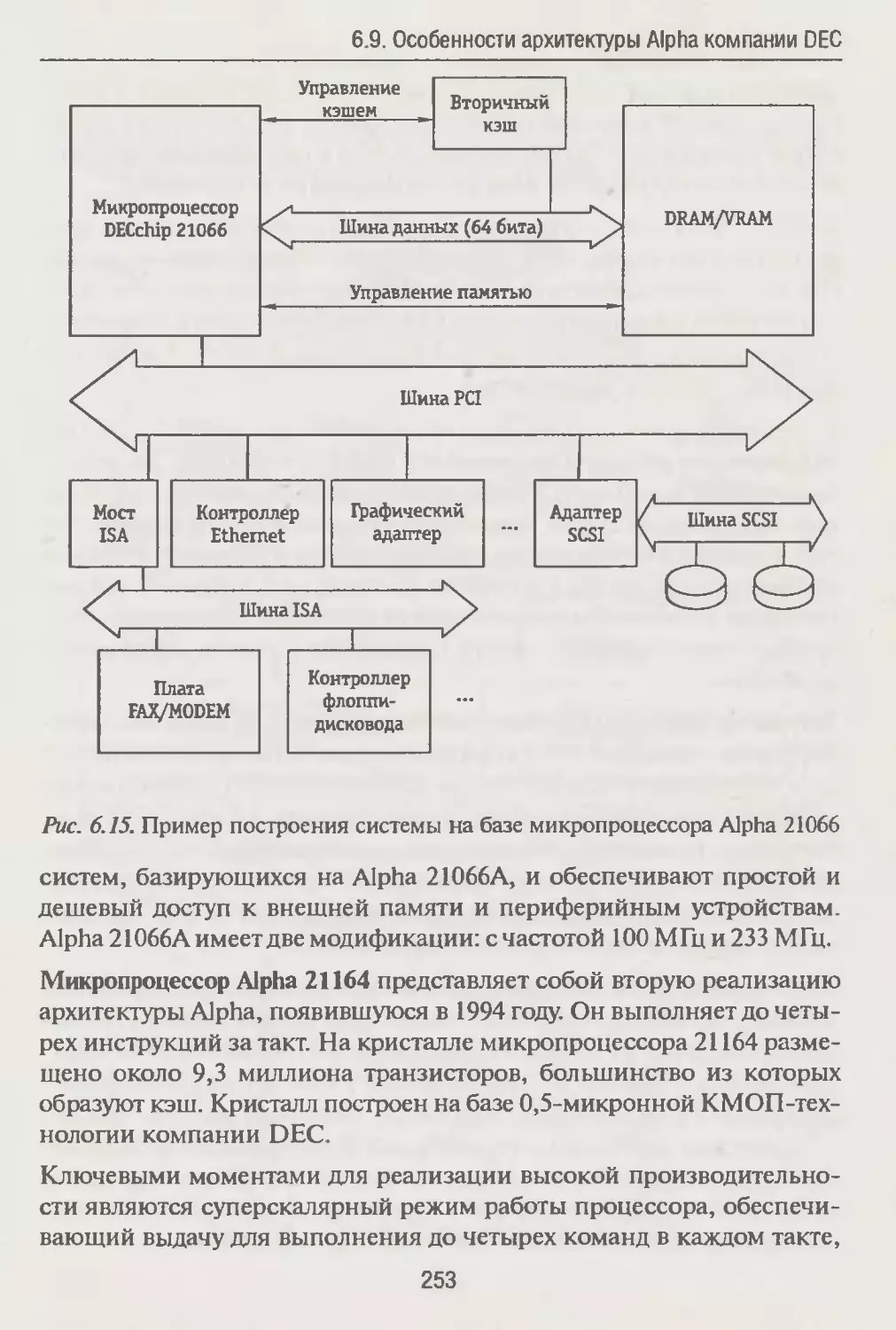
/














































































































































































































































































































































































































































































































































































Автор: Буза М.К.
Теги: компьютерные технологии оргсвязь информатика компьютер компьютерная техника
ISBN: 985-475-229-1
Год: 2006




Текст
КОМПЬЮТЕРОВ
М.К. Буза
АРХИТЕКТУРА
КОМПЬЮТЕРОВ
Утверждено Министерством образования Республики Беларусь
в качестве учебника для студентов специальностей
«Информатика», «Прикладная математика»,
«Вычислительные машины, системы и сети»
учреждений, обеспечивающих получение
высшего образования
МИНСК ООО «НОВОЕ ЗНАНИЕ» £00?
УДК 681.3(075.8)
ББК 32.988я73
Б90
Рецензенты:
кафедра численных методов и программирования
Белорусского государственного университета
информатики и радиоэлектроники;
доктор технических наук, старший научный сотрудник
Объединенного института проблем информатики С.Ф. Липницкий
Буза, М.К.
Б90 Архитектура компьютеров : учеб. / М.К. Буза. — Минск :
Новое знание, 2006. — 559 с.: ил.
ISBN 985-475-229-1.
Изложены теоретические основы построения современных вычислительных
систем. Приведены примеры существующих и перспективных архитектурных
решений. Рассмотрены направления развития высокопроизводительной техни-
ки. Материал подготовлен в полном соответствии с учебной программой дис-
циплины «Архитектура'Вычислительных систем». Отдельные главы можно
использовать при изучениизсМежныхкурсов «Операционные системы», «Систе-
мы параллельного действия», «Проектирование процессорной обработки» и т.д.
Для студентов вузов, обучаютцйхс^ по специальностям «Информатика»,
«Прикладная математика», «Вычислительные машины и сети». Будет полезен
специалистам в области системного программирования, информатики и всем,
кто заинтересован в разработке эффективных программных проектов.
УДК 681.3(075.8)
ББК 32.988я73
ISBN 985-475-229-1
© Буза М.К., 2006
© Оформление. ООО «Новое знание», 2006
Предисловие
Современное состояние компьютерных наук характеризуется интен-
сивным и многоплановым развитием, в связи с чем отсутствует строгое
и обоснованное разделение на самостоятельные учебные дисциплины.
Компьютерные науки прошли путь от создания языков програм-
мирования до цельной системы знаний, в том числе воплощенных
в серию учебных дисциплин, преподаваемых в университетах — про-
ектирование и анализ алгоритмов, базы данных, архитектура компь-
ютеров, операционные системы, компьютерные сети, компиляторы
и т.д.
Дисциплина «Архитектура компьютеров» изучает внутреннюю органи-
зацию вычислительной системы, знание которой позволяет програм-
мистам рационально использовать ресурсы системы и проектировать
эффективные программы.
Существенные успехи в развитии технологий проектирования средств
вычислительной техники, программного обеспечения и его надежно-
сти, инструментариев и методов инжиниринга, аттестации и верифи-
кации программных проектов, а также постоянно расширяющийся
спектр приложений вычислительной техники и программного обес-
печения привели к пересмотру и развитию существующих и созданию
новых архитектурных решений компьютеров. Вместо монопольной
концепции последовательного исполнения операций появились и реа-
лизованы идеи совместной, параллельной и распределенной обра-
ботки данных. Одновременно с однопроцессорными компьютерами,
базирующимися на принципах фон Неймана, используются много-
процессорные, конвейерные и параллельные архитектуры.
Концепции RISC (Reduced Instruction Set СотрШег)-процессоров,
воплотивших сокращенный набор регистровых команд, реализованы
в реальных компьютерах многочисленными фирмами наряду с тради-
ционными компьютерами на CISC (Complete Instruction Set Com-
puter) - процессорах.
Большое развитие получили компьютеры с VLIW (Very Long Instruction
Word)-apxHTeKiypofi, позволившей ускорить процесс обработки за счет
упаковки в одну связку нескольких команд, масштабируемости, пре-
дикации, загрузки по предположению, применения тегов и дескрип-
торов.
3
Предисловие
Широкое распространение получают векторно-конвейерные компью-
теры, массово-параллельные компьютеры с распределенной памятью,
компьютеры с кластерной архитектурой, позволяющей достигать прак-
тически неограниченной производительности. Все эти решения тре-
буют соответствующего осмысления и выбора, чему в немалой степени
способствует предлагаемая книга. Одна из ее целей — проследить
путь от компьютеров фон Неймана, их программного обеспечения
и концептуальных идей через семантический разрыв между сущест-
вующими архитектурными решениями, созданными и формирующи-
мися идеями, реализованными в различном окружении пользователей
компьютеров, до их совершенствования и создания новых архитек-
турных ансамблей.
Это издание о теоретических аспектах и реальных архитектурах, вопло-
щенных в действующих вычислительных системах и способствую-
щих развитию существующих архитектурных решений и генерации
новых идей в этой области.
Базируясь на понятии процесса, в книге рассмотрены ключевые тео-
ретические решения, многие из которых присутствуют в большинст-
ве современных вычислительных систем. Для изучения дисциплины
необходимы знания в области структур компьютеров, в проектирова-
нии программ и начальные сведения по операционным системам.
Учебник содержит 12 глав, каждая из которых представляет отдельный
интерес, что дает возможность включать некоторые главы в смежные
курсы: «Операционные системы», «Компьютерные сети», «Системы
параллельного действия», «Проектирование процессорной обработ-
ки» и т.д. Это позволяет читать книгу, не придерживаясь порядка,
предложенного автором.
Материал подготовлен в полном соответствии с учебной программой
дисциплины «Архитектура вычислительных систем» для высших учеб-
ных заведений Республики Беларусь.
Список литературы в основном содержит работы зарубежных авто-
ров, что свидетельствует об отсутствии соответствующей отечествен-
ной учебной литературы в данной предметной области.
Учебник ориентирован на студентов вузов, специализирующихся
в области системного программирования, разработки эффективных
программных проектов, особенно операционных систем, а также на
4
Предисловие
разработчиков новых архитектурных решений. Отдельные главы
могут быть полезны специалистам смежных областей информатики
и занимающихся проектированием эффективных приложений в со-
ответствующей предметной области.
Автор выражает глубокую благодарность рецензентам: доктору физи-
ко-математических наук, профессору А. К. Синицыну (Белорусский
государственный университет информатики и радиоэлектроники),
доктору технических наук, профессору С.Ф. Липницкому (Объеди-
ненный институт проблем информатики НАН Беларуси) за полезные
замечания и рекомендации, способствующие улучшению содержа-
ния книги.
Автор с благодарностью примет пожелания и предложения читателей
книги и просит направлять их по адресу: 220080, г. Минск, пр. Неза-
висимости, 4, к. 243.
5
Введение
В настоящее время развитие любой страны невозможно без компью-
теризации всех сфер деятельности. От скорости и полноты обработки
и передачи информации зависят успехи не только в научной, образо-
вательной, экономической деятельности, но и в сфере политики и за-
щиты государственных интересов, в совокупности способствующих
устойчивому развитию страны. Важная роль в этом процессе принад-
лежит суперкомпьютерам, производительность которых возрастала
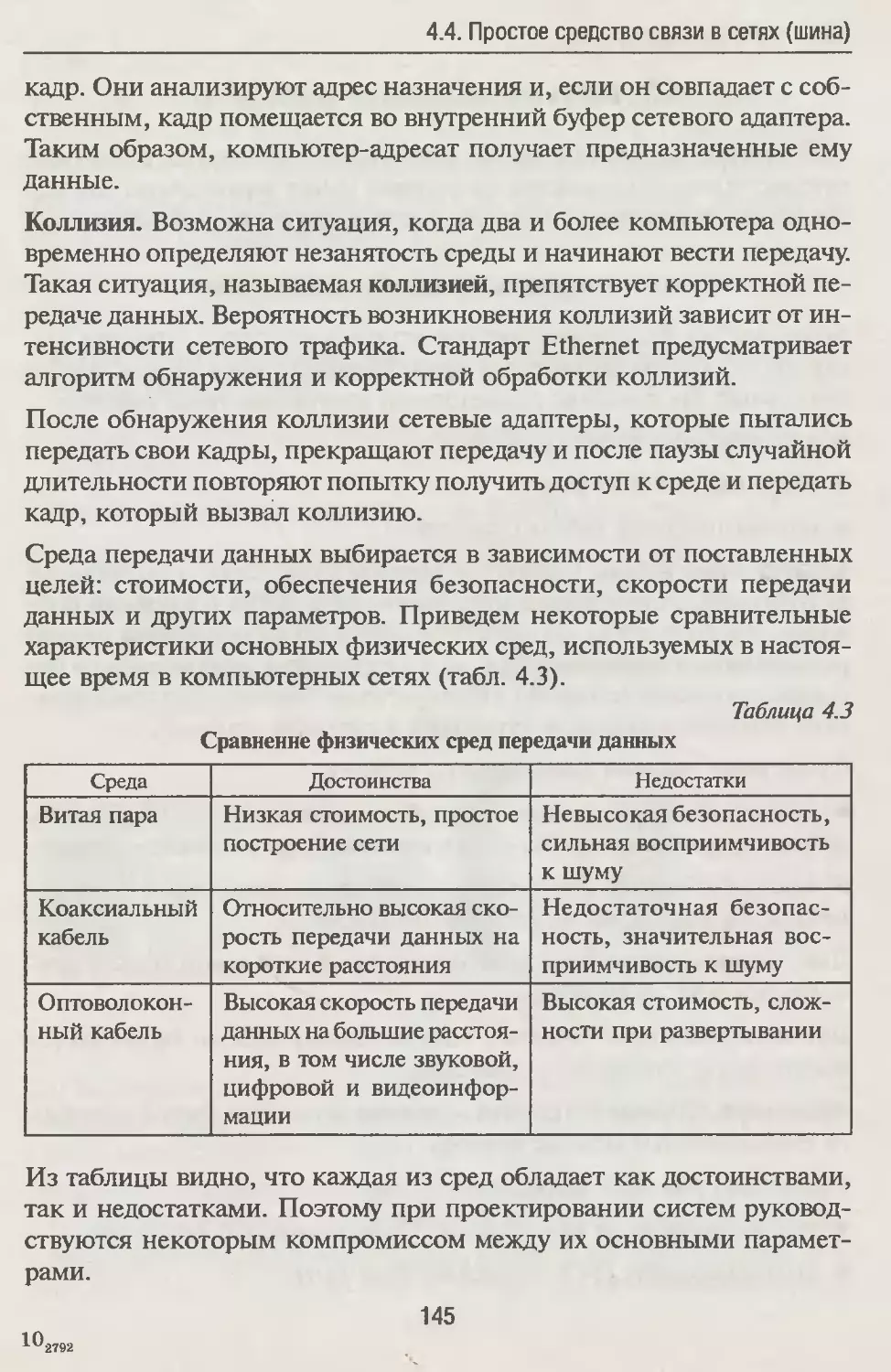
в последнее время на порядок за каждое пятилетие. К ним относят
компьютеры (как правило, с параллельной архитектурой), суммар-
ная производительность которых составляет от 10 до 1000 Гфлопс,
с оперативной памятью в несколько десятков терабайт (Тбайт).
Рассмотрим на примерах основные параметры машин этого класса.
CRAY Т932, векторно-конвейерный компьютер фирмы CRAY Research
Inc (в настоящее время это подразделение Silicon Graphics). Выпуска-
ется с 1996 года. Максимальная производительность одного процес-
сора — около 2 миллиардов операций в секунду, оперативная память
наращивается до 8 Гбайт, дисковое пространство — до 256 000 Гбайт
(то есть 256 Тбайт). Компьютер в максимальной конфигурации со-
держит 32 идентичных процессора, работающих над общей памятью,
поэтому максимальная производительность всей вычислительной си-
стемы составляет более 60 миллиардов операций в секунду.
IBM SP2, массово-параллельный компьютер фирмы IBM (иногда такие
компьютеры называют компьютерами с массовым параллелизмом)
строится на основе стандартных микропроцессоров POWERPC 604е
или POWER2 SC, соединяемых высокоскоростным коммутатором,
причем каждый из процессоров имеет свою локальную оперативную
память и дисковую подсистему. В частности, максимальная система,
установленная в Pacific Northwest National Laboratory (Richland, USA),
содержит 512 процессоров. Исходя из числа процессоров можно пред-
ставить суммарную мощность всей вычислительной системы.
Среди суперкомпьютеров с массовым параллелизмом можно выделить
Intel Red с пиковой производительностью 4 терафлопс и IBM White —
12 терафлопс.
HP Exemplar, компьютер с кластерной архитектурой фирмы Hewlett-
Packard. Например, модель V2250 (класс V) построена на основе мик-
6
Введение
ропроцессора РА—8200, работающего с тактовой частотой 240 МГц.
До 16 процессоров можно объединить в рамках одного узла с общей
оперативной памятью до 16 Гбайт. В свою очередь узлы в рамках од-
ной вычислительной системы соединяются между собой высокоско-
ростными каналами передачи данных.
ASCI RED — один из самых мощных компьютеров. Построенный по
заказу Министерства энергетики США, он объединяет 9152 процес-
сора Pentium Pro, имеет 600 Гбайт оперативной памяти и общую про-
изводительность 1800 миллиардов операций в секунду.
Компания Linux Networks создала высокопроизводительный кластер-
ный Linux-суперкомпьютер с 1323 процессорами для Министерства
обороны США.
Кластер Evolocity II предназначен для центра U.S.Army Research Labo-
ratory Major Shared Center и будет использоваться при проектирова-
нии новых видов вооружений, расчета динамики движения снарядов
в различных погодных условиях, оценки живучести техники в усло-
виях ведения боевых действий. Данная система, работа над которой
завершена в 2004 году, состоит из 1066 узлов, каждый из них оснащен
двумя процессорами Intel Хеоп с тактовой частотой 3,6 ГГц и опера-
тивной памятью в 2 Гбайт. Процессоры имеют 64-разрядные расши-
рения.
Возникает естественный вопрос: при решении каких задач требуется
применение суперкомпьютеров?
Чтобы оценить сложность решаемых на практике задач, возьмем
конкретную предметную область, например оптимизацию процесса
добычи нефти. Пусть имеется подземный нефтяной резервуар с не-
которым числом пробуренных скважин. По одним скважинам на по-
верхность откачивается нефть, по другим — в резервуар закачивается
вода. Требуется смоделировать ситуацию в данном резервуаре, чтобы
оценить запасы нефти, определить необходимость дополнительных
скважин, объем закачиваемой воды и т.п.
Примем упрощенную схему, при которой моделируемая область ото-
бражается кубом, однако и такой схемы будет достаточно для оценки
числа необходимых для моделирования арифметических операций.
Разумные размеры куба, при которых можно получить правдоподоб-
ные результаты, составляют 100 х 100 х 100 точек. В каждой точке куба
7
Введение
требуется вычислить от 5 до 20 функций: три компоненты скорости,
давление, температуру, концентрацию компонент (вода, газ и нефть —
это минимальный набор компонент, в более реальных моделях рас-
сматривают, например, различные фракции нефти). При этом значе-
ния функций находятся как решение нелинейных уравнений, что
требует от 200 до 1000 арифметических операций. И, наконец, если
исследуется нестационарный процесс, то есть нужно определить по-
ведение системы во времени, то расчеты осуществляются от 100 до
1000 шагов по времени.
В результате имеем:
106 (точек сетки) • Ю(функций) • 500(операций) • 500(шагов по време-
ни) = 2,5 • 1012,
то есть 2500 миллиардов арифметических операций для выполнения
одного лишь расчета!!! Если же учесть необходимость изменения па-
раметров модели, отслеживания ситуации при изменении входных
данных, многократности расчетов — все это накладывает очень жест-
кие требования на производительность используемых вычислитель-
ных систем.
Примеры использования суперкомпьютеров можно найти в косми-
ческих и геологических исследованиях, автомобилестроении, фар-
макологии, прогнозе погоды и моделировании изменения климата,
сейсморазведке и т.д.
Первый компьютер EDSAC (1949 год) со временем такта 2 микросе-
кунды (мкс) мог выполнить в среднем 100 арифметических операций
в секунду, а суперкомпьютер CRAY С90 имеет время такта около 4 на-
носекунд (нс), с пиковой производительностью около 1 миллиарда
арифметических операций в секунду.
Производительность компьютеров за этот период выросла приблизи-
тельно в десять миллионов раз. Уменьшение времени такта является
прямым способом'увеличения производительности, однако рост этой
составляющей (с 2 мкс до 4 нс) в общем объеме обеспечивает рост про-
изводительности лишь в 500 раз. Остальной рост производительности
приходится на новые архитектурные решения, среди которых значи-
тельное место занимает принцип параллельной обработки данных.
Параллельная обработка данных определяется конвейерностью и соб-
ственно параллельностью.
8
Введение
Идея конвейерной обработки заключается в выделении отдельных эта-
пов выполнения общей операции, причем результат работы каждого
этапа передается следующему с одновременным приемом новой пор-
ции входных данных. В результате увеличение скорости обработки
данных происходит за счет совмещения операций, раньше разнесен-
ных во времени.
Проанализируем историю основных нововведений в архитектуре
процессоров.
► IBM 701 (1953 год), IBM 704 (1955 год): разрядно-параллельная
память, разрядно-параллельная арифметика. Первые компьютеры
(EDSAC, EDVAC, UNIVAC) имели разрядно-последовательную па-
мять, из которой слова считывались последовательно бит за битом.
Первым компьютером, использующим разрядно-параллельную па-
мять и разрядно-параллельную арифметику, стал IBM 701, а наиболь-
шую популярность получила модель IBM 704, в которой впервые
была применена память на ферритовых сердечниках и аппаратное
арифметическое устройство (АУ) с плавающей точкой.
► IBM 709 (1958 год): независимые процессоры ввода/вывода. Про-
цессоры первых компьютеров сами управляли вводом/выводом.
Однако скорость работы самого быстрого внешнего устройства —
магнитной ленты — была в 1000 раз меньше быстродействия процес-
сора, поэтому во время операций ввода/вывода процессор фактиче-
ски простаивал. В 1958 году к компьютеру IBM 704 присоединили
шесть независимых процессоров ввода/вывода, которые могли рабо-
тать параллельно с основным процессором, а сам компьютер пере-
именовали в IBM 709.
► IBM STRETCH (1961 год): опережающий просмотр вперед, рас-
слоение памяти. Компьютер STRETCH имеет две принципиально
важные особенности: опережающий просмотр вперед для выборки
команд и расслоение памяти на два банка для согласования низкой
скорости выборки из памяти и скорости выполнения операций.
► ATLAS (1963 год): конвейер команд. Впервые конвейерный прин-
цип выполнения команд был использован в машине ATLAS, разрабо-
танной в Манчестерском университете. Выполнение команд разбито
на четыре стадии: выборка команды, вычисление адреса операнда,
выборка операнда и выполнение операции. Конвейеризация позво-
лила уменьшить время выполнения команд с 6 мкс до 1,6 мкс. Этот
9
Введение
компьютер оказал огромное влияние как на архитектуру ЭВМ, так
и на программное обеспечение. В нем впервые применена мульти-
программная операционная система (ОС), основанная на использо-
вании виртуальной памяти и системы прерываний.
► CDC 6600 (1964 год): независимые функциональные устройства.
Фирма Control Data Corporation (CDC) при непосредственном уча-
стии одного из ее основателей, Сеймура Р. Крэя (Seymour R. Cray),
выпустила компьютер CDC 6600 — первый компьютер, в котором
использовалось несколько независимых функциональных устройств.
Приведем некоторые параметры компьютера:
• время такта 100 нс,
• производительность 2—3 миллиона операций в секунду,
• оперативная память разбита на 32 банка 60-разрядных слов по
4096 слов в каждом;
• цикл памяти 1 мкс,
• 10 независимых функциональных устройств.
► CDC 7600 (1969 год): конвейерные независимые функциональные
устройства (ФУ). CDC выпускает компьютер CDC7600 с восемью
независимыми конвейерными функциональными устройствами —
сочетание параллельной и конвейерной обработки. Основные пара-
метры:
• время такта 27,5 нс,
• производительность 10—15 миллионов операций в секунду,
• восемь конвейерных функциональных устройств,
• двухуровневая память.
► ILLIAC IV (1974 год): матричные процессоры. Проектировалось
256 процессорных элементов (ПЭ), включающих 4 квадранта по 64 ПЭ,
возможность реконфигурации — 2 квадранта по 128 ПЭ или 1 квад-
рант из 256 ПЭ, время такта — 40 нс, производительность — 1 Гфлопс.
Реально реализована матрица из 64 ПЭ, все элементы которой рабо-
тали в синхронном режиме, выполняя в каждый момент времени
одну и ту же команду, поступившую от устройства управления (УУ),‘
но над своими данными; ПЭ имел собственное арифметико-логическое
устройство (АЛУ) с полным набором команд. Оперативная память (ОП)
10
Введение
содержала 2К слов по 64 разряда, цикл памяти 350 нс, каждый ПЭ
имел непосредственный доступ только к своей ОП. Сеть пересылки
данных — двумерный тор со сдвигом на единицу на границе по гори-
зонтали.
Стоимость проекта оказалась в четыре раза выше планируемой. Реа-
лизован лишь 1 квадрант с тактом 80 нс, реальная производитель-
ность составила до 50 Мфлопс. Проект оказал огромное влияние на
архитектуру последующих машин, построенных по схожему принци-
пу, в частности на PEPE, BSP, ICL, DAP.
► CRAY 1 (1976 год): векторно-конвейерные процессоры. Компания
Cray Research в 1976 году выпускает первый векторно-конвейерный
компьютер CRAY 1, имеющий время такта 12,5 нс, 12 конвейерных
функциональных устройств, пиковая производительность составляет
160 миллионов операций в секунду, оперативная память — до 1 М слов
(слово — 64 разряда), цикл памяти — 50 нс.
Главным новшеством проекта является введение векторных команд,
работающих с целыми массивами независимых данных и позволяю-
щих эффективно использовать конвейерные функциональные уст-
ройства.
Иерархия памяти прямого отношения к параллелизму не имеет,
однако, безусловно, относится к тем особенностям архитектуры ком-
пьютеров, которые имеют важное значение для повышения их про-
изводительности (сглаживание различий между скоростью работы
процессора и временем выборки из памяти). Основные уровни: реги-
стры, кэш-память, оперативная память, дисковая память. Время вы-
борки по уровням (от дисковой памяти к регистрам) уменьшается,
стоимость в пересчете на 1 слово (байт) растет. В настоящее время по-
добная иерархия поддерживается даже на персональных компью-
терах.
Современная высокопроизводительная техника развивается по четы-
рем основным направлениям.
1. Векторно-конвейерные компьютеры. Особенностью таких машин
являются, во-первых, конвейерные функциональные устройства
и, во-вторых, набор векторных инструкций в системе команд.
В отличие от традиционного подхода векторные команды опери-
руют целыми массивами независимых данных, что позволяет эф-
фективно загружать доступные конвейеры.
11
Введение
2. Массово-параллельные компьютеры с распределенной памятью. Идея
построения компьютеров этого класса проста — серийные микро-
процессоры снабжаются локальной памятью и соединяются посред-
ством некоторой коммуникационной среды. Они обладают свой-
ством масштабируемости. Недостатком таких компьютеров является
то, что межпроцессорное взаимодействие намного медленнее, чем
локальная обработка данных самими процессорами.
Сюда же можно отнести и сети компьютеров, которые все чаще рас-
сматриваются как дешевая альтернатива очень дорогим суперкомпь-
ютерам.
3. Параллельные компьютеры с общей памятью. Вся оперативная память
таких компьютеров разделяется между несколькими одинаковыми
процессорами. Это снимает проблемы предыдущего класса, но до-
бавляет новые: число процессоров, имеющих доступ к общей па-
мяти, по чисто техническим причинам нельзя сделать достаточно
большим.
4. Компьютеры с кластерной архитектурой. Это направление, строго
говоря, представляет собой комбинацию трех предыдущих. Из не-
скольких процессоров (традиционных или векторно-конвейерных)
и общей для них памяти формируется вычислительный узел. Если
полученной вычислительной мощности недост точно, то несколь-
ко узлов объединяются высокоскоростными каналами.
Данное направление признано наиболее перспективным. В странах
СНГ в этом направлении работают Объединенный институт проблем
информатики (НАН Беларуси), Институт проблем информатики РАН,
МГУ им. М.В. Ломоносова, Белорусский государственный универси-
тет, НИИ многопроцессорных вычислительных систем (Таганрог),
Сибирский государственный университет телекоммуникаций и ин-
форматики (Новосибирск) и др.
Влияние многопроцессорных компьютеров на скорость обработки
данных может быть выражено законом Амдала.
Предположим, что в программе доля операций, которые нужно вы-
полнять последовательно, равна/, где 0 </ < 1 (при этом доля пони-
мается по числу операций в процессе выполнения).
Предельные случаи в значениях / соответствуют полностью парал-
лельным (f= 0) и полностью последовательным (f= 1) программам.
12
Введение
Для того чтобы оценить, какое ускорение 5 может быть получено на
компьютере из р процессоров при данном значении f можно вос-
пользоваться законом Амдала:
5<-----------.
f + Q-DIP
Если 9/10 программы исполняются параллельно, а 1/10 по-прежнему
последовательно, то ускорения более чем в 10 раз получить в принци-
пе невозможно вне зависимости от качества реализации параллель-
ной части кода и числа используемых процессоров.
Обратная задача: какую часть кода надо выполнить эффективно, что-
бы получить заданное ускорение? Ответ можно найти в следствии из
закона Амдала: чтобы уменьшить время выполнения программы в q раз,
необходимо ускорить в q и более раз не менее чем (1 - 1/<?)-ю часть
программы. Следовательно, чтобы ускорить программу в 100 раз по
сравнению с ее последовательным вариантом, необходимо получить
ускорение, большее или равное 100, не менее чем на 99,99 % про-
граммного кода.
Для того чтобы вычислительная система работала с максимальной
эффективностью на конкретной программе, необходимо тщательное
согласование структуры программы и ее алгоритма с особенностями
архитектуры вычислительной системы.
13
Список основных сокращений
ADSL — Asymmetric Digital Subscriber Line
BIOS — Basic Input—Output System
BREQ — Bus Request Signal
CD — Compact Disk
CF — Compact Flash
CISC — Complete Instruction Set Computer
COMA — Cache Only Memory Access
CRC — Cyclic Redundancy Code (Check)
DSM — Distributed Shared Memory
EDO — Extended Date Output
EMS — Extended Memory System
FB — Feedback
FIFO — First In, First Out
FILO — First In, Last Out
FSM — Finite State Machine
HD — High Density
HDLC — High Level Data Link Control
HPF — Highest Priority First
IP — Internet Protocol
ISA — Industry Standard Architecture
ISO — International Organization for Standardization
LAN — Local Area Network
LD — Low Density
LLC — Logical Link Control
LRU — Least—Recently Used
MAC — Media Access Control
MAP — Multi Associative Processor
MIMD — Multiple Instruction stream / Multiple Data stream
MIPS — Millions of Instructions Per Second
MISD — Multiple Instruction stream / Single Data stream
MPI — Message Passing Interface
MPP — Massively Parallel Processing
14
Список основных сокращений
NUMA OSI — Non Uniform Memory Access — Open System Interconnection
PCI — Peripheral Compc nent Interconnect
РМА — Physical Medium Attachment
PS — Physical Signaling
PVM — Parallel Virtual Machine
RISC — Reduced Instruction Set Computer
ROM — Read Only Memory
RPC — Remote Procedure Call
RR — Round Robin
SCI — Scalable Coherent Interface
SIMD — Single Instruction stream / Multiple Data stream
SISD — Single Instruction stream / Single Data stream
SJF — Shortest Job First
SMP — Symmetrical Multi Processing
SPARC — Scalable Processor Architecture
SR — Second hand Resource
TCP — Transmission Control Protocol
UDP — User Datagram Protocol
UMA — Uniform Memory Access
USB — Universal Serial Bus
VDSL — Very high data rate DSL
VLIW — Very Long Instructions Word
WAN — Wide Area Network
АЛУ — арифметико-логическое устройство
AO — арифметическая операция
АПА — аппарат преобразования адресов
ВнУ — внешнее устройство
ВС — вычислительная система
ЗУ MBC — запоминающее устройство — многопроцессорная вычислительная система
МП — микропроцессор
НМД — накопитель на магнитных дисках
15
Список основных сокращений
ОЗУ — оперативное запоминающее устройство
ОП — оперативная память
ОС (OS) — операционная система
ПВВ — процессор ввода-вывода
ПК — персональный компьютер
ПО — программное обеспечение
ПУ — периферийное устройство
ПЭ — процессорный элемент
РОН — регистр общего назначения
СК — система команд
СКВ — система в коде вычетов
СОЗУ — сверхоперативное запоминающее устройство
ССП — слово состояния программы
УВМ — управляющая вычислительная машина
УУ — устройство управления
ФУ — функциональное устройство
ЦП — центральный процессор
ЯВУ — язык высокого уровня
ЯП — язык программирования
ЯПП — язык параллельного программирования
Я ПФ — ярусно-параллельные формы
16
Глава 1
Два подхода к понятию «архитектура»
Информатика — развивающаяся наука. Что касается ее названия, то
на немецком языке слово «informatik» в данном контексте было впер-
вые употреблено в 1968 году федеральным министром Штольтенбер-
гом по случаю открытия научной конференции в Западном Берлине,
а незадолго до этого слово «informatique» возникло во французском
языке. Со временем в голландском языке вошло в употребление слово
«informatika», в итальянском — «informatica», в польском — «infor-
matyka», в русском — «информатика», в испанском — «informatica».
В английском языке, по-видимому, остается термин «computer science»
(вычислительная наука), причем этот термин в большей степени от-
ражает теоретические аспекты данного направления.
Современная информатика является результатом бурного развития
исследований в различных областях знаний за последние годы. Но
многие ее корни уходят далеко в историю. Можно сказать, что ин-
форматика началась с попыток механизировать умственную деятель-
ность, что, конечно, не могло быть делом одного человека. Однако во
многих отношениях основателем информатики может быть назван
Готфрид Вильгельм Лейбниц.
В 1678 году Лейбниц занимается символьным языком как средством
построения универсальной науки, которая в рамках одного исчисле-
ния позволила бы дать ответы на все вопросы простейшим образом
и со свойственной математике достоверностью. Сюда же относятся
его философские сочинения («Discours de m6taphysique», 1685—1686)
и работа над рядом технических проектов. Построена и вычислитель-
ная машина (1694), и все же это не было полным успехом, ибо меха-
ника была в то время еще недостаточно развита. Лейбниц занимается
также двоичной системой счисления. В рукописи на латинском языке,
подписанной 15 марта 1679 года, Лейбниц описывает способы вычис-
лений в двоичной системе, а позже разрабатывает в общих чертах про-
ект вычислительной машины, работающей в этой системе. В много-
численных письмах и в трактате «Explication de L’Arithm6tique Binaire»
(1703) Лейбниц вновь возвращается к двоичной арифметике.
Исторически автоматизация умственной деятельности началась с до-
вольно специальных ее видов, таких как цифровые вычисления, про-
17
9
2792
Глава 1. Два подхода к понятию «архитектура»
изводимые над арабскими десятичными цифрами, получившими
широкое распространение в Европе с начала XVI века, и так называе-
мые «вычисления алгоритмических процессов», объектами которых
могут служить, например, понятия, формулируемые при помощи
символов, или логические высказывания и связки. Набросок подоб-
ной программы дал Лейбниц, а при ее полной разработке выяснились
сущность и содержание информатики. Сюда же относятся вопросы
кодирования, особенно двоичного кодирования, а также интересной
смежной области — криптографии. Эта разработка включает в себя
и полную автоматизацию процесс/вычислений (чего у Лейбница еще
нет), находящую выражение в алгоритмическом мышлении и разви-
тую в вопросах синтаксиса и семантики алгоритмических языков.
Как всякая прикладная наука, информатика значительно зависит от
инженерно-технических возможностей соответствующего времени,
и ее развитие происходит параллельно с развитием техники связи, тех-
ники автоматического регулирования и управления (механического,
электрического или электронного), а также техники реализации за-
поминающих устройств, включая устройства считывания и записи.
Корень встречающегося во многих языках слова «калькуляция» (счет,
вычисление, исчисление) происходит от «счетных камешков» римлян,
по-латыни calculi. Римский абак, китайский суан-пан, русские счеты
(последние два приспособления употребляются до сих пор) служили
для вычислений перемещением счетных марок (камешков, косточек,
монет) по направляющим проволочкам. Однако ни этот «счет по ли-
ниям», ни вычисления при помощи счетных палочек, на которых на-
резались насечки-числа (позднелатинское camputare), не знаменуют
собой начала механизации умственной деятельности. Только возник-
шие в Индии и пришедшие в Европу от арабов цифры, которые, бу-
дучи дополнены нулем, позволили записывать числа в позиционной
системе счисления, привели к техническому решению проблемы сче-
та, где место счетных косточек заняли зубчики шестеренок. Речь идет
об изобретенной Шиккардом в 1623 году суммирующей машине с пе-
реносом цифр, причем для умножения можно было пользоваться непе-
ровыми счетными палочками, считывая с их помощью кратные дан-
ного числа.
Проект суммирующей машины Паскаля был реализован к 1645 году.
Наконец в 1671—1674 годах Лейбницу удается построить машину,
18
1.1. Вычисления в компьютерах
выполняющую все четыре арифметических действия, введя пере-
движной челнок-счетчик и применив фиксацию сомножителей при
помощи уступчатого валика. Другое техническое решение, зубчатую
шестерню, нашел в 1709 году Джованни Полени из Падуи. Около
1726 года Антони Браун в Вене, а затем в 1770-х годах, Филипп Матеус
Хан в Эхтердингене создают машины со счетными шестеренками,
концентрически расположенными вокруг уступчатого валика, — пер-
вые устройства, которыми действительно можно было пользоваться.
Эта конструкция возродилась в 1948 году в виде похожей на чётки
машины «Curta» швейцарца Курта Хецштарка. В 1666 году англича-
нин С. Морлэнд, в 1678 году Грийе во Франции, в 1722 году К. Герстен
в Гессене изобретают сумматоры на зубчатых рейках (арифмометры),
применяемые до наших дней. Начиная с 1818 года серийное производ-
ство арифмометров наладил в Париже Шарль Ксавье Тома и к 1878 году
их продано уже около 1500 единиц.
Выполнение умножения автоматизируется в 1896 году Чебышевым
в Париже, а деление автоматизируется в машине «Madas» по принци-
пу, предложенному Александром Рехницером в 1902 году.
Печатающее устройство впервые подключается к механической на-
стольной счетной машине фирмой Burroughs в 1889 году. Однако ав-
томатическое составление печатных матриц предусматривалось еще
в машине «difference engine» Чарлза Бэббиджа, проектирование кото-
рой начато в 1823 году. Она предназначалась для вычисления таблиц
при помощи интерполяции, была доведена в Швеции Г. и Э. Шойца-
ми до возможности практического применения и работала в обсерва-
тории Дадли в Олбэни (США).
1.1. Вычисления в компьютерах
Системы счисления, отличные от десятичной, были довольно при-
вычны. Так, например, машина Паскаля в последних двух позициях
имела шестеренки с 20 и 12 зубцами в соответствии с делением то-
гдашнего ливра на 20 су по 12 денье. Лейбниц в 1679 году описывает
в общих чертах машину, работающую с использованием двоичной
системы счисления.
В 1931 году цифровые шестеренки с восемью позициями патентует
Р. Вальта во Франции. Конрад Цузе в 1933 году решил использовать
19
Глава 1. Два подхода к понятию «архитектура»
двоичную систему счисления как естественное следствие примене-
ния электромагнитных реле, которые могут находиться в двух состоя-
ниях (якорь опущен или поднят).
В 1936 году Л. Куффиньяль и Р. Вальта во Франции, Э. Филлипс
в Англии указывают на преимущества двоичных вычислений для
построения механических вычислительных устройств. Последний
демонстрировал механическую модель для умножения в двоичной
системе счисления и рекомендовал использовать для числовых таб-
лиц восьмеричную систему.
Электронные счетчики, работающие в двоичной системе, исполь-
зовал К. Уинн-Уильямс в 1931 году. Джон фон Нейман вместе
с X. Голдстайном применили двоичную систему в проекте «Прин-
стонской машины», отчет о котором получил широкое распростра-
нение в 1946—1948 годах. Разработка, начатая в 1945 году Вумерсли
и Хартри в Англии, основана на применении «внутри» двоичной
системы, а «снаружи» — восьмеричной. Другие английские разра-
ботки (Уилкс, Бут, Уильямс и Килбэрн) ориентировались на двоич-
ную систему счисления, а в США разработки, начатые X. Айкеном,
Дж. Штибицом, Дж. Эккертом, Дж. Маучли, а также У. Эккертом,
использовали десятичную систему.
Конрад Цузе ввел «полулогарифмическую форму», называемую сего-
дня представлением чисел с плавающей точкой, осознавая, что порядок
числа удобнее представлять его логарифмом. В первом устройстве
К. Цузе Z1 было семь двоичных разрядов для порядка и шестнадцать
двоичных разрядов для мантиссы. Эта идея с запозданием проникла
в США и Англию, если не считать модели Штибица (1947) на элек-
тромагнитных реле. Аппаратная реализация операций над числами
с плавающей точкой снова появляется в шведской разработке BARK,
в советских разработках БЭСМ, «Стрела» и др., а также в мюнхен-
ской PERM и цюрихской ERMETH.
Введение букв для обозначения произвольных математических объ-
ектов — это значительный вклад в развитие математики, который
внесла индийская математика раннего средневековья. Лейбниц не-
сколько десятилетий подряд развивал идею символьного представле-
ния смысла понятий, которое позволило бы проводить вычисления
над ними. В трактате «Об универсальном знании, или философском
исчислении», написанном около 1680 года, он выражает надежду, что
20
1.1. Вычисления в компьютерах
когда-нибудь научные споры можно будет разрешать посредством
вычислений. Лейбниц пытался сопоставлять понятиям числа, При
этом отношение подчинения понятий должно было выражаться от-
ношением делимости чисел. В современной терминологии, Лейбниц
ввел структуру понятий.
Чарлз Бэббидж в проекте своей аналитической машины, содержащей
арифметическое устройство, память, устройство ввода и устройство
печати, предусмотрел управляющие устройства, реализующие управ-
ление в зависимости от текущего результата вычислений. X. Бэббидж
(сын Ч. Бэббиджа) усовершенствовал отдельные части машины так,
что смог вычислить таблицу чисел, кратных л.
Леди Лавлейс, ученица Бэббиджа, убедительно показала, что машину
Бэббиджа нельзя ставить в один ряд с простыми «счетными машина-
ми» — «... она занимает совершенно особое место... среди механиз-
мов, предоставляющих возможность комбинировать произвольные
символы».
Перси Ладгейт (1909) понял значение условных переходов и ввел
трехадресные команды. В табулирующих машинах (1936 год, тип гер-
манского Холлерита) и фактурных машинах, а также в связанной со
счетной машиной пишущей машинке Торреса-и-Квебедо (1910) мож-
но найти первые попытки программирования.
К. Цузе к 1941 году удалось построить первую действующую вычисли-
тельную машину с программным управлением (модель Z3). В 1942 году
в лаборатории Bell Telephon была сдана в эксплуатацию вычислитель-
ная машина на электромагнитных реле, которую разработал Джордж
Штибиц. В 1944 году правительство США приняло в эксплуатацию
вычислительную машину Mark I, созданную X. Айкеном. Первая вы-
числительная машина на электронных лампах ENIAC Дж. Эккерта
и Дж. Маучли, проектирование которой велось с 1943 года, начала
функционировать в 1946 году. Эти устройства не достигли той уни-
версальности, которой обладал проект К. Цузе.
Основополагающая идея вычислительной машины, управляемой раз-
мещенной в ее памяти программой, впервые описана Джоном фон
Нейманом и его сотрудниками Дж. Маучли и Дж. Эккертом 30 июня
1945 года. Она была развита Морисом Уилксом, который в мае 1949 года
сдал в эксплуатацию первую вычислительную машину EDSAC.
21
Глава 1. Два подхода к понятию «архитектура»
В 1944 году Маучли, Эккерт и Голдстайн ввели принцип последова-
тельных вычислений, применив одноразрядный сумматор для после-
довательного суммирования «-разрядных чисел.
В 1948 году С.А. Лебедев (СССР) независимо от Дж. фон Неймана
обосновал принцип построения ЭВМ с хранимой в памяти про-
граммой.
Первая в СССР цифровая вычислительная машина (ЦВМ) МЭСМ
создана в 1951 году под руководством С.А. Лебедева. В 1952 году
появилась ЭВМ М-1 (руководители И.С. Брук, Н.Я. Матюхин),
а в 1953 году — ЭВМ «Стрела» (создатели Ю.Я. Базилевский, Б. И. Ра-
меев). В 1955 году в СССР организован первый ВЦ АН СССР (ди-
ректор А.А. Дородницин).
В 1958 году в СССР создана первая и единственная в мире ЭВМ «Се-
тунь» (Н.П. Брусенцов), работающая в троичной системе счисления
с симметричным представлением цифр, а также первая ЭВМ, приме-
няющая систему в коде вычетов (И.Я. Акушский, Д.И. Юдицкий).
Чтобы понять принцип действия ЦВМ, рассмотрим процесс вычис-
лений, пользуясь обычным арифмометром.
Вначале на листе бумаги выпишем исходные данные, формулы рас-
чета и приготовим таблицу для занесения промежуточных и конеч-
ных результатов. В процессе вычислений с листа бумаги переносим
на регистры арифмометра числа, участвующие в очередной опера-
ции, выполняем на арифмометре нужную операцию в соответствии
с расчетной формулой, и полученный результат переписываем с ре-
гистра арифмометра в таблицу на листе бумаги.
В этом процессе арифмометр выполняет арифметические операции
над числами, которые человек в нее вводит. Лист бумаги служит за-
поминающим устройством, хранящим программу вычислений (рас-
четные формулы), исходные данные, промежуточные и конечные
результаты. Человек осуществляет управление процессом вычисле-
ний, переносом информации с листа бумаги в счетную машину и об-
ратно, заставляет машину (арифмометр) выполнять необходимую
операцию и выбирает нужный вариант продолжения процесса вы-
числений в зависимости от результата, полученного на очередном
этапе счета.
Если эту механическую машину заменить электронным арифмети-
ческим устройством, существенно ускорится процесс выполнения
22
1.1. Вычисления в компьютерах
арифметических операций. Однако принципиальный эффект будет
достигнут, если к электронному быстродействующему арифметиче-
скому устройству добавить быстродействующую память, которая, как
лист бумаги при расчете, хранит программу вычислений, исходные
данные, промежуточные и конечные результаты, а также быстродей-
ствующее управляющее устройство, производящее необходимый для
реализации программы вычислений обмен числами между памятью
и арифметическим устройством и инициирующее последнее на вы-
полнение необходимой операции.
Если комплекс такой аппаратуры дополнить средствами связи с внеш-
ним миром, то есть устройствами ввода в память данных и программы
вычислений, а также устройствами вывода результатов вычислений, то
придем к классической блок-схеме ЦВМ, изображенной на рис. 1.1.
Рис. 1.1. Блок-схема цифровой вычислительной машины
ЦВМ содержит следующие основные устройства: арифметическое уст-
ройство (АУ), память (запоминающее устройство — ЗУ), устройство
управления (УУ), устройство ввода данных в машину (Вв) и вывода
из нее результатов расчета (Выв) и пульт ручного управления (ПУ)
(клавиатуру).
Арифметическое устройство производит арифметические и логические
операции над поступающими в него данными.
23
Глава 1. Два подхода к понятию «архитектура»
Память (запоминающее устройство) хранит информацию, передавае-
мую в него из других устройств, в том числе поступающую в машину
извне через устройство ввода, и выдает во все другие устройства ин-
формацию, необходимую для продолжения вычислительного процесса.
Память машины, как правило, состоит из двух частей: быстродействую-
щего оперативного запоминающего устройства (ОЗУ) и сравнительно
медленнодействующего, но способного хранить значительный объем
информации внешнего запоминающего устройства (ВЗУ).
ОЗУ состоит из ячеек, каждая из которых служит для хранения ма-
шинного слова, то есть кода определенной длины, представляющего
число или другой тип информации. Номера ячеек называются их ад-
ресами.
Запоминающие устройства используются для считывания хранимой
в них информации с целью передачи в другие устройства и записи ин-
формации, поступающей из других устройств. При считывании слова
из ячейки содержимое последней не меняется и при необходимости
слово может быть снова выбрано из той же ячейки. При записи хра-
нившееся в ячейке слово стирается и его место занимает новое слово.
Объем запоминающего устройства определяется количеством храни-
мых слов, а его быстродействие — временем обращения, то есть про-
должительностью операции записи или считывания нужного слова.
Для сокращения потерь времени при вычислениях быстродействие
ОЗУ должно соответствовать скорости работы электронного АУ.
Многие задачи требуют памяти большого объема для хранения необ-
ходимой информации, однако технически трудно и дорого строить
быстродействующее ЗУ большой емкости. В связи с этим ЦВМ, кроме
ОЗУ, содержит внешнее запоминающее устройство, способное хра-
нить большой объем информации.
ЦВМ выполняет вычисления только надданными, хранящимися в опе-
ративном запоминающем устройстве, и лишь после окончания от-
дельных этапов вычислений из ВЗУ в ОЗУ передается информация,
необходимая для последующих этапов решения задачи.
Если быстродействие ОЗУ оказывается недостаточным для получе-
ния нужной скорости работы машины, между АУ и ОЗУ размещают
сверхоперативное запоминающее устройство (СОЗУ) на несколько де-
сятков или сотен слов (рис. 1.1). Ячейки СОЗУ хранят главным обра-
24
1.2. Архитектура как набор взаимодействующих компонент
зом промежуточные результаты и другую информацию, многократно
используемую на текущем этапе вычислений.
Устройство управления автоматически управляет вычислительным про-
цессом, посылая всем другим устройствам сигналы, предписываю-
щие им те или иные действия. В частности, оно указывает ОЗУ, какие
слова должны быть переданы в АУ и в другие устройства, инициирует
АУ на выполнение нужной операции и помещает полученный ре-
зультат в ОЗУ, базируясь на принципе программного управления.
Как уже отмечалось, идея программного управления ЦВМ была су-
щественно развита американским математиком Джоном фон Нейма-
ном, который в 1945 году сформулировал принцип хранимой в памяти
программы.
Правда, некоторые исследователи считают, что данный принцип
принадлежит создателям компьютера ENIAC — инженерам Моучли
и Эккерту. Согласно этому принципу, программа, закодированная
в цифровом виде, хранится в памяти ЦВМ наравне с числами. В ко-
мандах указываются не сами участвующие в операциях числа, а адреса
ячеек ОЗУ, в которых они находятся, и адреса ячеек, куда помещают-
ся результаты операции. Поскольку программа хранится в памяти,
одни и те же команды могут нужное количество раз извлекаться из
памяти и выполняться, а так как команды представляются в машине
в форме чисел, то над командами, как над числами, машина может
производить операции.
При помощи пульта управления (клавиатуры) оператор запускает и ос-
танавливает машину, а при необходимости может вмешиваться в про-
цесс решения задачи.
1.2. Архитектура как набор взаимодействующих компонент
Серийно выпускаемые, надежные и дешевые, сверхбольшие инте-
гральные схемы (СБИС), массовое производство микропроцессоров,
возобновившийся интерес к разработке языков программирования
и программного обеспечения порождают возможность при проекти-
ровании компьютеров качественно продвинуться вперед за счет
улучшения программно-аппаратного интерфейса, то есть семантиче-
ской связи между возможностями аппаратных средств современных
25
Глава 1. Два подхода к понятию «архитектура»
компьютеров и их программного обеспечения. Организация вычис-
лительной системы на этом уровне лежит в основе понятия «архитек-
тура». Для неспециалистов в области программного обеспечения термин
«архитектура» ассоциируется, как правило, со строительными объек-
тами. И здесь, действительно, как увидим далее, есть много общего.
В самом деле, архитектура компьютера, характеризующая его логи-
ческую организацию, может быть представлена как множество взаи-
мосвязанных компонент, включающих, на первый взгляд, элементы
различной природы: программное обеспечение (software), аппаратное
обеспечение (hardware), алгоритмическое обеспечение (brainware), спе-
циальное фирменное обеспечение (firmware) — и поддерживающих его
слаженное функционирование в форме единого архитектурного ансамб-
ля, позволяющего вести эффективную обработку различных объектов
и своих данных.
С другой стороны, архитектура может быть определена как абстракт-
ное многоуровневое представление физической системы с точки зрения
программиста, с закреплением функций за каждым уровнем и установле-
нием интерфейса между различными уровнями.
В зависимости от типов данных и операций, поддерживаемых hardware,
можно рассматривать архитектуру системы на различных уровнях.
Первые компьютеры поддерживали только один тип данных — целые
числа со знаком, что требовало от программиста колоссальных уси-
лий по организации вычислений, например масштабирование чисел.
С появлением языка FORTRAN, определившим два типа данных — real
и integer, возникла необходимость аппаратной реализации этих типов
данных. Сегодняшние компьютеры аппаратно поддерживают разно-
образные типы данных — от битовых последовательностей до ато-
марных объектов машинной графики (пикселов), контролируя при
этом допустимость выполнения тех или иных операций над данными
определенного типа.
Знание особенностей разнообразных архитектурных решений дает
пользователям компьютеров возможность эффективно распоряжать-
ся всеми предоставляемыми ресурсами, осуществляя их направлен-
ный выбор и тем самым повышая эффективность обработки данных.
Ранее область применения вычислительных систем (ВС) определя-
лась их быстродействием. Однако существует достаточно большое
количество ВС, обладающих равным быстродействием, но имеющих
26
1.2. Архитектура как набор взаимодействующих компонент
различные способы представления данных, методы организации па-
мяти, режимы работы, системы команд, наборы внешних устройств
и т.д. Таким образом, ВС имеет, кроме быстродействия, ряд других
характеристик, существенно важных в той или иной области приме-
нения. Это стало особенно заметно при переходе к ВС четвертого
и пятого поколений. Совокупность таких характеристик и легла в ос-
нову понятия архитектуры ВС.
Архитектура ВС определяет основные функциональные возможности си-
стемы, сферу применения (научно-техническая, экономическая, управ-
ление и т.д.), режим работы (пакетный, мультипрограммный, разделения
времени, диалоговый и т.д.), характеризует параметры ВС (быстродей-
ствие, набор и объем памяти, набор периферийных устройств и т.д.),
особенности структуры (одно-, многопроцессорная) и т.д. Понятие
«архитектура» можно представить следующей схемой (рис. 1.2).
Рис. 1.2. Архитектура ВС
Вычислительные и логические возможности ВС. Они обусловливаются
системой команд (СК), характеризующей гибкость программирования,
форматами данных и скоростью выполнения операций определяющих
класс задач, наиболее эффективно решаемых на ВС. Система команд
27
Глава 1. Два подхода к понятию «архитектура;
ВС, базирующихся на архитектуре фон Неймана, сегодня мало чем
отличается от СК ЭВМ 50-х годов прошлого века. Большинство дос-
тижений в этой области остались незамеченными проектировщиками
и, соответственно, не нашли адекватного воплощения в архитектуре
современных компьютеров.
Анализ показывает, что в различных программах чаще всего встреча-
ются достаточно простые команды: команды пересылки и команды
процессора с использованием регистров и простых режимов адреса-
ции. Не нашли широкого применения и нетрадиционные способы
кодирования данных, несмотря на их значительные возможности при
разработке быстродействующих алгоритмов арифметических опера-
ций и повышении надежности вычислений (например, знакоразрядные
системы, системы в коде вычетов и др.).
Рассмотрим структуру системы команд в зависимости от класса ре-
шаемых задач (рис. 1.3).
1. Операции над числами
с фиксированной точкой
2. Операции над числами
с плавающей точкой
Экономи-
ческие Z
задачи '
Задачи >
управления'
3. Операции управления
Научно-
технические
задачи
Универсальный
набор команд
4. Операции десятичной
арифметики
Рис. 1.3. Классификация СК по назначению
К операциям управления отнесем команды ввода-вывода данных
и команды управления состоянием процессора, памяти и каналов.
Как видно из рис. 1.3, для решения задач любого класса необходимы
команды типов 2 и 3. Следовательно, эти типы команд должны при-
сутствовать в любом компьютере.
Большое влияние на точность выполнения операций оказывают фор-
маты данных. Современные компьютеры имеют развитую систему
форматов. Например, компьютеры ЕС ЭВМ и IBM имеют форматы
в 2, 4, 8 и 16 байт.
28
1.2. Архитектура как набор взаимодействующих компонент
Алгоритмы выполнения операций достаточно полно отражают про-
изводительность только однопроцессорных ВС.
Аппаратные средства. Простейшая ВС включает модули пяти типов:
центральный процессор, основная память, каналы, контроллеры
и внешние устройства.
Процессор (устройство управления (УУ) + арифметико-логическое
устройство (АЛУ) + память) управляет работой системы и обеспечи-
вает вычисления непосредственно по заданной программе. Инициа-
лизация и выполнение машинных команд, команд ввода-вывода
(I/O — Input/Output), обращение к памяти, управление состоянием
устройств производятся с помощью процессора.
Основная память предназначена для хранения команд и данных и обес-
печивает адресный доступ к ним от процессора. Современная память
работает со скоростью, близкой к скорости работы процессора.
Каналы — специальные устройства, управляющие обменом данных
с внешними устройствами. Каналы инициируют свою работу с помо-
щью процессора и затем переходят в автономный режим работы. Это,
по сути, специальный процессор (спецпроцессор) ввода-вывода, обес-
печивающий работу внешних устройств, контроль информации и т.д.
Контроллеры ввода-вывода служат для подсоединения внешних уст-
ройств (ВнУ) к каналам и обеспечивают обмен управляющей информа-
цией с внешними устройствами, присвоение приоритетов и выдачу
информации о состоянии ВнУ для канала, то есть это устройства
управления ВнУ.
ВнУ предназначены для ввода-вывода инфор-
мации с различных носителей.
Память может быть организована как много-
уровневая с различным объемом, стоимостью
хранения данных в расчете на 1 бит и временем
доступа к ней: внутренние регистры процессора
(ВнР), сверхоперативная (СОЗУ), оперативная
(ОП), внешняя (ВнП) (рис. 1.4), так и одно-
уровневая, виртуальная. Почти всегда вирту-
альная память есть переупорядоченное подмно-
жество реальной памяти.
29
Глава 1. Два подхода к понятию «архитектура»
Более высокий уровень памяти быстрее, меньше по объему в пере-
счете на бит, чем более низкий ее уровень. Кэш-память является
компромиссом между стоимостью памяти и ее объемом за счет дина-
мического копирования в быстродействующее ЗУ наиболее часто
используемой информации из медленного ЗУ.
Уровни иерархии памяти взаимосвязаны между собой: все данные
одного уровня могут быть найдены на более низком уровне.
Найденные или ненайденные на соответствующем уровне данные, то
есть успешное или неуспешное обращение к уровню памяти, называ-
ют соответственно попаданием (hit) или промахом (miss), а соответст-
вующее время — временем обращения (hit time или miss penalty).
Существенное влияние на производительность ВС оказывают каналы
ввода-вывода. Мультиплексный канал обеспечивает работу группы
медленных устройств, блок-мультиплексный — группы быстрых уст-
ройств, селекторный — занимает информационную магистраль толь-
ко одним быстродействующим устройством.
Для повышения пропускной способности каналов используют неко-
торые дополнительные меры, например буферизацию ВнУ путем
введения памяти в состав самого устройства или контроллера.
Аппаратные средства защиты памяти служат для управления доступом
к различным областям памяти, в соответствии с имеющимися у поль-
зователя полномочиями.
Программное обеспечение является составной частью архитектуры
компьютера и существенно влияет на весь вычислительный процесс,
в частности позволяет эффективно эксплуатировать аппаратные
средства системы.
Операционная система (ОС) управляет ресурсами, разрешает кон-
фликтные ситуации, оптимизирует функционирование системы в це-
лом, поддерживает дружественный интерфейс с пользователем.
Широкий спектр языков программирования позволяет описывать прак-
тически любые задачи, а разнообразие компиляторов — эффективно
их реализовывать.
Продуманный выбор языка программирования и ОС существенно
влияет на время решения задачи. Так, например, программа на языке
Pascal работает примерно в четыре раза медленнее, чем программа
30
1.3. Архитектура как интерфейс между уровнями физической системы
для той же задачи на языке C++ под управлением Windows. В ОС Linux
эта же программа на языке C++ будет выполняться еще быстрее, так
как язык С является внутренним языком данной ОС и все ее функ-
ции оптимизированы для данного языка.
Кроме широко распространенной в Беларуси ОС Windows в последнее
время начинают использовать различные разновидности ОС UNIX.
Среди них:
► AIX — версия IBM, запускаемая на RISC-системах серии RS/6000
и на мэйнфреймах;
► HP — UNIX-версия Hewlett-Packard;
► Solaris — версия Sun Microsystems;
► SVR4 — хорошо распространяется на компьютерном рынке. Мно-
гие разновидности ее происходят от System V Release 4;
► LINUX — бесплатная и хорошо функционирующая разновидность
UNIX;
► Sun OS — хорошая версия, однако в значительной степени вытес-
няется ОС Solaris.
Роль программного обеспечения (ПО) особенно значительна при ре-
шении прикладных задач. Важными являются методы и технологии
проектирования программ, позволяющие сокращать время реализа-
ции задачи от ее постановки до решения.
1.3. Архитектура как интерфейс между уровнями
физической системы
Применительно к ВС термин «архитектура» может быть определен
как распределение по различным уровням функций, выполняемых сис-
темой, и установление интерфейса между этими уровнями. На рис. 1.5
представлен набор уровней абстракции как специфического свойст-
ва архитектуры ВС. Остановимся лишь на ключевых уровнях.
Архитектура первого уровня определяет набор функций по обработке
данных, решаемых системой, а также функций, выполняемых вовне
системы — пользователем, оператором ЭВМ, администратором баз
данных и т.д. Система взаимодействует с внешним миром через два
31
Глава 1. Два подхода к понятию «архитектура.
Прикладные программы
пользователей
-(г)-------------------
5
«Языковые» процессоры
---------®—
Управление
ресурсами
на логическом
уровне
------©--------
-------------(£)—
Управление ресурсами
на физическом уровне
и----@—
Дч Выполнение
программы
-----®-------1-------1-----
Процессоры (б) ввода-вывода
-----------------а"
Контроллеры (б)
--------®---------L-
Каналы связи и внешние
устройства
Контроллеры (б)
------(Й)-----L-
Память
х
Я
Аппаратные
средства
Рис. 1.5. Многоуровневая организация архитектуры ВС
набора интерфейсов: языки (язык программирования, язык оператора
терминала, язык управления заданиями, язык общения с базой данных,
язык оператора ЭВМ) и системные программы (программы редактиро-
вания, связи, оптимизации, восстановления и обновления информа-
ции, интерпретации, управления и т.д., то есть программы, созданные
разработчиком системы). Оба интерфейса создаются в процессе раз-
работки архитектуры системы.
Уровни, определяемые интерфейсами внутри программного обеспе-
чения, могут быть представлены как архитектура программного обес-
печения. К примеру, если прикладные задачи реализованы на языках
программирования, отсутствующих в наборе языков, предоставляе-
мых системой пользователю, то здесь речь может идти об архитектуре
уровня, позволяющего определить указанные языки.
Уровень 5 является одним из центральных уровней архитектуры
и проводит разграничение между системным программным и аппа-
ратным (то есть схемным и микропрограммным) обеспечением. Он
позволяет представить физическую структуру системы независимо от
способа реализации.
32
1.3. Архитектура как интерфейс между уровнями физической системы
Остальные уровни отражают интерфейсы и распределяют функции
между отдельными частями физической системы.
Таким образом, можно сказать, что архитектура компьютера — это
абстрактное представление физической системы с точки зрения про-
граммиста.
Процесс проектирования архитектуры ВС включает все этапы созда-
ния типовых проектов:
► анализ требований, предъявляемых к системе;
► составление спецификаций;
► изучение известных решений;
► разработка функциональной схемы;
► разработка структурной схемы;
► отладка проекта;
► оценка проекта;
► апробация (опытная эксплуатация), включая и сопровождение;
► серийное производство на базе созданной архитектуры.
При анализе требований, например, учитывается спектр необходимых
языков программирования, способ взаимодействия с окружающей
средой, требования к операционной системе, некоторые технико-эко-
номические факторы — предполагаемое количество таких систем (ибо
это существенно влияет на соотношение между аппаратным и про-
граммным обеспечением), совместимость разрабатываемой системы
(по языкам программирования, операционным системам, форматам
данных, техническим устройствам) с существующими аналогичными
вычислительными системами и т.д.
При анализе требований и составлении перечня спецификаций пара-
метров системы необходимо разработать критерии (с их весовыми
коэффициентами), определяющие стоимость, надежность, защиту от
несанкционированного доступа, совместимость и т.д., и описать функ-
ции системы в соответствии с этими критериями. В спецификациях
учитывается и существующий или достижимый технологический
уровень для производства системы. Естественно, что возникающие
противоречивые требования должны быть разрешены в соответствии
с приоритетами или на другой основе.
33
О
2792
Глава 1. Два подхода к понятию «архитектура»
На этапе разработки функциональной схемы в первую очередь решает-
ся вопрос о разграничении функций между аппаратурой и программ-
ным обеспечением, а также между другими уровнями архитектуры.
Здесь же определяются необходимость работы с плавающей или фик-
сированной точкой, приоритетные прерывания, стековая организа-
ция памяти и т.д.
При структурной организации все вопросы детализируются и углуб-
ляются. В частности, здесь решаются проблемы типов и форматов
команд, способов представления данных, способов адресации, се-
мантики языка.
По завершении проекта осуществляется его отладка, согласование
взаимодействия отдельных уровней и оптимизация, например, по
количеству бит, пересылаемых между процессором и памятью при
выполнении данной программы, отыскание эффективного метода
кодирования команд и числовой информации и т.д.
При оценке проекта учет только быстродействия (которое иногда по-
нимается как производительность) недостаточен. Здесь необходимо
учитывать также время, требуемое на разработку программы. Исполь-
зуя известные статистические сведения о том, что преобладающее
количество разработанных программ выполняется только один раз,
простота программирования при оценке архитектуры может оказать-
ся важнее скорости выполнения команд.
Однако скорость выполнения операций — достаточно важный пара-
метр. Быстродействие, естественно, зависит как от технологической
элементной базы, влияющей на скорость обработки данных, так и от
архитектуры машины, которая определяет объем выполняемых ра-
бот. Часто архитектуры сравниваются по критерию эффективности
обработки информации. Для этого, как правило, анализируются сле-
дующие параметры:
S — размер программы, определяемый длиной команд, размером
косвенных адресов, объемом рабочих областей для временного раз-
мещения данных;
JV? — количество бит, передаваемых между процессором и памятью
машины (пересылка между регистрами) за время выполнения про-
граммы, характеризующее интерфейс, то есть «полосу пропускания»
34
1.3. Архитектура как интерфейс между уровнями физической системы
между процессором и памятью, что в значительной степени опреде-
ляет предел эффективности выполнения программ. Ясно, что параметр
должен учитывать и локальность ссылок, то есть близость располо-
жения в памяти используемых данных;
NR — количество бит, передаваемых между внутренними регистрами
процессора за время выполнения программы. Здесь учитываются те
пересылки, которые не охватывает параметр Np. Величина NR в зна-
чительной степени определяется набором функций, воплощенных
в АЛУ и в схемной реализации процессора.
Иногда архитектуры сравнивают лишь по параметрам S и Np, исклю-
чая параметр NR, тем самым игнорируя внутреннюю организацию
процессора.
Опытная эксплуатация позволяет сопровождать различные компо-
ненты архитектуры, выявлять неточности, модифицировать, совер-
шенствовать и уточнять отдельные аспекты.
Серийное производство позволяет создавать стереотип мь шления
определенной группы разработчиков и пользователей в области соз-
дания архитектур компьютеров.
Иногда в перечень последовательности проектирования включают
и этап вывода проекта из эксплуатации, состоящий в полной его за-
мене новой или модернизированной версией.
Во многом качество реализации проекта зависит от подбора команды
разработчиков. Например, кодекс разработчиков программных проек-
тов был создан объединенной специальной комиссией IEEE Computer
Society/ASM, входящей в организацию по обеспечению этики про-
граммирования и профессиональной практики (Software Engineering
Ethics and Professional Practices — SEEPP). Этот документ включает
следующие принципы:
► общественные интересы — действия программистов должны соот-
ветствовать общественным интересам;
► клиент — программисты должны максимально учитывать требова-
ния работодателя, но при этом соблюдать общественные интересы;
► продукт — программисты должны быть уверены в том, что разра-
батываемые ими проекты (и их модификации) соответствуют самым
высоким профессиональным стандартам;
35
Глава 1. Два подхода к понятию «архитектура»
► критицизм — программисты должны придерживаться целостности
и независимости своих суждений, формируя здоровый профессио-
нальный критицизм мышления;
► менеджмент — менеджеры, управляющие группами разработчи-
ков, обязаны придерживаться этических норм в процессе разработки
и сопровождения продукта;
► профессионализм — программисты обязаны быть честными и под-
держивать репутацию профессионалов, не забывая о соблюдении об-
щественных интересов;
► коллегиальность — программисты должны поддерживать своих кол-
лег, помогать им в их профессиональной деятельности, в частности
в освоении современных методик работы; рассматривать работу дру-
гих членов коллектива объективно, не препятствовать карьерному
росту коллег;
► самосовершенствование — постоянно повышать свою квалифика-
цию на всех этапах разработки, способствуя тем самым созданию на-
дежного, безопасного и полезного ПО за разумное время, подготовке
документации в хорошем стиле; изучать соответствующие стандарты
и правовые нормы; помнить, что ошибки в программном коде несо-
вместимы со званием программиста-профессионала.
Перечисленные требования к разработчикам ПО можно перенести
и на разработчиков других проектов, в частности на проектировщи-
ков новых архитектур.
1.4. Семантический разрыв
Все характерные особенности архитектуры большинства сегодняш-
них компьютеров появились уже к 1960 году. Среди них — индекс-
ные регистры, регистры общего назначения, данные в форме с пла-
вающей точкой, косвенная адресация, программные прерывания,
асинхронный ввод-вывод, виртуальная память, мультипроцессорная
обработка.
Сегодняшние компьютеры отличаются от прежних в основном лишь
стоимостью, надежностью, быстродействием и элементной базой. Кон-
цептуальные возможности не претерпели существенных изменений.
36
1.4. Семантический разрыв
При анализе особенностей архитектурных решений возникают сле-
дующие вопросы:
► оптимальны ли на все времена архитектурные решения, предло-
женные в 50—60-х годах прошлого века?
► достаточные ли изменения претерпела технологическая база (ап-
паратная и теоретико-концептуальная), чтобы считать оправданны-
ми изменения архитектуры компьютеров?
Рассмотрим архитектурные решения, базирующиеся на концепции
фон Неймана, и в первую очередь различия принципов, положенных
в основу современных языков программирования (ЯП) высокого уровня,
и принципов, определяющих архитектуру ЭВМ.
Различие этих принципов известно как семантический разрыв. Как
правило, современные компьютеры имеют нежелательно большой
семантический разрыв между объектами и операциями, описывае-
мыми в ЯП, и объектами манипулирования и соответствующими опе-
рациями, реализуемыми архитектурой ВС. Обобщая, можно говорить
о семантическом разрыве между архитектурой машины и средой исполь-
зования.
Как следствие такого семантического разрыва возникает ряд других
проблем: высокая стоимость разработки ПО, его ненадежность, боль-
шой объем программ, сложность компиляторов и ОС, наличие отсту-
плений от правил построения ЯП.
Для уяснения семантического разрыва можно проанализировать взаи-
мосвязи между ЯП (например, Pascal, C++, Java, PL/1) и архитекту-
рой компьютера (например, архитектурными решениями наиболее
распространенных в Беларуси компьютеров фирмы IBM) и оценить
«расстояние» между принципами, положенными в основу ЯП, и со-
ответствующими принципами, положенными в основу архитектуры
компьютера.
Попробуем в качестве примера сравнить несколько основополагаю-
щих принципов языка PL/1, широко используемых в ВС, с идеологи-
ей mainframe и определить их адекватность принципам, заложенным
в IBM 370.
Массивы. Это наиболее часто используемый тип организации дан-
ных. PL/1 позволяет использовать многомерные массивы, обращение
к отдельным элементам массива посредством индексов, операции
37
Глава 1. Два подхода к понятию «архитектура»
над целыми массивами, обращение к отдельным подмассивам внутри
массива, соединение массивов, защиту от выхода за пределы соответ-
ствующего массива.
Исследование архитектуры IBM 370 показывает, что в ней нет средств,
адекватных описываемым принципам работы с массивами, за ис-
ключением разве что примитивного подобия одного из принципов
языка — использование индексных регистров. Следовательно, реали-
зация принципа организации данных в виде массива возлагается на
компилятор, в распоряжении которого имеется лишь набор команд
IBM 370, весьма далекий по своим возможностям от задач, возни-
кающих при работе с массивами.
Структуры. Это второй из часто используемых типов организации
данных в виде наборов разнородных элементов данных (в некоторых
ЯП называемых записями). И здесь в системе IBM 370 отсутствуют
средства, адекватные структурам и операциям над ними.
Строки. В PL/1 используются строковые данные (или просто строка).
Допустимые операции — слияние, выделение заданной части (под-
строки), поиск строки по заданной подстроке, определение длины
текущей строки, проверка присутствия одной строки в другой строке.
Подобные возможности в системе команд IBM 370 не предусмотрены.
Более того, задача манипулирования строками бит (возможность, пре-
доставляемая PL/1) осложняется еще и тем, что в IBM 370 допускается
адресация к группам из 8 бит, то есть к байтам. И опять-таки все это
требуется реализовывать через компилятор, что существенно услож-
няет его работу.
Процедуры. При вызове процедуры требуется сохранить состояние теку-
щей процедуры, динамически назначить память для локальных пере-
менных вызванной процедуры, передать параметры и инициализи-
ровать выполнение вызванной процедуры. Что же для реализации
этого имеется в архитектуре IBM 370? Только команда BALR (переход
с возвратом). Но вклад этой команды в реализацию операций вызова
процедуры настолько мал, что ее отсутствие осталось бы незамечен-
ным. Компилятор вполне мог бы заменить ее двумя командами: LA
(загрузка адреса) и BR (переход безусловный).
Ясно, что эти трудности по несоответствию принципов ЯП и архи-
тектуры должны реализовываться за счет сложного компилятора.
38
1.4. Семантический разрыв
Важно также сравнить имеющийся семантический разрыв с частотой
использования соответствующих операций, предоставляемых ЯП.
Из литературы известно, что 45 % всех арифметических операторов
имеют дело с массивом или элементом массива, 16 % всех выпол-
няемых операторов языка высокого уровня — это обращение к под-
программам-процедурам, подпрограммам-функциям и операторы
возврата. Компилятор с ЯП Fortran, например, тратит до 15 % време-
ни своей работы на установление связей между подпрограммами.
Другие исследования показывают, что 19 % всех операторов програм-
мы составляют операторы CALL, RETURN, PROCEDURE.
Подобным образом можно проанализировать семантический разрыв
между архитектурой компьютера и операционной системой. В част-
ности, понятие процесса как принципа обработки в системах парал-
лельного действия никак не отражается в архитектуре компьютера,
а все вопросы, связанные с синхронизацией процессов, решаемые
через семафоры, критические секции, мониторы и передачи сообще-
ний, не нашли своего воплощения в интерфейсе ЭВМ.
Значительный разрыв существует между архитектурой ЭВМ и прин-
ципами построения программного обеспечения. Известно, напри-
мер, что около 50 % всех ресурсов тратится на тестирование и отладку
программ, однако архитектура ЭВМ дает ничтожные средства для
этого, хотя для обеспечения надежности аппаратных средств созда-
ются весьма существенные разработки.
Семантический разрыв между архитектурой и организацией памяти
программисту заметить труднее. Однако такой вопрос, как разный
тип адресации в зависимости от места хранения данных, проанали-
зировать достаточно просто. Действительно, оперативная память
адресуется линейным смещением, добавляемым к адресу, хранимому
в специальном регистре, а для данных на магнитном диске использу-
ются номер диска, цилиндра, дорожки и линейное смещение в преде-
лах записи. То же имеем и при выполнении операции. Так, операция
умножения может быть выполнена непосредственно, если оба опе-
ранда находятся в ОП, если же они находятся на магнитном диске, то
необходимо предварительно загрузить их в оперативную память. А по-
скольку эти принципы не заложены в архитектуре, имеющийся разрыв
программистам при создании ЯП приходится обходить за счет моде-
лирования организации памяти. Виртуальная память создает лишь
иллюзию решения проблемы.
39
Глава 1. Два подхода к понятию «архитектура»
Изложенные и другие проблемы семантического разрыва, не раз-
решенные в архитектуре компьютера, ухудшают надежность про-
граммного обеспечения, увеличивают непроизводительные затраты
и перекладывают их разрешение на компилятор, а последний, как
правило, на плечи прикладного программиста из-за отсутствия удач-
ных и оптимальных решений компиляции. Это, например, происхо-
дит при обращении к переменной, значение которой не определено,
или к элементу массива, один из индексов которого выходит за соот-
ветствующие пределы.
Семантический разрыв требует для своего разрешения через компи-
лятор значительных затрат машинного времени и памяти.
Так, компилятор языка PL/1 фирмы IBM генерирует 17 машинных
команд для реализации оператора сложения двумерных массивов:
C(I,J) = A(I,J)+B(I,J),
где А, В и С — массивы двоичных элементов одинакового размера
в форме с фиксированной точкой.
Если подсоединяется средство контроля данной операции, то ком-
пилятор генерирует уже 75 машинных команд, а время выполнения
оператора вырастает в три раза. При реализации на более быстродей-
ствующей машине соответствующего аппаратного контроля можно
избежать затрат дополнительной памяти и времени.
Здесь впору упомянуть об экономии памяти для хранения сгенериро-
ванных компилятором команд (объектного кода), а также обсудить
объем пересылок между памятью и процессором. И хотя бытует мне-
ние, что проблема «памяти» скоро исчезнет, тем не менее проблема
эта существует. Во-первых, из-за дороговизны памяти (стоимость ос-
новной памяти микропроцессорной системы значительно превосхо-
дит стоимость процессора), а во-вторых, потребность в памяти растет
пропорционально снижению ее стоимости.
Все изложенное с очевидностью показывает семантический разрыв
между архитектурой компьютера и принципами, определяющими
построение компиляторов. Таким образом, для уменьшения сущест-
вующего семантического разрыва требуется разработка сложного
компилятора.
40
1.4. Семантический разрыв
Существующий разрыв, естественно, можно уменьшить или полно-
стью устранить усложнением архитектуры компьютера. Ясно, что при
наличии нескольких компиляторов, содержащих средства вызова
процедур, описания массивов и т.д. (а это почти всегда так), выгоднее
ликвидировать этот разрыв один раз за счет соответствующей моди-
фикации архитектуры машины, даже если других преимуществ и не
будет.
Семантический разрыв порождает и некорректное использование
языка программирования. Так, если в PL/1 описать переменную В
как DCL В DECIMAL FIXED(2), то есть двухразрядной десятичной
переменной с фиксированной точкой, а при использовании операто-
ра присваивания указать В = 200, то естественно было бы появление
сообщения об ошибке. Но такового не возникает. И при выводе на
печать значения В также получим 200. Все дело в том, что система
IBM 370 может представлять десятичные числа, имеющие только
нечетное количество цифр. Чтобы при полном устранении семан-
тического разрыва не прийти к генерированию неэффективных объ-
ектных кодов, компилятор преобразует двухразрядные десятичные
переменные в трехразрядные операнды машины. Если бы соответст-
вующие правила языка PL/1 были изменены, то язык стал бы машин-
но-зависимым, с ориентацией только на IBM 370.
Тот же вариант некорректности может возникнуть при работе с деся-
тичными и двоичными числами, использование которых допускает
язык PL/1. Программисты иногда применяют двоичные числа вместо
десятичных, ибо первые занимают меньше памяти, не требуют преоб-
разования данных, а операции над ними выполняются быстрее, чем
над десятичными. Следовательно, архитектура используемого ком-
пьютера приводит к некорректному применению языка программи-
рования.
Подобные казусы можно найти и в других ЯП. Например, в языке
Fortran условный оператор IF имеет три точки перехода: = 0, > 0, < 0.
Но это не широкие возможности языка, а зависимость его от архи-
тектуры IBM 704, где встроенная операция сравнения в зависимости
от результата своего выполнения передает управление одной из трех
последующих команд.
В языке Ada для повышения надежности программирования тоже
введен ряд компромиссов и ограничений при использовании совре-
41
Глава 1. Два подхода к понятию «архитектура»
менных компьютеров, чтобы ошибки, появляющиеся, например, из-за
применения в арифметических операциях несовместимых операндов
или обращения за пределы допустимого адресного пространства, было
возможно выявить на стадии компиляции.
Как следствие семантического разрыва — низкая производительность
при проектировании программ. Создатель прикладного ПО тратит
больше времени на разработку управления памятью и пересылку дан-
ных, чем на реализацию алгоритма обработки данных. Последние ис-
следования показывают, что каждый 20-й оператор в PL/1-програм-
мах — это ввод и вывод информации.
Совершенствование архитектуры компьютера с целью устранения се-
мантического разрыва также ограничено принципами построения,
например, архитектуры процессора. Так, в случае реализации паралле-
лизма при организации процессора используются только два варианта
обработки: мультипроцессорный и поточный. Причем мультипро-
цессорная обработка решает проблему лишь частично из-за сложно-
сти выделения независимых фрагментов программы, которые можно
выполнять параллельно (задача декомпозиции), трудностей синхрони-
зации взаимодействующих процессов и перекрытия областей памяти.
1.5. Анализ архитектурных принципов фон Неймана
Архитектурные принципы формулировались фон Нейманом приме-
нительно к созданию автоматического устройства для решения диф-
ференциальных уравнений.
Основные характеристики архитектуры фон Неймановского типа сле-
дующие:
► последовательно адресуемая единственная память линейного типа
для хранения программ и данных;
► команды и данные различаются неявным способом лишь при вы-
полнении операций. Принимаемые по умолчанию соглашения типа
«операнды операции умножения — это данные, а объект, на который
указывает команда перехода, — это команда» позволяют обращаться
с командой как с данными, например, для ее модификации;
42
1.5. Анализ архитектурных принципов фон Неймана
► назначение данных определяется лишь логикой программы, так
как в памяти машины набор бит может представлять собой как деся-
тичное число с фиксированной точкой, так и строку символов.
Указанные свойства были исключительно важными для своего време-
ни. Однако появление языков высокого уровня (ЯВУ), новых методов
решения, логических способов ускорения операций, более совершен-
ной элементной базы требует наряду с имеющимися возможностями
архитектуры и принципиально новых. При этом требования ЯВУ
имеют следующие особенности:
► память состоит из набора дискретных именуемых переменных. Вовсе
не требуется, например, чтобы память для значений переменных одной
программы располагалась рядом с памятью для значений переменных
другой программы. Таким образом, принцип единственной последо-
вательной памяти имеет мало общего с организацией памяти в ЯВУ;
► ЯВУ наряду с линейными данными оперируют и с многомерны-
ми — массивами, структурами, списками;
► в ЯВУ четко разграничены операции и данные;
► данные определяют и операции над ними.
Например, смысл операции А+С определяется описанием Ап С. Се-
мантика операции «+» совершенно различна, например, для целых
чисел и символьных переменных.
Архитектура фон Неймана плохо ориентирована на выполнение
программ на ЯВУ. К сожалению, ЯВУ имитируют в своей структуре
архитектуру фон Неймановского типа: переменные — пассивное ЗУ;
оператор присваивания — арифметическое устройство (АУ); после-
довательное выполнение операторов управления (IF, GOTO) — уст-
ройство управления (УУ).
Много сложностей возникает из-за работы компьютера в двоичной
системе. Например, как отразится на экране дисплея вводимое деся-
тичное вещественное число, не будет ли потерь в его младшем разряде?
Это касается даже языка Ada, специально приспособленного для вы-
сокой точности вычислений, который также аппроксимирует деся-
тичные вещественные числа двоичными.
Общая взаимосвязь между ЯВУ и компьютером в зависимости от
уровня языка машины может быть представлена схемой на рис. 1.6.
43
Глава 1. Два подхода к понятию «архитектура’
Рис. 1.6. Соотношение программ на ЯВУ и машинном языке
На рисунке представлены следующие возможности взаимодействия
ЯВУ и компьютера:
1 — традиционный подход. После компилирования программа пере-
водится на машинный язык, а затем интерпретируется машиной;
2 — компиляция осуществляется на промежуточный машинный язык
более высокого уровня, чем машинный, сокращая тем самым семан-
тический разрыв между ЯВУ и машиной;
3 — ЯВУ рассматривается как язык ассемблера, то есть имеется вза-
имно однозначное соответствие между типами операторов и знаками
операций ЯВУ с командами машинного языка. В данном случае про-
изводится ассемблирование, а не компилирование, во время которого
удаляются комментарии и пробелы в исходной программе, преобра-
зуются в машинные коды разделители, ключевые слова и знаки опе-
раций, а в адреса полей памяти — имена. Таким образом, многие
привычные функции компилятора отсутствуют. Остальная привязка
программы происходит непосредственно перед ее выполнением;
4 — машинный язык является ЯВУ и происходит процесс интерпре-
тации программы на компьютере
Введение программно-адресуемых регистров (так называемых ре-
гистров общего назначения) существенно увеличивает количество
используемых команд LOAD (загрузка в регистр) и STORE (запись
44
1.6. Способы совершенствования архитектуры
в память), то есть команд перемещения данных из регистров в память
и обратно. Исследования на компьютере PDP для различных ЯВУ
показывают, что 42 % всех выполняемых команд затрачивается на
перемещение данных между памятью и регистрами. Ряд результатов
показывает что использование кэш-памяти позволяет достичь уве-
личения быстродействия за счет применения регистров общего на-
значения.
В настоящее время имеются конкретные проекты архитектур машин,
ориентированные на ЯВУ — Pascal, PL, Lisp, CoboL Однако больший
интерес представляют архитектуры, ориентирующиеся не на конкрет-
ный язык, а на общие семантические возможности некоторой группы
языков. Так, архитектура машины SWARD ориентирована на языки
PL/1, Ada, Fortran, Cobol и некоторые другие, создавая тем самым
благоприятную среду программирования.
Компьютеры фирмы Burroughs, начиная с модели В 1700, за счет вы-
зова различных микропрограмм динамически настраиваются на язык
написания выполняемой программы.
Отметим, что разработчику архитектуры компьютера не следует стро-
го ориентироваться на языки программирования, компиляторы, опе-
рационные системы и другие программы, чтобы не потерять главное
в архитектуре — учет современных требований задач и окружение
пользователя.
Необходимо искать разумный компромисс в распределении функ-
ций системы между аппаратной и программной реализациями с уче-
том стоимости, возможности модификации работы на микроуровне
и т.д. Следует помнить, что компьютер предназначен для эффектив-
ного выполнения программ с целью решения требуемых задач.
1.6. Способы совершенствования архитектуры
Архитектура компьютеров чаще всего совершенствуется за счет вве-
дения дополнительных средств. Рассмотрим некоторые из них.
1.6.1. Хранение информации в виде самоопределяемых данных
Обычно информация о типе хранимых в памяти данных содержится
в командах программы. Однако в ячейке памяти, где хранятся дан-
45
Глава 1. Два подхода к понятию «архитектура»
ные, можно указать и тип данных (целое, десятичное, символьное
и т.д.), дополнив их некоторым набором бит — тегом. Этот принцип
организации памяти получил название теговой памяти. Наряду с ти-
пом данных в теге можно хранить и другие характеристики, например
длину операнда, информацию об определении текущего значения
переменной, использующей данную ячейку памяти, и т.д.
Какие преимущества дает тег? Известно, что в IBM 370 имеется 15
различных команд ADD, формат одной из них требует двух 4-бито-
вых полей для указания длины обоих операндов. Использование те-
гов позволило бы ограничиться одной командой, а тип подлежащих
сложению операндов и их длину компьютер мог бы определить путем
анализа содержимого тегов соответствующих операндов.
Расширив тег еще одним битом, можно было бы использовать его
в случае обращения к этой ячейке для незапрограммированного пре-
рывания при возникновении определенной ситуации и перехода
к процедуре ее обработки.
Существует два типа тегов: статические, содержимое которых опре-
деляется перед выполнением программы и по ходу вычислений не
изменяется, и динамические — с наполнением его содержания во вре-
мя вычислений и периодическим обновлением.
Использование тегов позволяет выявить некоторые ошибки. Напри-
мер, может обнаружиться, что одним из операндов команды сло-
жения является строка символов, или число с плавающей точкой
записывается в качестве адреса, или значение одного из операндов
неизвестно и т.д., то есть производится защита типа данных.
При сложении чисел с фиксированной точкой может возникнуть си-
туация, когда позиции точки в числах разные, то есть необходимо
предварительно выровнять эти позиции. Данные могут отличаться
длиной или формой представления. Таким образом, возможно авто-
матическое преобразование данных.
Теги позволяют повысить скорость обработки команд. Это происхо-
дит, во-первых, из-за того, что в этом случае не требуется генерация
компилятором отдельных наборов команд для преобразования дан-
ных, а во-вторых, отпадает необходимость в извлечении из памяти
и декодировании команд преобразования данных.
Теги позволяют упростить алгоритмы некоторых операций. Так, для
сравнения двух величин необходимо произвести их выравнивание
46
1.6. Способы совершенствования архитектуры
(усечение до меньшей или дополнение до большей длины), на что
компилятор PL/1, например, генерирует код из 49 команд, а при те-
говой архитектуре потребуется всего одна машинная команда.
Структуры команд становятся более регулярными, за счет чего
уменьшается разнообразие команд. Однако следует задаться вопро-
сом: всегда ли уменьшение количества команд способно эквивалент-
но отразить исходное разнообразие операций? Например, всегда ли
эквивалентны операция арифметического сдвига и операция деле-
ния на 2?
При применении тегов компилятор становится более простым и бы-
стрым, что следует из предыдущих рассуждений. Не требуется гене-
рировать различный код в зависимости от типа данных, ибо набор
команд инвариантен к типу обрабатываемых данных, то есть разраба-
тываемые программные средства становятся независимыми от типов
данных.
Теги позволяют сделать отладку программ более совершенной. В ча-
стности, дамп памяти становится более информативным.
Что же в этом случае будет с объемом памяти для хранения программ
и данных? Оказывается, хотя все данные требуют наличия допол-
нительных полей, но за счет многократного и из многих команд об-
ращения к данным, а также благодаря устранению избыточности
информации в кодах операций команд в машинах с теговой органи-
зацией памяти потребуется меньший объем для хранения программ
и данных, чем в компьютерах с традиционной архитектурой. Прове-
денные эксперименты с программами на языке Cobol показали, что
при числе обращений к операнду больше 3,5 теговая организация уже
выгодна и по объему памяти. Среднее же число обращений к одному
операнду в некоторых наборах программ обработки экономической
информации имеет коэффициент обращения > 10,4.
Эти рассуждения еще раз подтверждают мысль, что оптимальное ре-
шение при проектировании архитектуры машины можно принимать
лишь при глубоком анализе ЯП и программ.
Экономия памяти происходит из-за ненадобности повторного гене-
рирования кодов для функций контроля и преобразования данных.
Экономия достигается и за счет того, что один тег можно заводить
для всего массива данных и для всех элементов строки символов, так
как последние содержат, как правило, одинаковые атрибуты.
47
Глава 1. Два подхода к понятию «архитектура»
Наряду с тегами во многих машинах используются и дескрипторы.
Это дополнительная информация, играющая роль косвенного адреса
ячейки памяти с данными. В таких компьютерах команды содержат
ссылки на дескрипторы, которые, в свою очередь, ссылаются на об-
ласти памяти, хранящие значения операндов команд.
Основное отличие тегов и дескрипторов состоит в следующем: деск-
рипторы создают дополнительный уровень адресации, что требует
увеличения затрат на формирование адреса, то есть дескрипторы —
это часть команды (программы), а теги — это часть данных.
Приведем пример дескриптора (рис. 1.7).
101 р I R W Длина Адрес
Рис. 7.7. Дескрипторы
Здесь первые три бита содержат тег. Если значение тега равно 101, то
данное слово — дескриптор. Бит Р указывает, находятся данные в ос
новной памяти или во вспомогательной; /определяет, одиночный ли
элемент описывает данный дескриптор или весь массив; R иденти-
фицирует непрерывную или разрывную область памяти; W означает
разрешение только чтения данных.
1.6.2. Области санкционированного доступа
Средства обеспечения доступа используются для защиты данных, на-
пример, области ОС от несанкционированной ревизии пользовате-
лем. Как правило, имеющиеся средства защиты не охраняют процесс
от самого себя, или одну программную секцию от другой, или секцию
проблемной программы пользователя от системного программного
обеспечения.
Для защиты памяти выделяются домены — области санкционирован-
ного доступа как локальное адресное пространство, определяющее
адреса которые могут формироваться или использоваться некото-
рым набором команд. Имеется в виду, что область памяти защищает-
ся и от случайного обращения, и от несанкционированного доступа
ввиду закрытости хранимой информации.
48
1.6. Способы совершенствования архитектуры
Каждой программной секции (это обычно отдельно компилируемая
программная единица) можно придать домен — некоторое адресное
пространство, доступное только ее (секции) локальным переменным.
Передачу фактических параметров подпрограмм (секции), занимаю-
щих некоторый домен, можно рассматривать как временное его рас-
ширение и решение проблемы передачи требуемых данных. Как только
доступ к данным (обмен) закончился, расширение «домен-секция»
исчезает.
Для большей защиты домена данных программной секции может
быть предоставлена только конкретная (или несколько) точка входа,
а не доступ к любому слову домена (рис. 1.8).
Домен-секция
Домен-данные
Рис. 1.8. Временное расширение домена
Использование доменов имеет ряд достоинств:
► улучшается отладка программ. Сфера действия любой ошибки ог-
раничивается размерами домена, в котором она произошла, что уве-
личивает вероятность ее обнаружения;
► повышается надежность защиты программ. Информация, принад-
лежащая одной секции, защищается от воздействия других секций.
Например, если модуль А вызывает модуль В для выполнения неко-
торых функций, то последний, будучи присоединенным к А, может
анализировать все данные модуля А, хотя они должны быть защищены
от подобных действий. Если же модуль Л разделен на домены, возмож-
ности адресации модуля В ограничены только фактическими пара-
метрами, которые передаются ему во время вызова. То же характерно
и для вызываемого модуля В.
Чтобы исключить доступ ко всем данным исходной программы, ее
сегментируют.
Для реализации аппарата доменов, естественно, необходимы изме-
нения и в архитектуре компьютера, например включение механизма,
не разрешающего при выборе одного значения из домена доступ
к другим его данным. Необходим механизм защиты и от несанкцио-
нированных точек входа в модуль.
49
4
^2792
Глава 1. Два подхода к понятию «архитектура»
1.6.3. Одноуровневая память
В зависимости от расположения данных в оперативной или внешней
памяти программист по-разному адресует память. При этом требуется
явное задание перемещения данных (операции ввода-вывода). В связи
с ограниченным объемом оперативной памяти необходимо прибегать
к другим принципам организации памяти, например к файловым
структурам. Все это повышает стоимость программирования.
Данные в программу обычно передаются через фактические парамет-
ры или через ввод-вывод (имеющий, например, файловую структуру).
Разная организация данных на различных носителях информации
может быть неприемлемой для одного и того же модуля.
Решение указанных проблем требует унификации ЗУ, чтобы програм-
мист оперировал одинаковой адресацией вне зависимости от органи-
зации ЗУ. В этом случае файлы станут элементами одноуровневой
памяти, функции перемещения данных между различными уровня-
ми ЗУ возлагаются на соответствующее программное обеспечение
и аппаратуру, что несколько напоминает виртуальную память. Одна-
ко одноуровневая память в отличие от виртуальной распространяется
на все запоминающее пространство системы, а не только обеспечи-
вает вопросы, связанные с недостатком оперативной памяти. Кроме
того, обслуживающий набор виртуальной памяти — это модель, ис-
чезающая при завершении работы.
Достоинства одноуровневой памяти:
► сравнительно низкая стоимость программного обеспечения;
► независимость адресации от принципа организации памяти.
Трудности, возникающие при этом:
► создание встроенного в архитектуру компьютера механизма иерар-
хии ЗУ;
► восстановление памяти;
► переносимость объектов на другие системы с традиционной орга-
низацией архитектуры.
50
1.7. RISC- и CISC-архитектура
1.7. RISC- и CISC-архитектура
Развитие компьютеров с архитектурой mainframe (мэйнфрейм) спо-
собствовало расширению спектра решаемых с их помощью задач.
Проектировались сложные команды, поддерживаемые путем интер-
претации (моделирования). Таким путем сокращался семантический
разрыв между возможностями компьютеров и требованиями вновь
возникающих языков программирования высокого уровня.
Группа разработчиков IВМ под руководством Джона Кока в противо-
вес большим компьютерам спроектировала несложный компьютер
801 с простыми командами. После публикации проекта многие фир-
мы начали работать над компьютерами с простыми командами без
интерпретации. Так, например, в 1980 году группой специалистов
(США, Калифорнийский университет в Беркли) во главе с Д. Пат-
терсоном и К. Секуином начата разработка процессора RISC без ин-
терпретации. Почти одновременно в Стэнфорде под руководством
Дж. Хеннеси была разработана микросхема MIPS. Оба процессора
были доведены до коммерческой реализации и воплощены в кон-
кретные компьютеры.
RISC (Restricted (reduced) instruction set computer) — это регистро-
ориентированная архитектура. Компьютеры с такой архитектурой ино-
гда называют компьютерами с сокращенным набором команд. Суть ее
состоит в выделении наиболее употребительных операций и создании
средств их быстрой реализации. Это позволило в условиях ограничен-
ных ресурсов разработать компьютеры с высоким быстродействием.
MIPS (Millions of Instructions Per Second) — это миллионы операций
в секунду. Такая архитектура предполагает параллельное выполнение
большого количества команд за короткий промежуток времени. Без-
условно, простые команды выполняются при этом быстро, но глав-
ное в этих архитектурах — количество команд, которое может быть
начато в единицу времени (чаще всего в секунду). Таким образом, па-
раллелизм в выполнении команд становится главным показателем
повышения производительности компьютера.
1.7.1. Основные принципы RISC-архитектуры
В компьютерной индустрии наблюдается настоящий бум производ-
ства систем с RISC-архитектурой. Рабочие станции и серверы, соз-
51
Глава 1. Два подхода к понятию «архитектура»
данные на базе концепции RISC, завоевали лидирующие позиции
благодаря своим исключительным характеристикам и уникальным
свойствам операционных систем типа UNIX, используемых на этих
платформах.
В самом начале 80-х годов прошлого века почти одновременно завер-
шились теоретические исследования в области RISC-архитектуры,
проводившиеся в Калифорнийском и Стэнфордском университетах,
а также в лабораториях фирмы IBM. Особую значимость приобрел
проект RISC1, который возглавили профессора Давид Паттерсон
и Карло Секуин. Именно они ввели в употребление термин RISC
и сформулировали четыре основных принципа RISC-архитектуры:
► каждая команда независимо от ее типа выполняется за один ма-
шинный цикл, длительность которого должна быть максимально ко-
роткой;
► все команды должны иметь одинаковую длину и использовать ми-
нимум адресных форматов, что резко упрощает логику управления
процессором;
► обращение к памяти происходит только при выполнении опера-
ций записи и чтения, вся обработка данных осуществляется исклю-
чительно в регистровой структуре процессора;
► система команд должна обеспечивать поддержку языков высокого
уровня. Имеется в виду подбор системы команд, наиболее эффектив-
ной для различных языков программирования.
Со временем трактовка некоторых из этих принципов претерпела
изменения. В частности, возросшие возможности технологии позво-
лили существенно смягчить ограничения на состав команд — вместо
полусотни инструкций, использовавшихся в архитектурах первого
поколения, современные RISC-процессоры реализуют около 150 ин-
струкций. Однако основной принцип RISC был и остается незыбле-
мым — обработка данных должна вестись только в рамках регистровой
структуры и только в формате команд «регистр-регистр-регистр».
В RISC-микропроцессорах значительную часть площади кристалла
занимает тракт обработки данных, а секциям управления и дешифра-
ции отводится очень небольшая его часть.
Аппаратная поддержка выбранных операций, безусловно, сокращает
время их выполнения, однако критерием такой реализации является
52
1.7. RISC- и CISC-архитектура
повышение общей производительности компьютера в целом и его
стоимость. Поэтому при разработке архитектуры необходимо анали-
зировать результаты компромиссов между различными подходами,
различными наборами операций и на основе такого анализа выбрать
оптимальное решение.
Развитие RISC-архитектуры в значительной степени определяется
успехами в области проектирования оптимизирующих компиляторов.
Только современная технология компиляции позволяет эффективно
использовать преимущества большого регистрового файла, конвейер-
ной организации и высокой скорости выполнения команд. Применя-
ются и другие свойства процесса оптимизации в технологии компи-
ляции, обычные для RISC-процессоров, — реализация задержанных
переходов и суперскалярная обработка, позволяющие в один и тот же
момент времени отсылать на выполнение несколько команд.
1.7.2. Отличительные черты RISC- и CISC-архитектур
Двумя основными архитектурами набора команд, используемыми ком-
пьютерной промышленностью на современном этапе развития вы-
числительной техники, являются архитектуры CISC и RISC. Осново-
положником CISC-архитектуры — архитектуры с полным набором
команд (CISC — Complete Instruction Set Computer) можно считать
фирму IBM с ее базовой архитектурой IBM/36O, ядро которой ис-
пользуется с 1964 года и дошло до наших дней, например, в таких со-
временных mainframe, как IBM ES/9000.
Лидером в разработке микропроцессоров с полным набором команд
считается компания Intel с микропроцессорами Х86 и Pentium, прак-
тически ставшие стандартом для рынка микропроцессоров.
Простота архитектуры RISC-процессора обеспечивает его компакт-
ность, практическое отсутствие проблем с охлаждением кристалла,
чего нет в процессорах фирмы Intel, упорно придерживающейся пути
развития архитектуры CISC. Стратегия CISC-архитектуры состоялась
в обеспечении технологической возможности перенесения «центра
тяжести» обработки данных с программного уровня системы на аппа-
ратный, в то время как основной путь повышения эффективности
для RISC-компьютера в первую очередь виделся в упрощении компи-
ляторов и минимизации исполняемого модуля. На сегодняшний день
CISC-процессоры почти монопольно занимают на компьютерном
53
Глава 1. Два подхода к понятию «архитектура»
рынке сектор персональных компьютеров, однако RISC-процессо-
рам нет равных в секторе высокопроизводительных серверов и рабо-
чих станций.
Сравнение основных черт RISC-архитектуры с аналогичными по ха-
рактеру чертами CISC-архитектуры можно отобразить следующим
образом (табл. 1.1):
Таблица 1.1
Основные черты архитектуры
CISC-архитектура RISC-архитектура
Многобайтовые команды Однобайтовые команды
Малое количество регистров Большое количество регистров
Сложные команды Простые команды
Одна команда или менее за один цикл процессора Несколько комацд за один цикл процессора
Традиционно одно исполнитель- ное устройство Несколько исполнительных устройств
Одним из важных преимуществ RISC-архитектуры является высокая
скорость арифметических вычислений. RISC-процессоры первыми
достигли планки наиболее распространенного стандарта IEEE 754,
устанавливающего 32-разрядный формат для представления чисел с
фиксированной точкой и 64-разрядный формат «полной точности»
для чисел с плавающей точкой. Высокая скорость выполнения ариф-
метических операций в сочетании с высокой точностью вычислений
обеспечивает RISC-процессорам безусловное лидерство в быстро-
действии по сравнению с CISC-процессорами.
Другой особенностью RISC-процессоров является комплекс средств,
обеспечивающих безостановочную работу арифметических устройств:
механизм динамического прогнозирования ветвлений, большое коли-
чество операционных регистров, многоуровневая встроенная кэш-
память.
Организация регистровой структуры — основное достоинство и основ-
ная проблема RISC. Практически любая реализация RISC-архитектуры
использует трехместные операции обработки, в которых результат
и два операнда имеют самостоятельную адресацию — Rl: = R2, R3.
Это позволяет без существенных затрат времени выбрать операнды
54
1.7. RISC- и CISC-архитектура
из адресуемых оперативных регистров и записать в регистр результат
операции. Кроме того, трехместные операции дают компилятору боль-
шую гибкость по сравнению с типовыми двухместными операциями
формата «регистр-память» архитектуры CISC. В сочетании с быстро-
действующей арифметикой RISC-операции типа «регистр-регистр»
становятся очень мощным средством повышения производительно-
сти процессора.
Вместе с тем опора на регистры представляет собой и ахиллесову пяту
RISC-архитектуры. Проблема в том, что в процессе выполнения задачи
RISC-система неоднократно вынуждена обновлять содержимое реги-
стров процессора, причем за минимальное время, чтобы не вызывать
длительных простоев арифметического устройства. Для CISC-систем
подобной проблемы не существует, поскольку модификация регистров
может происходить на фоне обработки команд формата «память-па-
мять».
Существует два подхода к решению проблемы модификации регист-
ров в RISC-архитектуре: аппаратный, предложенный в проектах RISC 1
и RISC 2, и программный, разработанный специалистами IBM и Стэн-
фордского университета. Принципиальная разница между ними за-
ключается в том, что аппаратное решение основано на стремлении
уменьшить время вызова процедур за счет установки дополнительно-
го оборудования процессора, тогда как программное решение бази-
руется на возможностях компилятора и является более экономичным
с точки зрения аппаратуры процессора.
Очевидные преимущества RISC-архитектуры, прежде всего в плане
производительности, могли бы полностью вытеснить с мирового рын-
ка компьютеры с CISC-архитектурой (Pentium и т.д.). Но этого не
случилось в силу следующих обстоятельств.
Во-первых, компьютеры с RISC-архитекгурой (например, компьютеры
Alpha фирмы DEC) несовместимы с другими моделями. Во-вторых,
многие компании осуществили значительные капиталовложения
в ПО для процессоров Intel. В-третьих, в процессоры Intel, начиная
с модели 486, внедрены идеи RISC для реализации ядра, включающе-
го самые простые и самые распространенные команды, а более слож-
ные команды интерпретируются по технологии CISC, что повышает
производительность Intel-процессоров, но в то же время позволяет
использовать накопленное программное обеспечение без доработок.
55
Глава 1. Два подхода к понятию «архитектура»
1.7.3. Проблемы реализации RISC-процессоров
Основные принципы, на которых базируется разработка современных
процессоров, во многом пересекаются с основными принципами
RI SC-архитектуры:
► все команды реализуются схемным путем без интерпретации в фор-
ме микрокоманд (сложные команды могут разбиваться на части);
► компьютеры за фиксированное время должны начать выполнение
значительного числа команд (безусловно, аксиома зависимости команд
по данным и управлению должна соблюдаться неукоснительно);
► простым должен быть процесс декодирования команд (это сущест-
венно влияет на количество одновременно вызываемых команд);
► к оперативной памяти должны обращаться лишь команды LOAD
и STORE (загрузки и сохранения);
► достаточный объем регистровой памяти, обеспечивающий сокра-
щение количества перемещений данных между процессором и ОП.
Возникает необходимость выбора оптимального набора операций, по-
зволяющего достичь желаемой производительности, реализуя прин-
ципы RISC-архитектуры. Такой выбор осуществляется по некоторой
репрезентативной смеси задач, для выполнения которых предназна-
чен компьютер, путем подбора пакета контрольных программ и по-
строения профиля их выполнения либо с помощью статических или
динамических измерений параметров этих программ.
При профилировании определяется доля общего времени центрального
процессора, затрачиваемого на выполнение каждого оператора (опера-
ции) программы. Анализ полученных результатов позволит выявить
характерные особенности профилируемой программы.
При статических или динамических измерениях подсчитывается, сколько
раз в программе встречается тот или иной оператор (операция) или
частота получения признаками положительных (отрицательных) зна-
чений в тексте программы (статика) либо в результате выполнения
(динамика).
Сочетание результатов, полученных в ходе таких исследований, дает
общую картину анализируемой программы. Приведем результаты
одного из таких измерений в статике, осуществленные для программ-
компиляторов: операторы присваивания — 48 %, условные операто-
56
1.7. RISC- и CISC-архитектура
ры — 15, циклы — 16, операторы вызова-возврата — 18, прочие опе-
раторы — 3 %.
Измерение трехсот процедур, используемых в операционных систе-
мах, в динамике показало следующую статистику по типам операндов:
константы — 33 %, скаляры — 42, массивы (структуры) — 20 и про-
чие — 5 %.
При этом статистика среди команд управления потоком данных сле-
дующая. В разных тестовых пакетах программ команды условного
перехода занимают от 66 до 78 %, команды безусловного перехода —
от 12 до 18 %, частота переходов на выполнение составляет от 10
до 16%.
Отсюда можно сделать вывод, что операторы присваивания занима-
ют основную часть в программах-компиляторах, а операнды типа
константа и локальные скаляры составляют большую часть операн-
дов в процедурах, к которым происходит обращение в процессе вы-
полнения программы.
Подобные количественные и качественные измерения образуют ос-
нову для оптимизации процессорной архитектуры.
Так, если операторы присваивания занимают 48 % всех операторов,
то ясно, что операцию доступа к операндам следует реализовать
аппаратно. Особенно это важно, если речь идет о нечисловых зада-
чах, в которых вычислительные операции, как правило, просты.
В условных операторах, операторах цикла и вызова-возврата произ-
водятся манипуляции над множеством операндов, что также под-
тверждает необходимость аппаратной реализации операции доступа
к операндам.
При анализе типов операндов учитывались три категории:
► константы — не меняются во время выполнения программы и име-
ют, как правило, небольшие значения;
► скаляры — обращение к ним происходит, как правило, явно по их
имени. Обычно скаляров немного и они описываются в процедурах
как локальные;
► обращение к элементам массивов и структур происходит посредст-
вом индексов и указателей, то есть через косвенную адресацию. Та-
ких элементов, как правило, достаточно много.
57
Глава 1. Два подхода к понятию «архитектура»
Для осуществления доступа к операнду необходимо вначале определить
физический адрес ячейки, где хранится операнд, а затем осуществить
доступ к операнду. Если операнд — константа, ее можно указать не-
посредственно в команде. Доступ к константе может быть осуществ-
лен немедленно после обращения. В других случаях все зависит от
типа памяти, где хранится операнд. Регистровые блоки и кэш-память
мало отличаются по емкости, скорости доступа и стоимости, однако
существенно различаются по накладным расходам на адресацию. Об-
ращение к кэш-памяти осуществляется при помощи адресов полной
длины, которые требуют более широкой полосы пропускания кана-
лов обмена. Как правило, этот адрес приходится формировать во время
выполнения программы, что, как минимум, требует полноразрядно-
го сложения и/или обращения к регистру. Регистровые блоки адресу-
ются короткими номерами регистров, которые обычно указываются
в команде, что упрощает декодирование команд. Однако регистровая
память позволяет хранить только определенные типы данных, в то
время как кэш-память может использоваться и как основная. В связи
с этим распределение скалярных переменных по регистрам достаточ-
но важно, ибо существенно влияет на скорость обработки.
Необходимо определить размер регистровых окон, ибо в обычной ар-
хитектуре окна однорегистровые, что требует операции запомина-
ния-восстановления при каждом вызове-возврате.
При вызовах процедур следует запоминать содержимое регистров,
а при возвращении — восстанавливать их, на что тратится значитель-
ное время. Вызовы процедур в современных структурированных про-
граммах довольно часты, при этом суммарные накладные расходы на
выполнение команд вызова и возврата из процедур на стандартных
процессорах занимают до 50 % всех обращений к памяти в программе.
Чтобы уменьшить время передачи данных между процедурами-роди-
телями и процедурами-дочерьми (в случае, когда глубина их вложен-
ности больше единицы), можно создать блок регистров, предоставив
и родителям и дочерям доступ к некоторым из них. Другими словами,
требуется создать перекрывающиеся блоки регистров. Такая возмож-
ность реализуется через перекрывающиеся «окна», накладываемые на
блок регистров. Этот механизм реализован в RISC-архитектуре. Многие
измерения показывают, что около 97 % процедур имеют не более
шести параметров, что требует перекрытия соседних окон, как пра-
вило, на пять регистров.
58
1.7. RISC- и CISC-архитектура
Процессор всегда содержит указатель текущего окна с возможностью
его модификации в рамках реализованной глубины вложения проце-
дур. Если таковой глубины не хватает, часть содержимого окон на-
правляется в основную память, освобождая место для новых процедур.
Для простоты реализации в ОП направляется содержимое целого окна.
Это говорит о целесообразности введения многооконного механизма
с заданным размером окна. Размер окна определяется количеством
передаваемых параметров, а количество окон — допустимой вложен-
ностью процедур.
Среди достоинств применения больших регистровых блоков можно
выделить высокую скорость доступа к блокам и увеличение частоты
вызова процедур. Среди недостатков — высокая стоимость большого
регистрового блока, организуемого в ущерб другим функциональным
блокам на кристалле.
Аппаратная реализация механизма перекрытия окон должна вводиться,
если получаемый выигрыш перекрывает затраты.
Так как значительная часть процедур требует от трех до шести пара-
метров, то следует подумать об оптимизации использования окон.
Во-первых, пересылать в ОП в случае переполнения регистрового
блока можно не все окна, а только содержимое регистров, используе-
мых для данной процедуры, и, во-вторых, применять механизм с ок-
нами переменных размеров, определяемых во время выполнения.
Перспективной разновидностью RISC-архитектуры явилась архитек-
тура SPARC (Scalable Processor Architecture1).
Новая серия SPARCSTATIONS фирмы Sun Microsystems базируется
на SPARC-архитектуре. Первые модели этой серии были изготовле-
ны уже в 1989 году. Операционной средой для всех станций фирмы
Sun является SunOS — разновидность ОС Unix, снабженная много-
оконным графическим интерфейсом Open Look.
Для повышения скорости обработки данных используются компью-
теры с VLIW (Very Long Instruction Шэгф-архитектурой. Структура
команды таких компьютеров наряду с кодом операции и адресами
операндов включает теги и дескрипторы. Такая архитектура, кроме
1 Scaling — масштабирование, то есть способность представлять данные таким обра-
зом, чтобы данные и результат проводимых с ними вычислений находились в диапа-
зоне чисел, которые могут обрабатываться в рамках данного процесса или на данном
оборудовании.
59
Глава 1. Два подхода к понятию «архитектура»
существенного ускорения обработки данных, позволяет экономить
память при достаточном количестве обращений к командам, сокра-
щать общее количество команд в системе команд и ускорять процесс
выборки команд из памяти.
1.8. Функционирование управляющего компьютера
Для автоматизации управления сложным производственным или тех-
нологическим процессом в контур управления включают компьютер,
представляющий собой управляющую вычислительную машину (УВМ).
Наиболее часто в качестве управляющего компьютера используют
цифровые ЭВМ благодаря следующим качествам:
► наличию больших и высоконадежных ЗУ различного типа;
► возможности решения на них сложных вычислительных и логиче-
ских задач;
► гибкости (за счет программного обеспечения);
► надежности и быстродействию.
В общем случае система автоматического управления с УВМ опреде-
ляет собой замкнутый контур (рис. 1.9).
Здесь
► X], X],..., хк — измеряемые параметры:
• нерегулируемые (характеристики исходного продукта);
• выходные параметры, характеристики качества продукции;
• выходные параметры, по которым непосредственно или путем
расчета определяется эффективность производственных про-
цессов (производительность, экономичность) или ограничения,
наложенные на условия его протекания;
► Уь Уг, —,УП — регулируемые параметры, которые мотуг изменяться
исполнительными механизмами (ИМ) — регуляторами и оператором;
► /ъ/ъ —>fn ~ нерегулируемые и неизмеряемые параметры (напри-
мер, химический состав сырья).
На вход УВМ от датчика Д (термопар, расходомеров и т.п.) подается
измерительная информация о текущем значении параметров хь
х2,..., хк. Согласно алгоритму управления УВМ определяет величины
60
1.8. Функционирование управляющего компьютера
Рис. 1.9. Принцип действия УВМ
управляющих воздействий {7Ь U2, Un, которые необходимо прило-
жить к исполнительным механизмам (ИМ) для изменения регули-
руемых параметров уъ ..., уп с тем, чтобы управляющий процесс
протекал оптимально. Измерительные датчики вырабатывают непре-
рывный сигнал (напряжение, ток, угол поворота и т.п.), а поскольку
ЦВМ работает в дискретной форме, то дважды происходит преобразо-
вание из непрерывной формы в дискретную (Н/Д) и наоборот (Д/Н).
Для уменьшения состава оборудования преобразователи Н/Д и Д/Н
выполнены многоканальными. Посредством коммутатора преобра-
зователь поочередно подключается к каждому датчику и осуществля-
ется преобразование Н/Д. Поступившее управляющее воздействие Ut
сохраняется в цепи до выработки следующего управляющего воздей-
ствия в УВМ.
В настоящее время наиболее распространен синхронный принцип
связи УВМ с объектом, при котором процесс управления разбивается
на циклы равной продолжительности с помощью тактирующих им-
пульсов электронных часов.
Цикл начинается с приходом тактирующего импульса на устройство
прерывания. В начале каждого цикла проводятся последовательный
опрос и преобразование в цифровую форму сигналов датчиков.
61
Глава 1. Два подхода к понятию «архитектура»
После выработки управляющих воздействий Ц- и преобразования их
в непрерывную форму УВМ приостанавливается до прихода нового
тактирующего импульса (или выполняет некоторую вспомогатель-
ную работу).
Для установления более тесной связи объекта с УВМ используют
асинхронный принцип связи с объектом. Вместо тактирующих им-
пульсов в УВМ поступают импульсы от датчиков прерывания (ДП),
непосредственно связанных с объектом (например, конечных вы-
ключателей аварийного состояния). Каждый импульс прерывания
эквивалентен требованию о прекращении производимых вычисле-
ний и переходе к выполнению подпрограммы, соответствующей дан-
ному каналу прерывания. УВМ реагирует на импульсы прерывания
с учетом приоритета одних сигналов прерывания над другими.
В некоторых системах применяют комбинированный способ — син-
хронизация «плюс» датчики аварийного состояния, переводящие
УВМ в режим аварийной рабо ы. В замкнутом контуре УВМ прямо
воздействует на ИМ, непосредственно управляя производственным
процессом. Это режим прямого цифрового управления.
Однако для сложных систем, а также для комплексов агрегатов, свя-
занных между собой технологическим процессом, система управле-
ния строится таким образом, что отдельные параметры процесса
регулируются соответствующими автоматическими регуляторами,
а УВМ обрабатывает «мерительную информацию, рассчитывает
и устанавливает оптимальные настройки регуляторов. Это повышает
надежность системы, так как ее работоспособность сохраняется
и при отказах УВМ. При такой схеме УВМ может быть более про-
стой, так как снижается требование к ее быстродействию.
УВМ в разомкнутой цепи используется:
► в системах автоматического программного управления;
► в сис емах, где УВМ выполняет функции советчика.
В первом случае уменьшается объем первоначально вводимой в УВМ
информации для расчета оптимальных настроек регуляторов. Деталь-
ный расчет программы управления с заданной точностью произво-
дится самим вычислительным устройством, которое в соответствии
с этой программой вырабатывает необходимые управляющие воздей-
ствия.
62
Упражнения
В режиме советчика УВМ обрабатывает измерительную информацию
и рассчитывает управляющие воздействия для оптимизации процесса.
Эта информация служит рекомендацией оператору, управляющему
технологическим процессом.
Упражнения
1. Чем различаются понятия «архитектура» и «структура» компьютера?
2. На конкретном примере продемонстрируйте семантический разрыв ме-
жду современными языками программирования и архитектурными ре-
шениями компьютера.
3. Какие пути усовершенствования архитектуры фон Неймана известны?
4. Разработайте и реализуйте механизм преобразования виртуального адре-
са в реальный.
5. Сформулируйте основные особенности суперкомпьютера.
6. Проанализируйте основные этапы разработки проекта архитектуры ВС
и функции, реализуемые на каждом из них.
7. Разработайте и реализуйте алгоритм управления простейшим технологи-
ческим процессом для компьютера, работающего в «замкнутом» цикле.
8. Проанализируйте особенности RISC- и CISC-архитектур компьютеров.
9. Приведите конкретные примеры воплощения RISC-архитектур в реаль-
ных компьютерах.
10. Проанализируйте и сравните по различным параметрам (быстродейст-
вию, объему памяти, сложности программирования) программы для од-
но-, двух-, трех- и безадресных компьютеров.
11. Проведите оптимизацию универсальной системы команд, если задан
конкретный набор решаемых задач.
12. Разработайте микропрограммы выполнения заданных операций для
реального компьютера. Проанализируйте целесообразность микропро-
граммной поддержки операций.
63
Глава 2
Конвейеризация
В большинстве ранних компьютеров команды выполнялись последо-
вательно, то есть сначала происходило чтение команды, затем де-
шифрация, выбор операндов и собственно исполнение операции.
Последовательный способ работы процессора определяет простоту
его логической организации. При этом для всей памяти системы дос-
таточно иметь один узел управления циклом памяти. Так как процес-
сор во время поиска команды свободен, он может быть использован
для индексных операций над адресами. Такое совмещение позволяет
эффективнее использовать процессор.
Стремление повысить быстродействие ВС привело к появлению про-
цессоров с совмещением операций, то есть к распараллеливанию про-
цессов, несмотря на удорожание оборудования
Идея об использовании принципа совмещения операций в целях по-
вышения скорости работы компьютеров была высказана академиком
С.А. Лебедевым на сессии АН СССР в 1957 году. Хотя эти идеи были
высказаны около 50 лет назад, они актуальны и сегодня.
Одна из возможностей совмещения операций состоит в модульной
организации памяти, при которой каждый модуль имеет собственный
адресный и числовой регистры, то есть модули способны работать
одновременно. Количество модулей обычно равно небольшой степени
числа 2. В начальных моделях IBM 7030 имелись две группы модулей
памяти с чередующимися в каждой группе адресами. Одна группа
главным образом используется для хранения команд, а другая — для
хранения операндов. Применяя указанные свойства в сочетании с со-
ответствующим программированием задачи, можно достичь более
высокой скорости поступления данных из памяти, чем скорость, ко-
торая обеспечивается физическим циклом памяти. Более сложные
способы реализации совмещения обращений к памяти состоят в по-
строении многовходовой памяти, что допускает одновременное об-
ращение к ней со стороны многих устройств, разрешая при этом
конфликт одновременного обращения.
Дальнейшим развитием идеи совмещения операций и совершенство-
вания методов ускорения обработки данных в компьютерах стала идея
64
2.1. Конвейерная обработка
конвейерной (pipeline) обработки, позволяющей совмещать во времени
выполнение различных шагов операций для некоторого множества
команд. Принцип конвейерной обработки основан на разбиении вы-
числительного процесса на несколько подпроцессов, каждый из ко-
торых выполняется в отдельном устройстве, как это имеет место при
выполнении сложных операций последовательно по подоперациям
на промышленном конвейере, в связи с чем этот метод и называют
конвейерным. Проблемы и достоинства такой технологии обсужда-
ются в данной главе.
2.1. Конвейерная обработка
Конвейерная обработка в общем случае основана на разделении под-
лежащей исполнению функции на более мелкие части, называемые
ступенями, и выделении для каждой из них отдельного блока аппара-
туры. Так, обработку любой машинной команды можно разделить
на несколько этапов, организовав передачу данных от одного этапа
к последующему. При этом конвейерную обработку можно использо-
вать для совмещения этапов выполнения разных команд. Произво-
дительность при этом возрастает благодаря тому, что одновременно
на различных ступенях конвейера выполняются различные этапы не-
скольких команд. Такая обработка применяется во всех современных
быстродействующих процессорах.
Конвейерная обработка — это технология, при которой несколько ко-
манд в процессе обработки выполняются одновременно, при этом каждая
команда (или ее этап) выполняется на отдельном функциональном уст-
ройстве с последующей передачей результатов обработки от i-й команды
(или этапа) к i+ 1-й, то есть используется параллелизм инструкций
в последовательном потоке команд.
Предположим, что набор команд проектируемого процессора вклю-
чает типичные арифметические и логические операции, операции
с плавающей точкой, операции пересылки данных, операции управле-
ния потоком команд и системные операции. В арифметических ко-
мандах используется трехадресный формат, типичный для RISC-про-
цессоров, адля обращения к памяти применяются операции загрузки
и записи содержимого регистров в память.
65
^2792
Глава 2. Конвейеризация
Выполнение типичной команды в этом случае можно разделить на
следующие этапы:
► выборка команды IF (Instruction Fetch): из памяти по адресу, задан-
ному счетчиком команд, извлекается команда;
► декодирование команды ID (Instruction Decode);
► выполнение операции EX (Execute);
► обращение к памяти MEM (Memory);
► запоминание результата WB (Write Back).
Для конвейеризации потока команд разобьем каждую из них на
указанные этапы, отведя для выполнения каждого этапа один такт
синхронизации, и в каждом такте начинаем выполнение очередной
команды.
Работа конвейера представляется в виде временных диаграмм
(табл. 2.1), на которых обычно изображаются выполняемые коман-
ды, номера тактов и этапы выполнения команд.
Таблица 2. J
Временная диаграмма конвейера
Номер команды Номер такта
1 2 3 4 5 6 7 8 9
I IF ID EX MEM WB
1+1 IF ID EX MEM WB
1+2 IF ID EX MEM WB
1+3 IF ID EX MEM WB
1+4 IF ID EX MEM WB
Такая организация функционирования направлена на максимизацию
загрузки всех компонент системы. Однако, во-первых, не все этапы
выполнения команды совпадают по времени, во-вторых, не все ко-
манды выполняются до конца (ветвления, циклы и т.д.), а в-третьих,
имеется информационная зависимость между операциями, в связи
с чем не все устройства ВС работают на полную мощность.
Конвейеризация увеличивает пропускную способность процессора
(количество команд, завершающихся в единицу времени), но не со-
кращает время выполнения отдельной команды. В действительности,
66
2.1. Конвейерная обработка
конвейеризация даже несколько увеличивает время выполнения ка-
ждой команды из-за накладных расходов, связанных с управлением
конвейером. Однако увеличение пропускной способности означает,
что в целом программа будет выполняться быстрее по сравнению
с простой неконвейерной схемой.
Тот факт, что время выполнения каждой команды в конвейере не
уменьшается, накладывает некоторые ограничения на практическую
длину конвейера. Кроме ограничений, связанных с задержкой кон-
вейера, имеются также ограничения, возникающие в результате несба-
лансированности задержки на каждой его ступени и из-за накладных
расходов на конвейеризацию. Частота синхронизации не может быть
выше, а, следовательно, такт синхронизации не может быть меньше
времени, необходимого для работы наиболее медленной ступени
конвейера. Накладные расходы на организацию конвейера возникают
из-за задержки сигналов в конвейерных регистрах (защелках) и из-за
необходимости синхронизации. Конвейерные регистры к длительно-
сти такта обработки процесса добавляют время его установки и за-
держку распространения сигналов.
При реализации конвейерной обработки возникают ситуации, кото-
рые препятствуют выполнению очередной команды из потока ко-
манд в предназначенном для этой команды такте. Такие ситуации
называются конфликтами. Конфликты снижают реальную произво-
дительность конвейера, достижимую в идеальном случае. Существует
три класса конфликтов:
1. Структурные конфликты, возникающие в случае, когда аппаратные
средства не могут поддерживать все возможные комбинации ко-
манд в режиме одновременного выполнения с совмещением (кон-
фликты по ресурсам).
2. Конфликты по данным, возникающие в случае, когда выполнение
одной команды зависит от результата выполнения предыдущей ко-
манды.
3. Конфликты по управлению, которые возникают при конвейериза-
ции команд переходов и других команд, изменяющих значение
счетчика команд.
Конфликты в конвейере приводят к необходимости приостановки
выполнения команд (pipeline stall). В простейших конвейерах приоста-
67
Глава 2. Конвейеризация
новление некоторой команды приводит к приостановке всех следую-
щих за ней команд. Команды, предшествующие приостановленной,
могут продолжать выполняться, но во время приостановки не выби-
рается ни одна новая (очередная) команда.
Структурные конфликты возникают, например, и в машинах, имею-
щих единый конвейер памяти для команд и данных (табл. 2.2). В этом
случае, если команда содержит обращение к памяти за данными, то
данное действие будет конфликтовать с выборкой более поздней ко-
манды из памяти. Чтобы разрешить эту ситуацию, можно просто
приостановить конвейер на один такт (команда Stall) при обращении
к памяти за данными. Подобная приостановка часто называется
«конвейерным пузырем» (pipeline bubble) или просто пузырем, по-
скольку пузырь проходит по конвейеру, занимая место, но не выпол-
няя никакой полезной работы.
Таблица 2.2
Пример структурного конфликта
Номер команды Номер такта
Команда загрузки 1 2 3 4 5 6 7 8 9 10
I IF ID. EX MEM WB
1 + 1 IF ID EX MEM WB
1 + 2 Stall IF ID EX MEM WB
1 + 3 IF ID EX MEM WB
1 + 4 IF ID EX MEM WB
1 + 5 IF ID EX MEM
2.2. Классификация конфликтов по данным
Конфликт по данным возникает при наличии зависимости между ко-
мандами, расположенными по отношению друг к другу настолько
близко, что совмещение операций, происходящее при конвейериза-
ции, может привести к изменению порядка обращения к операндам.
В зависимости от порядка операций чтения и записи различают три
возможных конфликта по данным.
68
2.2. Классификация конфликтов по данным
Рассмотрим две команды / и j, при этом команда I предшествует ко-
манде j. Возможны следующие конфликты:
► RAW (чтение после записи) — команда j пытается прочитать опе-
ранд — источник данных прежде, чем команда /запишет туда данные.
Таким образом, у может некорректно получить старое (предыдущее)
значение. Эта ситуация представляет собой наиболее общий тип кон-
фликтов, способ преодоления которых — механизм «обходов»;
► WAR (запись после чтения) — командаj пытается записать результат
в приемник прежде, чем он считывается оттуда командой Z, так что I
может некорректно получить новое значение. Этот тип конфликтов,
как правило, не возникает в системах с централизованным управлением
потоком команд, обеспечивающих выполнение команд в порядке их
поступления, так как последующая запись всегда выполняется позд-
нее, чем предшествующее считывание. Особенно часто конфликты
такого рода могут возникать в системах, допускающих выполнение
команд не в порядке их расположения в программном коде;
► WAW (запись после записи) — команда j пытается записать операнд
прежде, чем будет записан результат команды Z, то есть записи закан-
чиваются в неверном порядке, оставляя в приемнике значение, запи-
санное командой Z, а не j. Этот тип конфликтов присутствует только в
конвейерах, которые выполняют запись со многих ступеней (или по-
зволяют команде выполняться даже в случае, когда предыдущая ко-
манда приостановлена).
Указанные конфликты могут быть разрешены с помощью достаточно
простого аппаратного решения, называемого пересылкой или продви-
жением данных (data forwarding), обходом (data bypassing), иногда —
«закороткой» (short-circuiting). Эта аппаратура работает следующим
образом. Результат операции АЛУ с его выходного регистра снова по-
дается на входы АЛУ. Если обнаруживается, что предыдущая операция
АЛУ записывает результат в регистр, соответствующий источнику
операнда для следующей операции АЛУ, то логические схемы управ-
ления выбирают в качестве входа для АЛУ результат, поступающий
по цепи «обхода», а не значение, прочитанное из регистрового файла
(рис. 2.1).
Существуют аппаратные методы, позволяющие изменить порядок
выполнения команд программы так, чтобы минимизировать приос-
тановки конвейера. Эти методы получили общее название методов
69
Глава 2. Конвейеризация
Рис. 2.1. АЛУ с цепями обхода и ускоренной пересылки
динамической оптимизации (в англоязычной литературе в последнее
время часто применяются также термины «out-of-order execution» —
неупорядоченное выполнение и «out-of-order issue» — неупорядочен-
ная выдача).
Основными средствами динамической оптимизации являются:
1) размещение схемы обнаружения конфликтов в возможно более
низкой точке конвейера команд так, чтобы позволить команде продви-
гаться по конвейеру до тех пор, пока ей реально не потребуется опе-
ранд, являющийся также результатом логически более ранней, но
еще не завершившейся команды. Альтернативным подходом являет-
ся централизованное обнаружение конфликтов на одной из ранних
ступеней конвейера;
2) буферизация комацд, ожидающих разрешения конфликта, и выдача
последующих, логически не связанных команд, в «обход» буфера.
В этом случае команды могут выдаваться на выполнение не в том по-
рядке, в котором они расположены в программе, однако аппаратура
обнаружения и устранения конфликтов между логически связанными
70
2.2. Классификация конфликтов по данным
командами обеспечивает получение результатов в соответствии с за-
данной программой;
3) соответствующая организация коммутирующих магистралей, обес-
печивающая засылку результата операции непосредственно в буфер,
хранящий логически зависимую команду, задержанную из-за кон-
фликта, или непосредственно на вход функционального устройства
до того, как этот результат будет записан в регистровый файл или
в память (short-circuiting, data forwarding, data bypassing).
Еще одним аппаратным методом минимизации конфликтов по дан-
ным является метод переименования регистров (register renaming). Он
получил свое название от широко применяющегося в компиляторах
метода переименования, представляющего собой метод размещения
данных, способствующий сокращению числа зависимостей и тем са-
мым увеличению производительности при отображении необходимых
исходной программе объектов (например, переменных) на аппаратные
ресурсы (например, ячейки памяти и регистры).
При аппаратной реализации метода переименования регистров вы-
деляются логические регистры, обращение к которым выполняется
с помощью соответствующих полей команды, и физические регист-
ры, которые размещаются в аппаратном регистровом файле процес-
сора. Номера логических регистров динамически отображаются на
номера физических регистров посредством таблиц отображения, ко-
торые обновляются после декодирования каждой команды. Каждый
новый результат записывается в новый физический регистр. Однако
предыдущее значение каждого логического регистра сохраняется и мо-
жет быть восстановлено в случае, если выполнение команды должно
быть прервано из-за возникновения исключительной ситуации или
неправильного предсказания направления условного перехода.
В процессе выполнения программы генерируется множество времен-
ных регистровых результатов. Эти временные значения записываются
в регистровые файлы вместе с постоянными значениями. Временное
значение становится новым постоянным значением, когда заверша-
ется выполнение команды (фиксируется результат). В свою очередь,
завершение выполнения команды происходит, когда все предыдущие
команды успешно завершились в заданном программой порядке.
Программист имеет дело только с логическими регистрами. Реализация
физических регистров от него скрыта. Как уже отмечалось, номера
71
Глава 2. Конвейеризация
логических регистров ставятся в соответствие номерам физических
регистров. Отображение реализуется с помощью соответствующих
таблиц, которые обновляются после декодирования каждой коман-
ды. Каждый новый результат записывается в физический регистр.
Однако до тех пор, пока не завершится выполнение соответствую-
щей команды, значение в этом физическом регистре рассматривает-
ся как временное.
Метод переименования регистров упрощает контроль зависимостей
поданным. В машине, выполняющей команды не в порядке их рас-
положения в программе, содержимое логических регистров не всегда
соответствует результату, поскольку один и тот же регистр может быть
назначен последовательно для хранения различных значений. Но по-
скольку номера физических регистров уникально идентифицируют
каждый результат, все неоднозначности устраняются.
2.3. Предикация
При использовании конвейера возникают трудности, связанные с за-
висимостью потока команд от управления. Каждое изменение потока
команд прерывает работу конвейера и может служить причиной появ-
ления приостановки (bubbles) конвейера. Команды условного и безус-
ловного перехода, команды перехода к подпрограмме и выхода из нее
могут послужить причиной приостановки конвейера. Приостановки
уменьшают преимущества использования конвейеризации и значи-
тельно сокращают производительность процессора. Первой причиной
приостановок может быть зависимость по данным непосредственно
в конвейере, когда условие перехода вычисляется позже, чем нужно
на этапе выборки команд, чтобы определить верное направление пе-
рехода. Вторая причина — задержка выборки следующей инструкции
в потоке команд.
Использование конвейера выражается формулой
п+т i + m’
п
где п — число полезных инструкций; т — число приостановок (bubbles).
72
2.3. Предикация
Число приостановок можно выразить следующим соотношением:
m=b(]-p)Nb +bq-N0,
где b — число переходов; р — вероятность успешного прогнозирова-
ния направления перехода; Nb — штраф за неправильное предсказа-
ние перехода; q — частота предсказаний; No — штраф за остальные
предположения.
В итоге получаем, что
l + b(l-p)Nb+-qN0
п п
Количество приостановок конвейера может быть уменьшено с помо-
щью следующих методов:
I. Уменьшение штрафа Nb:
1.1. продвижение кода условия;
1.2. быстрое сравнение;
1.3. использование слотов задержки;
1.4. отложенные переходы;
1.5. отложенные переходы со сжатием.
2. Увеличение р-.
2.1. статическое предсказание переходов;
2.2. динамическое предсказание переходов;
2.3. предсказание переходов после профилирования.
3. Уменьшение штрафа 7V0:
3.1. введение кэш-инструкций;
3.2. улучшение предвыборки инструкций;
3.3. использование буфера целевых адресов перехода;
3.4. исполнение альтернативных путей.
Ниже приведены некоторые из указанных методов уменьшения ко-
личества приостановок конвейера.
73
Глава 2. Конвейеризация
Продвижение кода условия (рис. 2.2)
Быстрое сравнение (рис. 2.3)
Используется схема быстрых сравнений на равенство, неравенство
или соотношение с нулем (< 0, < 0, > 0, > 0).
Отложенны г переходы (рис. 2.4, с. 76)
Идея данного метода — уменьшить штраф за переход, позволяя вы-
полниться N полезным инструкциям перед передачей управления.
Установлено, что 67 % всех переходов в программе выполняется ус-
пешно (циклы в программе). Поэтому желательно использовать пред-
сказание «переход будет осуществлен».
forwarding
ofcmpdata
\stage
tinted fetch
cmp
branch
delay slot
target
target +1
correct next
instructions
decode
read
execute
forwarding
ofCC
write /
i-1
«Г -si * i-1
i+l i-1 /
t i+l i-1 f /
t+1 t i+l * ' ti ’ ,
E t+1 t i+l i A L
t+1 t i+l
t+1 t
' - ' ' t+1
1 ' ' ”
Puc. 2.2. Схемы продвижения кода условия
74
2.3. Предикация
Предсказание переходов (рис. 2.5, с. 76)
Выделяются два различных подхода — статическое и динамическое
предсказания.
Статическое предсказание связывается с каждой командой перехода
и не меняется в течение исполнения программы. Этот вид предсказа-
ния использует информацию о поведении перехода во время компи-
ляции. Задача компилятора — оптимизировать порядок инструкций
для организации правильного перехода.
Различаются четыре схемы предсказания — переход принят, не при-
нят, обратный переход, статический бит направления перехода.
Статическое предсказание переходов дает возможность продвижения
для бита предсказания и организации логики для изменения стратегии
выбора команд. Бит предсказания предоставляется этапом декодиро-
вания инструкции и определяет путь выбора инструкции, следующей
за инструкцией перехода, или целевой инструкции перехода.
\stage
time''- fetch
cmp
branch
delay slot
target
correct next
instructions
fast compare logic
forwarding
of fast cmp data
decode
read
write
execute.
i-l
i V.... i-l
i+l . . . < i-l
t i+l f . / i-l
t i+l i-l
Йй .. . t i+l . . ’ i
jgy:' WSv * t i+l
•. . :•:+ • '.л' t
M - :.:Л' 3
Рис. 2.3. Схемы быстрого сравнения
75
Глава 2. Конвейеризация
(a) branch taken
\ stage
decode read execute
• CC-false
ready
write
branch instruction £
delay slot instr.___
target instruction
target +1 instr,
successor instr.
i+l
t
t+1
i+2
i+l
t
i+l
t+i 3333
i+2
i+l
i
/forwarding
ofCC
“В control transfer
i+2 ^>^3
i+2
(b) b anch not taken
bubbles
in the pipeline
Puc. 2.4. Схемы отложенных переходов
Рис. 2.5. Схемы предсказания переходов
76
2.3. Предикация
Предсказание переходов после профилирования
Предсказание переходов после профилирования — частный случай
статического предсказания. При тестовом прогоне программы изу-
чается статистика переходов и на ее основе выставляются биты на-
правления переходов, имеющие более высокую степень правильного
предсказания.
Динамическое предсказание переходов
Динамическое предсказание переходов использует информацию
о поведении команд перехода во время исполнения программы. Ни-
какая статическая информация в этом случае не используется. Дина-
мическое предсказание не зависит от поведения перехода в прошлом,
и это поведение сохранено в таблице, индексами которой являются
адреса переходов. Как правило, в этой же таблице хранится и инфор-
мация о нескольких последних переходах для повышения точности
предсказания.
Использование предикатов
► «условные» инструкции — инструкция выполняется, если некото-
рое условие истинно;
► условие встроено непосредственно в инструкцию — переход вооб-
ще не используется;
► инструкции, использующие предикаты. Предикаты — предвы-
численные значения, сохраненные в регистре. Инструкция содержит
поле для выбора предиката из регистра.
«Условные» инструкции (рис. 2.6)
pl = true; р2 = not pl = false;
pl и р2 — предикаты.
< pl> а = а+1; <р2> b = Ь+1.
Приведем схему работы с использованием предикатов (рис. 2.7):
1. Команда перехода имеет два возможных варианта.
2. Компилятор назначает каждому варианту предикат.
3. Инструкции по данному пути.
4. Аналогично п. 3.
5. Начинается исполнение инструкций из обоих путей.
77
Глава 2. Конвейеризация
Рис. 2.6. Условные инструкции
Рис. 2.7. Схема работы с использованием предикатов
6. Инструкции исполняются параллельно, так как не имеют взаим-
ных зависимостей.
7. Когда становится известен результат предикатов, результаты вы-
полнения неправильного пути отбрасываются.
78
2.4. Конвейерные системы
2.4. Конвейерные системы
На сегодняшний день конвейерные (магистральные) системы полу-
чили большое распространение. Так, уже системы STAR 100, CDC
6600, CDC 7600, IBM 60/91, IBM 60/195 имели отдельные блоки для
магистральной обработки.
К примеру, в случае пятиступенчатой арифметико-конвейерной обра-
ботки каждая команда выполняется последовательно на пяти различ-
ных устройствах, а последовательность пяти следующих друг за другом
команд заполняет арифметическую магистраль так, что одновременно
на последнем, пятом, устройстве выполняется завершающий пятый
этап первой команды, а на первом — начальный, первый этап пятой
команды. После завершения выполнения первая команда выводится
из конвейера, вторая, третья, четвертая и пятая поступают на очеред-
ное устройство, а шестая входит на первое устройство конвейера.
В системе STAR 100, например, используется четырехступенчатая
магистраль для сложения и шестиступенчатая — для умножения.
Более высокий уровень конвейерной обработки — комавдно-конвей-
ерная обработка. Здесь каждая команда из потока команд выполняется
на соответствующих ей функциональных обрабатывающих устройст-
вах, которые могут работать одновременно. Для эффективной работы
подобных систем необходимо, чтобы команды были по возможности
независимы друг от друга, а распределение команд в потоке совпада-
ло с набором функциональных устройств. Типичный представитель
такой системы — CDC 6600, которая содержит 10 специальных уст-
ройств обработки (умножение с плавающей точкой, сложение целых
чисел и др.).
Суть макроконвейерной обработки состоит в следующем. Пусть мно-
жество исходных данных может быть обработано последовательным
решением двух и более задач. Обработка ведется двумя различными
процессорами, каждый из которых специализируется на решении своей
задачи. Данные из буфера поступают в первый процессор, обрабаты-
ваются (решается первая задача), затем результаты поступают во вто-
рой буфер, откуда передаются на второй процессор для дальнейшей
обработки (решается вторая задача). В это время первый буфер за-
полняется следующим набором данных и т.д. В результате оба про-
цессора работают одновременно.
79
Глава 2. Конвейеризация
Все три упомянутых типа конвейерных систем характеризуются
наличием конвейера (магистрали) обработки с независимыми ком-
понентами, которые при заполнении конвейера работают одновре-
менно и, по возможности, без перерывов.
Считается, что конвейерный принцип обработки повышает эффектив-
ность операций сложения на 47 %, а операций умножения — на 230 %.
Конвейерные структуры различаются и по типу команд: обычные
и векторные. Функциональные возможности конвейерной обработки
наиболее полно проявляются при векторной обработке данных, когда
выполняются однотипные операции над упорядоченной группой
данных.
Первым шагом на пути создания конвейерных систем явилось пере-
крытие операций. В большей мере это перекрытие операций I/O,
обработки в процессоре и обращения к ОП (UNIVAC, IBM 7094).
Из отечественных компьютеров следует отметить БЭСМ-6. В резуль-
тате эволюции структур компьютеров проектировщики пришли от
реализации отдельных блоков конвейерной обработки (IBM 360/91,
IBM 360/195) до полной реализации принципа конвейеризации
(STAR 100, CRAY 2, 3, 4 и т.д.). Первым конвейерным компьютером
общего назначения считается Stretch.
В настоящее время выработан стандарт конвейера, включающий пять
ступеней: чтение команды, декодирование, чтение операндов, ис-
полнение операции, запись результата.
В компьютерах Pentium Pro каждая из указанных ступеней может до-
полнительно разбиваться на подступени, так что общая «длина» кон-
вейера включает 12 подступеней. Естественно, что в зависимости от
типа выполняемой операции осуществляется настройка на конкрет-
ную длину конвейера.
Для обработки 12 подступеней конвейера в Pentium Pro включены
три устройства. Устройство выборки и декодирования поддерживает
шесть подступеней: выборку команд, распознавание команд в потоке
байтов, декодирование, постановку микрокоманд в очередь, запись
микрокоманд в таблицу регистров, формирование статуса микро-
команд. Устройство диспетчеризации и выполнения реализует под-
ступени: выбор готовых для исполнения микрокоманд, выполнение
80
2.4. Конвейерные системы
микрокоманд, изменение статуса микрокоманд, сравнение реального
и предсказанного результатов выполнения и осуществление соответ-
ствующей реакции. Устройство удаления выполненных команд осу-
ществляет удаление выполненных команд и микрокоманд из пула
и внесение соответствующих изменений в ряд таблиц.
Итак, конвейерная обработка позволяет существенно уменьшить время
решения задачи в целом, не сокращая времени выполнения отдельной
команды. Сложные и разнообразные команды в компьютерах с CISC-ар-
хитектурой потребовали существенного усложнения аппаратуры при
реализации конвейера. И только появление компьютеров с RISC-ар-
хитектурой придало новый импульс развитию технологии конвейе-
ризации. В частности, RISC-процессоры не требуют большого объема
конвейеризации. Так, например, в компьютере Pentium II чтение и де-
кодирование требуют семь циклов, в то время как в UltraSPARC лишь
три цикла.
Суперконвейеризация, то есть разбиение конвейера на большое ко-
личество ступеней, позволяет сократить работу, выполняемую за один
цикл, и увеличить частоту. Однако при реализации двух следующих
друг за другом команд, связанных по данным, будут образовываться
значительные приостановки конвейера. Поэтому наряду с суперкон-
вейеризацией желательно как можно больше операций реализовы-
вать параллельно.
Эффективность работы конвейера, как правило, определяется средней
латентностью, то есть средним количеством единиц времени между
двумя инициациями. Ясно, что чем меньше латентность конвейера,
тем выше его производительность.
Вторым подходом к оценке производительности конвейера является
загрузка его ступеней, то есть оценка частоты использования z-й сту-
пени конвейера за время одного вычисления.
Важную роль в повышении производительности конвейера имеет
стратегия диспетчеризации, главной целью которой является фор-
мирование последовательности моментов времени инициализации
(с целью максимизации темпа инициализации) или последователь-
ности латентностей между инициализациями для минимизации
средней латентности.
81
62792
Глава 2. Конвейеризация
Упражнения
1. Для 5-уровневого и 5-ступенчатого конвейера постройте временную
диаграмму выполнения цепочки операций: сложения, умножения, сло-
жения, умножения, сложения (при условии, что на каждую ступень име-
ется только одно обрабатывающее устройство). Оцените эффективность
использования конвейера. ’ читывайте приоритеты операций и следую-
щие условия:
• если четвертая операция использует результат выполнения второй
в качестве входного аргумента;
• если третья операция использует в качестве аргумента результат вы-
полнения первой и второй операций;
• если вторая операция использует в качестве аргумента результат вы-
полнения первой операции;
• если четвертая операция использует в качестве аргумента результат вы-
полнения первой и третьей операций;
• если пятая операция использует в качестве аргумента результат выпол-
нения первой и третьей операций;
• если третья операция использует в качестве аргумента результат выпол-
нения второй операции;
• если третья операция использует в качестве аргумента результат выпол-
нения второй и пятой операций;
• если четвертая операция использует в качестве аргумента результат вы-
полнения первой и второй операций;
• если пятая операция использует в качестве аргумента результат выпол-
нения первой и второй операций;
• если четвертая операция использует в качестве аргумента результат вы-
полнения второй и третьей операций.
2. Построить временную диаграмму 5-уровневого и 5-ступенчатого кон-
вейера для цепочки операций СЛ1, СЛ2, УМЗ, УМ4, СЛ5, при условии,
что результат операции СЛ1 используется в качестве аргумента операции
УМ4, а результат выполнения операции УМЗ в качестве аргумента в опе-
рации СЛ5. При этом учитывать приоритет выполнения операций.
82
Глава 3
Организация памяти
В состав базовых компонент архитектуры компьютеров входят орга-
низация памяти и способы взаимодействия информации на ее различ-
ных уровнях.
3.1. Иерархия памяти
Память компьютера может быть органи-
зована как многоуровневая с различным
объемом и временем доступа к ней —
сверхоперативная (СОЗУ), оперативная
(ОП), внешняя (ВнП) (рис. 3.1), так и од-
ноуровневая, виртуальная. Почти всегда
виртуальная память есть переупорядочен-
ное подмножество реальной памяти.
Уровни иерархии памяти взаимосвяза-
ны между собой — все данные одного
уровня могут присутствовать на более
низком уровне.
Рис. 3.1. Типы памяти
(К— объем,
S — быстродействие)
Основная память предназначена для хранения команд и данных
и обеспечивает адресный доступ к ним от процессора. Современные
устройства памяти работают со скоростью, близкой к скорости рабо-
ты процессора.
При обращении процессора к памяти сначала производится поиск
необходимых данных в СОЗУ. Так как время доступа к этому типу па-
мяти меньше, чем к ОП, и, как правило, большинство необходимых
для работы данных уже содержится там, то среднее время доступа
к памяти уменьшается.
Постоянная память (ПЗУ, ROM — read only memory) предназначе-
на только для чтения ее содержимого. В ней хранятся программы
проверки оборудования компьютера, инициирования загрузки опе-
рационной системы и выполнения базовых функций по обслужи-
ванию устройств, а также настройки конфигурации компьютера
(SETUP). Так как основное содержимое ПЗУ связано с обслужива-
83
Глава 3. Организация памяти
нием ввода-вывода, часто программы ROM-памяти называют BIOS
(Basic Input-Output System).
Небольшая по объему полупостоянная память используется для хране-
ния параметров конфигурации компьютера. По технологии изготовле-
ния ее часто называют CMOS-памятью (complementary metal-oxide
semiconductor), она имеет низкое энергопотребление.
3.2. Регистровая память
Простейшая регистровая структура используется для организации
стековой памяти. Стековая память представляет собой набор из п ре-
гистров, каждый из которых способен хранить одно машинное слово
(рис. 3.2). Одноименные разряды регистров Р2, ..., Р„ соединены
между собой цепями сдвига. Поэтому весь набор регистров может
рассматриваться как группа «-разрядных сдвигающих регистров,
составленных из одноименных разрядов регистров Рь Р2, ..., Рп.
Информация в стеке может продвигаться между регистрами вверх
и вниз.
Движение вниз: (/\) -> Р2, (Р2) —> Р3,..., а Р1 заполняется данными из
основной памяти.
Движение вверх: (Р„) —> P„_b (Pn_i) —> Рп-г, а Рп освобождается от ин-
формации.
Регистры Pi и Р2 связаны с АЛУ, образуя два операнда для выполне-
ния операции. Результат операции записывается в Pt. Следовательно,
АЛУ выполняет операцию (Р1)®(Р2) —
Одновременно с выполнением арифметической операции (АО) осу-
ществляется продвижение операндов вверх, не затрагивая содержи-
мого Р1; то есть (Р3) —> Р2, (Р4) —> Р3 и т.д., а содержимое регистра Р[
остается без изменений.
Таким образом, АО используют подразумеваемые адреса, что умень-
шает длину команды. В принципе, в команде достаточно иметь только
поле, определяющее код операции. Поэтому компьютеры со стековой
памятью называют безадресными. В то же время команды, осуществ-
ляющие вызов или запоминание информации из основной памяти,
требуют указания адреса операнда. Поэтому в компьютерах со стековой
84
3.2. Регистровая память
В память
Из памяти
Рис. 3.2. Стековая организация памяти
памятью используются команды переменной длины. Например, в KDF 9
команды арифметических операций могут включать одно, два или
три поля для определения кода операции и операндов, в зависимости
от типа операции (арифметическая, обращение к памяти, передача
управления).
Команды располагаются в памяти в виде непрерывного массива сло-
гов независимо от границ ячеек памяти. Это позволяет за один цикл
обращения к памяти вызвать несколько команд.
Для эффективного использования возможностей такой памяти в ком-
пьютерах вводятся специальные команды:
► дублирование (PJ —> Р2, (^г) —> Рз, — и т.д., a (PJ остается при этом
неизменным;
► реверсирование (Pl) —> Р2, а (Р2) —> Р1, что удобно для выполне-
ния некоторых операций.
85
Глава 3. Организация памяти
3.3. Организация кэш-памяти
Кэши — следующий уровень иерархии памяти. Кэши сравнительно
небольшие по объему, но имеют высокую скорость доступа. Исполь-
зование кэш-памяти основывается на двух принципах: локализация
в пространстве и локализация во времени. В кэш-памяти хранятся
команды и данные, которые часто используются и требуют малых
временных затрат для доступа к ним.
Кэши прозрачны к программному обеспечению. Обычно никакое
явное управление входами кэша невозможно. Данные распределяют-
ся и управляются кэшем автоматически. Однако некоторые процес-
соры осуществляют явный контроль над кэшированием данных.
Кэш-память позволяет организовать работу медленной оперативной
памяти как быстродействующей, оптимизируя следующие аспекты:
► максимизация коэффициента попадания;
► уменьшение времени доступа;
► уменьшение штрафа промаха;
► уменьшение непроизводительных затрат времени, требуемых для
поддержания консистентности1 кэша.
Характеристики кэша могут быть описаны следующей формулой:
Т 1 1
f ___________1 m______________________=______*_____
“* ~0-н)т.+н.т, (1_я)+я.2к\_яГ1_А]’
?т I тт)
где G — производительность кэша;
Н— hit ratio [0,..., 1];
(1 — Н) — miss ratio-,
Тт = tacc of main memory-,
Tc =tacc of cash memory.
1 Консистентность — согласованность, консенсус между программой и памятью.
(Примеч. авт.)
86
3.3. Организация кэш-памяти
Коэффициент попадания в кэш (в %) определяется отношением ко-
личества успешных входов к числу промахов. Время доступа к кэшу
должно быть значительно меньше, чем к оперативной памяти.
Кэши первого уровня (£1) обычно нуждаются в одном импульсе сиг-
нала, чтобы выбрать запись.
Доступ к внекристальным кэшам (£3) зависит от задержки протокола
управления передачей сообщений (chip-to-chip).
Два типа кэшей представлены на рис. 3.3 и рис. 3.4.
Рис. 3.3. Кэш прямого отображения
0
| x Bits | z Bits |
Word Byte
select select
m+n+x+z_________
m+rt Bits
hit|
Hardware Structure
(Address Path Only)
Address
Чт+п
Рис. 3.4. Полностью ассоциативный кэш
Тад
TagO
87
Глава 3. Организация памяти
3.3.1. Кэш-память: принципы создания
Быстродействующие процессоры не должны тратить большое время
на ожидание команд и данных из ОП. Одним из архитектурных реше-
ний механизма сокращения времени доступа к информации из ОП
является кэш-память.
Эффективность кэширования базируется на свойстве локализации
ссылок во времени (большую часть времени выполняются определен-
ные группы команд) и локализации в пространстве (высокая веро-
ятность выполнения в следующий момент времени команд, распо-
ложенных вблизи к текущей). Размещение в быстрой кэш-памяти
активных сегментов программ сокращает общее время их выполне-
ния. Реализуя принцип локализации во времени, каждый элемент
(команда, данные), к которому обращается процессор, копируется
в кэш, где он хранится до очередного востребования. Реализуя прин-
цип локализации в пространстве, наряду с текущим элементом в кэш
копируется и несколько близлежащих элементов. Набор элементов
с последовательными адресами определенного размера обычно на-
зывают блоком или строкой кэша.
Процессор Pentium 4 позволяет создавать кэш до трех уровней (£1,
L2, 13). На первом уровне имеется отдельная кэш-память данных
и кэш-память команд. Кэш данных объемом 8 Кбайт имеет четырех-
канальную множественно-ассоциативную организацию. Размер бло-
ка — 64 байта. Запись данных в кэш осуществляется по протоколу
сквозной записи. Целочисленные данные читаются из кэша за два так-
та. Доступ к данным требует менее 2 нс, так как микросхемы Pentium 4
могут работать на частоте более 1,3 ГГц. Кэш команд содержит деко-
дированные версии команд.
Второй уровень кэша (256 Кбайт) имеет восьмиканальную множест-
венно-ассоциативную организацию. Размер блока— 128 байт. Запись
данных идет по протоколу обратной записи. Время доступа составля-
ет семь тактов.
Кэши LI и L2 реализованы на микросхеме процессора. Архитектура
Pentium 4 позволяет организовать в микросхеме и кэш 13. В настоя-
щее время третий уровень используется лишь в процессорах для сер-
верных систем.
88
3.3. Организация кэш-памяти
3.3.2. Простейшая кэш-память
Память вычислительной машины представляет собой иерархию запо-
минающих устройств (внутренние регистры процессора, различные
типы сверхоперативной и оперативной памяти, диски, оптические дис-
ки, флэш-память), отличающихся средним временем доступа и стои-
мостью хранения данных в расчете на один бит (см. рис. 3.1). Причем
более высокий уровень памяти меньше по объему, быстрее и имеет
большую стоимость в пересчете на бит, чем более низкий уровень.
Уровни иерархии взаимосвязаны: все данные на одном уровне могут
быть также найдены на более низком уровне, а все данные на этом
более низком уровне могут быть найдены на следующем нижележащем
уровне и так далее, пока не будет достигнуто основание иерархии.
Важный способ увеличения производительности памяти — расслое-
ние памяти — состоит в одновременном доступе к Л' слоям памяти
(модулям памяти), при котором N последовательных адресов i, /+1,
/+2, ..., i+N— 1 приходится на N различных слоев. Последовательные
адреса разносятся по разным слоям таким образом, чтобы в одном
модуле были слова с адресами к N+i, 0<к< M—i, где М — число слов
в модуле I. Скорость доступа увеличивается в N раз (количество сло-
ев). Модуль памяти обычный (последовательный).
Имеются различные способы реализации таких расслоенных структур.
Большинство из них напоминают конвейеры, обеспечивающие рас-
сылку адресов в различные модули. Таким образом, коэффициент
расслоения определяет распределение адресов по модулям памяти.
Например, в суперкомпьютере NEC SX/3 используется 128 модулей
памяти.
Решением, которое позволяет увеличить пространство памяти и соз-
дать более быстрый доступ к ней, без роста стоимости компьютера,
является иерархия памяти.
Пользователи предпочитают иметь и недорогую и быструю память.
Кэш-память представляет некоторое компромиссное решение этой
проблемы.
Кэш-память — это способ организации совместного функционирова-
ния двух типов запоминающих устройств, отличающихся временем
доступа и стоимостью хранения данных, что позволяет уменьшить
среднее время доступа к данным за счет динамического копирования
89
Глава 3. Организация памяти
в «быстрое» ЗУ наиболее часто используемой информации из «мед-
ленного» запоминающего устройства.
Кэш-памятью часто называют не только способ организации работы
двух типов запоминающих устройств, но и одйо из устройств —
«быстрое» ЗУ. Оно стоит дороже и, как правило, имеет сравнительно
небольшой объем. Важно, что механизм кэш-памяти является про-
зрачным для пользователя.
Рассмотрим случай использования кэш-памяти для уменьшения
среднего времени доступа к данным, хранящимся в оперативной па-
мяти. Для этой цели между процессором и оперативной памятью по-
мещается быстрое ЗУ, называемое просто кэш-памятью. В качестве
его может быть использована, например, ассоциативная память. Со-
держимое кэш-памяти представляет собой совокупность записей обо
всех загруженных в нее элементах данных. Каждая запись об элемен-
те данных включает адрес, который этот элемент имеет в оператив-
ной памяти, и управляющую информацию: признак модификации
и признак обращения к данным за некоторый период времени.
В системах, оснащенных кэш-памятью, каждый запрос к оператив-
ной памяти выполняется в соответствии со следующим алгоритмом:
1) просматривается содержимое кэш-памяти с целью определения,
не находятся ли нужные данные в кэш-памяти;
2) при возникновении промаха контроллер кэш-памяти выбирает под-
лежащий замещению блок. Как правило, для замещения блоков при-
меняются две основные стратегии: случайная и LRU (Least-Recently
Used).
В первом случае для обеспечения равномерного распределения бло-
ки-кандидаты выбираются случайно. В некоторых системах, чтобы
получить воспроизводимое поведение, которое особенно полезно во
время отладки аппаратуры, используют псевдослучайный алгоритм
замещения.
Во втором случае, чтобы уменьшить вероятность удаления из кэша
информации, которая в ближайшее время может потребоваться, все
обращения к блокам фиксируются. Заменяется тот блок, который не
использовался самое длительное время (дольше всех) (стратегия LRU).
Достоинство случайного способа заключается в более простой ап-
паратной реализации, поскольку для поддержания стратегии LRU
90
3.3. Организация кэш-памяти
требуется увеличение количества блоков и данный алгоритм стано-
вится более дорогим и часто только приближенным.
При обращениях к кэш-памяти на реальных программах преобладают
обращения по чтению. Все обращения за командами являются обра-
щениями по чтению и большинство команд также ничего не записы-
вает в память — операции записи составляют менее 10 % общего
трафика памяти. Желание сделать данный общий случай более быст-
рым означает оптимизацию кэш-памяти для выполнения операций
чтения, однако при реализации высокопроизводительной обработки
нельзя пренебрегать и скоростью операций записи.
Общий случай является и более простым. Блок из кэш-памяти может
быть прочитан в то же самое время, когда читается и сравнивается его
тег. Таким образом, чтение блока начинается сразу, как только стано-
вится доступным адрес блока. И, если считанный тег и старшие 7 бит
адреса совпадают, то данный блок имеется в кэше.
Если некоторый блок основной памяти может располагаться в любом
месте кэш-памяти, то кэш называется полностью ассоциативным (fully
associative).
Механизм преобразования адресов должен быстро решать задачу опре-
деления наличия блока с произвольно указанным адресом в кэш-памя-
ти и адреса его расположения в кэше. Для этого используют ассоциа-
тивную память:
► входная информация — тег;
► выходная информация — адрес блока внутри кэш-памяти.
Если некоторый блок основной памяти может располагаться на огра-
ниченном множестве мест в кэш-памяти, то кэш называется множе-
ственно-ассоциативным (set associative). Обычно множество представ-
ляет собой группу из двух или большего числа блоков в кэше. Если
множество состоит из п блоков, то такое размещение называется мно-
жественно-ассоциативным с п каналами (n-way set associative). Для раз-
мещения блока прежде всего необходимо определить л, что задается
младшими разрядами адреса блока памяти (индексом).
Диапазон возможных организаций кэш-памяти очень широк: кэш-па-
мять с прямым отображением есть просто одноканальная множествен-
но-ассоциативная кэш-память, а полностью ассоциативная кэш-память
с т блоками может быть названа /и-канальной множественно-ассо-
91
Глава 3. Организация памяти
циативной. В современных процессорах, как правило, используется
либо кэш-память с прямым отображением, либо двух(четырех)-ка-
нальная множественно-ассоциативная кэш-память.
Покажем, как среднее время доступа к данным зависит от вероятно-
сти попадания в кэш. Пусть имеется основное запоминающее уст-
ройство со средним временем доступа к данным /1 и кэш-память,
имеющая время доступа /2, очевидно по определению, что fl < /1.
Обозначим через / среднее время доступа к данным в системе с кэш-па-
мятью, а черезр — вероятность попадания в кэш. По формуле полной
вероятности имеем:
t = tl(l-p)+tlp.
Из формулы следует, что среднее время доступа к данным в системе
с кэш-памятью линейно зависит от вероятности попадания в кэш
и изменяется от среднего времени доступа в основное ЗУ (при р = 0)
до среднего времени доступа непосредственно в кэш-память (при
Р = О-
В реальных системах вероятность попадания в кэш составляет при-
мерно 0,9. Высокое значение вероятности нахождения данных в кэш-
памяти связано с наличием у данных объективных свойств — времен-
ной и пространственной локальности.
Принцип временной локальности. Поскольку обращения к памяти но-
сят не случайный характер, а происходят в соответствии с выполняе-
мой программой, то при считывании данных из памяти с высокой
степенью вероятности можно предположить, что в ближайшем буду-
щем опять произойдет обращение к этим же данным. Поэтому их це-
лесообразно хранить в буфере в течение некоторого времени.
Принцип пространственной локальности. Если произошло обращение
по некоторому адресу, то с высокой степенью вероятности в ближай-
шее время произойдет обращение к соседним адресам.
Этот принцип предполагает считывание в кэш нескольких соседних
ячеек памяти, то есть блока информации. При этом возникает про-
блема определения требуемого размера блока, заключающаяся в сле-
дующем:
► чем больше размер блока, тем выше коэффициент удачных обра-
щений (количество обращений, которые пришлись на кэш, по отно-
шению к общему количеству обращений к памяти);
92
3.3. Организация кэш-памяти
► чем больше размер блока, тем меньшее количество блоков поме-
щается в кэш, то есть растет вероятность появления операции пере-
сылки блоков из ОП.
Д. Кнут установил, что линейные участки программ обычно не пре-
вышают 3—5 команд. Поэтому обычно размер блока — это 2—4 слова.
Все предыдущие рассуждения справедливы и для других запоминаю-
щих устройств, например для оперативной памяти и внешней памяти.
В этом случае уменьшается среднее время доступа к данным, распо-
ложенным на диске, а роль кэш-памяти выполняет буфер в оператив-
ной памяти.
Сегодня кэш-память имеется практически в компьютерах любого
класса, а в некоторых компьютерах — и в большом количестве.
Принципы размещения блоков в кэш-памяти определяют основные
типы их организации.
Если каждый блок основной памяти имеет только одно фиксиро-
ванное место, на котором он может появиться в кэш-памяти, то та-
кая кэш-память называется кэшем с прямым отображением (direct
mapped). Это наиболее простая организация кэш-памяти, при кото-
рой для отображения адресов блоков основной памяти на адреса
кэш-памяти просто используются младшие разряды адреса блока.
Таким образом, все блоки основной памяти, имеющие одинаковые
младшие разряды в своем адресе, попадают в один блок кэш-памяти,
то есть адрес блока кэш-памяти = (адрес блока основной памяти) mod
(число блоков в кэш-памяти).
Если чтение происходит с попаданием, то блок немедленно направ-
ляется в процессор. Если же происходит промах, то заранее считан-
ный блок не используется.
Другая ситуация возникает при выполнении операции записи. Обыч-
но размер записываемой информации составляет от 1 до 8 байт
и только эта часть блока должна быть изменена. В общем случае это
подразумевает выполнение последовательности операций над бло-
ком: чтение оригинала блока, модификацию его части и запись ново-
го значения блока. Более того, при наличии тега модификация блока
не может начаться до тех пор, пока проверяется содержимое тега,
чтобы убедиться, что данное обращение является попаданием. По-
скольку такая проверка не может выполняться параллельно с другой
93
Глава 3. Организация памяти
работой, операции записи занимают больше времени, чем операции
чтения.
Для записи в кэш-память имеются два способа:
► сквозная запись (write through, store through) — информация запи-
сывается сразу в две области: в блок кэш-памяти и в блок более низ-
кого уровня;
► запись с обратным копированием (write back, copy back, store in) —
информация записывается только в блок кэш-памяти. Модифициро-
ванный блок кэш-памяти записывается в основную память только
в случае его замещения. Для сокращения частоты копирования бло-
ков при замещении обычно с каждым блоком кэш-памяти связыва-
ется так называемый бит модификации (dirty bit), показывающий,
был ли модифицирован данный блок. Если он не модифицировался,
то обратное копирование отменяется, так как более низкий уровень
памяти содержит ту же информацию, что и кэш-память.
При записи с обратным копированием операции записи выполняют-
ся со скоростью кэш-памяти, и несколько записей в один и тот же
блок требуют только одной записи в память более низкого уровня.
Так как обращения к основной памяти происходят реже, то требуется
меньшая полоса пропускания памяти. При сквозной записи промахи
по чтению не влияют на записи в более высокий уровень, и, кроме
того, она проще для аппаратной реализации, чем запись с обратным
копированием.
Когда процессор ожидает завершения обращения к памяти при вы-
полнении сквозной записи, то говорят, что он приостанавливается
для записи (write stall). Общий прием минимизации приостановок по
записи связан с использованием буфера записи (write buffer), кото-
рый позволяет процессору продолжить выполнение других команд во
время обновления содержимого памяти. Следует отметить, что при-
остановки по записи могут возникать и при наличии буфера записи.
При промахе во время записи имеются две возможности:
► разместить запись в кэш-памяти (write allocate) (называется также
выборкой при записи — fetch on write). Блок загружается в кэш-па-
мять, вслед за чем выполняются действия, аналогичные действиям
при записи с попаданием. Это похоже на промах при чтении;
94
3.4. Концепция виртуальной памяти
► не размещать запись в кэш-памяти (называется также записью
в окружение — write around). Блок модифицируется на более низком
уровне и не загружается в кэш-память.
Обычно в кэш-памяти, реализующей запись с обратным копирова-
нием, используется размещение записи в кэш-памяти (в надежде, что
последующая запись в этот блок будет перехвачена), а в кэш-памяти
со сквозной записью размещение записи в кэш-памяти часто не про-
исходит, так как последующая запись в любом случае будет осуществ-
лена в основную память.
3.4. Концепция виртуальной памяти
Каждая часть среды компьютера имеет собственное обозначение:
ячейка — адрес, периферийное устройство — номер и т.д. В простей-
ших компьютерах собственные обозначения указываются непосред-
ственно в программе. В более сложных компьютерах программа отделе-
на от среды «аппаратом преобразования собственных обозначений».
Рассмотрим один элемент среды — память. Аппарат преобразования
адреса (АПА) не находится под прямым управлением программы
и связь с ним осуществляется только через процедуры, работающие
в управляющем режиме.
Если программист напрямую не использует АПА, то он работает с на-
бором ячеек и периферийных устройств, образующих «виртуальную
(математическую, мнимую) среду». Почти всегда виртуальная среда
есть переупорядоченное подмножество реальной среды. Каждому
виртуальному элементу соответствует реальный элемент, но обратное
не всегда верно.
Рассмотрим один из элементов виртуальной среды — виртуальную
память (ВП).
3.4.1. Задачи, решаемые виртуальной памятью
Виртуальный адрес — адрес, по которому ссылаются на ячейку вирту-
альной памяти. Область виртуальных адресов — это множество всех
виртуальных адресов.
Использование виртуальной адресации обусловливается следующи-
ми обстоятельствами.
95
Глава 3. Организация памяти
Однородность области адресов. Представим себе реальный компьютер
без виртуальной памяти. Пусть на нем выполняется параллельно не-
сколько процессов. У каждого процесса будет отдельная локальная
среда и каким-то образом распределяемые элементы общей среды.
Программисту требуется заранее знать, к каким конкретно частям
общей среды его процедура может обращаться. Это затруднительно
для пользователей ЭВМ, составляющих свои собственные программы.
Отвести наперед фиксированную область среды для каждого процесса
невозможно, ибо положение каждой конкретной программы опреде-
ляется положением всех других программ. И ситуация динамически
изменяется.
При виртуальной адресации каждый процесс в памяти может выпол-
няться с фиксированной (обычно нулевой) ячейки и на имеющей не-
обходимые размеры области ЗУ. Программисту безразлично, в каком
участке памяти размещается его программа, так как во время выпол-
нения программы каждое обращение к виртуальной памяти посред-
ством АПА преобразуется в реальное обращение. Следует учитывать,
что АПА работает не во время компиляции, а непосредственно во
время выполнения обращения.
Защита памяти. Общеизвестно, что основная цель защиты памяти со-
стоит в том, чтобы не дать возможности процессу, содержащему не-
корректные команды, испортить часть среды, относящуюся к другому
процессу. Особенно это важно при защите сред управляющих проце-
дур. Виртуальная адресация в данном случае используется следующим
образом: при каждой ссылке на память проверяется, принадлежит ли
данная ссылка к области виртуальных адресов, отведенных для ссы-
лающегося процесса.
Изменение структуры памяти. При проектировании больших программ
структура памяти машины с малой ОП явно усложняет проектируе-
мую программу. Применение виртуальной адресации позволяет пре-
образовать память на разных ступенях иерархии в «одноуровневую
память» с одинаковым доступом ко всем элементам и отобразить ее
на реальную память.
Для обеспечения однородности области адресов, защиты памяти
и изменения структуры требуется аппарат «страничной» организации
памяти.
96
3.4. Концепция виртуальной памяти
3.4.2. Страничная организация памяти
Отображение виртуальной памяти (ВП) в реальную обычно осущест-
вляется с помощью страничной организации памяти.
Виртуальную память в системе со страничной организацией памяти
делят на ряд «блоков» фиксированной длины, равной 2*, где к — це-
лое натуральное число. Так как первая ячейка очередного блока при-
мыкает к последней ячейке предыдущего блока, программисту факт
разбиения ВП на блоки учитывать не требуется.
Оперативная память компьютера при этом состоит из «страниц»,
а вспомогательная — из «сегментов» такого же размера.
Виртуальную память пользователя можно разделить на три типа:
► «активные» блоки,.которые содержат программу и данные, исполь-
зуемые в текущий момент;
► «пассивные» блоки, содержащие программу и данные, которые бу-
дут использоваться при выполнении программы;
► «мнимые» блоки, к которым не обращаются на протяжении выпол-
нения программы.
Соотношения между первым и вторым типами блоков ВП в процессе
выполнения программы изменяются. Третий тип блоков возможен
лишь при наличии очень большой области ВП.
Аппарат виртуальной адресации должен отображать виртуальную
среду на реальную, причем так, чтобы «активные» блоки находились
в оперативной памяти, «пассивные» — по возможности в оператив-
ной или вспомогательной, а мнимые — нигде.
Наиболее удачным из первых компьютеров со страничной организа-
цией памяти (СОП) является ATLAS (Ferranti). ВП в нем содержит
около 2 тысяч блоков по 512 слов, оперативная память — от 32 до 96
страниц такой же длины. Если ATLAS выполняет процесс, который
запрашивает блок из ВП, то некоторым блокам отводятся страницы
в оперативной памяти, остальные блоки помещаются на накопитель
на магнитном барабане. Фиксированных соотношений между номе-
рами страниц, блоков и сегментов не существует. Динамическое со-
отношение между сегментами отражено в соответствующей таблице
операционной системы.
97
7
‘2792
Глава 3. Организация памяти
Преобразование виртуального адреса в реальный происходит с помо-
щью регистров адресов страниц (РАС). Структура виртуального адреса:
Номер блока
Номер строки
Каждой странице ОП соответствует свой РАС, формат которого при-
веден на рис. 3.5. Аппарат виртуальной адресации отображает вирту-
альный адрес в реальный путем сравнения с содержимым всех РАС.
Номер блока, занимающего страницу в данный момент Бит использования Бит записи Бит активности
Рис. 3.5. Структура регистра адреса страницы
Единственным найденным РАС будет содержащий тот же номер бло-
ка и «1» в бите активности. РАС определяет номер страницы, с кото-
рой он связан. Для получения реального адреса памяти к номеру
страницы данного РАС присоединяется номер строки из виртуально-
го адреса (ВА). В последовательной интерпретации процесс преобра-
зования ВА в реальный можно отобразить схемой, представленной
на рис. 3.6.
Рис. 3.6. Схема отображения ВА в реальный адрес
Бит записи в РАС служит для экономии времени перезаписи «стра-
ницы» во внешнюю память (ВнП). Когда блок переносится из ВнП
в оперативную память, в бит записи заносится «О». Если некоторая
98
3.4. Концепция виртуальной памяти
строка данной страницы ОП изменяется в процессе обращения
к ней, то бит записи устанавливают равным «1». И пока содержимое
бита записи равно «О», эта страница является точной копией соответ-
ствующего блока во ВнП.
В бит использования «1» засылается при очередном обращении
к данной странице. Через равные промежутки времени содержимое
этого бита сканируется и записывается в определенную ячейку памя-
ти, тем самым создавая статистику использования данной страницы.
Подобная статистика полезна при замещении страниц в ОП.
Для создания РАС требуется очень дорогая ассоциативная память,
поэтому в mainframe-компьютерах число РАС меньше количества
страниц ОП. В таких компьютерах каждому блоку ВП отводится одна
последовательная ячейка памяти, указывающая место хранения это-
го блока (ОП, ВнПили нигде). Имеется небольшое количество ассо-
циативных регистров для РАС (обычно 8 или 16).
Полный процесс отображения ВП в реальную выполняется за три
этапа.
1. При обращении к блоку ВП, отображаемому на страницу ОП, РАС
которой является одним из 8 (16) ассоциативных регистров, про-
цесс отображения выполняется согласно схеме, приведенной на
рис. 3.7.
N стр. ОП
РАС
БЛ.0 0
БЛ.1 0
БЛ.2 0
БЛ.З 0
БЛ.2 1
БЛ.1 0
БЛ.0 0
БЛ.0 0
ВА
117
Рис. 3.7. Схема процесса отображения виртуального адреса (ВА)
в реальный адрес (РА) в ЭВМ ATLAS
РА (ОП)
117
99
Глава 3. Организация памяти
2. Если блок ВП не с тображен на странице ОП, то номер виртуально-
го блока служит указателем для обращения к таблице блоков (ТБ)
в оперативной памяти. Если из ТБ видно, что искомый блок нахо-
дится в оперативной памяти, то номер страницы также может быть
выбран из ТБ. Если же нужный блок находится во вспомогатель-
ной памяти или отсутствует вообще, то происходит прерывание
и осуществляется переход к управляющей процедуре (п. 3).
3. Обработк прерывания. Для эффективной работы системы необ-
ходимо, чтобы ассоциативные регистры сод» ржали РАС для наи-
более часто используемых страниц.
Основная цель методов оптимизации распределения реальной памяти
состоит в минимизации числа обменов между оперативной и вспомо-
гательной памятью. Отсюда следует, что необходимо корректно вы-
бирать стратегию замещения страниц. Наиболее часто на практике
используются следующие стратегии: циклическое изгнание, случай-
ная выборка, наименьшее число обращений с момента последнего
прерывания. Результаты экспериментов показали, что число обме-
нов, требуемых конкретной задачей при использовании указанных
стратегий, различается не более чем на 10 %.
Перенося концепцию виртуальной памяти на другие компоненты
компьютера, можно перейти к концепции виртуального компьютера.
3.5. Оперативные и постоянные запоминающие устройства
Все рассмотренные выше виды памяти характеризуются тем, что в них
можно как записывать, так и считывать информацию. Прежде всего
это оперативное запоминающее устройство (ОЗУ). ОЗУ бывает двух
типов: статическое и динамическое.
В статическом ОЗУ, конструируемом с помощью D-триггеров, ин-
формация сохраняется до тех пор, пока к нему подается питание.
Доступ к информации осуществляется за несколько наносекунд.
В связи с этим статическое ОЗУ используют в качестве кэш-памяти.
Динамическое ОЗУ — это набор ячеек, каждая из которых содержит
транзистор и конденсатор. Нули и единицы (биты) информации соот-
ветствуют заряженным и разряженным конденсаторам. Для предот-
100
3.5. Оперативные и постоянные запоминающие устройства
вращения исчезновения информации (так как электрический заряд
быстро исчезает) все конденсаторы должны каждые несколько мил-
лисекунд обновляться (перезаряжаться). Процесс обновления обес-
печивается внешней по отношению к ОЗУ логической схемой.
Динамическое ОЗУ имеет большой объем, хотя время доступа к нему
составляет десятки наносекунд.
Динамическое ОЗУ, требующее один транзистор и один конденсатор
на бит (статическое ОЗУ требует не менее шести транзисторов на
бит), имеет очень высокую плотность записи. Сочетание основной
памяти, реализованной на динамическом ОЗУ, с кэш-памятью, реа-
лизованной на статическом ОЗУ, позволяет использовать достоинст-
ва обоих типов ОЗУ.
Для динамических ОЗУ все еше используется тип памяти FPM (Fast
Page Mode) — быстрый постраничный режим, представляющий со-
бой матрицу битов. Аппаратная поддержка такого режима обеспечи-
вает поиск данных вначале по адресу строки, затем по адресу столбца.
Второй тип, применяемый для динамического ОЗУ, — EDO (Extend-
ed Date Output) — память с расширенными возможностями вывода.
Обеспечивает обращение к памяти еще до завершения предыдущего
обращения. Такой конвейерный режим не ускоряет доступ к памяти,
однако увеличивает пропускную способность вывода.
Очень часто данные следует сохранять даже при выключении пита-
ния. Это привело к созданию ПЗУ — постоянных запоминающих
устройств, не позволяющих изменять и стирать хранящуюся в них
информацию. Запись в ПЗУ производится во время его изготовле-
ния.
В отличие от обычных ПЗУ, программируемые ПЗУ позволяют осуще-
ствлять их программирование в условиях эксплуатации, например,
пережигая крошечные плавкие перемычки в нужных строках и столб-
цах и прилагая высокое напряжение к определенному выводу микро-
схемы.
Существует и стираемое программируемое ПЗУ, которое можно как
программировать во время эксплуатации, так и удалять из него ин-
формацию. Если на кварцевое окно в данном ПЗУ воздействовать
сильным ультрафиолетовым светом в течение 15 минут, то все биты
установятся в единицу.
101
Глава 3. Организация памяти
В настоящее время применяются и электронно-перепрограммируе-
мые ПЗУ, которые позволяют стирать информацию, не помещая ПЗУ
в специальную камеру. Однако самые большие электронно-пере-
программируемые ПЗУ по объему памяти в 64 раза меньше обычных
стираемых ПЗУ, работают медленнее, а стоят значительно дороже.
Поэтому такие ПЗУ используются только при необходимости сохра-
нить информацию при выключенном питании.
Современный тип электронно-перепрограммируемого ПЗУ — флэш-
память, которая стирается и записывается блоками. Многие произво-
дители создают небольшие печатные платы, содержащие сотни мега-
байт и даже десятки гигабайт флэш-памяти. Они используются для
хранения изображений в цифровых камерах, сотовых телефонах, для
хранения BIOS в ПК микропрограмм для микроконтроллеров HDD
и CDROM, а также для других целей.
Флэш-память — это особый вид памяти, который используется, как
правило, для мобильных устройств. Благодаря своим параметрам
флэш-память применяется во всех видах мобильных устройств. Она
не требует дополнительной энергии для хранения данных (энергия
требуется только для записи), допускает перезапись хранимых в ней
данных. Флэш-память не содержит механических движущихся час-
тей (как обычные жесткие диски или CD), а поэтому потребляет
значительно меньше энергии, что является одним из основных ее
преимуществ. В зависимости от типа флэш-памяти возможна переза-
пись информации от 10 000 до 1 000 000 раз.
Информация, записанная на флэш-память, может храниться дли-
тельное время (от 20 до 100 лет) и способна выдерживать значитель-
ные механические нагрузки, в 5—10 раз превышающие предельно
допустимые для обычных жестких дисков.
Флэш-память очень компактна. Размер флэш-карты составляет от 20
до 40 мм (по длине или ширине), толщина до 3 мм. Флэш-карта мо-
жет быть вмонтирована в мобильное устройство, а может быть пере-
носимой и использоваться в нескольких устройствах (например,
флэш-карта цифрового фотоаппарата может быть прочитана на
обычном компьютере). В настоящее время микросхемы флэш-памя-
ти производят более 50 компаний в мире. В техническом описании
любого мобильного устройства сейчас указывается тип используемой
флэш-памяти.
102
3.5. Оперативные и постоянные запоминающие устройства
В простейшем случае ячейка флэш-памяти хранит один бит инфор-
мации и состоит из одного полевого транзистора со специальной
электрически изолированной областью («плавающим» затвором —
floating gate), способной хранить заряд многие годы. Наличие или от-
сутствие заряда кодирует один бит информации.
При записи заряд помещается на плавающий затвор одним из двух
способов (зависит от типа ячейки): методом инжекции «горячих» элек-
тронов или методом туннелирования электронов. Стирание содержи-
мого ячейки (снятие заряда с «плавающего» затвора) производится
методом туннелирования.
Как правило, наличие заряда на транзисторе понимается как логиче-
ский «О», а его отсутствие — как логическая «1». Современная флэш-па-
мять обычно изготавливается по 0,13- и 0,18-микронной технологии.
Можно выделить несколько основных типов флэш-памяти.
CompactFlash (CF) выпускается двух типов — CF type I и CF type II.
Этот стандарт остается сегодня наиболее универсальным и перспек-
тивным, несмотря на больший по сравнению с другими картами раз-
мер (42 х 36 х 4 мм).
SmartMedia — дешевая и ультратонкая (толщиной всего 3/4 милли-
метра) флэш-карта. Невысокая цена за счет предельно простой кон-
струкции, но невысокая защищенность информации от случайного
стирания.
Multimedia Card (ММС) — основное достоинство этого типа заклю-
чается в миниатюрности и низком энергопотреблении, но при этом
достаточно низкая скорость чтения и записи. Размер стандартной
карты 24 х 32 х 1,4 мм, укороченной — 24 х 18 х 1,4 мм. Использует-
ся в мобильных телефонах и других миниатюрных устройствах.
SecureDigital (SD) — ее размер немногим больше ММС, но скорость
чтения и емкость значительно выше. В связи с этим карта стоит дороже.
SD и ММС обратно совместимы, то есть карты ММС можно вставить
и использовать в разъеме для карт SD, но не наоборот. Впрочем, сей-
час почти все устройства оборудованы именно разъемом SD (чаше
всего его называют SD/MMC).
MemoryStick — разработка фирмы Sony. Размер 24 х 32 х 1,4 (2,1) мм,
довольно высокая защита информации, скорость чтения и записи со-
поставимы с SecureDigital (SD), но емкость невысокая.
103
Глава 3. Организация памяти
На данный момент, по оценкам аналитиков, наиболее распростра-
ненными типами флэш-карт являются CompactFlash и SD/MMC.
CompactFlash, в частности, используется во многих цифровых фото-
аппаратах, например в популярной модели Canon digital ixus 400, а
SD/MMC — в «карманных» компьютерах, например в популярной
модели Rover рс рЗ. Цены на флэш-карты также оставляют потреби-
телю возможность выбора. К примеру, SD/MMC стоит от 34$ (32
Мбайт) до 315$ (512 Мбайт), a CompactFlash — от 31$ (32 Мбайт) до
290$ (1 Гбайт).
Возможно, со временем флэш-память вытеснит диски, учитывая бы-
стрый доступ к данным и постоянно возрастающую емкость.
3.6. Дополнительная память
Доступ к данным, расположенным в разноуровневой памяти, сущест-
венно различается по времени. Доступ к регистровой памяти измеря-
ется несколькими наносекундами (нс), к ОП — десятками наносе-
кунд, к оптическим дискам доступ может измеряться секундами.
Магнитные диски представляют собой алюминиевые диски с магнит-
ным покрытием; диаметр их колеблется от 12 до 3 см и менее. Головка
диска, поддерживаемая оздушной подушкой, записывает или счи-
тывает с соответствующего участка движущегося диска биты инфор-
мации. Последовательность бит, записанная по окружности диска за
его полный оборот, называют дорожкой.
Фрагмент дорожки диска показан на рис. 3.8.
Преамбула 4096 инф.бит
Преамбула 4096 инф.бит
1Ьловка записи-считывания
Рис. 3.8. Фрагмент дорожки диска из двух секторов
Как правило, сектор дорожки содержит 4096 информационных бит,
после них размещается код исправления ошибок, в качестве которого
применяется код Хемминга (см. гл. 5) или Рида-Соломона. Перед
104
3.6. Дополнительная память
данными расположено поле синхронизации головки диска. Межсек-
торный интервал разделяет соседние секторы. Указываемая произво-
дителями емкость неформатированного диска, как правило, после
форматирования уменьшается на 10—15 % за счет появления слу-
жебных полей. Плотность записи надиске около 105 бит/сь?Диски
герметично защищаются от проникновения пыли. В такой упаковке
(винчестере), как правило, помещается несколько дисков (рис. 3.9).
ТЬловки
Скорость вращения дисков около 180 оборотов в секунду. Время пе-
редачи информации зависит от времени поиска информации, объема
преамбул, кодов исправления ошибок и ожидания необходимого
сектора.
Высокая скорость вращения дисков приводит к их нагреванию и изме-
нению размеров, что требует периодической рекалибровки механиз-
мов перемещения головок. Для работы с мультимедиа-программами
выпускаются специальные аудио-видеодиски, не требующие терми-
ческих рекалибровок и обеспечивающие необходимый непрерывный
поток информации.
105
Глава 3. Организация памяти
В настоящее время усложнен процесс хранения информации надис-
ке за счет увеличения количества секторов при переходе от центра
диска к его краю, что повышает емкость диска.
Управляет диском специальная микросхема-контроллер, выполняю-
щая команды READ, WRITE, FORMAT, преобразование отдельных
поступающих байт в непрерывный поток бит и обратное преобразо-
вание, обнаружение, локализацию и исправление ошибок, буфериза-
цию совокупности секторов, их кэширование, замену неисправных
секторов резервными и т.д.
Дискета (floppy disk) имеет то же назначение, что и магнитные диски.
При чтении информации с дискеты головка непосредственно касает-
ся ее поверхности, в то время как головка магнитного диска пере-
мещается над его поверхностью на воздушной подушке. Дискеты
различаются физическими размерами, объемом хранимой информа-
ции и плотностью записи — низкой (LD — Low Density) и высокой
(HD — High Density).
Оптические диски имеют более высокую плотность записи, чем маг-
нитные, и обеспечивают хранение огромных объемов информации.
Впервые оптические диски были разработаны фирмой Philips. В 1980
году фирма Philips вместе с Sony разработали Compact Disk (CD). Для
обеспечения возможности хранения мультимедийной информации
была решена проблема размещения в одном секторе аудио-, видео-
и обычных данных. Большая емкость и низкая цена CD позволяют
использовать их для многих приложений, в частности, значительная
часть компьютерного программного обеспечения поставляется на
компакт-дисках.
Универсальная память, разработанная компанией Nantero на крем-
ниевой основе размером с компакт-диск, способна хранить 10 мил-
лиардов бит цифровой информации. Примечательно, что здесь для
кодировки бита не используется электрический заряд на элементе
схемы (обычная электронная память) и управление магнитным по-
лем (как в жестких дисках). Кодировка осуществляется физической
ориентацией наномерных структур. Каждая ячейка памяти изготов-
лена из углеродных нанотрубок. Она подвешивается на расстоянии
нескольких нанометров над электродом. В таком положении ток ме-
жду нанотрубкой и электродом не проходит (состояние «0»), Если
к нанотрубке приложить некоторое напряжение, она «провисает»
106
3.7. Управление памятью
в середине, соприкасаясь с электродом, и образует цепь (состояние «1»).
Положение нанотрубок сохраняется при снятом напряжении. В пер-
спективе такая память позволит хранить триллионы бит информации
на одном квадратном сантиметре.
3.7. Управление памятью
Управление памятью, как правило, требует решения двух задач:
► распределение памяти между процессами,
► защита памяти от несанкционированного доступа.
Для решения этих задач рассмотрим различные пространства адресов
и их взаимное отображение.
Пространство имен в программе представляет собой совокупность
идентификаторов, которые программа использует для обращения к тем
или иным областям памяти (например, имен переменных, точек вхо-
да для программных модулей и т.д.). Как правило, реальное располо-
жение соответствующих областей памяти не соответствует заданному
порядку имен. Исключением является описание массивов (элементы
массива должны идти непосредственно друг за другом в порядке воз-
растания их индексов) и структур (поля структуры также должны рас-
полагаться в смежных областях памяти).
Логическое пространство адресов представляет собой множество число-
вых значений, которые могут быть использованы для доступа к памя-
ти в машинных командах. Мощность этого множества определяется
архитектурой конкретной вычислительной системы. Так, процессор
18086 имеет 20-битовую шину адреса, следовательно, адресуемое ло-
гическое пространство этого процессора содержит 220 адресов, то есть
максимальный доступный адрес — 1 Мбайт. Переход к 32-разрядной
адресной шине дает возможность оперировать с адресами до 4 Гбайт.
Логический адрес часто представляется в формате «базовый адрес +
+ смещение», где в качестве базового адреса может выступать, напри-
мер, значение сегментного регистра.
Физическое пространство адресов ограничивается объемом реальной
памяти конкретного компьютера.
107
Глава 3. Организация памяти
Преобразование пространства имен в логическое пространство адресов
выполняется на этапе подготовки исполняемого модуля и его загрузки
в память перед выполнением. Рассмотрим этот этап подробнее.
При компиляции программы отдельным символьным именам ставят-
ся в соответствие логические адреса. Эти адреса имеют вид смещения
относительно некоторого базового адреса. Значение базового адреса
остается неопределенным. Оставшиеся символьные имена преобра-
зуются в так называемые внешние ссылки, которые должны быть
разрешены на последующих этапах обработки программы, в частно-
сти на этапе линкования (редактирования связей). Этот этап может
быть интегрирован в единое целое с компиляцией либо выделен в от-
дельный этап. При линковании выполняется разрешение ссылок, ос-
тавшихся после компиляции, за счет внешних библиотек и пр.
В идеальном случае в исполняемом модуле не должно быть неразре-
шенных внешних ссылок, за исключением динамически подключае-
мых имен. Полученный исполняемый модуль является, как правило,
перемещаемым, то есть все логические адреса в нем представлены
в виде смещений относительно одного или нескольких базовых адре-
сов. Наконец, на этапе загрузки программ осуществляется настройка
базовых адресов. Полученные адреса, тем не менее, остаются логиче-
скими.
При преобразовании логических адресов в физические возможны два
случая.
1. Пространство физических адресов больше пространства логических.
В этом случае для эффективного использования всей физической
памяти программы должны использовать специальные механизмы
расширения памяти. В качестве примера одного из таких механиз-
мов рассмотрим реализацию EMS (Extended Memory System), ха-
рактерную для поздних моделей операционной системы MS DOS.
Суть ее состоит в следующем: память свыше 1 Мбайт, объявленная
как EMS, разбивается на страницы размером 4 Кбайт. С другой
стороны, в области старших адресов памяти (то есть в границах ад-
ресов OAOOOOh — OFFFFh) выделяется фрейм размером 16 Кбайт,
в который перемещается информация из области EMS. Иллюстра-
ция этого механизма приведена на рис. 3.10.
2. Пространство логических адресов больше пространства физических.
В этом случае возможности преобразования значительно шире
108
3.7. Управление памятью
640 к
Рис. 3.10. Иллюстрация механизма EMS
и основаны на концепции виртуальной памяти — на диске созда-
ется специальный файл подкачки (файл виртуальной памяти),
разбитый на страницы. Подлежащая распределению оперативная
память также разбивается на страницы того же размера. Логиче-
ский адрес интерпретируется как «номер виртуальной страницы +
смещение в странице». Некоторые из логических страниц загружа-
ются в страницы оперативной памяти. Операционная система ве-
дет специальную таблицу соответствия логических и физических
страниц. При любом обращении к логическим адресам выполня-
ется проверка нахождения этой страницы в оперативной памяти.
Если страница отсутствует, происходит ее загрузка (возможно,
с вытеснением надиск одной из страниц, загруженных ранее). Ме-
ханизм работы с виртуальной памятью приведен на рис. 3.11.
Файл подкачки
Оперативная память
Рис. 3.11. Организация виртуальной памяти
109
Глава 3. Организация памяти
Различают следующие три типа исполняемых модулей в соответствии
с механизмом использования памяти:
► простые (линейные);
► оверлейные (с перекрытием);
► динамические.
В простых модулях каждая процедура получает свой блок логических
адресов, не пересекающийся с блоками адресов других процедур.
Такой механизм прост в использовании, поскольку после запуска
процесса нет необходимости применять загрузчик. Однако такая
структура исполняемого модуля приводит к неоправданно большому
размеру используемой памяти в случае, если схема взаимодействия
между процедурами имеет древовидную структуру. При этом может
сложиться ситуация, когда пространства физических (или логиче-
ских) адресов может не хватить для загрузки всей программы.
Альтернативой простой схеме является оверлейная структура. При
использовании такой схемы выделяются два или более модулей, ко-
торые не обращаются друг к другу, и для них указывается единая точка
перекрытия (точка оверлея). Все перекрывающиеся модули загружа-
ются в память начиная с этой точки. Это позволяет уменьшить сум-
марный объем загруженных модулей, но вынуждает тратить время
на подзагрузку перекрывающихся частей. Различия между простой
и оверлейной структурой показаны на рис. 3.12.
Оверлейные структуры могут быть созданы вручную (то есть про-
граммист указывает количество точек перекрытия и соответствующих
Рис. 3.12. Различие между простыми и оверлейными модулями:
а — схема вызова подпрограмм; б — структура простого модуля;
в —структура оверлейного модуля
110
Упражнения
им модулей) или автоматически. Кроме того, оверлеи реализуются
как средствами операционной системы, так и с помощью соответст-
вующих систем программирования.
Как простые, так и оверлейные схемы предполагают, что информа-
ция о подпрограммах, которые могут быть затребованы, известна до
начала работы соответствующего процесса. В отличие от них динами-
ческая схема позволяет определить это во время работы процесса.
Упражнения
1. Охарактеризуйте уровни иерархии памяти по объему и времени доступа
к данным.
2. Укажите содержимое стековой памяти до и после выполнения операции:
а) сложения,
б) умножения.
3. Для чего используется многоуровневая кэш-память?
4. Поясните параметры кэш-памяти: локализация в пространстве и лока-
лизация во времени.
5. Как организована кэш-память в Pentium 4?
6. Что такое «расслоение памяти»?
7. Какие функции выполняет виртуальная память?
8. Реализуйте алгоритм преобразования виртуального адреса в реальный.
9. Определите назначение динамического и статического ОЗУ.
111
Глава 4
Компьютерные сети
При решении ряда задач экономически нецелесообразно содержать
для каждого компьютера в организации накопитель на жестких маг-
нитных дисках большого объема, лазерный принтер, модем и другие
устройства. Кроме того, при решении сложной задачи, разбитой на
фрагменты, выполняемые на отдельных компьютерах разными ис-
полнителями, достаточно сложен процесс координации их работы.
Совместная работа над одной задачей требует постоянного и опера-
тивного обмена информацией и текущего контроля промежуточных
результатов для эффективного и успешного ее завершения.
Персональные компьютеры, работающие в автономном режиме,
пригодны лишь для решения индивидуальных (частных, персональ-
ных) задач, подготовки различных документов, графиков, таблиц
и т.п. При этом обычно возникает проблема обмена данными между
пользователями автономных компьютеров. Наиболее широко рас-
пространенными оказались два способа передачи сообщений: в виде
«твердой» (распечатанной на бумаге) копии данных или с помощью
копирования информации на дискету или другой носитель. Однако,
если над проектом работают одновременно несколько человек и каж-
дый ежедневно вносит в них изменения, возникают проблемы учета
этих изменений в динамике.
Существует ряд задач, решение которых непроизводительно или про-
сто невозможно без совместного использования информации. На-
пример, при резервировании и продаже билетов на транспорт, при
формировании бюджета страны, составлении прогноза погоды и т.п.
Справиться с указанными проблемами позволяет компьютерная сеть,
представляющая собой объединение отдельно работающих компьюте-
ров в один совместно функционирующий механизм, поддерживаемый
соответствующим программным и аппаратным обеспечением.
Компьютерные сети, обмен данными в которых осуществляется ко-
пированием информации на дискету (или другой носитель) и переда-
чей ее в такой форме на другие компьютеры, называют «переносной»
сетью.
112
Глава 4. Компьютерные сети
Компьютерная сеть позволяет обеспечить, по крайней мере, решение
трех проблем:
► экономить память на жестких магнитных дисках, так как группа
пользователей может применять одни и те же системные программы
и пакеты программ общего назначения;
► упростить и сделать оперативным процесс обмена информацией
между различными пользователями;
► получать одновременный доступ к одной и той же информации.
Организуют работу всех компонент сети и обеспечивают их эффек-
тивное функционирование сетевые операционные системы — NOS
(Network Operating Systems).
Компания Novell является одной из первых производителей компью-
терных сетей (оборудования и программного обеспечения). Разрабо-
танная ею NOS Netware способна поддерживать компьютеры (рабочие
станции), управляемые операционными системами DOS, Windows,
OS/2, UNIX, Windows NT, Mac System 7 и некоторыми другими ОС.
Наиболее распространенной NOS в Республике Беларусь является
Windows ХР (фирма Microsoft).
Windows NT Server позволяет работать в сети пользователям, персо-
нальные компьютеры (ПК) которых функционируют под управлени-
ем MS DOS, Windows 3.11 и Windows 95. Клиенты загружают свои зада-
ния, используя программное обеспечение, находящееся на жестких
дисках сети. Каждый клиент (или рабочая станция) с помощью сете-
вого адаптера с начальной программой сетевой загрузки (Remote Initial
Program Load — RPL) осуществляет удаленную загрузку (booting re-
motely) в сеть.
Одна из принципиальных особенностей операционной системы
Windows NT состоит в том, что сетевые возможности в нее встроены
изначально. В таких системах, как OS/2, Windows 3.11 или MS DOS,
возможности работы в сети добавлялись к готовым используемым
программным продуктам.
Одним из самых распространенных вычислительных комплексов в на-
стоящее время являются, пожалуй, локальные вычислительные сети
(ЛВС). Термин «локальная сеть» (LAN — Local Area Network) требует
пояснения, о каком масштабе «локальности» идет речь. Технические
113
®2Т92
Глава 4. Компьютерные сети
характеристики ЛВС имеют значительный разброс. Типовое расстоя-
ние между абонентами сети может составлять от нескольких метров
до нескольких километров. Термин «область действия ЛВС» (site) пе-
реводится в зависимости от контекста как «здание», «этаж», «поме-
щение».
Главное отличие ЛВС от глобальных (WAN — Wide Area Network) или
распределенных сетей — это наличие для всех абонентов высокоско-
ростного канала передачи данных, к которому компьютеры и другое
оборудование подключаются через специальные блоки сопряжения —
станции локальной сети. Большинство глобальных сетей представля-
ют собой объединение различных ЛВС посредством коммутационного
оборудования.
Системы LAN Manager и LAN Server содержат богатые возможности
для создания приложений типа клиент/сервер. Компьютер, работаю-
щий под управлением Windows NT, может выступать как в роли кли-
ента, так и в роли сервера. Windows NT Workstation и Windows NT
Server могут работать в качестве клиента сервера как в одноранговых
сетях, так и в среде распределенных приложений.
Первая компьютерная сеть ARPANET (Advanced Research Project
Agency NET) была разработана для потребностей Министерства обо-
роны США и начала функционировать в 1969 году. Для обеспечения
надежности передачи данных аналоговые сигналы были заменены
цифровыми, а любое сообщение разбивалось на отдельные фрагмен-
ты (пакеты, или дейтаграммы), передавалось по разным маршрутам
в сети и интегрировалось только у получателя информации. Фраг-
менты информации обрамлялись дополнительной информацией
(упаковывались), которую получатель должен был учитывать для оз-
накомления с полезной информацией. Набор правил, определивших
принципы обмена данными в сети, получил название протокола.
В 1971 году Ray Tomlinson разработал систему электронной почты,
где в адресе впервые был использован символ @ (коммерческое и).
В 1974 году рабочая группа, созданная агентством ARPA (руководи-
тель Vinton Cerf), разработала универсальный протокол передачи дан-
ных TCP/IP (Transmission Control Protocol), который успешно исполь-
зуется до сегодняшнего дня. В СССР в 1991 году была введена в ком-
мерческую эксплуатацию сеть RELCOM (разработка Института
атомной энергии АН СССР). Однако использование компьютерных
114
4.1. Эталонная модель сети
сетей порождает ряд проблем и трудностей. Назовем некоторые
из них:
► усложнение администрирования;
► удорожание средств приема/передачи данных;
► усложнение проблемы защиты информации;
► разрешение на поиск информации требует больших средств и вре-
мени, затрачиваемого на поиск, обеспечение достоверности и безо-
пасности получения информации;
► усугубление угроз жизнедеятельности общества от действий от-
дельных корпоративных объединений и лиц;
► восприятие «чужого» образа жизни вместе с получаемой информа-
цией: компьютерные программы, фильмы, реклама, музыка, вирту-
альная реальность и т.д.;
► проблема здоровья детей, использующих компьютер;
► расширение географии противоправных действий (перекачка денег
со счетов, использование несанкционированной информации и т.д.);
► технические средства воздействия на подсознание людей без их ве-
дома (25-й кадр, звуки определенного тембра и их сочетания, опреде-
ленная гамма цвета и т.д.).
Все эти и ряд других вопросов требуют обстоятельного изучения, ис-
следования, оценки и выработки соответствующих технических, ор-
ганизационных и правовых мер.
4.1. Эталонная модель сети
Наличие больших объемов вычислений внутри учреждений без выхо-
да (передачи) информации за их пределы и заметный рост информа-
ции, передаваемой между учреждениями, привели к тому, что рядом
фирм были разработаны вычислительные сети. Однако большое раз-
нообразие их архитектурных решений затрудняло обмен информацией
между сетями. Для упрощения решения этой проблемы требовалось
стандартизировать многие решения по сетям. Поэтому в 1977 году
при Комитете по вычислительной технике и обработке информа-
ции Международной организации по стандартизации (International
115
Глава 4. Компьютерные сети
Organization for Standardization — ISO) был образован новый подко-
митет с целью создания модели межсетевого взаимодействия, на базе
которой можно было бы разрабатывать основные направления стан-
дартизации по сетям.
В результате в 1979 году создана эталонная модель взаимодействия
открытых систем (Open System Interconnection — OSI), называемая
обычно «семиуровневой моделью» (рис. 4.1). OSI разделяет всевоз-
можные процессы, происходящие в сети во время сеанса связи, на
семь функциональных уровней (layers), строго организованных в со-
ответствии с естественным следованием событий, происходящих на
протяжении всего сеанса обмена информацией. Все уровни модели
взаимодействуют строго по иерархической системе — каждый уро-
вень обслуживает уровни, находящиеся выше его, и пользуется услу-
гами уровней, расположенных ниже. Иерархия уровней следующая
(снизу-вверх): физический, канальный, сетевой, транспортный, се-
ансовый, представления данных и прикладной.
Правила взаимодействия объектов одноименных уровней различных
систем называют протоколами, правила взаимодействия объектов смеж-
ных уровней одной и той же системы — межуровневым интерфейсом.
Все протоколы связи соответствующих уровней взаимодействующих
устройств сети стандартизованы. После определения полного набора
протоколов любые два устройства могут взаимодействовать, несмот-
ря на свои конструктивные особенности, функциональное назначе-
ние или внутренний интерфейс.
В модели OSI под открытой системой понимается система, выполняю-
щая стандартное множество функций взаимодействия, принятое в инфор-
мационно-вычислительной сети. На верхнем уровне взаимодействия
осуществляются прикладные процессы и в модель включаются те их
части, которые связаны с передачей информации между системами.
Основные же части прикладных процессов, связанные с хранением
и обработкой информации, в модели не рассматриваются. На нижнем
уровне функции взаимодействия связаны с физической средой со-
единения, по которой передается информация между системами. То-
пология, структура и параметры этой среды в эталонной модели не
рассматриваются.
В информационно-вычислительной сети используются три типа соеди-
нений: одностороннее (от одного объекта к другому либо к другим);
116
4.1. Эталонная модель сети
поочередное двухстороннее (передача информации поочередно в обе
стороны); одновременное двухстороннее (передача идет сразу в обе
стороны).
Тип процесса
Уровень OSI
(передатчик)
Информационные процессы 7 Прикладной
_ Представления О данных
5 Сеансовый
Транспортный процесс 4 Транспортный
Коммуникационные процессы 3 Сетевой
2 Канальный
1 Физический
Протоколы
Уровень OSI
Рис. 4.1. Эталонная модель взаимодействия открытых систем
Объекты N-ro уровня взаимодействуют друг с другом через соеди-
нения, создаваемые на (N— 1)-м уровне. Все уровни в эталонной се-
миуровневой модели существуют только для того, чтобы обеспечить
работу основного прикладного уровня.
Три верхних уровня модели OSI определяют информационные про-
цессы, выполняемые в системе, транспортный уровень определяет про-
цедуры передачи информации от системы-отправителя к системе-ад-
ресату. На трех нижних уровнях выполняются коммуникационные
процессы, осуществляющие передачу данных между взаимодействую-
щими системами.
Физический уровень (physical layer) обеспечивает интерфейс между
машиной, участвующей во взаимодействии, и средой передачи сиг-
налов, а также управляет потоком данных. Он принимает кадры дан-
ных от канального уровня и передает их содержимое бит за битом
в канал связи для формирования кадров. Среда передачи данных (ко-
аксиальный кабель, оптический кабель или витая пара) в физический
уровень не входит. Стандарты физического уровня включают реко-
мендации V.24 МККТТ, EIA RS232.
117
Глава 4. Компьютерные сети
Канальный уровень (data link layer) обеспечивает средства установления
соединения, его поддержки и освобождения линий передачи данных,
связывающих системы друг с другом. Как и для всех других уровней,
главной его функцией является прием и передача данных. Из данных,
передаваемых первым уровнем, здесь формируются так называемые
«кадры» или последовательности кадров, осуществляется управление
доступом к передающей среде, используемой несколькими машина-
ми, обнаруживаются и исправляются ошибки и обеспечивается цело-
стность передаваемых данных. Самым известным стандартом этого
уровня является стандарт ISO — протокол управления каналом HDLC
(High Level Data Link Control).
Сетевой уровень (network layer) реализует функции маршрутизации,
то есть определяет маршрут между передающим и принимающим
компьютером, чтобы «кадры» канального уровня (здесь уже называе-
мые «пакетами») могли передаваться через несколько каналов по од-
ной или нескольким сетям. Обычно это требует включения в пакет
сетевого адреса, причем этот адрес относится к принимающей маши-
не. На сетевом уровне осуществляется управление потоками данных,
которыми обмениваются системы, не связанные друг с другом физи-
ческими соединениями. Самый известный стандарт этого уровня —
рекомендации Х.25 МККТТ (для сетей общего пользования с комму-
тацией пакетов). Известный протокол IP (Internet Protocol) представ-
ляет собой пример интерфейса сетевого уровня.
Транспортный уровень (transport layer) обеспечивает взаимодействие
процессов в передающей и принимающей машинах и сквозное управ-
ление движением пакетов между ними. Если обнаруживаются пакеты,
некорректно распознанные маршрутизатором, то уровень формирует
запрос на их ретрансляцию. Одна из основных задач уровня — поддерж-
ка целостности данных. Уровень, если необходимо, упорядочивает
пакеты в соответствии с первоначальным направлением следования
и передает их на сеансовый уровень. Основными транспортными про-
токолами являются TCP (Transmission Control Protocol) и UDP (User
Datagram Protocol).
Рассмотренные уровни (с 1 по 4) можно определить как уровни пере-
дачи данных, уровни же 5—7 — это уровни обработки данных.
Сеансовый уровень (session layer) организует и поддерживает сеансы
взаимодействия (диалог) между прикладными процессами определен-
ие
4.1. Эталонная модель сети
ного типа, обрабатываемыми на разных компьютерах. Этот уровень
управляет потоком служебной информации, определяет тип соеди-
нения (одно- или двунаправленное) и гарантирует полную обработку
текущего запроса до приема следующего. Может быть использовано
несколько сеансовых уровней (а значит, и несколько протоколов) для
таких различных по типу процессов, как передача звука и видео
в цифровом коде и интерактивные вычисления.
Уровень представления данных (presentation layer) осуществляет интер-
претацию данных (форматов, кодов, структур, команд), передаваемых
во время диалога между прикладнь ми процессами. На передающем
компьютере этот уровень преобразует данные из формата, посылае-
мого прикладным уровнем, в общепринятый формат, а на прини-
мающем компьютере осуществляет обратное преобразование. При
управлении экраном терминала реализуются и другие функции, на-
пример выделение на экране особо важных полей, защита от стира-
ния некоторых частей экрана и т.д.
Прикладной уровень (application layer) реализует функции обслужи-
вания прикладных процессов, которые не были реализованы всеми
предыдущими уровнями. Это функции обслуживания сети, управле-
ния заданиями, протоколы обмена данными определенного типа и т.д.
Он предоставляет пользователю доступ к информации в сети через
использование протоколов, например: FTP — протокол передачи
файлов, DNS — доменная служба имен, Telnet — виртуальный терми-
нал, SMTP — протокол обмена сообщениями по электронной почте
И Т.Д.
Прикладным процессом называют основной компонент системы, осу-
ществляющий обработку информации для пользователей или адми-
нистративное управление сетью. Прикладной процесс является либо
источником, либо потребителем информации.
Примеры прикладных процессов:
► человеко-машинный, в котором человек-оператор работает у пульта
терминала;
► внутримашинный, определяемый программой работы с данными,
расположенными в компьютере, или с сетевыми ресурсами;
► производственный, обеспечивающий сбор информации и управ-
ляющий технологическим процессом.
119
Глава 4. Компьютерные сети
Прикладные процессы административного уровня связаны с управ-
лением ресурсами, расположенными на всех уровнях системы.
В реальных системах уровни эталонной модели реализуются по-раз-
ному. Имеются свои особенности и для ЛВС. На рис. 4.2 показано,
как в Windows NT реализована модель OSI.
Здесь NDIS (Network Driver Interface Specification) — спецификация
интерфейса сетевого драйвера, LLC (Logical Link Control) — подуро-
вень управления логической связью уровня канала данных, a RPC
(Remote Procedure Call) — поддержка удаленных вызовов процедур.
RPC
Поставщики
Именованные
каналы
7. Уровень приложения
---- Режим
пользователя
Режим
ядра
6. Уровень представления
5. Уровень сеанса Драйвер NETBIOS Редиректоры Серверы Драйвер WinSock
Интерфейс транспортного драйвера
4. Транспортный уровень ПОТОКИ
Транспортные протоколы
3. Сетевой уровень
2. Уровень канала данных (Ы£)
Интерфейс NDIS ПОТОКИ
Драйверы сетевых адаптеров
1. Физический уровень Интерфейс сетевого (ых) адаптера(ов)
Рис. 4.2. Уровни сетевой архитектуры Windows NT
120
4.2. Топология локальных сетей
4.2. Топология локальных сетей
Топология — это конфигурация соединения элементов ЛВС. Основные
топологические решения делят, как правило, на два типа:
► широковещательные, где каждый источник PS (Physical Signalling)
передает сигналы, которые могут восприниматься всеми приемниками
(остальными PS). К таким конфигурациям относятся «шина», «дерево»,
«звезда с пассивным центром», «ячейка»;
► последовательные, в которых каждый физический подуровень пе-
редает информацию только одному из PS. К таким топологиям отно-
сятся «кольцо», «цепочка», «звезда с интеллектуальным центром»,
«снежинка» и «сетка».
Рассмотрим широковещательные конфигурации.
Основной тип конфигурации ЛВС — «шина» (рис. 4.3). • •
Коммуникации между территориально распределенны-
ми устройствами в ЛВС несколько похожи на комму- ~] I
никации между модулями в компьютерах: высокая ско- I
рость передачи данных, частая смена структуры потока, * *
неравномерная загрузка. Основное их отличие состоит Pwc. 4.3.
в том, что скорость передачи данных в ЛВС может быть Топология
ниже, а длительность «взрывной» интенсивности боль- «шина»
ше. Наличие высокоскоростного общего канала — наиболее харак-
терная особенность современных локальных вычислительных сетей.
Из-за неравномерного характера потока данных последние обычно
передаются в форме пакетов, структура которых представлена на
рис. 4.4. Так как одно устройство может получать пакеты от несколь-
ких других устройств, то адрес отправителя — неотъемлемая часть
структуры пакета.
Адрес
получателя
Адрес
отправителя
Данные
Контрольная
сумма
Рис. 4.4. Структура пакета
Возможность широковещательного обращения реализуется резер-
вированием специального адреса получателя для значения «Всем».
Предполагается, что пакет с этим адресом будет обрабатываться все-
ми устройствами.
121
Глава 4. Компьютерные сети
Эффект использования шины в ЛВС состоит в том, что внутренние
шины компьютера как бы увеличиваются и охватывают целую тер-
риторию. Шины обеспечивают процессору доступ к периферийным
устройствам, блокам памяти или другим процессорам, находящим-
ся на значительном расстоянии от ЭВМ, но подключенным к шине
(рис. 4.5).
Интерфейсное устройство
Рис. 4.5. Подключение терминала в ЛВС
Сетевой контроллер управляет использованием шины, а процессор
вызовов (ПВ) управляет интерфейсом с терминалами. ПВ отвечает за
установку (создание) виртуального канала через сеть к порту ЭВМ
и за освобождение этого канала по окончании сеанса связи с терми-
налом. Во время сеанса ПВ получает данные от терминала, создает
пакеты для ЛВС и направляет их сетевому контроллеру, обеспечи-
вающему передачу пакета по шине.
Если, как это принято в UNIX, компьютер реагирует на любой вве-
денный символ, пакет должен приниматься и формироваться для ка-
ждого вводимого символа.
Шина обычно представляет собой пассивную среду и поэтому обла-
дает очень высокой надежностью.
Однако при использовании конфигурации «шина» возникает ряд
проблем:
► каждая станция должна успеть распознать свой адрес за время,
меньшее времени передачи данных;
► любая станция должна обеспечивать достаточную мощность сиг-
нала, посылаемого в шину, чтобы он мог достичь наиболее удаленных
станций;
122
4.2. Топология локальных сетей
► так как все станции наблюдают весь трафик, шина принципиально
не защищена, поэтому к защищаемым от несанкционированного дос-
тупа данным должны быть применены специальные способы защиты.
Конфигурация типа «дерево» (рис. 4.6) образуется путем соединения
нескольких шин активными повторителями или пассивными раз-
множителями. Она более гибкая, чем конфигурация «шина», и легко
позволяет охватить несколько этажей или несколько зданий.
Широкополосные ЛВС с конфигурацией «дерево» обычно имеют ко-
рень. Это означает, что сеть обладает особой управляющей позицией,
в которой размещаются самые важные компоненты ЛВС. Деревья
с корнем уязвимы, так как выход из строя оборудования, размещен-
ного в корне, блокирует работу сети.
Конфигурация типа «звезда» (рис. 4.7) — это дальнейшее развитие
конфигурации «дерево с корнем» с ответвлением к каждому подклю-
чаемому устройству. Эта топология традиционна в практике обычных
коммуникационных систем и дает высокую скорость обмена инфор-
мацией.
Рис. 4.6. Конфигурация типа
«дерево»
Рис. 4.7. Конфигурация типа
«звезда»
В центре «звезды» размещается коммутирующее устройство, которое
должно дублироваться, поскольку является очень важным для обес-
печения жизнедеятельности системы. Иногда в центре «звезды» мо-
жет находиться пассивный соединитель или активный повторитель
(простые и надежные устройства). В сетях ARCNet (фирма Datapoint)
используются оба варианта. Эта конфигурация требует значительно-
го расхода кабеля.
123
Глава 4. Компьютерные сети
Конфигурация типа «ячейка» предполагает, что каждый компьютер
в такой сети соединен с любым другим отдельным кабелем (рис. 4.8).
Сигнал от компьютера-отправителя к компьютеру-получателю мо-
жет проходить по разным маршрутам, поэтому разрыв какого-то ка-
беля не влияет на работоспособность сети. При построении больших
сетей данная топология используется в сочетании с другими тополо-
гиями в наиболее ответственных местах, где требуется высокая на-
дежность.
Топология «решетка» (рис. 4.9) может использоваться при большом
количестве узлов и характеризуется регулярностью связей.
Рис. 4.8. Конфигурация типа
«ячейка» (full interconnect)
Рис. 4.9. Топология «решетка»
Топология «двойной тор» (рис. 4.10) — это разновидность решетки
с соединенными краями и характеризуется большей, чем обычная ре-
шетка, отказоустойчивостью.
Рис. 4.10. Топология «двойной тор»
124
4.2. Топология локальных сетей
Количество различных переходов от источника к приемнику харак-
теризует размерность топологии.
Теперь остановимся на конфигурациях последовательного типа. Здесь
к передатчикам и приемникам предъявляются более низкие требова-
ния, чем в широковещательных конфигурациях.
В конфигурациях типа «кольцо» (рис. 4.11) и «цепочка» (рис. 4.12) для
устойчивого функционирования ЛВС требуется постоянная работа
всех блоков физической среды РМА (Physical Medium Attachment).
Чтобы ослабить это требование, в каждый блок включается реле.
В нормальном режиме реле замкнуты и размыкаются в случае потери
питания или других неисправностей.
Рис. 4.11. Конфигурация
типа «кольцо»
Рис. 4.12. Конфигурация
типа «цепочка»
Для упрощения разработки РМА и PS в конфигурации «кольцо» сиг-
налы передаются по кольцу только в одном направлении. Каждая стан-
ция располагает памятью объемом от нескольких байтов до целого
пакета. Наличие памяти замедляет передвижение данных в кольце
и обусловливает задержку, длительность которой возрастает с увели-
чением количества станций.
Если передача информации осуществляется по полному кругу, стан-
ция-получатель может установить в процессе обработки пакета некий
символ, подтверждающий факт получения информации. Например,
в ЛВС Cambridge Ring, включающей около 50 станций с кольцом в 2 км,
возврат подтверждения осуществляется за 20—25 мкс.
Удаление пакетов из сети может осуществляться либо станцией-по-
лучателем, либо, по завершении круга, станцией-отправителем.
125
Глава 4. Компьютерные сети
Существуют специальные программы — «сборщики мусора», кото-
рые в случае порчи отдельных станций опознают и уничтожают не-
востребованные пакеты.
Конфигурация «кольцо» имеет низкую от-
Центральный
блок
казоустойчивость, так как выход из строя * I / блок
какого-либо элемента кабеля останавли-
вает работу всей сети. Определенным раз- / / ]
решением этой ситуации является конфи- .А У
гурация типа «звездообразное кольцо» 9Г
(рис. 4.13), все «лучи» которой содержат JL
по две линии. Общение между станциями
осуществляется через центральный блок Рис.4.13. Конфигурация
(обычно пассивный), который использу- типа <,звездообРазное
КОЛЬЦО»
ют для локализации неисправностей.
Достоинство «звездообразного кольца» — простота управления. Отме-
тим и некоторые недостатки:
► значительно увеличивается длина кабеля,
► для каждой вновь подключенной машины необходимо проклады-
вать отдельный кабель.
Конфигурации «цепочка» и «кольцо», уязвимы в отношении отказов
и также требуют регенерации сигналов каждой станцией. Передача
информации через физическую среду здесь должна осуществляться в
двух направлениях.
Конфигурация типа «сетка» (рис. 4.14) применяется в глобальных се-
тях, поскольку позволяет выбирать наиболее оптимальный путь для
связывания абонентов. В ЛВС это достоинство менее важно, так как
передающая среда не является дорогостоящим ресурсом.
Конфигурация типа «снежинка» представлена на рис. 4.15.
В современных ЛВС применяются различные гибридные конфигура-
ции, вобравшие в себя лучшие свойства перечисленных топологиче-
ских решений.
При проектировании относительно больших компьютерных сетей на
разных участках сочетаются различные топологии. Приведем досто-
инства и недостатки некоторых топологий (табл. 4.1).
126
4.3. Примеры различных типов шин
Рис. 4.14. Конфигурация типа
Рис. 4.15. Конфигурация типа
«сетка»
«снежинка»
Таблица 4.1
Сравнение топологий
Топология Преимущества Недостатки
«Шина» Экономный расход кабеля. Относительно простая в ис- пользовании среда передачи данных. Легко расширяемая и надежная При больших объемах трафи- ка уменьшается пропускная способность сети. Выход ка- беля из строя прерывает рабо- ту многих пользователей
«Кольцо» Увеличение количества поль- зователей не оказывает значи- тельного влияния на произво- дительность сети Выход из строя какого-нибудь компьютера может остановить работу всей сети. В динамике невозможно реконфигуриро- вать сеть
«Звезда» Выход из строя какого-нибудь компьютера не влияет на ра- ботоспособность сети. Сеть легко модифицируется Выход из строя центрального узла приводит сеть в нерабо- чее состояние
«Ячейка» Относительно просто локали- зовать и диагностировать от- казы. Высокая надежность Высокая избыточность кон- фигурации требует больших затрат кабеля
4.3. Примеры различных типов шин
Одним из важных и простых способов объединения компонент ком-
пьютера и компьютеров в целом в слаженно функционирующий
механизм является шина. Шина состоит из набора разделяемых по
функциональным возможностям линий, применяемых для передачи
информации между различными устройствами сети.
127
Глава 4. Компьютерные сети
Классификация линий передачи осуществляется либо по назначению,
например шина данных, шина адреса, шина прерывания, шина син-
хронизации, либо в зависимости от подсоединяемых устройств, например
шина процессора, шина памяти, шина ввода-вывода, периферийная
шина.
Только одно устройство (master) в фиксированный момент времени
может быть активным на шине. Для одновременного доступа не-
скольких устройств используется специальный механизм, называе-
мый арбитром, который анализирует поступившие запросы на доступ
и предоставляет одному из них монопольное владение шиной. Другие
устройства (slaves) могут одновременно получать информацию, передавае-
мую устройством master. Именно широковещательность (broadcast) —
главное достоинство шины наряду с простотой ее реализации.
Рассмотрим три вида шин — ISA (Industry Standart Architecture —
стандартная промышленная), PCI (Peripheral Component Interconnect —
взаимодействие периферийных компонент) и USB (Universal Serial
Bus). Шина ISA представляет собой небольшое расширение первона-
чальной (исходной) шины IBM PC. Шина PCI шире ISA и работает
с более высокой тактовой частотой. Шина USB используется для под-
ключения периферийных устройств малого быстродействия (клавиа-
тура, мышь, проектор и т.д.).
Шина IBM PC — неофициальный стандарт систем с процессором
8088. Шина содержит 62 линии, из них 20—для адреса ячейки памяти,
8 — для данных, по одной линии для сигналов считывания информа-
ции из памяти, записи информации в память, считывания (записи)
с устройств ввода-вывода. Остальные линии предназначены для за-
просов на прерывание, их обработки, а также для прямого доступа
к памяти.
Первоначальный вариант шины ISA имел 16 линий для данных, а затем
шина была расширена до 32 разрядов. Более поздняя версия шины
EISA (Extended Indusrty Standart Architecture) предоставляла возмож-
ность параллельной обработки.
Появление игр и других приложений, применяющих полноэкранные
видеоизображения, потребовало создания новых шин. Для монитора
разрешением 1024 х 768 цветное отображение (3 байт/пиксел) одного
экрана содержит 2,25 Мбайт данных. Если учесть, что смена кадров
на экране для создания видимости плавного движения должна быть
128
4.3. Примеры различных типов шин
не менее 30 в секунду, то скорость передачи данных по шине должна
быть 67,5 Мбайт/с. При этом для передачи изображения данные
должны загрузиться с жесткого диска, компакт-диска или DVD-дис-
ка через шину в память, потом еще раз через шину — в графический
адаптер монитора. Таким образом, пропускная способность шины
должна быть 135 Мбайт/с. Но в компьютере действует центральный
процессор и другие устройства, которые пользуются шиной, что так-
же потребует существенного увеличения ее пропускной способности.
Максимальная частота передачи данных шины ISA — 8,33 МГц. При
передаче 2 байт за цикл ее максимальная пропускная способность
будет 16,7 Мбайт/с. Шина EISA может передавать 4 байта за цикл,
следовательно, ее пропускная способность достигает 33,3 Мбайт/с.
Ясно, что требованиям новых приложений она не удовлетворяет, по-
этому в 1990 году была разработана шина PCI, которая фактически
входит в каждый компьютер Intel, начиная с Pentium.
Первая версия PCI передавала 32 бита за цикл и работала с частотой
33 МГц с общей пропускной способностью 133 Мбайт/с. Шина PCI
2.1. работает с частотой 66 МГц, способна передавать 64 бита за цикл,
а ее общая пропускная способность составляет 528 Мбайт/с, что по-
зволяет решить задачу полноэкранного изображения. Однако такой
скорости недостаточно для шины памяти. В связи с этим компания
Intel разрабатывает компьютеры, имеющие несколько шин с разной
пропускной способностью, которые связывают через мосты (специ-
альные микросхемы) компоненты компьютера и различные шины.
Практически все компьютеры, начиная с Pentium II, выпускаются
с одним или несколькими свободными слотами PCI для подключения
дополнительных высокоскоростных периферийных устройств и с од-
ним или несколькими слотами ISA для подключения медленнодейст-
вующей периферии (рис. 4.16). Существуют универсальные платы,
поддерживающие разный уровень напряжения, которые можно вста-
вить в любой слот. Платы характеризуются разрядностью, при этом
32-битовые платы содержат 120 выводов, а 64-битовые — еще и 64 до-
полнительных вывода. Шина PCI, поддерживающая 64-битовые платы,
может поддерживать и 32-битовые, но не наоборот. Шины PCI и со-
ответствующие платы могут работать с частотой 33 МГц или 66 МГц.
В обоих случаях расположение контактов идентично. Чтобы не уве-
личивать количество выводов на плате, адресные и информационные
129
О
2792
Глава 4. Компьютерные сети
линии объединяются. В этом случае при операции считывания в цик-
ле 1 задающее устройство передает адрес на шину, в цикле 2 шина ревер-
сируется, открывая к ней доступ подчин иным устройствам, в цикле 3
подчиненное устройство выдает запрашиваемые данные. При опера-
ции записи шине не надо переключаться, ибо задающее пространство
помещает на нее и адрес, и данные. Тем не менее, минимальная тран-
закция занимает три цикла. Если подчиненное устройство не может
дать ответ в течение трех циклов, включается режим ожидания.
Шина Локальная Шина
кэш-памяти шина памяти
Рис. 4.16. Архитектура типовой системы Pentium II (толщина стрелки
характеризует пропускную способность соответствующей шины)
Чтобы устройство могло передать сигнал по шине PCI, вначале необ-
ходимо получить к ней доступ. Шина PCI управляется централизован-
ным арбитром, который, как правило, встраивается в один из мостов
между шинами (рис. 4.17). Каждое устройство PCI связано с арбит-
ром двумя специальными линиями. Одна из них (REQ#) служит для
запроса шины, а вторая (GNT#) — для получения разрешения на дос-
туп к шине.
130
4.3. Примеры различных типов шин
Чтобы осуществить запрос на доступ к шине, устройство PCI (в том
числе и центральный процессор) устанавливает сигнал REQ# и ждет,
пока арбитр не выдаст сигнал GNT#, после чего в следующем цикле
устройство может использовать шину. Алгоритм работы арбитра мо-
жет быть самым разнообразным (по приоритету, очереди, круговороту
и т.д.) и не зависит от технических характеристик шины РС1, однако
разрешение на доступ должно быть получено за разумное время.
Рис. 4.17. Использование централизованного арбитра в шине PCI
Как правило, доступ предоставляется на одну транзакцию, но при от-
сутствии конкуренции на доступ к шине устройство может повторять
транзакции снова и снова. Если устройство осуществляет очень дли-
тельную передачу, а другому устройству необходимо получить доступ
к шине, то арбитр может сбросить линию GNT#. После этого устрой-
ство, занимающее шину, должно в следующем цикле освободить ее.
Такое решение позволяет осуществить передачи большого объема.
Выводы шины используются для обязательных и вспомогательных
сигналов. Оставшиеся выводы задействованы для подключения пи-
тания, «земли» и некоторых других сигналов.
Некоторые устройства могут инициировать передачу информации по
шине (задающие устройства), то есть являются активными, другие же
ждут запросов (подчиненные устройства) — пассивные устройства
(табл. 4.2).
Если центральный процессор (ЦП) требует, например, от контролле-
ра диска считать или записать блок информации, то ЦП работает как
задающее устройство, а контроллер диска как подчиненное. Если же
131
Глава 4. Компьютерные сети
контроллер диска командует памяти принять слово, считанное с дис-
ка, то он выступает как задающее устройство. Память же ни при ка-
ких обстоятельствах не может быть задающим устройством.
Таблица 4.2
Примеры задающих и подчиненных устройств
№ Задающее устройство Подчиненное устройство Действие
1 ЦП Память Вызов команд и данных
2 цп Устройство I/O Инициализация передачи данных
3 ЦП Сопроцессор Передача команды от процессора к сопроцессору
4 Сопроцессор ЦП Вызов сопроцессором операндов и ЦП
Для активизации шины большинство устройств связаны с ней через
микросхему, которая по существу является усилителем двоичных сиг-
налов, посылаемых шине, и называется драйвером шины. Подчинен-
ные устройства таким же образом связываются через приемник шины.
Устройства, которые могут выступать в роли задающего и подчинен-
ного устройства, применяют приемопередатчик шины.
Шина PCI используется для подсоединения высокоскоростных уст-
ройств. Для подключения низкоскоростных устройств применяется
шина USB (Universal Serial Bus). При этом не требуется снятия кожу-
ха компьютера или его выключения (перезагрузки). Общая пропуск-
ная способность шины составляет 1,5 Мбайт/с, что достаточно для
таких устройств, как клавиатура, мышь, сканер, цифровой телефон,
флэш-память и т.д.
Шина USB содержит центральный хаб (концентратор) (см. 4.5.1), ко-
торый вставляется в разъем главной шины. Хаб имеет разъемы для
кабелей, подсоединяемых к устройствам ввода-вывода или дополни-
тельным хабам для обеспечения требуемого количества подключе-
ний. Следовательно, топология шины USB — это дерево с корнем
в центральном хабе, который находится внутри компьютера. Кон-
некторы кабеля со стороны устройства отличаются от коннекторов со
стороны хаба, чтобы пользователь случайно не подсоединил кабель
другой стороной. Центральный хаб определяет подсоединение ново-
го устройства и прерывает работу операционной системы, которая
распознает устройство и ряд его параметров. Если ОС решает, что
132
4.3. Примеры различных типов шин
пропускной способности шины для нового устройства достаточно,
ему присваивается уникальный адрес (1—127). Затем этот адрес и дру-
гая информация загружаются в регистры конфигурации внутри уст-
ройства.
В состав шины USB входит ряд каналов от центрального хаба к уст-
ройствам ввода-вывода. Каждое устройство может разбить свой ка-
нал максимум на 16 подканалов для различных типов данных (аудио,
видео и т.д.). В каждом канале или подканале данные перемещаются
от центрального концентратора к устройству и обратно. Между двумя
устройствами ввода-вывода обмен информацией не происходит.
4.3.1. Микросхемы процессоров и шины
Шина, как и процессор, имеет адресные линии, информационные
линии и линии управления. Однако между выводами процессора
и сигнальными линиями может и не быть взаимно однозначного со-
ответствия. Тогда в работу вступает микросхема-декодер, связываю-
щая процессор с требуемой шиной.
Микросхема процессоров содержит принимающие и передающие
выводы, а также выводы, осуществляющие как прием, так и передачу.
Все выводы микросхемы можно разделить на три типа: адресные,
информационные и управляющие. Эти выводы связаны с соответ-
ствующими выводами на микросхемах памяти и микросхемах уст-
ройств ввода-вывода через набор параллельных проводов, называе-
мых шиной.
Центральный процессор обменивается информацией с памятью и ус-
тройствами ввода-вывода, подавая сигналы на выходы и принимая
сигналы на входы. Чтобы вызвать, например, команду, ЦП посылает
в память адрес этой команды по адресным выводам. Затем он запус-
кает одну или несколько линий управления, чтобы сообщить памяти,
что ему надо, например, прочитать слово. Память выдает ответ, поме-
щая требуемое слово на информационные выводы процессора и по-
сылая сигнал о том, что задание выполнено. Получив этот сигнал,
ЦП принимает слово и выполняет вызванную команду. Для каждого
очередного слова весь процесс повторяется заново.
Важным параметром, определяющим производительность процессо-
ра, является количество адресных и информационных выводов. Если
133
Глава 4. Компьютерные сети
адресных выводов т, то процессор может обращаться к 2т ячейкам
памяти, а п информационных выводов позволяет считывать или запи-
сывать за одну операцию и-битовое слово.
Выводы управления регулируют и синхронизируют поток данных к про-
цессору и от него, а также выполняют некоторые другие функции.
Все процессоры содержат выводы питания (обычно +3,ЗВ или +5В),
«землю» и синхронизирующий сигнал (меандра). Остальные выводы
имеют разное назначение в зависимости от типа процессора.
Среди выводов управления можно выделить ряд основных типов: управ-
ление шиной, прерывание, арбитраж шины, состояние и прочие.
Выводы управления шиной в основном представляют собой выходы
из ЦП в шину (а значит, входы в микросхемы памяти и устройств вво-
да-вывода).
Выводы прерывания — это входы из устройств ввода-вывода в процес-
сор. Иногда процессор дает устройству ввода-вывода сигнал начала
операции с возможностью осуществления других действий до окон-
чания операции в устройстве. По окончании операции устройство
ввода-вывода через контроллер посылает сигнал на один из выводов
прерывания, чтобы прервать работу ЦП и заставить его обслуживать
устройство ввода-вывода (например, проверить ошибки ввода-выво-
да). Некоторые процессоры содержат выходной вывод для подтвер-
ждения факта получения сигнала прерывания.
Для разрешения конфликтных ситуаций по одновременному доступу
служит арбитр шины.
Многие ЦП работают с различными сопроцессорами (графическим,
с л-кратной точностью, с плавающей точкой и т.д.), для чего исполь-
зуются специальные выводы для передачи сигналов.
Процессоры могут использовать выводы для выдачи или приема ин-
формации о состоянии процесса, для перезагрузки компьютера, для
обеспечения совместимости с микросхемами устройств ввода-выво-
да ранних моделей и т.д.
Типичная схема микропроцессора изображена на рис. 4.18.
Шины, внутренние по отношению к процессору, служат для передачи
данных из АЛУ в АЛУ, а внешние связывают процессор с памятью и уст-
ройствами ввода-вывода. Первые персональные компьютеры имели
одну внешнюю шину, называемую системной, которая встраивалась
134
4.3. Примеры различных типов шин
Рис. 4.18. Типичная схема микропроцессора (короткие диагональные
линии указывают на наличие нескольких выводов)
в материнскую плату, содержащую разъемы для микросхем памяти
и устройств ввода-вывода. Современные персональные компьютеры
содержат специальную шину между ЦП и памятью и хотя бы одну
шину для устройств ввода-вывода.
Установлены четкие правила, определяющие работу шины. Все уст-
ройства, связанные с шиной, должны подчиняться этим правилам,
чтобы платы, выпускаемые третьими компаниями, могли работать
с шиной. Эти правила называют протоколом шины. Платы, конечно,
также должны удовлетворять некоторым техническим требованиям
(размеры, разъемы, потребляемая мощность, синхронизация и т.д.).
На скорость и пропускную способность шины существенно влияют
ее размеры, синхронизация, арбитраж и принципы работы.
Помимо рассмотренных существуют и другие типы циклов. Обычно
за один сеанс передается одно слово. При использовании кэш-памяти
(например, 16 последовательных 32-битовых слов) передача блоками
может оказаться более эффективной, чем последовательная передача
информации. После начала чтения блока задающее устройство сооб-
щает подчиненному количество передаваемых слов, помещая, на-
пример, общее число слов на информационные линии. Задающее
устройство выдает одно слово в течение каждого цикла до тех пор,
135
Глава 4. Компьютерные сети
пока не будет передано требуемое количество слов. В этом случае
в схеме передачи данных появляется дополнительный сигнал BLOCK,
указывающий, что запрашивается передача блока.
4.4. Простое средство связи в сетях (шина)
Перед обращением к шине процессор устанавливает сигнал BREQ
(bus request signal) и ждет, чтобы арбитр предоставил доступ к шине
с помощью сигнала BG (bus grant — допуск к шине).
Аппаратное устройство арбитра производит выбор BREQ сигналов
всех клиентов и затем генерирует маркер (token) одному клиенту, пре-
доставляя ему монопольное использование шины. Клиент становится
активным устройством (Master) и через Ts-driver управляет шиной.
В то же время все другие устройства (Slave) могут получать информа-
цию, передаваемую активным устройством, причем приемники всех
Slave могут получить фактические данные шины одновременно. Имен-
но свойство широковещательности (broadcast) передачи в каждом цикле
шины является ее главным достоинством наряду с простотой.
Арбитр получает сигналы запроса от всех устройств и определяет уст-
ройство, которому разрешается доступ к шине. Одновременно посту-
пающие запросы будут обслуживаться последовательно. Синхронизи-
рующий арбитр может быть реализован простым конечным автоматом
(FSM — Finite State Machine) (рис. 4.19).
Рис. 4.19. Реализация арбитра
136
4.4. Простое средство связи в сетях (шина)
4.4.1. Связь компьютера с периферийными устройствами
Механизмы взаимодействия компьютеров в сети аналогичны схеме
взаимодействия компьютера с периферийными устройствами (ПУ).
Для обмена данными между компьютером и ПУ предусмотрен внеш-
ний интерфейс, то есть набор проводов (линий), соединяющих компь-
ютер с ПУ, а также правил обмена информацией по этим проводам
(рис. 4.20).
Компьютер
Данные
Команды контроллера
«Установить начало листа»,
«Переместить магнитную головку»,
«Сообщить состояние устройства»
и др.
Рис. 4.20. Связь компьютера с периферийным устройством
Примерами интерфейсов, используемых в компьютерах, являются
параллельный интерфейс, предназначенный, например, для подклю-
чения принтеров, и последовательный интерфейс RS-232C.
Интерфейс реализуется со стороны компьютера контроллером ПУ
и специальной программой, управляющей контроллером (драйвер ПУ).
137
Глава 4. Компьютерные сети
Со стороны ПУ интерфейс реализуется аппаратным устройством управ-
ления.
Программа выполняется процессором, обменивается данными с ПУ
с помощью команд ввода/вывода.
Контроллеры ПУ принимают от процессора команды управления
и данные в свой внутренний буфер (порт), преобразуют их в соответ-
ствии с форматами ПУ и выдают на внешний интерфейс.
Периферийное устройство использует интерфейс для приема инфор-
мации, а также передает информацию в компьютер. Таким образом,
обмен данными по внешнему интерфейсу является двунаправленным.
Схема передачи одного байта информации от приложения на пери-
ферийное устройство следующая:
► программа обращается к драйверу устройства, сообщая ему адрес
байта памяти в качестве параметра;
► драйвер загружает значение этого байта в буфер контроллера;
► контроллер ПУ начинает последовательно передавать биты в ли-
нию связи, представляя их в виде электрических сигналов.
Перед передачей первого бита информации контроллер ПУ форми-
рует стартовый сигнал специфической формы, который для устройства
управления ПУ является признаком начала передачи. После послед-
него информационного бита аналогично формируется столовый сиг-
нал. Стартовый и столовый сигналы обеспечивают синхронизацию
передачи байта.
Кроме информацио иных бит, контроллер может передавать бит кон-
троля четности для повышения достоверности обмена.
Устройство управления, обнаружив на линии стартовый бит, начина-
ет принимать информационные биты, формируя из них байт в своем
приемном буфере.
Если передача сопровождается битом четности, то выполняется про-
верка правильности передачи. При правильно выполненной передаче
в соответствующем регистре устройства управления устанавливается
признак завершения приема.
Распределение функций между контроллером и драйвером жестко
не закреплено. Обычно на драйвер возлагаются наиболее сложные
138
4.4. Простое средство связи в сетях (шина)
функции (например, подсчет контрольной суммы последовательно-
сти байт, анализ состояния ПУ, правильность выполнения команд
и Т.Д.).
Существуют как специализированные интерфейсы для подключения
узкого класса устройств, так и интерфейсы общего назначения, являю-
щиеся стандартными. Пример стандартного интерфейса — RS-232C,
который поддерживается рядом терминалов, принтерами, манипуля-
торами типа «мышь» и многими другими устройствами.
4.4.2. Пример взаимодействия двух компьютеров
Взаимодействие двух компьютеров может быть реализовано на осно-
ве схемы взаимодействия компьютера с периферией, например, че-
рез последовательный интерфейс RS-232C. Главное отличие в том,
что происходит взаимодействие двух программ, работающих на каж-
дом из компьютеров.
Рассмотрим схему соединения двух компьютеров по кабелю связи через
COM-порты, которые, как известно, реализуют интерфейс RS-232C
(такое соединение называется нуль-модемным). Пусть для определен-
ности компьютеры работают под управлением операционной систе-
мы MS DOS (рис. 4.21).
Рис. 4.21. Взаимодействие двух компьютеров
139
Глава 4. Компьютерные сети
Драйвер COM-порта вместе с контроллером работают аналогично
взаимодействию ПУ с компьютером, однако при этом роль устройства
управления ПУ выполняют компьютер и драйвер COM-порта другого
компьютера. Драйвер компьютера периодически опрашивает признак
завершения приема, устанавливаемый контроллером при правильно
выполненной передаче данных, и при его появлении считывает при-
нятый байт из буфера контроллера в оперативную память, делая его
доступным для программ другого компьютера.
Пусть приложению, работающему на компьютере А, необходимо
прочитать информацию из некоторого файла, расположенного на
диске компьютера В.
В распоряжении программ компьютеров А и В имеются средства для
передачи одного байта информации. Приложение А должно сформи-
ровать сообщение — запрос для приложения В: имя файла, тип опе-
рации (в данном случае — чтение) и т.д. Для передачи сообщения
приложение Л обращается к драйверу СОМ-порта, передавая ему ад-
рес расположения сообщения в памяти. Драйвер обеспечивает необ-
ходимую передачу сообщения.
Приложение В, приняв запрос, считывает требуемый файл с диска
с помощью средств локальной ОС в буферную область своей опера-
тивной памяти, а затем с помощью драйвера COM-порта передает
считанные данные по каналу связи в компьютер А, где они доставля-
ются приложению А.
Функции взаимодействия двух компьютеров при передаче сообщений
в данном случае встроены непосредственно во взаимодействующие
приложения. Однако более эффективно создание специализирован-
ного программного модуля, который будет формировать запросы
и принимать результаты от всех приложений. Такой служебный мо-
дуль называют клиентом. На стороне В должен раб тать другой мо-
дуль — сервер, постоянно ожидающий запросы на доступ к файлам,
расположенным на этом компьютере.
Общая схема взаимодействия клиента и сервера с приложениями
и операционной системой приведена на рис. 4.22.
Полезной функцией клиентской программы является способность
отличить запрос к удаленному файлу от запроса к локальному файлу.
Редиректор — это часть клиентской программы, которая распознает и
перенаправляет запрос к удаленной машине.
140
4.4. Простое средство связи в сетях (шина)
Рис. 4.22. Взаимодействие программных компонент при связи
двух компьютеров
Редиректор унифицирует работу приложений, что позволяет не забо-
титься, с каким ресурсом идет работа (локальным или сетевым).
4.4.3. Объединение нескольких компьютеров
Линии передачи данных характеризуются активным сопротивлени-
ем, емкостью и индуктивностью (рис. 4.23).
Основные характеристики цепи:
► L' — характерная индуктивность на единицу длины;
► С' — характерная емкость на единицу длины;
Рис. 4.23. Схема цепи линии передачи
141
Глава 4. Компьютерные сети
► R' — характерное сопротивление на единицу длины;
► G' — характерная проводимость на единицу длины.
Важной характеристикой линии является волновое сопротивление,
называемое импедансом линии. Импеданс — комплексная величина,
измеряется в омах.
2= IjmL'+R'
у jaC'+G'
При высоких частотах передачи потерями (/?', G') можно пренебречь
по сравнению с импедансом и емкостью.
Приведенные соотношения могут быть применены, если время на-
растания сигнала tr в два раза меньше времени распространения tp.
В точке, где импеданс линии изменяется, волна, передаваемая по ка-
белю, частично отражается. Коэффициент отражения р показывает
количество энергии волны, отражаемой в определенной точке.
о -г2~г1 Zj +Z2 о -г1~г2 Р21 ~ Zi +Z2 _ Z2 Р12 Р21 Рп -0,2 р21 =-0,2 Zi =50Q z2=75Q 75—50 Р|2“ 50+75
Причины отражения волны можно отобразить следующими графи-
ками:
V , t<t, 1 .... 1 у. V<2tP . 1 V _ 2t,t<3tp (
’0 о 1
1 J—•— у
1 1
VA 1 1 1 д 1
i в 1 в 1 i в 1
При этом
142
4.4. Простое средство связи в сетях (шина)
Напряжение волны в генераторе на выходе A: VA = Ио--2—.
Ro +Zq
R —Z
Волна, отраженная в конце линии: Vrl = •рв, рв = — -—.
Rt +Z0
D __g
Волна, отраженная при выводе генератора: Vr2 = Vr\ рА, рА = —--
Ro +Z0
Отражения можно избежать, когда резистор Л, в точке В соответству-
ет импедансу линии Zo, то есть коэффициент отражения становится
равным нулю. Rt — резистор окончания линии передачи.
Приведем примеры линий передачи.
1. Коаксиальный кабель (Coaxial)
Центральная жила
2* - 50 Ом Оплетка
50 0м
2. Витая пара (Twisted Pair)
Рассмотрим объединение нескольких компьютеров в сеть на основе
самой простой и дешевой сетевой технологии Ethernet.
Стандарт Ethernet принят в 1980 году. Основной принцип Ethernet —
случайный метод доступа к разделяемой среде передачи данных.
В качестве такой среды может быть использован коаксиальный ка-
бель (тонкий либо толстый), витая пара, оптоволоконный кабель,
143
Глава 4. Компьютерные сети
радиоволны. Выделяют обычный Ethernet (10base-X), быстрый Fast
Ethernet (100base-XX), децентрализованный Ethernet (ISO Ethernet),
Gigabit Ethernet (1000 Мбит/с), отличающиеся скоростью передачи
данных и максимальной длиной сегмента.
В стандарте Ethernet строго зафиксирована топология электрических
связей. Рассмотрим способ подключения компьютеров к разделяемой
среде в соответст ии с типовой структурой «общая шина» (рис. 4.24).
В этом случае компьютеры подключаются к одному коаксиальному
кабелю по схеме «монтажное ИЛИ»: передаваемая информация может
распространяться в обе стороны. Управление доступом к линии связи
осуществляется специальными контроллерами — сетевыми адапте-
рами Ethernet. Каждый сетевой адаптер имеет уникальный физиче-
ский адрес.
Компьютеры
Рис. 4.24. Сеть Ethernet
Случайный метод доступа к разделяемой среде состоит из следующих
операций.
Определение доступности среды. Компьютер может начать передачу
данных по сети, только если она свободна. Доступность среды опре-
деляется по отсутствию сигналов, то есть никакой другой компьютер
в данный момент не ведет передачу.
Передача данных (захват среды). Если среда свободна, компьютер на-
чинает вести передачу и таким образом захватывает среду. Время моно-
польного использования разделяемой среды одним узлом ограничива-
ется временем передачи одного кадра. Кадр — единица информации,
которой обмениваются компьютеры в сети Ethernet. Кадр имеет фик-
сированный формат, содержит данные и служебную информацию,
например адрес получателя и адрес отправителя.
Прием данных. При попадании кадра в разделяемую среду передачи
данных все сетевые адаптеры одновременно начинают принимать
144
4.4. Простое средство связи в сетях (шина)
кадр. Они анализируют адрес назначения и, если он совпадает с соб-
ственным, кадр помещается во внутренний буфер сетевого адаптера.
Таким образом, компьютер-адресат получает предназначенные ему
данные.
Коллизия. Возможна ситуация, когда два и более компьютера одно-
временно определяют незанятость среды и начинают вести передачу.
Такая ситуация, называемая коллизией, препятствует корректной пе-
редаче данных. Вероятность возникновения коллизий зависит от ин-
тенсивности сетевого трафика. Стандарт Ethernet предусматривает
алгоритм обнаружения и корректной обработки коллизий.
После обнаружения коллизии сетевые адаптеры, которые пытались
передать свои кадры, прекращают передачу и после паузы случайной
длительности повторяют попытку получить доступ к среде и передать
кадр, который вызвал коллизию.
Среда передачи данных выбирается в зависимости от поставленных
целей: стоимости, обеспечения безопасности, скорости передачи
данных и других параметров. Приведем некоторые сравнительные
характеристики основных физических сред, используемых в настоя-
щее время в компьютерных сетях (табл. 4.3).
Таблица 4.3
Сравнение физических сред передачи данных
Среда Достоинства Недостатки
Витая пара Низкая стоимость, простое построение сети Невысокая безопасность, сильная восприимчивость к шуму
Коаксиальный кабель Относительно высокая ско- рость передачи данных на короткие расстояния Недостаточная безопас- ность, значительная вос- приимчивость к шуму
Оптоволокон- ный кабель Высокая скорость передачи данных на большие расстоя- ния, в том числе звуковой, цифровой и видеоинфор- мации Высокая стоимость, слож- ности при развертывании
Из таблицы видно, что каждая из сред обладает как достоинствами,
так и недостатками. Поэтому при проектировании систем руковод-
ствуются некоторым компромиссом между их основными парамет-
рами.
Ю2792
145
Глава 4. Компьютерные сети
4.5. Сетевые технологии (LAN/WAN)
При построении компьютерных сетей (КС) применяются различные
сетевые технологии, каждая из которых имеет характерную для нее
топологию соединения узлов сети и метод доступа к среде передачи.
4.5.1. Подключение сетевых компонентов
Большинство КС для соединения используют кабели, которые вы-
ступают в качестве физической среды передачи сигналов между ком-
пьютерами. На практике применяются следующие типы кабелей:
► коаксиальный кабель (coaxcial);
► витая пара (twisted pair);
► оптоволоконный кабель (fiber optic).
Коаксиальный кабель. Состоит из медной жилы (core), окружающей
ее изоляции, экрана в виде металлической оплетки и внешней обо-
лочки. Электрические сигналы передаются по жиле, оплетки играют
роль «земли» и защищают жилу от электрических шумов (noise) и пе-
рекрестных помех (crosstalk). Перекрестные помехи — это электриче-
ские наводки, вызванные сигналами в соседних проводах.
Существует два типа коаксиальных кабелей:
► тонкий (thinnet) коаксиальный кабель: диаметр около 0,5 см; отно-
сится к группе семейства RG-58, его волновое сопротивление — 50 Ом;
► толстый (thicknet) коаксиальный кабель: диаметр около 1 см; ис-
пользуется в качестве магистрали (backbone).
Для подключения тонкого коаксиального кабеля к компьютерам при-
меняются BNC-коннекторы.
Для подключения к толстому коаксиальному кабелю применяется
специальное устройство — трансивер.
Витая пара. Простая витая пара — это два перевитых вокруг друг дру-
га изолированных медных провода.
Существует два типа витой пары:
► неэкранированная витая пара (UTP — Unshielded Twist Pair);
► экранированная (STP — Shielded Twist Pair).
146
4.5. Сетевые технологии (LAN/WAN)
Несколько витых пар часто помещают в одну защитную оболочку. Их
количество может быть разным. Завивка проводов позволяет изба-
виться от электрических полей, наводимых соседними парами.
Нормативные характеристики UTP кабелей определены стандартом
EIA/TIA568, который включает пять категорий:
1. Традиционный телефонный кабель, по которому можно переда-
вать только речь.
2. Кабель содержит четыре пары и способен передавать данные со
скоростью до 4 Мбит/с.
3. Четыре витые пары, 9 витков на метр, скорость передачи — до
10 Мбит/с.
4. Четыре витые пары, скорость — до 16 Мбит/с.
5. Четыре витые пары, скорость передачи — до 100 Мбит/с.
Экранированная витая пара (STP) имеет медную оплетку, которая
обеспечивает надежную защиту от помех.
Для подключения витой пары к компьютеру используются коннекто-
ры RJ-45 (рис. 4.25).
Рис. 4.25. Коннектор RJ-45
f 2
Оптоволоконный кабель. Предназначен для передачи данных на очень
высоких скоростях. Данные передаются по оптическим волокнам
в виде модулированных световых импульсов.
Оптическое волокно — тонкий стеклянный цилиндр (соте), покрытый
стеклянной оболочкой, с иным, чем у ядра, коэффициентом прелом-
ления. Каждое оптоволокно передает сигналы в одном направлении,
поэтому кабель состоит из двух волокон с самостоятельными кон-
147
Глава 4. Компьютерные сети
некторами. Внешнее покрытие обеспечивает жесткость и прочность
кабеля.
Для передачи по кабелю кодированных сигналов используют две тех-
нологии — немодулированную передачу и модулированную передачу.
При немодулированной передаче данные передаются в виде цифровых
сигналов, которые представляют собой дискретные электрические
или световые импульсы. При таком способе передачи цифровой сиг-
нал использует всю полосу пропускания* кабеля. Передаваемый сиг-
нал обладает свойством к затуханию и, как следствие, искажается.
Поэтому в немодулированных системах при передаче на большие
расстояния используют повторители, которые усиливают сигнал.
Модулированные системы передают данные в виде аналогового сиг-
нала, использующего некоторую полосу частот. Сигналы кодируются
непрерывной электромагнитной или световой волной. Для восста-
новления сигнала в модулированных системах используются усили-
тели.
Любая технология локальных сетей имеет определенные ограниче-
ния. Рассмотрим способы увеличения размеров сети в реальной среде.
Повторитель (Repeater). При передаче сигнала по кабелю его ампли-
туда уменьшается вследствие затухания, поэтому длина кабеля огра-
ничена. Повторитель — это устройство, которое разбивает локальную
сеть на сегменты, принимает затухающий сигнал из одного сегмента,
восстанавливает и передает его в другой сегмент.
Повторитель (рис. 4.26) функционирует на физическом уровне модели
OSI и позволяет объединять сегменты, использующие только одина-
ковые пакеты и протоколы LLC. Однако повторители могут переда-
вать пакет из одного типа физического носителя в другой. Например,
из сегмента на витой паре в кабель на оптоволокне.
Рис. 4.26. Повторитель
Т - Terminator
* Полоса пропускания — здесь разность между максимальной и минимальной часто-
той, которая может быть передана по кабелю.
148
4.5. Сетевые технологии (LAN/WAN)
Концентратор (HUB). HUB — многопортовый повторитель (рис. 4.27),
осуществляет функции повторителя сигналов на всех витых парах,
подключенных к его портам, так что образуется единая среда переда-
чи данных — логический (виртуальный) сегмент.
Рис. 4.27. Концентратор (HUB)
Мост (Bridge). Мост разбивает сеть на несколько сегментов, обеспе-
чивая в них локализацию трафика (рис. 4.28).
Рис. 4.28 Мост
Мост позволяет:
► увеличить размер сети и количество компьютеров в нем;
► повысить производительность сети за счет снижения трафика;
► соединить разнородные физические средства передачи;
► объединить разнородные сегменты сети (например, Ethernet, Token
Ring).
Коммутатор (Switch). Коммутатор выполняет те же функции, что
и мост, — сегментацию сети. Однако каждый порт коммутатора снаб-
жается собственным процессором, каждый из которых работает па-
раллельно (рис. 4.29).
149
Глава 4. Компьютерные сети
Рис. 4.29. Коммутатор
Между портами коммутатора устанавливаются виртуальные цепи пе-
редачи. Порты могут работать в полудуплексном (одностороннем)
или дуплексном (двустороннем) режиме. Поэтому N-портовый ком-
мутатор может обеспечить до N/2 одновременно действующих вирту-
альных цепей в полудуплексном режиме. В режиме полного дуплекса
теоретически число таких цепей может достигнуть N.
Коммутаторы могут быть блокирующими и неблокирующими. Не-
блокирующий коммутатор способен с максимальной скоростью об-
рабатывать все кадры, приходящие на все его порты.
Для соединения портов в коммутаторе могут использоваться комму-
тационные матрицы, высокоскоростные шины и разделяемая память.
Маршрутизаторы (Router). Маршрутизатор — устройство, позволяю-
щее соединять сегменты с различными архитектурами и протоколами,
обеспечивая наилучший маршрут передачи и фильтрации трафика.
Маршрутизаторы работают на сетевом уровне модели OSI.
Работа маршрутизатора строится на основе таблиц маршрутизации,
которые включают все известные сетевые адреса, способы связи
с другими сетями, возможные пути между маршрутизаторами, стои-
мость* передачи данных по этим маршрутам.
Маршрутизатор, принимая пакеты, предназначенные для удаленной
сети, пересылает их маршрутизатору, который обслуживает сеть на-
значения (рис. 4.30).
* Стоимость — здесь совокупная весовая оценка маршрута передачи данных, завися-
щая в том числе от качества применяемых линий связи. (Примеч. ред.)
150
4.5. Сетевые технологии (LAN/WAN)
Рис. 4.30. Маршрутизатор
Маршрутизаторы подразделяются на два основных типа по способам
формирования таблиц маршрутизации:
► статические, где таблицу жестко заданных маршрутов определяет
администратор сети;
► динамические, где таблица маршрутизации строится автоматиче-
ски с помощью протоколов маршрутизации:
• OSPF (Open Shortest Path First) — алгоритм маршрутизации на
основе анализа состояния каналов сети,
• RIP (Routing Information Protocol) — дистанционно-векторный
алгоритм маршрутизации.
4.5.2. Сетевой адаптер
Сетевой адаптер представляет собой физический интерфейс между ком-
пьютером и средой передачи. Платы сетевого адаптера вставляются
в слоты расширения сетевых компьютеров или интегрируются на ма-
теринскую плату. Для обеспечения физического соединения между
компьютером и сетью к соответствующему разъему или порту платы
подключается сетевой кабель.
Назначение сетевого адаптера:
► подготовка данных, поступающих от компьютера;
► передача по сетевому кабелю;
► управление потоком данных.
Сетевой адаптер состоит из аппаратной части и встроенных программ,
записанных в ПЗУ.
151
Глава 4. Компьютерные сети
Внутри компьютера данные передаются по шинам. Большинство со-
временных компьютеров оснащены 32-разрядной шиной, где обес-
печивается параллельная передача Данных. В то же время по сетевому
кабелю данные должны передаваться в виде потока бит, то есть про-
исходит последовательная передача.
Сетевой адаптер принимает данные в параллельной форме и органи-
зует их для последовательной, побитовой передачи. Процесс завер-
шается переводом цифровых данных компьютера в электрические
или оптические сигналы, передающиеся по сетевым кабелям. Это
преобразование выполняет трансивер — приемопередатчик.
Сетевой адаптер должен указывать свое местоположение в сети, что
обеспечивается присвоением ему уникального сетевого адреса, запи-
санного в ПЗУ.
Перед отправкой данных в сеть адаптер согласует с принимающими
платами параметры передачи — максимальные размеры блоков пере-
даваемых данных, интервалы между передачами блоков, а также ско-
рости передачи.
Адаптеры отличаются рядом параметров, которые должны быть кор-
ректно определены в системе. В их число входят:
к номер прерывания (IRQ): физическая линия, по которой сетевая
карта организует прерывание, посылая запрос компьютеру. Плата се-
тевого адаптера должна использовать незанятую линию;
► базовый порт ввода/вывода: определяет канал, по которому переда-
ются данные между платой сетевого адаптера и центральным про-
цессором. Для процессора порт выглядит как адрес. Плата сетевого
адаптера, как и любое другое устройство компьютера, должна иметь
уникальный базовый порт ввода/вывода;
► базовый адрес памяти: область памяти компьютера, которая исполь-
зуется сетевым адаптером в качестве буфера для входящих и исходящих
блоков данных. Обычно выбирается адрес памяти, не занятый другим
устройством компьютера;
► выбор трансивера: указывается тип используемого трансивера. Сете-
вой адаптер поставляется с внешним или встроенным трансивером.
Для обеспечения совместимости компьютера и сети плата сетевого
адаптера должна соответствовать внутренней структуре компьютера
152
4.5. Сетевые технологии (LAN/WAN)
(архитектуре шины данных) и иметь соединитель, соответствующий
типу кабельной системы.
Большинство современных компьютеров используют 32-разрядную
шину PCI (Peripherical Component Interconnect) (см. 4.3), которая удов-
летворяют большинству требований технологии Plug and Play, авто-
матизирующей конфигурирование компьютера.
Каждый тип кабеля имеет различные физические характеристики,
поэтому плата сетевого адаптера ориентируется для работы с опреде-
ленным типом кабеля. Некоторые платы имеют возможность работы
с несколькими типами кабеля, выбор которых осуществляется с по-
мощью переключателей либо программным способом.
Сетевой адаптер оказывает существенное влияние на производитель-
ность сети, предоставляя дополнительные возможности: прямой дос-
туп к памяти, разделяемую системную память адаптера, управление
шиной, встроенный микропроцессор.
4.5.3. Модель IEEE Project 802
Данная модель конкретизирует физический и канальный уровни для
локальных сетей и представляет собой стандарты, называемые спе-
цификациями 802, определяющими способы доступа сетевых адапте-
ров к физической среде.
Стандарты LAN, определенные Project 802, делятся на категории, на-
пример:
802.1 — Объединение сетей;
802.2 — Управление логической связью;
802.3 — Ethernet;
802.5 — Token Ring;
802.12 — 100VG AnyLan.
В соответствии с данной моделью канальный уровень разделен на два
подуровня:
управление логической связью (Logical Link Control — LLC), который
устанавливает канал связи и определяет использование логических
точек интерфейса, называемых точками доступа к услугам (Service
Access Points — SAP);
153
Глава 4. Компьютерные сети
управление доступом к среде (Media Access Control — МАС), который
обеспечивает совместный доступ сетевых адаптеров к физическому
уровню.
Программное обеспечение, позволяющее компьютеру работать с опре-
деленным устройством, называется драйвером (driver). Соответствую-
щие сетевые драйверы обеспечивают связь между сетевыми адаптерами
и редиректорами. Драйвер сетевого адаптера обеспечивает связь между
компьютером и платой сетевого адаптера, которая связывает компь-
ютер с сетью.
Правила и процедуры передачи данных в сетевой среде определяют
сетевые протоколы.
Компьютеры используют протоколы для выполнения следующих про-
цедур:
► разбиение данных на пакеты;
► добавление к пакету адресной информации;
► подготовка пакетов для передачи по сети;
► прием пакетов, передаваемых по кабелю;
► копирование данных из пакета в буфер и передача их в компьютер.
Связь в сети обеспечивает множество работающих протоколов на
различных уровнях модели OSI.
Иерархическая последовательность протоколов, решающих задачу се-
тевого взаимодействия, называется стеком сетевых протоколов.
В качестве стандартных моделей протоколов наиболее широко ис-
пользуются следующие стеки:
► ISO/OSI — полный набор протоколов, соответствующих модели OSI;
► TCP/IP — набор протоколов Интернета;
► IPX/SPX — стек фирмы Novell;
► NetBEUI.
В зависимости от выполняемых действий выделяют три типа протоко-
лов: прикладные, транспортные, сетевые.
Прикладные протоколы работают на верхнем уровне модели OSI, обес-
печивая взаимодействие приложений и обмен данными между ними
(например, http — протокол стека TCP/IP для передачи Web-страниц).
154
4.5. Сетевые технологии (LAN/WAN)
Транспортные протоколы поддерживают сеансы связи между компь-
ютерами и гарантируют надежный обмен данными между ними (на-
пример, TCP — протокол стека TCP/IP).
Сетевые протоколы обеспечивают услуги связи (например, IP — про-
токол стека TCP/IP для передачи пакетов).
Протоколы, передающие данные из одной сети в другую, называют
маршрутизируемыми. Такие протоколы используются для построения
глобальных сетей.
4.5.4. Глобальные сети
Глобальная сеть представляет собой множество локальных сетей, со-
единенных каналами связи, в качестве которых применяются:
► сети с коммутацией пакетов;
► аналоговые каналы связи;
► цифровые каналы связи.
Каналы связи (аналоговые и цифровые) могут быть выделенными и ком-
мутируемыми. Выделенный канал имеет фиксированную пропускную
способность и постоянно соединяет двух абонентов. Коммутируемые
каналы разделяются между многими абонентами этих каналов.
Наиболее популярными коммутируемыми каналами являются каналы
телефонных сетей PSTN (Public Switched Telephone Network).
Для работы на коммутируемых аналоговых линиях используются мо-
демы.
Модем — устройство, которое модулирует цифровой сигнал в анало-
говый на передающей стороне и демодулирует аналоговый сигнал
в цифровой на принимающей стороне.
По типу передачи данных модемы бывают асинхронные и синхронные.
Цифровые выделенные линии образуются путем постоянной комму-
тации в первичных сетях.
Существует два поколения технологий первичных сетей:
► PDH (Plesiochronic Ditital Hierarchy) — плезиохронная цифровая
иерархия;
► SDH (Synchronous Digital Hierarchy) — синхронная цифровая
иерархия.
155
Глава 4. Компьютерные сети
Для подключения к цифровому каналу используется устройство, кото-
рое называется устройством обслуживания канала и обработки данных
(CSU/DSU — Channel Service Unit / Data Service Unit). Это устройство
преобразует цифровые сигналы, генерируемые компьютером, в циф-
ровые сигналы, применяемые для синхронной связи.
Технология коммутации пакетов предполагает представление данных
в виде пакетов и передачу их по доступным маршрутам.
При передаче данных сети с коммутацией пакетов используют вирту-
альные каналы, состоящие из цепочки логических связей между пере-
дающим и принимающим компьютерами.
Виртуальные каналы обеспечивают достаточную надежность достав-
ки данных при выполнении следующих условий связи:
► наличие подтверждения;
► управление потоком данных;
► контроль ошибок.
Виртуальные каналы могут быть:
► коммутируемые (SVC — Switched Virtual Circuit) — соединение меж-
ду компьютерами осуществляется по маршруту, который сохраняется
в течение всего сеанса связи;
► постоянные (PVC — Permanent Virtual Circuit) — соединение являет-
ся постоянным и существует реально.
Среди цифровых технологий DSL (Digital Subscriber Line) для гло-
бальных сетей наибольшее распространение получили технологии
ADSL (Asymmetric DSL) и VDSL (Very high data rate DSL).
Наиболее перспективной в настоящее время считается технология
ADSL. Это модемная технология, превращающая стандартные або-
нентские телефонные аналоговые линии в линии высокоскоростного
доступа. Технология ADSL позволяет передавать информацию к або-
ненту со скоростью до 8,448 Мбит/с. В обратном направлении ис-
пользуется скорость до 800 Кбит/с.
Технология ADSL создана для выполнения двух основных функций:
высокоскоростной передачи данных (доступ в Интернет, удаленный
доступ к корпоративным данным) и интерактивного видео (видео по
требованию, фильмы, игры и т.д.).
156
Упражнения
Основное преимущество данной технологии — использование суще-
ствующих телефонных линий для установления связи без ограниче-
ний на обычные телефонные переговоры и факсы.
ADSL реализуется с помощью модема ADSL и стойки модемов ADSL,
называемой DSL Access Module (DSLAM).
На участке между ADSL-модемом и DSLAM функционируют три пото-
ка: высокоскоростной поток к абоненту, двунаправленный служебный
поток и речевой канал в стандартном диапазоне частот (0,3—3,4 кГц).
Частотные разделители выделяют речевой поток и направляют его
к обычному телефонному аппарату.
Упражнения
1. Какое назначение семиуровневой модели?
2. Опишите функции каждого из уровней эталонной модели взаимодейст-
вия открытых систем и укажите соответствующие протоколы.
3. Опишите отличие широковещательных и последовательных конфигура-
ций соединения элементов ЛВС.
4. Сравните по надежности функционирования и скорости передачи ин-
формации различные сетевые конфигурации: «дерево», «звезда», «коль-
цо», «цепочка», «звездообразное кольцо», «сетка», «снежинка».
5. Охарактеризуйте достоинства и недостатки физических сред передачи
данных.
6. Какие типы шин вам известны? Охарактеризуйте их возможности.
7. Опишите функции концентратора, моста и коммутатора.
8. В чем суть технологии удаленного доступа?
9. Какие функции выполняет арбитр шины?
157
Глава 5
Кодирование данных в компьютерах
Система кодирования данных возникла в связи с необходимостью
счета, сравнения вещей и обмена. На протяжении истории развития
земной цивилизации на разных континентах зарождались и развива-
лись различные системы кодирования. В последние годы они во
многом унифицировались, но до сих пор идет поиск новых способов
кодирования уже в связи с использованием и развитием средств вы-
числительной техники, в частности эффективного использования
различных ресурсов: памяти, процессорного времени, удобочитае-
мости для пользователя и т.д. Среди многочисленных классифика-
ций подобных систем будем использовать только классификацию,
базирующуюся на зависимости значения числа от позиции цифры
в слове, то есть на позиционные и непозиционные системы кодиро-
вания.
5.1. Формы чисел с фиксированной и плавающей точкой
Двоичные числа в компьютерах представляются в двух видах: с фик-
сированной и с плавающей точкой.
В форме с фиксированной точкой последняя устанавливается за опре-
деленным разрядом числа, отделяя его целую часть от дробной.
Числа с фиксированной точкой масштабируются во избежание пере-
полнения разрядной сетки во время их обработки.
В форме с плавающей точкой числа представляются в виде
N =mgp,
где т — мантисса числа (правильная дробь, то есть tn < 1); р — поря-
док числа (целое число); g — основание системы счисления.
Порядок числа указывает положение точки в числе. При изменении
порядка положение точки изменяется (она «плавает»). Если абсолют-
ное значение мантиссы удовлетворяет условию
158
5.1. Формы чисел с фиксированной и плавающей точкой
то число называют нормализованным. В двоичной системе это усло-
вие запишется так:
1 >|ш| >0.1,
то есть мантисса числа меньше единицы и первая значащая цифра
непосредственно следует после точки. Если же в первой позиции по-
сле точки записан нуль, то число называют ненормализованным.
Представление чисел в нормализованном виде позволяет иметь в раз-
рядной сетке большее значение числа, чем в ненормализованном,
и, следовательно, повышает точность вычислений. Поэтому в разряд-
ной сетке компьютеров хранятся нормализованные числа с плавающей
точкой. Если в процессе вычислений появляется ненормализованное
число, то оно автоматически нормализуется путем сдвига мантиссы
с соответствующим изменением ее порядка.
Десятичные числа хранятся и обрабатываются в компьютере в двоич-
но-десятичном коде. Существует несколько способов кодирования
десятичных цифр, использующих знаки двоичного алфавита. Пред-
ставление знаков одного алфавита средствами (знаками, буквами,
словами) другого алфавита называют кодированием. Простейший
случай кодирования сообщения состоит в его дублировании. Про-
цесс обратного преобразования информации называют декодирова-
нием. Для представления информации в компьютере преимуществен-
но используется двоичное кодирование, при котором символы вводи-
мой в компьютер информации представляются средствами двоичного
алфавита, состоящего из двух знаков, в качестве которых использу-
ются символы «0» и «1». Двоичный алфавит по числу входящих в него
символов является минимальным, поэтому при двоичном кодирова-
нии алфавита, включающего большее число знаков, каждому знаку
ставится в соответствие последовательность нескольких двоичных
знаков или двоичное слово. Такие последовательности называются
кодовыми комбинациями.
Использование двоичного алфавита обусловливается сравнительной
простотой построения электронных элементов с двумя устойчивыми
состояниями.
Совокупность всех комбинаций из определенного количества сим-
волов, которые избраны для представления информации, называют
159
Глава 5. Кодирование данных в компьютерах
кодом. Общее количество кодовых комбинаций может быть меньше
или равно числу всевозможных комбинаций из заданного количества
символов.
Основная единица памяти — двоичный разряд, называемый битом.
Используют также следующие единицы: байт — 8 бит, килобайт
(Кбайт) — 1024 байт (210 байт), мегабайт (Мбайт) — 1024 Кбайт
(220 байт), гигабайт (Гбайт) — 1024 Мбайт (230 байт), терабайт
(Тбайт) — 1024 Гбайт (240 байт), петабайт (Пбайт) — 1024 Тбайт
(250 байт).
Обычно говорят, что IBM-совместимый персональный компьютер
работает в двоичной и десятичной арифметике. На самом деле ис-
пользуется двоичный и двоично—десятичный коды, где для каждой
десятичной цифры используется 4 бита, позволяющих представить
16 комбинаций. Однако из них шесть комбинаций не используются.
Двоично—десятичный код — это код «8421».
Пример. Число 1944 в двоично—десятичном коде использует 16 бит
и имеет вид: 194410 = 0001 1001 0100 OlOO2_io, а в двоичном коде
194410 = 00000111100110002, то есть 16 бит в 2—10-й форме хранит чис-
ло от 0 до 9999, следовательно, всего используется 10 000 различных
комбинаций. Именно по этой причине иногда говорят, что двоичная
система эффективна. Если бы удалось применить достаточно надеж-
ные устройства, способные поддерживать десять устойчивых состоя-
ний, то четыре таких устройства могли бы хранить числа от 0 до 9999,
то есть 10 000 комбинаций. В то же время такие устройства с десятью
устойчивыми состояниями могли бы хранить лишь 16 комбинаций
двоичных чисел. В этом случае более эффективной была бы десятич-
ная система.
В компьютерах, где используется двоичная система счисления (вклю-
чая восьмеричную и шестнадцатеричную), адреса памяти также вы-
ражаются в двоичном коде. Таким образом, если адрес состоит из
л бит, то максимально адресуемая память 2". Количество бит для зада-
ния адреса не зависит от количества бит в ячейке. А объем ячейки
в компьютерах различен. Например, в IBM PC — 8 бит, в IBM 1130 —
16 бит, в DEC PDP от 15 до 18 бит, в CDC—3600 — 48 бит, CDC
Cyber — 60 бит. Ячейка — минимальная единица, к которой можно
обращаться.
160
5.2. Пом хозащищенные коды
Всегда, вне зависимости от операции над кодовыми комбинациями
(хранение, передача, процессирование), необходимо быть уверенным,
что данные передаются и обрабатываются корректно. Для обеспече-
ния данного свойства используются корректирующие коды.
Приведем некоторые определения из теории кодирования.
Равномерный код — код, все комбинации которого содержат одина-
ковое количество символов.
Неравномерный код — код с различным количеством символов для
различных комбинаций (например, азбука Морзе).
В компьютерах обычно используют равномерные коды.
Кодовое расстояние — число позиций, в которых коды не совпадают.
Так, если А - alt а2,...» а„, В - Ь\, Ь2,..., Ь„, то кодовое расстояние (И^
вычисляется по формуле
W(A =
z=i
Пример. Пусть А - 101110, В - 000110, тогда W (А ® В) = 2.
Минимальное кодовое расстояние (d) — это минимальное расстояние
между двумя любыми кодовыми комбинациями в заданном коде.
5.2. Помехозащищенные коды
В зависимости от назначения и возможностей помехозащищенных
кодов различают коды самоконтролирующиеся, позволяющие автома-
тически обнаруживать наиболее вероятные ошибки, и самокорректи-
рующиеся, позволяющие автоматически исправлять ошибки.
Одна из основных задач теории кодирования — снижение вероятно-
сти появления ошибок, возникающих в результате помех в каналах
связи. Помехоустойчивое кодирование базируется на избыточности
информации за счет удлинения самого кода. Все символы исходного
и закодированного сообщения являются элементами одного и того
же конечного поля Вд=GF(q), где q = рт', т,ре N;p — простое число.
161
1 ^2792
Глава 5. Кодирование данных в компьютерах
Сам процесс кодирования состоит в трансформации исходного сооб-
щения at, а2, Fq в кодовую комбинацию
Ь\, Ь2, —,Ь„,
где Ь, &Fq, п> к.
В случае простейшего линейного кода исходное сообщение а1г а2,...,
ак кодируется словом вида
О], а2,ак, Ьм, Ьк+2,Ь„.
Здесь исходные (информационные) символы дополняются п—к сим-
волами bj е Fg, которые называют контрольными.
Если из того, что вектор (оь а2,а„) принадлежит линейному (л,^-ко-
ду С над полем Fq, следует, что его циклический сдвиг (а„, аь ..., a„_t)
тоже принадлежит С, то такой код называют циклическим.
5.2.1. Самоконтролирующиеся коды
Кодирование чисел в позиционной системе счисления (ПСС) ис-
пользует все кодовые комбинации для представления чисел. Так как
в ПСС нет избыточности, то использовать такие системы для контро-
ля информации невозможно.
Во всех помехозащищенных кодах минимальное кодовое расстояние d
должно быть больше единицы. Для обнаружения ошибки кратности t
требуется, чтобы d= t + 1, а для ее исправления — </= 2/ + 1. С увеличе-
нием значения d растет корректирующая способность кода, которая
количественно может быть выражена как вероятность обнаружения
или исправления ошибок различных типов. Избыточный код должен
иметь наряду с т информационными еще и к контрольных разрядов.
Количество контрольных разрядов характеризует а солютную избы-
точность кода, а отношение к/п, где п = т + к, — его относительную
избыточность.
Пусть р — вероятность того, что один символ в слове длины п неве-
рен. Если предположить, что п—s символов верны в слове длины л, то
вероятность того, что в s символах имеются ошибки, будет равна
р(5) = рЧ1-р)л-1.
162
5.2. Помехозащищенные коды
Количество кодовых комбинаций, каждая из которых содержит s
ошибочных элементов, равна числу сочетаний из л по s:
" s!(n—s)!
Наиболее часто на практике встречается ошибка в одном символе,
следовательно, обнаружение и исправление одиночной ошибки яв-
ляется очень важной задачей.
Код должен быть построен таким образом, чтобы при минимальной
избыточности обнаруживать часто встречающиеся ошибки. При этом
процедуры кодирования и декодирования по возможности должны
быть простыми в реализации и быстрыми в исполнении.
Код с проверкой на четность образуется добавлением к группе ин-
формационных двоичных знаков одного контрольного. Значение его
выбирается таким образом, чтобы общее количество единиц в слове
было четным или нечетным, то есть сумма цифр в числе по модулю 2
была соответственно равна 0 или 1. После чтения или записи данных
в память проверяется, сохранено ли это требование. Здесь d = 2.
Обнаруживаются одиночные ошибки и групповые ошибки с нечетной
кратностью. Целесообразно дополнять группу информационных раз-
рядов «до нечета», чтобы отличить значение 0 от отсутствия инфор-
мации в слове, ибо в этом случае в слове будет хотя бы одна единица.
5.2.2. Самокорректирующиеся коды
Применяя коды при d = 1 в качестве дополнительной информации,
можно использовать повторную передачу слова, что обеспечит воз-
можность операции сравнения и, следовательно, позволит обнару-
жить и исправить неустойчивые ошибки.
Вместо повторной передачи слов в компьютерах применяются избы-
точные коды, в которых для представления информации используются
практически все возможные кодовые комбинации, за исключением
запрещенных. Появление запрещенных комбинаций фиксируется
и расценивается как ошибка.
Для избыточных кодов d > 1. Если, например, d-2, то любые две комби-
нации данного кода отличаются не менее чем в двух разрядах. Любая
одиночная ошибка приведет к появлению запрещенной комбинации.
163
Глава 5. Кодирование данных в компьютерах
Такая ошибка будет обнаружена, то есть для обнаружения одиночной
ошибки достаточно иметь код с d = 2.
Чтобы можно было не только обнаружить, но и исправить одиночную
ошибку, необходимо иметь код с d> 3. В этом случае любая одиночная
ошибка создает запрещенную комбинацию. Этого достаточно, чтобы
определить ошибочный разряд и исправить его. Процесс исправления
состоит в поочередном изменении значения каждого разряда слова
(О на 1 и 1 на 0) с последующей проверкой на появление запрещенной
кодовой комбинации. Если после изменения разряда комбинация
остается запрещенной, данный разряд вновь восстанавливается. Задача
будет решена, когда будет инвертирован ошибочный разряд.
Аналогично можно показать, что для обнаружения двойных ошибок
необходим код с d = 3, а для их исправления — код с d= 5.
Равновесный код «2 из 5»
Особенность равновесного кода состоит в том, что в нем каждая кодо-
вая комбинация содержит фиксированное число единиц и нулей.
Комбинации отличаются только позициями единиц.
Среди равновесных кодов наибольшее практическое применение по-
лучил код «2 из 5», то есть 2 единицы и 3 нуля из пяти цифр кодовой
комбинации (табл. 5.1).
Таблица 5.1
Равновесный код «2 из 5»
Кодируемое число Код «2 из 5» Кодируемое число Код «2 из 5»
0 01100 5 00110
1 11000 6 10001
2 10100 7 01001
3 10010 8 00101
4 01010 9 00011
Количество кодовых комбинаций равно 32, но для изображения цифр
используется только 10 комбинаций. Комбинации выбираются та-
ким образом, чтобы минимальное кодовое расстояние было равно 2.
В связи с этим корректирующая способность рассматриваемого кода
выше, чем у кода с проверкой на четность.
Код «2 из 5» обнаруживает одиночные и групповые асимметрические
ошибки.
164
5.2. Помехозащищенные коды
Коды Хемминга
Наиболее известные из самоконтролирующихся и самокорректи-
рующихся кодов — коды Хемминга, ориентированные на двоичную
систему счисления.
Для построения самоконтролирующегося кода достаточно иметь один
контрольный разряд (код с проверкой на четность). Но при этом неиз-
вестно, в каком именно разряде произошла ошибка, и, следовательно,
отсутствует возможность ее исправления. Остаются незамеченными
ошибки, возникающие в четном числе разрядов.
Коды Хемминга имеют большую относительную избыточность, чем
коды с проверкой на четность, и предназначены либо для исправле-
ния одиночных ошибок (при d=3), либо для исправления одиночных
и обнаружения без исправления двойных ошибок (d = 4). В таком
коде л—значное число имеет т информационных и к контрольных
разрядов. Каждый из контрольных разрядов является знаком четно-
сти для определенной группы информационных знаков слова. При
декодировании производится к групповых проверок на четность.
В результате каждой проверки в соответствующий разряд регистра
ошибки записывается 0, если проверка была успешной, или 1, если
была обнаружена нечетность.
Группы для проверки образуются таким образом, что в регистре ошиб-
ки после окончания проверки получалось ^-разрядное двоичное число,
указывающее номер позиции ошибочного двоичного разряда. Изме-
нение значения этого разряда (0 на 1 или 1 на 0) исправляет ошибку.
Первоначально эти коды предложены Хеммингом в таком виде, при
котором контрольные знаки занимали особые позиции: позиция i-ro
знака имела номер 2'-1. При этом каждый контрольный разряд вхо-
дил лишь в одну проверку на четность. Позже указанные ограниче-
ния были сняты.
В качестве примера рассмотрим код Хемминга, предназначенный для
исправления одиночных ошибок, то есть код с минимальным кодо-
вым расстоянием d = 3.
Ошибка возможна в одной из п позиций. Если число контрольных
знаков к, то число разрядов регистра ошибок должно удовлетворять
условию
к > log 2 (л+1). (1)
165
Глава 5. Кодирование данных в компьютерах
Отсюда количество информационных разрядов
т <п—log2(n+l). (2)
Значения т и к для некоторых коротких кодов, вычисленные по фор-
мулам (1) и (2), приведены в табл. 5.2.
Таблица 5.2
Значения тип
п 3 4 5 6 7 8 9 10 11 12
т 1 1 2 3 4 4 5 6 7 8
к 2 3 3 3 3 4 4 4 4 4
Чтобы число в регистре ошибок (РОШ) указывало номер позиции
ошибочного разряда, группы для проверки выбираются по следую-
щему правилу:
I группа: все нечетные позиции, включая и позиции контрольного
разряда, то есть позиции, в первом (младшем) разряде которых в дво-
ичной системе стоит 1;
II группа: все позиции, номера которых в двоичном представлении
имеют 1 во втором разряде справа (например, 2, 3, 6, 7, 10) и т.д.;
III группа: разряды, номера которых в двоичном представлении име-
ют 1 в третьем разряде справа, и т.д.
Примечание. Каждый контрольный разряд входит только в одну прове-
рочную группу.
Пример 1. Пусть к = 5 (табл. 5.3).
Таблица 5.3
Формирование контрольных ipynn
Номер проверки Позиция контрольного разряда Проверяемые позиции
1 1 1, 3, 5, 7, 9, 11, 13,...
2 2 2, 3, 6, 7, 10, U,...
3 4 4, 5, 6, 7, 12, 13,...
4 8 8, 9, 10, 11, 12, 13,...
5 16 16, 17, 18, 19, 20, 21,...
166
5.2. Помехозащищенные коды
Пример 2. Рассмотрим семизначный код Хемминга, служащий для
изображения чисел от 0 до 9 (табл. 5.4). Пусть код числа 6 передан
в виде «0 1 10 0 1 1», а приняли его в виде «01000 1 1». Необходимо
проверить корректность принятого кода.
Формируем проверочные группы и осуществляем проверку.
I проверка: разряды 1, 3, 5, 7 — дает 1 в младший разряд РОШ.
II проверка: разряды 2, 3, 6, 7 — дает 0 во второй разряд РОШ.
III проверка: разряды 4, 5, 6, 7 — дает 1 в третий разряд РОШ.
Содержимое РОШ «101», значит, ошибка в пятой позиции.
Примечание. В каждый из контрольных разрядов при построении кода
Хемминга посылается такое значение, чтобы общее число единиц в его
контрольной сумме было четным. РОШ заполняется начиная с младше-
го разряда.
Таблица 5.4
Семизначный код Хемминга
Десятичное число Простой двоичный код Код Хемминга к к к
0 0 0 0 0 0 0 0 0 0 0 0
1 0 0 0 1 0 0 0 0 1 1 1
2 0 0 1 0 0 0 1 1 0 0 1
3 0 0 1 1 0 0 1 1 1 1 0
4 0 1 0 0 0 1 0 1 0 1 0
5 0 1 0 1 0 1 0 1 1 0 1
6 0 1 1 0 0 1 1 0 0 1 1
7 0 1 1 1 0 1 1 0 1 0 0
8 1 0 0 0 1 0 0 1 0 1 1
9 1 0 0 1 1 0 0 1 1 0 0
Вывод. Возрастание кодового расстояния позволяет увеличить кор-
ректирующую способность кода. Так, при d=2 у кода с проверкой на
четность возможно обнаружить одиночную ошибку, а код Хемминга
с d = 3 исправляет ее.
Для обнаружения и исправления кратных ошибок используют коды
Рида-Соломона. Они относятся к классу циклических кодов. Коди-
167
Глава 5. Кодирование данных в компьютерах
рование и декодирование в них — это вычислительные процедуры,
которые для циклических кодов выполняются как действия с много-
членами. Они допускают сравнительно простую схемотехническую
реализацию в виде цифровых автоматов на базе регистров с обратны-
ми связями.
Систематические правила кодирования дают кодовые слова, удоб-
ные для практики, ибо информационные слова размещаются в явном
виде в к старших разрядах кодовых слов.
Итак, если наборы символов образуют блок информации А, коди-
руемый с целью обнаружения и исправления ошибок, то процесс
кодирования состоит в формировании блока В, который получает
некоторую избыточность в виде дополнительных контрольных сим-
волов С. Избыточность кода строго дозируется в соответствии с за-
данной степенью помехозащищенности, определяемой количеством
допустимых ошибок.
Контроль по модулю
Рассмотренные выше коды используются лишь для повышения на-
дежности передачи информации. Они непригодны для контроля
выполнения операций в компьютере. Действительно, все рассмот-
ренные коды основаны на определении изменения исходного кода.
При выполнении же арифметических и логических операций (АЛО)
код изменяется всегда.
Известно много кодов для контроля выполнения АЛО. Например,
код «2 из 5» или «2 из 7» (2 единицы и 3 нуля и 2 единицы и 5 нулей со-
ответственно). Но эти коды имеют большую избыточность и требуют
сложной схемной реализации.
Рассматриваемый ниже контроль АЛО по модулю лишен указанных
недостатков. Приведем несколько определений.
Определение 1. Наименьшим неотрицательным вычетом C(7V) числа
N по модулю Р назовем число
C(N) = N-
'АП
168
5.2. Помехозащищенные коды
Определение 2. Два числа N3 и N2 сравнимы по mod Р, если равны их
наименьшие вычеты по этому модулю:
C(N{)=C(N2),
то есть
M = AT2(modP).
Верно соотношение
NsC(N) (modP).
Наибольшее распространение как в отечественных, так и в зарубеж-
ных компьютерах получил раздельный контроль АЛО с помощью
специального устройства, выполняющего арифметические операции
над контрольными разрядами. При этом контрольные знаки представ-
ляют собой двоичное изображение наименьшего вычета по mod Р. Такой
контроль получил название контроля по модулю.
Контроль АЛО основан на следующих свойствах:
► если Ni±N2=N3, то C(N3)±C(N2) = C(A3)(bmodP);
► если N\N2 = N3, то CfNdCfNd = C(N3) (mod P);
► если M = N2N3 + Na, to C(AT]) S [C(N2)C(N3) + C(A4)] (mod P).
Кодирование чисел состоит в определении C(Nj), а для обнаружения
ошибок АЛО вместо декодирования выполняется операция сравне-
ния C(N3) и (C(Nt) Ф C(N2)), где Ф — знак выполняемой операции.
Совпадение результатов является признаком отсутствия ошибки при
выполнении АЛО.
Принцип раздельного контроля по модулю может быть представлен
схемой, приведенной на рис. 5.1.
169
Глава 5. Кодирование данных в компьютерах
Кз-Nj + Nj
Рис. 5.1. Контроль по модулю
Для эффективного использования данного метода модуль, по которому
производится контроль, должен удовлетворять следующим свойствам:
► быть достаточно большим, так как от его значения зависит коррек-
тирующая способность кода;
► быть таким, чтобы наименьшие неотрицательные вычеты по нему
можно было легко определить.
Модуль с минимальным кодовым расстоянием d = 2 используют для
обнаружения одиночных и некоторых кратных ошибок. Чаще выби-
рают модуль Р, равный В - 1, где В — основание системы, что позво-
ляет упростить определение вычетов.
5.3. Сравнительные характеристики корректирующих кодов
Для оценки корректирующей способности кода пользуются величи-
ной его потенциальной эффективности К, показывающей, во сколько
раз уменьшается вероятность необнаруженных ошибок при контроле
на основе данного кода, если пренебречь вероятностью неверной ра-
боты контролирующей аппаратуры.
Этот показатель позволяет лишь ориентировочно оценить возмож-
ности кода, так как он определен для случая биномиального закона
распределения ошибок в кодовом блоке и в предположении о симмет-
рии всех устройств и каналов передачи данных, что не всегда спра-
ведливо.
Относительная избыточность R дает возможность в пределах каждой
группы кодов приблизительно оценить относительный объем допол-
170
5.3. Сравнительные характеристики корректирующих кодов
нительной аппаратуры, необходимой для реализации корректирую-
щей способности кода. Более точные оценки можно получить только
после выбора контрольных схем и элементной базы, на которой будет
реализована эта аппаратура.
В табл. 5.5 приведены выражения для относительной избыточности R
и потенциальной эффективности К в зависимости от длины слова п
и вероятности q ошибки в двоичном знаке. Для сравнения в таблице
даны их значения при п = 36 (разрядность чисел в большинстве ком-
пьютеров близка к этой величине).
При окончательном выборе того или иного корректирующего кода,
вообще говоря, необходимо учитывать предполагаемую структуру ком-
пьютера, требования по надежности, реальную надежность выбранных
элементов, заданное быстродействие, тип задач, для решения которых
предназначен компьютер, и т.д. Поэтому невозможно сформулиро-
вать общие рекомендации по применению методов и средств контроля
или даже по выбору способа кодирования информации, обеспечи-
вающего работу контрольных устройств. В связи с этим приведем
лишь некоторые соображения о целесообразности применения того
или иного кода.
Таблица 5.5
Относительная избыточность н потенциальная эффективность кода
Код и его минимальное расстояние d Относитель- ная избыточ- ность R Потенциальная эффективность К * *
при л = 36
Код с проверкой на чет- ность (d = 2) 1- и—1 2 (п-1)9 0,03 0,057 9
Код Хемминга, в том чис- ле его циклический вари- ант (d = 3) log2(n + l) п- log2(n + l) 6 (л-1)(и-2)92 0,2 0,0046 92
Код с вычетами по моду- лю 3 (d = 2) 2 и—2 4 (и-1)9 0,06 0,11 9
Код с вычетами по моду- лю 7 (d = 2) 3 и—3 12 (и-1)9 0,09 0,34 9
Код с вычетами по моду- лю 15 (d = 2) 4 и—4 16 (и-1)9 0,125 0,46 9
Код «2 из 5» (d = 2) 0,52 0,83 9 0,52 0,83 9
171
Глава 5. Кодирование данных в компьютерах
Код с проверкой на четность (d = 2) и код Хемминга (d = 3) целесооб-
разно применять в случаях, когда в компьютере предполагается кон-
тролировать схемными методами только хранение информации в ЗУ
и ее внутренние передачи. При параллельной передаче данных закон
распределения ошибок в слове обычно близок к биномиальному
и вероятность одиночных ошибок значительно превышает вероят-
ность групповых ошибок.
При отсутствии дублирования более эффективным представляется код
Хемминга, особенно для последовательной записи или чтения инфор-
мации, когда возможно применение циклического варианта кода,
требующего более простой кодирующей и декодирующей аппарату-
ры. Обнаружение всех одиночных и двойных ошибок с помощью та-
кого кода может обеспечить ббльший выигрыш в достоверности, чем
это следует из табл. 5.5.
Для кодов с вычетами по одному модулю вида 2*—1 при величине его
от 3 до 15 относительная избыточность, как видно из табл. 5.5, отли-
чается приблизительно в два раза. В таких же пределах будет изме-
няться относительный объем контрольной аппаратуры при переходе
от одного модуля к другому. Анализ различных возможных вариантов
схем устройств определения вычетов показывает, что количество
схемных элементов, приходящихся на один контрольный разряд
в слове, практически не изменяется с возрастанием общего числа
контрольных разрядов.
От модуля т, выбранного для образования кода, зависит сложность
контрольной аппаратуры. Эта аппаратура, помимо дополнительного
^-разрядного арифметического устройства, должна содержать, по край-
ней мере одно устройство для определения вычетов. В компьютерах
параллельного действия такое устройство составляет значительную
часть дополнительной аппаратуры.
Можно сформулировать следующие требования к величине модуля т.
1. Полученный код с наименьшими вычетами должен обеспечивать
обнаружение заданных типов ошибок с максимальной вероятно-
стью. Очевидно, с увеличением т возрастает не только корректирую-
щая способность кода, но и его избыточность, а следовательно,
объем контрольной аппаратуры.
2. Для облегчения контроля операции вычитания (сложения чисел
с разными знаками) код с наименьшими вычетами должен быть
172
5.3. Сравнительные характеристики корректирующих кодов
самодополняющимся. По существу, это значит, что при инверти-
ровании всех контрольных двоичных знаков должно получаться
дополнение до т.
Обычно ограничиваются небольшими величинами модуля т, даю-
щими код с минимальным кодовым расстоянием d = 2. Это обеспе-
чивает обнаружение всех одиночных ошибок, наиболее вероятных
в арифметических устройствах параллельного действия, а также не-
которых типов кратных ошибок.
Чтобы получить минимальное кодовое расстояние d = 2, величина т
должна быть взаимно простой с основанием системы счисления Ь.
В частности, можно положитьт =Ь±\.
Предпочтительнее выбрать т = b — 1, где b — основание системы
счисления. Это дает два важных преимущества.
Во-первых, в этом случае деление числа на т с целью определения
вычета можно заменить делением на т суммы fe-ичных цифр этого
числа.
Пусть задано число А в fe-ичной системе счисления:
л —1
А = а„_хЬп~х +а„_2Ьп~2 +... + а^‘ +а0 = ^а(Ь‘.
i О
Все степени основания Ь' имеют вычет по модулю b— 1, равный 1.
Следовательно, = o' (mod b— 1). Отсюда
л —I л —I
= J/iJmodi-l),
i=0 »=o
что подтверждает сформулированное выше положение.
Второе преимущество состоит в самодополняемости кода с вычетами
по модулю т = b — 1 для практически важных случаев, когда b = 2к.
Действительно, инвертирование двоичных знаков вычета дает двоич-
но-й-ичную цифру, являющуюся дополнением вычета до т. Но до-
полнение вычета до т есть вычет дополнения л-разрядного числа до
2"—1, то есть вычет обратного кода этого числа. Это следует из того,
что дополнение каждой цифры до b— 1 является вычетом по модулю
b— 1 в данном разряде. Но сумма вычетов цифр сравнима с вычетом
173
Глава 5. Кодирование данных в компьютерах
числа по тому же модулю. Следовательно, инвертирование двоичных
знаков всей кодовой комбинации дает обратный код числа вместе
с его вычетом по модулю b— 1.
Найдем выражения для вероятности обнаружения ошибок различ-
ной кратности, а также для потенциальной эффективности ^двоич-
ных кодов с вычетами по модулю вида т = 2* — 1 при к = 2, 3 и 4, то
есть при т = 3, 7 и 15.
Сделаем следующие допущения:
► ошибки в любом двоичном разряде являются независимыми слу-
чайными событиями и имеют одинаковую вероятность, равную q\
► ошибки, состоящие в исчезновении единицы и в ее возникнове-
нии вместо нуля, равновероятны;
► количество двоичных разрядов в числе п пропорционально к — ко-
личеству разрядов в модульных группах, то есть всегда п = ск, где с —
целое число.
При таких допущениях распределение ошибок в числе подчиняется
биномиальному закону, а поэтому вероятность одиночных ошибок
будет иметь порядок nq, двойных — л2<?2, тройных — л3</3 и т.д. При
малых значениях q, когда nq « 1, вероятность появления группо-
вых ошибок быстро убывает при выводе приближенного выраже-
ния для К.
1. Пусть т = 3 (к = 2). Определим вероятность обнаружения двойных
ошибок. Под двойной подразумевается такая ошибка, при которой
разность между правильным и искаженным числом равна
±2'+2J(i*j).
Числа вида 2' при /=0, 1,2, 3,4, 5,... имеют чередующиеся вычеты по
модулю 3, равные 1, 2, 2, 1, 2, ... Это означает, что наличие ошибок
в какой-либо позиции может изменить вычет числа либо на ±1, либо
на ±2. При двойной ошибке вычет изменяется на величину, равную
сумме или разности этих значений. Сумма будет в случае исчезнове-
ния или возникновения единицы на обеих позициях, а разность —
когда характер ошибок в двух позициях различен. Двойная ошибка
необнаружима, если эта сумма или разность равна 0 либо 3. При этом
число изменится по сравнению с истинным на величину, кратную 3.
174
5.3. Сравнительные характеристики корректирующих кодов
Всего возможны четыре комбинации чисел, изменяющих закодиро-
ванную величину, а именно:
2'+2'; —2'—27; 2'-2>; -2'+2<
Очевидно, если 2' и У имеют одинаковые знаки, то 2'+27 или —2'—У
кратно 3 в случаях:
a) Z четно, j нечетно;
б) i нечетно, j четно;
то есть в половине всех возможных сочетаний i и /.
Если же 2' и У имеют разные знаки, то 2' - 2! или -2' + У кратно 3
в случаях:
а) / четно, j четно;
б) i нечетно, / нечетно,
то есть также в половине всех возможных сочетаний i и /.
Следовательно, при сделанных допущениях вероятность обнаруже-
ния двойных ошибок равна 1/2.
Вероятность обнаружения тройных ошибок, определенная аналогич-
ным анализом всех возможных сочетаний, получается равной 3/4.
Тройные ошибки и тем более ошибки более высоких кратностей ма-
ловероятны, и их учет практически не повлияет на величину потен-
циальной эффективности кода.
Эффективность кода определяется как отношение вероятности всех
ошибок в числе к вероятности необнаружимых ошибок.
2. Пусть т = 7 (к = 3). Вычеты по модулю 7 для чисел вида 2' при / = О,
1, 2, 3,4, 5,... равны 1, 2,4, 1, 2,4,... Определим вероятность обнару-
жения двойных ошибок, изменяющих число на величину ±2' ± 2 Л
При одинаковых знаках 2' и У все двойные ошибки обнаруживаются,
так как 2' + У или -2' - У не может быть кратно 7.
При разных знаках 2' - 2! или -2' + У будет кратно 7 в случаях, когда/
отличается от / на ±3, ±6, ±9 и т.д., то есть в 1/3 всех возможных сочета-
ний / и j. Следовательно, вероятность обнаружения двойных ошибок
равна 5/6.
В результате анализа всех сочетаний для тройных ошибок определя-
ется вероятность их обнаружения. Она будет равна 8/9.
175
Глава 5. Кодирование данных в компьютерах
Таким образом, вероятность необнаружимых ошибок при контроле
по модулю 7 можно считать равной
Qk =|е2
о
(вероятностью групповых ошибок кратности выше второй по-преж-
нему пренебрегаем).
Для потенциальной эффективности кода получаем выражение
Х=——.
(л-1)?
3. Пусть т = 15 (к = 4). На основании рассуждений, аналогичных пре-
дыдущим, можно получить для этого кода
& =|°2
о
И
Как следует из полученных соотношений, эффективность кода с уве-
личением модуля значительно возрастает (даже при введенных упро-
щающих предположениях).
Значительное повышение эффективности можно получить, приме-
няя код с минимальным расстоянием d > 2. Это достигается добавле-
нием к числу в качестве контрольных разрядов вычетов этого числа
по нескольким различным модулям. При этом обнаруживаться будут
только такие ошибки, которые изменяют число на величину, кратную
одновременно всем модулям. Для любой ограниченной длины кода
числа всегда можно найти набор модулей, обеспечивающий заданное
минимальное кодовое расстояние.
Очевидно, для d= 3 модулей должно быть не меньше двух. Каждый из
них можно выбрать в виде 2* - 1, чтобы упростить процедуру опреде-
ления вычетов. При d > 3 возможно не только обнаружение, но и ав-
томатическое исправление одиночных ошибок.
Все приведенные в табл. 5.5 коды с вычетами имеют минимальное
кодовое расстояние d = 2. Поэтому их потенциальная эффективность
176
5.4. Кодирование данных с симметричным представлением цифр
при разных модулях, определенная при упомянутых выше упрощаю-
щих предположениях, отличается всего лишь в несколько раз. Это
позволяет утверждать, что контроль арифметических операций по
модулю 3, для реализации которого требуется наименьший объем до-
полнительной аппаратуры, может быть достаточно эффективным.
Однако в некоторых компьютерах на основе таких кодов организуется
единая система контроля для арифметических операций, для хране-
ния информации в запоминающих устройствах и для ее внутренних
передач. В этом случае находит применение код с вычетом по модулю 7,
который позволяет обнаруживать не только все одиночные ошибки,
но также и двойные ошибки, если они состоят в исчезновении двух
единиц, возникновении двух единиц, либо имеют разные знаки, но
произошли в смежных разрядах. При выборе модуля т = 15 обеспечи-
вается обнаружение всех тройных ошибок в смежных разрядах.
При расчете потенциальной эффективности кодов для биномиаль-
ного закона распределения ошибок указанные свойства этих кодов
оказывали незначительное влияние на конечный результат, так как
вероятность групповых ошибок в этом случае резко убывает с повы-
шением их кратности. Для хранения информации на магнитных дисках
биномиальный закон не применим. Характер причин, вызывающих
искажение информации при ее записи на диск, а также при чтении,
таков, что вероятность групповых ошибок в смежных разрядах следу-
ет ожидать близкой к вероятности одиночных ошибок.
В этих условиях увеличение значения модуля т приводит к резкому
повышению эффективности кода за счет групповых ошибок, хотя
минимальное кодовое расстояние остается равным 2.
5.4. Кодирование данных с симметричным
представлением цифр
В позиционных системах кодирования данных (СКД) для изображе-
ния положительных и отрицательных чисел обычно используются
знаки «+» и «—». В позиционных сокращенных системах кодирова-
ния, где разряды числа наряду с положительными могут принимать
и отрицательные значения, знак числа явно не указывается.
Глава 5. Кодирование данных в компьютерах
Особое место среди сокращенных систем занимает троичная СКД.
В ней введены цифры 0, 1, 1 для обозначения чисел 0, +1, —1. Таким
образом, базисные числа расположены симметрично относительно
нуля. СКД является позиционной, так как значение каждой цифры
в записи числа в три раза больше (меньше) значения той же цифры
в соседней позиции.
Число А в этой системе записывается в виде
А=ап ап-\ — fli °-2— >
где каждое а,- может принимать значения {0, 1,1}. Это сокращенная
запись полинома:
А — олЗи+ол_|Зи ^+...+ Gj3+Oo+g_j3 ^+o_j3 2+...,
где 3", 3" *,..., 3°, 3 *, 3 2, ... — веса разрядов.
Примеры представления чисел.
-1=1з 1=13 -ю=ТоТ3
—2=Т13 2=1Т3 10=1013
-з=То3 3=103 0=03
-4=ТТ3 4=н3_ 1/3 =0,(3) =0,13
—5 =Т113 5=1ТТ3 32/81 =0,11 TTj
Следует заметить, что знак числа в данной СКД определяется знаком
старшей значащей цифры троичного изображения числа.
Арифметические операции
1. Сложение.
Таблица сложения
а ь Примеры сложения чисел: +35 ~ 1 1 0 Т _35 - 1 1 0 Т 15 ~ 1 Т I 0 15 ~ Т 1 10 50-1Т1ТТ 50-1Т1Т
-1 0 +1
-1 Т1 Т 0
0 Т 0 1
+1 0 1 11
178
5.4. Кодирование данных с симметричным представлением цифр
2. Умножение.
Таблица умножения
а ь Примеры умножения чисел: 1 Т Т 0-15 1 Т Т 1 - 16 1 Т Т 0 Т 1 1 0 Т 1 1 0 1 Т Т о 0 1 0 0 0 Т 0 - 240
1 0 1
т 1 0 Т
0 0 0 0
1 Т 1 1
3. Деление. Если промежуточное делимое (полученное из остатка
путем сноса очередной цифры из делимого) содержит столько же раз-
рядов, сколько делитель, то независимо от того, больше это промежу-
точное делимое, чем делитель, или нет, в частное пишут «+1», если
первые цифры делимого и делителя совпадают, или цифру «1», если
нет. Если вслед за этим получается остаток, содержащий столько же
разрядов, сколько и делитель, то повторяют указанные действия, за-
писывая новую цифру частного в тот же разряд.
Пример.
1 о 1 Т о Т 1 Т Т 11 Т Т
Т 1 1 1 о о Т о о 1
1 Т Т 1 Г
Т 1 1 1 Т о Т 1 о о 1
о ТоТ
1 Т Т
т 2
1 т т
о 1 Т Т
Т 1 1
о
При наличии остатка от деления, то есть нацело деление не осущест-
вляется, в частном ставится запятая «,» и продолжается операция де-
ления.
179
Глава 5. Кодирование данных в компьютерах
Преимущества системы:
► знаковый разряд числа явно не указывается;
► отрицательные числа получаются из равных им по абсолютной
величине положительных простой инверсией знаков всех разрядов
числа;
► так как основание системы наиболее близко из целочисленных ос-
нований к числу е, то аппаратурная реализация операций в ней опти-
мальнее, чем в других (>3) основаниях системы.
Из трудностей реализации можно отметить появление нескольких
значений для одного и того же разряда частного.
Такая система кодирования впервые была использована в компьюте-
ре «Сетунь», разработанном в Московском государственном универ-
ситете (СССР).
5.5. Кодирование данных в системах
с отрицательным основанием
Известны компьютеры, работающие в С КД с отрицательными основа-
ниями. Обычно это машины последовательного действия. При вы-
полнении арифметической операции оба операнда поступают на вход
одновременно и обязательно младшими разрядами вперед, чтобы об-
легчить перенос в старшие разряды.
Целесообразность введения отрицательного основания обусловлива-
ется тем, что знак числа органически включается в представление
числа, в связи с чем не требуется специально отображать его.
Неудобство использования системы состоит в том, что при реализа-
ции процесса суммирования на один разряд могут прийтись два пере-
носа, что усложняет схему сумматора.
С точки зрения интервала представимых чисел при отрицательном
основании имеет место некоторая несимметричность. Так, при чет-
ном т (количестве разрядов) отрицательных чисел может быть пред-
ставлено больше, чем положительных, а при нечетном — наоборот.
180
5.5. Кодирование данных в системах с отрицательным основанием
Примеры.
Пусть основание системы п = —2. Тогда при количестве разрядов т = 4
имеем:
0001 =4-1 0110 =+2 1011 =-9
0010 = —2 0111 =+3 1100 =-4
0011 =-1 1000 =-8 1101 = —3
0100 =+4 1001 =-7 1110 =-6
0101=+5 1010 = -10 1111 = —5
Итак, положительные числа: 1, 2, 3, 4, 5 (их пять), а отрицательные:
—1, —2,..., —10 (их десять).
При т = 3:
001 =+1 100 =+4 110 =+2
010 =-2 101=+5 111 =+3
ОН = -1
Итак, положительные числа: 1, 2, 3, 4, 5, а отрицательные: —1, —2.
Известно, что каждое целое число Л может быть представлено в виде
i=0
где при п<— 1 имеет место 0 < С( < —л—1.
Для дробных чисел верно
Л = £с,л-’.
1=1
Рассмотрим наиболее известный частный случай СКД при л = —2.
Здесь С(€ {0; 1}. Предположим, что т = 5. Тогда таблица представле-
ния целых чисел от—10 до 10 будет иметь следующий вид (табл. 5.6).
181
Глава 5. Кодирование данных в компьютерах
Таблица 5.6
Представление целых чисел
\Beca (-2)4 (-2)3 (-2)2 (-2)1 (-2)° \Beca (-2)4 (-2)3 (-2)2 (-2)1 (-2)°
Числах 16 -8 4 —2 1 Числах 16 -8 4 —2 1
0 0 0 0 0 0 -10 0 1 0 1 0
1 0 0 0 0 1 —9 0 1 0 1 1
2 0 0 1 1 0 -8 0 1 0 0 0
3 0 0 1 1 1 —7 0 1 0 0 1
4 0 0 1 0 0 -6 0 1 1 1 0
5 0 0 1 0 1 -5 0 1 1 1 1
6 1 1 0 1 0 —4 0 1 1 0 0
7 1 1 0 1 1 -3 0 1 1 0 1
8 1 1 0 0 0 —2 0 0 0 1 0
9 1 1 0 0 1 -1 0 0 0 1 1
10 1 1 1 1 0
Из таблицы видно, что знак числа определяется местоположением
первой значащей цифры: если она в четном разряде, то число отрица-
тельное, если в нечетном — положительное.
Рациональные числа
Веса (-1/2) (-1/2)2 (-1/2)3 (-1/2)4
-1/2 1/4 -1/8 1/16
Числа -0,5 0,25 -0,125 0,0625
Арифметические операции
1. Сложение. Пусть ос,-, р,- — разряды слагаемых; Р;_{ — перенос из
(г— 1)-го разряда на z-й; Р, — перенос из z-го в (г+1) -й. Тогда справед-
ливо соотношение у, + Р,(—2) = а,- + Р,+Р,_|.
Таблица сложения
а. 0 0 1 1 0 0 1 1 0 0 1 1
₽/ 0 1 0 1 0 1 0 1 0 1 0 1
Л-1 0 0 0 0 т 1 т I 1 1 1 1
т. 0 1 1 0 1 0 0 1 1 0 0 1
Pt 0 0 0 т 1 0 0 0 0 т т Г
182
5.5. Кодирование данных в системах с отрицательным основанием
Возможные значения разрядов:
Л-ьЛе{0; 1;Т},у,е{0; 1},а„р,е {0; 1}.
Приведем пример. Пусть у, + Р,(—2) = 2, тогда у, = 0, Pt= — Ijyi+PX—2) =
= —1, тогда у, =1, Р, =1.
Примеры:
3 — 00 1 1 1 +9 - 1 1 0 0 1
5-00101 -6-01110
8-11000 +3 -00111
2. Вычитание. Так как a—b = a+b—lb = a+b+b(—2), причем Ь(—2) — это
число Ь, сдвинутое на один разряд влево, то алгоритм вычитания мо-
жет быть сформулирован следующим образом: для того чтобы из чис-
ла а вычесть число Ь, необходимо к а прибавить b и затем прибавить Ь,
сдвинутое на один разряд влево.
Примеры: а +6-1 1 0 1 "+3-0 0 1 1 б 0 -5-0 1 1 1 1 0 1 0 7-0 “-10 - 0 в 1 1 0 0 0 1 1 0
1 +4-0 0
1 1 0 0 1 0 0 0 1 1 1 1 0 0 1 1
0 0 1 1 1 (+ сдвинутое 3) 0 0 1 0 0 0 1 0 1 0
0 0 0 1 1 1 =+3 0 1 0 1 1 = -9 0 0 0 1 1 1 = +3
3. Умножение. Операция умножения осуществляется посредством по-
следовательности операций сложений и сдвигов.
Примеры:
а
2-001 10
Х 5 -0 0 1 0 1
0 0 110
0 110
0 1 1 1 1 0 =+10
б
3-0 0111
Х-3-0 110 1
0 0 111
0 0 111
0 0 111
0 О О О 1 О 1 1 =—9
183
Глава 5. Кодирование данных в компьютерах
4. Деление. Пусть требуется разделить число и на число а и получить
частное со, то есть о : а = со.
Введем следующие обозначения:
ак — это а, сдвинутое на к разрядов влево;
4+ 1 = V/ — «*, на каждом шаге алгоритма индекс у о,- увеличивается на 1;
N(v) — номер разряда старшей значащей цифры.
Разрядность частного со равна к + 1, а веса его разрядов будут иметь
вид:
(—2)* (—2)*-1, ..., (—2) °.
Алгоритм деления.
1. Сдвигаем а на к разрядов влево до тех пор, пока старшая значащая
цифра у а не станет под старшей значащей цифрой ъ, таким образом:
а-» аЛ, то есть а преобразуется в аА;
ц = v0, то есть V присваивается начальное обозначение t>0.
2. Вычитаем ъ0 — ак, то есть Vj = ц0 + а* + (—2) ак.
3. Если N(y>i+l) - N(ak), то записываем «1» в разряд (—2)* частного
и еще раз вычитаем ак.
4. Если N(vi+l) < N(ak), то записываем «1» в разряд (—2)* частного и ак
меняем на аЛ_], то есть сдвигаем ак на 1 разряд вправо и вычитаем
а*_].
5. Если N(vM) > N(ak), то записываем «О» в разряд (—2)* частного, ъ,+1
заменяем на ак меняем на ак_} и производим вычитание.
6. Процесс завершается, если t>/+1 = 0.
I Замечание 1. Результат «0» или «1» записывается в разряд частного
с весом (—2)*, где к — индекс у а.
Замечание 2. Возможен случай, когда в один и тот же разряд частно-
го записывается несколько значений. Формирование частного по-
требует дополнительно одну операцию сложения.
Замечание 3. Сравнение очередного ц- с нулем (п. 6 алгоритма) осу-
ществляется на каждом шаге после выполнения одного из пунктов
3, 4 или 5.
184
5.5. Кодирование данных в системах с отрицательным основанием
Пример 1. Пусть необходимо число 14 разделить на число 2, то есть
ъ0 = 14, а = 2.
Тогда 14 - 10010(_2), 2~110(_2).
Для выравнивания старших значащих цифр делимого и делителя
сдвигаем а на два разряда влево, то есть а-» а2 =11000.
Структура частного со:
Веса разрядов С-2)2 (-2)’ (-2)”
Частное +1 +1 +1
+1
ПО 1 1 = 7
Процесс деления:
1 0 0 1 0 1)0
1 1 0 0 0 «2
Записываем 1 1 0 0 0
«1» во второй разряд <- 0 1 1 0 10 1), = ДГ(сх2)
К, = 0? нет
1 1 0 0 0 «г
Записываем 1 1 0 0 0
«1» во второй разряд <- 0 0 0 0 1 0 т>2 Мт>г) < М«г)
И2 = 0? нет
1 10 0а,
Записываем 1 1 0 0 Мт>з) < N(ai)
«1» в первый разряд <- 0 0 0 1 1 0 v3 К3 = 0? нет
1 1 0 ас
Записываем 1 1 0
«1» в нулевой разряд <- 0 0 0 0 0 0 и4 Ми>) < М«о)
V4 = 0? да
Stop
Процесс деления завершен, так как ъ4 = 0.
185
Глава 5. Кодирование данных в компьютерах
Пример 2. Пусть t>0 = 12, а = 2. Тогда 12-11100(_2), 2 - 110(_2).
а-» а2 =11000.
Структура частного со:
Веса разрядов (—2)2 (-2)" (-2)”
Частное 1 0 1
1
ПО 1 0
Процесс деления:
1 1 1 0 0 ч>
1 1 0 0 0 <4
Записываем 1 1 0 0 0
«1» во второй разряд <-0 0 0 1 0 0 *>1 М4) < Ма2)
1 1 0 0 «1
Записываем 1 1 0 0
«0» в первый разряд <- 1 1 0 0 0 ^2 Mv2) > М<ч)
Vi возврат
0 0 1 0 0 4
0 1 1 0 “о
Записываем 0 1 1 0
«1» в нулевой разряд <— 0 0 1 1 0 Ч М^') = Мао)
0 1 1 0
Записываем 0 1 1 0
«1» в нулевой разряд <- 0 0 0 0 0 41 Мнз) < Мао)
Процесс окончен, так как = 0.
5.6. Кодирование данных с помощью вычетов
Поиск новых систем кодирования данных имеет целью оптимизацию
ресурсов, необходимых для обработки данных: памяти, процессор-
ного времени, средств обеспечения надежности, точности вычисле-
ний и т.д.
186
5.6. Кодирование данных с помощью вычетов
Не явилась исключением и система кодирования данных с применени-
ем вычетов. Она разработана с целью ускорения арифметических опе-
раций, повышения точности и надежности вычислений.
п
Пусть Р2,Рп — целые числа; Р,> 1, (Р„ /’)= 1, i*j; Л/ = ;х—
/=1
наименьшие неотрицательные решения системы сравнений
i4=x,(modPz), г = 1,2,..., л; А с [0,Л/)-
Тогда кортеж (хь х2, х„) будем называть кодом числа А в системе
кода вычетов (СКВ) при заданных основаниях Ръ Р2,..., Рп. Записы-
вают это обычно так: А ~ (хь х2,..., х„). Компоненты х,- называют разря-
дами числа А в СКВ. Своими корнями данная система восходит к так
называемой китайской теореме об остатках.
Теорема. Пусть числа Ms и M's определены из условий
Pt, Р2,..., Рк = MSPS, М, М’ = 1 (mod Ps)
и пусть
х0= Л/j М{ЬХ + М2 М2Ь2+...+ Мк Мк Ьк.
Тогда совокупность значений х, удовлетворяющих системе срав-
нения х = Z>](mod Рх), х = Z>2(m°d Рг)> • • ,х = Mmod Рк), определяет-
ся сравнением х = x0(mod Plt ..., Рк).
Среди особенностей СКВ исследователи отмечают следующие:
► каждый разряд числа несет информацию обо всем числе, откуда
следует независимость разрядов друг от друга;
► отсутствие переносов между разрядами при выполнении арифме-
тических операций упрощает их выполнение;
► малоразрядность компонент числа, в связи с чем арифметические
операции превращаются в однотактные, иногда просто в выборку ре-
зультата из таблицы.
Арифметические операции
Рассмотрим алгоритмы арифметических операций. Пусть необходи-
мо выполнить операцию А ® В=С, где Л - (х1гх2, ...,х„); В~ (УьУг,
УпУ, С~ (у,, у2, -.Y»)-
187
Глава 5. Кодирование данных в компьютерах
1. Если ® — сложение, то
Х=|х,+У,|д, то есть у,- =xt +yt -1,Р,
где /,
1, если xt + У{ > Р,,
О, если X; + yi <Pi ,i = 1, л.
2. Если ® — вычитание, то
Y< =1*/-У.1я> тоесть у, = х,-yt +ltP,
{1,еслих.- <у,,
О, если Xi >yi-
3. Если ® — умножение, то
Т*=1л7>71лэ тоесть у, = х,у,- -/,/>,
где/, =
[х] — наибольшее целое, не больше х.
я
4. Если ® — деление, то
где= 0, 1,..., Pi— 1.
Иногда операцию деления А/В заменяют операцией умножения А на
мультипликативную инверсию от В по модулю М, то есть выполняют
умножение:
(хьх2, ...,х„)(у[,у^...,у'„),
где (у!,У2, —, Ул ) — мультипликативная инверсия от В по модулю М.
Здесь
у.
то есть у, — решение уравнения ly/y^/? =1 или сравнения у/у/ =
= 1 (mod Pi). Мультипликативная инверсия существует, если (у„ Pj) = 1,
для всех i = 1,л.
188
5.6. Кодирование данных с помощью вычетов
Пример. Пусть Р| = 2, Р2 = 3, Р3 = 5. Л/= 30. Тогда числу А = 7 в данной
СКВ будет соответствовать код (1, 1, 2), а числу 3 - (1, 0, 3).
Выполним арифметические операции над кодами чисел 3 и 7 в СКВ
(1,1,2) (1,1,2) (1,1,2)
+ - х
(1,0,3) (1,0,3) (1,0,3)
(0, 1,0) (0, 1,4) (1,0, 1)
Следует отметить, что кодирование данных в СКВ в силу вышеука-
занных свойств позволяет существенно уменьшить время выполне-
ния основных арифметических операций.
Восстановление позиционного значения числа А по его коду (хь х2,
х„) в СКВ осуществляется из соотношения
<4 дес ~
i=l
где В, — ортогональные базисы; гА — ранг числа А.
Ортогональные базисы представляют собой целые числа, удовлетво-
ряющие соотношению
_ fl (mod/}) . .
1 [0 (mod Ру)’
i,j = l, 2, ..., п ,
и ищутся среди чисел вида
Пр>’
где е {1, 2, ..., Р, - 1}.
Перевод чисел из позиционной системы счисления (ПСС) в СКВ мо-
жет осуществляться различными способами. Приведем некоторые из
них.
1. Решение системы линейных сравнений
zl^x/modP,,), /=1,л.
Тогда (хь х2, ..., х„) — код числа А в СКВ.
189
Глава 5. Кодирование данных в компьютерах
2. Нахождение наименьших неотрицательных остатков от деления А
на все основания
Р„1 = Гл.
Полученные остатки и дадут представление А в СКВ.
3. Использование операций умножения и сложения по алгоритмам
СКВ.
В выбранной системе оснований Pi, Р2, Р„ заготовим В + 1 кон-
станту 0,1,2, ..., В, где В — основание ПСС. Затем представляем ис-
ходное число А по схеме Горнера:
((a„Z?+an_1)Z? + an_2)Z?+-+a0. (1)
Подставляя значения чисел а0, аь ..., а„и В в заданной СКВ в выше-
приведенной формуле (1) и выполняя операции сложения и умноже-
ния, получим для числа А = а„ а„_{ ... а0 его код в СКВ.
Для заданной системы оснований Р1г Р2,..., Р„ ортогональные базисы
фиксируются и хранятся как константы на протяжении всего време-
ни вычислений.
Из общих соображений можно предположить, что наиболее целе-
сообразна система оснований, требующая наименьшего числа мало-
разрядных модулей. Однако это не всегда верно. Целесообразность
выбранных модулей в каждом случае зависит от цели, поставленной
при проектировании компьютера на базе системы в коде вычетов.
Анализ алгоритмов выполнения различных операций в коде вычетов
показывает, что основным требованием, предъявляемым к модулям си-
стемы, является однозначность кодирования данных. Известно (из тео-
рии чисел), что д ля выполнения этого требования необходимо, чтобы
(Pi,Pj) = i для всех i*J, i,j= 1,...,л,
то есть необходима взаимная простота модулей системы.
Исследования показали, что полученные алгоритмы выполнения не-
модульных операций в рамках классической СКВ близки к предель-
ным. В связи с этим рассмотрим некоторое обобщение классической
СКВ, которое позволяет усовершенствовать алгоритмы основных
операций с целью уменьшения их вычислительной сложности, что
дает возможность расширить класс задач, решаемых на компьютерах
с базовой системой СКВ.
190
5.6. Кодирование данных с помощью вычетов
Итак, целое неотрицательное число А будем представлять в виде
(Xpcj + (1 - А,) (X! - PJ,\,хп + (1 - А„) (х„ - Р„)), (2)
где А,е|0, 1|, х, = |Л|р;. Значения А,- следует выбирать таким образом,
чтобы форма (2) для любого целого числа А из области определения
имела нулевой ранг. Назовем форму (2) формой нулевого ранга (ФНР).
Определение 1. Систему в коде вычетов, для которой любое целое
А е [О, М) допускает ФНР, назовем безранговой СКВ (БСКВ).
Из (2) следует, что разряды чисел в этой системе могут быть положи-
тельными, отрицательными или равными нулю.
Примеры, демонстрирующие представления целых чисел в БСКВ
для оснований 7? = 2, Р? = 3, Р3 = 5, даны в табл. 5.7. При этом в пред-
последнем столбце приведены коды чисел 0, 1,2, ..., 10, а в послед-
нем — коды чисел 0,-1, —2, ..., —10.
Из примера следует, что трансформирование положительных чисел
в равные по абсолютной величине отрицательные получаются инвер-
тированием знаков всех разрядов числа. Этот факт следует из (2)
и формы восстановления позиционного значения числа по его коду
в БСКВ. Суть инвертирования состоит в дополнении значения каж-
дого разряда до соответствующего Р„ /= 1, 2,..., п и замене знака каж-
дого разряда числа на противоположный.
Таблица 5.7
Примеры БСКВ
Числа в ПСС Форма СКВ Ранг Форма (1)
Положительные числа в БСКВ Отрицательные числа в БСКВ
0 (0, 0, 0) 0 (0, 0, 0) (0, 0, 0)
1 (1, 1, 1) 1 (Т, 1, 1) (1, Т, Т)
2 (0, 2, 2) 1 (0, 1, 2) (0, 1,2)
3 (1, 0, 3) 1 (1,0, 3) (1, 0, 3)
4 (0, 1, 4) 1 (0, 2, 4) (0, 2, 4)
5 (1,2, 0) 1 (1,2,0) (1, 2, 0)
6 (0, 0, 1) 0 (0, 0, 1) (0, 0, 1)
7 (1, 1,2) 1 (1, 2, 2) (1,2, 2)
8 (0, 2, 3) 1 (0, 1, 3) (0, 1, 3)
9 (1, 0, 4) 1 (1,0, 1) (1,0, 1)
10 (0, 1, 0) 0 (0, 1, 0) (0, 1,0)
191
Глава 5. Кодирование данных в компьютерах
Справедливы следующие теоремы.
Теорема 1. Для того чтобы в СКВ с основаниями Р2,Р„, ор-
тогональными базисами В1г В2,..., В„, весами mlf т2, .... т„ для лю-
бого целого Ае [О, М) с рангом гА существовала ФНР, необходимо и
достаточно, чтобы выполнялось соотношение
га = Ymi’ ЛГ = [1’ 2’ «]• (3)
j^Ni
Доказательство. Необходимость. Пусть (хь х2,..., х„) — код неко-
торого числа Ае D в заданной СКВ. Предположим, что его можно
представить в форме (2). Не нарушая общности рассуждений, бу-
дем считать, что А в форме (2) имеет вид
(ХЬХ2, ... ,ХкгХМ-РМ, ... ,Xj-Pj,Xj+l, ...,х„).
Тогда
i=i 1=*+1
Согласно формуле восстановления позиционного значения числа А
в СКВ имеем
/1 = ^XjBi —гАМ.
i=i
Но это две численные формы одного и того же числа А. Значит,
/=1 1=1 /=*+1
Тогда
~ГАМ = ^X/Bt - ^т,М =
i=i /=1 i=*+i
= YX‘B‘+ Ъ,(Х‘В‘ ~т> Ю+ Ъ,Х‘В' =
«=1 /=*+! |=у+1
192
5.6. Кодирование данных с помощью вычетов
= -Р^В..
i=l i=t+l
1*4+1, J
Значит,
j
ГЛ= Ym‘’
i=k+\
то есть число А имеет ФНР.
Необходимость доказана.
Достаточность доказывается аналогичным образом, проводя рассуж-
дения в обратном порядке, в предположении, что условие (2) выпол-
няется.
Следствие 1. Если для системы модулей Р\, Р2, ..., Рп веса ортого-
нальных базисов т l = m2^...=m„= 1, то для любого Ле [О, Л/) суще-
ствует ФНР.
Следствие 2. Число А в ФНР будет иметь столько отрицательных
разрядов, сколько слагаемых т, входит в сумму (3).
Следствие 3. Чтобы число Ле [О,М) имело единственную ФНР, не-
обходимо и достаточно, чтобы для указанного Л сумма (3) была
единственной.
Пусть РУ — область определения операций в БСКВ. Как следует из (2)
^maxL
где
^min = -£(Р/ -1>,, ЛП1ах = •
<=1 1=1
Установим связь между кодированием противоположных по знаку
чисел. Пусть (хь х2,..., х„) представление числа Л > 0 в ФНР. По опре-
делению БСКВ
Л = £х,Д. (4)
/=1
193
132ТЭ2
Глава 5. Кодирование данных в компьютерах
Поскольку В, > 0, то
-Л = £(-%,)/?,.
/=1
Следовательно, представление числа —А по представлению числа А
получается инвертированием знаков всех его разрядов. Отсюда сле-
дует, что множество U симметрично относительно нуля.
Пусть в классической СКВ ранги всех чисел Ае [О, М) заключены
в интервале [rb r2], a R — множество всех целых чисел из [гь г2].
Теорема 2. В классической СКВ минимальный элемент множест-
ва R равен нулю, а максимальный
-л -1.
1=1
где /] — ранг числа А = 1.
Доказательство. Из соотношения
A = ^XiBi-rAM
1=1
для классической СКВ следует, что
м=1 7
Но так как всегда А < М, а гА — целое, то можем записать
Га =
l/M^XiBi
i=i
Поскольку 0 < х, < Р„ то гА будет минимальным при х, = 0, то есть
/] = 0. Аналогично
Г2
1=1 /=1,
п
.1=1
(Pi -l)/n,
Pi
194
5.6. Кодирование данных с помощью вычетов
Л Л и
|_< = 1 <=1 г‘ J i=l
Следствие. Мощность множества R равна r2 + 1.
Исследуем структуру множества О'. Обозначим через О* и D'_ соот-
ветственно подмножества положительных и отрицательных элемен-
тов множества О'. Разобьем весь интервал Mmin, /1тах] на интервалы
длины М и перенумеруем их +0, ±1, ±2, ... соответственно влево
и вправо от нуля. Из определения (4) и симметричности множества О
следует, что (—А/,0] с С и [0,Л/) с О'.
Пусть Р — множество всевозможных наборов (хь х2 —, хи)> удовле-
творяющих условию — Pj < Х/< Ph i = 1, 2, ..., n, для системы модулей
Pb Р2,..., Р„, допускающих ФНР. Пусть (хь х2,..., х„) — произвольный
набор из Р, а ранги чисел Ае [0, Л/) принимают все целые значения из
интервала [0, г2]. Будем говорить, что заданный набор порождает во
множестве О' новый элемент, если возможно представление его в фор-
ме (2) таким образом, чтобы результаты подстановки обеих версий
наборов в (4) не были равны.
Утверждение 1. Каждый набор (хь ..., х„) порождает в D' столько
новых элементов, какова величина ранга числа, соответствующего
этому набору в СКВ.
Справедливость этого утверждения вытекает непосредственно из со-
отношения (2) и теоремы 1.
Следствие 1. Множества О± и DL имеют одну и ту же мощность, то
есть |£>+| =| ЕГ|.
Следствие 2. Мощность множества U меньше мощности множе-
ства целых чисел из интервала Ит1П, Лтах].
Обозначим через О] множество особых точек, то есть Ot — это такое
множество, что Ot с [>4min, Лтах], но О сгРУ. Наличие О] несколько
ухудшает характеристики БСКВ. Если окажется, что существуют мно-
жества О', для которых |/У| = |[/lmin, Лтах]| (рассматриваются только це-
лые числа из интервала), то указанный недостаток будет исключен.
195
Глава 5. Кодирование данных в компьютерах
______________________________ !___________________________
Вообще говоря, не совсем ясно, насколько существен данный недос-
таток, так как аналогичная ситуация, возникающая при округлении
чисел в позиционной системе счисления, не вызывает практических
затруднений, и тщательное ее исследование в научной литературе не
встречается.
Вышеизложенное позволяет сформулировать следующее утвержде-
ние.
Утверждение 2. Набор (хь х2,..., х„) из Рс рангом не порож-
дает в интервале с номером +N (а следовательно и —N) особую точ-
ку, если >N.
Следствие 1. Число Ае [О, Л/) не может быть порождающим ни для
какого элемента из интервала с номером N>r2.
Следствие 2. Мощность множества V равна
2 £(^|«П +D-D)
где |5,| — мощность множества элементами которого являются
числа из [О, М), имеющие ранг /7.
Выясним, как построить систему модулей, ортогональные базисы для
которых имели бы наперед заданные веса.
Теорема 3. Для того чтобы совокупность целых чисел Рь Р2,Р„
(Р,>1,1=1,2,..., п) представляла собой набор оснований системы
в коде вычетов, ортогональные базисы для которых имели бы за-
данные веса тиь т2,..., т„, необходимо и достаточно, чтобы для Р,
выполнялось соотношение
JJP7Wj+g,+1 , / = 1,2
(5)
гае &!+1 = -1» & 0’ = 1> 2,..., п) — целые числа, & * 0.
196
5.6. Кодирование данных с помощью вычетов
Доказательство теоремы 3 ведется методом индукции, причем
вначале доказывается необходимость условий теоремы, а потом и
их достаточность.
Для ускорения поиска оснований безранговых систем полезно полу-
чить оценки (верхние и нижние) для каждого из искомых наборов ос-
нований. Получим также оценки для БСКВ с единичными весами
ортогональных базисов.
БСКВ, для которых тх = т2 = ... = т„, полезны в том плане, что алго-
ритмы выполнения операций для соответствующих модулей Рь Р2,
..., Рп значительно проще, чем для оснований с произвольными веса-
ми ортогональных базисов.
Утверждение 3. Пусть Рх, Р2,..., Р„ — основания некоторой БСКВ,
ортогональные базисы для которой имеют единичные веса, а Р,. =
= (Р/) — соответственно нижняя (верхняя) оценка величины осно-
вания Pj. Верны следующие равенства:
=1/£/ПР,+1,
7=1
Р,‘ =ПЛ(«-/+!)•
7=1
Доказательство. Так как&+1 > 1, то, подставив в формулу (5) выра-
жение g,+1 = 1 (в предположении, что Р1; Р2,..., Pt_x известны), по-
лучим оценку для Р*.
В применении к БСКВ, указанным в утверждении 3, формула для
ортогонального базиса
А =£.ПЛ-£'+1 - —+1
7=1
примет вид
g, ПР> +1 = + +- • -+М” ’ <6>
7=1
где Л/, = M/Pi.
197
Глава 5. Кодирование данных в компьютерах
Отсюда
У 1U Pi+l Рп М)
Не нарушая общности рассуждений, предположим, что система
оснований упорядочена по возрастанию. Так как gt > 1 (Z = 1,2,..., п)
и Р, < Р2 < ... < Рп, то
1 1
Pi+i < Р, ’
то есть
KP^.J* +1)1,
откуда следует, что
/-1
/=1
Утверждение доказано.
Пусть 5(и) — множество всех БСКВ с /л,= 1, i = 1, 2,..., п. При нахож-
дении БСКВ всегда необходимо отыскивать величину g,. Используя
полученные результаты, дадим его оценку для некоторого п.
Из (6) следует, что
Вместо Рр можно взять z'-e простое число. Тогда для оценки g\ необхо-
п
димо подсчитать сумму Sn = 1 / Ру Оказалось, что минимальное п,
J=i
при котором Sn > 2, равно 59. Следовательно, S(n) для всех п < 59 име-
ет gt = 1. Так как для БСКВ, имеющих практическое значение, п < 59,
то фактически всегда можно считать gi = 1.
198
5.7. Стандарт IEEE 754
Приведем примеры безранговых систем с количеством оснований,
равным 3, 4 и 5:
п = 3: Р, = 2, Р2 = 3, Р3 = 5;
п =4: Р, = 2, Р2 = 3, Р3 = 7, Р4 = 41;
и = 5: Pt = 2, Р2= 3, Р3 = 7, Р4 = 83, Р5 = 85;
Pt = 2,Р2 = 3, Р3 = 7, Р4 = 43, Р5 = 1805;
р, = 2, Р2 = 3, Р3 = 11, Р4 = 17, Р5 = 59.
Из вышеизложенного следует, что БСКВ позволяет построить срав-
нительно простые алгоритмы выполнения немодульных операций.
Система в коде вычетов в основном применяется в специализирован-
ных вычислительных устройствах из-за высокой сложности опера-
ций определения знака числа и сравнения чисел.
5.7. Стандарт IEEE 754
Чтобы обеспечить корректность выполнения операций с плавающей
точкой и однотипность представления данных, обеспечивающую воз-
можность переноса данных с одного компьютера на другой, а также
снабжающую разработчиков аппаратуры точной моделью арифметики
с плавающей точкой, комиссия IEEE разработала и детально специ-
фицировала стандарт 754.
Институт инженеров по электротехнике и электронике (Institute of
Electrical and Electronics Engineers — IEEE) ввел обязательный стандарт
представления чисел с плавающей точкой в 32-разрядном формате.
В нем определены не только представление чисел, но и правила вы-
полнения четырех базовых арифметических операций. Любой ком-
пьютер, соответствующий стандарту IEEE, должен поддерживать как
минимум представление чисел с плавающей точкой одинарной точ-
ности (32 разряда).
Стандарт определяет три формата: с одинарной точностью (32 бита),
с удвоенной точностью (64 бита) и с повышенной точностью (80 бит).
Последний формат предназначен для уменьшения ошибок округления.
199
Глава 5. Кодирование данных в компьютерах
Форматы с одинарной и удвоенной точностью начинаются со знако-
вого разряда (0 соответствует знаку +, 1 соответствует знаку ), затем
следует порядок (excess — смещение) соответственно 8 и 11 бит и ман-
тисса — 23 и 52 бита.
Нормализованная мантисса начинается с двоичной запятой, за кото-
рой следует единичный бит и остаток мантиссы, причем первые два
бита присутствуют неявно. Следовательно, нормализованная ман-
тисса состоит из одного неявного бита (так как он всегда равен еди-
нице) и неявного бита для двоичной запятой, за которыми следуют 23
или 52 произвольных бита.
Для того чтобы обозначить такую «урезанную» мантиссу, использует-
ся термин significant! вместо термина mantissa. Поэтому, если все 23
или 52 бита мантиссы равны нулю, мантисса имеет значение 1,0.
Самое малое нормализованное число соответственно равно 2-126
и 2-1022, а самое большое число оценивается =2128 и =21024. Диапазон
десятичных дробей — от=10~38 до 1038 и от =1О-308 до Ю308, самое ма-
лое ненормализованное число будет ~ 1СГ45 и ~10-324.
Традиционные проблемы, связанные с работой над числами с плавающей
точкой, — что делать с переполнением, потерей значимости и неини-
циированными числами — решаются в IEEE 754 следующим образом.
Введены ненормализованные числа, имеющие порядок «0» и мантис-
су, представленную следующими 23 или 52 битами. Неявный бит «1»
слева от двоичной запятой здесь превращается в «0». Отличие таких
чисел от нормализованных чисел простое — у нормализованных чисел
порядок (экспонента) не может быть равен нулю. То есть здесь имеет-
ся положительный и отрицательный нуль, определяемые знаковым
битом (экспонента нуль и мантисса нуль), при этом бит слева от двоич-
ной запятой по умолчанию равен нулю, а не единице (табл. 5.8).
Таблица 5.8
Числовые типы стандарта IEEE
Нормализованное число ± 10 < Exp < Мах | Любой набор бит
Ненормализованное число ±|о| Любой ненулевой набор бит
Нуль ±|о | 0
Бесконечность ±| 111 ... 11 0
Не число ±|1П... 1| Любой ненулевой набор бит
200
Упражнения
Для обозначения переполнения принят тип бесконечность Это число
можно использовать в качестве операнда с обычными арифметиче-
скими правилами. Например, бесконечность и любое число в сумме
дают бесконечность; конечное число, разделенное на бесконечность,
равно нулю; любое конечное число, разделенное на нуль, стремится
к бесконечности.
При делении бесконечности на бесконечность результат не опреде-
лен. Для такого случая существует специальный формат NaN (Not
a Number — не число), который тоже можно использовать в качестве
операнда. Значение NaN — результат недопустимой операции. Он
может быть использован и в случае операций 0/0 и 4-1.
Характерная особенность всех ненормализованных чисел — отсутст-
вие подразумеваемой единицы слева от двоичной запятой, а их ман-
тисса представляет собой любую ненулевую 23-разрядную дробную
часть числа.
В настоящее время большинство процессоров (в том числе Intel,
SPARC и JVM) содержат команды с плавающей точкой, которые со-
ответствуют стандарту IEEE 754.
Упражнения
1. Какие требования предъявляются к коду данных, чтобы он мог обнару-
живать и исправлять ошибки кратности fl
2. Для кода Хемминга разработайте и реализуйте алгоритм обнаружения
ошибки при передаче данных.
3. Для системы с симметричным кодированием данных с основанием л = 3
разработайте и реализуйте алгоритмы выполнения операций умножения
и деления.
4. Для системы кодирования данных с основанием л = -2 разработайте
и реализуйте алгоритмы выполнения основных операций (сложение, ум-
ножение, деление).
5. Разработайте и реализуйте алгоритм поиска ортогональных базисов
с единичными весами для системы в коде вычетов.
6. Реализуйте алгоритмы выполнения арифметических операций в двоич-
ной системе с плавающей точкой.
201
Глава 5. Кодирование данных в компьютерах
7. Преобразуйте в формат стандарта IEEE 754 с одинарной точностью сле-
дующие числа: 7; 3/32; —3/32; 4,125. Представьте результаты в восьми
шестнадцатеричных разрядах.
8. Разработайте и реализуйте алгоритмы перевода числа из ПСС в систему
с отрицательным основанием.
9. Для системы кодирования данных в системе в коде вычетов разработайте
и реализуйте алгоритмы основных операций (сложение и умножение).
10. Разработайте и реализуйте алгоритм сравнения чисел в системе кода вы-
четов.
202
Глава 6
Микропроцессоры
Наряду с развитием и совершенствованием технологии производства
элементной базы совершенствуется и архитектура компьютеров. Ниже
рассмотрены архитектурные решения, предлагаемые ведущими миро-
выми фирмами по проектированию и производству компьютеров —
IBM, Intel, Microsystems, Hewlett Packard, Motorola, DEC, Apple и др.
Считается, что термин «микропроцессор» впервые прозвучал при пред-
ставлении фирмой Intel интегрального микропрограммируемого вы-
числительного устройства серии 4004 в 1972 году. Рассмотрим работу
микропроцессора (МП) на примере простейшей восьмиразрядной
конструкции (рис. 6.1). Каждый МП может реализовывать определен-
ный набор системы команд (СК), хранящихся в специальной области
памяти. Считывание и выполнение команд осуществляется в соот-
ветствии с тактовыми импульсами от генератора сигналов.
Управляющая программа задает адрес очередной команды для выпол-
нения. Считанный из памяти код этой команды по шине адреса (ША)
пересылается в регистр команд (РК). Дешифратор кода команд (ДШК)
Рис. 6.1. Функциональная схема восьмиразрядного микропроцессора
203
Глава 6. Микропроцессоры
расшифровывает ее и посылает в арифметико-логическое устройство
(АЛУ) для исполнения. Обрабатываемые данные поступают на вход
АЛУ через буферный регистр данных (БРД), используемый для вре-
менного хранения введенной информации. Результат обработки из
АЛУ направляется в устройство оперативного хранения, в качестве
которого используется регистр-аккумулятор (РА), затем по шине
данных (ШД) поступает на выход МП. В реальных МП оперативный
РА входит составной частью в регистры общего назначения (РОН),
являющиеся внутренней сверхоперативной памятью МП.
6.1. Методы адресации и типы команд
В компьютерах с регистрами общего назначения метод (или режим)
адресации объектов, с которыми манипулирует команда, может зада-
вать константу, регистр или ячейку памяти.
Система адресации определяет максимальный размер памяти, исполь-
зуемой компьютером. Так, например, при 16-разрядном адресе па-
мять составляет 216=64 Кбайт, при 32-разрядном адресе используется
память объемом 232 = 4 Гбайт.
В табл. 6.1 представлены основные методы адресации операндов, ко-
торые реализованы в компьютерах, рассмотренных в настоящей книге.
Методы адресации
Таблица 6.1
Метод адресации Пример команды Смысл команды Использование команды
Регистровая Add R4, R3 R4 = R4 + R3 Для записи требуемого значения в регистр
Непосредст- венная или литерная Add R4, #3 R4=R4 + 3 Для задания констант
Базовая со сме- щением Add R4, 100(Rl) R4 = R4 + + M(100 + Rl) Для обращения к ло- кальным переменным
Косвенная регистровая Add R4, (Rl) R4 = R4+M(R1) Для обращения по ука- зателю к вычисленному адресу
204
6.1. Методы адресации и типы команд
Окончание табл. 6.1
Метод адресации Пример команды Смысл команды Использование команды
Индексная Add R3, (R1+R2) R3 = R3 + + M(R1 + R2) Полезна при работе с массивами: R1 — база, R3 — индекс
Прямая или абсолютная Add Rl, (1000) Rl = Rl + M(1000) Полезна для обращения к статическим данным
Косвенная Add Rl, @(R3) Rl = Rl+ + M(M(R3)) Если R3 — адрес указа- теля, то выбирается зна- чение по этому указателю
Адресация непосредственных данных и литерных констант обычно
рассматривается как один из методов адресации памяти (хотя значения
данных, к которым в этом случае производятся обращения, являются
частью самой команды и обрабатываются в общем потоке команд).
В табл. 6.1 на примере команды сложения (Add) приведены наиболее
употребительные названия методов адресации, хотя при описании
архитектуры в документации производители компьютеров и ПО ис-
пользуют разные названия этих методов. Знак «=>> используется для
обозначения оператора присваивания, а буква М обозначает память
(Memory). Таким образом M(R\) обозначает содержимое ячейки па-
мяти, адрес которой определяется содержимым регистра R1.
Использование сложных методов адресации позволяет существенно
сократить количество команд в программе, но при этом значительно
увеличивается сложность аппаратуры.
Команды традиционного машинного уровня можно разделить на не-
сколько основных типов, которые показаны в табл. 6.2.
Таблица 6.2
Основные типы команд
Тип операции Примеры
Арифметические и логические Целочисленные арифметические и логи- ческие операции: сложение, вычитание, логическое сложение, логическое умно- жение и т.д.
Пересылки данных Операции загрузки/записи
205
Глава 6. Микропроцессоры
Окончание табл. 6.2
Тип операции Примеры
Управление потоком команд Безусловные и условные переходы, вызовы процедур и возвраты
Системные операции Системные вызовы, команды управления виртуальной памятью и т.д.
Операции с плавающей точкой Операции сложения, вычитания, умноже- ния и деления над вещественными числами
Десятичные операции Десятичное сложение, умножение, преоб- разование форматов и т.д.
Операции над строками Пересылки, сравнения и поиск строк
Ъш операнда может задаваться либо кодом операции в команде, либо
с помощью тега, который хранится вместе с данными и интерпрети-
руется аппаратурой во время обработки данных.
Обычно тип операнда (целый, вещественный, символьный) опреде-
ляет и его размер. Как правило, целые числа представляются в допол-
нительном коде. Для задания символов компания IBM использует
код EBCDIC, другие компании применяют код ASCII. Для представ-
ления вещественных чисел с одинарной и двойной точностью при-
держиваются стандарта IEEE 754.
В ряде процессоров применяют двоично кодированные десятичные
числа (двоично-десятичные числа), которые представляют в упако-
ванном и неупакованном форматах. Упакованный формат предпола-
гает, что для кодирования цифр 0—9 используют четыре разряда и две
десятичные цифры упаковываются в каждый байт. В неупакованном
формате байт содержит одну десятичную цифру, которая обычно изо-
бражается в символьном коде ASCII.
6.2. Компьютеры со стековой архитектурой
При создании компьютера одновременно проектируют и систему ко-
манд для него. Существенное влияние на выбор операций для их вклю-
чения в СК оказывают:
► элементная база и технологический уровень производства компью-
теров;
206
6.2. Компьютеры со стековой архитектурой
► класс решаемых задач, определяющий необходимый набор опера-
ций, воплощаемых в отдельные команды;
► системы комацд для компьютеров аналогичного класса;
► требования к быстродействию обработки данных, что может поро-
дить создание команд с большой длиной слова (VLIW-команды).
Анализ задач показывает, что в смесях программ доминирующую роль
играют команды пересылки и процессорные команды, использую-
щие регистры и простые режимы адресации.
На сегодняшний день наибольшее распространение получили сле-
дующие структуры команд: одноадресные (1А), двухадресные (2А),
трехадресные (ЗА), безадресные (БА), команды с большой длиной слова
(VLIW - БДС) (рис. 6.2):
Причем операнд может указываться как адресом, так и непосредст-
венно в структуре команды.
В случае БА-команд операнды выбираются и результаты помещаются
в стек (магазин, гнездо). Первыми (типичными) представителями
БА-компьютеров являются KDF-9 и МВК Эльбрус. Характерная
особенность таких компьютеров — наличие стековой памяти.
Стек — это область оперативной памяти, которая используется для вре-
менного хранения данных и операций. Доступ к элементам стека осуще-
ствляется по принципу FILO (first in, last out — первым вошел, послед-
ним вышел), причем только через вершину стека, то есть пользователю
«виден» лишь тот элемент, который помещен в стек последним.
Рассмотрим функционирование процессора со стековой организа-
цией памяти.
207
Глава 6. Микропроцессоры
При выполнении различных вычислительных процедур процессор
использует либо новые операнды, ранее не выбиравшиеся из памяти
компьютера, либо операнды, употреблявшиеся в предыдущих опера-
циях. В процессорах с классической структурой обращение к любому
операнду (1А-ЭВМ) требует цикла памяти.
Рассмотрим пример.
Пусть процессор вычисляет значение выражения
v _ аг+Ь2
Л---------_
b + c
Программа решения этой задачи для одноадресного компьютера мо-
жет быть следующей (табл. 6.3).
Таблица 6.3
Пример программы
Номер команды Команда Комментарии
1 C->Z’
2 (Е)+/>
3 Pj — рабочая ячейка
4 Л—
5 (Е)-а
6 (Е)^Р2 Р2 — рабочая ячейка
7 Ь—ьЕ.
8
9 (2) + (А)
10 (WO а2 +Ь2 Ь+с
Как следует из приведенной программы, операнд а выбирается из па-
мяти два раза (команды 4 и 5), b — 3 раза (команды 2, 7 и 8). Кроме
того, потребовались дополнительные обращения к памяти для запо-
Выполнение команды типа(£)®(Р) подразумевает, что результат операции поме-
щается в первый регистр, в данном случае в регистр Е.
208
6.2. Компьютеры со стековой архитектурой
минания и вызова из памяти результатов промежуточных вычисле-
ний (команды 3, 6, 9, 10).
Если главным фактором, ограничивающим быстродействие компью-
тера, является время цикла памяти, то необходимость в дополнитель-
ных обращениях к памяти значительно снижает скорость его работы.
Очевидно, что принципиально необходимы обращения к памяти за
данными только в первый раз. В дальнейшем они могут храниться в
триггерных регистрах или СОЗУ.
Указанные соображения получили воплощение в ряде логических
структур некоторых процессоров.
Рассмотрим тот же пример для новой ситуации (табл. 6.4):
_ а2+Ь2
Л —-------е
Ь + с
Таблица 6.4
Реализация программы со стековой памятью
№ п/п Команда А Pi Рз Ра
1 Вызов Ь Ь
2 Дублирование Ь Ъ
3 Вызов с С Ъ Ъ
4 Сложение Ь + с ъ
5 Реверсирование Ъ Ь + с
6 Дублирование ь Ъ Ь+с
7 Умножение Л2 Ь + с
8 Вызов а а ь2 Ь+с
9 Дублирование а а Ь2 Ь+с
10 Умножение а2 ь2 Ь+с
И Сложение а1+ Ь2 Ь + с
12 Деление а2+Ь2 Ь+с
Как следует из табл. 6.4, понадобились лишь три обращения к памяти
для вызова операндов (команды 1, 3,8). Меньшее количество обра-
щений принципиально невозможно. Операнды и промежуточные
209
Глава 6. Микропроцессоры
результаты поступают для операций в АУ из стековой памяти; 9 ко-
манд из 12 являются безадресными.
Вся программа размещается в трех 48-разрядных ячейках памяти.
Главное преимущество использования стековой памяти состоит в том,
что при переходе к подпрограммам (ПП) или в случае прерывания
нет необходимости в специальных действиях по сохранению содер-
жимого арифметических регистров в основной памяти. Новая про-
грамма может немедленно начать работу. При введении в стековую
память новой информации данные, соответствующие предыдущей
программе, автоматически продвигаются вниз. Они возвращаются
обратно, когда новая программа закончит вычисления.
Наряду с указанным преимуществом стековой памяти отметим также:
► уменьшение количества обращений к памяти;
► упрощение способа обращения к ПП и обработки прерываний.
Недостатки стековой организации памяти:
► большое число регистров с быстрым доступом;
► необходимость в дополнительном оборудовании, позволяющем
следить за переполнением стековой памяти, ибо число регистров па-
мяти конечно;
► приспособленность главным образом для решения научных задач
и в меньшей степени для систем обработки данных или управления
технологическими процессами.
Важным вопросом построения любой системы команд является опти-
мальное кодирование команд. Оно определяется количеством регистров
и применяемых методов адресации, а также сложностью аппаратуры,
необходимой для декодирования. Именно поэтому в современных
RISC-архитектурах используются достаточно простые методы адре-
сации, позволяющие резко упростить декодирование команд. Более
сложные и редко встречающиеся в реальных программах методы адре-
сации реализуются с помощью дополнительных команд, что, вообще
говоря, приводит к увеличению размера программного кода. Однако
такое увеличение программы с лихвой окупается возможностью про-
стого увеличения частоты RISC-процессоров. Этот процесс вполне
соответствует современному состоянию, когда максимальные так-
товые частоты практически всех RISC-процессоров (Alpha, R4400,
210
6.2. Компьютеры со стековой архитектурой
HyperSPARC и Power2) превышают тактовую частоту, достигнутую
процессором Pentium.
Общую технологию проектирования системы комавд для новой ЭВМ
можно определить следующим образом: зная класс решаемых задач,
выбираем некоторую типовую систему команд (СК) для широко рас-
пространенного компьютера и исследуем ее на предмет покрытия
всего разнообразия операций в заданном классе задач. Не встречаю-
щиеся или редко встречающиеся операции не включаем в СК. Часто-
ту применения операций для их задания в СК можно определить из
соотношений «стоимость затрат — сложность реализации — получае-
мый выигрыш».
Второй путь проектирования СК состоит в расширении имеющейся
системы команд. Один из способов такого расширения — создание
макрокоманд, второй —дополнение имеющегося языка СК новыми
командами, используя его синтаксис с последующим переассембли-
рованием через расширение функций ассемблера. Оба эти способа
принципиально одинаковы, но различаются в тактике реализации
аппарата расширения.
Так, система команд для ПК IBM покрывает следующие группы опе-
раций: передачи данных, арифметические операции, операции ветв-
ления и циклов, логические операции и операции обработки строк.
Разработанную СК следует оптимизировать. Один из способов оптими-
зации состоит в выявлении частоты повторений сочетаний двух или
более команд, следующих друг за другом в некоторых типовых задачах
для данного компьютера, с последующей заменой их одной командой,
выполняющей те же функции. Это приводит к сокращению времени
выполнения программы и уменьшению требуемого объема памяти.
Так же исследуются и часто генерируемые компилятором некоторые
последовательности команд, убирая из них избыточные коды.
Оптимизация проводится и в пределах отдельной команды, изучая ее
информационную емкость. Для этого можно применить аппарат тео-
рии информации, в частности для оценки количества переданной
информации — энтропию* источника. Тракт «процессор — память»
при этом можно считать каналом связи.
Энтропия — это мера вероятности пребывания системы в данном состоянии (в ста-
тистической физике). (Примеч. авт.)
211
Глава 6. Микропроцессоры
6.3. Процессоры с микропрограммным управлением
Для программиста язык ассемблерного типа является языком самого
низкого уровня, а выполнение команды такого языка — элементар-
ным шагом работы процессора. На самом деле такая комацда состоит
из ряда элементарных подкоманд, последовательное выполнение ко-
торых и реализует соответствующую команду языка ассемблера. Опе-
рация, реализующая каждую подкоманду, управляется отдельным
функциональным импульсом.
Известны два подхода к построению логики формирования функ-
циональных импульсов. Один из них — каждой операции процессора
соответствует набор логических схем, определяющих вид функцио-
нального импульса (ФИ) и такт, в котором он должен быть возбуж-
ден. Пусть некоторый ФИ должен появиться в такте j операции т при
условии наличия переполнения сумматора или в такте i операции п.
Требуемое действие будет выполнено, если подать сигналы, соответ-
ствующие указанным кодам операции, тактам и условиям на входы
схем И, а выходы последних через схему ИЛИ соединить с формиро-
вателем ФИ (рис. 6.3).
Такой принцип управления операциями получил название «жесткой»
или «запаянной» логики и широко применяется во многих компью-
терах.
Другой принцип организации управления состоит в следующем. Ка-
ждой микрооперации (МИО) ставится в соответствие слово (или часть
212
6.3. Процессоры с микропрограммным управлением
слова), называемое микрокомандой и хранимое в памяти подобно тому,
как хранятся в памяти команды обычного компьютера. В данном
случае команде соответствует микропрограмма, то есть набор микро-
команд (МИК), указывающих, какие ФИ и в какой последовательно-
сти необходимо возбуждать для выполнения данной операции. Такой
подход получил название микропрограммирования или «хранимой
логики». Таким образом в микропрограммном компьютере логика
управления реализуется не в виде электронной схемы, а в виде зако-
дированной информации, находящейся в некотором регистре.
Идея микропрограммирования, высказанная в 1951 году Уилксом, до
недавнего времени не находила широкого применения, ибо:
► не было надежных и быстродействующих ЗУ для хранения мик-
ропрограммы,
► неправильно понимались задачи и выгоды микропрограммиро-
вания.
Поясним второй аргумент. Так, считалось, что ценность микро-
программирования состоит в том, что каждый потребитель может
сконструировать из МИК нужный ему набор операций в данной кон-
кретной задаче. Замена наборов команд должна была достигаться за-
меной информации в ЗУ без каких-либо переделок в аппаратуре.
Однако в этом случае программисту необходимо знать все тонкости
работы инженера — разработчика компьютера. А основная тенден-
ция развития ЭВМ в связи с автоматизацией программирования со-
стоит в том, чтобы освободить программиста от детального изучения
компьютера и в максимальной степени приблизить язык компьютера
к языку человека. Поэтому микропрограммные компьютеры счита-
лись достаточно трудными для пользователя.
В последнее время интерес к микропрограммному принципу возро-
дился, поскольку:
► созданы односторонние (читающие) быстродействующие ЗУ с ма-
лым циклом памяти,
► микропрограммирование рассматривается не как средство повы-
шения гибкости программирования, а как метод построения системы
управления процессором, удобный для инженера — разработчика
компьютера.
213
Глава 6. Микропроцессоры
Под микропрограммированием обычно понимают метод проектирова-
ния и реализации функций устройства управления процессора в форме
последовательности управляющих сигналов, которые служат для интер-
претации операций обработки данных.
Микропрограммное управление позволяет сократить сроки разра-
ботки новых моделей компьютеров за счет разграничения функций
между схемотехниками и микропрограммистами, а также повысить
надежность работы компьютеров.
Программист может и не подозревать о микропрограммной структуре
компьютера и использовать все средства ПО и языки программиро-
вания самого высокого уровня. Использование микропрограммного
принципа позволяет облегчить разработку и изменение логики про-
цессора.
С появлением программного доступа к определению состояния про-
цессора после выполнения каждой МИК, представляющей собой
набор микроопераций, обеспечивается возможность создания эконо-
мичной системы автоматической диагностики неисправностей и по-
является способность к эмуляции, то есть к выполнению на данной
ЭВМ программы, составленной в кодах команд другого компьютера.
Это достигается введением дополнительного набора МИК, соответ-
ствующих командам эмулируемого компьютера.
Такие возможности способствуют распространению методов микро-
программирования при построении УУ в современных компьютерах.
6.3.1. Горизонтальнее микропрограммирование
Существует два вида микропрограммного управления — горизонтальное
и вертикальное. При горизонтальном микропрограммировании каждому
разряду МИК соответствует определенная микрооперация (МИО),
выполняемая независимо от содержания других разрядов. Микро-
программа может быть представлена в виде матрицы п х т, где п —
число ФИ, т — количество МИК, то есть строка соответствует одной
МИК, а столбец — одной МИО (рис. 6.4).
Примерные значения разрядов МИК приведены на рис. 6.5.
Наличие «1» в пересечении строки и столбца (рис. 6.4) означает по-
сылку ФИ в данную МИК, а наличие «О» — отсутствие импульса.
214
6.3. Процессоры с микропрограммным управлением
ФИ
Рис. 6.4. Микропрограмма при горизонтальном микропрограммировании
Рис. 6.5. Значение разрядов МИК (МИО):
1 — гашение сумматора; 2 — гашение указателя переполнения; 3 — обратный
код сумматора; 4 — гашение регистра множителя частного; 5 — инвертирова-
ние знака; 6 — сдвиг содержимого сумматора влево; 7 — сдвиг содержимого
сумматора вправо; 8 — увеличение содержимого сумматора на 1; 9 — чтение
из ЗУ в сумматор
Размещение «1» в нескольких разрядах МИК означает выполнение
нескольких МИО одновременно. Конечно, возбуждаемые МИО долж-
ны быть совместимы.
Пусть, например, разряды 9-разрядной МИК принимают следующие
значения: 001001101. Тогда, если заданные разряды соответствуют се-
мантике, указанной на рис. 6.5, МИО, определяемые разрядами 9, 7
и 6, несовместимы.
Для расширения возможностей МИК иногда используют многотакт-
ный принцип исполнения микрокоманд. При этом каждому разряду
присваивается номер такта, в котором выполняется соответствующая
ему МИО, то есть все совместимые МИО имеют один номер такта.
Все остальные такты нумеруются в порядке их естественного выпол-
нения. Однако универсальную нумерацию МИО в МИК указать за-
труднительно.
215
Глава 6. Микр< процессоры
Достоинства горизонтального микропрограммирования:
► возможность одновременного выполнения нескольких МИО;
► простота формирования ФИ (без схем дешифрации).
Недостатки:
► большая длина МИК, так как число ФИ в современных компьюте-
рах достигает нескольких сот, и соответственно большой объем ЗУ
для хранения МИК;
► из-за ограничений совместимости операций, а также из-за после-
довательного характера выполнения алгоритмов операций лишь не-
большая часть разрядов МИК будет содержать «1». В основном матрица
будет состоять из нулей. Неэффективное использование ЗУ привело
к малому распространению горизонтального микропрограммирования.
6.3.2. Вертикальное микропрограммирование
При вертикальном микропрограммировании каждая МИО определя-
ется не состоянием одного разряда, а двоичным кодом, содержащимся
в определенном поле МИК. Микрокоманда несколько напоминает
формат обычных команд. Отличие состоит в том, что:
► выполняется более элементарное действие — МИО вместо операции;
► адресная часть (в большинстве случаев) определяет не ячейку па-
мяти, а операционный регистр процессора.
Формат МИК при вертикальном микропрограммировании приведен
на рис. 6.6.
КМО Л
Код МИО Адресная часть МИК
Рис. 6.6. Формат вертикальной МИК
Поля Р\ и Р2 в адресной части МИК указывают двоичные номера опера-
ционных регистров, содержимое которых участвует в одной операции.
Одно из полей является одновременно и адресом результата. Таким
образом, реализация арифметической или логической МИО, указан-
ной в данной МИК, может быть выражена формулой (Р\) ® (P-fi -> Р\
или (Pii —*Р\, где ® — некоторая МИО.
216
6.3. Процессоры с микропрограммным управлением
Для МИК обращения к памяти поле Pt указывает регистр, куда прини-
мается информация, а Р2 — регистр, содержимое которого является
адресом обращения к ЗУ. Указанный формат МИК не единственный.
Каждая МИК выполняет следующие функции:
► указывает выполняемую МИО;
► указывает следующую МИО через задание «следующего адреса»;
► задает продолжительность МИК;
► указывает дополнительные действия — контроль, интерпретацию
разрядов, зависящих от типа МИК, и т.д.
Обычно в слове МИК имеются четыре зоны, соответствующие указан-
ным функциям. Вообще говоря, некоторые из зон могут указываться
неявно, например выбор очередной МИК может осуществляться из
следующей ячейки, продолжительность МИК может быть определена
одинаковой для всех МИК и т.д. Большую часть МИК занимает зона
микроопераций.
Кроме вертикального и горизонтального микропрограммирования
существует и смешанное, горизонтально-вертикальное, позволяющее
отдельные поля МИК объединять в наборы операций, допускающих
параллельное выполнение.
Микропрограммы записываются в специализированную память кон-
троля, управления и т.д., называемой памятью микропрограмм. Каждая
команда интерпретируется как обращение к памяти микропрограмм,
а именно к адресу первой микрокоманды соответствующей микро-
программы. Прочитанная микрокоманда помещается в регистр и де-
кодируется для определения последовательности ФИ, управляющих
необходимыми схемами выполнения этой микрокоманды.
Затем аналогично выбираются, декодируются и выполняются сле-
дующие микрокоманды, и так до завершения исполнения всей мик-
ропрограммы.
Обычно память для реализации микропрограмм осуществляется по
схеме 2D, то есть сеткой, образованной шинами слов и шинами раз-
рядов. Организация памяти по схеме 2D ориентирована на хранение
небольшого количества длинных слов и обеспечивает к ним быстрый
доступ.
217
Глава 6. Микропроцессоры
Первыми компьютерами с микропрограммным управлением
(в б. СССР) были МИР, НАИРИ, за рубежом — IBM 360/65, Spectra
70 и компьютеры компании RSA.
6.4. Процессоры с архитектурой 80x86 и Pentium
Архитектура 80x86 создавалась несколькими независимыми группа-
ми разработчиков, которые развивали ее более 15 лет, добавляя новые
возможности к первоначальному набору команд.
Микропроцессор 8080 построен на базе накапливающего сумматора
(аккумулятора), а архитектура 8086 была расширена дополнительны-
ми регистрами. Поскольку почти каждый регистр в этой архитектуре
имеет определенное назначение, 8086 по классификации частично
можно отнести к машинам с накапливающим сумматором, а частич-
но — к машинам с регистрами общего назначения, в связи с чем его
можно назвать расширенной машиной с накапливающим сумматором.
Микропроцессор 8086 (точнее его версия 8088 с 8-битовой внешней
шиной) стал основой завоевавшей впоследствии весь мир серии ком-
пьютеров IBM PC, работающих под управлением операционной сис-
темы MS DOS.
В 1980 году был анонсирован сопроцессор плавающей точки 8087.
Эта архитектура расширила 8086 почти на 60 команд работы с пла-
вающей точкой.
Анонсированный в 1982 году микропроцессор 80286 еще более рас-
ширил архитектуру 8086. Была создана сложная модель распределения
и защиты памяти, расширено адресное пространство до 24 разрядов,
а также добавлено несколько команд. Поскольку требовалось обеспе-
чить выполнение программ, разработанных для 8086, в 80286 без из-
менений был предусмотрен режим реальных адресов, позволяющий
машине выглядеть практически как 8086. В 1984 году компания IBM
объявила об использовании этого процессора в своей новой серии
персональных компьютеров IBM PC/AT.
В 1987 году появился микропроцессор 80386, который расширил
архитектуру 80286 до 32 бит. В дополнение к 32-битовой архитекту-
ре с 32-битовыми регистрами и 32-битовым адресным пространст-
вом в микропроцессоре 80386 появились новые режимы адресации
218
6.4. Процессоры с архитектурой 80x86 и Pentium
и дополнительные операции. Все эти расширения превратили 80386
в машину, по идеологии близкую к машинам с регистрами общего
назначения. Наряду с механизмом сегментации памяти в микропро-
цессор 80386 добавлена поддержка страничной организации памяти.
Как и 80286, микропроцессор 80386 имеет режим выполнения про-
грамм, написанных для 8086. Хотя базовой операционной системой
для этих микропроцессоров оставалась MS DOS, тем не менее 32-раз-
рядная архитектура и страничная организация памяти послужили
основой для переноса на эту платформу операционной системы UNIX.
Следует отметить, что для процессора 80286 была создана операци-
онная система XENIX (сокращенный вариант системы UNIX).
Последующие процессоры (80486 в 1989 году и Pentium в 1993 году)
были нацелены на увеличение производительности и добавили к ви-
димому пользователем набору команд только три новые команды,
облегчившие организацию многопроцессорной работы.
Семейство процессоров i486 (i486SX, i486DX, i486DX2 и i486DX4),
в котором сохранились система команд и методы адресации процес-
сора i386, уже имеет некоторые свойства RISC-микропроцессоров.
Например, наиболее употребительные команды выполняются за один
такт.
Процессоры i486SX и i486DX — это 32-битовые процессоры с внут-
ренней кэш-памятью емкостью 8 Кбайт и 32-битовой шиной данных.
Основное различие между ними состоит в том, что в процессоре i486SX
отсутствует интегрированный сопроцессор плавающей точки. Поэтому
он применяется в системах, для которых не критична производитель-
ность при обработке вещественных чисел. Для этих систем обычно
возможно расширение с помощью внешнего сопроцессора i487SX.
Процессоры Intel OverDrive и i486DX2 практически идентичны. Од-
нако кристалл OverDrive имеет корпус, который может устанавли-
ваться в гнездо расширения сопроцессора i487SX, применяемое в ПК
на базе i486SX. В процессорах OverDrive и i486DX2 используется тех-
нология удвоения внутренней тактовой частоты, что позволяет уве-
личить производительность процессора почти на 70 %. Процессор
i486DX4/100 применяет технологию утроения тактовой частоты. Он
работает с внутренней тактовой частотой 99 МГц, в то время как
внешняя тактовая частота (частота, на которой работает внешняя
шина) составляет 33 МГц. Этот процессор практически обеспечивает
равные возможности с машинами класса 60 МГц Pentium.
219
Глава 6. Микропроцессоры
Появившийся в 1993 году процессор Pentium ознаменовал собой новый
этап в развитии архитектуры х86, связанный с адаптацией многих
свойств процессоров с архитектурой RISC. Он изготовлен по 0,8-мик-
ронной БиКМОП технологии и содержит 3,1 миллиона транзисторов.
Появились процессоры Pentium, работающие с тактовой частотой 75,
90, 100 и 120 МГц. Главными особенностями процессора Pentium яв-
ляются:
► двухпотоковая суперскалярная организация, допускающая парал-
лельное выполнение пары простых команд;
► наличие двух независимых двухканальных множественно-ассо-
циативных кэшей для команд и для данных, обеспечиваюших выбор-
ку данных для двух операций в каждом такте;
► динамическое прогнозирование переходов;
► конвейерная организация устройства плавающей точки с восемью
ступенями;
► двоичная совместимость с существующими процессорами семей-
ства 80x86.
Основные характеристики микропроцессоров ведущей компании
в этом направлении представлены в табл. 6.5.
Таблица 6.5
Некоторые характеристики микропроцессоров фирмы Intel
Модель Разрядность (в битах) Тактовая частота, МГц Число команд Количество транзисторов
данных адреса
i286 16 24 10-33 134 14 • 104
1386 32 32 25-50 240 27,5 104
i486 32 32 33-100 240 12 105
Pentium 64 32 50-150 240 31 105
Pentium Pro 64 32 66-200 240 55 105
Pentium II 64 32 233-450 — 75 • 105
Pentium III 64 32 550-1200 — 85 • 105
Pentium IV — — 1400-2000 — от 42 106
Микроархитектура этого процессора базируется на идее суперска-
лярной обработки (с некоторыми ограничениями). Основные команды
распределяются по двум независимым исполнительным устройствам
220
6.4. Процессоры с архитектурой 80x86 и Pentium
(конвейерам U и V). Конвейер U может выполнять любые команды
семейства х86, включая целочисленные команды и команды с пла-
вающей точкой. Конвейер Vпредназначен для выполнения простых
целочисленных команд и некоторых команд с плавающей точкой.
Команды могут направляться в каждое из этих устройств одновре-
менно, причем при выдаче устройством управления в одном такте
пары команд более сложная команда поступает в конвейер U, а менее
сложная — в конвейер V. Такая попарная выдача команд возможна
только для ограниченного подмножества целочисленных команд.
Команды арифметики с плавающей точкой не могут запускаться в паре
с целочисленными командами. Одновременная выдача двух команд
возможна только при отсутствии зависимостей по регистрам. При ос-
тановке команды по любой причине в одном конвейере, как правило,
останавливается и второй конвейер.
Остальные устройства процессора предназначены для снабжения кон-
вейеров необходимыми командами и данными. В отличие от процессо-
ров i486 в процессоре Pentium используется раздельная кэш-память
команд и данных емкостью по 8 Кбайт, что обеспечивает независи-
мость обращений. За один такт из каждой кэш-памяти могут считы-
ваться два слова. Кэш-память данных построена на принципах дву-
кратного расслоения, что обеспечивает одновременное считывание
двух слов, принадлежащих одной строке кэш-памяти. Кэш-память
команд хранит сразу три копии тегов, что позволяет в одном такте
считывать два командных слова, принадлежащих либо одной строке,
.либо смежным строкам для обеспечения попарной выдачи команд,
при этом третья копия тегов используется для организации протокола
наблюдения за когерентностью состояния кэш-памяти. Для повыше-
ния эффективности перезагрузки кэш-памяти в процессоре приме-
няется 64-битовая внешняя шина данных.
В процессоре предусмотрен механизм динамического прогнозирова-
ния направления переходов. С этой целью на кристалле размещены
небольшая кэш-память, которая называется буфером целевых адресов
переходов (ВТВ), и две независимые пары буферов предварительной
выборки команд (по два 32-битовых буфера на каждый конвейер).
Буфер целевых адресов переходов хранит адреса команд, которые нахо-
дятся в буферах предварительной выборки. Работа буферов предвари-
тельной выборки организована таким образом, что в каждый момент
времени осуществляется выборка команд только в один из буферов
221
Глава 6. Микропроцессоры
соответствующей пары. При обнаружении в потоке команд операции
перехода вычисленный адрес перехода сравнивается с адресами, храня-
щимися в буфере ВТВ. В случае совпадения предполагается, что пере-
ход будет выполнен, и разрешается работа другого буфера предвари-
тельной выборки, который начинает выдавать команды для выпол-
нения в соответствующий конвейер. При несовпадении считается,
что переход выполняться не будет и буфер предварительной выборки
не переключается, продолжая обычный порядок выдачи команд Это
позволяет избежать простоев конвейеров при правильном прогнозе
направления перехода. Окончательное решение о направлении пере-
хода, естественно, принимается на основании анализа кода условия.
При неверном прогнозе содержимое конвейеров аннулируется и вы-
дача команд начинается с необходимого адреса. Неверный прогноз
приводит к приостановке работы конвейеров на 3—4 такта.
Следует отметить, что возросшая производительность процессора
Pentium требует и соответствующей организации системы на его ос-
нове. Компания Intel разработала и поставляет все необходимые для
этого наборы микросхем. Для согласования скорости с динамиче-
ской основной памятью используется кэш-память второго уровня.
Контроллер кэш-памяти 82496 и микросхемы статической памяти
82491 обеспечивают построение такой кэш-памяти объемом 256 Кбайт
и работу процессора без тактов ожидания. Для эффективной органи-
зации работы системы Intel разработала стандарт на локальную шину
PCI. Выпускаются наборы микросхем для построения мощных ком-
пьютеров на ее основе.
В настоящее время компанич Intel разработала новый процессор,
продолжающий архитектурную линию х86. Этот процессор получил
название Р6. В нем 4—5 миллионов транзисторов, что обеспечивает
повышение производительности до уровня 200 MIPS (66 МГц Pentium
имеет производительность 112 MIPS). Для достижения такой произ-
водительности используются технические решения, широко приме-
няющиеся при построении RISC-процессоров:
► выполнение команд в отличной от предписанной программой по-
следовательности, что во многих случаях устраняет приостановку кон-
вейеров из-за ожидания операндов операций;
► использование методики переименования регистров, позволяю-
щей увеличивать эффективный размер регистрового файла (малое
количество регистров — одно из самых узких мест архитектуры х86);
222
6.4. Процессоры с архитектурой 80x86 и Pentium
► расширение суперскалярных возможностей по отношению к про-
цессору Pentium, в котором обеспечивается одновременная выдача
только двух команд с достаточно жесткими ограничениями на их
комбинации.
Кроме того, в разработку нового поколения процессоров х86 вклю-
чились компании, ранее занимавшиеся изготовлением Intel-совмес-
тимых процессоров. Это компании Advanced Micro Devices (AMD),
Cyrix Corp и NexGen. С точки зрения микроархитектуры наиболее
близок к Pentium процессор Ml компании Cyrix. Так же как и Pentium,
он имеет два конвейера и может выполнять до двух команд в одном
такте. Однако в процессоре М1 число случаев, когда операции могут
выполняться попарно, значительно увеличено. Кроме того, в нем
применяется методика обходов и ускорения пересылки данных, позво-
ляющая устранить приостановку конвейеров во многих ситуациях, с ко-
торыми не справляется Pentium. Процессор содержит 32 физических
регистра (вместо 8 логических, предусмотренных архитектурой х86)
и применяет методику переименования регистров для устранения зави-
симостей поданным. Как и Pentium, процессор Ml для прогнозирова-
ния направления перехода использует буфер целевых адресов пере-
хода емкостью 256 элементов и поддерживает специальный стек воз-
вратов, отслеживающий вызовы процедур и последующие возвраты.
Основа процессоров К5 компании AMD и Nx586 компании NexGen —
очень быстрое RISC-ядро, выполняющее высокорегулярные опера-
ции в суперскалярном режиме. Внутренние форматы команд (ROP
у компании AMD и RISC86 у компании NexGen) соответствуют тра-
диционным системам команд RISC-процессоров. Все команды имеют
одинаковую длину и кодируются в регулярном формате. Обращения
к памяти выполняются специальными командами загрузки и записи.
Как известно, архитектура х86 имеет очень сложную для декодирова-
ния систему команд. В процессорах К5 и Nx586 осуществляется аппа-
ратная трансляция команд х86 в команды внутреннего формата, что
обеспечивает лучшие условия для распараллеливания вычислений.
В процессоре К5 имеется 40, а в процессоре Nx586 — 22 физических
регистра, которые реализуют методику переименования. В процессо-
ре К5 информация, необходимая для прогнозирования направления
перехода, записывается прямо в кэш команд и хранится вместе с каж-
дой строкой кэш-памяти. В процессоре Nx586 для этих целей ис-
пользуется кэш-память адресов переходов на 96 элементов.
223
Глава 6. Микропроцессоры
Таким образом, компания Intel более не обладает монополией на мето-
ды конструирования высокопроизводительных процессоров х86 и мож-
но ожидать появления новых процессоров, не только не уступающих,
но и, возможно, превосходящих по производительности процессоры
компании, стоявшей у истоков этой архитектуры. Следует отметить,
что сама компания Intel заключила стратегическое соглашение с ком-
панией Hewlett Packard на разработку следующего поколения микро-
процессоров, в которых архитектура х86 будет сочетаться с архитек-
турой очень длинного командного слова (VLIW-архитектурой).
С 1999 года в качестве настольных процессоров базового уровня ис-
пользуются процессоры Celeron (фирма Intel), начиная с частоты
366 МГц. В массовых персональных компьютерах, рабочих станциях
и серверах применяются процессоры Katmai и Tanner с частотой
500 МГц, а затем осуществляется переход на процессоры Cascades
и Coppermine, исполненные по новой 0,18-мкм технологии.
Процессор AMD Athlon™, архитектура и интерфейс которого отлича-
ются от Intel, появился в 1999 году с архитектурой следующих ти-
пов - К7, К75 и К76.
Технические характеристики:
► 22 миллиона транзисторов;
► технология производства 0,25—0,18 мкм;
► тактовая частота 500—1000 МГц;
► кэш первого уровня 128 Кбайт (кэш данных 64 Кбайт и кэш ко-
манд 64 Кбайт);
► кэш второго уровня 512 Кбайт, работающий на 1/2,2/5 или 1/3 час-
тоты процессора;
► процессорная шина — Alpha EV-6 200 МГц (DDR 100x2).
Первые модели AMD Athlon™ Thunderbird выпущены в 2000 году. Их
ядро основано на архитектуре К7 и К75. Основное отличие от преды-
дущих моделей — интеграция кэша £2, работающего на частоте про-
цессора, в ядро. Процессор содержит 37 миллионов транзисторов на
площади 120 мм2.
Технические характеристики:
► технология производства 0,18 мкм;
► тактовая частота 600—1400 МГц;
224
6.4. Процессоры с архитектурой 80x86 и Pentium
► кэш первого уровня 128 Кбайт (64 Кбайт данных и 64 Кбайт ко-
манд);
► кэш второго уровня 256 Кбайт (полноскоростной);
► общая разрядность 32;
► разъем Slot А, позднее — Socket A (Socket 462 в виде микросхемы);
► процессорная шина — Alpha EV-6 200 МГц и 266 МГц (DDR 100x2—
133x2).
Процессор AMD Athlon™ MP (2001 год) рассчитан на работу в двух-
процессорных системах и выполнен на ядре Palomino.
Технические характеристики:
► технология производства 0,18 мкм;
► тактовая частота 1000—1667 МГц;
► кэш первого уровня 128 Кбайт (64 Кбайт данных и 64 Кбайт ко-
манд);
► кэш второго уровня 256 Кбайт (полноскоростной);
► процессорная шина — Alpha EV-6 266 МГц (DDR 133x2);
► разрядность 32.
В 2002 году AMD объявила о переходе на технологию 0,13 мкм и о вне-
дрении новой технологии SOI (Silicon-on-Insulator — кремний на изо-
ляторе). Это процессоры Athlon ХР 2100+ и 2200+ на 0,13-микронном
ядре Thoroughbred (TBred).
Процессоры Athlon ХР 2500+, 2600+, 2800+, 3000+, 3200+, основанные
на ядре Palomino, были выпущены в 2003 году. Они работали с частотой
шины FSB, равной 167 МГц, а модели Athlon ХР 2900+, 3100+работали
с частотой 200 МГц. Ядро содержит 54,3 миллиона транзисторов и имеет
площадь 101 мм2.
Ядро Barton является последним представителем процессоров седь-
мого поколения.
Первые модели процессоров Athlon ХР (Thorton) выпущены в 2003
году. Все модели работают с частотой шины FSB, равной 133 МГц,
кроме модели 2600+, имевшей шину в 166 МГц.
225
1^2792
Глава 6. Микропроцессоры
Процессоры Athlon МР предназначены для многопроцессорных сис-
тем и основаны на ядрах:
► Mustang (аналог ядра Palomino) — модели Athlon 1000 МРи 1200 МР;
► Corvette (аналог ядра Palomino) — модели Athlon МР1500+, МР1600+,
МР1800+, МР1900+, МР2000+, МР2100+;
► Thoroughbred — модели Athlon МР2000+, МР2200+, МР2400+,
МР2600+;
► Barton — модели Athlon МР2600+ и МР2800+.
Процессоры Opteron архитектуры AMD64 были созданы в 2003 году.
Их можно применять в одно- и двухпроцессорных конфигурациях.
Частота процессоров от 1,4 до 1,8 ГГц. Разработаны три серии про-
цессоров для применения в одно-, двух-, четырех- и восьмипроцес-
сорных системах. Максимальная частота для процессоров Opteron
составляет 2 ГГц (модели ХХ6).
Сравнение моделей Athlon и Opteron приводится в табл. 6.6.
Таблица 6.6
Сравнительные характеристики моделей Athlon и Opteron
Параметры Athlon ХР Athlon 64 Athlon 64 FX Opteron
Сокет Socket А Socket 754 Socket 940 Socket 940
Рейтинг/ модель 3200+ 3200+ FX-51 146
Частота 2,2 ГГц 2,0 ГГц 2,2 ГГц 2,0 ГГц
Шина 3,2 Гбайт/с 6,4 Гбайт/с 6,4 Гбайт/с 6,4 Гбайт/с
Память, скорость 6,4 Гбайт/с 3,2 Гбайт/с 6,4 Гбайт/с 5,3 Гбайт/с
1Л I: 64 Кбайт D: 64 Кбайт I: 64 Кбайт D: 64 Кбайт I: 64 Кбайт D: 64 Кбайт I: 64 Кбайт D: 64 Кбайт
L2 512 Кбайт 1024 Кбайт 1024 Кбайт 1024 Кбайт
Процессоры Sempron (2004 год) имели размер кэша второго уровня
256 Кбайт и частоту шины 333 МГц.
Последним процессором Sempron с разъемом Socket А стала модель
2800+. Эти процессоры позиционируются в качестве конкурентов Intel
Celeron D.
226
6.4. Процессоры с архитектурой 80x86 и Pentium
Первые модели Athlon 64 Х2 выпущены в 2005 году. В ядрах с кэшем
£2 объемом 512 Кбайт на каждое ядро (Manchester и Toledo 1М) со-
держится 154 миллиона транзисторов, а площадь кристалла ядра со-
ставляет 147 мм2. В ядрах с кэшем £2 объемом 1024 Кбайт на каждое
ядро (Toledo) содержится 233 миллиона транзисторов, а площадь кри-
сталла ядра — 205 мм2. Процессор имеет общий на оба ядра контроллер
памяти и контроллер шины HyperTransport, а каждое ядро обладает
собственной кэш-памятью £1 и £2.
Ядро Manchester характеризуется наличием кэша второго уровня
с 512 Кбайт для каждого ядра. Процессоры на ядре Toledo изначально
комплектовались 1024 Кбайт £2 для каждого ядра, позже были выпу-
щены с 512 Кбайт £2 для каждого ядра.
Анализируя процессоры AMD, можно отметить, что компания практи-
чески полностью перешла на использование архитектуры Clawhammer/
Sledgehammer или x86-64. В классе наиболее производительных про-
цессорных решений AMD все чаще можно встретить двухъядерные
решения, которых со временем будет становиться всё больше и больше.
С точки зрения производственных возможностей AMD можно отме-
тить, что в 2005 году компания уверенно освоила нормы 90 нм тех-
процесса с применением технологии SOI.
Процессоры серий Opteron позиционируются компанией AMD пре-
жде всего в качестве элементов серверных систем, хотя некоторые серии
рассчитаны на применение в различных встраиваемых решениях.
Процессоры AMD Athlon 64 FX созданы на базе технологии AMD64,
которая поддерживает выполнение 64-разрядных приложений и обо-
рудована механизмом усовершенствованной антивирусной защиты
(Enhanced Virus Protection) при поддержке операционной системы.
Современный процессор серии Athlon 64 FX-57 выполнен на базе
ядра San Diego и выпускается с соблюдением норм 90 нм с примене-
нием SOI. Ядро San Diego имеет размер кэша £2 объемом 1 Мбайт.
Взаимодействие двух ядер в процессорах Athlon 64 Х2 с распределен-
ными шинами осуществляется через коммутатор Crossbar Switch.
В настоящее время компания AMD выпускает модели процессоров
Athlon 64 с различными ядрами, тактовыми частотами, объемами
кэша £2, под разъемы Socket 754 или Socket 939, имеют интегриро-
ванный контроллер памяти с поддержкой DDR400, работают с шиной
HyperTransport 800 МГц или 1000 МГц.
227
Глава 6. Микропроцессоры
В связи с развитием e-mail и Интернета фирма Intel остается на пе-
реднем крае разработки процессоров, высокий уровень произво-
дительности которых отвечает растущим требованиям современных
приложений.
6.5. Особенности процессоров с архитектурой SPARC
компании Sun Microsystems
Масштабируемая процессорная архитектура компании Sun Microsystems
(SPARC — Scalable Processor Architecture) является наиболее широко
распространенной RISC-архитектурой, отражающей доминирующее
положение компании на рынке UNIX-рабочих станций и серверов.
Первоначально архитектура SPARC была разработана в целях упро-
щения реализации 32-битового процессора. Впоследствии, по мере
совершенствования технологии изготовления интегральных схем, она
также постепенно развивалась, и в настоящее время имеется 64-би-
товая версия этой архитектуры.
В отличие от большинства RISC-архитектур SPARC использует реги-
стровые окна, которые обеспечивают удобный механизм передачи па-
раметров между программами и возврата результатов. Архитектура
SPARC стала первой коммерческой разработкой, реализующей меха-
низмы отложенных переходов и аннулирования команд. Это давало
компилятору ббльшую свободу заполнения времени выполнения ко-
манд перехода командой, которая реализуется в случае выполнения
условий перехода и игнорируется в случае, если условие перехода не
выполняется.
Первый процессор SPARC изготовлен компанией Fujitsu на основе
вентильной матрицы, работающей на частоте 16,67 МГц. На основе
этого процессора была разработана первая рабочая станция Sun-4
производительностью 10 MIPS, выпущенная осенью 1987 года (до
этого времени компания Sun использовала в своих изделиях микро-
процессоры Motorola 680x0). В 1988 году Fujitsu увеличила тактовую
частоту до 25 МГц, создав процессор производительностью 15 MIPS.
Позднее тактовая частота процессоров SPARC была повышена до
40 МГц, а производительность — до 28 MIPS.
228
6.5. Особенности процессоров с архитектурой SPARC компании Sun Microsystems
Дальнейшее увеличение производительности процессоров с архитек-
турой SPARC было достигнуто компаниями Texas Instruments и Cypress
за счет реализации в кристаллах принципов суперскалярной обра-
ботки. Процессор SuperSPARC компании Texas Instruments стал осно-
вой серии рабочих станций и серверов SPARCstation/SPARCserver 10
и SPARCstation/SPARCserver 20. Имеется несколько версий этого про-
цессора, позволяющего в зависимости от смеси команд обрабатывать
за один машинный такт до трех команд, отличающихся тактовой часто-
той. Процессор SuperSPARC (рис. 6.7) имеет сбалансированную произ-
водительность на операциях с фиксированной и плавающей точкой.
Рис. 6.7. Блок-схема процессора SuperSPARC
ПТ — плавающая точка. (Примеч. ред.)
229
Глава 6. Микропроцессоры
Он содержит внутренний кэш емкостью 36 Кбайт (20 Кбайт — кэш ко-
манд и 16 Кбайт — кэш данных), раздельные конвейеры целочисленной
и вещественной арифметики и при тактовой частоте 75 МГц обеспечи-
вает производительность около 205 MIPS. Процессор SuperSPARC при-
меняется также в серверах SPARCserver 1000 и SPARCcenter 2000 ком-
пании Sun.
Конструктивно кристалл монтируется на взаимозаменяемых процессор-
ных модулях трех типов, отличающихся наличием и объемом кэш-па-
мяти второго уровня и тактовой частотой. Модуль Mbus SuperSPARC,
используемый в модели 50, включает вышеописанный процессор
SuperSPARC. Модули Mbus SuperSPARC в моделях 51,61 и 71 содер-
жат по одному процессору SuperSPARC, работающему соответственно
на частоте 50,60 и 75 МГц, по одному кристаллу кэш-контроллера (так
называемому SuperCache), а также внешний кэш емкостью 1 Мбайт.
Модули Mbus в моделях 502, 612, 712 и 514 содержат два SuperSPARC
процессора и два кэш-контроллера каждый, а последние три моде-
ли — и по одному (1 Мбайт) внешнему кэшу на каждый процессор.
Использование кэш-памяти позволяет модулям ЦП работать с тактовой
частотой, отличной от тактовой частоты материнской платы; поэтому
пользователи всех моделей могут улучшить производительность своих
систем заменой существующих модулей ЦП вместо того, чтобы про-
изводить замену всей материнской платы.
Sun совместно с Fujitsu создали и новую версию кристалла MicroSPARC
II со встроенным кэшем емкостью 24 Кбайт. На его основе построены
рабочие станции и серверы SPARCstation/ SPARCserver 4 и SPARCstation/
SPARCserver 5, работающие на частоте 70, 85 и 110 МГц.
В начале 1995 года на рынке появились микропроцессоры HyperSPARC,
однопроцессорные и двухпроцессорные рабочие станции с тактовой
частотой процессора 100 и 125 МГц. К середине 1995 года тактовая
частота процессоров SuperSPARC была доведена до 90 МГц. Позже
появились 64-битовые процессоры UltraSPARC I с тактовой часто-
той от 167 МГц, в начале 1996-го — процессоры UltraSPARC II с такто-
вой частотой от 200 до 275 МГц, а в 1997—1998 годы — процессоры
UltraSPARC III с частотой 500 МГц.
Одной из главных задач, стоявших перед разработчиками микропро-
цессора HyperSPARC (рис. 6.8), было повышение производительности,
особенно при выполнении операций с плавающей точкой. Поэтому
230
6.5. Особенности процессоров с архитектурой SPARC компании Sun Microsystems
особое внимание разработчиков было уделено созданию простых
и сбалансированных шестиступенчатых конвейеров целочисленной
арифметики и плавающей точки.
Рис 6.8. Набор кристаллов процессора HyperSPARC
Производительность процессоров HyperSPARC может меняться неза-
висимо от скорости работы внешней шины (MBus). Набор кристал-
лов HyperSPARC обеспечивает как синхронные, так и асинхронные
операции с помощью специальной логики кристалла RT625. Отделе-
ние внутренней шины процессора от внешней позволяет увеличивать
тактовую частоту процессора независимо от частоты работы подсистем
памяти и ввода-вывода. Это обеспечивает удлинение жизненного цикла,
поскольку переход на более производительные модули HyperSPARC
не требует переделки всей системы.
Процессорный набор HyperSPARC с тактовой частотой 100 МГц по-
строен на основе технологического процесса КМОП с тремя уровня-
ми металлизации и проектными нормами 0,5 микрона. Внутренняя
логика работает с напряжением питания 3,3 В.
Центральный процессор RT620 состоит из целочисленного устройства,
устройства плавающей точки, устройства загрузки-записи, устройст-
ва переходов и двухканальной множественно-ассоциативной памяти
команд емкостью 8 Кбайт. Целочисленное устройство включает АЛУ
и отдельный тракт данных для операций загрузки-записи, которые
231
Глава 6. Микропроцессоры
представляют собой два из четырех исполнительных устройств процес-
сора. Устройство переходов обрабатывает команды передачи управ-
ления, а устройство плавающей точки состоит из двух независимых
конвейеров — сложения и умножения чисел с плавающей точкой.
Для увеличения пропускной способности процессора команды пла-
вающей точки, проходя через целочисленный конвейер, поступают
в очередь, где ожидают запуска в одном из конвейеров плавающей
точки. В каждом такте выбираются две команды. В общем случае, до
тех пор пока эти две команды требуют для своего выполнения раз-
личных исполнительных устройств при отсутствии зависимостей по
данным, они могут запускаться одновременно. RT620 содержит два
регистровых файла: 136 целочисленных регистров, сконфигуриро-
ванных в виде восьми регистровых окон, и 32 отдельных регистра
плавающей точки, расположенных в устройстве плавающей точки.
Кэш-память второго уровня в процессоре HyperSPARC строится на базе
RT625 CMTU, который представляет собой комбинированный кри-
сталл, включающий контроллер кэш-памяти и устройство управления
памятью, поддерживающее разделяемую внешнюю память и симмет-
ричную многопроцессорную обработку. Контроллер кэш-памяти обес-
печивает работу кэша емкостью 256 Кбайт, состоящего из четырех
RT627 CDU. Кэш-память имеет прямое отображение и 4 Кбайт тегов.
Теги в кэш-памяти содержат физические адреса, поэтому имеющиеся
в RT625 логические схемы для соблюдения когерентности кэш-па-
мяти в многопроцессорной системе могут быстро определить попа-
дания или промахи при просмотре со стороны внешней шины без
приостановки обращений к кэш-памяти от центрального процессора.
Поддерживается как режим сквозной записи, так и режим обратного
копирования.
В состав устройства управления памятью включена полностью ассо-
циативная кэш-память преобразования виртуальных адресов в физи-
ческие (TLB), состоящая из 64 строк и поддерживающая 4096 контек-
стов. RT625 содержит буфер чтения емкостью 32 байта, применяемый
для загрузки, и буфер записи емкостью 64 байта, используемый для
разгрузки кэш-памяти второго уровня. Размер строки кэш-памяти
составляет 32 байта. Кроме того, в RT625 имеются логические схемы
синхронизации, обеспечивающие интерфейс между внутренней шиной
процессора и SPARC MBus при выполнении асинхронных операций.
232
6.5. Особенности процессоров с архитектурой SPARC компании Sun Microsystems
RT627 представляет собой статическую память объемом 16 Кбайт
(32 Кбайт). Она организована как четырехканальная статическая па-
мять в виде четырех массивов с логикой побайтной записи, входны-
ми и выходными регистрами-защелками. RT627 для ЦП является
кэш-памятью с нулевым состоянием ожидания без потерь (то есть
приостановок) на конвейеризацию для всех операций загрузки и за-
писи, которые попадают в кэш-память. RT627 разработан специаль-
но для процессора HyperSPARC, в связи с чем для его соединения
с RT620 и RT625 не требуются никакие дополнительные схемы.
Набор кристаллов позволяет использовать преимущества тесной свя-
зи процессора с кэш-памятью. Конструкция RT620 допускает потерю
одного такта в случае промаха в кэш-памяти первого уровня. Для
доступа к кэш-памяти второго уровня в RT620 отведена специальная
ступень конвейера. Если происходит промах в кэш-памяти первого
уровня, а в кэш-памяти второго уровня имеет место попадание, то
центральный процессор не останавливается.
Команды загрузки и записи одновременно генерируют два обраще-
ния: одно — к кэш-памяти команд первого уровня емкостью 8 Кбайт,
другое — к кэш-памяти второго уровня. Если адрес команды найден
в кэш-памяти первого уровня, то обращение к кэш-памяти второго
уровня отменяется и команда становится доступной на стадии декоди-
рования конвейера. Если же во внутренней кэш-памяти произошел
промах, а в кэш-памяти второго уровня обнаружено попадание, то ко-
манда станет доступной с потерей одного такта, который встроен в кон-
вейер. Такая возможность позволяет конвейеру продолжать непрерыв-
ную работу до тех пор, пока имеют место попадания в кэш-память
либо первого, либо второго уровня, составляющие соответственно
90 % и 98 % для типовых прикладных задач рабочей станции. Для дос-
тижения архитектурного баланса и упрощения обработки исключи-
тельных ситуаций целочисленный конвейер и конвейер плавающей
точки имеют по пять стадий выполнения операций. Такая конструк-
ция позволяет RT620 обеспечить максимальную пропускную способ-
ность, недостижимую в противном случае.
Системы MicroSPARC обеспечивают высокую производительность при
умеренной тактовой частоте путем оптимизации среднего количества
команд, выполняемых за один такт. Это требует эффективного управ-
ления конвейером и иерархией памяти. Среднее время обращения
233
Глава 6. Микропроцессоры
к памяти должно сокращаться либо должно возрастать среднее коли-
чество команд, подаваемых для выполнения в каждом такте, увели-
чивая производительность на основе компромиссов в конструкции
процессора.
Основное назначение MicroSPARC II (рис. 6.9) — однопроцессорные
низкостоимостные системы. Он представляет собой высокоинтегриро-
ванную микросхему, содержащую целочисленное устройство, устрой-
ств управления памятью, устройство плавающей точки, раздельную
кэш-память команд и данных, контроллер управления микросхема-
ми динамической памяти и контроллер шины MBus.
Рис. 6.9. Блок-схема процессора MicroSPARC II
Основными свойствами целочисленного устройства MicroSPARC II
являются:
► пятиступенчатый конвейер команд;
► предварительная обработка команд переходов;
► поддержка потокового режима работы кэш-памяти команд и данных;
► регистровый файл емкостью 136 регистров (8 регистровых окон);
234
6.6. Процессоры РА-RISC компании Hewlett Packard
► интерфейс с устройством плавающей точки;
► предварительная выборка команд с очередью на четыре команды.
Целочисленное устройство использует пятиступенчатый конвейер ко-
манд с одновременным запуском до двух команд. Устройство плаваю-
щей точки выполняет операции в соответствии со стандартом IEEE 754.
Устройство управления памятью осуществляет четыре основные функ-
ции. Прежде всего, это формирование и преобразование виртуального
адреса в физический с помощью ассоциативного буфера TLB, реали-
зация механизма защиты памяти и арбитраж обращений к памяти со
стороны ввода-вывода, кэша данных, кэша команд и TLB.
Процессор MicroSPARC II имеет 64-битовую шину данных для связи
с памятью и поддерживает оперативную память емкостью до 256 Мбайт.
В процессоре интегрирован контроллер шины MBus, обеспечивающий
эффективную с точки зрения стоимости реализацию ввода-вывода.
6.6. Процессоры РА-RISC компании Hewlett Packard
Основой разработки современных изделий Hewlett Packard является
архитектура РА-RISC. Она была создана компанией в 1986 году и бла-
годаря успехам интегральной технологии прошла несколько стадий
развития: от многокристального до однокристального исполнения.
В 1992 году компания Hewlett Packard объявила о выпуске суперска-
лярного процессора РА-7100, который стал основой построения се-
мейства рабочих станций Н Р 9000 Series 700 и семейства бизнес-серве-
ров HP 9000 Series 800. Имеются 33, 50 и 99 МГц реализации кристалла
РА-7100. Кроме того, выпущены модифицированные, улучшенные
по многим параметрам кристаллы PA-7100LC с тактовой частотой 64,
80 и 100 МГц и РА-7150 с тактовой частотой 125 МГц, атакже РА-7200
с тактовой частотой 90 и 100 МГц. Компанией создан процессор сле-
дующего поколения — НР-8000, который работает с тактовой часто-
той 200 МГц. Кроме того, Hewlett Packard в сотрудничестве с Intel
создали процессор с длинным командным словом (VLIW-архитекту-
ра), который совместим как с семейством Intel х86, так и с семейст-
вом PA-RISC.
Особенность архитектуры РА-RISC — внекристальная реализация
кэша, что позволяет использовать различные объемы кэш-памяти
235
Глава 6. Микропроцессоры
и оптимизировать конструкцию в зависимости от условий применения
(рис. 6.10). Хранение команд и данных осуществляется в раздельных
кэшах, причем процессор соединяется с ними с помощью высоко-
скоростных 64-битовых шин. Кэш-память реализуется на высоко-
скоростных кристаллах статической памяти (SRAM), синхронизация
которых осуществляется непосредственно на тактовой частоте про-
цессора. При тактовой частоте 100 МГц каждый кэш имеет полосу
пропускания 800 Мбайт/с при выполнении операций считывания
и 400 Мбайт/с при выполнении операций записи. Микропроцессор
аппаратно поддерживает различный объем кэш-памяти: кэш команд
может иметь объем от 4 Кбайт до 1 Мбайт, кэш данных — от 4 Кбайт
до 2 Мбайт. Чтобы снизить коэффициент промахов, используется ме-
ханизм хеширования адреса. В обоих кэшах для повышения надеж-
ности применяются дополнительные контрольные разряды, причем
ошибки кэша команд корректируются аппаратными средствами.
Рис. 6.10. Блок-схема процессора РА-7100
Процессор подсоединяется к памяти и подсистеме ввода-вывода по-
средством синхронной шины. При этом обеспечивается возможность
работы с тремя разными отношениями внутренней и внешней такто-
вой частоты в зависимости от частоты внешней шины, а именно 1:1,
3:2 и 2:1. Это позволяет использовать в системах разные по скорости
микросхемы памяти.
Конструктивно на кристалле РА-7100 размещены целочисленный про-
цессор, процессор для обработки чисел с плавающей точкой, устрой-
236
6.6. Процессоры РА-RISC компании Hewlett Packard
ство управления кэшем, унифицированный буфер TLB, устройство
управления, а также ряд интерфейсных схем.
Устройство плавающей точки (рис. 6.11) реализует арифметику с оди-
нарной и двойной точностью в стандарте IEEE 754. Устройство ум-
ножения также выполняет операции целочисленного умножения.
Устройства деления и вычисления квадратного корня работают с уд-
военной частотой процессора.
Рис. 6.11. Управление командами плавающей точки
Арифметико-логическое устройство выполняет операции сложения,
вычитания и преобразования форматов данных.
Регистровый файл состоит из 28 регистров (по 64 бита), каждый из
которых может использоваться как два 32-битовых регистра для вы-
полнения операций с плавающей точкой одинарной точности. Реги-
стровый файл имеет пять портов чтения и три порта записи, которые
обеспечивают одновременное выполнение операций умножения,
сложения и загрузки-записи.
Большинство улучшений производительности процессора связано
с увеличением тактовой частоты до 100 МГц.
Конвейер целочисленного устройства включает шесть ступеней: чтение
из кэша команд (IR); чтение операндов (OR); чтение из кэша данных
237
Глава 6. Микропроцессоры
(DR); завершение чтения кэша данных (DRC); запись в регистры
(RW) и запись в кэш данных (DW). На ступени ID выполняется вы-
борка команд. Реализация механизма выдачи двух команд требует не-
большого буфера предварительной выборки, который обеспечивает
выборку команд за два такта до начала работы ступени IR. На ступени
OR все исполнительные устройства декодируют поля операндов в ко-
манде и начинают вычислять результат операции. На ступени DR
целочисленное устройство завершает свою работу. Кроме того,
кэш-память данных выполняет чтение, но данные не поступают до
момента завершения работы ступени DRC. Результаты операций сло-
жения (ADD) и умножения (MULTIPLY) также становятся достовер-
ными в конце ступени DRC. Запись в универсальные регистры
и регистры плавающей точки производится на ступени RW. Запись
в кэш данных командами записи (STORE) требует двух тактов. Наи-
более раннее двухтактное окно команды STORE возникает на ступе-
нях RW и DW Однако это окно может сдвигаться, поскольку записи
в кэш данных происходят только при появлении следующей команды
записи. Операции деления и вычисления квадратного корня для чи-
сел с плавающей точкой заканчиваются на много тактов позже ступе-
ни DW
Конвейер проектировался в целях максимального увеличения вре-
мени, необходимого для выполнения чтения внешних кристаллов
SRAM кэш-памяти данных. Это позволяет максимизировать частоту
процессора при заданной скорости SRAM. Все команды загрузки
(LOAD) выполняются за один такт и требуют только одного такта по-
лосы пропускания кэш-памяти данных. Так как кэши команд и дан-
ных размещены на разных шинах, в конвейере отсутствуют потери,
связанные с конфликтами по обращениям в кэш данных и кэш ко-
манд.
Процессор может в каждом такте выдавать на выполнение одну цело-
численную команду и одну команду плавающей точки. Полоса про-
пускания кэша команд достаточна для поддержания непрерывной
выдачи двух команд в каждом такте. Отсутствуют какие-либо ограни-
чения по выравниванию или порядку следования пары выполняемых
вместе команд. Кроме того, отсутствуют потери тактов, связанных
с переходом от выполнения двух команд на выполнение одной ко-
манды. Особое внимание уделено тому, чтобы выдача двух команд
в одном такте не приводила к ограничению тактовой частоты. Для
238
6.6. Процессоры РА-RISC компании Hewlett Packard
этого в кэше команд реализован специальный бит, отделяющий ко-
манды целочисленного устройства от команд устройства плавающей
точки. Этот бит предварительного декодирования минимизирует вре-
мя, необходимое для правильного разделения команд.
Потери, связанные с зависимостями поданным и управлению, в этом
конвейере минимальны. Команды загрузки выполняются за один такт,
за исключением случая, когда последующая команда пользуется реги-
стром-приемником команды LOAD. Как правило, компилятор позво-
ляет обойти подобные потери одного такта. Для уменьшения потерь,
связанных с командами условного перехода, в процессоре использу-
ется алгоритм прогнозирования направления передачи управления.
Количество тактов, необходимое для записи слова или двойного слова
командой STORE, уменьшено с трех до двух тактов. РА-7100 исполь-
зует отдельную шину адресного тега, чтобы совместить по времени
чтение тега с записью данных предыдущей команды STORE. Кроме
того, наличие отдельных сигналов разрешения записи для каждого
слова строки кэш-памяти устраняет необходимость объединения
имеющихся данных с новыми, поступающими при выполнении ко-
манд записи слова или двойного слова. Данный алгоритм требует,
чтобы запись в микросхемы SRAM происходила только после опре-
деления того, что данная запись сопровождается попаданием в кэш
и не вызывает прерывания. Это решение вызвало необходимость до-
полнительной ступени конвейера между чтением тега и записью дан-
ных. Такая конвейеризация не приводит к дополнительным потерям
тактов, поскольку в процессоре реализованы специальные цепи об-
хода, позволяющие направить отложенные команды записи после-
дующим командам загрузки или командам STORE, записывающим
только часть слова. В данном процессоре потери конвейера для команд
записи слова или двойного слова сведены к нулю, если последующая
команда не является командой загрузки или записи, в противном
случае потери равны одному такту. Потери на запись части слова мо-
гут составлять от нуля до двух тактов. Исследования показывают, что
подавляющее большинство команд записи работает с однословным
или двухсловным форматом.
Все операции с плавающей точкой, за исключением команд деления
и вычисления квадратного корня, полностью конвейеризованы и име-
ют двухтактную задержку выполнения как в режиме с одинарной, так
239
Глава 6. Микропроцессоры
и с двойной точностью. Процессор может выдавать на выполнение
независимые команды с плавающей точкой в каждом такте без ка-
ких-либо потерь. Последовательные операции с зависимостями по
регистрам приводят к потере одного такта. Команды деления и вы-
числения квадратного корня выполняются за 8 тактов при одиноч-
ной и за 15 тактов при двойной точности. Выполнение команд не
останавливается из-за команд деления/вычисления квадратного кор-
ня до тех пор, пока не потребуется регистр результата или не будет
выдаваться следующая команда деления/вычисления квадратного
корня.
Процессор может выполнять параллельно одну целочисленную ко-
манду и одну команду с плавающей точкой. При этом «целочислен-
ными командами» считаются и команды загрузки и записи регистров
плавающей точки, а «команды плавающей точки» включают коман-
ды FMPYADD и FMPYSUB. Эти последние команды объединяют
операцию умножения соответственно с операциями сложения или
вычитания, которые выполняются параллельно. Пиковая произво-
дительность составляет 200 М флопс для последовательности команд
FMPYADD, в которых смежные команды независимы по регистрам.
Потери при выполнении операций плавающей точки, использующих
предварительную загрузку операнда командой LOAD, составляют
один такт, если команды загрузки и плавающей арифметики являют-
ся смежными, и два такта, если они выдаются для выполнения одно-
временно. Для команд записи, использующих результат операции
с плавающей точкой, потери отсутствуют, даже если они выполняют-
ся параллельно.
При блочном копировании данных в ряде случаев компилятор заранее
знает что запись должна осуществляться в полную строку кэш-памяти.
Для оптимизации обработки таких ситуаций архитектура РА-RISC 1.1
определяет специальную кодировку команд записи («блочное копиро-
вание»), которая показывает, что аппаратура не должна осуществлять
выборку из памяти строки, при обращении к которой может про-
изойти промах кэш-памяти. В этом случае время обращения к кэшу
данных складывается из времени, которое требуется для копирования
в память предыдущей строки кэш-памяти по тому же адресу в кэше,
и времени, необходимого для записи нового тега кэша. В процессоре
РА-7100 такая возможность реализована как для привилегирован-
ных, так и для непривилегированных команд.
240
6.6. Процессоры РА-RISC компании Hewlett Packard
Последнее улучшение управления кэшем данных связано с реализа-
цией семафорных операций «загрузки с обнулением» непосредствен-
но в кэш-памяти. Если семафорная операция выполняется в кэше, то
потери времени при ее выполнении не превышают потерь обычных
операций записи. Это не только сокращает конвейерные потери, но
и снижает трафик шины памяти. В архитектуре РА-RISC 1.1 преду-
смотрен и другой тип специального кодирования команд, который
устраняет требование синхронизации семафорных операций с уст-
ройствами ввода-вывода.
Управление кэш-памятью команд позволяет при промахе продолжить
выполнение команд сразу же после поступления отсутствующей в кэше
команды из памяти. Используемая для заполнения блоков кэша ко-
манд 64-битовая магистраль данных соответствует максимальной по-
лосе пропускания внешней шины памяти 400 Мбайт/с при тактовой
частоте 100 МГц.
Конструкция процессора обеспечивает реализацию двух способов по-
строения многопроцессорных систем.
При первом способе каждый процессор подсоединяется к интерфейс-
ному кристаллу, который наблюдает за всеми транзакциями на шине
основной памяти. В такой системе все функции по поддержанию коге-
рентного состояния кэш-памяти возложены на интерфейсный кри-
сталл, посылающий процессору соответствующие транзакции.
Второй способ организации многопроцессорной системы позволяет
объединить два процессора и контроллеры памяти и ввода-вывода
на одной и той же локальной шине памяти. В такой конфигурации
не требуется дополнительных интерфейсных кристаллов и система
совместима с существующей системой памяти. Когерентность кэш-па-
мяти обеспечивается наблюдением за локальной шиной памяти. Пере-
сылки строк между кэшами выполняются без участия контроллеров
памяти и ввода-вывода. Такая конфигурация обеспечивает возмож-
ность построения очень дешевых высокопроизводительных много-
процессорных систем.
Процессор построен на базе КМОП-технологии с проектными нор-
мами 0,8 микрона, что обеспечивает тактовую частоту 100 МГц.
Процессор РА-7200 имеет ряд архитектурных усовершенствований по
сравнению с РА-7100, главными из которых являются добавление
241
Глава 6. Микропроцессоры
второго целочисленного конвейера, построение внутрикристального
вспомогательного кэша данных и реализация нового 64-битового ин-
терфейса с шиной памяти.
В процессоре РА-7200 реализован эффективный алгоритм предвари-
тельной выборки команд, хорошо работающий и на линейных участ-
ках программ.
Расширенный набор команд процессора позволяет реализовать сред-
ства автоиндексации для повышения эффективности работы с масси-
вами, а также осуществлять предварительную выборку команд, кото-
рые помещаются во вспомогательный внутренний кэш.
Процессор РА-7200 включает интерфейс 64-битовой мультиплекс-
ной системной шины Runway, реализующей расщепление транзак-
ций и поддержку протокола когерентности памяти. Этот интерфейс
включает буфера транзакций, схемы арбитража и схемы управления
соотношениями внешних и внутренних тактовых частот.
6.7. Процессор МС 88110 компании Motorola
Процессор 88110 относится к разряду суперскалярных RISC-процес-
соров. Основные особенности этого процессора связаны с использо-
ванием принципов суперскалярной обработки, двух восьмипортовых
регистровых файлов, десяти независимых исполнительных устройств,
больших по объему внутренних кэшей и широких магистралей данных.
На рис. 6.12 представлена блок-схема процессора, содержащего
1,3 миллиона вентилей. Центральной частью этой архитектуры явля-
ется шина операндов (в реализации это шесть 80-битовых шин), со-
единяющая регистровые файлы и исполнительные устройства.
Процессор содержит десять исполнительных устройств, которые рабо-
тают одновременно и независимо, и два регистровых файла. Файл реги-
стров общего назначения имеет 32-битовую организацию, а расширен-
ные регистры плавающей точки — 80-битовую. Эти регистровые файлы
снабжены шестью портами чтения и двумя портами записи каждый.
Внешняя шина процессора содержит отдельные линии данных (64 бита)
и адреса (32 бита), что позволяет реализовать быстрые групповые
операции перезагрузки внутренней кэш-памяти. Внешняя шина также
242
6.7. Процессор МС 88110 компании Motorola
Рис. 6.12. Блок-схема процессора МС 88110
имеет специальные сигналы управления, обеспечивающие аппарат-
ную поддержку когерентности кэш-памяти в мультипроцессорных
конфигурациях.
В процессоре имеются две двухканальные множественно-ассоциа-
тивные кэш-памяти емкостью по 8 Кбайт (для команд и для данных).
Суперскалярная архитектура процессора базируется на реализации
возможности завершения команд в порядке, отличном от порядка их
поступления для выполнения, что позволяет существенно увеличить
производительность, однако приводит к проблемам организации точ-
ного прерывания. Эта проблема решается в процессоре 88110 с помо-
щью так называемого буфера истории, который хранит старые значения
регистров при выполнении и завершении операций не в предписан-
ном программой порядке и позволяет аппаратно восстановить необ-
ходимое состояние в случае прерывания.
243
Глава 6. Микропроцессоры
В процессоре предусмотрено несколько способов ускорения обработ-
ки условных переходов. Один из них — предсказание направления
перехода — позволяет компилятору сообщить процессору предпоч-
тительное направление перехода. Для предсказанного направления
перехода разрешено условное выполнение команд. Если направле-
ние перехода предсказано неверно, исходное состояние процессора
восстанавливается с помощью буфера истории. Выполнение програм-
мы в этом случае будет продолжено с «правильной» команды.
В каждом такте процессор может выдавать на выполнение две коман-
ды. В большинстве случаев выдача команд осуществляется в предпи-
санном программой порядке. Команды записи и условных переходов
могут посылаться на буферные станции резервирования, из которых
они в дальнейшем выдаются на выполнение. Команды загрузки могут
накапливаться в очереди. В устройстве загрузки-записи реализованы
буфер загрузки FIFO на четыре строки и три станции резервирования
операций записи, что позволяет в каждый момент времени иметь до
четырех отложенных команд загрузки и до трех команд записи. Для
обеспечения большей эффективности выполнение этих команд внутри
устройства может переупорядочиваться.
При построении многопроцессорной системы все процессоры и основ-
ная память размешаются на одной плате. Высокая производительность
системы в такой конфигурации достигается включением в каждый
процессор кэш-памяти второго уровня емкостью 256 Кбайт. Протокол
поддержания когерентного состояния кэш-памяти (протокол наблю-
дения) базируется на методике записи с аннулированием, гаранти-
рующей размещение модифицированной копии строки кэш-памяти
только в одном из кэшей системы. Протокол позволяет нескольким
процессорам иметь одну и ту же копию строки кэш-памяти. При
этом, если один из процессоров выполняет запись в память (общую
строку кэш-памяти), другие процессоры уведомляются о том, что их
копии являются недействительными и должны быть аннулированы.
6.8. Архитектура MIPS компании MIPS Technology
Архитектура MIPS анонсирована в 1986 году и представляет собой
одну из первых RISC-архитектур, получивших признание со стороны
промышленности. Первоначально это была полностью 32-битовая
244
6.8. Архитектура MIPS компании MIPS Technology
архитектура, которая включала 32 регистра общего назначения дли-
ною в 32 бита, 16 регистров плавающей точки и специальную пару
регистров для хранения результатов выполнения операций целочис-
ленного умножения и деления. Широкую популярность приобрели
32-битовые процессоры R2000 и R3000, которые в течение длительного
времени служили основой для построения рабочих станций и серверов
компаний Silicon Graphics, Digital, Siemens Nixdorf и др.
На смену микропроцессорам семейства R3000 пришли новые 64-би-
товые микропроцессоры R4000 и R4400 (MIPS стала первой компанией,
выпустившей процессоры с 64-битовой архитектурой). Набор команд
этих процессоров (спецификация MIPS II) был расширен командами
загрузки и записи 64-разрядных чисел с плавающей точкой, командами
вычисления квадратного корня с одинарной и двойной точностью,
командами условных прерываний, а также атомарными (неделимыми)
операциями, необходимыми для поддержки мультипроцессорных
конфигураций. В процессорах R4000 и R4400 реализованы 64-бито-
вые шины данных и 64-битовые регистры. Кроме того, в них же при-
менен метод удвоения внутренней тактовой частоты.
Процессоры R2000 и R3000 имели стандартные пятиступенчатые
конвейеры команд. В процессорах R4000 и R4400 применяются более
длинные конвейеры (иногда их называют суперконвейерами). Коли-
чество ступеней в них увеличилось до восьми, что объясняется прежде
всего увеличением тактовой частоты и необходимостью распределения
логики для обеспечения заданной пропускной способности конвейера.
Процессор R4000 может работать с тактовой частотой 50/100 МГц.
В процессорах R4000 применяется внутренняя кэш-память емкостью
16 Кбайт, разделенная на кэш команд (8 Кбайт) и кэш данных
(8 Кбайт). С точки зрения реализации кэш-памяти процессор R4400
имеет более развитые возможности. Он выпускается в трех модифи-
кациях: PC (Primary Cash) имеет внутренние кэши команд и данных
емкостью по 16 Кбайт и предназначен главным образом для дешевых
моделей рабочих станций; SC (Secondaiy Cash) содержит логику управ-
ления кэш-памятью второго уровня; МС (Multiprocessor Cash) исполь-
зует специальные алгоритмы обеспечения когерентности и согласо-
ванного состояния памяти для многопроцессорных конфигураций.
Компания MIPS Technology создала новый суперскалярный процессор
R10000. По заявлениям представителей компании, R10000 обеспечи-
245
Глава 6. Микропроцессоры
вает пиковую производительность 800 MIPS при работе с внутренней
тактовой частотой 200 МГц за счет обеспечения выдачи для выполне-
ния четырех команд в одном такте синхронизации. При этом процессор
позволяет вести обмен данными с кэш-памятью второго уровня со
скоростью 3,2 Гбайт/с.
Чтобы обеспечить столь высокий уровень производительности, в про-
цессоре R10000 реализованы многие последние достижения в облас-
ти технологии и архитектуры процессоров. На рис. 6.13 показана
блок-схема этого микропроцессора.
Кэш-память данных первого уровня процессора R10000 имеет емкость
32 Кбайт и организована в виде двух одинаковых банков размером по
16 Кбайт, что обеспечивает двукратное расслоение при выполнении
обращений к данной кэш-памяти. Каждый банк представляет собой
двухканальную множественно-ассоциативную кэш-память с разме-
ром строки (блока) в 32 байта. Кэш данных индексируется с помо-
щью виртуального адреса и хранит теги физических адресов памяти.
Такой метод индексации позволяет выбрать подмножество кэш-па-
мяти в том же такте, в котором формируется виртуальный адрес. Од-
нако для того, чтобы поддерживать когерентность с кэш-памятью
второго уровня, в кэше первого уровня хранятся теги физических ад-
ресов памяти.
Интерфейс кэш-памяти второго уровня процессора R10000 поддержи-
вает 128-битовую магистраль данных, которая может работать с так-
товой частотой 200 МГц, обеспечивая скорость обмена 3,2 Гбайт/с.
Все стандартные синхронные сигналы управления статической памя-
тью вырабатываются внутри процессора. Минимальный объем кэш-па-
мяти второго уровня составляет 512 Кбайт, максимальный размер —
16 Мбайт. Размер строки этой кэш-памяти программируется и может
составлять 64 или 128 байт.
Устройство переходов процессора может декодировать и выполнять
одну команду перехода в каждом такте. Так как за каждой командой
перехода следует задержка, максимально могут быть выбраны одно-
временно две команды перехода, но только одна из них (более ранняя)
команда перехода может декодироваться в данный момент времени.
Бит признака перехода добавляется к каждой команде во время деко-
дирования команд. Эти биты помечают команды перехода в конвейере
выборки команд. Направление условного перехода прогнозируется
246
Рис. 6.13. Блок-схема процессора R10000
6.8. Архитектура MIPS компании MIPS Technology
Глава 6. Микропроцессоры
с помощью специальной памяти, которая хранит историю выполнения
переходов в прошлом. Двухбитовый код в этой памяти обновляется
каждый раз, когда принято окончательное решение о направлении
перехода. Все команды, выбранные вслед за командой условного пе-
рехода, считаются условными (спекулятивными). Это означает, что
в момент их выборки заранее неизвестно, будет ли завершено выпол-
нение этих команд. Процессор допускает предварительное прогнози-
рование направления четырех команд условного перехода, которые
могут разрешаться в произвольном порядке. Специальный стек перехо-
дов содержит строку для каждой выполняемой спекулятивно команды
условного перехода. Эти строки содержат информацию, необходи-
мую для восстановления состояния процессора, если спекулятивные
команды перехода были предсказаны неверно. Стек переходов по-
зволяет быстро и эффективно восстановить конвейер, если прогноз
направления перехода оказался неверным.
Процессор R10000 содержит три очереди (буфера) команд (очередь це-
лочисленных команд, очередь команд плавающей точки и очередь
адресных команд). С помощью этих операций осуществляется выдача
команд в динамике в соответствующие исполнительные устройства.
Команды в очереди хранятся с тегом команды, который перемещается
вместе с командой по ступеням конвейера. Каждая очередь осущест-
вляет динамическое планирование потока команд и может определить
моменты времени, когда становятся доступными операнды, необходи-
мые для выполнения команды. Кроме того, очередь определяет порядок
выполнения команд на основе анализа состояния со тветствующих
исполнительных устройств. Как только ресурс оказывается свобод-
ным, очередь выдает команду в соответствующее исполнительное
устройство.
Зависимости между командами могут привести к уменьшению про-
изводительности процессора. Чтобы этого избежать, применяется спе-
циальная методика переименования регистров. Ее основная задача —
определение зависимостей между командами и обеспечение точного
адреса прерывания программы. В процессе переименования регист-
ров каждый логический регистр, указанный в команде, заменяется
физическим регистром на основе таблицы распределения регистров.
Такое переименование происходит для каждого регистра результата
команды. Поэтому, когда команда записывает в логический регистр
новое значение, этот логический регистр переименовывается и будет
248
6.8. Архитектура MIPS компании MIPS Technology
применять имя нового физического регистра. Однако его предыду-
щее значение оказывается сохраненным в старом физическом реги-
стре. Сохранение значений старого регистра позволяет осуществлять
точные прерывания. В то время как все команды переименовывают-
ся, логические номера их регистров сравниваются для определения
зависимостей между четырьмя командами, декодированными в од-
ном и том же такте.
В процессоре R10000 имеются шесть полностью независимых исполни-
тельных устройств: два целочисленных АЛУ, два основных устройства
плавающей точки и два вторичных устройства плавающей точки, кото-
рые работают с длинными операциями, такими как деление и вычис-
ление квадратного корня.
Устройство загрузки-записи содержит очередь адресов, устройство
вычисления адреса, устройство преобразования виртуальных адре-
сов в физические (TLB), стек адресов, буфер записи и кэш-память
данных первого уровня. Это устройство выполняет команды загрузки,
записи, предварительной выборки, а также команды работы с кэш-па-
мятью.
Внешняя кэш-память второго уровня управляется с помощью внутрен-
него контроллера, который имеет порт для подсоединения кэш-па-
мяти. Специальная магистраль данных шириной в 128 бит осуществ-
ляет пересылки данных на тактовой частоте процессора 200 МГц.
В процессоре также применяется 64-битовая шина данных системного
интерфейса. Кэш-память второго уровня имеет двухканальную мно-
жественно-ассоциативную организацию. Максимальный размер —
16 Мбайт. Минимальный размер — 512 Кбайт Пересылки осуществ-
ляются 128-битовыми порциями (четыре 32-битовых слова).
Системный интерфейс процессора R10000 представляет собой шлюз
между самим процессором (со связанным с ним кэшем второго уров-
ня) и остальной системой. Интерфейс работает с тактовой частотой
внешней синхронизации, которая может составлять 200, 133, 100, 80,
67, 57 и 50 МГц.
Процессор поддерживает протокол расщепления транзакций, позво-
ляющий осуществлять выдачу очередных запросов процессором или
внешним абонентом шины, не дожидаясь ответа на предыдущий
запрос. Максимально поддерживается до четырех одновременных
транзакций на шине.
249
Глава 6. Микропроцессоры
Процессор R10000 допускает два способа организации многопроцес-
сорной системы.
Первый из них связан с созданием специального внешнего интер-
фейса для каждого процессора системы. Этот интерфейс обычно реа-
лизуется с помощью заказной интегральной схемы, которая организует
шлюз к основной памяти и подсистеме ввода-вывода. При таком
типе соединений процессоры не связаны друг с другом непосредст-
венно, а взаимодействуют через этот специальный интерфейс.
Второй способ предназначен для достижения максимальной произво-
дительности при минимальных затратах. Он подразумевает исполь-
зование от двух до четырех процессоров, объединенных шиной Claster
Bus. В этом случае необходим только один внешний интерфейс для
взаимодействия с другими ресурсами системы.
6.9. Особенности архитектуры Alpha компании DEC
В настоящее время семейство микропроцессоров с архитектурой Alpha
представлено несколькими кристаллами с различными диапазонами
производительности, работающими с разной тактовой частотой и по-
требляющими разную мощность.
Первым на рынке появился 64-разрвдный микропроцессор Alpha (DECchip
21064). Он представляет собой RISC-процессор в однокристальном
исполнении, в состав которого входят устройства целочисленной и пла-
вающей арифметики, а также кэш-память емкостью 16 Кбайт. Кри-
сталл проектировался с учетом реализации современных методов уве-
личения производительности, включая конвейерную организацию всех
функциональных устройств, одновременную выдачу нескольких ко-
манд для выполнения, а также средства организации симметричной
многопроцессорной обработки.
Кристалл содержит два регистровых файла по 32 регистра, имеющих
по 64 бита: один — для целых чисел, второй — для чисел с плавающей
точкой. Для обеспечения совместимости с архитектурами MIPS и VAX
архитектура Alpha поддерживает арифметику с одинарной и двойной
точностью как в соответствии со стандартом IEEE 754, так и в соот-
ветствии с внутренним для компании стандартом арифметики VAX.
250
6.9. Особенности архитектуры Alpha компании DEC
В конце 1993 года появилась модернизированная версия кристалла —
модель 21064А, имеющая на кристалле кэш-память удвоенного объе-
ма и работающая с тактовой частотой 275 МГц.
Затем были выпущены модели 21066 и 21068, оперирующие на частоте
166 и 66 МГц. Отличительной особенностью этой ветви процессоров
Alpha является реализация на кристалле шины PCI. Отличительная
особенность модели 21068 — низкая потребляемая мощность (около
8 Вт). Основное предназначение этих двух моделей — персональные
компьютеры и одноплатные ЭВМ. На рис. 6.14 представлена схема
микропроцессора 21066.
Рис. 6.14. Основные компоненты процессора Alpha 21066
251
Глава 6. Микропроцессоры
Кэш-память команд представляет собой кэш прямого отображения
емкостью 8 Кбайт. Команды, выбираемые из этой кэш-памяти, могут
выдаваться попарно для исполнения в одно из исполнительных уст-
ройств. Кэш-память данных емкостью 8 Кбайт также реализует кэш
с прямым отображением. При выполнении операций записи в память
данные одновременно записываются в этот кэш и в буфер записи.
Контроллер памяти или контроллер ввода-вывода шины PCI обраба-
тывает все обращения, проходящие через расположенные на кри-
сталле кэш-памяти первого уровня.
Контроллер памяти прежде всего проверяет содержимое внешней
кэш-памяти второго уровня, которая построена по принципу пря-
мого отображения и реализует алгоритм отложенного обратного ко-
пирования при выполнении операций записи. При обнаружении
промаха контроллер обращается к основной памяти для перезагрузки
соответствующих строк кэш-памяти. Контроллер ввода-вывода шины
PCI обрабатывает весь трафик, связанный с вводом-выводом.
На рис. 6.15 показан пример системы, построенной на базе микро-
процессора 21066. В представленной конфигурации контроллер па-
мяти выполняет обращения как к статической памяти, с помощью
которой реализована кэш-память второго уровня, так и к динамиче-
ской памяти, на которой построена основная память. Для хранения
тегов и данных в кэш-памяти второго уровня используются кристал-
лы статической памяти с одинаковым временем доступа по чтению
и записи.
Конструкция поддерживает до четырех банков динамической памяти,
каждый из которых может управляться независимо, что дает опреде-
ленную гибкость при организации памяти и ее модернизации. Один
из банков может заполняться микросхемами видеопамяти (VRAM)
для реализации дешевой графики. Контроллер памяти прямо работа-
ет с видеопамятью и поддерживает несколько простых графических
операций. Мостовая микросхема интерфейса ISA позволяет подклю-
чить к системе низкоскоростные устройства типа модема, флоппи-
дисковода и т.д.
Модернизированная версия этого микропроцессора, новый кристалл
Alpha 21066А, помимо интерфейса PCI, содержит на кристалле интег-
рированный контроллер памяти и графический акселератор. Эти ха-
рактеристики позволяют значительно снизить стоимость реализации
252
6.9. Особенности архитектуры Alpha компании DEC
Рис. 6.15. Пример построения системы на базе микропроцессора Alpha 21066
систем, базирующихся на Alpha 21066А, и обеспечивают простой и
дешевый доступ к внешней памяти и периферийным устройствам.
Alpha 21066А имеет две модификации: с частотой 100 МГц и 233 МГц.
Микропроцессор Alpha 21164 представляет собой вторую реализацию
архитектуры Alpha, появившуюся в 1994 году. Он выполняет до четы-
рех инструкций за такт. На кристалле микропроцессора 21164 разме-
щено около 9,3 миллиона транзисторов, большинство из которых
образуют кэш. Кристалл построен на базе 0,5-микронной КМОП-тех-
нологии компании DEC.
Ключевыми моментами для реализации высокой производительно-
сти являются суперскалярный режим работы процессора, обеспечи-
вающий выдачу для выполнения до четырех команд в каждом такте,
253
Глава 6. Микропроцессоры
высокопроизводительная неблокируемая подсистема памяти с быст-
родействующей кэш-памятью первого уровня, размещенная на кри-
сталле большая кэш-память второго уровня и уменьшенная задержка
выполнения операций во всех функциональных устройствах.
На рис. 6.16 представлена схема процессора, который включает пять
функциональных устройств: устройство управления потоком команд
(IBOX); целочисленное устройство (ЕВОХ); устройство плавающей
точки (FBOX); устройство управления памятью (МВОХ) и устройство
управления кэш-памятью и интерфейсом шины (СВОХ). На рисунке
показаны три вида кэш-памяти.
Кэш-память команд и кэш-память данных представляют собой пер-
вичные кэши, реализующие прямое отображение. Множественно-ас-
социативная кэш-память второго уровня предназначена д ля хранения
команд и данных. Длина конвейеров процессора 21164 варьируется
от 7 ступеней для выполнения целочисленных команд и 9 ступеней
для реализации команд с плавающей точкой до 12 ступеней при вы-
полнении команд обращения к памяти в пределах кристалла и пере-
менного числа ступеней — команд обращения к памяти за пределами
кристалла.
Устройство управления потоком комацд осуществляет выборку и деко-
дирование команд из кэша команд и направляет их для выполнения
в соответствующие исполнительные устройства после разрешения всех
конфликтов по регистрам и функциональным устройствам. Оно управ-
ляет выполнением программы и всеми аспектами обработки исключи-
тельных ситуаций, ловушек и прерываний. Кроме того, обеспечивает
управление исполнительными устройствами, контролируя все цепи
обхода данных и записи в регистровый файл.
Целочисленное исполнительное устройство выполняет целочисленные
команды, вычисляет виртуальные адреса для команд загрузки и запи-
си, обрабатывает целочисленные команды условного перехода и дру-
гие команды управления. Оно включает в себя регистровый файл и
несколько функциональных устройств, расположенных на четырех
ступенях двух параллельных конвейеров. Первый конвейер содержит
сумматор, устройство логических операций, сдвигатель и умножи-
тель. Второй конвейер содержит сумматор, устройство логических
операций и устройство выполнения команд управления.
254
6.9. Особенности архитектуры Alpha компании DEC
Устройство плавающей точки состоит из двух конвейерных исполни-
тельных устройств: конвейера сложения, который выполняет команды
плавающей точки, за исключением команд умножения, и конвейер
умножения, который выполняет команды умножения с плавающей
точкой.
Рис. 6.16. Блок-схема процессора Alpha 21164
255
Глава 6. Микропроцессоры
Устройство управления памятью выполняет команды загрузки, записи
и «барьерные» операции синхронизации. Оно содержит полностью
ассоциативный 64-строчный буфер преобразования адресов (DTB),
кэш-память данных с прямым отображением (8 Кбайт), файл адресов
промахов и буфер записи.
Отличительной особенностью микропроцессора 21164 является разме-
щение на кристалле вторичного трехканального множественно-ассо-
циативного кэша емкостью 96 Кбайт. Вторичный кэш резко снижает
количество обращений к внешней шине микропроцессора. Кроме
вторичного кэша, на кристалле поддерживается работа с внешним
кэшем третьего уровня.
6.10. Особенности архитектуры POWER
Существенное развитие RISC-архитектуры в компании IBM про-
изошло при разработке архитектуры POWER в конце 80-х годов про-
шлого века. Архитектура POWER (и ее поднаправления POWER2
и PowerPC) в настоящее время является основой семейства рабочих
станций и серверов RISC System /6000 компании IBM.
Развитие этой архитектуры происходило в следующих направлениях:
воплощение концепции суперскалярной обработки; улучшение ар-
хитектуры как целевого объекта компиляторов; сокращение длины
конвейера и времени выполнения команд и, наконец, приоритетная
ориентация на эффективное выполнение операций с плавающей
точкой.
Архитектура POWER во многих отношениях придерживается наибо-
лее важных отличительных особенностей RISC: фиксированной
длины команд, архитектуры регистр-регистр, простых способов ад-
ресации, простых (не требующих интерпретации) команд, большого
регистрового файла и трехоперандного формата команд. Однако ар-
хитектура POWER имеет несколько дополнительных свойств, которые
отличают ее от других RISC-архитектур.
Во-первых, набор команд основан на идее суперскалярной обработки.
В базовой архитектуре команды распределяются по трем независи-
мым исполнительным устройствам: устройству переходов, целочис-
ленному устройству и устройству плавающей точки. Команды могут
256
6.10. Особенности архитектуры POWER
направляться в каждое из этих устройств одновременно, выполнять-
ся также одновременно и заканчиваться не в порядке поступления.
Для увеличения уровня параллелизма архитектура набора команд оп-
ределяет для каждого из устройств независимый набор регистров.
Это минимизирует связи и синхронизацию, тем самым позволяя ис-
полнительным устройствам настраиваться на динамическую смесь
команд. Любая связь поданным между устройствами должна анализи-
роваться компилятором, который может ее эффективно спланировать.
Однако это только концептуальная модель. Конкретный же процессор
с архитектурой POWER может рассматривать любое из концептуаль-
ных устройств как множество исполнительных устройств для под-
держки дополнительного параллелизма команд. Но существование
модели приводит к согласованной разработке набора команд, кото-
рый, естественно, поддерживает степень параллелизма, по крайней
мере равную трем.
Во-вторых, архитектура POWER расширена несколькими «смешан-
ными» командами для сокращения времени выполнения. Возможно,
недостатком технологии RISC по сравнению с CISC является то, что
иногда RISC использует бульшее количество команд для выполнения
одного и того же задания. Во многих случаях увеличения размера
кода можно избежать путем небольшого расширения набора команд,
которое вовсе не означает возврат к сложным командам, подобным
командам CISC. Например, значительная часть увеличения программ-
ного кода содержится в кодах, связанных с сохранением и восстанов-
лением регистров во время вызова процедуры. Чтобы устранить этот
фактор, IBM ввела команды «групповой загрузки и записи», которые
обеспечивают пересылку содержимого нескольких регистров в память
(из памяти) с помощью единственной команды. Соглашения о свя-
зях, используемые компиляторами POWER, рассматривают задачи
планирования, разделяемые библиотеки и динамическое связывание
как единый механизм. Это было сделано с помощью косвенной адре-
сации посредством таблицы содержания (TOC — Table Of Contents),
которая модифицируется во время загрузки. Команды групповой за-
грузки и записи стали важным элементом этих соглашений о связях.
Архитектура POWER обеспечивает также другие способы сокращения
времени выполнения команд, такие как обширный набор команд ма-
нипуляции битовыми полями, смешанные команды умножения-сло-
жения с плавающей точкой, установку регистра условий в качестве
257
172792
Глава 6. Микропроцессоры
побочного эффекта нормального выполнения команды и команды
загрузки и записи строк, которые работают с произвольно выравнен-
ными строками байт.
Третьим фактором, отличающим архитектуру POWER от многих других
RISC-архитектур, является отсутствие механизма «задержанных пере-
ходов». Обычно этот механизм обеспечивает выполнение команды,
следующей за командой условного перехода, непосредственно перед
выполнением самого перехода. Этот механизм эффективно работал
в ранних RISC-машинах для заполнения «пузыря», появляющегося
при оценке условий выбора направления перехода и выборки нового
потока команд. Однако в более совершенных суперскалярных машинах
этот механизм иногда оказывается неэффективным, поскольку один такт
задержки команды перехода может привести к появлению нескольких
«пузырей», которые не могут быть покрыты с помощью одного такта
задержки. Архитектура переходов POWER реализована для поддержки
методики «предварительного просмотра условных переходов» (branch-
lockahead) и методики «свертывания переходов» (branch-folding).
Методика реализации условных переходов, используемая в архитекту-
ре POWER, является четвертым уникальным свойством по сравнению
с другими RISC-процессорами. Архитектура POWER определяет рас-
ширенные свойства регистра условий. Проблема архитектур с тради-
ционным регистром условий заключается в том, что установка бит
условий как побочного эффекта выполнения команды значительно
ограничивает возможность компилятора изменить порядок следования
команд. Кроме того, регистр условий представляет собой единственный
архитектурный ресурс, создающий серьезное затруднение в машине,
которая параллельно выполняет несколько команд или выполняет ко-
манды не в порядке их появления в программе. Некоторые RISC-архи-
тектуры обходят эту проблему путем полного исключения из своего
состава регистра условий и требуют установки кода условий с помощью
команд сравнения в универсальный регистр либо путем включения
операции сравнения в саму команду перехода. Последний подход по-
тенциально перегружает конвейер команд при выполнении перехода.
Архитектура POWER предусматривает:
а) специальный бит в коде операции каждой команды, что разрешает
модификацию регистра условий и тем самым восстанавливает спо-
собность компилятора реорганизовать код;
258
6.10. Особенности архитектуры POWER
б) наличие регистров условий (восемь) для того, чтобы обойти про-
блему одного ресурса и обеспечить ббльшее число имен регистра усло-
вий с целью его использования аналогично универсальным регистрам.
Другой причиной выбора модели расширенного регистра условий яв-
ляется то, что она согласуется с организацией машины в виде незави-
симых исполнительных устройств. Концептуально регистр условий
локален по отношению к устройству переходов. Следовательно, для
оценки направления выполнения условного перехода не обязательно
обращаться к универсальному регистровому файлу. Для той степени,
с которой компилятор планирует модификацию кода условия (и/или
загрузить заранее регистры адреса перехода), аппаратура может зара-
нее просмотреть и свернуть условные переходы, выделяя их из потока
команд. Это позволяет освободить в конвейере временной слот (такт)
выдачи команды, обычно занятый командой перехода, и дает воз-
можность диспетчеру команд создавать непрерывный линейный по-
ток команд для вычислительных исполнительных устройств.
Первая реализация архитектуры POWER появилась в 1990 году. Затем
компания IBM представила еще две версии процессоров POWER2 и
POWER2+, обеспечивающих поддержку кэш-памяти второго уровня
и имеющих расширенный набор команд.
По данным IBM, процессор POWER требует менее одного такта для
выполнении одной команды по сравнению с примерно 1,25 такта
у процессора Motorola 68040, 1,45 такта у процессора SPARC, 1,8 так-
та у Intel i486DX и 1,8 такта у Hewlett Packard РА-RISC. Тактовая час-
тота архитектурного ряда в зависимости от модели меняется от 25 до
62 МГц.
Процессоры POWER работают на частоте 33, 41,6, 45, 50 и 62,5 МГц.
Архитектура POWER включает раздельную кэш-память команд и дан-
ных (за исключением рабочих станций и серверов рабочих групп на-
чального уровня, которые имеют однокристальную реализацию про-
цессора POWER и общую кэш-память команд и данных), 64- или
128-битовую шину памяти и 52-битовый виртуальный адрес. Она так-
же имеет интегрированный процессор плавающей точки, что очень
важно для научно-технических приложений с интенсивными вычис-
лениями, хотя текущая стратегия RS/6000 нацелена и на коммерче-
ские приложения. RS/6000 показывает хорошую производительность
на операциях с плавающей точкой.
259
Глава 6. Микропроцессоры
Для реализации быстрой обработки ввода-вывода в архитектуре
POWER используется шина Micro Channel, имеющая пропускную
способность 40 или 80 Мбайт/с. Шина Micro Channel включает
64-битовую шину данных и обеспечивает поддержку работы несколь-
ких главных адаптеров шины. Такая поддержка позволяет сетевым
контроллерам, видеоадаптерам и другим интеллектуальным устрой-
ствам передавать информацию по шине независимо от основного
процессора, что снижает нагрузку на процессор и соответственно
увеличивает системную производительность.
Многокристальный набор POWER2 состоит из восьми полузаказных
микросхем (устройств):
► блока кэш-памяти команд (ICU) — 32 Кбайт, имеет два порта
с 128-битовыми шинами;
► блока устройств целочисленной арифметики (FXU) — содержит
два целочисленных конвейера и два блока регистров общего назначе-
ния (по 32 регистра размером 32 бита каждый). Выполняет все цело-
численные и логические операции, а также все операции обращения
к памяти;
► блока устройств плавающей точки (FPU) — содержит два конвейе-
ра для выполнения операций с плавающей точкой двойной точности,
а также 54 регистра плавающей точки размером 64 бита каждый;
► четырех блоков кэш-памяти данных — максимальный объем кэш-
памяти первого уровня составляет 256 Кбайт. Каждый блок имеет два
порта. Устройство реализует также ряд функций обнаружения и кор-
рекции ошибок при взаимодействии с системой памяти;
► блока управления памятью (MMU).
Набор кристаллов POWER2 содержит порядка 23 миллионов транзи-
сторов на площади 1217 мм2 и изготовлен по технологии КМОП
с проектными нормами 0,45 микрона. Потребляемая мощность на
частоте 66,5 МГц составляет 65 Вт.
Компания IBM распространяет влияние архитектуры POWER в на-
правлении малых систем с помощью платформы PowerPC. Архитектура
POWER в этой форме может обеспечивать уровень производительно-
сти и масштабируемость, превышающие возможности современных
персональных компьютеров. PowerPC базируется на платформе RS/6000
в простой конфигурации. В архитектурном плане основные отличия
260
6.10. Особенности архитектуры POWER
этих двух разработок состоят лишь в том, что системы PowerPC исполь-
зуют однокристальную реализацию архитектуры POWER, изготавли-
ваемую компанией Motorola, в то время как большинство систем
RS/6000 используют многокристальную реализацию. Первым на рынке
был объявлен процессор 601, предназначенный для использования
в настольных рабочих станциях компаний IBM и Apple. За ним после-
довали кристаллы 603 для портативных и настольных систем началь-
ного уровня и 604 для высокопроизводительных настольных систем.
Наконец, процессор 620 разработан специально для серверных кон-
фигураций, и ожидается, что со своей 64-битовой организацией он
обеспечит исключительно высокий уровень производительности.
При разработке архитектуры PowerPC для удовлетворения потребно-
стей трех различных компаний (Apple, IBM и Motorola) при сохране-
нии совместимости с RS/6000 в архитектуре POWER были сделаны
изменения в следующих направлениях:
► упрощение архитектуры в целях ее приспособления для реализа-
ции дешевых однокристальных процессоров;
► устранение команд, которые могут стать препятствием повышения
тактовой частоты;
► устранение архитектурных препятствий суперскалярной обработ-
ке и внеочередному выполнению команд;
► добавление свойств, необходимых для поддержки симметричной
многопроцессорной обработки;
► добавление новых свойств, считающихся необходимыми для буду-
щих прикладных программ;
► обеспечение длительного времени жизни архитектуры путем ее рас-
ширения до 64-битовой.
Архитектура PowerPC поддерживает ту же базовую модель програм-
мирования и назначение кодов операций команд, что и архитектура
POWER. В тех местах, где были сделаны изменения, которые могли
потенциально препятствовать процессорам PowerPC выполнять су-
ществующие двоичные коды RS/6000, были расставлены «ловушки»,
обеспечивающие прерывание и эмуляцию с помощью программного
обеспечения.
Микропроцессор PowerPC 601 выпускают компании IBM и Motorola.
Это процессор среднего класса и предназначен для использования
261
Глава 6. Микропроцессоры
в настольных вычислительных системах малой и средней стоимости.
Двоичные коды RS/6000 выполняются на нем без изменений, что
дало дополнительное время разработчикам прикладных систем для
перекомпиляции своих программ, чтобы полностью использовать
возможности архитектуры PowerPC. Процессор 601 базировался на
однокристальном процессоре IBM, разработанном к моменту созда-
ния альянса трех ведущих фирм. В Power 601 реализована суперска-
лярная обработка, позволяющая выдавать на выполнение в каждом
такте три команды, возможно, не в порядке их расположения в про-
граммном коде.
PowerPC 603 является первым микропроцессором в семействе PowerPC,
полностью поддерживающим архитектуру PowerPC (рис. 6.17).
Он включает пять функциональных устройств: устройство переходов,
целочисленное устройство, устройство плавающей точки, устройст-
во загрузки-записи и устройство системных регистров. Поскольку
PowerPC 603 — суперскалярный микропроцессор, он может подавать
в исполнительные устройства и завершать выполнение до трех ко-
манд в каждом такте. Кроме того, обеспечиваются программируемые
режимы снижения потребляемой мощности, которые дают разработ-
чикам систем гибкость в реализации различных технологий управле-
ния питанием.
В процессоре команды распределяются по пяти исполнительным
устройствам в порядке, заданном программой. Если отсутствуют за-
висимости по операндам, команды выполняются немедленно. Цело-
численное устройство выполняет большинство команд за один такт.
Устройство плавающей точки имеет конвейерную организацию и вы-
полняет операции с плавающей точкой, как с одинарной, так и с двой-
ной точностью. Команды условных переходов обрабатываются в уст-
ройстве переходов. Если условия перехода доступны, то решение о на-
правлении перехода принимается немедленно, иначе выполнение
последующих команд продолжается условно. Наконец, пересылки
данных между кэш-памятью данных, с одной стороны, и регистрами
общего назначения и регистрами плавающей точки — с другой, обра-
батываются устройством загрузки-записи.
В случае промаха при обращении к кэш-памяти обращение к ос-
новной памяти осуществляется с помощью 64-битовой высокопро-
изводительной шины, подобной шине микропроцессора МС 88110.
262
6.10. Особенности архитектуры POWER
Рис. 6.17. Блок-схема процессора PowerPC 603
263
Глава 6. Микропроцессоры
Для максимизации пропускной способности кэш-память взаимодей-
ствует с основной памятью главным образом посредством групповых
операций, которые позволяют заполнить строку кэш-памяти за одну
транзакцию.
Результаты выполнения команды направляются в буфер завершения
команд (completion buffer) и затем последовательно записываются
в соответствующий регистровый файл по мере изъятия команд из бу-
фера завершения. Для минимизации конфликтов по регистрам в про-
цессоре PowerPC 603 предусмотрены отдельные наборы из 32 цело-
численных регистров общего назначения и 32 регистров плавающей
точки.
Суперскалярный процессор PowerPC 604 обеспечивает одновремен-
ную выдачу до четырех команд. При этом параллельно в каждом такте
может завершаться выполнение до шести команд. Процессор вклю-
чает шесть исполнительных устройств, которые могут работать па-
раллельно:
► устройство плавающей точки (FPU),
► устройство выполнения переходов (BPU),
► устройство загрузки-записи (LSU),
► три целочисленных устройства (Ш),
► два однотактных целочисленных устройства (SCIU),
► одно многотактное целочисленное устройство (МСШ).
Такая параллельная конструкция в сочетании со спецификацией ко-
манд PowerPC, допускающей реализацию ускоренного выполнения
команд, обеспечивает высокую эффективность и большую пропуск-
ную способность процессора. Применяемые в процессоре 604 буфера
переименования регистров, буферные станции резервирования, дина-
мическое прогнозирование направления условных переходов и устрой-
ство завершения выполнения команд существенно увеличивают про-
пускную способность системы, гарантируют завершение выполнения
команд в порядке, предписанном программой, и обеспечивают реа-
лизацию модели точного прерывания.
В процессоре 604 имеются отдельные устройства управления памя-
тью и отдельные по 16 Кбайт внутренние кэши для команд и данных.
В нем реализованы два буфера TLB для преобразования виртуальных
264
6.11. Современные микропроцессоры
адресов в физические (отдельно для команд и для данных), содержа-
щие по 128 строк. Оба буфера являются двухканальными множест-
венно-ассоциативными и обеспечивают переменный размер страниц
виртуальной памяти. Кэш-памяти и буфера TLB используют для за-
мещения блоков алгоритм LRU.
Процессор 604 обеспечивает как одиночные, так и групповые пере-
сылки данных при обращении к основной памяти.
Процессор PowerPC 620 в отличие от своих предшественников полно-
стью 64-битовый. При работе на частоте 133 МГц его производитель-
ность на 40—100 % больше показателей процессора PowerPC 604.
Подобно другим 64-битовым процессорам, PowerPC 620 содержит
64-битовые регистры общего назначения и плавающей точки и обес-
печивает формирование 64-битовых виртуальных адресов. При этом
сохраняется совместимость с 32-битовым режимом работы, реализо-
ванным в других моделях семейства PowerPC.
6.11. Современные микропроцессоры
Начат выпуск микропроцессора Е2К (Эльбрус), включающего 50 мил-
лионов транзисторов с технологией 0,13 микронометра. Основной
особенностью его архитектуры в сравнении с обычными суперска-
лярными процессорами (например Pentium) является технология дво-
ичной компиляции, когда процессор может с одинаковой эффектив-
ностью выполнять команды любой платформы: Intelx86, PowerPC,
SPARC и др. Пиковая производительность Е2К составляет 6 милли-
ардов операций с 64-разрядными словами в секунду.
Фирма Intel работает над проектом Платформа 2015. Архитектура
микропроцессора Intel 2015 будет характеризоваться многообразием
вычислительных и коммуникационных возможностей, средством
управления питанием, повышенной надежностью и безопасностью.
Начав с суперскалярной архитектуры первого процессора Pentium
и многопроцессорной обработки в середине 90-х годов прошлого
века, компания Intel расширяет возможности процессора за счет пе-
реупорядочения исполняемых команд и использования технологии
Hyper Threading. Это позволяет осуществить переход к множеству ядер
на одном кристалле. Сегодня компания уже выпускает двухъядерные
265
Глава 6. Микропроцессоры
процессоры. Идея использования одного мощного ядра требуют прин-
ципиально нового решения проблемы тепловыделения.
Наличие большого количества маломощных ядер в какой-то мере по-
зволяет ослабить эту проблему, так как в конкретный момент времени
будут активизироваться только те ядра, которые необходимы для ре-
шения конкретной задачи. Технология многопроцессорной обработки
на одном кристалле (СМР) позволяет включать и специализированные
ядра для решения задач распознавания речи, графики, обработки
коммуникационных протоколов и т.д. Будут выпускаться процессоры
с динамической реконфигурацией ядер, межкомпонентных соедине-
ний и кэш-памяти, чтобы адаптироваться к многообразным потреб-
ностям пользователей. Многие из указанных средств уже внедрены.
Так, например, процессор IXP 2800 включает 16 независимых микро-
устройств, работающих с частотой 1,4 ГГц совместно с ядром Intel
XScole.
Еще одно направление развития — реконфигурируемая радиоархи-
тектура для адаптации к работе в различных беспроводных средах
(например, 802.11а, 802.11b и W-COMA). В последующем многие
функции ПО или специализированных микросхем будут перенесены
в процессор, что повысит скорость его работы и сократит потребляе-
мую энергию.
Фирма планирует снабдить микропроцессоры внутрикристальными
подсистемами памяти, что позволит перенести туда оперативную па-
мять. Можно будет динамически перераспределять память для работы
ядер с целью единоличного, группового или совместного использова-
ния, что упростит прогнозирование и разрешение проблемы тупиков.
Фирма Appro интегрировала 64-битовые процессоры Intel Хеоп с тех-
нологиями передачи данных InfiniBand и PCI Express в платформу
Xtreme Blade.
Японская фирма Hitachi разработала чипсет для поддержки работы
процессоров Intel Itanium 2 на частоте шины 667 МГц.
Упражнения
1. Проанализируйте и сравните по различным параметрам (быстродейст-
вию, памяти, сложности программирования) программы для одно-, двух-,
трех- и безадресных компьютеров.
266
Упражнения
2. Проведите оптимизацию системы команд, если задан конкретный набор
решаемых задач.
3. Разработайте микропрограммы выполнения заданных операций для ре-
ального компьютера. Проанализируйте целесообразность микропро-
граммной поддержки операций.
4. Разработайте систему команд для компьютера с VLIW-архитектурой.
5. Поясните семантику основных особенностей процессора Pentium.
6. Приведите пример масштабируемой процессорной архитектуры.
7. За счет чего достигнута высокая производительность микропроцессора
HyperSPARC?
8. Опишите функции конвейера целочисленного устройства процессора
PA-RISC.
9. Сравните основные характеристики RISC- и CISC-процессоров.
10. Разработайте алгоритм динамического прогнозирования переходов в про-
граммах.
267
Глава 7
Взаимодействие и управление процессами
Понятие «программа» представляется недостаточным для описания
операционных систем, однако детальное исследование программ по-
зволяет выделить ряд важных концепций, которые проясняют прин-
ципы построения операционных систем.
При выполнении программ явно выделяются три объекта:
► последовательность команд или процедура, которая определяет
программу;
► процессор, который выполняет процедуру;
► среда, то есть часть окружающего мира, которую процессор может
непосредственно воспринимать или изменять.
К среде относятся, например, память, универсальные и управляю-
щие регистры компьютера, поскольку они могут и восприниматься,
и изменяться программой.
Можно выделить следующие свойства программы:
► операции, заданные процедурой, выполняются строго последова-
тельно, то есть следующий шаг не начинается, пока предыдущий
полностью не завершится (таким образом, из определения программы
исключается любой процесс, содержащий совмещение операций);
► среда полностью управляется программой, а следовательно, и изме-
няется только в результате шагов, выполненных программой;
► время выполнения операций, а также временной интервал между
выполнением операций не имеют отношения к выполнению програм-
мы. Естественно, здесь не учитывается, что вся программа должна
быть выполнена за разумный интервал времени;
► совершенно не имеет значения, выполняется ли программа целиком
на одном процессоре, лишь бы не изменялась среда программы.
Программа в силу указанных свойств предполагает отсутствие внешнего
воздействия на ее выполнение. Приближением к такому роду программ
являются программы, написанные на языках высокого уровня, важ-
ное свойство которых — возможность точного повторения их работы,
если только программа не имеет доступа к часам реального времени.
268
7.1. Понятие процесса и состояния
Программы, удовлетворяющие указанным свойствам, не могут быть
операционными системами, ибо:
► предполагается, что операционная система эффективно использует
все ресурсы компьютера, а это требует совмещения операций различ-
ных компонент;
► ОС отвечает на поступающие запросы за определенное время, а так
как запросы поступают произвольным образом, то последователь-
ность операций определяется не только самой системой.
7.1. Понятие процесса и состояния
Понятие «процесс» в теории операционных систем встречается до-
вольно часто, однако вкладываемый в него смысл иногда значитель-
но различается. Будем пользоваться следующим определением:
Процесс есть тройка (Q,f, g), где Q — множество состояний процесса;
f— функция действия f Q —> Q\ g с Q — начальное состояние процесса.
Действия, реализуемые процессом, будем рассматривать как резуль-
тат выполнения некоторой программы на реальном (виртуальном)
процессоре.
Перечислим ряд свойств процесса:
► процесс не является закрытой системой и может взаимодействовать
с другими процессами, воспринимая или изменяя часть среды, кото-
рую он с ними разделяет;
► каждый процесс существует лишь временно. Имеется и «главный»
процесс, выполняемый вручную при включении компьютера и начи-
нающий всю цепочку процессов;
► в любой момент процесс может быть описан его состоянием. Все па-
раметры (переменные), характеризующие текущее состояние про-
цесса, объединяются в «вектор состояний» или «слово состояний»,
которые позволяют возобновить как процесс после его прерывания,
так и локальную среду.
Цикл жизни процесса может быть представлен как переход из одного
состояния в другое.
269
Глава 7. Взаимодействие и управление процессами
Пример. Пусть заданы три процесса (задания пользователя), одно-
временно присутствующие в системе с мультипрограммированием.
И пусть каждый из них может находиться в трех состояниях: ожида-
ние, готовность, выполнение.
Опишем эти состояния.
Ожидание. Процесс ожидает выполнения некоторого события (на-
пример, завершения операции I/O).
Готовность. Процесс готов к выполнению, но процессов больше, чем
процессоров, и он должен ждать своей очереди к процессору.
Выполнение. Процессору выделены все ресурсы, в том числе и про-
цессор, и его программы выполняются в настоящее время.
Схема, приведенная на рис. 7.1, отображает переход процессов из
одного состояния в другое в предположении, что процессы уже суще-
ствовали в памяти компьютера и будут существовать всегда. На прак-
тике пользователь должен эти процессы (задания) предоставить
системе. Тогда реальная схема будет выглядеть так, как отображено
на рис. 7.2. Здесь дополнительно введены состояния: предоставле-
ние, хранение и завершение. Поясним их.
Рис. 7.1. Схема перехода процессов из одного состояния в другое
Предоставление. Пользователь предоставляет системе задание, на ко-
торое она должна отреагировать.
Хранение. Задание преобразовано во внутреннюю форму, понятную
компьютеру, но ресурсы еще не выделены (например, задание запи-
сано на диск). Процесс в случае выделения ресурсов переходит в со-
стояние готовности.
270
7.2. Графическое представление процессов
Рис. 7.2 Полная схема обработки процесса
Завершение. Процесс завершил свои действия и все выделенные про-
цессу ресурсы могут быть освобождены и возвращены системе.
7.2. Графическое представление процессов
Чаще всего процесс представляется в виде некоторого графа, вклю-
чающего кружки-вершины, соединенные стрелками-дугами. По тра-
диции (терминологической) вершины означают состояния процесса,
а дуги — переходы между ними, при этом корневая вершина соответ-
ствует начальному состоянию процесса. Дуги помечаются именем
(номером) события, соответствующего данному переходу.
Пример 1. Изобразим графически действия автомата, продающего
билеты (рис. 7.3, а), и действия автомата, продающего билеты и рас-
писание (рис. 7.3, б).
На рис. 7.3 введены следующие сокращения: мон — опустить монету;
бил — получить билет; расп — получить расписание.
Вершина без выходных дуг соответствует состоянию СТОП. А если
процесс обладает неограниченным поведением, то для его изображе-
ния необходимо ввести непомеченную дугу, ведущую из висячей вер-
шины назад к некоторой вершине графа.
Пример 2. Представим автомат, изображенный на рис. 7.3, б, в более
компактной графической форме (рис. 7.4, а). Очевидно, что графы,
представленные на рис. 7.4, а и рис. 7.4, б, иллюстрируют в точности
один и тот же процесс.
271
Глава 7. Взаимодействие и управление процессами
Рис. 7.3. Графическое изображение действий автомата:
а — продающего билеты; б — продающего билеты и расписание
С помощью графической формы достаточно сложно представить про-
цесс с очень большим количеством состояний. Для отображения собы-
тий, в которых участвовал процесс, существует понятие протокола.
Протоколом поведения процесса называют конечную последователь-
ность символов, фиксирующую события, в которых процесс принял
участие до некоторого момента времени.
Обычно протокол обозначают последовательностью символов, за-
ключенных в угловые скобки:
о — пустая последовательность, не содержащая событий;
272
7.3. Управление процессами в многопроцессорном компьютере
< х > — последовательность, содержащая единственное событие х;
<х,у > — последовательность, состоящая из двух событий: х и следую-
щего за ним у.
Пример. После обслуживания первых двух покупателей протокол для
автомата, продающего билеты, будет иметь вид
< мон; бил; мон; бил >.
Протокол того же автомата перед тем, как второй покупатель вынул
билет, будет
< мон; бил; мон >.
Понятие протокола широко используется и в компьютерных сетях.
Например, в сети Интернет, состоящей из множества сетей различ-
ной природы, базовым протоколом является TCP/IP (Transmission
Control Protocol I Internet Protocol). TCP отвечает за доставку сообще-
ний по указанному адресу, a IP поддерживает адресацию сетевых
узлов. Вообще говоря, TCP/IP — это семейство протоколов и при-
кладных программ.
Графическая форма представления протоколов позволяет легче ана-
лизировать взаимодействие процессов и разрешать (или предупреж-
дать) различные возникающие ситуации, в частности тупики и гонки
(см. раздел 7.6).
7.3. Управление процессами
в многопроцессорном компьютере
Рассмотрим вычислительные системы (ВС), включающие три ком-
понента: среду, некоторое количество процессоров и управление. Отме-
тим, что центральный процессор управляется последовательностью
команд, вызываемых из среды, а периферийный процессор действует
в соответствии с фиксированной, встроенной последовательностью
команд.
ВС 1. Предположим, что имеется достаточное количество процессо-
ров различного типа, чтобы обслуживать любой инициированный
процесс, то есть бесконечное число процессоров (рис. 7.5).
273
182792
Глава 7. Взаимодействие и управление процессами
Рис. 7.5. Структура вычислительной системы
с бесконечным числом процессоров (ВС 1)
Управление будет состоять из центрального процессора (ЦП), руко-
водствующегося процедурой, расположенной в памяти. Управляю-
щий процессор соединен линиями связи с другими процессорами,
обеспечивая их запуск и получение информации об их состоянии.
Обычное состояние ЦП — ожидание некоторого события. При воз-
буждении управления ЦП определяет причину запроса, обрабатыва-
ет ее и, если возможно, запускает тот и/или иной процесс. Закончив
обслуживание устройства, ЦП, прежде чем перейти в режим ожида-
ния, проверяет пуста ли очередь на обслуживание.
Важной особенностью многопроцессорных систем является необхо-
димость защиты информации от несанкционированного чтения-за-
писи.
ВС 2. Ограничимся конечным числом процессоров различных типов.
В данном случае процессы будут выстраиваться в очередь из-за отсут-
ствия свободного процессора. При освобождении очередного процес-
сора управляющий процессор (УП) должен решить, какому процессу
его предоставить. Если снабдить УП механизмом прерывания всех
процессоров, то УП после сигнала об освободившемся процессоре
может перераспределить работу всех процессоров заново. Это реше-
ние оптимальнее предыдущего.
ВС 3. Поскольку УП часто простаивает, распределим его функции ме-
жду всеми ЦП. Центральные процессоры, работая в обычном режиме,
выполняют некоторый процесс и могут быть прерваны ЦП, работаю-
274
7.4. Управление процессами в однопроцессорном компьютере
щим в режиме управления. Последний не может быть прерван. Работой
всех ЦП в управляющем режиме руководит одна и та же управляю-
щая процедура.
ВС 4. Вполне естественно предположить, что в управляющем режиме
могут работать одновременно несколько ЦП. В таком случае следует
принять меры защиты информации при операциях с таблицами со-
стояния процессов. При этом возбуждение УП может происходить
одним из следующих способов:
► если процесс, выполняющийся в ЦП, выдает сигнал связи, то этот
же ЦП переключается в управляющий режим и выполняет соответст-
вующие действия;
► освободившийся от управления ЦП включается в выполнение не-
которого процесса;
► прерывание от периферийного устройства переводит один из ЦП
в режим управления. Просмотр всех ЦП происходит поочередно, и,
если все они находятся в режиме управления, прерывание помещает-
ся в очередь.
В целях упрощения реализации можно все прерывания адресовать
одному ЦП. Однако при этом увеличивается время обработки каждо-
го события.
7.4. Управление процессами
в однопроцессорном компьютере
Поскольку большинство существующих ВС имеют один централь-
ный процессор, рассмотрим этот случай подробнее.
Представим себе абстрактную ВС с ОП, одним ЦП, устройством вво-
да и устройством печати. Структура такой ВС приведена на рис. 7.6.
Пусть в исходном состоянии все периферийные устройства (ПУ) на-
ходятся в состоянии покоя, а ЦП выполняет процесс Ph управляемый
последовательностью команд. Если в момент Г, этот процесс выдает
код, возбуждающий процесс в ПУ, то ЦП переходит в управляющий
режим и посылает сигнал по линии связи Аъ А2 или А3. Затем ЦП воз-
вращается к выполнению своего процесса. По окончании работы
одно из ПУ посылает сигнал прерывания по линии Bh устанавливая
275
Глава 7. Взаимодействие и управление процессами
Рис. 7.6. Структура ВС с одним ЦП
тем самым Z-й разряд регистра прерываний в соответствующее состоя-
ние. ЦП переходит в управляющий режим, анализирует состояние
регистра прерываний для опознания ПУ, вызвавшего прерывание,
и выполняет соответствующие действия. До перехода в режим управ-
ления ЦП запоминает состояние прерываемого процесса. Если во
время обработки прерывания приходит новое прерывание, обработ-
ка предыдущего прерывания будет доведена до конца.
7.5. Форматы таблиц процессов
Рассмотрим структуру записей, описывающих соответствующие про-
цессы, в памяти компьютера. Любой процесс, управляемый хранящейся
в памяти программой, имеет два важных параметра:
► адрес, по которому выбирается следующая команда;
► адрес страницы (блока) данных, который следует прибавлять к ка-
ждой ссылке на данные во время обращения.
Периферийный процесс характеризуется типом устройства и адресом
данных, участвующих в обмене. Кроме того, процесс может быть «сво-
бодным» или «занятым», пока не выполнится определенное условие.
Каждому процессу в памяти компьютера соответствует запись, при-
мерный формат которой приведен на рис. 7.7.
276
7.5. Форматы таблиц процессов
Процесс Тип требуемого процессора Параметры Статус процесса
Рис. 7.7. Структура записи процесса
Статус процесса указывает, готов ли процесс к обработке или ожидает
выполнения некоторого условия.
Действия управляющей процедуры сводятся к обработке этих запи-
сей. Рассмотрим некоторые события процесса и действия управляю-
щей процедуры на эти события (табл. 7.1).
Примеры действий управляющей процедуры
Таблица 7.1
№ п/п Событие процесса Реакция управляющей процедуры процесса
1 Сигнал (запрос)* об- разования нового процесса Формирует новую запись и добавляет ее в спи- сок записей процессов
2 Запрос прерывания процесса до выпол- нения некоторого условия Проверяет, выполнено ли требуемое условие. Если нет, то отыскивается соответствующая этому процессу запись и отмечается, что про- цесс ждет выполнения данного условия
3 Сигнал прекращения процесса Находит и убирает нужную запись, подклю- чая ее к списку «свободного места». Затем выбирает запись, в поле «статус» которой имеется пометка «готов», и запускает соот- ветствующий ей процесс
4 Сигнал изменения значения семафора Изменяет значение семафора (см. раздел 7.6). Проверяет все записи прерванных процессов, не ждут ли они изменения состояния этого семафора и если да, то изменяет их статус на «готов»
Для ускорения обработки записей управляющей процедурой послед-
ние хранятся не последовательно (в виде массива), а в виде списковой
структуры. При организации списковой структуры проблема «сборки
мусора» решается автоматически, ибо свободная запись сразу под-
ключается к списку «свободного места».
277
Глава 7. Взаимодействие и управление процессами
Операции над процессами служат для их создания, обработки и унич-
тожения. Наиболее типичные операции над процессами:
► создать новый процесс,
► уничтожить процесс,
► приостановить процесс,
► активизировать процесс,
► установить приоритет процесса,
► определить состояние процесса.
7.6. Синхронизация процессов
Процессы, выполняемые в мультипрограммном режиме, можно рас-
сматривать как набор последовательных слабосвязанных процессов,
которые действуют почти независимо друг от друга, лишь изредка ис-
пользуя общие ресурсы. Взаимосвязь между такими процессами уста-
навливается с помощью различных сообщений и так называемого
механизма синхронизации, который позволяет согласовывать и коор-
динировать работу процессов
Хотя каждый процесс, выполняемый в мультипрограммном режиме,
имеет доступ к общим ресурсам, существует некоторая область, кото-
рую в фиксированный момент времени может использовать лишь
один процесс. Нарушение этого условия приведет к неопределенности
порядка обработки процессов. Назовем такую область критической.
При использовании критической области возникают различные про-
блемы, среди которых можно выделить проблемы состязания (гонок)
и тупиков (клинчей).
Условие состязания возникает, когда процессы настолько связаны ме-
жду собой, что порядок их выполнения влияет на результат операции.
Условие тупиков появляется, если два взаимосвязанных процесса
блокируют друг друга при обращении к критической области.
В системах, допускающих перераспределение любых ресурсов в про-
извольной последовательности, но имеющей и неосвобожденные ре-
сурсы, время от времени будут возникать тупиковые ситуации.
278
7.6. Синхронизация процессов
Пример. Пусть программе А нужен ресурс R1. Она запрашивает его
и получает. Программе В нужен ресурс R2. Она запрашивает его и по-
лучает (рис. 7.8). Далее, пусть программа А, не освобождая А1, за-
прашивает R2, а программа В, не освобождая R2, запрашивает R1.
Налицо типичный клинч, если только один из ресурсов или R2 не
может быть освобожден до момента завершения обработки соответ-
ствующего процесса.
Рис. 7.8. Пример тупиковой ситуации
Для разрешения подобных проблем наиболее часто используют раз-
личные приемы синхронизации процессов, тесно связанные с аппа-
ратным оборудованием.
Простейший прием — стандартные операции типа WAIT (ЖДАТЬ)
и SIGNAL (ОПОВЕСТИТЬ). Операция WAIT позволяет временно
заблокировать процесс, a SIGNAL информирует систему о необходи-
мости разблокирования процесса, задержанного из-за невыполнения
условия.
Следует отметить и такие приемы, как БЛОКИРОВКА ПАМЯТИ
(д ля реализации взаимного исключения одному процессу разрешается
выполнить операцию над памятью, а другому ждать, пока первый не
завершит работу); ПРОВЕРКА и УСТАНОВКА (аппаратная операция,
к которой обращаются с параметрами ЛОКАЛЬНЫЙ и ОБЩИЙ).
Эти приемы, хотя и решают задачу взаимного исключения, однако
неэффективно используют процессорное время из-за необходимости
пребывания в активном состоянии процесса, ожидающего разреше-
ния продолжить работу. Наиболее эффективным и простым средством
синхронизации процессов, исключающим состояние «активного»
ожидания, является семафор.
279
Глава 7. Взаимодействие и управление процессами
Параллельные процессы должны не только взаимодействовать, но
и синхронизировать свои действия, чтобы несколько процессов не
могли использовать одни и те же данные одновременно.
Среди базовых элементов (примитивов) синхронизации можно на-
звать семафоры, блокировки, мьютексы и критические секции. Все эти
средства действуют по одинаковому принципу: разрешают процессу
использовать некоторый ресурс (общую переменную, устройство
ввода-вывода и т.д.), при этом другим процессам запрещен доступ
к этому ресурсу. Если все же другой процесс запрашивает данный ре-
сурс, а первый процесс его еще не освободил, то второму процессу
доступ будет запрещен, пока первый процесс не освободит этот ре-
сурс.
Иногда используется блокирование всех процессов до тех пор, пока
определенная фаза работы не завершится. Наиболее распространен-
ным примитивом такого рода является барьер. При встрече барьера
процесс блокируется до тех пор, пока все остальные процессы также
не достигнут его. Когда последний процесс встречает барьер, все про-
цессы освобождаются и могут продолжить работу.
7.7. Операции Р и V над семафорами
В 1968 году Э. Дейкстра предложил удобную форму механизма захва-
та/освобождения ресурсов, которую он назвал операциями Р и V над
считающими семафорами. Считающим семафором называют цело-
численную переменную, выполняющую те же функции, что и байт
блокировки. Однако в отличие от последнего эта переменная может
принимать, кроме «О» и «1», и другие целые положительные значе-
ния.
Семафоры — это часть абстракции, поддерживающая очередь посто-
янно ожидающих процессов.
Операции PnVнад семафором 5 могут быть определены следующим
образом.
P(S)-
1. уменьшить значение 5 на 1, то есть 5: = S — 1;
2. если 5 < 0, выполнить ОЖИДАНИЕ ($).
280
7.7. Операции Р и I/ над семафорами
К(5):
1. увеличить значение 5на 1, то есть 5: = 5+ 1;
2. если 5> О, выполнить ОПОВЕЩЕНИЕ ($).
Операция ОЖИДАНИЕ (S) (WAIT) блокирует обслуживание процес-
са, делает соответствующую отметку об этом и связывает процесс со
значением переменной 5.
Операция ОПОВЕЩЕНИЕ (.S) (SIGNAL) просматривает связанный
с переменной S список блокированных процессов. Если в списке
имеются процессы, ожидающие освобождения некоторого ресурса,
управляемого (сигнализируемого) 5, то один из них переводится в со-
стояние готовности, а в соответствующей ему записи делается отметка.
С этого момента процесс вновь становится доступным планировщи-
ку (см. раздел 7.9).
По определению, ожидание, связанное с операцией P(S), не является
ожиданием «зависания», так как ожидающие процессы не использу-
ют центральный процессор. Так как несколько процессов могут ожи-
дать операцию P(S) над отдельным семафором, во время изменения
значения семафора должен быть осуществлен выбор контрольной
точки процесса, которую следует сделать доступной. Алгоритм выбора
не определен, за исключением требования равнодоступности процес-
сов, то есть никакой процесс не может быть оставлен без внимания.
Типичным примером использования алгоритма семафоров является
задача «производитель/потребитель». При заданной емкости храни-
лища производитель не должен переполнять его, а потребитель не
должен пытаться брать продукцию из пустого хранилища.
Наиболее употребительные операции над семафорами:
► создать семафор;
► запросить состояние семафора;
► изменить состояние семафора;
► уничтожить семафор.
Операции над семафорами в силу своей неделимости позволяют бло-
кировать или активизировать процессы при освобождении или запро-
сах ресурсов любого типа (памяти, процессоров, устройств ввода-вы-
вода и т.п.).
281
Глава 7. Взаимодействие и управление процессами
Наиболее показательно аппарат семафоров можно применить на за-
даче о трех курильщиках (см. упражнение 2 к настоящей главе).
Проблема взаимоисключения процессов требует нахождения прото-
кола, который может использоваться отдельными процессами в мо-
мент входа в критический раздел или выхода из него.
Рассмотренные приемы синхронизации просты и сравнительно эф-
фективны, однако их использование приводит порой к сложным
конструкциям, чувствительным к незначительным изменениям. Рас-
смотрим более простые в реализации приемы, которые дают уверен-
ность программисту в правильности написанной программы.
7.8. Почтовые ящики
Почтовый ящик — это информационная структура с заданием правил,
описывающих его работу. Она состоит из главного элемента, где рас-
полагается описание почтового ящика, и нескольких гнезд заданных
размеров для размещения сообщений. Такие структуры широко ис-
пользуются для установления связей между процессами.
Если процессpj желает послать процессу р2 некоторое сообщение, он
записывает его в одно из гнезд почтового ящика, откуда р2 в требуемый
момент времени может его извлечь. Иногда процессу р\ оказывается
необходимым получить подтверждение того, что р2 принял передан-
ное сообщение. Тогда образуются почтовые ящики с двусторонней
связью. Известны и другие модификации почтовых ящиков, в част-
ности порты, многовходовые почтовые ящики и т.д. Примером такого
применения может служить операционная система IPMX86 ВС фир-
мы Intel для вычислительных комплексов на основе микропроцессо-
ров IAPX86 или IAPX88. Для целей синхронизации разрабатываются
специальные примитивы создания и уничтожения почтовых ящиков,
отправки и запроса сообщений.
Можно выделить три типа имеющихся в системе запросов: с ограни-
ченным ожиданием, с неограниченным ожиданием или без ожидания.
В случае ограниченного ожидания процесс, выдавший запрос, некото-
рое время ожидает поступления сообщения (при пустом почтовом
ящике). Если по истечении заданного времени сообщение в почтовый
282
7.9. Монитор Хоара
ящик не поступило, процесс активизируется и выдает уведомление
о том, что запрос не обслужен.
Если время ожидания неограниченно, процесс не активизируется до
поступления сообщения в почтовый ящик. В случае запроса без ожи-
дания, если почтовый ящик пуст, указанные выше (для случая огра-
ниченного ожидания) действия выполняются немедленно.
Очевидно, что почтовые ящики позволяют осуществлять как обмен
информацией между процессами, так и их синхронизацию.
7.9. Монитор Хоара
Монитор — это набор процедур и информационных структур, кото-
рыми процессы пользуются в режиме разделения, причем в фиксиро-
ванный момент времени монитором может пользоваться только один
процесс.
Отличительная особенность монитора состоит в том, что в его распо-
ряжении находится некоторая специальная информация, предназна-
ченная для общего пользования, но доступ к ней можно получить
только при обращении к этому монитору.
Монитор не является процессом и представляет собой пассивный
объект, который приходит в активное состояние только в момент обра-
щения некоторого объекта к нему за услугами. Часто монитор сравни-
вают с запертой комнатой, услугами которой может воспользоваться
только тот, у кого есть единственный ключ. При этом процессу запре-
щается оставаться там сколь угодно долго, а другой процесс должен
ждать до тех пор, пока первый не выйдет из него и не передаст ключ.
В качестве примера программы-монитора может выступать плани-
ровщик ресурсов. Действительно, каждый процесс при возникновении
потребности в ресурсах обращается к планировщику. Но планиров-
щик одновременно может обслуживать только один процесс.
Иногда монитор задерживает обратившийся к нему процесс. Это
происходит, например, в случае обращения за занятым ресурсом.
Монитор блокирует процесс с помощью команды ЖДАТЬ, а в случае
освобождения ресурса выдает команду СИГНАЛ. При этом освободив-
шийся ресурс предоставляется одному из ожидавших его процессов
283
Глава 7. Взаимодействие и управление процессами
вместе с разрешением на продолжение работы. Управление передается
команде монитора, непосредственно следующей за операцией ЖДАТЬ.
Мониторы обладают достаточной гибкостью и с их помощью сравни-
тельно легко реализуются различные синхронизирующие примити-
вы, в частности семафоры и почтовые ящики. Кроме того, мониторы
позволяют нескольким процессам совместно использовать програм-
му, представляющую собой критический участок.
7.10. Проблема тупиков
При неосторожном применении во время мультидоступа процессов
к общим ресурсам рассмотренные выше приемы синхронизации мо-
гут привести к блокированию процессами друг друга и невозможно-
сти в течение длительного времени выхода из состояния блокировки
без принятия чрезвычайных мер, то есть к возникновению критиче-
ской тупиковой ситуации.
Подобную ситуацию можно хорошо продемонстрировать на примере
работы двух процессов р\ и р2 с одним читающим R\ и одним печа-
тающим R2 устройствами.
Тупиковая ситуация возникает при мультипроцессировании, когда
процессы pi, р2>..., Рл, заблокированные по одному и тому же ресурсу
Zm, не могут быть разблокированы, поскольку их запросы на этот ре-
сурс никогда не могут быть удовлетворены. Подобные конфликтные
ситуации разрешаются либо ликвидацией процессов, зашедших в ту-
пик, либо освобождением ресурса принудительным образом.
Комплекс программ, объединенных под общим названием ОБРА-
БОТКА ТУПИКОВ (ОТП), как правило, выполняет следующие
функции:
► анализирует возможности избежания тупиков и по возможности
предотвращает их;
► определяет множество процессов, находящихся в состоянии тупика;
► определяет способы и принимает меры для выхода из тупика.
Одним из ключей к решению проблемы распознавания тупиков яв-
ляется наличие в графах типа «ресурс-процесс» цикла, то есть на-
правленного пути от некоторой вершины к ней самой.
284
7.11. Тупик в случае повторно используемых ресурсов
7.11. Тупик в случае повторно используемых ресурсов
Повторно используемые ресурсы (Second hand resource — SR) — это ко-
нечное множество одинаковых ресурсов, обладающих следующими
свойствами:
► количество единиц ресурсов постоянно;
► каждая единица ресурса распределена или доступна только одному
процессу;
► процесс может освободить ресурс (или сделать его доступным) при
условии, что ранее он получал этот ресурс.
В качестве примера SR можно назвать ОП, ВнП, периферийные уст-
ройства и, возможно, процессоры, а также файлы данных и таблицы.
Графы SR
Граф типа «процесс-ресурс», отображающий состояние ОС, называ-
ют графом повторно используемых ресурсов. В случае SR такой граф
является направленным и его интерпретация следующая.
1. Множество N разделено на два непересекающихся класса: Р=
р2, —> Рп) — множество вершин для отображения процессов и р =
= {Ль R2,..., Rm} — множество вершин для представления ресурсов.
2. Граф является двудольным по отношению к Р и р. Каждое ребро
е с Есоединяет вершину из Рс вершиной из р. Если е = (ph Rj), то е —
ребро запроса от процессар, на единицу ресурса Rj. Если же е = (Яу, р,),
то е — ребро назначения единицы ресурса Лу процессу рЛ
3. Для каждого Р, е р целое неотрицательное число обозначает коли-
чество единиц ресурса Л(-.
Пусть | (а, Ь) | — число ребер, направленных от вершины а к вершине
Ь. Тогда система всегда будет работать при следующих ограничениях:
► может быть сделано не более чем /, назначений для Л„ то есть
У |(Р, ,ру)| <Г,- для всех /;
J
► I (Pi, Pj) I +1 (Рр Rj) I ДЛЯ V i,j, то есть сумма запросов и распреде-
лений для некоторого ресурса не должна превышать количества дос-
тупных единиц ресурса.
Состояние системы изменяется только в результате запросов, осво-
бождений или приобретений ресурсов одним процессом.
285
Глава 7. Взаимодействие и управление процессами
Следует отметить, что процессы являются недетерминированными,
так как не существует общего способа заранее определить ресурс, кото-
рый запросит или освободит процесс в конкретный момент времени.
Для распознания возможности перехода процесса в состояние тупи-
ка следует определить, сможет ли процесс быть незаблокированным,
что решается сокращением (редукцией) графа SR.
SR-граф сокращается процессом pt путем удаления всех ребер, входя-
щих в Pi и выходящих из него. Естественно, процесс р, не должен быть
заблокирован и не должен представляться изолированной вершиной
Рис. 7.9. Последовательность сокращений графа
286
7.12. Организация системы прерывания
в SR-графе. Если процесс интерпретируется как приобретение р, ра-
нее запрошенных ресурсов и затем освобождение всех его ресурсов,
тогда р, становится изолированной вершиной.
Граф SR несокращаем, если он не может быть сокращен ни одним
процессом. Граф SR полностью сокращаем, если существует последо-
вательность сокращений, которые устраняют все ребра графа. При-
мер сокращения показан на рис. 7.9.
Теорема. Состояние Sесть состояние тупика тогда и только тогда,
когда SR-граф в состоянии S не является полностью сокращаемым.
Следствие 1. Если S есть состояние тупика по SR-ресурсам, то по
крайней мере два процесса находятся в тупике в 5.
Следствие 2. Процесс р, не находится в тупике тогда и только то-
гда, когда серия сокращений приводит к состоянию, в котором р,
не заблокирован.
7.12. Организация системы прерывания
Появление системы прерывания в компьютерах конца 50-х годов
прошлого века позволило существенно продвинуться в разработках
компьютеров, заново переосмыслив их возможности и среды приме-
нения. Действительно, уже на первых компьютерах, обладающих этим
свойством, появилась возможность автономной работы периферийных
устройств после их запуска центральным устройством управления.
По окончании работы или в связи с другой причиной периферийное
устройство смогло через прерывание заставить центральный процес-
сор обратить на себя внимание. Это открыло путь к широкому совме-
щению операций, что повлекло за собой естественное усложнение
математического и программного обеспечения компьютеров. Совре-
менные операционные системы полностью разрабатываются и бази-
руются на развитой системе прерывания.
7.12.1. Основные параметры системы прерывания
Работу вычислительной системы можно представить как последо-
вательность программно—определяемых (порождаемых программой
и возможные моменты появления которых известны) и программно-
287
Глава 7. Взаимодействие и управление процессами
независимых (вызванных посторонними от программы источниками
или моменты возникновения которых неизвестны) событий.
События, происходящие вне процессора, как правило, программно—не-
зависимые (выход параметров объекта за дозволенные пределы, за-
просы оператора и т.д.) и происходят асинхронно. То же относится
и к периферийным устройствам, работающим одновременно с вы-
полнением программы в процессоре; хотя начало их работы и задает
процессор, однако окончание ее и последовательность операций не-
известны.
События, происходящие внутри процессора, могут быть двух типов.
Последовательность арифметических (и других) операций определя-
ется программой, в то время как особые ситуации (переполнение, по-
пытка деления на нуль и т.д.) зависят от сочетания операндов и преду-
смотреть их во время программирования практически невозможно.
ВС, вообще говоря, должна реагировать на любые события, которые
могут повлиять на процесс вычислений. В случае программно-опре-
деляемых событий для этого достаточно иметь специальный набор
команд (переход по нулю, по знаку и т.д.). Если же события про-
граммно-независимые, то, как правило, обычные программные ме-
тоды для их опознания неэффективны.
Предположим, имеется команда перехода по некоторому программно-
независимому событию.
При этом неизвестно, когда это событие произойдет, а также неясно,
как часто следует вставлять в программу команду перехода по данно-
му событию.
Повторение периодической проверки выполнения требуемого усло-
вия называют сканированием входов. Если сканирование производится,
например, через 25 команд, то объем памяти для программы увели-
чивается на 4 %, а реакция на событие может произойти с большой
задержкой (максимум через 25 команд). Большое количество прове-
ряемых условий вызывает значительные затруднения при програм-
мировании задач и увеличивает время ее решения.
Особый тип прерывания — ловушки (trap), действующие при возникно-
вении исключительных условий в выполняемой программе, обнару-
женных аппаратным обеспечением или микропрограммой. Примеры
таких ситуаций: переполнение и исчезновение значащих разрядов
288
7.12. Организация системы прерывания
при операциях с плавающей точкой, переполнение при операциях
с целыми числами, нарушение защиты, неопределяемый код опе-
рации, переполнение стека, попытка запуска несуществующих уст-
ройств ввода-вывода и т.д.
Чтобы ВС могла реагировать на программно-независимые события
при минимальных усилиях программиста и максимально возможном
быстродействии, ее надо снабдить дополнительными аппаратно-ло-
гическими средствами, совокупность которых называют системой
прерывания программ (СПП).
Прерывание программы — это свойство ВС временно прекратить вы-
полнение текущей программы при возникновении особых событий
и передать управление программе, специально предусмотренной для
обработки данного события.
В системе с прерыванием каждое программно-независимое собы-
тие (источник прерывания) должно, если оно может повлиять на ход
обработки, сопровождаться сигналом, говорящим о его возникно-
вении. Назовем эти сигналы запросами прерывания. Программы,
затребованные запросами прерывания, назовем прерывающими про-
граммами, в отличие от прерванных программ, выполнявшихся ком-
пьютером до появления запросов прерывания. Временною диаграмму
процесса прерывания можно упрощенно изобразить, как показано
на рис. 7.10.
Поскольку функции сохранения и восстановления состояния прерван-
ной программы возлагаются на прерывающую программу, то последняя
должна состоять из трех частей: подготовительной и восстановитель-
ной, обеспечивающих переход к нужной программе, и собственно
прерывающей программы.
По окончании работы прерывающей программы переход может быть
осуществлен либо к прерванной программе, либо к другой преры-
вающей программе.
Так как всевозможные запросы на прерывание вырабатываются неза-
висимо и асинхронно, то возможны следующие ситуации:
► приход запросов последовательный;
► одновременный приход нескольких запросов;
► приход запроса во время выполнения прерывающей программы.
289
1^2792
Глава 7. Взаимодействие и управление процессами
Прерванная программа
*-| —I
Рис. 7.10. Временная диаграмма прерывания
Следовательно, должен быть организован порядок удовлетворения
поступивших запросов. Если в ВС имеются средства обслуживания
запросов в порядке присвоенного им приоритета, то такие системы
прерывания называются приоритетными.
СПП, как правило, выполняют следующие основные функции:
► организуют вход в прерывающую программу;
► осуществляют приоритетный выбор между запросами прерывания;
► обеспечивают возврат к прерванной программе и программное из-
менение приоритетов программ.
Для сравнения различных СПП чаще всего используются следующие
параметры.
Время реакции — время между появлением запроса на прерывание и
началом выполнения первой команды прерывающей программы (Гр).
Так как tp зависит от приоритета программы, то для характеристики
системы используют время реакции для программы с наивысшим
приоритетом.
290
7.12. Организация системы прерывания
Время обслуживания прерывания — разность между полным временем
выполнения прерывающей программы (гпр) и временем выполнения
всех полезных команд (Гп), то есть Гобс = t3 + Гв.
Удельный вес прерывающих программ т] = -^~.
^пр
Глубина прерывания — максимальное число программ, которые могут
прерывать друг друга. Возможны следующие случаи:
► только один запрос воспринимается системой,
► глубина прерывания фиксирована (и0),
► программы могут сколько угодно раз прерывать друг друга.
Схема прерывания при выполнении прерывающих программ изобра-
жена на рис. 7.11.
а) Прерванная
программа
Глубина прерывания
равна 1
б) Прерванная
программа
Глубина прерывания
равна 2
Время поступления запроса на прерывание
12 3
Рис. 7.11. Запросы прерывания:
а — система с единичной глубиной прерывания;
б — система с глубиной прерывания, равной 2
Ясно, что чем больше глубина прерывания, тем лучше можно учесть
приоритетное обслуживание. Так, если при глубине прерывания и0
и во время выполнения л-го прерывания пришла п0 + 1-я программа
с наивысшим приоритетом, то она будет принята к исполнению толь-
ко после выполнения л0-й программы;
Насыщение системы прерывания. Если гр или /п запроса настолько ве-
лики, что запрос окажется необслуженным к моменту прихода нового
291
Глава 7. Взаимодействие и управление процессами
запроса от того же устройства, то возникает явление, называемое
насыщением системы прерывания. В этом случае факт посылки пре-
дыдущего запроса от данного источника будет утрачен. Параметры си-
стемы должны быть согласованы так, чтобы насыщение системы не
наступало.
7.12.2. Вход в прерывающую программу
Система прерывания программ должна определить допустимый мо-
мент прерывания текущей программы и начальный адрес прерывающей
программы. Наиболее простыми являются три следующих способа
определения допустимого момента прерывания.
Метод помеченного оператора (опорных точек). Суть метода состоит
в том, что в специальные разряды команд, после которых допускается
прерывание, записывается определенный символ, разрешающий (на-
пример, состояние «1» специального бита команды) или запрещаю-
щий (например, состояние «О») прерывание. Тогда вдоль программы
можно расставить все опорные точки прерывания таким образом,
чтобы информация, находящаяся в регистрах процессора после вы-
полнения данной команды, далее не использовалась. Это уменьшает
время обслуживания, но увеличивает время реакции.
Покомандный способ. Здесь прерывание допускается после выполне-
ния любой команды. Способ прост в реализации. При этом tp умень-
шается, а /об,, увеличивается.
Метод быстрого реагирования. Прерывание допускается по оконча-
нии выполнения очередного такта любой команды. При этом tp —> min,
a to5c —> max, поскольку надо запоминать и затем восстанавливать не-
которые (обычно программно-недоступные) элементы (например,
счетчик тактов и т.п.).
Из-за простоты и удачного сочетания характеристик прерывания
наибольшее распространение получил второй способ, хотя в послед-
них ВС используется и третий. Так, если обнаружено, что адрес опе-
ранда сформирован неверно, то целесообразно сразу же прервать
выполнение операции, чтобы ошибка не распространилась на другие
такты. Это особенно необходимо при мультипрограммной работе,
если адресованный операнд в команде принадлежит внешней памя-
ти, поскольку текущая операция не может быть продолжена, пока
оперативная память не получит данные из внешней памяти.
292
7.12. Организация системы прерывания
Распознавание начального адреса прерывающей программы можно осу-
ществлять как программным, так и аппаратным способом.
Суть программного распознавания состоит в следующем. Все линии
связи, по которым приходят запросы прерывания, объединяются в
схему ИЛИ, формирующую на выходе один и тот же сигнал, который
в допустимый момент прерывания поступает в прерывающую про-
грамму. Последняя распознает запросы и разветвляется для их вы-
полнения.
Поскольку осуществляется анализ запросов прерывания, то гр и гобс
сравнительно велики, что затрудняет приоритетное обслуживание.
При аппаратном распознавании причин прерывания каждому источ-
нику прерывания ставится в соответствие соответствующий адрес на-
чала прерывающей программы. Этот адрес формирует специальная
схема при появлении запроса. Вход системы прерывания, обладающей
способностью формировать собственный адрес начала прерывающей
программы, принято называть уровнем прерывания.
Таким образом, система с аппаратным распознаванием причин пре-
рывания может быть названа многоуровневой системой прерывания.
Простейший способ указания начальных адресов состоит в следующем.
Каждому уровню присваивается номер и в памяти отводится ячейка,
адрес которой, к примеру, равен номеру уровня. В такой ячейке памя-
ти может храниться команда перехода к остальной части прерываю-
щей программы, которая находится в любом месте памяти. Набор
фиксированных по отношению к своим уровням ячеек памяти обра-
зует таблицу входов в прерывающие программы, чье содержание про-
граммист может менять.
Удобный компромисс достигается в результате сочетания аппаратного
и программного методов распознавания причин прерывания. Можно
организовать систему, в которой каждый уровень используется для
обслуживания нескольких источников прерывания, а физически уро-
вень реализуется в виде некоторого количества прерывающих входов,
объединенных схемой ИЛИ. Так, управляющая машина IBM 1800,
используя подобный компромисс, имеет 24 уровня прерывания, к ка-
ждому из которых может подсоединяться до 16 прерывающих входов.
В определенную для данного уровня прерывания ячейку памяти за-
писывается состояние прерывающих входов в момент прерывания.
293
Глава 7. Взаимодействие и управление процессами
7.12.3. Приоритетное обслуживание прерываний
Аппарат приоритетов предназначен для повышения эффективности
использования ресурсов ВС. Так, например, неэффективным является
одновременное выполнение двух заданий, каждое из которых требует
большой загрузки устройств ввода—вывода и незначительно исполь-
зует центральный процессор. Приоритет задания может назначаться
исходя из:
► времени его выполнения («короткие» задания с небольшим временем
выполнения имеют более высокий приоритет по сравнению с «длин-
ными» заданиями, требующими значительных затрат времени);
► объема используемой оперативной памяти (задания, требующие
большого объема памяти, не должны иметь одинаковый приоритет);
► интенсивности и объема использования других ресурсов ВС;
► срочности выполнения;
► взаимодействия процессов;
► последствий задержки обработки процессов и т.д.
При программном распознавании причин прерывания прерываю-
щая программа начинает анализ с запросов на прерывание, имеющих
более высокий приоритет. При этом в процессе работы программным
путем можно изменить приоритет запросов. При аппаратном распо-
знавании причин прерывания указанные функции возлагаются на
специальное оборудование.
Существует два понятия приоритета в прерывании программ.
Предположим, что никаких ограничений на время поступления за-
просов прерывания не накладывается. При одновременном поступ-
лении нескольких запросов для немедленного удовлетворения может
быть принят только один. Этот тип приоритета, определяющий оче-
редность рассмотрения запросов прерывания, называют приоритетом
между запросами прерываний.
Прерывающие программы, однако, могут иметь относительно текущей
программы различную степень важности, и выполняющаяся програм-
ма не может быть прервана любым запросом. Чтобы иметь возмож-
ность прервать текущую программу, принятый СПП запрос должен
соответствовать программе с более высоким приоритетом, нежели
выполняемая в данный момент. Этот тип приоритета определяет
294
7.12. Организация системы прерывания
старшинство программ и его обычно называют приоритетом между
прерывающими программами.
В случае простейшей аппаратной реализации приоритета между за-
просами прерывания может быть использован метод последователь-
ного поиска (рис. 7.12).
счетчика
Рис. 7.12. Реализация метода последовательного поиска
Суть метода состоит в последовательном изменении содержимого
счетчика от 0 до 2" — 1 и в просмотре всех 2" уровней прерывания до
совпадения содержимого счетчика с номером уровня.
При одновременном появлении нескольких запросов жестко закре-
пляется запрос, пришедший от уровня с меньшим номером. Метод
последовательного поиска прост в реализации, но время реакции
достаточно велико, так как в общем случае необходимо прохождение
счетчиком всех 2" позиций, что при большом значении п может вы-
ходить за допустимые временные пределы. Особенно это важно при
работе в режиме реального времени.
Приоритет между прерывающими программами определяет програм-
мы, которые могут прервать данную программу. Этот вид приоритета
295
Глава 7. Взаимодействие и управление процессами
д ля многоуровневых систем с достаточной глубиной прерывания име-
ет гораздо большее значение, чем приоритет между запросами пре-
рывания.
Пример. Пусть одновременно возникли три запроса, соответствую-
щие трем уровням прерывания — № 1, № 2, № 3. Пусть по приоритету
предпочтение отдается запросу с меньшим номером. Предположим,
что приоритет между прерывающими программами, соответствую-
щими указанным уровням, установлен в обратном порядке. Тогда
в соответствии с приоритетами между запросами вначале процессор
приступает к выполнению программы № 1, однако, как только поиск
запросов прерывания возобновится, запрос № 2 прервет выполнение
программы № 1 и запустит программу № 2. Аналогично последняя
прервется программой № 3, которая и выполняется первой.
Таким образом, приоритет между запросами прерывания нужен лишь
для выбора одного запроса из многих, а приоритет между прерывающими
программами определяет фактический порядок выполнения программ.
Так как степень важности программ, их объем, требуемые ресурсы
и др. могут изменяться в ходе вычислительного процесса, то только
приоритеты между запросами прерывания строго фиксируются. При-
оритеты же между прерывающими программами должны быть про-
граммно-управляемыми.
Маска прерывания — шаблонная последовательность знаков, управляю-
щая сохранением или исключением отдельных частей другой последова-
тельности знаков. Простейшая маска — это двоичное число, каждый
разряд которого соответствует одному из уровней прерывания и раз-
решает (например, состояние «1») или запрещает (состояние «О»)
прерывание от запросов, относящихся к данному уровню. Управле-
ние приоритетом находится полностью в распоряжении программы.
Для каждой прерывающей программы может быть установлена своя
маска, указывающая программы, которые способны прерывать эту
программу. Каждый разряд маски соответствует отдельной программе.
Маски всех программ хранятся в памяти. Если некоторая программа
вызывается для выполнения, то ее маска посылается в регистр маски.
Физически маска обычно реализуется в виде триггерного регистра,
состояние которого можно изменить программным путем. При фор-
мировании маски состояние «1» получают лишь те триггеры, которые
296
7.12. Организация системы прерывания
соотве ствуют программам с более высоким, чем у данной програм-
мы, приоритетом.
В принципе нули и единицы в маске могут чередоваться в произволь-
ном порядке, однако отсутствие упорядоченности влечет за собой допол-
нительные трудности, связанные с определением приоритета соот-
ветствующей программы, а также с осуществлением обхода ситуации
«зацикливание приоритетов».
При «зацикливании приоритетов» происходит поочередное выпол-
нение нескольких команд каждой программы, что, естественно, рез-
ко увеличивает время обслуживания и снижает эффективность СПП.
Иногда создаются «групповые» маски, при которых каждый разряд
воздействует на несколько уровней одновременно. Уровни прерыва-
ний, которые управляются одним разрядом маски прерывания, обра-
зуют класс прерывания. Высшей степенью этой иерархии является
главный триггер прерывания, выключающий (или включающий) всю
СПП полностью.
В случае поступления запросов, запрещенных маской прерывания,
СПП либо запоминает запрос, чтобы при снятии запрета удовлетво-
рять его, либо игнорирует запрос, если его удовлетворение через вре-
мя t может отрицательно повлиять на ход вычислительного процесса.
Возможны и другие реакции СПП. В таком случае в маске на один
уровень прерывания отводится более одного бита.
Для осуществления возврата к прерванной программе необходимо
полностью восстановить ее начальное состояние. Информацию, ко-
торую следует сохранять при прерывании программы, можно разде-
лить на основную (которая запоминается всегда) и дополнительную
(необходимость запоминания которой зависит от содержания пре-
рванной программы).
В основную информацию обычно входит:
► содержимое счетчика адреса команд, то есть адрес первой невы-
полненной команды прерванной программы;
► триггер состояния системы: «рабочее» или «ожидание»;
► маска прерывания, устанавливаемая каждой новой программой;
► код прерывания — двоичное число, отдельное для каждого уровня,
по которому прерывающая программа опознает конкретный источ-
ник прерывания.
297
Глава 7. Взаимодействие и управление процессами
Так как код прерывания чаще всего находится в общем для всех уров-
ней регистре, то, если предыдущий код полностью еще не обработан
(а это почти всегда так), с приходом новой прерывающей программы
его следует запоминать.
Указанная информация образует так называемое «слово состояния про-
граммы» (ССП) (иногда его называют вектором состояния программы),
которое хранится в некотором поле памяти компьютера. В момент
прерывания старое ССП, относящееся к прерванной программе, заме-
няется ССП прерывающей программы, а в конце прерывания старое
ССП восстанавливается прерывающей программой. Для ускорения
процесса замены ССП эту процедуру выполняют обычно аппарат-
ным путем.
Заметим, что в период сохранения и восстановления ССП прерыва-
ния любого уровня запрещены.
К дополнительной информации относят содержимое:
► арифметических регистров;
► индексных регистров;
► прочих программно-доступных регистров, общих для всех про-
грамм, и т.п.
Сохранение дополнительной информации увеличивает время обслу-
живания. Поэтому программисту следует тщательно продумать, что
из дополнительной информации следует запоминать в каждом кон-
кретном случае. Более того, момент прерывания следует выбирать
так (если это возможно), чтобы дополнительной информации для со-
хранения было как можно меньше.
7.12.4. Функционирование типовой системы прерывания
Наибольшее распространение в компьютерах получили шесть уров-
ней прерывания:
► ввод-вывод;
► обращение к супервизору;
► программный сбой;
► внешние прерывания;
298
7.12. Организация системы прерывания
► прерывание повторного пуска;
► прерывание от схем контроля.
Прерывания ввода-вывода, идущие от каналов и периферийных уст-
ройств, сигнализируют системе о нормальном (или ненормальном)
окончании операции ввод-вывода.
Прерывание при обращении к супервизору позволяет пользователю
направлять работу супервизора на реализацию нужных действий (вы-
делить дополнительную область памяти, запустить операцию вво-
да-вывода и т.п.).
Прерывание по программному сбою возникает в результате различного
рода ошибок в программе: переполнение разрядной сетки, наруше-
ние защиты, появление привилегированной команды в состоянии
«задача» и т.п.
Внешние прерывания происходят от внешних по отношению к компь-
ютеру объектов — оператора путем нажатия определенной кнопки,
от датчика времени и т.п.
Прерывание повторного пуска — это средство, которое позволяет опе-
ратору или некоторому процессору вызвать выполнение требуемой
программы.
Прерывание от схем контроля сигнализирует о неисправности обору-
дования и обеспечивает ее локализацию и исправление.
Каждый уровень прерывания может обслуживать несколько причин.
Конкретная причина прерывания внутри уровня определяется про-
граммным путем по «коду прерывания» и некоторой дополнительной
информации, которая запоминается каждый раз в оперативной памяти
при возникновении прерывания. В качестве примера дополнительной
информации упомянем слово состояния канала при прерываниях от
ввода-вывода.
Каждому уровню прерываний соответствуют два ССП: новое и старое,
которые хранятся в специальных полях памяти. Общее назначение
ССП — управление последовательностью выборки команд, запомина-
ние и идентификация текущего состояния аппаратных средств отно-
сительно программы, выполняемой в фиксированный момент вре-
мени, и некоторые другие функции. При необходимости частично
изменить состояние процессора следует загружать только требуемую
299
Глава 7. Взаимодействие и управление процессами
часть нового ССП. Однако при прерываниях любого уровня проис-
ходит полная смена содержимого старого ССП на новое, которое ста-
новится текущим. Если в конце программы, которой было передано
управление по прерыванию, имеется команда ВОССТАНОВИТЬ
СТАРОЕ ССП, то процессор восстанавливает состояние, предшест-
вующее прерыванию, и прерванная программа продолжает свое вы-
полнение.
В ходе вычислительного процесса в один и тот же момент может воз-
никнуть несколько событий, вызывающих прерывания. Одновремен-
но появившиеся запросы на прерывание удовлетворяются в заранее
установленном порядке, в соответствии с их приоритетами. Такая же
ситуация наблюдается и с приоритетами между прерывающими про-
граммами. Чаще всего прерывание от аппаратуры контроля имеет
наивысший приоритет.
Общая схема обработки прерываний приведена на рис. 7.13.
Состояние «задача» | Состояние «супервизор»
Рис. 7.13. Схема обработки прерывания
Порядок приоритета может быть изменен программным изменением
маски прерывания. Чаще всего состояние «1» разряда маски разре-
шает прерывание данного уровня, а состояние «О» запрещает преры-
вание.
Если стандартные обработчики прерываний не устраивают про-
граммиста, он может разработать и использовать свои обработчики.
300
Упражнения
О наличии таких обработчиков операционная система должна знать
заранее. Иногда этот вопрос решается во время генерации операци-
онной системы.
Упражнения
1. Докажите графически, что процессы, представленные на рис. 7.4, а
и рис. 7.4, б, в точности иллюстрируют один и тот же процесс.
2. Три курильщика сидят за столом. У одного есть табак, у другого — бума-
га, у третьего — спички. На столе могут появиться извне одновременно
два из трех упомянутых предмета. Появившиеся предметы забирает тот
курильщик, у которого будет полный наб Jp предметов. Он сворачивает
папиросу, раскуривает ее и курит. Новые два предмета могут появиться
на столе только после того, как он кончит курить. Другие курильщики в
это время не могут начать курение.
Задание. Описать с помощью Ри И— операций над семафорами — сис-
тему процессов, которая моделирует взаимодействия этих курильщиков.
Указание. Выделить шесть процессов, три из которых соответствуют
трем курильщикам X, Y, Z, а три других имеют следующее назначение:
А — поставляет спички и бумагу, В — табак и спички, С— бумагу и табак.
Требование. Процессы-поставщики не знают, какие предметы находят-
ся у курильщиков.
3. Рассмотрим набор из восьми частично упорядоченных заданий {А, В, С,
D, Е, F,G,H}. Задание А должно предшествовать заданиям С, В и Е. Зада-
ния Ей D должны предшествовать заданию F. Задания С и В должны
предшествовать заданию D. Задание Г должно предшествовать задани-
ям G и Н.
а) Изобразите выполнение этой последовательности заданий в виде
программы с помощью элементарных операций «parbegin» и «parend»,
используя везде, где возможно, параллелизм заданий.
б) Теперь допустим, что добавлено дополнительное ограничение: зада-
ние Е должно предшествовать заданию С. Можете ли вы по-прежнему
найти «максимально использующее параллельность» решение с помо-
щью операций «parbegin» и «parend»?
в) Если бы было разрешено пользоваться семафорами, как бы измени-
лись ваши ответы на вопросы (а) и (б)?
4. Используя защиту памяти, организуйте взаимное исключение между п
процессами, у каждого из которых есть один критический участок.
301
Глава 7. Взаимодействие и управление процессами
5. Задача о спящем парикмахере (Дейкстра, 1968). Парикмахерская состоит
из комнаты ожидания W и комнаты В, в которой стоят парикмахерские
кресла. Через раздвижные двери D можно попасть из комнаты В в комна-
ту W, а из комнаты W на улицу. Если парикмахер заходит в комнату W
и никого там не обнаруживает, то он идет спать. Если клиент входит в па-
рикмахерскую и находит парикмахера спящим, то он должен его разбу-
дить. В комнате ожидания имеется конечное число стульев п. Запрограм-
мируйте парикмахера и клиентов как процессы. Для синхронизации их
работы воспользуйтесь аппаратом пересылки сообщений. Что, если бы
были два парикмахера?
6. Пусть дан обеденный стол с пятью стульями и пятью приборами. Около
каждого прибора имеется вилка. Чтобы съесть свою порцию спагетти,
гостю необходимы две вилки, находящиеся по соседству с его тарелкой.
Пусть за столом сидят пятеро гостей, которые попеременно то едят спагет-
ти, то говорят о политике (для разговоров о политике вилок не требуется).
Запрограммируйте гостей как набор процессов, используя семафоры для
передачи сообщений. Позаботьтесь о том, чтобы возможность тупика
между гостями была исключена.
7. Иногда в системе возникает необходимость передать от процесса к про-
цессу довольно длинное сообщение, например файл. Обычный аппарат
почтовых ящиков здесь, очевидно, будет неэффективен, поскольку он
предусматривает, что сообщение полностью переписывается из одного
места оперативной памяти в другое. Укажите способ передачи длинных
сообщений при условии, что существует возможность посылать корот-
кие сообщения.
8. Рассмотрим набор процессов, в котором каждому процессу однозначно
соответствует целое число. У каждого процесса есть особый участок,
в который можно войти только при условии, что сумма всех целых чисел,
соответствующих процессам, которые работают в данный момент в сво-
их особых участках, делится на три. Опишите реализацию этих особых
участков с помощью семафоров. Дайте краткое описание другой реали-
зации, использующей монитор Хоара. Сравните эти два решения.
9. Рассмотрим сеть вычислительных машин. Опишите аппарат, который
можно применить для организации общения между процессами, рабо-
тающими в различных узлах сети.
10. Разработайте и реализуйте систему приоритетов между запросами на пре-
рывание и между прерывающими программами.
11. Реализуйте программно алгоритм «последовательного поиска» уровня
прерывания.
302
Упражнения
12. Разработайте несколько нестандартных обработчиков (прерывающих
программ) различных запросов прерываний.
13. Разработайте программу распознавания конкретной причины прерыва-
ния по его коду для некоторого уровня прерывания.
14. Реализуйте программу сканирования запросов на прерывание и построе-
ние адреса входа в прерывающую программу (программу-обработчик).
303
Глава 8
Последовательные и параллельные
процессы
Человеку присущ последовательный образ мышления, поэтому ему
привычнее компьютеры последовательного действия, а следователь-
но, разработка последовательных алгоритмов и последовательная
обработка данных. И как следствие этого разработаны и широко ис-
пользуются «последовательные» языки программирования.
Но если внимательно рассмотреть процессы, происходящие вокруг
нас и в нас самих, то можно заметить, что многие операции выполня-
ются одновременно. И естественно предположить, что только имею-
щиеся возможности их реализации и адекватного отображения не
позволяют замечать эту одновременность. В частности, однопроцес-
сорные компьютеры — один из главных источников формирования
последовательного мышления. Этот процесс особенно усилился с по-
явлением и широким распространением персональных компьютеров
(ПК).
Под многопроцессорной вычислительной системой (МВС) будем пони-
мать комплекс вычислительных средств, связанных физически и про-
граммно, в котором одновременно (в один и тот же момент времени)
может выполняться несколько арифметических или логических опе-
раций по преобразованию данных.
Известно, что повышение производительности вычислительной си-
стемы при последовательном выполнении операций зависит от воз-
растания тактовой частоты ее элементов. Между тактовой частотой
работы машины и ее размерами существует определенная зависимость:
Knp^a^/y^Cl/v3), (1)
где Кпр — предельный физический объем вычислительной системы;
а — некоторый постоянный коэффициент, учитывающий геометрию
машины; с — скорость света; у — константа; v — тактовая частота ма-
шины.
Из (1) виден теоретический предел повышения производительности
при последовательном выполнении операций.
304
Глава 8. Последовательные и параллельные процессы
Рассмотрим концепцию параллельного выполнения операций, при ко-
торой производительность определяется как количеством элементов
так и частотой их работы. Увеличение производительности в этом
случае достигается за счет увеличения количества параллельно рабо-
тающих элементов при одновременном уменьшении тактовой часто-
ты. Итак,
P=bnv, (2)
где Р— производительность машины; п — число элементов; v — так-
товая частота; b — некоторый постоянный коэффициент.
Предельно допустимое число элементов (лпр) определяется соотно-
шением
Лпр = Л(с/т)3(1/т3). (3)
Из соотношений (2), (3) видно, что с уменьшением тактовой частоты
допускается сколь угодно высокая производительность вычислений.
Распределенная обработка информации базируется на модели кол-
лектива вычислителей, в основу которой положены следующие ак-
сиомы:
► аксиома параллельности задачи: всякая сложная задача может быть
представлена в виде связанных между собой простых задач, которые
при необходимости обмениваются информацией;
► аксиома параллельности алгоритмов: для задачи любой сложности
может быть предложен параллельный алгоритм, допускающий ее эф-
фективное решение;
► аксиома параллельности модели коллектива вычислителей: модель
может обеспечить при параллельной работе сколь угодно высокую
производительность;
► аксиома реконфигурации логической структуры: структура изменя-
ется как при переходе от задачи к задаче, так и в процессе решения
задачи.
Для решения задачи на параллельном компьютере необходимо рас-
пределить вычисления между процессорами системы так, чтобы каж-
дый процессор был занят решением части задачи. Желательно, чтобы
между процессорами пересылался минимально требуемый объем дан-
ных, ибо коммуникации более медленные операции, чем вычисления.
305
202792
Глава 8. Последовательные и параллельные процессы
Часто возникают конфликты между степенью распараллеливания за-
дачи и объемом коммуникаций при большом количестве процессоров
для решения одной задачи. Среда параллельного программирования
должна обеспечивать адекватное управление распределением и комму-
никациями данных.
Рассмотрим основные модели параллельного программирования.
Процесс/канал (Process/Channel)
Модель процесс/канал характеризуется следующими свойствами:
► процесс представляет собой последовательную программу с ло-
кальными данными;
► параллельное вычисление состоит из одного или более одновре-
менно исполняющихся процессов, число которых может изменяться
при выполнении программы;
► процесс имеет входные и выходные порты, служащие интерфей-
сом к среде процесса.
В дополнение к обычным операциям процесс может выполнять сле-
дующие действия:
► послать сообщение через выходной порт;
► получить сообщение из входного порта;
► создать новый процесс;
► завершить процесс.
Операция посылки — асинхронная, она завершается сразу, не ожидая
момента получения данных адресатом. Операция получения — син-
хронная, она блокирует процесс до момента поступления сообщения.
Пары из входного и выходного портов соединяются очередями сооб-
щений, называемыми каналами (channels). Каналы можно создавать
и удалять. Ссылки на каналы (порты) включаются в сообщения, так
что связность может изменяться динамически.
Процессы произвольным способом распределяются по физическим
процессорам, причем используемое отображение (распределение) не
воздействует на семантику программы. В частности, множество про-
цессов можно отобразить на одиночный процессор.
306
Глава 8. Последовательные и параллельные процессы
Обмен сообщениями (Message Passing)
Данная модель наиболее широко используется при параллельном
программировании. Программы этой модели, подобно программам
модели процесс/канал, создают множество процессов, с каждым из
которых ассоциированы локальные данные. Каждый процесс иденти-
фицируется уникальным именем. Процессы взаимодействуют, посылая
и получая сообщения. В этом отношении модель обмена сообщениями
является разновидностью модели процесс/канал и отличается только
механизмом, используемым при передаче данных. Она не накладыва-
ет ограничений ни на динамическое создание процессов, ни на выпол-
нение нескольких процессов одним процессором, ни на использова-
ние разных программ для разных процессов, то есть формальные
описания систем обмена сообщениями не рассматривают вопросы,
связанные с манипулированием процессами. Однако при реализации
таких систем приходится принимать определенное решение в этом
отношении. Большинство практических систем обмена сообщения-
ми при запуске параллельной программы создают фиксированное
число идентичных процессов и не позволяют создавать и завершать
процессы в течение работы программы.
Здесь каждый процесс выполняет одну и ту же программу (парамет-
ризованную относительно идентификатора либо процесса, либо про-
цессора), но работает с разными данными, поэтому о таких системах
говорят, что они реализуют SPMD (single program multiple data — одна
программа — множество данных) модель программирования. SPMD
модель приемлема и достаточно удобна для широкого спектра прило-
жений параллельного программирования.
Параллелизм данных (Data Parallel)
В этой модели единственная программа задает распределение данных
между всеми процессорами и операции над ними. Распределяемыми
данными обычно являются массивы. Распараллеливание операций
над массивами позволяет сократить время их обработки. Компилятор
отвечает за генерацию кода, осуществляющего распределение эле-
ментов массивов и вычислений между процессорами. Каждый про-
цессор обрабатывает то подмножество элементов массива, которое
расположено в его локальной памяти. Программы с параллелизмом
данных могут быть оттранслированы и исполнены как на MIMD, так
и на SIMD компьютерах.
307
Глава 8. Последовательные и параллельные процессы
Общая память (Common Memory)
В данной модели все процессы совместно используют общее адресное
пространство, к которому они асинхронно обращаются с запросами
на чтение и запись. Для управления доступом к общей памяти ис-
пользуются всевозможные механизмы синхронизации типа семафо-
ров и блокировок процессов. Преимущество этой модели с точки
зрения программирования состоит в том, что монопольное владение
данными отсутствует, следовательно, не требуется явного задания об-
мена данными между производителями и потребителями. Эта модель
упрощает разработку программы, но затрудняет управление локальными
данными и проектирование детерминированных программ. В основном
эта модель используется при программировании для архитектур с па-
мятью общего доступа.
В настоящее время в мире произведено большое количество компью-
теров, которые позволяют осуществлять параллельную обработку
множества процессов.
8.1. Предпосылки создания систем параллельного действия
Развитие информационно-компьютерных технологий теории и прак-
тики проектирования компьютеров и их программного обеспечения
(ПО) показало, что существующие компьютеры уже не удовлетворяют
потребностям пользователей в решении задач науки и производства.
В связи с этим все изыскания в области вычислительной техники на-
правлены на создание новых, более перспективных компьютеров.
Компьютеры и их ПО являются на сегодня, пожалуй, самыми доро-
гостоящими продуктами производства, поэтому эффективность их
применения требует большого внимания. Работа в пакетном режиме
использует это дорогостоящее оборудование крайне неэффективно.
Речь идет не только о том, что простои оборудования в среднем дос-
тигают 50 %, но и о том, что половина оставшегося времени идет на
отладку программ. Если сюда присовокупить время на процессы
трансляции, сборки, редактирования связей — необходимые этапы
подготовки задачи к счету, то доля полезного времени для обработки
данных по отлаженной программе окажется совсем незначительной.
308
8.1. Предпосылки создания систем параллельного действия
За время развития вычислительной техники накладные расходы на каж-
дую с пользой выполненную команду программы выросли на 3—4 по-
рядка. (В начальном периоде развития роль транслятора, сборщика,
редактора играл сам программист.) Созданные за это время средства
автоматизации проектирования программ и их подготовки к обработке
лишь в 40—50 раз повышают производительность работы программи-
ста. Поэтому проблема изменения соотношения времени, затрачи-
ваемого компьютером на подготовку задач и на получение «полезных
результатов» в пользу последнего, является актуальной.
Изменение указанного соотношения можно осуществить через пре-
образование структуры компьютера.
Для универсальных машин характерен широкий набор команд и дан-
ных. Во время трансляции, например, главным образом используется
небольшое подмножество этих команд, связанное с преобразованием
текстов. Возможности АУ по выполнению арифметических операций
с плавающей точкой и удвоенной точностью в этот момент не ис-
пользуются, при выполнении же вычислений все обстоит наоборот.
Что касается операций ввода-вывода, то на разных их этапах исполь-
зуются только определенные возможности компьютера. Поэтому це-
лесообразно иметь хотя бы два процессора в компьютере: один — для
обработки данных, другой — для подготовительных работ. Основная
трудность двухпроцессорной организации заключается в сбаланси-
ровании ее работы.
Аналогичную картину можно проследить с использованием памяти,
отдельные участки которой простаивают длительное время из-за от-
сутствия к ним обращений. При анализе динамики обращений к па-
мяти при решении некоторых классов вычислительных задач было
установлено, что ОЗУ активно используется лишь на 10—15 %.
Другим фактором, сдерживающим эффективное использование обо-
рудования, является последовательный характер проектируемых алго-
ритмов. Можно показать, что существует возможность построить такой
компьютер (гипотетический, разумеется), что любой заданный алго-
ритм будет обрабатываться параллельно. Идею доказательства такой
возможности продемонстрируем на конкретном примере.
Пусть требуется вычислить значение г по формуле
r=x+yz.
309
(4)
Глава 8. Последовательные и параллельные процессы
Формулу (4) можно рассматривать как некоторый преобразователь
чисел х, у, z в некоторое другое число r=x+yz. Пусть все числа заданы
в двоичной форме (на общность рассуждений это не влияет). Таким об-
разом, речь идет о преобразовании некоторого набора нулей и единиц,
представляющих собой последовательность чисел х, у, z в некоторый
другой набор нулей и единиц для г. Из алгебры логики известно, что
для любой функции можно построить дизъюнктивную нормальную
форму (ДНФ). В свою очередь, i-й двоичный разряд результата /-мож-
но рассматривать как логическую функцию
Г, = Г (X,, Х2,..., Х„, у2,у„, Zi, Z2,..., Z„),
где xit yt, Zi — двоичные разряды, представляющие возможные значе-
ния X, у, Z-
Так как любая функция (вычисление любого разряда г,) / = 1,и может
быть представлена ДНФ (через логические операции И, ИЛИ, НЕ),
то можно построить п схем (и процессоров), которые, работая одно-
временно, выдают все л разрядов результата г. Ясно, что подобные
рассуждения носят абстрактный характер и ими трудно воспользо-
ваться на практике, ибо количество конкретных алгоритмов пред-
ставляет собой бесконечное множество. Но тем не менее подобный
подход позволяет с общих позиций рассматривать попытку реализо-
вать вычислительные среды — многопроцессорные системы, дина-
мически настраиваемые на конкретный алгоритм. Принципиальная
возможность распараллелить любой алгоритм оправдывает те усилия,
которые предпринимаются для решения этой задачи.
Структура и архитектура наиболее распространенных сегодня компь-
ютеров ориентированы на алгоритм как на некоторую последова-
тельность конструктивных действий, в связи с чем эти компьютеры
слабо приспособлены для реализации параллельных вычислений.
Технические предпосылки для создания МВС накапливались посте-
пенно. Например, идея комплексирования компьютеров через общую
память была апробирована в многомашинном комплексе «Минск-222»
в 1966 году. Внутри машин ряда 1 серии ЕС ЭВМ были заложены ос-
новы комплексирования ЭВМ. Широкие возможности комплекси-
рования ЭВМ серии ЕС представлены в машинах ряда 2 и 3.
Можно выделить три основных направления создания компьютеров
следующих поколений.
310
8.2. Отношение предшествования процессов
1. Эволюционное направление. Оно связано с совершенствованием
компьютеров и их ПО с целью развития связи с удаленными термина-
лами и выхода в сети передачи данных, расширения спектра виртуаль-
ных операционных окружений, что позволяет использовать компью-
теры в многомашинных комплексах (МК) и компьютерных сетях.
2. Создание новых структур — МВС. При этом внутреннюю систему
команд компьютеров приближают к языкам высокого уровня.
3. Разработка и создание перестраиваемых однородных МВС, пригодных
для решения задач, распараллеливаемых на уровне входных алгорит-
мов. В них, например, центральная ВС может состоять из «однород-
ного управляющего поля» и «однородного решающего поля». Каждое
поле представляет собой набор однотипных специализированных
блоков, выполненных на микроэлементной интегральной базе. Эле-
менты управляющего поля независимо занимаются обработкой ко-
манд. Блоки управляющего поля могут одновременно обрабатывать
команды различных программ, выбирая их из разных областей общей
памяти. Блок, по существу, представляет собой УУ обычного компь-
ютера, которое выбирает команду, дешифрирует ее, вычисляет ис-
полнительный адрес, выбирает операнд и т.д.
Решающее поле состоит из однотипных элементов и представляет со-
бой АЛУ, способное выполнять арифметические и логические опера-
ции над некоторыми типами данных.
8.2. Отношение предшествования процессов
В научной литературе исследуются различные подходы к выделению
и описанию параллельных процессов. В связи с этим рассмотрим
различные типы параллелизма.
О параллельном программировании упомянуто уже в 1958 году в статье
Гилла (S. Gill) «Параллельные программы». Если система имеет толь-
ко одну начальную (В) и только одну конечную (F) вершину (apex), то
отношения предшествования, которые возможны между процессами
РъРг, > Рп, показаны на рис. 8.1.
Каждый граф на рис. 8.1 описывает трассу развития процесса во вре-
мени и указывает на отношение предшествования. Такие графы на-
зывают графами развития процесса.
311
Глава 8. Последовательные и параллельные процессы
Рис. 8.1. Граф развития процесса:
а — последовательные процессы; б — параллельные процессы;
в — последовательно-параллельные процессы
Пример. Вычислить значение выражения
(a+b)(c+d)-(e/f).
Процесс вычислений (в форме дерева) представ-
лен на рис. 8.2.
Если точность вычисления значения выражения
или другие побочные эффекты не предполагают
иного порядка выполнения операций, то вычис-
ления могут производиться параллельно.
Н. Вирт (1966) предложил для описания паралле-
лизма использовать простую конструкцию and.
Тогда предложения программы для вычисления
выражения (5) рис. 8.3 могут быть следующими:
(5)
Рис. 8.2. Дерево для
выражения (5)
begin
sl: = a + b ands2: = c + d ands4: = e/f;
s3: = si • s2;
s5: = s3 - s4
end.
312
8.3. Типы параллелизма
Рис. 8.3. Граф развития про-
цесса для вычисления выра-
жения (5)
С логической точки зрения каждый
процесс имеет собственный процессор
и программу. Реально два различных
процесса могут разделять одну и ту же
программу или один и тот же процес-
сор. Например, для вышеприведенной
задачи два разных процесса использу-
ют одну и ту же программу «сложить
(+)».
Таким образом, термин «процесс» не эк-
вивалентен термину «программа».
8.3. Типы параллелизма
Говорят, что задача обладает естественным параллелизмом, если она
сводится к операциям над многомерными векторами или над матри-
цами либо над другими аналогичными объектами (например, решетча-
тыми функциями). Каждый из этих объектов может быть представлен
совокупностью чисел, над соответствующими парами которых выпол-
няются идентичные операции. Например, сложение двух векторов
состоит из сложения соответствующих компонент векторов. Ясно, что
операции могут выполняться параллельно и независимо друг от друга.
Параллелизм множества объектов представляет собой частный случай
естественного параллелизма. Задача состоит в обработке информа-
ции о различных, но однотипных объектах по одной и той же или
почти по одной и той же программе. Здесь сравнительно малый вес
занимают так называемые интегральные операции.
Например, вычисление скалярного произведения для л-мерных век-
торов
i=l
включает два типа операций: попарное произведение компонент
векторов и «интегральную операцию» (операция над л-мерным
вектором) — суммирование между собой всех компонент этого век-
тора. Исходными операндами интегральных операций являются век-
торы, или функции, или множества объектов, а результатом — число.
313
Глава 8. Последовательные и параллельные процессы
Кроме того, при параллелизме множества объектов чаще, чем в об-
щем случае, встречаются ситуации, когда отдельные участки вычис-
лений должны выполняться различно для разных объектов.
Например, требуется найти значения функции ф (х, у), удовлетво-
ряющей уравнению
дф + дф = 0
Эх Эу
во всех точках внутри некоторой области на плоскости х, у при задан-
ных значениях ф (х, у) на границах области.
При решении задачи область покрывается прямоугольной сеткой. Во
всех узлах сетки, кроме граничных, задаются некоторые значения
функции <р (начальное приближение). Для вычисления очередного
приближения функции ф для каждого узла сетки вычисляется среднее
арифметическое из тех значений функции в четырех соседних узлах,
которые она имела в предыдущем приближении. Эти вычисления
выполняются совершенно одинаково для всех узлов сетки, кроме уз-
лов, расположенных на границе области, где должны всегда сохра-
няться заданные первоначальные значения (граничные условия).
При параллелизме множества объектов аналогичное положение встре-
чается сравнительно часто.
Основной количественной характеристикой задачи, решение кото-
рой предполагается вести параллельно, является ранг задачи R — коли-
чество параметров, по которым должна вестись параллельная обработка
(например, количество компонент вектора).
Параллелизм независимых ветвей — количество независимых частей
(участков, ветвей) задачи, которые при наличии в ВС соответствую-
щих средств могут выполняться параллельно (одновременно одна
с другой).
Ветвь программы Y не зависит от ветви X, если:
► между ними нет функциональных связей, т.е. ни одна из входных
переменных ветви Уне является выходной переменной ветви А'либо
какой-нибудь ветви, зависящей от X;
► между ними нет связи по рабочим полям памяти;
► они должны выполняться по разным программам;
314
8.3. Типы параллелизма
► независимы по управлению, то есть условие выполнения ветви Y
не должно зависеть от признаков, вырабатываемых при выполнении
ветви X или ветви, от нее зависящей. ,
Параллелизм смежных операций. Суть его состоит в следующем.
Если подготовка исходных данных и условий исполнения z-й опера-
ции заканчивается при выполнении (/ - А)-й операции (где к = 2, 3,
4,...), то i-ю операцию можно совместить с (/ - к + 1)-й, (i - к + 2)-й,
..., (/-1)-й.
На рис. 8.4 продемонстрирован сценарий обработки последователь-
ных и последовательно-параллельных процессов. Из иллюстраций
видно, что языки параллельного программирования (ЯПП) должны
а
6
в
Рис. 8.4. Сценарий обработки процессов:
а — последовательный процесс; б — последовательно-параллельный
процесс; в — параллельные процессы; -» порядок выполнения программы;
... — ожидание некоторого условия; □ — отдельные фрагменты программ
315
Глава 8. Последовательные и параллельные процессы
иметь средства для явного указания моментов ветвления программ,
их объединения, ожидания выполнения некоторого условия, обмена
необходимой информацией.
Вместе с развитием теории взаимодействующих процессов просле-
живаются две концептуальные цепочки проектирования структуры
компьютера:
последователь- последователь- последовательное
задача-» ныйалгоритм ныйязык мышление
компьютер
последовательного
действия
параллельный параллельный
Задача -» F язык
нетрадиционное
мышление
компьютер
параллельного
действия
8.4. Информационные модели
В любой системе параллельной обработки процессоры, выполняю-
щие разные части одной задачи, должны некоторым образом взаимо-
действовать друг с другом, чтобы обмениваться информацией. Были
предложены и реализованы две информационные модели взаимо-
действия — мультипроцессоры и мультикомпьютеры.
8.4.1. Мультипроцессоры
Если все процессоры разделяют общую физическую память, как по-
казано на рис. 8.5, а, то такая система называется мультипроцессором
или системой с совместно используемой памятью.
Мультипроцессорная модель распространяется и на программное
обеспечение. Все процессы, вместе работающие на мультипроцессо-
ре, могут разделять одно виртуальное адресное пространство, отобра-
женное в общую память. Любой процесс может считывать слово из
памяти или записывать слово в память с помощью команд LOAD
и STORE. Больше ничего не требуется. Два процесса могут обмени-
ваться информацией, если один из них будет просто записывать дан-
ные в память, а другой считывать эти данные.
Благодаря такой возможности взаимодействия двух и более процес-
сов мультипроцессоры весьма популярны. Данная модель понятна
316
8.4. Информационные модели
программистам и приложима к широкому кругу задач. Рассмотрим
программу, которая изучает битовое отображение и составляет спи-
сок всех его объектов. Одна копия отображения хранится в памяти,
как показано на рис. 8.5, б. Каждый из 16 процессоров запускает один
процесс, которому приписана для анализа одна из 16 секций. Если
процесс обнаруживает, что один из его объектов переходит через
границу секции, этот процесс просто переходит вслед за объектом
в следующую секцию, считывая слова этой секции. В нашем при-
мере некоторые объекты обрабатываются несколькими процессами,
поэтому в конце потребуется некоторая координация, чтобы опреде-
лить количество объектов разного типа: домов, деревьев и т.д.
----используемая-----
Рис. 8.5. Совместно используемая память
В качестве примеров мультипроцессоров можно назвать Sun Enterprise
10000, Sequent NUMA-Q, SGI Origin 2000 и HP/Convex Exemplar.
Обычно выделяют три вида мультипроцессоров в зависимости от ме-
ханизма реализации памяти совместного использования. Это архи-
тектуры:
UMA (Uniform Memory Access — с однородным доступом к памяти),
NUMA (NonUniform Memory Access — с неоднородным доступом
к памяти),
СОМА (Cache Only Memory Access—с доступом только к кэш-памяти).
Первая архитектура (UMA) обеспечивает одно и то же время доступа
к слову вне зависимости от его расположения внутри модуля и рас-
317
Глава 8. Последовательные и параллельные процессы
стояния модуля от процессора. Эта архитектура с предсказуемой про-
изводительностью.
В архитектуре NUMA доступ к данным существенно зависит от расстоя-
ния процессора до модуля с необходимыми данными. Следовательно,
расположение данных существенно влияет на производительность
мультипроцессора. В обоих случаях обеспечивается единое адресное
пространство, видимое для всех процессоров, однако программы, под-
готовленные для архитектуры UMA, будут на архитектуре NUMA вы-
полняться медленнее.
Архитектура NUMA может быть как с кэш-памятью CC-NUMA (Co-
herent Cache), так и без нее — NC-NUMA (No Caching). Наличие
кэш-памяти несколько сглаживает разницу во времени доступа к ин-
формации в разных модулях. Однако, если объем кэш-памяти суще-
ственно меньше объема требуемых данных, производительность
мультипроцессора снижается.
В архитектуре СОМА память каждого процессора используется как
кэш-память. В ней все физическое адресное пространство делится на
строки, которые мигрируют по системе по мере необходимости (attrac-
tion memory). Такая организация повышает частоту обращений к кэш-па-
мяти, повышая тем самым производительность системы.
8.4.2 Мультикомпьютеры
Параллельную архитектуру, при которой каждый процессор имеет
свою собственную память, доступную только этому процессору, на-
зывают мультикомпьютером или системой с распределенной памятью
(рис. 8.6, а). Мультикомпьютеры обычно (хотя не всегда) являются
системами со слабой связью. Ключевое отличие мультикомпьютера от
мультипроцессора состоит в том, что каждый процессор в мультиком-
пьютере имеет свою собственную локальную память, к которой этот
процессор может обращаться, выполняя команды LOAD и STORE,
но никакой другой процессор не может получить доступ к этой памя-
ти с помощью таких же команд. Следовательно, мультипроцессоры
имеют одно физическое адресное пространство, разделяемое всеми про-
цессорами, а мультикомпьютеры содержат отдельное физическое адрес-
ное пространство для каждого центрального процессора.
Так как процессоры в мультикомпьютере не могут взаимодействовать
друг с другом путем чтения из общей памяти и записи в общую память,
318
8.4. Информационные модели
Рис. 8.6. Сеть с передачей сообщений
необходим другой механизм взаимодействия. Здесь процессоры посы-
лают друг другу сообщения, используя сеть межсоединений. В качестве
примеров мультикомпьютеров можно назвать IBM SP/2, Intel/Sandia
Option Red и Wisconsin COW.
При отсутствии памяти совместного использования в аппаратном
обеспечении предполагается определенная структура программного
обеспечения. В мультикомпьютере невозможно иметь одно виртуаль-
ное адресное пространство, из которого все процессы могут считывать
информацию и в которое все процессы могут записывать информацию
через команды LOAD и STORE.
Например, если процессор в верхнем левом углу на рис. 8.5, б обнару-
живает, что часть его объекта попадает в другую секцию, относящуюся
к процессору 1, то он может продолжать считывать информацию из
памяти, чтобы получить вторую часть объекта. Однако если процес-
сор 0 на рис. 8.6, б обнаруживает такую ситуацию, он не может просто
считывать информацию из памяти процессора 1. Для получения не-
обходимых данных ему, в частности, нужно определить, какой про-
цессор содержит необходимые данные, и послать этому процессору
сообщение с запросом копии данных. Затем процессор 0 блокируется
до получения ответа. Процессор 1, получив сообщение, анализирует
его и отправляет адресату необходимые данные. Процессор 0, полу-
чив ответное сообщение, разблокируется и продолжит работу.
319
Глава 8. Последовательные и параллельные процессы
В мультикомпьютере для взаимодействия между процессорами часто
используются примитивы send и receive. Поэтому программное обес-
печение мультикомпьютера имеет более сложную структуру, чем
программное обеспечение мультипроцессора. При этом основной
проблемой становится правильное разделение данных и разумное их
размещение. В мультипроцессоре размещение частей не влияет на
правильность выполнения задачи, хотя может повлиять на произво-
дительность. Таким образом, мультикомпьютер программировать го-
раздо сложнее, чем мультипроцессор.
Возникает вопрос: зачем вообще создавать мультикомпьютеры, если
мультипроцессоры гораздо проще программировать? Ответ прост:
гораздо проще и дешевле построить большой мультикомпьютер, чем
мультипроцессор с таким же количеством процессоров. Реализация
общей памяти, разделяемой несколькими сотнями процессоров, —
это весьма сложная задача, а построить мультикомпьютер, содержа-
щий 10 000 процессоров и более, сравнительно легко.
Таким образом, мультипроцессоры сложно строить, но легко про<рам-
мировать, а мультикомпьютеры легко строить, но трудно про<раммиро-
вать. Поэтому стали предприниматься попытки создания гибридных
систем, которые относительно легко конструировать и сравнительно
легко программировать. Это привело к различной реализации совме-
стной памяти. Практически все исследования в области архитектур
с параллельной обработкой направлены на создание гибридных форм,
которые сочетают в себе преимущества обеих архитектур. Здесь важ-
но получить такую систему, которая была бы расширяема (масштаби-
руема), то есть продолжала исправно и с большей эффективностью
работать при добавлении новых процессоров.
Первый подход к решению такой задачи основан на том, что совре-
менные компьютерные системы не монолитны, а состоят из ряда
уровней. Это дает возможность реализовать общую память на любом
из нескольких уровней. На рис. 8.7 приведена память совместного
использования, реализованная в аппаратном обеспечении в виде ре-
ального мультипроцессора. В данной разработке имеется одна копия
операционной системы с одним набором таблиц, в частности табли-
цей распределения памяти. Если процессу требуется больше памяти,
он прерывает работу операционной системы, которая после этого начи-
нает искать в таблице свободную страницу и отображает эту страницу
320
8.4. Информационные модели
в адресное пространство вызывающей программы. Имеется единая
память, и операционная система следит, какая страница принадле-
жит тому или иному процессу. Существует множество способов реа-
лизации совместной памяти в аппаратном обеспечении.
С1
С2
Прикладной уровень Прикладной уровень
Система поддержки исполнения программ Система поддержки исполнения программ
ос ос
Аппаратное обеспечение Аппаратное обеспечение
Реальный
мультипроцессор
Рис. 8.7. Совместно используемая память
на уровне аппаратного обеспечения
Второй подход — использовать аппаратное обеспечение мультиком-
пьютера и операционную систему, которая моделирует разделенную
память, обеспечивая единое виртуальное адресное пространство,
разбитое на страницы. При таком подходе, который называется DSM
(Distributed Shared Memory — распределенная совместно используемая
память), каждая страница расположена в одном из блоков памяти.
Каждая машина содержит свою собственную виртуальную память
и собственные таблицы страниц. Если процессор выдает команду
LOAD или STORE над страницей, которой у него нет, происходит
прерывание операционной системы. Затем операционная система
находит нужную страницу и требует, чтобы процессор, обладающий
нужной страницей, преобразовал ее в исходную форму и послал по
сети межсоединений. По достижении пункта назначения страница
отображается в память и выполнение прерванной команды возоб-
новляется. По существу, операционная система просто вызывает не-
достающие страницы не с диска, а из памяти. Но у пользователя
создается впечатление, что машина содержит общую разделенную
память.
Третий подход — реализовать общую разделенную память на уровне
программного обеспечения. При таком подходе абстракцию разде-
321
2127,2
Глава 8. Последовательные и параллельные процессы
ленной памяти создает язык программирования, и эта абстракция
реализуется компилятором. Например, модель Linda основана на аб-
стракции разделенного пространства кортежей (записей данных, со-
держащих наборы полей). Процессы любой машины могут прочитать
кортеж из общего пространства или отправить его в общее пространст-
во. Поскольку доступ к этому пространству полностью контролируется
программным обеспечением (системой Linda), никакого специаль-
ного аппаратного обеспечения или специальной операционной сис-
темы не требуется.
Другой пример памяти совместного использования, реализованной
в программном обеспечении, — модель общих объектов в системе Orca.
Язык Огса базируется на языке программирования Modula-2 с до-
бавлением объектов (аналогичных объектам языка Java) и возможно-
стью создания новых процессов. В модели Огса процессы разделяют
объекты, а не кортежи, и могут выполнять над ними те или иные про-
цедуры. Если процедура изменяет внутреннее состояние объекта, опе-
рационная система должна проследить, чтобы все копии этого объекта
на всех машинах одновременно были изменены. И поскольку объек-
ты — это чисто программное понятие, их можно реализовать с помо-
щью программного обеспечения без вмешательства операционной
системы или аппаратного обеспечения.
8.4.3. Сети межсоединений
Сети межсоединений включают, как правило, пять компонент: процес-
соры, модули памяти, интерфейсы, каналы связи, коммутаторы. Про-
цессоры и модули памяти были обсуждены ранее.
Интерфейсы — это специальные устройства, которые вводят и выво-
дят сообщения из центральных процессоров и модулей памяти. Это,
как правило, микросхема или плата, к которой для передачи сигналов
процессору и локальной памяти подсоединяется локальная шина каж-
дого процессора. Интерфейс может перемещать данные за счет считы-
вания и записи информации в различные модули памяти. Интерфейс
часто содержит программируемый процессор с собственным ПЗУ.
Каналы связи служат для передачи данных и характеризуются макси-
мальной пропускной способностью. Каналы могут передавать ин-
формацию только в одном направлении (симплексные), поочередно
322
8.4. Информационные модели
в обоих направлениях (полудуплексные) и одновременно в обоих на-
правлениях (дуплексные).
Коммутаторы — это устройства с несколькими входными и несколь-
кими выходными портами. Пакет входного порта содержит информа-
цию для определения выходного порта, куда передается пакет. Задача
коммутатора — принимать пакеты, поступающие на любой входной
порт, и отправлять пакеты из соответствующих выходных портов. Ка-
ждый выходной порт связан через последовательный или параллель-
ный канал с входным портом другого коммутатора.
С каждым узлом сети межсоединений связан определенный набор
каналов, который называют степенью узла или коэффициентом ветв-
ления. Расстояние между двумя узлами в сети — это количество дуг,
которые надо пройти, чтобы попасть из одного узла в другой. Рас-
стояние между двумя наиболее удаленными узлами называют диа-
метром сети. Он определяет максимально возможную задержку при
передаче пакетов между двумя процессорами или между процессо-
ром и памятью.
Сеть соединений иногда характеризуют по ее размерности, опреде-
ляемой количеством возможных вариантов перехода из исходного
узла в пункт назначения. Если выбора нет, то сеть нульмерная, при
двух вариантах — одномерная и т.д. Примером нульмерной сети мо-
жет служить топология «звезда» или «дерево». Примером одномер-
ной сети является топология «кольцо».
Используется несколько стратегий переключения. При стратегии ком-
мутация каналов весь путь (порты и буферы) от начального до конечного
пункта резервируется заранее, что, естественно, требует предваритель-
ного планирования.
Стратегия коммутации с промежуточным хранением основана на по-
сылке всего пакета к первому коммутатору, где он целиком хранится
в буфере и по мере возможности продвигается в пункт назначения.
В определении производительности компьютеров параллельного
действия важнейшими параметрами являются время ожидания и
пропускная способность сети межсоединений. Скорость работы
процессоров и устройств ввода/вывода та же, что и в однопроцес-
сорных машинах.
323
Глава 8. Последовательные и параллельные процессы
8.5. Программное обеспечение для мультикомпьютеров
В системах с передачей сообщений все процессы работают независи-
мо друг от друга. Так, например, если один процесс (отправитель) же-
лает послать данные другому процессу (получателю), то нет никаких
гарантий, что второй процесс готов принять эту информацию, ибо
каждый из них реализует свою программу.
Возможны три варианта передачи сообщений:
► синхронная,
► буферная,
► неблокируемая.
Синхронная передача сообщений. Если отправитель сообщения вы-
полняет операцию send, а получатель еще не выполнил операцию
receive, то сообщение копируется, а отправитель блокируется для вы-
полнения получателем примитива receive. Если к отправителю воз-
вращается управление, это означает, что сообщение было отправлено
и получено. Существенный недостаток этого варианта — отправи-
тель блокируется, пока получатель примет и подтвердит прием сооб-
щения.
Буферная передача сообщений. Если получатель занят, отправляемое
сообщение посылается в буфер, а отправитель продолжает работу.
Если операция send выполнена, отправитель может снова использо-
вать буфер сообщений. Этот вариант сокращает время ожидания, од-
нако нет гарантий получения сообщения, так как даже при самой
надежной коммуникации получатель мог оказаться неисправным еще
до отправления сообщения.
Неблокируемая передача сообщений. Если отправитель вообще не бло-
кируется после выполнения операции send, то затруднено повторное
использование буфера, ибо существует ненулевая вероятность того,
что предыдущее сообщение из буфера не отправлено. И отправитель
с помощью достаточно сложного ПО (возможно, через прерывание)
должен определить, когда же он сможет использовать буфер снова.
Среди множества популярных систем с передачей сообщений рас-
смотрим две наиболее распространенные: PVM и МР1.
324
8.5. Программное обеспечение для мультикомпьютеров
8.5.1. Система PVM
PVM (Parallel Virtual Machine — виртуальная машина параллельного
действия) — система, изначально разработанная для машин COW
и операционной системы UNIX с управлением процессами и систе-
мой ввода-вывода.
PVM включает библиотеку, вызываемую пользователем, и «дежурный»
процесс, постоянно работающий на каждой машине мультикомпью-
тера. Перед началом работы PVM с помощью конфигурационного
файла определяет собственное подмножество компьютеров, входя-
щих в виртуальный компьютер. Количество машин можно изменять,
вводя команды на консоли PVM. Командой spawn—count п prog можно
запустить л процессов.
Каждый процесс начнет выполнение своей программы. PVM опреде-
ляет размещение процессов, но пользователь имеет право вмешаться
в это планирование. Процессы могут вызываться из работающего
процесса, могут быть организованы в группы, состав которых может
динамически изменяться.
С помощью примитивов передачи сообщений могут взаимодейст-
вовать даже компьютеры с разными системами счисления. В любой
момент времени процессы PVM имеют два активных буфера: пересы-
лочный и приемный. Отправляя сообщение, процесс вызывает библио-
течные процедуры, запаковывающие значения процесса с самоопи-
санием в активный пересылочный буфер, чтобы получатель мог узнать
их и преобразовать в исходный формат. Затем отправитель вызывает
библиотечную процедуру
pvm_send,
которая представляет собой блокирующий сигнал send.
При этом отправитель, во-первых, с помощью процедуры
pvm_recv
может заблокировать получателя до прихода ожидаемого сообщения.
По возвращении вызова сообщение будет находиться в активном при-
емном буфере. С помощью распаковывающих процедур оно может
быть распаковано и преобразовано в требуемый формат.
Во-вторых, отправитель процедурой
pvmtrecv
325
Глава 8. Последовательные и параллельные процессы
блокирует получателя на определенное время, и, если подходящее
сообщение за это время не пришло, получатель разблокируется. Та-
кая процедура необходима, чтобы процесс полностью не заблокиро-
вался.
В-третьих, процедура
pvmnrecv
сразу же возвращает значение — это может быть либо сообщение,
либо указание на его отсутствие. Вызов, естественно, можно повто-
рять, чтобы опрашивать входящие сообщения.
PVM поддерживает также широковещание (процедура pvm_bcast),
посылающее сообщение всем процессам в группе, и мультивещание
(процедураpvm mcasf), отправляющее сообщение только некоторым
процессам из группы.
Синхронизация осуществляется с помощью примитива, называемого
«барьер». Если процесс вызывает процедуру pvmjbarrier, он блокиру-
ется до тех пор, пока определенное число других процессов не вызо-
вет эту процедуру. Существует и ряд других процедур управления.
PVM представляет собой достаточно простой и легкий в применении
пакет и поэтому широко используется в системах параллельного дей-
ствия.
8.5.2. MPI-интерфейс с передачей сообщений
Пакет MPI (Message—Passing Interface) значительно сложнее PVM.
Он включает существенно больше библиотечных вызовов, которые
содержат большее количество параметров.
В MPI-1 пользователь должен сам создавать процессы с помощью
локальных системных вызовов. После создания процессы объединя-
ются в группы, которые уже не изменяются. С этими группами и ра-
ботает MPI.
Базовые понятия MPI: коммуникаторы, типы передаваемых данных,
операции коммуникации и виртуальные топологии.
Коммуникатор — это ipynna процессов и контекст. Контекст представ-
ляет собой метку, идентифицирующую некоторый фрагмент процес-
са (например, фазу выполнения). При отправке и приеме сообщений
контекст используется для разделения не связанных друг с другом со-
общений.
326
8.5. Программное обеспечение для мультикомпьютеров
Сообщения могут быть разных типов — символьные, целочисленные
(short, regular и long integers), с обычной и удвоенной точностью,
с плавающей точкой и т.д.
MPI поддерживает множество операций коммуникаций. Так, для от-
правки сообщений используется операция
MPI_Send (buffer, count, data type, destination, tag, communicator).
Такой вызов отправляет содержимое буфера (buffer) с элементами оп-
ределенного типа (data type) в пункт назначения. Количество эле-
ментов буфера определяет параметр count. Поле destination — индекс
списка процессов из определенной группы, tog помечает сообщение,
communicator показывает, к какой группе процессов принадлежит це-
левой процесс.
Соответствующий вызов для получения сообщения
MPI Recv(&buffer, count, data type, source, tag, communicator, &status)
определяет поиск получателем сообщения определенного типа из за-
данного источника с требуемым тегом.
МРТ поддерживает четыре основных типа коммуникации. Первый —
синхронная коммуникация, при которой отправитель не может начать
передачу данных, пока получатель не вызовет процедуру MPI Recv.
Второй — коммуникация с использованием буфера. Здесь ограничения
синхронного типа не действуют. Третий тип — стандартная комму-
никация. В зависимости от реализации такая коммуникация бывает
синхронной либо с буфером. В четвертом типе отправитель требует,
чтобы получатель был доступен, но без проверки. Каждый из этих
примитивов бывает блокирующим и неблокирующим.
MPI поддерживает коллективную коммуникацию — широковещание,
распределение и сбор данных, обмен данными, агрегацию и барьер. При
любой форме коллективной коммуникации все процессы в группе
должны делать вызов с совместимыми параметрами. Если, например,
процессы организованы в виде дерева, где значения передаются от
листьев к корню, подчиняясь определенной обработке на каждом
шаге, то это — типичная форма коллективной коммуникации.
Виртуальная топология — основное понятие, поясняющее организа-
цию процессов (дерево, кольцо, решетка, тор и т.д.), что, собственно,
и определяет способ наименования каналов связи.
327
Глава 8. Последовательные и параллельные процессы
В MPI-2 добавлены динамические процессы, доступ к удаленной
памяти, неблокирующая коллективная коммуникация, расширяемая
поддержка процессов ввода—вывода, обработка в режиме реального
времени и т.д.
Одной из причин появления систем с передачей сообщений PVM
и МР1 является отсутствие в архитектуре мультикомпьютеров совме-
стно используемой памяти. Правда, существуют возможности ввести
в модель программирования на мультикомпьютерах совместно ис-
пользуемую память при ее реальном (аппаратном) отсутствии. По-
добная иллюзия упрощает процесс программирования.
8.6. Повышение эффективности
функционирования компьютеров
Как было отмечено выше, общие подходы к повышению произво-
дительности вычислительной техники развиваются в двух основных
направлениях — увеличение быстродействия элементной базы и раз-
витие существующих и создание новых архитектур вычислительных
систем.
Первый подход ограничен параметрами физических элементов, связан-
ных со скоростью распространения сигнала по физическим линиям
связи, в частности скорость коммутации нельзя увеличивать безгра-
нично. Главная проблема — скорость света, ибо заставить протоны и
электроны перемещаться быстрее невозможно. Кроме того, из-за вы-
сокой теплоотдачи появляется проблема охлаждения кристалла.
Другой путь требует тщательного исследования механизма взаимо-
действия процессов в системах параллельного действия (СПД), в том
числе и в однопроцессорных системах при мультиобработке, и на ос-
нове такого исследования — дальнейшего совершенствования логики
вычислений, включая методы параллельной обработки информации.
СПД со даются путем объединения отдельных компонент (модулей)
в единую обрабатывающую среду. В качестве компонент такой среды
могут выступать вычислительные сети, отдельные компьютеры, про-
цессоры общего и специального назначения, транспьютеры и т.д.
Одной из разновидностей высокопроизводительных вычислительных
систем (ВС) являются однородные ВС, где в качестве функциональных
модулей исполь уются блоки, имеющие архитектуру компьютера.
328
8.6. Повышение эффективности функционирования компьютеров
Длительное время проектировщиками таких систем для достижения
сколь угодно большой производительности, гибкости в управлении,
надежности и высокой технологичности изготовления использовали
заложенные в их основу принципы:
► параллельность выполнения большого количества операций,
► автоматическая настраиваемость структуры на решаемую задачу,
► конструктивная однородность.
В настоящее время стало ясно, что разумной альтернативой систем
с последовательной обработкой данных является создание архитек-
тур, базирующихся на алгоритмах параллельной обработки данных
на многих процессорах.
8.6.1. Эффективность вычислений
Увеличение количества процессоров должно осуществляться таким
образом, чтобы система была расширяема (масштабируема), то есть
добавление процессоров должно приводить к увеличению произво-
дительности системы.
Пусть имеется четыре процессора, соединенных шиной (рис. 8.8, а).
Если Р бит/с — пропускная способность шины, то пропускная спо-
собность каждого процессора составит Р/4 бит/с. При увеличении
количества процессоров до 16 (рис. 8.8, б), пропускная способность
каждого из них уменьшится до Р/16 бит/с. Такая система не будет
расширяемой.
Процессоры
а
жж
б
Рис. 8.8. Топология соединения: а, б — шиной; в, г — решеткой
При тех же действиях с топологией типа решетка (рис. 8.8, в, г) соотно-
шение числа каналов к количеству процессоров будет соответственно
1,0 (4 процессора и 4 канала) и 1,5 (16 процессоров и 24 канала). Таким
329
Глава 8. Последовательные и параллельные процессы
образом, с увеличением количества процессоров интегральная про-
пускная способность на каждый процессор возрастает.
Если исследовать диаметр сети или время ожидания при отсутствии
трафика, то в случае топологии «шина» эти параметры не изменяются,
а в случае «решетки» размера их л ее диаметр равен 2(л - 1). Поэтому
максимальное время ожидания возрастает примерно пропорцио-
нально квадратному корню от числа процессоров. Отсюда следует,
что увеличение количества процессоров в 4 раза влечет за собой уве-
личение времени ожидания приблизительно в 2 раза.
В предельном случае желательно, чтобы с увеличением количества
процессоров среднее время ожидания было постоянным и средняя
пропускная способность на каждый процессор также была постоян-
ной. Рост среднего времени ожидания и в мультипроцессорных,
и в мультикомпьютерных системах при увеличении количества ком-
понент может оказаться критическим параметром для производи-
тельности системы.
Для уменьшения времени ожидания или, по крайней мере, сокрытия
этого факта применяют ряд технологий. Первая — копирование данных.
Чем больше мест для хранения копий данных, тем быстрее в среднем
будет доступ к данным от процессоров. Одна из возможностей реали-
зации такой технологии — кэш-память, другая — хранение нескольких
копий с разным статусом, причем в этом случае требуется определить
источник, время и место размещения этих копий. Здесь возможен
как вариант статического — предварительного размещения данных во
время загрузки, так и динамического — по требованию аппаратного
или программного обеспечения.
Вторая технология — упреждающая выборка, при которой данные вы-
бираются до момента их востребованности, что позволяет перекрыть
операции выборки и обработки. Упреждающая выборка может быть
как автоматической (на всякий случай подкачать данные в кэш), так и
управляемой, при которой компилятор заранее генерирует команду
подкачки данных, чтобы последние были доступны в нужный мо-
мент. Такие команды работают наиболее эффективно, если эти дан-
ные наверняка понадобятся.
Третья технология — многопоточная обработка. Идея этой техноло-
гии — возможность быстрого переключения процессора с обработки
процесса, для которого еще нет данных, из одного потока процессов,
330 ’
8.6. Повышение эффективности функционирования компьютеров
на активный процесс из другого потока процессов. Таким образом,
процессор всегда будет занят даже при длительном времени ожида-
ния в отдельных потоках. Некоторые компьютеры (например, CDC
6600) автоматически переключались от одного процесса к другому
после выполнения каждой команды, чтобы сделать незаметным дли-
тельное время ожидания.
Четвертая технология — неблокирующие записи. Как правило, про-
цессор ждет, пока команда STORE не закончится. При использова-
нии неблокирующих записей программа продолжает свою работу,
невзирая на начало операции записи в память. Если выполняется ко-
манда LOAD, то продолжить программу сложнее, но и это возможно
осуществить, если использовать выполнение с изменением последо-
вательности команд или процессов.
8.6.2. Основные подходы к проектированию программного
обеспечения для параллельных компьютеров
При проектировании компьютеров с параллельной архитектурой не-
обходимо учитывать особенности ПО. Рассмотрим несколько подхо-
дов к созданию ПО для параллельных компьютеров.
Первый подход — создание специальных библиотек для параллельной
обработки задач, хорошо поддающихся распараллеливанию, например
обработка матриц, решение систем линейных алгебрических уравне-
ний и т.д. Такие параллельные процедуры могут быть вызваны из
последовательной программы по мере необходимости, помимо тре-
бований программиста. Недостаток такого подхода в том, что только
незначительная часть программы будет исполняться параллельно.
Второй подход — создание библиотек, содержащих примитивы комму-
никации и управления. Здесь программист сам создает сценарий парал-
лельного исполнения программы и управляет им, применяя допол-
нительные примитивы.
Третий подход — дополнение последовательного языка программиро-
вания специальными конструкциями, порождающими параллельные
процессы, позволяющие одновременно обрабатывать тела циклов,
компоненты векторов, строки или столбцы матриц и т.д. Такой под-
ход получил сегодня широкое распространение.
Четвертый подход — разработка специального нового языка параллель-
ного программирования (ЯПП). Среди ЯПП известны императивные
331
Глава 8. Последовательные и параллельные процессы
(их команды изменяют переменные состояния), функциональные, ло-
гические и объектно-ориентированные языки. Такие языки позволяют
проектировать эффективные параллельные программы. Недостаток
подхода — требуется изучение языка программирования.
Все указанные подходы могут применяться на различных вычисли-
тельных установках. Рассмотрим основные позиции, которые фор-
мируют базис ПО для СПД, а именно модели управления, степень
распараллеливания процессов, вычислительные парадигмы, методы
коммутации, базовые элементы синхронизации.
8.6.3. Модели управления
Предположим, что имеется одна программа, один счетчик команд и не-
сколько обработчиков (исполнителей команды), при этом каждый
выполняет одну и ту же операцию одновременно, но над своими дан-
ными.
Например, пусть необходимо вычислить среднее значение цены на
нефть за сутки в разных торговых точках.
С помощью команды
LOAD THE OIL PRICE FOR 1 A.M. INTO REGISTER Rl
в регистр Л1 загружается цена нефти в 1 час дня, причем каждый
процессор выполняет эту команду, используя свои данные и свой
регистр /?1.
Затем командой
ADD THE OIL PRICE FOR 2 A.M. TO REGISTER Rl
каждый процессор будет выполнять эту команду над собственными
данными, учитывая цену на нефть в своих точках уже в 2 часа дня.
В конце вычислений каждый процессор вычисляет среднее значение
цены на нефть для своей точки.
Такая модель управления позволяет иметь в качестве обработчиков
АЛУ с памятью, без схем дешифрации команд. Один центральный
процессор вызывает команды, дешифрирует их и дает указание всем
АЛУ, что им делать.
Альтернативная модель предполагает несколько потоков управления,
каждый из которых имеет собственный счетчик команд, дешифраторы,
332
8.6. Повышение эффективности функционирования компьютеров
регистры. Каждый поток управления выполняет свою собственную
программу над своими данными.
Еще один вариант в дополнение к предыдущей модели может преду-
сматривать периодическое взаимодействие между различными пото-
ками управления.
8.6.4. Степень распараллеливания процессов
На самом низком уровне распараллеливание процессов может осу-
ществляться на уровне команд, то есть распараллеливается выполне-
ние отдельных микроопераций (например, в архитектуре 1А-64). Про-
граммист об этом уровне не подозревает, так как распараллеливание
происходит на уровне аппаратного или программного обеспечения.
Следующий уровень — параллелизм на уровне блоков, где програм-
мист управляет последовательностью выполнения вычислений. Со-
временные ЯПП позволяют с помощью операторных скобок begin/end
или посредством других разделителей описывать параллельные и по-
следовательные блоки для исполнения.
Очередной уровень — крупные структурные единицы. В этом случае
вызывающая программа может не ждать завершения вызванной про-
цедуры и выполняться с ней одновременно. Если вызывающая про-
грамма работает в цикле, каждое прохождение которого требует вызова
данной процедуры, не ожидая ее завершения, то очень большое ко-
личество параллельных процедур будет выполняться параллельно.
Совсем иная форма параллелизма состоит в том, что для каждого про-
цесса порождается несколько потоков, причем все они работают в пре-
делах адресного пространства этого процесса. Каждый поток имеет
свой счетчик команд, регистры, стек, но разделяет все остальное ад-
ресное пространство процесса со всеми потоками. Потоки обрабаты-
ваются независимо и, как правило, на разных процессорах. В одних
системах ОС планирует потоки, в других — каждый пользователь-
ский процесс сам осуществляет планирование потоков и управляет
ими, а ОС об их существовании ничего не известно.
Наконец, параллелизм на уровне крупных подзадач, которые вместе
работают над одной задачей. В отличие от потоков подзадачи не раз-
деляют общее адресное пространство.
333
Глава 8. Последовательные и параллельные процессы
8.7. Вычислительные парадигмы
Существует ряд вычислительных парадигм для структуризации рабо-
ты большого количества потоков или независимых процессов. Рас-
смотрим наиболее употребительные из них.
Первая парадигма — SPMD (Single Program Multiple Data) — одна про-
грамма, несколько потоков данных. В данном случае все процессы вы-
полняют одну и ту же программу, но над разными наборами данных,
то есть производят одни и те же вычисления, но каждый в своем ад-
ресном пространстве.
Вторая парадигма — конвейер (рис. 8.9, а). Данные поступают в пер-
вый процесс, трансформируются и передаются второму процессу для
в
Рис. 8.9. Вычислительные парадигмы
334
8.8. Методы коммуникации
чтения, и т.д. Если поток данных имеет большой объем (например
обработка изображений), все процессоры конвейера могут функцио-
нировать одновременно. Таким образом организован конвейер в UNIX.
Третья парадигма — фазированные вычисления (рис. 8.9, б). В этом
случае выполняемая работа разделяется на фазы, в качестве которых,
например, могут выступать повторения цикла. На каждой фазе одно-
временно работают несколько процессов, но каждый из них ожидает
завершения остальных процессов фазы, после чего начинается новая
фаза.
Четвертая парадигма — разделяй и властвуй (рис. 8.9, в), где каждый
начавшийся процесс порождает новые процессы, которым он пере-
дает часть работы. Причем порожденные процессы могут в свою оче-
редь породить ряд новых процессов с передачей им части работы.
Пятая парадигма — порождающая работа (replicated worker) (рис. 8.9, г).
Организуется центральная очередь, рабочие процессы получают за-
дачи из этой очереди и выполняют их. Если задача порождает новые
задачи, они добавляются в центральную очередь. Завершая выполне-
ние текущей задачи, рабочий процесс получает из центральной оче-
реди следующую задачу.
8.8. Методы коммуникации
Процессы, выполняющиеся на различных устройствах, могут взаи-
модействовать с помощью либо общих переменных, либо передачи со-
общений.
В первом случае взаимодействующие процессы имеют доступ к общей
памяти и взаимодействуют, считывая и записывая информацию в эту
память. Один процесс, например, может записывать информацию
в ячейку памяти, а второй — считывать эту информацию. Отображая
одну и ту же страницу в адресное пространство каждого процесса
в мультипроцессоре, разделяют переменные между несколькими про-
цессами. Затем общие переменные считываются и записываются
с помощью обычных команд LOAD и STORE.
Альтернативный подход — взаимодействие через передачу сообщений
посредством использования примитивов send и receive. Они реализу-
ются как системные вызовы. Один процесс отправляет сообщение,
335
Глава 8. Последовательные и параллельные процессы
обозначая другой процесс в качестве пункта назначения. Как только
второй процесс применяет примитив receive, сообщение копируется
в адресное пространство получателя. Таким способом взаимодейст-
вуют процессы в мультикомпьютере, так как они не получают досту-
па к памяти других процессоров с помощью команд LOAD и STORE.
Эти различия полностью меняют модель программирования.
Каждый узел в мульти компьютере состоит из одного или нескольких
процессоров, общего для данного узла ОЗУ, диска и/или других уст-
ройств ввода-вывода, а также процессора передачи данных (ППД).
ППД разных узлов связаны между собой по высокоскоростной ком-
муникационной сети. Все мультикомпьютеры при передаче сообще-
ний действуют одинаково: когда программа выполняет примитив send,
ППД получает уведомление и передает блок данных в целевую маши-
ну (возможно, после предварительного запроса и получения разре-
шения). Схема мульти компьютера дана на рис. 8.10.
Рис. 8.10. Схема мультикомпьютера
Можно обозначить два типа мультикомпьютеров: МРР (Massively
Parallel Processors) — процессоры с массовым параллелизмом и COW
(Cluster of Workstations) — кластер рабочих станций или NOW (Network
of Workstations) — сеть рабочих станций.
МРР — огромные суперкомпьютеры, используемые для выполнения
сложных вычислений, обработки большого числа транзакций в еди-
ницу времени или для хранения больших баз данных и управления ими,
например семейство СгауТЗЕ, Option Red, Option Blue, Option White.
COW — это сотни персональных компьютеров или рабочих станций,
соединенных через сетевые платы, например DAS (Distributed ASCII
Supercomputer).
Очень важный вопрос при передаче сообщений — количество полу-
чателей. Простейший случай «один отправитель — один получатель»
336
8.9. Алгоритмы выбора маршрутов для доставки сообщений
называют двухточечной передачей сообщений. Отправление сообще-
ния всем процессам — широковещательная передача, а в случае задан-
ного (фиксированного) набора процессов — мультивещание.
8.9. Алгоритмы выбора маршрутов
для доставки сообщений
В сетях межсоединений всегда осуществляется выбор пути передачи
пакета от одного узла к другому. Выбор одной последовательности уз-
лов среди множества возможных для прохождения пакета от исход-
ного пункта к пункту назначения называют алгоритмом выбора пути.
Алгоритмы должны способствовать равномерному распределению
нагрузки по каналам связи, чтобы максимально использовать пропу-
скную способность каналов, избегая при этом ситуации взаимобло-
кировки.
Обычно алгоритмы делят на два класса: маршрутизация от источника
и распределенная маршрутизация.
В первом случае весь путь по сети формируетсяаранее, то есть источ-
ник определяет список номеров портов, которые надо будет прохо-
дить на всем пути к пункту назначения. Если путь проходит через п
коммутаторов, то первые п байтов в каждом пакете будут содержать п
номеров выходных портов. Доходя до /-го коммутатора, 7-й байт оп-
ределяет номер 7-го выходного порта. Часть пакета, за вычетом пер-
вых 7 байт, направляется в соответствующий порт. Таким образом,
содержимое первого байта пакета всегда определяет номер следую-
щего порта.
При распределенной маршрутизации каждый коммутатор определяет
порт назначения для пришедшего пакета. Если по заданному пункту
назначения коммутатор задает один и тот же выходной порт, то мар-
шрутизацию называют статической. Если при принятии решения
коммутатор учитывает текущий трафик, то маршрутизацию называ-
ют адаптивной.
В случае межсоединений типа «прямоугольная решетка» произволь-
ного размера, где никогда не возникают тупиковые ситуации, исполь-
зуется пространственная маршрутизация. Согласно этому алгоритму
пакет вначале перемещается по оси х до нужной координаты, затем
337
222792
Глава 8. Последовательные и параллельные процессы
вдоль оси у до требуемой координаты и так далее до последней коор-
динаты (точки назначения). Например, если надо перейти из точки
с координатами (2,6, 7) в точку (5, 8, 9), то по точкам (3,6, 7), (4,6, 7)
осуществляется переход в точку (5,6,7). Затем через (5,7, 7) — в (5,8, 7)
и, наконец, через (5, 8, 8) — в точку (5, 8, 9). Такой алгоритм предот-
вращает тупиковые ситуации.
8.10. Метрика аппаратного и программного обеспечения
Проектирование СПД ставит целью достичь максимального быстро-
действия при минимальных затратах. Рассмотрим вопросы произво-
дительности, связанные с проектированием архитектур СПД.
Основными параметрами аппаратного обеспечения метрики СПД явля-
ются параметры функционирования системы межсоединений — вре-
мя ожидания и пропускная способность.
Полное время ожидания состоит из времени на отправку пакета и вре-
мени получения ответа. При посылке пакета в память — это время
чтения и записи в память, при пересылке «процессор-процессор» —
это время процессорной связи для пакетов минимального размера
(как правило, одного слова).
При коммутации каналов время ожидания состоит из времени уста-
новки и времени передачи. Для установки схемы передачи следует
выслать пробный пакет с целью резервирования требуемых ресурсов
и передачи подтверждения. Затем готовый пакет может быть передан
достаточно быстро. Если общее время установки Ти, объем пакета р
бит, а пропускная способность b бит/с, то время ожидания в одну сто-
рону будет Ти + р/b. При дуплексной схеме минимальное время ожи-
дания для передачи пакета объемом р бит и получения ответа при
такой же пропускной способности составит 7^ + 2 р/b секунд.
Пакетная коммутация не требует посылки пробного пакета в пункт
назначения, но для нее необходимо некоторое время Тк на коммутацию
пакета. Тогда время передачи пакета в одну сторону будет Тк + р/Ь,
причем за это время пакет дойдет только до первого коммутатора,
проход через который потребует задержки Td, после чего пакет пере-
ходит в очередной коммутатор. Td включает время обработки пакета
и время освобождения выходного порта. Если коммутаторов п, то об-
338
8.10. Метрика аппаратного и программного обеспечения
щее время ожидания в одну сторону будет Тк + п (p/b + Td) + p/b, при
этом последнее слагаемое с тражает время копирования пакета из по-
следнего коммутатора в пункт назначения.
В случае коммутации без буферизации пакетов «wormhole routing» (чер-
воточина) время передачи пакета в наилучшем случае будет прибли-
жаться к Тк+р/b, ибо здесь отсутствует как посылка пробных пакетов
для установки схемы, так и задержка промежуточного хранения. За-
держкой на распространение сигнала можно пренебречь, поскольку
она незначительна.
Очень важное значение имеет возможность быстрой передачи боль-
ших объемов информации. Это свойство отражает суммарная про-
пускная способность, определяемая суммированием пропускной
способности всех каналов связи. Естественно, должна быть полная
согласованность между пропускной способностью отдельного про-
цессора и суммарной пропускной способностью каналов, иначе воз-
можна задержка.
На практике достичь теоретически возможной пропускной способ-
ности сложно, так как пакет содержит много служебных сигналов
и информацию о компоновке, построении заголовка, отправке. При
посылке большого числа малообъемных пакетов невозможно дос-
тичь той же пропускной способности, что и равного по суммарному
объему, но малого количества пакетов. С другой стороны, пакеты
большого объема на длительное время занимают каналы связи, что
увеличивает время ожидания. В результате возникает конфликтная
ситуация между суммарной пропускной способностью и временем
ожидания, для разрешения которой требуется принимать компро-
миссное решение. Теоретически лучше вначале обеспечить мини-
мальное время ожидания, а затем достичь необходимой пропускной
способности с помощью дополнительного оборудования.
В отношении программного обеспечения можно сказать, что пользова-
телей параллельных компьютеров естественно интересует вопрос: на-
сколько быстрее будут работать их программы на СПД по сравнению
с однопроцессорным компьютером. Литературные источники утвер-
ждают, что л-кратного увеличения быстродействия нельзя достичь на
СПД с л процессорами.
Наибольшее ускорение возможно при решении TV-объектных задач.
Например, задачу инвертирования матриц нельзя ускорить более чем
339
Глава 8. Последовательные и параллельные процессы
в пять раз вне зависимости от числа процессоров. И для этого имеет-
ся ряд причин.
Во-первых, все программы содержат последовательную часть — счи-
тывание данных, инициализация, интегрирование результата Пусть
линейная часть программы есть/, тогда параллельная будет 1—/. Если
на однопроцессорном компьютере время решения задачи Т, то общее
время решения задачи не может быть лучше fT + (1 — У) Т/п. Только
при f= 0 возможно линейное ускорение. Это явление называют зако-
ном Амдала. Во-вторых, невозможность линейного ускорения связана
со временем ожидания в коммуникациях, в-третьих, оказывает влияние
ограниченная пропускная способность, в-четвертых — неэффектив-
ные алгоритмы, в-пятых — непроизводительные задержки для запуска
большого количества процессоров.
Для достижения высокой (требуемой) производительности можно про-
сто увеличивать количество процессоров даже при их неэффектив-
ном использовании. Если увеличение количества процессоров ведет
к повышению производительности системы, то систему называют
расширяемой.
8.11. Классификация компьютеров
Разумной альтернативой последовательной обработки является соз-
дание архитектур, базирующихся на параллельной обработке алго-
ритма и распределенности данных по многим процессорам.
В настоящее время существует классификация многопроцессорных си-
стем по Флинну, базирующаяся на порядке поступления потоков ко-
манд и данных на обработку. Их структуры образуют следующие четыре
класса:
► одиночный поток команд — одиночный поток данных (SISD). Сюда
относятся типичные машины последовательного действия;
► одиночный поток команд — множественный поток данных (SIMD).
Это матричные и ассоциативные структуры;
► множественный поток команд — одиночный поток данных (MISD).
В данный класс включаются конвейерные или магистральные струк-
туры;
340
8.11. Классификация компьютеров
► множественный поток команд — множественный поток данных
(MIMD). К этому классу принадлежат структуры, содержащие не-
сколько процессоров, одновременно выполняющих различные фраг-
менты одной и той же программы.
Классификация Флинна, как видно из приведенного, базируется лишь
на множестве потоков команд и данных для обработки и не является
классификацией внутренней организации (архитектуры) компьюте-
ра. В отличие от Флинна систематика Шора основана на формирова-
нии компьютера из различных компонент. Выделяется шесть типов
компьютеров со сквозной нумерацией.
Ml — одно устройство управления (УУ), обработчик (УО), память
команд (ПК) и память данных (ПД). Устройство обработки может со-
держать множество функциональных устройств как векторного, так
и скалярного типа. В связи с этим к классу М1 относят конвейерную
векторную (CRAY-1) и конвейерную скалярную (CDC 7600) вычис-
лительные системы.
М2 — здесь чтение разрядов данных из ПД осуществляется (в отли-
чие от Ml) из одноименных разрядов всех слов памяти. Примером
могут служить системы DAP и STARAN.
М3 — считывание и обработка данных осуществляется в двух измере-
ниях: по вертикальным и горизонтальным срезам памяти. Примером
может служить ортогональная машина Шумана и OMEN-60.
М4 — включает многократно дублирующие ПД и УО, образующие
процессорные элементы (ПЭ), а команды для исполнения поступают
из единственного УУ. Примером этого класса может служить система
РЕРЕ без связи между отдельными ПЭ.
М5 — это тип М4 со связями между каждым ПЭ и его ближайшим со-
седом. К этому классу относится система ILLIAC IV.
Мб — этот тип представляет собой матрицу с функциональной логи-
кой. Сюда можно отнести различные ассоциативные ансамбли запо-
минающих устройств и процессоров.
Создание многопроцессорных систем, промышленный выпуск транс-
пьютеров позволяют формировать единые среды, разрешающие про-
блему параллельной обработки информации для массового пользо-
вателя.
341
Глава 8. Последовательные и параллельные процессы
Опыт разработки и исследования конвейерной архитектуры от ЭВМ
Star 100, IBM 360/91, Cyber 205 до ETA Systems, Cray Research и ряда
других показывает многообразие структурных решений, способствую-
щих значительному увеличению максимальной производительности.
Однако существенное увеличение быстродействия на конвейерных
ВС может быть достигнуто лишь для задач, векторизуемых более чем
на 90 %. Векторизация в реальных задачах не превышает 70 %. Выход
из этой ситуации, как правило, отыскивается в двух направлениях.
С одной стороны, акцентируется внимание на повышении мощности
скалярных вычислений в векторных ВС. Здесь показательны, напри-
мер, разработки фирмы Cray Research. Так, если первые ее модели
Cray Х-НР, Сгау-2 имели до четырех процессоров, то Сгау-3 содержа-
ла 16 процессоров, а Сгау-4 — уже 64.
Интерес представляет суперкомпьютер Cray ТЗЕ/1200 — масштаби-
руемая массово-параллельная система, состоящая из отдельных про-
цессорных элементов (ПЭ). Производит его компания Cray Research,
подразделение Silicon Graphics. В нем используются процессоры
DECchip (DEC Alpha EV5) с тактовой частотой 600 МГц и пиковой
производительностью 1200 Мфлопс. Системы ТЗЕ масштабируются
до нескольких тысяч процессоров. Каждый процессорный элемент
располагает своей памятью (DRAM) объемом от 256 Мбайт до 2 Гбайт.
При этом память системы глобально адресуема. Процессорные эле-
менты связаны высокопроизводительной сетью с топологией трехмер-
ного тора и двунаправленными каналами. Скорость обмена достигает
480 Мбайт/с в каждом направлении. Поддерживается явное парал-
лельное программирование через пакет Cray Message Passing Toolkit
(MPT), включающий высокопроизводительные реализации интер-
фейсов MPI и PVM, атакже библиотеку Shmem компании Cray Research
для работы параллельных процессов над общей памятью. Для Фор-
тран-программ возможно неявное распараллеливание в моделях CRAFT
и НРЕ Среда разработки также вклю ает набор визуальных средств
анализа и отладки параллельных программ. Компьютер работает под
управлением операционной системы UNICOS/mk.
С другой стороны, ведутся альтернативные разработки конвейерной
архитектуры, так называемое микромультипрограммирование. Пред-
ложена альтернативная теория конвейеризации Context Flow, где вы-
числения рассматриваются как набор логических преобразований на
342
8.11. Классификация компьютеров
контекстах процессов. Этот подход дает лучшее соотношение произ-
водительность-стоимость, чем обычные конвейеры.
При разработке параллельных компьютеров существенную трудность
представляет решение задачи разбиения алгоритмов на значительные
по объ му вычислений фрагменты, которые были бы информационно
независимы. Большое затруднение при этом вызывают условные пере-
ходы, встречающиеся в среднем через каждые 8—10 команд. Решением
проблемы условных переходов стал компилятор планирования трас-
сы Trace Scheduling (фирма Multiflow Computer), который позволяет
прогнозировать направление переходов в программах для решения
инженерно-технических задач на основе статистического анализа.
Производство ВС стимулировало создание теории параллельных вы-
числений и разработку параллельных алгоритмов решения задач. Тео-
рия параллельных вычислений позволяет оценить предельные возмож-
ности ВС и разработать методы адаптации параллельных алгоритмов
на конкретные архитектуры параллельных компьютеров.
В последние годы интерес к параллельным вычислениям концентри-
руется на осмыслении общих закономерностей разработки парал-
лельных алгоритмов.
Работы в указанной области условно можно разбить на три основных
направления.
1. Разработка моделей параллельных вычислений и установление соот-
ношений между ними, определение класса задач, допускающих
эффективное распараллеливание (класс NC), и класса задач, наи-
более трудных для распараллеливания (P-полных задач).
2. Разработка общих методов построения параллельных алгоритмов
и распараллеливание последовательных алгоритмов. Исследова-
ние сложности параллельных алгоритмов в различных областях
применений.
3. Создание методов и средств отображения параллельных алгоритмов
на реальные параллельные архитектуры.
Интуитивное представление о параллельных вычислениях имеет много
формализаций, которые реализуются в различных моделях параллель-
ных вычислений. Среди них:
► параллельная машина с произвольным доступом к памяти;
► машины Тьюринга;
343
Глава 8. Последовательные и параллельные процессы
► машины с управлением потоком данных (data flow);
► модели, базирующиеся на сетях Петри и схемах синхронизации,
И Т.Д.
Благодаря абстрагированию от многих специфических особенностей
параллельных архитектур предлагаемые модели позволяют сравни-
тельно просто реализовать параллельные алгоритмы.
Исследуются вопросы сложности моделирования одних типов моде-
лей на других моделях и вычислительные возможности моделей в за-
висимости от вводимых ограничений на разрешение конфликта по
одновременной записи и чтению. Известны исследования о вычис-
лительной мощности различных моделей при ограничении на размер
используемой памяти и количество процессоров.
В теории параллельных вычислений имеется ряд нерешенных про-
блем. Основная из них — это проблема эффективного распараллели-
вания алгоритмов. Она формулируется как соотношение классов NC
и Р. Это вопрос такой же важности, как соотношение классов Р и NP
в теории сложности вычислений, и очень далек от своего решения,
ибо предполагает получение сверхполилогарифмических оценок па-
раллельной сложности решения некоторых задач из класса Р.
К конкретным задачам, для которых неизвестна их принадлежность
ни к NC, ни к P-классу, относится, например, задача возведения це-
лого в степень: для заданных л-битовых чисел а, b и т вычислить о*
mod т.
8.12. Некоторые модели параллельных программ
Развитие точных методов в программировании привело к возникно-
вению различных формальных моделей программ, в том числе и мо-
делей параллельных программ.
Рассмотрим модели параллельных программ, прототипом которых
явились операторные схемы программ, в частности схемы Янова.
В.Е. Котовым и А.С. Нариньяни была предложена формальная мо-
дель параллельных вычислений, названная асинхронной моделью.
Асинхронная программа над памятью М (Л-программа) представля-
ет собой множество X блоков и массивов блоков. Блок х образован
344
8.12. Некоторые модели параллельных программ
парой (у, О), где у — предикат над Мс с: М, Мс — управляющая па-
мять, О — оператор над памятью М. С О-оператором связаны входные
и выходные наборы переменных из М. По входному набору О-опера-
тор вычисляет значение переменных выходного набора. Предикату —
спусковая функция блока х.
Кроме асинхронной программы, в понятие асинхронной модели вхо-
дит и асинхронная система. Асинхронная система представляет собой
совокупность правил, позволяющих для заданной асинхронной про-
граммы X и заданного начального значения памяти М осуществить
некоторый процесс вычислений.
Чтобы получить более формальное определение пары «программа — си-
стема», вводится конструкция метасистемы, которая сопоставляет каж-
дому начальному состоянию памяти некоторое множество вычисли-
тельных процессов. Приведем некоторые понятия и обозначения.
Пусть А — множество операторов над памятью М.
Для каждого момента t множество операторов вычислительного про-
цесса можно разбить на 4 непересекающихся множества:
+А, — включающиеся в t;
~At — выключающиеся из г;
pAt — находящиеся во включенном состоянии;
°А, — находящиеся в выключенном состоянии.
Q = {#} — множество состояний метасистемы, q0 — начальное состоя-
ние.
F— функция, однозначно сопоставляющая каждому множеству /Те А
одно из его подмножеств в соответствии с состоянием q.
V — функция, ставящая в соответствие каждому набору (Л/0,Р|| ,)
некоторое состояние q (Р|| , — предыстория процесса Рао момента t
включительно).
Каждому оператору а, е А сопоставляется счетчик с, с начальным
значением 0. Текущее значение счетчика с, фиксирует разность между
числом имевших место включений и числом имевших место выклю-
чений оператора а,-.
345
Глава 8. Последовательные и параллельные процессы
Тогда модель Котова — Нариньяни можно записать в виде рекурсив-
ных соотношений:
А = A- i\+A-1 А- ь
’А = Fi(°A, 0,);
+А с*А;
pAl=pAl.l\~Al_lu+At;
"А с %.
В основу модели Карпа—Миллера положено представление програм-
мы как множества элементарных операторов, использующих ячейки
памяти и воздействующих на них. Для операторов указаны правила
включения и выключения. Формально параллельная схема програм-
мы R = (М, А, Г) определяется следующим образом.
1. М — множество ячеек памяти.
2. А = {а, Ь,...} — конечное множество операторов; для каждого опе-
ратора из А заданы:
К(а) — количество символов выключения оператора а (целое поло-
жительное число);
Д(а)< М — множество входных ячеек оператора а;
Т(а) < М — множество выходных ячеек оператора а.
3. Четверка Г= {a, q0, Е, т) — управление схемы, где q0 — выделенное
начальное состояние.
При этом каждому оператору а сопоставлены один символ включе-
ния а и множество символов выключения {а(,..., а^а)}; £= Х ’
где Е= U{«} X,=U
СЕ/I CEj4
1 — функция переходов - частичная функция из Q - Е в Q, всюду оп-
ределенная на Q Е,.
Управление Сформирует последовательность выполнения операторов.
Элементы из Е,- обозначают акты включения операторов, элементы из
Е, — акты выключения. Включение оператора а допустимо лишь в та-
ком состоянии q, что значение т (q, а) определено. После включения
оператора завершение его работы допустимо в произвольном состоя-
346
8.12. Некоторые модели параллельных программ
нии, поскольку функция т всюду определена на Q Е,. При включе-
нии оператор а использует значения ячеек из Д(а), при выключении
он засылает свои результаты в ячейки из Т(а) и формирует символ
выключения, который соответствует одному из К(а) направлений ус-
ловной передачи.
Полезным для эффективного распознавания свойств параллельных
схем программ является класс счетчиковых схем.
Счетчиковой схемой называется схема R=(М, А, Г), для которой управ-
ление Г задается следующим образом.
Пусть к — целое неотрицательное число;
Е — конечное множество;
5 — множество с выделенным элементом 50;
л е N*, где N* — множество неотрицательных целых чисел;
v — функция из Е в N*, такая, что если о е Е„ то v(o) > 0;
0: 5 Е —> 5 — частичная функция, всюду определенная на 5 Е,.
Полагаем, что значение т((5, х),о) определено, если определено 0(5,о)
и выполнено х + v (о) > 0. Если значение определено, то
т((5, х),о) = (0(5, o),x+v(o)).
Более простыми и наглядными являются параллельные операторные
схемы — частный случай счетчиковых схем.
Параллельной операторной схемой называется произвольная счетчи-
ковая схема, обладающая следующими свойствами:
!)$=№);
2) для каждого а е Е значение О(5о, о) определено;
3) если о — символ выключения, то каждая компонента вектора v(o)
равна 0 или 1;
4) если о — символ включения, то каждая компонента вектора v(o)
равна 0 или -1;
5) для любых двух неравных символов включения о, o' из v(o), = -1
следует v(g')/ = 0.
Параллельную операторную схему можно представить в виде ориен-
тированного графа с операторными вершинами Оа, Оь, Ос, ... и вер-
347
Глава 8. Последовательные и параллельные процессы
шинами-счетчиками dt, d2,..., dk. Каждый счетчик </, помечается
числом л„ которое является начальным значением этого счетчика.
Дуги графа направлены либо от операторных вершин к счетчикам,
либо от счетчиков к операторным вершинам. Дуги сопоставлены не-
нулевым компонентам векторов v(o).
Если (v(oy)),- = 1, то выключение оператора а с символом выключения
aj увеличивает значение счетчика i на 1. Если (v(o))f = — 1, то включе-
ние оператора а уменьшает значение счетчика i на 1. Условие 5 из оп-
ределения параллельной операторной схемы (см. выше) означает, что
из произвольного счетчика выходит не более чем одна дуга.
Пример. Пусть необходимо перемножить матрицу
(а11 а12 ••• а1т
а22 а2т)
на вектор (Ь\ Ь2 ... Ьт)', а результат поместить в (сь с2).
Графовое представление некоторой интерпретированной операторной
схемы, задающей алгоритм такого умножения, приведено на рис. 8.11.
Рассмотрим теперь другие модели программ, которые в меньшей мере
опираются на понятие операторных схем программ.
В качестве модели программы иногда предлагается пара R = (М,С),
где М определяет ее информационную, а С — управляющую структу-
ру. Для представления информационной структуры М используются
простые вычислительные модели, а для представления управляющей
структуры — сети Петри. Сеть Петри — двудольный граф, множество
вершин которого состоит из переходов Ги позицийр, g Р. Кроме
того, заданы две функции инцидентности:
F: Р Т->{0,1};
В:
Они задают множество дуг, ведущих из позиций в переходы и из пере-
ходов в позиции. No: Р—> {0,1,2,...} — начальная разметка сети. Сеть
Петри функционирует, переходя от одной разметки к другой. Каждая
разметка — это функция N. Р—ь {0,1,2,...}. Схема разметок проис-
ходит в результате срабатывания одного из переходов. Переход t
может сработать, если для него выполнено условие срабатывания
348
8.12. Некоторые модели параллельных программ
Рис. 8.11. Графовые структуры
(7V(p) — > 0 \/р. После срабатывания перехода t разметка N сме-
няется разметкой № по следующему правилу:
V/XTV'O) = N(p) - F(p,t) + В(р, Г)).
Переходы срабатывают последовательно, но недетерминированно.
Сеть останавливается, если при некоторой разметке ни один из пере-
ходов не срабатывает.
349
Глава 8. Последовательные и параллельные процессы
Сети Петри используются также для описания различных типов управ-
ления. Здесь тип управления задает семейство регулярных абстрактных
структур управления. По уровням рассматриваются базовые средства
управления следующих классов:
► безусловные, которые не зависят от текущих значений переменных
в исполняемой программе;
► условные, которые принимают во внимание текущие значения
данных.
Для исследования операционных проблем параллельного программи-
рования удобной явилась модель UCLA-графа. UCLA-граф представ-
ляет собой ориентированный граф, вершины которого соответствуют
операторам параллельной программы, дуги — управляющим или ин-
формационным связям между операторами. С каждой вершиной свя-
заны входное управление и выходное управление, которые могут быть
двух типов — конъюнктивными и дизъюнктивными. При дизъюнктив-
ном входном управлении выполнение оператора может начаться в том
случае, если «активизируется» одна и только одна из дуг, входящих
в эту вершину-оператор. В случае конъюнктивного входного управления
выполнение оператора может начаться в том случае, если активизиро-
ваны все дуги, заходящие в вершину. После завершения исполнения
вершины с дизъюнктивным входным управлением активизируется
одна и только одна из дуг, исходящая из вершины. В случае конъюнк-
тивного выходного управления активизируются все дуги, исходящие
из вершины. Существенным недостатком UCLA-графов является тре-
бование развертки циклов.
8.13. Формальная модель программ на сетях Петри
Информационная зависимость фрагментов программ (ФП) имеет оп-
ределяющую роль при построении параллельных программ. Однако
при решении задачи распараллеливания последовательных алгоритмов
следует учитывать и логическую подчиненность ФП, которая может
существенно препятствовать распараллеливанию наиболее связан-
ных на элементарном уровне ФП. В связи с этим в моделях программ,
ориентированных на микроуровень ФП, требуется в значительной
степени отражать режим управления вычислениями с учетом логиче-
350
8.13. Формальная модель программ на сетях Петри
ской подчиненности ФП в исходных последовательных схемах и про
граммах. Для этого достаточно удобен и пригоден в практических
целях аппарат сетей Петри, на базе которого построен целый ряд мо-
делей параллельных вычислений.
Графически сеть Петри изображается как ориентированный бихро-
матический граф (рис. 8.12).
Рис. 8.12. Графический образ сети Петри (| — переход; О — место)
Иногда функцию инцидентности Fкак компоненту сети Петри пред-
ставляют в виде двух функций: PRE: Рх Т—> |0,1|, POST: ТкР-^ {0,1}.
Из вершиныр е Рв вершину Г g Тдуга ведет тогда и только тогда, ко-
гда PRE(p, Г)=1 > а из вершины t е Тв вершину р g Р тогда и только то-
гда, когда POST(/, р) = 1. Разметка изображается точками в местах
(см. рис. 8.12).
Разметка сети позволяет описывать ее состояние. Сеть Петри функцио-
нирует посредством перехода от одной разметки к другой. Изменение
разметок происходит вследствие срабатывания переходов. Переход t
может сработать, если для него выполняется условие
Vp (М(р) - PRE(p, f)>0),
где М — текущая разметка.
В приведенном на рис. 8.12 примере такому условию удовлетворяют
переходы и t2. Срабатывание перехода t приводит к изменению раз-
метки — входные места перехода теряют по одной метке, а выход-
ные — получают по одной метке.
Разметку М сети называют достижимой из Мо, если существует по-
следовательность срабатываний переходов, в результате которой раз-
метка сети из Мо переходит в М. Рассмотрим формальную модель
351
Глава 8. Последовательные и параллельные процессы
программ, в основу которой положено специальное расширение се-
тей Петри — ПМ-сети.
Обобщенная сеть Петри — это набор (Р, Т, F, Н, Мо), где Р — мно-
жество мест; Т — множество переходов; F. Р х Т —> N о{0} и Н:
7х Р—> 7Уо{0} — функция инцидентности Мо: Р—> 7Уо{0} — началь-
ная разметка; N — множество натуральных чисел.
Определим для сетей два типа меток: плюс-метки и минус-метки. То-
гда область значений функции разметки будет М: Р—ь {..., —1,0,1,...}.
Обозначим Р+ = {р| М(р) > 0}, Р~ = {р| М (р) < 0}. Введем функционал
(предикатный функционал) С: HkjF-^ {+, -}, то есть каждая дуга сети
помечается либо плюсом, либо минусом.
Изменим в соответствии с введенными дополнениями и правила функ-
ционирования сетей. Будем считать, что одновременно в месте не
могут находиться плюс- и минус-метки. В связи с этим определим
операцию аннигиляции меток, то есть одновременного уничтожения
равного количества плюс- и минус-меток для одного и того же места.
Будем использовать следующие обозначения: */ = {р | F (р, f)>0}; t * =
= {р| Н (t, р) > 0}; */+( */_) — множество таких мест, что существуют
дуги из этих мест в переход и эти дуги помечены плюсом (минусом);
t'+ (/_) — множество таких мест, что существуют дуги из перехода t
в эти места и эти дуги помечены плюсом (минусом). Отметим, что
t+ п /_ = 0 для любого I, то есть если из места в переход существуют
кратные дуги, то они должны быть помечены одним и тем же симво-
лом. Иначе из-за операции аннигиляции невозможно включение
перехода t и он будет заведомо недостижим от любой начальной раз-
метки сети.
Переход t может сработать, если для него выполнены условия:
а) для Х/р g */+ имеет место М(р) > F(p, f),
б) для Vp g *t_ имеет место М(р) < 0 и |А/(р)| > F(p, t).
Срабатывание перехода t приводит к изменению разметки М на М'
по правилам:
1) если р g t*_, то М’(р) = М(р) — H(t, р)\
2) если р g t\, то Л/'(р) = М(р) + H(t, р);
3) если р g */_, то Л/'(р) = М(р) + F(p, Г);
352
8.13. Формальная модель программ на сетях Петри
4) если то Л/'(р) = М(р) - F(p, t);
5) если ре 't\Jt *, то М'(р) = М(р).
Сети, введенные выше, назовем ПМ-сетями. Проведем сопостави-
тельный анализ выразительных способностей ПМ-сетей с известными
расширениями сетей Петри, для чего сравним семейства формаль-
ных языков, генерируемых различными классами сетей Петри.
Будем говорить, что разметка М' достижима из М в результате после-
довательности срабатываний т = Гь t2 ... tk, где Г, g Т, 1 < i < к, если су-
ществует последовательность следующих друг за другом разметок:
М—>Л/] —>...—или сокращенно М——*М'.
Свободным языком сети N называется
L(N) = {Г g Т’ | ЭЛ/, Л/о —
где 1* — множество всевозможных цепочек, составленных из симво-
лов алфавита Т.
Введем помечающую функцию о: Е и {X}, где X — некоторый ал-
фавит, а X — пустое слово. Функция о легко обобщается на последо-
вательности срабатываний у t.
<>('), если у = Х,
' ' [о(у)о(0, если у * X.
L\N) = {о(у) | у g L(N)} называется Х-языком сети N. Сети Ni и N2
эквивалентны (Nt - N2), если (Nj) = I? (N2). Говорят, что класс се-
тей Aj мощнее класса Л2 (Л2 с А]), если для любой A2g Л2 существует
Ni е Л! и - N2. Классы сетей Л] и Л2 называются эквивалентными
(Aj - Л2), если Aj £ Л2 и Л2 с Ab
Известно, что структурированные сети, приоритетные сети сети с пе-
реключателями и дизъюнктивными правилами, ингибиторные сети
эквивалентны. Докажем, что введенные здесь ПМ-сети обладают не
меньшими выразительными способностями, чем отмеченные выше
классы. Обозначим Л(//) — класс ингибиторных сетей, К(ПМ) —
класс ПМ-сетей.
353
2^2792
Глава 8. Последовательные и параллельные процессы
Теорема. Имеет место следующее включение Л(Я) с
Для доказательства необходимо показать, что по любой /У1еЛ(/7)
можно построить эквивалентную сеть N2<e. К(ПМ).
Пусть — ингибиторная сеть с начальной разметкой Мо и помечаю-
щей функцией о. Разделим сеть Nt на п фрагментов (л — число мест
в сети ЛГ|), каждый из которых включает одно место и переходы, ин-
цидентные данному месту. Обозначим рк = р) > 0}; рк0 — мно-
жество переходов, для которых рк является входным местом, причем
между рк и этими переходами не существует ингибиторных дуг; р'к\ —
множество переходов, для которых рк является входным местом и су-
ществуют ингибиторные дуги между рк и данными переходами.
Для каждого фрагмента ингибиторной сети построим эквивалент-
ный фрагмент ПМ-сети. Если исходный фрагмент не содержит инги-
биторных дуг, то он остается без изменений. Если же некоторый Л-й
фрагмент включает хотя бы одну ингибиторную дугу, то выполняются
следующие построения. В новом фрагменте будут соответственно те
же переходы и то же место, что и в. исходном, но отличным образом
задаются связи между ними и разметка места.
1. Если в исходном фрагменте переход t е'рк, то в новом фрагменте
каждой исходной дуге из t в рк будут соответствовать две дуги, веду-
щие из t в рк и помеченные плюсом.
2. Если в исходном фрагменте переход t е. рк1, то в новом фрагменте
строим минус-дугу изрк в t и минус-дугу из Г в рк.
3. Если в исходном фрагменте переход t е р*.о,то в новом фрагменте
строим минус-дугу из г в рк и 21— 1 плюс-дуг из рк в t, где / — кратность
дуг из рк в t в исходном фрагменте.
4. Если в исходном фрагменте М(р^) = т, то в новом фрагменте
М(рк) = 2m - 1.
Для иллюстрации данного построения на рис. 8.13 изображен фраг-
мент ингибиторной сети и соответствующий фрагмент ПМ-сети (на
рисунке ингибиторная дуга изображена дугой, которая оканчивается
кружком вместо стрелки).
После построения для каждого фрагмента ингибиторной сети экви-
валентного фрагмента ПМ-сети остается осуществить сочленение
354
8.13. Формальная модель программ на сетях Петри
Рис. 8.13. Ингибиторная сеть (а) и ПМ-сеть (б)
полученных фрагментов по переходам, помеченным одинаковыми
символами. Такое построение производится на основе операции нало-
жения. Полученное объединение фрагментов и будет являться ПМ-се-
тью N2, эквивалентной Nt.
Сконструируем ПМ-сеть специального вида (СПМ-сеть). Базовым
элементом выберем сеть, называемую в дальнейшем Р-фрагментом:
а,Ь,с— места; а, Р, у, 8 — переходы: связи выражаются отношением
Рд т, n,a на множествах Р, T,N,Am отношением ру р, n,a на множест-
вах Т, Р, N, А, заданных матрицами:
о,а,1,—
я,РД,+
«,у,1,+
о,8,1,-
/>,«,!,+
с,8,1,+
Pp.t.n.a
РД1,+ .
у,с,1,+
/^-фрагменты могут объединяться в кортежи. Пусть Rx = (Pb Т\, F\, Нх,
Мол),..., Rn = (Р„, Т„, Fn, Н„, МОп) — P-фрагменты, причем Р, = {о„ £>,, с,},
Тх = {а„ Р„ у;, 8J, 1 < i < п. Тогда кортежем P-фрагментов называется
сеть 5 = (Ps, Ts, Fs, Hs, MOs), где Ps = (Jp}, Ts = Tx<jT2<J..xjT„<Jts —
/=1
некоторый переход, называемый в дальнейшем входным переходом
355
Глава 8. Последовательные и параллельные процессы
Л
кортежа), М0>,- — есть объединение Hh 1 < i < п, и дополни-
»=1
тельных плюс-дуг, которые соединяют переход ts с ah 1 <i<n. Назо-
вем с, и dj, 1 < / < п, выходными местами кортежа /^-фрагментов.
На множестве /^-фрагментов кортежа можно задавать отношения,
аналоги которых существуют в реальных программах. Эти отноше-
ния задаются в кортежах путем комбинаций дополнительных плюс-
и минус-дуг, соединяющих переходы и места различных фрагментов.
Пример одного из таких отношений будет рассмотрен ниже.
Будем считать, что объединение кортежей друг с другом может осу-
ществляться лишь с помощью операции 0, которая определяется сле-
дующим образом. Пусть 5] = (Р1г Т\, Ft, Н\, Мо\) и S2 = (Р2, Т2, F2, Н2,
Л/о,г) кортежа /^-фрагментов, тогда 5]0 S2 — сеть = (Р', Т', F', Н',
М'о), у которой Р’ = Р^Р2, Т' = Т^Т2, IF = H^jH2, F' — есть объеди-
нение f|, F2 и дополнительных плюс-дуг, выходящих из некоторого
подмножества выходных мест кортежа 5) и входящих во входной пе-
реход кортежа S2. Выбор подмножества выходных мест существенно
зависит от отношений, задаваемых на множестве /^-фрагментов.
Операция 0 аналогично определяется для кортежа и просто перехода.
Переходы, добавленные в СПМ-сеть посредством операции 0, назы-
ваем висячими.
СПМ-сеть определяется следующим образом:
1) кортеж Л-фрагментов есть СПМ-сеть;
2) сеть, полученная из СПМ-сети добавлением к одному из состав-
ляющих ее кортежей либо кортежа, либо перехода посредством опе-
рации 0, является СПМ-сетью.
Сети Петри и их модификации могут успешно применяться в теории
параллельного программирования как семантические модели струк-
тур параллельных программ, в частности для отображения безуслов-
ного уровня управления. СПМ-сети послужили основой построения
модели параллельных программ с большим количеством условных
операторов. Безусловный уровень управления в такой модели может
быть описан непосредственно СПМ-сетями, условный уровень зада-
ется специальными операторами-распознавателями. Каждому /?-фраг-
менту приписан один оператор-распознаватель, связанный плюс-дугой
с переходом Р и минус-дугой с переходом у (см. выше определение
356
8.13. Формальная модель программ на сетях Петри
/(-фрагмента). Плюс-дуга соответствует выработке оператором-рас-
познавателем значения «истина», минус-дуга соответствует значению
«ложь». Таким образом, переход Р (переход у) может сработать, если
место а содержит плюс-метку и оператор-распознаватель выработал
значение «истина» («ложь»).
Информационно операторы-распознаватели, приписанные /(-фраг-
ментам одного кортежа, независимы и поэтому могут включаться
асинхронно, что и обеспечивается структурой кортежа. Тем не менее
в программах может иметь место отношение логической подчинен-
ности операторов-распознавателей. Из-за этого при параллельном
выполнении кортежа операторов-распознавателей срабатывание одних
операторов-распознавателей с определенными результатами может
сделать несущественными результаты срабатываний других операто-
ров-распознавателей- Поэтому выполнение последних необходимо
либо прервать, либо запретить их включение, если они еще не включа-
лись, либо уничтожить результаты их работы, если они уже выполня-
лись. Это обеспечивается заданием дополнительных плюс- и минус-дуг,
соединяющих соответствующие переходы и места различных фраг-
ментов.
Например, пусть выполнение оператора-распознавателя, приписанно-
го /?,-фрагменту, несущественно, если оператор-распознаватель, при-
писанный /^-фрагменту, выработал значение «истина». Тогда соеди-
няем переход Р, минус-дугой с местом а,-, что позволит не включать
фрагмент R, (так как произойдет аннигиляция плюс- и минус-меток),
либо, если он уже сработал, разметить его выходные места нулем
(так как сработает либо переход а,-, либо переход Р,). Таким образом,
в данном случае отношение логической подчиненности операторов-рас-
познавателей задает соответственно и отношение на множестве /(-фраг-
ментов кортежа.
Подводя итог приведенным выше рассуждениям, можно определить
модель параллельных программ как набор Р= S, Y, L), где
1) W— множество ячеек памяти (переменных);
S — безусловный уровень управления модели, представленный
СПМ-сетью с заданными, если необходимо, отношениями (в частно-
сти, логической подчиненности) на множествах /(-фрагментов кор-
тежей. (Отметим, что места СПМ-сетей можно рассматривать как
ячейки памяти специального вида — управляющей памяти W', при-
чем можно считать, что W' n W= 0);
357
Глава 8. Последовательные и параллельные процессы
2) Y — условный уровень управления, заданный операторами-распо-
знавателями, являющимися предикатными термами над Ж; при этом
операторы-распознаватели можно рассматривать как связующее зве-
но между памятью Ж и управляющей памятью Ж', поскольку вход-
ными переменными для них являются элементы из Ж, а результаты
они помещают в Ж'.
3) L — множество цепочек операторов-преобразователей. Входные
и выходные переменные операторов-преобразователей принадлежат
множеству Ж. Мощность множества L равна числу висячих перехо-
дов в соответствующей СПМ-сети, поскольку каждому висячему
переходу приписывается одна цепочка операторов-преобразователей
из L.
Упражнения
1. Постройте граф развития заданного процесса.
а) Сортировка слиянием. Во время /-го прохода в стандартной сортиров-
ке слиянием второго порядка пары сортируемых списков длины 2'-1 сли-
ваются в списке длины 2'. Все слияния в пределах одного прохода могут
быть выполнены параллельно;
б) Умножение матриц. При выполнении умножения матриц А = В • С все
элементы матрицы А могут быть вычислены одновременно;
в) Оцените требуемое минимальное время как функцию и для вычисле-
ния выражения at + а2 + ... + а„, п > 1 в предположении, что:
• параллельно может быть выполнено любое число операций сложения;
• каждая операция (включая выборку операндов и запись результата) за-
нимает одну единицу времени.
2. Оцените требуемое минимальное время как функцию и для вычисления
выражения а, + а2 + ... + ап, n > 1 в предположении, что:
• параллельно может быть выполнено любое число операций сложения;
• каждая операция (включая выборку операндов и запись результатов)
занимает одну единицу времени.
3. Постройте сценарий последовательно-параллельного выполнения алго-
ритма решения СЛАУ методом Гаусса.
4. Как организована память в мультипроцессорах и мультикомпьютерах?
5. Какими свойствами должна обладать масштабируемая система?
358
Упражнения
6. Какие технологии используются для уменьшения времени ожидания
в мультипроцессорах и мультикомпьютерах?
7. Сравните основные подходы в проектировании программного обеспече-
ния для параллельных компьютеров.
8. Охарактеризуйте основные вычислительные парадигмы.
9. В чем основное различие классификации компьютеров у Флинна и Шора?
359
Глава 9
Системы параллельного действия
Исследование разработок по применению персональных компьюте-
ров показывает, что сложилась устойчивая тенденция к усилению их
персонализации за счет развития дружественного человеко-машин-
ного интерфейса, с одной стороны, и углублению проблемной ори-
ентации за счет специализации в конкретной сфере деятельности —
с другой. Однако наука и практика в последнее время выдвигают ряд
жизненно важных задач, которые требуют для своего решения вы-
полнения 1015—1017 операций в секунду. Среди таких задач называют
задачи обработки изображений, системы динамических испытаний,
искусственного интеллекта, ядерной физики, экономики и т.д. Напри-
мер, задача квантовой хромодинамики, вычисление массы протона
и нескольких связанных частиц, требует выполнения 1017 операций
в секунду.
Поток информации в указанных и других системах настолько возрос,
а необходимость в быстрой и экономной ее обработке так жизненно важ-
на, что потребность в их скорейшем разрешении во многом определяет
устойчивое функционирование общества в целом.
В связи с этим никак нельзя ограничиваться использованием и разви-
тием только персональных компьютеров. Возникает настоятельная
потребность в создании мощных высокопроизводительных машин,
чаще называемых высокопроизводительными вычислительными си-
стемами (ВС).
9.1. Вычислительные системы и многомашинные
комплексы на базе однопроцессорных компьютеров
Современные однопроцессорные компьютеры можно комплексиро-
вать по следующим четырем уровням:
► на уровне процессоров для синхронизации и управления;
► на уровне каналов I/O через adapter channel-to-channel (адаптер
«канал-канал») — аппаратное устройство, используемое для связи
двух каналов, входящих в одну или разные ВС;
360
9.1. Вычислительные системы и многомашинные комплексы...
► на уровне оперативной памяти (за счет многовходовой памяти);
► на уровне внешней памяти.
Возможны различные сочетания предложенных уровней комплекси-
рования компьютеров. При этом, как правило, уровень оперативной
памяти используется для двухпроцессорных ВС.
Первым экспериментальным двухмашинным комплексом был, пожалуй,
комплекс, созданный в 1964 оду из двух ЭВМ SEAC и DESEAC, кото-
рые, будучи различными по конструкции, имели одинаковые системы
команд и способы кодирования данных. Комплекс оказался способным
решать такие задачи, которые были не под силу одному компьютеру.
В1966 году в БССР был создан многомашинный комплекс (МК) Минск-222,
позволявший соединять от 2 до 16 машин типа Минск-2(22) (мин-
ский завод им. Г.К. Орджоникидзе, Сибирское отделение АН СССР)
(рис. 9.1). Связь между машинами осуществлялась через каналы и си-
стему коммутации, образованную из коммутаторов (К), входящих в от-
дельные машины. Коммутаторы реализуют некоторый набор систем-
ных операций, которые позволяют осуществить обмен информацией
между данной ЭВМ и ее ближайшим соседом. Все выполняемые сис-
темные операции координируются содержимым регистров настройки
(PH). Коммутатор ЭВМ и блок системных операций (БОС) составляют
элементарную машину. Системные операции позволяют изменять ха-
рактер взаимодействия ЭВМ за счет изменения содержимого PH,
Рис. 9.1. Структура МК Минск-222
361
Глава 9. Системы параллельного действия
осуществлять обмен информацией и другие действия. Системные уст-
ройства занимают примерно 1 % всего МК.
Минск-222 — это система со множественным потоком команд и дан-
ных, с низкой степенью связанности и однородной структурой. Меж-
машинные связи осуществляются с помощью каналов, причем эти
связи линейные — между каждой парой соседних ЭВМ.
На базе ЭВМ БЭСМ-6 и ЭВМ Днепр-21 (Институт кибернетики АН
УССР) был создан единый двухмашинный комплекс. БЭСМ-6 вы-
полняла функции обработчика информации, а Днепр-21 — функции
I/O. При этом обеспечивалась связь между многочисленными, в том
числе и удаленными терминалами. Связь между машинами реализо-
вана через селекторный канал Днепр-21 и седьмой канал БЭСМ-6.
Вся вводимая информация накапливается в компьютере Днепр-21
и передается в БЭСМ-6 в таком виде, как будто она вводилась с перфо-
карт. Редактирование и вычисления выполняла БЭСМ-6. Выводимая
информация поступает в оперативную память Днепр-21 и выводится
по мере необходимости. Синхронизация работы машин осуществля-
ется посредством передачи управляющей информации между опера-
ционными системами машин по диспетчерскому каналу, в качестве
которого со стороны БЭСМ-6 использован канал I/O на перфоленту,
а со стороны Днепр-21 — мультиплексный канал.
Вычислительная система Объединенного института ядерных исследова-
ний (ОИЯИ) имеет развитую иерархическую структуру. Один из ее ва-
риантов был устроен следующим образом.
Верхний уровень составлен ЭВМ БЭСМ-6 и CDC 6200 суммарной
производительностью около 2 миллионов операций в секунду. Этот
вариант использовался для сложных расчетов и обработки огромных
массивов экспериментальной информации, получаемой на ускори-
телях.
Средний уровень системы предназначался для автономного решения
задач каждой лаборатории. Он образован из машин типа ЕС 1040,
БЭСМ-4, CDC 1604, Минск-32 (Минск-22) и др. Некоторые из этих
машин имели кабельную связь с БЭСМ-6.
Нижний уровень применялся для накопления и предварительной
обработки информации в системах контроля и управления работой
физических установок. Он включал как отечественные компьютеры
362
9.1. Вычислительные системы и многомашинные комплексы
(М-6000, М-400, Электроника-100), так и ЭВМ стран СЭВ (ТРА,
ЕС 1010) и компьютеры некоторых западных фирм (PDP-8, CDC 160А
и др.).
Обмен между ЭВМ разных уровней осуществлялся как физическим
переносом носителей информации, так и (для БЭСМ-6) по быстро-
действующим кабельным линиям связи с пропускной способностью
до 500 Кбайт/с.
Структура компьютеров серии ЕС ЭВМ позволяет осуществлять ком-
плексирование машин на уровне процессора, каналов, внешней памяти
(внешних устройств) и оперативной памяти. При комплексировании
на первых трех уровнях, что характерно для малых и средних машин
ряда 1 (1010, 1012, 1020), создаются мультикомпьюгерные системы.
При комплексировании на уровне оперативной памяти с сохранением
возможности комплексирования на других уровнях (ЕС 1050 и ряд 11 —
1015,25,35,45,55,60,65) создаются мультипроцессорные системы.
Отметим, что программная организация работы процессоров с об-
щим полем оперативной памяти принципиально сложнее, нежели
взаимодействие процессоров на уровне внешнего оборудования, хотя
является наиболее гибкой и быстрой.
Обмен информацией между процессорами или между процессором
и ВнП (управляющей или синхронизирующей информацией) исполь-
зует средства прямого управления, к которым относятся команды
ПРЯМАЯ ЗАПИСЬ и ПРЯМОЕ ЧТЕНИЕ. Связь между процессора-
ми или процессором и ВнП осуществляется с помощью указанных
команд и механизма внешних прерываний.
При комплексировании на уровне каналов применяется адаптер, кото-
рый обладает двумя выходами на стандартный интерфейс I/O и под-
ключается к селекторным (или мультиплексным) каналам двух моду-
лей ЕС ЭВМ.
Наибольшую возможность комплексирования имеют компьютеры
ЕС 1030 — из двух ЭВМ, соединенных линиями прямого управления;
из нескольких ЭВМ, имеющих доступ к общему полю внешней памя-
ти или соединенных адаптером «канал-канал».
В случае прямого управления обмен информацией выполняется по ко-
мандам прямого управления. По ним из одного процессора передает-
ся один байт информации, прерывающий работу другого процессора.
363
Таблица 9.1
Комплексирование ЭВМ серии ЕС
Устройства ЭВМ. Уровни ком- плексирования Технические и программные средства комплексирования Что реализуется в результате комплексирования Что обеспечивается в результате комплексирования
Процессор Средства прямого управления (включая шины прямого управле- ния, линии синхронизации и спе- циальные команды) и механизм внешних прерываний Прямая связь между дву- мя процессорами Обмен управляющей информаци- ей между процессорами и необхо- димая при этом синхронизация их работы
Оперативная память Пульт реконфигурации, средства операционной системы и средст- ва прямого управления Общее поле оперативной памяти и прямая связь между двумя процессо- рами Быстрый параллельный доступ процессоров к программной и чи- словой информации в общем поле оперативной памяти, реализуе- мый с участием расширенных средств прямого управления
Каналы Адаптер «канал-канал» и средст- ва операционной системы Соединение канала од- ного компьютера с кана- лом другого Синхронизированная передача программной и числовой инфор- мации из оперативной памяти од- ного компьютера в оперативную память другого
Внешняя память Двухканальный переключатель (входной коммутатор) устройств управления внешними устройст- вами и средства ОС Общее поле внешней па- мяти Одновременный и разнесенный во времени доступ процессоров к большим объемам информации в общем поле внешней памяти
лава 9. Системы параллельного действия
9.1. Вычислительные системы и многомашинные комплексы
Такая система эффективна, если объем и скорость передачи инфор-
мации невелики.
При организации многомашинного комплекса, связанного общим
полем внешней памяти, передача информации одним процессором
и прием ее другим происходят неодновременно, в результате чего
производительность взаимодействующих систем не снижается. Эта
связь эффективнее объединения с помощью линий прямого управ-
ления.
С помощью адаптера «канал-канал» прямая связь между каналами
ЭВМ осуществляется через стандартный интерфейс. Интерфейсом
могут быть аппаратурный блок, связывающий два устройства, а так-
же часть области памяти или регистры, доступные двум или более
программам. Скорость обмена информацией определяется пропуск-
ной способностью каналов.
Основные сведения о комплексировании компьютеров серии ЕС даны
в табл. 9.1.
Результат комплексирования двух компьютеров 1030 — это МК 1010.
ЭВМ в нем соединены между собой по шинам прямого управления
через блок состояния вычислительного комплекса, раздельные внеш-
ние устройства и через адаптер «канал-канал».
Структурная схема адаптера «канал-канал» приведена на рис. 9.2.
Каждый канал обслуживается своим блоком управления. Эти блоки
связаны непосредственно при помощи сигнальных линий и через об-
щий однобайтовый буферный регистр.
ЭВМ-1 Селектор- ный канал - i Блок управления 1 . -—- Буферный регистр — — Блок управления t - ЭВМ-2 Селектор- НЫЙ канал
Рис. 9.2. Структурная схема адаптера «канал-канал»
Текущее состояние каждой ЭВМ фиксируется и в виде байта состоя-
ния (флажок) хранится в блоке состояния МК. Задание режима работы
МК и перевод в требуемый режим осуществляются оператором с пульта
ЭВМ. Изменить байт состояния компьютера в блоке состояния МК
можно и программным путем с помощью команд прямого управления.
365
Глава 9. Системы параллельного действия
Ряд особенностей имеет ЕС 1035: расширенную систему команд (СК),
виртуальную память, коррекцию одиночных ошибок при чтении
информации из ОП и обнаружение двойных ошибок, совмести-
мость с ЭВМ Минск-32 (разработаны конверторы языков Fortran
и Cobol, эмулятор программ Минск-32 на ЕС 1035 и средства перено-
са данных).
Известны многомашинные и многопроцессорные системы на базе
ЕС 1050.
9.2. Многопроцессорный вычислительный
комплекс Эльбрус
При разработке МВК Эльбрус ставились следующие задачи:
► повысить эффективность использования оборудования;
► обеспечить возможность достижения предельной производитель-
ности;
► создать высоконадежные резервируемые структуры, обладающие
возможностью постепенного наращивания производительности с уче-
том адаптации к решаемым задачам.
В состав семейства МВК Эльбрус входит система Эльбрус-1 произ-
водительностью от 1,5 миллиона операций в секунду до 10 миллио-
нов операций в секунду и Эльбрус-2 с суммарным быстродействием
120 миллионов операций в секунду.
9.2.1. Структура вычислительного комплекса
МВК характеризуется следующими особенностями.
Все процессоры комплекса имеют одну и ту же систему команд и оди-
наковую по функциям операционную систему ЕОС (Единую ОС).
Основными модулями системы являются:
► центральные процессоры (ЦП) в количестве от 1 до 10;
► модули оперативной памяти (от 4 до 32) объемом от 576 Кбайт до
4608 Кбайт;
► модули процессоров ввода-вывода (ПВВ) (от 1 до 4);
366
9.2. Многопроцессорный вычислительный комплекс Эльбрус
► модули процессоров передачи данных (ППД) (от 1 до 16);
► модули управления накопителями на магнитных барабанах и дис-
ках, образующие систему управления массовой памятью.
Оперативная память для всех процессоров системы доступна через
коммутатор, на который возлагаются функции замены неисправных
блоков резервирования (рис. 9.3). Аппаратный контроль охватывает
не только работу процессоров, но и работу по обмену информацией
на всех уровнях.
Система команд центрального процессора базируется на принципе
магазинного обращения к памяти с аппаратной реализацией стека.
Внутренний язык машины подобен польской инверсной записи
(ПОЛИЗ). В вершине стека могут находиться не только сами операн-
ды, но и ссылки на них, а также ссылки на процедуры вычисления
операндов. По принципу построения СК для ЦП МВК Эльбрус близка
к СК KDF-9 и ЭВМ фирмы Burroughs. Однако МВК Эльбрус имеет
более развитый аппарат описания типов данных, их защиты, спосо-
бов распределения памяти, а также развитый аппарат дескрипторов.
Каждый объект данных в памяти снабжен дополнительным управ-
ляющим разрядом (тегом), в котором содержится информация о типе
данных (целое, вещественное, набор, дескриптор, адрес, метка, фор-
мат) и различные управляющие признаки, включая признаки защиты
по чтению и записи. Все это позволяет строить чистые (иногда их на-
зывают реентерабельные, повторно входимые) процедуры, не имею-
щие явных ссылок на адреса объектов в логической или физической
памяти. Это очень важно, ибо позволяет одно и то же тело процедуры
использовать разными процессорами над разными данными. Аппа-
рат дескрипторов и косвенных ссылок позволяет разным програм-
мам обращаться к общим данным.
Многие функции синхронизации процессов реализованы аппаратно
(используется аппарат семафоров).
Модуль ПВВ (процессор ввода-вывода) — это, по сути, специальная
ЭВМ с локальной памятью и доступом к основной оперативной па-
мяти. Он служит для управления связью системы с внешними уст-
ройствами.
В состав ПВВ входят блоки быстрых каналов, состоящие из 4 селек-
торных каналов, каждый из которых может обслужить до 64 быстрых
367
Глава 9. Системы параллельного действия
Алфавитно- Перфо- Перфо- Алфавитно- Графический Графо-
цифровое карточный ленточный цифровые дисплей построители
печатающее jyo Г/0 дисплеи
устройство
Рис. 9.3. Структурная схема МВК
абонентов, и блоки стандартных каналов, каждый из которых в свою
очередь содержит 16 каналов, обслуживающих до 256 внешних або-
нентов. Стандартный канал обеспечивает мультиплексное обслужи-
вание медленных абонентов. Кроме того, в состав ПВВ входит блок
сопряжения с процессорами передачи данных (до 4 каналов).
368
9.2. Многопроцессорный вычислительный комплекс Эльбрус
Основное назначение ПВВ — освободить ЦП от функций организа-
ции очередей обмена, реакций на прерывание по I/O, а также от оп-
тимизации обслуживания очередей запросов на обмен.
Логическая память разбивается на страницы длиной в 512 слов.
В основу программного обеспечения положен принцип достижения
высокой эффективности вычислений при помощи гибкости и адап-
тируемости МВК. Здесь МВК и его ПО как бы адаптируются к решае-
мым задачам, а не наоборот, как сделано во многих системах, когда
алгоритм решаемой задачи модифицируется, чтобы его можно было
реализовать в рамках жесткой ВС.
МВК Эльбрус может выполнять программы пользователей БЭСМ-6
благодаря спецпроцессору, реализующему систему команд БЭСМ-6.
Модули ЦП, ОП и процессоров I/O связаны между собой при помощи
центрального коммутатора (К). Процессоры приема-передачи дан-
ных, промежуточная и внешняя память, а также устройства I/O под-
ключаются к центральной части системы через процессоры I/O.
Модули системы работают параллельно и независимо друг от друга,
ресурсы системы динамически распределяются ЕОС, которая обеспе-
чивает мультипрограммный режим пакетной обработки, режим раз-
деления времени и терминальную обработку.
Для повышения быстродействия аппаратно реализованы базовые
конструкции и общепринятые механизмы воплощения ЯП, лежащие
в основе систем программирования.
9.2.2. Системы программирования комплекса
Рассмотрим общие программные средства, применяемые для созда-
ния приложений в системах программирования МВК Эльбрус.
Язык и система программирования (СП) Эль-76. Универсальный базо-
вый язык Эль-76 — язык высокого уровня, обеспечивающий сочетание
современных средств программирования с доступом ко всем систем-
ным возможностям. При реализации большинство конструкций язы-
ка имеет полную аппаратную поддержку. Язык Эль-76 используется
как язык системного программирования (на нем написаны основные
компоненты общего системного программного обеспечения — ОС,
включая файловую систему; трансляторы; система динамической
369
2^2792
Глава 9. Системы параллельного действия
диагностики; комплексатор; отладчик и др.); язык проблемного про-
граммирования (применен для создания ряда прикладных программ —
системы управления, системы автоматизации проектирования, пакеты
прикладных программ и др.); язык взаимодействия с операционной
системой (выполняет функции языка управления заданиями, через
него доступны такие компоненты ОС, как управление памятью, управ-
ление процессами, управление программами).
Система динамической диагностики. Осуществляет диагностику дина-
мических ошибок в терминах программы на исходном языке с указа-
нием номера строки, фрагмента исходного текста, имен и текстовых
координат вызванных процедур, имен и значений их локальных пе-
ременных.
Многоязыковый комплексатор. Осуществляет сборку программ из
процедур, написанных на одном или нескольких языках программи-
рования.
Отладчик программ в терминах исходного текста.
Технологические пакеты для разработки трансляторов.
Система формирования словаря идентификаторов программы. Позво-
ляет получить документ, содержащий информацию о точках и характере
использования идентификаторов. Компилятор при этом генерирует
еще одну структуру — файл ссылок на вхождение идентификаторов.
Системы программирования на базе широко распространенных языков:
Algol-60, Algol-68, Cobol, PL/1, Симула-67, Fortran, Ada, Modula-2,
Pascal, Эль-76.
Клу (Clu) — язык для разработки больших программных комплексов
с использованием абстрактных типов данных (АТД). Требования
практического программирования в повышении модульности, на-
дежности и наглядности программ позволило в начале 70-х годов
прошлого века Н. Вирту, О. Далу, Ч. Хоару сформулировать принци-
пы АТД. Суть концепции АТД состоит в том, что создание и обра-
ботка объектов некоторого (абстрактного) типа возможны лишь
с применением определенного набора операций, связанных с этим
типом. Таким образом программист абстрагируется от конкретного
представления объектов данного типа и от реализации операций. Та-
кое представление недоступно (инкапсулировано в определении типа).
Аксиоматика, определяющая свойства типа и любой его реализации
370
9.2. Многопроцессорный вычислительный комплекс Эльбрус
как элемент концепции АТД, часто описывается неформально, в виде
комментариев.
Язык Clu, созданный коллективом Массачусетсского технологиче-
ского института (США), является одним из простых в реализации ЯП
с концепцией АТД. Программа на нем состоит из группы модулей:
процедур (абстракций исполнения), кластеров (абстракций данных)
и итераторов (абстракций управления). Кластерные модули, к при-
меру, определяют класс родственных абстрактных типов данных как
список с произвольным типом элементов t (параметром кластера).
Над АТД данного класса определяются некоторые операции.
СНОБОЛ-4, РЕФАЛ, ЛИСП, ПЛЭНЕР — языки для решения задач
обработки нечисловой информации.
СНОБОЛ-4 — широко распространенный язык символьной обра-
ботки. Язык РЕФАЛ разработан для задач обработки текстов, анали-
тических выкладок, автоматического доказательства теорем и т.д.
Программа на данном языке определяет, по существу, систему под-
становки термов, под управлением которой выполняется вывод из
исходного текстового выражения другого текстового выражения.
Программа на языке РЕФАЛ представляет собой последовательность
предложений (правил вывода):
£|£| E=F,
тва К — начальный символ конкретизации (признак начала предло-
жения); D — детерминатив (идентификатор, играющий роль имени
функции); Е—текстовое выражение (аргумент); F— также текстовое
выражение (результат конкретизации).
Пример рефал-программы для «переворачивания слова»:
£|/7|Е1У2 = У21 /7|£1.
Пусть имеется строка символов «течаз». Укажем состояние «поле зре-
ния» после каждого шага вывода:
К|П|ТЕЧАЗ.->3 К|П|ТЕЧА,—>ЗА К|П|ТЕЧ.->...-»ЗАЧЕТ К|П|.->
-> ЗАЧЕТ
АБВ — язык для разработки систем программирования. Это расши-
ренный язык программирования, созданный как базовый язык для
371
Глава 9. Системы параллельного действия
разработки трансляторов. Конструкции АБВ-языка делятся на три
группы: анализатор (аппарат работы со строками), базу (средства име-
нования и управления) и вычислитель (конструкции низкого уровня
для выполнения вычислений, настраиваемые на конкретную ЭВМ).
СОЛ — язык для решения задач моделирования.
МИС — язык для автоматизации разработки пакетов прикладных
программ.
ФОРТ (СП на базе расширяемого языка FORTH-83). Язык ФОРТ
рассчитан на работу в диалоговом режиме. Стандартные слова языка
ФОРТ обеспечивают адресную арифметику, доступ к реальным адре-
сам и другие возможности языков ассемблерного типа.
ДИАШАГ — система для разработки и отладки программ в интерак-
тивном режиме на основе пошагового транслятора с языка Algol-60.
Система программирования МВК Эльбрус — это открытая система.
Она пополняется языками С, Prolog и др.
9.3. Матричные компьютеры
Типичным представителем матричных компьютеров является ЭВМ
ILLIAC-1. Она появилась в то время, когда эпоха «mainframe houses»
находилась в эволюционном развитии. Данный проект зародился в не-
драх системы Solomon, когда руководитель разработки Д. Слотник
перешел в Иллинойский университет.
Система Solomon включала 1024 элементарных процессора, которые
выполняли одну и ту же команду одновременно, но с различными
операндами. Каждый процессор имел собственную память для опе-
рандов.
ILLIAC-IV— разработка Иллинойского университета (США) совме-
стно с фирмой Burroughs. ЭВМ специализированная.
Изначально проект предназначался для создания матричной вычис-
лительной системы с производительностью порядка 1 миллиарда опе-
раций в секунду. В систему планировалось включить одно управляю-
щее звено, в качестве которого предполагалось использовать В-6500
с быстродействием около 500—600 тысяч операций в секунду и четыре
372
9.3. Матричные компьютеры
независимых блока по 64 обрабатывающих элемента каждый. Это
типичный представитель SIMD-машин. Арифметический процес-
сор рассчитан на обработку 64-битовых слов с плавающей точкой.
Однако технические трудности не позволили полностью воплотить
данный проект. Пришлось остановиться на одноблочном варианте.
Разработки велись на новом алголоподобном языке TRANQUIL, од-
новременно разрабатывалось ПО еще и на ассемблере GLYPNIR.
Язык TRANQUIL имел возможности для задания параллельных
(векторных) конструкций.
Реализованный вариант содержал 64 процессора и ЭВМ 7500 общей
производительностью до 200 миллионов операций в секунду. Он рас-
считан на решение задач, хорошо поддающихся распараллеливанию
(от проблем линейного программирования до задач метеорологии),
простейшие из которых — решение СЛАУ, обработка матриц и т.д.
Оценки авторов проекта показывают, что для задач, поддающихся
распараллеливанию, время решения уменьшается примерно в 220 раз
по сравнению со временем их выполнения на однопроцессорных ВС
с последовательным выполнением команд.
В ILLIAC-IV отказались от строгой синхронизации работы элемен-
тарных процессоров, допуская произвольное выполнение (по време-
ни) общей команды. Каждый процессор здесь превращен, по сути, в
целый компьютер, допускающий модификацию выполнения команд
в зависимости от операнда, тем самым обеспечив почти независимую
работу процессоров. Оперативная память содержит 2048 слов длиной
64 бита. Цикл ЗУ составляет примерно 350 нс. Хотя каждый процес-
сор получает для обработки одну и ту же последовательность команд,
характер работы каждого зависит от типа локальных данных.
В ILLIAC-IV заложена возможность выполнения в разных процес-
сорах различных программ. Реализуется это следующим образом:
в 64-разрядный регистр маски центрального УУ (каждый разряд со-
отнесен определенному процессору) заносится значение, блокирую-
щее (или разрешающее) работу соответствующего процессора, что
позволяет приостанавливать работу определенной группы процессо-
ров. Это в принципе и дает возможность выполнять разные последо-
вательности команд на различных процессорах.
При разработке ILLIAC-IVбыл решен ряд важнейших проблем. В ча-
стности, проблема информационного обмена между отдельными
373
Глава 9. Системы параллельного действия
индивидуальными ЗУ каждого процессора обеспечивалась возмож-
ностью обращения к ЗУ соседних процессоров.
Вторая проблема — организация работы всех процессоров в целом, то
есть задача координации функционирования системы. Функции ко-
ординатора программ, их трансляции и распараллеливания возложе-
ны на универсальную ЭВМ В-7500.
Третья проблема — обеспечение живучести и надежности (ILLIAC-IV
включает до 7 миллионов электронных компонент). С этой целью
разработана система контроля работы устройств и передачи данных
между узлами и блоками ЗУ. Имеется мощная система технической
диагностики.
1LLIAC-IV включает ПЗУ большого объема — лазерное ПЗУ, пред-
ставляющее собой металлическую пленку, которая покрывает бара-
бан с выжженными лазерным путем микроотверстиями. Такое ЗУ
используется для длительного и надежного хранения информации.
Система ILLIAC-IV оказала содействие развитию компьютерной нау-
ки. Она, в частности, продемонстрировала, что SIMD-архитектура
может быть эффективно использована для некоторых важных приме-
нений; показала, что система такой сложности может быть использо-
вана производительно и надежно.
Главный недостаток, препятствующий широкому использованию
ILLIAC-IV, постоянная эволюция применений и высокая стоимость.
9.4. Концепции вычислительных систем
с комбинированной структурой
Одна из первых концепций ВС с комбинированной структурой — ор-
тогональная машина Шумана, состоящая из горизонтальных и вер-
тикальных АУ, совместно использующих ортогональную память.
Ортогональная память — это ЗУ, обеспечивающее горизонтальному
АУ доступ кданным, расположенным на горизонтальном срезе памя-
ти, а вертикальному АУ — доступ кданным по вертикально располо-
женным разрядным срезам.
На базе концепции ортогональной машины создана реальная систе-
ма — OMEN 60 с ЭВМ PDP-11 в качестве горизонтального АУ, что
374
9.4. Концепции вычислительных систем с комбинированной структурой
позволило применить развитое ПО этой системы (рис. 9.4). В качестве
вертикального АУ используется 64 идентичных процессорных эле-
мента. Ортогональная память построена таким образом, что для гори-
зонтального АУ она представляется обычной памятью с 16 разрядны-
ми словами (2 байта), а для вертикального АУ — памятью длиной
в 64 разряда. Программное обеспечение систем семейства OMEN 60
содержит расширенные версии языков Fortran и Basic, реализован-
ных на PDP-11, а также ОС PDP-11, дополненную расширенной вер-
сией языка APL.
Рис. 9.4. Структурная схема семейства OMEN 60
Значительный интерес представляет концепция системы MAP (Multi
Associative Processor), которая сочетает в себе черты ансамблей про-
цессоров матричных и ассоциативных систем, то есть основных пред-
ставителей класса ОКМД и МКМД (рис. 9.5). На рисунке:
ПЭ — процессорный элемент;
ОП — модуль оперативной памяти;
УУ — устройство управления;
S — коммутатор сектора процессорных элементов.
Система содержит 1024 ПЭ и 8 УУ. Допускается программное управ-
ление связями между ПЭ вместо обычных фиксированных связей.
Такая организация позволяет использовать ПЭ как распределяемые
ресурсы, что в сочетании с 8 УУ дает возможность одновременно
решать несколько программ, причем одни программы могут обраба-
тываться в параллельном режиме, а другие — в последовательном.
Одновременная работа в параллельном и последовательном режимах
375
Глава 9. Системы параллельного действия
(в отличие от матричных и ассоциативных систем) позволяет отка-
заться от универсальной ВС в качестве сопрягаемого ведущего про-
цессора.
Рис. 9.5. Структурная схема системы МАР
376
9.5. Архитектура типа гиперкуб
Недостатки системы МАР:
► невозможен, как в ILLIAC-IV, быстрый ввод-вывод информации
в собственное ЗУ для ПЭ. Загрузка памяти ПЭ осуществляется через
ОП и УУ, за которым в данный момент закреплен рассматриваемый
процессорный элемент;
► скорость обмена информацией между соседними ПЭ ограничена.
По оценкам авторов и пользователей системы МАР, стоимость вы-
полнения одной команды в ней в два раза меньше, чем в обычном
компьютере с аналогичными характеристиками.
9.5. Архитектура типа гиперкуб
Гйперкуб представляет собой архитектуру с большим числом процес-
соров (2"), связанных в систему таким образом, что каждый из них
можно представить одной из вершин л-мерного двоичного гиперкуба.
Архитектура отличается регулярностью и простотой. Каждый про-
цессор связан только с п другими соседними, и при этом переход ме-
жду любой парой процессоров не более чем через п ребер.
Гиперкубы размерностью 0, 1, 2, 3, 4 показаны соответственно на
рис. 9.6—9.10. Ясно, что двоичный л-мерный куб регулярным образом
связывает 2" процессоров, представляемых вершинами, через п х 2"“*
связей, представляемых ребрами, причем каждая вершина связана с п
соседними. Максимальный кратчайший путь между вершинами име-
ет всего log2n ребер.
Рис. 9.6. Гиперкуб размерности 0
Рис. 9.8. Гиперкуб размерности 2
Рис. 9.9. Гиперкуб размерности 3
377
Глава 9. Системы параллельного действия
Рис. 9.10. Гиперкуб размерности 4
Примером компьютера, использующего архитектуру гиперкуба, мо-
жет служить построенная фирмой Thinking Machine параллельная
ЭВМ с общим управлением Connection Machine-2 с 216 = 65 536 про-
цессорными элементами.
Можно получить различные схемы связи, убирая те или иные ребра.
На рис. 9.11 и 9.12 продемонстрированы возможности преобразования
архитектуры четырехмерного гиперкуба в трехмерную сетку. Убирае-
мые ребра на этих рисунках отмечены штриховой линией.
Рис. 9.11. Гиперкуб размерности 4 с разорванными связями
378
9.6. Нейрокомпьютеры
Рис. 9.12. Архитектура трехмерной сетки
Следует отметить, что трехмерная сетка не имеет внутренних вер-
шин. Угловые вершины связаны ребрами с тремя соседними верши-
нами, а остальные — с четырьмя вершинами.
9.6. Нейрокомпьютеры
При проектировании любого вычислительного устройства всегда воз-
никает вопрос о классе задач, который наиболее эффективно будет
на нем решаться.
Что касается нейрокомпьютеров, то такой класс задач представляет
собой не только неформализуемые или плохо формализуемые задачи,
в алгоритм решения которых включается процесс обучения на реаль-
ном экспериментальном материале (как правило, задачи распознава-
ния образов), но и задачи с естественным параллелизмом (например,
обработка изображений).
Нейрокомпьютерные архитектуры в будущем будут занимать все
большее место среди других архитектур. Уже сегодня существенно
расширяется интерес к общематематическим задачам, решаемым
в нейросетевом компьютерном базисе. Среди таких задач отметим:
► линейные и нелинейные алгебраические уравнения;
► системы нелинейных дифференциальных уравнений;
► уравнения в частных производных;
► линейное и нелинейное программирование.
379
Глава 9. Системы параллельного действия
В нейрокомпьютерах все нейроны, реализованные в одно- или мно-
гослойной структуре, в идеальном варианте должны быть связаны
линиями передачи данных по принципу «каждый с каждым», так что
при одновременной работе обеспечивается максимальная произво-
дительность.
Получив исходные данные, нейрон выполняет некоторую функцию
(функцию активации). Все связи между нейронами имеют весовые
коэффициенты. Весовые коэффициенты после умножения на значе-
ния функции активации, поступившие от других нейронов, суммиру-
ются. Данная сумма является аргументом функции активации для
принимающего нейрона.
Нейроподобную вычислительную сеть можно настраивать на решение
различных задач распознавания образов, искусственного интеллекта
и им подобных, регулируя соответствующим образом веса связей и пра-
вила вычисления функций в узлах.
Нейрокомпьютер — вычислительная система шестого поколения, со-
стоящая из большого числа параллельно работающих простых вычис-
лительных элементов (нейронов). Элементы связаны между собой,
образуя нейронную сеть. Они выполняют единообразные вычисли-
тельные действия и не требуют внешнего управления. Большое число
параллельно работающих вычислительных элементов обеспечивают
высокое быстродействие.
Нейрокомпьютеры, в отличие от классической ЭВМ предыдущих по-
колений, не просто имеют большие возможности, но и принципиально
по-другому используются. Место программирования занимает обучение
посредством корректировки весов связей, в результате чего каждое
входное воздействие приводит к формированию соответствующего
выходного сигнала. После обучения сеть может применять получен-
ные навыки к новым входным сигналам. При переходе от програм-
мирования к обучению повышается эффективность решения плохо
формализуемых задач. Таким образом, нейрокомпьютеры использу-
ют не заранее разработанные алгоритмы, а специальным образом по-
добранные примеры, на которых обучаются. В нейронной сети нет
локальных областей, в которых запоминается конкретная информа-
ция. Она запоминается во всей сети.
Толчком к развитию нейрокомпьютинга послужили биологические
исследования. По данным нейробиологии нервная система человека
380
9.6. Нейрокомпьютеры
и животных состоит из отдельных клеток — нейронов. Каждый ней-
рон связан с множеством других нейронов и выполняет сравнительно
простые действия. Время срабатывания нейрона составляет 2—5 мс.
Совокупная работа всех нейронов обусловливает сложную работу
мозга, который в реальном времени решает сложнейшие задачи.
Можно сформулировать следующие свойства нейрокомпьютеров:
► параллельная работа большого количества простых вычислитель-
ных устройств;
► способность к обучению, осуществляемая через настройки парамет-
ров сети;
► высокая помехо- и отказоустойчивость;
► новые физические принципы обработки информации для аппарат-
ных реализаций нейронных сетей в силу простого строения отдель-
ных нейронов.
Разработки в области нейрокомпьютинга ведутся по следующим на-
правлениям:
► разработка нейроалгоритмов,
► создание специализированного программного обеспечения для мо-
делирования нейронных сетей,
► разработка специализированных процессорных плат для имита-
ции нейросетей,
► электронные и оптоэлектронные реализации нейронных сетей.
К настоящему времени сформировался значительный рынок нейросе-
тевых продуктов. Подавляющее большинство последних представлено
в виде моделирующего программного обеспечения. Разрабатываются
специализированные нейрочипы или нейроплаты в виде приставок
к персональным ЭВМ. Наиболее ярким прототипом нейрокомпью-
тера можно считать систему обработки аэрокосмических изображений,
разработанную в США по программе «Силиконовый мозг». Объяв-
ленная производительность нейрокомпьютера составляет 80 х 1015
операций с плавающей точкой в секунду при физическом объеме,
равном объему человеческого мозга, с потребляемой мощностью
около 20 Вт.
Особый интерес к нейрокомпьютерам проявляют работники фи-
нансовой сферы. Основные классы задач из финансовой области,
381
Глава 9. Системы параллельного действия
которые можно эффективно решать с помощью нейронных сетей,
следующие:
► прогнозирование временных рядов на основе нейросетевых мето-
дов обработки (валютный курс, спрос и котировка акций, фьючерс-
ные контракты и др.),
► страховая деятельность банков,
► прогнозирование банкротств различных структур,
► биржевая деятельность,
► прогнозирование экономической эффективности финансирования
экономических и инновационных проектов,
► предсказание результатов займа.
9.6.1. Формальная модель нейрона Маккалоки и Пипа
Биологический нейрон имеет вид, пред-
ставленный на рис. 9.13.
В 1943 году Дж. Маккалоки и У. Питт
предложили формальную модель био-
логического нейрона как устройства,
имеющего несколько входов (входные
синапсы — дендриты) и один выход
(выходной синапс — аксон) (рис. 9.14).
Дендриты получают информацию от
источников информации (рецепторов)
£,, в качестве которых могут выступать
и нейроны. Набор входных сигналов
{£,} характеризует объект, его состоя-
ние или ситуацию, обрабатываемую
нейроном.
Рис. 9.13. Структура
биологического нейрона
Каждому /-му входуj-го нейрона ставится в соответствие некоторый
весовой коэффициент /&-, характеризующий степень влияния сигнала
с этого входа на аргумент передаточной (активационной) функции,
определяющей сигнал Yj на выходе нейрона. В нейроне происходит
взвешенное суммирование входных сигналов и полученное значение
используется в качестве аргумента активационной (передаточной)
функции нейрона.
382
9.6. Нейрокомпьютеры
Входные
сигналы
Выходной
сигнал
Блох
нелинейного
преобразования
Синаптические Блок
веса суммирования
Рис. 9.14. Классическая модель нейрона Маккалоки и Питта
9.6.2. Примеры решения задач одним нейроном
Пусть требуется решить задачу определения пола студентов по их
внешним признакам.
Для примера будем рассматривать следующие шкалы и градации:
1. Длина волос, длинные, средние, короткие.
2. Наличие брюк', да, нет.
3. Использование духов или одеколона', да, нет.
Составим таблицу для определения весовых коэффициентов (табл. 9.2).
Пусть столбцы этой таблицы соответствуют состояниям нейрона, а стро-
ки — дендритам, соединенным с органами восприятия, которые спо-
собны распознавать градации соответствующего признака.
Таблица 9.2
Определение весовых коэффициентов нейронов
на основе эмпирических данных
Описательные шкалы и градации Классификационные шкалы и градации
Юноши Девушки
Длина волос:
длинные 5 15
средние 10 10
короткие 15 5
Наличие брюк:
да 30 10
нет 0 20
Использование духов или одеколона:
да 5 20
нет 25 10
383
Глава 9. Системы параллельного действия
Тогда один из простейших способов определить значения весовых
коэффициентов на дендритах будет заключаться в том, чтобы на пе-
ресечениях строк и столбцов просто проставить суммарное количест-
во студентов в обучающей выборке, обладающих данным признаком.
Если нейрон должен выдавать высокий выходной сигнал, когда на
входе ему предъявляется юноша, и низкий — когда девушка, то весовые
коэффициенты на дендритах берутся из столбца «Юноши». И наобо-
рот, если нейрон должен выдавать высокий выходной сигнал, когда
на входе ему предъявляется девушка, и низкий — когда юноша, то ве-
совые коэффициенты на дендритах берутся из столбца «Девушки».
Можно представить себе сеть из двух нейронов, в которой весовые
коэффициенты на дендритах взяты из столбцов «Юноши» и «Девушки».
Для повышения надежности идентификации объектов нейронной
сетью можно использовать большее количество нейронов, тогда раз-
личные нейроны будут применять независимые друг от друга рецеп-
торы.
Например, если можно не только видеть идентифицируемый объект,
но и обонять, и ощупывать, то это повышает надежность идентифи-
кации объекта. В этом состоит принцип наблюдаемости, согласно ко-
торому объекты и явления объективно существуют, если этот факт
установлен, по крайней мере, двумя независимыми способами.
В общем случае, в нейронной сети каждому классу (градации класси-
фикационной шкалы) будет соответствовать один нейрон и объект,
признаки которого будут измерены рецепторами на входе нейронной
сети и который будет идентифицирован сетью как класс, соответст-
вующий нейрону с максимальным уровнем сигнала на выходе.
Психологические тесты обычно позволяют тестировать респондента
сразу по нескольким шкалам. Очевидно, нейронные сети, реализую-
щие эти тесты, будут иметь как минимум столько нейронов, сколько
шкал в психологическом тесте.
9.6.3. Однослойная нейронная сеть
Исторически первой искусственной нейронной сетью, способной к
перцепции (восприятию) и формированию реакции на воспринятый
сигнал, явился Perceptron Розенблатта (Е Rosenblatt, 1957). Термин
384
9.6. Нейрокомпьютеры
Perceptron (персептрон) происходит от латинского perceptio, что оз-
начает восприятие, познавание.
Простейший классический персептрон содержит элементы трех ти-
пов: S, A, R (рис. 9.15), назначение которых в целом соответствует
нейрону рефлекторной нейронной сети, рассмотренному выше.
А-элементы
Рис. 9.15. Элементарный персептрон Розенблатта
5-элементы — это сенсоры (рецепторы), принимающие двоичные
сигналы от внешнего мира. Каждому 5-элементу соответствует опре-
деленная градация некоторой описательной шкалы.
Далее сигналы поступают в слой ассоциативных или Л-элементов
(показана часть связей от S- к /1-элементам). Только ассоциативные
элементы, представляющие собой формальные нейроны, выполняют
совместную аддитивную обработку информации, поступающей от
5-элементов с учетом изменяемых весов связей. Каждому /1-элементу
соответствует определенная градация некоторой классификацион-
ной шкалы.
5-элементы с фиксированными весами формируют сигнал реакции
персептрона на входной сигнал. 5-элементы обобщают информацию
о реакциях нейронов на входной объект, например могут выдавать
сигнал о принадлежности данного объекта к некоторому классу толь-
ко в том случае, если все нейроны, соответствующие этому классу,
выдадут результат именно о такой идентификации объекта. Это озна-
чает, что в 5-элементах может использоваться мультипликативная
функция от выходных сигналов нейронов. 5-элементы, так же как
и /1-элементы, соответствуют определенным градациям классифика-
ционных шкал.
385
252792
Глава 9. Системы параллельного действия
Розенблатт считал такую нейронную сеть трехслойной, однако по со-
временной терминологии представленная сеть является однослой-
ной, так как имеет только один слой нейропроцессорных элементов.
Если бы Л-элементы были тождественными по функциям Л-элемен-
там, то нейронная сеть классического персептрона была бы двух-
слойной. Тогда /(-элементы выступали бы для А-элементов в роли
S-элементов.
Однослойный персептрон характеризуется матрицей синоптических
связей ЦГРЦ от S- к /(-элементам. Элемент матрицы соответствует свя-
зи, ведущей от /-го S'-элемента (строки) ку-му /4-элементу (столбцы).
Эта матрица очень напоминает матрицы абсолютных частот и ин-
формативностей, формируемые в семантической информационной
модели.
На однослойном персептроне могут быть изучены основные понятия
и простые алгоритмы обучения нейронных сетей.
Обучение классической нейронной сети состоит в настройке весовых
коэффициентов каждого нейрона.
Пусть имеется набор пар векторов {х“, у“}, а = 1...р, называемый обу-
чающей выборкой, состоящей из р объектов.
Вектор {х“} характеризует систему признаков конкретного объекта а
обучающей выборки, зафиксированную S-элементами.
Вектор {у“} характеризует картину возбуждения нейронов при предъ-
явлении нейронной сети конкретного объекта а обучающей выборки:
„ (1, если у объекта а наблюдается /-й признак;
=<
[О, если у объекта а признак не наблюдается;
1, если при предъявлении объекта а активизируется
у-й нейрон;
О, если при предъявлении объекта а у-й нейрон
не активизируется.
Будем называть нейронную сеть обученной на данной обучающей
выборке, если при подаче на вход сети вектора {х“} на выходе всегда
386
9.6. Нейрокомпьютеры
получается соответствующий вектор {у“}, то есть каждому набору
признаков соответствуют определенные классы.
Розенблаттом предложен итерационный алгоритм обучения из трех
шагов, который состоит в настройке матрицы весов, последователь-
но уменьшающей ошибку в выходных векторах (при этом начальные
значения весов всех нейронов полагаются случайными). Сети предъ-
является входной образ х“, в результате формируется выходной образ.
Вычисляется вектор ошибки, формируемый сетью на выходе. Векторы
весовых коэффициентов корректируются таким образом, что величина
корректировки пропорциональна ошибке на выходе и равна нулю,
если ошибка равна нулю:
1. модифицируются только компоненты матрицы весов, отвечающие
ненулевым значениям входов;
2. знак приращения веса соответствует знаку ошибки, то есть поло-
жительная ошибка (значение выхода меньше требуемого) приводит
к усилению связи;
3. обучение каждого нейрона происходит независимо от обучения ос-
тальных нейронов, что соответствует важному с биологической точки
зрения принципу локальности обучения.
Шаги 1—3 повторяются для всех обучающих векторов. Один цикл
последовательного предъявления всей выборки называется эпохой.
Обучение завершается по истечении нескольких эпох, если выполня-
ется, по крайней мере, одно из условий:
► вектор весов больше не изменяется;
► полная просуммированная по всем векторам абсолютная ошибка
меньше некоторого малого значения.
Данный метод обучения был назван Розенблаттом методом коррекции
с обратной передачей сигнала ошибки. Имеется в виду передача сигнала
ошибки от выхода сети на ее вход, где и определяются и используются
весовые коэффициенты. Позднее этот алгоритм назвали J-правилом.
Данный алгоритм относится к широкому классу алгоритмов обучения
с учителем, так как в нем считаются известными не только входные
векторы, но и значения выходных векторов, то есть имеется учитель,
способный оценить правильность ответа ученика, причем в качестве
последнего выступает нейронная сеть.
387
Глава 9. Системы параллельного действия
9.6.4. Нейроматематика
Одной из важных математических задач, возникающих при нейросе-
тевых вычислениях, является установление адекватности сети мате-
матической модели заданного процесса.
По состоянию на сегодняшний день в основном сформировались три
раздела нейроматематики: общий, прикладной и специальный.
Нейроматематика — это раздел вычислительной математики, связан-
ный с решением задач с помощью алгоритмов, представимых в нейросе-
тевом логическом базисе.
Раздел общей нейроматематики представляет собой решение общих
математических задач в нейросетевом логическом базисе с целью ис-
ключения потерь на разработку специальных алгоритмов и повыше-
ния эффективности их решения. Даже, казалось бы, такие простые
задачи, как извлечение корня, сложение и умножение чисел, пыта-
ются решать на нейрокомпьютерах, поскольку при их ориентации на
нейросетевую физическую реализацию алгоритмы можно выполнить
значительно эффективнее, чем на известных булевских элементах.
Прикладная нейроматематика включает задачи, в принципе не ре-
шаемые известными типами вычислительных устройств. Примерами
таких задач являются:
► контроль кредитных карточек (диагностика фактической принад-
лежности карточки владельцу с настройкой нейронной сети в про-
странстве признаков покупаемых товаров);
► система скрытого обнаружения веществ с помощью устройств на
базе типовых нейронов и нейрокомпьютера на заказных цифровых
нейрочипах, что достаточно важно при обнаружении наркотиков,
ядерных материалов и т.д.
Сюда можно отнести задачи обработки изображений (сжатие с боль-
шим коэффициентом с последующим восстановлением, выделение
на изображении движущихся целей и т.д.), задачи обработки сигналов
(определение координат цели, прогнозирование надежности элек-
тродвигателей и Т.Д.).
Специальная нейроматематика включает задачи повышения качества
и увеличения динамических свойств изображения в системах вирту-
альной реальности, прямые и обратные задачи в системах защиты
информации и т.д.
388
9.6. Нейрокомпьютеры
Логической основой нейрокомпьютеров является теория нейронных
сетей (НС). Нейронная сеть — это сеть с конечным числом слоев из
однотипных элементов — аналогов нейронов с различными типами
связей между слоями нейронов.
Основными преимуществами НС как логического базиса алгоритмов
решения сложных задач являются:
► инвариантность методов синтеза НС по отношению к размерности
пространства признаков и размеров НС;
► отказоустойчивость в смысле монотонного, а не катастрофическо-
го изменения качества решения задачи в зависимости от числа вы-
шедших из строя элементов.
Развитие технологий микроэлектроники позволяет реализовать новые
идеи в архитектурных решениях. В середине 70-х годов прошлого века
появление средних интегральных схем (СИС) породило ЭВМ с архи-
тектурой SIMD, в начале 80-х — большие интегральные схемы (БИС)
позволили создать транспьютер и компьютер с архитектурой MIMD.
Во второй половине 80-х годов, когда появилась возможность аппа-
ратной реализации в одном кристалле каскадируемого фрагмента НС
с настраиваемыми или фиксированными коэффициентами, начали
активно проектироваться нейрокомпьютеры.
Понятие нейрокомпьютера наиболее реально определить с точки зре-
ния конкретной области применения.
В вычислительной технике нейрокомпьютер — это вычислительная систе-
ма с архитектурой MSIMD, в которой реализованы следующие прин-
ципиальные решения:
► упрощен до уровня нейрона процессорный элемент однородной
структуры;
► резко усложнены связи между элементами;
► программирование вычислительной структуры перенесено на из-
менение весовых связей между процессорными элементами.
Наиболее общее определение нейрокомпьютера может быть следую-
щим.
Нейрокомпьютер — это вычислительная система с архитектурой про-
граммного и аппаратного обеспечения, адекватной выполнению алго-
ритмов, представленных в нейросетевом логическом базисе.
389
Глава 9. Системы параллельного действия
9.7. Процессоры с архитектурой VLIW
Одной из перспективных архитектур компьютеров, ориентированных на
параллельную обработку данных, является VLIW (\fery Long Instruction
АМэгф-архитектура. Среди компаний, ведущих разработку в этом на-
правлении, можно отметить Intel, Texas Instruments и др.
Архитектура IA-64, предложенная в последние годы компанией Intel,
включает ряд новых свойств. Процессор Itanium, разработанный
в соответствии с IA-64, обладает следующими особенностями:
► масштабируемость архитектуры путем изменения количества функ-
циональных устройств;
► явное описание параллелизма в машинном коде (EPIC—Explicity
Parallel Instruction Computing). Поиск зависимостей между команда-
ми производит компилятор;
► предикация (Predication). Команды из разных ветвей условного
ветвления снабжаются предикатными полями (полями условий) и за-
пускаются параллельно;
► загрузка по предположению (Speculative loading). Данные из медлен-
ной основной памяти заранее загружаются в предположении их буду-
щей обработки.
9.7.1. Структура процессора Itanium
Архитектура IA-64 содержит значительное количество ресурсов раз-
личного назначения, включая большой набор регистров общего (РОН)
и специального назначения. Это значительно сокращает частоту об-
ращения к памяти для загрузки и выборки промежуточных данных.
В Itanium имеется 128 РОН (по 64 разряда), каждый из которых содер-
жит дополнительный бит NaT (Not a Thing), указывающий достовер-
ность значения в регистре. Установку этого бита могут производить
команды исполнения по предположению.
Конвейер вычислительного ядра включает 10 ступеней, обрабатывает
команды в порядке их расположения в программе и функционально
разделен на 4 блока:
► блок выборки команд обеспечивает выборку и предвыборку до
6 команд за такт, устанавливает иерархию ветвлений, связывает буфе-
ры (содержит три ступени);
390
9.7. Процессоры с архитектурой VLIW
► блок доставки команд обеспечивает диспетчирование до 6 команд
на 9 портах, переименование регистров, управление регистровым сте-
ком (содержит две ступени);
► блок доставки операндов обеспечивает связь блока регистров с па-
мятью и АЛУ, наблюдение и управление состоянием регистров, пред-
сказание зависимостей (содержит две ступени);
► блок исполнения управляет работой нескольких комплектов одно-
тактных АЛУ и устройств обращения к памяти, обеспечивает упреж-
дающую выборку данных, обработку предикатов, выполнение ветвле-
ний (содержит три ступени).
Аппаратура для выполнения операций с плавающей точкой содержит
82-разрядное АЛУ, которое обеспечивает поддержку вычислений в ши-
роком диапазоне числовых применений.
9.7.2. Параллелизм
В IA-64 в ассемблерных программах, обычно создаваемых компиля-
тором, [руппы команд, предназначенные для параллельного исполнения,
должны отмечаться явно. Эти группы в ассемблерном коде разделены
признаком stop (s-разряд), и все команды одной группы могут испол-
няться параллельно без дополнительной проверки, но в зависимости
от доступности ресурсов.
Команды IA-64 упаковываются (группируются) компилятором в связ-
ку длиною в 128 бит. Связка содержит три команды и шаблон, в котором
указываются зависимости между командами (можно ли с командой
к1 запустить параллельно к2, или же к2 должна выполняться только
после к1), атакже между другими связками (можно ли с командой кЗ
из связки cl запустить параллельно команду к4 из связки с2).
Например:
/1 || /2 || /3 — все команды исполняются параллельно;
/1 5 /2 || /3 — сначала rl, затем исполняются параллельно /2 и /3.
Одна такая связка, состоящая из трех команд, соответствует набору
из трех функциональных устройств процессора. Благодаря тому, что
в шаблоне указана зависимость и между связками, процессору с N
одинаковыми блоками из трех функциональных устройств будет со-
ответствовать командное слово из N*3 команд (А связок). Таким об-
разом, должна обеспечиваться масштабируемость IA-64.
391
Глава 9. Системы параллельного действия
Команды IA-64 имеют уникальный формат, который позволяет ком-
пилятору управлять аппаратным исполнением без существенного
увеличения объема программного обеспечения. На рис. 9.16 показа-
на единая 128-разрядная связка, содержащая три команды вместе
с шаблоном (template), содержащим информацию о связке. Каждая
команда содержит после кода операции предикатный регистр (6 бит),
адрес операнда (7 бит), адрес другого операнда (7 бит), адрес резуль-
тата (7 бит), код операции расширения. Поле Шаблон содержит ин-
формацию о параллелизме внутри связки и между связками.
Команда 1 Команда 2 Команда 3 Шаблон
41 41 41 5
Рис. 9.16. Структура связки
Команды IA-64 определяют шесть типов операций — целочисленная
операция в АЛУ, целочисленная операция вне АЛУ, обращение к па-
мяти, операция с плавающей точкой, операция ветвления, операция
с непосредственным операндом, а также четыре типа исполнитель-
ных устройств — команды, память, плавающая точка и ветвление.
Поле шаблона используется процессором для быстрого декодирова-
ния связки и посылки команд на соответствующие устройства. Послед-
ний (пятый) разряд шаблона отмечает, может ли следующая связка
команд выполняться параллельно с текущей связкой.
9.7.3. Предикация и загрузка по предположению
Еще одной особенностью IA-64 и, соответственно, процессора Itanium
является кардинально новый подход к работе с пере одами, названный
предикацией (predication). Для этого в архитектуру IA-64 введены 64
одноразрядных регистра предикатов, каждый из которых может на-
ходиться в состоянии «ложь/истина». К командам IA-64 добавляется
поле-предикат, указывающее аппаратуре, следует ли выполнять дан-
ную команду. Рассмотрим следующий код:
ri = г2 + гЗ.
Если использовать предикацию, то код будет иметь следующую форму:
if (р5) ri = г2 + гЗ.
392
9.7. Процессоры с архитектурой VLIW
Более сложный пример выглядит так:
if (а > Ь) с = с + 1
else d = d*e + f
Этот код может быть реализован в IA-64 с использованием предика-
тов, так что ветвления вследствие этого устраняются.
Благодаря большому числу функциональных устройств, МП может
выполнять две небольшие ветви программы параллельно, в связи
с чем некоторые потенциальные команды перехода исключаются.
Технология «отмеченных команд» является наиболее характерным
примером «дополнительной ноши», перекладываемой на компиля-
торы.
Обычно компилятор транслирует оператор ветвления (например,
IF-THEN-ELSE) в блоки машинного кода, расположенные в потоке
последовательно. В зависимости от условий ветвления процессор вы-
полняет один из этих блоков и пропускает остальные.
Современные процессоры пытаются предсказать результат вычисле-
ния условий ветвления и предварительно выполняют предсказанный
блок (частично это делает и Itanium). В случае ошибки предсказания
много тактов тратится впустую. Сами блоки зачастую весьма малы —
всего две или три команды, а ветвления встречаются в коде в среднем
каждые шесть команд. Такая структура кода делает крайне сложным
и неэффективным его параллельное выполнение.
Если компилятор IA-64 находит оператор ветвления в исходном коде,
то он исследует ветвление, определяя необходимость его «отметки».
В случае принятия такого решения компилятор помечает предикатом
с уникальным идентификатором все команды, относящиеся к одному
пути ветвления. Например, путь, соответствующий значению усло-
вия ветвления TRUE, помечается предикатом Р1, а каждая команда
пути, соответствующего значению условия ветвления FALSE, — пре-
дикатом Р2.
После этого компилятор транслирует исходный код в машинный
и упаковывает команды в 128-битовые связки. Команды в связках не
обязательно должны быть расположены в том же порядке, что и в ма-
шинном коде, и могут принадлежать к различным путям ветвления.
393
Глава 9. Системы параллельного действия
Во время выполнения программы IA-64 просматривает шаблоны, вы-
бирает взаимно независимые команды и распределяет их по функцио-
нальным узлам. После этого производится распределение зависимых
команд.
Испытания показали, что описанная технология позволяет устранить
более половины ветвлений в типичной программе и, следовательно,
уменьшить более чем в два раза число возможных ошибок в предсказа-
ниях. Программа для IA-64 обладает также большим параллелизмом.
Кроме отмеченных выше (параллелизм и предикация) IA-64 имеет
и такую особенность, как применение загрузки по предположению
(speculation), то есть предварительную загрузку данных. Она позволя-
ет не только загружать данные из памяти до того, как они понадобят-
ся программе, но и генерировать исключение только в случае, если
загрузка прошла неудачно. Цель предварительной загрузки — разде-
лить собственно загрузку и использование данных, что позволяет избе-
жать простоя процессора. Как и в технологии «отмеченных команд»,
здесь также сочетается оптимизация на этапе компиляции и на этапе
выполнения.
Создание микропроцессоров, способных конкурировать с Itanium,
ведется и в России. Микропроцессор Е2К (Эльбрус-2000), производ-
ство которого началось в конце 2001 года, также относится к архитек-
туре EPIC.
К VLIW-архитектуре можно отнести и программируемые цифровые
сигнальные процессоры TMS20C6xx корпорации Texas Instruments.
В серии выпускаются процессоры для работы с фиксированной (С62х)
и плавающей (С67х) точкой.
9.8. Потоковые компьютеры
Обычно последовательность операторов в программе задает порядок
вычислений и значения результата вычисления зависят только от это-
го порядка. В системе с управлением потоком операндов вычисления
упорядочиваются по готовности самих операндов. Первая схема ос-
нована на топографическом управлении, где значения данных подчи-
нены командам управления. Вторая схема одновременно применяет
394
9.8. Потоковые компьютеры
вычисления не ко всем готовым значениям данных, необходимым
в дальнейшем для вычислений других значений данных или формиро-
вания конечного результата.
9.8.1. Концепция управления потоком данных
В общем случае команда считается готовой к исполнению, как толь-
ко вычислены ее операнды. Для примера рассмотрим решение урав-
нения
Ах2 — Вх+С= 0 (при В2 — 4АС> 0).
Рис. 9.17. Граф потока операндов для решения уравнения
Граф потока операндов (рис. 9.17) фиксирует исходное состояние пе-
ред вычислением, признаки в виде точек на дугах отмечают готов-
ность значений. Используя язык однократного присваивания, это
вычисление можно записать в виде
Р\: XI = (В+ SQRT(B**2 - 4*А*С))/(2*А)
XI = (В SQRT(/?**2 - 4*Л*С))/(2*Л)
395
Глава 9. Системы параллельного действия
или
Р2: Л1 = 2*Л 11
В\ = В**2 12
С1=Л*С*4 13
D = B\-C\ 14
D\ = SQRT(D) 15
B2 = B + D\ 16
B3 = B-Dl 17
Л = 52/Л1 18
X2 = ЯЗ/Л1 19
Вершины в графе потока операндов или операторы в программе
активируются по мере готовности их аргументов. Такая активация
поглощает входные и выдает выходные значения, которые вместе
с предыдущими значениями активируют новые вершины или опе-
раторы. Активация осуществляется в произвольном порядке, что
приводит к недетерминированной программе. Например, операторы
11, 12 и 13 в программе Р2 готовы к исполнению в момент времени t0.
Они могут определить значения для Л1, В1 и С1 в любой момент вре-
мени в любом порядке, что активирует вычисления операторов 14
и 15, затем 16 и 17 и, наконец, 18 и 19.
9.8.2. Граф потока операндов
1)>аф потока операндов представляет собой двудольный ориентиро-
ванный граф с двумя типами вершин — соединительными и испол-
нительными. Дуги графа обеспечивают процесс признаков вместе
с вычисленными значениями от одного исполнителя к другому с по-
мощью соединительных вершин. Соединительные вершины будут
определены как выходные. Соединительная вершина, не являющая-
ся выходной, должна иметь, по крайней мере, одну выходящую из
нее дугу. Вершины имеют дело с двумя видами информации — дан-
ными и сигналами управления.
Различные типы вершин и их активация показаны на рис. 9.18.
Вычисление графа потока операндов описывается последовательно-
стью смен состояний графа. Каждое состояние отображает поток опе-
рандов программы с признаками и соответствующими значениями,
396
9.8. Потоковые компьютеры
Соединительная
вершина
для данных
Соединительная
вершина
для управления
Рис. 9.18. Активация различных типов вершин
размещенными на дугах графа программы. Вычисление переходит от
одного состояния к другому после срабатывания вершин обоих типов.
Значения, переносимые дугами управления, — булевы, а переноси-
мые дугами данных — целочисленные, вещественные или символь-
ные. В зависимости от модели потока операндов дуга обеспечивает
запоминание отдельного признака, действует как очередь признаков
или может рассматриваться как память прямого доступа для запоми-
нания и выборки «раскрашенных» признаков. Вычисление графа по-
тока операндов в рассмотренном примере происходит параллельно.
9.8.3. Языки потока операндов
Для сложных задач представление в виде графа достаточно затруднено,
что вызвало создание языков высокого уровня, позволяющих описать
процесс функционирования потоковых компьютеров. Кроме того,
397
Глава 9. Системы параллельного действия
исполнение программ потока операндов требует определенного вида
машинного языка, отображающего исходный граф, или механизмов
нижнего уровня для интерпретации программ высокого уровня. Поч-
ти все такие языки являются языками однократного присвоения (см.
раздел 9.8.4).
Язык ID был создан в Калифорнийском университете (Ирвин) в 1976
году. Он имеет блочную структуру, причем переменная всегда означа-
ет имя строки (а не ячейки памяти). Основные конструкции языка
ID — блоки, циклы, условия, определения процедур, абстрактные
типы данных и мониторы.
Условный оператор имеет две модификации:
a<-(IFZ>THENx+yELSEx*y)
или
IFZ>THENa<-x+yELSEa<-x*y
Блок задается операторами в скобках, один из них указывает на вы-
ходные переменные:
(х <- а*а, у <- b*b, z*- x + y;w <— х — у, RETURN SGRT (3/w))
Цикл представляет собой блок, содержащий итерационные операто-
ры и возвращаемые переменные:
(INITIAL х <-Да); WHILE (р(х,п) DO
у <- g(x,b)
х <- Л (а)
RETURNS ALL у, г(х))
CAJOLE — это непроцедурный язык высокого уровня, созданный
в Вестфилдском колледже (Лондонский университет). Особенности
языка:
► программа представляет собой список определений, то есть отсут-
ствует явная последовательность исполнения операторов;
► однократное присваивание функционального типа;
► имеются команды защиты для реализации механизма управления
доступом к данным в динамике;
398
9.8. Потоковые компьютеры
► существует механизм локализации имен для устранения их дубли-
рования:
а = b+с WITH b = 16, с=b* b WEND
► имеется механизм, позволяющий пользователю задавать собствен-
ные синтаксические конструкции. Общий вид такого оператора име-
ет вид:
[список параметров} макроимя - определяемое выражение.
Язык однократного присваивания с управлением потоком операндов
LAPSE разработан в Манчестерском университете. Он допускает струк-
турированные значения данных, функциональные подпрограммы и упо-
рядочивает применение итерации.
Как и в других языках однократного присваивания, для программи-
рования потока операндов возможности реализации итераций сильно
ограничены тем, что управление осуществляется только в пределах
одного блока операторов, так что описать итерационный процесс,
состоящий из нескольких подпроцессов, достаточно сложно.
В Массачусетсском технологическом институте разработана версия
языка потока операндов высокого уровня однократного присваива-
ния VAL. Это функциональный язык, так как каждый активный опера-
тор можно рассматривать как функцию, получающую входные данные,
действие которой приводит только к выработке некоторого набора
результатов. И программист, и компилятор могут выделить большин-
ство случаев параллелизма без специальных описаний, если не считать
конструкцию DOFORALL, подобную конструкциям, встречающимся
в расширениях языка Fortran для матричных машин. Система управ-
ления и контроля за динамическими ошибками в языке VAL исполь-
зует специальные признаки как элемент каждого типа данных.
Язык VAL работает со значениями, а не с переменными в том смысле,
что термин «переменная» указывает на изменяемый элемент данных,
которых в языках однократного присваивания нет. Для всех выраже-
ний в языке VAL используется нотация, близкая к алгебраической,
вместо функциональной записи.
Из недостатков языка \AL следует отметить отсутствие операторов
ввода/вывода. Добавим также некоторую неопределенность, кото-
рая проявляется в рассмотренном выше примере (см. раздел 9.8.1).
399
Глава 9. Системы параллельного действия
Создатели языка VAL считают, что COUNT и FIB, используемые как
операнды, относятся к предыдущим значениям. Означает ли это, что
новые значения COUNT и FIB, вычисленные на текущей итерации,
не могут быть использованы в качестве операндов других операторов
на этой же итерации? Если это так, то возникает ряд проблем при
программировании на этом языке.
9.8.4. Принцип однократного присваивания
Все языки, базирующиеся на управлении потоком операндов, в боль-
шей или меньшей степени должны использовать правило однократного
присваивания. Это правило является основным принципом написания
программ и непосредственно не связано с вычислениями по принципу
потока операндов.
Рассмотрим два варианта правила однократного присваивания.
Первый подход к программированию: переменной можно присвоить
значение только в одном операторе программы.
Следовательно, в языке однократного присваивания каждый опера-
тор при выполнении вычисляет некоторое значение, уникальное в те-
чение всего времени работы программы. После вычисления это значе-
ние можно использовать в любой момент времени другими операто-
рами. Поэтому последовательность выполнения операторов опреде-
ляется только готовностью значений данных. Программист явным
образом выражает параллелизм задачи (или даже алгоритма) для па-
раллельной асинхронной интерпретации на машине типа MIMD.
Обычные правила программирования, связанные с относительной
адресацией операторов в пределах программы, перестают действо-
вать в качестве ограничений, и все они заменяются правилом одно-
кратного присваивания.
Первым известным проектом языка однократного присваивания был
язык COMPEL. Все операторы в этом языке являются операторами
присваивания. Имеются три типа переменных: числа, списки и функ-
ции. Блочная структура обеспечивает локализацию имен. В заголовке
блока указываются входные переменные этого блока, а завершается
блок заданием множества выходных переменных. Специальные функ-
ции (EACH и LIST OF) обеспечивают обработку списков. Конструкция
EACH [а] вычисляет одновременно все значения списка а. Конструкция
400
9.8. Потоковые компьютеры
LIST OF [Z>] формирует одновременно список различных значений
некоторой переменной типа списка:
а = ЁАСН [1, 2, 4]
Ь = а*2
с = LIST OF [Z>]
Итерация (конструкция типа цикл) реализуется с помощью задания
некоторого списках и выбора последнего вычисленного элемента
г = EACH [vo BY 2 FOR л]
a = LIST OF [Z>*r]
x = LAST [a]
Специальный оператор PRECEDING(I) позволяет выделять 1-й ра-
нее вычисленный элемент списка.
Имеется и другой подход к правилу однократного присваивания: пе-
ременная может получить значение в программе только один раз.
На этой идее создан язык SAMPLE. В выражениях используются два
типа переменных: числа и множества. В язык включены конструкции
IF, FOR и WHILE, однако при их использовании требуется учитывать
ряд ограничений. В частности, в итерационных конструкциях при-
меняется специальный символ OLD X для ссылки на значение X из
предыдущей итерации. У Чемберлина содержатся предложения по
многопроцессорной архитектуре с управлением потоком операндов,
включая сложные механизмы управления динамической генерацией
шаблонов инструкций, структур данных и управления. Счетчик ко-
манд заменен на файлы команд, готовых к исполнению и ожидаю-
щих свободные процессоры.
9.8.5. Система LAU: многопроцессорная система
с управлением потоком операндов
Проект LAU начат в 1973 году с формального изучения идеи одно-
кратного присваивания. В 1976 году была завершена работа по специ-
фикации языка.
В результате на машинном уровне определены примитивы для управле-
ния потоком операндов и проведены эксперименты на языке высокого
уровня с задачами малой размерности из нескольких прикладных об-
ластей (матричные вычисления, сортировка, синтаксический анализ,
401
Глава 9. Системы параллельного действия
методы Монте-Карло, полиномиальные вычисления, платежные ве-
домости и обработка изображений). Одновременно разрабатывались
принципы адаптации алгоритмов для управления потоком операндов.
На основе имитатора к 1979 году была построена и опробована машина
типа MIMD, которая содержала четыре процессорных блока, а 10-про-
цессорная система LAU была введена в действие в конце 1981 года.
Одновременно с проектированием машины значительные усилия были
сосредоточены на программировании методов конечных разностей
и конечных элементов для решения задач аэродинамики в рамках
системы LAU и соответствующего языка программирования. В язык
введены основные примитивы для управления потоком операндов
и рассмотрено их использование при компиляции операторов высо-
кого уровня.
Потенциальные возможности системы LAU были продемонстриро-
ваны на примере реализации методов конечных разностей и конеч-
ных элементов при решении задач аэродинамики.
Упражнения
1. Покажите возможность построения такого компьютера, что любой за-
данный алгоритм может быть обработан параллельно.
2. Проанализируйте параметры функционирования вычислительной сис-
темы, если комплексирование будет осуществлено на уровне:
• процессоров,
• каналов ввода-вывода,
• оперативной памяти,
• внешней памяти.
3. Промоделируйте работу арифметико-магистральной, командно-магист-
ральной и макромагистральной обработки. Оцените для конкретного
класса задач эффективность их конвейерной обработки.
4. Разработайте эффективный (для конкретного класса задач) аппарат тегов
и дескрипторов.
5. В чем различаются два подхода к формированию принципа однократного
присваивания?
6. Сформулируйте особенности вычислений, базирующихся на идее управ-
ления потоком данных.
7. Объясните организацию вычислений в компьютерах с VLIW-архитектурой.
8. Постройте гиперкуб размерности 4.
402
Глава 10
Коммуникационные технологии
Коммутационные среды обычно включают адаптеры вычислителей
и коммутаторы, устанавливающие соединения между ними. Различа-
ют коммутаторы простые и составные, компонуемые из простых.
Простые коммутаторы имеют малую временную задержку при уста-
новлении полнодоступных соединений, но в силу физических ог-
раничений могут быть применены только для систем с малым числом
вычислителей. Если количество входов и выходов большое, то соз-
даются составные коммутаторы, состоящие из простых путем объеди-
нения их в многокаскадные схемы линиями «точка-точка». В настоя-
щее время коммутаторы, как правило, используют в качестве базовой
одну из следующих схем:
► коммутационная матрица,
► разделяемая многовходовая память,
► общая шина.
Иногда эти способы взаимодействуют в одном коммутаторе.
10.1. Коммутаторы вычислительных систем
Коммутаторы на основе коммутационной матрицы обеспечивают основ-
ной и самый быстрый способ взаимодействия портов процессоров.
Такой способ взаимодействия был реализован в первом промышлен-
ном коммутаторе. Однако реализация матрицы возможна лишь для
ограниченного числа портов. Известно, что сложность схемы воз-
растает пропорционально квадрату количества портов коммутатора.
Схема коммутирующей матрицы имеет вид, показанный на рис. 10.1.
Управляющие сигналы Ur управляют структурой коммутатора таким
образом, что п входных и п выходных линий взаимно коммутируются
требуемым способом. Максимальное число переключений составля-
ет л!, а верхней границей числа необходимых управляющих сигналов
является г = log2(n!). Сеть называется коммутирующей, если она вы-
полняет функцию коммутатора между входами и выходами. Схема
и состояния одной коммутирующей ячейки показаны на рис. 10.2.
403
Глава 10. Коммуникационные технологии
Управление (г)
Рис. 10.1. Схема коммутирующей матрицы
Q1
Рис. 10.2. Состояния коммутирующей ячейки
Из ячеек такого типа можно образовать разные типы коммутаторов.
Варианты переключений приведены на рис. 10.3.
Множество входных сигналов Х1г Х2, —,Хп отображается в множество
выходных сигналов Yh Y2,..., Yn в виде произвольной перестановки,
которую определяет вектор управляющих сигналов иг Число необхо-
димых ячеек составляет 0,5(л2 - п). Для квадратной матрицы требует-
2
ся п ячеек.
404
10.1. Коммутаторы вычислительных систем
Треугольная В = N коммутирующая матрица показана на рис. 10.4.
Рис. 10.4. Треугольная матрица
Классической стала коммутирующая сеть Клоса вида Q(n, т, г), кото-
рая содержит три ступени пхт, гхгнтхпс перекрестными комму-
таторами в модулях с номерами п, т, г (рис. 10.5).
Из сети типа Клоса была получена сеть Бенеша, которая имеет те
же свойства, что и перекрестный коммутатор, но содержит только
O(N logTV) элементов для сети N х N. Время прохождения сигнала
в сети равно O(logTV).
На рис. 10.6. приведена бинарная сеть Бенеша. Сеть содержит (2л—1)
уровней, каждый уровень состоит из 2"_| коммутирующих модулей.
Коммутирующий модуль 2x2 имеет два состояния: прямая коммута-
405
Глава 10. Коммуникационные технологии
ция и перекрестная коммутация. Эта сеть может бесконфликтно осу-
ществлять все перестановки вектора входов на выходе.
Другой важный тип коммутирующих сетей известен под названием
омега-сетей.
В качестве примера омега-сети рассмотрим коммутацию между век-
тором элементарных процессоров и вектором модулей памяти.
Омега-сети основаны на концепции математического представления
целых чисел по основанию омега. Сначала рассмотрим сети с N вхо-
дами и N выходами, где /V — степень числа 2. Сети других размеров
могут быть получены построением сети с N, равным наиболее близкой
(большей) степени числа 2, и удалением ненужных коммутирующих
элементов или использованием небинарной омега-сети. Омега-сеть
Nx TV состоит из Z = log2TV идентичных ступеней. Каждая ступень
производит переупорядочение элементов, в качестве которых может
406
10.1. Коммутаторы вычислительных систем
Рис. 10.6. Бинарная сеть Бенеша
быть бит, слово или битовое сечение, за которым следует N/2 комму-
Каждый коммутирующий элемент может нахо-
диться в одном из четырех состояний, показан-
ных на рис. 10.8.
Оба входа коммутируются с разными выходами.
Группа элементов делится на две подгруппы, и
элементы этих подгрупп переупорядочиваются
таким образом, что выход образуется из Z первых
элементов первой подгруппы, за которыми сле-
дуют Z элементов второй подгруппы и т.д.
Каждый элемент сети находится в одном из че-
тырех показанных на рис. 10.8 состояний, и дан-
ные переходят от входов к выходам, реализуя
Рис. 10.8. Состояние
коммутирующих
элементов
407
Глава 10. Коммуникационные технологии
отображение входного вектора в выходной. При этом возникают две
проблемы:
► построение алгоритма, определяющего состояние коммутирую-
щих элементов, необходимых для настройки сети за промежуток вре-
мени того же порядка, которого требует сеть для коммутации данных;
► определение всех отображений входа на выход.
Рассмотрим коммутацию входа S сети на выход D. Покажем, что суще-
ствует один и только один путь между конкретной парой вход-выход.
Пусть D=d2, —, dt — бинарное представление номера выхода, с ко-
торым должен быть скоммутирован вход S, и пусть S = s2, ..., $/ —
бинарное представление номера входа. Первый коммутирующий эле-
мент сети, к которому присоединен вход S, подает сигнал на верхний
выход, если = 0, или на нижний выход, если d} = 1 (вариант S = 010
и D = 110 показан на рис. 10.7). На следующем шаге вход также пере-
ключается на верхний выход, если d2 = 0, или на нижний, если d2 = 1.
Продолжая коммутировать элементы сети на каждом шаге / в соот-
ветствии с dh получим нужный выход. Таким образом, на произволь-
ном шаге / вход, который преобразовался к видуед-+1,..., s^,..., dj_i,
тасуется и приобретает вид 5,+ii(+2>—а затем становится
5,+15,-+2, S/di,..., dj-idj. Следовательно, после I-\og2Nопераций вход
S должен быть соединен с выходом d}d2...dh Аналогичный алгоритм
может начать работу на выходе D и идти обратно по сети, переключая
/-Й элемент в соответствии с s,.
Для осуществления необходимой коммутации входов на выходы опи-
санная процедура выполняется одновременно для всех входов или
выходов. Алгоритм всегда выбирает единственный путь по сети меж-
ду произвольными входом и выходом. Однако может быть множество
путей, которые сеть не способна реализовать. Например, на рис. 10.9
показаны пути, полученные для отображений 000 —> 000 и 100—>010,
пересекающиеся на выходе первой ступени. Такая конфликтная си-
туация недопустима, поскольку два различных сигнала используют
один общий проводник (предполагается, что два сигнала могут ис-
пользовать общий проводник, только если они имеют общий источ-
ник). Следовательно, алгоритм будет выбирать единственный путь
в сети для каждого произвольно заданного отображения, но пути
в этом множестве не обязательно будут разделенными, то есть могут
возникнуть конфликты.
408
10.1. Коммутаторы вычислительных систем
Рис. 10.9. Пример множества путей
Существует несколько способов реализации омега-сетей. Рассмот-
рим некоторые из них.
Коммутирующие элементы на рис. 10.7 имеют размер 2x2. При ис-
пользовании элементов 4x4 можно построить более мощную сеть.
Элементы 4x4 могут быть омега-сетями 4x4, построенными из эле-
ментов 2 х 2. В этом случае сеть идентична сети, построенной из эле-
ментов 2x2.
В коммутаторах с общей шиной процессоры портов связываются вы-
сокоскоростной шиной, функционирующей в режиме разделения вре-
мени. Пример такой архитектуры приведен на рис. 10.10.
Чтобы шина не блокировала работу коммутатора, ее производитель-
ность должна по крайней мере равняться сумме производительности
всех портов коммутатора. Кадр должен передаваться по шине неболь-
шими частями, объем которых определяется производителем коммута-
тора, по нескольку байт, чтобы передача кадров между несколькими
портами происходила в псевдопараллельном режиме, не внося задер-
жек в передачу кадра в целом. Шина, так же как и коммутационная
матрица, не может осуществлять промежуточную буферизацию, но,
поскольку данные кадра разбиваются на небольшие ячейки, задержек
с начальным ожиданием доступности выходного порта в такой схеме
нет — здесь работает принцип коммутации пакетов, а не каналов.
409
Глава 10. Коммуникационные технологии
Рис. 10.10. Коммутаторы с общей шиной
Еще одна базовая архитектура взаимодействия портов — двухвходо-
вая разделяемая память. Пример такой архитектуры приведен на
рис. 10.11.
Рис. /Л/7. Двухвходовая память
Входные блоки процессоров портов соединяются с переключаемым
входом разделяемой памяти, а выходные блоки этих же процессо-
ров — с переключаемым выходом этой памяти. Переключением входа
410
10.2. Коммуникационная среда SCI
и выхода разделяемой памяти управляет менеджер очередей выход-
ных портов. В разделяемой памяти менеджер организует несколько
очередей данных, по одной для каждого выходного порта. Входные
блоки процессоров передают менеджеру портов запросы на запись
данных в очередь того порта, который соответствует адресу назначе-
ния пакета. Менеджер по очереди подключает вход памяти к одному
из входных блоков процессоров и тот переписывает часть данных
кадра в очередь определенного выходного порта. По мере заполнения
очередей менеджер также производит поочередное подключение вы-
хода разделяемой памяти к выходным блокам процессоров портов,
и данные из очереди переписываются в выходной буфер процессора.
Память должна быть достаточно быстродействующей для поддержания
скорости передачи данных между Nпортами коммутатора. Примене-
ние общей буферной памяти, гибко распределяемой менеджером ме-
жду отдельными портами, снижает требования к размеру буферной
памяти процессора порта.
В каждой из описанных архитектур имеются преимущества и недос-
татки, поэтому часто в сложных коммутаторах рассмотренные архи-
тектурные решения комбинируются, что позволяет уменьшить влияние
недостатков и интегрально усилить достоинства.
10.2. Коммуникационная среда SCI
Масштабируемый когерентный интерфейс (Scalable Coherent Interface)
принят как стандарт ANSI/IEEE Std 1596—1992. Для обозначения
этого стандарта общепринято сокращение SCI.
10.2.1. Структура коммуникационных сред на базе SCI
SCI предусматривает реализацию когерентности посредством стан-
дартно организованной кэш-памяти, размещаемой в узле SCI. Эта
кэш-память располагается в интерфейсе между вычислительным мо-
дулем (ВМ) и узлом и вписывается в механизм реализации когерент-
ности ВМ следующим образом:
► если на предыдущих уровнях иерархии памяти ВМ обнаруживается
отсутствие необходимых данных, то производится их поиск в кэш-па-
мяти узла;
411
Глава 10. Коммуникационные технологии
► при нахождении данных, если последние состоятельны, их копия
перемещается внутрь иерархии памяти ВМ. Если же данные находят-
ся в состоянии модификации, запись осуществляется после ее завер-
шения;
► при отсутствии данных вырабатывается сигнал промаха, который
активизирует адаптер интерфейса на выполнение действий по дос-
тавке данных с удаленных блоков памяти.
Мультипроцессорный (МР) сервер, компонуемый пользователем из рабочих
станций или персональных компьютеров (материнских плат)
МР сервер повышенной отказоустойчивости
с малой задержкой установления соединений
Локальная сеть на основе адаптеров и линков SCI
Рис. 10.12. Использование SCI
412
10.2. Коммуникационная среда SCI
Стандарт SCI обеспечивает построение легкой в реализации, масшта-
бируемой, эффективной в стоимостном аспекте коммуникационной
среды для объединения процессоров и памяти, создания распреде-
ленной сети рабочих станций, организации ввода/вывода суперЭВМ,
высокопроизводительных серверов и рабочих станций на базе мик-
ропроцессоров. Стандарт предусматривает наличие пропускной спо-
собности не менее 1 Гбайт/с для сосредоточенных систем и не менее
1 Гбайт/с для распределенных систем типа сети рабочих станций.
Каждый узел имеет входной и выходной каналы. Узлы связаны одно-
направленными каналами «точка-точка» либо с соседним узлом, либо
подключены к коммутатору. При объединении узлов должна обяза-
тельно формироваться циклическая магистраль (кольцо) из узлов,
соединенных каналами «точка-точка», между входным и выходным
каналами каждого узла. Один из узлов в кольце, называемый scrubber,
выполняет следующие функции: инициализации узлов кольца с уста-
новлением адресов, управления таймерами, уничтожения пакетов,
не нашедших адресата. Этот узел отмечает проходящие через него па-
кеты и уничтожает уже помеченные пакеты. В кольце может быть
только один scrubber.
Возможные структуры систем с использованием SCI показаны на
рис. 10.12.
При реализации интерфейса на задней панели возможны соединения
в последовательное кольцо или кольцо с чередованием, как показано
на рис. 10.13. Для обхода пустых разъемов предполагается использо-
вать либо платы-проходники, либо пары переходных плат.
Возможно построение многокольцевых систем, связанных через
агентов. Агент-коммутатор или агент-мост обеспечивают соединение
Последовательное кольцо
Кольцо с чередованием
Рис. 10.13. Одномерный тор
413
Глава 10. Коммуникационные технологии
между разными кольцами или между кольцом и коммутационной
средой с другим протоколом, например шинами PCI, S-bus. Посред-
ством SCI могут быть реализованы различные структуры межсоеди-
нений, некоторые из них показаны на рис. 10.14—10.16.
Рис. 10.14. Двумерная решетка
Возможности, функционально эквивалентные предоставляемым при
взаимодействии устройств на шине, реализуются путем образования
однонаправленной магистрали между узлами, состоящей из цепочки
соединений «точка-точка» между узлами и коммутаторами межузло-
414
10.2. Коммуникационная среда SCI
Драф связей коммутатора
1Ьризонтальные каналы
Диагональные каналы
Рис. 10.16. Реализация коммутатора
вых соединений. Однонаправленность передач в SCI имеет принци-
пиальный характер, так как исключает переключение выходных ножек
микросхем с передачи на прием и обратно (такое переключение соз-
дает большие электрические помехи). Таким образом, вместо физиче-
ской шины используется множ ство парных соединений, обеспечиваю-
щих высокую скорость передачи. Преодолевается фундаментальное
ограничение шин — одна передача в каждый промежуток времени
предоставления шины передающему устройству, а также ограничения,
связанные со скоростью распространения сигналов по проводникам.
В случае асинхронных шин ограничение обусловлено временем пере-
415
Глава 10. Коммуникационные технологии
дачи сигналов «запрос-подтверждение», в случае синхронных шин —
разницей времени распространения тактового сигнала от его генера-
тора и времени распространения данных из передающего устройства.
SCI узлы защищены от механических воздействий и электромагнит-
ных излучений и могут заменяться без отключения питания. В SCI
принята следующая система обозначения каналов: <тип/число сигна-
лов>—<род сигналов:»—<частота передачи в МГЦ/С>- Например, запись
I8-DE-500 означает передачу 18 бит параллельно с использованием
дифференциальных электрических сигналов в передатчиках и при-
емниках и передачей информации по переднему и заднему фронту на
частоте 250 Мгц. SCI использует 16-битовую магистраль данных,
а также одну магистраль для передачи тактового сигнала и одну для
флагового бита. Эти связи реализуются как 18 пар проводов с пропу-
скной способностью 1 Гбайт/с. Оптоволоконный канал применяется
для побитовой передачи с пропускной способностью 1,25 Гбайт/с.
10.2.2. Логическая структура SCI
Информационный обмен между узлами SCI, реализуемый посредст-
вом транзакций, включает помимо обычных для шинных структур
«чтения» и «записи» средства синхронизации (замок — lock), поддерж-
ку когерентности строк кэш-памяти и основной памяти, передачу со-
общений и сигналов прерываний. Все транзакции пересылают SCI
пакеты между узлом-источником и узлом-получателем. Транзакции
предусматривают передачу пакетов с блоками данных фиксированной
длины в 64 и 256 байт, переменной длины 1—16 байт. Фиксированная
длина пакетов упрощает логику и увеличивает быстродействие ин-
терфейсных схем. Протоколы передачи пакетов обеспечивают управ-
ление передачами, устранение последствий отказов, предотвращение
дедлоков.
Транзакция инициируется узлом-источником, а завершается узлом-по-
лучателем. Схема выполнения транзакции показана на рис. 10.17.
Транзакция состоит из двух субакций — субакции запроса, во время
которой от узла-источника к узлу-получателю передаются адрес и ко-
манда, и субакции-ответа, во время которой от узла-получателя пере-
дается статус завершения. Субакция состоит из передачи двух пакетов
и инициируется источником путем посылки пакета, а завершается
вторым участником путем посылки инициатору пакета-эха.
416
10.2. Коммуникационная среда SCI
и
с
т
о
ч
н
и
к
Посылка запроса
Субакция
запроса 1
Эхо запроса
Посылка ответа
Эхо ответа
} Субакция
ответа
П
О
Л
У
Ч
А
Т
Е
Л
Ь
Рис. 10.17. Схема выполнения транзакций
Если транзакция выполняется не внутри одного кольца, то в ней также
принимают участие агенты. Каждый агент ведет себя как изготови-
тель пакетов для адресата. С точки зрения источника агент представляет
собой получателя, формируя эхо-пакет.
Транзакции записи и чтения. При команде «запись» данные передаются
в субакции запроса, при команде «чтение» — в субакции ответа либо
в обеих субакциях при записи-чтении. Транзакция чтения (readxx)
копирует данные из устройства-получателя в устройство-источник,
транзакция записи (writexx) копирует данные из устройства источни-
ка в устройство-получатель, где хх — разрешенные размеры блоков
данных (0,16, 64, 256 байт).
Транзакция пересылки. Транзакция пересылки movexx не предполагает
ответа от устройства-получателя, как, например, при последовательно-
сти передаваемых телевизионных кадров, и не возвращает источнику
статус ошибок.
Транзакции блокировки. Транзакция блокировки locksb копирует дан-
ные из узла-источника в узел-получатель, который обновляет упомя-
нутый в транзакции адрес. Субакция ответа возвращает предыдущее
(еще не обновленное) состояние данных и статус. Эта транзакция,
используемая при синхронизации, поддерживает два списка блоки-
рующих примитивов — кэшированный и некэшированный. Кэширо-
ванная блокировка выполняет временное блокирование строки кэша
в only-dirty (модифицируемом) состоянии, пока исполняется требуемая
последовательность команд. Некэшированные блокирующие транзак-
ции, включающие swap (обмен) и compare-and-swap (сравнение и об-
мен), используются для доступа к разделяемым данным.
417
27
л ' 2792
Глава 10. Коммуникационные технологии
Транзакция прерывания. Распространение прерываний между процес-
сорами и/или мостами с вводом/выводом поддерживается транзак-
циями записи в регистры управления и состояния.
Транзакция передачи сообщений. SCI поддерживает передачу сообще-
ний по стандарту IEEE Std 1212. Некогерентная транзакция записи
(write 64) используется для посылки коротких незапрошенных сооб-
щений в специфичные регистры управления и состояния адресуемого
узла. Типичное применение таких транзакций — получение доступа
к управляющим регистрам мостов и устройств ввода/вывода.
10.2.3. Архитектура SCI
В SCI принята 64-разрядная архитектура с 64-битовым адресным
пространством. Старшие 16 бит задают адрес узла и используются для
маршрутизации SCI пакетов между узлами системы. Остальные 48 бит
адресуют внутреннюю память узла. SCI ориентирован на поддержку
строк размером 64 байта. Другие размеры строк автоматически под-
держиваются в многоуровневых кэш-памятях. Структура адресного
пространства показана на рис. 10.18.
Рис. 10.18. Структура адресного пространства
Упрощенный формат пакета показан на рис. 10.19. Пакет состоит из
трех частей: заголовка, адресной и информационной части, а также
кодов обнаружения и коррекции ошибок.
418
10.2. Коммуникационная среда SCI
Флаг Данные (16 бит)
targetid
Управление потоком; Команда
sourceid
Время уничтожения
Адрес/статус
Данные (могут отсутствовать)
Циклический избыточный код (ЦИК)
Маскировано от подсчета ЦИК (принят 0)
Рис. 10.19. Формат пакета
Первые 16 бит заголовка содержат идентификационный код targetid —
адрес узла-получателя. При получении очередного сообщения узел
по этому коду определяет, его ли это сообщение или транзитное.
Промежуточные агенты просматривают его во время прохождения
для маршрутизации пакета между кольцами.
Второе поле заголовка пакета (управление потоком) задает режим
прохождения пакета, содержит тип транзакции и длину пакета. Поле
управления потоком может изменяться при прохождении пакета
и поэтому не учитывается при подсчете циклического избыточного
кода (ЦИК) пакета. ЦИК — последовательно-параллельная версия
16-битового кода.
Поле «команда» содержит команду, которую должен выполнить узел-
получатель. Командное поле в пакете запроса определяет действие
(чтение 00, чтение sb, запись sb и другие), в пакете ответа командное
поле извещает о количестве возвращаемых данных, а в пакете-эхо
указывает, был ли принят посланный пакет.
Следующее 16-битовое поле заголовка содержит адрес sourceid узла,
отправившего сообщение. Все пакеты имеют 6-значный порядковый
номер, позволяющий различать пакеты одного отправителя.
419
Глава 10. Коммуникационные технологии
В конце каждого пакета находится ЦИК, проверяемый при передачах
пакетов.
В пакеты также могут быть включены:
► время уничтожения — время, когда пакет должен быть уничтожен;
► начальный относительный 48-разрядный адрес;
► 48-разрядное поле, возвращающее статус от получателя к источнику;
► расширенный заголовок — дополнительные 16 байт заголовка, что
указывается в командном поле. Всего в пакете может быть 0, 16 или
64 байта данных.
10.2.4. Когерентность кэш-памятей
Протоколы когерентности кэш-памятей определяют механизмы ра-
боты с многими локальными копиями одних и тех же данных. Если
протокол когерентности реализован аппаратно, то снижаются требо-
вания к сложности операционной системы и системы программиро-
вания. В SCI протокол основан на распределенных директориях, как
показано на рис. 10.20.
Узлы
головной
внутренний
внутренний
Рис. 10.20
оконечный
ЦП_А
Все узлы с копиями данных участвуют в распределенном списке узлов,
использующих одну и ту же строку данных. Тег каждой кэш-строки
содержит указатели на предыдущий и последующий узлы, разделяю-
420
10.2. Коммуникационная среда SCI
щие эту строку (имеющие копии строки в своей кэш-памяти). Голов-
ной узел содержит указатель на контроллер блока памяти, который,
в свою очередь, имеет указатель на головной узел. Оконечный узел не
содержит указателя на последующий узел. Таким образом, каждая
разделяемая строка памяти связана с распределенным списком уз-
лов, разделяющих эту строку. Все узлы, разделяющие строку, участву-
ют в формировании этого списка.
В зависимости от архитектуры процессора и исполняемой приклад-
ной программы строки памяти могут когерентно кэшироваться, не ко-
герентно кэшироваться либо не кэшироваться вовсе.
Когда узел когерентно обращается к памяти за данными строки, па-
мять сохраняет адрес этого узла и возвращает адрес предыдущего
узла, запрашивавшего эту же строку. Это выполняется посредством
быстрого безусловного обмена между узлом и памятью. Если данные
в памяти состоятельные (никакой узел не запрашивал доступа для из-
менения содержимого элементов строки), то данные из памяти сразу
передаются запросившему их узлу. Если данные строки памяти не со-
стоятельны, а состоятельные данные находятся в каком-либо кэше,
то возвращается только адрес узла, запрашивавшего эту строку послед-
ним (без строки данных). Узел, запрашивающий доступ к данным,
используя этот адрес, обращается непосредственно в узел, имеющий
состоятельные данные. Затем завершается формирование списка уз-
лов, разделяющих строку памяти.
Доступ по записи в строку памяти предоставлен только узлу, находя-
щемуся в начале списка. Для получения доступа по записи узел, быв-
ший элементом списка, удаляет себя из списка и запрашивает доступ
к памяти с правом записывать данные. Так как узел обращается к раз-
деляемой строке, он ставится в начале очереди и вправе модифици-
ровать данные, но обязан очистить (отметить как несостоятельные)
все последующие элементы списка.
Стандарт SCI предусматривает как слабую, так и сильную поддержу
последовательного выполнения программного кода. В случае слабой
поддержки операция записи может быть произведена до завершения
очистки списка. При сильной поддержке последовательного выполне-
ния запись должна производиться только после очистки списка.
SCI поддерживает как линейное, так и логарифмическое (древовид-
ное) распространение очистки списка. Стандарт SCI позволяет паре
421
Глава 10. Коммуникационные технологии
узлов обмениваться данными, не прибегая к использованию памяти,
пока некоторый другой узел не запросит данные. Достоинство ис-
пользуемого в SCI протокола когерентности состоит в том, что при
расширении системы не требуется изменений в уже существующей.
Недостатком является необходимость дополнительной памяти для
хранения указателей.
10.2.5. Функциональная организация узла SCI
Узлы SCI должны отсылать сформированные в них пакеты с возмож-
ным одновременным приемом других пакетов, адресованных узлу,
и пропуском через узел транзитных пакетов. Структура узла показана
на рис. 10.21.
Интерфейс с микропроцессором
или другой прикладной системой
Рис. 10.21. Структура узла
Для транзитных пакетов, прибывающих во время передачи узлом соб-
ственного пакета, предусмотрена проходная FIFO очередь. При дис-
циплине, когда собственный пакет не передается до тех пор, пока
есть транзитные, необходимая длина проходной очереди определяется
длиной передаваемых узлами пакетов. Размер проходной очереди дол-
жен быть достаточен для приема пакетов без переполнения. В узле
вводятся также входная и выходная FIFO очереди для пакетов, при-
нимаемых и передаваемых узлом соответственно.
Узел SCI принимает поток данных и передает другой поток данных.
Эти потоки состоят из SCI пакетов и свободных (пустых — idle) сим-
волов. Через каналы непрерывно передаются либо символы паке-
тов, либо свободные символы, которые заполняют интервалы между
422
10.2. Коммуникационная среда SCI
пакетами. Если нечего передавать и проходная очередь узла пуста, он
передает на выход свободный символ.
Появление сигнала «1» на флаговой магистрали отмечает начало па-
кета. Если адрес получателя в пакете совпадает с адресом узла, пакет
извлекается в узел. Информация из заголовка пакета используется
для формирования эхо-пакета, который заносится в проходную FIFO
очередь для отправки от получателя к отправителю. Если входная
FIFO очередь узла полна, пакет исключается, и в управляющем поле
эхо-пакета устанавливается бит занятости, что извещает отправителя
о необходимости повторно передать пакет. Когда узел в состоянии
принять этот пакет, его пакет направляется во входную FIFO очередь.
Затем вычисляется ЦИК и сравнивается со значением ЦИК пакета.
При совпадении — прием пакета окончен, иначе этот пакет игнори-
руется, а ЦИК эхо-пакета изменяется так, чтобы эхо-пакет был от-
брошен (это позднее должно вызвать его повторную передачу). Если
на вход прибывает пакет, не предназначенный узлу, то он поступает
в проходную FIFO очередь. Пересылаемый пакет накапливает ин-
формацию для управления передачей пакетов. Управляющая инфор-
мация помещается в заголовок пакета и, как минимум, в один свобод-
ный символ, отделяющий данный пакет от последующего пакета. На
основе этого механизма выполняются все функции управления пото-
ком пакетов: арбитраж, приоритетность, продвижение пакетов.
Узел может передавать пакет, если его проходная FIFO очередь пуста.
Передача пакета инициируется его перемещением в выходную FIFO
очередь. Когда пакет передается, для него вычисляется ЦИК, кото-
рый конкатенируется к концу пакета. Передача начинается помеще-
нием слова на выход и установкой высокого значения выходного
флага, которое сохраняется все время передачи пакета. ЦИК добав-
ляется к концу пакета, когда значение выходного флага становится
низким.
Узел, отправляя пакет, помечает его номером, который возвращается
узлу при приеме эхо-пакета от узла-адресата. Если в течение времени
тайм-аута не поступает ответный пакет, то выполняется повтор пере-
дачи пакета. После выдачи пакета его копия сохраняется в выходной
очереди до получения эхо-пакета. Узел-получатель, принимая пакет,
создает эхо-пакет и направляет его отправителю. При возможности
сохранить пакет в узле возвращается эхо-пакет «выполнено», иначе
423
Глава 10. Коммуникационные технологии
возвращается эхо-пакет «повтор». По возвращении эхо-пакета «вы-
полнено» соответствующий пакет посылки ликвидируется. Когда воз-
вращается эхо-пакет «повтор», исходный пакет высылается заново.
Узел может послать до 64 пакетов, прежде чем будет получен ответный
эхо-пакет. Эхо-пакеты могут приходить не в том порядке, в котором
были посланы инициировавшие их пакеты, поэтому необходима их
нумерация для установления соответствия между пакетами и эхо-па-
кетами.
Управление предусматривает арбитраж, предотвращение блокировок
(деддоков), борьбу с заторами и переполнениями.
Для предотвращения блокировок всем узлам предоставляется право
доступа к интерфейсу. Это означает, что все возможные 64К устройств
могут начать передачу одновременно. Алгоритм управления базируется
на предоставлении всем устройствам равных возможностей и приори-
тетности и функционирует на основе информации в заголовках паке-
тов и свободных символов между пакетами. Уровень приоритета пакета
определяется командой, содержащейся в заголовке. Узел, которому
требуется передать пакет с бблыпим приоритетом, чем приоритет
проходящего через него пакета, вносит соответствующий код в заголо-
вок проходящего пакета. Узел, пославший пакет, информирует о том,
что другой узел требует передачи пакета с бблыпим приоритетом.
Указанная информация, управляющая потоками пакетов, также рас-
пространяется среди узлов посредством свободных символов между
пакетами. SCI имеет несколько механизмов эффективного продвиже-
ния пакетов. Для предотвращения деддоков SCI содержит отдельные
очереди для пакетов и эхо-пакетов, а также механизмы, запрещающие
генерировать новые пакеты по получении эхо-пакета с требованием
повторной передачи пакета.
Для борьбы с заторами используются протоколы назначений (allo-
cation protocols). Среди них выделяются протоколы распределения
пропускной способности и протоколы распределения очередей. Первые
протоколы способны запрещать передачу пакетов от совокупности
узлов в том случае, если один из узлов не может передать свой пакет.
Вторые протоколы используются для распределения объема входной
очереди в случае, если несколько узлов посылают пакеты одному
узлу. Это может быть реализовано как отказ от приема пакета с по-
сылкой эхо-пакета «занято» и дальнейшим резервированием места
в очереди для приема пакета при одной из повторных его передач.
424
10.3. Коммуникационная среда MYRINET
10.3. Коммуникационная среда MYRINET
Логический протокол Myrinet был развит в Caltech Submicron Systems
Architecture Project. Эта среда стандартизует формат пакета, способ
адресации ВМ, набор управляющих символов протокола передачи
пакетов.
10.3.1. Структура среды
Коммуникационная среда образуется адаптерами «шина компью-
тера — линк сети» и коммутаторами линков сети. Каждый линк со-
держит пару однонаправленных каналов, образуя дуплексный канал.
Возможные структуры вычислительных систем, построенных с ис-
пользованием адаптеров и коммутаторов Myrinet, показаны на
рис. 10.22.
Линки передают пакеты заданной структуры, состоящие из заголовка
данных пакета и концевика. Поток передачи по линку может быть
Адаптер
Myrinet
Адаптер
Myrinet
Система, образованная прямым соединением лиихов адаптеров
Рис. 10.22. Структура систем с использованием Myrinet
425
Глава 10. Коммуникационные технологии
остановлен получателем на заданный промежуток времени, напри-
мер на время подготовки буфера приема. Если передающий адаптер
заблокирован получателем на время большее, чем требует пересылка
222 байт, то этот адаптер посылает получателю сигнал сброса. Плата
адаптера встраивается в шину ВМ и подсоединяется к питанию ком-
пьютера. Допускается подключение произвольного числа адаптеров
к шине в пределах ее коммуникационных возможностей. Адаптер со-
держит 128 Кбайт памяти, используемых как для хранения пакетов,
так и для управляющей программы адаптера. Эта программа испол-
няется процессором LANai адаптера. Микропроцессор LANai реали-
зован как заказная СБИС фирмой MYRICOM, распространяющей
сеть Myrinet.
10.3.2. Коммутаторы и маршрутизация
Выпускаются коммутаторы с 4, 8, 12 и 16 портами. Если коммутатор
имеет к портов, то они именуются 0, 1,..., к—1. Пакеты, адресуемые
портам с именами вне этого диапазона, пропадают аналогично тем
пакетам, которые адресованы неиспользуемым портам или портам,
подсоединенным к каналам, приводящим в обесточенные адаптеры.
В коммутаторе используется передача пакетов путем установления
соединения на время передачи. Соединение выполняется после прие-
ма заголовка и определения порта, через который пакет должен выйти
из коммутатора. Если этот порт свободен, то вначале передается заго-
ловок, затем байт за байтом тело пакета и концевик, после чего раз-
рывается установленное в коммутаторе соединение. Если требуемый
выходной порт занят передачей другого пакета, прием блокируется
входным портом. Коммутатор имеет собственное питание и может
функционировать автономно.
Заголовок пакета, передаваемого в сеть Myrinet для прохождения через
п— 1 коммутатор, состоит из п байтов, п > 0, причем старший бит в пер-
вых п—1 байтах равен 1, а в байте п — равен 0. Когда пакет прибывает
в порт коммутатора или адаптера, анализируется только первый байт
поступившего заголовка. При поступлении в коммутатор этот байт
задает номер порта, через который пакет должен покинуть коммутатор.
Если пакет прибыл в порт адаптера, то первый байт интерпретируется
как тег, используемый управляющей программой адаптера для иден-
тификации пакетов пользователей и управляющих пакетов. Алгоритм
маршрутизации пакетов иллюстрируется рис. 10.23.
426
10.3. Коммуникационная среда MYRINET
Порт з
Порт 5
Адаптер Myrinet - Коммутатор Коммутатор *- Адаптер Myrinet
Заголовок Заголовок Заголовок Пакет
пакета пакета пакета с тегом
10000011 10000101 00000001 00000001
10000101 00000001
00000001
Рис. 10.23. Алгоритм маршрутизации пакетов
Принятый пакет анализируется, после чего из него удаляется первый
байт заголовка. Если старший бит первого байта заголовка равен 0,
этот пакет игнорируется. Если в адаптер поступает первый байт заго-
ловка со старшим битом 1, то пакет подлежит анализу. Коммутаторы
Myrinet используют относительную адресацию, при которой содержи-
мое первого байта заголовка рассматривается как 6-битовое смеще-
ние, заданное в дополнительном коде. Номер порта, через который
пакет должен покинуть коммутатор, вычисляется как сумма по моду-
лю 64 номера порта, через который пакет поступил, и содержимого
первого байта заголовка.
Циклический избыточный код (ЦИК) обнаруживает повреждение
пакета, в том числе в результате технических проблем. Полностью
нулевой байт будет иметь ЦИК, состоящий из нулей. ЦИК вычисляет-
ся для всего пакета, включая заголовок. Так как заголовок модифици-
руется коммутатором через отбрасывание первого байта, необходимо
при выдаче пакета перевычислять его ЦИК. Коммутатор вычисляет
ЦИК поступившего пакета и складывает его по модулю 2 с ЦИК, со-
держащимся в пакете, сохраняя результат в позиции ЦИК пакета.
При этом правильный пакет даст результат, состоящий из нулей. Далее
коммутатор вычисляет ЦИК сформированного для выдачи пакета
и складывает его по модулю 2 с содержимым позиции ЦИК пакета.
Когда пакет достигнет адаптера, решение о правильности пакета
принимает управляющая программа.
10.3.3. Логический уровень
Пакеты состоят из 9-битовых символов:
► набор из 256 символов данных (старший бит всегда равен 1);
► набор управляющих символов.
427
Глава 10. Коммуникационные технологии
Управляющие символы могут перемежаться с символами данных па-
кета, окаймляя пакет, управляя потоком пакетов и реализуя другие
функции. Например, последовательность ...GAP, GO, IDLE, dO, dl,
IDL1 GO, STOP, d2, d3, GAP, STOP, GAP,... включает 4 байта данных
dO, dl, d2, d3. Коды управляющих символов позволяют обнаруживать
некоторые однократные ошибки.
Управляющие символы GAP, GO, STOP, IDLE, FRES обязательны
для любой реализации Myrinet протокола. Другие управляющие сим-
волы могут использоваться для расширения функций протокола. Ло-
гика реализации протокола показана на рис. 10.24.
Рис. 10.24. Логика реализации протокола Myrinet
Управляющие символы GAP, GO, STOP и IDLE генерируются адап-
тером. Входная логика адаптера игнорирует символ IDLE (пусто),
а остальные символы обрабатывает следующим образом:
► символы данных и управляющий символ GAP направляются в при-
ливно-отливный буфер;
► символы STOP/GO направляются для передачи в выходной линк
противоположного направления для управления блокировками в пе-
редающем адаптере;
► все остальные управляющие символы направляются в устройство
управления.
Управляющий символ GAP указывает, что все данные предшест-
вующего пакета переданы и следующие данные будут принадлежать
заголовку очередного пакета. Между двумя пакетами могут быть
428
10.3. Коммуникационная среда MYRINET
множественные избыточные символы GAP. После включения пита-
ния не обязательно появление первого символа GAP, как указателя
начала заголовка пакета. Управляющие символы STOP и GO исполь-
зуются для блокировки/разблокировки отправителя пакетов на про-
тивоположном конце линка. Блокировка распространяется только на
пакеты данных. Управляющие символы STOP, GO имеют приоритет
над всеми остальными в силу того, что они управляют потоком паке-
тов. Этот механизм аналогичен X-off/X-on, используемому в протоко-
ле RS-232.
В каждый временной интервал линк передает либо пакет данных,
либо управляющий символ, отличный от IDLE. Управляющие сим-
волы GO и STOP могут появляться между пакетами в произвольном
количестве и используются для заполнения пустых интервалов. Поток
символов, генерируемых отправителем, состоит из пустых символов
IDLE и значимых символов. Получение любого значимого символа
запускает счетчик тайм-аута. Если по истечении 16 тайм-аутных пе-
риодов не произойдет передача, то принимается решение об отказе.
Управляющий символ FRES может быть выдан либо управляющим
интерфейсом адаптера, либо по завершении временного интервала
блокировки передачи пакетов.
При получении FRES входная управляющая логика устанавливает
в исходное состояние приливно-отливный буфер и всю управляю-
щую логику. Все управляющие символы, кроме GAP, обрабатываются
нормально. Получатель остается в исходном состоянии вплоть до
приема управляющего символа GAP, завершающего исходное состоя-
ние. Если линк был установлен в исходное состояние в середине при-
нимаемого пакета, то получатель теряет оставшуюся часть пакета,
включая и завершающий управляющий символ GAP. В процессоре
LANai и в интерфейсных кристаллах отправитель генерирует GAP
немедленно после выдачи FRES или на один цикл позднее, если по-
слан символ STOP или GO. Если отправитель не успел полностью пере-
дать пакет, то оставшаяся часть пакета игнорируется. Поток пакетов
в каждом линке может быть заблокирован либо в месте назначения,
либо в месте посылки. Блокировка в месте назначения может происхо-
дить при нормальном функционировании сети. Это случается, напри-
мер, в коммутаторах, когда требуемый выходной порт занят передачей
другого пакета. Блокировка может возникнуть вследствие ошибок
429
Глава 10. Коммуникационные технологии
в пакетах, неправильно адресованных пакетов и неисправностей
в аппаратуре. Блокировка в источнике может происходить, если, на-
пример, завершающий символ GAP, не был сгенерирован или был
потерян. В таком случае путь, по которому следует пакет, остается
занятым, и ни один пакет не может быть передан по нему. Для упреж-
дения таких блокировок отправитель включает продолжительный
тайм-аут. Если отправитель был остановлен символом STOP или на-
ходится в процессе посылки пакета в течение интервала времени,
превышающего 222 периода посылки символов, то отправитель ини-
циирует генерацию управляющего символа FRES.
Упражнения
1. Какой производительностью должна обладать шина, чтобы она не бло-
кировала работу коммутатора?
2. Как реализуется транзакция в коммуникационной среде SCI?
3. Проранжируйте по времени все операции в SCI.
4. Сравните по функциональным возможностям и производительности
коммуникационные среды SCI и Myrinet.
5. Проанализируйте на предмет «сильных» и «слабых» мест алгоритм мар-
шрутизации пакетов в среде Myrinet.
6. Охарактеризуйте основные параметры, определяющие производитель-
ность коммутаторов.
7. В чем различие коммутирующих сетей Клоса и Бенеша?
430
Глава 11
Языки описания параллельных процессов
Как уже отмечалось, для повышения эффективности многопроцессор-
ных ВС возникла необходимость в параллельных алгоритмах, а, следо-
вательно, и в языках параллельного программирования (ЯПП), имеющих
специальные средства для описания параллельных процессов. ЯПП
в первую очередь должны предоставлять программистам средства для
описания явного и обнаружения скрытого параллелизма. Были раз-
работаны параллельные алгоритмы во многих областях обработки
информации и потребовался язык, который позволял бы описывать
параллельные алгоритмы. На создание подобных языков существен-
ное влияние оказывают принципы, заложенные в языках моделирова-
ния различных явлений, ибо они включают мощные средства отобра-
жения параллельных процессов. Кроме того, при разработке языков
необходимо учитывать средства описания параллелизма, которые
присутствуют в современных языках программирования (Algol-68,
PL/1, C++, Java, Modula и др.), и структуру параллельных методов
численного решения задач.
Исходя из средств задания взаимодействий между параллельными про-
цессами можно выделить две группы языков:
► взаимодействие фрагментов (процессов) с помощью доступа к общим
переменным;
► взаимодействие посредством передачи межпроцессорных сообщений.
Кроме того, ЯПП классифицируются по числу вовлекаемых во взаи-
модействие процессов. Можно выделить языки, обеспечивающие яв-
ное задание:
► индивидуальных (парных) взаимодействий между фрагментами: ме-
ханизм подчиненных процессов ОС/360, язык взаимодействующих
процессов Хоара, OCCAM, язык граф-схем;
► групповых взаимодействий между фрагментами (процессами): ОВС-
Cobol (Fortran), параллельный Cobol, языковые средства суперком-
пьютера ILLIAC-IV.
Для решения проблемы планирования, то есть распределения за-
дач по процессорам (машинам), необходимо разрабатывать методы
431
Глава 11. Языки описания параллельных процессов
распознавания и выделения независимых фрагментов программ. При
этом решение этой задачи базируется на определении вопросов:
► кто и когда осуществляет разбиение исходной программы и рас-
пределение по процессорам;
► какие критерии используются при разбиении и распределении;
► какое время сохраняется разбиение;
► каковы максимально неделимые участки.
11.1. Основные подходы к проектированию языков
параллельного программирования
Средства описания вычислительного процесса, заложенные в боль-
шинстве языков программирования, носят, как правило, последо-
вательный характер. Это связано с тем, что применяемое понятие
алгоритма (уточненное с помощью нормального алгоритма Маркова
или одноголовочной машины Тьюринга) использует пошаговый про-
цесс его реализации. Однако в связи с созданием и эксплуатацией
многопроцессорных систем и компьютерных сетей назрела и посте-
пенно начала воплощаться в жизнь идея описания алгоритмов в по-
следовательно-параллельной форме, что позволило явно указывать
в программе элементы, допускающие их параллельное выполнение.
Программирование задач д ля таких вычислительных установок полу-
чило название параллельного программирования, а соответствующие
языки называют языками параллельного программирования. Под па-
раллельным программированием будем понимать создание объектов —
параллельных npoipaMM, каждая из которых есть организованная сово-
купность модулей с возможностями одновременного выполнения и взаи-
модействия.
Рассмотрим основные пути создания ЯПП. Можно выделить два под-
хода к проектированию ЯПП.
При параллельно-последовательном подходе ЯПП должен иметь сред-
ства явного указания параллельных ветвей и порядка следования
участков параллельности. При выполнении программы управление
переходит от одного участка параллельности к другому, каждый раз
разветвляясь на требуемое число независимых управлений. Переход
432
11.1. Подходы к проектированию языков параллельного программирования
между участками программы осуществляется только после достиже-
ния всеми независимыми управлениями конца своих ветвей.
При асинхронном подходе параллельные ветви явно не задаются
и лишь в некоторые моменты времени при выполнении программы
выясняется возможность (готовность) выполнения отдельного фраг-
мента задачи независимо от других фрагментов.
При проектировании ЯПП работа ведется как в направлении создания
дополнительных средств в существующих последовательных языках,
так и в плане создания ЯПП на совершенно новых принципах.
Популярность языков программирования может определяться раз-
личными причинами: хорошо продуманной реализацией на компью-
тере, имеющимися приложениями, традицией использования и т.д.
Однако проектирование ЯП всегда должно сопровождаться опреде-
ленными требованиями. Язык программирования — это формальный
язык связи человека с компьютером, предназначенный для описания
данных и алгоритмов их обработки. В отличие от языка общения меж-
ду людьми он не должен допускать двусмысленностей и неопреде-
ленностей.
Приведем некоторые требования к ЯП:
► ясность, простота и согласованность понятий языка с простыми
и регулярными правилами их конструирования;
► ясность структуры программы, написанной на ЯП и возможность
ее модификации;
► естественность в приложениях (наличие подходящих для реализа-
ции требуемых задач структур данных, операций, управляющих
структур и естественный синтаксис языка);
► легкость расширения за счет моделирования простыми средствами
сложных структур, имеющихся в конкретных задачах;
► мощное внешнее обеспечение (средства тестирования, отладки,
редактирования, хранения);
► эффективность создания, трансляции, тестирования, выполнения
и использования программ.
Однако следует отметить, что проблема удобства и простоты ЯП для
создания программ «с нуля» сегодня малоактуальна. Уже написаны
программы для решения такого количества задач (некоторые из них
433
2®2Т92
Глава 11. Языки описания параллельных процессов
многократно на различных ЯП и в разных программных средах), что
в соответствии с поставленной задачей достаточно просто отобрать
необходимые компоненты (программы), настроить их и проинтегри-
ровать, то есть объединить в одну систему. Такие действия адекватны
технологии крупноблочного проектирования, в основе которой ле-
жит понятие компонентной объектной среды (КОС). КОС — это совре-
менный фундамент для накопления и использования знаний. Она
базируется на компонентной объектной модели и включает готовые
компоненты и инструментальное окружение, позволяющее выбирать
необходимые компоненты, настраивать их и связывать между собой,
создавая необходимое приложение.
КОС обладает всеми свойствами, присущими объектно-ориентиро-
ванному подходу:
► инкапсуляция объектных компонент скрывает от пользователя
сложности их реализации, делая видимым лишь предоставляемый
интерфейс;
► наследование позволяет совершенствовать компоненты, не нару-
шая целостности объектной оболочки;
► полиморфизм, по сути, позволяет группировать объекты, характе-
ристики которых в определенном смысле можно считать подобными.
К языкам параллельного программирования могут быть предъявле-
ны дополнительные требования. В частности, ЯПП должен:
► иметь средства максимального выражения в программе присущего
данной задаче естественного параллелизма;
► быть независимым от структуры конкретного компьютера, в част-
ности от числа процессоров, доступных для программ, от времени
выполнения отдельных ветвей программы и т.д.;
► обладать простотой диспетчеризации параллельных программ, за-
писанных на нем;
► обеспечить простоту записи (преобразования) программ на ЯПП
по заданным последовательным алгоритмам.
При расширении последовательных ЯП обычно используются опера-
торы FOR-JOIN, PARBEGIN-PAREND, COBEGIN-COEND - аналог
операторных скобок в обычных ЯП, окаймляющих фрагменты па-
раллельного выполнения.
434
11.1. Подходы к проектированию языков параллельного программирования
Типичным примером расширения возможностей последовательных
ЯП служит дополнение языков Algol-60 и Fortran операторами типа
FORK <список метою и JOIN <список метою. Оператор FORK от-
крывает участок параллельности в заданной программе, а оператор
JOIN закрывает его. После выполнения каждой ветви с заданной
в операторе FORK меткой управление передается оператору JOIN.
Последний не передает управление на продолжение программы до
тех пор, пока управление от всех сегментов, метки которых указаны
в операторе JOIN, ему не переданы.
Чтобы ЯП Algol-60 обладал необходимыми свойствами языка парал-
лельного программирования, его можно дополнить (кроме FORK
и JOIN) операторами типа:
TERMINATE < список меток > — блокировка фрагментов программы
(если он предшествует оператору JOIN, то блокируется выполнение
фрагментов программы с общими у обоих операторов метками);
OBTAIN < список переменных > — блокировка использования пере-
менных, участвующих в вычислительном процессе;
RELEASE < список переменных > — снятие блокировки с указанных
в нем переменных.
Если, например, в программе встретилась запись
k) JOIN 5b S2, S7
к +1) FOR i = 1 STEP 1 UNTIL N DO,
то управление от оператора к будет передано оператору к + 1 только в
случае завершения фрагментов с метками S2, S2. Если, например,
необходимо одновременно выполнить целый массив параллельных
ветвей, то в параллельном ЯП следует организовать некоторый спе-
циальный цикл. Синтаксически он напоминает обычный цикл в ЯП.
Пусть в последовательном ЯП определен цикл
FOR i = L STEP 1 UNTIL N DO R(i),
который задает последовательное выполнение вычислений
R(L), R(L + 1), ... , R(N).
Тогда их одновременная обработка требует конфигурации
FOR z = L STEP 1 UNTIL N DO PAR R(i),
задающей параллельное выполнение этих же вычислений.
435
Глава 11. Языки описания параллельных процессов
В связи с тем что понятие параллельного выполнения может быть
трактовано различным образом, в общем случае можно принять сле-
дующее описание параллельного цикла:
FOR i = < индексное множество > DO < тип параллельности >,
где < индексное множество > задает цикл типа арифметической про-
грессии, перечисления, логического выражения и т.д., а < тип парал-
лельности > определяет семантику оператора, например ориентацию
на асинхронные ВС с общей памятью, с разделенной памятью, ВС с
единым потоком команд ОКМД, возможность синхронизации вет-
вей с обменом или без обмена информации и т.д.
11.2. Примеры языков параллельного программирования
В настоящее время существует достаточно много языков параллель-
ного программирования, однако трудно выбрать наиболее приемлемый
для использования. Это зависит от решаемой задачи, возможностей
компьютера, поставленных целей и ряда других факторов.
Ниже в качестве примеров ЯПП рассмотрим некоторые модельные
языки, идеи которых используются в большинстве современных язы-
ков параллельного программирования.
11.2.1. Р- и К-языки
Пожалуй, одним из первых ЯПП был матричный P-язык, разработан-
ный в Институте математики с ВЦ Сибирского отделения АН СССР.
Программа, записанная на этом языке, представляет собой матрицу,
элементами которой являются операторы. Среди этих операторов
имеются операторы настройки, производящие изменение коммута-
торов элементарных машин (ЭМ) либо параметров, управляющих
структурой ЭМ; операторы обмена информацией между ЭМ и «пус-
тые» операторы, пропускающие выполнение одного шага вычисле-
ний. Каждый столбец матрицы включает независимые операторы,
которые можно выполнять параллельно. Процесс выполнения про-
граммы сводится к последовательному прохождению всех столбцов
матрицы.
Основной принцип последовательного программирования — явное
указание порядка выполнения операций — в P-языке остается, однако
436
11.2. Примеры языков параллельного программирования
здесь вводится двухкоординатная система записи, где одна координата
указывает последовательность выполнения операций во времени, другая —
распределение операций между ветвями вычислений. P-язык, однако,
не позволяет сохранить природную асинхронность задач и требует
учитывать структуру конкретной вычйслительной системы.
В качестве языка параллельного программирования был разработан
так называемый К-язык, суть которого заключается в задании множе-
ства элементарных операторов и множества порождающих правил
построения алгоритмов, образующих в совокупности некоторое исчис-
ление. Запись вывода в этом исчислении и является К-программой.
Имеются три типа основных порождающих правил: суперпозиция,
дизъюнкция, рекурренция. Правило суперпозиции означает, что ре-
зультаты выполнения операторов Ь\, Ь2,..., Ьк служат аргументами для
некоторого оператора В. Порядок выполнения операторов Ьъ Ь21 ...,
Ьк безразличен, что и порождает параллелизм в их выполнении. Пра-
вило дизъюнкции задает ветвление в К-программе, а правило рекур-
ренции — цикличность. К-язык относится к языкам асинхронного
типа.
11.2.2. ЯПФ-язык
От некоторых из недостатков в какой-то мере избавлен язык ярус-
но-параллельных форм (ЯПФ) Д.А. Поспелова. Программа на ЯПФ
представляет собой мультиграф, задаваемый, например, в матричной
форме. Вершинами мультиграфа являются операторы, мультиграф не
имеет контуров. Дуги мультиграфа могут быть двух типов — инфор-
мационные и управляющие. При выполнении программы на ЯПФ
первоначально выделяется нулевой ярус (множество операторов, не
имеющих непосредственных предшественников по информацион-
ным дугам) (рис. 11.1) и инициируется выполнение операторов из
этого множества. После их выполнения убираются все информаци-
онные дуги, выходящие из нулевого яруса, и в оставшемся графе та-
ким же образом выделяется первый ярус.
Процесс продолжается от яруса к ярусу. После выполнения управ-
ляющего оператора, из которого выходят управляющие дуги, проис-
ходит выбор одного из операторов, в которые заходят эти дуги.
Процесс обработки ЯПФ-программы завершается после выполне-
ния всех операторов из яруса с наибольшим номером.
437
Глава 11. Языки описания параллельных процессов
Рис. 11.1. ЯПФ-представление алгоритма
Однако представление программы в Я ПФ требует «развертки» цик-
лических участков программы, что не позволяет использовать ее как
язык практического параллельного программирования.
11.2.3. Язык диспозиций
Определим некоторый класс формальных описаний задач, которые бу-
дут включать в себя как основные известные определения алгоритмов,
так и некоторые неалгоритмические описания. Последние отличаются
от алгоритмических тем, что в них, кроме предписаний выполнить
данное преобразование текста по некоторому правилу, используются
также разрешения выполнять некоторые другие преобразования. Та-
кие схемы описания задач будем называть диспозициями. Предписа-
ние является вырожденным случаем разрешения, когда разрешается
только одно преобразование.
Будем задавать диспозицию D знаковой системой S, множеством
операторов М= {Ль Аг, ..., А„} (в дальнейшем оно предполагается ко-
нечным) и графом диспозиции I\D). Каждый оператор Л, имеет один
вход и Р, выходов (5b S2,..., 5Й). Оператор Я, осуществляет некоторое
преобразование Aj текстов в знаковой системе S и проверяет серию
условий соо', со/,..., со/. Когда оператор Л,- применяется к тексту Т, он
проверяет, удовлетворяет ли текст Т серии условий со/, со/, ..., со/, и
преобразует текст Т по правилу А, в текст Т'. Особую роль играет ус-
ловие со/, которое будем называть условием применимости оператора
Ah Если оно выполняется (со/ = 1), то оператор работает, как описано
438
11.2. Примеры языков параллельного программирования
выше. Иначе (соо=0) оператор Л, оставляет текст неизменным (то есть
Т'=Т).
Для каждого оператора Л, задается Р функций:
ф/ (соо*’, ы/, со/);
фг' (соо1, со/, со/);
фр/ (соо', «о/, -, со/).
Каждая из этих функций может принимать два значения: «1» (воз-
можно) и «0» (невозможно). Будем называть систему функций пра-
вильной, если для каждой функции существует по крайней мере
один набор значений аргументов, при котором она принимает значе-
ние «1».
Графом диспозиции Г(£>) будем называть связный граф, вершинам ко-
торого сопоставлены либо операторы диспозиции D, либо знак #.
Вершины обладают следующими свойствами:
► имеется только одна вершина, называемая входом диспозиции,
обозначаемая авх;
► имеется, по крайней мере, одна вершина, из которой не исходит
ни одна дуга и которой сопоставлен знак #. Такие вершины называ-
ются выходами диспозиции и обозначаются авых1, аВЬ1х2, —> сХвыхл!
► вершинам, которые не являются выходами, сопоставлены операторы
диспозиции. При этом, если из вершины исходит п дуг, ей может быть
сопоставлен только тот оператор Л„ число выходов которого Р, > и.
Каждый выход оператора Л, сопоставляется одной из дуг, исходящих
из соответствующей вершины а. Каждой дуге, исходящей из а, дол-
жен быть сопоставлен по крайней мере один из выходов оператора Л,.
Граф Г(£>) и соответствующую ему диспозицию D назовем правильны-
ми, если выполняются следующие дополнительные требования:
► из любой вершины графа Г существует путь по крайней мере
в один выход;
► для каждой вершины графа Г существует путь, ведущий из входа
в эту вершину.
Таким образом определенная диспозиция задает систему допустимых
последовательностей преобразований текста, а именно: если задан
439
Глава 11. Языки описания параллельных процессов
начальный текст То, то оператор, сопоставленный входу диспозиции
ОвХ, проверяет условие coq. Если это условие не выполнено (coq = 0), то
текст То не меняется, если же cbq = 1, то к тексту То применяется пре-
образование, соответствующее данному оператору, причем до выпол-
нения этого преобразования вычисляются значения со/, со/, ..., со*.
После преобразования текста вычисляются значения функций ср/,
Фз> ф/
Те функции сру, которые принимают значение «1», определяют дуги,
исходящие из входной вершины графа диспозиции, по которым воз-
можен переход в следующую вершину. Один из этих переходов должен
быть осуществлен. Тем самым на следующем шаге процесса реализа-
ции диспозиции выбирается одна из смежных с предыдущей верши-
на графа Г(О).
Если все функции сру = 0, то процесс останавливается. Эта ситуация
называется безрезультатной остановкой.
Оператор диспозиции, сопоставленный этой вершине, применяется
к полученному тексту таким же образом, как входной оператор при-
меняется к исходному тексту То. Если этой вершине сопоставлен
знак #, то процесс на этом заканчивается и образовавшийся к этому
моменту текст считается результатом диспозиции.
Одному и тому же начальному тексту может соответствовать несколь-
ко результатов (если один, то диспозиция однозначна).
Диспозиция называется алгоритмической, если для любого начально-
го текста на каждом шаге возможен (а следовательно, и предписан)
переход только к одной вершине графа Г(О).
Заметим, что алгоритмическая диспозиция не обязательно представ-
ляет собой алгоритм, так как сами преобразования Moiyr быть опре-
делены неоднозначно (например, марковские подстановки без ука-
зания на то, какое вхождение слова берется). Определим реализацию
диспозиции D формально.
Будем рассматривать в графе Д£>) пути (называемые сквозными), со-
стоящие из последовательности вершин
®/0 —®вх» ®/1> > ®/и> ®/л+1 = ®вьсу-
Так как а*- -> Ат/ (кроме a^!,..., Оцы^), то каждому сквозному пути
будет сопоставлена сквозная последовательность операторов Ат<,
440
11.2. Примеры языков параллельного программирования
Ат2,..., Ат*. Пусть оператор Ат> (сопоставленный вершине ап) при-
менен к тексту То, а каждый оператор Ат. преобразует текст
в текст 7}. Тогда, если в сквозной последовательности операторов
после применения каждого оператора Ami (кроме ) к тексту 7}_!
возможно применение Am/ i к тексту Ть данную сквозную последова-
тельность операторов и соответствующую ей последовательность
текстов То, Th Тп будем называть реализацией диспозиции/), а текст
ТП — результатом применения диспозиции к тексту То.
Этот факт запишем так:
То - »Г1 - —2-~>Т2--->... 4п" ->Т„
Знак —> означает: поставлен в соответствие.
Иногда удобнее описывать метод решения ряда задач как диспози-
цию, а затем уже тем или иным способом переходить к алгоритмам
решения этих задач. Чтобы выделить алгоритмические диспозиции,
следует рассматривать только такие наборы М операторов, что для
ХЛ4,- g М не более чем одна из функций ср/, <р2,..., <р/- принимает значе-
ние «1» вне зависимости от набора значений аргументов.
Пример. Рассматриваются слова в алфавите Z. Задан список слов П
в алфавите Z. Слово В называется возможной основой слова С, если
последнее может быть представлено в виде
D2... DnB,
где n > 0 и Vi (£>, g Z7).
Требуется для каждого слова найти все его возможные основы.
Пусть Z= {а, Ь, с, d}, Z' = {Z\j®} и П = {а, ab, Ьа}.
Тогда возможными основами слова abacd будут слова abacd, bacd, acd,
cd, а слова babcd — слова babcd, abed, bed, cd.
Построим диспозицию для решения этой задачи:
Af= {Ai,A2,A3,A4,Aj}.
Граф-схема диспозиции показана на рис. 11.2.
441
Операторы преобразования слова
Таблица 11.1
Опе- ратор Правило Слова, соответствующие СОО, W1, (0„ Количе- ство выходов <Pi Ф2 Фз Ф4
аргу- менты значение функции аргу- менты значение функции аргу- менты значение функции аргу- менты значение функции
At Л* -> ® Ио (0| <0„ Мо Мо Мо Мо
Л — — 4 1 0 1 1 1 0 1 1
а2 ®а -> Л (0, 0)! <0„ Мо Мо
®а — — 2 1 0 1 1 1 0 1 1
А3 ®ab-> Л Ио Мо <0„ Мо Мо
®Ь — — 2 1 0 1 1 1 0 1 1
А4 ®Ьа-> Л Мо Мо
®Ьа - — 2 1 0 1 1 1 0 1 0 1 1
а5 ® -> Л <0„ 1 соо
® — — 1 0 1 1
* Л — пустое слово
Глава 11. Языки описания параллельных процессов
11.2. Примеры языков параллельного программирования
Рис. 11.2. Граф схема диспозиции
Оператор Л । приписывает к исходному слову слева букву ®. Опера-
торы А2, А3, А4 отделяют от слова, к которому они применяются, соот-
ветственно префиксы a, ab и Ьа (вместе с начальной буквой ®).
Описание операторов дано в табл. 11.1.
11.2.4. Язык OCCAM
Для многотранспьютерных систем английскими учеными был создан
специальный язык параллельного программирования OCCAM, детальное
описание которого было дано в 1984 году в книге «INMOS Limited
Occam Programming Manual». В отличие от ЯПП, например Concurent
Fortran или Concurent Pascal, этот язык не построен путем расшире-
ния известных последовательных ЯП.
Теоретической основой данного языка является язык CSP (Communi-
cating Sequential Processes), разработанный Т. Хоаром. Основным по-
нятием языка является процесс (примитивный, составной, именован-
ный), напоминающий процедуры и подпрограммы обычных языков
программ рования.
Простейшим примитивным процессом является процесс SKIP.
Если именованный процесс имеет список формальных параметров,
то они следуют в описании процесса после его имени с указанием
ключевых слов VALUE, VAR и CHAN, обозначающих их природу —
соответственно значение, переменная или канал.
Процессы взаимодействуют с помощью каналов и могут выполнять-
ся как последовательно, так и параллельно. Так как в системе команд
транспьютера имеются команды, предназначенные для компиляции
443
Глава 11. Языки описания параллельных процессов
примитивных процессов считывания из канала и записи в канал, то
эти процессы хорошо согласуются с транспьютерной архитектурой.
При этом операции создания процессов, их планирования и синхро-
низации представляются программисту столь же «примитивными»
действиями, как и такие операции, как, например, вызов процедуры
в языках последовательного действия.
Последовательный процесс задается перечислением за ключевым
словом SEG всех его компонент, которые должны выполняться по-
следовательно.
Для описания параллельного процесса после ключевого слова PAR
задаются его необходимые составляющие. Выполнение параллель-
ной композиции (PAR-процесса) состоит в выполнении каждой его
компоненты до полного их завершения.
Выбор процесса для исполнения в зависимости от готовности других
процессов задается через ALT-процесс.
Все имена в Occam-программе до их использования должны быть
описаны. Описания позволяют именовать значения констант (клю-
чевое слово DEF), переменных (ключевое слово VAR) и каналы
(ключевое слово CHAN). При этом должны быть определены два па-
раллельных процесса: передача в канал и прием из канала в области
действия описания каждого канала.
В языке OCCAM существует только один вид структурированных
данных — одномерный массив. В Оссаш-2 допускается использова-
ние двумерных и трехмерных массивов различных объектов: кон-
стант, переменных и каналов. Описание массива включает его имя, за
которым в квадратных скобках записывается константное выраже-
ние имя [количество}.
Например, выбор символов строки string [ ] через канал output будет
иметь вид
PROC write, string (CHAN output, VALUE string []).
Язык OCCAM постоянно развивается в связи с совершенствованием
транспьютеров и приближается к языку высокого уровня с естествен-
ным расширением класса решаемых задач. При этом выдерживается
основной принцип языка — число сущностей не следует умножать
без надобности.
444
11.2. Примеры языков параллельного программирования
Пока трудно судить о наличии качественного и практичного ЯПП.
Все зависит от класса решаемых задач, архитектур разрабатываемых
компьютеров и, естественно, подвержено фактору времени. Для ВС,
содержащих небольшое число процессоров, можно с успехом исполь-
зовать ЯП ALGOLPP, ADA, MODULA-2, OCCAM, имеющие средст-
ва организации параллельных ветвей, синхронизации управления
в параллельных ветвях и обмена информацией между ветвями.
11.2.5. Язык Erlang
Erlang — язык программирования для параллельных и распределенных
систем. Он создан в Ericsson and Ellemtel Computer Science Labaratories.
Многие примитивы языка Erlang специально разработаны для реше-
ния проблем, наиболее часто встречаемых при программировании
параллельных RTS (Real-time systems — систем реального времени).
Модель параллелизма в языке Erlang основана на понятии процесса
и задается в явном виде. Единственный способ, которым в Erlang
процессы могут обмениваться информацией, — это передача сообще-
ний (message passing). Поэтому приложения, созданные для однопро-
цессорных систем, могут быть легко адаптированы для применения
на многопроцессорных системах. Передача сообщений между про-
цессами производится асинхронно. Язык имеет встроенные механиз-
мы распределенного программирования, что позволяет достаточно
просто разрабатывать программы, которые могут быть запущены как
на одном, так и на совокупности компьютеров.
Рассмотрим основные функции и примитивы, реализующие парал-
лелизм в языке Erlang.
Создание процессов и взаимодействие между ними осуществляются
явным образом.
Основным примитивом для создания и запуска процесса является
Pid = spawn(Module, FunctionName, ArgumentList),
который создает и запускает процесс для вычисления функции с име-
нем FunctionName и аргументами ArgumentList, находящейся в модуле
Module, а также возвращает идентификатор созданного процесса.
Вызов spawn возвращает управление сразу же после того, как новый
процесс был создан, и не ожидает вычисления функции. Создан-
ный процесс автоматически уничтожается после вычисления задан-
ной функции.
445
Глава 11. Языки описания параллельных процессов
Основной примитив передачи сообщений между процессами обозна-
чается символом *!’(например, Pid!Message). Поскольку передача со-
общений асинхронная, то передающий процесс не ждет прибытия
или приема сообщения. Даже если процесс-получатель уже уничто-
жен, система не оповестит об этом процесс-отправитель. В связи с этим
приложение должно реализовывать все виды подобных проверок. Со-
общения доставляются в том порядке, в котором были отправлены.
Выбор принимаемых сообщений может осуществляться как по за-
данному шаблону, так и по процессу отправителя с помощью прими-
тива receive. Каждый процесс имеет свой почтовый ящик {mailbox),
в который попадают все сообщения, посланные этому процессу в по-
рядке отправления. Все сообщения, которые не совпали ни с одним
шаблоном, остаются в почтовом ящике в той же очередности до сле-
дующего вызова receive. При этом задача избежания переполнения
системы полностью возлагается на программиста. Примитив receive
может быть расширен значением тайм-аута — времени, после кото-
рого завершается ожидание следующего сообщения.
Пример использования примитива receive:
receive
Messagel — >
Actionsl;
Message2 — >
Actions2;
after
TimeOutExpr — >
ActionsTimeOut;
end.
Точность, с которой вычисляется значение тайм-аута функцией
TimeOutExpr, ограничена операционной системой и аппаратным
обеспечением, на котором реализован Erlang. Если нет сообщений,
совпадающих с заданными шаблонами, текущий поток блокируется
до появления таковых. За счет этого свойства появляется возмож-
ность создавать переходы от параллельного исполнения к последова-
тельному, и наоборот. Наличие же тайм-аутов позволяет избежать
блокировок и зависаний процессов, ожидающих сообщений.
446
11.2. Примеры языков параллельного программирования
Одним из достоинств языка Е iang является то, что все свойства при-
митивов параллелизма, которые доступны при работе на одном про-
цессоре или компьютере в кластере (совокупности) компьютеров,
могут быть использованы и на многопроцессорных, и на мульти-
компьютерных системах. Рассмотрим примитивы, реализующие рас-
пределенное программирование на языке Erlang:
spawn {Node, Mod, Func, Args) — порождает процесс на удаленном
узле;
spawn_link{Node, Mod, Func, Args) — порождает процесс на удаленном
узле и создает соединение с ним;
monitor_node {Node, Flag) — если Flag = true, то текущий процесс сле-
дит за узлом Node, то есть при недоступности или отсутствии узла
Node сообщение {nodedown, Node} посылается текущему процессу. При
Flag=false текущий процесс прекращает «слежение» за узлом Node-,
node () — возвращает имя текущего узла;
nodes () — возвращает список известных узлов;
node {Item) — возвращает имя узла, которому принадлежит Item-,
disconnect node {Nodename) — разрывает соединение с узлом Nodename.
Пример использования примитива monitor node-.
monitor_node (Node, true)
receive ->
{nodedown. Node) ->
monitornode (Node, false)
end.
При помощи этого примитива реализуются сложные механизмы от-
казоустойчивых систем реального времени.
Примитивы spawn, spawn link возвращают универсальный идентифи-
катор созданного удаленного процесса, который может использо-
ваться подобно идентификатору локального процесса. Например,
сообщения, посланные удаленному процессу, доставляются в поряд-
ке их отправки и никогда не теряются. Данное качество поддержива-
447
Глава 11. Языки описания параллельных процессов
ется средой исполнения. Это свойство позволяет легко переходить от
локального исполнения процедур к распределенному, для чего доста-
точно лишь знать имя нужного узла.
11.2.6. Язык программирования трС
Язык трС — это расширение языка С, разработанное для программи-
рования параллельных вычислений в компьютерных сетях. Основ-
ной целью параллельных вычислений является ускорение решения
задачи. Поэтому главное внимание в языке трС уделяется средствам,
позволяющим максимально облегчить разработку эффективных про-
грамм для решения задач в компьютерных сетях.
Основные особенности языка трС. Параллельная программа представ-
ляет собой множество параллельных процессов, взаимодействующих
(т.е. синхронизирующих свою работу и обменивающихся данными)
посредством передачи сообщений. Программист на трС управляет
вычислениями, выполняемыми каждым из процессов, составляю-
щих программу.
Рассмотрим простую программу:
♦include <stdio.h>
int [*]main() (
[host]printf («Hello, world. \n>>);
}
Первое отличие этой программы от программы на языке С — специ-
фикатор [*] перед именем main в определении главной функции. Он
специфицирует вид функции, указывая, что ее код выполняется всеми
процессами параллельной программы. Функции, подобные функции
main, называют в трС базовыми. Корректная работа таких функций
возможна только при условии их вызова всеми процессами парал-
лельной программы. Контроль корректности осуществляется компи-
лятором.
Второе отличие — это конструкция [Лол/J перед именем функции printf
в выражении, вызывающем эту стандартную библиотечную функцию
языка С. В отличие от функции main, для корректной работы функ-
ции printf не требуется ее параллельного вызова всеми процессами
программы. Вполне содержателен и корректен вызов этой функции
любым отдельно взятым процессом параллельной программы. Такие
448
11.2. Примеры языков параллельного программирования
функции называются в трС узловыми. Язык предоставляет возмож-
ность вызова узловой функции как отдельным процессом параллель-
ной программы, так и параллельным вызовом группой процессов.
В приведенном примере функция printf выполняется только одним
процессом параллельной программы, а именно процессом, связан-
ным с терминалом пользователя, из которого он запускал ее на вы-
полнение. Ключевое имя host жестко связано в языке трС именно
с этим процессом.
Таким образом, при выполнении данной программы хост-процесс
вызывает функцию printf, все остальные процессы программы ника-
ких действий не производят.
Программа
♦include <stdio.h>
int [*]ntain() {
printf («Hello, world.\n>>);
}
осуществляет вызов функции printf всеми процессами. Результат ра-
боты этой программы зависит от операционного окружения, в кото-
ром она выполняется. В некоторых окружениях стандартный вывод
всех параллельных процессов направляется на терминал пользователя,
с которого он запускал программу. В этом случае пользователь увидит
столько приветствий «Hello, world!» на своем терминале, сколько парал-
лельных процессов составляют программу — по одному от каждого
процесса. В других окружениях приветствия будут получены только
от процессов, выполняющихся на том же компьютере, что и хост-про-
цесс, или даже только от хост-процесса.
Непереносимость приведенной программы (различные результаты
работы в разных окружениях) является серьезным недостатком.
Программа:
♦include <{mpc.h}>
int [*]main() {
MPC_Printf («Hello, world. \n>>) ;
}
выводит на терминал пользователя приветствия от всех процессов па-
раллельной программы. Библиотечная узловая функция MPCJPrintf
449
Глава 11. Языки описания параллельных процессов
языка трС гарантирует вывод приветствия на терминал пользователя
от каждого выполняющего ее процесса параллельной программы.
В программе
♦include <stdio.h>
♦include <sys/utsname.h>
int [*]main() {
struct utsname [host]un;
[host]uname(&un) ;
[host]printf («Hello world! Host-process runs on \»%s\«.\n>>,
un.nodename);
]
хост-процесс выводит на терминал пользователя более содержательное
послание, в то время как остальные процессы параллельной програм-
мы по-прежнему ничего не делают. А именно, кроме приветствия
«Hello, world!», хост-процесс сообщает имя компьютера, на котором
он выполняется. С этой целью в программе определяется перемен-
ная ип, размещенная в памяти хост-процесса (этот факт специфици-
руется с помощью конструкции [Aorf] перед именем переменной в ее
определении). После выполнения хост-процессом вызова узловой
(библиотечной) функции ипате, поле nodename структуры ип будет
содержать ссылку на имя компьютера, на котором этот процесс вы-
полняется.
Программа
♦include <mpc.h>
♦include <sys/utsname.h>
int [*]main() {
struct utsname un;
uname (Sun) ;
MPC_Printf(«Hello world! I’m on \»%s\«.\n>>, un.nodename);
]
выводит на терминал пользователя более содержательные послания
уже от всех процессов параллельной программы. Кроме приветствия
«Hello, world!» каждый процесс сообщает имя компьютера, на кото-
ром он выполняется. С этой целью в программе определяется распре-
деленная переменная ип.
450
11.2. Примеры языков параллельного программирования
Переменная ип называется распределенной, потому что каждый про-
цесс параллельной программы содержит в своей памяти копию этой
переменной, и тем самым область памяти, представляемая этой пере-
менной, распределена между процессами параллельной программы.
Таким образом распределенная переменная ип есть не что иное, как
совокупность нераспределенных переменных, каждая из которых,
в свою очередь, является проекцией распределенной переменной на
соответствующий процесс.
Каждый из процессов параллельной программы выполняет вызов
функции ипате, после чего поле nodename соответствующей проек-
ции распределенной структуры ип содержит ссылку на имя того ком-
пьютера, на котором этот процесс выполняется.
Значения распределенных переменных и распределенных выражений,
таких как un.nodename или &ип, естественным образом распределены
по процессам параллельной программы и называются распределен-
ными значениями.
Программа
((include <mpc.h>
#include <sys/utsname.h>
int [*]main() (
struct utsname un;
repl int one;
repl int number_of_processes;
uname(&un);
one = 1;
number_of_processes = one[+];
MPC_Printf(«Hello world! I'm one of %d processes»
«and run on \»%s\«.\n»,
number_of_processes, un.nodename);
}
расширяет вывод предыдущей программы информацией об общем
числе процессов параллельной программы. Для этого в программе опре-
делены две целые распределенные переменные one и number_pf_processes.
Сначала в результате выполнения присваивания one = 1 всем проекци-
ям переменной one присваивается значение 1. Результатом применения
451
Глава 11. Языки описания параллельных процессов
постфиксной операции [+] к переменной one будет распределенное
значение, проекция которого на любой из процессов равна сумме
значений проекций переменной one. Другими словами, проекция зна-
чения выражения опе[+] на любой из процессов параллельной про-
граммы будет равна их общему количеству. В результате присваивания
этого значения распределенной переменной number_of_processes все
проекции последней будут содержать одно и то же значение, а имен-
но общее число процессов параллельной программы.
Определение распределенной переменной one содержит ключевое сло-
во repl (сокращение от replicated), которое информирует компилятор
о том, что в любом выражении проекции значения этой переменной
на разных процессах параллельной программы равны между собой.
Такие переменные называются в трС распределенными. Компилятор
контролирует объявленное программистом свойство распределенности
и предупреждает обо всех случаях, когда оно может быть нарушено.
Программа
(include <mpc.h>
♦include <sys/utsname.h>
int [*]main() (
struct utsname un;
uname (Sun) ;
MPC_Printf(«Hello world! I'm one of %d processes»
«and run on \»%s\«.\n>>,
MPC_Total_nodes(), un.nodename);
)
обеспечивает такой же результат, что и предыдущая, используя библио-
течную узловую функцию MPC_Total_nodes языка трС, которая воз-
враща т общее число процессов параллельной программы. Она более
эффективна, так как параллельный вызов функции MPC_Total_nodes,
в отличие от вычисления выражения опе[+], не требует обмена дан-
ными между процессами программы.
Программа
♦include <mpc.h>
♦include <sys/utsname.h>
int [*]main() {
struct utsname un;
452
11.2. Примеры языков параллельного программирования
int [host]local_one;
repl int one;
repl int number_of_processes;
uname(Sun);
local_one = 1;
one “ local_one;
number_of^processes “ one[+];
MPC_Printf(«Hello world! I'm one of %d processes»
«and run on \»%s\«.\n>>,
nurober_of^processes, un.nodename);
}
получена небольшим изменением предыдущей программы и менее
эффективна. Зато она демонстрирует, как в языке трС присваивание
может быть использовано для обмена данными между процессами.
Переменная local_pne размещена в памяти хост-процесса и инициа-
лизируется значением 1. Выполнение присваивания one=local_one за-
ключается в рассылке значения переменной local one всем процессам
программы с последующим его присваиванием проекциям перемен-
ной one.
Сети в трС. Часто число процессов, вовлеченных в параллельное ре-
шение задачи, зависит от самой задачи и/или параллельного алгорит-
ма ее решения и определяется входными данными. Если, например,
для параллельного моделирования N групп тел под влиянием взаим-
ного притяжения используется отдельный процесс для каждой группы
тел, то в соответствующие параллельные вычисления должны быть
вовлечены в точности N процессов, независимо от общего числа про-
цессов, составляющих параллельную программу. Запуск параллель-
ной программы осуществляется внешними по отношению к языку
трС средствами, и, следовательно, общее число составляющих эту
программу процессов не определяется разработчиком программы на
трС — у него имеются лишь языковые средства д ля определения это-
го числа.
Программа
♦include <mpc.b>
♦define N 3
453
Глава 11. Языки описания параллельных процессов
int [*]main() (
net SimpleNet(N) mynet;
[mynet]MPC_Printf («Hello, world! \n>>);
}
представляет собой первое знакомство с языковыми средствами, по-
зволяющими программисту описывать параллельные вычисления на
нужном числе процессов. Сами вычисления по-прежнему предельно
просты — каждый из участвующих в них процессов просто выводит
на терминал пользователя приветствие «Hello, world!». Число же уча-
ствующих процессов (N= 3) задается программистом и не зависит от
общего числа процессов, составляющих параллельную программу.
1)>уппе процессов, совместно выполняющих некоторые параллельные
вычисления, в языке трС соответствует понятие сети.
Сеть в трС — это абстрактный механизм, облегчающий программи-
сту работу с реальными физическими процессами параллельной про-
граммы (подобно тому как понятия объекта данных и переменной
в языках программирования облегчают работу с памятью).
В простейшем случае, сеть — это множество виртуальных процессо-
ров. Для программирования вычислений на нужном числе парал-
лельных процессов прежде всего следует определить сеть, состоящую
из соответствующего числа виртуальных процессоров. Затем можно
приступать к описанию параллельных вычислений на этой сети.
Сеть формирует группу процессов так, что каждый виртуальный про-
цессор представляется отдельным процессом параллельной программы.
Описание вычислений на сети вызывает выполнение соответствующих
вычислений процессами параллельной программы, представляющи-
ми виртуальные процессоры сети. В разные моменты выполнения
параллельной программы один и тот же процесс может представлять
различные виртуальные процессоры различных сетей. Другими сло-
вами, определение сети вызывает отображение ее виртуальных процес-
соров на реальные процессы параллельной программы, и это отобра-
жение сохраняется в течение всей жизни сети.
В приведенной программе сначала определяется сеть mynet, состоя-
щая из N виртуальных процессоров, а затем на ней вызывается узло-
вая библиотечная функция MPC_Printf. Выполнение этой программы
заключается в параллельном вызове функции MPC Printf теми N
454
11.2. Примеры языков параллельного программирования
процессами программы, на которые отображены виртуальные про-
цессоры сети mynet. Это отображение осуществляется системой про-
граммирования языка трС во время выполнения программы. Если
система программирования не может выполнить отображение (напри-
мер, если значение N превышает общее число процессов программы),
то программа завершается аварийно с соответствующей диагностикой.
Заметим сходство конструкций [mynet] и [йоЛ]. Действительно, клю-
чевое слово host можно рассматривать как имя предопределенной
сети из одного виртуального процессора, который всегда отобража-
ется на связанный с терминалом пользователя хост-процесс.
Программа
♦include <mpc.h>
♦include <sys/utsname.h>
♦define N 3
int [*]main() {
net SimpleNet(N) mynet;
struct utsname [mynet]un;
[mynetJuname(Sun);
[mynet]MPC_Printf («Hello world! I'm on \»%s\«.\n>>, un.nodename);
}
выводит на терминал пользователя более содержательные послания
от тех процессов параллельной программы, на которые отображаются
виртуальные процессоры сети mynet. Кроме приветствия «Hello, world!»
такой процесс сообщает имя компьютера, на котором он выполняется.
Для этого в программе определяется переменная ип, распределенная
по сети mynet. Только процессы, реализующие виртуальные процес-
соры сети mynet, содержат в своей памяти копию этой переменной.
И только эти процессы выполняют вызов функции ипате (это специ-
фицируется конструкцией [mynet] перед именем функции), после чего
поле nodename каждой проекции распределенной структуры ип будет
содержать ссылку на имя того компьютера, на котором соответствую-
щий процесс выполняется.
Программа
♦include <mpc.h>
♦include <sys/utsname.h>
♦define N 3
455
Глава 11. Языки описания параллельных процессов
int [*]main() {
net SimpleNet(N) mynet;
[mynet}: (
struct utsname un;
uname (&urf) ;
MPC_Printf («Hello world! I'm on \»%s\«.\n>>, un.nodename);
}
}
семантически полностью эквивалентна предыдущей программе, но
за счет использования специальной распределенной метки [mynel]
имеет более простой синтаксис. Помеченный такой меткой оператор
(в нашем случае это составной оператор) полностью выполняется
виртуальными процессорами соответствующей сети.
Программа
♦include <stdio.h>
♦include <stdlib.h>
♦include <mpc.h>
♦include <sys/utsname.h>
int [*]main(int [hostjargc, char **[host]argv) {
repl n;
if(argc<2)
n = 1;
else
n = [host]atoi(argv[l]) ;
if (n<l)
[host]printf («Wrong input (%d processes required) . \n>>, [host]n);
else if(n>MPC_Total_nodes())
[host]printf(«Required too many processes (%d against %d
available) . \n>>,
[host]n, [host]MPC_Total_nodes());
else {
net SimpleNet(n) mynet;
struct utsname [mynet]un;
[mynet]uname(Sun);
456
11.2. Примеры языков параллельного программирования
[mynet]MPC_Printf(«Hello world! I'm on \»*s\«.\n», un.nodename);
}
MPCPrintf(«* »);
}
демонстрирует, что число виртуальных процессоров сети может зада-
ваться динамически. Эта программа интерпретирует свой единствен-
ный внешний параметр как такое число. Данный параметр задается
пользователем при запуске программы и доступен, по крайней мере,
хост-процессу. Выражение [Ao5f]aror(a/gv[l]) вычисляется хост-про-
цессом, а затем присваивается целой переменной л, распределенной
по всем процессам параллельной программы. Выполнение этого при-
сваивания заключается в рассылке вычисленного значения всем про-
цессам программы с последующим его присваиванием проекциям
переменной л. Прежде чем определять (создавать) сеть, состоящую
из заданного пользователем числа виртуальных процессоров, и вы-
полнять требуемые вычисления на этой сети, программа проверяет
корректность исходных данных. Если заданное число виртуальных
процессоров некорректно (меньше 1 или больше общего числа про-
цессов параллельной программы), программа выводит на терминал
пользователя соответствующее сообщение. В противном случае оп-
ределяется сеть mynet, состоящая из л виртуальных процессоров, и оп-
ределяется переменная ип, распределенная по этой сети. Затем на сети
mynet вызывается узловая функция ипате, после чего поле nodename
каждой проекции распределенной структуры ип будет содержать ссылку
на имя того компьютера, на котором система программирования языка
трС разместила соответствующий виртуальный процессор. Наконец,
вызов узловой функции MPC_Printf на сети mynet выводит на терми-
нал пользователя приветствие от каждого виртуального процессора
и имя компьютера, на котором он находится.
Время жизни сети mynet, как и время жизни переменной ип, ограни-
чено блоком, в котором эта сеть определяется. При выходе из этого
блока все процессы программы, захваченные под виртуальные процес-
соры сети mynet, освобождаются и могут быть использованы при соз-
дании других сетей. Такие сети называются в трС автоматическими.
В отличие от автоматических время жизни статических сетей ограни-
чено лишь временем выполнения программы. Следующие две програм-
мы демонстрируют различие статических и автоматических сетей.
457
Глава 11. Языки описания параллельных процессов
Программы выглядят практически идентичными. Обе они заключа-
ются в циклическом выполнении блока, включающего определение
сети, и выполнении уже знакомых вычислений на этой сети. Единст-
венным, но существенным отличием является то, что в первой про-
грамме определяется автоматическая сеть, а во второй — статическая.
В программе
♦include <mpc.h>
♦include <sys/utsname.h>
♦define Nmin 3
♦define Nmax 5
int [*]main() {
repl n;
for (n=Nmin; n<=Nmax; n++) {
auto net SimpleNet(n) anet;
[anet]: {
struct utsname a;
uname(&a);
MPC_Printf («I'm from an automatic network on \»%s\« (n=%d) .\n>>,
a.nodename, n) ;
)
}
}
при входе в блок на первом витке цикла создается автоматическая
сеть из трех виртуальных процессоров (л = Nmin = 5), которая при вы-
ходе из цикла уничтожается. При входе в блок на втором витке цикла
создается новая автоматическая сеть уже из четырех виртуальных
процессоров, которая также прекращает свое существование по выходе
из блока, так что к моменту выполнения повторной инициализации
цикла (л++) эта 4-процессорная сеть уже не существует. Наконец,
на последнем витке при входе в блок создается автоматическая сеть
из пяти виртуальных процессоров (n=Nmax=5).
В программе
♦include <mpc.h>
♦include <sys/utsname.h>
♦define Nmin 3
♦define Nmax 5
458
11.2. Примеры языков параллельного лрограммирования
int [*]main() {
repl п;
for(n=Nmin; n<=Nmax; n++) {
static net SimpleNet(n) snet;
[snet]: {
struct utsname s;
uname(&s);
MPC_Printf («I'm from the static network on \»%s\« (n=%d).\n>>,
s.nodename, n);
)
)
}
при входе в блок на первом витке цикла также создается сеть из трех
виртуальных процессоров, однако по выходе из блока она не уничто-
жается, а просто перестает быть видна. В этом случае блок является
не областью существования сети, а областью ее видимости. Поэтому
во время выполнения повторной инициализации цикла и проверки
условия цикла данная статическая 3-процессорная сеть существует,
но недоступна (эти точки программы находятся вне области видимо-
сти сети snet). При повторных входах в блок на последующих витках
цикла никакие новые сети не создаются, а просто становится видна
та статическая сеть, которая была создана при первом входе в блок.
Таким образом, в отличие от первой программы, в которой одно и то
же имя anet на разных витках цикла обозначает совершенно разные
сети, во второй программе имя snet определяет уникальную сеть, су-
ществующую с момента первого входа в блок, в котором она опреде-
ляется, и до конца выполнения программы.
Если класс сети не специфицирован явно путем использования клю-
чевого слова auto или static в ее определении, то по умолчанию она
считается автоматической, если определена внутри функции, и статиче-
ской, если определена вне функции.
Ъшы сетей. В приведенных программах все виртуальные процессоры
сетей выполняли параллельно одинаковые вычисления. Поэтому не
было необходимости различать их внутри сети. Если же програм-
мируемый параллельный алгоритм предполагает, что различные
параллельные процессы должны выполнять разные вычисления, то
необходимы средства для выделения отдельных виртуальных процес-
459
Глава 11. Языки описания параллельных процессов
соров внутри сети. Такие средства предусмотрены в языке трС. Они
позволяют привязывать виртуальные процессоры любой сети к неко-
торой системе координат и выделять отдельный виртуальный про-
цессор путем задания его координат.
Вообще говоря, в программе на трС нельзя определить просто сеть,
а можно определить лишь сеть того или иного типа. Тип является
важнейшим атрибутом сети, в частности конкретизирует операции
доступа к ее виртуальным процессорам. Указание типа является обя-
зательной частью определения любой сети. В рассмотренных приме-
рах определение используемого сетевого типа SimpleNet находится
среди прочих стандартных определений языка трС в заголовке mpc.h
и включается в программу с помощью директивы #include препроцес-
сора. Выглядит это определение следующим образом:
nettype SimpleNet(int n) {
coord I=n;
);
Оно вводит имя SimpleNet сетевого типа, параметризованного целым
параметром л. В теле определения объявляется координатная перемен-
ная I, изменяющаяся отОдо л—1. Тип SimpleNet является простейшим
параметризованным сетевым типом и соответствует сетям, состоя-
щим из л виртуальных процессоров, линейно упорядоченных своим
местоположением на координатной прямой.
Программа
tinclude <mpc.h>
♦define N 5
int [*]main() {
net SimpleNet(N) mynet;
[mynet}: {
int my_coordinate;
my_coordinate - I coordof mynet;
if(my_coordinate%2==0)
MPC_Printf(«Hello, even world! \n>>);
else
MPC_Printf(«Hello, odd world!\n»);
)
)
460
11.2. Примеры языков параллельного программирования
демонстрирует способ программирования различных вычислений
виртуальными процессорами с различными координатами. В ней ис-
пользуется бинарная операция coordof, левым операндом которой
в данном случае является координатная переменная I, а правым —
сеть mynet. Результатом операции будет целое значение, распределен-
ное по сети mynet, такое, что его проекция на любой из виртуальных
процессоров будет равна значению координаты I этого процессора
в сети. После присваивания
my_coordinate = I coordof mynet
значения проекций переменной mycoordinate будут равны координа-
там соответствующих виртуальных процессоров в сети mynet. В ре-
зультате виртуальные процессоры с четными координатами выведут
на терминал пользователя приветствие «Hello, even world!», а виртуаль-
ные процессоры с нечетными координатами — приветствие «Hello,
odd world!».
Программа
♦include <mpc.h>
♦include <sys/utsname.h>
nettype Mesh(int m, int n) {
coord I=m, J=n;
);
♦define M 2
♦define N 3
int (*]main() {
net Mesh(M,N) mynet;
[mynet]: {
struct utsname un;
uname(Sun);
MPC_Printf («I'm on \»%s\« and have coordinates (%d, %d).\n>>,
un.nodename, I coordof un, J coordof un);
)
)
демонстрирует сеть, виртуальные процессоры которой привязаны
к двумерной системе координат. Каждый из виртуальных процессо-
ров сети выводит на терминал пользователя свои координаты в сети
461
Глава 11. Языки описания параллельных процессов
и имя компьютера, на котором его разместила система программиро-
вания. Заметим, что в качестве второго операнда операции coordof
в этой программе используется не сеть, а переменная ип. В общем
случае, если вторым операндом операции coordof является не сеть,
а выражение, то данное выражение не вычисляется, а используется
лишь для определения сети, по которой распределено его значение.
При этом операция выполняется так, как если бы в качестве второго
операнда использовалась эта сеть.
Родитель сети. Время жизни автоматической сети ограничено бло-
ком, в котором она определена. При выходе из этого блока сеть пре-
кращает свое существование, а процессы программы, захваченные
под виртуальные процессоры сети, освобождаются и могут быть ис-
пользованы при создании других сетей.
Возникает вопрос, каким образом результаты вычислений, выпол-
ненных на такой автоматической сети, сохраняются и могут быть ис-
пользованы в дальнейших вычислениях. В приведенных программах
такой проблемы не было, так как единственным результатом вычис-
лений на любой из сетей был вывод на терминал пользователя того
или иного сообщения.
На самом деле, сети в языке трС не являются абсолютно независи-
мыми друг от друга. Каждая вновь создаваемая сеть имеет в точности
один виртуальный процессор, общий с уже существующими сетями.
Этот виртуальный процессор называют родителем создаваемой сети.
Он является тем связующим звеном, через которое передаются резуль-
таты вычислений на сети в случае прекращения ее существования.
Родитель сети явно или неявно специфицируется ее определением.
До сих пор ни одна из сетей не была определена с явным указанием
родителя. Во всех случаях родитель специфицировался неявно, и этим
родителем являлся виртуальный хост-процессор. Такое решение оче-
видно, так как при выполнении любой программы гарантируется суще-
ствование лишь одной сети — предопределенной сети host, состоящей
из единственного виртуального процессора, который всегда отобра-
жается на связанный с терминалом пользователя хост-процесс.
Программа
♦include <mpc.h>
♦include <sys/utsname.h>
462
11.2. Примеры языков параллельного программирования
nettype Mesh (int m, int n) {
coord I=m, J-n;
parent [0,0];
};
♦define M 2
♦define N 3
int [*]main() {
net Mesh(M,N) [host]mynet;
[mynet]: {
struct utsname un;
uname(Sun);
MPC_Printf («I'm on \»%s\« and have coordinates (%d, %d).\n>>,
un.nodename, I coordof un, J coordof un);
}
}
отличается от предыдущей программы тем, что в определении сети
неявная спецификация родителя сети заменена на явную.
Еще одно различие можно найти в определении сетевого типа, где
добавлена строка, явно специфицирующая координаты родителя
в сетях этого типа (по умолчанию родитель имеет нулевые координа-
ты в создаваемой сети). Для того чтобы родитель сети mynet имел не
наименьшую, а наибольшую координату, в определении сетевого типа
Mesh вместо спецификации parent [0,0] следовало бы использовать
спецификацию parent [тя-1, л-1].
В любой из уже рассмотренных программ в каждый момент времени
выполнения одновременно существует не более одной сети. Это не
ограничение языка, поскольку трС позволяет создавать программы
с произвольным числом параллельно существующих сетей. Единствен-
ным ограничением является общее число процессов, составляющих
параллельную программу, на которые отображаются виртуальные
процессоры сетей.
В программе
♦include <mpc.h>
nettype TrivialNet(int n, int m) {
coord I=n;
463
Глава 11. Языки описания параллельных процессов
parent [m] ;
);
int [*]main() {
[host]MPC_Printf(«I'm host. I'll be a parent of netl.\n\n>>);
{
net TrivialNet(3,0) netl;
int [netl]mycoordinnetl;
mycoordinnetl = I coordof netl;
[netl]:
if(mycoordinnetl)
MPC_Printf(«I'm a regular member of netl. »
«My coordinate in netl is %d.\n»
« I'll be a parent of net%d.\n\n>>,
mycoordinnetl, mycoordinnetl+1) ;
else
MPC Printf(«I'm a parent of netl. »
«My coordinate in netl is %d.\n\n>>, mycoordinnetl);
{
net TrivialNet(3,1) [netl:I==l]net2;
net TrivialNet(3,2) [netl:I==2]net3;
[net2]: {
int mycoordinnet2;
mycoordinnet2 = I coordof net2;
if(mycoordinnet2!=1)
MPC_Printf(«I'm a regular member of net2. »
«My coordinate in net2 is %d.\n\n>>,
mycoordinnet2);
else
MPC_Printf («I'm a parent of net2. »
«My coordinate in net2 is %d.\n\n>>,
mycoordinnet2);
)
[net3]: {
int mycoordinnet3;
464
11.2. Примеры языков параллельного программирования
mycoordinnet3 - I coordof net3;
if(mycoordinnet3!=2)
MPC_Printf(«I'm a regular member of net3. »
«My coordinate in net3 is %d.\n\n>>,
mycoordinnet3) ;
else
MPC_Printf(«I'm a parent of net3. »
«My coordinate in net3 is %d.\n\n>>,
mycoordinnet3);
)
)
[netl]:
if(mycoordinnetl)
MPC_Printf(«I'm a regular member of netl. »
«My coordinate in netl is %d.\n>>
« I was a parent of net%d.\n\n>>,
mycoordinnetl, mycoordinnetl+1);
}
[host]MPC_Printf («I'm host. I was a parent of netl.\n\n>>);
)
параллельно существует три сети — netl, netl и nefi. Родителем сети
лей является виртуальный хост-процессор. Родитель сети net! — вир-
туальный процессор сети netl с координатой 1. Родитель сети net3 —
виртуальный процессор сети ле/1 с координатой 2.
Синхронизация процессов. Приведенные средства языка трС позво-
ляют специфицировать требуемое для параллельного решения задачи
число процессов и распределять вычисления между ними. Этих средств
достаточно для описания синхронизации процессов.
Основным механизмом синхронизации параллельных процессов,
взаимодействующих с помощью передачи сообщений, является
барьер. Барьер — это точка параллельной программы, в которой про-
цесс ожидает все остальные процессы, с которыми он синхронизирует
свою работу. Лишь только после того, как все процессы, синхронизи-
рующие свою работу, достигли барьера, они продолжают дальнейшие
вычисления.
465
зо2792
Глава 11. Языки описания параллельных процессов
Пусть требуется создать программу, в которой сообщения от виртуаль-
ных процессоров с нечетными координатами выводятся на терминал
пользователя только после того, как будут выведены сообщения от
всех виртуальных процессоров с четными координатами.
Программа
♦include <mpc.h>
♦define N 5
int [*]main() {
net SimpleNet(N) mynet;
[mynet]: {
int my_coordinate;
my_coordinate - I coordof mynet;
if(my_coordinate%2==0)
MPC_Printf(«Hello, even world! \n>>);
Barrier:
{
int [host]bs[N], b=l;
bs [ ] - b;
b = bs[];
}
if(my_coordinate%2==l)
MPC_Printf(«Hello, odd world! \n>>);
}
}
представляет один из вариантов решения такой задачи. Здесь в блоке,
помеченном меткой Barrier, определяется размещенный на хост-про-
цессе автоматический массив bs, число элементов которого равно
числу виртуальных процессоров в сети mynet, и распределенная по
этой сети переменная Ь. Выполнение присваивания Zw[] = b состоит
в том, что каждый из виртуальных процессоров сети mynet посылает
значение своей проекции переменной b виртуальному хост-про-
цессору, где это значение присваивается элементу массива bs, индекс
которого равен координате процессора, пославшего это значение.
Выполнение присваивания b = Zw[] состоит в том, что значение /-го
элемента массива bs посылается виртуальному процессору сети mynet
466
11.2. Примеры языков параллельного программирования
с координатой I = г, где оно присваивается соответствующей проек-
ции переменной Ь. Нетрудно показать, что ни один из виртуальных
процессоров сети mynet не покинет этого блока до тех пор, пока все
они не войдут в него и не завершат свою часть работы по выполнению
первого из присваиваний. Только после этого виртуальный хост-про-
цессор сможет завершить выполнение первого присваивания и перейти
ко второму, освобождая задержанные на нем виртуальные процессоры,
завершившие свою часть работы по выполнению первого присваива-
ния. Следовательно, этот блок представляет собой барьер, разделяю-
щий операторы, выводящие сообщения на терминал пользователя
с четных и нечетных виртуальных процессоров сети mynet соответст-
венно.
В программе
♦include <mpc.h>
♦define N 5
int [*]main() {
net SimpleNet(N) mynet;
[mynet]: {
int my_coordinate;
my_coordinate = I coordof mynet;
if(my_coordinate%2==0)
MPC_Printf(«Hello, even world!\n»>;
Barrier:
{
int b=l ;
b[ + ] ;
}
if(my_coordinate%2==l)
MPC_Printf («Hello, odd world! \n>>);
}
]
аналогичный барьер реализован проще, а по эффективности не усту-
пает первому варианту (наиболее очевидная схема реализации опе-
рации [+] отличается от барьера из предыдущей программы лишь
дополнительным суммированием на хосте, время выполнения кото-
467
Глава 11. Языки описания параллельных процессов
рого мало по сравнению со временем передачи сообщения). Язык
трС предоставляет две библиотечные функции, эффективно реали-
зующие барьерную синхронизацию для той операционной среды,
в которой выполняется параллельная программа. Во-первых, это ба-
зовая функция MPC_Global_barrier, синхронизирующая работу всех
процессов параллельной программы. Ее описание находится в заго-
ловке mpc.h и записывается так:
int [*]MPC_Global_barrier(void);
Программа
♦include <mpc.h>
♦define N 5
int [*]main() {
net SimpleNet(N) mynet;
int [mynet]my_coordinate;
my_coordinate = I coordof mynet;
if(my_coordinate%2==0)
[mynet]MPC_Printf («Hello, even world! \n>>);
MPC_Global_barrier();
if(my_coordinate%2==l)
[mynet]MPC_Printf («Hello, odd world! \n>>);
)
демонстрирует использование этой функции для разделения барье-
ром двух параллельных операторов. В этой программе, в отличие от
двух предыдущих, на барьере ждут не только процессы, реализующие
сеть mynet, но и свободные процессы. Это, естественно, приводит
к большему числу сообщений, пересылаемых при выполнении барь-
ера, и, следовательно, к определенному замедлению программы.
Сетевые функции. Библиотечная функция MPC Barrier позволяет
синхронизировать работу виртуальных процессоров любой сети.
Программа
♦include <mpc.h>
♦define N 5
int [*]main() {
net SimpleNet (N) mynet;
[mynet]: {
468
11.2. Примеры языков параллельного программирования
int my_coordinate;
my_coordinate = I coordof mynet;
if(my_coordinate%2==0)
MPC_Printf(«Hello, even world!\n»);
([(N)mynet])MPC_Barrier() ;
if(my_coordinate%2==l)
MPC_Printf(«Hello, odd world! \n>>);
)
)
демонстрирует использование этой функции. В данном случае на
барьере ждут только процессы, реализующие сеть mynet.
Вызов функции MPC_Barrier выглядит несколько необычно. Дейст-
вительно, эта функция принципиально отличается от всех ранее
встречавшихся функций и представляет так называемую сетевую
функцию. В отличие от базовых функций, которые всегда выполня-
ются всеми процессами параллельной программы, сетевые функции
выполняются на сетях и, следовательно, могут выполняться парал-
лельно с другими сетевыми или узловыми функциями. В отличие от
узловых функций, которые также могут выполняться параллельно
всеми виртуальными процессорами той или иной сети, виртуальные
процессоры сети, выполняющей сетевую функцию, могут обмени-
ваться данными и в этом подобны базовым функциям.
Описание функции MPC_Barrier находится в заголовке mpc.h и вы-
глядит следующим образом:
int [net SimpleNet(n) w] MPC_Barrier( void );
Любая сетевая функция имеет сетевой формальный параметр, пред-
ставляющий сеть, на которой вызывается эта функция. Описание
этого формального параметра в сетевой функции располагается
в квадратных скобках слева от имени функции и выглядит аналогич-
но обычному определению сети. Описание сетевого параметра через
функцию MPCBarrier имеет вид:
net SimpleNet(n) w
Это описание, наряду с формальной сетью w, на которой выполняет-
ся функция MPC Barrier, вводит параметр п этой сети. Последний,
как и обычные формальные параметры, доступен в теле функции так
же, как и при описании его со спецификаторами repl и const. Согласно
469
Глава 11. Языки описания параллельных процессов
определению сетевого типа SimpleNet, параметр п имеет тип int, сле-
довательно, параметр п интерпретируется в теле функции MPC_Barrier
как обычный формальный параметр, описанный следующим образом:
repl const int n
Все обычные формальные параметры по умолчанию считаются рас-
пределенными по формальному сетевому параметру.
Таким образом, распределенный по сети w целый неизменяемый па-
раметр п задает число виртуальных процессоров этой сети.
Если бы функция MPCBarrier не была библиотечной, она могла бы
определяться следующим образом:
int [net SimpleNet (n) w] MPC_Barrier( void ) {
int [w:parent]bs[n], [w]b=l;
bs[]=b;
b=bs[];
)
В теле функции определяется автоматический массив bs из п эле-
ментов (язык трС допускает динамические массивы), размещенный
на родителе сети w (это специфицируется с помощью конструкции
[w:parent\, помещенной перед именем массива при его описании).
Кроме того, там же определяется распределенная по сети w перемен-
ная Ь. Следующая за этим определением пара операторов реализует
барьер для виртуальных процессоров сети w.
Вызов сетевой функции MPC Barrier в предыдущих двух программах
задает фактический сетевой аргумент — сеть mynet, на которой в дей-
ствительности вызывается функция, а также фактическое значение
единственного параметра сетевого типа SimpleNet. Последнее, на
первый взгляд, кажется избыточным. Однако надо учесть, что факти-
ческим сетевым аргументом функции MPC_Barrier может быть сеть
любого типа, а не только типа SimpleNet.
В программе
♦include <mpc.h>
♦include <sys/utsname.h>
nettype Mesh (int m, int n) {
coord I=m, J=n;
parent [0,0];
470
11.2. Примеры языков параллельного программирования
);
«define М 2
«define N 3
int [w]main() {
net Mesh(M,N) [host]mynet;
[mynet]: {
struct utsname un;
uname (&un);
if ( I coordof un == 0 )
MPC_Printf(«I'm on \»%s\« and have coordinates (%d, %d).\n»,
un.nodename, 0, J coordof un);
([(M*N)mynet])MPC_Barrier();
if (I coordof un != 0 )
MPC_Printf («I'm on \»%s\« and have coordinates (%d, %d)-\n>>,
un.nodename, I coordof un, J coordof un) ;
)
)
таким фактическим аргументом является сеть типа Mesh. По сущест-
ву, функция MPC Barrier лишь интерпретирует ту совокупность про-
цессов, на которой она вызвана как сеть типа SimpleNet.
Подсети. В вышеописанных обменах данными участвовали либо все
процессы программы, либо все виртуальные процессоры той или иной
сети, а сами обмены в основном состояли либо в рассылке от одного
из процессов некоторого значения всем участвующим процессам, либо
в сборе значений со всех участвующих процессов на одном из про-
цессов. Для описания более сложных пересылок данных, например
обмена данными между группами виртуальных процессоров сети или
параллельному обмену данными между соседними в той или иной
системе координат виртуальными процессорами сети, нужны допол-
нительные средства.
Главным средством для этой цели являются подсети. Подсеть — это
любое подмножество виртуальных процессоров некоторой сети. Напри-
мер, любая строка или столбец решетки виртуальных процессоров
сети типа Mesh(m,n) представляет собой подсеть этой сети.
471
Глава 11. Языки описания параллельных процессов
В программе
♦include <string.h>
♦include <mpc.h>
♦include <sys/utsname.h>
nettype Mesh (int m, int n) {
coord I=m, J=n;
parent [0,0];
);
♦define MAXLEN 256
int [*]main() {
net Mesh(2,3) [host]mynet;
[mynet]: {
struct utsname un;
char me[MAXLEN], neighbour[MAXLEN];
subnet [mynet:I==0]rowO, [mynet:I==l]rowl;
uname(Sun);
strcpy(me, un.nodename);
[rowO]neighbour[] = [rowl]me[];
[rowl]neighbour [] = [row0]me[];
MPC_Printf («I 'm on \»%s\« and have coordinates (%d, %d), \n>>
«My neighbour with coordinates (%d, %d) is on \»%s\«. \n\n>>,
me, I coordof mynet, J coordof mynet,
(I coordof mynet + 1)%2, J coordof mynet, neighbour);
)
)
каждый виртуальный процессор сети mynet типа Mesh(2,3) выводит
на терминал пользователя не только имя компьютера, на котором его
разместила система программирования, но и имя компьютера, на ко-
тором система программирования разместила ближайший виртуаль-
ный процессор с соседней строки. С этой целью определяются две
подсети rowO и rowl сети mynet. Подсеть rowO состоит из всех вирту-
альных процессоров сети mynet, у которых значение координаты I
равно нулю, то есть соответствует нулевой строке решетки виртуаль-
ных процессоров сети mynet. Это специфицируется с помощью конст-
рукции [/пуиеГ.1=0], помещенной перед именем подсети в ее опреде-
472
11.2. Примеры языков параллельного программирования
лении. Аналогично подсеть rowl соответствует первой строке решетки
виртуальных процессоров сети mynet. Логические выражения, выде-
ляющие виртуальные процессоры подсетей, могут быть довольно
сложными. Например, выражение I< J && J % 2 = 0 выделяет вирту-
альные процессоры решетки, расположенные над главной диагона-
лью в четных столбцах.
Операция присваивания lrowO]neighbour[]=[rowl]me[] состоит в па-
раллельной пересылке содержимого соответствующей проекции мас-
сива те от каждогоу'-го виртуального процессора строки гом'1 каждо-
му у-му виртуальному процессору строки rowO с последующим его
присваиванием соответствующей проекции массива neighbour. Выпол-
нение присваивания [rowl]neighbour[] = [rowO]we[] состоит в параллель-
ной пересылке содержимого проекций массива те от виртуальных
процессоров подсети гомЮ соответствующим виртуальным процессо-
рам подсети rowl с последующим их присваиванием проекциям мас-
сива neighbour. В результате, проекция распределенного массива
neighbour на виртуальный процессор сети mynet с координатами (Оу)
содержит имя компьютера, на котором система программирования
разместила виртуальный процессор с координатами (1,у), а проекция
этого массива на виртуальный процессор с координатами (1,у) содер-
жит имя компьютера, на котором размещен виртуальный процессор
с координатами (Оу).
Программа
♦include <string.h>
♦include <mpc.h>
♦include <sys/utsname.h>
nettype Mesh (int m, int n) {
coord I=m, J=n;
parent [0,0];
];
♦define MAXLEN 256
int [*]main() {
net Mesh(2,3) [host]mynet;
[mynet] : (
struct utsname un;
char me[MAXLEN], neighbour[MAXLEN];
473
Глава 11. Языки описания параллельных процессов
uname(Sun);
st гсру(me, un.nodename);
[mynet:I==0]neighbour[] “ [mynet:I=“l]me [];
[mynet: I“l] neighbour [] - [mynet:I==0]me[];
MPC_Printf(«I'm on \»%s\« and have coordinates (%d, %d),\n»
«My neighbour with coordinates (%d, %d) is on \»%s\«.\n\n»,
me, I coordof mynet, J coordof mynet,
(I coordof mynet + 1)%2, J coordof mynet, neighbour);
)
)
отличается от предыдущей программы лишь тем, что используемые
в ней в качестве подсетей строки решетки процессоров сети mynet не
определены явно с помощью объявления подсети subnet. Использо-
вание неявно определенных подсетей упрощает программу без поте-
ри эффективности или функциональных возможностей. Но сетевые
функции можно вызывать лишь на явно определенных подсетях.
Векторные вычисления. В последних двух программах наряду с подсе-
тями впервые использованы средства описания векторных вычисле-
ний языка трС. Подобно универсальному языку параллельного про-
граммирования HPF (High Performance Fortran), язык трС допускает
в качестве операндов большинства операций не только скалярные
выражения, но и выражения, представляющие множества скаляров,
например массивы или сегменты массивов. Выражения neighbour]]
и те[] в предыдущих двух программах представляют массивы neighbour
и те как единое целое, а не просто адреса их начальных элементов.
Присваивание вида neighbour]] - те[] означает присваивание значе-
ния выражения те[] (вектора значений типа сЛаг)массиву neighbour.
С одной стороны, векторные выражения дают возможность програм-
мисту упростить описание вычислений над массивами, а с другой —
позволяют компилятору сгенерировать код, более эффективно ис-
пользующий как внутрипроцессорный параллелизм, так и иерархию
памяти.
В программе
♦include <stdio.h>
♦include <mpc.h>
474
11.2. Примеры языков параллельного программирования
void init_vector(int n, double (*vec)[n]> {
static double base=1.0;
int i;
for(i=0; i<n; i++)
(*vec) [i] = base;
base++;
int [*]main(int [host]argc, char *[host]argv[]) {
[host] : (
int n;
n = atoi(argv[l]);
if (n<=0)
printf(«Wrong input: n = %d\n», n) ;
else {
double vl[n], v2[n];
init_vector(n, 4vl);
init_vector(n, Sv2);
printf(«Dot product of the vectors is equal to %g\n»,
[ + ] (vl[]*v2 [ ])) ;
)
]
)
единственное векторное выражение [+](vl []*v2[]) используется для
вычисления скалярного произведения двух векторов, хранящихся в
массивах vl и v2. Бинарная операция заключается в покомпонентном
умножении векторных операндов, а результатом префиксной унар-
ной операции [+] является сумма элементов ее векторного операнда.
Программа
♦include <stdio.h>
♦include <stdlib.h>
♦include <mpc.h>
void init_matrix(int n, double (*a)[n][n]> (
int i,j;
475
Глава 11. Языки описания параллельных процессов
for(i=0;i<n;i++)
for (j=0; j<n; j++)
(*a) [i] [j]=10.;
for(i=0;i<n;i++)
(*a)[i][i]=10.*n;
}
void print_matrix(int n, double (*a)[n][n]) {
int i,j;
for(i=0;i<n;i++) {
for (j=0; j<n; j++)
printf(«%lf\t», (‘a)[i] [j]);
printf(«\п»);
}
}
int [*]main(int [host]argc, char *[host]argv[]){
[host] :
{
int n, i, j;
n = atoi(argv[l]);
if (n<=0)
printf («Wrong input: n = %d\n>>, n);
else {
double a[n][n];
init_matrix(n,&a) ;
printf («\n Source matrix :\n>>);
print_matrix(n, 4a) ;
for(i=0; i<n-l; i++) [
for(j=i+l; j<n; j++) {
double t;
t = a[j] [i] / a[i] [i] ;
if(a[j] [i] !=0)
a[j][i:n-l] -= t * a[i][i:n-l];
)
)
476
11.2. Примеры языков параллельного программирования
printf(«\п Matrix after LU transformation: \п») ;
printmatrix(n,4a);
}
}
}
реализует L(/-разложение квадратной матрицы методом Гаусса, демон-
стрируя использование сегментов массивов в векторных вычислениях.
Так, выражение д[/][/:л— 1] обозначает отрезок г-й строки массива а,
включающий все элементы начиная с а[<][/] по ар] [и— 1].
Неоднородные параллельные вычисления. Определение сети в программе
вызывает отображение виртуальных процессоров на реальные про-
цессы параллельной программы, сохраняемое все время жизни сети.
Покажем, как система программирования осуществляет это отобра-
жение и каким образом программист может управлять им.
Основным критерием при отображении виртуальных процессоров
сети на реальные процессы является минимизация времени выпол-
нения соответствующей параллельной программы. При выполнении
отображения система программирования, с одной стороны, основы-
вается на информации о конфигурации и производительности компо-
нент параллельной вычислительной системы, выполняющей програм-
му, а с другой — на информации о сравнительном объеме вычислений,
которые предстоит выполнить различным виртуальным процессорам
определяемой сети.
В рассмотренных программах объемы вычислений никак не специ-
фицировались. П умолчанию предполагалось, что всем виртуальным
процессорам всех определяемых сетей следовало выполнять одина-
ковые объемы вычислений. При таком отображении все процессы,
представляющие виртуальные процессоры сети, выполняют вычис-
ления приблизительно с одинаковой скоростью, то есть параллельная
программа оказывается сбалансированной в том смысле, что процессы
не ждут друг друга в точках синхронизации.
Такое отображение оказывалось вполне приемлемым для всех рас-
смотренных программ, так как вычисления, выполнявшиеся разными
виртуальными процессорами одной сети, приблизительно одинаковы
и весьма незначительны по объему. Однако если объемы вычислений,
выполняемых различными виртуальными процессорами, значительно
477
Глава 11. Языки описания параллельных процессов
различаются, такое распределение может привести к существенному
замедлению программы, ибо выполнение процессами вычислений
с одинаковой скоростью приводит к тому, что процессы, быстро вы-
полнившие свои вычисления, будут ожидать в точках синхронизации
и точках обмена данными процессы, выполняющие более объемные
вычисления. К более сбалансированной программе приводит ото-
бражение, обеспечивающее скорости процессов, пропорциональные
объемам выполняемых ими вычислений. Язык трС предоставляет
программисту средства для спецификации относительных объемов
вычислений, выполняемых различными виртуальными процессора-
ми той или иной сети.
Программа
♦include <stdio.h>
♦include <stdlib.h>
♦include <math.h>
♦include <mpc.h>
♦define DELTA (0.5)
typedef struct {
double len;
double wid;
double hei ;
double mass;
} rail;
nettype HeteroNet(int n, double v[n]) {
coord I=n;
node {
I>=0: v[I);
);
parent [ 0 ] ;
);
double Density(double x, double y, double z) {
return 6.0 * sqrt ( exp ( sin( sqrt ( x*y*z ) ) ) );
}
int [*]main(int [host]argc, char ’*[host]argv) {
repl N=3;
if(argc>l)
N = [host]atoi(argv[l]);
if(N>0) (
478
11.2. Примеры языков параллельного программирования
static rail [host]steel_hedgehog[[host]N];
repl double volumes[N], [host]start;
int [host]i;
repl j;
for(i=0; i<[host]N; i++) {
steel_hedgehog[i].len = 200.0*(i+l);
steelhedgehog[i].wid = 5.0*(i+l);
steel_hedgehog[i].hei = 10.0*(i+l);
]
start = [host]MPC_Wtime () ;
for(j=0; j<N; j++)
volumes[j] =
steel_hedgehog[j].len * steel_hedgehog[j].wid *
steel_hedgehog[j].hei;
{
net HeteroNet{N, volumes) mynet;
[mynet]: {
rail myrail;
double x, y, z;
myrail = steel_hedgehog[];
for(myrail.mass=0., x=0.; xcmyrail.len; x+=DELTA)
for(y=0.; ycmyrail.wid; y+=DELTA)
for(z=0.; zcmyrail.hei; z+=DELTA)
myrail.mass += Density (x,y, z) ;
myrail.mass *= DELTA*DELTA*DELTA;
MPC_Printf («Rail #%d is %gcm x %gcm x%gcm and weights %g kg\n>>,
I coordof mynet, myrail.len, myrail.wid,
myrail.hei, myrail.mass/1000.0) ;
[host] printf («The steel hedgehog weights %g kg\n>>,
[host]( (myrail.mass)[+]) / 1000.0 );
)
)
[host]printf («\nlt took %. If seconds to run the program. \n>>,
[host]MPC_Wtime () - start);
)
else
[host]printf («Wrong input (N=%d) \n>>, [host]N);
)
479
Глава 11. Языки описания параллельных процессов
знакомит с вышеописанными средствами. В ней определяется сете-
вой тип HeteroNet, параметризованный двумя параметрами — целым
скалярным параметром п, задающим число виртуальных процессо-
ров сети, и векторным параметром v, состоящим из п элементов типа
double, используемым при спецификации относительных объемов
вычислений, выполняемых различными виртуальными процессора-
ми. Определение сетевого типа HeteroNet содержит особое объявле-
ние
node { I > = О: v[I] },
которое задает следующее: для любого / >= 0 относительный объем
вычислений, выполняемых виртуальным процессором с координа-
той I, задается значением v[/|-
Программа рассчитывает массу металлической конструкции, сварен-
ной из Nнеоднородных рельс. Для параллельного вычисления общей
массы конструкции создается сеть mynet из N виртуальных процес-
соров, каждый из которых вычисляет массу одной из этих рельс.
Вычисление массы рельсы осуществляется численным трехмерным
интегрированием с фиксированным шагом заданной функции плот-
ности Density по объему рельсы. Очевидно, что объем вычислений по
расчету массы рельсы пропорционален объему этой рельсы. Поэтому
в определении сети mynet в качестве второго фактического параметра
сетевого типа HeteroNet используется распределенный массив volumes,
i-й элемент которого содержит объем z-й рельс. Тем самым специфи-
цируется, что вычисления, выполняемые z-м виртуальным процессо-
ром сети mynet, пропорциональны объему рельсы, массу которой этот
виртуальный процессор рассчитывает.
Программа, используя библиотечную узловую функцию МРС_ Wtime,
выводит на терминал пользователя астрономическое время, затра-
ченное на параллельное решение задачи, начиная от введения исходных
данных и до получения результатов, и замеренное на хост-процессе.
Это явление представляет собой наиболее объективную и интересую-
щую конечного пользователя временною характеристику програм-
мы. Минимизация этой характеристики и составляет основную цель
параллельных вычислений.
480
11.3. Преобразование последовательных программ
11.3. Преобразование последовательных программ
в последовательно-параллельные
Задача распараллеливания. Параллельное программирование должно
иметь способы получения параллельной программы из обычной ал-
горитмической записи, которая представляет собой фиксацию по-
следовательной логики рассуждений, так как в процессе создания
алгоритма любые вычисления, проводимые как вручную, так и авто-
матически, выполнялись последовательно. Однако оказывается, что
при детальном рассмотрении любой реальный процесс выполняется
параллельно. И чем внимательнее и детальнее его описать, тем боль-
ше это описание будет приближаться к параллельной форме. Следо-
вательно, задача состоит в том, чтобы с помощью некоторых понятий
научиться достаточно просто и полно описывать естественные па-
раллельные процессы.
Сложность задачи распараллеливания во многом определяется язы-
ком, на котором записан исходный алгоритм. Наиболее просто эта
задача решается, если язык не содержит циклических структур. При-
мером таких языков можно назвать языки «геометрического описания
деталей со сложной объемной конфигурацией». Это язык, в котором
предложение является последовательностью директив.
Как правило, основное время выполнения программ, созданных на
обычных языках, связано с реализацией циклов. Поэтому важной за-
дачей является распараллеливание циклов.
Как указывалось выше, некоторые языки программирования имеют
средства для описания параллелизма. Однако все параллельные фраг-
менты программы должны быть указаны явным образом. Более того,
должна быть указана последовательность их выполнения, организо-
вана передача необходимых управлений и т.д.
При использовании языка PL/1, например, программист должен:
► выделить и пометить независимые фрагменты программы (напри-
мер с помощью операторов CALL и TASK);
► обеспечить синхронизацию при выполнении фрагментов (исполь-
зуя, скажем, оператор DELAY);
► осуществить взаимное управление фрагментами (операторы
COMPLETE, WAIT, RETURN).
481
312792
Глава 11. Языки описания параллельных процессов
Следовательно, все трудности организации параллельной обработки
ложатся на программиста, так как он, по существу, должен предвари-
тельно определить весь «сценарий» решения задачи в параллельном
режиме.
На разработку математического и программного обеспечения, со-
гласно различным литературным источникам, тратится от 70 до 90 %
всех затрат на создание ВС. Это представляет собой одну из основных
причин необходимости эффективного использования накопившегося
программного и математического обеспечения однопроцессорных ЭВМ,
которое следует адаптировать при переходе к многопроцессорной си-
стеме. Таким образом, появилась актуальная проблема — преобразова-
ние последовательных программ в последовательно-параллельные. Посколь-
ку такое преобразование очень трудоемко, то этот процесс следует ав-
томатизировать. Решение указанной проблемы позволяет, во-первых,
высвободить значительные трудовые ресурсы, во-вторых, использовать
накопленные за долгие годы развития ЭВМ информационно-про-
граммные ресурсы без ручного перепрограммирования и, в-третьих,
осуществить переход на многопроцессорные системы с меньшими
затратами труда и времени.
Распараллеливание программ можно осуществлять как на уровне отдель-
ных задач, так и на уровне отдельных процедур, операторов, операций
и микроопераций. Целесообразность преобразования на указанных
уровнях должна решаться в каждом отдельном случае в зависимости
от структуры ВС, типа программы и цели, которая ставится при ре-
шении данной задачи.
Рассмотрим общую схему преобразования последовательных программ
в последовательно-параллельные. Организовать параллельные вычис-
ления можно с помощью некоторой формальной процедуры, выпол-
няемой автоматически над каждой программой, состоящей из после-
довательности операторов обычного ЯП. Эта процедура позволяет
избавить пр граммиста от анализа собственной программы и помо-
гает выявить ее внутренний параллелизм. Выявление параллелизма
заключается в разбиении всех операторов на два класса: тех, которые
могут выполняться параллельно, и тех, которые должны быть завер-
шены прежде, чем следующие последовательности операторов нач-
нут выполняться.
Такой подход к распараллеливанию основывается на представлении
программы в виде ориентированного графа G, множество вершин кото-
482
11.3. Преобразование последовательных программ
рого И= {V|, v2,..., v„) соответствует либо отдельным операторам про-
граммы, либо совокупности этих операторов (типа подпрограмм
в языке Fortran либо процедур в языках Algol или Pascal). Множество
направленных дуг U = {иь и2, ит} соответствует возможным пере-
ходам между операторами программы.
Из теории графов известно, что ориентированный граф полностью
описывается соответствующей матрицей смежности, такой, что ее
элемент
1, если существует дуга (и, ,иу )
О, если такой дуги нет.
Пусть рассматриваемый граф G является произ-
вольным циклическим графом с одной входной
и одной выходной вершинами. Следуя определе-
нию сильносвязного подграфа, будем идентифи-
цировать его с таким фрагментом в программе, из
любого оператора которого существует переход
в любой другой оператор, принадлежащий этому
же фрагменту. Например, сильносвязным подгра-
фом будут фрагменты 2, 3, 4 (рис. 11.3).
Подграфу, представляющему собой последова-
тельность различных вершин, каждая из которых
Рис. 11.3. Сильно-
связный подграф
имеет единственную входную и единственную выходную вершины,
будем ставить в соотв тствие линейный участок в программе.
Итак, требуется преобразовать алгоритм решения задачи, заданный по-
следовательной программой, для его параллельной реализации на много-
процессорной вычислительной системе.
Для преобразования программы из одной (последовательной) формы
в другую (последовательно-параллельную) используем представле-
ние программы в виде орграфа. Вообще говоря, идея использовать
некоторый «формализм» в качестве посредника для преобразования
программ встречалась и раньше в связи с другими задачами. Так,
в трансляторе системы АЛЬФА был введен дополнительный проход,
во время которого по исходной программе строилась ее модель в виде
схемы Лаврова, что позволяло обнаруживать и анализировать инфор-
мационные связи в целях глобальной экономии памяти.
483
Глава 11. Языки описания параллельных процессов
Построим схему алгоритма распараллеливания программ, используя
некоторые сведения из теории графов.
Схема алгоритма будет выглядеть следующим образом.
1. Представление исходной про1раммы в виде графа. Этот процесс дос-
таточно подробно изложен выше.
2. Сведение циклического графа к ациклическому. Большое количество
вершин графа G приводит к большому порядку матрицы смежности
С. Для уменьшения порядка матрицы произведем сжатие линейных
участков программы в отдельные обобщенные операторы, то есть вы-
делим в исходном графе G линейные подграфы и поставим им в соот-
ветствие одну обобщенную вершину графа, не нарушая при этом ни
одного из существующих ориентированных циклов. Таким образом,
из исходного графа G получаем граф G'. Затем в графе G' выделим
множество сильносвязных подграфов. Каждый сильносвязный под-
граф заменим отдельной вершиной. После выполнения указанных
действий в общем случае циклический граф Gпревращается в сжатый
ациклический граф G", представляющий собой модель исходной
программы. Вершинами графа G" будут фрагменты исходной про-
граммы в виде линейных участков и сильносвязных областей.
3. Наложение информационных связей, заданных между операторами
программы, на связи возможных переходов. До этого момента инфор-
мационно-логические связи, заданные между операторами программы,
не претерпевали существенных изменений. Преобразуем их, учитывая
взаимосвязи укрупненных вершин графа G".
Если в графе G" существует переход от вершины v, к вершине v7, то
это вовсе не означает, что начало выполнения оператора, соответствую-
щего вершине у,, должно следовать тут же за окончанием оператора,
соответствующего вершине v,-. Однако если результат оператора v, яв-
ляется аргументом оператора Vj, то в таком случае выполнение операто-
ра Vj не может начаться ранее окончания выполнения оператора v,-.
После анализа входов и выходов для всех компонент приведенного
графа G’ производится наложение информационных связей на связи
возможных переходов, то есть на связи, представленные в матрице
смежности графа G’. Для анализа входов и выходов всех компонент
графа G' необходимо составить матрицу //информационной зависи-
484
11.3. Преобразование последовательных программ
мости, элементы которой hy принимают соответственно значения О
или 1. При этом
1,если у-й оператор зависит от значений переменных,
Л,у -
полученных в z-м операторе;
О, в противном случае.
Чтобы построить матрицу Н, для каждого оператора программы оп-
ределяем множество изменяемых и множество упоминаемых пере-
менных. Затем берем первую изменяемую переменную из первого
оператора программы и просматриваем все остальные операторы
программы до тех пор, пока исследуемая переменная не встретится
в упоминаемом множестве одного из операторов. Если эта перемен-
ная присутствует в упоминаемом множестве одного из операторов, то
в матрицу информационной зависимости на место пересечения стро-
ки с номером, равным номеру оператора с проверяемой перемен-
ной, и столбца с номером, равным номеру оператора, в упоминаемом
множестве которого присутствует проверяемая переменная, заносим
единицу.
Выполняем этот процесс со всеми изменяемыми переменными первого
оператора. Затем выделяем изменяемые переменные второго операто-
ра и повторяем заново весь процесс, и так далее до последнего опера-
тора. Число строк и столбцов в матрице информационной зависимо-
сти равно числу операторов в программе. Число единиц в столбце
матрицы указывает количество операторов, от которых зависит опе-
ратор, соответствующий данному столбцу.
В результате выполнения этого этапа граф G' преобразуется в графС,
в матрице смежности С которого учтены как информационные связи
между операторами, так и связи возможных переходов.
4. Распределение вершин графа по уравнениям готовности. На данном
этапе, исходя из графа G и матрицы С, строится так называемое Е-раз
деление, то есть выделяются классы Еь Ег, Е3,..., Е„ операторов и ме-
жду ними устанавливается отношение предшествования. Е-разделе-
ние определяет класс операторов, параллельное выполнение которых
должно быть завершено до начала выполнения операторов следую-
щего класса. По завершении этого этапа все операторы (вершины
графа G) будут распределены по уровням готовности.
485
Глава 11. Языки описания параллельных процессов
5. Формирование ветвей решения. На пятом этапе анализируются ком-
поненты каждого уровня. Если анализируемая вершина уровня пред-
ставляет собой сильносвязный подграф, то в нем выделяются элемен-
тарные циклы, компонентами которых являются отдельные линейные
фрагменты. Если же исследуемая вершина отображает сжатый линей-
ный участок программы, то анализируются информационные связи
внутри этого линейного участка.
В результате указанных действий каждый уровень разбивается на не-
сколько подуровней и производится их согласование. Операторы
исходной программы, окончательно распределенные по уровням го-
товности, объединяются в ветви решения, что и является окончатель-
ным результатом рассматриваемой процедуры распараллеливания.
11.4. Распределение задач по процессорам
Ветви решений, полученные после вышеприведенного формирования
параллельной программы, или исходный набор задач для обработки
на компьютере (в случае многопроцессорных систем или компьютер-
ных сетей) должны быть распределены по процессорам (или компью-
терам) для выполнения.
Ниже рассмотрим некоторые подходы и методы назначения задач на
процессоры.
Эффективный способ априорного определения числа процессоров,
для которого может быть получено наилучшее среди всех возможных
распределение, неизвестен. Как правило, рассматриваются алгорит-
мы распределения при фиксированном числе процессоров.
Задача может быть сформулирована следующим образом.
Пусть имеется Р процессоров и множество задач Z = {Z\, Z2, ..., Z„},
которые требуется решить на МВС. Каждая задача из Zможет характе-
ризоваться некоторыми параметрами, в частности объемом требуемой
памяти, необходимым временем занятости центрального процессора
и т.д. Следует построить распределение S2,..., Sm задач по процес-
сорам МВС, учитывая параметры задач, с тем чтобы минимизиро-
вать, например, общее время решения всего множества задач Z.
При распределении множества задач следует учитывать существующие
связи между ними и обеспечивать экстремальное значение некоторому
486
11.4. Распределение задач по процессорам
критерию качества при определенных ограничениях. Достижение
экстремума может производиться и за счет изменения структуры
МВС. Однако динамическая адаптация структуры МВС дос аточно
сложна и поэтому ограничена. В связи с этим обычно считают, что
состав и структура МВС не изменяются во время ее работы.
Вообще говоря, методы распределения наборов задач существенно за-
висят от мощности набора, момента его поступления, времени обра-
ботки отдельных задач на каждой машине, связности задач, степени
однородности компонент системы, методов обмена информацией
между отдельными компонентами и т.д. При этом многие из указан-
ных параметров известны, как правило, с невысокой достоверно-
стью. Кроме того, учет всех параметров при распределении задач
очень сложен, в связи с чем обычно строятся распределения при раз-
личных упрощающих ограничениях. Широкое распространение при
распределении процессоров в случае параллельных вычислений по-
лучили методы теории расписаний. Наибольший эффект при этом
достигается, если набор задач на распределение поступает одновре-
менно и известно время реализации каждой задачи.
Укажем только на некоторые случаи однократных алгоритмов по-
строения расписания, то есть алгоритмов, не изменяющих момент
начала выполнения задач при последующем составлении расписа-
ния. Это так называемые алгоритмы диспетчирования.
Известны два подхода к проблеме диспетчирования.
При первом подходе каждая задача из входного набора предваритель-
но назначается для обслуживания на некоторую машину. Задачи на-
чинают выполняться только после окончания диспетчирования всего
входного набора. Метод, основанный на таком подходе, называют
статическим диспетчированием. Задача статического диспетчирования
допускает оптимальное решение, которое можно в принципе полу-
чить полным перебором возможных вариантов. Однако с ростом чис-
ла вариантов эффект от использования оптимального распределения
(по сравнению с некоторым случайным распределением) может быть
сведен к нулю трудоемкостью получения оптимального результата.
При втором подходе задачи назначаются для выполнения по мере ос-
вобождения машин (процессоров) отрешения ранее распределенных
задач. В данном случае проблема, решаемая диспетчером, значитель-
но упрощается, так как будет анализироваться не весь входной набор,
487
Глава 11. Языки описания параллельных процессов
а только некоторые подмножества его задач, готовых к выполнению
и ожидающих своего распределения. Этот подход называют динами-
ческим диспетчированием. Применение динамического диспетчиро-
вания приводит, как правило, к субоптимальному решению задачи
распределения. Такое решение получаем, применяя алгоритмы со
сравнительно малой трудоемкостью, при этом качество полученного
решения незначительно отличается от оптимального.
Для конкретной МВС при заданном входном наборе задача диспет-
чирования может быть сформулирована как одна из задач математи-
ческого программирования, а именно «задача о назначениях», для
решения которой можно использовать известные методы целочис-
ленного программирования. Однако с ростом числа задач во входном
наборе трудоемкость применения этих методов превосходит полу-
чаемый от их использования эффект. МВС может быть занята в этом
случае решением задачи диспетчирования более длительное время,
чем временной выигрыш, полученный в результате ее решения. По-
этому второй подход, основанный на методах динамического диспет-
чирования, считается более перспективным.
Чаще всего в качестве критерия оценки решения задачи диспетчиро-
вания выбирается время выполнения всего набора задач, хотя исполь-
зуются и другие: минимальное время простоя (максимальная загрузка)
различных устройств МВС; минимальное среднее время ожидания
решения для всего набора задач; минимальное число используемых
процессоров при заранее заданном времени окончания решения за-
дач и т.д. Иногда используются обобщенные критерии в виде функции,
устанавливающей зависимость между отдельными частными крите-
риями. В этом случае качество решения данной задачи оценивается
отклонением от экстремального значения обобщенного критерия.
Большую сложность здесь представляет процедура обоснованного
формирования функции, задающей обобщенный критерий.
11.5. Планирование в мультипрограммных системах
Все задания (процессы), находящиеся в системе с мультипрограмми-
рованием, конкурируют между собой из-за процессорного времени.
Кроме процессов пользователя, имеются и системные процессы, для
выполнения которых также требуется процессорное время.
488
11.5. Планирование в мультипрограммных системах
Имеются, как правило, две очереди процессов:
► очередь готовых процессов — активные процессы, ожидающие
кванта времени ЦП (Ог);
► очередь заблокированных процессов, ожидающих выполнения ка-
кого-нибудь события (Об).
Пусть Р— процессор, тогда схема планирования ресурса-процессора
выглядит следующим образом (рис. 11.4).
Рис. 11.4. Схема планирования ресурса
Каждый процесс Р, может находиться в одном из состояний: готовом,
заблокированном или выполняемом. Если Р, е Ог и ему выделен квант tpi
процессорного времени, то он будет выполняться, пока не произой-
дет одно из событий:
► истечет квант его времени;
► процесс будет заблокирован;
► процесс будет вытеснен более приоритетным процессом;
► процесс будет завершен.
Если произошло одно из указанных событий, процесс переводится
либо в очередь Ог, либо в очередь Об, либо оставляет систему. По
окончании блокировки процессы переводятся из очереди Об в оче-
редь Ог. Алгоритм планирования для такой системы включает способ
выбора готового процесса из заданной совокупности процессов
и способ вычисления величины кванта tpi для него.
Каждому Р, е Ог поставлен в соответствие приоритет — целое число,
учитывающее важность процесса Р„ занимаемый им объем памяти,
срочность выполнения и объем операций I/O, а также внешний при-
оритет, назначаемый пользователем. На определение приоритета
влияют также и динамические характеристики: общее время ожида-
ния; ресурсы, находящиеся в распоряжении процесса; процессорное
489
Глава 11. Языки описания параллельных процессов
время, полученное в последний раз; общее время нахождения про-
цесса в системе и т.д. Отсюда следует, что приоритет процесса может
перевычисляться несколько раз за время его существования.
Внешний приоритет играет важную роль при переводе Р, в активное
состояние и выводе полученных результатов на печать.
Такие системные процессы, как учет, управление стандартными про-
граммами, выполняются так же, как и задания пользователей. Но
многие из них (например, управление освободившимся внешним
устройством, перекачка страниц памяти, обслуживание прерываний
и некоторые другие) должны иметь привилегии, позволяющие им
быстрее получать процессорное время. Все алгоритмы планирования
должны учитывать привилегированные процессы, а также тот факт,
что ни один процесс в системе не может ждать бесконечно долго.
Система должна планировать процессы так, чтобы свести к миниму-
му средние потери или ограничить максимальные потери по всем за-
даниям, что не всегда согласуется с эффективным использованием
всех компонент системы.
11.5.1. Планирование по наивысшему приоритету
В методе планирования по наивысшему приоритету (highest priority
first — HPF) процессор предоставляется процессу, имеющему наивысший
приоритет. И если не допускается вытеснение процесса, то он выпол-
няется до тех пор, пока не выполнится или не будет заблокирован.
Если вытеснение разрешено, то поступивший процесс с более высо-
ким приоритетом прервет текущий процесс и начнет выполняться.
Вытесненный процесс перейдет в очередь готовых процессов. Если
процессор освободился, то ему из Ог назначается процесс с наивыс-
шим приоритетом.
Если очередь Ог отсортирована по приоритетам, то выбрать первый
элемент просто. Если же такой сортировки нет (а при динамическом
изменении приоритетов ее никогда нет), необходимо по истечении
некоторого времени Тпроводить сортировку всей очереди Ог или не-
которой ее части. Здесь возможны различные модификации.
В стратегии HPF необходимо задать те параметры, которые лягут
в основу формирования приоритета. Иногда первым выбирается самое
короткое задание (shortest job first — SJF). Здесь, как правило, исполь-
490
11.5. Планирование в мультипрограммных системах
зуется ожидаемое время выполнения процесса, ибо точное время из-
вестно очень редко. При этом следует помнить, что некоторые поль-
зователи занижают это значение.
В SJF также возможны варианты с вытеснением. В этом случае надо
следить, чтобы процессы не слишком часто вытесняли друг друга, так
как и на вытеснение тратится процессорное время. Кроме того, если
до завершения процесса осталось мало времени, то вытеснять его не
рекомендуется. При этом (особенно если разрешено вытеснение)
особое внимание должно быть обращено на выполнение частично
обработанных процессов.
В задачах планирования необходимо предусмотреть обеспечение за-
нятости внешних устройств. С этой целью процессам можно присваи-
вать высокий приоритет в периоды интенсивного использования ими
ввода-вывода.
Количество различных правил вычисления приоритета неограниче-
но. Применяемая стратегия обеспечивает многим процессам хоро-
шее обслуживание, тем не менее процессы с низким приоритетом
могут ждать очень долго, что во многих случаях неприемлемо, напри-
мер при работе в режиме реального времени.
11.5.2. Метод круговорота (карусель)
Простой круговорот (round robin — RR) не использует никакой инфор-
мации о приоритетах. Порядок обслуживания процессов следующий:
первый пришедший процесс получает квант времени t0 и встает в оче-
редь на обслуживание, если только он себя не заблокирует. Поэтому
при наличии N процессов в системе будем считать, что скорость ра-
боты процессора равна V/N, где V — истинное быстродействие про-
цессора. Если t0—> оо, то стратегия простого круговорота SRR (simple
round robin) сводится к стратегии «первым пришел — первым ушел»
FIFO (first in first out). С уменьшением t0 улучшается обслуживание
коротких процессов. Но t0 не должно быть слишком мало: если это
значение будет сравнимо по порядку со временем переключения
с одного процесса на другой, то задержка в выполнении процессов
становится заметной. Метод RR часто применяется в системах разде-
ления времени (СРВ) с большим числом пользователей. Системы
СРВ должны гарантировать каждому пользователю приемлемое вре-
мя ответа. Время ответа в случае 7V пользователей составляет прибли-
зительно t0N.
491
Глава 11. Языки описания параллельных процессов
Одна из модификаций данного метода — raund robin cicle (RRC).
В нем в качестве to выбирается максимально возможное время ожида-
ния. Суть метода заключается в формировании множества Рг — гото-
вых для выполнения процессов. Пусть мощность этого множества No.
Выбирается время цикла Ти для очереди Рг, равное максимально
достижимому времени ответа. Тогда t0 = Tu/N0, и t0 вычисляется для
каждого прохождения цикла Рг. Процессы, вновь появляющиеся для
обслуживания в Рг, не включаются в очередь до завершения цикла.
Если г0 оказывается слишком мало (сравнимым со временем пере-
ключения процессов), то выбирается некоторая нижняя оценка для
величины t0, что позволяет сократить потери на переключение про-
цессов.
Существуют и другие разновидности метода RR, например «эгоисти-
ческий» RR. Суть его в том, что, войдя в систему, процесс ждет, пока
его приоритет не достигнет величины приоритетов работающих про-
цессов, затем он выполняется в круговороте с другими процессами.
Можно выделить ведущую и фоновую очередь готовых процессов
в зависимости от вероятности затребования определенного количе-
ства квантов времени ЦП для их завершения.
11.5.3. Очереди с обратной связью
Основной алгоритм очередей с обратной связью FB (feedback) ис-
пользует п очередей, каждая из которых обслуживается в порядке
поступления. Новый процесс поступает в первую очередь, затем, по-
сле получения кванта времени, он переходит в очередь со следующим
номером и так далее после каждого очередного кванта времени. Вре-
мя процессора планируется таким образом, что он обслуживает не-
пустую очередь с наименьшим номером. В методе FB каждый, вновь
поступающий на обслуживание процесс получает (в неявном виде
безусловно и в соответствии со стратегией обслуживания) высокий
приоритет и выполняется подряд в течение такого количества кван-
тов времени, пока не придет следующий процесс. Но если приход
нового процесса задерживается, то текущий процесс не может прора-
ботать большее количество квантов, чем предыдущий процесс.
Процессы, требующие незначительного времени обслуживания, обес-
печиваются в этом случае лучше, чем при круговороте. Однако боль-
шое число очередей может увеличить накладные расходы времени.
492
11.5 Планирование в мультипрограммных системах
Для уменьшения числа очередей можно разрешить каждому процессу
фиксированное, большее единицы, число раз прохождения цикла,
прежде чем переходить в очередь с другим номером. При этом очере-
ди, упорядоченные по FB, обслуживаются в соответствии с методом
круговорота внутри каждой очереди и по тому же правилу распреде-
ляется время процессора между очередями.
Для лучшего использования преимуществ метода FB пользователи
могут разбить свои процессы на мелкие. Основное преимущество
очередей FB и RR по сравнению с обслуживанием по наивысшему
приоритету заключается в том, что FB и RR позволяют хорошо обслу-
живать короткие задания, не требуя предварительной информации
о времени выполнения процесса.
При необходимости использовать информацию о приоритетах можно
применить круговорот со смещением, когда каждому процессу выде-
ляется квант времени ЦП в зависимости от внешнего приоритета.
11.5.4. Многоуровневое планирование
В большинстве современных систем процессоры взаимодействуют
с помощью прерываний. В ЦП прерывание происходит по истечении
отведенного кванта времени, окончании работы канала или запроса
от выполняемой программы на ввод-вывод. Затем управление пере
дается СУПЕРВИЗОРУ, который после осуществления некоторых
действий (разблокирование или порождение процесса, запуск канала
и т.д.) передает процессор новому процессу из очереди. Следует отме-
тить, что эту работу приходится проделывать каждый раз при появлении
прерываний, что требует больших затрат времени. Поэтому предлага-
ется метод многоуровневого планирования, который сохраняет всю ин-
формацию о процессах, выполняет перевычисления приоритета и т.д.,
но делает это достаточно редко.
В основе этого метода лежит следующий принцип — операции, кото-
рые встречаются часто, должны требовать меньше времени, чем те, ко-
торые встречаются редко. С этой целью все операции в зависимости
от частоты выполнения разбиваются на уровни. В основном исполь-
зуется трехуровневая система планирования: диспетчер, краткосроч-
ный планировщик и долгосрочный планировщик.
Диспетчер вызывается после завершения обработки прерывания и вы-
бирает следующий готовый процесс для выполнения. Так как диспетчер
493
Глава 11. Языки описания параллельных процессов
вызывается часто, то должен срабатывать очень быстро. Например,
взять первый процесс из очереди и запустить, то есть предоставить
ему процессор.
Краткосрочный планировщик вставляет процесс в очередь. Здесь воз-
можен анализ состояния процесса. Но так как процессы ставятся
в очередь довольно часто, краткосрочный планировщик не должен
вносить сложных изменений в состояние и приоритет процесса, ос-
тавляя подобные действия для долгосрочного планировщика. Дол-
госрочный планировщик может осуществлять глубокий анализ состоя-
ния процессов.
Если наперед известна частота появления вызовов на каждом уровне,
то, пользуясь многоуровневым планированием, можно ввести огра-
ничения надопустимый объем вычислений на каждом уровне, что во
многом определяет алгоритмы планирования на каждом уровне.
Рассмотренные алгоритмы планирования представляют собой ряд
приемов распределения процессорного времени между процессами.
Однако многие из них могут быть с успехом применены и к распреде-
лению других ресурсов в операционных системах.
Какими бы ни были методы планирования, должны существовать
способы доказательства эффективности этих методов или установле-
ния источников потери эффективности.
11.5.5. Генетический алгоритм
Генетический алгоритм (genetic algorithm) — это алгоритм направ-
ленного случайного поиска, основанный на принципах эволюции
и генетики. Он сочетает использование предыдущих результатов
с исследованием новых областей поиска оптимального решения.
Применяя технику естественного отбора и структурированный, но
все же случайный обмен информацией, генетический алгоритм может
имитировать способность человека к рациональному поиску. Хотя
в основе алгоритма и лежит случайная составляющая, генетический
алгоритм не является простым перебором. Он разумно использует
уже имеющуюся информацию для выявления новых направлений
поиска с ожидаемым успехом.
Генетический алгоритм поддерживает популяцию возможных решений,
которая со временем развивается и предельно расширяется. Особи
494
11.5. Планирование в мультипрограммных системах
в популяции представлены хромосомами. Каждая особь имеет значе-
ние пригодности, которое указывает, насколько хорошо разрешается
задача. Генетический алгоритм имеет три оператора. Оператор выбора
(selection operator) среди особей текущей популяции отбирает наиболее
оптимальную (с наилучшим значением пригодности), которая будет
родителем следующего поколения. Оператор скрещивания (crossover
operator) случайным образом выбирает две особи и обменивает некото-
рые их характеристики. Оператор мутации (mutation operator) выбирает
случайным образом какую-то особь и изменяет ее. Как и в естественной
генетике, вероятность мутации должна быть очень низкой по сравне-
нию с вероятностью скрещивания. Популяция развивается итератив-
но, последовательно улучшая пригодность каждой особи.
По структуре генетический алгоритм представляет собой цикл, состоя-
щий из операции выбора и последовательности операций скрещивания
и мутации. Вероятности скрещивания и мутации являются константа-
ми и фиксируются до начала работы алгоритма Итерации цикла выпол-
няются до тех пор, пока условие завершения (termination condition)
не будет достигнуто. В качестве такого условия может быть количест-
во итераций, время выполнения, устойчивость результатов и др.
В отличие от статических и детерминированных динамических алго-
ритмов генетический алгоритм очень гибко приспосабливается к лю-
бому набору входных данных независимо от характеристик набора
и выбирает близкое к оптимальному решению в большем числе слу-
чаев. Однако этот алгоритм эффективен по времени только в тех слу-
чаях, когда время исполнения планируемых задач намного меньше
времени работы самого алгоритма. В остальных же случаях время ра-
боты этого алгоритма слишком велико. Кроме того, в общем случае
алгоритм является трудным в реализации. Однако существуют моди-
фикации генетического алгоритма, которые эффективно устраняют
какой-нибудь из недостатков.
Рассмотрим пример задачи, к которой применим данный алгоритм.
Пусть имеется мультипроцессорная система с т одинаковыми про-
цессорами. Они соединены между собой коммуникационной сетью,
в которой все соединения одинаковы. Каждый процессор может вы-
полнять только одну задачу в фиксированный момент времени. Пре-
рывание выполнения задачи запрещено. Решением задачи является
присвоение каждой задаче времени начала исполнения и номера
495
Глава 11. Языки описания параллельных процессов
процессора. В качестве значения пригодности можно взять разность
между максимальным временем выполнения всех задач и временем
выполнения в рассматриваемом решении (особи).
Примером такого алгоритма может служить алгоритм РСА (Partitioned
Genetic Algorithm), использующий принцип «разделяй и властвуй».
Упражнения
1. Проверьте, удовлетворяет ли требованиям, предъявляемым к языкам па-
раллельного программирования, P-язык, К-язык, ЯПФ-язык, язык дис-
позиций, язык OCCAM.
2. Разработайте и реализуйте алгоритм построения графа информацион-
ной зависимости для фрагментов конкретной программы.
3. Разработайте и реализуйте алгоритм преобразования графа программы:
• при заданном количестве процессоров в вычислительной системе;
• для минимального времени реализации алгоритма при неограничен-
ном количестве процессоров.
4. Разработайте и реализуйте алгоритм наложения информационных свя-
зей на связи возможных переходов в графе программы.
5. Разработайте диспозицию D для задачи умножения матриц.
6. Выделите и обоснуйте выбор минимально неделимых единиц в программе
при ее параллельном выполнении. Осуществите Е-разделение фрагмен-
тов программы. Разработайте и реализуйте алгоритм поддержки задан-
ного разбиения в течение некоторого времени.
7. Расширьте заданный язык (например, Pascal) последовательного про-
граммирования средствами описания параллельных процессов и реали-
зуйте их.
8. Опишите подробно алгоритм планирования процессов в конкретной си-
стеме (по вашему выбору). Связано ли как-либо распределение памяти
с алгоритмом планирования?
9. Во что обходится простой центрального процессора в течение 10 % вре-
мени в вашей системе? Сравните эти издержки с другими основными
расходами на содержание вычислительной машины.
10. Предположим, что у вас имеется компьютер с единственным процессором,
причем вытеснения процессов не допускаются. Разработайте алгоритм
планирования, который бы минимизировал среднее время ожидания, если
потребности в процессорном времени известны заранее. Придумайте
496
Упражнения
другой алгоритм, который будет минимизировать максимальное время
ожидания. Если бы были разрешены вытеснения, как это повлияет на
ваш алгоритм?
11. Во многих теоретических работах принято допущение, что промежутки
времени между моментами поступления заданий распределены по экс-
поненциальному закону. Проделайте эксперимент на своей машине,
чтобы проверить эту гипотезу.
12. Рассмотрим множество процессов, в котором взаимное исключение реа-
лизовано посредством механизма семафоров. Если процесс Р теряет
процессор в момент выполнения критического участка, то все остальные
процессы будут блокированы, пока Р не получит процессор вновь. Опи-
шите способ, которым планировщик может избежать остановки про-
цессов в критических участках. Рассмотрите тот же вопрос, используя
другие механизмы связи, например передачу сообщений или мониторы.
497
3^2792
Глава 12
Сжатие и защита данных
В последние годы в связи с широким применением информацион-
ных технологий во всех сферах жизни общества и увеличением объема
информации необычайно остро встает проблема надежного хранения,
передачи и обработки информации.
Весь спектр вопросов по работе с информацией можно условно раз-
бить на три группы:
► философский аспект, состоящий в изучении информационных по-
требностей общества (духовных, социальных, экономических) и созда-
нии возможностей (методов и средств) их эффективного удовлетво-
рения. При этом должно соблюдаться право человека на получение
информации;
► технический аспект, обусловливающий технические средства, кото-
рые обслуживают информационные процессы, предоставляя возмож-
ности их качественного обеспечения, в том числе гарантируя безо-
пасность;
► управленческий аспект, заключающийся в реализации идеи, что
всякий процесс управления есть информационный процесс, бази-
рующийся на сборе, хранении, обработке и передаче информации.
При этом качество управления в значительной степени определяется
качеством этих действий.
На надежность информации в компьютерных системах, исключая не-
счастные случаи (отключение электроэнергии, стихийные бедствия
и тому подобное), существенно влияют:
► большое количество устройств, собранных из комплектующих
низкого качества или любителями-сборщиками;
► нелицензионное ПО;
► несовместимость программного и аппаратного обеспечения;
► недостаточная компетентность сотрудников, ответственных за под-
держание компьютерных систем;
► экономия средств на главном — качественном оборудовании и обу-
чении персонала.
Проблема безопасности информации должна рассматриваться вместе
с информационной безопасностью, под которой чаще всего понимают
498
12.1. Сжатие данных
предупреждение отрицательного воздействия информации на любой
объект: будь то мировая цивилизация или отдельный человек вне за-
висимости от формы воздействия — непосредственной, косвенной,
направленной или случайной.
Некоторые аспекты сжатия и защиты данных рассматриваются в дан-
ной главе.
12.1. Сжатие данных
Иногда пользователь с сожалением констатирует нехватку места на
жестком диске. И хотя на страницах компьютерных журналов можно
встретить массу всевозможных вариантов решения этой проблемы —
быстродействующие дисковые накопители большой емкости, сохра-
нение данных на магнитной ленте, оптические накопители с возмож-
ностью перезаписи или с однократной записью и другие способы
хранения сотен мегабайт информации, — всего этого может оказать-
ся недостаточно, например, при работе с изображениями, примене-
нии сканера и т.п.
Например, при считывании сканером цветных или полутоновых изо-
бражений размерами в половину машинописной страницы, диск
в 100 Мбайт окажется заполнен менее чем за час. Более того, размеры
файлов, содержащих графические объекты (от 400 Кбайт до несколь-
ких Мбайт), таковы, что пересылать коллегам в другой город их мож-
но, только отправив диск по почте, поскольку модем в этом случае не
решает проблемы.
Сферы деятельности, где требуется обработка больших объемов дан-
ных, известны уже многие годы. Первый пример — спутниковая
телеметрия. Представьте объем информации, которая содержится
в цветном снимке Нептуна и которую необходимо передать на Зем-
лю. Кроме того, такие же большие объемы информации и в задачах
сейсморазведки, картографии и ряде других применений.
На сегодняшний день проблемами сжатия и восстановления информа-
ции занимается ряд фирм-разработчиков программного обеспечения,
представляющих реализацию на различных компьютерах всевозмож-
ных решений этой проблемы.
В настоящее время применяются два подхода к сжатию и восстановле-
нию информации.
499
Глава 12. Сжатие и защита данных
Первый подход — чисто программный. Для сжатия и восстановления
информации применяют либо специализированные автономные
программы, либо соответствующие приемы и методы в прикладных
программах. Второй подход представляет собой сочетание программных
и аппаратных средств. Применение специальных устройств (акселе-
раторов) позволяет сократить время цикла «сжатие-восстановление»
с минут до секунд.
Однако сжатие сжатию рознь. Поскольку текстовые файлы, файлы
контурных и полутоновых изображений содержат разную информа-
цию, то для них требуются и различные способы архивации.
Таким образом, рассматривая различные схемы сжатия данных, сле-
дует представлять тип информации, над которой производятся соот-
ветствующие действия.
12.1.1. Простые алгоритмы
Начнем с обычных текстовых файлов. Файл состоит из символов
и, возможно, «невидимых» кодов управления печатью. Каждый сим-
вол в коде ASCII представлен одним байтом (восемью битами).
Алгоритм кодирования Хаффмана. В основе алгоритма лежит простой
принцип: символы заменяются кодовыми последовательностями различ-
ной длины. Чем чаще используется символ, тем короче соответствующая
последовательность. Например, для английского текста символам е,
t, а можно поставить в соответствие 3-битовые последовательности,
а символам j, Z,q — 8-битовые. В одних вариантах алгоритма Хафф-
мана используются готовые кодовые таблицы, в других — кодовая
таблица строится на основе статистического анализа содержимого
файла (табл. 12.1). Применение кода Хаффмана гарантирует возмож-
ность правильного декодирования. Это важно, так как «упакованные»
кодовые последовательности имеют различную длину, в отличие от
обычных, длина которых постоянна и равна 8 бит на символ.
Алгоритм Лемпеля — Зива (LZ) или Лемпеля — Зива — Уэлча (LZW).
Эта схема сжатия основана на минимуме избыточности кодирова-
ния. Вместо кодирования каждого отдельного символа LZ-алгоритм
кодирует часто встречающиеся символьные последовательности. На-
пример, можно заменить краткими кодами слова «который», «так же»,
«там», оставляя имена собственные и другие слова, встречающиеся
единожды, незакодированными. Программа, реализующая LZ-алго-
500
12.1. Сжатие данных
ритм, просматривает файл, содержащий текст, символы или байты
графической информации, и выполняет статистический анализ для
построения своей кодовой таблицы.
Таблица 12.1
Кодирование Хаффмана для текста «The sample you see here is fairty standard*
(«Этот пример достаточно типичен»)
Символ Количество символов в тексте Код
1 2 3
(пробел) 7 000
е 6 001
а 4 010
! s 4 011
г 3 11000
t 2 11001
h 2 пою
1 2 11011
i 2 11110
d 2 11111
У 2 100000
f 1 100110
m 1 100001
n 1 100010
о 1 100011
p 1 100100
u 1 100101
При сжатии текстовых файлов часто встречающиеся символы или последо- вательности символов заменяются кодовыми последовательностями длиной меньше обычных 8 бит. Длина исходного файла = 336 бит (42 символа х 8 бит). Длина сжатого файла = 187 бит.
Если заменить 60—70% текста символами, длина кода которых со-
ставляет менее половины первоначальной длины, можно достигнуть
сжатия приблизительно в 50%. При попытке применить этот алго-
ритм к исполняемым файлам сжатие уменьшается (от 10 до 20%), так
как избыточность кода, создаваемого компиляторами, значительно
меньше избыточности текста на естественном языке. Файлы баз дан-
501
Глава 12. Сжатие и защита данных
ных также плохо поддаются сжатию, поскольку записи в них обычно
оригинальны (например, имена, адреса и номера телефонов), и редко
повторяются. В то же время файлы монохромных изображений в фор-
мате PICT архивируются довольно хорошо, так как зачастую обладают
большой избыточностью, например, содержат много белого простран-
ства. Файлы полутоновых и цветных изображений также можно архиви-
ровать с помощью алгоритма Хаффмана, хотя и с меньшим успехом.
Большинство пользователей компьютеров Macintosh знакомы с ути-
литами архивации общего назначения. В качестве примера можно
привести популярные программы Stuffit Classic и Stuffit Deluxe фирмы
Aladin Systems и Compactor фирмы Goodman. Такие программы в ос-
новном используют для сжатия нескольких файлов в один архивный
файл. Другая программа сжатия — DiskDoubler фирмы Salent Software —
представляет собой скорее утилиту для работы с диском, чем архива-
тор. Двойное нажатие клавиши на манипуляторе «мышь» автомати-
чески запускает программу разархивирования отмеченного файла,
а при сохранении после окончания работы на диске DiskDoubier ав-
томатически выполнит обратную операцию.
12.1.2. Сжатие документов как изображений
Работа телефакса полностью основана на сжатии информации. Если
бы образ листа бумаги размером 297 х 210 мм, снятый с разрешением
8 точек/мм, не был сжат, он занял бы 4 Мбайт памяти, и для его пере-
дачи со скоростью 9600 бит/с потребовался бы почти час. На самом
деле это занимает значительно меньше времени благодаря сжатию.
Какие же приемы сжатия используют в факсах?
В самых популярных телефаксах, относящихся к группе III по класси-
фикации Международного консультативного комитета по телеграфии
и телефонии (МККТТ), используются встроенные статистические таб-
лицы кодирования изображений. В этих таблицах содержится инфор-
мация не о частоте появления символов и их комбинаций, а о частоте
появления черно-белых линий различной длины. Например, в деловой
корреспонденции самая распространенная строка — пустая линия
длиной 210 мм, поэтому такая строка кодируется короткой последо-
вательностью. Телефакс на приемном конце линии расшифровывает
код и пропускает строку. Более содержательные строки содержат от-
резки черного и белого цветов различной длины. Можно сказать, что
типичный документ содержит количество перемен цвета от белого
502
12.1. Сжатие данных
к черному и обратно, примерно равное удвоенному числу символов
в строке. Сжатая таким образом 80-символьная строка становится
набором приблизительно из 160 переходов, а не из 1728 элементов
изображения. С учетом числа строк на странице такой способ пред-
ставляет собой весьма компактную схему кодирования видеоинфор-
мации, снятой с разрешением 8 точек/мм (рис. 12.1). Рекомендации
Donuts Inc
Когда факсимильный аппарат группы Ш
встречает строку пробелов, он сжимает ее,
посылая короткую кодовую последователь-
ность «пустая строка». Этот код поступает
в приемный факс, который восстанавливает
пустую строку.
Когда две одинаковые строки следуют одна
за другой, факс на передающем конце
посылает короткую кодовую последова-
тельность, по принятии которой приемный
факс повторит строку. Код «повторение
предыдущей» используется как для
заполненных, так и для пустых строк.
Передающий факс сжимает строку, посылая
кодовую последовательность, содержащую
информацию о длине и цвете каждой компо-
ненты. Например, для кодирования этой
строки нужно передать, что сначала следует
белая линия длиной X, затем черная линия
длиной Y, потом еще одна белая линия
длиной Z.
Эта строка потребует передачи более
длинной кодовой последовательности:
сначала белая линия, затем черная, потом
белая, черная и снова белая.
По мере того как строка становится более
сложной, например содержит печатные
символы, соответствующая кодовая последо-
вательность удлиняется. Эта строка состоит
из многих отрезков черного и белого цвета.
Рис.12.1. Сжатие данных в телефаксах
503
Глава 12. Сжатие и защита данных
МККТТ делают эту схему сжатия еще более эффективной — можно
учитывать и взаимосвязи между строками. Предусмотрены, напри-
мер, короткие кодовые комбинации для «следующая строка такая же,
как эта» и «этот фрагмент такой же, как предыдущий», что еще более
повышает эффективность сжатия.
12.1.3. Программы для обработки изображений документов
Хотя алгоритмы сжатия, применяемые в телефаксах, непригодны
для цветных и полутоновых изображений, они, очевидно, могут быть
полезны для сжатия деловых документов, содержащих только текст
и штриховые рисунки. Поэтому многие фирмы использовали алго-
ритмы сжатия, подобные применяемым в телефаксах, для обработки
деловой документации. Этот подход реализован в самых разных про-
граммных изделиях, от простых программ для однопользовательских
систем до насыщенных мощными средствами программно-аппарат-
ных комплексов, предназначенных для архивации и индексирования
документации отделений корпорации, находящихся в географически
отдаленных точках.
Один из таких примеров — система Hurdler CER для шины NuBus
фирмы Creative Solutions, выполняющая сжатие и преобразование
данных. На плате через встроенное ПЗУ реализована схема сжатия
данных группы IV (по классификации МККТТ), в которой несколь-
ко улучшена обработка ошибок (небольшие ошибки могут не иметь
значения при приеме документов по факсу, но перерастают в боль-
шую проблему при записи информации на диск). Быстродействую-
щая микросхема сопроцессора позволяет комплексу CER сжимать
файлы, полученные в результате обработки сканером монохромного
изображения, со скоростью 16 миллионов элементов изображения
в минуту. Фирма Creative Solutions поставляет вместе с комплексом
CER специальные драйверы, позволяющие пользователям переда-
вать файлы непосредственно в интерфейс NuBus, при этом не требу-
ется никакого дополнительного программного обеспечения.
Система архивации документов Arclmage фирмы First Financial Technology
обладает более широкими возможностями. Эта система первоначаль-
но предназначалась для удовлетворения внутренних потребностей фирм,
связанных с обработкой банковских документов. В состав системы
504
12.1. Сжатие данных
входят плата-акселератор с интерфейсом NuBus и программное обес-
печение. В комплекте поставки имеются также простая в обращении
обучающая программа и документация. Плата д ля шины NuBus с си-
стемой Arcimage позволяет в режиме реального времени обрабаты-
вать информацию с выхода быстродействующего сканера (Fujitsu
с автоматической подачей бумаги со скоростью 12 листов в минуту).
Система сохраняет два разных файла — файл низкого разрешения
для вывода на дисплей и файл высокого разрешения для печати. Это
позволяет, с одной стороны, быстро выводить изображение на экран,
а с другой — печатать его с хорошим качеством на лазерном принте-
ре. Система Arcimage в полной конфигурации состоит из драйвера
оптического диска, высокоскоростного сканера и сетевого оборудо-
вания, но вполне можно ограничиться жестким диском и сканером.
На высшей ступени иерархической лестницы систем д ля архивирова-
ния черно-белой документации находятся три больших комплекса.
В их состав входят всевозможное оборудование (от сканеров до нако-
пителей) и программное обеспечение, необходимое д ля сжатия фай-
лов документов и микрофильмированных изображений так, чтобы их
можно было быстро восстановить с помощью компьютера Macintosh.
Система FastTYax фирмы Du Pont Electronic предназначена для архи-
вации, хранения и восстановления файлов чертежей. Она работает
в сети компьютеров Macintosh и использует устройство, которое фир-
ма Du Pont называет «оптическим накопителем башенного типа».
Предназначено оно для хранения файлов изображений, объединен-
ных в индексированную базу данных.
В системе MD Mars фирмы Micro Dynamics используются сканеры,
работающие с документацией и микрофильмами, и обеспечивается
преобразование документов в архивные файлы на переписываемых
оптических дисках. Пользователи сети Appie Talk могут впоследствии
вызвать и восстановить эти файлы. Предусмотрена даже возможность
создания копий предыдущих версий файлов на оптических дисках
с однократной записью (WORM). Как в системе FastTrax, так и в MD
Mars для сжатия данных используется плата Hurdler CER.
Основное отличие программы Visualink фирмы CSX Technology от
программ FastTrax или MD Mars состоит в возможности сжимать
принимаемые по факсу документы непосредственно во время их
приема.
505
Глава 12. Сжатие и защита данных
12.1.4. Кодирование цветных изображений
Алгоритмы сжатия информации группы IV не годятся для работы
с полутоновыми или цветными изображениями. Такие изображения
содержат большое количество информации. Каждый элемент изобра-
жения, считанного с разрешением 12 точек/мм, описывается 32 битами
информации: 8 бит на интенсивность красного цвета, 8 бит — зелено-
го, 8 бит — синего, а также 8 дополнительных бит (RGB-описание).
Даже для передачи градаций серого цвета в полутоновом изображе-
нии требуется 8 бит. Объем информации здесь значительно больше,
и ее характер непрерывно меняется вдоль линии сканирования, поэто-
му схемы сжатия, разработанные для текстовых файлов и штриховых
рисунков, в данном случае неприменимы. Алгоритмы сжатия цветных
образов основаны на применении особенностей оценки цветовой
чувствительности человеческого глаза.
При рассмотрении цветного изображения человек неосознанно вы-
деляет цветные пятна и переходы между ними. Многие мелкие детали,
изменения оттенков и абсолютная яркость глазом не воспринимают-
ся. Возьмем, например, абсолютную яркость. Очевидно, что никакая
точка телевизионного изображения не может быть чернее, чем серый
цвет выключенного экрана. Когда же человек смотрит телевизион-
ную программу, видимый им иссиня-черный цвет - не более чем ил-
люзия, которая возникает из-за соседства с ним контрастных ярких
тонов.
Как уже отмечалось, алгоритмы сжатия цветных образов, преобразуя
обычное описание изображения, основанное на содержании в нем
красного, зеленого и синего цветов (RGB), в представление, основан-
ное на характеристиках цветности и яркости, базируются на специфике
человеческого цветовосприятия. Эти алгоритмы исключают инфор-
мацию, которая не воспринимается глазом, и таким образом умень-
шают сохраняемый объем данных. Соответствующая схема сжатия,
предложенная Объединенной группой экспертов в области фотогра-
фии (JPEG) в 1990 году, завоевала практически всеобщее признание
как стандартный метод обработки неподвижных изображений. Дру-
гой коллектив, группа экспертов в области движущихся изображений
(MPEG), разработал схемы сжатия для видеозаписей.
Работа с цветностью и яркостью, а не с RGB-описанием, позволяет
алгоритму JPEG использовать тот факт, что на большой площади
506
12.1. Сжатие данных
изображения изменения цвета и интенсивности незначительны.
Чистое голубое небо, например, на залитом солнцем пейзаже состоит
из множества элементов изображения, но содержит мало информа-
ции. При обработке этим алгоритмом каждого участка изображения
размером 8x8 элементов применяются последовательно три процеду-
ры: дискретное косинус-преобразование, квантование и схема коди-
рования, подобная алгоритмам обработки текстовых файлов. При
восстановлении к каждому такому участку применяется обратная
процедура. Все это требует, безусловно, значительного объема вычис-
лений.
Пользователи алгоритма JPEG могут устанавливать требуемую степень
сжатия, идя на компромисс между качеством изображения и разме-
ром файла. Время, которое требуется для сжатия (и восстановления)
образа, больше зависит от его содержания, чем от требуемой степени
сжатия. Это происходит потому, что картинка, воспринимаемая че-
ловеком как очень сложная, может оказаться совсем простой для
программы, выполняющей сжатие.
12.1.5. Сжатие цветных изображений
Рассмотрим два программных продукта: пакеты Colorsgueeze фирмы
Kodak и PicturePress фирмы Storm Technology.
Программа Colorsgueeze является наиболее простой в обращении из
программ, предназначенных для сжатия цветных изображений. При
использовании этого изделия, реализующего алгоритм JPEG, можно
задать один из трех уровней сжатия — высокое, среднее или нормаль-
ное — для исходных файлов в 24-битовом формате PICT или TIFF.
В результате получаются файлы, размеры которых составляют соот-
ветственно около 1/24, 1/13 и 1/6 размера исходного файла.
При использовании Colorsgueeze разницу между исходным и восста-
новленным после сжатия изображением можно заметить глазом только
для самого высокого уровня сжатия.
При среднем уровне сжатия можно различить «брызги» у острых краев,
а при нормальном уровне разницу заметить практически невозмож-
но, даже рассматривая сильно увеличенные фрагменты изображения.
При обработке на компьютере графики и необходимости хранения
большого числа цветных и полутоновых изображений применение
507
Глава 12. Сжатие и защита данных
Colorsgueeze — самый простой способ освободить место на перегру-
женном жестком диске.
Пакет PicturePress (рис. 12.2) предназначен для пользователей, имею-
щих определенный опыт в обработке изображений. Кроме выбора од-
ного из четырех стандартных уровней сжатия, PicturePress позволяет
полностью управлять всеми аспектами сжатия изображения, вплоть
до подбора весовых коэффициентов в таблицах цветности и яркости,
а также осуществлять сжатие без потерь и использовать расширения
стандарта JPEG.
JPEG Custom Settings
<- Help Text
— Subsampling
2:1:1V
I Horizontal:
| Vertical--
2:1:1V
13 | Custom Huffman Tables
[ Help )
[ Cancel ] [ OK ]
Puc. 12.2. Возможности пакета PicturePress
Storm Technology предусмотрела несколько интересных расширений
по сравнению со стандартом JPEG. Стандарт JPEG++ позволяет за-
давать разные уровни сжатия для различных частей изображения.
Другое расширение стандарта — режим сжатия без потерь, обеспечи-
508
12.1. Сжатие данных
вающий максимальную экономию места на диске с полным сохране-
нием всей информации (при этом достигается сжатие в 2—3 раза).
Отметим, что обычный алгоритм JPEG называется «алгоритмом с по-
терями», так как при его применении программа намеренно исклю-
чает «излишнюю» часть информации.
Фирма Storm Technology выпустила плату PicturePress Accelerator. Плата
с интерфейсом NuBus, поставляемая вместе с пакетом PicturePress,
содержит два процессора обработки сигналов, которые выполняют
арифметические операции при сжатии. PicturePress автоматически
«перепоручает» вычисления процессорам на плате, при этом время, тре-
буемое на выполнение сжатия, уменьшается приблизительно в 20 раз.
Вычисления все же происходят недостаточно быстро для восстанов-
ления видеоизображений. Тем не менее восстановление сжатых обра-
зов требует столько же времени, сколько и загрузка с жесткого диска
в память исходного несжатого файла или даже меньше.
Отметим еще несколько разработок. Фирма C-Cube выпустила систему
Compression Master, плата для шины NuBus которой содержит специ-
альную микросхему CL 550, разработанную фирмой и предназна-
ченную для сжатия файлов изображений. В систему входит также
утилита DiskDoubler Plus фирмы Salient, используемая для сжатия
файлов в форматах PICT и TIFE
Компания Advent Computer Products выпустила плату Neotech Image
Compressor на основе микросхемы CL 550.
12.1.6. Инструменты разработчиков
Программно-аппаратные средства сжатия данных предназначены не
только для конечных пользователей, но и для разработчиков, расши-
ряющих области применения сжатия данных.
Если говорить о рынке систем общего назначения, то комплекты
средств для разработчиков систем сжатия информации предлагают
фирмы Aladdin Systems и Salient Software. Эти пакеты позволяют ис-
пользовать алгоритмы, реализованные соответственно в программах
Stuffit Deluxe и DiskDoubler, в новых прикладных программах через
подсистему взаимодействия прикладных программ ICA.
У программистов, занимающихся обработкой цветных и полутоно-
вых изображений, также есть выбор. Одна из лидирующих фирм
509
Глава 12. Сжатие и защита данных
в этой области, Electronic for Imaging (EFI), предлагает J PEG-совмес-
тимую библиотеку функций Ecomp. Эту библиотеку можно использо-
вать как для создания новых программ обработки изображений, так
и для модификации уже имеющихся с целью включения в них функ-
ции сжатия образов.
Фирма C-Cube создала интерфейс сжатия образов ICI (набор согла-
шений, в соответствии с которыми прикладные программы могут
взаимодействовать с аппаратными и программными средствами ар-
хивации). Фирма разработала Compression Workshop — набор исходных
текстов на стандартных диалектах языков С и Pascal, который позво-
ляет использовать ICI в прикладных программах. Интерфейс ICI обес-
печивает сопряжение средств сжатия с программами Photoshop фирмы
Adobe, QuarkXPress 3.0, Stuflit Deluxe, Studio—32, а также DiskDoubler
Plus. C-Cube также предлагает программно-аппаратный инструмен-
тальный комплекс, позволяющий разработчикам использовать мик-
росхему CL 550, аппаратно реализующую алгоритм JPEG.
Так, например, фирма Next создала Nextdimension — 32-разрядный
адаптер цветного дисплея. В состав адаптера входят: 64-разрядный
графический RISC-сопроцессор и процессор обработки изображе-
ний CL 550 фирмы C-Cube.
Но разработка аппаратных средств — не единственный путь к повыше-
нию быстродействия при обработке изображений. Фирма Radius вы-
пустила программу сжатия данных под условным названием Piculator,
которая сравнима с аппаратными средствами, реализующими JPEG-ал-
горитмы, и поэтому может стать приемлемым вариантом для использо-
вания в приложениях, интенсивно работающих с графикой. Программа
сжимает файл изображения в формате PICT размером 1 Мбайт менее
чем за 6 с на компьютере MacIIcx, и при этом его размер уменьшается
в 20 раз и более. При такой скорости работы программы время вос-
становления файла пренебрежимо мало по сравнению со временем,
необходимым для загрузки прикладной программы.
12.2. Методы защиты информации
Сохранение информации в защищенном от несанкционированного
вмешательства виде включает множество различных механизмов:
► программные методы;
510
12.2. Методы защиты информации
► аппаратные средства;
► защитные преобразования;
► организационные мероприятия.
Программные методы защиты — это совокупность алгоритмов и про-
грамм, обеспечивающих разграничение полномочий пользователей
по доступу и исключение несанкционированного использования ин-
формации.
Суть аппаратной защиты состоит в том, что в устройствах и техниче-
ских средствах обработки информации предусматриваются специ-
альные технические решения, обеспечивающие защиту и контроль
информации, например экранирующие устройства, локализующие
электромагнитные излучения, или схемы контроля передачи информа-
ции между различными устройствами в информационных системах.
Защитные преобразования обеспечивают представление информации,
хранимой в системе и передаваемой по каналам связи, в некотором
коде, исключающем возможность ее непосредственного использо-
вания.
Организационные мероприятия по защите включают в себя совокупность
действий по подбору и проверке персонала, участвующего в подго-
товке и эксплуатации программ и информации, контролю устанав-
ливаемого оборудования, регламентированию процесса разработки
и функционирования информационных систем и т.п.
Программные механизмы защиты строятся, как правило, на принципе
проверки определенных параметров машины на предмет совпадения
некоторых данных, хранящихся в памяти компьютера, на жестком
диске, ключевой дискете.
При разработке программ защиты, которые в дальнейшем предпо-
лагается устанавливать на любой компьютер, может использоваться
ключевая дискета. В защитном механизме в этом случае должна осу-
ществляться проверка на присутствие на ключевой дискете опреде-
ленной информации. Ввиду того что в настоящее время существует
большое количество программ по полному копированию дискет, не-
обходимо предусмотреть механизм нестандартного форматирования
ключевой дискеты.
511
Глава 12. Сжатие и защита данных
12.2.1. Классификация и особенности
программных методов защиты от копирования
Защитные механизмы по способу внедрения в защищаемый програм-
мный модуль могут быть пристыковочными и/или встроенными.
В пристыковочной защите работа модуля защиты по времени не пере-
секается с работой защищаемого модуля. Как правило, вначале отра-
батывает модуль защиты, затем — защищенный модуль. Слабым
местом такой защиты является возможность отследить момент пере-
дачи управления от пристыковочного модуля к защищаемому и обойти
систему защиты без ее анализа.
Эффективной и надежной является та система, «взлом» которой зани-
мает достаточно длительное время и трудоемок. Основным парамет-
ром, определяющим эффективность средства защиты, является время,
необходимое на снятие защиты, поскольку при этом программа за вре-
мя снятия ее защиты может потерять свою актуальность (например,
устареет обрабатываемая ею информация), а также затраты на снятие
защиты превысят стоимость программы.
Современная защита от копирования строится на внедрении в защи-
щаемый модуль дополнительного модуля, осуществляющего некото-
рую проверку перед запуском основного модуля. В случае совпадения
сравниваемых признаков осуществляется передача управления ос-
новному модулю. Иначе происходит выход в операционную систему
или «зависание» программы.
Более эффективной является встроенная защита, которая может отра-
батывать как до начала, так и в процессе работы функционального
модуля. Для создания эффективной встроенной защиты наиболее
приемлемы защитные механизмы, проверяющие некоторые специ-
фические характеристики компьютера. Наиболее типичными харак-
теристиками компьютера, к которым чаще всего осуществляется «при-
вязка» защищаемой программы, являются:
► временные характеристики (быстродействие различных компонент
компьютера: процессор, память, контроллеры и т.д.; скорость враще-
ния двигателей дисководов; время реакции на внешние воздействия);
► тип микропроцессора и конфигурация машины (тип микропроцессо-
ра и разрядность шины данных, наличие и тип контроллеров внеш-
них устройств);
512
12.2. Методы защиты информации
► характерные особенности компьютера (контрольная сумма BIOS;
содержимое CMOS-памяти; длина конвейера шины данных; аномаль-
ные явления при программировании микропроцессора).
Временные характеристики компьютера в наибольшей степени отра-
жают индивидуальные особенности машины. Однако ввиду нестабиль-
ности электронных элементов компьютера возможна нестабильность
показателей быстродействия его компонент. Это приводит к услож-
нению защитного механизма, в функции которого должно входить
нормирование замеренных временных показателей.
С точки зрения защиты программ от исследования отладочными средст-
вами очень интересно использование конвейера шины данных мик-
ропроцессора. Программа в этом случае должна определить, идет ли
выполнение программы с трассировкой или нет, и осуществить ветв-
ление в зависимости от принятого решения.
Еще одним интересным и эффективным способом защиты программ от
несанкционированного копирования является использование ано-
мальных явлений, с которыми приходится сталкиваться при програм-
мировании микропроцессора и информацию о которых чаще всего
можно получить лишь экспериментальным путем. Это такие особен-
ности работы компьютера, которые являются исключением из общих
правил его функционирования. В качестве примера может служить
потеря одного трассировочного прерывания после команд, связан-
ных с пересылкой сегментных регистров. Это свойство может приме-
няться для недопущения работы программы под отладчиком.
Наиболее эффективным методом программной защиты выполняемых
программ от несанкционированного копирования является их защита
на этапе разработки. Модули защиты могут располагаться в нескольких
местах программы, что значительно затруднит работу «взломщика»
по поиску в дизассемблированной программе тех мест, где произво-
дится проверка параметров машины. Это особенно эффективно, если
программа написана на языке высокого уровня (С, Pascal и др.).
При этом рекомендуется два существенных момента:
► не использовать для зашиты нескольких программ стандартные про-
граммные модули;
► не оформлять эти модули в виде процедур и функций, вызов которых
производится в основной программе.
513
332792
Глава 12. Сжатие и защита данных
Первая рекомендация обусловлена тем, что стандартный защитный
модуль может быть обнаружен «взломщиком» при сопоставлении не-
скольких защищенных таким образом программ. Этот модуль будет
иметь один и тот же вид в дизассемблированных кодах различных
программ.
Вторая рекомендация обусловлена легким поиском в дизассемблиро-
ванной программе места вызова модуля зашиты.
Вышеизложенное позволяет сделать следующий вывод: для создания
достаточно эффективной и надежной программной защиты от несанк-
ционированного копирования (НСК) необходим индивидуальный под-
ход к созданию нестандартных механизмов защиты и включению их
в основную программу на этапе ее разработки.
12.2.2. Способы увеличения эффективности
и надежности защиты от копирования
Остановимся на существенных недостатках известных программных
механизмов защиты от НСК и укажем основные пути и способы уве-
личения эффективности и надежности этих механизмов:
► большинство защитных механизмов являются пристыковочными
и отрабатывают, как правило, один раз перед передачей управления
на исполняемый код защищенной программы;
► отсутствует возможность формальной оценки надежности системы
защиты от НСК. Качество защитных механизмов того или иного
пакета оценивается субъективно по времени, которое требуется для
снятия защиты конкретным специалистом;
► в большинстве случаев в системах защиты от НСК используются
аппаратные заглушки или специальным образом физически помеченные
дискеты. Эти методы недостаточно эффективны, так как известны
способы вскрытия такой защиты, а именно:
• при наличии аппаратной заглушки используется способ скани-
рования компьютеров при помощи подключения через «про-
зрачную» аппаратную заглушку второго компьютера, который
отслеживает все передаваемые между компьютером и заглушкой
сигналы;
• при использовании специальной дискеты с помощью специ-
альной резидентной программы осуществляется захват соответ-
514
12.2. Методы защиты информации
ствующего аппаратного прерывания от устройства и подмена
выдаваемых им кодов возврата на требуемые;
• дефектные секторы можно определить предварительным тесто-
вым считыванием ключевой дискеты, после чего она уже не
нужна.
Важным аспектом разработки защитных механизмов является защита
от исследования под отладчиком и с помощью дизассемблеров. В данном
случае речь идет о принципиально новом подходе к программирова-
нию. В отличие от общепринятого наглядного структурного програм-
мирования при программировании защитных механизмов следует
говорить о специальном, «изощренном» программировании, создаю-
щем сложный и запутанный исполняемый модуль. Защищать испол-
няемый код защитного модуля от дизассемблеров и отладчиков можно
и путем динамического изменения кода модуля.
Наличие механизмов защиты от дизассемблеров и отладчиков стано-
вится первым и наиболее сложным препятствием для «взломщика».
Задача таких механизмов защиты — недопущение или максимально
возможное затруднение анализа исполняемого кода программы.
Наиболее распространенные методы скрытия исходного текста про-
граммы от стандартных средств дизассемблирования — шифрование
и архивация. Непосредственное дизассемблирование защищенных
таким способом программ, как правило, не дает нужных результатов.
Но так как зашифрованная или архивированная программа чаще всего
выполняет и обратную операцию (дешифрацию или разархивирова-
ние) в первых же своих командах, на которые передается управление
сразу после запуска программы, то для снятия такой защиты необхо-
димо определить лишь момент дешифрации или разархивирования,
а затем программными средствами можно «снять» дамп памяти, за-
нимаемой исследуемой программой для последующего дизассембли-
рования.
Для усложнения процесса снятия такой защиты можно использовать
поэтапную дешифрацию программы. В этом случае программа будет
дешифрироваться не сразу в полном объеме, а отдельными участками
в несколько этапов, разнесенных по ходу работы программы.
Предварительная архивация кода программы более эффективна по
сравнению с шифрованием, так как решает сразу две задачи: умень-
515
Глава 12. Сжатие и защита данных
шение размера защищаемого модуля и скрытие кода программы от
дизассемблера. Файлы, с здаваемые с помощью архиваторов, долж-
ны быть самораспаковывающимися.
Еще один способ защиты от дизассемблирования — использование
самогенерируемых кодов. Самогенерируемые коды — это исполняемые
коды программы, полученные в результате выполнения некоторого
набора арифметических и/или логических операций над определен-
ным, заранее рассчитанным, массивом данных. Самогенерируемые
коды вырабатываются непосредственно защищаемой программой,
которая по ходу выполнения как бы сама себя «достраивает». Для
большей эффективности в качестве массива исходных данных само-
генерируемых кодов можно использовать часть исполняемого кода
защищаемой программы.
От дизассемблирования можно защитится также применением не-
стандартных приемов выполнения некоторых команд (с нарушением
общепринятых соглашений). Среди них:
► использование нестандартной структуры программы;
► скрытые переходы, скрытые вызовы программ и прерываний;
► переходы и вызовы подпрограмм по динамически изменяемым ад-
ресам.
Первый способ основан на предположении, что программа, не имею-
щая стандартной сегментации, может быть неправильно воспринята
дизассемблером. В связи с этим защитные механизмы программ чаще
всего располагаются в одном сегменте.
Второй способ предполагает использование нестандартной реализа-
ции команд типа JMP, CALL, INT, RET, IRET.
Третий способ подразумевает модификацию байтов адреса перехода
или вызова подпрограммы.
Не менее сложная задача для «взломщика» — преодолеть запрещение
исследования программ стандартными отладчиками. Эффективным
средством против пошагового выполнения программы отладчиком
является назначение стека в тело программы. Если в целях недопу-
щения переназначения стека за пределы исполняемого кода в стек
помещены данные, необходимые для работы программы, то проблема
вскрытия защиты еще более осложняется. Для повышения эффектив-
516
12.2. Методы защиты информации
ности метода можно часто менять местоположение стека в программе.
Защитные механизмы, которые будут использовать стек, делают прак-
тически невозможным применение стандартных отладочных средств.
Бороться с дизассемблерами и отладчиками можно методом подсчета
и проверки контрольных сумм определенных участков программы, что
позволяет определить, не установлены ли в теле проверяемого участ-
ка точки останова. Для установки точки останова отладчик заменяет
код байта программы по указанному адресу (предварительно сохра-
нив его) на код вызова прерывания, чем, конечно же, изменяет кон-
трольную сумму программы. Этот факт и использует метод подсчета
и проверки контрольных сумм.
Противодействовать средствам дизассемблирования и отладки также
можно с помощью контроля времени выполнения некоторых участков
программы. Пользуясь этим методом, необходимо заранее подсчи-
тать по таймеру время выполнения некоторого участка программы,
а затем в процессе работы программы вычислить его заново, сравни-
вая с эталоном. Если программа работает под управлением отладчи-
ка, то очевидно, что время выполнения контрольного участка будет
значительно большим, чем время его «чистой» работы. Данный метод
эффективен в сочетании с механизмом защиты от НСК, имеющим
привязку к аппаратным особенностям машины.
Одним из способов затруднения работы «взломщика» при анализе
работы программы является метод так называемых «пустышек». В ка-
честве таковых выделяются участки программы достаточно большого
объема, производящие некоторые значительные вычисления, но не
имеющие никакого отношения к работе программы. В «пустышки»
необходимо включать фрагменты, которые могли бы заинтересовать
«взломщика». Например, это могут быть вызовы таких прерываний,
как 13Н, 21Н, 25Н, 26Н, их перехват и т.п.
Принципиально новым подходом к защите программного обеспече-
ния от исследований отладочными средствами и дизассемблерами
является метод динамического изменения кода исполняемого модуля.
Полное изменение исполняемого кода становится возможным бла-
годаря адекватной замене одной или нескольких команд программы
другой последовательностью команд без изменения выполняемых
программой функций. Например, команда MOV может быть заменена
парой команд PUSH и POP, команда CALL — парой PUSH и JMP и т.д.
517
Глава 12. Сжатие и защита данных
Всегда можно организовать работу программы так, чтобы при каждом
ее выполнении происходила замена исполняемых команд на эквива-
лентные, которые выбирались бы из специальной таблицы эквива-
лентных команд, хранящейся в определенном месте программы. При
этом необходимо постоянно изменять и саму таблицу, переставляя
в ней местами эквивалентные команды. Можно также внести в таб-
лицу случайный признак модификации таблицы. В результате после
каждого выполнения программы ее код будет изменен до неузнавае-
мости (случайным образом), однако все свои функции программа бу-
дет выполнять точно так же, как и раньше. Единственное, что может
при этом изменяться, — это время выполнения программы.
12.2.3. Особенности защиты информации в компьютерных сетях
В последнее время в связи с широким распространением локальных
и глобальных компьютерных сетей особое значение приобрела про-
блема защиты информации при передаче или хранении в сети. Дело
в том, что разработанные программы и подготовленные данные для
отдельного компьютера предназначены для локального использова-
ния и практически не содержат средств зашиты. Теперь, когда любой
пользователь сети может попытаться заглянуть в чужой компьютер
и файл, защита информации в сети приобрела значительную актуаль-
ность. Особенно это важно в распространенной в настоящее время
технологии типа «клиент—сервер».
Работа в сети по технологии «клиент—сервер» привлекательна своей
открытостью. Однако построение систем защиты информации в та-
кой сети усложняется тем, что в одну сеть объединяется разнообразное
ПО, построенное на различных аппаратно-программных платформах.
Поэтому система защиты должна быть такой, чтобы владелец инфор-
мации мог быстро ею воспользоваться, а пользователь, не имеющий
соответствующих полномочий, испытывал бы значительные затруд-
нения в доступе к этой информации. Системы защиты информации
в таких сетях различны. Даже простой вариант смены паролей требует
согласования, поскольку эта процедура должна происходить с опре-
деленной периодичностью. Для доступа к информации необходимо
преодолеть несколько охранных рубежей. В связи с этим возникает
задача синхронизации работы средств безопасности всех платформ,
то есть создание своеобразного «зонта безопасности» для всей компь-
ютерной системы.
518
12.2. Методы защиты информации
Работа в распределенных вычислительных средах в связи с наличием
различных точек входа: рабочие станции, серверы баз данных, файл-сер-
веры LAN — усложняет решение проблемы безопасности.
Многие разработчики баз данных (БД) перекладывают функции кон-
троля доступа кданным на ОС, чтобы упростить работу пользователя
ПК. Особенно это показательно для ОС Unix, где реализована надеж-
ная защита информации. Однако такой подход позволяет взломщи-
кам, маскируясь под клиентов Unix, получить доступ к данным.
Более того, распределенные системы имеют, как правило, несколько
БД, функционирующих локально и позволяющих иметь собственный
механизм защиты. В распределенных системах однотипная инфор-
мация может быть размещена в различных (территориально удален-
ных) БД или информация из одной (по семантике) таблицы может
храниться на различных физических устройствах. Однако для голов-
ного пользователя распределенной системы необходимо организо-
вать работу так, чтобы по одному запросу он мог получить полную
информацию, то есть с точки зрения пользователя должен соблю-
даться принцип географической прозрачности.
В БД Oracle, например, принцип географической прозрачности
и фрагментарной независимости реализуется механизмами связей
(links) и синонимов (synonyms). Посредством связей программирует-
ся маршрут доступа к данным: указываются реквизиты пользователя
(регистрационное имя и пароль), тип сетевого протокола (например,
TCP/IP) и имя БД. К сожалению, все эти параметры приходится
описывать в тексте сценариев (scripts). Чтобы засекретить указанную
информацию, пароли можно хранить в словаре данных в зашифро-
ванном виде.
Наличие нескольких БД в распределенных системах в некоторой сте-
пени усложняет работу пользователей, не имеющих соответствую-
щих полномочий по доступу к данным, ибо код должен преодолевать
автономные защиты данных в различных БД.
Защита информации в распределенной среде многоуровневая. Чтобы
пользователю получить доступ к требуемым данным, например, с по-
мощью штатных программ администрирования, ему необходимо
сначала попасть в компьютер (уровень защиты рабочей станции), по-
том в сеть (сетевой уровень защиты), а уже затем — на сервер БД. При
этом пользователь сможет оперировать конкретными данными лишь
519
Глава 12. Сжатие и защита данных
при наличии соответствующих прав доступа (уровень защиты БД).
Для работы с БД через клиентское приложение придется преодолеть
еще один барьер — уровень защиты приложения.
В арсенале администратора системы «клиент — сервер» имеется не-
мало средств обеспечения безопасности, в частности встроенные воз-
можности БД и различные коммерческие продукты третьих фирм.
Важность внутренних средств защиты состоит в том, что контроль
доступа происходит постоянно, а не только в момент загрузки прило-
жения.
Каждый пользователь системы имеет определенные полномочия по
работе сданными. В широко известных базах данных Sybase и Microsoft
SQL Server, например, тип доступа регулируется операторами GRANT
и REVOKE, допускающими или запрещающими операции чтения,
модификации, вставки и удаления записей из таблицы, а также вызо-
ва хранимых процедур. К сожалению, во многих БД минимальным
элементом данных, для которого осуществляется контроль доступа,
является таблица. В то же время во многих практических задачах кон-
троль доступа требуется осуществлять даже по отдельным полям или
записям. Эта задача может быть реализована либо с помощью таблич-
ных фильтров (на уровне приложения), либо путем модификации
структуры БД, используя денормализацию таблиц.
Современные злоумышленники имеют широкий спектр интересов
к чужой информации — от простого любопытства до хищения денег
и военных и производственных секретов. Система безопасности
в компьютерной сети не только охраняет от несанкционированного
доступа, но и упреждает попытки доступа к удаленным службам ли-
цами, не имеющими на это права. Она также решает проблемы пере-
хвата и повторного использования сообщений, а также уточнения
адресата посланного сообщения.
Можно классифицировать следующие проблемы безопасности:
секретность (упреждение попадания информации неавторизованным
пользователям);
аутентификацию (определение подлинности пользователя);
обеспечение точного исполнения обязательств (как правило, это связа-
но с электронной подписью);
520
12.2. Методы защиты информации
целостность информации (упреждение модификации и замены ин-
формации по пути следования).
Решение проблемы безопасности в сети требует принятия мер на всех
уровнях сети — от прикладного до физического, привлекая протоколы
всех уровней. Физический уровень защищается физико-техническими
средствами, связанными с помещением линий связи, например, в ох-
раняемые оболочки. Решение проблемы безопасности на всех других
уровнях, как правило, базируется на принципах криптографии.
В криптографии строго различаются термины шифр (побитовое или
посимвольное преобразование информации) и код (замена одного
слова другим словом или символом).
Способность генерировать шифры (криптотрафия) и взламывать их
(криптоанализ) принадлежит к прикладному научному направлению —
криптологии.
Среди методов шифрования выделяют две группы: методы подста-
новки и методы перестановки.
При подстановке каждый символ или группа символов заменяется на
другой символ или группу символов.
Например,
открытый текст a b с d е f... z
шифрующий текст MDKBRS... А
Тогда исходный текст cad будет принят в виде КМВ. Ключом к такой
подстановке является 26-символьная строка (для английского алфа-
вита), соответствующая заданному преобразованию всех символов.
В методах перестановки сами символы не изменяются, меняют лишь
порядок их следования. Исходный текст может быть представлен в виде
матрицы заданного размера и передаваться в форме другой матрицы
с переставленными строками или столбцами. Ключом к такому шиф-
ру может служить слово или несколько слов с неповторяющимися бу-
квами.
Существует проблема создания шифра, который невозможно взломать.
Оказывается, такой шифр можно создать с помощью метода одноразо-
вого блокнота. Суть его в следующем. Выбирается произвольная бито-
вая строка с длиной, равной длине исходного текста. Открытый текст
преобразуется в последовательность двоичных разрядов с помощью
521
Глава 12. Сжатие и защита данных
некоторой кодировки. Обе двоичные строки складываются пораз-
рядно по модулю 2. Полученную в результате этого зашифрованную
информацию взломать достаточно сложно, используя любые вычис-
лительные мощности. Практическое применение такого метода за-
труднительно из-за необычайно длинного ключа.
12.3. Контроль данных
Проблема обеспечения достоверности функционирования ВС имеет
много общего с проблемой обеспечения достоверности передачи
дискретной информации по каналам связи (КС). В обоих случаях она
включает две труппы мероприятий:
► совершенствование элементов аппаратуры в целях снижения вероят-
ности появления ошибок;
► разработку эффективных методов контроля, то есть методов обнару-
жения ошибок и их исправления.
12.3.1. Специфика передачи информации в вычислительных системах
Вычислительные системы с точки зрения задач контроля и возможно-
стей его организации имеют следующие существенные особенности:
1. К достоверности ВС предъявляются более высокие требования, чем
к достоверности передачи информации по КС, поскольку работа
в ВС осуществляется автоматически, без участия человека.
2. Помимо передачи информации, в ВС осуществляются ее длитель-
ное хранение и обработка, связанная с выполнением большого чис-
ла арифметико-логических операций. В вычислительных системах
методы контроля, используемые в КС, применимы лишь при хра-
нении и передаче информации (проверяется возможное изменение
информации). Совершенно другая задача контроля при обработке
информации, ибо она в этом случае изменяется и при отсутствии
ошибок. Используемые методы контроля должны проверять пра-
вильность произведенных изменений, то есть правильность выпол-
нения операций. Особенность ВС состоит еще и в том, что каждое
передаваемое слово может оказаться результатом других операций.
Поэтому несвоевременно обнаруженная даже одиночная ошибка
522
12.3. Контроль данных
может привести к искажению многих данных, в то время как в КС
отдельные слова с точки зрения достоверности не связаны друг
с другом.
3. В ВС используется обрабатываемая и управляющая информация.
С точки зрения контроля эти два вида информации существенно
различаются. Ошибка в команде, произошедшая в результате ее
хранения, передачи или расшифровки, обычно приводит к более
тяжким последствиям, чем ошибка в операнде, ибо могут уничто-
житься результаты многих предыдущих операций (этапов задачи).
Особенно опасна такая ситуация в управляющих машинах, рабо-
тающих в реальном времени, то есть система контроля в первую
очередь должна обеспечить защиту программы.
4. Обычно каждой выполняемой операции предшествуют поиск и вы-
борка из ЗУ очередной команды и операнда. При искажении адреса
будет выполнена не та команда или не над теми операндами. От-
сюда возникает необходимость контроля адресного тракта в ВС.
5. Все элементы ВС в отличие от КС территориально находятся, как
правило, в одном месте. Исправление ошибки может начаться не-
замедлительно после ее обнаружения.
6. С точки зрения вероятности возникновения ошибок различные уст-
ройства ВС отличаются. Наиболее слабым местом, нуждающимся
в строгом контроле, является внешний накопитель информации
на МД, а также устройства ввода-вывода.
В последнее время компьютеры выпускаются с модульной структурой.
В них основные устройства выполнены в виде отдельных модулей,
имеющих самостоятельное функциональное значение, то есть каж-
дое устройство может выполнять свои функции при наличии в его
составе лишь одного модуля. В случае подключения нескольких мо-
дулей повышаются универсальность и гибкость ВС. Компьютер оста-
ется работоспособным и при отказе некоторого модуля, но на время
его восстановления ухудшаются характеристики компьютера (на-
пример, нет совмещения операций, уменьшается скорость обработ-
ки и т.д.). Любой подключаемый модуль принимает на себя часть
функций, улучшая гибкость ВС. Только глубокий и всесторонний
контроль позволяет вовремя изменять структуру вычислительной
системы и использовать все преимущества модульных структур.
523
Глава 12. Сжатие и защита данных
12.3.2. Классификация ошибок и их характеристики
Систематические ошибки. Такие ошибки появляются, как правило,
в результате отказов одного или нескольких схемных элементов, вхо-
дящих в цепи передачи информации или в устройства, с помощью
которых выполняются арифметические и логические операции. Если
повторяется одна и та же операция над одними и теми же данными,
ошибка будет повторяться всякий раз. При других данных или других
операциях она может и не повторяться. Тем не менее вычисления
бессмысленны.
Случайные ошибки представляют собой результат сбоя в элементах
машины. Эти ошибки — источник основных затруднений для эф-
фективной эксплуатации ВС. Единственный способ установить на-
личие или отсутствие ошибки — контроль каждой операции или всего
решения в целом.
Определение одиночных и кратных ошибок зависит от вида обработки
информации, характера операции и т.д. При хранении информации
или ее передаче одиночная ошибка состоит в изменении одного двоич-
ного знака. Если же изменению подверглось несколько знаков, ошибку
называют кратной. Так же определяются ошибки результата пораз-
рядных логических операций.
Иначе дело обстоит с ошибками в результатах арифметических опе-
раций. При выполнении сложения, например, ошибка в одном раз-
ряде из-за переносов может привести к тому, что двоичные символы
в нескольких позициях будут неправильными. То же самое — сбой
в цепи переноса. Тем не менее такие ошибки классифицируются как
одиночные, ибо разность между правильным и ошибочным результа-
тами будет иметь единицу только в одной позиции. Например, пусть
правильный результат есть 101111, а в результате операции получен
110000. Результаты отличаются в пяти позициях, но их разность равна
000001. Следовательно, ошибка одиночная.
Кратными в этом случае считаются ошибки (две и более), которые
произошли независимо при выполнении одной операции в несколь-
ких разрядах С повышением кратности обнаружение и исправление
ошибок затрудняются. Поэтому важно выяснить законы распределе-
ния вероятностей ошибок в числе или слове.
Наиболее просто это сделать для компьютера параллельного действия.
Здесь каждый двоичный разряд передается по отдельному каналу
524
12.3. Контроль данных
и обрабатывается в отдельных устройствах связанных друг с другом
только цепями переноса. Следовательно, возникновение ошибок
в отдельных двоичных разрядах можно считать независимыми слу-
чайными событиями, имеющими одинаковую вероятность. Тогда для
ошибок /-й кратности в «-разрядном числе справедлив биномиаль-
ный закон распределения:
Qi =С‘д‘(1-фп-‘, (1)
Где Qi — вероятность ошибки /-Й кратности в числе; q — вероятность
ошибки в одном разряде при выполнении одной операции.
Формула (1) позволяет определить вероятность ошибки /-й крат-
ности при условии, что в остальных п — / разрядах ошибок нет. Из
формулы (1) следует, что для очень малых значений q наибольшую
вероятность имеет одиночная ошибка.
Для компьютеров последовательного действия положение осложняется
тем, что ошибки в разных разрядах числа происходят, в общем слу-
чае, в разное время. Поэтому кратность ошибок в числе, очевидно,
зависит от соотношения между быстродействием узлов компьютера
и длительностью сбоя. Во всяком случае, вероятности кратных оши-
бок следует ожидать более высокими, чем для компьютеров парал-
лельного действия, при одинаковой вероятности сбоя в аппаратуре.
То же можно сказать о ЗУ на МЛ и МД. Запись и чтение информации
на них обычно выполняются последовательным или последователь-
но-параллельным способом. Кроме того, причиной ошибок могут
быть различные механические повреждения магнитной поверхности.
При большой плотности записи последняя ситуация является источ-
ником целой группы ошибок.
12.3.3. Методы обнаружения и исправления ошибок в ЭВМ
Автоматический контроль функционирования ЭВМ предполагает
получение информации об ошибках.
Существует два вида контроля, отличающиеся способами получения
такой информации: программный и схемный (аппаратурный) кон-
троль.
Программный контроль состоит в том, что в программу решения задачи
включаются дополнительные операции, имеющие математическую
525
Глава 12. Сжатие и защита данных
или логическую связь с алгоритмом задачи. Сравнение результатов
введенных операций с результатом решения всей задачи в целом или
отдельных этапов ее решения позволяет установить с определенной
вероятностью наличие или отсутствие ошибки. На основании срав-
нения появляется возможность исправления обнаруженной ошибки.
Такой дополнительной операцией может быть двойной (тройной) счет
программы или ее частей, позволяющий исправить ошибку без ее об-
наружения. Возможность исправления обусловлена тем, что ошибка
носит случайный характер и в дальнейшем не повторяется.
Достоинства программных методов:
► простота реализации;
► отсутствие дополнительного оборудования;
► возможность применения в любом компьютере.
Недостатки:
► значительное снижение скорости решения задач;
► проблематичность использования в компьютерах, работающих
в режиме управления.
Схемный контроль связан с введением в состав ЭВМ дополнительной
аппаратуры, предназначенной для выявления ошибок в контроли-
руемом устройстве. Принцип действия такой аппаратуры обычно свя-
зан со специальным кодированием операндов и команд программы.
Такой код содержит дополнительные разряды, несущие требуемую
для контроля избыточную информацию. Иногда избыточная инфор-
мация получается дублированием основной аппаратуры без приме-
нения специальных кодов.
Достоинство схемных методов заключается в небольшом времени
контроля, поскольку операции контроля почти полностью удается
совместить с выполнением основных операций.
Недостаток — необходимость увеличения объема аппаратуры.
Схемно-профаммный метод заслуживает особого внимания. Сущность
его состоит в том, что задача обнаружения ошибок возлагается на
контрольные схемы, встроенные во все устройства и тракты машины.
Исправление же обнаруженных ошибок осуществляется специаль-
ной исправляющей программой, которая берет на себя управление
по сигналу ошибки.
526
12.3. Контроль данных
Достоинства комбинированного метода:
► производительность компьютера снижается незначительно, по-
скольку исправляющая программа включается редко;
► объем дополнительного оборудования гораздо меньше того, кото-
рый требуется при схемном методе.
12.3.4. Программные методы контроля
Программные методы контроля используют специальные методы и па-
кеты контролирующих программ. Применяются тестовый и программ-
но-логический контроль.
Тестовый контроль осуществляется периодически с помощью про-
грамм-тестов, которые различают по назначению:
► наладочные — для комплексной наладки компьютера;
► проверочные — для проверки устойчивости работы элементов ком-
пьютера во время профилактики;
► программы контрольных задач — запускаются во время решения ос-
новной задачи в целях проверки работоспособности компьютера;
► диагностические — для локализации обнаруженных отказов путем
программного анализа ошибок.
Программно-логический контроль имеет целью непосредственную про-
верку правильности решения задачи при выполнении основной про-
граммы. Можно дополнительно вводить некоторые операции для кон-
троля основных выполняемых операций. Рассмотрим ряд способов
такого контроля.
Контроль решений методом двойного счета. Суть метода состоит в по-
вторном вычислении всей задачи или отдельных ее частей. Результаты
сравниваются, и их совпадение считается признаком достоверности
результата. При несовпадении результатов решение повторяется до
двух одинаковых результатов, которые считаются верными. Если ре-
шением задачи является таблица, то проверка осуществляется по ее
контрольной сумме.
Достоинство метода в простоте, однако необходимо предварительно
предусмотреть контрольные точки.
527
Глава 12. Сжатие и защита данных
Недостатки:
► затраты времени с контролем значительно превышают затраты
времени на решение задачи без контроля;
► использовать метод можно лишь тогда, когда исходные данные
при решении задачи не разрушаются или могут быть легко восста-
новлены;
► исправляются лишь случайные ошибки, как результат сбоя.
Математические и смысловые проверки (МС-проверки). МС-проверки
основаны на анализе промежуточных результатов решения задачи.
Для этого предварительно необходимо произвести исследование
алгоритма решения задачи с целью выявления границ изменяемых
величин, дополнительных условий, которым они должны удовлетво-
рять, и т.д. Общие принципы МС-проверок сформулировать сложно,
ибо многое зависит от конкретной задачи и искусства программиста.
Рассмотрим некоторые типовые примеры.
Способ подстановки. Суть способа заключается в программной под-
становке полученных решений в условие задачи. После этого сравни-
ваются правые и левые части уравнений для определения невязок.
Если невязки не выходят за пределы заданной точности, решение
считается правильным. Затраты времени на контроль небольшие
в сравнении с повторным счетом, тем не менее обнаруживаются как
случайные, так и систематические ошибки. Для исправления необхо-
дим повторный счет.
Дополнительные связи переменных. Суть способа — в применении до-
полнительных связей между искомыми величинами. Типичные при-
меры — связи между тригонометрическими функциями:
11 2 2 I л z .
1—snra-cos od-£<0 (£>0); --------=tg a.
1 1 cos a
Поскольку определить подобные связи не всегда возможно, такой
контроль трудно сделать глубоким. Иногда в задачу вводят дополни-
тельные переменные, удовлетворяющие вместе с вычисляемыми ве-
личинами некоторым соотношениям, и используют их для контроля.
Проверка предельных значений. В большинстве задач нетрудно зара-
нее определить пределы, в которых должны находиться некоторые
528
12.3. Контроль данных
искомые величины. Это обычно делается на основе приближенного
анализа алгоритма вычислений. Тогда в программе в определенных
точках выполняется проверка на нахождение величин в заданных
пределах.
Адресное кодирование. В целях повышения быстродействия компью-
тера используется модификация команд. Она состоит в изменении
адресной части базовой команды. В некоторых случаях в адресной
части базовой команды индексируются и адреса команд. Этот прием
используется в программах, состоящих из нескольких вычислитель-
ных блоков. Операции, связанные с изменением адресов, не застра-
хованы от ошибок. Один из методов снижения вероятности таких
ошибок состоит в особом кодировании, применяемом при програм-
мировании. Речь идет о выборе из ЗУ ячеек, совокупность адресов
которых составляет некоторый корректирующий код, например код
с проверкой на четность.
Пример. Пусть программа разделена на ряд вычислительных блоков,
начальные адреса которых хранятся в виде таблицы. Основная функ-
ция общей части программы — правильно определить вход в эту таб-
лицу.
Пусть таблица имеет восемь входов. Выберем для их хранения 8 из
16 последовательных ячеек ЗУ, которые имеют адреса с четным чис-
лом единиц (табл. 12.2). Во все остальные ячейки поместим одну и ту
же команду перехода к исправляющей программе (ПкИП). Опреде-
лить вход в таблицу несложно. Например, для определения номера
входа (7V) надо брать все числа от 0 до 7 и сложить их с числом, сдви-
нутым влево на один разряд. Таким образом, номер ячейки с адресом
входа в блок А равен NBX л = А + 2А.
Таблица 12.2
Пример адресного кодирования
Nячейки
0000 0
ПкИП 0001
ПкИП 0010
ООП 3
ПкИП 0100
0101 5
529
Глава 12. Сжатие и защита данных
Окончание табл. 12.2
Nячейки
ОНО 6
ПкИП 0111
ПкИП 1000
1001 15
1010 10
ПкИП 1011
1100 12
ПкИП 1101
ПкИП 1110
1111 9
Вычислим номера ячеек, в которых записаны адреса входов во все во-
семь блоков.
1) 000 2) 001 3) 010 4) 011 5) 100 6) 101 7) ПО 8) 111
000 001 010 011 100 101 ПО 111
000 011 ПО 101 1100 11111 1010 1001
Л’=0 N=3 7V=6 N=5 W=12 JV=15 JV=10 N=9
Замечание. Межразрядные переносы и выходы за интервал при вы-
полнении операции не учитываются. Одиночная ошибка (любая)
при определении входа в блок передает управление к повторному
вычислению ее номера.
Упражнения
1. Разработайте алгоритм сжатия простого текстового документа.
2. Разработайте и реализуйте алгоритм сжатия цветного изображения.
3. Разработайте программу встроенной защиты данных, базирующейся на
некоторых специфических особенностях компьютера (временные харак-
теристики, тип микропроцессора, конвейер шины данных и т.д.).
530
Упражнения
4. Разработайте и реализуйте алгоритм зашиты от дизассемблера, используя:
• механизм самогенерируемых кодов;
• метод динамического изменения кода исполняемого модуля.
5. Охарактеризуйте достоинства и недостатки программных и аппаратных
методов обнаружения ошибок при передаче информации.
6. Сравните по сложности реализации программно-логические методы
контроля процесса решения задачи.
7. Какие задачи решает адресное кодирование?
531
Приложение 1
Языки параллельного программирования
Linda — параллельный язык программирования. Программа на этом
языке рассматривается как совокупность процессов, которые могут
обмениваться данными через пространство кортежей. Язык исполь-
зуется вместе с другими языками высокого уровня как средство об-
щения параллельных процессов.
Modula-З — универсальный язык программирования, дальнейшее
развитие языков Pascal и Modula-2. Включает возможности разработ-
ки многопоточных приложений.
NESL — язык параллельного программирования, предложенный как
для проектирования параллельных программ, так и для обучения.
Поддерживает задание параллельного выполнения любых функций
над однотипными данными. Содержит средства анализа производи-
тельности компьютера.
Orca — язык параллельного программирования для компьютеров
с распределенной памятью. Предоставляет средства динамического
порождения процессов и наложения их на процессоры, а также сред-
ства коммуникации процессов через разделяемые объекты.
Parallaxes — структурный язык параллельного программирования,
базирующийся на языке Modula-2. Пользователю предоставляется
возможность задавать конфигурацию виртуальной машины для ис-
полнения программы.
Phantom — язык интерпретации, предназначенный для разработки
больших распределенных интерактивных приложений. Он основы-
вается на языке Modula-3.
Sisal — функциональный язык программирования. Компилятор опре-
деляет все информационные зависимости в программе, распределяет
работу по процессорам, обеспечивает синхронизацию, необходимые
передачи.
SR (Synchronizing Resources) — параллельный язык программирова-
ния. Основные конструкции языка — ресурсы (процессоры и данные)
и операции для взаимодействия ресурсов. Поддерживаются различ-
ные типы синхронизации, передачи сообщений, динамическое соз-
дание процессов, использование разделяемых переменных.
532
Приложение 1. Языки параллельного программирования
ZPL — параллельный язык программирования. Включает средства
поддержки операций над целыми массивами и секциями массивов.
Параллельные свойства программы извлекаются компилятором ав-
томатически.
Параллельные расширения и диалекты языков С и C++
А++/Р++ — это реализация в рамках языка C++ операций над масси-
вами языка Fortran 90. Включает систему визуализации распределе-
ния массивов.
СС++ (Compositional C++) — параллельный язык программирования,
основанный на языке C++. Предоставляет средства одновременного
выполнения нескольких функций, указания независимости итера-
ций цикла и синхронизации.
Chann/Charm++ — параллельные расширения языков С и C++ соот-
ветственно. Программы, подготовленные с их применением, могут
выполняться на компьютерах как с общей, так и с распределенной
памятью.
Cilk — язык программирования, базирующийся на языке С, обеспе-
чивает реализацию многопоточности. Программист обеспечивает
максимальный параллелизм, а его использование и планирование
работы процессоров определяет Cilk runtime system. Программы на
языке Cilk не зависят от числа процессоров в системе.
НРС (High Performance С) — проект, разрабатываемый в CRIM (Centre
de Recherche Informatigue de MontrBal). Цель проекта — создание на
основе языка С средства поддержки параллельных вычислений на раз-
личных платформах. Параллельные расширения языка с роятся по
аналогии с языком HPF (см. ниже).
НРС++ (High Performance C++) — параллельная библиотека языка
C++. Включает средства поддержки многопоточности, параллельно-
го выполнения циклов, синхронизации глобальных операций. Ос-
новная ориентация — на компьютеры с общей памятью.
Maisie — параллельный язык программирования, основанный на язы-
ке С. Параллельным процессам ставятся в соответствие логические
процессы. Общение процессов осуществляется через сообщения.
MPL (Mentat Programming Language) — объектно-ориентированный
язык программирования, базирующийся на языке C++. Программист
533
Приложение 1. Языки параллельного программирования
задает распределение данных. Компилятор определяет необходимые
пересылки и синхронизации, которые реализуются во время испол-
нения с помощью Mentat run-time system.
mpC — язык программирования, основанный на языках С и C++.
Имеет средства создания параллельных процессов для компьютеров
с распределенной памятью. Пользователь может задавать топологию
сети, распределение данных и вычислений и необходимые пересыл-
ки данных. Посылка сообщений осуществляется с использованием
интерфейса MPI.
МРС++ — расширение языка C++для проектирования параллельных
программ. Каждому процессору многопроцессорного компьютера
ставится в соответствие один процесс, который может состоять из не-
скольких потоков. Предоставляются средства коммуникации и син-
хронизации как потоков, так и процессов.
Parsec — параллельный язык программирования, основанный на
языке С. Является развитием языка Maisie.
рС++ — параллельный язык программирования, основанный на язы-
ке C++. Пользователю предоставляется возможность распределять
структуры данных аналогично распределению массивов в НРЕ
sC++ — параллельный язык программирования, позволяющий опи-
сывать многопоточность.
иС+ч— параллельный язык программирования, основанный на язы-
ке C++. Позволяет использовать многопоточность и эмулировать
разделяемую память. Программа на иС++ транслируется в программу
на C++, компилируется штатным компилятором C++, затем к ней
присоединяется runtime библиотека.
Параллельные расширения и диалекты языка Fortran
Fortran 90/95 — развитие языка Fortran 77, включающее элементы па-
раллелизма, в частности операции над массивами и секциями масси-
вов и глобальные операции, а в Fortran 95 — еще и средства задания
параллелизма циклов. Существует множество реализаций для самых
различных платформ. Последний стандарт — ISO/IEC 1539:1997.
HPF (High Perfomance Fortran) — дальнейшее развитие языка Fortran 90.
Включены различные средства распределения данных по процессорам.
534
Приложение 1. Языки параллельного программирования
Необходимые коммуникации и синхронизации реализуются компиля-
тором. Некоторые расширения реализованы в виде функций и операто-
ров языка, другие задаются в виде директив компилятору (с помощью
комментариев языка Fortran).
Fortran D95 — экспериментальный язык программирования, основан-
ный на НРЕ Расширения направлены на поддержку основных клас-
сов параллельных приложений, работающих в основном с большими
массивами данных, нерегулярными и разреженными матрицами.
Fortran М — расширение языка Fortran с возможностью модульной
разработки последовательных и параллельных программ. Имеются
средства порождения процессов и их коммуникации передачей сооб-
щений.
Fx — расширение языка НРЕ Созданы средства управления процес-
сами, включающие возможности динамического разбиения на груп-
пы и подгруппы, выполняющие независимую работу.
Opus — параллельное расширение языка НРЕ Включены средства
управления процессами (независимыми программными модулями).
Для коммуникаций и синхронизаций модулей используется понятие
ShareD Abstraction (SDA) — набор данных, описывающих состояние
модуля, и набор методов для работы с этими данными. Данные SDA
могут быть распределены обычным образом, что и позволяет SDA
быть распределенным. Связь между модулями осуществляется по-
средством специальных модулей, а синхронизация осуществляется
специальными языковыми конструкциями.
Vienna Fortran 90 — дальнейшее развитие языка Fortran 90. Включает
богатые возможности распределения массивов данных и итераций
циклов по секциям процессоров.
535
Приложение 2
Пример программы на MPI
Задача: вычислить число л методом Монте-Карло.
Алгоритм решения задачи базируется на моделировании случайного
попадания точек в фигуру, которая представляет собой круг радиуса
R, вписанного в квадрат и основан на формуле:
л = 4* число_точек_попавших_в_круг / число_точек_попав-
ших_в_квадрат.
Моделирование выполняется параллельно на множестве процессов.
Входным параметром задачи является число испытаний points, которое
необходимо провести. Результаты статистик накапливаются в глобаль-
ной переменной globs с помощью операции редукции MPI_Reduce.
♦include <stdio.h>
♦include <stdlib.h>
♦include <time.h>
♦include "mpi.h"
♦include <sys\timeb.h>
♦define R 32767
♦define R2 1073676289
double realtime(void);
long test (int myrank, int ntasks, long points)
{
long x, y;
long in — 0;
long j;
for (j = myrank; j < points; j += ntasks)
{
x = 1 + rand ();
у = 1 + rand();
if (x‘x + y*y < R2) in++;
)
536
Приложение 2. Пример программы на MPI
return in;
)
void main (int argc, char ** argv)
{
long points;
int myrank, ranksize;
double pi, send[2],recv[2];
long locS, globS;
int i;
MPI_Status status;
double tl,t2;
double t3, t4, t5, t6,t7;
srand( (unsigned) time( NULL ) );
globS = 0;
tl=realtime();
MPI_Init (&argc, &argv); /* initialize MPI system */
t2=realtime();
MPI_Comm_rank (MPI_C0MM_W0RLD, imyrank) ;
/* my place in MPI system */
MPI_Comm_size (MPI_COMM_WORLD, iranksize);
/* size of MPI system */
if (myrank =- 0) /* I am the master */
{
printf ("Calculation of PI by Monte-Carlo method\n”);
printf ("Number of points: ");
scanf ("%ld", ipoints);
}
MPI_Barrier (MPI_C0MM_W0RLD); /* make sure all MPI tasks are
running */
if (myrank == 0) /* I am the master */
{
/* distribute parameter */
printf ("Master: Sending # of intervals to MPI-Processes \n");
537
Приложение 2. Пример программы на MPI
t3 = MPI_Wtime();
for (i = 1; i < ranksize; i++)
{
MPI_Send (Spoints, 1, MPI_LONG, i, 98, MPI_COMM_WORLD);
}
}
else{ /* I am a slave */
/* receive parameters */
MPI_Recv (&points, 1, MPI_LONG, 0, 98, MPI_COMM_WORLD, &status);
}
/* compute my portion of interval */
t4 = MPI_Wtime();
locS = test (myrank, ranksize, points);
t5 = MPI_Wtime();
/* collect results, add up*/
MPI_Reduce (&locS, &globS, 1, MPI_LONG, MPI_SUM, 0,
MPI_COMM_WORLD);
MPIBarrier (MPI_COMM_WORLD);
t6 = MPI_Wtime();
if (myrank == 0) /* I am the master */
/‘print results */
{
pi = (double) 4*globS/points;
t7 = MPI_Wtime();
printf ("Master: Has collected sum from MPI-Processes \n”);
printf ("\nPi estimation: %.201f\n", pi);
printf ("%ld tasks used - Execution time: %.31f
sec\n",ranksize, t7 -t3) ;
printf("\nStatistics:\n") ;
printf("Master: startup: %.01f msec\n",t2-tl);
printf("Master: time to send # of points:%.31f sec\n",t4-t3);
printf("Master: waiting time for sincro after calculation:%.21f
sec\n",t6-t5);
printf("Master: time to collect: %.31f sec\n",t7-t6);
538
Приложение 2. Пример программы на MPI
printf("Master: calculation time:%.31f sec\n”,t5-t4);
/* collect there calculation time */
for (i = 1; i < ranksize; i++)
{
MPI_Recv (recv, 2, MPI_DOUBLE, i, 100, MPI_COMM_WORLD,
Sstatus);
printf (’’process %d: calculation time: %.31f sec\twaiting time
for sincro.: %.31f sec\n”,i,recv[0],recv[1]);
}
}
else{ /* I am a slave */
/* send my result back to master */
send[0]=t5-t4;
send[l]=t6-t5;
MPI Send (send, 2, MPI DOUBLE, 0, 100, MPI COMM WORLD) ;
}
MPI_Finalize ();
}
double realtime() /* returns time in seconds */
{
struct _timeb tp;
_ftime(&tp);
return((double)(tp.time)*1000+(double)(tp.millitm));
539
Приложение 3
Современные суперкомпьютеры из ТОР500
Лтах — максимальная производительность по UNPACK (Мфлопс)
Лреак — теоретическая пиковая производительность (Мфлопс)
№ п/п Место положения Компьютер Количе- ство про- цессоров Год ^max ^pcak
1 DOE/NNSA/LLNL United States BlueGene/L — eServer Blue Gene Solution IBM 131072 2005 280600 367000
2 IBM Thomas J. Whtson Research Center United States BGW — eServer Blue Gene Solution IBM 40960 2005 91290 114688
3 DOE/NNSA/LLNL United States ASC Purple — eServer pSeries p5 575 1.9 GHz IBM 10240 2005 63390 77824
4 NASA/Ames Research Center/NAS United States Columbia — SGI Altix 1.5 GHz, Vbltaire Infiniband SGI 10160 2004 51870 60960
5 Sandia National Laboratories United States Thunderbird — Power Edge 1850, 3.6 GHz, Infiniband Dell 8000 2005 38270 64512
6 Sandia National Laboratories United States Red Storm Cray XT3, 2.0 GHz Cray Inc. 10880 2005 36190 43520
7 The Earth Simulator Center Japan Earth—Simulator NEC 5120 2002 35860 40960
8 Barcelona Supercomputer Center Spain MareNostrum — JS20 Cluster, PPC 970, 2.2 GHz, Myrinet IBM 4800 2005 27910 42144
9 ASTRON/U niversity Groningen Netherlands Stella - eServer Blue Gene Solution IBM 12288 2005 27450 34406.4
10 Oak Ridge National Laboratory United States Jaguar - Cray XT3, 2.4 GHz Cray Inc. 5200 2005 20527 24960
540
Приложение 3. Современные суперкомпьютеры из ТОР500
№ п/п Место положения Компьютер Количе- ство про- цессоров Год ^max ^pcak
11 Lawrence Livermore National Laboratory United States Thunder — Intel ltanium2 Tiger4 1.4 GHz — Quadrics California Digital Corporation 4096 2004 19940 22938
12 Computational Biology Research Center, AlST Japan Blue Protein — eServer Blue Gene Solution IBM 8192 2005 18200 22937.6
13 Ecole Polytechnique Federate de Lausanne Switzerland eServer Blue Gene Solution IBM 8192 2005 18200 22937.6
14 ERDC MSRC United States Cray XT3, 2.6 GHz Cray Inc. 4096 2005 16975 21299
15 COLSA United States MACH5 — Apple XServe, 2.0 GHz, Myrinet Self-made 3072 2005 16180 24576
16 Korea Meteorological Administration Korea, South Cray XIE (4GB) Cray Inc. 1020 2005 15706 18442
17 Oak Ridge National Laboratory United States Cray XIE (2GB) Cray Inc. 1014 2005 14955 18333
18 Los Alamos National Laboratory United States ASCI Q — AlphaServer SC45, 1.25 GHz Hewlett-Packard 8192 2002 13880 20480
19 Lawrence Livermore National Laboratory United States eServer pSeries p5 575 1.9 GHz IBM 2048 2005 13090 15564.8
20 Virginia Tep h United States System X — 1100 Dual 2.3 GHz Apple XServe/Mellanox Inftniband 4X/Cisco GigE Self-made 2200 2004 12250 20240
21 Japan Atomic Energy Research Institute Japan SGI Altix 3700 Bx2, 1.6 GHz, NUMALink SGI 2048 2005 11814 13107
22 IBM — Rochester United States BlueGene/L DD1 Prototype (0.5 GHz PowerPC 440 w/Custom) IBM 8192 2004 11680 16384
541
Приложение 3. Современные суперкомпьютеры из ТОР500
№ п/п Место положения Компьютер Количе- ство про- цессоров Год ^max ^peak
23 Wright—Patterson Air Force Base/DoD ASC United States SGI Altix 3700 Bx2, 1.6 GHz, NUMALink SGI 2048 2003 11652 13107
24 University of Southern California United States HPC — Pentium4 Xeon, EM64T, Opteron, Opteron dual core, Cluster, Myrinet IBM 2904 2005 10750 17280
25 US Army Research Laboratory (ARL) United States John Van Neumann - LNX Cluster, Xeon 3.6 GHz, Myrinet Linux Networx 2048 2005 10650 14745.6
26 China Meteorological Administration China eServer pSeries 655 (1.7 GHz Power4+) IBM 3200 2005 10310 21760
27 Naval Oceanographic Office (NAVOCEANO) United States eServer pSeries 655 (1.7 GHz Power4+) IBM 2944 2004 10310 20019.2
28 NCSA United States Tungsten — PowerEdge 1750, P4 Xeon 3.06 GHz, Myrinet Dell 2500 2003 9819 15300
29 IBM — Almaden Research Center United States eServer Blue Gene Solution IBM 4096 2005 9360 11468.8
30 IBM — Deep Computing Capacity on Demand Center United States eServer Blue Gene Solution IBM 4096 2005 9360 11468.8
31 IBM Research Switzerland eServer Blue Gene Solution IBM 4096 2005 9360 11468.8
32 IBM Thomas J. Whtson Research Center United States eServer Blue Gene Solution IBM 4096 2005 9360 11468.8
33 ECMWF United Kingdom eServer pSeries 690 (1.9 GHz Power4+) IBM 2176 2004 9241 16538
542
Приложение 3. Современные суперкомпьютеры из ТОР500
№ п/п Место положения Компьютер Количе- ство про- цессоров Год ^max ^peak
34 ECMWF United Kingdom eServer pSeries 690 (1.9 GHz Power4+) IBM 2176 2004 9241 16538
35 UCSD/San Diego Supercomputer Center United States DataStar — eServer pSeries 655/690 (1.5/1.7 GHz Power4+) IBM 2464 2005 9121 15628
36 Australian Partnership for Advanced Computing (APAC) Australia SGI Altix 3700 Bx2, 1.6 GHz, NUMALink SGI 1536 2005 8974 9830
37 HWW/U niversitaet Stuttgart Germany SX8/576M72 NEC 576 2005 8923 9216
38 Hitachi Ltd. Enterprise Server Division Japan SRI 1000—KI Hitachi 80 2005 8893 10752
39 Institute of Physical and Chemical Res. (R1KEN) Japan RIKEN Super Combined Cluster Fujitsu 2048 2004 8728 12534
40 Pacific Northwest National Laboratory United States Mpp2 — Cluster Platform 6000 rx2600 Itanium2 1.5 GHz, Quadrics Hewlett-Packard 1936 2003 8633 11616
41 Caltech United States CITerra — PowerEdge 1850, 3.2 GHz, Myrinet Dell 2048 2005 8408 131072
42 Shanghai Supercomputer Center China Dawning 4000A, Opteron 2.2 GHz, Myrinet Dawning 2560 2004 8061 11264
43 Los Alamos National Laboratory United States Lightning — Opteron 2 GHz, Myrinet Linux Networx 2816 2003 8051 11264
44 Pittsburgh Supercomputing Center United States Cray XT3, 2.4 GHz Cray Inc. 2060 2005 7935.82 9888
543
Приложение 3. Современные суперкомпьютеры из ТОР500
№ п/п Место положения Компьютер Количе- ство про- цессоров Год ^peak
45 Lawrence Livermore National Laboratory United States MCR Linux Cluster Xeon 2.4 GHz - Quadrics Linux Networx 2304 2002 7634 11060
46 HPCx United Kingdom eServer pSeries p5 575 1.5 GHz IBM 1536 2005 7395 9216
47 Lawrence Livermore National Laboratory United States ASCI White, SP Power3 375 MHz IBM 8192 2000 7304 12288
48 NERSC/LBNL United States Seaboig — SP Power3 375 MHz 16 way IBM 6656 2002 7304 9984
49 NCSA United States TeraGrid, Itanium2 1.3/1.5 GHZ, Myrinet IBM 1776 2004 7215 10259
50 US Army Research Laboratory (ARL) United States eServer Opteron 2.2 GHz. Myrinet IBM 2320 2004 7185 10208
51 University of Sherbrooke Canada Mp — PowerEdge SC1425 3.6 GHz— Infiniband Dell 1152 2005 6888 8294.4
52 Nagoya University Japan PRIMEPOWER HPC2500 (2.08 GHz) Fujitsu 1664 2005 6860 13844
53 Lawrence Livermore National Laboratory United States xSeries Cluster Xeon 2.4 GHz — Quadrics IBM 1920 2003 6586 9216
54 NERSC/LBNL United States eServer pSeries p5 575 1.9 GHz IBM 976 2005 6415.13 7417.6
55 NASA/Goddard Space Flight Center United States Explore — SGI Altix 3700 Bx2, 1.5 GHz, NUMAlink, Infiniband SGI 1152 2005 6309.1 6912
56 Lawrence Livermore National Laboratory United States Lilac — xSeries x335 Cluster, Xeon 3.06 GHz, Quadrics IBM 1540 2004 6232 9425
544
Приложение 3. Современные суперкомпьютеры из ТОР500
№ п/п Место положения Компьютер Количе- ство про- цессоров Год ^max
57 НРСх United Kingdom eServer pSeries 690 (1.7 GHz Power4+) IBM 1600 2004 6188 10880
58 Grid Technology Research Center, AIST Japan AIST Super Cluster P-32 - AIST Super Cluster P—32, Opteron 2.0 GHz, Myrinet IBM 2200 2004 6155 8800
352792
545
Приложение 4
Кластеры семейства СКИФ
Кластерные суперкомпьютерные конфигурации СКИФ создаются
в рамках программы Союзного государства «Разработка и освоение
в серийном производстве семейства высокопроизводительных вы-
числительных систем с параллельной архитектурой (суперкомпьюте-
ров) и создание прикладных программно-аппаратных комплексов на
их основе».
(2) Кластерный
I уровень (КУ)
(3) Вычислительные
узлы КУ
SMP
Вспомогательная сеть
(ВС LAN, TCP/IP)
(1) Рабочие станции
Jc доступом
к суперкомпьютеру
(7) Возможность реализации
интерфейсов
Рис. 4.1. Архитектура суперкомпьютера СКИФ
SMP
Системная сеть (CC-SAN)
I Д-
(4) овс
управл.
(5) Модуль ОВС
(6) Средства взаимодействия
\| (СВКУиОВС),
возможные варианты
управл^ |
[ управл.
546
Приложение 4. Кластеры семейства СКИФ
Архитектура суперкомпьютера СКИФ, представленная на рис. 4.1,—
это двухуровневая открытая масштабируемая архитектура, включаю-
щая в себя кластерный и потоковый уровень.
На кластерном уровне использована технология SCALI.
СКИФ представляет собой 32-процессорный кластер, системная сеть
которого построена на основе SCI (по топологии 2И-тор 4x4 —
квадратная матрица 4x4, где каждый узел связан с четырьмя сосед-
ними), а вспомогательная сеть, служащая для управления кластером
с головного компьютера, базируется на технологии Switched Fast
Ethernet.
На потоковом уровне используется однородная вычислительная сре-
да (ОВС) — вычислительная среда с топологией плоской решетки из
большого числа микропроцессоров, объединенных потоковыми ли-
ниями передачи данных.
Открытая и масштабируемая архитектура не накладывает жестких
ограничений на программно-аппаратную платформу узлов кластера,
топологию вычислительной сети, конфигурацию и диапазон произ-
водительности суперкомпьютеров. Такой подход позволяет созда-
вать прикладные суперкомпьютерные системы в широком диапазоне
производительности.
Кластер СКИФ К-500 создан в 2003 году для отработки принципов
построения моделей суперкомпьютеров СКИФ сверхвысокой произво-
дительности (триллионы операций в секунду). Создание этого кластера
является качественно новым результатом, позволившим вплотную
приблизиться к терафлопному диапазону.
СКИФ К-500, структурная схема которого показана на рис. 4.2, пред-
ставляет собой кластер из 128 процессоров Xeon с частотой 2,8 ГГц.
Реальная производительность кластера в 475,3 миллиарда операций
в секунду, достигнутая на тесте LinPack, стала основанием для его
включения под номером 407 в 22-й выпуск списка 500 самых произ-
водительных компьютерных систем в мире top500.
Пиковая производительность каждого узла кластера СКИФ К-500 —
11,2 Гфлопс. SCI интерфейс обеспечивает задержку при передаче со-
общений в соответствии со стандартом MPI — 3 мкс, скорость обме-
на узел-узел — 263 Мбайт/с.
547
Приложение 4. Кластеры семейства СКИФ
Вычислительные узлы соединяются высокоскоростной сетью SCI
и образуют трехмерный тор (3D-Top) 4 х 4 х 4 (L0 х Ll х L2) — кубиче-
ской структуры. Блоки по 16 узлов в отдельных шкафах соединены
в двухмерный тор (2D-Top 4 х 4). ЗО-тор образуется с помощью 16 ко-
лец внешних связей SCI интерфейса между соответствующими вы-
числительными узлами разных шкафов по линку L2.
Вспомогательный сетевой интерфейс GB Ethernet 0 предназначен
для загрузки программ, данных, управления и мониторинга. Он име-
ет звездообразную топологию, в которой к коммутатору, соединенно-
му с управляющей ПЭВМ, подключены три коммутатора остальных
шкафов. Вычислительные узлы одного шкафа подключаются к сво-
ему коммутатору. GB Ethernet 1 предназначен для доступа из внеш-
ней локальной сети к управляющей ПЭВМ.
Рис. 4.2. Структурная схема СКИФ К-500
Дополнительная дисковая память (файловый сервер) подключена
к каждому из четырех коммутаторов отдельным GB Ethernet каналом.
С управляющей ПЭВМ она связана по GB Ethernet перекрестным ка-
белем, использует технологию хранения данных RAID5 и имеет об-
щую емкость дисковой памяти около 800 Гбайт.
Сервисная сеть RS-485 предназначена для выполнения включения/
выключения электропитания вычислительного узла, аппаратного
сброса узла и выполнения взаимодействия с вычислительным узлом
в консольном режиме с управляющей ПЭВМ.
548
Приложение 4. Кластеры семейства СКИФ
KVM обеспечивает подключение любого из вычислительных узлов
каждого шкафа к общей клавиатуре, видеомонитору, мыши для сер-
висного обслуживания.
Программное обеспечение кластера:
► операционная система LINUX RED HAT с поддержкой SMP;
► система управления, администрирования кластером и поддержка
стандарта MPI 1.2 фирмы Scali (SSP 3.0.1);
► компиляторы С, C++;
► система программирования и управления выполнением вычисле-
ний — Т-система.
Суперкомпьютер СКИФ К-1000 создается с целью комплексной реа-
лизации принципов построения моделей суперкомпьютеров СКИФ
Ряда 2 кластерного уровня с массовым параллелизмом сверхвысокой
производительности (триллионы операций в секунду), включая сете-
вые (метакластерные) конфигурации.
Суперкомпьютер СКИФ К-1000 является старшей моделью семей-
ства СКИФ и представляет собой кластер из 288 двухпроцессорных
узлов. Реальная производительность кластера 2,028 Тфлопс достиг-
нута на тесте LinPack. Пиковая производительность СКИФ К-1000 —
2,53 Тфлопс.
Каждый узел кластера содержит двухпроцессорную системную плату
SMP с микропроцессорами Opteron 2.2 с частотой 2,2 ГГц, дисковую
подсистему, средства для подключения к системной сети и вспомога-
тельной сети Gigabit Ethernet и имеет следующие параметры:
► емкость основной памяти — 2,0 Гбайт;
► емкость дисковой подсистемы — 80 Гбайт.
Сетевые коммутаторы Infiniband обеспечивают работоспособность
всех серверных узлов в топологии Fat Tree. Система управления вы-
числительными узлами обеспечивает для любого вычислительного
узла операции включения-выключения питания, аппаратного сброса
(reset), возможность организации консольного доступа к любому сер-
верному узлу с управляющего узла на этапе загрузки BIOS, а также
загрузки и работы операционной системы. Теоретическая пиковая
производительность вычислительного узла кластера — 8,8 Гфлопс.
549
Приложение 4. Кластеры семейства СКИФ
В программное обеспечение суперкомпьютера СКИФ К-1000 входит:
► ядро ОС Linux, адаптированное для работы на суперкомпьютерах
семейства СКИФ;
► параллельная файловая система PVFS-SKIF;
► система очередей задач для кластерного уровня суперкомпьютеров
семейства СКИФ;
► система мониторинга FLAME (Functional Active Monitoring Envi-
ronment);
► распределенная программная система отладки MPI-программ (ПС
TDB);
► ядро Т-системы;
► компилятор TGCC языка ТС;
► средство поддержки ТС-режима для среды XEmacs;
► свободно распространяемые параллельные библиотеки и прило-
жения, адаптированные для работы на суперкомпьютерах СКИФ.
Суперкомпьютер СКИФ К-1000 включен под номером 330 в 26-й
выпуск списка 500 самых производительных компьютерных систем
в мире.
550
Приложение 5
Микропроцессоры AMD за 2000-2006 годы
Серия К7 (1999 — 2004)
Athlon (Slot A) (Pluto/Argon/Orion/Thunderbird) (1999)
Athlon (Socket A) (Thunderbird) (2000)
Duron (Spitfire/Morgan/Appaloosa/Applebred) (2000)
Athlon MP (2001) (Palomino/Thoroughbred/Thorton) (2001)
Athlon 4 (Corvette/Mobile Palomino) (2001)
Athlon XP (Palomino/Thoroughbred (A/B)/Barton/Thorton) (2001)
Mobile Athlon XP (Mobile Palomino) (2002)
Mobile Duron (Camaro/Mobile Morgan) (2002)
Sempron (Thorton) (2004)
Серия K8 (2003 - 2006)
Семейства: Opteron, Athlon 64, Sempron, Turion 64, Athlon 64 X2
Opteron (SledgeHammer) (2003)
Athlon 64 FX (SledgeHammer) (2003)
Athlon 64 (ClawHammer/Newcastle) (2003)
Mobile Athlon 64 (Newcastle) (2004)
Athlon XP—M (Dublin) (2004) (инструкции AMD64 заблокированы)
Sempron (Paris) (2004) (инструкции AMD64 заблокированы)
Athlon 64 (Winchester) (2004)
Turion 64 (Lancaster) (2005)
Athlon 64 FX (San Diego) (1st Half 2005)
Athlon 64 (San Diego/Venice) (1st Half 2005)
Sempron (Palermo) (1st Half 2005)
Athlon 64 X2 (Manchester) (1st Half 2005)
Athlon 64 X2 (Toledo) (1st Half 2005)
Athlon 64 X2 (Windsor) (Expected 1st Half 2006)
Athlon 64 (Orleans) (Expected 1st Half 2006)
Sempron (Manilla) (Expected 2006)
551
Литература
Алгоритмы, математическое обеспечение и архитектура многопроцессорных
вычислительных систем / отв. ред. А.П. Ершов. М.: Наука, 1992.
Буза М.К. Введение в архитектуру компьютеров / М.К. Буза. Мн.: БГУ, 2000.
Буза М.К. Архитектура как интерфейс между различными уровнями физиче-
ской системы / М.К. Буза. Мн.: БГУ, 1994.
Буза М.К. Windows-приложения: от операции к реализации / М.К. Буза,
Л.В. Певзнер. Мн.: Вышэйш. шк., 1998.
Головкин Б.А. Вычислительные системы с большим числом процессоров /
Б.А. Головкин. М. : Радио и связь, 1995.
Гук М. Аппаратные средства IBM PC. Энциклопедия / М. Гук. 2-е изд. СПб.:
Питер, 2001.
Джоунз Г. Программирование на языке ОККАМ / Г. Джоунз. М.: Мир, 1989.
Зарубежная радиоэлектроника. М.: Наука. 1997. № 2.
Карп Р.М. Параллельные схемы программ / Р.М. Карп, Р.Е. Миллер // Киб. сб.
Новая серия. М.: Мир, 1976. № 13.
Корнеев В.В. Параллельные вычислительные системы / В.В. Корнеев. М.: Но-
лидж, 1999.
Майерс Г. Архитектура современных ЭВМ: в 2 ч. / Г. Майерс. М.: Мир, 1985.
Наринъяни А.С. Теория параллельного программирования: Формальные мо-
дели / А.С. Нариньяни // Кибернетика. 1974. № 3, № 5.
Олифер В.Г. Компьютерные сети / В.Г. Олифер, Н.А. Олифер. 2-е изд. СПб.,
2005.
Проблемы построения и обучения нейронных сетей / под ред. А.И. Галушки-
на и В.А. Шахнова. М.: Машиностроение, 1999.
Системы параллельной обработки : пер. с англ. / под ред. Д. Ивенса. М. :
Мир, 1985.
Смирнов А.Д. Архитектура вычислительных систем / А.Д. Смирнов. М.: Нау-
ка, 1990.
Таненбаум Э. Архитектура компьютеров / Э. Таненбаум. СПб.: Питер, 2002.
Шнайер Б. Прикладная криптография. Протоколы, алгоритмы, исходные тек-
сты на языке С / Б. Шнайер. М.: ТРИУМФ, 2002.
Шнитман В. Современные высокопроизводительные компьютеры / В. Шнит-
ман / http://www.citforum.ru/hardware/svk/.
Шоу А. Логическое проектирование операционных систем / А. Шоу. М. :
Мир, 1981.
552
Литература
Шпаковский Г.И. Программирование для многопроцессорных систем в стан-
дарте MPI / Г.И. Шпаковский, Н.В. Серикова. Мн.: БГУ, 2002.
Bernstein A. Concurrency in Programming and Database Systems I A. Bernstein,
P. Lewis. Boston; London, 1993.
Hack M. Petri net languages: Tech. Rep. I M. Hack // MIT. 1976. № 159. 128 p.
Hennessy J. Computer Architecture a Quantitative Approach / J. Hennessy, D. Pat-
terson. 3-th edit. San Francisco, 2003.
Lastovetsky A. Parallel Computing on Herogeneous Clusters I A. Lastovetsky. John
Willy & Sons, 2003.
Tanenbaum A.S. Modem Operating Systems / A.S. Tanenbaum. Prentice Hall,
2001.
http://dfe3300.karelia.ru/koi/www/neucom.html
http://parallel.srcc.msu.su/computers/
http://www. ixbt.com/storage.shtml
www.amd.com
www.en.wikipedia.org/wiki/AMD
www.ixbt.com
553
Оглавление
Предисловие..............................................3
Введение.................................................6
Список основных сокращений..............................14
Бгава 1. Два подхода к понятию «архитектура» ...........17
1.1. Вычисления в компьютерах ..........................19
1.2. Архитектура как набор взаимодействующих компонент .25
1.3. Архитектура как интерфейс между уровнями физической
системы................................................31
1.4. Семантический разрыв...............................36
1.5. Анализ архитектурных принципов фон Неймана ........42
1.6. Способы совершенствования архитектуры .............45
1.7. RISC- и CISC-архитектура...........................51
1.8. Функционирование управляющего компьютера ..........60
Упражнения..............................................63
Бгава 2. Конвейеризация.................................64
2.1. Конвейерная обработка..............................65
2.2. Классификация конфликтов по данным ................68
2.3. Предикация ........................................72
2.4. Конвейерные системы ...............................79
Упражнения..............................................82
Бгава 3. Организация памяти.............................83
3.1. Иерархия памяти....................................83
3.2. Регистровая память.................................84
3.3. Организация кэш-памяти.............................86
3.4. Концепция виртуальной памяти.......................95
3.5. Оперативные и постоянные запоминающие устройства.100
3.6. Дополнительная память.............................104
554
Оглавление
3.7. Управление памятью .............................. 107
Упражнения.............................................111
Бгава 4. Компьютерные сети.............................112
4.1. Эталонная модель сети ............................115
4.2. Топология локальных сетей........................ 121
4.3. Примеры различных типов шин ......................127
4.4. Простое средство связи в сетях (шина) ........... 136
4.5. Сетевые технологии (LAN/WAN) .................... 146
Упражнения.............................................157
Бгава 5. Кодирование данных в компьютерах..............158
5.1. Формы чисел с фиксированной и плавающей точкой .. 158
5.2. Помехозащищенные коды............................ 161
5.3. Сравнительные характеристики корректирующих кодов . 170
5.4. Кодирование данных с симметричным представлением
цифр .................................................177
5.5. Кодирование данных в системах с отрицательным
основанием .......................................... 180
5.6. Кодирование данных с помощью вычетов............. 186
5.7. Стандарт IEEE 754 ............................... 199
Упражнения.............................................201
Бгава 6. Микропроцессоры...............................203
6.1. Методы адресации и типы команд ...................204
6.2. Компьютеры со стековой архитектурой ..............206
6.3. Процессоры с микропрограммным управлением ........212
6.4. Процессоры с архитектурой 80x86 и Pentium.........218
6.5. Особенности процессоров с архитектурой SPARC
компании Sun Microsystems.............................228
• 6.6. Процессоры РА-RISC компании Hewlett Packard.......235
555
Оглавление
6.7. Процессор МС 88110 компании Motorola................242
6.8. Архитектура MIPS компании MIPS Technology...........244
6.9. Особенности архитектуры Alpha компании DEC..........250
6.10. Особенности архитектуры POWER .....................256
6.11. Современные микропроцессоры........................265
Упражнения...............................................266
Глава 7. Взаимодействие и управление процессами..........268
7.1. Понятие процесса и состояния .......................269
7.2. Графическое представление процессов.................271
7.3. Управление процессами в многопроцессорном
компьютере ...........................................273
7.4. Управление процессами в однопроцессорном
компьютере............................................275
7.5. Форматы таблиц процессов............................276
7.6. Синхронизация процессов ............................278
7.7. Операции Р и Vнад семафорами........................280
7.8. Почтовые ящики .....................................282
7.9. Монитор Хоара ......................................283
7.10. Проблема тупиков ..................................284
7.11. Тупик в случае повторно используемых ресурсов......285
7.12. Организация системы прерывания ....................287
Упражнения...............................................301
Глава 8. Последовательные и параллельные процессы........304
8.1. Предпосылки создания систем параллельного действия .308
8.2. Отношение предшествования процессов ................311
8.3. Типы параллелизма ..................................313
8.4. Информационные модели...............................316
8.5. Программное обеспечение для мультикомпьютеров.......324
8.6. Повышение эффективности функционирования
компьютеров...........................................328
556
Оглавление
8.7. Вычислительные парадигмы .......................334
8.8. Методы коммуникации ............................335
8.9. Алгоритмы выбора маршрутов для доставки сообщений .337
8.10. Метрика аппаратного и программного обеспечения.338
8.11. Классификация компьютеров .....................340
8.12. Некоторые модели параллельных программ ........344
8.13. Формальная модель программ на сетях Петри .....350
Упражнения...........................................358
Бгава 9. Системы параллельного действия..............360
9.1. Вычислительные системы и многомашинные комплексы
на базе однопроцессорных компьютеров ................360
9.2. Многопроцессорный вычислительный комплекс Эльбрус ... 366
9.3. Матричные компьютеры ...........................372
9.4. Концепции вычислительных систем с комбинированной
структурой...........................................374
9.5. Архитектура типа гиперкуб ......................377
9.6. Нейрокомпьютеры ................................379
9.7. Процессоры с архитектурой VLIW..................390
9.8. Потоковые компьютеры ...........................394
Упражнения...........................................402
Бгава 10. Коммуникационные технологии................403
10.1. Коммутаторы вычислительных систем .............403
10.2. Коммуникационная среда SCI ....................411
10.3. Коммуникационная среда MYRINET ................425
Упражнения...........................................430
Бгава 11. Языки описания параллельных процессов......431
11.1. Основные подходы к проектированию языков
параллельного программирования ......................432
11.2. Примеры языков параллельного программирования .436
557
Оглавление
11.3. Преобразование последовательных программ
в последовательно-параллельные........................481
11.4. Распределение задач по процессорам .............486
11.5. Планирование в мультипрограммных системах.......488
Упражнения............................................496
Глава 12. Сжатие и защита данных......................498
12.1. Сжатие данных ..................................499
12.2. Методы защиты информации .......................510
12.3. Контроль данных.................................522
Упражнения............................................530
Приложение 1. Языки параллельного программирования....532
Приложение 2. Пример программы на MPI.................536
Приложение 3. Современные суперкомпьютеры из ТОР500...540
Приложение 4. Кластеры семейства СКИФ.................546
Приложение 5. Микропроцессоры AMD за 2000—2006 годы...551
Литература............................................552
558
Учебное издание
Буза Михаил Константинович
Архитектура компьютеров
Учебник
Редактор Б.С. Славин
Художник обложки С.В. Ковалевский
Компьютерная верстка С. И. Лученок
Корректор К.А. Степанова
Подписано в печать с готовых диапозитивов 31.08.2006.
Формат 60x84 '/16. Бумага газетная. Гарнитура Ньютон.
Печать офсетная. Усл. печ. л. 32,55. Уч.-изд. л. 29,5.
Тираж 2010 экз. Заказ № 2792.
Общество с ограниченной ответственностью «Новое знание .
ЛИ № 02330/0133439 от 30.04.2004. Минск, пр. Пушкина, д. 15, ком. 16.
Почтовый адрес: 220050, Минск, а/я 79.
Телефон/факс: (10-375-17) 211-50-38. E-mail: nk@wnk.biz
В Москве:
Москва, Колодезный пер., д. 2а.
Телефон (495) 234-58-53. E-mail: ru@wnk.biz
http://wnk.biz
Отпечатано в полном соответствии с качеством предоставленных
диапозитивов на ГУП РК “Республиканская типография
им. П. Ф. Анохина”, 185005, г. Петрозаводск, ул. Правды, 4