/






























































































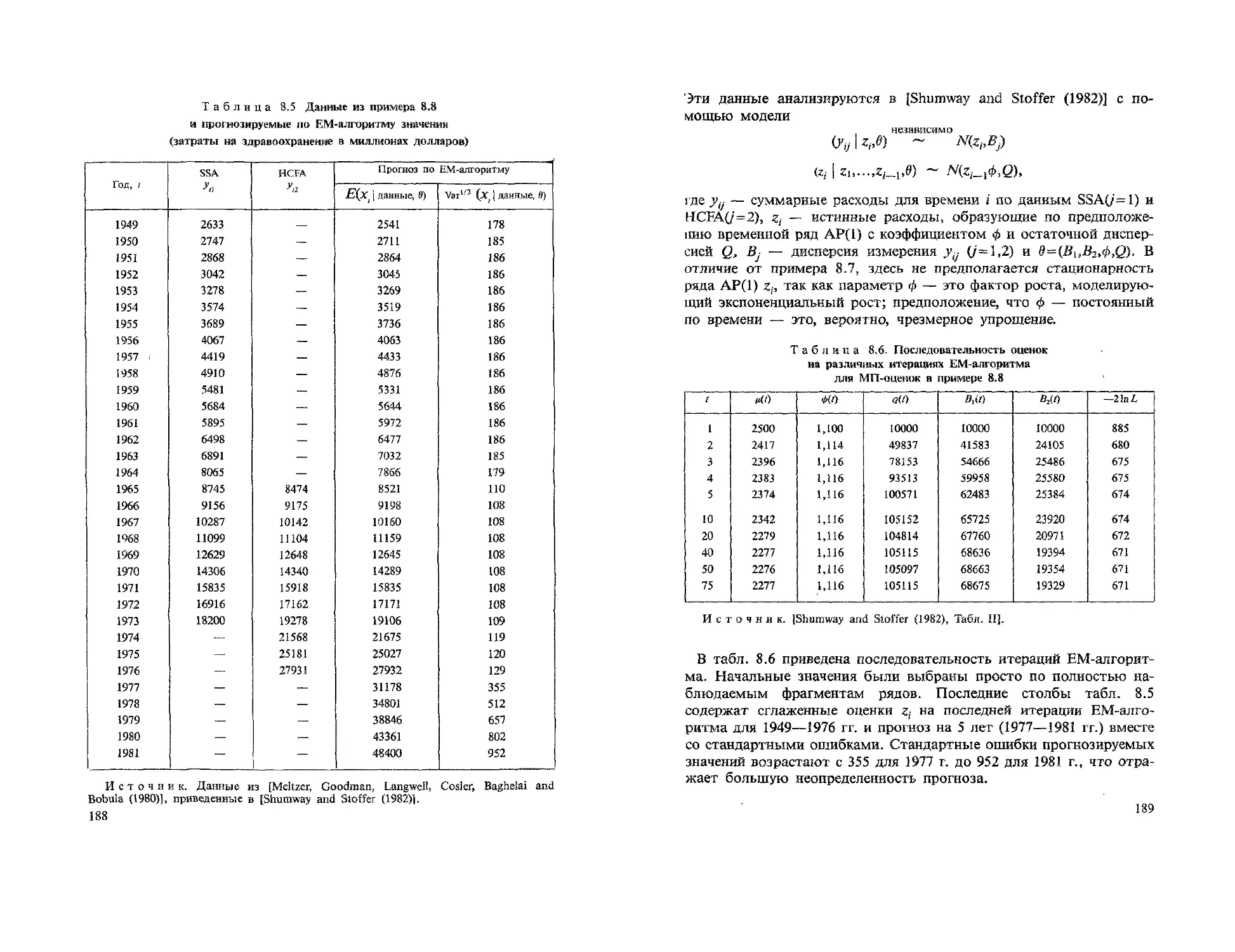














































































Текст
STATISTICAL ANALYSIS
WITH MISSING DATA
RODERICK J.A.LITTLE
University of California at Los Angelas
DONALD B.RUBIN
Harvard University
JOHN WILEY & SONS
New York- Chichester • Brisbane • Toronto • Singapore
РДж-АЛиттл
ДБ. Рубин
СТАТИСТИЧЕСКИЙ
АНАЛИЗ ДАННЫХ
С ПРОПУСКАМИ
Перевод с английского А.М. НИКИФОРОВА
Москва,’’Финансы и статистика’,’ 1991
ББК 16.2.9
Л 64
МАТЕМАТИКО-СТАТИСТИЧЕСКИЕ
МЕТОДЫ ЗА РУБЕЖОМ
Серия основана в 1977 юду
ВЫШЛИ ИЗ ПЕЧАТИ
1. Ли Ц., Джадж Д., Зельнер А.
Оценивание параметров марковских
моделей по агрегированным времен-
ным рядам.
2. Райфа Г., Ш л ейфер Р . При-
кладная теория статистических
решений.
3. К л е й н е и Дж. Статистические
методы в имитационном моделиро-
вании. Вып, 1 и 2.
4. Бард Й. Нелинейное оценивание
параметров.
5. Бол ч Б. У., X у а н ь К. Д. Мно-
гомерные статистические методы
для экономики.
6. И б е р л а К. Факторный анализ.
7. 3 е л ь н ер А. Байесовские методы
в эконометрии.
8. X е й с Д. Причинный анализ в ста-
тистических исследованиях.
9. П у а р ь е Д. Эконометрия струк-
турных измерений.
10. Д р а й м з Ф. Распределенные лаги.
11. Мостеллер Ф., Т ь ю к и Дж.
Анализ данных и регрессия. Вып. 1
и 2.
12. Бикел П., Доксам К. Матема-
тическая статистика. Вып. 1 и 2.
13. Л и м е р Э. Статистический анали$
неэкспериментальных данных.
14. П е с а р а н М., С л е й т е р Л. Ди-
намическая регрессия: теория и ал-
горитмы.
15. Дидэ Э. и др. Методы анализа
данных.
16. Бартоломью Д. Стохастиче-
ские модели социальных процессов.
17. Дрейпер Н., Смит Г. При-
кладной регрессионный анализ. Кн.
1 и 2.
18. Хетгманспергер Т. Стати-
стические выводы, основанные на
рангах.
19. Д э й в и с о н М. Многомерное
шкалирование. Методы наглядного
представления данных.
20. Жа мбю М. Иерархический кла-
стер-анализ и соответствия.
21. К о к с Д. Р., Оукс Д. Анализ
данных типа времени жизни.
22. Мэйн доналд Дж. Вычисли-
тельные алгоритмы в прикладной
статистике.
ГОТОВИТСЯ К ПЕЧАТИ
Миллер Р . Дисперсионный ана-
лиз и последующие методы. Основы
прикладной статистики.
Редколлегия: А. Г. Аганбегян. Ю. П.
Адлер, С. А. Айвазян, ЮН. Благо-
вещенский, Б. В. Гнеденко, Э. Б. Ер-
шов, Е. М. Четыркин
0702000000^126 f
010 (01) — 91
ISBN 0-471-80254-9 (США)
(с>1987 by John Wiley & Sons, Inc.
ISBN 5-279-00^43-X (СССР)
(c)A. M. Никифоров, перевод, предисло-
вие, дополнение, 1991
• ПРЕДИСЛОВИЕ К РУССКОМУ ИЗДАНИЮ
С проблемой обработки пропусков в данных приходится сталки-
ваться в самых разнообразных приложениях статистического анали-
за. Многие исследователи стремятся как можно быстрее избавиться
от пропусков с тем, чтобы впоследствии провести обработку «пол-
ных» данных стандартными средствами, мало задумываясь над
тем, что такой подход может приводить к сильному различию ста-
тистических выводов, сделанных при наличии в данных пропусков
и при их отсутствии. Самыми распространенными приемами анали-
за данных с пропусками являются исключение некомплектных на-
блюдений (т. е. содержащих пропуски хотя бы одной из
переменных) и традиционные методы заполнения пропусков —
средневыборочными по присутствующим значениям, с помощью
регрессии или главных компонент. Эти методы в общем случае
имеют малую эффективность, ведут, как правило, к смещенности и
несостоятельности, к нарушению уровней значимости критериев и
другим искажениям статистических выводов, не обладают устойчи-
востью к распределению пропусков. Эти свойства можно отнести и
к так называемым парным методам вычисления ковариационной
матрицы и вектора средних.
Достаточно низкий уровень культуры обработки пропусков нахо-
дит свое отражение в современном состоянии статистического про-
граммного обеспечения. Подавляющее большинство отечественных
и зарубежных статистических программных средств, в которых
предусмотрена возможность наличия пропусков в данных, содержит
лишь перечисленные выше простые методы или их модификации.
Вниманию читателя предлагается первая работа по статистиче-
скому анализу данных с пропусками, выходящая на русском языке.
Несмотря на несомненную актуальность, в нашей стране этой про-
блеме уделялось очень мало внимания, в то время как за рубежом
она изучалась активно и с нарастающим интересом на протяжении
последних 30 лет.
Книга известных американских специалистов Р. Дж. А. Литтла и
Д. Б. Рубина «Статистический анализ данных с пропусками» поды-
тоживает эти многолетние исследования по многим направлениям.
Она знакомит с историей зарубежных исследований по проблеме
5
пропусков, позволяет понять, почему применяемые средства обра-
ботки неполных данных приводят, как правило, к искаженным ста-
тистическим выводам, помогает освоить современные методы, не
обладающие этими недостатками. В книге содержится систематиче-
ское описание ЕМ-алгоритма — одного из самых популярных за ру-
бежом в настоящее время вычислительных статистических методов.
Авторы рассматривают и SWEEP-оператор для матричных опера-
ций, характерных для многомерного статистического анализа.
Основной предмет статистического исследования в книге
Р. Дж. А. Литтла и Д. Б. Рубина — выборка многомерных наблю-
дений с пропусками. Удобно представлять г-мерное наблюдение с
пропусками в виде пары (Х,М), где X — исходный r-мерный вектор
значений переменных, а М — r-мерный вектор пропусков, координа-
ты которого имеют значения «пропуск» либо «нет пропуска», отве-
чая присутствию или отсутствию соответствующей переменной.
Случайный вектор (Х,М) имеет распределение Р*". Проблема за-
ключается в построении по данным с пропусками статистических
выводов относительно распределения Р*' вектора X.
В книге охвачен широкий круг вопросов, касающихся распределе-
ния в том числе оценивания средних и ковариационной матри-
цы многомерного нормального распределения, дисперсионного,
регрессионного и факторного анализа, анализа таблиц сопряженнос-
ти и логлинейной модели, временных рядов, устойчивого оценива-
ния, анализа данных при неслучайных пропусках и т. п. Несколько
обособленно излагается теория выборочных обследований при на-
личии пропусков.
Подход, систематически используемый авторами, состоит в пост-
роении модели совместного распределения значений вектора X и
пропусков (т. е. распределения Р*-") и развитии алгоритмов оцени-
вания параметров распределения Р* на основе метода максималь-
ного правдоподобия. Наибольшее внимание уделено поиску
методов анализа в таких условиях, когда требуются минимальные
априорные сведения о распределении пропусков, т. е. когда распре-
деление пропусков можно игнорировать. Для параметрических по-
становок, характерных для книги Р. Дж. А. Литтла и Д. Б. Рубина,
таким условием является независимость пропусков от значения пе-
ременных, отсутствующих в наблюдении (условие ОС, см. гл. 5). В
задаче оценивания условию ОС соответствует обобщение метода
максимального правдоподобия на случай данных с игнорируемыми
пропусками (в дополнении к переводу это обобщение называется
методом максимального маргинального правдоподобия).
К настоящему времени достаточно хорошо разработаны методы
анализа данных с пропусками только для параметрических моделей,
причем лишь для задачи оценивания неизвестных параметров. Это
отразилось в содержании книги: по сути, основная часть ее посвя-
6
щена построению ЕМ-алгоритма для вычисления оценок макси-
мального маргинального правдоподобия в различных моделях. В
пополнении к переводу сделана попытка частично восполнить эти
пробелы. В частности, предлагаются непараметрические критерии
лтя проверки гипотез однородности двух и нескольких выборок и
независимости случайных величин при наличии пропусков; рассмот-
рена также задача дискриминантного анализа неполных данных.
Условия на распределение пропусков, требуемые при непарамет-
рических постановках, намного слабее, чем при соответствующих
параметрических. Иными словами, непараметрические методы, по-
строенные для неполных данных, оказываются устойчивыми к рас-
пределению пропусков или, точнее, к зависимости пропусков от
значений переменных в наблюдении. Так, например, слабыми явля-
ются условия, обеспечивающие применимость упомянутых критери-
ев однородности и независимости. Можно привести и другие
примеры подобной устойчивости, относящиеся к задачам непара-
метрического оценивания, классификации и т. д. В свою очередь,
метод исключения некомплектных наблюдений, методы заполнения
пропусков, парные методы требуют выполнения довольно жесткого
условия независимости пропусков от значения'всех переменных (ус-
ловия ОПС, см. гл. 5 книги).
В дополнении к переводу содержится также теоретическое под-
крепление описанных в книге методов оценивания, обсуждается
проверка гипотез относительно распределения пропусков и другие
вопросы. Для читателя представит интерес текст программы, в ко-
торой реализован ЕМ-алгоритм для многомерного нормального
распределения.
Современный статистический анализ опирается в большой степе-
ни на применение компьютеров. Книга Р. Дж. А. Литтла и Д. Б.
Рубина может служить хорошим практическим руководством для
специалистов, разрабатывающих статистическое программное обес-
печение. Она будет также полезна исследователям — прикладникам
и математикам, связанным с проблемой обработки данных с про-
пусками.
/
А. М. Никифоров
ПРЕДИСЛОВИЕ
В начале 70-х годов начался расцвет исследований по статистиче-
скому анализу данных с пропусками, последовавший за успехами в
развитии компьютерной техники, которая сделала доступными вы-
числения, очень трудоемкие ранее. Цель этой книги — описать со-
временные методы обработки данных с пропусками и представить
теорию анализа неполных данных, основанную на понятии правдо-
подобия, которая систематизирует эти методы и служит фундамен-
том для дальнейших разработок. В части I книги обсуждаются
предложенные ранее подходы к проблемам, касающимся данных с
пропусками, в трех важных областях статистики: дисперсионном
анализе планируемых экспериментов, выборочных обследованиях и
многомерном анализе. Хотя эти методы и представляют некоторый
интерес, они носят частный характер и предложены практическими
исследователями, неглубоко изучавшими их теоретические свойства.
В части II представлен систематический подход к анализу данных с
пропусками, при котором выводы основываются на правдоподо-
бии, вычисляемом с помощью формальных статистических моделей
данных и механизма порождения пропусков. Применение этого под-
хода рассматривается в различных областях, включая регрессион-
ный и факторный анализ, таблицы сопряженности, временные ряды
и выборочные обследования. Многие из старых методов из части 1
книги можно вывести как частный случай (или как аппроксимацию)
подхода, основанного на правдоподобии.
Книга предназначена для прикладных статистиков, поэтому изло-
жение в ней основано преимущественно на примерах, а не на точных
формулировках условий регулярности и доказательствах теорем. Тем
не менее читатель должен быть знаком с принципами построения
выводов по правдоподобию, коротко рассмотренными в гл. 5. Книга
требует также понимания стандартных моделей при анализе полных
данных — нормальной линейной модели, полиномиальных моделей
для категориальных данных и свойств общеупотребительных стати-
8
стических распределений, особенно многомерного нормального рас-
пределения. При чтении некоторых глав необходимо знакомство с
такими областями активной статистической деятельности, как пла-
нирование экспериментов в дисперсионном анализе (гл. 2), выбо-
рочные обследования (гл. 4 и 12), логлинейные модели (гл. 9). В
отдельных примерах затрагиваются и другие разделы статистики,
например факторный анализ и временные ряды (гл. 8). Обсуждение
этих примеров не требует обращения к каким-либо источникам или
специальных знаний, но такие знания, конечно, будут способство-
вать более глубокому пониманию основных статистических идей.
Нам удалось охватить три четверти материала, представленного в
книге, в 40-часовом курсе для выпускников-статистиков.
Несмотря на последние достижения в анализе данных с пропуска-
ми, в опубликованных работах есть определенные недостатки, кото-
рые нашли свое отражение и в книге. В частности, значительная
часть книги посвящена точечному оцениванию параметров и при-
ближенных стандартных ошибок, а основой для интервального оце-
нивания и проверки гипотез служила асимптотическая теория
больших выборок. Критерии и интервальные оценки для малых вы-
борок развиты очень слабо, хотя в разделе 6.3.2 представлено байе-
совское решение одной конкретной задачи. Далее, методы основаны
на довольно стандартных статистических моделях, таких, как мно-
гомерная нормальная и полиномиальная модели. Пока выполнена
очень небольшая работа по критериям справедливости этих моде-
лей при неполных данных или по устойчивости оценок для этих мо-
делей. Надеемся, что наше систематическое описание методов для
данных с пропусками стимулирует работу в этой области. Мы рас-
считываем также, что книга даст толчок к разработке программно-
го обеспечения анализа данных с пропусками для широкого
пользователя. Сейчас эта область практику недоступна.
Многим мы благодарны за помощь при работе над этой книгой.
Национальный научный фонд (NSF) и Национальный институт здо-
ровья (NIMH) оказали нам поддержку в некоторых направлениях
исследований. Марк Шлухгер провел необходимые для раздела 8.5
вычисления, Лейза Успд и Г. Е. Рагхунатан внимательно прочитали
окончательный вариант рукописи и высказали свои предложения, а
студенты-биоматематики из группы М 232 Калифорнийского уни-
верситета и студенты-статистики из i руппы 220г Гарвардского уни-
верситета сделали полезные замечания. Наконец, мы благодарим
Джуди Сизен за то, что она напечатала множество черновых вари-
антов нашей книги, и Би Шуб — за искреннюю поддержку.
9
В заключение нам хотелось бы добавить, что многие статистиче-
ские задачи удобно рассматривать как задачи анализа данных с про-
пусками, даже когда совокупность данных полностью зарегистри-
рована, и, более того, что изучение и построение методов анализа
-данных с пропусками может служить прекрасной путеводной нитью
при изучении статистики в целом. Мы надеемся, что читатели со-
гласятся с нами и сочтут книгу полезной.
Лос-Анджелес, Калифорния, Кембридж, Р. Дж. А. Литтл,
Массачусетс, январь, 1987 Д. Б. Рубин
1
I
Часть I. АНАЛИЗ ДАННЫХ
С ПРОПУСКАМИ: ОБЗОР
Глава I. ВВЕДЕНИЕ
Большинство прикладных статистических методов предназначе-
но для анализа прямоугольных таблиц данных. Строкам таблицы
данных соответствуют объекты, называемые также наблюдениями,
случаями и т. д. в зависимости от контекста, столбцы представля-
ют переменные (признаки), измеряемые для каждого объекта. Эле-
ментами таблицы являются действительные числа — значения
непрерывных (например, возраст или размер дохода) или дискрет-
ных переменных. Дискретные (категориальные) признаки могут
быть упорядоченными (например, образование) или неупорядочен-
ными (раса, пол). Настоящая книга посвящена анализу данных в
тех случаях, когда в таблице часть значений переменных отсутству-
ет. Например, часть респондентов (опрашиваемых), участвующих в
обследовании семей, может отказаться сообщить размер дохода. В
промышленном эксперименте некоторые результаты могут отсут-
ствовать вследствие поломок оборудования, не связанных с экспе-
риментальным процессом. При опросе общественного мнения часть
опрашиваемых, возможно, не окажет предпочтения одному канди-
дату перед другими. В первых двух примерах естественно рассмат-
ривать ненаблюдаемые значения как утерянные («пропущенные»).
Таким пропускам соответствуют истинные значения, которые были
бы получены при более совершенных методах обследования или бо-
лее высоком качестве оборудования. Однако в третьем примере ме-
нее правдоподобно, что за отсутствием 'ответа кроется предпочте-
ние определенному кандидату, поэтому рассматривать отсутствую-
щие значения как пропуски менее естественно. Скорее, отсутствие
ответа — это дополнительная точка выборочного пространства из-
меряемой переменной, которая определяет часть популяции (гене-
ральной совокупности), не имеющую предпочтений.
В большинстве пакетов программ по статистическому анализу
допускается выделение отсутствующих элементов в таблице данных
с помощью определенного кода (кодов). Для выделения отсутству-
ющих элементов различней о вида могут потребоваться несколько
кодов, например «не знаю», «отказ отвечать», «недопустимый от-
11
вет». В статистических пакетах объекты, имеющие код пропуска хо-
тя бы по одной из анализируемых переменных, обычно исключа-
ются. Такая стратегия в общем случае неприемлема, поскольку
обычно интересны выводы относительно всей исследуемой популя-
ции, а не той ее части, для которой получены значения всех ана-
лизируемых переменных. Нашей целью является описание методов,
приемлемых в более общем случае. Некоторые из них уже вошли в
состав пакетов (например, программа BMDPAM, Dixon, 1983), а
многие другие, скорее всего, будут включены в ближайшее время.
Пример 1.1. Отсутствие значений бинарной переменной, изме-
ряемой трижды в различные моменты времени. Вулсон и Кларк
[см. Woolson and Clarke, 1984} анализируют данные долговременно-
го исследования факторов риска для сердечных заболеваний у
школьников. В табл. 1.1а представлены структуры пропусков в таб-
лице данных. Значения пяти переменных (пол, возраст и наличие
ожирения в каждом из трех обследований — в 1977, 1979 и 1981 гг.)
были зарегистрированы у 4856 школьников: пол и возраст полнос-
тью, а данные по ожирению не полностью. Структура пропусков
имела шесть вариантов. Поскольку возраст был разбит на пять ка-
тегорий, а переменная ожирения бинарна, данные можно предста-
вить как целые числа в таблице сопряженности (см. табл. 1.16). В
табл. 1.16 пропуск переменной ожирения рассматривается как ее
третье значение. О означает ожирение, N — отсутствие ожирения,
М — пропуск значения. Структура MON, например, означает про-
пуск при первом обследовании, ожирение — при втором, отсутст-
вие ожирения — при третьем. Остальные структуры определяются
аналогично.
Таблица 1.1а. Структуры пропусков в данных
при обследовании детей (1 — присутствие значения, 0 — пропуск)
Структура Переменные Число детей с данной структурой пропусков
возраст пол вес 1 вес 2 вес 3
А 1 1 1 1 1 1770
В 1 1 1 1 0 631
С 1 1 1 0 1 184
D 1 1 0 1 1 645
F. 1 1 1 0 0 756
F 1 1 0 1 0 370
G 1 1 0 0 1 500
12
Таблица 1.16. Число детей, классифицированных по полу,
возрасту и степени полноты в трех этапах обследования
Структура ответов* Мальчики Девочки
Возрастная группа, лет Возрастная группа, лез
5—7 7—9 9—11 11—13 13—15 5—7 7—9 9—11 11—13 13—15
NNN 90 150 152 119 101 75 154 148 129 91
NNO 9 15 11 7 4 8 14 6 8 9
NON 3 8 8 8 2 2 13 10 7 5
NOO 7 8 10 3 7 4 19 8 9 3
ONN 0 8 7 13 8 2 2 12 6 6
ONO 1 9 7 4 0 2 6 0 2 0
OON 1 7 9 11 6 1 6 8 7 6
ООО 8 20 25 16 15 8 21 27 14 15
NNM 16 38 48 42 82 20 25 36 36 83
NOM 5 3 6 4 9 0 3 0 9 15
ONM 0 1 2 4 8 0 1 7 4 6
OOM 0 11 14 13 12 4 И 17 13 23
NMN 9 16 13 14 6 7 16 8 31 5
NMO 3 6 5 2 1 2 3 1 4 0
OMN 0 1 0 1 0 0 0 1 2 0
OMO 0 3 3 4 1 1 4 4 6 1
MNN 29 42 36 18 13 109 47 39 19 и
MNO 18 2 5 3 1 22 4 6 1 1
MON 6 3 4 3 2 7 1 7 2 2
MOO 13 13 3 1 2 24 8 13 2 3
NMM 32 45 59 85 95 23 47 53 58 89
OMM 5 7 17 24 23 5 7 16 24 32
MNM 33 33 31 23 34 27 23 25 21 43
MOM 11 4 9 6 12 5 5 9 1 15
MMN 70 55 40 37 15 65 39 23 23 14
MMO 24 14 9 14 3 19 13 8 10 5
Источник. [Woolson and Clarke (1984)].
* NNN означает отсутствие ожирения в 1977, 1979, 1981 гг., О означает ожирение, М — про-
пуск значения в соответствующем году.
13
Вулсон и Кларк исследуют эти данные, оценивая для каждого
столбца табл. 1.16 полиномиальное распределение по З3 — 1 = 26
значениям данных об ожирении. Таким образом, явно выделена
часть популяции, для которой характерно наличие пропуска. По на-
шему мнению, в приведенном примере естественно рассматривать
отсутствие значения как пропуск некоторого истинного значения пе-
ременной ожирения. Поэтому следует оценивать совместное распре-
деление трех бинарных переменных по данным с пропусками. Со-
ответствующие методы обработки таких неполных категориальных
данных описаны в гл. 9. В этих методах довольно прямолинейно
модифицируются существующие алгоритмы анализа категориаль-
ных данных, реализованные в настоящее время в пакетах статисти-
ческих программ.
1.2. ОБЗОР МЕТОДОВ ОБРАБОТКИ ДАННЫХ С ПРОПУСКАМИ
Работы по анализу данных с пропусками появились сравнитель-
но недавно. Среди обзоров назовем следующие: [Afifi and Elashoff
(1966); Hartley and Hocking (1971); Orchard and Woodbury (1972);
Dempster, Laird and Rubin (1977); Little (1982)]. Предложенные мето-
ды можно грубо разделить на четыре (пересекающиеся) группы.
1. Метод исключения некомплектных объектов. При отсутст-
вии у некоторых объектов значений каких-либо переменных прос-
тым приемом, упомянутым в разделе 1.1, является удаление таких
некомплектных объектов из анализа и обработка данных без пропу-
сков [см., например, Nie, Hill, Jenkins, Steinbrenner and Bent (1975)].
Этот подход обсуждается в гл. 3. Он легко реализуется и может
быть удовлетворительным при малом числе пропусков. Однако
иногда он приводит к серьезным смещениям и обычно не очень эф-
фективен.
2. Методы с заполнением. Пропуски заполняются и получен-
ные «полные» данные обрабатываются обычными методами. Как
правило, используются следующие процедуры: заполнение с (при-
страстным) подбором, когда подставляются значения переменных
других объектов выборки, заполнение средними, когда подставля-
ются средние присутствующих значений, и заполнение с помощью
регрессии, когда пропущенные значения оцениваются с помощью
регрессии на присутствующие для анализируемого объекта перемен-
ные. Применение методов заполнения в планировании эксперимен-
тов, многомерном анализе и выборочных обследованиях описано в
гл. 2, 3 и 4. Чтобы получить корректные выводы, в стандартные
методы анализа следует ввести модификации, позволяющие отли-
чать заполненные пропуски от реальных данных. Эти модификации
относительно просты в обобщении с многократным заполнением
каждого пропуска (см. гл. 12).
14
3. Методы взвешивания. Рандомизированные выводы по дан-
ным выборочных обследований с пропусками обычно построены на
весах плана, обратно пропорциональных вероятности выбора. Путь
yt — значение переменной Y z'-го объекта популяции. Тогда среднее
популяции часто оценивают величиной
Етг/у/Етг;1, (1)
где суммы берутся по извлеченным объектам, т, — вероятность
извлечения z-ro объекта, тг/ — вес плана z'-го элемента. Методы
взвешивания изменяют веса, чтобы учесть отсутствие значений.
Оценка (1) заменяется оценкой
(2)
где суммы берутся по извлеченным объектам, в которых нет пропу-
сков, а Д — оценка вероятности присутствия значения для z-ro
объекта (обычно доля объектов выборки с присутствующим значе-
нием). Взвешивание связано с заполнением средними. Например, ес-
ли веса плана постоянны в подгруппах выборки, то заполнение
пропусков в каждой подгруппе средними подгруппы и взвешивание
присутствующих значений с помощью их доли в каждой подгруппе
ведут к одинаковым оценкам среднего популяции, хотя оценки вы-
борочной дисперсии различны, если только не используются по-
правки на заполнение средними. Методы взвешивания описаны в
гл. 4.
4. Методы, основанные на моделировании. Широкий класс ме-
тодов основывается на построении модели порождения пропусков.
Выводы получают с помощью функции правдоподобия, построен-
ной при условии справедливости этой модели, с оцениванием пара-
метров методами типа максимального правдоподобия. Преиму-
щества такого подхода состоят в том, что он гибок, позволяет от-
казаться от методов, разработанных для частных случаев (предпо-
ложения модели, на которых основаны наши методы, можно рас-
смотреть и оценить), и оценивать в приближении большой выборки
дисперсии оценок с помощью матрицы вторых производных функ-
ций правдоподобия для неполных данных. Описание методов, осно-
ванных на моделировании, — основная цель этой книги. Они об-
суждаются в гл. 5—12, составляющих часть II настоящей книги.
15
1.3. СТРУКТУРЫ ПРОПУСКОВ
Некоторые методы анализа, рассмотренные в гл. 6, предназна-
чены для определенных структур пропусков и предполагают только
обычные способы обработки полных данных. Другие же методы,
например ЕМ-алгоритм, описанный в гл. 7—9, применимы для
структур более общего вида, но они, как правило, требуют больше
вычислений, чем методы для специальных структур. Поэтому необ-
ходимо пытаться формировать таблицу данных так, чтобы образо-
вать упорядоченную структуру.
Пример 1.2. Структура пропусков специального вида. Данные,
структура которых отражена в табл. 1.2, где 1 означает присутст-
вие значения и 0 — пропуск, были получены по результатам обсле-
дования учащихся десяти школ в Иллинойсе и проанализированы
Марини, Олсеном и Рубином [см. Marini, Olsen and Rubin (1980)].
Переменные блока 1 зарегистрированы для всех учеников в начале
исследования, следовательно, присутствуют полностью. Блок 2 со-
стоит из переменных, полученных для обследованных на втором
этапе, который проводился через 15 лет. На этом этапе получены
данные для 79% респондентов, изначально участвовавших в иссле-
довании, т. е. можно считать, что доля присутствия переменных
блока 2 — 79%. Таким образом, переменные блока 1 присутствуют
больше переменных блока 2. Сбор данных на втором этапе (через
15 лет) проводился в несколько фаз, и в целях экономии группа пе-
ременных, сформировавших блок 3, была зарегистрирована у части
респондентов, участвовавших во втором этапе. Значит переменные
блока 2 присутствуют больше переменных блока 3. Блоки 1, 2 и 3
образуют монотонную структуру пропусков. Блок 4 состоит из не-
большого числа признаков, полученных при опросе по почте роди-
телей учащихся из первоначальной выборки. Ответили 65% роди-
телей. Четыре блока не образуют монотонной структуры. Однако,
жертвуя сравнительно небольшой частью данных, можно сформи-
ровать монотонную структуру. Авторы анализируют два моно-
тонных множества данных. В первом исключены значения пере-
менных блока 4 структур С и Е (помечены двумя звездочками), что
дает монотонную структуру, в которой переменные блока 1 присут-
ствуют больше переменных блока 2, переменные блока 2 — больше
переменных блока 3, переменные блока 3 — больше переменных
блока 4. Во втором исключаются значения переменных блока 2
структур В и D (помечены звездочкой) и формируется такая моно-
тонная структура: переменные блока 1 присутствуют больше пере-
менных блока 4, переменные блока 4 — больше переменных блока
2, переменные блока 2 — больше переменных блока 3. В отличие
от этого примера формирование монотонной структуры для дан-
ных из примера 1.1 привело бы к существенным потерям ин-
формации.
16
Таблица 1.2. Структура пропусков
для четырех блоков переменных
Структура Блок ] Блок 2 Блок 3 Блок 4 Число наблюдений Число наблюдений, %
А 1 1 1 1 1594 36,6
В 1 1‘ 1* 0 648 14,9
С 1 1 0 722 16,6
D 1 1* 0 0 469 10,8
Е 1 0 0 1*’ 499 11,5
F 1 0 0 0 420 9,6
4352 100,0
Источник. [Marini, Olsen and Rubin (1980)].
* Наблюдения, исключенные из 2-й .монотонной структуры пропусков (перемен-
ные блока 1 присутствуют больше переменных блока 4, переменные блока 4 присут-
ствуют больше переменных блока 2, переменные блока 2 присутствуют больше
переменных блока 3).
Наблюдения, исключенные из 1-й монотонной структуры пропусков (перемен-
ные блока 1 присутствуют больше переменных блока 2, переменные блока 2 присут-
ствуют больше переменных блока 3, переменные блока 3 присутствуют больше
переменных блока 4).
1.4. МЕХАНИЗМЫ ПОРОЖДЕНИЯ ПРОПУСКОВ
Знание (или незнание) механизма, приводящего к отсутствию
значений, является ключевым при выборе метода анализа и интер-
претации результатов. Иногда этот механизм управляется статисти-
ком. Например, мы можем считать, что выборочному обследова-
нию пропуски присущи, так как значения части переменных в обсле-
довании (переменных плана) присутствуют у всех объектов популя-
ции, а исследуемые переменные «пропущены» у объектов, не вклю-
ченных в выборку. Здесь механизм порождения пропусков — про-
цесс извлечения выборки. Если объекты извлекаются из популяции
случайно, то механизм управляется исследователем (при успешной
реализации плана) и его можно назвать «игнорируемым». Если пра-
вило извлечения выборки не соблюдается или для некоторых объек-
тов выборки значения отсутствуют, то механизм порождения про-
пусков не столь ясен. В этом случае анализ зависит от предположе-
ний о механизме образования пропусков, которые следует явно ого-
варивать.
17
Метод двойного выбора (double sampling) в теории выбороч-
ных обследований — еще один пример, когда структура пропусков
подконтрольна исследователю. Извлекается большая выборка, и
определенные базовые характеристики регистрируются. Затем из
этой выборки случайно извлекается подвыборка, для которой изме-
ряются дополнительные переменные. Получаемые данные образу-
ют монотонную структуру. Методы регрессии, используемые для
анализа таких данных, можно рассматривать как методы обработ-
ки данных с пропусками, хотя обычно эти методы рассматривают
с другой точки зрения.
Цензурирование — пример ситуации, когда механизм порожде-
ния пропусков может быть неуправляемым, но известным статис-
тику. Данными является время наступления события (смерть жи-
вотного в эксперименте, рождение ребенка, перегорание лампочки).
Для некоторых объектов выборки время события цензурировано,
поскольку событие не успело наступить до окончания эксперимента.
Если известна точка (время) цензурирования, то мы имеем частич-
ную информацию о том, что время наступления ненаблюденного
события больше времени цензурирования. Такую информацию надо
учитывать при анализе, чтобы избежать смещений.
Многие методы обработки механизм порождения пропусков яв-
но не включают. Подразумевается, что этот механизм игнорирует-
ся. Однако механизм пропусков можно вводить в статистическую
модель, включая в нее распределение индикаторов присутствия,
равных 1 для присутствующего значения признака и 0 — для про-
пуска. В общем случае механизмом пропусков нельзя пренебречь.
Например, отказ от ответа в обследовании доходов может быть
связан с тайными доходами, что нельзя игнорировать. Эти идеи
развиты в гл. 5, где излагается теория правдоподобия при наличии
пропусков. Гл. 11 посвящена неигнорируемым механизмам порож-
дения пропусков.
1.5. ОДНОМЕРНЫЕ ВЫБОРКИ С ПРОПУСКАМИ
Возможно, простейшей структурой данных является одномер-
ная случайная выборка с пропусками. Пусть означает значение
признака Y для /-го объекта. Предположим, что в простой случай-
ной выборке объема п присутствуют ylt .... ут и пропущены ут+],
..., уп. В этом примере обработка данных с пропусками, очевидно,
сводится к уменьшению объема выборки с и до т. Мы можем об-
работать сокращенную выборку так же, как обработали бы полную
выборку объема п. Например, если мы предполагаем нормаль-
18
иость распределения и хотим получить выводы о среднем, то мож-
но оценить его выборочным средним по присутствующим значени-
ям, а дисперсию оценить величиной s2/m, где s2 — выборочная
дисперсия по присутствующим значениям. Поступая так, мы факти-
чески игнорируем механизм порождения пропусков.
Этот механизм пренебрежим для одномерной выборки, если
пропуски случайны в том смысле, что наблюдаемые объекты явля-
ются случайной подвыборкой объектов выборки. Если вероятность
того, что присутствует, зависит от значения yjt то механизмом
пропусков пренебрегать нельзя, и анализ по сокращенной выборке,
не учитывающий это, ведет к смещениям.
Пример 1.3. Случайное цензурирование одномерной нормаль-
ной выборки. Данные на рис. 1.1 показывают важность учета про-
цесса, приводящего к пропускам. Рис. 1.1а представляет диаграмму
«стебель с листьями» (stem and leaf), т. е. гистограмму, отражаю-
щую значение каждого наблюдения, выборки объема 100 из стан-
дартного нормального распределения. Выборочное среднее — оцен-
ка среднего популяции (равного нулю) по этой выборке равна —
0,03. Рис. 1.16 представляет подвыборку, полученную из начальной
выборки независимым исключением объектов с вероятностью 0,5.
Вероятность исключения не зависит от значения у, следовательно,
получаемая выборка объема т = 52 — случайная подвыборка, ее
выборочное среднее, —0,11, может использоваться как несмещенная
оценка среднего популяции.
Рис. 1.1 в и 1.1г иллюстрируют неигнорируемые механизмы
пропусков. На рис. 1.1 в из начальной выборки удалены неотрица-
тельные значения, т. е.
/ 1, >, < °>
РГ(Я,. = 1 | у) = Pr(j,. присутствует | yt) = у
где R} — индикатор пропуска. Вероятность присутствия зависит от
у. Результаты обычных методов анализа с игнорированием меха-
низма пропусков в таких данных в общем случае смещены. Напри-
мер, средневыборочное, —0,89, — явно заниженная оценка среднего.
Такой механизм пропусков называют цензурированием: значения
цензурируются сверху (или справа) в точке нуль.
Рис. 1.1г отображает случайное цензурирование, когда вероят-
ность присутствия yt лежит между единицей и нулем и равна Ф
(—2,05у,), где Ф — функция стандартного нормального распределе-
ния. Вероятность увеличивается с ростом j,-, поэтому большинство
присутствующих значений отрицательно. Механизмом пропусков
снова нельзя пренебрегать. Средневыборочная оценка систематичес-
ки занижает среднее популяции.
19
Рис. 1.1. Диаграмма "стебель с листьями” для нормального распределения при стохастическом цензурировании.
20
Теперь предположим, что мы столкнулись с неполной выбор-
кой такого типа, как на рис. 1. 1в или 1.1г, и хотим оценить среднее
популяции. Если способ цензурирования известен, применяются
методы с введением поправок к средневыборочному, которые
устраняют смещение, возникающее при формировании выборки.
Эти методы обычно основаны на методе максимального правдопо-
добия. Если же способ цензурирования неизвестен, задача намного
труднее. Принципиальным указанием на то, что механизм пропу-
сков неигнорируем, является асимметрия наблюдаемой выборки,
противоречащая предположению, что исходная выборка извлечена
из (симметричного) нормального распределения. Если мы убежде-
ны, что нецензурированная выборка имеет симметричное распреде-
ление, то можно использовать эту информацию для поправок на
смещение, применяя, например, метод максимального правдоподо-
бия. С другой стороны, если статистик плохо представляет себе
форму нецензурированного распределения, то он не способен ска-
зать, являются ли данные цензурированной выборкой из симмет-
ричного распределения или случайной подвыборкой из асимметрич-
ного распределения. В первом случае средневыборочное — смещен-
ная оценка среднего популяции, во втором — несмещенная.
Пример 1.4. Пример 1.3 в приложении к историческим данным
о росте людей. Уочтер и Трасел [см. Wachter and Trussell (1982)] да-
ют любопытную иллюстрацию этой задачи, связанную с оценкой
роста людей в прошлом. Распределение роста в «исторических» по-
пуляциях представляет значительный интерес, поскольку несет ин-
формацию о питании, а, значит,
Большая часть информации содер-
жится в данных о росте призывни-
ков в армию. Выборки цензуриро-
вались, поскольку часто использо-
вались ограничения на минималь-
ный рост. Ограничения соблюда-
лись с различной строгостью в за-
висимости от наличия призывников
и потребности в них. Поэтому ти-
пичное наблюдаемое распределение
роста имеет вид незаштрихованной
гистограммы на рис. 1.2, заимство-
ванном из [Wachter and Trussell
(1982)]. Заштрихованная область
представляет рост людей, исклю-
ченных из выборки призывников.
Она получена в предположении,
что в нецензурированной выборке
рост распределен нормально. Ав-
даемос распределение и распределение
в популяции. Распределение в популя-
ции нормально, наблюдаемое распре-
деление представлено гистограммой.
Заштрихованная область соответству-
ет отсутствующим данным
21
торы обсуждают методы оценивания среднего и дисперсии нецензу-
рированного распределения при таком сильном предположении.
Выводы для этого примера вполне справедливы, так как существу-
ют убедительные свидетельства в пользу того, что в полной попу-
ляции распределение роста действительно близко к нормальному.
Во многих других задачах с пропусками подобная информация недо-
ступна или очень недостоверна. Как указано в гл. 11, чувствитель-
ность выводов по неполной выборке к предположениям, которые
невозможно или трудно проверить, — основная проблема анализа
данных с неизвестным механизмом порождения пропусков. Она мо-
жет возникнуть, например, в выборочных обследованиях.
1.6. МНОГОМЕРНЫЙ СЛУЧАЙ С ПРОПУСКАМИ
В ОДНОЙ ПЕРЕМЕННОЙ
Предположим теперь, что к переменной У из раздела 1.5 мы
добавили измененную X, значения которой наблюдаются без про-
пусков, т. е. зарегистрированную для всех объектов выборки. Тогда
мы получим монотонную структуру данных (рис. 1.3). К этой
Объекты х у структуре приводит множество ситуаций. В выбороч-
i р__ ных обследованиях переменная У может быть разделом
вопросника, на который не всегда дают ответ (напри-
’ меР> доход), а X — признаком со значениями для всех
7 объектов выборки (например, переменная плана, такая,
•’ как место жительства, или всегда присутствующий при-
"1 ЭМ знак — возраст). В эксперименте X может быть случай-
нотонная * °" н0®’ РегистРиРУем°й без пропусков, или цетерминиро-
структура. X ванной величиной, управляемой экспериментатором,
присутствует например индикатор включения в выборку в рандоми-
больше У зированном плане. Данные по У могут отсутствовать
вследствие неуправляемых событий в процессе сбора таких данных,
как отказ от ответа, недопустимые значения, удаленные из выбор-
ки, ошибки при регистрации данных. С другой стороны, их от-
сутствие может быть связано с планом, как в калибровочном
эксперименте, где X — дешевое измерение, полученное для большой
выборки, а У — дорогостоящее измерение, получаемое для под-
выборки.
X а У могут быть как непрерывными, так и категориальными
признаками. Ситуация, когда (X У) — двумерная нормальная слу-
чайная величина, подробно изучена и обсуждается в гл. 6 в контекс-
те монотонных структур неполных данных. Если X — категори-
22
альный, а У — непрерывный признак, то вид данных соответствует
однофакторному дисперсионному анализу с пропусками некоторых
значений внутри групп, определяемых значением X. Этот случай
подробно обсуждается в гл. 2. Если X и Y — категориальные, то
объекты без пропусков можно расположить в двумерной таблице
сопряженности, ячейки в которой определяются значениями обеих
переменных. Объекты, у которых присутствует только X, дают до-
полнительные маргинальные по У частоты. Методы анализа ча-
стично классифицированных таблиц сопряженности такого типа
изложены в гл. 9. Механизм образования пропусков для данных
этой структуры полезно расклассифицировать в соответствии с за-
висимостью вероятности пропуска значения 1) от У и, возможно, от
X, 2) от X, но не от Y, 3) ни от X, ни от Y. Рубин [см. Rubin (1976)]
предлагает следующую терминологию, отчасти использованную в
разделе 1.5. Если верен случай 3, то мы говорим, что отсутствую-
щие данные отсутствуют случайно (ОС) и присутствующие данные
присутствуют случайно (ПС) или в целом данные отсутствуют пол-
ностью случайно (ОПС)*. В этом случае наблюдаемые значения У
образуют случайную подвыборку, как на рис. 1.1а. В случае 2 мы
говорим, что отсутствующие данные отсутствуют случайно (ОС).
Наблюдаемые значения У не обязательно являются случайной под-
выборкой извлеченных значений, но образуют случайную подвы-
борку в каждой подгруппе, определяемой значением X. В случае 1
данные ни ПС, ни ОС. В случаях 2 и 3 в выводах, основанных на
функции правдоподобия, механизм пропусков можно игнорировать.
В случае 3 этот механизм игнорируем для выводов, основанных как
на выборочных статистиках, так и на функции правдоподобия. В
случае 1 механизм неигнорируем. Эту классификацию можно пояс-
нить примером.
Пример 1.5. Две непрерывные переменные. Пусть X означает
возраст, У — размер дохода. Если вероятность того, что доход реги-
стрируется, одинакова для всех независимо от возраста и дохода, то
данные ОС и ПС (т. е. ОПС). Если эта вероятность меняется в зави-
симости от возраста, но не зависит от размера дохода респондента
внутри возрастной группы, то данные ОС, но не ПС (т. е. не ОПС).
Если вероятность пропуска зависит от дохода внутри возрастной
группы, то данные ни ОС, ни ПС. Этот последний неигнорируемый
случай труднее всего поддается анализу, что очень жаль, поскольку
в приведенном примере наиболее вероятна именно такая ситуация.
* В оригинале соответственно: MAR (missing at random), OAR (observed at
random), MCAR (missing completely at random). На русском языке аббревиатуру ОПС
можно расшифровывать и как «отсутствуют и присутствуют случайно». — Примеч. пер
23
Предположения о механизме пропусков зависят в некоторой
степени от цели анализа. Если нас интересует маргинальное распре-
деление X, то данные об У и механизм пропусков обычно нам без-
различны («обычно», поскольку можно сконструировать примеры,
для которых это неверно, хотя они имеют скорее теоретическое, чем
практическое значение). Если же мы хотим исследовать условное по
X распределение величины К например при изучении зависимости
дохода от возраста, то анализ по т комплектным объектам может
быть удовлетворительным, если данные ОС. С другой стороны, ес-
ли мы изучаем маргинальное распределение или общие характери-
стики, например среднее Y, то анализ, основанный на т
комплектных объектах, будет в общем случае смещенным, если не
выполняется предположение ОПС. Если X и Y присутствуют для
всех п объектов, значения X при оценивании среднего Y обычно бес-
полезны, однако для структуры, представленной на рис. 1.3, значе-
ния X нужны как для повышения эффективности оценки среднего Y,
так и для устранения смещения, если неверно ОПС. Это замечание
очень важно и будет обсуждаться в других главах.
Оценивание совместного распределения Хи У по данным с мо-
нотонной структурой (см. рис. 1.3) в предположении ОС часто мож-
но упростить факторизацией распределения, которая подробно
обсуждается в гл. 6. Пусть f(X, У) — плотность совместного рас-
пределения X и У Эту плотность можно факторизовать в виде
/(X У) = /(Х)/(У| X), (1.1)
где f(X) — маргинальная плотность X, a. f{Y\ X) — условная по X
плотность Y. Здесь и далее функции можно различать по аргумен-
там. Выводы о маргинальном распределении возраста могут быть
основаны на п наблюденных значениях возраста. Выводы об услов-
ном по возрасту распределении дохода могут быть основаны на т
комплектных объектах. Результаты этого анализа можно объеди-
нить, чтобы оценить совместное распределение возраста и дохода
или распределение возраста, условное по доходу. Оценивание рас-
пределения дохода, условного по возрасту, часто является разновид-
ностью регрессионного анализа, а техника факторизации связана с
идеей заполнения пропусков по доходу при использовании регрессии
дохода на возраст и при вычислении прогноза дохода. Таким обра-
зом, анализ данных, приведенных на рис. 1.3, можно рассматри-
вать как классическую задачу предсказания значения по регрессии.
Пример 1.6. р + 1 переменных с пропусками в одной перемен-
ной. Во многих задачах полностью присутствуют значения р > 1
переменных для всех и объектов. Такие данные можно представить
рис. 1.3, где X обозначает матрицу п х р. В задаче, в которой пред-
24
полагался анализ данных с пропусками и которая впервые система-
тически исследовалась в статистической литературе, данные имели
именно такую структуру. Необходимо было решить задачу при от-
сутствии данных в планируемых экспериментах. В контексте сель-
скохозяйственных исследований эту задачу часто называют «зада-
чей о пропуске участков». В ней нужно установить связь между за-
висимой переменной (урожаем) и рядом факторов (видом культуры,
типом удобрения, температурой), п наблюдений выбираются так,
чтобы матрица плана была легко обращаема, как при полной или
частичной повторной реализации факторных планов. Задача с про-
пусками возникает тогда, когда по завершении эксперимента значе-
ния зависимой переменной У для п — т объектов отсутствуют
из-за невозможности их получить (на некоторых участках семена не
дали всходов) или вследствие утраты зарегистрированных значений.
При обычном анализе неполных данных используют предположе-
ние ОС, т. е. предполагают, что вероятность пропуска yt может
меняться в зависимости от переменных плана, но при данном значе-
нии Xj, i-vL строки X, вероятность отсутствия yt не зависит от yt. В
практических приложениях следует проверять допустимость такого
предположения. Анализ строится так, чтобы использовать «почти
сбалансированность» получаемого множества данных для упроще-
ния вычислений. Например, одним из способов является подстанов-
ка оценок пропущенных значений вместо пропусков и последующий
анализ в предположении, что данные полные. Здесь требуют внима-
ния такие вопросы, как выбор значений для подстановки и модифи-
кации методов с целью учета подстановок. Эта проблема обсуж-
дается в гл. 2.
Задачи с пропусками признаков в выборочных обследованиях
часто имеют такую же структуру, как на рис. 1.3. Y соответствует
признаку с пропусками, X — «фоновым» признакам, наблюдаемым
полностью. Главным является оценивание маргинального распреде-
ления У, в отличие от задачи дисперсионного анализа, где исследу-
ется условное по X распределение У. Тем не менее эти две задачи
до некоторой степени сходны.
Все описанные в литературе методы выборочных обследований
при наличии пропусков требуют предположения, что данные ОС,
хотя для многих практических задач это крайне сомнительно. В до-
полнение к обсуждению в гл. 4 методов, основанных на рандомиза-
ции, мы осветим в гл. 12 некоторые новые работы по ослаблению
предположений ОС и опишем методы с применением функции прав-
доподобия.
25
1.7. МНОГОМЕРНЫЕ ДАННЫЕ С ПРОПУСКАМИ.
ОБЩИЙ СЛУЧАЙ
Структуры пропусков, описанные в разделах 1.5 и 1.6, одно-
мерны в том смысле, что только в одной переменной есть пропус-
ки. Теперь обсудим многомерные структуры пропусков.
Многие методы многомерного статистического анализа, вклю-
чая метод наименьших квадратов для поиска регрессии, факторный
анализ, дискриминантный анализ, основаны на редукции данных к
вектору выборочных средних и выборочной ковариационной матри-
це. Поэтому важен вопрос оценивания этих величин по неполным
данным. В ранее опубликованных работах, частично обсуждаемых
в гл. 3, предлагалось решение для частных случаев. Более система-
тический подход, которому посвящена часть II настоящей книги,
основан на функции правдоподобия. Он обсуждается в гл. 5 и при-
меняется во многих ситуациях, рассмотренных в последующих
главах.
Пример 1.7. Оценивание среднего и ковариационной матрицы
по данным с монотонной структурой. Предположим, данные
можно расположить в монотонную структуру. Простейшим подхо-
дом будет анализ только комплектных объектов. Этот метод, одна-
ко, приводит к большой потере данных. К тому же во многих
случаях, включая данные табл. 1.2, комплектные объекты не явля-
ются случайным подмножеством исходной выборки, т. е. предполо-
жение ОПС не выполняется, и результаты будут смещены. Более
разумно предположить, что распределение данных — многомерное
нормальное, и оценивать среднее и ковариационную матрицу мето-
дом максимального правдоподобия. В гл. 6 мы покажем, что для
монотонных данных эта задача не так сложна, как можно думать,
поскольку оценивание упрощается при факторизации совместного
распределения, как в (1.1), что позволяет найти оценки максималь-
ного правдоподобия по последовательности регрессионных задач.
Пример 1.8. Оценивание среднего и ковариационной матрицы
для общей структуры пропусков. Во многих наборах данных с про-
пусками удобная монотонная структура или ее близкая аппроксима-
ция, какая была возможна для данных табл. 1.2, отсутствует.
Разработаны методы для оценивания среднего и ковариационной
матрицы, применимые для любой* структуры пропусков. Как и в
предыдущем примере, эти методы часто основаны на методе макси-
мального правдоподобия в условиях многомерной нормальности.
Оценивание проводится итеративно.
* При условии идентифицируемости. — Примеч. пер.
26
Подход, основанный на ЕМ-алгоритме (expectation-maximiza- '
tion), развитый в гл. 7, представляет собой общий подход к поиску
оценок максимального правдоподобия по неполным данным. Для
многомерного нормального случая он описан в гл. 8. В этой ситуа-
ции он особенно нагляден, поскольку тесно связан с итеративным
вариантом метода заполнения пропусков значениями, полученными
по регрессии. Таким образом, даже в этой сложной задаче можно
установить связь между эффективными теоретически обоснованны-
ми методами и более традиционными прагматическими подходами
с заполнением пропусков подходящими значениями. В гл. 8 пред-
ставлены также малоизвестные способы применения ЕМ-алгоритма
в таких областях, как компонентный дисперсионный анализ, фак-
торный анализ, временные ряды. Эти задачи рассмотрены как зада-
чи анализа неполных данных из многомерного распределения со
средним и ковариационной матрицей определенного вида.
Пример 1.9. Оценивание при наличии категориальных призна-
ков. Редукция данных к среднему и ковариационной матрице для ка-
тегориальных признаков в общем случае неприемлема. Данные
можно расположить в частично классифицированной таблице со-
пряженности, как в примере 1.1. Методы анализа таких данных об-
суждаются в гл. 9.
В гл. 10 рассматриваются многомерные данные, когда некото-
рые признаки непрерывные, а остальные — категориальные. Про-
блема, описываемая обычно по-иному, — оценивание конечных сме-
сей распределений, также рассматривается как задача анализа дан-
ных с пропусками.
Пример 1.10. Оценивание, когда предположение ОС о пропусках
может не выполняться. По существу, во всех работах по анализу
многомерных данных с пропусками предполагается, что данные
ОС, а во многих из них — что данные к тому же и ПС. В гл. 11
в явном виде рассматривается случай, когда предположение ОС не-
верно. Последняя глава (гл. 12) посвящена подходу к обработке
пропусков при выборочных обследованиях, основанному на приме-
нении функции правдоподобия. В ней обсуждаются ситуации, когда
это предположение выполняется и когда оно не выполняется.
27
ЛИТЕРАТУРА
Afifi, A. A., and Elashoff, R. M. (1966). Missing observations in multivariate statistics I: Review
of the literature, J. Am. Statist. Assoc. 61, 595-604.
Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977). Maximum likelihood from incomplete
data via the EM algorithm (with discussion), J. Roy. Statist. Soc. B39. 1 -38.
Dixon, W J (Ed.) (1983). BMDP Statistical Software, 1983 revised printing, University of Cali-
fornia Press: Berkeley.
Hartley, H. O., and Hocking, R.R. (1971). The analysis of incomplete data. Biometrics 27,783-808.
Little, R. J. A. (1982). Models for nonresponse in sample surveys. J Ant. Statist. Assoc. 77,
237-250.
Marini, M. M., Olsen, A. R., and Rubin, D. B. (1980). Maximum likelihood estimation in panel
studies with missing data. Sociological Methodology 1980, San Francisco: Jossey Bass.
Nie, N. H., Hull, С. H., Jenkins, J. G., Steinbrenner, K., and Bent. D. H. (1975). SPSS, 2nd ed.
McGraw-Hill. New York.
Orchard, T,, and Woodbury, M. A. (1972). A missing information principle: Theory and applica-
tions. Proc. 6lh Berkeley Symposium on Math. Statist, and Prob. 1, 697-715.
Rubin, D. B. (1976). Inference and missing data, Biometrika 63, 581-592.
Wachter, K. W., and Trussell, J. (1982). Estimating historical heights, J. Am. Statist. Assoc. 77,
279-301.
Woolson, R. F., and Clarke, W. R. (1984). Analysis of categorical incomplete longitudinal data,
J. Roy. Statist. Soc. A147, 87-99.
I
I
ЗАДАЧИ
1. Определите для данных из примера 1.1 монотонную структуру, требующую
минимального числа удалений присутствующих значений. Можете ли вы найти кри-
терий для выбора удаляемых значений, который оказался бы лучше?
2. Составьте список методов обработки пропусков данных, имеющих отношение
к области ваших интересов, основываясь на опыте или соответствующей литературе.
3. Какие предположения относительно механизма порождения пропусков счита-
ются выполненными в статистических методах из задачи 2? Реалистичны ли эти
предположения?
4. Какое влияние оказывают пропуски на а) оценки, б) критерии и доверитель-
ные интервалы в методах из задачи 2? Состоятельны ли, например, оценки соответ-
ствующих параметров популяции; имеют ли критерии заданный уровень
значимости?
5. Пусть У = (у-) — матрица данных, R = (R/y ) — соответствующая матрица
индикаторов пропуска, в которой R^ — 1 обозначает присутствие, a R^ = 0 — про-
пуск значения.
а) Предложите ситуацию, где двух значений R,-,. недостаточно.
б) Почти всегда предполагают, что R наблюдается полностью. Опишите реали-
стичную ситуацию, когда имеет смысл рассматривать часть самой R как отсут-
ствующую.
28
в) Допустим, Rjj есть 0 или 1. Когда проводится анализ только полных наблю-
дений, оценивается условное распределение у,- при заданном Rj = (1, .... 1), где j>(- и
R, — i-я строка У и R соответственно. Предположите ситуации, в которых имеет
смысл оценивать условное распределение yj при другой фиксированной структуре
пропусков, а также ситуации, в которых оценивать такие условные распределения
бессмысленно.
г) Выразите маргинальное распределение у{ через условные распределения y-t при
фиксированных структурах пропусков для различных структур и их вероятности.
Глава 2. ПЛАНИРОВАНИЕ ЭКСПЕРИМЕНТОВ
И ПРОПУСКИ В ДАННЫХ
2.1. ВВЕДЕНИЕ
Планирование экспериментов проводится обычно таким обра-
зом, чтобы статистический анализ можно было осуществить путем
несложных вычислений. В частности, стандартному плану экспери-
ментов соответствует анализ на основе метода наименьших квадра-
тов, обеспечивающий оценки параметров, стандартные ошибки
контрастов параметров и таблицу дисперсионного анализа. Оценки,
стандартные ошибки и таблицы легко вычисляются в большинстве
планируемых экспериментов благодаря сбалансированному плану.
Например, при исследовании двух факторов анализ особенно прост,
когда для каждого сочетания уровней факторов берется одинаковое
число наблюдений. В [Cochran and Сох (1957); Davies (1960); Kemp-
thorne (1952); Winer (1962)] и более поздних работах по планирова-
нию экспериментов собрано много соответствующих примеров.
Поскольку в эксперименте значения факторов задаются иссле-
дователем, то пропуски, если они есть, содержатся в выходной пе-
ременной Y намного чаще, чем в значениях факторов X. Поэтому
мы ограничимся ситуацией, когда пропуски только в Y. Если такие
пропуски есть, то исходный баланс отсутствует. В результате соот-
ветствующий анализ наименьших квадратов намного усложняется,
даже при предположении ОПС. В этой ситуации интуитивно при-
влекателен подход с заполнением пропусков, позволяющий восста-
новить баланс и затем использовать стандартные методы анализа.
Преимущества заполнения пропусков перед анализом фактиче-
ских данных состоят в следующем: 1) легче определить структуру
данных в терминах планируемых экспериментов (например, как сба-
лансированный неполный блок); 2) легче вычислить необходимые
итоговые значения статистик; 3) легче интерпретировать результа-
29
ты анализа, так как можно опираться на традиционные характери-
стики и суммарные значения. Было бы прекрасно, если бы можно
было найти такой способ заполнения пропусков, при котором ана-
лиз полученных полных данных оказывался бы корректным. В дей-
ствительности в этом направлении можно еще многое сделать.
При условии независимости пропусков от значений выходной
(зависимой) переменной, т. е. при ОС, существует большое число
различных методов заполнения, дающих правильные оценки всех
параметров эффектов, подлежащих оцениванию. Кроме того, мож-
но легко ввести поправки к остаточному среднему квадрату (оши-
бок), стандартным ошибкам и суммам квадратов, имеющим одну
степень свободы. К сожалению, поправки к суммам квадратов с
числом степеней свободы больше одного ввести сложнее, хотя и это
можно сделать.
Методы, при которых каждый пропуск заполняется только
одним значением, непосредственно применимы только для анализа
однофакторной модели с фиксированными эффектами с одним чле-
ном для ошибки. К линейным моделям с фиксированными эффекта-
ми с числом факторов более одного относятся, например,
иерархические модели, в которых суммы квадратов приписываются
эффектам в определенном порядке при подборе модели по последо-
вательности вложенных (nested) моделей с фиксированными эффек-
тами, расщепленные планы с повторными измерениями, в которых
для исследования эффектов используются различные слагаемые
ошибки, а также модели со случайными и смешанными эффектами,
в которых отдельные параметры интерпретируются как случайные
величины. Для анализа, при котором рассматривается более одной
модели с фиксированными факторами, в общем случае для каждой
модели надо заполнять различные множества пропущенных значе-
ний. Более подробное обсуждение приведено, например, в [Anderson
(1946); Jarrett (1978)], см. также раздел 8.5 настоящей книги.
2.2. МЕТОД НАИМЕНЬШИХ КВАДРАТОВ
ДЛЯ НЕПОЛНЫХ ДАННЫХ
Пусть X — п х р-матрица, в которой г-я строка
xt = (xllt ...,xip) содержит фиксированные значения факторов для
/-го объекта. Например, для плана 2 X 2 с двумя наблюдениями в
ячейке и уровнями факторов, обозначенных 0, 1,
30
1
1
1
1
1
1
1
1
о о
о о
О 1
О 1
1 о
1 о
1 1
1 1
Предполагается, что для выходной переменной Y = (j^, ..., ^л)т
верна линейная модель
Y = + е, (2.1)
где е = (ен еп)т, е; независимо и одинаково распределены с ну-
левым средним и одинаковой дисперсией а2, /3 — оцениваемый па-
раметр — вектор длины р. Оценка наименьших квадратов 0 равна:
/3 = (ХТХ)~'(ХТХ), (2.2)
если {X1 X) имеет полный ранг и не определена в противном слу-
чае. Если (ХТХ) невырождена, то /3 — несмещенная оценка /3 с ми-
нимальной дисперсией. Если распределены нормально, & —
оценка максимального правдоподобия /3, распределенная нормально
со средним /3 и дисперсией о2(ХтХ)~
Наилучшей несмещенной оценкой а2 является
где Если е,- нормальны, то (и — р)а2/а2 имеет распреде-
ление хи-квадрат с п — р степенями свободы. Наилучшая несме-
щенная оценка ковариационной матрицы равна:
V=a2(XTX)-'. (2.4)
Если et распределены нормально, то (/3;—/З^/д/Т,-,- (где v(/ —
/-й диагональный элемент И) имеет распределение Стьюдента с
п — р степенями свободы, а ((3 — (3) — многомерное распределение
Стьюдента с параметром масштаба И1/2.
Гипотезу о равенстве всех элементов некоторого множества ли-
нейных комбинаций от координат /3 нулю проверяют, вычисляя
31
сумму квадратов, относящуюся к этому множеству. Точнее, пусть
С — р х ^-матрица, определяющая и> линейных комбинаций (3,
участвующих в проверке. Тогда сумма квадратов, относящаяся к ли-
нейным комбинациям, равна:
5= (СТ^)Т1СТ(ХГХ)~1С]-1(СТР). (2.5)
Проверку гипотезы Сг3 = 0 проводят, сравнивая S/ w и о2:
F = (S/w)/а2. (2.6)
Если et распределены нормально, то F в (2.6) есть критерий отно-
шения правдоподобий для гипотезы Ст(3 = 0; если при этом гипо-
теза верна, то F имеет распределение Снедекора с w и п — р
степенями свободы: S/a2 и (л—р)<у2/а2 — независимые случай-
ные величины, распределенные по х2 с w и п — р степенями свобо-
ды. Доказательства приведенных результатов можно найти в кни-
гах по регрессионному анализу, например в [Draper and Smith
(1981); Weisberg (1980)]. Как указано в этих книгах, при неортого-
нальных планах может потребоваться аккуратная интерпретация
этих критериев, например критерий для набора эффектов по А в
модели с эффектами по А, по В и эффектами взаимодействия требу-
ет, чтобы фактор А был скорректирован на фактор В и взаимо-
действия.
Традиционные планы экспериментов выбирают так, чтобы лег-
ко и точно проводить оценивание и проверку гипотез. В частности,
матрица ХТХ обычно легко обратима, а значит, легко вычисляют-
ся /3, а2, V и сумма квадратов, относящаяся к заданному набору ли-
нейных комбинаций 0, например к эффектам обработок и эффектам
блоков. Как правило, эти величины вычисляются по данным путем
простого усреднения наблюдений и их квадратов. Эта простота мо-
жет играть важную роль при изучении нескольких факторов с оце-
ниванием большого числа параметров, поскольку при этом ХТХ
может иметь большие размеры. Обращение больших матриц было
особенно обременительным до появления современного программ-
ного обеспечения, но и сейчас еще может создавать затруднения
при некоторых вычислениях, если р велико (например, более 50).
2.3. КОРРЕКТНАЯ РЕАЛИЗАЦИЯ МЕТОДА НАИМЕНЬШИХ
КВАДРАТОВ ПРИ ПРОПУСКАХ В ДАННЫХ
Мы предполагаем, что X представляет такой план эксперимен-
та, что при присутствии всех Y анализ данных можно проводить с
помощью известных стандартных формул и программ. Вопрос со-
стоит в том, как использовать эти формулы и программы (для пол-
ных данных), когда часть Y пропущена.
32
Точный анализ наблюдаемых данных легко описывается в пред-
положении, что причина появления пропусков в У не зависит от
значения У (т. е. при условии ОС). Надо просто игнорировать стро-
ки X, соответствующие пропущенным у;, и провести вычисления,
рассмотренные в разделе 2.2, по оставшимся строкам X, соответ-
ствующим наблюденным yt. Затруднения, связанные с таким пред-
ложением, состоят в том, что специальные формулы и программы,
предназначенные для полных У уже нельзя использовать, так как
отсутствует исходная сбалансированность. Вследствие этого 1)
труднее описать структуру данных, поскольку теперь надо оговари-
вать всю матрицу плана, а не просто дать указание на один из тра-
диционных планов экспериментов; 2) вычислительные затраты по
оперативной памяти и процессорному времени могут оказаться
больше, поскольку необходимы формулы в общем виде, как, напри-
мер, в (2.2), а не специальные выражения для отдельных различных
планов; 3) может быть утрачена ясность статистической интерпре-
тации, поскольку не даются результаты и выводы, соответствую-
щие традиционным специальным планам.
Тем не менее, применяя уравнения из раздела 2.2 к т объектам
с присутствующими у.', мы получим корректные оценки наимень-
ших квадратов, стандартные ошибки, суммы квадратов и /'’-крите-
рии, если в данных будут пропуски. Для обозначения величин,
полученных из уравнений (2.2)—(2.5) по т объектам с присутствую-
щими y-t, мы будем использовать символы V, и S,. В
остальной части этой главы описаны способы получения этих вели-
чин с применением только тех процедур, которые нужны для пол-
ных данных и в которых для упрощения вычислений используется
специальная структура X.
2.4. ПОДСТАНОВКА ОЦЕНОК НАИМЕНЬШИХ КВАДРАТОВ
2.4.1. Метод Йейтса
Классический и общепринятый подход к пропускам в дисперси-
онном анализе обязан своим происхождением в основном Йейтсу
[Yates (1933)]. Он состоит в следующем: 1) заменить все пропущен-
ные значения их оценками наименьших квадратов = х,/3., где /3.,
определенное в (2.2), получено по т строкам (Y, X) с присутствую-
щими у,; 2) применить метод анализа для полных данных. Этот
подход с подстановкой оценок наименьших квадратов на первый
взгляд создает порочный круг и бесполезен на практике, так как для
него вроде бы требуется знать при оценивании у, величиной х(|8.
до получения /3.. Как это ни удивительно, но можно относительно
2. Р Дж А Литтл, Д Б Рубин 33
легко вычислять yt = xt0, для пропущенных yt до непосредственно-
го вычисления /3,, если отсутствует небольшое число значений.
Процедура Йейтса обосновывается тем, что она дает 1) пра-
вильные оценки наименьших квадратов /3, 0„ и 2) правильную ос-
таточную сумму квадратов, т. е. получаемая оценка о1 (п — р) бу-
дет правильна и равна (т — р). Доказать два этих факта до-
вольно легко. Пусть yt = х;0,, г = 1, ..., т0, обозначает оценки
наименьших квадратов т0 отсутствующих значений, которыми для
простоты обозначений мы будем считать первые т0 наблюдений.
Методы для полных данных, примененные к заполненным данным, -
минимизируют величину
SS(/3) = Е (у. — х.0)2 + Е О — х,/3)2
1 = 1 i=m0 + l
по (3. По определению /3 = 0. минимизирует вторую сумму в
SS(/3), но /3 = 0. минимизирует и первую сумму, делая ее равной
нулю. Следовательно, при заполнении пропусков оценками наимень-
ших квадратов 1) SS(0) достигает минимума при 0 = 0. и 2)
SS(0.) равна минимальной сумме квадратов остатков по т присут-
ствующим значениям уг Отсюда 1) правильная оценка наименьших
квадратов 0, 0., равна оценке наименьших квадратов 0, получен-
ной с помощью программы дисперсионного анализа для полных
данных и 2) правильная оценка наименьших квадратов a2, а*, полу-
чается из оценки а2 для полных данных, а2-.
«2 (ft — Р)
- ° ТИГ-V)
Анализ с подстановкой yt вместо пропущенных у, несоверше-
нен: он приводит к заниженной оценке ковариационной матрицы 0,
суммы квадратов, относящиеся к набору линейных комбинаций 0,
завышены, хотя при небольшой доле пропусков эти смещения часто
относительно малы. Теперь мы приступим к рассмотрению мето-
дов вычисления значений уг
2.4.2. Формулы для пропущенных значений
Один из подходов состоит в том, чтобы заменять пропущен-
ные значения с помощью явного выражения. Впервые применяя эту
идею, Аллан и Уишарт [см. Allan and Wishart (1930)] вывели фор-
мулы для оценки наименьших квадратов для одного пропущенного
значения в плане рандомизированных блоков и в плане латинских
квадратов. Например, для рандомизированных блоков при Т обра-
ботках и В блоках оценкой наименьших квадратов пропущенного
значения для обработки t в блоке Ъ является
34
Ту('\ + By(b>—y+
(T-1)(S-1) ’
। де _v+ и ylb> — соответственно сумма наблюденных значений У для
обработки t и блока Ь, а у + — сумма всех наблюденных У. Уил-
кинсон [см. Wilkinson (1958а)] обобщил эту работу, приведя табли-
цу с формулами для многих планов и структур пропусков.
2.4.3. Итеративный подбор пропущенных значений
Хартли [Hartley (1956)] предложил общий неитеративный ме-
тод оценки одного пропущенного значения, который по его предло-
жению следует использовать итеративно при большем числе про-
пусков. Метод для одного пропуска состоял в подстановке трех раз-
личных пробных значений вместо пропуска и вычислении суммы
квадратов остатков для каждого из этих значений. Тогда, поскольку
сумма квадратов остатков квадратична по пропущенному значению,
можно найти значение для одного пропуска, минимизирующее эту
сумму. Этот подход менее привлекателен, чем другие методы.
Хили и Уэстмакот [Healy and Westmacott (1956)] описали из-
вестный итеративный метод, который иногда приписывают Йейтсу,
а иногда — даже Фишеру. В этом методе 1) вместо всех пропусков
подставляют начальные значения; 2) проводят анализ для полных
данных; 3) для пропусков получают предсказываемые значения; 4)
подставляют эти значения вместо пропусков; 5) снова проводят ана-
лиз для полных данных и т. д., пока значения для пропусков не ста-
нут меняться мало, или, что эквивалентно, пока остаточная сумма
квадратов не перестанет существенно уменьшаться.
Как мы покажем в примере 8.5, метод Хили и Уэстмакота —
пример ЕМ-алгоритма, описываемого в гл. 7. Каждая итерация
уменьшает остаточную сумму квадратов или (что то же самое при
соответствующей нормальной модели) увеличивает правдоподобие.
В некоторых случаях сходимость может быть медленной. Были
предложены специальные методы ускорения [см. Pearce (1965),
с. Ill: Preece (1971)]. В некоторых случаях они увеличивают ско-
рость сходимости, в других же нарушают монотонное уменьшение
остаточной суммы квадратов (см. сводку условий в [Jarrett (1978)]).
2* 35
2.4.4. Ковариационный анализ
с сопеременными пропусков
Общий неитеративный метод, предложенный Бартлетом [см.
Bartlett (1937)], заключается в подстановке начальных значений вме-
сто пропусков и проведении ковариационного анализа с соперемен-
ной (covariate, сопутствующая переменная) пропусков для каждого
пропущенного значения. По определению i-я сопеременная пропу-
сков — это индикатор /-го пропущенного значения, т. е. всегда
нуль, за исключением случая, когда пропущено i-e значение, тогда
она равна 1. При вычитании коэффициента для сопеременной /-го
пропуска из начального значения получается оценка наименьших
квадратов /-го пропуска. Кроме того, остаточный средний квадрат
и суммы квадратов для всех контрастов, пересчитанные по сопере-
менной пропусков, принимают свои истинные значения. Мы дока-
жем эти результаты в разделе 2.5.
Хотя этот метод привлекателен в определенных отношениях,
его часто нельзя реализовать непосредственно, потому что специа-
лизированные программы дисперсионного анализа могут не обла-
дать возможностью вести обработку при многих сопеременных.
Оказывается, однако, что метод Бартлета можно применять, распо-
лагая только имеющимися программами дисперсионного анализа
для полных данных и программой обращения симметричной матри-
цы т0 X т0. В следующем разделе доказано, что метод Бартлета
дает правильные результаты, в других же разделах рассмотрено по-
лучение этих результатов только с помощью программ дисперсион-
ного анализа для полных данных.
2.5. МЕТОД БАРТЛЕТА
2.5.1. Полезные свойства метода Бартлета
Метод Бартлета имеет следующие полезные свойства. Во-пер-
вых, он неитеративный, и, следовательно, снимается вопрос о схо-
димости. Во-вторых, если структура пропусков обладает вырож-
денностью (например, в том случае, когда нельзя оценить некото-
рые параметры, как при отсутствии всех значений для какой-то об-
работки), этот метод «предупреждает» исследователя, тогда как
итеративные методы приводят к ответу, возможно, недопустимому.
Еще одно достоинство заключается в том, что метод, как указано
выше, дает не только правильные оценки и остаточные суммы ква-
дратов, но и верные стандартные ошибки, суммы квадратов, F-
критерии.
36
2.5.2. Обозначения
Допустим, что каждый пропуск заполняется начальным зна-
чением, чтобы вектор значений Y был полон. Обозначим начальные
значения у,, i = 1, ..., т0. Пусть Z — и х m-матрица та сопере-
менных пропусков: первая строка Z, zi, равна (1, 0, ..., 0), .... стро-
ка т0 равна (0, ..., О, 1), а все г,- при i > т0 равны (0, .... 0), так
как они соответствуют присутствующим у(. При ковариационном
анализе используется и X, и Z для предсказания У.
Аналогично (2.1) моделью для У теперь является
У = Хв + Zy + е, (2.7)
где 7 — вектор-столбец из т0 коэффициентов регрессии для сопере-
менных пропусков. Остаточная сумма квадратов, минимизируемая
по (/3, у), равна:
и, _ п
SS(/3, 7) = Е (у. — х,-/3 — z,-7)2 +. Е oz — х,./3 — Z/7)2.
1 = 1 / = /поч-1
По определению Z
SS(/3, 7) = Е” (£ - х,/3 - 7,.)2 +. Е ,0, - xfif. (2.8)
'-1 <-т„+1
2.5.3. Оценки параметров и пропущенных значений У
Как и ранее, пусть /3. — правильная оценка наименьших ква-
дратов /3, полученная в (2.2) по присутствующим значениям, т. е. по
последним т = п — т(, строкам (К X). Она минимизирует вторую
сумму в (2.8). Но если при /3 = @, положить у = (71, ..., ТШ[))т, где
7/ = У< — 1 = Ь ™о, (2.9)
то будет минимизирована и обратится в нуль первая сумма в (2.8),
так что
SS((3., 7) = Е (у,. - хД)2. (2.10)
i=m„ + l
Значит, (/§., 7) минимизирует SS(/3, 7) и является оценкой наимень-
ших квадратов (/3, 7), получаемой из модели ковариационного ана-
лиза (2.7). Уравнение (2.9) означает также, что точная оценка
наименьших квадратов отсутствующего значения у,-, т. е. у(. = х,/3,,
есть у,- — у,-, или в словесной формулировке:
(прогноз /-го пропущенного значения методом наименьших
квадратов) есть (начальное значение для /-го пропуска) минус (2.11)
(коэффициент для сопеременной /-го пропуска).
37
В работе Бартлета все у] приравниваются по этому методу ну-
лю, однако с вычислительной точки зрения использование в каче-
стве у-: общего среднего более привлекательно и дает Точную
сумму квадратов отклонений от среднего.
2.5.4. Оценки остаточной суммы квадратов
и ковариационной матрицы
Уравнение (2.10) означает, что остаточная сумма квадратов, по-
лучаемая по методу Бартлета, совпадает с точной суммой квадра-
тов. Число степеней свободы, соответствующее этой остаточной
сумме квадратов, равно п — р — т0 = т — р, что также верно.
Следовательно, остаточный средний квадрат вычислен точно и ра-
вен а2,. Если ковариационная матрица полученная этим мето-
дом, будет равна V., вычисленному в (2.4) по т объектам с
присутствующими yjt то все стандартные ошибки, суммы квадра-
тов и критерии значимости также будут правильны. Оценка ковари-
ационной матрицы 3., получаемая при применении этого метода,
равна оценке среднего квадрата остатков а2, умноженной на верх-
нюю левую подматрицу р х р матрицы [(X Z)T(X Z)]“', которую
мы обозначим U. Так как оценка среднего квадрата остатков пра-
вильна, нам нужно лишь показать, что (Л-1 — это сумма пере-
крестных произведений для X по объектам с присутствующими у(.
Из матричной алгебры
U = [Х^Х — (XTZ)(ZTZ)“1(ZTX)]-1- (2-12)
По определению z-t
Xх Z = Е х]Z, (2.13)
г = 1 1 1
И
ZTZ = E°zTz. = I. (2.14)
Из (2.13) и (2.14)
(XrZ)(ZTZ)-](ZTA3 = (е (2.15)
Но
Г 1, если / = J,
т
ZZ = \
‘ J 0 — в противном случае,
38
поэтому (2.15) равно Е xf х., а в соответствии с (2.12)
и = Е х]х,\ ,
I ак что S2.U = V, — ковариационной матрице /3., получаемой при
исключении объектов с пропуском Y, что и требовалось для завер-
шения доказательства, что метод, основанный на ковариационном
анализе, дает для всех статистик решения, соответствующие реше-
ниям по методу наименьших квадратов.
2.6. ОЦЕНКИ НАИМЕНЬШИХ КВАДРАТОВ
ДЛЯ ПРОПУЩЕННЫХ ЗНАЧЕНИЙ МЕТОДОМ СОПЕРЕМЕННЫХ
С ПОМОЩЬЮ ПРОЦЕДУР ДЛЯ ПОЛНЫХ ДАННЫХ
Изложенная теория, связывающая дисперсионный анализ для
полных данных с ковариационным анализом для неполных дан-
ных, представляла бы только академический интерес, если бы тре-
бовалось специальное программное обеспечение. Мы опишем, как
реализовать вычисление оценок наименьших квадратов т0 пропу-
щенных значений по методу сопеременных, используя лишь про-
граммы дисперсионного анализа для полных данных и программу
обращения симметричной матрицы т0 х т0 (для последней цели
можно применять оператор, описанный в разделе 6.5). В разделе 2.7
дается обобщение метода, позволяющее вычислять верные стан-
дартные ошибки и суммы квадратов для гипотез «с одной степенью
свободы». Обоснование будет строиться на результатах для ковари-
ационного анализа. Непосредственное алгебраическое доказатель-
ство содержится в [Rubin (1972)].
Согласно теории ковариационного анализа вектор -у можно пе-
реписать так:
7 = 5”‘е, (2-16)
где В — та х /л0-матрица перекрестных произведений для остатков
т0 сопеременных пропусков после коррекции на матрицу плана X,
ар — вектор дгох1 взаимных произведений У и остатков сопере-
менных. Если В вырождена, значит, структура пропусков такова,
что мы пытаемся оценить параметры, которые невозможно оцени-
вать, например влияние обработки, когда все наблюдения для этой
обработки отсутствуют. Итак, требуется: 1) вычислить В и р по
39
программам дисперсионного анализа для полных данных; 2) обра-
тить В, чтобы вычислить -у по (2.16); 3) вычислить по (2.11) значе-
ния для пропусков.
Чтобы найти В и q , надо сначала провести дисперсионный ана-
лиз для сопеременной первого пропуска, т. е. в качестве зависимой
переменной использовать не Y, а первый столбец Z, в котором все
числа — нули, за исключением одной единицы, соответствующей
первому пропуску. Остатки для т0 пропусков, полученные в резуль-
тате, составят первую строку В. Будем повторять анализ для z'-й со-
переменной, z=l, ..., т0, в которой все нули, кроме единицы,
соответствующей z'-му пропуску, определяют остатки для пропусков
в качестве z-й строки В. Вектор q вычислим, проводя дисперсион-
ный анализ для Y по реальным данным вместе с начальными значе-
ниями 5\, z = 1, ..., т0. Остатки для т0 пропущенных значений
составят вектор q.
Эти процедуры работают в силу следующих причин: zy-й эле-
мент В равен:
где z,k и zlk (zjk и zjk) — присутствующее и подобранное при дис-
персионном анализе по X для z-й (у-й) сопеременной значения для
к-г о объекта. Для всех переменных X в матрице плана (zlk —
— z>k)xik ~ 0 вследствие элементарных свойств оценок наименьших
квадратов. Отсюда Y-[zlk — zlk)zjk = 0, так как zjk — фиксирован-
ная линейная комбинация переменных X, [х1к: 1=1, р}, для
к-ro объекта. Следовательно,
— Y<(zlk Zlk)Zjk — Zy Z,j
— остаток z-й сопеременной для у-го пропуска, поскольку zjk = l,
если j = к, и Z]k=®, если j # к. Аналогично у-я компонента р —
это сумма по всем п объектам остатков Y (у подставленными на-
чальными значениями), умноженная на остаток у'-й сопеременной.
Из выкладок, подобных только что приведенным, следует, что это
просто остаток у-й сопеременной.
Пример 2.I. Оценка пропущенных значений в плане с рандоми-
зированными блоками. Следующий пример с рандомизированными
блоками взят из [Cochran and Сох (1957), с. Ill; Rubin (1972,
1976b)]. Допустим, что отсутствуют два значения, ut и из, как пока-
зано в табл. 2.1. Примем модель (2.1) с семимерным параметром
i6, состоящим из пяти параметров — средних для пяти обработок и
40
двух параметров для эффектов блоков*. Средний квадрат остатков
формируется по взаимодействию обработка — блок с (5 — 1) х
х(3—1) = 8 степенями свободы при отсутствии пропусков.
Таблица 2.1. Значения показателя
прочности хлопкового волокна
в эксперименте с рандомизированными блоками
Обработка (фунты минеральных удобрений на акр) Блоки Суммы
1 2 3
36 «1 8,00 7,93 15,93
54 8,14 8,15 7,87 24,16
72 7,76 «2 7,74 15,50
108 7,17 7,57 7,80 22,54
144 7,46 7,68 7,21 22,35
30,53 31,40 38,55 100,48
Подставляя вместо пропусков общее среднее у" = 7,7292, нахо-
дим остатки для ячейки м1; —0,0798, и для ячейки и2, —0,1105. Сле-
довательно, q = —(0,0798, 0,1105)т. Вычислим также точную об-
щую сумму квадратов: TSS, = 1,1679.
Взяв для И) единицу, а для остальных объектов — нули, най-
дем, что остаток для ячейки Wj равен 0,5333, а для и2 он составляет
0,0667. Аналогично, взяв единицу для и2, найдем остатки: 0,0667 —
для И[, 0,5333 — для и2. Отсюда
’ 0,5333
В =
0,0667
0,06671 Г 1,9048
и =
0,5333 0,2381
—0,2381
1,9048
Оценки наименьших квадратов для пропущенных значений сле-
дующие:
(У, у) — В-1 Q = (7,8549, 7,9206)т.
Итак, оценки наименьших квадратов И| и w2 равны соответственно
7,8549 и 7,9206. Оценки наименьших квадратов для пропусков, дан-
ные Кокреном и Коксом, были получены итеративно и совпадают
с нашими значениями.
* /31 + 02 + /31 = 0. — Примеч. пер.
41
Оценки параметров, основанные на анализе заполненных дан-
ных, будут совпадать с оценками наименьших квадратов. Напри-
мер, верными оценками средних по обработкам будут просто
средние по обработкам присутствующих и подставленных значений
(7,9283, 8,0533, 7,8069, 7,5133, 7,4500). Далее, будет получена верная
остаточная сумма квадратов, а значит, и верный остаточный сред-
ний квадрат S1,, если из числа степеней свободы остатков п — р
вычесть число пропусков т0. Однако в общем случае суммы квадра-
тов и стандартные ошибки будут неверными.
2.7. ОЦЕНКИ НАИМЕНЬШИХ КВАДРАТОВ
СТАНДАРТНЫХ ОШИБОК И СУММ КВАДРАТОВ
С ОДНОЙ СТЕПЕНЬЮ СВОБОДЫ
Верные оценки наименьших квадратов стандартных ошибок и
сумм квадратов с одной степенью свободы можно получить с по-
мощью простого обобщения методов из раздела 2.6.
Пусть X = Ст/3 (где С — вектор из р констант) — линейная
комбинация /3 с оценкой £ = Ст/3, полученная в результате диспер-
сионного анализа по данным, заполненным по методу наименьших
квадратов. Поскольку были подставлены оценки наименьших ква-
дратов пропущенных значений, то 0 = /3. и, значит, X = X. — вер-
ная оценка наименьших квадратов X. Стандартная ошибка X,
полученная с помощью дисперсионного анализа по полным дан-
ным, равна:
SE = , (2.17)
а сумма квадратов, относящаяся к X, есть
X2
ss = (2Л8)
Правильная стандартная ошибка X = X. согласно разделу 2.5.4
представляет собой
SE = d.\rC4JC , (2.19)
а правильная сумма квадратов, относящаяся к X, —
г2 '
SS, = —, (2.20)
42
Пусть Н — вектор т0 х 1 оценок X, полученных с помощью
дисперсионного анализа для полных данных, при котором в каче-
стве зависимой переменной вместо У берут каждую из т0 сопере-
менных пропусков, т. е. в матричных обозначениях
Ят = СЧХТХУ-'ХТ/. (2.21)
Ясно, что Н можно вычислять одновременно с В: i-ю компо-
ненту Н и /-ю строку В получают из анализа для i-й сопеременной
пропусков. Теория ковариационного анализа или матричная алгебра
вместе с результатами из раздела 2.5.4 позволяют получить
CTL/C = + /ГВ-'Н. (2.22)
Выражения (2.17), (2.19), (2.21), (2.22) и равенство
<52 = а2 (л — p)/(w — р)
означают, что SE. можно просто выразить с помощью результа-
тов, традиционно вычисляемых при дисперсионном анализе для
полных данных:
SE. = V^^(SE2 + a2fTB-'H). (2.23)
т—р
Аналогично (2.18), (2.20) с X = X., (2.21) и (2.22) означают, что
можно также просто выразить SS.:
SS, = SS/[1 + (SS/X2)//1 В~ХН]. (2.24)
Пример 2.2. Уточнение стандартных ошибок при заполненных
пропусках (продолжение примера 2.1). Чтобы применить описан-
ный метод, требуется тй + 2 раз провести дисперсионный анализ
для полных данных: первый раз — для заполненного начальными
значениями У, по одному разу для каждой сопеременной и, нако-
нец, для заполненного по методу наименьших квадратов У Следуя
[Rubin (1976а)], рассмотрим данные из табл. 2.1 и линейную комби-
нацию, соответствующую сравнению обработок 1 и 2. В принятой
в примере 2.1 параметризации Ст = (1, —1, 0, 0, 0, 0, 0) и Х1Х —
блочно-диагональная матриц,а 7x7, в которой верхняя левая под-
матрица 5x5 диагональьа с элементами, равными 3. Тогда X —
просто разность среднего трех наблюдений для обработки 1 и сред-
него трех наблюдений для обработки 2 со стандартной ошибкой,
соответствующей полным данным, равной aV2/3, и суммой квадра-
тов ЗХ2/2.
43
Как в примере 2.1, сначала оценим оба пропуска общим сред-
ним и получим остатки р = —(0,0798, 0,1105) и верную общую сум-
му квадратов TSS. = 1,1679.
При I— 1, 2, ..., т0 для i-ro пропуска будем подставлять 1, а для
всех остальных значений — 0 и проводить анализ получаемой г-й
сопеременной пропусков с помощью программы дисперсионного
анализа для полных данных. Пусть г, — вектор остатков, соответ-
ствующий т0 пропускам, и h, — оценка исследуемой линейной
комбинации параметров. Тогда В = (г'г, г2\ как указано в примере
2.1, Л/1 = (Л,, й2) = (0,3333, 0,0000), и, следовательно, Н1B~lН =
= 0,2116.
Теперь заполним пропуски оценками наименьших квадратов,
найденными в примере 2.1 (7,8549, 7,9206), и проведем дисперсион-
ный анализ по заполненным данным. Получаем оценку X: X =
= —0,1250, 62 = 0,0368, SE = 0,1567, SS = 0,0235. Из (2.23) получа-
ем правильную стандартную ошибку X:
SE. = V(8/6) (0,0246 + 0,0368 - 0,2116) = 0,2077,
а из (2.24) — правильную сумму квадратов, относящуюся к X:
SS. = 0,0235/(1 + 1,5 0,2116) = 0,0178.
2.8. ВЫЧИСЛЕНИЕ СУММЫ КВАДРАТОВ
МЕТОДОМ НАИМЕНЬШИХ КВАДРАТОВ
ПРИ НЕСКОЛЬКИХ СТЕПЕНЯХ СВОБОДЫ
Обобщая метод из раздела 2.7, мы получаем возможность вы-
числять верные суммы квадратов с несколькими степенями свобо-
ды. Методы, изложенные здесь, рассмотрены в [Rubin (1976в)];
более ранние работы, посвященные этим проблемам, — [Tocher
(1952); Wilkinson (1968)], более поздняя — [Jarrett (1978)].
Пусть X = Ст3, где С — матрица р х w констант, определяю-
щих w линейных комбинаций /3, для-которых нужны суммы квадра-
тов, и пусть X, = Ст/3. — оценка наименьших квадратов X. Если
вместо пропущенных значений были подставлены их оценки на-
именьших квадратов, то 3 = 3. и поэтому X = X.. Для простоты
допустим, что были выбраны w ортонормальных при полных дан-
ных линейных комбинаций, т. е. что
^(А^АЭ-’С = I.
(2.25)
44
Таким образом, ковариационная матрица X при полных данных рав-
на аг1. Значит, сумма квадратов, относящаяся к X при полных дан-
ных, равна:
SS = ХТХ. (2.26)
Сумма квадратов, которую нам следует отнести к X, равна:
SS. = XlCC^t/O-'X.. (2.27)
Пусть Н — матрица т0 х w оценок X, полученных с помощью
дисперсионного анализа для полных данных по т0 сопеременным
пропусков. Из теории ковариационного анализа или матричной ал-
гебры вместе с результатами раздела 2.5.4 следует, что (2.22) вы-
полняется и в общем случае, поэтому вследствие ортонормальности
компонент X и равенства X = X. при оценивании пропущенных зна-
чений методом наименьших квадратов
SS. = Хт(/ + (2.28)
или, в силу тождества Вудбери [Rao (1965), с. 29] и (2.26),
SS. = SS — (ЯК)Т(ЯНТ + В)-'(НХ). (2.29)
Для уравнения (2.28) требуется обращение симметричной мат-
рицы w х w, а для (2.29) — матрицы т0 х т0. Следовательно,
(2.28) предпочтительнее (2.29) при w < т0.
Пример 2.3. Уточнение сумм квадратов при заполнении пропу-
сков (продолжение примера 2.2). Сумма квадратов для обработок
имеет 4 степени свободы, которые мы разложим по следующим ор-
тонормальным контрастам средних пяти обработок:
V J(4, -1, -1, -1, -1, 0, 0),
V ^(0, 3, -1, -1, -1, 0, 0),
V ^-(0, 0, 2, —1, —1, 0, 0),
V ^(0, 0, 0, 1, —1, 0, 0).
Заметим, что при полных данных линейные комбинации имеют
ковариационную матрицу а2/.
45
Значения четырех контрастов, полученных в результате диспер-
сионного анализа для сопеременной первого пропуска, дают первую
строку H, а в результате анализа для второй сопеременной — вто-
рую строку: 0,5164 0,0000 0,0000 0,0000
Н = —0,1291 —0,1667 0,4714 0,0000
Таким образом, Н вычислена одновременно с В.
Наконец, проводя дисперсионный анализ по данным, в которых
пропуски заполнены оценками наименьших квадратов, мы получим
SS = 0,8191, Хт = (0,3446, 0,6949, 0,4600, 0,0775). Из (2.29)
SS. = 0,7755.
Результаты г лунного анализа приведены в табл. 2.2, где
сумма квадратов 'я* *з коррекции на обработки) была по-
лучена вычитаю ”ов остатков для обпаботок и оши-
бок (0,7755 и С м’, ' мнений от
среднего), 1,16
Источи ж дисперсии
ки (без ’ .d ос ток)
ботки (с учето'м _ ия)
» 2
* 4 и,
б 0,2947
1,1679
7,5133, 7,4500
..cd 2 = —0,1250
Allan, F G, and Wishart, J (19 j j) A method of estimating the yield of a missing plot in field
experiments, J Agnc Sci 20, 399 406
Anderson. R L (1946) Missing plot techniques, Biometrics 2,41-47
Bartlett, M S (1937) Some examples of statistical method» of research in agriculture and applied
botany,./ Roy Statist Soc B4, 137-170
46
< ochran, W G, and Cox, G (1957) Experimental Design London Wiley
Davies, О L (1960) The Design and Analysis of Industrial Experiments New York Hafner
Draper, N R, and Smith, H (1981) Applied Regression Analysis New York Wiley
Hartley, H О (1956) Programming analysis of variance for general purpose computers, Biometrics
12, 110-122
Healy, M J R, and Westmacott, M (1956) Missing values m experiments analyzed on automatic
computers, Appl Statist 5, 203-206
Jarrett,R G (1978) The analysis of designed expenmen ts with missing observations, Appl Statist
27, 38-46
Kempthorne, О (1952) The Design and Analysis of Experiments New York Wiley
Pearce, S C (1965) Biological Statistics An Introduction New York McGraw-Hill
Preece, D A (1971) Iterative procedures for missing values in experiments, Technometrics 13,
743-753
2
Rao, C R (1965) Linear Statistical Inference New York Wiley
Rubin, D В (1972) A non-iterative algorithm for least squares estimation of missing values m
any analysis of variance design, Appl Statist 21,136-141
Rubin, D В (1976a) Inference and missing data (with discussion), Biometrika 63, 581-592
Rubin, D В (1976b) Non-iterative least squares estimates, standard errors and F-tests for any
analysis of variance with missing data, J Roy Statist Soc B38, 270-274
Snedecor.G W , and Cochran, W G (1967) Statistical Methods, Ames Iowa State University
Press
Tocher, К D (1952) The design and analysis of block experiments, J Roy Statist Soc B14,
45-100
Weisberg, S (1980) Applied Linear Regression New York Wiley
Winer, В J (1962) Statistical Principles in Experimental Design New York McGraw-Hill
Wilkinson, G N (1958a) Estimation of missing values for the analysis of incomplete data,
Biometrics, 14, 257-286
Wilkinson, G N (1958b) The analysis of variance and derivation of standard errors for in-
complete data, Biometrics, 14, 360-384
Yates, F (1933) The analysis of replicated experiments when the field results are incomplete, Emp
J Exp Agnc 1,129-142
ЗАДАЧИ
1. Познакомьтесь с литературой по дисперсионному анализу от [Allan and Wishart
(1930)] до [Jarrett (1978)]
2. Докажите, что 0 в (2 2) является а) оценкой наименьших квадратов, б) несме-
щенной оценкой с минимальной дисперсией, в) оценкой максимального правдоподо-
бия при нормальной модели Какими из этих свойств обладает <г ? Почему9
1 Русский перевод: Дрейпер Н., Смит Г. Прикладной регрессионный анализ.- М.: Финансы и
статистика. — Кн. 1, 1986; кн. 2, 1987.
Русский перевод: Рао С.Р. Линейные статистические методы и их применения. — М.: Наука,
1968.
47
3. Докажите, что (2.6) имеет /•’-распределение.
4. Приведите все возможные аргументы в пользу того, что метод Бартлета поз-
воляет получить верные оценки наименьших квадратов для пропущенных значений.
5. Докажите, что (2.12) следует из определения U~'.
6. Проведите промежуточные вычисления, ведущие к (2.13), (2.14) и (2.15).
7. Используя обозначения и результаты из раздела 2.5.4, докажите (2.16) и по-
стройте метод вычисления В и j, вытекающий из этих результатов.
8. Проведите вычисления, ведущие к результатам из примера 2.1.
9. Докажите (2.17)—(2.20).
10. Выведите (2.22), а затем (2.23) и (2.24).
11. Проведите вычисления, ведущие к результатам из примера 2.2.
12. Проведите вычисления, ведущие к результатам из примера 2.3.
13. Выполните стандартный дисперсионный анализ для следующих данных, где 3
значения удалены из латинского квадрата [см. Snedecor and Cochran (1967), с. 313]:
Сборы проса (в граммах) с участков в латинском квадрате*
Строка Столбец
1 2 3 4 5
1 В: — Е: 230 А: 279 С: 287 D: 202
2 D: 245 А: 283 Е: 245 В: 280 С: 280
3 Е: 182 В: — С: 280 D: 246 А: 250
4 А: — С: 204 D: 227 Е: 193 В: 259
5 С: 231 D: 271 В: 266 А: 334 Е: 338
* Интервалы (в дюймах): А — 2; В — 4; С — 6; D — 8; Е — 10.
Глава 3. БЫСТРЫЕ МЕТОДЫ ОБРАБОТКИ
МНОГОМЕРНЫХ ДАННЫХ С ПРОПУСКАМИ
3.1. ВВЕДЕНИЕ
В гл. 2 обсуждался анализ данных с пропусками только в одной
выходной переменной К линейно зависящей от полностью наблю-
даемых предикторных переменных. В этой главе мы рассмотрим
три быстрых метода решения более общей задачи, когда пропуски
48
содержатся в нескольких переменных: анализ комплектных наблю-
дений, анализ доступных наблюдений и простые методы заполне-
ния. В [Afifi and Elashoff (1966)] приведен обзор более ранних работ
по пропускам, содержащий описание некоторых из обсуждаемых
здесь методов. Хотя эти методы включены в статистическое про-
граммное обеспечение и широко используются, мы в целом не реко-
мендуем применять какой-либо из них, за исключением частных
случаев, когда доля пропусков ограничена. Методы, описанные в
части II настоящей книги, обеспечивают более обоснованные реше-
ния в более общих условиях.
Рассмотрим прямоугольную матрицу данных Y = (д,), где у^ —
значение переменной Yj для /-го наблюдения, i = 1, ..., п, J = 1,
..., К. При отсутствии пропусков многие виды многомерного стати-
стического анализа основаны на начальном сведении данных к век-
тору выборочных средних у = (уь ..., ук) и выборочной
ковариационной матрице S = (sJk), где sjk = (и — I)-1 х Б (у^ —
— У^(У1к— УД Таким образом, при наличии пропусков'важно
уметь вычислять у~ и S. Мы рассмотрим быстрые методы анализа
данных с пропусками в основном для этой задачи.
Как было подчеркнуто в гл. 1, свойства любого метода обра-
ботки пропусков сильно зависят от механизма порождения пропу-
сков. За исключением особо оговоренных случаев, методы этой
главы непригодны, когда выполняется только условие ОС, а не
ОПС (напомним, что условие ОС означает зависимость пропусков
от наблюдаемых, а не от отсутствующих данных). Напротив, мето-
ды из части II, основанные на правдоподобии, применимы при ме-
нее жестком условии ОС, что очень существенно для многих
практических приложений.
3.2. АНАЛИЗ КОМПЛЕКТНЫХ НАБЛЮДЕНИЙ
Обработка данных по полным (комплектным) наблюдениям
сводится к использованию только тех наблюдений, в которых при-
сутствуют все К переменных. Достоинства этого подхода состоят в
1) его простоте, так как можно непосредственно применять стан-
дартные методы анализа для полных данных, и 2) сравнимости од-
номерных статистик, так как все они вычисляются по одному
множеству наблюдений. Недостатки такого подхода обусловлены
потерей информации при исключении неполных наблюдений.
Уменьшение объема данных может быть значительным, особенно
49
при больших К. Например, если К = 20 и пропуск каждой пере-
менной происходит независимо по закону Бернулли с 10%-ной ве-
роятностью потери данных, то ожидаемая доля полных наблюде-
ний равна 0,920 = 0,12, и, значит, будет использовано только
0,12/0,9 = 0,13, т. е. 13% присутствующих данных.
Очень важен вопрос — ведет ли выбор комплектных наблюде-
ний к смещениям выборочных оценок. При условии ОПС, введенном
в разделе 1.4, выборка полных наблюдений является простой случай-
ной подвыборкой исходной выборки, и исключение неполных данных
не приводит к смещению оценок. Однако, как правило, полностью
зарегистрированные наблюдения существенно отличаются от выбор-
ки в целом. Например, при выборочном обследовании те, кто не
прошел последующее обследование, часто чем-то отличаются от тех,
кто проходит дальнейшее обследование. В таких случаях анализ по
полным данным может привести к сильно смещенным результатам.
Природа этих смещений зависит от механизма порождения
пропусков, дающих неполные наблюдения, и от особенностей обра-
ботки. Рассмотрим простой пример, когда К = 2, где Y{ (возраст)
и Y2 (доход) — две регистрируемые переменные. Допустим, что мо-
гут отсутствовать и Yit и У2 и что пропуски зависят только от У2,
но не от У1. Точнее, РгСУн отсутствует, yi2 присутствует I yj{,
yj2) = *>01 (Уц)', Рг(-У1 присутствует, yi2 отсутствует | уа,
yi2) = ^ю(У/2) и Рг0’/1 и Ун присутствуют I у;1, yi2) = 1 —
— Р01 (Уа) — ^ю(У/2)> где ^10 и ^01 — функции от j>,2, но не от уа.
Допустим, ЧТО <£>01 И ^10 таковы, что пропуски при низких и при вы-
соких доходах более вероятны, чем при средних доходах. Тогда
частные распределения возраста и дохода искажены чрезмерно
большой долей наблюдений, соответствующих людям со средним
доходом. Оценки коэффициента корреляции между У и К2 и пара-
метров регрессии У] на У2 по полным наблюдениям также смеще-
ны. С другой стороны, для линейной регрессии У] на У2 не будет
смещений, обусловленных извлечением подвыборки, поскольку вы-
бор связан только с независимой переменной У2, но не с зависимой
переменной Уь Для некоторых задач приемлемы даже менее сла-
бые условия на зависимость между пропусками и значениями пере-
менных. Например, если и У2 — дихотомические признаки и
требуется сделать выводы об отношении шансов* в частотной таб-
лице 2x2, полученной по У] и У2, то анализ комплектных наблю-
дений не приведет' к смещениям, если логарифм вероятности
присутствия значения — аддитивная функция У[ и У2 [см. Klein-
baum, Morgenstern and Kupper (1981)].
* С отношением шансов (как мерой связи в таблицах 2x2) можно познако-
миться по книге Дж. Флейса «Статистические методы для изучения таблиц долей и
пропорций». — М.: Финансы и статистика, 1989. — Примеч. пер.
50
Информацию, которая содержится в исключенных неполных
наблюдениях, можно использовать для того, чтобы исследовать,
являются ли полные наблюдения случайной подвыборкой исходной
выборки, т. е. допустимо ли предположение ОПС. Простой способ
проверки этой гипотезы — сравнить распределение отдельной пере-
менной Yj для полных наблюдений с распределением для тех не-
полных наблюдений, в которых присутствует Y. Объемы выборок
часто настолько малы, что возможно сравнивать лишь характери-
стики типа средних, как в программе BMDP8D [см. Dixon (1983)].
Значимое различие указывает на то, что условие ОПС неприемлемо
и что анализ по полным наблюдениям приводит к смещенным
оценкам. Такие тесты полезны, но они ограничены по мощности,
когда выборка для неполных наблюдений мала. К тому же такие
тесты не могут непосредственно подтверждать справедливость ус-
ловия ОС.
Для уменьшения смещений при выборе полных наблюдений
применяют метод, при котором перед обработкой каждому полно-
му наблюдению присваивают некоторый вес. Такой способ особен-
но распространен в выборочных обследованиях, в частности при
анализе с полным отсутствием данных о части объектов, т. е. когда
объекты не участвовали в обследовании. При присваивании весов
можно использовать информацию, известную как об опрошенных,
так и о неопрошенных, например данные о месте проживания. Спо-
соб выбора подходящих весов мы обсудим в гл. 4.
3.3. МЕТОДЫ ДОСТУПНЫХ НАБЛЮДЕНИЙ
Анализ по полным наблюдениям, видимо, не имеет смысла в
одномерном случае, например при оценивании средних и маргиналь-
ных частотных распределений, так как значения для отдельного
признака исключаются, если они относятся к наблюдениям, в кото-
рых отсутствуют другие переменные. Естественным выходом при
анализе одной переменной является обработка по всем наблю-
дениям, в которых присутствует интересующая нас переменная.
Этот способ мы будем называть методом или анализом доступ-
ных наблюдений (available-case analysis). При таком способе ана-
лиза данных используются все имеющиеся значения. Его недо-
статок заключается в том, что совокупность наблюдений, по кото-
рым строится выборка, меняется от признака к признаку в соот-
ветствии с матрицей пропусков. Как известно многим исследова-
51
телям, имеющим дело с большими объемами данных, это обстоя-
тельство создает затруднения на практике, особенно когда вычисле-
ния ведутся для нескольких различных выборок (например, все
женщины, женщины, состоящие или состоявшие в браке, и замуж-
ние женщины — при демографическом обследовании рождаемости).
Исследователю хотелось бы иметь выборки постоянного объема,
чтобы проверять правильность формирования разнообразных таб-
лиц для вычислений. Изменение числа наблюдений, по которым
строится выборка, при анализе доступных наблюдений затрудняет
проведение таких простых проверок, а также создает трудности при
сравнении признаков, если отсутствие данных — функция значений
изучаемых признаков, т. е. если данные не ОПС.
Для вычисления оценок средних и дисперсий при ОПС можно
применять описанную процедуру, но для вычисления таких мер за-
висимости, как коэффициенты корреляции и ковариации, требуются
модификации. Естественным обобщением метода доступных на-
блюдений в многомерном случае являются парные методы доступ-
ных наблюдений, когда мера зависимости между Y- и Yk
вычисляется по наблюдениям i, для которых присутствует и у^, и
yjk. В частности, можно вычислять парные ковариации:
4к} (3.1)
где nW — число наблюдений, в которых одновременно присут-
ствуют Yj и Yk, а средние у j , у к и сумма в (3.1) вычисляются
по этим наблюдениям. Обозначим выборочные диспер-
сии у - и ук по доступным наблюдениям. В сочетании с sjk они
позволяют получить следующую оценку корреляции:
г-, = <>/V4i4). (з.2)
Недостаток оценки (3.2) состоит в том, что rjk может оказаться
вне отрезка [—1, 1] в отличие от истинной корреляции. Это затруд-
нение можно обойти, вычисляя парные корреляции по оценкам дис-
персий, полученным по той же подвыборке наблюдений, что и ко-
вариации:
(3.3)
52
(акая оценка обсуждается в [Matthai (1951)]. Она соответствует сле-
дующей оценке ковариации:
s'jk = ГТ (3.4)
Можно получить еще несколько вариантов оценок, заменяя средние
в (3.1)—(3.4) их оценками по всем доступным наблюдениям. Приме-
няя такой способ к (3.1), получим оценку
= Е/Л; -y^(yjk -y^/(nW _ 1), (3.5)
которая называется ALLVALU-оценкой в программе BMDP8D [см.
Dixon (1983)]. Она рассматривается также в [Wilks (1932)].
В парных оценках по доступным наблюдениям типа (3.1)—(3.5)
делается попытка сохранить часть информации, содержащейся в не-
комплектных наблюдениях и теряющейся при анализе полных на-
блюдений. При ОПС уравнения (3.1)—(3.5) дают возможность по-
лучить состоятельные оценки ковариаций и корреляций по отдель-
ности. Однако если рассматривать их в совокупности, то выяснит-
ся, что они обладают недостатками, сильно снижающими их
практическую применимость.
Как мы уже отметили, с помощью (3.2) можно найти для кор-
реляции значения, находящиеся вне допустимых границ. С другой
стороны, (3.3) всегда дает значения, лежащие между —1 и +1. При
К 3 переменных оба выражения (3.2) и (3.3) могут дать оценку
корреляционной матрицы, не являющуюся положительно опреде-
ленной. Рассмотрим крайний случай с 12 значениями для трех пере-
менных (— обозначает пропуск):
У,: 1 2 3 4 1 2 3 4 — — — —
У,: 1 2 3 4 — — — — 1 2 3 4
У3: — — — — 1 2 3 443 2 1
Из выражения (3.3) получим г^ = 1, r™ = 1, г’^3’ —1. Эти оценки
явно неприемлемы, поскольку из Согг (У3, У2) = Corr (Ун У2) = 1
следует Corr (У2, К3) = 1, а не —1. Аналогично ковариационные
матрицы, получаемые в (3.1) или (3.4), не обязательно положитель-
но определены. Для многих способов анализа, опирающихся на ко-
вариационную матрицу, включая множественный регрессионный
анализ, нужны положительно определенные ковариационные мат-
рицы. В связи с этим необходимы специальные модификации об-
суждаемых методов, когда это условие не удовлетворено.
53
Поскольку в методах доступных наблюдений используются все
данные, можно ожидать, что они будут лучше методов полных на-
блюдений. Это заключение подтверждается экспериментально в
[Kim and Curry (1977)] для ситуации, когда данные ОПС и корреля-
ции невелики. Другие эксперименты, однако, показывают превос-
ходство метода полных наблюдений при больших коэффициентах
корреляции [см. Haitovsky (1968); Azen and Van Guilder (1971)]. Ни
один из этих методов, тем не менее, не является удовлетворитель-
ным в общем случае.
3.4. ЗАПОЛНЕНИЕ ПРОПУСКОВ
3,4.1. Введение
В методах полных наблюдений и доступных наблюдений дан-
нь’“ с пропусками У, не используются при оценивании маргиналь-
I о распределения Y} или мер связи (корреляции) между Y, и
ругими признаками. Допустим, что в наблюдении с пропущенным
Y присутствует значение переменной Yk, сильно коррелирующей с
Yj. Естественно попытаться предсказать значение Уу по Yk и затем
включить эту подстановку (или заполненный пропуск) в анализ по
переменной У.
Заполнение — это общий и гибкий метод решения задач при на-
личии пропусков в наблюдениях. Тем не менее ему присущи недо-
статки. В [Dempster and Rubin (1983)] отмечается: «Идея заполнения
и соблазнительна, и опасна. Исследователь может успокоиться и
прийти к приятному выводу, что в конце концов его данные не со-
держат пропусков. Опасность этого подхода в том, что он не позво-
ляет отличать ситуации, где задача не очень трудна и может быть
корректно решена таким способом, от ситуаций, где обычные оцен-
ки по реальным и подставленным данным сильно смещены». В раз-
деле 3.4 мы обсудим некоторые простые методы заполнения и за-
дачу оценивания среднего и ковариационной матрицы У, ..., У* по
заполненным данным.
3.4.2. Заполнение безусловными средними !
Самый простой вид заполнения — это оценка отсутствующих
значений у средним уу по присутствующим значениям перемен-
ной Y . Ясно, что среднее наблюдаемых и подставленных значений
равно у У’', оценке методом доступных наблюдений. Дисперсия на-
блюденных и подставленных значений равна [(nW — 1)/ (п — 1)1 У/ >
54
где Sj’ — оценка дисперсии методом доступных наблюдений. При
условии ОПС s^j — состоятельная оценка истинной дисперсии,
так что выборочная дисперсия для данных после заполнения — за-
ниженная в (п^— 1)/(л— 1) раз оценка дисперсии. Это заниже-
ние — естественное следствие заполнения пропусков значением в
центре распределения. Выборочная ковариация Y и Yk по запол-
ненным данным равна [(и^к>— 1)/(л— гДе опреде-
лена с помощью уравнения (3.5). Поскольку s jk) — состоятельная
оценка ковариации при ОПС, оценка по заполненным данным зани-
жает ковариацию в (nyfc> — 1)/(« — 1) раз. Значит, несмотря на
положительную полуопределенность оценки ковариационной матри-
цы по заполненным данным, дисперсии и ковариации оцениваются
смещенно с занижением*. Очевидные поправки для дисперсии и
ковариации Yj и Yk, (п — 1)/(л<Л— 1) и (п — \)/ (nW — 1) соот-
ветственно, дают оценки (3.5), в общем случае неудовлетворитель-
ные, как указано в разделе 3.3.
3.4.3. Заполнение условными средними.
Метод Бака
Более перспективным способом заполнения пропусков выгля-
дит подстановка средних, условных по присутствующим в наблюде-
нии переменным. Если переменные Yt, Yk распределены по
многомерному нормальному закону со средним ц и ковариационной
матрицей Е, то регрессия пропущенных значений в данном наблю-
дении линейна по присутствующим значениям с коэффициентами,
которые являются хорошо известными функциями от ц и Е. В ме-
тоде, предложенном Баком [см. Buck (I960)], сначала оценивают ц
и Е выборочными средним и ковариационной матрицей по полным
наблюдениям, а затем используют эти оценки для вычисления ли-
нейной регрессии пропущенных переменных по присутствующим
для каждого наблюдения. Подставляя значения переменных, при-
сутствующих для данного наблюдения, в регрессионное уравнение,
получаем прогноз пропущенных переменных для этого наблюдения.
* Действуя в том же духе, можно показать, что оценки коэффициентов корреля-
ции также смещены (завышены), хотя их (относительное) смещение меньше. — При-
меч. пер.
55
Вычисление регрессионных уравнений для различной структуры
пропусков может показаться затруднительным, но на деле оно от-
носительно просто, если использовать оператор свертки, обсуждае-
мый в разделе 6.5.
Метод Бака для двух переменных проиллюстрирован на рис.
3.1. Точки, отмеченные знаком +, соответствуют наблюдениям с
обеими присутствующими переменными. По этим точкам методом
наименьших квадратов вычисляются прямые регрессии Уг на Уь
- —(c) —(c) —(c),
скажем у2 = у г + V 2, (г, — у , ), где индекс с означает полные на-
блюдения. Наблюдения с присутствием yf и пропуском У2 пред-
ставлены кружочками на оси УУ Бак заменяет их точками,
лежащими на прямой регрессии. Если бы наблюдения были с про-
пусками У1 и присутствием У2, то после заполнения они расположи-
лись бы на прямой регрессии Yt
диаграмме.
Рис. 3.1. Метод Бака для двух переменных
на У2 — другой прямой на
Средние по присутствую-
) щим и подставленным с по-
мощью этого метода значе-
ниям — состоятельные оцен-
ки средних при ОПС и сла-
бых предположениях отно-
сительно моментов распре-
деления [см. Buck (I960)].
Они состоятельны, когда ме-
ханизм порождения зависит
от наблюдаемых перемен-
ных, хотя в этом случае для состоятельности оценок нужны допол-
нительные условия. Допустим, для данных на рис. 3.1 присутствие
Уг зависит от У, так, что выполняется условие ОС, несмотря на то,
что распределение У] для полных и неполных наблюдений различ-
но. В методе Бака неполные наблюдения проецируются на регресси-
онную прямую. При этом используется предположение о
линейности регрессии У2 на У1. Это предположение особенно со-
мнительно, если заполнение включает экстраполяцию за границы
для полных данных, как для двух неполных наблюдений с наиболь-
шим и наименьшим значениями У, на рис. 3.1.
Данные, заполненные по методу Бака, обеспечивают разумные
оценки средних, в частности, если приемлемо предположение о нор-
мальности наблюдений. Выборочная ковариационная матрица по
заполненным данным занижает величину дисперсий и ковариаций,
хотя и не так сильно, как при подстановке безусловных средних.
56
Рассмотрим, например, выборочную дисперсию Y2, полученную по
заполненным данным на рис. 3.1. Выражая дисперсию У2 как сумму
дисперсии среднего У2 при фиксированном У, и ожидаемой диспер-
сии У2 при заданном YIt получаем
= /321 а! 1 + а22.1,
где /321 = ап/а\\ — коэффициент регрессии У2 на У, 022laIt — часть
дисперсии, объясняемая регрессией У2 на Уи a a2i-i — остаточная
дисперсия. Разброс подставляемых значений У2 включает компонен-
ту дисперсии /32] ап, но при этом приравнивает компоненту a22-i ну-
лю, поскольку подставляемые значения лежат точно на прямой.
Следовательно, выборочная дисперсия У2, вычисленная по реаль-
ным значениям вместе с подставленными значениями, смещена и
занижает сг22 на (п — п^)(п — 1)—’cr22.i, где (л — и<2>) — число
пропусков У2. Заметим, что величина смещения мала, когда У дает
хороший прогноз У2 в том смысле, что а22ч мало по сравнению с
а22. Однако смещение не стремится к нулю при увеличении п, если
только доля пропусков не стремится к нулю, т, е. эта оценка а22,
как правило, несостоятельна.
В общем случае выборочная дисперсия по данным, за-
полненным по методу Бака, — оценка а у, заниженная на
(я — I)-1 Eayy.obs ,, где ayy.obSj, — остаточная дисперсия от регрессии
У: на присутствующие в наблюдении i переменные, когда пропу-
щен, и нуль, когда у^ присутствует. Выборочная ковариация Уу и
Yk смещена на (л — 1)—1 Ea7)t.obs Здесь ад.оЬ51— остаточная кова-
риация Yj и Yk от многомерной регрессии У,., Yk на присутствую-
щие в наблюдении переменные, когда пропущены и yjk, и нуль
— в противном случае. Состоятельную оценку S можно получить
при условии ОПС, подставляя состоятельные оценки 0y7.obs,; и
y-^.obs, i (например, оценки, вычисленные, если позволяет объем вы-
борки, по выборочной ковариационной матрице для полных наблю-
дений) в выражения для смещений, а затем добавляя полученные
величины к выборочной ковариационной матрице для заполненных
данных. Этот метод тесно связан с одной итерацией алгоритма для
метода максимального правдоподобия, описанного в разделе 8.2, и
в отличие от поправок на заполнение безусловными средними он не
сводится к оценкам доступных наблюдений из раздела 3.3.
57
На первый взгляд кажется, что для регрессионного заполнения
методом Бака нужно, чтобы переменные У,, Yk измерялись на’
интервальной шкале. Однако этот метод можно применить и к ка-
тегориальным переменным, заменяя каждую из них набором фик-
тивных переменных, причем их число на единицу меньше числа
категорий. Если категориальная переменная присутствует полнос-
тью, то при методе Бака фиктивные переменные входят в регресси-
онное уравнение только как независимые переменные, и проблем не
возникает. Если часть ее значений пропущена, то набор фиктивных
переменных будет входить в регрессии и как зависимые перемен-
ные. Тогда подстановки по регрессии — это линейная оценка веро-
ятности попадания в категорию, представленную фиктивной пере-
менной. Здесь трудности могут возникать из-за того, что для про-
гноза этих вероятностей используется линейная регрессия, а значит,
предсказанные значения могут выйти за пределы (0, 1). Следова-
тельно, применимость метода Бака ограничена при наличии катего-
риальных данных.
3.4.4. Другие подходы
Если мы примем условие ОПС и будем пренебрегать разбросом
оценок /I и Б по полным наблюдениям, то условные средние из раз-
дела 3.4.3 будут наилучшими точечными оценками пропущенных
значений в смысле минимизации ожидаемой квадратичной ошибки.
Однако, как мы видели, даже в этих условиях для состоятельности
оценок дисперсии по заполненным данным требуются поправки.
Вообще говоря, маргинальные распределения для заполненных дан-
ных искажаются при подстановке средних. Влияние этих искажений
особенно сильно, когда исследуются «хвосты» распределений или
стандартные ошибки оценок. Например, при подстановке условных
средних вместо пропущенных данных о доходе следует ожидать за-
нижения доли людей, чей доход за чертой бедности.
Эти обстоятельства служат основанием для поиска другого
подхода, когда подстановки выбираются случайным образом из
всего распределения допустимых значений, а не из его центра. Один
из путей реализации этой идеи — добавление к условному среднему
подходящих возмущений. Методы такого типа часто используются
в выборочных обследованиях. Мы отложим их обсуждение до гл. 4
и 12.
58
В целом трудно рекомендовать какой-либо из обсуждавшихся
простых методов, поскольку 1) они ненадежны; 2) для них часто
требуется введение специальных поправок, чтобы получить удов-
летворительные оценки; 3) трудно определить ситуации, когда эти
методы приемлемы, а когда — нет. Кроме того, с помощью этих
методов нельзя получить простые верные решения, если требуется
установить точность оценок, как при интервальном оценивании. В
гл. 2 мы видели это в частном случае пропусков в одной пере-
менной.
Главной целью этой книги (гл. 5—12) является целостное описа-
ние методов обработки данных с пропусками, основанных на пост-
роении статистической модели порождения данных и пропусков.
Методы, базирующиеся на этой теории, надежны в том смысле,
что в четко оговоренных условиях они обладают оптимальными
статистическими свойствами, по меньшей мере асимптотически.
Эти методы не требуют специальных поправок ни для точечных, ни
для интервальных оценок, и ситуации, в которых они применимы,
явно задаются описанием моделей. На практике мы редко знаем
точную модель, поэтому можно пытаться перебирать различные
модели.
ЛИТЕРАТУРА
Afifi, A. A., and Elashoff, R. М. (1966). Missing observations in multivariate statistics I:
Review of the literature, J. Am. Statist. Assort. 61, 595-604.
Azen, S., and Van Guilder, M. (1981). Conclusions regarding algorithms for handling incomplete
data, Proceedings oj the Statistical Computing Section, American Statistical Association 1981.
53 56.
Buck, S. F. (1960). A method of estimation of missing values in multivariate data suitable for
use with an electronic computer, J. Roy. Statist. Soci. B22, 302-306.
Dempster, A. P., and Rubin, D. B. (1983). Overview, in Incomplete Data in Sample Surveys, Vol.
II: Theory and Annotated Bibliography (W. G. Madow, 1. Olkin, and D. B. Rubin, Eds.).
New York: Academic Press, 3-10.
Dixon, W. J. (ed.), (1983). BMDP Statistical Software, 1983 revised printing, Berkeley: Univer-
sity of California Press.
Haitovsky, Y. (1968). Missing data in regression analysis. J. Roy. Statist. Soci. B30. 67-81.
Kim, J. O., and Curry, J, (1977). The treatment of missing data in multivariate analysis,” Social.
Meth. Res. 6, 215-240.
Kleinbaum, D. G., Morgenstern, H., and Kupper, L. L. (1981). Selection bias in epidemiological
studies. American Journal of Epidemidogy, 113,452-463.
Matthai, A. (1951). Estimation of parameters from incomplete data with application to design
of sample surveys. Sttnkhya, 2, 145-152.
Wilks, S. S. (1932). Moments and distribution of estimates of population parameters from
fragmentary samples, Annals oj Mathematical Statistics 3, 163-195.
59
ЗАДАЧИ
1. Укажите несколько видов традиционного статистического анализа, основанных
на выборочных средних, дисперсиях и корреляциях.
2. Покажите, что выборочная регрессия У! на У2, основанная на полных наблюде-
ниях, дает несмещенные оценки параметров регрессии, если пропуски зависят только
от У, и регрессия У, на У2 линейна.
3. Покажите, что для дихотомических признаков У, и У2 выборочное отношение
шансов по полным данным — состоятельная оценка отношения шансов в популяции,
если логарифм вероятности пропуска имеет вид ^ДУ,) + Фг(Уг)-
4. Постройте набор данных, для которого оценка корреляции (3.2) находится вне
интервала (—1, 1).
5. а) Почему оценка корреляции (3.3) всегда находится между —1 и 1? б) До-
пустим, что в (3.1) средние у у и у заменены оценками по методу доступных
наблюдений. Всегда ли при этом получаемые в (3.3) оценки корреляции лежат в ин-
тервале (—1, 1)? Докажите это или приведите контрпример.
6. Сравните достоинства и недостатки методов полных наблюдений и доступных
наблюдений при оценивании а) средних, б) корреляций, в) коэффициентов регрессии,
когда не выполняется ОПС.
7. Познакомьтесь с результатами работ [Haitovsky (1968); Kim and Curry (1977);
Azen and Van Guilder (1981)]. Опишите ситуации, когда анализ полных наблюдений
более чувствителен, чем анализ доступных наблюдений, и наоборот.
8. Докажите утверждение из раздела 3.4.4, предполагая ОПС и пренебрегая выбо-
рочным разбросом оценок, что заполнение условными средними минимизирует ожи-
даемую квадратичную ошибку прогноза подстановки.
9. Рассмотрите двумерную выборку объема 45 с 20 полными наблюдениями, 15 на-
блюдениями с присутствием только У, и 10 наблюдениями с присутствием только
У2. Пропуски заполняются безусловными средними, как в разделе 3.4.2. Определите
в предположении ОПС смещение (в процентах) оценок следующих величин, получен-
ных по заполненным данным; а) дисперсии KJcrn), б) ковариации У, и У2(от2), в) ко-
эффициента регрессии У2 на У1(т12/тц). Для в) можно пренебречь в смещении
членами порядка 1/п.
10. Рассмотрите предыдущую задачу, когда пропуски заполняются по методу Бака,
и сравните ответы.
11. Опишите условия, в которых метод Бака явно лучше метода полных наблюде-
ний и метода доступных наблюдений.
12. Предположим, что наши данные — случайная выборка по У, и У2 с пропуска-
ми, где У, распределен по N(ni, л2,), У2 распределен по N(0O + (3, У, + 82У2, о2#1)
при заданном и 6 = (mi, <Гр /?1, <г2.,) Данные ОПС, первые т наблюдений —
полные, г.. наблюдений содержат только У,, а г, — только У2. Рассмотрите свойства
метода Бака, применяемого к а) У, и У2, б) У,, У2 и У, = У2, при вычислении оце-
нок 1) безусловных средних £ (У, j 6) и Е(У2 ) 9); 2) условных средних £(У, | У2, 9),
Е(У2 | У2, 9) и Е(Уг | У,, 9).
13. Покажите, что метод Бака дает состоятельные оценки средних, если выполня-
ется ОПС и распределение переменных имеет конечные четвертые моменты.
14. Выведите приведенные в разделе 3.4.3 выражения для смещений оценок и
ад при методе Бака.
60
Глава 4. ПРОПУСКИ В
ВЫБОРОЧНЫХ ОБСЛЕДОВАНИЯХ
4.1. ВВЕДЕНИЕ
Проблема неполных данных в выборочных обследованиях от-
личается от проблем, которые мы рассматривали в гл. 2 и 3, по
двум главным аспектам. Во-первых, изучаемая популяция (явно) ко-
нечна, и поэтому оцениваемые величины, например средние или
суммы, в популяции часто являются характеристиками конечной по-
пуляции. Во-вторых, при проведении анализа определяющее значе-
ние традиционно имеет метод сбора данных. В большинстве работ
по пропускам в выборочных обследованиях принят рандомизацион-
ный* подход к выводам, когда параметры популяции считаются
фиксированными и выводы строятся исходя из распределения, соот-
ветствующего методу извлечения выборки. В отличие от этого под-
хода выводы, рассматриваемые в гл. 5—12 этой книги, основаны на
статистической модели для значений переменных, и метод получе-
ния. выборки «участвует» в анализе, лишь косвенно влияя на выбор
моделей. Эту главу мы начнем с показа различия между двумя эти-
ми подходами как для полных данных, так и для данных с пропу-
сками. Затем обсудим общепринятые методы обработки пропусков,
широко обсуждаемые в литературе по подходу от рандомизации.
Более полное изложение проблемы пропусков данных в обследова-
ниях с точки зрения и рандомизации, и моделирования см. в
[Madow, Olkin, Nisselson and Rubin (1983), т. 2].
4.2. РАНДОМИЗАЦИОННЫЕ ВЫВОДЫ ДЛЯ ПОЛНЫХ ДАННЫХ
Допустим, что требуется сделать выводы о популяции, состоя-
щей из N объектов или индивидуумов, и пусть Y = (уу), где
у, = (у„, ..., ylk) представляет вектор из к признаков для объекта
i, i = 1, ..., N. Определим для i-го объекта индикаторную функцию:
* В оригинале — randomization mode of inference. Мы вводим термин рандоми-
зационный, чтобы избежать возможной путаницы между обсуждаемым в книге под-
ходом к построению выводов в выборочном обследовании, рандомизированными
выводами (критериями) и рандомизированными планами (экспериментами). — При-
меч. пер.
61
1, г-й объект включен в выборку,
' j 0 — в противном случае
и
* I = (Ц, iNy.
Пусть множество inc = [z 11, = 1}. Процесс извлечения выборки
можно характеризовать распределением I при заданном Y. Напри-
мер, простой случайный выбор при выборке объема п определяется
распределением
17м-| *
Н п J , если Е7, - п,
f(I\Y) = f(I) = !
10 — в противном случае,
где (^) — число сочетаний, в которых п единиц можно извлечь из
популяции.
При простом случайном выборе определение того, какие едини-
цы выбирать, не опирается на априорную информацию о популя-
ции. В более эффективных планах такая информация используется,
если она доступна. Например, может оказаться, что популяция раз-
делима на слои (страты), в которых объекты относительно одно-
родны. Тогда можно проводить расслоенный (стратифицирован-
ный) случайный выбор. Из у-го слоя с N, единицами извлекают пу-
тем простого случайного выбора лу объектов. В итоге получается
выборка с объемом п = Е п . В более общем случае используется
J=1 J
матрица Z = (т,у), в которой /я строка z, представляет информа-
цию об i-м объекте, известную до начала обследования и используе-
мую в плане обследования. Например, при расслоенном выборе z,
указывает слой, к которому относится z-й объект. Выборочное рас-
пределение в таких планах определяется условным распределением
7 при заданных Y и Z, которое мы будем обозначать f(l\ Y, Z).
Рапдомизационные выводы в общем случае требуют, чтобы
объекты извлекались путем случайного выбора, который характери-
зуется следующими двумя свойствами:
1) выборочное распределение задается исследователем до того,
как станет известно хотя бы одно значение у. Точнее, /(71 Y, Z) =
= /(71 Z), так как распределение не может зависеть от неизвестных
значений Y, которые надо получить в обследовании;
62
2) для каждого объекта существует положительная (известная)
вероятность извлечения. Обозначим тг, = 2?(Л ] Y, Z) = Рг(/; =
= 1 | Y, Z), тг, > О для всех I. При равновероятном плане выбора,
таком, как простой случайный выбор, эта вероятность одинакова
для всех объектов.
Цель состоит в оценивании характеристик конечной популяции,
таких, как среднее Y переменной Y, выборочными величинами, та-
кими, как выборочное среднее. Выводы основываются на распреде-
лении выборочных величин при повторном выборе из
распределения I, f(I \ Z). Подробное описание рандомизационных
выводов можно найти в книгах по теории выборочных обследова-
ний, например в [Cochran (1977), Hansen, Hurwitz and Madow
(1953)]. Вкратце: при построении выводов о параметре популяции Т
совершают следующие шаги:
а) выбирают статистику ЦУШС), функцию выборочных значе-
ний Утс, которая представляет собой (приближенно) несмещенную
при повторном выборе оценку Т. Например, если Т - Y — среднее
популяции, то t может быть выборочным средним у, которое яв-
ляется несмещенной оценкой Y при равновероятном выборе;
б) выбирают статистику 4ЦУ1ПС), которая является (приближен-
но) несмещенной оценкой дисперсии ЦУ1ПС) для повторного выбо-
ра. Например, можно показать, что для простого случайного
выбора дисперсия выборочного среднего есть
Var(J) = («—1 — N~1)Sy,
где S2 — дисперсия значений (у,, ..., yN) в популяции. Статистика
v(Ymc) = (n~l — N~l)sy, (4.1)
где sy — дисперсия значений У в выборке — несмещенная оценка
Var(y) при простом случайном выборе;
в) вычисляют интервальную оценку Т, предполагая, что t рас-
пределено приближенно нормально со средним Т и дисперсией
у(У1пс). Например, 95%-ный доверительный интервал для У при
простом случайном выборе дается выражением
С95(У) = У ± 1,9б7(и-1 —N-^s2, (4.2)
где 1,96 — процентиль 97,5% нормального распределения. Нор-
мальное приближение выполняется в силу центральной предельной
теоремы для конечной популяции [Hajek (I960)].
63
Отметим, что при таком построении значения yt, уN счита-
ются фиксированными. Привлекательной чертой рандомизационно-
го подхода является то, что не требуется задавать модель для
значений в популяции, хотя для (4.2) нужно, чтобы распределение Y
в популяции обеспечивало применимость нормального приближения
t при выборке объема п из популяции объема N.
При другом подходе к построению выводов о параметрах ко-
нечной популяции, кроме выборочного распределения, определяют
модель для Y, часто в виде плотности /(Y | Z, в) с неизвестным па-
раметром в. Эта модель используется затем для предсказания зна-
чений у, не попавших в выборку. Например, среднее популяции Y
можно оценить как
Л)/2Ч
где у,- — ожидаемое значение у,- для данной модели, в которой 0
заменено на оценку 9, такую, как среднее апостериорного распреде-
ления у;, если задана байесовская модель. Мы обсудим этот под-
ход в приложении к выборочным обследованиям в гл. 12.
4.3. КВАЗИРАНДОМИЗАЦИОННЫЕ ВЫВОДЫ
ПО ДАННЫМ С ПРОПУСКАМИ
Ключевое положение рандомизационного подхода — известное
распределение вероятностей, определяющее, какие значения наблю-
даются, а какие — нет, теряет свою силу при наличии пропусков.
Для примера допустим, что п объектов извлечены при простом слу-
чайном выборе, и положим
f 1, если у,- наблюдается при включении в выборку,
R: = J
[о — в противном случае
и
* = (*!. -, *л)Т-
Значения Y присутствуют в том случае, если 7?; = /, = 1- Теперь
невозможно определить статистику, которая является функцией
присутствующих значений Y и несмещенной оценкой среднего попу-
ляции Y по отношению к распределению I. Например, Кокрен [см.
Cochran (1963)] показал, что среднее присутствующих значений
yR = E7,./?,.y,./£/,/?,. (4.3)
64
- смещенная оценка Y с приближенным смещением
b(yR । К Л) = Yr - У = (1 - ХЯ)(УЙ - yNR), (4.4)
ine \R — доля объектов в популяции, дающих ответ (отклик), и
У NR — среднее объектов популяции, не дающих ответа. При от-
сутствии информации о У NR мы не можем в у R ввести поправку
на это смещение.
Для преодоления таких затруднений существуют два способа:
делается некоторое модельное предположение относительно части
популяции, не дающей отклика (например, что средние У в частях
популяции, дающих ответ и не дающих, равны), или делают пред-
положение о распределении R без каких-либо предположений о рас-
пределении У в популяции. Первый, путь связан с построением
моделей для значений у и, значит, с модельным подходом к обсле-
дованиям при отсутствии пропусков. Второй путь, с привлечением
распределения R, — более прямое обобщение рандомизационных
выводов на случай пропусков. Для него мы будем использовать
термин квазирандомизационный подход, следуя [Oh and Scheuren
(1983)].
Составляющими элементами квазирандомизационного подхода
являются: 1) известное распределение /(Z[ Z) значений, извлекаемых
в выборку при отсутствии пропусков; 2) предполагаемое распреде-
ление индикаторов ответа R при заданных I, У и Z (это распределе-
ние строится, как правило, на предположении, что внутри каждой
отдельной подгруппы популяции присутствие откликов у объектов
соответствует второму этапу равновероятного случайного выбора);
3) функция t от присутствующих значений — приближенно несме-
щенная оценка изучаемого параметра Т при повторном выборе из
совместного распределения I и R; 4) функция v от присутствующих
значений — приближенно несмещенная оценка дисперсии t при по-
вторном выборе из распределения I и R. Доверительные интервалы
для Т можно строить по t и v, как и ранее, в предположении нор-
мальности.
В дальнейшем в этой главе будет рассматриваться квазирандо-
мизационный подход. Модельный подход будет обсуждаться в
гл. 12.
Пример 4.1. Отсутствие ответа как пример случайного под-
выбора. Рассмотрим популяцию объема N с Е Rt = М респонден-
тами. Извлечена простая случайная выборка объема п, в которой
3 I1 Дж А Литгя, Д Б Р561111 65
ответ дали £ RJt - т респондентов. Допустим, что распределение
R при заданных I и исследуемых переменных Y определяется выра-
жением Г / » , \
f (й)-’. £«, = «
f(R / У) =
1 10 — в противном случае. (4.5)
Заметим, что это распределение не зависит от значений I и Y, так
что выполняется ОПС. Вероятность получения ответа равна M/N
и она не зависит от извлекаемых объектов или значений признаков.
Пусть D, = Rjlt и D = (Dt, ..., Dn)t. Распределение D при усло-
вии Y,Dt — т есть
I (В“‘,
f(D /, У) = а
1 < 0 — в противном случае,
что является распределением простой случайной выборки объема т.
Отсюда 95%-ный доверительный интервал для среднего популяции
У есть yR ±\,9бУ{т~1 — N~l)s2YR, где yR и — среднее и
дисперсия среди ответивших.
В основе (4.5) лежит сильное предположение о независимости R
от 7 и Y:
R Я (4 У).
Это обозначение независимости из [Dawid (1979)]. На практике та-
кое предположение часто нереалистично. Оценка взвешенных групп,
обсуждаемая в следующем разделе, ослабляет предположение ОПС
и приводит к необходимости его выполнения только внутри под-
групп популяции, так что выполняется ОС, а не ОПС.
4.4. МЕТОДЫ ВЗВЕШИВАНИЯ
4.4.1. Оценки весовых групп
Один из способов интерпретации вероятностного выбора —
считать, что объект, извлекаемый с вероятностью тг(, представляет
тг^1 объектов популяции, так что ему следует присвоить вес тг“1 в
оценке параметра популяции. Такая точка зрения, без сомнения,
верна для расслоенного случайного выбора: пусть из Nj объектов
слоя j выбираются объектов, тогда т,- = Hj/Nj для /-го объекта из
слоя j, и каждый объект в выборке представляет Nj/ tij объектов
66
популяции. В частности, при отсутствии пропусков суммарное зна-
чение Т переменной У можно оценивать величиной
/ = Еу/Л,-1, (4.6)
1=1
называемой оценкой Хорвица—Томпсона [Horvitz and Thompson
(1952)]. Среднее популяции У можно оценить величиной
yw = Е w,y,, (4.7)
/ = 1
где
w,. = ^тг-’/Е/^тг^1 —
вес, приписываемый ьму объекту. Так как £(/,• | У) = тг,, то
£(Г| У) = Ел^тг-’ = Т
1= 1
и оценка суммарного значения по Хорвицу—Томпсону несмещенная
при повторном выборе. Величина у w — несмещенная оценка сред-
него У для многих выборочных планов, а для некоторых планов
приближенно несмещенная. Конечно, t и yw можно вычислить
только при отсутствии пропусков, когда у( присутствует обязатель-
но, т. е. Ij = 1. Оценки весовых групп обобщают этот подход на
случай пропусков, присваивая объектам с присутствием ответа вес,
обратный вероятности выбора и присутствия ответа.
Пример 4.2. Оценка весовых групп при пренебрежимых пропу-
сках. Допустим, что мы можем разделить популяцию на J групп,
внутри которых наличие ответа не зависит от (У Г). Определим пе-
ременную группы С, которая принимает значение j для всех объек-
тов из у-й группы. Предположим, что распределение наличия ответа
равно:
п(Й‘X1. Р Ri=Mj Для всех у)
у-i J l-Cj—J
О — в противном случае, (4.8)
где Nj — число объектов в у-й группе, Mj — число объектов, даю-
щих ответ при включении в выборку. Пусть <bj = Mj / Nj — доля
ответов в у-й группе. Если бы значение было известно, то оцен-
ки среднего и суммы по Хорвицу—Томпсону получились бы при
присвоении /-му ответившему объекту из группы у веса *.
На практике неизвестно, но может- быть заменено оценкой <5у,
f(R 11, У С) =
з
67
основанной на доле присутствующих ответов в выборке внутри
группы j. В результате получается оценка У, равная
Е Е Е *7ХФ7\ (4.9)
где обозначает совокупность объектов выборки из у-й группы,
давших ответ. Естественной оценкой ф} является доля ответов в
выборке в у-й группе: ф} = т}/п}, где п} — число объектов в вы-
борке, trij — число ответивших среди них. При равновероятном
выборочном плане и такой оценке (4.9) сводится к оценке весо-
вых групп:
yVc = n~\pinjyjR’ (4Л0)
__ J
где у jR — среднее по ответившим в у-й группе и п = Е лу — объем
выборки.
Допустим, что применяется простой случайный выбор и выпо-
лняется (4.8). Ох и Шойрен [см. Oh and Scheuren (1983)] вывели
среднее и дисперсию ywt по распределению 7? и I при заданных
m = (m,....mj) и n = («i, ..., и7):
in, Y, _ j n,(Y — У)
£(ywc | Y, C, m, n) = Y +Д~^п---------’
K(7WC I Y, C, m, n) = E (> (A- - -^) S], (4.12)
где Tj и S2 — среднее и дисперсия Y в у-й группе и в популяции.
Заметим, что ywc — смешенная в общем случае условно по m и п
оценка К. Ох и Шойрен предлагают следующую оценку средне-
квадратичной ошибки Уис:
mSe(ywc) = Е@2(1
mjn}sjK , N — п _ (УjR У wc)2
п^' mJ + nJ п2
где SjR — дисперсия ответивших объектов из выборки из группы у.
100(1 — а)%-ный доверительный интервал для Y можно постро-
ить в видеужс ± Zi __a/2(mse(ywc))1/2, где Zj _а/2 — 100(1 — а/2)-я
процентиль стандартного нормального распределения, но свойства
этих интервальных оценок в приложениях изучены слабо.
68
4.4.2. Выбор весовых групп
Весовые группы можно формировать по переменным плана об-
следования Z или по переменным Y из выборки, зарегистрирован-
ным как для ответивших, так и для неответивших. Взвешивание
применяется в первую очередь для обработки пропусков объектов,
когда отсутствуют все изучаемые переменные. В этих случаях для
формирования групп доступны только переменные плана Z.
Точной теории формирования групп в настоящее время нет, но
можно предложить некоторые общие рекомендации. Группы следу-
ет выбирать так, чтобы 1) выполнялось предположение (4.8) о рас-
пределении ответов и 2) минимизировалась при (4.8) среднеквадра-
тичная ошибка оценки типа Fwc. В выборках, полученных при рав-
новероятном плане, дисперсия (4.12) превосходит с большой вероят-
ностью компоненту смещения среднеквадратичной ошибки в (4.11).
Дисперсия (4.12) минимизируется при таком выборе групп, когда,
во-первых, они однородны по отношению к У, так что мала SjR,
и, во-вторых, отсутствуют группы с малым объемом выборки от-
вечающих тг Ключевым моментом (4.8) является независимость R
от У и / внутри группы:
ДК(У7)|С. (4.13)
Теория степени вкладов (propensity scores) [см. Rosenbaum and
Rubin (1983), (1985)], обсуждаемая в контексте пропусков в обследо-
ваниях [см. Little (1986)], предписывает выбирать Стак, чтобы при-
ближенно выполнялось (4.13). Пусть X — множество переменных,
присутствующих как для ответивших, так и для неочветивших. До-
пустим,
2? 11 (У Г)|Л (4.14)
так что (4.13) выполняется, если в качестве С выбрано X. Однако
в общем случае нельзя сформировать отдельную группу для каждо-
го значения X, поскольку тогда в группах, где есть неответившие,
может совсем не оказаться ответивших или их будет мало, что при-
ведет к сильному увеличению дисперсии. Определим вклад Ответа у
м о объекта как
р{х,) = Рг(2?, = 1 | х()
и пусть
р(Х) = (р(х,), ..., p(xN))T.
69
Можно показать, что если р(х) положительно для всех I и выпо-
лняется (4.14), то /?Д (X Г)\р(Х), так что расслоение по степени
вкладов обеспечивает выполнение (4.13).
На практике р(х,) надо оценивать по выборочным данным.
Естественна следующая процедура: 1) оценить р(х,) с помощью ло-
гистической или пробит-регрессии индикатора ответа 7?, на х,-; 2)
сформировать сгруппированную переменную, огрубляя оценку р(х,)
до пяти или шести значений; 3) приравнять С этой переменной, что-
бы внутри у-й группы все ответившие и неответившие имели бы од-
но и то же значение этой сгруппированной переменной.
4.4.3. Другие процедуры взвешивания
Некоторые варианты оценки (4.10) заслуживают внимания.
Кессел и его коллеги [Cassel, Sarndal and Wretman (1983)] определя-
ют веса для отсутствия ответа, обратные оценкам степени вклада
p(Xj) объектов с присутствием значений. В предположении справед-
ливости модели этот метод позволяет устранить смещение из-за от-
сутствия ответов, но он может давать оценки с чрезвычайно
большой дисперсией, так как респонденты с очень низкими вклада-
ми получают довольно большие веса при отсутствии ответов, что
может оказать существенное влияние на оценки средних и сумм.
Кроме того, взвешивание непосредственно с помощью р(х,) может
оказаться более чувствительным к точности определения модели
регрессии Л, на х,-, чем расслоение, при котором р(х,) используется
только в процессе формирования групп для взвешивания.
Иногда доля популяции Nj/N в каждой (J-н) группе известна
либо извне, либо в связи с тем, что группы формируются при рас-
слоении по переменным Z в плане обследования. В этом случае аль-
тернативой у wc является среднее пострасслоения:
yps = N-^N}yJK. (4.15)
При условии ОС, т. е. при (4.13), у ps — несмещенная оценка Y с
дисперсией 2
Var(yps|K С, 7V,, ..., Nj) = (4.16)
Оценку (4.16) можно получить, подставляя вместо SjR выборочные
дисперсии по ответившим в у-й группе sJX. В большинстве случаев
yps лучше ywt, кроме ситуаций, когда объемы выборок ответив-
ших mj и дисперсия У между группами малы. Более подробно эти
проблемы обсуждаются в [Little (1986)].
70
Интересный вариант yps получается, когда группы задаются
по совместным уровням двух классифицирующих факторов Ху и Х2
с J и К уровнями соответственно. Допустим, что в группе сХ,- j,
Х2 — к, j = 1, ..., J, к = 1, ..., К, извлечены nJk из Njk объектов
популяции. Значение переменной Y зарегистрировано у nijk из njk
объектов, включенных в выборку в (J, к)-й группе. Оценки пострас-
слоения и весовых групп принимают вид
и
У^ = ^Р=1П)кУjkR/ п’
где yJkR — среднее по ответившим в (j, к)-й группе. Комбиниро-
ванную оценку можно получить, допуская, что частоты Njk в попу-
ляции неизвестны, но маргинальные частоты для Ху и Хг, NJ+ =
= Е Njk и N+k = Е Njk известны для всех j и к, как при публика-
ции” данных переписи (например, Ху — пол, Х2 — раса, тогда име-
ются маргинальные распределения по полу и расе, но не совместное
распределение в таблице пол х раса).
Метод выравнивания (raking) для групповых частот njk состоит
в вычислении оценок N"jk для Njk, которые удовлетворяют «марги-
нальным» ограничениям
Ny+ = Л'М/ь = Nj+ , j = 1, ..., J,
^k=^jk = N+k, k=\,...,K,
и которые отличаются от наблюдаемых частот njk на факторы
строк и столбцов, т. е. могут быть выражены в виде
N’j,' = а}Ькп}к, j = 1, ..., J, к = 1, ..., К,
для определенных постоянных строк [or ,у = 1, ..., J] и столбцов
{Ьк, к = 1, ..., К]. В таблице маргинальные частоты равны
известным величинам 2У-+ и N+k, а взаимодействие между факто-
рами такое же, как в таблице с частотами njk. Выравненные груп-
повые частоты можно вычислять с помощью итеративной
процедуры пропорционального подбора, в которой текущие оценки
умножаются на фактор строки или столбца, чтобы маргинальные
частоты были равны соответственно Nj+ и N+k. Таким образом,
на первом шаге вычисляются оценки
^}k = nJk(Nj+/nj+),
71
удовлетворяющие ограничению на маргинальные частоты по стро-
кам Nj f . Затем находят оценки
согласующиеся с маргинальными частотами по столбцам, затем —
и т. д., пока процесс не сойдется. Сходимость и статистические
свойства этой процедуры обсуждаются в [Ireland and Kullback
(1968)], где показано, в частности, что выравненные опенки N*k/N
пропорций групп — оптимальные, асимптотические нормальные
оценки в предположении полиномиального распределения для час-
тот в группах rijk и они асимптотически эквивалентны оценкам
максимального правдоподобия (МП-оценкам) для полиномиальной
модели (вычислять МП-оценки труднее).
Сглаживание объемов выборок rijk дает сглаженную оценку У:
У RH ~ j Njky
дисперсия которой, видимо, будет обладать свойствами, средними
между свойствами yps и ywc. Отметим, что эта оценка не опреде-
лена, если mjk = 0, a rijk # 0, и тогда требуется другая опенка. Та-
кие оценки в рамках модельного подхода к отсутствию ответов при
обследованиях обсуждаются в гл. 12.
4.5. МЕТОДЫ ЗАПОЛНЕНИЯ ПРОПУСКОВ
4.5.1. Введение
Теперь в общих словах мы обсудим методы заполнения пропу-
щенных значений. Они относятся к уже рассмотренным в разделе
3.4 быстрым методам. Перечислим основные методы заполнения в
выборочных обследованиях.
а) Заполнение средними по присутствующим значениям в вы-
борке. Этот метод был изложен в разделах 3.4.2 и 3.4.3. Средние
могут формироваться и внутри групп аналогично группам, образуе-
мым для взвешивающих процедур. При таком подходе заполнение
средними ведет к оценкам, сходным с оценками методами взвеши-
вания при условии постоянства выборочных весов в классах взве-
шивания.
72
б) Процедуру заполнения пропусков с (пристрастным) подбо-
ром* можно, в общем, описать как метод, при котором подстанов-
ка выбирается для каждого пропущенного значения по оценке рас-
пределения в отличие от заполнения пропусков средними, когда
подставляется среднее распределения. В большинстве приложений
эмпирическое распределение задается присутствующими значения-
ми, поэтому при заполнении с подбором подставляются различные
значения из данных для сходных объектов без пропусков. Заполне-
ние с подбором широко распространено. Оно может включать
очень сложные схемы отбора объектов. Хотя практика подтвердила
достоинства этого метода, литературы, посвященной его теоретиче-
ским свойствам, явно недостаточно. Читателю можно рекомендо-
вать работы [Ernst (1980); Kalton and Kish (1981); Ford (1983)].
Ссылки на последние публикации содержатся в [David, Little, Samuhel
and Triest (1986)].
в) Замена — метод обработки пропусков на этапе сбора данных
при обследовании. Он состоит в замене объекта с отсутствием отве-
та на другой объект, не включенный в выборку. Например, если не-
возможен опрос домовладельца, то можно опросить его соседа, не
включенного в списки опрашиваемых. Было бы неверно рассматри-
вать получаемую таким образом выборку как полную, поскольку
те, кто дает ответы, могут систематически отличаться от тех, кого
не удается опросить. Поэтому при анализе следует рассматривать
эту замену как заполнение определенного вида.
г) Заполнение без подбора (cold deck imputation). Пропуск запо-
лняется постоянным значением из внешнего источника, например
значением предыдущего наблюдения из этого же обследования. Как
и при замене, полученные данные принято рассматривать как пол-
ную выборку, т. е. последствия заполнения игнорируют. Удовлетво-
рительной теории анализа данных, полученных при заполнении без
подбора, не существует.
д) Заполнение по регрессии (см. также раздел 3.4.3) состоит в
заполнении пропусков значениями, предсказываемыми регрессией
пропущенных для данного объекта переменных на присутствующие,
вычисляемой обычно по комплектным объектам. Заполнение сред-
ними можно рассматривать как частный случай заполнения по ре-
грессии, если считать предикторами фиктивные переменные, указы-
вающие группу, внутри которой происходит подстановка средних.
Регрессионное заполнение является, по существу, модельным мето-
дом. Более подробно оно будет рассмотрено в гл. 12.
* В оригинале — hot deck imputation, что означает подстановку из подгосов-
ленной колоды полученных перфокарт. — Примеч. пер.
73
е) Стохастическое заполнение по регрессии основано на замене
пропуска значением, подставляемым при заполнении по регрессии,
в сумме с остатком, отражающим неопределенность предсказывае-
мого значения. При нормальной линейной регрессионной модели
естественны нормальные остатки с нулевым средним и дисперсией,
равной остаточной дисперсии регрессии. При бинарной переменной,
как в логистической регрессии, предсказываемое значение — вероят-
ность наблюдения 1 или 0, а подставляемые значения (1 или 0) вы-
бираются с этой вероятностью. Херцог и Рубин [см. Herzog and
Rubin (1983)] описывают двухэтапную процедуру, при которой испо-
льзуется стохастическая регрессия для нормальных и бинарных дан-
ных. Стохастическая регрессия также относится к модельному
подходу и поэтому будет обсуждаться в гл. 12.
ж) Составные методы основаны на идеях нескольких методов.
Например, можно объединить заполнение с подбором и заполнение
по регрессии, вычисляя предсказываемое регрессией значение и до-
бавляя затем остаток, случайно выбираемый из эмпирических
остатков для предсказанных величин при формировании значений
для подстановки (см., например, гибридную двухшаговую процеду-
ру, приписываемую Шойрену в работе [Schieber (1978)]). В [David,
Little, Samuhel and Triest (1986)] проводится сравнение составных ме-
тодов и подстановки с подбором при пропусках величины заработка
в текущем обследовании населения (Current Population Survey).
з) При методах многократного заполнения [см. Rubin (1978),
(1987)] пропуск заполняется несколькими значениями. Существен-
ный недостаток методов однократного заполнения заключается в
том, что обычные формулы приводят для заполненных данных к
систематически заниженным оценкам дисперсии оценок, даже если
верна модель, применяемая для вычисления подставляемых значе-
ний. При многократном заполнении получаются правильные оценки
дисперсии, которые можно получать обычными методами анализа
полных данных. Методы многократного заполнения обсуждаются в
гл. 12.
4.5.2. Заполнение средними
Пусть ytj — значение Y для г-го объекта в группе j, i = 1.
Nj, j = 1, ..., J. При заполнении средними для объектов выборки,
не давших ответ, подставляется среднее yjR по /и, ответившим в
у-й группе. Для равновероятного плана среднее популяции Y можно
оценить средним присутствующих и подставленных значений, а
именно
74
। де уj — среднее присутствующих и подставленных значений в У-й
। руппе. Теперь
7; - [mjyjR + («; - / nj = yjR, *
так что получаемая оценка Y — просто оценка с взвешиванием
групп (4.10). Если в популяции известна доля каждой группы, то
оценку пострасслоения у ps также можно вывести как оценку, осно-
ванную на заполнении средними.
Мы показали, что для планов с равными весами взвешивание
объектов, дающих ответ, по доле отвечающих в каждой группе поз-
воляет получить такие же оценки средних и сумм, как подстановка
средних по отвечающим для объектов, не дающих ответ. Это заме-
чание относится и к неравновероятным планам при условии, что
выборочные веса отражаются в оценках доли отвечающих и в под-
ставляемых средних. Связи между заполнением пропусков и взве-
шиванием групп рассматриваются в [Oh and Scheuren (1983); David,
Little, Samuhel and Triest (1983); Little (1986)].
Метод заполнения средними реализуется просто, но он облада-
ет нежелательными свойствами, указанными в разделе 3.4.2. Во-
первых, правильные оценки дисперсий 7WC (или yps) нельзя полу-
чить с помощью обычных формул для дисперсии, примененных к
заполненным данным. Реально объем выборки занижен из-за отсут-
ствия ответов, поэтому обычные формулы приводят к заниженной
оценке истинной дисперсии. Во-вторых, величины, не линейные по
данным, такие, как дисперсия У или корреляция между двумя пере-
менными, нельзя состоятельно оценить с помощью стандартных
методов для полных данных, если их применить к заполненным
данным. В-третьих, подстановка средних искажает эмпирическое
распределение значений Y, что важно при исследовании распределе-
ния У по гистограммам или по другим графикам, отображающим
данные. Аналогичная проблема возникает, если значения У объеди-
нены в группы для образования частотной таблицы, потому что
пропуски в группах заполняются общим средним значением и, сле-
довательно, относятся в результате к одной и той же группе У Эта
проблема побуждает искать распределенные значения для пропу-
сков, используя методы их заполнения типа подстановки с подбо-
ром. Обратимся теперь к этому методу.
75
4.5.3. Подстановка с подбором
При большинстве методов подстановки с подбором (этот тер-
мин пока не стал общепринятым) пропуски заполняются значения-
ми, полученными для другого сходного объекта выборки. Допус-
тим, как и ранее, что извлечена выборка объема п из N объектов,
и у т из п объектов выборки зарегистрированы значения Y, где п,
N и т считаются в этом разделе фиксированными. Для простоты
пронумеруем объекты так, что первые п объектов находятся в вы-
борке, и первые т < п из них дали ответ. При равновероятной схе-
ме выбора среднее Y можно оценить как среднее по имеющимся и
по подставленным значениям, что можно записать в виде
Уно = ^Уя + (и — ™)У^п> (4.17)
где yR — среднее по ответившим, и
-* _ Н‘у>
•^NR “j п—т >
где Н — кратность, с которой у, использовалось для подстановки
вместо пропуска К Заметим, что Е Нг равно п — т — числу объ-
ектов с пропуском.
Свойства у HD зависят от способа формирования чисел (Hi, ...,
Нт). Проще всего вывести формулы, если рассматривать подстав-
ленные значения как выборку значений для ответивших, получен-
ную при вероятностном плане выбора, когда известно
распределение (Hi...Нт) при повторном применении подстанов-
ки с подбором.
Допустим, что Н' задается случайным выбором с возвращени-
ем из зарегистрированных значений Y. Условно по зарегистрирован-
ным значениям выборки распределение (Hi, ..., Нт) при
повторениях процедуры подстановки с подбором полиномиальное с
объемом выборки п — т и вероятностями 1/т, ..., 1/т (см. [Coch-
ran (1977), раздел 2.8]. Отсюда
Е(Н, | К R, Г) = (п — т)/т,
Уаг(Н, | X R, Г) = (п — т)(1 ~ 1/т)/т,
Соу(Н,, H'\Y, R, Г) = —(п — т)/т2, i * i'.
Пусть yHD1 — оценка (4.17) для Y по распределению (Н,, ..., Нт).
Тогда
^(Thdi I R> Г) - УR
76
и
Var(.»’HDI | У Л = (1 —— m/ri)s2vK/n. (4.18)
Моменты _>'HD| при повторном выборе из Н, R и / равны:
F(yHI)1 | У) = £-(£-(Уно1 I У Л | У), (4.19)
х’агО’но1 I >’) = Var(f(yHDI | У R, Л + £'(Var(JHD11 Y, R, I) | У).
(4.20)
При простом случайном выборе и в предположении ОПС о распре-
делении ответов по уравнению (4.5) мы получим
£-(yHD1 I Ю = г,
Var(THDI I П = (/?;-' — W-nsJ + (1 — т~')(1 — m/n)S2/n.
Отметим, что подстановка с подбором ведет к оценкам с большей
дисперсией по сравнению с оценкой ук, получаемой при заполне-
нии средним. Из (4.20) следует, что дисперсия любой оценки J>HD
при подстановке с подбором, для которой E(yHD | У R, /) = У«,
больше дисперсии среднего Jу. Преимущество метода подстановки
с подбором в отличие от заполнения средним заключается в том,
что искажения распределения выборочных значений отсутствуют.
Дополнительная дисперсия от выборочной подстановки с воз-
вращением, определяемая уравнением (4.18), не является пренебре-
жимо малой. Ее можно уменьшить, задавая более эффективный
план выбора. Допустим, например, что подставляемые значения из-
влекаются без возвращения. Если п — т < т, то мы можем вы-
брать (н — т) из т зарегистрированных значений у без
возвращения и при этом равно 1, если 7-й объект отобран, и О
— в противном случае. Чтобы определить процедуру в общем слу-
чае, запишем
п — т = кт + Г,
где к — натуральное и 0 t < т. При подстановке с подбором без
возвращения к раз выбирают все зарегистрированные объекты, а
затем «добирают» t дополнительных объектов, чтобы обеспечить
все п — т значений, необходимых для пропусков. Таким образом,
У nr = (кту R + ty,)/{n — т),
где у, — среднее t добавочных значений У Согласно теории прос-
того случайного выбора
Е(У, | У R, Г) = yR, Var(J, | У R, Г) = (1 - t/m)s2yR/t.
77
Если ,yHD2 — оценка У, полученная с помощью этой процедуры,
то
?HD2 = (к + 1)тп~'уК + tn-'y,
И
£(yHD2| Y, R, /) = yR,
Уаг(Уног1 Y R, I) = {t/n){\ — t/m)syR/n, (4.21)
что всегда меньше соответствующей добавочной компоненты дис-
персии yHD1 в (4.18). Точнее, в предположении простого случайного
выбора и бернуллиевского распределения присутствия ответов, иг-
норируя поправку на конечную популяцию, мы получим, что 1) дис-
персия yHD1 не превосходит дисперсию yR более чем в 1,25 раза, и
этот максимум достигается, если т/п = 0,5; 2) дисперсия yHD2 не
превосходит дисперсии у R более чем в 1,125 раза, и этот максимум
достигается при к = 0, I = л/4 и т - Зл/4, т. е. когда пропущена
четверть значений [см. Kalton and Kish (1981)].
Другой метод генерирования значений для заполнения пропу-
сков — последовательный подбор, при котором все объекты распо-
лагают в последовательность и пропущенное значение заменяется
значением Y ближайшего предшествующего в этой последователь-
ности объекта, давшего ответ. Например, если п - 6, т = 3, yt, у4
и у5 присутствуют, а у г, Уз и у6 отсутствуют, то уг и уз заменяются
на 71, а Уь — на у5. Если пропущен у,, то потребуется некоторое
начальное значение, выбранное, возможно, методом без подбора.
Главным преимуществом последовательного подбора является его
вычислительная простота. На его основе построены старые схемы
заполнений для текущих обследований населения Бюро переписи
(Census Bureau).
Допустим, что объекты выборки случайно упорядочены и из-
влечены путем простого случайного выбора, а также что действует
бернуллиевский механизм порождения пропусков. Байлар и его со-
авторы [см. Bailar, Bailey and Corby (1978)] показали, что в этом
случае оценка Y методом последовательного подбора, скажем
УН1ЭЗ, — несмещенная с дисперсией, приближенно равной (при
больших т и п и без поправок на конечную популяцию)
Var(yHD31 У) = (^//и)(1 + (п т)/п).
Значит, дисперсия Унпз увеличивается по сравнению с yR в (п—т)/
п + 1 раз, что равно доле пропущенных значений.
78
Можно уменьшить дополнительную дисперсию при подстанов-
ке с подбором, выбирая подстановку для пропусков с помощью са-
мих значений у для образования выборочных слоев [Bailar and
Bailar (1983); Kalton and Kish (1981)]. Самый крайний вид расслое-
ния — упорядочить присутствующие значения К а затем системати-
чески выбрать t значений из этого списка.
Оценки подстановки с подбором, которые мы обсуждали до
сих пор, не смещены только при общем нереальном предположе-
нии, что вероятность ответа не связана со значением Y. Если имеет-
ся некоторая дополнительная информация об объектах, дающих
ответ и не дающих его, то ее можно использовать для уменьшения
смещения, возникающего из-за пропусков. Внимания заслуживают
следующие два подхода.
а) Подстановка с подбором внутри групп. Формируются груп-
пы, и пропуски в каждой группе заполняются присутствующими
значениями из нее же. При этом выбор групп основывается на тех
же соображениях, что и выбор групп для взвешенных оценок. Сред-
нее и дисперсию полученных таким методом оценок Y можно най-
ти, применяя приведенные выше формулы отдельно внутри групп,
а затем объединяя полученные значения. Поскольку группы форми-
руются по совместным уровням категориальных переменных, они
не идеально подходят для переменных в интервальной шкале.
б) Подбор ближайшего соседа. Этот подход основан на введе-
нии метрики d для измерения расстояния между объектами, опреде-
ленной в пространстве сопутствующих переменных, и выборе
подстановки по объекту с присутствующим значением, ближайшему
к объекту с пропуском. Например, пусть х;1, ..., хи — значения J
сопеременных, измеренных в нормированных шкалах, у объекта i с
пропуском yt. Определим расстояние
d(i, i') = max | xZj — xfj |
J
между объектами I и Мы можем выбирать подстановку для
из тех i'-x объектов, у которых 1) наблюдаются yjt, х,-/,, ..., х^ и
2) d(i, i') меньше некоторого порога d0. Число «кандидатов» —
подходящих i'-x объектов — можно выбирать, изменяя d0. В [Sande
(1983)] данные о «кандидате» должны удовлетворять еще некото-
рым дополнительным логическим ограничениям (например, неотри-
цательный возраст). Схемы ближайшего соседа требуют значитель-
ных вычислительных затрат. Они стали применяться сравнительно
недавно. Существует много работ по методам подбора, написанных
в контексте исследований, в которых для «обрабатываемых» объек-
79
тов подбирается («связанный») контрольный объект [см. Rubin
(1973а, b); Cochran and Rubin (1973); Rubin (1976a, b)]. Поскольку
подставляемые значения являются довольно сложными функциями
от присутствующих признаков, квазирандомизационные свойства
оценок в таких процедурах подбора пока мало изучены.
Пример 4.3. Последовательный подбор с упорядочением по со-
переменной. В [Colledge, Johnson, Pare and Sande (1978)] описан при-
мер широкого применения метода подбора в обследовании строи-
тельных фирм в Канаде. Обследование охватило 50538 фирм, из ко-
торых 41432 были подвергнуты анализу. Признаки разделялись на
четыре группы: а) полностью присутствующие ключевые показате-
ли по данным об уплачиваемых налогах, включая район, стандарт-
ную индустриальную классификацию (SIC), общий доход (GBI),
чистый доход (NBI) и показатель заработной платы и годового до-
хода (SWI); б) основные финансовые показатели по данным об уп-
лачиваемых налогах, часть из которых отсутствовала; в)
вторичные финансовые показатели и г) переменные обследования,
собранные для различных, но пересекающихся подвыборок, и иног-
да отсутствовавшие. Только в 908 из 41432 записей была зареги-
стрирована вся информация о переменных четырех групп, в боль-
шинстве записей (34 181) наблюдались только ключевые показате-
ли, в 2316 записях содержались только ключевые и основные финан-
совые показатели и в 4027 записях содержались ключевые показа-
тели и переменные обследования. Подстановка с подбором была
проведена в несколько этапов. На каждом этапе пропуски в пере-
менных одной группы заполнялись значениями из «донорских» за-
писей, в которых содержались все переменные данной группы.
Чтобы подобрать подходящие объекты из числа «доноров», показа-
тели во всех записях были расслоены по провинции (району), по
SIC и по SWI. На каждом этапе определялся набор «доноров» (на-
бор подстановок) и набор «кандидатов» (объектов с пропусками).
Внутри каждого слоя записи были упорядочены по GBI.
При подстановке значений в определенную запись для объекта-
кандидата рассматривалось только по 5 доноров с каждой стороны,
что давало 10 возможных доноров приблизительно с таким же зна-
чением GBI. Из этих десяти возможных доноров выбирался один,
минимизировавший функцию расстояния, задаваемую в общем виде
как
DIST (с, d) = 11пТЕХРс — lnTEXPd | ,
80
। ле TEXP -- GBI — NBI — суммарные расходы (total expenses), ин-
декс с означает «кандидат», d — «донор». Расстояние измерялось
по расходам из-за тою. что подстановка требовалась для многих
показателей, которые являлись просто детальным разложением рас-
ходов или сильно коррелировали с ними. Заметим, что подбор до-
норов и кандидатов был основан только на ключевых показателях,
которые наблюдались полностью. Кроме того, расстояние было
обобщено так, чтобы оно зависело, кроме расходов, и от других по-
казателей, и модифицировано для более широкого охвата доноров
>а счет превращения расстояния в возрастающую функцию от числа
включений на данном этапе потенциального донора d в действи-
гельные доноры.
После того как выбирался донор, пропущенные показатели у
кандидата заменялись соответствующими значениями показателей
донора. Иногда, чтобы гарантировать выполнение определенных
ограничений, были необходимы некоторые преобразования или по-
правки. Например, допустим, что три неотрицательных показателя
х, у и z должны удовлетворять условию х -У у z. Значения этих
показателей у донора равны xd, yd и zd, тогда как у кандидата из-
вестно лишь значение zc. Если просто записать значения ха и yd
как соответствующие показатели у кандидата, то может случиться,
что xd + yd > , а это недопустимо. В данном случае xd и yd про-
порционально уменьшали, чтобы выполнялось ограничение, а в ка-
честве значений соответствующих показателей у кандидата под-
ставляли
JQ = (xd/zd)Zc, У\ = (yd/Zd)Zc.
4.6. ОЦЕНИВАНИЕ ВЫБОРОЧНОЙ ДИСПЕРСИИ
ПРИ НАЛИЧИИ ПРОПУСКОВ
До сих пор в основном обсуждался вывод оценок параметров
популяции при наличии пропусков. В этом разделе мы рассмотрим
с квазирандомизационной позиции построение оценок выборочной
дисперсии, которые включают дополнительный член для учета про-
пусков.
Важно подчеркнуть, что для многих приложений вопрос смеще-
ния из-за пропусков часто более важен, чем оценка дисперсии. Мож-
но сказать, что получить правильную оценку выборочной дисперсии
хуже, чем вовсе не получить ее, если смещение оценки параметра ве-
лико и превосходит среднеквадратическую ошибку. Оценки дис-
, 81
Персии, описанные здесь, по существу, основаны на предположении,
что сделан ввод поправок на наличие пропусков, устранивших сме-
щения, порождаемые ими.
К настоящему времени формулы для дисперсии, учитывающие
пропуски, выведены только для простой случайной выборки (без
расслоения или с расслоением). В разделе 4.4 приведены примеры,
в которых применяются формулы для взвешенных оценок. В разде-
ле 4.5 обсуждались добавочные члены дисперсии для процедур с
подбором, когда выбор подставляемых значений осуществляется по
простой вероятностной схеме. В этой области многое требует даль-
нейшего развития, хотя сомнительно, что можно получить явные
оценки для обследований, проводимых сложными последователь-
ными методами с подбором типа метода из примера 4.3, если толь-
ко не принимать чрезмерно упрощающих предположений.
Вычисление состоятельных оценок дисперсии для сложных вы-
борочных планов, часто применяемых на практике, — непростая за-
дача даже при полных данных. Вследствие этого были развиты
приближенные методы, применимые к широкому кругу выбороч-
ных планов. Простота этих методов обусловлена тем, что вычисле-
ния сводятся к расчету величин для множества единиц выбора,
называемых конечными кластерами (КК, ultimate clusters). КК —
самая большая единица выбора, извлекаемая из популяции. Напри-
мер, в первый этап планирования построения выборки домовла-
дельцев может входить выбор районов из переписного перечня.
Выборка может быть составлена из «самопредставляющих» райо-
нов, включаемых в выборку с вероятностью 1, и из «несамопред-
ставляющих» районов, извлекаемых из популяции. Тогда конечны-
ми кластерами являются «несамопредставляющие» районы и едини-
цы выбора, формирующие первый этап извлечения «самопредстав-
ляющих» районов.
Оценивание дисперсии, проводимое по оценкам для КК, осно-
вано на следующей лемме.
Лемма. Пусть ..., 9к — случайные величины, которые
1) некоррелированы и 2) имеют общее среднее ц. Пусть
к (9. - в )2
Тогда 1) § — несмещенная оценка д и 2) v(9 ) — несмещенная оценка
дисперсии 9.
82
Доказательство. Е(9) = t,E(&.)/k = ц, что доказывает 1).
J-I J
Чтобы доказать 2), заметим, что
Е, (9, -Т)2 = Е (0, - цУ - к(0 - ц.у.
J=1 J у=1 J
Отсюда
к . _ _
£(Е(0, — еу) — к(к— l)Var(0) =
7=1 J
= Е Var(£) — к\'аг(~в ) — к(к — 1)\'аг(& ) =
7 = 1 3
= Е Var (0,) — кг Var(0). (4.22)
7=1 J
Но
fc2Var(0) = Var(E 0.) = Е Var(0~),
J— 1 J J—\
поскольку оценки 0, некоррелированы. Значит, (4.22) равно нулю,
что доказывает 2).
Эту лемму можно непосредственно применять к линейным
оценкам в выборочных планах со случайным извлечением конечных
кластеров с возвращением. Заслуживающая особого внимания ситу-
ация приведена в следующем примере.
Пример 4.4. Стандартные ошибки, вычисленные по выборкам
кластеров. Пусть популяция состоит из К конечных кластеров и
пусть выборочный план задает извлечение к кластеров простым
случайным выбором с возвращением. Пусть — сумма для пере-
менной Y в у'-м кластере. Допустим, что мы оцениваем сумму в по-
пуляции
к
t = Е t.
по Хорвицу—Томпсону:
, t = Y t / тг ,,
7=1 J J
где суммирование ведется по выбранным КК (1, .... к), ij — не-
смещенная оценка t} и тгу — вероятность выбора у-го КК. Тогда
1) t и все (kij/Kj, j = 1, ..., к) — несмещенные оценки t и 2) оцен-
83
ки (ktj/тгг j = 1, ..., к) некоррелированы для данного метода вы-
бора. Отсюда по лемме
_ к (kt:/ К , - О2
V(,lr|-,yl Ш-П-- <4'2’
несмещенная оценка дисперсии I.
Допустим, что в этом примере есть пропуски и мы выводим
оценки tj сумм в КК с помощью одного из методов обработки
пропусков, обсуждавшихся выше. Тогда мы по-прежнему можем ис-
пользовать (4.23) для оценки дисперсии, если 1) оценки не смеще-
ны по распределению I и R, т. е. процедуры заполнения или
взвешивания не приводят к смещениям за счет пропусков, и 2) по-
правки на заполнение или взвешивание выбираются внутри каждого
КК независимо, так что оценки остаются некоррелированными.
Таким образом, чтобы можно было применять лемму, весовые
группы не должны расчленяться конечными кластерами. Это требо-
вание может приводить к недопустимо малым весовым группам,
особенно если число КК велико. Значит, построение правильной
оценки дисперсии может войти в противоречие с необходимостью
обеспечивать достаточно малое смещение, по крайней мере при ис-
пользовании методов, обсуждавшихся до сих пор. Это противоре-
чие в некотором смысле аналогично проблеме, возникающей при
построении выборочного плана, когда систематический выбор мо-
жет быть самой эффективной формой расслоения, но при этом не-
возможно вычислять правильные оценки дисперсий без дополни-
тельных модельных предположений.
На практике редко происходит выбор КК с возвращением. Ког-
да извлечение проводится простым случайным выбором без возвра-
щения, оценки КК отрицательно коррелированы и оценки вида
(4.23), основанные на лемме, завышают дисперсию. Можно попы-
таться устранить завышение, вводя поправку на конечность популя-
ции (1 — к/К), однако в результате это приводит к занижению.
Для несмещенной оценки требуется информация о втором и после-
дующих этапах извлечения выборки. Таким образом, нужно, чтобы
при построении простых оценок дисперсии, основанных на КК, до-
ля извлеченных КК была мала, что даст возможность пренебре-
84
1.11 ь смещением, обусловленным выбором без возвращения. В пран
I пческих исследованиях такая ситуация встречается часто.
Большинство выборочных планов включает расслоение при вы-
боре КК. Снова предполагая, что доля извлеченных КК в каждом
< юе мала, получим, что с помощью оценок по конечным кластерам
можно вывести верные оценки дисперсий линейных статистик. До-
пустим, что всего имеется Н слоев. Пусть thj — несмещенная оцен-
ка суммы thj для у-го конечного кластера в слое h, h = 1, ..., Н,
! = 1, .... Kh.
Можно оценивать t величиной
Н к>‘ t. н „
t = Е Е -У- = Е th
Л-I j-1 Tfhj h-l "
i де суммирование ведется по Н слоям и kh объектам, включенным
в выборку из слоя h, vhj —- вероятность выбора (h, у)-го КК в слое
h, a th — оценка суммы в /?-м слое. Оценкой дисперсии t является
Л =
«hfltj/vhj-thy
> kh(kh-l)
В частности, при выборе двух КК из каждого слоя (этот план осо-
бенно популярен) оценкой дисперсии является 1
-/"1ч Д Сг’7" 7ГЛ2)2
v(r|y) = Ei--------------д-----------
Условия, при которых можно получить эти оценки по заполненным
данным, такие же, как и для случайного выбора: подстановки надо
выполнять независимо в каждом КК.
В рамках обсуждавшихся выше задач рассматривались также
нелинейные оценки с предварительной линеаризацией с помощью
разложения в ряд Тейлора или с применением других приближенных
методов, таких, как «складной нож», бутстреп* или сбалансирован-
ное повторное воспроизведение. В [Cochran (1977); Wolter (1985)]
можно найти сведения об этих методах и соответствующие библио-
графические ссылки.
* Подробнее с этими методами можно познакомиться в книге: Эфрон Б.
Нетрадиционные методы многомерного статистического анализа (М.: Финансы и
статистика, 1988). — Примеч. пер.
85
ЛИТЕРАТУРА
Bailar, В. A., and Bailar, J. С. (1983). Comparison of the biases of the “hqt deck”
imputation procedure with an “equal weights” imputation procedure, in Incomplete Data
in Sample Surveys, Vol. Ill: Symposium on Incomplete Data, Proceedings (W. G. Madow
and I. Olkin, Eds.). New York: Academic Press.
Bailar, B. A., Bailey, L., and Corby, C. (1978). A comparison of some adjustment and weighting
procedures for survey data, American Statistical Association 1978, Proceedings of the Survey
Research Methods Section, pp. 175-200.
Cassel, С. M., Sarndal, С. E., and Wretman, J. H. (1983). Some uses of statistical models in
connection with the nonresponse problem, in Incomplete Data in Sample Surveys, Vol. Ill:
Symposium on Incomplete Data, Proceedings (W. G. Madow and I. Olkin, Eds.) New York:
Academic Press.
1
Cochran, W. G. (1963). Sampling Techniques, 2nd ed. New York: Wiley.
Cochran, W. G. (1977). Sampling Techniques, 3rd ed. New York: Wiley.
Cochran, W. G., and Rubin, D. B. (1973). Controlling bias in observational studies: A review,
Sankhya A35,417-446.
Colledge, M. J., Johnson, J. H., Pare, R., and Sande, I. G. (1978). Large scale imputation of
survey data, American Statistical Association 1978, Proceedings of the Survey Research
Methods Section, pp. 431 -436.
David, M. H., Little, R. J. A., Samuhel, M. E., and Triest, R. K. (1983). Imputation methods
based on the propensity to respond, American Statistical Association 1983, Proceedings of
the Business and Economics Section.
David, M. H , Little, R. I. A., Samuhel, M. E., and Triest, R. K. (1986), Alternative methods
for CPS income imputation, J. Am. Statist. Associ., 81, 29-41.
Dawid, A. P. (1979). Conditional independence in statistical theory (with discussion), J. Roy.
Statist. Soc. B41, 1-31.
Ernst, L. R. (1980). Variance of the estimated mean for several imputation procedures, American
Statistical Association 1980, Proceedings of the Survey Research Methods Section, pp. 716-
720.
Ford, B. N. (1983). An overview of hot deck procedures, in Incomplete Data in Sample Surveys,
Vol. II: Theory and Annotated Bibliography (W. G. Madow, I. Olkin, and D. B. Rubin, Eds.).
New York: Academic Press.
Hajek, J. (1960). Limiting distributions in simple random sampling from a finite population, Pub.
Math. Inst. Hung. Acad. Sci. 4, 49-57.
Hansen, M. H., Hurwitz, W.N., and Madow, W. G. (1953). Sample Survey Methods and Theory.
Two volumes. New York: Wiley.
I »
Русский перевод: Кокрен У. Методы выборочного исследования. — М.: Статистике, 1976.
8(1
11< i zog 1 N . and Rubin, D В (1983) Using multiple imputations to handle nonresponse in
sample surveys, m huonipkte Data in Sample Suites, I'ol II Theory and Annotated
Bibliography (W G Madow, I Olkin, and D В Rubin, Eds) New York Academic Press
llorvit? D G , and Thompson, D J (1952) A genet nitration of sampling without i eplacement
honi a finite population, J Am Statist Associ 47,663 685
Inland СД and Kullback. S (1968) Contingency tables with given marginals, Biometuka 55,
179 188
Kahon, G , and Kish L (1981) Two efficient random imputation procedures American Staits-
tical Association 1981, Proceedings of the Stotci Research Methods Section,рр 146 151
1 ittle. R J A (1986) Survey nonresponse adjustments. Zzz/ Statist Rev 54, 139 157
MadowW G Olkin 1 Nisselson II and Rubin. Г) В (cds)(1983) Bu ample te Data in Sample
Saric i v, three volumes New York Academic Press
Oh H I andScheurcn F S (1983) Wcightingadiustmcnlsforunitnonresponse.inZ/rcomp/e/e
Data in Sample Sun vvv, Vol ll Iheoi t and Annotated Bibhographx (W G Madow,I Olkin,
and D В Rubin, eds ) New York Academic Press
Rosenbaum, P R, and Rubin, D В (1983) The central role ol the propensity score in
obscivational studies for causal effects, Biometrika 70. 41 55
Rosenbaum P R , and Rubin Г) В (1985). Constructing a control group using multivariate
matched sampling incorporating the propensity score Am Statist 39, 33 38
Rubin, D В (1973a) Matching to remove bias m observational studies. Biometries 29, 159-
183
Rubin, D В (1973b) The use of matched sampling and regression adjustment to remove bias
in observational studies, Biometrics 29, 185 203
Rubin, D В (1976a) Multivariate matching methods that are equal percent bias reducing,
I Some examples, Biometric s 32, 109 120 Printer's correction note p 955
Rubin Г) В (1976b) Multivariate matching methods that aie equal percent bias reducing. II
Maximums on bias reduction for fixed sample sizes,” Biometrics 32, 121 132 Printer's
con ection note p 955
Rubin, D В (1978) Multiple imputations in sample surveys, American Statistical Association
1978, Procceduicjs of the Sune\ Research Methods Section, pp 20 34
Rubin, Г> В (1987) Multiple Imputation for Numespmise in Stoic vs New York Wiley
Sandc. I G (1983) Hot deck imputation procedures, in Incomplete Data in Sample Satie) v, Vol
III Symposium cm Incomplete Data, Proceedings (W G Madow and I Olkin, Eds) New
York Academic Press
Schiebcr, S J (1978) A compauson oi three alternative techniques for allocating unicpoitcd
social security income on the Survey of the Low-Income Aged and Disabled. American
Statistical Association 1978, Proceedings of the Survey Research Methods Section, pp 212-
218
Wolter. К M (1984) Introduction to Variance Estimation New York Spnnger-Verlag
ЗАДАЧИ
Данные для задач 1—3 простая случайная выборка, состоящая из 100 человек из
одного округа, со следующими результатами обследования состояния здоровья:
87
Возрастная группа, лет Объем выборки Число рес- пондентов Холестерол
среднее ciандартное отклонение
20—30 25 22 220 30
30—40 35 27 225 35
40—50 28 16 250 44
50—60 12 5 270 41
I. Вычислите средний уровень холестерола для респондентов и его стандартную
ошибку. Вычислите 95%-ный доверительный интервал для среднего у отвечающих в
округе, предполагая распределение значений нормальным. Можно ли распространять
этот интервал на всех людей в округе?
2. Вычислите оценку среднего уровня холестерола по методу весовых групп в по-
пуляции и оценку ее среднеквадратической ошибки по формуле, следующей за (4.12).
Постройте приближенный 95%-ный доверительный интервал для среднего популя-
ции и сравните его с результатом из задачи 1. Какие при этом делаются предположе-
ния о механизме порождения пропусков?
3. Допустим, что данные переписи дают следующее распределение по возрасту в
изучаемом округе: 20—30 лет —• 20%, 30—40 лет — 40%, 40—50 лет — 30%, 50—60
лет — 10%. Вычислите оценку пострасслоения среднего уровня холестерола, соответ-
ствующую стандартную ошибку и 95%-ный доверительный интервал для среднего
популяции.
4. Найдите оценку Хорвица—Томпсона и оценку весовых групп в следующем вы-
мышленном примере расслоенной случайной выборки, где даны присутствующие
значения х и у , вероятности извлечения л(. известны, а вероятности ответа <f>(- из-
вестны для оценки Хорвица—Томпсона, но неизвестны для взвешенных оценок. Об-
ратите внимание, что можно построить несколько различных взвешенных оценок.
Выборочные значения
Х1 1 2 3 4 5 6 7 8 9 10
У! 1 4 3 2 6 10 14 7 7 7
0,1 0,1 0,1 0,1 0,1 0,5 0,5 0,5 0,5 0,5
Ф, 1 1 1 0,9 0,9 0,8 0,7 0,6 0,5 0,1
5. Постройте оценку Кессела и его соавторов, рассмотренную в разделе 4.4.3, по
данным задачи 4. Сравните полученные веса с весами в оценке весовых групп.
6. В приведенной ниже таблице показаны средние неполной переменной V (ска-
жем, доход в тыс. дол.) по отвечающим и доли отвечающих (число отвечающих/
объем выборки) при классификации по трем полностью наблюдаемым переменным:
возраст (больше 30 лет, меньше 30 лет), семейное положение (холост, состоит в
88
Праке), пол (мужской, женский). Обратите внимание, что построить весовые группы
По полу, семейному положению и возрасту нельзя, так как есть одна группа с че
1 ырьмя индивидуумами, из которых не ответил никто. Вычислите следующие оцен-
ки среднего У для всей популяции и для подпопуляции мужчин:
а) нескорректированные средние, основанные на полных наблюдениях;
б) взвешенное среднее при расслоении по степени вклада. Слои формируются объ-
единением групп в таблице со степенью вклада менее 0,4, от 0,4 до 0,8, более 0,8;
в) среднее после заполнения средними внутри весовых групп, определенных в б).
Объясните, почему скорректированные оценки больше нескорректированных.
Средние по ответившим и их доля в группах
с различным полом, возрастом и семейным положением
Возраст, лет Мужчины Женщины
холост женат незамужем замужем
20,0 21,0 16,0 16,0
< 30 24/25 5/16 11/12 2/4
30,0 36,0 18,0
> 30 15/20 2/10 8/12 0/4
7. Ох и Шойрен (Oh and Scheuren (1983)] предполагают другой вариант выравнен-
ной оценки Укк из раздела 4.4.3, в котором оценки частот ищут выравниванием
объемов выборок ответивших вместо Покажите, что I) в отличие от
Fкк эта оценка существует, если т-,^ — 0, rij^ # 0, 2) она смещена, если ожидание
rrijk / n,f, нельзя записать как произведение эффектов строк и столбцов.
8. Покажите, что выравнивание по объемам выборок в группах и по объемам вы-
борок отвечающих дают одинаковый ответ, если и только если
PijPkl/(PilPjk'> = 1 для всех ’> J’ кк 1>
где Pj, — доля ответивших в (4 у)-й группе.
9. Вычислите выравненные оценки частот в группах по частотам выборки и по ча-
стотам ответивших в а) и б), используя маргинальные частоты популяции из в):
а) выборочные частоты б) число ответивших &Jk> в) частота в популяции
8 Ы
10 / 18 5 9 14 Ч ? 300
15 17 32 5 8 13 2 2 700
23 27 50 10 17 27 500 500 1000
89
10, Для данных задачи 9 найдите отношение шансов для долей ответивших, вве-
денных в задаче 8. Повторите вычисления, поменяв местами числа ответивших 5 и
8 во второй строке таблицы б) в задаче 9 Сравнив отношения шансов, покажите, ка-
кой набор выравненных частот ответивших ближе к выравненным частотам выбор-
ки. Получите выравненные частоты для б) с измененной второй строкой и проверьте
ваше решение,
11. Докажите по формулам для дисперсии у и )’HD2 результат из раздела
4.5.3 относительно максимума увеличения дисперсии в процедурах подстановки с
подбором по сравнению с дисперсией среднего ответивших.
Часть II»
АНАЛИЗ ДАННЫХ
С ПРОПУСКАМИ НА ОСНОВЕ
ФУНКЦИИ ПРАВДОПОДОБИЯ
Глава 5. ТЕОРИЯ ВЫВОДОВ, ОСНОВАННЫХ
НА ПРИМЕНЕНИИ ФУНКЦИИ ПРАВДОПОДОБИЯ
5.1. ПОЛНЫЕ ДАННЫЕ
Многие методы оценивания для неполных данных можно интер-
претировать как методы максимизации функции правдоподобия при
определенных предположениях относительно модели. В этом разде-
ле мы обсудим основы теории оценивания методом максимального
правдоподобия и опишем ее приложение к ситуации неполных дан-
ных. Сначала мы рассмотрим оценки максимального правдоподо-
бия для полных наборов данных, приводя только основные
результаты и опуская вычислительные подробности. Более полное
изложение этих вопросов приведено, например, в [Сох and Hinkley
(1974)].
Обозначим данные через Y. Y может быть скаляром, вектором
или матрицей в зависимости от контекста. Предполагается, что
данные порождаются согласно модели, описываемой функцией рас-
пределения или плотностью ДУ| 0), зависящей от скалярного или
векторного параметра в. При заданных модели и параметре 9/(У | 0)
является функцией Y, значениями которой служат вероятность зна-
чений Y или плотность в У.
Определение 5.1. Функцией правдоподобия Ц9 | У) называется лю-
бая функция от в, пропорциональная f(Y | 0), при фиксированном У
Заметим, что функция правдоподобия, или, короче, правдоподо-
бие, представляет собой функцию параметра 0 при фиксированном
У, в то время как вероятность или плотность является функцией У
при фиксированном 0. В обоих случаях мы пишем первым аргумент
функции. Несколько неточно говорить об одной функции правдопо-
добия, поскольку существует множество функций правдоподобия,
отличающихся друг от друга на произвольный множитель, не зави-
сящий от 0.
Определение 5.2. Логарифмической функцией правдоподобия
lift | Y) называют натуральный логарифм (In) функции правдоподо-
бия L(0 | У).
Во многих задачах работать с логарифмом правдоподобия удоб-
нее, чем с правдоподобием.
91
Пример 5.1. Одномерная нормальная выборка. Совместная плот
ность п независимых одинаково распределенных наблюденш
У=О1, , Уп)т из нормальной популяции со средним g и диспер
сией а2 равна:
/(У | M,ff2) = (21ra2)-"/2exp[-l£ .
При фиксированном У логарифм правдоподобия равен:
W! У) = 1п[/-(У|^а1)],
или, опуская аддитивную постоянную,
W | У) = -|1па2-4£^< (5.1)
что следует рассматривать как функцию от 9-~(у.,о2'^ при фиксиро-
ванных наблюденных данных У.
Пример 5.2. Экспоненциальная выборка. Совместная плотность
независимых и одинаково распределенных наблюдений из экспо-
ненциального распределения равна:
/(У|0) = 0-"ехр(-Е^).
Следовательно, логарифм правдоподобия, рассматриваемый как
функция 9 при фиксированных наблюденных данных У, равен:
7(0 | У) - 1п)(0~")ехр(—Е^)] = —л1п0—Е^-. (5.2)
Пример 5.3. Пуассоновская выборка. Вероятность и независимых
наблюдений У = (у1( ..., у„)т из пуассоновского распределения со
средним 9 равна:
f(Y\ 0)=ехр(—и0)0Ел/(П j,!),
где у,!=О,)хО,—1)...х(1). Поэтому логарифм правдоподобия от
9 равен:
1(9 | У)= — п9 + £у,1п9. (5.3)
Пример 5.4. Многомерная нормальная выборка. Пусть У=(у,7),
где у'=1,...,А?, — матрица, представляющая выбофку из п
независимых и одинаково распределенных наблюдений из много-
92
мерного нормального распределения с вектором средних
/1. -(/и, р.*) и ковариационной матрицей Е = (од,
к К). Значит, yi} — это значение у-го признака у /-го наблю-
дения выборки. Плотность Y равна:
f(Y\/l,L) = (2тГв/г)пК | Е | -п/2ехр[- Е V,^)T/2](5.4)
1=1
где | Е | обозначает детерминант Е, Т — транспонирование матри-
цы или вектора, а у, — вектор значений признаков /-го наблюдения
(/-я строка Y). Правдоподобием от (д,Е) будет это выражение, рас-
сматриваемое как функция от ц и Е при фиксированной наблюден-
ной Y.
Предположим, что рассматриваются два возможных значения 6
при фиксированных данных Y: 9' и 6''. Пусть, кроме того,
Цв7 | У)=2Ё(0" | У). Можно сказать, что полученные данные Y в
два раза правдоподобнее при в7, чем при 0". Рассмотрим более об-
щую ситуацию. Пусть 0 — такое значение, что L(§ | У) > L(0 | У) при
любом возможном в. Тогда при в наблюдаемые данные Y по мень-
шей мере так же правдоподобны, как при любом другом возмож-
ном значении 0. В определенном смысле 9 — значение, лучше всего
соответствующее данным. Это довольно естественно побуждает ис-
кать значение 6, максимизирующее функцию правдоподобия. Более
формальное обоснование такого выбора приведено в разделе 5.2.
Определение 5.3. Оценкой максимального правдоподобия (ОМП,
МП-оценкой) 0 называется значение 0, которое максимизирует прав-
доподобие L(0 | У), или, что эквивалентно, логарифм правдоподо-
бия 1(0 | У).
Сформулированное определение подразумевает возможность су-
ществования более одной ОМП. Тем не менее во многих важных
моделях ОМП единственна, и, кроме того, функция правдоподобия
дифференцируема и ограничена сверху. В таких случаях МП-оценку
можно найти, приравнивая производную правдоподобия (или лога-
рифма правдоподобия) по 0 к нулю и решая получаемое уравнение
относительно 6. Уравнение
5(0 | У>^Р==О
называют уравнением максимального правдоподобия, а производ-
ную логарифма правдоподобия 5(0 | У) — функцией вкладов (score
function). Обозначим через d число компонент в 0. Уравнение мак-
симального правдоподобия, по существу, — это система из d урав-
нений, определяемых дифференцированием /(0 | У) по всем d
компонентам 0.
Пример 5.5. Экспоненциальная выборка (продолжение примера 5.2).
Логарифм правдоподобия для выборки из экспоненциального рас-
93
пределения определяется выражением (5.2). Дифференцирование по
О приводит к уравнению максимального правдоподобия
__— + v =0
ft + ь » и-
Решая его относительно 9, получаем ОМП 9=у =53у,/п — среднее
выборки Y.
Пример 5.6. Пуассоновская выборка (продолжение примера 5.3).
Логарифм правдоподобия для пуассоновской выборки определяется
выражением (5.3). Дифференцирование по 9 позволяет получить
уравнение
—л + Еу,/0 = О.
Корнем уравнения является ОМП 9=у, выборочное среднее.
Пример 5.7. Одномерная нормальная выборка (продолжение при-
мера 5.1). Согласно (5.1) логарифм правдоподобия для выборки
объема п из нормального распределения равен:
!(ц,а21 У) = — 41п<г2— 4-2 =
2 2 |=] (7
11 !п.г’ 1 "(F — Д)2 I ns1
2 2 <7‘ 2 о-
где s'- = п~'^г'={(у,-—у~У — выборочная дисперсия (со знаменателем
п, а не п—1, т. е. без поправки на число степеней свободы). Диффе-
ренцируя по ц и приравнивая производную нулю при ц=(1 и а- = а2,
получаем
(У—f2)/6=2 = 0,
что приводит к g=J7. Дифференцируя по д2 и приравнивая произ-
водную нулю в р.=у и аг=а2, получаем
/I П(У~—А)2 . Д5;_П
2& 2<г 2а и>
что приводит к <г2=52, так как jl=y. Итак, мы получим МП-
fl цен ку:
Д=У, a1=s1.
Пример 5.8. Многомерная нормальная выборка (продолжение
примера 5.4). Стандартные вычисления из многомерного анализа
(см., например, [Wilks (1963); Rao (1972); Anderson (1965)]) показыва-
ют, что максимизация (5.4) по g и £ приводит к
Д=У, t.~S,
94
। це у —(у н ...( jA) — вектор-строка выборочных средних, a S=(s,*) —
выборочная ковариационная кх^-матрица с (J, к)-м эле-
ментом sjk = n-l£"=i(y,j—у)(у,к—у к).
Свойство 5.1. Пусть g(0) — взаимнооднозначная функция пара-
метра 0. Тогда ОМП для g(0) равна g(0), значению функции, взято-
му в ОМП § параметра В.
Свойство 5.1 играет важную роль во многих задачах. Оно триви-
ально вытекает из того, что функцией правдоподобия oTj/>=.g(0) яв-
ляется Ц£~'(Ф) | У), достигающая максимума при $=g(§).
Пример 5.9. Условное распределение для двумерного нормально-
го распределения. Данные образованы п независимыми и одинаково
распределенными наблюдениями (у,}, у,2), /=1, п, из двумерного
нормального распределения со средним (дь /t2) и ковариационной
матрицей
<7И «Гц
<212 °22
Как и в примере 5.4, МП-оценки равны:
~У j >
Ojk = $jk>
>1,2,
j, к=\,2
где у 1 и у 2 — выборочные средние, aS — выборочная ковариаци-
онная матрица со знаменателем п. Из свойств двумерного нормаль-
ного распределения следует, что условное распределение уа при
данном _y,i нормально со средним + —/и) и дисперсией
<т22 1, где
021 1 = <212/О'], И <2221 = с,22—<xfz/all
соответственно коэффициент регрессии и остаточная дисперсия для
регрессии у,2 на ylt. По свойству 5.1 ОМП этих величин равны:
021 1 = CJ2/СГ> I =^12/^11,
оценке наименьших квадратов коэффициента регрессии, и
ff22-l = ff22—<Г'|2 /<7ц = S22-I,
где s22.i =п~1^= ]!у2—У-—0211СУ1~У')>2’ остаточной сумме квадра-
тов от регрессии для п выборочных значений, деленной на п.
95
ОМП /321 ] и а221 можно вывести и непосредственно по правдопо-
добию для условного распределения у,2 при данном у,]. Как показа-
но в следующем примере, связь между оцениванием нормальной
линейной регрессионной модели методом максимального правдопо-
добия и методом наименьших квадратов оказывается более общей.
Пример 5.10. Множественная линейная регрессия. Данные состо-
ят из п наблюдений (у„хЛ,...,х,р), i=l,...,n, над зависимой пере-
менной у и р предсказывающими признаками. Мы предполагаем,
что при заданном х, = (%,!,..., х,р) значения у, независимо распреде-
лены по нормальному закону со средним и дисперсией
<т2. Логарифм правдоподобия от 0=(3о,Зь...,Зр,о2) при фиксирован-
ных данных у„ х„ 1=1,...,п, равен
—f In a2-—f Зо—З.х,,--. . 13рХ1рУ. (5.5)
Максимизируя это выражение по 6, мы обнаружим, что ОМП для
(Зо, 3Р) есть оценки наименьших квадратов свободного члена и
коэффициентов регрессии. МП-оценка а1 равна s2, где ns2 — оста-
точная сумма квадратов от наименьшей квадратической регрессии.
Значит, как и ранее, оценка максимального правдоподобия а2 не
учитывает потерю степеней свободы при оценивании р+1 парамет-
ров положения.
5.2. ПОСТРОЕНИЕ ВЫВОДОВ ПО ОМП
5.2.1. Интервальное оценивание
В этом разделе приведены некоторые основные свойства МП-оце-
нок. Подробное описание их можно найти в книгах [Rao (1972); Сох
and Hinkley (1974)].
Пусть S обозначает МП-оценку в, построенную с помощью дан-
ных Y. Наиболее важным с практической точки зрения свойством ё
является то, что во многих случаях, особенно для выборок большо-
го объема, применима следующая аппроксимация.
Аппроксимация 5.1.
(0—0") ~ N(0, Q, (5.6)
где С — ковариационная dх «/-матрица для (0—0). С байесовской
точки зрения в (5.6) 0, наблюдаемая ОМП, фиксирована, а 0 — слу-
чайная величина, в то время как с частотной точки зрения 0 фикси-
рована и неизвестна, а оценка 0 — случайная величина. В обоих
случаях С считается фиксированной и подразумевается, что плот-
ность /( | •), по которой вычисляется правдоподобие, задана.
96
Частотная интерпретация (5.6) состоит в том, что при плотности
/(• | •) оценка 6 в повторных выборках распределена приближенно
нормально со средним, равным истинному значению 0, и ковариа-
ционной матрицей С, которые менее вариабельны, чем 6. Байесов-
ская же интерпретация (5.6) заключается в том, что апостериорное
распределение в условно по /(• | •) и по наблюденным данным, нор-
мально со средним в и ковариационной матрицей С, где 6 и С —
статистики, значения которых зафиксированы в соответствии с на-
блюденными данными.
Вывод аппроксимации 5.1 с байесовской позиции основан на раз-
ложении логарифма правдоподобия в ряд Тейлора около ОМП:
1(6 \ Y) = l(6\ Y) + (6—6)TS(6\ Y)—^(6—6)4(6 \ Y)(6—6) + r(6\ Y)>
где S(6 | У) — функция вкладов, a 1(6 | У) — наблюдаемая информа-
ция, которая определяется как
По определению S(61 У) = 0. Поэтому, считая остаточный член
г(6 | Y) пренебрежимо малым, а априорное распределение 6 равно-
мерным в области значений 6, допускаемых данными, получим, что
апостериорное распределение 6 имеет плотность
ле\ y)~exp[-y(0-e)W| Y)(6-0]
нормального распределения для аппроксимации 5.1 с ковариацион-
ной матрицей
С=г'(§ I У),
которая обратна наблюдаемой информации в 6. Более подробное
изложение этих вопросов приведено в [Lindley (1965)].
Частотный вывод аппроксимации 5.1 более сложен. Сначала мы
раскладываем S(6 | У) в ряд Тейлора около истинного значения 6 до
первого члена
0 = 5(0 | У) = 5(0 | У)—1(6 | Y)(6—6) + г(д | У).
Если остаточный член г(6\ У) пренебрежимо мал, мы имеем
S(6 | У) = 7(0 | Y)(6—6).
4 Р Дж А Литтл, Д Б Рубин 97
Можно показать с помощью центральной препельной теоремы, что
в определенных условиях регулярности 5(0 | У) при повторном вы-
боре асимптотически нормальна со средним 0 и ковариационной
матрицей
7(0)=ад |у) j 0) = 1/(0 ; y)f(y j 0)dy,
называемой ожидаемой информационной матрицей. По одной из
форм закона больших чисел
J(0) = J(0)^/(0 | Y). j
Объединение этих результатов и приводит к аппроксимации 5.1 с '
ковариационной матрицей
I
обратной к ожидаемой информационной матрице в 0 = 0.
В любом случае, полагая С равной Г‘(9\ или некото- '
рой другой близкой матрице, аппроксимацию 5.1 можно использо- '
вать для доверительного оценивания в. Например, 95%-ные
интервалы для скалярного 9 равны:
0±1,96С1/2, (5.7)
где на практике можно часто заменять 1,96 на 2. Для векторного 9
95%-ные эллипсоиды определяются неравенством
(5.8)
где х20 9, d—95-я процентиль распределения хи-квадрат с d степеня-
ми свободы. В более общей форме 95%-ные эллипсоиды для q<d
компонент 0(1) параметра в можно задать неравенством
(0(1) 0(1))ТС(11)' (0(1) 0(1>)^Уо,95,<?> (5-9)
где 0(1) — ОМП 0(1) и С(11) — подматрица С, соответствующая 0(1).
Выводы, основанные на аппроксимации 5.1, не только справедли-
вы, если определена /(• | •) и объемы выборок достаточно велики,
но и оптимальны. Поэтому неудивительно, что подход с использо-
ванием ОМП и аппроксимации 5.1 весьма популярен, особенно если
учесть, что во многих областях прикладной математики методы
максимизации функций развиты очень хорошо.
На протяжении части II настоящей книги мы сконцентрируем
внимание главным образом на больших выборках и постараемся из-
бежать сложностей, связанных с различиями между байесовской и 1
частотной интерпретациями, присущими ситуации, когда выборки
малы.
98
Пример 5.11. Экспоненциальная выборка (продолжение примера
5.2). Дважды дифференцируя (5.2) по 0, получаем
1(f) | У) = —п/02+2Уу1/02.
Вычисляя математическое ожидание по У, находим
J(0) = —n/02 + 2E(Ly, | 0)/0’=—п/в2 + 2пв/02.
Подставляя вместо 0 МП-оценку 6=у~, имеем
1(f) \ Y) = J(0) = n/y2.
Следовательно, дисперсия (0—в) для больших выборок равна у 2/п.
Пример 5.12. Одномерная нормальная выборка (продолжение
примера 5.1). Дважды дифференцируя (5.1) по ц и а2 и подставляя
ОМП параметров, получаем
Обращение этой матрицы дает асимптотические значения вторых
моментов: Var(/x—р)= о2/п,~ Cov(/i—fi, а2—<j2) = 0, Var(a2—а2) = 2дЧп,
где из примера 5.7 д=У, а2 = х2.
5.2.2. Проверка гипотез о значении 0
Согласованность значений 0 с данными часто характеризуют не
эллипсоидами типа (5.8), а уровнями значимости*, в особенности
когда число d компонент 0 больше двух. При этом вычисляют рас-
стояние от некоторого гипотетического значения 0О до 0:
Dc(Oo, §) = (0.-§ус-1(да-ё).
Эта величина — левая часть (5.8), вычисляемая в 0=9О. Соответ-
ствующая процентиль распределения хи-квадрат с d степенями сво-
боды есть уровень значимости или p-значение для 0у.
рс = Рг^>£>с(0о,0)].
С частотной точки зрения уровень значимости при заданном 0 = 0О
дает величину априорной вероятности того, что оценка максималь-
ного правдоподобия будет не дальше от 0О, чем наблюдаемая ОМП
0. Мы получим (двусторонний) критерий размера а для проверки
* Имеется в виду фактически достигаемый уровень значимости. — Примеч. пер.
4
99
нулевой гипотезы Н„:9 = в0, если будем отвергать Но, когда /«-значе-
ние рс меньше а. Обычно берут а равным 0,1, 0,05 или 0,01.
С байесовской точки зрения рс позволяет получить асимптотиче-
скую апостериорную вероятность множества значений 0, имеющих
меньшую апостериорную плотность, чем 0о: Pr[OeJO | У)</(0О | У))].
Примеры и обсуждение этих проблем см. в [Box and Tiao (1973)].
При справедливости предположения 5.1 асимптотически эквива-
лентна процедура определения уровня значимости по расстоянию
между 0 и в0, измеренному с помощью статистики отношения прав-
доподобия, которая дает
р£=рг^>ед, в)},
где
£>£(0оЛ) = 21п[Л(0 | Y)/U60 | У)] = 2[/(0 | У)-1(в01 У)].
Рассмотрим более общий случай. Пусть 0 = (0(1), 9(2)). Предполо-
жим, что нас интересует, насколько нулевое значение 0(1), 0(1)О, со-
ответствует данным. Число компонент равно q. Эта ситуация
обычно возникает при сравнении адекватности двух моделей А и Б,
называемых вложенными (nested), поскольку параметрическое про-
странство модели Б получается из параметрического пространства
модели А, если положить 6(1) равным нулю. Два асимптотически
эквивалентных подхода к определению уровня значимости, соответ-
ствующих применению рс или pL, выглядят следующим образом:
77c^(i)o) = f>r7(| > (#(1)0 ^(1))7'С(Г11) С#(1)0 0(i))i,
где С(П) — ковариационная матрица для 0{1), такая же, как в (5.9), и
р£(%0) = Рг^ > 2С],
где
Х2 = 2[1(9 | У)—1(9 | У)],
а в — значение в, максимизирующее 1(в | У) при ограничении
б//; = б(])0. В соответствии с критериями уровня а мы отвергаем ги-
потезу Но: 0(i) = 0(1)o, если P-значение для 0(1)О меньше а.
Пример 5.13. Одномерная нормальная выборка (продолжение
примера 5.1). Допустим, что (9“~(/т, а2), 9([} = н, в^2} = а2. Статистика
критерия отношения правдоподобия для проверки гипотезы Но:
д= /и равна:
X2 = 2(—п/2 In s2—п/2+п/2 In si + л/2) = п Infs®/s1),
100
где So = n—1Y"=l(yl—no)2 = s2+(y—nt>)2. Значит, A^=nln(l + t2/n), где,
согласно примеру 5.12, t2 = n(y—Ho)2/s2 — статистика для проверки
Нп, основанная на асимптотической дисперсии для (р—рГ:). Асимпто-
тически X1 равна t2 и распределена при справедливости Но по хи-ква-
драт с q=l степенями свободы. Точный критерий для данного случая
будет получен, если сравнивать t2 непосредственно с F-распределени-
см с 1 и п—1 степенями свободы. Как правило, для малых выборок
такие точные критерии отсутствуют, когда мы применяем критерий
отношения правдоподобия к данным с пропусками.
5.3. ОЦЕНИВАНИЕ МЕТОДОМ МАКСИМАЛЬНОГО ПРАВДОПОДОБИЯ
ПО НЕПОЛНЫМ ДАННЫМ
Формально говоря, между оцениванием методом максимального
правдоподобия по неполным и по полным данным разницы нет: ис-
пользуя неполные данные, получают функцию правдоподобия пара-
метров и находят МП-оценки, решая уравнения максимального
правдоподобия. Несколько более проблематичен, однако, вывод
асимптотических стандартных ошибок из информационной матри-
цы, поскольку наблюдения уже не являются в общем случае н. о. р.
(независимыми одинаково распределенными) и простые результа-
ты, основанные на асимптотической нормальности функции правдо-
подобия, непосредственно не применимы. Дополнительные
трудности связаны с процессом, который порождает пропуски в
данных. При обсуждении этих трудностей мы до некоторой степени
поступимся точностью формулировок, чтобы сохранить простоту в
обозначениях. Математически строгое обсуждение этих вопросов
содержится в [Rubin (1976)], где затронуты частотные подходы, не
основанные на правдоподобии*.
Как и ранее, обозначим через Y данные, которые наблюдались бы
при отсутствии пропусков. Тогда У=(Уоь5« Ут»)> где ^obs обозначает
наблюденные, a ymis— пропущенные значения. Обозначим /(У|0) =
=/(Уоь8, ^mis I 0) вероятность или плотность совместного распреде-
ления УоЬ5 и Ут15. Интегрированием по пропущенным данным Ут15
получим плотность вероятности
ЛУоь5|Й)=1/(^ rmls|^rmis.
* По поводу этих замечаний и указанной работы Рубина см. дополнение к перево-
ду, разделы 1—2. — Примеч. пер.
101
Определим правдоподобие от 0, основанное на У()Ьч, без учета
механизма порождения пропусков как любую функцию от 9, про-
порциональную ДУоЬч | ву.
Ц0\
(5.10)
С помощью данной функции правдоподобия можно делать выводы
относительно в, если механизм порождения пропусков пренебрежим
в том смысле, который обсуждается ниже.
В более общем случае мы включаем в модель распределение пере-
менной, указывающей наличие каждого элемента из Y. Индикато-
ром пропуска будем называть величину, принимающую значение 1,
если данный элемент наблюдается, и 0, если он не наблюдается.
Например, если У=(У,) есть лхЛЛ-матрица п наблюдений над К-
мерной переменной, индикатор пропуска будет определяться следу-
ющим образом:
R.,=
। 1 , у„ наблюдается,
I 0, уи пропущен,
В нашей модели R рассматривается как случайная переменная и
определяется совместное распределение R и У. Плотность этого
распределения можно задать как произведение плотности распреде-
ления У и плотности условного распределения R при фиксирован-
ном У, т. е.
/(У,Л|0,^)=/(У|0)/(Л|У^.
Будем называть условное распределение R при данном У, зависящее
от неизвестного параметра распределением пропусков. В некото-
рых случаях это распределение известно точно, и параметризация с
помощью не нужна.
Фактически наблюдаемые данные состоят из значений перемен-
ных (УоЬ,1?), Распределение наблюдаемых данных будет получено,
если проинтегрировать совместную плотность У=(УоЬ5, Ут„) и R по
Ym,s:
AYobs,R | W = >/(yobs, Ути i | yobs, ymis, ^dYmK. (5.11)
Правдоподобие от 0 и ф — это любая функция, пропорциональная
(5.И):
Yob„R)~f(Yobs,R\e,V). (5,12)
Теперь встает вопрос: когда следует строить выводы относитель-
но 9 на основе правдоподобия ( Y^,VR) в (5.12), а когда — на
основе более простого выражения Ц9 | УоЬ,) в (5.10), в котором ме-
102
\aini3M порождения пропусков игнорируется. Заметим, что при не-
ывисимости распределения пропусков от пропущенных значений
т. е. при
f(R | УоЬ„ Ymn,V=f(R | УоЬ,Л), ' (5.13)
in (5.11) следует, что
/(yobs,7? I 6^)=f{R I yobs, •T'/T.bs, r,,.s I 0)dYml,=
=/(/?, yabs)^yobs И)-
Во многих важных приложениях параметры 0 и ф раздельны в
юм смысле, что совместное параметрическое пространство (0, i/>)
есть произведение параметрических пространств для 0 и для 1Д.Если
О и ф раздельны, то выводы относительно 0, основанные на правдо-
подобии L(fi, ф | УоЬ,, R), будут совпадать с выводами, основанными
на L(f) | yobs). Поэтому, если верно уравнение (5.13), то механизмом
порождения пропусков можно пренебрегать — получаемые правдо-
подобия пропорциональны.
По определению [см. Rubin (1976)] пропущенные данные отсут-
ствуют случайно (ОС), когда выполняется (5.13). Заметим, в част-
ности, что если верно (5.13), то вероятность отсутствия данного
элемента не может зависеть от его значения, когда он отсутствует.
Уравнение (5.13) — это более точное выражение интуитивного по-
нятия об условии ОС, обсуждавшегося в гл. 1. В практическом от-
ношении важен тот факт, что для эффективного применения
методов, основанных на правдоподобии, при которых игнорируют
механизм порождения пропусков, требуется выполнение лишь усло-
вия ОС, а не более жесткого условия ОПС.
Пример 5.14. Неполная экспоненциальная выборка. Допустим,
мы имеем неполную одномерную выборку, в которой присутствует
5,Obs = 0'i> •>Лп)Т и отсутствует Yms = (ym^, уп). Чтобы конкре-
лизировать наш пример, примем, что yt — экспоненциально рас-
пределенные случайные величины. Значит, как в примере 5.2,
/(У|0) = 0-пехр(-Е^).
Правдоподобие, когда механизм порождения пропусков игнорирует-
ся, пропорционально плотности УоЬй при заданном 0, определяемой
выражением
/(yobs|9) = ^'"exp(-E ^-). ' (5.14)
В данном примере /? = (/?,, ..., R„)\ где Rt = l, /=1, ..., т, и А,=0,
i=m + 1, ..., п.
103
ч
Допустим, что каждый элемент наблюдается с вероятностью ф,
так что справедливо (5.13). Тогда
и
/(yobs, R I 9, ф) = ^-(1 —ехр(—£ ).
Если ф и 0 раздельны, выводы относительно в можно строить по
ДУоЬч I 0), пренебрегая механизмом порождения пропусков. В част-
ности, МП-оценка 6 равна просто L'"y,/w — среднему по присут-
ствующим значениям Y.
Теперь предположим, что пропуски в данных образуются вследст-
вие цензурирования в некоторой известной точке с, так что присут-
ствуют только значения, которые меньше с. Тогда
/(Я|Е^) = ПЖ1лЖ
I 1
где
1, /?,-1 и У'<с или -О и у^с,
О — в противном случае.
Ж1зЖ)=
Следовательно,
т /1
R I 0)=п j\y,,R, I 0)П J\R I 9)=
I ] i т <- 1
= n/cd«W?, 1л)П Рг(у>с|0) = (5.15)
/1 / т + I
= 0-'"ехР(-Е )exp[-<fl7'4
поскольку Рг(у; > с | в) = ехр(—с/в) согласно свойствам экспоненци-
ального распределения. В этом случае механизм порождения пропу-
сков нельзя игнорировать, и точное правдоподобие (5.15)
отличается от (5.14). Максимизация (5.15) по 9 дает ОМП 0 =
=(Е™у1 + (п—т)с)/т, которая больше по сравнению с ранее найден-
ной оценкой у/т. Положительная поправка к выборочному
среднему вызвана цензурированием ненаблюдаемых значений.
Пример 5.15. Двумерная нормальная выборка с пропусками в
одной переменной. Допустим, мы получили двумерную нормаль-
ную выборку, как в примере 5.9, но значения г(2, ; = w-l, ..., п,
второй переменной отсутствуют. Таким образом, мы имеем моно-
104
тонную структуру, как на рис. 1.3. Логарифм правдоподобия, в ко-
тором механизм порождения пропусков игнорируется, равен:
/U.S I YobS) = -1 win | Е | | m)t-
Z Z/=m+i (Уц
(5.16)
Это выражение может служить основой для построения выводов,
если распределение R (и, в частности, вероятность пропуска уа) не
зависит от значений уь, хотя, возможно, зависит от значений уп, а
fl = U, Е) и параметр механизма пропусков раздельны. При таких ус-
ловиях ОМП для /I и Е можно вычислять, максимизируя (5.16). В
гл. 6 описан простой подход к решению этой задачи, основанный на
факторизации правдоподобия.
5.4. МЕТОД ОДНОВРЕМЕННОЙ МАКСИМИЗАЦИИ
ПО ПАРАМЕТРАМ И ПРОПУЩЕННЫМ ЗНАЧЕНИЯМ
5.4.1. Описание метода
В литературе часто рассматривается другой подход к обработке
неполных данных, при котором пропущенные значения рассматри-
ваются как параметры и проводится одновременная максимизация
правдоподобия для полных данных по параметрам и пропущенным
значениям. Точнее, пусть
^is I robs)=Z(0 | УоЬМ=Л¥оЬ^ I 9) (5.17)
интерпретируется как функция от (0, ymis) при фиксированном У0(к,
и оценку 9 получают, максимизируя £mis(0, ymis | yobs) по 9 и по Утй.
Если пропущенные данные не ОС или 9 и не раздельны, то 9 надо
было бы оценивать, максимизируя
Ф, rmis I Yobs,R)=L(9, ф I yobs, ymis,7?) =
(5.18)
no (M,ymis).
Несмотря на пригодность для некоторых задач, этот подход не-
приемлем для анализа неполных данных в общем случае*.
• Данный подход можно считать одним из методов заполнения пропусков: пропус-
ки заполняются значениями ymjs, найденными при максимизации (5.17) (или
(5.18)).—Примеч. пер.
105
В частности, Литтл и Рубин [Little and Rubin (1983)] показали, что'
он не обладает оптимальными свойствами, присущими МП-оцени-
ванию, за исключением тривиальной асимптотики, когда доля про-
пусков с увеличением объема выборки стремится к нулю.
5.4.2. Некоторые сведения о методе
Классический пример рассматриваемого подхода — обработка
отсутствующих значений при дисперсионном анализе, где отсут-
ствующие выходные переменные Ут15 интерпретируются как пара-
метры и оцениваются вместе с параметрами модели, чтобы в
процессе анализа можно было использовать эффективные с вычис-
лительной точки зрения методы (см. гл. 2). Сравнительно недавно
этот подход предлагался в [DeGroot and Goel (1980)] как один из
возможных способов анализа смешанной двумерной нормальной
выборки, где отсутствующими данными являются индексы, по ко-
торым связываются в пары значения двух переменных, причем все
парные комбинации предполагаются равновероятными. Пресс и
Скотт [Press and Scott (1976)] описывают байесовский анализ непол-
ной многомерной нормальной выборки, который эквивалентен мак-
симизации Lmis в (5.17) по (б, Ут]5). Бокс и его коллеги [Box, Draper
and Hunter (1970)], а также Бард [Bard (1974)] предлагали этот же
подход в более общей постановке: вектор средних многомерного
нормального распределения подчинялся уравнению регрессии.
Формально истинным правдоподобием от 6, основанным на на-
блюденных данных Уо(к, при выполнении условия ОС является
Ц9\ УоЬ5), определенное в (5.10). Функция Lmis не является правдо-
подобием, поскольку в ее аргументы входят случайные величины
Ут14, имеющие согласно модели некоторое распределение, и их,
следовательно, нельзя рассматривать как фиксированные парамет-
ры. С этой точки зрения метод максимизации £m.s по в и по Ут15
не является методом максимального правдоподобия.
Рассматривая 9 и Ут15 как параметры, сталкиваются с такой j
серьезной проблемой, как увеличение числа параметров с ростом ,
числа наблюдений. Максимизация £т15 обеспечивает оптимальные
свойства, присущие МП-оценкам, лишь когда доля пропусков стре- ’
мится к нулю с ростом объема выборки. Параметр 9, напротив, не 1
зависит от объема данных, и поэтому, грубо говоря, имеют место ।
обычные асимптотики при максимизации L(fi | У(1Ь5), если количе- !
ство информации увеличивается с объемом выборки. Указанный не- j
достаток интерпретации Ут15 как параметров хорошо i
иллюстрируется в простых примерах, приведенных в следующем j
разделе. «
106
+4.3. Примеры
Пример 5.16. Одномерная нормальная выборка с пропусками. До-
пустим, что У=(УоЬ5, Ут15) состоит из п реализаций нормальной
с лучайной величины со средним ц и дисперсией ст2. УоЬ5 представля-
ei т наблюденных значений, Ут15 представляет п—т отсутствую-
щих значений, для которых верно ОС. Параметр 0 = (д, <г2)
предполагается раздельным с параметрами механизма пропусков.
1огда
/(У|е) = П/О,|0) = П f(y, |0). П >,|0), (5.19)
(-1 /-1 f-171+1
откуда следует, что /(УоЬ, | 0) = П'" /(у, | 9) и /(Ут151 0) = п”т+1/(у, | 9).
Значит, L(6 | yobs) идентично правдоподобию для выборки объема
т без пропусков из нормального распределения. Согласно примеру
5.7 максимизация Ц9 | УП]15) по 9 ведет к ОМП
£ 0*,-д)2 ,,
/г /л * (5.2(7)
С другой стороны,
I ^obs)=/(yobs|0)/(ymls|e). (5.21)
Это выражение надо максимизировать по в и по Ут18. Максимизи-
руя второй фактор в (5.21) по Ут15, получаем решение:
у, —у , 1 = т+1, ..., п, (5.22)
где ц — максимизирующее значение д. Из примера 5.1 следует, что
решениями для д и <т2 будут:
т п
д = (£у, + Е У,)/п и
1 771+1
Подставляя (5.22) в (5.23) и
д2 = (Е О,—д )2 + Е (У,— a Wn. (5.23)
1 т+1
сравнивая результат с (5.20), находим
А = д
и ог=агт/п.
Таким образом, мы получили МП-оценку среднего, но оценкой дис-
персии стала ОМП, умноженная на долю присутствующих значс-
107
ний. Если доля пропусков существенна (например, т4г^0,5), то
оценка дисперсии о 2 сильно смещена, и при п—.><--тю смещение
сохраняется, если только не выполняется асимптотика т/п-^ 1. Бо-
лее естественные асимптотики сохранили бы фиксированное значе-
ние т/п при увеличении объема выборки.
Пример 5.17. Допустим, мы добавили в предыдущий пример
множество значений сопеременной X, присутствующих во всех п на-
блюдениях. Предположим, что значение Y в i-м наблюдении при
значении сопеременной Х=х, распределено нормально со средним
/3()+х(/3 и дисперсией а2. Обозначим 0-(/Зо,/3,оД. Для того чтобы
получать оценки максимального правдоподобия ,б0, /3 и и2, максими-
зирующие L(0 | У„ь,), можно применить метод наименьших квадра-
тов к т комплектным наблюдениям. Оценки 130 и 0, получаемые
при максимизации LmK, совпадают с ОМП, однако, как и в приме-
ре 5.16, оценкой дисперсии становится МП-оценка, умноженная на
долю присутствующих значений.
Пример 5.18. Экспоненциальная выборка с цензурированными
значениями. В примерах 5.16 и 5.17 оценивание с помощью макси-
мизации £mls по крайней мере приводило к разумным оценкам па-
раметров положения, хотя оценки параметров масштаба требовали
поправок. Тем не менее можно привести примеры, когда сильно
смещены и оценки параметров положения. Рассмотрим, как в при-
мере 5.14, цензурированную выборку из экспоненциального распре-
деления со средним в, где УоЬч представляет т присутствующих
значений, находящихся левее точки цензурирования с, a Ут1, пред-
ставляет п—т отсутствующих (цензурированных) значений, превы-
шающих с. ОМП 0 — это §=у+(п—т)с/т. Максимизация Lmis в
(5.18) по в и по Kmis (положим ф равным нулю) приводит к тому,
что цензурированные значения У оцениваются величиной с, а оцен-
кой 9 является (wh)9. Итак, в этом случае оценка среднего несосто-
ятельна, если только доля пропусков не стремится к нулю при
увеличении объема выборки.
Как показано в [Press and Scott (1976); Little and Rubin (1983)], сме-
щенные оценки параметра положения могут получаться при макси-
мизации Lms и в задачах, связанных с нормальным
распределением.
108
ЛИТЕРАТУРА
Anderson, Т. W. (1965). An Introduction to Multivariate Statistical Analysis. New York: Wiley?
Bard, Y. (1974). Nonlinear Parameter Estimation. New York: Academic Press.
Box, M. J., Draper, N. R., and Hunter, W. G. (1970), Missing values in multi-response nonlinear
data fitting, Technometrics 12, 613-620.
Box, G. E. P. and Tiao, G. C. (1973). Bayesian Inference in Statistical Analysis. Reading, MA:
Addison-Wesley.
о
Cox, D. R., and Hinkley, D. V. (1974). Theoretical Statistics. New York: Wiley.
DeGroot, M. H., and Goel, K. (1980). Estimation of the correlation coefficient from a broken
random sample, Ann. Statist. 8, 264-278.
Little, R. J. A., and Rubin, D. B. (1983). On jointly estimating parameters and missing data by
maximizing the complete-data likelihood, Am. Statist. 37, 218-220.
Lindley, D. V. (1965). Introduction to Probability and Statistics from a Bayesian Viewpoint, Part
2, Inference. Cambridge, Cambridge University Press.
Press, S. J., and Scott, A. J. (1976). Missing variables in Bayesian regression, II, J. Am. Statist.
Associ. 71, 366-369.
Rao, C. R. (1972). Linear Statistical Inference. New York: Wiley.
Rubin, D. B. (1976). Inference and missing data, Biometrika 63, 581-592.
Wilks, S. S. (1963). Mathematical Statistics. New York: Wiley?
ЗАДАЧИ
1. Выпишите функцию правдоподобия для выборки независимых одинаково рас-
пределенных случайных величин из: а) бета-распределения, б) полиномиального рас-
пределения, в) распределения Коши.
2. Найдите функции вкладов для распределений в задаче 1 и МП-оценки, которые
для этих распределений представляются в явном виде.
3. Найдите ОМП коэффициента вариации о/p для одномерной нормальной
выборки.
4. а) Выясните, как связаны МП-оценки и оценки наименьших квадратов для моде-
ли из примера 5.10.
б) Покажите, что если данные ...»— н. о. р. наблюдения из распределения
Лапласа (двойного экспоненциального),
./О', | 0) = О,5ехр(— |я—|),
1 Русский перевод: Андерсон Т. Введение в многомерный статистический анализ. — М.:
Физматгиз, 1963.
® Русский перевод: Кокс Д., Хинкли Д. Теоретическая статистика. — М.: Мир, 1978.
$ Русский перевод: Рао С.Р. Линейные статистические методы и их применения. — М.: Наука,
1968.
Русский перевод: Уилкс С. Математическая статистика. — М.: Наука, 1968.
109
где д(х1) = 0Оч-+ . + /3^, то МП-оценки f}0, ..., 0к получаются минимизацией
суммы абсолютных отклонений значений у от их ожидаемых значений л(х).
5. Объясните теоретические и практические различия между частотной и байесов-
ской интерпретациями аппроксимации 5.1.
6. Вычислите наблюдаемую и ожидаемую информацию для распределений в
задаче 1.
7. Покажите, что для случайной выборки из регулярного распределения (можно пе-
реносить дифференцирование под знак интеграла) ожидаемый квадрат функции вкла-
дов равен ожидаемой информации.
8. Покажите, что для больших и в примере 5.13
9. Найдите опенки дисперсий двух ОМП в примере 5.14.
10. Определите: 1) выполняется ли условие ОС, 2) пренебрежим ли механизм по-
рождения пропусков при построении выводов по (У^ У2) с помощью правдоподобия
для двумерной нормальной выборки с параметром 6 = (^д1, g2, аи, а22, а12) и пропуска-
ми в У2 при следующих механизмах пропусков:
а) Рг(у2 пропущен | у,, ^2, fl, 0)=exp(V-o + V'i>’i)/|l+exp(^o+в и f=(MJ
раздельны,
б) Рг(у2 пропущен |у„ у2, &, ^)=ехр(^0+^,у,)/;1+ехр(й + 9 и
раздельны,
в) Рг (у2 пропущен |у,,у2, 0, й=0,5ехр(/1| + ,Ду1)/!1+ехр(д1 + |/у1)]1 9 и скаляр V"
раздельны.
Глава 6. ФАКТОРИЗАЦИЯ ПРАВДОПОДОБИЯ ДЛЯ
МЕТОДОВ, КОГДА МЕХАНИЗМ ПОРОЖДЕНИЯ
ПРОПУСКОВ ИГНОРИРУЕТСЯ
6.1. ВВЕДЕНИЕ
Логарифм правдоподобия 1(6 | Kobs) для неполных данных УоЬ5
может быть сложной функцией, максимум которой найти нелегко и
которая, конечно, может порождать информационную матрицу
сложного вида. Однако для определенных моделей и структур про-
пусков удается анализировать 1(6 | Eobs) с помощью обычных мето-
дов для полных данных. В общих чертах идея описывается в
настоящем разделе, частные случаи для нормальных данных рас-
смотрены в остальных разделах главы, а для полиномиальных (пе-
рекрестно классифицированных) данных — в гл. 9.
ПО
Для некоторых моделей и структур пропусков существует такой
вариант параметризации ф = ф(0) (где ф — взаимнооднозначная
функция от 0), что логарифм правдоподобия разделяется на ком-
поненты:
КФ I Yobs) = l^} I robs) + /(021 Kobs)+... Ч-<ХА/1 robs), (6.1)
причем
1) Фн Ф1, , ФJ — раздельные, т. e. совместное параметрическое
пространство для ф~(ф1, ф2...ф7) является произведением пара-
метрических пространств для отдельных ф}, J=i, J;
2) компоненты /;(ф? | УоЬ8) — это логарифмы правдоподобия для
задачи с полными данными, или в общем случае, для более прос-
тых задач с неполными данными.
Если можно определить разложение с такими свойствами, то
благодаря раздельности фи ..., максимум !(ф | Kobs) можно най-
ти, максимизируя //(</)/1 Yobs) отдельно для каждого j. Если в ре-
зультате получена МП-оценка ф, то МП-оценку любой функции 9(ф)
от ф можно получить, используя свойство 5.1, т. е. полагая 9 = 6(ф).
С помощью разложения (6.1) можно также вычислить прибли-
женную ковариационную матрицу для ОМП, матрицу С в (5.6).
Двукратное дифференцирование (6.1) и 0t, .... дает блочно-
диагональную матрицу вида
Д0 I ^obs) =
Л01 I ^obs) О
Д021 ГоЬв)
о Д0/1 Kobs)
Значит, ковариационная матрица С также блочно-диагональная и
имеет вид
С(ф I robs)=
1-ЧФ1 I ^Obs) О
'' 1-КФ11 robs).
(6.2)
Ш
Поскольку компоненты этой матрицы вычисляются для полных
данных, найти их относительно легко. Приближенную ковариацион-
ную матрицу МП-оценок для функции в = в(ф) от ф можно опреде-
лить по формуле
I yobs)=П(в)С(ф I Kobs) W), (6.3)
где D — матрица частных производных по ф:
£>((?)= ^(0)j, где djk(6)= Д-,
а 6 — вектор-столбец.
6.2. ДВУМЕРНЫЕ НОРМАЛЬНЫЕ ДАННЫЕ
С ПРОПУСКАМИ В ОДНОЙ ПЕРЕМЕННОЙ:
МП-ОЦЕНИВАНИЕ
Впервые факторизация правдоподобия была предложена Андерсо-
ном [см. Anderson (1957)] для нормальных данных, вид которых
описан в примере 5.15.
Пример 6.1. Двумерная выборка с пропусками в одной перемен-
ной (продолжение примера 5.15). Логарифм правдоподобия для дву-
мерной нормальной выборки с т полными двумерными
наблюдениями ;(у(1, у;2), 1=1, ..., т\ и п—т одномерными наблюде-
ниями [у(1, i=m +1,..., п] определен в (5.16). ОМП у. и Е можно
найти, максимизируя это выражение по у и Е. Однако уравнения
максимального правдоподобия не имеют явного решения. Андерсон
разложил совместное распределение у;1 и уа на маргинальное рас-
пределение уЛ и условное распределение у,2 при заданном у;1:
Жр У,2 I ! Ml, H11W,2 I Лр ^20 1, ^21-P ff22 1)>
где, согласно свойствам двумерного нормального распределения,
рассмотренным в Примере 5.9, /(yzl | yi, <тц) — нормальное распреде-
ление со средним /21 и дисперсией ал, а Ауа\уЛ, $2о-р ^21-р °22i) —
нормальное распределение со средним
$20 1 + ^21 1Л1
и дисперсией а221- Параметр
ф — П11, /?20р @21 Р а22-1)Г
112
является взаимнооднозначной функцией исходного параметра
0=(дь М2, стп, Огг}т
совместного распределения ytl и yl2. В частности, gi и «и присут-
ивуют при обоих способах параметризации, а другие компоненты
Ф определяются следующими функциями от компонент в:
021-1 = >
020 1 = М2 (6.4)
022-1 = ff22-С?2 /Он-
Аналогично компоненты в, отличные от и <тц, можно выразить
через функции компонент ф:
р2 ~ 020-1 + /?21ТМ1,
от2 = (6.5)
«22= °22'1 + 021 1°П.
Плотность данных yobs факторизуется следующим образом:
m п
/(УоЬ510) = п Ж, у12 I 0) п+1Ж I в) =
m п
= I (W,2 I У„. 0)] [ , П+/(Л1 I 0)] = (6-6)
= I <j’1^ ^1ЛУ,2 I Л1’ 020-1’ 021 1’ °22т)]-
Первый фактор в скобках в (6.6) — плотность выборки из п незави-
симых наблюдений из нормального распределения со средним и
дисперсией «ц. Второй фактор — плотность для m наблюдений из
условного нормального распределения со средним 0го-1 + 02Г1Л1 и
дисперсией «22 р Далее, если параметрическое пространство 0 обыч-
ное и априорно никак не ограничено, то (/н, Оц) и (/32o.j, 021.р <г221)
раздельны, так как значение (/щ «ц) не дает никакой информации о
(020 о 021-р a22-i)- Следовательно, МП-оценку ф можно получить,
независимо максимизируя правдоподобия, соответствующие этим
двум компонентам.
Максимизация первого фактора дает
(67)
113
и
Ju =л—'£ ол—до2,
т. е. выборочные среднее и дисперсию п наблюдений ун, ул1.
Максимизация второго фактора проводится с использованием
стандартных результатов для регрессии (см. пример 5.9) и дает
^21'1 =‘S'12y/'S’lb
$20-1 ~Уг &21{У1’ (6-8)
<722-1 — 522-Р
где у} = т-^=1Уу,5}к = т-^=1(у1Г-y)(yik—ук) для j, к=\,2 и
S22-1 ~s12—s?2 /^1.
Теперь, используя свойства 5.1, можно получить ОМП других па-
раметров. В частности,
|“2 = ^20-1 +^2Г1/‘<
из выражения (6.5) или
Д2=Л + /321.1(м1—У) (6.9)
из (6.7) и (6.8). Из (6.5)
ff22 = ff221 "* н21-1стЧ
или из (6.7) и (6.8)
^22 =^22 + ^-1(^11—Sil). (6.10)
Наконец, для корреляции из (6.5) следует
6 = <Г12(И11И22)-1/2 = 021-! 4-311-1СГ11)-1/2,
так что из (6.7) и (6.8) имеем
е = [з> 2(5, ,322)-1 /21 (а,, /St ,)V2 (s22/a22)l/2. (6.11)
Первые члены в правой стороне (6.3), (6.10) и (6.11) — ОМП д2, а12
и е по выборке, из которой удалены п—т неполных наблюдений.
Значит, вторые слагаемые представляют поправки, основанные на
дополнительной информации, содержащейся в и—т неполных на-
блюдениях.
114
Пример 6.2. Численная иллюстрация результатов из примера
(> I. В табл. 6.1 в первых ш=12 наблюдениях зарегистрирован сбор
яблок с дерева в сотнях плодов (у;1) и процент червивых яблок, ум-
ноженный на 100(yl2). В этих наблюдениях просматривается отри-
цательная зависимость между урожаем и процентом червивых
яблок. Допустим, что наша цель — оценить среднее у,2, причем
для некоторых деревьев с малым сбором, занесенных в таблицу под
номерами от 13 до 18, значение уа неизвестно. Выборочное сред-
нее, Кг = 45, — заниженная оценка процента червивых яблок, по-
скольку следует ожидать более высокого процента червивых плодов
у последних шести деревьев, так как эти деревья в целом меньше
(г. е. данные, видимо, ОС, но скорее всего, не ОПС). МП-оценка
равна =49,33, в то время как оценка по полным наблюдениям —
у 2 =45,0. Проведенные вычисления — всего лишь численная иллю-
страция. При серьезном анализе этих данных следует рассмотреть
1акие вопросы, как, например, преобразование уа и yl2 (логарифми-
рование, извлечение квадратного корня), чтобы предположение о
нормальности больше соответствовало данным.
Таблица 6. 1. Данные об урожае яблок (ун)
и доля (в %) червивых плодов (у;2)
Номер дерева Сбор (в сотнях) О'.,) Доля червивых плодов (yj2) Предсказание по регрессии (pd)
1 2 3 4 5 б 7 8 9 10 И 12 13 14 15 16 17 18 8 6 И 22 14 17 18 24 * 19 23 26 40 4 4 5 6 8 10 59 58 56 53 50 45 43 42 39 38 30 27 56,1 58,2 53,1 42,0 50,1 47,0 46,0 39,9 45,0 41,0 37,9 23,7 60,2 60,2 59,2 58,2 56,1 54,1
у , = 19, У 2=45, ^=49,3333, /1, = 14,7222 sn=77,O, т2~—78,0, ja = 101,8333, <rn =89,5340. Источник. [Snedecor and Cochran (1967), табл. 5.9.1].
115
ОМП (6.9) среднего yl2 представляет особый интерес. Ее можно
записать в виде
(6.12)"
где
У,2 =У2 + 02М О’, i-J’i)-
Следовательно, g2 — это вид регрессионной оценки, обычно исполь-
зуемой в выборочных обследованиях [см., например, Cochran
(1977)], в которой вместо пропущенных ул фактически подставля-
ются значения yj2, предсказанные линейной регрессией yi2 на у;1, вы-
численной по полным наблюдениям.
6.3. ДВУМЕРНЫЕ НОРМАЛЬНЫЕ ДАННЫЕ
С ПРОПУСКАМИ В ОДНОЙ ПЕРЕМЕННОЙ:
ТОЧНОСТЬ ОЦЕНИВАНИЯ
Важным результатом раздела 6.1 является определение точности
получаемых ОМП.
6.3.1. Асимптотическая ковариационная матрица
Асимптотическую ковариационную матрицу С для (ф—ф) мы най-
дем, вычисляя и обращая информационную матрицу. Логарифм
правдоподобия ф равен по (6.6):
т э 1
КФ I ^obs)= (20221) ^О’/г @20-1 ^2Г1Л1) 2~Ш^ПО221
—(2an)-’E (у;1—ц,)2—уnlno
Дважды дифференцируя по ф, получаем
K/Й’ 011 | ^obs)
ДФ I
Л$20Т> ^211’ 022-1 I ^obs)
116
1 не
<711 I ^obs)-
«/ffll
О
О
«/(2Й.)
и
ту О
Л^20-Р ^21 1’ а22 1 I ^obs)~ ту t/ff22 i Е,= | У,1 /<*22-1
О
О 0 т/(2а^г,1^
Обращение этих матриц дает
I (дь *211 |
о
о
^21-1> а22-1 I ^Obs)
где
<Тц/«
I 1(Яь Щ 1 I ^obs) —
2<7п /п
и
^2 .(riv^/s,,)/»’’1 —7,^22 ,/т5„ О
I 4020-1’ ^21-1» ff22-l I ^obs) —
~~У а22 \/ms\ 1 a22.1/ms},
О
О 2а^2 /га
Асимптотическую ковариационную матрицу (0—0) можно получить по
уравнению (6.3). Чтобы продемонстрировать вычисления, рассмотрим
117
параметр ^2, среднее переменной с пропусками. Поскольку
g2 = /?2o i+ после подстановки МП-оценок im и мы имеем
П _ ( аАг дцг dfi2 d/i2 дд2 \ ,я n 1 ~
Dfl2 ( ’ да,, ’ 302Q.J ’ ’ да22., I (02’'1’ °’ ’’ 0)-
Проводя дальнейшие вычисления, находим асимптотическую дис-
персию (иг—Мг):
DCDT = a22.1 [^ +
ё2
п(1-е3)
! О. -а.)2]
win -I'
(6.13)
Третий член в скобках имеет порядок 0(т~2), если данные ОС и
ПС (т. е. ОПС), так как в этом случае (Ji—Пренебре-
гая этим членом, получим
I т +
Q2 1 = W. -2 п—т\
п(1—е2) 1 w @ п '
(6.14)
Эти выражения можно сравнить с дисперсией у2, ч22/т. Оказывает-
ся, что в больших выборках уменьшение дисперсии за счет исполь-
зования п—т наблюдений с присутствием только Ji пропорцио-
нально е2, умноженному на долю наблюдений с пропусками.
6.3.2. Выводы о параметрах по малым выборкам
Если объем выборки велик, интервальные оценки параметров
можно получить, применяя аппроксимацию 5.1 (уравнение (5.6)) и
следуя схеме из раздела 5.2. В частности, 95%-ный интервал для ц2
имеет вид
g2 ± 1,96Vvar(;2—М2), (6.15)
где Var(/22—/i2) дана в (6.13).
Построение выводов по малым выборкам более затруднено. Рас-
смотрим, например, с частотной точки зрения выводы относи-
тельно Ц2- Величина (д2—Аг)/Vvar (ji2—/i2), полученная из (6.13), в
больших выборках имеет стандартное нормальное распределение,
но в малых выборках ее распределение сложно и зависит от пара-
метров. В качестве полезной аппроксимации распределения этой ве-
личины, хорошо согласующейся с результатами моделирования,
118
(|ыло предложено /-распределение с т—1 степенями свободы [ см. Lit-
tle (1976)]. Такое же /-распределение было предложено и для выводов
относительно разности средних д2—Дь основанных на (/t2——
—Mz + ^i)/Vvar(/z2—щ—д2 + д|). Приближенные методы построения
доверительных интервалов по малым выборкам для других пара-
метров, например для g, пока не развиты.
Другой подход к интервальному оцениванию по малым выборкам
включается в следующем. Задают априорное распределение пара-
метров, а затем выводят апостериорное распределение при фикси-
рованных данных. Точнее, пусть мы предполагаем, что ац>
i®2o i> $211 и ff22 i априорно независимы и распределены согласно
плотности
ffll, $20-1’ $211’ ff221) ~ • (6.16)
Выбор а=с=1 приводит к априорному распределению Джефриса
(Jeffreys) для факторизованной плотности [см. Box and Tiao (1973)].
Применяя обычную байесовскую теорию к случайной выборке
[у(1:/= 1, ..., п\, получим такое апостериорное распределение (д1( <тц):
1) плц/пн имеет распределение хи-квадрат с п + 2а—3 степенями
свободы; 2) апостериорное распределение при заданном <гц нор-
мально со средним щ и дисперсией <тн/л. В соответствии с байесов-
ской теорией регрессии для случайной выборки [(у(1, _у(2), (=1, ..., т]
получим такое апостериорное распределение (Зго-г, $2i i> ff22 i)i
3) mci22.} / распределена по хи-квадрат с т + 2с—4 степенями
свободы; 4) апостериорное распределение ^2У1 при заданном <r22.j
нормально со средним ^2i i и Дисперсией 5) апостериор-
ное распределение (32О.У при заданных jS2i i и °22 i нормально со
средним Я—/321.1Я и дисперсией о22Л/т. Вывод этих результатов
см. в [Lindley (1965)]. Кроме того, 6) (/ц, ап) и ($2o i> $2i i> ff22 i)
апостериорно независимы.
Результаты 1—6 означают, что апостериорное распределение лю-
бой функции ф(ф) от ф можно моделировать, генерируя значения ф,
следующим образом:
1) независимо извлечь хги а Хъ из распределения хи-квадрат с
п + 2а—3 и т + 2с—4 степенями свободы соответственно. Извлечь
три независимые величины zu, z2t и z3t из стандартного нормально-
го распределения;
2) вычислить ф</>=(0-р1), Где
а[р = лпп/х21г,
119
l41} = lh+zu(0tf>/n)l/2,
°22-l = ma22-1^2/>
@21-1= ^21 1 + Z2t (a22-1 (msl l))1 /2>
02О-1=Л—^i-l^ +Z3l(°22-l /тУП>
3) вычислить i/-, = 1Хф(,>). Например, если ^(ф)^д2 = )320.1 +/32I.j^],
ТО ^2t~P10-l +02?Т^1'^' 1
6.3.3. Численный пример
Теперь применим методы, описанные в двух предыдущих разде-
лах, к данным табл. 6.1.
Пример 6.3. Интервальное оценивание для двумерного нормаль-
ного распределения (продолжение примера 6.2). В табл. 6.2 пред-
ставлены 95%-ные доверительные интервалы для р,2, а-п и g для
данных из табл. 6.1. Интервалы строятся с помощью четырех ме-
тодов: 1) в соответствии с асимптотической теорией, основанной на
обратной наблюдаемой информационной матрице, как в (6.15) для
/г2; 2) с помощью 1-аппроксимации интервалов для ^2, которая полу-
чается при замене в (6.15) нормальной процентили 1,96 на процен-
тиль 97,5 /-распределения с т—1 = 11 степенями свободы, т. е. на
2,201; 3) вычисление интервалов, заключенных между процентиля-
ми порядка 2,5 и 97,5% байесовского апостериорного распределения
с априорной плотностью (6.16) при я=с=1 (распределение модели-
ровалось 9999 сгенерированными по методу из раздела 6.3.2 значе-
ниями); 4) вычисление нормальных интервалов, полученных
подгонкой нормального распределения под модель апостериорного
распределения по методу 3 (подгонка состояла в использовании
среднего и дисперсии апостериорно сгенерированной выборки). Ме-
тоды 3 и 4 были реализованы для двух независимых множеств А и
В случайных чисел, чтобы получить представление о дисперсии при
моделировании.
Как и следовало ожидать, самые узкие интервалы получились по
асимптотической теории (метод 1), и, скорее всего, уровень доверия
этих интервалов меньше требуемых 95%. Остальные интервалы для
р.2 сходны. В байесовских интервалах для alz, полученных моделиро-
ванием, процентили порядка 2,5% намного ближе к МП-оценке
114,7, чем процентили 97,5%. Это отражает существенную ассимет-
рию апостериорного распределения <т22 вправо. Нормальная аппрок-
120
Таблица 6.2. 95%-ные доверительные интервалы
для параметров двумерного нормального распределения, основанные на данных табл. 6.1
CU (—1,0018, —0,7882) (—0,964, —0,662) (-1,029, —0,717) (—0,964, —0,656) (—1,033, —0,710) —0,895
Параметры ъ (30,68, 198,71) (60,06, 289,73) (15,91, 256,68) (59,18, 293,93) (14,62, 257,19) 114,70
i-ri (43,98, 54,69) (43,38, 55,28) (43,71, 54,42) (43,50, 55,21) (43,54, 55,68) (43,42, 55,22) 49,33
Метол 1 Асимптотическая теория 1-аппроксимация Байесовская имитация А Нормальная аппроксимация А Байесовская имитация В Нормальная аппроксимация В МП-оценки
121
симация не может отобразить эту ассиметрию, но она обладает ре-
алистическим свойством: приближенные интервалы значительно ши-
ре интервалов, полученных в соответствии с асимптотической
теорией, а значит, они лучше обеспечат 95%-ное накрытие повторно-
го выбора. Аналогичные замечания относятся и к интервалам для р.
Обратите внимание, что нижние границы для р во всех интерва-
лах, построенных по нормальному распределению, меньше мини-
мально допустимого значения (—1). На практике их нужно
заменить на —1. Смоделированные байесовские интервалы для q
выглядят более разумными. Вероятность накрытия истинного зна-
чения этими интервалами при повторном выборе требует дальней-
шего исследования. Литтл [см. Little (1986)] рассматривает эту
вероятность для /-аппроксимации апостериорного распределения
при различных значениях а и с.
6.4. МОНОТОННЫЕ СТРУКТУРЫ ДАННЫХ
В МНОГОМЕРНОМ СЛУЧАЕ
Методы, описанные в разделах 6.2 и 6.3, можно легко обобщить
для монотонных структур данных, изображенных на рис. 6.1, где
для каждого (г-го) наблюдения у,-у присутствует, если присутствует
У;у+1(/=1> J—1), так что У, наблюдается больше, чем У2, кото-
рый наблюдается больше, чем У3, и т. д. Мы рассмотрим только
МП-оценивание, а точность оценивания можно анализировать, не-
посредственно обобщая методы из раздела 6.3.
Рис. 6.1. Схематическое представ-
ление данных с монотонной
структурой
Подходящая для данной структуры
факторизация такова:
ПДр уи | Ф) =
= П/(у/1 | 4>1)П/(Уд | л-р Фг)---
где Дуи | Л1> Уи-ь Фр — Условное
распределение у^ при заданных
У,!’ ••> З'у—1’ зависящее от параметра
фу, j Если (у(1, ...,7,j) распределены по многомерному нор-
мальному закону, то Ду,}J уп, .... фу) — нормальное распреде-
ление со средним, линейным по у;1, ..., и с постоянной
дисперсией. При обычном параметрическом пространстве для ф без
122
oi раничений </>7- раздельны и, значит, МП-оценки получаются с
помощью регрессии ytJ на уп, ..., у^_}, определяемой по наблюде-
ниям, у которых присутствуют все ..., у^.
Пример 6.4. К+1 переменных, пропуски в одной переменной. В
простом, но важном обобщении примера 6.1 yit заменяется на мно-
жество К полностью наблюдаемых переменных, так что получается
структура данных, как на рис. 1.3. В результате мы имеем частный
случай монотонных данных с J=2 и при К переменных. МП-
оценки ц2 и а22 равны:
Mz —Уг + G»i—У1)^211’
(6.17)
°22 = ‘S22 + ^22Т (°И-
где /I), ys — lx^-векторы средних, /32].! — вектор Кх1 коэффициен-
тов регрессии для множественной регрессии уа на yjlt оц и sH —
ковариационные Хх/С-матрицы, ои построена по всем п значениям
у(1, 5ц построена по т значениям уп, для которых наблюдается уа.
МП-оценка /г2 соответствует заполнению пропусков уа с помощью
МП-оценок множественной регрессии yi2 на у(1.
Оценка (6.17) является ОМП, если (уп, у17) есть (Л"+ 1)-мерные
нормально распределенные независимые случайные величины, а
данные ОС. Более того, (6.17) есть ОМП, если данные ОС и
1) у12 при заданном уй распределен нормально со средним
(^201+Л118211) и Дисперсией
2) распределение — любое распределение, для которого: а) —
МП-оценка среднего у(1, б) и ^2i i> °22 i раздельны с пара-
метрами этого распределения.
Важный частный случай связан с регрессией на фиктивные пере-
менные, в которой у;1 — это К фиктивных переменных, указываю-
щих одну из АГ+1 групп, при этом k-я компонента у(1 равна 1,
когда г-е наблюдение относится к к-й группе, и равна нулю в про-
тивном случае. Для наблюдения из группы 1 уп =(1,0,0,...,0), для
наблюдения из группы 2 уа =(0,1,0,...,0), для наблюдения из груп-
пы А- Уц =(0,0,...,0,1) и для наблюдения из группы ХЧ-1 уа =
= (0,0,...,0,0). (АГ+1)-ю группу часто называют контрольной.
При этом соглашении — вектор, состоящий из пропорций чис-
ла наблюдений выборки в первых К группах, /ij — соответствую-
щий вектор ожидаемых пропорций и условие 2 выполнено. Условие
1 эквивалентно предположению, что все значения уа в группе к
нормальны со средним цк и дисперсией a^.j.
123
По свойствам регрессии на фиктивные переменные предсказывае-
мое значение yi2 для наблюдения из группы к — среднее присут-
ствующих значений уа в группе к. Следовательно, ОМП
соответствует заполнению пропусков yi2 внутригрупповыми средни-
ми — одному из видов заполнения средними, который мы обсужда-
ли в гл. 4, посвященной анализу данных с пропусками в
выборочных обследованиях.
Пример 6.5. Монотонные многомерные нормальные данные.
МП-о11енивание по монотонным данным с J> 2 численно иллюстри-
руется в работе [Marini, Olsen and Rubin (1980)] на данных опроса
4352 человек. Структура этих данных, отображенная в табл. 1.2, не
монотонна. Однако, как указано в гл. 1, можно получить монотон-
ную СТРУКТУРУ, удаляя часть данных, например данные с индексом
** в тД-бл. 1.2. В результате получается монотонная структура (см.
рис. 6.1) с J=4. В предположении нормальности МП-оценки средне-
го и ковариационной матрицы переменных можно найти с по-
мощыО следующей процедуры:
]) вычислить по всем наблюдениям вектор средних и ковариаци-
онную матрицу для полностью присутствующих переменных блока
1;
2) вычислить по наблюдениям, в которых присутствуют значения
переменных блока 1 и блока 2, многомерную линейную регрессию
для переменных блока 2;
3) вычислить по наблюдениям с присутствующими переменными
блоков 1—3 многомерную линейную регрессию переменных блока 3
на переменные блоков 1 и 2;
4) вычислить по наблюдениям, в которых присутствуют все пере-
менные, многомерную линейную регрессию переменных блоков 4 на
переменные блоков 1—3.
ОМГ1 средних и ковариационной матрицы для всех переменных
можно получить как функции оценок параметров, найденных в
пунктах 1—4. Подробное обсуждение вычислений, включая приме-
нение мощного SWEEP-оператора, отложено до раздела 6.5. Резуль-
таты приведены в табл. 6.3.
В первом столбце дано название переменных. Следующие два
столбца содержат МП-оценки средних (дмь) и стандартных откло-
нений (aMi) каждой переменной. В остальной части таблицы срав-
ниваются оценки, полученные двумя другими способами
оценивания.
124
Таблица б.З. МП-оценки средних и их стандартные отклонения,
вычисленные по исходной выборке, и сравнение их с двумя другими наборами оценок
Переменная МП-оценки Оценки по доступным наблюдениям Опенки по комплектным наблюдениям
Среднее Стандар- тное от- клонение Среднее Стандар- тное от- клонение aML х 100 Среднее Стандар- тное от- клонение ч-w
"ml X 100 °ML ' X [00 ffML х 100
Блок 1 переменных (зарегистриро- ваны в юношеском возрасте) Образование отца 11,702 3,528 11,702 3,528 0,0 0,0 12,050 3,449 9,9 —1,6
Образование матери 11,508 2,947 11,508 2,947 0,0 0,0 11,864 2,865 12,1 —2,4
Профессия отца 6,115 2,904 6,115 2,904 0,0 0,0 6,407 2,868 10,1 —1,2
Коэффициент интеллекта 106,625 12,910 106,625 12,910 0,0 0,0 109,036 11,174 18,7 —13,4
Учеба на подготовительных курсах при поступлении в колледж 0,411 0,492 0,411 0,492 0,0 0,0 0,528 0,499 13,4 1,4
Время, проводимое за выполне- нием домашних заданий 1,589 0,814 1,589 0,814 0,0 0,0 1,633 0,795 5,4 —2,3
Средний выпускной балл 2,324 0,773 2,324 0,773 0,0 0,0 2,594 0,701 34,9 —9,3
Намерение поступать в колледж 0,488 0,500 0,488 0,500 0,0 0,0 0,595 0,491 21,4 —1,8
Намерения друзей поступать в колледж 0,512 0,369 0,512 0,369 0,0 0,0 0,572 0,354 16,3 —4,1
Участие в пополнительных занятиях 0,413 0,492 0,413 0,492 0,0 0,0 0,492 0,500 15,8 1,4
Входит ли в группу лидеров в классе 0,088 0,283 0,088 0,283 0,0 0,0 0,131 0,338 8,6 19,4
Входит ли в «промежуточную» группу 0,170 0,376 0,170 0,376 0,0 0,0 0,198 0,399 5,6 4,1
Отношение к приготовлению пищи и к алкоголю 0,570 1,032 0,570 1,032 0,0 0,0 0,483 0,835 -8,4 -9,4
Частота свиданий 4,030 4,802 4,030 4,802 0,0 0,0 3,701 4,523 —6,8 —5,8
Самооценка 2,366 0,525 2,366 0,525 0,0 0,0 2,364 0,515 —0,4 —1,9
Оценка одноклассников 2,432 1,048 2,432 1,048 0,0 0,0 2,496 1,064 6,1 1,5
Продолжение
Переменная МП-оценки Оценки по доступным наблюдениям Оценки по комплектным наблюдениям
Среднее Стандар- тное от- клонение Среднее Стандар- тное от- клонение WW х 100 Среднее Стандар- тное от- клонение <»C-W (^-“41’
"ml х 100 °ML ~ X 100 %L " х 100
Блок 2 переменных (зарегистриро- ваны у участников дополнитель- ного обследования) Полученное образование 13,625 2,295 13,274 2,262 6,5 —1,4 14,196 2,204 24,9 —4,0
Престиж профессии 44,405 13,008 45,085 12,893 5,2 —0,9 47,056 12,745 20,4 —2,0
Семейное положение 0,940 0,238 0,940 0,238 0,0 0,0 0,940 0,237 0,0 —0,4
Число детей 1,991 1,306 1,973 1,304 — 1,4 —0,2 1,928 1,242 —4,8 —4,9
Возраст 30,629 1,221 30,655 1,225 2,1 0,3 30,726 1,152 7,9 —5,4
Престиж профессии отца 43,998 14,821 44,258 14,786 1,8 —0,2 44,782 14,333 5,3 —3,2
Блок 3 переменных (зарегистриро- ваны в дополнительном обсле- довании только у ответивших на вопросы в первом обследовании) Вес в обществе 3,128 0,377 3,148 0,378 5,2 0,3 3,148 0,373 5,3 —1,1
Частота свиданий в студенчес- кие годы 4,374 3,408 4,202 3,261 —5,1 — 1,4 4,213 3,352 —4,7 — 1,6
Число братьев и сестер, родных по отцу и матери 2,219 1,748 2,099 1,744 —6,9 -0,2 2,055 1,660 —9,4 —5,0
Блок 4 переменных (получены по анкетам опроса родителей) Семейный доход 4,902 1,530 4,075 1,538 —1,1 0,5 4,215 1,570 8,0 2,6
Отношение родителей к учебе в колледже 0,714 0,434 0,706 0,455 —1,6 4,8 0,754 0,431 8,0 —0,7
Число детей в семье 3,039 1,539 3,067 1,671 1,8 8,6 2,975 1,551 —4,2 0,8
Оценки (jiA, ал) метода доступных наблюдений — это выборочные
средние и стандартные отклонения по всем наблюдениям с присут-
। ищем данной переменной (см. раздел 3.3). В двух столбцах после
оценок — величина различия между ОМП и оценками метода до-
i । упных наблюдений в процентах от стандартного отклонения.
Оценки метода доступных наблюдений близки к ОМП, что указы-
вает на неплохие качества этого метода. Однако этот метод не ре-
комендуется для измерения связи (например, с помощью
коэффициентов ковариации или регрессии), как указано в гл. 3.
В последних четырех столбцах даны и сравниваются оценки, по-
с'1 роенные по 1594 полным наблюдениям, т. е. методом полных на-
блюдений, описанным в гл. 3. Оценки среднего, полученные по
ному методу, могут заметно отличаться от ОМП. Например, оцен-
ка среднего выпускного балла на 0,35 стандартного отклонения
больше МП-оценки. Это означает, что студенты, не обследованные
в дальнейшем, имели балл ниже среднего.
6.5. ПРИМЕНЕНИЕ SWEEP-ОПЕРАТОРА
ДЛЯ МОНОТОННЫХ НОРМАЛЬНЫХ ДАННЫХ
Этот раздел посвящен применению SWEEP-опсратора (или опера-
тора «свертки», см. [Beaton (1964)]) в линейной регрессии для пол-
ных данных”. Мы покажем, что SWEEP-оператор позволяет просто
и удобно вычислять оценки максимального правдоподобия для дан-
ных с пропусками. Вариант, который здесь рассматривается, не со-
впадает с описанным в ]Beaton(1964)], скорее, это вариант из
[Dempster (1969)]. Другой доступный источник соответствующих
сведений — [Goodnight (1979)]. К SWEEP-оператору мы вернемся
также в гл. 8 при описании МП-оценивания по нормально распреде-
ленным данным со структурой пропусков общего вида* **.
* Возможны и другие варианты перевода термина sweep. Например, Е. 3. Деми-
денко предлагает «выметание» в предисловии к книге Дж. Мэйндоналда «Вычисли-
тельные алгоритмы в прикладной статистике» (М.: Финансы и статистика, 1988).
Однако введенный здесь термин вполне уместен, по крайней мере, в качестве рабоче-
го: свертку функций едва ли можно спутать со сверткой .матрицы. В то же время
этим термином удобно обозначать как операцию, так и ее результат. — При.меч.
пер.
** В дополнении к переводу приводится текст программы, реализующей SWEEP-
оператор. — Примеч. пер.
127
Оператор «свертки» для симметричных матриц определяется сле-
дующим образом: свертка симметричной рхр-матрицы G по стро-
ке и столбцу к есть симметричная />хр-матрица Н с элементами
hkk = -\/gkk,
(6-18)
gJkgkl/gkk, k^j, к*1.
Например, для матрицы 3x3
gll gl3 -1/gu g^g, > Sl.Au
G = g<2 g22 g23 , H=SWP[1]G= gn/gi, g22~ g 12 All Й23—g^g^/g,.
g,3 git gt git gl3gl2^gll g3J—g2i3/g:i
Матрица, полученная в (6.18), обозначена SWP[Ar]G. Результат по- 1
следовательного применения оператора свертки по строкам и
столбцам к}, к2, kt будем обозначать SWP^, к2, kt]G. На
практике свертку удобнее начинать с вычисления hkk =—^^кк, за-
тем вычислять элементы в к-х строке и столбце, hjk = hkj =—gjkhkk,
и, наконец, вычислять элементы вне этих строки и столбца, й7=
=gji—hjkgkl. Объем памяти можно сэкономить, размещая элемент
(j, к) симметричной рхр-матрицы при k^J в позиции j(J—V)/2 + k
вектора длины р(р+1)/2.
Алгебраические вычисления показывают, что оператор комму-
тативен:
SWP[/, fc]G=SWP[fc, j]G.
Из этого следует
SWPD'„ ...J,]G=SWP[/c,, ..., k,]G,
где (/и — любая перестановка множества (к,, ..., к,). Таким
образом, алгебраически порядок выполнения свертки не влияет на
результат, хотя в вычислениях один порядок может оказаться точ-
нее другого.
Оператор свертки тесно связан с линейной регрессией. Например,
пусть G — ковариационная матрица 2x2 двух переменных Yt и Y2.
128
l ain /7=SWP[1]G, то Л|2 — коэффициент регрессии У2 на Уь a /г22 —
остаточная дисперсия Уг. Далее, если G — выборочная ковариаци-
онная матрица для п независимых наблюдений, то —huhn/n —
опенка дисперсии выборочного коэффициента регрессии Л12.
Рассмотрим более общий случай. Пусть по выборке р-мерных на-
блюдений объема п построена симметричная (р+ 1)х(р+ 1)-матрица
У
П~'£у?~
n~iYypyl
G =
У к
n-'Ly^
П-~^УхУр
где — выборочные средние, а суммирование проводится
ио п наблюдениям. Для удобства мы пронумеровали строки и
столбцы от 0 до р, чтобы строка и столбец j соответствовали пере-
менной Yj.
Свертка по строке и столбцу 0 дает
— 1
л . . • yj
*11
SWP[0]G =
(6.19)
Л
где Sjk — выборочная ковариация Yj и Yk с делителем п~‘, а не с
(и—I)-1. Эта операция соответствует вычитанию из сумм взаим-
ных произведений, деленных на п, поправок на средние У,, .... Yp,
что приводит к выборочной ковариационной матрице '.sjk. В тер-
минах регрессии средние в первых строке и столбце матрицы
SWP[0]G — это коэффициенты регрессии Уи .... Yp на постоянную
5. Р. Дж. А. Литтл, Д. Б. Рубни
129
Уо = 1. а полученная матрица [sjk] — остаточная ковариационная
матрица от этой регрессии. В соответствии со сказанным будем
также называть эту операцию сверткой по постоянному члену, а
(6.19) назовем дополненной ковариационной матрицей переменных
У„ Yp.
Свертка по строке и столбцу 1, соответствующим Уь дает сим-
метричную матрицу
SWP[0, 1]G =
—(1+/?>%) -TiZ-STi Л—(•SuA.DJ’i
l/Sn Siz/'S’ii
S22—
yP-(siP/^)yi
slp/s,t
s2p--51р512/^11
—А В
BT c
где размер A — 2x2 , В — 2x(p—1), C — (p—l)x(p—1). В этой
матрице результаты для многомерной регрессии У2, ..., Yp на У]. В
частности, у-й столбец В содержит свободный член и коэффициент
наклона для регрессии YJ+l на Уь у=1, ..., р—1. Матрица С —
остаточная ковариационная матрица У2, ..., Ур при фиксированном
Ур Наконец, элементы А после умножения на соответствующие
остаточные дисперсии или ковариации из С и деления на п позволя-
ют определить дисперсии и ковариации оценок коэффициентов ре-
грессии в В.
Проводя свертку по постоянному члену и первым q элементам,
получаем результаты для многомерной регрессии У9+1, •>Ур на
Уь ..., Yq. Точнее, пусть
130
SWP[O, 1, <?]G =
i не размеры
D — (q+ 1)x(q + 1), E — (<?+ l)x(p—q), F — (p—q)*(p—q).
Тогда j-й столбец E содержит вычисленные по методу наименьших
квадратов свободный член и коэффициент наклона для регрессии
Yj+4 на У,, Yq, j-=l,...,p—q, матрица F — остаточная ковариа-
ционная матрица Yq+l, ..., Yp, а элементы D можно использовать,
как описано выше, чтобы получить дисперсии и ковариации оценок
коэффициентов регрессии в Е.
Итак, МП-оценки многомерной линейной регрессии Yq+i, ..., Yp
на Уи Yq можно найти, проводя свертку матрицы G нормиро-
ванных сумм взаимных произведений по строкам и столбцам, соот-
ветствующим постоянному члену и предсказывающим перемен-
ным (регрессорам) Ун ..., Yq.
Свертка по некоторой переменной, по существу, переводит эту пе-
ременную их зависимых в предсказывающие (независимые) пере-
менные. Существует также и оператор, обратный к свертке и
переводящий независимую переменную в зависимую. Этот оператор
называется обратной сверткой (RSW, reverse sweep) и определяется
как
H=RSW[fc]G,
где
kkk~ ^gkk’
hjk =hkj = Sjk ^kk - k (6-20)
hji = gji—gjkgki/gk^ l*J-
Легко проверить, что обратная свертка также коммутативна и явля-
ется операцией, обратной к свертке, т. е.
RSW[£]SWP[£]G = SWP[fc]RSW[A:]G = G.
Пример 6.6. Двумерные нормальные монотонные данные (про-
должение примера 6.1). С помощью операторов свертки и обратной
свертки можно легко связывать различные параметризации двумер-
ного нормального распределения. Так, посредством обозначений
SWP[ ] и RSW[ ] можно компактно выразить связь (6.4) и (6.5) меж-
ду параметрами 9 и ф из примера 6.1. Существенной является и воз-
можность получения с помощью этих операторов численных
результатов для МП-оценок.
5* 131
Допустим, мы расположили fl = (g,, р.2, Он, он, ог2)г в следующей
симметричной матрице, которая представляет собой аналог (6.19)
для популяции:
— 1 Mi
0* = <711 СЦ2
М2 О2| 022
Матрица 0* представляет параметры двумерного нормального рас-
пределения после свертки по постоянной. Свертка 9* по строке и
столбцу 1 согласно (6.18) даст
—(1 +/м/Дц) Р1/оц М2 /21 <Т12 /ff| j
SWP[1]/?* = Pl/o'll —аГГ1 <Г|2/<7ц
g2 /2|<712/ <7| 1 О|/<7ц 012 а~11/ Oil
Сравнение с (6.4) показывает, что вторая строка (и столбец)
SWP[1]0‘ содержит свободный член (р2—piau/оц), коэффициент ре-
грессии У2 на ^(о-^/си) и остаточную дисперсию ~аг1—oii/ffn-
Матрица 2x2, образованная строками и столбцами О' и 1, содержит
(хотя и не в самом удобном виде) параметры распределения Yt.
Чтобы увидеть это, запишем:
— 1 А'. fto-1
SWP[1]
ф* =SWP[1]0*== Д| Он ft,-, (6.21)
fto-1 ftl-1 °22-1
где ф* — параметр ф = (/ц. <тц, ft0.,, ft,.,, <Ь2,)Г> представленный в
виде матрицы. В соответствии со свойством 5.1 аналогичное выра-
жение связывает МП-оценки ф с МП-оценками 0:
—1 Ai fto-i
SWP[1]
ф* =SWP[1]0* = on fti-i
fto-i ftii ff22-1
132
Применяя к обеим сторонам оператор RSW[1], получаем
=RSW[1] SWP[1] —1 Mi tfii 020 1 021'1
020'1 021'1 ff22-
(6.22)
Выражение (6.22) определяет преобразование ф в § через операторы
свертки и обратной свертки и показывает, как эти операторы мож-
но использовать при вычислении в и ф.
Пример 6.7. Многомерные нормальные монотонные данные
(продолжение примера 6.5). Теперь обобщим пример 6.6 и покажем,
как можно применять операторы свертки и обратной свертки для
поиска МП -оценок среднего и ковариационной матрицы для данных
с монотонной структурой из многомерного нормального распреде-
ления. Мы полагаем, что после соответствующей перестановки дан-
ные имеют структуру, изображенную на рис. 6.1. Для простоты
рассмотрим случай с 7=3 блоками переменных. Обобщение для
большего числа блоков проводится совершенно аналогично.
Шаг I. Найти МП-оценки Ц и £„ среднего и ковариационной
матрицы переменных первого блока, наблюдаемого полностью.
Это оценки — просто выборочные средние и ковариационная мат-
рица по всем наблюдениям.
Шаг 2. Панги МП-оценки 02(Н, 021,| и £221 свободных членов,
коэффициентов регрессии и остаточной ковариационной матрицы
для регрессии У2 на У,. Эги оценки можно найти, проводя свертку
по У, дополненной ковариационной матрицы переменных У, и У2,
построенной по наблюдениям, в которых присутствуют эти пере-
менные.
Шаг 3. Найги МП-оценки 0ЗО)2, 031 12, 032 )2 и £33 12 свободных
членов, коэффициентов регрессии и остаточной ковариационной
матрицы для регрессии Y3 на Yx и У2. Их можно найти, проводя
свертку по У1 и У2 дополненной ковариационной матрицы перемен-
ных У., У2 и У(, основанной на полных наблюдениях, где присуг-
ствуют У,, Y2, Y3.
133
Шаг 4. Вычислить матрицу
—1 •’'г я ап ai2
X = SWP[1]
Ml £и «21 Л 22
где SWP[1] — сокращенное обозначение свертки по переменным Yt.
Шаг 5. Вычислить матрицу
«и «12 020-1 «11 «12 «13
B=SWP[2] «21 л 22 0Б-; = «21 «22 «23
020-1 @211 ^22-1 «31 «32 «33
где SWP[2] — сокращенное обозначение свертки по переменным У2.
Шаг б. Окончательно МП-оценка дополненной ковариационной ,
матрицы Yi, Y2 и Y} дается выражением 1
- Си «12 «13 030-12
— 1 М7 «21 «22 «23 0*31-12
= RSW[1, 2]
/2 £j «31 «32 «33 032-12
030-12 031-12 032-12 ^33-12_
Эта матрица содержит, как указано, МП-оценки средних и ковариа-
ционной матрицы Уь У2 и У3.
Шаги 4—6 можно компактно записать с помощью уравнения
—1 -г Ml $20-1 $Го-12
-1 SWP[2] SWP[1] Ml $2Г1 $Г1-12
=RSW[1,2] —
м £ $20'1 $2Г1 ^22-1 $32-12
—
$3012 $31-12 $32-12 ^33-12
134
< очевидным обобщением на случай более трех блоков переменных.
' )то уравнение определяет преобразование ф в 6 для данной задачи.
Пример 6.8. Численный пример. Рубин [Rubin (1976)] применил
описанную выше схему вычислений к данным табл. 6.4, взятым из
[Draper and Smith (1968)]. Исходно переменные были обозначены
Х{, ..., Х5. Данные имеют структуру, как на рис. 6.1 с 7=3 и
У =(JG, Х5), Y2 = (Xi, Х2) и Y3=X2. МП-оценки маргинального рас-
пределения (Х3, Х5), вычисляемые на шаге 1, равны /23 = 11,769,
/15 = 95,423, <гзз = 37,87О, J35 = —47,566, <755=208,905.
Шаг 2 основан на наблюдениях 1—9 и позволяет получить коэф-
фициенты регрессии (Уь Y2) на (У3, У5):
$10-35 = 2>8О2, ^1з-з5= 0,526, /315.3S =0,105,
020-35 “ 74,938. 023-35 ~ 1>062, /З25.35 = 1,178
и оценку остаточной ковариационной матрицы
У. 3,804 —8,011
£ 12-35 =
У2 —8,011 24,382
Yr Уг
Шаг 3 основан на наблюдениях 1—6 и дает возможность найти
следующие оценки коэффициентов и остаточной дисперсии регрес-
сии У4 на остальные переменные:
040 1235 = 85 >753, 041-1235” 1,863, 042-1235 =—1,324,
043-1235 - 1,533, 045.1235=0,397, ff44 1235 =0,046.
Проводя вычисления на шагах 4—6, получаем:
—1 /Д
М £
Хз х5 •г, х2 х4
—1 11,769 95,423 2,802 —74,938 85,753
SWP[35] 11,769 37,870 —47,566 —0,526 1,062 —1,533
SWP[12] 95,423 -47,566 208,905 0,105 1,178 0,397
= RSW[1235J 2,802 —0,526 0,105“ 3,804 —8,011 —1,863
—74,938 1,062 1,178 —8,011 24,382 —1,324
85,753 —1,533 0,397 —1,863 —1,324 0,046
135
Таблица 6.4. Данные для примера 6.8
(значения в скобках считаются в примере пропусками)
Объекты Переменные
X хг X, ха У-Л,
1 7 26 6 60 78,5
2 1 29 15 52 74,3
3 И 56 8 20 104,3
4 11 31 8 47 87,6
5 7 52 6 33 95,9
6 11 55 9 22 109.2
7 3 71 17 (6) 102,7
8 1 31 22 (44) 72,5
9 2 54 18 (22) 93,1
10 (21) (47) 4 (26) 115,9
11 (1) (40) 23 (34) 83,8
12 (И) (66) 9 (12) 113,3
13 (10) (68) 8 (12) 109,4
Вычисляя правую сторону и переставляя переменные, получаем
МП-оценки:
Х1 х2 х3 Xj Л"3
(6,655 49,965 11,769 27,047 95,423]
21,826 20,864 —24,900 — 11,473 4б,953~
20,864 238,012 —15,817 —252,072 195,604
£ = --24,900 —15,817 37,870 —9,599 —47,556
—11,473 —252,072 —9,599 294,183 —190,599
46,953 195,604 —47,556 —190,599 208,905
136
ft ft ФАКТОРИЗАЦИЯ ДЛЯ НЕМОНОТОННЫХ СТРУКТУР
( ПЕНИАЛЬНОГО ВИДА
I Гемонотонные структуры неполных данных, для которых можно
факторизовать правдоподобие, рассмотрены в [Anderson(1957)J, где
каждый фактор был правдоподобием для полных нормальных дан-
ных, и в общей форме — в [Rubin (1974)]. Типичный случай изобра-
жен на рис. 6.2, взятом с изменениями из [Rubin (1974)].
Переменные размещены в трех блоках (У1; У2, У3), таких, что:
1) Y; наблюдается больше Уь т. е. для любого объекта, в кото-
ром Yi наблюдается по крайней мере частично, У3 наблюдается
полностью;
2) У1 и У2 никогда не наблюдаются вместе, т. е. для любого объ-
екта, в котором У2 наблюдается по крайней мере частично, У, пол-
ностью отсутствует, и наоборот;
3) строки Yt условно независимы, набор параметров распределе-
ния один и тот же.
Если опустить У2, а взять скалярные У[ и У3, то структура
рис. 6.2 сведется к двумерным монотонным данным. При условии
ОС логарифм правдоподобия распадается на два слагаемых: первое
соответствует маргинальному распределению У2 и У3 с параметром
Ф13 и строится по всем объектам, второе — условному распределе-
нию У1 при фиксированном У3 с параметром фг} и строится по
объектам с полностью наблюдаемым У3. Доказательство этого ре-
зультата, включающего факторизацию для монотонных данных,
приводится в [Rubin (1974), § 2].
Параметры ф23 и ф1 3 часто раздельны, поскольку ф23 можно пе-
репараметризовать через ф2.3 и ф3 (обозначения не требуют поясне-
ний) и параметры фх 3, ф23, ф3 раздельны во многих моделях.
Важный аспект этого примера в том, что ф23 и ф{ 3 не обеспечива-
Ю1 полную перепараметризапию параметров совместного распреде-
ления Уп У2 и У3, так как параметры условной зависимости между
Yj и У2 при фиксированном У3 (например, частная корреляция) от-
сутствуют. Эти параметры не входят в правдоподобие и не подда-
ются оцениванию по таким данным.
Рубин [Rubin (1974)] показал, как, повторно проводя редукцию
данных структуры на рис. 6.2, факторизовать правдоподобие на-
столько полно, насколько это возможно. Хотя в общем случае не
все получаемые факторы можно анализировать, независимо приме-
няя методы для полных данных, мы проиллюстрируем основные
идеи на двух примерах, которые сводятся к задачам для полных
данных.
137
Пример 6.9. Нормальное трехмерное распределение. Лорд [Lord
(1965)] и Андерсон [Anderson (1957)] рассматривают трехмерную
нормальную выборку со структурой, как на рис. 6.2, где Уь У2 и
Уз — одномерные, полных наблюдений нет, по У1 и У3 есть mt на-
блюдений, по У2 и У3 — т2 наблюдений, п = т3 + т2. В предположе-
нии, что данные ОС, правдоподобие факторизуется на три
компоненты: 1) mt +т2 наблюдений из маргинального нормального
распределения У3 с параметрами и а33; 2) т3 наблюдений из ус-
ловного распределения У] при заданном У3 со свободным членом
(310.3, коэффициентом регрессии 013.3 и дисперсией лп.3; 3) т2 на-
блюдений из условного распределения У2 при заданном У3 со сво-
бодным членом /320.3, коэффициентом /З23.3 и дисперсией л22.3. Эти
три компоненты содержат 8 раздельных параметров, в то время
как исходное
Объекты
Рис. 6.2. Структура данных, при которой Y, наблюдается больше, чем Y. и У2
совместно не наблюдаются
совместное распределение Ун У2 и У3 включало 9 параметров, а
именно 3 средних, 3 дисперсии и 3 ковариации. Параметр, который
пропал после перепараметризации, — это частный (условный) коэф-
фициент корреляции между Уз и У2 при заданном У3,
а12-з^ё\1-за22-з' информация о котором отсутствует в данных.
Данные рассматриваемой структуры встречаются нередко. С та-
кой структурой, когда У, многомерны, сталкиваются при решении
138
проблемы файлового подбора (file matching), возникающей при объ-
единении больших правительственных баз данных. Например, пусть
мы имеем один файл, представляющий случайную выборку записей
Internal Revenue Service, IRS (с удаленными идентификаторами объ-
ектов), и другой файл, представляющий случайную выборку записей
Social Security Administration, SSA (также с удаленными идентифика-
торами). Файл IRS содержит подробную информацию о доходе (Yt)
и общие данные (Уз), тогда как файл SSA содержит подробную ин-
формацию о местах работы (Уг) и такую же общую информацию
(У3). Объединенный файл можно считать выборкой, в которой У3
присутствует для всех объектов, а У, и К2 вместе не наблюдаются.
Для обозначения подобной ситуации взят термин «файловый под-
бор», так как часто пытаются заполнить отсутствующие значения
У1 и У2, подбирая и связывая в файле объекты по значению У3 с за-
меной пропусков значениями для связанных объектов. Такие задачи
обсуждаются в [Rubin (1986)].
Пример. 6.10. Данные об образовании. В задачах проверки уров-
ня образования типа описанных в [Rubin and Thayer (1978)] обычна
ситуация, когда нужно оценить несколько разных тестов по различ-
ным случайным выборкам из одной популяции. Пусть, например,
X=(Xi, ..., Хр) представляет р стандартных тестов, проведенных с
объектами всех выборок. Допустим, что новый тест Yi проведен в
первой выборке с объектами, новый тест У2 — во второй выбор-
ке с т2 объектами и так далее до У?, причем в выборках нет об-
щих объектов. Вследствие случайности выбора отсутствующие
значения У ОПС. На рис. 6.3 изображена ситуация, когда q=3, яв-
ляющаяся небольшим обобщением структуры из примера 6.9.
В строгом смысле коэффициенты частной корреляции между раз-
личными Yj при заданном X нельзя оценить, поскольку в данных
нет информации об их значении. Простые коэффициенты корреля-
ции между Yj часто более интересны при проверке уровня образо-
вания. Хотя МП-оценки этих коэффициентов не единственны, в
данных содержится информация об их значении.
Непосредственные алгебраические вычисления показывают, что
корреляция между Уу и Yk зависит от частной корреляции меж-
ду Yj и Yk, но не от частных корреляций между другими парами
переменных. При увеличении частной корреляции между Уу и
Yk увеличивается простая корреляция этой пары, более того, эта
зависимость линейна. Значит, оценив корреляцию при двух различ-
ных значениях частной корреляции (например, 0 и 1), можно оцени-
вать корреляцию при любом значении частной корреляции с по-
139
Подвыборка Обьек г Стандартные тесты Новые гесты
Г, г2 Y
1 1 1 ... 1 1 0 0
1 .. . 1 1 0 0
2 т, + 1 1 ... 1 0 1 0
+ т< 1 ... 1 0 1 0
3 тх t + 1 1 ... 1 0 0 1
1 ... 1 0 0 1
Рис 6.3. Структура данных при трех новых I'fcia.’:
(1— значение присутствует, 0 — отсутствует)
мощью линейной интерполяции (или экстраполяции, в зависимости
от выбранных значений). На рис. 6.4. изображен график оценки ко-
эффициента корреляции как функции частной корреляции для данных
Рис. 6.4. Простые корреляции как функции частных
корреляций [Rubin and Thayer (1978)].
Службы проверки
уровня образования
(Education Testing Ser-
vice) со структурой,
как на рис. 6.3 при
тх = 1325, т2 = 1345,
т з=2000 и двумер-
ном X [см. Rubin and
Thayer (1978)].
Как и при моно-
тонных нормальных
данных, SWEEP-опе-
ратор очень полезен
при записи и в вычис-
140
Нениях для этого рисунка. Вычисления можно описать так.
Шаг 1. Найдите МП-оценки параметров маргинального распреде-
ления X, цх и Это просто выборочные средние и ковариацион-
ная матрица для всех п наблюдений, цх и Ё^.. Этот шаг дает
(43,27,26,79) и ,
330,33
118,92
118,92
138,13
Шаг 2. Найдите МП-оценки /31О.Х, |Slx.x и ап.х коэффициентов ре-
। рессии и остаточной дисперсии для регрессии У) на X. Их можно
получить, проводя свертку по переменным X дополненной ковариа-
ционной матрицы У] и X, вычисленной по тх наблюдениям, в кото-
рых присутствуют и X, и У|. На этом шаге получаем (|310.х,
(0,9925, 0,1010, 0,1718) и 5п.х = 11,О887.
Шаг 3. Найдите МП-оценки @10.х, и ^п-х коэффициентов ре-
। рессии и остаточной дисперсии для регрессии У2 на X. Их можно
получить, проводя свертку по переменным х дополненной ковариа-
ционной матрицы У2 и X, вычисленной по тг наблюдениям, в кото-
рых присутствуют Хи Y2. На этом шаге находим (Д20.х, ££.*) =
= (—0,4444, 0,1760, 0,2278) и дг2.х =27,3818.
Шаг 4. Найдите МП-оценки (Ззо.х, @3х.х и а33.х коэффициентов ре-
грессии и остаточной дисперсии для регрессии У3 на X. Их можно
получить, проводя свертку по переменным X дополненной ковариа-
ционной матрицы У3 и X, вычисленной по т3 наблюдениям, в кото-
рых присутствуют и Л, и У3. Этот шаг дает (/?30.х, @Jx.x)=
= (0,3309, 0,2298, 0,5731) и <?33х = 71,4943.
Шаг 5. Приравняйте нулю все коэффициенты частной корреляции,
не поддающиеся оценке. Найдите (единственную) МП-оценку векто-
ра средних n=(jax, цу)Т и ковариационной матрицы
~ух ^уу
141
всех переменных следующим образом:
1 Р«»
/‘(О) 2(0)
010-х
01х-х
SWP
=RSW[x]
030-х
020-х
02хх
о
°22-х
0
030-х
03Х-Х
о
о
^11 -X
(6.23)
—1
где нулевые индексы в левой части (6.23) обозначают оценки, услов-
ные по нулевой частной корреляции. Шаг 5 позволяет получить
#=(9,96, 13,27 , 25,63),
22,66 17,61 32,84^
17,61 54,31 49,61
32,84 49,61 165,64
53,78 85,22 144,08
£х,=
36,74 52,39 106,50
Шаг 6. Приравняйте единице все коэффициенты частной корреля-
ции, не поддающиеся оцениванию. Найдите соответствующие МП-
оценки:
-1
я-щ 2(1)
142
Jin оценки можно получить, замещая нижнюю правую ЗхЗ-под-
Мйтрицу в правой стороне (6.23) на
<*11-.г 1 х^22-х 1 х^ЗЗ-х
А1Л-Г • °22х ^°22х°33-х
^И-х^ЗЗ-х ^^22хРзЗх $33-х
Получаем те же значения jiy и Ёуу, но оценки остальных парамет-
ров другие. В частности, оценки корреляций между переменными Y
равны 0,999, 0,996, 0,990. На шаге 5 соответствующие оценки рав-
нялись 0,50, 0,54 и 0,52.
Проводя линейную интерполяцию между значениями корреляций
на 5-м и 6-м шагах, получаем рис. 6.4. В [Rubin and Thayer (1978)]
рассмотрены и другие параметры, например коэффициент множест-
венной корреляции. В общем случае они не линейны по (неоценивае-
мым) частным корреляциям, но также легко вычисляются.
ЛИТЕРАТУРА
Anderson, Т. W. (1957). Maximum likelihood estimates for the multivariate normal distribution
when some observations are missing, J. Am. Statist. Assoc. 52, 200-203.
Heaton, A. E. (1964). The use of special matrix operations in statistical calculus, Educational
Testing Service Research Bulletin, RB-64-51.
Box, G. E. P., and Tiao, G. C. (1973). Bayesian Inference in Statistical Analysis. Reading
MA: Addison-Wesley.
Cochran, W. G. (1977). Sampling Techniques. 3rd ed. New York: Wiley?
Dempster, A. P. (1969). Elements of Continuous Multivariate Analysis. Reading, MA: Addison-
Wesley.
Dixon, W. J. (Ed.) (1983). BMDP Statistical Software, 1983 revised printing. Berkeley: University
of California Press.
2
Draper, N. R., and Smith, H. (1968). Applied Regression Analysis, New York: Wiley.
Goodnight. J. H. (1979). A tutorial on the SWEEP operator. American Statistician, 33,149-158
Lindley, D. V. (1965). Introduction to Probability and Statistics from a Bayesian Viewpoint,
Vol. 2. Cambridge: Cambridge University Press.
Little, R J. A. (1976), Inference about means from incomplete multivariate data, Biometrlka
63, 593-604.
1 Русский перевод: Кокрен У. Методы выборочного исследования. - М.: Статистика, 1976.
2
Русский перевод: Дрейпер И., Смит Г. Прикладной регрессионный анализ. — М.: Финансы и
статистика. - Кн. '1, 1986; кн. 2, 1987.
143
Little, R. J. A. (1986). Some methods for interval estimation with incomplete data. !
Little, R. J A. and Rubin. D. B. (1983). On jointly estimating parameters and missing data by
maximizing the complete-data likelihood. American Statistician 37, 218-220. :
Lord, F. M. (1955). Estimation of parameters from incomplete data, J. Am. Statist. Assoc,
50, 870- 876.
Marini, M. M., Olsen, A. R., and Rubin, D. B. (1980). Maximum likelihood estimation in panel
studies with missing data, in Sociological Methodology 1980. San Francisco. Jossey-Bass.
Morrison, D. F. (1971). Expectations and variances of maximum likelihood estimates of the
multivariate normal distribution parameters with missing data, J. Am. Statist. Assoc. 66,
602-4. ’
Rubin, D. B. (1974), Characterizing the estimation of parameters in incomplete data problems,
J. Am. Statist. Assoc. 69, 467 -474.
Rubin, D B. (1976). Comparing regressions when some predictor variables are missing, Tech- I
nometries 18, 201 206. 1
Rubm, D. B„ and Thayer, D. (1978). Relating tests given to different samples, Psychometrika
43, 3-10.
Rubin, D. B. (1986). Statistical matching using file concatenation with adjusted weights and
multiple imputation, J. Business Econ. Stat. 4, 87-94.
Snedecor, G. W., and Cochran, W. G. (1967). Statistical Methods, 6th ed. Ames: Iowa State
University Press.
ЗАДАЧИ
1. Познакомьтесь с работами по данным co структурной из примера 6.1, пред-
шествовавшими [Anderson (1957)].
2. Допустим, что данные в примере 6.1. ОС. Покажите, что при заданных
О'Си, Т„1^2от и — несовмещенные оценки и 021-1' Покажите исходя из
этого несмещенность
3. Допустим, что данные в примере 6.1 ОПС. Найдите точную дисперсию д2, ус-
ловную по (уи, ... уп]. 'Указания. Если и распределена по хи-квадрат с d степенями
свободы, то £(1/и)=1/(<7—2) [см. Morrison (1971)]. Выведите отсюда, что ц2 имеет
дисперсию меньше, чем у2, если и только если g’-> 1/(т—1), где т — число полных
наблюдений.
4. Сравните асимптотическую дисперсию /и—у.г, определяемую выражениями
(6.13) и (6.14), с точной дисперсией, вычисленной в задаче 3.
5. Докажите результаты 1—6 из раздела 6.3.2 (за указаниями обратитесь к га. 2
в [Box and Tiao (1973)].
6. Выведите асимптотическую дисперсию МП-оценок 1по22 для данных из раздела
6.2, выражая 1па22 как функцию ф и применяя метод, описанный в разделе 6.3.1. Вы-
числите асимптотический 95%-ный доверительный интервал для 1па22 по данным из
табд. 6.1, преобразуйте его в интервал для <г2г и сравните с другими интервалами для
агг в таб. 6.2.
7. Выразите коэффициент регрессии X, на Х2, 012.,, Для двумерного нормального
распределения через параметры ф из раздела 6.2 и выведите МП-оценку для данных
примера 6.1.
144
И. Покажите в условиях задачи 7, что оценка (312.2, получаемая максимизацией ло-
(ирифма правдоподобия для полных данных по параметрам и пропущенным значе-
ниям, равна 0l2.2~$i2-2?n''$2b где (в обозначениях раздела 6.2)
Й22= Р2\-1 ! Уп~уг~Ai10,1 — Г1)]2-
Исходя из ЭТОГО покажите, ЧТО $ 12.2 — несостоятельная оценка 3122, если
Линя пропусков не сходится к нулю (см. раздел 5.4, решение см. в [Little ano Rubin
(1983)].
Ч. Покажите, что факторизация в примере 6.1 не дает раздельных параметров ;<^j
пни двумерной нормальной выборки с пропусками в У2 при средних (jii, цг), корреля-
ции р и общей дисперсии а2.
1(1. Сгенерируйте на компьютере или другим способом двумерную нормальную
пыборку из 20 наблюдений с параметрами ^t=/i2=0, а,, = 1, пи=2, а12 = 1 и удалите
шачения У2 так, чтобы вероятность отсутствия уг была равна 0,2 при У) <0 и 0,8 при
г0.
а) Постройте критерий проверки условия ОПС и примените его к вашим данным
(воспользуйтесь программой BMDP8D в руководстве к пакету BMDP [см. Dixon
(1483)]).
б) Вычислите 95%-ный доверительный интервал для используя а) данные до
удаления части У2. б) полные наблюдения, в) Г-аппроксимацию (см. раздел 6.3.2).
< 'делайте выводы относительно свойств этих интервалов для данного механизма по-
рождения пропусков.
11. Докажите, что оператор свертки коммутативен и что порядок проведения свер-
i ок алгебраически не существен ( хотя можно показать, что этот порядок может вли-
я гь на точность и диапазон вычислений).
12. Покажите, что RSW обратная к SWP операция.
13. Покажите, как вычислять коэффициенты частной и множественной корреляции
с помощью SWP.
14. Оцените параметры распределения Хг, Х3 и Х5 в примере 6.8, считая, что
X, совсем не наблюдается. Если вместо Х< будет- полностью отсутствовать Х3, вы-
числения окажутся проще или сложнее?
15. Постройте таблицу факторизации [см. Rubin (1974)] для данных из примера
6.10. Покажите, почему оценки, полученные в этом примере, — это МП-оценки.
16. Пусть данные ОС. Если статистик удаляет значения, чтобы получить набор
данных, в котором факторы соответствуют полным данным, то обязательно ли в
результате отсутствующие данные отсутствуют случайно? Приведите пример, иллю-
стрирующий существенные моменты.
Глава 7. МЕТОД МАКСИМАЛЬНОГО ПРАВДОПОДОБИЯ
ДЛЯ СТРУКТУР ПРОПУСКОВ ОБЩЕГО ВИДА:
ВВЕДЕНИЕ И ТЕОРИЯ МЕТОДА
ПРИ ИГНОРИРУЕМОМ МЕХАНИЗМЕ ПРОПУСКОВ
7.1. МЕТОДЫ ВЫЧИСЛЕНИЙ
Структура неполных данных на практике часто не позволяет яв-
но вычислять ОМП с помощью факторизации правдоподобия. Кро-
ме того, для некоторых моделей факторизация существует, но пара-
метры каждого из факторов не раздельны, и поэтому мак-
145
симизация факторов по отдельности не приводит к максимуму
правдоподобия. В этой главе мы рассмотрим итеративные методы
вычислений, когда ОМП не выражаются в явном виде. В некоторых
случаях эти методы можно применить к факторизованным непол-
ным данным, описанным в разделе 6.6.
Предположим, как и ранее, что мы имеем модель для полных
данных У, которой соответствует плотность f(Y | 0), зависящая от
неизвестного параметра 0. Введем обозначение У=(УоЬ5, ymis), где
УоЬ5 представляет собой наблюдаемую часть У, a ymis — пропущен-
ные значения. В этой главе для простоты примем, что данные ОС
и что целью является максимизация правдоподобия
Ь(0 | УоЬ£)= iA^obs. rmi81 № (7.1)
по 0. Аналогичный анализ применим в более общей ситуации, когда
данные не ОС, а значит, член, представляющий механизм порожде-
ния пропусков, включается в модель. Такие случаи рассматривают-
ся в гл. 11.
Если правдоподобие дифференцируемо и одномодально, ОМП
можно найти, решая уравнение максимального правдоподобия
5(0 I robs)=31^12ks)=0. (7.2)
OV
Когда нельзя явно найти корень (7.2), можно применить итератив-
ные методы. Пусть 0(О) — начальная оценка 0, вычисленная, напри-
мер, по наблюдениям без пропусков. Обозначим 0<4 оценку на Лй
итерации. Алгоритм Ньютона—Рафсона определяется уравнением
0<'+1) = | robsW« I yobs), (7.3)
где 1(0 | УоЬ5) — наблюдаемая информация:
м | у 3 д21(в I
Л0 I Fobs)-----
Если логарифм функции правдоподобия выпуклый и одномодаль-
ный, то последовательность значений 0^ сходится к ОМП 0 пара-
метра 0 (за одну итерацию, если логарифм правдоподобия —
квадратичная функция от 0) Вариантом этой процедуры является
метод функции вкладов (method of scoring), при котором в (7.3) на-
блюдаемую информацию заменяют ожидаемой:
0(гИ) = 0«+/-1(0(')),$(0(') | yobs),
(7-4)
146
। ле
W)=E[I(fi | Kobs) | 6] 1 <Wobs-
При обоих методах вычисляется матрица вторых производных ло-
гарифма правдоподобия. Для сложных структур пропусков элемен-
। ы этой матрицы являются сложными функциями от б. К тому же
на матрица велика при большей размерности б. Как следствие,
чюбы применять эти методы, могут потребоваться тщательные
алгебраические выкладки и высокоэффективное программирование.
Еще один алгоритм [см. Berndt, Hall, Hall and Hansman (1974)]
основан на том факте, что выборочная ковариационная матрица
вклада 8(6 | Уо1к) является состоятельной оценкой информации в
окрестности б. Получается такое итеративное уравнение:
6((+1>=6w+x,<2-3(6W)S(6« | yote),
где Q(6) = E"=] (д1,/дв)(д1/д0)т, lt — логарифм правдоподобия z-ro
наблюдения, а \ — положительный шаг, вводимый таким обра-
зом, чтобы обеспечить сходимость к локальному максимуму. Дру-
гие варианты алгоритма Ньютона—Рафсона позволяют
аппроксимировать производные логарифма правдоподобия числен-
но, при использовании первых и вторых разностей между двумя по-
следовательными итерациями.
Альтернативной вычислительной стратегией для задач с неполны-
ми данными, которая не требует вычисления или аппроксимации
вторых производных, является ЕМ-алгоритм (expectation-maximi-
zation algorithm) — метод, который связывает МП-оценивание б по
/(б | УоЬ!.) с оцениванием по логарифму правдоподобия 7(6 | У) для
полных данных. Во многих важных ситуациях ЕМ-алгоритм удиви-
тельно прост как в содержательном, так и в вычислительном отно-
шении. Оставшаяся часть этой главы посвящена ЕМ-алгоритму.
7.2. ЕМ-АЛГОРИТМ. ВВЕДЕНИЕ
ЕМ-алгоритм — очень общий итеративный алгоритм для МП-
оценивания в задачах с неполными данными. На деле круг задач,
которые можно решать с помощью ЕМ-алгоритма, очень широк.
Он охватывает задачи, постановка которых обычно не связана с
проблемой отсутствующих и неполных данных (например, оценива-
ние компонент дисперсии, итеративно взвешиваемые оценки на-
именьших квадратов).
147
В ЕМ-алгоритме формализована относительно старая идея обра-
ботки неполных данных: 1) заполнение пропусков оценками пропу-
щенных значений; 2) оценивание параметров; 3) повторное
оценивание пропущенных значений, при этом оценки параметров
считаются точными; 4) повторное оценивание параметров и так да-
лее до сходимости процесса. Такие алгоритмы являются ЕМ-алго-
ритмами для моделей, где логарифм правдоподобия для полных
данных 1(6 | robs> ymis) = ln£(0 | Tobs, У^) линеен по y„lis, или в бо-
лее общей форме, где надо оценивать не отдельные пропуски, а от-
сутствующие достаточные статистики, и более того, где на каждой
итерации алгоритма надо оценивать логарифм правдоподобия
ко | у).
Поскольку ЕМ-алгоритм тесно связан с основанной на интуиции
идеей заполнения пропусков и совершения итераций, неудивительно,
что он уже давно предлагался в частных случаях. Одним из первых
его предложил МакКендрик [McKendrick (1926)] для медицинских
приложений*. Хартли [Hartley (1958)] рассмотрел общий случай дис-
кретных данных и довольно широко разработал теорию. В его
статье содержится много ключевых идей современной теории. Баум
и соавторы [Baum, Petrie, Soules and Weiss (1970)] использовали этот
алгоритм для марковской» модели и доказали важные математиче-
ские результаты, которые довольно легко обобщаются. Орчард и
Вудбери [Orchard and Woodbery (1972)] первыми отметили широкую
применимость основной идеи, названной ими «принципом отсут-
ствующей информации». Сандберг [Sundberg (1974)] рассмотрел
свойства общих уравнений максимального правдоподобия, а Бил и
Литтл [Beale and Little (1975)] развили теорию для нормальной мо-
дели. Термин «ЕМ» был введен в [Dempster, Laird and Rubin (1977)].
В этой работе показана высокая общность алгоритма. В ней: 1) до-
казаны общие результаты о поведении алгоритма и, в частности,
отмечено свойство, что каждая итерация увеличивает правдоподо-
бие 1(6 | yobs); 2) приведено множество примеров. С 1977 г. появи-
лось большое число работ по применению ЕМ-алгоритма и с
исследованием его сходимости (см., например, [Wu (1983)]).
Каждая итерация ЕМ-алгоритма состоит из шага Е (вычисление
математического ожидания) и шага М (максимизация)— Эти шаги
можно легко представить содержательно, запрограммировать и раз-
* В статье Butler R. W. Predictive likelihood inference with applications. J. Roy. Stat.
Soc., Ser. B, vol. 48 (1986), No. 1, p. 1—38 даются ссылки на несколько нетривиальных
примеров ЕМ-алгоритма, в частности для расщепления смеси распределений. Эти
примеры относятся к прошлому веку. — Примеч. пер.
148
местить в памяти компьютера. Далее, каждый шаг имеет непосред-
ственную статистическую интерпретацию. Еще одним достоин-
ством алгоритма является надежная сходимость, т. е. в
определенных нестрогих условиях каждая итерация увеличивает ло-
гарифм правдоподобия /(0 | Kobs), и если 1(0 | УоЬ8) ограничен, то по-
следовательность 1(9^ | Kobs) сходится к стационарному значению
/(0 j Kobs). С достаточной степенью общности можно сказать, что
если последовательность 0® сходится, то она сходится к локально-
му максимуму или точке перегиба 1(0 | Fobs). Недостаток ЕМ-алго-
ритма заключается в том, что скорость сходимости может быть
очень низкой, если пропущено много данных. В [Dempster, Laird and
Rubin (1977)] показано, что сходимость линейна со скоростью, про-
порциональной наблюдаемой доле информации о в в 1(0 | У), о чем
более точно говорится в разделе 7.5. Кроме того, ЕМ-алгоритм не
обладает свойством, присущим алгоритму Ньютона—Рафсона или
методу вкладов, согласно которому оценки, получаемые после од-
ной итерации, асимптотически эквивалентны ОМП.
7.3. ОПИСАНИЕ ЕМ-АЛГОРИТМА
Описание шага М совсем просто: «Проводить максимально прав-
доподобное оценивание 0 так, как будто нет пропусков, т. е. как
будто они заполнены». Таким образом, на шаге М ЕМ-алгоритма
используются те же вычислительные методы, что и при МП-оцени-
вании по /(0 | У).
На шаге Е находят условное ожидание «пропущенных данных»
при фиксированных наблюденных данных и текущих оценках пара-
метров, а затем заменяют «пропущенные данные» найденными
ожидаемыми значениями. «Пропущенные данные» взяты в кавыч-
ки, так как на практике в ЕМ-алгоритме не обязательно происходит
действительное заполнение пропусков. Ключевая идея ЕМ-алгорит-
ма, оформившаяся из частной идеи итеративного заполнения пропу-
сков, состоит в том, что «пропущенные данные» — это не ymis, а
функции от Ут|5, входящие в логарифм правдоподобия для полных
данных, т. е. 1(f) | У).
Точнее, пусть 0W — текущая оценка параметра 0. На шаге Е ЕМ-
алгоритма находят ожидаемый логарифм правдоподобия при усло-
вии 0 = 0W;
Q(0 | 0«)= \l(9 | y)/(ymi81 yobs, 0=0<Wmis.
149
На шаге М ЕМ-алгоритма определяют максимизируя этот
ожидаемый логарифм правдоподобия:
Q(0(z+,) | 0W) ^Q(9 | 6(г)) для всех 6*.
Пример 7.1. Одномерные нормальные данные. Допустим, что у,
и. о. р. по Мд, а2), где у,, наблюдаются, a yt, i-m+
+1, ..., п, отсутствуют, и предположим, что выполняется ОС. Ожи-
даемое значение каждого пропуска при заданных УоЬз и 0 = (д, а2)
равно д. При этом, согласно примеру 5.1, логарифм правдоподобия
1(f) | У) для всех yjt i=l, ..., п, линеен по достаточным статистикам
ЕГу; и Efy?. Значит, на шаге Е алгоритма получаются значения
£(£ у,-1 £ Л + (7.5}
Е(£у? | yobs)= £ у? + (л- т)[(д»)2 + (о<'))2] (7.6)
для текущих оценок 0(,) = (д(г), <r2W) параметров. Заметьте, что прос-
тая подстановка д(^ вместо пропусков .... уп привела бы к от-
сутствию в (7.6) члена (п—т)(оМу.
Для полных данных ОМП д равна а ОМП а2 — это
—(Е^/л)2. На шаге М используются эти же выражения с
текущими ожиданиями достаточных стсs метик, вычисленными на
шаге Е и подставляемыми вместо не полностью наблюдаемых до-
статочных статистик. Следовательно, на шаге М вычисляются
д^»=Е(£Л|0(О УоЬ5)/И, (7.7)
»)2=£(Еу2 I УоЬ5)/'ь-(д(м D)2. (7.8)
Полагая в уравнениях (7.5) — (7.8) дм-д<,+ 1) = д и </г> = </'+1> = а,
получаем, что итерации сходятся к
д=Еу,- /т
и
о2=Ъ у2/т—д2 —
ОМП параметров д и а2 по УоЬ, при условии ОС. Конечно, в этом
примере ЕМ-алгоритм не нужен, поскольку можно получить ОМП
(д, а2) в явном виде.
• Можно показать, что ЕМ-алгоритм эквивалентен следующей процедуре: шаг Е:
генерировать значения для заполнения пропусков У согласно плотности /(У | X,
условной по присутствующим данным X и с текущей оценкой в качестве параметра,
формируя бесконечную «выборку» Z=(X, Yt) U (А. У2)... —объединение независимо
заполненных выборок; шаг М: найти по «выборке» без пропусков Z МП-оценку
0(н-1)_ — Примеч. пер.
150
Пример 7.2. Полиномиальный случай. Этим примером начина-
лось описание ЕМ-алгоритма во введении к [Dempster, Laird and
Rubin (1977)]. Пусть постулируется, что вектору данных наблюден-
ных частот yobs=(38, 34, 125) соответствует полиномиальное рас-
пределение с вероятностями (1/2 —1/20, 1/40, 1/2+1,40). Ставится
цель найти ОМП 0. Определим y = Olty21y31y4) как полиномиальную
случайную переменную с вероятностями (1/2—1/20, 1/40. 1/40, 1/2),
где У^^Очлаз+У*)- Заметим, что если бы наблюдались «полные
данные» У, ОМП была бы получена немедленно:
. (7.9)
Л+Л+Л
Заметим, также, что логарифм правдоподобия линеен по 0, так что
поиск математического ожидания 1(6 | У) при заданных 0 и УоЬ!,
включает те же вычисления, которые требуются для определения
математического ожидания У при заданных 0 и УоЬ8, когда, по су-
ществу, происходит подстановка оценок пропущенных значений:
Е(у21 0, УоЬ8) = 34,
Е(у} | 0, УоЬ8)= 125 (1/40)/(1/2+1/40),
Е’(Л I о, yobs)= 125 (1/2)/(1/2+1/40).
Таким образом, на t-й итерации мы имеем на шаге Е при оценке
0»
= 125 (1 /40»)(1/2+1/40»), (7.10)
а на шаге М, согласно (7.9)
0('+1)^(34+Я>)/(72+уд)). (7.11)
Итеративное повторение шагов (7.10) и (7.11) и определяет ЕМ-ал-
горитм для этой задачи. На деле, полагая 00+0 = 0(0 = ^ и объединяя
два уравнения, мы получим квадратное уравнение относительно 0 и,
значит, явное решение для ОМП. В табл. 7.1 показано, как последо-
вательность значений оценок в ЕМ-алгоритме сходится к этому ре-
шению с начальной точки 0(О) = 1/2.
151
Пример 7.3. Двумерное нормальное распределение с пропусками^
в обеих переменных. Простой, но нетривиальный пример ЕМ-алго-f
ритма возникает в случае двумерного нор-'
мального закона с общей структурой про-
пусков: в первой группе объектов
наблюдается Уь но отсутствует У2, во вто-
рой группе наблюдаются и Уь и У2, в
третьей группе наблюдается У2, но отсут-
ствует У) (рис. 7.1). Мы хотим вычислить
ОМП /I и Е среднего и ковариационной
матрицы У: и У2.
В отличие от примера 7.2 (и аналогично
примеру 7.1) заполнение пропусков на шаге
Е «не работает», так как логарифм правдо-
подобия 1(9 | У) линеен не по данным, а по
следующим достаточным статистикам:
= = sn = iynyi2, (7.12)
которые являются простыми функциями выборочных средних, дис-
персий и ковариаций. Следовательно, на шаге Е нужно найти услов-
ные ожидания сумм (7.12) при заданных УоЬ5 и 0=(/t, Е). Для
группы объектов с присутствием и у;Р и уа условное ожидание ве-
личин (7.12) равно их наблюдаемым значениям. Для группы, где
уп присутствуют, а уа пропущены, ожидания jZ5, и у\ равны на-
Переменные
Y1 /2
1 О
Объекты
1 о
О 1
О 1
1 = значение,
О = пропуск
Рис. 7.1. Структура пропу-
сков для примера 7.3.
Таблица 7.1. Последовательность оценок
в ЕМ-алгоритме для примера 7.2
1 №-6 ё)
0 0,500000000 0,126821498 0,1465
1 0,608247423 0,018574075 0,1346
2 0,624321051 0,002500447 0,1330
3 0,626488879 0,000332619 0,1328
4 0,626777323 0,000044176 0,1328
5 0,626815632 0,000005866 0,1328
6 0,626820719 0,000000779
7 0,626821395 0,000000104
8 0,626821484 0,000000014
152
блюдаемым значениям, ожидания yl2, у?2и ytiya мджно найти с по-
мощью регрессии уа на j’(]:
Е(Уа I Zi’#4’ ^)=020-1 + ^21-1Л’1>
Ё(Уа1 Уп’Р’ ^) = (020’1 + 021-1Л1)2+ °22-1’
Е^УцУн i У)1’ £) = (02О-1 + 021-Л1)Л1>
где /SjQ.j, /321.j и а22Л — функции от Е, соответствующие регрессии уй
на yit (детали см. в примере 6.1). Для группы с присутствующими у[2
и пропущенными ,у;1 вычисление отсутствующих членов в достаточ-
ных статистиках проводится с помощью регрессии на уа. Най-
дя ожидания уп, уа, у^, у^я УцУ^ для каждого объекта в трех груп-
пах, вычислим ожидания достаточных статистик (7.12) как суммы
этих величин по объектам. На шаге М по «заполненным» достаточ-
ным статистикам определяются обычные моментные оценки д и S:
fi.2=s2/n,
8\~su/n—jit , 6}=S22/n—ji2, di2=si2/n—jitjii-
ЕМ-алгоритм для этой задачи состоит в итеративном повторении
этих шагов. Другие детали для этого примера рассматриваются в гл.
8, где описан ЕМ-алгоритм для многомерного нормального распреде-
ления общего вида с любой структурой пропусков.
7.4. ТЕОРИЯ ЕМ-АЛГОРИГМА
Распределение полных данных У можно факторизовать следующим
образом:
/(У I &)=AYobs, Yobs | (?)=Arobs | 0WY™ | robs,0), (7.13)
где /(ypbs | 0) — плотность наблюдаемых данных Уо1в> а ДУ^ | УоЫ,в)
— плотность отсутствующих данных Утк при заданных наблюден-
ных данных. Разложение логарифма правдоподобия, соответствую-
щее (7.13), — это
153
1(0 I Y)=l(0 I y()bs, ymis) = /(0 I УоЬь)т1пДУт151 yob5,₽).
Нам нужно оценить в, максимизируя правдоподобие для неполных
данных 1(0 | УоЬ8) по в при заданных Уо1,5. Однако непосредственное
решение этой задачи может оказаться трудным.
Запишем:
1(0 | УоЬ5)=^ I ^-ln/(ymis | УоЫ, в), (7.14)
где 1(f) | УоЬ5) — максимизируемый логарифм правдоподобия для на-
блюдаемых данных, 1(9 | У) — полный логарифм правдоподобия,
максимум которого по предположению относительно легко найти,
а 1пЛУгаи | УоЬ8,0) — отсутствующая часть полного логарифма прав-
доподобия.
Математическое ожидание по распределению пропущенных дан-
ных ymis, взятое по обеим сторонам (7.14) при заданных наблюден-
ных данных У01к и текущей оценке 6, скажем, равно:
1(9 | УоЬ8) = е(0 | №)-Н(9 | 0И),
где
Q(9 | 0»)=И | yobs, УтиУ(Ут181 yob5>Wmis
И
H(9 | 9«)= j[ln/(yrais j yobs,0)]ДУШ151 Yobs,eW)dYmis.
Заметим, что по неравенству Йенсена [см. Rao (1972), с. 47]
Н(в ( < Н(0О) j 0(0). (7.15)
Рассмотрим последовательность 0f°\ где 0</+Ч=М(б<4) для
некоторой функции М(-). Разность значений 1(0 | УоЬ5) на двух по-
следовательных итерациях определяется выражением
^(Z+I) I I yobs)=[Q«?<z+n I 0»)-<2(0w 10W)j-
(7.16)
—[W'+1) 10W)~Я(0(!> j 6>w)].
ЕМ-алгоритм выбирает значение 0(,+ 1\ максимизирующее
Q(f) j 9®) по 0. В более общем случае GEM, обобщенный ЕМ-алго-
ритм (generalized ЕМ), выбирает такое, что Q(0</+1) | 0W) боль-
ше б(0(/) 19W). Поэтому разность между функциями Q в (7.16)
положительна для любого ЕМ- или GEM-алгоритма. Далее, заме-
тим, что разность между функциями Я в (7.16) отрицательна со-
гласно (7.15). Следовательно, для любого ЕМ- или GEM-алгоритма
переход от 0О~> к 00-и) увеличивает логарифм правдоподобия. Ска-
занное доказывает теорему, являющуюся ключевым результатом в
[Dempster, Laird and Rubin (1977)].
154
Теорема 7.1. Любой GEM-алгоритм увеличивает 1(91 Yobs) на
каждой итерации, т. е.
^((+!)Kobs)>^(,)l^obS).
причем равенство выполняется в том и только в том случае, если
О I 0(0) = Q(9(0 |0(О).
Следствие 1. Допустим, что для некоторого 9*, принадлежащего
параметрическому пространству 9, 1(9* | Yobs) > 1(6 | YobsJ для всех 9.
Тогда для любого GEM-алгоритма
| Yobi) = /(6* | yobs),
Q(M(9*) | 9*)^Q(9* | 6*)
И
почти наверное.
Следствие 2. Допустим, что для некоторого 9*, принадлежащего
параметрическому пространству 6, 1(9* | Yobs) > 1(9 | Yobs) для всех 9.
Тогда для любого GEM-алгоритма М(9*)=6*.
Теорема 7.1 указывает, что 1(9 | Yobs) не убывает на каждой ите-
рации GEM-алгоритма и строго возрастает на таких итерациях, где
возрастает Q (т. е. Q(0('| 0*0, Yobs) > Q((№ | 9(‘\ Yobs)). Следствия
означают, что ОМП 9 является стационарной точкой GEM-ал-
горитма.
Другой важный результат, касающийся ЕМ-алгоритма, представ-
лен в теореме 7.2, которая выполняется, когда Q(6 | (№) максимизи-
руют, полагая первую производную равной нулю.
Теорема 7.2. Допустим, что последовательность значений в ЕМ-
алгоритме такова, что
a) Dl°Q(0(/+y> | 0<О)=О, где О10 обозначает первую производную по
первому аргументу, т. е.
D!W“+1’ | б(0)= A Q(e | й(0) | w,+n;
б) 0W сходится к 0*;
в) /(Ymis | Yobs,0) — гладкая по 9, где гладкость определена в до-
казательстве. Тогда
Dl0l(9* | Yobs)= ~1(9 | Yobs) | ^=0,
155
так что если 0*г) сходится, то сходится к стационарной точке.
Доказательство.
| robs) = DlW(,+ n I 9(‘0--£>10Н(91'И) I 0W)=
= - 2>/(УШ151 УЛ)адУю | Yobi,9^)dYmii |
39
В условиях предполагаемой гладкости, достаточной, чтобы менять порядок интегри-
рования и дифференцирования, эта величина сходится к
-j YobsJ*)dYms,
что оказывается равным нулю после перемены порядка интегриро-
вания и дифференцирования.
Другие результаты по ЕМ-алгоритму в [Dempster, Laird and Rubin
(1977); Wu (1983)], касающиеся сходимости, включают следующее:
1) если 1(9 | yobs) ограничен, то /(0W j Kobs) сходится к некоторому
/“;
2) если f(Y | 9) — общее (выпуклое) экспоненциальное семейство и
1(9 I ^obs) ограничен, то Z(0W | Kobs) сходится к стационарному значе-
нию /*;
3) если/(У| в) — регулярное экспоненциальное семейство и 1(91 Уо!и)
ограничен, то сходится к стационарной точке 0*.
7.5. ОТСУТСТВУЮЩАЯ ИНФОРМАЦИЯ
Матрицу присутствующей информации 1(9 | Kobs) можно найти,
непосредственно дважды дифференцируя логарифм правдоподобия
/(0 | УоЬб) по 9, или другим способом: заметим, что двукратное диф-
ференцирование (7.14) по 0 дает для любого Утв
№ | Yob^I(9 | УоЬ> rmJ тЭЧп/(Утв | ¥оЫ,Г)/д9д6,
где 1(9 | УоЬ5, УТО15) — «наблюдаемая» информация, содержащаяся в
Y=(Yobs> Yms), а второй член, взятый со знаком минус, — это (от-
сутствующая) информация в Ут18. Вычисляя ожидания по распреде-
лению У^ при заданных УоЬ8 и 9, получаем:
1(9 I УоЬ5)-~Л2О<2(0 | ff)+DwH(9 | (?) (7.17)
156
при условии, что дифференцирование по & можно переносить за з^ак
интеграла. Если мы назовем — D2aQ(f) | &) полной, a D2OH(0 | 0) — От_
сутствукицей информацией, то (7.17) получит следующую примеча-
тельную интерпретацию:
Наблюдаемая информация = полная информация — отсутствующая информац^
Скорость сходимости ЕМ-алгоритма тесно связана с этими вели-
чинами: чем больше доля отсутствующей информации, тем мец^д.
нее сходимость. Точнее, Дэмпстер, Лэйрд и Рубин [Dempster,
and Rubin (1977)] показали, что для последовательности (№ зц9че_
ний в ЕМ-алгоритме, сходящейся к в*,
j=X|0W-0’ I (7.18)
для 0<rt в окрестности 0*, где X — отношение отсутствующей ин.
формации к полной при скалярном в или наибольшее собстве^ное
значение соответствующей матрицы при векторном 6.
Луи [Louis (1982)] выразил отсутствующую информацию в терми.
нах величин для полных данных и показал, что
-о»же 19)=w I robs. ymisW I vobs, xmi3) I robs,0}-
-s(o | yobsw I rob6),
где, как и раньше, S обозначает функцию вкладов, а Г — транспо-
нирование матрицы. В МП-оценке 5(0 | УоЬ5)=0 и в последнее вы-
ражении остается первый член. Уравнение (7.17) принимает цйд
(7.19)
-£ДО1 robs, ymisW I ^obs’ ^is) I Tobs,0] I
что может оказаться полезным в процессе вычислений.
Выражение для ожидаемой информации J(0), аналогичное (7.17)
находят после вычисления математического ожидания (7.
Tobs- Точнее,
J^J<$)+E[D2OH(9 | 8}],
(7.20)
157
где JC(G) — ожидаемая полная информация для Y- (70bs, ymis). В ра-
боте [Orchard and Woodbery (1972JJ это выражение приведено в дру-
гом виде.
Пример 7.4 (продолжение примера 7.2). Для «полиномиального»
примера 7.2 логарифм правдоподобия для полных данных равен
ytln(l—0) + (у2+уэ)1п0
с точностью до члена, не зависящего от д. Дифференцирование по
& приводит к
Stf | у)=—у, /(1 —6)+(у2 +у3) (8,
z(0| к)=ь/(1~е)2+О’2+у3)/е2.
Следовательно,
W | У) I Yobs,e] =У1/(1-еу+(у2 + ;3)/(Pj
ElS^(fi I У) I Y^,e\ =Var{S(0 | У) ( Fobs} = F/02,
где Л =£’0'31 Fobs, 0)=О3+У4)(О,250)(0,250+0,5)~i и F=Var(>3 ] Fobs,0)=
=О’з+У4)(О,5)(О,250)(0,250+0,5)~2 . Подставляя в эти выражения
У1=38, Уг = 34, Уз+Л=125 и 0 = 0,6268215, получаем
У) j Fobs,0J |9=#=435,3,
£^(0| У)| 7^,051^=57,8.
Следовательно, I<£\ Eobs)=435,3—57,8=377,5, что можно проверить
непосредственным вычислением. Заметим, что отношение отсутству-
ющей информации к полной равно 57,8/435,3=0,1328, что определя-
ет скорость сходимости ЕМ-алгоритма около §, отраженную в
последнем столбце табл. 7.1.
7.6. ТЕОРИЯ ЕМ-АЛГОРИТМА
ДЛЯ ЭКСПОНЕНЦИАЛЬНОГО СЕМЕЙСТВА
ЕМ-алгоритм имеет особенно простую и наглядную интерпрета-
цию, когда полным данным У соответствует распределение из регу-
158
парного экспоненциального семейства, определяемого плотностью
и ид а
/(У I в) = Ь(У)ехр(5(У)в)/а(в), (7.21)
|де 9 обозначает (Jx 1)-вектор параметров, 5(У) — (1 хс?)-вектор до-
статочных статистик для полных данных, а а и b — соответственно
функции от 9 и Y Многие задачи с полными данными моделируют-
ся распределением вида (7.21), охватывающим, по существу, все
примеры из части II книги как частные случаи. Шаг Е для (7.21) за-
ключается в оценивании достаточной статистики для полных
данных
sW=E(s(y)| yobs,e«). (7.22)
На шаге М определяется новая оценка 0, в^+1\ как решение уравне-
ний максимального правдоподобия
E(s(Y) | 0)=s«, (7.23)
являющихся просто уравнениями максимального правдоподобия
для полных данных У, в которых 5(У) заменено на s(tK Решение
уравнения (7.23) относительно 9 часто можно получать явно или, по
крайней мере, с помощью имеющихся компьютерных программ для
полных данных. В таких случаях вычислительные проблемы факти-
чески сводятся к шагу Е для оценивания статистики «(У) («заполне-
ние пропусков») с помощью (7.22). Разложение наблюдаемой
информации (7.19) в данном случае особенно просто. Полная ин-
формация есть Уаг(д(У) | 0), а отсутствующая информация —
Var(s(y) | УоЬ5,0). Значит, наблюдаемая информация есть
1(9 | УоЬ5)=Уаг(5(У) | 0)-Уаф(У) | УоЬ5,0) - (7.24)
разность между безусловной и условной дисперсиями достаточной
статистики для полных данных. Отношение условной и безусловной
дисперсии определяет здесь скорость сходимости.
159
ЛИТЕРАТУРА
Baum, L. E., Petrie, T., Soules, G., and Weiss, N. (1970). A maximization technique occurring
in the statistical analysis of probabilistic functions of Markov chains, Ann. Math. Statist.
41,164 171.
Beale, E. M. L., and Little, R. J. A. (1975). Missing values in multivariate analysis, J. Roy. Statist.
Soc. B37, 129- 145.
Berndt, E. B., Hall, B., Hall, R., and Hausman, J. A. (1974). Estimation and inference in
nonlinear structural models, Ann. Econ Soc. Meas.,3, 653- 665.
Dempster, A. P., Laird, N. M., and Rubin, D. B. (1977). Maximum likelihood estimation from
incomplete data via the EM Algorithm (with discussion), J. Roy. Statist. Soc. B39, 1-38.
Hartley, H. O. (1958). Maximum likelihood estimation from incomplete data, Biometrics 14,
174-194.
Louis, T. A. (1982). Finding the observed information when using the EM algorithm, J. Roy.
Statist. Soc. B44, 226-233.
McKendrick, A. G. (1926). Applications of mathematics to medical problems, Proc. Edinburgh
Math. Soc. 44, 98-130.
Orchard, T., and Woodbury, M. A. (1972). A missing information principle: theory and
applications. Proceedings of the 6th Berkeley Symposium on Mathematical Statistics and
Probability, 1,697-715.
Rao, C. R. (1972). Linear Statistical Inference and Its Applications. New York: Wiley?
Sundberg, R. (1974). Maximum likelihood theory for incomplete data from an exponential
family. Stand. J. Statist. 1, 49 58.
Wu,C. F. J. (1983). On the convergence properties of ihe EM algorithm, Ann. Statist. 11,95-103.
ЗАДАЧИ
1. Покажите, что для скалярного параметра алгоритм Ньютона—Рафсона сходит-
ся за одну итерацию, если логарифм правдоподобия — квадратичная функция.
2. Охарактеризуйте устно функции шагов Е и М ЕМ-алгоритма.
3. Докажите, что логарифм правдоподобия в примере 7.3 линеен по статистикам
(7.12).
4. Докажите следствия 1 и 2 теоремы 7.1.
5. Какие результаты по сходимости ЕМ-алгоритма вам известны?
6. Покажите, что (7.22) и (7.23) — это шаги Е и М для регулярного экспоненциаль-
ного семейства (7.21).
7. Допустим, что ..., У„)г — независимые случайные величины с гамма-
распределением с неизвестным показателем степени к и средним =£(£/37х-), где
g — известная функция, = ..., 0f) — неизвестные коэффициенты регрессии, а
Л'1Р ..., xtJ — значения сопеременных .... X, для /-го объекта. При каких g у при-
' Русский перевод: Рао С.Р. Линейные статистические выводы и их применения.— М.: Наука,
1968.
160
надлежит регулярному «.(J+ 1)-параметрическому» экспоненциальному семейству и
клтовы естественные параметры и достаточные статистики для полных данных?
X. Допустим, что значения у/ в задаче 7 отсутствуют в том и только в том случае,
сели У[ > с, где с — некоторая неизвестная точка цензурирования. Опишите шаг Е
( M-алгоритма для оценивания a) вг когда к предполагается известным,
(О |3„ .... и к, когда к также надо оценивать.
9. Проведите вручную вычисления для «многомерно! о нормального» ЕМ-алгорит-
ма с данными табл. 6.1, взяв в качестве начальных оценки, полученные по полным
наблюдениям. Проверьте, что для этой структуры данных и при таком выборе на-
чальных значений алгоритм сходится за одну итерацию (т. е. последующие итерации
дают тот же результат, что и первая). Почему в данном случае не выполняется
(7.18)? Указание. Рассмотрите следствие 2 теоремы 7.1 при =
10. Найдите логарифм правдоподобия от в для наблюденных данных из примера
7.2. Покажите непосредственным дифференцированием, что I(fi ( yobs)=453,3, как по-
казано в примере 7.4.
11. Определите асимптотическую дисперсию ОМП 8 в примере 7.2 и сравните ее
с дисперсией ОМП, когда складываются первая и третья частоты (т. е. 38 и 125),
приводя в результате к частотам (163, 34) из биномиального распределения с вероят-
ностями (1—9/4, 9/4).
12. Допустим, что во второй части примера 5.14 с цензурированной экспоненциаль-
ной выборкой наблюдаются у,, ..., ут, ауга+1, ..., уп цензурированы в с. Покажите,
что в этой задаче достаточная статистика для полных данных есть х(У) = Е_[ и
что естественно взять в качестве параметра ф=1/в, обратное от среднего. Найдите
наблюдаемую информацию для ф, вычисляя безусловную и условную дисперсию з(У)
и проводя вычитание, как в (7.24). Найдите долю информации, теряемой при цензу-
рировании, и асимптотические дисперсии ё—в и ф—ф.
Глава 8. NOT-ОЦЕНИВАНИЕ
В ЗАДАЧАХ, СВЯЗАННЫХ
С МНОГОМЕРНЫМ НОРМАЛЬНЫМ РАСПРЕДЕЛЕНИЕМ
8.1. ВВЕДЕНИЕ
В этой главе мы рассмотрим ЕМ-алгоритм в приложении к не-
скольким задачам для моделей, связанных с многомерными нор-
мально распределенными данными с пропусками: оценивание
вектора средних и ковариационной матрицы в общем случае и при
наличии ограничений на ковариационную матрицу, множественную
линейную регрессию (в том числе дисперсионный анализ и много-
мерную регрессию), модели повторных измерений (в том числе
6 Р Дж А Литтл Д Ь Рубил
161
модели регрессии со случайными коэффициентами, в которых сами
коэффициенты рассматриваются как отсутствующие данные) и не-
которые модели временных рядов. Описание методов анализа кате-
гориальных данных с частично наблюдаемыми или отсутствующи-
ми данными отложено до главы о таблицах сопряженности (гл. 9).
Анализ смешанных нормальных и ненормальных данных обсужда-
ется в гл. 10. Во всех примерах предполагается выполненным усло-
вие ОС.
8.2. ОЦЕНИВАНИЕ ВЕКТОРА СРЕДНИХ
И КОВАРИАЦИОННОЙ МАТРИЦЫ
8.2.1. ЕМ-алгоритм для неполных многомерных
нормальных выборок
Многие методы многомерного статистического анализа, включая
множественную линейную регрессию, анализ главных компонент,
дискриминатный анализ и канонический корреляционный анализ,
основаны на преобразовании матрицы данных в выборочные сред-
ние и матрицу ковариаций переменных. Поэтому эффективное оце-
нивание этих величин для произвольных структур пропусков в
данных является очень важной проблемой. В этом разделе мы обсу-
дим МП-оценки среднего и ковариационной матрицы по неполной
многомерной нормальной выборке, предполагая, что данные от-
сутствуют случайно (ОС). Хотя предположение многомерной нор-
мальности выглядит ограничительным, методы, обсуждаемые
здесь, могут обеспечить состоятельные оценки при более слабых
предположениях об исследуемых распределениях. Кроме того, пред-
положение о нормальности будет в некоторой степени ослаблено
при рассмотрении линейной регрессии в разделе 8.4. Робастные
МП-оценки среднего и ковариационной матрицы для многомерного
^распределения и многомерной нормальной модели с загрязнением
обсуждаются в разделе 10.5.
Предположим, что мы имеем дело с К-мерной переменной
(Y[t Y2, ..., YK), нормально распределенной со средним
1л=(р,1, ..., цк) и ковариационной матрицей E = (a;jt). Обозначим
У=(УоЬ5, Y представляет выборку объема п из векторов
(Уь ..., Ук), Ут13 — пропущенные данные, Kobs — множество на-
блюдаемых значений:
H>bs O'obs.l’ -lobs,2’ • • • i УоЬ8,л) ’
162
где _ynhs>j представляет множество переменных с присутствующими
значениями в наблюдении I, 1=1, ..., п.
Чтобы вывести ЕМ-алгоритм, заметим, что гипотегические пол-
ные данные Y извлекаются из распределения из регулярного экспо-
ненциального семейства (7.21) с достаточными статистиками
j=1’ к> •••’ *)•
Пусть на Лй итерации #w=(/xw, Е(/1).~ Шаг Е алгоритма состоит в
вычислении
E(Ey,y|yobs,e«) = £^) j=l,...,K, (8.1)
MS УцУ* I Sobs,= E (<<?+<> J’k= i’ K’
где
yV)= 1 yv’ если yU пРисУтствУет,
‘J l E(yfJ |^obS;/,6»W), если y(7 пропущено,
c(2 _ f 0, если ytj или yik присутствует,
1' I CovQ>,7, yik | yobsi, 0<‘У), если ytJ и yik пропущены.
Таким образом, отсутствующие значения у/у заменяются средни-
ми у(У, условными по присутствующим значениям yobsy в этом на-
блюдении. Эти условные средние и ненулевые добавочные
ковариации легко получаются из текущих оценок параметров сверт-
кой приращенной ковариационной матрицы, так что переменные
yobsy — предикторы в уравнении регрессии, а остальные перемен-
ные — выходные. Оператор свертки описан в разделе 6.5.
Вычисления на шаге М ЕМ-оператора проводятся очень просто.
Оценка 0(t+v> вычисляется по оценкам достаточных статистик для
полных данных:
>1,
ай+И =п-1Е( Ey,yy,.J robs)-^+ ‘М+1) = (8-2)
=«->£ [(уЮ-/гу+1))(у^-^Г1)) + с^1, УЛ=1, , К.
Бил и Литтл [Beale and Little (1975)] предлагают заменить п~1 в
оценке ayjt на (п—I)-1 по аналогии с поправкой на число степеней
свободы в случае полных данных.
б„.
163
Остается определить начальные значения параметров. Простей-
шими являются следующие четыре варианта:
1) использовать решение раздела 3.2 (брать только полные на-
блюдения);
2) использовать одно из решений по доступным наблюдениям
(раздел 3.3);
3) вычислять выборочные среднее и ковариационную матрицу по
данным, пропуски в которых заполнены одним из методов раздела
3.4;
4) вычислять средние и дисперсии по присутствующим данным
каждой переменной, положив все корреляции равными нулю. Вари-
ант 1 позволяет получить состоятельные оценки параметров, если
верно ОПС и присутствует по меньшей мере К+1 комплектных на-
блюдений. При варианте 2 используются все данные, но существует
возможность, что оценка ковариационной матрицы не является по-
ложительно определенной. Это может приводить к трудностям на '
первой итерации. Варианты 3 и 4 дают оценки ковариационной
матрицы, которые несостоятельны в общем случае, но положитель-
но полуопределены и поэтому обычно пригодны как начальные зна-
чения. В программной реализации, видимо, следует иметь
несколько вариантов начальных значений, чтобы в различных ситу-
ациях выбирать наиболее подходящий.
Связь между МП-оценкой и эффективными формами заполнения
пропусков хорошо видна в ЕМ-алгоритме. На шаге Е пропуски за-
полняются наилучшим линейным прогнозом по текущей оценке па-
раметров. Также вычисляются коэффициенты cjk, чтобы учесть
заполнение пропусков при оценивании ковариационной матрицы.
ЕМ-алгоритм, описанный выше, был впервые описан в [Orchard
and Woodbury (1972)]. Для решения этой проблемы ранее в [Ttawin-
ski and Bargmann (1964)] был описан метод вкладов, а в [Hartley and
Hocking (1971)] в изящной форме были представлены итеративные
уравнения. Важным отличием ЕМ-алгоритма от метода вкладов яв-
ляется то, что последний требует обращения информационной мат-
рицы /I и Е на каждой итерации. Эта матрица служит оценкой
асимптотической ковариационной матрицы МП-оценок, непосред-
ственно не вычисляемой при ЕМ-алгоритме. Однако обращение ин-
формационной матрицы на каждой итерации может оказаться
трудоемким при большом числе переменных. Для К’-мерного случая
информационная матрица 9 имеет К(К+1)/2 строк и столбцов. При
А"=30 она содержит более 100 000 элементов! В ЕМ-алгоритме
асимптотическая ковариационная матрица может быть получена
164
и результате единственного обращения информационной матрицы,
вычисленной при окончательном значении оценки в.
Можно выделить три версии ЕМ-алгоритма. В первой хранятся
исходные данные [Beale and Little (1975)]. Во второй хранятся сумма
ио переменной, суммы квадратов и суммы взаимных произведений
для каждой матрицы пропусков [Dempster, Laird and Rubin (1977)].
Наиболее предпочтителен по объему памяти и вычислений третий
вариант, в котором смешаны обе предыдущие версии. В этой вер-
сии сохраняются исходные данные для структур пропусков, кото-
рые повторяются менее чем в (Л+1)/2 наблюдениях, и достаточные
статистики — в противном случае.
8.2.2. Оценивание асимптотической ковариационной матрицы
(0—в) по информационной матрице
Если данные ОС, то ожидаемая информационная матрица пара-
метра в = (р,, Е), записанного в виде вектора, имеет вид
Лд) =
J(E)
Здесь (j, к)-й элемент JQi), соответствующий строке и столбцу р.к,
равен
где
(/Л)-й элемент Е^., если присутствуют xi} и xik,
L О — в противном случае,
a Eobs, — ковариационная матрица переменных, присутствующих в
i-м наблюдении. (1т, г.$)-й элемент ДЕ), соответствующий строке
<7//п и столбцу ors, равен
’/4(2 3//и)(2 Зга)Е.= 1 ($lri$msi +
где 81т = 1 при 1=т и 0 при l^-т. Как указывалось выше, матрица,
обратная к .7(0), дает оценку ковариационной матрицы МП-оценки 0.
165
Матрица J(9) оценивается и обращается на каждом шаге при вычис-
лениях методом вкладов. Заметим, что ожидаемая информационная
матрица блочно-диагональна по среднему и ковариациям, поэтому,
чтобы получить асимптотические дисперсии МП-оценок средних
или их линейных комбинаций, нужно лишь вычислить и обратить
информационную матрицу для среднего Др.), имеющую относитель-
но малые размеры.
Наблюдаемая информационная матрица, которую вычисляют и
обращают на каждой итерации алгоритма Ньютона—Рафсона, не
является блочно-диагональной по р, и Е, так что такое упрощение
не проходит, если стандартные ошибки определяются по этой мат-
рице. С другой стороны, стандартные ошибки, определяемые по на-
блюдаемой информационной матрице, вычисляются более условно
по отношению к данным и, значит, они более точны, когда данные
ОС, но не ОПС, и в приложениях предпочтительнее ошибок, вычис-
ляемых по J(0).
В ЕМ-алгоритме не используется ни наблюдаемая, ни ожидае-
мая информационная матрица, поэтому если какая-либо из них слу-
жит для вычисления стандартных ошибок, ее нужно вычислять и
обращать после того, как получены МП-оценки.
8.3. ОЦЕНИВАНИЕ ПРИ ОГРАНИЧЕНИЯХ
НА КОВАРИАЦИОННУЮ МАТРИЦУ
В разделе 8.2 мы не налагали ограничения на параметр 0 много-
мерного нормального распределения и он мог принимать любые
значения из естественного параметрического пространства. Однако
в некоторых статистических моделях на значения 0 налагаются не-
которые ограничения. МП-оценки по неполным данным в рамках
таких моделей можно также без затруднений получать с помощью
ЕМ-алгоритма, если параметры легко оцениваются по данным без
пропусков. Шаг Е ЕМ-алгоритма не изменяется при наличии огра-
ничений. Изменения требуются лишь на шаге М: максимизацию на-
до проводить с учетом ограничений.
Для некоторых ограничений неитеративные МП-оценки не суще-
ствуют даже при полных данных. В некоторых из таких случаев
можно применять ЕМ-алгоритм для итеративного вычисления МП-
оценок, создавая фиктивные ненаблюдаемые переменные таким об-
разом, чтобы шаг М выполнялся неитеративно. Эту идею иллю-
стрируют следующие два примера. Их можно модифицировать на
случай, когда в наблюдаемых переменных есть пропуски.
166
Пример 8.1. Ковариационная матрица заданной структуры. Не-
которые структурированные ковариационные матрицы, не имею-
щие явных МП-оценок, могут рассматриваться как подматрицы
больших структурированных матриц, для которых явные ОМП уже
существуют. В таких случаях меньшую ковариационную матрицу,
скажем Ен, можно считать ковариационной матрицей наблюдае-
мых переменных, а большую матрицу, скажем Е, — ковариацион-
ной матрицей наблюдаемых и отсутствующих переменных. Для
вычисления МП-оценок в исходной задаче применим ЕМ-алгоритм,
как описано в [Rubin and Szatrowski (1982)}.
В качестве примера рассмотрим стационарную ковариационную
Зх 3-матрицу Ец и 4х 4-матрицу Е с круговой симметрией:
Ей
$1 (?2 03
02 01 02
03 02 01
01 02 03 ! 02
02 01 02 ! 03
03 02 01 1 02
02 03 02 01
Еп ; е12
Ezi I Е22
Допустим, что мы имеем случайную выборку yit ..., уп из много-
мерного нормального распределения 7V3(O, Еи). Эти наблюдения
можно считать первыми тремя из четырех компонент наблюдений
в случайной выборке (yt, Zi), , (У„, Z„) из многомерного нормаль-
ного распределения .V4(0, Е), где первые 3 компоненты в каждом
(yjy Z/) присутствуют, а последняя компонента z, отсутствует. yt —
наблюдаемые, (у,-, z,) — полные данные, и присутствующие, и от-
сутствующие. Обозначим C=E(y;,z/-)r(y,-,zi)/n и Си = И(у[у?)/п.
Матрица С — достаточная статистика для полных, а матрица Си
— для присутствующих данных. Явные оценки максимального
правдоподобия Е получаются по полным данным (по Q простым
усреднением [см. Szatrowski (1978)], а шаг М ЕМ-алгоритма задает-
ся тогда в виде
е<]+’)= ^(Ес%), ' =i(c0 + с$+с£> + сЙ>),
(8-3)
^+1> = 4 Ш+с®),
где с$> — (к, у)-й элемент с О ожидаемого значения С на 1-й итера-
ции шага Е. Эти оценки 0i, 0г и 03 дают новую оценку Е на (1+ 1)-й
итерации.
3
167
Поскольку здесь есть только одна структура пропусков (yt при-
сутствует, z, отсутствует), на шаге Е ЕМ-алгоритма нужно вычис-
лить ожидаемое значение С при заданной наблюдаемой
достаточной статистике Сц и текущей оценке Ew матрицы Е, т. е.
Ст~Е(С/Сп, Ew). Сначала находим сверткой текущей оценки Е,
Е <'), по У параметры регрессии условного распределения z, при за-
данном и получаем
Е/р-1 Е/р-’ЕЙ» Eg) ЕЙ>
=SWP(1,2,3)
EIPEK’-1 Eff-Eg’EgJ-^Eg) Eg’ Eg’
Ожидаемое значение z,, условное по наблюденным данным и
Е = Е(/), равно yzEg)—1Eg), так что ожидаемое значение
Ci2 = Ezyfz/n, условное по Ctl и Е<г’, равно СцЕЙ’-1 ЕЙ’. Ожидае-
мое значение z/’z, при заданных наблюдаемых данных и E = EW
равно
(Eg) Eg’) + 2Й2-ЕЙ’Е.Ф-1 ЕЙ’,
так что ожидаемое значение C22 = E/’zf4i-/w равно
Eg’-Eg) ЕЙ^’ЕЙ’У EffEfi)-!C„Efi)“’Eff.
Итог этих вычислений таков:
Й(С| С,,,£(')) =
С,, ’ Eg)—S1P(.E ff-1 — Е /р-1 С,, Е j
(8.4)
Это новое значение С используется в (8.3) для вычисления новых
оценок 0г, 02 и 93, т. е. Е^”1’.
Преимуществом ЕМ-алгоритма является возможность одновре-
менно иметь дело с неполными данными и структурированными
ковариационными матрицами. И то и другое часто встречается в
«образовательных» тестах. В некоторых из этих задач единствен-
ные МП-оценки для неструктурированных ковариационных матриц
не существуют из-за пропусков в данных, а структуры матриц легко
проверить и обосновать теоретическими соображениями и результа-
тами практических исследований аналогичных данных [см. Holland
and Wightman (1982); Rubin and Szatrowski (1982)]. Когда число
168
структур пропусков больше одной, на шаге Е вычисляют ожидае-
мые достаточные статистики для всех (а не для одной, как в (8.4))
структур по отдельности.
Пример 8.2. Факторный анализ. Пусть У — наблюдаемая п*К-
матрица данных и Z — ненаблюдаемая лхд-матрица «факторных
течений», q<K. Строки (KZ) распределены независимо и одинако-
во. Маргинальное распределение каждой строки Z, факторов, нор-
мально со средними (0,,..,0), дисперсиями (1,...,1) и корреляционной
матрицей В. Условное распределение i-й строки X У,. при заданной
строке i Z, zt, нормально со средним a+zfi и остаточной ковариа-
ционной матрицей T2=diag(r?,...,т^). Это предположение об услов-
ной независимости переменных при заданных факторах очень
важно. Матрицу коэффициентов регрессии /3 обычно называют мат-
рицей факторных нагрузок, а остаточные дисперсии в т2 — специ-
фичностями.
Вообще говоря, оцениванию подлежат параметры а, /3, тг и В.
Поскольку маргинальное распределение каждой строки нормально
со средним а и ковариационной матрицей т’+РтВ^, МП-оценка а
равна У. Значит, при оценивании методом максимального правдо-
подобия мы можем заменить (ytJ—a) на (у,/—.Ур и рассматривать
только параметры (j3,rz,B). Чтобы упростить обозначения, примем
J^=0 (т. е. отцентрируем наблюденные переменные по выборочным
средним). Следовательно, маргинальное распределение наблюдаемых
данных у при параметрах нормально со средним 0 и ковариа-
ционной матрицей т2 +- @ТВ(3 — структурированной матрицей специ-
ального вида. Чтобы вывести ЕМ-алгоритм для факторного анализа
методом максимального правдоподобия, можно применить общие
результаты из примера 8.1. В частности, шаг Е — это (8,4) с первым
блоком переменных, соответствующим наблюдаемым признакам У,
и вторым блоком, соответствующим отсутствующим факторам Z.
В [Rubin and Thayer (1982), (1983)] описаны детали шага М для трех
случаев, определенных такими ограничениями на параметры:
1) В=1 (ортогональные факторы) и неограниченный /3;
2) В-l и в /3 есть априорно заданные нули;
3) В произвольна и в /3 есть априорно заданные нули.
Случай 1 иногда называют разведочным, а случаи 2 и 3 — под-
тверждающим (confirmatory) факторным анализом.
169
В случае 1 МП-оценки (Зит2 находят просто сверткой по Z теку-
щей оценки матрицы перекрестных произведений, вычисленной пе-
ред этим на шаге Е:
tP2 . . . 0
0 . . . (3«r = SWP[Z] CH c/p c№ CW . (8.5)
/3» -(С2ф)-‘ _
В случае 2 МП-оценки коэффициентов регрессии и остаточных
дисперсий (|8;-,т?) для у-й переменной Y находят, проводя свертку
только по факторам с ненулевыми коэффициентами в /За. Поэтому
для каждой группы признаков Y с различными наборами априор-
ных нулей в /3 надо проводить в (8.5) свертку С по различным мно-
жествам факторов Z. В [Rubin and Thayer (1982)] вычисления
иллюстрируются на примере с девятью признаками и четырьмя
факторами. Случай 3, обобщение случая 2, включает оценивание В.
МП-оценка ковариационной матрицы переменных Z — это просто
текущая ожидаемая матрица перекрестных произведений для Z,
С$. Если равенство дисперсий факторов единице интерпретируют
в том смысле, что существует бесконечное число множеств данных
по маргинальному распределению каждого фактора с выборочной
дисперсией 1, то МП-оценка В — это С$, нормированная под кор-
реляционную матрицу.
Как и в примере 8.1, нужны лишь небольшие модификации для
того, чтобы ЕМ-алгоритм для факторного анализа подходил для
данных с пропусками. Конкретнее: на шаге Е надо вычислять ожи-
даемые достаточные статистики для каждой, а не для одной струк-
туры неполных данных, когда все К, наблюдаются без пропусков.
Пример 8.3. Компоненты дисперсии. Большое число структу-
рированных ковариационных матриц встречается в дисперсионных
компонентных моделях, также называемых моделями дисперсион-
ного анализа со случайными или смешанными эффектами. Для вы-
числения МП-оценок дисперсионных или, более общо,
ковариационных компонент можно применять ЕМ-алгоритм [см.
Dempster, Laird and Rubin (1977); Dempster, Rubin and Tsutakawa
(1981)]. Следующий пример взят из [Snedecor and Cochran (1967),
c. 230].
170
При исследовании искусственного осеменения коров в выборке из
К=6 быков были взяты образцы семенной жидкости для проверки
возможности оплодотворения ею. Число образцов л(, взятых у
каждого из быков, было различным. Данные приведены в табл.
8.1. Наибольший интерес представляет различие быков. Если бы у
каждого быка было взято бесконечное число образцов, можно было
бы вычислить дисперсию шести средних, чтобы оценить дисперсию
Таблица 8.1. Данные для примера 8.3
Бык Процент успешного осеменения по образцам П Сумма (х)
1 46, 31, 37, 62, 30 5 206
2 70, 59 2 129
3 52, 44, 57, 40, 67, 64, 70 7 394
4 47, 21, 70, 46, 14 5 198
5 42, 64, 50, 69, 77, 81, 87 7 470
6 35, 68, 59, 38, 57, 76, 57, 29, 60 9 479
Сумма 35 1876
по быкам в популяции. Значит, в реальных данных есть одна ком-
понента дисперсии, возникающая благодаря различию быков, из-
влекаемых из популяции, которое и представляет основной интерес,
и вторая, появляющаяся из-за вариабельности образцов.
Обычная нормальная модель для таких данных — это
= +
(8.6)
где
а. нД?р- N(jifa2a) — эффект различия быков,
etJ н.ар. /у(о>с,2) — эффект вариабельности образцов.
Интегрируя по а,, получим, что совместное распределение нор-
мально с общим среднимц, общей дисперсией и ковариаци-
ей для образцов от одного быка и 0 — от разных быков.
Значит,
( (l + o-2/цу-^р, если /=/',
корреляция {у..у.Л =
J 0, если
171
где q обычно называют коэффициентом внутриклассовой кор-
реляции.
Рассматривая ненаблюдаемые случайные величины а1(...,а6 — как
пропуски (а все y.j — как присутствующие), получим ЕМ-алгоритм
вычисления МП-оценок параметра 9 —(ft, <у2а, а2), а именно правдопо-
добие для полных данных состоит из двух факторов, первый из ко-
торых соответствует распределению у^, условному по а; и 0, а
второй — распределению а;, условному по в:
„ 1 1 Г-
‘J V 2>га’ r L аге J , V 2тг<г *L <Уа J
Логарифм правдоподобия линеен по следующим достаточным ста-
тистикам для полных данных:
Ti--=Ea/s
Г2 = Еа2,,
' Т, = Е Q’rf)2 + Е
МП-оценки для полных данных — это «
Эти уравнения определяют шаг М ЕМ-алгоритма. На шаге Е вы-
числяются ожидания Ti, Тг и Т3 условно по текущей оценке & и на-
блюденным данным yijt i=l,...,K, J=I,...,ni, что можно сделать,
применяя теорему Байеса к совместному распределению а; и у^
так, чтобы получить условное распределение при заданных Уу.
независимо
(aj LVy],6>) ~ Mw^+(1—W,)^, Vf),
где
w(. = <v2v,,
v,=(a72 +и,<72)~!.
Отсюда
7?+1 ’ = E[wМц W + (1 — w/O)j?|,
7У+1) =E[wWM« + (l—wP))jjp + £VOT( (8.8)
Л/+1) =E (Уу-Л)2+ E
172
МП-оценки, получаемые таким способом, равны /2=53,3184,
<i;', = 54,8223 и <^ = 249,2235. Последние две опенки сравнимы с оцен-
ками а ^ = 53,8740 и а z=248,1876, полученными приравниванием
наблюдаемого и ожидаемого среднего квадрата в дисперсионном
анализе со случайными эффектами [см., например, Brownlee (1965),
раздел 10.4].
(' помощью ЕМ-алгоритма можно анализировать намного более
сложные компонентные модели, включая модели с многомерными
г,, а; и X [см., например, Dempster, Rubin and Tsutakawa (1981); La-
ird and Ware (1982)].
8.4. МНОЖЕСТВЕННАЯ ЛИНЕЙНАЯ РЕГРЕССИЯ
8.4.1. Множественная линейная регрессия
с пропусками только в зависимой переменной
Когда строится регрессия скалярной выходной переменной Y на р
предсказывающих переменных (регрессоров) Аг],...,Л'р и частично
отсутствуют лишь значения Y, неполные наблюдения не несут ин-
формации о параметрах регрессии 6Y.x-(f$Y.x, azY.x), если f)Y.x —
раздельный, а также если X рассматриваются как фиксированные
постоянные. Тем не менее можно применить ЕМ-алгоритм по всем
наблюдениям и итеративно получить те же МП-оценки, что были
бы получены неитеративно только по полным наблюдениям. В не-
которых случаях легче найти МП-оценки с помощью ЕМ-алгорит-
ма, чем неитеративным способом.
Пример 8.4. Пропуски в дисперсионном анализе. В планируемых
экспериментах набор значений (Xi,...,Xp) выбирают так, чтобы
провести вычисления параметров методом наименьших квадратов.
При нормальном распределении Y, условном по заданным
(%i,...,Хр), метод наименьших квадратов дает МП-оценки. Когда
часть значений Y, скажем у,-, /=1,...,ш0> отсутствует, то исходный
план с оставшимися наблюдениями не сбалансирован. По множе-
ству причин, изложенных в гл. 2, может быть желательным оста-
вить все наблюдения и рассматривать эту задачу как задачу с
пропусками.
В ЕМ-алгоритме для этой задачи шаг М соответствует методу на-
именьших квадратов для исходного плана, а на шаге Е ищут ожида-
емые значения и ожидаемые квадраты пропущенных значений у;
условно по текущим оценкам параметров О^х=(0^х, а^)ху.
173
У’’
I
гХ’
Е(У}\ХУоЫ,0^\
если у. присутствует (/«т0 + 1,
если у. отсутствует (/= l,...,zw0),
если У; присутствует,
если у{ отсутствует,
где X — (л хр)-матрица значений X. Пусть У — (лх1)-вектор зна-
чений У, У(,) — вектор У, в котором пропуски замещены оценка-
ми на t-й итерации шага Е. На шаге М вычисляют
=(АТ¥)-1А^’У«, (8.9)
Е ,(Л—/3<!)Д,.)2+щоа«; ]. (8.Ю)
/и0 + 1
Алгоритм можно упростить, заметив, что в (8.9) не входит , и
после того, как процесс сошелся, мы имеем
„.«+!) =(7«’ -А2
UYX UYX VYX ’
так что из (8.10)
1 л - т
ИЛИ
1 ' яггх = —~Е О’,- -- Ру.х ху.
) ух п—т0 m0+i ' ух "
(8.И)
Следовательно, в ЕМ-алгоритме можно опустить итеративное оце-
нивание агу.х на шаге М и Е (у? | данные, 6^)х) на шаге Е и итера-
тивно вычислять только РуХ. По окончании итераций мы можем
вычислить 8гу.х непосредственно по (8.11). Эти итерации, в кото-
рых повторяется заполнение пропусков и переоценивание подставля-
емых значений из дисперсионного анализа, и составляют алгоритм,
предложенный в [Healy and Westmacott (1956)] и упомянутый в раз-
деле 2.4.3.
174
К.4.2. Линейная регрессия
< пропусками в регрессорах
В общем случае пропуски могут быть и в выходных переменных,
и в регрессорах. Предположим сначала совместную многомерную
нормальность (Y, Хх, Хр). Тогда мы можем получать МП-оцен-
ки для регрессии УнаХь Хр непосредственно с помощью ЕМ-
алгоритма для многомерного нормального распределения, описан-
ного ранее. Пусть
—1 01 llp+l
0 = Д1 О-Ц al,p+l
/*/>+! ffl,p+l °p+l,p+l
обозначает дополненную ковариационную матрицу, соответствующую
переменным Хх, ..., Хр и XpJrl^Y. Свободный член, коэффициенты
регрессии и остаточная дисперсия для регрессии У на Хх, Хр нахо-
дятся в последнем столбце матрицы SWP[1, ..., р]0 — свертке в по
постоянному члену и регрессорам. Тогда, если в — МП-оценка 9, най-
денная методом из раздела 8.2, то МП-оценки параметров регрессии
находятся в последнем столбце SWP[l,...,p]0.
Пусть @YX и a1YX — МП-оценки коэффициентов регрессии Y на X
и остаточная дисперсия У при фиксированном X, найденные с по-
мощью ЕМ-алгоритма, как описано выше. Эти оценки являются
МП-оценками в более общих условиях, чем многомерная нормаль-
ность У и (Xi,...,Xp. Точнее, допустим, мы разбили (Х^-.^Хр на
(Х(0),Х(1)), где переменные в Х(]) наблюдаются больше и перемен-
ной Y, и переменных Х(щ (см. раздел 6.6), т. е. в любом объекте
хотя бы с одним наблюдением в У или Х(0) присутствуют все пере-
менные из Х(]). Особенно простая ситуация, когда Х=(Хх,...,Хр)
наблюдается полностью, так что Х(1)=Х. Общий случай представ-
лен на рис. 6.1, где Yx будет соответствовать (X Х(0)), У3—Х(1), а
У2 — пустое множество. Тогда, если условное распределение (КХ^)
при заданном Х(1) — многомерное нормальное, то цгх и oYYX —
МП-оценки. Детальное изложение этих проблем содержится в гл. 6.
Это предположение намного слабее, чем многомерная нормаль-
ность Х1,...,Хр+1, поскольку предикторы (регрессоры) в Х(!) могут
быть категориальными, как в регрессии на фиктивные переменные,
и, кроме того, можно вводить в регрессию взаимодействие между
полностью наблюдаемыми регрессорами или степени регрессоров,
не нарушая свойства процедуры для неполных данных.
175
К сожалению, в отличие от полных данных (рхр)-подматрица из
р первых строк и столбцов SWP[l,...,p] § при наличии пропусков но
соответствует ковариационной матрице оценок коэффициентов ре-
грессии. Для вычисления асимптотической ковариационной матри-
цы оценок коэффициентов, основанной на обычной аппроксимации
для растущего объема выборки, в общем случае требуется обраще-
ние полной информационной матрицы средних, дисперсий и ковари-
аций, приведенной в разделе 8.2.2. При моделировании,
проведенном в [Little (1979)], хорошие свойства обнаружил прибли-
женный метод оценивания этой ковариационной матрицы, предло-
женный в [Beale and Little (1975)]. При этом методе определяют
Var(/3rx)=1а2г х,
где — р хр-матрица взвешенных сумм квадратов и перекрест-
ных произведений с (/Л)-м элементом, равным:
Xj)(xik %)>
где ху-и xjk — наблюдаемые или оцениваемые значения соответ-
ственно %у и х|А., полученные на последней итерации ЕМ-алгоритма,
Xj=Eiwl-xly/E1wi — взвешенное среднее, a ил определяется как
, /8\ х , если у, присутствует,
W, =
( 0, если yt отсутствует,
где — МП-оценка дисперсии у, условной по независимым
переменным, присутствующим в г-м наблюдении.
МП-оценки для многомерной линейной регрессии можно полу-
чить, применяя алгоритм из раздела 8.2.1 и проводя затем свертку
по независимым переменным в получаемой дополненной ковариаци-
онной матрице. Точнее, если Yi,...,YK — зависимые, а Xlt...,Xp —
независимые переменные, то сначала дополненная ковариационная
матрица объединенного множества переменных (Хи...Хр,
оценивается с помощью многомерного нормального ЕМ-алгоритма,
а затем проводится свертка по Х^-.-.Х . Получаемая матрица со-
держит МП-оценки матрицы руК коэффициентов регрессии Y на X
и ковариационной матрицы Ку К остатков от регрессии У на X при
заданном X.
Пример 8.5. Пропуски в нескольких зависимых переменных. Те-
перь мы проиллюстрируем регрессионный анализ с несколькими за-
висимым# переменными и несколькими предикторами при наличии
пропусков (преимущественно в зависимых переменных) на данных о
сроках проявления признаков развития на первом году жизни детей
[см. Reinisch, Rosenblum, Rubin and Schulzinger (1985)]. В выборке из
4653 здоровых детей содержались данные о датах проявления десяти
176
признаков развития (например, первая улыбка) и о 9 сопеременных,
связанных с развитием ребенка. Пол был зарегистрирован для всех
детей, 9 сопеременных — почти для всех детей, но в данных о при-
шаках развития были существенные пробелы, поскольку они реги-
стрировались по дневникам матерей.
МП-оценки средних, дисперсий и корреляций между всеми пере-
менными были получены с помощью ЕМ-алгоритма из раздела 8.2.
Затем сверткой матрицы МП-оценок по полу была построена ре-
грессия 10 признаков развития на пол, чтобы получить оценки сред-
них возрастов проявления признака у мальчиков и девочек и опенки
различий для этих возрастов между мальчиками и девочками. Стан-
дартные ошибки параметров были вычислены подстановкой МП-
оценок параметров в обычные выражения стандартных ошибок для
полных данных, взятых с числом наблюдений, равным числу запи-
сей о проявлении признаков развития. Другими словами, ОМП
средних, дисперсий и ковариаций были введены в стандартную про-
грамму регрессионного анализа полных данных при п = 4653 и было
проведено только одно изменение результатов — пересчет стан-
дартных ошибок и статистик критериев на действительное число
присутствующих значений зависимой переменной. Эта процедура
согласуется с предложением в [Beale and Little (1975)], так как пол
присутствует всегда. Результаты даны в табл. 8.2.
Таблица 8.2. Различие между мальчиками и девочками
по срокам проявления признаков развития
Признак развития Число за- писей о проявле- нии приз- нака Среднее для маль- чиков Среднее для де- вочек Сравнение
без учета по- переменны ч с учетом со- переменнык*
А т Д т
Поднимает голову 3273 32,1 34,8 2.7 3,16 2,2 2,51
Улыбается 3229 49,1 48,4 0,7 0,87 1,4 1,69
Держит голову 2658 118,5 116,9 1,6 1,18 2,0 1,27
Достигает предмет 2593 137,9 138,8 0,9 0,66 0,6 0,46
Самостоятельно сидит 3036 230,0 227,5 2,5 1,69 2,8 1,91
Стоит с поддержкой 3840 279,8 285,4 5,6 3,25 5 4 3.05
Самостоятельно ползает 3391 306,5 313,9 7,4 3,72 7,1 3,55
Ходит с поддержкой 3689 3'14,6 325,6 1,0 1,71 2,0 1,35
Самостоятельно сто- ит 2128 337,/ 339,8 2,1 1,28 1,7 1,04
Самостоятельно ходит 1985 361,2 361,1 0,1 0.04 0,2 0,2
* Учитывались следующие сопеременные: вес при рождении, длительность бере-
менности, социальное и материальное положение, предрасположенность к осложне-
ниям беременности и родов, осложнения беременности, родовые осложнения, оценка
физического состояния новорожденного, оценка неврологического состояния ново-
рожденного, оценка незрелости новорожденного.
177
В правых столбцах табл. 8.2 приведены также результаты анализа
с учетом 9 сопеременных. Оценки были получены сверткой матри-
цы МП-оценок средних, дисперсий и ковариаций по полу и этим 9
сопеременным. Стандартные ошибки вычислялись в соответствии с
числом присутствующих значений для каждой зависимой перемен-
ной, поскольку сопеременные наблюдались практически полностью.
Последним этапом обработки был регрессионный анализ разно-
стей выходных переменных (т. е. промежутков времени между про-
явлением признаков развития), взятых в качестве зависимых
переменных. Снова использовались при вычислении стандартных
ошибок методы регрессии для полных данных, и проводился лишь
пересчет на объем выборки зависимой переменной, равнявшийся
числу детей с присутствием обоих признаков, составляющих дан-
ную переменную. Эти объемы составляли от 1262 для разности
между «самостоятельно ходит» и «самостоятельно стоит» до 3524
для разности между «стоит с поддержкой» и «самостоятельно
сидит».
8.5. ОБЩАЯ МОДЕЛЬ ПОВТОРНЫХ ИЗМЕРЕНИЙ
С НЕПОЛНЫМИ ДАННЫМИ
Неполные данные часто встречаются в долговременных исследо-
ваниях, когда объекты наблюдаются в различные моменты времени
и/или в разных экспериментальных условиях. Нормальные модели
для таких данных часто объединяют структуры ковариационных
матриц, аналогичные описанным в разделе 8.3, и структуры сред-
них, которые связывают средние повторных измерений с перемен-
ными плана. Следующая общая модель повторных измерений
основана на работах [Ware (1985); Helms (1984)] и приведена в [Jen-
nrich and Schluchter (1987)].
Допустим, что гипотетические полные данные для случая i состо-
ят из К измерений У; = (Уд,---»У;^) выходной переменной Y и что
по предположению — независимые многомерные нормальные на-
блюдения со средним /1;- и ковариационной матрицей Е. Мы
запишем:
rf=Xfi, E = W), (8.12)
где Xt — известная (А\щ)-матрица плана для случая i, ft — (mxl)-
вектор неизвестных коэффициентов регрессии, а элементы Е — из-
вестные функции от множества v неизвестных параметров Итак,
модель задает структуру средних, определяемую набором матриц
178
плана [A7J и ковариационную структуру, определяемую формой ко-
вариационной матрицы Е. Присутствующие данные состоят из
матриц плана и jyobs/,п], где Jobs, — наблюденная часть
вектора уг Предполагается, что пропущенные значения j, ОС, Ло-
шрифм правдоподобия для полных данных линеен по величинам
\У,уТУр 1=1,...,и]. Поэтому шаг Е представляет собой вычисление
средних yt и yTyt при заданных _yobsi, Xt и текущих оценках /3 и Е.
Эта операция проводится с помощью свертки текущей оценки Е,
аналогичной свертке в многомерной нормальной модели в разделе
8.2.1. Шаг М для этой модели является итеративным за исключени-
ем частных случаев, и, таким образом, самая привлекательная чер-
та ЕМ-алгоритма — простота шага М — утрачивается. Дженрич и
Шлухтер [Jennrich and Schluchter (1987)] представляют GEM-алго-
ритм (см. раздел 7.4), а также обсуждают метод вкладов и алго-
ритм Ньютона—Рафсона, которые могут быть удобными при
зависимости Е от умеренного числа параметров
Комбинируя различные структуры средних и ковариационных
матриц, можно смоделировать большое число ситуаций. Дженрич и
Шлухтер обсуждают такие ковариационные структуры:
Независимость: $ — скаляр, I — единичная матрица
КхК.
Составная симметрия: Е= >Д1 и — скаляры, U —
Кх ^-матрица из единиц, 7 — единичная Х^хХ-матрица.
Авторегрессия порядка 1: Е = (ау), <ту = 7 L ’А.’А — скаляры.
Полосовая структура: = = где г= |/—у|+1,
г=1,...,х:
Факторная: Е = ГГ7’+1Д, Г — матрица Kxq неизвестных фактор-
ных нагрузок, — диагональная матрица специфических дис-
персий.
Случайные эффекты: L=Z^ZT+a2I, Z — известная матрица
Kxq, $ — неизвестная матрица рассеяния qxq, о2 — скаляр, I —
единичная матрица qxq.
Отсутствие структуры: Е = (<г|у), ^1 = Щь ф2 = о12, ^з = о22,
’А = °кк-
Структура средних также очень гибка. Если Xt = Г, единичная
матрица КхК, то /х( = /?7 для всех i. Такая структура постоянного
среднего в сочетании с неструктурированной или факторной ковари-
ационной матрицей или с матрицей составной симметрии дает мо-
дели, рассмотренные в разделе 8.2, а также в примерах 8.2 и 8.3.
Выбирая другие варианты Xt, можно легко формировать модель
для межобъектных и внутриобъектных эффектов, как в следующем
примере.
179
Пример 8.6. Модели кривых роста при неполных данных. В
[Potthoff and Roy (1964)] приведены данные табл. 8.3 о росте 11 дево-
чек и 16 мальчиков. Для каждого объекта в возрасте 8, 10, 12 и 14
лет регистрировалось расстояние от подмозгового придатка до че-
люстной борозды. Дженрич и Шлухтер подгоняют под эти данные
8 моделей. Мы подгоняем эти же модели под данные, полученные
удалением девяти значений в скобках в табл. 8.3. Механизм удаления
соответствовал условию ОС, но не ОПС. Точнее, для детей обоих по-
лов с малыми значениями в 8 лет были удалены значения для воз-
раста 10 лет. В табл. 8.4 для всех моделей даны значения логарифма
правдоподобия, умноженного на —2 (—2Х), и хи-квадрат-статистики
отношения правдоподобия (х2) для сравнения моделей. Последний
столбец содержит значения последней статистики для полных дан-
ных до удаления [см. Jennrich and Schluchter (1987)].
Пусть yt обозначает 4 замера расстояний для /-го объекта и пусть
х, — переменная плана, равная 1, если ребенок — мальчик, и 0 —
если девочка. Модель 1 задает различные средние для каждого
Таблица 8.3. Данные о росте 11 девочек и 16 мальчиков
Девочки Возраст, лет Мальчики Возраст, лет
8 10 12 14 8 10 12 14
1 21 20 21,5 23 1 26 25 29 31
2 21 21,5 24 25,5 2 21,5 (22,5) 23 26,5
3 20,5 (24) 24,5 26 3 23 22,5 24 27,5
4 23,5 24,5 25 26,5 4 25,5 27,5 26,5 27
5 21,5 23 22,5 23,5 5 20 (23,5) 22,5 26
6 20 (21) 21 22,5 6 24,5 25,5 27 28,5
7 21,5 22,5 23 25 7 22 22 24,5 26,5
8 23 23 23,5 24 8 24 21,5 24,5 25,5
9 20 (21) 22 21,5 9 23 20,5 31 26,0
10 16,5 (19) 19 19,5 10 27,5 28 31 31,5
11 24,5 25 28 28 И 23 23 23,5 25
12 21,5 (23,5) 24 28
13 17 (24,5) 26 29,5
14 22,5 25,5 25,5 26
15 23 24,5 26 30
16 22 (21,5) 23,5 (25)
Источник. Данные из [Potthoff and Roy (1964)], приведенные в [Jennrich and
Schluchter (1987)]. Значения в скобках считаются пропусками в примере 8.7.
180
- пола и возраста и неструктурированную ковариационную матрицу
4x4. Матрицу плана для z-го объекта можно записать как
1 X; О О О О О О
О 0 1 х; О О О О
0 0 0 0 1 х( О О
0 0 0 0 0 0 1 л;
При отсутствии пропусков МП-оценка {3 — это вектор из восьми
выборочных средних, МП-оценка Е = 3/и, где S — объединенная
внутригрупповая матрица сумм квадратов и взаимных перекрест-
ных произведений.
Таблица 8.4. Анализ моделей, рассмотренных в примере 8.7
Номер модели Описание Число парамет- ров —2Х Сравни- ваемая модель X2 Число степеней свободы X2 ДЛЯ ПОЛНЫХ данных*
1 8 различных средних, неструктурированная ковариационная
2 матрица 2 прямые, неравные коэффициенты рег- рессии, неструктури- 18 386,956
3 рованная матрица 2 прямые, равные ко- эффициенты регрес- сии, неструктуриро- ванная ковариацион- 14 393,288 1 6,332 4 2,968
4 ная матрица 2 прямые, неравные коэффициенты рег- рессии, полосовая ’ 13 397,400 2 4,112 1 6,676
5 структура 2 прямые, неравные коэффициенты рег- рессии, структура 8 398,030 2 4,742 6 5,166
6 АР(1) 2 прямые, неравные коэффициенты рег- рессии, случайные коэффициенты рег- рессии и свободные 6 409,524 2 16,236 8 21,204
7 члены 2 прямые, неравные коэффициенты рег- рессии, случайные свободные члены (составная симмет- 8 400,452 2 7,164 6 8,329
8 рия) 2 прямые, неравные коэффициенты рег- рессии, некоррели- рованные наблю- 6 401,312 2 8,024 8 9,162
дения 5 441,582 7 40,270 1 50,833
* Источник. [Jennrich and Schluchter [1987)].
181
Эта неограниченная модель, модель 1 в табл. 8.4, оценивалась по
неполным данным табл. 8.3. Остальные семь моделей также оцени-
валась по этим данным. Графики наводили на мысль о линейности
зависимости между средним расстоянием и возрастом с различны-
ми свободными членами и коэффициентами регрессии для мальчи-
ков и девочек. Структуру средних для такой модели можно
записать в виде
И =хр=
1
1
—3
—1
1
1
-Зх;.
Зх;
/3.
&
03
0<
(8.13)
где 0! и 0i+ 02 представляют общие средние, а 03 и 0з + 04 — коэф-
фициенты регрессии соответственно для девочек и для мальчиков. В
модели 2 была такая структура средних неограниченная Е.
Статистика отношения правдоподобия модели 1 к правдоподо-
бию модели 2 равна х2 = 6,332 при четырех степенях свободы, что
указывает на достаточно удовлетворительное согласие для модели
2. Модель 3 получается из модели 2, если положить 04 — О, т. е. если
опустить последний столбец Xv Это ограничение означает, что
прямые регрессии расстояния на возраст имеют одинаковый наклон
для обеих половых групп. Отношение правдоподобия для сравнения
модели 3 с моделью 2 равно 4,312 при одной степени свободы, что
указывает на плохое согласие. Поэтому надо предпочесть структуру
средних модели 2.
Остальные модели табл. 8.4 имеют структуру средних модели 2,
но налагают ограничения на Е. Ковариационные структуры авторе-
грессии (модель 5) и независимости (модель 8) не согласуются с
данными, судя по статистике хи-квадрат отношения правдоподо-
бия. Полосовая структура (модель 4) и две структуры со случайны-
ми эффектами (модели 6 и 7) хорошо подходят под данные. Из этих
моделей мы предпочтем по соображениям экономии модель 7. Ее
можно интерпретировать как модель со случайными эффектами с
фиксированным коэффициентом регрессии для каждого пола и слу-
чайным свободным членом, который варьирует от объекта к объек-
ту около общего по полу среднего. В дальнейшем анализе
следовало бы рассмотреть оценки параметров выбранной модели.
182
Н.6. МОДЕЛИ ВРЕМЕННЫХ РЯДОВ
8.6.1. Введение
В коротком обсуждении моделей временных рядов с неполными
данными (пропусками) мы ограничимся параметрическими моделя-
ми во временной области с нормальными возмущениями, поскольку
они больше всего подходят под метод максимального правдоподо-
бия, развитый в гл. 5 и 7 В приложениях, очевидно, особенно важ-
ными выглядят два класса моделей этого вида: модели
авторегрессии — скользящего среднего (АРСС), описанные в (Box
and Jenkins (1976)], и модели пространства состояний или фильтры
Калмана, впервые рассмотренные в технической литературе [Kal-
man (I960)] и интенсивно разрабатываемые в настоящее время в ли-
тературе по временным рядам в эконометрии и статистике [Harvey
(1981)]. Как показано в следующем разделе, модели авторегрессии
относительно легко оцениваются по неполным данным с помощью
ЕМ-алгоритма. Анализ мо тлей Бокса—Дженкинса с компонентами
скользящего среднего не гдк прост, однако МП-оценивание можно
проводить, трансформируя их в модели общего пространства со-
стояний, как описано в [Harvey and Phillips (1979); Jones (1980)]. Мы
опускаем детали этого преобразования, хотя МП-оценивание моде-
лей общего пространства ..остояний по неполным данным описано
в общих чертах в разделе 8.6.3 в соответствии с подходом [Shumway
and Staffer (1982)].
8.6.2. Авторегрессионные модели
одномерных временных рядов с пропусками
Пусть У=(у01у],...,уг) обозначает полностью наблюденный одно-
мерный временной ряд с П1 наблюдениями. Модель авторегрессии
порядка р (АР(р>) предполагает, что yt, значение в момент времени
i, связано со значениями в р предыдущих точках времени урав-
нением
О,-1 Л^ь-.-.Л-i^) ~N(a+ _! + ... + fipyi_p,<J2), (8.14)
где а — постоянная, /Зь.,.,/3^ — неизвестные
регрессионные коэффициенты, а2 — неизвестная дисперсия ошибки.
Оценки наименьших квадратов ai,0i,...,13р и а1 можно найти с по-
мощью регрессии yi на xJ = (yi_1, 3’,_2,---1У/-_р) по наблюдениям
183
i=p, p+1,..., T. Эти оценки будут только приближенно МП-оценка
ми, так как игнорируется вклад маргинальных распределении
/о> Уь---, Ур—i в правдоподобие. Это допустимо при малых р ни
сравнению с Т.
При отсутствии некоторых наблюдений в ряде может прийаи
мысль применить методы регрессионного анализа с пропусками из
раздела 8.4. Этот подход может давать полезные грубые приближе
ния, но это не будет соответствовать МП-оцениванию. даже если
5 считать, что пренебрегать маргинальным распределением
У а, Уь--; Ур допустимо, так как 1) переменные с пропусками y^i^p}
выступают и как зависимые, и как независимые переменные в ре-
грессии, и 2) модель (8.14) задает специальную структуру вектора
средних и ковариационной матрицы Y, не используемую в анализе.
Поэтому для оценивания модели АР(р) по неполным временным
рядам необходимы специальные варианты ЕМ-алгоритма. Эти ва-
рианты относительно легко реализуемы, хотя их описание нетриви-
ально. Мы ограничиваемся случаем, когда р-1.
Пример 8.7. Модель АР(1) для временного ряда с пропусками.
Полагая в (8.14) р-1, получим
Ряд АР(1) будет стационарным с постоянным по времени марги-
нальным распределением yt только при | 0 | < 1. Тогда совместное
распределение уг имеет постоянные маргинальное среднее
^=Е'(у;) = а(1—/З)-"1, дисперсию Var(y() = а2(1—(Р)—1 и ковариации Cov
CyI-J'l+it) = i8Z;a2(l—для к~^\. Пренебрегая вкладом маргинально-
го распределения у0, получим, что логарифм правдоподобия для
полного Y равен 1(а,0,а21 у) = ---0!5<эт2Е^1 «—j3j(._.1)2—0,57'log<T2
и эквивалентен логарифму правдоподобия для нормальной линей-
ной регрессии yi на xf=y,-„] для данных [(х^), Достаточ-
ные статистики для полных данных — это s-s^,Si,,ss), где
s2 = Ek_i, = s4 = S^_p =
i — 1 i = 1 t =•-1 : — 1 i = I
МП-оценка 0=(a,j3,a) — это 6=(а,|3,ст), где
a = (5!—fisJT-1,
8 = (5,— T-'StSdfSt— .
(8.16)
a2= ;.s3—5? T~l— ^(s4—Si
184
Теперь допустим, что некоторые наблюдения отсутствуют и выпо-
лняется ОС. С помощью ЕМ-алгоритма, по-прежнему игнорируя
маргинальное распределение уа, можно получить МП-оценку 9.
Пусть = — оценки 0 на 1-й итерации. На шаге М
|||.1числяют 0(,+ ') из (8.16), где достаточные статистики для полных
данных s заменены оценками на шаге Е.
На шаге Е вычисляют = где
= .^ = Еу«1, = £ !(yW)2 + cW],
4г> = £
и
, y:, если У[ присутствует,
j?0 =
Е(у; | yobs,0W), если у, отсутствует,
О,
Cov (у,у,-1 Yobs,0«),
если у, или yj присутствует,
если у,- и yj отсутствуют.
На шаге Е выполняются обычные операции по свертке ковариаци-
онной матрицы наблюдений. Однако матрица ГхГ, как правило, ве-
лика, поэтому желательно использовать свойства модели АР(1) для
упрощения вычислений. Допустим, что Е^й=(у7-+]Уу+2,...1) — по-
следовательность пропусков между присутствующими наблюдения-
ми у, и ук. Тогда 1) при заданных Kobs и 0Y'J]is не зависит от других
пропущенных значений и 2) распределение l^*is при заданных Yobs и
0 зависит от Yobs только через «граничные» наблюдения уу- и ук.
Последнее распределение — многомерное нормальное с постоянной
ковариационной матрицей и средними, которые являются взвешен-
ными средними /х=а(1—/3)~!, yj и ук. Веса и ковариационная мат-
рица зависят только от1 числа пропусков в данной последователь-
ности и могут быть найдены сверткой текущей оценки ковариаци-
онной матрицы (УуУу+1,...у^) по элементам, соответствующим на-
блюдениям уу- и ук.
В частности, допустим, что у; и у;+2 присутствуют, а у?+1 отсут-
ствует. Ковариационная матрица уу-, у/+1 и Уу+2 равна:
185
Свертка по yj и yJ+2 дает
SWP[/k/ + 2M=
—а 2
0
—02а2
0
а2
0
(8.17)
Из (8.17) и стационарности следует
Е'у^! | yjyj+2,0] = д+ 0(1 + +0(1 + 02)”1(У/—й)=
= м f1 ' ! - з-- ] + г5- yj+yj^’
Var(yy+1 | yjyj+2,9) = a2(l + 02)-1.
Подставляя в эти выражения, получаем и c^1J+l для
шага Е. Заметим, что у(Д.г — оценка пропущенного значения на
последней итерации алгоритма*.
8.6.3. Калмановская фильтрация
В [Shumway and Staffer (1982)] рассмотрен фильтр Калмана
независимо
(yt | М^,0) ~ Wz-^B),
to|0) ~ N(y,L), (8.18)
~ М^ФО),
где У; — вектор 1 х q наблюдаемых в момент времени i перемен-
ных, М, — известная рх //-матрица плана, которая связывает сред-
нее у/ с ненаблюдаемым случайным 1 х уз-вектором z,-, и
0 = (Д//,Е,ф,<2) представляет неизвестные параметры, где В, S и Q —
ковариационные матрицы, д — среднее Ze, ф — /зхр-матрица коэф-
фициентов авторегрессии z, на z;_j. Случайный ненаблюдаемый
ряд z,-, моделью которого является многомерный процесс авторе-
грессии первого порядка, и представляет основной интерес.
* Реализовать ЕМ-алгоритм для процесса АР(1) в общем случае, когда надо вы-
числять E(yi | у} у,) и VarOj | yj^j) при произвольных а не только при
7=/i + l=Zi—l, будет особенно просто, если пользоваться не SWEEP-оператором, а
явными выражениями, полученными в разделе 4 дополнения к переводу. Выражения,
выведенные выше, соответствуют выражениям (9) ьри ку=кг^$ (fc, и к2 равны числу
пропусков, отделяющих у. от у ь — Прик- чер.
186
Эту модель можно расс.матривать как разновидность модели слу-
чайных эффектов для временных рядов, где вектор эффектов z,
имеет корреляционную структуру по времени. Основной целью яв-
ляется оценка ненаблюдаемого ряда z(- для i=l,2,...,n (сглаживание)
и для i=n + l, п+2,... (прогнозирование) по наблюдаемому ряду
у^Уг,...Уп- Если бы параметр 0 был известен, оптимальными оцен-
ками Zj были бы их средние, условные по параметру 0 и данным Y,
называемые калмановскими оценками сглаживания. Набор рекур-
сивных формул для их вычисления называют фильтром Калмана.
На практике 0 неизвестен, процедуры сглаживания и прогнозирова-
ния включают МП-оценивание 0 с последующей подстановкой в
фильтр Калмана МП-оценки 0 вместо 0.
Такой же подход применяют, когда данные Y неполные, заменяя
Y на наблюденную часть Y — УоЬ|.. МП-оценивание Q можно про-
водить методом Ньютона—Рафсона [Gupta and Mehra (1974);
Ledolter (1979); Goodrich and Caines (1979)]. Удобной альтернативой
этим методам является ЕМ-алгоригм, в котором отсутствующая
часть Y, ymis и Zi рассматриваются как отсутствующие данные.
Привлекательное свойство этого метода состоит в том, что ожидае-
мые значения вычисляются при заданных УоЬ8 и текущей оценке
О, что совпадает с калмановским процессом сглаживания, описан-
ным выше. Подробности шага Е приведены в [Shumway and Stoffer
(1982)]. Шаг М реализуется довольно просто. Оценки ф и Q вычис-
ляются по авторегрессии для ожидаемых значений достаточных
статистик для полных данных, полученных на шаге Е:
Е Z,, Y, zfZi, Y, Zi_i, £, zT ,Zi_i и Y, zT. .Zi-
Оценкой В служит ожидаемое значение остаточной ковариационной
матрицы л_1Е.= 1 (у;—ziM)T(yi—ziM). Наконец, оценка м — это ожи-
даемое значение Zo, а Е выбирается из содержательных соображе-
ний. Теперь мы опишем частный случай этой очень общей модели.
Пример 8.8. Двумерный временной ряд, измеренный с ошибками.
Табл. 8.5 содержит два неполных временных ряда с данными о сум-
марных расходах на медицинское обслуживание, где Y. — данные,
полученные службой Social Security, Administration (SSA), a
У2 — Health Care Financing Administration (HCFA).
187
Таблица 8.5 Данные из примера 8.8
и прогнозируемые по ЕМ-алгоритму значения
(затраты на здравоохранение в миллионах долларов)
Год, i SSA HCFA У,2 — 1 " — ... । Прогноз по ЕМ-алгоритму
E(Xt [ данные, 9) Varv2 (-X J данные, 9)
1949 2633 — 2541 178
1950 2747 — 2711 185
1951 2868 — 2864 186
1952 3042 — 3045 186
1953 3278 — 3269 186
1954 3574 — 3519 186
1955 3689 — 3736 186
1956 4067 — 4063 186
1957 i 4419 — 4433 186
1958 4910 — 4876 186
1959 5481 — 5331 186
1960 5684 — 5644 186
1961 5895 — 5972 186
1962 6498 — 6477 186
1963 6891 — 7032 185
1964 8065 — 7866 179
1965 8745 8474 8521 110
1966 9156 9175 9198 108
1967 10287 10142 10160 108
1968 11099 11104 11159 108
1969 12629 12648 12645 108
1970 14306 14340 14289 108
1971 15835 15918 15835 108
1972 16916 17162 17171 108
1973 18200 19278 19106 109
1974 — 21568 21675 119
1975 — 25181 25027 120
1976 — 27931 27932 129
1977 — — 31178 355
1978 — — 34801 512
1979 — — 38846 657
1980 — — 43361 802
1981 — — 48400 952
Источник. Данные из [Meltzer, Goodman, Langwell, Cosier, Baghelai and
Bobula (1980)], приведенные в [Shumway and Staffer (1982)).
188
Эти данные анализируются в [Shumway and Stoffer (1982)] с по-
мощью модели
независимо
(у,у I Zi,ff) -
(Zi I - N{Zi_^,Q),
где ytj — суммарные расходы для времени i по данным SSA(/= 1) и
HCFA(/ = 2), Zj — истинные расходы, образующие по предположе-
нию временной ряд АР(1) с коэффициентом ф и остаточной диспер-
сией Q, Bj — дисперсия измерения у^ (/=1,2) и 0=(В1,В2,Ф,О). В
отличие от примера 8.7, здесь не предполагается стационарность
ряда АР(1) z;, так как параметр ф — это фактор роста, моделирую-
щий экспоненциальный рост; предположение, что ф — постоянный
по времени — это, вероятно, чрезмерное упрощение.
Таблица 8.6. Последовательность оценок
на различных итерациях ЕМ-алгоритма
для МП-оценок в примере 8.8
/ М ФИ) <М ВМ ВМ —2 In 2
1 2500 1,100 10000 10000 10000 885
2 2417 1,114 49837 41583 24105 680
3 2396 1,116 78153 54666 25486 675
4 2383 1,116 93513 59958 25580 675
5 2374 1,116 100571 62483 25384 674
10 2342 1,116 105152 65725 23920 674
20 2279 1,116 104814 67760 20971 672
40 2277 1,116 105115 68636 19394 671
50 2276 1,116 105097 68663 19354 671
75 2277 1,116 105115 68675 19329 671
Источник. [Shumway and Stoffer (1982), Табл. II].
В табл. 8.6 приведена последовательность итераций ЕМ-алгорит-
ма. Начальные значения были выбраны просто по полностью на-
блюдаемым фрагментам рядов. Последние столбы табл. 8.5
содержат сглаженные оценки г; на последней итерации ЕМ-алго-
ритма для 1949—1976 гг. и прогноз на 5 лет (1977—1981 гг.) вместе
со стандартными ошибками. Стандартные ошибки прогнозируемых
значений возрастают с 355 для 1977 г. до 952 для 1981 г., что отра-
жает большую неопределенность прогноза.
189
ЛИТЕРАТУРА
Beale, Е М L , and Little, R J A (1975) Missing values in multivariate analysis, J Roy Statist*
Soc B37, 129 146
Bentler,P M , and Tanaka, J S (1983) Problems with EM for ML factor analysis, Fsychometrika
48,247 253
Box, G E P , and Jenkins, G M (1976) Time Series Analysis Forecasting and Control San
Francisco Holden-Day
Brownlee, К A (1965) Statistical Theory and Methodology in Science and Engineering Nevi
York Wiley
Dempster, A P , Laird, N M , and Rubin, D В (1977) Maximum likelihood estimation from
incomplete data via the EM algorithm, (with discussion), J Roy Statist Soc B39, 1-38
Dempster, A P , Rubin, D В ,and Tsutakawa, R К (1981) Estimation in covariance component
models, J Am Statist Assoc 76,341-353
Goodrich, R L , and Caines, P E (1979) Linear system identification from nonstationary
cross-sectional data, IEEE Trans Aut Control AC-24,403-411
Gupta, N K,andMehra, R К (1974) Computational aspects of maximum likelihood estimation
and reduction in sensitivity function calculations, IEEE Trans Aut Control AC-19, 774-783
Hartley, H О , and Hocking, R R (1971) The analysis of incomplete data, Biometrics 14,
174-194
Harvey, A C (1981) Time Series Models, New York Wiley
Harvey, A C, and Phillips, G D A (1979) Maximum likelihood estimation of regression
models with autoregressive-moving average disturbances, Biometrika 66, 49-58
Healy, M J R , and Westmacott, M (1956) Missing values in experiments analyzed on auto-
matic computers, Appl Statist 5,203 206
Helms, R W (1984) Linear models with linear covariance structure for incomplete longitudinal
data, Biometiics Section, Ameiican Statistical Association 1984
Holland, P W , and Wightman, L E (1982) Section pre-equating A preliminary investigation,
m Test Equating (P W Holland and D В Rubin, Eds ) New York Academic Press
Jcnnnch, R I , and Schluchter, M D (1987) Incomplete repeated measures models with
structured covariance matrices, to appear in Biometrics 42
Jones, R H (1980) Maximum likelihood fitting of ARMA models to time scries with missing
observations, Technomet/ics22, 389 395
Kalman, R E (1960) A new approach to linear filtering and prediction problems, Trans ASME
J Basic Eng 82, 34-35
Laird, N M , and Ware, J H (1982) Random-effects models for longitudinal data, Biometrics
38,963 974
Ledolter, J (1979) A recursive approach to parameter estimation in regression and time series
problems, Commun Statist Theory Meth A8, 1227-1245
Little, R J A (1979) Maximum likelihood inference for multiple regression with missing values
A simulation study, J Roy Statist Soc B41, 76-87
i
Русский перевод: Бокс Дж., Дженкинс Г. Анализ временных рядов. Прогноз и управле-
ние. — М.: Мир, 1974.
190
Meltzer, A., Goodman, C., Langwell, K., Cosier, J., Baghelai, C., and Bobula, J. (1980). Develop
physician and physician extender data bases, G-155, Final Report, Applied Management
Sciences, Inc., Silver Springs, MD.
I lichard, T., and Woodbury, M. A. (1972). A missing information principle: theory and
applications, Proceedings of the 6th Berkeley Symposium on Mathematical Statistics and
Probability 1, 697-715.
Putthoff, R. F., and Roy, S. N. (1964). A generalized multivariate analysis of variance model
useful especially for growth curve problems, Biometrika 51, 313-326.
Reinisch, J. M., Rosenblum, L. A., Rubin, D. B., and Schulzinger, M. F. (1985). Sex differences
in behavioral milestones during the first year of life, Kinsey Institute report.
Rubin,D. B., and Szatrowski,T. H. (1982). Findingmaximum likelihood estimates for patterned
covariance matrices by the EM algorithm, Biometrika 69, 657-660.
Rubin, D. B., and Thayer, D. T. (1982). EM algorithms for factor analysis, Psychometrika
47, 69-76.
Rubin, D. B., and Thayer, D. T. (1983). More on EM for ML factor analysis, Psychometrika
48, 253-257.
Shumway, R. H., and Stoffer, D. S. (1982). An approach to time series smoothing and forecasting
using the EM algorithm, J. Time Series Anal. 3, 253-264.
Snedecor, G. W., and Cochran, W. G. (1967). Statistical Methods, Ames: Iowa State University
Press.
Szatrowski, T. H. (1978). Explicit solutions, one iteration convergence and averaging in the
multivariate normal estimation problem for patterned means and covariances, Ann. Inst.
Statist. Math. 30, 81-88.
Trawinski, I. M.,and Bargmann, R. W. (1964). Maximum likelihood with incomplete multivariate
data, Atm. Math. Statist. 35, 647-657.
Ware, J. H. (1985). Linear models for the analysis of longitudinal studies, Am. Statist. 39,95-101.
ЗАДАЧИ
1. Покажите, что оценки средних и дисперсий неполной многомерной выборки ме-
тодом доступных наблюдений, описанным в разделе 3.3, являются МП-оценками,
когда данные имеют многомерное нормальное распределение с неограниченными
средними и дисперсиями и нулевыми корреляциями при игнорируемых пропусках. В~
каких ситуациях приемлем метод доступных наблюдений для многомерных данных
с пропусками?
2. Напишите программу, реализующую ЕМ-алгоритм для двумерных нормальных
данных с произвольной структурой пропусков.
3. Опишите ЕМ-алгоритм для двумерных нормальных данных со средними
корреляцией р, общей дисперсией аг и произвольной структурой пропусков. Если вы
решили задачу 2, модифицируйте свою программу для анализа зтой модели. Указа-
ние. Проведите преобразование U, = У,+Т2, 172 = у|_у2.
191
4. Выведите выражение для ожидаемой информационной матрицы из раздела 8.2,^
для двумерных данных.
5. Найдите МП-оценки коэффициента корреляции q двумерною распределения по
а) двумерной выборке объема т с известными средними д2 и дисперсиями cf и oj,
б) по двумерной выборке объема т и двум дополнительным бесконечным выборкам
из маргинальных распределений обеих переменных. Отметьте довольно удивитеш.
ный факт: а) и б) имеют различные ответы.
6. Докажите утверждение перед уравнением (8.3), что МП-оценки Е по полным
данным получаются из С простым усреднением. Указание. Рассмотрите ковариаци
онную матрицу четырех переменных (7, =У,+У2 + У3 + У4, 1?2 = У1—У> + У3—У4,
У3 = У,-У5 и 1Л, = У2--У4.
7. Познакомьтесь с обсуждением ЕМ-алгоритма для факторного анализа в [Rubin
and Thayer (1978), (1982); Bentler and Tanaka (1983)].
8. Выведите ЕМ-алгоритм для модели из примера 8.3, расширенной предположе
нием д - N(0,r2), где ц рассматривается как отсутствующие данные. Затем рассмот
рите случай т1 -> <=«.» (что дает равномерное априорное распределение по д).
9. Проверьте приближенный метод оценивания ковариационной матрицы оценок
коэффициентов регрессии (см. раздел 8.4.2) для одного регрессора X по данным, в
которых a) Y присутствует полностью, X подвержен пропускам, б) X присутствует
полностью, У подвержен пропускам. Дает ли этот метод точные асимптотические
ковариации в обоих случаях?
10. Дополните детали, которые приводят к выражениям для среднего и дисперсии
Уу4 ] при заданных 7^, yj+2 и из примера 8.7. Прокомментируйте вид ожидаемого
значения у ( при /3-» 1 и |3-»0.
11. Обобщите задачу 10 и вычислите средние, дисперсии и ковариации yj+i и _Уу4.2
при заданных у у у;+3, 6 в последовательности, в которой и уу+3 присутствуют,
a yj + 1 и yJ+2 отсутствуют.
Глава 9. АНАЛИЗ ЧАСТИЧНО КЛАССИФИЦИРОВАННЫХ
ТАБЛИЦ СОПРЯЖЕННОСТИ
БЕЗ УЧЕТА МЕХАНИЗМА
ПОРОЖДЕНИЯ ПРОПУСКОВ
9.1. ВВЕДЕНИЕ
Эта глава посвящена анализу неполных данных для категориаль-
ных переменных. Хотя категории могут быть образованы путем раз-
биения интервальной шкалы, упорядоченность категорий переменной
такого вида или другой порядковой переменной здесь не учитывает-
ся. Методы обработки категориальных данных с учетом упорядочен-
ности категорий, разработанные недавно [(см., например, [Goodman
(1979); McCullagh (1980)]), можно обобщить на случай неполных дан-
ных с помощью теории правдоподобия, описанной в гл. 6 и 7.
192
Прямоугольную п х ^матрицу данных, состоящую из п наблюде-
иий по V категориальным переменным Y.,....Yl7, можно преобразо-
пать в Имерную таблицу сопряженности с ячейками, определяемыми
совокупностью категорий переменных. Элементами этой таблицы
являются целые числа [njklJ, где njkl t — число наблюдений в ячейке
с Yi~j, Y2 = k, Y3-l,...,Yy=i. Если матрица данных содержит пропус-
ки, то некоторые из наблюдений в описанной таблице сопряженнос-
। и классифицированы частично. Полностью классифицированные
наблюдения образуют Кмерную таблицу частот а частично
классифицированные — дополнительные маргинальные подтаблицы,
определяемые подмножеством наблюдаемых переменных из множе-
ства (У15...,УГ). Например, первые восемь строк табл. 1.16 представ-
ляют полные наблюдения в пятимерной таблице сопряженности с
переменными: пол, возрастные группы и наличие ожирения в три
различных момента времени. Остальные восемнадцать строк содер-
жат данные для шести частично классифицированных таблиц с от-
сутствием одной или двух переменных о наличии ожирения. Мы
будем обсуждать МП-оценивание по данным такого вида.
В следующем разделе факторизация правдоподобия, аналогичная
факторизации, описанной для нормального случая в гл. 6, применяет-
ся к неполным категориальным данным со специальной структурой
частного. В разделе 9.3 обсуждается МП-оценивание для общих струк-
тур с помощью ЕМ-алгоритма. В разделе 9.4 рассматривается МП-
оценивание по частично классифицированным данным, когда вероят-
ности классификации определяются логлинейной моделью. Обсужде-
ние моделей с неигнорируемыми пропусками отложено до гл. И.
Более общий вид неполные данные будут иметь, когда категория
j определенного признака, например Уь неизвестна, но зато извест-
но, что наблюдению соответствует одно из подмножеств S значений
Ki. Если У1 отсутствует полностью, то S состоит из всех возмож-
ных значений Ys. Если У, отсутствует, но записано значение У] в
менее подробной кодировке YT , то S будет соответствующим под-
множеством значений Ур Пример таких данных, где возможна и
точная, и грубая классификация, приведены в разделе 9.2.
Проблемы данных с пропусками, обсуждаемые здесь, нельзя ни в
коем случае смешивать с задачей о структурных нулях, где опреде-
ленные ячейки содержат нулевые частоты, поскольку в модели при-
нимается, что вероятности появления наблюдений в этих ячейках
равны нулю. Например, если У| — год рождения, а У2 — год перво-
го брака и браки до 10 лет запрещены, то клетки, в которых
У2^ У, +9, — структурные нули совместного распределения и У2.
Отсутствие данных в ячейках (нулевые частоты) не рассматривается
здесь как пропуски. Обсуждение проблемы структурных нулей см.
в [Bishop, Fienberg and Holland (1975), гл. 5].
7. P Дж А Литг'1, Д Б Рубин 193
9.2. ФАКТОРИЗАЦИЯ ПРАВДОПОДОБИЯ
ДЛЯ МОНОТОННЫХ ПОЛИНОМИАЛЬНЫХ ДАННЫХ
9.2.1. Введение
В этом и следующем разделах мы предполагаем, что:
1) частоты в полных данных имеют полиномиальное рас-
пределение с параметром п и вероятностями {яд/...,];
2) механизм порождения пропусков пренебрежим в смысле, ука-
занном в гл. 5. Следовательно, правдоподобие для вероятностей 0
получается интегрированием правдоподобия для полных данных
(9.1)
по отсутствующим данным. МП-оценки в получаются при максими-
зации получаемого правдоподобия при условии, что сумма вероят-
ностей в ячейках равна 1.
Альтернативу модели, определяемой предположением 1, задает
предположение, что частоты nJkl, — независимые пуассоновские
случайные величины со средними nJkkJ и вероятностями для ячеек
^*м..л = Если механизм порождения пропусков пре-
небрежим, выводы о {n*ki...t} по правдоподобию совпадают с вы-
водами для lvjki...t} из полиномиальной модели. Этот факт следует
из соображений, аналогичных тем, что в случае полных данных
[см. Bishop, Frienberg and Holland (1975)]. Мы ограничимся рас-
смотрением полиномиальной модели, так как с практической точки
зрения она выглядит более общей по сравнению с пуассоновской
моделью.
Для полных данных правдоподобие (9.1) дает МП-оценку
= nJkL„t/ п
с асимптотический дисперсией
Var(%yw ..,) = TtjkL. .,(1 — iJkl л)/п.
Нашей целью является получение аналогичных величин по непол-
ным данным. В этом разделе мы обсудим структуры неполных
данных частного вида, которые приводят к явным МП-оценкам.
9.2.2. МП-оценивание для монотонных структур
Проиллюстрируем сначала МП-оценки в простом случае двумер-
ной таблицы сопряженности с дополнительной таблицей по одному'
фактору.
Пример 9.1. Двумерная таблица сопряженности с дополнитель-
ной одномерной подтаблицей. Рассмотрим две категориальные пе-
ременные: У| с категориями y=l,...,J и У2 с категориями к=1,...,К.
194
Данные состоят из т наблюдений (у([, уа, j=l,...,m) с зарегистри-
рованными уц, yi2 и г=п—т наблюдений (yii; i=m+l,...,n) с у(1 и
отсутствующими уа. Структура данных идентична структуре в
примере 6.1, но теперь переменные категориальны, т полностью
классифицированных таблиц можно расположить в таблицу сопря-
женности J*K, у которой в ячейке с Уц =j, Уа = к естъ mjk наблюде-
ний; г остальных наблюдений образуют дополнительную подтабли-
цу Jxl, у которой в ячейке с Уц~] rj наблюдений (рис. 9.1).
Для обозначения суммирования по индексам j и к мы будем ис-
пользовать стандартный способ с помощью знака +. В нашей задаче
Как в приме-
ре 6.1, мы бу-
дем работать
с другим на-
бором пара-
метров ф,
соответствую-
щим марги-
нальному рас-
пределению Y,
и условному
распределе-
нию У2 при
J К
0=Огц, 7Ti2,...,7rJjr) И £ irJk~T++ =1.
J
Категории 1 ... К Суммы Категории
1 1
У. ' °
J J
Суммы in Сумма г -- n - rr?
Полные наблюдения
Неполные наблюдения
Рис. 9.1. Данные из примера 9.1
заданном Логарифм правдоподобия данных можно записать в
виде
7(ф|{mjk, +91пт;+ + Lmjklmrk.j, (9.2)
где первое слагаемое — логарифм правдоподобия полиномиального
распределения маргинальных частот дау+ с параметром п и ве-
роятностями лу+, второе — логарифм правдоподобия условного
полиномиального распределения mjk при заданном т7-+ с парамет-
рами rrij+ и вероятностями
w-=Pr(n=fcir> =/)= тл/ъ + .
Итак, (9.2) — это факторизация правдоподобия вида (6.1) с ф^ =
= {vj+, и ф2= к=1,..,,К}, фх и фг раздель-
ны. Максимизируя каждую компоненту по отдельности, получаем
МП-оценки
поэтому
7'
-> mi*+ri ~
^j+ п ’ *k.j т-^ ’
7rjft 7rj+ ^k-j— n
(9.3)
195
Значит, согласно МП-оценке в (j, к)-к> ячейку распределяется доля
mjk/mji неклассифицированных наблюдений.
Пример 9.2. Монотонные двумерные дискретные данные. Мы
численно проиллюстрируем результаты примера 9.1 на данных
табл. 9.1, где Yt — дихотомическая, а У2 — трихотомическая пере-
менная. Оценивание маргинальных вероятностей У проводится по
полностью и частично классифицированным объектам:
тг1+=190/140, т2+=220/410.
Таблица 9.1. Пример со структурой данных на рис. 9.1
Полные объекты y2 Сумма Неполные объекты
1 2 3
1 20 30 40 90 1 100
У У
2 50 60 20 130 2 90
Сумма 70 90 60 220 Сумма 190
Условные вероятности отнесения к категориям У2 при заданном
У1 оцениваются по полностью классифицированным объектам:
ть1 = 20/190, f2.j =30/90, яз.! =40/90,
^.2 = 50/130, я2.2 = 60/130, тг3.2 = 20/130.
Сочетание этих оценок дает вероятности в (9.3):
7Гц = (20/90)(190/410)=0,1030,
тг13 = (40/90)(190/410)=0,2060,
тг22=(60/130)(220/410) = 0,2377,
тг!2 = (30/90)(190/410)=0,1545,
тг21 = (50/130)(220/410) = 0,2064,
т23 = (20/130)(220/410) = 0,0826.
В отличие от них оценки по полностью классифицированным на-
блюдениям равны:
ти= 20/220=0,0909, 5'12 = 30/220=0,1364, ?13 =40/220 = 0,1818,
т21 =50/220=0,2273, £^ = 60/220 = 0,2727, т23 = 20/220=0,0909.
Оценки [тд) менее эффективны, чем МП-оценки {тгд}. Однако
принципиальное преимущество МП-оценивания состоит, как и в
нормальном случае, обсуждавшемся в примере 6.1, в уменьшении
или устранении смещения, когда данные не отсутствуют и присут-
ствуют случайно (не выполняется ОПС). Оценки {т^к} — МП-
оценки, когда данные ОС и, в частности, когда вероятность пропус-
196
ка К зависит or У,, но не от У2. {тг — состоятельные в общем
спучае оценки {яд], только если данные ОПС, т. е. пропуски не за-
нисяг ни от Yi, ни от Y2. Маргинальные распределения У в полнос-
। ью и не полностью классифицированных выборках, видимо,
различаются (критерий хи-квадрат дает xi =5,23 с соответствую-
щим р значением, которое меньше 0,01), поэтому эти данные про-
1иворечат предположению ОПС.
Обобщения этого примера на случай других монотонных струк-
тур можно получить с помощью аналогичной факторизации прав-
доподобия.
Пример 9.3. Анализ шестифакторной таблицы. Фухс [Fuchs (1982)]
представляет данные Protective Services Project for Older Persons —
долговременного исследования 165 людей, предпринятого для оцен-
ки влияния социальных условий на состояние здоровья (табл. 9.2).
Исследователи собирали данные цо шести дихотомическим пере-
менным: D — жив или умер, G — принадлежность к опытной или
контрольной группе, S — пол (мужской, женский), А — возраст
(меньше 75 лет, больше 75 лет), Р — физическое состояние здоровья
(плохое, хорошее), М — психическое состояние (плохое, хорошее). У
101 обследованного человека были зарегистрированы все перемен-
ные (табл. 9.2,а)). Состояние здоровья не было обследовано у 1 че-
ловека (табл. 9.2,6)). Запись о психическом состоянии отсутствовала
у 33 человек (табл. 9.2,в)). Наконец, не было записей о физическом
состоянии наряду с психическим у 29 человек (табл. 9.2,г)).
Если опустить информацию о психическом состоянии одного че-
ловека в табл. 9.2,6), данные будут иметь монотонную структуру,
и МП-оценки вероятностей в ячейках можно вывести с помощью
факторизации
Pr (D, G, A, S, Р, M)=Pr (D, G, A, S) Pr (P|D, G, A, S) Pr (M|D, G, A, S, Р).
Наблюденные частоты для оценивания трех распределений в пра-
вой стороне приведены в табл. 9.3,а). Вычисленные ожидаемые ча-
стоты, равные оценке вероятности для ячейки, умноженной на 164
(суммарный объем выборки), приведены в табл. 9.3,6). Например,
частота в ячейке с D — жив, G — экспериментальная группа, А —
больше 75 лет, S — мужской, Р — хорошее, М — хорошее, равна:
164(13/164)(10/11)(б/8) = 8,863б.
Замена D — жив на D — умер дает ожидаемую частоту
164(21 /164)(6/19)(4/16)=4,4211.
Следовательно, ожидаемая условная вероятность выжить для лю-
дей из опытной группы старше 75 лет мужского пола с хорошим
физическим и психическим состоянием равна (8,8636/(8,8636 +
4,4211))=0,6672. Эта оценка сравнима с оценкой 10/(10+6)=0,6 по
полным наблюдениям табл. 9.2.
197
Таблица 9.3. МП-оценки для монотонных данных из табл. . = иг.
полученные с помощью факторизации правдоподобия
(информация о психическом состоянии обследуемых в табл. 9.2,6) опущена)
Состояние Исход Мужчины Женщины
психическое физическое <75 >75 <75 >75
э К Э К Э К э К
а) Таблицы для монотонных структур
1. Данные, содержащие информацию о D, G, А и S
Умерли 4 4 21 17 5 2 10 8
Выжили 13 25 13 16 5 8 5 8
2. Данные, соде ржащие информацию о D, G, A, S и Р
Плохое Умерли 2 2 13 7 1 1 5 3
Выжили 5 2 1 5 0 1 1 2
Хорошее Умерли 2 1 6 8 3 1 2 4
Выжили 6 15 10 9 4 6 2 4
3. Дан ные табл. 9.2, а), содерз кащие информацию о всех переменных (D, G, A, S, Р, М)
б) Ожидаемые частоты в ячейках
Плохое Плохое Умерли 1,00 2,67 8,98 5,95 0,63 0,50 4,76 1,14
Выжили 1,48 0,00 0,00 0,00 0,00 0,00 0,00 2,67
Хорошее Умерли 0,00 0,00 2,21 2,27 1,25 1,00 2,86 0,00
Выжили 0,00 3,68 2,95 0,00 0,00 0,00 0,00 0,00
Хорошее Плохое Умерли 1,00 0,00 5,39 1,98 0,63 0,50 2,38 2,28
Выжили 4,43 2,94 1,18 5,71 0,00 1,14 1,67 0,00
Хорошее Умерли 2,00 1,33 4,42 6,80 2,50 0,00 0,00 4,57
Выжили 7,09 18,38 8,86 10,29 5,00 6,86 3,33 5,33
Источник. [Fuchs (1982)].
Пример 9.4. Таблицы грубой и точной классификации. Данные и
табл. 9.4,а) и б), представленные и проанализированные в [Hockinp.
and Oxspring (1974)], иллюстрируют другую ситуацию, в которой
можно вычислять МП-оценки, факторизуя правдоподобие. В табл.
9.4 содержатся данные об использовании лекарств для лечения про
казы. 196 пациентов были классифицированы по степени инфиль
трации и по общему клиническому состоянию после определенною
времени со дня начала приема лекарств. Дополнительные данные о
400 других пациентах, грубо классифицированных по улучшению
здоровья, приведены в табл. 9.4,6). Такого рода данные естествен
вы в крупных диспансерных обследованиях, в которых подобные
детальные результаты можно получить для небольшой группы, а
грубо классифицированные данные можно собрать для большей
группы людей без особых затрат.
Правдоподобие факторизуется в соответствии с совместным рас-
пределением объединенных частот из двух таблиц, классифициро-
ванных, как табл. 9.4,6), для всех 596 пациентов и условным
распределением степени улучшения (сильное, умеренное, слабое) при
заданном улучшении и степени инфильтрации для 196 пациентов.
Полученные МП-оценки вероятностей в ячейках приведены в табл.
9.4,в), так что виден ход вычислений. Совместные вероятности ин-
фильтрации и грубо классифицированного клинического состояния
получены объединением данных из а) и б), что дает значения в по-
следних двух столбцах и первые факторы первых трех столбцов.
Последние умножаются на условные вероятности степени улучше-
ния, вычисленные по первым трем столбцам а). В частности, значе-
ние в левом верхнем углу равно т1( =(224/596)(11/80)=0,0517, что
сравнимо с кц —11/196 = 0,0561, полученным только по точно клас-
сифицированным данным.
9.2.3. Оценивание точности МП-оценок
Асимптотическую ковариационную матрицу, соответствующую
МП-оценкам (9.3), можно получить, вычисляя информационную
матрицу для параметров в форме под факторизованное правдоподо-
бие, обращая эту матрицу, а затем проводя преобразование пара-
метров для исходного вида методом, описанным в разделе 6.1.
Можно также непосредственно вычислить дисперии и ковариации.
Например, чтобы вычислить асимптотическую дисперсию кд =
= в примере 9.1, запишем
Var^k-E(Vari#| (У, ])+Уаг(£’тдЦУ1 ]),
где {Ki ] — набор маргинальных частот Уь Отсюда асимптотически
с точностью порядка l/mj+
Va.njk =£’[ij+ —тг^)/да ч ] + Var {+к k.j ] =
= Tk.j)/mj+ + K^yTj+(l—7Гу+)/п.
200
Таблица 9.4. Классификация пациентов
по степени инфильтрации и изменению состояния
а) Точно классифицированные наблюдения
Степень инфильтрации Изменение состояния Сумма
улучшение без изменения ухудшение
сильное умеренное слабое
Малая 11 27 42 53 11 144
Большая 7 15 16 13 1 52
Сумма 18 42 58 66 12 196
б) Грубо классифицированные наблюдения
Степень инфильтрации Изменение состояния Сумма
улучшение без изменения ухудшение
Малая 144 120 16 280
Большая 92 24 4 120
Сумма 236 144 20 400
в) МП-оценки вероятностей в ячейка* по таблицам а} и о)
Степень инфиль- трации Изменение состояния
улучшение без изме- нения ухудше- ние
сильное умеренное слабое
Малая (224/596)(11/80) (224/596)(27/80) (224/596)(42/80) 173/596 27/596
Боль- шая (130/596X7/38) (130/596X15/38) (130/596X16/38) 37/596 5/596
Источник. [Hocking and Oxspring (1974)].
201
Простые выкладки дают
Уагт?1=>(1~Тл)-Г1
т
J^=^k
где Cj = m‘Kj+/mj —1. Подставляя оценки параметров, получаем
(9.4)
А jk' т I п J j
т
Левая сторона (9.4) записана в измененном виде, чтобы показать,
что байесовский анализ асимптотической апостериорной дисперсии
тгд дает аналогичные результаты. Для ковариаций получаем
СОУ(7ГЛ-ТУЬ к*1,
Cov^Jk—^jk,
Если данные ОПС, то Cj мал и (9.4) сводится к выражению, анало-
гичному (6.14):
(9.5)
В этом выражении х^(1—тг^У/т — оценка дисперсии оценки тд=
-mjk/m, полученной без учета добавочных маргинальных частот, а
остальная часть правой стороны описывает пропорциональное
уменьшение дисперсии за счет маргинальных частот.
Пример 9.5 (продолжение примера 9.2). Применим эти формулы
к оценкам чгц по данным табл. 9.1. Оценка тц =0,0909, не учитыва-
ющая дополнительные маргинальные частоты, имеет асимптотиче-
скую дисперсию тгц(1—7гп)/т, равную (после подстановки МП-
оценок):
Уаг(тц) = 0,1030(1—0,1030)7220 = 0,00042.
Аналогично из (9.5) получаем, что оценка асимптотической диспер-
сии МП-оценки Tn =0,1030 равна:
v А ПОЛПЯЭЛ (0,2222-0,1030)190. „ ппп,„
Уаг(тг) j) = 0,00042(1-— 0,8970-410 У ~ 0,00039.
Итак, уменьшение дисперсии за счет использования дополнитель-
ных маргинальных частот мало. Тем не менее данные скорее всего
не ОПС, как указано в примере 9.2. Поэтому ?ц — смещенная
оценка хн. В предположении ОС — несмещенная оценка тгн, так
что грубая оценка смещения тгн равна тги—Гц =0,0121. Отсюда гру-
бая оценка средней квадратической ошибки тц равна:
MSE(5r11) = O,O12P+Var(x11)=O,00057.
202
Заменяя (9.5) на более точную формулу (9.4), получаем для диспер-
сии 7Гц
Var(r.,)=0,00042(0,9384+0,1151) = 0,00044.
Значит, метод максимального правдоподобия дает значительно
Оолее точную оценку тц благодаря учету того, что данные, видимо,
не ОПС.
9.3. МП-ОЦЕНИВАНИЕ ДЛЯ ПОЛИНОМИАЛЬНЫХ ВЫБОРОК
С. ОБЩЕЙ СТРУКТУРОЙ ПРОПУСКОВ
Как и для нормальных данных, неполные полиномиальные дан-
ные без монотонной структуры требуют применения итеративных
процедур для МП-оценивания. ЕМ-алгоритм здесь особенно прост,
гак как логарифм правдоподобия линеен по пропущенным значени-
ям. Для монотонных данных в примерах 9.1 и 9.2 МП-оценивание,
но сути, распределяет частично классифицированные данные по
полной таблице исходя из условных вероятностей, вычисленных по
полностью классифицированным данным. На шаге Е ЕМ-алгорит-
ма для общей структуры выполняется как раз эта функция за ис-
ключением того, что условные вероятности вычисляются по теку-
щим оценкам вероятностей в клетках, а не по полностью классифи-
цированным данным. На шаге М вычисляются новые вероятности
и ячейках по заполненным данным. Впервые этот алгоритм появил-
ся в статистической литературе в работе [Hartley (1958)]. Мы фор-
мулируем ЕМ-алгоритм для общего случая, применяя его к
различным частным случаям.
Допустим, что исходные полные данные — это полиномиальная
выборка объема п при J ячейках с лу- наблюдениями в су- и
параметром где irj — вероятность отнесения к Cj. На-
блюденные данные состоят из т полностью классифицированных
наблюдений с наблюдениями в су, т=^=1т^, и п—т
неполных наблюдений, попадающих в подмножества J ячеек. Мы
разбиваем множество частично классифицированных объектов на К
групп, так что все объекты внутри каждой группы имеют одинако-
вый набор возможных ячеек. Пусть гк частично классифицирован-
ных объектов попадает в к-ю группу, a Sk — множество ячеек, к
которым могут относиться эти объекты. Далее, определим индика-
торную функцию b(jeSk), j= к=\,...,К, такую, что 5(/б5^) = 1,
если Cj принадлежит Sk и 3(/gSp=0 — в противном случае.
Опишем шаг Е ЕМ-алгоритма. Обозначим через [irj ,
текущую оценку параметров (на Лй итерации). Распределение исход-
ных полных данных относится к регулярному экспоненциальному
семейству с достаточными статистиками
[лу,у=1,.
203
Поэтому шаг Е состоит в вычислении
=E{nj I данные, 7гР....,7г)0) -=m,+ ^гк фУ>8/,
где j
J „к J I -1 *
текущая оценка условной вероятности попадания в ячейку J при ус-
ловии, что наблюдение относится к набору категорий Sk. Шаг Е,
по сути, распределяет частично классифицированные наблюдения
по таблице в соответствии с этими вероятностями.
На шаге М вычисляются новые оценки параметров:
,г(/-и> = и(/)/л.
Это довольно общая формулировка. Ячейки могут образовывать
многофакторную таблицу с наблюдениями, классифицируемыми по
V переменным где У5, имеет jv категорий и jv=J.
Тогда частично классифицированные наблюдения могут формиро-
вать добавочные маргинальные подтаблицы, в которых одна или
более переменных Yv не зарегистрированы. Мы приведем простой
численный пример для такой структуры неполных данных.
Таблица 9.x Таблица 2х 2 с дополнительными
маргинальными частотами по обеим переменным
Классификация по Kj и У2 Классификация по У, Классификация по У2
1 2 Сумма 1 30а Г2 1 2 Сумма
1 100 50 150 Г, 2 75 75 150 Сумма 175 125 300 У, 2 60б Сумма 90 28“ 60г 88
Замечание. Индексы а, б, в, г относятся к дополнительным маргинальным часто-
там и используются в табл. 9.6.
Пример 9.6. Таблица 2x2 с дополнительными маргинальными
частотами по обеим переменным. МП-оценивание для двумерных
таблиц с дополнительйыми данными о частотах для обеих перемен-
ных впервые рассматривалось в [Chen and Feinberg (1974)]. В табл.
9.5 приведены данные, проанализированные в [Little (1982)]. В табл.
9.6 показаны первые три итерации ЕМ-алгоритма, в котором на-
чальные оценки вероятностей в ячейках вычислялись по полностью
классифицированной подтаблице. Затем эти вероятности использо-
вались для распределения частично классифицированных наблюде-
204
пий, как показано в табл. 9.6. Например, 28 частично классифици-
рованных наблюдений с У2 = 1 имели Ki = l с вероятностью 100/
(100+75) и Yi=2 с вероятностью 75/(100+75). Значит, из 28 объек-
тов 28-100/175 = 16 будут отнесены к = 1 и 28-75/175 = 12 объектов
— к У] =2. На следующем шаге по заполненным данным вычисля-
ют новые вероятности и итерации продолжаются далее. Сходи-
мость наступает при значениях вероятности классификации,
равных:
хн=0,28, тг12=0,17, т21=0,24, я22=0,31.
Таблица 9.6. ЕМ-алгоритм дли данных табл. 9.5
(механизм порождения пропусков игнорируется)
Опенки вероятностей Распределение объектов
Шаг 1 У2
1 2
1 100/300 50/300 1 100 <-20а+ 16В 50+10а+24Г зоа
У1 2 75/300 75/300 Ki 6 и 2 75 + 30 +12 б г 75+30 +36 60б
28В 60Г
Шаг 2
136/478 84/478 100+18,6 + 15,1 50+11,4+22,4
117/478 141/478 75+27,2+12,9 75 + 32,8 + 37,6
Шаг 3
0,28 0,18 100+18,4+15,1 50+11,6+21,9
0,24 0,30 75+20,5 + 12,9 75+33,5+38,1
Шаг 4
0,28 0,17
0,24 0,31
Замечание. Индексы в правой верхней таблице указывают частично классифициро-
ванные наблюдения из табл. 9.5. Например, из 28 объектов с Е-1 (индекс в) 16 от-
несены к У, = 1 и 12 — к У2 = 2.
Пример 9.7. Применение к ПЭТ. Варди и др. [Vardi, Shepp and
Kaufman (1985)1 приводят интересный пример ЕМ-алгоритма для
двухфакторных категориальных данных, получаемых при позитрон-
эмиссионной томографии (ПЭТ). Описание, предлагаемое здесь, взя-
то из [Rubin (1985)]. При ПЭТ «картина» органа (например, мозга)
создается при подсчете частот эмиссии в D детекторах, упорядоченно
расположенных вокруг органа. Орган моделируется как В ящиков
или точек, каждая из которых характеризуется своим параметром
интенсивности Х(6), 6=1,...,В, определяющим скорость эмиссии. Из
физических соображений определяется матрица DxB известных ве-
роятностей Рг (детектор=<7)точка= 6) того, что эмиссия из точки b
будет зарегистрирована детектором а. Цель — использовать эти из-
вестные условные вероятности совместно с наблюденными частота-
ми в D детекторах, чтобы оценить интенсивность (или
маргинальную вероятность эмиссии) в каждой из В точек.
205
Пусть -it=[ir(d, £>)) — матрица D*B совместных вероятностей
того, что эмиссия происходит в точке Ъ и регистрируется детекто-
ром d. т определяется через Pr(d|Z») и Х(й). Гипотетические полные
данные — это п н.о.р. наблюдений 5;= [Sj(d, fe)}, где b^d, &) = 1, ес-
ли z-й отсчет возник в Ь-й точке и зарегистрирован d-м детектором,
и нуль — в противном случае. Наблюденные (т. е. неполные) дан-
ные состоят из п маргинальных частот по й;- по строкам, т. е. это
векторы Dxl, указывающие детектор для каждой из п эмиссий.
ЕМ-алгоритм работает следующим образом:
1) задать начальные значения для X, скажем Х<°>, что определяет
начальные значения для к,
2) на шаге Е распределить наблюденные отсчеты для детектора
d=l,...,D но В точкам в соответствии с условными вероятностями,
заданными ir<0);
3) на шаге М оценить Х(1) с помощью маргинальных частот по
точкам (суммированных по всем детекторам отсчетов);
4) повторить шаг Е с новой оценкой X и так далее до наступления
сходимости.
9.4. ЛОГЛИНЕЙНЫЕ МОДЕЛИ
ДЛЯ ЧАСТИЧНО КЛАССИФИЦИРОВАННЫХ
ТАБЛИЦ СОПРЯЖЕННОСТИ
9.4.1. Полные данные
Для полных У-факторных таблиц сопряженности с вероятностями
в ячейках [ ] часто важно перейти к моделям, в которых веро-
ятности имеют определенную структуру. Например, независимость
факторов соответствует модели, в которой вероятности выражают-
ся в виде
<9-6)
при некоторых мультипликативных факторах г, |.
Удобно выражать (9.6) как логлинейную модель:
1птгt = а + с/1' + а ® +... + , (9.7)
где — и т. д. Различные наборы а в правой стороне (9.7)
могут давать одно и то же множество вероятностей {тг;7И t ]. Поэ-
тому для того, чтобы единственным образом задать а, нужны V
ограничений. Обычно полагают
206
Таблица 9.7. Иерархические логлииейные модели
для трехфакторных таблиц сопряженности
Модель Обозначение Члены в (9.8), приравниваемые к нулю
(1) 1123} Нет
(2) {12, 23, 31}
(3) {12, 13)
(4) U, 23} 1
(Д {23} {<4?, <>, c/J3’, off>]
(6) {1.2,3} О
(7) {2,3} <*№> <№ “Л
(8) {!) 44 <>, 44 «pi
(9) (0! (<$4 «<?, 44 4»>, «<4 44
Уравнения (9.6) или (9.7) задают логлинейную модель для вероят-
ностей в ячейках. Более общий класс моделей получается при разло-
жении логарифма вероятностей в ячейках на сумму константы,
главных эффектов вида (9.7) и взаимодействий более высоких по-
рядков и приравнивании некоторых членов разложения нулю. На-
пример, для трехфакторной таблицы
ln^w=«+ af > + а<2> + а® + а^ + о!™ + + с$3>, (9.8)
где сумма а по любому из индексов равна нулю. Члены {ajn},
называются главными эффектами соответственно
У2 и У3. Члены называются двухфакторными
взаимодействиями соответственно между У] и У2, Y3 и У3, У2 и Y3.
Наконец, члены называются трехфакторными взаимодейст-
виями между У1, Ji и У3. Полагая все двух- и трехфакторные взаи-
модействия равными нулю, получим модель независимости (9.7)
для И=3 переменных. Другие модели получаются, если приравнять
нулю другие члены в (9.8).
Важным классом моделей, которые можно получить таким пу-
тем, являются иерархические логлииейные модели. Они облада-
ют таким свойством: если в модель входит v-факторная зависи-
мость между множеством факторов 5, то в модель входят и все
(у—1)-факторные взаимодействия, взаимодействия более низких по-
рядков и главные эффекты, относящиеся к подмножествам факто-
ров из S. Для трехфакторной таблицы имеется 19 иерархических
моделей. В табл. 9.7 приведены девять из них, остальные 10 можно
получить, меняя факторы в моделях (3), (4), (5), (7) и (8).
МП-опенивание для иерархических моделей различно по сложнос-
ти в зависимости от подбираемой модели. В частности, для всех
моделей в табл. 9.7 можно найти явные оценки, за исключением
{12, 23, 31), где необходима итеративная процедура оценивания.
207
Для сравнения качества выбора логлинейных моделей широко ис-
пользуются две асимптотически эквивалентные статистики. Отно-
шение правдоподобия равно:
G2=2E«fln"c, (9.9)
где сумма ведется по всем с ячейкам в таблице, пс — наблюденная
частота в ячейке с и Лс — птс — ожидаемая частота в с, оцененная
по модели. Статистика хи-квадрат Пирсона определяется как
= (9.10)
с йс
Если подбираемая модель верна, то и G2 и X2 асимптотически рас-
пределены по хи-квадрат с числом степеней свободы, равным числу
независимых ограничений по вероятности в ячейках. Подробности о
вычислении числа степеней свободы и другие сведения о
логлинейных моделях для полных данных можно найти в [Good
man (1970); Haberman (1974); Bishop, Fienberg and Holland (1975);
Fienberg (1980)].
Пример 9.8. Полная трехфакторная таблица. Таблица 9.8,а)
представляет таблицу сопряженности 23, содержащую данные о
смертности новорожденных [см. Bishop (1975), табл. 2. 4—2]. В
табл. 9.9 показаны оценки вероятностей в ячейках и статистики для
подбора некоторых логлинейных моделей для этих данных.
Таблица 9.8. Таблица сопряженности 23
с частично классифицированными наблюдениями
Клиника (К) Предродовой уход (П) Исход (И)
умерли ВЫЖИЛИ
а) Полностью классифицированные случаи рп=715 случаев)
А хуже 3 176
лучше 4 293
В хуже 17 197
лучше 2 23
б) Частично классифицированные случаи
(данные о клинике отсутствуют, г=255 случаев)
хуже 10 150
лучше 5 90
Источник, a) [Bishop (1975), табл. 2.4—2], б) вымышленные данные.
208
Модель [ИПК] в табл. 9.9,а) не налагает ограничения на вероят-
ности в ячейках и полностью согласуется с наблюденными пропор-
циями. Поэтому обе статистики согласия равны нулю при нулевой
степени свободы. Две ненасыщенные модели в табл. 9.9,6) и 9.9,в)
характеризуются очень низкими значениями G2 и X1, а именно [ИК,
ПК} указывает, что смертность связана с клиникой, но смертность
к предродовой уход условно по клинике не связаны, что касается
I ИК, ПК, ИП}, то здесь к предыдущей модели добавляется взаи-
модействие ИП. Поскольку разница в согласии пренебрежима и
первая модель менее загруженная, надо, видимо, отдавать пред-
почтение ей. Модель [ИК, ИП) плохо подходит к данным и вклю-
чена в иллюстративных целях.
Таблица 9.9. Оценки вероятностей в ячейках tjWx100
по насыщенной модели {ИПК) и три логлинейные модели,
подобранные по данным табл. 9.8, а)
Клини- ка (К) Послеродовой уход (П) Исход (И) Согласие
умерли ВЫЖИЛИ
а) Модель {ИПК]
А хуже 0,42 24,62
лучше 0,56 40,98 ч.с.с.=0, G2=0, ^=0
В хуже 2,38 27,55
лучше 0,28 3,22
б) Модель ИК, ПК, ИП]
А хуже 0,39 24,64
лучше 0.59 40,95 ч.с.с.= 1, G2=0,04, А-2=0,04
В хуже 0,41 27,52
лучше 0,25 3,24
в) Модель {ИК, ПК)
А хуже 0,36 24,67
лучше 0,62 40,92 ч.с.с.=2, G2=0,08, А2=0,08
В хуже 2,38 27,55
лучше 0,28 3,22
г) Модель {ИК, ИП)
А хуже 0,76 35,51
лучше 0,22 30,08 ч.с.с. = 2, G2= 188,1, X1 =169,5
В хуже 2,04 16,66
лучше 0,62 14,11
209
9.4.2. Логлинейные модели
для частично классифицированных таблиц
Как и для насыщенных моделей из разделов 9.2 и 9.3, при МП-
оценивании логлинейных моделей частично классифицированные
наблюдения распределяют по полной таблице, используя оценки ус
лонных вероятностей, а затем оценивают вероятности классифика-
ции по заполненной таблице. Единственная разница заключается в
том, что все вероятности оценивают, соблюдая ограничения, нала-
гаемые логлинейной моделью. Эти ограничения могут увеличить
объем вычислений, требуемых для получения МП-оценок, по двум
причинам. Во-первых, факторизация правдоподобия для монотон-
ных структур не обязательно приводит к явным МП-оценкам, так
как параметры в факторах не обязательно являются раздельными.
Во-вторых, шаг М ЕМ-алгоритма для немонотонных структур мо-
жет сам быть итеративным. Мы проиллюстрируем каждое из этих
обстоятельств примером.
Таблица 9.10. МП-оценки для моделей |ИПК), (ИП, ИК, ПК)и (ИП, ИК)
по данным табл. 9.8,а) и 9.8,6)
Клиника Предродовой уход Исход
умерли ВЫЖИЛИ
А хуже а) модель (ИПК) 100(3/20)(30/970)=0,46 100(176/373)(523/970) = 25,44
В лучше хуже 100(4/6)(И/970)=0,76 100(17/20)(30/970)=2,63 100(293/316)(406/970) = 38,81 100(197/373)(523/970) = 28,48
А лучше хуже 100(2/6)(11/970)=0,38 б) модель ( ИП, ИК, П 100(2,8/20)(30/970)=0,43 1ОО(23/31б)(4О6/97О)=3,О5 Сумма = 100,0 К) 100(176,2/373)(523/970)=25,47
В лучше хуже 100(4,2/6X11/970)=0,79 100(17,2/20)(30/970)=2,66 100(292,8/316X406/970)=38,78 100(196,8/373)(523/970)=28,45
А лучше хуже 100(1,8/6)(11/970)=0,34 в) модель (ИП, ИК) 100(5,4/20)(30/970)=0,84 100(23,2/316)(406/970)=3,07 Сумма = 100,0 100(253,9/373X523/970) = 36,70
В лучше хуже 100(1,6/6)(11/970)=0,30 100(14,6/20X30/970)=2,26 100(215,1/316X406/970) = 28,49 100(119,1/373X523/970)= 17,22
лучше 100(4,4/6)(11/970)=0,83 100(100,9/316X406/970) = 13,26 Сумма = 100,0
Пример 9.9. МП-оценивание в неполной трехфакторной таблице |
(продолжение примера 9.8). Допустим, что к данным табл. 9.8,a), j
проанализированным в примере 9.8, добавлены дополнительные
данные табл. 9.8,6). В них есть сведения об' исходе (И) и предродо-
вом уходе (П), но данных о клинике (К) нет. В результате получа-
ются данные с монотонной структурой, где П и И наблюдаются
210
больше К. Правдоподобие для объединенных данных табл. 9.8,а) и
9.8,6) факторизуется на член для распределения ИП, включающий
г+т=970 случаев, и член для распределения К при заданном ИП,
включающий /л=715 полностью классифицированных случаев. Эти
два распределения содержат раздельные параметры для моделей
{ИПК}, {ИП, ИК, ПК} и {ИП, ИК}. Следовательно, для этих мо-
делей методом факторизации правдоподобия из гл. 6 можно выве-
сти МП-оценки. В табл. 9.10,а) показаны МП-оценки 100-лд/ для
насыщенной модели {ИПК|, рассчитанные по методу из раздела
9.2. В табл. 9.10, б) и 9.10,в) показаны МП-оценки для (ИП, ИК,
ПК} и {ИП, ИК}. Поскольку в этих моделях подбираются пара-
метры маргинального взаимодействия [ИП}, оценки вероятностей
для этого взаимодействия такие же, как и для {ИПК}. Условная ве-
роятность того, что К=А при заданном ИП, получается из соот-
ветствующей модели по 715 полным случаям. Для {ИП, ИК} эти
вычисления неитеративны, но для {ИП, ИК, ПК} требуются итера-
тивные вычисления. Два множества МП-оценок объединяются как
для насыщенных моделей, чтобы получить по свойству 5.1 МП-
оценки оценки совместных вероятностей тгу^.
Таблица 9.11. МП-оценки для модели {ИК, ПК},
вычисляемые с помощью ЕМ-алгоритма по данным табл. 9.8,а) и 9.8,6)
Шаг NL Оценки вероятнос- тей в ячейках (х 100) Шаг Е. Частоты в ячейках после заполнения
Итера- Кли- Пред- Исход Исход
ВОЙ уход выжили умерли выжили умерли
1 А хуже 0,36 24,67 3+(10)(0,36)72,74=4,33 176+150(24,62)752,22 =246,86
лучше 0,62 40,92 4+5(0,62)70,90 = 7,44 293 +90(40,92)744,14= 376,44
В хуже 2,38 27,56 17+10(2,38)72,74=25,67 197+150(27,56)752,22=276,14
лучше 0,28 3,22 2+5(0,28)70,90=3,56 23 + 90(3,22)744,14 = 29,56
2 А хуже 0,48 25,42 4,50 246,84
лучше 0,73 38,84 7,56 376,32
В хуже 2,72 28,40 25,50 276,16
лучше 0,30 3,12 3,44 29,68
3 А хуже 0,49 25,42 4,55 246,83
лучше 0,75 38,82 7,59 376,31
В хуже 2,69 28,41 25,45 276,17
лучше 0,30 3,12 3,41 29,69
4 А хуже 0,50 25,42 4,56 246,83
лучше 0,76 38,82 7,60 376,31
В хуже 2,68 28,41 25,44 276,17
лучше 0,29 3,12 3,40 29,69
211
Параметры распределений ИП и К при заданном ИП не раздет,
ны для модели [ИК, ПК), поэтому методы факторизации правде>
подобия неприменимы. В табл. 9.11 приведены четыре итерации
ЕМ-алгоритма для этой модели, оценки 100-7tyw на шагах 4 и 5 со
впадают с точностью до двух десятичных знаков. Вычисления uu
шаге Е проводились с помощью микрокалькулятора, а шаг М осу
ществлялся подбором [ИК, ПК] по заполненной таблице с по
мощью стандартной программы логлинейного анализа (BMDP4F я
пакете BMDP [см. Dixon(1983)]). Заполненные частоты, полученные
на шаге Е, были преобразованы в целые умножением на 100, так
как программа логлинейного анализа усекает вводимые веществен
ные числа до их целой части. Для более крупных задач можно за
программировать шаг Е, чтобы избавиться от обременительных
расчетов. Заметим, что здесь шаг М неитеративный. Та же процеду
ра будет действовать и в той ситуации, когда шаг М итеративный,
но тогда в ЕМ-алгоритме присутствуют вложенные итерации.
В предыдущем примере начальные значения для ЕМ-алгоритма
основывались на полностью классифицированной таблице. В боль-
ших таблицах с нулевыми ячейками эта процедура может давать не-
удовлетворительные начальные значения, что указано в [Fuchs(1982)].
Например, допустим, что в полной таблице маргинальная таблица,
соответствующая некоторому члену в модели, имеет пустую ячейку,
а в дополнительной таблице частота в той же ячейке положительна.
Если строить начальные значения по полностью категоризованной
таблице, то ЕМ-алгоритм никогда не позволит, чтобы в ячейке с
нулем была ненулевая вероятность, что противоречит информации
из дополнительной таблицы. Эту проблему можно решить, вычис-
ляя начальные значения после того, как к ячейкам полностью клас-
сифицированной таблицы будут добавлены положительные значе-
ния таким образом, что начальные оценки будут находиться в допу-
стимом параметрическом пространстве. На последующих итерациях
эти добавки исчезнут.
9.4.3. Критерии для подбора моделей
по частично классифицированным данным
Статистики хи-квадрат, аналогичные (9.9) и (9.10), можно вычис-
лять по частично классифицированным данным, проводя суммиро-
вание по ячейкам в полной таблице и в частично классифициро-
ванной дополнительной таблице. Заметим, что для насыщенной мо-
дели (в примере 9.9 — [ИПК]), в отличие от полных данных, полу-
чают ненулевые значения G2 и Хг. Эти значения служат для про-
верки условия ОПС.
212
Статистики хи-квадрат для модели с ограничениями можно полу-
чить, вычисляя G2 (или JV2) для модели с ограничениями и для на-
сыщенной модели и вычитывая второе из первого [Fuchs (1982)].
Получаемая разность имеет такое же число степеней свободы, как
статистика хи-квадрат для модели с ограничениями для полных
данных.
Хотя на первый взгляд кажется, что эти процедуры требуют
ОПС, на деле критерии остаются верными и при условии, что про-
пущенные данные ОС. При последнем предположении компоненты
правдоподобия, соответствующие механизму порождения пропу-
сков, сокращаются при вычитании значений G2 (или .№) для двух
моделей.
Пример 9.10 (продолжение примера 9.9). Статистики для выбо-
ра модели в неполной трехфакторной таблице. Статистики G2 и Хг
для насыщенной модели [ИКП] из примера 9.9 равны:
^(ИКП) = 7,96, б2(ИКП) = 7,80, ч.с.с. =3.
Вычисление числа степеней свободы (ч.с.с.) выполнено так: всего в
данных 8 + 4=12 ячеек, что дает 11 степеней свободы для оценива-
ния 7 вероятностей в ячейках и 1 вероятности получения ответа,
или 8 параметров. Отсюда ч.с.с. = 11—7—1=3. Поскольку 95-я про-
центиль распределения хи-квадрат с 3 степенями свободы равна
7,815, нулевая гипотеза, что данные ОПС, имеет P-значение меньше
0,05 по статистике Хг и около 0,05 по статистике G1. Ненасыщен-
ные модели дают:
.¥2(ИП, ИК, ПК) = 7,99, О2(ИП, ИК, ПК) = 7,84, ч.с.с. = 11— 6—1=4,
^(ИП, ПК) = 8,29, С2(ИП, ИК) = 8,00, ч.с.с. = 11—5—1=5,
^(ИП, ИК)=178,55, С2(ИП, ИК)=195,92, ч.с.с. = 11—5—1 = 5.
Вычитая значения статистик хи-квадрат для насыщенной модели,
получаем:
ДХ2(ИП, ИК, ПК)=0,03, ДС2(ИП, ИК, ПК)=0,04, ч.с.с. =8—6—1 = 1,
ДА^ИП, ПК)=О,33, Д6“(ИП, ПК)=0,20, ч.с.с. = 8—5—1 = 2,
ЛЛ^ИП, ИК)= 170,59, ДС2(ИП, ИК)= 188,12, ч.с.с. = 8—5—1=2,
что вполне сопоставимо со статистиками, основанными на полнос-
тью классифицированных случаях из табл. 9.9. Как и ранее, мы от-
даем предпочтение модели {ИП, ПК].
213
ЛИТЕРАТУРА
Bishop, Y. M. M., Fienberg, S. E., and Holland, P. W. (1975). Discrete Multivariate Analysis'.
Theory and Practice. Cambridge, MA: MIT Press.
Chen, T., and Fienberg, S. E. (1974). Two-dimensional contingency tables with both completely
and partially classified data, Biometrics 30, 629-642.
Dixon, W. J. (Ed.) (1983). BMDP Statistical Software, 1983 revised printing, Berkeley CA:
University of California Press.
Fienberg, S. E. (1980). The Analysis of Crossclassified Data, 2nd ed. Cambridge, MA: MIT Press,
Fuchs, C. (1982). Maximum likelihood estimation and model selection in contingency tables with
missing data, J. Am. Statist. Assoc. 77, 270 278.
Goodman, L. A. (1970). The multivariate analysis of qualitative data: Interaction among multiple
classifications, J. Am. Statist. Assoc. 65, 225 256.
Goodman, L. A. (1979). Simple Models for the Analysis of Association in Crossclassifications
Having Ordered Categories, J. Am. Statist. Assoc. 74, 537 552.
Haberman, S. J. (1974). The Analysis of Frequency Data. Chicago: University of Chicago Press.
Hartley, H. O. (1958). Maximum likelihood estimation from incomplete data, Biometrics 14,
174-194.
Hocking, R. R., and Oxspring, H. H. (1974). The analysis of partially categorized contingency
data, Biometrics 39, 469-483.
Little, R. J. A. (1982). Models for nonresponse in sample surveys, J. Am. Statist. Assoc. 77,
237-250.
McCullagh, P. (1980). Regression models for ordinal data, J. Roy. Statist. Soci. B42, 109-142.
Rubin. D. B. (1985), Comment on “A statistical model for positron emission tomography,” J.
Am. Statist. Assoc. 80, 31-32.
Vardi, Y., Shepp, L. A., and Kaufman, L. (1985). A statistical model for positron emission
tomography, J. Am. Statist. Assoc. 80, 8 37.
ЗАДАЧИ
1. Покажите, что для полных данных пуассоновская и полиномиальная модели
для многофакторных частотных данных дают на основании правдоподобия одинако-
вые выводы для вероятностей в ячейках. Покажите, что результат остается верным,
если данные ОС.
2. Выведите МП-оценки и соответствующие дисперсии для правдоподобия (9.1).
Указание. Сумма вероятностей равна 1.
3. Проверьте результаты критерия хи-квадрат на условие ОПС в примере 9.2.
4. Вычислите долю отсутствующей информации в примере 9.2 с помощью мето-
дов из разделов 7.5 и 7.6.
5. Вычислите ожидаемые частоты в ячейках в первом столбце табл. 9.3,6) и срав-
ните ответ с результатами для полных случаев.
6. Допустим, что в примере 9.3 нет наблюдений со структурой г. Какие параметры
не поддаются оцениванию, т. е. не входят в правдоподобие? Оцените вероятности в
ячейках, используя предполагаемые значения для этих параметров (см.раздел 6.6).
7. Выразите словами предположение о механизме порождения пропусков, при ко-
торых оценки в табл. 9.4,в) являются МП-оценками для примера 9.4.
8. Приведите подробности вывода уравнения (9.4).
9. Повторите вычисления в примере 9.4 для оценок тг12.
214
10. Проведите вычисления в примере 9.4, предполагая, что грубо классифициро-
ванные данные в табл. 9.4 были сведены к градациям «улучшение» или «без улучше-
ния» (без изменений или ухудшение).
11. Проведите вычисления для ЕМ-алгоритма для данных табл. 9.5, поменяв места-
ми значения с индексами а, б и в, г в дополнительной таблице. Сравните МП-оценки
отношения шансов с оценками по полным случаям. Совпадают лн они?
12. Покажите, что в примере 9.9 факторы в факторизованном правдоподобии раз-
дельны для моделей (ИП, ИК, ПК) и (ИП, ИК), но не раздельны для (ИК, ПК).
13. Приведите явные МП-оценки для всех моделей табл. 9.7, кроме (12, 23, 31).
14. С помощью результатов из задачи 12 выведите опенки для моделей (ИПК)
(ИК, ПК) и (ИП, ИК) в табл. 9.9.
15. Вычислите ОМП для модели (ИП, ИК) для всех данных табл. 9.8, в которых
частоты в дополнительной таблице 9.8,6) увеличены в 10 раз.
16. Почему начальные значения, в которые входят нулевые вероятности, могут на-
рушить нормальную работу ЕМ-алгоритма? Указание. Рассмотрите правдоподобие.
Глава 10. СМЕШАННАЯ МОДЕЛЬ ДЛЯ НОРМАЛЬНО
И НЕНОРМАЛЬНО РАСПРЕДЕЛЕННЫХ.
НЕПОЛНЫХ ДАННЫХ С ИГНОРИРОВАНИЕМ
МЕХАНИЗМА ПОРОЖДЕНИЯ ПРОПУСКОВ
10.1. ВВЕДЕНИЕ
В гл. 8 мы рассмотрели различные модели для непрерывных пе-
ременных с пропусками, опирающиеся на многомерное нормальное
распределение. Категориальные переменные участвовал» лишь как
полностью наблюдаемые сопеременные в регрессионных моделях.
В гл. 9 мы обсуждали модели для категориальных переменных с
пропусками. В настоящей главе мы рассмотрим методы анализа
данных с пропусками для смешанной совокупности нормальных и
ненормальных переменных. В этом направлении было сделано со-
всем немного исследований, где ограничивались моделями, в кото-
рых механизм порождения пропусков считается пренебрежимым.
Литтл и Шлухтер [Little and Schluchter (1985)] описали модель для
данных с пропусками для смешанных нормальных и категориаль-
ных переменных и вывели относительно простой и вычислительно
осуществляемый ЕМ-алгоритм. Основной вариант этой модели
представлен в разделе 10.2. В разделе 10.3 выведены важные обоб-
щения. В разделе 10.4 проводится сравнение с ранее разработанны-
ми алгоритмами. Наконец, в разделе 10.5 мы рассматриваем моде-
ли смесей нормальных распределений, которые дают устойчивые
МП-оценки средних и ковариационной матрицы, а также других па-
раметров, связанных с ними, как для полных, так и для неполных
данных.
215
10.2. ОБЩАЯ МОДЕЛЬ ПОЛОЖЕНИЯ
10.2.1. Модель и оценки для полных данных
Допустим, что гипотетические полные данные представляют со
бой случайную выборку объема п по К непрерывным переменным
X и V категориальным переменным Y. Категориальная переменная
j имеет Tj уровней, так что категориальные переменные задают Г
факторную таблицу сопряженности с C=njl17y ячейками. Обозна
чим через х, вектор 1хА непрерывных переменных, а через у,—век
тор 1 х V категориальных переменных у /-го объекта. По
построим 1 х С-вектор w;-, равный Ет, если объект / относится к
щ-й ячейке таблицы сопряженности, где Ет—вектор 1хС с т-м
элементом, равным 1, и остальными элементами, равными нулю.
Олкин и Тэйт [Olkin and Tate (1961)] определяют общую модель
положения для распределения (x^w^ в терминах маргинального рас-
пределения wi и условного распределения при заданном w,:
1) Wj — н.о.р. сл. в. с вероятностями ячеек
Pr(Wj=Em)~ тгт, т = Етгга--1;
2) при заданном Wj=Em
A-мерное нормальное распределение со средним ут = (у.т1,...,у.тК') и
ковариационной матрицей Я. Обозначим П=(тг1,...,тгс) вектор 1хС
вероятностей в ячейках и Г= — матрицу С* К средних в ячей-
ках. Модель содержит С—1+КС+1/2Х(Х+1) параметров (?=(П,Г,Я).
Следует упомянуть следующие свойства модели: 1) ковариацион-
ная матрица Q предполагается одинаковой во всех ячейках таблицы
сопряженности; 2) если какая-то бинарная переменная, скажем Уь
со значениями 0 и 1 выбрана в качестве зависимой переменной, то
получится модель логистической регрессии. Это значит, что услов-
ное распределение У] при постоянных значениях других перемен-
ных — бернуллиевское с Рг(У] =l) = eL/(l+eL), где L линейна по
остальным переменным; 3) если в качестве зависимой выбрана ка-
кая-то непрерывная переменная, то получается нормальная регрес-
сионная модель, т.е. условное распределение X, при фиксации
значений других переменных нормально со средним, являющимся
линейной комбинацией других переменных и константы.
Свойства 2 и 3 означают, что МП-оценки для данной модели ло-
гистической регрессии с пропусками и для данной модели линейной
регрессии с пропусками в непрерывных и категориальных пре-
дикторах можно найти, вычисляя МП-оценки 6 = (П,Г,(1) и преобра-
зуя их к виду, дающему параметры соответствующего условного
распределения. Преобразования легко провести с помощью опера-
тора свертки, как это делается в разделе 10.2.3.
216
Логарифм правдоподобия для этой модели равен:
/(ГДП) = Д 1п/(хХ,Г,П)+ .Eln/CwJII)-
= .S хЦ +trf)-T(.£ nfo) + (10.1)
+ Иот)(1П1Г« Т Дда)^ >
где wim — т-я компонента tr — след матрицы, h(Q) =
= —ул {Х1п(2зг) + 1п|12|). Максимизация (10.1) приводит к ОМП для
полных данных
II=h-1Lwz,
f = (ExJ'wi)(EwTw,)~1, (10.2)
О=л~-,Е(х,—w,f)T(x—^-f),
которые являются просто наблюденными относительными частота-
ми в ячейках, средними в ячейках и объединенной ковариационной
матрицей X внутри ячеек соответственно.
10.2.2. МП-оценивание при пропусках
Теперь допустим, что некоторые значения в X и в Ж отсутству-
ют. Пусть xobsj — вектор присутствующих непрерывных перемен-
ных у <-го объекта, xmisi — вектор пропущенных непрерывных
переменных, a S, — множество ячеек, в которых может находиться
г-й объект при присутствующем наборе категориальных перемен-
ных. Рассмотрим ЕМ-алгоритм для МП-оценивания & по данным
&obs,i’
Плотность (10.1) относится к регулярному экспоненциальному се-
мейству с достаточными статистиками полных данных Exjx,, Еи’/х,
и Ew,-, являющимися соответственно суммой квадратов и взаимных
произведений в X, суммами X в ячейках и частотами в ячейках.
Следовательно, мы можем применить упрощенную форму ЕМ-алго-
ритма из раздела 7.6. На t-я итерации на шаге Е вычисляют ожида-
емые значения достаточных статистик при заданных (xobsi, Sb i—
= и текущих оценках параметров Для каж-
дого объекта вычисляют:
Шаг Е:
Т^Щх^х^, S', №), (10.3)
T2; = E(wTx.|Xo^. $. 00)), (Ю.4)
T3,.=E(w,.|xofe,., S,-, 6«). (10.5)
217
Шаг Е подробно рассмотрен в разделе 10.2.3. На шаге М вычисля-
ют МП-оценки (10.2), где достаточные статистики полных данных
заменены на их оценки на шаге Е.
Шаг М:
W+r> = n-l£T3i,
Г(г+1)=П->(.Е7’2/), (10.6)
Г /Л \ Т / И \т
П('+,, = л-1[ ,Е T2^D-^ Г2;)],
где D — диагональная матрица с ненулевыми элементами ET3i.
После этого снова проводят вычисления на шаге Е по (10.3)—(10.5)
с новыми оценками параметров, и циклы продолжаются, пока про-
цедура не сойдется.
Таблица 10.1. Данные для примера 10.1
Низкий риск (G=l) Средний риск (G = 2) Высокий риск (G=3)
первый ребенок второй ребенок первый ребенок второй ребенок первый ребенок второй ребенок
К, И, О, «2 D, Л1 У, D. К, V2 D. Vt D, я2 Г2 л2
НО — — — 150 1 88 85 2 16 73 - 98 110 — 112 103 2
118 165 1 — 130 2 — 98 — 114 133 — 127 138 1 92 118 1
116 145 2 114 125 — 108 103 2 90 100 2 ИЗ — — —
—• — — 126 — — ИЗ — 2 95 115 2 107 93 — 92 75 —
118 140 1 118 123 — — 65 — 97 68 2 — _ j 101 — 2
— 120 — 105 128 — 118 — 2 — — 2 — 87 98 2
1 - I 96 ИЗ — 92—2 114 — 2 — — 2
138 163 1 130 140 — 90 — 1 НО — 2 56 58 2 88 105 1
115 153 1 — — — 98 123 — 96 88 — 96 95 1 87 100 2
— 145 2 139 185 2 113 ПО — 112 115 — 126 135 2 118 133 —
126 138 1 105 133 1 102 130 - 114 120 — — — — 130 195 —
120 160 — 109 150 — 89 ИЗ 2 130 135 — — 116 — 2
— 133 — 98 108 — 90 80 2 91 75 2 64 45 2 82 53 2
— — — 115 140 2 —. — — 109 88 2 128 — 2 121 — 2
115 158 2 — 135 1 75 63 1 88 73 1 — 120 1 108 118 —
112 115 2 93 140 — 93 — 1 — — — 100 140 2
133 168 1 126 158 2 — — — 115 — 2 105 138 1 74 75 1
118 180 1 123 — 1 100 — 1 118 138 1 103 108 — 121 155 1 116 148 — ПО 155 1 101 120 1 — 110 1 — 100 2 — — 1 104 118 1 87 85 1 — 63 — 123 170 1 114 130 2 — — 2 113 — 2 117 122 — 1 105 — 2 115 138 2 104 123 2 ИЗ 123 2 — — 2 82 103 2 114 — 2 — — 1 88 118 — 84 103 —
218
Пример 10.1. Данные для исследования групп риска. В [Little and
Schluchter(l 985)] анализируются данные исследовательского проекта
St. Louis Risk Research Project, приведенные в табл. 10.1. Одна из
целей исследования состояла в том, чтобы оценить влияние психи-
ческих расстройств родителей на различные стороны развития их
детей. В предварительном исследовании были собраны данные о
/2=69 семьях с двумя детьми. Семьи классифицировались по группе
риска родителей (G) по следующим категориям:
1) G=1 — контрольная группа нормальных семей из местного
населения;
2) G=2 — группа умеренного риска, где один из родителей болен
вторичной шизофренией или страдает другим психиатрическим за-
болеванием или где один из родителей имеет непсихиатрическое
хроническое заболевание;
3) G=3 — группа высокого риска, где один из родителей болен
шизофренией или страдает сильными психическими расстройствами.
В табл. 10.1 приводятся также данные по двум другим категори-
альным переменным: Dt — число симптомов у первого, D2 — у вто-
рого ребенка (1 — мало, 2 — много). Значит, всего есть И=3
категориальные переменные, образующие таблицу сопряженности
3x2x2 с 0=12 ячейками. Есть также К=4 непрерывные перемен-
ные Rt, Vi, R2 и Рг> где Rc и Vc — стандартизованные коэффициен-
ты индекса развития навыков чтения и речи с-го ребенка в семье,
с=1,2. Переменная G наблюдается всегда, но остальные перемен-
ные имеют пропуски в самых разных сочетаниях.
Анализ структур пропусков показывает, что все параметры об-
щей модели положения поддаются оцениванию, несмотря на мно-
жество пробелов в матрице данных. Например, хотя R2 не присут-
ствует в полностью классифицированной таблице при G=l, L>i=2,
D2 — l, есть пять других семей с известным значением R2, которые
могли оказаться в этой ячейке. Эти наблюдения содержат информа-
цию, по которой можно оценить среднее R2 в этой ячейке.
В табл. 10.2 (модель А) показаны МП-оценки, вычисленные по
ЕМ-алгоритму для модели без ограничений. Соответствующий мак-
симум логарифма правдоподобия равен 872,73. Было найдено не-
сколько локальных максимумов правдоподобия, возможно, в связи
с относительно высокой долей пропусков в категориальных пере-
менных Д и D2, и требовалось до 50 итераций в зависимости от на-
чальных значений, чтобы логарифм правдоподобия сходился к
максимуму с точностью до двух десятичных знаков. Между средни-
ми в некоторых ячейках, соответствующими различным максиму-
мам правдоподобия, были обнаружены существенные отличия.
Подробности указаны в [Little and Schluchter (1985)]. Эти обстоя-
тельства показывают, что выводы надо делать аккуратно, так как
данных недостаточно для того, чтобы обеспечить соответствие с
предположением об асимптотической нормальности.
219
Таблица 10.2. МП-оценки по данным табл. 10.1
а) ожидаемые частоты и средние в ячейках
Ячейка Ожидаемые частоты Средние в ячейках
Я, Г,
G £>, 1>2 А В А й А й А В А В
1 1 1 10,2 4,8 110,2 113,6 99,8 103,0 133,7 140,9 119,4 129,5
1 1 2 9,0 8,8 123,4 122,8 116,0 115,4 161,1 160,1 132,1 131,0
1 2 1 3,6 3,7 111,2 105,3 110,0 101,7 147,7 136,9 126,9 111,6
1 2 2 4,2 9,7 118,0 114,5 111,9 111,1 123,9 120,8 151,4 148,0
2 1 1 2,2 4,3 87,6 88,4 101,1 101,5 81,1 81,7 103,3 104,2
2 1 2 7,2 7,8 104,3 104,4 109,4 109,6 134,6 134,8 109.6 109,9
2 2 1 2,3 3,3 96,4 96,1 134,5 134,3 122,6 122,0 146,1 145,3
2 2 2 12,3 8,6 106,7 106,6 97,0 96,8 104,3 104,5 102,4 102,3
3 1 1 2,1 3,2 115,8 115,7 82,9 82,8 137,7 137,5 96,3 96,0
3 1 2 7,8 5,9 105,7 100,7 100,8 96,1 127,9 119,4 128,3 117,1
3 2 1 1,0 2,5 56,2 76,2 88,2 108,3 58,3 90,4 105,4 148,6
3 2 2 7,1 6,4 107,3 107,4 107,0 107,3 107,2 107,2 104,8 104,8
б) стандартные отклонения и корреляции
Модель Стандартные отклонения Корреляции
R-. Vi (КМ (Я.Л) (Я.Л) (ЛУд («2,К2) (Г„К2)
А 13,2 11,9 20,7 24,1 0,701 0,832 0,825 0,663 0,835 0,885
В 13,1 11,9 20,1 23,3 0,685 0,832 0,822 0,654 0,836 0,881
А — модель без ограничений на средние или вероятности в ячейках;
В — модель без ограничений на средние и с ограничением на вероятности в ячей-
ках (Р, и Т>2 предполагаются независимыми от G).
10.2.3. Вычисления на шаге Е
Опишем теперь более подробно, как по уравнениям (10.3)—(10.5)
вычисляются величины {1\pT2i,T3i, /=1,...,п). Все параметры в ни-
жеследующих выражениях равны текущей оценке параметра (№.
При вычислении Ти находят £’(v»’(-/^obs,i>^i’^W) Для каждого объекта
т-ю компоненту этого вектора будем обозначать
<liim--=Pr(wi=Em | xobs(, SZ,0W). Таким образом, для ти = 1,...,С u>im —
условная апостериорная вероятность, что объект I относится к ячей-
ке т при заданных наблюденных непрерывных переменных xobs>p
т. е. информация о том, что объект i относится к одной из ячеек из
Sj и д=(№. Эта вероятность положительна, если m^Sj, причем она
имеет вид
= exp(6m)/ Js.exp(5m), (10.7)
где _ т 1 -1
=Jt-obsp^obs,iEobs,i,m 2^/tobs,<,zn^obs,z/tobs,/,zn +ln(7rm) (10.8)
и |“оЬ8,1,ж и ®obsz — среднее и ковариационная матрица в ячейке т
непрерывных переменных xobs/-, присутствующих у /-го объекта.
220
Теперь обозначим непрерывные переменные для z-го объекта через
(Л'у, У-1 >-••>-&)• Если Ху пропущен, обозначим через х^ = E(xy\xobsy,
прогноз значения Ху по регрессии в /и-й ячейке Ху
ни xobs>(- при 0=№. Элемент в m-й строке и j-м столбце T2i для
///=1,..’.,С и j=l,...,К получается при умножении Ху или его оценки
на условную апостериорную вероятность, что z-й объект относится
к т-й ячейке:
Г a>jmx№\ если Ху отсутствует,
£,(w;fr,xIy|xobspS;,0<r)) =
t ы/тХу, если Ху присутствует.
Обозначим для отсутствующих Ху и xik через оук^у условную ко- •
вариацию Ху и xik при заданных xobsy и условии ’wj=Em. Тогда j-й
шемеят Ту для j, равен:
E&ij Xik\x0^,i,Si,^) = ^(.XyX^x^yWj=Em,№) =
XyXjk, Xy, xik присутствуют,
X/k^mzs^im x^, Ху отсутствует, xik присутствует
= < Xij^mzS^im^ik^-- xij присутствует, xik отсутствует,
^-obsA Zs.4mx^x№\ Xy, xik отсутствуют.
Вычисления удобно проводить с помощью оператора свертки,
описанного в разделе 6.5. Рассмотрим матрицу
М=
^obs,/ ^cov,/' obs,/
О . Q . . ГТ, .
"cov,/ “mis,/ mis,/
^obs,/ 1 mis,/ E
где P — диагональная матрица CxC с т-м диагональным элемен-
том, равным 21птг,„, т=1,...,С, и где
0=
^obs,/ ^cov,/
^cov,/ ^mis,/ _
и E-[fobs>;, rmis>;] —
текущие оценки 0 и Г, разделенные в соответствии с присутствую-
щими и отсутствующими переменными X у z-го объекта. Проводя
свертку по элементам М, соответствующим присутствующим X,
получаем
SWP[xobs>;]M=
Gn G&
G12 G12 Gji
Gb G2j G33
221
где Gn=—Bobs(-, Gi2 = fi0bSli ^covi “ коэффициенты регрессии пре
пущенного X на xobS;(-, G22 = Q?0V)Z Uobs.z °cov,i содержит осн<
точные дисперсии и ковариации ojk.obsl для Ху, xike.xQbsi, G13 = fi()|(,,
robs,j Дает коэффициенты для xobs(- в линейной дискриминант! ни'1
функции (10.8), а m-й диагональный элемент 1/2G33 = 1/2P—- 1/2Г(11„,
^obs,z r’obs.z Равен сумме второго и третьего членов в правой сторо
не (10.8). Таким образом, GB и G33 вместе с чгт дают линейную
дискриминантную функцию 6т и, следовательно, iljm, как и в (10.7)
Значительный выигрыш в вычислениях можно получить, группируй
объекты с одинаковой структурой пропусков в X, чтобы избежав,
ненужной повторной свертки.
10.3. ОБОБЩЕНИЕ ОБЩЕЙ МОДЕЛИ ПОЛОЖЕНИЯ
НА СЛУЧАЙ ОГРАНИЧЕНИЙ НА ПАРАМЕТРЫ
10.3.1. Введение
Модель из раздела 10.2 задает различные векторы средних /i,zl
для т разных ячеек таблицы и не налагает ограничений на верояз
ности ячеек, кроме очевидного Етги = 1. В этом разделе мы опишем
более общую модель, в которой допустимы ограничения на цт, ти
пичные для дисперсионного анализа, и на тг™, применяемые в ло>
линейной модели с ограничениями. Эта обобщенная модель рае
смотрена в [Krzanowski (1982)] для дискриминантного анализа при
полных данных.
10.3.2. Ограничения на средние в ячейках
Пусть Z/ — вектор 1хг, г<С, переменных плана для /-го объекта;
Z, можно получить из вектора индикатора ячейки путем Zj—w^A,
где А — известная матрица Схг, представляющая выбранный
план. Обобщенная модель определяет, что условное распределение
Xj при заданном w, зависит от wt только через г,, т. е. /(х,-| м>;)~
~Nk(z.jB‘, 0), где В — матрица гхК неизвестных параметров. Отме-
тим, что Дх(-|и/;)= Wj АВ, так что Г=ЛВ. В модели из раздела 10.2
А — единичная матрица СхС.
10.3.3. Логлинейная модель
для вероятностей ячеек
Другой путь уменьшения размерности модели — это введение
ограничений на вероятности П с помощью логлинейной модели, об-
суждавшейся в разделе 9.4. Например, допустим, что ячейки форми-
222
руются путем совместной классификации по трем категориальным
m-ременным Yit У2 и Y3 с Ц, 12 и 13 уровнями соответственно,
(' Лх12х/3. Изменим обозначения: пусть — вероятность, что
•'| J, Уг — к, у3=! для j= 1,...,Д, к=1,...,12 и 1=1,...,13. Логлинейная
модель задается уравнением
и приравниванием некоторых подмножеств элементов а нулю. В
разделе 9.4 приведено более подробное изложение.
10.3.4. Модификация алгоритма из раздела 10.2.2
Пусть а — ненулевые элементы а в логлинейной модели для V-
факторной таблицы с С=П]1г1 Ij ячейками. Обозначим irm(a) веро-
игность попадания в т-ю ячейку с учетом ограничений, т = 1,...,С.
Мы коротко опишем модификации алгоритма из раздела 10.2.2,
нужные для подгонки моделей из разделов 10.3.2 и 10.3.3 по непол-
ным данным.
Пусть </0), 0(0) и В(0) — начальные оценки параметров для какой-
либо модели разделов 10.3.2 и 10.3.3, вычисленные, возможно, по
полным наблюдениям. Пусть где А — известная матри-
ца плана, и т® = 7rw(a<°>), m=l,...,C. Модель с ограничениями из
разделов 10.3.2 и 10.3.3 относится к регулярному экспоненциально-
му семейству с такими минимальными достаточными статистиками
для полных данных: Exjx,-, Ew-WjA и линейными комбинациями
частот Ем/,, определяемыми подбираемой логлинейной моделью.
Так как эти величины — линейные комбинации достаточных стати-
стик для полных данных при модели из разделов 10.2, шаг Е состо-
ит в вычислении Y,Tljt %T2j и ЕТ3(- по уравнениям (10.3)—(10.5) и
формировании линейных комбинаций этих функций, дающих мини-
мальные достаточные статистики для полных данных для модели с
ограничениями.
Вычисления на шаге М отличаются от вычислений для модели
без ограничений. Оценки Г, П и 0 получают, соблюдая ограниче-
ния, наложенные на модель. П оценивают, образуя сначала много-
факторную таблицу с частотами ячеек, задаваемыми вектором LT3i
(уравнение (10.5)). Эта таблица содержит элементы из частот ча-
стично классифицированных объектов, распределенных по таблице
на шаге Е. Новые частоты в ячейках получают, подбирая предло-
женную логлинейную модель по частотам в Y,T3i методами для
полных данных, которые сами могут быть итеративными, если нет
явных оценок. Вероятности в подогнанной таблице — новые оценки
{тгт(а)), используемые на следующем шаге М. На практике при
отсутствии явного вида для оценок на шаге М на первых итерациях,
223
возможно, будет достаточно улучшать оценки вероятностей про
хождением одного шага итеративного алгоритма пропорционаш.
ного подбора, что исключает необходимость в двух вложенных
уровнях итераций. В результате получается обобщенный ЕМ-алю
ритм из раздела 7.3, поскольку алгоритм пропорционального под
бора обладает свойством увеличивать правдоподобие данных ни
каждом шаге до того, как алгоритм сойдется [Brown (1959)].
При полных^ данных МП-оценки Вий равны 11
Q = n~1L(xi—-Zj£i) (см. [Anderson (1958), гл. 8]). Мы полу
чим на шаге М оценки В и Q, если в приведенных уравнениях для
В и П запишем zp=WjA и заменим Exfx,-, Ewjx; и Ewjwr- на
^T2i и D соответственно, где D — матрица с диагональными эле
ментами и нулевыми внедиагональными элементами. Тогда
пересчитанные на шаге М оценки В, Г и 0 на 6-й итерации равны:
даы) = (ATDA)-lA t(E7’2,), (10.9)
Г<'+»=ЛВ<'+1> (10.10)
ОДЫ) = „-1 [ Д Tij_( £ T^A^DAy-'A'1^ Д Т2/)]. (10.11)
Если на средние не наложено никаких ограничений, А — единичная
матрица СхС, и уравнения (10.9)—(10.11) для и Г(/+1) эквива-
лентны соответствующим уравнениям в (10.6). Новые оценки П(г+,\
Г(,+1) и подставляются в следующий шаг Е, задаваемый урав-
нениями (10.3)—(10.5).
10.3.5. Модели с ограничениями
для данных примера 10.1
Пример 10.2 (продолжение примера 10.1). В разделе 10.2.2 по
данным табл. 10.1 подбиралась модель положения без ограничений.
В этой модели слишком много параметров — 69 при 69 неполных
наблюдениях. В этом разделе мы подберем и проверим модели с
меньшим числом параметров, соответствующее гипотезам, пред-
ставляющим основной интерес. Допустим, в частности, что мы хо-
тим проверить гипотезу, что развитие патологических психиатри-
ческих симптомов у детей не связано с группой риска родителей.
Эта гипотеза означает, что
vjkl~ j~ 1,2,3, к,1=1,2,
где TTjki — вероятность, соответствующая уровню j фактора G и
уровням к и I факторов П} и Д. На средние непрерывных перемен-
ных в ячейках ограничений нет. В [Little and Schluchter (1985)] эта
модель подгоняется по данным методом из раздела 10.3.4.
224
В табл. 10.2 (модель В) приведены ОМП для модели с ограниче-
ниями. Максимум логарифма правдоподобия составил —877,64. На-
помним, что логарифм правдоподобия для полной модели, вычис-
ленной в разделе 10.2.2, был равен —872,73. Значит, хи-квадрат-
етатистика отношения правдоподобий для проверки независимости
Pi и Z>2 от G равна 2-(—872,73+ 877,64) = 9,82 при шести степенях
свободы, что означает отсутствие доказательств несоответствия
модели. Для этой модели был найден также другой локальный мак-
симум (—877,72).
Затем в поисках более простой модели Литтл и Шлухтер обрати-
лись к модели, в которой взаимодействия GxDt, GxD2 и GxDtxD2
не влияют на средние непрерывных переменных при тех же ограни-
чениях на вероятности ячеек. Ограничения на средние непрерывных
переменных можно записать в виде Eix^z^—ZtB, где В — матрица
параметров 6x4, a Zi=WjA, где
1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 0 0 0 0 —1 -1 —1 —1
0 0 0 0 1 1 1 1 —1 —1 —1 —1
лт= 1 0 0 —! 1 0 0 —1 1 0 0 —1
0 1 0 —1 0 1 0 —1 0 1 0 --1
_о 0 1 —1 0 0 1 —1 0 0 1 —1 _
и 12 ячеек в векторе и»,- расположены так, что индекс D2 пробегает
значения быстрее всех, a G — медленнее всех Эта модель уменьша-
ет число параметров, нужных для описания средних, с 48 до 24.
Снова были обнаружены локальные максимумы функции правдо-
подобия. Глобальный максимум логарифма правдоподобия соста-
вил —910,46, так что критерий отношения правдоподобий для
сопоставления этой модели с полной моделью равнялся %2 = 75,46
(при 30 с.с.), что означает, что ограниченная модель не согласуется
с данными. Авторы также вычислили параметры модели, в кото-
рой нулевым был только эффект взаимодействия GxDixD2 при тех
же ограничениях на вероятности ячеек. Эта модель также обнару-
жила несоответствие данным при сравнении с полной моделью
(х2=59,39 при 14 с.с.). P-значения не приводились, поскольку они
бессмысленны в связи с наличием локальных максимумов правдо-
подобия. Тем не менее эти результаты означают, что степень влия-
ния психического состояния родителей на развитие навыков чтения
и речи у детей зависит от психического состояния ребенка, как и
следовало ожидать.
8. Р Дж А Литсл, Д Б Рубни
225
10.4. СВЯЗЬ С ДРУГИМИ ЕМ-АЛГОРИТМАМИ
ДЛЯ НЕКОТОРЫХ СТРУКТУР ПРОПУСКОВ
При отсутствии категориальных переменных У алгоритм из pai
дела 10.2 сводится к ЕМ-алгоритму для многомерного нормальною
распределения, описанному в разделе 8.2.1. Если отсутствуют не
прерывные переменные и категориальные переменные содержа!
пропуски, то данные можно расположить в виде многомерной таб
лицы сопряженности с дополнительными таблицами для частично
классифицированных наблюдений. Тогда алгоритм соответствует
МП-оцениванию для частично классифицированных таблиц сопря
женности, обсуждавшихся в разделе 9.4.
Говоря более общо, алгоритмы из разделов 8.2.1 и 9.4 можно
применять также для структуры данных рис. 10.1. В этих данных
V категориальных переменных наблюдаются больше К непрерыв-
ных переменных в том смысле, что у объектов с присутствием од-
ной или более непрерывных переменных наблюдаются также все
категориальные переменные. Следуя теории факторизации правдо-
подобия из гл. 6, можно получать МП-оценки для модели из разде-
ла 10.3 следующим образом:
1) оценить параметры совместного распределения Y по первым V
столбцам рис. 10.1. Поскольку все данные только категориальные,
здесь применимы алгоритмы поиска ОМП для частично классифи-
цированных таблиц сопряженности;
Переменные
Объекты Yt ... Yv Х, . . .
1 1 ... 1 х ... х
т 1 ... 1' х ... х
т+1 х ... х > 0 ... 0
п х ... х 0 ... 0
Рис. 10.1. Структура пропусков, дающая простые ОМП. Обозначения: 1 — присут-
ствует, 0 — отсутствует, х — присутствует или отсутствует. Источник. [Little
and Schluchter (1985)].
2) оценить параметры условного распределения X при заданном
Y по первым т строкам рис. 10.1. Здесь можно использовать мно-
гомерный нормальный ЕМ-алгоритм, несмотря на присутствие ка-
тегориальных переменных. При этом в ЕМ-алгоритм включают
фиктивные переменные, представляющие эффекты Z- в плане дис-
персионного анализа, рассматривая их как непрерывные перемен-
ные. Затем проводят свертку окончательной оценки ковариационной
226
матрицы всех переменных по элементам, соответствующим фиктив -
ным переменным, что дает оценки В и б параметров условного рас-
пределения X при заданном К Они и являются МП-оценками в
соответствии с теорией факторизации правдоподобия гл. 6.
Алгоритм из раздела 10.2.2 вместе с модификациями для модели
с ограничениями из раздела 10.3.4 также дает МП-оценки В и Q (и
11), когда категориальные переменные присутствуют полностью, но
алгоритм отличается от «нормального» ЕМ-алгоритма, поскольку
свертка проводится только по непрерывным переменным (подроб-
ности см. в разделе 10.2.3). Основное достоинство этого алгоритма
заключается в возможности обрабатывать данные со структурой,
не соответствующей рис. 10.1, так как методы из разделов 8.2.1 и
9.4 уже нельзя применять для вычисления ОМП.
Если непрерывные переменные присутствуют полностью, a Y
представляет полностью отсутствующую переменную с к категори-
ями, то алгоритм из раздела 10.2.2 сводится к алгоритму Дэя [Day
(1969)] Для смеси к нормальных многомерных распределений. Так
как наш алгоритм работает при пропусках в непрерывных перемен-
ных, он является обобщением алгоритма Дэя на случай неполных
данных. Как и во многих других моделях смеси, весьма вероятна
многоэкстремальность правдоподобия [Aitkin and Rubin (1985)], так
что мы советуем запускать алгоритм несколько раз с различными
начальными значениями параметров.
Таблица 10.3. Результаты применения ЕМ-алгоритма
для смесей к данным Дарвина
а) Данные о разностях высоты самоопыленных и перекрестно опыленных растений
1 2 3 4 5 6 7 8 9 10 11 12 13 I2 15
—67 —48 6 8 4 16 23 24 28 29 41 49 56 6( 75
б) Результаты для модели нормального распределения: —2 логарифма доподобия: 122,9, Д= 20,93, 6*= 1329,7. прав-
в) Результаты применения ЕМ-алгоритма для смеси двух нормальных рас- пределений
Hanamtaik выбор (номер наблюдения в первой компоненте) —2 логарифма правдоподобия th & а1 И/,
1 116,0 —57,4 33,0 385,4 2,00
15 122,9 21,62 20,91 1330,0 0,957
любое подмножество [ 1-.-9) любое подмножество [10...15) 116,0 122,9 —57,4 оценки чальног 33,0 зависят о э значени 385,4 т точног я о 2,00 на-
227
Пример 10.3. Одномерная модель смеси для биологических дан-
ных. В [Aitkin and Wilson (1980)] проверяли поведение ЕМ-алгориг-
ма для моделей смеси на нескольких малых наборах данных. Одним
из них были данные Дарвина о разностях по высоте в парах с само
опыленными и перекрестно опыленными растениями. Они приведс
ны в табл. 10.3,а). В табл. 10.3,6) вместе со значением логарифма
правдоподобия (в котором опущена константа л1п2тг) приведены
обычные МП-оценки в предположении нормальности выборки со
средним ц и дисперсией а2. С помощью ЕМ-алгоритма была подо-
брана модель двухкомпонентной нормальной смеси со средними ц,
и ц2, общей дисперсией а2 и смешивающей пропорцией р при раз-
личных начальных значениях. Все начальные значения определяли,
относя наблюдения к первой или второй компоненте (т. е. все на-
чальные апостериорные вероятности принадлежности к компоненте
были равны 0 или 1) и применяя для вычисления начальных оценок
параметров шаг М. Результаты приведены в табл. 10.3,в). Они по-
казывают чувствительность окончательных оценок к начальным
значениям. Правдоподобие, видимо, двумодально с высокой крутой
модой при оценках, получаемых для первого или третьих началь-
ных значений, и с низкой широкой модой при оценках для второго
начального значения.
10.5. АЛГОРИТМ РОБАСТНОГО МП-ОЦЕНИВАНИЯ
10.5.1. Введение
В примере 10.3 моделью данных была смесь нормальных распре-
делений с различными средними и равными дисперсиями. Другая
модель, особенно полезная в робастном оценивании, — смесь нор-
мальных распределений с равными средними и различными диспер-
сиями. Рассмотрим выборку (х(-, /=!,...,«), подверженную
загрязнению, и пусть обозначает ненаблюдаемую бернуллиев-
скую случайную величину, так что _у;-=1 соответствует «правиль-
ной» реализации, a j’,=2 означает, что х,- — загрязняющая реали-
зация. Мы предполагаем, что при условии У{ = 1 х, распределен нор-
мально N(ji,a2), а при _у;- = 2 — нормально W(/i,a2/X), где X считается
известным. Например, если принято, что загрязнение в 10 раз уве-
личивает дисперсию, то Х=0,1. Результат — загрязненная нормаль-
ная модель. МП-оценка среднего занижает веса резко выделяющих-
ся наблюдений, как мы увидим в следующем разделе.
Модели такого типа могут быть оценены с помощью ЕМ-алго-
ритма, в котором у, рассматриваются как пропущенные данные.
Мы представим общую модель смеси для робастного оценивания,
которая включает загрязненную нормальную модель как частный
228
1’иучай, а также включает модели, где маргинальное распределение
— f-распределение. В разделе 10.5.2 рассматривается одномер-
ный случай, описанный в [Dempster, Laird and Rubin (1977, 1980)].
Случай многомерной xt, описанный в [Rubin (1983)], рассмотрен в
разделе 10.5.3. Раздел 10.5.4 обобщает анализ на многомерную xt
при наличии пропусков [Little (1986)].
10.5.2. Устойчивое оценивание
для одномерной выборки
Пусть Х=(Х1,...,хй)т — случайная выборка из такой популяции,
что
w, а2/^),
где Qi — ненаблюдаемые н.о.р положительные случайные величины
с известной плотностью h(q^. Целью является вычисление МП-
оценки 0 = (£,сг2)т параметра 0=(g,<72)T с помощью ЕМ-алгоритма,
считая значения Q~(Qi.#я)т пропущенными данными.
Если бы присутствовали и X, и Q, то МП-оценки (/л,а2) получа-
пись бы методом взвешенных наименьших квадратов:
S^x,/(10.12)
32= Д „ (10.13)
г-! п л 7
где 5о = Ел=1дг, 51 = Е”=!^хг- и 52 = E"= — достаточные статисти-
ки полных данных, определенные в разделе 7.6. Значит, при «про-
пусках» <2(?+1)-я итерация ЕМ-алгоритма выглядит следующим
образом.
Шаг Е. Взять в качестве оценок s0, Si и s2 их условные ожидания
при заданных X и текущих оценках 0=((им,<//)2). Поскольку sQ, St и
s2 линейны по qj, шаг Е сводится к вычислению оценок весов
(10.14)
Шаг М. Вычислить новые оценки по (10.12) и (10.13)
с (тоЛА), замененными их оценками на шаге Е, т. е. с заменен-
ными на wf из (10.14).
Итак, здесь ЕМ-алгоритм — это разновидность метода наимень-
ших взвешенных квадратов. Конкретный вид оценок весов (10.14)
зависит от предполагаемого распределения q^ В [Demster, Laird and
Rubin (1977,1980)] обсуждаются две модели, в которых получаются
простые веса.
229
Пример 10.4. Одномерная модель нормального распределения <’
Загрязнением. Допустим, что Л(^) сосредоточена в двух значениям
Ql, 1 и X, так что
&(<?,) =
r 1—тг, если =
i тг, если Qj = X (известно),
О — в противном случае,
(10.15)
где 0<тг< 1. Тогда маргинальное распределение х,- — смесь П(ц,а2)
и N(ji,a2/X), т. е. мы имеем загрязненную нормальную модель, опи
санную в разделе 10.5.1, с вероятностью загрязнения тг. Применяя
теорему Байеса, получаем
ИХ =Е^\х^,а2) = l-T+rX»^xp((l-X)ffi2| (10 16)
' 11 ' l-T+TX^expUl-XWf/Z)
где
d/ = (x~A)Va2. (10.17)
Веса wf* для ЕМ-алгоритма получаются при подстановке текущих
оценок и <Д0 в (10.17) и использовании (10.16). Обратите внима-
ние, что значения х,-, далекие от среднего, имеют большое значение
d- и (при Х<1) уменьшенный вес на шаге М. Следовательно, алго-
ритм ведет к устойчивым оценкам д, в которых выделяющиеся на-
блюдения имеют низкий вес.
Пример 10.5. МП-оценивание для выборки из (-распределения.
Вторая модель, рассмотренная в [Dempster, Laird and Rubin (1977,
1980)], задает q—kja, где &, имеет гамма-распределение:
h(kj) = fc“~‘exp(—к')/Г(а). (10.18)
Здесь Г(-) обозначает гамма-функцию. При этом маргинальное рас-
пределение Xj есть t-распределение Стьюдента со средним ц, пара-
метром масштаба <т2 и я=2а степенями свободы. Таким образом,
модель приводит к МП-оцениванию по выборке из ^-распределения
с v степенями свободы, v известно.
Введем 0* = 1 +0,5d,?/(a— 1), где d2 определено в (10.17). Можно
легко показать, что при заданном х, kfi* имеет гамма-распределе-
ние (10.18), в котором а заменено на а+1/2. Отсюда
w;-=£’(^|x[-,/i,a2)/a=(у + I)/(r+«??). (10.19)
Как и в предыдущем примере, веса wf* находят, подставляя теку-
щие оценки параметров /г и а2 в (10.17) и вычисляя (10.19) по най-
денному значению v. В (10.19) занижается вес выделяющихся
наблюдений со степенью, связанной обратной зависимостью с v.
Последний параметр можно фиксировать на каком-либо подходя-
230
тем значении (например, 4). Можно также повторно проводить вы-
числения при различных значениях из целочисленных значений v и
выбирать то, которое максимизирует логарифм правдоподобия.
((«местное оценивание v,fi и ст2 можно также осуществлять за счет
некоторого усложнения шага М.
Непосредственным и важным обобщением моделей из примеров
10.4 и 10.5 является моделирование среднего линейной комбинацией
предикторов X, дающее алгоритм наименьших взвешенных квадра-
юв для линейной регрессии с ошибками, имеющими загрязненное
нормальное или /-распределение [Rubin (1983)]. В [Pettitt (1985)]
описано МП-оценивание для загрязненной нормальной и /-модели,
когда значения X группированы и округлены.
10.5.3. Устойчивое оценивание средних
и ковариационной матрицы по полным данным
Рубин [Rubin (1983)] обобщил модель из раздела 10.5.2 на много-
мерный случай и применил ее для вывода МП-оценок для много-
мерных выборок из загрязненного нормального или из /-распреде-
ления. Пусть Х( — вектор IxjRT значений переменной Xit...,XK. До-
пустим, что х,- имеет А'-мерное нормальное распределение
(10.20)
где q, — ненаблюдаемые н.о.р положительные случайные скаляр-
ные величины с известной плотностью h{c$. МП-оценки ц и ф мож-
но найти, если применить ЕМ-алгоритм, считая Q=(qi,---,qn)T про-
пущенными данными.
Если бы Q наблюдались, МП-оценки ц и $ можно было бы найти
по многомерным аналогам (10.12) и (10.13):
Д= ’ (10.21)
Д (10.22)
где 5о = ^"=1?|> 51 =Ел=]<?/х(- и s2 = 'E"=iqiXj — достаточные статисти-
ки полных данных. Значит, при отсутствии 2(/+ 1)-я итерация ЕМ-
алгоритма выглядит следующим образом.
Шаг Е. Взять в качестве оценок s0, и s2 их условные ожидания
при заданных X и текущих оценках параметров. Так как s0,
Si и з2 линейны по qit шаг Е снова сводится к вычислению оценок
весов
231
Шаг М. Вычислить по (10.21) и (10.22) новые оценки (/,+1)' и).
заменив sc, и s2 их оценками, полученными на шаге Е.
Если qt распределены по (10.15), маргинальное распределение xt -
смесь и значит мы получим АГ-мерную нормальную
модель с загрязнением. Веса находят следующими обобщениями
(10.16) и (10.17):
ж=Е'(9.|х..,/1,^)= i-^+Tx^+1exP((i-X)rf?/2), (Ю 21)
1—т+ jrX^/2exp((l—X)rf?/2)
где теперь dj — квадрат расстояния для /-го объекта:
rf?=(x,-^^-4x-^)T (10.24)
Модель приписывает низкие веса объектам с большим значением
4
Если, с другой стороны, kj = aqj имеет гамма-распределение, как
в (10.18), то маргинальное распределение хг- — это многомерное /
распределение со средним ц, параметром масштаба ф и г = 2а степе
ними свободы. Веса при этом определяются следующим обобщени-
ем (10.19):
W~F(9,.|x;,g,V')/a=(p+JK)/(>' + ^), (10.25)
где dj по-прежнему разно (10.24).
Рубин [Rubin (1983)] рассматривает также обобщение этих моде-
лей для многомерной регрессии.
10.5.4. Устойчивое оценивание среднего
и ковариационной матрицы по данным с пропусками
Литтл [Little (1986)] обобщил эти алгоритмы для ситуаций, когда
некоторые значения X отсутствуют. Пусть xobs j обозначает множе-
ство переменных, наблюденных у /-го объекта, — множество
отсутствующих переменных. Обозначим Xobs = (xobs>z-, /=!,...,«] и
-^mis= {xmis,i> Допустим, что 1) (xj распределены со-
гласно (10.20) и 2) отсутствующие данные ОС. МП-оценки д и ф
можно найти, применяя ЕМ-алгоритм, в котором отсутствующими
данными считаются Xmis и Q.
Шаг М такой же, как и при полных X, и описан в предыдущем
разделе. На шаге Е оценивают достаточные статистики полных
данных So, Si, s2 с помощью их условных ожиданий при заданных
232
Vl)bs и текущей оценке = параметра в. Получаем
Ду0|0«,ЛГоЬ8)=£(Д ?^<0,хоЬм) = Д
|де wP=E(qj\(W,xahfii), j-я компонента £(si|0('),A'obs) равна:
Z П ‘ х п
£(£^yR^obs) = ;lI1£j^P«,xobs>z,<?/)|^,xobsJ =
=j?X’<
|де х^=Е(ху | 6w,xobs>(), так как условное среднее Хц при заданных
^'^’^obw И 1i не зависит от Яг Наконец, и,к)-й элемент
l '(s2 [ ^>,Xobs) равен:
= E>fW+^U,/)-
। де поправки ’Aj^-obsi Равны нулю, если присутствуют х^ и xjk, и
остаточной ковариации х,у и xik при заданных лрЬ5>г-, умноженной на
<!,, если и Xjj, и х!/( отсутствуют. Величины и ^д.оЬ5>г- находят
сверткой ф^ текущей оценки ф так, чтобы xobs z- являлись предик-
горными переменными. Вычисления такие же, как и для «нормаль-
ного» ЕМ-алгоритма (см. раздел 8.2.1). Единственной модифика-
цией, нужной для данного алгоритма, является взвешивание с по-
мощью весов сумм и сумм квадратов и перекрестных произве-
дений, которые затем используются на шаге М.
Веса wf1 для загрязненной нормальной и для /-модели вычисля-
ются, как и для случая полных данных, по уравнениям (10.23) и
(10.25) соответственно, лишь со следующими небольшими измене-
ниями: 1) К заменяют на Kt, число наблюдаемых у /-го объекта пе-
ременных, и 2) квадрат расстояния (10.24) вычисляют только по
наблюдаемым у /-го объекта переменным.
Обе многомерные модели — с загрязненным нормальным и с
/ распределением — приписывают малые веса объектам с большим
расстоянием dj. Распределение весов, однако, как показывает сле-
дующий пример, у этих двух моделей различно.
Пример 10.6. Распределение весов при многомерных моделях с
загрязненным нормальным и с (-распределением. Рассмотрим рис.
10.2, где показано распределение весов для а) многомерного /-рас-
пределения с v=6,0, б) многомерного /-распределения с г=4,0 и в)
загрязненного нормального распределения при тг=0,1, Х=0,077 в
случае искусственных данных из многомерного /4-распределения с
К~4 переменными, п-80 наблюдениями, в которых 72 из 320 значе-
ний случайно удалены. Обратите внимание, что веса для /-распреде-
лений при г=4 разбросаны шире, чем при v = 6, а занижение весов
в загрязненной нормальной модели проявляется преимущественно
на нескольких выделяющихся наблюдениях.
233
Интервал
0,16 +
0,24 + * * *
0,32 + *
0,40 + **
0,48 + *
0,56 f- *
0,64 +
0,72 -г ***** *
0,80 +******
0,88 +******
0,96 +•****
1,04 *********
1,12 +’*****•
1,20 •! ***********
1,28 ************
1,36 ******
1,44 +*‘
1,52 *****
1,60 -5*
*----------+-----+-----+-----ь-----+
5 10 15 20 25
а) Модель с многомерным k - распределением
Интервал
0,09 н
0,18 +***
0,27 * *
0,36 + * * *
0,45 •+• *
0,54 +
0,63 *******
0,72 *******
0,81 т * * * * * *
0,90 н ******
0,99 ******
1,08 ******
1,17 +*..*.*.
1,26 +*** ******
1,35 *******
1,44 *******
1,53 + ***
1,62 + *
1,71 *****
1,80 + *
1,89 +
5 10 15 20
б) Модель с многомерным t4 - распределением
Интервал
0,09 *****
0,18 ***
0,27 +
0,36 * *
0,45 +
0,54 +
0,63 +
0,72 +
0,81 + *
0,90 +
0,99 + *
1,08 +»♦*».»♦»»♦**»»
1,17 +****»*********»****»********»***********«*.********»•**•»»♦ .*►>******«*,
1,26 +
1,35 F
+ + — г — +------I-----Ь-----J-----1------[----н------1------р----+
5 10 15 20 25 30 35 40 45 50 55 60
в) Модель с загрязненным нормальным распределением
Рис. 10.2. Распределение весов для устойчивых МП-оценок, вычисляемых по данным
из многомерного ^-распределения (веса отнормированы на единицу)
Литтл [Little (1986)] показал в имитационных экспериментах, что
оценки для этих моделей могут быть оценками средних, коэффици-
ентов регрессии и корреляций, которые защищены от выбросов,
когда данные ненормальны, а потеря эффективности при справедли-
вости нормального распределения невелика. В статье представлена
также графическая процедура для оценивания нормальности.
234
10.5.5. Обобщение модели
Одно из ограничений, наложенных на описание модели, требует
равенства масштабного множителя qit нужного для моделирования
хвостов тяжелее нормального, для всех переменных из множества
данных. Может оказаться полезным допустить различие масштаб-
ных множителей для разных переменных, например, чтобы отра-
шть различие загрязнения переменных. В частности, для устойчи-
вого оценивания регрессии с пропусками в предикторах лучше всего
может подойти модель с масштабным множителем только для за-
висимой переменной.
К сожалению, если обобщить модель до различных масштабных
множителей у различных переменных, утрачивается простота шага
li ЕМ-алгоритма для общей структуры пропусков. Несколько ис-
ключений, о которых следует сказать, основаны на том факте, что
модели можно легко обобщить для работы с набором полностью
наблюдаемых сопеременных Z так, что у/ выражается через много-
мерную нормальную линейную регрессию на z, со средним EPjZy
и ковариационной матрицей ф/qj условно по неизвестному масш-
табному множителю. Допустим, что данные можно представить в
виде множества с монотонной структурой пропусков, в котором
при К блоках переменных Хх,...,Хк Xj наблюдается у всех объек-
тов, у которых присутствует Xj+1, Тогда совместное
распределение Xi,...,XK можно выразить произведением распреде-
лений:
f{Xx,... ,Хк,ф) ^/(Х^фУЯХг^фК .-,Хк^,ф),
как обсуждалось в гл. 6. Тогда условное распределение
для этой факторизации можно описывать как многомерное нор-
мальное распределение со средним и ковариационной
матрицей j^/qij, где теперь масштабный множитель q^ может
принимать различные значения в зависимости от J. Параметры
каждой компоненты правдоподобия оцениваются в рамках рассмот-
ренного обобщения многомерной регрессионной модели. После это-
го с помощью преобразования, подобного преобразованию, обсуж-
давшемуся в гл. 6, получают МП-оценки других параметров сов-
местного распределения Л-],...,^.
235
ЛИТЕРАТУРА
Aitkin, М , and Rubin, D В (1985) Estimation and hypothesis testing in finite mixture пю<1< I
J Roy Statist Soc B47, 67-75
Aitkin, M and Wilson, G T (1980) Mixture models, outliers, and the EM algorithm, h h
nometrics 22, 325 331
Anderson, T W (1958) An Introduction to Multivariate Statistical Analysis New York Wih t '
Brown, D T (1959) A note on approximations to discrete probability distributions, 7n/ Conhol
2,386 392
Day, N E (1969) Estimating the components of a mixture of normal distributions, Biomeii А и
56, 464-474
Dempster, A P , Laird, N M , and Rubin, D В (1977) Maximum likelihood estimation fioni
incomplete data via the EM algorithm (with discussion), J Roy Statist Soc B39, 1 38
Dempster, A P, Laird, N M , and Rubin D В (1980) Iteratively reweighted least squares Im
linear regression when etrors are normal/mdependent distributed Multivariate Analysis V
35 37
Krzanowski, W J (1980) Mixtures of continuous and categorical variables in discriminant
analysis, Biometucs 36, 493-499
Krzanowski, W J (1982) Mixtuies of continuous and categorical variables in discriminant
analysis a hypothesis-testing approach, Biometrics 38 991 -1002
Little, R J A (1986) Robust estimation of the mean and covariance matrix from data with
missing values, paper given at the Joint Statistical Meetings, Chicago, August 1986
Little, R J A , and Schluchter, M D (1985) Maximum likelihood estimation for mixed con
tinuous and categorical data with missing values, Biometnka 72, 497-512
Olkin, I, and Tate, R F (1961) Multivariate correlation models with mixed discrete and
continuous variables, Ann Math Statist 32, 448-465
Pettitt, A N (1985) Re-weighted least squares estimation with censored and grouped data An
application of the EM algorithm J Rov Statist Soc 847,253-261
Rubm, D В (1983) Iteratively reweighted least squares, Encyclopedia of the Statistu al Sciences,
Vol 4 New York, Wiley, pp 272-275
ЗАДАЧИ
1. Докажите свойства 2) и 3) модели из раздела 10.2 1
2. Покажите, что (10.2.) дает МП-оценки параметров по логарифму правдоподобия
для полных данных (10 1)
3. Выведите МП-оценки для общей модели положения в частном случае одной
полностью присутствующей категориальной переменной Y и одной непрерывной пе-
ременной X с пропусками, используя методы факторизации правдоподобия из гл 6
4. Допустим, что в задаче 3 X присутствует полностью, а У имеет пропуски Пока
жите, что МП-оценки общей модели положения нельзя найти с помощью факториза-
ции правдоподобия, так как параметры соответствующих факторов не раздельны.
Предложите другую модель, в которой факторы раздельны. Выведите для нее
МП-оценки.
5. Покажите с помощью теоремы Байеса, что (10.7) следует из определения общей
модели положения
1 Русский перевод: Андерсон Т. Введение в многомерный статистический анализ. - М.:
Физматгиз, 1963.
236
6. Выведите из свойств общей модели выражения из раздела 10,2.3 для условного
математического ожидания и ХцХ1к при заданных xobsj-, 8,- и
7. В исследовании 20 выпускников'’ университетской группы спустя 5 лет после
окончания университета по переменным: пол (1 — мужской, 2 — женский), раса
(I — белый, 2 — другая раса) и годовой доход, представленный на логарифмической
шкале, были получены такие результаты
Номер 1 2 3 4 5 6 7 8
Пол 1 1 1 2 2 2 2 2
Раса 11111111
Доход 25 46 31 5 16 26 8 10
(— означает пропуск):
9 10 11 12 13 14 15 16 17 18 19 20
22211221112 2,
1 1 1 2 2 2 2 ------
2 -- 20 29 — 32 - 38 15 —
а) Вычислите МП-оценки для общей модели только по полным наблюдениям.
б) Выведите явные формулы (10.3)—(10.6) для шагов Е и М для этих данных и сде-
лайте 3 итерации ЕМ-алгоритма, используя оценки из а) в качестве начальных.
8. Повторите задание 7,6), введя такое ограничение: переменные пола и расы не-
зависимы.
9. Вычислите логарифм правдоподобия для данных задачи 7 для моделей из задач
7 и 8. Получите значение хи-квадрат-статистики отношения правдоподобий для про-
верки независимости пола и расы. Заметьте, что объем выборки слишком мал, что-
бы считать, что в этом примере статистика распределена по хи-квадрат (см. [Little
and Schluchter (1985)]).
10. Выведите весовые функции (10.16) и (10.19) для моделей в примерах 10.4 и 10.5.
11. Выведите весовые функции (10.23) и (10.24) для моделей из раздела 10.5.3.
12. Выведите уравнения для шага Е из раздела 10.5.4.
Глава 11. МОДЕЛИ С НЕИГНОРИРУЕМЫМИ ПРОПУСКАМИ
11.1. ВВЕДЕНИЕ
В разделе 5.3 мы ввели разделение У= (Tobs^mis) полных данных
У на присутствующие yobs и отсутствующие значения УтЬ, и инди-
каторную матрицу R, которая определяет структуру пропусков. Мы
сформулировали модель через распределение Y с плотностью ДУ|6),
зависящей от неизвестного векторного параметра в и распределение
R с плотностью /(/?|У,ф), условной по заданному У и зависящей от
векторного параметра ф. Правдоподобие, игнорирующее механизм
порождения пропусков, определялось как любая функция 0, про-
порциональная f{ yobs|6):
M0|yobs)~/(EObS|0). (ПЛ)
где /(УоЬ8|0) получается интегрированием плотности ДУ|0)=/(У„Ь8,
ymis|0) по y„is. Полное правдоподобие определялось как любая
функция 0 и ф, пропорциональная f(Yobs,R|0,^):
£(0,0|Л,УоЬ8) ~AYobs,R\M), (11-2)
237
где f(Yobs,R\0,$) получается интегрированием плотности
/(^|yobs>ymis^) ЖьЛ^) по Ymis. Было показано, что выводы
относительно 0, основанные на (11.1), эквивалентны МП-оценива-
нию по (П.2), если 1) пропущенные данные ОС, т. е.
/(^lyobs’ymis>^)=/(J?lyobs’V') при любых ф и ymis, взятых при наблю-
денных значениях R и yobs, и 2) параметры $ и 0 раздельны в со-
ответствии с определением в разделе 5.3. Все примеры в гл. 6—10
касались моделей с правдоподобием в виде (11.1) и, значит, были
основаны на предположении о справедливости условий 1) и 2). В
этой главе мы обсуждаем модели, в которых не выполняется ОС,
и для МП-оценивания надо иметь модель механизма пропусков и
максимизировать полное правдоподобие (11.2).
Важно различать модели, в которых механизм порождения про-
пусков неигнорируем, но известен, в том смысле, что распределение
R при заданных ^=(^obs>ymis) зависит от ymis, но не зависит от не-
известного параметра ф, и модели, в которых механизм порожде-
ния пропусков неигнорируем и неизвестен, что отражается в не-
знании параметра ф. Простым примером известного неигнорируе-
мого механизма является цензурированная экспоненциальная вы-
борка, ведущая к правдоподобию (5.15). Так как в этом случае
значения отсутствуют, если они больше известного цензурирующего
значения с, то распределение R при заданном У полностью опреде-
лено. Другие примеры с известным неигнорируемым механизмом
даны в разделе 11.3. В этих случаях МП-оценки часто можно вычис-
лять с помощью ЕМ-алгоритма. В разделе 11.2 обсуждается ЕМ-ал-
горитм в общем случае известного или неизвестного неигнорируе-
мого механизма.
Разделы 11.4—11.6 посвящены моделям с неигнорируемым меха-
низмом порождения пропусков и неизвестным ф. Это значит, что
пропуск считается связанным со значениями У некоторым лишь
частично известным образом, даже после учета сопутствующей ин-
формации X об объектах с пропусками и без пропусков. Большин-
ство рассматриваемых в литературе моделей такого типа относятся
к случаю пропусков только в одной переменной. Например, У мо-
жет быть размером дохода, X — множеством полностью зареги-
стрированных переменных, таких, как возраст, пол, образование, и
можно предполагать, что отсутствие ответа на вопрос о доходе сре-
ди людей с одинаковым значением X зависит от размера дохода, но
точно эта зависимость неизвестна.
Можно сформулировать два подхода к моделям с неигнорируе-
мыми пропусками. Как и в разделе 5.3, мы можем записать сов-
местное распределение R и У в виде
f(R,Y\X,f), =/( Y\XJ)f(R\Y,X,V), (11.3)
где первая компонента характеризует распределение У при задан-
ном X в популяции, а вторая — моделирует присутствие ответа
238
как функцию X и Y. С другой стороны, можно записать
Л^,Г\Х,^)^ЛУ\Х,Л,Ш1Х\Х,Ш), (11.4)
где первая плотность характеризует распределение у, при заданном
Xj в слое, определяемом структурой пропусков, а вторая моделиру-
ет распределение структур пропусков как функцию только от X. Об-
ратите внимание: когда пропуски есть только в одной переменной,
так что R принимает значения 0 и 1, мы обычно не располагаем
данными, по которым можно было бы оценить распределение
ДУ|А',7?=0,^) в (П.4), поскольку это распределение относится к объ-
ектам с пропуском. Формулировка модели в виде (11.4) позволяет
явно увидеть основную трудность, связанную с пропусками в дан-
ных. Для успешного развития теории надо уметь связывать распре-
деление f(Y\X,R = 0,ty для объектов с пропуском с соответствующим
распределением /(У| X,R = 1 ,£) для объектов без пропуска. В разделе
11.5 это достигается за счет использования байесовского априорно-
го распределения, связывающего параметры двух распределений.
Формулировка (11.3) применяется для моделей, обсуждаемых в
разделах 11.3 и 11.4. Мы увидим, что в некоторых случаях парамет-
ры модели можно оценить, не включая в явном виде информацию,
связывающую объекты с пропуском и объекты без пропуска, в от-
личие от моделей, основанных на (11.4). Однако данное свойство
обманчиво, поскольку здесь эта информация задается неявно. Сле-
довательно, для обоих вариантов, (11.3) и (11.4), чувствительность
к формулировке модели является в одинаковой степени серьезной
научной проблемой. Во многих приложениях исследователю нужно
вычислять оценки для нескольких различных моделей порождения
пропусков, а не полагаться исключительно на одну модель.
£1.2. ТЕОРИЯ ПРАВДОПОДОБИЯ ДЛЯ МОДЕЛЕЙ
С НЕИГНОРИРУЕМЫМИ ПРОПУСКАМИ
Теория правдоподобия для выводов от 0 и ф, основанная на
(11.2), сходна с теорией выводов относительно 0 для игнорируемых
пропусков, обсуждавшейся в гл. 5—7. В частности, МП-оценки (0,fy
находят при максимизации (11.2), а обратная информационная мат-
рица, полученная двукратным дифференцированием логарифма
правдоподобия по (0,ф), дает оценку ковариационной матрицы оце-
нок параметров, если эта матрица существует и выборки достаточ-
но велики, чтобы логарифм правдоподобия был квадратичен в
окрестности (0,fy.
В частных случаях можно вывести явные оценки, как в примере
5.8. Однако часто для максимизации правдоподобия нужны итера-
тивные методы, обсуждавшиеся для игнорируемых пропусков в
239
разделе 7.1. В частности, ЕМ-алгоритм при неигнорируемых пропу-
сках имеет следующий вид: 1) найти 0(О), ф*® — начальные оценки
(0,<Д), 2) на Лй итерации вычислить на шаге Е при найденных теку-
щих оценках (0W ^(0) величину
д<0,ф\0МфМ) = yobs,ymis,/?y(ymis|yobs,7?,0= O^^dY^,
где l(0^\Yobs,Ymis,R) — логарифм правдоподобия полных данных и
— плотность условного распределения отсутству-
ющих данных при заданных присутствующих значениях 0 и ф. На
шаге М найти максимизирующее Q:
ДЛЯ всех 0,ф.
Заменить 0(‘\ ф® на следующей итерации алгоритма на
По теории, аналогичной теории из раздела 7.3, каждая итерация
этого алгоритма увеличивает Ь(0,ф\ Yobs,R) и при довольно слабых
общих условиях алгоритм сходится к стационарному значению
правдоподобия.
11.3. МОДЕЛИ С ИЗВЕСТНЫМИ НЕИГНОРИРУЕМЫМИ
МЕХАНИЗМАМИ ПОРОЖДЕНИЯ ПРОПУСКОВ:
ГРУППИРОВАННЫЕ И ОКРУГЛЕННЫЕ ДАННЫЕ
С помощью ЕМ-алгоритма можно получать МП-оценки по
данным, в которых некоторые наблюдения сгруппированы в катего-
рии, хотя можно применять и традиционные алгоритмы, обсуждае-
мые, например, в [Kulldorf (1961)]. Использование ЕМ-алгоритма
демонстрируется в следующих трех примерах.
Пример 11.1. Сгруппированная экспоненциальная выборка. До-
пустим, что гипотетические полные данные являются случайной вы-
боркой (yi,...yn) из экспоненциального распределения со средним 0.
Пусть в действительности известны значения У в т<п наблюдени-
ях. Остальные п—т значений сгруппированы по J категориям, та-
ким, что j-я категория содержит значения У, лежащих между а, и
bj. Эта постановка включает случай цензурирования, когда ^>0 и
Ь.=^у как и ситуацию, когда т—0 и все данные представлены в
сгруппированном виде.
В данном примере надо обобщить бинарный индикатор пропу-
сков R до переменной с J+1 значениями. Точнее, положим 7?;=1,
если у,- известно точно, и 7?,=у+1, если у; попадает в j-ю катего-
рию, т. е. лежит между aj и bj (/=!,.
Гипотетические полные данные относятся к регулярному экспо-
ненциальному семейству с достаточной статистикой полных данных
Е"=1У(.. Следовательно, шаг Е ЕМ-алгоритма на /-й итерации состо-
ит в вычислении
240
। де предсказываемые значения у, равны:
у^=Е(у\а^у< =
= j\ exp(-£)dy/\bj exp(~^)dy
“J aj
>10 определению экспоненциального распределения. Интегрируя по
частям, получаем
На шаге М вычисляют
0((+1) = п-/(
Предсказываемое значение для наблюдения, цензурированного в
Uj, получают, полагая ^ = сзсэ, что дает
^ = 0« + а/
Если все п—т наблюдений цензурированы, то можно найти явные
МП-оценки. Объединяя шаги Е и М, получим
0И+1) = ( £ у + £- (0(0 + а\ \
4=1 z = r J 7
Полагая = & и решая уравнение относительно 6, имеем
§=т~1 ( Ly^ra},
Г 1 ;_1J
В частности, если для всех j = с, т. е. точка цензурирования у всех
наблюдений одинакова, то
0=т-‘ (г^,+(я—Ш)с),
что совпадает с оценкой, выведенной непосредственно в примере
5.14.
Пример 11.2. Группированные данные из нормального распреде-
ления с сопеременными. Допустим, данные по переменной У сгруп-
пированы таким же способом, что и в примере 11.1, но теперь
гипотетические полностью присутствующие значения У — независи-
мые наблюдения из нормальной линейной регрессии на полностью
наблюдаемые сопеременные Xi, Х2,..., ХР, т. е. значение yi в /-м
наблюдении распределено нормально со средним + по-
241
стоянкой дисперсией 52. Достаточные статистики полных данных
есть Т,у-,^урс-к(к=\,...р) и Ev2- Отсюда на шаге Е ЕМ-алгоритма вы-
числяют
E(^yi\Yobs,R,9-e^= £л+ /=£ 3^,
Е Ж,.|ГоЬ5,Я0= = Д ypcik + Е y(0,Xik, к= 1,2,....д
E(Ey;\Yobs,R,e=ew^ .Е/ + ,J+[3+32,
где 9 = (j30,pl,...,/3p,ai'), 0W = (/?JO,...,/J/W,o<z)I) — текущая оценка 0,ур)*
= /л«+ </%«, ^2 = о«)2(1—7/Ю), /4Й = /Зо«) + ^=1/3№, 5/'> и y,W -
это поправки на неигнорируемые пропуски. В данном случае они
имеют вид
' Ф(</}(>}—Ф(С<'>) ’
7 (о=§ (02 +
' ' ф(4/>)—ф(с&) ’
где ф и Ф — плотность и функция стандартного нормального распре
деления, и
ср)=(aj—fip)/^), dp) = (bp-ур))^)
для Его наблюдения в у-категории (7?(=у+1, или, что эквивалентно,
а}<у^Ьр.
На шаге М вычисляют регрессию Y на Xj,...Xp, используя ожида-
емые значения достаточных статистик, найденные на шаге Е. Эта
модель применялась в [Hasselblad, Stead and Galke (1980)] при регрес-
сионном анализе логарифма содержания свинца в крови по сгруппи-
рованным данным.
Пример 11.3. Цензурированные нормальные данные с соперемен-
ными (тобит-моделъ). Важный частный случай предыдущего приме-
ра; положительные значения У присутствуют полностью, а
отрицательные цензурируются, т. е. могут находиться в произволь-
ных точках интервала (—«=. 0). В обозначениях примера 11.2 все
присутствующие yt положительны, J=l, ах-—и bt = Q. Для цен-
зурированных наблюдений = dp) =—цр)/^), 8р) =—ф(бр))/
Ф(бр)) и yp) = 5pXdp)+p.^/d‘))t отсюда
j)p) =E(yi\e«),xiyi^ 0) = g Й---<Ж(—g/W')),
где Х(г)=Ф(д)/Ф(г) (величина, обратная к так называемому отноше-
нию Милса), а —— поправка на цензурирование.
242
11одставляя МП-оценки параметров, получаем прогноз значений
X' 0)= Д; <^( А/ <?) (11-5)
для цензурированных наблюдений, где /i(-=0o + L0pc(-A. Эту модель в
тонометрической литературе [см. Amemiya (1984)] иногда называ-
ют тобит-моделью в связи с ее применением в эконометрии [Ibbin
(1958)].
11.4. МОДЕЛИ СТОХАСТИЧЕСКОГО ЦЕНЗУРИРОВАНИЯ
11.4.1 МП-оценивание моделей
стохастического цензурирования
Интересные обобщения модели в примере 11.3 сопряжены с пере-
менной У] с пропусками, связанной линейной регрессией с сопере-
менными, как и в примере 11.3, и наблюдаемой, если и только если
значение другой полностью отсутствующей переменной У2 превы-
шает некоторый порог (например, нуль). Общая формулировка дана
в следующем примере.
Пример 11.4. Модель двумерного нормального стохастического
цензурирования. Допустим, что У1 наблюдается не полностью, У2
совсем не наблюдается, р сопеременных X наблюдаются полностью
и для /-го объекта f(Y\X,ff) определяется выражением
(«у— *“")). «п-6)
где хг = (хю,х;1 — постоянный член хюэ1, хЛ,...,х!р — предик-
торы для /-го объекта, 01 и 02 — векторы (р+1)х1 коэффициентов
регрессии, некоторые из них могут быть априори приравнены ну-
лю, a Nz(a,c) обозначает двумерное нормальное распределение со
средним d и ковариационной матрицей с. Далее, f{R\X,Y,^) опреде-
ляется как вырожденное распределение:
г 1, если уй>0, п . 71
Мо,еси^О, 01-7)
Я;2=0,
где — индикатор пропусков у^, равный Ry=i, если Уц присут-
ствует, и Лу=0, если отсутствует.
Для этой модели подходит и другой вариант факторизации (11.3),
в которой приведено интегрирование по У2 и R относится только к
пропускам Уь Пусть R означает множество значений [А1(], 8=(fit,
of), и 0=O3i,02,е). Из (11.6) и (11.7) получаем, что распределение R
243
при заданных X и — бернуллиевское с вероятностью прив!
ствия значения у z-ro объекта, равной
Рг(7?,. = 1 | ул ,х)=Рг(уд > 0 j ул ,х)
(11Л'
L ^Г=Г2 J ’
При е^0 эта вероятность является монотонной функцией Уь шт
чения которой иногда отсутствуют. Отсюда по теории гл. 7 мехи»
низм порождения пропусков неигнорируем. Если, напротив, р=0, ц
02 и (01,су2) раздельны, то механизм пропусков игнорируем, и МП-
оценки (01,п2) можно получать методом наименьших квадратов для
линейной регрессии по полным наблюдениям.
Эту модель ввел Хекман [Heckman (1976)], чтобы описать отбор
женщин при приеме на работу. В [Amemiya (1984)] она названа то»
бит-моделью типа И. Заметим, что тобит-модель из примера 11Л
получается при У^щУг.
Для этой модели были предложены две процедуры оценивания -
МП-оценивание и двухшаговый метод, введенный в [Heckman
(1976)]. Первоначально МП-оценки предлагалось получать с по-
мощью алгоритма, приведенного в [Berndt, Hall, Hall and Hausman
(1974)]. Мы опишем ЕМ-алгоритм для случая, когда на коэффициен-
ты 01;02 не наложены ограничения. Будем считать, что гипотетиче-
ские полные данные — это наблюдения с присутствием У1 и У2.
Тогда достаточные статистики полных данных равны [Е^дХу,
Ед»,-^, Е^;1У/2> ПРИ 2=0,1...,р. Поскольку все [х,у] присут-
ствуют, шаг Е состоит в замене отсутствующих j(1, j>a, улуа и
на их математические ожидания при заданных параметрах и присут-
ствующих данных. Из свойств двумерного нормального распределе-
ния получаем:
•Б'О'й I
Е(Уц IУ а > 0) = + X(/ij2),
Е(Уц I З’ц0) =в<Г1Х(
Е(У,2 IУ a ^0)= 1 + g,-2 Аа^( /*2;2),
Е<Уп IУ/2 > °) =1 + /4 + W»
Е<Ун I л-2^0>=^1
Е(УцУа I Л2^°) = М,10‘й”-М—/il2))+ е^1-
В этих выражениях 1) Х(-) определена в примере 11.3; 2) не указано
явно, что ожидание условно по х; и параметрам; 3) zz(1=x,-0i, /iG =
=xz02; 4) относится к наблюдениям с пропуском и и У2, а
у/2>0 —- к наблюдениям с пропуском только У2. Вычисления на
шаге Е проводятся после подстановки текущих оценок параметров.
244
На шаге М проводят следующие операции с оценками достаточ-
ных статистик для полных данных, полученными на шаге Е:
1) вычисляют регрессию Y2 на X, что дает коэффициенты /32 для
уравнения пропусков;
2) вычисляют регрессии Yi и У2 на X, что дает коэффициенты S'
для К2 и для X и остаточную дисперсию^
3) полагают /?1 = $1* + 5|§2><?? = <7?2+-<52 и q~8/6i.
Если на коэффициенты и р2 наложены ограничения, то на
шаге М нужны итеративные вычисления, и алгоритм теряет свою
простоту.
(1.4.2. Чувствительность МП-оценок
к отклонению от нормальности
В модели примера 11.4 прогноз отсутствующего значения опреде-
ляется таким образом:
Ё(Уц I = 6^1Х( Дд), (11.9)
где =x,/3i, Заметим, что поправка на цензурирование
— g<?iX(—Дд) зависит от оценки корреляции g. Этой оценки нет ц
уравнении прогноза (11.5) для «чистой» модели цензурирования в
примере 11.3. Таким образом, несмотря на то, что Yi и У2 никогда
не наблюдаются совместно, корреляцию g надо уметь оценивать.
Следующие предположе-
ния О модели дают инфор- -----Исходное распределение
мацию о g, которую мож-
но использовать для МП-
оценивания: 1) априорные
ограничения на коэффици-
енты /31 и /32 и 2) предполо-
жения о нормальности iti
при заданном xt в исход-
ной популяции. Чтобы по-
казать роль второго пред-
положения, рассмотрим мо-
дель при отсутствии сопе-
ременных, когда х, = 1 —
постоянный член. На рис.
11.1 дано распределение У)
в исходной популяции и в
популяции наблюдений без
пропуска. Последнее рас-
пределение отнормировано
так, чтобы показать «оста-
ток» от истинного распре-
деления. По предположе-
нию исходное распределе-
ние Yj — нормальное. Рас-
Наблюдаемое распределение
Рис. 11.1. Модель нормального стохастическое
цензурирования в выборке
245
пределение присутствующих значений скошено за счет стохастиче
ского цензурирования, если р=0. Имея выборку присутствующих
значений, можно оценить q по степени отклонения выборки от нор
мальности. Другими словами, пропуски заполняются таким обра
зом, чтобы выборка без пропусков была максимально близка к
нормальной. Ясно, что эта процедура целиком основана на предпо
ложении о нормальности значений У1 в исходной популяции, кото
рое невозможно проверить. При отсутствии сведений об этом
распределении с таким же успехом может оказаться верным предпо
ложение, что отсутствующие значения имеют то же скошенное рас
пределение, что и наблюдаемые значения на рис. 11.1. Если эта
гипотеза действительно верна, то поправка на избирательность в
нормальной модели скорее добавит смещение, чем устранит его. t
Следующий пример иллюстрирует это.
Пример 11.5. Пропуски в данных о размере дохода в текущем
обследовании населения. В [Lillard, Smith and Welch (1982), (1986)]
модель из примера 11.4 применялась для анализа пропусков значе-
ний дохода по данным четырехкратного опроса о размерах дохода
при текущих обследованиях населения (Current Population Survey,
CPS) в 1970, 1975, 1976 и 1980 гг. Выборка 1980 г. состояла из 32879
белых работающих городских жителей мужского пола от 16 до 65
лет, подтвердивших получение заработной платы или жалованья
(но не обязательно его размер PF), и не занятых индивидуальной
трудовой деятельностью. Из них 27909 сообщили значение W, а
4970 не сообщили. В обозначениях примера 11.4 Yi равно по опреде-
лению (И^— !)/у, где у — показатель степенного преобразования,
предложенного в [Box and Сох (1964)]. Предикторы X были выбра-
ны такими:
1) постоянный член;
2) образование (5 фиктивных переменных — по сроку обучения:
8, 9—11, 12, 13—15, 16 + );
3) стаж (4 переменные по интервалам: 0—5, 5—10, 10—20, 20 + );
4) вероятность иметь стаж меньше года (вер. 1);
5) район (юг или другой район);
6) ребенок главы семьи (1 — да, 0 — нет);
7) другой родственник главы семьи или член другой родственной
семьи (да, нет);
8) опрашивался лично или нет (1 — да, 0 — нет);
9) срок участия в обследовании (1 или 2 года).
Последние четыре переменные были исключены из «уравнения до-
ходов», т. е. соответствующие члены в были приравнены к нулю.
Переменные образования, стажа и района были исключены из
«уравнения пропусков» — соответствующие коэффициенты в бы-
ли приравнены нулю.
246
Таблица 11.1. Оценки коэффициента 13,
регрессии логарифма дохода на соперемениые (по данным 1980 г.)
Переменная МНК (по ответившим) ММП для модели цензурирования Двухшаговый метод
Постоянная 9—11 Образе- < 12 ваиие 13—15 46+ 5—10 Стаж Ю—20 |20 + Вер.1 Район е = Сыг(у„уг\х) 9,5013 (0,0039) 0,2954 (0,0245) 0,3870 (0,0206) 0,6881 (0,0188) 0,7986 (0,0201) 1,0519 (0,0199) —0,0225 (0,0119) 0,0534 (0,0038) 0,0024 (0,0016) —0,0052 (0,0008) —1,8136 (0,1075) —0,0654 (0,0087) 0 27909 9,6816 (0,0051) 0,2661 (0,0202) 0,3692 (0,0169) 0,6516 (0,0158) 0,7694 (0,0176) 1,0445 (0,0178) —0,0294 (0,0111) 0,0557 (0,0039) 0,0240 (0,0016) —0,0036 (0,0008) —1,7301 (0,0945) —0,0649 (0,0085) —0,6842 32879 10,0373 (0,0173) 0,2615 (0,0241) 0,3718 (0,0203) 0,6713 (0,0185) 0,8096 (0,0198) 1,0418 (0,0195) —0,0425 (0,0117) 0,0561 (0,0037) 0,0448 (0,0017) —0,0033 (0,0008) —1,5311 (0,1059) —0,0893 (0,0086) 32879
В большинстве эмпирических исследований модель строят для ло-
гарифма дохода. Такое преобразование получается при у->0. В
табл. 11.1 показаны оценки коэффициентов регрессии Д для лога-
рифма размера дохода, вычисленные 1) обычным методом на-
именьших квадратов (МНК) по ответившим при предположении,
что пропуски, по сути, игнорируемы (е=0) и 2) методом макси-
мального правдоподобия (ММП) для модели примера 11.4. МП-
оценка q составила е=—0,6812, что соответствует положительной
поправке —p5jX(—Д2() на цензурирование размеров дохода (см.
(11.9)). Коэффициенты регрессии для МНК и ММП в табл. 11.1
сходны, хотя разница свободных членов для МНК и ММП (9,68—
0,50=0,18 на логарифмической шкале) означает примерно 20%-ную
разницу прогноза размера дохода для неигнорируемых пропусков,
что является довольно существенной поправкой.
Таблица 11.2. Максимум логарифма правдоподобия
как функция 7 и соответствующие значения @
У Максимум логарифма правдоподобия е
0 —300613,4 —0,6812
0,45 —298168,4 —0,6524
1,0 —300563,1 0,8569
Источник. [Lillard, Smith and Welch (1982)].
247
В [Lillard, Smith and Welch (1982)] было подобрано несколько мо
лелей стохастического цензурирования при различных значениях 7
В табл. 11.2 приведены значения максимума логарифма правдопо
добия при трех значениях, а именно при 0 (логарифм), при 1 (тож
дественное преобразование) и при 0,45, и МП-оценки для случайной
подвыборки из данных. Максимум правдоподобия намного больше
при 7=0,45, чем при 7=0 или 7=1, что указывает на плохое cooi
ветствие модели нормального цензурирования для исходных и для
логарифмированных значений размера дохода.
В табл. 11.2 показаны также значения q как функции 7. Земетим,
что при 7=0 и 7=0,45 р отрицателен, т. е. распределение дохода по
ответившим скошено в левую сторону, и значения дохода для отка-
завшихся отвечать должны быть большими, чтобы заполнять пра-
вый хвост. Напротив, при 7=1 q положителен и распределение по
ответившим скошено направо, а значения дохода для отказавшихся
отвечать должны быть малыми, чтобы заполнить левый хвост. Та-
ким образом, таблица отражает чувствительность поправки к асим-
метрии распределения преобразованного дохода по ответившим.
Наилучшая модель из [Lillard, Smith and Welch (1982)] с у=0,45
предсказывает большие доходы для отказывающихся отвечать, в
среднем на 73% больше подстановок, предлагаемых Бюро перепи-
си, которые выбирались методом подстановки с подбором в пред-
положении игнорируемости пропусков. Как отметил Рубин [Rubin
(1983)], эта большая поправка вычислена в соответствии с предпо-
ложением о нормальности значений в популяции при 7 = 0,45. Впол-
не вероятно, что пропуски можно игнорировать и что распределе-
ние значений среди неответивших такое же (скошенное), асиммет-
ричное, как и среди ответивших. Действительно, сравнение подста-
новок, предлагаемых Бюро переписи, со значениями, взятыми из
данных IRS о доходе при проведении файлового подбора для фай-
лов CPS/IRS*, не обнаруживает существенного занижения оценки
[David, Little, Samuchel and Triest (1986)].
11.4.3. Двухшаговый метод Хекмана
Процедура определения параметров модели, предложенная в
[Heckman (1976)], не дает МП-оценок. В ней требуются намного
более простые вычисления по сравнению с МП-оцениванием. Этому
свойству обязана широкая распространенность этой процедуры.
Основу процедуры Хекмана в большой степени составляют не под-
дающиеся проверке предложения об априорных нулях в векторах
регрессионных коэффициентов & ft- Это может привести к сильно
искаженным результатам, если эти предположения неверны. Поэто-
му применять мегод надо с большой осторожностью.
’ См. раздел 6.6.—Примеч. пер
248
При описании метода удобно использовать разные обозначения
для предикторов У1 и для предикторов У2. Пусть Хг обозначает
подмножество сопеременных X, которые по предположению до-
лжны предсказывать У2 (и, значит, наличие пропуска), а /32 — со-
ответствующий подвектор ненулевых значений в /32. Аналогично
сопеременные Xt — предикторы У1 и /3* — подвектор ненулевых
значений в /3Р Тогда из моделей (11.6) и (11.7) следует, что
Рг(Ка = 1 | х,) = Ф(хД)« Ф(ха/3 2‘) (11.10)
И
£(У,1 | = 1 ,х;) =х,(31 + ga,X(x,/32)=хя/3‘ + даД^/Зг), (11.11)
где х;] и xi2 обозначают значения Ху и Хг у l-го объекта. Отсюда
состоятельные оценки /3* и /32 получаются так.’ 1) оценить вели-
чиной по пробит-регрессии Rn на х12 с помощью всей выборки;
2) оценить (3* и Qat по МНК-регрессии yzi на хг1 и на X z = X(x;-2/3j) с
помощью выборки с присутствующими значениями. Это и есть
двухшаговый метод Хекмана. Можно сформулировать немного бо-
лее эффективные варианты метода, заменяя на втором шаге МНК
на обобщенный метод наименьших взвешенных квадратов.
Двухшаговый метод «не работает» при отсутствии сопеременных
пропуска, поскольку если ха — постоянная для всех I, то Х(хй/3|) —
также постоянная, которая смешивается с постоянным членом в
(11.11). Если Х2 неодинаковы для различных объектов, но Xt=X и
Хг — подмножество переменных X,, то параметры /3( и qoi в
(11.11) идентифицируемы только благодаря нелинейности преобра-
зования X. Для работоспособности метода на практике необходимо,
чтобы в Х2 были переменные, которые являются хорошими пре-
дикторами наличия пропуска и отсутствуют в Х1г т. е. не связаны
с У], когда остальные переменные фиксированы. Например, в при-
мере 11.5 предполагается, что переменная «ребенок главы семьи»
влияет на наличие ответа, но не связана с доходом. Однако едва ли
можно поверить в такое отсутствие связи, поскольку эта перемен-
ная может быть «законным» предиктором дохода, не включенным
в Х\. Если она связана с доходом, то поправки на неигнорируемые
пропуски могут оказаться ложными.
Последний столбец в табл. 11.1 показывает результаты примене-
ния двухшагового метода к данным примера 11.5. Самое сильное
отличие этого метода от ММП проявляется в большем свободном
члене (10,0373 вместо 9,0816), что означает, что предлагаемые зна-
чения примерно на 60% больше, чем при МНК. Это не слишком
правдоподобная поправка. Лилард и др. [Lillard, Smith and Welch
(1982)] обнаружили также на данных CPS заметную нестабильность
двухшаговых оценок в зависимости от выборки. Литтл [Little
(1985а)] пытается объяснить эту нестабильность и приводит обсуж-
дение предположений для этого метода.
249
Рассматривались также другие варианты модели нормально! <>
стохастического цензурирования, в которых пробит-модель npouyt,
ка заменяется на равномерную [Olsen (1980)] и логистическую моде
ли [Olsen (1980); Greenlees, Reece and Zieschang (1982)]. Последняя it ।
этих работ касается пропусков значений дохода в текущем обследо
вании населения CPS. Естественно, оценки в этих моделях также
чувствительны к выбору априорных нулей в 01 и (см. задачу 6),
11.5. ПРЕДИКТОРНЫЙ БАЙЕСОВСКИЙ ПОДХОД
К АНАЛИЗУ СМЕЩЕНИЙ ПРИ ПРОПУСКАХ
При этом подходе к смещению за счет пропусков, предложенном
Рубином [Rubin (1977)], строят модель распределения для объектов
с пропусками и без пропусков с отдельными параметрами, как в
(11.4) и связывают параметры подходящим байесовским априор-
ным распределением. Неигнорируемый пропуск связан с априорно
фиксированными параметрами, а оставшиеся параметры распреде-
ления оцениваются с помощью соответствующего байесовского
апостериорного распределения. Влияние пропуска оценивается ин-
тервалом, основанным на распределении, предсказывающем гипо-
тетическую статистику для полных данных при заданных присут-
ствующих значениях. Основная идея иллюстрируется в следующем
простом примере. Более общий случай, описанный Рубином, пред-
ставлен в примере 11.7.
Пример 11.6. Чувствительность выборочного среднего к неигно-
рируемым пропускам. В простой случайной выборке по переменной
Y объема п доля пропусков равна р=(п—т)/п. Исследуемой харак-
теристикой является среднее значение Y, которое можно выразить в
виде
y = (l-p)7R+p7NR!
где yR — наблюдаемое среднее для отвечающих, yNR — ненаблю-
даемое среднее для отказывающихся отвечать. Допустим, что зна-
чения Y распределены нормально со средним aR и дисперсией aR у
первых, aNR и aNR — у вторых. Для простоты сначала примем,
что дисперсии равны, т. е. <rR = aNR = o2, и что ог известно. Значения
для отвечающих независимы при заданных aR, aNR и а2. Отсюда
О' r I aR,<r2)~7V(aR, a2/(n пр)), (у NR | aNR,a2)~^aNR^p),
ult N(a,o2) — нормальное распределение со средним а и дисперсией
а2. Субъективные априорные представления о сходстве респондентов
и отказывающихся отвечать можно формализовать, задавая априор-
250
ное распределение aNR, зависящее от aR и а2. В тех приложениях,
которые обсуждал Рубин, подходящим считалось нормальное апри-
орное распределение
(«nr I
при некотором значении ф2. Среднее этого распределения, aR, озна-
чает, что среднее по неотвечающим с одинаковой вероятностью мо-
жет оказаться больше или меньше среднего по отвечающим.
Величина /2 отражает субъективное представление о коэффициенте
разброса среднего по отказывающимся около среднего по респон-
дентам. Например, исследователь может считать с уровнем доверия
95%, что среднее по неотвечающим попадет в интервал
aR(l ± 1,96^2)-
Если </'2=0, то распределение Y для первых и вторых совпадает, и
механизм порождения пропусков игнорируем.
Влияния пропусков можно оценить по предикторному распределе-
нию у при заданных yR и ф2. Можно легко показать с помощью
теоремы Байеса, что оно нормально со средним у R и дисперсией
Var(y |rR,ff2)=pzVar(yNR |у R,a2)=p2Var(aR |yR,a3) +
+p2£(Var(y NR I aNR) jyR,tr2} + p2E[ Var(aNR | aR) | у R,a2 J.
В этом уравнении последний член не зависит от объема выборки.
Он отражает неопределенность неигнорируемой компоненты моде-
ли. Считая априорное распределение aR равномерным и вычисляя
априорную дисперсию aNR при заданных aR и с2, мы получим
Var(y | у R,c2)=p2 {<т2/(л/?)+а2/(л—лр)+ ^(Jr + о2/(п—пр))} =
=/>2 {<т2/(лр—пр2) + ф22(Ук + л2/(л—лр))) •
Отсюда 95%-ный байесовский интервал для у при заданных у R и
а2 равен
уR± 1,96Warty |Ук,’2)=Ук± 1,96р(а2/(лр—пр2)-1?
+ ’A&’r + <г2/(п—пр))}1/2.
Это уравнение соответствует формуле (2.1) в статье Рубина при
^NR=^R’ ^1=0-
Заметим, что при больших п длина этого интервала равна при-
мерно 4p^jrR и описывает неопределенность, вносимую неигнори-
руемой компонентой модели. Выражая ее в долях среднего,
получим, что она равна априорному параметру ^2, умноженному на
4 и на долю пропусков.
251
Пример 11.7. Чувствительность выборочного среднего к неигни
рируемым пропускам при наличии сопеременных. Существенно!
развитие предыдущего примера мы получим, если включим в мо
дель сопеременные X=(Xi,...,Xq), присутствующие для всех o6i.cii
тов выборки. Если У линейно связана с X как в популяции
респондентов, так и в популяции отказывающихся отвечать, мы по
лучим ожидаемые значения
E(yR | aR,/?R,a2JO = aR+XR/3R, Var(y R | aR,^R,a2,X) = a2/(n—np),
E(y NR | aNR,/?NR,ff2,A) = aNR+A’NR/3NR, Var(y NR | aNR,/3NR,j2,.¥) = <?/(«/;),
где X R и XNR — наблюдаемые выборочные средние для первых и
вторых, a aR, aNR, /3R, /3NR и a2 — неизвестные параметры. Чтобы
связать параметры для этих двух групп, будем считать, что пара
метры для неотвечающих имеют следующие условные по парамет
рам отвечающих априорные распределения:
^NR~ M0r,^2^r)>
где Nq(a,B) — ^-мерное нормальное распределение со средним а и
ковариационной матрицей Д а </>NR = aNR+-^R^NR,_0R = aR+XR/3R —
параметры, представляющие средние У при X-XR в популяциях
отвечающих и неотвечающих. Параметр измеряет априорную не-
определенность коэффициентов регрессии. Обозначим /3^* и /?{^ у-е
компоненты (h и /?2 соответственно. Введенные априорные распре-
деления означают, что исследователь на 95% уверен, что попа-
дет в интервал
/?“(! ±1,96^)
при любом J. Параметр ^2 отражает неопределенность скорректи-
рованного среднего и соответствует 1Д2 в примере 11.6 в случае от-
сутствия сопеременных. Механизм пропусков игнорируем в выводах
по функции правдоподобия при ^=^=0.
В предложении равномерного априорного распределения и
/Зк95%-ный байесовский интервал для у при имеющихся данных
принимает вид
yR(l + й0± 1,96(^й2 + ФУ^ + И})1'2),
гДе _
ho =Р(Х NR X л)Ьк/у R,
h\- h2 + (p24/7^(Xnr-Xr)S-1(Xnr-X R)r,
h\=p2{\ +sR/[yRn(l—p)]],
A23=P2(4/yR)[l/(»/’-^2) + (^NR-^R)S“1(TNR-^R)]T-
252
tnccb bR и sR — коэффициенты регрессии и остаточная дисперсия,
полученные методом наименьших квадратов для регрессии на
Лк, a SB — матрица сумм квадратов и взаимных произведений по
X для отвечающих. В частности, предсказываемое значение средне-
го равно:
У r(1 + М = У r +р(Х nr % r)
Последний член представляет поправку на сопеременные (на разли-
чие средних X в выборках отвечающих и неотвечающих). Длину ин-
тервала
+ й2),/2
определяют 3 компоненты. Первая, ^2й2 — относительная диспер-
сия, возникающая за счет недостатка информации о возможном ра-
венстве коэффициентов регрессии У на X в обеих группах. Член
^2й^_ отражает неопределенность для равенства средних У при
Х=Х R. Член h\ отражает неопределенность, вносимую пропуска-
ми, которая присутствует даже при равенстве распределений в обе-
их группах, т. е. когда ^ = ^2=0и механизм пропусков игнорируем.
Поучительно исследовать эти выражения, когда объем выборки
отвечающих стремится к бесконечности. Компонента й2 стремится
к нулю^ и длина интервала становится равна примерно 4py‘R{i/'2 +
+ —-^r^r^rI2}''2 (в предыдущем примере длина равня-
лась 4pyR^2). Кажущееся увеличение длины интервала при наличии
сопеременных противоречит тому, что поправка на сопеременные
должна уменьшить неопределенность предсказания у. Однако в
этих двух примерах субъективный параметр неодинаков. Поправ-
ка на сопеременные должна уменьшать разности между условными
средними при XR в популяциях отвечающих и неотвечающих, и
это должно приводить к меньшему значению ^2 в априорном рас-
пределении в данном примере по сравнению с примером 11.6. Не-
приятным свойством этой модели является невозможность оценить
улучшение прогноза за счет сопеременных, так как оно зависит от
относительной величины ф2 из примера 11.6 и и 02 в данном при-
мере, а эти величины назначаются до начала анализа данных.
Пример 11.8. Приложение результатов из примера 11.7. Рубин
иллюстрирует метод с помощью данных обследования 660 школ. В
472 школах заполнили анкету о дополнительных занятиях (для от-
стающих) с 80 вопросами. Были выбраны 21 зависимая переменная
(У) и 35 сопутствующих переменных (X).
Зависимые переменные характеризовали дополнительные занятия
по частоте их проведения и лежали в диапазоне от 0 (никогда) до
1 (всегда). Ограниченная шкала затрудняет интерпретацию перемен-
ных со средними на концах отрезка, поэтому мы ограничим вни-
253
мание на семи переменных, лежащих в середине шкалы. Выбранные
зависимые переменные соответствовали частоте:
17В: дополнительных занятий, проводимых в часы школьных
занятий;
18А: дополнительных занятий, проводимых за счет занятий об
шественными науками, иностранными языками и/или научных ис-
следований;
18В: дополнительных занятий, проводимых за счет занятий по
математике;
23А: дополнительных занятий с разбиением отстающих на груп-
пы по уровню занятий;
23С: дополнительных занятий с разделением учащихся на группы
по интересам;
32А: дополнительных занятий с использованием, кроме основно-
го пособия, других учебников;
32D: дополнительных занятий с материалами, подготовленными
преподавателем.
Сопутствующие переменные X в исследовании описывали успехи
в школе и социально-экономическое положение учащихся.
Табл. 11.3 представляет значение статистик yR, J?2 (квадрата
множественной корреляции между Y и X для отвечающих), h0, hit
h2 и h3. Значения h0 описывают (пропорциональные) поправки сред-
них, основанные на регрессии на X. Они в целом малы, хотя увели-
чение среднего переменной 18В составляет 6%. Это означает, что
неотвечающие занимаются дополнительно за счет занятий по мате-
матике намного чаще, чем респонденты.
Таблица 11.3. Значения статистик
для 7 переменных в обследовании школ
Переменная у* Rz Ло Й1 *2 *3
17В 0,39322 0,54763 0,02096 0,02647 0,28549 0,02786
18А 0,23132 0,54378 0,00080 0,02300 0,28615 0,03961
18В 0,09067 0,53405 0,06331 0,07749 0,28974 0,07701
23А 0,65796 0,54942 0,00814 0,01020 0,28494 0,01060
23С 0,45240 0,59361 0,00368 0,00679 0,28492 0,00983
32А 0,33968 0,66787 0,00394 0,00394 0,28487 0,00596
32D 0,41489 0,57689 0,00130 0,00334 0,28487 0,00531
Значения hit h2 и h3 определяют вклады $\h р и h2 в квадрат
длины интервала. Длина 95%-ного интервала как функция и
приводится в табл. 11.4. Малые значения hi означают, что неопре-
деленность различия коэффициентов регрессии в двух группах, мо-
делируемая величиной 1Д1, практически не влияет на интервал. Зна-
чения h2 почти совпадают с долей пропусков р=0,2848, поэтому
вклад неопределенности различия средних с поправками в двух
группах описывается величиной 4h2^2=4pt//2 = l,14^2.
254
Основное влияние на длину интервала оказывает величина фг. На-
пример, увеличение ^2 с 0 до 0,3 приводит к увеличению длины ин-
тервала для переменных 23А и 23С в 3 раза, а для 32А и 32D — в
S раз. С другой стороны, для переменных 17В, 18А и особенно 18В
более существенна компонента hi, относящаяся к остаточной дис-
персии регрессии, хотя другие переменные также играют роль при
^2>0,1.
Таблица 11.4. Длина 95%-ных интервалов
для У в процентах от
Переменная ^ = 0 ^i=0,4
1^2 = 0 ^2-0,1 ^=0,2 i/q=0,4 ^2 = 0 ^2 = 0,1 1^1=0,2 ^=0,4
17В 5,6 8,0 12,7 23,7 6,0 8,3 12,9 23,6
18А 7,9 9,8 13,9 24,2 8,1 9,9 14,0 24,3
18В 15,4 16,5 19,3 27,8 16,6 17,6 20,2 28,5
23А 2,1 6,1 11,6 22,9 2,3 6,1 11,6 22,9
23С 2,0 6,0 11,6 22,9 2,0 6,1 11,6 22,9
32А 1,2 5,8 11,5 22,8 1,2 5,8 11,5 22,8
32D 1.1 5,8 11,4 22,8 1,1 5,8 11,4 22,8
Этот пример наглядно демонстрирует возможное влияние смещения
из-за пропусков и степень того, как смещение зависит от величин
типа 1^2, которые нельзя в общем случае надежно оценить по дан-
ным. Единственное удовлетворительное решение проблемы неигно-
рируемых пропусков связано с дополнительной информацией о
наблюдениях с пропусками, что обсуждается в разделе 12.6.
11.6. НЕИГНОРИРУЕМЫЕ МОДЕЛИ
ДЛЯ КАТЕГОРИАЛЬНЫХ ДАННЫХ
Для неполных категориальных данных рассматривались два вида
моделей с неигнорируемыми пропусками. В [Pregibon, (1977); Little
(1982); Nordheim (1984)] предлагалось вводить априорные вероят-
ности пропусков для категорий в таблице, которые видоизменяют
правдоподобие. В [Baker and Laird (1985); Fay (1986); Little (1985b)]
рассматривались логлинейные модели для совместного распределе-
ния категориальных переменных и индикаторов пропусков. Здесь
мы обсудим второй подход, поскольку он ближе по содержанию к
моделям таблиц сопряженности, рассмотренным в гл. 9. В отличие
от этих моделей, модели, обсуждаемые ниже, касаются тонких во-
просов идентифицируемости, которые мы не будем подробно ана-
лизировать. Мы изложим основные идеи, ограничившись примером
двухфакторной таблицы сопряженности с одной дополнительной
подтаблицей. 255
Пример 11.9. Двухфакторная таблица сопряженности с оОт<
дополнительной маргинальной таблицей. Допустим, что дашп.
такие же, как в примере 9. Ей наблюдений по двум категориалып.1
переменным, Yi с уровнями и Y2 с уровнями к=\,.,
наблюдений полностью классифицированы и образуют двухфак к ч
ную таблицу сопряженности [т^, а г=п—т наблюдений класси(|и
цированы по Yi, но не по Y2 и образуют дополнительна
маргинальную таблицу [л]. В качестве иллюстрации возьмем дин
ные из табл. 11.5. с J=K=2.
Таблица 11.5. Таблица сопряженности 2x2
с одной дополнительной маргинальной подтаблицей
И У2
1 2 1 znH = 100 /п12=20 т, + = 120 Гг 2 Ш21=30 тгг=50 тз+ = 8О m+1 = 130 т+2=70 т = 200 1 2 У 1 Гц =? Л2=? л =40 2 Г21 = ? Г22 = ? Г2 = 60 г=100
Полностью классифицированные (R=l) Частично классифицированные (R=0)
Пусть принимает значение 1, если Уг присутствует, и 0 — если
отсутствует. Допустим, что при фиксированном п гипотетические
полные наблюдения распределены полиномиально по таблице
<7хКх2, образованной У1, Уг и R. Пусть тг А=Рг(У1=у, Yi=k) и
ф)к=Рг(Я = 11У =/, Уг=/г), так что Pr(Yi-j,Y2 = k, К=1)=тг,кф]к и
Рг(У1=у, Yi = k, й=0)=тгд(1—Эта модель содержит 2JK—-1 па
раметров. Данные обладают JK+J—1 степенями свободы для ее
оценки: JK — в полностью классифицированной таблице, J — в до-
полнительной таблице, и одна степень свободы уходит на ограниче-
ние: сумма вероятностей равна 1. 'Отсюда в модели содержится
2J'K— 1—(JK+J— 1) лишних параметров. Мы уменьшим
число параметров, вводя ограничения на вероятности в ячейках в
виде иерархической логлинейной модели (заметим, что логлииейные
модели в разделе 9.4 описывают совместное распределение У, а
здесь мы строим модель совместного распределения У и индикато-
ра пропусков R).
Все иерархические модели, включающие главные эффекты У>, Уз.
и R, приведены в табл. 11.6. первый столбец описывает модель с
помощью обозначений, введенных в разделе 9.4. Следующие три
столбца дают число параметров в модели, число степеней свободы
256
для проверки качества модели и число неидентифицируемых пара-
метров модели, т. е. не входящих в правдоподобие. Для этих вели-
чин справедлива взаимосвязь
ч.с.с. в модели + ч.с.с. для проверки модели—
число неидентифицируемых параметров=JX+J— 1.
11оследнее число — число степеней свободы в данных. Остальные
шесть столбцов показывают результаты проверки соответствия мо-
делей данных в табл. 11.5 — статистика отношения правдоподобий
для этой проверки, соответствующее число степеней свободы и
оценки вероятностей в ячейках (хЮО).
Таблица 11.6. Модели для двухфакторной таблицы сопряженности
с одной дополнительной подтаблицей
Модель Число степеней свободы Значение для данных табл. 11.5
Модель Критерий Неиденти- фицируе- мость Критерий X2 Оценки вероятностей в ячейках (х 100)
X2 Ч.С.С. Тц ^12 ^21 я-22
(1) (Уад (2) {Y^Y^R} (3) [уу2,ул) (4, (уу2,ад (5) (У,У2,Я) (6) (У,Я,У2Х) (7) (У,Я,У2) (8) !У,ад (9) [ У1ГУ2,Н] 2JK— 1 JK+J+K—2 JK+J—X JK+K—1 JK 2(7+79—3 2J+K— 2 2K+J— 2 J+K— 1 0 0 0 шах(7—Х,0) 7—1 (7-1ХЛ-1) (Л—1)(JC—I) (7-1И 7(К-1) 1 0 шах(Х—7,0) 0 К— 1 0 К— 1 0 0 10,75 44,99 44,99 55,74 55,74 0 0 1 1 1 2 2 44,4 39,4 44,4 34,7 34,7 8,9 14,0 8,9 18,7 18,7 17,5 11,8 17,5 30,3 30,3 29,2 34,9 29,2 16,3 16,3
Следующие аспекты моделей из табл. 11.6 заслуживают некоторого
внимания.
1. Неидентифицируемостъ. Модели (У1У>, Y-fi, Y2R),
{YiR,Y2R}, {Yi, Y2R} и, если K>J, то и [У1У2, Y2R}, содержат пара-
метры, не поддающиеся оцениванию. Для оценки вероятностей ячеек
в этих моделях требуется дополнительная информация. Соответ-
ствующие оценки в таблице отсутствуют.
Отметим, что две из этих моделей, !УЯ,У2/?) и {У1,У2Л>, неиденти-
фицируемы, хотя число параметров в них меньше JK+J—1 числа сте-
пеней свободы для данных. Рассмотрим, например, модель услов-
ной независимости Yi и У2 при заданном R, т. е. (У1 R,Y2R j. В
этой модели 2 J+2K— 3 параметров: один — для маргинальной ве-
роятности пропуска, J+K— 2 — для условного распределения У) и
У2 при заданном R = \ и J+K—2 — для условного распределения У;
и У2 при /?=0. Последние два распределения вместе содержат JK—1
9. Р. Дж А. Литтл. Д. Б Рубин 257
вероятностей без (7—1)(Х—1) степеней свободы, так как Yt и У2 нс
зависимы условно по R. Правдоподобие для неполных данных рае
падается на три компоненты с разделительными параметрами, соог
ветствующие маргинальному распределению R, условному распре
делению и У2 при Л=1 и условному распределению Yt при R= 0.
Эти компоненты обеспечивают оценки \+(J+K—2)+(7— \)=2J+K- ')
параметров. Остальные К—1 параметров, отвечающие распределс
нию У2 при R = 0, неидентифицируемы. Остается (JK+J— 1)—(271
+К— 2) = (J— 1)(Х— 1) степеней свободы для данных, что cootbci
ствует числу степеней свободы при проверке условной независимое
ти У] и У2 при заданном 7? = 1.
2. Игнорируемость пропусков. Это свойство выполняется для
моделей (У^г.У! 7?} и {У2,У|Т?}, так как пропуски зависят только от
У15 наблюдаемой полностью. Эти модели можно подгонять по дан-
ным методам гл. 9. То же справедливо и для моделей (У] Y2,R) и
[Yi,Y2,R}, поскольку в них предполагается независимость пропусков
от У] и У2, т. е. условие «данные ОПС». Они дают такие же оценки
{тг/А.}, что и их аналоги при условии ОС, т. е. {У1У2,У1Т?) и
(У^Уг.У)??} соответственно.
3. Проверка качества. Статистика хи-квадрат для проверки спра-
ведливости модели (У^.Т?) основана на критерии независимости
У) от 7? по двухфакторной маргинальной таблице ytx7?, модели
(У1Т?,У2) — на критерии независимости Y, и Уг по полностью клас-
сифицированным наблюдениям. Статистика для модели (У1,У2,Т?) —
сумма двух первых статистик.
4. Оценивание. МП-оценка лд для {У1У2,У1Т?} или {У,У2,7?] равна
T/fc=(myA. + /ylt)/(m + r), где ^=(Щд/ту+)Гу — подставляемые частоты
(см., например (9.3)). Можно считать, что эта оценка получается при
таком распределении частично классифицированных наблюдений по
таблице, которое отвечало бы распределениям {т^+т^}, полнос-
тью наблюдаемым внутри строк, как в примерах 9.1 и 9.2.
Из 5 моделей табл. 11.6 с неигнорируемыми пропусками только
одну можно определить без дополнительной априорной информа-
ции, а именно {У1У2,У2Т?), которую можно оценить при K^J. Эта
модель означает, что пропуск У2 зависит от значения У2, но не
от УР МП-оценки для этой модели также имеют вид ftjk=
=Hmjk + но теперь подставляемые значения f*k таковы,
что = mjk/m,k, т. е. они согласуются с распределениями
полностью классифицированных данных внутри столбцов. Эти
ограничения вместе с условием Ед>д=Гу для всех j приводят к
JK—K+J — линейным уравнениям относительно JK неизвестных f*k.
258
Если K>J, то параметров больше, чем уравнений, и поэтому нуж-
ны априорные условия, чтобы однозначно определить [гд] (и,
значит, 7cjk). Если K<J, то уравнений больше, чем параметров, и
МП-оценки r*jk не могут точно удовлетворять условиям. В таких
случаях для вычисления [/д] можно использовать ЕМ-алгоритм
(см., например, [Baker and Laird (1985)]). Если K=-J. то JK линейных
уравнений можно решить непосредственно, не прибегая к ЕМ-алго-
ритму. В частности, при J=K~1 мы получим следующие уравнения
относительно /п, r*i2, /21 и г22.
T*lW?21/Wll,r22 = /W22/Wl2, *2 +/'ll = Л, ^21 + ^22 = гг-
Решения равны fn=(r2—Гхгп22/mi2)(mu/mn—Шгг/лйг)-1 и т. д. Для
данных табл. 11.5 мы получим
/’71=200/11, Л]2 = 240/11, r2‘i=60/ll, ^=600/11,
что дает оценки {irjk) в строке (4) табл. 11.6.
Оценки, получаемые при решении этих линейных уравнений, мо-
гут быть отрицательными, т. е. не совпадать с МП-оценками. Как
показано в [Baker and Laird (1985)], чтобы такой случай не имел ме-
ста, шансы в маргинальном столбце должны лежать между
наименьшими и наибольшими значениями шансов {mjk/mlk] в
столбцах к=1....К. В нашем примере i\/r2 =40/60 находится между
шн/т21 = 100/30 и mi2/m22 =20/50, так что это условие выполняется.
Подробности см. в [Baker and Laird (1985)].
5. Выбор модели. Важно отметить, что в нашем примере обе мо-
дели, [У1,У2,У!.К] и |У|,У2,У2Я), идеально согласуются с данными
ввиду отсутствия степеней свободы на проверку согласия. Поэтому
невозможно отдать предпочтение одному из двух наборов оценок
[тгд] для этих моделей, не обращаясь к априорным рассуждениям
о том, какой механизм порождения пропусков в имеющихся данных
более правдоподобен.
В [Little (1985)] идеи этого примера обобщены на случай двухфак-
торной таблицы с двумя дополнительными маргинальными под-
таблицами. В этой ситуации вводятся индикаторы R> и R2
пропусков в У, и К. и рассматриваются модели четырехфакторной
таблицы для Yi, У2, Rt и R2. Можно рассматривать и таблицы
большей размерности, по крайней мере в принципе.
!!
259
ЛИТЕРАТУРА
Amemiya, Т (1984) Tobit models a survey, J Econometrics 24, 3 61 (
Baker, S , and Laird, N (1985) Categorical response subject to nonresponse, Department
Biostatistics, Harvard School of Public Health, Boston, MA
Berndt, E B, Hall, B, Hall, R, and Hausman, J A (1974) Estimation and inference
nonlinear structural models, Ann Econ Soc Meas 3, 653 665
Box, G E P , and Cox, D R (1964) An analysis of transformations, J Roy Statist Sih
B26, 211-252
David, M H , Little, R J A , Samuhel, M E,andTriest R К (1986) Alternative methods hn
CPS income imputation, J Am Statist Assoc 81,29 41
Fay,R E (1986) Causal models for patterns of nonresponse, J Am Statist Assoc 81,354 Ui”!
Greenlees, W S , Reece, J S , and Zieschang, К D (1982) Imputation of missing values wln'ti
the probability of response depends on the variable being imputed, J Am Statist
77,251-261
Hasselblad, V , Stead, A G , and Galke, W (1980) Analysis of coarsely grouped data from Hu
lognormal distribution, J Am Statist Assoc 75,771 778
Heckman, J (1976) The common structure of statistical models of truncation, sample selection
and limited dependent variables, and a simple estimator for such models, Ann Econ S<><
Meas 5, 475 492
Kulldorff, G (1961) Contributions to the Theory of Estimation from Giouped and Partntlh
Grouped Samples Stockholm Almquist and Wiksell and New York Wiley
Lillard, L Smith, J P , and Welch, F (1982) What do we really know about wages I hr
importance of nonreporting and census imputation, The Rand Corporation, Santa Monica
CA
Lillard, L, Smith, J P and Welch, F (1986) What do we really know about wages7 Hu
importance of nonreportmg and Census imputation, Journal of Political Economy, 94
489 506
Little, R J A (1982) Models for nonresponse in sample surveys, J Am Statist Assoc 77
237-250
Little, R J A (1985a) A note about models for selectivity bias, Econometnca 53, 1469-1474
Little, R J A (1985b) Nonresponse adjustments in longitudinal surveys models foi categorical
data. Bulletin of the International Statistical Institute, 15,1, 1-15
Nordheim, E V (1984) Inference from nonrandomly missing data An example from a genet к
study on Turner’s Syndrome, J Am Statist Assoc 79,772-780
Olsen, R J (1980) A least squares correction for selectivity bias, Econometnca 48, 1815 1820
Pregibon, D (1977) Typical survey data estimation and imputation Survey Methodol 2,
79 102
Rubin, D В (1977) Formahzingsubjectivenotionsabouttheeffectofnonrespondentsmsample
surveys, J Am Statist Assoc 72,538 543
Rubin, D В (1983) Imputing Income in the CPS, in The Measurement of Labor Cost (Jack
Triplett, Ed ) Chicago University of Chicago Press
Tobin, J (1958) Estimation of relationships for limited dependent variables, Econometnca
26,24 36
260
ЧЛДАЧИ
1. Проведите интегрирование, необходимое для вывода шага Е в примере 11.1.
2. Выведите выражения для шага Е в примере 11.2. Опишите в явном виде шаг
М для этого примера.
3. Выведите выражения для шага Е в примере 11.4.
4. Покажите правильность описания шага М в конце примера 11.4. Почему оцен-
ку о? не вычисляются просто по регрессии Y на -V?
5. Сравните ММП и двухшаговый метод оценивания параметров модели стоха-
। шческого цензурирования из примера 11.4. Чем они сходны, чем различаются?
6. Рассмотрите модель цензурирования из примера 11.4, когда х~(х^, Z-), где
— одна бинарная переменная, влияющая на цензурирование, но с нулевым коээфи-
цпентом регрессии У! на X. Ниже даются средние при заданных х(-, классифици-
рованные по и по присутствию (Ry = l) или отсутствию (R;y=O) значения у^-.
О или 1
xfii + е^Мтц)
Xt/3, + gffiX(—7И)
xfii
хД + eoiM7,o)
Xfi, + gciX(—710)
x/1
1
О
В этой таблице Х(-) определено в примере 11.3, a y(j — среднее Уг для объектов со
। качением сопеременных (х,-, fl =/).
а) Выведите выражения в таблице.
б) Рассмотрите разность средних Yi для объектов с пропуском и со значением при
различных значениях Покажите, что модель отвечает приблизительно аддитив-
ной структуре средних в таблице (подробности см. в [Little (1985а)]).
7. Допустим, что для модели из примера 11.4 обследована случайная подвыборка
объектов с пропуском и для них получены значения Yi. Выпишите функцию правдо-
подобия для получаемых данных и опишите ЕМ-алгоритм.
8. Покажите в контексте примера 11.7, что апостериорное распределение упри
жданном Y=sf( нормально со средним yR(l + /и) и дисперсией +
+ Л|). Каковы апостериорные средние и дисперсия переменной 32D при
- фг — 0,5?
9. Выпишите факторизованное правдоподобие для моделей [У1Уг,У1Л], 'YiYi.YiR],
|У1Я,У2/?] и [YiYzR} из примера 11.8 в подходящей параметризации. Укажите для каж-
дой модели неидентифицируемые параметры (если они есть).
10. Проверьте пять наборов оценок вероятностей в ячейках в табл. 11.6.
11. Постройте повторно табл. 11.6 по данным табл. 11.5, где пип умножены
Глава 12. МОДЕЛЬНЫЙ ПОДХОД К ПРОПУСКАМ
ПРИ ВЫБОРОЧНЫХ ОБСЛЕДОВАНИЯХ
12.1. БАЙЕСОВСКАЯ ТЕОРИЯ ДЛЯ ПОЛНЫХ ДАННЫХ ’
В гл. 4 мы рассматривали пропуски при обследованиях с позиции
квазирандомизационного подхода, в котором значения переменных
(KZ) считались фиксированными, а выводы строились на основе hi
вестного распределения выборки и модели распределения про
пусков f(R\I,Y,Z). При другом подходе к построению выводои
вводят модель распределения переменных Y и используют методо
логию, служившую нам основой в гл. 5—11. Для выводов о пара
метрах конечной популяции более естественно использова 11.
байесовский подход, при котором задают априорное распределение
неизвестных параметров, чем подход, опирающийся только на
правдоподобие. Поэтому мы принимаем в этой главе байесовский
подход аналогично разделу 11.5. Более полное исследование дано В
[Rubin (1987), гл. 2].
Данные обследования при отсутствии пропусков можно предста-
вить на рис. 12.1, на
Переменные
плена
Z
ременные
плана об-
следования
Z и инди-
каторная
переменная
I известны
для всех
объектов
популяции.
Перемен-
ные Y за—
регистри-
рованы у
Рис. 12.1. Данные выборочного обследования И объектов
при отсутствии пропусков Выборки С
7, = 1. Анализ полных данных обследования можно рассматривать
как задачу с неполными данными при монотонной структуре, изо-
браженной на рис. 12.1. Целью является построение выводов о
значениях У, отсутствующих в выборке.
262
котором строки соответствуют объектам,
столбцы—
перемен
ным. Пе
Индикатор
включения
в выборку
Исследуемые
переменные
При построении байесовской модели для таких данных значения
/ и Y считают реализациями случайных переменных с совместным
распределением
f(Y,I\Z)=f(Y\Ztf(I\ Y,Z). (12.1)
обозначим У=(У;пс,УеХс). гДе Ушс — множество значений У в вы-
порке, Уехс — множество вне выборки. Таким образом, при отсут-
I 1вии пропусков данные состоят из_У;пс,/ и, конечно, Z. Выводы о
параметре популяции, таком, как Y, среднее Y, получают из его
распределения при заданных наблюдаемых значениях yinc, I и Z.
>то распределение определяется присутствующими данными Yinc, I
и Z и распределением отсутствующих данных Уехс при заданных
7 и Z;
ЛУехс I yinc,4Z)= . (12.2)
В этой формулировке явно видно, что апостериорное распределе-
ние Уехс в (12.2) условно не только по У;пс и Z, но и по /. Часто ис-
следователи игнорируют это дополнительное условие при построе-
нии байесовских моделей и основывают выводы на распределении
Следуя [Rubin (1976), (1978), (1987)] и [Little (1982)], мы будем гово-
рить, что механизм извлечения выборки игнорируем, если распреде-
ления Уеж (12.2) и (12.3) совпадают. Достаточным условием для
этого является независимость распределения I при заданных У и Z
от Уехс:
f(l\ Y,Z)-f(I\ (12.4)
Если (12.4) выполняется, то правая часть (12.2) равна:
ftY\Ztf(l\ Y,Z) _ /(У | 2W| Y^Z) _ /(y|Z)
ЖI Wl Y,Z)dY~~ [ДУ| ZV(/| rjnc.Z)rfrHc ~ ’
что означает идентичность (12.2) и (12.3).
Примечательно, что если выбор объектов в соответствии с меха-
низмом извлечения выборки f(I | Y,X) проводится случайно, то функ-
ция f(I | Ущ^У^рТ) известна и не зависит от У;пс или У^.. Поэтому
любой случайный выбор игнорируем, и его распределение не играет
непосредственной роли в байесовских выводах. Другие способы
формирования выборки могут быть «неигнорируемы», и тогда вы-
воды по (12.3) могут быть смещенными. В этом случае полную мо-
дель (12.1) описать трудно, если только исключение объектов из
263
выборки не проводится с помощью известного механизма, напри
мер цензурирования с известной точкой цензурирования. Таким об
разом, случайный выбор играет важную роль при моделировании,
хотя выборочное распределение не участвует в построении выводом,
Это обстоятельство отмечалось в литературе (см., например,
[Rubin (1976), (1978); Scott (1977)]), однако оно заслуживает того,
чтобы его еще раз подчеркнуть, поскольку это — важнейший apiy
мент против представления о том, что модельный подход исключи
ет необходимость в случайном выборе объектов. Более того, даж<
при игнорируемом механизме выбора последствия ошибок постриг-
ния модели зависят от плана выбора, который, следовательно, не
явно влияет на выбор модели.
Пример 12.1. Расслоенный случайный выбор при отсутствии
пропусков. Проиллюстрируем изложенное. Пусть Z — переменная,
указывающая номер слоя популяции, т. е. z,=y, если /-й объект m
носится к у'-му слою, Y — переменная, измеряемая в обеги-
довании для всех объектов выборки. Распределение /(Y|Z)
определим в виде
f(Y\Z)=\f{Y\Z,9W\Z)d9,
где j=\,...,J) — промежуточные параметры модели с
априорной плотностью
Ж = Па-,2
7=1 J
a f(Y\ Z,t)) = Hi!^f(y. | £.,0), где для объектов из у'-го слоя
Ж I г, =у,0) = (2тга2) 1/2ехр[—(у,—ду)2/2ау| —
нормальная плотность со средним и дисперсией а2. Использова-
ние промежуточного параметра 6 для условий независимости объек-
тов — распространенный подход при байесовском моделировании.
Распределение f(I\ Y,Z') соответствует расслоенному случайному
выбору nj из Nj объектов у-го слоя. Это значит, что значение
f(l\ Y,Z) одинаково у всех выборок /=(/],...,ZV)T с П: объектами в
слое j, и равно нулю в противном случае. Поскольку это
распределение не зависит от Уехс, выборочный механизм игнориру-
ем, и выводы об отсутствующих значениях можно строить с по-
мощью распределения (12.3). В частности, выводы о среднем
популяции можно основывать на j\Y | Z,Yinc).
Пусть и sj — выборочные средние и дисперсия в слое у. Апо-
стериорное распределение асимптотически нормально со средним
y~j и дисперсией Sj/nj. Теперь среднее Y j в у-м слое популяции име-
ет вид
Уу=( Еу,+ 'ZyJ/Nj-,
feinc r€exc
264
апостериорное среднее Yj равно:
£(^|yinc,Z) = (£/i7+ £ E^Y^/N^y.,
поскольку для исключительных объектов
Е(Уц\ rinc,Z)=£[£(y,y|^)yinc)Z>| Yi0C,Z] =ЕЦ| У^Х)^.
Можно также показать, что априорная дисперсия Уу равна:
Var(y; |yinc,Z) = (l~nj/N^/nj.
Таким образом, поправка на конечность_популяции (1—Иу/Ny) по-
является в оценке точности параметра Yj популяции в таком же
виде, как и при расслоенном случайном выборе в теории от рандо-
мизации. В этом и других примерах выводы о параметрах отли-
чаются от их аналогов в конечной популяции Yf на поправку на
конечность популяции, которую можно игнорировать, если доли
объектов в выборках nj/Nj малы. Значит, апостериорное распреде-
ление У асимптотически нормально со средним
E(y|yinclZ)= £р^ (12.5)
и дисперсией
¥аг(У |yinc,Z)= £ Pfor'-N^, (12.6)
где Pj=Nj/N. Заметим, что при подходе от рандомизации (гл. 4)
выражение (1_2.5) — это расслоенное среднее, обычно применяемое
для оценки У, а (12.6) — стандартная оценка дисперсии повторного
выбора [Cochran (1977)]. Поэтому байесовские интервалы, основан-
ные на (12.5) и (12.6), эквивалентны доверительным интервалам,
получаемым в теории от рандомизации.
12.2. БАЙЕСОВСКИЕ МОДЕЛИ
ДЛЯ ДАННЫХ ОБСЛЕДОВАНИЯ С ПРОПУСКАМИ
Для изложения переменные удобно разделить в обследовании
на две группы U и У, где U присутствует у всех объектов выбор-
ки, а У подвержена пропускам. Структура пропусков в У описы-
вается матрицей индикаторов пропусков R=(RJ, где 7^ = 1, если
зарегистрировано, и 7?,у=0 — в противном случае. Представим
схематично данные на рис. 12.2, как в [Little (1982)]. Значения U, R,
Y, присутствующие в выборке, обозначим Цпс, 7?inc, Ук1с, а исклю-
ченные значения — U^, R^, Y^.. Включенные значения ytac можно
265
далее разбп 1i,
на присутствую
щие yobs и си
сутствующю
y,nis. Заштрпхи
ванная облас, ь
на диаграмм,
представляв ।
данные (Z,1,U{W
^inc’’^obs)' Зна'к
ния индикатором
включения в вы
борку и nponyi
ков показаны па
диаграмме как
блоки нулей и
единиц. Объек
ты расположены по строкам, так что первые т объектов содержа!
все переменные, следующие п—т объектов включены в выборку, но
неполны, а остальные N—n объектов не вошли в выборку.
На диаграмме показан частный случай с монотонной структурой
пропусков в У, обсуждавшейся в гл. 6. В этом случае все множество
данных также имеет монотонную структуру: Z и I присутствую!
полностью и наблюдается больше У и A, a Z, I, U и R наблюдается
больше У. Как указано в гл. 6, вывести эффективные методы обра
ботки пропусков легче при монотонной, чем при более общей струк
туре, хотя теория, излагаемая ниже, рассматривает самую общую
ситуацию. Частный случай монотонной структуры возникает при
пропуске всего объекта, когда все частично наблюдаемые перемен-
ные отсутствуют у некоторых объектов и когда нет полностью на-
блюдаемых переменных U.
В чисто байесовской модели задают совместное распределение /,
U, R и У условно по Z. Это распределение можно определить как
произведение условных распределений
f{Y,R,U,I\Z)=J[Y,U\Z\f{R\Y,U,Z)f(I\ Y,R,U,Z). (12.7)
Первый фактор в правой части (12.7) совершенно аналогичен первому
фактору в (12.1) с заменой У на (Y,U). Последний фактор в (12.7) ана-
логичен второму в (12.1) и заменой У на (Y,U) и дополнительным ус-
ловием по R, которое появляется из-за возможных пропусков (т. е.
выводы могут зависеть от структуры пропусков). В связи с этим до-
полнительным условием при возможности пропусков мы будем гово-
рить, что механизм извлечения выборки игнорируем, если /(/| К/?Д2)
зависит только от наблюдаемых значений (УоЬ8, 2?jnc, Цпс2):
Л1\ YR,U.Z)=f(I\ Yobs,Rinc,Uiac,Z). (12.8)
266
Наконец, второй фактор в (12.7) новый и представляет механизм
пропусков — условное распределение R при заданных (Y,U,Z). Фак-
торизация (12.7) имеет такую же общую форму, что и факториза-
ция (11.3) для неигнорируемых пропусков, с дополнительным
фактором, отражающим выборочный механизм.
Теперь выводы о параметрах популяции следуют из присутству-
ющих значений (УоЬ8,/?1пс,Цпс,/,Х) и условного распределения отсут-
ствующих значений (Texc,Tmic,t/exc) при заданных присутствующих
значениях:
Л Уехс,Ут!8,С/ж|УоЬ5,Л111С,Цпс,/,7) =
j/(W,7|Z)<ZRro (12.9)
imY,R,W\Z)dYeKdYmisdR^dUx
Здесь в явном виде представлено, что апостериорное распределение
(12.9) условно по I и Rjnc, кроме (Yobs,Yiac,Z). Это дополнительное
условие часто игнорируют, даже сталкиваясь с пропусками, и стро-
ят байесовские выводы с помощью распределения
Л ^exc’^mis’^excl^obs’^inc’^) ~
ftY,U\Z)
^(YMZ)dY№cdYmisdUaQ
(12.10)
Следуя [Rubin (1976), (1987)] и определению из раздела 12.1, мы
будем говорить, что механизмы извлечения выборки и пропусков
одновременно игнорируемы, если распределения (12.9) и (12.10) со-
впадают. Достаточным условием для игнорируемости механизма
пропусков при игнорируемости выборочного механизма является
независимость распределения R при заданных Y, U и Z от отсут-
ствующих значений Y^U^U^:
f(R\Y,U,Z)=AR\Yobs,UilK,Z).
Если верны это уравнение и (12.8), то
f(YAUJ\Z)=f(Y&\^^
поэтому (12.9) равно (12.10).
Детальное изложение условий игнорируемости механизмов из-
влечения выборки и пропусков дано в [Little (1982)]. Перефразируя
формулировки, мы можем сказать, что при случайном выборе эти
механизмы игнорируемы, если распределение пропусков не зависит
от значений признаков, отсутствующих у некоторых объектов. В
частности, предполагается, что пропуск не зависит от отсутствую-
щей переменной внутри подклассов, определенных значением пере-
менных плана Z и полностью наблюдаемых переменных t/ilK. Эти
условия сходны с условием ОС и условием раздельности парамет-
ров из предыдущих глав, налагаемых в рамках теории правдоподо-
бия. Это соответствие обсуждается в [Rubin (1978), гл. 2].
В следующем разделе мы опишем методы, основанные на модели
с распределением в виде (12.9), которая построена в предположении
игнорируемости механизмов выбора и пропусков. Почти все анали
тические процедуры с обработкой пропусков в выборочных обсле-
дованиях, применяемые на практике, опираются, по сути, на эт|
предположение.
12.3. МЕТОДЫ ДЛЯ МОДЕЛЕЙ
С ИГНОРИРУЕМЫМИ ПРОПУСКАМИ
Теперь продемонстрируем применение байесовской теории из раз
дела 12.2 на ряде простых примеров. Некоторые результаты согласу
ются с оценками и стандартными ошибками квазирандомизациоп-
ного подхода из гл. 4, однако, как можно показать с помощью прос-
тых обобщений этих стандартных результатов, модельному подходу
присуща гибкость при выводе оценок и стандартных ошибок в' не-
традиционных ситуациях. Во всех примерах взят простой случайный
выбор из конечной популяции с пропусками в Y, но не в U. Посколь-
ку ни один из примеров не опирается на существование переменных
плана Z, они не включены в выражения, хотя легко провести непо-
средственное обобщение на случай расслоения. Во всех примерах
предполагается, что пропуски игнорируемы, но, возможно, зависимы
от значений полностью наблюдаемых переменных Цпс.
Пример 12.2. Модели весовых групп с известными частотами в
группах. Допустим, что из популяции с N объектами извлечена
простая случайная выборка объема пив значениях переменной Y
есть пропуски, соответствующие случайному подвыбору значений
выборки внутри групп, формируемых по переменной U, зарегистри-
рованной у всех объектов выборки. Пусть Nj и Yj означают соот-
ветственно число объектов и среднее в у-й группе популяции (U=j).
Нашей целью является оценить общее среднее в популяции
Y =Y.PjYj,
где Pj — Nj/N.
Допустим, что значения Y в у-й группе н.о.р. по нормальному за-
кону со средним fij и дисперсией a2- it что и Inoj- имеют локально
равномерные априорные распределения, как и в примере 12.1. Счи-
тая объем выборки большим, а известными, получим (с по-
мощью выкладок, аналогичных примеру 12.1), что данные по отве-
чающим (по объектам без пропусков) нормальны со средним
ДУ|УоЬ5,Цпс, (AJ- }) = ^PjyjR (12.11)
и дисперсией
Var(T\Yobs,UiDC,{Nj ))= ^(m/-Nj')s]R, (12.12)
где mj — число ответивших, и SjR— выборочные среднее и дис-
персия значений Y в выборке отвечающих в у-й группе. Обратите
268
внимание, что (12.11) — это среднее пострасслоения, а (12.12) — его
дисперсия, полученные в (4.15) и (4.16) соответственно в рамках
квазирандомизационной теории. Значит, эти выражения дают байе-
совские интервалы, совпадающие с доверительными интервалами
для частотного подхода из раздела 4.4.3.
Пример 12.3. Модели весовых групп с неизвестными частотами
в группах. Допустим, что мы имеем такую же постановку, как в
предыдущем примере, но с неизвестными (Nj) в группах, что
обычно бывает, когда U— переменная, изучаемая в обследовании.
Байесовские выводы о Y основаны на его апостериорном распреде-
лении при заданном yobs, которое получают из апостериорного
распределения У, условного по заданным yobs и (?^), из примера
12.2, интегрируя по апостериорному распределению [Nj}, условно-
му по Kobs, Цпс:
f(Y |УоЬ8,Цпс) = Ж |robs,C/inc, [Nj \WNj) I yobs,L/inc)d(Af J.
В частности, среднее и дисперсия этого распределения равны:
E(Y |УоЬ5,Цпс)=£[£(У |УоЬ8,Цпс, [AJ ] | УоЬ5,Цпс)] =
(12.13)
и
Уаг(У |УоЬ5,Цпс)=Д Уаг(У | {Ц}
>^obs>^inc)l ^obs’^inJ
+Уаг[£(У | [Nj) ,yobs,t/inc)| УоЬ5,Цпс] = (12.14)
= E[E(P)| УоЬ5,Цпс)/щу-£(Ру| yobs,t/inc)/N)^ +
+Var(E/y .у’щ | УоЬ8,Цпс) ’
где суммирование проводится по весовым группам j=l,...,J. Допу-
стим, что объекты распределены по весовым группам как н.о.р. по-
линомиальные случайные величины с вероятностями (₽!,...,6j) и
индексом 1 при локально равномерном по (вг,...,в^ априорном рас-
пределении. Тогда
Var(0y|yobs,t7inc)=p/l-py)/n,
Cov(^,^|yobs,I/inc) = —PjPk/n,
где Pj-nj/n, выборочная доля в у-й группе. Далее
E(Pj\ [ ) ,УоЬ5,Цпс) = [«у + (N-n)0j\/N,
VarlPj] {%) ,УоЬ8,Цпс) = (N-nWjtl-djy/Ni,
Cov(Pj,Pk\ {dj} ,yobs,^nc) = -{N-ri^/W.
269
Отсюда
E(Pj\ YoiK,Uin^=E[E(Pj\ (0;} ,yobs,Uinc)| yobs,l/inc] =
= [иу + ^-и)р;]Ж=ру,
Var(Py| yobs,t/inc) =E[Var(P,-| ($ ] ,УоЬ8,Цпс)] +
+Var[£(Py| (9j},УоЬ5,Цпс)| Kobs,t/inc) =
= (1—1/2V)(1— n/N)Pj(l-~pj)/n,
Cov(P/,Pfc|yobs,l/inc)=£[Cov(P/,Pfe| }
’^obs’^incl-^obs’^incl +
+ Cov[E(Py| {9j} ,yobs,t7ihc), E(Pk((0j) ,УоЬз>Цпс)| yobs.^ind =
= — (1—1/JV)(1 ~n/N)PjPk /n.
Подставляя эти выражения в (12.13) и (12.14), получаем
Е(У |yobs,t^inc)— jPPjyjR ~3wc
— оценку весовых групп (4.10) и после некоторых выкладок
Уаг(У |yobs,C/inc)= £rf[l-mj/(NPj)] SJR/mj+
+«-1(1-i/M(1-«/M74 [p7^-7wc)2+
+P/1—Pj)s}R/mj\.
Это выражение приближенно равно оценке среднеквадратической
ошибки оценки весовых групп, приведенной после (4.12).
Гибкость модельного подхода при вычислении оценок и стандарт-
ных ошибок можно легко увидеть на примере, когда весовые груп-
пы формируются совместно по уровням двух или более факторов.
Пусть j
Y = j^ik^iPjkYjk<
где индекс jk относится к группе, соответствующей уровням U}=j
и иг = к двух классифицирующих переменных. Модель
0/1 «п Ч, иц = кЧ ~ N^jba/k>
для отвечающих и неотвечающих объектов в группе (j,k) с
0 = (/1уА.,<гД, к=1,...,К) и локально равномерными априор-
ными распределениями для и 1псД ведет к оценкам весовых
групп или пострасслоения, как и ранее. Если число отвечающих
270
nijk мало в некоторых группах, можно подобрать более экономную
модель для описания средних в группах. Например, данным может
хорошо соответствовать аддитивная модель
О'/I И/1=Л ui2 = k,6)~N{li+aj + ^k,
где теперь к=1,...,К). Эту модель можно оце-
нивать методом наименьших квадратов, обеспечивая прогноз отсут-
ствующих значений Y. Можно строить также объединенную оценку
дисперсии, подбирая модель, в которой дисперсии crj. считаются
равными при всех J и (или) к.
Другой модельный подход, с помощью которого можно умень-
шить добавочную дисперсию оценки весовых групп (по сравне-
нию с оценкой пострасслоения (12.11)), — моделирование
вероятности групп Р:к. Например, может оказаться приемлемым
предположение о независимости классифицирующих факторов Ui и
иг, что ведет к оценкам (без учета поправок на конечность попу-
ляции)
Pjk = nJ+n + к/п2>
к .
где = ^njk, п+к=£.^п/к.
Гибкость модельного подхода при сглаживании средних в груп-
пах, дисперсий и пропорций вероятностей особенно полезна, когда
весовые группы определяются совокупностью трех или более фак-
торов, т. е. в случаях, когда для оценки пострасслоения и весовых
групп требуется достаточно большое число отвечающих в каждой
группе, где есть пропуски. Как видно из следующего примера, мо-
дельный подход можно также приспособить и для случая с присут-
ствием сопеременных для прогноза пропущенных значений.
Пример 12.4. Заполнение по регрессии. Рассмотрим более общий
случай. Пусть извлечена простая случайная выборка объема л(у;,
Иц,...,н(^), где К переменных UX,...,UK зарегистрированы у всех
объектов выборки, а наличие пропуска не зависит от У условно по
Ui,...,UK. Предположим, что
О’/ I «/!,..
(12.15)
где Vj = — известная функция, характеризующая разно-
родность дисперсии. Априорные распределения параметров 0 =
= (/30,...,/Зх,1п<72) предполагаются локально равномерными. Тогда
оценками пропущенных значений Y служат их апостериорные
средние
где (/ЗоА,...,^) — оценки коэффициентов методом наименьших
квадратов с весом z-ro объекта, равным vj .
271
Частные случаи оценок, основанных на этой модели, включают
оценки из предыдущего примера, получаемые из (12.5) при v; = l и
при иь...,ик, представляющих фиктивные переменные для весовых
групп. В их число также входят оценки отсутствующих yt по от-
ношению __
« R
где yR и uR — средние Y и единственной переменной U у отве-
чающих. Эту оценку получают, полагая в (12.15) К=\, /?о = О и
v; = w;1. Если ^=1 и v, = l, получается регрессионная оценка отсут-
ствующих У['.
У1=Ук + 0(и~йд)- (12.16)
Эта оценка появляется также в соответствии с рандомизационной
теорией при двойном выборе [Cochran (1977), гл. 12], когда U — пе-
ременная, зарегистрированная в большой исходной выборке, а У —
переменная, зарегистрированная в случайно извлеченном подмноже-
стве объектов этой выборки.
При непосредственном применении модельных методов регресси-
онную модель (12.15) можно использовать не только для оценки от-
сутствующих значений, но и для построения выводов о параметрах
популяции. При этом важно выбирать модели, которые «приспо-
сабливаются» к выборочному плану, т. е. нечувствительны к неточ-
ному выбору модели. Последними работами по этой важной теме
для полностью зарегистрированных данных являются, например,
[Royall and Herson (1973)] или [Hansen, Madow and Tepping (1982)],
обсуждение этой работы см. в [Rubin (1985)].
Эту модель можно использовать более узко — просто для вычис-
ления значений для подстановки с последующим оцениванием ха-
рактеристик популяции по заполненным данным, проводимым с
помощью рандомизационных методов. Конечно, при заполнении
пропусков модельный подход не ограничивается линейными моде-
лями вида (12.15). Например, для бинарной У обычно предпочти-
тельнее логистическая регрессия. Для категориальных У и Ut,...,UK
данные образуют частично классифицированную таблицу сопряжен-
ности с полными объектами, классифицированными по У,
Uit...,UK, и неполными объектами, классифицированными только
по По этим данным можно .строить логлииейные модели
для таблиц сопряженности, описанные в гл. 9. Эти модели дают
оценки p(c\Ui,...,UK) условной вероятности p(c\U\,...,UK) того, что
объект с пропуском имеет категорию У=с при заданных соперемен-
ных U\,...,UK. Подстановки можно получать, приписывая частично
классифицированный объект к ячейке с с вероятностью
р(с\иг,...,и^). Эта процедура близка к ЕМ-алгоритму для МП-оце-
нивания, обсуждавшемуся в гл. 7.
272
Поскольку одна подстановка обычно не может представлять нео-
пределенность в выборе подставляемых значений для пропуска (при
заполнении каждого пропуска одним значением), для справедливос-
ти выводов в общем случае при проведении анализа нужны специ-
альные процедуры. Одним из таких подходов является многократ-
ное заполнение.
12.4. МНОГОКРАТНОЕ ЗАПОЛНЕНИЕ
Под многократным заполнением мы будем понимать процедуру за-
мены каждого пропущенного значения на вектор М>2 подстановок.
М значений упорядочены в том смысле, что с помощью векторов
подстановок можно создать М заполненных множеств данных: замена
каждого пропуска первой компонентой из его вектора подстановок да-
ет первое заполненное множество, замена пропусков второй компо-
нентой вектора подстановок — второе множество и т. д. Для анализа
каждого множества используются обычные методы для полных дан-
ных. Если М наборов подстановок — повторные случайные выборки
при одной модели пропусков, то М выводов для заполненных данных
можно объединить, чтобы построить вывод, отвечающий неопреде-
ленности из-за пропуска в рамках этой модели. Если подстановки сде-
ланы в соответствии с двумя или более моделями пропусков, то
объединенные выводы при этих моделях можно сравнивать друг с
другом, чтобы выявить чувствительность анализа к моделям пропу-
сков, что особенно важно, когда пропуски неигнорируемы.
Многократные подстановки были впервые предложены в [Rubin
(1978)], хотя эта идея появилась в [Rubin (1977)]. В [Rubin (1987)] на
высоком уровне дается полное обсуждение этого вопроса. Можно
рекомендовать также работы [Rubin (1986); Herzog and Rubin (1983);
Li (1985); Schenker (1985); Rubin and Schenker (1986)]. Метод потенци-
ально применим во многих областях. Особенно многообещающе он
выглядит в сложных обследованиях, в которых трудно аналитичес-
ки модифицировать общепринятые методы анализа полных данных
на случай пропусков. Ниже мы коротко обсудим многократное за-
полнение и продемонстрируем его применение.
Как уже указывалось в гл. 2—4, заполнение пропусков широко ис-
пользуется в приложениях. Очевидным практическим преимущест-
вом однократного заполнения является возможность применять
обычные методы анализа для полных данных. Заполнение обладает
еще одним достоинством в тех частых случаях, когда сбор и анализ
данных проводится разными лицами или учреждениями (например,
Бюро переписи и университетским ученым-социологом), поскольку
при сборе данных можно получить информации больше и лучше по
качеству, чем при анализе. Например, в некоторых случаях можно
использовать информацию, закрытую по условиям конфиденциаль-
ности (например, почтовые индексы домов, в которых проживают
273
опрашиваемые), для получения подстановок для пропусков (напри
мер, годового дохода). Очевидным недостатком однократного за-
полнения является то, что подстановка одного значения, рассматри-
ваемого как известное, т. е. без специальных поправок, не можсз
отразить выборочный разброс при какой-либо модели пропуске»
или неопределенность выбора правильной модели пропусков.
Многократные подстановки обладают достоинствами однократно
го заполнения, но лишены его недостатков. Точнее, если М заполпе
ний проводятся при одной модели пропусков, то результаты М по-
второв анализа для полных данных можно легко объединить, строя
вывод, который правильно отражает выборочную дисперсию, возни
кающую за счет пропущенных значений. Если многократное заполпе
ние проводится в рамках различных моделей, то вариабельность
выводов, верных для этих моделей, отражает неопределенность вы
бора точной модели. Единственный недостаток многократного запо-
лнения по сравнению с однократным состоит в увеличении объема
работы за счет вычисления подстановок и анализа результатов.
Однако для современных компьютеров дополнительная работа по
анализу данных оказывается очень небольшой, так как она, по сути,
сводится к М повторным решениям одной задачи вместо одного.
Теоретически многократное заполнение надо проводить в соот-
ветствии со следующей схемой. Для каждой из рассматриваемых
моделей М заполнений Kmis — это М повторных извлечений вы-1
борки из апостериорного предикторного распределения Ymis. Каж-
дое повторение соответствует независимому выбору параметров и
подстановок. На практике часто можно использовать неявные мо-
дели вместо явных. Оба этих типа моделей продемонстрированы в
[Herzog and Rubin (1983)], где повторные подстановки создаются с
помощью 1) явной регрессионной модели и 2) неявной модели, яв-
ляющейся модификацией подстановки с подбором, принятой в Бю-
ро переписи.
Переход от обычного анализа к анализу многократно заполнен-
ных данных проводится довольно прямолинейно. Во-первых, каж-
дое заполненное множество данных анализируется с помощью од-
ного и того же метода для полных данных, который применялся
бы при отсутствии пропусков. Пусть 0/, И7), 1=1,...,М, — М оценок
для «полных» данных и соответствующие дисперсии оценок О, вы-
численные по М повторным заполнениям при условии справедли-
вости одной модели. Например, в примере 12.1 Oj дается правой
частью (12.5), a Wt — правой частью (12.6) по /-му набору подста-
новок Объединенная оценка равна:
« Мб,
(12-17)
Вариабельность, соответствующая этой оценке, имеет две компоне-
нты: средняя дисперсия внутри одной подстановки "
__ М й/,
WM=&^~ (12-18)
274
и дисперсия между различными подстановками
вм= <12.19)
(при векторном 0(-)2 заменяют на ( )г(-))- Суммарная вариабель-
ность, отвечающая Им, равна:
TM=WM + *£~BM, (12.20)
где (M+Y)/M — поправка на конечность М. При скалярном 9 апри-
орное распределение для интервальных оценок и критериев значи-
мости — это /-распределение:
(б-^)^'2-/,, (12.21)
где число степеней свободы
г 1 IV 1
(12'22>
основано на аппроксимации Сэтертуэйта_[Rubin and Schenker (1986);
Rubin (1987)]. Интересно заметить, что WM/BM — оценка величины
(1—у)/у, где у — доля информации о 6, отсутствующая вследствие
пропусков. Наблюдаемая и отсутствующая информация определена
в разделе 7.5.
Если в 9г компонент, то уровни значимости для гипотез относи-
тельно 6 можно получить из М повторных оценок для полных дан-
ных 0/ и ковариационных матриц U[ с помощью многомерных ана-
логов (12.17)—(12.21). Менее точные /г-значения можно получить
непосредственно по М повторным уровням значимости. Подробнос-
ти можно найти в [Rubin (1987)].
Несмотря на то что многократное заполнение наиболее естествен-
но объясняется при байесовском подходе, можно показать, что по-
лучаемые выводы обладают хорошими свойствами с частотной
точки зрения. Например, как показано в [Rubin and Schenker (1986)],
во многих случаях интервальные оценки, получаемые только по
двум заполнениям, близки по накрытию к номинальным уровням
при рандомизационном подходе.
Пример 12.5. Выводы по расслоенной случайной выборке при
многократном заполнении (продолжение примеров 12.1. и 12.2).
Чтобы проиллюстрировать многократное заполнение, исследуем
среднее популяции Y по расслоенной случайной выборке, щпользуя
модель из примера 12.1. При полных данных выводы о Y следует
строить, опираясь на утверждение
<12-23>
275
Допустим теперь, что в j-м слое только mj из л, объектов имею!
значения. При многократном заполнении каждый из Еу(Лу—/др
объектов будет иметь М подстановок, образуя М заполненных пп
боров данных и М значений средних и дисперсий в каждом слог
(обозначим их yJ(r> и 1=1,...М). Из (12.17) и (12.23) получим
оценку Y многократного заполнения — среднее М оценок по за
полненным данным:
м г j ,
г = <12-24>
Из (12.13), (12.20) и (12.23) получим дисперсию — сумму двух ком
понент, отраженных в (12.25):
M.J _i л М-1-1 М J
/В [&pW~Nj <12-25>
Из (12.21) и (12.22) получаем, что окончательные выводы о У
следуют из того, что (У — Y) имеет /-распределение с нулевым
средним, квадратом параметра масштаба, определяемым выраже-
нием (12.25), и числом степеней свободы (12.22).
Пример 12.6. Получение многократных подстановок для рассло-
енной случайной выборки с игнорируемыми пропусками (продолже-
ние примера 12.5). Поскольку многократные подстановки вычисля-
ются по предикторному распределению, интуитивно напрашивается
метод получения подстановок с подбором, при котором пропущен-
ные значения случайно извлекаются из множества присутствующих
значений в одном слое. Используя утверждения в [Rubin (1979);
Herzog and Rubin (1983)], можно показать, что при бесконечном М
получаемая оценка многократного заполнения (12.24) равна оценке
пострасслоения из примера 12.2, определяемой выражением (12.12).
Суть проблемы здесь заключается в том, что подстановка с подбо-
ром не отражает неопределенность выбора параметров в слоях. Эту
неопределенность можно все-таки представить в простых обобщени-
ях подстановки с подбором и, значит, получить при больших М не
только оценку пострасслоения, но и правильную дисперсию.
Сначала рассмотрим метод, основанный на неявной модели, на-
званной в [Rubin and Schenker (1986)] приближенным байесовским
бутстрепом. Независимо для 1= 1,...,М выполним следующие ша-
ги: 1) получим для каждого слоя П; возможных значений Y, случай-
но извлекая значений с возвращением из пу присутствующих зна-
чений Y в у-м слое и 2) случайным образом извлечем и,—пу про-
пущенных значений с возвращением из этих nj значений. Чтобы по-
казать, что этот метод пригоден при больших М, т. е. что он будет
давать оценку пострасслоения и ее дисперсию в этом случае, можно
привлечь результаты из [Rubin and Schenker (1986)] или [Rubin
(1987)].
276
В этом же смысле пригоден также выбор многократных подстано-
вок с помощью явной нормальной модели из примера 12.2, где значе-
ния Y внутри слоя j распределены независимо и нормально со
средним и дисперсией а? и априорное распределение (/тДшь) ло-
кально равномерно. Этот метод, названный в [Rubin ana Schenker
(1986)] полностью нормальным заполнением, задается М независимы-
ми повторениями следующих двух шагов: 1) извлечь для каждого слоя
(ju.j.crp из их совместного апостериорного распределения и 2) извлечь
л,—Ш] значений для пропусков Y как н.о.р., нормально распределен-
ные со средним и дисперсией, равными извлеченным pj и cj.
12.5. НЕИГНОРИРУЕМЫЕ ПРОПУСКИ
До сих пор мы рассматривали модельный подход к пропускам в
обследованиях, основываясь на предположении об игнорируемости
пропусков, т. е. подразумевалось, что объекты с пропуском и без
пропуска с одинаковыми значениями зарегистрированных перемен-
ных не различаются систематически по значениям переменных, от-
сутствующих у объектов с пропусками. Таким образом, предпола-
галось выполненным условие ОС. С помощью моделей неигнориру-
емых пропусков, аналогичных моделям из гл. 11, можно применять
модельный подход к обследованиям с пропусками, которые предпо-
лагаются неигнорируемыми. По сути, в примерах 11.5 и 11.7 ис-
пользованы модели неигнорируемых пропусков для данных из ре-
альных обследований.
При неигнорируемых пропусках возникает важный вопрос: явля-
ется ли целью статистического анализа: 1) дать единственный вер-
ный вывод или 2) выявить чувствительность выводов к неигнори-
руемым пропускам, делая несколько выводов, каждый из которых
справедлив для предполагаемой модели пропусков. Естественно, по-
лучение единственного верного вывода в общем случае очень труд-
ная задача, поскольку обычно на практике нет убедительных фак-
тов, исходя из которых можно было бы определить одну точную
модель пропусков. Следовательно, исследование чувствительности
выводов, верных при различных условиях, — намного более реаль-
ная цель по сравнению с получением единственного верного выво-
да, хотя и менее удовлетворительная. В примере 11.7 проводилось
такое исследование чувствительности. Многократное заполнение
при подстановке вместо пропусков значений, вычисленных по раз-
ным моделям, служит удобным способом выявления чувствитель-
ности выводов к этим моделям.
Пример 12.7. Модели весовых групп с неигнорируемыми пропуска-
ми. Допустим, что, как и в примере 12.3, группы для взвешивания
выбраны таким образом, чтобы в у-й группе распределение У было
одинаковым для объектов с пропуском и без пропусков — нормаль-
ным со средним fij и дисперсией aj. Однако в отличие от примера
12.3 переменная, по которой определяются весовые группы, зареги-
277
стрирована только для объектов выборки без пропусков. Например,
пусть пропуск игнорируем внутри категорий дохода, а доход зареги
стрирован у отвечающих, но не у отказывающихся отвечать. Тогда
нам известно число mj респондентов в у-й группе, но не известно
число отказывающихся дать ответ (иу-—mj), см. табл. 12.1.
Таблица 12.1. Выборка, классифицированная
по наличию пропуска и по переменной весовых групп,
известной только для респондентов
(в скобках указаны ненаблюдаемые величины)
Индикатор пропуска R
/?, = 1 Л,=0 Сумма
1 т. (л,—т,) <Л1)
Труппа j (Лу)
J (nj-mj) («у)
Сумма т п—т п
Мы хотим оценить среднее популяции
у =
J = 1 J J
где, как и ранее, Pj и Yj — доля популяции и среднее в у-й группе.
Если бы объемы выборок rij в каждой группе были известны, мы
могли бы оценить Y с помощью оценки весовых групп:
Е(У |Kobs, 7?inc, {nj })=£^ = iiPjyjR =7WC.
Вместо этого мы оценивали У апостериорным средним
E(y|yobs,Z?inc) = Ji5fL, (12.26)
где hj=E(rij\ yobs,^inc) — оценка частоты в у-й группе. Оценивание
«у очень чувствительно к априорным условиям, что можно легко
увидеть из табл. 12.1, если заметить, что проблема состоит в рас-
пределении п—т отказавшихся отвечать по весовым группам.
Предположение об игнорируемости соответствует независимости
строк и столбцов в этой таблице и ведет к оцениванию среднего по-
пуляции средневыборочным yR по респондентам.
Пусть V'y — априорная вероятность присутствия значения ответа в
у-й группе. Примем (нереалистичное) предположение, что извест-
ны. Считая распределение частот в таблице полиномиальным, а
278
априорное распределение вероятностей групп — равномерным, мы
получим j
I ^obs^inc) = nmj (12.27)
Поэтому один из подходов основан на том, чтобы определить воз-
можные значения вероятностей ответа, а затем вычислить оценку
У, подставляя (12.27) в (12.26). По сути, оценка У зависит от от-
носительных разностей вероятностей ответа, поэтому надо опреде-
лить не J, a J— 1 величин. Выбирая различные значения ) и
вычисляя соответствующие оценки, мы выявили чувствительность
оценки к априорным предположениям о механизме пропусков.
Пример 12.8. Модели неигнорируемых пропусков для частично
классифицированных таблиц сопряженности. Модели неигнорируе-
мых пропусков при категориальных переменных рассмотрены в раз-
деле 11.6. В [Little (1982)] представлены МП-оценки для модели,
связанной с обсуждавшейся в [Pregibon (1977)] моделью для задачи
с непрерывными и категориальными переменными. Здесь мы опи-
шем частный случай этой модели, когда пропуски содержатся толь-
ко в одной категориальной переменной.
Допустим, что мы имеем т объектов, классифицированных по ка-
тегориальным переменным У, U\,...,Ufr> и п—т объектов, классифи-
цированных только по UX,...,UK. Пусть p(c\UA,...,UK) обозначает
условную вероятность, что случайно выбранный объект популяции
имеет значение у=с при заданных значениях сопеременных UX,...,UK.
При игнорируемом механизме пропусков шаг Е ЕМ-алгоритма со-
стоит в приписывании доли р^\с\их,...,ик) подмножества п—т ча-
стично классифицированных объектов со значениями U},...,UK к
группе у=с, где р<д обозначает оценку р на 1-й итерации (подроб-
ности даны в гл. 9). Таким образом, шансы отнести объект к груп-
пе у=с против группы у=с равны
p^c\U^...,UK)/p4c\Ui,...,UK). (12.28)
Допустим теперь, что априорные шансы отнести объект с пропу-
ском к категории у=с против у=с' равны тг(с,с). Апостериорные
шансы вычисляются по теореме Байеса как априорные шансы, ум-
ноженные на (12.28). Значит, чувствительность оценки к неигнори-
руемым пропускам можно легко исследовать как априорные шансы,
когда оценивание проводится с помощью ЕМ-алгоритма или с по-
мощью многократного заполнения при различных предположениях
об априорных шансах.
12.6. НЕИГНОРИРУЕМЫЕ ПРОПУСКИ
И ОТСЛЕЖИВАНИЕ ОБЪЕКТОВ
Единственным путем снизить чувствительность выводов к неиг-
норируемым пропускам является уменьшение доли пропусков или
сбор информации о том, как объекты с пропусками отличаются от
респондентов по исследуемым выходным переменным. Существует
279
довольно обширная прикладная статистическая литература, освети
ющая методы уменьшения исходно присутствующих пропуске» и
обследованиях. Три тома, опубликованные Комиссией по неполным
данным (Panel on Incomplete Data) Национальной академии наук
(США), представляют собой прекрасный библиографический путе.
водитель [Madow, Nisselson and Olkin (1983); Madow, Olkin and Rubin
(1983); Madow and Olkin (1983)]. Наиболее прямолинейный метод
сбора информации об объектах с пропусками — проследить по
крайней мере за частью из них, чтобы получить нужную информа-
цию. Даже если удается проследить лишь за несколькими объекта
ми, это может стать чрезвычайно полезным для уменьшения
чувствительности и неустойчивости выводов, что продемонстриро
вано в следующем численном эксперименте.
Пример 12.9. Уменьшение неустойчивости выводов при отсле-
живании объектов. В [Glynn, Laird and Rubin (1986)] описан ряд
имитационных экспериментов для нормальных и логнормальных
данных, которые можно использовать для исследования уменьше-
ния неустойчивости выводов при наличии данных об отслеженных
объектах. Для нормального случая была извлечена выборка из 400
значений из стандартного нормального распределения (из бесконеч-
ной популяции). С применением логистического механизма пропу-
сков Pr(R;=l|j’j)=exp(l+y;)/[l+exp(l+yj)] был порожден 101 про-
пуск. После этого случайным образом были извлечены различные
подмножества из 101 объекта, чтобы образовать данные об отсле-
женных объектах. В итоге получились данные, состоявшие из (y^R-)
для объектов без пропусков и отслеженных объектов с пропусками,
и только из Rj для неотслеженных объектов с пропусками.
Для анализа этих данных применялись две модели. Использова-
лась байесовская модель, аналогичная модели из примера 11.5, в
которой исходные наблюдения без пропусков считались распреде-
ленными а с пропусками — с априорным распреде-
лением (/ri,go,lnai,ln<ro), пропорциональным константе. В этой
модели значения У, были распределены как смесь двух нормальных
популяций с неизвестной смешивающей пропорцией. Данные анали-
зировались также при нормально-логистической модели пропусков:
(Уг|ц,^)~Мд,Л2),
logit [Рг(7?; = 1|у1-,ао,«1)] = ао + «1Ур
где априорное распределение (/i,ao>“i>lnn) также было пропорцио-
нально константе. Эта модель аналогична модели стохастического
цензурирования, рассмотренной в разделе 11.4.
Весь эксперимент был повторен с другим набором данных с 400
логнормальными наблюдениями (т. е. экспонентами значений из
стандартного нормального распределения). С помощью логистиче-
ского механизма отсутствия пропуска Pr(Rf= 1/у,-) = ехр(у;)/(1+ехр(у;))
было образовано 88 пропусков. Снова для создания данных об от-
слеживании объектов с пропусками были случайно извлечены раз-
280
личные подмножества объектов с пропусками. Для анализа лог-
нормальных данных использовались те же две модели. Заметим,
что если для нормальных данных модель цензурирования была по-
добрана правильно, а модель смеси — неправильно, то для логнор-
мальных данных обе модели были неверными.
Таблица 12.2. Выборочные моменты
сгенерированных данных*
Нормальные данные Логнормальные данные
N выборочное среднее выборочное стандартное отклонение N выборочное среднее выборочное стандартное отклонение
Объекты без пропуска Объекты с 299 0,150 0,982 312 1,857 2,236
пропуском 101 —0,591 0,835 88 0,724 0,571
Сумма Значения в 400
популяции 0,0 1,0 1,649 2,161
* Нормальные данные извлечены из нормального (0,1) распределения, логнор-
мальные данные — экспонента от значений из того же распределения. Пропуск
определяется логистической функцией: Рг(7? = 1/у)=ехр(а0 + а1у)/[1+ехр(а0 + а1у)],
где (о0,а,)=(!,!) для нормальных данных и (0,1) — для логнормальных.
В табл. 12.2 приведены результаты для сгенерированных дан-
ных — и нормальных, и логнормальных. В табл. 12.3 даны оценки
среднего популяции для обеих моделей и для обоих типов данных.
Сразу можно заметить несколько очевидных обстоятельств. Во-пер-
вых, модель смеси выглядит несколько более устойчивой по сравне-
нию с моделью цензурирования и проявляет себя почти так же
хорошо, как и модель цензурирования, когда верна последняя, и
лучше ее, когда обе модели неверны. Во-вторых, чем больше доля
отслеженных объектов, тем лучше оценки при обеих моделях. В-
третьих, даже малое число отслеженных приводит при использова-
нии модели смеси к разумным оценкам. В [Glynn et al. (1986)] испо-
льзуется многократное заполнение, чтобы построить выводы по
данным обследования пенсионеров с применением модели смеси,
включающей сопеременные.
Таблица 12.3. Оценки среднего популяции
по данным об объектах без пропусков из табл. 12.2
и по данным об отслеживании некоторых объектов с пропусками
Число «отслежен- ных» Нормальные данные Число «отслежен- ных» Логнормальные данные
модели смеси модель цен- зурирования модель смеси модель цен- зурирования
11 —0,010 —0,009 9 1,58 0,934
24 —0,025 —0,029 21 1,60 1,030
28 —0,006 —0,008 25 1,61 1,054
101 —0,037 —0,037 88 1,61 1,605
281
ЛИТЕРАТУРА
Box, G E P , and Tiao, G C (1973) Bayesian Inference m Statistical Analysis Reading, MA
Addison-Wesley
Cochran, W G (1977) Sampling Techniques New York Wiley*
Glynn, R , Laird, N , and Rubin, D В (1986) Selection modelling versus mixture modelling
with nonignorable nonresponse, Proceedings of the 1985 Educational Testing Service Con
ference on Selection Modelling
Hansen, M H , Madow, W G , and Tepping, J (1983) An evaluation of model-dependent and
probability-sampling inferences in sample surveys, J Amer Statist Assoc 78, 776-807
Herzog, T, and Rubin, D В (1983) Using multiple imputations to handle nonresponse in
sample surveys, Incomplete Data in Sample Surveys, Volume 2 Theory and Bibliograohy,
New York Academic Press, pp 209-245
Li, К H (1985) Hypothesis testing in multiple imputation—with emphasis on mixed-up fre-
quencies in contingency tables, Ph D Thesis, The University of Chicago
Little, R J A (1982) Models for nonresponse in sample surveys, J Amer Statist Assoc 77,
237 250
Madow, W G , Nisselson, H , and Olkin, I (1983) Incomplete Data in Sample Surveys, vol 1
Report and case studies New York Academic Press
Madow, W G , and Olkin, I (1983) Incomplete Data in Sample Surveys, vol 3 Proceedings oj
the Symposium, New York Academic Press
Madow, W G , Olkin, I, and Rubin, D В (1983) Incomplete Data in Sample Surveys, vol 2
Theory and Bibliographies New York Academic Press
Pregibon, D (1977) Typical survey data estimation and imputation, Survey Methodol 2,
70-102
Royall, R M , and Herson, J (1973) Robust estimation from finite populations, J Amer
Statist Assoc 68, 883 889
Rubin, D В (1976) Inference and missing data, Biometnka 63, 581 592
Rubin,D В (1977) Formalizmgsubjectivenotionsabouttheeffecl of nonrespondents m sample
surveys J Amer Statist Assoc 72 538-543
Rubin, D В (1978) Multiple imputations in sample surveys—a phenomenological Bayesian
approach to nonresponse, Imputation and Editing of Faulty or Missing Survey Data, U S
Department of Commerce, pp 1 -23
Rubin, D В (1979) Illustrating the use of multiple imputation to handle nonresponse in sample
surveys, Proceedings of the 1979 Meetings of the ISI-IASS, Manila
Rubin, D В (1985) The use of propensity scores m applied Bayesian inference Bayesian
Statistics 2 (Bernardo, J M , De Groot, M H , Lindley, D V , and Smith, A F M Eds)
Amsterdam North Holland, pp 463-472
Rubin, D В (1986) Statistical matching using file concatenation with adjusted weights and
multiple imputations, J Business Econ Statist 4,87 94
Rubin, D В (1987) Multiple Imputation for Nonresponse in Surveys New York Wiley
Rubin, D В , and Schenker, N (1986) Multiple imputation for interval estimation from simple
random samples with ignorable nonresponse, J Amer Statist Assoc 81, 366-374
Scott, A J (1977) On the problem of randomization in survey sampling, Sankhya C39, 1-9
* Русский перевод: Кокрен У. Методы выборочных обследований. — М.: Статистика, 1976.
282
ЗАДАЧИ
1. Пусть 7 hs1 — выборочные средние и дисперсия у в простой случайной выбор-
ке объема п из популяции объема N. Покажите, что при нормальной модели асимп-
тотическое апостериорное распределение среднего популяции Y нормально со
средним У и дисперсией (л~*—N~l)sz. Получите отсюда (12.11) и (12.12).
2. Познакомтесь с результатами байесовской теории для полиномиального распре-
деления, ведущими к апостериорным моментам в и у в примере 12.3 (см., напри-
мер, [Box and Tiao (1973)]. __
3. Приведите подробный вывод среднего и_дисперсии У в примере 12.3.
4. Покажите, что апостериорная дисперсия У в примере 12.3 и средняя квадратиче-
ская ошибка оценки весовых групп в примере 4.2 асимптотически совпадают.
5. Предположите в примере 12.5, что многократные подстановки получаются с по-
мощью подбора и что М и_все п велики. Покажите, что в результате оценка много-
кратного заполнения У, У в (12.24), равна (12.11), а соответствующая дисперсия,
равная (12.25), меньше, чем (12.12).
6. Покажите, что методы приближенного байесовского бутстрепа и полностью
нормального заполнения, описанные в примере 12.6, дают при больших М и Hj оцен-
ку пострасслоения с соответствующей дисперсией.
ДОПОЛНЕНИЕ К ПЕРЕВОДУ
А.М.НИКИФОРОВ
МЕТОДЫ АНАЛИЗА ДАННЫХ С ПРОПУСКАМИ
И ИХ СВОЙСТВА. ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ
СТАТИСТИЧЕСКОЙ ОБРАБОТКИ
НЕПОЛНЫХ ДАННЫХ
1. ВВЕДЕНИЕ
Предлагаемое дополнение посвящено тем направлениям и пробле-
мам статистического анализа данных с пропусками, которые не рас-
сматривались в книге Р.Дж.А.Литтла и Д.Б.Рубина совсем или
рассматривались недостаточно подробно. Их обсуждение, на наш
взгляд, уместно в рамках данной книги и будет интересно для чи-
тателя.
По сути, теоретическое обоснование методов, изложенных в кни-
ге, было сведено к ссылке на работу [Rubin (1976)]. В этой работе
при довольно слабо формализованных условиях были продемон-
стрированы некоторые свойства инвариантности для трех видов
статистик (в том числе для отношения правдоподобия). Эти свой-
ства и указание на аналогию со случаем полных данных, конечно,
не могут заменить доказательств. Так, наблюдения в выборке при
наличии пропусков принадлежат различным подпространствам ис-
ходного выборочного пространства, что противоречит традицион-
ным постановкам, требуют уточнения обычные условия
идентифицируемости и т.п.
Для конкретных задач и моделей приходится определять специфи-
ческие условия, связанные с наличием пропусков. Такой подход не
только дает возможность получить строгое теоретическое обосно-
вание результатов, но и полезен методически: появляется возмож-
ность ослабить условия на распределение пропусков, по-новому
раскрываются свойства различных методов и т.д.
В первых разделах дополнения к переводу сформулированы обоб-
щения некоторых классических результатов на случай наблюдений с
пропусками; исследованы асимптотические свойства оценок макси-
мального правдоподобия, обобщенных на случай пропусков в наблю-
дениях, — оценок максимального «маргинального правдоподобия»,
вычисление которых с помощью ЕМ-алгоритма является основным
предметом данной книги; рассмотрены задачи анализа классификации,
анализа временных рядов.
284
В рамках важнейшего раздела математической и прикладной ста-
тистики — теории проверки гипотез, практически не обсуждавшего-
ся в книге, рассматриваются подходы к построению и применению
статистических критериев при наличии пропусков для типичных ну-
левых гипотез: однородности двух и нескольких выборок и незави-
симости случайных величин. Предлагаются критерии, для
применимости которых достаточно наложить на распределение
пропусков условия, которые намного слабее условий ОПС и ОС
(формулировку этих условий см. в разделе 5.3 книги, а также в раз-
деле 2.1 дополнения). Обсуждается проблема проверки случайности
пропусков (условий ОС и ОПС), также не рассматриваемая в книге.
Кроме того, в дополнении обсуждаются некоторые важные свой-
ства различных методов заполнения. Показано, что метод «локаль-
ного заполнения» пропусков (см. раздел 7 дополнения) не имеет тех
серьезных недостатков, которые присущи простым методам запол-
нения из гл. 3 книги.
Наконец, в дополнении рассматривается современное состояние
программного обеспечения прикладного статистического анализа
данных с пропусками, даются предложения по составу методов ана-
лиза данных с пропусками в общестатистическом пакете. Приводит-
ся текст программы, реализующей ЕМ-алгоритм для многомерного
нормального распределения.
2. СВОЙСТВА ОЦЕНОК
МАКСИМАЛЬНОГО МАРГИНАЛЬНОГО ПРАВДОПОДОБИЯ
2.1. ОБОЗНАЧЕНИЯ
Пусть А—измерения г показателей объекта, часть из которых от-
сутствует в соответствии с r-мерным вектором пропусков М со зна-
чениями координат «пропуск» либо «нет пропуска». Будем назы-
вать r-мерным наблюдением с пропусками 2г-мерный случайный
вектор (АГ,Л/), принимающий значения в измеримом пространстве
[Х-ЛГ, где sc =Xix...yfCr, JU, =Ж^...хМг,
- ( «пропуск», «нет пропуска»], гЛи ifi1— соответствующие o'-
алгебры. Через Р*^ обозначим распределение случайного вектора
(сл.в.) еХ-М будет обозначать математическое ожидание по
распределению Р*^.
285
Статистический эксперимент [fltcA, Р*] с отсутствием пропусков
является проекцией статистического эксперимента с пропусками
Е = [Х.хМ, UXx UM, р^‘М\ (см. [Ибрагимов, Хасьминский (1979),
с. 18]). Случаю выборки независимых одинаково распределенных
(н.о.р.) наблюдений с пропусками объема п соответствует произве
дение п экспериментов Е. Нас будут интересовать прежде всего вы
воды о распределении случайного вектора X, т. е. о распределении
Р* = Р*’м [ЛхЛб], где AOJX.
Будем называть z-й структурой пропусков i-ю из 2' мыслимых
реализаций случайного вектора М. Знак Е будет обозначать сумми-
рование по всем возможным структурам пропусков.
Условия на распределение пропусков формализуются так.
Условие ОС.
р(т\х) = р(т\х^3), (1)
где р(т\х) — условная вероятность наблюдения х со структурой
пропусков т при Х=х, x0^s — присутствующие в соответствии с т
компоненты х (таким образом, вероятность (1) одинакова для всех
отсутствующих значений *„” )•
В общем случае
р(т) = Рх,м(Х,т)=^р(т\х) dP*
будет обозначать безусловную вероятность наблюдения со структу-
рой т. Условие ОПС определяется равенством:
р(т\х)=р(т).
Далее в обозначениях xm'f' и мы будем часто опускать индекс
т, а также индексы obs и mis в аргументах плотностей и функций
распределения, если это не вызовет недоразумений.
2.2. СОСТОЯТЕЛЬНОСТЬ ММП-ОЦЕНОК
В задаче оценивания будем считать, что [P^]=[P0,0€e £ —
параметрическое семейство, доминированное мерой у=гт х...х>;,
с соответствующим семейством плотностей {/(х,0), 0€0 £ R^}. Как
и в книге, далее предполагается, что р(т\х) не зависит от в.
Для каждой структуры пропусков т определим соответствующую
маргинальную плотность:
fm(x,ff)=^f(x,&) dvijx...xdvilc,
286
(2)
где интегрирование ведется по компонентам й, ik вектора х, от-
сутствующим в соответствии с т. Напомним, что индекс obs у ар-
гумента маргинальной плотности опущен.
Обобщение метода максимального правдоподобия на случай дан-
ных с пропусками приводит к оценке максимального «маргинально-
го правдоподобия» (ОММП):
9(Х,М) = arg max Д/А^б).
9
Для выборки н.о.р. наблюдений с пропусками (Xv М\),...,
(Хп,Мп) ОММП равна
п
arg max П /м( (Xt,9).
9 t=i
Покажем теперь, что при выполнении некоторых условий ММП-
оценка обладает асимптотическими свойствами, которые проявляет
обычная ОМП. Обозначим 0О истинное значение оцениваемого пара-
метра, соответствующее распределению Хх. Укажем сначала на
свойство сильной состоятельности ОММП в весьма слабых услови-
ях регулярности.
Условие И. Для любого 0#0О найдется такая структура пропусков
т, что fm(x,9)^fm(x,9^ на множестве С(0) £fT, таком, что
LX"*IW f(x,9^dv > 0.
Приведем несколько примеров, в которых выполняется условие
идентифицируемости И.
1. При оценивании параметров многомерного нормального рас-
пределения условие выполняется, если вероятность совместного на-
блюдения переменных в любой из попарных комбинаций больше
нуля. 1с
2. Оценивание параметров смеси к распределений G(x) = E р, F(x,9-)
«=1
по неклассифицированной выборке можно рассматривать как задачу
обработки данных с пропусками (у каждого наблюдения пропущен
инд екс класса). Условие И выполняется, если смесь идентифицируе-
ма, т.е. если заданное распределение G(x) однозначно определяет чис-
ло классов к, веса р, и параметры 0, каждого класса (определение
см., например, в [Патрик (1980); Миленький (1975)]). Таким образом,
значения переменной могут полностью отсутствовать в выборке,
однако параметры, определ яющие ее распределение, могут быть со-
стоятельно оценены, как параметр (pi,..., рк) распределения индекса
класса в данном примере.
287
3. В Вероятность появления полностью комплектного наблюдения
больнице нуля, выполняется условие ОПС, в при 0#0О. Эго
самое >е распространеннное условие (см. [Бурлаков (1979); Titteringtoil,
Jiang £ (1983)]).
Обоэозначим g(0,<£) метрику в 0 и = sup /т(х,ф).
Услсловие Н. f(x,9) непрерывна по 0 на множестве В(0)£(Ц
Р9о(Ж(0))=1.
Услсловие J. Для всех 0^0, т, для которых р(т)>0, существует та-
кое д:д>о, что
j In (/^ (х,0) /fm(x,0o) f(x,90) dv < •
(по уьумолчанию область интегрирования — {х: f(x,0o) > 0]).
Услсловие J налагает ограничения на маргинальные плотности для
всех в возможных структур пропусков. Следующее условие проще,
предъяьявляется только к полной плотности и влечет за собой вы-
полненение условия J: для всех 0е0 существует такое Д>0, что
J/(x,0) dv <•-•.
Теорорема 1. Если выполняются условия ОС, Н, И, J, а 0 — ком-
пакт, то ОММП в случае выборки н.о.р. наблюдений с пропусками
сильно состоятельна.
Дококазательства теорем 1,3 и 4 (при условии ОПС) содержатся в
[Никикифоров (1987)], их формулировки в насятощем дополнении сле-
дуют т [Никифоров (1989)]. Теорема 1 соответствует одному из вари-
антов >в в [Боровков (1984), раздел 2.27], обобщенному на случай
пропупусков.
2.3. АСАСИМПТОТИЧЕСКАЯ НОРМАЛЬНОСТЬ
И ЭФФ&ФЕКТИВНОСТЬ ОММП
Интчтересно получить неравенство Крамера—Рао для данных с про-
пускамами, т.е. указать для регулярного случая нижнюю границу кова-
риациционных матриц оценок 0 (Х,М) = 0 (А^, М), получаемых по
присутутствующим данным. В традиционной форме [Ибрагимов,
Хасьмьминский (1979), с.104; Боровков (1984), с. 158] неравенство не-
примеиенимо для данных с пропусками, так как аргумент плотности,
.г'5> г, является случайным (он меняется в зависимости от М)*. Тем
• ТочГочнсе, можно применять для данных с пропусками неравенство Крамера—Рао в
обычноной форме, но лишь условно по М.
288
не менее для данных с пропусками остается верной запись
ЕЛ'-м(^-0о)(0-0о)г>(/+£>(9о))Г’1(0о)(/+/?(0о)) + с/(0о)(с?(0о))г, (3)
где J — единичная матрица, D(0)~ V a(d(0)T), d(0o)=Ex,Mff~~0o —
смещение, если определить информационную матрицу как
I(fi) = Е j V0 ln/m(x,0) [vfl In/Jx^j^lx obs№A) dv. (4)
Точнее, справедлив следующий результат.
Теорема 2. Пусть (Дх,0))1/2 непрерывно дифференцируема по О
для п.в. [9] значений х, для оценки 0 верно Е^^О1 < С < вы-
полняется условие ОС, матрица 1(0) положительно определена и не-
прерывна по Об®. Тогда выполнено (3).
При условии ОПС информационная матрица (4) имеет более
простой вид:
Z(0)=Ep(m) J lnfm(x,O)[Vg\nfm(x,0)]Tf(x,0o) dv.
Введем следующее условие регулярности.
Условие R. Для всех 0 и т, для которых р(т)>0, функции
In fm(x,ff) трижды дифференцируемы по 0, все производные первого
и второго порядков мажорируются интегрируемыми функциями, а
третьи производные — функциями, интегрируемыми по f(x,f))dv.
Теорема 3. Пусть выполняются условие ОС и условие регулярнос-
ти R, 1(0) положительно определена в О. Тогда:
1) ОММП по выборке н.о.р. сл.в. (X,, Mi),... асимптотически нор-
мальна с ковариационной матрицей I (в0), т.е. при п — «=«= имеет
место сходимость по распределению уЯ~(0 — 0О) ^(0,1(Ой))\
2) среди решений уравнения ve^n^ = 0, начиная с некото-
рого случайного п, существует по /’''^-вероятности только одно
состоятельное решение.
Таким образом, асимптотическое поведение ММП-оценки в усло-
виях регулярности аналогично поведению ОМП в задаче без пропу-
сков, т.е. ОММП асимптотически нормальна и эффективна.
3. КЛАССИФИКАЦИЯ ПО ДАННЫМ С ПРОПУСКАМИ
Следующей задачей, в которой мы рассмотрим применение под-
хода с заменой исходного (полного) распределения на маргинальные
распределения, является дискриминантный анализ многомерных на-
блюдений с пропусками.
Пусть мы получаем (с пропусками) измерения характеристик объ-
екта, которые зависят от того, к какому из к классов принадлежит
объект, т.е. X есть случайный вектор, имеющий одно из к распреде-
лений Pi,...,Pi., которые мы будем считать известными. Потери при
отнесении наблюдения из класса j в класс i обозначим через c(i\j),
априорную вероятность принадлежности к классу j — через Pj.
10. Р. Дж. А. Литтл, Д. Б. Рубин
289
Решающее правило есть отображение d(X,M)~d(XObs) [1
т.е. классификация объектов с использованием той части данных,
которая доступна нам в соответствии с вектором пропусков М. За-
дачей является поиск оптимального решающего правила D, мини-
мизирующего средние потери
R(d) = Е pj Ejc (d (Х,М) |У),
где Ej — математическое ожидание по распределению случайного
вектора (Х,М) в классе j. Обозначим через f (х|у) и полную и
маргинальную (в соответствии со структурой пропусков т) плот-
ности, отвечающие распределению Pj случайного вектора X в клас-
се J.
Теорема 4. Пусть выполняется условие ОС и распределение про-
пусков не зависит от класса:
p(m/xj) = p(m/xobs), j = 1,..., к. (5)
Тогда оптимально (минимизирует средние потери) решающее пра-
вило, основанное на маргинальны^ плотностях:
£>(XM)=arg min Epj c(i\j) fM(X\j).
i j
Исходя из этого простого результата с помощью геометрических
представлений несложно показать, что предварительное заполнение
пропусков в распознаваемом наблюдении (предлагаемое, например
в [Kennedy, Chien (1982)]) не может улучшить качество классифици-
рования, а в широком круге задач приводит к увеличению средних
потерь (вероятности ошибочной классификации при антидиагональ-
ной матрице потерь). Этот результат верен в условиях теоремы,
т.е. при известных распределениях, или при оценивании распределе-
ний по обучающим выборкам, по крайней мере, в асимп-
тотике роста объемов выборок.
Приведенная формулировка включает случай [Krzysko (1983)]
дискриминантного анализа временных рядов (см. также раздел 4).
К проблеме классификации можно отнести и задачу о разладке
[Клигене, Текльснис (1983)], в которой качество методов характери-
зуется, как правило, длительностью периода от изменения состоя-
ния наблюдаемого объекта (разладки) до подачи сигнала об
обнаружении разлодки (при заданной интенсивности ложных тре-
вог). Ясно, что оптимальная обработка пропусков может быть
очень важной при практическом применении методов обнаружения
разладки, будь то анализ технологическогог процесса, обработки
данных сейсмического слежения и т.п. Следует ожидать, что испо-
льзование маргинальных плотностей в (асимптотически) оптималь-
ных методах, например в алгоритме кумулятивных сумма (см.,
например, [Никифоров (1983)]), позволит сохранить их свойства при
наличии пропусков.
290
4. ОБРАБОТКА НАБЛЮДЕНИЙ
ИЗ ВРЕМЕННЫХ РЯДОВ
ПРИ НАЛИЧИИ ПРОПУСКОВ
В этом разделе мы обсудим применение подхода с использовани-
ем маргинальной плотности при наличии пропусков, когда наблю-
дения выборки уже не являются независимыми.
Как и в разделе 8.6 книги Р.Дж.А. Литтла и Д.Б.Рубина, мы рас-
смотрим процесс авторегрессии р-го порядка АР(р), см. уравнение
(8.14) книги, не замыкаясь, однако, на задаче построения ЕМ-алгорит-
ма. Условная плотность вероятности выборки Х^=(Х0,Х1....Х„) из
временного ряда за время от t~0 до t=n есть
Ж I ' Ж Л & ? ЖJ
Для АР(р) плотность (6) определена , если известны р значений ря-
да до Z=0, т.е. X_p,...,X_j .
Пусть в выборке за время от t=S —р до t=n отсутствуют значе-
ния Х^, Xi2,... . Обсуждаемый подход ведет к использованию при на-
личии пропусков в статистических выводах вместо плотности (6)
условной маргинальной плотности
/м I X-ZL & = fM (Х_п^ ,0) / ,&), (7)
где в числителе и знаменателе стоят маргинальные плотности, полу-
ченные интегрированием по Х^, Х&... . Для процесса АР(р) плот-
ность (7) будет теперь определена, если есть р наблюдений ряда под-
ряд до (=0 с известными значениями, и через s выше обозначен мо-
мент времени, с которого начинается «серия» наблюдений без
пропусков (т.е. > з+р). Случай, когда такой «серии» не существует,
относится к проблеме анализа временных рядов при отсутствии на-
чальных значений, обсуждаемой в конце раздела.
Итак, при наличии пропусков предлагается использовать (7) в ста-
тистических выводах. В задачах дискриминантного анализа времен-
ных рядов использование (7) дает оптимальный классификатор (см.
предыдущий раздел).
Что касается точечного .оценивания для зависимых наблюдений, то
исследуемый подход приводит к оценкам максимального маргиналь-
ного правдоподобия (2) с фукцией правдоподобия в ввде (7). Утверж-
дения о состоятельности, асимптотической нормальности и эффек-
тивности ОММП в условиях регулярности для данных с пропусками,
видимо, поддаются обобщению на обсуждаемый случай зависимых
наблюдений.
Ю
291
Теперь рассмотрим процесс авторегрессии первого порядка АР(1):
Xt = + er, /3 € (-1,1),
где ет — случайная величина, распределенная нормально А(0,а2).
Здесь и далее для краткости принято, что среднее процесса g=0 и
0 = (/3,а2). При ненулевом ц потребуется лишь простая замена Xt
на Х^.
Предложение. Маргинальная плотность наблюдения Л/+1 для од-
номерного гауссовского процесса АР(1) при наличии к пропусков
подряд есть:
-(И-У+... + (1»*>-^ „р [ _<Х,^*'Х,^ ] (8)
vS о 2а2(1+-/?2+...+-(82*)
Доказательство просто: в [Никифоров (1987)| используется метод
математической индукции, еще проще ограничиться вычислением
условных математического ожидания и дисперсии нормально рас-
пределенной случайной величины Х/+1.
Пусть теперь выборка с пропусками из процесса АР(1) обра-
зована наблюдениями ... Xti> Xti,...,Xt2, причем —1, а
О tz С ...^ t{ < п. Тогда (7) равно
f(xh I xtl, 9)f(xt31 xtz, в) ...f(xti\xtri,e)t
где сомножители имеют вид (8) при числе пропусков k=tI+i—tf
z=O,...,l.
С помощью (8) можно полностью описать ЕМ-алгоритм (см. раз-
дел 8.6.2 книги) для авторегрессионного процесса АР(1). Для этого
нужно вывести условные математическое ожидание и дисперсию
Xt, E(Xt | Xtj, X<2) и Var (Xt | Xt., Xh), при произвольной структуре
пропусков, т.е. когда Xt — один “из к пропусков между Xti и
Xt2 : ti <t<t2, к~!Дг—Д—1) 1 (в книге получены выражения для
k=i, а в задаче 8.11 предлагается вывести их для случая к=2). Обо-
значим через ki число пропусков, отделяющих отсутствующее зна-
чение Xt от Xti : kt - t—— 1, и аналогично k2~t2—t—1, тогда
к==к-,+к2 + 1. Далее, для АР(1)
ЛХ^Х^ ~ /(XJX,) ДХ^
ДХ^Х(1Х/2) -= /(XfXi) - f(Xf2|Jiy
Подставляя в правую часть этого выражения плотности вица (8) с
параметрами к2, к^ и к (в силу нормальности Xt достаточно распи-
сать только числитель), получим:
292
E(Xt\Xh,Xt) = (Xtp^ + lv2 + xhak‘1 'r,)/K
(9)
Var^jX^,^) = Vx V^/V,
где Izi = l+32 + ... + i32*1, и2-1 + ... + ^к1, K^l + .-. + jS2*. Выражения, полу-
ченные в книге в конце раздела 8,6.2, следуют из (9) при кх=к2 = 0
(в обозначениях раздела 8.6 Xt следует заменить на Yt—/г).
В заключение обсудим проблему, связанную с отсутствием ина-
чальных значений при обработке временных рядов и весьма сущест-
венную в том случае^ когда мы имеем дело с короткими
реализациями временного ряда. Пусть мы начали наблюдения в мо-
мент времени 1=0, т.е. в реализации отсутствуют значения X_j,
...,X_,p,X___p_t... . Обычный способ [Бокс, Дженкинс (1974)] вычис-
ления плотности в этом случае — «прогнозирование назад» доста-
точно большого числа реализаций временного ряда (например, для
процесса АР(р) «прогнозируют» р реализаций). Этот способ сходен
с заполнением пропусков. В подходе с использованием маргиналь-
ного распределения эта проблема решается естественным образом.
В самом деле, можно рассматривать наблюдения, отсутст-
вующие до 1~0, как бесконечное множество пропусков. Например,
пусть мы наблюдаем временной ряд АР(1) с момента времени 1=0.
Тогда маргинальная плотность для наблюдения Хо есть (8), где по-
ложено к = *^:
'Em 2а2
Как мы видим, это выражение совпадает с выражением в [Бокс,
Дженкинс (1974)], полученным для «точной» функции правдоподо-
бия из других соображений (а именно из условия обратимости
процесса).
5. УСЛОВНЫЕ ПЕРЕСТАНОВОЧНЫЕ КРИТЕРИИ
ОДНОРОДНОСТИ МНОГОМЕРНЫХ ВЫБОРОК
ПРИ НЕСЛУЧАЙНЫХ ПРОПУСКАХ
В этом разделе будут сформулированы критерии и результаты
для двухвыборочной задачи, а затем описаны их аналоги для не-
скольких выборок и провеедно обсуждение методов вычисления.
293
5.1. ОПИСАНИЕ КРИТЕРИЕВ
Рассмотрим задачу проверки однородности двух многомерных
выборок с пропусками с нулевой гипотезой
/4 •• F = G
и общей альтернативой
H, :F A G.
Нас будут интересовать критерии со статистиками типа Смир-
нова и омега-квадрат. В одномерном случае эти критерии свободны
от распределения в классе непрерывных функций распределения
(ФР). Для их прямых многомерных обобщений это свойство утра-
чивается вследствие зависимости между элементами случайного
вектора. Естественным и простым выходом является построение
критериев, условных по объединенной выборке (для ранговых кри-
териев — условных по матрице рангов объединенной выборки).
Этот подход был предложен еше в начале 60-х годов: в [David, Fix
(I960)] и [Sen, Chatterjee (1964)] «было указано, что классический
принцип перестановок Фишера... в приложении к ранговым крите-
риям для многомерных задач ведет к процедурам, которые свобод-
ны от распределения и которые, по крайней мере теоретически,
могут быть протабулированы» [Bickel (1969), с. 1]. Применяя этот
принцип к многомерному обобщению двухвыборочного критерия
Смирнова, П. Бикел [Bickel (1969)] доказал, что такой условный
критерий состоятелен и свободен от распределения.
Оказывается, можно предложить такие обобщения условных
критериев Смирнова и омега-квадрат на случай многомерных на-
блюдений с пропусками, что они будут состоятельными и свобод-
ными от распределения при очень слабых ограничениях на
распределение пропусков.
Пусть
две независимые выборки r-мерных наблюдений с пропусками. По-
строим для этих выборок маргинальные эмпирические функции рас-
пределения (ЭФР) для всех наблюденных структур пропусков
(напомним, что структурой пропусков в r-мерном наблюдении на-
зывается r-мерный вектор М с координатами «пропуск» или «нет
пропуска», а ^-мерной эмпирической функцией распределения вы-
294
борки (Xi,...,Xn) называется
РЧХ ё Uу) = F'W = 1/п i lXj О),
где иу — угол в Rk с вершиной у, 1х = П /г(у;- — х;) — функция
распределения с массой 1 в точке х=(xi,...,x^)T, h(z) — функция Хе-
висайда). Пусть > 0 обозначает число наблюдений с г-й структу-
рой пропусков в 1-й выборке, /=l,...,s, rij > 0 — число наблюдений
с у-й структурой пропусков во 2-й выборке,t (подмножества
структур пропусков в выборках могут не совпадать, структуры в
одном подмножестве пронумерованы независимо от другого под-
множества). Таким образом, мы получим два множества ЭФР:
Им,..., \рмх\...,
где F1^ — гг-мерная ЭФР, построенная по /г наблюдениям с г-й
структурой пропусков из первой выборки, — размерность соот-
ветствующего подпространства Rri £ Rr, GjJ — ЭФР во
второй выборке, а х в качестве аргумента по-прежнему обо-
значает подмножество x0”s переменных исходного r-мерного случай-
ного вектора х, присутствующих согласно i-й (/-й) структуре
пропусков m = mllm = mj). Далее индексы и л,- в обозначениях ЭФР
опущены.
Критерий типа Смирнова основан на статистике
D = sup | /^-(х)// — £ njGj(x)/n | . (10)
Заметим, что если число s (или /) наблюденных структур пропусков
в первой (второй) выборке больше единицы, то соответствующая
сумма в (10) уже не является функцией распределения. Далее, если
не выполняется условие ОПС, то эти суммы не являются в общем
случае состоятельными оценками соответствующих линейных ком-
бинаций маргинальных функций распределения исходной ФР F(x)
или G(x).
Верхняя грань в (10) берется по х € Rr. Статистика D сравнива-
ется с критическим значением с(а, где \Х,М\, — объединен-
ная выборка наблюдений с пропусками: [Х,М\ = A^JBn. Точнее,
r 1, если D>c,
Ф(Р | [Х,М}) = J w, если D=c,
(П)
0, если О<с,
295
где Ф — критическая функция, а с и w — величины, зависящие от
[Х,ЛД и обеспечивающие нужный уровень значимости а. Значения с
и w определяются единственным образом для любого 0<а<1.
Уточнять способ их выбора мы не будем, поскольку на практике
обычно оперируют фактически достигаемым уровнем значимости,
способ вычисления которого обсуждается ниже.
Распределение статистики D при нулевой гипотезе определяется
на множестве перестановок, условном по объединенной выборке
P(D^d | [Х,М\ = ("0~‘ S/ (12)
где I — индикатор события, Z>, — значение статистики (10) для ьго
возможного способа выбора (без возвращения) наблюдений из
[X,М\ в выборку объема I, ?=1..
Теорема 5. Пусть распределение пропусков в выборках оди-
наково:
p(m|x,l) = р(т\х,2) = p(w|x), (13)
где p(m\x,i) — вероятность наблюдения /-й выборки со структурой
т при значении сл.в. Х—х, а в остальном произвольно. Тогда услов-
ный критерий (10), (11) уровня а>0 состоятелен против альтер-
нативы Н[ : F(x) & G(x), причем найдутся такие т и х € Хо^>
х т т
что И/? (нг|х) d[F—G](x)=0. Здесь через Xobsn обозначены под-
X
mis г
пространства R , соответствующие присутствующим и отсутствую-
щим переменным при структуре т.
Дополнительное условие, конкретизирующее альтернативу в
формулировке теоремы, означает, упрощенно говоря, что критерий
обнаруживает любое различие между распределениями на множе-
стве, вероятность наблюдения из которого больше нуля (т.е. разли-
чие, не «маскируемое» пропусками).
Наблюдения с различным числом присутствующих значений
имеют в (10) одинаковый вес. Более общий вид статистики (10):
D = sup | Е — Е bfij |, (14)
и при выборе где г(- — число присутствующих перемен-
ных в структуре /и(- (и аналогичном выборе 4у) эта ситуация
изменится. При этом коэффициенты, соответствующие «пустым»
наблюдениям с т - («пропуск»,..., «пропуск»), будут равны нулю,
т.е. различие выборок по таким наблюдениям уже не будет при-
296
ниматься в расчет. Вообще говоря, выбор коэффициентов а и b до-
вольно произволен. При способах выбора, обсуждавшихся выше,
учитывается различие выборок по распределению структур пропу-
сков. Можно отказаться от этого: значения а,-1/5 и bj=Vt или
aj = bj = 1 также обеспечивают справедливость теоремы 5.
Статистика Смирнова для многомерных ЭФР допускает и дру-
гие обобщения при пропусках, например
D=max suplajF/x/—Ьр,(х)\, (15)
где максимум берется по множеству структур [т^ присутствую-
щих в [ХМ! (в (15) принято, что индексы Z(. и п. в обозначениях F;
и Gs относятся к одной и той же структуре пропусков т^тах, что
допускается /,=0 или п; = 0, При выборе Ь^п/п
или a^ljr^l, b—nfj/n формулировка теоремы 5 для статистики
(15) сохраняется дословно.
Статистикой типа омега-квадрат в обсуждаемой постановке
будет:
и .£ а^(х)-Ъ bjG/xrfdWfx), (16)
где W — некоторая весовая функция (не обязательно ФР).
Возможны, конечно, и другие способы обобщения статистик
типа Смирнова и омега-квадрат.
Так, супремум в (10), (14), (15) берется по xf.Rr. Это эквива-
лентно поиску максимума на множестве U точек х из Rr, у кото-
рых координаты Xj принимают значения у-ой переменной,
имеющиеся в объединенной выборке [ХМ> во всех возможных со-
четаниях, т. е. и~[х€Кг:х^Хц, i—l,...,l+n, /=!,...у], где X- — значе-
ние-у-ой переменной у /-го объекта объединенной выборки, если оно
присутствует, и +“=, если отсутствует. В случае двух выборок объ-
емов I и п при отсутствии пропусков и совпадений число элементов
множества U составит Ц+п)г. Таким образом, объем вычислений
увеличивается экспоненциально с ростом размерности наблюдений,
по крайней мере, для простого перебора по множеству U.
Другой путь прямого обобщения статистик типа Смирнова —
брать максимум модуля в выражениях (10), (14), (15), только в
(1+п) выборочных точках, т. е. на множестве F=[x€Z?r:xtf=X^
у = 1,...г], где Х(у, означает то же, что и выше. Обозначим
статистики, полученные таким способом, через Т Очевидно, T^D.
Заметим, что критерии, основанные на втором способе обобщения
297
статистики Смирнова, также состоятельны. Относительно сравне-
ния двух подходов по мощности соответствующих критериев и дру-
гим свойствам пока ничего нельзя сказать.
В случае статистик типа омега-квадрат можно по-разному вы-
бирать функцию W в (16) в согласии с этими двумя подходами. В
первом интеграл (16) обратится в сумму подынтегральной функции
по множеству U, во втором — в сумму по множеству V (второй ва-
риант соответствует формальному прочтению для многомерного
случая статистики Лемана—Розенблатта с W=H, где Н — ЭФР
объединенной выборки [Болыпев, Смирнов (1983), с. 86]).
В многовыборочном случае это обилие вариантов множится на
несколько способов построения статистик для к выборок (см. на-
пример, [Гаек, Шидак (1971), с. 133—136]). Один из наиболее извест-
ных способов (см. [Черномордик (1980)] и ссылки там) можно
обобщить на случай данных с пропусками следующим образом:
к . S, к Sj S,
D = sup .Е dj[ Cj ,Е а^/х)/ Е Cj atJ\ , (17)
где Sj — число структур пропусков в у’-ой выборке, F^- — /^-мерная
ЭФР, построенная по наблюдениям с r-й структурой в у-й выбор-
ке, Су, d,, atj — некоторые положительные коэффициенты, напри-
мер, lj — объем у-й выборки. Распределение
статистики (17) определяется аналогично (12). Обобщение (12) и ус-
ловия (13) очевидно. Переформулировка для многовыборочного
случая теоремы 5 и следующих за ней предложений также не соста-
вит труда для читателя.
Из (12) следует, что условные критерии типа (14) — (17) как пе-
рестановочные критерии свободны от распределения, поскольку при
заданной объединенной выборке (X'Mj и при нулевой гипотезе рас-
пределение статистики одно и то же в семействе всех распределений
Рх-М на ^Х<Ж, т. е.
Р*>мх... х PX-M(D sS d| [Х;М])
не зависит от Рх>м. Это свойство, конечно, верно для обоих подхо-
дов к многомерному обобщению критериев типа Смирнова и омега-
квадрат.
Заметим также, что в предлагаемых критериях не требуется не-
прерывности ФР, так что совпадения в наблюдениях в выборке по
одной или более переменным не требуют модификаций процедур.
Это обстоятельство — естественное следствие построения критери-
ев как условных по (объединенной) выборке [см. Кокс, Хинкли
(1978), гл 6].
298
5.2. МЕТОДЫ ВЫЧИСЛЕНИЙ
Задачу вычисления фактически достигаемого уровня значимос-
ти Q для условных перестановочных критериев, рассмотренных вы-
ше, можно представить как задачу оценивания среднего конечной
совокупности с числом элементов C(l,n)=[ I ) (в ^-выборочном
случае вместо С(1,п) надо взять Од + где пи...,
пк — объемы выборок). В самом деле, пусть ^, = 0, если для г-го из
С(1,п) возможных способов извлечения выборки объема I из объеди-
ненной выборки^,М) статистика Djid, где d — наблюденное зна-
чение статистики D, и <7, = 1 — в противном случае. Тогда
Q—hq/C^nk При практическом использований критерия можно
пренебрегать конечностью С(1,п) (в случаях, когда С(1,п) мало, не-
трудно точно вычислять Q с помощью полного перебора), при этом
мы приходим к задаче оценивания параметра Q биномиального рас-
пределения.
К сожалению, эффективная схема точного вычисления Q для
статистик типа Смирнова [Черномордик (1980)] не поддается обоб-
щению на многомерный случай, а для критерия омега-квадрат —
даже на одномерный случай. Это относится и к другим методам, в
которых задачи об однородности к выборок анализируются с по-
мощью модели случайных блужданий, поскольку в многомерном
случае трудно установить связь между траекторией блуждания и
значением статистики. Естественным (и приемлемым с практиче-
ской точки зрения) методом является метод статистических испыта-
ний (Монте-Карло), в котором в качестве оценки Q используется
число испытаний, в которых статистика имела значение, не меньшее
наблюденного. Точность оценивания Q естественно характеризовать
доверительным интервалом уровня 95%, 99% и т. п. Для его вы-
числения можно использовать биномиальную аппроксимацию, ука-
занную выше, а при достаточно большом числе испытаний —
пуассоновскую аппроксимацию биномиального распределения (для
Q, близких к 0 или 1) или нормальную аппроксимацию.
Поскольку с ростом объемов выборок и особенно размерности
наблюдений время счета быстро возрастает, целесообразно после
одного или нескольких испытаний пересчитывать оценку Q и соот-
ветствующий доверительный интервал и выводить эти величины на
экран, чтобы пользователь мог остановить процесс (например, уве-
личение точности оценки Q, как правило, не имеет смысла, если те-
кущий 99%-ный доверительный интервал для Q равен (0,3, 0,8)).
Заметим, что прерывание итераций по достижении заданной
точности (длины интервала) будет приводить в среднем к оптими-
стическому доверительному интервалу и к оценке Q, смещенной к
299
значению 0 либо 1. На практике можно пренебречь этим эффектом,
считая, что пользователь, прерывая счет, подвержен воздействию
многих внешних факторов, так что выбор точности и момента
остановки счета случайны.
Вообще говоря, точность вычисления Q в методе Монте-Карло
не существенна для свойств состоятельности критерия и свободы от
распределения и важна, по сути, лишь для его мощности. Это вы-
текает из следующего утверждения.
Пусть задан уровень значимости 0<а<1. Назовем «прибли-
женным критерием уровня а с К испытаниями» критерий, в кото-
ром за фактически достигаемый уровень значимости принимается
его оценка QK методом Монте-Карло после К испытаний. (Замеча-
ние. Уровень значимости приближенного критерия совпадает с
уровнем значимости точного критерия благодаря тому, что QK —
несмещенная оценка Q при любом К>0.)
Теорема б. В условиях теоремы 5 приближенные критерии уров-
ня а>0 при А>0 испытаниях состоятельны.
Теорему 5 можно считать частным случаем этого результата.
Она соответствует теореме 6 при К=С(1,п). (При выборе без возвра-
щения. При выборе с возвращением .) Обобщение формули-
ровки теоремы 6 для критериев со статистиками (14) — (17) и для
других предложений из раздела 5.1 достаточно прозрачно и опу-
скается.
6. АНАЛИЗ ТАБЛИЦ СОПРЯЖЕННОСТИ И ПРОВЕРКА
НЕЗАВИСИМОСТИ СЛУЧАЙНЫХ ВЕЛИЧИН
При проверке независимости непараметрическими методами
также допустимы очень слабые условия на распределение пропу-
сков. Рассмотрим сначала задачу проверки независимости двух фак-
торов в двумерной таблице сопряженности.
Пусть в эксперименте получают двумерные наблюдения с про-
пусками (Х,М), где Х=(х1,х2)т, М=(т1,тгУ, где Xi принимает зна-
чения z€[l,...,/?], х2 — значения у€[1,...,С]. Допустим, что
распределение подчиняется одному из следующих условий
(различие функций может, как и ранее, задаваться различием аргу-
ментов):
р(т |л'1 ,х2) |Х1)Хщ2 |х2) (18а)
или
p(m|%i,x2)=p(mj \x3)p(m3]xi). (186)
В данном примере условие ОС не является одним из частных случа-
ев (186).
300
Пусть при отсутствии пропусков (т. е. в соответствии с распре-
делением ft*) вероятности ячеек в таблице сопряженности RxC
равны Ру , i=1,...,R, Тогда при наличии пропусков и усло-
вии (18а) (случай (186) рассматривается аналогично) вероятности
ячеек в таблице сопряженности, составленной по комплектным на-
блюдениям, равны
Ap-jp'iPj, (19)
где А — константа нормировки, а р\ и pj — вероятности pfrrh-
=«яет пропуска»|xi=i) и р(т2=«нет пропуска»\x2=j). На протяже-
нии раздела будет предполагаться, что р‘ >0 и р^ >0 при всех / и J.
Из (19) вытекает, что при наличии пропусков, подчиняющихся
условию (18а) или (186), можно проверять гипотезу независимости
по комплектным наблюдениям с помощью обычных критериев от-
ношения правдоподобия или хи-квадрат без каких-либо изменений.
В самом деле, считая справедливой гипотезу независимости,
т. е. принимая ру = р° + р°+,, где р°+ = Epy,p“Ai= S ру , после
простых выкладок получаем p(y=pi+p+J-, где р(у — вероятности яче-
ек в таблице, образуемой комплектными наблюдениями, pl+,p+j —
соответствующие маргинальные вероятности по строкам и столб-
цам. С другой стороны, указанные критерии сохраняют состоятель-
ность против общей альтернативы зависимости: р°у ?*р?+р° •>
поскольку это условие влечет выполнение неравенства p^Ap^p^j
при любых р,->0, Pj>0, p]j, Еру=1, (=1,...,Д, j=l.С. Чтобы дока-
зать это, надо убедиться в том, что система уравнений относитель-
но /?С+1 неизвестных А, р°^
0 а V* 1 2 0 0 0 4
Pkl=A S. PiPjPkjPil’ T+Pij~K
имеет единственное решение p°j =p°j + p\j.
Выкладки, связанные с доказательством этого утверждения,
мы опустим.
Для проверки независимости в таблицах 2x2 (эквивалентной
гипотезе 6 =р,!р“2/(р,2р®]) = 1) известны равномерно наиболее мощ-
ные несмещенные условные критерии, основанные на гипергеомет-
рическом распределении. Проводя доказательство аналогично
[Леман (1979), с. 163—165], получим, что при пропусках оптималь-
ны эти же критерии, вычисляемые по комплектным наблюдениям,
если верно (18а) или (186). Более того, равномерно наиболее мощ-
ными останутся несмещенные критерии для проверки различных
301
гипотез о В при альтернативных, указанных в [Леман (1979), с. 153[,
если при наличии пропусков типа (18а) или (186) эти критерии так
же будут вычисляться только по наблюдениям с присутствием обо-
их факторов.
Перечисленные выше результаты отражают то обстоятельство,
что наблюдение с присутствием одной из компонент вектора X не
несет информации о зависимости двух факторов, если выполняется
условие (18).
Сходные явления будут наблюдаться и при логлинейном анали
зе ^-факторных таблиц сопряженности. Например, при проверке об-
щей независимости (гипотезы об~ отсутствии взаимодействия
высшего порядка в логлинейной модели) аналогом условий (18а) и
(186) является
р(т |х) = П р(т}\х^, (20)
где теперь т та х — ^-мерные случайные векторы, a (z(l),..., Цк)) —
произвольная перестановка множества (1,..,,к).
В общем случае проверки независимости к случайных величин,
не обязательно являющихся дискретными с конечным числом гра-
даций, ситуация сохраняется, т. е. независимость случайных вели-
чин при отсутствии пропусков, Px(x)=Pl(xi)P2(xz)...Pk(xk), ведет при
выполнении условия (20) к независимости в комплектных наблю-
дениях:
р(х|ш*)=р!(х) |т*).. .рк(хк\т*),
где т* — структура пропусков, соответствующая комплектному на-
блюдению. Таким образом, при справедливости (20) можно прове-
рять независимость случайных величин по комплектным
наблюдениям с помощью тех же непараметрических критериев (на-
пример, ранговых критериев Спирмена или Кендалла при к=2), ко-
торые применяются для данных без пропусков. Справедливости
ради отметим, что такой подход при к>2 может сильно снижать
эффективность критериев при альтернативах, включающих частич-
ную зависимость (т. е. зависимость внутри подмножества перемен-
ных в наблюдении) и большом числе пропусков.
7. МЕТОДЫ ЗАПОЛНЕНИЯ ПРОПУСКОВ И ИХ СВОЙСТВА.
ЛОКАЛЬНОЕ ЗАПОЛНЕНИЕ
Обобщенно говоря, методам заполнения пропусков присущи
следующие два принципиальных недостатка.
1. Как правило, параметры для алгоритма заполнения пропу-
сков вычисляются по присутствующим данным, что вносит зависи-
302
мость между наблюдениями. Конечно, такой искусственной зависи-
мости не возникает, если проводится заполнение константой или
случайными значениями, не зависящими от присутствующих на-
блюдений в выборке, или методом «подстановки без подбора» (см.
раздел 4.5 книги). На практике эти методы представляют малую
ценность. Зависимости можно также избежать, разделяя исходную
выборку на две подвыборки и вычисляя подстановки (например,
средневыборочные значения) для анализируемой подвыборки по
значениям наблюдений во второй подвыборке. При таком подходе
жертвуется часть информации, чтобы заполнить пропущенные
значения.
2. Распределение данных после заполнения будет отличаться от
истинного, даже если пренебречь зависимостью, указанной выше.
Этот факт особенно нагляден для простых методов заполнения —
средневыборочными, по регрессии и т. п. (см. раздел 3.4 книги или
[Basilevsky et al. (1985)]). Так, заполнение средневыборочными Xj,
по присутствующим значениям даст распределение в виде
смеси, одной из компонент которой является истинное распределе-
ше по присутствующим значениям (соответствующее комплектным
заблюдениям), а остальными компонентами — распределения, со-
ответствующие некомплектным наблюдениям с различными струк-
турами пропусков и вырожденные в
[Xj=Xj,
де — множество признаков с пропусками ьй структуры,
= 1,...дЧ N — число наблюденных структур пропусков. Различные
.арианты методов заполнения с помощью регрессии, главных ком-
понент и аналогичных методов снова приведут к смеси истинного и
порожденных распределений с вырождением на гиперплоскостях,
;а которых располагаются предсказываемые значения.
Анализ таких «полных» данных стандартными методами не-
равомерен и приводит к недостаткам, подробно обсуждавшимся в
азделе 3.4: несостоятельность, смещенность оценок параметров,
качество оценок ухудшается с ростом доли пропусков. Аналогич-
ые явления (несостоятельность, искажение номинального уровня
начимости) характерны и для статистических критериев проверки
ипотез, применяемых к заполненным данным.
Рассмотрим теперь метод, который естественно назвать мето-
ом локального заполнения пропусков. Он сходен по идее с одним
з методов подстановки с подбором, применяемых для задачи оце-
ивания среднего одномерной переменной в конечной популяции
303
(см. гл. 4), — с методом «ближайшего соседа». Разберем такой ва-
риант метода локального заполнения.
Пусть Rr — r-мерное евклидово пространство. Примем, что ве-
роятность комплектного наблюдения больше нуля. Пусть F(x),
xtR', — функция распределения случайного вектора X (соответ-
ствующая Рх), а (Х1,М1),...,(ЛГЛ,Л/И) — выборка независимых на-
блюдений с пропусками. Допустим, что распределение Рх
абсолютно непрерывно относительно некоторой меры на Rr, так
что существует плотность f относительно этой меры.
Допустим, что в z-м наблюдении Xt отсутствуют переменные
^imis и присутствуют .X30bs. Вычислим евклидовы расстояния меж-
ду z-м и всеми комплектными наблюдениями Xj в подпространстве,
соответствующем присутствующим в переменным:
(2D
Пусть Ij= [/1,...— подмножество индексов с минимальным зна-
чением расстояния (21). Если, в Z, входит только один объект jx, то
берут подстановку A',-mis==A3 mis. Если к>\, то из Z, извлекают слу-
чайным образом индекс j и полагают JQmis=JQmis.
Обозначим через F„M эмпирическую функцию распределения,
построенную по заполненной этим методом выборке.
Теорема 7. При п —► =-= и условии ОПС
sup|F„W-WI ~*0. (22)
Приведенное утверждение означает, что при неограниченном увели-
чении объема выборки локальное заполнение обеспечивает совпаде-
ние распределения заполненной выборки с истинным.
Из теоремы вытекает, в частности, что оценки, непрерывные в
F в равномерной метрике [см. Боровков (1984), с. 26], а к ним отно-
сятся очень многие «разумные» оценки, состоятельные при полных
данных, будут состоятельны и для данных с пропусками после ло-
кального заполнения.
Описанный простейший способ можно обобщить в нескольких
направлениях. Во-первых, можно использовать самые разные рас-
стояния — метрики Махаланобиса, Хемминга, Колмогорова, их
комбинации, взвешивание переменных, неметрические расстояния и
т. д. Во-вторых, возможны варианты, не ограничивающиеся подбо-
ром по комплектным объектам, например заполнение по наблюде-
ниям с возрастающим числом присутствующих переменных с «на-
304
коплением» значений (такой вариант более «равномерно» использу-
ет присутствующую в выборке информацию). При этом для спра-
ведливости (22), однако, обязательна вложенность подмножеств
переменных с присутствующими значениями в последовательности
объектов.
В общем случае, когда распределение пропусков может не под-
чиняться условию ОПС, наблюдениям со структурой т при запол-
нении описанным способом будет соответствовать плотность
/о(Щ <bsK(*Sj
в предположении существования соответствующих плотностей, где
Jo — плотность, условная по присутствию комплектного наблюде-
ния, a fm — плотность, условная по присутствию наблюдения со
структурой т. В результате предельное распределение заполненной
выборки имеет плотность
т
При условии ОПС для всех т (в правой ча-
сти этого равенства стоит маргинальная плотность распределения
Р*), что отвечает результату (22).
Обратимся теперь к известному алгоритму ZET [Загоруйко, Ел-
кина, Тимеркаев (1976)]. Внешне он сходен с методом локального
заполнения. Однако с точки зрения математика его нельзя признать
удовлетворительным. Провести сколько-нибудь строгое исследова-
ние свойств алгоритма практически невозможно, так как он пред-
ставляет собой последовательность достаточно сложных
эвристических процедур. Вместо этого мы продемонстрируем на
простых примерах действие механизмов, которые будут приводить
в общем случае к искажениям исходного распределения при запол-
нении пропусков алгоритмом ZET. Обсуждаемые ниже явления на-
до учитывать также при конструировании локальных методов за-
полнения.
Рассмотрим более подробно последнюю модификацию алго-
ритма ZET — алгоритм ZETM [Загоруйко и др. (1986), гл. 2]. В
этом алгоритме пропуски заполняются величиной, которая является
линейной комбинацией (взвешенным средним) регрессионных оце-
нок пропущенного значения. Оценки вычисляются по предсказыва-
ющей подматрице исходной таблицы «объект-признак». Размеры
подматрицы малы (в примере, сопровождающем описание алгорит-
ма, фигурируют значения от 3x3 до 10x10). Конкретный способ
1 1. Р. Дж. А. Литтл, Д. Б. Рубин 305
вычисления в [Загоруйко и др. (1986)] не указан, однако при любом
разумном толковании (используется ли простая или множественная
регрессия и т. п.) будут задействованы следующие механизмы.
1. Если в вычислении подстановок используется не один, а не-
сколько объектов, то усреднение прогнозируемых значений может
привести к неприятным последствиям, даже если число этих объек-
тов мало. Рассмотрим неполную выборку двумерных векторов (зд),
в которой часть объектов комплектна, а часть объектов содержит
значения х и пропуски у. Будем проводить заполнение по методу
«двух ближайших соседей»: подбирать для Z-ro объекта с пропуском
yt два комплектных объекта iiti2 с минимальными расстояниями
|х,.—х(-|, |х,-2—х,-| и заполнять пропуск значением Тог"
да в пределе при «-»“’ для распределений, непрерывных по х, ус-
ловная дисперсия подстановок у при заданном х будет в 2 раза
меньше истинной условной дисперсии у. Значит, если зависимость
между х и у не очень сильна, то занижение дисперсии будет заметно
уже при сравнительно небольшой доле пропусков. Свойство (22) бу-
дет верно в общем случае только при у=у(х) п. в. (Заполнение по
регрессии не изменит характер рассматриваемых искажений.)
2. Отбор признаков связан с еще одной опасностью. Это проще
всего проиллюстрировать на примере выборки независимых трех-
мерных бинарных векторов (xy.zjj, i=l,2,...,n, которую можно пред-
ставить в виде трехфакторной таблицы сопряженности 2x2x2.
Пусть распределение сосредоточено в трех точках — (0,0,0), (0,1,1)
и (1,0,1) с массами 1/3 каждая. Пусть p-я часть наблюдений содер-
жит пропуски в переменной z. По-прежнему будем считать верным
условие ОПС. Заполняя пропуски локальным методом (т. е. подби-
рая ближайший объект и случайно выбирая значения, если число
таких объектов с минимальным расстоянием более одного), но ис-
пользуя только переменную х и игнорируя значения у, мы получим,
что в заполненной выборке часть наблюдений имеет недопустимые
значения: (0,0,1) и (0,1,0). В пределе эта часть составляет
р/3.
То, что в алгоритме ZETM «столбцы» (признаки) отбираются
по степени близости друг к другу [см. Загоруйко и др. (1986), с. 20],
может уменьшить подобный эффект, но, конечно, не устранит его
полностью (за исключением случая строгой линейной зависимости).
В приведенном примере столбцы х и у одинаково близки к столбцу
Z в евклидовой метрике, используемой в ZETM.
3. Сходной природой обладает и еще один возможный источ-
ник искажений. Речь идет о таком способе поиска подстановок.
Пусть требуется заполнить пропуск у-го признака у Z-ro объекта,
х . Если вычислять подстановки по подмножеству наблюдений с
присутствием признака j и это подмножество формируется незави-
симо от аналогичных подмножеств, образуемых для заполнения
306
пропусков в других признаках, то такой подход тоже может приво-
дить к «выбросам» — объектам с неестественным сочетанием зна-
чений признаков, а также к другим искажениям. Этот подход был
реализован в алгоритме ZET.
4. В алгоритме ZETM имеется итеративный режим вычисления
новых значений подстановок с учетом значений, вычисленных и
подставленных на предыдущем шаге [Загоруйко и др. (1986), с. 21,
115], что может вносить дополнительную искусственную зависи-
мость между объектами выборки и усиливать «центростремитель-
ные тенденции», особенно если доля пропусков велика.
В разделе 4.5.1 книги упомянуты еще два подхода к заполне-
нию пропусков. Для обоих свойство (22) в общем случае не вы-
полняется. В первом (пункт е), см. также [Titterington, Jiang (1983);
Little, Smith (1987)]) к подстановке для пропуска, вычисляемой по ре-
грессионному уравнению, добавляют случайное значение, сгенериро-
—ванное согласно распределению, условному по присутствующим
значениям, со значением параметра, равным его текущей оценке §.
Распределение подстановок будет «подгонять» истинное распреде-
ление к распределению выбранной параметрической модели со зна-
чением параметра в. Составной метод (пункт ж)) также не
удовлетворителен: ясно, что при различном распределении отклоне-
ний от регрессии для различных значений независимых переменных
добавление к регрессионному предсказанию случайно выбранных
остатков может заметно исказить исходное распределение.
Более приемлемо выглядит вариант, близкий к одному из пред-
ложений в [Little, Smith (1987)], — комбинация регрессионного и ло-
кального заполнения, при которой к регрессионному прогнозу
пропущенных значений добавляют остаток от регрессии для бли-
жайшего (в пространстве известных переменных) комплектного на-
блюдения. Свойства такого метода будут близки к описанному
выше простому методу локального заполнения, в частности, при
ОПС будет выполняться (22). Вопрос о том, какой из этих двух
подходов предпочтительнее (и в каких условиях), остается от-
крытым.
Что касается свойств методов заполнения, описанных в книге в
разделе 4.5.3, то они близки к свойствам описанного простого ло-
кального метода. Заметим, что методы из гл. 4 предназначены для
решения частной задачи — оценивания характеристики скалярной
переменной, поэтому здесь ситуация проще. В частности, вести под-
бор по полному подмножеству «сопеременных» xt не обязательно в
отличие от локального заполнения в общем многомерном случае.
11
307
В заключение раздела коротко обсудим, как заполнение пропу-
сков влияет на характер выводов при так называемых методах ана-
лиза данных, и назовем некоторые альтернативные подходы. К
этим методам относятся методы кластерного анализа, многомерно-
го шкалирования, разведочные методы (например, визуализация
данных). Их применение обычно не опирается на какую-либо веро-
ятную модель, поэтому бессмысленно характеризовать их свойства
в статистических терминах состоятельности, (несмещенности кри-
териев и оценок параметров, устойчивости и эффективности. Тем не
менее и для этих методов заполнение, как правило, искажает приро-
ду данных и характер выводов. Так, если пропуски не зависят от
значений признаков, то заполнение средними, по регрессии или ана-
логичными методами приведет к искусственному увеличению доли
объектов со значениями признаков в центре совокупности (выборки)
или на соответствующих гиперплоскостях. Искусственно компакт-
ными будут классы в кластер-анализе после заполнения пропусков
внутригрупповыми средними или с помощью алгоритма ZETM.
При этом степень искажения также увеличивается с ростом доли
пропусков. Поэтому в методах анализа данных желательно искать
методы обработки пропусков, не связанные с их заполнением (а при
отсутствии таковых обращаться к локальному заполнению).
К методам невероятностного анализа данных с пропусками без
их заполнения относится подход, описанный в гл. 5 книги Э. Дидэ
с соавторами «Методы анализа данных. Подход, основанный на
методе динамических сгущений» (М.: Финансы и статистика, 1985),
для кластер-анализа эталонного типа (обобщение алгоритма типа
ISODATA). Для методов анализа данных, основанных на матрице
расстояний между объектами (иерархический кластер-анализ, мно-
гомерное шкалирование), можно «заполнять» не пропуски, а те
компоненты расстояний, которые невозможно вычислить из-за про-
пусков наблюдений, т. е. добавлять к расстоянию djt вычисленному
в подпространстве Si возможно большей для каждой (i-й) пары
объектов размерности, средневыборочное расстояние в дополнении
5; до полного пространства (такой способ реализован в одном из
пакетов ЦСМИ, см. раздел 9), или это же расстояние, умноженное
на величину, пропорциональную В многомерном шкалировании
при наличии пропусков естественно минимизировать сумму ^Pi(di—
—б?,)2 по всем i=l,...,n(n—1)/2 парам объектов, dt — исходное, —
модельное расстояния для /-й пары, когда в /т вводится множи-
тель, монотонно возрастающий при увеличении числа признаков,
участвовавших в вычислении расстояния с/,. Все эти подходы тре-
буют изучения.
308
8. ИССЛЕДОВАНИЕ РАСПРЕДЕЛЕНИЯ ПРОПУСКОВ.
ПРОВЕРКА СЛУЧАЙНОСТИ
Условия случайности пропусков (ОС и ОПС) являются необхо-
димыми условиями применимости большинства известных методов
анализа неполных данных, в том числе и описанных в книге Литтла
и Рубина. Между тем к настоящему времени предложено лишь не-
сколько частных методов проверки случайности пропусков, напри-
мер простейший метод сравнения одномерных распределений,
упомянутый в книге (раздел 3.2) и более подробно обсуждаемый в
[Little, Smith (1987)], или метод проверки условия ОПС для незави-
симых переменных в задаче анализа линейной регрессионной моде-
ли в [Simonoff (1988)].
Тем не менее можно построить полезные многомерные крите-
рии для проверки ОПС и ОС. Сразу оговоримся, что проверить ус-
ловие ОС принципиально возможно только в том случае, когда
станут известны первоначально отсутствовавшие значения — при
проведении более дорогостоящих или разрушающих измерений или
по данным об объекте, полученным через некоторое время после
проведения исследования и т. п. (но не за счет заполнения пропу-
сков тем или иным способом, в котором само условие ОС или ОПС
будет считаться справедливым).
Несмотря на то что новые методы корректны при условии ОС
и не требуют более жесткого условия ОПС, проверка условия ОПС
также важна, поскольку простые методы обработки неполных дан-
ных (например, анализ полных наблюдений или методы локального
заполнения, обсуждаемые в настоящем дополнении), приемлемые в
общем случае только при выполнении ОПС, видимо, еще долго бу-
дут использоваться в приложениях. Новые методы (описанные, в
частности, в этой книге) требуют довольно больших вычислитель-
ных ресурсов. Может оказаться дешевле получить дополнительные
наблюдения и провести анализ полных наблюдений, чем обрабаты-
вать исходную выборку с пропусками. Кроме того, для многих за-
дач проверки гипотез методы, успешно работающие при ОС, еще не
развиты. Сюда относятся, в частности, традиционные задачи про-
верки гипотез в предположении нормальности распределения (ре-
грессионный, корреляционный, дискриминантный анализ и др.).
Начнем с критериев проверки условия ОС по восстановленным
данным. Нулевая гипотеза:
Н'0-.р(т\х) =р(т |xobs,xmis) =р(т |xobs). (23)
Пусть в случайной выборке н.о.р. r-мерных наблюдений с пропуска-
ми (А'1,М1),...,Х/ё2?г, присутствуют наблюдения с s различными
структурами пропусков Тогда из (23) следует, что для
309
каждой структуры т:, z = l,распределение переменных, отсут-
ствующих согласно mt (с функцией распределения F-), является
маргинальным распределением исходного распределения Рх (с ФР
F(x))\
FAmis)=F(xmi8>“’)> (24)
где условная запись в правой части означает, что аргументом F яв-
ляется x=(xinis,xobs) со значениями переменных, относящихся к xobs,
равными +== (считаем, что из множества исключена
структура, соответствующая комплектному наблюдению).
Построим по восстановленным значениям пропусков х эмпири-
ческих функций распределения (FF*] для s структур. Таким об-
разом, z-я ЭФР F* определена в подпространстве переменных,
отсутствующих согласно mt. Построим также FFx) — г-мерную
ЭФР «восстановленной» выборки Х\,...,Хп.
Для проверки (24) предлагаются непараметрические перестано-
вочные критерии, близкие по духу к критериям из раздела 5, со ста-
тистиками, аналогичными (14) — (17) (разумеется, данная задача не
сводится к проверке однородности s выборок, поскольку выборки
заведомо неоднородны по структуре пропусков). Статистикой типа
Смирнова будет
D= sup ^-[^(xJ-F^x)]2, (25)
где Fg/x) — маргинальная ФР эмпирической функции распределе-
ния F'(x) в подпространстве переменных, отсутствующих согласно
rrij, — некоторые веса, например су. может быть числом отсут-
ствующих значений при числом объектов со структурой их
произведением и т. п. Распределение (25) определяется условно по
восстановленной выборке Х\,...,Хп. Нетрудно сконструировать кри-
терии с другими статистиками типа (15) или (16), типа омега-
квадрат (17) и т. п.
Условие ОПС
Н'ь.р(т\х)=р(т)
означает, что распределение X одинаково для каждой структуры
пропусков, имеющейся в выборке (Х^М^),... (совпадает с распреде-
лением F(x)).
Проверять условие ОПС по исходной выборке с пропусками
можно лишь относительно присутствующих переменных:
F"(xobs)=F(xobs,~-), z = l,...A (26)
310
где теперь аргументом ФР F является вектор х с xmis = (+—>,.„,
+ *«’), a F" — ФР переменных, присутствующих согласно те.
(здесь принято, что из множества исключена структура,
соответствующая наблюдению с полным отсутствием значений).
Таким образом, принципиально невозможно обнаруживать по ис-
ходной выборке такие отклонения от ОПС, для которых выполня-
ется (26), но нарушено условие ОС.
Построить простые перестановочные критерии типа (25) для
проверки ОПС трудно, поэтому рассмотрим случай, когда Рх от-
носится к параметрическому семейству многомерных распределений
(например, нормальных). Тогда гипотеза состоит в том, что s выбо-
рок извлечены из распределений, маргинальных по отношению к
Рх, и подходящим критерием будет обобщение критерия отноше-
ния правдоподобий на случай данных с пропусками типа ОС (крите-
рий отношения «маргинальных правдоподобий»). Действия будут
таковы: получить произведение Т, функций правдоподобия для всех
s выборок, вычисленных по отдельности с помощью обычных ме-
тодов для данных без пропусков, а затем вычислить функцию прав-
доподобия L2 исходной выборки с пропусками (А),Л/j),...,(,¥„,
считая, что все X/ имеют распределение Рх (если Рх — нормальное
распределение, то это можно сделать с помощью ЕМ-алгоритма
для многомерного нормального распределения, см. раздел 8.2 книги
и текст соответствующей программы в разделе 10 дополнения).
Тогда величина 2(ln£j—1пТ2) имеет асимптотическое распределение
хи-квадрат (число степеней свободы зависит от вида модели Рх, а
также от г(- — числа присутствующих значений при i-й структуре
пропусков). Кстати, можно конструировать подобные (на самом де-
ле более простые) параметрические критерии проверки условия ОС
по данным с восстановленными значениями пропусков, а не только
перестановочные критерии типа (25).
Проверка условия ОПС по восстановленнной выборке сводится
к обычной задаче об однородности г г-мерных выборок, которую
можно решать, используя как параметрические критерии, например
из [Андерсон (1963)], так и непараметрические критерии. Конечно,
располагая восстановленными значениями, можно строить крите-
рии проверки не только для ОС и ОПС, но и для других условий,
например (18), (20) из раздела 6 или условий (5), (13), использован-
ных в теоремах 4 и 5 (см. разделы 4 и 5).
Поскольку пропуски являются случайными объектами, они мо-
гут сами по себе представлять предмет статистического иссле-
дования.
311
В r-мерной выборке объема N пропуски порождают случайную
матрицу rxN со значениями элементов «пропуск» и «нет пропус-
ка». При независимых наблюдениях с пропусками имеется N неза-
висимых r-мерных бинарных случайных векторов. Можно
выдвигать гипотезу о равной вероятности пропуска в переменных:
Pij=pik, где Ру — вероятность пропуска у-й переменной в /-м на-
блюдении, j,k=\,...,r, и проверять ее как в предположении
одинаковой распределенности пропусков для различных объектов,
т. е. при рц=ргр так и без него (соответствующие асимптотические
критерии можно найти в [Флейс (1989), раздел 8.4] и в цитирован-
ных там работах), а также в [Орлов (1982); Никифорова (1989)]). По
критериям, описанным в [Флейс (1989), гл. 13], можно проверять
гипотезы о наличии зависимости между пропусками в различных
переменных, также не полагаясь на предположение об одинаковой
распределенности пропусков по объектам. Следуя указанным выше
работам, можно строить и другие гипотезы подобного рода и соот-
ветствующие критерии.
9. ПРОГРАММНОЕ ОБЕСПЕЧЕНИЕ
СТАТИСТИЧЕСКОГО АНАЛИЗА
ДАННЫХ С ПРОПУСКАМИ
9.1. СОВРЕМЕННОЕ СОСТОЯНИЕ ПРЕДМЕТА
Основным инструментом прикладной статистической обработ-
ки данных служат пакеты программ, библиотеки и другие про-
граммные продукты. Можно констатировать, что современное
статистическое программное обеспечение анализа данных с пропу-
сками в целом находится на уровне 60-х годов (в этом разделе мы
не затрагиваем методы анализа в рамках теории надежности и
т. п., имея в виду лишь те задачи, в которых механизм порождения
пропусков не представляет прямого интереса для исследователя).
Практически все статистические программные средства, в которых
предусмотрена возможность наличия пропусков в данных, содержат
лишь простые методы — исключение некомплектных наблюдений,
заполнение пропусков средними, заполнение с помощью регрессии
или главных компонент, вычисление ковариационной матрицы и
вектора средних парными методами и т. д., т. е. методы, которые
были реализованы еще в первых версиях пакетов SSP, IMSL, BMD
(BMDP). Как было показано выше (см. гл. 3, а также дополнение),
эти методы, как правило; неудовлетворительны. В связи с этим не
имеет смысла подробно рассматривать состав методов анализа дан-
ных с пропусками, реализованных к настоящему времени в про-
граммных средствах, относящихся к прикладной статистике (их
насчитывается несколько сотен [см. Сильвестров (1988)]). Доста-
312
точно указать читателю краткий обзор И. С. Енюкова в [Айвазян,
Енюков, Мешалкин (1983)], где представлены возможности пакетов
BMDP 3-й и 4-й версий, SPSS, ППСА, ОТЭКС, ПНП (развитие би-
блиотеки SSP), DIAS по обработке неполных данных. В этих и
практически во всех других программных средствах прикладного
статистического анализа реализовано лишь некоторое подмноже-
ство указанных простых методов или их модификаций (за исключе-
нием пакета ОТЭКС, в котором важное место отводится алгоритму
ZETM, обсуждавшемуся в разделе 7).
Тем не менее разработка статистического программного обеспе-
чения, основанного на новых подходах, рассмотренных в данной
книге, началась, и, видимо, через несколько лет многие статистиче-
ские программные средства будут содержать реализации современ-
ных, теоретически обоснованных методов.
Одним из первых общестатистических пакетов, представляю-
щих новые методы, описанные в настоящей книге, будет пакет
BMDP последней, шестой версии, выпуск которого планируется в
1990 г. В этом пакете предполагается реализовать, например, мето-
ды анализа для многих из моделей, связанных с многомерные* нор-
мальным распределением и порождаемых структурами из раздела
8.5*.
В нашей стране в Центре статистических методов и информати-
ки (ЦСМИ) разрабатывается статистическое программное обеспече-
ние, в состав которого включены современные методы обработки
неполных данных, в том числе описанные в данной книге и в до-
полнении.
Один из программных продуктов ЦСМИ — диалоговая стати-
стическая система ДИСАН (разработана под руководством О. М.
Черномордика), которая, по сути, является специализированным
средством обработки таблиц данных типа «объект-признак» с про-
пусками. Все разделы этой системы рассчитаны на наличие пропу-
сков. В системе реализованы методы проверки случайности
пропусков. В мощном экранном редакторе, входящем в ее состав,
каждая таблица исходно считается состоящей из пропусков. Каж-
дый пропуск может иметь два состояния — «отсутствующее» и
«стертое» значение. Отсутствующие или стертые значения отобра-
жаются на экране как пустые ячейки, поэтому пользователю не
нужно кодировать пропуск числовым значением.
* Профессор Р. Дж. А. Литтл, один из авторов этой книги, является участником
разработки проекта последней версии пакета BMDP.
313
Система не предлагает методы заполнения, которые.могли бы
стать источником искаженных выводов. Если в какой-либо задаче
существует несколько корректных вариантов обработки пропусков,
то вычисления проводятся для всех вариантов (если при этом не
требуется слишком больших вычислительных затрат). Система «по-
могает» пользователю избежать ошибочных выводов, связанных с
наличием пропусков. Так, например, в регрессионном анализе для
метода комплектных наблюдений проводится дисперсионный ана-
лиз регрессии, а для ЕМ-алгоритма выводятся только соответ-
ствующие оценки.
9.2. МЕТОДЫ АНАЛИЗА ДАННЫХ С ПРОПУСКАМИ
В ОБЩЕСГАТИСГИЧЕСКОМ ПАКЕТЕ
В данном разделе описывается примерный набор методов обра-
ботки данных с пропусками, которые целесообразно включать в на-
стоящее время в общестатистические пакеты, исходя из
современного уровня их развития и обоснованности. Совокупность
описанных ниже функций близка к набору методов, реализованных
в диалоговой системе статистического анализа данных с пропуска-
ми Центра статистических методов и информатики.
Для каждого метода указывается один или более приемлемых
способов обработки пропусков, а также соответствующие условия на
распределение пропусков. Используются следующие сокращения:
АКН — анализ комплектных наблюдений, ПМ — парный метод. Ес-
ли не оговаривается особо, то условием на распределение пропусков
для АКН и ПМ является условие ОПС, а для ЕМ-алгоритма — ус-
ловие ОС.
1. Работа с данными. Ввод и редактирование данных с пропуска-
ми. Возможность удаления значений и восстановление «стертых»
значений. Удаление по условию. Стандартные средства манипулиро-
вания данными*.
2. Проверка случайности пропусков и исследование распределе-
ния пропусков. Простейшие методы проверки по одномерным рас-
пределениям. Проверка условий ОПС и ОС с помощью условных
• Выше указано, что заполнение пропусков не входит (явно) в функции диалоговой
системы, чтобы не провоцировать их применение пользователем (что может привести
к ошибочным выводам). Тем не менее, используя возможности редактора таблиц (и,
например, раздел одномерной статистики или регрессионного анализа), при необходи-
мости можно легко провести заполнение средневыборочными, по регрессии, по регрес-
сии с добавлением случайных возмущений, другими способами.
314
многомерных перестановочных критериев по статистикам типа
Колмогорова—Смирнова, омега-квадрат, с помощью критерия от-
ношения правдоподобия для многомерного нормального распреде-
ления. Проверка гипотез о равной вероятности пропусков в
переменных и о зависимости между пропусками в различных пере-
менных.
3. Статистика одномерных случайных величин. Вычисление вы-
борочных характеристик (среднего арифметического, дисперсии, ко-
эффициента вариации, размаха), их погрешностей (ошибки среднего,
дисперсии, коэффициента вариации и т. д.), доверительных границ.
Проверка нормальности. Непараметрический одномерный анализ
(вычисление медианы, квантилей, межквартильного расстояния, мо-
ды). Робастные оценки характеристик. Построение гистограммы и
оценки функции распределения. Парзеновская оценка плотности.
Проверка однородности двух независимых выборок с помощью
критериев Крамера—Уэлча, Стьюдента, обобщенного критерия
Смирнова. Обнаружение эффекта воздействия (проверка однород-
ности двух связанных выборок): критерий Стьюдента, непарамет-
рические критерии знаков, критерий Смирнова симметрии
распределения и другие.
Способ обработки пропусков — исключение пропусков из вы-
борки (при проверке однородности двух связанных выборок — ис-
ключение пары, в которой отсутствует хотя бы одно из
наблюдений). Условия на распределение пропусков зависят от вида
анализа: для большинства параметрических задач игнорировать
пропуски допустимо в общем случае лишь при ОПС (или ОС, что
эквивалентно в одномерном случае при независимых наблюдениях).
Для непараметрического анализа условия слабее. Так, при точечном
и доверительном оценивании медианы достаточно равенства веро-
ятностей пропуска относительно точки F~I(l/2), при проверке од-
нородности — одинакового распределения пропусков в выборках
(условие (13)).
4. Проверка однородности двух независимых многомерных вы-
борок с помощью критериев Хотеллинга, Беннета [см. Андерсон
(1963)] (метод обработки пропусков — АКН), отношения правдопо-
добия (для этого критерия вычисления основаны на ЕМ-алгоритме).
Проверка гипотез о значении среднего многомерного нормаль-
ного распределения с помощью критериев Хотеллинга (АКН) и от-
ношения правдоподобия (используется соответствующий вариант
ЕМ-алгоритма). Проверка однородности двух связанных многомер-
ных выборок с помощью этих критериев (при этом в каждой паре
наблюдений вычисляются разности значений только для одновре-
менно присутствующих переменных, в противном случае разность
считается пропуском).
315
Проверка однородности нескольких многомерных выборок с
помощью непараметрических критериев (см. раздел 5 дополнения,
условие (13)).
5. Оценка матрицы парных (АКН, ПМ, ЕМ-алгоритм) и част-
ных (АКН, ЕМ-алгоритм) коэффициентов корреляции, коэффициен-
тов Кендалла и Спирмена (ПМ). Проверка гипотез о значении
коэффициентов корреляции: парных (АКН, ПМ), частных (АКН).
Проверка независимости двух случайных величин по коэффициен-
там корреляции Кендалла и Спирмена, (условия (18)).
6. Регрессионный анализ. Множественная линейная регрессия,
нелинейная регрессия, непараметрическая регрессия, многофактор-
ный дисперсионный анализ (оценивание — АКН, ЕМ-алгоритм;
проверка гипотез — АКН).
7. Классификация. Линейный дискриминантный анализ (АКН,
ЕМ-алгоритм). Кластер-анализ (метод обработки пропусков описан
в конце раздела 7). Анализ смесей распределений (ЕМ-алгоритм).
Метод к ближайших соседей (для этого метода возможны, напри-
мер, такие подходы. В первом поиск ближайших соседей ведется
среди тех объектов обучающих выборок, у которых присутствуют
все переменные, имеющиеся у классифицируемого объекта из кон-
трольной выборки, во втором — только среди тех объектов обуча-
ющих выборок, у которых структура пропусков такая же, как у
данного классифицируемого объекта. При условии ОПС качество
первого классификатора, естественно, будет выше, в то время как
второй подход применим при следующем слабом условии на рас-
пределение пропусков: пропуски не зависят от класса (можно по-
строить разумный классификатор, отказавшись даже от этого
условия), в остальном распределение произвольно.)
8. Снижение размерности и визуализация данных. Факторный
анализ (АКН, ЕМ-алгоритм), метод главных компонент, проекции
на плоскость любых главных компонент (АКН). Диаграммы рассе-
ивания (ПМ). Двумерное шкалирование (метод обработки пропу-
сков описан в конце раздела 7).
10. ТЕКСТ ПРОГРАММЫ ЕМ-АЛГОРИТМА
ДЛЯ МНОГОМЕРНОГО НОРМАЛЬНОГО РАСПРЕДЕЛЕНИЯ
Приводимый в распечатке текст адаптирован из текста програм-
мы, входящей в состав диалоговой статистической системы ЦСМИ
(см. раздел 9), функционирующей под управлением операционной
системы РАФОС для ЭВМ, программно совместимых с ЭВМ СМ-4.
316
Данный вариант программы оформлен как независимая совокуп-
ность модулей (подпрограмм, написанных на Фортране), практичес-
ки готовая для обращения.
Для вызова программы пользователь должен лишь написать
три простые дополнительные процедуры-функции DEF, DEFOBS и
COND (тип функций — LOGICAL *1). В DEF должен быть один
входной параметр X вещественного типа, в DEFOBS — два вход-
ных параметра: первый — М, число признаков, второй — вещест-
венный массив Y длины М (вектор значений одного объекта).
Значение DEF должно быть равно .FALSE., если X — значение, и
.TRUE., если X — пропуск. Значение DEFOBS должно быть равно
.FALSE., если в Y нет ни одного пропуска, и .TRUE., если в У есть
хотя бы один пропуск. Значение COND, равное .TRUE., должно
означать, что условие сходимости не удовлетворено (самое простое
условие — достижение заданного числа итераций — реализовано в
подпрограмме, содержащейся в тексте).
Структура программы хорошо видна из текста. Дополнительно
прокомментируем лишь подпрограмму COVAR, в которой вычисля-
ются вектор сумм по переменным и матрица сумм взаимных произ-
ведений по всем присутствующим переменным:
п п
>1....К, (27)
В этих выражениях используются обозначения из раздела 8.2 книги,
а штрих в знаке суммирования обозначает, что суммы вычисляются
только по наблюдениям, в которых присутствуют значения пере-
менной j (в первой сумме) или переменных j и к (во второй сумме).
Далее эти суммы складываются в (8.1) и (8.2), см. раздел 8.2 книги,
с соответствующими компонентами для пропущенных значений.
Суммы (27) вычисляются однократно за время работы программы.
Благодаря этому приему увеличивается эффективность алгоритма.
Входной массив данных (таблица «объект-признак») X не до-
лжен содержать «пустых» переменных или наблюдений (т. е. пол-
ностью состоящих из пропусков), а также переменных, состоящих
только из совпадающих значений.
В программе присутствует большое число массивов — вход-
ных, выходных и рабочих, поэтому целесообразно оформить их ди-
намический вызов через один массив допустимого размера (что
сделано в упомянутой системе). Из исходного текста исключены
проверки на пустые переменные и т. п., поскольку, может быть,
удобнее проводить их до обращения к программе, и, кроме того, их
присутствие в тексте ухудшает восприятие алгоритма.
317
В распечатке имеется текст программы, реализующей опера-
тор «свертки», описанный в разделе 6.5 (подпрограмма SWEEP2).
Еще один доступный источник — [Clarke (1982)], программа в кото-
ром отличается от приведенной по двум пунктам: во-первых, в
[Clarke (1982)] проводится проверка на вырожденность обрабатыва-
емой матрицы*, во-вторых, входная матрица разрушается в процес-
се вычисления**.
Цель этой публикации — служить иллюстрацией к материалу
книги, а также быть основой для разработки собственных программ
по ЕМ-алгоритму, в том числе и для более сложных моделей, свя-
занных с многомерным нормальным распределением. В распечатке
продемонстрирована требующаяся в ЕМ-алгоритме для многомерно-
го нормального распределения последовательность процедур и сами
процедуры, типичные технические приемы и т. п. При профессио-
нальном программировании, конечно, может потребоваться ввести в
данный текст более эффективный алгоритм сортировки, включение
проверок на правильное функционирование программы, способы бо-
лее точного вычисления ковариаций и дисперсий, другие варианты
вычисления начальных значений (см. раздел 8.2 книги) и т. п.
* Оба варианта можно модифицировать с тем, чтобы получать детерминант
матрицы в качестве промежуточного результата.
•• В книге «Статистические методы для ЭВМ» (М.: Наука, 1986.—С. 458) приво-
дится вариант программы для невекторизоваииой матрицы, требующий в два раза
больше времени и памяти.
318
C SUBROUTINE ЕМ
С
С ЕМ-АЛГОРИТМ ДЛЯ МНОГОМЕРНОГО НОРМАЛЬНОГО РАСПРЕДЕЛЕНИЯ
С
С ВХОДНЫЕ ПАРАМЕТРЫ:
С
С X - МАТРИЦА ДАННЫХ РАЗМЕРА NCVR*M. НЕ ДОЛЖНА СОДЕРЖАТЬ ПУСТЫЕ
С НАБЛЮДЕНИЯ И ПЕРЕМЕННЫЕ. МАССИВ X - ВЕКТОРИЗОВАННЫЙ,
С УЛОЖЕН ПО НАБЛЮДЕНИЯМ: 1, .... J, М, М+1... NOVR*M.
С ( I.JJ-ЫЙ ЭЛЕМЕНТ (J-ЫЙ ПРИЗНАК, I-ЫЙ ОБЪЕКТ) ИМЕЕТ
С ПОЗИЦИЮ J+M*(1-1).
с М - ЧИСЛО ПРИЗНАКОВ о О)
С NOVR - ЧИСЛО НАБЛЮДЕНИЙ (>1)
С ITER - ПРЕДЕЛЬНОЕ ЧИСЛО ИТЕРАЦИЙ (>О)
С
С ВЫХОДНЫЕ ПАРАМЕТРЫ:
С
С WT - ОЦЕНКА СРЕДНИХ (МАССИВ ДЛИНЫ М)
С ST - ОЦЕНКА КОВАРИАЦИОННОЙ МАТРИЦЫ (ВЕРХНИЙ ТРЕУГОЛЬНИК,
С ВЕКТОРИЗОВАННЫЙ МАССИВ ДЛИНЫ М*(М+1)/2).
С
С РАЗМЕРЫ РАБОЧИХ МАССИВОВ:
С
С ITYP - NTYP+1 (NTYP - ЧИСЛО СТРУКТУР ПРОПУСКОВ В X,
С NOVR >= NTYP >0, ITYP(I) - НОМЕР ПЕРВОГО
С ОБЪЕКТА С I-ОЙ СТРУКТУРОЙ ПРОПУСКОВ)
С таг - М (СУШ) ПРИСУТСТВУЮЩИХ ЗНАЧЕНИЙ ПЕРЕМЕННЫХ)
С SCOMP - М*(М+1)/2 (МАТРИЦА СУММ ВЗАИМНЫХ ПРОИЗВЕДЕНИЙ)
С WT1 - М (МАССИВ ДЛЯ НАКОПЛЕНИЯ ПОДСТАНОВОК НА ИТЕРАЦИИ Т+1)
С ST1 - М*(М+1)/2 (МАССИВ ДЛЯ НАКОПЛЕНИЯ ПОПРАВОК К
С КОВАРИАЦИЯМ НА ИТЕРАЦИИ Т+1)
С SW3R - М*(М+1)/2
С Y - М
С
С ВЫЗЫВАЮТСЯ: EEFOBS, COVAR, RPLACE, EXCHNB, INTIAL, ITERA
С =======__=_=____-=-=-=»_»==>!=_=-_-=_™-____=_=„==„_=======
С
SUBROUTINE ЕМ
XX,М,NOVR, ITER, TONP.SCONP, ITYP,VT1,STI, Y.SVOR, WT.ST)
c
DIMENSION X(l) ,WCOMP(1),SCOMP(1), ITYP(l), W( 1), ST( 1),
Ж m(l),STl(l),SW3R(l),Y(l)
LOGICAL*! DEFOBS
C
С ВЫЧИСЛЕНИЕ ВЕКТОРА СУММ ПО ПЕРЕМЕННЫМ И МАТРИЦЫ СУММ ВЗАИМНЫХ
С ПРОИЗВЕДЕНИЙ
CALL COVAR (X.NOVR.M, WCOMP,SCOMP)
с
с —- ЦИКЛ ИСКЛЮЧЕНИЯ КОМПЛЕКТНЫХ НАБЛЮДЕНИИ
IREADY=1
С
С LSL - НОМЕР ТЕКУЩЕГО ПРОСМАТРИВАЕМОГО НАБЛЮДЕНИЯ
LSL='READY
С
5 IF(.NOT.DEFOBS(M,X((,LSL-1)*M<-1))) GO ТО 10
С
С ПОМЕНЯТЬ МЕСТАМИ ОБЪЕКТЫ О НОМЕРАМИ IREADY И LSL:
CALL R PLACE (X,LSL,IREADY, M)
IREADY=IREADY+1
С
10 LSL-LSL+1
IFCLSL. LE. NOVR) SO TO 5
C
c ==== ВЫХОД ИЗ ЦИКЛА ИСКЛЮЧЕНИЯ КОМПЛЕКТНЫХ ОБЪЕКТОВ:
NMISIN=IREADY-1
С
С ПЕРЕТАСОВКА ОБЪЕКТОВ ПОД СТРУКТУРЫ ПРОПУСКОВ
CALL EXCHNG (X,NMISIN,M, ITYP.NTYP)
С
С ВЫЧИСЛЕНИЕ НАЧАЛЬНЫХ ЗНАЧЕНИЙ ПАРАМЕТРОВ
CALL INTIAL (NOVR,NMISIN.M,WCOMP,SCOMP,WT,ST,X)
С
60 IF(NMISIN. EQ. 0) GO ТО 5000
С
С ОСНОВНАЯ ИТЕРАТИВНАЯ ПРОЦЕДУРА (СОБСТВЕННО ЕМ-АЛГОРИТМ)
CALL ITERA
* (X,NOVR,М, WCOMP,SCOMP, ITYP,NTYP, ITER, W1,STI, Y,SW3R. VT.ST)
C
5000 RETURN
END
C
C =======,================================================
C
C SUBROUTINE ITERA
C
С РЕАЛИЗУЕТ СОБСТВЕННО ЕМ-АЛГОРИТМ (DEMPSTER ET AL. ,
C J. ROY. STAT. SOC. , SER. B, 19'77, P. 1-37) ДЛЯ МП-ОЦЕНКИ
С ПАРАМЕТРОВ НОРМАЛЬНОГО РАСПРЕДЕЛЕНИЯ КОВАРИАЦИОННОЙ
С МАТРИЦЫ И ВЕКТОРА СРЕДНИХ.
С
С ВХОДНЫЕ ПАРАМЕТРЫ:
С
С X - ПЕРЕТАСОВАННАЯ (ПО СТРУКТУРАМ ПРОПУСКОВ) МАТРИЦА ДАННЫХ,
С НЕ СОДЕРЖИТ КОМПЛЕКТНЫХ НАБЛЮДЕНИЙ, ВЕКТОРИЗОВАННЫЙ
С МАССИВ, УЛОЖЕН ПО НАБЛЮДЕНИЯМ: 1, ..., J ... , NMISIN*M.
С (I,J)-bB? ЭЛЕМЕНТ (J-ЫЙ ПРИЗНАК, I-ЫЙ ОБЪЕКТ) ИМЕЕТ
С В X ПОЗИЦИЮ J+M*( 1-1)
С NOVR - ОБЩЕЕ ЧИСЛО ОБЪЕКТОВ (>1)
С М - ЧИСЛО ПРИЗНАКОВ
С WCOMP - СУММЫ ПРИСУТСТВУЮЩИХ ЗНАЧЕНИЙ ПЕРЕМЕННЫХ
С SCOMP - МАТРИЦА СУММ ВЗАИМНЫХ ПРОИЗВЕДЕНИЙ ПРИСУТСТВУЮЩИХ
С ПЕРЕМЕННЫХ (ВЕКТОРИЗОВАННЫЙ МАССИВ ДЛИНЫ М*(М+1)/2)
С ITYP - МАССИВ НОМЕРОВ ОБЪЕКТОВ С РАЗЛИЧИЛИ СТРУКТУРАМИ ПРОПУСКОВ
С NTYP - ЧИСЛО СТРУКТУР ПРОПУСКОВ (>0)
С ITER - ПРЕДЕЛЬНОЕ ЧИСЛО ИТЕРАЦИЙ
С
С ВЫХОДНЫЕ ПАРАМЕТРЫ:
С
С И - ОЦЕНКА СРЕДНИХ
С ST - ОЦЕНКА КОВАРИАЦИОННОЙ МАТРИЦЫ
С (ВЕКТОРИЗОВАННЫЙ МАССИВ ДЛИНЫ М*(М+1)/2)
С
С РАБОЧИЕ МАССИВЫ:
С
С SWOR - МАССИВ ДЛИНЫ М*(М+1)/2
С WT1.ST1 - МАССИВЫ ДЛЯ НАКОПЛЕНИЯ СУММЫ ПОДСТАНОВОК
С К ПОПРАВОК К КОВАРИАЦИЯМ ДЛЯ ИТЕРАЦИИ Т+1,
С ДЛИНЫ МАССИВОВ М И М*( М+1)/2.
С Y - ВЕКТОР ЗНАЧЕНИЙ-ПОДСТАНОВОК ДЛЯ ОДНОГО ОБЪЕКТА
С НА ТЕКУЩЕЙ ИТЕРАЦИИ
С
С ВЫЗЫВАЮТСЯ: SETNUL, DEF, SWEEPS, SUBST, COND
С =======я==„==========!===================и===
С
SUBROUTINE ITERA
*( X,NOVR,М, WCOMP,SCOMP, ITYP,NTYP, ITER, WTl.STl, Y,SWOR, VT.ST)
C
DIMENSION X(1),WCOMP(1) ,SCOMPf 1),
* ITYP(l) ,WT(1) ,ST(1) ,WT1(1) ,ST1(1),SW3R(1),Y(1)
LOGICAL +1 DEF,COND
C
MDIM=M*(M+1)/2
C
С ТЕЛО ИТЕРАТИВНОГО ЦИКЛА
1 CALL SET NUL (WT1,M)
CALL SET NUL (STI,M DIM)
DO 100 K=1,NTYP
LT=( ITYP(K)-1)*M
C
С ДЛЯ КАВДОЙ СТРУКТУРЫ ОПЕРАЦИЯ SWEEP ПРОВОДИТСЯ ОДИН РАЗ
00 10 J=1,M
10 IF(DEF(X(LT+J))) CALL SWEEPS (M,J,ST,SW0R)
C
С ВЫЧИСЛЕНИЕ АДДИТИВНЫХ СОСТАВЛЯЮЩИХ СРЕДНИХ И КОВАРИАЦИОННОЙ МАТРИЦЫ
DO ICO L=ITYP(K), ITYP(K+1)-1
U=0
KU=(L-1)*M
DO 100 J=1,M
YLJ=X(KU+J)
IF(. NOT. DEF(YLJ)) GO TO 40
C
С ВЫЧИСЛЕНИЕ ТЕКУЩЕЙ ПОДСТАНОВКИ ДЛЯ ПРОПУСКА
YLJ-SUBST( J, WT, SWOR, X( KU+1) , M)
WT1( J)=WT1( J)+YLJ
40 Y(J)=YLJ
C
DO 100 1=1,J
С ВЫЧИСЛЕНИЕ ПОПРАВОК К КОВАРИАЦИЯМ
IJ-IJ+1
YLI=Y( I)
IF(DEFCYLJ)) GO TO 80
IF(.NOT. DEF(YLI)) GO TO 100
00 ST(IJ)=ST(IJ)+YLI*YLJ
GO TO 100
80 IFI.NOT. DEF(YLI)) GO TO 60
ST( IJ)=ST( IJ)+YLI*YLJ+SWOR( I J)
100 CONTINUE
C
С ОКОНЧАТЕЛЬНОЕ ВЫЧИСЛЕНИЕ ОЦЕНОК ПАРАМЕТРОВ ДЛЯ ТЕКУЩЕЙ ИТЕРАЦИИ
IJ-0
OVR=1. /NOVR
DO 110 J=1,M
С
С ВЫЧИСЛЕНИЕ СРЕДНИХ
WTJ=( WT1(J)+WCOMPC J))*OVR
WTC JJ =WTJ
c
С ВЫЧИСЛЕНИЕ КОВАРИАЦИОННОЙ МАТРИЦЫ
DO 110 1=1,J
U=U+1
110 ST( IJ)-( ST1( IJ)+SCOMP( I J)) *OVR-WTJ*WT( I)
c
С ПРОВЕРКА УСЛОВИЯ сходимости
IF(COND(ITER)) GO TO 1
RETURN
END
с
С =============;===============!==============!=!========„-.
с
С SUBROUTINE 00VAR
С
С ВЫЧИСЛЕНИЕ ВЕКТОРА СУММ ПО ПЕРЕМЕННЫМ И МАТРИЦЫ СУММ
С ВЗАИМНЫХ ПРОИЗВЕДЕНИИ ПО ВСЕМ ПРИСУТСТВУЮЩИМ ЗНАЧЕНИЯМ
С
С ВХОДНЫЕ ПАРАМЕТРЫ:
С
С X - МАТРИЦА ДАННЫХ РАЗМЕРА NOVR*M.
С МАССИВ X - ВЕКТОРИЗОВАННЫЙ, УЛОЖЕН
с ПО НАБЛЮДЕНИЯМ: 1, .... J..............М; УН-1... NOVR*M.
С М - ЧИСЛО ПРИЗНАКОВ (>0)
С NOVR - ЧИСЛО (.НЕПУСТЫХ) НАБЛЮДЕНИИ С>1)
С
С ВЫХОДНЫЕ ПАРАМЕТРЫ:
С
С WCOMP - ВЕКТОР СУММ
С SCOMP - МАТРИЦА СУММ ВЗАИМНЫХ ПРОИЗВЕДЕНИИ
С
С ВЫЗЫВАЮТСЯ: DEF, SETNUL
с ==============-=«======
с
SUBROUTINE 00VAR (X,NOVR,M, WCOMP,SCOMP>
REAL WCOMP?1). SCOMP( 1), X( 1)
LOGICAL * 1 DEF
C
С ВЫЧИСЛЕНИЕ СУММ
CALL SETNUL ( WCOMP,M)
C
KU=O
DO 15 K=1,NOVR
DO 15 J=1,M
KU-KU+l
xx=x( ад
15 IF(. NOT. DEF(XX)) WCOMP(. J) =WCOMP(J)+XX
C
С ВЫЧИСЛЕНИЕ СУММ ВЗАИМНЫХ ПРОИЗВЕДЕНИИ
L=0
DO 55 J=1,M
DO 55 1=1,J
TIJ=O.
L=L+1
KU=O
DO 38 K=1,NOVR
XX=X( I+KU)
YY=X(J+KU)
IF (.DEF(XX)) GO TO 38
IF (DEF(YY)J GO TO 38
TI J=TIJ+XX*YY
38 KU=KU+M
55 SCOMP(L)=TIJ
C
RETURN
END
C
C =========«=».=»=—_================_=_======.=—===—>
SUBROUTINE INTIAL (.NOVR,NMISIN,M,WCOMP,SCOMP,WT,ST,X)
C
С НАЧАЛЬНЫЕ ЗНАЧЕНИЯ ПАРАМЕТРОВ
С ВЫЧИСЛЯЮТСЯ МЕТОДОМ ALL-VALUE
С
С ВЫЗЫВАЮТСЯ: SETNUL, DEF
С __»===========_„„=====
С
DIMENSION WCOMPt 1) ,SCOMP(1), WT(.l),ST( 1) ,X(1)
LOGICAL *1 DEF
C
CALL SETNUL(WT.M)
CALL SETNUL(ST,M*(.M+l)/2)
C
NCOMPL=NOVR-NMISIN
COMPL-NCOMPL
IF(NMISIN. EQ. 0) GO TO 60
C
С ОПРЕДЕЛЕНИЕ ЧИСЛА П0НРИЗНАК0ВЫХ И ПОПАРНЫХ НАБЛЮДЕНИИ
ки=о
DO 15 K=1,NMISIN
DO 15 J=1,M
KU=KU+1
15 IF(. NOT. DEF(X( KU))') WT(. J) “Ж J)+1.
C
L=0
DO 55 J=1,M
DO 55 I-l.J
NIJ=O
L=L+1
KU=O
DO 38 K=1,NMISIN
IF(. NOT. DEF(X( I+KU)). AND.. NOT. DEF(X( J+KU))) NIJ=NIJ+1
38 KU=KU+M
55 ST(L)=NIJ
C
С ОПРЕДЕЛЕНИЕ НАЧАЛЬНЫХ ЗНАЧЕНИЙ ПАРАМЕТРОВ
60 IJ--0
DO 110 J-I.M
c
с ВЫЧИСЛЕНИЕ НАЧАЛЬНЫХ СРЕДНИХ
VTJ=WOMP(,J)/CWr( J) +COMPL)
VT(J>WT.J
c
С ВЫЧИСЛЕНИЕ НАЧАЛЬНОЙ КОВАРИАЦИОННОЙ МАТРИЦЫ
DO 110 M.J
IJ-IJ+1
110 ST( IJ)=SCOMP( I J)/(ST( IJ)+COMPL)-VTJ*WT( I)
c
RETURN
END
C
c =====™=======================™======„============
c
SUBROUTINE EXCHNG (X,NMISIN,M, ITYP,NTYP)
С
С ПЕРЕСТАНОВКА ОБЪЕКТОВ ПОД СТРУКТУРЫ ПРОПУСКОВ: ОБЪЕКТЫ
С С ОДИНАКОВОЙ СТРУКТУРОЙ ПРОПУСКОВ РАСПОЛАГАЮТСЯ ПОДРЯД
С
С ВЫЗЫВАЮТСЯ CMWEQ, RPLACE
с =============================
С
DIMENSION Х(1), ITYPU)
LOGICAL.*! CMPNEQ
C
NTYP-0
IREADYU
C
С БОЛЬШЕ НЕТ НАБЛЮДЕНИИ CO СТРУКТУРОЙ NTYP,
С ИНИЦИАЦИЯ СБОРА НАБЛЮДЕНИИ С НОВОЙ СТРУКТУРОЙ NTYP+1
5 NTYP=NTYP+1
ITYP(NTYP)=IREADY
IREADY=IREADY+1
С
С ЕСЛИ ЗДЕСЬ ПРОИСХОДИТ ВЫХОД, ТО ПОСЛЕДНИЙ ОБЪЕКТ ПОРОЖДАЕТ
С НОВУЮ СТРУКТУРУ
IF( IREADY. GT. NM1SIN) GO TO 50
C
С НОМЕР ТЕКУЩЕГО НАБЛЮДЕНИЯ, СРАВНИВАЕМОГО ПО СТРУКТУРЕ С
С ОБЪЕКТОМ НОМЕР ITYP(NTYP):
LSL=IREADY
С
10 IF(CMPNEQ(X, ITYP(NTYP) ,LSL,MJ) GO TO 20
C
с ПОМЕНЯТЬ МЕСТАМИ ОБЪЕКТЫ С НОМЕРАМИ IREADY И LSL:
CALL RPLACE IX, LSL, IREADY, М)
IREADY=IREADY+1
IF( IREADY. GT. NMISIN) GO TO 50
C
20 LSL-LSL+1
IF(LSL. GT. NMISIN) GO TO 5
GO TO 10
C
С ВЫХОД ИЗ ПЕРЕТАСОВКИ:
50 ITYP(NTYP+1)=NMISIN+1
RETURN
END
C
C =.=========_========_==_=========
SUBROUTINE R PLACE (X,L1,L2,M)
C
С ПЕРЕСТАВЛЯЕТ СТРОКИ (ОБЪЕКТЫ) LI И L2
С В ПОСТРОЧНО УЛОЖЕННОМ МАССИВЕ X
с ==================================
с
REAL Х(1)
С
IF(L1.EQ. L2) GO ТО 30
KU1=( L1-1)*M
KU2=( L2-1)*M
DO 1'1 J-1,M
KU1J=J+KU1
KU2J=J+KU2 |
Y-X(KUIJ) ’
X(KU1J)=X(KU2J) ’
GO TO 11
11 X(KU2J)=Y
C
30 RETURN
END
C
C ==================================-»™====-==-=-=-
C
FUNCTION CNPNEQ (X,L1,L2,M)
C
С ОПРЕДЕЛЯЕТ, СОВПАДАЮТ ЛИ СТРУКТУРЫ ПРОПУСКОВ В ДВУХ
С ОБЪЕКТАХ С НОМЕРАМИ L1 И L2 В ПОСТРОЧНО УЛОЖЕННОМ МАССИВЕ X
С .FALSE. - СОВПАДАЮТ
С .TRUE. - НЕТ
С
С ВЫЗЫВАЕТСЯ: DEF
с _==_=========„====
REAL X.(l)
LOGICAL *1 DEE, CMPNEQ ,D1, D2
C
KU1=(L1-1)*M
_ KU2=(L2-t)*M
DO 11 J=1,M
D1=DEF(,X( J+KU2))
D2=DEF(.XU+KU1))
С НЕСОВПАДЕНИЕ ХОТЯ БЫ ПО ОДНОМУ ПРИЗНАКУ -> TRUE
IFC(D1. OR. D2). AND. (. NOT. DI. OR. . NOT. D2)) GO TO 400
11 CONTINUE
C
CMPNEQ-. FALSE.
333 RETURN
C
400 CMPNEQ=. TRUE.
GO TO 333
END
C
C ==--====================-======================================
FUNCTION COND ( ITER)
C
С ОПРЕДЕЛЯЕТ ВЫПОЛНЕНИЕ УСЛОВИЯ ВЫХОДА ИЗ ИТЕРАТИВНОГО ПРОЦЕССА:
С .TRUE. - ПРОДОЛЖАТЬ
С .FALSE. - НЕТ
С ===__.._================
С
LOGICAL *1 COND,START
DATA START/. TRUE. /
C
COND-. TRUE.
IF (START) GO TO 11
1 1=1+1
IF( ITER. LT. I) COND-. FALSE.
RETURN
C
11 1=0
START=. FALSE.
GO TO 1
END
C
c ™=======================
SUBROUTINE SETNUL!X,M)
C ============_============Ji
DIMENSION X(l)
DO 1 J=1,M
1
X(J)=O.
RETURN
END
C
C === =======================^============:=======
FUNCTION SUBST (J, WT, SWOR, X,M)
C
С ВЫЧИСЛЯЕТ ТЕКУЩУЮ ПОДСТАНОВКУ ДЛЯ ПРОПУСКА
С
С ВЫЗЫВАЕТСЯ: DEF
С =================
с
REAL X(1),W(1),SW3R(1)
LOGICAL *1 DEF
С
SU-C.
DO 11 I-l.M
YI=X( I)
11 IF(.NOT. DEF(YI)) SU=SU+SWOR( I+JJ)*(YI-WT( D)
0
SUBST=SU+WT( J)
RETURN
END
C
c ========================================================
C SUBROUTINE SWEEPS 4
c ?
С СВЕРТКА СИММЕТРИЧНОЙ МАТРИЦЫ G ПО СТРОКЕ/СТОЛБЦУ NSWEEP.
С
С ВХОДНЫЕ ПАРАМЕТРЫ: ID, NSWEEP, G
0 ВЫХОДНОЙ ПАРАМЕТР: OUT
С
С ID - РАЗМЕР МАТРИЦЫ
С OUT - РЕЗУЛЬТАТ СВЕРТКИ, О НЕ ИЗМЕНЯЕТСЯ
С
С G, OUT - ВЕКТОРИЗОВАННЫЕ МАССИВЫ ДЛИНЫ ID*( ID+1) /2
С (ВЕРХНИЕ ТРЕУГОЛЬНИКИ СООТВЕТСТВУЮЩИХ МАТРИЦ)
С
с 1 =< к =< ID, 1 =< ID
С =======================
С
SUBROUTINE SWEEP2 (ID, NSWEEP, G, OUT)
REAL G(1),OUT(1)
C
K-NSWEEP
NKK=K*(K+l)/2
KK=NKK-K
GKK1= l./G(NKK)
C
С ВЫЧИСЛЕНИЕ ЭЛЕМЕНТА (К,К)
OUT( NKK]=-GKKl
JJ-0
C
DO 30 J=l,ID
IFf J. EQ. KIGOTO 30
IFCK.GT. J)GOTO 5
JK=K+JJ
GO TO 10
5 JK=J+KK
C
С ВЫЧИСЛЕНИЕ СТРОКИ/СТОЛЕЦА К
10 GJK=G( JK)*GKK1
OIJT(JK)=GjK
LL=O
C
DO 27 L=1,J
IF( L. EQ. K) GO TO 27
JL=L+JJ
IF(K-GT.L) GOTO 23
KL=K+LL
GOTO 25
23 KL=L+KK
C
С ВЫЧИСЛЕНИЕ ОСТАЛЬНЫХ ЭЛЕМЕНТОВ
25 OUT(JL)= G(JL)-G(KL)*GJK
27 LL=LL+L
30 JJ=JJ+J
C
RETURN
END
ЛИТЕРАТУРА
Айвазян С. А., Енюков И. С., Мешалкин Л. Д. Прикладная статистика. Основы
моделирования и первичная обработка данных. — М.: Финансы и статистика, 1983. —
472 с.
Андерсон Т. Введение в многомерный статистический анализ. — М.: Физмат-
гиз, 1963.
Бокс Дж., Дженкинс Г. Анализ временных рядов. Прогноз и управление. — М.:
Мир, 1974. — 406 с.
Большее Л. Н., Смирнов Н. В. Таблицы математической статистики. — М.: На-
ука, 1983. — 416 с.
Боровков А. А. Математическая статистика. — М.: Наука, 1984. — 472 с.
Бурлаков И. А. Исследование и разработка диалоговой диагностической систе-
мы с оптимизацией процесса обследования: Автореф. дис.... канд. физ.-мат. наук. —
М., 1979. — 25 с.
Гаек Я., Шидак 3. Теория ранговых критериев. — М.: Наука, 1971. — 376 с.
Загоруйко Н. Г., Елкина В. Н., Емельянов С. В., Лбов Г. С. Пакет прикладных
программ ОТЭКС. — М.: Финансы и статистика, 1986. — 160 с.
Загоруйко Н. Г., Елкина В. Н., Тимеркаев В. С. Алгоритм ZET-75 заполнения
пробелов в эмпирических таблицах и его применение //Машинные методы обнаруже-
ния закономерностей. — Новосибирск: Наука, 1976. — С. 57—63.
Ибрагимов И. А., Хасьминский Р. 3. Асимптотическая теория оценивания. —
М.: Наука, 1979. — 528 с.
Клигене Н., Текльснис Л. Методы обнаружения моментов изменения свойств
случайных процессов //Автоматика и телемеханика, 1983. — № 10. — С. 5—56.
Кокс Д., Хинкли Д. Теоретическая статистика. — М.: Мир, 1978. — 560 с.
Леман Э. Проверка статистических гипотез. — М.: Наука, 1979. — 498 с.
Методы анализа данных: подход, основанный на методе динамических сгуще-
ний: /Пер. с фр.; Под ред. и с предисл. С. А. Айвазяна и В. М. Бухштабера. — М.:
Финансы и статистика, 1985. — 357 с.
Миленький А. В. Классификация сигналов в условиях неопределенности (Стати-
стические методы самообучения в распознавании образов). — М.: Сов. радио, 1975. —
328 с.
Никифоров И. В. Последовательное обнаружение изменения свойств временных
рядов. — М.: Наука, 1983. — 200 с.
Никифоров А. М. Разработка и исследование статистических методов распозна-
вания образов с самообучением и обработки неполных данных. Дис. ... канд. физ.-
мат. наук. — М.: 1987. — 144 с.
Никифоров А. М. Статистический анализ наблюдений со случайными пропуска-
ми //Пятая Международная Вильнюсская конференция по теории вероятностей и ма-
тематической статистике: Тез. докл. — Вильнюс, 1989. — С. 98—99.
Никифорова Г. В. Непарамегрические критерии проверки гипотез о случайных
бинарных матрицах в асимптотике растущего числа параметров //Пятая Междуна-
родная Вильнюсская конференция по теории вероятностей и математической стати-
стике: Тез. докл. — Вильнюс, 1989. — С. 100—101.
Орлов А. И. Парные сравнения в асимптотике Колмогорова //Экспертные оцен-
ки в задачах управления. — М.: ИПУ, 1982 — С. 58—66.
Сильвестров Д. С. Программное обеспечение прикладной статистики. — М.:
Финансы и статистика, 1988. — 240 с.
Патрик Э. Основы теории распознавания образов. — М.: Сов. радио, 1980. —
408 с.
Флейс Дж. Статистические методы для изучения таблиц долей и пропорций. —
М.: Финансы и статистика, 1989. — 319 с.
Черномордик О. М. Об одном непараметрическом критерии однородности не-
скольких выборок //Теория вероятностей и ее применение. — 1980. —Т. XXVIII. —
В. 4. — С. 758—760.
Basilevski A., Sabourin D„ Hum D„ Anderson А. (1985). Missing data estimators in
the general linear model: an evaluation of simulated data as an experimental desing.
Commun. Statist. — Simula. Computa. 14 (2), pp. 371—394.
Bickel P. I. (1969). A distribution free version of the Smirnov two sample test in the
p-variate case Ann. Math. Statist., vol. 40, pp. 1—23.
Clarke M. R. B. (1982). The Gauss-Jordan Sweep operator with detection of
collinearity, Applied Statistics, vol. 31, pp. 166—168.
David E N., Fix E. (1960). Rank correlation and regression in a nonnormal surface.
Proc. Fourth Berkeley Symp. Math. Statist. Prob. 6, pp 177—197. Univ, of California Press.
Kennedy D. P, Chien Y. T. (1982). Optimal estimation for full space classification of
incomplete data, in Pattern Recognition and Image Processing, Proceedings. Las Vegas, pp.
152—154.
Krzvsko M. (1983). The discriminant analysys of multivariate time series. IEEE Trans,
on Inform. Theory, vol. 29, pp. 612—614.
Little R. J. A., Smith P. J. (1987) Editing and imputation for quantitative survey data.
Journal of American Statistical Association, vol. 82, No. 397, pp. 58—68.
Rubin D. B. (1976) Inference and missing data. Biometrika, vol. 63, pp. 581—592.
Sen P. K., Chatterjee S. K. (1964) Nonparametric tests for the bivariate two sample
location problem. Calcutta Statist. Ass. Bull., vol. 13, pp. 18—58.
Simonoff J. S. (1988). Regression diagnostics to detect nonrandom missingness in
linear regression. Tfechnometrics, vol. 30, No. 2, pp. 205—214.
Titterington D. M., Jiang J.-M. (1983). Recursive estimation procedures for missing da-
ta problems. Biometrika, vol. 70, pp. 613—624.
ОГЛАВЛЕНИЕ
Предисловие к русскому изданию........................................ 5
Предисловие........................................................... 8
Часть I. Анализ данных с пропусками: обзор....................... 11
Глава 1. Введение................................................ 11
Глава 2. Планирование экспериментов и пропуски в данных......... 29
Глава 3. Быстрые методы обработки многомерных данных с
пропусками.............................................. 48
Глава 4. Пропуски в выборочных обследованиях..................... 61
Часть II. Анализ данных с пропусками на основе функции правдопо-
добия ............................................................... 91
Глава 5. Теория выводов, основанных на применении функции
правдоподобия........................................... 91
Глава 6. Факторизация правдоподобия для методов, когда механизм
порождения пропусков игнорируется....................... НО
Глава 7. Метод максимального правдоподобия для структур пропусков
обшего вида: введение и теория метода при игнорируемом ме-
ханизме пропусков...................................... 145
Глава 8. МП-оценивание в задачах, связанных с многомерным нор-
мальным распределением.............................................. 161
333
Глава 9. Анализ частично классифицированных таблиц сопряженнос-
ти без учета механизма порождения пропусков...................... 192
Глава 10. Смешанная модель для нормально и ненормально распреде-
ленных неполных данных с игнорированием механизма по-
рождения пропусков................................... 215
Глава 11. Модели с неигнорируемыми пропусками................ 237
Глава 12. Модельный подход к пропускам при выборочных обследо-
ваниях 262
Дополнение к переводу. А.М.Никифоров. Методы анализа данных с пропу-
сками и их свойства. Программное обеспечение статистической обработки
неполных данных................................................... 284
Литтл Р. Дж.А., Рубин Д.Б.
Л64 Статистический анализ данных с пропусками/Пер. с
англ. — М.: Финансы и статистика, 1990. — 336 с.:
ил.—(Математико-статистические методы за рубежом).
ISBN 5-279-00443-Х.
Книга известных американских статистиков является первым на русском языке сис-
тематическим изложением современных методов, алгоритмов и вычислительных
процедур обработки пропущенных значений в различных задачах статистического
анализа.
Для статистиков, преподавателей и студентов вузов.
0702000000—126
Л 110—90
010(01)—90 ББК 16.2.9
Научное издание
Литтл Родерик, Рубин Доналд
Статистический анализ
данных с пропусками
Книга одобрена на заседании редколлегии
серии «Математико-статистические методы
за рубежом» 29.12.87
Зав. редакцией К.В.Коробов
Редактор Е.В.Крестьянинова
Мл. редакторы Т.Т.Гришкова, Е.В.Рожкова
Худож. редактор Ю.И.Артюхов
Техн, редактор И.В.Юдинцева
Корректоры Г.В.Хлопцева, Е.М.Смирнова, Т.М.Иванова
ИБ № 2457
Сдано в набор 2.03.90. Подписано в печать 24.09.90.
Формат 60x88 1/16. Бумага офсетная. Гарнитура «Литературная»
Печать офсетная. Усл.п.л. 20,58. Усл.кр.-отт. 20,58. Уч.-изд.л. 20,39.
Тираж 8000 экз. Заказ 2877 Цена 3 р. 10 к.
Издательство «Финансы и статистика», 101000, Москва,
ул.Чернышевского, 7.
Типография им И Е Котлякова издательства «Финансы и статистика;»
Государственного комитета СССР по печати
195273. Ленинград, ул Руставели, 13