/

































Текст
1
Аннотация
Данная методическая разработка является введением в канальный уровень компьютерных сетей. Разобраны задачи, решаемые на канальном уровне, и особое внимание уделено задаче надёжной предачи данных по каналу с помехами. Здесь вы
найдёте описание классические идей и кодов: CRC (циклических кодов) и кодов Хемминга. Подробно рассмотрен вопрос об
их эффективности и приведены теоретические оценки коэффициентов содержания полезной информации.
В качестве примера приведено краткое описание стандартного протокола передачи данных HDLC.
Канальный уровень: помехоустойчивое
кодирование
Ворожцов Артём
12 мая 2001 г.
Содержание
1 Канальный уровень
1.1 Сервис, предоставляемый сетевому
1.2 Разбиение на кадры . . . . . . . . .
1.3 Контроль ошибок . . . . . . . . . .
1.4 Управление потоком . . . . . . . .
уровню
. . . . .
. . . . .
. . . . .
2 Помехоустойчивое кодирование
2.1 Характеристики ошибок . . . . . . . . . . .
2.2 * Элементы теории передачи информации .
2.3 Метод “чётности” и общая идея . . . . . . .
2.4 Циклические коды . . . . . . . . . . . . . . .
2.5 * Теоретический предел . . . . . . . . . . .
2.6 Коды Хемминга . . . . . . . . . . . . . . . .
2.7 Анализ эффективности . . . . . . . . . . . .
2.8 Коды как линейные операторы . . . . . . .
2.9 *Коды Рида-Соломона . . . . . . . . . . . .
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
.
3
3
5
7
8
.
.
.
.
.
.
.
.
.
8
8
9
12
15
16
18
20
24
27
3 Примеры протоколов канала данных
28
3.1 HDLC протокол . . . . . . . . . . . . . . . . . . . . . . . . 28
2
3
Введение
Здесь мы рассмотрим основные принципы и методы надёжной и эффективной передачи данных между двумя машинами, соединёнными
проводом. Под проводом следует понимать любую физическую среду передачи данных. Посредством этой физической среды нужно научиться передавать биты так, чтобы они безошибочно принимались
получателем точно в той последовательности, в какой они были переданы.
Эта простая, на первый взгляд, задача при детальном рассмотрении оказывается весьма сложной и, более того, нерешаемой, поскольку в реальных каналах присутствуют помехи и временные задержки.
Но можно обеспечить передачу данных с очень малой вероятностью
ошибки. Решением этой задачи занимается канальный уровень. C его
обзора мы начнём изложение.
1
Канальный уровень
На уровне канала данных решается ряд проблем, присущих только
этому уровню:
• реализация сервиса для сетевого уровня,
• объединение битов, поступающих с физического уровня
в кадры,
• обработка ошибок передачи, управление потоком кадров.
1.1
Сервис, предоставляемый сетевому уровню
Основная задача канального уровня — обеспечить сервис сетевому
уровню, а это значит помочь передать данные с сетевого уровня одной
машины на сетевой уровень другой машины. Так как это показано на
рис. 1а. Фактически же передача будет происходить так, как показано
на рис. 1б.
Канальный уровень может создаваться для различного сервиса,
который может варьироваться от системы к системе. Есть три вида
сервиса:
1. Сервис без уведомления и без соединения
2. Сервис с уведомлением без соединения
4
Host 1
Host 2
Host 1
Host 2
4
4
4
4
3
3
3
3
2
2
2
1
1
2
Virtual
data path
1
1
Actual
data path
(а)
(б)
Рис. 1: Виртуальное соединение на канальном уровне
3. Сервис с уведомлением и соединением
Сервис без уведомления и без соединения не предполагает, что приём переданного кадра должен подтверждаться, что до начала передачи должно устанавливаться соединение, которое после передачи должно разрываться. Если в результате помех на физическом уровне кадр
будет потерян, то никаких попыток его восстановить на канальном
уровне не будет. Этот класс сервиса используется там, где физический
уровень обеспечивает высокую надёжность при передаче, так что восстановление при потери кадров можно оставить на верхние уровни. Он
также применяется при передаче данных в реальном времени там, где
лучше потерять часть данных, чем увеличить задержку в их доставке.
Например, передача аудио и видео информации.
Следующий класс сервиса — с уведомлением без соединения. В
этом классе получение каждого посланного кадра должно быть подтверждено. Если подтверждения не пришло в течении определенного
времени, то кадр должен быть послан опять. Этот класс сервиса используется над ненадёжной физической средой передачи, например,
беспроводной.
Наиболее сложный класс сервиса на канальном уровне — сервис с
уведомлением и соединением. Этот класс сервиса предполагает, что
до начала передачи между машинами устанавливается соединение и
данные передаются по этому соединению. Каждый передаваемый кадр
нумеруется и канальный уровень гарантирует, что он будет обязатель-
5
но получен и только один раз и все кадры будут получены в надлежащей последовательности. При сервисе без соединения этого гарантировать нельзя потому, что потеря подтверждения получения кадра
приведет к его пересылке так, что появиться несколько идентичных
кадров.
При сервисе с уведомлением и соединением передача разбивается
на три этапа. На первом этапе устанавливается соединение: инициируются переменные на обоих машинах и счётчики, отслеживающие
какие кадры были приняты, а какие нет. На втором этапе один или
несколько кадров передается. На третьем соединение разрывается: переменные, счётчики, буфера и другие ресурсы, использованные для
поддержки соединения, освобождаются.
1.2
Разбиение на кадры
Сервис, создаваемый канальным уровнем для сетевого, опирается на
сервис, создаваемый физическим уровнем. На физическом уровне протекают потоки битов. Значение посланного бита не обязательно равно
принятому, и количество посланных битов не обязательно равно количеству принятых. Всё это требует специальных усилий на канальном
уровне по обнаружению и исправлению ошибок.
Типовой подход к решению этой проблемы — разбиение потока
битов на кадры и подсчёт контрольной суммы для каждого кадра
при посылке данных.
Контрольная сумма — это, в общем смысле, функция от содержательной части кадра (слова длины m), область значений которой —
слова фиксированной длины r:
f : B m → B r , где B = {0, 1}
Эти r бит добавляются обычно в конец кадра. При приёме контрольная сумма вычисляется заново и сравнивается с той, что храниться в кадре. Если они различаются, то это признак ошибки передачи. Канальный уровень должен принять меры к исправлению ошибки,
например, сбросить плохой кадр, послать сообщение об ошибке тому
кто прислал этот кадр. Разбиение потока битов на кадры — задача не
простая. Один из способов — делать временную паузу между битами
разных кадров. Однако, в сети, где нет единого таймера, нет гарантии, что эта пауза сохраниться или, наоборот, не появятся новые. Так
как временные методы ненадёжны, то применяются другие. Здесь мы
рассмотрим четыре основных:
1. Счетчик символов
6
2. Вставка специальных стартовых и конечных символов
или последовательностей бит
3. Специальная кодировка на физическом уровне
Первый метод очевиден. В начале каждого кадра указывается сколько символов в кадре. При приёме число принятых символов подсчитывается опять. Однако, этот метод имеет существенный недостаток —
счётчик символов может быть искажён при передаче. Тогда принимающая сторона не сможет обнаружить границы кадра. Даже обнаружив не совпадение контрольных сумм, принимающая сторона не сможет сообщить передающей какой кадр надо переслать, сколько символов пропало. Этот метод ныне используется редко.
Второй метод построен на вставке специальных символов. Обычно
для этого используют управляющие последовательности: последовательность DLE ST X для начала кадра и DLE ET X для конца кадра. DLE — Data Link Escape; ST X — Start TeXt, ET X — End TeXt.
При этом методе если даже была потеряна граница текущего кадра,
надо просто искать ближайшую последовательность DLE ST X или
DLE ET X. Но нужно избегать появления этих комбинаций внутри
самого тела кадра. Это осуществляется дублированием комбинаций
DLE, встречающихся внутри тела кадра, и удаление дублей после получения кадра. Недостатком этого метода является зависимость от
кодировки (кодозависимость). По мере развития сетей эта связь становилась все более и более обременительной и был предложен новый
очевидный кодонезависимый метод — управляющие последовательности должны быть бит-ориентированными. В частности, в протоколе HDLC каждый кадр начинается и заканчивается со специального
флаг-байта: 01111110. Посылающая сторона, встретив последовательно 5 единиц внутри тела кадра, обязательно вставит 0. Принимающая
сторона, приняв 5 последовательных единиц обязательно удалит следующий за ними 0, если таковой будет. Это называется bit-stuffing.
Если принято шесть и за ними следует ноль, то это управляющий
сигнал: начало или конец кадра, а в случае, когда подряд идут более
шести единиц, — сигнал ожидания или аварийного завершения.
(а) 0 1 1 0 1 1 1 1 1 1 1 1 1 1 1 0 0 1
(б) 0 1 1 0 1 1 1 1 1 0 1 1 1 1 1 0 1 0 0 1
Рис. 2: Bit Stuffing. (a) исходные данные (б) посылаемые данные. Жирным отмечены вставленные нули.
Таким образом, кадр легко может быть распознан по флаг-байту.
7
Если граница очередного кадра по какой-то причине была потеряна,
то все что надо делать — ловить ближайший флаг-байт.
И наконец, последний метод используется там, где конкретизирована физическая среда. Например, в случае проводной связи для передачи одного бита используется два импульса. 1 кодируется как переход
высокое-низкое, 0 — как низкое-высокое. Сочетания низкое-низкое или
высокое-высокое не используются для передачи данных, и их используют для границ кадра.
На практике используют, как правило, комбинацию этих методов.
Например, счётчик символов с флаг-байтами. Тогда, если число символов в кадре соответствует кодировке границы кадра, кадр считается
переданным правильно.
1.3
Контроль ошибок
Решив проблему разбиения на кадры, мы приходим к следующей проблеме: как обеспечить, чтобы кадры, пройдя по физическому каналу с
помехами, попадали на сетевой уровень по назначению, в надлежащей
последовательности и в надлежащем виде?
Частичное решение этой проблемы осуществляется посредством
введения обратной связи между отправителем и получателем в виде
кадра подтверждения, а также специального кодирования, позволяющего обнаруживать или даже исправлять ошибки передачи конкретного кадра.
Если кадр-подтверждение несет положительную информацию, то
считается что переданные кадры прошли нормально, если там сообщение об ошибке, то переданные кадры надо передать заново.
Однако, возможны случаи когда из-за ошибок в канале кадр исчезнет целиком. В этом случае получатель не будет реагировать никак,
а отправитель будет сколь угодно долго ждать подтверждения. Для
решения этой проблемы на канальном уровне вводят таймеры. Когда
передаётся очередной кадр, то одновременно устанавливается таймер
на определённое время. Этого времени должно хватать на то, чтобы
получатель получил кадр, а отправитель получил подтверждение. Если отправитель не получит подтверждение раньше, чем истечёт время, установленное на таймере то он будет считать, что кадр потерян
и повторит его еще раз.
Однако, если кадр-подтверждение был утерян, то вполне возможно, что один и тот же кадр получатель получит дважды. Как быть?
Для решения этой проблемы каждому кадру присваивают порядковый номер. С помощью этого номера получатель может обнаружить
дубли.
8
Итак, таймеры, нумерация кадров, флаг-байты, кодирование и обратная связь — вот основные средства на канальном уровне, обеспечивающие надёжную доставку каждого кадра до сетевого уровня в единственном экземпляре. Но и с помощью этих средств невозможно достигнуть стопроцентной надёжности передачи.
1.4
Управление потоком
Другая важная проблема, которая решается на канальном уровне —
управление потоком. Вполне может случиться, что отправитель будет слать кадры столь часто, что получатель не будет успевать их
обрабатывать(например, если машина-отправитель более мощная или
загружена слабее, чем машина-получатель). Для борьбы с такими ситуациями вводят управления потоком. Это управление предполагает
обратную связь между отправителем и получателем, которая позволяет им урегулировать такие ситуации. Есть много схем управления
потоком и все они в основе своей имеют следующий сценарий: прежде, чем отправитель начнёт передачу, он спрашивает у получателя
сколько кадров тот может принять. Получатель сообщает ему определённое число кадров. Отправитель после того, как передаст это число
кадров, должен приостановить передачу и спросить получателя опять
как много кадров тот может принять и т.д.
2
2.1
Помехоустойчивое кодирование
Характеристики ошибок
Физическая среда, по которой передаются данные не может быть абсолютно надёжной. Более того, уровень шума бывает очень высоким,
например в беспроводных системах связи и телефонных системах.
Ошибки при передаче — это реальность, которую надо обязательно
учитывать.
В разных средах характер помех разный. Ошибки могут быть одиночные, а могут возникать группами, сразу по несколько. В результате
помех могут исчезать биты или наоборот — появляться лишние.
Основной характеристикой интенсивности помех в канале является параметр шума — p. Это число от 0 до 1, равное вероятности
инвертирования бита, при условии что, он был передан по каналу и
получен на другом конце.
Следующий параметр — p2 . Это вероятность того же события, но
при условии, что предыдущий бит также был инвертирован.
9
Этими двумя параметрами вполне можно ограничиться при построении теории. Но, в принципе, можно было бы учитывать аналогичные вероятности для исчезновения бита, а также ипользовать полную информацию о пространственной корреляции ошибок, — то есть
корреляции соседних ошибок, разделённых одним, двумя или более
битами.
У групповых ошибок есть свои плюсы и минусы. Плюсы заключаются в следующем. Пусть данные передаются блоками по 1000 бит, а
уровень ошибки 0,001 на бит. Если ошибки изолированные и независимые, то 63% (0.63 ≈ 1 − 0.9991000 ) блоков будут содержать ошибки.
Если же они возникают группами по 100 сразу, то ошибки будут содержать 1% (0.01 ≈ 1 − 0.99910 ) блоков.
Зато, если ошибки не группируются, то в каждом кадре они невелики, и есть возможность их исправить. Групповые ошибки портят
кадр безвозвратно. Требуется его повторная пересылка, но в некоторых системах это в принципе невозможно, — например, в телефонных системах, использующие цифровое кодирование, возникает эффект пропадания слов/слогов.
Для надёжной передачи кодов было предложено два основных метода.
Первый заключается в добавлении в передаваемый блок данных
нескольких “лишних” битов так, чтобы, анализируя полученный блок,
можно было бы сказать есть в переданном блоке ошибки или нет. Это,
так называемые, коды с обнаружением ошибок.
Второй — внести избыточность настолько, чтобы, анализируя полученные данные, можно не только замечать ошибки, но и указать, где
именно возникли искажения. Это коды исправляющие ошибки.
Такое деление условно. Более общий вариант — это коды обнаруживающие k ошибок и исправляющие l ошибок, где l < k.
2.2
* Элементы теории передачи информации
Информационным каналом называется пара зависимых случайных величин {ξin , ξout }, одна из них называется входом другая выходом канала. Если случайные величины дискретны и конечны, то есть имеют
конечные Ω:
Ωin = {x1 , . . . , xa }, Ωout = {y1 , . . . , yb },
то канал определяется матрицей условных вероятностей krij k, rij —
вероятность того, что на выходе будет значение yi при условии, что
на входе измерено значение xj .
10
Входная случайная величина определяется распределением
{p1 , . . . , pa } на Ωin , а распределение на выходе вычисляется по
формуле
qi =
a
X
rij pj
j=1
Объединённое распределение на Ωin × Ωout равно
Pij = rij pj
Информация I({ξin , ξout }), передаваемая через канал, есть взаимная информация входа и выхода:
I({ξin ξout }) = H(ξin ) + H(ξout ) − H({ξin, ξout }),
где
H(ξin ) =
a
X
H(ξout ) =
i=1
a
X
(1)
pi log2 pi
qi log2 qi
i=1
H({ξin , ξout }) =
X
Pij log2 Pij
i,j
Если случайные величины ξin и ξout независимы (то есть
Pij = qi pj ), то через канал {ξin , ξout } невозможно передавать информацию и I({ξin , ξout }) = 0 Понять суть формулы (1) можно из следующего соображения: энтропия случайной величины равна информации,
которую мы получаем при одном её измерении. H(ξin ) и H(ξout ) — информация, которая содержится по отдельности во входе и в выходе. Но
часть этой информации общая, её нам и нужно найти. H({ξin, ξout })
равна величине объединённой информации. В теории меры1 есть выражений аналогичное (1):
µ(A ∧ B) = µ(A) + µ(B) − µ(A ∨ B)
Входное распределение мы можем варьировать и получать различные значения I. Её максимум называется пропускной способностью
канала
C(krij k) = max I({ξin ξout })
(2)
pi
1 Идея
рассмотрения информации как меры на множестве ещё не до конца исчерпала себя — такой меры ещё не построено. Однако доказано, что с помощью
этой аналогии можно доказывать неравенства, например I({ξin ξout }) > 0.
11
C
1
0.8
0.6
0.4
0.2
0
p
0
0.1
0.2
0.3
0.4
0.5
Рис. 3: C(p) — Пропускная способность канала как функция вероятности инвертирования бита.
Эта функция есть решение задачи
Задача 1 Каково максимальное количество информации, которое
можно передать с одним битом по каналу {ξin , ξout }?
Итак, пропускная способность есть функция на множестве стохастических матриц2 .
Стандартный информационный канал это
Ωin = Ωout = {0, 1}
krij k =
1−p
p
p
1−p
(3)
То есть канал с бинарным алфавитом и вероятностью помехи p (p —
вероятность того, что бит будет случайно инвертирован). Его пропускная способность равна
C = 1 − H(p) = 1 + p log2 p + (1 − p) log2 (1 − p)
Она являтся решением задачи на максимум (2) для матрицы (3).
2 Матрица
называется стохастической, если все её элементы неотрицательны
и сумма элементов в каждом столбце равна единице.
12
Эта функция C(p) (рис. 3) определяет предел помехоустойчивого
кодирования — если мы хотим с абсолютной надёжностью передать по
каналу с пропускной способностью C сообщение длиной m, то минимальное количество бит, которое нам нужно будет передать n > m/C.
А точнее, всякое помехоустойчивое кодирование, обеспечивающее вероятность незамеченной ошибки в переданном слове меньше, чем ε,
раздувает данные в kε (m, p) раз и
lim lim kε (m, p) > 1/C(p)
ε→0 m→∞
Кодирование, при котором в этом пределе достигается равенство, называется эффективным. Отметим, что абсолютно надёжного способа
передачи конечного количества данных по каналу с помехами не существует: то есть k0 (m, p) = ∞.
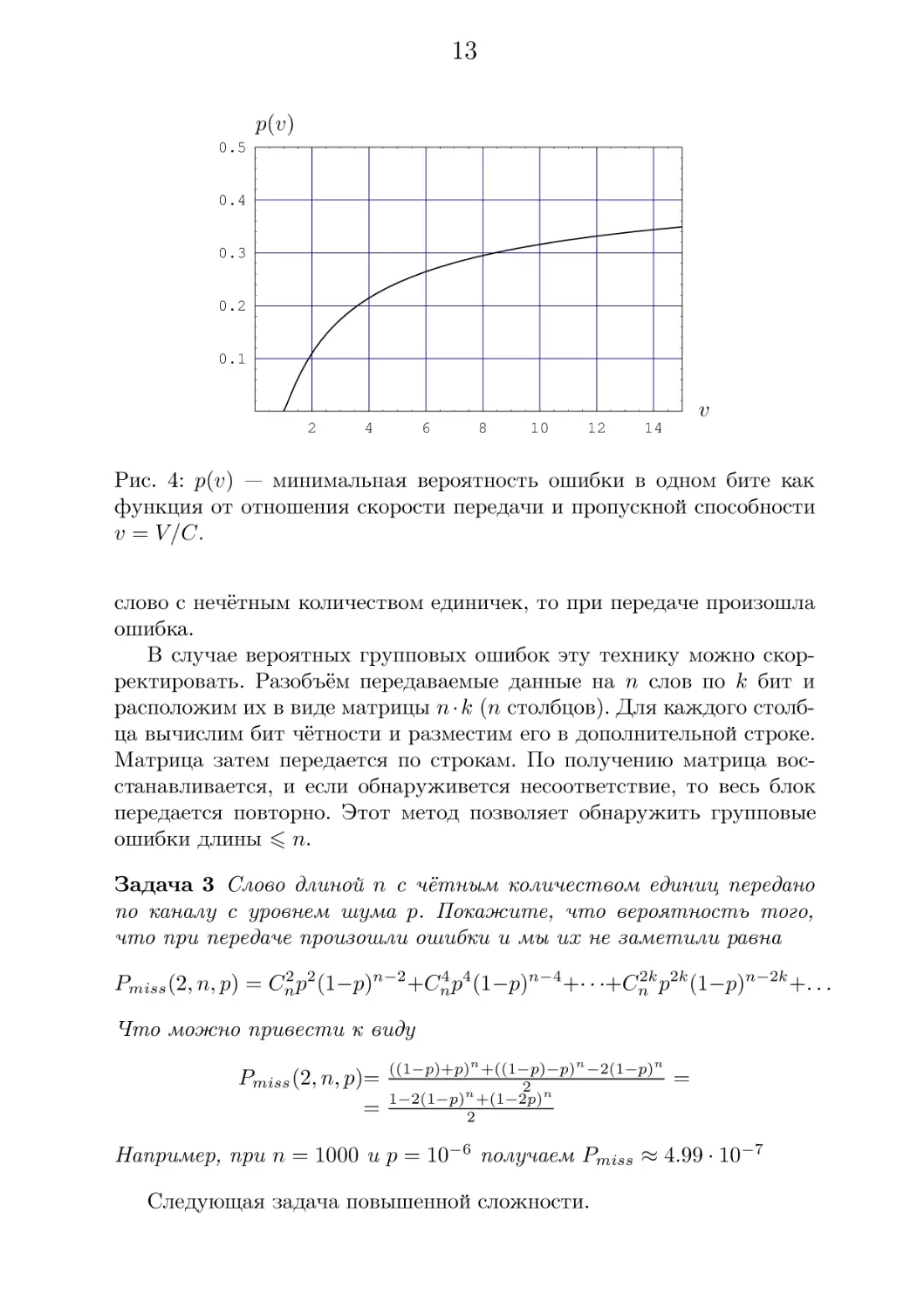
Задача дуальная 1 формулируется следующим образом
Задача 2 Мы хотим передавать информацию со скоростью V по
каналу с пропускной способностью C. Какова минимальная вероятность ошибочной передачи одного бита?
Решением будет функция заданная неявно
C/V = 1 + p log2 p + (1 − p) log2 (1 − p), если V /C > 1
p(V /C) = 0, если V /C 6 1
Оказывается, вероятность ошибки растет не так уж и быстро. Например, если по каналу передавать данных в два раза больше, чем
его пропускная способность, то лишь 11 бит из ста будут переданы с
ошибкой.
Построение конкретных способов кодирования, приближающихся по
пропускной способности к теоретической границе — сложная математическая задача.
2.3
Метод “чётности” и общая идея
Простым примером кода с обнаружением одной ошибки является код
с битом чётности. Конструкция его такова: к исходному слову добавляется бит чётности. Если в исходном слове число единичек чётно, то
значение этого бита 0, если нечётно — 1. Таким образом допустимые
слова этого кода имеют чётное количество единичек. Если получено
13
p(v)
0.5
0.4
0.3
0.2
0.1
v
2
4
6
8
10
12
14
Рис. 4: p(v) — минимальная вероятность ошибки в одном бите как
функция от отношения скорости передачи и пропускной способности
v = V /C.
слово с нечётным количеством единичек, то при передаче произошла
ошибка.
В случае вероятных групповых ошибок эту технику можно скорректировать. Разобъём передаваемые данные на n слов по k бит и
расположим их в виде матрицы n · k (n столбцов). Для каждого столбца вычислим бит чётности и разместим его в дополнительной строке.
Матрица затем передается по строкам. По получению матрица восстанавливается, и если обнаруживется несоответствие, то весь блок
передается повторно. Этот метод позволяет обнаружить групповые
ошибки длины 6 n.
Задача 3 Слово длиной n с чётным количеством единиц передано
по каналу с уровнем шума p. Покажите, что вероятность того,
что при передаче произошли ошибки и мы их не заметили равна
Pmiss (2, n, p) = Cn2 p2 (1−p)n−2 +Cn4 p4 (1−p)n−4 +· · ·+Cn2k p2k (1−p)n−2k +. . .
Что можно привести к виду
Pmiss (2, n, p)=
=
((1−p)+p)n +((1−p)−p)n −2(1−p)n
2
1−2(1−p)n +(1−2p)n
2
=
Например, при n = 1000 и p = 10−6 получаем Pmiss ≈ 4.99 · 10−7
Следующая задача повышенной сложности.
14
Задача 4 (*) Пусть у нас есть возможность контролировать
сумму единичек по модулю d. Тогда вероятность нефиксируемых
ошибок в слове длиной n при передаче его по каналу с шумом p равна
Pmiss (d, n, p):
n
Pmiss (2, n, p)= 1+(1−2p) 2−2(1−p)
Pmiss (3, n, p)=
1+(1−p+e
n
2π i
− 2π i
3 p)n +(1−p+e
3 p)n −3(1−p)n
3
2π
3π
π
1+(1−p+e 2 i p)n +(1−p+e 2 i p)n +(1−p+e 2 i p)n −4(1−p)n
Pmiss (4, n, p)=
n 4
p
)−4(1−p)n
1+(1−2p)n +2((1−p)2 +p2 ) 2 cos(n arctan (1−p)
=
4
=
Примечание Интерес здесь представляет неявно заданная функция n(d, Pmiss , p), а точнее даже коэффициент содержания полез2d
в переданных n бит как
ной информации КПС(n, Pmiss , p) = n−log
n
функция от величины шума и вероятности незамеченных ошибок.
Чем выше желаемая надёжность передачи, то есть чем меньше
вероятность Pmiss , тем меньше коэффициент содержания полезной
информации.
Итак, с помощью одного бита чётности мы повышаем надёжность
передачи, и вероятность незамеченной ошибки равна Pmiss (2, n, p).
Это вероятность уменьшается с уменьшением n. При n = 2 получаем
Pmiss (2, 2, p) = p2 , это соответствует дублированию каждого бита. Рассмотрим общую идею того, как с помощью специального кодирования
можно добиться сколь угодно высокой надёжности передачи.
Общая идея На множестве слов длины n определена метрика
Хемминга: расстояние Хемминга между двумя словами равно количеству несовпадающих бит. Например
ρH (10001001, 10110001) = 3.
Задача 5 Докажите, что ρH метрика.
Если два слова находятся на расстоянии r по Хеммингу, это значит,
что надо инвертировать ровно r разрядов, чтобы преобразовать одно
слово в другое. В описанном ниже кодировании Хемминга любые два
различных допустимых слова находятся на расстоянии ρH > 3. Если
мы хотим обнаруживать d ошибок, то надо, чтобы слова отстояли
друг от друга на расстояние > d + 1. Если мы хотим исправлять
ошибки, то надо чтобы кодослова отстояли друг от друга на > 2d + 1.
Действительно, даже если переданное слово содержит d ошибок,
оно, как следует из неравенства треугольника, все равно ближе к
правильному слову, чем к какому-либо еще, и следовательно можно
15
определить, исходное слово. Минимальное расстояние Хемминга
между двумя различными допустимыми кодовыми словами называется расстоянием Хемминга данного кода. Элементарный пример
помехоустойчивого кода — это код, у которого есть только четыре
допустимых кодовых слова:
0000000000, 0000011111, 1111100000, 1111111111.
Расстояние по Хеммингу у этого кода 5, следовательно он может
исправлять двойные ошибки и замечать 4 ошибки. Если получатель
получит слово 0000000111, то ясно, что исходное слово имело вид
0000011111. Коэффициент раздувания равен 5. То есть исходное слово
длины m будет кодироваться в слово длины n = 5m
Отметим что имеет смысл говорить о двух коэффициентах:
КПС(n) = m(n)
— коэффициент содержания полезной информации
n
n(m)
k(m) = m — коэффициент раздувания информации
Первый есть функция от переменной n, а второй, обратный ему, — от
переменной m.
Здесь мы подошли к довольно трудной задаче — минимизировать
коэффициент раздувания для требуемой надёжности передачи. Она
рассматривается в 2.5.
2.4
Циклические коды
На практике активно применяются полиномиальные коды или циклические избыточные коды (Cyclic Redundancy Code — CRC).
CRC коды построены на рассмотрении битовой строки как строки
коэффициентов полинома. k-битовая строка соответствует полиному
степени k − 1. Самый левый бит строки — коэффициент при старшей
степени. Например, строка 110001 представляет полином x5 + x4 +
x0 . Коэффициенты полинома принадлежат полю GF(2) вычетов по
модулю 2.
Отправитель и получатель заранее договариваются о конкретном
полиноме-генераторе G(x). Пусть степень G(x) равна l. Тогда длина
блока конторольной суммы также равна l. Идея состоит в том, чтобы
добавить контрольную сумму к передаваемому блоку так, чтобы получился полином кратный генератору G(x). Когда получатель получает
блок с контрольной суммой, он проверяет его делимость на G. Если
есть остаток 6= 0, то были ошибки при передаче.
Алгоритм вычисления контрольной суммы:
Дано слово W длины m. Ему соответствует полином W (x)
16
1. Добавить к исходному слову W справа r нулей. Получиться
слово длины n = m + r и полином
xr · W (x);
2. Разделить полином xr · W (x) на G(x) и вычислить остаток от
деления R(x)
xr W (x) = G(x)Q(x) + R(x);
3. Вычесть остаток (вычитание в F2 то же самое, что и сложение) из полинома xr · W (x)
T (x) = xr W (x) − R(x) = xr W (x) + R(x) = G(x)Q(x).
Соответствующее получившемуся полиному T (x) слово и есть
результат.
Рис. 5 иллюстрирует этот алгоритм для блока 1101011011 и
G(x) = x4 + x + 1.
Этот метод позволяет отлавливать одиночные ошибки и групповые
ошибки длины не более степени полинома.
Существует три международных стандарта на вид G(x):
• CRC − 12 = x12 + x11 + x3 + x2 + x + 1
• CRC − 16 = x16 + x15 + x2 + 1
• CRC − CCIT T = x16 + x12 + x5 + 1
CRC − 12 используется для передачи символов из 6 разрядов. Два
остальных — для 8 разрядных. CRC − 16 и CRC − CCIT T ловят
одиночные, двойные ошибки, групповые ошибки длины не более 16 и
нечётное число изолированных ошибок с вероятностью 0.99997.
2.5
* Теоретический предел
В примечании к задаче 4 было указано
ние коэффициента содержания полезной
бит, если передавать данные по каналу
n бит, при условии, чтобы вероятность
меньше Pmiss .
как можно получить значеинформации (КПС) на один
с шумом p словами длиной
незамеченной ошибки была
17
Слово
G(x)
Результат
:
:
:
1101011011
10011
11010110111110
1 1 0 0 0 0 1 0 1 0
10011
1 1 0 1 0 1 1 0 1 1 0 0 0 0
1 0 0 1 1
1 0 0 1 1
1 0 0 1 1
0 0 0 0 1
0 0 0 0 0
0 0 0 1 0
0 0 0 0 0
0 0 1 0 1
0 0 0 0 0
0 1 0 1 1
0 0 0 0 0
1 0 1 1 0
1 0 0 1 1
0 1 0 1 0
0 0 0 0 0
1 0 1 0 0
1 0 0 1 1
0 1 1 1 0
0 0 0 0 0
1 1 1 0
Остаток
Рис. 5: CRC — полиномиальное кодирование
Но ясно, что указанная там функция дает лишь оценку снизу оптимального значения КПС — возможно, существует другие методы
контролирования ошибок, для которых он выше. Теория информации
позволяет нам найти точное значение этого коэффициента.
Сформулируем задачу о кодировании, обнаруживающем ошибки.
Для начала предположим, что наличие ошибки фиксируется с абсолютной точностью.
18
Задача 6 Мы хотим передавать информацию блоками, которые содержали бы m бит полезной информации, так, чтобы вероятность
ошибки в одном бите равнялась p, а правильность передачи “фиксировалось контрольной суммой”. Найти минимальный размер блока
n(m, p) и коэффициент раздувания k = n(m)
m .
Решение Для передачи m бит с вероятностью ошибки в отдельном
бите p требуется передать mC(p) бит (см. задачу 2). Кроме того мы
хотим сообщать об ошибке в передаче. Её вероятность равна (1 − p)m ,
а значит информация, заложенная в этом сообщении, H((1 − p)m ). В
итоге получаем n = mC(p) + H((1 − p)m ) и
H((1 − p)m )
k(m, p) = C(p) +
.
m
Заметим, что k(1, p) = 1 — когда блок имеет размер один бит, сообщение об ошибке в нём равносильно передаче самого бита.
Если передавать эти сообщения по каналу с уровнем помех p, то
количество бит на одно сообщение равно mk(m, p)/C(p), то есть теоретическая оценка для количества лишних бит равна
H((1 − p)m )
C(p)
Понятно, что данная теоретическая оценка занижена.
2.6
Коды Хемминга
Элементарный пример кода исправляющего ошибки был показан на
странице 15. Его обобщение очевидно. Для подобного кода, обнаруживающего одну ошибку, КПС равен 13 . Оказывается это число можно
сделать сколь угодно близким к единице с помощью кодов Хемминга.
В частности, при кодировании 11 бит получается слово длинной 15
11
.
бит, то есть КПС = 15
Оценим минимальное количество контрольных разрядов, необходимое для исправления одиночных ошибок. Пусть содержательная
часть составляет m бит, и мы добавляем ещё r контрольных. Каждое из 2m правильных сообщений имеет n = m + r его неправильных
вариантов с ошибкой в одном бите. Такими образом, с каждым из
2m сообщений связано множество из n + 1 слов и эти множества не
должны пересекаться. Так как общее число слов 2n , то
(n + 1)2m 6 2n
(m + r + 1) 6 2r .
19
Этот теоретический предел достижим при использовании метода,
предложенного Хеммингом. Идея его в следующем: все биты, номера
которых есть степень 2, — контрольные, остальные — биты сообщения. Каждый контрольный бит отвечает за чётность суммы некоторой
группы бит. Один и тот же бит может относиться к разным группам.
Чтобы определить какие контрольные биты контролируют бит в позиции k надо разложить k по степеням двойки: если k = 11 = 8+2+1, то
этот бит относится к трём группам — к группе, чья чётность подсчитывается в 1-ом бите, к группе 2-ого и к группе 8-ого бита. Другими
словами в контрольный бит с номером 2k заносится сумма (по модулю 2) бит с номерами, которые имеют в разложении по степеням
двойки степень 2k :
b1
b2
b4
b8
= b3 + b5 + b7 + . . .
= b3 + b6 + b7 + b10 + b11 + b14 + b15 . . .
= b5 + b6 + b7 + b12 + b13 + b14 + b15 . . .
= b9 + b10 + b11 + b12 + b13 + b14 + b15 . . .
(4)
Код Хемминга оптимален при n = 2r − 1 и m = n − r. В общем
случае m = n − [log2 (n + 1)], где [x] — ближайшее целое число 6 x.
Код Хемминга мы будем обозначать Hem(n, m) (хотя n однозначно
определяет m).
Пример для Hem(15, 11):
10110100111 → 0 0 1 1 011 0 0100111
b1 b2 b3b4
b8 b9
b15
Получив слово, получатель проверяет каждый контрольный бит
на предмет правильности чётности и складывая номера контрольных
бит, в которых нарушена чётность. Полученное число, есть XOR номеров бит, где произошла ошибка. Если ошибка одна, то это число
есть просто номер ошибочного бита.
Например, если в контрольных разрядах 1, 2, 8 обнаружено несовпадение чётности, то ошибка в 11 разряде, так как только он связан
одновременно с этими тремя контрольными разрядами.
Задача 7 Покажите, что КПСHem(n,m) → 1 при n → ∞.
Код Хемминга может исправлять только единичные ошибки. Однако, есть приём, который позволяет распространить этот код на случай групповых ошибок. Пусть нам надо передать k кодослов. Расположим их в виде матрицы одно слово — строка. Обычно, передают
20
Char.
H
a
m
m
i
n
g
c
o
d
e
ASCII
Контрольные биты
1001000
00110010000
1100001
10111001001
1101101
11101010101
1101101
11101010101
1101001
01101011001
1101110
01101010110
1100111
11111001111
0100000
10011000000
1100011
11111000011
1101111
00101011111
1100100
11111001100
1100101
00111000101
Order of bit transmission
Рис. 6: Кодирование Хемминга
слово за словом. Но мы поступим иначе, передадим слово длины k, из
1-ых разрядов всех слов, затем — вторых и т.д. По приёме всех слов
матрица восстанавливается. Если мы хотим обнаруживать групповые
ошибки размера k, то в каждой строке восстановленной матрицы будет не более одной ошибки. А с одиночными ошибками код Хемминга
справиться.
2.7
Анализ эффективности
Начнём c небольшого примера. Пусть у нас есть канал с уровнем ошибок p = 10−6 . Если мы хотим исправлять единичные ошибки при передаче блоками по 1023 = 210 − 1 бит, то среди них потребуется 10 контрольных бит: 1, 2, . . . , 29 . На один блок приходится 1013 бит полезной
информации. При передаче 1000 таких блоков потребуется ∆ = 10 000
контрольных бит.
В тоже время для обнаружения единичной ошибки достаточно одного бита чётности. И если мы применим технику повторной передачи,
то на передачу 1000 блоков надо будет потратить 1000 бит дополнительно и примерно 0.001 ≈ p1014 = 1 − (1 − 10−6 )1014 из них придется
пересылать повторно. То есть на 1000 блоков приходится один попорченый, и дополнительная нагрузка линии составляет ∆ ≈ 1000 + 1001,
что меньше 10 000. Но это не значит, что код Хемминга плох для такого канала. Надо правильно выбрать длину блока — если n > 3444,
21
то код Хемминга эффективен.
Рассмотрим этот вопрос подробнее. Пусть нам нужно передать информацию M бит. Разобьем её на L блоков по m = M/L бит и будем
передавать двумя способами — с помощью кодов Хемминга и без них.
При этом будем считать, что в обоих случаях осуществлено предварительное кодирование, позволяющее с вероятностью 1 − ε определять ошибочность передачи. Это осуществляется путем добавления
“лишней” информации. Обозначим коэффициент раздувания для этого кодирования kε (m). После этого кодирования каждый блок несёт
информацию m′ = kε (m)m
1) Без кода Хемминга.
Если пересылать информацию блоками по m′ бит с повторной пересылкой в случае обнаружения ошибки, то получим, что в среднем нам
придётся переслать D бит:
D = Lm′
1
1 − Pr
′
Где Pr = (1 − (1 − p)m )(1 − ε) — вероятность повторной передачи
равная вероятности ошибки умноженной на вероятность того, что мы
её заметим. Коэффициент раздувания равен
k(m, p, ε) =
kε (m)
D
=
M
ε + (1 − ε)(1 − p)kε (m)m
2) С кодом Хемминга.
При кодировании методом Хемминга слова длины m′ получается слово
длины n бит:
′
2n = 2m (n + 1), то есть
(5)
kε (m)m = n − log2 (n + 1)
Для отдельного блока вероятность безошибочной передачи равна
P0 = (1 − p)n . Вероятность одинарной ошибки P1 = np1 (1 − p)n−1 . Вероятность того, что произошло более чем одна ошибка, и мы это заметили
Pr = (1 − P0 − P1 )(1 − ε) = 1 − ε − (1 − ε)(1 − p)n−1 (np + 1 − p)
— в этом случае требуется повторная передача кадра. Количество передаваемых данных:
DH = Ln
1
Ln
=
1 − Pr
ε + (1 − ε)(1 − p)n−1 (np + 1 − p)
22
И коэффициент раздувания
kH (m, p, ε) =
n
,
m ε + (1 − ε)(1 − p)n−1 (np + 1 − p)
где n(m) неявно определённая с помощью (5) функция. Удобно записать соответствующие коэффициенты полезного содержания:
КПС = КПСε n ε + (1 − ε)(1 − p)n
′
КПСH = КПСε m′ mn ε + (1 − p)n−1 (np + 1 − p)(1 − ε) ,
где m′ = n − log2 (n + 1).
(6)
Легко обнаружить что при n > 3444 и p = 10−6 код Хемминга
оказывается эффективнее, то есть КПСH /КПС > 1
кпс
кпс
1
1
0.99
0.99
0.98
0.98
0.97
0.96
0.97
0.95
0.94
2000
4000
6000
8000
n
n
20000 40000 60000 80000 100000 120000
Рис. 7: КПС(n, p, ε) — Коэффициент полезного содержания в канале
с помехами как функция размера элементарного блока.
Светлый график — без кодирования Хемминга;
Темный график — с кодированием Хемминга;
Параметры: ε = 10−6 ; p = 10−6 .
Значение КПСε (n) используемое в формулах (6) можно оценить
как
log2 (1 − ε(2n − 1))
КПСε (n) =
n
Напомним, что ε есть параметр желаемой надёжности передачи — чем меньше ε, тем надёжнее передача. По определению ε =
23
C
1
0.8
0.6
0.4
0.2
0
p
0.02
0.04
0.06
0.08
0.1
Рис. 8: C(p, ε) — максимальный коэффициент полезного содержания
в канале с помехами как функция уровня помех.
Светлый график — без кодирования Хемминга;
Темный график — с кодированием Хемминга;
Тонкий график — теоретический предел, задаваемый функцией C(p)
Параметры: ε = 10−6 .
Pmiss /(1 − P0 ) — вероятности ошибочной передачи блока при условии,
что “контрольная сумма сошлась” и кадр засчитан правильно переданным. Такое выражение для КПСε (p, n) = m
n получается из формулы
2m − 1
ε= n
2 −1
Но это безусловно лишь оценочная формула. Оптимальное значение КПСε значительно сложнее и зависит от p.
Из графика на рисунке 7 хорошо видно, что при больших n код
Хемминга начинает работать на пользу.
Но зависимость КПС от n не есть критерий эффективности кода.
Эффективность кода определяется функцией
C(p, ε) = min KПС(p, n, ε)
n
На рисунке 8 показан график этой функции и из него ясно, что
код Хемминга можно использовать с пользой всегда — при любых ε и
p, если у нас есть возможность выбирать подходящее n.
24
2.8
Коды как линейные операторы
То, что на множестве {0,1} есть структура числового поля, позволяет
осуществлять алгебраические интерпретации кодирования. Заметим,
в частности, что как коды Хемминга, так и циклические коды линейны:
1) отношения (4) на с. 19, связывающие контрольные биты кода Хемминга с другими линейны,
2) остаток от деления суммы многочленов на третий равен сумме
остатков.
То есть кодирование в этих двух случаях есть линейное отображение из GF(2)m в GF(2)n . Поясним на примерах. Ниже
представлена матрица кода Хемминга Hem(7, 4) (см. соотношения (4)). Исходное слово есть win = b3 b5 b6 b7 , а результирующее
wout = b1 b2 b3 b4 b5 b6 b7 = AHem(7,4) win (слова мы будем воспринимать
как столбцы).
AHem(7,4)
1
1
1
= 0
0
0
0
1
0
0
1
1
0
0
0
1
0
1
0
1
0
1
1
0
1
1
0
1
Процесс выявления ошибок тоже линейная операция, она осуществляется с помощью проверочной матрицы H. Пусть принято слово
w′ out . Слово s = s1 s2 s3 = Hw′ out в случае правильное передачи wout
должно быть равно 000. Значение s называется синдромом ошибки.
i-ый разряд слова s контролирует i-ое соотношение в (4) и, таким образом, s равно сумме номеров бит в которых произошла ошибка, как
векторов в GF(2)3 .
HHem(7,4)
1
= 0
0
0 1
1 1
0 0
0 1
0 0
1 1
0 1
1 1
1 1
Заметим, что столбцы проверочной матрицы представляют собой последовательно записанные в двоичной форме натуральные числа от 1
до 7.
Вычиcление рабочей матрицы для циклических кодов основывается на значениях Gn (x) = xn mod G(x). Верхняя её часть равна
единичной, так m бит сообщения помещаются без изменения в начало слова, а нижние r строчек есть m столбцов высоты r состоящие
25
из коэффициентов многочленов Gn , Gn−1 , . . . , Gn−r . Например, для
G(x) = x3 + x + 1 и m = 4 имеем r = 3, n = 7 и
G0 G1 G2
G3
1
2
1
x
x
x+1
001 010 100 011
G4
G5
2
x +x x +x+1
110
111
2
G6
x +1
101
2
G7
1
001
Рабочая и проверочная матрицы равны
A=
E4
G6 G5 G4 G3
и H = kG6 G5 G4 G3 E3 k
то есть
1
0
0
A= 0
1
0
1
0
1
0
0
1
1
1
0
0
1
0
1
1
0
0
0
0
1
0
1
1
1
H= 0
1
1 1
1 1
1 0
0 1
1 0
1 0
0
1
0
0
0
1
Кроме рабочей и проверочной матриц есть ещё множество порождающих матриц G и декодирующих матриц D. Понятно, что в
случае линейных кодов допустимые слова образуют линейное подпространство L ⊂ GF(2)n равное Im(A). Любая матрица, столбцы которой образуют базис этого подпространства, называется порождающей. В частности, рабочая матрица является порождающей. Способность обнаруживать и исправлять ошибки однозначно определяется
подпространством L. Порождающих, рабочих и проверочных матриц
соответствующих L несколько.
Действительно, в порождающей и рабочей матрицах можно осуществлять элементарные операции со столбцами, а в проверочной —
со строчками. Матрицы A, H и G всегда удовлетворяют отношениям
H · A = 0rm , H · G = 0rm ,
где 0rm — нулевая матрица r × m.
Любая порождающая матрица может использоваться как рабочая.
Декодирующая матрица D должна декодировать: win = D · wout .
Матриц с таким свойством может быть несколько. Множество декодирующих матриц определяется рабочей матрицей:
D · A = Em ,
26
где Em — единичная матрица m×m. На подпространстве L все декодирующие матрицы действуют одинаково. Они отличаются на подпространстве ортогональном L. Приведём декодирующую матрицу для
Hem(7, 4) и CRCn=7, m=7 :
DH7,4
0
0
=
0
0
0
0
0
0
1
0
0
0
0
0
0
0
0
1
0
0
0
0
1
0
0
0
0
1
DC7,4
1
0
=
0
0
0
1
0
0
0
0
1
0
0
0
0
1
0
0
0
0
0
0
0
0
0
0
0
0
К каждой строчке декодирующей матрицы можно добавить любую
линейную комбинацию строчек из проверочной матрицы. Следует отметить, что процесс исправления ошибок для кодов Хемминга нелинеен и его нельзя “внедрить” в декодирующую матрицу.
Сформулируем теперь основные моменты, касающиеся линейных
кодов.
1. Процесс кодирования и декодирования — линейные операторы.
′
′
′
wout = Awin , канал : wout 7→ wout
, win
= Dwout
2. Обнаружение ошибок равносильно проверке принадлежности
полученного слова подпространству L допустимых слов. Для
этого необходимо найти проекцию s (синдром ошибки) полученного слова на L⊥ — тоже линейная операция. Для правильно
переданного слова s = 0.
′
s = Hwout
3. В случае, когда векторы подпространства L достаточно удалены
друг от друга в смысле метрики Хемминга, есть возможность обнаруживать и исправлять некоторые ошибки. В частности, значение синдрома ошибки в случае кода Хемминга равно векторной
сумме номеров бит, где произошла ошибка.
4. Комбинация (композиция) линейных кодов есть снова линейный
код.
Практические методы помехоустойчивого кодирования все основаны на линейных кодах. В основном это модифицированные CRC, коды Хемминга и их композиции. Например Hem(7, 4) плюс проверка на
чётность. Такой код может исправлять уже две ошибки. Построение
эффективных и удобных на практике задача сходная с творчеством
27
художника. На практике важны не только корректирующая способность кода, но и вычислительная сложность процессов кодирования и
декодирования, а также спектральная характеристика результирующего аналогового сигнала. Кроме того, важна способность исправлять
специфические для данного физического уровня групповые ошибки.
Задача 8 Для данной проверочной матрицы постройте рабочую и
декодирующую матрицу. Докажите, что кодовое расстояние равно
4.
1 0 1 0 1 0 1 0
0 1 1 0 0 1 1 0
H=
0 0 0 1 1 1 1 0
1 1 1 1 1 1 1 1
Подсказка
1) Это проверочная матрица Hem(7, 4) плюс условие на чётность
числа единичек в закодированном слове вместе с дополнительным
восьмым контрольным битом.
2) Кодовое расстояние равно минимальному количеству линейно зависимых столбцов в H.
Задача 9 Посторойте декодирующую и проверочную матрицу для
циклического кода с G(x) = x3 + x + 1 и m = 4 при условии, что в
качестве рабочей матрицы использовалась матрица
0
0
0
A= 1
0
1
1
2.9
0
0
1
0
1
1
0
0
1
0
1
1
0
0
1
0
1
1 .
0
0
0
*Коды Рида-Соломона
После перехода на язык линейной алгебры естественно возникает желание изучить свойства линейных кодов над другими конечными числовыми полями. С помощью такого обобщения появились коды РидаСоломона.
Коды Рида-Соломона являются циклическими кодами над числовым полем отличным от GF(2).
Напомним, что существует бесконечное количество конечных полей, и количество элементов в конечном поле всегда равно степени
28
простого числа. Если мы зафиксируем число элементов n = qk , то найдётся единственное с точностью до изоморфности конечное поле с таким числом элементов, которое обозначается как GF(n). Простейшая
реализация этого поля — множество многочленов по модулю неприводимого3 многочлена p(x) степени k над полем Fq вычетов по модулю q.
В случае многочленов с действительными коэффициентами неприводимыми многочленами являются только квадратные многочлены с
отрицательным дискриминантом. Поэтому существует только квадратичное расширение действительного поля — комплексные числа. А
над конечным полем существуют неприводимые многочлены любой
степени. В частности, над F2 многочлен g(z) = z 3 + z + 1 неприводим
и множество многочленов по модулю g(z) образуют поле из 23 = 8
элементов.
3
Примеры протоколов канала данных
3.1
HDLC протокол
Здесь мы познакомимся с группой протоколов давно известных, но
по-прежнему широко используемых. Все они имеют одного предшественника – SDLC (Synchronous Data Link Control) – протокол управления синхронным каналом, предложенным фирмой IBM в рамках
SN A. ISO модифицировала этот протокол и выпустила под названием HDLC — High level Data Link Control. M KT T модифицировала
HDLC для X.25 и выпустила под именем LAP – Link Access Procedure.
Позднее он был модифицирован в LAP B.
Все эти протоколы построены на одних и тех же принципах. Все
используют технику вставки специальных последовательностей битов.
Различия между ними незначительные.
Bits
8
8
8
>0
16
8
01111110
Address
Control
Data
Checksum
01111110
Рис. 9: Типовая структура кадра
3 Многочлен
называется неприводимым, если он не разлагается в произведение
многочленов меньшей степени.
29
На рис. 9 показана типовая структура кадра. Поле адреса используется для адресации терминала, если их несколько на линии. Для
линий точка-точка это поле используется для различия команды от
ответа.
• Поле Control используется для последовательных номеров кадров, подтверждений и других нужд.
• Поле Data может быть сколь угодно большим и используется для
передачи данных. Надо только иметь ввиду, что чем оно длиннее
тем, больше вероятность повреждения кадра на линии.
• Поле Checksum — это поле используется CRC кодом.
Флаговые последовательности 01111110 используются для разделения кадров и постоянно передаются по незанятой линии в ожидании кадра. Существуют три вида кадров: Inf ormation, Supervisory,
U nnumbered.
Организация поля Control для этих трех видов кадров показана
на рис. 10. Как видно из размера поля Seq в окне отправителя может
быть до 7 неподтверждённых кадров. Поле N ext используется для посылки подтверждения вместе с передаваемым кадром. Подтверждение
может быть в форме номера последнего правильно переданного кадра,
а может быть в форме первого не переданного кадра. Какой вариант
будет использован — это параметр.
Bits
1
3
1
3
(а)
0
Seq
P/F
Next
(б)
1
0
Type
P/F
Next
(в)
1
1
Type
P/F
Modifier
Рис. 10: Cтруктура поля Control
(а) Информационный кадр (Inf ormation)
(б) Управляющий кадр (Supervisory)
(в) Ненумерованный кадр (U nnumbered)
30
Разряд P/F использует при работе с группой терминалов. Когда
компьютер приглашает терминал к передаче он устанавливает этот
разряд в P . Все кадры, посылаемые терминалами имеют здесь P . Если
это последний кадр, посылаемый терминалом, то здесь стоит F .
Supervisory кадры имеют четыре типа кадров.
• Тип 0 — уведомление в ожидании следующего кадра (RECEIVE
READY). Используется когда нет встречного трафика, чтобы передать уведомление в кадре с данными.
• Тип 1 — негативное уведомление (REJECT) — указывает на
ошибку при передаче. Поле N ext указывает номер кадра, начиная с которого надо перепослать кадры.
• Тип 2 — RECEIVE NOT READY. Подтверждает все кадры, кроме указанного в Next. Используется, чтобы сообщить источнику
кадров об необходимости приостановить передачу в силу какихто проблем у получателя. После устранения этих проблем получатель шлет RECEIVE REDAY, REJECT или другой надлежащий управляющий кадр.
• Тип 3 — SELECTIVE REJECT — указывает на необходимость
перепослать только кадр, указанный в Next. LAP B и SDLC не
используют этого типа кадров.
Третий класс кадров — U nnubered. Кадры этого класса иногда
используются для целей управления, но чаще для передачи данных
при ненадёжной передаче без соединения.
Все протоколы имеют команду DISConnect для указания о разрыве
соединения, SNRM и SABM — для установки счётчиков кадров в ноль,
сброса соединения в начальное состояние, установки соподчинённости
на линии. Команда FRMR — указывает на повреждение управляющего кадра.