую-
ся на ветру и др. Сферы применения ДТ во многом схожи с таковыми для обычных
текстур - это детектирование, сегментация, распознавание объектов и индексация
изображений для цифровых видеоархивов. Однако использование и анализ ДТ от-
личаются от обработки традиционных статичных текстур. Связано это в первую
очередь с появлением дополнительного измерения, в качестве которого выступает
время. Помимо этого, многие ДТ, такие, например, как дым, довольно трудно сег-
ментировать вследствие того, что их границы непрерывно меняются и плохо раз-
личимы. ДТ могут быть частично прозрачными, что предполагает решение задачи
отделения текстуры от фона. Кроме того, категории при классификации ДТ гораз-
до более расплывчаты и нечетки по сравнению с традиционными текстурами.
Глава 4 посвящена алгоритмам слежения за объектами, или. как их еще на-
зывают, алгоритмам сопровождения объектов, или трекинга. Целью трекинга
является установление соответствия между объектами в последовательности
кадров, а также определение их траекторий и скорости движения. Сопрово-
ждение выделенных объектов в видеопотоке представляет собой чрезвычайно
сложную задачу вследствие влияния следующих факторов:
• изменения изображения, освещенности сцены, наличия шума камеры,
• присутствия меняющих форму объектов.
• наличия нескольких одновременно движущихся объектов с близкими харак-
терными признаками и пересекающимися траекториями,
• неправильной сегментации объектов на предыдущих этапах обработки,
• необходимости осуществлять слежение в масштабе реального времени.
Ошибочное выполнение операции трекинга приводит в дальнейшем к некор-
ректной интерпретации действий анализируемых объектов. Поскольку трекинг
объектов должен часто проводиться в реальном времени, необходимо использовать
алгоритмы, которые не слишком требовательны к вычислительным ресурсам.
Выбор алгоритма трекинга существенным образом зависит от способа пред-
ставления объектов. Обычно используются следующие описания:
• точечный объект, т. е. объект, который представляется одной точкой, обыч-
но являющейся центром масс объекта либо центроидом блоба;
• совокупность характерных точек, по которой можно однозначно распознать
объект на соседних точках;
• геометрический примитив, например эллипс или прямоугольник, описанный
вокруг объекта;
• внешний контур объекта;
• набор движущихся областей;
http://www itv.ru
Компания ITV - генеральный спонсор издания книги
14
Цифзая обработка видеоизображений
• инвариантные характеристики, такие как текстуры, статистические момен-
ты и т. п.
При трекинге точечных объектов существует несколько разновидностей ал-
горитмов: модели трекинга отдельных точек, групп точек и модель глобального
движения, в которой учитывается движение всей совокупности точек на всех рас-
сматриваемых кадрах. Для каждой из моделей вводятся различные ограничения
и целевые функции, из которых формируются так называемые «функционалы
стоимости». В процессе минимизации построенных функционалов устанавлива-
ется наилучшее соответствие между объектами на соседних кадрах. Для сокраще-
ния времени при оптимизации чаще всего применяются локально-оптимальные
алгоритмы. В этих алгоритмах, вместо того чтобы находить оптимальные пути
на всей последовательности кадров, находятся пути, оптимизирующие целевую
функцию для каждой последовательной пары кадров. Замена объекта геометри-
ческим примитивом, эллипсом или прямоугольником, позволяет построить до-
вольно эффективный алгоритм сопровождения. При этом на каждом шаге нужно
подстраивать всего несколько параметров, определяющих положение и форму
примитива. Такой способ трекинга удобен при слежении за хорошо разделимыми
объектами, например за положением головы при проведении видеоконферен-
ции. Методы, основанные на описании контуров объектов, используют в своей
работе динамически обновляемые кривые, ограничивающие область движуще-
гося объекта. Эти методы считаются наиболее устойчивыми как к изменению
освещения, так и к наличию шумов в исходном изображении. Наиболее широко
на практике применяется метод выделения активного контура, который обычно
называют змейкой. Форма контура, задаваемого в параметрическом виде, опре-
деляется из условия минимизации специально сконструированного функционала
энергии. При слежении за движущимися областями удается построить систему
работающую в широком диапазоне скоростей, с которыми движутся объекты.
Единственным недостатком этого подхода являются сравнительно высокие тре-
бования к вычислительным ресурсам, хотя существует ряд специальных алгорит-
мов, позволяющих существенно сократить объем вычислений. Для отождествле-
ния найденных областей на соседних кадрах могут быть использованы различные
инвариантные характеристики, такие как текстуры, статистические моменты,
главные компоненты и др. В результате можно добиться не только инвариант-
ности относительно изменения масштаба и поворотов, но также до некоторой
степени решить проблему частичного загораживания объектами друг друга. В
завершении главы рассмотрено большое число практических алгоритмов, осно-
ванных на использовании различных наборов характерных признаков, за счет
чего удается существенно повысить качество трекинга.
Глава 5 посвящена современным адаптивным методам распознавания образов
и классификации. Использование описанных методов в системе видеонаблюде-
ния позволяет придать ей законченный вид, поскольку на всех этапах обработки
видеоряда,описанных выше, получается, как правило, набор характерных призна-
ков, на основе которых можно распознать обнаруженные объекты. И только в са-
мых простых системах эта задача решается сравнением с известными шаблона-
ми либо вычислением корреляций, что для реальных задач не позволяет получить
высокого процента верно распознанных объектов. Сложность задачи распознава-
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. ru
'лава 1. Введение
15
ния состоит в том, что, как правило, характерные признаки являются многомер-
ными векторами, в совокупности описывающими некоторые свойства рассматри-
ваемых объектов, например: гистограммы, набор моментов, текстур и т. п . И чрез-
вычайно неприятным является то обстоятельство, что сами характерные призна-
ки весьма изменчивы и для различных объектов из одного и того же класса мо-
гут существенно отличаться. Рассматриваемые в Езаве 5 методы являются адап-
тивными, т. е. способными к автоматической подстройке к свойствам обрабаты-
ваемых данных, что в итоге позволяет разработать распознающую систему с не-
плохими характеристиками. В первом разделе главы приводятся различные ме-
тоды для подготовки исходных данных к некому стандартному виду, пригодному
для настройки адаптивной системы. Традиционно процесс подготовки данных за-
ключается в их разбиении на входные и выходные с последующей нормализаци-
ей. Входные данные подаются на вход системы, в то время как выходные данные
используются как эталон, который адаптивная система должна в идеале выдавать
в качестве результата, например номер класса, к которому должны быть отнесе-
ны входные данные. В Отаве 5 рассматриваются следующие разновидности адап-
тивных методов:
• искусственные нейронные сети.
• метод опорных векторов,
• методы кластеризации данных.
• методы бустинга.
Искусственные нейронные сети появились в результате попыток моделиро-
вания процессов распознавания мозгом живых существ, поэтому даже терми-
нология. применяемая в этой области, частично заимствована из биологии. В
разделе рассматриваются два наиболее часто применяемых типа нейросетей:
прямого распространения (персептрон) и нейросеть с нейронами радиального
базиса. Большое внимание уделено организации процесса настройки нейросети,
поскольку он, как правило, вызывает большие затруднения даже у квалифициро-
ванных специалистов.
Метод опорных векторов был предложен отечественными учеными В. Вап-
ником и А. Червоненкисом. В иностранной литературе он известен как Support
Vector Machine (SVM). Метод опорных векторов основан на идее построения
оптимальной гиперплоскости, разделяющей два множества. Основное структур-
ное отличие SVM от нейросетей заключается в том, что для нейросети количе-
ство настраиваемых коэффициентов должно априорно задаваться пользовате-
лем на основании некоторых эвристических соображений. В случае применения
SVM количество настраиваемых параметров автоматически определяется во
время настройки и обычно существенно меньше, чем число векторов в обучаю-
щей последовательности. Отличными от нуля остаются только коэффициенты
при так называемых опорных векторах, с помощью которых и строится разде-
ляющая гиперповерхность.
Методы кластерного анализа используются для решения задачи, в которой
требуется разбить заданную выборку объектов на непересекающиеся подмно-
жества, называемые кластерами, так, чтобы каждый кластер состоял из схожих
объектов, а любые два объекта, принадлежащие разным кластерам, существен-
но отличались. Процесс построения кластеров принадлежит к разряду адаптив-
-:tp://www.itv.ru
Компания ITV - генеральный спонсор издания книги
16
Цифвая обработка видеоизображений
ных алгоритмов, однако, в отличие от ранее рассмотренных нейросетей и мето-
да опорных векторов, он относится к классу методов обучения «без учителя».
Это означает, что в примерах, используемых при обучении, присутствуют только
входные данные и отсутствует какая-либо информация об их принадлежности к
тому или иному классу.
Методы бустинга (от англ, boosting - повышение, усиление) предназначе-
ны для повышения качества распознающей системы за счет использования набо-
ра экспертов, которых также называют «элементарными распознавателями», или
классификаторами. В качестве эксперта может выступать любая распознающая
система, например основанная на применении искусственной нейронной сети. Не-
обходимым требованием к эксперту является только одно: он должен обладать до-
стоверностью распознавания не менее 50%. Линейная комбинация из набора та-
ких экспертов, обученных соответствующим образом, может достигать надежно-
сти распознавания, близкой к 100%’. В разделе рассмотрено несколько методов бу-
стинга, применяемых для разделения как двух, так и произвольного числа классов.
Следующие главы книги посвящены решению различных прикладных задач,
которые возникают при разработке систем видеонаблюдения. В Главе 6 рассма-
триваются алгоритмы для обнаружения и детектирования оставленных объектов.
Интерес к этой задаче особенно возрос в последние годы в связи с проблемой мо-
ниторинга мест скопления людей (аэропорты, супермаркеты, вокзалы и др.) с це-
лью предотвращения террористических актов. Сложность задачи заключается в
том, что обычно не существует даже приблизительной априорной информации о
предмете, который может быть оставлен, и, кроме того, этот предмет обычно вре-
менами перекрывается (например, проходящими людьми). В Главе 6 рассмотрены
различные алгоритмы, начиная со статистических, позволяющих построить спе-
циальный детектор оставленных предметов, и заканчивая более сложными, осно-
ванными на использовании уже работающих блоков сопровождения движущихся
объектов. В последнем случае оставленный предмет может быть определен как
некий объект, внезапно появившийся на переднем плане, либо скорость движе-
ния которого стала равной нулю. Отметим, что рассматриваемые алгоритмы мо-
гут также быть использованы и для обнаружения унесенных (похищенных) пред-
метов, для детектирования припаркованных автомобилей, обнаружения транс-
портных средств, остановившихся в туннеле, выявления посторонних объектов на
взлетно-посадочной полосе и для решения других подобных задач.
[лава 7 посвящена проблеме детектирования и локализации лиц на видеоизобра-
жениях. Начиная с семидесятых годов прошлого века, задаче распознавания лиц на
изображениях всегда уделялось большое внимание. Однако в последнее десятиле-
тие эта область переживает настоящий бум, связанный с возрастающим с каждым
годом числом возможных приложений и появлением новых технологий и методов
решения указанной проблемы. Несмотря на достигнутые успехи, надежное распо-
знавание лиц на изображениях, полученных вне помещений, а также с меняющи-
мися условиями освещения и угла поля зрения, представляет собой до сих пор нере-
шенную задачу.
Большинство существующих в этой области работ относится ко второму этапу
данной проблемы - непосредственно к самому распознаванию. Первому, не менее
важному этапу, - детектированию и выделению лиц - уделено значительно мень-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 1. Введение
17
шс внимания. В целом, эта задача может быть сформулирована следующим обра-
зом: в данном кадре видеопоследовательности определить наличие или отсутствие
лиц людей и при положительном ответе найти границы прямоугольных рамок, це-
ликом включающих лица. При этом решение указанной проблемы должно быть
инвариантным к изменениям условий освещенности, масштаба и ориентации. По-
строение системы, отвечающей перечисленным требованиям, представляет собой
чрезвычайно сложную задачу*. Причем в случае обработки не статических изобра-
жений. а видеоизображения существует ряд факторов, существенно усложняющих
анализ. Во-первых, это низкое качество видеоизображения и наличие во многих
случаях объектов, частично перекрывающих лица. Во-вторых, размеры лиц на ви-
деоизображениях обычно значительно меньше, чем на фотоснимках.
Первые попытки решить поставленную задачу заключались в использовании
простых алгоритмов сравнения последовательных кадров, основываясь на их
попикссльном сопоставлении. Естественно, что при наличии нескольких движу-
щихся объектов и их взаимных перекрытий данный класс алгоритмов является
неэффективным. Поэтому в последующих методах для сегментации лиц на ви-
деоизображениях стали активно использовать потоковую (относящуюся к дви-
жению). а также цветовую информацию. Это позволило значительно улучшить
качество выделения лиц. При этом обычно выделяются границы не самого лица,
а только прямоугольника, его содержащего. После этого, как правило, применя-
ются методы, разработанные для анализа статических изображений.
После выделения лица на изображении можно непосредственно переходить к
его распознаванию. И здесь исторически первыми появились методы, разработан-
ные для отдельных изображений. К ним. в первую очередь, следует отнести ме-
тод построения «собственных лиц» (eigenfaces), основанный на выделении глав-
ных компонент изображения; метод построения и сравнения специальных графов
j elastic graph matching); различные варианты метода бустинга и др. Хотя, как и для
задач выделения лиц, для закрытых помещений с постоянным освещением и ма-
лым числом людей здесь достигнуты значительные успехи, в случае распознава-
ния на открытых пространствах при меняющейся освещенности сцены до сих пор
существует ряд проблем, препятствующих полному и надежному решению зада-
чи. Поэтому большие надежды в настоящее время возлагаются на использование
когерентности временной информации, содержащейся в видеопоследовательно-
сти. Тем более что, как известно из области психофизиологии, человек значитель-
но лучше распознает лица людей на видеоизображениях, чем на отдельных изо-
бражениях. Среди методов, использующих для распознавания временную согласо-
ванность отдельных кадров, можно выделить построение идентифицирующих по-
верхностей (identity surfaces) и использование широко и успешно применяющегося
для решения и других задач метода конденсации (condensation algorithm).
Во многих ситуациях возникает необходимость распознавать транспортные
средства и на статических изображениях. Действительно, когда автомобиль по-
падает в дорожный затор и перестает двигаться, то через некоторое время он бу-
дет сегментирован в объект фона. Аналогичная сложность возникает и при раз-
работке системы автоматической парковки, поскольку большую часть времени
автомобили являются неподвижными, а потому невидимыми для детектора дви-
жения. Проблеме распознавания объектов заданного класса, в первую очередь,
~ttp://www.itv.ru
Компания ITV - генеральный спонсор издания книги
18
Цифвая обработка видеоизображений
разнообразных транспортных средств, посвящена Гзава 8. Основная трудность
при обнаружении и локализации объектов на изображении заключается в видо-
вом многообразии объектов и сильной внешней изменчивости одного и того же
объекта при наблюдении его в разных условиях. Существует большое число ме-
тодов для обнаружения и распознавания объектов на статическом изображении.
При этом обычно на изображении выделяются области, обладающие свойства-
ми, характерными для исследуемых объектов, и производится их проверка для
выявления областей, релевантных поставленной задаче. Сущность этой провер-
ки зависит от характера используемых признаков и может быть основана на не-
котором эмпирическом алгоритме, на статистике взаимного расположения при-
знаков, собранной по изображениям транспортных средств, на моделировании
процессов, происходящих в мозгу человека при распознавании визуальных обра-
зов. на применении шаблонов различного рода и т. д.
В принципе, для детектирования и локализации транспортных средств могут
быть использованы многие методы из предыдущей главы. Однако существу-
ет ряд особенностей рассматриваемой задачи, которые приводят к разработке
алгоритмов, специфичных только для выделения транспортных средств. В Гла-
ве 8 рассмотрены современные методы, хорошо зарекомендовавшие себя для
решения поставленной задачи: статистические методы, использование много-
масштабных текстур, а также применение всевозможных классификаторов и
повышение достоверности распознавания за счет методов бустинга, т. е. орга-
низации системы «экспертов», качество работы которой существенно превос-
ходит способности отдельных экспертов.
Втава 9 посвящена имеющей давнюю историю проблеме автоматического
распознавания регистрационных номеров автомобилей. Еще в 1976 г. научно-
исследовательский отдел Управления полиции Великобритании начал разработку
системы для считывания с помощью телекамеры и последующего анализа номер-
ных знаков автомобилей. В 1979 г. такая система была создана, и уже в 1981 г с ее
помощью был задержан подозреваемый в угоне автомобиля. В настоящее время
системы автоматического распознавания номерных знаков находят самое широ-
кое применение, начиная от сбора пошлины на пропускных пунктах автодорог и
контроля дорожной обстановки и заканчивая выявлением угнанных автомобилей.
Как правило, распознавание регистрационных номеров автомобилей прово-
дится по следующей схеме. На первом этапе, являющемся основой эффективной
и надежной работы всей системы, производится обнаружение и сегментация но-
мерного знака на видеоизображении. Решение данной задачи осложняется низ-
ким качеством имеющихся изображений, резкой сменой освещенности объектов,
наличием на изображении нескольких знаков, а также букв и цифр, не относя-
щихся к искомым регистрационным номерам, большим разнообразием номер-
ных знаков, перспективными искажениями, загрязненностью номеров. Кроме
того, выделенная область в большинстве случаев не является ориентированной
строго горизонтально. Если не осуществлять ее поворота на данном этапе, то в
дальнейшем это может сказаться на результатах работы всей системы.
Второй этап состоит в сегментации отдельных букв и цифр на выделенном но-
мерном знаке. Наиболее простой и быстрой процедурой здесь является построение
вертикальной проекции предварительно приведенного к бинарному виду номер-
ProSystem CCTV — журнал по системам видеонаблюдения
http://www.procctv.rij
лава 1. Введение
19
ного знака. Отметим, что данный класс алгоритмов в большой степени подвержен
влиянию шумов, всегда присутствующих на изображениях. Помимо этого, на дан-
ном этапе широко применяются методы, основанные на анализе областей.
Третий (и последний) этап в работе рассматриваемых систем заключается в
непосредственном распознавании сегментированных на номерном знаке букв и
цифр. Данная задача полностью укладывается в рамки давно исследуемой обла-
сти по оптическому распознаванию символов. В целом, все существующие для
этого методы либо используют базы данных из предварительно построенных
^шаблонов. либо основаны на применении адаптивных распознающих систем.
В Главе 10 рассматриваются методы детектирования огня и дыма по видео-
изображению. При возникновении очага возгорания минимальная латентность
з детектировании данного события чрезвычайно важна, так как это позволяет
уменьшить ущерб от пожара, а в ряде случаев и спасти человеческие жизни. Все
современные детекторы дыма фиксируют наступление критического события
только после того, как частицы дыма достигнут точки расположения сенсора.
При этом в помещениях с направленной вентиляцией (туннели, шахты), а также
с типичной стратификацией воздушных слоев (ангары.склады) на это может по-
требоваться довольно много времени. Па открытых пространствах методы хими-
ческого анализа вообще бесполезны. Таким образом, детектирование дыма с по-
:эщью видеопоследовательности обладает рядом преимуществ по сравнению с
~гхдиционными методами:
• возможность обнаружения дыма и огня на открытых пространствах и в тун-
нелях.
• точное определение местоположения очага возгорания и степени распро-
странения пламени,
• минимальная реакция на возникновение нештатной ситуации.
Ясно, что разработка подобной системы имеет большие перспективы. Дей-
."лтельно, по данным МЧС, появившимся в прессе в апреле 2007 года, ежеднев-
з России происходит в среднем 558 пожаров, на которых погибают 55 человек
3> человек получают травмы. Ежедневный материальный ущерб от пожаров
. ставляет 22.7 млн. руб.
К сожалению, вследствие ряда причин детектирование дыма и огня по видеои-
'ражению пока еще уступает с точки зрения эффективности традиционным
годам. Это объясняется следующими обстоятельствами:
• большие разнообразие и изменчивость плотности дыма, заднего плана и
условий освещения.
• ни один из таких простейших характерных признаков, как интенсивность,
движение, краевые точки не позволяет достаточно полно описать дым,
• сложность создания визуальной модели дыма.
Тем не менее, в последние годы были разработаны методы и алгоритмы, по-
.тяющие значительно увеличить надежность соответствующих видеосистем
.“актирования. Это привело к созданию нескольких успешно работающих ком-
.гческих систем.
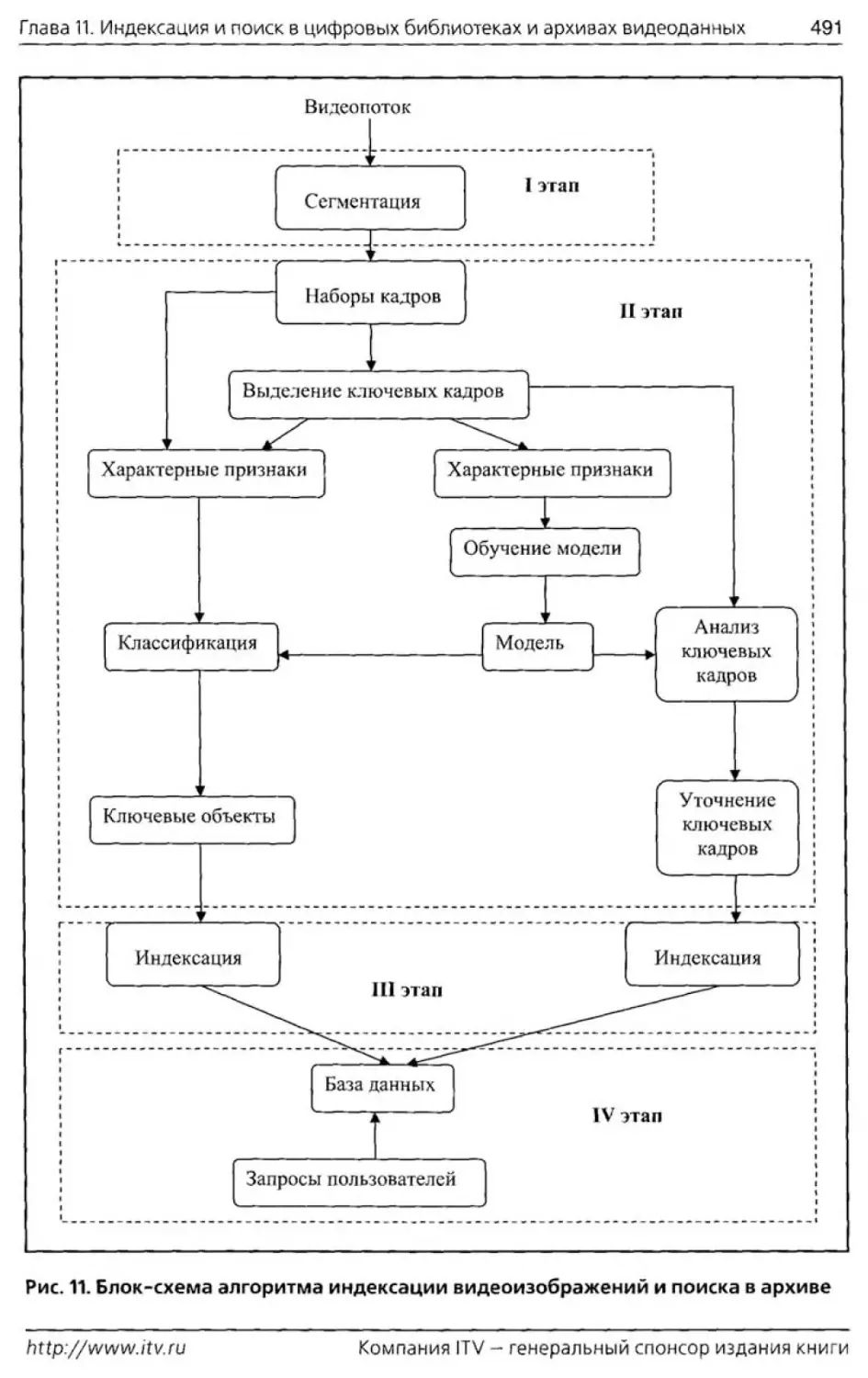
Ттава 11 посвящена проблеме индексации видеоизображений и поиску в циф-
-ых библиотеках и архивах видеоданных. Повсеместное распространение ви-
. “ехнологий и развитие компьютерной техники привело к тому, что цифровые
www.itv.ru
Компания ITV - генеральный спонсор издания книги
20
Цифвая обработка видеоизображений
архивы видеоинформации стали неотъемлемой частью самых разных систем.
Однако методы поиска в этих огромных хранилищах данных остаются весьма
примитивными и явно не отвечают современным требованиям. Обычно системы
управления цифровыми видеоархивами состоят из двух частей. Функции первой
из них заключаются в анализе поступающей видеоинформации, ее сегментации
на отдельные более мелкие фрагменты и индексации, основанной на содержании
этих фрагментов. Вторая часть системы позволяет извлекать необходимые дан-
ные в зависимости от запроса пользователя и организует взаимодействие с ним.
Большинство существующих в настоящее время систем базируется на различ-
ных текстовых аннотациях содержимого. В простейшем случае это могут быть
подписи к кадрам, ключевые слова или даже имена файлов. Очевидно, что в том
случае, когда необходимо отыскать определенный объект или событие в длинной
видеопоследовательности, методы, использующие текстовые аннотации, являются
бесполезными. Более того, для ряда объектов в принципе невозможно подобрать
лаконичное, но в то же самое время адекватное текстовое описание. Поэтому бо-
лее совершенные системы используют для индексации видеоинформации комби-
нацию нескольких характерных признаков, которые объединяются в вектор боль-
шой размерности. Эти векторы затем сохраняются в базе данных. Данные призна-
ки могут быть как низкоуровневыми (примитивными), так и высокого уровня (се-
мантическими). Когда от пользователя поступает запрос, то начинается просмотр
всей или части указанной базы данных и в качестве результатов поиска выдается
несколько кадров, ранжированных в соответствии с мерой их схожести с запросом.
Для формирования векторов характерных признаков в видеопоследовательност и
производится ее сегментация и выделяются или ключевые кадры, в большинстве
случаев отмечающие начало или конец какого-либо события, или ключевые объ-
екты. В зависимости от типа архива с этой целью могут быть использованы различ-
ные методы, некоторые из которых изложены в Птаве 11. Отметим, что в отличие
от предыдущих разделов книги методы данной главы не рассчитаны на исполнение
в режиме реального времени, что позволяет снять ряд весьма жестких ограничений.
Каждая глава имеет независимую нумерацию иллюстраций, формул и списка
использованных источников. При описании различных алгоритмов, предназна-
ченных для решения задач одного класса, мы старались расположить их по воз-
растанию сложности.
Вследствие того, что для ряда устоявшихся англоязычных терминов и поня-
тий в отечественной литературе до сих пор не существует соответствующих эк-
вивалентов, авторы взяли на себя смелость использовать или собственные рус-
скоязычные аналоги, или те. которые достаточно активно используются в среде
разработчиков методов и программ анализа видеоизображений. Для того чтобы
у читателя, знакомого с иностранными работами по обработке видеоизображе-
ний, в этом случае не возникло вопросов по ходу прочтения книги, мы добавили
специальный раздел (глоссарий), где приведены основные термины с их опреде-
лениями и англоязычными аналогами.
Несмотря на то. что мы тщательно выверяли материал книги, в работе такого
объема могут остаться ошибки. Авторы будут весьма признательны читателям,
которые сообщат о найденных неточностях. Отзывы и замечания просьба направ-
лять по адресу: book2008@ic.msu.su.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
ГЛАВА 2.
ПОСТРОЕНИЕ МОДЕЛЕЙ ФОНА И
ВЫДЕЛЕНИЕ ПЕРЕДНЕГО ПЛАНА
24
Цифвая обработка видеоизображений
При обработке видеоизображений появляется возможность отделить движу-
щиеся объекты от неподвижных. Заметим, что для систем мониторинга как раз
движущиеся объекты и представляют основной интерес. При этом всю совокуп-
ность неподвижных объектов называют фоном или задним планом, в отличие от
которых движущиеся объекты часто называют переднеплановыми. Задача вы-
деления фона является довольно непростой, поскольку на изображениях, полу-
чающихся в реальной видеосъемке, отсутствуют абсолютно нс изменяющиеся
фрагменты. Это связано как со свойствами реальных камер, которые обладают
довольно заметными собственными шумами, так и тракта передачи видеоинфор-
мации от камеры к системе обработки, в котором изображение перед пересыл-
кой часто сжимается, а потом декодируется, что может привести к дополнитель-
ным искажениям сигнала. Более того, на сцене часто присутствуют объекты,
которые хоть и являются в нашем понимании неподвижными, однако обладают
определенными динамическими характеристиками (например, деревья, качаю-
щиеся на ветру). Учет перечисленных факторов при выделении фона приводит
к необходимости разработки довольно гибкой системы, которая, как принято го-
ворить, формирует модель заднего плана.
При построении модели заднего плана следует в той или иной степени учи-
тывать свойства объектов, которые могут присутствовать на видеоизображении.
Эти объекты можно разбить на следующие группы:
• неподвижные объекты,
• временно неподвижные объекты,
• медленно движущиеся объекты,
• объекты, совершающие периодические колебания,
• неподвижные объекты с динамически меняющимся изображением,
• движущиеся объекты.
К неподвижным объектам относятся различные стационарные объекты,
такие как сооружения, покрытие дорог, столбы и т. п., т. е. все объекты, ко-
торые являются неподвижными в течение достаточно длительного периода
времени. Временно неподвижными объектами являются запаркованные авто-
мобили, ограждения при дорожных работах и т. п., т. е. объекты, являющиеся
неподвижными во временном диапазоне от нескольких минут до нескольких
дней. К медленно движущимся объектам относятся автомобили, находящиеся
в дорожной пробке, тени от облаков и зданий, т. е. объекты, все время находя-
щиеся в движении, которое практически невозможно различить на большин-
стве соседних кадров при регистрации камерой. Объектами, совершающими
периодические колебания, являются деревья и кусты, флаги, рекламы на пере-
тяжках, т. е. объекты, которые периодически перемещаются около некоторо-
го положения равновесия, как правило, под действием ветра. К неподвижным
объектам с динамически меняющимся изображением относятся световые ре-
кламные табло, огни светофоров и аварийно припаркованных автомобилей и
т. п. Эти объекты находятся на одном месте (т. е. не движутся), однако создава-
емый ими световой поток достаточно быстро изменяется во времени. И, нако-
нец, движущиеся объекты - это всевозможные транспортные средства, иду-
щие и бегущие люди, животные, тени от них, т. е. все то, что перемещается с
достаточно заметной скоростью.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 2. Построение моделей фо*а и выделение переднего плана
25
Еще раз заметим, что обнаружение движущихся объектов, или иначе выделе-
ние переднего плана, является самым важным элементом системы мониторинга.
От того, насколько аккуратно и корректно выделены движущиеся объекты, за-
висят все последующие этапы, а также требуемые вычислительные ресурсы. Все
методы, которые были разработаны к настоящему моменту, можно разделить на
следующие группы:
• методы вычитания фона.
• вероятностные методы.
♦ методы временной разности.
• методы оптического потока.
Методы из разных групп имеют различную сложность реализации и, соот-
ветственно, отличаются необходимыми требованиями к вычислительным ресур-
сам. В большинстве случаев задача обработки видсопотока осуществляется в ре-
альном времени, и зачастую на одном компьютере обрабатывается информация,
получаемая одновременно от нескольких камер. Ясно, что при разработке по-
добной системы разработчики отдадут предпочтение более простым методам
вычитания фона в ущерб качеству, нежели методу оптического потока, который
требует достаточно больших ресурсов. В то же время при обработке видеоархи-
вов, (например, для их индексирования), можно применить более сложные мето-
ды, позволяющие достичь лучшего качества обработки.
2.1 МЕТОДЫ ВЫЧИТАНИЯ ФОНА
Вычитание фона - это наиболее широко распространенный в настоящее вре-
мя подход к обнаружению движущихся объектов в видеоизображениях, получен-
ных с помощью стационарной телекамеры. Суть таких методов заключается в
попиксельном сравнении текущего кадра с шаблонным, который обычно назы-
вают моделью фона. Как правило, эта модель, представляющая собой описание
сцены без движущихся объектов, должна регулярно обновляться, чтобы отра-
жать изменения освещенности и геометрических параметров [1-14].
Рассмотрим видеопоследовательность, получаемую со стационарной теле-
камеры. Для каждого кадра этой последовательности нам необходимо постро-
ить двоичную маску изображения, в которой значение 1 соответствует передне-
му плану, а 0 - фону. Обычно считается, что в течение п первых кадров в видео-
последовательности нет движущихся объектов. Это требование необходимо для
корректного построения фоновой модели. Однако оно не всегда может быть вы-
полнено, поэтому вместо него часто рассматривают так называемую динамиче-
скую модель фона, когда считается, что в п первых кадрах могут присутствовать
движущиеся объекты (например, ветви деревьев, колышущиеся на ветру), но они
не представляют интереса для проводимого анализа. На Рис. 1 приведен пример
обработки видеопоследовательности с использованием метода вычитания фона.
Простейший алгоритм вычитания фона заключается в вычислении для
каждого пикселя абсолютного значения разности сохраненного первого кадра
В(х, у) видеопоследовательности и текущего кадра 1(х, у). Полученное значение
сравнивается с порогом <5:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
26
Цифвая обработка видеоизображений
Рис. 1. Пример обработки изображения с помощью метода вычитания фона. А - ис-
ходное изображение, Б - двоичная маска, В - модель фона, Г - выделенный перед-
ний план
|В(х,у)-/(х,>)|><5, х = у = (1)
Здесь N и Л/ - соответственно ширина и высота изображения. Если данное нера-
венство выполняется, то пиксель (х, у) считается переднеплановым, иначе - фо-
новым. Для устранения шума можно обновлять задний план с помощью фильтра
с бесконечным импульсным откликом:
Дя=а/,+(1-а)Д, (2)
где индекс t обозначает номер кадра, а а обычно лежит в пределах от 0.05 до 0.15.
Кроме (2) можно использовать другие, несколько более сложные фильтры. На-
пример. пиксели, относящиеся к фоновому изображению, определять из следую-
щего соотношения:
в, (*»>’) = a rg min £|/м (х,у) - (х,у)|. (3)
,=0." /=0
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 2. Построение моделей фона и выделение переднего плана
27
Естественно, для этого метода требуется увеличение необходимых вычислитель-
ных ресурсов, так как приходится хранить информацию из п предыдущих кадров.
Вместо неравенства (1) также можно применить следующее неравенство:
I у) ~ Л .у) ”
1 Л -<—'> и > 5, (4)
О'
где и о - среднее значение и стандартное отклонение величины В (х, у)-Цх, у).
Для усиления контрастности в темных областях, таких как тени, иногда ис-
пользуется относительная разница фона и текущего изображения:
|Д(х.>)-/(»,у)|>г (5)
в,(х>у)
Тем не менее, данная модификация алгоритма не будет работать, например, для
изображений, полученных в густом тумане.
Отметим, что единственным достоинством указанных алгоритмов являет-
ся простота их реализации. К недостаткам данных методов относятся высокая
чувствительность к изменению освещенности сцены (при этом большая часть
сцены может быть сегментирована в передний план) и шуму камеры, невозмож-
ность обработки динамического фона, большая вероятность ошибок первого и
второго рода при классификации конкретных пикселей изображения. Одной из
причин этого является постоянство порогового значения 8. В идеале порог дол-
жен быть свой для каждого пикселя. Например, для областей с низкой контраст-
ностью он должен быть меньше. Хотя с помощью варьирования значений пара-
метров фильтрации и порога 8 можно в каждом конкретном случае сократить
число получаемых ошибок, алгоритмы (1)-(5) в указанном виде практически ни-
когда не используются в действующих системах обработки видеоизображений.
Поэтому далее мы будем рассматривать различные модификации простейше-
го метода вычитания фона, позволяющие избавиться от одной или же сразу не-
скольких из перечисленных здесь проблем.
Одним из возможных способов преодоления указанных недостатков, в част-
ности корректного учета изменения освещенности сцены, а также периодиче-
ских фоновых движений (ветви деревьев), при выделении переднего плана яв-
ляется использование двух моделей фона. Предположим, что в момент времени t
имеется первичное фоновое изображение В/ и вторичное В/ (х,у). Соответ-
ственно можно получить две разности фона и текущего изображения:
(*. у) = \в? (х*у)~ Л (х»у)|. (6)
D< (х> у)-Iй/ (*» у) - Л (*> у)|- <7)
Обозначим через q тот индекс (р или $), для которого указанная выше разность
Dt меньше, а через q- другой индекс. Тогда обновление фоновых изображений
проводится по следующей схеме:
(1-а')Вг’(х,^) + а7((х,у), (x,y)eFG,
1(1 - а) В,’ (х, j) + al, (х, у), (х, е BG,
(*,у)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
28
Цифвая обработка видеоизображений
В^х,у) = В'(х,у). (9)
Здесь FG и BGt обозначают области изображения, относящиеся к передне-
му плану и фону в момент времени t соответственно. Обычно а' выбирают мень-
ше, чем а, а для инициализации фоновых изображений в качестве Btp(x,y) ис-
пользуются средние значения для нескольких первых кадров. При этом величи-
на В/ (х,у) определяется как
В;(х,у) = В1р(х,у) + и(х,у). (10)
где функция и (x,j>) описывает шум. присутствующий в изображении.
Другим возможным улучшением простейшего алгоритма вычитания фона
является адаптивное определение величины порога, что, в принципе, можно осу-
ществлять различными способами. Например, можно сначала рассчитать раз-
ность фона и текущего изображения:
D(x,y) = |s(x,^)-7(x,jy)|, (11)
а затем для нес построить гистограмму
0.
D(x,y) = k
D(x,y)* к
(12)
где Л=0,...255. Найдем значение /и, при котором достигается максимум,
S = max Н (к\Тогда можно найти такое 8. что
Н(8) = Р8т, 8 > arg max Н {к\ (13)
к
Для параметра Д рекомендуется выбирать небольшое значение, порядка
0,05. Далее при определении фона применяется следующая схема. Для перво-
го кадра фон считается совпадающим с текущим изображением и вычисляется
маска
Л/(х,^) =
1,
о,
D(x,y)>8
D(x,y)<8
(14)
Для всех пикселей, для которых М(х, у)=0,фон обновляется по формуле (2).
При этом в случае меняющегося освещения или изменения положения камеры
будут появляться области изображения, для которых М(х, у)=1 на протяжении
многих кадров (например, движение тени от стационарного объекта). Для устра-
нения этого недостатка проводится подстройка маски:
Ч (^>')=-’(Ч-я (^.^)& Ч-я+1 (х,у)&...& М, (x,j))
где п - наперед заданное количество кадров. Аналогично для всех пикселей, для
которых М (х,^) = 0, фон меняется по формуле (2).
Помимо величины порога 5, можно также адаптивным образом изменять и
фоновую модель. При этом существенное изменение внешних условий,таких как
смена дня и ночи, учитываются при помощи адаптивной схемы в зависимости от
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. ргосс tv. г и
Глава 2. Построение моделей фона и выделение переднего плана
29
того, является ли рассматриваемый пиксель переднеплановым ((x,y)eFG) или
фоновым G BG):
аВ, (х, _у) + (1 - а) /, (х, у), (х, у) 6 BG
рВ, (х, у) + (1 - Д) I, (х,у), (х,у) е FG
(15)
«4 (^.^)+(1 - «)(Y |Л См’)- в.
(х,у)е BG
(х,у)е FG.
(16)
Здесь а,Р е [0,1] и у - весовые коэффициенты, определяющие степень об-
новления фона и порога S. Как видно из приведенных формул, в данном методе
не только фон, но также и пороговое значение обновляются для каждого пиксе-
ля в отдельности. Кроме того, фон обновляется для всех типов пикселей: как для
переднеплановых, так и для фоновых. Это приводит к тому, что данная модифи-
кация метода вычитания фона позволяет учитывать повторяющиеся изменения
внешних условий, а также избегать сегментации движущихся объектов, появля-
ющихся на изображении, как фоновых.
Для корректной работы представленного метода необходимо аккуратно вы-
бирать значение р. Если оно будет слишком мало, то объекты переднего плана
будут быстро классифицироваться как фоновые, что приведет к неправильной
сегментации в последующих кадрах. Кроме того, будет невозможным детекти-
рование остановившихся объектов. Если же выбрать значение Д слишком боль-
шим, переднеплановые объекты никогда не будут переходить в фоновые, не по-
зволяя отражать долговременные изменения сцены.
Указанные соображения приобретают особенно большое значение в та-
ких сферах применения систем видеонаблюдсния, как мониторинг транспорт-
ных средств на автомобильных парковках. Там постоянно встречается ситуация,
когда автомобиль, долгое время стоявший на парковочном месте, выезжает со
стоянки. При этом фоновое изображение обязательно должно быть обновлено.
Обратный процесс - остановка автомобилей в поле зрения камеры. Через неко-
торое время такой автомобиль должен быть отнесен к фоновому изображению.
Данная операция называется интеграцией объекта. Существенным недостатком
всех рассмотренных выше алгоритмов является то, что время интеграции чрез-
вычайно сложно контролировать. Во-первых, оно зависит от окраски объекта.
Действительно, если объект многоцветный, то некоторые области интегрируют-
ся в фон быстрее других. Во-вторых, если объект двигается медленно или оста-
навливается на короткое время, то в фоновое изображение могут быть внесены
ошибочные возмущения.
Для учета этих соображений иногда вводятся специальные индикаторы, по-
зволяющие контролировать процесс интеграции объектов. Основная идея за-
ключается в обновлении пикселей только в том случае, если достигнута так на-
зываемая «стабильность наблюдений», т.е. за определенный промежуток вре-
мени не зафиксировано никаких изменений в данной области изображения. Для
того чтобы алгоритм был рекурсивным, индикаторы стабильности учитывают
историю изменений каждого пикселя. Как только будет зафиксировано движе-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
30
Цифвая обработка видеоизображений
ние в области, к которой принадлежит рассматриваемый пиксель, индикатор
стабильности для него принимает минимальное (нулевое) значение. Если в сле-
дующих кадрах изменений не наблюдается, индикатор постепенно увеличива-
ется, пока не достигнет своего максимального значения, равного 1. Шаг измене-
ния индикатора 0 определяется величиной, называемой задержкой интеграции,
и зависит от контекста анализируемой информации. Обновление фона проис-
ходит только тогда, когда индикатор стабильности становится равным 1. Это
позволяет не обновлять те части фонового изображения, которые были недав-
но обновлены, и где теперь снова зафиксировано движение. Остановившийся
объект автоматически сегментируется в фон через промежуток времени, рав-
ный задержке интеграции.
При выполнении условия
(17)
индикатор стабильности 5 определяется из следующего соотношения:
(18)
Для учета медленных изменений, происходящих в анализируемой сцене, в мо-
дели вычитания фона можно использовать простые статистические соображе-
ния. Например, для каждого пикселя в текущем кадре t вычисляются скользящее
среднее It и стандартное отклонение которые затем обновляются с помощью
следующих формул:
4+1 = a/Itl+(l-a)/„
(19)
^i = a[7M-A,i]+(l-a)q, (20)
где а = т /, /- количество кадров в секунду, а постоянная величина т определя-
ет, насколько быстро должен изменяться фон при изменении внешних условий.
Влияние старых изменений уменьшается со временем по экспоненциальному за-
кону, тем самым, позволяя фону отражать текущее состояние внешних условий.
Если значение пикселя / (х, у) отличается от 7t более чем на 2ar, то такой
пиксель считается переднеплановым. Для него инициализируется новый на-
бор статистических параметров а исходный набор временно сохраня-
ется. Если по прошествии времени Т = Зт значение пикселя не вернулось к ста-
рым статистическим параметрам, то новые статистики окончательно заменяют
старые.
В качестве статистических характеристик отдельных пикселей могут так-
же выступать следующие величины: минимальное (/mm) и максимальное (Zmax)
значения интенсивности, а также максимум разницы интенсивности (Д) по-
следовательных кадров. Все указанные величины рассчитываются в началь-
ный период наблюдения, когда сцена не содержит движущихся объектов.
Тогда пиксель (х, у) в текущем кадре / считается переднеплановым, если вы-
полнено хотя бы одно из условий:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 2. Построение моделей фона и выделение переднего плана
31
knuo(x.y)-A(x.y)|>AUA <21)
|/пИ»(^>’)-/1(х.>')|>д(х’>’). (22)
Как уже упоминалось, большое значение при анализе видеоизображений
имеет корректный учет шумовой составляющей сигнала. Одним из возможных
решений, отвечающих указанному требованию, является использование филь-
тра Кальмана. Пусть процесс изменения значений фоновых пикселей описывает-
ся системой для обработки цифровых сигналов, состояние которой в момент вре-
мени г с учетом шума может быть оценено с помощью следующего фильтра:
7(х,у,/) = 7(х,у,г) + Л:(х)у,/)[/(х,.у./)-//(г)/(х,7,/)], (23)
l(x,y,t) = A(t) (24)
Здесь I(x, у, t) - оценка интенсивности пикселя (х, у) в момент времени Z,
A(t) - системная матрица, H(t) - матрица измерений. К(ху у, t) - матрица усиления
Кальмана, получающаяся из ковариационной матрицы ошибки предсказания со-
стояния системы (усиление велико для небольшого шума и наоборот). При по-
мощи уравнений (23) и (24) предсказывается новое состояние системы, затем оно
сравнивается с действительным значением и получается новая оценка путем ком-
бинации измеренного и предсказанного значений с весовыми коэффициентами.
Поэтому те измеренные значения, которые не соответствуют реальному поведе-
нию системы, входят в уравнения с меньшим весом. Данный алгоритм является
рекурсивным, т. е. оценка состояния системы включает в себя всю предыдущую
информацию, при этом не храня все измеренные значения.
Помимо оценки значения интенсивности пикселя 1(х, у, t), можно также
использовать оценку /(х, у, t) изменения интенсивности между двумя после-
довательными кадрами. В этом случае уравнения (23) и (24) примут следую-
щий вид:
Переменным а12 и рекомендуется присвоить значения порядка 0.7. Для полуто-
новых изображений матрица Н может быть выбрана постоянной:
Н = [1 0], (28)
а переменные для усиления заданы в следующей форме:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
32
Цифвая обработка видеоизображений
K{x,y,t)
(29)
где
к\ (*> У>0 = ^2 (х»У*t)= а 'М (х,У,t -1) + Р[1 - М (х,у,t -1)]. (30)
Значения М(х, у, I) представляют собой маску сегментации изображения в перед-
ний план (М=1) или в фон (Л/=0):
M(x,y,t) =
1,
0,
£>(х,у,г-1)> 5
D(x, у,/-1)< 5
(31)
D(х,у,t) -1/ (х, у,г) -I (х, у,/)|. (32)
Значение 8 следует выбирать таким образом, чтобы небольшие отличия в интен-
сивностях пикселей приводили к быстрому изменению фона, а значительная раз-
ница интенсивностей сегментировалась в передний план.
Хотя такой алгоритм и используется для выделения переднего плана и тре-
кинга объектов, однако в рассмотренном виде он накладывает слишком боль-
шие ограничения на свойства входной видеопоследовательности.Так, например, из
уравнений (30)-(32) следует, что усиление К в кадре t зависит от сегментации в мо-
мент времени /-1. Это означает, что пиксель в момент /, ставший в действительно-
сти частью переднего плана, адаптируется туда на первом же шаге фильтрации
с использованием большего, отвечающего за изменение фона коэффициента Д,
вместо того чтобы задействовать меньший по величине и соответствующий адап-
тации переднего плана коэффициент а. Если мы хотим отразить изменения осве-
щенности в фоновой модели, при этом невозможно избежать изменений переднего
плана. А это нежелательно по той причине, что медленно движущиеся и периоди-
чески останавливающиеся объекты закрывают пиксели фона на более продолжи-
тельное время по сравнению с быстро движущимися объектами. Если объект пре-
кратил свое движение, то через несколько итераций он будет сегментирован в фон.
Начав через некоторое время свое движение вновь, он будет детектирован дваж-
ды: в своем нынешнем положении и в том, где он останавливался.
Для устранения указанных недостатков метод может быть модифицирован
путем замены уравнения (30) на следующее:
kt(x,y,t) = k2(x,y,t) =
а,
Р.
(d'(x,y,t) > 5)и[(</'(х«^’0<5)П(^"(х>л0* 5)] 33)
(d'(x,y,t)< 5)
где
d'(x,y,t) = \l(x,y,t)-I(x,y,t)[
d"(x,y,t) = |/ (x,y,t)~ 7'(х,7>4
i'(x,y,t) = l (x,y,t)+ /3-[1 (х,у,/)-7(х,у,/)],
(34)
(35)
(36)
ProSystem CCTV - журнал по системам видеонаблюдения
http://wwwprocctv.ru
“лава 2. Построение моделей фона и выделение переднего плана
33
Таким образом, если разность (Г превышает пороговое значение, то этот пиксель
принадлежит к переднему плану и оценка значения пикселя производится с ис-
пользованием коэффициента а. Если же меньше порога, то такой пиксель мо-
жет принадлежать к фону. В этом случае вычисляется предварительная оценка
Г(х, у, t) с использованием р. Если разность между предварительной оценкой и
истинным значением 1(х, у, t) превышает пороговое значение, то такой пиксель
сегментируется в передний план с использованием а. Если же разность меньше
порога, то окончательная оценка совпадает с предварительной.
Использование здесь в качестве порогового значения постоянной величины
приводит к тому, что тени, падающие от движущегося объекта, сегментируют-
ся в передний план. Для устранения этого недостатка следует считать значение 8
зависящим от дисперсии оценок фоновых значений, т. е. порог должен быть про-
порционален дисперсии:
<5(x,y,f) = 56 + v(x,y,r-l), (37)
где 8- некое фиксированное значение и
(38)
(40)
(41)
Отсюда следует, что в начальной стадии пороговое значение равно фиксиро-
ванной величине 8Ь. В дальнейшем оно определяется дисперсией v(x, у, 1~\). В вы-
числениях п обычно лежит в пределах от 10 до 20.
Когда фон временно закрыт объектом переднего плана, невозможно по-
лучить никакую информацию о происходящих с фоном изменениях. Одна-
ко можно экстраполировать фоновые значения на тот период, когда фон сно-
ва будет открыт. При этом в случае совершения объектами переднего плана
быстрых движений считается, что в то время, пока фон был закрыт, измене-
ния освещения там были минимальными. Отсюда следует, что в качестве поро-
гового значения может быть выбрана такая константа, чтобы новое (после от-
крытия) фоновое значение не сегментировалось в передний план, хотя может
существовать весьма значительная разница между оценкой фонового значения
Цх, у, г), вычисленной до закрытия, и реальной величиной 1(х, у, t) вновь откры-
того фона. Поэтому модифицируем значение v(x, у, t) для определения порого-
вого значения:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
Цифвая обработка видеоизображений
(42)
Величину г (г - / ) следует выбирать таким образом, чтобы выполнялось нера-
венство у(х,Ь^Уехр[г(г-//6)]<2у(х,y.tlb\ где tlh- время, когда последний раз
данный пиксель был сегментирован в фон. Предполагается, что фоновые зна-
чения нормально распределены. Используя /-распределение Стьюдента, задан-
ный доверительный коэффициент у и среднее значение //=/'(х,у,/), можно
рассчитать доверительный интервал для дисперсии:
G^=[r(x,Jv,/)-a(x,y,r)^'(x,y,/) + a(x,y,/)] = [Gr/,Gr/], (43)
£
a(x,y,t) = v(x,y,/)-=.
П
(44)
Если предположить, что у = 99.8% и и = 10, то с = 43. Фоновые значения попе-
ременно приравниваются то к нижней границе доверительного интервала, то к
верхней:
I'(x,y,t) =
/(x,y,t), M(x,y,t) = 0
G^, M (x,y,t) = 1 U(r,r + 2,t + 4,...)
Gcum/, M(x,y,t) = \{J(t-\,t+l,t + 3,...).
(45)
Следует заметить, что хотя такое определение порогового значения и позволя-
ет обрабатывать временно неподвижные объекты, оно приводит к снижению ро-
бастности разделения фона и переднего плана.
До сих пор мы рассматривали полутоновые изображения. Однако для вы-
деления переднего плана с учетом теней и медленных изменений освещенно-
сти большую помощь может оказать использование цветовой информации.
Будем предполагать, что шум камеры по трем цветовым каналам имеет нор-
мальное распределение. Оценим дисперсии шума <J2Rcam, £>1сат и 02Всат и с помо-
щью ряда начальных кадров создадим модель фоновых пикселей, зависящую
от математического ожидания и дисперсии интенсивности каждого пикселя
[дЛ.ДС,Дв ,a2R,a2G,о2в]. Обновление этих параметров будем проводить по следу-
ющей схеме:
(*> У) = «Я (х, у) + (1 - а) /<+1 (х, у\ (46)
(*• у) = « [tf.2 (*• у)+(Д1+1 (*. Я - Д, (*. У))’ ] + (1 - а )(Л.1 (А у) - Дж (х> у))\ (47)
где а - константа (например, 0.9). Обозначим через R величину интенсив-
ности канала R для пикселя (х, у) и аналогично и Вху. Тогда пиксель счи-
тается принадлежащим к переднему плану в первом приближении, если вы-
полняется хотя бы одно из трех неравенств (здесь использовано правило
трех сигм):
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ri/
Глава 2. Построение моделей фона и выделение переднего плана
35
К, - (*, у)| > 3 max [аЛ, <тЛям1 ],
|<Ъ, " До (*> У)| > 3 тах » ^ссо». ], (48)
| В,., - Д8 (х, у )| > 3 max [стй, аВсат ].
Если же ни одно из этих трех неравенств не выполняется, то пиксель считается
фоновым.
Сделанное выше предположение о медленном изменении освещенности на-
рушается в случае отбрасывания теней движущимися объектами. Тени не долж-
ны быть сегментированы в передний план. Поэтому используем тот факт, что
области изображения, накрываемые тенями, претерпевают сильные изменения
освещенности, хотя хроматичность при этом почти не изменяется.
Вычислим величину хроматичности для каждого пикселя:
RC = R/(R + G + B\
GC = G/(R + G + В).
а также найдем средние значения и дисперсии хроматичности ’^r, >°с, )•
предполагая, что они являются независимыми случайными величинами (их зна-
чения обновляются в каждом кадре по формулам (46)-(47)).
Часто встречаются ситуации, когда разница между величиной хроматич-
ности переднего плана и фона незначительна (например, движение черного
автомобиля по темно-серой дороге). В таком случае невозможно, основыва-
ясь на изменениях параметров, введенных выше, определить, принадлежит
ли данный пиксель теневой области или нет. Поэтому будем вычислять гра-
диенты интенсивности VZ(x,y) = [Э//Эх,Э//Эу] в данной точке. Для этого вос-
пользуемся оператором Собеля [16] и найдем свертку ядра размером 3x3 с
исходным изображением:
а/
Эх
'-1
-2
<-1
э/
Эу
ч
о
<1
О 0 */.
2 1;
(49)
О
о
о
р
2 ♦ /,
2 П
Для каждого фонового пикселя определим средние значения и диспер-
сию вектора V7(x,y): (д,я,//уЯ), (д.с.Д.с). (д,я,Д,я) и a2gB, <т’с, О2В соответствен-
но. Кроме того, рассчитаем средние значения дисперсий по всему изображению
5^,5^.Если обозначить через = ((dI/dx)R ,(Э//Эу)л)- градиент интен-
сивности пикселя (х, у) по каналу R и аналогично для двух других каналов, то пик-
сель считается переднеплановым, если выполняется хотя бы одно неравенство:
+[(Э//ЭА -д,«]2 > Зтах[^.^я],
+ [(3//^)c-^]2 >3max[CTgG,CTgC], (50)
-Д>8]2 >3ma*[tfgeAe]-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
36
Цифвая обработка видеоизображений
Таким образом, пиксель сегментируется в передний план только в том случае,
если выполняется хотя бы одно из условий (48) и (50) или (48) и условие, анало-
гичное ему для хроматичности.
2.2 ВЕРОЯТНОСТНЫЕ МЕТОДЫ
—(52)
(2-) X /
Рассмотренные в данном разделе алгоритмы разделения фона и переднего
плана основаны на вероятностных моделях. Хотя в предыдущем разделе в ряде
моделей использовались простейшие статистические соображения, тем не менее,
такие модели обычно не относят к вероятностным, ввиду того что в них значения
пикселей описываются без учета функций распределения.
В вероятностных методах изменения значений пикселей со временем рассма-
триваются как пиксельный процесс.т.е. временной ряд,состоящий из скалярных
величин для полутоновых изображений и векторов - для цветных [16-17,19-26].
В произвольный момент времени t для каждого пикселя (х0, у0) известна его
предыстория:
{%р...Л,} = {/(хй,у0,/):1<1</}. (51)
Здесь Х,= I(xQ, yQ, i) - значение пикселя (х0, у0) в Лом кадре. Изменения пикселей
фона моделируются с помощью нормально распределенной случайной величины
с плотностью В ~ П (ЛА, L,).
_____1
(2^Г2
где п=1 для полутоновых изображений. п=3 - для цветных.
По нескольким последовательным кадрам для каждого пикселя производит-
ся оценка параметров модели и а затем с помощью порогового значения
определяется принадлежность пикселя к переднему плану или фону. Для оцен-
ки параметров модели и Z, для каждого пикселя можно применять выбороч-
ное среднее:
= (53)
t 1=1
а ковариационную матрицу считать имеющей следующий вид:
L,=<r,2I. (54)
^=А^(х/-д.)2. <55)
' 1 1=1
где 1 - единичная матрица. Такой вид ковариационной матрицы предполагает, что
для цветных изображений (7?,G,B) значения пикселей являются независимыми и
обладают одинаковой дисперсией. Хотя это довольно грубое приближение, оно
позволяет сильно сократить количество вычислений за счет исключения опера-
ции обращения матрицы.
После начальной оценки параметров Ц, и для каждого следующего кадра и
для каждого пикселя (х0, у0) рассматривается неравенство
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Vaea 2. Построение моделей фона и выделение переднего плана
37
^<5 (56)
°,
Если оно выполняется, то данный пиксель сегментируется в задний план, иначе -
в передний план.
Если не пользоваться предположением о независимости значений интенсив-
ностей по различным каналам и равенстве их дисперсий, то приходится вычис-
лять полную ковариационную матрицу. Однако можно найти ковариационную
матрицу S, один раз. а дальше се и среднее значение обновлять по следую-
щей схеме:
Д, =0-а)Я-1+а^г <57>
I, =(l-a)Z,.|+avvr. (58)
где v = v(x0,^0,t) - Х( - /1га - параметр, характеризующий скорость изменения
фона. После обновления данных величин вычисляется логарифмическая вероят-
ность Р, отличия текущего изображения от фона v (здесь л=3):
1 1 т
р, (хо. Уь>0 = 2 S"' V - - 1л ЭД- -ln (2 л). (59)
Пиксель (х0, у0) считается переднеплановым, если Р, (х0, у0, t) < 5, в противном
случае он относится к фону.
Более аккуратными являются алгоритмы, создающие попиксельную модель
сцены, в которых для фона, переднего плана и теней используются свои собствен-
ные нормальные распределения, как это показано на Рис. 2:
= (6О)
/в {b,sj}_
Здесь индексы Ь, s и / обозначают соответственно фон, тени и передний план, а
распределение задается формулой (52).
Каждому слагаемому в сумме соответствует процесс в пикселе сце-
ны, который характеризуется параметрами нормального распределения
0 = {фрДрЕ,} с весовым коэффициентом который является показателем
того, насколько часто данный процесс в данном пикселе попадал в поле зре-
ния камеры. Вероятность того, что текущий пиксель примет значение и
будет относиться к классу / при данном наборе 0, определяется по следую-
щей формуле:
P(L = I, X, = Хо 10)= П, (*0,Д,,Л.,)- (61)
Вычислив данные вероятности, можно классифицировать отдельные пиксе-
ли путем отнесения их к тому классу, для которого апостериорная вероятность
Р(L=l\X') принимает наибольшее значение. Параметры 0 выбираются таким об-
разом, чтобы максимизировать величину
http://www./tv.ru
Компания ITV - генеральный спонсор издания книги
38
Цифвая обработка видеоизображений
Рис. 2. А - распределение значений интенсивности для одного из пикселей изобра-
жения в течение 1000 кадров, полученное экспериментальным путем; Б - распреде-
ления для каждого типа пикселей и их взвешенная сумма
flP(£ = /„Xr|0), (62)
/=|
где п - число рассматриваемых последовательных кадров, a lf - класс, к которому
относится пиксель в кадре г.
Для определения и обновления набора параметров 0 предположим, что на
протяжении всех п кадров нам известны метки каждого пикселя. Обозначим че-
рез L( метку пикселя (х, у) в гом кадре. Эта величина принимает одно из трех
возможных значений (6, у, f} и определяет принадлежность пикселя одному из
указанных выше классов. Введем следующие обозначения.
ProSystem CCTV - журнал по системам видеонаблюдения http://www.procctv.ru
Глава 2. Построение моделей фона и выделение переднего плана
39
• nt - число кадров, для которых L =Д
• ............
• Z'=;S«.......*Л. <
Тогда набор параметров 0 определяется по следующим формулам:
(63)
п
S,
= Л (64)
X/ = Zt — /j.t Ц/, (65)
ni
К сожалению, для произвольного обучающего множества нам неизвестны
метки каждого пикселя для последовательности, состоящей из п кадров. Поэто-
му вместо (62) будем максимизировать величину
L(0)=flp(^ie), (66)
r=i
для чего воспользуемся методом ожидания-максимизации (ОМ).
Предположим, что мы имеем некий набор параметров 0'4 В этом случае мы
можем использовать вероятности различных классов с этими параметрами как
приближения к их истинным распределениям. При этом ожидаемые значения
S, и Z; выражаются формулами:
£[n,|0] = £p(L,=/|%„0'‘)). (67)
/ = |
£[5/|0]=£/’(л,=/|^>0(‘))^, (68)
Г-1
£[z, |0] = £ p(l, = 11 х„ ©<*>)X, • X'. (69)
г-1
Теперь новые значения параметров 0(А+1) могут быть найдены по формулам
(63)-(65) с заменой nr Sf и Z, на их ожидаемые значения (67)-(69).
Указанный процесс обладает двумя важными свойствами. Во-первых, так как
). то с помощью 0(*+1> можно точнее описать имеющиеся данные,
чем с помощью Q(k>. Во-вторых, если 0<*+,)= 0f*\ то &k) представляет собой не-
подвижную точку (а, следовательно, глобальный максимум) оператора Л(0). По-
этому из этих двух свойств следует, что рассматриваемый процесс сходится к не-
подвижной точке [19].
Описанная выше процедура требует хранения всех изображений последо-
вательности из п кадров. Однако существует модификация данного алгоритма,
основанная на том, что алгоритм ОМ можно рассматривать как метод, постоян-
http://www. itv.ru
Компания ITV - генеральный спонсор издания книги
40 Цифвая обработка видеоизображений
но улучшающий свои статистические параметры. Таким образом, если на каждом
новом шаге удалять какой-либо из старых членов суммы и добавлять новый, то
вероятность того, что новый набор данных аппроксимирует реальный набор луч-
ше, чем старый, только увеличивается. Поэтому весь алгоритм можно преобразо-
вать к следующему. В начальный момент времени определяются nrSt и Zt по фор-
мулам:
n,=kwh (70)
St = кш, (71)
(72)
где к-const. Для каждого последующего кадра переоценка параметров произво-
дится следующим образом:
л( = л; + Р(£,=/|Хр0), (73)
5,=5, + Р(£г=/|Х„0)Х„ (74)
Z^Z^P(L,^l\X„e)X,-X^ (75)
Далее с помощью найденных значений nr Sf и Zf вычисляется набор параметров 0.
Теперь остается только классифицировать компоненты смеси. Это осущест-
вляется следующим образом: самая темная компонента помечается как теневая,
а из двух оставшихся компонента с большей дисперсией классифицируется как
переднеплановая. Соотнесение текущего пикселя с одним из классов произво-
дится на основании определения наибольшей апостериорной вероятности.
Хотя в данной модели используется три нормальных распределения, для опи-
сания фона используется только одно из них. Однако можно построить модель
фона, в которой применяется смесь из К нормальных распределений:
= п(^,Я.,Лм). (76)
i«l
где плотность задается формулой (52).
Параметр К - максимальное количество распределений в смеси - выбирает-
ся в соответствии с ресурсами компьютера (обычно берут значения от 3 до 5).
На основе этой модели можно создать алгоритм, который справляется со мно-
гими из перечисленных выше проблемами. Если процесс изменения значений
пикселей можно было бы рассматривать как стационарный процесс, то стан-
дартным методом для максимизации вероятности наблюдаемых событий был
бы метод ожидания-максимизации. Но, вследствие того что в рассматриваемой
модели для каждого пикселя используется смесь нормальных распределений, ис-
пользование указанного метода потребовало бы больших вычислительных ре-
сурсов. Кроме того, изменение освещенности сцены и появление или исчезно-
вение стационарных объектов предполагает уменьшение зависимости текущих
событий от прошедших с течением времени. Все это приводит к необходимо-
сти использовать приближение К-средних метода ожидания-максимизации для
ProSystem CCTV - журнал по системам видеонаблюдения
http://wwwprocctv.ru
Глава 2. Построение моделей фона и выделение переднею плана
обновления фоновой модели, и процесс построения фона может быть описан в
виде следующего алгоритма:
1. Инициализация.
На первом кадре видеопоследовательности происходит инициализация модели.
В каждом пикселе создается одно распределение со следующими параметрами:
~ Ь Ди =
и задаваемой наперед ковариационной матрицей. Все пиксели считаются фоно-
выми в первом кадре.
Для всех последующих кадров выполняется указанная ниже последователь-
ность действий.
2. Проверка на принадлежность к существующим распределениям.
Каждое новое значение пикселя X, проверяется на соответствие его имею-
щимся к < К нормальным распределениям. Соответствие считается найденным,
если выполняется следующее неравенство (т. н. расстояние Махаланобиса):
(77)
где 8 обычно выбирается равным 2-2.5
При этом данное распределение помечается как текущее, имеющее индекс fc0,
и происходит переход к пункту 4. Если неравенство не выполняется ни для одно-
го распределения, то выполняется следующий пункт.
3. Создание нового распределения.
Оценки параметров для нового распределения выбираются, как и для перво-
го кадра, за исключением весового коэффициента. Если количество распределе-
ний в модели уже равно К. то ищется распределение с наименьшим весом, этот
вес и выбирается для нового распределения, которое заменяет найденное. После
этого новое распределение помечается как текущее (имеющее индекс &0), и осу-
ществляется переход к пункту 6. Если количество распределений в модели мень-
ше максимально возможного, то новое распределение просто добавляется к спи-
ску распределений с весом, равным 0, оно становится текущим и осуществляется
переход к п.5.
4. Переоценка математического ожидания и ковариационной матрицы те-
кущего распределения.
Данные параметры обновляются с помощью следующего низкочастотного
фильтра:
p^=(l-p)pv_,+pX„ (78)
= (1 -р)+р(%, -p^f (79)
Р = ап(%, Ip^.,, ) = а-----(80)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
42
Цифвая обработка видеоизображений
где а - параметр фильтра, позволяющий регулировать скорость обучениям Р(Х)
задастся формулой (76).
5. Подстройка весовых коэффициентов.
Весовые коэффициенты изменяются по следующей формуле:
(81)
Здесь
Г1, k-kQ
Mk, = \
О, иначе
Формулу (81) можно интерпретировать как линейную интерполяцию между дву-
мя точками. Часто ее записывают в альтернативном виде:
(82)
6. Классификация пикселей.
Теперь остается только классифицировать каждый пиксель как фоновый или
переднеплановый. Сначала упорядочиваются все К распределений по возраста-
нию величины а)А ,/||ZA /||. Это упорядочивание приводит к тому, что распределе-
ния, соответствующие данному значению пикселя в наибольшей степени, ока-
зываются вверху списка, в то время как наименее соответствующие опускаются
вниз и со временем заменяются новыми распределениями. Тогда фоновыми счи-
таются такие первые В, распределений, что
/ ь \
Bt = arg min (83)
b V*=i J
a 8, - минимальный объем данных, который обязаны описывать фоновые рас-
пределения. Вместо условия (83) часто используют аналогичное ему [23]:
V*=i
Если выбрать для величины порога 6Г малое значение, то модель для фона полу-
чится унимодальной. Если же 8Т достаточно велико, то это приводит к тому, что
сразу несколько распределений будут принадлежать к фону. Благодаря этой осо-
бенности алгоритма по прошествии определенного периода времени возможна
его автоматическая подстройка к имеющимся в видеоизображении периодиче-
ским движениям (через некоторое время после изменения вес созданного распре-
деления превысит порог и оно станет описывать фон). Данный алгоритм также
способен отражать медленные изменения освещения, так как по мере плавного
изменения цвета фоновых пикселей им будут присвоены новые значения.
Однако быстрые изменения фона и освещения, а также движение теней дан-
ный алгоритм отразить не в состоянии. Предположим, например, что некий пик-
сель сегментирован в передний план и для него существует только одно распре-
деление с весовым коэффициентом, равным 1. Если в последующих кадрах этот
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 2. Построение моделей фона и выделение переднего плана
43
пиксель в действительности будет относиться к фону то пройдет log(l_a)5r кадров
прежде, чем он будет сегментирован в фон. Если выбрать для параметров значения
а - 0.002 и 8Т= 0.6,то указанная выше величина будет соответствовать 255 кадрам.
Кроме того, величина р слишком мала, это приводит к чрезвычайно медленному
обновлению величин pt и Zr. Избежать указанных недостатков можно следующим
образом. Первые L кадров обновление проводится но следующим формулам:
(85)
(86)
^-4.1 ~ ^4,1-1
После первых L кадров вычисления проводятся по новым формулам:
1 М,
;----------Д*,-. >
L\ J
(87)
(88)
(89)
t = L +1, L + 2,...
(90)
Рассмотренный алгоритм позволяет фоновой модели адаптироваться к изме-
нениям освещенности. Проблему быстрого изменения освещенности сцены мож-
но решить и другим способом, используя характерные параметры, не зависящие,
по крайней мере локально, от указанных изменений. Для этого предполагается,
что существует константа С такая, что
I (х + Дх, у + Ду, /) = С • I (х + Дх, у + Ду, Z +1), (Дх, Ду) € (91)
где £2(л v) обозначает окрестность пикселя (х, у). Последовательность изображе-
ний, удовлетворяющую условию (91), называют локально пропорциональной.
Локальная пропорциональность обычно выполняется, по крайней мере прибли-
зительно, для большинства пикселей (х, у). Чтобы воспользоваться этим свой-
ством, введем два фильтра: А, : R2 R и /^ : R2 —> R. Обычно эти фильтры вы-
бираются таким образом, что носители hx и й2 удовлетворяют соотношению
supp с supp т. е. Л, * 0 только на тех множествах, где h2 * 0. Теперь можно
ввести следующую величину:
j\x,y,t) =
/(х,_М)*Л,(х,.и)’
(92)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
44
Цифвая обработка видеоизображений
где операция свертки определяется как
/ (х,у,/)*Л(х,у) = I (x-a,y-b,t)h(a,b)dadb.
(93)
Из предположения локальной пропорциональности следует, что для 1(х, у, г) и
С/(х, у, Z+1) значение f будет одним и тем же, те. функция (91) не зависит от бы-
стрых изменений освещения, если только supp h с supp /t, с v).
Функции распределения вероятности P(Xt) становятся теперь функциями
P(f (*, У> 0)- Дальнейшие шаги по изменению средних значений, весовых коэф-
фициентов и ковариационных матриц осуществляются аналогично вышеопи-
санным. Для вычисления функций (92) можно использовать быстрое преобра-
зование Фурье, при котором для обработки изображения М х /V потребуется
O(AfNlog(A/N)) операций. Если же в качестве фильтров hk выбрать простые
функции вида
hk(x,y)=
к = 1,2
0, иначе
(94)
к
то можно воспользоваться понятием интегрального изображения для ускорения
процесса вычислений. В каждой точке (х, у) оно содержит сумму интенсивностей
пикселей, находящихся левее и выше этой точки, включая ее саму:
f(x,y,/) = J j l(a,byt)dadb, (95)
Для вычисления интегрального изображения требуется 4MN операций. Для вы-
полнения условия supp h} с supp /?2 выберем ск так, чтобы 0 < < с2.Тогда для на-
хождения
l(x,y,t)*ht(x,y) = I(x-ct,y-ct,t)+i(x+ck,y+ck,t)-
7(x-ct>^ + cA,z)-7(x + c4,j-q,/),
к = 1,2
(96)
требуется только четыре операции сложения для каждого пикселя (х, у).
Дальнейшее обобщение представленных выше методов находит свое отра-
жение в модели стохастических процессов, происходящих в каждом пикселе. В
каждый момент времени для всех пикселей функция распределения вероятности
оценивается при помощи оператора с гауссовским ядром, примененного к окну,
состоящему из нескольких последних кадров:
Здесь {Хр...,Х£} - это последние L значений интенсивности пикселя (х, у). В ка-
честве ядра К(Х) может выступать нормальное распределение. Тогда выражение
(97) с учетом (54) переходит в следующее:
(97)
2'
р(^)=;ХП-7==7ехР
2 а*
(98)
Пиксель считается переднеплановым, если
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 2. Построение моделей фона и выделение переднего плана
45
Р(Х,)<8. (99)
где 8 - общее пороговое значение для всего изображения, которое устанавлива-
ется из заданного заранее числа ошибочного определения класса пикселя. Для
определения дисперсии а2. (в случае цветных изображений - для каждого цвето-
вого канала) считается т - медианное значение величин |X, - для всей рас-
сматриваемой последовательности из L кадров:
_ т
" 0.68V2
(100)
Неверное классифицирование пикселя происходит из-за случайного шума
камеры, равномерно распределенного по всему изображению, а также из-за тех
перемещений в фоновом изображении, которые нс описываются построенной
моделью. Например, ветка дерева может качнуться сильнее, чем это происходи-
ло во время обучения модели. Для устранения таких ошибок в модели считает-
ся. что между последовательными кадрами могут происходить только неболь-
шие смещения объектов. Тогда классификация пикселя производится путем
рассмотрения фонового распределения пикселей в окрестности детектирован-
ного движения.
Пусть X, - интенсивность пикселя (х, у). классифицированного как передне-
плановый с помощью неравенства (99). Определим вероятность смещения пик-
селя Po(Xt) как максимальную вероятность того, что наблюдаемое значение
Xf принадлежит фоновому распределению некой точки (х0, у0) из окрестности
Q (х, у) точки (х, у):
Pn(X,)=rmax Р(У,|ЯГ). (101)
где BY - значение интенсивности пикселей У, являющихся фоновыми, а для вы-
числения Р(Хг|Ву) используется выражение (98). При помощи установления по-
рогового значения для величины (101) можно избавиться от многих ошибок сег-
ментации, возникающих из-за небольших смещений в фоновом изображении.
Однако ряд пикселей, действительно относящихся к переднему плану, также бу-
дет сегментирован в задний план вследствие их схожести с соседними фоновыми
пикселями. Чтобы избежать этого, в модели полагается, что объект переднего
плана может перемещаться только целиком, а не отдельные его пиксели. В моде-
ли вводится вероятность перемещения Рс некой связной области С:
рс = П Ром (102)
Для областей, действительно относящихся к переднему плану, вероятность того,
что эта область сместилась с фона, будет очень мала. Поэтому пиксель (х, у) сег-
ментируется в задний план только в том случае, когда для него одновременно
справедливы следующие неравенства:
Рп>5|ИРс>52. (103)
Как правило, используется окрестность пикселя с радиусом, равным 5 пикселям.
Порог 5, выбирается совпадающим со значением из (99).
http://www.itv.ru
Компания (TV - генеральный спонсор издания книги
46
Цифвая обработка видеоизображений
Для обновления фона обычно применяются два механизма:
1. Выборочное обновление. Новое значение Xt добавляется к фоновой по-
следовательности только в том случае, если оно сегментируется
как фоновое.
2. «Слепое» обновление. Новое значение добавляется вне зависимости от
каких-либо условий.
При добавлении нового значения самое первое из последовательности уда-
ляется. У первого типа обновления недостатком является то, что, если теку-
щее значение неверно классифицировано как фоновое, оно в дальнейшем бу-
дет приводить к заведомо ложным результатам. Во втором типе обновления
модели добавление в последовательность псреднеплановых значений сни-
жает вероятность корректного определения фона в последующие моменты
времени.
Так как описанные выше методы требуют довольно значительных ресур-
сов компьютера, рассмотрим статистический непараметрический подход к вы-
делению фона полутонового изображения с учетом шума камеры, не требую-
щий большого объема вычислений. Обозначим через STXY последовательность
8-битных значений, принимаемых пикселем (х, у):
$хг, ={*„...,ХГ}, (104)
а через hTxy (и\ - относительную частоту принятия им значения и 6[0,255]. Вели-
чины Цху и т'хv обозначают среднее и медианное значения пикселя (х, у) для вре-
менной последовательности Т.
Как уже упоминалось ранее, значения, которые может принимать пиксель,
можно рассматривать как некий стохастический процесс Рх v(t). Тогда пред-
ставляет собой его реализацию. Рассмотрим стационарный фоновый пиксель
(х, у), считая изменения освещенности и движения фона пренебрежимо малыми.
Стохастический процесс данного пикселя можно представить как сумму детер-
минированного постоянного процесса Вх v, определяющего значение фонового
пикселя, как если бы оно измерялось идеальной камерой без шума, и стохастиче-
ского процесса Nx Д г), описывающего шум камеры:
Ку 0) = Ъ.у (0+ (0 = (4 <105)
Для /V (г) потребуем выполнения следующих трех условий:
1. Nx (t) представляет собой скалярный случайный процесс, т. е. пренебре-
гаем любой пространственной статистической зависимостью (на самом
деле шум камеры, присутствующий в данном пикселе, статистически кор-
релирован с шумом соседних пикселей).
2. Nx y(t) - стационарный и эргодический стохастический процесс (СЭСП).
3. Статистические свойства y(t) зависят только от В v, т. е. от детермини-
рованного бесшумового значения пикселя (х, у).
Как показали многочисленные эксперименты, второе и третье условия обыч-
но выполняются на практике. Основываясь на этих трех условиях, шум камеры
для М-битовых стационарных полутоновых последовательностей можно опи-
сать при помощи 2м скалярных СЭСП \(t) - один процесс для каждого значе-
ния и е [0,2м-11 Следовательно, выражение (105) можно переписать как
ProSystem CCTV - журнал по системам видеонаблюдения
http://wwvv.procctv.ru
Глава 2. Построение моделей фона и выделение переднего плана
47
Л’(106)
Так как СЭСП полностью определяется своей функцией распределения ве-
роятности и рассматриваются полутоновые 8-битные изображения, то шумо-
вая модель камеры состоит из 256 функций где ие[0,255]. Как следует из
условия 2, стационарность означает, что статистические параметры всего этого
набора постоянны во времени. Эргодичность означает, что статистические пара-
метры приблизительно эквивалентны временным в том случае, если кардиналь-
ность набора данных превышает некую величину (из экспериментов следует, что
ее можно положить равной 25). Вследствие того что Nu(t) и Вх v являются СЭСП,
можно утверждать, что стохастический процесс Р*. (/) для стационарного фоно-
вого пикселя также является СЭСП. Из всего вышесказанного следует, что
Л" *<,(4 (107)
Инициализация модели проводится в два этапа: Г1=[^М и При этом
требуется, чтобы фон был все время стационарным, однако допускается присут-
ствие движущихся объектов. На первом этапе происходит грубое определение
фона для каждого пикселя с помощью временного медианного значения v:
Px., = <’r (108)
На следующем этапе определяется истинный фон. Для этого проверяется вы-
полнение неравенства:
|/(х,у,/)-5Х>.| < 8, teT2. (109)
Для каждого пикселя строится подмножество Т2 с Г2, содержащее только те ка-
дры. в которых неравенство (109) выполняется для данного пикселя. Таким об-
разом, последовательность Sx'y содержит только фоновую информацию. Кроме
того, так как фон считается стационарным во время стадии инициализации,
представляет собой часть реализации СЭСП Р* (/) (105) для каждого пикселя.
Следовательно, мы можем поменять Т на Тху в (107).Так как для данного распре-
деления вероятности среднее значение представляет собой величину, которая ми-
нимизирует ожидаемую ошибку предсказания, в качестве окончательного фоно-
вого значения выберем
(п°)
Из (106) и (110)получим
(ill)
Таким образом, временную последовательность значений шума камеры для
пикселя (х, у) можно рассматривать как реализацию стохастического процесса
представляющего собой шум камеры для значения и-Вх у. Поэтому вре-
менные последовательности значений шума камеры для пикселей, которые име-
ют те же самые значения в соответствии с (110), представляют собой реализа-
ции одного и того же случайного процесса. Теперь можно построить относитель-
ную гистограмму, отвечающую статистической модели шума камеры, для каж-
дого значения и е [0,255]. При этом найдем 256 пар минимальных и максималь-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
48
Цифвая обработка видеоизображений
ных значений <5f(zz) и <5,(н)« После этого пиксель считается переднеплановым,
если
- вх>. (/)) г <, (0. Л, = [* (/));53 (я,., (/))]. (112)
Обновление фона проводится по формуле
в,., 0+0=0 - «)5х., (0+(*. >’«0- ( .
где а € [0,1]. ( )
2.3 МЕТОДЫ ВРЕМЕННОЙ РАЗНОСТИ
Данные методы позволяют отделить передний план от фона при помощи
операции попиксельного вычитания двух или более последовательных кадров.
Методы временной разности хорошо определяют динамические изменения сце-
ны, но обычно не могут выделить целиком все однородные пиксели одного объ-
екта, что приводит к фрагментированности блобов (чаще всего внутри них появ-
ляются пробелы). Кроме того, с помощью этих методов не удается обнаруживать
остановившиеся объекты. Поэтому чаще всего методы временной разности ис-
пользуются совместно с другими методами (например, вероятностными), что по-
зволяет достаточно устойчиво отделять передний план от фона.
Существует несколько вариантов методов временной разности [27-30, 32].
Простейший из них заключается в следующем. Для каждого пикселя текуще-
го кадра составляется его разность с соответствующим пикселем предыдущего
кадра:
Д (х, у, t) = 11 (х, у, /) -/ (х, у, t -1 )|. (114)
Если эта величина превышает пороговое значение 5, то данный пиксель счи-
тается переднеплановым, в противном случае - относящимся к фону. Основную
трудность вызывает правильный выбор порогового значения. Для его выбора
можно использовать следующий алгоритм. Вычислим для каждого пикселя сна-
чала усредненное значение величины Д(х, у, t) по области изображения Q вокруг
рассматриваемого пикселя:
= X &(x,y,t\ (115)
Л (х,.у)еП
где W - количество пикселей в Q. Затем определим разность между (114) и (115):
дс (x,y,t) = b(x,y,t) - A, (x,y,t\ (116)
И, наконец, найдем число пикселей, лежащих в тех областях изображения, кото-
рые считаются фоновыми:
М = {(х>у): (|де (*>У>01 < 2°Л)П(|Д/ (х,у,г)| < тл)}, (117)
где ад - стандартное отклонение для шума камеры, рассчитанное для разности
кадров, а обозначает медианное значение Д,(х, у г). Тогда пороговое значение
8 определяется как
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://w w w. procct v. ru
Глава 2. Построение моделей фона и выделение переднего плана
49
a = <||8>
где |Л/| - число элементов множества М. К этому значению порога может быть
также добавлено слагаемое, представляющее собой пороговое значение для
шума камеры.
Более точные результаты можно получить, если принимать во внимание ди-
намику сцены, зафиксированную на более чем двух последовательных кадрах.
Например, если составлять временную матрицу из разности отдельных блоков
изображения размером N х /V по L следующим друг за другом кадрам. Введем
приведенную к диапазону [0.1] интенсивность пикселя (х, у) в момент времени г,
которую обозначим как / (х,у,г). Для каждого блока(и,у),в котором координата
верхнего левого пикселя равна (uN.vN). составим симметричную матрицу
размером L х L:
। Л-1 Л-1 _
М^хУ = —X X Р + •/’r) “ + + Л т)|- (119)
N 1=0 /=0
Отсюда видно, что элемент матрицы Mt т представляет собой сумму модулей
разности интенсивностей между блоками в кадре t и Т для пикселей, имеющих
одни и те же координаты.
Для тех временных отрезков, на которых содержимое блоков не меняет-
ся, соответствующие квадратные блоки с центром на главной диагонали будут
включать в себя малые величины, что видно из Рис. З.Тем временным отрезкам,
на которых содержимое блоков изменялось, соответствуют элементы матрицы
с большими значениями.
Рис. 3. Структура матрицы М. Элементы матрицы, имеющие малые значения,
окрашены в белый цвет, большие - в темный.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
50
Цифвая обработка видеоизображений
Чтобы выделить отрезки времени, на которых содержимое блока соответ-
ствует фону изображения, можно разбить матрицу М на две части: стационар-
ную (элементы с малыми значениями) и нестационарную (элементы с больши-
ми значениями). Пусть с - множество таких кадров, когда блок
(w, v) содержит только фоновое изображение. Элемент матрицы считает-
ся стационарным тогда и только тогда, когда Г, т е Так как стационарные
элементы обладают малыми значениями, то можно отделить их от нестацио-
нарных, выбрав таким образом, чтобы они обладали как можно меньши-
ми значениями, а нестационарные, наоборот, - большими. Для этого будем ис-
кать минимум функции
Z ^Г)+ £ (1-Ч(Г‘)
г.твН*'’4 /«Tourer*"
(120)
при помощи итерационного процесса. Обычно требуется не больше 2-3 итераций
до сходимости процесса.Так как данный процесс сходится к локальному миниму-
му. близкому к начальному приближению Т'“Л то необходимо аккуратно выби-
рать это значение.
Заметим, что глобальный минимум нс обязан соответствовать истинным фо-
новым отрезкам времени. Если последовательность кадров содержит много пе-
реднеплановых объектов одного цвета, и, кроме того, эти объекты присутствуют
большую часть времени, то глобальный минимум может соответствовать пери-
одам, когда в блоке находятся переднеплановые объекты. Во избежание это-
го предлагается до начала процесса оптимизации исключать из те момен-
ты времени, когда в блоке отмечается движение (при помощи выражения (119)),
а затем использовать информацию о корреляции фоновых временных отрезков
между соседними блоками.
Если объект осуществляет движение поперек блока, то с большой степенью
уверенности можно утверждать, что он также движется и поперек соседних бло-
ков в течение близких временных отрезков. Следовательно, вычисляя мож-
но использовать значения Т^""1и для инициализации процесса оптимиза-
ции. Если кадр tвходит в и то он включается также и в Если же
он содержится только в одном из множеств и T^u'v}\tq он включается в
случайным образом. На левой и верхней границах решение принимается в зави-
симости от результата для верхнего и левого блоков соответственно.
Для повышения точности проблема выделения переднего плана с помощью
методов временной разности может быть решена на трех различных уровнях,
пиксельном, областей и кадровом. Первому соответствует построение фоновых
моделей для каждого пикселя изображения. На этом уровне можно попытать-
ся обойти такие известные проблемы, как постепенное изменение освещенности
сцены, наличие движущихся объектов, в действительности являющихся фоном, и
др. При этом все пиксели обрабатываются независимо друг от друга. На уровне
областей при помощи модифицированного метода временной разности рассма-
триваются взаимодействия между отдельными пикселями. И, наконец, на послед-
нем кадровом уровне система адаптируется к внезапным изменениям освещенно-
сти путем выбора из нескольких имеющихся моделей фона.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
"лава 2. Построение моделей фона и выделение переднего плана
51
Основу первого пиксельного уровня составляет модель линейного предска-
зания значения данного пикселя в следующем кадре. Все пиксели, значение ко-
торых сильно отличается от предсказанного, считаются переднеплановыми. Для
данного пикселя его значение в следующем кадре предсказывается как
7(х,_М) = -£ад/(х,у,Г-Л). (121)
*=1
где ак - коэффициенты линейного предсказания. Таким образом, для предсказа-
ния нового значения используются предыдущие р значений. Ожидаемая ошибка
квадрата предсказания Е(е2(г)) определяется как
р
£(e2(/))=£(/2(x,y,r))+^aA£(/(x,y,i)/(x,yj-A)). (122)
*=!
Коэффициенты ак могут быть определены одним из хорошо известных спосо-
бов [32]. Считается, что если предсказанное значение пикселя отличается от из-
меренного больше, чем на 8 = 4 ^Е(/(г)). то такой пиксель относится к перед-
неплановым.
Если в течение какого-то периода времени рассматриваемый пиксель отно-
сился к переднеплановым, а большую часть до и после этого был фоновым, то
это искажает точность предсказания. Поэтому следует хранить не только истин-
ные предыдущие значения пикселя, но и его предсказанные значения. Для каж-
дого пикселя новое значение предсказывается на основе указанных двух после-
довательностей. Если хотя бы одно из двух предсказанных значений меньше
порогового значения 5, то данный пиксель сегментируется в фон.
Так как отделять от фона необходимо объекты целиком, а не отдельные
пиксели, то на уровне областей рассматриваются взаимные связи между пиксе-
лями. Движущиеся равномерно, окрашенные в один цвет предметы всегда окру-
жены пикселями, имеющими с внутренними пикселями идентичные свойства.
Поэтому те пиксели, которые на первом уровне были сегментированы в перед-
ний план, подвергаются дальнейшей обработке, алгоритм которой представлен
ниже.
1. Вычисляется разность двух кадров и сравнивается с порогом:
У(ж,Л/)=|11 1'(АУ,<)-/(х.Л<-1)|>6,
О, иначе
Значение порога ^зависит от свойств камеры и обычно имеет величину в ди-
апазоне от 10 до 30.
2. Определяется подмножество пикселей, которые образуют пересечение
переднего плана F(x, у, г-1) в предыдущем кадре и разности двух изобра-
жений в моменты времени t и г-1:
£ (х, /) = J (х, /) n J (х, у, / -1) n F (х, у, / -1). (124)
3. В этом множестве пикселей находятся4-связанныеобласти Я.состоящие
не менее чем из ктм=8 пикселей.
4. Для каждой области R, составляется нормированная гистограмма:
(123)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
52
Цифвая обработка видеоизображений
А, (5) =
|{(х. j): (х,у) е п/ (х,у,г -1) = s}|
!л.|
(125)
где через |/?,| обозначено число пикселей в 7?,.
5. Гистограммы проецируются в изображение 7(х, у, t): для каждой области
Rt находится пересечение F(xf у, г-1) А 7? и для каждой точки из этого пе-
ресечения принимается решение о ее сегментации:
ht [l(x,y,t^> £
иначе
(126)
где Е- 0.1.
Шаги 1 и 2 определяют те области, которые с уверенностью можно отнести
к псреднеплановым. На последующих двух шагах вычисляется гистограмма та-
ких областей. И, наконец, на последнем шаге некоторые из пикселей, которые на
первом пиксельном уровне были сегментированы в фон, теперь считаются отно-
сящимися к переднему плану.
На последнем, кадровом, уровне алгоритм автоматически выбирает наиболее
соответствующую данному изображению модель фона. Для этого служит ста-
дия предварительного обучения по методу кластеризации Передних. Критерием
для выбора из имеющихся моделей является наименьшее число пикселей, кото-
рое сегментируется в передний план. Решение о смене модели фона принимается,
если доля пикселей переднего плана в общем числе пикселей превышает 0.7.
Более точных результатов при использовании методов временной разности
можно добиться, если использовать не два предыдущих кадра, а три. Обозначим
через £>2(х, у, r-1, t) меру соответствия изображений в моменты времени Г-1 и г:
O2(x,^,Z,Z-l) =
где Q - окрестность пикселя (х, у) (обычно размером 3 х 3), V,7(x, у, г-1) - вели-
чина градиента интенсивности, а С - константа для предотвращения численных
неустойчивостей.
Для получения переднего плана используется следующее выражение:
M2(x,y,t-l,t) =
1, если D1(x9y9t-l9t)>
(x,y,t -l.z) > 62 n{3(x0,^0) g Q => D2(x,,y9,t - l,z)> 5,}), (127)
0, иначе
где <5j > S2.
Теперь можно получить меру соответствия и маску с использованием трех по-
следовательных кадров:
D(х9 у, l) = D2 (х, у, t -1,/) • D2 (х, у, t - 2, /). (128)
М (х, у, t) = М2 (х, у, г -1, г) • М2 (х, у, t - 2,г). (129)
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
"гава 2. Построение моделей фона и выделение переднего плана
53
Заметим, что при этом учитываются изменения в изображении между кадра-
ми (/-1) и (г), а также между (/-2) и (г). Это приводит к лучшим результатам
по сравнению с обычно используемыми трехкадровыми разностными мето-
дами. в которых сравниваются кадры (г) с (г-1) и (г—1) с (z-2). Такой подход
позволяет избежать проблем, возникающих в случае, когда однородно окра-
шенная область изображения сдвигается на расстояние, меньшее своей дли-
ны, за время между двумя последовательными кадрами. Многие другие мето-
ды при этом дают нулевые значения для меры D практически во всех точках
исследуемой области.
2.4 МЕТОДЫ ОПТИЧЕСКОГО ПОТОКА
Методы оптического потока в применении к задаче выделения переднего
плана основаны на том, что для видеофрагмента, содержащего некоторые объ-
екты в движении, можно вычислить направление и величину скорости движе-
ния в каждой точке кадра. Информация об оптическом потоке используется
для пространственного сегментирования изображения: группу расположенных
близко друг от друга точек, движущихся с примерно одинаковыми скоростями
(или хотя бы приблизительно однонаправленными), можно считать движущим-
ся объектом. Также можно получить информацию о расположении, размерах
и некоторых других параметрах таких областей. Выделение переднеплановых
объектов часто проводится на основе предположения о том, что пиксели при-
надлежат одному объекту, если они отстоят друг от друга не более чем на задан-
ное число г пикселей, и направления скоростей в них отличаются не более чем
на заданное значение у.
Все существующие алгоритмы вычисления оптического потока можно раз-
бить на 4 группы: дифференциальные, частотные, фазовые и алгоритмы, осно-
ванные на сопоставлении характерных признаков областей [33-43].
Дифференциальные методы основываются на предположении, что при дви-
жении объекта интенсивность составляющих его точек практически не меняет-
ся за малые промежутки времени. Таким образом, если пиксель (х, у) за время St
сместился на (5х, 5у), то можно записать
1 1 (* + у+Sy,t + St), (130)
Разложив правую часть в ряд Тейлора и оставив только члены первого порядка,
получим:
Э/ Q Э/ Э/ ~
— Зх + — 5у + — St = 0. (131)
дх ду dt
Разделим это выражение на St:
dl д1 д!
— U + — Р + —
Эх ду dt
где и = Sx/St, и = Sy/St - компоненты скорости изображения или, иначе, оптиче-
ского потока. Обозначив /,= dl/dt. придем к выражению
http://www. itv.ru
Компания ITV - генеральный спонсор издания книги
54
Цифвая обработка видеоизображений
V/(x, у. t) • (и. и, 0) + It (х, у, Г) = 0. (133)
Мы получили одно линейное уравнение для двух неизвестных компонент
оптического потока. Для его разрешения необходимо ввести дополнительные
ограничения, что может быть сделано различными способами. При исполь-
зовании методов регуляризации оценка оптического потока рассматривается
как некорректная задача, решение которой получается за счет минимизации
специальным образом сконструированного функционала. На гладкость это-
го функционала обычно накладывают определенные ограничения, которые
позволяют найти единственное решение. При этом для смежных кадров мо-
жет оцениваться как сдвиг каждой точки изображения, так и сдвиг только то-
чек контуров движущихся объектов. Предполагая гладкое изменение значения
скорости от точки к точке:
|Vu(x,j)||‘ +||Vv(x,^)||2 =0 (134)
или, иначе,
(135)
для определения вектора скорости используют результаты минимизации
функционала:
min jfrv/v + Z,)2 + Л2(|Ы|2+||?НГ (136)
q L J
где Q- множество точек изображения, v = (и, у), а Л - параметр, определяющий
вес слагаемого, отвечающего за гладкость оптического потока.
Условие минимума данного функционала можно свести к следующей систе-
ме уравнений:
(Л2 + У2 + У2)(« - «) = -У, (lxu + 1уи + У,)
1/ , V (137)
(Л2 + У2 + У2 )(р - v) = -У„ (Ухи + Iyv +I,)
где й и й - усредненные значения и и и по соседним точкам:
«(х,^) = ^(и(х»>’-1)+и(х+1,^)+и(х,/+1) + и(х-1,>'))+
+ (х + 1, у -1) + И (х +1, J +1) + И (х -1, +1) + U (х -1, у -1)),
(138)
Д(х,у)= -(у(х,у-1) + 1?(х + 1,у) + р(х,у+ 1)+м(х~1,у)) +
6
+ ^(м(х+1,у-1) +v(x + 1,у + 1) + у(х-1,у + 1) + у(х-1,у-1)).
Данная система линейных уравнений может быть решена, например, итерацион-
ным методом Iaycca-Зейделя:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 2. Построение моделей фона и выделение переднего плана
55
м*+| = ик
Гн
(139)
Vм = ук
ик + 1ук +
(140)
л2
ик и ик - компоненты вектора скорости в соответствующей точке кадра на к ите-
рации. Их начальные приближения считаются равными нулю.
Компоненты оптического потока также могут быть найдены при помощи
минимизации следующего функционала:
(141)
min 7, ।
U,y)eQ
где VV’(x, у) обозначает оконную функцию, которая позволяет дать больший вес
ограничениям в области, находящейся в непосредственной близости от пикселя
(х, у) по сравнению с более удаленными пикселями. Минимум функционала (141)
достигается на следующей функции:
v = [ATW2A]~'ATWb.
Здесь
И = [ V/ (х, ,у(),..., W(x„, уп )]г
W^diag[fV(x},yi),...,l¥(Xn,yn)]
Ь = -[А(х1,у1),...,/,(хя,Л)Г
для п-т2 (например, 25) соседних т х т пикселей (х, yj е Q. АТ W2А представ-
ляет собой квадратную матрицу следующего вида:
(142)
(143)
ArW2A =
(144)
где суммирование ведется по всем (х., у4) gQ.
Иной способ задания дополнительных ограничений для уравнения (141) за-
ключается в предположении, что условие неизменности яркости изображения
справедливо и для некоторой другой функции, в качестве которой могут высту-
пать. например: контрастность, выборочное среднее, кривизна, величина гради-
ента. локальная интенсивность, спектр и др. Используя набор таких функций,
оцененных в одной и той же точке изображений, можно получить систему урав-
нений для неизвестных параметров. Другой, более частный, прием состоит в ис-
пользовании ограничений относительно вторых частных производных яркости
изображения.
В методах, основанных на ограничениях, для улучшения оценок применяют
предварительную фильтрацию изображений (например, с помощью фильтра Га-
усса), увеличение локальной области исследования, а также фильтрацию полу-
ченных оценок. Однако указанные операции приводят также к некоторым не-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
56
Цифвая обработка видеоизображений
точностям в оценке границ движущегося объекта. Компромисс между точностью
оценок и вычислительными затратами достигается за счет выбора размера ло-
кальной области, в которой осуществляется фильтрация. Как правило, эта об-
ласть имеет размеры от 3 х 3 до 10 х Ю элементов. Гладкость решения может быть
улучшена увеличением размера обрабатываемой локальной области, но это ве-
дет к потере точности решения на границах подвижного объекта, когда в область
попадает не только его изображение.
Частотные методы вычисления оптического потока основаны на использова-
нии набора соответствующим образом подобранных полосовых фильтров. Пре-
образование Фурье для области изображения выглядит следующим образом:
/(£,<») =/0(£)5(й>+йгТ), (145)
где /0(А) - образ !{х, у, 0) в частотном пространстве, <5(Л)- дельта-функция, со -
частота, £ = (kx,kY)- волновой вектор.Тем самым неявно предполагается, что вся
энергетическая плотность преобразования проецируется на плоскость, проходя-
щую через начало координат в частотном пространстве.
Для получения скоростей оптического потока из видеопоследовательности
можно использовать набор из 12 фильтров Габора Л/ различного пространствен-
ного разрешения с откликом /? (и, и). Если обозначить через £ величину энергии,
полученную в результате измерений, то для определения (и, р) необходимо найти
минимум следующей функции:
/(w.y)=Z
/=1
р л. к1')
(146)
что может быть сделано методом наименьших квадратов. Здесь
Д = Л,(ц,у)=£Л,(М,у).
1=1 1=1
(147)
Одним из наиболее точных методов определения оптического потока явля-
ется фазовый метод. Он основан на использовании набора полосовых фильтров,
комплексный отклик которых имеет следующий вид:
R (х, y,t) = р (х, у, t) exp [/(р (х, у, z)], (148)
где р(х, у, г) и ф(х, у, /) - амплитуда и фаза R. Компонента скорости vw=jn, нор-
мальная к линиям уровней фазы, вычисляется с использованием следующих вы-
ражений:
<р, (x,yj)
(149)
(150)
где V<p(x,y,z) = (<px(x,y,r),<pv (х,у,/))Г. Фактически фазовый метод аналогичен диф-
ференциальным алгоритмам с той лишь разницей, что вместо интенсивности
здесь выступает фаза. Производные фазы вычисляются с помощью выражения
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 2. Построение моделей фона и выделение переднего плана
57
1тГ/Г'(х, v.l)R, (х. >’,()]
ч>А*.у.‘)= I , J- («о
где R* - величина, комплексно сопряженная R. Использование фазы основано на
том факте, что эволюция фазовых линий уровня является хорошей аппроксима-
цией проекции движения интересующих областей. Кроме того, фазовая компо-
нента полосовых фильтров более устойчива по сравнению с амплитудной для ма-
лых возмущений изображения.
Аккуратное численное дифференцирование часто невозможно из-за наличия
шума камеры, малой частоты смены кадров и т. д. В этом случае дифференциаль-
ные и частотно-фазовые методы могут оказаться непригодными к применению, и
единственным выходом из положения является использование методов, основан-
ных на сопоставлении характерных признаков областей. Эти методы определя-
ют скорость оптического потока как сдвиг d =(de d,), минимизирующий расстоя-
ние между двумя соответствующими областями в различные моменты времени:
£ £^(ЛУ)[/1(х+Лг + 7,О-Д(х + < + /,>' + </>, + у,/)]2. (152)
i=-n
Здесь - оконная функция, а сдвиг d =(rf%, dx) принимает целочисленные
значения. Далее используются три последовательных кадра для вычисления сле-
дующего выражения:
Do = DOi(x,y,d ) +D0^(x,y,-d). (153)
С помощью (153) можно построить распределение вероятности с плотностью
ЛД<1) = е’*У (154)
где к = - In 0.95/mi n DQ-константа нормировки.Теперь оценка скорости ис)
может быть найдена как среднее по всем целым значениям смещения d этого
распределения:
ис = ,
(155)
Ус = ------•
Zw
Отсюда получается следующая ковариационная матрица:
s =—
£/?f(d)«-«e)2
S^(d)[£^(dX<-«eXrf,-ve)
£^(d)(4.-«eXdy-v,)
£/?f(d)(rf, -vc)2
(156)
а собственные значения Ег‘ служат мерой соответствия для vr.
Аналогично могут быть получены компоненты (мп, ц,), взвешенные средние
значения vc=(uc, ис) по небольшой области изображения, и составлена ковариа-
ционная матрица Тогда компоненты оптического потока могут быть найдены
в результате минимизации суммы усредненных расстояний Махаланобиса между
ними и двумя распределениями vf и v„:
http://wwwjtv.ru
Компания ITV - генеральный спонсор издания книги
58
Цифвая обработка видеоизображений
JJ (v - V.)S;' (v - v„) + (v - vf )Z;‘(v - Vr )dxdy. (157)
При этом собственные значения ковариационной матрицы Ч-L"1]"1 служат
мерой соответствия результатов регуляризационного процесса. Для нахождения
значений v t и необходимо знать скорости в каждой точке окрестности, поэто-
му используется следующая итерационная процедура:
V?
= Vc
(158)
(159)
Обычно требуется не больше 25 итераций для сходимости процесса.
2.5. СПИСОК ЛИТЕРАТУРЫ
1. Лукьяница А.А., Шишкин А.Г Проблемы обработки видеоизображений в си-
стемах мониторинга // ProSystem CCTV. - М., 2007. - №1 (25). - С.42-51.
2. J. Heikkila, О. Silvcn. A Real-time System for Monitoring of Cyclists and
Pedestrians. In: Proc. IEEE Workshop on Visual Surveillance. Fort Collins, p. 74-81,
1999.
3. R. Cucchiara, C. Grana, M. Piccardi, A. Prati. Detecting Moving Objects, Ghosts
and Shadows in Video Streams. IEEE Transactions on Pattern Analysis and
Machine Intelligence, v. 25, p. 1337-1342,2003.
4. S.-C. Cheung, C. Kamath. Robust Background Subtraction with Foreground
Validation in Urban Traffic Video. EURASIP Journal on Applied Signal
Processing. №14, p. 2330-2340,2005.
5. L. Fuentes, S. Velastin. From Tracking to Advanced Surveillance. In: Proc. IEEE
International Conference on Image Processing. Barcelona, vol. 3, p. Ill 121-124,
2003.
6. N. Agarwal, N. Andrisevic, K. Vuppla et al. Vehicle Detecting and Tracking in Video
for Incident Detection. Report of Minnesota Dept, of Transport, USA, 2003.
7. C. Motamed. Motion Detection and Tracking Using Belief Indicators for an
Automatic Visual-Surveillance System. Image and Vision Computing, vol. 24, p.
1192-1201,2006.
8. R. T. Collins, A.J. Lipton, T. Kanade. A System for Video Surveillance and
Monitoring. Technical report CMU-R1-TR-00-12, Robotics Institute, Carnegie
Mellon University, 2000.
9. I. Haritaoglu, D. Harwood, L. S. Davis. W4: Real-Time surveillance of People
and Their Activities. IEEE Transactions on Pattern Analysis and Machine
Intelligence, v. 22, p. 809 830,2000.
10. K.-P. Karmann, A. Brandt. Moving Object Recognition Using an Adaptive
Background Memory. In V Cappellini (ed.)t Time-varying Image Processing
and Moving Object Recognition. 2. Elsevier Publishes В.V, Amsterdam, p.297-
307, 1990.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 2. Построение моделей фона и выделение переднего плана
59
11. D. Koller, J. WeberJ. Malik. Robust Multiple Car Tracking with Occlusion Reasoning,
Computer Science Division (EECS), Report No. UCB/CSD 93-780, University of
California, Berkeley. USA. 1993.
12. M. Kilger. A Shadow Handler in a Video-based Real-time Traffic Monitoring
System. In: Proc. IEEE Workshop on Applications of Computer Vision, Palm
Springs, p.11-18,1992.
13. C. Ridder, O.Munkelt. H. Kirchner. Adaptive Background Estimation and
Foreground Detection Using Kalman Filtering. In: Proc. International Conference
on Recent Advances in Mechatronics.p. 193-199.1995.
14. А. Каир. T. Aach. Efficient Prediction of Uncovered Background in Interframe
Coding Using Spatial Extrapolation. In: Proc. IEEE International Conference
on Acoustics, Speech and Signal Processing, v.5: I Image and Multidimensional
Signal Processing. Adelaide. p.V501-V504.1994.
15. S. J. McKenna, S. Jabri, Z. Duric et al.Tracking Groups of People. Computer Vision
and Image Understanding, v.80. p.42-56.2000.
16. Прэтт У Цифровая обработка изображении. Кн. 1,2.- М.: Наука. 2000.- 1024 с.
17. С. R. Wren, A. Azarbayejani.T. J. Darrell. А. Р. Pentland. Pfinder: Real-time Tracking
of the Human Body. In: IEEE Pattern Recognition and Machine Intelligence, v.
19. p. 780-785.1997.
18. N. Friedman, S. Russell. Image Segmentation in Video Sequences: A Probabilistic
Approach. In: Proc. Annual Conference on Uncertainty in Artificial Intelligence,
Rhode Island, p. 175-181,1997.
19. G. J. McLachlan,T. Krishnan.The EM Algorithm and Extensions. Wiley Interscience,
1997.
20. S. J. Nowlan. Soft Competitive Adaptation: Neural Network Learning Algorithms
Based on Fitting Statistical Mixtures. Ph.D. Thesis, School of Computer Science,
Carnegie Mellon University, 1991.
21. C. Stauffer. W E. L. Grimson. Adaptive Background Mixture Models for Real-time
Tracking. In: Proc. Conference on Computer Vision and Pattern Recognition. Ft.
Collins, p. 246-252,1999.
22. C. Stauffer, W E. L. Grimson. Learning Patterns of Activity Using Real-time
Tracking. IEEE Pattern Recognition and Machine Intelligence, v. 22, p. 747-757,
2000.
23. Q. Zang, R. Klette. Object Classification and Tracking in Video Surveillance. In:
Proc. International Conference on Computer Analysis of Images and Patterns.
Groningen, p.198-205,2003.
24. P. Kaew TraKulPong, R. Bowden. An Improved Background Mixture Model for
Real-time Tracking with Shadow Detection. In: Proc. European Workshop on
Advanced Video Based Surveillance Systems. London, p. 1-5,2001.
25. H. Ardo, R. Berthilsson, K. Astrom. Real-time Viterbi Optimization of Hidden
Markov Models for Multi-target Tracking. In: Proc. IEEE Workshop on Motion
and Video Computing. Austin, p. 2-2,2007.
26. A. Elgammal, D. Harwood. L. Davis. Non-parametric Model for Background
Subtraction. In: Proc. European Conference on Computer Vision. Dublin, vol. 2,
p. 751-761,2000.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
60
Цифвая обработка видеоизображений
27. A. Bevilacqua. L. Di Stefano, A. Lanza. An Efficient Change Detection Algorithm
Based on a Statistical Non-parameteric Camera Noise Model. In: Proc.
International Conference on Image Processing. Singapore, v.4, p. 2347-2350,2004.
28. A. J. Lipton, H. Fujiyoshi. R. S. Patil. Moving Target Classification and Tracking
from Real-time Video. In: Proc. IEEE Workshop on Applications of Computer
Vision. Princeton, p.129 136,1998.
29. L. Li, M. К. H. Leung. Integrating Intensity and Texture Differences for Robust
Change Detection. IEEE Transactions Image Process., v.l Lp. 105-112,2002.
30. D. Farin, P. H. N. de With, W. Effelsberg. Robust Background Estimation for Complex
Video Sequences. In: Proc. International Conference on Image Processing (ICIP).
Barcelona, p. 145-148,2003.
31. K.Toyama, J. Krumm, B. Brumitt. B. Meyers. Wallflower: Principles and Practice of
Background Maintenance. In: Proc. IEEE International Conference on Computer
Vision. Kerkyra, p. 255-261,1999.
32. Рабинер Л., Шафер P Цифровая обработка речевых сигналов. М.: Радио и
связь, 1981.-496 с.
33. A. Selingcr, L. Wixson. Classifying Moving Objects as Rigid or Non-rigid without
Correspondence. In: Proc. DARPA Image Understanding Workshop. Monterey,
p. 341-347,1998.
34. J. L. Barron. D. J. Fleet, S. S. Beauchemin. Performance of Optical Flow Techniques,
International Journal of Computer Vision, v. 12, p. 43-77,1994.
35. В. К. P. Horn, B. G. Schunk. Determining Optical Flow, Artificial Intelligence, v. 17,
p. 185-201,1981.
36. B. Lucas,T. Kanade. An Iterative Image Registration Technique with Applications
in Stereo Vision, In: Proc. DARPA Image Understanding Workshop .Washington,
p. 121-130,1981.
37. B. Lucas. Generalized Image Matching by the Method of Differences, PhD Thesis,
Dept, of Computer Science, Carnegie Melon University, 1984.
38. A. Vcrri, E Girosi, V Torre. Differential Techniques for Optical Flow, Journal of the
Optical Society of America, v. 7, p. 912-922,1990.
39. A. Bimbo, P. Nesi, L. C. Sanz. Optical Flow Computation Using Extended
Constraints, IEEE Transactions on Image Processing, v. 5, p. 720-738,1996.
40. D. J. Heeger. Optical Flow using Spatio-temporal Filters, International Journal of
Computer Vision, v. l,p. 279-302,1988.
41. D. J. Fleet, A. D. Jepson. Computation of Component Image Velocity from Local
Phase Information, International Journal of Computer Vision, v. 5, p. 77-104,
1990.
42. P Anandan. A Computational Framework and an Algorithm for Measurement of
Visual Motion, International Journal of Computer Vision, v. 2, p. 283-310,1989.
43. A. Singh. Optic Flow Computation: A Unified Perspective, IEEE Computer Society
Press, 1992.
44. A. Singh. An Estimation-theoretic framework for Image-flow Computation. In:
Proc. IEEE International Conference on Computer Vision, Osaka, p. 168-177,
1990.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
ГЛАВА 3.
ВЫДЕЛЕНИЕ И КЛАССИФИКАЦИЯ
ДВИЖУЩИХСЯ ОБЪЕКТОВ
64
Цифвая обработка видеоизображений
Видеопоток может содержать большое разнообразие движущихся объектов.
Одни из них представляют интерес для мониторинга - например, изображения
людей, транспортных средств, животных и т. п. Другие объекты, такие как кача-
ющиеся ветви деревьев, тени, вращающиеся двери, создают помехи при видеона-
блюдении. Вся совокупность движущихся объектов составляет так называемый
передний план, причем априорно неизвестно число таких объектов, какого они
размера и их взаимное расположение.
Напомним, что передний план может быть получен с помощью методов,
описанных в Птаве 2. а модуль, выделяющий движущиеся объекты, обыч-
но называется детектором движения. Для того чтобы провести классифика-
цию движущихся объектов, нужно сначала отделить каждый объект от дру-
гих. Эта операция называется сегментацией объектов. Результатом проведе-
ния сегментации является либо помеченный набор пикселей переднего плана,
либо указание вершин минимально возможного прямоугольника (МВП). вну-
три которого находится выделенный объект (см. Рис. 1).
Рис. 1. Выделение движущихся объектов: А - с помощью описанного прямоуголь-
ника, Б - путем выделения «блобов», В - описанием границы блобов
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 3. Выделение и классификация движущихся объектов
65
В первом случае говорят о выделении блоба, который задается набором ко-
ординат составляющих его пикселей. Понятия блоба было введено в работах
11.2] для описания компактных структурно значимых областей, в которых цвето-
вые и пространственные характеристики пикселей близки друг другу. Для пред-
ставления блобов удобны методы, основанные на выделении контуров. Выде-
ление описанного прямоугольника (МВП) дает более грубое описание объекта,
хотя требует значительно меньшего времени обработки. Когда объекты хорошо
отделимы друг от друга, по соотношению сторон прямоугольника можно предва-
рительно определить тип объекта. Но такой способ классификации требует по-
следующего уточнения. Рассмотрим, например. Рис. 2. на котором автоматиче-
ски были детектированы три движущихся объекта: человек, автомобиль и груп-
па людей. По отношению сторон прямоугольников можно уверенно отличить че-
ловека от автомобиля, однако по этому признаку группа людей будет классифи-
цирована как автомобиль. Анализ же контуров, изображенных на Рис. 2В. воз-
можно позволит избежать этой ошибки.
А Б
В
Рис. 2. Выделение движущихся объектов: А - с помощью описанного прямоуголь-
ника, Б - путем выделения блобов, В - описанием границы блобов
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
66
Цифвая обработка видеоизображений
Практика показывает, что после сегментации объектов переднего плана не
следует сразу приступать к их классификации, а нужно провести дополнитель-
ную обработку, цель которой заключается в устранении дефектов в изображени-
ях выделенных объектов. Действительно, из-за наличия шумов полученные бло-
бы обычно имеют внутри полости, неровные границы, и даже нередко один объ-
ект может быть раздроблен на множество не связанных между собой фрагмен-
тов. Такие изъяны проще всего устранить путем выполнения подходящих морфо-
логических операций, например дилатации и последующей эрозии. При правиль-
ном выборе для этих операций структурирующего элемента целостность объек-
тов будет восстановлена, а контуры объектов станут более плавными.
Поскольку анализ видеоряда, как правило, проводится в масштабе реального
времени, алгоритмы классификации должны быть относительно быстрыми, эффек-
тивными и инвариантными к изменяющимся условиям освещения. Анализ большо-
го числа методов, удовлетворяющих этим условиям, показал, что все они могут быть
разделены на три большие группы: геометрические методы, методы, основанные на
динамических характеристиках движения, и методы, основанные на динамических
текстурах. Первые основаны на выделении ряда признаков, характеризующих гео-
метрическую форму объекта, накоплении такой информации за определенный пе-
риод времени, создании базы данных многочисленных шаблонов (во время периода
обучения) и сравнении интересующего объекта с шаблонами. К первой группе от-
носятся методы, основанные на сегментировании объектов и различные контурные
методы. Вторая группа методов использует периодичность двигательных процессов,
присутствующую практически во всех объектах (например, вращение колеса авто-
мобиля). Один из возможных алгоритмов - устойчивая к шумам технология опреде-
ления характеристик оптического потока (поля скоростей). Однако ее главным не-
достатком являются высокие требования к ресурсам компьютера. И. наконец, тре-
тья группа методов базируется на использовании динамических текстур (ДТ) - трех-
мерных вариантов обычных двумерных текстур. В качестве дополнительного изме-
рения в ДТ выступает время. Применение ДТ для классификации объектов является
одним из наиболее перспективных и многообещающих в настоящее время.
В настоящей главе рассматриваются все этапы обработки движущихся объ-
ектов, а также разнообразные методы получения характерных признаков, кото-
рые в дальнейшем могут быть использованы для построения распознающей си-
стемы. О том, как создать и настроить распознающую систему, читатель может
узнать из главы, посвященной адаптивным методам обработки информации.
3.1. СЕГМЕНТАЦИЯ ОБЪЕКТОВ.
Сегментацией называется процесс разбиения изображения на составляющие его
объекты. Эта задача тщательно изучается в большинстве книг, посвященных цифро-
вой обработке изображений. Применительно к задачам обработки видеоряда возни-
кает ряд особенностей, как облегчающих ее решение, так и затрудняющих. Посколь-
ку процессу сегментирования подвергаются только движущиеся объекты, суммар-
ная площадь которых обычно существенно меньше площади, занимаемой всем изо-
бражением, то объем обрабатываемой информации меньше, чем при сегментирова-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 3. Выделение и классификация движущихся объектов
67
нии статических изображений. К тому же движущиеся объекты часто бывают изо-
лированными друг от друга. Эти факторы облегчают решение поставленной задачи.
К затрудняющим обстоятельствам можно отнести проблему сборки наблюдаемых
объектов из частей, на которые они были поделены в результате работы детекто-
ра движения. Такая проблема может возникнуть, например, в том случае, если часть
движущегося объекта имеет цвет, совпадающий с цветом фона, в результате чего в
этом месте могут появиться пустоты причудливой формы. А главным требованием
к применяемому алгоритму обычно является возможность его использования в ре-
альном времени, что накладывает весьма жесткие ограничения [3,4].
Очень эффективным с точки зрения вычислительных ресурсов является ис-
пользование для сегментации методов кластерного анализа. Суть кластеризации
состоит в том, что все исходные объекты (в данном случае пиксели) разбивают-
ся на несколько непересекающихся групп таким образом, чтобы объекты, по-
павшие в одну группу, имели сходные характеристики, в то время как у объектов
из разных групп эти характеристики должны значительно отличаться. Получен-
ные группы называются кластерами. Исходными значениями для кластеризации
в случае полутоновых изображений являются трехмерные векторы (х, у, /(х, у)),
где х, у, - координаты пикселя в произвольной системе координат, /(х, у) - его ин-
тенсивность. В случае использования цветных изображений векторы становятся
пятимерными. В результате такого кодирования в один кластер должны попасть
группы пикселей, расположенные близко друг к другу и при этом имеющие близ-
кую интенсивность (в случае полутоновых изображений) или похожий цвет.
Алгоритмы построения кластеров можно разбить на две группы [5]. Алго-
ритмы первой группы применяются в том случае, если нам априорно известно
число кластеров К. Типичными представителями этой группы являются объеди-
няющий (агломеративный), разделяющий, а также алгоритмы Х-средних. Для
алгоритмов второй группы обычно задаются ограничения на размер создавае-
мых кластеров, а само число кластеров автоматически определяется в процессе
работы алгоритма. Наиболее эффективным алгоритмом этого типа является ме-
тод адаптивного резонанса Гроссберга (ART. Adaptive Resonance Theory).
Аглоыеративные методы. Основная идея этих алгоритмов заключается в по-
следовательном объединении отдельных элементов и уже построенных кластеров
в более крупные кластеры. В начальный момент считается, что каждый элемент
обучающего множества образует свой кластер,т.е. в начальный момент мы имеем
N кластеров, каждый из которых содержит ровно один элемент. Далее выбирают-
ся два кластера с наименьшим расстоянием между ними. Эти кластеры объединя-
ются в новый, после чего число кластеров становится N - 1. Описанный процесс по-
вторяется до тех пор, пока число кластеров не станет равным заданному числу К.
Разделяющие методы. Эти методы основаны на принципах, которые диаме-
трально противоположны лежащим в основе агломеративных методов, а имен-
но, на делении крупных кластеров на более мелкие. В первоначальный момент
предполагается, что все объекты принадлежат одному кластеру. После этого в
нем находятся два объекта с наибольшим расстоянием между ними. Они счита-
ются центрами двух новых кластеров. Далее находится наибольший кластер, ко-
торый делится на две части таким же способом. Процесс деления останавливает-
ся при достижении заданного числа кластеров.
http://ww w. itv. ги
Компания ITV - генеральный спонсор издания книги
Глава 3. Выделение и классификация движущихся объектов
69
На Рис. 3 приведены результаты сегментации движущихся объектов с помо-
щью алгоритма К-средних. Максимальное число кластеров было выбрано рав-
ным девяти. На Рис. ЗА изображены найденные кластеры, а на Рис. ЗБ - класте-
ры. полученные после объединения объектов, для которых описанные прямоу-
гольники пересекаются. Читатель может убедиться, что Рис. ЗБ практически не
отличается от Рис. 1 А. который получен при использовании метода сегментации,
основанном на выделении контура.
3.2. ПОСТОБРАБОТКА ИЗОБРАЖЕНИЙ ОБЪЕКТОВ
После сегментации изображение часто имеет ряд недостатков в виде мелких
областей, линий и отдельных пикселей, не отнесенных ни к какой области. Суще-
ствуют различные факторы, которые приводят к таким недостаткам в сегменти-
рованном изображении:
• интенсивность пикселя, находящегося на границе двух окрашенных в раз-
ный цвет объектов, может быть отнесена к одному цвету в начальном ка-
дре и к другому - в следующем кадре;
• когда источник света, например солнце, движется, то при этом некоторые
части в фоновом изображении отражают свет. Это приводит к тому, что
алгоритмы выделения фона неверно сегментируют отражающие свет об-
ласти в передний план;
• некоторые части объектов могут быть окрашены в цвет фона. В резуль-
тате они будут исключены из переднего плана:
• тени, падающие на объекты, большинством алгоритмов сегментируются
в передний план. Кроме того, внезапное изменение освещенности сцены
также приводит к неправильной сегментации изображения.
В зависимости от характера недостатка на сегментированном изображении
следует применять процедуры слияния областей и операции морфологической
фильтрации изображения.
Морфологическая фильтрация. К бинарному изображению применяются
последовательно такие операции математической морфологии, как расширение
(дилатация) и сжатие (эрозия). Пусть подмножество 5 - совокупность точек изо-
бражения, принадлежащих интересующему объекту. В - структурирующий эле-
мент. Операция эрозии определяется в математической морфологии следующим
образом [6]:
Ев(5) = $-Я = {5Ас$|АбЕ}. (1)
где означает эрозию подмножества 5 со структурирующим элементом Я;
Е - дискретная плоскость; h - вектор, определяющий каждую позицию В на Е;
Bh - перенос В вдоль вектора Л:
Bh={b + h\be В}. (2)
Во время процедуры эрозии элементы не удаляются с изображения, а лишь поме-
чаются для удаления после окончания всей процедуры. Пример применения опе-
рации эрозии приведен на Рис. 4.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
68
Цифвая обработка видеоизображений
Алгоритм К-средних (К-means). В исходном множестве выбираются произволь-
ным образом К объектов, которые считаются центрами искомых кластеров, где
К - заданное число кластеров. Затем проводится распределение всех оставшихся
элементов множества этим кластерам по принципу близости к соответствующему
центру. Далее производится уточнение положения центров, которые вычисляют-
ся как среднее по совокупности всех объектов, попавших в каждый кластер. Этот
процесс повторяется до тех пор. пока изменение центров кластеров по сравнению
с вычисленным на предыдущей итерации не станет достаточно малым.
Кластеризация методом ART при неизвестном числе кластеров. В этом слу-
чае необходимо ввести параметр £ - ограничение на взаимную удаленность со-
седних объектов, принадлежащих одному кластеру. Из исходного множества про-
извольным образом выбирается один объект, который назначается центром пер-
вого кластера. Далее для каждого элемента множества вычисляется расстояние
до центров уже построенных кластеров. Если для какого-либо кластера это рас-
стояние меньше значения £, то элемент приписывается этому кластеру и прово-
дится уточнение положения центроида с учетом нового члена. Если же новый
элемент не попадает ни в один кластер, он становится центром нового кластера.
Подробно алгоритмы кластеризации приведены в Главе 5. посвященной адап-
тивным методам распознавания образов и задачам классификации. Отметим, что
алгоритмы К-средних и AR1 являются наиболее эффективными в вычислитель-
ном плане, поэтому они могут быть использованы в задачах реального време-
ни. При использовании алгоритма К-средних следует задать число кластеров, ко-
торое. вообще говоря, в задачах видеонаблюдения обычно априорно неизвест-
но. В этом случае можно поступить следующим образом: назначить этому числу
значение, несколько превышающее число объектов, обычно присутствующих на
сцене, фиксируемой конкретной камерой. После построения кластеров их следу-
ет окружить описанными прямоугольниками и объединить в один кластер объ-
екты, для которых прямоугольники пересекаются.
Рис. 3. Выделение движущихся объектов с помощью алгоритма К-средних: А - по-
сле нахождения 9 кластеров, Б - после объединения объектов с пересекающими-
ся прямоугольниками
ProSystem CCTV - журнал по системам видеонаблюдения
http;//www. procctv.ru
70
Цифвая обработка видеоизображений
Рис. 4. Пример применения операции эрозии: А - исходное изображение, Б - ре-
зультат применения операции эрозии к изображению А, В - структурирующий
элемент
Расширение (дилатация) определяется как:
6B(S) = S®B = {s + b\seS-,bGB}. (3)
где 5Д(5(означает расширение подмножества 5 со структурирующим элемен-
том В. Пример применения операции дилатации приведен на Рис. 5.
Рис. 5. Пример применения дилатации: А - исходное изображение, Б - резуль-
тат применения операции дилатации к изображению А, В - структурирующий
элемент
Последовательное применение эрозии и дилатации ведет к сглаживанию би-
нарных изображений [7].
Результат обработки существенно зависит от двух факторов: конфигурации
структурирующего элемента и его размера [8]. Как известно, выбор конфигу-
рации является скорее эмпирическим и интуитивным процессом. Структуриру-
ющий элемент для эрозии может представлять собой, например, совокупность
ProSystem CCTV - журнал по системам видеонаблюдения
h ttp.//ww w. procctv. ru
Глава 3 Выделение и классификация движущихся объектов
71
дальних соседей опорного пикселя, а для расширения - полное множество со-
седей опорного пикселя. Что касается размера структурирующего элемента, то
очевидно, что операции эрозии и дилатации должны использовать один и тот же
размер, в противном случае толщина линий объекта изменится по окончании
процесса обработки.
Однако корректный выбор размера структурирующего элемента для кон-
кретного изображения или его отдельных частей является оптимизационной за-
дачей. решение которой зависит от ряда факторов. Во-первых, желательно осво-
бодить изображение от дефектов настолько, насколько методы математической
морфологии позволяют это сделать в принципе: во-вторых, одним из основных
условий является сохранение топологии интересующего объекта: в-третьих, вре-
мя обработки должно быть достаточно малым.
Слияние. Маленькая область, количество пикселей которой меньше заданно-
го порога, присоединяется к ближайшей к ней по яркости большой области. Оди-
ночный пиксель добавляется к ближайшей к нему по яркости области, или ана-
лизируется принадлежность пикселей его окрестности к соседним областям, и
принимается решение об его добавлении к той области, к которой принадлежит
большинство его соседей. Пример слияния областей изображен на Рис. 6.
А Б
Рис. 6. Пример слияния областей: А - исходное изображение с отделившими-
ся «колесами» автомобиля, Б - изображение, получившееся в результате слияния
областей
Этот вид постобработки рекомендован для алгоритмов наращивания обла-
стей и алгоритмов с применением кластерного анализа.так как часто в результа-
те их работы получаются мелкие области или пиксели, не отнесенные ни к какой
области. Проще всего слияние областей выполнить путем применения морфоло-
гической операции замыкания, которая определяется как
S*B = (S®B)-B.
Эту запись нужно понимать следующим образом. К множеству S применяет-
ся операция дилатации со структурирующим элементом В, а к полученному ре-
зультату применяется операция эрозии с тем же структурирующим элементом В.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
72
Цифвая обработка видеоизображений
Рис. 7. Между движущимся автомобилем и камерой находится столб. А - исходное
изображение, Б - соответствующий блоб, который разделился на части, В - резуль-
тат оконтуривания блобов
При видеонаблюдении часто возникает ситуация, когда между движущим-
ся объектом и камерой находится какое-либо препятствие, например дерево или
столб. В результате сегментирования этот объект разбивается на две части, что
может привести к ошибке при классификации. Эта ситуация изображена на Рис. 7.
Видно, что когда автомобиль проезжает мимо столба, расположенного ближе к
камере, то соответствующий автомобилю блоб рассекается столбом на две ча-
сти. Поскольку область, которую загораживает столб, имеет незначительные по
сравнению с автомобилем размеры, то применение операции слияния позволяет
восстановить изображение блоба.
3.3. МЕТОДЫ, ОСНОВАННЫЕ НА ВЫДЕЛЕНИИ КОНТУРОВ
Проблеме выделения контуров посвящено большое количество литературы.
Задача обработки видеоизображения в реальном времени накладывает на вы-
бранный алгоритм существенные ограничения по производительности, поэтому
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 3. Выделение и классификация движущихся объектов
73
из всех алгоритмов следует в первую очередь выбирать наиболее быстрые, мо-
жет быть, даже в ущерб качеству На практике хорошо себя зарекомендовал ме-
тод. заключающийся в последовательном прохождении бинарного изображения
сверху вниз и слева направо, нахождении связанных областей (далее компонент)
и присвоении им меток [9]. При этом все операции можно условно разделить на
четыре этапа.
I) Находится первая точка внешнего контура, которая на Рис. 8А обозначе-
на буквой А. после чего весь внешний контур проходится целиком, пока
опять не встретится точка А. Ей и всем точкам внешнего контура присва-
ивается одна и та же метка.
2) Для всех точек внешнего контура, перебираемых сверху, выполняет-
ся следующая операция. Начиная с этой точки, обозначенной на Рис. 8Б
как А ’. осуществляется сканирование соответствующей строки пикселей,
чтобы определить все последующие черные пиксели (если они существу-
ют) путем присвоения им той же метки, что и у А'.
3) Когда в первый раз встречается точка внутреннего контура В (Рис. 8Б.
В), ей присваивается та же метка, что и у соответствующей точки того
же ряда А' внешнего контура. Далее обходится весь внутренний контур, и
всем его точкам присваивается та же метка, что и у точки В (Рис. 8В).
4) Когда встречается точка В' внутреннего контура, уже имеющая метку
(Рис. 8Г).то продолжаем идти вдоль этого ряда, чтобы определить все по-
следующие черные пиксели (если таковые существуют) и присвоить им
ту же метку, что и у В’.
Рис. 8. Последовательность построения контура
Для простоты предположим, что первая строка изображения состоит из бе-
лых пикселей (если это не так.то к изображению можно добавить еще одну стро-
ку из белых пикселей). Создадим рабочий массив той же размерности, что и исхо-
дное изображение, и будем в нем хранить метки каждого пикселя. Обозначим че-
рез С индекс метки для компонент: пусть в начальный момент он имеет значение
1. Пиксели, которым будут присвоены одинаковые метки, будут принадлежать
одному найденному объекту, а номер метки будет соответствовать номеру этого
объекта. Обозначим буквой Р текущий рассматриваемый пиксель.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
74
Цифвая обработка видеоизображений
1 этап. Выделение внешнего контура. Если у пикселя Р нет метки и пиксель
над ним белый, как это показано на Рис. 9. это означает, что Р лежит на внешнем
контуре. Пикселю Р присваивается метка С. после чего осуществляется переход
к процедуре выделения контура Contour Tracing, описываемой ниже, в результа-
Рис. 9. Р- начальная точка внешнего контура, 1 - непомеченные черные пиксели
те выполнения которой всем точкам этого контура присваивается метка С. После
выполнения процедуры Contour Tracing значение индекса С увеличивается на 1.
2 этап. Если пиксель под Р является открытым (значение этого термина см.
ниже) белым пикселем, то Р лежит на новом внутреннем контуре. При этом су-
ществует две альтернативы:
• Р уже имеет метку (Рис. 10А). В этом случае Р также является точкой и
внешнего контура.
• У Р нет метки (Рис. 10Б). В этом случае предшествующий пикселю Р в
этой строке пиксель /V должен иметь метку.Тогда Р получает ту же метку,
что и N.
Рис. 10. А. Р-начальная точка внутреннего контура; Ртакже принадлежит внешне-
му контуру. Б. Р - начальная точка внутреннего контура; Р не принадлежит внеш-
нему контуру. 1 - непомеченные черные пиксели, А - помеченные.
ProSystem CCTV - журнал по системам видеонаблюдения
http://w ww.procctv. ru
Глава 3. Выделение и классификация движущихся объектов 75
Далее в любом случае переходим к Contour Tracing, чтобы определить весь
внутренний контур, которому принадлежит Р. и присвоить ему те же метки.
3 этан. Если Р не является точкой, рассмотренной на предыдущих шагах (т. е.
она не принадлежит никакому контуру), то в этом случае точка слева от Р долж-
Для того чтобы избежать повторного обхода контуров, белые пиксели,
окружающие помеченные точки, помечаются как закрытые. Эта ситуация изо-
бражена на Рис. 12, на котором окружающие точку Q белые пиксели помече-
ны как закрытые. Поэтому, когда вдоль строки мы дойдем до точки Q. то бе-
лый пиксель внизу уже не будет открытым, поэтому не произойдет переход к
процедуре Contour Tracing. В то же время пиксель, расположенный под впер-
вые встретившимся пикселем внутреннего контура Р на Рис. 12. все еще явля-
Рис. 12. Закрытые белые пиксели отмечены ”, открытые - пустые
ется открытым, так как внутренний контур, содержащий этот пиксель, еще не
был пройден.
Закрывая окружающие белые пиксели, мы тем самым обеспечиваем про-
хождение каждого внутреннего контура только один раз. Как следует из Рис. 13.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
76
Цифвая обработка видеоизображений
когда внутренний контур пройден, пиксель под R уже больше не является от-
крытым, и поэтому нам не надо будет проходить внутренний контур еще раз.
когда вдоль строки мы дойдем до R (необходимо проходить внутренний контур
только в тех точках, когда белые пиксели под ними являются открытыми).
Процедура Contour Tracing.
Целью данной процедуры является определение всех точек внутренних и внеш-
них контуров, начиная с некой точки S. Если 5 определяется как изолированная
точка (т. е. среди ее восьми соседей нет черных точек), то осуществляется выход из
процедуры. В противном случае находится точка контура Г.следующая за S: далее
находится точка, следующая за Т и т. д. Процедура выделения контура продолжа-
ется до тех пор. пока не будут выполнены следующие два условия одновременно:
1. процедура дошла до исходной точки S.
2. следующей за ней точкой контура будет точка Т.
На Рис. 14 приведен пример контура, который может быть найден с помощью
описанной процедуры даже в таком достаточно непростом случае, когда он со-
стоит из одной линии, причем поиск начинается из средней точки контура.
Если не требовать выполнения условия 2. то был бы найден контур STUTS,
что составляет лишь часть от верного контура.
Каждая следующая точка контура ищется среди восьми соседних точек дан-
ного пикселя. Пусть, например, нам надо найти точку, следующую за точкой Р.
Рис. 14. В данном случае контур будет таким: STVTSVWVS
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ri/
Глава 3. Выделение и классификация движущихся объектов
77
Каждой из этих восьми точек присваивается индекс, как показано на Рис. 15А.
Поиск производится по часовой стрелке, причем начало обхода определяется
следующим образом.
Если Р лежит на новом внешнем контуре, то начальной точкой будет точ-
ка с индексом 7. так как точка над Р является белым пикселем, а следующей точ-
кой по часовой стрелке будет именно точка с номером 7. Если же Р лежит на но-
вом внутреннем контуре, то начальной точкой будет точка 3. так как точка под
Р - белый пиксель, а следующей точкой по часовой стрелке будет точка с индек-
сом 3. С другой стороны, если существует предыдущая точка контура, и это. на-
пример. точка 3. то начальной точкой будет 5, так как точка 4 уже должна была
быть пройдена (изначально идем сверху вниз и слева направо). Эта ситуация по-
казана на Рис. 15Б. В общем случае, когда сточки Р не начинается ни внешний, ни
внутренний контур, номер начальной точки для осуществления обхода определя-
Рис. 15. А - нумерация пикселей вокруг текущей точки Р, Б - выбор начальной
точки для обхода соседей по часовой стрелке
После того как начальная точка обхода соседей определена, по часовой
стрелке находится первый черный пиксель. Это и будет точка, следующая за Р.
Если такую точку найти не удается, то Р является изолированной точкой.
Закрытие окрестных белых пикселей производится во время поиска следую-
щей точки. Как следует из Рис. 16, если А - текущая точка, а С - следующая точ-
ка контура, и при проверке соседей точки А до нахождения черной точки С был
найден белый пиксель В. то он закрывается.
пиксель В, встретившийся при сканировании, закрывается.
http://wwvvjfv.ru
Компания ITV — генеральный спонсор издания книги
78 Цифвая обработка видеоизображений
3.4. ИСПОЛЬЗОВАНИЕ КЛАССИФИКАЦИОННЫХ МЕТРИК И
ВРЕМЕННОЙ СОГЛАСОВАННОСТИ
Методы, описываемые в данном разделе, основаны на двух ключевых поня-
тиях: классификационной метрике (позволяющей определить меру близости рас-
сматриваемого объекта к одному из шаблонов, хранящихся в созданной базе дан-
ных) и временной согласованности (т.е. классифицируются только те объекты,
которые присутствуют в видеопотоке в течение ряда последовательных кадров; в
противном случае они считаются фоновым шумом). Особую трудность при клас-
сификации создает следующее обстоятельство: в текущем кадре истинная приро-
да объекта может быть искажена вследствие наложения нескольких объектов.
Например, группа идущих рядом людей в отдельных кадрах может выглядеть как
едущий автомобиль. Для решения этой проблемы можно использовать подход,
основанный на порождении и проверке ряда гипотез [10-14].
На первом шаге для r-ого кадра при помощи метода временной разности вы-
деляется Nt потенциальных объектов F,(j). Эти объекты классифицируются при
помощи выбранного метрического оператора d(x). и результат отмечается как
гипотеза х(*):
/(') = P(F< ('))}’ '=1.М (4)
Дальше в действие вступает принцип временной согласованности: каждый
из этих потенциальных объектов должен присутствовать в последующих ка-
драх для продолжения классификации. Поэтому в новом кадре ищется соответ-
ствие всех переднеплановых областей предыдущего кадра F(i) переднеплано-
вым областям текущего Ft}(j) при помощи метрики d(x). Все потенциальные
псреднеплановые объекты из предыдущего кадра, которым не соответствует
ни один объект текущего кадра, выбрасываются из дальнейшего рассмотрения.
Переднеплановые объекты текущего кадра, не соответствующие никакому
объекту из предыдущего кадра, считаются новыми потенциальными объекта-
ми. Таким образом, в каждом кадре происходит обновление классификационной
гипотезы:
z(0=z(/)^ {</(/=;(/))}. (5)
Тем самым могут быть накоплены статистические данные об объекте за
определенный промежуток времени, что позволит принять правильное класси-
фикационное решение. Более того, такие посторонние движения, как качание
ветвей дерева, будут исключены из рассмотрения.
Выбор метрического оператора основывается на том обстоятельстве, что
люди, как правило, имеют меньшие размеры и более сложные контуры, чем
транспортные средства. Для учета этой закономерности весьма эффективным
является следующий метод. Введем систему координат, в которой по одной оси
будем откладывать размер объекта А (общее число пикселей), а по другой - ве-
личину £>, определяемую по следующей формуле:
р=Д (6)
А
ProSystem CCTV - журнал по системам видеонаблюдения
http://www procctv.ru
Глава 3 Выделение и классификация движущихся объектов
79
где р - это периметр объекта. После этого на основе данных, полученных во вре-
мя обучения системы, на координатной плоскости можно выделить области, со-
ответствующие людям и транспортным средствам. Дальнейшее разделение меж-
ду этими двумя классами проводится путем разбиения массива данных или ли-
нейным образом, или при помощи меры Махаланобиса. На Рис. 17 приведены
изображения автомобилей и люден, под которыми стоит значение параметра D.
округленное до целого значения.
D=21
D=22
Рис. 17. Значения параметра D для некоторых изображений автомобилей и людей
Можно заметить, что для изображений людей параметр D принимает значе-
ния, примерно в полтора раза большие, чем для изображений автомобилей, в то
время как общее число пикселей А для автомобилей, как правило, на порядок
больше, чем для присутствующих на той же сцене людей. В результате этого об-
ласти, соответствующие изображениям автомобилей и людей, будут достаточно
далеко разнесены на плоскости (A, D). как это показано на Рис. 18.
Рис. 18. Взаимное расположение областей, соответствующих изображениям людей
и автомобилей, на плоскости (A, D)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
80
Цифвая обработка видеоизображений
Чтобы избежать неверной классификации объектов во время их перекры-
тия или в тех случаях, когда объект на изображении появился только частич-
но (при этом автомобиль может выглядеть как человек), можно использовать
метод максимального правдоподобия. Для каждого переднепланового объекта
следует построить классификационную гистограмму, у которой число ячеек со-
впадает с числом различных типов объектов. Например, если считать, что в ви-
деопотоке могут присутствовать автомобили, группы людей и отдельные люди,
то размер такой гистограммы будет равен трем, а каждая ее ячейка будет ото-
бражать количество раз, когда рассматриваемый объект был отнесен к конкрет-
ному классу. Вводится время классифицирования t uпо прошествии которого
объект считается отнесенным к классу, имеющему наибольшее значение в гисто-
грамме. При t > классификация объекта может быть изменена.
Аналогичный подход состоит в создании на первом этапе базы данных ша-
блонов контуров различных объектов, которая в дальнейшем используется для
анализа видеопотока. В созданную базу данных могут входить контуры лю-
дей в различных позах, автомобили, снятые в различных ракурсах, и т. п. При
этом храниться будут не сами изображения, а их характерные расстояния. Пусть
Р = {рг р,,.... pj - контур объекта F, состоящий из л точек, упорядоченных по
часовой стрелке, начиная от верхней центральной точки. Обозначим через
С = (х . у ) центр масс объекта F:
(7)
? т
n п т
Тогда компоненты вектора характерных расстояний объекта D = (Dj,D2,...,Dw)
определяются как расстояние от центра масс до соответствующей точки контура:
D=d{Cm,p,), ' = 1....п. (8)
где d(a, b) представляет собой евклидово расстояние между точками а(ха, уа)
и b(xh, yh). Процесс нахождения характерных расстояний объекта поясняет-
ся на Рис. 19.
Рис. 19. Вычисление характерных расстояний объекта. С - центр масс объекта,
D - расстояние от центра масс до точки контура р .
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
рава 3. Выделение и классификация движущихся объектов 81
Так как различные объекты имеют отличающиеся размеры, то, естествен-
но, и размеры их контуров тоже не совпадают. Более того, для одного и того же
объекта размеры контура могут меняться со временем. Поэтому для того чтобы
иметь возможность сравнивать объекты разного размера, необходимо иметь ме-
трику, не зависящую от масштаба. С этой целью введем постоянную целую ве-
личину Q. позволяющую фиксировать размер вектора характерных расстояний
объекта, следующим образом:
'=и.,е. (9)
Теперь можно нормировать полученные величины:
D, . (10)
г»!
Мера соответствия рассматриваемого объекта Ги шаблона Т из базы данных
определяется как
do
1=1
Чтобы определить, к какому классу относится объект, необходимо найти дан-
ное расстояние для каждого шаблона из базы данных. Тот шаблон, для которого
эта величина будет минимальной, считается имеющим наилучшее соответствие
рассматриваемому объекту. Для соблюдения принципа временной согласованно-
сти строится классификационная диаграмма [10].
В качестве характерных признаков объекта можно рассматривать инвари-
антные моменты [11]:
w ы
= Р-9 = 0,1,2,. (12)
/=| /=1
где Г(х, у) представляет собой переднеплановый объект, а именно блоб изобра-
жения. Однако такое определение момента не является инвариантным. Инвари-
антным к перемещению будет центральный момент (р + ^)-порядка:
м N
vp.4 = mL(x-'xn.Y(y,-y^4 F(xny^ = 0,1,2,...., (13)
«=1 у=1
где (х^, уш) - центр масс блоба:
хп, = m\,o/mo.o. Ут = "’o.i /™о.о- О4)
Для выполнения условия инвариантности к изменениям масштаба необходи-
мо нормировать центральный момент [12]:
= 05)
"*0,0
Инвариантными к изменениям масштаба, вращению и перемещению явля-
ются следующие моменты:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
82
Цифвая обработка видеоизображений
Ф^Дз.о + До.з,
ф2=(Д2.о-До.2):+4Рш
Ф, =(д3()-Зд,2)2+(Зд2|-Д03)‘,
Ф4=(Дз.о + К;)'+(Я2.1+Яоз)\
Ф< = (д} 0 -Зд,,)(ц}0 + д,, )[(д3.0 + д, 2)* - 3( д2, + д03)* ] +
+(ЗДи - ДозХДм + Доэ)[з(д3,« + Ди)' -(д:л +До,3)']
(16)
ф^ =(Д2.о-До.з)(д3.о + Д1.2)‘ -(Дз.1 +Дол)‘ +4Д1.1(Дз.о+Д1.2)(д2.1 +До.з).
Ф- = 3(д:л + До.3)(д3.о - Ди)(я» + Ди)' -3(д;., + Д„,3)' -
— (Дз.о — ЗД1,3)(Д2,| + дДз(Дзо + Д12) — (Дзд+До.з) j
Иной подход для извлечения характерных признаков из изображения объекта
состоит в том. что каждый выделенный блоб заключается в минимально возмож-
ный прямоугольник.который делится на четыре меньших прямоугольника QvQr
Qv Qv называемые квартилями [13]. Точкой пересечения отрезков, делящих ис-
ходный прямоугольник, является центр масс блоба С. как это показано на Рис. 20.
Далее определяются центры масс квартилей qr q2. qr q* и расстояния
dvd2,dyd4 до них от центра масс блоба. Для увеличения робастности характерно-
го набора данных рассчитываются также углы I/,. которые составля-
ют векторы d с горизонтальным отрезком, делящим исходный блоб. Вектор ха-
рактерных признаков блоба состоит из восьми величин:
Рис. 20. Процесс построения квартилей (?,. Q,. (X. Q, а также нахождения набо-
ра характерных признаков (d}, d2. dx, d4, . I//.. ЦЛ, ). Здесь С - центр масс блоба.
ProSystem CCTV - журнал по системам видеонаблюдения
h ftp://www. procctv. г и
'гава 3. Выделение и классификация движущихся объектов
83
(4,^2,</,Л,У|,г2»Гэ.%). О7)
Для подробной классификации объектов можно воспользоваться методом
линейного дискриминантного анализа. Введем несколько классов объектов и вы-
числим выборочную ковариационную матрицу для точек внутри каждого класса
£и и между различными классами £/у:
Z»' = £ Ё & " ** )& " ** У- <18)
*=1 1=1
ze = £«t(A-^)(A-^o). (19)
*=|
Здесь К - число классов объектов. nk - количество обучающих приме-
ров для класса к. xik - вектор характерных признаков z-го обучающе-
го примера для класса к. хК - центроид класса к. вектор х - общий цен-
троид для всех классов. Далее находятся собственные векторы bi и соб-
ственные значения Л матрицы при помощи решения уравнения
(£я - Л = 0. Найденные собственные значения упорядочиваются по убы-
ванию: Л, > Л2 >... > где/V - размерность пространства характерных призна-
ков. Собственный вектор bt. соответствующий собственному значению Л, пред-
ставляет собой коэффициенты z-й дискриминантной функции, которая отобра-
жает вектор характерных признаков х в точку дискриминантного пространства.
Снижения размерности можно добиться, рассматривая только М < N наиболь-
ших собственных значений (и, соответственно, собственных векторов), таким об-
разом отображая N-мерное пространство векторов характерных признаков х в
М-мсрный вектор у\
у = [бД...6м]Гх. (20)
На практике М выбирается из условия
£Л,>0.99£Л,. (21)
1=1 /=|
Во время классификации определяется вектор х для рассматриваемого бло-
ба и отображается в точку у дискриминантного пространства. Для определения
класса объекта находятся к ближайших соседей точки у, каждый из которых со-
ответствует одному из классов. Далее класс, наиболее часто встречающийся сре-
ди к соседей, считается классом рассматриваемого объекта.
Одним из эффективных характерных признаков рассматриваемого объекта
может служить его цветовая гистограмма. Обозначим через Л (й) (й = (/?, G, В))
гистограмму объекта i. Тогда распределение вероятности появления того или
иного цвета объекта в момент времени t может быть записано следующим
образом:
= (22)
где At - размер объекта.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
84
Цифвая обработка видеоизображений
В каждом кадре гистограммы объектов пересчитываются по формуле (22).
После этого может быть найдено окончательное значение вероятности
+ 4 (23)
Для величины Д рекомендуется выбирать значение порядка 0.8.
3.5. МЕТОДЫ, ОСНОВАННЫЕ НА АНАЛИЗЕ ПЕРИОДИЧНОСТИ
ДВИЖЕНИЯ
В настоящем разделе описываются методы, основанные на анализе перио-
дичности движения, присущей многим движущимся объектам. Например, у че-
ловека во время ходьбы довольно легко можно выделить повторяющиеся через
определенное время позы.То же самое относится и к животным. Поэтому перио-
дичность движения можно с успехом использовать для классификации ряда дви-
жущихся объектов [15-19].
Будем считать движение точки X (/) в момент времени t периодическим, если
оно повторяется с постоянным периодом Т:
X(t) = X(t + T) + r(t). (24)
где г (/) - смещение точки. Если Т нс является константой, то движение считает-
ся циклическим. Далее предполагается, что ориентация и размер объектов не ме-
няются значительно в течение нескольких периодов, а частота смены кадров до-
статочно высока, чтобы уловить периодичность движения (по крайней мере в два
раза больше его частоты).
Пусть на первом этапе сегментации выделены переднеплановые объекты F.
Для обнаружения периодичности в движении размеры каждого объекта необ-
ходимо привести к стандартному размеру. В противном случае невозможно бу-
дет учесть изменения размеров объекта при его удалении или приближении к
камере. Так как на этапе выделения переднего плана неизбежно появление шу-
мов, желательно сначала осуществить медианную фильтрацию изображения, по-
сле чего размеры объектов оцениваются по нескольким соседним кадрам. По-
сле этого каждый объект имеет следующие атрибуты: размер, центр масс, мини-
мально возможный прямоугольник (МВП), ограничивающий объект, скорость и
время существования объекта, измеряющееся в кадрах.
Будем вычислять величину самоподобия объекта в моменты времени Г( и I/
$01Л) = £ (25)
(x.j)efi
где Q - МВП для объекта F(x, у г,). Минимум величины 5 находится следующим
образом:
ФО’Й, £ \F(x + dx,y + dy,t})-F(x,y,t2l (26)
1 W (х.у)еЯ
где, например, можно задать значение R = 2. Для периодического движения S'
также будет периодической. На Рис. 21 [19] представлен типичный вид величины
5'для всех комбинаций / и вычисленной для последовательности кадров, на ко-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 3. Выделение и классификация движущихся объектов
85
Рис. 21. График подобия идущего человека
торых был изображен идущий человек (темные области означают большую сте-
пень подобия).
Очевидно, что график подобия должен быть симметричен относительно
главной диагонали. Кроме того, главная диагональ всегда будет самой темной
линией рисунка, так как объект подобен самому себе в любой момент времени
5'(Л 0=0. Периодическое движение будет представлено темными линиями, па-
раллельными главной диагонали, так как S'(t, kT/2+f) = 0. где Т - период, а Л -
целое. Темные линии, перпендикулярные главной диагонали, образованы вслед-
ствие того, что S'(t, Л 772-0=0 из-за симметрии идущего человека (Рис. 22) [19].
Однако не всем периодическим движениям отвечает график S' с прямыми,
перпендикулярными главной диагонали. Например, для бегущей собаки, изобра-
я
11
12
13
3 4 5
ж" Ж! О
14
15 16
17
18
19
20
10
21
22 23
24
25
ивг
26 27 28
29
30
31 32
о
1
2
6
7
8
9
< I
1 \
Л
Д:
»
j
Рис. 22. Полный период идущего человека (Т = 32)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
86 Цифвая обработка видеоизображений
женной на Рис. 23 [19], в течение периода не существует двух подобных кадров
(т. е. » 0.0 < < С < Г). График подобия для бегущей собаки приведен на
Рис. 24 [19]. Это отличие в графиках подобия может быть использовано для клас-
сификации объектов.
Определить, является ли движение периодическим, можно двумя способами:
при помощи вычисления спектральной мощности и автокорреляционной функ-
ции. В первом случае спектральная мощность оценивается для фиксированно-
го значения г, и всех значений Г,. Периодическое движение проявляется пиками в
спектре мощности Р. При этом будем считать такой пик/ значимым, если
Р(./,)>Д,+&Т„ (27)
где 8 - пороговое значение (например, равное 3). и ор- среднее значение и
стандартное отклонение Р.
Во втором способе используется А - автокорреляционная функция 5*. Если
5'является периодической величиной.то А будет иметь максимумы, равномерно
расположенные на плоской решетке М р где d - расстояние между узлами решет-
ки. Пики 0 в автокорреляционной функции проецируются на решетку Мd при по-
мощи меры соответствия е:
<28>
i
В, = {е, I \Mj.t - | < min\Mdd - 0, |n \Mdd - 0, | < 8„ n A(0,) < /U }. (29)
Здесь В - ближайший пик к узлу решетки 8п - пороговое значение
(8{)<d/2). а Лпшч - минимальное значение автокорреляционной функции, которое
может принимать соответствующий пик функции. Между 0 и Md имеется соот-
ветствие. если
min e(Md)<8t. (30)
<f| idid^
Здесь 8 - пороговое значение соответствия: [rfr г/,] - диапазон изменения d.
Для описанных величин рекомендуются следующие значения: 8п = 1.<5 = 2|Л/р|,
Дпмх= 0,25. Диапазон [г/,. d,] определяет возможную область изменения периода,
причем 0 < d} < с/, < L, где L - задержка автокорреляционной функции.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 3 Выделение и классификация движущихся объектов
87
10 20 30 40 50 60 70 80 90 100
Рис. 24. График подобия бегущей собаки
-30 -20 -10 0 10 20 30
Рис. 25. Автокорреляционная функция идущего человека
На Рис. 25 [19] изображена автокорреляционная функция для видеопоследо-
вательности. изображающей идущего человека. Отчетливо видна решетчатая
структура функции Л. отражающая ее пики.
Автокорреляционная функция для бегущей собаки имеет вид параллельных
полос (Рис. 26 [ 19]). Это является отражением того факта, что в течение периода
для этого видеопотока не существует двух подобных кадров (см. Рис. 24).
Еще более значительно отличаются функции подобия и автокорреляционная
функция движущегося автомобиля, приведенные на Рис. 27 и Рис. 28 [19].
Так как периодичности в движении транспортных средств не наблюдается, то
график автокорреляционной функции представляет собой одну широкую поло-
су. идущую вдоль главной диагонали.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
88
Цифвая обработка видеоизображений
Рис. 26. Автокорреляционная функция бегущей собаки
Рис. 27. График подобия движущегося автомобиля
-30 -20 -10 0 10 20 30
Рис. 28. Автокорреляционная функция движущегося автомобиля
ProSystem CCTV - журнал по системам видеонаблюдения
http://wwwprocctv.ru
Глава 3. Выделение и классификация движущихся объектов
89
3.6. МЕТОДЫ, ОСНОВАННЫЕ НА ИСПОЛЬЗОВАНИИ
ДИНАМИЧЕСКИХ ТЕКСТУР
Динамические текстуры - это пространственно повторяющиеся, изменяю-
щиеся во времени зрительные образы, которые образуют последовательность
изображений с определенной временной устойчивостью. В случае динамических
текстур (ДТ) понятие самоподобия, являющееся ключевым для обычных тек-
стур, расширяется на пространственно-временную область. Типичными примера-
ми ДТ служат видеопоследовательности, изображающие дым, огонь, волны, ли-
ству, колышущуюся на ветру и др.
Так как ДТ являются трехмерным вариантом обычных статичных текстур
благодаря присутствию зависимости от времени, то для их анализа можно ис-
пользовать обобщение соответствующих двумерных методов. Однако вслед-
ствие того, что большинство изменений во времени обусловлено наличием дви-
жения на изображении, имеет смысл предварительно получить информацию о
движении. Поэтому естественным выбором в данной ситуации являются методы
оптического потока. Основным источником информации при этом является ме-
няющееся со временем векторное поле, представляющее собой аппроксимацию
двумерного поля движения, отображающего перемещения в пространстве. Такое
поле содержит значительно больше информации, чем скалярное поле при ана-
лизе обычных текстур. Более того, направление и величина движения более тес-
но связаны с конкретными событиями по сравнению со значением интенсивно-
сти отдельного пикселя. Это открывает новые возможности с точки зрения рас-
познавания объектов.
Существует несколько различных подходов к анализу динамических текстур,
основными из которых являются методы оптического потока и методы, исполь-
зующие в качестве характерных признаков ДТ параметры построенной моде-
ли текстуры. Наиболее распространенным методом в настоящее время являет-
ся использование нормальной компоненты оптического потока [20-26]. При этом
особую важность приобретает вопрос корректности рассмотрения только одной
компоненты оптического потока. Как известно, нормальный поток может быть
эффективно вычислен и. кроме того, содержит полезную информацию о движе-
нии объектов. Однако даже с учетом его сглаживания он является чрезвычайно
чувствительным к шуму. Тесная связь нормального потока с пространственны-
ми градиентами проявляется в корреляции характерных признаков на его осно-
ве и внешних визуальных характеристик. В целом, поля нормального потока не
слишком хорошо отражают визуальную динамику процессов. Полный оптиче-
ский поток в этом отношении является значительно лучшей характеристикой.
К сожалению, его вычисление в реальном времени на подавляющем большин-
стве компьютеров не представляется возможным в настоящее время.
3.6.1. Использование оптического потока
В настоящем разделе будет использоваться только нормальная составляю-
щая оптического потока, что позволит избежать большого объема вычислений,
и в то же время этой компоненты вполне достаточно для решения рассматрива-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
90
Цифвая обработка видеоизображений
емых задач. Нормальный поток.т. е. поток в направлении градиента интенсивно-
сти W(x, у), записывается следующим образом:
di dt _
Ml "
(*.?)=-
(31)
где п - единичный вектор в направлении V/(x, у). Нормальный поток содержит
в себе как временную, так и пространственную информацию о динамических
текстурах: временная информация связана с движением краевых точек, а про-
странственная - с их градиентами. Недостатком применения нормального по-
тока является его относительно высокая чувствительность к шуму. Однако она
может быть уменьшена путем применения сглаживающих фильтров и последу-
ющей эквализации гистограмм или с помощью пороговой обработки простран-
ственных градиентов. Кроме того, если градиент V/(p) достаточно равномерно
распределен по направлениям в окрестности точки р = (х, у), то выражение (31)
можно заменить на взвешенное усреднение что сделает его вычисление бо-
лее устойчивым:
v^=—(---------------т
max а, £ j|V/(^)||"
(32)
где F(p) - окно размером 3 х 3 с центром в точке р.а- заданная положитель-
ная константа, определяющая уровень шума в однородных областях и предот-
вращающая деление на нуль в некоторых однородных областях изображения,
в которых градиент равен нулю. Величина vo представляет собой меру локаль-
ного движения. Связанная с этим потеря информации о направлении движения
нс так важна, так как нас в первую очередь интересует динамика общего ха-
рактера.
Как известно, для вычисления характерных признаков статичных текстур
могут быть использованы матрицы вхождений, представляющие собой двумер-
ные массивы, в которых индексы строк и столбцов образуют множество допу-
стимых на изображении значений пикселей [27]. При этом элементы массива
указывают, сколько раз значение первого индекса встречалось на изображе-
нии в некотором заданном пространственном отношении со значением второго
индекса. В качестве такого отношения может выступать, например, соседство
пикселей.
Обычная пространственная матрица вхождений может быть объединена
с получаемыми значениями нормальной компоненты оптического потока для
разделения изображений с ДТ и с обычным движением объектов [20]. Одна-
ко таким способом невозможно описать временную эволюцию: изучаемые при
этом взаимодействия будут чисто пространственными и могут характеризовать
только стационарные движения. Кроме того, вычисление матриц вхождений с
разными пространственными отношениями требует значительных временных
затрат. Поэтому будем рассматривать временные матрицы вхождений, которые
определяются следующим образом [21]:
ProSystem CCTV - журнал по системам видеонаблюдения
http//www.procctv.ru
~лава 3. Выделение и классификация движущихся объектов
91
(33)
где b - дискретный аналог vo, d - рассматриваемый временной интервал,
Cd = {(r,s) в одной и той же точке изображения Зг: г € /г, s е I,_d J, a |Q| обозна-
чает число элементов множества Q.
Фактически величина (33) представляет собой вероятность появления в
одной и той же точке изображения двух величин нормальной составляющей ско-
рости. разделенных временным интервалом d. Теперь мы можем составить еще
несколько характерных признаков, производных от (33):
<34)
м
= <35>
М
А2
8 = ~ (36)
ст
« = (37)
О/)
С = Х('“-/)2р< (*’•/)• (38)
М
Этот набор характерных признаков вычисляется или для заданных блоков
изображения, или для областей, являющихся результатом пространственной сег-
ментации. С помощью данных признаков учитывается временной аспект движе-
ния. В принципе, можно расширить описанный метод, для того чтобы отразить
также и пространственную составляющую движения при помощи введения ста-
тистических характеристик появления соответствующих значений нормальных
составляющих скорости и использования многомасштабных временных моделей
Гиббса [22].
3.6.2. Различные модели динамических текстур
Для анализа большинства существующих текстур с успехом могут быть ис-
пользованы статистические методы. Например, несколько первых моментов ги-
стограммы области изображения представляют собой простейшие характери-
стики текстуры. Однако данный подход обладает серьезным недостатком: совер-
шенно разные текстуры могут иметь практически одинаковые гистограммы.
Модель STAR
Достаточно простым и в то же самое время мощным средством анализа яв-
ляются авторегрессионные модели, в которых предполагается, что каждый пик-
сель последовательности изображений может быть представлен как линейная
комбинация соседних с ним точек с дополнительным гауссовым шумом. Одной
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
92
Цифвая обработка видеоизображений
из таких моделей является линейная пространственно-временная авторегресси-
онная модель (STAR) [28-29]:
(-V+A-V,, г + Ду,)+м(х,г./). (39)
1=1
где л(х, у, г) - белый гауссов шум. (р. - параметры модели.
Основным ограничением модели STAR является требование того, чтобы
входные данные подчинялись многомерному нормальному распределению с по-
стоянными средним и ковариацией.Тем самым последовательность изображений,
представляющих вращение, сжатие или расширение, не могут быть описаны с по-
мощью этой модели. Более того, статистический характер модели предполагает
использование значительного числа пикселей для корректного анализа текстур.
Для окончательного построения модели необходимо задание вида окрестно-
сти в выражении (39). а также способа оценки параметров модели ф. Традицион-
но в анализе временных рядов спецификация модели производится путем вычис-
ления автокорреляционной функции и нахождения ее экстремумов. Для рассма-
триваемой трехмерной модели STAR такой путь является слишком затратным.
Поэтому рассмотрим несколько других подходов.
Для оценки параметров модели простейшим способом является использова-
ние только одного параметра, с помощью которого каждый пиксель связан с со-
седними. Данный параметр определяется путем следующего усреднения:
0 = ------------------• (40)
^/Дх+Ау.у+Ду.)
1=1
Однако одного параметра в большинстве случаев недостаточно для успеш-
ного распознавания динамических текстур. Лучшие результаты можно полу-
чить. если разбить ДТ во премени и в пространстве на кубы размером т х т х tn
и вычислять усреднение (р по каждому такому кубу. В таком случае текстура
будет характеризоваться т3 параметрами. Другой подход состоит в разбиении
текстурных областей кхкк/ (I- длина видеопоследовательности) на j равных
частей. Для каждой такой части рассматривается к/2 трехмерных окрестностей
центрального пикселя. При этом первый параметр получается при анализе цен-
трального пикселя и его ближайших соседних точек; второй параметр - при
использовании ближайших соседей центрального пикселя и точек, соседних с
ними, к/2 параметр получается при рассмотрении всех к/2 окрестностей цен-
трального пикселя. Таким образом, для описания текстуры нужно определить
fc
— х j параметров.
Выше была рассмотрена модель первого порядка. В принципе, можно исполь-
зовать модели более высокого порядка (MSTAR). Если модель STAR подразу-
мевает, что каждый пиксель текстуры выражается с помощью линейной комби-
нации пикселей из некоторой окрестности фиксированного размера, то MSTAR
представляет собой ту же модель STAR, но определяемую на различных окрест-
ностях изменяющегося размера. Так, для модели восьмого порядка на уровне де-
тализации / каждый пиксель представляется как
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
Глава 3. Выделение и классификация движущихся объектов
93
8
а = (41)
1=1
где р0 - рассматриваемый пиксель. pt t - пиксели в углах куба с центром в а s t -
параметры, подлежащие оцениванию.
Модель ARMA
Если рассматривать обычные статичные текстуры, то их можно считать ре-
зультатом стационарного стохастического процесса с пространственно инвари-
антными статистиками. Для последовательности изображений отдельные кадры,
очевидно, не являются независимыми реализациями стационарного распреде-
ления, так как существует временная корреляция, присущая рассматриваемому
процессу.Таким образом, разумно предположить, что отдельные изображения яв-
ляются результатом действия динамической системы с независимыми и одинако-
во распределенными процессами [30-34].
Пусть {/,}, ( r./ eR"' является видеопоследовательностью, состоящей из Т от-
дельных изображений. Предположим, что в каждый момент времени t мы име-
ем зашумленную версию изображения y; = /r + w, где we/?"’ описывается распре-
делением рД*),ау/бЯ'"> t = 1,...,т. Тогда будем считать, что последовательность {/|
представляет собой линейную динамическую текстуру, если существует набор из
п фильтров (ра: R -» R”\ а = 1,...,н и стационарное распределение q такое, что для
xeR" и 1=(р(х) получим
X, = X + Bvr (42)
1=1
где v е Rn - независимые и одинаково распределенные величины с плотностью
<?(•),a AeRn'n, z = l,...,Zc,BeRn,n их0=х0. Без потери общности будем считать, что
к = 1. Тогда динамические текстуры описываются с помощью авторегрессион-
ной модели скользящего среднего (ARMA) с неизвестным входным распре-
делением:
x/+I = Ах + Bv
’ (43)
где х0 = х0, v - q(*) и w ~ ри(*) - независимые и одинаково распределенные, v - не-
известны, w заданы так, что / =ф(х).
Очевидно, что для дальнейшего анализа нам необходимо задать вид филь-
тров (ра. Это может быть сделано несколькими способами. Простейший из них со-
стоит в рассмотрении динамики отдельных пикселей ^=7. Но более адекватным
является следующий выбор: 44
(44)
1=1
где С = [0р... ,0J а 0 представляет собой ортонормированный базис в про-
странстве L2 или же набор главных компонент. Возможна также нелинейная
форма фильтров.
Имея последовательность зашумленных изображений {у,}/=1 г, описание ди-
намической текстуры сводится к заданию параметров модели А, В, С и распреде-
http://www. itv.ru
Компания ITV — генеральный спонсор издания книги
94
Цифвая обработка видеоизображений
ления плотности <?(•) в (43). Это так называемая задача системной идентифика-
ции [32]. когда необходимо построить динамическую модель с помощью времен-
ных рядов. Однако в отличие от рассматриваемого случая при изучении динами-
ческих систем распределение обычно известно.Таким образом, задача описа-
ния динамических текстур выглядит следующим образом:
для заданных ур...,уг найти
А,В,С, </(•) = argmax logгт). (45)
A.B,C.q
при выполнении (43) и условии, что v - независимые одинаково распределен-
ные с плотностью <?(•) величины.
Как известно, стационарный процесс второго порядка с произвольной кова-
риацией может быть представлен как результат действия линейной динамиче-
ской системы, описываемой гауссовым распределением с нулевым средним [32].
Поэтому будем считать, что существует положительное целое число и, процесс
x^Rn с начальным условием х0 = x(eRn и симметричные положительно опреде-
ленные матрицы QeR'"" и Ge R”' т такие, что
х,+|=Лх,+у„ v,~r7(0,C), х0 = х0
у, = Cx, + w(, w, ~n(0,G)
для некоторых матриц A eRn'n и CeR"'1". Здесь tj(/z, 5) - нормальное распреде-
ление со средним р и дисперсией 5. Задача системной идентификации состоит в
оценке параметров модели A, C,Q,Gc помощью данных ур...,уг. Заметим, что В и
v в модели (43) удовлетворяют условиям ВВ1 = Q и v - rj(O, Еп), где Еп - единич-
ная матрица размером пу х nv.
Из (46) следует, что для получения одной и той же последовательности (yj
матрицы 4, С и Q можно выбрать неединственным способом. Другими словами,
каждый процесс описывается не одной моделью, а целым классом эквивалент-
ных моделей. Поэтому нам необходимо наложить дополнительные условия для
получения единственной канонической модели. Например, это могут быть следу-
ющие предположения:
т » п; rang [С) = п, (47)
СТС = ЕЯ, (48)
где Еп - единичная матрица размером п х п.
Теперь стоящая перед нами задача формулируется следующим образом: для
данных ур....уг, Т » п найти А. В, С и G - каноническую модель для процесса [yj:
Л . Q,, G, = arg max р (у, yr). (49)
A,C,Q,G
Существует асимптотически оптимальное решение этой задачи, однако его
получение предъявляет чрезвычайно жесткие требования к вычислительным
ресурсам. Поэтому мы рассмотрим субоптимальное решение, которое значи-
тельно быстрее с точки зрения его численной реализации.
Обозначим = [ур...,уг]е Х,г = [х|,.>.,хт]б Rn'T, Т>п и
ИГ1Г =[w|,...,wr]e Лт,г. Тогда
Y{T = CX; + W}\ C^Rm'n\ СгС = Еп. _ (50)
ProSystem CCTV - журнал по системам видеонаблюдения
h ttp://w w w. procctv. ru
Глава 3. Выделение и классификация движущихся объектов
95
Предположим, что представляет собой SVD-разложение. где Y* = UZV1 \
U € UlU = Еп\ V е Rz'n\ = Etr Z- диагональная матрица
(51)
Будем искать С и X такие, что Сх> Xz = arg min 1 при условии (50). Здесь нор-
ма понимается в смысле Фробениуса: сх‘
(52)
Тогда единственное решение определяется следующим образом:
Ct=U; Xr = ZKr. (53)
а матрица А может быть определена единственным образом из решения следую-
щей линейной задачи:
Ат = arg min ||X* - Яхог 1 ||f. (54)
Учитывая (52). получим
Аг = £-*, (55)
где
Величина Q может быть найдена из следующего выражения:
1 1=1
(57)
где
V, = х,ж1 - Агх,-
(58)
В рассмотренном алгоритме значение п предполагалось заданным. Однако
порядок модели можно определить с помощью значений ......выбрав п таким
образом, чтобы все величины ст нс превышали некоего порогового значения, ко-
торое может, например, зависеть от разности а и а г
Найдя параметры модели, можно производить сегментацию изображения,
для чего необходимо установить меру соответствия между областями.Трудность
заключается в том. что эти области описываются не просто параметрами модели,
а целым классом эквивалентных параметров, которые могут быть получены пу-
тем изменения базиса переменных состояния х{ в модели (43). Поэтому адекват-
ная мера соответствия должна сравнивать между собой не параметры, а их экви-
валентные классы.
Одним из возможных путей решения данной проблемы является определе-
ние углов между многомерными подпространствами пространства всех возмож-
ных изображений. Пусть М(|) и Мр) представляют собой две модели (43) одной
http://www. itv. ru
Компания ITV - генеральный спонсор издания книги
96
Цифвая обработка видеоизображений
и той же размерности, которые характеризуются соответственно системны-
ми матрицами Д(1) и и выходными матрицами С(1) и С(2). Введем следующие
матрицы:
(59)
и определим следующие углы:
= *=2....................." (61>
при условии х'щО^ОщХ = 0 и У^О^РтУ = ° Аля 1 = 1-2, .... к-1.
Тогда соответствие различных моделей определяется как
<(Л/„Л/2) = 1пП—• (62)
' 21 t=lcos20t
Модели на основе импульсных характеристик
До сих пор нами предполагалось, что на изображении присутствует только
какой-либо один тип текстуры. На практике довольно часто встречаются ситу-
ации, когда сразу несколько различных текстур занимают отдельные области
изображения и необходимо проводить их распознавание. В принципе, можно вос-
пользоваться описанным выше подходом с вычислением углов, однако существу-
ют более простые и менее ресурсоемкие методы, к которым относится использо-
вание импульсных характеристик систем.
С точки зрения системной идентификации две динамические модели мо-
гут быть сопоставлены путем сравнения их переменных состояния, которые в
свою очередь эффективно представляются с помощью их импульсных характе-
ристик. Последние определяются с использованием параметров модели А как
х,+| = Ах, [35]. Эти импульсные характеристики являются л-мерными последо-
вательностями (примеры которых приведены на Рис. 29 [35]), определяемыми
единственным образом динамическими свойствами исходной последовательно-
сти изображений.
Будем применять метод выделения главных компонент к импульсным ха-
рактеристикам различных текстур для построения оптимального линейного
пространства, в рамках которого можно провести их сравнение. Это позволит
рассматривать импульсные характеристики как траектории в и-мерном линей-
ном пространстве. Пример такой траектории для п = 3 приведен на Рис. 30 [35].
Так как такие траектории являются единственными для каждой ДТ, то клас-
сификация последних может быть осуществлена путем определения близости
рассматриваемой траектории и уже имеющихся траекторий, принадлежащих к
различным классам.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 3. Выделение и классификация движущихся объектов
97
Рис. 30. Траектория, полученная с помощью проецирования импульсных характе-
ристик в оптимальное линейное пространство. В случае устойчивой динамической
системы траектория должна сходиться к началу координат.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
98
Цифвая обработка видеоизображений
Таким образом, схема классификации текстур распадается на два этапа: обу-
чение и распознавание. На первом этапе исходная последовательность изображе-
ний разбивается на несколько подпоследовательностей, каждая из которых соот-
ветствует одному из блоков, на которые поделено изображение. Каждый блок
включает свой тип текстур. Далее к каждой последовательности блоков при-
меняется описанный выше алгоритм, и находятся параметры модели Ау С и Q.
При помощи матриц А для всех последовательностей вычисляются л-мерные им-
пульсные характеристики. Наконец, эти характеристики используются для по-
строения линейного пространства, куда они затем проецируются для получения
траекторий. Таким образом, в конце первого этапа мы получаем набор линей-
ных пространств, в каждом из которых имеются траектории, отвечающие одной
и той же текстуре.
На стадии распознавания с помощью матрицы Л, полученной для рассматри-
ваемой последовательности блоков, находятся импульсные характеристики, из
которых затем получаются соответствующие траектории в каждом линейном
пространстве (соответствующем отдельной текстуре), построенном на стадии
обучения. Для классификации текстуры в рассматриваемой последовательно-
сти блоков используется процедура поиска такой траектории среди имеющих-
ся. которая обладает наибольшим числом точек, близлежащих к точкам класси-
фицируемой траектории. Это можно сделать путем анализа гистограммы, высо-
та столбцов которой соответствует числу точек, наиболее близких к точкам рас-
сматриваемой траектории, как это показано на Рис. 31 [35].
Рис. 31. Пример гистограммы, соответствующей числу точек, близлежащих к дан-
ной траектории
В общем случае траектории динамических текстур часто пересекаются, и
два различных типа текстур могут иметь много близких точек. Поэтому для
определения степени соответствия двух текстур имеет смысл вычислять следу-
ющую величину:
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv.ru
Глава 3. Выделение и классификация движущихся объектов
99
Л = Х(г#~4 <5 = 0,8(^ + 1). (63)
7=1
где i - номер типа текстуры, nt - число модельных блоков в последовательности
текстуры z-го типа, zf/ - наибольшее число близлежащих точек для /-го блока в
последовательности текстуры /-го типа. 8 - пороговое значение, kf - число чле-
нов последовательности.
Смесь текстур
Распознавание динамических текстур различного типа, которые присут-
ствуют на изображении, может быть также реализовано путем построения мо-
дели смеси текстур. В отличие от ранее рассмотренного случая (43) предполо-
жим, что начальное состояние х(| имеет нормальное распределение x0~7j(p, s).
Тогда динамическая текстура полностью определяется своими параметрами
0 = {Л, С, Q, G, р, s) [36].
Можно показать [37]. что
/’(Xo)=7?(JCO’P-S)»
pUlx,)=z?(y,»Cx„G),
где величина
(64)
(65)
(66)
7)(х,//,£) = (2л) "/2|Z|
ехр -|||х-д||2
(67)
представляет собой плотность n-мерного нормального распределения, а
H=xrZ-x.
Тогда совместная плотность записывается как
г=2 1=1
(68)
Пусть в видеопоследовательности присутствует К различных ДТ. Для за-
к
данных значений вероятностей [ap...,aj, где = 1. и наборов параметров
/=1
текстур (0^.0J выбираем у-ю компоненту из распределения («1..ак\, а за-
тем У]т из соответствующей компоненты 0 Вероятность выбора последователь-
ности У/ равна
р(г)=2>л(>7). «”)
/»1
где ру(У;т) = p^Y* | 0) - условная вероятность у-й динамической текстуры.
Эквивалентная модель может быть получена, если явным образом предста-
вить состояние каждой компоненты j при помощи условного распределения:
|x2i) =
(70)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
100
Цифвая обработка видеоизображений
Для наблюдаемой переменной получим:
V, - = 7)=;/|; (71)
где с помощью скрытой переменной г производится выбор соответствующего
состояния х^1 и параметров С°’ и G* для /-й динамической текстуры. Далее для
нахождения параметров распределения вероятностей может быть применен ал-
горитм ожидания-максимизации.
3.6.3. Характерные признаки текстур
Локальная ориентация. Для классификации текстур может быть использо-
вана их локальная ориентация (или отсутствие таковой). С геометрической точ-
ки зрения ориентация отражает локальную корреляционную структуру текстур,
которые в целом могут быть разбиты на несколько больших классов. Примеры
таких классов приведены на Рис. 32. где для простоты рассмотрено только одно
пространственное измерение [38].
Рис. 32. Примеры пространственно-временных классов текстур. В верхнем ряду
представлены сами образы, следующий ряд изображает соответствующую струк-
туру частотного пространства. В нижних четырех рядах показаны соответствую-
щие компоненты энергии изображения.
Наиболее простая ситуация наблюдается в том случае, когда рассматрива-
емая область является неструктурированной, т. е. интенсивность изображения
приблизительно постоянна или очень слабо меняется во времени и простран-
стве. При этом подавляющая часть энергии области сосредоточена около на-
чала координат.
В остальных рассматриваемых классах основной интерес представляет пре-
обладающее направление в ориентации текстур. Например, для стационар-
ных объектов имеет место вытянутая по форме структура в пространственно-
ProSystem CCTV - журнал по системам видеонаблюдения
http://w w w.procctv. ru
Глава 3 Выделение и классификация движущихся объектов
101
временной области с энергией, сконцентрированной вдоль пространственной
частотной оси. Напротив, если же структура является однородной в простран-
стве. но меняется со временем, то в пространственно-временной области она
будет ориентирована параллельно оси х. а ее энергия будет сконцентрирована
вдоль временной частотной оси.
Следующие два класса связаны с движущимися объектами. В первом случае
так называемого когерентного (т. е. в одном направлении) движения.траектория
объектов имеет наклон в пространственно-временной области, пропорциональ-
ный их скорости. Если же в пространственной области несколько локальных на-
правлений перемешаны и наложены друг на друга, то имеет место некогерент-
ное движение, примерами которого могут служить колебания, границы перекры-
тий объектов и др.
Наконец, для случая изотропной структуры невозможно выделить какое-
либо преобладающее направление. Обычно такие структуры являются хаотич-
ными или стохастическими по своей природе (например, блеск отражающей по-
верхности).
После введения указанных классов анализ пространственно-временных дан-
ных в соответствии с их локальной ориентацией может быть проведен с помо-
щью направленной энергии. Это подразумевает использование набора фильтров,
которые разбивают ДТ на ряд диапазонов направленной энергии. Размер и вид
частотной характеристики фильтров определяет, каким образом будет описана
(покрыта) пространственно-временная область.
Фильтрация может быть осуществлена при помощи вторых производных
от гауссовых фильтров Ge в направлении в и их преобразований Гильберта
We[39]:
£e(x’/) = (Ge (x,z)*/(xj))‘+(/7e(x,r)*/(x,/))*. (72)
Для описания основных направлений, указанных ранее, фильтрация должна
быть проведена ортогонально к пространственной оси. ортогонально к времен-
ной оси и вдоль обеих пространственно-временных диагоналей (см. Рис. 33 [38]).
Рис. 33. Ориентированные фильтры энергии для пространственно-временного
анализа
http://wwwjtv.ri/
Компания ITV - генеральный спонсор издания книги
102
Цифвая обработка видеоизображений
Таким образом, для классификации текстур достаточно рассмотреть отно-
сительное распределение энергии по четырем выделенным направлениям. Ре-
зультат фильтрации входного изображения с помощью фильтра, ортогонально-
го к пространственной оси. будем называть 5 -изображением, а с помощью филь-
тра. ортогонального к временной оси. - F-изображением (см. Рис. 32). Инфор-
мация. которая может быть получена при использовании по отдельности остав-
шихся двух направлений, является неоднозначной, так как не позволяет разли-
чить когерентное и некогерентное движение. Поэтому будем рассматривать сум-
му R + L и модуль разности - L\ изображений, полученных путем фильтрации
исходного изображения в направлениях двух диагоналей. Результаты примене-
ния рассмотренных фильтров к различным динамическим текстурам показаны
на Рис. 34 [38]. Как следует из рисунка, введенные выше энергетические призна-
ки достаточно хорошо отражают анализируемую структуру изображений.
Неструктурированная Статичная Мери амие Когерентное движение н когерентное движение Блеск
► V Fi
И1 I ди одо о.; 30 11.37 36 0.53 0.05 0.58 0.02 0.50
И | Шт» и LJ ц
Рис. 34. Результаты применения ориентированных фильтров к различным текстурам
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 3 Выделение и классификация движущихся объектов
103
Объемные локальные двоичные образы. Несмотря на отличие в размерно-
сти пространств, некоторые методы для анализа обычных текстур могут быть
с успехом использованы при рассмотрении ДТ. Кроме того, ряд характерных
признаков для статичных текстур может быть весьма эффективно применен
для ДТ лишь с незначительными модификациями. Естественно, что при этом
основным критерием при выборе признаков является малость их изменения в
пределах рассматриваемой текстуры и в то же время значительное отличие для
различных текстур.
Как известно, одной из простых (но в то же время эффективных) текстурных
характеристик являются локальные двоичные образы (ЛДО). Обобщением дан-
ного характерного признака на случай динамических текстур являются объем-
ные локальные двоичные образы (ОЛДО) [40]. Они обладают инвариантностью
к вращению и перемещению, что чрезвычайно важно при анализе ДТ. которые
могут быть ориентированы произвольным образом.
Будем рассматривать динамическую текстуру V для последовательности по-
лутоновых изображений как совместное распределение ЗР + 3 (Р > 1) пикселей:
где / - интенсивность центрального пикселя локальной окрестности в текущем
кадре, / t и / , - интенсивность центральных пикселей в предыдущем и последу-
ющем кадрах, отстоящих от текущего на L кадров:/гг(Г = г- L. t.t + L‘. р = 0 Р-1)
соответствует интенсивности Р равностоящих на окружности радиуса R (R > 0)
пикселей в момент времени Г.
Предположим, что координаты центрального пикселя с интенсивностью /
равны (х, г, г). Тогда координаты пикселей в локальной окрестности / , будут
равны (х. - Psin^^, vt + Pcos2^,/) (см. Рис. 35 [40]).
Для инвариантности распределения (73) вычтем интенсивность центрально-
го пикселя из значений пикселей окрестности:
Рис. 35. Иллюстрация к понятию ОЛДО. Слева - объем, состоящий из динамических
текстур с L = 1 и L = 2, в центре - множества соседних точек (R = I и Р = 8), спра-
ва - соседние точки на поверхности цилиндра (Р - 4).
/ittp://www,/tv. г и
Компания ITV - генеральный спонсор издания книги
104
Цифвая обработка видеоизображений
У = -Ilc,
..............Ал-.-4.. • (74)
^t^L,0 ~~ 1t~L,P-' ~ ’ h^L.c ~ /.<)
Предположим, что разность ITf - /, не зависит от Ilc. Тогда
У - v(/f,r)v(4.tx -/1х,/,_£.о -Л.с,
А.о-А.г>-.Ал-.-4,е, • <75)
А+ло — Ах»*”’ А*£.< *“ Ах)
Аналогично Л ДО, распределение v(7, ) описывает общую яркость изображения
и не имеет отношения к локальной текстуре и. следовательно, может быть исключе-
но при анализе ДТ Поэтому вместо v будем использовать следующее распределение:
^1 ~~ V^l-L'C 1i.c’lt-L.O fx’***’^t-L,P-\ ~~
Ax’A.o-Ax’***’A^i-Ax’ * (76)
А+Д.О ~ Ihc*”**lt+L,P-l t.c>li+L,c
Будем учитывать только знаки разностей в распределении:
= vWt-L,c - Ах)ХА д.о - х)’***^(А-^-1 -AJ’
5(А,с’А.о ” Ах )’•••’5(A.p-i “ А.с-)’ » (77)
5(А+£.О “ Ах )’••*’^(А+А.Р-! “ Ax),,S(A+£x “Ах))
где
х>0
х<0
(78)
Для упрощения выражения (77) обозначим отдельные аргументы распреде-
ления через у.:
K2 = v(v0,...,v, v3P+1). (79)
Тогда величина ОЛДО определяется как
yLBPLPR = Yv>2‘- <8°)
i=0
На Рис. 36 [40] показан пример расчета величины VLBP]4]. Таким об-
разом, для динамической текстуры X х Y х Т (хс € |0,...,Х - 1], уе е [О,...,У - 1),
t € |0v..,T - 1|)выражение (80) вычисляется для каждого пикселя, за исключени-
ем ряда граничных, и распределение используется как вектор характерных при-
знаков D.
D = V(VLBPt „ х Е {ГЯ]...........X -1 - р]},
J'Spl............................Г-1-М}), (81)
где обозначает наименьшее целое, большее или равное R.
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. ргосс tv.ru
Глава 3. Выделение и классификация движущихся объектов
105
Динамические текстуры могут быть ориентированы произвольным образом
и, кроме того, нередки случаи их вращения. При этом в отличие от статичных
текстур, где вращение происходит вокруг одного пикселя, последовательность
ДТ вращается вокруг одной или нескольких осей. Это не позволяет использо-
вать VLBP как одно целое для получения характеристик, инвариантных к вра-
щению. Поэтому разобьем условно К на 5 частей, для трех из которых вычислим
величину
ЬВРг.р.н = ^!!(,г.р-1'Л2Р' T = t-L,t,t + L. (82)
р=0
Для устранения эффекта вращения найдем
LBi^PK = mm{ROR(LBPlPK,i)\i = OA Р-1}. (83)
где ROR(x, i) осуществляет побитовый сдвиг вправо числа х / раз [41].Тогда инва-
риантной к вращению будет величина
VLBP?PK = ( VLBPlpp п (23P+2 -1)) + ROR ( LBP^lpk , 2 P +1) +
+ROR(LBP"PJt.P + \}+ROR(LBPZl pk, 1)+(VLBP, PK П1).
http://wwwjfv.ri/
Компания ITV - генеральный спонсор издания книги
106
Цифвая обработка видеоизображений
Число найденных таким образом характерных признаков слишком велико.
Поэтому воспользуемся понятием «равномерных» образов [41] и определим те-
перь величину VLBP"pr как
ЗР-1
где
УЬВРЬя
X
1=0
ЗР+З,
U^LBPl\k)<2
иначе
УР~\
-Ф Х1ФФ
1=1
(85)
(86)
Ч»
V' = (Vq,...,УзМ) получен после преобразования (84).
Направленная регулярность. В качестве характерных признаков для клас-
сификации ДТ может быть использовано максимальное значение направленной
регулярности текстур /?(<) [42]. что позволяет добиться аффинной инвариантно-
сти полученных результатов. Данный подход основывается на том факте, что ре-
гулярные (периодические) текстуры воспринимаются таковыми в широком ди-
апазоне углов зрения [43, 44]. До некоторой степени это справедливо даже для
объемных текстур и меняющейся освещенности сцены. Поэтому определенная
адекватным образом степень регулярности рассматриваемых объектов может
служить в качестве инвариантного, физически обоснованного характерного при-
знака. Для этого для изображения размером М х N введем нормированную авто-
корреляционную функцию
.w-i .V-I
4>. (<Ф,) = -——.л"----------------(87)
££/2(т,л)
т-0 п=0
которая может быть эффективно определена с помощью быстрого преобразо-
вания Фурье. Значения смещений dx. dx изменяются в пределах от 0 до полови-
ны размера изображения. Нам необходимо определять максимальное значение
/?(/) для всех направлений, поэтому автокорреляционную функцию будем опре-
делять в полярных координатах Apol(a. d) на сетке а = Аа /. d- &d • j. Получен-
ную в результате этого матрицу обозначим и нормируем ее таким обра-
зом, чтобы ее значения лежали на отрезке [0,1]. Для узлов полярной сетки, не со-
впадающих с узлами прямоугольной сетки, воспользуемся линейной интерполя-
цией. Значения Асе и Ad выберем равными 1. Вместо A будем рассматривать
матрицу
(88)
Строка данной матрицы называется функцией контрастности F(d), ко-
торая показывает, как изменяется величина контрастности в зависимости
от радиуса d в данном направлении а. Пример такой функции приведен на
Рис. 37 [42].
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 3. Выделение и классификация движущихся объектов
107
А
Б В Г Д
Рис. 37. Вычисление функции контрастности: А - исходное изображение и выбран-
ное направление, Б - дискретное преобразование Фурье изображения, В - авто-
корреляционная функция, Г - матрица Л/ , Д - функция контрастности
Для направления а направленная регулярность определяется следующим
образом:
Л(а.) = |Л,(«,) (89)
где ) и /? iot(a) - регулярность интенсивности и положения. Первая из этих
величин показывает, насколько регулярной (стабильной) является интенсив-
ность, а вторая - отражает регулярность (периодичность) расположения элемен-
тов, составляющих рассматриваемый объект. В дальнейшем аргумент у этих двух
функций, там где это не вызывает недоразумений, будем опускать.
I________________I
б/j С^2
d,
Б
Рис. 38. Пример квазипериодической функции контрастности. А - нормальный
случай, Б - особый случай
На Рис. 38 показан типичный вид квазипериодической функции контрастно-
сти. При этом выделяются два случая: нормальный, когда величина квазиперио-
дического минимума является монотонной функцией d: особый, когда указанная
монотонность нарушается. Направленная регулярность R вычисляется следую-
щим образом.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
108
Цифвая обработка видеоизображений
1.
2.
3.
4.
5.
6.
7.
8.
9.
Для уменьшения шума к функции контрастности F(d) применяется меди-
анный фильтр с шириной, равной 3. Функцию контрастности до фильтра-
ции обозначаем Ftj(rf).
Находятся экстремумы F(d). за исключением d = 0 и d = d . Число мини-
мумов и максимумов обозначается через Л'т п и .V соответственно.
Вычисляется амплитуда каждого максимума. Для этого, начиная с точки
очередного максимума, смещаемся в направлении роста d и находим мак-
симум. значение которого больше, чем у предыдущего максимума (т. е.
находим очередной квазипериодический максимум). Определяем мини-
мальное значение на этом интервале и разность между начальным макси-
мумом и данным минимальным значением.
Находим тот максимум у которого разность, вычисленная в
п.З. максимальна. Соответствующее ему минимальное значение обозна-
чаем F^n.
Уточняем значение F^ при помощи поиска большего значения у FQ(d) в
окрестности ±2 пикселя точки d'^. Если такое значение найдено, то
F' = #' .
max max
Аналогичным образом уточняем значение F^.
Вычисляем значение регулярности интенсивности Я n| = 1 - F^-JF^.
Если существует только один минимум (Nratn = 1), находим точку dmax наи-
большего максимума и точку d} > rf наименьшего минимума. Вычис-
ляем R = 1 - \d- 2d \/ dt.
Если 7Vmin > 1, находим два наименьших минимума (Jr F}) и (dy Г2). где
d{ < d2. Если между d{ и dy нет других квазипериодических минимумов
(нормальный случай. Рис. 38). вычисляем Rf ( $ = 1 - |1 - 2d, ld21. Если же су-
ществуют другие квазипериодические минимумы между d} и d2 (особый
случай. Рис. 38), то дополнительно вычисляем
j-|i-3rf,M|, i-|i-3rf,/rf2|>o
0, иначе
и выбираем максимальное значение из Rpos и R'^.
В п.9 R и R' могут быть также определены следующим образом:
2у, 0<у < 1/2
" 2-2у, 1/2<у <Г
Зу, 0<у <1/3
^ = р-3у, 1/3 <у <2/3,
0, 2/3 < у < 1
RP0,
(90)
rpey = djdr
Теперь можно определить максимальное значение направленной регулярно-
сти (89)
М R = max R (at).
Величина MR лежит в пределах 0 < MR < 1, где MR = 0 соответствует текстурам
случайного вида, a MR = 1 отвечает текстурам с хорошо выраженной регулярно-
ProSystem CCTV - журнал по системам видеонаблюдения
ht tp://w w w. procctv. ru
Глава 3 Выделение и классификация движущихся объектов
109
стью. Величина (90) вычисляется для набора перекрывающихся окон, полностью
содержащих область объекта, полученную на предыдущем этапе, и выбирается
максимальное значение Р = тахЛ/ДИ7). Здесь через Wобозначены окна, размер
которых определяется таким образом, чтобы включать в себя как минимум два
периода функции контрастности. Так как описанная процедура повторяется для
нескольких последовательных кадров, то таким образом мы получаем времен-
ную зависимость P(t).
В качестве характерных признаков текстур можно использовать следующие
усредненные по всем кадрам видеопоследовательности величины:
• средние значения divvs (х,у)и rotvs (х,у), где vN задается выражением (31),
• отношение среднего значения нормального потока и его стандартного от-
клонения,
• степень однородности ориентации нормального потока
||2(хЛеП Л
где Q - множество пикселей, где значение нормального потока отлично от
нуля,
• среднее значение Р(г),
• дисперсия Р(г).
Все указанные величины являются инвариантными к перемещению и вращению.
3.7. СПИСОК ЛИТЕРАТУРЫ
1. А. R Pentland. Classification by Clustering. In: Proc. Symposium on Machine
Processing of Remotely Sensed Data. Purdue, 1976.
2. R. J. Kauth, A. P. Pentland, C. S. Thomas. Blob: An Unsupervised Clustering
Approach to Spatial Preprocessing of Mass Imagery. In: Proc. International
Symposium on Remote Sensing of the Environment. Ann Arbor, p. 1309-1317,1977.
3. D. Zhang, G. Lu. Segmentation of Moving Objects in Image Sequence: A Review.
In: Circuits, Systems and Signal Processing, v. 20, p. 143-183,2001.
4. R Salembier, J. Serra. Flat Zones Filtering, Connected Operators, and Filters by
Reconstruction. In: IEEE Transactions on Image Processing, v.4, p. 1153-1160,1995.
5. A. K. Jain, R. C. Dubes. Algorithms for Clustering Data. Prentice Hall, New Jersey,
1988,320 p.
6. H. J. A. M. Heijmans. Connected Morphological Operators for Binary Images. In:
Computer Vision and Image Understanding, v. 73, p. 99-120,1999.
7. U. Braga-Neto, J. Goutsias. Automatic Target Detection and Tracking in Forward-
looking Infrared Image Sequences Using Morphological Connected Operators. Tn:
Proc. Conference on Information Sciences and Systems. Baltimore, v. 1, p. 173-178,1999.
8. S. Batman, N. Osman, J. Prince, J. Goutsias. Automatic Myocardial Segmentation of
Tagged MR Cardiac Images Using Morphology. In: Proc. Conference on Information
Sciences and Systems. Princeton, v. 1, p. 65-70,2000.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
110
Цифвая обработка видеоизображений
9. Е Chang, C.-J. Chen, and С.-J. Lu. A Linear-time Component-labeling Algorithm
Using Contour-tracing Technique. In: Computer Vision Image Understanding, v. 93,
p.206-220.2004.
10. A. J. Lipton, H. Fujiyoshi. R. S. Patil. Moving Target Classification and Tracking
from Real-time Video. In: Proc. IEEE Workshop on Applications of Computer
Vision, Princeton, p. 129-136.1998.
11. G. L. Foresti, C. Micheloni. L. Snidaro. Advanced Visual-based Traffic Monitoring
systems for Increasing Safety in Road Transportation. In: Advances in
Transportation Studies An International Journal. v. 1, p. 22-47,2003.
12. M. K. Hu. Visual Pattern Recognition by Moment Invariant. In: IEEE Transactions
on Information Theory, v. 8, p. 179-187. 1962.
13. J. E. Hollis. D. J. Brown. I. C. Luckraft. C. R. Gent. Feature Vectors for Road Vehicle
Scene Classification. In: Neural Networks. v. 9. p.337-344,1996.
14. R. T. Collins, A. J. Lipton. T. Kanade. A System for Video Surveillance and
Monitoring. Technical Report CMU-RI-TR-00-12, Robotics Institute, Carnegie
Mellon University. 2000.
15. S. M. Seitz, C. R. Dyer. View-invariant Analysis of Cyclic Motion. In: International
Journal of Computer Vision, v. 25. p. 1-23.1997.
16. P. Tsai, M. Shah, K. Keiter, T. Kasparis. Cyclic Motion Detection. In: Pattern
Recognition, v. 27. p. 1591—1603,1994.
17. E Liu, R. Picard. Finding Periodicity in Space andTime. In: Pxoc.IEEE International
Conference on Computer Vision, Bombay, p. 376-383,1998.
18. B. Heisele, C. Wohler. Motion-based Recognition of Pedestrians. In: Proc.
International Conference on Pattern Recognition, Brisbane, p. 1325-1330,1998.
19. R. Cutler, L. Davis. View-based Detection and Analysis of Periodic Motion. In:
Proc. International Conference on Pattern Recognition, Brisbane, p. 495-500,1998.
20. R. C. Nelson, R. Polana. Qualitative Recognition of Motion Using Temporal
Texture. In: CVGIP: Image Understanding, v. 56, p. 78-89,1992.
21. R Bouthemy, R. Fablet. Motion Characterization from Temporal Cooccurrences
of Local Motion-based Measures for Video Indexing. In: Proc. International
Conference on Pattern Recognition, Brisbane, v. I, p. 90-908,1998.
22. R. Fablet, P. Bouthemy. Motion Recognition Using Spatio-temporal Random
Walks in Sequence of 2D Motion-related Measurements. In: IEEE International
Conference on Image Processing, Thessalonique, p. 652-655.2001.
23. R. Fablet, P Bouthemy. Motion Recognition Using Non-parametric Image Motion
Models Estimated from Temporal and Multi-scale Co-occurrence Statistics. In: IEEE
Transactions on Pattern Analysis and Machine Intelligence, v. 25, p. 1619-1624,2003.
24. R. Peteri, D. Chetverikov. Qualitative Characterization of Dynamic Textures for
Video Retrieval. In: Computational Imaging and Vision, v. 32, p. 33-38,2006.
25. R. Peteri, D. Chetverikov. Dynamic Texture Recognition Using Normal Flow and
Texture Regularity. In: Proc. Iberian Conference on Pattern Recognition and Image
Analysis, Estoril, p. 223-230,2005.
26. Z. Lu, W. Xie, J. Pei, J. Huang. Dynamic Texture Recognition by Spatio-temporal
Multi-resolution Histogram. In: Proc. IEEE Workshop on Motion and Video
Computing, Breckenridge, v. 2, p. 241-246.2005.
ProSystem CCTV - журнал no системам видеонаблюдения
h t tp://www. procc t v. г и
Глава 3. Выделение и классификация движущихся объектов
111
27. Шапиро Л., Стокман Дж. Компьютерное зрение. - М.: Бином, 2006. - 752 с.
28. М. Szummer. Temporal Texture Modeling. Technical Report 346. MIT, 1995.
29. E. Ardizzone. A. Capra. M. La Cascia. Using Temporal Texture for Content-based
Video Retrieval. In: Journal of Visual Languages and Computing, v. 11, p. 241-252,
2000.
30. G. Doretto, A. Chiuso. S. Soatto. Y.N.Wu. Dynamic textures. In: International
Journal of Computer Vision. v. 51. p. 91-109.2003.
31. S. Soatto. G. Doretto and Y.N. Wu. Dynamic Textures. In: Proc. International
Conference on Computer Vision. Vancouver, p. 439-446,2001.
32. Льюнг Л. Идентификация систем.Теория для пользователя. - М.: Наука, 1991.- 432 с.
33. Р van Overschce. В. de Moor. N4SID: Numerical Algorithms for State Space
Subspace System Identification. In: Proc. I FAC World Congress, Sydney, p. 361-
364,1993.
34. G. Doretto. D. Cremers. P Favaro. S. Soatto. Dynamic Texture Segmentation. In:
Proc. International Conference on Computer Vision, Nice, p. 1236-1242,2003.
35. K. Fujita, S.K. Nayar. Recognition of Dynamic Textures Using Impulse Responses
of State Variables. In: Proc. International Workshop on Texture Analysis and
Synthesis. Nice, p. 31-36.2003.
36. A. Chan, N. Vasconcelos. Mixtures of Dynamic Textures. In: Proc. IEEE
International Conference on Computer Vision, Beijing, v. 1, p. 641-47,2005.
37. S. Roweis, Z. Ghahramani. A Unifying Review of Linear Gaussian Models. In:
Neural Computations. 11, p. 305-345.1999.
38. R. P Wildes, J. R. Bergen. Qualitative Spatio-temporal Analysis Using an Oriented
Energy Representation. In: Proc. European Conference on Computer Vision.
Dublin, p. 768-784,2000.
39. B. Jahne. Digital Image Processing, Berlin: Springer-Verlag, 1993.
40. G. Zhao, M. Pietikainen. Dynamic Texture Recognition Using Volume Local
Binary Patterns. In: Proc. European Conference on Computer Vision Workshop on
Dynamical Vision, Graz, p. 165-177,2006.
41. T. Ojala, M. Pietikainen, T. Maenpaa. Multi-resolution Grayscale and Rotation-
invariant Texture Analysis with Local Binary Patterns. In: IEEE Transactions on
Pattern Analysis and Machine Intelligence, v. 24, p. 971-987.2002.
42. D. Chetverikov. Pattern Regularity as a Visual Key. In: Proc. British Machine Vision
Conference, Southampton, p. 23-32,1998.
43. H. C. Lin, L. L. Wang, S. N. Yang. Extracting Periodicity of a Regular Texture-
based on Autocorrelation Functions. In: Pattern Recognition Letters, v. 18,
p. 433-443, 1997.
44. E Liu, R. W. Picard. Periodicity, Directionality and Randomness: World Features
for Image Modeling and Retrieval. In: IEEE Transactions Pattern Analysis and
Machine Intelligence, v. 18, p.722-733,1996.
http://wwwjtv.rL/
Компания ITV - генеральный спонсор издания книги
ГЛАВА 4.
АЛГОРИТМЫ СЛЕЖЕНИЯ ЗА
ОБЪЕКТАМИ
114
Цифвая обработка видеоизображений
Целью данного этапа анализа видеоинформации является установление со-
ответствия между различными объектами или их частями в последовательности
кадров и нахождение траекторий объектов, а также вычисление их динамиче-
ских характеристик, таких как скорость и направление движения. В дальнейшем
задачу слежения за объектами будем называть также задачей сопровождения
объектов, или трекингом. В более простой форме задача сопровождения объ-
ектов заключается в назначении соответствующих меток одним и тем же объ-
ектам в различных кадрах. Трекинг представляет собой чрезвычайно сложную
задачу, поскольку при ее решении следует одновременно учитывать влияние
следующих факторов:
• изменение изображения, освещенность сцены, наличие шума камеры,
• присутствие объектов, изменяющих свою форму (например, бегущий
человек),
• временное исчезновение объектов, возникающее из-за загораживания
(перекрытия) их другими объектами, в результате чего траектории вре-
менно прерываются,
• наличие нескольких одновременно движущихся объектов с близкими ха-
рактерными признаками и пересекающимися траекториями,
• искажения, связанные с неправильной сегментацией объектов на предыду-
щих этапах обработки.
• необходимость, как правило, осуществлять сопровождение в масштабе ре-
ального времени.
Ошибочное выполнение операции трекинга приводит в дальнейшем к не-
корректной интерпретации действий анализируемых объектов и, как след-
ствие, к ошибочной работе системы в целом. Для осуществления трекин-
га нужно выделить объекты, за которыми ведется наблюдение, установить
между ними соответствие на различных кадрах, а также проанализировать
траекторию с целью прогнозирования параметров движения. Чтобы решить
эти задачи, в первую очередь нужно определить, в какой форме будут описы-
ваться объекты наблюдения, для чего существует несколько возможностей,
изображенных на Рис. 1:
• одной точкой, характеризующей центр масс объекта или центр минималь-
но возможного прямоугольника (МВП), описанного вокруг объекта,
• набором особых (ключевых) точек, по которым объект может быть одно-
значно распознан на следующих кадрах,
• геометрическим примитивом, таким как эллипс или МВП, описанным во-
круг объекта,
• внешним контуром объекта,
• набором областей, максимально устойчивых при движении объекта, либо
всей областью, занимаемой объектом,
• инвариантными характеристиками изображения объекта, такими как тек-
стуры, цветовая гамма, статистические моменты и т. п.
В зависимости от способа описания существуют эффективные алгоритмы,
позволяющие реализовать слежение за объектами. Конечно, если наблюдае-
мые объекты расположены далеко друг от друга и перемещаются с неболь-
шой скоростью, то практически все алгоритмы работают одинаково хорошо. В
ProSystem CCTV — журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 4 Алгоритмы слежения за объектами
115
Рис. 1. Различные способы представления объектов при трекинге. А - центром масс,
Б - набором характерных точек, В - описанным прямоугольником, Г - описанным
эллипсом, Д - контуром, Е - областью, занимаемой объектом.
то же время проведение детального анализа ситуации не всегда представляет-
ся возможным из-за жестких требований на производительность системы, свя-
занных с использованием в реальном времени. Поэтому разработчик системы
должен подобрать оптимальный алгоритм в зависимости от условий, в которых
предстоит работать системе.
Повысить производительность системы наблюдения могут также различные
ограничения, накладываемые на изменение размеров объекта от кадра к кадру
(Рис. 2). на изменение скорости (Рис. 3). а также на изменение направления тра-
ектории (Рис. 4).
Рис. 2. Ограничение на изменение размера объекта. Области Q, и занимае-
мые объектом на соседних кадрах, не должны сильно отличаться.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
116
Цифвая обработка видеоизображений
Рис. 3. Ограничение на скорость движения. Поиск объекта на следующем кадре
проводится в пределах окружности радиуса dmav
Рис. 4. Ограничение на изменение направления траектории. Объект на следующем
кадре может находиться в пределах угла ±а, отложенного от направления скорости
объекта.
Для большинства задач эти ограничения кажутся разумными и в результате по-
зволяют сократить область поиска одного и того же объекта на соседних кадрах.
4.1. АЛГОРИТМЫ ОБНАРУЖЕНИЯ ОСОБЫХ ТОЧЕК.
При слежении за несколькими объектами нужно иметь достаточно простой
механизм, позволяющий отождествлять один и тот же объект на разных кадрах.
Технически несложным и надежным способом является способ описания объекта
набором его особых точек. Эти точки должны обладать следующими свойства-
ми: их не должно быть много и их расположение должно слабо меняться при ма-
лом изменении размера и ориентации объекта и не зависеть от изменения осве-
щения. В полной мере этими свойствами обладают угловые точки на изображе-
нии объекта. Далее мы также будем называть особые точки ключевыми точка-
ми (в англоязычной литературе они обычно называются interest points или points
of interest), а алгоритмы, которые используются для обнаружения на изображе-
нии угловых точек, для краткости называть детекторами углов.
Один из первых детекторов углов, предложенный в [1]. основан на сравне-
нии интенсивностей изображений в небольшом локальном окне, окружающем
каждый пиксель исходного изображения. Если рассматриваемый пиксель соот-
ветствует углу, то при сдвиге окна разность интенсивностей должна существен-
но измениться, в противном случае эта разность должна слабо меняться. Обо-
значим интенсивность изображения в точке (х,у) как Z(x,y) , тогда при сдвиге
окна на (Дл, Ду) соответственно вдоль осей абсцисс и ординат изменение суммы
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 4. Алгоритмы слежения за объектами
117
квадратичных разностей в каждой точке изображения (х0,у0) запишется следу-
ющим образом:
i-Iq-h 2j=>0-fc 2
(1)
где w и h - соответственно ширина и высота локального окна. Детектор работает
следующим образом. Для всех допустимых сдвигов находится минимальное зна-
чение суммы квадратичных разностей (1). Если это значение является наиболь-
шим в заданной окрестности, то считается, что данная точка соответствует углу.
Обычно используются единичные сдвиги по горизонтали, вертикали и по диа-
гонали. Ясно, что если направления сторон угла не совпадают с направлениями
сдвигов, то такие углы не будут детектированы.
Рис. 5. А, Б - маски Превита, В, Г - маски Собеля для вычисления производных
1Х и Соответственно
Детектор Харриса [2] позволяет определить углы без использования операции
сдвига окон, которая, вообще говоря, требует значительных вычислительных ре-
сурсов. Рассмотрим следующую матрицу:
у с2 Улл)
НЬл М (2)
где Л и Л соответственно обозначают производные изображения по х и у, кото-
рые могут быть найдены, например, с помощью операторов Превитта или Собе-
ля, маски которых изображены на Рис. 5.
Детектор Харриса основан на анализе значения следующей величины:
fl = det(Af)-*Zr2(A/), (3)
где det(M) - определитель матрицы М. tr (М) - ее след, а к - параметр, опреде-
ляющий чувствительность метода. Обычно для него рекомендуется выбирать
значение из диапазона 0.05-0.15. Значение величины R положительно в области,
содержащей угол, отрицательно для области, содержащей ребро, и принимает не-
большое по модулю значение для прочих областей.
Детектор KLT [3] основан на анализе величин собственных чисел матрицы
М. Считается, что область содержит особую точку, если выполняется следую-
щее условие:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
118
Цифвая обработка видеоизображений
min (Л,, Аз )> А,
(4)
где к - заданное значение. Здесь Аь Аг- собственные числа матрицы М.
Детектор Китчена-Розенфильда [4] анализирует изменения направления гра-
диента. который определяется следующей величиной:
(5)
Значение С сравнивается с пороговым значением: чем меньше С, тем «луч-
ше» угол.
Наиболее устойчивым к всевозможным искажениям изображения являет-
ся метод SIFT (Scale Invariant Feature Transform) [5]. Он состоит из следующих
шагов [6]. На первом этапе осуществляется свертка изображения с гауссовыми
фильтрами
/ \ 1 ( — у:
Ф’Ь*7 =T“Texpi------
2ка ( 2а
(6)
имеющими различные значения параметра о. С их помощью вычисляется опера-
тор разности гауссианов:
D(x,y,a) = (ri(x,y,ka)-ii(x,y,a))*I(x,y), (7)
где к - параметр изменения масштаба, а символом * обозначена операция сверт-
ки.Точки, в которых D(x, у, а) достигает экстремума, отбираются в качестве кан-
дидатов в ключевые точки.
На следующем этапе отбрасываются точки, расположенные вдоль ребер.
Для этого используются свойства матрицы Гессе
вычисленной в точках, отобранных на предыдущем этапе. Поскольку главная
кривизна вдоль ребра принимает намного большее значение, чем в перпенди-
кулярном к нему направлении, а собственные числа матрицы Гессе пропорцио-
нальны главной кривизне D(x, у, о), то для исключения лишних точек достаточ-
но сравнить собственные числа. Для того чтобы не вычислять собственные чис-
ла, можно воспользоваться следующей идеей [2]. Предположим, что нам извест-
ны собственные значения Ai и А2 матрицы Н. тогда
det(^ = A,A2> (9)
tr(H) = \ + X2. л
Пусть Aj > Ар тогда г = — > 1,и справедливо следующее тождество:
<гг(Я) _ (г + 1)2 (10)
det(ZZ) г
Таким образом, для того чтобы выделить точки, в которых главная кривизна
меньше заданного значения, достаточно проверить выполнение условия
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. г и
Глава 4. Алгоритмы слежения за объектами
119
Jr+1)2
det(H) г <11>
Для порога обычно используется величина г » 10.
И, наконец, для достижения инвариантности относительно вращения для
каждого значения а находятся экстремумы у гистограммы ориентации, которая
строится с выбранным шагом в области вокруг ключевой точки:
п/ \ L(x,y + 1)-L(x,y-1)
9(хуу} = arctg—}----(----)-----(12)
k ' 6 L(x + l,y)-L(x-l,y) k ’
Здесь использовано обозначение Lfx, у) = т?(х, у. о)* 1 (х, у) . Для уточнения
положения ключевой точки значения гистограммы могут быть аппроксимиро-
ваны параболой по трем точкам, ближайшим к найденному пику.
Для инвариантного описания области вокруг особой точки может быть исполь-
зован метод PCA-SIFT [7]. Суть этого метода заключается в следующем. После
того как ключевая точка была обнаружена, вокруг нес выбирается часть изобра-
жения заданного размера. В каждой точке выделенного изображения вычисляет-
ся градиент, после чего полученный вектор градиентов нормируется. Набор харак-
терных признаков, описывающих данную область, получается путем замены век-
тора градиентов заданным числом его главных компонент. При этом происходит
как сокращение числа признаков, так и достигается определенная инвариантность
относительно аффинных преобразований, поскольку первые главные компонен-
ты располагаются вдоль главных осей в пространстве вычисленных градиентов.
4.2. СЛЕЖЕНИЕ ЗА ТОЧКАМИ
Предположим, что в поле зрения камеры попали М точек: Эти точ-
ки были зарегистрированы камерой в виде последовательности, состоящей из п
кадров. Пусть хк- координаты проекции у-й точки на кадре с номером /с, как это
показано на Рис. 6.
Координаты проекций описываются двумерными векторами. Посколь-
ку некоторые точки могут отсутствовать на каких-то кадрах, например, когда
они скрываются за препятствиями, то обозначим число точек на к-м кадре как
Рис. 6. хк - координаты полученной с помощью камеры проекции j-й точки на
кадре с номером к
http://www.itv.ru
Компания IТV - генеральный спонсор издания книги
120
Цифвая обработка видеоизображений
Рис. 7. Траекторией Т* является следующая последовательность: {xJ^Xp^Xj}
тк, тк<М. Будем называть траекторией Т* )-й точки до кадра с номером к
последовательность ,x22,...,x*z}. Иными словами, точке х' первого кадра со-
ответствует точка на втором кадре, точка третьего кадра и т. д., как это
показано на Рис. 7.
Если объекты в процессе наблюдения могут появляться и исчезать со сцены,
то для них траектория может начинаться нс с первого кадра и заканчиваться не
на последнем кадре. Кроме того, траектория может прерываться на несколько
кадров, например, когда соответствующий объект в процессе движения пере-
крывается другим объектом. Будем обозначать через Т траекторию /-й точки,
которая началась на первом кадре и закончилась на последнем, т. е. Т= Т".
Алгоритмы нахождения траекторий могут быть разделены на три группы:
слежение за отдельными точками, слежение за компактными набором точек, а
также модель глобального слежения (движения). Для определения критериев,
по которым будут выбираться траектории, удобно ввести матрицу назначений
Ак -[atJk 1 и матрицу отклонений Dk =[ ск ], характеризующую стоимость отклоне-
ния найденных траекторий от оптимальных. Строки этих матриц соответствуют
М траекториям, а столбцы - тк*{ точкам, присутствующим на &+1 кадре. Эле-
менты матрицы Ак определяются следующим образом: а * =1, если траектории
Т* соответствует одна и только одна точка х в противном случае а,* = 0. Из
такого определения следует, что если какая-либо точка не назначена ни одной
траектории, то ей соответствует столбец, состоящий из нулей. Если же какой-
нибудь траектории не была назначена ни одна точка,то соответствующая строка
будет состоять из нулей. Формально эти свойства матрицы Ак могут быть записа-
ны следующим образом:
ZX<1, (13)
/=*|
£<<1, (14)
«‘€{0,1}. (15)
Таким образом, матрица назначений описывает соответствие точек последо-
вательных кадров.
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://w w w. procc t v. г и
Глава 4. Алгоритмь слежения за объектами
121
Элементы матрицы Dk определяются как величина стоимости с.*, которую
получит назначение точки х**1 траектории ГА. Для вычисления этих стоимостей
существует несколько критериев.
4.2.1. Модели слежения за точками
Ниже представлены модели слежения за отдельными точками, за груп-
пой точек и модель глобального движения, в которой учитывается движение
всей совокупности точек на всех рассматриваемых кадрах [8-10]. Для каж-
дой модели приведены различные формулы, по которым можно вычислить
коэффициенты отклонения от оптимальных траекторий eft зависимости от
ограничений на свойства движения. Каждая из моделей также характеризу-
ется параметром rf, который обозначает число кадров видеопоследователь-
ности, которые нужно рассмотреть в дополнение к текущему для вычисле-
ния этих коэффициентов.
4.2.1.1. Модели слежения за отдельными точками
Модель ближайшего соседа. Эта модель учитывает только пространствен-
ную близость точек на соседних кадрах и не использует информацию о скорости
движения и гладкости траектории. Коэффициенты рассчитываются по следую-
щей формуле:
<=1К’-4 (16)
Для вычисления коэффициентов достаточно знать лишь расположение то-
чек на предыдущем кадре, поэтому d=l.
Модель плавного движения. Эта модель основана на предположении, что как
величина скорости, так и направление движения, должны изменяться постепен-
но. Количественно это может быть выражено следующим соотношением:
где af определяется следующим образом:
а‘=/«.а‘=1, (18)
а для весовых коэффициентов и рекомендуются следующие значения:
= 0.1, w2 = 1 — и/j = 0.9.
В формуле (17) первый член является штрафом за отклонение от направ-
ления движения, а второй член - штрафом за изменение абсолютной величины
скорости. Для вычисления ct * нужно иметь информацию о распределении точек
еще на двух кадрах, поэтому d=2.
Модель однородного движения. В основе этой модели лежит требование не-
больших изменений как модуля скорости, так и перемещения точки от кадра к
кадру. Величины с.* в данной модели рассчитываются по формуле
http://www.itv.ru
Компания I TV - генеральный спонсор издания книги
122
Цифвая обработка видеоизображений
В этой модели также используется информация о значениях координат точек
на двух дополнительных кадрах, поэтому d =2.
Из формул (17) и (19) следует, что для последних двух моделей 0 < с* < 1.
4.2.1.2. Модели слежения за набором точек
Эти модели позволяют избежать конфликтов при установлении соответ-
ствий. которые часто возникают при слежении за отдельными точками, по-
скольку происходит слежение одновременно за всеми траекториями. В каче-
стве критерия, позволяющего проводить назначения, теперь выступает суммар-
ный критерий для всего набора точек С*. который является функцией относи-
тельно матриц Ak и Dk
Модель среднего отклонения. Эта модель основана на подсчете среднего от-
клонения от оптимальных траекторий по всему набору рассматриваемых точек:
1
1 и fn*-i V
<20)
В формуле (20) использовано обобщенное среднее с параметром г, выбор ко-
торого позволяет усилить различие между большими и малыми отклонениями от
оптимальных индивидуальных траекторий рассматриваемых точек.
Модель среднего отклонения со штрафами. В этой модели назначение точек
траекториям происходит по принципу минимального отклонения от оптималь-
ных траекторий, и при этом назначаются штрафы при выборе неоптимальных
назначений. Стоимость вычисляется по следующей формуле:
с‘- -л (О- »ЛЫ). <21>
где
(22)
'И*-!-! «=|
Здесь Ra(i) представляет собой осредненную стоимость выбора траектории Г*,
a Rc(j) - среднюю стоимость назначения точке х**1.
4.2.1.3. Модель глобального движения
Эти модели предназначены для нахождения оптимальных траекторий для
всего набора из М точек на всей рассматриваемой последовательности из п ка-
дров. Качество назначений можно характеризовать следующим функционалом
стоимости:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www. procctv. г и
Глава 4. Алгоритмы слежения за объектами
123
S(D) = iwngc*(^,D‘),
(23)
где U- набор матриц А. удовлетворяющих условиям (13)-(15). Нахождение мини-
мума этого функционала является довольно сложной оптимизационной задачей,
требующей больших вычислительных ресурсов. Поэтому на практике обычно
используются методы локальной оптимизации, которые описаны ниже.
4.2.2. Алгоритмы построения траекторий
Большинство алгоритмов построения траекторий состоят по крайней мере
из двух шагов - инициализации и последующей обработки всего видеоряда (на-
хождение траекторий). Некоторые алгоритмы имеют еще третий этап - пост-
обработку позволяющую провести коррекцию найденных траекторий.
4.2.2.1. Инициализация алгоритма
В простейшем случае инициализация проводится по первым двум кадрам на
основании принципа ближайшего соседа,т. е. когда каждой точке на втором ка-
дре в соответствие ставится ближайшая точка на первом кадре. Однако этому
способу в некоторых ситуациях присущи ошибки. Рассмотрим траектории Т, и
Т2 движения двух точек на Рис. 8.
Поскольку точка х* ближе к точкех*, и в то же время х22 ближе к точке х2’.то
при использовании принципа ближайшего соседа траектории будут выглядеть, как
это показано на Рис. 9 (напомним, что верхний индекс соответствует номеру кадра).
На Рис. 8 изменение направления движения точек происходит плавно, что ка-
жется естественным, в то время как на Рис. 9 направления изменяются резко. Для
ряда задач подобная ошибка является несущественной, в то время как для других
практических задач это может приводить к серьезным коллизиям (особенно в
тех ситуациях, когда точки могут появляться и исчезать в процессе наблюдения).
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
124
Цифвая обработка видеоизображений
Рис. 9. Траектории движения двух точек, инициализация которых выполнялась
по принципу ближайшего соседа
Для исключения подобных коллизий обычно вводятся ограничения на ско-
рость движения точки dmM и предельный угол изменения траектории атах. Для ис-
пользования этих ограничений нужно рассмотреть по крайней мере три последо-
вательных кадра. Приведем основные шаги алгоритма инициализации по трем
первым кадрам, который хорошо зарекомендовал себя на практике [И].
Рассмотрим последовательность из первых трех кадров. Выберем на вто-
ром кадре произвольную точку хД спроектируем ее на 1 и 3 кадры и определим
в окрестностях проекций области поиска 5; и являющиеся окружностями
радиуса dm3X. как это показано на Рис. 10.
Рис. 10. Первый шаг инициализации. В первом и третьем кадрах строятся
области поиска, соответственно 52‘ и 52*, вокруг проекции на эти кадры
выбранной точки X2 со второго кадра.
Здесь знак «-» означает проекцию на предыдущий кадр, в то время как знак
«+» - проекцию на последующий кадр. Далее рассмотрим всевозможные трой-
ки точек (хп‘, х2 хт\такие что х‘ 6 S,2". х„ 6 S,2\ и упорядочим их по возрастанию
следующей функции стоимости:
(24)
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctvru
Глава 4 Алгоритмы слежения за объектами
125
выражение для которой, как нетрудно заметить, вычисляется по формуле (17),
записанной для тройки точек (xj, х;, хт3).
Пусть некоторая тройка (xj, х2, х*) минимизирует этот функционал. Будем
рассматривать эту тройку как первоначальную гипотезу о принадлежности этих
точек к траектории. Спроектируем точку х2 на второй кадр, построим вокруг
проекции область поиска и найдем все точки, попавшие в эту область. Пред-
положим. что была найдена некоторая точка х\ как это показано на Рис. 11.
Тогда на первом кадре вокруг проекции на него точки х 2 построим область
поиска Sq2~ и найдем все точки, попавшие в нее (см. Рис. 12).
Рис. 12. Поиск третьей точки х', потенциально принадлежащей траектории
Если в S найдется такая точка хг’, что для нее справедливо неравенство
С(х'г,х2ч,х3ь)<С(х'а,Х^,х1), (25)
то первоначальная гипотеза отвергается, и следует перейти к проверке следующей
по порядку тройки. В противном случае аналогичным образом тестируется точка
ха[. Если результаты проверки окажутся успешными, тройка (xj, х2, хь3) считается
началом траектории, выходящей из точки хД.
Если все гипотезы для точки х.2 были отвергнуты, это означает, что данная
точка нс принадлежит ни одной траектории, проходящей через первые три ка-
дра. Но, тем не менее,х2 может являться исходной точкой для другой траектории,
начинающейся со второго кадра. Если при проверке всех точек второго кадра на
первом кадре остались несвязанные точки, они считаются исчезнувшими со сце-
ны. Если же такие точки остались на третьем кадре, их надо проверить на воз-
можность того, что они являются началом новых траекторий.
h 11 р: //www. itv.ru
Компания ITV - генеральный спонсор издания книги
126
Цифвая обработка видеоизображений
4.2.2.2. Нахождение траекторий
Представим имеющуюся информацию о наборе наблюдаемых точек на п ка-
драх в виде графа, вершины которого разбиты на п слоев - V Вершины
&-го слоя соответствуют тк точкам, присутствующим на к-м кадре: х* —> v(x*j,
i < тк. Вершины могут быть соединены направленными ребрами, имеющими вес.
причем допускаются только направления в сторону увеличения номера кадра,
как это показано на Рис. 13.
Рис. 13. Представление информации о наблюдаемых точках в виде графа.
Каждый слой Vk соответствует набору из тк точек, присутствующих на к-м
кадре. Направленные связи соответствуют траекториям.
Каждая траектория моделируется набором ребер:
Т> = vMv(xM’ v(xMv(xb)’-’ v(x‘<*'
причем каждая вершина может быть связана только с одной вершиной из преды-
дущих кадров и не более чем с одной вершиной на последующих кадрах (так на-
зываемый принцип попарных связей).
Задача нахождения траектории состоит в нахождении набора ребер, связы-
вающих по возможности все точки, чтобы их суммарный вес был минимальным.
Эта задача относится к классу так называемых NP-полных, и решить ее полным
перебором можно только в случае слежения за небольшим числом точек. Дей-
ствительно, предположим, что на каждом кадре присутствует М точек, тогда чис-
ло возможных путей будет порядка (М!)л 1. Рассмотрим, например, случай: М = 5
точек и п =10 кадров. Даже при столь незначительном количестве точек число
путей будет порядка 5-10'*. Поэтохму для решения поставленной задачи были раз-
работаны специальные методы, являющиеся локально-оптимальными (в англо-
язычной литературе они называются Greedy - «жадные» методы). В этих мето-
дах вместо того, чтобы находить оптимальные пути на всей последовательности
кадров, находятся пути, оптимизирующие целевую функцию для каждой последо-
вательной пары кадров. Иными словами, решение задачи (23) аппроксимируется
набором локально-оптимальных задач:
(26)
k~d
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 4. Алгоритмы слежения за объектами
127
Такая замена позволяет существенно понизить сложность задачи и получить
решение даже в реальном времени, однако это решение может быть несколько
хуже, чем при глобальной оптимизации. Рассмотрим несколько алгоритмов.
Предположим, что к моменту времени к — \ в графе Gk~x определены все
пути Г*-1. Добавим к графу новый слой вершин Vky соответствующих кадру с
номером к. При этом каждая из добавленных вершин потенциально может быть
соединена с любой из терминальных вершин графа G*‘l (вершина называется
терминальной, или конечной.если из нее нс выходит ребро). Граф с потенциально
возможными связями назовем расширенным графом G*. На Рис. 14 показан рас-
ширенный граф при к=4. Пунктиром показаны потенциально возможные связи.
Г1 Г2 Г5 Г4
Рис. 14. Расширенный граф Gk при к=4. Пунктиром показаны потенциально
возможные связи.
Поскольку каждая терминальная вершина связана с каждой из новых вер-
шин, для расширенного графа нарушено правило попарной связи вершин. Задача
свелась к тому, чтобы из расширенного графа G* получить граф G* путем удале-
ния лишних связей таким образом, чтобы остались только попарные связи и при
этом достигался минимум функционала Ск(Ак, Dk).
На Рис. 15 изображен граф Gk, полученный из &. Далее описанный процесс
повторяется вплоть до достижения последнего кадра.
Рис. 15. Граф Gk, полученный из расширенного графа G* в результате удаления
лишних связей
http://w ww. itv. г и
Компания ITV - генеральный спонсор издания книги
128
Цифвая обоаботка видеоизображений
Существует достаточно много конкретных реализаций данного алгоритма,
которые отличаются выбором целевых функций для задач слежения за отдель-
ными точками и набором точек, ограничениями на изменение скорости и направ-
ления и другими параметрами. В модели S&S (Salari & Sethi [12]) для оценки ин-
дивидуального движения используется соотношение (17), а для оценки группо-
вого движения - формула (20) с параметром г = 1. При выборе кандидатов для
продолжения траектории накладывается ограничение на величину скорости drnax>
что позволяет сократить число переборов. Для того чтобы у модели была воз-
можность следить за временно закрытыми точками, вводятся так называемые
«фантомные» точки, которыми заменяются временно исчезнувшие. В алгорит-
ме R&S (Rangarajan & Shah [9]) предполагается наличие фиксированного числа
точек, и при этом он способен обрабатывать ситуации с временно исчезнувшими
точками путем экстраполяции их движения. Для оценки индивидуального движе-
ния используют соотношение (19). а для оценки группового движения - модель
(21), (22). При этом не накладывается никаких ограничений на величину скоро-
сти. Еще в одном алгоритме (Shafique & Shah [13]) используется модель плавно-
го движения (17), а для уточнения найденных траекторий используется процеду-
ра обратного прохода, которая выполняется по тем же правилам.
Задача нахождения оптимального пути может быть рассмотрена как класси-
ческая задача о назначениях: найти минимум функционала
<27>
1=1 J=l
с дополнительными ограничениями:
1=1
(28)
Ч*€{0,1}.
Эта задача может быть эффективно решена с помощью венгерского ал-
горитма. который за конечное число итераций позволяет найти оптимальное
решение. Для определения весов можно использовать любой из следующих
методов [10]:
».=«)' (®)
или
% = - W'Ra (') - W2R'c (Д (30)
где
*0)—(31)
а в качестве модели индивидуального движения - любую из моделей (16), (17)
или (19).
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 4 Алгоритмы слежения за объектами
129
4.3. СЛЕЖЕНИЕ ЗА ЭЛЛИПТИЧЕСКИМИ ОБЛАСТЯМИ
При слежении за локализованными объектами может быть применен следу-
ющий прием: вокруг объекта описывается эллипс, после чего положение и ори-
ентация объекта определяются по этому эллипсу, как это показано на Рис. 16.Та-
кой способ удобен, например, при слежении за положением головы человека при
проведении видеоконференций. В этом случае достаточно эффективным являет-
ся использование простейшей модели [14]. которая имеет только три параметра
5 = (х. у. о), где (х, у) - положение центра эллипса (т. е. точка пересечения малой
и большой осей эллипса), а о - длина малой оси. Предполагается, что отношение
осей эллипса имеет постоянное значение, которое, например, для головы челове-
ка выбирается в диапазоне от 1.2 до 1.6. а ориентация эллипса сохраняется верти-
кальной, т. е. направление большой оси является вертикальным.
Подстройка положения и размера эллипса проводится путем нахождения та-
ких значений параметров $. при которых достигается максимум модулей гради-
ентов по периметру эллипса:
5’ = arg max
(32)
где gt - градиент, вычисленный в /-том пикселе, принадлежащем границе эллипса.
N - число пикселей по периметру эллипса. S - область поиска, размеры которой
определяются ограничениями на скорость перемещения объекта по горизонтали
и вертикали (rfx, dy) и скорость изменения его размера dcr.
S = р: |х- хр| < dx4 |у - ур\ < dy,\a - ар| < Jaj. (33)
Рис. 16. Положение объекта наблюдения определяется по описанному эллипсу
http://wwwjfv. ги
Компания ITV - генеральный спонсор издания книги
130
Цифвая обработка видеоизображений
Здесь (х р, у р, а1') - прогнозируемые координаты центра эллипса и его разме-
ров на следующем кадре, которые в предположении постоянной скорости движе-
ния могут быть определены по значениям, найденным на предшествующих кадрах:
Xt ^Xt-\ Xt-2'
У? = 1у, I -У, 2.
(34)
Несмотря на простоту модели, она позволяет достаточно надежно следить за
положением головы при повороте человека на 360 градусов вокруг вертикаль-
ной оси. наклонах головы, изменении расстояния относительно камеры (увели-
чение или уменьшение размеров), а также при частичном перекрытии головы,
например, рукой.
Чувствительность модели может быть улучшена, если границы эллипса на-
ходить из следующего условия:
s* — arg max
res
(35)
где nt- единичный вектор нормали к эллипсу, вычисленный в /-ом пикселе,
лежащем на границе эллипса, а (л .#г) является скалярным произведением гра-
диента на нормаль. Однако в этом случае также возрастает чувствительность
к шумам.
Если для наблюдения используется цветная камера, то свойства этой модели
могут быть улучшены путем учета цветовой информации. В этом случае под-
стройка размера и положения эллипса может быть выполнена путем максимиза-
ции следующего функционала [15]:
= arg max (s)+£ (s)}, (36)
где (p?(s) и (pc(s) определяют зависимость от градиента интенсивности и цветовой
гистограммы соответственно:
= (37)
EminK (/),Я(/))
= —-----S----------• (38)
ЕМО
1=1
Здесь М - число отрезков, представляющих гистограмму. Н и h - гистограм-
мы, построенные соответственно по цветовой модели и части изображения, по-
павшего внутрь эллипса. Цветовая модель определяется объектом, за которым
ведется наблюдение. Например, если это автомобиль, то гистограмма Н строит-
ся на основе распределения его цвета с первого кадра. Если же осуществляется
слежение за головой человека, то цветовая модель составляется на основе рас-
пределения цвета кожи и волос. Для того чтобы вклад членов (37) и (38) учи-
ProSystem CCTV - журнал по системам видеонаблюдения
ht tp://ww w. procct v. ru
Глава 4. Алгоритмы слежения за объектами
131
тывать в равной мере, в формуле (36) используются нормированные величины,
приведенные к диапазону [0.1]:
7Z _ T'twn
Sr *"
(39)
4.4. СЛЕЖЕНИЕ ЗА КОНТУРАМИ ОБЪЕКТОВ
Методы, основанные на слежении за контурами, считаются наиболее устойчи-
выми как к изменению освещения, так и к наличию шумов в исходном изображе-
нии. А для некоторых задач, таких как распознавание жестов, контур объекта содер-
жит большую часть информации, на основе которой происходит принятие решения.
Наиболее широко на практике применяется метод выделения активного кон-
тура, который обычно называется змейкой (snake в англоязычной литературе
[16]). Классическая змейка представляет собой замкнутую гладкую кривую, ко-
торая аппроксимирует контур объекта. Змейку удобно задавать в параметриче-
ском виде: (s)|, где s € 0.1,. Она определяется из условия минимиза-
ции следующего функционала энергии [1]:
Е=+^1ж,/(5)Г}-и£«« и*))! <4°)
0 ' '
где а и /3- весовые коэффициенты, характеризующие напряжение и изгиб кон-
тура, а Еел1 представляет собой энергию внешних сил. которые определяются
на основе исходного изображения таким образом, чтобы вынуждать змейку
приближаться к контуру объекта. Контур, который минимизирует функционал
(40). должен удовлетворять уравнению Эйлера:
ax"(s)-[3x,''(s)-^Eal=0, (41)
где x"(s) и хА(^) обозначают соответственно вторую и четвертую производные, а
V - оператор градиента. Последнее уравнение можно записать в виде баланса
внутренних и внешних сил:
VF.4 (42)
где
F„, = *
Из такой записи видно, что внутренние силы препятствуют растяжению и
изгибу, а внешние силы прижимают змейку к контуру объекта.
Если исходное изображение I (х, у) является полутоновым, то для энергии
внешних сил Еех1 чаще всего применяется одно из следующих выражений:
C(x,y) = -|V/(x,^)|2. (43)
(*»у) = -|^|т?(х,у,ст)* 1 (х, j)j|2, (44)
где 7) (х,у, а) - двумерная плотность распределения Гаусса с параметром о:
http://www. itv.ru
Компания ITV - генеральный спонсор издания книги
132
Цифвая обработка видеоизображений
Свертка с гауссовым ядром применяется для компенсации влияния шума на
форму контура.
Решение уравнения (41) может быть найдено методом установления, т. е. пу-
тем нахождения стационарного решения следующего уравнения:
xt(s9t) = ax"(s9t)—Зх1' VEt, =0 (46)
с начальным условием
x(s,0) = xo(.s) (47)
и граничными условиями
х(0,1) = хо(О), *(!,/) = х0{1).
x'(0,r) = x;(0), x'(l,r) = xj(l).
(48)
Поскольку искомая змейка должна быть близка к внешнему контуру объек-
та, можно облегчить процесс ее построения, если заменить исходное изображе-
ние бинарным, содержащим только краевые точки изображения. В этом случае
энергию внешних сил Еех, вычисляют по одной из следующих формул [17]:
Е1«(Х’У) = НХ’У) (49)
(50)
Для нахождения краевых точек чаще всего используются алгоритмы, осно-
ванные на вычислении градиента изображения с помощью операторов Роберт-
са, Превитта и Собеля. и последующим сравнении градиента с выбранным по-
рогом. Наиболее удачным методом нахождения краев является метод Кэнни
[18], который в литературе часто называют оптимальным благодаря его сле-
дующим свойствам: хорошее отношение сигнал/шум, правильное определение
контуров, а также гарантированное получение краев толщиной в один пиксель.
Алгоритм Кэнни состоит из следующих шагов:
1. Сглаживание исходного изображения путем свертки с дискретной гауссо-
вой маской G(x,y, о). На практике обычно применяют маски небольших
размеров, порядка 5x5. Например, такая маска с параметром о=1.4 пред-
ставлена на Рис. 17А.
Применение сглаживания позволяет снизить влияние шума, однако увели-
чение размеров маски может привести к увеличению ошибок при опреде-
лении координат граней.
2. Вычисление абсолютной величины G(x, у) и направления 6(х, у) градиентов
интенсивности в каждой точке изображения. Для этого, как правило, использу-
ют оператор Собеля размером 3x3. маски которого приведены на Рис. 17 Б. В.
Абсолютная величина градиента определяется по следующей формуле:
g(x,7) = |V/| = (51)
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. ru
Глава 4. Алгоритмы слежения за объектами
133
Рис. 17. А - дискретная гауссова маска 5x5 с параметром О = 1.4. Б, В - маски
оператора Собеля для определения градиентов 1Х и 1у соответственно
а направление градиента - по формуле
в[х,у) = aragy.
* г
(52)
3. Выделение множества точек, которые потенциально могут являться крае-
выми. Как известно, модуль градиента интенсивности изображения G(x,y)
увеличивается по мерс приближения к краям, достигая на них своего мак-
симума. Цель настоящего этапа - оставить только те точки, которые име-
ют локальный максимум G(x, у). что позволит в результате получить ре-
бра толщиной в один пиксель. Для этого рассматривается окрестность 3x3
для каждого пикселя, в которой G(x, у) сравнивается с градиентами вдоль
линии, перпендикулярной краю на границе этой области. На Рис. 18 сплош-
ной линией показано направление края в точке /(х, у), а пунктиром - на-
правление градиента в этой точке. Мы должны пометить точку (х.у) как
Рис. 18. Сплошная линия - направление края в точке 1(х, у), пунктирная линия
направлена вдоль нормали к краю
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
134
Цифвая обработка видеоизображений
потенциально являющуюся краевой точкой, если модуль градиента в ней
больше, чем в точках А и В, которые являются точками пересечения пря-
мой, направленной вдоль градиента, и границами области 3x3 пикселя.
Модули градиентов в точках А и В вычисляются путем интерполяции по
ближайшим точкам, например:
Ga = a-G(x + 1,y+ 1) + (1 -q)G(x —1, у).
Учитывая, что а = tg G, получим
G4 = ^-G(x + l>y + l)+^-^G(x-l,.r). (53)
Gs = ^G(x-l,y-l)+^y^G(x-l,r). (54)
Если G(x,y) >Ga и G(x,y) > GB. то точка (х, у) рассматривается далее как
потенциальная краевая точка.
4. Выделение краевых точек. Для этого вводятся два пороговых значе-
ния, 3, > & , после чего на множестве точек, которые были помечены на
предыдущем этапе как потенциально краевые, осуществляется выделе-
ние краев. Процесс начинается с произвольной точки (х0,у0), для которой
G(x0.y0) > 3Р В окрестности этой точки находят следующую - (x^yj, для
которой G(xl,y1) > 3?. Если таких точек не оказалось, то данный край за-
кончился, иначе продолжают обход изображения, по пути помечая все точ-
ки, относящиеся к данному краю. Если вернулись в начальную точку, либо
попали в конечную точку края, снова отыскивают непомеченную точку
(х,, у,), для которой выполняется условие G(xry1) > ЗрОна помечается как
первая точка нового края, и описанный процесс повторяется до тех пор,
пока не закончатся непомеченные точки, в которых абсолютное значение
градиента превышает порог Зг
Описанный метод построения классической змейки иногда имеет тенденцию
слишком скруглять контур объекта, что может оказаться неприемлемым, если
объект имеет границу с многочисленными небольшими, но глубокими выпукло-
стями и вогнутостями. В этом случае лучшие результаты позволяет получить
модификация описанного метода, основанного на использовании векторного по-
тока градиента (GVF - Gradient Vector Flow, [19]). Этот метод состоит в опреде-
лении векторного поля v(x,y) = [ u(x,y), v(x,y)], которое доставляет минимум сле-
дующему функционалу:
E=ff^+u'+v'+v")+1 wf lv - W|2 dxdy, (55)
где в качестве /(х,у) можно использовать /(x,y) = -£^f (х,у) при любом
i = 1,2,3,4. Градиент такой функции V/ направлен в сторону краев, имеет наи-
большее значение в окрестности края и близок к нулю в областях с однородной
интенсивностью. Параметр р играет роль параметра регуляризации: он должен
увеличиваться при возрастании шума. Уравнения Эйлера для функционала (55)
имеют следующий вид:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 4. Алгоритмы слежения за объектами
135
дД«-(и-Л)(/;^/;)=о, (56)
ц Д V - (V - fy) (/; + f;) = О,
где А - оператор Лапласа. Эти уравнения могут быть решены методом установ-
ления. Для этого нужно найти стационарные решения двух двумерных параболи-
ческих уравнений в частных производных:
и, (х,у,г) = /хДи (х,у,/)- («(х. у./) - У, (х, у))(/х2 (х, у) + f* (х, у)) = 0, (57)
v, (*> Д'» О = МДv(х,у,t) - (v(х.у,t) - у (х.у))(У/ (х, у) + у2 (х, у)) = 0.
В качестве начального значения выбирают произвольный контур. Производ-
ные в правой части (57) аппроксимируют конечными разностями на пятиточеч-
ном шаблоне, производные по времени заменяют разностной производной впе-
ред, например:
/ \ и(хуу4 + т)~и(х,
и, (х, у, /)« ------L--——,
т
после чего динамика контура описывается следующими рекуррентными соотно-
шениями:
и (х, у, t +1) = и (х, у, z) 4- А и (х, у, t) + Ви (х, у), (58)
v(x,y,Z +1) = v(x,y,/) + Jv(x,y,z) + Bv (x,y),
где
(*. Д') = т/х (*» Д’) (/? (*> Д')+fy (*» Д'))» (59)
в, (*, Д') = ТУ, (х, у) (У2 (х, у) + у2 (х, у)).
Итерации прекращаются, когда контур перестает изменяться.
Если существует априорная информация о том, что контур объекта будет
достаточно выпуклым, очень эффективной процедурой построения контура яв-
ляется метод, основанный на схеме динамического программирования [20]. Пе-
рейдем для удобства в полярную систему координат (г, ф) . В качестве начала
координат выберем точку (х0,у0). являющуюся центром масс изображения:
£ЕУл EEVz
Х°=ТЕГ’Л=ТЕГ’ (60)
I J • /
где (х^уД- координаты сетки в исходных декартовых координатах соответствен-
но по горизонтали и вертикали, ItJ = /(х^у,) - интенсивность изображения в узлах
сетки. Введем в полярных координатах равномерные сетки по радиусу г,= / • Аг и
по углу фу= j где Аг и Дф - соответственно шаги сеток по радиусу и по углу,
/ = 0,/V, / = 0.Т. Сетка в полярных координатах показана на Рис. 19. Интер-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
136
Цифвая обработка видеоизображений
Рис. 19. Сетка полярной системы координат
полируем значение интенсивности изображения в узлы полярной сетки, напри-
мер, билинейным сплайном, /(х, v).
Обозначим двойным индексом г,, значение радиуса г, на у-м луче. Тогда кон-
тур определяется как последовательность г,((р^ которая минимизирует следую-
щий функционал:
Ф(г,= [«,/?, + а3Я3 -а4Я4 +а5Я5
(6!)
где R}..R< - внутренние силы, которые имеют следующий смысл:
Л,
— ) - условие минимальной длины контура.
- условие наибольшего радиуса.
— 2г 4-/; Н|) - условие гладкости контура.
Л4 =(rt -г z j)(/;,-г условие гладкости производной вдоль границы контура.
Н-^/И)-2т; jZj ^jCOsA^ - условие выпуклости.
ар...,а5 - весовые множители, учитывающие вклад каждой компоненты вну-
тренних сил в функционал. Отметим, что результаты численных экспериментов
показали, что наиболее чувствительными являются первые два коэффициента.
Для минимизации функционала Ф(г. <р) применяется специальная схема
динамического программирования. Обозначим для краткости 1Ч =1(г,. (рг),
R = —аД+а2Я2 — +а4Я4 — а5Я5 - сумму внутренних сил. Предложенная
схема состоит из следующих шагов:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 4. Алгоритмы слежения за объектами 137
1. Инициализация:
6(/,0) = Ф(/\0),
^(цО) = i . i = 0.N.
где 8 и у/ - вспомогательные переменные.
2. Индуктивный переход:
j) = mm [й(|, j’ -1) + Rt) j + /„.
0(<, j) = arg min [6(i, j -1) 4 R„ ].
i = 0..N. j = 1...T.
3. Обратный проход (определение траектории):
iT = argmin6(i, J),
b-i =
Вычислительная сложность алгоритма ~N3 арифметических операций,таких
как сложение и сравнение, где N - максимальное число точек вдоль луча.
Для получения траекторий объектов нужно установить соответствие между
их контурами на последовательных кадрах. Для этого желательно использовать
какие-либо характеристики контура, которые будут достаточно устойчивыми
относительно его небольших искажений. К таким характеристикам относятся
точки локального максимума абсолютной кривизны контура. Пусть мы имеем
параметризованное представление контура х($) = [х($),у ($)], тогда его кривиз-
на определяется следующей формулой:
(62)
(*2+л2)5
где х, и х„ - соответственно первая и вторая производные по параметру. Знак k(s)
определяет, будет ли кривая в точке у выпуклой или вогнутой. Однако если для
нахождения ключевых точек непосредственно использовать формулу (62), то
результат будет сильно чувствителен к шуму. Существенно лучшие результаты
позволяет получить следующий метод [21J. Вместо исходного контура рассма-
тривается семейство контуров
x(5,o-) = [<(s>ct),V’(j,o-)], (63)
где
£($,<7)=x(s)*g(s,<7), V(s,a) = y(s)*g(s,a), (64)
I ( х2 \
&(х,сг)=_7^=—ехр| -ттт •
>/2ло 2о J
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
138
Цифвая обработка видеоизображений
При малых значениях а контур остается близким к исходному, а при увеличе-
нии этого параметра становится более гладким. Кривизна может быть вычисле-
на по следующей формуле:
K[S,a) —--------------------j-----------• (О?)
(е+€)5
где
£(s,<r) = x(s)*g,(s,ff), = (66)
(^<т) = y(s)*g$ (s,<r), if’„ (s.a) = y(s)*ga (s,a).
Для нахождения ключевых точек следует поступить следующим образом.
Для параметра о выбирается достаточно большое значение crmiv после чего на
контуре находятся точки локального максимума |A(.s.a)|. Эти точки принимаются
в качестве начального приближения для «угловых» точек на контуре, при этом,
чем больше значение |А(5.а)|.тем острее угол. Далее значение параметра G умень-
шается. и в окрест ности точек, найденных на прежнем шаге, снова отыскиваются
точки локального максимума абсолютного значения кривизны. Описанный про-
цесс продолжается для достижения заданной точности. При этом сохраняются
только те точки, кривизна в которых превышает некий заданный порог. На за-
ключительном шаге абсолютное значение кривизны в найденных точках |А' |
сравнивается с двумя соседними локальными минимумами кривизны |Л*1П| и |£m)n|.
Для угловых точек должны выполняться оба следующих соотношения:
L kJ>2к, I
| max | | nun I* I max | | min p
Это позволяет избавиться от точек, которые лежат на округлых фрагмен-
тах контура. В результате выполнения указанной процедуры мы получаем набор
Рис. 20. А - исходное изображение, Б - его эластичный контур, В - набор
ключевых точек
ProSystem CCTV - журнал по системам видеонаблюдения
h ttp://w w w. procctv. ru
Глава 4. Алгоритмы слежения за объектами
139
ключевых точек, описывающих топологию выделенного контура. Взаимное рас-
положение этих точек дает достаточно устойчивый набор характерных призна-
ков, позволяющий идентифицировать заданные объекты на последовательности
кадров. Пример выделения особых точек приведен на Рис. 20.
Поиск на следующем кадре контура, наиболее похожего на заданный, может
также быть осуществлен с помощью обобщенного преобразования Хафа [22].
Для этого по эталонному контуру строится так называемая R-таблица, кото-
рая в параметрической форме хранит информацию об этом контуре. На осно-
ве этой таблицы проводится преобразование изображения, содержащего набор
контуров-претендентов. Наиболее подходящий из них определяется в результате
нахождения максимального элемента в массиве-аккумуляторе, который запол-
няется в процессе выполнения обобщенного преобразования Хафа.
Рассмотрим эталонный контур, образованный совокупностью точек
Для построения R-таблицы выберем произвольную
точку (хс ,ус). находящуюся внутри контура, и для каждой точки (х,.у,) выполним
следующие действия:
1. проведем линию, соединяющую (х,. у,) и (хс, ус), как это показано на Рис. 21;
Рис. 21. В строку R-таблицы, соответствующую углу фу, заносятся величины г, и Д
2. вычислим расстояние г, между этими точками, а также найдем угол Д меж-
ду направлением оси Охи проведенной линией:
3. вычислим величину угла ср, между нормалью к контуру в точке (х,.у,) и
осью Ох.
4. занесем полученные значения г, и Д в строку R-таблицы, которая соответ-
ствует значению ф,
Структура полученной R-таблицы изображена на Рис. 22.
После того, как R-таблица построена, к имеющемуся изображению мож-
но применить преобразование Хафа, которое состоит в следующем. Обнулим
массив-аккумулятор Д(х,у), после чего для каждой точки (х„ у() изображения, со-
держащего набор контуров, выполним следующие действия:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
140 Цифвая обработка видеоизображений
1. вычислим угол ф, между нормалью к контуру в точке (х,.у,) и осью Ох\
2. для всех наборов которые находятся в строке R-таблицы, соответ-
ствующей углу ф.. вычислим возможное положение точки (хс.ус):
хс = xtt- г* cos 3*, (67)
Ус-У,
и увеличим значение аккумулятора:
3(хс,ус)= Л(хс,ус)->-1. (68)
После завершения описанной процедуры место расположения наиболее по-
хожего контура находится при значении (хс. ус). которое соответствует макси-
мальному значению аккумулятора Д(хс.ус).
Этот алгоритм может быть легко обобщен на тот случай, когда ориентация
и размер сравниваемых контуров могут быть изменены. Пусть параметр 4 ха-
рактеризует возможное изменение поворота контура, а параметр 5 - изменение
масштаба. Тогда второй пункт обобщенного преобразования Хафа изменится
следующим образом: положение точки (хс,ус) следует вычислять по формулам
хс =х, +r/Scos(3; 4-4), (69)
3'c = X+'i'5sin(*3* +<)>
и соответственно массив-аккумулятор будет зависеть от четырех параметров,
поэтому его увеличение будет выглядеть следующим образом:
Л(хг,уо5,С) = ^(xc.jc,S,C)+l. (70)
4.5. СЛЕЖЕНИЕ ЗА ОБЛАСТЯМИ, СОДЕРЖАЩИМИ ИЗОБРАЖЕНИЕ
Описываемая в настоящем разделе техника слежения за объектами может
быть крайне полезной в ситуациях, в которых другие методы могут потерпеть
неудачу. Предположим, что мы осуществляем наблюдение за автомобилем, ко-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 4. Алгоритмы слежения за объектами
141
торый подъехал к перекрестку и остановился у светофора. Когда автомобиль
движется, он является видимым для детектора движения, а через некоторое
время после остановки он. как правило, начинает становиться частью фона. В
результате объект трекинга на какое-то время исчезает. Аналогичная ситуа-
ция возникает при слежении за автомобилями, которые попали в дорожный за-
тор. Для того чтобы «не терять» остановившиеся объекты, могут быть приме-
нены методы слежения за областями изображения. Суть этих методов состоит
в следующем. Если объект хорошо различим, то можно «запомнить» его изо-
бражение, и далее отыскивать его на следующем кадре. Ясно, что это удастся
сделать лишь при условии незначительного изменения изображения от кадра
к кадру. Такими свойствами обычно обладают «жесткие» объекты, например,
транспортные средства, и полужесткие объекты, такие как человеческие лица.
В простейшем случае для нахождения на следующем кадре наиболее схо-
жей области может быть осуществлен поиск в ближайшей окрестности. На
начальном этапе нужно определить область, которую занимает объект. Эту
область можно задать в виде маски Л/, например: = 1 - если соответствую-
щий пиксель (/.у) принадлежит объекту, и Л/,, = 0 - в противном случае. Пример
маски приведен на Рис. 23.
Рис. 23. Изображение объекта, за которым ведется наблюдение (слева), и
соответствующая объекту маска, показанная черным (справа)
Пусть на кадре с номером t прямоугольник, в который вписан объект, име-
ет координаты верхнего левого угла (/(Ъу0) .Тогда смещение этого прямоуголь-
ника на следующем кадре может быть найдено путем минимизации следующе-
го функционала:
Ф, (Д/, Д/j=Е £ d ), (71)
где /' - интенсивность пикселя с координатами (/. j) в кадре с номером z. а (Л, и ) -
соответственно высота и ширина прямоугольника, в который вписан объект, как
это показано на Рис. 24. a d(x, у) -функция сравнения .г су. Чаще всего в качестве
этой функции используется квадрат разности аргументов:
J(x,y) = (x-y)\
хотя иногда для ускорения расчетов применяют модуль разности аргументов:
J(x,y) = |x-y|.
http://www.itv.ru
Компания ITV — генеральный спонсор издания книги
142
Цифвая обработка видеоизображений
Рис. 24. Наблюдаемый объект вписан в прямоугольник размерами (Л, и).
Изображению на кадре / (слева) соответствует изображение на кадре с номером
Г+1, сдвинутое на Д/ и Ду (справа).
Максимальная величина смещений Д/ и Д/ определяется ограничениями на
скорость движения объекта:
—< Д/ < ,
mu — — mu ’
(72)
Если изображение наблюдаемого объекта имеет слабо меняющуюся ин-
тенсивность. близкую к интенсивности фона, то формула (71) на каждом шаге
может приводить к погрешностям в определении положения объекта, в резуль-
тате чего через несколько кадров можно вообще «потерять» объект. В этом
случае вместо сравнения изображений более эффективной может оказаться
процедура, основанная на сравнении градиентов:
ф6. (д/. д/)=£ £ ), (73)
либо на комбинации из этих функционалов:
ФС(МДО»(+ (Д«,Д7) + пФс(ДЛД/)), (74)
где а - коэффициент, выравнивающий значимости суммируемых компонент.
Смещение наиболее схожей области | Д/\Ду’ ) определяется в результате нахож-
дения минимума функционала сравнения:
(Д/\Дул) = arg min Ф( Аг, Ду), (75)
где в качестве Ф( Д/, Ду) может быть использован любой из перечисленных функ-
ционалов.
Нетрудно заметить, что описанный метод является крайне неэффективным с
вычислительной точки зрения. Опишем его модификацию, которая позволяет
существенно сократить количество вычислений. Вместо того чтобы вычислять
функционал Ф(Д/, Ду) для каждого смещения Д/ и Ду. можно ввести пороговое
ProSystem CCTV - журнал по системам видеонаблюдения
hup://www. procctv. ru
Глава 4. Алгоритмы слежения за объектами
143
Рис. 25. Первые три шага поэлементного сравнения функционалов. Слева -
фрагмент изображения на кадре с номером Г, справа - соседние окна на
следующем кадре. Темные квадраты соответствуют сравниваемым элементам,
зачеркнуты отброшенные окна.
значение 3. и для каждого из окон, по которым производится сравнение, первые
элементы функционала, как это показано в верхней строке на Рис. 25. сравнить с
этим порогом.
Все окна, для которых первый элемент оказался выше порога, отбрасыва-
ются. и проводится сравнение суммы первых двух элементов, как показано во
второй строке на Рис. 25. и т. д. Ясно, что количество сравнений на каждом шаге
все время уменьшается. Если порог был выбран слишком низким, описанный
процесс может завершиться еще до того момента, когда все элементы будут
сравнены. В этом случае можно либо воспользоваться результатами последнего
шага, либо увеличить порог и начать все сначала. Заметим, что из-за шума мо-
жет быть отброшено нужное окно. Это особенно часто происходит на началь-
ном этапе сравнения, когда значимость каждого пикселя велика. Для снижения
влияния отдельных пикселей может быть предложена следующая процедура:
к изображениям в сравниваемых окнах применяется преобразование, перево-
дящее его в частотную область, после чего по описанной схеме сравниваются
гармоники: первая - со всеми первыми и т. д. В качестве преобразования может
использоваться дискретное преобразование Фурье
F(u,v) = —— 5\У^/(х,у)ехр -2тг/| —-h —| ,
V 1 V 4 {М N JJ (76)
w = 0...й-1,
v =
где (Л.и*) - размер сравниваемых окон. Если размер окна по каждому направле-
нию равен степени двойки, h = w=N.N = 2*. то существенный выигрыш может
быть получен при использовании двумерного преобразования Адамара-Уолша
[23]. для которого существует быстрый алгоритм, аналогичный алгоритму бы-
строго преобразования Фурье. Это преобразование описывается следующими
соотношениями:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
144
Цифвая обработка видеоизображений
^(“’v) = 77E£/(x’>')(-I)X «
/V д-Q ?=о
.V-1
A(x,y,u,v) = (w) x, +gi (v). r,|,
1-0
где
g. (“) = «.V-P
g. (“) = «V-l+“.V-2>
g2 (“) = «V-2+«V-J.
....................
ЯУ_1(и) = И|+и0,
(77)
(78)
(79)
а переменные ui9^,,xl>yi принимают значения 0 или 1 в зависимости от того, ка-
кая цифра стоит на Лм месте в двоичном представлении чисел w,v,x,y соответ-
ственно. Например, если и = 10, в двоичном представлении 10 = (1010)2 , поэтому
u3 = 1, и2 = 0, и{ = 1, м0 = 0. Базисные функции Адамара-Уолша принимают значе-
ния (+1) и (-1) (см. Рис. 26), что особенно удобно как для вычислений на стандарт-
ном компьютере, так и при аппаратной реализации.
I ни
ННЙИ
Рис. 26. Базисные функции преобразования Адамара-Уолша при W=4. Черный
цвет соответствует значению +1, белый - значению -1.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www. procctv.ru
Глава 4. Алгоритмы слежения за объектами
145
К недостаткам описанных методов относятся чувствительность к шумам, за-
висимость от изменения освещенности от кадра к кадру, отсутствие инвариант-
ности относительно поворота и изменение масштаба объекта, а также сложность
обработки ситуаций, в которых происходит даже частичное загораживание объ-
екта. Большинства из этих недостатков можно избежать, если использовать ме-
тод максимально стабильных экстремальных областей (MSER - Maximally Stable
Extremal Regions [24]). Суть этого метода состоит в следующем. Возьмем полуто-
новое изображение и получим на его основе ряд изображений 1Р путем сравнения
значений пикселей с порогом Р. пробегающим все значения в диапазоне [0,256].
Будем называть все пиксели, интенсивность которых ниже порога, черными, а
остальные - белыми. Если из полученных изображений сделать фильм, то снача-
ла мы увидим белое изображение, потом на нем появятся черные пятна, соответ-
ствующие локальным минимумам интенсивности, которые будут расти по мере
увеличения значения порога Р. Последний кадр окажется сплошь черным. В ре-
зультате описанного процесса мы получим набор экстремальных областей
Q вложенных друг в друга.И,С
Нумерацию экстремальных областей можно выполнить следующим обра-
зом. Сначала проводится сортировка всех пикселей изображения по возрас-
танию. Далее они объединяются в связанные области, что может быть эф-
фективно осуществлено с помощью алгоритма union-finding [25]. Этот
алгоритм имеет вычислительную сложность О (л log log л), т. е. почти линей-
ную. Описанный процесс позволяет получить такую структуру данных, в ко-
торой будут отсортированы связанные области в зависимости от интенсивно-
сти. Слияние двух областей прекращает существование меньшей из них путем
добавления ее пикселей к содержимому большей области. В результате нахо-
дятся области, которые являются максимально стабильными при осуществле-
нии этого процесса. Экстремальная область Q, является максимально ста-
бильной, если функция
|Ч|
имеет в точке /* локальный минимум. Здесь | Q | обозначает число элементов
множества Q, а А - параметр метода. Чем больше значение параметра А, тем
меньше получается областей.
Для установления инвариантного соответствия найденных областей на
последовательных кадрах может быть применена следующая эффективная
процедура. По совокупности точек, попавших в каждую область, относи-
тельно ее центра строится ковариационная матрица, которая приводится к
диагональной форме (например, с помощью преобразования Якоби). Далее
по диагональным элементам вычисляются моменты, инвариантные относи-
тельно вращения. В результате получается набор признаков, инвариантный к
аффинным преобразованиям. Для снижения зависимости от размера изобра-
жения указанную процедуру можно применить с различными масштабами,
что приведет к увеличению набора характерных признаков. Окончательное
соответствие областей устанавливается на основе вычисления корреляции
найденных признаков.
http://www. itv.ru
Компания ITV - генеральный спонсор издания книги
146
Цифвая обработка видеоизображений
4.6. МЕТОДЫ СЛЕЖЕНИЯ, УЧИТЫВАЮЩИЕ СОВОКУПНОСТЬ
РАЗЛИЧНЫХ ПАРАМЕТРОВ
4.6.1. Использование информации переднего плана
Часто в системах, осуществляющих наблюдение, строятся модели фона и пе-
реднего плана, а движущиеся объекты характеризуются блобами - т. е. замкну-
тыми областями, внутри которых находится объект. В этом случае, как правило,
для всех объектов доступна следующая информация: размер, центр масс, мини-
мально возможный ограничивающий объект прямоугольник (МВП) и цветовая
гистограмма. Для установления соответствия между неким объектом
Ft (z — l) — Ft (x, y,Z — 1) из предыдущего кадра 1(х, у, Г—1) и объектом Fy (z) текуще-
го кадра 7(х, у, г) обычно предполагается, что смещение объектов между двумя
последовательными кадрами мало. Тогда критерием близости объектов является
выполнение следующего неравенства.
(8i)
где d(a, b) представляет собой евклидово расстояние между точками а и Ь, а С^1 и
Ст - центры масс объектов F, (J— 1) и F, (Z) соответственно. Так как выполнение
данного неравенства нс гарантирует корректного соответствия двух объектов,
можно проверить, насколько близки их размеры (кажется естественным, что
размеры объекта также не меняются сильно от одного кадра к другому):
Л (О А
(82)
ИЛИ
Л(')
(83)
Здесь 5Л - заранее заданное пороговое значение. Такая проверка особенно по-
лезна, если в предыдущем кадре объект распался на два блоба - большого и значи-
тельно меньшего размера — вследствие ошибочного выделения переднего плана.
Если ограничиться только двумя этими проверками, то получим, что объекту
F, (z— 1) из предыдущего кадра может соответствовать сразу несколько объектов
из текущего (например, Fy (z) и Fk (z)). Для разрешения этого противоречия нахо-
дится расстояние d4 между центрами масс F, (z—1) и Fi (z), а затем расстояние dlk
между центрами масс F( (z— 1) и Fk (t). Если dtJ < dlk, то считается, что объекту Ft
(z—1) соответствует объект Fy (z), в противном случае - Fk (t).
В целом при установлении соответствия между объектами последователь-
ных кадров могут встретиться пять различных случаев.
1. Один к одному. Установлено соответствие между объектом из предыдуще-
го кадра F, (z—1) и единственным объектом из текущего кадра Fy (z).
2. Один ко многим. Найдено соответствие объекта F, (z—1) сразу нескольким
объектам текущего кадра. В этом случае выбирается объект с минималь-
ным расстояниям до F, (z— 1) (см. выше).
3. Один к ни одному. Не найдено соответствия объекта F, (z—1) ни одному
объекту Fi (t). Это случай исчезновения объекта из видеопоследовательно-
ProSystem CCTV - журнал по системам видеонаблюдения
hi tp://www.procctv. ru
Глава 4. Алгоритмы слежения за объектами
147
сти или перекрытия одного объекта другим. В последнем случае объект со-
храняется до разъединения объектов. В противном случае он уничтожает-
ся из дальнейшего рассмотрения.
4. Ни один к одному. Не найдено соответствия новому объекту Ff (/) ни для
одного объекта (г— 1). Это случай появления нового объекта в видеопос-
ледовательности или разъединения ранее перекрытых нескольких объек-
тов. В последнем случае находится соответствие объекту, которое он имел
до перекрытия (см. ниже). Если же в кадре появился новый объект, то он
включается в список существующих объектов.
5. Многие к одному. Найдено соответствие объекта Ft (г) сразу нескольким
объектам предыдущего кадра. Как и в случае 2, выбирается объект с мини-
мальным расстояниям до F (г).
Для обнаружения перекрытия нескольких объектов используется следую-
щая несложная схема. Когда объекту Fr (г— 1) не найдено ни одного соответствия
в текущем кадре (случай 2). проверяется существование объекта (г), чей МВП
пересекается с МВП объекта F, (/—1) и для которого найдено соответствие
Fn (г— 1). В этом случае велика вероятность того, что произошло наложение
объектов Ff (/—1) и Fn (/—1). в результате чего образовался новый объект Ff (г)
(Рис. 27). Тогда объект Ft (j— I) не удаляется из дальнейшего рассмотрения, но
помечается как участвующий в перекрытии объектов. Создается группа из
объектов, участвующих в перекрытии, и ей присваивается уникальный иден-
тификационный номер. Если один из участвующих в наложении объектов уже
принадлежит к какой-либо группе, то такие группы соединяются в одну. Также
сохраняются цветовые гистограммы объектов до перекрытия, чтобы в дальней-
шем иметь возможность идентифицировать их после разъединения.
Рис. 27. Наложение объектов F, (Z—1) и Fn (г— 1)
Процедура определения разъединения объектов аналогична вышеописан-
ной. Когда в кадре появляется новый объект Ft (г) (случай 4), проверяется, имел
ли он ранее соответствующий ему объект Fn (t— 1), чей МВП пересекается с
МВП объекта Ft (г). При этом объект Fn (/— 1) принадлежит к одной из групп пе-
рекрытия и имеет соответствие другому новому объекту Fm (t). В этом случае
фиксируется разъединение перекрытых ранее объектов. Из предыдущих объек-
тов выбираются те, которые принадлежали той же группе перекрытия, что и Fn
(г—1). Предположим, что найден объект ГДг— 1), принадлежащий к той же груп-
пе перекрытия, что и Fn (t— 1). Это означает, что эти два объекта в предыдущем
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
148
Цифвая обработка видеоизображений
кадре были перекрыты один другим. Таким образом, нам нужно установить соот-
ветствие между [F„ (t— 1), F, (t— 1)} и (F (г), Fm (г)}.
Для этого используются цветовые гистограммы старых и новых объектов
(установить соответствие на основании их положения в данной ситуации не пред-
ставляется возможным). Расстояние djh между двумя нормированными цветовы-
ми гистограммами ha и hb размерности .V определяется как
(84)
1-1
Объекты, для которых это расстояние минимально, считаются соответству-
ющими друг другу.
Для построения системы слежения за объектами может быть с успехом
использован другой сравнительно небольшой набор параметров, характери-
зующий каждый блоб. Будем для определенности называть силуэтами все
выделенные в новом кадре блобы, если для них не установлены соответ-
ствия с имеющимися на предыдущих кадрах объектами. Каждый силуэт бу-
дем описывать следующим набором характерных признаков (Д, Н, Л), где
А - размер, IV - ширина. Н - высота, a h - гистограмма силуэта F, с заданной
размерностью к [26]. Расстояние между векторами характерных признаков
объектов F, и F, определим как
Пб 2
V *=i
(85)
Вся процедура трекинга разбивается на восемь шагов. В начальный момент
не существует объектов для установления соответствия с выделенными силуэта-
ми. Поэтому сразу выполняется п.8, где достаточно большие блобы, не имеющие
соответствия, добавляются в список объектов. В моменты времени, отличные от
начального, алгоритм сопоставляет силуэты с существующими объектами, при
этом предпочтение отдается объектам, существующим более длительное время.
1. Определяется расстояние между центрами масс всех объектов q и всех вы-
деленных силуэтов s. образуя при этом матрицу V размером (и, ш), где п -
количество имеющихся объектов, а т - число силуэтов. При этом сравни-
ваются только объекты, лежащие друг от друга не далее, чем на заданное
количество г пикселей. Таким образом, Vy = 1. если расстояние между цен-
трами масс объектов не превышает г. Каждому ненулевому элементу ма-
трицы V ставится в соответствие скалярная величина
<86)
где dk(Fj (/—1), F, (г)) - к-я компонента вектора (85).a/*(F7 (/—1)) - вектор
характерных признаков объекта F; (t — 1). Компоненты вектораД(^ (г— 1)),
относящиеся к гистограмме Fj(t— 1),трансформированы в скалярную ве-
личину при помощи вычисления евклидовой длины вектора.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 4. Алгоритмы слежения за объектами
149
Матрица соответствия объектов и силуэтов М инициализируется путем
соотнесения силуэтов и объектов, при этом один силуэт может соответ-
ствовать сразу нескольким объектам: Л/ч.= У^.где
v = arg min [с (Fj (г— 1).F, (Z))]. (1 </ < п, 1 < z < т). Здесь ненулевые значе-
ния означают установление соответствия между Ff (z— 1) и F, (z).
2. После первого этапа один и тот же силуэт может соответствовать несколь-
ким объектам. Поэтому все объекты делятся на два класса: временные и
постоянные. Для первых из них только в первый раз было найдено соот-
ветствие в предыдущем кадре. Объект становится постоянным, если ему
было найдено соответствие на протяжении не менее двух последователь-
ных кадров. Если силуэт соответствует постоянному и временному объ-
ектам, то выбирается постоянный.
3. Если силуэт соответствует двум постоянным объектам F) (z— 1) и F)y (t— 1),
то возможной причиной этого может быть перекрытие силуэтов. Чтобы
удостовериться в этом, такие объекты объединяются в один макрообъект
0 с одним вектором характерных признаков. Если величина коэффициента
(86) для макрообъекта и силуэта меньше, чем значения этого коэффици-
ента для объектов в отдельности и силуэта, то считается, что имеет место
перекрытие силуэтов. При вычислении коэффициента для макрообъекта и
силуэта используется следующая формула:
(,ад) Wj'-i))’ (87)
где j0 = argrnin[c(FA (/-!),/:;(/))]
Таким образом, если c(0,F,(z))< c(F/f (z—1), F, (z)) и c(0,Ff (z))< c(FJ2 (t— 1), F,
(z)), то имеет место перекрытие, которое разрешается в п.5. В противном
случае устанавливается соответствие с объектом FJf) (Z—1). Соответствие
с оставшимися объектами устанавливается по степени убывания величи-
ны коэффициента (87) между ними и силуэтами. При этом могут возникать
новые конфликты между соответствием постоянных объектов и силуэтов,
поэтому п.2 и п.З повторяются до разрешения таких конфликтов или до тех
пор, пока не будет установлено, что произошло перекрытие силуэтов.
4. Итеративное повторение п.2 и п.З может привести к тому, что постоянные
объекты станут соответствовать силуэтам, уже имеющим соответствие с
временными объектами. В этом случае такие соответствия с временными
объектами уничтожаются, а каждый силуэт, соответствующий постоян-
ному объекту, помечают как имеющий «надежное соответствие».
5. На данном этапе решается проблема с перекрытыми силуэтами. Для это-
го методом наименьших квадратов строится прямая /у линейной регрессии
у = а + Ъх для пикселей (х, у) силуэта:
http://www.itv. ги
Компания ITV - генеральный спонсор издания книги
150
Цифвая обработка видеоизображений
OJ&)E£H5>)E*) (88)
t_wS^-E»)E>) (89)
лЕУЧЕ*)'
Каждый пиксель проецируется на регрессионную прямую, при этом по-
лучается гистограмма распределения массы силуэта вдоль этой прямой.
Силуэт делится на несколько частей вдоль прямой /у в точках, которые
вычисляются в зависимости от размеров при f—1 объектов, участвую-
щих в перекрытии. Для п объектов будет и —1 прямая, перпендикуляр-
ная /у и делящая силуэт на основе распределения массы среди п объек-
тов. Если считать, что протяженность силуэта вдоль оси х заключена
на интервале (0, 1). то координаты разделения находятся при помощи
следующих отношений:
т
= (1<«<л-1). (90)
Ел
*-!
При этом считается, что перекрытия объектов не слишком велики. Для
каждой части силуэта определяется вектор характерных признаков, а затем
разность между такими векторами для объектов, участвующих в перекры-
тии. и разбиениями силуэта. После этого может быть найден коэффициент,
аналогичный (86):
Здесь FAV (/—1) представляет собой объект, чей вектор характерных при-
знаков получен путем усреднения векторов объектов, участвующих в пере-
крытии. Для каждого частичного силуэта устанавливается соответствие с
объектами из перекрытия. После этой операции матрица М обновляется с
учетом новых соответствий.
6. На данном этапе решается проблема фрагментации объектов, которые мо-
гут быть представлены как несколько отдельных силуэтов. Силуэты, соот-
ветствующие постоянным объектам, объединяются с силуэтами, не имею-
щими «надежного соответствия» (см. п.4), в пределах радиуса г. Объединяя
несколько силуэтов в один Т. можно получить силуэт. лучше соответству-
ющий объекту. Для определения этого находится коэффициент
с(Г (/ -1), Ф (г)) = (92)
ProSystem CCTV - журнал по с/.стемам видеонабг.юден/я
h!tp://vvww.procct v. ru
Глава 4. Алгоритмы слежения за объектами
151
Если с (Ft(t— 1 ),Чф)) < с (F,(t— 1), F,(z)). т. с. объединенный силуэт Ч7 лучше
соответствует объекту Ft(t~ 1), чем каждая составляющая F,(z). то прини-
мается окончательное решение об объединении силуэтов в один.
7. Временные объекты могут быть проявлением шума в сигнале или же яв-
ляться новыми объектами в действительности. Для всех временных объ-
ектов вычисляется коэффициент как в п.6 и рассматривается их соответ-
ствие всем свободным силуэтам.
8. На заключительном этапе, используя матрицу Л/, происходит обновле-
ние списка имеющихся объектов. Объекты, не имеющие соответствия,
удаляются из списка, а каждый силуэт размером больше наперед задан-
ной величины и, кроме того, не имеющий соответствия, считается но-
вым объектом.
Качество слежения за объектами может быть повышено за счет увеличения
числа признаков, которыми описывается каждый объект. В качестве таких при-
знаков можно использовать следующие характеристики:
• размер объекта X,(z).
• периметр p,(t\
• максимальная протяженность по горизонтали IV, (г) и по вертикали Н,(0 ,
• их отношение e,(t) = (если
или e,(r) = И, (z) (если Н, (z) < W, (z)).
• МВП объекта,
• компактность контура с, (г) = A, (z) /(Н, (г) W, (г)),
• иррегулярность контура г, (z) = р; (z) /(4я А, (О)»
• смещение A, (z) = (Au, Ан),
• направление движения и, (z) = (цх, цу),
• положение центра масс СШ| (z).
Кроме того, для установления более надежного соответствия между объек-
тами можно использовать нелинейную схему, состоящую из двух этапов - пред-
сказание и коррекция [27]. На первом этапе находится соответствие между ха-
рактерными признаками двух объектов, а на втором - выбираются два объекта
в случае имеющегося неоднозначного соответствия объектов. Для вычисления
меры схожести 5 и различия q между двумя объектами F, (z) и Ft (z—1) исполь-
зуется z = s + q сравнений. Соответствие Mh : Ft (z—1) —> Ft (z) между Ft (z—1)
и F, (z) считается установленным, если эти объекты пространственно близки,
смещение F, (z) мало и оба объекта в достаточной мере схожи (дЛ > 8г):
: К < Wfo ><)П(|ДИ(/)|< Дпаж)П(|Д)> (/)|< Д^). (93)
где dti - расстояние между центрами масс объектов, 8Г - радиус поиска:
бг = -4-тах(^(/-!),Я,(г-1)), 150<19<500, (94)
R
R - число кадров в секунду, A, (z) = (Aa (г), An (z)) - смещение F/ (t— 1) по сравне-
нию с F, (Z), Атах - максимально возможное смещение.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
152
Цифзая обработка видеоизображений
s/z, S = q
(q-s)/z, {s<q}r\{s!q<L}.
|s — q.jz, иначе
(95)
0 < 3Z < 1 - пороговое значение, уменьшающееся при наложении объектов.
Меры 5 и q вычисляются сразу по нескольким категориям характерных призна-
ков. Так. для размера объекта они определяются следующим образом:
s++: (Рль > 3,)
s++: (Pw„ > Д)
*++: (РиЛ > 5,) (96)
?++: (Pnh < 5J
Я++- (Pwh < 3,)
Здесь $++ и означает увеличение на единицу значений 5 и q соответствен-
но,0 <3V <1 - пороговое значение.
р< = (97а)
Рч. = (976)
Рн<. - Я,(г-1)<ЯДг) (97в)
Аналогично вычисляются значения 5 и q для контура объекта:
s++: «(1 < 5„)
*++:«/, < 0-53р)
х++: < 25р)
q++: (dtu > 5„)
9++: (dt/l > 0.53,)
<7++= « > 23р)
(98)
где 0 < 8р <1 - пороговое значение для контура, е, (t—1), ct(t — 1), г, (t — 1) - отноше-
ние протяженности, компактность и иррегулярность контура объекта F, (t — 1),
<4=|е,(/-1)-е,(/-1)|, (99а)
<= Iе/('"О0|» (996)
d. (99в)
Формулы для вычисления значений s и q для движения объекта выглядят сле-
дующим образом:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 4. Алгоритмы слежения за объектами
153
5++: (д„ (0 > О Р д,(> > о) и (Д„ (О С о Р Д1(, < 0)J
(Д,у (t) > О п Д,„ > 0) и (Д„ (/) < о Р д,6 со),
q++: (д„ (г) > О П Д,„ < 0) U (Д„ (г) < О Р ДЛ > 0)и
(Л,, (Г) > О Р ДЛ < 0) d (д„ (г) < О О ДЛ > 0)
(100)
где (Д„ (О-Д<> (0) - текущее горизонтальное и вертикальное смещение F, (/) ,а
(ДЛ (г), Д,,Л. (г)) - горизонтальное и вертикальное смещение F, (г) относительно
Как следует из выражений (93) и (95). соответствие может быть установлено
даже в случае s<q (в зависимости от величины 8,). Это важно в тех случаях, ког-
да характерные признаки соответствующих друг другу объектов могут довольно
существенно различаться вследствие некорректной сегментации объектов (на-
пример. после разъединения перекрытых объектов).
В случае установления неоднозначного соответствия между объектами, на-
пример:
Л(0 и ЗД}или
(,-!)_» Г,(0 и Чш. Лл(г-1)^ F, (/)}.
применяется следующий критерий:
• sh > sij
(Ю1)
где sh и stJ - меры схожести между объектами F, (t— 1) и F, (г), а также Ft (t—1) и
Fj (г) соответственно. Для их определения, как и при вычислении s и q, последова-
тельно используются выражения по нескольким категориям. Для расстояния они
выглядят следующим образом:
st, ++: (ddi/ > 3rf) A (dh < dti)
Sij ++• (ddi/ > 8d) A (4 > dtj)'
(Ю2)
где dh - расстояние между центрами масс F, (t— 1) и Ft (t). dh - расстояние между
центрами масс Ft (t— 1) и F; (r), ddij =\dlt- dh | и 8d - пороговое значение. Условие
dd.{ > 8d позволяет сравнивать характерные признаки объектов только в том слу-
чае, когда они различаются в достаточной мере.
Для размера объекта выражения выглядят следующим образом:
St. ++ (daij> 8S) П (pali < P'J
Sn++- (dhil>8,) П (phli<phl)
Sh ++: (dWjj > <5J Л
St, ++: (dail > 5,) П (pah > paii)
su ++: (d4 > 5<) n (Р>ч, > Pht)
stl ++: (dw. > 8S) Л > pwl/),
где (см. (97)) daii = | pah - pal. |, dhii = | p,.b - phli |, duij = | pK„ - pwll |, 0 <8P <1 - пороговое
значение для размера объекта.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
154
Цифвая обработка видеоизображений
Выражения для степени правдоподобия М:
«« + + :(<> 4) л(?А
«♦++••(< (104)
где = | Q, - gf |, 0 < 3; < 1 - пороговое значение.
Выражения для контура объекта:
+-н(<7 >^)л(ла <Р. )'
$„+ + :(< ><5р)п(р< <pj,
** + + •(< <Рг )•
+ + :(</,, >6,)л(р, >Р' ), (105)
^+ + :К>^)П(Л;>А.).
5»++:К>Мп(л„>а).
где (см. (98)) dri/ = | dr„- del] |. d((/ = | d(ll- dcll |. d,tj = | d,h- drl. |. 0 <8P <1 - пороговое
значение для контура объекта.
Так как движение объекта представляет собой один из важнейших характер-
ных признаков, то в выражениях для смещения объекта меры sh и sh могут быть
увеличены сразу на несколько единиц:
+1 :(</д > < Д№/7)л(|Д„|<|Д/у|),
5/( + 2: « > ) Л (Д/7 < < < Дт„) П (|Д„ | < | ДJ),
+3:(</д >6д)л(</д > Двих)л(|Дй|<|Д,|),
+1:(^ >5Д)Л(^ <Д№/7)П(|ДЛ|>|Д,У|), (106)
+ 2 •• ) Л (Д™ /7 < < Д№) Л (|Дл | > |Д» |).
^+3:(^>^)л(</д>ДЮ1я)л(|Д#|>|Дв|),
где Д/4 = (Д/п- Д//у) - смещение F, (f— 1) относительно F, (г),
Д// = (А//г“ А/,у) ” смещение Ft (г — 1) относительно F (г),
^=|11Д'-Н-11М1|- 0 < Зд < 3 - пороговое значение для смещения (увеличива-
ется во время перекрытия объектов), Дтах - максимально возможное смещение
объекта (см. выше), 0 < у < 5 - параметр для адаптации к ошибкам сегментации
(уменьшается во время перекрытия объектов).
Когда после проведения сравнения по всем категориям оказывается, что sb = 5Z/,
проводится следующее сравнение:
^ + + :(А/, <д//)л(уиМ=1’ь(г))л(цДг) = у(1(/)), (107)
: (ДА > А/Jл(уа (г) = vk (/))Л(ия. (г) = vb (/)),
ProSystem CCTV - журнал по системам видеонаблюдения
http://www. procctv. г и
Глава 4 Алгоритмы слежения за объектами
155
где ц (г) = (цх (z). цч. (г)) - текущее направление движения объекта F, (г). Если
и это сравнение не позволяет выявить соответствие объектов, то выбирается
объект, имеющий более длинную траекторию (т. е. присутствующий в большем
числе кадров).
В случае перекрытия объектов, т. е. когда МВП объектов пересекаются,
по крайней мере, одна из сторон МВП претерпит довольно существенное сме-
щение по сравнению с другими сторонами. Пусть объект Л, (z) представляет со-
бой перекрытие одним из двух объектов Fk(t— 1) и Ft(t— 1) другого, и при этом
Mkl:Fk(t— 1) —>F,(z). Обозначим: dkl расстояние между центрами масс Fk(t— 1) и
Fi (i— 1); A* (z— 1) = (Ajt, (z— 1). AH(z— 1)) текущее смещение Fk (z— 1) (т. e. между
кадрами (z—2) и (z—1)): Av/ - вертикальное смещение нижней границы МВП
Fk(t— 1): А114- вертикальное смещение верхней границы МВП F\(t—1):Ahr- го-
ризонтальное смещение правой стороны МВП Fk(t— 1): Ам - горизонтальное
смещение левой стороны МВП Fk(j— 1): и 6j - пороговые значения для смеще-
ния и расстояния (обратно пропорциональны частоте кадров R). Тогда фикси-
руется перекрытие объектов в том случае (Рис. 28).если: 1) текущее смещение
и смещение какой-либо одной из сторон объекта FJz—1) значительно отлича-
ются друг от друга: 2) благодаря смещению протяженность объекта в одном из
направлений увеличивается: 3) существует объект Fz(z—1). близкий к Fk(t—1) (в
смысле расстояния):
Рис. 28. Перекрытие и разбиение объектов. А - при наложении изображений
автомобиля и пешехода МВП увеличивается в вертикальном направлении на
величину А. Б - при разделении изображения на две части (например, когда
между ним и камерой находится столб), МВП уменьшается в горизонтальном
направлении.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
156
Цифвая обработка видеоизображений
[(|дь - дА,| > бд)п(д„ > о)п(</„ < <,)|и
[(k\u ~Д*/|><6j)jb (108)
[(|дъ -д4|>дд)п(д„ >o)n(du <л))и
|(|дн-дш|>бд)п(дте<о)п(4 <<,)]
В случае перекрытия объектов все они помечаются для отслеживания их в по-
следующих кадрах (даже в том случае, когда условия (108) перестают выполняться).
Это необходимо, так как впоследствии эти объекты могут появиться вновь (после
разъединения). При этом они должны быть пространственно близки друг к другу.
Объект, получившийся в результате перекрытия F, (г), разбивается на два или
более объектов в зависимости от того, сколько объектов участвует в перекры-
тии. Разбиение производится при помощи предсказания положения объектов из
кадра t— 1 в кадре /.Так как в рассматриваемом нами случае Mkl: Fk (г — 1) —> F:(f),
а объект Ft (/—1) не выделяется на этапе сегментации в кадре t (вследствие пере-
крытия), то смещения Fk (t— 1) и Ft (t—1) оцениваются следующим образом:
Д,(г-1) = (/(Д(1(/-1),Д,(г-2),Д,1(^3)),/(Д,1(/-1),Д/>(/-2)А(^3))). (Ю9)
ДА^-1) = (/(ДА,(г-1),Дь(/-2),Дь(г-3)),/(ДД/-1),Дъ,(/-2),Дъ,(/-3))),
где f - функция, которая может быть задана различными способами (например,
как среднее или медианное значение), Ah (t— 1), Ah (/—2), A/t (г—3)- горизонталь-
ные смещения объекта F, (t— 1); Ад (t— 1), A/v (/—2), АЛ (г—3) - вертикальные сме-
щения Г/ (г—1); (Аь (/—1)» А^ (г—2), Аь (г—3)) - соответственно горизонталь-
ные смещения Fk (г—1); Ак> (г— 1), Дъ (г—2), Лку (г—3) - вертикальные смещения
Fk (t— 1). После этого список объектов и их характерные признаки для кадров t и
/— 1 обновляются, например, в нашем случае добавляется объект F, (t— 1) в кадр t.
Если в список добавляются новые объекты,то процедура сравнения характерных
признаков объектов и мониторинг движения объекта повторяются вновь.
Процедура разъединения объектов в некотором смысле является обратной
к процедуре перекрытия. Однако возможно также и некорректное разбиение
одного объекта (не участвующего в перекрытии) на несколько объектов в ре-
зультате неправильной сегментации. Пусть Fk (г—1) ошибочно разбит на Fq (г)
и F,2 (г), a Mkll : Fk (г—1) -> Fq (г). Обозначим через dl[2 расстояние между цен-
трами масс Fq (г) и Fl2 (г). Разбиение объектов фиксируется в том случае, если:
1) текущее смещение и смещение какой-либо одной из сторон объекта Fk (t— 1)
значительно отличаются друг от друга; 2) благодаря смещению протяженность
объекта в одном из направлений уменьшается; 3) существует объект Fq (/ — 1) ,
пространственно близкий к F,2 (/—1):
[(|ДЬ - Д*,| > 5д)п(Да, < о)п(^ < <5rf)]u
|(1^ъ “ | > ) I"1 (> 0) О < bd )| U
[(|Д^-ДЛ>6д)п(Д,<0)п(^ <^)|и • (110)
|(|ДАи-Д11,|>6д)п(Д1„>0)п(<и<6а)|
ProSystem CCTV - журнал по системам видеонаблюдения
http//www.procctv.ru
Глава 4. Алгоритмы слежения за объектами
157
В таком случае ошибочного разбиения объекта две области Fq (г) и F,2 (г)
сливаются в одну F, (г). Слияние желательно, так как оно уменьшает число об-
рабатываемых объектов и. следовательно, ускоряет процесс трекинга. Процеду-
ра слияния объектов Fq (t) и Fn (t) в F, (г) производится тогда, когда выполняют-
ся следующие условия:
1. Mkl: Fk(t—V) —» F,(z).t. е. установлено соответствие Fk(t— 1) и F,(r);
2. Fq(r) пространственно близок к F,.(z), который в свою очередь близок к
3. размер получаемого в результате слияния объекта F, (z) близок к размеру
ЛО-i);
4. направление движения объекта Fk(t— 1) близко к направлению движения
5. если ошибочное разбиение объекта произошло на одной из сторон МВП,
то смещение остальных трех сторон МВП Fk(t— 1) не должно быть значи-
тельным при слиянии объектов.
Большинство используемых выше пороговых значений адаптируются к
таким параметрам видеопотока, как частота смены кадра R, размер кадра F5,
а также размер объекта А. Пространственные пороги выбираются в соответ-
ствии со значениями FS и А: если объекты большие, то можно допустить мень-
шую точность по сравнению с объектами меньшего размера. Поэтому пороги,
например, для выражения (98) выбираются исходя из условий:
(111)
гДе 5min и 5max устанавливаются эмпирическим путем,
Am3* = aFS, 4min=/3FS, Д * 0.0001а, 0.1< а < 0.25
Для выражений (96) пороговые значения устанавливаются следующим об-
разом:
<$2 = (Зт1П + 5max) —
Временные пороги ((93), (102), (106) и (108)) определяются исходя из часто-
ты смены кадров:
6, л.
3 R
где $ - то же самое, что и в (94).
Уточнение соответствия объектов может также проводиться с помощью так
называемого алгоритма обратного распространения [28, 29]. Предполагается,
что размер объектов не меняется значительно от кадра к кадру. В качестве меры
пространственной близости объектов используется евклидово расстояние между
http://www. itv. г и
Компания ITV - генеральный спонсор издания книги
158
Цифвая обработка видеоизображений
Рис. 29. Схема алгоритма обратного распространения
их центрами масс. МВП объекта (MBR) задается с помощью координат левого
верхнего S’ и правого нижнего угла Г, как это показано на Рис. 29:
MBR = (S,T), S = (SltS2), T = (Tt,T2), S,<T„ » = 1,2. (112)
Расстояние между точкой Р = (Рь и МВП объекта определяется следую-
щим образом:
(113)
/-1
где
^<5,
Pt>T, .
иначе
(И4)
Исходя из такого определения, если точка находится внутри прямоугольника,
то расстояние между ними равно 0. Если же точка лежит вне прямоугольника, то
расстояние считается как квадрат евклидова расстояния между точкой и ближай-
шим краем прямоугольника.
Пусть теперь 1) и MBRk(t — 1) - центр масс и МВП объекта Fk(t— 1), а
Ст. (г) и MBRt (/) соответствующие значения для F, (/). Сначала находятся все со-
ответствия между объектами из кадра t— 1 и текущего кадра ( при помощи одно-
временного выполнения следующих условий:
ProSystem CCTV - журнал по системам видеонаблюдения
http://ww w. procctv.ru
Глава 4. Алгоритмы слежения за объектами
159
(Ц5)
|4-4|<«г
Здесь А - площадь МВП объекта. 5| и & - пороговые значения.
На следующем шаге определяются все объекты из кадра t— 1, которым не
найдено соответствия в кадре t. Для каждого такого объекта Fk(t— 1) находят-
ся объекты из текущего кадра F, (г). чьи МВП пересекаются с МВП Fk(j— 1) и,
кроме того. 32min< Ак lAt < 32mdX. Последнее неравенство используется для устра-
нения шумовых областей. Если таких объектов F, (т) несколько, то из них выби-
раются два с минимальными значениями: D(C„,c MBR^) и D(Cme MBR/2). Таким
образом, объект Fk(t— 1) считается родительским для объектов Fl{(t) и Ft2 (f).
На третьем шаге определяются соответствия для следующего кадра, а также
параметры для уточнения размеров МВП на последнем шаге. Если для найден-
ных на предыдущем шаге объектов F/((r) и Fh(t) находятся соответствия в кадре
г+1, то определяются следующие величины:
1и;(/+1)-ад|
ад • <116)
И'+0-".('Л
/70 = -----7-Г----.
Здесь принято, что объекту Fz(z) соответствует объект F, (z+1), W - ширина,
а Н - высота соответствующих объектов. Если WS > HS, то считается, что объ-
ект F/(r) более чувствителен к изменениям ширины,т.е. последние встречаются
чаще, чем изменения высоты, и могут быть более значительными. Если W5< HS,
то считается, что объект Ft(f) более чувствителен к изменениям высоты. Ког-
да мы не можем найти соответствие объекту /*}(/) в кадре (/+1) вследствие на-
ложения объектов или их исчезновения, то указанные выше величины опре-
деляются как
»'S = -44. (117)
«.(')
На последнем шаге производится обновление объектов предыдущих
кадров и уточнение их размеров. После того как установлено, что объекту
Fk (j— 1) соответствуют Fl}(t) и F/2(f), эту информацию можно использовать,
чтобы обновить объекты в кадре Г—1, в частности выделить два отдельных
МВП на общем МВП объекта Fk(t— 1). Для этого необходимо установить со-
ответствие между их вершинами и вершинами МВП Fk(t— 1). Например, для
Fl}(t) это делается путем вычисления минимального значения D(P, MBR;1),где
Р - одна из вершин Fk(t— 1). Теперь соответствующая ей вершина fZl(r) на-
кладывается на нее таким образом, чтобы МВП целиком лежал в МВП
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
160
Цифвая обработка видеоизображений
Fk(t— 1). Аналогичная процедура применяется и к F/?(r). Однако часто этого сде-
лать нельзя, и тогда используется информация, полученная на третьем шаге. На-
пример, если известно, что F/,(f) более чувствителен к изменениям ширины, то
путем увеличения ширины МВП можно достичь более точных результатов.
4.6.2. Трекинг, основанный на алгоритме смещения среднего
Вследствие того, что трекинг объектов должен проводиться в реальном
времени, необходимо использовать алгоритмы, не слишком требовательные
к вычислительным ресурсам. Этими качествами обладает так называемый ал-
горитм «смещения среднего» (Mean Shift [30-33] в англоязычной литературе).
Этот алгоритм позволяет достаточно быстро находить максимумы функции
плотности распределения на динамических изображениях как для полутоно-
вых, так и для цветных. Цвета каждого кадра для слежения за цветными объ-
ектами на видеопоследовательности необходимо преобразовывать в распре-
деление вероятности. С этой целью используются гистограммы цветов. Рас-
пределение цвета, основанное на видеопоследовательности, меняется со вре-
менем. Алгоритм смещения среднего является адаптивным, поскольку он спо-
собен динамически подстраиваться под то распределение, которое отслежива-
ется. Суть этого алгоритма состоит в следующем.
Пусть некий объект F, (х, у, t) описывается множеством точек [xj, =,.„ в
d-мерном пространстве Rd.Тогда функция
dis,
1=l I п J ' '
называется оценкой плотности с ядром К(х) радиуса h в точке х. В качестве ядра
наиболее часто используется плотность нормального распределения
или же ядро Епанечникова
К(х) =
lc;'(<f+2)(i-|M!). М<1
о. М>1’
(119а)
(1196)
где cd - объем единичной d-мерной сферы.
Введем к: [0, <=») -^ /? - профиль ядра К(х) такой, что /С(х) = к (||х||2)- Для ядра
(119а) профиль выглядит следующим образом:
Л(х) = (2тг)“?/2ехр1-|х
Тогда функция (118) принимает вид
(120)
(121)
ProSystem CCTV - журнал по системам видеонаблюдения
http.y/www.procctv.n/
Глава 4. Алгоритмы слежения за объектами
161
Обозначим g(x) = - к'(х). предполагая при этом, что производная функции
к(х) существует для всех х е [0. оо), за исключением, быть может, конечного мно-
жества точек. Определим ядро G как
G(x) = Cg(||x|f), (122)
где С - константа нормировки. Тогда, вычисляя градиент от функции (121), получим:
(123)
где предполагается, что
^0.
(124)
Выражение (123) в качестве сомножителя содержит в себе вектор смещения
среднего для ядра G
(125)
и оценку плотности с ядром G
(126)
Используя (125) и (126), выражение (123) можно переписать следующим
образом:
VA(x)=7c(x)^A/a,c(x),
(127)
откуда
Мh,G (х)—
h2 УЛ(х)
2/С Л(х) ’
(128)
Из выражения (125) следует, что вектор смещения среднего является разни-
цей между локальным средним и центром окна. Из формулы (128) видно, что
смещение среднего представляет собой нормализованный градиент плотности.
http://ww w. itv. г и
Компания ITV - генеральный спонсор издания книги
162
Цифвая обработка видеоизображений
Теперь можно сформулировать задачу нахождения объекта в данном кадре с
помощью метода смещения среднего. Для этого сначала вручную создается мо-
дель объекта, обычно представляющая собой эллипс или прямоугольник, огра-
ничивающий интересующую область изображения - блоб (далее под блобом по-
нимается именно ограничивающая его область). После этого составляется цве-
товая гистограмма блоба. При помощи метода смещения среднего определяется
его местоположение в текущем кадре.
Пусть множество точек модели объекта с центром z имеет цветовые и/или
текстурные характеристики с плотностью распределения вероятности qt. Через
у и рх(у) обозначим соответствующие значения для рассматриваемого блоба,
являющегося одним из возможных кандидатов на положение объекта в данном
кадре. Задача заключается в нахождении такого расположения у, для которого
плотность распределения рг(у) наиболее близка к qt.
В качестве меры соответствия блоба-кандидата и модели объекта часто рас-
сматривается расстояние Бхатачарья [34]:
р(у) = р(р(у).?] = J Jp, W&di- (129)
Для оценки плотностей р и q строятся гистограммы. Обозначим через
/ т \
ч=Щ.«...... 2л.=1
\ М=1 /
гистограмму модели объекта с размерностью т, а через
P={AJ...i... LA-=1
k“=‘ /
гистограмму рассматриваемого блоба для данного расположения у. Тогда в каче-
стве оценки для коэффициента (129) примем следующее выражение:
р(у>р[р(у),ч]=1Ж(уЧ. (1зо)
И=1
Теперь расстояние между двумя распределениями можно определить как
£>(у) = 7,~/’[₽(у)’Ч]- (131)
Данная величина представляет собой метрику в пространстве Rd [31].
Пусть теперь (х,*)м „ - множество координат точек, составляющих модель
объекта, с началом координат в центре модели (z = 0). Определим функцию
b : R2 —> [1,..., т), которая каждому пикселю х*ставит в соответствие индекс ги-
стограммы b (х,*), соответствующий цвету этого пикселя. Вероятность появ-
ления цвета и определяется в соответствии с выпуклым и монотонно убываю-
щим ядром к, которое присваивает меньшие значения весовых коэффициентов
тем пикселям, которые находятся дальше от центра масс модели. Это сделано
для того, чтобы уменьшить влияние периферийных пикселей, значение кото-
рых определяется с меньшей надежностью вследствие перекрытий или близости
фона. Радиус профиля ядра выбирается равным единице,так как предполагается,
что координаты модели х и у нормированы на hx и Ку (представляющие собой по-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www procctv. ru
Глаза 4. Алгоритмы слежения за объектами
163
луоси эллипса или половины длин сторон прямоугольника) соответственно. По-
этому можно записать
(132)
где 3(х) - дельта-функция. Константа нормировки С выбирается из условия
। qu = 1 откуда следует что
1
(133)
Пусть теперь {х,)<=। - множество координат точек, составляющих модель
рассматриваемого блоба, с центром у. Используя тот же самый профиль ядра к,
но с радиусом Л, вероятность появления цвета и можно записать как
Лк !! If-1
А(у)=с*
(134)
где Ch - константа нормировки. Радиус h определяет количество пикселей блоба.
Из условия полУчим:
1
У-х
h
(135)
Данная константа не зависит от у, так как пиксели х, представляют собой узлы
решетки правильной формы, а у - один из таких узлов. Таким образом, Ch может
быть вычислена заранее для данного профиля ядра и различных значений h.
Наиболее вероятное положение центра блоба у в текущем кадре можно по-
лучить, если найти минимум расстояния (131) или же максимум коэффициента
р(у). В качестве начального приближения для положения блоба в текущем ка-
дре используется его положение у0 в предыдущем. Тогда, используя разложение
Тейлора в точке рм(у0), выражение (130) можно записать как:
р|р(у)>ч] «+ ~Ё Ри (у) .7775
Z u=l Z u=l \Ри(Уо)
(136)
где предполагается, что Д,(у0) > 0 для всех и = 1,..., т. Подставляя (134) в (136),
получим:
(137)
где
(138)
h “
.21
Следовательно, для минимизации расстояния (131) необходимо максими-
зировать второй член в уравнении (137) (первый член не зависит от у). Для
http://wwvv.itv.ru
Компания ITV - генеральный спонсор издания книги
164
Цифвая обработка видеоизображений
этого используется следующий алгоритм, составляющий основу метода сме-
щения среднего.
1. Начальное положение блоба в текущем кадре выбирается из предыдуще-
го кадра уо, вычисляется распределение {pw (у0)}и । т и расстояние
т___________
р[р(Уо).ч]=Е7л(Уо)?а-
«=1
2. Вычисляются веса (wjl=1.в соответствии с выражением (138).
3. Исходя из вектора смещения среднего, определяется новое положение блоба:
пересчитывается {ри (у: )}*_| „ и расстояние
m --------
p[p(y,),q|=EvA(y1)?u-
u—I
4. Пока не будет выполнено условие pjp(yj,qj < p[p(y0),q|, пересчитывают-
ся значения у по формуле
У| = 2(Уо + У1)-
5. Если ||у, — у0|| <£,то вычисления прекращаются. В противном случае пола-
гают уо = у( и переходят к п.1.
В дан- ном методе в п.З с помощью вектора среднего смещения необхо-
димо увеличивать коэффициент (137). Однако это происходит не всегда, поэто-
му в алгоритм добавлен пункт 4, обеспечивающий нужное изменение коэффи-
циента. Как показывают эксперименты, этот пункт приходится использовать
только в 0.1% случаев.
Одним из центральных моментов при использовании метода смещения
среднего является выбор размера блоба в новом кадре. Так как с течением
времени размеры объекта могут меняться (и весьма значительно), то, очевид-
но, что необходимо каким-то образом масштабировать блоб в текущем кадре.
Для этого можно ввести новое локальное (относительно рассматриваемого
блоба) трехмерное пространство, в котором новое измерение - это масштаб
блоба о . Характерные черты объектов в таком пространстве можно опреде-
лять путем нахождения локальных максимумов различных дифференциаль-
ных операторов [35,39]:
(VxL)(x0;o0) = 0,
(139)
(8<,£)(х0;а0) = 0.
где в качестве L может выступать
1.6
----гехР
2яо2
2ст2
I
2по21.6
ехр
2о2-1.6
(140)
ProSystem CCTV - журнал по системам видеонаблюдения
h ttp://ww w. procctv. ru
Глава 4. Алгоритмь слежения за объектами
165
Определим новое ядро Н (х; а) таким образом, что
кн (х) = -с*(х),
(141)
где с > 0 - константа, а к - профиль ядра (119). Введем набор масштабов ядра от-
носительно текущего масштаба блоба оп:
{°s=aoPS> -»<*<л}’ (142)
где р > 1. Для фиксированной точки х<» ядро Н выберем как
W(Xo;a) = H(j) = l-(j/«)2, (143)
а для каждого масштаба о, - как
Я(х;а) = Н(х0;а,) = £(Лод!1/Лг, 1 hy j(x-x0);q,j.
Введем обозначение
(144)
exp к Г y • ггА — h-M2 2ст- ! h-xoll2! exp - •' ^-1 -1 2ст; 1
Л. г 1 л.и / —
X \ ’ / 2ла^ 2nOj
(145)
где О| = о, /1.6, о2 = 1-6 о, •
Теперь метод смещения среднего выглядит следующим образом.
1. Начальное положение блоба в текущем кадре выбирается из предыдуще-
го кадра у0, вычисляется распределение (Д (у0)}„ , т и расстояние
р[р(Уо).ч]=Е\Щуо)?и-
U-I
2. Вычисляются веса |wjl=1 nh в соответствии с выражением (138).
3. Исходя из вектора смещения среднего, определяется новое положение бло-
ба для фиксированного значения а0:
Х=-Я 1=1 "
Пересчитывается {Д (у,)} ( и расстояние р[р(у, )>ч] = )?>•
11=1
4. Пока не будет выполнено условие р[р(у, ),q| < p'p(y0),ql,пересчитывают-
ся значения по формуле
У|=у(Уо+У|).
5. Если || у j - у у || < 6, то переходят к п.6. В противном случае полагают у0 = у и
переходят к п.1.
6. Для данного у находят новое значение s' по формуле
h t tp://ww w.it v. ru
Компания ITV - генеральный спонсор издания книги
166
Цифвая обработка видеоизображений
s' = .
S=-ft 1=1
7. 5 = s'. Если || 5 - s' Ц < ё , то переходят к п.8. В противном случае переходят к
пункту 6.
8. а0 = о0рг - изменяют размер блоба в соответствии с новым масштабом.
Рассмотренные выше реализации метода смещения среднего могут быть ис-
пользованы для видеопотоков с достаточно высокой частотой смены кадров,
так как в них предполагается, что за время, прошедшее между двумя последо-
вательными кадрами, блобы смещаются на малое расстояние (см. (136)). Для
случая, когда частота смены кадров составляет порядка 1-3 кадров в секунду,
схема метода смещения среднего должна быть модифицирована [36]. В каче-
стве модели (шаблона) объекта выступает матрица (WxH)xD, где W - ширина,
Н - высота шаблона, a D - число предшествующих кадров. Таким образом, все
время используется информация из нескольких последних кадров. Теперь вы-
ражение (132) будет выглядеть следующим образом:
п D ! -»\ г т
^=с££к М )6*(х«)~4 (146)
1=1 >1 х '
Второй индекс у х* появляется вследствие зависимости модели объекта от
предыдущих кадров. Вместо коэффициента (130) предложено использовать но-
вую меру сходства объектов:
n(y) = a/p|p(y),q]-aip[p(y),s(y)|. (147)
Здесь s(y) - гистограмма фона на месте расположения блоба. Коэффициен-
ты af и аь позволяют управлять мерой сходства гистограмм переднего плана и
фона. Так как пиксели, составляющие блоб в текущем кадре, должны быть от-
личны от фоновых, то ah следует выбирать меньшим, чем af. Для коэффициен-
тов рекомендуются значения af = 1 и аЛ= 0.5. Выражение (147) можно переписать
следующим образом:
11(у)=Ё>/Дй(а/7Е-о‘*>/Е(у))- (148)
и=1
Аналогично рассмотренному выше случаю, используя разложение Тейлора в
А(Уо)и^«(Уо)> получим:
т1(у)а!Е7А(Уо)(а/7Е-а6А(Уо))+ (149)
и=)
~ yl^u ( У 0 ) / - / х * / ‘'//Л/ ( Уо ) ( * /\ * / х\
+Е </: (у) - Ри (Уо)' Е х (у) -(Уо))-
ЧрМ 2^и(у0)
Обозначим постоянные члены в этом выражении через СР Тогда
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://w w w. procc t v. ru
Глава 4. Алгоритмы слежения за объектами
167
Используя определения р(у) и s(y), получим
(150)
•n(y)«ci+c2£w^
У-х/
А |Ц
(151)
(152)
где hf и bh- функции, которые каждому7 пикселю х< переднего плана и фона ставят
в соответствие индекс гистограммы, соответствующий цвету этого пикселя. После-
довательность действий в данной модификации метода среднего смещения такая же,
как и выше, но условие окончания итераций теперь выглядит следующим образом:
*(Уо)>^> d53)
(154)
(155)
Здесь Лг= 16, и, - трехмерный (R,G.B) вектор блоба, a vAy - аналогичный век-
тор для шаблона, зависящий от D предыдущих кадров. Выражение (155) пред-
ставляет собой вероятность того, что пиксель х, внутри МВП блоба с центром у
принадлежит самому блобу. Выражение (154) - это вероятность того, что центр
блоба находится в у. Lmax - это максимальное, полученное до данного момента
времени значение L для всех блобов в данном кадре.
Одним из способов решения проблемы перекрытия объектов является исполь-
зование цветовых гистограмм объекта [37]. Обозначим через Л,(и) (u =
гистограмму объекта z, а через А, - размер объекта до наложения. Тогда вероят-
ность того, что данный пиксель в группе перекрытия соответствует объекту z,
может быть записана как
(156)
р^:
Здесь суммирование ведется по всем объектам, участвующим в перекрытии.
Для каждого объекта и каждого пикселя (х,у) в группе перекрытия может быть
найдена вероятность P(jcy)(u | z) по формуле
Л,
Тогда по формуле Байеса вероятность того, что данный пиксель принадле-
жит объекту z, равна
http://\n\nw. itv. ru
Компания ITV - генеральный спонсор издания книги
168
Цифвая обработка видеоизображений
(157)
Большое значение этой величины указывает на то, что данный пиксель
с большой вероятностью принадлежит той части объекта z, которая не пере-
крыта ни одним другим объектом. ;Малое, отличное от нуля значение указы-
вает на то, что, хотя пиксель и может принадлежать объекту /, скорее всего,
это видимая часть другого, участвующего в перекрытии объекта. С помощью
формулы (157) можно определить, какая часть объекта I не загорожена дру-
гими объектами:
Е^,('|и)
v(i) = ^------. (158)
At
Когда объекты разъединяются, их цветовые модели используются, чтобы
определить состав новых групп. Для сравнения гистограмм объектов можно ис-
пользовать следующий метод [38]. Для гистограммы hc вновь образованной груп-
пы и гистограммы объекта z рассчитывается индекс их соответствия друг другу
по следующей формуле:
Е™ф4“б.,))Л (“('•>))]
/(G.i) = ----—-------.-----. (159)
EMuU
(*./)
Объекты распределяются по новым группам таким образом, чтобы максими-
зировать f (G,i).
4.6.3. Применение метода оптического потока
Для трекинга объектов могут быть весьма успешно использованы методы,
основанные на свойствах оптического потока. Обозначим через г = (х, у) коорди-
наты пикселя изображения. Если кадры видеопотока отстоят друг от друга во
времени на величину 8t, то каждый пиксель за это время сместится на z>(r)6t, где
= (ь>х(г),уу (г)) - скорость пикселя. Для ее нахождения определим область
изображения IV(r) Д(г), умножив интенсивность изображения /,(г) в момент вре-
мени I на оконную функцию W(r) размером (Wx , WJ с центром в точке г. Образу-
ем свертку этой области со следующим кадром //+1(г), получив при этом корреля-
ционную поверхность D(r; d) [40]:
DM
нон
(160)
Диапазон значений величины d е [d0; d}], представляющей собой линейное пре-
образование (dx,dy) рассматриваемой области из предыдущего кадра в последую-
щий, задается заранее. Константа нормировки ||W(r)|| выглядит следующим образом:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.proccfv.ru
Глава 4. Алгоритмы слежения за объектами
169
kwii= Е »'('-)•
(161)
Минимум выражения (160) определяется с точностью до пикселя при помо-
щи аппроксимации D(r; d) квадратичной зависимостью
<in =y(r)6r = min[z>(r;</)]. (162)
Установив соответствие между объектами F(r, г) и F(r; г+1) и определив их
относительную скорость, мы можем вычислить поток для любого переднепла-
нового пикселя. Основная идея заключается в том, чтобы выделить небольшую
область вокруг каждого пикселя в F(r, t) и установить соответствие с областью
в F(r; t+1). При этом необходимо, чтобы как в горизонтальном, так и в верти-
кальном направлениях вокруг центрального пикселя г содержалось достаточно
информации для установления корректного соответствия. Для этого область
вокруг г итерационно увеличивается и измеряется ее информационное содер-
жание в горизонтальном Ен и вертикальном Ev направлениях, которые вычис-
ляются следующим образом:
(163)
еу= £ М'ОМ')» (164)
где WE(г)- оконная функция с центром в точке г, a SH(r) и Sv(r) обозначают резуль-
таты свертки исходного изображения с фильтрами Собеля:
(165)
(166)
Алгоритм определения необходимых размеров окна начинается с установ-
ления первого приближения, в качестве которого выбирается размер 3x3. За-
тем определяются Ен и Ev. Если Ен меньше порогового значения 8Z, то ширина
окна увеличивается на 2 пикселя. Если Ev меньше порогового значения 8Z, то
высота окна увеличивается на 2 пикселя. Эта процедура повторяется до тех
пор, пока оба Ен и Ev не будут больше 8Z.
Движение отдельных пикселей можно рассматривать как сумму движения
всего блоба йд и движения пикселя относительно блоба vR. Следовательно,
^(г) = ^в+^(г)- (167)
При этом предполагается, что относительное движение пикселей внутри F,
невелико. В этом случае корреляционная поверхность D(r; d) может быть опре-
делена только для небольшого диапазона значений вокруг d = vBbt. Скорость
h tip://www. itv. ru
Компания ITV - генеральный спонсор издания книги
170
Цифвая обработка видеоизображений
v(r) определяется из выражений (160)-( 162). При этом фоновые текстуры могут
исказить истинное значение потока. Во избежание этого оконная функция W(r)
заменяется новой
ГГ/(г) = ^(г)(1 + Л/,(г)), (168)
которая отдает предпочтение переднеплановым пикселям. Здесь М, (г)=1 для
переднего плана и М, (г)= 0 для фона. Относительная скорость пикселей
-"в (169)
может быть использована для определения постоянства формы объекта. Есте-
ственно предположить, что объекты с постоянной формой (автомобили) будут
иметь малую относительную скорость, в то время как изменяющие при дви-
жении свою форму объекты (человек) - большую. Мерой постоянства формы
может служить величина среднего относительного потока, приходящегося на
один пиксель:
ЕХ(г)
(170)
где W - число пикселей блоба.
С помощью оптического потока возможен также трекинг объектов в слу-
чае их перекрытия. При этом для случая, когда несколько пикселей из F(r; /)
могут соответствовать единственному пикселю в F(r; f+1) или, наоборот, во-
обще не иметь соответствия в F(r; /+1), можно воспользоваться понятием меры
пиксельного согласования Рс, которое определяется как число пикселей F(r; г),
у которых либо потоковые векторы оканчиваются на одном общем пикселе из
F(r; z+1), либо для них не найдено хорошего соответствия в F(r; г+1)[40]. Таким
образом, согласованный пиксель гс - это такой пиксель, для которого справед-
ливо следующее:
3(г0,г,):
го+^М^ = гс
r,+u(rt)bt = rc
(171)
или
minD(rc;d)>5r, (172)
где 5С - пороговое значение. Следовательно, мера пиксельного согласования
определяется как
г=—, (173)
с N
где | гс | - количество пикселей, удовлетворяющее условиям (171) или (172). Если
выполняется условие (171), то выбирается тот вектор, который минимизирует
D(r,d):
r = nun[D(r0;rf),D(r,;rf)]. (174)
Если же выполняется условие (172), то потоковый вектор для данного пиксе-
ля просто отбрасывается.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 4. Алгоритмы слежения за объектами
171
Когда один из объектов Ft и Ft перекрывает другой, важно знать их взаим-
ное расположение, т. е. какой из объектов находится на переднем плане. Оче-
видно, что для него мера пиксельного согласования будет значительно мень-
ше. Однако введенная абсолютная мера может быть неудачным критерием,
когда объекты сильно различаются по величине (например, грузовой и легко-
вой автомобили). Для этого мера пиксельного согласования для каждого объ-
екта нормируется на средние значения, определяемые для каждого объекта
до перекрытия:
Ро = |. (175)
Теперь тот блоб, для которого величина (175) будет больше, считается рас-
положенным на заднем плане.
4.7. СПИСОК ЛИТЕРАТУРЫ
1. Н. Moravec. Obstacle Avoidance and Navigation in the Real World by a Seeing
Robot Rover. Technical Report CMU-RI-TR-3, Carnegie-Mellon University,
Robotics Institute, 170 p, 1980.
2. C. Harris, M. Stephens. A Combined Corner and Edge Detector. In: Proc. Alvey
Vision Conference, Manchester, p. 147-151,1988.
3. J. Shi, C. Tomasi. Good Features to Track. In: Proc. Conference on Computer Vision
and Pattern Recognition, Seattle, p. 593-600,1994.
4. L. Kitchen, A. Rosenfeld. Gray Level Corner Detection. In: Pattern Recognition
Letters, v. 1, p. 95-102,1982.
5. K. Mikolajczyk, C. Schmid. A Performance Evaluation of Local Descriptors.
In: Proc. IEEE Computer Society Conference on Computer Vision and Pattern
Recognition, Madison, p. 1305-1312,2003.
6. D. Lowe. Distinctive Image Features from Scale-invariant Keypoints. In:
International Journal of Computer Vision, v. 60, p. 91-110,2004.
7. Y. Ke, R. Sukthankar. PCA-SIFT: A More Distinctive Representation for Local
Image Descriptors. In: Proc. IEEE Computer Society Conference on Computer
Vision and Pattern Recognition, Washington, p. 506-513,2004.
8. I. K. Sethi, R. Jain. Finding Trajectories of Feature Points in a Monocular Image
Sequence. In: IEEE Transactions on Pattern Analysis and Machine Intelligence, v.
9, p.56-73,1987.
9. K. Rangarajan, M. Shah. Establishing Motion Correspondence. In: Computer
Vision, Graphics, and Image Processing, v. 54, p.56-73,1991.
10. C.J. Veenman, Marcel J.T. Reinders,E. Backer. Resolving Motion Correspondence
for Densely Moving Points. In: IEEE Transactions on Pattern Analysis and
Machine Intelligence, v. 23, p. 54-72,2001.
11. D. Chetverikov, J. Verestoy. Tracking Feature Points: A New Algorithm. In: Proc.
International Conference on Pattern Recognition, Queensland, p. 1436-1436,1998.
12. V Safari, I. K. Sethi. Feature Point Correspondence in the Presence of Occlusion.
IEEE Transactions on Pattern Analysis and Machine Intelligence, v. 12, p.87-91,1990.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
172
Цифвая обработка видеоизображений
13. К. Shafique. М. Shah. A Non-iterative Greedy Algorithm for Multi-frame Point
Correspondence. IEEE Transactions on Pattern Analysis and Machine Intelligence,
v. 27, p.51-65,2005.
14. S. Birchfield. An Elliptical Head Tracker. In: Proc. Asilomar Conference on Signals,
Systems and Computers, Pacific Grove, p. 1710-1714. 1997.
15. S. Birchfield. Elliptical Head Tracking Using Intensity Gradients and Color
Histograms. In: Proc. Conference on Computer Vision and Pattern Recognition,
Santa Barbara, p.232-237,1998.
16. M. Kass,A.Witkin,D.Terzopoulos. Snake: Active Contour Models. In: International
Journal of Computer Vision, p. 321-331.1988.
17. L. D. Cohen. On Active Contour Models and Balloons. In: Computer Vision
Graphics Image Processing: Image Understanding, v. 53, p. 211-218.1991.
18. J. F. Canny. A Computational Approach to Edge Detection. In: IEEE Transactions
on Pattern Analysis and Machine Intelligence, v. 8. p. 679-698,1986.
19. C. Xu, J. L. Prince. Snakes, Shapes, and Gradient Vector Flow. In: IEEE Transactions
on Image Processing, v. 7. p. 359-369.1998.
20. Костомаров Д. П., Лукьяница А. А.. Зайцев Ф. С. и др. Восстановление гра-
ницы тороидальной плазмы по видеоизображению И Вопросы атомной на-
уки и техники, сер. Математическое моделирование физических процессов.
-вып.4,2005.-С. 53-68.
21. Р Tissainayagam, D. Suter. Object Tracking in Image Sequences Using Point
Features. In: Pattern Recognition, v. 38, p. 105-113,2005.
22. D. H. Ballard. Generalizing through Transform to Detect Arbitrary Shapes. In:
Pattern Recognition, v. 13, p.l 11-122,1981.
23. Прэтт Y Цифровая обработка изображений, том 1. - М.: Мир, 1982. - 311 с.
24. J. Matas, О. Chum, М. Urban, Т. Pajdla. Robust Wide Baseline Stereo from
Maximally Stable Extremal Regions. In: Proc. British Machine Vision Conference,
Cardiff, p. 384-393,2002.
25. R. Sedgewick. Algorithms. Addison-Wesley, 1983,552 p.
26. J. Owens, A. Hunter, E. Fletcher. A Fast Model-free Morphology-based Object
Tracking Algorithm. In: Proc. British Machine Vision Conference, Cardiff, p. 767-
776.2002.
27. A. Amer. Voting-based Simultaneous Tracking of Multiple Video Objects. In: Proc.
SPIE International Symposium on Electronic Imaging, Santa Clara, p. 500-511,2003.
28. S.-C. Chen, M.-L. Shyu, C. Zhang, R. L. Kashyap. Object Tracking and Multimedia
Augmented Transition Network for Video Indexing and Modeling. In: Proc. IEEE
International Conference on Tools with Artificial Intelligence, Vancouver, p. 250-
257,2000.
29. C. Zhang, S.-C. Chen, M.-L. Shyu, S. Peeta. Adaptive Background Learning for
Vehicle Detection and Spatio-temporal Tracking. In: Proc. IEEE Pacific-Rim
Conference on Multimedia, Singapore, p. 1-5,2003.
30. D. Comaniciu, P. Meer. Mean Shift Analysis and Applications. In: Proc. IEEE
International Conference on Computer Vision, Kerkyra, p. 1197-1203,1999.
31. D. Comaniciu, V. Ramesh, P. Meer. Real-time Tracking of Non-rigid Objects Using
Mean Shift. In: IEEE Computer Vision and Pattern Recognition, v. 2, p. 142-149,
2000.
ProSystem CCTV - журнал по системам видеонаблюдения
ht tp://w ww. procctv. ru
Глава 4. Алгоритмы слежения за объектами
173
32. D. Comaniciu, Р Meer. Mean Shift: A Robust Approach toward Feature Space
Analysis. In: IEEE Transactions on Pattern Analysis and Machine Intelligence,
v.24,p. 603-619.2002.
33. D. Comaniciu. V. Ramesh. P. Meer. Kernel-based Object Tracking. In: IEEE
Transactions Pattern Analysis and Machine Intelligence, v. 25. p. 564-577, 2003.
34. T. Kailath. The Divergence and Bhattacharyya Distance Measures in Signal
Selection. In: IEEE Transactions on Communication Technology, COM-15, p. 52-
60,1967.
35. R. T. Collins. Mean Shift Blob Tracking through Scale Space. In: Proc. IEEE
Computer Society Conference onComputerVisionand Pattern Recognition,Madison,
p. 234-240.2003.
36. EPorikli.O.Tuzel. Object Tracking in Low-frame Video.Technical Report TR2005-
013, Mitsubishi Electric Research Laboratories, 2005.
37. S. J. McKenna, S. Jabri, Z. Duric et al. Tracking Groups of People. In: Computer
Vision and Image Understanding, v. 80. p. 42-56.2000.
38. M. J. Swain and D. H. Ballard. Colour Indexing. In: International Journal of
Computer Vision, v. 7, p. 11-32. 1991.
39. T. Lindeberg. Feature Detection with Automatic Scale Selection. In: International
Journal of Computer Vision, v. 30. p. 79-116. 1998.
40. A. J. Lipton. Local Application of Optic Flow to Analyse Rigid Versus Non-rigid
Motion.Technical report CMU-RI-TR-99-13. Robotics Institute. Carnegie Mellon
University, 1999.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
Рис. 5.25. Разделение двух классов методом опорных векторов: А - линейное раз-
деление, Б - нелинейное разделение. Интенсивность цвета указывает на расстоя-
ние до разделяющей поверхности.
Рис. 10.1. Исходные изображения (сверху), под ними созданные вручную маски
огня (снизу).
Рис. 10.2. Изображение полупрозрачного пламени с книгой на заднем плане.
Рис. 10.3. Изменение формы пламени между двумя последовательными кадрами.
Рис. 10.4. В левом нижнем углу первого снимка (до применения эрозии) наблю-
дается отражение пламени, выделенное белым цветом. Правый снимок - ре-
зультат применения операции эрозии.
Рис. 10.7. А - возможное расположение цветовой гаммы огня и Б - смесь гауссов-
ских распределений, описывающих ее.
Рис. 10.11. А - изображение девушки в свитере, окрашенном в цвет, близкий к
цвету огня; Б - сумма 7 ' (л\ у)| + |/Л,(х, у)|2 + |/ЛЛ(л\ у)| для области, ограниченной
прямоугольником на рисунке А.
Рис. 10.12. А - изображение огня; Б - сумма |//А(х,у)| + |/'’'(л\ v)p + \lhh(x. у) для об-
ласти, ограниченной прямоугольником на рисунке.
ГЛАВА 5.
АДАПТИВНЫЕ СИСТЕМЫ
РАСПОЗНАВАНИЯ ОБРАЗОВ
176
Цифвая обработка видеоизображений
Наиболее совершенные системы видеонаблюдения должны обладать умени-
ем распознавать обнаруженные объекты, иногда в упрощенной форме, напри-
мер, распознать только класс, к которому принадлежит объект: легковой авто-
мобиль, грузовик, человек и т. п. В более сложной постановке нужно идентифи-
цировать объекты, например, найти лицо заданного человека среди всех лиц. вы-
деленных на изображении. Настоящая глава посвящена методам, которые заре-
комендовали себя наилучшим образом при решении задач такого типа. Эти ме-
тоды называются адаптивными, потому что они обладают способностью настра-
иваться или, как часто говорят, обучаться на обрабатываемых данных. Перед тем
как приступить к обучению, необходимо должным образом подготовить данные.
Элементарную порцию данных для настройки обычно называют примером. Каж-
дый пример, как правило, имеет следующую структуру: (вход, выход). (%, £)), где
X = хр...,хя - л-мерный входной вектор. D - либо число (например, номер клас-
са), либо D = dx,...,dk - Л-мсрный выходной вектор. Входным вектором обычно
является набор характерных признаков, полученных в результате обработки
входного изображения. Различные способы выделения характерных признаков
изложены ниже. Выходные данные, т. е. результаты, которые должна выдавать
система при предъявлении ей на вход конкретного образца, задаются разработ-
чиком при обучении. Важной характеристикой распознающей системы являет-
ся так называемая способность к обобщению, которая заключается в умении
системы корректно обрабатывать данные, не использованные при обучении.
5.1. ПОДГОТОВКА ДАННЫХ ДЛЯ ОБУЧЕНИЯ
Первая проблема, с которой сталкиваются при подготовке примеров для обу-
чения адаптивных систем,- это проблема размерности. Предположим, требуется
научить систему определять тип транспортного средства, и для этого мы имеем
базу данных, содержащую изображения различных транспортных средств. При-
меры таких изображений приведены на Рис. 1.
Обрабатываемые изображения имеют разные размеры, а на вход распозна-
ющей системы обычно нужно подавать вектор фиксированной длины (напри-
мер, для нейросети длина вектора должна быть равной числу нейронов входного
слоя). Если предполагается, что изображения будут обрабатываться в растро-
вом виде, то все они должны быть приведены к одному размеру, что проще все-
го сделать с помощью соответствующего преобразования сжатия-растяжения.
Далее можно, например, построить развертку изображения, в результате чего
оно будет преобразовано к одномерному вектору, который уже пригоден к по-
даче на вход распознающей системы. Одна из возможностей построения раз-
вертки приведена на Рис. 2.
Однако такой способ представления информации имеет ряд недостатков.
Во-первых, теряется естественная близость пикселей, что в результате может
сказаться на распознающих свойствах системы. А главное, при обучении ней-
росети придется столкнуться с большой размерностью данных. Если, напри-
мер, стандартное изображение имеет размер 8 х 8,то входной вектор будет со-
стоять из 64 компонент. Но при увеличении размера изображения до, напри-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
Глава 5. Адаптивные системы распознавания образов
177
Рис. 1. Примеры изображений транспортных средств из базы данных
мер. 32 х 32 пикселей входной вектор будет иметь почти тысячу компонент!
И при этом очевидно, что входная информация является весьма избыточной.
Для снижения избыточности известно большое число способов. Приведем не-
сколько наиболее распространенных способов снижения избыточности.
Рис. 2. Построение «развертки» растрового изображения
http://ww w. itv.ru
Компания ITV - генеральный спонсор издания книги
178
Цифвая обработка видеоизображений
Замена изображения гистограммой. В этом случае исходное изображение
/. имеющее размер N х М. заменяется вектором х(# +Л/) = (/?,,//,), который по-
лучается в результате суммирования интенсивностей всех пикселей по вертика-
ли и горизонтали:
(I)
Я, ()=£'..,
/-1
/ = !,...Л.
Описанный процесс изображен на Рис. 3.
Рис. 3. Замена исходного изображения гистограммой
Использование расстояния до границы. Другим распространенным спосо-
бом снижения избыточности данных является метод использования расстояния
от сторон описанного прямоугольника до границы изображения. Суть этого ме-
тода можно понять из Рис. 4.
Вокруг изображения объекта описывается прямоугольник, в котором вво-
дится сетка размером N х М. Далее вычисляются расстояния вдоль линий сетки
от границ прямоугольника до границы изображения, как это показано стрелками
на левом рисунке. После этого выбирается начальная точка и направление обхо-
да сетки, и в результате исходное изображение заменяется вектором, компонен-
тами которого являются 2(N х М) найденных расстояний, как это схематически
показано на правой половине Рис. 4.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 5. Адаптивные системы распознавания образов
179
Рис. 4. Использование расстояния от границы описанного прямоугольника до гра-
ницы изображения
Замена изображения Фурье-спектром. Как известно, тригонометрическое
преобразование Фурье обладает тем замечательным свойством, что его ампли-
тудный спектр инвариантен относительно сдвигов изображения. Благодаря это-
му можно к тому же добиться определенной инвариантности представления ис-
ходного изображения. Прямое дискретное преобразование Фурье определяется
следующим образом:
Ф щ..аг) =-----> > / у,х)ехр -2я/ ——.
' 1 21 А \ М N ))
(2)
(У, = 0,...,У-1. й>2=0...М-\.
Избыточность сокращают путем отсечения старших гармоник спектра, ко-
торые содержат информацию лишь о мелких деталях изображения, зачастую не
играющих важной роли при распознавании объектов:
/(/,>) -> |Ф(ю,.й>.)| =
(3)
где Re(COr 60J и 101(60;. fi),) - соответственно действительная и мнимая части
Ф(Шр fi),). а п и т - заданные числа, такие, что n«N. т«М. При этом следует
учитывать, что
1 M-IJV-1
<t>(°.°)=77?XZ/(y.4 (*>
х=0 у=0
т. е. значение преобразования Фурье в начале координат равно средней интенсив-
ности изображения, поэтому эту величину обычно исключают из набора харак-
терных признаков.
h 1tp://www.it v. г и
Компания ITV - генеральный спонсор издания книги
180
Цифвая обработка видеоизображений
Использование коэффициентов дискретного косинус-преобразования
Фурье. Это преобразование обладает тем замечательным свойством, что при об-
работке действительных сигналов, к которым относятся и изображения, являет-
ся чисто действительным, т. е. не содержит мнимой части. Коэффициенты преоб-
разования определяются по следующей формуле:
, . А (ш,) А (to,) JU1 я<о.(2у + 1Й (лй)2(2х + 1Й
С (to,, to,) = v 17 v у у /(у х) cos —cos ——-----------------------. (5)
' 1 MN “iri { 2N J ( 2M J
где
(6)
Нетрудно заметить, что эти коэффициенты могут быть получены умноже-
нием исходного изображения на заранее вычисленные и запомненные величи-
ны, являющиеся произведением косинусов с соответствующими аргументами
на функцию Д(ю). Сокращение избыточности может быть достигнуто путем ис-
пользования нескольких первых коэффициентов с младшими номерами со} и со2,
которые удобно выбирать по правилу «змейки», как показано на Рис. 5.
Рис. 5. Упорядочивание коэффициентов по правилу «змейки». Пары чисел, указан-
ные в ячейках, соответствуют номерам гармоник по ш и 0)2.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 5. Адаптивные системы распознавания образов
181
Использование инвариантных моментов. Инвариантными к изменениям
масштаба, вращению и перемещению являются следующие моменты [1]:
Ф1=Д2.о+До,г
Ф2=(Д2.0-До.2)2+4К1.
фз = (Дз.о ” 2 ) + (З/Л, — До.з) •
Ф4=(Дз.о+Д|.г)2+(Д2.1+До.з):.
фз = (Дз.о — ^Д|.г)(Дз.о+Д|.2)^(Дз.о+Д|.:) “^(Дзл+До.з) j +
(ЗД2.1 ~До.з)(Дгл + До.з)^3(Дзо + Д1.;) ~(Дзл + До.з) j,
Ф6 = (д2.о "ДоДДз.о +Д|.2)2 - (Дзл + Роз)? + 4Ди (Дз.о + Ди)(Дц +Доз).
ф7 = ^(Дгл +До.з)(Дз.о ~Д|з)(Дз,о + Д|.г) ~^(Дзл+До.з) ~
(Дз.о —^Д1.г)(Д2л + До.з)^-3(Дз.о "* Д1.2) “(Дгл + До.з) j. (?)
VP4
Где^=-Й7^’
'"о.о
тр.< = £Хх<Д>'’/(х->л)> р.? = 0,1,2,...
>=1
.W V
VP.4 = ZSU ~ХЛ U ~Ут)4 = 0,1,2,...
/=| /=|
хт=тко/тм, Уп = т0Л/т00
Таким образом, в качестве входной информации можно использовать набор
всего из нескольких чисел <3^..Ф7, которые вычисляются по исходному изо-
бражению.
Применение полярно-логарифмического преобразования. Полярно-лога-
рифмическое (в англоязычной литературе Log-Polar) преобразование считается
одним из наиболее перспективных для задачи инвариантного распознавания об-
разов (2,3]. Формально оно описывается следующими соотношениями:
Р=1о£ьг'
<р = arctg ———
Attp.'//www./tv.ri/
Компания ITV - генеральный спонсор издания книги
182
Цифвая обработка видеоизображений
г = 7(г-х0):+(у-у0)\
Здесь (х0,у0) - центр изображения (см. Рис. 6). а основание логарифма выби-
-1-т^
рается как b = ег™ . где гтэх - максимальное значение г. Как видно из приведен-
ных формул, (г,ф) являются полярными координатами, так что
х = rcos<p + x0,
y = rsin(p + yQ. (9)
r = bp.
Рис. 6. На левом рисунке показаны декартовы прямоугольные координаты, на пра-
вом - полярно-логарифмические
На Рис. 7 приведен пример преобразования изображения автомобиля из де-
картовых в полярно-логарифмические координаты.
Рис. 7. На левом рисунке показано исходное изображение, на правом - оно же в
полярно-логарифмических координатах
ProSystem CCTV - журнал по системам видеонаблюдения
h ttp://ww w. procctv. ru
Глава 5. Адаптивные системы распознавания образов
183
Рассмотрим Рис. 8. На нем изображена равномерная сетка в полярно-
логарифмических координатах. Инвариантность полярно-логарифмических
преобразовании состоит в том. что при повороте изображения в декартовых
координатах происходит параллельный перенос изображения вдоль оси Оср в
полярно-логарифмических координатах.
Поворот
Рис. 8. Равномерная сетка в полярно-логарифмических координатах. Поворот изо-
бражения приводит к параллельному сдвигу вдоль оси Оф, а изменение масшта-
ба - к параллельному сдвигу по оси Ор.
Изменение же масштаба приводит к параллельному переносу изображения
вдоль оси Ор. Это непосредственно следует из свойств логарифма:
logAx = log Л+logx
На Рис. 9 приведены три изображения, два из которых получены из первого
путем выполнения поворота и растяжения.
Из рисунка видно, что поворот приводит к сдвигу по оси абсцисс, а увели-
чение масштаба * к сдвигу вдоль оси ординат. После выполнения полярно-
логарифмического преобразования к полученному изображению можно приме-
нить дискретное преобразование Фурье, которое, как известно, инвариантно от-
носительно сдвигов. Это позволяет построить распознающую систему, инвари-
антную относительно поворотов и изменения масштаба [4].
Мы перечислили только малую часть возможностей, позволяющих преобра-
зовать исходные изображения к виду, подходящему для настройки адаптивных
систем, а также снизить при этом избыточность информации и получить опреде-
ленную инвариантность получаемых признаков. Читатель может найти еще мно-
го различных преобразований в специальной литературе, например, в хорошо из-
вестных монографиях [4-9].
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
Рис. 9. Сверху показаны исходные изображения, снизу - они же в полярно-
логарифмических координатах
5.2. ИСКУССТВЕННЫЕ НЕЙРОННЫЕ СЕТИ
Применение искусственных нейронных сетей позволяет в наикратчайшее
время решать самые разнообразные задачи, возникающие при анализе изобра-
жений: распознавание, классификация, подавление шумов, аппроксимация и т. п.
Искусственные нейросети появились в результате моделирования некоторых
функций человеческого мозга [10], благодаря чему они стали мощным матема-
тическим инструментом для решения ряда сложных проблем, которые не имеют
четко сформулированного алгоритма решения.Типичным представителем таких
задач являются задачи распознавания образов. Кажется удивительным, что го-
довалый ребенок может отличить своих близких от остальных людей, хотя к на-
стоящему моменту задача столь надежного распознавания людей по внешности
или по голосу непосильна даже современным суперкомпьютерам. Поэтому ка-
жется разумной следующая идея: вместо того, чтобы конструировать алгоритм
для конкретной задачи распознавания, которую легко может решить даже мозг
ребенка или животного, построить модель самого мозга. А к настоящему време-
ни уже хорошо известно, что мозг состоит из простейших «решающих» элемен-
тов - нейронов, смоделировать которые не представляет труда. Интеллектуаль-
ная сила мозга определяется наличием огромного числа связей между различ-
ными нейронами. В процессе эволюции живого организма происходит измене-
ние силы связи между отдельными нейронами, в результате чего мозг становит-
ся способным адекватно реагировать на все поступающие к нему сигналы. Этот
процесс адаптации по биологической аналогии называется обучением нейросети.
Далее в тексте мы также часто применяем более привычный технический тер-
мин «настройка», поскольку, по сути, процесс обучения является последователь-
ным нахождением величин оптимальных связей между нейронами для решения
конкретных задач. Можно сказать, что искусственная нейросеть является уни-
версальной нелинейной системой, которая способна настраивать свои параметры
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://w w w.procc tv. ru
Глава 5. Адаптивные системы распознавания образов
185
на основе предъявляемых ей данных. Важнейшим свойством нейросетей являет-
ся способность к обобщению: научившись на нескольких примерах решать зада-
чи какого-либо класса, она становится способной давать разумные решения для
всех задач из того же класса. Естественно, чем больше различных примеров бу-
дет предъявлено нейросети, тем адекватнее будет ее поведение в дальнейшем.
5.2.1. Искусственный нейрон.
Несмотря на большое разнообразие известных к настоящему времени нейро-
сетей, они состоят из одних и тех же элементарных единиц - искусственных ней-
ронов, являющихся моделью биологических нейронов. Искусственный нейрон,
который также часто называют нейроном Мак-Каллока-Питтса [11], имеет не-
сколько входов и один выход. Каждый вход характеризуется своим весовым мно-
жителем W (см. Рис. 10).
На входы подаются сигналы %,которые преобразуются нейроном в выходной
сигнал Y. Переработка сигналов нейроном осуществляется в два этапа. На первом
из них входные сигналы умножаются на соответствующие весовые множители, в
результате чего нейрон вычисляет так называемое входное возбуждение:
5 = (10)
t-1
На втором этапе входное возбуждение пропускается через нелинейную пере-
даточную функцию нейрона £(•), в результате чего получается выходной сигнал:
У = Г(5-6). (Н)
http://www./tv.ru
Компания ITV - генеральный спонсор издания книги
186
Цифвая обоаботка видеоизображений
Здесь буквой b обозначено так называемое постоянное смещение, которое
является настраиваемым параметром. Для однородности обозначений обычно
смещение учитывают путем введения дополнительного входа с весом 1¥0= Ь, на
который всегда подается единичный сигнал. Тогда входная активация нейрона
определяется как
= (12)
1=1
а выходной сигнал образуется просто путем трансформации этого возбуждения
передаточной функцией:
K = F(S). (13)
В качестве нелинейной функции нейрона (ее также называют активацион-
ной, или трансформирующей функцией) чаще всего используют сигмоидную
функцию
F(x) = -Tf. (14)
1 + е р
графики которой для различных значений Д приведены на Рис. И.
Рис. 11. Графики сигмоидной передаточной функции нейрона при различных зна-
чениях параметра Д
Выбор сигмоидной функции в качестве активационной не случаен: такую же
передаточную функцию имеют биологические нейроны [12] и операционные
усилители, которыми моделируют нейроны при аппаратной реализации нейро-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
Глава 5. Адаптивные системы распознавания образов
187
сетей. Кроме того, значения этой функции лежат в диапазоне от 0 до 1, что позво-
ляет сохранять величину сигналов ограниченной вне зависимости от числа ней-
ронов нейросети. Эта функция наиболее быстро изменяется в окрестности нуля,
приближаясь асимптотически к единице при росте х и к нулю при уменьшении х.
Путем изменения параметра Д можно добиться нужной скорости роста: при ма-
лых [i функция близка к линейной
Г(х|Д«1) = | + ^Дх. (15)
в то время как при больших Д - к ступенчатой (пороговой) функции:
Именно такие функции используют в логических устройствах при аппарат-
ной реализации. Производная сигмоидной функции вычисляется по следующей
формуле:
dF
— = /JF(l-F). (17)
dx
Графики производной при различных значениях Д приведены на Рис. 12.
Рис. 12. Графики производной сигмоидной функции при различных значениях па-
раметра р
Из графиков видно, что сигмоидная функция наиболее быстро изменяется в
окрестности точки х=0, при этом, чем больше значение параметра Д тем сильнее
изменяется производная.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
188
Цифвая обработка видеоизображений
Некоторые авторы используют в качестве активационной функции биполяр-
ную сигмоиду
1-е д'
= 7-^- (18)
1 + е р
или гиперболический тангенс
Я(х) = 7^- (19)
Эти функции имеют область значений в интервале (-1,1), а их графики внеш-
не похожи на график функции F(x) (см. Рис. 13).
Рис. 13. Графики биполярной сигмоиды Н(х) и гиперболического тангенса G(x)
Это неудивительно, поскольку эти функции могут быть получены друг из
друга простой заменой переменных:
G(x) = 2F(x)-l, (20)
/7(х) = G(2x) = 2F(2x) -1. (21)
Производные этих функций вычисляются по следующим формулам:
^L = £(1-G2Y (22)
dx 2' '
^- = р(\-Н2). (23)
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. г и
Г лава 5. Адаптивнь е системы распоз^ава^/я образов
189
5.2.2. Геометрический смысл функционирования нейрона
Рассмотрим нейрон, имеющий два входа. Пусть на первый из них подается ко-
ордината х некоторой точки плоскости, а на второй - координата у той же точки.
Обозначим веса этих входов соответственно через А и В. а смещение - через С.
Тогда входное возбуждение нейрона будет определяться как
S = Ax + By + C. (24)
Правая часть этого соотношения определяет уравнение прямой на плоскости.
Если точка с координатами (х. у) лежит на этой прямой, то У=0. Для точек, лежа-
щих по разные стороны от прямой, значения у 5 будут отличаться знаками. Если
взять передаточную функцию нейрона тождественной, т. е. F(S)=S. то выходной
сигнал нейрона 5=4хтВу*С будет иметь смысл расстояния от точки (х, у) до пря-
мой Дх+Ву+С=0 с учетом знака, означающего, в какой полуплоскости относи-
тельно прямой (в положительной или отрицательной) лежит эта точка. Напом-
ним, что расстояние d от некоторой точки (хи, у0) до прямой 4х+Ву+С=0 опреде-
ляется по следующей формуле:
|Лхп + Ву0 + Cj
d— ' °, '° (25)
>Ja2 + b2
Пусть, например, 4=2. В=-1. С=1. Тогда все точки плоскости, находящиеся
ниже прямой у=2х+1. будут соответствовать значению У>0. И соответственно
при подстановке в правую часть (24) координат любой точки, лежащей выше
прямой у=2х+1, получим значение У<0, как это показано на Рис. 14.
Рис. 14. Нейрону с двумя входами и смещением (левый рисунок) соответствует на
плоскости разделяющая прямая (правый рисунок)
Таким образом, нейрону с двумя входами соответствует разделяющая пря-
мая. Нетрудно заметить, что нейрону с п входами соответствует гиперплоскость
в «-мерном пространстве. Нелинейная передаточная функция нейрона нужна для
того, чтобы привести расстояние до этой прямой к диапазону [0. 1] или [-1,1] в
зависимости от типа выбранной функции. При этом функции сигмоидного типа
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
190
цифвая обработка видеоизображений
наиболее чувствительны к небольшим расстояниям, когда точки находятся вбли-
зи разделяющей прямой, и почти не меняют своего значения при значительных
увеличениях этого расстояния. Из приведенного примера становится ясной роль
постоянного смещения: оно определяет величину сдвига прямой от начала коор-
динат. Если бы не было смещения, все разделяющие прямые проходили бы через
точку (0.0) и отличались бы лишь углом наклона.
5.2.3. Нейронная сеть прямого распространения
Искусственные нейронные сети образуются путем соединения нескольких
нейронов для их совместной работы. В зависимости от способа соединения ней-
ронов говорят о топологии (архитектуре) нейросети. В итоге именно архитек-
тура нейросети определяет ее свойства. Как правило, нейроны располагаются
слоями, причем нейроны каждого слоя не взаимодействуют друг с другом. Сиг-
нал передается от одного слоя к другому, начиная от входного слоя и заканчи-
вая выходным слоем, на котором формируется итоговый сигнал. К настоящему
времени хорошо изучено большое число нейросетей с различной архитектурой
(см., например, [13, 14]). В данном разделе мы опишем наиболее распростра-
ненные сети, хорошо зарекомендовавшие себя при решении задач распозна-
вания образов.
Нейросеть прямого распространения. Чаще всего на практике применяют
нейросеть прямого распространения, также называемую персептроном, посколь-
ку нейросети этого типа являются наиболее универсальными и, как следствие,
имеют наибольшее число приложений. Архитектура нейросети прямого распро-
странения приведена на Рис. 15.
Рис. 15. Архитектура нейросети прямого распространения
ProSystem CCTV - журнал по системам видеонаблюдения
http://www. procctv. г и
Глава 5. Адаптивные системы оаспознава^ия обоазов
191
Нейросеть прямого распространения состоит из нескольких слоев нейронов:
входного, выходного и нескольких «скрытых» слоев. На входной слой подают-
ся обрабатываемые данные, затем они проходят по очереди все слои нейросе-
ти, а с выходного снимаются результаты обработки. Ясно, что число нейронов
входного слоя должно совпадать с размерностью входных данных, а выходной
слой должен содержать число нейронов, соответствующее размерности выход-
ных данных. Все слои, кроме входного и выходного, остаются невидимыми поль-
зователю, поэтому они и называются скрытыми. Чаще всего используются ней-
росети с одним скрытым слоем - так называемые трехслойные сети. Нейроны
в пределах любого слоя не связаны между собой. Выходной сигнал от каждого
нейрона подается на входы всех нейронов следующего слоя. Нейроны входного
слоя не осуществляют преобразования сигналов, их функция состоит в распре-
делении входного сигнала между нейронами первого скрытого слоя. По мере
прохождения сигнала по нейросети он претерпевает изменения, которые зави-
сят от его начального значения, весовых коэффициентов нейронов и активаци-
онных функций. Опишем формально процесс прямого распространения сигнала
в трехслойном персептроне.
Прямое распространение сигнала. Пусть нейросеть имеет три слоя, входной
содержит п нейронов, скрытый - т. а выходной - к нейронов. Обозначим веса
между входным и скрытым слоями как а между скрытым слоем и выходным -
ГТ*.Тогда функционирование нейросети описывается следующими формулами:
1=1
5*=Z^X+W,o2.
(26)
Л = ^(5*2)-
Здесь п,- сигнал, вырабатываемый у-м нейроном скрытого слоя,у*- сигнал, вы-
рабатываемый к-м выходным нейроном. Верхние индексы обозначают номер
слоя.
Для того чтобы нейросеть корректно функционировала, т. е. по заданным
входным сигналам выдавала на выходе сигналы, близкие к желаемым, нужно
правильно выбрать значения весовых множителей и РКД, а также параметры
активационных функций нейронов. Веса нейросети определяют в процессе на-
стройки или, как принято говорить, в результате обучения. Параметры активаци-
онных функций, как правило, выбирают один раз и оставляют неизменными. Рас-
смотрим процесс настройки нейросети.
Настройка (обучение) нейросети. Нейросеть прямого распространения обу-
чают на примерах. Этим, наверное, и объясняется высокая популярность нейро-
сетей: вместо того, чтобы конструировать алгоритм решения задачи, достаточно
подготовить набор примеров, для которых известно решение этой задачи. Обу-
чившись на предъявленных примерах, нейросеть становится способной выдавать
http://www. itv.ru
Компания ITV - генеральный спонсор издания книги
192
Цифвая обоабогка видеоизображений
правильные решения для других данных, ранее нейросети «не известных». В этом
проявляется так называемая способность нейросети к обобщению.
Примером называется пара (А'.О).где X ~ х,...,хп-л-мерный входной вектор.
D = d{,..., dk - Zc-мерный выходной вектор, такой, что. если на вход нейросети подать
X, она должна на выходе выработать Ь. Например, при создании системы монито-
ринга на некотором этапе выделяются блобы, и нам требуется научить нейросеть
определять, какому объекту соответствует этот блоб - транспортному средству или
другому объекту? Для этого необходимо собрать достаточное число изображений,
содержащих транспортные средства, а также их не содержащих, и преобразовать все
имеющиеся изображения в набор характерных признаков, например, используя ста-
тистические инварианты. Компонентами вектора X в данном случае будут компо-
ненты характерных признаков, а выходной вектор Ь будет одномерным, т. е. иметь
всего одну компоненту’ dv принимающую всего два значения:
fl, ТС
1 0, не ТС.
Если бы нам понадобилось определять тип транспортного средства (напри-
мер, большегрузный автомобиль, легковой автомобиль, мотоцикл или велоси-
пед), то выходной вектор Ь был бы четырехмерным:
- большегрузный автомобиль.
- легковой автомобиль.
- мотоцикл (велосипед),
- другой объект.
Совокупность всех доступных примеров называется обучающей выборкой.
Ясно, что чем она будет представительнее, тем лучшие результаты мы получим.
Процесс обучения состоит в следующем. В начальный момент всем весам
нейросети с помощью датчика случайных чисел назначаются небольшие случай-
ные значения. Входной вектор из каждого примера пропускается через нейро-
сеть, в результате чего нейросетью вырабатывается результат У, который, ско-
рее всего, будет отличаться от желаемого Ь. На каждом р-м примере вычисляет-
ся среднеквадратичная ошибка нейросети:
(27)
Z *=!
а общая ошибка на всех примерах является суммой этих парциальных ошибок:
(28)
Р^
ProSystem CCTV - журнал по системам видеонаблюдения
http.//www.procctv. г и
Глава 5. Адапт/вные системы распознавания обоазов
193
где Р - общее число примеров, предъявляемых при обучении, а ук и dk - соот-
ветственно компоненты векторов Y и Ь. Хорошо настроенная нейросеть должна
иметь небольшую ошибку, поэтому процесс обучения состоит в минимизирова-
нии ошибки Е относительно весовых множителей. Для коррекции весов обычно
используют различные модификации метода градиентного спуска, т. с. постепен-
ного изменения весов пропорционально их градиенту -—.который характеризу-
ет степень вклада данного веса в ошибку:
1Г(/ + 1) = FF(/)-«——.
(29)
где Г - фиктивный параметр, имеющий смысл номера итерации (или шага обуче-
ния). а ~ параметр, характеризующий скорость обучения. Если выбрать значе-
ние параметра а слишком малым, настройка будет проводиться крайне медлен-
но; если же выбрать его слишком большим, возникнут «биения» - веса будут ра-
сти, все время меняя свой знак, не уменьшая при этом ошибку. Оптимальное зна-
чение для параметра а обычно находится экспериментально.
Градиенты вычисляются по следующим формулам:
аи'л
э»-'
(30)
3F
'* as'
Если в качестве передаточной функции используется сигмоидная функция с
параметром Д, производная которой определяется как F' = pF() - F), то вместо
этих соотношений удобнее использовать следующие формулы:
(31)
-^- = 5' х
' -
Эти формулы имеют простой смысл: переменная 8 содержит ошибку, ко-
торая «пришла» справа (от выхода сети), а градиент равен произведению этой
ошибки на величину возбуждения, «пришедшего» слева (от входа сети), как изо-
бражено на Рис. 16.
Изменение данного веса будет тем сильней, чем больший вклад он вносит в
ошибку, и чем больший сигнал проходит по нему. Сигналы в сети проходят от вхо-
да к выходу, поэтому эти нейросети называются сетями прямого распростране-
ния. При настройке ошибка вычисляется в обратном направлении - от выхода ко
http://www. itv.ru
Компания I TV - генеральный спонсор издания книги
194
цисвая обработка видеоизображений
входу Поэтому данный метод обучения часто называют методом обратного рас-
пространения ошибки (в англоязычной литературе Error Back Propagation).
Рис. 16. Градиент для каждого веса нейросети И'равен произведению возбуждаю-
щего сигнала х на величину ошибки 8
5.2.4. Нейросеть с радиальными базисными функциями
Как мы уже видели, нейрон Мак-Каллока-Питтса способен строить разде-
ляющую гиперплоскость в пространстве входных образов, а нейросеть, состо-
ящая из этих нейронов, может аппроксимировать множества достаточно слож-
ной структуры в виде комбинации нужного числа нейронов. Здесь разработчик
сталкивается с известной проблемой: сколько нейронов выбрать в скрытых
слоях. Если их число будет слишком малым, то качество аппроксимации будет
низким. Если же нейронов слишком много, то, во-первых, ресурсы компьюте-
ра при обучении и использовании нейросети будут использоваться неэффек-
тивно, а главное, у нейросети могут появиться так называемые «ложные» со-
стояния, когда она начнет распознавать, и вообще говоря, неправильно,те объ-
екты, которые не использовались при обучении. Иными словами, способность
нейросети к обобщению будет проявляться на некоторых примерах странным
образом, напоминая галлюцинации. Аналогичная ситуация возникает при ре-
шении системы линейных алгебраических уравнений, когда число уравнений
больше числа неизвестных.
Если же нам известна структура исходных данных, то можно построить до-
вольно компактную нейросеть, основанную на так называемых нейронах ради-
ального базиса. Каждый такой нейрон расположен в некоторой точке входного
пространства b = , Ь2,..., Ьп /, а его выходной сигнал определяется трансформи-
рующей функцией Ф, аргументом которой является расстояние от входного сиг-
нала до точки локализации нейрона:
и, =Ф,(|х-6,|). (32)
Архитектура типичной трехслойной нейросети радиального базиса с п входа-
ми, т скрытыми нейронами и к выходами приведена на Рис. 17.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
Глава 5. Адаптивные сис’емы оаспознава^/я сбсазоз
195
Скрытый слой состоит из нейронов радиального базиса, а выходной слой - из
стандартных нейронов, как правило, с тождественной передаточной функцией.
Сигнал на j-м выходе нейросети определяется по следующей формуле:
У/(*)=£^,ф((|М|)+^о.г (33)
где Wtf ~ веса сети между скрытым и выходными слоями. Веса между нейронами
входного слоя и нейронами скрытого слоя служат лишь для тождественной пе-
редачи входного сигнала, поэтому все они имеют фиксированное значение, рав-
ное единице.
Для определения числа нейронов скрытого слоя, а также точек их локали-
зации проще всего использовать технику кластерного анализа, описанную ниже.
В результате кластеризации все множество исходных примеров разбивается на
несколько подмножеств, называемых кластерами. Элементы каждого класте-
ра должны быть близки между собой и отличаться от объектов других класте-
ров. Представляется естественным выбрать число нейронов в скрытом слое рав-
ным числу полученных кластеров, для точек локализации нейронов использо-
вать центроиды соответствующих кластеров, а в качестве базисных функций ис-
пользовать функции следующего вида:
Ф, (|* “ Ь [)= ехР ( ’ (* “ (х - Ь,) (34)
где 5 - ковариационная матрица, компоненты которой определяются по следую-
щей формуле:
http.//wwwjtv.ru
Компания ITV - генеральный спонсор издания книги
196
Цифвая обсаботка видеоизображений
s4r = 7 X (ХР-W)(х₽ ~ь'\ ч^=1.....Л.
nt
(35)
Здесь хчр - q-ая компонента входного р-го вектора из обучающего множества,
а и - число примеров, попавших в кластер Qr. Нетрудно заменить, что в (34) в
качестве расстояния используется расстояние Махаланобиса. которое позволяет
наилучшим образом учесть структуру полученных кластеров. Однако часто для
сокращения объема вычислений вместо полной ковариационной матрицы S ис-
пользуют только ее главную диагональ, что соответствует применению в каче-
стве базисных функций laycca:
ехр
2а;
(36)
Настройка нейросети состоит в минимизации ошибки на всей совокупности
примеров:
р
min Е = £ Ер,
р=|
где
1 к
Z k=\
(37)
(38)
- ошибка на примере номер р.
В простейшем случае настраивают только веса нейросети что проще все-
го сделать методом градиентного спуска:
ЭЕ
^(< + 1) = ^(0-а—, (39)
где t - номер шага настройки, a - параметр, характеризующий скорость обуче-
ния. Градиент вычисляется по следующей формуле:
ЭЕр _ ,« = 0
(40)
Можно также проводить подстройку остальных параметров. Например,
при использовании функций Гаусса можно уточнять точку локализации ней-
ронов Ь, а также значения параметров а. В этом случае градиенты находят-
ся по формулам
Э*.
Эст,
*=|
а,2 . i = 1,
-Г2-, : =
(41)
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 5. Адаптивные системы распознавания образов
197
5.2.5. Организация процесса настройки нейросети
Несмотря на сравнительно несложную математическую модель нейросети,
запрограммировать которую в состоянии даже программист средней квалифи-
кации, попытки ее обучения и применения часто терпят провал. Нейросеть то
«не хочет» обучаться, то в процессе использования выдает странные результа-
ты. А поскольку нейросеть является «черным ящиком», разобраться в возникших
проблемах обычно не представляется возможным. В настоящем разделе описа-
на техника организации обучения нейросети, позволяющая избежать описан-
ных проблем. Несмотря на интуитивно понятную очевидность некоторых эта-
пов, многие разработчики их игнорируют, тратя в результате драгоценное время
для поиска несуществующих ошибок. Поэтому мы настоятельно советуем при-
держиваться предлагаемой схемы, по крайней мере, пока у читателя не появится
собственный опыт. Здесь приведены только общие принципы, каждый разработ-
чик может придумать их собственную реализацию.
Процесс настройки нейросети, как правило, состоит из следующих этапов:
1. Приведение данных к виду, воспринимаемому нейросетью.
2. Разбиение данных на три множества: обучающее, контрольное и тестовое
(которые будут далее называться соответственно обучающей, контроль-
ной и тестирующей выборками).
3. Обучение нейросети на обучающем множестве с учетом контрольной
выборки.
4. Тестирование нейросети на тестовом множестве.
5. Если результаты тестирования неудовлетворительны, внести необходи-
мые изменения и вернуться к шагу 2.
Рассмотрим эти этапы подробнее.
Приведение данных к виду, воспринимаемому нейросетью. Если все исполь-
зуемые данные являются численными,желательно провести их перенормировку.
В принципе, перенормировка входных данных необязательна, однако она может
в ряде случаев существенно облегчить настройку нейросети. Дело в том, что про-
цесс настройки в значительной мере зависит от величины параметра а, характе-
ризующего скорость обучения: слишком малые значения замедляют процесс на-
стройки. слишком большие - приводят к биениям и даже к нарушению сходимо-
сти итерационного процесса. Выбор оптимального а может занять значительное
время, поскольку в зависимости от диапазона изменения входных сигналов опти-
мальное значение этого параметра может меняться на несколько порядков. Если
входные данные приведены к некоторому стандартному значению, чаще всего к
интервалу [0, 1], то можно начинать с некоторого стандартного значения а, на-
пример а=0.1, а затем в зависимости от ситуации уменьшить его или увеличить
(каким образом, будет сказано несколько ниже).
Если в качестве передаточных функций у выходных нейронов использует-
ся сигмоидная функция F(x), то выходные данные следует привести к диапазону
(0,1]; при использовании биполярной сигмоидной функции G(x) или гиперболи-
ческого тангенса Н(х) данные следует привести к интервалу [-1,1].
Если какие-либо данные не являются числовыми, их нужно преобразовать
к числовому виду. Здесь обычно существуют следующие возможности. Когда по
смыслу данные являются некоторыми переходящими категориями, например
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
198
Цифвая обработка видеоизображений
«плохо», «удовлетворительно», «хорошо», «отлично», их можно заменить неко-
торыми упорядоченными числами 0.1.0.4.0.7.1.0 . Если нейросеть выдаст значе-
ние 0.8. можно сделать заключение, что это несколько лучше, чем «хорошо», но
до «отлично» еще далеко. Если же данные не имеют смысла упорядоченной шка-
лы. их лучше кодировать двоичными наборами. Часто переменные такого типа
используются при решении задачи классификации, когда входной набор требует-
ся отнести к какому-либо из перечисленных классов. Пусть, например, некая пе-
ременная может принимать значения «мотоцикл», «автомобиль», «автобус». Для
такой переменной рекомендуется использовать трехмерный вектор, тогда пер-
вом}’ классу будет соответствовать набор (1.0. 0). двум друтим - соответственно
(0.1,0) и (0.0.1). Конечно, при такой кодировке возрастает избыточность данных,
но при этом также повышается устойчивость нейросети к шумам и ошибкам, ко-
торые зачастую присутствуют в данных.
Разделение данных на обучающее, контрольное и тестовое множества.
Нейросеть прямого распространения обладает двумя свойствами - запоминать и
обобщать данные. Первое из них состоит в способности сети в точности воспро-
изводить данные, на которых она была обучена. Свойство обобщения заключа-
ется в способности нейросети выдавать достаточно правильные ответы на во-
просы. которые не предъявлялись в процессе обучения. На начальной стадии
обучения оба указанные свойства улучшаются. Однако в некий момент способ-
ность к обобщению начинает ослабевать: срабатывает так называемый эффект
переобучения. Для корректного обучения нейросети используется следующий
прием. Все имеющиеся примеры разбиваются на три части. В первую отбирается
порядка 70% от общего числа примеров, во вторую - около 10%, в третью - все
оставшиеся данные. Первую часть обычно называют обучающей выборкой, вто-
рую - контрольной, третью - тестирующей. На обучающей выборке проводит-
ся настройка нейросети, а контрольная используется для контроля качества об-
учения. Пусть, например, мы решаем задачу аппроксимации экспериментальных
данных, которые были получены с некоторыми ошибками. На Рис. 18 отображе-
ны результаты аппроксимации в различные моменты времени: после нескольких
начальных шагов, в некий оптимальный момент времени и в конце процесса, ког-
да достигнута минимальная ошибка нейросети.
Рис. 18. Динамика процесса аппроксимации функции с помощью нейросети: А -
после нескольких шагов обучения, Б - оптимально обученная нейросеть, В - «пе-
реобученная» нейросеть
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv ги
Глава 5. Адаптивные системы распознавания образов
199
На всех рисунках пунктиром изображена аппроксимируемая функция,
сплошной линией - результат аппроксимации посредством нейросети, чер-
ными кружками - данные из обучающего множества, белыми - из контроль-
ной выборки. Видно, что в начале обучения нейросеть плохо аппроксими-
рует все данные. Оптимально настроенная нейросеть хорошо аппроксими-
рует как данные из обучающей выборки, так и контрольные данные. И, на-
конец, нейросеть, обученная до достижения минимальной ошибки на обуча-
ющем множестве, хорошо аппроксимирует данные из обучающей выбор-
ки, в то время как на контрольных примерах дает большую погрешность.
В первом случае говорят о недообученной нейросети, в последнем - о пере-
обученной. Интуитивно ясно, что правильно настроенная нейросеть долж-
на давать приблизительно одинаковую точность на всех данных. Добить-
ся хороших результатов можно двумя способами - прерыванием процес-
са обучения в нужный момент на основании ошибки на контрольной выбор-
ке либо изменением числа нейронов в скрытом слое по ошибке на тестовом
множестве.
Обучение нейросети. Процесс обучения нейросети состоит в настройке
се весов на примерах из обучающей выборки. Напомним, что примером назы-
вается пара (%,£>), где X = хр...,хи - и-мерный входной вектор, D-d^...,dk -
известный Л-мерный выходной вектор. Если на вход правильно настроенной
нейросети подать вектор X. участвовавший в обучении, на выходе она долж-
на сформировать Л-мерный вектор Y. незначительно отличающийся от «пра-
вильного» выходного вектора D. Количественно степень настройки нейросети
определяется величиной ошибки на обучающем множестве:
^4 = 7 X ЕР'
ь Р=1
где L - число примеров в обучающей выборке, а
Ер = F)2-ошибка на данном примере.
В принципе, ошибку нейросети можно сделать как угодно малой, однако на
практике этого добиваться не нужно по следующим обстоятельствам. Как вход-
ные, так и выходные данные обычно задаются с определенной погрешностью,
поэтому «точно настроенная» нейросеть, по сути, учится повторять эти погреш-
ности. Кроме того, в какой-то момент у нейросети происходит снижение спо-
собности к обобщению. Поэтому процесс обучения следует прерывать. Для это-
го используется контрольное множество. На примерах из контрольного множе-
ства тоже вычисляется ошибка нейросети:
1 с
ЕС = ~У ЕР>
С Г' Р'
с Р=1
где С - размер контрольной выборки. Очень важно, чтобы для настрой-
ки весов эти примеры не использовались! На следующем рисунке приведе-
на типичная картина изменения указанных ошибок в зависимости от времени
обучения.
http://www. itv.ru
Компания ITV - генеральный спонсор издания книги
200
цифвая обработка видеоизображений
Рис. 19. Типичная картина изменения ошибок на обучающем множестве EL и на
контрольном множестве Е( в зависимости от времени обучения t
Ошибка на обучающей выборке все время снижается, в то время как ошиб-
ка на контрольных примерах сначала уменьшается, а затем начинает расти. На-
чало роста соответствует снижению способности нейросети к обобщению, поэ-
тому рекомендуется прервать обучение в тот момент, когда появляется тенден-
ция к росту ошибки на контрольной выборке. На графике этот момент обозна-
чен как t .
Тестирование нейросети. После того как нейросеть настроена, следует убе-
диться в том, что она обучена с приемлемым для нашей задачи качеством. Для
этой цели используются примеры из тестовой выборки, для которых нам извест-
ны правильные выходные сигналы. Все примеры из тестового множества пропу-
скаются через нейросеть, в процессе чего вычисляется ошибка:
Ет = “ X
1
где Т - размер тестового множества. Обычно эта ошибка больше, чем на при-
мерах из обучающего множества. Однако теперь у нас есть основания полагать,
что на новых данных, для которых у нас нет известных «ответов», нейросеть бу-
дет выдавать их с точностью Ег которая была продемонстрирована на тестовых
примерах.
Если результаты тестирования неудовлетворительны. Ошибку нейросе-
ти Ег полученную при тестировании, удобно выражать в процентах.Тогда мы мо-
жем соотнести ее с точностью, которой требуется достичь при решении постав-
ленной задачи. Причин тому, что требуемая точность не была достигнута, суще-
ствует несколько: было сделано слишком мало итераций; произошло попадание
в локальный минимум; в скрытых слоях выбрано недостаточное число нейронов;
используются противоречивые данные.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
Глава 5. Адаптивнье системы распознавания образов
201
Причину можно выявить путем анализа графиков изменения ошибки нейросе-
ти во время обучения. Если кривые ошибки нейросети имеют устойчивую тенден-
цию к снижению, что изображено на Рис. 20А. это означает, что было сделано не-
достаточно шагов настройки. В этом случае обучение должно быть продолжено.
Рис. 20. А - ошибки нейросети на обучающем множестве Е{ и на контрольном
множестве Е( имеют устойчивую тенденцию к снижению; Б - ошибки снижаются
медленно
Если же ошибки очень медленно снижаются, т. е. их графики близки к пря-
мым линиям, как показано на Рис. 20Б, то, скорее всего, для параметра скорости
сходимости а было выбрано слишком малое значение. В этом случае следует
увеличить значение а и продолжить настройку.
При попадании в локальный минимум, как правило, прекращается изменение
ошибки нейросети, как это изображено на Рис. 21 А.
Рис. 21. Попадание в локальный минимум: А - ошибки на обучающем и контроль-
ном множествах перестали уменьшаться; Б - локальные минимумы ошибки:
£, - при векторе весовых коэффициентов Wj и Е2 - при векторе весовых коэффи-
циентов
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
202
Цифвая обработка видеоизображений
(42)
Что такое локальный минимум. можно понять из Рис. 21 Б. на котором изо-
бражена зависимость ошибки нейросети Е от значения весов W. На этом графи-
ке можно заметить два локальных минимума, соответствующих значениям аргу-
мента W х и Wr Если значения весовых множителей оказались близкими к И^^то
производная от ошибки нейросети по весам будет близка к нулю:
Я-о.
dw
и. следовательно, изменение весов будет тоже незначительным:
AJ7 = -й^- = 0.
В результате прекратится изменение ошибки нейросети, значение которой
застынет у отметки Ег хотя, как видно из рисунка, правее точки она может
быть меньше, чем Е}. Это явление называется попаданием в локальный минимум,
что приводит к прекращению обучения. Для того чтобы выбраться из локально-
го минимума, нужно либо на некоторое время резко увеличить значение параме-
тра скорости сходимости а, либо начать обучение заново. В большинстве про-
грамм, реализующих нейросети, для преодоления локальных минимумов исполь-
зуют следующий прием: при изменении весов учитывают не только градиент, но
и его значение на предыдущем шаге:
ДЕ ЙЕ
+ = -П—(г-|).
Последний член в этой формуле называют моментом, или инерционным членом.
Параметр rj определяет величину инерции: обычно он имеет величину порядка а.
Если в скрытых слоях было выбрано недостаточное число нейронов, внешне
это проявляется как попадание в локальный минимум, т. е. ошибка нейросети за-
мирает на некотором уровне, не достигнув заданного значения. Если при повтор-
ных запусках обучения с другими начальными весами ошибка нейросети ведет
себя аналогичным образом, то причина, вероятнее всего, в недостаточном числе
нейронов скрытых слоев, число которых следует увеличить.
Будем называть примеры для обучения противоречивыми, если одинако-
вым входным векторам соответствуют различные выходные векторы.Такие дан-
ные могут быть легко выявлены при тестировании: на них ошибка нейросети
существенно больше, чем на других. Рассмотрим следующий пример: предполо-
жим, нам нужно аппроксимировать с помощью нейросети окружность х2+у2=Е2
(см. Рис. 22А). Нейросеть будет содержать один вход и один выход. В качестве
входных данных будем использовать значения аргумента в виде набора значений,
распределенных на интервале [-R, Е],а в качестве выходных - соответствующие
значения функции y = ±\/R2 -х2. При этом каждое значение х будет входить в
два примера, соответствующие двум значениям у: (х,-д/Е2 -х2) и (х,+>/Е2 -х2 ).
В результате насгройки нейросеть для любого входного значения х будет выда-
вать на выходе у=0, что соответствует минимуму среднеквадратичной ошибки на
описанных данных (см. Рис. 22Б). Зависимость ошибки нейросети от значения х
приведена на Рис. 22В.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
Глава 5. Адаптивные системы распознавания образов
203
Рис. 22. Аппроксимация окружности нейросетью: А - данные для обучения, Б -
жирная линия соответствует выходным результатам настроенной сети, В - значе-
ния ошибки в зависимости от входных данных
Таким образом, при наличии противоречивых данных ошибку нейросети не
удастся сделать малой. Что делать в этой ситуации? В процессе тест ирования пер-
вым делом нужно выявить противоречивые данные (напомним, что ошибка на
них будет существенно больше, чем на других данных). Далее следует выделенные
данные проанализировать. Возможно, они были введены с ошибками,тогда ошиб-
ки нужно исправить. Этот процесс обычно называется верификацией данных.
Если же данные противоречивы по сути проблемы, как в разобранном нами при-
мере с окружностью, следует установить причину неоднозначности и ввести до-
полнительные аргументы и, соответственно, в нейросеть добавить входы. В при-
мере с окружностью нужно было добавить еще один вход, соответствующий вет-
ви, по которой обходится окружность, например -1 должен соответствовать обхо-
ду снизу, +1 - обходу сверху.Тогда примеры стали бы иметь вид (-1, x,-\jR2 -х2)
и (+1, х, 4- у/R* -х*)< и данные перестали бы быть противоречивыми.
Для более глубокого ознакомления с искусственными нейронными сетями
рекомендуется следующая литература: [15-21].
5.3. МЕТОД ОПОРНЫХ ВЕКТОРОВ
Как мы видели, нейрон способен построить разделяющую гиперплоскость
между двумя множествами, и за счет большого числа нейронов нейросеть спо-
собна аппроксимировать границу между множествами, имеющую довольно
сложную структуру. Однако, как только найдена любая гиперплоскость, позво-
ляющая разделить классы, процесс настройки нейросети прекращается. Альтер-
нативой является метод опорных векторов, позволяющий построить оптималь-
ную разделяющую гиперплоскость [22-24]. Под оптимальной мы будем понимать
гиперплоскость, которая перпендикулярна кратчайшему отрезку, соединяюще-
му выпуклые оболочки разных классов, и проходит через середину этого отрез-
ка. Изображенная на Рис. 23А. гиперплоскость Нг построенная нейросетью, об-
ладает худшей способностью к обобщению, чем разделяющая гиперплоскость
Нг построенная методом опорных векторов, показанная на Рис. 23Б. Действи-
тельно, точка хр которая явно расположена ближе к множеству будет класси-
фицирована нейросетью как точка множества Qr поскольку она лежит по ту же
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
204
Цифвая обработка видеоизображений
сторону гиперплоскости Н,. что и множество Нетрудно заметить, что анало-
гичная ситуация наблюдается и с точкой л\. Гиперплоскость построенная ме-
тодом опорных векторов, осуществит правильную классификацию, что видно из
Рис. 23Б. Ясно, что последняя ситуация является более предпочтительной с точ-
ки зрения обобщения.
Рис. 23. Разделение двух множеств Q. и Q. гиперплоскостью Н: А - нейронной се-
тью, Б - методом опорных векторов
В настоящем разделе кратко описаны принципы, лежащие в основе метода
опорных векторов, а также приведены различные модификации этого метода,
позволяющие строить как линейные, так и нелинейные классификаторы.
5.3.1. Линейная модель
Линейная модель основана на идее построения оптимальной гипер-
плоскости, разделяющей два множества. Пусть нам известны N примеров
гДе е R" - п -мерные векторы, yi е - пере-
менная, принимающая всего два значения в зависимости от того, к первому или
второму множеству принадлежит вектор признаков х.. Задача состоит в построе-
нии разделяющей функции /(х) = у.
Предположим, что множества линейно разделимы, т. е. существует такая ги-
перплоскость, относительно которой все элементы обоих множеств лежат по
разные стороны. Запишем уравнение гиперплоскости в следующем виде:
(wx)-fe = 0, we/?", beR. (43)
Тогда соответствующий классификатор будет иметь следующее представление:
/(x) = sgn((wi)-Z>). (44)
Будем называть разделяющую гиперплоскость оптимальной, если она
а) перпендикулярна кратчайшему отрезку, соединяющему выпуклые оболоч-
ки разных классов, и
б) проходит через середину этого отрезка, как это показано на Рис. 24.
ProSystem CCTV - журнал по системам видеонаблюдения
ht tp://ww w. procct v. ru
Глава 5. Адаптивные системы распознавания образов
205
Рис. 24. Множества Q | и Q, разделяются оптимальной гиперплоскостью Н
Иными словами, оптимальная гиперплоскость должна максимизировать ши-
рину разделяющей полосы между классами, т. е.
maxmin{ ||x-xj|:x 6R\[w-x)-b= 0,i = (45)
Рассмотрим две гиперплоскости Н{ и Нг параллельные оптимальной гипер-
плоскости Н
(46)
H2:(w х,)-6 = -1,
такие, что между ними не существует точек из обучающего множества, а рассто-
яние между этими гиперплоскостями является максимально возможным. Оче-
видно, что Н{ должна проходить по крайней мере через одну точку из множе-
ства с yf.=+l, а Н2 - через одну точку из множества cyf=-l. Эти точки называют-
ся опорными векторами, потому что лишь они определяют оптимальную гипер-
плоскость, а остальные точки могут быть безболезненно удалены из обучающей
выборки. Поскольку расстояние от любой точки, лежащей на Нг до плоскости
//:(wx)-b = 0 равно
= -L. (47)
н И
2
то расстояние между и Н, равно тр-г. Следовательно, для того чтобы максими-
М
зировать расстояние между этими гиперплоскостями, нужно минимизировать ве-
http://www.itv. ги
Компания IТV - генеральный спонсор издания книги
206 Цифвая обоаботка видеоизображений
личину |’|и| с дополнительным условием, что между Н и нет точек обучающе-
го множества, которое можно записать в виде системы неравенств:
(й х ) —6 > +1 для примеров су. =*1.
(й х )-/>< -1 для примеров су=-1.
Условия (48) можно объединить в одно:
z((w*,)-6)£l. (49)
Таким образом, задачу построения оптимальной разделяющей гиперплоскости
можно сформулировать в виде задачи минимизации квадратичного функционала
min — йгй (50)
2
с ограничениями (49).
Эта задача является хорошо известной задачей выпуклого квадратичного
программирования, для решения которой нужно минимизировать функционал
Лагранжа
L(w,b\a) = l||wf -£ а, (у, ((й-х)-б)-1). (51)
где а >0 - множители Лагранжа. Лагранжиан L должен быть минимизирован от-
носительно исходных переменных й и b при ограничениях а >0. Поскольку как
Ь.так и ограничения являются выпуклыми функциями, то исходную задачу мож-
но заменить двойственной задачей: максимизировать L по переменным at>0 при
условии, что производные от L по й и b обращаются в нуль. Иными словами, нам
нужно найти седловую точку Лагранжиана.
u « dL dL
Найдем производные —_____и приравняем их нулю, в результате получим
следующие условия: ^6
Л’
1=1
.V
Z<V, = ° (53)
/-1
Подставив (52) и (53) в (51), получим формулировку двойственной задачи:
Л’ । .V Л’
максимизировать LD (а) = а, — (54)
i=i 2 ;=1
N
при условиях а>0, (55)
1=1
Классифицирующая функция (44) может быть переписана в следующем виде:
/(x) = sgnf £а,.у,(х x,)-b 1 (56)
\ i=l /
ProSystem CCTV — журнал по системам видеонаблюдения
http://w w w. ргосс t v. г и
Глава 5. Адаптивные системы оаслознавания образов
207
хотя в линейном случае для нее проще использовать исходное выражение. Вели-
чина переменной b может быть определена из условий Куна-Таккера:
а,[л((^х,)-б)-1] = 0. (57)
Векторы для которых а не равны нулю (т. е. а >0). называются опорны-
ми. Из условия (57) следует, что эти векторы лежат на гиперплоскостях и Н2.
Ясно, что суммирование в (56) можно проводить только по опорным векторам.
Число таких векторов обычно составляет малую долю от общего числа векто-
ров. благодаря чему метод опорных векторов является крайне эффективным с
вычислительной точки зрения. Для решения задачи квадратичного программи-
рования (54). (55) разработано большое число эффективных методов, которые
могут быть найдены в работах [22-23].
5.3.2. Нелинейная модель
Если данные из обучающей выборки не могут быть разделимы гиперплоско-
стью (т. е. они не являются линейно разделимыми), то. возможно, существует не-
которая нелинейная поверхность, которая может их разделить. Для построения
такой поверхности можно построить нелинейное отображение Ф исходных дан-
ных в другое многомерное пространство, в котором они станут линейно раздели-
мы. Задачу построения отображения существенно упрощает то обстоятельство,
что и в функционал LD. и в классифицирующую функцию (56) исходные пере-
менные xt входят в форме скалярного произведения.
После применения преобразования Ф к исходным данным получим
(а) = X -1Е £ «. (Ф(*.) Ф(*,)). (58)
Скалярное произведение Ф(л ) -Ф(^) удобно представить в виде ядра
К(х,у) = (Ф(х)Ф[у)).
(59)
На практике наиболее часто используются ядра следующего вида:
1. Ядро Гаусса (функция радиального базиса)
(*->)2
К(х,у) = е г°' (60)
2. Полиномиальное ядро
^(xj) = (ry+c)\ (61)
c>0. d- степень полинома.
3. Сигмоидное ядро
K(xj) = th(k(xy)+6), (62)
где к - крутизна, в - величина порога.
http.//www itv. ги
Компания ITV - генеральный спонсор издания книги
208
Цифвая обработка видеоизображений
В нелинейном случае задача формулируется следующим образом:
у । У у
максимизировать LD (й) = У а/ — (63)
i-i 2 /=I у=|
при ограничениях а > 0, £<v,=o. (64)
а классифицирующая функция принимает следующий вид:
/у \
/(x) = sgn £а„у, к(х х,)-6 . (65)
\ 4=1 /
На Рис. 25 приведены примеры линейного и нелинейного разделения двух
классов с помощью метода опорных векторов.
Рис. 25. Разделение двух классов методом опорных векторов: А - линейное разде-
ление, Б - нелинейное разделение. Интенсивность цвета указывает на расстояние
до разделяющей поверхности.
Видно, что в нелинейном случае разделяющая поверхность может иметь до-
статочно сложную форму.
5.3.3. Нечеткое разделение классов
Рассмотрим ситуацию, когда не существует гиперплоскости, разделяющей
классы. Эта ситуация возникает в случае взаимно перекрывающихся данных,
либо когда данные сильно зашумлены. Такая ситуация отображена на Рис. 26.
Видно, что линейное разделение множеств Q] и Q, невозможно, поскольку точка
л*4 из множества й5 «проникла» в множество й .
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 5. Адаптивные системы распознавания образов
209
Рис. 26. Линейное разделение множеств Q и Q. невозможно, поскольку точка л4 из
множества Q, «проникла» в множество Q,
В этой ситуации можно допустить появление некоторых точек из обучающе-
го множества между гиперплоскостями Н и однако за это их нужно «нака-
зать» путем введения штрафа С. Введем в неравенства (48) дополнительные пе-
ременные £ > 0. в результате чего неравенства (48) примут следующий вид:
(wx)-6>+l-£ для примеров с у=+1.
(й- х) - b < -1 ч- £ для примеров с у=-1.
(66)
6*0.
Первые два неравенства (66) эквивалентны следующему неравенству:
(67)
В функционал (50) следует добавить штрафной член вида С(^£)\ где
С > 0 - величина штрафа, к - целое число, большее нуля. При к. равном 1 или 2,
задача остается задачей квадратичного программирования, поэтому для просто-
ты обычно используют А'=1. Таким образом, минимизируемый функционал при-
мет следующий вид:
min
(68)
Вводя множители Лагранжа а и Д. сконструируем следующий лагранжиан:
http://wwwjtv.ru
Компания ITV - генеральный спонсор издания книги
210 Цифвая обработка видеоизображений
L (w, b, I; а, р\ = 11| uf + с£ $- £ а, (г, ((w • х) - b) -1 + %,) - £ Д =
i —1 >и?
у • (69)
= г НГ - X а,у. («•• *) + ^Х а,У, + X (С - а, - Д )< + X «
i=l z=I г=1 1=1
Продифференцируем (69) по исходным переменным и приравняем произво-
дные нулю, получим:
ЭА - 'Л - л
— = w-\ а,у,х, =0.
dw l=j
?Г = Х«1У. =°- (70)
OD 1=1
^ = С-а,-Д=0.
Подставив полученные соотношения в выражение для лагранжиана (69). по-
лучим функционал для двойственной задачи:
v । Л V
найти max Д>(а)= £а, -“ХХа- (*<Л) (71)
а 1=1 *• 1=1 /=|
.V
при ограничениях 0<а<С, Л=1....ЛС (72)
i=i
Отметим, что эта задача отличается от задачи (54). (55) лишь ограничением
сверху на а в (72). Весовые векторы для разделяющей функции определяются из
того же соотношения
=X а>у^
1=1
что следует из (70).
Условия Куна-Таккера принимают следующий вид:
«,(z((wjc)-b)-l+^) = °.
(73)
= 0
для всех i=l,...7V.
5.4. КЛАСТЕРНЫЙ АНАЛИЗ
Кластеризация - это задача машинного обучения, в которой требуется раз-
бить заданную выборку объектов на непересекающиеся подмножества, называ-
емые кластерами, так, чтобы каждый кластер состоял из схожих объектов, а лю-
бые два объекта, принадлежащие разным кластерам, существенно отличались.
ProSystem CCTV — журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 5. Адаптивные системы распознавания образов
211
Кластеризация находит широкое применение на различных этапах обработки
видеоизображения. Наиболее очевидным приложением является решение зада-
чи о классификации обнаруженных объектов. Кроме этого, кластеризация ис-
пользуется и при конструировании детекторов движения, детекторов оставлен-
ных предметов, при обработке видеоархивов и при сегментации изображений.
Процесс построения кластеров принадлежит к разряду адаптивных алгорит-
мов, однако в отличие от ранее рассмотренных нейросетей и метода опорных
векторов он относится к классу методов обучения «без учителя». Это означа-
ет, что в примерах, используемых при обучении, присутствуют только входные
данные и отсутствует какая-либо информация об их принадлежности к тому или
иному классу. Термин кластер происходит от английского слова cluster - кисть,
пучок, гроздь. В этом названии неявно указывается способ построения класте-
ров: объекты, слабо отличающиеся друг от друга, должны находиться в одном
кластере, в то время как значительно различающиеся объекты должны принад-
лежать различным кластерам.
Сформулируем задачу автоматической кластеризации. Пусть у нас есть мно-
жество Q = состоящее из N л-мерных векторов ). В
дальнейшем это множество мы будем часто называть обучающим множеством
по аналогии с терминологией, принятой в искусственных нейросетях. Процесс
кластеризации заключается в разбивке обучающего множества на К непересе-
к
кающихся подмножеств Q = со, fl = О при / * ;. Подмножества будем
1*1
называть кластерами. С каждым кластером щ будем связывать вектор С., кото-
рый будем называть центром кластера или его центроидом.
Рис. 27. Разбиение множества двумерных векторов (п=2) на четыре кластера (К=4)
http://www.itv.ru
Компания ITV — генеральный спонсор издания книги
212
Цифвая обработка видеоизображений
На Рис. 27 приведен пример разбиения исходного множества двумерных век-
торов (п=2) на четыре кластера со{.cov К=4.
Методы построения кластеров можно разбить на две группы. Алгорит-
мы первой группы применяются, когда известно число кластеров К. Типичны-
ми представителями этой группы являются объединяющий (агломеративный) и
разделяющий (partition) алгоритмы, а также алгоритм К-средних (K-mean). Для
второй группы алгоритмов обычно задаются ограничения на размер создавае-
мых кластеров, а их число определяется в процессе построения автоматически.
Наиболее эффективным алгоритмом этого типа является метод адаптивного ре-
зонанса Гроссберга (ART. Adaptive Resonance Theory, [25,26]).
Результаты кластеризации существенным образом зависят от того, каким
образом выбрано расстояние как между объектами кластеризации, так и между
кластерами. Обозначим dtl = d (А', )- расстояние между двумя и-мерными век-
торами Х> и X . Наиболее часто применяются следующие способы определения
расстояния между двумя объектами.
Обобщенное расстояние Минковского.
Определяется соотношением:
=(Ё1х:-х*Г
kt=l
где р>1.
Манхэттенское (Manhattan) расстояние (или расстояние «городских кварта-
лов». city block).
Является частным случаем расстояния Минковского при р=\.
Рис. 28. Определение Манхэттенского расстояния между двумя точками А и Б на
плоскости
ProSystem CCTV - журнал по системам видеонаблюдения
ht tp://w ww. procctv. ги
Глава 5. Адаптивные системы распознавания образов
213
Рис. 28. Определение Манхэттенского расстояния между двумя точками А и Б на
плоскости
d>.=Xk -4
Ы
Таким образом вычисляется расстояние между объектами на улицах города,
состоящего из кварталов: при этом предполагается, что двигаться можно только
по улицам, а движение через любой квартал «наискосок» запрещено. Эта ситуа-
ция в двумерном случае отображена на Рис. 28.
Если компоненты векторов являются бинарными, т. с. принимают только два
значения, то это расстояние называется расстоянием Хэмминга. Численно оно
равно количеству несовпадающих компонент у сравниваемых векторов.
Евклидово расстояние.
Частный случай расстояния Минковского при р=2. Определяется как .
*=1
Это расстояние является самым естественным в прямоугольных декартовых
координатах. В двумерном случае это выражение превращается во всем хорошо
известную теорему Пифагора: квадрат гипотенузы равен сумме квадратов кате-
тов (см. Рис. 29).
Расстояние Чебышева.
Определяется как d = maxlx!
J .л '
СКОГО при р —> СО.
-xJk. Является пределом расстояния Минков-
Расстояние Махаланобиса. г
Определяется формулой: - X}) S"1 (%, - XJ), где символом S 1 обо-
значена матрица, обратная к ковариационной матрице генеральной совокупно-
сти векторов, из которой извлекаются сравниваемые векторы.
На Рис. 30 приведены результаты кластеризации двумерных данных на
5 кластеров одним и тем же методом при использовании различных рассто-
яний. Интенсивность цвета отображает близость к своему классу: чем тем-
нее, тем ближе. Видно, что результаты качественно отличаются, при этом
использование расстояния Махаланобиса позволяет наилучшим образом
учесть структуру множеств. Однако вычисление этого расстояния требует
значительных вычислительных ресурсов, поэтому оно редко применяется в
задачах реального времени.
http://wwwjtv.ru
Компания ITV - генеральный спонсор издания книги
214
Цифвая обработка видеоизображений
Рис. 30. Результаты кластеризации двумерных данных на пять кластеров одним
и тем же методом при использовании различных расстояний: А - евклидово, Б -
манхэттенское, В - Махаланобиса, Г - Минковского при Р=3
В качестве расстояния plf = p(C0i,(0f) между двумя кластерами со и со наибо-
лее часто используются следующие метрики:
Расстояние по принципу «ближнего соседа*:
Расстояние, измеренное по принципу «дальнего соседа»:
Р, = max.d(Xi,X,\
Расстояние между «центрами тяжести» (центроидами) кластеров:
где С, и С, - центроиды кластеров со и со .
ProSystem CCTV - журнал по системам видеонаблюдения
http://www procctv. ru
Глава 5. Адаптивные системы распознавания образов
215
Рис. 31. Расстояния между кластерами: А - по принципу «ближнего соседа», Б - по
принципу «дальнего соседа», В - расстояние между центроидами кластеров
На Рис. 31 приведены способы вычисления описанных расстояний между кла-
стерами на плоскости.
5.4.1. Кластеризация при заданном числе кластеров
Поскольку конкретная реализация каждого метода кластеризации зависит
от решаемой задачи и различных дополнительных ограничений, задаваемых раз-
работчиком, ниже описываются главные принципы, лежащие в основе каждого
метода, и приводятся базовые алгоритмы.
Агломеративные методы
Название этих алгоритмов происходит от латинского agglomero - присоеди-
няю, накапливаю, поскольку они основаны на идее последовательного объедине-
ния отдельных элементов и кластеров в более крупные кластеры. В начальный
момент считается, что каждый элемент обучающего множества образует свой
кластер. Иными словами, первоначально мы имеем N кластеров, каждый из ко-
торых содержит ровно один элемент. Далее вычисляются расстояния между все-
ми кластерами, после чего выбираются два кластера, расстояние между которы-
ми наименьшее. Эти кластеры объединяются в один, после чего число кластеров
становится N-1. Описанный процесс повторяется до тех пор, пока число класте-
ров не станет равным заданному числу К. Алгоритмы этой группы различаются
способом нахождения расстояния между кластерами. Для облегчения последую-
щего анализа процесс объединения объектов в кластеры агломеративными ме-
тодами принято отображать с помощью графика, называемого дендрограммой
(от греческого dendron - дерево). Пример дендрограммы приведен на Рис. 32.
http://www. itv.ru
Компания ITV - генеральный спонсор издания книги
216 Цифвая обработка видеоизображений
Рис. 32. Отображение процесса кластеризации в виде дендрограммы
По оси абсцисс отложены классифицируемые объекты (в данном случае их
шесть), а по оси ординат - расстояние между кластерами. Из приведенной дендро-
граммы видно, что вначале были объединены объекты с номерами 3 и 4, посколь-
ку расстояние между ними было меньше всех остальных и равным ровно единице.
На следующем шаге объединяются объекты 1 и 2. На третьем шаге к кластеру, со-
держащему два объекта (3 и 4). присоединяется объект номер 5 и т. д.
Алгоритм
1. Инициализация.
Назначить значение К - требуемое число кластеров;
k~N~ начальное число кластеров;
для всех назначить центры кластеров: С,. = Хг
2. Рекурсия.
2.1. Поиск ближайших кластеров.
Найти индексы для которых
d. . = min t/fc.jCA
2.2. Объединение ближайших кластеров
/ = min(z J ),J = max(/ ,/ ),
co, = cot U co - объединение элементов кластера;
С, = z-Ц: У X - центр нового кластера;
к := к -1 - уменьшить число кластеров;
удалить индекс J из списка номеров кластеров.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 5. Адаптивные системы распознавания образов
217
Здесь символом обозначено общее количество векторов, которые попа-
дают в кластер а)г
2.3. Проверка на достижение заданного числа кластеров.
Если к = /Сто получено заданное число кластеров, СТОП;
Иначе возврат к пункту 2.1.
Разделяющие методы.
Эти методы основаны на идее последовательного деления крупных кластеров
на более мелкие до тех пор, пока не получим заданное число кластеров. В перво-
начальный момент считаем, что все объекты принадлежат одному кластеру. На-
ходим в нем два объекта С, и С,, между которыми наибольшее расстояние. Они
считаются центроидами двух новых кластеров. Затем проводится назначение
всех оставшихся элементов множества этим кластерам по принципу близости к
соответствующему центру; т. е. для каждого объекта Xt вычисляются расстояния
и d2 = d(%pC2). Если d.< d^. то Xt относят к первому кластеру, в про-
тивном случае - ко второму. Далее для каждого кластера вычисляют его размер,
после чего наибольший кластер делят на две части описанной выше процедурой.
Процесс деления останавливается по достижении заданного числа кластеров.
Для поиска наибольшего кластера вводится понятие диаметра кластера, для
вычисления которого можно использовать следующую формулу:
Di = maxd(X/9Xk} - «диаметр» /- го кластера.
Алгоритм
1. Инициализация.
Назначить значение К - требуемое число кластеров;
к = 1 - начальное число кластеров;
2. Рекурсия.
2.1. Поиск кластера с наибольшим диаметром:
Dm = max D,
т ‘
2.2. Поиск в кластере с номером >и, имеющим наибольший диаметр, двух наи-
более удаленных элементов:
du = maxd(Xl9X\
X
2.3. Деление кластера с номером т на два кластера.
2.3.1. Определение центров новых кластеров.
к~к + \\
сп = х-,
ск = х,.
2.3.2. Определение элементов новых кластеров.
Для всех Xt 6 щ выполнить:
Если d[Xl9C\<d(Xi9Ck\
то X' е (От.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
218
Цифвая обработка видеоизображений
иначе % е (ос
2.3.3. Уточнение центров кластеров.
ст=л-Ц У X.
ни А
ск = п-Ц У х.
НИ Х.сш,
2.4. Проверка на достижение заданного числа кластеров.
Если к = К,то получено заданное число кластеров, СТОП;
Иначе возврат к пункту 2.1.
Алгоритм К-средних (K-means)
Этот алгоритм является итерационным. Из кластеризуемого множества вы-
бираются произвольным образом К объектов, которые считаются центрами ис-
комых кластеров. Затем проводится назначение всех оставшихся элементов мно-
жества этим кластерам по принципу близости к соответствующему центру. Да-
лее производится уточнение положения центроидов, которые вычисляются как
среднее по совокупности всех объектов, попавших в каждый кластер. Этот про-
цесс повторяется до тех пор. пока изменение центров кластеров по сравнению с
вычисленным на предыдущей итерации не станет достаточно малым. K-tneans
алгоритм считается наиболее быстрым среди описанных выше алгоритмов.
Алгоритм
1. Инициализация.
Выбираем К произвольных попарно несовпадающих векторов и назначаем
их центрами кластеров (центроидами) - Сг
2. Поиск ближайших соседей.
Для каждого вектора из обучающего множества Х} находим ближайший цен-
троид СР i = arg min d \ X , Ct) и назначаем вектор кластеру с центром в Сг
3. Уточнение положений центроидов.
Вычисляем новые координаты центров кластеров как среднее по совокупно-
сти векторов, попавших в этот кластер, т. е. для всех i, 1 < i < К. С = и——п У X..
‘ 7
Здесь символом ||<у.|| обозначено общее количество векторов, попавших в кла-
стер (ОГ
4. Проверка условия окончания итераций.
Вычисляем относительное изменение координат центроидов
а = £|с((0-с,(г-1)|.
/I
Если координаты центров кластеров изменились менее чем на заданную ве-
личину <5,т. е. Д< 8 - СТОП, кластеризация завершена.
В противном случае возврат к пункту 2.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 5. Адаптивные системы распознавания образов
219
5.4.2. Кластеризация при неизвестном числе кластеров
В этом случае необходимо ввести параметр Е - ограничение на взаимную
удаленность соседних объектов, принадлежащих одному кластеру. Введение
такого ограничения вовсе не означает, что объекты каждого кластера будут
находиться внутри л-мерной сферы радиуса £, поскольку топология кластеров
зависит от выбранных функционалов расстояния. Рассмотрим эффективный
метод кластеризации, основанный на принципах теории адаптивного резо-
нанса.
Произвольным образом выбирается один объект который назначается
центром первого кластера: С. = Xv Далее для всех остальных объектов ^ вы-
полняется следующее. Вычисляются расстояния dk = d(X.,CJ от вектора %, до
всех найденных к текущему времени центров кластеров Q. из которых выбира-
ется наименьшее dm. Если dm< £. считается, что рассматриваемый объект при-
надлежит кластеру номер tn: в этом случае корректируется положение центра
кластера Ст с учетом вновь добавленного вектора. Если же не нашлось ни одно-
го кластера, к которому можно отнести вектор Xt (т. е. dk> £ для всех к), то об-
разуется новый (&+1 )-й кластер, центром которого назначается вектор Xt: См=
X. . Далее процесс продолжается до тех пор, пока не закончатся кластеризуе-
мые векторы. В результате описанного алгоритма получим число к - количе-
ство созданных кластеров, а также множество, состоящее из к векторов - цен-
тров кластеров: (Сг С2.CJ.
Алгоритм
1. Инициализация.
Назначить следующие значения:
£ - ограничение на взаимную удаленность объектов, принадлежащих одно-
му кластеру;
а - параметр, используемый при корректировке кластеров, 0 < а < 1;
К=1 - число кластеров;
Ct=%| - центроид первого кластера.
2. Рекурсия.
Для всех i-2y...N выполнить следующее:
2.1. Поиск ближайшего кластера
d=wnd(XiyCk\
2.2. Проверка на принадлежность.
Если dm< Еу то скорректировать положение центра /и-го кластера
Cm = aCm + (l-a)X(;
Иначе создать новый кластер:
Х:=К + 1,
Ск = X,
Более подробно ознакомиться с техникой кластерного анализа можно по
книгам [27-32].
http://www. itv. ru
Компания ITV - генеральный спонсор издания книги
220
Цифвая обработка видеоизображений
5.5. МЕТОДЫ БУСТИНГА
Надежность распознавания любой реальной системы, к сожалению, обычно
далека от желаемых 100%. Оказывается, существует возможность улучшить ее
характеристики за счет применения так называемого бустинга (от английского
boosting - повышение производительности, усиление). В основе бустинга лежит
принцип «разделяй и властвуй», т. е. исходная проблема делится на несколько бо-
лее простых задач, а решение каждой из подзадач поручается отдельному «экс-
перту». В качестве эксперта может использоваться существующая распознаю-
щая система, но только обученная особым образом. Идея использования набора
экспертов, по-видимому, впервые была высказана в 1965 году Нильсоном [33]. Он
предложил структуру, состоящую из слоя персептронов, которые были объеди-
нены в сеть для выработки итогового решения по принципу голосования. Даль-
нейшим развитием этой идеи явилась разработка современных методов бустин-
га, с помощью которых стало возможным повысить существенным образом про-
изводительность распознающей системы.
Итак, назначение бустинга - повысить качество распознающей системы
за счет использования набора элементарных распознавателей (классифика-
торов), обученных на различных выборках из обучающего множества. В ан-
глоязычной литературе элементарные распознаватели обозначают как Weak
Learning Algorithm и часто называют «слабыми распознавателями», посколь-
ку от них обычно требуется, чтобы они обладали достоверностью распозна-
вания несколько лучшей, чем 50%. Ниже мы их также будем называть сла-
быми распознавателями или пользоваться аббревиатурой WLA. Чаще всего
используют два способа бустинга: первый основан на фильтрации обучаю-
щих примеров, а второй - на использовании различных выборок из обучаю-
щего множества.
1. Бустинг за счет фильтрации. В этой группе методов примеры из обучаю-
щего множества для различных слабых распознавателей отбираются спе-
циальным образом. Предполагается, что существует очень большое, тео-
ретически бесконечное число примеров для обучения, из которых можно
выбрать необходимый набор с нужными свойствами.
2. Бустинг за счет различного распределения примеров из фиксированного об-
учающего множества. В этом случае каждый из элементарных распознавате-
лей обучается на различных выборках из заданного обучающего множества,
причем закон распределения выборки в процессе эволюции системы изменя-
ется для обеспечения наилучшей производительности системы в целом.
Ниже рассматриваются алгоритмы, основанные на указанных принципах.
5.5.1. Бустинг за счет фильтрации
Рассмотрим простейший вариант этого метода, когда используются всего три
эксперта. Эти эксперты обучаются индивидуально в соответствии со следующим
алгоритмом [34]:
1. Первый эксперт обучается на произвольной обучающей выборке, состо-
ящей из Aj примеров.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 5. Адаптивные системы распознавания образов
221
2. После настройки первый эксперт используется в качестве фильтра для фор-
мирования обучающей выборки для второго эксперта следующим образом.
С использованием генератора равномерно распределенных случайных чисел
разыгрывается значение случайной величины <£. Если £ < 0.5, то примеры из обу-
чающего множества подаются на вход первого эксперта до тех пор, пока он не
выдаст неправильный ответ. Пример, на котором первый эксперт ошибся, добав-
ляется в обучающую выборку для второго эксперта. Если £ > 0.5, то на вход пер-
вого эксперта подаются примеры из исходного множест ва до тех пор, пока он не
выдаст правильный ответ. Пример, на котором первый эксперт выдал верное за-
ключение, заносится в обучающую выборку для второго эксперта.
Описанный процесс повторяется до тех пор, пока размер обучающей выбор-
ки для второго эксперта не достигнет числа Nv Ясно, что на полученной выбор-
ке достоверность первого эксперта будет порядка 0.5. Этим достигается отличие
выборок, на которых обучаются первые два эксперта.
3. Второй эксперт обучается на сформированной выборке.
4. Формируется обучающая выборка для третьего эксперта.
Очередной пример из обучающего множества предъявляется одновременно
первому и второму экспертам. Если их решения различаются, этот пример добав-
ляется к обучающей выборке для третьего эксперта.
Описанный процесс повторяется до тех пор, пока размер обучающей выбор-
ки для второго эксперта не достигнет числа Nv
5. Третий эксперт обучается на созданной выборке.
В описанной процедуре для обучения первого эксперта использовались
примеров, для формирования обучающей выборки для второго просматрива-
лись N2> N} примеров, а для третьего N3> N2 - примеров. Таким образом, через на-
бор экспертов было так или иначе пропущено N}+ N2+ разных примеров, что
превосходит число примеров ЗЛ/Г участвовавших в независимом обучении всех
трех экспертов по отдельности. Поэтому можно надеяться, что набор экспертов
«умнее», чем три независимых эксперта.
Набор экспертов принимает решение следующим образом. Новый образец
подается на вход первым двум экспертам. Если они выдают одинаковое заклю-
чение, оно принимается за решение задачи. Если же их мнения различаются, то в
качестве итогового принимается заключение третьего эксперта.
Предположим, что ошибка каждого из трех экспертов при их индивидуаль-
ном обучении равна £, причем £ < 1/2. В работе [34] доказано, что ошибка набора
из трех экспертов не превышает
£,<Зе2-2е\ (74)
откуда следует, что система, состоящая из трех экспертов, выдает заключение с
большей достоверностью, чем любой из экспертов по отдельности.
5.5.2. Бустинг за счет распределения примеров
Недостатком предыдущего алгоритма является требование неограниченно-
го числа примеров для обучения, что не всегда можно выполнить на практи-
ке. При фиксированном наборе примеров повысить производительность набо-
http://www. itv. ги
Компания ITV - генеральный спонсор издания книги
222
Цифвая обработка видеоизображений
ра экспертов можно за счет правильно сформированной выборки для обучения
каждого эксперта. Наиболее хорошо зарекомендовали себя на практике алго-
ритмы из семейства AdaBoost (Adaptive Boosting) [35-36]. основанные на после-
довательной адаптации системы экспертов к обрабатываемым данным.
Для настройки AdaBoost используется набор примеров S = d„)
в стандартном виде. Здесь xt е X - входной векторХ, G D = номер клас-
са, которому принадлежит входной вектор. AdaBoost обращается к слабому рас-
познавателю WLA заданное число раз Тс новым распределением Dt примеров из
обучающего множества S. При этом на каждом новом шаге от WLA получается
очередной вариант проведенной распознавателем классификации исходной ин-
формации. Результат классификации на шаге t называют гипотезой: Л,: X -> D,
и на основании этой гипотезы вычисляется очередное распределение примеров
Dt. Целью элементарного распознавателя является нахождение такой гипотезы
ftf, которая минимизирует ошибку классификации (ошибку обучения) £. После
повторения описанного процесса Т раз полученные гипотезы h?...,hT комбиниру-
ются в итоговую гипотезу, за счет чего и происходит повышение достоверности
распознавания.
Рассмотрим практически важный случай разделения двух классов. Такого
рода задачи возникают, например, при создании распознающих систем, которые
должны ответить на вопрос: есть ли на предъявленном изображении заданный
объект, допустим, человеческое лицо или автомобиль? Распознающая система
должна выдать заключение в форме «да» или «нет». Иными словами, все возмож-
ные изображения делятся на два класса в зависимости от того, присутствует на
них заданный объект (1 класс) или нет (2 класс). Предположим, что первому клас-
су соответствует значение d-1. а второму — d=0. В описываемой версии алгорит-
ма предполагается, что элементарный распознаватель выдает заключение в виде
гипотезы принадлежности входного вектора заданному классу следующего вида:
Л(х): X -+ [0,1} Значение й(х) может интерпретироваться следующим образом:
вектор х принадлежит классу d=l с вероятностью Л(х) и классу d=0 с вероятно-
стью 1-Л(х) . Ошибкой гипотезы служит математическое ожидание величины
£(|A(x)-J(x)|).
Алгоритм AdaBoost для разделения двух классов
Пусть нам дан набор примеров = где xt е X - входной
векторХ е D = {0,1}- номер класса, которому принадлежит входной вектор. За-
дадим Т - число итераций.
1. Инициализация. Равномерно распределить весовые коэффициенты:
w (0 = V для всех
2. Для всех выполнить:
Вычислить для всех
„ (Л - МО:
р, (О - ~а--
2X0
Обратиться к WLA с распределением Pt = {р, рД*)} и получить от
WLA гипотезу ht: X —> [О,1].
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 5. Адаптивные системы распознавания образов
223
N
Вычислить ошибку h( гипотезы на всей выборке: = X А (г)|Л,(х, )-</,.
1=1
Вычислить для гипотезы h( весовой коэффициент: Д
Модифицировать вектор весов: и; (f +1) = w (/) Д d,i.
Вернуться к шагу 2.1
Сформировать итоговую гипотезу:
если
z[,ogyW)^|x(iogj
/-I k Pl J z r=i \ Р/ 7
в противном случае
Как видно из приведенного алгоритма, весовые коэффициенты ил(г) после-
довательно подстраиваются для всех обучающих примеров. По этим коэффици-
ентам путем перенормировки определяется закон распределения примеров Р.
В соответствии с этим распределением примеры подаются на вход элемен-
тарному распознавателю WLA. который после обучения формирует гипоте-
зу h, имеющую малую ошибку по отношению к данному распределению. По
полученной ошибке для гипотезы ht вычисляется весовой коэффициент Д, на
основании которого при формировании итоговой гипотезы hf будет учиты-
ваться значимость f-й гипотезы. Далее AdaBoost порождает новые весовые
коэффициенты vv(/+l), и описанный процесс повторяется. Итоговая гипоте-
за формируется из полученных в процессе работы алгоритма путем взвешен-
ного голосования.
Для разделения нескольких классов используется другая версия этого алго-
ритма, получившая названия AdaBoost.Ml [35]. Пусть число возможных классов
равно А,т. е. множество возможных меток классов D={1,...,A|. Нам известен набор,
состоящий из N примеров,S = (хрД),...,(Яд,,dN), где х, 6 X.di е D. Зафиксируем
значение Т - число итераций.
Алгоритм AdaBoost.Ml
1. Инициализация: и>. (1) = 1//V для всех N.
2. Для всех выполнить:
2.1 Вычислить для всех 7=1,...,7V
2.2. Обратиться к WLA с распределением Pt = (г),,
от WLA гипотезу ht: X D.
23. Вычислить ошибку гипотезы А на всей выборке:
£( = £а(')[а, (*,)*<]•
1=1
Рдг (/)} и получить
2.4. Если Et >
то назначить Т := t -1 и перейти к пункту 3.
Компания ITV - генеральный спонсор издания книги
224
цифвая обработка видеоизображений
2.5. Вычислить для гипотезы ht весовой коэффициент: Д =
2.6. Модифицировать вектор весов:и;(f + l) = wr(t) Д1
3.
2.7. Вернуться к шаг}’ 2.1.
Сформировать итоговую гипотезу:
Главным отличием от предшествующего алгоритма является способ вычис-
ления ошибки: вместо (xj -dt используется [fy (х ) * dt ]]: по определению, для
любого предиката Р
1 , если Р выполняется
р]= ’
О, в противном случае.
Изменения также появились при определении итоговой гипотезы: выбирает-
ся тот класс, который минимизирует сумму взвешенных гипотез ht.
Как и в предыдущем случае, при формировании нового распределения мы
уменьшаем вес примера, если он был классифицирован правильно, и увеличива-
ем в противном случае.Таким образом «легкие» примеры в новом распределении
получают меньший вес, чем примеры, на которых слабый распознаватель оши-
бается, вынуждая его «сконцентрироваться на трудных примерах» на очередном
этапе обучения. Финальная гипотеза является результатом взвешенного голосо-
вания слабых гипотез, выработанных в процессе настройки. Весом гипотезы Л
является величина log (1/Д), так что большие веса имеют гипотезы с наимень-
шей ошибкой. Для описанного алгоритма справедлива следующая теорема [35].
Теорема
Предположим, что алгоритм WLA, который использует метод AdaBoost.Ml,
порождает гипотезы с ошибкой £, меньшей 1/2.Тогда для ошибки итоговой гипо-
тезы справедлива следующая оценка:
-1{': (xf) * < }| < П 71-4/,2 ехР ( -2^ 1 <75)
п Z=| \ /=| 7
где у, = 1/2
Из этой теоремы следует, что если слабый распознаватель имеет ошибку, не-
много меньшую, чем 1/2, то ошибка итоговой гипотезы стремится к нулю экспо-
ненциально быстро. Главным недостатком алгоритма AdaBoost.Ml является то
обстоятельство, что он не может корректно обрабатывать гипотезы, у которых
точность не превышает значение 1/2. При случайном угадывании ошибка в опре-
делении правильного класса оценивается как 1-1/л, где п - число классов. Поэто-
му при использовании алгоритма AdaBoost.Ml для п>2 на качество слабого рас-
познавателя должны быть наложены более сильные требования.
В следующей версии алгоритма, названной AdaBoost.M2 [35], была пред-
принята попытка исправить этот недостаток за счет лучшего взаимодействия
бустинг-алгоритма и элементарного распознавателя. Предположим, что слабый
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://w w w. procc t v. г и
Глава 5. Адаптивные системы распознавания образов
225
распознаватель способен выдавать не номер класса, а вектор [0,1] 6 Rn. Каждая
компонента этого вектора характеризует степень доверия, с которой входной
сигнал может быть отнесен к тому' или иному’ классу. Взамен ранее использовав-
шейся ошибки предсказания удобно использовать другую меру - псевдопотерю,
которую также можно измерять с учетом распределения обучающих примеров.
Формально ошибку классификации можно определить как пару (/, у), где / - ин-
декс примера, а у - неверный ответ, выданный элементарным распознавателем.
Введем множество ошибочных классификаций:
Ошибочное распределение Df определяется на множестве В. Путем опреде-
ленных манипуляций с этим распределением бустинг-алгоритм пытается сосре-
доточить внимание слабого распознавателя на наиболее трудных примерах. Сла-
бый распознаватель формирует гипотезу ht в виде й,: X х Y -»[0,1].
Гипотеза й(х,у) характеризует степень доверия тому, что у - коррект-
ный класс, ассоциируемый с х. Если й(х,у) =1, то гипотеза принимается, а если
h(x,y) = 0 - не принимается. Нетрудно проверить, что для любого входного век-
тора х. из обучающего множества вероятность неправильного ответа равна
AdaBoost.M2
1. Инициализация: ,.(1) = 1/(М(£-1))для всех 7=1,...,7V, у е £>-{</,}.
2.
Для всех г=1,...,7'-1 выполнить:
2.1. Вычислить для всех i=l,...,N
^(0=
2.2. Для всех iN ну * dt вычислить
,, ^(0
Pl (0 N
м
2.3. Обратиться к WLA с распределением Р, = {р, (/),.
от WLA гипотезу Л,: X х Y —>[О,1].
2.4. Вычислить ошибку гипотезы Л( на всей выборке:
1 * f
2 *=1 \ )
pN (/)} и получить
2.5. Вычислить для гипотезы Л весовой коэффициент: Д
2.6. Для всех ну * dt модифицировать вектор весов:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
226
Цифвая обработка видеоизображений
M+lJsWfr
2.7. Вернуться к шагу 2.1.
3. Сформировать итоговую гипотезу:
hf (х) = arg max
Для описанного алгоритма справедлива следующая теорема [35].
Теорема
Предположим, что алгоритм WLA. который использует метод AdaBoost.M2,
порождает гипотезы с нссвдопотерями £, каждая из которых меньше 1/2.
Тогда для ошибки итоговой гипотезы справедлива следующая оценка:
-1{*: А (х() # < }| < (л -1) fj - 4у; <(л-1)ехрГ-2£у,21 (76)
где у, = 1/2 -£г ап - число классов.
5.6. СПИСОК ЛИТЕРАТУРЫ
1. М. К. Hu. Visual Pattern Recognition by Moment Invariant. In: IEEE Transactions
on Information Theorys. 8, p.I79-187, 1962.
2. S. Zokai, G.Wolberg. Image Registration Using Log-polar Mappings for Recovery
of Large-scale Similarity and Projective Transformations. In: IEEE Transactions on
Image Processings- 14, p. 1422-1434,2005.
3. L. A.Torres-Mendez, J. C. Ruiz-Suarez, Luis E. Sucar, G. Gomez.Translation, Rotation,
and Scale-invariant Object Recognition. In: IEEE Transactions on Systems, Man
and Cybernetics, v. 30, p. 125-130,2000.
4. Гончарский А.В., Кочиков И.В., Матвиенко А.Н. Реконструктивная обработ-
ка и анализ изображений в задачах вычислительной диагностики. - М.: Изд-во
Московского университета, 1973.- 140 с.
5. ТЪнсалес Р, Вудс Р Цифровая обработка изображений. - М.:Техносфера,2006.-1072 с.
6. Форсайт Д., Понс Ж. Компьютерное зрение. Современный подход. - М.: Изд.
дом ’’Вильямс", 2004. - 928 с.
7. Методы компьютерной обработки изображений / Под ред. В.А.Сойфера. - М.: Физ-
матлит, 2003. - 784 с.
8. Шапиро Л., Стокман Дж. Компьютерное зрение. - М.: "Бином. Лаборатория
знаний, 2006.-752 с.
9. A.D. Kulkarni. Artificial Neural Network for Image Understanding. New York, Van
Nostrand Reinhold, 1994,210 p.
10. E Rosenblatt. The Perceptron: A Probabilistic Model for Information Storage and
Organization in the Brain. In: Psychological Reviews. 65, p. 386-408,1958.
11. W. S. McCulloch, W. Pitts. A Logical Calculus of the Ideas Immanent in Nervous
Activity. In: Bulletin of Mathematical Biophysics, v. 5, p. 115-133,1943.
12. Соколов E. IL, Вайткявичус Г Г Искусственный интелект: от нейрона к нейро-
компьютеру. - М.: Наука, 1990. - 237 с.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 5. Адаптивные системы распознавания образов
227
13. Уоссер.маен Ф. Нейрокомпьютерная техника. Теория и практика. - М.: Мир,
1992.-237 с.
14. Гордиенко Е. К.. ЛукьяницаА. А. Искусственные нейронные сети. 1. Основные
определения и модели. Изв. Академии наук, сер. Техническая кибернети-
ка.- № 5.1994. - С.79-92.
15. Горбань А. Н. Обучение нейронных сетей. - М.: СП Параграф, 1991. - 160 с.
16. Хайкин С. Нейронные сети. Полный курс. - М.: Изд. Дом "Вильямс? 2006. -1104 с.
17. Каллан Р Основные концепции нейронных сетей. - М.: Изд. Дом “Вильямс?
2003.-288 с.
18. N. К. Kasabov. Foundations of Neural Networks. Fuzzy Systems and Knowledge
Engineering. MIT Press. Cambrige. 1996.550 p.
19. J. A. Hertz. R. G. Palmer. A. Krogh. Introduction to the Theory of Neural
Computation. Westview Press. 1991.352 p.
20. Минский M.. Пейперт С. Персептроны. - M.: Мир. 1971. - 261 c.
21. Оссовский С. Нейронные сети для обработки информации. - М.: Финансы и
статистика. 2002. - 344 с.
22. Вапник В. Н, Червоненкис А. Я. Теория распознавания образов. - М.: Наука.
1974.-415 с.
23. Advances in Kernel Methods. Support Vector Learning. B. Scholkopf C.J.C. Burges,
A. J. Smola (eds.), MIT Press, Cambridge, 1998,376 p.
24. V N. Vapnik. The Nature of Statistical Learning Theory (Statistics for Engineering
and Information Science), 2nd edition. New York, Springer-Verlag, 1999,304 p.
25. S. Grossberg. Adaptive Pattern Classification and Universal Recoding, I. Parallel
Development and Coding of Neural Feature Detectors. In: Biological Cybernetics,
v. 23, p. 121-134,1976.
26. S. Grossberg. The ART of Adaptive Pattern Recognition by a Self-organizing Neural
Network. In: Computer^. 21, p. 77-88,1988.
27. Мандель И.Д. Кластерный анализ. - M.: Финансы и статистика, 1988. - 176 с.
28. Ким Дж. О., Мьюллер Ч. У, Клекка У Р. и др. Факторный, дискриминантный и
кластерный анализ. Пер. с англ. / Под ред. И.С.Енюкова. - М.: Финансы и ста-
тистика, 1989. - 215 с.
29. Айвазян С. А., Бухштабер В. М., Енюков И. С., Мешалкин Л. Д. Прикладная
статистика: Классификация и снижение размерности. - М.: Финансы и стати-
стика, 1989. - 607 с.
30. Дюран Б., Одел П. Кластерный анализ. - М.: Статистика, 1977. - 128 с.
31. Классификация и кластер / Под ред. Дж. Вэн Райзина. М.: Мир, 1980. - 390 с.
32. А. К. Jain, R. С. Dubes. Algorithms for Clustering Data. Prentice Hall College Div,
1988,320 p.
33. N. J. Nilsson. Learning Machines: Foundation of Trainable Pattern-classifying
Systems. New York, McGraw-Hill, 1965,137 p.
34. R. E. Schapire.The Strength of Weak Learnability. In: Machine Learning, v.5,p. 197-
227,1990.
35. Y Freund, R. E. Schapire. A Decision-theoretic Generalization of On-line Learning and an
Application to Boosting. In: Journal of Computer and System Sciences, v. 55, p. 119-139,1997.
36. Y. Freund, R. E. Schapire. A Short Introduction to Boosting. In: Journal of Japanese
Society for Artificial Intelligence, v. 14, p. 771-780,1999.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
ГЛАВА 6.
ДЕТЕКТИРОВАНИЕ
ОСТАВЛЕННЫХ ПРЕДМЕТОВ
230 Цифвая обработка видеоизображений
В последние годы резко возрос интерес к проблеме автоматического обна-
ружения оставленных предметов, что вызвано повышением требований к безо-
пасности аэропортов, магазинов и других мест массового скопления людей. Ка-
залось бы, что для решения данной задачи можно использовать стандартную си-
стему сопровождения движущихся объектов: как только наблюдаемый объект
остановился и остается неподвижным в течение заданного времени, то класси-
фицировать его как оставленный. Такая система действительно будет работать в
некоторых простых случаях, однако она не сможет корректно обработать боль-
шое число ситуаций, которые встречаются на практике. Рассмотрим, например,
развитие ситуации, которая была проанализирована реальным видеодетекто-
ром оставленных предметов. Эта ситуация представлена на Рис. 1. На левой ча-
сти рисунка изображены события, произошедшие в различные моменты време-
ни, а на правой половине - соответствующие модели заднего плана (фона). Че-
ловек подходит к стенду на выставке (Рис. 1В), при этом он четко распознает-
ся системой видеонаблюдения как движущийся объект в результате сравнения
с моделью фона, построенной системой к этому моменту (Рис. 1Г). Далее чело-
век неподвижно стоит продолжительное время (Рис. 1Д), в результате чего систе-
ма начинает сегментировать его в фон (Рис. 1Е). И, наконец, человек уходит; при
этом можно заметить, что он успел прикрепить на стену какой-то черный объект
(Рис. 1Ж). Однако этот объект не был опознан как оставленный системой видео-
наблюдения, поскольку его цвет практически совпадает с текущим цветом фона,
в данном случае с черным цветом брюк (Рис. 1И).
В настоящей главе рассматриваются три группы алгоритмов детектирования
оставленных предметов, основанные на статистических методах, использующих
модель фона, а также методы бустинга.
6.1. СТАТИСТИЧЕСКИЕ МЕТОДЫ
На первом этапе алгоритма необходимо детектировать движущиеся пиксе-
ли. Пусть и и v скорости пикселя с интенсивностью / в направлении х и у соот-
ветственно. Тогда уравнение оптического потока выглядит следующим образом:
Э/ 3Z 3Z
7Г = t-u + t-v.
dt дх ду
(1)
Использование оптического потока в настоящее время не представляется
возможным в реальном времени вследствие высоких требований к производи-
тельности компьютера. Однако если нам необходимо только детектировать дви-
жение (т. е. |и| > 0 и/или |v| > 0), а конкретные значения и и v нас не интересуют,
то можно просто проверить выполнение условия |Э//Э/| > 0. Единственным недо-
статком такого подхода является невозможность обнаружить движение однород-
но окрашенных объектов, для которых д1/дх ~ 0 и д!/ду = 0 [1].
Для того чтобы проверить выполнение условия |Э//Э/| > 0, будем вычислять
разность значений пикселей в текущем и предшествующих кадрах:
Д = X-T|Cf-C(|, (2)
т=г-я
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 6. Детектирование оставленных предметов
231
Рис. 1. Развитие ситуации, в которой стандартная система видеонаблюдения не
способна детектировать оставленный объект: А, В, Д, Ж - изображения сцены в
различные моменты времени, Б, Г, Е, И - соответствующие им модели фона.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
232
Цифвая обработка видеоизображений
где wr - весовые коэффициенты, подбираемые таким образом, чтобы более отда-
ленные кадры имели меньший вес. Через С здесь обозначена интенсивность теку-
щего пикселя. Функция распределения значений величины (2) для статичных пик-
селей, т. е. пикселей, не изменяющих своего значения, поскольку в соответствую-
щей точке изображения не наблюдается никакого движения, является унимодаль-
ной с математическим ожиданием равным нулю. Это легко показать, если пред-
ставить наблюдаемое значение пикселя С, в момент времени г, как сумму гауссов-
ского шума nt со средним /лп и дисперсией и истинного значения пикселя Г.
Ct=I^n,. (3)
Составив разность С, и С/И. мы уничтожим член Доставив только шум п-пиГ
который имеет такую же плотность распределения, как и Dt:
(4)
exp------5- .
4cr
Величина представляет собой вероятность отсутствия движения, и даже
при сильном перекрытии объектов ее функция распределения может быть оце-
нена с помощью набора разностей Dt и учета того факта, что она является уни-
модальной с нулевым средним. Такая оценка может быть выполнена следующим
образом. Сначала находится ближайший к нулю максимум/0. Обозначим через/,
и /г соседние с/0 максимумы соответственно слева и справа. Построим гистограм-
му по трем ячейкам, значения которых будут /0/(/0+ / + /г), ///(/0 + fi + Л) и
+ fi + f,) соответственно. Дисперсия функции распределения будет равна
/[2ж(/./(л+у;+Г.))!}
Пример такой плотности распределения показан на Рис. 2, где отчетливо вид-
ны множественные пики, обусловленные движением.
Отметим, что с помощью построенной плотности распределения невозмож-
но отличить статичные пиксели от однородных, которые соответствуют движе-
0.08
0.06
0.04
002
D.
о
-150 -100
Рис. 2. Частота появления определенных значений разности и соответствующая ей
плотность распределения.
100 150
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. г и
Глава 6. Детектирование оставленных предметов
233
нию объекта с однородной интенсивностью изображения. Чтобы устранить эту
проблему, можно увеличить значение п в (2). Однако слишком большие значения
приведут к тому, что неподвижные пиксели будут ошибочно классифицироваться
как подвижные. Указанная проблема движения объектов, которые имеют одно-
родную интенсивность изображения, а также тот факт, что вследствие перекры-
тия объектов фоновые пиксели видны только в течение короткого времени, су-
щественно усложняют задачу корректного выделения фона. Для ее решения бу-
дем рассматривать полутоновые изображения и сначала получим ряд значений
пикселя (С( ..С{ J и разности (2) {D, v.D .} для моментов времени от г-Дг
до Г-1. Будем оценивать частоту f появления каждого значения пикселя С (они
лежат в пределах от 0 до 255):
£ P(|Cr-Cl) Р(/Х) ,
ф.) ~4дс-D)- <5)
где Р(ДС | D) - условная вероятность того, что значение С наблюдается при от-
сутствии движения. [С - С1 и £>г считаются независимыми друг от друга, и поэто-
му их совместная вероятность может быть представлена как произведение веро-
ятностей. Вероятность P(\Cr - Cty может быть также вычислена с помощью (4).
Величина ft может быть с успехом использована для определения фоновых пик-
селей даже в случае перекрытия объектов и наличия однородных движущихся
областей. Очевидно, что для пикселей таких областей/^ будет принимать малые
значения, так как указанные пиксели считаются неподвижными только для ко-
ротких отрезков времени, и отдельные движущиеся однородные области обычно
обладают сильно различающимися цветовыми характеристиками. В то же время
для фоновых пикселей значениябудут большими, потому что когда пиксель яв-
ляется видимым, то данная частота возрастает.
На основе п значений пикселя, которые он принимает в п последовательных
моментов времени, плотность фонового распределения может быть записана как
гауссовская, и поэтому плотность вероятности появления нового значения пиксе-
ля С выражается следующим образом:
(6)
где о определяется, например, по формуле (100) из Главы 2.
С помощью величины (5) фоновая модель может быть инициализирована по-
сле того, как будет получено достаточно наблюдений фонового пикселя. После
этого пиксели переднего плана, соответствующие оставленным предметам и за-
гораживающие фоновые пиксели, могут быть классифицированы как неподвиж-
ные. Однако при сильном перекрытии объектов движущиеся однородные объек-
ты также будут определены как неподвижные. Поэтому для каждого пикселя в
период времени от z-Д/ до t рассмотрим гистограмму его значений, частота появ-
ления которых вычисляется следующим образом:
Р(|С,-С,|) Р(О,) Р(С,)
Г. р(о,)р(с,)
= Р(ДС,|О,Г).
(7)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
234
Цифвая обработка видеоизображений
где Р(ДС [ D, F) - условная вероятность наблюдения С при условии, что этот пик-
сель неподвижен и относится к переднему плану. Совместная вероятность опять
вычисляется исходя из предположения о независимости отдельных событий. Ве-
роятность наблюдения С в качестве пикселя переднего плана P(Ct) вычисляется
по формуле P(Ct) = 1-Р(С). Таким образом.можно построить распределение зна-
чений пикселя за определенный период времени, выбрать из них максимальное
Р(р) и подсчитать величину из (6) как ст = 1/2яР2 (д) при условии нормально-
сти соответствующего распределения. Данная величина дисперсии отражает ве-
роятность того, что пиксель принадлежит оставленному объекту, и будет исполь-
зована в дальнейшем при кластеризации таких пикселей.
При этом можно ввести пороговое значение дисперсии <т, на основании ко-
торого классифицировать пиксели как принадлежащие оставленным объектам.
Можно использовать другой подход, который не требует использования порого-
вого значения. Для этого рассмотрим множества f = иг/ = ],
где т - число пикселей изображения. Каждая величина f е f может принимать
значения 1 или 0, в зависимости от того, принадлежит данный пиксель оставлен-
ному объекту или нет. Плотность вероятности для такого множества может быть
записана следующим образом [2]:
P(/) = |eXp[-|t/(M (8)
Л/ \ J J
где Т называют температурой и обычно полагают равным 1. Если обозначить че-
рез F множество всех возможных конфигураций/.то разбиение Z выражается как
а £/(/) можно записать в следующем виде:
^(/) = £1у(/-Л)2, 00)
где /V - 8 ближайших соседних пикселей L Чтобы получить конфигурацию/тах с
наибольшей апостериорной вероятностью, воспользуемся множеством d, кото-
рое дает нам дисперсию для каждого пикселя оставленных объектов. Чем мень-
ше эта величина, тем больше вероятность того, что пиксель действительно при-
надлежит оставленному объекту. Введем весовые функции Wff:
n;(a,IZ) =
exp -боехр
(ID
Они построены таким образом, чтобы одновременно удовлетворять несколь-
ким условиям. Во-первых, для f= 1 функция должна монотонно убывать с увели-
чением дисперсии, а для / = 0 должно выполняться обратное утверждение. Во-
вторых, нам необходимо найти максимальную апостериорную вероятность, не
ProSystem CCTV - журнал по системам видеонаблюдения
http //www.procctv.ru
Глава 6. Детектирование оставленных предметов
235
прибегая к вычислению Z. Это достигается при помощи использования экспо-
ненциальных функций. Наконец, сумма значении вероятности, даваемых обеими
функциями, должна быть как можно ближе к 1. Это можно обеспечить, напри-
мер, выбрав 0С= 4. а в. = 12.
С помощью выражения (11) плотность вероятности P(d | /) может быть запи-
сана следующим образом:
^l/)=n^(^iZ)- О2)
1=1
Учитывая, что
P(f\d)« ехр(-С/(/ </)). (13)
lnP(/|rf)~P(rf|/)P(/). (14)
получим
U(f\d) = U(d\f)+U(f). (15)
где
t/(^l/) = Z(l-XXexp|-J| + Z-J. (16)
i=l \ ”
Теперь .можно найти/^j
Лах = arg mint/ (f\d). (17)
f
К сожалению, нахождение оптимального решения (17) потребует перебора
2т различных комбинаций f. Однако задачу можно упростить, если учесть, что
оставленные объекты достаточно редки в поле зрения систем видеонаблюдения.
Поэтому на каждой итерации будем рассматривать только ограниченное подмно-
жество всех возможных комбинаций/. Разобьем все пиксели на несколько мно-
жеств, каждое из которых имеет достаточно небольшой размер. Оптимизацию
будем выполнять последовательно таким образом, чтобы на каждом очередном
множестве учитывались результаты оптимизации предыдущих множеств. Отме-
тим, что, в принципе, подобная процедура может приводить к нахождению ло-
кального максимума вместо глобального.
После того как все пиксели получат значения 0 или 1, мы можем кластеризовать
те из них, которые получили метку 1. Это происходит при помощи процедуры,которая
объединяет пиксель с его восьмью соседями, если все они имеют одинаковые метки.
Полученные объекты, которые рассматриваются в качестве возможных кан-
дидатов на оставленные предметы, в ряде случаев не могут быть с уверенностью
отнесены к последним. Это происходит вследствие того. что. например, возмож-
но ошибочно классифицировать стоящего человека как оставленный предмет.
Проведение классификации на основе размеров объектов также не может быть
признано надежным, так как шумы на стадии отделения фона и переднего плана
иногда приводят к тому, что объекты разбиваются на несколько более мелких,
или же объект может быть только частично виден вследствие перекрытия. Поэ-
тому будем считать, что оставленный объект остается абсолютно стационарным,
т. е. его форма и цвет нс меняются с течением времени.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
236
Цифвая обработка видеоизображений
Пусть мы рассматриваем возможный оставленный объект, обнаруженный в
момент времени г. Будем вычислять его размер форму Зг положение pt и цве-
товую гистограмму Hist/Пак как оставленный объект стационарен.то в последу-
ющих кадрах мы будем искать его в том же месте Pf и с тем же размером Затем
будем проверять 8t и Histe Для сравнения полученных гистограмм будем исполь-
зовать расстояние Хаусдорфа. Внутри будем выделять краевые точки, получая
при этом множества At - в момент обнаружения, и В, - в следующем кадре.Тогда
расстояние Хаусдорфа между ними выглядит следующим образом:
//(Л,.Я,) = тах(Л(4,5,),й(5,Л)). (18)
где
h(A,,B,) = maxminP(Z)/))|a- Д (19)
ЬсВ,
Здесь P(Db) - вероятность отсутствия движения в b (пиксели должны быть
стационарными). После сравнения формы оценивается разница в цветовых свой-
ствах. Для этого начальный и последующий кадры преобразуются в полутоно-
вые изображения и строятся гистограммы Х{ и У. состоящие из к ячеек каждая. В
качестве меры сходства гистограмм используется величина
(X,, Y,) = (X, - Y, )' VPD> (X, - У,). (20)
где V - матрица размером к х к. с помощью которой находится сходство между
различными ячейками. На се диагонали находятся единицы, а оставшиеся эле-
менты вычисляются как И = 1 —
4 к
Здесь PD, - матрица вероятности наблюдения движения для каждого пикселя,
участвующего в вычислениях. С помощью введенных мер сходства получим на-
боры ...Н(А(, Я,^,)} и \dhJXt, У У^)} , после чего будем
классифицировать кластер как соответствующий оставленному объекту в том
случае, если вероятность
Р(В,|Рс).Р(°"ИРе) (21)
1 \ис)
превышает наперед заданное пороговое значение. Здесь P(DH) и P(DC) - вероятно-
сти наблюдения различий в мерах Хаусдорфа и цветовых гистограмм соответствен-
но. Как и раньше, будем считать, что P(D/t) и P(DC) унимодальны и с нулевым сред-
ним, и будем применять к ним ту же самую процедуру для оценки их плотностей.
Таким образом, для реализации данного алгоритма мы должны выполнить
следующую последовательность действий:
1. Для каждого пикселя изображения в момент времени t вычисляем часто-
ту появления различных значений по формуле (7).
2. Находим значение Р(р) наибольшего экстремума функции ft и вычисляем
дисперсию кака2 = X/IkP2 (^).
3. Вводим множества f = и </ = |a2,..а2}, где ли - число пиксе-
лей изображения, и присваиваем всем / е f значения 1 или 0 путем реше-
ния оптимизационной задачи /тах = arg mint/ (/ \d). Здесь U(f |t/) опреде-
ляется по формулам (10), (15) и (16).
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 6. Детектирование оставленных предметов
237
4. Кластеризуем пиксели с меткой 1, объединяя пиксели в 8-окрестности,
если они имеют одинаковые метки.
5. Проверяем статичность полученных после кластеризации объектов. Для
этого вычисляем их размер форму 5,. положение pt и цветовую гисто-
грамму Histe По формулам (18)-(20) находим меры сходства таких объек-
тов с соответствующими им кластерами во времени. При этом, если веро-
ятность (21) превышает наперед заданное пороговое значение, считаем
данные объекты оставленными предметами.
6.2. ИСПОЛЬЗОВАНИЕ МОДЕЛИ ФОНА
Если имеется предварительно полученное фоновое изображение сцены, можно
воспользоваться несложными, но быстрыми методами временной разности для по-
лучения объектов переднего плана [3-8]. После этого обычно изображение сглажи-
вается с помощью применения морфологических операций. Затем связанные компо-
ненты объединяются в блобы и находится их минимально возможный ограничиваю-
щий прямоугольник (МВП). Стишком маленькие МВП обычно не рассма триваются.
После того как найдены объекты переднего плана, необходимо сравнить их
с объектами из предыдущих кадров. Это осуществляется на основе следующих
критериев:
• сходство формы и местоположения (вычисляется путем нахождения пе-
ресечения МВП двух объектов).
• сходство интенсивностей (вычисляется путем нахождения суммы квадра-
тов разностей интенсивностей двух объектов),
• сходство краев (вычисляется путем нахождения меры Хаусдорфа).
Каждому найденному объекту присваивается два атрибута: возраст и тип.
Первый из них - это число кадров, в котором данный объект не двигался. Тип
представляет текущий статус объекта. Он имеет следующие градации: новый, со-
впадение и перекрытие.
Пусть Осиг и Oprev- два множества объектов соответственно текущего и пред-
ыдущих кадров. Атрибут тип присваивается на основе следующих соображений.
Если объект из Оргп< соответствует некоторому объекту из Осиг, то имеем совпа-
дение. Если же он не соответствует никакому объекту из О и не пересекает-
ся ни с каким объектом из Осиг> считается, что данный объект удален из сцены.
В этом случае удаляем его из О . Если объект из Оргеу не соответствует полно-
стью никакому объекту из О , но большая его часть пересекается с каким-либо
объектом Оаг. то имеем перекрытие. Остальные объекты из Осиг, которым не
найдено соответствие в О . считаются новыми и добавляются в О , прежде
чем начнется обработка следующего кадра. Атрибут возраст увеличивает свое
значение на единицу для каждого нового кадра (даже если имеет место перекры-
тие). Каждый объект с атрибутом тип, равным совпадение в течение времени,
превышающим заданное пороговое значение, считается статичным.
Обнаружение оставленных предметов существенно облегчается, если на бо-
лее раннем этапе были выделены объекты переднего плана, определен их тип и
траектории.Типы объектов включают в себя людей, переносимые предметы, ав-
h t tp ://w ww.it v. г и
Компания ITV - генеральный спонсор издания книги
238 Цифвая обработка видеоизображений
томобили и предметы обстановки (дверь, лестница и т.д.). Траектории объектов
сглаживаются при помощи медианного фильтра. Вычисляются такие параметры
объектов, как местоположение, скорость, направление движения и расстояние
между объектами. Так как указанные параметры должны измеряться в трехмер-
ном пространстве, то двумерные траектории отображаются в трехмерные коор-
динаты. При этом подразумевается, что для объекта, находящегося на земле, вер-
тикальная координата его нижней точки равна нулю. Такая точка определяется
как центральная точка нижнего отрезка МВП объекта.
Для моделирования поведения объектов можно использовать байесовский
подход, в котором события рассматриваются как гипотезы. Например, для дви-
жущегося объекта А и зоны В в терминах местоположения А существует четы-
ре возможных случая (гипотезы):
• Нх . А снаружи В.
• //,: А входит в зону В,
• Н3: А внутри В,
• НА: А выходит из зоны В,
При этом рассмотрим два признака:
• : расстояние между А и В некоторое время назад (например, 0.5 с),
• Е2: расстояние между Л и В в данный момент.
Полная модель включает в себя априорные вероятности каждой гипотезы
и условные вероятности каждого признака. Для рассмотренного выше примера
априорные вероятности всех гипотез могут быть выбраны равными: Р(Н) = 0.25,
i = 1.4, а условные вероятности заданы следующим образом:
P(£,=0|//J : {0,0,1,!}
Р(ЕХ> 0|Я,) : {1,1,0,0}
Р(£2 = 0|Н,) : {0,1,1,0}
Р(£2>0|Я,) : {1,0,0,1}
Здесь набор из четырех чисел, стоящих в фигурных скобках, соответствует
истинности (1) либо ложности (0) перечисленных выше гипотез. Рассмотрим, на-
пример, гипотезу И2: А входит в зону В и пусть Е{ > 0, а Е2= 0. Это означает, что
А был снаружи В некоторое время назад, а теперь А внутри В. Учитывая введен-
ные выше признаки, вероятность гипотезы Н2 вычисляется по формуле Байеса:
Р (Н21 £,, £2 )= |Я2)Р(Я2) (22)
£р(£„£2|//,.)Р(Н/)
1=1
Если предположить, что каждый признак условно независим для данной ги-
потезы, то выражение (22) можно переписать следующим образом:
(и)
£/(£,\н.)р(е, \н,)р(н,)
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 6. Детектирование oczasre—ь х гред^етсв
239
В приведенном выше примере используется простейший способ задания ве-
роятностей - пороговая функция (расстояние между объектами может быть или
положительным или равным нулю). Поэтому вероятность может принимать
только два значения: 0 или 1. Для более адекватного описания событий можно
использовать следующие функции распределения вероятностей: гистограммная,
пороговая, равномерная, гауссовская, максвелловская. Рэлея. Параметры этих
функций распределения задаются с помощью обучающих множеств.
Если для данной гипотезы И не существует альтернативной, то рассматрива-
ется противоположная гипотеза И, а апостериорная вероятность гипотезы вы-
числяется следующим образом:
ПР(£ Н)Р(Н)
Р(Н\Е1,...,Е„) = ~------------------------------- (24)
Пр(£. н)р(н)+Y[p(ei,h)p(h)
Когда вероятность P(Et Н) неизвестна или ее трудно оценить, она считается
равной 0.5. Для задачи детектирования оставленных предметов рассматривают-
ся следующие события:
1. Оставление предмета (обозначается как £>). Используются три следую-
щих признака:
• Ех: данного предмета не было некоторое время назад (обычно 0.1 с),
• Е, : предмет обнаруживается в данный момент,
• Е3: расстояние между предметом и человеком в данный момент меньше
порогового значения 6D (например, 1.5 м).
Е( и Е, накладывают временные ограничения на рассматриваемую ситуацию:
человек нес предмет перед тем, как оставить его, поэтому для предмета на дан-
ный момент времени не существует самостоятельной траектории. Как только
она появляется, это свидетельствует об оставлении предмета.
Е3 - это пространственное ограничение: владелец предмета должен быть бли-
зок к предмету, когда оставляет его. С помощью Е3 можно исключить из рассмо-
грения людей, проходящих мимо в момент оставления предмета. В случае, когда
около предмета находятся несколько человек в момент его оставления, выбира-
ется ближайший из них и считается владельцем предмета.
Априорные и условные вероятности задаются следующим образом:
• P(D) =?(£)) = 0.5.
• P(Et|£>) = 0.99, i = 1,2,3.
• Pfa |О) = 0.5, / = 1,2,3.
2. Оставленный предмет (обозначается как А). Используются следующие
признаки:
• Ех : расстояние между предметом и человеком некоторое время назад
(обычно 0.1 с) было меньше порогового значения (например, 3 м),
• Е2: расстояние в данный момент больше порогового значения.
Здесь Е, и Е, накладывают пространственные ограничения на рассматрива-
емую ситуацию.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
240
Цифвая обработка видеоизображений
Априорные и условные вероятности задаются следующим образом:
• Р(Л) = Р(Я) = 0.5.
• Р(Е' И) = 0.99, 1 = 1,2.
• Р(Е,;й) = 0.5, 1 = 1,2.
Сначала путем рассмотрения всех пар человек-предмет детектируется со-
бытие «оставление предмета» путем отбора пар с наибольшей вероятностью.
Такие пары рассматриваются дальше с точки зрения их соответствия событию
«оставленный предмет». Если для данного кадра t вероятность этого события
велика и то же самое можно сказать о любом предыдущем кадре t - Аг (А/ лежит
в пределах 30 с), то значение вероятности для кадра t - Аг уменьшается.
Для снижения влияния шума в качестве модели фона для каждого пикселя
можно использовать медианное значение t каждой цветовой компоненты. Ме-
диана вычисляется по нескольким кадрам, выбранным с интервалом 1 с в нача-
ле видеопоследовательности. Для сегментации изображения используется стан-
дартная методика вычитания фона, где пороговое значение вычисляется следую-
щим образом. Рассматривается разность
--------- <25>
значений пикселей и медианного значения, и порог устанавливается таким обра-
зом, чтобы ошибка классификации фоновых пикселей не превышала 1%. Здесь
N - число кадров, по которым вычисляется медианное значение. На Рис. 3 пока-
зана типичная гистограмма числа пикселей в зависимости от d.
Рис. 3. Зависимость числа пикселей от величины d
Данная форма гистограммы практически не зависит от типа камеры и ви-
деопоследовательности. Поэтому потенциальные объекты переднего плана удо-
влетворяют неравенству
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 6. Детектирование оставленных предметов
241
(26)
Далее необходимо избавиться от теней. Для этого пиксели, имеющие опреде-
ленный уровень яркости и хроматического искажения, считаются тенями. Изо-
лированные пиксели устраняются при помощи операции эрозии, после чего при-
меняется операция дилатации с той же маской, что и эрозия. В результате полу-
чаются отдельные блобы, для которых строятся МВП.
На следующем этапе рассматриваются только координаты центроида блоба
(х, у). число пикселей блоба .V ч и его МВП. Данный этап выполняется за три шага:
1. сопровождение блоба от кадра к кадру.
2. детектирование пространственно-временных разветвлений,
3. обнаружение неподвижных блобов.
В результате выполнения этих шагов может быть обнаружен подозрительный
объект, если детектируется разветвление, одна ветвь которого (оставленный пред-
мет) неподвижна, а другая (владелец предмета) находится на расстоянии более 3 м
от предмета. Если же владелец предмета остается на расстоянии более 3 м от пред-
мета в течение времени, превышающем 30 с. то объект считается оставленным, и
поэтому оператору системы видеонаблюдения подается сигнал тревоги.
При сопровождении объектов блобы моделируются как круги радиуса
р= ^р1Х/ Я- Два блоба считаются касающимися друг друга, если их круги пере-
секаются, т. е. если
[(*>» У.) - (*2. У2 )||2 * (Pl + р2). (27)
где (лр у,) и (х2, у2) - координаты центроидов блобов, а р} и р2 - их радиусы. Если
два блоба в последовательных кадрах касаются друг друга, то они считаются при-
надлежащими одной пространственно-временной структуре. История каждой та-
кой структуры фиксируется. Поэтому, когда две различные структуры касаются
одного и того же блоба в новом кадре, этот блоб помещается в ту структуру, ко-
торая содержит в себе большее число блобов.
Пространственно-временные разветвления соответствуют объектам, кото-
рые, будучи ранее в непосредственном контакте, в настоящий момент времени
разделились. Распознавание таких разветвлений является очень существенным
для обнаружения оставленных предметов. Особенно важны разветвления, при
которых одна ветвь удаляется, а другая остается неподвижной.
В идеальных условиях неподвижный объект описывается блобом, который
остается совершенно неподвижным. На практике блобы подвержены различ-
ным ошибкам локализации, шумам и др. Поэтому будем считать объект непод-
вижным, если в каждом кадре существует блоб на расстоянии, не превышающем
30 см (на реальной сцене), и в течение более 3 с. Таким образом, неподвижный
объект существует, пока есть блоб, расположенный не далее 30 см от него. Поло-
жение неподвижного объекта yt (после его существования в t кадрах) определя-
ется как среднее ближайших блобов в каждом кадре:
= (28)
i=l
где xs - блоб, ближайший к ук среди всех блобов, обнаруженных в кадре г.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
242
Цифвая обработка видеоизображений
х, = argminjx-yj. (29)
X
Расстояние 30 см соответствует неопределенности в локализации центрои-
да блоба. Данная величина получена экспериментальным путем при анализе рас-
пределения расстояний блобов от потенциального неподвижного объекта. За-
держка в 3 с необходима, чтобы ограничить число потенциальных неподвижных
объектов. Кроме того, положение вновь оставленного предмета является неу-
стойчивым вследствие его близости к владельцу, и эта временная задержка по-
зволяет стабилизировать положение объекта.
Процедура идентификации оставленных предметов обычно использует в ка-
честве входных данных результаты сегментации изображения и трекинга объек-
тов, что включает в себя их число.тип. расположение и МВП. При этом считают-
ся истинными следующие предположения:
1. оставленные предметы остаются стационарными;
2. они обычно имеют меньший по сравнению с людьми размер;
3. эти предметы должны иметь владельца.
На первом этапе процесса обнаружения оставленных предметов рассматри-
ваются блобы с МВП О'. полученные после сегментации изображения. Вычисля-
ются средние значения координат х и у. а также размер блоба. Затем находятся
скорости блобов в каждый момент времени. Определяются функции правдопо-
добия для размера и скорости блоба таким образом, чтобы небольшие и медлен-
но двигающиеся объекты с наибольшей вероятностью были идентифицированы
как интересующие нас предметы:
рДд'=1|^)осТ)(<д„аЛ). (30)
рД2Г=1|<й)«ехр(-Лч'). (31)
где 7) - гауссовское распределение. Р - функция правдоподобия размера, Р -
функция правдоподобия скорости. В1 = 1 означает, что z-й блоб является интере-
сующим нас предметом: s' - размер /-го блоба в момент времени /, - средний
размер такого блоба, - его дисперсия, v' - скорость и Л - входной параметр. По-
скольку блобы с наибольшим временем жизни являются наиболее вероятными
кандидатами на оставленные предметы, то будем суммировать значения правдо-
подобия для отдельных кадров, не производя нормировку на их число:
р(в‘ = 1|о,;)ос^п(^.^.^)ехр(-^;). (32)
/=|
Кандидаты на интересующие нас оставленные предметы отбираются с помо-
щью сравнения с пороговым значением:
p(zr = i|<X)>56. (33)
Вследствие ошибок трекинга часть таких кандидатов будет ложной. Поэто-
му потребуем, чтобы нужные нам блобы удовлетворяли двум дополнительным
условиям:
• они не должны лежать на границе изображения, предотвращая тем са-
мым идентификацию граничных артефактов,
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 6. Детектирование оставленных предметов
243
• их местоположение не должно совпадать с другими кандидатами, что устра-
няет проблем}’ неоднократного трекинга для одного и того же объекта.
Далее необходимо определить продолжительность жизни каждого выбран-
ного объекта. Для этого создается шаблон формы Т по самому длинному сег-
менту видеопоследовательности, на котором рассматриваемый объект имел ско-
рость ниже порогового значения 8. Шаблон представляет собой нормирован-
ную сумму двоичных изображений объекта. Тогда функция правдоподобия су-
ществования оставленного предмета определяется для блоба-кандидата при по-
мощи поэлементного умножения изображения блоба I, в момент времени г и ша-
блона формы:
р(Е, =1|В-)«££т (x,y)xl.(x,r). (34)
’ У
где Е' = 1 означает, что предмет существует в момент времени /. Функция (34)
вычисляется на всей последовательности кадров для каждого блоба-кандидата.
Предмет считается существующим в кадре, если величина (34) превышает поро-
говое значение 8е.
После того как найдены оставленные предметы, необходимо идентифициро-
вать их владельцев. Обычно это объект, который удаляется от предмета. При
этом нужно рассмотреть два возможных случая:
• исходный МВП. который был общим для владельца и предмета до насто-
ящего момента времени, связан с удаляющимся владельцем, а для предме-
та генерируется новый МВП,
• исходный МВП связан с предметом, а для владельца генерируется новый.
Первый случай очевиден, а во втором случае, если исходный МВП остается
стационарным, то в пределах окружности радиусом г пикселей от него произво-
дится поиск новых блобов.
Главным препятствием для надежной работы методов вычитания фона явля-
ются трудности при определении момента начала движения объектов, которые
до этого были стационарными, поскольку прежнее изображение совпадает с фо-
новым. Методы временной разности успешно решают эту проблему, однако они
не могут эффективно выделять форму движущихся предметов. Совместное ис-
пользование данных методов помогает корректно выделять объекты передне-
го плана.
Пусть /(х, у) - интенсивность пикселя (х, у) в момент времени t. В методе
трехкадровой временной разности пиксель считается движущимся, если выпол-
няются следующие неравенства:
k (*.y)-4-i (*>у)| > 8, (35)
к, (*> у) - A-г (*. у)| > s, (*» у), (36)
где <5г(х, у) - пороговое значение. Основную проблему здесь создают внутренние
однородные пиксели движущихся объектов, так как они не будут идентифициро-
ваны как движущиеся. Однако после объединения движущихся пикселей в свя-
занные области, классификация внутренних пикселей в пределах МВП таких об-
ластей может быть скорректирована при помощи адаптивного вычитания фона.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
244
Цифвая обработка видеоизображений
Обозначим через Bt(х, у) интенсивность фонового пикселя (х, у) в момент време-
ни г. Тогда блоб Ь может быть определен как
Ь1 = [(х,у)еМВП-.\1,(х.у)-В1(х.у)\>31(х.у)}. (37)
В начальный момент Ви = .a положительное число. В последующие мо-
менты времени они вычисляются следующим образом:
(х.у) + (1-а)/,(х,у), (х,у)-стационарный
Дя(*»Я = 'ft, ч ( \ л . (38)
В, >’)э (х*у) “ движущийся
(Jc>j)=
а5,(х,>) + (!-а)(5 7,(.г,у)-В,(х,у)|),
(х, у) - стационарный
(х, у) - движущийся
где значение а определяет, насколько весомей новая информация по сравнению
со старой.
После выделения фона классификация типов объектов производится как на
уровне отдельных пикселей, так и на уровне областей изображения. Цель перво-
го из них - определить, является ли пиксель стационарным или переходным на
основе анализа его интенсивностей за определенный промежуток времени. За-
тем происходит объединение разрозненных пикселей в связанные области, отве-
чающие движущимся или остановившимся (оставленным) объектам. Из резуль-
татов обработки реальных ведеоизображений следует, что существует всего три
различных типа временных профилей интенсивностей в зависимости от тех со-
бытий, которые происходят в данной точке:
1. Объект, двигающийся через данную точку, приводит к появлению скачка
в профиле интенсивности, последующего периода неустойчивости и об-
ратного падения к прежнему фоновому значению (Рис. 4).
2. Объект, двигающийся через данную точку и остановившийся, также при-
водит к скачку в профиле интенсивности и последующему периоду неу-
стойчивости. Однако впоследствии обратного падения не происходит, и
профиль стабилизируется на новом значении, соответствующем интен-
сивности остановившегося объекта.
3. Изменения в освещенности сцены приводят к достаточно плавным изме-
нениям профиля интенсивности.
Рис. 4. Характерные профили интенсивности
ProSystem CCTV - журнал по системам видеонаблюдения
http://wwwprocctv.ru
Глава 6. Детектирование сставгеннь х предметов 245
Таким образом, для определения характера изменения в профиле интенсив-
ности пикселя важны следующие два фактора: наличие скачка в профиле ин-
тенсивности и значение интенсивности, на котором происходит стабилизация по-
сле периода неустойчивости. Чтобы правильно интерпретировать скачок интен-
сивности (двигающийся мимо объект, остановившийся или начинающий движе-
ние), необходимо анализировать профиль интенсивности после его стабилиза-
ции. Будем вычислять две следующие величины, характеризирующие движение
Т и меру стабилизации S:
г = (40)
Г. __ /'0____\/=0
*(*-П
Составим по изображению /(л; у) карту А/(х, у). в которой каждый пиксель
может принимать три различных значения: 0 - фон. 1 - переходный, 2 - стацио-
нарный. Если для данного пикселя Л/(х. у) = 0 или М(х, у) = 2. а Т превышает не-
которое пороговое значение 8 г то данный пиксель считается переходным и для
него теперь А/(х, у) = 1. В противном случае, если М(х, у) = 1 и 5 меньше порога
то Л/(х, у) = 0 (если значение интенсивности после стабилизации совпадает с фо-
новым) или Л/(х, у) = 2 (в противном случае).
Не относящиеся к фоновым в карте Л/(х, у) пиксели объединяются в об-
ласти R' при помощи пространственного фильтра ближайшего соседа с радиу-
сом г., выбор которого зависит от размеров рассматриваемого объекта. Каж-
дая получившаяся область Rt анализируется в соответствии со следующим
алгоритмом:
1. Если R, - переходная область (т. е. для всех ее пикселей А/(х, у) = 1), то Я
считается движущимся объектом.
2. В противном случае, если Я - стационарная область (т. е. для всех ее пик-
селей М(х, у) = 2), то исключим из нее те пиксели, которые когда-либо
были фоновыми (т. н. слои L(0) + L(l) + ... + Если при этом оста-
нутся какие-либо пиксели в области Я .то сформируем из них новый слой
L(j + 1) = Я и будем считать Rt остановившимся (оставленным) объектом.
3. Если не выполняются пункты 1 и 2. это означает, что Rt представляет со-
бой сочетание переходных и стационарных пикселей. Поэтому проведем
кластеризацию пикселей Rt - [ЦО) + L(l) + ... + Получим набор об-
ластей SRk.
4. Для всех к:
• Если SRk - переходная область, то считаем SRk движущимся объектом.
• Если SRk - стационарная область, то создаем новый слой L(j + I) = SRk и
считаем SRk остановившимся (оставленным) объектом.
• Если SRk - сочетание стационарных и переходных пикселей, то считаем
SRk движущимся объектом.
Области, которые состоят из стационарных пикселей, добавляются в каче-
стве нового слоя к фону. Использование слоев дает возможность определить,
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
246
Цифвая обработка видеоизображений
когда остановившийся объект продолжит движение или он будут закрыт другим
движущимся или остановившимся объектом.
Модуль, осуществляющий детектирования неподвижных объектов, мож-
но использовать параллельно с модулем сопровождения движущихся объектов.
Первый из них ищет пиксели переднего плана, значительно отличающиеся от
фоновых в течение определенного промежутка времени. В результате получает-
ся промежуточное изображение 5. в котором каждый пиксель представляет со-
бой меру принадлежности к неподвижному объекту. Значения данной меры на-
ходятся в пределах [0.255]. где 0 обозначает фоновый пиксель, а 255 - пиксель,
принадлежащий стационарному* объекту. В самом начале обработки все пиксе-
ли s(x, у) промежуточного изображения принимают значение 0. В дальнейшем
их значения изменяются в зависимости от соотношения текущей интенсивности
пикселя /(х, у), фоновой модели Вц<9(х. у) и длительности их соответствия. При
этом вводится счетчик числа последовательных кадров С(х, у), в которых рассма-
триваемый пиксель(х, у) не соответствовал фоновой модели. Этот счетчик обну-
ляется каждый раз, когда /(х, у) лежит в пределах, соответствующих фоновой мо-
дели. При этом значения s(x, у) изменяются следующим образом:
s(x,^)=5(x,/)+C(x,y)
(42)
Здесь/- частота смены кадров, a t - параметр, определяющий время, по про-
шествии которого пиксель считается стационарным. Аналогично вводится счет-
чик Z)(x, у), который начинает увеличивать свое значение, когда обнуляется
С(х, у), и осуществляет подсчет числа последовательных кадров, в которых /(х, у)
соответствует фоновой модели. Тогда:
( 255 I
$(х,у) = ф,у)-г£>(х,у)1 — I (43)
где параметр г > 0 определяет время для того, чтобы считать пиксель движу-
щимся.
Пиксели, которые принадлежат неподвижному объекту, не будут соответ-
ствовать фоновой модели в течение всего времени, пока объект остается на сво-
ем месте. При этом s(x, у) увеличивает свое значение до максимально возможно-
го, равного 255, через t секунд. Одновременно цветовая информация для пикселя
(х, у) может быть использована для построения гистограммы неподвижного объ-
екта. Пиксели такого объекта будут отличаться от фоновых независимо от того,
какому объекту они принадлежат - неподвижному или движущемуся и закрыва-
ющему неподвижный.
6.3. ПРИМЕНЕНИЕ МЕТОДОВ БУСТИНГА
Как уже отмечалось ранее, для обнаружения оставленных предметов не всег-
да подходят стандартные процедуры сегментации изображения. Нам необходи-
мо не только отделять фон от переднего плана, но и различать известные объек-
ты (например, людей) от неизвестных (оставленных предметов). Поэтому мож-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www. procctv. ги
Глава 6. Детектирование ооавген*ых предметов
247
но попытаться скомбинировать фоновую модель и модель идентификации объ-
ектов. Последняя обычно настраивается при помощи обучающей последователь-
ности. после чего становится возможным исключать распознанные объекты из
сегментированного изображения. В результате мы получаем области, которые
не могут быть описаны фоновой моделью и. следовательно, представляют собой
неизвестные объекты.
Для построения фоновой модели может быть использован метод бустин-
га, основы которого изложены в Главе 5. Главная идея этого метода заключа-
ется в формировании каскада «слабых классификаторов», каждый из которых
должен обладать надежностью распознавания, хоть ненамного превышающей
50%. Формируемая в результате система обладает надежностью, существен-
но превосходящей каждый отдельный классификатор, поэтому она называет-
ся «сильным классификатором». Данный метод был весьма успешно исполь-
зован для ограниченного набора характерных признаков изображения, напри-
мер вейвлетов Хаара. При этом каждый характерный признак соответствовал
одному слабому классификатору. Недостатком этой процедуры является тре-
бование предварительного наличия обучающей последовательности. Однако
можно усовершенствовать данный метод таким образом, чтобы обучение и об-
новление классификаторов происходило в реальном времени по мере посту-
пления очередного изображения - так называемый онлайн-бустинг в отличие
от традиционного, который работает в режиме офлайн. Можно показать, что
если использовать для режимов онлайн и офлайн одну и ту же обучающую по-
следовательность. то слабые классификаторы первого асимптотически будут
близки к классификаторам традиционного метода. Основное отличие этих ме-
тодов заключается в том. что для режима офлайн фиксируется обучающая по-
следовательность. и все примеры используются для обновления и выбора но-
вого классификатора. При этом число слабых классификаторов определяет-
ся в процессе обучения. Для режима онлайн наоборот, число классификаторов
определено заранее, и для их обновления и изменения их весов каждый раз ис-
пользуется только один новый пример [9-12].
Введем понятия селектора, который из данного набора М слабых классифи-
каторов Нптак = {h?eak,Кпквыбирает только один:
А„,(-)=АГ1(-) (44)
где т выбирается исходя из текущего критерия оптимизации. Например, в каче-
стве критерия можно использовать минимум ошибки е каждого слабого класси-
фикатора h*eak е так что т = arg min er
Заметим, что таким образом введённый селектор можно интерпретиро-
вать как классификатор. Обучение селектора - это обучение и обновление
всех слабых классификаторов и выбор наилучшего из них (с наименьшим зна-
чением е). Далее с каждым слабым классификатором будем связывать опре-
деленные характерные признаки изображения. Селекторы будут работать с
ограниченным подмножеством Fvub = | / е F} исходного набора
всех признаков F. Основная идея заключается в применении метода не к сла-
бым классификаторам непосредственно, а к селекторам (см. Рис. 5, где пред-
ставлена схема метода).
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
248 Цифвая обработка видеоизображений
На первом этапе фиксированный набор N селекторов h^1 инициали-
зируется случайным образом (каждый селектор со своим собственным подмно-
жеством характерных признаков F ). Когда поступает новый обучающий пример
(х, у), все селекторы обновляются в соответствии с весом Л текущего приме-
ра. Обновление слабых классификаторов производится с помощью стандарт-
ной процедуры ожидания-максимизации (ОМ). Селектором выбирается слабый
классификатор с наименьшей ошибкой:
arg min(e„m),
m ' '
кrung
в _ -----------лл»--------
n,tn fcnrr I '
(45)
где en tn - ошибка ш-го слабого классификатора в /ьм селекторе, полученная
с помощью весов правильно Лл” и неправильно классифицированных при-
меров к настоящему моменту времени. Наконец, соответствующие веса селекто-
ров и вес примера обновляются и передаются на вход следующего селектора Л^.
Для того чтобы увеличить робастность процедуры и адаптировать ее к измене-
ниям. происходящим в изображении, худший из слабых классификаторов заменя-
ется новым, случайно выбранным из исходного набора признаков F. Данные дей-
ствия повторяются для всех селекторов. Окончательно сильный классификатор
получается как линейная комбинация селекторов
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 6. Детектирование оставленных предметов
249
_ sgn (conj- (46)
У агЛТ'(.г)
conf(x) = ^.---------. (47)
П~1
В отличие от стандартного метода бустинга при описанной процедуре силь-
ный классификатор существует в любой момент обучения.
В качестве характерных признаков могут быть использованы разновидно-
сти вейвлетов Хаара. ориентированные гистограммы и локальные двоичные об-
разы (ЛДО) [13-19]. Разновидности вейвлетов Хаара - это разности между сум-
мами интенсивностей пикселей в различных смежных областях. Среди них выде-
ляются три разных типа. Первый тип представляет собой разность между сумма-
ми интенсивностей пикселей, лежащих в двух прямоугольных областях (Рис. 6А
и Б). Эти области имеют одинаковый размер и являются вертикально или гори-
зонтально смежными. Второй тип определяется как разность сумм интенсивно-
стей пикселей в средней и в двух внешних областях (Рис. 6В). Наконец, послед-
ний тип задействует уже четыре области и вычисляет разность двух диагональ-
ных пар областей (Рис. 6Г).
Рис. 6. Примеры характерных прямоугольных признаков, использующихся для
классификации
Данные признаки могут быть вычислены довольно быстро, если ввести про-
межуточное представление изображения - так называемое интегральное изо-
бражение. В каждой точке (х, у) оно содержит сумму интенсивностей пикселей,
находящихся левее и выше этой точки, включая ее саму:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
250 Цифвая обработка видеоизображений
Лх’^)= X 1 <48)
где /(х, у) - интенсивность исходного изображения в точке (х, у). Используя сле-
дующие рекуррентные соотношения:
s(x,y) = s(x,y-l)+/(x,>). (49)
I(x,y) = 7(х-1,у) + $(х, г). (50)
вычисление интегрального изображения может быть сделано за один проход ис-
ходного изображения. Здесь s(x. у) - сумма интенсивностей пикселей в данной
строке х до пикселя у включительно ($(х, -1) = 0,/(-1,у) = 0).
При помощи интегрального изображения можно легко получить все три типа
характерных признаков.Так. первый тип выражается как (Д -2В + C-D + 2E-F)
(см. Рис. 7), второй - (А - 2В + 2С - D - Е + 2F-2G + Н) и третий - (Д - 2В + С -
-2D + 4E-2F + G-2H + F).
Рис. 7. Пример вычисления характерных признаков
Ориентированные гистограммы вычисляются следующим образом. С помо-
щью свертки изображения с фильтром Собеля S находим градиенты в точке (х, у):
Gx(X’>')=\*/(X«y). <51)
и величину G.
G (х>
Чтобы уменьшить влияние шума, введем пороговое значение 8:
Г'( \ G(x>y)*s
C(^) = lo, G(,.y)<S
Теперь ориентация края может быть вычислена как
0(x,y) = arctg •
(52)
(53)
(54)
(55)
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 6. Детектирование оставленных предметов
251
Разделим значения краев на К ячеек. Значение к-й ячейки определяется как
Ч'Лх,у) =
G'(x,y),
О,
0(х,у) е (Л-u ячейке)
иначе
(56)
Воспользуемся опять интегральным изображением, введенным выше. Тогда
для любой прямоугольной области R изображения следующая величина может
быть вычислена всего лишь с помощью извлечения четырех значений из состав-
ленной заранее таблицы:
МЛ) = Е Vk(x,y).
(Х.>)£Л
(57)
Определим теперь набор характерных признаков А следующим образом:
Л1Л(Л)=
W + g
МЛ) + £'
(58)
Здесь величина £ добавлена в числитель и знаменатель с целью сглажива-
ния. Заметим, что Ak д (/?) принадлежит множеству действительных чисел, и,
следовательно, каждый такой признак позволяет сформулировать две гипотезы:
Ak k (Я) > 8 и Ak k (/?) < 5 для некоего порогового значения 5- Для первой из них
характерные признаки Ak k (Я) позволяют выделить те области R изображения,
для которых направление /с, является преобладающим по сравнению с направле-
нием kr Можно также найти доминантное направление для всей области Я:
£ДЛ) + £
££,(£)+£
(59)
Для вычисления локальных двоичных образов для данного пикселя использу-
ется его окрестность размером 3x3. Значение центрального пикселя выступает
в качестве порога, и все пиксели, чьи значения не меньше порога, становятся рав-
ными 1, а остальные - обнуляются. После этого ЛДО для данного пикселя вычис-
ляется как линейная комбинация окрестных пикселей с их весовыми коэффици-
ентами, которые приведены на Рис. 8.
Шаблон = 11110001
ЛДО= 128 + 64 + 32 + 16 ♦ 1 = 241
Рис. 8. Вычисление локального двоичного образа (ЛДО)
btfp://www./tv.ri/
Компания ITV - генеральный спонсор издания книги
252
Цифвая обработка видеоизображений
Ниже приводится схема онлайн-бустинга. слабые классификаторы которо-
го обучаются на описанных признаках. Вес первого обучающего примера пола-
гается равным 1, т. е. Л = 1. Далее для всех селекторов N выполняются следующие
шаги (и = 1.N):
1. Обновление очередного селектора Ляе/. Для всех т = 1.М выполняется:
1.1 Обновление очередного слабого классификатора h*™k.
1.2 Вычисление ошибки. Если (х) = у, то А^ = А^ 4-1. В противном
случае А"™* - А*™* +1. Ошибка вычисляется по формуле
ЛНГООД
п.т
е —--------------
п,т Acorr । *
п.т п,т
2. Выбор слабого классификатора с наименьшей ошибкой:
=arg min(e„ m)
= ел.«-’ = ~ • Если е, > 0 или еп > 0.5, то переходим к следующему
селектору. (\-е'
3. Вычисление веса селектора:о/ - 0.5-In ---- .
{ eJ
4. Обновление веса примера. Если h”' (х)
- . 1
. . 1
= у, то А = А —т-
* 2(1-е,
случае л = л -—.
5. Замена худшего слабого классификатора новым: m = arg шах(еЯ Я| I,
Acarr = 1,А"ГОЯ* = 1, новый классификатор hweak.
Если данный процесс продолжать достаточно длительное время, то будет за-
действовано большое число характерных признаков, но при этом лишь часть из
них будет использована для обновления селектора. Кроме того, обучение ведется
непрерывно, поэтому качество модели будет постоянно улучшаться.
Осталось показать, как строятся и обновляются слабые классификаторы.
Пусть /у (х) - значение характерного у-го признака на изображении х. Тогда бу-
дем считать, что вероятность для положительных Р(1(/у(х)) (отрицательных
Р(-1 |/у (х)}) примеров можно оценить с помощью гауссовского распределения со
средним /г (/Г) и стандартным отклонением от* (а"). Предположим, что послед-
ние изменяются во времени по следующему закону =/1,^ + nt и а 2 = G 2_t + nt.
Здесь nt ~ - нормально распределенный случайный шум. Положим
<Уг - 0.01, Ро = 1000, р0 = 0 и ст2 = 0. Тогда для обновления параметров слабых
классификаторов используются следующие выражения:
к, =
д( = ^Л(5)+0-^К.,
=к, и (*) - )2+о - к>)
(60)
(61)
(62)
Р, = (1-К,)Р,.}.
(63)
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 6. Детектирование оставленных предметов
253
Сами классификаторы для вейвлетов Хаара определяются как
A7‘(x)=p75gn(/.(x)-0.). (64)
= !---—!» Р, = sgn (р'-р ). (65)
Для ориентированных гистограмм и локальных двоичных образов использу-
ется обучение по методу ближайших соседей с функцией расстояния D, в каче-
стве которой выступает обычное евклидово расстояние. Центры кластеров для
положительных р, и отрицательных й примеров находятся при помощи примене-
ния фильтров Кальмана к каждой отдельной ячейке:
Л7*(х)= «,)). (66)
Отметим, что при построении фоновой модели не существует отрицательных
примеров. Однако исходную задачу можно рассматривать как задачу классифи-
кации с одним классом и для обновления классификаторов использовать толь-
ко положительные примеры. Будем оценивать полутоновое значение каждого
пикселя как равномерно распределенное со средним значением, равным 128, и
дисперсией, равной 2562/12 (для 8-битового изображения). Применяя стандарт-
ные статистические методы, мы можем найти параметры распределения отрица-
тельных примеров для вейвлетов Хаара. Для ориентированных гистограмм отри-
цательный кластер Я состоит из равномерно распределенных направлений. Для
ЛДО с 16 ячейками получим йу =
образов [00002,0001,.1111J.
После построения фоновой модели область изображения считается принад-
лежащей к переднему плану, если выполняется неравенство
confix) < S^t (67)
где 5ето/ - пороговое значение. Слабые классификаторы обновляются в том слу-
чае, если
S, <conf(x)<8u. (68)
Обычно 3, = 8nal = 0,a8u = 0.5.
Для обнаружения и идентификации объектов может быть использова-
на следующая схема. Начальное множество положительных примеров полу-
чается при помощи анализа аспектного отношения движущихся блобов. Если
рассматриваемый блоб не удовлетворяет заложенным ограничениям, то он в
дальнейшем не рассматривается. Отрицательные примеры получаются из изо-
бражений, где не детектируется никакого движения. Обнаруженные ложные
объекты снова подаются на вход классификатора в качестве отрицательных
примеров, а истинные объекты - в качестве положительных. Таким образом,
качество классификатора непрерывно улучшается. Комбинируя результаты
классификатора, модуля трекинга и фоновой модели, можно выделить пред-
меты, ранее не принадлежавшие к фону, но в настоящий момент неподвижные,
т. е. оставленные предметы.
[б, 4,4,1,4,1,1,4,4,1,1,4,1,4,4,6] для двоичных
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
254
Цифвая обработка видеоизображений
6.4. СПИСОК ЛИТЕРАТУРЫ
1. S.-N. Lim, Н. Fujiyoshi. R. Patil. A One-threshold Algorithm for Detecting Abandoned
Packages Under Severe Occlusions Using a Single Camera. Technical Report CS-
TR-4784. University of Man land. Computer Science Department, 2006.
2. P Clifford. Markov Random Fields in Statistics. In: Disorder in Physical Systems:
A Volume in Honour of John M. Hammerslew G. Grimmett and D. Welsh (eds.),
p. 19-32.1990.
3. J. Wang, W.-T. Ooi. Detecting Static Objects in Busy Scenes.Technical Report TR99-
1730, Cornell University. 1999.
4. F Lv, X. Song. V K. Singh. R. Nevatia. Left Luggage Detection Using Bayesian
Inference. In: Proc. IEEE Workshop on Performance Evaluation of Tracking and
Surveillance. New York. p. 83-90.2006.
5. E. Auvinet, E. Grossmann. C. Rougier. M. Dahmane. J. Meunier. Left Luggage
Detection Using Homographies and Simple Heuristics. In: Proc. IEEE Workshop
on Performance Evaluation of Tracking and Surveillance. New York, p. 51-58,2006.
6. K. Smith, P Quelhas. D. Gatica-Perez. Detecting Abandoned Luggage Items in a
Public Space. In: Proc. IEEE Workshop on Performance Evaluation of Tracking and
Surveillance. New York, p. 75-82,2006.
7. R. T. Collins. A. J. Lipton. T. Kanade. A System for Video Surveillance and
Monitoring. Technical Report CMU-RI-TR-00-12, Robotics Institute, Carnegie
Mellon University, 2000.
8. S. Guler, M. K. Farrow. Abandoned Object Detection in Crowded Places. In: Proc.
IEEE Workshop on Performance Evaluation of Tracking and Surveillance. New
York,p. 99-106.2006.
9. P Viola, M. Jones. Rapid Object Detection Using a Boosted Cascade of Simple
Features. In: Proc. IEEE Computer Society Conference on Computer Vision and
Pattern Recognition. Kauai, p. 511-518,2001.
10. H. Grabner and H. Bischof. On-line Boosting and Vision. In: Proc. IEEE Computer
Society Conference on Computer Vision and Pattern Recognition. New York. p. 260-
267,2006.
ll. N. Oza, S. Russell. Experimental Comparisons of On-line and Batch Versions
of Bagging and Boosting. In: Proc. ACM SIGKDD International Conference on
Knowledge Discovery and Data Mining. San Francisco, p. 359-364,2001.
12. N. Oza, S. Rusell. Online Bagging and Boosting. In: Proc. International Workshop
on Artificial Intelligence and Statistics. Key West. p. 105-112,2001.
13. H. Grabner. R M. Roth, M. Grabner. H. Bischof. Autonomous Learning of a
Robust Background Model for Change Detection. In: Proc. IEEE Workshop on
Performance Evaluation of Tracking and Surveillance. New York, p. 39-46,2006.
14. K. Levi, Y. Weiss. Learning Object Detection from a Small Number of Examples:
the Importance of Good Features. In: Proc. IEEE Computer Society Conference on
Computer Vision and Pattern Recognition. Washington, v. 2. p. 53-60,2004.
15. T. Ojala, M. Pietikainen. T. Maenpaa. Multi-resolution Grayscale and Rotation-
invariant Texture Classification with Local Binary Patterns. In: IEEE Transactions
on Pattern Analysis and Machine Intelligence, v. 24. p.971-987,2002.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www. procctv. ru
Глаза 6. Детект/рова^ие осгазленнь х ~седметов
255
16. Т. Maenpaa. Т. Ojala. М. Pietikainen. М. Soriano. Robust Texture Classification
by Subsets of Local Binary Patterns. In: Proc. International Conference on Pattern
Recognition. Barcelona, v.3. p. 3947-3950.2000.
17. P S. Carbonetto. Robust Object Detection Using Boosted Learning. Project Report,
Department of Computer Science. University of British Columbia. Vancouver, 2002.
18. D. Skocaj. A. Leonardis. Weighted and Robust Incremental Method for Subspace
Learning. In: Proc. IEEE International Conference on Computer Vision. Nice, p.
1494-1501.2003.
19. M. Spengler. B. Schiele. Automatic Detection and Tracking of Abandoned
Objects. In: Proc. Joint IEEE International Workshop on Visual Surveillance and
Performance Evaluation of Tracking and Surveillance. Nice. p. 149-156,2003.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
ГЛАВА 7.
МЕТОДЫ ДЕТЕКТИРОВАНИЯ
РАСПОЗНАВАНИЯ ЛИЦ
258
Д/евая обработка видеоизображений
В настоящее время задача распознавания лиц находит применение в различ-
ных сферах человеческой деятельности (в первую очередь, в системах безопас-
ности). Это связано с тем. что традиционные средства идентификации личности
во многих случаях оказываются недостаточно надежными и удобными. Распозна-
вание лиц представляет собой бесконтактный и. возможно, наиболее естествен-
ный способ установления личности. Хотя для этого существует немало биоме-
трических методов (например, использование отпечатков пальцев, изображений
зрачка и радужной оболочки глаза, геометрии руки, особенностей голоса), все
они в той или иной мере опираются на готовность пользователя сотрудничать с
системой. В то же время распознавание лиц может быть осуществлено даже без
ведома испытуемого. Сферами применения распознавания лиц являются, напри-
мер, сравнение фотографий на паспортах пли водительских удостоверениях, кон-
троль доступа к безопасным компьютерным сетям и оборудованию в учреждени-
ях. верификация пользователя при проведении финансовых транзакций, наблю-
дение за аэропортами и вокзалами для предотвращения террористических актов
и многие другие. Во всех этих приложениях требуется корректно устанавливать
личность как по отдельному статическому изображению лица, так и на видео-
последовательности. Естественно, что анализ входной информации должен осу-
ществляться в режиме реального времени.
Проблема распознавания лиц - это задача идентификации или верификации
одного или нескольких человек путем сравнения входных изображений с уже
имеющимися в базе данных. Под идентификацией подразумевается процесс уста-
новления личности пользователя на основе сравнения введенного изображения
с образцами, хранимыми в нужном виде в базе данных. Верификация заключает-
ся в подтверждении или опровержении того, что пользователь действительно яв-
ляется тем. за кого себя выдает. Для увеличения надежности процесса распозна-
вания может быть использована такая дополнительная информация, как возраст,
расовая принадлежность, выражение лица. Человеческие лица выглядят весьма
похожими по своей структуре, отличаясь лишь в деталях для каждого конкретно-
го индивидуума. В классических задачах распознавания образов обычно имеется
ограниченное число классов с большим числом обучающих примеров для каждо-
го из них. При распознавании лиц, напротив, мы сталкиваемся с тем, что возмож-
ных классов может быть очень много, в то время как число обучающих приме-
ров относительно невелико.
Хотя для людей проблема распознавания лиц не представляет особой слож-
ности даже при меняющихся внешних условиях и спустя весьма значительное
время после общения с данным человеком, задача автоматического распознава-
ния лиц на изображениях может быть решена с достаточно высокой степенью
надежности только при наложении определенных, весьма жестких ограниче-
ний. В общем случае лицо представляет собой трехмерный объект, освещенный,
как правило, несколькими источниками света с разных направлений и к тому же
окруженный фоновыми объектами. Поэтому внешний вид лица значительно из-
меняется при проецировании его на двумерную плоскость изображения. Различ-
ные углы поворота головы относительно камеры также приводят к существен-
ным изменениям внешнего вида. Робастная система должна с высокой точностью
осуществлять распознавание лиц вне зависимости от указанных условий съемки
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 7. Методы детектирования и распознавания лиц
259
изображения. Кроме того, надежная система должна быть малочувствительной
к шумам камеры и к оптическим искажениям, при этом разрешение обрабатыва-
емого изображения должно быть достаточно высоким для достижения заданной
эффективности системы.
Процесс распознавания лиц может быть разделен на два этапа. На первом из
них осуществляется нахождение и выделение лица на изображении - так называ-
емый процесс «детектирование лиц». Второй этап представляет собой непосред-
ственно распознавание лица - т. е. установление степени сходства с одним из лиц,
«известных» системе. Рассмотрим эти этапы более подробно.
7.1. ДЕТЕКТИРОВАНИЕ ЛИЦ НА ИЗОБРАЖЕНИЯХ
Корректное детектирование и выделение лица на изображении является
основой для последующего распознавания. Для некоторых приложений, напри-
мер таких, как сравнение фотографий на документах, выделение лиц не пред-
ставляет особого труда, а проблема детектирования просто отсутствует. Для дру-
гих задач (например, видеонаблюдение в аэропортах) детектирование и выделе-
ние лиц являются чрезвычайно сложными. Помощь в детектировании лиц может
оказать использование движения объекта, полученное из видеопоследователь-
ности. Цветовая информация также оказывается полезной, хотя в ряде случаев,
когда на заднем плане находится много объектов и при этом условия освещенно-
сти меняются, ее использование может быть затруднено.
Наибольшую трудность представляет детектирование лиц вне помещений,
где типичным осложняющим фактором является постоянная смена освещенно-
сти объектов. Как уже было сказано, лица являются трехмерными объектами, и
поэтому изменения в освещенности приводят к появлению теней на лицах. Этим
объясняется преимущественное применение существующих систем распознава-
ния лиц в помещениях, где легко контролировать условия освещенности путем
использования искусственной внешней подсветки. Однако это отвлекает испы-
туемых и, кроме того, явным образом свидетельствует о наличии системы видео-
наблюдения, что в некоторых случаях нежелательно.
Детектирование лиц можно рассматривать как особый случай задачи распо-
знавания, в котором существует всего два класса - «лица» и «не лица». Некото-
рые методы распознавания лиц могут быть непосредственным образом примене-
ны и для их обнаружения на изображении. Однако в большинстве случаев они яв-
ляются весьма ресурсоемкими и не отражают большого разнообразия в изобра-
жениях лиц. Поэтому для детектирования и выделения лиц используются спец-
ифичные для этой задачи методы. В связи с широким распространением в по-
следнее время биометрических методов идентификации и аутентификации боль-
шое внимание уделяется обработке статичных изображений (см., например, об-
зоры [1-3]), на которых присутствует фронтальный образ человеческого лица.
При этом проблеме детектирования и локализации лица в видеопоследователь-
ности уделяется крайне мало внимания. Однако в системах видеонаблюдения и
индексации цифровых видеоархивов именно эта задача приобретает первосте-
пенное значение.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
260
л'Озая обработка видеоизображений
Проблема детектирования и локализации лиц на видеоизображении может
быть сформулирована следующим образом: в данном кадре видеопоследователь-
ности определить наличие или отсутствие лиц людей и при положительном отве-
те найти границы прямоугольных рамок, целиком включающих лица. При этом
решение указанной проблемы должно быть инвариантным к изменениям усло-
вий освещенности, масштаба и ориентации. Заметим, что построение системы,
отвечающей всем перечисленным требованиям, т. е. способной выделять лица
всех размеров при произвольных условиях и любом повороте головы, представ-
ляет собой чрезвычайно сложную задачу Например, система видеонаблюдсния
не должна быть рассчитана на анализ только фронтальных изображений лиц при
минимальном уровне помех. Напротив, такая система должна непрерывно анали-
зировать видеоизображение, дожидаясь момента, когда будет получено изобра-
жение, наиболее близкое к фронтальному. В противном случае эта система долж-
на синтезировать всю имеющуюся разноплановую информацию для робастного
детектирования лица, повернутого под определенным углом к камере.
Выделение лиц в видеопоследовательности осложняется следующими фак-
торами:
• изображение лица меняется значительным образом в зависимости от вы-
ражаемых в данный момент эмоций, возраста, наличия или отсутствия ма-
кияжа и волос на лице, условий освещения, угла поворота к камере, пере-
крытия части лица другими объектами;
• присутствие большого числа объектов на заднем плане и низкое разре-
шение видеоизображения, что в результате может привести к большому
количеству ошибок как первого, так и второго рода;
• детализированная визуальная информация часто представляется с помо-
щью векторов характерных признаков, имеющих очень большую раз-
мерность;
• лица, присутствующие на изображении, часто имеют весьма небольшой
размер, что приводит к потере существенной информации и ненадежно-
му сегментированию интересующих областей:
• детектирование лиц в видеопоследовательностях должно осуществляться
в реальном времени, что накладывает гораздо более жесткие ограниче-
ния по сравнению с методами выделения объектов на статичных изобра-
жениях;
• число лиц на изображении заранее, как правило, неизвестно.
Все методы сегментации лиц могут быть классифицированы в соответствии с
различными критериями и. вполне естественно, что отдельные методы при этом
будут относиться сразу к нескольким категориям. Мы будем придерживаться
следующей классификации:
• методы, основанные на сравнении с шаблоном.
• методы, основанные на выделении характерных признаков.
В принципе, для детектирования и локализации лиц могут быть использова-
ны некоторые методы из числа описанных в разделе, посвященном выделению
номерных знаков. Однако существует ряд особенностей рассматриваемой зада-
чи, которые приводят к разработке методов, специфичных только для данной
проблемы. Далее мы сконцентрируемся именно на таких алгоритмах.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
распознавания лиц
261
7.1.1. Методы, основанные на сравнении с шаблоном
Наиболее естественным методом детектирования лиц представляется метод
сравнения выделенной области изображения с неким эталонным изображени-
ем, характерным для большинства человеческих лиц, которое мы будем назы-
вать шаблоном. Использование для этой цели метода динамического програм-
мирования позволяет построить довольно эффективную вычислительную про-
цедуру. Обозначим через F шаблон изображения лица размером М х N пикселей.
Задача заключается в поиске в рассматриваемом изображении Z(x, у) (размером
XxY) области, наиболее близкой к шаблону. Будем считать, что высота и шири-
на лица в 1(х, у) не меньше, чем в шаблонном изображении, и могут превышать
их не более чем в два раза. Тем самым определяются размеры областей исходно-
го изображения, которые необходимо рассмотреть. Кроме этого, предположим,
что каждой строке/столбцу шаблона соответствует одна или две строки/столбца
рассматриваемой части исходного изображения.
Пусть Z - это текущая рассматриваемая область размером X' х У' исхо-
дного изображения Z(x, у), a f и g - функции, осуществляющие отображение /
на F [4]:
/0=т, i = X
,g0=«> / =
и такие, что:
/0=1.
g(l)=u g(Y')=N
т = \,..,М
n = l,..,N
(1)
(2)
f(i)+1 > /(»+1)> /0, /(/+ 2)> /0
gGO+^gG+O^gG). gG+2)>gG)-
Результирующее изображение f(m, n) вычисляется как среднее Z (47) по всем
(47) таким, что Д/) = т, a g(y) = п, где т = 1.М; п = Степень соответствия
Z и F определяется с помощью вычисления величины:
MEf.g U>F)= XX Н™,и))-
(3)
Очевидно, что для нахождения минимума (3) необходимо рассмотреть 2м х 2,v
комбинаций различных/и g, что при типичных значениях М и N делает невозмож-
ным решение этой задачи в реальном времени. Для сокращения числа вычислений
воспользуемся методом динамического программирования. Предположим,что/'’'
и это части,расположенные в верхнем левом углу изображений / и /^размером
ixj и тхп соответственно. Определим частичную ошибку РЕ как минимальное
значение степени соответствия ME между /‘и и Fmn:
PE(m,n,ij)=minMEr /1^ ,F”H).
Тогда наилучшее соответствие между / и F выражается как
} РЕ (M.N,/,/)'
2oiMN ;
(4)
MV(I,F) = max
i-M...,2M; j^N,..,2N
(5)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
262
Цифвая обработка видеоизображений
где 0>F - среднеквадратическое отклонение интенсивности для шаблона. Если ве-
личина MV превышает заданное пороговое значение, то соответствующая часть
/ считается возможным изображением лица.
При использовании метода динамического программирования необходимо
найти оптимальный путь из начальной точки (0.0.0.0) в конечную (Л/, N. Х\ У')
на четырехмерной сетке, на которой заданы значения РЕ(т, п, ij). Для этого бу-
дем применять следующую итерационную процедуру. Предположим, что пред-
ставляет собой локальную функцию, осуществляющую отображение столбцов
/ на F. На /-й итерации (/ > 1) зафиксируем величину и будем применять ме-
тод динамического программирования для нахождения оптимальной функции /'
(осуществляющей отображение строк / на F), т. е. функции, минимизирующей
величину MEf. t (/S,F). После того как будет получена такая функция, зафикси-
руем се и будем искать функцию g. минимизирующую MEf, \IS, F). Эта проце-
дура продолжается до тех пор. пока нс будет получено окончательное решение.
Данный алгоритм является сходягцимся. так как на каждом шаге итераций мы по-
лучаем нс возрастающую величину степени соответствия / и F.
Для того чтобы иметь возможность детектирования лиц различного разме-
ра, указанная процедура выполняется для нескольких разрешений изображения.
Так как одно из установленных ранее ограничений не позволяет анализировать
лица, имеющие размеры, более чем в два раза превышающие размеры шабло-
на, то последовательные разрешения изображения должны отличаться тоже в
два раза. Изображение при самом низком разрешении должно иметь размеры
не меньше размеров шаблона. После нахождения всех возможных изображений
лица при различных разрешениях они упорядочиваются по величине ME. Чтобы
окончательно определить границы лица, исключаются те изображения лица, ко-
торые перекрываются другими изображениями с более высоким значением ME.
7.12. Использование специальных характерных признаков
При поиске лиц на изображениях могут быть использованы многие из харак-
терных признаков, рассмотренных в разделе, посвященном выделению и распо-
знаванию номерных знаков автомобилей. Кроме них, существует еще ряд при-
знаков, доказавших свою эффективность при сегментации изображений. Неко-
торые из таких признаков приведены ниже.
Локальные двоичные образы (ЛДО)
ЛДО являются мощным средством описания текстурных областей и могут
быть весьма эффективными при выделении лиц на изображении [5, 6]. Для это-
го в качестве характеристик текстуры области изображения используется гисто-
грамма, состоящая из 256 ячеек, значения которых определяются в локальной
окрестности рассматриваемого пикселя (Рис. 1).
5 9 1
4 4 6
7 2 3
1 1 0
1 1
1 0 0
Двоичное значение: 11010011
Десятичное значение: 211
Рис. 1. Пример оператора ЛДО
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 7. Методы детектиоования и распознавания лиц
263
Помимо анализа восьми соседних пикселей могут быть использованы
другие типы отношений. Например, оператор РВРАХ основан на отноше-
нии четырех соседних пикселей, a LBP.b^ использует 16 точек, расположен-
ных на окружности радиуса 2. В общем случае оператор LBPpR использует
Р равномерно распределенных на окружности радиуса R точек. При этом
получается 2Р различных двоичных образов, некоторые из которых содер-
жат больше информации, чем остальные. Поэтому для описания текстурно-
го содержимого можно использовать только определенное подмножество
2Р локальных двоичных образов. Такое подмножество образов, называемых
однородными, состоит из тех элементов, в которых существует лишь малое
число переходов от 0 к 1 и наоборот. Например. 00000000 и 11111111 содер-
жат 0 переходов, а 00000110 и 01111000 содержат 2 перехода. Поэтому мож-
но отнести все образы, в которых число переходов превышает /V, к одной
ячейке гистограммы, что позволит значительно сократить размерность ги-
стограмм. Формируемые таким образом локальные двоичные векторы обо-
значаются как LBPp*R.
Локальные двоичные образы, рассчитанные для всего изображения лица,
отражают достаточно тонкую его структуру, но не дают представления об ее
пространственном распределении. Для устранения этого недостатка можно
разбить изображение на несколько небольших непересекающихся блоков,
для каждого из которых строятся гистограммы ЛДО. которые затем объеди-
няются в одну гистограмму. В таком представлении лицевая текстура кодиру-
ется при помощи ЛДО. а форма кривой, ограничивающей лицо, определяется
конкатенацией р отдельных гистограмм для каждого блока.
Отметим, что такое представление является более адекватным для изобра-
жений лиц достаточно большого размера и. кроме того, описывается векторами
характерных признаков, имеющими длину в несколько тысяч элементов. Для
изображений низкого разрешения можно рассмотреть пересекающиеся обла-
сти и операторы LBPAV а также дополнительно общую гистограмму ЛДО для
всего изображения лица. Это позволит избежать статистической недостоверно-
сти. возникающей при формировании состоящих из большого числа ячеек ги-
стограмм незначительных по размеру областей.
Последовательности гистограмм локальных двоичных образов Габора
Эти признаки [7] являются не только устойчивыми к изменениям условий
съемки, но и более надежными при детектировании заданных объектов. Устой-
чивость к шумам и относительная инвариантность к локальным трансформаци-
ям изображения вследствие изменений освещенности, частичному перекрытию
и повороту достигается при помощи разномасштабных гистограмм, содержа-
щих как распределения локальной интенсивности, так и пространственную ин-
формацию. Более того, при формировании пространственных гистограмм пере-
секающихся прямоугольных областей сначала используются разномасштабные
и ориентированные в различных направлениях фильтры Габора для декомпози-
ции изображения лица, а затем применяются операторы ЛДО. На заключитель-
ном этапе отдельные гистограммы объединяются в последовательность, моде-
лирующую изображение лица.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
264
Цифвая обработка видеоизображений
Локальные гистограммы направлений краевых точек
Эти признаки [8] хорошо зарекомендовали себя при классификации задан-
ных объектов с помощью небольшого числа обучающих примеров. Обычно при
формировании указанных гистограмм используются маски Собеля для вычис-
ления вертикальных G;(x, у) и горизонтальных Сд(х, у) градиентов, после чего
для уменьшения влияния шума производится сравнение величины градиента
G(x,y)= + G2 с пороговым значением 3:
C(X-V)<5 (6)
О, иначе
Основным недостатком при этом является необходимость задания 3. Направ-
ление в краевой точке (х, у) определяется с помощью следующего выражения:
\ fG. (х,у)А
e(x,y)=arctg —у-----г . (7)
Все краевые точки относятся к одной из К ячеек, значения которых задают-
ся как
G'(x,y\ 0(х,у)е[0»-|Д] к = \,..,К
ГЛ • W
О, иначе
Vifay)
Здесь значения вкч и 6к задают /с-ю ячейку. Окончательно гистограмма на-
правлений краевых точек определяется путем суммирования величин (8):
Ek(R)= ^^>у\ (9)
где R - рассматриваемая область изображения. На основе гистограммы (9) могут
быть заданы следующие характерные признаки:
(10)
, ч Et (/?)+£
Ал 00=-ЧЧ—•
£*,(*)+*
Если ввести пороговое значение 3,то при д (/?)><5 направление /с, прсоб-
ладает над направлением к2 в области R. Здесь £ > 0 - малый параметр, который
добавлен для исключения возможности деления на ноль.
Помимо (10), можно рассмотреть несколько иной набор признаков, показы-
вающих соотношение одного выбранного направления к сумме всех остальных:
i
С помощью (11) можно найти доминирующее направление в R.
Кроме направлений, имеет смысл также учитывать наличие симметрии в изо-
бражении:
£|е4(я()-Ш)|
, r2)=,
12 е(А)
(12)
где R} и R2 - прямоугольники, имеющие одинаковый размер и расположенные по
обеим сторонам оси симметрии, Q(R^ - площадь /?гТак же, как и для двух преды-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 7. Методы детектирования и распознавания лиц
265
дущих наборов, данные признаки могут быть использованы не только для поис-
ка симметрии в изображении, но и для обнаружения областей, где симметрия от-
сутствует (например, верхняя и нижняя части лица несимметричны друг другу).
Признаки, основанные на отдельных фрагментах изображения
Они получаются из исследуемых объектов при различных трансформаци-
ях, изменении углов зрения и условий освещенности путем выделения отдель-
ных фрагментов, содержащих одну и ту же область объектов [9]. Использова-
ние комбинации фрагментов основано на том факте, что изображения различ-
ных объектов внутри одного класса имеют структурное сходство и поэтому мо-
гут быть представлены как комбинация общих субструктур. Грубо говоря, идея
заключается в аппроксимации нового изображения лица комбинаций изобра-
жений отдельных областей, таких как глаза, рот и других характерных изобра-
жений. Фрагменты, используемые при таком представлении объектов, выбира-
ются путем максимизации взаимной информации между ними и классом лиц.
Фрагмент F является представителем класса лиц С, если условная вероятность
его принадлежности классу С выше, чем классу С изображений, не содержащих
лиц. т. е.
где 3 - заданное пороговое значение. Необходимо отметить, что фрагменты, ко-
торые удовлетворяют данному неравенству, но при этом встречаются чрезвы-
чайно редко, должны быть по возможности исключены из рассмотрения. Напри-
мер, изображение отдельного фрагмента является характерным представителем
класса С,однако вероятность нахождения этого фрагмента в других изображени-
ях чрезвычайно низка. С другой стороны, такая характеристика лица, как бровь,
встречается во многих изображениях лиц, но также может быть обнаружена и в
изображениях, принадлежащих классу С.
7.1.3. Адаптивные методы классификации
Среди методов классификации, основанных на использовании характерных
признаков, при решении задачи выделения лиц на изображениях наиболее ши-
роко применяются искусственные нейросети, методы использования набора экс-
пертов (бустинг) и метод опорных векторов.
Использование искусственных нейронных сетей
Нейронные сети находят применение во многих задачах распознавания об-
разов. Не является исключением и обнаружение лиц на изображениях. Преиму-
ществом использования нейросетей по сравнению с другими методами является
их способность адаптироваться к самым сложным условиям видеосъемки. Одна-
ко для этого приходится потратить немало времени на выбор оптимальной архи-
тектуры сети (количество слоев, число нейронов в скрытых слоях и т. д.). Ниже
приведен один из наиболее удачных способов использования нейросетей для де-
тектирования лиц [10-13]. Данный метод состоит из двух этапов. На первом эта-
http://wwwJtv.ru
Компания ITV - генеральный спонсор издания книги
266
Ц/Овая обработка видеоизображений
пе к всевозможным областям изображения, имеющим заданные размеры N х N
пикселей, применяется фильтр в виде нейронной сети, который обучен выдавать
на выходе значение 4-1 или -1 в зависимости от того, присутствует на изображе-
нии лицо или нет. Чтобы иметь возможность обнаружения лиц различного раз-
мера, исходное изображение рассматривается на нескольких уровнях разреше-
ния, на каждом из которых проводится настройка фильтра. В результате это-
го достигается определенная инвариантность к изменению масштаба. Описыва-
емый фильтр включает в себя модуль предварительной обработки изображения
и многослойную нейросеть.
Предварительная обработка заключается в интерполировании значений ин-
тенсивности в каждой квадратной области (окне) с помощью линейной функ-
ции и последующем ее вычитанием для компенсации изменений освещенности.
Затем для увеличения контрастности изображения путем расширения диапазона
интенсивностей производится эквализация гистограмм. После чего полученное
изображение подается на вход нейросети.
В качестве нейросети используется трехслойный персептрон с N х N входами,
одним выходом и одним скрытым слоем. Нейроны скрытого слоя разбиты на три
слоя: первый обрабатывает четыре подобласти окна размером —х— пикселей;
« A A A N N
второй обрабатывает подобласти вдвое меньшего размера----х— пикселей;
4 4
третий применяется к перекрывающимся горизонтальным подобластям разме-
Kr N * V
ром /Ух— пикселей. Каждая группа скрытых нейронов предназначена для вы-
4
деления определенных локальных признаков изображения лиц. Например, груп-
па третьего типа позволяет обнаруживать такие характерные области лица, как
рот, оба глаза одновременно, в то время как второй тип служит для детектирова-
ния отдельно глаз, носа, углов рта.
При подготовке данных для обучения нейросети на изображении вручную
отмечаются глаза, кончик носа, углы и центр рта и используются впоследствии
для приведения лица к одному и тому же масштабу, ориентации и местополо-
жению. Отрицательные примеры, т. е. изображения, на которых отсутствуют
лица, нарезаются произвольным образом из фотографий, не содержащих изо-
бражений лиц.
Получаемые результаты содержат большое количество ошибок второго
рода. Поэтому второй этап метода заключается в их устранении и объединении
множественных выделений одного и того же лица. Такое объединение основа-
но на том факте, что при правильном обнаружении лица происходит его неод-
нократное выделение на каждом из используемых масштабов приблизитель-
но в одной и той же области. Если число таких выделений на каждом масшта-
бе превышает пороговое значение, принимается решение о наличии лица в дан-
ной области.
Для устранения ложных выделений лиц совместно используется несколько
нейросетей, имеющих такую же архитектуру. При этом каждая нейросеть обу-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 7. Методы детектирования л распознавания гиц 267
чается схожим образом, но со случайным образом заданными начальными ве-
сами и на произвольно выбранных для обучения изображениях, как положи-
тельных. содержащих лица, так и отрицательных. Хотя результаты, выдавае-
мые различными нейросетями, являются близкими, тем не менее, каждая сеть
склонна к своим собственным ошибкам из-за отличающихся условий обучения.
Поэтому результаты обнаружения лица отдельной сетью в определенном ме-
сте изображения для конкретного масштаба рассматриваются вместе с заклю-
чениями, выданными в этом же месте изображения другими нейросетями с по-
мощью операции логического умножения. В результате происходит повыше-
ние достоверности распознавания.
Главным недостатком описанного метода является увеличение ошибок при
нахождении нефронтальных изображений лиц. Данный алгоритм можно адап-
тировать к поиску лиц, повернутых к камере под произвольным углом, путем их
преобразования к канонической ориентации. Однако при этом снижается сте-
пень правильного обнаружения фронтальных изображений лиц.
Альтернативой применению нейросетей для детектирования и выделения
лиц на изображениях является использование статистических методов. При этом
необходимо оценивать отношение условных вероятностей
где I - это рассматриваемое изображение. Основная сложность заключается в
том, что истинные статистические характеристики класса лиц С и противопо-
ложного ему класса С нам неизвестны. Обычно P(I | С) и P(I | С) представля-
ются с помощью или параметрических мультимодальных распределений, или
различных параметрических моделей, например, с использованием окон Парзе-
на. В первом случае велика вероятность попадания в локальный минимум при
оценке параметров модели. Во втором случае необходимо осуществлять срав-
нение рассматриваемого изображения со всеми членами обучающей последо-
вательности, что неэффективно с вычислительной точки зрения. Одним из воз-
можных решений проблемы является использование нескольких отдельных ги-
стограмм для различных характерных признаков лиц [13]. При этом для адек-
ватного описания объектов необходимо учитывать пространственные, частот-
ные и ориентационные характеристики. Для этого изображение лица разбива-
ется на отдельные части. Размер этих областей должен соответствовать харак-
терным признакам лиц, которые могут встречаться в достаточно широком ди-
апазоне масштабов. Осуществляя пространственное разбиение лица, необходи-
мо сохранять взаимные отношения между отдельными частями, так как такие
отношения являются важным фактором при детектировании объектов.Так, на-
пример, взаимное расположение глаз, носа и рта для любых лиц фиксировано в
геометрическом плане. Выделяемые ориентационные характеристики лиц по-
зволяют надежно обнаруживать признаки, обладающие определенной направ-
ленностью (например, рот).
Указанные характеристики могут быть получены путем осуществления
вейвлет-преобразования изображения. Как правило, применяются трехуровне-
вые 5/3 вейвлеты Добеши. При помощи комбинирования вейвлет-коэффициентов
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
268
Цифвая обработка видеоизображений
различных субдиапазонов можно получить набор характерных признаков, для ко-
торых затем формировать гистограммы. После этого уже можно оценить отно-
шения вероятностей (14). Данный метод может быть применен для обнаружения
не только фронтальных изображении лиц. но также и профильных. Для этого не-
обходимо осуществлять раздельное обучение двух разных классификаторов.
Применение бустинга
Для детектирования лиц на изображениях в последнее время широко приме-
няется метод повышения достоверности распознающей системы за счет исполь-
зования набора экспертов - так называемый бустинг [14-20]. Каждый «эксперт»
является распознающей системой, обучаемой на различных наборах характер-
ных признаков; таких экспертов еще называют слабыми классификаторами. Для
детектирования лиц наиболее часто в качестве характерных признаков использу-
ются вейвлеты Хаара. что связано с простотой их вычисления. Однако существу-
ют и другие признаки, которые с успехом могут быть применены для решения
задачи. Одними из таких признаков являются краевые точки. В отличие от вейв-
летов Хаара непосредственное использование краевых точек не позволяет нахо-
дить объекты разного размера при заданном разрешении изображения. Возмож-
ным решением проблемы является построение пирамиды изображений. К сожа-
лению, это ведет к существенному увеличению вычислений и препятствует реа-
лизации детектора в реальном времени. Для этого на каждом уровне пирамиды
сначала анализируется изображение в квадратном окне с размером стороны nG
точек. Если в какой-либо точке (х0.у0) степень соответствия с моделью, постро-
енной на основе обучающей последовательности методом бустинга. будет выше
порогового значения, то рассматриваются точки в окрестности (х0, у0), но уже
по
в окне со стороной = — Эта процедура может повторяться до тех пор, пока
размер окна nf не станет равным 1.Такое последовательное уменьшение величи-
ны окна позволяет исключить из рассмотрения большую часть не представляю-
щих интерес пикселей изображения. В выбранных точках классификация осу-
ществляется в несколько этапов, начиная с нескольких характерных признаков
(в качестве которых выступают направления краевых точек), обладающих наи-
большей дискриминантной способностью, и постепенно добавляя к ним менее
значительные признаки.
Поле Г(х,у) краевых точек изображения вычисляется с использованием опера-
тора Собеля для тех пикселей, где величина градиента превышает пороговое зна-
чение. Слабые классификаторы в методе бустинга задаются следующим образом:
• Пусть даны пары (Ггс1),...,(<Гт,ст). где с. = 0 для области Г из класса лиц С
и с = 1 для Г из противоположного класса С.
• Зададим функции
g^(x,y,<p)=YD^(r= °)> (15)
g' (x>y^)='ZjDl(i)-\ri(x,y)=<p)j(ci = 1), (16)
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. ru
Глава 7. Методы детектирования и распознавания гид
269
где индикатор J равен 1. если его аргумент принимает истинное значение, и 0 - в
противном случае, значения угла (р берутся с шагом Д<р.
• Слабые классификаторы для пикселя (х,у) определяются как
о. gf(x,y,<p)>gl,^y,<p)
1, иначе
^{х,у,(р) =
(17)
• Слабый классификатор для рассматриваемой области размером М х N
имеет вид:
*,(Г) =
(18)
1, иначе
Окончательно сильный классификатор, определяющий модель лица, вычис-
ляется как взвешенная сумма слабых классификаторов:
Я(г)=£а,й,(г). (19)
/=1
Если Н(Г) < 5, то в рассматриваемом окне детектируется лицо. Величи-
на порогового значения 3 задается таким образом, чтобы максимизировать
эффективность обнаружения лиц на тестовой последовательности изобра-
жений.
Другим вариантом увеличения эффективности метода бустинга является раз-
деление всего пространства входных изображений на несколько частей и исполь-
зование для анализа образов из каждого полученного подпространства соот-
ветствующих классификаторов. Обозначим через S = {Р = (X, У)) исходное про-
странство образов, где X - (х} - образы, У = {у} - результаты классификации, Р =
{р, = (х,> Все пространство образов по отношению к данному классификатору
Т(х) можно разбить на следующие подпространства:
5 = ^ + ^+ $« + $«. (20)
где
= |PJ - образы, которые могут быть легко классифицированы с помо-
щью Т(х);
S р = {PJ - образы, которые могут быть правильно классифицированы Т(х)
при соответствующей настройке параметров;
5^ = ]^]- зашумленные образы;
образы, правильная классификация которых представляет зна-
чительные трудности.
Первые два подпространства могут быть объединены в одно пространство
Sod нормальных образов, а последние два - в пространство сложных для класси-
фикации образов Sol:
SOd = Sno+S„, (21)
оа по лр» \ /
Sol=Snt+ShJ. (22)
о! ns nd' v /
Пример типичного входного пространства образов показан на Рис. 2 [18].
http://wwwjtv.ru
Компания ITV - генеральный спонсор издания книги
270
Цифвая обработка видеоизображений
Рис 2. Пространство входных образов
Как следует из рисунка, разделение всех образов из 5 при помощи одного
классификатора Т(х) может представлять собой весьма непростую задачу. Тем нс
менее, после разбиения S на 5 ^ и So/ достаточно просто классифицировать обра-
зы из Sod. Однако, чтобы верно классифицировать как так и Sol, одним клас-
сификатором Т(х), необходимо достичь разумного компромисса между сложно-
стью и общностью алгоритма. Использование более сложного классификатора
Т(х) приводит к меныпим ошибкам при обучении, но при этом ограничивает ди-
апазон входных изображений, которые могут быть правильно классифицирова-
ны. Хорошо известно, что, классифицируя Sod и S , метод бустинга в основном бу-
дет выбирать образы из Sol, тем самым снижая эффективность выделения задан-
ных объектов. Таким образом, разделив пространство 5 на Sol и Sod, будем исполь-
зовать их подмножества для обучения двух классификаторов: 7^ (х), обладающе-
го высокой способностью к обобщениям, и ТДх), способного верно классифици-
ровать сложные образы. В методе бустинга всем образам соответствуют свои ве-
совые коэффициенты. Причем после каждой итерации вес более сложных обра-
зов увеличивается, а более простых - уменьшается. Когда значение весового ко-
эффициента превышает определенный порог 5, соответствующий образ вклю-
чается в пространство Sol. Оптимальное значение 8 зависит от рассматриваемой
задачи и типа входных образов. Если <5 < 0, то все образы S рассматриваются как
сложные для классификации (S = Sol) и используется только Ту(х). Если же 8 > 0,
то (5 = Sod) и применяется только классификатор 7^(х). Для объединения резуль-
татов, полученных Tod(x) и ГДх), можно использовать простую трехслойную ней-
росеть, содержащую два нейрона на входе, несколько нейронов в скрытом слое и
один - в выходном слое.
В качестве характерных признаков в методах бустинга могу быть использо-
ваны отдельные фрагменты изображения лица, такие как глаз, нос, рот и т. п. Для
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 7. Методы детектирования и распознавания лиц
271
этого изображение последовательно разбивается на блоки различного размера
для нахождения фрагментов, отличающихся местоположением и величиной. Для
каждого блока вычисляются вейвлеты Хаара. которые затем используются ка-
скадом классификаторов для того, чтобы определить, содержится ли в данном
блоке отдельный фрагмент лица. При этом может оказаться, что будет найде-
но несколько идентичных фрагментов (например, два левых глаза) или же ряд
фрагментов будет отсутствовать. Поэтому все найденные фрагменты исследу-
ются модулем проверки топологии для нахождения такой комбинации, которая
может представлять изображение лица.
Проверка топологии основывается на представлении лица с помощью гра-
фа G - (И Е), где V- множество узлов, а Е - множество ребер. В качестве узлов
v g V выступают отдельные фрагменты вместе с дополнительной информа-
цией об их типе (левый или правый глаз, рот, нос) и размере. Ребрам е € Е на-
значаются веса, равные евклидову расстоянию между центрами фрагментов.
На основе обучающей последовательности строится шаблонный граф /?, кото-
рый затем используется для поиска среди различных подграфов Gt оптималь-
ного G*.
После того как на изображении найдены отдельные фрагменты, все они ста-
новятся узлами v графа G. Узлы различного типа соединяются ребрами е. Для
каждой пары узлов /, j е V в графе G можно определить две величины, пред-
ставляющие разность с соответствующими узлами г(/), г(/) в шаблонном графе R:
Е(Л j) (разность размеров) и А(/. j) (разность расстояний). На следующем шаге ре-
бра, нарушающие топологию, характерную для лиц, уничтожаются (с помощью
сравнения с пороговыми значениями Z и А).
В результате получается граф G. Если пороговые значения 2 и А выбраны
правильно, то в графе присутствуют только ребра, соединяющие узлы, отвеча-
ющие одному и тому же лицу. Тем не менее, обычно граф G остается слишком
большим, и в нем существует множество связанных фрагментов, отвечающих
различным лицам. Поэтому в графе G можно выделить отдельные подграфы G?,
z = которые будут соответствовать отдельным лицам. Нам необходимо
найти такой оптимальный по отношению к шаблонному графу R подграф Gp ко-
торый состоит ровно из четырех фрагментов (левый и правый глаза, рот и нос).
Оптимальность подграфов определяется с помощью вычисления минимума по
всем подграфам Gy следующей функции:
(23)
V (t/.v) н
Здесь Y(v) описывает степень различия с шаблонным графом при использо-
вании только одного фрагмента V. В(н, v) - двух фрагментов, a J(w) - недостаю-
щих фрагментов лица. Подграф G. для которого достигается минимум (23), счи-
тается оптимальным G*. Если при этом значение C(G’) меньше заданного порога,
то G* отвечает изображению лица.
Применение метода опорных векторов
Поскольку задача детектирования лиц заключается в разбиении входных
образов на два класса, то для ее решения может быть с успехом применен ме-
http://www.itv ги
Компания ITV - генеральный спонсор издания книги
272
Ц/фвая обработка видеоизображений
(24)
(25)
(26)
тод опорных векторов, позволяющий построить оптимальную разделяющую по-
верхность [21-23]. И хотя процесс настройки системы может занять существен-
ное время, это будет с избытком компенсировано последующей высокой скоро-
стью распознавания.
В методе опорных векторов для построения классификатора
/л >
f (х) = sgn £а,у,К(х,Х')+Ь
\ 1=1 >
необходимо решить следующую оптимизационную задачу:
л 1 \
тах£(а) = тпах ayrytX(x4,xy)
° ° _ 1=1 :. =!
при дополнительных ограничениях
.V
£«,^=о.
«=|
0<а, <С.
Здесь К(х, х) = (р(х)(р(х) - ядро преобразования, <р(х) - заданная нелиней-
ная функция, а - множители Лагранжа. С - штраф за нарушение условия опти-
мальности, а у - переменная, принимающая значение 4-1. если входной вектор
х, соответствует изображению лица, и -1 - в противном случае. Значение пере-
менной b в формуле для разделяющей поверхности (24) находится из условия
Куна-Таккера. В процессе настройки классификатора (24), как правило, оказы-
вается, что большинство коэффициентов а равны нулю, поэтому соответству-
ющие им входные векторы xt не принимают участие в построении классифика-
тора. Остальные векторы, для которых а > 0, называются опорными, посколь-
ку именно они формируют разделяющую поверхность. Подробное описание ме-
тода опорных векторов приведено в главе 5, посвященной адаптивным системам
распознавания образов.
Дальнейшее усовершенствование стандартного метода опорных векторов
связано с тем. что для правильной классификации образов, не являющихся изо-
бражением лиц, достаточно использовать всего лишь несколько векторов, полу-
ченных из опорных. Это позволяет создать иерархическую последовательность
усложняющихся классификаторов, использующих большее число векторов, эф-
фективным образом отсеивающих ложные образы.
Предположим, что существует вектор i/д который может быть представлен
следующим образом:
<27)
i=l
где х е е F- пространству признаков и Д' —> F. Будем аппроксимировать у/ с
помощью редуцированного набора векторов:
.V.
= (28)
/=|
при N{« Ne Для нахождения z и Д минимизируем разность:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 7 Метода детектирования и распознавания ли и
273
= £a,a^(U,)+ <29)
»./=1 4.7=1 «=1 /=1
Будем искать последовательность аппроксимаций 1/7. что позволит создать
набор усложняющихся классификаторов:
)•/=!...X- (30>
1=1
Редуцированный набор векторов 5. и коэффициенты ; находятся с помо-
щью итерационного процесса. Для нахождения первого вектора zx необходимо
аппроксимировать 1/7 величиной = /3<£(z). Вместо нахождения минимума (29)
можно минимизировать
«и= р»
\{Ф{=)Ф{г))
или. что то же самое, максимизировать следующую величину
(У ?(г) Г
(p(z)p(z))’
(32)
Итерации для определения л, задаются с помощью следующего выражения:
(33)
где в качестве ядра К (x^z) выступает гауссова функция
/C(x„z) = ехр[-||х, - z|7(2<r)l
Остальные векторы z.i > 1 получаются аналогичным образом заменой 1/7 на
—_ <=1 м
При поиске лиц на изображении каждый пиксель является потенциальным
центром лица. Поэтому использование всех опорных векторов и даже их реду-
цированного набора может оказаться неэффективным с вычислительной точки
зрения. Поэтому будем использовать следующую иерархическую схему:
1. Положим У = 1.
2. Найдем yf sgn
\ 4=1
3. Если yf < 0, х считается изображением, не являющимся лицом.
4. Если у, > 0. то j =j + 1.
5. Если j < N,, переходим к п. 2.
6. Если / = Nz, к вектору х применяем полный набор векторов, т. е.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
274
цифвая обработка видеоизображений
f (х) = sgn [ j а,у, К (х, X.)+b
\ 1=1
Отличительной чертой данного алгоритма является использование неболь-
шого числа j « N. векторов для классификации подавляющего большинства об-
разов. Отметим, что для гауссова ядра К использование только одного вектора
представляет собой простое сравнение с шаблоном.
Последовательное применение нескольких классификаторов
В отличие от рассмотренных выше методов возможно также последователь-
ное применение нескольких классификаторов, сильно отличающихся по своему
типу и сложности [24]. В первом классификаторе можно использовать свойство
хроматических компонент (ССг) цветового пространства УСьСг для цветных
изображений лиц людей образовывать довольно компактный эллипс, как это по-
казано на Рис. 3. Определяя, лежат ли конкретные пиксели изображения внутри
данного эллипса, можно быстро исключить фоновые области, не содержащие
интересующие нас объекты.
Для построения второго классификатора анализируется полутоновый вари-
ант исходного изображения и рассматриваются окна заданного размера. Строит-
ся вертикальный профиль изображения, и при помощи вычисления вторых про-
изводных в точках локальных экстремумов определяются особые линии, как это
изображено на Рис. 4. Эти линии соответствуют относительно «плоским» и «свет-
лым» участкам лица (щекам). При этом используются следующие эвристические
соображения для выделения интересующих нас изображений:
• во входном окне присутствует, по крайней мере, одна особая линия,
Рис. 3. Распределение хроматических компонент для лиц
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 7. Методы детектирования и распознавания лиц
275
Возможное расположение глаз
---- Особая линия
Возможное расположение рта
Рис. 4. Пример вертикального профиля изображения
• существуют минимумы профиля, лежащие выше и ниже особой линии,
• верхний и нижний минимумы лежат в определенных пределах.
После определения вертикальных положений возможных характерных при-
знаков (глаза и рот) применяется вероятностный подход для уточнения выде-
ленных признаков. Для каждого е е Es (Es - множество претендентов на изо-
бражение глаз) осуществляется его сравнение с имеющимися шаблонами, кото-
рые описывают вертикальные и горизонтальные смещения, тем самым позволяя
учесть небольшие вращения объектов. Результат такого сравнения может быть
записан следующим образом:
LFM = 7Г JJ(255 ’ JJ (255 - / (х,у))Л?. (34)
А в
где wA и wB - весовые коэффициенты, etQ - один из имеющихся шаблонов для глаз,
SA - площадь изображения глаз и SB - площадь области вокруг глаз, содержащая
пиксели с большей яркостью. Тот шаблон, на котором достигается максимум вы-
ражения (34). выбирается из имеющегося набора. Аналогично поступают с ша-
блонами рта: из всех претендентов m е Ms выбирают тот, на котором достигает-
ся максимум выражения, аналогичного (34).
После получения таких локальных характеристик оценивается их отношение
при помощи следующих соображений:
• расстояние между ртом и глазами D(ee т,) лежит в определенных преде-
лах по отношению к размеру окна Ws,
• две присутствующие в окне относительно яркие области между левым
(правым) глазом и ртом отвечают изображению щек.
Основываясь на данных критериях, для каждой комбинации признаков
(е, е Es х Ms вычисляется следующая функция вероятности:
GF (е,,mj = JJI (х, у)dC + w,LF(е,) + wnLF(т,), (35)
D е.т -
где w, и - весовые коэффициенты.
Наконец, в качестве третьего классификатора может быть использована искус-
ственная нейросеть, на вход которой может подаваться следующая информация:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
276
Цифвая обработка видеоизображений
Рис. 5. Представление изображения с помощью частичных профилей
• Пиксельное представление изображения. Оно наиболее часто используется
при детектировании объектов с помощью нейросетей. Его преимуществом
является использование полной информации о входном изображении. К не-
достаткам следует отнести наличие избыточности, достаточно низкую эф-
фективность и высокие требования к вычислительным ресурсам.
• Представление изображения с помощью частичного профиля, как пока-
зано на Рис. 5. Оно содержит интегральную информацию о распределе-
нии интенсивностей пикселей и является достаточно общим для всех лиц.
Данное представление требует в несколько раз меньше вычислений по
сравнению с пиксельным.
• Представление изображения с помощью декомпозиции по методу глав-
ных компонент. Такое представление является самым компактным, так
как использует всего лишь несколько параметров.
7.2. МЕТОДЫ РАСПОЗНАВАНИЯ ЛИЦ НА ИЗОБРАЖЕНИЯХ
Все существующие методы распознавания лиц можно разбить на две группы:
аналитические и холистические [26]. Аналитические методы основаны на выделении
геометрических признаков лица, описывающих его индивидуальные особенности.
Исторически эти методы возникли одними из первых. Местоположение различных
черт лица, а также топологические особенности его контура, позволяют сформиро-
вать вектор характерных признаков, который в дальнейшем используется для распо-
знавания. При выборе опорных точек обычно учитывается степень их важности при
описании лица и легкость выделения. С помощью указанных точек могут быть вы-
числены различные геометрические величины: площади, расстояния и углы, на осно-
ве которых можно построить набор инвариантных признаков. А поскольку процесс
обнаружения опорных точек предшествует основному анализу, то такие системы ма-
лочувствительны к изменению местоположения объектов на изображении.
В холистических методах рассматриваются общие свойства изображений че-
ловеческих лиц. Лицо распознается как нечто целое, а не состоящее из отдель-
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. г и
Глава 7. Методы детектирования и распознавания лиц
277
ных частей, таких как глаза, нос. рот. уши и т. и. Другими словами, в методах дан-
ного класса используются представления изображения всего лица, основанные
на наборе интенсивностей составляющих его пикселей, без выделения отдель-
ных черт лица. Это приводит к тому, что холистические методы проще реали-
зовать по сравнению с аналитическими. Кроме того, они обычно осуществляют
преобразование изображения в пространство характерных признаков гораздо
меньшей размерности, в котором значительно легче проводить классификацию.
Это позволяет значительно уменьшить число требуемых арифметических опе-
раций. Однако холистические методы более чувствительны к изменению место-
положения объекта и его размеров. Лица обычно должны быть или хорошо сег-
ментированы. или располагаться на однородном фоне. Надежность методов дан-
ного класса может снижаться при неравномерном освещении и большом числе
объектов заднего плана.
Поскольку настоящая книга посвящена обработке видеоизображения, нам
следует четко различать, каким образом происходит распознавание - на отдель-
но взятом кадре, либо используются несколько последовательных изображений
видеоряда. Поэтому соответствующие методы распознавания мы будем в даль-
нейшем делить на статические и динамические.
Статические методы распознавания лиц, которые основаны на анализе от-
дельно взятого изображения, исторически появились раньше. Естественно, ста-
тические методы могут использоваться и при анализе видеоизображений. При
этом в видеопоследовательности выбирается наилучший для распознающей си-
стемы кадр, который затем подвергается детальному анализу без использования
временной информации.
Распознавание лиц. опирающееся на видеопоследовательности, обладает
рядом преимуществ по сравнению с отдельными изображениями, так как ана-
лиз движения объектов служит вспомогательной информацией [27,28]. Иссле-
дования показывают, что человек значительно лучше узнает знакомые лица,
если ему показать упорядоченные по времени последовательности кадров, а не
те же кадры в случайном порядке. Хотя распознавание яиц по видеопоследо-
вательности является непосредственным развитием распознавания по отдель-
ным изображениям, динамических методов, совместно использующих про-
странственную и временную информацию, до сих пор существует не так уж
много. Объясняется это тем. что распознавание лиц на основе видео осложня-
ется несколькими факторами:
• качество видеоизображения обычно значительно хуже отдельных сним-
ков, особенно это относится к съемке вне помещений;
• возможна резкая смена освещенности объектов;
• угол зрения лица может постоянно изменяться:
• размеры лиц на видеоизображениях обычно намного меньше (типичны-
ми являются размеры, не превышающие 20 х 20 пикселей), чем на отдель-
ных снимках, где они часто занимают в 5-10 раз большую область;
• на видео задний план во многих случаях имеет сложную изменяющуюся
структуру.
Придерживаясь введенной выше классификации, рассмотрим сначала стати-
ческие методы.
http://www.iiv.ru
Компания ITV - генеральный спонсор издания книги
278
Цифвая обработка видеоизображений
7.2.1.Статические методы
Обычно изображение представляется в виде матрицы, элементы которой
имеют значения интенсивностей соответствующих пикселей. Эту матрицу мож-
но представить в виде одномерного вектора, например, поместив второй стол-
бец под первым, третий - под вторым, и т. д.. что часто бывает удобным для
выполнения различных преобразований. И хотя полученные векторы лежат в
пространстве очень большой размерности, необходимые для анализа данные
обычно принадлежат многообразию гораздо меньшей размерности. Поэтому
основная цель большинства рассматриваемых в данном разделе методов за-
ключается в том. чтобы найти такое оптимальное многообразие существенно
меньшей размерности, в котором можно выявить и компактно описать индиви-
дуальные особенности каждого лица.
Метод выделения главных компонент
Для надежного распознавания лиц из всей имеющейся в изображении инфор-
мации нужно выделить ее наиболее релевантную часть и представить ее в та-
ком виде, чтобы существенно облегчить задачу сравнения текущего изображе-
ния лица с имеющимися в базе данных. Для этой цели могут быть использова-
ны главные компоненты распределения лиц. которые представляют собой соб-
ственные векторы ковариационной матрицы набора соответствующих изобра-
жений. Собственные векторы упорядочиваются в соответствии с величиной соб-
ственного значения, и каждый из этих векторов описывает определенные изме-
нения в изображении лица.
Таким образом, эти векторы можно рассматривать как набор характерных
признаков, описывающих все возможные вариации в изображениях лиц. Так
как каждый участок изображения вносит больший или меньший вклад в каж-
дый собственный вектор, это позволяет нам представить векторы как некое
приближение к изображению лица. Поэтому их принято, следуя работам [29-
32], называть собственными лицами (eigenfaces). На Рис. 6 [32] представлено не-
сколько исходных изображений лиц, а на Рис. 7 - семь соответствующих им соб-
ственных лиц.
Каждое изображение лица может быть представлено как линейная комбина-
ция собственных лиц. Причем для аппроксимации исходного изображения доста-
точно использовать только несколько «лучших» собственных лиц, т. е. те, кото-
рым соответствуют наибольшие собственные значения и которые, следователь-
но, описывают наибольшие вариации в пределах всего множества изображений.
Эти «лучшие» собственные лица образуют подпространство (размерность кото-
рого равна числу векторов) в пространстве всех возможных изображений.
Представим теперь изображение размера N х N пикселей как вектор 1 раз-
мерности 7V2 и будем искать такие векторы, которые наилучшим образом описы-
вают распределение изображений лиц внутри всего пространства изображений.
Пусть у нас имеется набор изображений /ЛГ Составим «среднее» изобра-
жение, осреднив значения каждого пикселя по всем изображениям:
<36>
и вычтем его из каждого изображения:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 7 Методы детектирования и распознавания лиц
279
Рис. 6. Несколько изображений, являющихся элементами обучающей
последовательности
Ф = А-/0. (37)
Построим набор из М ортогональных векторов наилучшим образом опи-
сывающих распределение изображений. Каждый /-й вектор определяется из
условия максимизации следующего выражения:
Л = 77 L <«’ = 77 Z «/ = 77<Ь‘ (38)
4 = 1 М 4х| М *=|
при дополнительном условии ортогональности
= 5и =
1=к
иначе
(39)
Векторы й и величины Л являются собственными векторами и собственны-
ми значениями следующей ковариационной матрицы:
http://www itv.ru
Компания ITV - генеральный спонсор издания книги
280
Цифвая обработка видеоизображений
Рис. 7. Семь собственных лиц, полученных на основе изображений предыдущего
рисунка
1 Л/
Z = —Уффг = ллг (40)
где А = {фр....Фм Заметим, что стоящую перед нами задачу можно сформули-
ровать как нахождение такой матрицы U . которая максимизирует следующий
определитель:
Uop, = arg max |C/'Zt/|. (41)
где U = {«...w„ }.
К сожалению, матрица L имеет размерность V2 х № и нахождение /V2 соб-
ственных векторов и значений представляет собой нереальную задачу для типич-
ных размеров изображений. Однако если число имеющихся изображений мень-
ше размерности пространства (М < V2). то в этом случае будет только М - 1 соб-
ственных векторов с ненулевыми собственными значениями.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 7. Методы детектирования и распознавания лиц 281
Рассмотрим собственные векторы v матрицы АТА:
ArAvf = ^lvl. (42)
Умножив обе части равенства на А. получим
AArAv, = ntAv,. (43)
Отсюда следует что Av. являются собственными векторами Е = ААТ. Поэто-
му достаточно найти Л/ собственных векторов матрицы АТА. составив линейную
комбинацию которых, получим собственные лица й;.
м
«, = 5Х<М=1.....-W. (44)
*=!
Так как обычно Л/ « V. то это позволяет свести задачу к разумной размер-
ности.
Рассмотрим теперь, как осуществляется распознавание лиц с помощью по-
лученного представления. Когда на вход системы поступает новое изображение
лица 7, то оно раскладывается по имеющимся собственным лицам. При этом со-
ответствующие коэффициенты разложения определяются следующим образом:
И'=«1Г(7-7О)< = 1.М- (45)
Из этих коэффициентов затем составляется вектор
£2Г={®!...(46)
который описывает вклад каждого собственного лица в представление входно-
го изображения. Теперь мы можем определить, насколько новое лицо похоже на
каждое известное:
^=Р-^Г- <47>
Когда для какого-то класса лиц имеется более одного изображения, весовые
коэффициенты (46) находятся путем усреднения по всем примерам. Если вели-
чина dk меньше порогового значения 8 для некоторого к, то анализируемое изо-
бражение лица считается принадлежащим /с-му классу. В противном случае лицо
считается новым и образуется еще один дополнительный класс.
При введении меры (47) подразумевалось, что входное изображение является
изображением лица. Для того чтобы проверить истинность этого, спроецируем
изображение в пространство лиц и рассмотрим разность между проекцией изо-
бражения и им самим. Проекция изображения находится путем вычисления раз-
ности между величиной (37) и следующей суммой:
м
^>f = Y(0>Ur
/=1
Расстояние d2 = Цф-Ф^Ц определяет расстояние между самим изображением
и его проекцией. При этом существует четыре возможных случая:
1) dk< 8,d <5. Это означает, что входное изображение близко к простран-
ству изображений лиц и к определенному классу. Следовательно, оно счи-
тается принадлежащим этому классу.
http://www itv.ru
Компания ITV - генеральный спонсор издания книги
282
Цифвая обработка видеоизображений
2) dk < 3. d > 8. Это свидетельствует о том. что входное изображение пред-
ставляет собой шум и должно быть отвергнуто.
3) dk > 8.d < 3. В этом случае входное изображение близко к пространству
изображений лиц. но не близко ни к одному классу. Следовательно, изо-
бражение представляет собой изображение неизвестного лица.
4) dk>8.d> 3. Входное изображение не является изображением лица.
Линейный дискриминантный анализ
Рассмотренный выше метод, основанный на нахождении линейной про-
екции многомерного вектора изображения в пространство характерных при-
знаков гораздо меньшей размерности, максимизирует дисперсию по всем
классам, т. е. по всем изображениям всевозможных лиц. Тем самым сохраня-
ются нежелательные вариации, вызванные изменением освещенности и вы-
ражения отдельных лиц. Как известно, такие вариации для конкретного лица
в большинстве случаев превышают вариации между лицами разных людей
[33]. Таким образом, метод выделения главных компонент, являясь оптималь-
ным с точки зрения снижения размерности пространства и последующего
восстановления изображения, не дает наилучшего решения при классифика-
ции изображений.
Поскольку у нас есть обучающая последовательность изображений лиц, в ко-
торой известна принадлежность каждого изображения к одному из имеющихся
классов, то представляется целесообразным использовать эту информацию при
уменьшении размерности пространства и построении там достаточно простых
классификаторов. Линейный дискриминантный анализ является одним из таких
методов. Он максимизирует отношение дисперсии между различными классами
и внутриклассовой дисперсии.
Введем две матрицы - матрицу разброса между классами Ед и матрицу вну-
триклассового разброса Ен.:
2в = 1ч(4'-4)(/о-4)г. (48)
£(4-/o)(4-Zj)r,
1=1 /*€С.
(49)
где /д- среднее изображение для Z-го класса Сс С - число классов, Л/ - количество
изображений в классе С. Если матрица невырожденная, то в качестве опти-
мальной проекции Uopt выбирается матрица с ортонормированными столбцами,
максимизирующая в отличие от (41) отношение определителей матрицы меж-
классового разброса и матрицы внутриклассового разброса:
= arg max
и
итъ„и
={«.....>«•}.
(50)
где {й, | i = представляют собой обобщенные собственные векторы и
Ew,соответствующие пг наибольшим обобщенным собственным значениям Л:
Евм. = k£wut,i -
(51)
ProSystem CCTV - журнал по системам видеонаблюдения
http.//wivw.procctv.ru
Глава 7 Методы детектирования и распознавания лиц
283
Заметим, что существует нс более С - 1 ненулевых обобщенных собственных
значений, и, следовательно, т не превышает С - 1.
В задачах распознавания лиц матрица внутриклассового разброса (разме-
ром N2 х /V2) всегда вырожденная. Это связано с тем, что ранг Zvv не превышает
М - С, а число изображений в обучающем множестве М много меньше /V2. Сле-
довательно, можно выбрать матрицу U таким образом, что внутриклассовый раз-
брос проекций изображений будет в точности равен нулю.
Для того чтобы обойти эту трудность, заменим выражение (51) на альтернатив-
ное. При этом проекция изображений в пространство меньшей размерности будет
вычисляться так. чтобы получающаяся матрица внутриклассового разброса была
невырожденной. Это достигается путем использования метода выделения главных
компонент для снижения размерности пространства до М - С и последующего при-
менения линейного дискриминантного анализа (выражение (51) для уменьшения раз-
мерности до С- 1.Теперь матрица U п( будет выглядеть следующим образом [34]:
= ' (52)
где
= arg max|(7r£ С/]. (53)
U2 = arg max
uTu^№.utu\
(54)
Здесь при нахождении U} используются матрицы с ортонормированными столб-
цами размером № х (М- С), а при нахождении Ц - матрицы с ортонормирован-
ными столбцами и размером (М -С) хш.При вычислении U} пренебрегают толь-
ко наименьшими С компонентами.
Несмотря на то, что в большинстве случаев линейный дискриминантный
анализ является более предпочтительным по сравнению с методом выделения
главных компонент, существуют ситуации, когда это не так. Это иллюстриру-
ет Рис. 8 [35], на котором изображены два различных класса, чьи распределения
показаны пунктирными эллипсами. Очевидно, что метод выделения главных
компонент найдет вектор, с которым будет связан наибольший разброс по все-
му массиву данных. Это изображено вертикальной прямой. С другой стороны, с
помощью линейного дискриминантного анализа мы получим вектор, который
наилучшим образом проведет разделение между классами. Этот вектор пока-
зан диагональной прямой. Решения, принятые на основе метода ближайшего
соседства, изображены как и D2. Как следует из рисунка, в данном случае ме-
тод выделения главных компонент приводит к заведомо лучшим результатам.
В целом, можно заметить, что описанная ситуация наблюдается в тех случа-
ях, когда количество обучающих примеров для каждого класса мало или когда
лежащие в основе отдельных классов распределения представлены обучающими
примерами неравномерно во всей области их определения.
Совместное использование метода выделения главных компонент и линейно-
го дискриминантного анализа
Широко распространенное мнение о том, что между результатами, получа-
емыми с помощью метода выделения главных компонент (МВГК) и линейно-
http://wwvv.itv.ru
Компания ITV - генеральный спонсор издания книги
284
Цифвая обработка видеоизображен/
Рис. 8. Пример разделения для двух различных классов с помощью МВГК и ЛДА
го дискриминантного анализа (ЛДА). существует сильная корреляция, особен-
но для фронтальных изображений лиц. препятствует их совместному использо-
ванию. Однако в действительности применение дискриминантного анализа к уж.
найденным главным компонентам может породить пространство характерны'
признаков, существенно отличающееся от такого, полученного с помощью одно-
го только МВГК. Поэтому комбинация ЛДА и МВГК при распознавании лиц мо-
жет дать весьма неплохие результаты.
Объединение двух указанных методов можно проводить различными спосо-
бами. Обозначим через d расстояние между входным изображением и /-м изо-
бражением из базы данных. В качестве такого расстояния может выступать, на-
пример, расстояние, вычисляемое по формуле (47). Будем нормировать все рас-
стояния таким образом, чтобы они лежали на отрезке [0,1]:
d =------5 (55
d -d
max mm
где ^min и ^max ” минимальное и максимальное значения t/.Тогда простейшим спо-
собом объединения методов будет сложение расстояний [36]:
<. = rf(,) + rf(2),/=1.М (561
где d(l) - расстояние для МВГК, a d<2> - для ЛДА. Принадлежность изображения к
тому или иному классу определяется как
с = arg mind.. (57)
ProSystem CCTV - журнал no системам видеонаблюдения
http://www.procct v. ги
Глава 7. Методы детектирования и распознавания лиц
285
Другим возможным способом является использование нейросети [37]. Для
этого составим вектор
d = rf’2’.(58)
и будем использовать его как входной вектор для нейросети, в качестве которой
может, например, выступать простой трехслойный персептрон или сеть радиаль-
ного базиса. В ней будет 2.W входов и С выходов (по числу классов). На выход-
ном слое тот класс, для которого будет получено минимальное значение, счита-
ется отвечающим входному изображению. Число узлов в скрытом слое обычно
выбирается экспериментальным путем в зависимости от числа узлов на входном
и выходном слоях.
Нелинейное преобразование исходного пространства
Вследствие присущей им линейности МВГК и ЯДА могут привести к весьма
скромным результатам в случаях, когда распределение входной информации но-
сит явно нелинейный характер. Чтобы решить указанную проблему, можно спро-
ецировать данные в пространство характерных признаков высокой размерно-
сти с помощью нелинейного преобразования и уже в полученном пространстве с
помощью МВГК или ЯДА проводить дальнейший линейный анализ, тем самым
учитывая сложную структуру входной информации.
Пусть Т представляет собой нелинейное преобразование исходного прост-
ранства изображений в пространство характерных признаков 4х (7 ) и такое, что
м
X Т (4) - 0. Составим ковариационную матрицу следующим образом:
*=1
1 4 т
s=^Z4'(a)4'(Z). (S9)
При выделении главных компонент нам необходимо найти собственные зна-
чения Л и собственные векторы v.;
Svf = i = 1...М. (60)
Подставив (59) в равенство (60), заметим, что все решения Ц можно представить
как линейную комбинацию Ч/(71^(7^ )• Отсюда следует, что мы можем рас-
смотреть эквивалентную систему:
¥ (4 ) • Lv = Л, У (7,) V,, к = 1.Л/, i = 1 (61)
и что существуют коэффициенты такие, что
Ч = £а;^(74). (62)
*=!
Подставив (59) и (62) в (61), получим:
М^Ка‘=К2а‘, (63)
где матрица К задается следующим образом:
к,=(Ч'(А)*(Л)) <«)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
286
Цифвая обработка видеоизображений
a at - представляет собой вектор
(65)
Таким образом, задача (63) представляет собой задачу на собственные значения:
Ка' = МЛ,&. (66)
Очевидно, что все решения (66) удовлетворяют (63). Кроме того, можно пока-
зать, что любые дополнительные решения (66) не вносят изменений в разложе-
ние (62) и. следовательно, не представляют для нас никакого интереса [38].
Можно перенормировать те решения аг которые отвечают ненулевым соб-
ственным значениям, потребовав, чтобы соответствующие векторы удовлетво-
ряли равенству (v • v) = 1.Тогда из (62). (64) и (65) получим:
м л/
i=£ £ «;«; (*(л) • ^(7,))=(«* ) = л, («* • ). <67>
4=1 ;=!
Для выделения главных компонент найдем проекции анализируемого изображе-
ния 7:
(4'f(/))=Z«1('f(a)4'(/"))- (68)
4=1
Заметим, что при вычислении выражений (64) и (68) не требуется в явном
виде задавать т(/А): в выражения входит только скалярное произведение этих
функций. Поэтому можно выбрать ядро к = к (х, у) таким образом, что будет су-
ществовать отображение 4* в некоторое пространство (возможно, бесконечно-
мерное), в котором к будет представлено скалярным произведением. В качестве
таких ядер обычно используют полиномиальные, сигмоидные и функции ради-
ального базиса (см. раздел 5.3.2).
Заменив всюду скалярное произведение (Ч'(х)’Ч'(у)) соответствующим
ядром к[х,у\получим следующий алгоритм нахождения главных компонент:
1) Вычисляем матрицу скалярного произведения (64) К .
2) Решаем систему (61).
3) Нормируем коэффициенты разложения а' с помощью (67).
4) Находим главные компоненты (соответствующие ядру к) для анализиру-
емого изображения 7 с помощью вычисления проекции (68).
Напомним, что в приведенных выше выражениях предполагалось, что
м
= Однако в общем случае этого гарантировать нельзя. Поэтому
л=|
следует вычитать среднее значение из ):
1 м
При этом вместо матрицы К необходимо рассматривать К:
КУ = К- Е„К - КЕМ + ЕМКЕ^ (70
где все элементы матрицы Еч равны -—- [39].
М
ProSystem CCTV - журнал по системам видеонаблюдения
ht tp://vv ww. procct v.
Глава 7. Методь детектирования и распознавания лиц
287
Для случая линейного дискриминантного анализа все рассуждения аналогич-
ны приведенным выше. Ковариационные матрицы (48)-(49) теперь будут выгля-
деть следующим образом:
(71)
1=1
=f £ (*(л)-^)(т(7‘)-ч'о)г- (72)
1=1 /4еС,
где
^=^-£*(4). (73)
1к*С
Выражение (50) теперь должно быть записано в виде скалярного произведе-
ния входных изображений, которое можно заменить соответствующим ядром к.
Проводя рассуждения, подобные приведенным выше для метода выделения глав-
ных компонент, получим, что классификация изображений будет происходить на
основе вычисления следующего выражения:
&opt = аг8 тах
(а'Г
(75)
где а - коэффициенты разложения по Т(/. | проекции изображения в простран-
стве характерных признаков, а матрицы ъв и £и определяются как:
у* - я Аг
^в ~ лвлв^
1 1 м
(76)
*:=дл
Щ=Ч7Л)-^£*(Ш V7/eC/’ « = = (77)
Проекция I входного изображения I в пространство характерных признаков
задается с помощью следующего выражения:
м
4 = £«'*(7’7)- (78)
1—1
Использование специальных графов
Рассмотренные выше методы в качестве исходной информации использова-
ли непосредственно интенсивность пикселей. Однако в последние годы все чаще
к изображениям сначала применяются вейвлеты Гйбора, а затем уже обрабаты-
h£tp.//www./tv.ru
Компания ITV - генеральный спонсор издания книги
288
Ц/фзая обработка видеоизображений
ваются полученные трансформированные данные. Это связано с тем, что дей-
ствие фильтров Габора некоторым образом напоминает работу зрительной си-
стемы человека. Одним из таких методов является метод распознавания лиц с по-
мощью эластичных графов [40].
Вейвлеты Габора для точки х = (х, г) задаются с помощью формулы
с\ к< I
<//,(х) = -^ехр -
ехр(/£.х)-ехр
\ 2 /
(79)
2а'-
Обычно используют пять различных частот v = 0..4 и восемь направлений
Д = 0.7:
М
к«,
к,=
fcvCOS^
, kv = 2 - . К =
О
(80)
где / = Д + 8v.
Введем теперь для каждой точки изображения набор J из 8 х 5 = 40 комплекс-
ных коэффициентов:
(81)
Учитывая (79)-(80),эти коэффициенты можно представить в виде
J, =a;exp(z<pj. (82)
где амплитуды aj (х) являются медленно меняющимися функциями точки изо-
бражения, а фазы (х) изменяются со скоростью, определяющейся волновым
вектором к .
Вейвлеты Габора имеют низкую чувствительность к изменениям яркости изо-
бражения. Благодаря ограниченной локализации по частоте и в пространстве они
в определенной степени обладают инвариантностью к перемещению, вращению
и изменению масштаба. Однако при перемещениях возникают значительные из-
менения величины фазы. Вследствие этого наборы J, расположенные на рассто-
янии всего лишь несколько пикселей друг от друга, обладают сильно отличаю-
щимися коэффициентами, хотя фактически они описывают один и тот же ло-
кальный характерный признак. Это может вызывать серьезные проблемы при их
сравнении, вследствие чего в большинстве случаях фазой просто пренебрегают.
Однако использование фазы несет в себе ряд преимуществ. Во-первых, она
позволяет различать изображения с одинаковыми амплитудами. Во-вторых,
сильная зависимость фазы от точки изображения дает возможность точной ло-
кализации наборов J в изображении. Предположив, что два набора J и /'соответ-
ствуют двум расположенным на расстоянии d друг от друга пикселям, получим
функцию, определяющую степень схожести наборов:
cos
(83)
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://w w w. procctv. ru
Глава 7 Ме^одь’ дефлирования и распознавания лиц
289
Для того чтобы найти величину £)р. необходимо оценить смещение d = \dx,dv)-
Это может быть сделано с помощью нахождения экстремума D . Для этого раз-
ложим ее в ряд Тейлора до членов второго порядка и получим:
(84)
Приравняв производные от DQ по dwd к
найдем выражения для смещения при Г Г
г»
-г
1
г„г. -г г х
нулю и решив полученную систему,
*П.ГЖ:
-г.
Г„
ф2
Ф
/ /
г«>=ХаАчЛ-
у (8^)
г« =
/
)
J
Будем теперь для каждого изображения лица определять опорные точки,
такие как углы рта, кончик носа, зрачки и т. д. Модельный граф G, описываю-
щий лицо, будет состоять из N узлов, совпадающих с этими опорными точками
xt, i = и Е ребер между ними. Каждому узлу поставим в соответствие на-
бор J, а ребру - расстояние Дх, = х. -xr, j = где ребро/ соединяет узлы i и
Для того чтобы найти опорные точки в новом изображении, необходимо
иметь общее представление для лиц. В противном случае нам бы пришлось лю-
бое самое незначительное изменение в лице описывать с помощью нового мо-
дельного графа. Вместо этого мы объединим репрезентативную выборку от-
дельных модельных графов в стекоподобную структуру, называемую графом со
связками лиц. Все наборы Л относящиеся к одной опорной точке, будем называть
связкой. Например, связка для отдельного глаза включает в себя наборы, соот-
ветствующие мужскому, женскому, закрытому, открытому, прищуренному глазу,
как это изображено на Рис. 9. Предположим, что для некоторого угла поворо-
та лица к камере у нас существует М модельных графов G,n (т = 1,...,Л/) с оди-
наковой структурой, полученных из различных изображений лиц. Соответству-
ющий граф со связками лиц В будет иметь такую же структуру, его узлам будут
соответствовать связки наборов 7/. а
„ А-Я
ребрам - средние расстояния Дх. = д—
http://www.itv.ru
Компания ITV — генеральный спонсор издания книги
290
Цифвая обработка видеоизображений
Рис. 9. Граф со связками лиц, являющийся общим представлением для
изображений лиц
Размер такого графа со связками лиц определяется степенью изменения отдель-
ных лиц и требуемой точностью распознавания.
После того как каждое лицо будет описано с помощью модельного графа, для
каждого конкретного поворота головы к камере можно получить граф со связка-
ми лиц. В начальный момент это делается вручную, а затем графы для новых изо-
бражений получаются автоматически посредством так называемого эластичного
сравнения графов со связками. Ключевую роль в этом сравнении играет функ-
ция, оценивающая схожесть графа для рассматриваемого изображения и графа со
связками лиц для того же самого поворота головы к камере. Для графа G1 изобра-
жения 1 с узлами i - 1»..., /V и ребрами j = 1,..., Е и графа со связками лиц В, вклю-
чающего в себя модельные графы т = 1,..., Л/, степень схожести определяется как
' 7 \ ; )
где Л задает относительную важность наборов .Л в узлах i и расстояний Дх; для ре-
бер/.Так как в графе со связками лиц для каждой опорной точки существует не-
сколько наборов Л то для сравнения используется лучший из них. Таким образом,
целью эластичного сравнения графов при поступлении нового изображения яв-
ляется поиск в нем опорных точек и выделения из него графа, максимизирующе-
го схожесть (86) с графом со связками лиц.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 7 Методы детек’иоования и оасчозназания лиц
291
После этого мы уже можем проводить распознавание лиц путем сравнения
графа G1 для нового изображения со всеми модельными графами G"\ содержа-
щимися в базе данных:
Dc(G/,G'n) = -A7£D.(Z.Jm)./n= 1..АЛ (87)
где
Уаа',
Da (JJ') = (88)
узел Л в модельном графе соответствует узлу Г в графе рассматриваемого изо-
бражения. а суммирование в (87) распространяется только на те N’ узлов в нем,
для которых существуют соответствующие им узлы в модельном графе. Тот мо-
дельный граф, для которого величина (87) максимальна и превышает пороговое
значение, считается отвечающим рассматриваемому изображению.
Применение метода AdaBoost
Успешное использование методов бустинга в задачах обнаружения заданных
объектов на изображениях, в том числе лиц людей, дало толчок к исследованию
возможностей их применения при распознавании лиц. Однако в отличие от про-
блемы детектирования лиц, которое заключается в классификации на два мно-
жества, распознавание лиц представляет собой задачу классификации с большим
числом классов. Так как стандартный алгоритм AdaBoost (Adaptive Boosting)
предполагает наличие только двух классов, то необходимо свести задачу рас-
познавания лиц к задаче бинарной классификации. Для этого можно ввести два
множества - межклассовых и внутриклассовых различий. Первое будет образо-
вано благодаря изменениям в различных изображениях различных людей, а вто-
рое - с помощью различных изображений одного и того же лица.Таким образом,
для двух изображений обучающего множества, полученных для одного и того же
лица, разность векторов их характерных признаков будет помещена во множе-
ство внутриклассовых различий 5”. В противном случае такая разность попадет
во множество межклассовых различий ЗГ.Тем самым проблема сводится к зада-
че бинарной классификации и можно непосредственно использовать методы бу-
стинга. Однако теперь основную сложность создает тот факт, что размеры мно-
жества межклассовых различий намного превосходят размеры множества вну-
триклассовых различий. В типичных случаях данные размеры отличаются в сот-
ни раз. Это приводит к ухудшению качества получаемого классификатора. Од-
ним из способов решения указанной проблемы является случайный выбор эле-
ментов из множества S’ таким образом, чтобы на каждом этапе гарантировать
использование наиболее характерных образцов и поддерживать постоянным от-
ношение положительных и отрицательных примеров.
Опишем теперь такой алгоритм бустинга с учетом указанных требований
[41]. Пусть {(Д, yf). i = 1....JV) представляет собой обучающую последователь-
ность. где Д( - это вектор разности характерных признаков двух изображений,
http://www.itv. г и
Компания ITV - генеральный спонсор издания книги
292
Цифвая обработка видеоизображений
yt е {0.1}. где yf = 1 обозначает принадлежность к множеству S’, a yt - 0 - к S .
В начальный момент все положительные примеры образуют положительную,
не меняющуюся в дальнейшем обучающую последовательность размером N\
Случайным образом выберем .V отрицательных примеров, чтобы получить на-
чальную отрицательную обучающую последовательность So. Далее отношение
ЛГ/ЛС остается неизменным.
Для всех значений / = 1.L:
1) Инициируем весовые коэффициенты для всех примеров из обучающей
последовательности
2N+ ’У'
—,у=о
2N ‘
2) С помощью стандартного метода бустинга получим очередной класси-
фикатор:
C,(A) = 5gn .
где Tt - число слабых классификаторов на данном уровне. Остальные
обозначения совпадают с обозначениями, использованными в разделе 6.3.
3) Объединим С, с уже имеющимися классификаторами, чтобы получить /-й
сильный классификатор:
я, (Д) = sgn(H,_' (д)+с,) = sgn(£a,h, (Д)-1 £а,
\ 1-1 2 /-1
где Г = ^Те
1=1
4) Получим новую отрицательную обучающую последовательность S,~:
a. Sf~ = 0.
b. Случайным образом выберем отрицательный пример Д* из оставшихся
в исходном множестве S образов. Если ДА неверно классифицируется с
помощью
(ДЛ) = Sgn [ £ а,Л, (Д*) -1$,£ а, 1
то он добавляется в Sf: Sf = Sf kJ {ДА.}. Отметим, что < 1 и постепен-
но увеличивается с ростом I.
с. Повторяем предыдущий шаг до тех пор. пока размер S/ не достигнет N .
Окончательно получим следующий классификатор:
( т 1 г 1
tft(x) = sgn £аД(х)--£а, .
\ 1=1 2 1=1 /
где т = £?;.
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp ://www. procc tv.ru
Глава 7. Методы детектирования и распознавания лиц
293
В качестве характерных признаков в простейшем случае можно использо-
вать вейвлеты Хаара. но наилучшим образом при распознавании лиц себя заре-
комендовали фильтры Габора (79). Однако размерность получающихся при этом
признаков слишком велика. Поэтому представляется разумным применять ме-
тод бустинга для снижения размерности исходной задачи и выбора наилучших
признаков, учитывая тот факт, что признаки, использованные при построении
слабых классификаторов, являются наиболее информативными. После получе-
ния с помощью метода AdaBoost заданного числа Т характерных признаков Га-
бора к ним может быть применен метод выделения главных компонент для даль-
нейшего снижения размерности [42]. Окончательное решение может быть при-
нято с помощью метода линейного дискриминантного анализа. Подробнее с ме-
тодом AdaBoost можно ознакомиться в Главе 5.
Модели активной формы и активного внешнего вида
Одним из наиболее эффективных подходов в задачах детектирования и распо-
знавания объектов является построение соответствующих моделей. Тем не менее,
когда форма и внешний вид объектов могут варьироваться в достаточно широких
пределах, возникают значительные трудности, хотя для их преодоления в послед-
нее время был создан ряд методов, базирующихся на использовании деформируе-
мых (гибких) шаблонов [43]. Однако эти методы для описания как можно большей
изменчивости объектов вынуждены пренебрегать индивидуальной специфично-
стью людей. В действительности модель должна отражать только те изменения, ко-
торые являются типичными для описываемого класса объектов. Именно это поло-
жено в основу моделей активной формы [44,45] и активного внешнего вида [45-47].
Модели активной формы представляют собой параметрические гибкие (де-
формируемые) модели, строящиеся статистическим образом на основе наблю-
дения изменений объектов, встречающихся в обучающей последовательности.
Каждый объект представляется с помощью множества точек, которые могут
описывать границу объектов или, например, некоторые внутренние характер-
ные признаки. Точки располагаются аналогичным образом для всех имеющихся
изображений объекта из обучающей последовательности. При этом они вырав-
ниваются так, чтобы минимизировать дисперсию расстояний между соответству-
ющими друг другу в разных изображениях точками. На основе изучения стати-
стики положений точек строится модель распределения точек (в англоязычной
литературе Point Distribution Model), с помощью которой определяются их сред-
ние положения. В данной модели обычно бывает несколько параметров, для того
чтобы отразить изменения, которые существуют в обучающей последовательно-
сти. При такой модели и таком изображении моделируемого объекта интерпре-
тация изображения состоит в выборе значений параметров, наилучшим образом
описывающих объект.
Пусть форма объекта (лица) описывается с помощью л-угольника с коорди-
натами вершин (х, у(). Составим из его компонент следующий вектор:
Х = (х|^|,...,хл,Л)Г (89)
Для того чтобы проводить сравнение отдельных форм, нам необходимо пере-
вести их в одну и ту же систему координат. Потому применим к вектору X пре-
http://www itv.ru
Компания ITV - генеральный спонсор издания книги
294
Цифвая обработка видеоизображений
образования, включающие в себя перемещения (fr, / масштабирование (s) и
поворот (0):
(90)
Средняя форма объекта при этом определяется как
(91)
Отклонение каждой формы от средней находится с помощью следующего вы-
ражения:
dxt=xt-xz. (92)
Построим ковариационную матрицу:
Е = — У (93)
* ‘
Тогда основным направлением для точек в данном 2л-мерном пространстве явля-
ются собственные векторы Д ковариационной матрицы:
2А = ЛЛ (94)
Построим матрицу Л состоящую из собственных векторов, расположенных в по-
рядке убывания соответствующих собственных значений:
/’ = (А -РгЛ (95)
Теперь форма объекта может быть описана как деформация средней формы с
помощью линейной комбинации собственных векторов:
х = х0 + РЬ, (96)
где
£ = Рг(х-х0). (97)
Вектор b определяет множество параметров модели. Изменяя значения компо-
нент этого вектора, можно варьировать форму объекта х, что видно из формулы
(96). Дисперсия z-го параметра b в обучающей последовательности равна Л. На-
кладывая ограничения
-з7л<ь,<з7л> (98)
мы гарантируем, что полученная форма объекта схожа с имеющимися в обу-
чающей последовательности. Таким образом, полностью модель описывается
вектором:
v = (tx,ty,s,e,b). (99)
Для того чтобы с помощью модели активной формы найти на изображении
заданный объект, на изображение помещается средняя форма х0 приблизитель-
но в месте расположения объекта. После этого необходимо провести согласова-
ние средней формы и краевых точек объекта. Это делается с помощью минимиза-
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www.procctv. г и
Рис. 10. Совмещение модели и объекта на входном изображении
ции расстояния Махаланобиса для каждой краевой точки (см. Рис. 10). Затем точ-
ки формы сдвигаются в соответствующем направлении, что дает новый вид фор-
мы. При этом параметры модели удовлетворяют условию (98). Такой итерацион-
ный процесс повторяется до выполнения заданного критерия сходимости. Алго-
ритм поиска в модели активной формы позволяет находить соответствующие точ-
ки на новом изображении, используя введенные в модели ограничения, наклады-
ваемые на форму объектов. Однако при этом совершенно не учитывается инфор-
мация о текстуре объекта. Чтобы воспользоваться всеми преимуществами, кото-
рые даст учет текстурных данных, были разработаны модели активного внешне-
го вида. Они включают в себя статистические модели не только формы объекта,
но и его так называемого внешнего вида, представляемого с помощью текстуры.
Предположим, что gim - это вектор, состоящий из значений интенсивности
пикселей, находящихся внутри области, ограниченной формой объекта. Чтобы
уменьшить влияние изменений освещенности, применим к каждому изображе-
нию операцию масштабирования а и сдвига р:
g = (100)
а
где е - единичный вектор. Значения а и Р выбираются таким образом, чтобы
полученный вектор в наибольшей степени соответствовал среднему значению.
Пусть gQ - это среднее значение имеющихся данных, масштабированное и сдви-
нутое так, чтобы сумма его элементов была равна нулю, а дисперсия - единице.
Тогда значения а и Р выбираются следующим образом:
a = g*.fo. Д= —. (Ю1)
п
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
296
Цифвая обработка видеоизображений
где п - размерность векторов. Естественно, нахождение среднего значения является
рекурсивным процессом, так как преобразование данных (100) само зависит от него.
Применив, как и в модели активной формы, метод выделения главных ком-
понент, получим:
g = g0 + Rc. (102)
где R - матрица, состоящая из собственных векторов, а с - вектор параметров,
описывающих текстуру объектов.
Таким образом, в целом, форма и внешний вид объектов могут быть описаны
с помощью векторов b и с.Так как между ними может существовать корреляция,
применим еще раз к имеющимся данным метод выделения главных компонент.
Для этого введем вектор:
fW •bWwr' (х-х0Й
< с ) [^r(g-g0)j
(103)
где W - диагональная матрица весовых коэффициентов для каждого параметра Ь,
позволяющих привести к одним и тем же единицам измерения форму и внешний
вид объекта. Применив МВГК к этим векторам, получим новую модель:
7 = 2* А. (104)
Здесь Q - матрица, состоящая из собственных векторов, a h - вектор параметров
внешнего вида, описывающих как форму, так и текстуру объекта.
Линейный характер модели позволяет выразить форму и текстуру непосред-
ственно как функцию /г.
x = x0 + PWlQsh, g = g0 + RQgh, (105)
где
(а а
е=Ь} (106)
После того как модель активного внешнего вида построена, возникает во-
прос: как с ее помощью и при наличии достаточно хорошего начального прибли-
жения проанализировать новое изображение? Обычно для этого используется
эффективный метод корректировки параметров модели таким образом, что по-
лучающееся синтезированное изображение будет наилучшим приближением для
рассматриваемого изображения. Следовательно, задача сводится к нахождению
минимума разности между новым входным изображением и синтезированным с
помощью построенной модели. Вектор разности 81 может быть определен как
5/(107)
где /. - вектор значений интенсивностей нового изображения, а 1т- вектор зна-
чений для текущих параметров модели.
Для нахождения минимума квадрата разности А = |5/|2 изменяют параметры
модели Л. Так как модель может иметь большое число параметров, то данная за-
дача представляет собой сложную многомерную задачу оптимизации. Впрочем,
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 7. Ме’одь детектирования и оасгознава-ия лид
297
если заранее сделать предположения о том. как будут меняться во время поис-
ка параметры модели, то можно значительно упростить нахождение решения за-
дачи. В этом случае проблема разбивается на две части: нахождение зависимо-
сти между 81 и ошибкой в определении параметров модели 8h и в использовании
этой зависимости в итерационном алгоритме для минимизации Д [46].
7.2.2. Методы, основанные на динамической информации
Несмотря на то. что в распознавании лиц на отдельных изображениях за по-
следние годы был достигнут* значительный прогресс, существует относительно
небольшое число методов, в которых непосредственным образом учитывается
динамическая информация, содержащаяся в видеопоследовательностях. Причи-
ны этого уже были приведены ранее, отметим только еще одну, а именно алго-
ритмическую. В то время как весьма непросто выделить устойчивые характер-
ные признаки лица на отдельном изображении, для видеопоследовательностей
сложность этой задачи возрастает во много раз.
В большинстве случаев распознавание лиц на видеоизображении происходит
в два этапа. Вначале модуль трекинга и детектирования определяет местоположе-
ние лица в текущем кадре на основе имеющейся информации о координатах лица
в предшествующие моменты времени. После этого модуль распознавания анали-
зирует выделенную область текущего кадра с учетом информации, обнаружен-
ной на предыдущих кадрах. Очевидно, что в видеопоследовательностях наклон и
поворот головы могут значительно меняться со временем, что вносит дополни-
тельные трудности в процесс распознавания. Кроме того, ряд ошибок возника-
ет вследствие неточностей и несогласованностей модуля трекинга. И, наконец, в
отдельных кадрах лицо может быть частично или полностью скрыто от камеры.
Причем такая ситуация встречается особенно часто в системах видеонаблюдения,
установленных в общественных местах с большим скоплением людей.
Использование информации из нескольких отдельно взятых кадров
Наиболее простым способом использования видеопоследовательности для
распознавания лиц является выбор нескольких отдельных кадров без учета их
временной зависимости [48-51]. Предположим, что изображения лица из клас-
са к, к = 1.С описываются с помощью функции распределения вероятности ре
а п изображений |. принадлежность которых к одному из классов
требуется определить, описываются функцией р0. Тогда задача распознавания
состоит в нахождении функций рк (к = 1.С), наилучшим образом описываю-
щих набор изображений Очевидно, что существует С различных гипотез Нк,
к = 1..С. о принадлежности лица тому или иному классу:
............................................................. (Ю8)
Яс
Если предположить, что Гс независимы и одинаково распределены, а все классы
имеют одинаковую априорную вероятность, то выбор гипотез можно осущест-
влять следующим образом:
http://www.itv.cu
Компания (TV - генеральный спонсор издания книги
298
Цифвая обработка видеоизображений
нк = arg max £log(px (/')). (109)
* i=l
Проверку гипотез (108) можно рассматривать как оценку дивергенции Кульбака-
Лейблсра между распределениями для входной последовательности изображений
р() и для имеющихся классов [48]. Тогда (109) можно записать в следующем виде:
Нк = arg max[-£>ю (р0,рк)]. (110)
где
OttU,A) = Jp0(/)logМп И- (Ш)
\РЛч )
Когда размерность данных велика (в нашем случае она совпадает с т - числом
пикселей изображений), оценка выражения (111) представляет собой достаточно
сложную задачу с высокими требованиями к вычислительным ресурсам. Одна-
ко для нормальных распределений его можно представить в следующем виде [52]:
Ма>.а)=|108-70)г)-у, (112)
где 1к и 70 - средние изображения для класса к и для входной последовательно-
сти, a и Zo - ковариационные матрицы соответствующих гауссовых распре-
делений. Пусть теперь Uk - матрица, столбцами которой являются собственные
векторы матрицы = (1^ -1к “Л У’ Введем также диагональную матри-
цу ЛА из собственных значений Sk и таких, что ЛА1 > ЛЛ2 > ...> Л^. Так как истин-
ная размерность данных обычно значительно меньше, чем т, то выберем М <п
первых собственных векторов, удовлетворяющих, например, условию
м-\ м
£лй<5<£л4„ (113)
1=1
где 8 - наперед заданное число. Тогда для ковариационной матрицы Lk может
быть построено следующее факторизованное представление:
\=икК[иТк, (114)
где
0 • • • •)
(И5)
I ° • • • • рк)
1__
т- М
(116)
Недостатком представления (111) для DKL(p0,pk) является его несимметрич-
ность. поскольку, поменяв местами аргументы, мы получим другой результат. По-
этому лучше его преобразовать к симметричному виду [49]:
ProSystem CCTV - журнал по системам видеонаблюдения
http://w ww. procctv. г и
Глава 7. Методы детектирования и распознавания лиц
299
Brad (Ро»Рк ) ~ ( А)’ Р*) + ^kl [Рк ’ А) )] •
или заменить расстоянием Бхатачарья:
(Н7)
о, (л. А) = i(4 - 4)' (Z, + £.) 1 (/, - 4) +1 log(118)
Иногда использующееся выше предположение о нормальности распределе-
ний может не выполняться на практике. Поэтому более близким к реальности
может быть применение смеси гауссовых распределений.
Идентифицирующие поверхности
Одной из основных проблем при распознавании лиц на видеоизображении
является изменение положения головы относительно камеры. Изменение пово-
рота и наклона головы со временем приводит к тому, что распознающая система
начинает относить это лицо к другому классу. Устранить эту проблему помога-
ет использование временной когерентности изображений в видеопоследователь-
ности.
Если предположить, что изменения внешнего вида лица на изображениях
могут происходить только за счет вариаций поворота головы (т. е. не учитывать
изменения освещенности, выражения лица и т. д.), то каждый класс может быть
описан с помощью уникальной гиперповерхности. Другими словами, к вектору
характерных признаков изображения, которые, например, описывают форму и
текстуру лица, положение его центроида и параметры сдвига и масштаба, до-
бавляются еще две координаты, описывающие поворот и наклон головы. Каж-
дой паре значений поворота и наклона отвечает единственная точка для данно-
го класса лиц. Распределение всех таких точек одного и того же класса образует
гиперповерхность в пространстве характерных признаков лиц и поворотов. У ка-
занные поверхности называются идентифицирующими поверхностями (identity
surfaces) [53-55]. Процесс распознавания лиц заключается в вычислении и срав-
нении расстояний между входными данными и множеством идентифицирующих
поверхностей.
В том случае, когда имеется достаточное число изображений лица, получен-
ных с различных углов зрения, идентифицирующие поверхности для данного
класса могут быть найдены с высокой степенью точности. В противном случае
такие поверхности могут быть аппроксимированы набором из N плоскостей,
разделенных заданным числом /V углов зрения.
Предположим, что х и у представляют соответственно поворот и наклон
головы, [(x0P>y0I),...,(x0v ,^0Л;)] - заданная совокупность поворотов и накло-
нов для всех классов, a z - вектор характерных признаков изображения лица.
Тогда идентифицирующая поверхность может быть описана следующим об-
разом:
z — ах Л-by-‘г с. (119)
Пусть Лой плоскости отвечает М образов: (хл, уп, za),..., {xtM , yiM , ziM ). Тогда бу-
дем искать следующий минимум функции [53-55]:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
300
Цифвая обработка видеоизображений
Л₽ Л/ - 2
min Q = min £ £|а,х„ + bty4 +с, - =,Ц* (120)
1=1 у=1
при условии, что плоскости с индексами i и j пересекаются в (х0Л, у0А):
ЙЛ>* + Ь.Уок = 5,хм +blyOk + с?, к = 0,1,... Л... (121)
Для входных данных (х, у, 5,) расстояние до одной из идентифицирующих поверх-
ностей определяется как евклидово расстояние между z0 и соответствующей точ-
кой z на идентифицирующей поверхности:
rf = ||z0-4 (122)
где z задается с помощью выражения (119).
Использование видео позволяет нс только получить дополнительную инфор-
мацию из нескольких кадров и с различных углов зрения, но также воспользо-
ваться временной когерентностью, содержащейся в последовательности кадров.
После того как лицо на изображении обнаружено, можно производить его со-
провождение в последующих кадрах. В результате получим текущую траекто-
рию объекта в пространстве характерных признаков. Ее проекция на каждую из
имеющихся идентифицирующих поверхностей с теми же самыми позами и по-
рядком следования во времени образуют модельную траекторию данного лица.
Распознавание теперь будет заключаться в сравнении траекторий объекта с мо-
дельными траекториями.
В момент времени t расстояние между траекторией объекта и модельной тра-
екторией для класса с определяется как
< = (123)
(=1
где d(i - расстояние (122) между рассматриваемым образом в Лом кадре и иденти-
фицирующей поверхностью с-го класса, - весовой коэффициент, задаваемый
на основе имеющейся информации о степени изменения изображения по сравне-
нию с предыдущим кадром, угле обзора лица (для профиля лиц значения весовых
коэффициентов меньше) и т. п.
Окончательно принадлежность к тому или иному классу определяется на
основе выражения
с0 = arg min dc. (124)
c=lr,..C
По сравнению со статичными методами данный алгоритм будет более надеж-
ным и точным. Например, трудно определить, к какому из классов (Д или В) от-
носится X на Рис. 11 [53]. Однако, обладая информацией о траектории объекта,
легко можно прийти к выводу, что X принадлежит к классу А.
Метод конденсации
Качественное распознавание лиц с использованием видео предполагает со-
провождение объекта во времени. В условиях перекрытия объектов и измене-
ния условий освещенности данная задача представляет значительные трудности.
Часто используемый для этого фильтр Кальмана не всегда является адекватным
ProSystem CCTV - журнал по системам видеонаблюдения
ht tp://ww w. procctv. ги
Ггава7. Методе дете<~иэовани₽ и оаспсз-авания ли~
301
Рис. 11. Пример использования идентифицирующих поверхностей (ИП) при
распознавании лиц
выбором, так как основан на предположении о нормальном виде распределений,
которые, будучи унимодельными. не могут описать сложные ситуации. Алгоритм
конденсации (condensation algorithm) [56.57] использует вероятностные модели
формы и движения объекта, что позволяет осуществлять их сопровождение в
условиях значительных перекрытий.
Обозначим через xt состояние моделируемого объекта в момент времени г, а
через X, = {хр...,х,} - набор всех его состояний до текущего момента времени t.
Аналогичным образом множество характерных признаков изображения обозна-
чим через zf, а через Z, = {zp...,z,} - набор всех характерных признаков до мо-
мента времени t. Заметим, что на данном этапе мы не делаем никаких предполо-
жений о характере распределений х иг. Однако будем считать, что новое состо-
яние объекта зависит только от предыдущего, т. е.
р (*, I Л-i)=р UI )• (125)
Стандартной задачей распознавания образов является нахождение объекта
х с априорной плотностью вероятности р(х) на основе имеющихся признаков z,
присутствующих на одном изображении. Плотность апостериорной вероятности
p(x|z), из которой можно получить информацию о х, может быть получена с по-
мощью теоремы Байеса:
p{x\z)-kp(z\x)p(x\ (126)
где к - константа нормировки, не зависящая от х. В тех случаях, когда p(z |х) име-
ет достаточно сложный вид, применяется следующий итерационный алгоритм.
Сначала на основе плотности априорной вероятности р(х) генерируются величи-
ны «у(ЛН Затем индекс i = 1..../V выбирается с вероятностью w такой, что
http.//www.itv.ru
Компания ITV - генеральный спонсор издания книги
302
Цифвая обработка видеоизображений
Рис. 12. Множество точек ,?h’ (центры блобов) получено путем случайной выборки с
плотностью априорной вероятности р(х). Вес каждого элемента w пропорциона-
лен площади блоба.
где р.(х) = p(z|x). Значения х' = хг выбранные указанным образом, имеют рас-
пределение, аппроксимирующее p(x\z) тем лучше, чем больше величина Л‘
(см. Рис. 12).
В основе метода конденсации лежит описанный выше алгоритм, который
применяется к последовательным кадрам в видеопотоке. При этом вместо
мы имеем множество i = 1,..., N] с весами аппроксимирующими услов-
ную плотность вероятности p(xJZr) в момент времени г. Процесс получения
множества начинается с вычисления априорной плотности p(xt\Zt х). В об-
щем случае эта плотность является мультимодальной и для нее невозможно в
явном виде выписать функциональную зависимость. Обычно она находится из
i = 1,...,N}, являющегося приближением для p(xi_x\Zl в) - величины, по-
лученной на предыдущем шаге.
Итерационный процесс метода конденсации изображен на Рис. 13 [56]. Для
каждого момента времени t он начинается с инициализации начальных данных
значениями / = 1,...,/V}, известными в момент времени г-1. Целью яв-
ляется поддержание в последующие моменты времени множества фиксирован-
ного размера N. Поэтому сначала из множества выбирается N значений,
каждое с вероятностью Некоторые элементы с большими весами могут
быть выбраны неоднократно, другие - вообще ни разу. Далее выполняются два
шага - так называемые дрейф и диффузия. На первом шаге идентичные элемен-
ты дрейфуют одинаково (см. Рис. 13). Второй шаг - диффузия - является по сво-
ему характеру случайным процессом, и поэтому идентичные элементы разбива-
ются на несколько более мелких элементов, прежде чем каждый из них незави-
симо от других начнет броуновское движение. В результате этого для нового мо-
мента времени t получено множество {5^}. Новые значения весов w рассчитыва-
ются по формуле (127).
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
S33
Рис. 13. Одна из итераций в алгоритме конденсации
Таким образом, алгоритм конденсации состоит из следующих этапов:
• В момент времени г-1 имеем , i = 1./V}, где - кумулятивные
веса. Необходимо определить в момент времени t. Определя-
ем /-й из N новых элементов следующим образом:
1. Выбираем элемент
- случайным образом выбираем одно г е [0.1] из равномерно распределен-
ных на этом отрезке чисел;
- находим ), для которого с}') > г;
- назначаем = з^.
2. Находим новое значение исходя из p(xjx/s'^).
3. Определяем веса:
^0 = р(г,|х,=^0)
и нормируем их таким образом, чтобы и/'* = 1. Определяем кумулятивные
веса: «
cj0> = 0,
с(о _ С(»-П + w(')
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
304
Цифвая обработка видеоизображений
• После того как найдены необходимые значения, можно, например, опреде-
лить среднее местоположение объекта:
ХЧ1’^’
Для того чтобы можно было применить алгоритм конденсации для решения
конкретной задачи, необходимо задать вид плотностей вероятности p(xjxr-l) и
p(z|x). Это можно сделать разными способами. При этом для алгоритма конден-
сации не требуется линейности параметризации кривой, задающей форму объек-
та в отличие от большинства других методов, опирающихся на это предположе-
ние. Однако линейность параметризации является привлекательной по той при-
чине, что позволяет значительно упростить вычисления и анализировать дина-
мику объекта.
При решении задачи распознавания лиц удобно записать вектор состояния
в следующем виде: хг= (н,, 0). где через л, обозначен класс лица, а 0{ - параметры
траектории, и p(xi\xi,) = p(nt\n, ,)р(0,'0 :). Временная модель лица полностью
определяется с помощью вероятности перехода из одного состояния в другое
p(nt, 3t\n(,, 3t х) и условной плотности вероятности p(z\nf, 0). Наша задача за-
ключается в нахождении p(/ijZz). Выпишем сначала выражение для p(/V, 0 |Zr)
[57-60]:
„Кё, „к. A, ,Z.,).
P\zt I A-i)
- PI «1 > Ш Z| 111--/ - ,---------- . (128)
У-2 P^JZ^J
p^IZ^,)
Здесь Nt = = [0p..„ 0J и предполагается, что p(nt\nt= <5(nz - n( J,
т. e. класс объекта co временем не изменяется. Отсюда можно получить следую-
щее выражение:
р(п,|2,) = р(п,|г,)Р]^(ё,|г,)П/?^|П,Л —(129)
в, в, 7=2
Предположим теперь, чтор(п||г|) имеет равномерное распределение:
Р(ЛЛ*1) = 7? (13°)
где С - число классов, a ^(©JZj) и р(0 | 0 J подчиняются гауссову распределе-
нию со своими средними и ковариационными матрицами. Апостериорная ве-
роятность (129) может быть представлена с помощью следующего множества
{(л}‘\0^, и/*’),/ = 1,... ,7V). Воспользуемся для вычислениями,, 0|Zz) алгоритмом кон-
денсации. В отличие от описанного ранее величина 5^ теперь состоит из и 0,(,\и
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глаза 7. Ме~одэ де~ект/сова*-ияоасгсз»-аБа-«/я
305
соответственно всюду должны быть внесены небольшие изменения. Например, в
пункте 2 алгоритма конденсации новые значения п,:' и в^ определяются исходя из
p(nt; nt_< = п' ') и р(в. О -в' ). Кроме того, можно показать, что набор
{(нг, ДД л. = 1.С}, представляющий собой p(?z; Z). может быть получен следу-
ющим образом:
v
Дп. = £ (bi)
г=1.
я*
где nt выступает в качестве индекса. Осталось задать вероятность p(zjn/,0/). Для
этого воспользуемся выражением, основанным на использовании «обрезанного»
лапласиана:
L expl-Ijrji сг).
Lexp(-A). гД>Лст
(132)
где ]/(/?)“) = У 1(г\- сг и Л - наперед заданные величины, L - константа норми-
re/f
ровки. a v. описывающая шум изображения, обычно имеет гауссово распределе-
ние и не меняется во времени. В качестве параметров траектории объекта 0, как
правило, выступает вектор, состоящий из величин, отвечающих за деформацию
(а|Г...,дг) и сдвиг (tet) объекта:# = (п.:,ар, ft. fj.
7.3. УЧЕТ ИЗМЕНЕНИЯ ОСВЕЩЕННОСТИ СЦЕНЫ ПРИ ДЕТЕКТИРОВА-
НИИ И РАСПОЗНАВАНИИ ЛИЦ
Наилучшие результаты при распознавании лиц на изображениях достига-
ются внутри небольших помещений, в которых довольно легко контролиро-
вать уровень освещенности объектов. Однако часто системы видеонаблюдения
устанавливаются в местах, где освещенность объектов может весьма значи-
тельно меняться за короткие промежутки времени. Хотя во многих существую-
щих системах используются различные методы для достижения частичной ин-
вариантности к изменениям освещенности сцены, например, выравнивание ги-
стограмм, тем не менее, надежность распознавания при изменяющихся параме-
трах освещения сильно падает.
Как известно.большинство методов сегментации изображения основано на ис-
пользовании той или иной разновидности адаптивных моделей построения фона.
Однако эти методы являются достаточно эффективными только для постоянно-
го или очень медленно меняющегося освещения сцены. В случае резких измене-
ний освещенности (например, при включении внешнего источника света), проис-
ходит резкое изменение сцены, в результате чего многие объекты фона начина-
ют сегментироваться в объекты переднего плана. В настоящем разделе описаны
методы, позволяющие детектировать моменты внезапной смены освещенности.
Для детектирования таких изменений можно использовать, например, симме-
тричную дивергенцию Кульбака-Лейблера. Будем считать, что изменение осве-
ht tp://w w w. i t v. ru
Компания ITV - генеральный спонсор издания книги
306
Цифвая обработка видеоизображений
щенности влечет за собой одновременное возмущение в распределении интен-
сивностей пикселей. Для момента времени t построим гистограмму изображения
Нг состоящую из .V ячеек. Тогда дивергенция Кульбака-Лейблера между гисто-
граммами в двух последовательных кадрах определяется как [61]
(133)
Чем ближе гистограммы двух кадров.тем меньше будет величина DKL. Кроме
того, она является неотрицательной, но не является симметричной. Поэтому луч-
ше воспользоваться симметричным аналогом дивергенции Кульбака-Лейблера:
KLsyrn
(134)
Если Ht и H( } рассматривать в качестве распределения двух классов, то вели-
чина (134) представляет собой ошибку байесовского оптимального классифика-
тора, производящего разделение образов между этими классами. Когда (134) пре-
вышает наперед заданное пороговое значение, фиксируется изменение в осве-
щенности сцены.
Изменения освещенности сцены могут быть также интерпретированы
как некое преобразование изображения из исходного состояния 1г в текущее
1( [62]. Поэтому, если построить оператор, инвариантный к такому преобра-
зованию, можно зафиксировать все изменения в изображении, не относящи-
еся к его действию. В качестве последних могут, например, выступать дви-
жущиеся объекты.
Подавляющее большинство встречающихся в природе поверхностей, и лица
в том числе, не являются идеальными, поэтому некоторая часть отраженного
от них света является рассеянной. При этом значение интенсивности конкрет-
ного пикселя изображения будет зависеть от интенсивностей соседних с ним
пикселей. Поэтому, для того чтобы получить информацию о рассматриваемой
поверхности, наиболее близкую к истинной, необходимо рассматривать не от-
дельные пиксели, а наборы соседних пикселей. Для этого можно использовать
прямоугольные окна W размером гп х п. Будем составлять из элементов окон
векторы а. Например, для окна размером 3x3 такой вектор будет иметь вид:
«(»./) = {Г (/-1,У-1), /(/-1,7 + 1), /(/,7).
/(/+1,7-1), /(/+1,7). /(/+1,7+1)}.
Если два вектора, а,, относящийся к исходному изображению, и ас - к текущему,
являются линейно зависимыми, то справедливо следующее равенство:
5г-Айс = 0, (136)
где к - некое число. Условие (136) можно переписать в следующем виде:
— = А, ас *0, V(z = w . (137)
Здесь w - множество всех индексов вектора 5, N = п • т. Очевидно, что (137) вы-
полняется. когда векторы dr и ас - параллельны. Обозначим через
ProSystem CCTV - журнал по системам видеонаблюдения
http://www. procctv. г и
Глава 7 Методы детектирования и распознавания лиц
307
и
ст2= —
W-1
V а'
Z —д
ТГ. а.
(138)
(139)
среднее значение и выборочную дисперсию отношений (137). Тогда с помощью
последней величины можно ввести критерий изменений между двумя кадрами -
исходным и текущим: если (У2 ~ 0. то изменений между этими кадрами не происхо-
дило: если (У2 > 0. то векторы d и а не являются параллельными и, следователь-
но, происходили некие изменения. Таким образом, в качестве оператора, инвари-
антного к преобразованиям изображения вида
аг = кае (140)
может быть использована величина дисперсии а2.
В ряде существующих алгоритмов выделения лиц на изображениях RGB-
значения пикселей непосредственно используются для составления модели фона.
Однако они не являются устойчивыми к изменению освещенности сцены. Для
устранения этого недостатка при построении фоновой модели можно использовать
цветовую информацию совместно с данными об интенсивности изображения [63].
Обычно освещенность сцены меняется достаточно плавно в пространстве, и ей от-
вечают низкочастотные компоненты в Фурье-разложении изображения, в то вре-
мя как компоненты, отвечающие за отражение света, являются высокочастотны-
ми. Следовательно, представляется возможным их разделение при помощи гомо-
морфной фильтрации (см. выражения (143)-( 145)). После того как будут получены
инвариантные к изменениям освещенности сцены компоненты, связанные с отра-
жением, мы можем их использовать в дальнейшем для моделирования фона.Тем са-
мым будет достигнута независимость фоновой модели от изменений освещенности.
Как известно, изображение объекта создается падающим светом, который
отражается от его поверхности. Цветовые компоненты пикселя изображения
могут быть получены следующим образом [64]:
1 ('J) = e(i, У)[тА (л,?)*, (/,/) + т, (л, s,v)/(»,/)], (141)
где е - распределение спектральной мощности падающего света, mb(n,s) и
(h,s,v) выражают зависимость отражения от геометрических свойств объек-
та (его объема и площади поверхности), кс учитывает характеристики конкрет-
ной матрицы камеры,/- параметр зеркального отражения. Выражение (141) мо-
жет быть записано в более простой форме как
/(«, у)=/(«,?)•'•(«, у). (М2)
Здесь г(/, ]) - множитель, инвариантный к освещенности и описывающий отра-
жающие свойства поверхности объекта. Он полностью определяется материа-
лом поверхности. В свою очередь /(г, /) зависит от освещенности. Задача состо-
ит в разделении этих двух сомножителей. Для этого сначала прологарифмируем
выражение (142):
http://www.itv.ru
Компания IТV - генеральный спонсор издания книги
308 Цифвая обработка видеоизображений
ln/(i,j)= \nl(i,j) + \nr(i.j). (143)
Для большинства приложений предположение о гладком изменении осве-
щенности по пространству является вполне обоснованным. Фоновая модель
должна быть инвариантной не только к глобальным, но также и к локальным из-
менениям освещенности. Поэтому для разделения 7(7, /) и г(/, /) будем выбирать
локальный 3x3 гауссов низкочастотный фильтр G3<3:
In Z = G3x3 *1п7.
О44)
г = ехр(1п/-1п/).
где * означает операцию свертки. Отсюда следует, что отдельные цветовые ком-
поненты отражения выражаются следующим образом:
<.6 = exp(,n h.g.b -1п/)- О45)
Будем теперь предполагать, что изменения, происходящие в фоновом пикселе,
могут быть описаны с помощью гауссова процесса с параметрами
Здесь ER - ожидаемые инвариантные к освещенности цветовые компоненты
пикселя, <5r = [ст,, crg,(J6]. а Gl стандартное отклонение /. Для задания этих пара-
метров применяется следующая процедура. Любой отдельный пиксель в видео-
последовательности большую часть времени принадлежит к фоновым пикселям
и только иногда бывает закрыт движущимися объектами. История каждого пик-
селя может быть описана с помощью набора гистограмм. Ожидаемые значения
ER могут быть оценены по максимальным значениям гистограмм, аналогично
могут быть получены стандартные отклонения. Естественно, что в таких обуча-
ющих видеопоследовательностях желательно иметь кадры с изменениями в осве-
щенности сцены для получения наиболее робастных результатов.
Хотя учет изменений освещенности сцены необходимо отражать в модели
уже на стадии ее разработки, в ряде случаев удается в ранее разработанную си-
стему интегрировать модель, отвечающую за корректную обработку внезапных
изменений освещенности сцены [65]. Вообще говоря, полученное в цифровом
виде изображение может нелинейным образом передавать энергетическую яр-
кость сцены. Однако при этом должна сохраняться монотонность:
Е<Е2^1<12. (146)
Здесь через Е обозначена падающая энергетическая яркость для данной точ-
ки, а через / - значение пикселя, соответствующее этой точке, на выходе камеры.
Таким образом. 1 = h(E), где h - монотонная функция. Разобьем теперь изображе-
ние на две части, одна из которых только косвенным образом зависит от измене-
ний освещенности, а другая непосредственно связана с меняющими свою силу ис-
точниками света. Первая часть изображения не подвержена воздействию осве-
щения напрямую, но значения конкретных пикселей в ней, тем не менее, зави-
сят от меняющихся внешних условий. Предположим, что значения энергетиче-
ской яркости в неких двух точках равны и Ег причем Е} < Ег Для соответ-
ствующих значений пикселей справедливо соотношение < 7^. При изменении
освещенности сцены меняется функция Л, однако соотношение между значения-
ми пикселей остается тем же: 7, ' < 7$2’. Таким образом, изменение освещенности
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 7. Ме^одь дете<т/сования / оасгознавания лиц
309
не меняет порядок следования значений пикселей, соответствующих точкам сце-
ны, не подверженных прямому воздействию света.
Для непосредственно освещенных участков сцены энергетическая яркость в
точке может быть записана следующим образом [66]:
Е(х) =
_1___
г(х) + к
' (х) А. + KJ (*)X L (-г)cosе, (х) +
(147)
(х)Х 4 WcosK ”[<>, W] ••
Здесь г(х) - расстояние между камерой и точкой х: Ка(х), Kd(x) и К (х) - рас-
сеянный, диффузионный и зеркальный коэффициенты отражения в точке х; La -
интенсивность рассеянного света сцены: L (x) - интенсивность падающего света
от z-ro источника в точке х: в (х) - угол, под которым падает свет от z-го источни-
ка в точке х: <pt(x) - угол между точкой обзора и зеркально отражающимся све-
том: л(х) - положительное целое число, определяющее степень рассеяния зер-
кального света в точке х: к - числовой параметр.
Далее мы будем рассматривать только рассеянные и диффузионные отраже-
ния. Для близких друг к другу точек значения r(x), L/x) и 0(х) приблизительно
равны, поэтому вместо них будем использовать г, L и 6. Тогда выражение (147)
можно записать как
1
г + к
Е(х) =
' К„ (Х) La + Kd (Х) У A C0S
Разность энергетических яркостей в двух близлежащих точках равна
£(хг)
f • Av
' (*.(x2)-^(x,))z,e (x2)-Kd(х,))£д cos0,
Сделаем следующее предположение:
(148)
(149)
(150)
т. е. поверхность, на которой лежат точки X! и хг обладает одинаковыми свойства-
ми относительно рассеянного и диффузионного отражений. Поэтому
s8n (£ (х2) - Е (х,)) = sgn (Kd (b)-Kd (х,)). (151)
Отсюда видно, что порядок следования значений энергетических яркостей
для двух близлежащих точек определяется коэффициентами диффузионного от-
ражения. которые в свою очередь зависят от материала поверхности. С учетом
предположения о локальном постоянстве освещенности и гладкости геометрии
поверхности указанный порядок следования является квазиинвариантным к из-
менениям интенсивности как окружающих, так и локальных источников света.
Тогда из (146) следует, что порядок следования значений пространственно близ-
ких пикселей, непосредственно подверженных действию внезапно меняющихся
источников света, также сохраняется. Маловероятно, что это будет справедли-
вым для пикселей движущихся объектов. Поэтому можно использовать это свой-
ство в качестве критерия для разграничения изменений, связанных с источника-
http://www.itv.ru
Компания IT V - генеральный спонсор издания книги
310
Цифвая обработка видеоизображений
ми света и с объектами наблюдения. Однако значения пикселей могут быть ис-
кажены вследствие шумов камеры, учесть которые можно путем создания спе-
циальной модели.
В основу такой модели положим алгоритм [67], где входящее значение энер-
гетической яркости преобразуется модулем «баланса белого» к значениям рас-
пределения спектральной мощности падающего света е в интервале [0,1]. Зна-
чения е в свою очередь искажаются шумом N, вносимым при выполнении сним-
ка, с дисперсией, пропорциональной Е. и тепловым шумом N , в результате чего
регистрируется искаженная величина ё. Поэтому после аналогово-цифрового
преобразования в камере на выходе окончательно получим искаженное изобра-
жение 1. Обычно для камеры используется следующий функциональный вид
/ = /(ё) = 255ёа, где а < 1.
Поскольку шум можно рассматривать как малое аддитивное возмущение, для
приблизительного нахождения / мы можем воспользоваться разложением Тейло-
ра до первого порядка включительно:
J = f(e) = f[e+Ns + Ne) = f(e)^Ne (152)
И
Nt = f'(e)(N, + Nc} (153)
Так как дисперсия Nf пропорциональна £, то
< =(/4e)i~*))2[(s(z)-6H+<]• <154)
где g - функция, обратная к f. В большинстве случаев b = 0. Поэтому
7 = 2 + ЛГ/=/(е)+Уг (155)
где
< =< +(//WleS^))2[^(z)c^ + (Tc.]- (156)
Здесь (J2 - дисперсия шума, вносимого при выполнении снимка, <7* - дисперсия те-
плового шума и - дисперсия шума квантования. Когда камера является отка-
либрованной, из уравнения (156) следует, что шум камеры можно считать функ-
цией значения пикселя, а не энергетической яркости.
Для получаемого на выходе камеры значения пикселя / его истинное значе-
ние может быть аппроксимировано гауссовым распределением со средним значе-
нием, равным 7, и дисперсией . Рассмотрим два пикселя, лежащих вблизи друг
от друга, в двух последовательных кадрах 7/'*1*, / = 1,2. Обозначим = 1\} -
Предполагая, что измерения значений пикселей являются независимыми,
получим, что ~ г? (-/(2'},ст’„ + ст’„ j и ~ г/ - 7*'+|), ст’,.ч + ст’,.ч j. где
П(...) обозначает нормальное распределение.
Пусть Р = P(d{,} > 0) и Р = P(d('n) > 0). Заметим, что эти величины являются
параметрами двух биномиально распределенных случайных величин. Постоян-
ство порядка следования определяется с помощью расстояния между двумя рас-
пределениями с параметрами Pt и Р г в качестве которого можно использовать
расстояние Бхатачарья:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
Глава 7. Методы детектирования и распознавания гиц
311
0 = ^-1 +V(1-^)0-^)- (157)
Когда обе величины Р, и Р , стремятся к 1 или к 0, значение D близко к 1, и
порядок следования сохраняется. В случае, когда одна из величин стремится к 0, а
другая - к 1, D близко к 0, свидетельствуя о том, что порядок следования наруша-
ется в двух последовательных кадрах. Надежность таких выводов зависит от ве-
личин d(0 и Если они распределены нормально с нулевым средним, преобла-
дает шум камеры, и сделанные выводы о порядке следования не являются досто-
верными. Следовательно, для повышения надежности необходимо использовать
высококонтрастные пиксели.
Таким образом, весь алгоритм выглядит следующим образом.
1.
2.
Для кадра в момент времени t рассматривается окрестность размером
2 х 2. и из нее выбирается верхний левый пиксель для последующего срав-
нения с оставшимися тремя пикселями. Пусть/(х) - индекс, соответствую-
щий индексу j пикселя, для которого разность / (х) - / (у) принимает мак-
симальное значение. Тогда мы имеем пару (х, ;(х)). с помощью которой
можно вычислить Р(х) для каждого пикселя х. Этот шаг необходим для
повышения надежности сравнения (можно было просто выбрать для это-
го два любых пикселя). Р вычисляются исходя из разности значений пик-
селей и их дисперсий.
Для нового кадра в момент времени г+1 аналогично вычисляется вероят-
ность Р^,(х) для каждого пикселя х. После этого с помощью Р(х) и Ри1(х)
можно рассчитать £)(х) и построить карту расстояний.
Карта расстояний содержит локальную информацию о сохранении порядка
следования значений пикселей. Существуют различные способы использования
такой карты для классификации областей изображений на движущиеся объекты
или изменения освещенности. Например, можно сравнивать значение D с неким
заранее заданным порогом 5Л. Если D < пиксель считается относящимся к
движущемуся объекту.
В большинстве случаев основной характеристикой изображения является ин-
тенсивность его пикселей. При наличии цветной камеры становится возможным
использование цветовой информации. При этом интенсивность всех цветовых
каналов является пропорциональной, независимо от того, находится объект в
тени или непосредственно освещен источником света [68]. Пропорциональность
между цветовыми каналами в пространстве RGB может быть представлена с по-
мощью вектора 7 = (JRJG, каждая компонента которого
'--------11--—, к = R. G. В
П
является постоянной для данного объекта даже при изменении условий освеще-
ния. Векторы 1 могут быть описаны с помощью смеси гауссовых распределений,
аналогично тому, как это было сделано ранее для интенсивностей (см. раздел 2.2).
Однако использование только интенсивностей или только цветовой ин-
формации приводит в ряде случаев к некорректным результатам. Поэтому для
сегментации движущихся объектов следует использовать как интенсивности
/д /7з, так и цвета (158) [68].
(158)
к ~
^ + Н
л <7
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
312
Цифвая обработка видеоизображений
Модель, основанная на интенсивностях пикселей, чувствительна как к изме-
нению освещенности, так и к движению объектов. Цветовая модель позволяет
выделять только движущиеся объекты. Поэтому изменение освещенности мож-
но детектировать в тех областях, где величины (158) являются постоянными, а
интенсивности / меняются значительным образом. Предположим, что S, и Sc -
бинарные изображения, полученные при использовании двух моделей, основан-
ных соответственно на использовании интенсивности и цвета. При этом пиксели
со значениями, равными 1. на таких изображениях отвечают переднеплановым
объектам, а 0 - фону. Область, где происходит изменение освещенности, состоит
из множества пикселей х. которые удовлетворяют следующему условию:
S1(x) = S/(x)(Sf©fi)(x). (159)
где © обозначает операцию дилатации. В - структурирующий элемент (напри-
мер. размером 3x5 или 3 х 7). а черта сверху - операцию отрицания. Решение об
использовании той или иной модели может быть принято на основании получен-
ных после операции (159) результатов.
Модель, основанная на цветовой информации, подвержена ошибкам при де-
тектировании объектов в тусклых, а также насыщенных областях, где хромати-
ческая цветовая информация является ненадежной. В противоположность это-
му, модель, использующая интенсивность пикселей, дает некорректные резуль-
таты в случаях внезапного изменения освещенности. Поэтому отношение сум-
мы площадей областей с меняющейся освещенностью к площади всего изобра-
жения, а также среднее значение интенсивности могут рассматриваться в каче-
стве критерия использования конкретной модели. Например, на закате, когда
средняя интенсивность изображения мала, разумно использовать модель, бази-
рующуюся именно на интенсивности. Только, когда средняя интенсивность пре-
вышает некое пороговое значение, можно применять обе модели одновремен-
но. Если же средняя интенсивность становится слишком большой, использует-
ся только цветовая модель.
Модель, основанная на интенсивности, не может детектировать объекты, у
которых интенсивность пикселей близка к фоновой. Цветовая модель перестает
работать, когда хроматичность объектов становится схожей с фоновой. Следо-
вательно. возможно частичное объединение обеих моделей для получения более
надежных результатов. Например, в случае предпочтительного использования
цветовой модели к Sc может быть добавлено некоторое пространственно близ-
кое к нему подмножество Sr Это позволит получить правильные результаты в
случае близости цветовой хроматичности объектов и фона. Множество точек
переднего плана S2 получается тогда следующим образом:
S2 (*) = $С (*) + $(-(*)• (*)• (5С Ф (160)
В реальных ситуациях освещенность сцены может изменяться мгновен-
но (например, при включении внешнего источника света). В таких случаях ис-
пользование инвариантных к изменениям освещенности цветовых характер-
ных признаков вместо построения сложных фоновых моделей является пред-
почтительным. Один из таких простейших инвариантов в пространстве RGB
получается, если разделить каждую цветовую компоненту на сумму всех трех
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www procct v. ru
Глава 7. Методы детек^ирсван/я / оасгоз^ава-/я луц
313
компонент. Несколько более сложным преобразованием цветовых кана-
лов является следующее [69]: / = (R - G)2 D. Ц- (R - B}~/D. L = (G - B)2/D, где
D = (Я- G)2* (R-B)' - (G-В)2. Недостатком таких представлений является мень-
шая информативность новых цветовых координат по сравнению с исходными.
Одним из методов, позволяющих избавиться от возникающих ошибок вто-
рого рода и в значительной мере от шума камеры, является использование цве-
товых гистограмм изображения с локальными ядрами [70.71]. В отличие от
стандартных гистограмм они позволяют в реальном времени учитывать про-
странственную информацию при помощи построения небольших по размеру
локальных гистограмм. При этом также применяется процедура сглаживания,
что дает возможность избежать шума камеры и небольших движений на заднем
плане. Гистограммы с локальными ядрами можно адаптировать таким образом,
чтобы их совместное использование с другими характерными признаками изо-
бражения привело к выделению переднего плана изображения, которое было
бы инвариантно к изменениям освещенности.
Для построения гистограмм с локальными ядрами разобьем все изображение
на квадраты размером п х п пикселей, перекрывающиеся на g пикселей. Таким
образом, за исключением пикселей, находящихся по краям изображения, каждый
пиксель лежит в Л’и= (л/g)2 областях. С одной стороны, п должно быть достаточ-
но большим для сглаживания вибраций камеры и небольших движений (напри-
мер. порядка 12-15). С другой стороны, слишком большие значение приводят к
неправильному выделению переднеплановых объектов.
Вследствие шума камеры количество различимых цветов значительно
снижается.Так как нам необходимо вычислять гистограммы в реальном вре-
мени, то для уменьшения числа операций выберем из имеющихся цветов пс
наиболее представительных (например. лс=15). Тогда формируемые гисто-
граммы будут иметь и(+1 ячейку, где последняя ячейка соответствует всем
цветам, которые не попали в пс выбранных цветов. Вместо того чтобы связы-
вать каждый пиксель с одной единственной областью и единственной ячей-
кой гистограммы, введем гауссовы функции как в цветовом, так и в геоме-
трическом пространствах, и будем классифицировать пиксели нечетким об-
разом. Отметим, что вводимые гауссовы функции могут быть вычислены за-
ранее. Для построения локальной гистограммы Ht в каждой области вклад
пикселя определяется в соответствии с его весом, рассчитываемым с помо-
щью гауссовой плотности:
<№)»
1 ( <+<)
-----ехр г2-
2я<7-l 2<т*
5 \ 4 /
dx = xk-xh
(161)
d> = У^~Уг
Здесь индекс / соответствует конкретной области изображения, S* = Sk(xk,yk) -
пиксель из этой области. (xr yt) - координаты центра области, а - стандартное
отклонение. Относительные веса граничных и центральных пикселей области
должны быть небольшими, чтобы обеспечить достаточную гладкость.
Аналогично вводятся гауссовы функции для цветового пространства:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
314
Цифвая обработка видеоизображений
(162)
у j
<.=f/4-t/y.
d^Vk~Vr
где (I/r Vk) - цветовые компоненты пикселя Sk = S^x^yJ в цветовом простран-
стве YUV, (I/, У) - отдельная ячейка гистограммы. Стандартное отклонение (Ус
выбирается в соответствии с шумом камеры.
Теперь можно построить локальные гистограммы. Для области I значение
ячейки гистограммы h. соответствующей выбранному цвету (1 < j < nJ, опреде-
ляется как
hj = ^(Sk)G^Sl). (163)
Значение ячейки, соответствующей всем не попавшим в выбранные цвета
(пг выбирают порядка 40). равно:
Лу+. = £ (164)
Построенные таким образом гистограммы совместно с цветовыми характе-
ристиками изображения позволяют достичь корректных результатов при выде-
лении фона в случае постоянного освещения. Однако такая модель по-прежнему
остается чувствительной к изменениям освещенности. Если же рассматривать
локальные гистограммы совместно с контурными признаками изображения, то
возможно достижение инвариантности даже к внезапному изменению освещен-
ности сцены. Поэтому вместо цветовых гистограмм (162) построим гистограм-
мы, связанные с краевыми точками.
Для каждой краевой точки изображения можно найти норму Це5|| и направ-
ление dir(Es) вектора градиента Es. Стандартные отклонения для величины
градиента и его направления могут быть измерены экспериментально с помо-
щью анализа изображений линий с различным контрастом. На Рис. 14 [71] пока-
зана типичная зависимость этих стандартных отклонений. Из рисунка следует,
что если мы будем описывать норму градиента с помощью гауссовых распре-
делений Gn {цп,ап) со средним, равным норме градиента = ||es||,to стандарт-
ное отклонение будет пропорционально величине градиента (5п = ап • ||^т||-ь .
Аналогично для направления градиента можно рассматривать гауссово рас-
пределение со средним /Ло = dir(Es) и стандартным отклонением
Для данного пикселя S с градиентом Es ячейки гистограммы й; для раз-
личных направлений д рассчитываются в соответствии с гауссовым ядром
Go (Ё5), <зо [Es]} следующим образом:
Ло5 = Св(дв(Ё5),ав(Ё5)).||£,|| (165)
Добавив сюда пространственную информацию, вместо (163) для области / получим
ProSystem CCTV - журнал по системам видеонаблюдения
http.//www.proccfv.ru
Глава 7. Методы детектирования и распознавания лиц
315
Рис. 14. Стандартные отклонения для величины градиента и его направления в за-
висимости от нормы градиента
(166)
Пусть Н1 - это гистограмма, соответствующая области /, a hlo - одна из ячеек этой
гистограммы, отвечающая направлению о. Тогда для вероятностей справедливы
следующие выражения:
= = (167)
в„
/=’
Для ячеек гистограммы направлений области / текущего изображения h'~ и
шаблона hl* вычислим среднее значение Д:
Тогда
Р? = P(h': < р) = F(p,G„ (А> ,стл (й^ ))) (170)
Р? = Р(Ц~ <p)=F(p,G„(h‘~,an(h1-))) (171)
Как следует из этих формул, если то = р* = 0.5. В противном слу-
чае одно из значений вероятностей р'~ или р* близко к 0. а другое - к 1. Теперь
мы можем найти расстояние Бхатачарья, характеризующее степень схожести
ячеек гистограмм:
р’о = TpFpF + Jp^P?. (172)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
316 Ц/фвая обработка видеоизображений
где р* = 1-р^‘ и р*° =1-ра\ Степень схожести между гистограммами Hlnf и
н'пг в целом
р'=ПХ <173>
о
может рассматриваться как вероятность того, что область / является фоновой.
7.4. СПИСОК ЛИТЕРАТУРЫ
1 . Е. Hjelmas, В.К. Low. Face Detection: A Survey. In: Computer Vision and Image
Understanding, v. 83. p. 236-274.2001.
2 . M.-H. Yang. D.J. Kriegman. N. Ahuja. Detecting Faces in Images: A Survey. In: IEEE
Transactions on Pattern Analysis and Machine Intelligence, v. 24. p. 34-58,2002.
3 .T.V Pham. M. Worring. Face Detection Methods: A Critical Evaluation.Technical Report
2000-11. Intelligent Sensory Information Systems. University of Amsterdam. 2000.
4 . Z. Liu, Y. Wang. Face Detection andTracking in Video Using Dynamic Programming.
In: Proc. IEEE International Conference on Image Processing, Vancouver, v. 1,
p. 53-56.2000.
5 .T. Ojala. M. Pietikainen. D. Harwood. A Comparative Study of Texture Measures
with Classification Based on Feature Distributions. In: Pattern Recognition, v. 29, p.
51-59,1996.
6 .Т. Ojala, M. Pietikainen, T. Maenpaa. Multi-resolution Grayscale and Rotation
-invariant Texture Classification with Local Binary Patterns. In: IEEE Transactions
on Pattern Analysis and Machine Intelligence, v. 24. p. 971-987,2002.
7 W. Zhang. S. Shan. W Gao, X. Chen, H. Zhang. Local Gabor Binary Pattern Histogram
Sequence (Igbphs): A Novel Non-statistical Model for Face Representation and
Recognition. In: Proc. International Conference on Computer Vision, Beijing, v. 1,
p. 786-791,2005.
8. K. Levi, Y. Weiss. Learning Object Detection from a Small Number of Examples:
The Importance of Good Features. In: Proc. IEEE Computer Society Conference on
Computer Vision and Pattern Recognition. Washington, v. 2, p. 53-60,2004.
9. S. Ullman, E. Sali, M. Vidal-Naquet. A Fragment-based Approach to Object
Representation and Classification. In: Proc. International Workshop on Visual Form,
Capri, p. 85-100.2001,
10. H. Rowley, S. Baluja.T Kanade. Neural Network-based Face Detection. In: IEEE
Transactions Pattern Analysis and Machine Intelligence, v. 20, p. 23-38,1998.
11. K.-K. Sung. Learning and Example Selection for Object and Pattern Detection.
Technical Report 1572, MIT Al Lab, 1996.
12. H. Rowley, S. Baluja, T. Kanade. Rotation Invariant Neural Network-based Face
Detection. In: Proc. Conference on Computer Vision and Pattern Recognition, Santa
Barbara, p. 38-44,1998.
13. H. Schneiderman,T. Kanade. A Statistical Method for 3D Object Detection Applied
to Faces and Cars. In: Proc. Conference on Computer Vision and Pattern Recognition,
Hilton Head.v. 1, p. 746-751,2000.
ProSystem CCTV - журнал no системам видеонаблюдения
h t tp://www.procctv. ru
детектирования и оас^ознавания лиц
317
14. В. Froba, A. Ernst. С. Kublbeck. Real-time Face Detection. In: Proc. International
Conference on Signal and Image Processing. Kauai. № 359-106.2002.
15. M.-H. Yang. D. Roth. N. Ahuja. A SNoW-based Face Detector. Advances in Neural
Information Processing Systems, S.A. Solla, T.K. Leen, K.-R. Muller (eds.). MIT
Press, Cambridge, v. 12. p. 855-861.2000.
16. M.-H. Yang. N. Ahuja. D. Kriegman. Face Detection Using Mixtures of Linear
Subspaces. In: Proc. International Conference on Face and Gesture Recognition,
Grenoble, p. 70-76.2000.
17. D. Zhang. S. Z. Li, D. Gatica-Perez. Real-time Face Detection Using Boosting
in Hierarchical Feature Spaces. In: Proc. International Conference on Pattern
Recognition. Cambridge, v. 2. p. 411-414.2004.
18. J. L. Jiang, K.-E Loe, H. J. Zhang. Robust Face Detection in Airports. In:./. Applied
Signal Processing, p. 503-509.2004.
19. P. Viola, M. Jones. Fast and Robust Classification Using Symmetric AdaBoost and
a Detector Cascade. In: Proc. Neural Information Processing Systems. Vancouver, p.
1311-1318,2001.
20. L.Goldmann.M. Krinidis.N. Nikolaidis, S.Asteriadis,T Sikora. An Integrated System
for Face Detection and Tracking. In: Proc. Workshop on Immersive Communication
and Broadcast Systems. Berlin. 2005.
21. E. Osuna, R. Freund,E Girosi.Training Support Vector Machines: An Application to
Face Detection. In: Proc. Conference on Computer Vision and Pattern Recognition.
San Juan. p. 130-136.1997.
22. V. Vapnik. The Nature of Statistical Learning Theory. Springer, New York, 1995.
23. S. Romdhani. P Torr, B. Scholkopf, A. Blake. Efficient Face Detection by a Cascaded
Support-Vector Machine Expansion. In: Proceedings of Royal Society of London A.
p.3283-3297,2004.
24. E Zuo, P H. N. de With. Fast Human Face Detection Using Successive Face Detectors
with Incremental Detection Capability. In. Proc. International Conference on Visual
Communications and Image Processing. Santa Clara, p. 831-841,2003.
25. R. Brunelli, T. Poggio. Face Recognition: Features Versus Templates. In: IEEE
Transactions on Pattern Analysis and Machine Intelligence, v. 15, p. 1042-1052,1993.
26. A. J. Goldstein, L. D. Harmon, A. B. Lesk. Identification of Human Faces. In:
Proceedings of the IEEE. v. 59, p.748-760,1971.
27. V Bruce, P. J. B. Hancock, A. M. Burton. Human Face Perception and Identification.
Face Recognition: From Theory to Applications, H. Wechsler, P J. Phillips, V. Bruce, E
E Soulie, T. S. Huang (eds.). Springer-Verlag, Berlin, p. 51-72,1998.
28. B. Knight. A. Johnston. The Role of Movement in Face Recognition. Visual
Cognition, v. 4, p. 265-274,1997.
29. L. Sirovich, M. Kirby. Low-dimensional Procedure for the Characterization of
Human Face. In: Journal of Opical Society of America, v. 4, p. 519-524,1987.
30. M. Kirby, L. Sirovich. Application of the Karhunen-Loeve Procedure for the
Characterization of Human Faces. In: IEEE Transactions on Pattern Analysis and
Machine Intelligence, v. 12, p. 103-108.1990.
31. M. Turk, A. Penlland. Eigenfaces for Recognition. In: Journal of Cognitive
Neuroscience, v. 3, p. 72-86,1991.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
318
Цифвая обработка видеоизображений
32. М. Turk. A. Pcntland. Face Recognition Using Eigenfaccs. In: Proc. Conference on
Computer Vision and Pattern Recognition. Maui. p. 586-591.1991.
33. Y. Moses. Y. Adini. S. Ullman. Face Recognition: The Problem of Compensating for
Changes in Illumination Direction. In: Proc. European Conf on Computer Vision,
Stockholm, p. 286-296.1994.
34. P N. Belhumeur. J. P. Hespanha. D. J. Kriegman. Eigenfaccs vs. Fisherfaces:
Recognition Using Class Specific Linear Projection. In: IEEE Transactions on
Pattern Analysis and Machine Intelligence, v. 19. p. 711-720,1997.
35. A. M. Martinez. А. С. Как. PCA versus LDA. In: IEEE Transactions on Pattern
Analysis and Machine Intelligence. \. 23. p. 228-233.2001.
36. J. Kittier. M. Hatef. R. Duin. J. Matas. On Combining Classifiers. In: IEEE Transactions
on Pattern Analysis and Machine Intelligence, v. 20. p. 226-239,1998.
37. X. Lu, Y. Wang. A. K. Jain. Combining Classifiers for Face Recognition, In: Proc.
IEEE International Conference on Multimedia & Expo. Baltimore, vol. Ill, p. 13-16,
2003.
38. B. Scholkopf, A. Smola. K.-R. Muller. Kernel Principal Component Analysis.
Advances in Kernel Methods: Support Vector Learning, B. Scholkopf C.J.C. Burges,
A.J. Smola (eds.). MIT Press. Cambridge, p. 327-352,1999.
39. B. Scholkopf. A. Smola. K.-R. Muller. Non-linear Component Analysis as a Kernel
Eigenvalue Problem. In: Neural Computation, v. 10, p. 1299-1319,1998.
40. L. Wiskott. J. M. Fellous. C. von der Malsburg. Face Recognition by Elastic
Bunch Graph Matching. In: IEEE Transactions on Pattern Analysis and Machine
Intelligence, v. 19, p. 775-779.1997.
41. S. Shan. P Yang. X. Chen, W. Gao. AdaBoost Gabor Fisher Classifier for Face
Recognition. In: Proc. IEEE International Workshop Analysis and Modeling of
Faces and Gestures. Beijing, p. 278-291,2005.
42. Y. Su, S. Shan. B. Cao, X. Chen, W Gao. Multiple Fisher Classifiers Combination for
Face Recognition Based on Grouping AdaBoosted Gabor Features. In: Proc. British
Machine Vision Conference. Oxford, 2005.
43. A. K. Jain,Y. Zhong,M.-P. Dubuisson-Jolly DeformableTemplate Models: A Review.
In: Signal Processing, v. 71, p. 109-129,1998.
44. T. F Cootes. C. J. Taylor, D. H. Cooper, J. Graham. Active Shape Models: Their
Training and Application. In: Computer Vision and Image Understanding, v. 61, p.
38-59,1995.
45. T. E Cootes, C. J. Taylor. Statistical Models of Appearance for Computer Vision.
Technical Report, University of Manchester, 2004.
46. T. E Cootes, G. J. Edwards, C. J. Taylor. Active Appearance Models. In: IEEE
Transactions on Pattern Analysis and Machine Intelligence, v. 23, p. 681-685,2001.
47. T. E Cootes, G. J. Edwards, C. J. Taylor. A Comparative Evaluation of Active
Appearance Model Algorithms. In: Proc. British Machine Vision Conference.
Southampton, v. 2, p.680-689,1998.
48. G. Shakhnarovich, J. W. Fisher, T. Darrel. Face Recognition from Long-term
Observations. In: Proc. European Conference on Computer Vision, Copenhagen,
v.3,p. 851-868,2002.
49. O.Arandjelovic.R.Cipolla.An Information-theoretic Approach to Face Recognition
from Face Motion Manifolds. In: Image and Vision Computing, v.24, p. 639-647,2006.
ProSystem CCTV - журнал no системам видеонаблюдения
http://www.pmcc tv. ru
Глава 7 Методь. детектирования и распознавания лиц
319
50. О. Arandjelovic. G. Shakhnarovich. J. Fisher. R. Cipolla.T. Darrell. Face Recognition
with Image Sets Using Manifold Density Divergence. In: Proc. IEEE Computer
Society Conference on Computer Vision and Pattern Recognition. San Diego, v. 1, p.
581-588.2005.
51. H. Wechsler. V Kakkad. J. Huang. S. Gutta. V Chen. Automatic Video-based Person
Authentication Using the RBF Network. In: Proc. International Conference on Audio
and Video-Based Biometric Person Authentication. Crans Montana, p. 177-183,1997.
52. S. Yoshizawa. K. Tanabe. Dual Differential Geometry Associated with the
Kullback-Leiblcr Information on the Gaussian Distributions and Its 2-parameter
Deformations. In: SUT Journal of Mathematics. v. 35. p. 113-137,1999.
53. Y. Li. S. Gong. H. Liddell. Modelling Faces Dynamically Across Views and Over
Time. In: Proc. IEEE International Conference on Computer Vision. Vancouver, v. I,
p. 554-559.2001.
54. Y. Li. S. Gong. H. Liddell. Video-based Online Face Recognition Using Identity
Surfaces. In: Proc. IEEE ICCV Workshop on Recognition, Analysis, and Tracking of
Faces and Gestures in Real-Time Systems. Vancouver, p. 40 - 46,2001.
55. Y. Li. S. Gong. H. Liddell. Constructing Face Identity Surface for Recognition. In:
International Journal on Computer Vision, v. 53, p. 71-92,2003.
56. M. Isard. A. Blake. CONDENSATION - Conditional Density Propagation for
Visual Tracking, In: International Journal on Computer Vision, v. 29, p. 5-28,1998.
57. U. Grenander. Y. Chow. D.M. Keenan. HANDS. A Pattern Theoretical Study of
Biological Shapes. Springer-Verlag. New York. 1991.
58. S. Zhou, V Krueger. R. Chellappa. Face Recognition from Video: A
CONDENSATION Approach. In: Proc. IEEE International Conference on
Automatic Face and Gesture Recognition. Washington, p. 221-228,2002.
59. S. Zhou. R. Chellappa. Probabilistic Human Recognition from Video. In: Proc.
European Conference on Computer Vision. Copenhagen. Part III. p. 681 - 697,
2002.
60. S. Zhou. V. Krueger, R. Chellappa. Probabilistic Recognition of Human Faces from
Video. In: Computer Vision and Image Understanding, v. 91, p. 214-245,2003.
61. M. Sridharan. P. Stone. Color Learning on a Mobile Robot:Towards Full Autonomy
under Changing Illumination. In: Proc. International Joint Conference on Artificial
Intelligence. Hyderabad, p. 2212-2217.2007.
62. E. Durucan. T. Ebrahimi. Robust and Illumination Invariant Change Detection
on Linear Dependence for Surveillance Application. In: Proc. European Signal
Processing Conference.Tampere, p. 1041-1044,2000.
63. J. Lou. H. Yang, W. Hu. T Tan. An Illumination Invariant Change Detection
Algorithm. In: Proc. Asian Conference on Computer Vision. Melbourne, 2002.
64. TGevers.A.WM.Smeulders.H.Stokman. Photometric Invariant Region Detection.
In: Proc. British Machine Vision Conference. Southampton, p. 659-669,1998.
65. B. Xie. V Ramesh, T. Boult. Sudden Illumination Change Detection Using Order
Consistency. In: Image Vision Computing, v. 22, p. 117-125.2004.
66. P Bui-Tong. Illumination for Computer Generated Pictures. In: Communications of
the ACM. v. 18. p.311-317.1975.
67. Y.Tsin. V Ramesh,T. Kanade. Statistical Calibration of the CD Imaging Process. In:
Proc. International Conference on Computer Vision. Vancouver, p. 480-487,2001.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
320 Цифвая обработка видеоизображений
68. М. Xu, Т Ellis. Illumination-invariant Motion Detection Using Colour Mixture
Models. In: Proc. British Machine Vision Conference, Manchester, p. 163-172,2001.
69. T. Gevers, A. Smeulders. A Comparative Study of Several Color Models for Color
Image-invariant Retrieval. In: Proc. International Workshop on Image Databases &
Multimedia Search. Amsterdam, p. 17-24.1996.
70. P. Noriega, B. Bascle. O. Bernier. Local Kernel Color Histograms for Background
Subtraction. In: Proc. International Conference on Computer Vision Theory. Setubal,
v. l,p. 213-219.2006.
71. P. Noriega. O. Bernier. Real-time Illumination-invariant Background Subtraction
UsingLocalKcrnelHistograms.ln:Proc.Z?r/7/5AMac/nrteH'szori Coherence,Edinburgh,
p. 979-988,2006.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
ГЛАВА 8.
ОБНАРУЖЕНИЕ ТРАНСПОРТНЫХ
СРЕДСТВ
324
Цифвая обработка видеоизображений
Одной из важных проблем видеонаблюдения является задача обнаружения
на изображении объектов заданного класса. И хотя людям удается справлять-
ся с этой проблемой с высокой степенью эффективности и без видимых усилий,
до сих пор не существует компьютерных алгоритмов, способных обеспечить та-
кую же надежность распознавания. Несмотря на то что за последние десятилетия
данному аспекту машинного зрения было уделено много внимания, рассматрива-
емая проблема еще далека от своего окончательного решения. При разработке
систем видеонаблюдения эта задача осложняется также жесткими требованиями
к производительности системы, с которыми всегда приходится сталкиваться в си-
стемах реального времени.
Основная трудность при обнаружении и локализации объектов на изображе-
нии заключается в видовом многообразии объектов и сильной внешней изменчи-
вости одного и того же объекта при наблюдении его в разных условиях. Напри-
мер. автомобили различаются по размеру, форме, цвету, а также в отдельных сво-
их деталях, таких как фары, радиаторная решетка, колеса и т. п. Ориентация ав-
томобиля и расстояние до камеры также играют огромную роль при его распо-
знавании. Другими словами, визуальная информация является неоднозначной. Ге-
ометрическая неоднозначность связана с тем. что трехмерные по своей сути объ-
екты проецируется в двумерные изображения. В процессе проецирования на ка-
чество получаемого изображения влияют многие факторы, например: источни-
ки освещения (их расположение, цветовая температура, интенсивность), окружа-
ющие объекты, которые могут отбрасывать тень или, наоборот, отражать до-
полнительный свет, отражательная способность рассматриваемого объекта и т. д.
Обнаружение объектов затрудняется также и тем, что обрабатываемое изобра-
жение содержит огромный объем информации. Обычно это тысячи пикселей,
несущих в себе, как правило, избыточные данные.
В основной массе объектами видеонаблюдения являются автомобили и
люди. Детектирование транспортных средств является гораздо более сложной
задачей, чем обнаружение лиц людей [1-4]. Это связано с тем, что человеческое
лицо имеет достаточно простую полужесткую структуру, в которой локализация
отдельных частей лица является в значительной мере предопределенной и мало
меняется среди разных индивидуумов. Автомобили также имеют полужесткую
структуру, которая сильно варьируется даже внутри заданного типа транспорт-
ных средств из-за большого разнообразия имеющихся форм и размеров кузова.
Помимо внутриклассовых вариаций по цвету, форме и внешним деталям, что ха-
рактерно и для человеческих лиц (правда, в меньшей степени), для автомобилей су-
ществует еще ряд особенностей, затрудняющих их обнаружение на изображениях.
Во-первых, транспортные средства необходимо детектировать независимо от
угла зрения и вращения объекта. По сравнению с задачами других типов, задача
обнаружения автомобилей во многих случаях представляет интерес в широком
диапазоне углов зрения. При этом вид транспортных средств может кардинально
изменяться. Обнаружение лиц обычно осуществляется только для фронтальных
и профильных изображений.
Во-вторых, если в качестве характерных изображений использовать отдель-
ные части транспортных средств, мы столкнемся с тем, что для многих углов зре-
ния они могут быть не видны. Например, если в качестве основного признака при
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 8. Обнаружение транспортных средств 325
детектировании будет использоваться номерной знак, то будут пропущены все
кадры, на которых присутствуют изображения автомобилей сбоку либо номер-
ной знак на автомобиле вообще отсутствует. Поэтому при создании распознаю-
щей системы приходится использовать большую комбинацию видов отдельных
частей автомобилей для их корректного детектирования. Дополнительную труд-
ность этому процессу придает возможное перекрытие нескольких объектов, ког-
да видимыми остаются только отдельные части транспортных средств.
Существует большое число методов для обнаружения и распознавания транс-
портных средств на изображении произвольной сцены. При этом обычно на изо-
бражении выделяются области, обладающие характерными свойствами исследуе-
мых объектов, и производится их проверка для выявления областей, релевантных
поставленной задаче. Сущность этой проверки зависит от характера используемых
признаков и может быть основана на некотором эмпирическом алгоритме, стати-
стике взаимного расположения признаков, собранной по изображениям транспорт-
ных средств, моделировании процессов, происходящих в мозгу человека при распо-
знавании визуальных образов, применении шаблонов различного рода и т. д. Ниже
перечислены основные отличия применяемых способов описания объектов.
1. Объект может быть описан явно с помощью трехмерной модели или не-
явно посредством набора двумерных моделей. Обычно при этом двумер-
ная информация представляется в виде непрерывной функции, проециру-
ющей трехмерные виды объекта на плоскость [5-6].
2. Ряд методов трактует объекты как единое целое [5-8]. В других же объ-
екты считаются состоящими из набора отдельных частей (краев, углов,
сложных характерных особенностей) [9-11]. В то время как первые бо-
лее точно учитывают взаимоотношения внутри всего объекта, последние
превосходят их в детализации малых фрагментов объекта.
3. При описании объекта как набора отдельных частей большее внимание
может быть уделено или представлению самих частей [9,12], или же их
геометрическим отношениям [13-14]. Кроме того, достаточно сложным
является выбор указанных частей. Они могут задаваться изначально [15-
16], выбираться автоматически по мере выполнения распознавания [17-18]
или равномерно распределяться по всему объекту. Естественно, что точ-
ность решения возрастает с увеличением числа отдельных частей.
4. Объект может быть представлен с помощью жестко фиксированного
шаблона. Такой подход будет хорошо работать только в том случае, когда
форма объекта и освещение практически не меняются на изображении. С
другой стороны, возможно применение статистических методов для обна-
ружения объектов. При этом возникает проблема снижения размерности
пространства признаков, которая может быть решена с помощью метода
главных компонент, факторного анализа и т. п. Статистические свойства
каждого класса могут быть смоделированы отдельно или же с использо-
ванием дискриминантной функции.
Для обнаружения и классификации объектов в задачах реального времени
лучше всего зарекомендовали себя статистические методы, алгоритмы, основан-
ные на применении разномасштабной текстурной информации, а также исполь-
зование специальных классификаторов.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
326
Ц/фвая обработка видеоизображений
Среди группы статистических методов [19-23] отметим, прежде всего, байе-
совские сети. Обычно такие методы основываются на построении эмпирической
плотности распределения объектов на основе обучающей выборки в предполо-
жении о независимости компонент вектора признаков. При таком подходе воз-
можен учет большой межклассовой дисперсии, а также использование в моде-
ли новой поступающей информации. К недостаткам этих методов можно отне-
сти довольно высокие требования к вычислительным ресурсам, сильную зависи-
мость результатов от выбранного алгоритма преобразования, а также сложность
характерных признаков, описывающих объекты.
Группа методов, основанная на применении текстурной информации, позво-
ляет получить для описания объектов достаточно представительный набор ха-
рактерных признаков, которые затем используется при классификации. Чаще
всего исходное изображение преобразуется при помощи пирамид, после чего
строится смесь гауссовских распределений, основанная на результатах кластери-
зации по методу К-средних. Эти методы обладают достаточно высокой эффек-
тивностью, а также частичной инвариантностью к изменениям масштаба и вра-
щению объектов. Однако применение таких алгоритмов ограничивается слож-
ностью обучения на больших объемах данных из-за высокой ресурсоемкое™ и
их низкой эффективности на объектах с малым объемом текстурной информа-
ции (например, для гладких поверхностей) или с ее резкими изменениями.
К последней группе методов относятся алгоритмы классификации, в которых
модель объекта автоматически строится по отдельным его частям с использовани-
ем предварительно собранной последовательности изображений. При этом также
формируется класс, который не содержит изображений интересующих нас объек-
тов. В результате такой обработки получается набор векторов характерных при-
знаков, полученный из исходного изображения заданным преобразованием (на-
пример, сверткой с набором фильтров), отображающим изображение в простран-
ство действительных векторов. К преимуществам этих методов можно отнести до-
статочно высокую эффективность классификации при наличии репрезентативной
обучающей последовательности, возможность использовать в качестве входных
данных большое число свойств изображений и затем отбрасывать несуществен-
ные свойства во время обучения. Однако следует отметить и недостатки этого под-
хода: зависимость от ориентации и размера объектов, т. е. низкая инвариантност ь к
вращению и изменению масштаба; возможность выделения вторичных, нс являю-
щихся главными признаков в качестве основных в том случае, если обучающая по-
следовательность была недостаточно репрезентативна; сложность построения ре-
презентативной выборки изображений для объектов, не относящихся к искомому
классу; чувствительность к шуму, а также большое время обучения системы.
8.1. СТАТИСТИЧЕСКИЕ МЕТОДЫ
Детектирование и сегментация различных объектов, в том числе и транс-
портных средств, могут быть осуществлены, при помощи двухэтапной байесов-
ской классификации. На первом этапе при помощи оконного сканирования изо-
бражения создается набор частичных изображений, которые классифицируются
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 8. Обнаружение тоанспортнь»х средств
327
и ранжируются на основании значений апостериорной вероятности, полученной
из оценок безусловной плотности вероятности и условной плотности вероятно-
сти для класса объекта. На втором этапе устраняются ошибки второго рода, воз-
никшие на предыдущем этапе.
Если полученное частичное изображение содержит какую-то часть искомо-
го объекта или весь объект целиком, то оно считается принадлежащим классу
С~. Используя двухклассовый классификатор Байеса, можно определить, что ча-
стичное изображение принадлежит классу С., если апостериорная вероятность
превышает наперед заданное пороговое значение. Здесь Ff - вектор характер-
ных признаков рассматриваемого частичного изображения. Вероятность Р(С.)
может быть включена в пороговое значение. В этом случае остается опреде-
лить две величины: P(F,) и P(F\ С.). Для этого необходимо выбрать набор ха-
рактерных признаков, которыми описывают распознаваемые объекты. Каж-
дое частичное изображение можно рассматривать в пространстве HSV. Тогда
в качестве характерных признаков можно, например, выбрать следующие ве-
личины: значения цветового тона (//) и насыщенности (5), полученные с поло-
винным разрешением (так как они довольно медленно меняются в геометри-
ческом пространстве), а также признаки, описывающие краевые и граничные
точки объекта. В работе [35] в качестве таких признаков рекомендуется ис-
пользовать симметричные 5/3 двухуровневые вейвлет-коэффициенты Коэна-
Добеши-Фово компоненты (V). Таким образом, для используемого при скани-
ровании окна размером 20 х 20 получится по 100 признаков цветового тона и
насыщенности и 400 вейвлет коэффициентов.
Найдем теперь выражение для безусловной плотности вероятности P(Fj).
Оценка ее значения может быть проведена предварительно на основе обработки
большого числа частичных изображений (в типичном случае порядка нескольких
сотен тысяч), могущих содержать интересующие нас объекты. В общем случае
...Л). (2)
где/( ~ х-я компонента вектора характерных признаков Ft. Однако это выраже-
ние, как правило, имеющее очень высокую размерность, не может быть оцене-
но эффективным образом. Поэтому необходимо ввести некие предположения
о способе параметризации используемой модели. Часто используется предпо-
ложение о гауссовском характере распределений вероятности, что в ряде слу-
чаев может привести к ухудшению качества сегментации. Вместо этого введем
требование ограниченной зависимости характерных признаков и представим
плотности вероятности для зависимых признаков непараметрическим образом.
Зависимости между рядом характерных признаков могут быть оценены при по-
мощи вычисления величины взаимной информации различных пар признаков.
Будем считать, что в каждой группе зависимых признаков содержится не более
чем D элементов. Тогда
http://wwwjtv.ru
Компания ITV — генеральный спонсор издания книги
328
Цифвая обработка видеоизображений
.............-4)- (3)
1=’.
где N - число независимых групп./. - /-й характерный признак, a ft/ - ;-й харак-
терный признак, зависящий от/, в наибольшей степени (это определяется с по-
мощью величины взаимной информации). Данная модель известна как «полуна-
ивная» модель Байеса. Для оценки функций совместной плотности вероятности
для каждой группы зависимых признаков соответствующие характерные при-
знаки разбиваются на определенное число ячеек. Затем с помощью ряда частич-
ных изображений, являющихся типичными представителями исследуемого набо-
ра снимков, вычисляются D-мерные гистограммы для каждой группы зависимых
характерных признаков.
В такой непараметрггческой модели число параметров растет экспоненци-
ально с ростом D. Поэтому для оценки плотности условной вероятности P(FZ| С+)
будем использовать искусственно созданные примеры изображений, а также сде-
лаем предположение о виде априорной вероятности для значений характерных
признаков и малом числе взаимозависимых признаков.
Для каждого изображения, положительно классифицированного на стадии
обучения, создадим набор искусственных примеров, полученных при помощи пе-
реноса и масштабирования исходного изображения. Тем самым можно добиться
частичной инвариантности к указанным деформациям изображений. Далее огра-
ничим значения величины D < 2. Используя введенные выше обозначения, запи-
шем условную плотность вероятности следующим образом:
= ...Л>;С.) (4)
4=1
В качестве априорной вероятности характерных признаков проще всего вы-
брать однородный вид вероятности, однако он приводит к некорректным результа-
там, так как распределение вейвлет-коэффициентов и совместная плотность двух и
более зависимых признаков далеки от равномерного. Поэтому в качестве априор-
ной вероятности будем использовать оценку безусловной плотности вероятности.
Таким образом, для оценки величины P(FZ| CJ сначала создаются искусствен-
ные примеры изображений, после чего производится разбиение характерных
признаков, как и при оценке безусловной плотности вероятности (3). D-мерные
плотности вероятности каждой группы зависимых признаков оцениваются по ги-
стограммам, созданным на основе последовательности искусственных обучаю-
щих примеров. Наконец, априорные плотности вероятности вычисляются путем
добавления к каждой ячейке гистограммы значения, пропорционального оценке
безусловной плотности вероятности.
Как уже не раз было сказано, для сегментации и классификации объектов
возможно использование отдельных фрагментов снимков. Эта задача может
быть разбита на две части: выбор на основе характерных изображений подходя-
щих фрагментов для корректного описания рассматриваемого класса объектов
и непосредственно детектирование и классификация объектов при помощи по-
лученных фрагментов. На Рис. 1 приведены образцы различных фрагментов изо-
бражений автомобилей.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 8 Обнаружение транспортных средств
329
Рис. 1. Примеры различных фрагментов автомобилей
В отличие от широко используемого метода распознавания при помощи ком-
понент фрагменты могут быть не универсальными, а специфичными для каждо-
го рассматриваемого класса. Полученные фрагменты и их всевозможные комби-
нации затем используются в качестве основы для представления различных объ-
ектов. принадлежащих к одному и тому же классу. Кроме того, выделенные фраг-
менты разбиваются на множества эквивалентности, которые включают в себя
различные виды одной и той же общей области объектов, полученные при помо-
щи различных преобразований и изменений условий наблюдения.
Использование комбинации фрагментов для описания внутриклассового раз-
нообразия основывается на том факте, что изображения различных объектов,
принадлежащих одному классу, имеют структурное сходство: они могут быть
представлены как комбинации неких общих субструктур. Иначе говоря, идея за-
ключается в аппроксимации нового снимка, например, автомобиля, комбинацией
изображений различных фрагментов, таких как ветровое и боковое стекла, ли-
ния капота и других им подобных.
Алгоритм начинается с детектирования новых фрагментов с помощью срав-
нения полутоновых версий хранящихся фрагментов и входного изображения.
Для учета искажений и изменений масштаба фрагмента указанное сравнение
проводится сначала между частями фрагментов в небольшом окне, например,
размером 5x5 пикселей. В качестве меры сходства используется комбинация
мер. основанных на смещении фрагментов и на использовании градиентов и ори-
ентации фрагментов. Таким образом, мера сходства D(E Н) между областью но-
вого изображения Н и частью фрагмента F выражается как взвешенная сумма их
упорядоченных смещений г/. модуля разности ориентации \aF- ан\ и модуля раз-
ности градиентов |Gf- Gff\:
D(F,H)=kiYdl + k2\aF-aH\+kJ\GF-GH{ (5)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
330
цифвая обработка видеоизображений
При детектировании фрагментов сравниваются только те области, где имеет
место достаточное изменение интенсивности. Для учета изменений размера объ-
ектов алгоритм выполняется на изображениях в различном масштабе (в преде-
лах 30-40%). На основании набора фрагментов для нового снимка необходимо
определить, присутствует ли искомый объект в изображении. При этом возмож-
ны два пути. Первый заключается в использовании простых характерных при-
знаков (таких как наличие углов, функции Габора, вейвлетные базисные функ-
ции. текстуры) и учете их различных комбинаций (например, взаимное располо-
жение, статистические взаимодействия между ними). Второй путь состоит в при-
менении достаточно сложных характерных признаков, неявным образом вклю-
чающих в себя информацию о принадлежности к тому или иному классу, и систе-
мы классификации. Как показывает практика, оба этих пути приводят к прибли-
зительно одинаковым результатам.
В общем случае проблема определения наличия объектов данного класса в
изображении основана на вычислении величины P(F\CJ/P(F\C ),где P(F|CJ и
P(F\ С ) - условные вероятности присутствия и отсутствия объектов рассматри-
ваемого класса. В первом из указанных выше способов используется так называ-
емый «наивный» классификатор Байеса. В этом случае
p(Fic) = p(f;,F2,...,Fs)=np(?jc). (6)
»=>
Сомножители в правой части могут быть непосредственно получены из обучаю-
щего набора. Метод предполагает условную независимость различных фрагмен-
тов между собой.
Во втором способе в качестве классификатора выступает байесовская сеть,
которая описывает распределение вероятности для попарно зависимых фраг-
ментов. Характерные признаки при этом организованы в древовидную структу-
ру. Классификатор в данном случае имеет следующее представление:
P(F|С) = P(F„F,....Fv) = P(F, |С)П?(/ |F,w.c). (7)
где j (z) является родительским узлом для узла /, F} - корневой узел дерева. Услов-
ные вероятности оцениваются на стадии обучения сети. На Рис. 2 [20] представ-
лены результаты детектирования автомобилей в различных изображениях на
основе использования различных фрагментов автомобилей, объединенных в не-
сколько характерных групп (ветровое стекло, боковая линия и т. п.).
Для нахождения заданных объектов на изображении может быть также
использован метод классификации при помощи максимального отклонения.
Предположим, что два введенных выше класса (С+ и С.) принадлежат про-
странству Rn. Характерным для рассматриваемой задачи является значитель-
ное превышение числа элементов класса С по сравнению с классом С+: иско-
мые объекты встречаются гораздо реже, чем изображения, не относящиеся к
ним. Кроме того, они часто занимают незначительную часть анализируемых
снимков. Таким образом,
Р(С+)«Р(С_), (8)
ProSystem CCTV - журнал по системам видеонаблюдения
h ttp://www. procct v. ги
Глава 8. Обнаружение транспортных средств
331
Рис. 2. Примеры детектирования автомобилей
где Р(С.) - априорная вероятность того, что входной сигнал, в качестве которого,
как правило, выступает некоторая часть изображения, принадлежит классу С\.
Обычно применяемые классификаторы типа метода опорных векторов не при-
нимают во внимание выражение (8) и подразумевают, что Р(С.) = Р(С ). Более
того, классы считаются линейно разделимыми. В действительности часто имеет
место обратная ситуация. В изложенном ниже методе предполагается выпуклая
разделимость классов, что является гораздо менее жестким требованием.
Как и в обычных линейных классификаторах, спроецируем входной сигнал z
на некий пока неизвестный вектор и и присвоим метку принадлежности к опре-
деленному классу в зависимости от величины а = u'z. Проецируя таким обра-
зом классы С. и С. получим плотности распределения вероятностей Р(а\ CJ и
Р(а\ С ). Определим следующие множества изменения а.
л;={а| P(a|Cj>0,P(a|C ) = о}.
X. = {а| Р(а|С) = 0.Р(а|С.)>о}. (9)
Хи ={а| Р(а |С.) > 0. Р( а|С.)> о}.
После проецирования входной сигнал помечается как принадлежащий классу С\.
С или неизвестному классу (индекс «и» в выражениях (9)) в зависимости от зна-
чения величины а. Вероятность отнесения к неизвестному классу равна
/> = [ P(C.)P(a|Cj</a+J P(C_)P(a\C.)da. (10)
Для решения поставленной задачи необходимо найти вектор и. минимизиру-
ющий выражение (10). Очевидно, что если Р{а | С.) и Р{а | С ) находятся далеко
друг от друга и не пересекаются, то Р будет мало. Поэтому достаточно миними-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
332
ц/фвая обработка видеоизображений
зироватъ возможное перекрытие двух плотностей вероятности. Это требование
может быть записано при помощи выражения для расстояния между точкой ав и
распределением с плотностью Р(а):
/ / w г (afl-a) P(a)da +а2
D(a0 \Р(а)) = J ~~р--------< (11)
где /л и ст - соответственно математическое ожидание и дисперсия этого распре-
деления. Используя выражение (11).расстояние между Р(а\С^ и Р(а\С_) можно
переписать следующим образом:
D(p(ajCj|С )) = £,О(а'|1Р(а <)Р(а'|>С ))<7а' =
J Р(а' С )da' = ’ °2*
Ja' а: а;
где р.'Р и О’.. О’ - математическое ожидание и дисперсия соответственно плотно-
стей вероятности Р(а| CJ и Р(а | С ). Следовательно, исходная задача сводится к
максимизации выражения (12) или же к минимизации d(P(a\ CJ, Р(а\ CJ) - бли-
зости между плотностями Р(а । С.) и Р(а [ CJ, что может быть представлено как
<Г
4/(р(а|СД,Р(а|С )) =
----- Р(а|С>
(д.-дЛ + а2 + сг
r'W.)
(д.-д+) +<Т2 + Ст2
Учитывая (8), выражение (13) можно упростить:
d (р(а |С.), Р(а |С )) = --Р(а |С. ).
(д_-д+) +<у2 + <г2
Таким образом, оптимальное значение и находится как минимум d(«):
4«)=
(13)
(14)
(15)
(Я.-д,)2+ст2+(т2.’
где и О’, являются функциями переменной и.
Минимизация d(u) может быть осуществлена за счет увеличения разности
математических ожиданий, стоящих в знаменателе (15). или за счет малой вели-
чины отношения ajo_. Первый случай представляется маловероятным, так как
типичной является ситуация, изображенная на Рис. 3 [23]. Из него следует, что
класс С\ обычно окружен элементами класса С и, следовательно, рассматрива-
емые математические ожидания должны быть близки. Второй случай означает,
что проекции входных сигналов, принадлежащих классу С+, стремятся сконцен-
трироваться в узком интервале, в то время как проекции сигналов из С имеют
большую дисперсию.
Получим теперь конкретный вид функций /1^/л ,О\ и сг_. Легко видеть, что
/Л* = игМ^
2 Т (16)
СТ2 = uTR^u,
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. ru
Глава 8. Обнаружение транспортных средств
333
Рис. 3. Примеры первого и второго проецирования исходного сигнала
где
A/+=J zP{z\C^dz,
с т (17)
/?„ = J (z-A/J(z-A/+) P(z\C.)dz.
Аналогичным образом можно получить выражения для и оЛ
На практике значения вероятностей P(z | CJ и P(z| С ) обычно неизвестны,
и поэтому предположения о классах С+ и С_ строятся на основе имеющихся на-
боров изображений. Для двух наборов изображений У+ = {Х и ।
величины из (16) и (17) можно заменить приближенными значениями, получен-
ными эмпирическим путем
ь к=\
(18)
к-1
Выражение для функции d(u) теперь принимает следующий вид:
(19)
Можно показать, что значение м, минимизирующее выражение (19), удовлетво-
ряет соотношению
(20)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
334
Цифвая обработка видеоизображений
и должно соответствовать наименьшему возможному Л. Таким образом, получе-
на хорошо известная задача на собственные значения.
После нахождения оптимального вектора и интервалы X и Хи опреде-
ляются согласно формулам (9). Таким образом, мы получили следующее пра-
вило для классификации: входной сигнал z относится к классу С\(С_), если ве-
личина u'z принадлежит Х\Х ). На Рис. 3 изображен этот этап классификации
для случая, когда Х~ является пустым, т. е. нет входных сигналов, принадлежа-
щих Q.
Для тех входных векторов, чьи проекции попадают в Хц, необходимо выпол-
нить следующий шаг классификации, где вместо P(z\ CJ и P(z\ С ) выступают
P(z|C4 &u?ze % J и । С & e Xu). Теперь новый вектор u, определяется
как вектор, который минимизирует меру близости между этими двумя распреде-
лениями вероятности. На Рис. 3 (справа) представлен второй этап классифика-
ции. Аналогично выполняются последующие этапы. Вследствие оптимальности
векторов на каждом этапе большая часть входных векторов и будет помещать-
ся в класс С_.
Так как мы аппроксимировали вероятности рассматриваемых классов набо-
рами точек, то не следует пользоваться выражениями (9) для определения Хф, X
и Хи. Это объясняется тем. что данные интервалы будут состоять из многих фраг-
ментов, каждый из которых является результатом одного конкретного изобра-
жения. Более того, область изменения а не может быть покрыта при помощи ко-
нечного числа изображений. Поэтому следует определить два пороговых значе-
ния, ограничивающих область изменения а. В типичных случаях интервал для
класса С\ находится внутри интервала С_. Поэтому для каждого вектора проек-
ции можно определить единственный интервал [Тг Т2]. После проецирования все
точки, не попавшие в данный интервал, будут соответствовать векторам из клас-
са С , а попавшие в него - векторам Си.
8.2. ТЕКСТУРНЫЕ МЕТОДЫ
При использовании текстурной информации возможен учет достаточно
больших изменений во внешнем облике объектов по сравнению с байесовски-
ми методами, что позволяет построить более надежную классифицирующую си-
стему. Один из возможных подходов заключается в применении кратномасштаб-
ной обработки изображения и вычисления так называемых «родительских век-
торов». Затем производится их кластеризация, и для каждого кластера распреде-
ление векторов оценивается с помощью смеси гауссовых функций [12,36,37]. Та-
кой способ обработки позволяет построить классификатор, инвариантный отно-
сительно изменения масштаба объектов.
На начальном этапе из исходного изображения / создается гауссова пирами-
да: Go = /, = 2 1 (g * Gt)),..., G M = 2 X (g * G), где через 2 i обозначено прорежи-
вание изображения с фактором 2, a g представляет собой фильтр низких частот.
На каждом уровне пирамиды к полученному изображению применяется направ-
ленный полосовой фильтр £ : FJ =f.* G.. Тогда для произвольного пикселя (х, у)
его «родительский вектор» определяется следующим образом:
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://ww w. procctv. ru
Глава 8. Обнаружение транспортных средств
335
Г (*.>0 = {Fo° <*’>’)’Fo' (*♦>*).....Л? (*.>’)’
(21)
где |х| обозначает наибольшее целое, меньшее или равное х, М - число уровней
пирамиды, а /V- количество характерных признаков.
Следующий этап заключается в кластеризации полученных «родительских
векторов». Вследствие огромного объема данных стандартная процедура по ме-
тоду К-средних потребовала бы неприемлемо больших затрат времени. Поэтому
для ускорения процесса кластеризации можно ввести вектор пороговых значе-
ний 8 - {5р...,5^} размерности d (совпадающей с размерностью «родительских
векторов»), расстояние D
D^’^=|a|+|6|ll (22)
и функцию близости векторов R (v(, v2). равную нулю,если хотя бы для одной ком-
поненты векторов v, = } и v2 = выполняется условие
,V2J)> 8Г и единице - в противном случае. Тогда те кластеры, для которых
Я(рг, Д,) - 1, объединяются в один общий кластер, что позволяет значительно
уменьшить их число. Здесь // - вектор средних значений для кластера i. Отме-
тим. что в начальный момент каждый «родительский вектор» образует свой соб-
ственный кластер.
Для полученных кластеров строятся многомерные гауссовы распределения.
Вероятность того, что вектор V принадлежит классу С, определяется следующим
выражением:
где К - число кластеров,
(23)
(24)
wk - отношение числа «родительских векторов» в кластере к к общему числу век-
торов.
Несмотря на то что число имеющихся кластеров было уменьшено с помощью их
объединения, оно может быть по-прежнему слишком большим для использования в
режиме реального времени. Для сокращения объема вычислений можно построить
две гистограммы, показывающие, сколько раз «родительские векторы» из положи-
тельной и отрицательной обучающих последовательностей оказывались принадле-
жащими к положительным кластерам. После этого следует оставить только те кла-
стеры, для которых найденное число положительных векторов значительно превы-
http://www. itv.ru
Компания ITV - генеральный спонсор издания книги
336
Цифвая обработка видеоизображений
шает соответствующее значение для отрицательных. Обозначим через 7/с[Г] число
положительных «родительских векторов», относящихся к кластеру i,а через ~
число отрицательных векторов, попавших в кластер /.Тогда, если
>5.
(25)
кластер i сохраняется. В противном случае данный кластер уничтожается.
С помощью модели (23) можно определить вероятность класса С на основе
«родительского вектора» V*.
Р(С|К) =
р(у с)р(с)
р(у 1С)р(С) + р(й с)р(с)’
(26)
Объект классифицируется как принадлежащий к классу С в том случае, когда
£/’(c|rw)
---------->6. (27)
А
где 8 - пороговое значение. В противном случае объект принадлежит к классу С.
8.3. ПОСТРОЕНИЕ СПЕЦИАЛЬНЫХ КЛАССИФИКАТОРОВ
Для классификации объектов в последнее время весьма широко применяется
метод повышения достоверности классификации путем использования набора экс-
пертов, так называемый метод бустинга, подробно изложенный в Главе 5. В роли
экспертов выступают «слабые классификаторы», от которых требуется умение
выдавать прогноз с достоверностью, хоть на сколько-нибудь превышающей 50%.
Основная идея метода бустинга заключается в итеративной минимизации выпукло-
го функционала ошибки классификации при помощи добавления очередного клас-
сификатора. Можно сказать, что данный метод пытается спроецировать исходные
данные в пространство особого вида, где классы будут линейно разделимы[24-26].
Как правило, процедура детектирования и классификации объектов осно-
вывается на использовании характерных признаков, которые получаются путем
сравнения интенсивностей изображения в соседних окнах. Первый тип признаков
представляет собой разность между суммами интенсивностей пикселей, лежащих
в двух прямоугольных областях (Рис. 4А и Б). Эти области имеют одинаковый
размер и являются вертикально или горизонтально смежными. Второй тип опре-
деляется как разность сумм интенсивностей пикселей в средней и в двух внешних
областях (Рис. 4В). Наконец, последний тип задействует уже четыре области и
вычисляет разность двух диагональных пар областей (Рис. 4Г). В отличие от ба-
зиса Хаара, являющегося полным, этот набор признаков сильно переопределен.
Данные признаки могут быть вычислены довольно быстро, если ввести про-
межуточное представление изображения - так называемое интегральное изо-
бражение. В каждой точке (х, у) оно содержит сумму интенсивностей пикселей,
находящихся левее и выше этой точки, включая ее саму:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Рис. 4. Примеры характерных прямоугольных признаков, использующихся для
классификации
X 7 (*'»/). (28)
х'$л,у'£у
где Z(x, у) - интенсивность исходного изображения в точке (х, у). Используя сле-
дующие рекуррентные соотношения:
5(x,y) = i(x,^-l)+7(x,y), (29)
i(x,y)=i(x-\,y) + s(x,y), (30)
вычисление интегрального изображения может быть сделано за один проход ис-
ходного. Здесь s(x, у) - сумма интенсивностей пикселей в данной строке х до пик-
селя у включительно, s(x, -1) = 0, /(-1, у) = 0
При помощи интегрального изображения можно легко получить все три типа
характерных признаков.Так, первый тип выражается как (a ~2b + с - d + 2е-/), вто-
рой - (а - 2Ь + 2с - d - е + 2/- 2g + h) и третий - (а - 2Ь + с - 2d + 4е - 2f + g - 2h +i)
[26] - см. Рис. 5.
Как нетрудно увидеть, для каждого изображения существует огромное число
рассматриваемых характерных признаков. И хотя все они могут быть вычисле-
ны достаточно быстро, затрачиваемое на это время неприемлемо велико. Поэто-
му предположим, что небольшое число этих признаков может быть использова-
но для эффективного решения поставленной задачи. Будем выбирать единствен-
ный характерный признак, наилучшим образом отделяющий положительные и
отрицательные примеры изображений. Для каждого признака введем оптималь-
http://wwwjtv.ri/
Компания ITV - генеральный спонсор издания книги
338
Цифвая обработка видеоизображений
Рис. 5. Пример вычисления характерных признаков
ное пороговое значение, исходя из условия минимально возможного числа невер-
но классифицируемых примеров.Таким образом, слабый классификатор А (х) для
характерного признака/, и заданного порогового значения <5 определяется как
/ \ И» f, (х)>
М*)= L • (31>
[О, иначе
Здесь х - окно определенного размера (например. 24 х 24 пикселя). Весь алго-
ритм классификации может быть записан следующим образом.
1. Рассмотрим (х„ у().(х^ уп). где yt = 0 для отрицательных и у, = 1 положи-
тельных примеров.
2. Зададим начальные значения весовых коэффициентов vv1, = l/2m для yt = О
и Wj, = 1/2/ для yt = 1 соответственно,где тмЛ- число отрицательных и по-
ложительных примеров.
3. Для Г=
а. Нормируем веса
Совокупность w можно рассматривать как распределение вероятности.
Ь. Для каждого признака j настроим классификатор Л, который использу-
ет только один характерный признак. Тогда ошибка будет вычисляться
при помощи следующего выражения:
л
/=|
с. Выберем классификатор А, с наименьшей ошибкой Е.
d. Подстроим веса:
4.
Здесь е = 0, если пример х классифицирован правильно, и е. = 1 - в
противном случае; Д = ——.
Итоговый классификатор определяется как
ProSystem CCTV — журнал по системам видеонаблюдения
http.//www.procctv. ги
Глава 8. Обнаружение транспортных средств
339
Л(х) =
О, иначе
где а, = log (1/Д,).
Указанный выше выбор а гарантирует, что ошибка обучения не превыша-
ет величины
exp("2Z^(°-5"£«):) (32)
и, следовательно, убывает экспоненциально по отношению к числу шагов обу-
чения Т.
Осталось определить величину порогового значения <5. Для этого введем
множества Со = = 0} и С. = {х |yt = 1), представляющие собой отрицательные
и положительные примеры соответственно^?]. Тогда
а
(33)
(34)
Для минимизации влияния различной освещенности все примеры, которые
будут использоваться для обучения, следует перенормировать на величину дис-
персии изображения. Дисперсия вычисляется как
где N - число пикселей изображения.
8.4. ИСПОЛЬЗОВАНИЕ ИНВАРИАНТНЫХ МОМЕНТОВ
Для инвариантной классификации объектов на изображении в качестве харак-
терных признаков могут быть применены различные наборы моментов. Изобра-
жение можно рассматривать как элемент векторного пространства, так что оно
может быть разложено по ортогональному базису этого пространства. Рекон-
струкция изображения по ряду его моментов нс имеет единственного решения, т.
е. является некорректной задачей. Поэтому для единственности решения необхо-
димо использовать дополнительные ограничения. Стандартная процедура рекон-
струкции изображения методом наименьших квадратов накладывает такие огра-
ничения на сами моменты. Однако возможно также введение ограничений, кото-
рые определяются через свойства самого изображения, например, его разрешение.
Геометрические моменты являются интегралами от неких функций изобра-
жения по всему пространству. Моменты низших порядков относятся к общим
свойствам изображения и обычно используются для определения положения,
ориентации и масштаба изображения. Инварианты моментов представляют со-
http://www. itv. ru
Компания ITV - генеральный спонсор издания книги
340
Цифвая обработка видеоизображений
бой линейную комбинацию геометрических моментов и обеспечивают незави-
симость результатов распознавания от преобразований масштабирования и вра-
щения. В принципе, инварианты моментов обладают рядом недостатков: они чув-
ствительны к шумам и несут в себе избыточную информацию. Однако существу-
ет набор моментов, обладающих необходимыми для классификации объектов
свойствами и достаточной устойчивостью к шуму.
Из теоремы единственности моментов следует, что изображение однознач-
но определяется своими геометрическими моментами всех порядков. Моменты
низших порядков несут в себе меньше информации об изображении, а моменты
высших порядков чувствительны к шумам. Поэтому необходимо найти компро-
мисс между числом использующихся моментов и точностью описания изображе-
ния. Для использования в качестве характерных признаков хорошо подходят мо-
менты Цернике: они инвариантны к вращению, являются ортогональными и их
несложно вычислять [28-30].
Полиномы Цернике представляют собой множество комплексных ортого-
нальных полиномов, определенных внутри единичного круга х2 + у2 = 1:
(36)
(л-т) 2
«..(₽)= Z (-1)'
3=0
(37)
где п - неотрицательное целое, т - целое такое, что п - |гл| четное и |т| < лг.
Р = V* + У >0 = arctS
х
Раскладывая интенсивность изображения по данному базису, получим:
^=~№(х<уКМ х2+у2<\. (38)
х у
Моменты Цернике, примененные к изображению, полученному из исходно-
го изображения путем выполнения преобразования поворота, отличаются от ис-
ходных моментов сдвигом по фазе, но совпадают по величине [30]. Поэтому |Лпш|
могут быть использованы в качестве инвариантных к вращению характерных
признаков изображения. Так как Ап т = Апт, то |Лл J = |Ллш|, и в качестве харак-
терных признаков можно использовать только величины |ДЛШ|.
Недостатком моментов Цернике является их низкая эффективность при
использовании с изображениями малого размера. Кроме того, они не являют-
ся ортогональными для дискретных переменных. Поэтому в ряде случаев ока-
зывается предпочтительным использование ортогональных моментов Фурье-
Меллина, которые свободны от указанных недостатков[31].
Круговое преобразование Фурье и радиальное преобразование Меллина,
определенные в полярных координатах, применяются для инвариантного отно-
сительно изменения масштаба и вращения распознавания образов. Для s > 0 мо-
менты Фурье-Меллина (МФМ) определяются следующим образом:
= J j r7(r,0)exp(-/7n0)r</rrf0 , (39)
о о
ProSystem CCTV - журнал по системам видеонаблюдения
h t Тр://\лг ww. procc t v. ги
Глава 8. Обнаружение транспортных средств
341
где j - мнимая единица. Определим теперь ортогональные моменты Фурье-
Меллина (ОМФМ):
= 7^— J J1 №№ (r)exp(-jmO)rdrde. (40)
^ап о о
где ап - постоянная нормировки, a Qt (г) - полином степени п. Базисные функции
(2n(r) ехр(- jm в) ОМФМ являются ортогональными внутри единичного круга
0 < г < 1. Полиномы Qr(r) определяются из следующего выражения:
£('') = X<V’- (41)
4 = 0
где
(42)
а ап из формулы (40) записывается как ап = 1 /[2(лг +1)]. Приведем явные выраже-
ния для нескольких первых ОМФМ:
2,(г) = -(2-Зг),
& (г) = 3-12г+ 10/, (43)
Qy (г) = - (4 - 30г + 60г2 - 35г’),
а (г) = 5 - 60г + 21 Or2 - 280г’ +126/.
ОМФМ могут быть представлены как линейная комбинация МФМ:
(44)
71 f=o
или комплексных моментов
П 4" 1 ч-ч
“ ~~~ X (45)
71 4=0
где
с„ = JLI (х, ,у)(х + У'у/ (х - jy? dxdy. (46)
Здесь р nq - неотрицательные целые числа.
Для классификации объектов в качестве характерных признаков использу-
ется конечное число ОМФМ:
7(г,0) = £ £ фшЯ2я('-)ехр(>в). (47)
л=0 т=-М
Благодаря ортогональности Qn(r)exp(jm в) каждый ОМФМ вносит независимый
от других вклад в реконструкцию исходного изображения.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
342
Цифвая обработка видеоизображений
ОМФМ можно перенормировать таким образом, чтобы они стали инвари-
антными относительно сдвига и вращения, а также изменений масштаба и интен-
сивности изображения. Когда изображение 1(г> 6) масштабируется в к раз, а его
интенсивность меняется в b раз, то его МФМ принимают вид:
2я I
Ч'ж = J jbi(r/k,e)r’rdrde =
о о
Здесь к и b определяются следующим образом:
(48)
(49)
(50)
Нормированные инвариантные к сдвигу и вращению МФМ получаются при по-
мощи следующего выражения:
М'
__
Msm
sm Ьк
(51)
Отметим, что М10 и М00 имеют одни и те же значения для всех изображений в
обучающем и тестовом наборах. Поэтому просто положим = 1. Согласно вы-
ражению (49) отношение M]Q/MQQ связано с величиной к. Выберем это отноше-
ние немного меньшим, чем минимум М^/М^ по всем изображениям в обучаю-
щей последовательности, для того чтобы перенормированные изображения ле-
жали внутри единичного круга.
Наконец, вычислим ОМФМ через нормированные МФМ с помощью выра-
жения (44). Поворот изображения на угол 0П входит одним и тем же множителем
exp(jm 0О) во все МФМ в (44). Абсолютное значение ОМФМ |Фяя1| является инва-
риантным к сдвигу, вращению и изменениям масштаба и интенсивности.
Расстояние между анализируемым и шаблонным изображениями может
быть вычислено по следующей формуле:
(52)
где )Ф„ J - абсолютное значение ОМФМ анализируемого объекта, (|ФП„,|), - ша-
блонного объекта класса /, a (O‘rtW)2l - внутриклассовая дисперсия (|Фят|)г Распо-
знаваемый объект относится к классу с минимальным значением rf.
8.5. ИСПОЛЬЗОВАНИЕ ФИЛЬТРОВ ГАБОРА
Помимо инвариантных моментов при распознавании образов одним из эф-
фективных методов является использование двумерных фильтров Габора [32-33].
ProSystem CCTV — журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 8. Обнаружение транспортных средств
343
Это обусловлено некоторой схожестью механизма их действия с работой рецеп-
торов нейронов коры головного мозга. Общий функциональный вид семейства
двумерных фильтров Табора может быть представлен как функция Гаусса, про-
модулированная комплексным синусоидальным сигналом:
g(x,y) = -------СХР
где
1 X' V
ехр [2л j ГГх],
х = xcos0 + ysin#
у = -xsinG + ycosG
(53)
(54)
(У1 и (J - параметры масштабирования фильтра, определяющие эффективную
окрестность пикселя (х. у), в которой производится взвешенное суммирование,
в е [0, л) определяет ориентацию фильтра Габора, W - радиальная частота сину-
соиды. Прямое преобразование Фурье для функции Габора выглядит следующим
образом:
G(u,v) = ехр
(55)
1 1
где ст = -ла. а, = -ла .
и 2 х v 2
Каждый фильтр полностью определяется набором четырех параметров
Л = (fl, W, ах,акТаким образом, выбор фильтра для конкретной задачи заклю-
чается в оптимизации данных параметров. Если использовать набор из N филь-
тров, то необходимо решить многопараметрическую (4W параметров) задачу
оптимизации. Для этой цели хорошо подходит генетический алгоритм. Каждый
фильтр может быть представлен с помощью М бит. Если обозначить через ^де-
сятичное число, закодированное п битами, относящимися к параметру G, то зна-
чение последнего вычисляется как
2" '
(56)
Аналогично для W получим
= + (W -W
nun \ max min J ’
(57)
где W е [ Wmin, WmaJ. Параметры ст, и ст, лежат на отрезке [стт1П, сттах]. Здесь верх-
ний предел СТтах определяется шириной маски w [32] как СТтах < и>/5. Величина СТт1П
задается с помощью теоремы Котельникова-Найквиста СТт,„ > 0.796. Для СТ, и СТ,
используются выражения, совершенно идентичные (57):
= °™ + - ^пйп ) Y-> (58)
Da
= °™ + (t^rnax - <7ml„ ) ~~ (59)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
344
Цифвая обработка видеоизображений
В результате решения оптимизационной задачи могут получиться фильтры
с очень близкими наборами параметров. Для исключения избыточного числа
фильтров может быть использована процедура кластеризации фильтров в про-
странстве их параметров:
1. Первый фильтр помещается в новый кластер.
2. Вычисляется расстояние между очередным фильтром и центроидом каж-
дого кластера.
3. Находится наименьшее расстояние.
4. Если это расстояние меньше порогового значения, фильтр помещается в
соответствующий кластер. В противном случае этот фильтр помещается
в новый кластер.
5. Шаги 2-4 повторяются для всех оставшихся фильтров.
6. Фильтры в каждом кластере заменяются одним фильтром с параметрами,
соответствующими центроиду кластера.
Обозначим параметры фильтра через а параметры центрои-
да /-го кластера - через }, (/ е {1.L), L - число существующих кла-
стеров). Тогда фильтр помещается в z-й кластер, если выполняются следующие
условия:
0’--5в<6>п<0, + -5в. (60)
2*2 z
+ (61)
(62)
(63)
Если же эти условия не выполняются, то фильтр помещается в новый кластер.
Для порогов рекомендуются следующие значения: 8в -7i/K,8w = (ИЛгпах
8a = (o^-<ymm)lK. К = 2^.
Нахождение оптимального набора фильтров Габора является первым этапом
задачи детектирования и классификации объектов. На втором этапе необходи-
мо получить характерные признаки изображения, используя отклики найденных
фильтров, и обучить с их помощью классификатор. Для данного входного изо-
бражения /(х, у) характерные признаки получаются путем его свертки с набо-
ром фильтров:
г (х> у) = JJ1 (£ и) g - & у - п) d^dп. (64)
Далее для окончательного получения признаков используется следующая
процедура. Входное изображение делится на более мелкие части, например, раз-
мером 32 х 32 пикселя. Каждое из полученных частичных изображений в свою
очередь делится на 9 перекрывающихся окон размером 16 х 16 пикселей. В каж-
дом таком окне вычисляется модуль отклика фильтров ГЬбора, после чего опре-
деляются математическое ожидание среднеквадратичное отклонение <7,
ProSystem CCTV - журнал по системам видеонаблюдения
ht tp://www. procctv. ru
Глава 8 Обнаружение тоанспортных средств
345
и асимметрия где индекс i относится к фильтру, а / - к окну Например, для
/V - 6 фильтров получим вектор характерных признаков, состоящий из 162 эле-
ментовх = {р||)сг11,>с,|.р,2,(т;;,к-1,,...,д69Чсг69,к-69}.
8.6. СПИСОК ЛИТЕРАТУРЫ
1. В. Leung. Component-based Саг Detection in Street Scene Images. Master Thesis,
MIT Massachusetts. 2004.
2. N. Matthews, P An, D. Charnley. C. Harris. Vehicle Detection and Recognition in
Greyscale Imagery: In: Control Engineering Practice, v. 4, p. 473-479,1996.
3. H. Schneiderman. A Statistical Approach to 3D Object Detection Applied to Faces
and Cars.Technical Report CMU-RI-TR-00-06, Robotics Institute. Carnegie Mellon
University. 2000.
4. C. Papageorgiou.T Poggio. A Trainable System for Object Detection. In: International
Journal of Computer Vision, v. 38, p. 15-33,2000.
5. D. Casasent. L. Neiberg. Classifier and Shift-invariant Automatic Target Recognition
Neural Networks. In: Neural Networks. v. 8. p. 1117 - 1129,1995.
6. H. Murase. S. K. Nayar. Visual Learning and Recognition of 3-D Objects from
Appearance. In: International Journal of Computer Vision, v. 14, p. 5-24,1995.
7. M. Turk, A. Pentland. Eigenfaces for Recognition. In: Journal of Cognitive
Neuroscience, v. 3, p. 71-86,1991.
8. P N. Bclhumeur, J. P Hespanha, D. J. Kriegman. Eigenfaces vs.Fisherfaces: Recognition
Using Class-specific Linear Projection. In: IEEE Transactions on Pattern Analysis
and Machine Intelligence, v. 19, p. 711-720,1997.
9. B. Schiele, J. L. Crowley Recognition without Correspondence using Multi-
dimensional Receptive Field Histograms. In: International Journal of Computer
Vision, v. 36, p. 31-50,2000.
10. B. Schiele, A. Pentland. Probabilistic Object Recognition and Localization. In: Proc.
International Conference on Computer Vision. Kerkyra,v. l,p. 177-182,1999.
11. E. Simoncelli. J. Porlilla. Texture Characterization via Joint Statistics of Wavelet
Coefficient Magnitudes. In: Proc. IEEE International Conference on Image
Processing. Chicago, p. 4-7,1998.
12. T D. Rikert, M. J. Jones, P Viola. A Cluster-based Model for Object Detection. In:
Proc. International Conference on Computer Vision. Kerkyra, p. 1046 - 1053,1999.
13. M. D. Wheeler, K. Ikeuchi. Sensor Modeling, Probabilistic Hypothesis Generation,
and Robust Localization for Object Recognition. In: IEEE Transactions on Pattern
Analysis and Machine Intelligence, v. 17. p. 252 - 265,1995.
14. Geometric Invariance in Computer Vision. J. L. Mundy. A. Zisserman (eds). MIT
Press. Cambridge, 1992.
15. M. C. Burl, P Perona. Recognition of Planar Object Classes. In: Proc. Conference on
computer Vision and Pattern Recognition. San Francisco, p 223 -230,1996.
16. B. Moghaddam, A. Pentland. Probabilistic Visual Learning for Object Representation.
In: IEEE Transactions on Pattern Analysis and Machine Intelligence, v. 19, p. 696 -
710,1997.
http://www. itv. ru
Компания ITV - генеральный спонсор издания книги
346
Цифвая обработка видеоизображений
17. С. Р. Papageorgiou, М. Oren,T. Poggio. A General Framework for Object Detection.
In: Proc. International Conference on Computer Vision. Bombay, p. 555-562,1998.
18. R A. Viola. Complex Feature Recognition: A Bayesian Approach for Learning to
Recognize Objects. In: Al Memo No. 1591,1996.
19. D. Hoiem. R. Sukthankar. H. Schneiderman, L. Huston. Object-based Image
Retrieval Using the Statistical Structure of Images. In: Proc. IEEE Computer
Society Conference on Computer Vision and Pattern Recognition. Washington, p.
490-497,2004.
20. S. Ullman, E. Sali. M. Vidal-Naquet. A Fragment-based Approach to Object
Representation and Classification. In: Lecture Notes in Computer Science; v. 2059,
p. 85-102,2001.
21.1 . Biederman. Human Image Understanding: Recent Research and Theory. In:
Computer Vision. Graphics and Image Processing, v. 32, p. 29-73,1985.
22. D. Bhat. K. S. Nayar. Ordinal Measures for Image Correspondence. In: IEEE
Transactions on Pattern Analysis and Machine Intelligence, v. 20, p. 415-423,1998.
23. M. Elad, Y. Hel-Or, R. Keshet. Pattern Detection Using a Maximal Rejection
Classifier. In: Proc. International Workshop on Visual Form. Capri, p. 514-524,2001.
24. P Viola, M. Jones. Robust Real-time Object Detection. In: Proc. International
Workshop on Statistical Learning and Computational Theories of Vision - Modeling.
Learning. Computing and Sampling. Vancouver, p. 747-761,2001.
25. P. Viola, M. Jones. Rapid Object Detection Using a Boosted Cascade of Simple
Features. In: Proc. IEEE Computer Society Conference on Computer Vision and
Pattern Recognition. Kauai, p. 511-518,2001.
26. P S. Carbonetto. Robust Object Detection Using Boosted Learning. Project Report,
Department of Computer Science, University of British Columbia, Vancouver, 2002.
27. К. H. Tieu. Boosting Sparse Representations for Image Retrieval. Masters Thesis,
2000.
28. J. Martinez, F. Thomas. On the Reconstruction of an Image from its Moments. In:
Proc. International Conference on Image Processing. Bellaterra, v. 1, p. 217-220,2003.
29. H. Hse, A. R. Newton. Sketched Symbol Recognition Using Zernike Moments. In:
Proc. International Conference on Pattern Recognition. Cambridge, v. I, p. 367-370,
2004.
30. A. Khotanzad, Y. H. Hong. Rotation-invariant Image Recognition using Features
Selected via a Systematic Method. In: Pattern Recognition, v. 23, p. 1089-1101,1990.
31. Y. Sheng, L. Shen. Orthogonal Fourier-Mellin Moments for Invariant Pattern
Recognition. In: Journal of Optical Society of America A. v. 11, p. 1748-1757,1994.
32. Z. Sun, G. Bebis, R. Miller. On-road Vehicle Detection Using Evolutionary Gabor
Filter Optimization. In: IEEE Transactions on Intelligent Transportation Systems, v.
6, p. 125-137,2005.
33. Z. Sun, G. Bebis, R. Miller. Object Detection Using Feature Subset Selection. In:
Proc. IEEE Conference on Advanced Video and Signal Based Surveillance. Miami,
p. 290-296,2003.
34. Добеши И. Десять лекций по вейвлетам. - М.: Регулярная и классическая ди-
намика, 2001. - 464 с.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 8. Обнаружение транспортных средств
347
35.1 De Bonet. Р. Viola. Texture Recognition Using a Non-parametric Multi-scale
Statistical Model. In: Proc. Conference on Computer Vision and Pattern Recognition,
Santa Barbara, p. 641-647.1998.
36. E. Simoncelli. W. Freeman. The Steerable Pyramid: A Flexible Architecture for
Multi-scale Derivative Computation. In: Proc. International Conference on Image
Processing. Washington, vol. III. p. 444-447,1995.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
ГЛАВА 9.
МЕТОДЫ ВЫДЕЛЕНИЯ И
РАСПОЗНАВАНИЯ НОМЕРНЫХ
ЗНАКОВ ТРАНСПОРТНЫХ СРЕДСТВ
350
Цифвая обработка видеоизображений
В последние годы большое внимание уделяется развитию интеллектуальных
транспортных систем, в которых существует подсистема автоматического рас-
познавания регистрационных номеров автомобилей. Эта подсистема позволяет
не только распознавать и подсчитывать транспортные средства (ТС), но и разли-
чать их между собой посредством считывания уникального для каждого автомо-
биля регистрационного номера. Благодаря этому нет необходимости устанавли-
вать дополнительные датчики на ТС для его корректного опознания.
Системы автоматического распознавания номеров автомобилей возникли
около 20 лет назад и в настоящее время находят самое широкое применение:
• на контрольно-пропускных пунктах,
• при идентификации украденных ТС,
• на автоматических парковках.
• на бензозаправочных станциях.
• при детектировании ТС. движущихся со скоростью выше разрешенной
или совершающих другие нарушения правил дорожного движения,
• при идентификации ТС. находящихся в зоне наблюдения охраняемых
объектов.
Вследствие многообразия внешних условий, в которых приходится рабо-
тать системам автоматического распознавания номеров автомобилей, методи-
ки, используемые при их создании, могут в значительной степени различаться.
Однако все имеющиеся на сегодняшний день системы состоят из двух основных
устройств: получения изображения и блока его последующего анализа, результа-
ты которого во многом зависят от качества полученных снимков.
Для получения изображений применяются камеры, которые могут вклю-
чаться при появлении в заданной области автомобиля либо работают в непре-
рывном режиме. В первом случае, часто применяемом в практических системах,
камера включается по специальному сигналу от триггерного устройства, кото-
рое управляется датчиком с индуктивной петлей. У такого метода есть ряд се-
рьезных недостатков. Во-первых, точно определить местоположение транспорт-
ного средства удается не всегда; во-вторых, возрастает стоимость всей системы,
и, наконец, на получаемых изображениях номерной знак может быть виден лишь
частично. Система с одной непрерывно работающей камерой компактнее и де-
шевле, однако алгоритмически она сложнее, поскольку должна выделять из по-
тока транспорта отдельные автомобили и находить на них номера.
Вне зависимости от того, какой подход используется для получения изобра-
жений, важнейшую роль играет тип применяемой камеры. Узость динамического
диапазона широко применяемых камер является серьезной проблемой при соз-
дании робастных систем автоматического распознавания регистрационных но-
меров автомобилей, так как наблюдаемые сцены обычно имеют гораздо более
значительные пределы изменения яркостей, чем фиксирует камера. Существуют
два способа решения этой проблемы: использовать камеры с улучшенными ха-
рактеристиками или разрабатывать специализированные алгоритмы анализа ви-
деоизображений. Первый способ подразумевает значительное увеличение стои-
мости всей системы, что, естественно, является нежелательным. Во втором слу-
чае возможно получение изображений с динамическим диапазоном, большим,
чем у камеры, путем комбинации снимков, сделанных при разных условиях экс-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 351
позиции (например, технология Sony DoubleScan). Для устранения эффекта сма-
зывания изображений, возникающего вследствие быстрого движения ТС, необ-
ходимо или использование камер с высокой скоростью электронного затвора,
или применение специализированных методов обработки и анализа.
После того как изображение получено, оно передается блоку обработки и
анализа изображений. Обычно он включает в себя три этапа: выделение номер-
ного знака, сегментация на нем отдельных букв и цифр и их распознавание. Пер-
вый этап является чрезвычайно важным, так как от того, насколько аккурат-
но выделен номерной знак на изображении, зависят результаты двух последую-
щих этапов. Существует целый ряд факторов, оказывающих негативное влия-
ние на корректную сегментацию номера автомобиля: низкое качество изображе-
ния, меняющиеся внешние условия освещения, перспективные искажения, нали-
чие на автомобиле других знаков и надписей, помимо номера, отражение света от
поверхности ТС. близкое сходство цвета номерного знака и автомобиля и другие.
Для сегментации номерных знаков известен целый ряд методов, которые мо-
гут быть сгруппированы в зависимости от используемых характерных признаков
изображения. Основными признаками являются краевые точки, текстуры, цвет
и симметрия. Выделение вертикальных краев - наиболее распространенный спо-
соб локализации номерного знака, поскольку на изображении большинства ав-
томобилей гораздо больше горизонтальных линий, чем вертикальных. Для кор-
ректного выделения номерного знака достаточно правильно локализовать его
четыре угла. Чтобы уменьшить объем вычислений, обычно выделяют только
вертикальные краевые точки, после чего для устранения нежелательных объ-
ектов применяют операции морфологии с заданными свойствами. Окончатель-
но выделение производится на основе заранее известного отношения высоты к
ширине номерного знака. Недостатком данного метода является его повышен-
ная чувствительность к нахождению лишних краевых точек. Кроме того, неявно
предполагается, что только изображение номерного знака имеет в своем соста-
ве вертикальные края. Это допущение неверно для ТС, имеющих, например, ре-
шетку радиатора со многими вертикальными отрезками, а также в случае двух и
более номерных знаков, присутствующих на изображении. Использующийся для
нахождения вертикальных краев метод Хафа чрезвычайно чувствителен к де-
формации границ номерного знака и требует больших объемов памяти и време-
ни обработки.
В основе метода выделения номерных знаков на основе текстур лежит пред-
положение о том, что величина интенсивности цифр и букв на нем сильно отли-
чается от таковой для фона. Это дает возможность воспользоваться следующи-
ми вытекающими свойствами:
• область номерного знака всегда имеет высокую степень контрастности
по сравнению с остальным изображением ТС,
• изменения интенсивности в области номерного знака являются более ча-
стыми, что, в свою очередь, приводит к образованию там большого коли-
чества краевых точек (особенно, вертикальных),
• если анализируемая область действительно является номерным знаком,
то пиксели переднего плана распределены там более равномерно по срав-
нению с областями простой структуры.
http://www./tv.ri/
Компания ITV - генеральный спонсор издания книги
352
Цифвая обработка видеоизображений
В методах этого класса для окончательного принятия решения о коррект-
ности выделения требуемой области обычно используются дополнительные
сведения о номерном знаке, такие как отношение сторон, количество пикселей
в выделенной области, ее ориентация, плотность, т. е. отношение числа передне-
плановых и фоновых пикселей. Недостатком данных методов является невоз-
можность с их помощью провести различие между областью, занимаемой но-
мером. и областями, включающими в себя посторонние знаки, а также решет-
ку радиатора в некоторых типах ТС. В этих случаях даже использование допол-
нительных данных не позволяет существенно повысить робастность сегмента-
ции номерного знака.
Для выделения номерных знаков на изображении может быть использова-
на цветовая информация. Во многих странах номерные знаки обладают уни-
кальным сочетанием цветов фона и расположенных на нем букв и цифр. В ка-
честве характерных признаков номерного знака используется последователь-
ность цветовых кодов, получаемая при поперечном сканировании изображе-
ния слева направо. Далее применяемые методы классификации, такие как ис-
кусственные нейронные сети и генетические алгоритмы, позволяют локализо-
вать область номерного знака. Хотя использование цветовой информации дает
ряд преимуществ, в то же время сохраняются проблемы, связанные с изменени-
ем освещенности сцены и близостью цветов номера и самого автомобиля. Кро-
ме того, существенно возрастает объем необходимых вычислений и стоимость
оборудования.
Вторым этапом анализа в системах автоматического распознавания номе-
ров автомобилей обычно является сегментация отдельных знаков на уже вы-
деленном номере автомобиля. Для этого наиболее часто используется постро-
ение вертикальной проекции предварительно приведенного к черно-белому
виду номерного знака. Данные методы просты и требуют малого времени вы-
числения. Однако изменение положения камеры относительно ТС приводит к
перспективным искажениям изображения, чьи вертикальная и горизонталь-
ная оси уже не будут параллельны осям номерного знака. Вследствие этого
в случаях наклона номера ТС проекционные методы приводят к значитель-
ным ошибкам. Альтернативой таким методам являются методы, основанные
на анализе областей.
Заключительный этап работы систем автоматического распознавания номе-
ров автомобилей посвящен распознаванию сегментированных знаков на номере
автомобиля. В целом, существующие для этого методы либо используют предва-
рительно построенные шаблоны, либо основаны на обучении. В первом случае
для каждого возможного знака создаются специальные шаблоны, которые поме-
щаются в базу данных. После этого производится сравнение вновь поступивше-
го на вход знака со всеми шаблонами путем вычисления какого-либо расстояния
(евклидова, Махаланобиса и т.п.). Естественно, что при этом необходимо приве-
дение всех знаков к одному и тому же размеру. Однако такой метод обычно обла-
дает значительными ошибками даже при небольшом изменении в цвете и осве-
щенности объектов. Поэтому, вместо того чтобы сравнивать сами знаки, выделя-
ют некие их характерные признаки (гистограммы, сумма проекций интенсивно-
стей и т. д.), что приводит к повышению надежности распознавания.
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procct v. г и
Глава 9. Методь’ выделения и распознавания номерных знаков транспортных средств 353
К методам распознавания, основанным на обучении, в первую очередь, относят-
ся многослойные нейронные сети и методы опорных векторов. Как правило, они
обеспечивают большую точность распознавания, чем методы сравнения с шабло-
нами. Однако при этом возрастает время вычислений. Для его уменьшения необ-
ходимо аккуратное выделение наиболее информативных характерных признаков.
9.1. ВЫДЕЛЕНИЕ НОМЕРНОГО ЗНАКА
9.1.1. Предварительная обработка изображения
Предварительная обработка изображения необходима для контрастирова-
ния краевых точек, устранения шума, присутствующего на снимке, и проведения
корректной бинаризации изображения [1-9]. В принципе, можно работать и с по-
лутоновыми изображениями и применять, например, морфологические опера-
ции непосредственно к ним. Однако бинаризация позволяет получать в большин-
стве случаев более адекватные результаты.
Контрастирование краевых точек необходимо для последующего коррект-
ного выделения области номерного знака. Так как знак имеет прямоугольную
форму, то контрастировать следует только вертикальные и горизонтальные
края. Для этих целей наиболее часто используются операторы Собеля и Превит-
та размером 3 х 3 и 5 х 5 пикселов. Чтобы скомбинировать результаты последо-
вательного применения вертикальных и горизонтальных операторов, вычисля-
ется величина градиента.
Помимо контрастирования краевых точек на стадии предобработки очень
важно избавиться от шума. Присутствующий шум нарушает структуру изобра-
жения и приводит к некорректному выделению области номерного знака. Поэ-
тому к исходному изображению, как правило, применяют фильтр низких частот.
В качестве такого фильтра может быть использован стандартный гауссов или
параметрический фильтр:
(1)
позволяющий путем изменения параметра b добиться желаемых результатов.
Для устранения шума также можно воспользоваться методами кратномас-
штабной обработки и разложить исходный сигнал (изображение) по вейвле-
там. При этом шумовые составляющие будут иметь значительно меньшую ам-
плитуду, чем у содержательной части изображения, что позволит от них изба-
виться с помощью пороговой обработки. После этого можно выполнить обрат-
ное преобразование и получить изображение без шума. Преимуществом такого
метода является практически полное сохранение полезной информации. Одна-
ко необходимо адекватным образом выбрать пороговое значение для вейвлет-
коэффициентов. Если задать его слишком большим, то изображение получит-
ся размытым, а в противоположном случае малого порогового значения мно-
гие края станут разорванными.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
354 Цифвая обработка видеоизображений
Проблема устранения шумов на изображении может быть сформулирована
следующим образом. Пусть У ( - это искаженное шумом наблюдение исходного
сигнала / :
^=1^i = j = (2)
где Ej/ ~ riffler2) - шум. который нс зависит от сигнала и распределен по нормаль-
ному закону с нулевым средним и дисперсией су2. Тогда необходимо найти опти-
мальное значение / г наиболее близкое к исходному изображению l f в заданной
метрике. Обозначим через Y. I и е матрицы наблюдаемых и исходных данных, а
также вносимых шумом искажений.Тогда процедура устранения шума из изобра-
жения распадается на три этапа:
1. Вычисление матрицы вейвлет-коэффициентов w с помощью применения
к имеющимся данным вейвлет-преобразования W:
w = WY = WI +We. (3)
2. Изменение вейвлет-коэффициентов (например, при помощи пороговой
обработки):
w —> w. (4)
3. Выполнение обратного вейвлет-преобразования для получения изобра-
жения с устраненным шумом:
I = W'w. (5)
Число вейвлет-коэффициентов п в выражении (3) зависит от типа используемо-
го преобразования, в качестве которого могут выступать вейвлеты Добеши, койф-
леты, В- и V-сплайны. Обозначим через Л - пороговое значение, через <5; - порого-
вую функцию, а через д - оценку стандартного отклонения шума а в (2). Тогда
w = <j«5a(w/<j) (6)
ИЛИ
w=5a(w), (7)
в зависимости от того, используется ли нормировка дисперсии шума (6) или нет,
как в выражении (7). Остается выбрать конкретный вид пороговой функции и за-
дать значения порога и оценок шума.
На Рис. 1 представлены четыре различные пороговые функции, приведен-
ные к интервалу [-1,1]. По оси абсцисс отложены вейвлет-коэффициенты w, а по
оси ординат - соответствующие значения пороговых функций 5A(w). С помощью
вертикальных пунктирных линий обозначены универсальные пороговые значе-
ния ±Л для «жесткой» 5" (w) (Рис. 1А), «мягкой» (w) (Рис. 1Б) и сглаженной
«мягкой» (w) (Рис. 1В) пороговых функций. «Полумягкая» пороговая функция
8%^ (w) требует задания двух пороговых значений и ±Л2, что иллюстрируют
четыре пунктирные вертикальные линии на Рис. 1Г Введем обозначение:
1, |м/|>Л
О, |w|<A
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 9 Методы выделения и распознавания номерных знаков транспортных средств 355
Рис. 1. Пороговые функции
Тогда рассматриваемые пороговые функции могут быть записаны следую-
щим образом:
^i(“’)=sgn(“')(M"'l)Jf*j|. <10>
(1|)
о, Н<л,
w, |w|>A2
л, <Н<л2.
(12)
В качестве оценок для шумовой составляющей изображения могут быть исполь-
зованы как глобальные, так и зависящие от конкретного субдиапазона вейвлет-
разложения.
Величина порогового значения может быть как независимой от вида порого-
вой функции, так и зависеть от него. Наиболее простым способом задания Л яв-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
356
Цифвая обработка видеоизображений
ляется выбор глобального значения для всего изображения:Л = y]2]ogMN, где N
и М - высота и ширина изображения соответственно. Можно также минимизиро-
вать ошибки второго рода, что равносильно заданию отношения числа коэффи-
циентов. используемых для обратного вейвлет-преобразования. к общему числу
вейвлет-коэффициентов ниже определенного уровня q. При этом для п вейвлет-
коэффициентов зг сначала вычисляются следующие величины:
л = 2[1-Ф(и/а)]. (в)
где Ф - функция распределения стандартного нормального закона, ad- оценка
дисперсии шума. Затем величины (13) упорядочиваются по возрастанию:
р(1)<р(2)<...<р(и).
Пусть т - это наибольший индекс / такой, что
п
Тогда
Л = аФ-,[1-^.
< 2 >
(М)
(15)
(16)
Наконец наиболее аккуратным способом задания порогового значения яв-
ляется его спецификация для каждого субдиапазона вейвлет-преобразования [5]:
d2
= (17)
где дх - оценка дисперсии сигнала для рассматриваемого субдиапазона. Эта оцен-
ка получается как отклонение диагональных коэффициентов для масштаба пер-
вого уровня:
дх = Jmax(dj-d2,o), (18)
где
^Y= — ^w, (19)
представляет собой оценку дисперсии наблюдаемого изображения, a п5 - число
вейвлет-коэффициентов в рассматриваемом субдиапазоне. Такое задание поро-
гового значения обычно используется вместе с «мягкой» пороговой функцией.
Опытным путем можно получить оптимальные значения для введенных выше
параметров. Так, например, q в выражении (15) лежит в пределах от 0.2 до 0.3.
Для оценок шумовой составляющей в [4] использовался метод медианного абсо-
лютного отклонения, в результате чего было получено, что d = 10.52 при истин-
ном значении <7 = 10. Наилучшие результаты показало использование выраже-
ний (17)-( 19) для определения порога вместе с «мягкой» пороговой функцией (10).
После устранения шумов изображение переводится в двоичный вид, для чего
используется пороговая обработка. Определение величины порога может быть
выполнено различными способами. Наиболее распространенным является ме-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 357
тод, базирующийся на построении гистограммы полутонового изображения.
Вначале находятся среднее значение и дисперсия:
д = (20)
/
= £ О-Д)2/>(')• (21)
/
Затем вводится некое пороговое значение 8 и определяются среднее значение и
дисперсия ниже и выше порога (фактически условная вероятность):
£-1 255
vi=£p(Z)’ v2=£p(/)- (22)
/=0 /=б+!
= X/p(0/vp Рз= £/р(0Л,г (23)
/=о /=5-1
= £0-А1.)2 P(')/Vi> ст2 = £ 0 - Д2)2 p(0/vr (24)
/=0 /-<5-1
Обозначим у/2 = v,cr2 + v2<j2. Величина D = а2 - у/2 определяет качество вы-
бранного порога <5. Будем теперь вычислять значение D для всех возможных 8
и выберем то пороговое значение, для которого достигается максимум D. Недо-
статком данного метода является внесение дополнительного шума в полученное
двоичное изображение.
Лучших результатов можно достичь при использовании градиента изобра-
жения. При этом выбирается одна или несколько строк, вдоль которых вы-
числяется значение градиента. Вводится переменная Q. принимающая толь-
ко два значения: 0 и 1. Причем переход от одного значения к другому проис-
ходит только в момент перехода от фона к объекту и наоборот. Когда пере-
ходов нет, то мы имеем пиксели с некой интенсивностью, равной /.Тогда мож-
но вычислить сумму значений интенсивности пикселей и число пикселей для
каждого состояния:
SQ = SQ + I, (25)
nQ — Hq + 1* (26)
Дойдя до конца строки, мы сможем определить среднее значение для каждого со-
стояния:
^Q~^olnQ' (27)
Пороговое значение вычисляется следующим образом:
(28)
«о + ”|
Альтернативным методом определения порога для бинаризации изображе-
ния является использование критерия максимума энтропии. Пусть /(х, у) пред-
ставляет собой полутоновое изображение размером Wx Л/ елп градациями (уров-
http;//www./tv.ri/
Компания ITV - генеральный спонсор издания книги
358
Ц/фвая обработка видеоизображений
нями) серого цвета. Обозначим Gm = {0.1.т -1| nft е Gm - частоту появления
/-го уровня в /(х, у). Тогда вероятность /-го уровня в изображении равна:
р. = ——
' /УЛ/
/ е Gm.
(29)
Таким образом мы получим некое распределение |/ е GJ. Для данного уровня
5-1
у если 0 < £ р. < 1, можно получить следующие два распределения:
1=0
Ро Р\ A-I
nJ Р, А.|
ll-P(s)’l-P(5)
где
р(*)=£р.-
1=0
(30)
А,-1
1-Р(5)
(31)
(32)
Основная идея метода максимума энтропии заключается в выборе такого по-
рогового значения, которое максимизирует количество информации, получае-
мой от объектов и фона. Так как мерой информации является энтропия, то пол-
ное количество информации, даваемое А и В, равно:
E(s) = Е. (s) + Ев (s) = -У ( In f | - У [ A. J In f А.-Д (33)
Пороговое значение определяется из условия нахождения максимума следу-
ющей величины:
Е (/) = max Е (5). (34)
Для получения более точных результатов все описанные выше этапы пред-
обработки изображения могут быть повторены несколько раз. Например, по-
сле применения оператора Собеля, бинаризации изображения при помощи по-
роговой обработки и устранения шума с помощью гауссова сглаживания вы-
числяются вертикальные и горизонтальные гистограммы. Они являются ин-
дикаторами количества белых пикселей (соответствующих краевым точкам)
в горизонтальном и вертикальном направлениях. Затем указанные шаги по-
вторяются от 9 до 16 раз. При этом каждый раз используются разные значе-
ния порога для бинаризации изображения. Вертикальные и горизонтальные
гистограммы усредняются по числу проведенных итераций и сглаживаются од-
номерным гауссовым фильтром. Усреднение гистограмм позволяет увеличить
отношение сигнал/шум за счет устранения большей части шума и сохранения
только самых важных характерных признаков изображения.Тем самым дости-
гается частичная инвариантность к неоднородному освещению, отражениям,
загрязнениям номерного знака и др.
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://w w w. procc t v. г и
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 359
9.1.2. Преобразование Хафа
Как известно, одним из эффективных методов нахождения на изображении
заданных параметрически плоских кривых является преобразование Хафа. Есте-
ственно. что для выделения прямоугольных границ области номерного знака
можно также воспользоваться этим методом. При этом в случае отсутствия на-
клона номерного знака достаточно искать только горизонтальные и вертикаль-
ные прямые. В оригинальном виде алгоритм Хафа позволяет находить только
прямые линии. Однако нетрудно модифицировать его таким образом, чтобы ре-
зультатом его работы являлись отрезки прямых. Для этого всего лишь надо учи-
тывать. какие точки в исходном изображении дают вклад в конкретную найден-
ную прямую. После этого точки одной прямой сортируются в соответствии с их
расположением на прямой и группируются в отрезки. Так как точки уже упоря-
дочены. то для этого достаточно проверить, лежит ли следующая точка прямой
не далее заранее определенного (как правило, эмпирическим путем) расстояния.
Если это условие выполняется, то к рассматриваемому отрезку добавляется дан-
ная точка. Кроме того, на этом этапе можно избавиться от всех отрезков, длина
которых меньше заданной величины.
В полярных координатах, в которых обычно и выполняется преобразование
Хафа. ячейка с параметрами (р;. в ) соответствует прямой, задаваемой уравнением:
cos(0, + я/2)
sin (б> + л/2)
Р,cos
Р, s*n Ф
(35)
Для каждой точки нужно вычислить значение t и затем отсортировать точ-
ки в зависимости от величины t. В результате получим требуемое множество от-
резков изображения. Для нахождения области номерного знака это множество
анализируется с целью выделения пар отрезков, удовлетворяющих следующим
требованиям:
• они должны начинаться и заканчиваться приблизительно в одной точке;
• отношение их длины к высоте должно совпадать с таким же отношением
для номерного знака.
Эта процедура позволяет получить два списка областей: один - с горизонтальны-
ми парами, а другой - с вертикальными. После этого полученные списки сравни-
ваются друг с другом и области, не содержащиеся в обоих списках, исключаются
из дальнейшего рассмотрения. Оставшиеся области являются возможными обла-
стями номерного знака.
Преимуществами данного метода нахождения области номерного знака яв-
ляются его инвариантность к изменению масштаба и относительная независи-
мость от цвета номера автомобиля. Действительно, при выполнении алгоритма
никоим образом не фиксируется размер номерного знака. В то же время, если
область номерного знака имеет яркость выше, чем у окружающих областей, она
обычно выделяется с достаточной точностью.
Однако преобразованию Хафа свойственны и серьезные недостатки. Его при-
менение часто приводит к ошибочному выделению или пропуску вертикальных
краев. Эти отрезки в номерном знаке, как правило, в несколько раз короче гори-
зонтальных. Как следствие этого, вертикальные края обычно довольно сильно за-
http://www. itv. ru
Компания ITV - генеральный спонсор издания книги
360
Цифвая обработка видеоизображений
шумлены. Кроме того, в случае наклона номерного знака надежность нахождения
отрезков может снижаться. Отметим также, что результатом применения метода
Хафа к изображению обычно является список из нескольких возможных областей
номерного знака. Это требует дополнительных усилии для выбора из них един-
ственно верного, когда на изображении присутствует только один номерной знак.
9.1.3. Выращивание областей
Основная идея этого метода заключается в установлении одного или не-
скольких критериев, которым отвечает искомая область изображения. После
этого находятся пиксели, удовлетворяющие заданным условиям, и к ним присо-
единяются те пиксели из числа их соседей, которые по своим свойствам близ-
ки к найденным.
При поиске области номерного знака наиболее очевидным критерием, отде-
ляющим ее от фона, является ее яркость (большинство номерных знаков изго-
тавливается из светоотражающего материала). Исключение составляют автомо-
били белого цвета и загрязненные номера. Кроме того, как правило, предпола-
гается. что символы на номерном знаке окрашены в черный цвет (в противном
случае изображение можно инвертировать), а он сам имеет строго определен-
ные размеры. Отсюда следует, что необходимо осуществлять поиск ярких прямо-
угольных областей с заданным соотношением сторон. При этом необходимо сле-
дить за тем. чтобы одна и та же область не анализировалась несколько раз.
Полученные в результате выращивания области, скорее всего, не будут иметь
прямоугольную форму с заданным соотношением сторон. Существует два основ-
ных метода для решения этой проблемы [10]:
• Внутри найденной области выделяется максимально возможный прямо-
угольник. Этот метод подвержен шуму, так как отдельные черные пик-
сели создают препятствия для выделения прямоугольника оптимально-
го размера (Рис. 2).
• Выделяется минимальный прямоугольник, целиком включающий в себя
найденную область. Этот метод уменьшает влияние шума, но при этом
Рис. 2. Максимальный прямоугольник, лежащий внутри выделенной области
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 9. Методы выделения и распознавания ^омеоных знаков транспортных средств 361
может ошибочно идентифицировать произвольные белые области как
прямоугольные. Тем не менее, метод гарантирует, что область номер-
ного знака целиком будет содержаться в построенном прямоугольнике
даже в том случае, когда номерной знак расположен не точно горизон-
тально (Рис. 3).
Рис. 3. Минимальный прямоугольник, целиком включающий в себя выделенную
область
Достоинствами метода выращивания областей являются его быстрота, инва-
риантность к расстоянию между камерой и автомобилем и относительная устой-
чивость к шуму. В то же время данный метод предъявляет достаточно высокие
требования к объему памяти. Кроме того, яркость во многих случаях не является
наилучшим критерием для выделения области номерного знака.
9.14. Сравнение с шаблоном
Как следует из названия, методы данного класса определяют степень соот-
ветствия отдельных частей анализируемого изображения и построенного шабло-
на номерного знака. Область, имеющая наибольшее сходство с шаблоном, сег-
ментируется как искомый номерной знак.
Способ построения шаблона играет чрезвычайно важную роль для по-
лучения надежных результатов. Очевидно, что шаблон должен максимально
отражать все характерные признаки, присущие области номерного знака на
изображении. Частичный шаблон для букв (цифр) строится путем последо-
вательного добавления слоев, каждый из которых соответствует одной букве
(цифре). Полученные слои затем объединяются в один общий слой. Обычно
при этом предполагается, что вероятности появления отдельных букв (цифр)
равны. Результатом является полутоновое изображение, пример которого
показан на Рис. 4.
После того как шаблон построен, необходимо определить способ нахожде-
ния степени соответствия между выделенной областью изображения и шабло-
ном. Наиболее часто с этой целью применяется перекрестная корреляция, ко-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
362
Цифвая обработка видеоизображений
ВВ 88 888
Рис 4. Шаблон, полученный путем объединения отдельных слоев. Шаблон для
букв (слева) и цифр (справа).
торая основана на вычислении квадрата евклидова расстояния между шабло-
ном и изображением:
d2 («»v)=Z Z [; (х«у) ~ т(х - м> у -v)]2 <36)
х У
Здесь /(х, у) - интенсивность в точке (х, у) изображения, а Т(м, v) - построен-
ный шаблон. Отметим, что при вычислении величины (36) шаблон обязан цели-
ком лежать внутри изображения, поэтому пиксели, находящиеся около границы,
обычно игнорируются. В принципе, возможно введение фиктивных пикселей за
границами изображения. Однако в данном случае это нецелесообразно, так как
конечной целью метода является нахождение целой области номерного знака,
содержащейся в изображении, а не отдельной ее части.
Возведя выражение под знаком суммы в (36) в квадрат, получим:
d2 (“*v)=Z Z [72 (x> -27 (^.y)T (x -«> у ~v)+?2 (x -u' у ~v) ]• (37)
X у
Заметим, что последнее слагаемое в (37) является
х У
константой, так как представляет собой сумму квадратов интенсивностей пик-
селей шаблона. Предполагая, что интенсивность изображения слабо меняется в
областях, имеющих размеры шаблона, будем считать первый член в (37) также
постоянным. Тогда получим, что степень соответствия изображения и шаблона
определяется величиной
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procc tv.ru
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 363
c(«-v)=Z ZJ (х->')г(х v)- <38)
м X у „ м
называемой перекрестном корреляцией. Однако предположение о том, что
является постоянной величиной, в большинстве случаев является
< у
некорректным и приводит к тому, что величина (38) для более ярких областей
превышает значения, получаемые в областях, действительно совпадающих с ша-
блоном. Поэтому вместо (38) обычно пользуются выражением для нормирован-
ной перекрестной корреляции:
y(«,v)=-r >L-_ — ----------(39)
JX.XPU- >) -] X. Е. [г(* -и’ у -v) - ГТ
Здесь Iu v - среднее значение интенсивности в области изображения, накрытой
шаблоном, Т - среднее значение интенсивности для шаблона. В отличие от (38)
выражение (39) не приводит к ложному выделению ярких областей, так как со-
держит нормировочный множитель из суммы квадратов отклонений от средних
значений шаблона. Тем самым мера сходства становится независимой от разме-
ра шаблона.
При сравнении с шаблоном возможно также использование метода выделе-
ния главных компонент. В отличие от предыдущего случая при этом необходи-
мо иметь не только усредненное изображение шаблона Ф, но также и всю по-
следовательность изображений Гр..., Гм. использованную для его построения
(обучающую последовательность). Здесь Г - векторы с длиной, которая равна
числу пикселей изображения. После этого составляются разности Ф = Г - Ф,
i = из них образуется матрица А = [Ф, Ф,... Ф ], и находятся собственные
векторы и* и собственные значения ковариационной матрицы Е =
Из полученных М собственных векторов отбирается М'< М наиболее значи-
мых^. е. отвечающих наибольшим собственным значениям. Теперь каждый век-
тор Г из обучающей последовательности проецируется в это подпространство
при помощи вычисления весовых коэффициентов = «{(Г - V), к = 1,...,ЛГ. По-
лученные коэффициенты W - [и^ w2 ... wM,]7 используются при классификации
нового изображения. Для этого среди векторов весовых коэффициентов обуча-
ющей последовательности ищется вектор IF, минимизирующий евклидово рас-
стояние Е = ||1Г - W\\.
Поскольку нам необходимо выделить области изображения, являющиеся
возможными областями номерного знака, то указанное расстояние переходит в
£ = ||Ф - Фг||, где Ф(. - проекция вектора Ф. Изображения номерных знаков будут
достаточно слабо меняться при их проецировании, в то время как области, не яв-
ляющиеся номерными знаками, будут подвержены значительным изменениям.
При помощи выбора соответствующего порогового значения можно устанавли-
вать вероятность того, что входное изображение является возможной областью
номерного знака.
К достоинствам метода сравнения с шаблоном относятся простота вычисле-
ния меры сходства, помимо которой не требуется нахождения каких-либо дру-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
364
Ц/фвая обработка видеоизображений
гих величин. Недостатками данного метода являются большой объем требуе-
мых вычислений (особенно в случае применения алгоритма выделения главных
компонент) и неинвариантность к вращению, масштабированию и перспектив-
ным искажениям. Последние свойства метода представляют собой существен-
ную проблему, так как даже незначительные изменения в размерах и угле на-
клона номерного знака приводят к некорректному выделению его области.
9.1.5. Применение преобразования Фурье
Поскольку символы, расположенные на номерном знаке, представляют со-
бой один из самых значимых характерных признаков, то для выделения номеров
автомобилей можно воспользоваться методами сегментации текста на изобра-
жении, в частности, дискретным преобразованием Фурье. Когда размеры номер-
ного знака известны с достаточном точностью (допускается 15% варьирование),
для каждой составляющей спектра мощности можно вычислить соответствую-
щее ей среднее значение мощности [11]. Для данной частоты ft оно равно сумме
мощностей всех се гармоник:
(40)
I
Пики в профиле периодограммы (40) свидетельствуют о присутствии номерно-
го знака. Однако при этом необходимо точное знание размеров символов и рас-
стояния между ними.
Большей гибкостью обладает метод, основанный на усреднении по опреде-
ленному диапазону частот [12]. Для этого выделяется изображение размером
М х N пикселей, которое потенциально может содержать номерной знак. Для
каждой строки этого изображения строится периодограмма значений интен-
сивности:
1
П(и,у) =
.VI 2
У, ехр[-;2ямл]
г-0
(41)
Она является оценкой плотности спектральной мощности, что в данном случае
представляет собой полную энергию изображения. Периодограмма позволяет
получить распределение энергии по частотным диапазонам. Величина (41) мо-
жет быть эффективно вычислена с помощью быстрого преобразования Фурье.
Чтобы получить спектр только в положительной области, используются первые
/V/2+ 1 компоненты. Так как периодограмма для одной строки может быть
сильно зашумлена, то общий вид спектра мощности может быть найден путем
усреднения периодограмм по нескольким строкам. Для максимизации вероят-
ности обнаружения строк, проходящих через область номерного знака, обыч-
но вычисляется среднее значение в периодограмме по частотному интервалу
[up щ], где предполагается доминирование энергии, соответствующей симво-
лам номера автомобиля. Профили таких усредненных значений по строкам
изображения должны дать хорошо различимые максимумы в области номер-
ного знака, что видно из Рис. 5.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Г лава 9. Методы выделения и распознавания номерных знаков транспортных средств 365
Рис. 5. Пример профиля периодограммы
Найдя таким образом вертикальные границы номерного знака, аналогичным
образом поступают со столбцами изображения, что позволяет локализовать не-
обходимую область изображения.
9.1.6. Построение вертикальной и горизонтальной проекций
Методы данной категории основываются на вычислении проекций интен-
сивностей изображения и последующем нахождении в них максимумов. Для того
чтобы найти вертикальную проекцию Р (у) изображения, осуществляется сум-
мирование значений интенсивности вдоль каждой строки. После этого можно
найти максимум этой величины [13]:
^« = argmaxPv(y). (42)
Верхняя и нижняя границы области номерного знака определяются следующим
образом:
*™ х ars[^(-v) = (43)
plast *- “*
Уь о,,от= min arg[^,(y) = 0.2/’v(^to,f)l. (44)
Операции max arg и min arg нужно понимать следующим образом: находятся все
значения аргумента, для которых выполняется условие в скобках. Затем из них
выбирается соответственно максимальное и минимальное значения. Константа
0.2 была определена экспериментальным путем. Горизонтальная проекция Ph(x)
изображения находится как его свертка с фильтром, длина импульсной характе-
ристики которого приблизительно равна длине номерного знака (длина номер-
ного знака может быть найдена, так как известно соотношение сторон номера, а
в выражениях (43)-(44) была получена оценка его высоты. Аналогично опреде-
ляется положение максимума горизонтальной проекции, которая служит отправ-
ной точкой для поиска левой xteft и правой х границ номерного знака:
/ittp.*//www./tv.ru
Компания I TV - генеральный спонсор издания книги
366 Цифвая обработка видеоизображений
х1г/1 = max arg[P5(х)< 0.005&PL(x)< 0.5]. (45)
Х^' = х m<‘" ,v arg [Р' W < 0 005 & Р» W < 0,51 (46)
где
Л(х) = -^~ Z Р*(А (47)
*total j—x-S
C.W = 7-E/’a(A (48)
Гtotal J-}
/,«W = 7LZ/>*(A (49)
^toial /-x-H
^W=W (so)
/=0
Величина Д может быть выбрана, например, равной 0.2.
Помимо вычисления проекций интенсивностей на горизонтальную и верти-
кальную оси можно находить профили интенсивности вдоль отдельных строк
изображения [14]. Пусть интенсивность изображения нормирована и лежит в
пределах от 0 до 1:0 < /(/, к) < 1./ = 0,...,N* 1,4 = 0.....М - 1. Составим новое изо-
бражение, получаемое путем выборки каждой десятой строки из исходного изо-
бражения: В(п. к) = 7(10/2. к), п = 1,2,...,К и разобьем область значений интенсив-
ности на девять уровней г = 0.1л??, где т = 1,2,...,9. Тогда алгоритм нахождения об-
ласти номерного знака записывается следующим образом:
1. Определяем число пересечений В(п, к). В(п + 1, к) и В(п + 2, к) с каждым
из девяти введенных уровней значений интенсивности.
2. Если это число превышает наперед заданное значение,то (лр/с) = (10/2 + 5, к)
принимается в качестве верхней границы номерного знака, а значение п
увеличивается на единицу: п = п + 1. В противном случае п = п + 1, и пере-
ходим к п.1.
3. Определяем число пересечений В(/г, /с), В(п + 1, к) и В(п + 2, к) с каждым
из девяти введенных уровней значений интенсивности.
4. Если это число меньше наперед заданного значения, то (п2, к) = (10/2 + 5, &)
принимается в качестве нижней границы номерного знака. В противном
случае и = и + 1, и переходим к п.З.
5. Вводим величину С(т) = /(п2 - 5, т + 100), т. е. величину интенсивности
изображения в строке, являющейся нижней границей номерного знака, с
отступом 100 пикселей от края изображения.
6. Определяем число пересечений С(т) с каждым из девяти введенных
уровней значений интенсивности.
7. Если это число больше наперед заданного значения, то (и2, т) принимается
в качестве левой границы номерного знака. В противном случае т = т + 1
и переходим к п.6.
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. ргосс tv. г и
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 367
8. Определяем число пересечений С(т) с каждым из девяти введенных
уровней значений интенсивности.
9. Если это число меньше наперед заданного значения, то (м2, т) принима-
ется в качестве правой границы номерного знака. В противном случае
т = т + 1, и переходим к п.8.
Рис. 6. Определение границ области номерного знака с помощью значений интен-
сивности
На Рис. 6 показаны профили нормированной интенсивности вдоль восьми
строк изображения. Справа и снизу отрезками выделены найденные границы об-
ласти номерного знака.
9.1.7. Применение морфологических операторов
Морфологические операторы являются достаточно эффективным нелиней-
ным инструментом обработки изображений, основывающимся на понятиях мак-
симума и минимума. Морфология обладает рядом достоинств, среди которых
особенно стоит выделить возможность эффективной программной реализации и
простоту физического смысла осуществляемых операций, что позволяет прово-
дить тонкую настройку параметров в зависимости от поставленной цели.
При выделении области номерного знака с помощью морфологических опе-
раций обычно предполагается, что символы на номере состоят из тонких линий,
которые значительно темнее (в отдельных случаях ярче) фона [15-17]. Для наи-
h t tp://www. itv. г и
Компания ITV - генеральный спонсор издания книги
368
Цифвая обработка видеоизображений
более часто встречающейся ситуации черных символов на белом фоне обработ-
ка начинается с операции замыкания со структурирующим элементом, чей раз-
мер превышает размер символов. Если теперь вычесть из результата обработки
исходное изображение, то получим сегментированные символы номерного знака
наряду с другими объектами (Рис. 7А).
Рис. 7. А - разность замыкания и исходного изображения; Б - замыкание с гори-
зонтальным структурирующим элементом, длина которого больше максимально-
го расстояния между символами
Для случая белых символов на черном фоне следует из исходного изобра-
жения вычесть его размыкание. Теперь необходимо найти границы прямоуголь-
ника, заключающего в себе выделенные символы номерного знака. Для этого
осуществляется операция замыкания с горизонтальным структурирующим эле-
ментом. чей размер превышает максимальное расстояние между символами
(Рис. 7Б). Чтобы удалить все объекты малой высоты, можно применить опера-
цию размыкания с вертикальным структурирующим элементом, размер которо-
го равен минимальной высоте символов (Рис. 8А).
Рис. 8. А - размыкание с вертикальным структурирующим элементом, высота ко-
торого равна минимальной высоте символов; Б - размыкание для удаления объек-
тов, высота которых не превышает максимальную высоту символов
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.nj
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 369
Применив операцию размыкания повторно, на этот раз таким образом, что-
бы удалить все объекты, чья высота не превышает максимальную высоту симво-
лов (Рис. 8Б), составим затем новое изображение путем вычитания полученного
изображения из предыдущего (Рис. 9А). Как видно из рисунка, помимо области
номерного знака, осталось несколько шумовых блобов. Их можно устранить с
помощью размыкания с горизонтальным структурирующим элементом, размер
которого меньше минимальной ширины номерного знака (Рис. 9Б).
Рис. 9. А - разность изображений на Рис. 8А. и Рис. 8Б.; Б - размыкание с горизон-
тальным структурирующим элементом, размер которого меньше минимальной
ширины номерного знака
Окончательно область номерного знака получается после применения опе-
рации дилатации, которая необходима для тех случаев, когда отдельные символы
касаются выделенной границы.
Так как бинаризация изображений - это всегда потеря части информации, а
также зашумление имеющейся, то по возможности ее следует избегать. С этой
целью базовые морфологические операции могут быть обобщены на случай по-
лутоновых изображений. С помощью полученных таким образом операторов
можно выделить все связанные компоненты изображения определенного разме-
ра, например, чья длина и высота превышают соответствующие пороговые зна-
чения [18]. Отмстим, что подавляющее большинство морфологических методов
предполагает знание конкретного размера символов номерного знака. Кроме
того, они достаточно чувствительны к зашумленным изображениям.
9.1.8. Применение ковариационных дескрипторов
Большая часть из рассмотренных до сих пор методов не является инвариант-
ной к вращению и изменениям освещенности. В принципе, при использовании,
например, классификаторов возможно расширение обучающей последователь-
ности изображениями, на которых область номерного знака повернута относи-
тельно осей координат или внесены дополнительные перспективные искажения.
Однако это может привести к обратному результату, т. е. увеличению числа оши-
бок второго рода. Поэтому желательно было бы выделить такие характерные
http://ww w. itv.ru
Компания ITV - генеральный спонсор издания книги
370
Цифвая обработка видеоизображений
признаки, которые отражали бы не только внешние черты конкретных обла-
стей изображения, но и обладали бы определенными статистическими свойства-
ми. При этом они не должны иметь высокую размерность и предъявлять завы-
шенные требования к вычислительным ресурсам. Одним из таких признаков яв-
ляются ковариационные дескрипторы [19.20].
Обозначим через [zk }* . п d-мерные векторы характерных признаков для
области R изображения размером М х V состоящей из п пикселей. Представим
область R с помощью ковариационной матрицы размером d х d:
(51)
Л~1 ы
где Д - вектор средних значений характерных признаков для области R. Рассто-
яние между двумя такими ковариационными матрицами может быть найдено по
формуле [21]
р(ад) = Л>Ч (2.Л)- (52)
V »«!
Здесь {Л, (£г Z2))rl yi “ обобщенные собственные значения матриц и полу-
чаемые из решения уравнений
Л.Х.х, - Е2х. = 0, i = 1,..., d, (53)
a xt - обобщенные собственные значения.
Отдельный элемент (/,;) ковариационной матрицы может быть записан как
(>))• (54)
п -1 t=l
Последнее выражение эквивалентно следующему:
(55)
Для значительного ускорения в вычислении ковариационной матрицы области R
воспользуемся интегральными изображениями. Пусть Р - это М х N х d тензор
интегральных изображений:
P(x',y',i) = £ F(x,y,i), i = l,...,d, (56)
х<х',у<у‘
a Q - М х W х dx d тензор второго порядка интегральных изображений:
Q(x',y\i,j)= X P^y^P^yj}, i,J=l,...,d, (57)
х<х\у</
где F(x, у, /) - значение z-го характерного признака в точке (х, у). Обозначим
А./=[р(х.У»0»-»р(х>Л^)]Г. (58)
0(х,.у,!,</)'
Q(x,y,d,d^
(59)
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
Глава 9 Методы выделения и распознавания номерных знаков транспортных средств 371
Тогда ковариационную матрицу для области /?(х\ у \ х", у "), где (х', у *) и (х", у ") -
координаты ее левого верхнего и правого нижнего углов соответственно, можно
записать как
Л(х,/;х.>-) n_]L^r > > л Vr.>
I г] (60)
--(Рх'.Г + Р.у - Ре.у- -Pe.y}(Pe.f + -Рее - Ре,у-} .
Здесь п - (х”-хг)(у,,-уг).
Для дальнейшего анализа необходимо конкретизировать вид векторов ха-
рактерных признаков zk. В качестве них могут, например, выступать следующие
векторы:
х* = [''(х,у),0(х,у),Z(х,у),Z, (х,у),Z, (х,у)(61)
где(х,у) = (х-х0,у-у0), (хо,Уо)-Центр области R.
r(x,y) = Vx2 + y\ (62)
0(х,у) = (63)
Однако такой выбор не является инвариантным к вращению, поэтому заме-
ним (61) на следующее представление:
X* = [g(x,y),r(x,y),Z(x,y),ZP(x,y),ZJ,(x,y)>...]> (64)
где
g(x,y) = exp ;|2я Г-Х’^+в(х,у) ] , (65)
\ ^гпах /
a rmax - константа нормировки, равная максимальному радиусу рассматриваемой
области. Так как выражение (65) является комплексным, то при построении ко-
вариационных матриц будем вычислять абсолютное значение ковариационных
коэффициентов.
После того как определены векторы характерных признаков и построены
ковариационные матрицы, последние могут использоваться в качестве входных
данных для распознающей системы, например основанной на нейронных сетях.
9.1.9. Использование текстурного анализа
Наличие на номерном знаке весьма специфичных краевых точек и линий по-
зволяет воспользоваться методами анализа текстур для сегментации номера ав-
томобиля. Наиболее распространенными подходами в этом классе являются ис-
пользование фильтров Габора и вейвлетов Хаара.
Фильтры Габора могут использоваться для анализа текстур вне зависимости
от направления и масштаба. Для выделения номерных знаков это является чрез-
вычайно важным, так как характерные краевые точки символов номера транс-
портного средства могут быть ориентированы в различных направлениях [22].
htfp.//wwvv./tv.ru
Компания ITV - генеральный спонсор издания книги
372
Цифвая обработка видеоизображений
В общем виде фильтры Габора для двумерного случая записываются следующим
образом:
^-Vexp
ст
ку cos 6fi
kt sin
ехр[дгх]-ехр .
. z J/
X = (x. у).
(66)
(67)
Каждая функция Т представляет собой плоскую волну, характеризующуюся
своим волновым вектором к,. имеющим вид гауссова распределения с дисперсией
О’2. Первый член в (66) описывает колебательные процессы, а второй - постоян-
ную составляющую. Центральная частота /-го фильтра определяется вектором кр
который имеет масштаб и ориентацию, задаваемые парой [кх,6ц).
Декомпозиция исходного изображения при помощи фильтров Габора дости-
гается с помощью их свертки:
/?,(x) = J/(x')T,(x-x')<£c'. (68)
Фильтры Габора хорошо выделяют на изображении короткие отрезки пря-
мых и резкие изменения кривизны линий. Поэтому они могут быть использова-
ны для получения характерных признаков низкого уровня. Для нахождения но-
мерных знаков фиксируется определенный масштаб, например, kv = 2 , и для него
составляется гребенка из п фильтров (обычно п = 8 - 12) различной ориентации
f л-1
=0,...,---Л L Затем исходное изображение обрабатывается при помощи
данных фильтров, что дает п отфильтрованных изображений. Они в свою оче-
редь разбиваются на отдельные блоки (например, 16 х 16), и для каждого из них
вычисляется усредненное значение его элементов. Таким образом, для каждого
блока получается n-мерный вектор характерных признаков. Эти векторы затем
могут быть поданы на вход нейросети, с помощью которой происходит сегмента-
ция искомой области номерного знака.
Альтернативным подходом для текстурного анализа изображения является
использование вейвлетов Хаара [23]. При этом изображение разлагается на со-
ставляющие (субдиапазоны), каждая из которых имеет ограниченный диапазон
частот. Для сегментации символов номерного знака наиболее подходящими яв-
ляются три субдиапазона (HL, LH и НН). Это объясняется тем, что только вейв-
леты, которые локализованы около краевых точек, имеют большие значения.
Именно это и позволяет находить символы номерного знака в высокочастотных
субдиапазонах.
Масштабирующие функции и сами вейвлеты Хаара записываются следую-
щим образом:
0 W = X Л0(2х ~ *) = 0(2х)+0(2х -0’ (69)
А W=X 9* •И2* --0(2х) - <К2х - *)’ (70)
k*Z
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 373
где
/ ч П- ^(Х) = 1п 0<х<1 (71)
0 , иначе
1, £ = 0,1
Рк = L (72)
о, иначе
1, к = 0
<h = -1> к = 1. (73)
о, иначе
Если обозначить
l0.0 *0.1 ••• Z0.2V-l
Т(х,у)= V V 7 Ч’1 , (74)
J2.V-I.0 Z2V-|J ••• Z2.V-I.2V-1,
то двумерное вейвлет-преобразование Хаара для /(х, у) выглядит следующим об-
разом [24]:
2. v ~ л 2^ РкуРк\+2хЛг+2у 4< /2х,2> + Z2x,2>*) + Z2v+l,2>- + *2x4l.2yfl)’ (75)
LHt, = 7 X Pk/hjk,+2x,k2*2) ^к{,кГО " 4 (Z2x.2y * Z2x,2y*l + ~ bx+Uy+l)? (76)
= 7 X ^P*2**l+2x,tj+2r Л| .*2 =0 /2хЛу +Z2x,2y^l ”^2*4i,2y “ )• (77)
= д X " 4 (^2х.2> " Ьх.2>+1 “ hx+Kly + Z2x+l,2y+1 )• (78)
Из полученной декомпозиции исходного изображения необходимо извлечь
характерные признаки. В качестве таковых могут выступать среднее значение,
а также второй и третий центральные моменты, которые для отдельного блока
изображения размером Л/ х /V вычисляются по следующим формулам:
1 V-l N-1 ^(/)=ттХХ/(‘>Л 7V (=0 ;:=0 (79)
Мг(/)=^тХХ(/0.У)-Ди))2. W i^O J=Q (80)
i 1 А/з(/) = -7^ХХ(/('>»-^(/))- /V 1=0 у=0 (81)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
374
Цифвая обработка видеоизображений
Если задать /V = 16. то получим, что число уровней декомпозиции рав-
но 3. Таким образом, вектор характерных признаков для каждого блока бу-
дет состоять из 27 значений: 3 уровня декомпозиции. 3 субдиапазона (76)-
(78) и 3 момента (79)-(81). Размерность такого вектора может быть уменьше-
на, если учесть, что наиболее важными являются следующие 8 величин [23]:
Дзяя> где чсРез К обозначен k-w мо-
мент для /-го субдиапазона на j-м уровне декомпозиции. Полученный вектор ха-
рактерных признаков теперь может быть использован для сегментации обла-
сти номерного знака с помощью обученной нейросети.
9.1.10. Построение каскада классификаторов
Так как область номерного знака содержит набор символов, то проблема ее
обнаружения может рассматриваться как задача сегментации текста на изобра-
жении. Одним из перспективных методов здесь является использование техни-
ки усиления слабых классификаторов [25-27]. При этом изображение разбивает-
ся на прямоугольные блоки (окна) и в качестве характерных признаков выбира-
ются разновидности вейвлетов Хаара. представляющие собой суммы интенсив-
ностей пикселей в указанных блоках. Учитывая разнообразие видов номерных
знаков, а также различные их наклоны и степени освещенности, необходимо рас-
ширение множества характерных признаков (например, с помощью добавления
производных и их дисперсий в горизонтальном и вертикальном направлениях).
Кроме того, поскольку области номерных знаков содержат много краевых то-
чек, в качестве эффективного характерного признака может быть использова-
на плотность градиента:
О»=^£ХС('.Л
где - величина градиента в точке (/,;), а М - число пикселей блока. По-
мимо краевых точек, номерные знаки содержат переднеплановые символы,
распределенные относительно равномерно. Это приводит к тому, что гради-
ент в областях номерного знака имеет более равномерное пространственное
распределение по сравнению с другими областями. Для получения еще одного
характерного признака разобьем каждый блок на п равных частей. Пусть gt -
среднее значение величины градиента в каждой части блока, a g - среднее зна-
чение градиента во всем блоке. Тогда дисперсия плотности блока определяет-
ся как
Zls,-sl
= -. (83)
ng
Недостатком такого подхода классификации является огромное количество
требуемых вычислений, несмотря на простоту самих характерных признаков.
Например, для изображения размером 640 х 480 пикселей и прямоугольного окна
100 х 30 пикселей существует порядка 200 тыс. различных положений последне-
го. Поэтому число областей, которые необходимо проанализировать и которые
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www.procc t v. ru
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 375
не содержат номерного знака, намного превышает число областей, действитель-
но включающих в себя номер транспортного средства. Возможным решением
является построение иерархического каскада классификаторов.
Идея каскада классификаторов заключается в группировании отдельных
классификаторов по уровням возрастающей сложности с тем, чтобы отклонить
очередную облаезъ при помощи всего лишь небольшого числа классификаторов.
Хотя область, содержащая номерной знак, и будет обработана всеми уровнями
каскада, таких событий будет чрезвычайно мало по отношению к общему числу
анализируемых областей.
Обучение каскада классификаторов производится последовательно для каж-
дого уровня, на первом из которых используются все положительные и отрица-
тельные примеры. На втором уровне обучение проводится с помощью всех по-
ложительных примеров и ошибок второго рода первого уровня в качестве отри-
цательных примеров. Аналогично поступают на последующих уровнях.Такой ал-
горитм имеет под собой то основание, что большая часть областей будет откло-
нена уже на первых двух уровнях каскада классификаторов и поэтому обучение
дальнейших уровней должно осуществляться на том наборе данных, который мо-
жет преодолеть начальные уровни. Естественно, более высокие уровни характе-
ризуются увеличением ошибок второго рода и поэтому должны включать в себя
большее число классификаторов.
Как известно, в методе AdaBoost сильный классификатор определяется как
О, иначе
(84)
где Т обычно равно 0.5. Увеличивая это значение, можно уменьшить количество
ошибок второго рода за счет ухудшения качества классификации. Однако это
позволяет построить каскад классификаторов с заданным значением ошибок
первого рода на каждом уровне.Так как число ошибок первого рода задается вы-
ражением
к
»=ПЛ<’ (85>
где п( - степень ошибок первого рода на z-м уровне, К - число уровней в каскаде
классификаторов, то, задав = 0.99 и К = 10, получим надежность классифика-
ции, равную 90 % (0.9910 = 0.9). Уровень ошибок первого рода 99 % - вполне до-
стижимая величина, если уменьшать значение т, хотя при этом и увеличивается
число ошибок второго рода, которое находится как
Р = п А. (86)
где pt - степень ошибок второго рода на /-м уровне. Даже высокая степень оши-
бок второго рода, равная 40 %, на каждом уровне каскада классификаторов, дает
весьма незначительную общую величину 0.01 % (0.4ю ~ 0.0001).
Построение эффективного каскада классификаторов является нетривиаль-
ной задачей. Задавая величину ошибок первого и второго рода, можно опреде-
ли tp://w ww. itv. ги
Компания ITV - генеральный спонсор издания книги
376
Цифвая обработка видеоизображений
лить необходимое число характерных признаков на каждом уровне каскада. Од-
нако при этом подразумевается, что все признаки являются равнозначными в
смысле ресурсоемкое™ компьютера. Если же использовать признаки различно-
го типа, то можно руководствоваться принципом помещения простых признаков
на первые уровни, а более ресурсоемких признаков - на высокие уровни каска-
да. Например, на первом и втором уровнях могут быть использованы плотность
градиента (82) и дисперсия плотности (83). а на последующих уровнях - вейвле-
ты Хаара.
9.1.11. Метод смещения среднего
Наилучшис результаты при выделении области номерного знака следует
ожидать от применения гибридных методов, где используется комбинация не-
скольких характерных признаков и подходов. Одним из таких методов являет-
ся метод смещения среднего, с помощью которого сначала выделяются области
изображения, с наибольшей вероятностью содержащие в себе номерной знак ав-
томобиля. После этого производится исключение несоответствующих областей
на основе ряда характерных признаков.
Пусть некая область описывается множеством точек (х }|=, п в d-мерном про-
странстве Ж Тогда функция
(87)
называется оценкой плотности с ядром К(х) радиуса h в точке х. В качестве ядра
наиболее часто используется нормальная плотность
А'(х) = (2лг)'</2ехр^-|||х||2| (88)
Введем к : [0, ©о) -> R - профиль ядра К(х) такой, что К(х) = К(||х||2). Для ядра
(88) профиль выглядит следующим образом:
*(х) = (2я)-'/2ехр(~х
(89)
Тогда функция (87) принимает вид
(90)
Обозначим g(x) = -к'(х)л предполагая, что производная функции к(х) суще-
ствует для всех х е [0, оо), за исключением, быть может, конечного множества то-
чек. Ядро G может быть определено как
G(S)=C«(hf) (9П
где С - константа нормировки. Тогда, вычисляя градиент от функции (90), по-
лучим, что для нахождения ее максимумов достаточно найти такие точки х,
где разность
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 9. Методы выделения и оасгознавания номерных знаков транспортных средств 377
(92)
стремится к нулю. Обозначим последовательные приближения к таким точкам
через {у;1,=и_,где
7 = 1,2,...
(93)
значение в точке х = у.
Пусть (z j; 1 п - пределы последовательностей (93), a л - множество
меток для различных областей изображения.Тогда алгоритм смещения среднего
для выделения возможных областей номерного знака выглядит следующим об-
разом:
1. Для каждого j - 1.п:
а. положим к = 1 и yt = х;
Ь. находим уАЧ по формуле (93); к = к + 1 до тех пор, пока не будет найден
предел последовательности у.;
с. определим z = х, /(z) = /(у,).
2. Проводим разбиение z на кластеры (С | , т, в каждый из которых поме-
щаем точки, которые лежат друг от друга не далее, чем на расстоянии /?$1
и чьи значения интенсивности отличаются не более чем на hf.
3. Для каждого j = 1.п устанавливаем = {р | z g С ).
4. Удаляем области, чьи размеры не превышают заранее заданных границ.
После того как выделены возможные области номерных знаков, необхо-
димо использовать характерные признаки номеров для отбора корректных об-
ластей. Так как номерные знаки имеют прямоугольную форму, определенное
соотношение сторон и равномерно распределенную дисперсию интенсивно-
стей пикселей, то именно эти признаки и будем использовать в качестве харак-
терных.
Прямоугольность области определяется как
Амвп
(94)
где Ао - площадь области, а Амвп - площадь минимально возможного прямоу-
гольника (МВП), целиком включающего в себя эту область. Так как номерной
знак может быть наклонен под определенным углом к горизонтали, то при вы-
числении Ачпп используется последовательность поворотов области на угол
Д0=1°.
Соотношение сторон области представляет собой отношение ширины МВП
к его высоте. С помощью указанных двух характерных признаков можно отсеять
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
378
Цифвая обработка видеоизображений
большую часть из найденных на первом этапе областей. Но, тем не менее, оста-
нется еще много областей, в действительности не являющимися областями но-
мерных знаков. Поэтому введем еще один параметр, а именно, плотность крае-
вых точек области:
(95)
где Е(/, /) - значение краевой точки (/, /). NR - число пикселей области. Инфор-
мация о краевых точках может быть получена, например, с помощью операто-
ра Собеля.
Таким образом, для каждой области мы получим трехмерный вектор харак-
терных признаков и* = (w и ,), где и*, - это прямоугольность области, vv2 - со-
отношение сторон области, а - плотность краевых точек. Отмстим, что соот-
ношение сторон для номерных знаков может различаться (в зависимости от типа
номера). Поэтому введем три класса: два - для областей номерных знаков с дву-
мя типами аспектных отношений и один - для областей, не являющимися номер-
ными знаками. При помощи обучающих последовательностей найдем для каж-
дого класса средние значения характерных признаков (Др Д2, Д3) и ковариацион-
ные матрицы (Ег Е,.£3). Принадлежность области к тому или иному классу будем
определять из расстояния Махаланобиса:
=Ж-Д*1Г =(й'-д*)г£;'(й>-д*). *=1,2,3. (96)
9.2. СЕГМЕНТАЦИЯ СИМВОЛОВ НОМЕРНОГО ЗНАКА
9.2.1. Бинаризация выделенной области
После того как на изображении выделена область номерного знака, не-
обходимо провести ее бинаризацию. В принципе, если на этапе предваритель-
ной обработки уже выполнялась бинаризация исходного изображения, мож-
но воспользоваться ее результатами. Однако в большинстве случаев этого де-
лать не стоит, так как бинаризация проводилась на основе характеристик, со-
ответствующих всему изображению. Они, естественно, не могут точно отраз-
ить тонкую структуру отдельных областей, что может привести к весьма гру-
бым результатам.
Теоретически интересующая нас область включает символы одного цвета
(например, черного) на фоне другого цвета (например, белого). Однако цвета за-
ранее неизвестны и, кроме того, могут меняться от одного автомобиля к другому.
Более того, обычно существуют нулевые градиенты интенсивности как в преде-
лах самих символов, так и на фоновом изображении. Все это осложняет процесс
бинаризации.
В идеальном случае гистограмма полутонового изображения выделенной об-
ласти имеет бимодальный характер. При этом один из типов гистограммы соот-
ветствует фону, а другой - символам номерного знака. В этом случае величина
порога бинаризации может быть выбрана как минимум между двумя модами ги-
стограммы, как это показано на Рис. 10.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 379
Рис. 10. Оптимальная величина порога бинаризации выбирается как минимум
между двумя модами гистограммы
В реальных ситуациях часто наблюдаются иные типы гистограмм:
• впадина между пиками может быть очень широкой, что ведет к неопреде-
ленности при выборе порогового значения;
• мод может быть больше двух;
• гистограмма может быть унимодальной;
• один из пиков может существенно превышать другой.
Рис. 11. Пример гистограммы, трудной для выбора порогового значения
Пример такой гистограммы приведен на Рис. 11. Как нетрудно заметить, ги-
стограмма имеет пять максимумов, среди которых один изолированный глобаль-
ный (5) и четыре локальных (1-4). Из анализа данной гистограммы весьма грудно
найти правильное пороговое значение. В действительности, на этом рисунке пи-
ками, отвечающими фоновым и переднеплановым пикселям, являются первый и
третий соответственно, а пороговое значение 6 лежит между ними. Однако боль-
шинство существующих методов пороговой обработки выберут другое значение.
http://www. itv.ru
Компания ITV - генеральный спонсор издания книги
380
Цифвая обработка видеоизображений
учитывая глобальный минимум на распределении, вызванный в данном конкрет-
ном случае сильным отражением.
К сожалению, такая ситуация является обычной в связи с неравномерными
условиями освещения, довольно большим разнообразием номерных знаков ав-
томобилей и их физическим состоянием. Использование адаптивной пороговой
обработки приводит к лучшим результатам, но также не может быть признано в
достаточной мере надежным. Поэтому имеет смысл воспользоваться следующим
методом, который сочетает в себе лучшие черты различных пороговых методов.
Суть его заключается в следующем:
1. Вычисляется гистограмма выделенной области и проводится ее сглажи-
вание путем последовательного применения гауссова фильтра.
2. Находятся нелокальные максимумы, которые определяются как пики,
отличающиеся от ближайших локальных минимумов не менее чем на ве-
личину Тг представляющую собой определенную долю вертикального
размера области.
3. Если два наибольших нелокальных максимума соответствуют значениям
интенсивности /, и отличающимся не менее чем на (гистограмма име-
ет, по крайней мере, две моды), а медиана лежит между этими двумя мак-
симумами, то пороговое значение устанавливается равным 0.5 • (/, + /2).
Если разность этих двух наибольших нелокальных максимумов превы-
шает определенный предел, заданный как доля наибольшего из двух зна-
чений, то пороговое значение корректируется с помощью введения весо-
вых коэффициентов.
4. Если два наибольших нелокальных максимума соответствуют значениям ин-
тенсивности. отличающимся менее чем на 5, (т. е. принадлежат одной и той
же моде), или если медиана не лежит между двумя этими пиками, то вместо
второго максимума ищется новый, который удовлетворял бы условиям из
п. 2. Если такой пик существует, то переходим к п. 3. Когда такой пик не най-
ден (гистограмма унимодальна), то от единственного максимума спускаемся
до тех пор, пока ширина охватываемой части гистограммы нс достигнет 75%
всего диапазона значений [0;255] (отметим, что в п.1, предполагается, что ги-
стограмма была расширена на весь диапазон [0;255J линейным преобразова-
нием). Выбираем пороговое значение в середине охватываемой части гисто-
граммы и сравниваем его с медианой. В том случае, когда эти значения близ-
ки, в качестве окончательного оставляем выбранное пороговое значение. В
противном случае переходим к адаптивной пороговой обработке.
5. Для каждого пикселя выбираем окрестность размером 3 х 3 и находим в
ней локальный диапазон интенсивности. Устанавливаем пороговое зна-
чение посередине этого локального диапазона.
9,2.2. Устранение рамки номерного знака
Область, выделенная на первом этапе обработки, помимо символов номер-
ного знака может также содержать изображение ограничивающей номер рамки.
Все области, в которых присутствует номерной знак, можно разбить на 3 группы
[15,16], которые изображены на Рис. 12:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www. procctv.ru
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 381
А. на изображении присутствует замкнутая рамка, ограничивающая симво-
лы номерного знака;
Б. на изображении небольшая часть рамки отсутствует;
В. на изображении присутствует только небольшая часть рамки.
Рис. 12. Возможные типы областей, содержащих рамку номерного знака
Предположим, что после бинаризации символы окрашены в черный цвет,
а фон - в белый. Тогда процедура классификации всех областей по указанным
группам выглядит следующим образом:
1) Выделяются связные компоненты белого цвета. Обычно для этого ис-
пользуется итеративный процесс:
Х„ = (ХЯ.1Ф5)ПЛ л = 1.2,.... (97)
где Хп - выделенная компонента, А - исходное изображение, ® - опе-
рация дилатации, а В - структурирующий элемент. Самый большой из
полученных объектов представляет собой фон. Если этот объект до-
статочно велик, чтобы включать все символы номерного знака и при
этом не касается границ изображения, то эта область относится к пер-
вой группе. Отметим, что объект включает в себя все символы номер-
ного знака, если его ширина превышает nw (п - число символов, w - ми-
нимальная ширина символа), а высота - минимальную высоту символа.
2) Выделяются связные компоненты черного цвета. Самый широкий объ-
ект должен представлять собой части рамки. Если он достаточно широк,
чтобы включать в себя все символы, то эта область относится ко второй
группе. В противном случае она принадлежит к третьей группе.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
382 Цифвая обработка видеоизображений
Способ удаления рамки зависит от того, к какой группе принадлежит область:
1 группа. В этом случае рамка совпадает с контуром самого большого фоно-
вого объекта. Возможные ошибки могут возникнуть при этом для
символов, касающихся рамки.
2 группа. В этом случае граница представляет собой самый большой объект
черного цвета. Тогда удаляются его вертикальные контуры и все
связные черные компоненты, ширина которых превышает макси-
мальную ширину символов. Так как граница для этой группы обла-
стей более тонкая, то вероятность ее касания символами номерного
знака значительно меньше, чем в предыдущем случае.
3 группа. Для данной группы областей рамка уже практически удалена в про-
цессе предшествующей обработки. Поэтому остается устранить
только связные компоненты черного цвета, чьи горизонтальные
или вертикальные размеры превышают соответствующие макси-
мальные значения для символов.
9.2.3. Методы сегментации отдельных символов
Для окончательной сегментации отдельных символов номерного знака наи-
более простым методом является разбиение области на блоки в предположении,
что символы всегда занимают одно и то же положение. При этом область номер-
ного знака делится на п частей, где п - число символов, с использованием стати-
стической информации о расположении отдельных символов. Единственным до-
стоинством такого метода является его простота и независимость от качества
изображения при условии корректного выделения области номерного знака. Не-
достатком этого подхода являются высокий риск установления неверных границ
символов (это напрямую зависит от результатов этапа выделения области но-
мерного знака). Кроме того, данный метод только отделяет один символ от дру-
гого вместо того, чтобы находить их точные границы.
К лучшим результатам приводит метод, основанный на построении гори-
зонтальной проекции изображения. При этом переход от впадины к пику сви-
детельствует о начале нового символа и наоборот. В зависимости от качества
выделения области номерного знака и устранения рамки этот метод может да-
вать очень хорошие результаты вследствие его независимости от местонахож-
дения символов. Однако он также является достаточно чувствительным к каче-
ству изображения.
Для выделения отдельных символов можно также воспользоваться анализом
связных компонент, тем более что в ряде случаев (при устранении рамки) они
уже были получены. Естественно, что часть из них не является искомыми симво-
лами и должна быть устранена. Для этого могут быть использованы такие харак-
терные признаки, как:
• минимальная и максимальная высота символов,
• минимальная и максимальная площадь символов;
• число составляющих символ пикселей;
• расстояние до соседних символов (это позволяет удалять остатки рамки,
которые легко спутать, например, с цифрой «1»).
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 383
Преимуществами такого подхода являются его инвариантность к вращению
и точное нахождение границ символов. Среди недостатков этого метода пере-
числим чувствительность к качеству изображения и к результатам бинаризации
области номерного знака. Плохая бинаризация обычно ведет к слиянию двух и
более символов в одну связную компоненту. Малые расстояния между символа-
ми - также одна из проблем для данного метода.
Одним из возможных способов преодоления указанных выше трудностей яв-
ляется применение метода, в котором выделение символов номерного знака про-
изводится на основе совместного использования полутонового и бинаризованно-
го изображений. Как известно, контраст между пикселями символов знака и фо-
ном достаточно высок, в то время как между соседними пикселями фона он зна-
чительно меньше. Принимая это во внимание, будем устанавливать различные
начальные точки в верхней строке полутонового изображения области номерно-
го знака (предполагается, что рамка, если она существовала, была удалена) и на-
ходить пути с «наименьшей стоимостью». Стоимость пути определяется как сум-
ма разностей интенсивностей соседних пикселей вдоль всего пути:
$=LIa-44 (98)
к
где индекс к пробегает все значения, относящиеся к рассматриваемому пути,
а Ik - соответствующие значения интенсивности пикселей, лежащих на данном
пути. Такая операция позволит нам отделить символы друг от друга, поскольку
путь с наименьшей стоимостью только в очень небольшом числе случаев будет
пересекать сами символы (например, при значительном загрязнении номера, но
в таких условиях и все остальные методы также окажутся неэффективными).
Будем рассматривать каждый пиксель как вершину графа, соединенную с
тремя соседними пикселями (слева, справа и снизу) [31] - см. Рис. 13.
Стоимость перехода от одной вершины к другой равна модулю разности зна-
чений интенсивности в этих точках. Устанавливая начальные вершины в разных
точках верхней строки изображения, будем вычислять стоимость путей до ниж-
ней строки. Отметим, что преимуществом такого подхода является отсутствие
какого-либо порогового значения.
Однако число операций, необходимое для расчета всех путей, весьма велико.
Поэтому проведем оптимизацию алгоритма следующим образом:
http://www. itv. г и
Компания ITV - генеральный спонсор издания книги
384
Цифвая обработка видеоизображений
1) Зная количество символов номерного знака и ширину и высоту выделен-
ной области, оценим минимальную ширину W отдельного символа.
2) В качестве начальных вершин в верхней строке изображения будем вы-
бирать каждый WI2 пиксель (Рис. 14 (а)).
3) Вычисляем пути, имеющие наименьшую стоимость для первого (крайне-
го левого) и последнего (крайнего правого) начальных пикселей. Поме-
чаем их как «принадлежащие к пути» пиксели (Рис. 14 (Ь)).
4) Выбираем из начальных пикселей тот. который находится посередине
между двух «принадлежащих к пути» пикселей (Рис. 14 (с)). Вычисляем
для него путь с наименьшей стоимостью и также помечаем его как «при-
надлежащий к пути» пиксель.
5) Если два пути с наименьшей стоимостью оканчиваются в одной и той же
точке (Рис. 14 (d) и (е)). все начальные пиксели, лежащие между двумя
этими путями, помечаются как «принадлежащие к пути».
6) Если еще остались начальные пиксели, не помеченные как «имеющие
путь», переходим к п.4.
Рис. 14. Вычисление пути с наименьшей стоимостью
После того как символы номерного знака отделены друг от друга, необходи-
мо найти их точные контуры. Дтя этого воспользуемся результатами бинариза-
ции изображения и найдем средние значения р и р, и стандартные отклонения ст,
и ст, интенсивностей для пикселей, отнесенных при бинаризации к переднему пла-
ну (к символам) и к фону соответственно. Будем теперь последовательно рассма-
тривать все полученные подобласти - части исходного изображения, соответству-
ющие одному символу номерного знака. Все пиксели этих подобластей разделим
на символьные, фоновые и неопределенные при помощи следующего алгоритма:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www. procctv. ги
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 385
1) В начальный момент все пиксели подобласти считаются неопределен-
ными.
2) Все пиксели, интенсивность которых лежит в пределах стандартного от-
клонения Qj от среднего значения считаем символами.
3) Все неопределенные пиксели, примыкающие к верхней и нижней грани-
цам подобласти, считаются фоновыми.
4) Для оставшихся неопределенных пикселей находим разность между их ин-
тенсивностью и средними значениями и р2. В зависимости от получен-
ных результатов классифицируем пиксель как символьный или фоновый.
9.3. РАСПОЗНАВАНИЕ СИМВОЛОВ НОМЕРНОГО ЗНАКА
Подавляющее большинство методов распознавания символов можно раз-
бить на два больших класса: сравнение с шаблоном и классификация на основе
выделенных характерных признаков.
9.3.1. Сравнение с шаблоном
Данный метод начинается с составления базы данных шаблонов изображе-
ний всех возможных символов номерного знака - букв и цифр. В такую базу дан-
ных могут быть включены изображения как для одного, так и для целого ряда
масштабов. Для распознавания очередного символа он приводится к одному из
допустимых размеров и производится его последовательное сравнение с каждым
из имеющихся шаблонов.
Для уменьшения числа сравнений возможно вычисление каких-либо допол-
нительных характеристик, например количества замкнутых областей белого
цвета в символе, предполагая, что сами символы черного цвета, и сравнение толь-
ко с соответствующими шаблонами. В качестве меры сходства двух изображе-
ний обычно используется нормированный коэффициент перекрестной корреля-
ции (39).
Другой возможной мерой сходства является расстояние Хаусдорфа между
объектами А и В:
Я(Л,В) = тах(Л(Я,В),Л(В,Л)), (99)
где
Л(Л,Д) = тахпип||а-Ь||. (100)
а€.Л ЬеН
Расстояние Хаусдорфа можно вычислить с помощью морфологических опе-
раций. Для этого сначала выполняется дилатация объекта А с помощью кругло-
го структурирующего элемента радиусом /?,. Затем значение R} последовательно
увеличивается до тех пор, пока результат дилатации А не будет целиком вклю-
чать в себя объект В. После этого аналогичные действия проводятся с объектом
В и структурирующим элементом радиуса R2. Расстояние Хаусдорфа между А и
В определяется как максимальное значение из R} и Rr
Основной проблемой при использовании метрики Хаусдорфа является
большое число вычислений, которое может быть уменьшено с помощью вве-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
386
Цифвая обработка видеоизображений
дения так называемого преобразования расстояния D(B) [32]. Для произволь-
ного множества В оно представляет собой трехмерную поверхность, определя-
емую следующей функцией:
rf(x)=™nilx-4 (101)
ПС О
Выражение (101) можно графически интерпретировать как процесс полу-
чения полутонового изображения, как это показано на Рис. 15. Отметим так-
же, что преобразование расстояния для имеющихся шаблонов может быть по-
лучено заранее, сохранено в базе данных и в дальнейшем использовано при
вычислениях.
R
Рис. 15. Символ и его преобразования расстояния D(B)
Другой недостаток расстояния Хаусдорфа - его высокая чувствительность к
шуму - может быть устранен с помощью следующей модификации [33]:
MHD(A, В} = max (mhd {А, В}, mhd (В, А)). (102)
где
mhd (Л В) = пип ||а - />|| = £ d (а) (103)
представляет собой среднее значение D(B) на множестве А.
Таким образом, сравнение очередного символа номерного знака с имеющи-
мися шаблонами производится путем вычисления величины MHD. При этом не-
обходимо принимать во внимание следующие соображения:
• приведение анализируемого изображения к определенному масштабу
должно выполняться с сохранением аспектного отношения символа;
• небольшие отклонения могут быть учтены с помощью перемещений
входного изображения влево и вправо на несколько пикселей. Это под-
разумевает вычисление модифицированного расстояния Хаусдорфа
MHD более одного раза и выбор минимального значения;
• допустимые малые изменения (±1 пиксель) масштаба шаблона (для чего
также требуется вычислять MHD несколько раз) позволяют довольно
значительно улучшить степень правильного распознавания символов;
• если минимальное расстояние между символом и определенным шабло-
ном, полученное в результате всех сравнений, превышает наперед задан-
ное пороговое значение, такой символ считается нераспознанным.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctvjr/
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 387
9.3.2. Выделение характерных признаков
Символы номерного знака могут быть описаны многочисленными харак-
терными признаками, различающимися степенью детализации изображения.
При выделении большинства характерных признаков требуется, чтобы симво-
лы всегда имели одинаковый размер, для чего изображения обычно приводятся к
одной и той же высоте. Это делается потому, что в то время как ширина всех сим-
волов на номерном знаке различна, высота должна оставаться неизменной. Да-
лее представлены основные используемые характерные признаки и методы для
их извлечения из изображения.
• Площадь, Для ее нахождения подсчитывается число фоновых пикселей изо-
бражения.
• Вертикальная и горизонтальная проекции. Вертикальные проекции явля-
ются более характерными для каждого символа. Горизонтальные проекции
для цифр более схожи по своей структуре, имея или один широкий пик. или
пики в начале и конце, что видно на Рис. 16.
• Концевые точки. Их расположение довольно сильно варьируется между сим-
волами и, следовательно, может быть использовано при распознавании. На-
пример, цифра “6” имеет только одну концевую точку в верхней половине
и ни одной - в нижней. Хотя расположение таких точек меняется также и в
горизонтальном направлении, часто бывает трудно правильно отнести най-
денную концевую точку к правой или левой половине изображения. Поэто-
му обычно рассматривают расположение концевых точек исключительно по
вертикали. Концевые точки находятся при помощи построения остова симво-
ла толщиной один пиксель и определяются как те пиксели, которые имеют
только одну связную компоненту в области, образованной восемью смежны-
ми пикселями. При построении остова символа необходимо использовать ал-
горитм, который не уничтожал бы истинных концевых точек, а, кроме того,
нс нарушал связности между пикселями, что может приводить к возникнове-
нию ложных концевых точек [34]. Получающийся в результате остов содер-
жит в себе даже самые мелкие структурные компоненты, что в ряде случа-
ев приводит к нежелательным последствиям. Так. например, хотя цифра “О”
не имеет концевых точек, она может быть идентифицирована как имеющая
одну такую точку - см. Рис. 17. Поэтому используемый алгоритм должен осо-
http;//wwwj'fv.ru
Компания ITV - генеральный спонсор издания книги
388
Цифвая обработка видеоизображений
бым образом обрабатывать структуры длиной менее п пикселей, где п - за-
данное значение, зависящее от конкретного изображения.
Рис. 17. Некорректные результаты работы алгоритма построения остова символа
• Периметр. Данная величина определяется путем подсчета пикселей, ле-
жащих на внешней границе символа. Значение периметра является весьма
устойчивым к шуму.
• Число составных частей. Каждый символ состоит из одной или несколь-
ких частей, которые определяются как области, содержащие пиксели с оди-
наковыми значениями. Фоновые пиксели считаются составной частью толь-
ко в том случае, когда они со всех сторон окружены пикселями символа. На-
пример, из Рис. 18 видно, что “0” имеет две составные части, а “1” - одну. Для
определения числа составных частей используется свертка изображения с ла-
пласианом и подсчет связных линий. Альтернативным подходом является ис-
пользование морфологической операции (97).
Рис. 18. Составные части для двух символов
♦ Компоненты Кирша. Они представляют собой результаты применения гра-
диентных операторов Кирша к исходному изображению. Всего существует
четыре такие компоненты: горизонтальная, вертикальная, правая диагональ-
ная (из левого верхнего угла в правый нижний) и левая диагональная. Для
пикселя (/,/) введем следующие обозначения:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 389
Ч А Л5
А (»./)
< -^6 ^5 ^4 >
Тогда
— Ак +
?к ~ + Ль 5 + Л *6 + Л>7'
(104)
(Ю5)
(106)
где к вычисляется по модулю 8. Общий вид градиента Кирша в точке (/,/)
определяется следующей формулой:
= max |^1, max [5S* -3Ta[J (107)
Мы будем рассматривать частные случаи этого оператора для получения не-
скольких компонент:
• горизонтальная: Gz/ (/,у) = max(|5S0 -ЗТ0|,|554 -ЗТ4|),
• вертикальная:Gr (i,j) = max(|5S2 -ЗТ2|, |556 -ЪТЬ|),
• правая диагональная: GR (i,j) = max(|5St -37[|,|5S5 -ЗТ5|),
• левая диагональная: GL (i,j) = max(|5S3 - ЗГ3|, |557 -3T7|).
Для вычисления этих операторов можно воспользоваться следующими ма-
сками:
' 5 5 5 5 <-3 -3 -3"
• горизонтальная: -3 0 -3 -3 0 -3 -
-3 -3, 5 5>
<_ 3 3 5' <5 -3 -3"
• вертикальная: 3 0 1 5 5 0 -3 >
V 3 - 3 5, <5 -3 -з>
г-3 5 5 г-3 -3 -3 д
• правая диагональная: -3 0 5 5 0 -3
-3 -3 -3 Ч 5 -3
/ -3 - -3 -3А 5 5 -3х
• левая диагональная: -3 0 5 5 0 -3
-3 5 5> -3 -3 -3>
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
390
Цифвая обработка видеоизображений
Рис. 19. Векторы, полученные при горизонтальном сканировании изображения
Рис. 20. Вектор до и после устранения шума
• Горизонтальные или вертикальные компоненты. В этом случае изображе-
ние сканируется в горизонтальном или вертикальном направлении т раз, как
это показано на Рис. 19 для т = 12 [14]. Результатом каждого такого скани-
рования являются чередующиеся последовательности белых и черных пик-
селей, которые можно объединить в двоичный вектор. При этом необходи-
мо избавиться от имеющегося в изображении шума, который впоследствии
может привести к ошибкам распознавания. Для этого измеряется длина каж-
дой последовательности, и если она не превышает половины установлен-
ной заранее ширины линии, то такая последовательность считается шумом
(см. Рис. 20). После того как шум устранен, каждый полученный вектор срав-
нивается с кодовыми словами, пример которых приведен на Рис. 21. В этих
словах сочетания "п + b + п" или "Ь + п + /?" означают комбинацию указанных
выше последовательностей, где "л" и "Ь" соответствуют последовательно-
стям, состоящим из черных и белых пикселей соответственно. Черта над сим-
волами (п и Ь) обозначает, что данная последовательность имеет большую
длину по сравнению с соседней.Такая кодировка позволяет различать схожие
символы (например, “1” и “7”).
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ri/
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 391
Рис. 21. Кодовые слова
• Геометрические моменты. Для бинарного изображения размером Мх /V ука-
занные моменты были приведены в Главе 3.
• Моменты Цернике. Они представляют собой множество комплексных орто-
гональных полиномов, определенных внутри единичного круга х2 + у2 = 1 (37]:
(*. у)=Упт (р, 0) = (рив. (108)
л„„(р)= £ —Тр" 2>’ (109)
З.|я+Н Д[”-М д
\ 2 Д 2 /
где п - неотрицательное целое, т - целое такое, что п - |т| четное и |/п| < и,
р = \]х2 + у2 0 - arctg
х
Для бинарного изображения, разложенного по данному базису, получим:
x‘ + /sl. (ПО)
X V
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
392
Цифвая обработка видеоизображений
Моменты Цернике. примененные к изображению, полученному поворотом
исходного, отличаются от исходных моментов сдвигом по фазе, но совпада-
ют по модулю [38]. Поэтому величины |XrtJ могут быть использованы в ка-
честве инвариантных к вращению характерных признаков изображения. Так
как Ап т = Апт, то |Л^ J = |ЛЯ/Я|, что позволяет сократить число характерных
признаков.
• Эллиптические Фурье-дескрипторы. Если аппроксимировать контур симво-
ла {х(0,у(01 параметрическим выражением, то коэффициенты такой параме-
тризации могут быть использованы в качестве характерных признаков [39]:
ao=:T^£^[cos0.-cos4 J (И1)
&.=7ТЗ^а715'п^-5'й"1 (112)
Л /Г J=| АГ
Т Ду г 1
(113)
Zn К t=| АГ.
(ii4)
где
Дх, = х( - хм, Ду, = у, - yt_t, (115)
Д/, = 7Дх-+Ду,2, t, = £ Д/г (116)
j-i
г=/- = Хч- (117)
/=|
а т - число пикселей контура. Инвариантными к вращению признаками яв-
ляются следующие комбинации этих коэффициентов [40]:
Ф4-а*2+Ь’+с’+<£ (118)
J к = ~ЬкСк> Щ9)
Ki.i = (а|2 +^)W +г>/) + (с2 +di2)(cJ +rf2) + 2(aici +Mi)(V; + Mj- <120)
9.4. МЕТОДЫ КЛАССИФИКАЦИИ СИМВОЛОВ
9.4.1. Статистические методы
Основу методов данного класса составляет байесовское правило принятия
решений. Введем 5 классов Q = каждый из которых соответствует
одному из символов номерного знака, и обозначим через х набор характерных
признаков изображения. Тогда для распознавания символа необходимо вычис-
ProSystem CCTV - журнал по системам видеонаблюдения
h ttp://w w w. procctv. ru
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 393
лить апостериорную вероятность P(CDt | х) (т. е. вероятность того, что входной
символ х принадлежит классу (О). Входной символ х считается принадлежащим
тому классу, для которого эта вероятность максимальна.Так как согласно фор-
муле Байеса
Р(й>, |х) =
/>(х|<Р,)Р(й),)= р(х|ш,)Р(<о,)
(121)
ар(х) не зависит от то, следовательно, достаточно определить максимум вели-
чины р(х | ш) • Р(ф). Предполагая гауссово распределениер(х | й)),р(х | ш) • P(to)
можно представить в виде следующей дискриминантной функции:
]_
2
(122)
где Mt - количество наблюдений х{‘] для класса со,(У2 - дисперсия, а Р(со) - априор-
ная вероятность появления символа из класса со, которая обычно считается по-
стоянной и исключается из дальнейшего рассмотрения.
9.4.2. Применение искусственных нейронных сетей
Этот способ классификации является наиболее распространенным при рас-
познавании символов. Существует большое разнообразие архитектур исполь-
зуемых нейросетей, ведущее место среди которых занимает трехслойный пер-
септрон, имеющий входной, выходной и один скрытый слой. Число нейронов
входного слоя совпадает с числом используемых характерных признаков, а чис-
ло нейронов выходного слоя - с числом распознаваемых символов. Количество
нейронов в скрытом слое обычно подбирается экспериментально: если их чис-
ло недостаточно, то при обучении нейросеть не может достичь заданной точ-
ности. При слишком большом количестве у нейросети могут появиться так на-
зываемые «ложные» состояния, что в итоге может привести к неправильному
распознаванию.
На вход нейросети при обучении подаются наборы характерных признаков;
при этом добиваются появления на выходе заданных сигналов, в которых закоди-
рован номер нужного класса. Например, при кодировании цифр нейросеть долж-
на содержать 10 выходов, которые кодируются следующим образом:
0->000...0001
1-эООО. ..0010
9—>100...0000.
Когда обученная таким образом нейросеть используется при распознавании,
достаточно определить номер выходного нейрона, который выдает наибольший
сигнал. Этот номер будет соответствовать номеру распознанного символа.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
394
Цифвая обработка видеоизображений
В качестве альтернативы для распознавания символов можно использовать
сети адаптивного резонанса [41]. Нейросети этого типа способны увеличивать
число нейронов, добиваясь в итоге однозначной реакции определенных групп
нейронов на предъявляемые признаки: чем ближе входной сигнал к образцу «за-
помненному» нейроном, тем больше выдаваемый им сигнал. Этот процесс напо-
минает явление резонанса, с чем и связано название данного типа нейросетей.
Подробно про методы настройки нейросетей можно прочитать в разделе 5.2.
9.4.3. Метод опорных векторов
В своем изначальном виде этот метод предназначен для разделения всего
множества векторов х е X на два различных класса [42]. Для этого строится ре-
шающая функция /(х,ф) = sgn(A(x,cy)). принимающая два значения (±1|. где
Л(х,<о)= (&), <р(х)) +Ь (123)
представляет собой разделяющую гиперплоскость в расширенном пространстве F.
Здесь coeFbGR,a(p:X-> F осуществляет нелинейное отображение исходного про-
странства X на расширенное пространство F. В случае, когда число классов s > 2,
обычно осуществляется комбинирование бинарных решающих функций при помо-
щи декомпозиции: разбиение выходного пространства на 5 классов представляется
с помощью набора из L разбиений на 2 класса [43]. Затем производится синтез L ре-
зультатов бинарной классификации для выбора одного (возможно ни одного) из 5
классов. Существуют и другие модификации метода опорных векторов, делающие
возможным его применение к проблеме распознавания символов [44].
Подробнее с методом опорных векторов можно ознакомиться в разделе 5.3.
9.4.4. Метод выделения главных компонент
В качестве характерного признака может быть использовано изображение
номерного знака целиком, а одним из возможных методов классификации при
этом является метод выделения главных компонент. Вся процедура классифика-
ции выглядит следующим образом [45]:
1) Составляется обучающая последовательность из т изображений, каждое
из которых относится к одному из возможных классов. Все изображения
представляются в виде одномерных векторов р{ (/ = размерности п.
2) Вычисляется «средний вектор» обучающей последовательности:
- 1 V* -
ж"
Очевидно, что он также имеет размерность п х 1.
3) Из обучающих векторов составляется матрица А размером п х т. Столб-
цами такой матрицы являются разности векторов р. и \jf:
Л = (Д-? рг~У ... P„-v\.
4) Вычисляются собственные векторы ковариационной матрицы обучаю-
щей последовательности, которая определяется как
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 395
£= ААТ.
Ковариационная матрица имеет размер п х л. Так как п может быть доста-
точно велико, то вместо Z можно рассмотреть матрицу L:
L- Ат А
размером m х т. где m обычно много меньше п. Можно показать, что соб-
ственные векторы Z могут быть получены из собственных векторов L пу-
тем линейной комбинации А и собственных векторов L [46]. Действитель-
но, предполагая, что г и Л представляют собой соответственно собствен-
ный вектор и собственное значение Л, получим:
Lvt = Afv.
(A1 A^vt = A(v
а(Ага)У' = АЛу(
[аАг)Ау( = Л,АУ'
ZAv = ZtAvt.
Отсюда следует, что Ах\ является собственным вектором матрицы L.
Пусть V - это матрица, столбцами которой являются m собственных век-
торов L. Тогда матрица Г/, столбцы которой представляют собой соб-
ственные векторы £. может быть получена как U = AV. Так как матрица V
имеет размер m х т, а матрица А - п х т, то U - это матрица размером п
х т.
5) Выбираются к (к < т) собственных векторов матрицы Z, из которых со-
ставляется матрица главных компонент. Выбранные собственные векто-
ры - это столбцы матрицы U, соответствующие наибольшим собствен-
ным значениям, полученным при нахождении собственных векторов ко-
вариационной матрицы. После этого в матрице U оставляются только
эти к столбцов:
{/ = [!/, U2 ... 1/J
Так как каждый собственный вектор имеет размерность п х 1, то получа-
ем матрицу размером п х к.
6) Каждый вектор обучающей последовательности проецируется в про-
странство к собственных векторов:
со, = Ur (Д -1/) i =
Полученный вектор имеет размерность к х 1. Таким образом, размер век-
торов обучающей последовательности уменьшился с и х 1 до к х 1.
Пусть теперь ptest -это изображение символа, который требуется распознать.
Тогда процедура классификации состоит из двух шагов:
1) Из предъявленного вектора ptat вычитается вектор средних значений об-
учающей последовательности, и результат проецируется в пространство
собственных векторов U:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
396 Цифвая обработка видеоизображений
4».= и'
2) Среди всей обучающей последовательности отыскивается такой вектор
(й.для которого
z0 = argmin|wft,„-Gj,||.
Входное изображение относится к тому же классу, что и вектор (Ц.
9.4.5. Использование кластерного анализа
Проблема распознавания символов представляет для кластерного анализа
классический случай, когда априорно известно число классов. В данном случае
оно совпадает с числом символов, которые нужно распознать. Для построения
кластеров нужно накопить как можно больше образцов символов, преобразо-
вать каждый из них к набору выбранных характерных признаков, а затем прове-
сти кластеризацию - т. е. разбить все эти наборы на непересекающиеся классы
(например, с помощью метода К-средних).
Распознавание новых символов проводится следующим образом. Пусть х -
это вектор характерных признаков. Для каждого из К полученных кластеров Q;,
j = 1,...,К, находится минимальное расстояние среди всех расстояний от вектора
признаков до элементов кластера:
= minrf(x»xf), (124)
а потом находится индекс /0, соответствующий минимальному значению из всех
d^j = Считается, что предъявленное изображение принадлежит классу с
номером /
Эта процедура фактически требует сравнения вектора характерных призна-
ков со всеми векторами, участвовавшими в построении кластеров, что приводит
к значительным затратам времени. Для ускорения процесса распознавания мож-
но сравнивать новый вектор признаков х с центрами кластеров, т. е. вместо (124)
использовать следующее выражение:
dy=j(x,Cy), (125)
где Cj - центроид /-того кластера. В этом случае произойдет снижение качества
распознавания, зато значительно возрастет скорость, что так необходимо в си-
стемах реального времени.
Подробнее ознакомиться с различными методами кластеризации можно в
разделе 5.4.
9.4.6. Комбинация нескольких методов
Объединение нескольких методов используется для повышения надежности
распознавания символов [47]. Существуют многочисленные способы комбини-
рования результатов работы отдельных классификаторов. Наиболее часто ис-
пользуется параллельное их объединение, в то время как последовательное объ-
единение применяется в основном для ускорения категоризации больших набо-
ров данных. Для достижения оптимальных результатов необходимо, чтобы клас-
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv.ru
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 397
сификаторы были взаимно дополняющими друг друга. При распознавании сим-
волов эффективной является комбинация классификаторов, использующих раз-
личные типы характерных признаков и модели классификации.
Возможная схема комбинации нескольких классификаторов и метода сравне-
ния с шаблоном показаны на Рис. 22. Отметим, что вычисления во всех указанных
блоках могут проводиться одновременно. В качестве комбинированного последо-
вательного метода можно предложить использование сначала метода сравнения с
шаблоном, а затем метода опорных векторов. При этом на этапе сравнения с ша-
блоном входного изображения выбирается несколько наиболее близких ему клас-
сов. После этого применяется метод опорных векторов в предположении, что ис-
тинное решение находится среди выбранных на первом этапе классов. Это позволя-
ет уменьшить требуемое время вычислений и улучшить надежность распознавания.
ВХОДНОЕ ИЗОБРАЖЕНИЕ
распознанный символ
Рис. 22. Возможная схема комбинации нескольких классификаторов
Несмотря на то, что работы по созданию систем автоматического распозна-
вания регистрационных номеров автомобилей ведутся уже достаточно длитель-
ное время и было предложено большое количество самых разнообразных мето-
дов, целый ряд существующих проблем до сих пор не позволяет разработать дей-
ствительно эффективную систему. Одну из самых больших проблем представ-
ляет качество изображений. Низкое качество связано как с неправильными на-
стройками, узостью динамического диапазона и расположением камеры, так и с
внешними факторами, определяющими большое разнообразие условий наблю-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
398
Цифвая обработка видеоизображений
дения. Как следствие, на изображении присутствуют области значительного от-
ражения, с разной степенью освещенности и контраста. Гистограммы таких сним-
ков могут быть унимодальными, бимодальными или мультимодальными с много-
численными пиками, вызванными отражением света от объектов. Все это в зна-
чительной мере затрудняет сегментацию и бинаризацию изображений.
Другой важной проблемой является чрезвычайно низкое в большинстве слу-
чаев качество изображений номерных знаков, которые могут быть сильно за-
грязнены, иметь отверстия и предметы, закрепленные на их поверхности. Это
означает, что отдельные символы могут иметь соединения как с границами но-
мерного знака, так и между собой, а также быть частично закрытыми посторон-
ними предметами. В результате сегментация символов и их последующее распо-
знавание могут быть некорректными. Наконец, нельзя не упомянуть о важности
работы алгоритмов в режиме реального времени и разумных требованиях к объ-
ему имеющейся памяти.
Проведенный анализ позволяет заключить, что при использовании одного кон-
кретного метода на каждом этапе работы системы автоматического распознава-
ния регистрационных номеров автомобилей практически невозможно добиться удо-
влетворительной надежности результатов. Выход из сложившейся ситуации видит-
ся в последовательном или параллельном комбинировании взаимно дополняющих
друг друга методов. При этом возможно установление обратной связи между после-
довательными этапами для модификации параметров и увеличении эффективно-
сти системы в целом. Так, например, в зависимости от степени надежности распозна-
вания символов, могут быть скорректированы параметры их сегментации и даже в
ряде случаев применен альтернативный алгоритм выделения отдельных символов.
На последнем этапе работы систем автоматического распознавания номеров
выбор фактически заключается в применении или статистических методов, или
классификаторов, основанных на нейросетях и методе опорных векторов. У каж-
дого типа алгоритмов есть свои достоинства и недостатки. Время обучения при ис-
пользовании статистических методов распознавания (статистические классифика-
торы) линейно зависит от числа имеющихся классов, а добавление нового класса
не представляет особой трудности. Кроме того, возможна адаптация уже настро-
енных параметров класса при поступлении новых наблюдений. В противополож-
ность этому время обучения нейросетей и метода опорных векторов (дискрими-
нантные классификаторы) пропорционально квадрату числа классов, и для надеж-
ного распознавания процедура обучения таких классификаторов должна быть про-
ведена с самого начала при добавлении новых векторов характерных признаков.
С другой стороны, точность дискриминантных классификаторов при имеющих-
ся больших обучающих последовательностях выше, чем у статистических. Вслед-
ствие того, что число параметров у дискриминантных классификаторов обычно
меньше, чем у статистических, они менее требовательны к вычислительным ресур-
сам (после того, как их обучение уже проведено). Из всего сказанного можно сде-
лать вывод, что при распознавании символов следует отдать предпочтение дискри-
минантным классификаторам, хотя в последнее время появились весьма эффек-
тивные комбинации статистических и дискриминантных классификаторов [49].
Если же сравнивать между собой нейросети и метод опорных векторов, то
можно заметить, что время обучения нейросетей меньше, чем у метода опорных
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 399
векторов, хотя для него в последнее время также были разработаны алгоритмы
быстрого обучения [48]. Сходимость процесса обучения для нейросетей подвер-
жена нахождению локальных минимумов, в то время как метод опорных векто-
ров гарантирует получение глобального оптимума. Кроме того, во многих экспе-
риментах метод опорных векторов показал лучшую по сравнению с нейросетя-
ми точность распознавания. Но время, затрачиваемое на вычисления, в нем зна-
чительно больше, что может оказаться существенной проблемой при его исполь-
зовании в режиме реального времени.
9.5. СПИСОК ЛИТЕРАТУРЫ
1. R. Brad. License Plate Recognition System. In: Proc. International Conference on
Information, Communications and Signal Processing. Singapore, p. 2D3.6,2001.
2.1. K. Fodor. C. Kamath. Denoising Through Wavelet Shrinkage: An Empirical Study.
In: Journal of Electronic Imaging.?. 12. p. 151-160.2003.
3. P G. Hou. J. Zhao. M. Liu. A License Plate Locating Method Based on Tophat-Bothat
Changing and Line Scanning. In: Journal of Physics: Conference Series, v. 48, p. 431-436,2006.
4. D. L. Donoho, I. M. Johnstone. Adapting to Unknown Smoothness via Wavelet
Shrinkage. In: Journal of the American Statistical Association,\\W, p. 1220-1245.1995.
5. S. G. Chang. B. Yu, M. Vetterli. Adaptive Wavelet Thresholding for Image Denoising
and Compression. In: IEEE Transactions on Image Processing, v.9, p. 1532-1546,2000.
6. N. Otsu. A Threshold Selection Method for Gray Level Histograms. In: IEEE
Transactions on System, Man and Cybernetics, v. 9, p. 377-393,1979.
7. E Hermidax, E M. Rodriguez, E J. L. Lijo. P E Sande, P M. Iglesias. A System for the
Automatic and Real-time Recognition of V L. P. s (Vehicle License Plate). In: Proc.
International Conference on Image Analysis and Processing, Florence, p. 552-559,1997.
8. J.C.Yen.F.J.Chang,S.Chang.ANewCriterion for AutomaticMulti-levelThresholding.
In: IEEE Transactions on Image Processing, v. 4. p. 370-378,1995.
9. S. Draghici. A Neural Network-based Artificial Vision System for License Plate
Recognition. In: International Journal of Neural Systems, v. 8, p. 113-126.1997.
10. H. Hansen, A. W. Kristensen, M. P. K0hler, A. W. Mikkelsen, J. M. Pedersen,
M.Trangeled. Automatic Recognition of License Plates.Technical Report IN6-621,
Aalborg Universitet, 2002.
11. R. Parisi, E. D. Di Claudio, G. Lucarelli, G. Orlandi. Car Plate Recognition by
Neural Networks and Image Processing. In: Proc. IEEE International Symposium
on Circuits and Systems. Monterey, v. 3, p. 195-198,1998.
12. B. D. Acosta. Experiments in Image Segmentation for Automatic US License Plate
Recognition. Master of Science Thesis. Virginia Polytechnic Institute and State
University, 2004.
13. V Shapiro, D. Dimov, S. Bonchev, V Velichkov, G. Gluhchev. Adaptive License Plate
Image Extraction. In: Proc. International Conference on Computer Systems and
Technologies, Rousse,p. III.A.3-1 - Ш.А.3-6,2004.
14. N. Vazquez, M. Nakano, H. Perez Meana. Automatic System for Localization
and Recognition of Vehicle Plate Numbers. In: Journal of Applied Research and
Technology, v. I, p. 63-77,2003.
http.7/www.itv.ru
Компания ITV - генеральный спонсор издания книги
400
Цифвая обработка видеоизображений
15. Е Martin, М. Garcia, J. L. Alba. New Methods for Automatic Reading of VLP’s
(Vehicle License Plates). In: Proc. Signal Processing, Pattern Recognition and
Applications. Crete. 370-084,2002.
16. E Martin, D. Borges. Automatic Car Plate Recognition Using a Partial Segmentation
Algorithm. In: Proc. Signal Processing, Pattern Recognition and Applications,
Rhodes, 404-045.2003.
17. H. A. iMaarif. S. Sardy. Plate Number Recognition by Using Artificial Neural
Network. In: Proc. Teknologi Simulasi dan Komputasi serta Aplikasi, 2006.
18. A. Albiol. J. M. Mossi. A. Albiol. V. Naranjo. Automatic License Plate Reading
Using Mathematical Morphology. In: Proc. 1ASTED International Conference on
Visualization, Imaging and Image Processing. Marbella, 452-137.2004.
19. O.Tuzel, E Porikli. P Meer. Region Covariance: A Fast Descriptor for Detection and
Classification. In: Proc. European Conf, on Computer Vision, Graz, v. 2, p. 589-600,
2006.
20. E Porikli, T. Kocak. Robust License Plate Detection Using Covariance Descriptor
in a Neural Network Framework. In: Proc. IEEE International Conference on
Advanced Video and Signal-based Surveillance, Sydney, p. 107-112,2006.
21. W. Forstner, B. Moonen. A Metric for Covariance Matrices. Technical Report.
Stuttgart University, 1999.
22. A. K. Jain. E Farrokhnia. Unsupervised Texture Segmentation Using Gabor Filters,
In: Proc. IEEE International Conference on Systems, Man and Cybernetics, Los
Angeles, p. 14 - 19,1990.
23. H. Li, D. Doermann, O. Kia. Automatic Text Detection and Tracking in Digital
Video. In: IEEE Transactions on Image Processing, v. 9, p. 147-156,2000.
24. S. G. Mallat. Multi-resolution Approximations and Wavelet Orthonormal Bases of /2(r).
In: Transactions of American Mathematical Society, v. 315, p. 69 - 87,1989.
25. P. Viola, M. Jones. Robust Real-time Object Detection. In: Proc. International
Workshop on Statistical Learning and Computational Theories of Vision - Modeling,
Learning, Computing and Sampling.VancouveT, p. 747-761,2001.
26. X. Chen, A. Yuille. Detecting and Reading Text in Natural Scenes. In: Proc. IEEE
Conference on Computer Vision and Pattern Recognition, Washington, v. 2, p. 366-
373,2004.
27. H. Zhang,W Jia,X.He,Q.Wu. Learning-based License Plate Detection UsingGlobal
and Local Features. In: Proc. International Conference on Pattern Recognition, Hong
Kong, p. 1102-1105,2006.
28. D. Comaniciu, P. Meer. Mean Shift Analysis and Applications. In: Proc. IEEE
international Conference on Computer Vision, Kerkyra, p. 1197-1203,1999.
29. D. Comaniciu, P Meer. Mean Shift: A Robust Approach toward Feature Space
Analysis. In: IEEE Transactions on Pattern Analysis and Machine Intelligence, v. 24.
p. 603-619,2002.
30. W Jia, H. Zhang, X. He, M. Piccardi. Mean Shift for Accurate License Plate
Localization. In: Proc. IEEE International Conference on Intelligent Transportation
Systems, Vienna, p. 566-571,2005.
31. S. Kopf, T. Haenselmann, W Effelsberg. Robust Character Recognition in Low-
resolution Images and Videos. Technical Report TR-05-002, University c:
Mannheim, 2005.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procct\,
Глава 9. Методы выделения и распознавания номерных знаков транспортных средств 401
32. J. Ruckiidge. Efficiently Locating Objects Using the Hausdorff Distance. In:
International Journal o f Computer Vision. v. 15, p. 251-270,1997.
33. M. P Dubuisson, A. K. Jain. A Modified Hausdorff Distance for Objects Matching,
In: Proc. International Conference on Pattern Recognition. Jerusalem, p. 566-568,
1994.
34. Тонсалес R. Вудс P. Цифровая обработка изображений. - M.: Техносфера, 2006.
-1072 с.
35. М. К. Hu. Visual Pattern Recognition by Moment Invariant. In: IEEE Transactions
on Information Theory, v. 8. p. 179-187.1962.
36. T. H. Reiss. The Revised Fundamental Theorem of Moment Invariants. In: IEEE
Transactions on Pattern Analysis and Machine Intelligence, v. 13. p. 830-834,1991.
37. H. Hse, A. R. Newton. Sketched Symbol Recognition Using Zernike Moments.
In: Proc. International Conference on Pattern Recognition. Cambridge, v. 1,
p. 367-370,2004.
38. A. Khotanzad. Y. H. Hong. Rotation-invariant Image Recognition Using
Features Selected via a Systematic Method. In: Pattern Recognition, v. 23,
p.1089-1101, 1990.
39. F P. Kuhl.C. R. Giardina. Elliptic Fourier Features of a Closed Contour. In: Computer
Vision, Graphics and Image Processing, v. 18, p. 236-258,1982.
40. C.-S. Lin, C.-L. Hwang. New Forms of Shape Invariants from Elliptic Fourier
Descriptors, In: Pattern Recognition, v. 20, p. 535-545,1987.
41. Y.K.Siah,T.Y.Haur.M.Khalid,T.Ahmad. Vehicle License Plate Recognition by
Fuzzy Artmap Neural Network. In: Journal of Henan University of Technology.
№1,2004.
42. V Vapnik. The Nature of Statistical Learning Theory. Springer Verlag, New York,
1995,332 p.
43. U. Kressel. Pairwise Classification and Support Vector Machines. Advances in
Kernel Methods: Support Vector Learning, B. Scholkopf C.J.C. Burges, A.J. Smola
(eds.). MIT Press, Cambridge, p. 255-268,1999.
44. C. Angulo, A. Catala. K-SVCR. A Multi-class Support Vector Machine. In: Lecture
Notes In Computer Science, v. 1810, p. 31-38,2000.
45. L. R. A. Curado, A. Bauchspiess, V В. E Curado. Using PCA to Recognize Characters
in Vehicle License Plate. In: Proc. International Conference on Image Processing and
Computer Vision. Las Vegas, p. 264-268,2006.
46. M. Turk, A. Pentland. Eigenfaces for Recognition. In: Journal of Cognitive
Neuroscience, v. 3, p. 71-86,1991.
47. A. F R. Rahman. M. C. Fairhurst. Multiple Classifier Decision Combination
Strategies for Character Recognition: A Review. In: International Journal on
Document Analysis and Recognition, v. 5, p. 166-194.2003.
48. F. P£rez-Cruz, P. L. Alarcon-Diana, A. Navia-Vazquez, A. Artes-Rodriguez. Fast
Training of Support Vector Classifiers. Advances in Neural Information Processing
Systems, S.A. Solla, TK. Leen, K.-R. Muller (eds.), MIT Press, Cambridge, v. 13, p.
734-740.2000.
49. R. Raina, Y. Shen, A. Y. Ng and A. McCallum. Classification with Hybrid Generative/
Discriminative Models. A dvancesin Neural Information Processing System, S.A. Solla,
T. K. Leen, K.-R. Muller (eds.). MIT Press, Cambridge, p. 1840-1848,2004.
h t tp://ww w .it v. ru
Компания ITV - генеральный спонсор издания книги
ГЛАВА 1О.
ОБНАРУЖЕНИЕ ДЫМА И ОГНЯ
ПО ВИДЕОИЗОБРАЖЕНИЮ
404
Цифвая обработка видеоизображений
В настоящее время наиболее распространенными методами для обнаруже-
ния задымления и огня являются пробы частиц воздуха, измерение внешней тем-
пературы и прозрачности среды [1.2]. Однако все они требуют размещения со-
ответствующих датчиков и приборов в непосредственной близости от источника
возгорания. Кроме того, указанные методы не являются в достаточной степени
надежными (особенно это относится к объектам, расположенным на открытом
воздухе), так как по большей части основаны на обнаружении дыма, который в
ряде случаев может не представлять никакой опасности.
Детектирование огня по видеоизображению имеет ряд преимуществ по
сравнению с традиционными методами. Во-первых, к ним следует отнести
возможность обнаружения дыма и огня даже на открытых пространствах, где
обычные методы химического анализа бесполезны. Во-вторых, реакция на
возникновение опасной ситуации является практически мгновенной: обнару-
жение огня происходит в момент его возникновения. В-третьих, видео позво-
ляет точно определить месторасположение очага возгорания. Наконец, воз-
можно проведение анализа уже имеющихся изображений с целью обнаруже-
ния огня и дыма на них, т. е. осуществление поиска соответствующих кадров
в видеоархивах.
Методы визуального обнаружения огня и дыма до недавнего времени осно-
вывались исключительно на спектральном анализе, который проводился с ис-
пользованием малораспространенной и крайне дорогостоящей аппаратуры. Бо-
лее того, такие методы также могут приводить к ложным срабатываниям систем
на объектах, по некоторым характеристикам напоминающих огонь.
В последнее десятилетие появились методы, которые при помощи обработки
изображений, поступающих с камеры, позволяют с той или иной степенью точ-
ности сделать заключение о появлении дыма или огня в области наблюдения [3-
8]. Эти методы можно разбить на три большие группы:
1. Гистограммные методы. Они основаны на вычислении гистограммы рас-
сматриваемого изображения и ее последующем анализе с целью опреде-
ления наличия дыма и/или огня в кадре. Построенную гистограмму мож-
но сравнивать с гистограммами изображений, на которых заведомо при-
сутствуют огонь и дым. Возможно также применение статистических ме-
тодов и вычисление соответствующих характеристик для детектирова-
ния пламени.
2. Методы, основанные на учете временных изменений. Данные методы
используют разность между двумя или несколькими кадрами видеопос-
ледовательности. После того как указанная разность найдена, применя-
ются различные подходы к идентификации объектов, например стати-
стические.
3. Комбинация предыдущих методов.
Однако большинство из этих методов являются работоспособными лишь
в идеальных условиях. Например, возможно использование цвета и движения
объектов для классификации областей изображения [3]. При этом инициа-
лизация камеры требует выделения вручную прямоугольников на изображе-
нии в зависимости от расстояния их содержимого до камеры. Следствием та-
кой сложной процедуры является требование неподвижности камеры. В ра-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ri/
Глава 10. Обнаружение дыма и огня по видеоизображению
405
боте [4] используются статистические методы, которые применяются к по-
лутоновым изображениям, полученным с камер с большой частотой смены
кадров. Хотя данный подход не является особенно сложным для реализации,
он практически неприменим в ситуациях, когда существует несколько объек-
тов. которые могут быть приняты за огонь. Так же, как и в [3], камера долж-
на быть стационарной для использования этого метода. Кроме того, его эф-
фективность значительно снижается при обработке видеопотока с невысо-
кой частотой смены кадров.
Принципиально другой подход использован в [9], где описана система специ-
альных распределенных по объему температурных датчиков, меняющих интен-
сивность свечения при повышении температуры. За этими изменениями интен-
сивности ведется наблюдение с помощью черно-белой камеры. Недостатком та-
кой системы является наличие большого числа сенсорных датчиков, расположе-
ние которых должно быть откалибровано должным образом для надежной ра-
боты данного алгоритма.
10.1. МЕТОД ОБНАРУЖЕНИЯ ОГНЯ, ОСНОВАННЫЙ НА ЦВЕТОВЫХ И
ДИНАМИЧЕСКИХ ХАРАКТЕРИСТИКАХ
Появившиеся в последние несколько лет методы частично используют
подходы, применявшиеся в ранних работах. Они в большинстве своем свобод-
ны от указанных выше ограничений вследствие их дальнейшего развития. При
этом в большинстве случаев в качестве входных данных используется видеопо-
ток с цветной камеры. На этапе обучения происходит выделение цвета и созда-
ние маски огня изображения. Для этого в качестве обучающей последователь-
ности выступают ранее полученные изображения, на которых выделяются об-
ласти, где присутствует пламя. При создании маски создается сглаженная гауссо-
выми фильтрами цветовая гистограмма. Отметим, что эта операция производит-
ся вручную и зависит от конкретной сцены, что, безусловно, является определен-
ным недостатком [10].
Алгоритм для создания маски и гистограмм предлагается следующий:
1. Для каждого изображения из обучающей последовательности создается
маска того же размера, элементы которой равны 1, если соответствую-
щий пиксель изображения имеет заданный цвет, и равны 0 для фоновых
пикселей. Обычно для формирования такой таблицы достаточно поряд-
ка десяти обучающих изображений. При этом необходимо, чтобы на них
всех были представлены разные сцены. На Рис. 1 показаны обучающие
изображения и полученные маски.
2. При построении цветовых гистограмм для каждого пикселя, имеюще-
го в маске значение «1», к гистограмме добавляется гауссово распреде-
ление, центрированное на цветовом значении рассматриваемого пиксе-
ля. Если же данный пиксель имеет в маске значение «0», то из цветовой
гистограммы вычитается самое меньшее гауссово распределение. При
этом в первом случае дисперсия распределения считается равной двум, а
во втором - единице.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
406
Цифвая обработка видеоизображений
Рис. 1. Исходные изображения (сверху), под ними созданные вручную маски огня
(снизу)
3. Для построенной гистограммы применяется фиксированное пороговое
значение, в результате чего получается функция С(/(л*. у)). которая для
любых (R.G. В) возвращает 0 или 1 в зависимости от того, принадлежит
ли этот цвет заданному цветовому диапазону. Здесь /,(дг. у) - это (R. G. В)
значения пикселя (х.у) в момент времени г.
Рис. 2. Изображение полупрозрачного пламени с книгой на заднем плане
Так как пламя имеет специфическую природу, то, помимо того, что
оно может быть полупрозрачным, оно также может исчезать со вре-
менем, в результате становясь практически незаметным (см. Рис. 2).
Это приводит к необходимости использования временных окон при обработке
цветов пламени. Самым простым способом вычисления вероятности события,
при котором пиксель имеет цвет пламени в некой последовательности кадров.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 10. Обнаружение дыма и огня по видеоизображению 407
является усреднение по времени вероятности того, что данный пиксель принад-
лежит области огня на изображении:
£с(/,(х,у))
Р(х, у) = —---------. (1)
п
[1, Р(х,у)>5,
Со/ог(х,у) = < , (2)
0, Р(х,у)<5,
где п - число кадров последовательности. - пороговое значение. При частоте
смены кадров, равной 30 кадрам в секунду, для п рекомендуется выбирать значе-
ние в диапазоне отЗдо 10. а для - значение порядка 0.2. Р(х.у) представляет со-
бой вероятность появления цвета пламени на изображении в данном месте (х.у) в
последовательности из п кадров. Бинарная величина Color(x.у) обозначает, при-
сутствует ли в данной точке пламя или нет.
Одного признака, каковым является цвет, недостаточно для корректной
идентификации огня на изображениях. Существует множество объектов, имею-
щих тот же цвет, что и пламя (например, красные листья на деревьях или солнце
на закате). Ключевым отличием при этом является характер движения объектов.
В промежутке между двумя последовательными кадрами форма пламени может
меняться весьма существенно, присутствуя в конкретном пикселе только опреде-
ленное время, как это проиллюстрировано на Рис. 3.
Рис. 3. Изменение формы пламени между двумя последовательными кадрами
Поэтому для корректного детектирования огня необходимо использовать
признаки, основанные на динамических изменениях сцены D(x. у) в сочетании с
признаками, определяющими цвет пламени. Динамические изменения определя-
ются при помощи усреднения по п кадрам модуля разности интенсивностей одно-
го и того же пикселя между двумя последовательными кадрами:
D(x,y) = . (3)
/7-1
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
408
Цифвая обработка видеоизображений
где J - функция, которая для данных значений (/?. G, В) возвращает значение, рав-
ное (R ч- G + В)13.
Однако вычисление одной такой разности может приводить к неверным ре-
зультатам, так как интенсивность пикселя может меняться также вследствие дви-
жения объектов. Поэтому точно такая же разность М(х<у) вычисляется для фо-
новых пикселей:
N(x,y) = -------
и вычитается из D(x.y) для устранения эффектов движения:
А (х, у) = D (х, у) - N (х, г).
(4)
(5)
здесь М - это количество пикселей изображения, являющихся фоном.
Наибольшие значения величина D(x. у) принимает для пикселей, соответ-
ствующих отблескам огня, а движения объектов обычно характеризуются мед-
ленными временными изменениями интенсивности. Это свойство используется
для удаления пикселей, которые ошибочно были детектированы как огонь:
Color(х,у) = 1, Д(х,у)><52
иначе
(6)
где 82 - экспериментально определенное пороговое значение.
Тем не менее, существует ряд случаев, когда вычисления выражения (6) недо-
статочно для корректной идентификации огня на изображении. Например, солн-
це может отражаться случайным образом от различных объектов, приводя к по-
явлению и исчезновению новых источников света. Поэтому часто в изображени-
ях, где присутствует солнечное освещение, ряд пикселей, не относящихся к пла-
мени, имеет весьма большие значения Д(х,у). Последовательности кадров, на ко-
торых детектируется большое число пикселей цвета огня, но малое число бы-
стро движущихся пикселей, помещаются в специальный класс С, - «пламя мало-
вероятно и не обнаружимо». На практике подсчитывается число пикселей изо-
бражения Nv для которых Fr(x,y) = 1, и сравнивается с числом пикселей Nr для
которых Co/or(x,y) = 1. Если N2 меньше порогового значения 8Vто считается, что
огня в изображении нет. Если N2 > 8r a IN2 < <54, то изображение помещается в
класс Сг Для 83 и <54 рекомендуются соответственно значения порядка 10 и 0.001.
Возможна также ситуация, когда изображение огня занимает практически все
изображение, при этом детектирование огня будет осуществляться некорректно.
Поэтому, если контрастность изображения мала, а интенсивность, наоборот, ве-
лика, изображение помещается в класс С2 - «пламя вероятно, но не обнаружимо».
Одной из главных проблем при выделении огня на изображениях являет-
ся отражение пламени от объектов, расположенных рядом с очагом огня. Опе-
рация эрозии может устранить большую часть таких отражений. При этом для
каждого пикселя огня рассматриваются восемь соседних с ним пикселей, и если
не более четырех из них являются пикселями огня, то рассматриваемый пик-
сель исключается из их числа. На Рис. 4. показан результат применения опера-
ции эрозии к изображению.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 10. Обнаружение дыма и огня по видеоизображению
409
Рис. 4. В левом нижнем углу первого снимка (до применения эрозии) наблюдается
отражение пламени, выделенное белым цветом. Правый снимок - результат при-
менения операции эрозии.
Результатом применения операции эрозии будут пиксели, являющиеся наи-
более вероятными пикселями огня. Однако, избежав ложного выделения пиксе-
лей. можно также потерять некоторую часть пикселей, в действительности яв-
ляющихся пикселями огня. т. е. пиксели, находящиеся в центре пламени (вслед-
ствие отсутствия там какого-либо движения). Следовательно, для нахождения та-
ких пикселей необходимо применить процедуру укрупнения областей огня, рас-
сматривая при этом только один признак - цвет.
Будем рекурсивно рассматривать все точки, соседние с пикселями огня, и счи-
тать их искомыми, если они окрашены в необходимый цвет. т. е. временные из-
менения теперь учитывать не будем. Фактически в результате выполнения этой
операции происходит как бы снижение ранее установленного порогового значе-
ния. поскольку к огню теперь будут отнесены точки, являющиеся соседними с
пикселями огня. Данная процедура рекурсивно повторяется до тех пор. пока су-
ществуют изменения в классификации пикселей. Во время каждой итерации по-
роговое значение постепенно повышается.
10.2. УЧЕТ ПРОСТРАНСТВЕННОЙ СТРУКТУРЫ ОГНЯ.
Главным недостатком описанного выше подхода является упрощенное опи-
сание области огня на изображении, не учитывающее пространственной струк-
туры огня, а именно того факта, что центр пламени ярче, чем периферия. Кроме
того, динамика изменения цвета пикселя должна согласовываться с изменения-
ми изображения огня как целого, например, пиксели в центральной части пламе-
ни меняют свои свойства со временем в гораздо меньшей степени, чем на пери-
ферии. При обнаружении огня на изображении важны не только цвет, но также
форма и движение рассматриваемой области. Последняя может быть описана в
терминах характеристик составляющих ее пикселей и с помощью спектральных
изменений их пространственной структуры. Форма области огня обычно посто-
янно изменяется и при этом осуществляет стохастические перемещения, завися-
щие от внешних факторов, таких как тип горящего материала и охватывающие
очаг возгорания воздушные потоки.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
410
Цифвая обработка видеоизображений
Пиксели огня имеют характерный цвет. Например, в цветных снимках центр
огня обычно ярко-белого цвета, который постепенно переходит в желтый, оран-
жевый и красный, если двигаться по направлению к периферии пламени. В по-
лутоновых изображениях центральная часть значительно более яркая по срав-
нению с приграничными областями. Необходимо отметить, что область огня мо-
жет включать в себя несколько отдельных ярких участков (Рис. 5). Таким обра-
зом, область огня на отдельно взятом изображении может быть описана как,
во-первых, имеющая наибольший контраст с соседними областями и, во-вторых,
имеющая вложенную кольцевую структуру цвета, начиная от белого в центре и
заканчивая красным на периферии.
Рис. 5. Примеры вложенной кольцевой структуры огня. Один очаг пламени (слева),
два очага пламени (справа).
Огонь обычно имеет достаточно стабильную форму (в глобальном смысле),
определяемую формой горящего материала, и быстро меняющуюся локальную
форму при отсутствии внешней границы. Следовательно, низкочастотные ком-
поненты границы области огня относительно стабильны во времени, а высоко-
частотные компоненты меняются случайным образом. Поэтому для описания ха-
рактерного движения границы огня со временем можно использовать стохасти-
ческую модель.
Обычно сначала на изображении выделяются потенциальные области огня
при помощи спектральных и пространственных моделей. Затем границы выде-
ленных областей представляются коэффициентами разложения Фурье. После
этого оцениваются параметры авторегрессионной модели для каждой области
и соответствующей ей области в предыдущих кадрах видеопотока. И, наконец,
коэффициенты Фурье и параметры авторегрессионной модели используются в
качестве характерных признаков для выделения на изображении областей, дей-
ствительно содержащих огонь.
Нахождение потенциальных областей огня чаще всего выполняется в полу-
тоновых изображениях с помощью выделения областей высокой интенсивности.
Каждая выделенная область затем расширяется в направлении градиента спек-
тра путем присоединения соседних пикселей, которые с высокой вероятностью
имеют цвета, соответствующие выбранной цветовой модели. Плотность вероят-
ности внутренней части области описывается смесью гауссовых распределений в
цветовом пространстве (например, HSV). Для каждой выделенной области про-
ProSystem CCTV - журнал по системам видеонаблюдения
http://wwvv.proccfv.ru
Глава 10. Обнаружение дыма и огня по видеоизображению
411
изводится обход вдоль границы, в процессе которого осуществляется следующая
проверка: не совпадает ли цвет половины граничных точек с цветом внутренней
части области? Это позволяет эффективно устранять области, в которых боль-
шая часть пикселей имеет очень высокую интенсивность (например, совершен-
но белые области) [11].
Для описания непрерывной границы области огня можно использовать раз-
личные методы. Одним из наиболее эффективных подходов является использо-
вание цепных кодов, которые применяются для представления границы в виде
последовательности отрезков прямых линий определенной длины и направле-
ния. Обычно в основе этого представления лежит 4- или 8-связная прямоуголь-
ная решетка. Направление каждого отрезка кодируется числом в соответствии с
выбранной схемой. Например, на Рис. 6 представлена схема нумерации для 8-связ-
ного цепного кода. Как правило, при обработке изображений используется сет-
ка с постоянным шагом, поэтому для кодирования границы достаточно указы-
вать номер направления отрезка, соединяющего соседние пиксели границы при
ее обходе.
Рис. 6. Нумерация направлений для 8-связного цепного кода
Предположим, что мы получили /V точек цепного кода границы. Выразим их
в комплексной форме:
+ (7)
где (х,уг) - координаты граничных точек при обходе границы по часовой стрел-
ке, а / - комплексная единица. Тогда коэффициенты дискретного преобразования
Фурье, примененного к комплексному вектору z с компонентами {z. }.=р выглядят
следующим образом:
1 Л ( Л
z> exiv7 V' j’ (8)
a j - мнимая единица. Если использовать М главных
гармоник М <
N~\
2
то коэффициенты {аЛ}^_
можно применять для опи-
1 V
сания формы границы области огня. Заметим, что ao = 7/2jz» представляет
-м
где к = -
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
412
Цифвая обработка видеоизображений
собой центр масс одномерной границы и нс несет в себе никакой информации о
ее форме. Поэтому этот коэффициент лучше не использовать, так как при этом
появится инвариантность к смещению.
Форма пламени не является инвариантной к вращению, поэтому всегда мож-
но выбрать в качестве начальной точки обхода границы области самую верхнюю
точку ее контура. В данном случае только внешняя граница области описывается
с помощью коэффициентов Фурье. В общем случае граница каждой вложенной
кольцевой области может быть представлена аналогичным образом.
Стохастические характеристики движения границы области огня можно оце-
нить с помощью авторегрессионной модели изменений коэффициентов Фурье.
Эта модель основывается на предположении о том, что каждый член временного
ряда линейно зависит от нескольких предыдущих членов и шума. Так как низко-
частотные коэффициенты практически стационарны, а высокочастотные силь-
но меняются со временем, то такая модель позволяет описать различные уровни
динамической зависимости коэффициентов Фурье.
Предположим, что vk - это m-мерный случайный вектор, наблюдаемый че-
рез равные промежутки времени. Тогда авторегрессионная модель р-го порядка
определяется как
р
vt='^A.vk-l+nk- (9)
1=1
Здесь матрицы At е содержат коэффициенты авторегрессионной модели, а
ш-мерные векторы nk представляют собой некоррелированные случайные век-
торы с нулевым математическим ожиданием. Если используется М гармоник ко-
эффициентов Фурье, тогда 2М-мерные случайные векторы vk описывают форму
области в момент времени к. Будем считать, что в каждый момент времени все
коэффициенты являются независимыми друг от друга. В этом случае матрицы At
будут диагональными.Таким образом, задача сводится к моделированию 2М вре-
менных рядов.
Для того чтобы выбрать оптимальный порядок авторегрессионной модели,
можно воспользоваться байесовским критерием Шварца [12], суть которого со-
стоит в минимизации предсказанной среднеквадратичной ошибки. Можно пока-
зать, что минимальная ошибка получается при р = 1,т. е.
v* = ^v*-i + «*. (Ю)
Параметры авторегрессионной модели можно оценить с помощью алгорит-
ма Ньюмайера-Шнайдера [13].
10.3. ПРИМЕНЕНИЕ ВЕЙВЛЕТОВ ДЛЯ ДЕТЕКТИРОВАНИЯ ПЛАМЕНИ
При появлении дыма на изображении снижается его резкость, что в свою
очередь приводит к уменьшению высокочастотных составляющих энергии.
Это свойство может быть с успехом использовано для детектирования дыма
в видеопоследовательности. Для анализа высокочастотных компонент энер-
гии наиболее разумным является применение вейвлетов [14-18]. С их помо-
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. ргосс t v. г и
Глава 10. Обнаружение дыма и огня по видеоизображению
413
щью может быть разработан многоступенчатый алгоритм, включающий в
себя следующие этапы:
1. определение движущихся пикселей или областей в данном кадре видеопотока,
2. проверка соответствия цвета выделенных движущихся пикселей заранее
определенной цветовой гамме огня.
3. вейвлет-преобразования во временной области,
4. вейвлет-преобразования в пространстве для определения высокочастот-
ных компонент в движущихся областях.
Рассмотрим эти этапы более подробно.
103.1. Определение областей движения.
Движущиеся пиксели и области в видеопотоке определяются при помощи ме-
тода выделения фона. Пусть /г(х. у) значение интенсивности (яркости) в точке (х,у)
в момент времени /.Тогда фон в момент времени t + 1 вычисляется как
аВ/(х,у)-ь(1-а)//(х,у), (х,у) не двигается
пДх,у), (х,у) двигается
где В{(х,у) - значение фона в той же самой точке (х,у) в предыдущий момент вре-
мени. Параметр а представляет собой действительное число, близкое к 1. В на-
чальный момент времени положим В0(х,у) = /0(х,у). Пиксель (х,у) считается дви-
жущимся, если выполняется следующее неравенство:
IА (*» у) - А-i (*, у)| > 8, (*. Л (12)
где 5(х,у) - адаптивное пороговое значение. Предполагается, что области, суще-
ственно отличающиеся от фоновых, являются движущимися. Поэтому из теку-
щего кадра вычитается фон для определения движущихся пикселей:
оз)
Найденные пиксели, удовлетворяющие (13), группируются в связные области
(блобы). В результате получается бинарная карта Blobs(x,y),c помощью кото-
рой определяется, является ли пиксель (х,у) движущимся.
Для определения движущихся пикселей можно также применять более со-
вершенные методы. Однако для данной задачи точность определения движущих-
ся областей не так критична, как при трекинге. Необходимо всего лишь в реаль-
ном времени приблизительно определить движущиеся пиксели, которые затем
будут использованы в качестве начального грубого приближения для детекти-
рования огня. Потому основной упор следует делать на вычислительную эффек-
тивность алгоритма.
103.2. Проверка цвета движущихся пикселей
Цвет выделенных движущихся пикселей сравнивается с заранее задан-
ным цветовым распределением, которое представляет собой возможную
цветовую гамму огня в пространстве RGB. Такое распределение получается
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
414
Цифвая обработка видеоизображений
при помощи обработки изображений, содержащих области огня. Возможная
цветовая гамма образует набор точек в трехмерном пространстве, как пока-
зано на Рис. 7А. Такой набор точек можно описать смесью гауссовых распре-
делений в пространстве RGB. На Рис. 7Б изображена модель, состоящая из
десяти распределений.
Рис. 7. Возможное расположение цветовой гаммы огня (А) и смесь гауссовых рас-
пределений, описывающих ее (Б)
Пусть /(х. у) - пиксель с координатами (х. у) и цветовым значением
[г а (. J. Будем проверять, лежит ли данный пиксель в пределах двух
стандартных отклонений от центров гауссианов. Другими словами, если цвет
данного пикселя попадает внутрь сферы, показанной на Рис. 7Б. то он считается
имеющим цвет огня. Введем бинарную маску, определяющую, имеет ли рассма-
триваемый пиксел ьцветогня. Ее пересечение с маской Я/о/>.\.описанной на преды-
дущем этапе, дает новую маску, называемую Fire.
10.3.3 . Вейвлет-анализ во временной области
На данном этапе алгоритма анализируется эволюция частотной компо-
ненты пикселей в областях огня. Для того чтобы надежно обнаружить вы-
сокочастотные области и осцилляции значений пикселя огня, необходимо,
чтобы видеопоследовательность имела достаточно высокую частоту смены
кадров. Например, чтобы детектировать области, возникающие с частотой
10 Гц. видео должно иметь не менее 20 кадров в секунду. Однако в большин-
стве систем видеонаблюдения это требование не выполняется, и частота сме-
ны кадров меньше 20 Гц. При этом возникает наложение частот, но отблески,
тем не менее, могут быть обнаружены в видеопотоке. Например. 8-герцовая
синусоида проявится как синусоида с частотой 2 Гц в видео с частотой смены
кадров, равной 10 Гц.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 10. Обнаружение дыма и огня по видеоизображению
415
— ВЧ фильтр |2
/Дх^у) ВЧ фильтр 1 1 2 —
НЧ фильтр j 2
[ НЧ фильтр 1 2
Рис. 8. Двухступенчатая система фильтрации
Каждый пиксель /(х. >•) из бинарной маски Fire подается на вход двухсту-
пенчатой системы фильтрации, как показано на Рис. 8. Сигнал /(х, у) - это од-
номерный сигнал, представляющий собой временные изменения значений цве-
та в точке (х, у) в момент времени t. Временное вейвлет-преобразование мо-
жет быть осуществлено или с использованием У компоненты в цветовом про-
странстве YUV или R компоненты в пространстве RGB. Двухступенчатая си-
стема фильтрации состоит из высокочастотного и низкочастотного фильтров,
t
Рис. 9. Изменения во времени значений /^-компоненты интенсивности //х, у) и
вейвлет-сигналов (A), dt(х, у) (Б) и е/х, у) для одного из пикселей, являющегося
частью огня в кадрах 1-3,19, 23, 24, 41 и 50 (В)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
416
Цифвая обработка видеоизображений
каждый из которых охватывает половину всего частотного диапазона и име-
ет следующие коэффициенты {-0.25: 0.5: -0.25) и {0.25: 0.5; 0.25), т. е. сигналы
на выходе фильтров определяются как -0.25/ t(x, у) + 0.57 (х, у) - 0.25 7к1(х, у) и
0.25/, ,(х. у) + 0.5/Дх. у) + 0.25 У ,(х. у) соответственно. В результате фильтра-
ции и прореживания получаются вейвлет-сигналы б/,(х,у) и с(х, у). Если в точке
(х.у) наблюдаются высокочастотные осцилляции, то сигналы d и et будут иметь
ненулевые значения. Для стационарных пикселей их значения будут нулевыми
или очень близкими к нулю. Если пиксель в некоторый момент времени явля-
ется частью границы пламени (Рис. 9). то в течение секунды будут появляться
пики вследствие перехода цвета фона к цвету пламени и наоборот. Если же объ-
ект. окрашенный в цвет огня, движется через точку (х, у), то в одном из профи-
лей сигналов появится только один пик из-за перехода от фонового цвета к цве-
ту объекта (Рис. 10).Таким образом, количество переходов через нуль сигналов d
и С' может быть использовано для отличия пикселей огня от пикселей объектов,
имеющих цвет огня. Для этого всего лишь требуется ввести пороговое значение.
Количество необходимых этапов вейвлет-преобразований определяется ча-
стотой смены кадров в видеопотоке. На первом этапе получается низкочастот-
ный сигнал и высокочастотный вейвлет-сигнал rf(x,y) исходного сигнала 7(х,у).
Рис. 10. Изменения во времени значений /?-компоненты интенсивности 7(х, у) (А) и
вейвлет-сигналов J (х, у) (Б) и е (х, у) для одного из пикселей, являющегося частью
имеющего цвет огня объекта в кадрах 4-8 (В)
ProSystem CCTV - журнал по системам видеонаблюдения
ht tp://www.procctv. •
Глава 10. Обнаружение дыма и огня по видеоизображению
417
Сигнал dt(х. у) содержит диапазон [2.5 Гц; 5 Гц] исходного сигнала /(х. у) при
10 кадрах в секунду. На втором этапе обрабатывается низкочастотный сигнал
е(.г. у), содержащий частотный диапазон [1.25 Гц; 2.5 Гц].Таким образом, анализи-
руя вейвлет-сигналы dt(x.y) и е^х.у). можно определить флуктуации в точке (х,у)
в диапазоне от 1.25 Гц до 5 Гц.
10.3.4 . Пространственный вейвлет-анализ
На последнем этапе алгоритма детектирования огня для определения изме-
нения цветовых значений производится вейвлет-анализ движущихся областей,
содержащих пиксели маски Fire. В обычном объекте, имеющем цвет огня, изме-
нения цвета в движущихся областях будут незначительными (Рис. ПА). В движу-
щихся областях, соответствующих пламени на изображении.такие изменения бу-
дут весьма существенными (Рис. 12А). Поэтому производится пространственный
вейвлет-анализ. Изображения на Рис. 11Б и Рис. 12Б получены после осуществле-
ния двумерного вейвлет-преобразования с использованием системы фильтрации,
описанной выше. В результате вычисляется параметр v4:
v4 = ^£l^'\^y)|2+|w'*'k>')|2+|w'‘AU.y)|2. (14)
где Wlh(x\ у) - коэффициенты пространственного вейвлет-преобразования. по-
лучающиеся после применения сначала низкочастотных, а потом высокочастот-
ных фильтров. Whl(x. у) - после применения сначала высокочастотных, а потом
низкочастотных фильтров и Whh(x. у) - после двухразового применения высо-
кочастотного фильтра, MN - число пикселей изображения, соответствующих
Рис. 11. Изображение девушки в свитере, окрашенном в цвет, близкий к цвету огня
(А); сумма абсолютных значений коэффициентов пространственного вейвлет-
преобразования |VV/A(x. у)| + |IV''(a. у)| + |HF/,/,(.v. у)| для области, ограниченной
прямоугольником (Б)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
418
Цифвая обработка видеоизображений
движущимся областям цвета огня. Если найденный параметр v4 превышает на-
перед заданное пороговое значение, то существует большая вероятность того,
что эта движущаяся и имеющая цвет огня область в действительности являет-
ся областью огня.
После осуществления описанных выше четырех этапов необходимо принять
решение: являются ли выделенные области действительно областями огня? Для
этого используется следующая схема. Вычисляется величина
4
H = (15)
где и; - заданные весовые коэффициенты, г - результаты четырех этапов алгорит-
ма. Если значение Н превышает порог 5. то считается, что данный пиксель являет-
ся пикселем огня. Параметры г могут принимать значения 0 или 1. соответствую-
щие отсутствию или наличию огня. Параметр = 1.если пиксель является движу-
щимся. и V! = 0 - если он стационарен. Параметр v, = 1 .если пиксель имеет цвет огня
и 0 - в противном случае. Параметр v3 = 1, если число переходов через 0 сигналов
е,(ху) и rf(.v.у) в течение нескольких секунд превышает пороговое значение и 0 - в
противном случае. Параметр г4 определяется с помощью выражения (14).
В случае неконтролируемого распространения огня он будет иметь невы-
пуклую границу. Поэтому, для того чтобы исключить ложные тревоги, добавля-
ется еще один этап, на котором проверяется выпуклость области огня. Границы
областей маски Fire проверяются на выпуклость вдоль равномерно расположен-
ных 5 вертикальных и 5 горизонтальных прямых, составляющих сетку размером
5x5. Анализ состоит в проверке того, принадлежат ли пиксели на каждой прямой
исследуемым областям или нет. Если, по крайней мере.три последовательных пик-
селя принадлежат к фоновым, тогда эта область нарушает условия выпуклости.
Область маски Fire. которая имеет фоновые пиксели не пересекающихся верти-
кальных и/или горизонтальных прямых.считается имеющей невыпуклую границу.
Рис. 12. Изображение огня (А) - сумма абсолютных значений коэффициентов про-
странственного вейвлет-преобразования |И'/Л(.г. у)| + у)| + у)| для
области, ограниченной прямоугольником (Б)
ProSystem CCTV - журнал по системам видеонаблюдения
http://w w w procctv. ru
Глава 10. Обнаружение дыма и огня по видеоизображению 419
10.4. СКРЫТЫЕ МАРКОВСКИЕ МОДЕЛИ ДЛЯ ОПИСАНИЯ
ДВИЖУЩИХСЯ ОБЛАСТЕЙ ОГНЯ
Известно, что турбулентные процессы в пламени протекают с частотой по-
рядка 10 Гц [19]. Поэтому методы обнаружения огня могут быть сделаны более
надежными при помощи детектирования высокочастотных колебаний в движу-
щихся точках, имеющих цвет огня. На практике частота таких колебаний не по-
стоянна, а меняется со временем. Более того, эти изменения можно рассматри-
вать как случайные события. Поэтому представляется вполне естественным ис-
пользование скрытых марковских моделей [20].
Если контуры некоего объекта совершают быстро меняющиеся во време-
ни движения, то это является важным показателем наличия огня.Такие колеба-
ния можно обнаружить, анализируя значения пикселей по всем цветовым ка-
налам. Поэтому представляется реальным построить модель, включающую в
себя состояния, представляющие относительное расположение пикселей в цве-
товом пространстве. Такая модель, обученная по имеющимся изображениям
огня, впоследствии будет успешно имитировать пространственно-временные
характеристики пламени. При этом обучение необходимо также вести и по изо-
бражениям, где отсутствует пламя. В противном случае невозможно будет от-
личить действительное изображение огня от изображений объектов, имеющих
схожий с пламенем цвет. Кроме того, в пламени существуют пространственные
изменения цвета, что также может быть описано в рамках марковских моделей.
Форму областей огня можно описать с помощью Фурье преобразования [11].
Однако оно не несет в себе никакой временной информации.Такое преобразова-
ние необходимо осуществлять в окнах, размер которых очень важен для получе-
ния корректных результатов. Если эти окна будут слишком большими, то мы не
получим ряд максимумов в преобразованных данных. Для слишком маленьких
окон возможен пропуск отдельных циклов, и, следовательно, максимумы в Фу-
рье данных могут вообще отсутствовать. Кроме того, практически невозможно
обнаружить периодичность в быстро растущих областях огня. Использование
скрытых марковских моделей позволяет решить указанные проблемы.
Хотя существует достаточно большое разнообразие в типах огня, цветовая
гамма в них, особенно в начальной стадии горения, попадает в диапазон от крас-
ного до желтого цвета. В терминах tfGB-пространства этот факт можно записать
как R > G > В. Кроме того, красная компонента должна быть не просто больше
зеленой и синей, она должна превосходить некоторое пороговое значение <5*,так
как эта компонента является доминирующей в изображениях огня. Однако усло-
вия освещения фона могут оказывать воздействие на значения насыщенности
пламени, в результате чего появляются пиксели со значениями R, G и В, близки-
ми к таковым для огня. Поэтому значения насыщенности для пикселей огня так-
же должны превышать некий порог. Таким образом, для того чтобы считать, что
пиксель соответствует огню, должны выполняться следующие условия:
1. R > 8R,
2. R>G>B,
http://www. itv. ги
Компания ITV - генеральный спонсор издания книги
Рис. 13. Марковские модели с тремя состояниями для движущихся пикселей огня
(слева) и не являющихся пикселями огня (справа)
g
3. S >(255- R) —где S - насыщенность, a 3S - значение насыщенности
при R - 8К.
Как известно, насыщенность уменьшается при увеличении значений R. Этот
факт отражен в правой части третьего неравенства. Типичные значения 8S лежат
обычно в пределах от 40 до 60, a 3R - от 170 до 190.
Структура скрытых марковских моделей, которые будут использованы для
обнаружения огня на изображении, представлена на Рис. 13. Состояние F0 со-
Рис. 14. Диаграмма переходов из состояния в состояние для цепи Маркова
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. ргосс t v. ги
Глава 10. Обнаружение дыма и огня по видеоизображению
421
ответствует пикселю, имеющему цвет огня. т. е. удовлетворяющему трем выше-
перечисленным условиям. Состояние F1 также соответствует пикселям огня, но
цветовой диапазон F1 отличен от F0. Так как значения пикселей огня меняются
в некоторых пределах, то состояния F0 и F1 описывают такие изменения. Состо-
яние F2 зарезервировано для пикселей, не являющимися пикселями огня. Пусть
5r(z) - состояние пикселя л в момент времени t. Условия для перехода из одного
состояния в другое для пикселя х показаны на Рис. 14. На представленной там ди-
аграмме RJj) обозначает значение R компоненты для пикселя х в момент време-
ни г, а 5х'(г) - состояние И. если 5х(г) - состояние F0 и наоборот.
Пороговые значения должны удовлетворять неравенству < 5,, например
иметь значения «10» и «40» соответственно. Переход из состояния F0 в состояние
FI происходит в том случае, когда существуют довольно значительные измене-
ния в значениях канала R пикселя, имеющего цвет огня. Когда такие изменения
превышают верхнее пороговое значение 8Г происходит переход в состояние F2.
Когда указанные изменения не превосходят нижнего порогового значения 8}, пе-
рехода из текущего состояния не происходит.
Такая модель представляет собой основу для временного и пространствен-
ного анализа как пикселей огня, так и пикселей, таковыми не являющимися. Ве-
роятности перехода для огня aif и обычных объектов h вычисляются заранее на
основе изображений, отобранных для обучения.
Таким образом, алгоритм обнаружения огня состоит из четырех этапов. Пер-
вые два - определение областей движения и проверка цвета пикселей в них - пол-
ностью аналогичны описанным в предыдущем разделе, посвященном вейвлет-
анализу. Если цвета пикселей движущихся областей соответствуют цветам огня,
то используются марковские модели для динамического (третий этап) и про-
странственного (четвертый этап) анализа на предмет того, что выделенные пик-
сели в действительности являются пикселями огня.
10.5. ИСПОЛЬЗОВАНИЕ ИЗМЕНЕНИЯ КОНТРАСТНОСТИ
ИЗОБРАЖЕНИЯ ДЛЯ ОБНАРУЖЕНИЯ ДЫМА
При наличии дыма изображения теряют контрастность, что и может быть
использовано для обнаружения задымлений [21-22]. Для простоты будем рассма-
тривать только контрастность яркости. Контрастность С изолированного объек-
та, рассматриваемого на однородном протяженном фоне, определяется как
С = ^£-~-£-\ (16)
где Ьо и Lb - яркости объекта и фона соответственно. Яркость количественно
оценивается отношением силы света источника в рассматриваемом направлении
к площади проекции светящейся поверхности на плоскость, перпендикулярную
этому направлению. При появлении дыма контрастность на расстоянии R умень-
шается до величины
Ск =Сехр(-/^ R\ (17)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
422
Цифвая обработка видеоизображений
где коэффициент К, характеризующий ослабление силы света вследствие дыма,
может быть выражен через концентрацию частиц дыма по следующей формуле:
АЛ/
K = 2.3D = 2.3Dm---. (18)
т у v '
Здесь D - оптическая плотность, Dn - массовая оптическая плотность, АЛ/ - по-
теря массы горящего объекта. V - объем помещения, где произошло возгорание.
Значения Dm затабулированы (например, в [23]). Когда задымление происходит в
туннеле, выражение (18) с учетом потоков ветра приобретает вид
К = 23D (19)
т dV dt
где dMIdt - потеря массы горящего объекта, a dVIdt - объемный поток воздуха
в туннеле. Для правильной оценки dVIdt необходимо принять во внимание суще-
ствующие потоки воздуха как вследствие разности температур, возникшей из-
за огня, так и вследствие искусственной вентиляции в замкнутых пространствах
(так называемые естественная и вынужденная конвекция). Анализируя соответ-
ствующие реакции горения, можно соотнести объем выделяющегося газа и по-
терю массы горящего объекта.
На ранних стадиях возгорания происходит разложение преимущественно ор-
ганических материалов. Это означает, что можно ограничиться рассмотрени-
ем наиболее общих для органических субстанций элементов, а именно, углеро-
да, водорода, кислорода и серы, последняя из которых часто встречается в каче-
стве примеси. Благодаря принципу суперпозиции химических реакций достаточ-
но рассмотреть следующие реакции горения:
С + О2 = СО2, (20)
4Я + О2=2Я2О, (21)
S + O2=SO2. (22)
В случае недостатка кислорода дополнительно образуется монооксид угле-
рода, и в то же самое время происходит реакция СО с водой:
2С + О2=2СО, (23)
СО+Н2О = СО2+Н2. (24)
Последняя реакция является эндотермической и, следовательно, зависит от
температуры в зоне горения. Если в горении также задействованы субстан-
ции, содержащие галогены, то они реагируют в основном с водородом с обра-
зованием кислот. Но, учитывая, что в настоящее время галогены практически
не используются в современных материалах, в дальнейшем мы их рассматри-
вать не будем.
Принимая во внимание стехиометрические реакции (20)-(24), масса кислоро-
да тОУ необходимая для полного сгорания 1 кг горящего материала, может быть
найдена по следующей формуле:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 10. Обнаружение дыма и огня по видеоизображению
423
то = 2.664ис + 7.937и”я + 0.998и*5 — wo. (25)
Здесь и’к обозначает массовую долю элемента X в горящем материале. Исполь-
зуя уравнение идеального газа, эта доля может быть преобразована в эквивалент-
ный объем при заданных давлении, температуре и составе горящего материала.
Уравнение, описывающее поведение огня во времени, может быть записано
следующим образом:
~q = q = Abt\ (26)
где dqldt описывает высвобождение тепла при горении, А - площадь зоны горе-
ния. Ь - константа, t - время, прошедшее с момента возгорания. Величина dqldt воз-
растает до тех пор. пока не достигнет максимального значения, зависящего от гео-
метрии формы пламени и от природы горящего материала. С помощью энтальпии
dqldt можно связать с потерей массы dMIdt. Энтальпия горения выражается как
h = (338 • 1 О’ wc +1004 10$ и„ + 95 105 w5 - wo) Дж/кг. (27)
Так как dqldt = h • dMldt.ro можно записать
= (28)
В качестве примера рассмотрим возгорание автомобиля в туннеле с площа-
дью поперечного сечения Ашппе1 = 60 м2. Будем считать, что горящий материал
имеет следующий состав: и*с = 0.78, и’;/ = 0.12, wo = 0.1, что является типичным для
пластика и углеводородов. Из уравнения (25) получим, что масса кислорода, не-
обходимая для сгорания 1 кг материала, равна 0.852 кг или 26.7 молей атомарного
кислорода, т. е. И = 0.33 м3 при нормальных условиях. Так как процентное содер-
жание кислорода в воздухе составляет 21 %, этот объем соответствует приблизи-
тельно 1.5 м3 воздуха. Это относительно небольшой объем, если сравнивать его
с конвекцией, равной 120 м3/с при скорости ветра 2 м/с. Отсюда становится ясно,
что, по крайней мере, на начальных стадиях возгорания будет обеспечен доста-
точный приток кислорода, благодаря конвекции. Поэтому будет оправданным
положить dVIdt равным произведению скорости ветра и площади поперечного
сечения туннеля. С помощью данного упрощения можно теперь оценить время,
необходимое для обнаружения возгорания: из уравнений (19) и (28) получим:
Aht1
К = 23Dm (29)
hV
После начала возгорания пройдет определенное время, прежде чем дым достиг-
нет зоны обнаружения, по которой интегрируется величина KR из формулы (17).
В течение этого времени ничего обнаружено не будет. Затем KR начнет возрас-
тать, пока не достигнет максимума.
Например, пусть состав горящего материала такой же, как и выше,
Aiunnd = 60 м2, расстояние между огнем и камерой равно 150 м, длина интегрирова-
ния R = 10 м. максимальное значение dqldt равно 5 МВт, А = 2 м2, Ь = 30 Вт/ (м2с2).
Тогда h = 12 МДж/кг и Dm = 0.5 м2/г, и дым от огня достигнет зоны обнаружения
через 70 с после начала возгорания.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
424
Цифвая обработка видеоизображений
Рис. 15. Снимки, сделанные в туннеле Шенберг около Зальцбурга (Австрия). Шири-
на туннеля 10 м, высота 6 м. Скорость ветра 1-1.2 м/с. Площадь возгорания 1 м2, ма-
териал горения 20 л бензина и 5 л дизельного топлива. Расстояние между камерой
и очагом возгорания 60 м.
Для тестирования описанного алгоритма несколько камер были установ-
лены в туннеле Шенберг около Зальцбурга и в одном из туннелей недалеко
от Цюриха [21]. В первом случае камеры работали в тестовом режиме, во вто-
ром - в рабочем, что позволило увидеть работу метода в реальных условиях ав-
томобильных аварий.длительных пробок, включения и выключения света. При
этом четыре камеры были установлены на боковой стороне туннеля на высо-
те 2.75 м. и четыре камеры - непосредственно по центру на потолке на высоте
4.3 м. На Рис. 15 показаны изображения, полученные в туннеле Шенберг [21].
10.6. БЛОЧНО-ТЕКСТУРНЫЙ МЕТОД ВЫДЕЛЕНИЯ ДЫМА НА
ВИДЕОИЗОБРАЖЕНИЯХ.
Данный метод выделения и сопровождения дымовых объектов на видеоизо-
бражениях частично основывается на идеях, изложенных в работах [24-26. 31]. и
состоит из следующих этапов:
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procct v. г и
Глава 10. Обнаружение дыма и огня по видеоизображению
425
1. выделение на изображении движущихся блоков,
2. пространственная кластеризация движущихся блоков,
3. временная кластеризация движущихся блоков,
4, определение формы объектов,
5. классификация выделенных объектов с помощью текстур и принятие ре-
шения о наличии дыма на изображении.
Рассмотрим эти этапы более подробно.
10.6.1. Выделение на изображении движущихся блоков.
В системах видеонаблюдения размеры объектов в основном довольно малы,
а изображения сильно зашумлены. Поэтому установить наличие движения объ-
ектов с высокой точностью (например, до одного пикселя) не представляется
возможным. Кроме того, это потребовало бы неоправданно больших вычисли-
тельных ресурсов. Следовательно, мы не можем применять с этой целью мето-
ды оптического потока. Параметрические методы,такие как построение аффин-
ных моделей, также не могут быть использованы, так как они позволяют отсле-
живать движение объектов с жесткой границей, к каковым дым не относится.
Поэтому в дальнейшем будем использовать блочный метод определения движе-
ния на изображении.
Для этого разобьем все изображение на блоки В. размером п х п пикселей.
Значение п зависит от размера объектов и разрешения изображения. Предпо-
ложим, что центр блока В находится в точке (х,у) в момент времени t и в точке
(х + Дх, у -ь Ду) в момент времени t + I.Тогда величины соответствия блоков и их
смещения для двух последовательных моментов времени выражаются следую-
щим образом:
d(s-) = *4 X |/<.1(х’3?)-А(х+Дх+‘^+д^+У)|2, (30)
п
Цв,) = ^ЦЛуУ. (31)
Для устранения ошибок второго рода (ложные движущиеся блоки), воз-
никающих вследствие шума, необходимо, чтобы величина D превышала по-
роговое значение За, которое может быть определено с помощью теста зна-
чимости. Для пикселя (х, у), где не происходит никакого движения, величина
d(x, у) = /(х,у) - /и(х,у) представляет собой шум камеры. Он, как известно, мо-
жет быть описан гауссовым распределением с нулевым средним и дисперсией ст2,
равной удвоенной дисперсии шума камеры [27]. Поэтому, если обозначить через
HQ гипотезу о том. что в точке (х,у) не происходит никаких изменений, функция
плотности вероятности шума камеры будет выглядеть как
p(d(x,y)\H0) = ехр
(32)
Пусть теперь
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
426 Цифвая обработка видеоизображений
г=J-т Z d''M (33)
п (х,у)еВ,
Предположим, что шум камеры статистически независим и переменная Т подчи-
няется закону х2 с п2 степенями свободы. Тогда уровень значимости а, соответ-
ствующий пороговому значению За, выражается следующим образом:
а = рДТ> <5„|//0). (34)
где (Т)- х2 распределение.
Таким образом, уровень значимости а можно рассматривать как вероятность
обнаружения блока Bt в качестве движущегося блока, хотя в действительности
он является неподвижным (ошибка второго рода). Если выбрать размер блоков
п = 16 и положить 8а = 1. то это будет соответствовать вероятности, равной 0.9.
10.6.2. Пространственная кластеризация движущихся блоков.
На данном этапе необходимо объединить отдельные схожие движущиеся
блоки, для которых величина D превышает пороговое значение <5а, в движущи-
еся области. Будем считать два блока соседними, если у них есть общая сторо-
на (или ее часть) или вершина, т. е. они связаны отношением смежности со все-
ми своими восемью соседями. В качестве характерных признаков блоков будем
использовать связность С(Вг В^ нормированную разность соответствия блоков
D(Br Bf) и нормированное смещение блоков Д(В, В ):
с(з..«,)=
1, /?, В/ - соседние
оо, иначе
(35)
о(в,)-о(в,)
°(3..3,) =
D(Br) + D(e,)
(36)
Д(«„В,) =
|д(В,)-Д|
Д(в,) + Д| (з,)
(37)
Расстояние между движущимися блоками будем определять как
оДя„57) = С(в„57) [0 £>(в„5у) + (1-0) д(в„Ву)], (38)
где в - параметр, для которого рекомендуется значение 0.3. Блоки Bt и В объеди-
няются в одну область, если значение (37) меньше порога 5с, равного 0.5.
Введем следующие обозначения:
• о(1) - индекс /-го элемента множества,
• 5(/с) - /с-й элемент множества 5,
• М - множество движущихся блоков.
• R- множество движущихся блоков в области с индексом /,
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 10. Обнаружение дыма и огня по видеоизображению
427
• R - множество движущихся областей,
• TB(Rr Bk) - функция, которая возвращает ссылку на блок из Rt, который
касается блока Вк\ при этом Вк е Rt. TB(Rt> Вк) = Bt означает, что В е /? и
С(В. BJ = 1.
Применим для слияния движущихся блоков алгоритм кластеризации, кото-
рый состоит из следующих шагов:
1 Инициализация. R - М (следовательно, В = В;
Счетчик областей / = 1.
До тех пор пока М # 0:
2.1 Для всех к от 1 до \М\:
2.1.1 Если TB(Rot f В Ц)) * 0 (т. е. проверяем, касается ли Л-й блок в М
z-й области в В):
2.1.1.1 Определяем В = TB^R^, Во{к})\
2.1.12 Если D (Я . В„(М) < 5, то = /?*„ U [В,|. А, = A, U
(о(&)}, т. е. если к-н блок кластеризуется в z-ю область,
то включаем его в нее и запоминаем индекс блока. Та-
ким образом, At - это множество индексов блоков, ка-
сающихся Z-й области.
V-1
3
4
5
6
7
- удаляем кластеризованные блоки;
Для всех Л от 1 до |В| (удаляем области, покрытые /-й облаегью из В, для
того чтобы нс было их дублирования):
4.1 Если Я^,G ЯЧ1), то Я = Я \ jflj.
В = В U (Вр(/)) - обновляем множество В, включая туда обновленную z-ю
область;
i - i + 1 - переходим к кластеризации следующей области.
Результат: движущаяся область В.
10.6.3. Временная кластеризация движущихся блоков.
Проблемой при сегментации газообразных объектов типа дыма является
возможная их разрывность: в различные моменты времени изначально единый
объект может состоять из нескольких отдельных областей. Однако применяе-
мый алгоритм должен идентифицировать их как один и тот же движущийся объ-
ект. Поэтому будем сопровождать движущиеся области от кадра к кадру. Тогда,
хотя области, составляющие один объект, могут не касаться друг друга в каком-
либо кадре, траектории таких объектов будут пересекаться. Таким образом, от-
дельные объекты могут быть объединены во временной области.
Введем следующие обозначения:
• В' - движущаяся область с индексом i в момент времени t (она должна
быть пространственно связной),
• В' - множество движущихся областей в момент времени г,
• О' - движущийся объект с индексом i в момент времени t (может состоять
из нескольких областей, пространственно не связных),
• О' - множество движущихся объектов в момент времени ,
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
428
Цифвая обработка видеоизображений
• ОТ' - траектория объекта Ot до настоящего момента времени,
• ОТ' - множество траекторий всех объектов,
• Т' - множество индексов объектов, касающихся ОТ' в момент времени
г-1,
• VV' - множество индексов траекторий, соединяющихся с ОТ' в момент
времени г.
Алгоритм временной кластеризации движущихся объектов записывается
следующим образом.
1
2
Инициализация: ОТ' = R' (т. с. ОТ; = R' для всех /);
Для всех т от t до t - 1:
2.1 WEWT=0:
2.2
Для всех / от 1 до ОТ :| (проверка по всем траекториям объектов)
2.2.1 Т; = 0:
2.2.2 Для всех р от 1 до О *г 1 ’[ (расширяем траекторию, чтобы вклю-
чить объекты, которые ее касаются, и запоминаем их):
Если отгп о"Лто т;= т;и Н;
( т? Р'
UC ио<';
к* 4’1 >
от; =
2.2.3
2.2.4
Для всех к от 1 до /-1 (объединяем ветвящиеся траектории в
одну траекторию с наименьшим индексом и запоминаем индексы этих
траекторий):
2.2.4.1 Если ОТ'ПОГ.(т’|)*0.то Wr= W'U|^);
/>• А ’
2.2.5 ог;.(0= уог;.и
U ОТ/ (объединяем ответвления в одну
траекторию);
2.2.6 NEWT = {NEWT\j\oT' Й\ I JOT'
\ I " WJ/
V '
2.3 ОТ(Г~ = ОТ (обновляем траектории объекта);
*Г(*>
к 2
3
4
Каждая движущаяся область, входящая в траекторию, должна быть отне-
сена к какому-либо объекту Поэтому сначала О' = 0 и
Для всех i от 1 до |О Т°-2)|:
4.1 trac = 0 (множество индексов объектов, включенных в текущую
траекторию);
4.2 Для всех к от 1 до |/?'|:
4.2.1 Если OTJ'2) о О/, то trac - trac U {&);
43 01 = U °C
4.4 О'= О'U {О');
Пространственно-временные кластеры в момент времени г. О', О('-2)=О0"0,
Оо-о = О1.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава '0. Обнаружение дыма и огня по видеоизображению
429
10.6.4. Определение формы объектов
Полученные на предыдущем этапе кластеры состоят из нескольких блоков.
Однако нам необходимо установить точную форму объектов. Для этого восполь-
зуемся процедурой выделения краевых точек по методу Канни. Полученные кра-
евые точки для газообразных объектов (дыма) обычно бывают не связаны друг
с другом. Для построения замкнутой границы из таких краев необходимо приме-
нить операции морфологии. Вначале мы удалим очень короткие края, так как
они в основном представляют собой влияние шума. Затем воспользуемся опера-
цией дилатации, чтобы соединить лежащие рядом краевые точки. Наконец, сгла-
дим полученные границы для придания им более естественного вида.
Пусть X - это бинарное изображение обнаруженных краевых точек. Значе-
ние пикселя, равное 1. означает, что этот пиксель является краевой точкой. Опре-
делим следующие морфологические операции:
«стирание»: Х0 Vp = |х: '(А' \ К ) П V, | > з|,
«дилатация»: X © Vd = {х: X П К, * О},
«сглаживание»: X ® Vb = {х: |X П > 3},
где структурирующие элементы задаются как
d d
0 d
d d
Кг» 0 0 0’ 0 1 0 0 0 0 0 1 О' 1 1 1 -° 1 °. 1 0 1 0 d 0 1 0 1 »
(40)
(41)
(42)
Здесь d может принимать любое значение 0 или 1.
Теперь комбинация морфологических операций для построения границы
объекта из разрозненных краевых точек выглядит следующим образом:
((X0Vc)©Vd)®Vb.
(43)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
430
Цифвая обработка видеоизображений
Рис. 16. Реконструкция области объекта
Следующий шаг заключается в восстановлении внутренней области объек-
та по полученной границе. Если области слабой интенсивности являются очень
длинными, то даже с помощью морфологических операций невозможно вос-
становить границу. Это означает, что обнаруженная граница будет незамкнутой
и может не полностью включать в себя внутреннюю область объекта. Поэто-
му необходимо различать области, не охватываемые полученной границей (см.
Рис. 16), и самостоятельные отдельные области. Для этого будем искать пересе-
чения с границей в горизонтальном и вертикальном направлениях. Только если
горизонтальная и вертикальная линии, проходящие через данный пиксель, пере-
секают одну и ту же границу, будем считать такой пиксель принадлежащим вну-
тренней области объекта [24].
10.6.5. Классификация выделенных объектов
Классификацию выделенных объектов будем проводить с помощью динами-
ческих текстур. Как известно, одним из основных методов классификации с помо-
щью динамических текстур является использование оптического потока. Мы бу-
дем определять не полный оптический поток, а только его нормальную составля-
ющую vN (х,^). Этого вполне достаточно для целей распознавания типа объекта
и в то же самое время позволит избежать большого объема вычислений [25,26].
В качестве характерных признаков текстур будем использовать следующие
усредненные по всем кадрам видеопоследовательности величины [28-30]:
1. средние значения divvN (х,у) и rotvN (х,у),
2. отношение среднего значения нормального потока и его стандартного
отклонения,
3. степень однородности ориентации нормального потока
где Q - множество пикселей, в которых значение нормального потока
отлично от нуля.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 10. Обнаружение дыма и огня по видеоизображению
431
4. среднее значение максимума направленной регулярности Р(г),
5. дисперсия P(t).
Все указанные величины являются инвариантными к перемещению и вра-
щению. Принадлежность рассматриваемого объекта к классу объектов, соответ-
ствующих дыму и огню на изображении, может быть определена с помощью ме-
тода опорных векторов или нейросетей. Более подробно алгоритм вычисления
величины направленной регулярности изложен в разделе, посвященном динами-
ческим текстурам главы 3.
10.7. СПИСОК ЛИТЕРАТУРЫ
1. Т. Cleary, W Grosshandler. Survey of Fire Detection Technologies and System
Evaluation/Certification Methodologies and Their Suitability for Aircraft Cargo
Compartments. US Dept, of Commerce, Technology Administration, National
Institute of Standards and Technology. 1999.
2. W. Davis, K. Notarianni. NASA Fire Detection Study. US Dept, of Commerce,
Technology Administration. National Institute of Standards and Technology, 1999.
3. G. Healey, D. Slater. T Lin. B. Drda, A.D. Goedeke. A System for Real-Time Fire
Detection. In: Proc. Conference Computer Vision and Pattern Recognition, New York,
p. 605-606,1993.
4. S.Y. Foo. A Rule-based Machine Vision System for Fire Detection in Aircraft Dry Bays
and Engine Compartments. In: Knowledge-based Systems, v. 9, p. 531-541,1995.
5. B. Aird, A. Brown. Detection and Alarming of the Early Appearance of Fire Using
CCTV Cameras. In: Proc. Nuclear Engineering International Fire and Safety Conference,
London. 1997.
6. T. Oikawa. M. Tomizawa, S. Degawa. New Monitoring System for Thermal Power
Plants Using Digital Image Processing and Sound Analysis. In: Proc. IFAC Symposium
on Control of Power Plants and Power Systems, Cancun, p. 221-224,1995.
7. V Cappellini, L. Maltii, A. Mecocci. An Intelligent System for Automatic Fire Detection
in Forests. In: Proc. International Conference on Image Processing, Warwick, p. 563-570,
1989.
8. S. Noda. K. Ueda. Fire Detection in Tunnels Using an Image Processing Method. In:
Proc. Vehicle Navigation & Information Systems Conference, Yokohama, p. 57-62,1994.
9.0. A. Plumb. R. E Richards. Development of an Economical Video-based Fire
Detection and Location System. US Dept, of Commerce. Technology Administration,
National Institute of Standards and Technology, 1996.
10. W. Phillips III, M. Shah, N. V Lobo. Flame Recognition in Video. In: Pattern Recognition
Letters, v. 23, p. 319-327,2002.
11. С. B. Liu. N. Ahuja. Vision-based Fire Detection. In: Proc. International Conference on
Pattern Recognition, v. 4. p. 134-137,2004.
12. G. Schwarz. Estimating the Dimension of a Model. In: Annals of Statistics, v. 6, p. 461-
464,1978.
13. A. Neumaier, T. Schneider. Estimation of Parameters and Eigenmodes of Multi-
variate Autoregressive Models. In: ACM Transactions on Mathematical Software, v. 27,
p. 27-57,2001.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
432
Цифвая обработка видеоизображений
14. В. U.Toreyin, Y. Dedeoglu. U. Gudukbay. А.Е. Cetin. Computer Vision-based Method
for Real-time Fire and Flame Detection. In: Pattern Recognition Letters, v. 27 p. 49-
58,2006.
15. R.T. Collins, A. J. Lipton.T. Kanade. A System for Video Surveillance and Monitoring.
Technical Report CMU-RI-TR-00-12, Robotics Institute,Carnegie Mellon University,
Pittsburgh, 2000.
16. E Heijden. image-based Measurement Systems: Object Recognition and Parameter
Estimation. Wiley, 1996.
17 M. Bagci.Y. Yardimci, A. E. Cetin. Moving Object Detection Using Adaptive Subband
Decomposition and Fractional Lower Order Statistics in Video Sequences, In: Signal
Processing, v. 82, p. 1941-1947 2002.
18. C. Stauffer. W. E. L. Grimson. Adaptive Background Mixture Models for Real-time
Tracking. In: Proc. IEEE Computer Society Conference on Computer Vision and
Pattern Recognition, v. 2, p. 246-252.1999.
19. Fastcom Technology SA. Method and Device for Detecting Fires Based on Image
Analysis. Patent Coop. Treaty (PCT) Pubn. No: V/002/069292, CH-1006, Lausanne.
Switzerland. 2002.
20. B. U. Toreyin, Y. Dedeoglu. A. E. Cetin. Flame Detection in Video Using Hidden
Markov Models. In: Proc. IEEE International Conference on Image Processing,
Genoa, p. 1230-1233,2005.
21. D. Wieser, T Brupbacher. Smoke Detection in Tunnels Using Video Images. In: Proc.
International Conference on Automatic Fire Detection, Gaithersburg, p. 79-90,2001.
22. Драйздейл Д. H. Введение в динамику пожаров. - М.: Стройиздат, 1990. - 424 с.
23. G. W Mulholland. Smoke Production and Properties. SFPE Handbook of Fire
Protection Engineering, DiNemmo et al. (eds.), 2nd Edition, Chapter 15, Section 2,
p. 217-227,1995.
24. W.-H. Kim, C. Brislawn. Plume Detection and Tracking in Video Data. FY99 Progress
Report LAUR-00-15, Los Alamos National Laboratory, 1999.
25. D. Chetverikov, Z. Foldvari. Affine-invariant Texture Classification Using Regularity
Features. In: Proc. International Conference on Pattern Recognition, Barcelona, v. 3, p.
901-904,2000.
26. R. Peteri, D. Chetverikov. Dynamic Texture Recognition Using Normal Flow and
Texture Regularity. In: Proc. Iberian Conference on Pattern Recognition and Image
Analysis, Estoril, p. 223-230,2005.
27. T. Aach, А. Каир. Statistical Model-based Change Detection in Moving Video. In:
Signal Processing, v. 31, p. 165-180,1993.
28. D. Chetverikov. Pattern Regularity as a Visual Key. In: Proc. British Machine Vision
Conference, Southampton, p. 23-32,1998.
29. H. C. Lin, L. L. Wang, S. N. Yang. Extracting Periodicity of a Regular Texture Based
on Autocorrelation Functions. In: Pattern Recognition Letters, v. 18, p. 433-443,1997.
30. F. Liu, R. W Picard. Periodicity, Directionality and Randomness: World Features
for Image Modelling and Retrieval. In: IEEE Transactions on Pattern Analysis and
Machine Intelligence, v. 18, p. 722-733,1996.
ProSystem CCTV — журнал no системам видеонаблюдения
http://www.procctv.ru
ГЛАВА 11.
ИНДЕКСАЦИЯ ВИДЕОИЗОБРАЖЕНИЙ
И ПОИСК В ЦИФРОВЫХ
БИБЛИОТЕКАХ И АРХИВАХ
ВИДЕОДАННЫХ
436
Цифвая обработка видеоизображений
С каждым годом возрастает объем информации, хранимый в видеоархи-
вах и специальных библиотеках цифровых видеоизображений. Эти архивы со-
держат огромные объемы данных, вследствие чего быстрый поиск необходи-
мой информации становится все более проблематичным. При поиске в архи-
вах систем видеонаблюдения обычно единственно возможной дополнительной
информацией, облегчающей поиск, являются сведения о дате, приблизитель-
ном времени и номере камеры, которой было зарегистрировано нужное собы-
тие. Чтобы не просматривать потом несколько часов видеозаписей, хотелось
бы иметь возможность «попросить» систему поиска отыскать заданное собы-
тие (например, когда к офису подъехал красный автомобиль). Для решения
этой задачи служат методы индексации видеоизображений, которые тем или
иным способом позволяют описать содержимое отдельных наборов кадров ви-
деопотока. Сложность заключается в построении подходящего представления
информации, содержащейся в изображении. Вручную аннотировать все имею-
щиеся видеофрагменты не представляется возможным, так как это потребует
гигантских усилий, а в перспективе, скорее всего, придется заново переиндек-
сировать все разделы архива вследствие его непрерывного пополнения. Кро-
ме того, подготовка хорошего описания изображения - весьма нетривиальная
задача.
Методы индексации видеоизображений и поиска информации в видеоархи-
вах имеют сравнительно недавнюю историю, а в последнее время интерес к этой
проблеме значительно возрос, поскольку благодаря развитию компьютерной
техники появилась возможность ставить задачи, решение которых еще лет де-
сять назад было нереальным [1-4]. Перечислим типичные сферы применения ин-
дексации видеоизображений:
• Архивы фото- и видеоматериалов.
о Архивы фильмов.
о Архивы новостных и информационных программ.
о Архивы систем видеонаблюдения.
• Поиск подозрительных и оставленных предметов в местах большого ско-
пления людей (аэропорты, вокзалы, торговые центры и т. д.).
• Контроль дорожной обстановки (выбор моментов ДТП, нарушений
правил дорожного движения автомобилями и пешеходами, монито-
ринг заторов).
• Наблюдение за автомобильными стоянками и парковками.
• Выявление случаев правонарушений в метро, в подъездах жилых домов,
офисов.
• Архивы спутниковых видеоснимков.
• Музейные коллекции.
• Поиск изображений в сети Интернет. Поиск изображений определенного
типа (например, объединенных какой-либо тематикой) или конкретных
видеосюжетов.
• Медицинские видеоархивы. Создаваемые в настоящее время приложе-
ния позволят по запросу пользователя находить в хранящихся видеомате-
риалах необходимую информацию, что может оказать помощь в постановке
правильного диагноза и выборе путей правильного излечения заболевания.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных
437
Ручная индексация видеоданных требует больших усилий, огромных затрат
времени и вдобавок подвержена ошибкам двух типов. Первый тип - это ошибки,
связанные с индивидуальным восприятием информации человеком, производящим
индексацию; второй - это типичные ошибки, допускаемые из-за усталости, недо-
статочной степени освещенности и т. д. Методы индексации на основе ключевых
слов, обычно применяемые в системах управления базами данных (СУБД) имеют
ряд существенных недостатков. Видеоизображения по-разному воспринимаются
каждым человеком, поэтому для одного и того же изображения можно получить
десятки различных описаний, а также нельзя предвидеть все возможные интерпре-
тации одних и тех же данных во время их индексации. Кроме того, описание не-
большого видеофрагмента с помощью огромного числа ключевых слов ведет к не-
оправданному разрастанию требуемых объемов для хранения данных во время ин-
дексации. Ключевые слова не могут успешно описать динамический характер ви-
деоданных, а также они не поддерживают семантические взаимоотношения (пра-
вила следования, иерархии, дескрипторы схожести «подобно этому» и другое). Та-
ким образом, большое количество ключевых слов, необходимых для формулиров-
ки запроса, делает этот процесс длительным, утомительным и неэффективным.
С ростом объемов видеоархивов стоящие перед пользователем проблемы
только усугубляются. Часто пользователь может использовать априорные зна-
ния о содержимом архива для более эффективного извлечения необходимой ин-
формации. Однако громадные размеры архивов сдерживают способность поль-
зователя понять содержание видеоданных. Пользователю приходится исследо-
вать все большие объемы данных, чтобы найти необходимую информацию. Зна-
ние структуры архива и модели данных необходимы для решения такой задачи.
Но обладание детализированной информацией о больших видеоархивах не пред-
ставляется возможным. Поэтому необходимо предоставить пользователю инту-
итивно понятные способы восприятия содержимого архивов.
Только после того как информация описана с помощью соответствующей
модели и извлечена из видеоданных, пользователь сможет впоследствии осу-
ществлять поиск в хранящихся данных. Поэтому сначала видеоряд разбивается
на отдельные сегменты, для которых выделяются характерные признаки, осно-
вывающиеся на требованиях используемой модели (например, архивы систем ви-
деонаблюдсния парковок, мест скопления людей и т. д.). Извлеченные признаки
помещаются в базу метаданных. Если некоторая информация о содержимом ви-
деоданных в ней пока отсутствует, то система должна обладать возможностью
извлекать ее «на лету» и помещать в эту базу. Общая схема организации систем
индексации и поиска данных в видеоархивах приведена на Рис. 1.
11.1. СЕГМЕНТАЦИЯ ВИДЕОПОТОКА
При поступлении новых видеоданных первым этапом обработки является
сегментация. Подобно тому, как связный текст состоит из предложений, видеопо-
ток можно разбить на более короткие ряды, как это показано на Рис. 2. Длитель-
ные видеоряды состоят из сцен, которые в свою очередь включают в себя мно-
жества, образованные набором кадров, т. е. более короткие ряды данных, на ко-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
438
Цифвая обработка видеоизображений
Рис. 1. Общая схема организации систем индексации и поиска данных в видеоар-
хивах
торых в основном изображены одни и те же объекты. Каждый такой набор мож-
но описать с помощью характерных признаков (например, ключевых кадров), а
на основе последних можно организовать поиск нужного видео. Нахождение гра-
ниц набора кадров и является окончательной целью данного этапа.
Дополнительную сложность этой задаче придает тот факт, что существует
несколько типов границ наборов кадров. Простейшим из них является резкий пе-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных
439
DnOOOODDDDOOODODODDODOflODODDBDOiJOODDDOODOODODDOODOllDO
Рис. 2. Иерархия модели видеопотока, используемая при его сегментации
реход (cut), когда происходит простое соединение двух различных наборов. «Рас-
творение» (dissolve) представляет собой плавный переход от одной сцены к дру-
гой, когда два изображения на короткий период времени накладываются друг на
друга. «Угасание/проявление» (fade-out/fade-in) - это медленно меняющаяся ин-
тенсивность изображений, что производит впечатление исчезающего или появ-
ляющегося набора кадров. Наконец, «стирание» (wipe) представляет собой заме-
ну одного набора другим в виде пересекающей экран горизонтальной или верти-
кальной прямой линии.
Автоматическое нахождение указанных границ является важным этапом в
задачах индексации видеоизображений. При этом необходимо использовать та-
кой алгоритм, который эффективным образом позволяет находить кадры, где
изображение в значительной степени отличается от изображения на предыду-
щих кадрах. В том случае, когда введенное «расстояние» между изображения-
ми превышает заданное пороговое значение, фиксируется новая граница набо-
ра кадров.
Для вычисления разницы между изображениями используются различные
методы, основные из которых перечислены ниже:
• Пиксельные методы. Данные алгоритмы используют попиксельное
сравнение двух кадров, на основе которого вычисляют соответствую-
щую меру [5-11]. Этот способ не является в достаточной мере эффектив-
ным, поскольку требует большого числа арифметических действий. Кро-
ме того, он является весьма чувствительным к внешним шумам и неболь-
шим движениям камеры.
• Гистограммные методы. Алгоритмы данного класса основаны на по-
строении гистограмм интенсивностей для отдельных кадров и вычисле-
нии расстояния между ними [12-20]. Существует довольно большое чис-
ло методов для определения такого расстояния. В отличие от пиксельных
методов гистограммные алгоритмы являются устойчивыми к небольшо-
му смещению камеры, так как не содержат информации о пространствен-
ном распределении интенсивностей.
• Блочные методы. В этих методах все изображение разбивается на от-
дельные квадратные или прямоугольные блоки, которые затем сравни-
ваются между собой [21-26]. Преимуществом методов данного класса по
сравнению с гистограммными является возможность учета простран-
http://wwwjtv.ru
Компания ITV - генеральный спонсор издания книги
440
Цифвая обработка видеоизображений
ственной структуры изображения, что в значительной мере повышает ре-
левантность проводимой сегментации.
• Методы, основанные на вычислении оптического потока. Для сегмен-
тации видеопотока могут быть использованы уравнения движения. Так
как движение по своей природе обычно непрерывно в видеопотоке, то
разрывы в функциях оптического потока соответствуют границам на-
бора кадров.
• Комбинированные методы. Последнюю группу методов представляют
алгоритмы, сочетающие в себе преимущества сразу нескольких из пере-
численных выше методов. Обычно при этом повышается надежность сег-
ментации, но увеличивается также и время обработки видеопотока.
11.1.1 Пиксельные методы
В простейшей своей реализации алгоритм попиксельного сравнения опреде-
ляет глобальную разность в интенсивности пикселей в двух последующих кадрах
в моменты времени t и f + Г.
££<иу)
Х=1 >=! X I 1=1
N-M
(1)
Можно также вычислять указанную разность для пикселей, имеющих одинако-
вое положение в двух кадрах, т. е.
.V ч
м— (2)
- для полутоновых изображений, и
.V м
X £ £ IА (*> У'с) - (х> у> с)1
d (t, t +1) = -------------------- (3)
v ' NM v’
- для цветных. Здесь N и M - количество пикселей кадра по горизонтали и вер-
тикали соответственно, / (х, у)~ интенсивность в точке (х, у) в момент време-
ни t для полутоновых изображений, а /f(x, у, с) - интенсивность цветовой ком-
поненты с в точке (х, у) в момент времени t. Граница набора кадров фиксиру-
ется в том случае, когда величина d(t> t + 1) превышает некое наперед заданное
пороговое значение:
d(t,t + \)>8. (4)
Основным недостатком этого метода является его неспособность провести
различие между малыми изменениями в большой области изображения и боль-
шими изменениями в малой области. Например, ложная граница набора кадров
фиксируется при значительном и быстром изменении во всего лишь небольшом
участке кадра. Поэтому методы, основывающиеся на попиксельном сравнении,
очень чувствительны к движениям камеры и объектов. Одним из возможных пу-
ProSystem CCTV - журнал по системам видеонаблюдения
h ttp://www. procctv. ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 441
тей решения указанной проблемы является подсчет числа пикселей, изменение
интенсивности которых превышает пороговое значение. После этого получен-
ное число сравнивается со вторым порогом:
£>(/,Г + 1,х,у) = <
иначе
(5)
d (/,/ + !) =
£££>(М + 1,х,у)
ж*| yl___
NM
(6)
Если выполняется неравенство (4), то фиксируется граница набора ка-
дров. Хотя ряд ложных границ теперь исчезает, тем не менее, этот метод
остается чувствительным к движению камеры и объектов. Например, если
камера начинает панорамирование, большое число пикселей будет рассма-
триваться как изменившие свою интенсивность, хотя на самом деле произо-
шло только смещение нескольких пикселей. Существует возможность до не-
которой степени уменьшить этот эффект при помощи введения сглаживаю-
щих фильтров, например, перед сравнением заменить величину интенсивно-
сти каждого пикселя средним значением интенсивности соседних пикселей.
Кроме того, можно разницу в интенсивности пикселей двух соседних кадров
делить на интенсивность пикселя в текущем кадре. Это позволяет сделать ал-
горитм более устойчивым.
Дальнейшее улучшение метода попиксельного сравнения может быть до-
стигнуто путем использования статистических величин, таких как нормирован-
ная энергия разностей
d(z,z + l) =
N М
(х>у))
Х=1 ух}
(N М ^\( N М „А
х=1 у=1 /\дг*1 y=l )
(7)
и нормированная сумма модулей разности
.V м
£Е1а(х>^)-а+|(х.Я1
+1) = --------• (8)
Х-1 y=l X=l yal
Предыдущие алгоритмы, основанные на сравнении пикселей из двух кадров,
могут быть обобщены на случай большего числа последовательных кадров. При
этом каждому пикселю присваивается метка в соответствии с динамикой изме-
нения интенсивности: «константа», «скачок (А)», «линейный (/»/)» и «без мет-
ки». Эти метки характеризуют соответственно пиксели с постоянными значения-
ми интенсивности, меняющие ее значение в момент времени г, монотонно меняю-
щие свое значение на отрезке времени от г, до t2 и принимающие случайные зна-
h t tp://w w w. i t v, г и
Компания ITV - генеральный спонсор издания книги
442
Цифвая обработка видеоизображений
чсния вследствие движения камеры или объекта. Также определяются две буле-
вы величины 0, (lt j) и02 (/, j):
истинно,
иначе
(9)
ложно,
e.(WvM=' истинно, ложно, иначе <8. (Ю)
где
°"
Введенные таким образом величины используются для определения метки
каждого пикселя L\lt на последовательности, включающей в себя
п +1 кадр:
Далее для каждого типа метки подсчитывается количество пикселей, имею-
щих эту метку. Граница набора кадров определяется путем нахождения отноше-
ния количества пикселей, имеющих метку «скачок (/)», к общему числу помечен-
ных пикселей:
N И
X X ^*скачок(/,)" ( Ао ’ J )
- ----------------------> 5. (13)
/»1 /«1
Аналогичным образом определяется граница при «растворении» между кадра-
ми г, и t2:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 443
4^ ^~>п 1инейный[/,. ,f,y)” ( <о ’ 1п ’
i*1 J=\_________________’ *_____________________
N М
i-\ /=|
(14)
Для сегментации видеопотока можно использовать частные производные
первого порядка по времени от интенсивности изображения Э/, (х,у)/Э/. При
резком переходе или «стирании» ЭД (х,у)/Э/ будет иметь локальный максимум.
Во время «растворения» или «угасания/проявления» интенсивность меняется
медленно, и это приводит к достаточно плавному подъему ЭД (х, ,у)/Э/ на про-
тяжении нескольких кадров. В качестве глобальной меры, позволяющей фик-
сировать границы набора, можно использовать следующую величину:
D(z)=
U.x)
(15)
а для ее вычисления применять свертку с производной по времени гауссова
фильтра
dG(x,y,t)
dt
а2 2ясг
ехр
( x2 + y2+t2]
V 2а2 /
(16)
> 5.
где а - масштаб преобразования. При помощи этой величины осуществляется
контроль видеопотока на нескольких последовательных кадрах и, следователь-
но, возможно определение плавных переходов. Границы набора определяются
как максимумы функции (15).
Однако не все максимумы D(z) соответствуют границам наборов кадров.
Во время плавных переходов возникают рядом расположенные максимумы
(с, d и е на Рис. 3), из которых выбирается наибольший за определенный пе-
риод времени (в данном случае точка d). Поэтому будем использовать две ве-
личины пороговых значений. Первая необходима для устранения небольших
пиков, возникающих вследствие шума (точки а и b на Рис. 3). Вторая исполь-
зуется для удаления локальных максимумов, соответствующих пикам относи-
тельно малой величины (как в точках /, g и А), появившимся из-за движения
камеры или объектов.
Несмотря на это, ряд максимумов функции D(t) по-прежнему не будет со-
ответствовать реальным границам наборов вследствие относительно неболь-
ших движений. Для отсечения таких максимумов можно исключить из рассмо-
трения точки, в которых хотя бы одна из пространственных производных интен-
сивности изображения dlt(x,y)/dx и dlt(x,y)/ ду принимает ненулевые значе-
ния. Устранив вклад в D(t) от пикселей с ненулевыми пространственными произ-
водными, мы тем самым снизим влияние движения. Такие пиксели находятся пу-
тем сравнения угла между векторами (Э/, (х, >>)/Эх, Э/Дх,^)/Эу, Э/Г(х,у)/dt) и
(О, 0, dlt(xyy)/dt) с заданным пороговым значением. Выражение (15) при этом
переходит в следующее:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
igO<tgOm
О, иначе
где вт - это максимально возможный угол между векторами,
lg0 =
11.1.2. Гистограммные методы
Если пиксельные алгоритмы представляют собой локальные методы,то гисто-
граммные основаны на использовании глобальных характеристик изображения.
Это позволяет сделать эти методы более устойчивыми к движению как камеры,
так и объектов. Кроме того, гистограммы инвариантны к небольшому вращению
и слабо зависят от изменений масштаба. Однако два совершенно разных изображе-
ния могут иметь практически идентичные гистограммы, поскольку в последних не
содержится информации о расположении пикселей относительно друг друга.
Гистограммные методы чрезвычайно разнообразны. Простейшие из них вычис-
ляют обычную разность между гистограммами двух кадров. Более совершенные ме-
тоды используют при этом специальным образом рассчитанные весовые коэффи-
циенты. В наиболее развитых методах определяется оператор пересечения между
гистограммами или же используются специально подобранные меры их сходства.
Простейший метод основан на вычислении следующего выражения:
4мП)=£|я(7,+ру)-Я(7,,у)|, (19)
v--0
где Н - гистограмма интенсивностей изображений, V - число ячеек квантования
гистограммы. Аналогичным образом находится расстояние между гистограмма-
ми для цветных изображений. Его также можно определить как максимум сум-
мы разностей
d ('>'+ 0 = к^в} X Iя (4+.. ск, V) - н (7,, ск, v)|, (20)
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 445
где ск обозначает цветовую компоненту. В цветных изображениях одни цвето-
вые компоненты могут быть более важны, чем другие, поэтому не обязательно
использовать все три компоненты цветового пространства: можно задействовать
только одну или две из них. например, в пространстве HSV - цветовой тон и на-
сыщенность:
</(z,/ + l) = ££|//(/,.I,q.v)-//(/„c*,v)|, (21)
vO
или же только один цветовой тон:
d (z, t +1) = ---v.-----------------. (22)
v=0
Для ускорения вычислений иногда используют урезанное цветовое пространство
RGB. В результате гистограммы имеют только, например, по 64 ячейки, что по-
зволяет существенно снизить время вычислений:
63
d (М +1) = й------------------• (23)
£hm(/„v)
V=0
Для составления разности между гистограммами можно использовать ана-
лог скалярного произведения двух векторов. Сначала для каждого кадра строят-
ся 3 гистограммы, состоящие из 64 ячеек, в цветовом пространстве YUV. Затем
они объединяются в одну гистограмму со 192 ячейками. После этого уже форми-
руется величина d:
21 Hyuv (A+i >v) yuv (A >v)
d (m +1) = -----------v----------. (24)
21 Hyuv (A+I»V) 21^Aw(A>V)
v=0 v=0
Границу набора кадров можно определять при помощи составления разно-
сти гистограмм двух кадров с весовыми коэффициентами, позволяющими учесть
важность той или иной цветовой компоненты:
7^|Я(А.с*л)-Н(/,+1,сд,у), (25)
Д=1 у=0 * mean
где /(с*) и 1теап - интенсивность fc-й цветовой компоненты кадра t и средняя ин-
тенсивность для этого же кадра по всем трем цветовым компонентам. Весовые
коэффициенты можно задавать другими способами. Например, сначала при по-
мощи выражения (19) составить обычную гистограмму. Затем решить оптимиза-
ционную задачу минимакса, которая позволяет выбрать в выражении (25) наи-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
446
Цифвая обработка видеоизображений
лучшие веса. В качестве весов можно использовать также разность усредненных
цветов гистограммы:
3 / г г \2
4М + 1)=£ Z//(/oc*’')v-Xw(/,4,cl,v)v . (26)
Л=1\1=0 »=0 /
Довольно большое распространение получил так называемый алгоритм
двойного сравнения [6]. Основу метода составляют операции сравнения с двумя
порогами: большим 8f и меньшим 8Г На первом этапе используется больший по-
рог 8h для определения резких переходов (F и1 на Рис. 4А). После этого задейству-
ется второе пороговое значение 8, для определения возможного начала F плав-
ного перехода. Как только d(t, t + 1) превышает 8Г начинается вычисление сум-
мы разностей d по всем последующим кадрам. Это продолжается до тех пор, пока
разность для двух очередных кадров нс будет меньше 8Г При этом, если сумма
d превышает 5Л, то фиксируется конец плавного перехода F. Если же сумма d
меньше 8h, то граница набора кадров не фиксируется, F удаляется и продолжает-
ся дальнейшая обработка видеопотока. Пороговые значения могут быть заданы
автоматически при помощи стандартного отклонения и математического ожи-
дания разности гистограмм для последовательных кадров во всем видеопотоке.
Для сегментации видеопотока возможно использование генетических алго-
ритмов. Для этого рекомендуется снизить частоту видеопотока (например, до
двух кадров в секунду), после чего из полученного множества кадров F отби-
раются те, расстояние между которыми превышает сумму среднего значения и
стандартного отклонения. Полученное множество обозначим через F':
F' = {teF\d(t-l,t)> J + ст}. (27)
Здесь в качестве d может выступать любое из перечисленных в данном разделе
расстояний, a d - среднее значение d. На данном множестве F' определяется дли-
на /(г) элемента г, представляющая собой число кадров в F между элементом t и
следующим за ним элементом в F'. Аналогично вводится расстояние d\ в каче-
стве аргументов которого выступают элементы множества F'.
Рис. 4. Разность гистограмм для двух последовательных кадров (А) и сумма разно-
стей (Б) в методе двойного сравнения.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11 Индексация и поиск в цифровых библиотеках и архивах видеоданных 447
Когда необходимо не просто произвести сегментацию видсопотока, но при
этом также отобрать характерные кадры, различающиеся наиболее сильно,
можно ввести другую функцию сходства f. Пусть Sk - это подмножество F\ состо-
ящее из к отобранных кадров. Тогда
/(М = £ (28)
tx
где а - весовая функция. В простейших случаях она может быть выбрана кон-
стантой или положена равной а(/р^)= 1/|г, -г2| , что позволит уменьшить вес
тех кадров, которые расположены на большем расстоянии друг от друга. Одна-
ко более эффективным представляется использование выражения, вычисляемо-
го следующим образом. Введем для этого понятия «важности» элемента множе-
ства и понятие «предшествования». Для этого определим множество С, элемен-
тов, близких к
с,, ={/6 F'l </'(/„/)< rf' + a}, (29)
и множество = |cJ/|F'|. Здесь d' среднее значение d' Тогда «важность» мо-
жет быть определена как
e^iog^rjjiogfi/^). (зо)
Пусть
^={/6 г}. (31)
Тогда «предшествование» определяется как
Л =|ej/|c„|. (32)
Используя это понятие, «важность» можно переопределить:
e^^iogf/ojjiogti/^). оз)
Теперь весовые функции задаются следующим образом:
к’</ ” (34)
О, иначе
Функцию (28) с коэффициентами, задаваемыми выражением (34), можно ис-
пользовать в качестве целевой функции в генетическом алгоритме. Видсопо-
ток кодируется как строка двоичных значений, где 1 и 0 представляют соответ-
ственно наличие и отсутствие границы набора в данном кадре. Операции скре-
щивания и мутации применяются таким же образом, как в классических гене-
тических алгоритмах.
Для сегментации изображений возможно использование цветовых таблиц.
Цветовая таблица представляет собой довольно грубое разбиение цветового
пространства RGB на несколько десятков трехмерных цветовых частей, кото-
рые являются ячейками трехмерной гистограммы Нге/
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
448
Цифвая обработка видеоизображений
v=0
где веса задаются выражением
w(v,/) =
fa (/,^)>о)гу(нп1 (/,,v)>0)
I, иначе
(35)
(36)
Довольно часто сходство между двумя изображениями оценивается при
помощи пересечения гистограмм, которое можно вычислить по следующим
формулам:
d (/, Z +1) = —------------ (37)
v ’ NM V 7
или
“Jmax(/7(7,4,v),//(7 v))
d(t,t + \} = —---V ----------—d-. (38)
V 7 NM
В наиболее совершенных методах вычисляют более сложные меры сходства,
основанные на нормализованных гистограммах. Обозначим через //Л(/г, v) веро-
ятность появления интенсивности v в кадре г.Тогда для сегментации изображений
могут быть использованы такие характеристики, как кросс-энтропия:
+ (39)
v=0 ** N vP^/
дивергенция:
х / х //v(Z1+1,v) / х /Zv(Z,,v)
+1) = £ Н, (/„„v)log + X Н„ {!„ v) log 7 " (40)
v=0 v=0 ^.V\A+PV/
расстояние Кульбака-Лейблера:
................................
и расстояние Бхатачарьи:
d (t, t +1) = - log Y (7,,v). (42)
11.1.3. Блочные методы
Данные методы применяются для улучшения качества сегментации, посколь-
ку в отличие от пиксельных и гистограммных методов они учитывают простран-
ственную неоднородность изображений, а также для уменьшения времени вы-
числений. После того как исходное изображение разбито на блоки, к каждому из
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 449
них возможно применение методов, описанных выше. Основным преимуществом
блочных методов является их относительная нечувствительность к шумам и дви-
жению камеры и объектов.
Обычно блоки, имеющие одинаковое расположение в последовательных
кадрах, сравниваются попарно между собой. Мера их сходства основана на ис-
пользовании среднего значения и дисперсии, полученных на всем изображении.
Степень схожести для блока b из двух кадров в моменты времени t и r + 1 опре-
деляется как
(43)
где fit b и - соответственно среднее значение и дисперсия значений пиксе-
лей в блоке b в момент времени t. Затем величина (43) сравнивается с порого-
вым значением:
<А>(А,А+1.*)=
1, d(l,J^b)>8D
О, иначе
(44)
Теперь граница набора кадров фиксируется в том случае, если выполняется сле-
дующее неравенство:
£chJo(/(,/M,6)>5, (45)
6=1
где В - общее число блоков, а коэффициенты сь используются для придания раз-
ных весов отдельным блокам. В большинстве случаев они равны 1 для всех блоков.
Вместо выражения (43) можно использовать меру Якимовского [9]:
4А>А+..ь) =
(46)
где через |+|| ь обозначена дисперсия интенсивностей пикселей блока b сразу
из двух кадров в моменты времени t и t + 1.
Еще одной возможной мерой является статистика Фройнда:
(47)
Аналогичным образом проводится сегментация цветных изображений. Напри-
мер, в цветовом пространстве HSV для каждого блока обычно определяются
средние значения цветового тона и насыщенности. Для двух последовательных
блоков определяются следующие величины:
dn (А, >А,»6) = И А,'Ь’сн)-^;>Ь’СН)!•
ds (А, , А, .*) = (A, >b,cs) - Д (/,2 ,b,cs )|.
(48)
(49)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
450
Цифвая обработка видеоизображений
где д(/, ск) - среднее значение интенсивностей пикселей в блоке b в момент
времени t для /с-й цветовой компоненты. dH и ds относятся к цветовому тону и
насыщенности. С их помощью определяется, произошли ли изменения в кон-
кретном блоке:
1, (dH (/,. /,; ,b) > 8„)n(ds (/,,, Ih ,b) > 8S)
0, иначе
Наконец, находится отношение числа изменившихся блоков к общему числу бло-
ков и производится сравнение этой величины с порогом
(51)
Я ь=\
где т - временная задержка, используемая в процессе сегментации.
Можно сначала произвести классификацию пикселей в соответствии с их
цветовым уровнем в пространстве HSV. Если пиксель характеризуется боль-
шими значениями насыщенности и яркости, то ему присваивается дискретное
значение цвета при помощи компоненты цветового тона. В противном случае
классификация основывается на значении интенсивности в градациях серого.
Таким образом, для данного пикселя /(Ь,х,у) определяются два взаимно допол-
няющих состояния:
8llur^l(b,x>y)) =
1,
0,
(/, (b,cs,x,y)>8s)r>(l' (Ь,сх,х,у)> 8и)
иначе
(52)
(/, (М,у)) = 1 - (/, (b,x,y)), (53)
где lt(b, ск. х, у) обозначает интенсивность &-й цветовой компоненты пикселя
(х,у) в блоке Ь. Для каждого блока обычным способом строятся две выборочные
гистограммы и Я^п<(/,Ь).Вводятся обозначения Hhuf(Ipb3v)
которые представляют собой число пикселей в блоке b в момент времени г, для
которых состояние Shue (S гау) принимает значение, равное 1, а насыщенность (ин-
тенсивность или значение в полутоновом изображении) равна v. Построенные
таким образом гистограммы используются для определения границ наборов ка-
дров путем сравнения следующей величины с пороговым значением:
в ( V V \
Z + >5. (54)
6=1 \ v=0 v=0 )
Для увеличения надежности сегментации иногда используется цветовое про-
странство HIS, в котором строятся гистограммы по цветовому тону и насыщен-
ности для последовательных кадров, разбитых на несколько блоков. После этого
определяются следующие две величины:
v
D{t,t + \,b)= X £(//(Z„6,ct,v)-/7(/rt„b,cA)v)), (55)
ke{H,S} v=0
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 451
в в
j(0=£D(/,/ + l,h)-£D(r-U,6). (56)
6=0 6=0
Граница между наборами кадров фиксируется в том случае, если справедливо
условие
(Р (0 > 0)п(</ 0 +1) < о))и(р (г) < о)n (d (t +1) > 0)). (57)
Для определения границы, при которой происходит изменение изображе-
ния, можно использовать комбинацию разности гистограммы и степени по-
добия. В этом случае метод будет состоять из двух последовательных шагов
с заданием трех пороговых значений. Сначала с помощью выражения (19)
определяется величина d(tj + 1). которая сравнивается с первым порогом для
устранения ложных границ наборов. Если величина d меньше первого поро-
га, то она сравнивается со вторым пороговым значением. Когда d превышает
второй порог, выполняется второй этап метода, где вычисляется степень по-
добия кадров. Каждый из сравниваемых кадров разбивается на 64 блока, из
которых выбираются 16 центральных. После этого рассчитывается степень
подобия между блоком b в момент времени t + 1 и блоками Ь' в момент време-
ни /, где через Ь' обозначены ближайшие соседи блока Ь. Из полученных зна-
чений степени подобия выбирается наименьшая, затем вычисляется среднее
значение из 16 таких минимумов. Это среднее значение сравнивается с тре-
тьим наперед заданным порогом, и если оно превышает указанный порог, то
фиксируется граница набора кадров.
Можно также сравнивать два последовательных кадра, используя цветовые
отношения соседних блоков. Для каждого блока вычисляется следующая усред-
ненная величина:
+ А (б,х,у -1) + /, (b,x,y +1)),
(58)
на основе которой сравниваются пары блоков:
</(/„/,_4.l>) = l-min
да л'да)
да)
(59)
где А - временной интервал между двумя рассматриваемыми кадрами. Граница
набора фиксируется в том случае, если среднее значение величины d превыша-
ет заданный порог.
11.1.4. Методы, основанные на выделении характерных признаков
Рассмотренные выше методы были основаны на использовании довольно
простых характеристик изображения. В настоящем разделе рассмотрены мето-
ды, основанные на выделении из входного видеоизображения более совершен-
ных характерных признаков, таких как инвариантные моменты, краевые точ-
ки, цветовые переходы, статистические параметры и некоторые другие [27-36].
http://wwwjfv.ru
Компания ITV - генеральный спонсор издания книги
452
Цифвая обоаботка видеоизображений
Для обнаружения границ наборов кадров довольно успешно могут быть ис-
пользованы инвариантные моменты в комбинации с пересечениями гистограмм.
Момент изображения / определяется следующим образом:
.V м
= XSxV4U»y). /м = о.1.2,... (60)
•»=> > = |
Физическая интерпретация этого понятия следующая: если рассматривать
интенсивность пикселя как его массу, то будет являться массой всего изобра-
жения, а и - моментами инерции в направлении х и у соответственно.
Инвариантные моменты обладают свойствами, которые делают их очень
удобными для использования при сегментации видеоизображений. Они оста-
ются постоянными при изменении масштаба, вращении и перемещении. Инва-
риантные моменты получаются из нормированных центральных моментов q
(см. раздел 4 из главы 3).
Образ кадра в момент времени t может быть выражен как вектор, компонен-
тами которого являются инвариантные моменты Ф,:
д(г)={ФрФ2,...,Ф7}. (61)
Для вычисления расстояния между двумя кадрами обычно используется евкли-
дова мера:
<0i.^)=|^Gi)-^(^)|- (62)
Выберем в качестве еще одной характерной черты пересечение гистограмм,
аналогичное (37):
£min(//(/(+1,v),H(Z„v))
(‘,1 + О = ----й----------------• (63)
v=0
После того как найдены значения d, и d2, проводится их объединение:
3, ^<5,
Ofe)=- 2, 5,<£<52, (64)
1, <52<£
где g = d\ (г, t + 1) для инвариантных моментов и
ЦпОД4('.' + 1))е{1.2,3},
(65)
а для гистограмм g = d2 (t9 t + 1) и
(66)
Здесь и 82 - наперед заданные пороговые значения, и П = 3 означает близкое
сходство кадров, Q = 1 - сильное различие, a Q = 2 является промежуточным слу-
чаем. Окончательное решение принимается на основании следующей таблицы:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Г лава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 453
Моменты Гистограмма Результат
3 3 3
3 2 3
3 1 2
2 3 3
2 2 2
2 1 1
1 3 1
1 2 1
1 1 1
Резкое изменение яркости изображения чаще всего возникает на границах
объектов: это может быть изображение светлого предмета на темном фоне или
темного предмета на светлом фоне. Кроме того, резкие изменения яркости ча-
сто бывают следствием изменения отражательной способности на достаточно
характерных структурах. Наконец, к существенным скачкам яркости изображе-
ния также часто приводят изменения ориентации поверхности.
Точки изображения (края или краевые точки), в которых яркость изменяет-
ся особенно сильно, могут быть применены для сегментации видеопотока и вы-
деления как резких, так и плавных границ наборов кадров. При этом использует-
ся простой подход, основанный на том, что на границе набора кадров новые края
появляются довольно далеко от старых, а старые края исчезают на некотором
удалении от новых краев. Путем подсчета появляющихся и исчезающих краев
можно фиксировать резкие границы набора кадров, а также «раст ворение». Ана-
лизируя пространственное распределение появляющихся и исчезающих краевых
пикселей, можно обнаруживать такие плавные границы, как «стирание».
На первом этапе алгоритма при помощи сравнения величины градиента ин-
тенсивности с наперед заданным пороговым значением осуществляется выделе-
ние краев в двух последовательных кадрах / и /м, в результате чего появляют-
ся два бинарных изображения Et и Е . Обозначим через р/п долю краевых пиксе-
лей в EfI, которые удалены более чем на расстояние г от ближайшего краевого
пикселя в Е'. Таким образом, рт представляет собой относительное число появля-
ющихся краевых пикселей. Эта величина должна принимать большие значения
при резких границах, «проявлении» и в конце «растворения».
Аналогично через ром обозначим долю краевых пикселей в Ег, которые уда-
лены более чем на расстояние г от ближайшего краевого пикселя в Е р т. е.
Рош ~ это относительное число исчезающих краевых пикселей. роиг велико при
«угасании», в начале «растворения», а также при резких границах набора кадров.
В качестве основной меры различия введем
р = тах(р,л1р„„,). (67)
Эта величина представляет собой долю изменяющихся (появившихся или исчез-
нувших) краевых пикселей. Границы набора кадров должны совпадать с макси-
мумами этой функции. Остается получить выражения для pin и р0Ш. Пусть 8х и 8
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
454
Цифвая обработка видеоизображений
у представляют собой перемещения, необходимые для преобразования кадра / в
кадр /41 (например, в случае движения камеры 8х и 8у представляют собой про-
стые смещения). К бинарным изображениям £ и применим операцию дила-
тации с радиусом г. Эти изображения обозначим как Е( и Еж. Таким образом, Et
представляет собой копию Ez, где каждый пиксель заменен ромбом с диагоналя-
ми длиной 2r + 1.
Рассмотрим рои(. Черный пиксель (х.у) изображения Et является исчезающим
пикселем в том случае, когда £/и(х. у) - белый пиксель (так как черными пиксе-
лями в Е1л1 являются только те пиксели, которые лежат не далее чем на расстоя-
нии г от краевых пикселей в Е, Поэтому формула для определения рош выгля-
дит следующим образом:
Рош=1-
У ж>. Е,(х + 8х,у + Зу]Е,.. (х, у)
(68)
Аналогично определяется величина pin:
X ,> £< (х+ (*'>’)
Zx./,(x +5x^+5^)
(69)
Теперь границы наборов кадров определяются при помощи поиска локаль-
ных максимумов у функции р. Основная задача состоит в классификации зафик-
сированных границ. Проще всего определяются резкие переходы, которым соот-
ветствуют изолированные максимумы р. Остальным типам границ соответству-
ют интервалы, где значения функции р сначала растут до локального максиму-
ма, а затем начинают убывать.
«Угасание/проявление» и «растворение» могут быть распознаны по относи-
тельным значениям рп и рош на определенном временном интервале. Во время
«проявления» рт будет намного больше рош вследствие большого числа появля-
ющихся краевых пикселей и всего лишь нескольких исчезающих. Наоборот, во
время «угасания» раи( будет больше рт (много исчезающих и мало появляющих-
ся краевых пикселей). «Растворение» состоит из накладывающихся друг на друга
«проявления» и «угасания». Во время первой фазы «растворения» рт будет боль-
ше Pqui, а во время второй фазы - наоборот.
«Стирание» может быть отделено от других типов плавных переходов при
помощи исследования пространственного распределения появляющихся и ис-
чезающих (далее меняющихся) краевых пикселей. Метод заключается в вычис-
лении процентного отношения таких пикселей в верхней и в левой половинах
кадра. Тогда для горизонтального «стирания» подавляющее большинство ме-
няющихся пикселей будет возникать в левой половине изображения в первой
фазе «стирания» и в правой половине - во второй фазе. Аналогично для верти-
кального «стирания» в первой фазе большая часть меняющихся пикселей будет
в верхней половине кадра, а во второй фазе - в нижней.
Помимо предложенной выше меры различия двух кадров (68), может быть
также использовано расстояние Хаусдорфа, которое для множеств А и В опреде-
ляется следующим образом:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных
455
й(Я,/?) = rnaxrninj|a-h|j. (70)
аеЛ he. В
Если теперь рассмотреть такое расстояние между изображениями Et и Е , то
при выполнении условия h(ElV Et) < г все краевые пиксели в Е л находятся не да-
лее чем на расстоянии г от ближайшего краевого пикселя в Е{, нет появляющих-
ся краевых пикселей, и поэтому рщ = 0. Аналогично, если Л(Е, Е1}) < г, то нет ис-
чезающих краевых пикселей и. следовательно, ром == 0.
Обычно используется так называемое обобщенное частичное расстояние
Хаусдорфа:
ЛДЛ,5)=С/,тт||а-4 (71)
ле о
При этом выбирается Х"'-е по рангу расстояние от точки в А до ближайшей ей
точки в В. Очевидно, что если выбрать первое по рангу расстояние, то получим
обычное расстояние Хаусдорфа. Используя меру (71). можно задать процентное
отношение точек множества А. которые должны быть близки к их ближайшей
соседней точке в В, и найти конкретное расстояние. Или же, наоборот, можно за-
дать расстояние, тогда придется минимизировать процентное отношение указан-
ных точек в А.
Если необходимо зафиксировать только плавные переходы, то можно сначала
аналогично описанному выше методу выделить края, а затем сравнить их с двумя
пороговыми значениями для определения «сильных» и «слабых» краевых точек:
Е,(х,у], 3„<E,(x,y)<3s
0, иначе
Е’{х,у) =
Е,{х,у), 8s<E,(x,y)
0, иначе
(72)
(73)
где 8 и 8к - нижний и верхний пороги для выделения «слабых» и «сильных» кра-
евых точек соответственно. В качестве окончательной величины вычисляется
основанный на краях контраст:
N М N М
ес.=\+^--------------------------- <74>
£ X е; (*,у)+£ £ е; (х,у)+1
х=1 /ж! х=1 >-!
«Растворение» фиксируется в те моменты времени, когда величина (74) имеет ло-
кальные минимумы.
Если резкие переходы уже были найдены с помощью какого-либо метода,
то для определения плавных переходов можно вычислить число краевых точек
NE(t) для всех кадров между двумя следующими друг за другом резкими перехо-
дами в моменты времени и t2. Затем для каждого локального минимума /VE(r%
меньшего наперед заданного порогового значения, произвести поиск ближайших
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
456
Цифвая обработка видеоизображений
локальных максимумов и где t'< t' < Тогда между /'и /'фиксирует-
ся «угасание», если
v ч <'=< /
(75)
где ё[° и - пороговые значения для «угасания». Аналогично для «проявления»
имеем
(тА? (')- AU' -1)|] е [аЛ#']. (76)
V2 1 l=l’ )
Для фиксирования «растворения» введем новую меру, которая рассчитывает-
ся для каждого кадра из интервала гф
DCZ)(0 = f . (77)
х=1 у I
Если кадр rmin, в котором достигается глобальный минимум величины (77), до-
статочно близок к г',т. е. |/'- г | < £ (£ мало), то между кадрами г' и V фиксирует-
ся «растворение».
Проблема нахождения границ наборов кадров также может быть сформули-
рована как задача выбора одной из двух гипотез:
1. Гипотеза 5: между кадрами t и t+l находится граница набора.
2. Гипотеза 5: между кадрами t и /+/ нет границы набора.
При этом могут возникнуть два вида ошибок. Ложное определение границы
имеет место в случае, когда принята гипотеза 5, bjo время как истинной является
гипотеза 5. И. наоборот, если принята гипотеза 5, а истинной является гипотеза
5, то говорят о пропущенной границе набора кадров. Если предположить равно-
значность всех типов ошибок, качество фиксирования границ определяется сред-
ней вероятностью РЕ того, что возникает какая-либо ошибка. Введем Рм - веро-
ятность пропуска границы:
Pw = Jp(2|5)<fe, (78)
и РЕ - вероятность ложного фиксирования границы:
Pf = (79)
г.
Область Zs (Zs) включает все значения величины z(f, t + /), в качестве кото-
рой выступает мера сходсгва между кадрами t и /_+ /, для которой принята гипо-
теза 5(5). Плотности вероятностей p(z | 5) и p(z | 5) вычисляются с помощью об-
учающей последовательности данных.
Средняя вероятность возникновения ошибки может быть записана с помо-
щью формулы полной вероятности следующим образом:
ProSystem CCTV - журнал по системам видеонаблюдения
http://w w w. procctv. г и
Глава 11. Индексация и гоиск в цифровых библиотеках и архивах видеоданных 457
ZS Zs
Здесь Р (5) и Pf(S) вероятности истинности гипотез S и S между кадрами t и t + I.
Так как у нас есть всего две гипотезы, то, следовательно:
^(S) = l-^(S). (81)
Определим теперь Р(5) как произведение априорной вероятности Р* (5) и услов-
ной вероятности P,{S <//(/)) для гипотезы S между кадрами t и t + /.Условная ве-
роятность зависит от дополнительной информации !//(/), полученной из видеопо-
тока. Таким образом:
^(S) = /f(5)/j(S|^(/)). (82)
Для оптимального фиксирования границ набора следует минимизировать сред-
нюю вероятность ошибки Рг Тогда для гипотезы S с помощью (80) получим сле-
дующее неравенство:
p(z|s) !-<;($) i-^(s)/;(s|fW)
I ^(s) HsWwH) '
Для гипотезы S знак неравенства меняется на противоположный. Условие (83)
может быть переписано как
z(t,t + l)> 8(t), (84)
где 8(f) - пороговое значение.
Для определения величины z(r, t + /) разделим кадр t на NB непересекаю-
щихся блоков 6f(f) и будем искать соответствующие им блоки bim(t + /) в кадре
t + I. В качестве меры сходства между блоками будем рассматривать средние
по блоку значения каждой компоненты цветового пространства YUV:
of*. ,.('+'))!+
+|<7(AM)-0(»o.('+'))|+|fF(i’.('))-’7(^(i+/))l (85)
После того как соответствующие блоки найдены по формуле
W) = ^(')Ая(' + 0) = min D(bf(/)А,(/ + /)), (86)
величина z(z, t + /) может быть выражена как
1 "в
Z ' + X D (* (Z) Ат (' + '))• (87)
/V В 1 = 1
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
458
Цифвая обработка видеоизображений
В (86) L обозначает число блоков, которые рассматриваются в качестве кандида-
тов на соответствие блоку 6 (г).
Для фиксирования резких границ наборов значение / выбирается равным еди-
нице. Для плавных переходов эта величина должна быть меньше длины набора и
быть больше единицы, чтобы включать начало и конец перехода (например, 20).
Зададим теперь вид плотностей p(z| 5) и p(z| 5). Хорошим аналитическим
приближением для p(z | S) служит следующее семейство функций:
P(z\S) = ^e^.
Плотность p(z I 5) может быть описана с помощью гауссовой функции
p(z|S) = —
СТл/2 л
(88)
(89)
Параметры (Лг Л2, Л3,) и (а. ц) определяются экспериментально таким образом,
чтобы ошибки при определении границ набора на обучающей последовательно-
сти были минимальны.
Для задания априорной вероятности ^а(5)будем считать, что она зависит от
числа кадров за последней границей набора и удовлетворяет следующим двум
условиям:
• Рга (5) должна монотонно возрастать при увеличении времени, т. е. индек-
са кадра г;
• Po“(S) = O, a lim^“ (S) = 0.5.
Исследования, основанные на статистических измерениях длин наборов на
большом числе различных видеорядов, показали, что лучше всего указанным
двум условиям отвечает распределение Пуассона [34,35]:
(90)
Параметр /1 описывает среднюю длину набора видеопоследовательности, w -
счетчик кадров, который сбрасывается каждый раз, когда фиксируется очеред-
ная граница набора, а Л(г) - текущая длина набора в момент времени I. Хотя па-
раметр /J. следует выбирать для каждого типа видеопоследовательности отдель-
но, оказалось, что он довольно слабо меняется в широком диапазоне типов ви-
деосюжетов.
Для того чтобы определить условную вероятность Pt(S | необходимо
каким-то образом получить дополнительную информацию уф). Одним из воз-
можных решений является вычисление отношения максимума z(r, t + 1) ко вто-
рому по величине значению z т и сравнение получившейся величины с порогом
для определения резких переходов между кадрами. Выберем указанное отно-
шение в качестве уф) с небольшими изменениями, а именно: вместо отношения
будем рассматривать относительную разность между z(t, t + 1) и zsm:
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. ги
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 459
Рис. 5. Характерная форма функции z(t, t+l) для резких (А) и плавных (Б) границ
наборов.
Здесь /V- наперед заданная фиксированная величина.
Для «растворения» задание функции гораздо сложнее. Учтем, что при
плавных переходах z обычно имеет треугольную форму (см. Рис. 5) и потребуем
выполнения двух условий:
• значение г (г, t + 1) в средней точке окна длиной N является максималь-
ным;
• максимумы в окне справа и слева от середины окна должны быть к ней
как можно ближе.
Введем функцию (г):
Здесь Д^ и Д^ - расстояния до максимумов справа и слева от середины окна.
Введем также функцию у<2(г). как относительное изменение интенсивности в
середине окна, т. е. интенсивность в кадре / + (/V / 2) по отношению к интенсивно-
сти в кадрах, близких к краям окна:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
460
Цифвая обработка видеоизображений
0,
Здесь сг(г') - дисперсия кадра в середине окна с t' = t + (/V I 2), a <j(r' - (N / 2)) и
cr(z' + (N12)) - дисперсии кадров на разных концах окна.Третий случай в выраже-
нии (93) соответствует случаю, когда дисперсия в середине окна больше, чем на
его краях.Так как этого не может быть для случая обращенного вниз параболиче-
ского профиля z, то, естественно, это не может соответствовать «растворению».
Умножая (//)(/) на ул/г), получим функцию ул которая входит в выражение (83):
v0)=Vi(0v2(0- <94)
Осталось получить выражение для условной вероятности P[S 11/(г)).Так как
она является неубывающей функцией i//(r), а значения последней лежат в преде-
лах [0,100], то P((S | у/(0) должна удовлетворять следующим условиям:
• уф) = о -> Р, (s I <//(/)) = 0;
* =100
Кроме того, как следует из экспериментов, Р (5 | у/(г)) не должна быть очень
чувствительна к значениям i/(r), близким к границам отрезка [0,100]. Область
наиболее сильного изменения Р должна находиться в средней части указанно-
го отрезка. Этим условиям удовлетворяет, например, следующее представление
Р,(5|И0):
уф)"7
(95)
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ri/
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 461
где erf(x) - функция ошибок:
erf (х) = — ( ехр (-Г )dt. (96)
* о
Параметры (т. O rt) для резких границ и «растворений» равны соответственно
(60,2) и (21,2).
11.1.5. Методы, основанные на движении
Так как движение в видеопоследовательностях обычно носит непрерывный
характер, то оно может быть использовано для определения границ наборов ка-
дров. Существует несколько различных подходов, но практически все они осно-
ваны на сравнении характеристик движения блоков, на которые разбиваются все
кадры. Обычно для каждого блока в кадре t ищется соответствующий ему блок
в кадре t + 1. Это может быть осуществлено путем вычисления нормированной
корреляции между блоками и фиксации ее максимума. Вычисление нормирован-
ной корреляции является весьма ресурсоемким процессом, поэтому вместо этого
можно находить нормированную корреляцию в частотной области [37]:
р(£)- V . т
^]|х|(щ)| dcoj |х2 (щ)| dco
где и со - пространственная и частотные координаты, х (щ) обозначает Фурье-
преобразование блока b (£),а F 1 и * - соответственно операторы обратного пре-
образования Фурье и комплексного сопряжения. Перед вычислением (97) к изо-
бражению применяется полосовой фильтр, пропускающий только высокие ча-
стоты. Это объясняется тем, что корреляция, полученная из высокочастотных
областей, будет содержать больше различимых пиков. Низкие частоты приводят
к плоскому виду корреляционной функции, в результате чего неверно определя-
ются ее максимумы. Вследствие применения высокочастотного фильтра корре-
ляция между блоками становится инвариантной к изменениям средней интенсив-
ности изображения, поскольку последняя не пропускается фильтром. Нормируя
корреляцию, мы тем самым делаем метод нечувствительным к изменениям мас-
штаба интенсивности. Большинство методов ложно фиксирует границу набора
в случаях резкого изменения освещенности сцены. Данный подход избавлен от
этих недостатков вследствие высокочастотной фильтрации и нормирования ко-
эффициента корреляции.
С помощью максимума коэффициента корреляции можно определить, как
изменилось местоположение конкретного блока при переходе от кадра t к ка-
дру t + 1. Для этого вводится степень соответствия блоков pt = max(p(£)) для i-ro
блока, значения которой лежат в диапазоне от 0 (полное расхождение) до 1 (пол-
ное соответствие). Для кадров одного и того же набора значение этой величины
близко к 1. Большое же число малых значений свидетельствует о наличии гра-
ницы набора.
Мера сходства двух кадров определяется как комбинация степеней соответ-
ствия блоков. Для этого рассчитывается среднее значение степени соответствия Д:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
462 Цифвая обработка видеоизображений
в
Za
Д = (98)
О
где В - общее число блоков. В пределах одного набора могут встречаться блоки с
очень маленькой степенью соответствия вследствие перекрытия объектов. Что-
бы исключить влияние таких эффектов на меру сходства, значения лежащие
вне пределов одного стандартного отклонения от р, не принимаются в расчет.
Окончательная суммарная мера сходства d, между кадрами / и t + 1 представляет
собой среднее значение оставшихся степеней соответствия. Введем величину d:
К
d = . (99)
Г-1
где отсчет начинается от последней фиксированной границы набора.Тогда новая
граница набора фиксируется в том случае, если
d-d, >6. (100)
11.1.6. Комбинация нескольких методов
Для увеличения надежности определения границ набора кадров возможно
применение комбинированных подходов, когда совместно используется сразу
несколько методов разного типа. Так. одним из возможных является алгоритм,
основанный на следующих методах:
1. извлечение частотных характеристик изображения,
2. определение разности в значениях интенсивности,
3. построение гистограмм полутоновых изображений [38].
На первом этапе цветное изображение преобразуется в полутоновое, а за-
тем при помощи быстрого преобразования Фурье находится его спектр. После
этого вычисляются две величины: суммы действительных 2?s и мнимых Is ча-
стей первых 25 частотных характеристик. Наконец, для двух последовательных
кадров определяется сумма абсолютных значений разностей действительных и
мнимых частей:
^(г,Г + 1) = |лДг + 1)-^(г)| + |/Дг + 1)-75(г)|. (Ю1)
На следующем этапе каждый кадр переводится в цветовое пространство
YUV. После этого У-значения всех пикселей кадра суммируются:
.V м
= (102)
х=1 у=1
а затем составляется разность этих величин для двух последовательных кадров:
М'>'+,)=|М'+1)-Ш (юз)
На заключительном этапе извлечения характерных признаков строится ги-
стограмма HG для преобразованного в полутоновое изображения и вычисляется
их нормированная разность для двух последовательных кадров:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 463
Н (t Г + Й = У + ^g(z>0)
С°* ’ £тах{Яс(г4Ч,/),Яс(м)}’
(104)
После того как все три основные величины определены, начинается процесс
нахождения границ набора. Для этого все они сравниваются с соответствующим
пороговым значением, которое задается или явным образом, или адаптивно ме-
няется во времени:
max{T(0tl),T(l,2),...,r(rj+l)}gc
100
(105)
где 5 задается в процентах, а через Т(Л t + 1) обозначена одна из величин:
1) . 1) «лиЯОд,(<.<. 1).Есл»
Hoa,>S„UFs>SfWa,>Sr.
то фиксируется граница набора кадров.
(106)
11.2. ОПИСАНИЕ СОДЕРЖАНИЯ ПОСЛЕДОВАТЕЛЬНОСТИ КАДРОВ
После того как исходная видеопоследовательность разбита на наборы ка-
дров, можно проиндексировать информацию, содержащуюся в полученных на-
борах. Для этого необходимо каким-то образом описать содержимое каждого на-
бора, чтобы использовать полученное описание в качестве индекса для последу-
ющего поиска в архиве. При этом чаще всего используются два метода: выделе-
ние ключевых кадров и выделение ключевых объектов. Выбор метода зависит
от требований, предъявляемых к системе видсонаблюдения.
11.2.1. Выделение ключевых кадров
Под ключевыми кадрами понимаются отдельные кадры набора, являющие-
ся наиболее характерными его представителями. Для того чтобы стать эффек-
тивным индексом, ключевые кадры должны описывать все содержимое набо-
ра: объекты, фон, а также последовательность событий, при этом обладая ми-
нимальной избыточностью. Простейшие методы выделения ключевых кадров
предполагают использование отдельных фиксированных кадров набора, напри-
мер, только первого или среднего. Единственным достоинством таких методов
является их простота, однако они не позволяют учесть изменения изображений
набора кадров во времени. Кроме того, одного ключевого кадра обычно бывает
недостаточно для описания всего набора в случае сложной динамики объектов в
видеопотоке. Поэтому в дальнейшем мы рассматриваем более совершенные ме-
тоды выделения ключевых кадров, позволяющие выделять необходимое их чис-
ло в зависимости от характера видеопотока [39-42].
Одним из возможных методов описания ключевых кадров является исполь-
зование дискретного косинус-преобразования (ДКП), которое позволяет эффек-
тивно переводить изображение в частотное пространство. Так как в большин-
bttp.//wwvv./tv.ru
Компания ITV - генеральный спонсор издания книги
464
Цифвая обработка видеоизображений
стве случаев основная часть энергии сосредоточена в области низких частот, то
можно описать сигнал, используя только небольшое число коэффициентов ДКП.
Двумерное ДКП АС(р. q) изображения 1(х,у), где pwq обозначают частотные ин-
дексы, записывается следующим образом:
х V'1^' ,, х я(2х + 1)р
/<С(р)9) = ара.,ХХ/(х, у) cos ——-— cos
х=0 >=0
к(2у + 1)д
М
(107)
Здесь 0<р<УУ-1,0<<7<М-1,а
р = 0
\<p<N-\
(Ю8)
\/4м, q = 0
Jl/M, 1 < q < М -1
(Ю9)
После преобразования большая часть высокочастотных компонент может быть
отброшена без существенных потерь и довольно эффективным приближением
является ограничение р + q < 6. где коэффициенты пробегаются в порядке, пока-
занном на Рис. 6.
Рис. 6. Последовательность обхода коэффициентов ДКП
Коэффициенты ДКП содержат только пространственную информацию о
кадре. Чтобы использовать также и временную информацию, с помощью ко-
эффициентов ДКП, соответствующих одной и той же частоте, строятся ги-
стограммы. Вначале производится дискретизация их значений на В уровней.
Число квантовых ячеек гистограмм также будет равно Врд. Значение ячей-
ки - это вероятность появления соответствующего дискретного значения ко-
эффициента ДКП. Значения квантовых ячеек упорядочиваются по убыванию:
(S., (>)) г (2))г * (V, Ы).
где
"„('.) = * ’1.2..В„,
/=0
(ПО)
(111)
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 465
т = 1
т п
5(w-«) =
1,
О,
(И2)
Здесь индекс / относится к номеру кадра видеопоследовательности длиной L.
Hp,q(xp.q) - это гистограмма, образованная соответствующими коэффициентами
ДКП с индексом (р. q) во всех L кадрах, а Нр q(xpq(k\) - значение квантовой ячей-
ки, соответствующей дискретному значению ДКП хр q(k).
Оптимальное значение коэффициента ДКП для данной частоты соответ-
ствует ячейке с максимальным значением. Для лучшего представления видеопос-
ледовательности может быть выбрано более одного (максимального) значения
для каждой частоты. Таким образом, оптимальные коэффициенты ДКП вычис-
ляются следующим образом:
DCT(p,q,k) = xpq(k), 1< к < kd(p,q\
(ИЗ)
где kd(p, q) - число выбранных значений для частоты (р, q). В зависимости от ин-
формативности коэффициентов ДКП используется разное число значений. Для
низких частот оно больше, чем для высоких. В таблице 1 приведены значения
kd(p, q) для различных частот. Например, для ЛС00 используется 67 величин из
общего числа 256 значений.
Таблица 1
67 35 16 8 4 2 1
35 16 8 4 2 1 0
16 8 4 2 1 0 0
8 4 2 1 0 0 0
4 2 1 0 0 0 0
2 1 0 0 0 0 0
1 0 0 0 0 0 0
Значения величины kd(p, q). Здесь q меняется слева направо, ар- сверху вниз
После того как получены оптимальные коэффициенты ДКП, становится
возможным рассчитать степень сходства между ключевым кадром и кадром, ко-
торый предъявляется в качестве запроса при поиске. Обозначим через 7?f(p, q)
оптимальные коэффициенты ДКП /-го видеонабора:
Л, (/>,<?) = DCT, (р, q,кор1 (р,<?)),
где кор((р, q) выбирается исходя из следующего критерия:
коР, (р, <?) = arg min {|ЛС7; (p,q,k)- DCT^ (/m)|}.
(114)
(115)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
466
Цифвая обработка видеоизображений
Здесь 1 < к < kd(p. q). a DCT (р. q) - коэффициенты ДКП, рассчитанные для ка-
дра запроса. Расстояние между этим кадром и /-м видеонабором рассчитывается
следующим образом:
6 6
п'5(0=ХХ(Л.(/’’?)_£)С7'^(/’’^)) > р+?^6- (116)
р-0 q- О
Чтобы уменьшить число операций ДКП. каждый коэффициент кадра запроса
сравнивается с соответствующим коэффициентом для всех видсонаборов. На
первом этапе используются только постоянные ЛС00 значения. Если для каких-
то из них расстояние (116) превышает наперед заданный порог, то такие виде-
онаборы исключаются из дальнейшего рассмотрения. На следующем этапе ис-
пользуются ЛС01 и АС} 0 и применяется аналогичная процедура. Таким образом,
на каждом этапе происходит исключение некоторого числа видеонаборов, что
ускоряет процесс поиска в архиве.
Из коэффициентов ДКП можно сформировать векторы характерных при-
знаков изображения, которые затем используются для описания видеонабо-
ров. При этом ДКП коэффициенты вычисляются для каждого цветового кана-
ла и затем объединяются в один вектор характерных признаков z. Таким обра-
зом, для набора из N кадров получим следующее множество векторов Z = [z.: I =
1,...JV|. Будем считать, что исходный набор кадров подразделяется на части - сег-
менты. Мера сходства между отдельным кадром и сегментом из нескольких ка-
дров может быть определена как среднее значение расстояния между этим ка-
дром и всеми кадрами сегмента. Пусть сегмент Qk состоит из кадров т. е.
бА = I? :i = /»...»r)cZ,a
Z= и Qk. (117)
*=1.К
Тогда мера сходства 5 между кадром / и сегментом Qk выражается следующим
образом:
sUe.)=4| Z'(w-). 'Ш'. (ns)
где в качестве d может быть выбрана величина, обратная какому-либо из выра-
жений для вычисления расстояний, приведенных в предыдущем_разделе. Пусть
С - это мера сходства кадра; со всеми сегментами из множества Qk = Z\ Qk:
cUeJ=|^ njsr. (ii9)
Для ключевого кадра сегмента в данном наборе значения 5 будут большими, так
как такой кадр должен быть в достаточной мере схож со всеми другими кадрами
сегмента. С другой стороны, он должен быть отличен от кадров других сегмен-
тов набора. Поэтому величина С для него должна быть малой. Разница или отно-
шение величин S и С показывает, насколько хорошо рассматриваемый кадр удо-
влетворяет указанным выше требованиям:
F(;,ej=sue*)-c(j,e*) (120)
или
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 467
<12,)
Для получения большей гибкости при этом можно ввести весовые коэффи-
циенты а и ft:
F(j,Q>) = aS(j,Qk)-pC(j,Qk) (122)
ИЛИ
f (ле.)= (>»>
(С(у, <2а))
В обоих случаях, изменяя один весовой коэффициент относительно другого,
мы имеем возможность придавать большее значение или схожести ключевого
кадра с кадрами из того же самого сегмента, или различию его с кадрами из дру-
гих сегментов. Ключевой кадр для данного сегмента определяется из следующе-
го выражения:
г‘ = arg max F (j, Qk\ (124)
Рассмотренный алгоритм можно объединить с методом, основанным на ли-
нейном дискриминантном анализе. Для каждого из К сегментов вычислим век-
тор средних значений характерных признаков Обозначим через jl такой же
вектор для всего набора кадров и определим матрицу рассеяния внутри сегмента:
^ = 1 (125)
*=i
и вне его:
^ = Х^(Д4-д)(Дл-Д)г, (126)
где Nk - число кадров в сегменте Qk. Определим следующее преобразование:
JT = arg max
X
XTSBX
XTSWX
(127)
проецирующее характерные признаки на матрицу Z- WrZ.Тем самым осущест-
вляется кластеризация признаков одного сегмента и разделение их с признаками
из других сегментов. В результате в качестве ключевого используется тот кадр
сегмента, который имеет вектор характерных признаков, ближе всех располо-
женный к среднему вектору характерных признаков каждого сегмента:
z; = argmm||lF7(z7-M4)|.
(128)
Чтобы при выделении ключевых кадров учесть движения объектов и самой
камеры, необходимо определить изменения масштаба и смещение в направле-
ниях х и у между двумя кадрами. Точка pt - (х, у) в кадре t - 1 переходит в точку
р\ = (х',у/) в кадре t в соответствии со следующим правилом:
http://www. itv. си
Компания ITV - генеральный спонсор издания книги
468
Цифвая обработка видеоизображений
'И
У/ W-x-z.)'*-0»,
(129)
где (хг, уг) - точка отсчета, в качестве которой наиболее часто выступает центр
кадра. Вектор параметров вп = (б*,#*,#*) описывает изменения масштаба и сме-
щения в направлениях х и у соответственно.
При движении камеры для адекватного описания содержимого видеопосле-
довательности необходимо выделение не одного, а нескольких ключевых кадров.
Данная проблема может быть решена при помощи направленных графов, ветвям
которых присвоены определенные веса. Кратчайшим путем между двумя верши-
нами графа является тот. который имеет наименьший суммарный вес. Чтобы из-
бежать избыточности при выделении ключевых кадров, необходимо минимизи-
ровать меру схожести кадров. Поэтому граф формируется таким образом, чтобы
его узлы соответствовали кадрам видеопоследовательности, а весовые коэффи-
циенты его ветвей - мерс схожести кадров. Кадры, соответствующие узлам, со-
ставляющим кратчайший путь через весь граф, и являются ключевыми для дан-
ного набора.
В качестве меры схожести d(i.j) (0 < d(jj) < 1) выберем степень пересечения
содержимого двух кадров i иу. При этом будем считать, что содержимое кадров
существенно меняется только вследствие движения камеры, т. с. при его отсут-
ствии d(ij) = 1. Для каждого видеонабора имеется вектор параметров соответ-
ствующий каждой паре последовательных кадров. Для данных кадров I и у (t < j)
сформируем новый вектор Д = (Д’,Д’,Д*'),гдс
азо)
Л=1+1
а Д:Х(У_|) = ПРИ z = J “ 1- Следовательно. Д’, Д’ и Д< - это накопленные значе-
ния изменения масштаба, смещения соответственно в направлениях х и у между
кадрами i и у. Эти величины используются для нахождения степени пересечения
кадров. Необходимо отдельно рассмотреть два случая: Д’ < 1 и Д’ > 1.
В каждом из этих случаев будем считать, что кадры имеют постоянные ши-
рину w, высоту h и площадь A = wh, а начало отсчета (0,0) находится в их цен-
тре. Применим преобразование Д1} к кадру и получим новый вспомогательный
кадр zj;, имеющий ширину z* = w • Д’ высоту z* = й • Д’ и площадь z~ = z* • z*.
а его центр будет находиться в (Д’. Др. Этот вспомогательный кадр отражает
размеры и положение содержимого кадра i по отношению к кадру j. Другими
словами, определение степени пересечения ф(/,у) между кадром i и вспомогатель-
ным кадром эквивалентно вычислению степени пересечения между содержи-
мым кадров i и у. Если Д’ < 1,то изменения масштаба либо не было совсем, либо
было его уменьшение и, возможно, смещение в направлениях х и у. В этом случае
необходимо подсчитать, какую часть кадра у занимает содержимое кадра z и. сле-
довательно, = /А. Противоположный случай Д’ > 1 соответствует уве-
личению масштаба и возможному смещению в направлениях х и у. Рассмотрен-
ные возможности отображены на Рис. 7. Здесь d(Lj)
Определим теперь набор кадров, как направленный граф G = (V, Е), состо-
ящий из множества узлов V = (vr v2.vv) и множества ветвей Е £ V х V, сое-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procct v. ги
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 469
Рис. 7. Возможные случаи изменения масштаба и смещения изображения
диняющих узлы и имеющих некие веса. Обозначим через ш|у. у) - весовой ко-
эффициент ветви, соединяющей у и у.. Путь от узла у к узлу vm представляет
собой множество направленных ветвей |(у. у), (у. vj.(у. уп)| из Е. Вес пути
р = <v0, Vj.vk) определяется как сумма весов составляющих его ветвей:
к
(131)
1=1
Если существует более одного пути от у( к vr то кратчайшим считается тот. кото-
рый имеет наименьший общий вес (131).
Связность графа может быть представлена как матрица близости Л/, в кото-
рой каждому элементу (/./) соответствует ветвь между узлами у и v. Если ветвь
(у. у) существует.то Л/ = fi)(y. у), в противном случае - М = 0. Для каждого набо-
ра кадров нужно сформировать матрицу близости, в которой узлы соответству-
ют отдел ьным кадрам и со( у. у) = d(/./). Следовательно, кратчайший путь от пер-
вого к последнему кадру набора будет минимизировать величину пересечения
содержимого ключевых кадров. Если между кадрами / и j нет пересечения, то
М = d(i,j) = 0. Отсюда следует, что содержимое ключевых кадров, соответ-
ствующих узлам кратчайшего пути, всегда должно пересекаться. Поэтому
введем пороговое значение 5min. которое определяет минимальную степень
пересечения между ключевыми кадрами. Тогда ветвь (у. у) будет существо-
вать только в том случае, если d(i.j) > <5min. Для того чтобы исключить нару-
шения временной последовательности кадров, потребуем, чтобы кадр / пред-
шествовал кадру /.
Для выделения ключевых кадров осталось найти кратчайший путь от перво-
го к последнему кадру набора. Для этого используем функцию оценки для упоря-
дочивания узлов в пространстве поиска
^(ч) = «(ч)+А(уД (132)
где g(v.) - стоимость достижения узла у. начиная с первого кадра, а Л(у) - эври-
стическая оценка стоимости достижения последнего кадра из узла v. В нашем
случае й(у) - это минимальный вес всех исходящих из у ветвей.
Возможно существование более чем одного кратчайшего пути в графе. В
этом случае выбирается тот. где кадры распределены более равномерно во
времени. Для этого подсчитывается среднеквадратичное отклонение О всех
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
470
Цифвая обработка видеоизображений
весов ветвей на данном пути и выбирается путь, для которого ст принимает
наименьшее значение. На практике вероятность того, что для двух путей р
и р' выполняется Q(/?) = Q(p')- весьма мала из-за ошибок округления. Поэ-
тому несколько ослабим введенное выше условие и будем считать, что если
|Q(p) - Q(p')l - £* где е - заданная малая величина, то предпочтение отдается
пути с меньшим (У.
Для того чтобы при поиске кратчайшего пути учитывать необходимость ма-
лости величины ст. нужно модифицировать веса. Для пути р с Q(p) и <7(р) введем
новый весовой коэффициент
Y(p) = Q(p)+<t(/>). (133)
Теперь путь р выбирается в том случае, если У(р) < Y(p'). в противном случае
предпочтение отдается пути р\ Узлы графа упорядочиваются в соответствии с
величиной e(v). Если существует несколько узлов с приблизительно равными
значениями е(т).то можно определить новую эвристическую функцию
г(ч) = е(у,) + <т(е(р,)). (134)
с помощью которой будем упорядочивать узлы. Это позволит отдавать предпо-
чтение путям, для которых стандартное отклонение весов ветвей будет мини-
мальным.
Описанный алгоритм выделяет, по крайней мере, два ключевых кадра из каж-
дого видеонабора. Однако когда движение камеры отсутствует, может быть до-
статочно только одного ключевого кадра. Поэтому введем еще одно пороговое
значение <5тах, определяющее степень максимального пересечения между двумя
ключевыми кадрами. Если существует более двух узлов в кратчайшем пути или
только два узла с Q(p) < 5max. то такой путь адекватно описывает содержимое ви-
деонабора. Если же в пути р существует только два узла v и v и Q (р) > <5тах. то вы-
бирается единственный узел, наилучшим образом представляющий ветвь (v, v).
Иными словами, выбирается кадр, соответствующий узлу с наибольшим пере-
сечением со всеми кадрами между i и /, включая их самих. Таким узлом vk являет-
ся узел с наибольшей суммой всех весов ветвей:
тах<
к
2>(п.
/=/
ч)г»
Vi<k< j.
(135)
Для ^тач и ^тт рекомендуются значения соответственно 0.8 и 0.2.
Для выделения ключевых кадров могут быть также использованы простые
геометрические характеристики видеопоследовательности. При переходе от
одного кадра к другому образуется три типа областей:
• исчезнувшая область, присутствующая в кадре t - 1 и отсутствующая в
кадре г;
• общая область, присутствующая как в кадре t - 1, так и в кадре г,
• новая область, присутствующая в кадре t и отсутствующая в кадре t- 1.
Обозначим их площади соответственно через sL. sc и sv. Определим теперь
число ключевых кадров в наборе. Для этого необходимо проанализировать всю
информацию, заключенную в последовательности кадров. Наиболее простым и
быстрым способом является нахождение суммы площадей новых областей:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 471
S«=I>v(/). (136)
где N - число кадров набора. Тогда число ключевых кадров 7V* определяется как
ближайшее целое к отношению величины £Л/ к площади всего кадра.
После того как /V* известно, необходимо выбрать ключевые кадры из данно-
го набора. Для этого введем следующую величину:
$(*) = £МА (137)
/=|
где sv(l) равна площади первого кадра набора a S(N) = Lv . Как только значе-
ние S(k) превышает величину / х £и/ /V*.фиксируется новый ключевой кадр. Кро-
ме того, первый кадр набора всегда включается в число ключевых кадров.
Полученные таким образом ключевые кадры представляют собой толь-
ко первое приближение к истинным ключевым кадрам. Для их нахождения
используется следующий алгоритм. Пусть Т = г2,...,гЛ„} - моменты време-
ни, когда были выделены начальные ключевые кадры. Их можно представить
при помощи марковских моделей. Обозначим через sN = (sv(l), sn(N)} и
sc = {s (1), sc (2),...,sr(W)| все новые и общие области в наборе. Введем функцию
энергии U(J\sc, 5V), определяющую модель Маркова и состоящую из трех частей
Ц(Т), U2(T\sc) и (7,(T,5v). Первая выражает разницу во времени между изначаль-
ными ключевыми кадрами и выбранными на данном этапе. При этом последние
не должны отстоять слишком далеко от изначальных {z®). Вторая часть функции
энергии служит для уменьшения общих областей между ключевыми кадрами,
при этом она не должна быть равна 0, чтобы сохранять разумную непрерывность
между кадрами. Наконец, третья часть отражает тот факт, что сумма новых об-
ластей выбранных ключевых кадров должна быть близка к 2Л/. Таким образом,
U(T,Sc,sN) = t/((r)+j3t/2(r,5c)+y^(r,s.v), (138)
где
/V’
^1(Т’) = £к-4 (139)
(140)
1=1 а
^з (^^.v)= E.w • (141)
/Х*1
Здесь Р и у - весовые коэффициенты, величина а зависит от /V*. Для нахожде-
ния ключевых кадров необходимо минимизировать функцию энергии U(l\sc, sN).
11.2.2. Выделение ключевых объектов
Когда человек просматривает кадры видсопотока, его зрительная система
в первую очередь выделяет движущиеся объекты и их самые общие характер-
ные черты, фокусируясь на характерных признаках высокого уровня (семанти-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
472
Цифвая обоаботка видеоизображений
ческих). и только затем - на признаках низкого уровня, к которым относятся та-
кие параметры, как форма объекта, его цвет и т. и. Благодаря этому человек спо-
собен быстро находить необходимую информацию в видеопоследовательности,
выделяя интересующие его события и действия. При автоматическом поиске в
видеоархивах в настоящее время в основном используются лишь признаки низко-
го уровня, что приводит к неполным и некорректным результатам поиска.
Характерные признаки высокого уровня включают в себя движение объек-
та, а также связанные с ним действия и события.Такие признаки особенно важ-
ны при анализе видеоархивов систем видеонаблюдения. Сами же движущиеся
объекты можно представить с помощью количественных и качественных ха-
рактерных признаков низкого уровня. Семантические характеристики объек-
тов вводятся с помощью таких характерных признаков высокого уровня, как
события. Семантические признаки описываются с помощью аппроксимирую-
щих словесных моделей. Это осуществляется при помощи постоянного монито-
ринга изменений в характерных признаках низкого уровня. Когда выполняют-
ся некие заданные заранее условия, происходит фиксирование определенных
событий. Для большей степени абстракции указанные описания извлекаются
независимо от контекста видеопоследовательности. Несколько контекстно-
независимых событий строго определяются и автоматически детектируют-
ся при помощи характерных признаков, извлеченных на этапах сегментации,
оценки движения и слежения за объектами.
Система индексации видеопотока в каждый момент времени выделяет спи-
сок объектов, каждый из которых имеет свой идентификатор, характерные при-
знаки низкого уровня (местоположение.форма,размер, движение),траекторию,
продолжительность существования, участие в событиях и пространственно-
временные отношения с другими объектами [43-45]. Далее мы будем считать,
что из видеопоследовательности уже выделены фон и объекты переднего пла-
на, а также осуществляется сопровождение данных объектов. Под событиями
будем понимать совокупное поведение конечного множества объектов в не-
большом числе следующих друг за другом кадрах видеопоследовательности.
Событие состоит из контекстно-независимых и контекстно-зависимых компо-
нент, связанных со временем и положением объектов. Примерами основных со-
бытий служат появление, исчезновение, передвижение, остановка. Определе-
ние, например, передвижения выглядит следующим образом. Объект О е It пе-
редвигается в кадре /, если:
1. /И : Ор —> Ot (т. е. объект О в кадре - это объект О в кадре /), и
2. медианное значение величины движения объекта О,рассчитанное по
последним к кадрам, превышает пороговое значение.
Следующим типом событий являются так называемые внутриобъект-
ные - аномальные и доминантные движения. Первые из них представляют со-
бой слишком быстрые/медленные движения объекта или его слишком про-
должительное пребывание на одном месте. Доминантное движение возника-
ет в том случае, когда объект имеет самую большую скорость, самые боль-
шие размеры или самое продолжительное время существования. Например,
слишком продолжительное пребывание объекта Ot на одном месте опреде-
ляется следующим образом:
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. г и
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 473
1. gt > 8^ . т. е. О' остается в кадре в течение заданного периода времени, где
8я является функцией частоты смены кадров и минимально возможной
скорости, a gt - время пребывания объекта в кадре и
2. d < 8 , т. е. расстояние между текущим положением объекта в кадре /
и его положением в кадре /г где / < t, меньше порога др , являющегося
функцией частоты смены кадров, движения и размеров объекта.
Последним типом рассматриваемых событий являются межобъектные собы-
тия, включающие в себя взаимодействие двух и более объектов. Примерами слу-
жат: перекрытие, препятствие, добавление и удаление. Последнее определяет-
ся следующим образом. Пусть О е / и Ор, Oq е / р a : Ор -> О . Тогда объект Ор
удаляет объект О. если:
1. в кадре lt ( происходило перекрытие О и О ,
2. <2уе/и
3. площадь А объекта О меньше, чем площадь объекта Ot,T. e.Aql А<8а<\,
где 8Л - пороговое значение.
Удаление всегда фиксируется только после перекрытия. Объект, имеющий
большие размеры остается, а меньший удаляется.
Аналогично определяется добавление. Объект О добавляет объект О, если:
1. Оре/гГО,О е/{иМ:Ор->О.
3. AjIAi<8a<1,
4. Л + Af = Ар п [(Я, + Я = Нр) U (W + IV = MQ], где Я и IV - высота и шири-
на объекта,
5. О расположен близко к одной из сторон s минимально возможного пря-
моугольника (МВП) объекта Of,T. е. это расстояние d должно находить-
ся в пределах 5min < < 5max, где и 5max - пороговые значения,
6. за время от г - 1 до г происходят изменения высоты или ширины объекта
О' со стороны 5 его МВП.
Помимо указанных событий, в систему могут быть добавлены и другие, необ-
ходимые конкретному пользователю.
Будем считать, что на начальном этапе уже проведена сегментация видеопо-
тока, для чего использовался модифицированный метод попиксельной разности
с одним кадром, выбранным как фоновый. Помимо разбиения всего потока на
отдельные наборы, разобьем последние в свою очередь на более мелкие сегмен-
ты,также состоящие из нескольких кадров одной и той же категории. На следую-
щем этапе определим «количество» и локализацию движения в таких сегментах.
Для этого вычислим две матрицы, позволяющие описать общее «количество»
движения TMMs (Total Motion Matrix) в сегменте и его среднее значение AMMs
(Average Motion Matrix).
Алгоритм выделения событий, происходящих в видеопотоке, состоит из сле-
дующих шагов:
Шаг 1. Для уменьшения влияния шумов (ложного выделения движения) коли-
чество цветов изображения уменьшается до 64.
Шаг 2. Для сегмента s задаются матрицы TMMs и /ШМ .элементы которых
равны 0:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
474
Цифвая обработка видеоизображений
% '12 '13 •••
ТММЛ = 12\ Z22 Г23 ’ ’ • Gv (142)
Си2 Сиз •••
'а11 fll2 fll3 «15 ''и/ 'п *п Сз/ 'п • ^п У
а21 fl22 fl23 а-\ In '22/ 'п *23/ In ’ * Gn i In
АММ, = ... — • . (143)
kaMi ° 42 а.из аМУ > Л1 /« ^М2 /п 1МЗ /п . MN
Здесь N х М - размер кадра, ап- число кадров в сегменте.
Шаг 3. Все кадры данного сегмента сравниваются с фоновым кадром (вы-
бранным на начальном этапе сегментации) попиксельно, и в случае ненулевой
разницы соответствующее значение г г матрицы увеличивается на единицу.
Шаг 4. При помощи матриц TMMs и AMMs определяются две величины:
.V м
(144)
1-1 /-1
X м
(145)
/=1
представляющие собой сумму всех элементов этих матриц. Таким образом, ТМ>п
AMs позволяют определить «количество» движения во всем сегменте.
Сравнивая сегменты только по «количеству» движения, мы не сможем полу-
чить адекватные результаты, так как необходимо еще знать локализацию движе-
ния в изображении. Для этого введем два новых вектора, элементы которых рав-
ны сумме элементов матрицы ЛММ5 по столбцам SCл и по строкам SR л-
“ ( 51 5- а>2 *” 51 1
\ i=l i=l HI /
(ММ М \
X % £ - £ aNj •
;=1 У=1 )
(146)
(147)
Далее для кластеризации сегментов сформируем векторы характерных при-
знаков сегментов, в качестве которых выступают категория сегмента и величи-
ны TMeAMeSCA и SRa. Кластеризация состоит из двух этапов. На первом сегмен-
ты распределяются в соответствии с их категориями, а на втором этапе каждый
из уже имеющихся кластеров разбивается на более мелкие, используя остальные
характерные признаки. Весь алгоритм кластеризации может быть представлен в
следующем виде.
Шаг 5. Выбирается начальное приближение для центроидов кластеров:
1. Для v р-мерных векторов характерных признаков число их измерений
разбивается на к отрезков, т. е.
[1,2,...,р], [р+1,р+2,2р],...,[(£- 1 )р+1,(к - 1 )р+2,...,кр]угде р-р!к.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 475
2. На каждому-м отрезке [(& - 1)р+1, ...,ур] для вектора характерных призна-
)р
ков F вычисляется величина f/ = £ (р).
р=О-0р
3. Начальное приближение для центроидов /1к, выбирается как
р = arg max f1
J p |«<V
Шаг 6. Векторы характерных признаков относятся к соответствующим кла-
стерам исходя из выражения = arg min D(F,/jf), где
!</<* v '
(148)
/«I 1=1
(149)
Шаг 7. Положения центроидов уточняются по следующей формуле:
(150)
где v - число сегментов, попавших в кластер у, a - Z-й вектор характерных
признаков в этом же кластере.
Шаг 8. Если хотя бы один центроид меняет свое значение на предыдущем
шаге, то переходим к шагу 6, в противном случае считаем кластеризацию закон-
ченной.
Для реализации указанного алгоритма необходимо задать число кластеров к.
При этом желательно минимизировать внутрикластерное расстояние и максими-
зировать межкластерное расстояние. Мера различимости кластеров записывает-
ся следующим образом:
<15»
1=1
где
(152)
Vy 4 = 1
^ = £>(дрд.). (153)
£1у представляет собой межкластерное расстояние, а т/- внутрикластерное. Опти-
мальное число кластеров к' выбирается как к' = min<p(Zr). Другими словами,
вышеописанный алгоритм (шаги 5-8) выполняется для к = 1,2,...,<7 и выбирается
то значение к, для которого достигается минимум
После того как осуществлена кластеризация сегментов, можно выделить из
видеопоследовательности необходимые события. Для этого введем величину
близости данного сегмента s к другим сегментам кластера у:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
476 Цифвая обработка видеоизображений
Ч=—;-----------• (154)
По этой формуле вычисляется близость для всех сегментов кластера и находится
среднее значение для кластера Д'. Теперь определение того, является ли сегмент
ключевым, выглядит следующим образом:
А7 > Д', сегмент s - нормальный
Д7 < А', сегмент s - ключевой.
Можно также вычислить степень отклонения данного сегмента от нормы:
Д'-Д'
Ilf = -----
11.3. ИНДЕКСАЦИЯ ВИДЕОДАННЫХ И ПОИСК В ВИДЕОАРХИВАХ
Все типы запросов пользователей к видеоархивам условно можно разделить на
три группы, в соответствии с которыми следует проводить индексацию видеодан-
ных. Первая группа, наиболее часто использующаяся при поиске данных в архи-
вах видеонаблюдения, включает в себя запросы по ключевым словам. Примерами
такого типа запросов могут служить поиск автомобилей, въехавших на парковку
в определенный период времени, или поиск оставленных в зоне наблюдения пред-
метов. Во вторую группу входят запросы по образцу, заключающиеся в предъяв-
лении пользователем системе изображения с заданием найти в архиве кадры, наи-
более близкие к исходному (например, поиск конкретных людей по фотографии,
определенного расположения автомобилей на парковке и т. д.). И, наконец, тре-
тья группа запросов объединяет в себе запросы по наброску, когда пользователем
в качестве входных данных используется сделанный от руки набросок и требует-
ся найти изображения, в наибольшей степени схожие с ним, или же найти в архиве
объекты, имеющие аналогичную нарисованной траекторию движения.
Показателем качества производимого в архиве поиска данных являются
обычно две величины: точность и эффективность. Первая из них представля-
ет собой отношение числа верных результатов к сумме верных и неверных ре-
зультатов. Вторая величина равна отношению числа верных результатов к сум-
ме верных и ненайденных верных результатов.
11.3.1. Запросы по ключевым словам
Если планируется использовать запросы данного типа, то в процессе индек-
сации видеопоследовательностей и формировании соответствующей базы дан-
ных обычно применяются признаки объектов низкого уровня (размер, цвет, фор-
ма, текстура и т. д.), либо дескрипторы описания простейших событий (вход в за-
прещенную зону, появление нового объекта и т. д.). Поэтому запросы пользо-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www. procctv. г и
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных
477
вателя выглядят, например, следующим образом: «найти все кадры, где присут-
ствуют объекты определенного цвета или размера» (признаки низкого уровня)
или «найти все кадры, где автомобиль выезжает с парковки» (дескрипторы про-
стейших событий). Если попытаться объединить характерные признаки объек-
тов низкого уровня и семантические характеристики видеопотока, то это в зна-
чительной мере поможет улучшить релевантность поиска в видеоархиве.Так как
в анализируемой видеопоследовательности может существовать сразу несколь-
ко объектов, выполняющих аналогичные действия, то использование характери-
стик низкого уровня часто позволяет выделить из них один, отвечающий запросу
пользователя в наибольшей степени [58-62].
При этом на первом этапе производится сегментация видеопотока, извлече-
ние ключевых объектов из наборов кадров и слежение за ними. После этого мо-
дуль извлечения информации о происходящих событиях присваивает каждому из
них соответствующую метку. Может рассматриваться несколько типов основных
событий (например, оставление предмета, подбор предмета, встреча двух лиц)
и несколько вспомогательных (появление/исчезновение людей и/или объектов,
объединение нескольких лиц в одну группу и другое), которые могут служить
индикатором возможных критических ситуаций. Входной информацией для дан-
ного модуля служат движущиеся объекты. Подсчет числа таких объектов в ка-
дре дает возможность своевременного определения того или иного события, по-
скольку количество объектов может меняться с наступлением события.
Детектирование событий может осуществляться весьма простым способом.
Например, в случае оставления предмета неким лицом модуль сопровождения
объектов фиксирует сначала в момент времени движение группы объектов.
Затем в момент времени t2 определяется движение двух различных объектов
и Ог В момент времени Z2+ 1 фиксируется движение только одного объекта Ог
Поэтому считается, что в кадре t2 произошло возможное оставление предмета, и
в базу данных заносится информация, содержащая метку события, время его на-
ступления (г2) и характерные признаки низкого уровня (вектор цветности и век-
тор формы) для объектов, участвующих в данном событии. Кроме того, в ар-
хив заносятся характеристики, отражающие пространственные взаимоотноше-
ния объектов.
Основными типами запросов являются обычно следующие: запросы, относя-
щиеся к одному объекту (появление/исчезновение объекта), и запросы, связан-
ные с несколькими объектами (оставлсние/подбор объекта, пересечение траек-
торий движения объектов). Для выполнения запросов на основе языка SQL ча-
сто разрабатываются специальные интерпретаторы, позволяющие формировать
запрос в естественной для пользователя форме.
В качестве хранящихся характерных признаков могут выступать, например,
следующие характеристики изображения:
• число объектов в кадре,
• класс объекта (человек, группа людей, транспортное средство),
• характеристики объекта, т. е. его цвет, текстура, форма, размер, и их изме-
нения стечением времени.
• расположение объекта в кадре, его скорость и траектория,
• параметры перекрытия объектов в случае необходимости,
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
478
Цифвая обработка видеоизображений
• изменения фона вследствие изменившихся условий освещенности или на-
личия остановившихся или начавших движение объектов,
• информация о событиях, в качестве которой могут выступать любые дан-
ные об активности в кадре.
Обычно вся индексируемая информация хранится в виде XML-документов.
Однако в случае необходимости она может быть конвертирована в реляцион-
ные базы данных, позволяя осуществлять пользователю SQL-запросы. При
этом основной хранящейся единицей в базе данных является событие, под ко-
торым подразумевается, например, автомобиль, попавший в поле зрения каме-
ры в момент времени Г, и исчезнувший из поля зрения камеры в момент време-
ни Пользователь может направлять к системе запросы следующего вида: по-
казать все события.
• произошедшие за определенный промежуток времени;
• в которых размеры участвующих объектов лежат в определенном диапа-
зоне;
• в которых участвуют объекты определенного класса (человек, группа
людей, транспортное средство):
• в которых объекты двигались с определенной скоростью (лежащей в за-
данном диапазоне) и в определенном направлении;
• в которых участвовали объекты заданного цвета;
• в которых участвовали объекты, схожие с предъявленным пользовате-
лем системе;
• которые произошли в определенной области изображения (пользователь
может выделить любую замкнутую многоугольную область).
Также возможна любая комбинация из перечисленных выше типов запросов.
Наибольшую сложность для индексации представляют видеопоследователь-
ности, изображающие большое число постоянно движущихся объектов. Такие
видеонаборы характерны, например, для систем видеонаблюдения за дорожной
обстановкой на перекрестках оживленных магистралей, позволяющих осущест-
влять сбор видеоданных, их индексацию, хранение и поиск. При этом иногда сег-
ментация видеопогока не производится, и вычисления проводятся для всех ка-
дров, что приводит к хранению больших объемов данных. Положительной сто-
роной такого подхода является то, что результаты запросов пользователя при
этом отличаются весьма высокой точностью.
В качестве примера рассмотрим одну из таких систем индексации, применя-
емую при анализе дорожного движения. Для каждого кадра сформируем карты
объектов и векторов движения. Первые представляют собой распределение объ-
ектов в кадре, причем каждому объекту присвоен свой идентификационный но-
мер. Таким образом, карта объектов - это функция пространственных координат
и времени Здесь кадр предварительно разбивается на непересекающи-
еся блоки с координатами (х,у). Карта векторов движения v(x,y, t) определяется
также для каждого блока.
Эти карты являются основными единицами для всех последующих вычисле-
ний и анализа статистики дорожно-транспортных происшествий и транспортно-
го потока в целом. Применяя к этим картам описанные ниже операции, мож-
но извлечь семантическую информацию из видеопотока. Однако вычисления на
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 479
основе таких примитивных индексов могут занимать неоправданно большое вре-
мя. Поэтому для хранения информации о видеопотоке будем использовать про-
изводные величины, вычисляемые на основе этих карт (что, правда, приводит к
несколько повышенным требованиям к объему хранимых данных). Все произ-
водные величины, называемые в дальнейшем атрибутами, разделим на три типа.
Атрибуты местоположения. Они не связаны ни с конкретным автомоби-
лем. ни со временем. Основываясь, например, на структуре перекрестка, которая
определяется разделительными линиями, наблюдаемая зона делится на несколь-
ко областей. В соответствии с координатами блока (х, у) определяется область
г = R(x,y), к которой он принадлежит. Введем также дополнительную величину
dr=D(r),служащую для описания направления пересекающихся магистралей. При
этом dr е \сверху, снизу, слева, справа, сверху слева, внутри перекрестка и т.д.}
и зависит от конкретной конфигурации перекрестка.
Атрибуты транспортного средства (ТС). Эти величины связаны с опреде-
ленным автомобилем, имеющим идентификатор id:
1. Существование ТС. Функция E(id,x,y, t) показывает, находится ли в бло-
ке (х,у) в момент времени г ТС с идентификатором id:
E[id,x,y,t) =
1,
о,
ID(x,y,t) = id
ID(x,y,t) Ф id
(157)
2. Расположение ТС. Местоположение ТС с идентификатором id описыва-
ется его центром масс g(id, t):
I \ X/ £(1<х,^,/)(х,^)
= k (*)»«,(')) = —V—Ш(158)
robAid^=R(s(id,t)\ (159)
где robj - область, в которой находится рассматриваемое ТС.
3. Моментальная скорость ТС. vw(W, t) - вектор моментальной скорости
ТС id в момент времени t. Она рассчитывается как мода (наиболее часто
встречающееся значение) v(x,y,r) для всех блоков (х,у),где E(id,x,y,t) = 1.
Скорость ТС представляет собой усредненное значение модулей момен-
тальных скоростей по нескольким последовательным кадрам:
v(irf,O = -£jv„,(jW,z-A)| (160)
1 k=Q
4. Время существования ТС. Предположим, что ТС с идентификатором id
проезжает через перекресток в промежуток времени от z0 до Это экви-
валентно существованию данного ТС в указанном временном интервале.
Поэтому время появления ТС Ta(id) и время его исчезновения Td(id) опре-
деляются как:
= (161)
(162)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
480 Цифвая обработка видеоизображений
при этом:
3(х,>’) E(id.x.y.t) = \(t0<t<t.)
V(x,y) E(/W,x,y,r) = 0(r</0J, <t)
5. Направление движения. Направление движения ТС с идентификатором
id обозначим как d(id) = (da, dd), где da - направление при появлении ТС, а
dd - при его исчезновении:
d.=z>(rw(w,Te(f</)))=D(i?(g(w,re(w)))). (164)
d„ = D(rohl (id,Td (id))) = D[R(g(id,Td(id)))). (165)
6. Скорость прохождения перекрестка. Она определяется как максималь-
ная скорость ТС:
‘'*(Й) = г.Ы'гй,и,<1б6)
Атрибуты транспортного потока (ТП). Эти величины связаны не с от-
дельными ТС, а со всем транспортным потоком в целом.
1. Объем ТП. Q(dr> t) определяется как число ТС, проходящих через пере-
кресток в единицу времени. Поэтому Q(dr, - это число ТС, удовлетво-
ряющих условию t < Td(id) <t + Дг и d(id) = dr.
2. Средняя скорость потока. V(dr) - средняя скорость ТП в направлении dr:
(167)
3. Плотность ТП. Определяется как:
/- , Q(dr,t)
(,68)
4. Затор. Определяется при помощи двух пороговых значений Q} и V.. При
выполнении условий
Q(dr,t) = Qj (169)
P(d„r)=K, (170)
фиксируется затор.
5. Сигнал светофора. Определяется исходя из распределения вектора ско-
рости ТС. В том случае, когда продольная компонента этого вектора ве-
лика, сигнал светофора в этом направлении считается разрешающим.
При этом среднее значение вектора скорости должно быть равно 0 (если
движение в обе стороны приблизительно одинаково). Поэтому предста-
вим вектор скорости следующим образом:
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 481
V, (/)+/ • V, (/) = I - *£ (V, +i • v, (id, t))2,
id
(171)
где v(jd. t) = (vjjd, t). vjjd. t)). Тогда направление ТП может быть оценено
как arg (v (/) + i • V (/))
В качестве языка запросов можно использовать естественный язык, для ин-
терпретации значений которого нужно разработать специальный модуль, осу-
ществляющий разбиение фраз на составные части с последующим их анализом.
11.3.2 Запросы по образцу
В качестве характерного признака при запросах по образцу довольно ча-
сто используется цвет. При этом обычно формируются цветовые гистограммы
представленного пользователем изображения, которые сравниваются с гисто-
граммами ключевых кадров, хранящихся в базе данных. Помимо гистограмм,
могут быть использованы цветовые наборы, представляющие собой бинарные
маски гистограмм. Естественно, они значительно уменьшают число необхо-
димых вычислений, однако обработка с их помощью многоцветных областей
приводит в большинстве случаев к некорректным результатам. Для индекса-
ции применяются также цветовые коррелограммы - таблицы, каждая строка
которых отвечает определенной паре пикселей. Например, к-й элемент в стро-
ке, отвечающей паре (/,;), представляет собой вероятность нахождения пиксе-
ля цвета j на расстоянии к от пикселя, имеющего цвет L Данный метод позволя-
ет учесть изменения не только локального, но и глобального характера, отно-
сящегося ко всему изображению в целом.
На основе цветовой информации могут выполняться такие запросы, как «найти
все кадры, имеющие цветовое распределение, схожее с распределением предъяв-
ленного изображения»; «найти все кадры, имеющие процентное соотношение цве-
товых каналов, аналогичное представленному»; «найти все кадры, имеющие цве-
товое распределение в определенной области изображения, схожее с выделенной
областью представленного изображения»; «найти все кадры, имеющие цветовое
распределение в определенных областях изображения, схожее с выделенными об-
ластями представленного изображения и расположенные аналогичным образом».
Следующим характерным признаком при запросах по образцу является фор-
ма объектов. При этом рассчитываются такие величины, как площадь, эксцен-
триситет, основные моменты, периметр, тангенсы углов относительно выбран-
ных осей координат. Форма объекта также является основным характерным
признаком при запросах по наброску (см. раздел 11.3.3).
При сравнении цветовых гистограмм двух изображений используются мето-
ды, изложенные в разделе 11.1.2. Для нахождения расстояния в случае анализа
формы объектов также можно формировать гистограммы углов между векто-
рами отдельных пикселей и неким базовым вектором. Но часто при этом приме-
няются методы, основанные на расчетах углов поворота. Описание 0F(s) области
Р с помощью углов поворота представляет собой набор тангенсов углов накло-
на к осям координат как функцию длин дуг 5. Угол поворота в данной точке кри-
http7/w wwjtv.ru
Компания ITV - генеральный спонсор издания книги
482
Цифвая обработка видеоизображений
вой, ограничивающей область Л - это отложенный против часовой стрелки угол
между касательной в данной точке и осью х. На Рис. 8 показаны характерные
виды ломаных для двух простейших областей.
Пусть 0л($) и - представления с помощью углов поворота для двух об-
ластей А и В. Тогда расстояние между ними может быть найдено из следующе-
го выражения:
t/(AS) = [j|04(s)-0e(s)p5],₽.
(172)
Помимо цвета и формы, для каждого объекта изображения можно выде-
лить множество его внутренних пикселей Рр множество граничных пикселей Рв,
центр масссш и центр минимально возможного прямоугольника (МВП) счвв [60].
Тогда в качестве индекса объекта в базу данных заносятся, например, следующие
характеристики цвета и формы:
1. Гистограмма расстояний, которая содержит евклидовы расстояния между
центром масс объекта с и всеми внутренними пикселями объекта. Рас-
стояния между пикселями и центром масс накапливаются в соответству-
ющих ячейках гистограммы.
Рис. 9. Вектор пикселя для данной области
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. г и
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 483
2. Гистограмма углов, которая содержит отложенные против часовой стрел-
ки углы между векторами отдельных пикселей и единичным вектором
оси х. Векторы пикселей - это векторы, направленные от центра масс
объекта ст к конкретным пикселям (см. Рис. 9).
3. Цветовая гистограмма, содержащая трехмерные векторы с компонента-
ми, соответствующими отдельным цветовым каналам с = (h? s., v) или
ct = (гр gr b) для всех пикселей pt объекта.
Использование в качестве точки отсчета центра масс объектов имеет ряд
преимуществ:
• Гистограмма расстояний ограничена сверху разумным числом благода-
ря тому, что МВП объекта имеет четыре взаимно перпендикулярных
касательных:
О < < < ^тах(^: + //:). (173)
где W и Н - ширина и высота МВП. Для большинства объектов ст распо-
ложен недалеко от центра МВП,и поэтому du близка к ^тах (jy2 + Я2) Д.
• Угол а для пикселя pt хранится в гистограмме углов и при выборе соот-
ветствующей схемы квантизации число ячеек в гистограмме углов близ-
ко к числу ячеек в гистограмме расстояний.
• Расположение см не зависит от ориентации и размещения объекта.
При выполнении запросов пользователей в качестве меры схожести изобра-
жений используется пересечение гистограмм (см. раздел 11.1.2). Общая мера схо-
жести изображения вычисляется как
J П А
dr =--------т2------, (174)
™c + ws
где dc,dDndA-меры схожести гистограмм цвета,расстояний и углов,и w5- ве-
совые коэффициенты. В простейшем случае wr и wv могут быть выбраны равны-
ми. Однако в большинстве случаев необходимо по-разному взвешивать цветовые
и геометрические характеристики объекта. Поэтому предлагается в качестве ве-
совых коэффициентов использовать рассчитанные по отдельности и усреднен-
ные меры схожести.
В большинст ве существующих систем индексации на первых этапах выделя-
ются ключевые кадры, в которых проводится сегментация объектов, выделяют-
ся их характерные признаки, и затем на их основе формируются характерные
признаки всего кадра. Как уже говорилось ранее, в качестве характерных при-
знаков объектов могут выступать их размеры, цвет и положение, скорость и дру-
гое. В результате для каждого ключевого кадра формируется многомерный век-
тор. Так как количество объектов может меняться, то производится их класси-
фикация в соответствии с заранее заданным числом классов. Для того чтобы из-
бежать возможных ошибок, таких как помещение близких объектов в разные
классы, можно на основе методов нечетких множеств рассчитать степень при-
надлежности для каждого класса [57].
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
484
Цифвая обработка видеоизображений
Рис. 10. Нечеткая классификация для одномерного случая
Для простого одномерного случая, когда вектор х лежит в пределах от 0 до 1,
это иллюстрируется Рис. 10. Нечеткое разбиение пространства характерных при-
знаков на Q классов (на рисунке Q = 5) определяется при помощи Q функций
принадлежности pn(x), п = Форма таких функций и степень их перекры-
тия может варьироваться в широких пределах. На основе такой схемы разбиения
могут быть сформированы нечеткие гистограммы по большому числу характер-
ных признаков.
Пусть и I (St) обозначают размер, цвет и местоположение /-го
объекта S.Тогда L-мерный вектор
xw =[P(S,),c(S, ).?(S,)] (175)
описывает свойства объекта S с помощью L характерных признаков. Вместо
цветовых характеристик в (175) могут также быть использованы характеристи-
ки движения. Разобьем теперь пространство характерных признаков на Q обла-
стей и присвоиму-му элементу ху вектора индекс разбиения nj е (1,2,.по-
казывающий, в какую область попадает данный элемент. Степень принадлежно-
сти объекта S L-мерному классу п = J определяется как
A/-(«)=n^W))e[°’1l’ <176>
где (х^)- степень принадлежности х^ области дг Если просуммировать соот-
ветствующие степени принадлежности по всем объектам, получим результат не-
четкой классификации всего кадра:
F(й) = f М, (п) = £ П (х?)’ <177>
/=| 1=1 j=\
где К - число объектов в рассматриваемом ключевом кадре. Окончательно век-
тор характерных признаков кадра формируется при помощи перебора всех воз-
можных значений Р(л) для всех комбинаций индексов nv...,nL е (1,2,...,()|,что дает
N = QL элементов.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 485
После того как сформирован вектор характерных признаков для каждого
ключевого кадра, он заносится в базу данных вместе с информацией о време-
ни записи. Когда пользователь предъявляет системе искомое изображение, то
из него извлекаются характерные признаки и описанным способом формирует-
ся соответствующий вектор х. Далее производится поиск в базе данных и выби-
раются М ключевых кадров с векторами характерных признаков у, наилучшим
образом соответствующие предъявленному пользователем изображению. Взве-
шенное расстояние между х и у вычисляется следующим образом:
у , .V
< (*> у)=£и'. (х, - у, )" = £ (178)
где w - N-мерный вектор весовых коэффициентов, е=х-у - вектор ошибки. В ка-
честве результата запроса пользователю предъявляются те М кадров с векторами
характерных признаков / = 1...Л/, для которых расстояние d(x, у) минималь-
но. Пользователь может выбрать tn кадров, которые, как он считает, наилучшим
образом соответствуют его запросу. В этом случае оставшиеся М-т кадров счи-
таются ошибочными. Далее производится коррекция весовых коэффициентов,
чтобы наилучшим образом учесть выбор пользователя. В результате при следую-
щем запросе будут получены кадры, лучше отвечающие интересам пользователя.
Пусть уг i = 1.т (т < М) - векторы характерных признаков для кадров,
выбранных пользователем. Тогда для получения оптимальных результатов не-
обходимо минимизировать расстояния между х и у., i = 1,..., tn и при этом макси-
мизировать расстояния между х и yr i = т + Определим соответствующий
функционал
/(*) =£<,(*, У,)~ £ <(*.уД (179)
1=1 г=т+1
для которого надо найти минимальное значение при условии, что величина w по-
стоянна. Без потери общности можно считать, что ||vv|| = 1. Тогда
vv° = arg min J (vv). (180)
H=|
В результате минимизации получим:
/ v yl/2
й? = А £4,| > k = (181)
\ ы )
где
Л = £(** -Д'»’)2 - £ (** -У**)2, (182)
/»| *=«+1
ау*\л = элементы вектора уе Указанная процедура минимизации вычисля-
ет оптимальные весовые коэффициенты для предъявленного пользователем изо-
бражения с вектором характерных признаков х. В общем случае, когда проводится
несколько последовательных запросов, входные и выходные векторы х и yt можно
рассматривать как дискретные временные последовательности х(л) и у£п). Вве-
дем коэффициент Л (0 < Л < 1), который будет учитывать результаты оптимизации,
полученные на предыдущих шагах. При этом результаты последних запросов бу-
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
486
Цифвая обработка видеоизображений
дут приниматься во внимание в текущем запросе, а степень их влияния будет опре-
деляться при помощи коэффициента Л. Уравнение (181) переходит в следующее:
( v Y12
^(л) = ДДл) , k = l,...,N, (183)
\ i=i /
где
<184>
а(«)=£(х* (")>’*'(”)) X (х*(и)-^’(и))2- (185)
Вычисление Bk(n) может быть сведено к следующему рекуррентному выражению:
(«) = Л (и) + |5* («-!)’ k = l,...,Ny (186)
Л
что позволяет существенно сократить время вычислений.
11.3.3. Запросы по наброску
В ряде случаев при работе с видеоархивами требуется найти объекты, име-
ющие заданную траекторию движения. В этом случае может быть использован
третий тип запросов пользователя, а именно запросы по наброску. Для этого с
помощью методов сопровождения объектов в последовательности кадров выде-
ляется кривая L(/, х(г), у(г)), представляющая собой параметрическое представ-
ление движения определенного объекта. Эта кривая в общем случае представ-
ляет собой незамкнутый многоугольник. Нарисованная же пользователем фигу-
ра может иметь более высокую степень гладкости. Эта кривая может быть заме-
нена ломаной с большим числом вершин. Для сокращения объема вычислений
при сравнении траекторий необходимо использовать алгоритмы, позволяющие
уменьшать число вершин ломаной с минимальными потерями информации. Од-
ним из таких методов является метод эволюции кривых [63-65].
Основная идея данного метода заключается в следующем. На каждом шаге
эволюции пара последовательных отрезков ломаной заменяется одним отрез-
ком, соединяющим начальную точку первого и конечную точку второго отрезка.
Ключевым свойством такой эволюции является порядок замены отрезков, осу-
ществляющийся в соответствии со значением меры соответствия
(187)
где Д(л;, s и) - угол поворота в общей вершине отрезков s и a /($) - длина от-
резка 5, нормированная на общую длину ломаной. При использовании эволюци-
онного алгоритма подразумевается, что вершины, из которых выходят отрезки с
большим значением меры соответствия, являются важными и должны быть со-
хранены. Вершины, окруженные отрезками с малым значением К, могут быть
заменены одним отрезком.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 487
При индексации полученных ломаных в базу данных заносятся координаты
оставшихся вершин. Когда система получает запрос от пользователя, она или за-
меняет исходную кривую ломаной, или аппроксимирует ее сплайном, для того
чтобы впоследствии сравнивать с имеющимися в базе данных образцами (кото-
рые также могут быть сглажены сплайнами в зависимости от применяемой меры
соответствия кривых).
Для установления соответствия между кривыми наиболее часто используют-
ся следующие меры:
1. Мера, основанная на параметризации кривой. На первом этапе ломаная
сглаживается кубическим сплайном, узлы которого совпадают с верши-
нами ломаной. В отдельных случаях число узлов сплайна может превы-
шать число вершин ломаной. В параметрическом виде полученная кри-
вая может быть представлена как /(р) = (х(р),у(р)] или в векторной фор-
ме /(р) = [с'£?(р),с'(>(р)]. где С*х у - координаты узлов сплайна, a Q - его
ортонормированный базис. Перед тем как сравнивать две кривые, не-
обходимо провести процедуру их выравнивания. Так как порядок узлов
сплайна известен, для нахождения параметров 8,0,рх,р преобразования
подобия, необходимого для выравнивания кривых, можно использовать
метод наименьших квадратов:
( ?1.х <у 1
С«.У ~ с1.> С\.х 0
С2.х С2.х С2.У 1
С2.У — ~с1.у С2,ж 0
£*,х Ъ.У 1
С* V \ ** ) Ск.У Ск,х 0
О
1
О
1
О
^costT
ssinO
Рх
(188)
где сху- координаты узлов сплайна для заданного изображения, - для
находящегося в базе данных. Теперь мера соответствия кривых может
быть рассчитана как
2. Мера, основанная на углах поворота. Одна из таких мер была приведе-
на выше (см. формулу (172)). Так как число точек для исходной функ-
ции углов поворотов, соответствующей запросу и взятой из базы данных
может не совпадать, применяются методы нелинейного преобразования
временного масштаба. Для нахождения наилучшего соответствия меж-
ду 0j и 02 может возникнуть ситуация, когда несколько значений 01 бу-
дут соответствовать одному значению 02 и наоборот. Таким образом, на-
ходятся две последовательности ivir...yik и такие, что или i = i,
или /|+| = 1 (аналогичное справедливо и для индекса/). После этого ми-
нимизируется расстояние
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
488
Цифвая обработка видеоизображений
(189)
которое в дальнейшем используется в качестве меры соответствия кривых.
3. Мера, основанная на знаке кривизны. В каждой точке аппроксимирующе-
го кривую сплайна вычисляется значение кривизны
det
'с(р) = —
ар ар
з
(190)
Ир
и если оно превышает первый наперед заданный порог то такая точ-
ка считается имеющей положительную кривизну. Если значение кри-
визны меньше второго порогового значения 5, < <5р то точка имеет от-
рицательную кривизну. В промежуточном случае она обладает нуле-
вой кривизной. Далее формируется массив значений функции кривиз-
ны, элементы которого равны 1 для положительной кривизны,-1 - для
отрицательной и 0-для нулевой. Тогда расстояние между кривыми на-
ходится следующим образом:
= (191)
1=1
где и 5 - указанные выше массивы для двух различных кривых.
4. Модифицированное расстояние Хаусдорфа. Для каждого из узлов сплай-
на такое расстояние вычисляется следующим образом:
(192)
где ||я - Ь\\ - евклидово расстояние между точками анЬ, а с и с - множе-
ства узлов сплайна для исходной кривой и кривой из базы данных. Полу-
ченные значения d : z е [1,...,/с] упорядочиваются в порядке возрастания.
Окончательное значение расстояния d представляет собой п элементов
такого списка, где выбор величины п < к служит для устранения вноси-
мых шумов.
До сих пор в каждом отдельном методе индексации изображений мы рассма-
тривали признаки только одного типа (геометрические, цветовые и т. п.). Одна-
ко совместное использование информации разного типа ведет к увеличению эф-
фективности системы поиска в видеоархивах. Так, например, можно использо-
вать цветовую и пространственную информацию об изображении [66]. В каче-
стве первой может выступать цветовая гистограмма HSV, в качестве второй - па-
раметры а , получаемые при разбиении изображения на классы. Для этого изо-
бражение сначала переводится в полутоновое и разбивается на несколько обла-
стей. Каждая область считается отдельным классом, характеризующимся набо-
ром параметров в. Сами классы и их параметры находятся итерационным мето-
дом, основанным на свойствах функций вероятности.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 489
Пусть Y = {уо = i = 1....N, j = 1,...,Л/| - матрица интенсивностей пиксе-
лей изображения, и существует п классов Sk с плотностью вероятности pk(yi}),
к = 1,..., п. Будем считать, что
Уи = akQ + + апУ\ (193)
У* = Фа*. (194)
а4=(фгф)'фгУ4 (195)
для Vi, j таких, что Yk = {у е $г к = 1 л), аАЮ, akV akV акз - параметры, характери-
зующие класс SA, а каждая строка матрицы Ф - это (1, /,/, у). Обозначим через
С = {cp...,cj переменную разбиения на классы, а через в = |0р..., 0J - параметры
класса, где вк = аг.ак3}т. Предположим, что значения интенсивностей пик-
селей и остальных параметров независимы и равномерно распределены. Будем
считать также, что функция ошибки yif является нормальной с математическим
ожиданием, равным 0, и дисперсией, равной 1. Под функцией ошибки здесь пони-
мается выражение
еч = У а - Цо + aj + ak2 j + akiij). (196)
Теперь можно оценить С и 0 при помощи максимизации апостериорной вероятности
переменной разбиения и параметров класса при заданной матрице Y. Полученные
значения, которые мы обозначим как (с,#) , выражаются следующим образом:
\ 'МАР
= аг6 Я р(с'в I у) = ^(у I с.в) Р(С,е). (197)
Это выражение можно упростить и записать в следующем виде:
PL = argma^(^IC0) = argmin J(C,0), (198)
= 1 £-1паЦА). (199)
Минимизация J(C, в) может выполняться попеременно по С и по в при помощи
итерационного процесса. Окончательный результат для функционала можно за-
писать как
" дг
J (С, 0) = arg min у —- In рк, (200)
г* *=i 2
где рк - оценки дисперсии ошибки для каждого класса, a Nk - число пикселей в
классе. Алгоритм начинается с произвольного разбиения данных и вычисляет со-
ответствующие параметры классов. После этого производится новое разбиение.
После сравнения разбиений текущей и предыдущей итераций алгоритм останав-
ливается при достижении заданной точности. В противном случае выполняется
новая итерация.
При выполнении запроса пользователя для определения расстояния
J (/, Iq) между цветовыми гистограммами используется формула (19). Рас-
стояние между параметрами класса находится как
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
490
Цифвая обработка видеоизображений
4=1 V / О
где индекс q относится к изображению пользователя, a i - к изображению из
базы данных.
Для ранжирования полученных результатов необходимо использовать оба
расстояния - d( и г/. Так как эти значения могут довольно сильно различаться,
производится их нормировка. Окончательно расстояние между изображениями
вычисляется следующим образом:
max d(y max d\1'
/=1..к с
(202)
где К - число просматриваемых кадров из базы данных. Эта величина намного
меньше общего числа индексированных изображений в архиве, что достигает-
ся применением цветовой и пространственной фильтрации. В первом случае ис-
пользуется небольшое пороговое значение, чтобы сразу отсеять часть изображе-
ний и тем самым уменьшить число просматриваемых далее вариантов. При этом
устраняется порядка 80% изображений. Оставшиеся кадры сортируются в зави-
симости от значений d(. На втором этапе применяется пространственный фильтр,
в результате чего отсеиваются близкие по цвету, но далеко отстоящие друг от
друга в пространственном смысле изображения. Число изображений при этом
уменьшается еще приблизительно на 50%. Для получившегося набора кадров
вычисляется расстояние (202). После этого производится сортировка и отбира-
ется несколько наилучших изображений.
11.4. АЛГОРИТМЫ ДЛЯ ИНДЕКСАЦИИ ВИДЕОИЗОБРАЖЕНИЙ И
ПОИСКА В АРХИВАХ СИСТЕМ ВИДЕОНАБЛЮДЕНИЯ
Характерной особенностью видеопоследовательностей, получаемых в систе-
мах видеонаблюдения, является их очень большая длительность. Так как время
обработки данных должно быть разумным (часто требуется индексация в режи-
ме реального времени), то это накладывает определенные ограничения на вы-
числительную сложность используемых методов. Кроме того, признаки, получа-
емые в процессе описания содержимого и индексации, должны быть, с одной сто-
роны, надежными, а с другой - минимизировать содержащуюся в них избыточ-
ную информацию, чтобы не перегружать хранилища данных. При разработке
алгоритмов индексации для систем видеонаблюдения необходимо также учиты-
вать, что во многих случаях изображение может быть статичным в течение до-
вольно длительного времени [46-49].
Рассматриваемый ниже алгоритм использует для сегментации видеопотока
методы, не предъявляющие значительных требований к ресурсам компьюте-
ра. Кроме того, для описания содержания используется комбинированный са-
мосогласованный подход на основе выделения ключевых кадров и ключевых
объектов, что позволяет использовать его для широкого класса задач и типов
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных
491
Видеопоток
Рис. 11. Блок-схема алгоритма индексации видеоизображений и поиска в архиве
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
492
Цифвая обработка видеоизображений
видеосистем. Опишем сначала вкратце суть алгоритма, после чего будет при-
ведена подробная последовательность действий.
На первом этапе происходит разбиение видеопотока на наборы кадров
(Рис. И). Для этого применяются характерные признаки, использующие инфор-
мацию как о пространственном, так и о временно.м изменении изображений.
Следующий этап - это выделение характерных признаков для описания со-
держимого набора кадров и кластеризация признаков. При этом используются
как временные, так и пространственные характеристики видеопоследователь-
ности. В результате получаем N векторов характерных признаков z, каждый из
которых связан с конкретными пикселями или целыми областями во входной
последовательности. После этого с помощью процесса кластеризации этих век-
торов выделяются К кластеров, фактически соответствующих объектам. Каж-
дый кластер характеризуется моделью которую можно рассматривать как
некий обобщенный центроид кластера к. Степень соответствия между векто-
ром z и моделью выражается условной вероятностью P(z |ЛД). Помимо кла-
стеризации, на данном этапе проводится обучение построенной модели и клас-
сификация данных.
Обучение модели Л = (Ap....AJ необходимо для того, чтобы определить ее па-
раметры - математическое ожидание и ковариационную матрицу. В настоящем
алгоритме используется метод максимального правдоподобия, при котором не-
обходимо максимизировать величину Р(г|Л).Так как для вектора z. справедливо
следующее соотношение:
P(z1|A) = £p(AJ/’(Z,.|AJ, (203)
*=1
К
где 0 < Р(ЛЛ) < 1 и = 1’ то нашей целью является поиск такого вектора
к=\
Z ~ {z|V..,zv}, для которого достигается максимум величины:
N N ( К \
P(Z I Л) = £ log P(z, I Л) = £ log £ '’КИ*. К) • (204)
1=1 1=1 \Л=1 )
После этого можно произвести классификацию данных, т. е. окончательно от-
нести вектор характерных признаков z к тому кластеру Л*, у которого величина
P(AJz) имеет наибольшее значение.
Обучение модели на основе всей видеопоследовательности является нера-
циональным вследствие огромных объемов данных. Поэтому можно рассмо-
треть подмножество Z множества Z и на нем провести обучение модели. Есте-
ственно, что в этом случае мы получим не исходную модель Л, а ее некий со-
кращенный аналог Л. Но мы будем считать, что если Z является эффективным
представлением Z,to после проведения обучения на этом подмножестве мы по-
лучим модель Л, адекватную полной модели Л. Это позволит нам существенно
сократить время вычислений. Очевидно, что при этом необходимо оптималь-
ным образом построить подмножество Z. Широко применяемый для этих це-
лей метод выделения главных компонент использовать в данном случае неце-
лесообразно вследствие того, что он не позволяет учесть нелинейный характер
исходных видеоданных, а также предъявляет серьезные требования к ресурсам
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных
493
компьютера, поскольку он использует весь набор данных. То же самое относит-
ся и к стохастическим методам типа метода Монте-Карло. Поэтому мы будем
использовать в качестве Z ключевые кадры, которые будем выделять из исхо-
дной видеопоследовательности. Это позволит существенно сократить время об-
учения модели.
Таким образом, данный этап состоит из пяти следующих шагов:
1. выделение ключевых кадров из исходного набора,
2. выделение характерных признаков для ключевых кадров.
3. обучение модели на ключевых кадрах,
4. вычисление векторов характерных признаков для всего исходного видео-
набора и их кластеризация.
5. анализ и уточнение существующих ключевых кадров для более точного
и компактного представления видеонабора на основе результатов класте-
ризации.
Третий этап - это индексация полученных ключевых кадров и объектов с по-
следующим занесением векторов характерных признаков в базу данных.
Наконец, последний, четвертый этап - это формирование запросов поль-
зователя разного типа, выделение для них соответствующих характерных
признаков и сравнение при помощи одной из выбранных метрик с векторами
из базы данных.
Рассмотрим описанные этапы подробнее.
I этап
Для сегментации видеопотока на наборы кадров будем вычислять параме-
тры, описывающие пространственные и временные изменения в изображениях.
Первым таким параметром является история изменений значений пикселя в при-
менении к двум последовательным кадрам, предварительно сглаженным следую-
щим фильтром:
PCH(x,y,t) =
min (РСЯ (х, -1) + а, 255),
max(PCH(x,y,t 1)-Д255),
|/(x,y,z)-/(x,j,f-l)|> 8d
иначе
.(205)
где 8d - пороговое значение, а значения параметров а и Д выбираются порядка 50.
Разобьем теперь изображение на блоки размером 5 х s и будем вычислять сте-
пень активности (т. е. изменение интенсивности) каждого блока, принимающую
значения 0 или 1 в зависимости от выполнения следующего условия:
ВС4(х,у,/) =
У У. [ PCH {xs + i, ys + j, t) > 8p ] I > 8C,
(206)
где 8 - пороговое значение для определения активности данного пикселя, а 8е -
порог для числа активных пикселей, используемых для определения активности
блока.
Будем также вычислять время, прошедшее с момента последней активации
блока:
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
494
Цифвая обработка видеоизображений
ASYN(x,y,t) =
t-l(x,y,t)<3a
(207)
t-l(x,y,t),
8а, иначе
где /(х, у. г) - последнее значение г. когда рассматриваемый блок был активен,
а 5о - наибольшая допустимая временная задержка.
С помощью величины (206) будем сравнивать активность соответствующих
блоков в последовательных кадрах и разобьем все множество блоков на три под-
множества: F, - соответствующие блоки активны. F2 - соответствующие блоки
неактивны, Fy - из двух соответствующих блоков один активен, а другой - нет.
Обозначим число элементов этих множеств через Л/г Nr Ny и найдем меру схо-
жести двух кадров:
(N
(208)
Для того чтобы учесть временную задержку несовпадающих блоков, будем вы-
числять величину Л/3 следующим образом:
(209)
(Г,>Д 8 Д ° а /
где /V4(x, у) - количество активных блоков в окрестности 3x3 данного блока.
Среди двух рассматриваемых кадров t1 и t2 здесь выбирается тот, где неактивен
данный блок (х,у).
Определим величину когерентности кадров [53]:
н*/2
^rned(p(t-i,t + j),J = l,...,w/2)
С(/) = , (210)
w/2
где w - размер кадра, a med - медиана мер (208) для различных значений у. Грани-
цы набора будем определять как минимум величины (210).
II этап
1. Выделение ключевых кадров из исходного набора. Для выделения клю-
чевых кадров проводится кластеризация видеопоследовательности. При этом
основной задачей является разбиение набора $ = {/р состоящего из п ка-
дров, на некое число М кластеров kv причем значение А/ определяется в
процессе кластеризации. В качестве меры схожести двух кадров предлагается ис-
пользовать цветовые гистограммы. При этом можно использовать цветовое про-
странство HSV. в котором для построения гистограмм берутся две компоненты
Н и 5 с 16 и 8 квантовыми ячейками соответственно (в случае полутоновых изо-
бражений можно использовать одну из мер, рассмотренных в разделе 11.1.2).Тог-
да мера сходства кадров i и j выражается следующим образом:
16 8
-g)=XX min {н- (А> 5)>н/ (A> д <21 о
/1=1 5=1
При кластеризации с априорно неизвестным числом кластеров следует за-
дать пороговое значение 3, определяющее «чувствительность» метода (см. раз-
ProSystem CCTV - журнал по системам видеонаблюдения
http://www. procctv. ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 495
дел 5.4.2.). Чем меньше значение 5. тем больше будет кластеров. Прежде чем но-
вый кадр будет отнесен к какому-либо кластеру, вычисляется мера сходства с
центроидом этого кластера. Если полученное значение больше 5, то это озна-
чает, что данный кадр не может быть отнесенным к данному кластеру. Так как
цветовые гистограммы могут не вполне корректно описывать локальную про-
странственную информацию в данном кадре, то в качестве пороговой величины
8 следует выбирать относительно небольшое значение. Это позволит получать
избыточное количество ключевых кадров, содержащих характерные особенно-
сти, которые впоследствии будут использоваться при выделении объектов. Если
же в качестве 8 выбирать большое значение, то это приведет к выделению не-
большого числа ключевых кадров и к возможной потере в дальнейшем необхо-
димой информации об объектах.
Таким образом, схема алгоритма кластеризации кадров состоит из следую-
щих шагов:
1. Стадия инициализации. Формируется первый кластер кг его центроидом
ск становится первый кадр 7Г Число кластеров М = 1, счетчик числа ка-
дров i = 1.
2. i: = i’ + 1. Если i > п, то переход к п.7.
3. С помощью выражения (211) вычисляется мера схожести d(7, к/) между
кадром / и центрами всех существующих кластеров к^ / = 1,2,...,Л/.
4. Определяется кластер Л ближайший к / : dj = min*l0 d[liik/). Если dy > 5,
то кадр / недостаточно близок ни к одному кластеру и выполняется п. 5. В
противном случае 7 относится к кластеру J, и выполняется п. 6.
5. Число кластеров увеличивается на единицу: М = М + 1. Формируется но-
вый кластер, куда помещается кадр 7.
6. Обновляется центроид кластера. Предположим, что старый центроид
кластера к был с*, a L - число кадров в кластере. Тогда новый центро-
ид определяется как ск = L/^L 4- 1)с* +1/(7, +1)7. Далее выполняется воз-
врат к п. 2.
7. Окончание кластеризации.
После того как все кластеры сформированы, необходимо выбрать ключе-
вые кадры. Для этого сначала определим ключевые кластеры, в качестве кото-
рых будем рассматривать только такие кластеры, которые содержат достаточно
большое число кадров. В качестве меры, определяющей размер кластера, можно
использовать величину я/Л/, представляющую собой средний размер кластера. В
каждом ключевом кластере будем считать ключевым кадром тот, который наи-
более близок к его центроиду.
2. Выделение характерных признаков. В качестве характерных признаков
для каждого пикселя выберем следующие величины: три цветовые компоненты
(в случае цветного изображения; для полутоновых - интенсивность пикселя), две
пространст венные координаты пикселя (х,у), номер кадра в видеонаборе I и из-
менение интенсивности пикселя во времени dl = - 7(х,у). Последний при-
знак получается при помощи двух последовательных кадров или двух следующих
друг за другом ключевых кадров. Таким образом, для цветных изображений каж-
дый пиксель характеризуется семимерным вектором характерных признаков.
http://wwvvjtv.ru
Компания ITV - генеральный спонсор издания книги
496
Цифвая обработка видеоизображений
3. Обучение модели на основе ключевых кадров. На данном шаге предпо-
лагается, что цвета и их пространственное распределение в плоскости изобра-
жения описываются с помощью смеси гауссовых функций. Так как ключевые
кадры содержат в себе самые существенные особенности всего видеонабора, то
векторы характерных признаков, полученные на ключевых кадрах, являются
компактным отображением всех исходных данных. Вследствие незначительно-
го числа ключевых кадров, обучение модели с их помощью может быть прове-
дено достаточно быстро и эффективно. Пусть z- это вектор характерных при-
знаков. Тогда плотность смеси нормальных распределений выражается следу-
ющим образом:
Лг|0)=1>л(г1р,Л). (212>
где
Г|(21*'Л) =---7----Гехр[-|(2-Д,)Г£;'(г-^)) (213)
К к
параметры 0 = , Е,} необходимо определить. Здесь 0 < р. < 1, У. = 1,
j-i
z = (z; 1 < i < N}, "L' - положительно определенная ковариационная матрица разме-
ром г х г. Если ввести функцию правдоподобия
£(zi0)=nX^(z.i^’zJ’ (214)
1=1 /•!
то оценка параметров в по методу максимального правдоподобия выражается
следующим образом:
= argmax£(z|0). (215)
в
Величина 6ML находится с помощью итерационного метода ожидания-макси-
мизации (ОМ) [54].
Шаг ожидания: Для / = иу = 1,...,£ вычисляем величину
„(в-}- 12Ю
)-~к’ (216)
£А"т?(г(1я,мг)
/=|
т - номер итерации.
Шаг максимизации:
<217)
1 %(«)’.
М7*' = ^------. (218)
Е-.(е')
(=1
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. procctv. ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 497
s;+' = —-------*--------------. (219)
1»-)
*=:
На каждой итерации должны выполняться следующие соотношения:
к к
Z%(0m)=i; Zp7 = 1- (220)
y=l J=\
Число компонент К в смеси гауссовых распределений выбирается исходя из
условия максимизации величины
logL(z|0)- — log /V,
z
где
logZ (z |0) =
1=1 [ /=|
(221)
(222)
lk - число свободных параметров в модели с К компонентами. В случае с полной
ковариационной матрицей L имеем:
4 = (к-\)+к.г+к
(223)
4. Вычисление векторов характерных признаков и их кластеризация. По-
сле того как обучение модели проведено, вычисляются r-мерные векторы харак-
терных признаков для всего исходного набора данных, т. е. для всей видеопосле-
довательности, а не только для ключевых кадров, как ранее. Далее предположим,
что в процессе обучения модели из смеси гауссовых распределений в качестве па-
раметров выбраны 0О = | . Обозначим
(224)
Тогда пиксель, которому соответствует вектор характерных признаков z, отно-
сится к определенному кластеру исходя из следующего условия:
arg max /у (z | р’, д’, Е’). (225)
Вероятность того, что пиксель с вектором характерных признаков z будет отне-
сен к кластеру равна следующей величине:
/(zie°)
(226)
/7ttp.//www. itv.ru
Компания ITV - генеральный спонсор издания книги
498
Цифвая обработка видеоизображений
Благодаря соответствующему выбору характерных признаков такой процесс
кластеризации дает связные области как в пространстве, так и во времени в рамках
одного или нескольких последовательных кадров видеонабора.Таким образом, каж-
дая компонента из смеси гауссовых распределений в r-мерном пространстве харак-
терных признаков соответствует некой области в видеоизображении. Различные об-
ласти и объекты могут быть сегментированы путем выделения в пространственной
и во временной областях пикселей, относящихся к одному и тому же кластеру Более
того, параметры каждой компоненты из гауссовой смеси позволяют сделать предва-
рительное заключение о характере описываемой области или объекта.
Для этого рассмотрим следующие корреляционные коэффициенты
yjCu\[^
(227)
где Ctt - коэффициенты ковариационной матрицы Z. Большие значения коэффи-
циента Rxi свидетельствуют о движении вдоль оси х. Малые значения соответ-
ствуют статичности данной области. То же самое относится к коэффициенту Rxt с
заменой оси х на ось у. Коэффициент Rti отражает дисперсию области во време-
ни. Однако в случае колебательных движений, например, вдоль оси х. коэффици-
ент Rit будет мал. Поэтому помимо корреляционных коэффициентов можно так-
же использовать изменение интенсивности пикселя dk поскольку его среднее зна-
чение явным образом отражает изменение величины движения данной области.
5. Сокращение числа ключевых кадров. Для наиболее точного описания ви-
деонабора ранее было выделено избыточное количество ключевых кадров. Те-
перь, используя построенную вероятностную модель, сократим число ключевых
кадров, выбрав из них самые существенные.
Пусть мы имеем множество F, состоящее из Nr ключевых кадров 7Р т. е.
F = {7,,...,7^ }. Заметим, что здесь индексу i в множестве Fсоответствует индекс
t(i) в исходной видеопоследовательности. Каждый ключевой кадр 7, был разбит
на К областей = 1........К на предыдущем этапе. Каждая такая область соот-
ветствует одной из компонент смеси распределений Для определения рассто-
яния между компонентами модели, которые соответствуют областям и
воспользуемся мерой Кульбака-Лейблера [47]:
KL {д'/, О'/'}) = k . (228)
где
/ ч 1 £ P(zjft)
(229)
Nk - число векторов в кластере k, {z; z = - векторы из этого кластера. Рас-
стояние между двумя последовательными ключевыми кадрами определяется как
к
(230)
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 499
Алгоритм сокращения числа ключевых кадров выглядит следующим образом:
1. Определяется значение £)(/р 7Й1) для всех последовательных ключевых
кадров из множества F.
2. Полученные значения упорядочиваются от максимального к минималь-
ному.
Те ключевые кадры, для которых D находится среди М - 1 первых значений,
выбираются в качестве окончательных ключевых кадров. Величина М опреде-
ляется как
М = т(до)(^-2)-1, (231)
где
.Vf-2
X О(А.Л.)
’ (И2)
т. е. среднее К /.-расстояние между кадрами, 0 < т(др) < 1 - параметр, линейным об-
разом зависящий от pD и позволяющий контролировать число ключевых кадров.
Ill этап
После того как выделены характерные признаки ключевых кадров и объ-
ектов, производится их индексация и занесение в базу данных. При этом будем
использовать комбинированный подход с применением дескрипторов низкого
уровня (характерные признаки, полученные на предыдущем этапе) и семантиче-
ского описания объектов. Для этого введем различные классы, каждый из кото-
рых описывает определенный тип наблюдаемых событий. Например, для систе-
мы видеонаблюдеиия за дорожной обстановкой на перекрестке в качестве таких
классов могут выступать следующие: затор, столкновение ТС, остановка ТС в ре-
зультате поломки, пересечение сплошной линии разметки и т. д.
Будем считать, что распределение ключевых кадров и объектов внутри
каждого класса может быть описано с помощью смеси гауссовых распределе-
ний (212). Сформируем обучающую последовательность, каждому члену кото-
рой присвоим метку, показывающую, к какому классу он принадлежит. Получим
пары (z,, C(zz)), где C(zz) обозначает, что вектор zz принадлежит классу у. Для
нахождения параметров смеси распределений опять воспользуемся алгоритмом
ожидания-максимизации, описанным на предыдущем этапе. Необходимо выпол-
нить следующие действия.
Шаг 1, После выполнения ОМ-алгоритма получим оптимальные (в локаль-
ном смысле) значения в = { p^p./Lj } Проверим эффективность их использо-
вания, для чего классифицируем ключевые объекты и кадры, не участвовавшие
в процессе обучения. Если f(C |z,0) > 5Г где 5j - пороговое значение, то считаем
найденные параметры смеси распределений окончательными. В противном слу-
чае переходим к шагу 2.
Шаг 2. Добавляем новую компоненту с весом рт в смесь распределений
^(г|дтЛи). (233)
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
500
Цифвая обработка видеоизображений
При этом распределение внутри класса поменяется следующим образом:
7(г|ё)=рЛ(-'к^т) + (1-^)/('|б). (234)
Опять применяем ОМ-алгоритм для нахождения в. Для определения бли-
зости двух распределений вероятности /(с|0) и 7(-|в) используется формула
Кульбака-Лсйблера:
4 = J7(z|0)log
(235)
Шаг 3. Если Д < 8^ то искомые параметры получены. В противном случае до-
бавляем новые характерные признаки и переходим к шагу 1.
При получении новых ключевых кадров и объектов они добавляются в тот
класс, для которого достигается наибольшее значение величины
7>(С,|г,е) =
Z'(с,)/(-•:«,)
(236)
где Р(С) - вес данной метки в базе данных.
IV этап
В этой системе предполагается использовать два типа запросов пользовате-
лей: по ключевым словам и по образцу. В первом случае для уменьшения числа
релевантных запросу результатов поиска возможно использование времени со-
бытия в качестве одного из характерных признаков, описывающих ключевые
кадры или объекты. В случае применения цветных камер учет цвета объекта
также позволяет существенно уменьшить круг поиска в архиве.
Для запросов по образцу большую роль играет обратная связь с пользова-
телем, что позволяет построить адаптивную систему поиска. В качестве резуль-
татов запроса система выдает определенное пользователем число кадров/объ-
ектов с минимальным расстоянием до исходного. Для определения расстояния
между представленным пользователем изображением и кадрами, хранящимися
в базе данных, используется расстояние Кульбака-Лейблера (228). После того
как получены результаты запроса, пользователь может отобрать из них, по его
мнению, наиболее подходящие. Тогда новый вектор запроса, которым вначале
является вектор характерных признаков представленного пользователем изо-
бражения Q\определяется следующим образом:
Q = aQ'+P -
(237)
где а и [3 - весовые коэффициенты, которые подбираются экспериментальным
путем, z - векторы характерных признаков для отобранных пользователем ка-
дров, Dp - множество таких кадров, a Np - кардинальность Dp.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных
501
11.5. СПИСОК ЛИТЕРАТУРЫ
1. G. Ahanger.T. D. С. Little. A Survey of Technologies for Parsing and Indexing Digital
Video. In: Journal of Visual Communication and Image Representation, special issue
on Digital Libraries, v. 7, p. 28-43.1996.
2. F. I. Bashir. A. A. Khokhar. Video Content Modeling. An Overview.Technical Report
CS 09/2002, University of Illinois, Chicago, 2002.
3. P. Aigrain, H. J. Zhang. D. Petkovic. Content-based Representation and Retrieval of
Visual Media: A State-of-the-Art Review. In: Multimedia Tools and Applications, v.
3. p. 179-202.1996.
4. C. G. M. Snoek. M. Worring. Multimodal Video Indexing: A Review of the State-of-
the-Art. In: Multimedia Tools and Applications, v. 25, p. 5-35,2005.
5. T. Kikukawa, S. Kawafuchi. Development of an Automatic Summary Editing System
for the Audio-Visual Recources. In: Transactions on Electronics and Information,
J75-A, p. 204-212,1972.
6. H. Zhang, A. Kankanhalli, W. Smoliar. Automatic Partitioning of Full-motion Video.
In: Multimedia Systems, v. 1. p. 10-28,1993.
7. A. Nagasaka, Y.Tanaka. Automatic Video Indexing and Full-Video Search for Object
Appearances. Visual Database Systems II, E.Knuth, L.M.Wegner (eds.), Elsevier, p.
113-127,1995.
8. A. Hampapur. R. Jain, T. Weymouth. Production Model Based Digital Video
Segmentation. In: Multimedia Tools and Applications, v. 1, p. 1-38,1995.
9. W. Ren, M. Sharma, S. Singh. Automated Video Segmentation. In: Proc. International
Conference on Information, Communication and Signal Processing, Singapore,
2001.
10. Y. Taniguchi, A. Akutsu, Y Tonomura. Panorama Excerpts: Extracting and Packing
Panoramas for Video Browsing. In: Proc. ACM International Conference on
Multimedia. Seattle, p. 427-436,1997.
11. S. Lawrence, D. Ziou, M. E Auclair-Fortier, S. Wang. Motion-insensitive Detection
of Cuts and Gradual Transitions in Digital Videos. Technical Report 266, DMI,
University of Sherbrooke, Canada, 2001.
12. Y. Tonomura, S. Abe. Content-oriented Visual Interface Using Video Icons for
Visual Database Systems. In: Journal of Visual Languages and Computing, v. 1, p.
183-198,1990.
13. U. Gargi, R. Kasturi. An Evaluation of Color Histogram-based Methods in Video
Indexing. In: Proc. International Workshop on Image Databases and Multimedia
Search, Amsterdam, p. 75-82,1996.
14. D. Pye, N. J. Hollinghurst, T. J. Mills, K. R. Wood. Audio-visual Segmentation for
Content-based Retrieval. In: Proc. International Conference on Spoken Language
Processing, Sydney, 0517,1998.
15. M. Ahmed, A. Karmouch, S. Abu-Hakima. Key Frame Extraction and Indexing for
Multimedia Databases. In: Proc. Vision Interface Conference,Trois-Rivieres, p. 506-
511,1999.
16. C. O’Toole, A. Smeaton, N. Murphy, S. Marlow. Evaluation of Automatic Shot
Boundary Detection on a Large Video Test Suite. In: Proc. Conference on Challenge
of Information Retrieval, Newcastle, 1999.
http://wwwjtv.ru
Компания ITV - генеральный спонсор издания книги
502
Цифвая обработка видеоизображений
17. Р. Chiu, A. Girgensohn. W. Polak, Е. Rieffel, L. Wilcox. A Genetic Algorithm for
Video Segmentation and Summarization. In: Proc. IEEE International Conference
on Multimedia and Expo. New York, v. 3, p. 1329-1332,2000.
18. A. Dailianas, R. B. Allen, P. England. Comparison of Automatic Video Segmentation
Algorithms. In: Proc. SPIE Conference on Integration Issues in Large Commercial
Media Delivery Systems. Philadelphia, v. 2615, p. 2-16,1995.
19. W. Zhao, J. Wang. D. Bhat, K. Sakiewics, N. Nandhakumar, W Chang. Improving
Color-based Video Shot Detection. In: Proc. IEEE International Conference on
Multimedia Computing and Systems. Florence, v. 2. p. 752-756,1999.
20. S. Kim, R. H. Park. A Novel Approach to Scene Change Detection Using a Cross
Entropy. In: Proc. IEEE International Conference on Image Processing. Vancouver,
v. 3, p. 937-940,2000.
21. R. Kasturi, R. C. Jain. Dynamic Vision. Computer Vision: Principles, Kasturi R, Jain
RC (eds.). IEEE Computer Society Press, Washington, p. 469-480,1991.
22. M. S. Lee, Y. M. Yang, S.W. Lee. Automatic Video Parsing Using Shot Boundary
Detection and Camera Operation Analysis. In: Pattern Recognition, v. 34, p. 711-
719,2001.
23. С. M. Lee. M. C. Ip. A Robust Approach for Camera Break Detection in Color Video
Sequences. In: Proc. I APR International Workshop on Machine Vision Applications.
Kawasaki, p. 502-505.1994.
24. M. Bertini, A. Del Bimbo, P Paia. Content-based Indexing and Retrieval of TV
News. In: Pattern Recognition Letters, v.22. p. 503-516,2001.
25. R. Dugad, K. Ratakonda, N. Ahuja. Robust Video Shot Change Detection. In: Proc.
IEEE Workshop on Multimedia Signal Processing. Redondo Beach, p.345-356,
1998.
26. D.A.Adjeroh,M.C.Lee,C U.Orji.Techniques for Fast Partitioning of Compressed
and Uncompressed Video. Multimedia Tools and Applications, v. 4, p. 225-243,
1997.
27. F Arman, R. Depommier, A. Hsu, M. Y Chiu. Content-based Browsing of Video
Sequences. In: Proc. ACM International Conference on Multimedia, San Francisco,
p. 97-103,1994.
28. R. Zabih, J. Miller, K. Mai. A Feature-based Algorithm for Detecting and Classifying
Production Effects. Multimedia Systems, v. 7, p. 119-128,1999.
29. J. Canny. A Computational Approach to Edge Detection. In: IEEE Transactions on
Pattern Analysis and Machine Intelligence, v. 8, p. 679-698,1986.
30. D. Huttenlocher, E. Jaquith. Computing Visual Correspondence: Incorporating
the Probability of a False Match. In: Proc. International Conference on Computer
Vision,p. 515-522,1995.
31. R. Lienhart. Comparison of Automatic Shot Boundary Detection Algorithms. In:
Proc. SPIE Conference on Storage and Retrieval for Image and Video Databases,
San Jose, v. 3656, p. 290-301,1999.
32. H. Yu, G. Bozdagi, S. Harrington. Feature-based Hierarchical Video Segmentation.
In: Proc. IEEE International Conference on Image Processing, Santa Barbara, v. 2,
p. 498-501,1997.
33. A. Hanjalic. Shot-boundary Detection: Unraveled and Resolved? In: IEEE
Transactions on Circuits and Systems for Video Technology, v. 12, p. 90-105,2002.
ProSystem CCTV - журнал no системам видеонаблюдения
h t tp://w w w. procc t v. г и
Глава 11. Индексация и поиск в цифровых библиотеках и архивах видеоданных 503
34. D. С. Coll, G. К. Choma. Image Activity Characteristics in Broadcast Television. In:
IEEE Transactions on Communications. v. COM-24, p. 1201-1206,1976.
35. B. Salt. Statistical Style Analysis of Motion Pictures. In: Film Quarterly, v. 28, p.
13-22,1973.
36. B.-L. Yeo, B. Liu. Rapid Scene Analysis on Compressed Video. In: IEEE Transactions
on Circuits and Systems for Video Technology, v. 5, p. 533-544,1995.
37. S. Porter, M. Mirmehdi, B. Thomas. Detection and Classification of Shot Transitions.
In: Proc. British Machine Vision Conference. Manchester, p. 73-82,2001.
38. A. Miene, A. Dammeyer. Th. Hermes, O. Herzog. Advanced and Adaptive Shot
Boundary Detection. In: Proc. ECDL WS Generalized Documents, D. W. Fellner, N.
Fuhr and I. Witten (eds.). p. 39-43.2001.
39. C. Cai, К. - M. Lam. Z.Tan. An Efficient Video Shot Representation for Fast Video
Retrieval. In: Proc. Visual Communications and Image Processing, Beijing, p. 230-
238,2005.
40. M. Cooper, J. Foote. Discriminative Techniques for Keyframe Selection. In: Proc.
IEEE International Conference on Multimedia & Expo, Amsterdam, p. 502-505,2005.
41. S. Porter, M. Mirmehdi. B. Thomas. Video Indexing Using Motion Estimation. In:
Proc. British Machine Vision Conference. Norwich, p. 659-668,2003.
42. Форсайт Д.. Понс Ж. Компьютерное зрение. Современный подход. - М.: изд-
во «Вильямс». 2004. - 928 с.
43. A. Amer, Е. Dubois. A. Mitiche. A Real-time System for High-level Video
Representation: Application to Video Surveillance. In: Proc. SPIE Visual
Communications and Image Processing. Santa Clara, v. 5022, p. 530-541,2003.
44. S. Chen, M. Shyu, C.Zhang, J. Strickrott. Multimedia Data Mining for Traffic Video
Sequences. In: Proc. International Workshop on Multimedia Data Mining, San
Francisco, p. 78-86.2001.
45. J.-H. Oh. J.-K. Lee, S. Kote. Real-time Video Data Mining for Surveillance Video
Streams. In: Proc. Pacific-Asia Conference on Knowledge Discovery and Data
Mining, Seoul, p. 222-233.2003.
46. Y. Zhuang, Y. Rui,T. S. Huang, S. Mehrolra. Adaptive Key Frame Extraction Using
Unsupervised Clustering. In: Proc. IEEE International Conference on Image
Processing, Chicago, p. 866-870,1998.
47. S. Kullback. Information Theory and Statistics. Dover, N. -Y, 1968.
48. A. Graves, S. Gong. Spotting Scene Change for Indexing Surveillance Video. In:
Proc. British Machine Vision Conference, Norwich, p. 469-478,2003.
49. J. Ng, S. Gong. On the Binding Mechanism of Synchronised Visual Events. In: Proc.
IEEE Workshop on Motion and Video Computing, Orlando, p. 112-117,2002.
50. E. Keogh, B. Celly, C.-A. Ratanamahatana, V Zordan. A Novel Technique for
Indexing Video Surveillance Data. In: Proc. ACM SIGMM Workshop on Video
Surveillance, Berkeley, p. 98-106,2003.
51. S.-C. Chen, M.-L. Shyu, S. Peeta, C. Zhang. Learning-based Spatio-temporal
Vehicle Tracking and Indexing for Transportation Multimedia Database Systems,
in: IEEE Transactions on Intelligent Transportation Systems, v. 4, p. 154-167,2003.
52. B. Fauvet, P. Bouthemy, P. Gros, F Spindler. A Geometrical Key-frame Selection
Method Exploiting Dominant Motion Estimation in Video. In: Proc. International
Conference on Image and Video Retrieval, Dublin, p. 419-427,2004.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
504
Цифвая обработка видеоизображений
53. J. R. Kender. В. L. Yeo. Video Scene Segmentation via Continuous Video Coherence.
In: Proc. IEEE Conference on Computer Vision and Pattern Recognition, Santa
Barbara, p. 367-373,1998.
54. R. Hammoud, R. Mohr. A Probabilistic Framework of Selecting Effective Key-
frames for Video Browsing and Indexing. In: Proc. International Workshop on Real-
Time Image Sequence Analysis. Oulu, p. 79-88.2000.
55. E. §aykol, U. Gudukbay. O. Ulusoy. A Database Model for Querying Visual
Surveillance Videos by Integrating Semantic and Low-level Features. In: Lecture
Notes in Computer Science, v. 3665, p. 163-176,2005.
56. C. Kim, J.-H. Hwang. Object-based Abstraction for Video Surveillance Systems. In:
IEEE Transactions on Circuits and Systems for Video Technology, v. 12, p. 1128-1138,
2002.
57. Y. S. Avrithis. A. D. Doulamis, N. D. Doulamis. S. D. Kollias. An Adaptive Approach
to Video Indexing and Retrieval Using Fuzzy Classification. In: Proc. International
Workshop on Very Low Bitrate Video Coding. Urbana, p. 69-72,1998.
58. E. Saykol, U. Gudukbay, O. Ulusoy. A Database Model for Querying Visual
Surveillance Videos by Integrating Semantic and Low-level Features. In: Proc.
International Workshop on Multimedia Information Systems, Sorrento, p. 163-176,
2005.
59. В. C. Toreyin, A. Cetin. A. Aksay, M. Akhan. Moving Object Detection in Wavelet
Compressed Video. In: Signal Processing: Image Communication, v. 20, p. 255 -264,
2005.
60. E. Saykol, U. Gudukbay, O. Ulusoy. A Histogram-based Approach for Object-based
Query-by-Shape-and-Color in Image and Video Databases. In: Image and Video
Computing, v. 23, p. 1170-1180,2005.
61. A. Hampapur et al. S3-R1 :The IBM Smart Surveillance System - Release 1. In: Proc.
ACM SIG MM Workshop on Effective Telepresence. New York, p. 59-62,2004.
62. T. Nishida,T. Matsushita, S. Kamijo, M. Sakauchi. Interactive System of Analyzing
Traffic Event Statistics Based on Occlusion Robust Vehicle Tracking Method. In:
Proc. World Congress on Intelligent Transport System, Chicago, 2002.
63. L. J. Latecki, D. de Wildt. Automatic Recognition of Unpredictable Events in Videos.
In: Proc. International Conference on Pattern Recognition, Quebec City, p. 889-892,
2002.
64. B. Scassellati, S. Alexopoulos, M. Flickner. Retrieving Images by 2D Shape: A
Comparison of Computation Methods with Human Perceptual Judgments. In: Proc.
Society of Photo-optical Instrumentation Engineers, San Jose, v. 2, p. 2-14,1994.
65. А. Каир. J. Heuer. Polygonal Shape Descriptors - An Efficient Solution for Image
Retrieval and Object Localization. In: Proc. Asilomar Conference on Signals, Systems
and Computers, Pacific Grove, p. 59-64,2000.
66. X. Li, S.-C. Chen, M.-L. Shyu, B. Furht. An Effective Content-based Visual Image
Retrieval System. In: Proc. International Computer Software and Applications
Conference. Oxford, p. 914-919,2002.
ProSystem CCTV - журнал no системам видеонаблюдения
h t tp://www. procc t v. г и
505
ГЛОССАРИЙ
Активного внешнего вида модель (active appearance model) - параметрические
гибкие статистические модели не только формы объекта, но и его так называе-
мого внешнего вида, представляемого с помощью текстуры.
Активной формы модель (active shape model) - параметрические гибкие (де-
формируемые) модели формы объекта, строящиеся статистическим образом на
основе наблюдения изменений объектов, встречающихся в обучающей последо-
вательности.
Блоб (blob) - компактная структурнозначимая область, в которой цветовые и
пространственные характеристики пикселей близки друг другу.
Бустинг (boosting) - метод усиления слабых классификаторов (экспертов).
Временная разность (temporal differencing) - метод выделения переднего плана
при помощи попиксельного вычитания двух и более последовательных кадров.
Вычитание фона (background subtraction) - метод, применяемый для детектиро-
вания движущихся объектов путем вычисления попиксельной разности между
текущим кадром и моделью фона.
Граф со связками лиц (face bunch graph) - стекоподобная структура, состоящая из
репрезентативной выборки отдельных модельных графов, относящихся к одной
опорной точке изображения, и использующаяся при распознавании лиц.
Динамическая текстура (dynamical texture) - расширение понятия обычных тек-
стур с учетом их повторяемости с течением времени.
Задний план - статическая, т. е. неизменяемая или крайне медленно изменяемая
часть сцены. Часто называют фоном или фоновым изображением.
Идентифицирующие поверхности (identity surfaces) - гиперповерхность в про-
странстве характерных признаков лиц, включая поворот и наклон головы.
Интегральное изображение (integral image) - сумма интенсивностей пикселей, на-
ходящихся левее и выше рассматриваемой точки изображения, включая ее саму.
Ключевые кадры (keyframes) - отдельные кадры видеонабора, являющиеся
наиболее характерными его представителями и использующиеся для его ин-
дексации.
Линейный дискриминантный анализ (linear discriminant analysis) - метод класси-
фикации объектов, при котором исходное пространство разбивается на отдель-
http://wwwjtv.ru
Компания ITV - генеральный спонсор издания книги
506
Цисвая обработка видеоизображений
ные области таким образом, чтобы минимизировать ошибки классификации в
заданном классе областей.
Локальный двоичный образ (ЛДО) (local binary pattern) - одна из простей-
ших, но в то же время эффективных текстурных характеристик, для полу-
чения которой производится сравнение значений интенсивности выбранно-
го пикселя с его восемью соседями. Результат представляется в виде двоич-
ного числа, в котором биты равны 1 только в том случае, когда значение ин-
тенсивности фиксированного пикселя превосходит значение соответствую-
щего биту соседнего.
Максимального правдоподобия метод (maximal likelihood method) - метод на-
хождения статистических оценок неизвестных параметров распределения, со-
гласно которому в качестве оценок выбираются те значения параметров, при
которых данные результаты наблюдения «наиболее вероятны».
Минимально возможный прямоугольник (МВП) (minimum bounding rectangle) -
прямоугольник минимальных размеров, целиком включающий в себя заданный
объект на изображении.
Ожидания-максимизации метод (expectation-maximization method) - метод для
нахождения оценок максимального правдоподобия параметров в вероятност-
ных моделях, зависящих от скрытых переменных.
Объемный локальный двоичный образ (ОЛДО) (volume local binary pattern) -
эффективная текстурная характеристика, обобщение локальных двоичных об-
разов на случай динамических текстур.
Опорных векторов метод (support vector machine (SVM)) - набор алгоритмов
типа «обучение с учителем», использующихся для задач классификации путем
перевода исходных векторов в пространство более высокой размерности и по-
иск максимальной разделяющей гиперплоскости в этом пространстве.
Оптический поток (optical flow) - направление и величина скорости движения в
каждой точке кадра видеоряда.
Передний план - динамическая, т. е. сравнительно быстро изменяемая во време-
ни часть наблюдаемой сцены.
Структурирующий элемент (structuring element) - бинарное изображение неболь-
шого размера, использующееся при морфологических операциях.
Трекинг (tracking) - сопровождение объекта, т. е. определение его траектории в
последовательных кадрах видеоряда.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctvxu
507
ПРЕДМЕТНЫЙ УКАЗАТЕЛЬ
1. Автоматическое распознавание регистрационных номеров автомобилей 18.350,397.398.
2. 3. 4. 5. 6. 7. 8. 9. 10. 11. 12. 13. 14. 15. Авторегрессионная модель 91.92,410,412. Авторегрессионная модель скользящего среднего 93. Агломеративные методы кластеризации 67,212,215. Адаптивная пороговая обработка 380. Алгоритм Ньюмайера-Шнайдсра 412. Алгоритм обратного распространения 157,158. Анализ областей 19.352. Атрибуты местоположения 479. Атрибуты транспортного потока 480. Атрибуты транспортного средства 479. База метаданных 437. Байесовские сети 326.330. Бинаризация изображения 353.357,358,369,378.381,383,384,398. Блоб 11-13,48,64-66.72.81-83,146,148,162-167,169-171,192,237,241-244,253, 302,369,413.
16. 17. 18. 19. 20. 21. 22. 23. 24. 25. 26. 27. 28. 29. 30. 31. 32. 33. 34. Блочные методы 425.439,448,449. Бустинг 15-18,220,224,225,230,246-249,252,265,268-270.291-293,336. Бустинг за счет распределения примеров 220,221. Бустинг за счет фильтрации 220. Вейвлет-коэффициенты Коэна-Добсши-Фово 327. Вейвлет-преобразование 267,354,356,373,413,415-418. Вейвлеты Габора 288. Вейвлеты Добеши 267,354. Вейвлеты Хаара 247,249,253,268,271,293.371-376. Векторный поток градиента 134. Вертикальная компонента 390. Вертикальная проекция 352,365,382,387. Веса нейросети 191,194,196. Видеоархив 2,13,20,25,211,259,404.436-438,472,476,477,486,488. Видеоряд 8.10,14,66,123,277,437,458. Внутрикластерное расстояние 475. Выделение контуров 65.72. Выращивание областей 360,361. Гауссово распределение 94,242,252,298,299,304,310,311,314,326,335,372, 393,405.414,425,497-499.
35. 36. 37. 38. 39. 40. 1енетический алгоритм 343,352,446,447. Геометрические моменты 340,391. Гистограммные методы 404,439,444. Гистограммы локальных двоичных образов ГЬбора 263. Гистограммы с локальными ядрами 313. Гистограммы углов 481,483.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
508
Цифвая обработка видеоизображений
41. Горизонтальная компонента 390.
42. Горизонтальная проекция 365.366.387.
43. Граница набора кадров 438-442.445.446.449.451.453,456,462,463,467.
44. Градиент Кирша 389.
45. Граф со связками лиц 289.290.
46. Датчик с индуктивной петлей 350.
47. Двухступенчатая система фильтрации 415.
48. Дендрограмма 215.216.
49. Дескрипторы простейших событий 476,477
50. Детектирование событий 477.
51. Детектор KLT 117.
52. Детектор Китчена-Розенфильда 118.
53. Детектор особых точек 116.
54. Детектор SIFT 118.119.
55. Детектор углов 116.
56. Детектор Харриса 117.
57. Дрейф в алгоритме конденсации 302.
58. Дивергенция гистограмм 298.305,306,448.
59. Динамическая текстура 11.13.66.89-94,98-100,102-106,430,431.
60. Динамический диапазон камеры 350.397.
61. Дискретное косинус-преобразование (ДКП) 180,463-466.
62. Диффузия в алгоритме конденсации 302.
63. Задача квадратичного программирования 206,207.209.
64. Задача системной идентификации 94.
65. Задний план 7,8-12.19.24,26,37.45,171.259,260,277,313,406.
66. Запросы по ключевым словам 476.
67. Запросы по наброску 476,481.486.
68. Запросы по образцу 476,481,500.
69. Змейка 14,131.132.134,180.
70. Идентифицирующая поверхность 17,299-301.
71. Импульсные характеристики 96-98,365.
72. Инвариантные моменты 81,181,339,342,451,452.
73. Индексация видеоизображений 19,435,436,439,490,491.
74. Интегральное изображение 44,249-251,336,337.370.
75. Кадр запроса 466.
76. Карта векторов движения 478.
77. Карта расстояний 311.
78. Каскад классификаторов 271,374,375.
79. Квартиль 82.
80. Классификатор 16,18,204,220,247-249,252,253,268-275,282,291-293,306,
325,327,330,331,334,336,338, 344,369,374,375,396-398.
81. Классификационная диаграмма 81.
82. Классификационная метрика 12,78.
83. Классификация выделенных объектов 425,430.
84. Кластеризация характерных признаков 426,497.
85. Ключевые кадры 20,438,463,465^71,481,483-485,490,493^98.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv. ги
Предметный указатель
509
86. Ключевые объекты 20.463.471.477,490,499.
87. Ключевые точки 116.118.119.
88. Ковариационные дескрипторы 369,370.
89. Компоненты Кирша 388,389.
90. Контрастность изображения 266,408,421.
91. Концевые точки 387.
92. Коэффициент диффузионного отражения 309.
93. Коэффициент корреляции 461.
94. Коэффициенты ДКП 464-466.
95. Краевые точки 19. 132. 134. 236,264,268, 295, 314, 351, 358, 371, 378, 429,
451,453.
96. Края 132-134. 158.237.250,251,313,325,351,353,359,366.429,453,455,
459.460.
97. Кривизна 55,118.137.138.372,488.
98. Критерий максимума энтропии 357,358.
99. Критерий Шварца 412.
100. Кросс-энтропия гистограмм 448.
101. Линейная динамическая система 94.
102. Локально-оптимальный метод 126.
103. Локальная ориентация текстур 100.
104. Линейный дискриминантный анализ (ЛДА) 83,282-285,287,293,467.
105. Локальные гистограммы направлений краевых точек 264.
106. Локальные двоичные образы (ЛДО) 103.104,249,251,253,262,263,506.
107. Манхэттенское расстояние 212-214.
108. Маска огня 405.406.
109. Массовая оптическая плотность 422.
110. Матрица близости 469.
111. Матрица внутриклассового разброса 282,283.
112. Матрица Гессе 118.
113. Матрица назначений 120.
114. Матрица отклонений 120.
115. Матрица соответствия объектов 149.
116. Медианная фильтрация 84.
117. Межкластерное расстояние 475.
118. Межобъектные события 473.
119. Мера различимости кластеров 475.
120. Мера стабилизации 245.
121. Мера Якимовского 449.
122. Метод AdaBoost 222-226,291,293,317,318,375.
123. Метод PCA-SIFT 119,171.
124. Метод SIFT 118.
125. Метод ближайшего соседа 123,124.
126. Метод временной разности 8-11,25.50,52,78,237,243.
127. Метод выделения активного контура 14,131.
128. Метод выделения главных компонент 96,276.278,282,283, 285-287,293,
296, 325,363. 364,394, 395,492.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
510
Цифвая обработка видеоизображений
129. 130. 131. 132. 133. 134. 135. 136. 137. 138. 139. 140. 141. 142. 143. Метод вычитания фона 8-11,25-30,240.243. Метод двойного сравнения 446. Метод динамического программирования 135.136.261,262. Метод Канни 429. Метод конденсации 17.300.302. Метод К-средних 68.69.218.396. Метод максимально стабильных экстремальных областей 145. Метод максимального правдоподобия 80.492.496. Метод максимизации апостериорной вероятности 489. Метод максимума энтропии 358. Метод медианного абсолютного отклонения 356. Метод обратного распространения ошибки 194. Метод ожидания-максимизации 39.40.100,248,499. Метод онлайн-бустинга 247.248. 252. Метод опорных векторов 15. 16. 203. 204, 207, 208, 211,265, 271-273, 331, 353,394,397-399.431.
144. 145. 146. 147. 148. 149. 150. 151. 152. 153. 154. Метод смещения среднего 160-162.164-166.376.377. Метод собственных лиц 17.228-230. Метод усиления слабых классификаторов 374. Метод Хафа 351,359.360. Метод эволюции кривых 436. Методы оптического потока дифференциальные 53. Методы оптического потока частотные 53,56. Методы оптического потока фазовые 53. Методы распознавания лиц аналитические 276. Методы распознавания лиц холистические 276. Минимально возможный прямоугольник (МВП) 64. 65, 82, 84. 114, 146, 147,151,155,157-160,174,237,238,241-243,377,473,482,483.
155. 156. 157. 158. 159. 160. 161. 162. 163. 164. 165. 166. 167. 168. 169. 170. 171. 172. Модель ARMA 93. Модель MSTAR 92. Модель R&S 128. Модель S&S 128. Модель STAR 91,92. Модель активной формы 293-296. Модель активного внешнего вида 293,295,296. Модель ближайшего соседа 121,123.124. Модель глобального слежения 120. Модель заднего плана 9,10,24,230. Модель Маркова 471. Модель однородного движения 121. Модель плавного движения 121,128. Модель переднего плана 146. Модель распределения точек 293. Модель слежения за компактными наборами точек 120. Модель слежения за отдельными точками 120. Модель среднего отклонения 122.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
Предметный указатель
511
173. Модель среднего отклонения со штрафами 122.
174. Модель фона 3,8.10.23.25-27.40.50,52,146,230,231,237,240,307.
175. Моменты Фурье-Меллина 340.341.
176. Моменты Цернике 340.341.392.
177. Морфологическая фильтрация 69.
178. Множители Лагранжа 206.209.272.
179. Набор кадров 436-443. 445. 446, 449-454. 456, 461-463, 466-469. 477, 490,
492,493.
180. «Наивный» классификатор Байеса 328,330.
181. Направленная регулярность 106-108,431.
182. Направленный граф 468.
183. Настройка нейросети 15.191.196-199,202,203,394.
184. Нахождение траекторий объектов 114.120,123,126,127.
185. Нейрон Мак-Каллока-Питтса 185,194.
186. Нейронные сети 10.15.16.184.190,203,227,265,266,352,353,371,393.
187. Нейросеть прямого распространения 15,190,191,193,198.
188. Нейросеть с радиальными базисными функциями 194.
189. Нечеткие множества 483.
190. Нечеткое разделение классов 208.
191. Нормализованная гистограмма 448.
192. Нормальный поток 89.90,109,430.
193. Нормированная корреляция 461.
194. Нормированная разность блоков 426.
195. Обобщенное частичное расстояние Хаусдорфа 455.
196. Обучающая последовательность 363.369. 378. 394-396,398.405,456,458,
499.
197. Объемные локальные двоичные образы (ОЛДО) 103,104.
198. Оператор Превитта 117.132,353.
199. Оператор разности гауссианов 118.
200. Оператор Робертса 132.
201. Оператор Собеля 35,117,132,268,353,358,378.
202. Операции морфологии 12. 66, 69, 71, 237, 351, 353, 367, 369, 388, 429,
430.
203. Операция дилатации 12,66,70,71,241,312,369,381.454.
204. Операция замыкания 71,368.
205. Операция размыкания 368,369.
206. Операция слияния 69,71,72.
207. Операция эрозии 12,66,69-71,241,408,409.
208. Оптическая плотность 422.
209. Оптический поток 8,9.25,53-57,66,89,90, 168,170,230,425,430,440.
210. Особые точки 116,117,119.
211. Оставленный объект 16,231,234-236.
212. Ошибки второго рода 27,260,266,313,327,356,369,375,425,426.
213. Ошибки первого рода 375.
214. Параметрический фильтр 353.
215. Передаточная функция 189.
http://www.itv.ru
Компания ITV - генеральный спонсор издания книги
512
^ифвая обработка видеоизображений
216. Передний план 7-9.12.16.23.25-29.32-37,42.45,48,50-53,64,66,69,84. 146, 166. 167. 170. 171. 233-235. 237. 240. 243, 246. 253, 305, 312, 313, 351, 384,472
217. 218. 219. 220. 221. 222. 223. 224. 225. 226. 227. 228. 229. 230. 231. 232. 233. 234. Переднеплановый объект 29.50.53.78.80.81.84,312,313. Перекрытие объектов 101.147. 150.154-156,167.232,233,300,462,477. Пересечение гистограмм 448.452.483. Переходный пиксель 245. Периодограмма 364.365. Персептрон 15,190. 191.220.227.266.285,393. Пиксельные методы 439.440. Плотность краевых точек 378. Полиномы Цернике 340. Полосовой фильтр 56.57.334.461. «Полунаивная» модель Байеса 328. Полярно-логарифмическое преобразование 181-184. Попиксельное сравнение 25.439-441. Порог бинаризации 378.379. Постобработка изображений 69. Преобразование Адамара-Уолша 143,144. Преобразование Гильберта 101. Преобразование Фурье 44. 56, 106, 107. 143, 179, 180, 183, 343, 364, 411, 461,462.
235. 236. 237. 238. 239. 240. 241. 242. 243. 244. 245. 246. 247. 248. 249. 250. 251. 252. 253. 254. 255. 256. 257. Преобразование Хафа 139,140,359,360. Принцип попарных связей 126. Пространственно-временные разветвления 241. Проявление 439,443.453,454,456. Прямоугольность области 377,378. Разделяющая гиперплоскость 194,203-208.394. Разделяющие методы кластеризации 67,217. Распределение Пуассона 458. Расстояние Бхатачарьи 448. Расстояние внутрикластерное 475. Расстояние Кульбака-Лейблера 448,498,500. Расстояние манхэттенское 212-214. Расстояние Махаланобиса 41,57,196,213,214,295,352,378. Расстояние межкластерное 475. Расстояние Минковского 212-214. Расстояние по принципу «ближнего соседа» 214,215. Расстояние по принципу «дальнего соседа» 214,215. Расстояние Хаусдорфа 236,237,385,386,454,455. Расстояние Хаусдорфа модифицированное 488. Расстояние Хэмминга 213. Расстояние Чебышева 213. Растворение 439,442,443,453-456,459-461. Сегментация видеопотока 437, 440, 443, 446, 447. 453, 473, 474. 477. 478, 490, 493.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ri/
Предметный указатель
513
258. Сегментация объектов 13,64.66,114,153,483.
259. Семантические характерные признаки 20,472,477.
260. Сети адаптивного резонанса 394.
261. Сеть Байеса 326,330.
262. Система индексации видеоизображений 438,472,478,483.
263. Скрытые модели Маркова 419-421,471.
264. Слабый классификатор 247, 248, 252, 253, 268, 269, 292, 293, 336, 338,
374.
265. Слежение за контурами объектов 131.
266. Слежение за эллиптическими областями 129.
267. Смесь текстур 99.
268. Смещение блоков 426.
269. Собственные лица 17,278.280,281.
270. Сопровождение объектов 13,114,241,477,486.
271. Сравнение с шаблоном 260.261,274,361,363,385.397.
272. Стационарный пиксель 245,416.
273. Статистика Фройнда 449.
274. Стационарный и эргодический стохастический процесс (СЭСП) 46,47.
275. Стирание 439.443,453,454.
276. Структурирующий элемент 12,66,69-71,312,368,379,381,385.429.
277. Субдиапазон 268,355,356.372,374.
278. Точность поиска в видеоархиве 476-478.489.
279. Трекинг 7, 13. 14,32, 114, 115, 141,148,157,160, 168. 170,242.243,253,297.
413.
280. Триггерное устройство 350.
281. Угасание 439,443,453,454,456.
282. Углы поворота 258,260,289,290,481,482,486,487.
283. Уровень декомпозиции 374.
284. Условия Куна-Таккера 207,210.
285. Фильтр Габора 56,263,288,293,342-344,371,372.
286. Фильтр Кальмана 31,253,300.
287. Фон 8,28-30,32,33,47,230,246,381,413,472.
288. Функция автокорреляционная 86-88.92,106,107.
289. Функция активационная 186,188,191.
290. Функция дискриминантная 83,325,393.
291. Функция контрастности 106-109.
292. Функция подобия 87.
293. Функция пороговая «жесткая» 354.
294. Функция пороговая «мягкая» 354.
295. Функция пороговая «полумягкая» 354.
296. Характерные признаки низкого уровня 372,472,476,477.
297. Хроматические компоненты 274.
298. Цветовая гамма огня 413,414.
299. Цветовая таблица 447.
300. Цветовые коррелограммы 481.
301. Цветовые наборы 481.
http://www. itv. ги
Компания ITV - генеральный спонсор издания книги
514
Цифвая обработка видеоизображений
302. Центр масс объекта 13.80-82.84. 114. 115.135.146, 148,151,153,155, 156,
158.162.412.479.482.483.
303. Центроид кластера 68. 195. 211. 214. 215. 217-219. 344, 396, 474, 475, 492,
495.
304. Цепные коды 411.
305. Эластичные графы 288.290.
306. Эллиптические Фурье-дескрипторы 392.
307. Энергетическая яркость 308-310.
308. Энтальпия горения 423.
309. Эффективность поиска в видеоархиве 476.488.
310. Ядро Гаусса 132.207.274.314.
311. Ядро Епанечникова 160.
312. Ядро полиномиальное 207.
313. Ядро сигмоидное 207.
ProSystem CCTV - журнал по системам видеонаблюдения
http://www.procctv.ru
515
СОДЕРЖАНИЕ
Глава 1. Введение...................................................5
Глава 2. Построение моделей фона и выделение переднего плана.......23
2.1. Методы вычитания фона....................................25
2.2. Вероятностные методы.....................................36
2.3. Методы временной разности................................48
2.4. Методы оптического потока................................53
2.5. Список литературы........................................58
Глава 3. Выделение и классификация движущихся объектов.............63
3.1. Сегментация объектов.....................................66
3.2. Постобработка изображений объектов.......................69
3.3. Методы, основанные на выделении контуров.................72
3.4. Использование классификационных метрик
и временной согласованности.................................78
3.5. Методы, основанные на анализе периодичности движения.....84
3.6. Методы, основанные на использовании динамических текстур.89
3.6.1. Использование оптического потока.......................89
3.6.2. Различные модели динамических текстур..................91
3.6.3. Характерные признаки текстур..........................100
3.7 Список литературы........................................109
Глава 4. Алгоритмы слежения за объектами.........................113
4.1. Алгоритмы обнаружения особых точек......................116
4.2. Слежение за точками.....................................119
4.2.1. Модели слежения за точками............................121
4.2.2. Алгоритмы построения траекторий.......................123
4.3. Слежение за эллиптическими областями....................129
4.4. Слежение за контурами объектов..........................131
4.5. Слежение за областями, содержащими изображение..........140
4.6. Методы слежения, учитывающие совокупность
различных параметров.......................................146
4.6.1. Использование информации переднего плана..............146
4.6.2. Трекинг, основанный на алгоритме смещения среднего....160
4.6.3. Применение метода оптического потока..................168
4.7. Список литературы.......................................171
Глава 5. Адаптивные системы распознавания образов.................175
5.1. Подготовка данных для обучения..........................176
5.2. Искусственные нейронные сети............................184
5.2.1. Искусственный нейрон..................................185
5.2.2. Геометрический смысл функционирования нейрона.........189
http://www. itv.ru
Компания ITV - генеральный спонсор издания книги
516 Цифвая обработка видеоизображений
5.2.3. Нейронная сеть прямого распространения................190
5.2.4. Нейросеть с радиальными базисными функциями...........194
5.2.5. Организация процесса настройки нейросети..............197
5.3. Метод опорных векторов..................................203
5.3.1. Линейная модель.......................................204
5.3.2. Нелинейная модель.....................................207
5.3.3. Нечеткое разделение классов...........................208
5.4. Кластерный анализ.......................................210
5.4.1. Кластеризация при заданном числе кластеров............215
5.4.2. Кластеризация при неизвестном числе кластеров.........219
5.5. Методы бустинга.........................................220
5.5.1. Бустинг за счет фильтрации............................220
5.5.2. Бустинг за счет распределения примеров................221
5.6. Список литературы.......................................226
Глава 6. Детектирование оставленных предметов.....................229
6.1. Статистические методы...................................230
6.2. Использование модели фона...............................237
6.3. Применение методов бустинга.............................246
6.4. Список литературы.......................................254
Глава 7. Методы детектирования и распознавания лиц................257
7.1. Детектирование лиц на изображениях.....................259
7.1.1. Методы, основанные на сравнении с шаблоном...........261
7.1.2. Использование специальных характерных признаков......262
7.1.3. Адаптивные методы классификации......................265
7.2. Методы распознавания лиц на изображениях...............276
7.2.1. Статические методы...................................278
7.2.2. Методы, основанные на динамической информации........297
7.3. Учет изменения освещенности сцены при детектировании
и распознавании лиц.........................................305
7.4. Список литературы.......................................316
Глава 8. Обнаружение транспортных средств.........................323
8.1. Статистические методы...................................326
8.2. Текстурные методы.......................................334
8.3. Построение специальных классификаторов..................336
8.4. Использование инвариантных моментов.....................339
8.5. Использование фильтров [абора...........................342
8.6. Список литературы.......................................345
Глава 9. Методы выделения и распознавания номерных знаков
транспортных средств..............................................349
9.1. Выделение номерного знака...............................353
9.1.1. Предварительная обработка изображения.................353
9.1.2. Преобразование Хафа...................................359
ProSystem CCTV - журнал по системам видеонаблюдения
http: //ww\n procctv. г и
Содержание
517
9.1.3. Выращивание областей.................................360
9Л.4. Сравнение с шаблоном..................................361
9.1.5. Применение преобразования Фурье......................364
9.1.6. Построение вертикальной и горизонтальной проекций....365
9.1.7. Применение морфологических операторов................367
9.1.8. Применение ковариационных дескрипторов...............369
9.1.9. Использование текстурного анализа....................371
9.1.10. Построение каскада классификаторов..................374
9.1.11. Метод смещения среднего.............................376
9.2. Сегментация символов номерного знака...................378
9.2.1. Бинаризация выделенной области.......................378
9.2.2. Устранение рамки номерного знака.....................380
9.2.3. Методы сегментации отдельных символов................382
9.3. Распознавание символов номерного знака.................385
9.3.1. Сравнение с шаблоном.................................385
9.3.2. Выделение характерных признаков......................387
9.4. Методы классификации символов..........................392
9.4.1. Статистические методы................................392
9.4.2. Применение искусственных нейронных сетей.............393
9.4.3. Метод опорных векторов...............................394
9.4.4. Метод выделения главных компонент....................394
9.4.5. Использование кластерного анализа....................396
9.4.6. Комбинация нескольких методов........................396
9.5. Список литературы......................................399
Глава 10, Обнаружение дыма и огня по видеоизображениям...........403
10.1. Метод обнаружения огня, основанный на цветовых
и динамических характеристиках.........................405
10.2. Учет пространственной структуры огня.................409
Ю.З.Применение вейвлетов для детектирования пламени........412
10.3.1 . Определение областей движения.....................413
10.3.2 . Проверка цвета движущихся пикселей................413
10.3.3 . Вейвлет-анализ во временной области...............414
10.3.4 . Пространственный вейвлет-анализ...................417
10.4. Скрытые марковские модели для описания
движущихся областей огня....................................419
10.5. Использование изменения контрастности изображения
для обнаружения дыма........................................421
10.6. Блочно-текстурный метод выделения дыма на
видеоизображениях...........................................424
10.6.1. Выделение на изображении движущихся блоков.........425
10.6.2. Пространственная кластеризация движущихся блоков...426
10.6.3. Временная кластеризация движущихся блоков..........427
10.6.4. Определение формы объектов.........................429
10.6.5. Классификация выделенных объектов..................430
10.7. Список литературы......................................431
ht tp://w w w. itv. ru
Компания ITV - генеральный спонсор издания книги
518
Цифвая обработка видеоизображений
Глава 11. Индексация видеоизображений и поиск в цифровых
библиотеках и архивах видеоданных............................435
11.1. Сегментация видеопотока................................437
11.1.1. Пиксельные методы....................................440
11.1.2. Гистограммные методы.................................444
11.1.3. Блочные методы.......................................448
11.1.4. Методы, основанные на выделении характерных признаков.451
11.1.5. Методы, основанные на движении.......................461
11.1.6. Комбинация нескольких методов........................462
11.2. Описание содержания последовательности кадров..........463
11.2.1. Выделение ключевых кадров............................463
11.2.2. Выделение ключевых объектов..........................471
11.3. Индексация видеоданных и поиск в видеоархивах..........476
11.3.1. Запросы по ключевым словам...........................476
11.3.2. Запросы по образцу...................................481
11.3.3. Запросы по наброску..................................486
11.4. Алгоритмы для индексации видеоизображений и поиска
в архивах систем видеонаблюдения.............................490
11.5. Список литературы......................................501
Глоссарий.........................................................505
Предметный указатель..............................................507
ProSystem CCTV - журнал по системам видеонаблюдения
h t tp://www. ргосс t iz. г и
/SiTTV ОХХ^'П
»i i rrxxanarvA иипво *>•• ..»« •• <> *•>.<
А. А. Лукьяница, А. Г. Шишкин
Цифровая обработка
видеоизображений
В настоящее время в нашу жизнь все больше
проникает видеоинформация, требующая применения
специальных методов обработки и анализа. В книге
рассмотрен широкий круг алгоритмов, применяемых
для решения важных практических задач:
детектирование движения, отслеживание траекторий,
поиск и распознавание объектов заданных классов,
таких как человеческие лица, транспортные средства,
автомобильные номера, дым и огонь. Большое
внимание уделено проблеме поиска разноплановой
информации в цифровых видеоархивах. Книга может
быть полезна научным сотрудникам, аспирантам и
студентам старших курсов технических ВУЗов, а также
всем специалистам в области обработки изображений
и распознавания образов.
ISBN 978-5-9901899-1-1
Москва 2009