/


















































































































































































































































































































Автор: Бейзер Б.
Теги: компьютерные технологии программирование программное обеспечение тестирование программного обеспечения
ISBN: 5-94723-698-2
Год: 2004




Текст
Тестирование черного ящика
Технологии функционального тестирования программного обеспечения и систем
Борис Бейзер
ПИТЕР
Boris Beizer
BLACK-BOX TESTING
Techniques for Functional Testing of Software and Systems
Wiley
John Wiley & Sons, Inc.
New York Chichester Brisbane Toronto Singapore
Борис Бейзер
Тестирование черного ящика
Технологии функционального тестирования программного обеспечения и систем
ПИТЕР
Москва • Санкт-Петербург • Нижний Новгород • Воронеж Новосибирск • Ростов-на-Дону • Екатеринбург • Самара Киев • Харьков • Минск
2004
ББК 32.973-018-07
УДК 681.3.06
Б 41
Бейзер Б.
Б 41 Тестирование черного ящика. Технологии функционального тестирования программного обеспечения и систем. — СПб.: Питер, 2004. — 318 с.: ил.
ISBN 5-94723-698-2
Книга доктора Бейзера «Тестирование черного ящика» давно была признана классическим трудом в области поведенческого тестирования разнообразных систем. В ней глубоко рассматриваются основные вопросы тестирования программного обеспечения, позволяющие отыскать максимум ошибок при минимуме временных затрат. Чрезвычайно подробно излагаются основные методики тестирования, покрывающие все спектры аспекюв разработки программных систем. Методичность и широта изложения делают эту книгу незаменимым помощником при проверке правильности функционирования программных решений.
Книга предназначена для тестировщиков программного обеспечения и программистов, стремящихся повысить качество своей работы.
ББК 32.973-018-07
УДК 681.3.06
Права на издание получены по соглашению с издательством Wiley.
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было форме без письменного разрешения владельцев авторских прав.
Информация, содержащаяся в данной книге, получена из источников, рассматриваемых издательством как надежные Тем не менее, имея в виду возможные человеческие или технические ошибки, издательство не может гарантировать абсолютную точность и полноту приводимых сведений и не несет ответственности за возможные ошибки связанные с использованием книги
ISBN 0-471-12094-4 (англ.)
ISBN 5-94723-698-2
© by John Wiley & Sons, Inc
© Перевод на русский язык, ЗАО Издательский дом «Питер», 2004
© Издание на русском языке, оформление ЗАО Издательский дом «Питер», 2004
Содержание
Введение...............................................................12
Пропущенные модели.....................................................14
1. Общие положения...............................................14
2. Маерс. «Искусство тестирования программ»......................14
3. Логические модели.............................................16
4. Языковые модели...............................................16
RE ADME.DOC...........................................................18
Зачем нужен Readme.doc?...........................................18
План книги........................................................18
Структура главы...................................................20
Бланки налоговой декларации и ссылки на них.......................22
Что должен знать читатель.........................................22
Не только программное обеспечение.................................23
Использование алфавитного указателя...............................23
Ссылки............................................................23
Контроль качества.................................................24
Благодарности.....................................................24
Отказ от ответственности..........................................25
От издательства...................................................25
Глава 1 • Введение.....................................................26
1.1. Обзор........................................................26
1.2. Основные термины.............................................26
1.3. О тестировании...............................................31
1.3.1. Тестировщик и программист............................31
1.3.2. Почему мы тестируем программное обеспечение?.........31
1.3.3. Стратегия тестирования...............................33
1.3.4. Парадокс пестицида...................................34
1.3.5. Природа и причины ошибок.............................34
6 Содержание
1.3.6. Когда надо остановиться...............................36
1.3.7. Тестирование черного ящика — это еще не все...........36
1.3.8. Тестирование — это еще не все.........................37
1.4. Процесс разработки программного обеспечения...................39
1.4.1. То, что на самом деле важно............................39
1.4.2. Десять и одна заповедь управления процессом............40
1.5. Вопросы для самопроверки......................................43
Глава 2 • Графы и отношения..............................................44
2.1. Обзор.........................................................44
2.2. Основные термины..............................................44
2.3. Примеры графов, используемых в тестировании...................50
2.3.1. Обзор.................................................50
2.3.2. Модель потока транзакций (Глава 6)....................51
2.3.3. Модель меню с конечным числом состояний (Глава 9).....51
2.3.4. Модель потока данных (Глава 5)........................51
2.3.5. Модель времени выполнения.............................52
2.4. Отношения.....................................................52
2.4.1. Обзор.................................................52
2.4.2. Транзитивные и нетранзитивные отношения...............52
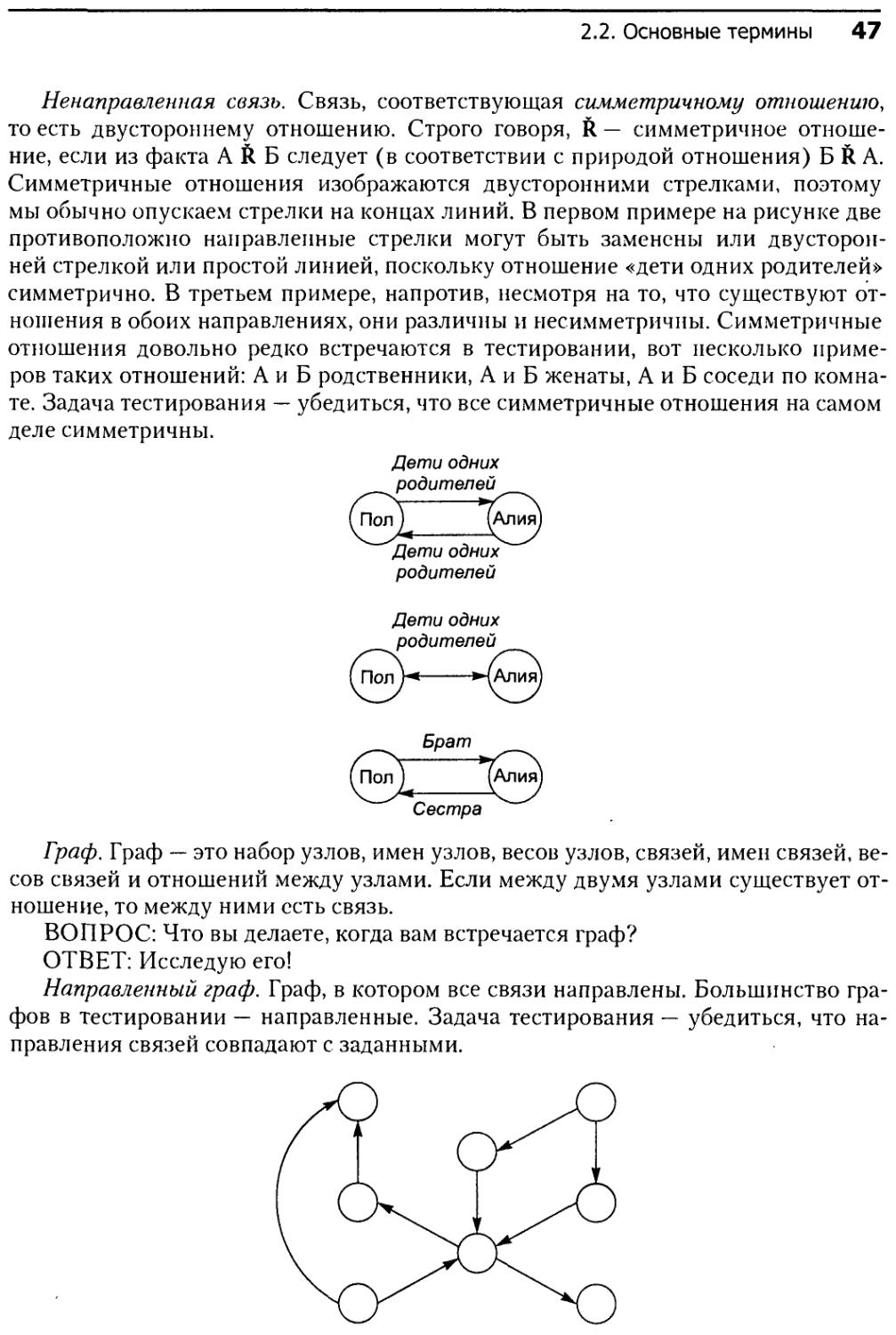
2.4.3. Симметричные и несимметричные отношения...............53
2.4.4. Рефлексивные и нерефлексивные отношения...............54
2.4.5. Классы эквивалентности и разбиения....................55
2.4.6. Альтернатива графам...................................55
2.5. Основополагающие принципы тестирования........................57
2.5.1. Обзор.................................................57
2.5.2. Построение графа......................................58
2.5.3. Определение отношений.................................58
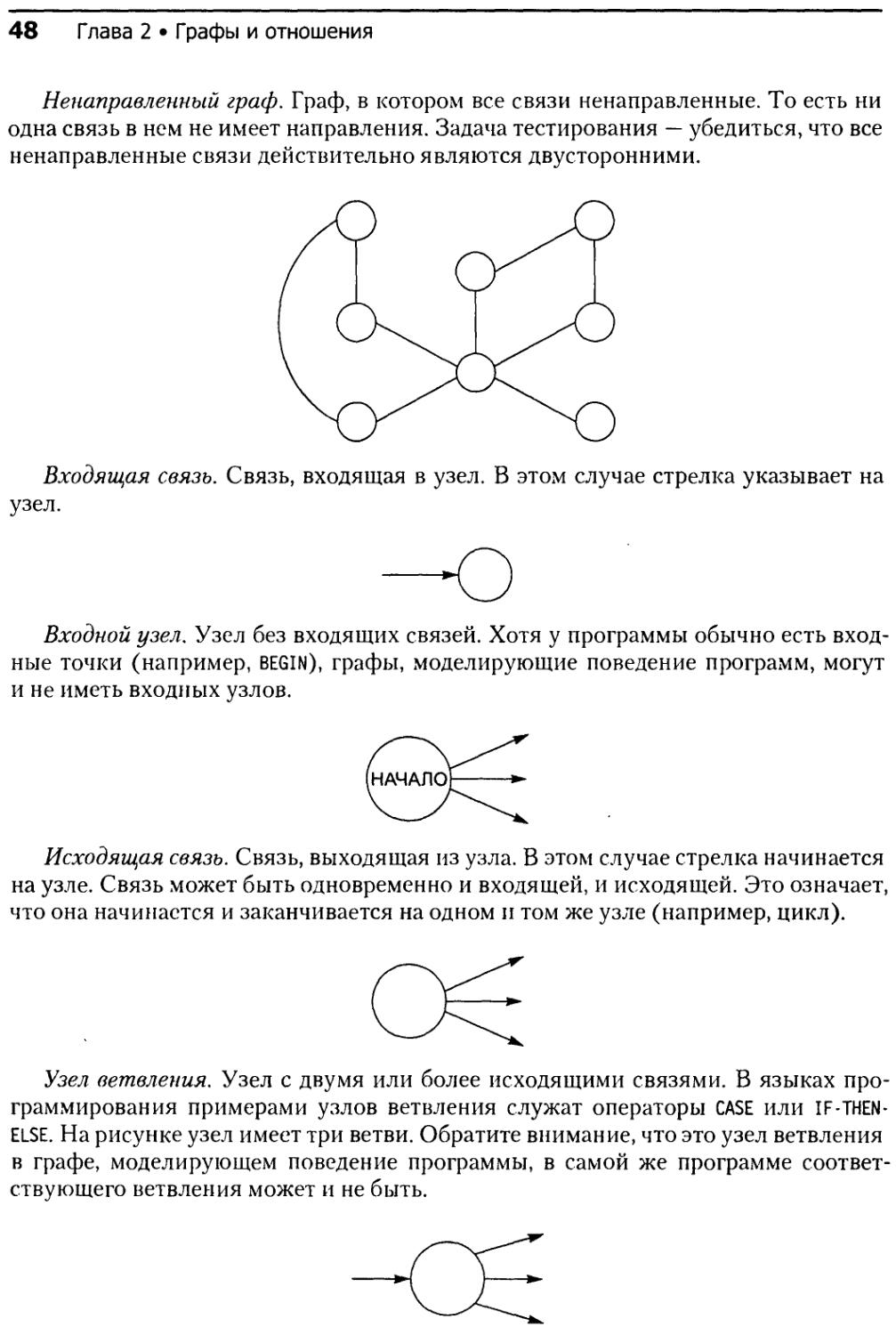
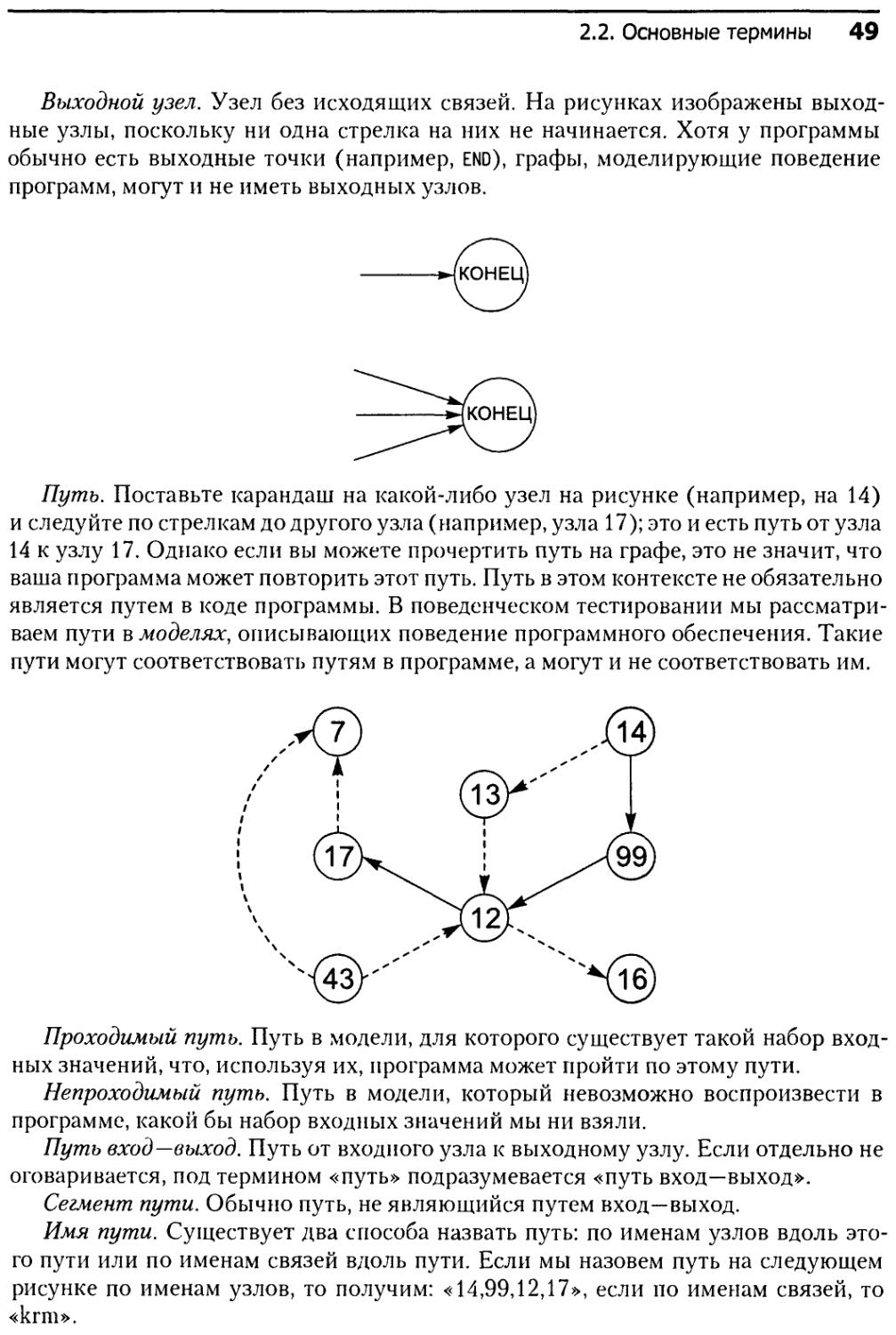
2.5.4. Проверка узлов........................................59
2.5.5. Проверка связей.......................................59
2.5.6. Тестирование весов....................................60
2.5.7. Тестирование циклов...................................60
2.6. Резюме........................................................61
2.7. Вопросы для самопроверки......................................62
Глава 3 • Тестирование потока управления.................................63
3.1. Обзор.........................................................63
3.2. Основные термины..............................................63
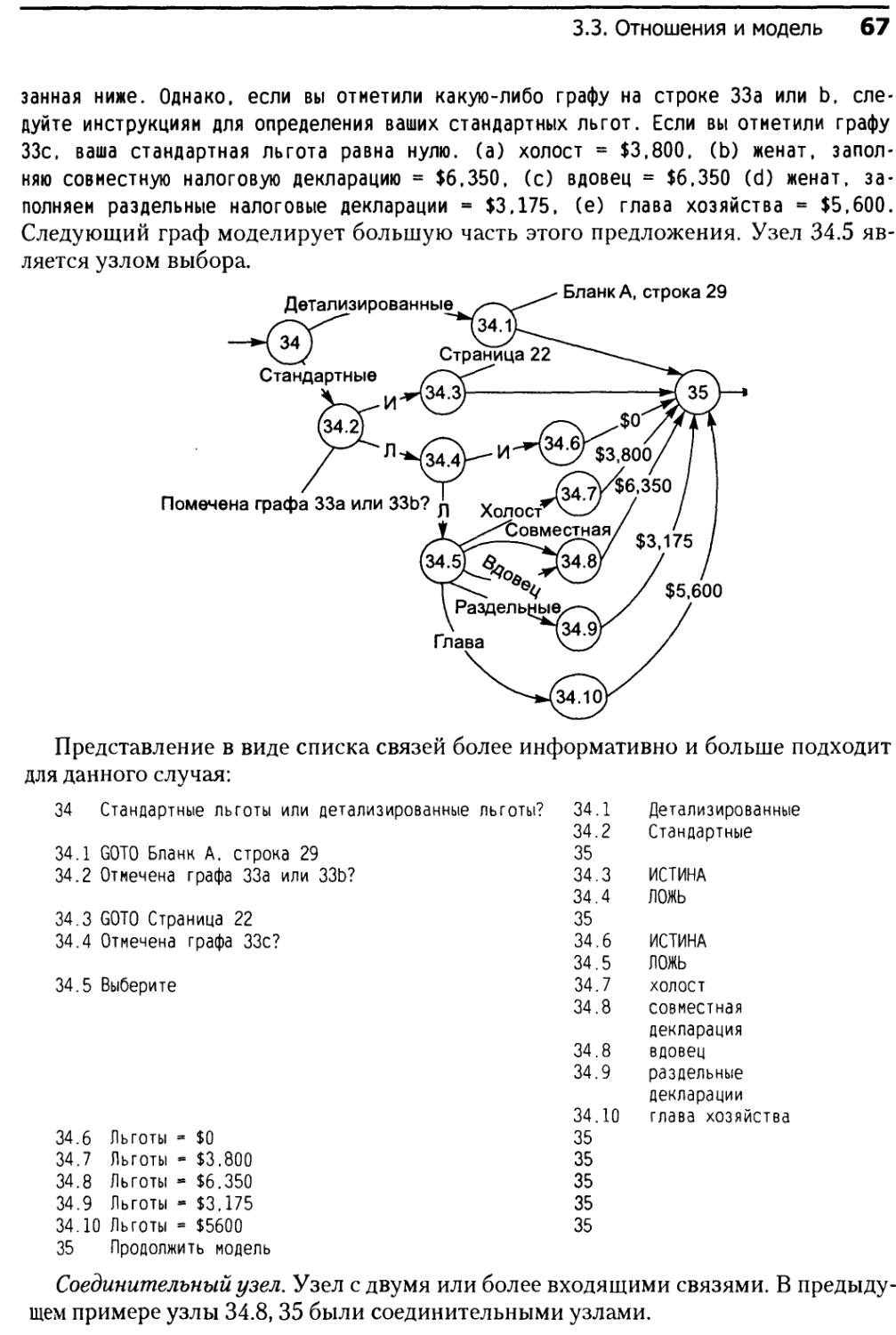
3.3. Отношения и модель............................................65
3.3.1. Основы ...............................................65
3.3.2. Моделирование составных предикатов....................69
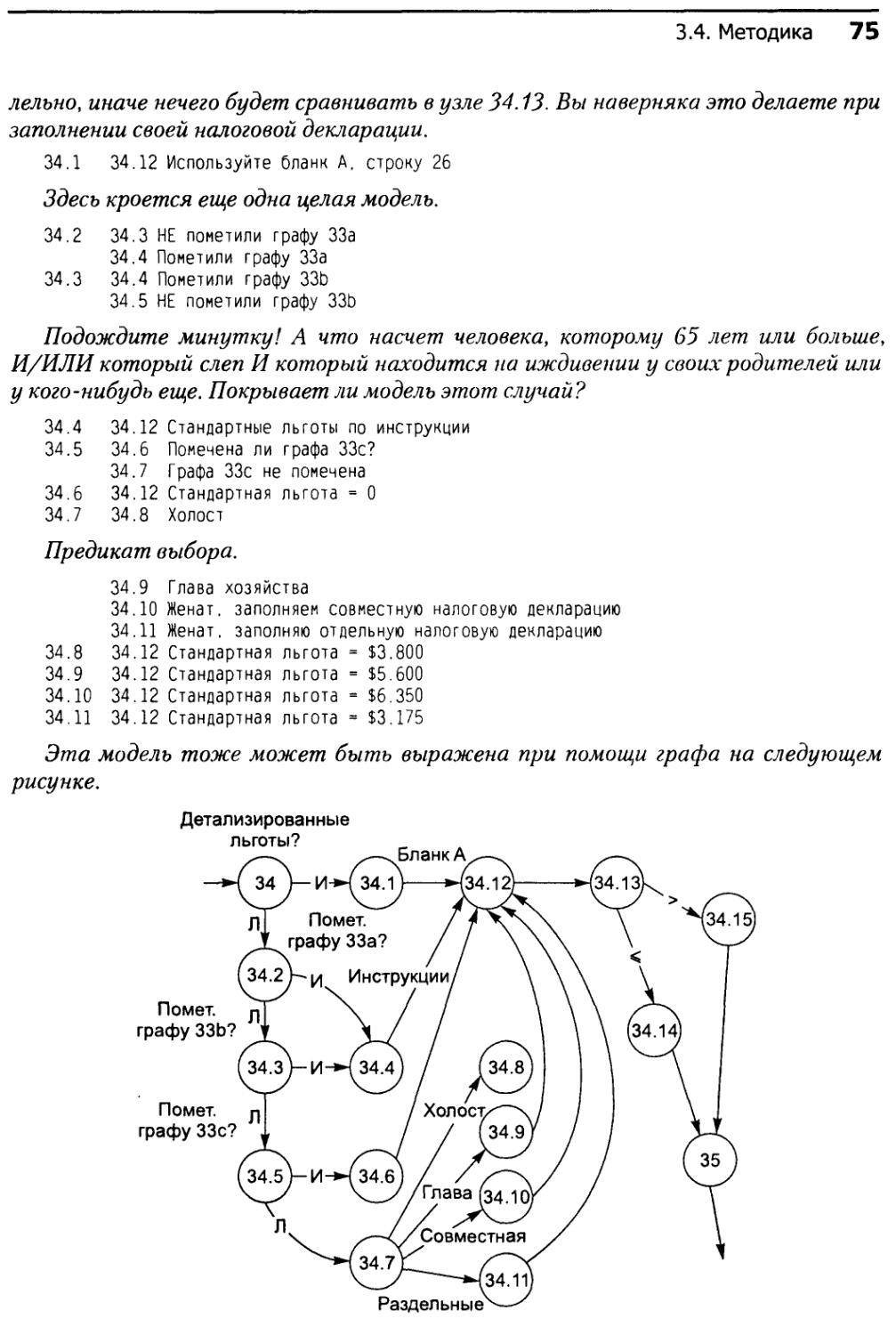
3.4. Методика......................................................71
3.4.1. Основы................................................71
3.4.2. Построение модели.....................................72
Содержание
7
3.4.3. Выбор путей тестирования.............................77
3.4.4. Активизация..........................................83
3.4.5. Предсказание итогов..................................88
3.4.6. Проверка соответствия пути...........................90
3.5. Рассмотрение приложения......................................91
3.5.1. Индикаторы приложений................................91
3.5.2. Предположения об ошибках.............................91
3.5.3. Ограничения и предостережения........................92
3.5.4. Автоматизация и инструментальные средства............92
3.6. Резюме.......................................................93
3.7. Вопросы для самопроверки.....................................94
Глава 4 • Тестирование циклов..........................................97
4.1. Обзор........................................................97
4.2. Основные термины.............................................97
4.3. Отношения и модель...........................................99
4.3.1. Основы...............................................99
4.3.2. Детерминированные циклы.............................100
4.3.3. Недетерминированные циклы...........................101
4.3.4. Вложенные циклы.....................................103
4.3.5. Неструктурированные (ужасные) циклы.................103
4.4. Методы......................................................104
4.4.1. Критические тестовые значения.......................104
4.4.2. Детерминированные циклы.............................106
4.4.3. Недетерминированные циклы...........................107
4.4.4. Вложенные циклы.....................................109
4.5. Рассмотрение приложения.....................................110
4.5.1. Индикаторы приложений...............................110
4.5.2. Предположения об ошибках............................110
4.5.3. Ограничения и предостережения.......................110
4.5.4. Автоматизация и инструментальные средства...........110
4.6. Резюме......................................................111
4.7. Вопросы для самопроверки....................................111
Глава 5 • Тестирование потоков данных..................................113
5.1. Обзор........................................................из
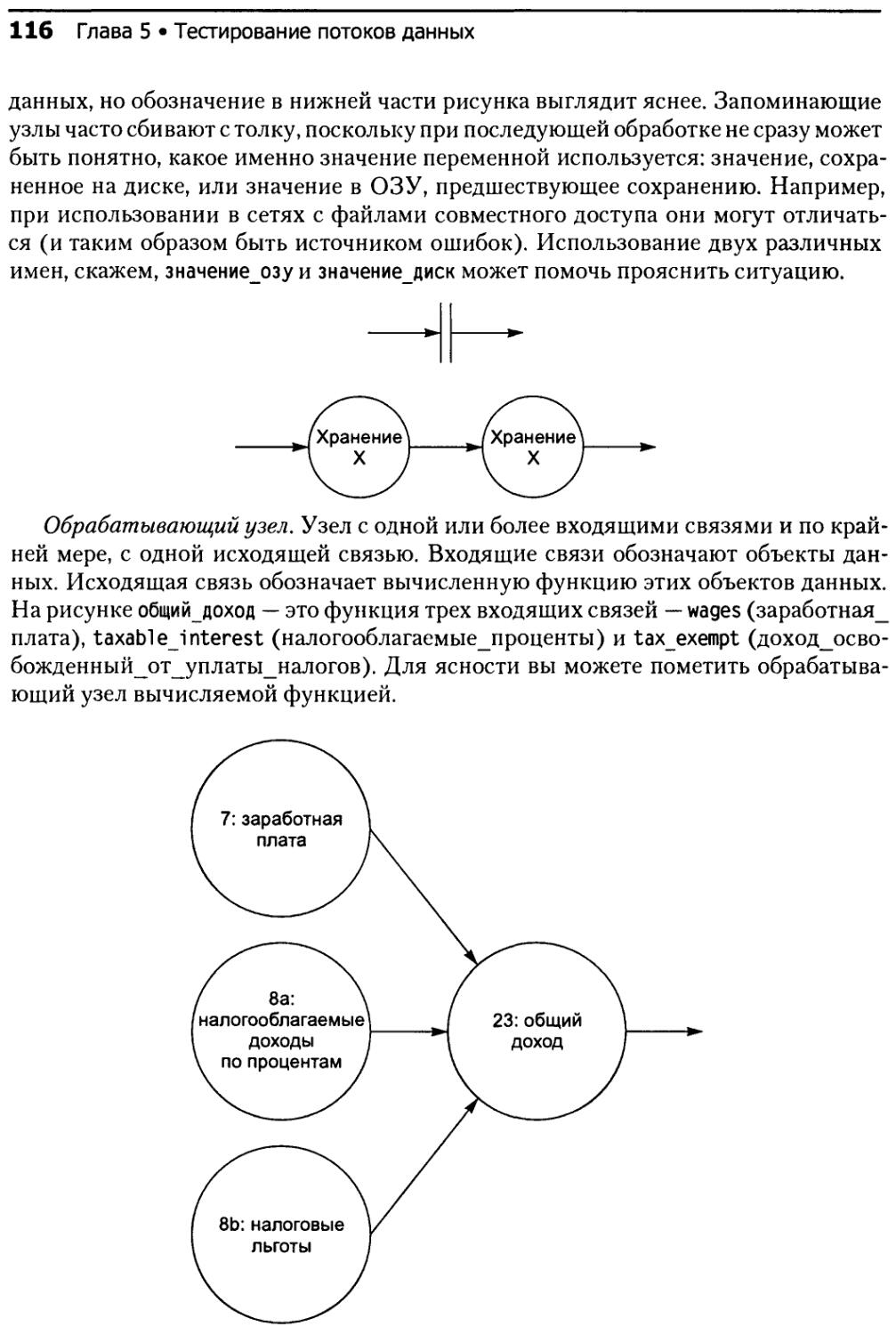
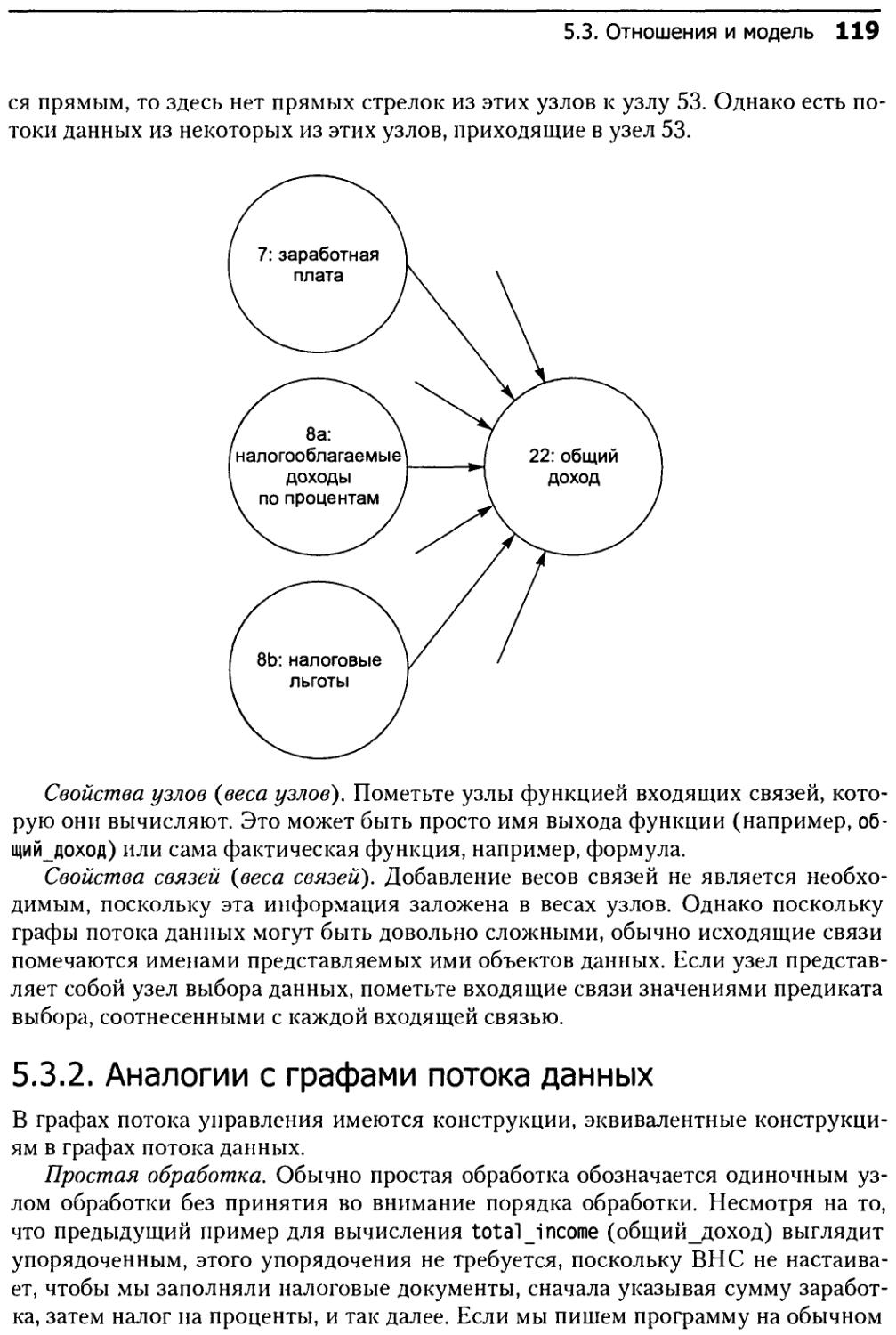
5.2. Основные термины............................................113
5.3. Отношения и модель..........................................118
5.3.1. Основы..............................................118
5.3.2. Аналогии с графами потока данных....................119
5.3.3. Короткие замечания и упрощенные методы..............125
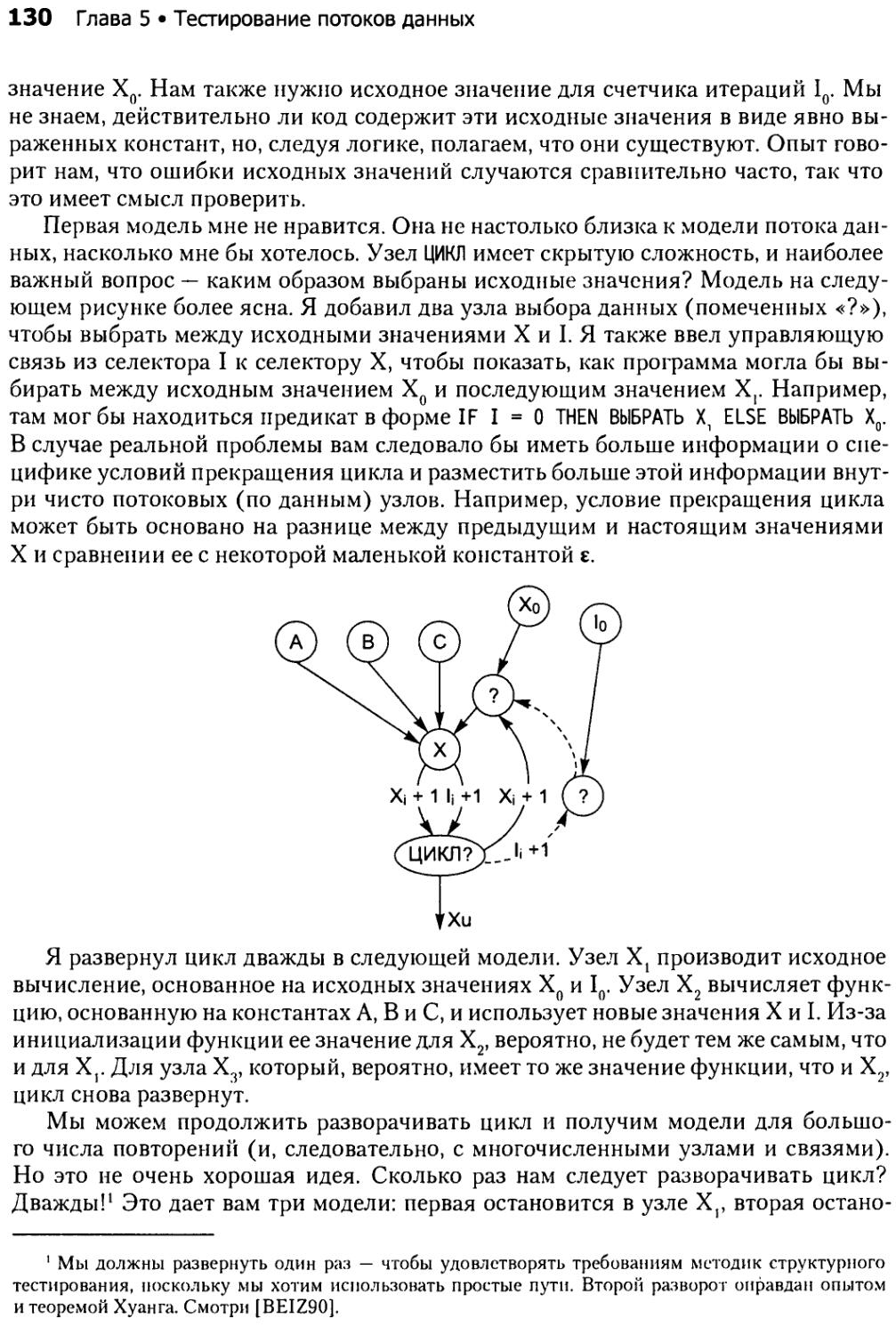
5.3.4. Упорядочение, совмещение потока управления и потока данных, циклы.....................................127
5.4. Методы......................................................131
8 Содержание
5.4.1. Основы ..............................................131
5.4.2. Иерархия покрытия....................................133
5.4.3. Построение модели....................................136
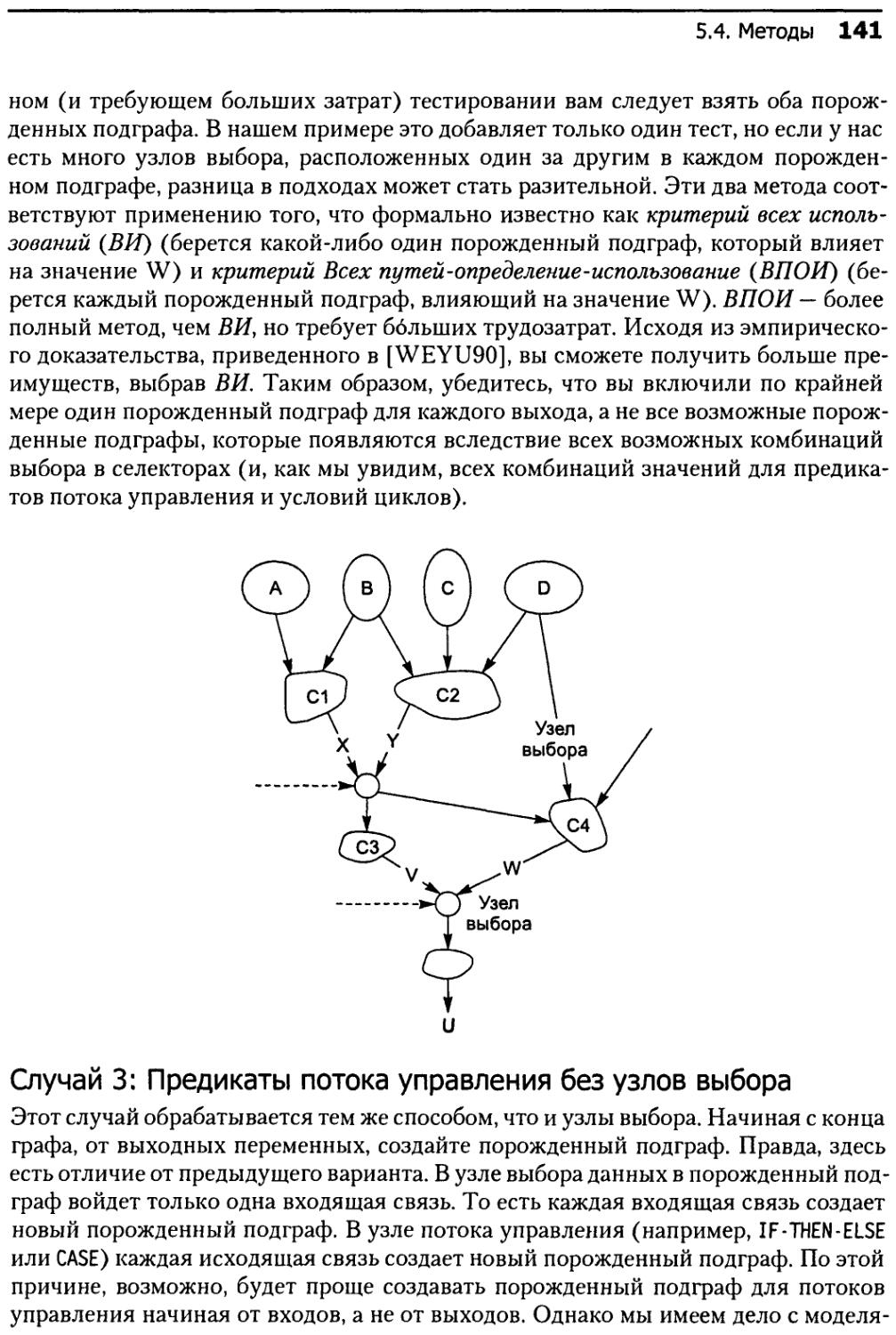
5.4.4. Выбор основного порожденного подграфа................138
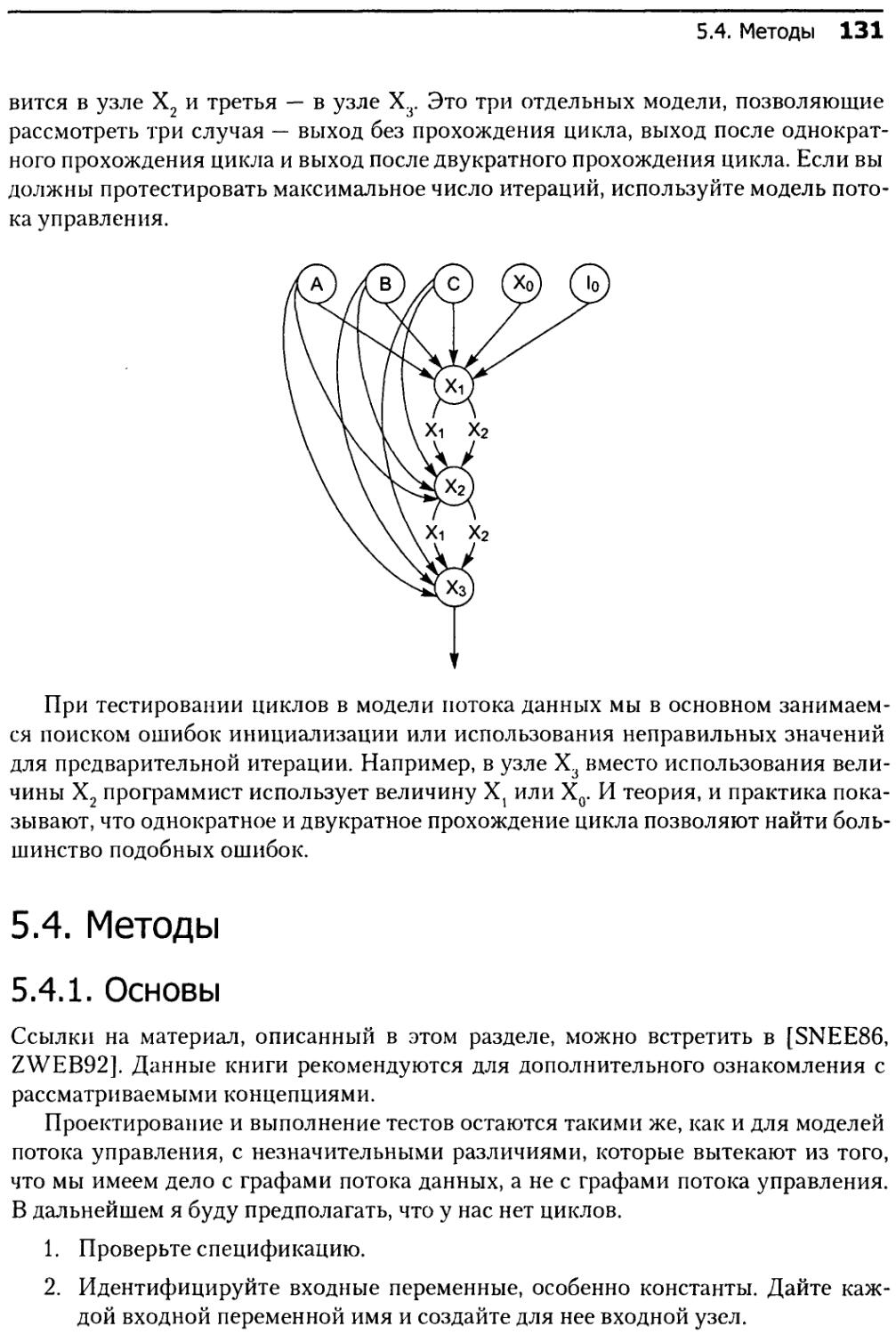
5.4.5. Итоговый пример......................................143
5.4.6. Активизация..........................................145
5.4.7. Предсказание итогов..................................147
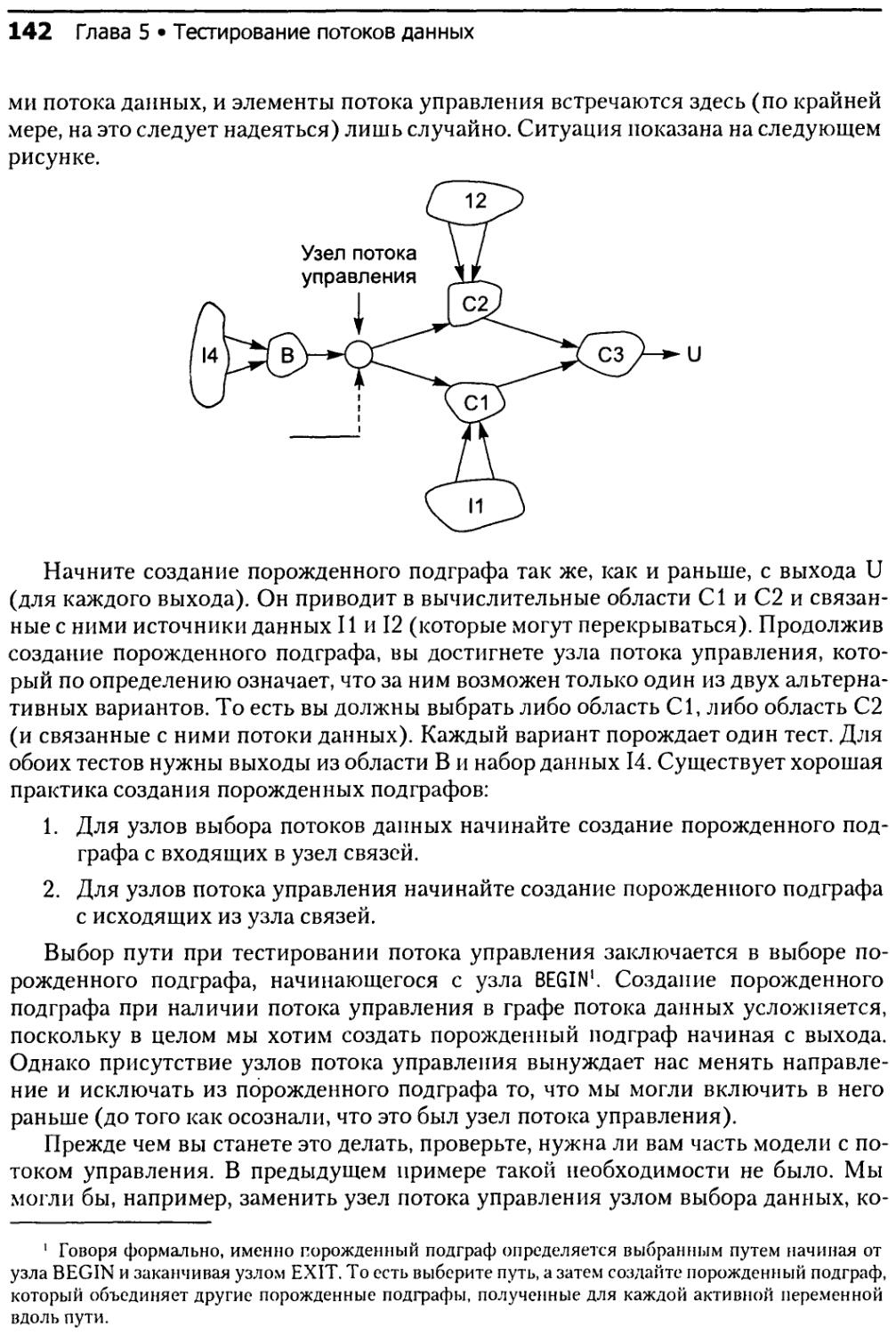
5.4.8. Проверка соответствия пути...........................147
5.5. Анализ приложений............................................148
5.5.1. Виды приложений......................................148
5.5.2. Предположения об ошибках.............................148
5.5.3. Ограничения и предостережения........................149
5.5.4. Автоматизация и инструментальные средства............149
5.6. Резюме.......................................................150
5.7. Вопросы для самопроверки.....................................150
Глава 6 • Тестирование потоков транзакций...............................152
6.1. Обзор........................................................152
6.2. Основные термины.............................................152
6.3. Отношения и модель...........................................155
6.3.1. Основы...............................................155
6.3.2. Маркировки...........................................156
6.3.3. Очереди..............................................157
6.3.4. Слияние и поглощение.................................158
6.3.5. Циклы................................................159
6.3.6. Фокус и иерархические модели.........................159
6.4. Методика.....................................................160
6.4.1. Основы...............................................160
6.4.2. Иерархия покрытия....................................163
6.4.3. Построение модели....................................164
6.4.4. Выбор путей и/или порожденных подграфов тестирования .... 165
6.4.5. Тестирование синхронизации...........................168
6.4.6. Тестирование очереди.................................169
6.4.7. Активизация..........................................171
6.4.8. Предсказание итогов..................................172
6.4.9. Проверка соответствия пути...........................173
6.5. Рассмотрение приложений......................................174
6.5.1. Индикаторы приложений................................174
6.5.2. Предположения об ошибках.............................174
6.5.3. Ограничения и предостережения........................174
6.5.4. Автоматизация и инструментальные средства............175
6.6. Резюме.......................................................176
6.7. Вопросы для самопроверки.....................................176
Содержание 9
Глава 7 • Тестирование доменов..........................................179
7.1. Обзор........................................................179
7.2. Основные термины.............................................179
7.3. Отношения и модель...........................................184
7.3.1. Обоснование...........................................184
7.3.2. Основы................................................186
7.3.3. Анализ неопределенностей и противоречий...............191
7.3.4. Нелинейные домены.....................................193
7.4. Методы.......................................................194
7.4.1. Основы................................................194
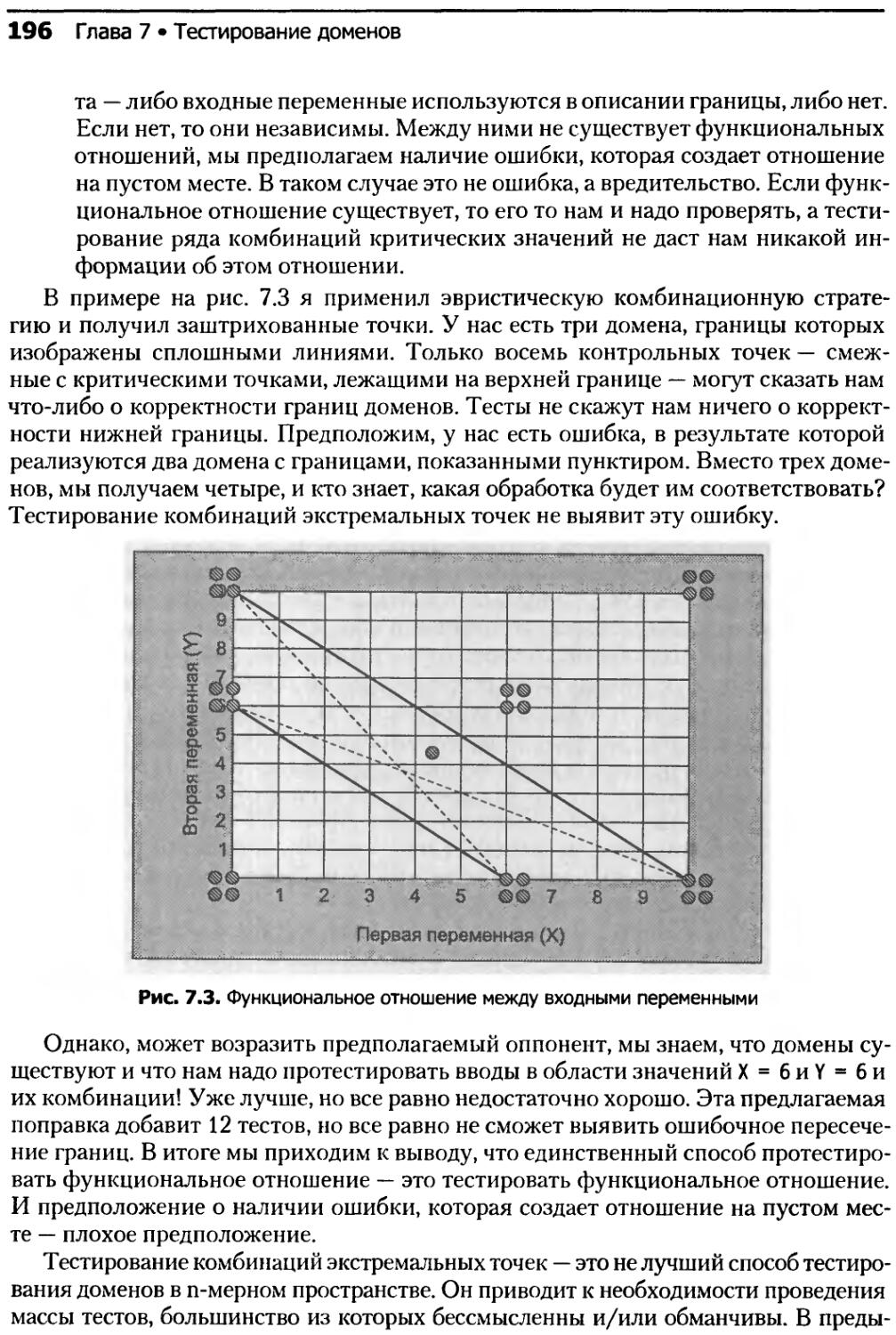
7.4.2. Недостатки комбинирования экстремальных точек.........195
7.4.3. Слабая стратегия 1x1, одномерное пространство.........197
7.4.4. Слабая стратегия 1x1, пространство с размерностью два и выше...................................................199
7.4.5. Вырожденный случай....................................201
7.4.6. Стратегии более высокого порядка для пространства с размерностью два и более..................................201
1А.1. Сильное тестирование доменов...........................206
7.5. Рассмотрение приложений......................................207
7.5.1. Индикаторы приложений.................................207
7.5.2. Предположения об ошибках..............................208
7.5.3. Ограничения и предостережения.........................208
7.5.4. Автоматизация й инструментальные средства.............209
7.6. Резюме.......................................................209
7.7. Вопросы для самопроверки.....................................209
Глава 8 • Синтаксическое тестирование...................................211
8.1. Обзор........................................................211
8.2. Основные термины.............................................211
8.3. Отношения и модель...........................................216
8.3.1. Основы................................................216
8.3.2. Комментарий о трудозатратах...........................219
8.4. Методы.......................................................219
8.4.1. Основы................................................219
8.4.2. Иерархия покрытия.....................................221
8.4.3. Чистое синтаксическое тестирование....................221
8.4.4. Грязное синтаксическое тестирование...................223
8.4.5. Предсказание итога....................................228
8.4.6. Хорошие и плохие разновидности тестирования...........228
8.5. Рассмотрение приложений......................................230
8.5.1. Индикаторы приложений.................................230
8.5.2. Предположения об ошибках..............................232
8.5.3. Ограничения и предостережения.........................233
8.5.4. Автоматизация и инструментальные средства.............234
10 Содержание
8.6. Резюме.......................................................234
8.7. Вопросы для самопроверки.....................................234
Глава 9 • Тестирование систем с конечным числом состояний...............237
9.1. Обзор........................................................237
9.2. Основные термины.............................................237
9.3. Отношения и модель...........................................242
9.3.1. Основы...............................................242
9.3.2. Модели Мили и модели Мура............................245
9.3.3. Таблицы переходов....................................246
9.3.4. Вложенные автоматы...................................248
9.3.5. Улучшаем модель......................................249
9.4. Методы.......................................................250
9.4.1. Основы...............................................250
9.4.2. Что необходимо проверить.............................252
9.4.3. Проверка лишних состояний............................254
9.4.4. Иерархия покрытия....................................256
9.4.5. Активизация и предсказание итога.....................258
9.4.6. Подсчет состояний....................................258
9.4.7. Средства поддержки и тестируемость...................259
9.5. Рассмотрение приложений......................................260
9.5.1. Индикаторы приложений................................260
9.5.2. Предположения об ошибках.............................261
9.5.3. Ограничения и предостережения........................262
9.5.4. Автоматизация и инструментальные средства............263
9.6. Резюме.......................................................264
9.7. Вопросы для самопроверки.....................................264
Глава 10 • Инструментальные средства и автоматизация....................268
10.1. Обзор.......................................................268
10.2. Основные термины............................................268
10.3. Обязательная автоматизация..................................269
10.4. Базовый пакет инструментов..................................272
10.4.1. Основы..............................................272
10.4.2. Инструменты для покрытия............................273
10.4.3. Автоматизация проведения тестирования...............275
10.4.4. Автоматизация проектирования тестов.................277
10.4.5. Рекомендации по выбору производителя инструментов тестирования.................................................278
10.4.6. Не обманывайте сами себя............................279
10.5. Будущее тестирования........................................279
10.5.1. Основы..............................................279
10.5.2. Зачем и почему я не верю в тестирование.............279
Содержание 11
10.5.3. Зачем и почему я не верю в независимое тестирование.280
10.5.4. Будущее тестирования ...............................281
10.6. Вопросы для самопроверки..............................282
Приложение А...........................................................283
Список литературы......................................................299
Алфавитный указатель...................................................314
Введение
Для кого написана эта книга? Для разработчиков и тестировщиков программного обеспечения. Говоря «тестировщик», я имею в виду людей, которые регулярно или в настоящее время тестируют программы, написанные другими людьми. Под «разработчиками» я подразумеваю людей, разрабатывающих программное обеспечение, но, сейчас занимающихся тестированием своих программ. Тестирование, выполняемое и теми и другими, слабо зависит от внешнего вида программы, оно подразумевает, что вы ставите себя на место пользователя и проверяете, что программа ведет себя так, как должна, вне зависимости от способа ее создания. Это и означает тестирование методом черного ящика.
Большинству начинающих тестировщиков, особенно если они нигде этому не учились, приходится самим исследовать тестирование методом черного ящика (иначе его называют поведенческим тестированием или функциональным тестированием). Без соответствующей подготовки они изучают по книгам эвристические версии методов, для которых могут существовать специально написанные коммерческие инструментальные средства. Для таких пользователей в данной книге содержатся основные сведения о надежных и доступных методах поведенческого тестирования.
На освещение этих вопросов меня подталкивали производители инструментов для тестирования, поскольку они создают сложные продукты, основанные отчасти на технологиях, описанных в этой книге, но пользователи не владеют методами, реализованными в их инструментах. Возникает замкнутый круг. Тестировщики с большой неохотой вкладывают деньги в обучение новым методам. Особенно те из них, кто полагается на автоматику, хотя для этого уже существуют специальные коммерческие инструменты. Производители не могут инвестировать средства в разработку инструментов, включающих такие методы, пока не появятся тестировщики, владеющие этими методами. Эта книга призвана помочь разрушить замкнутый круг. Прочитайте ее, затем отправляйтесь к производителю, чьими инструментальными средствами вы пользуетесь, и требуйте включить в них методы
Введение 13
из соответствующей главы. А если я отправлю производителям данные о продажах этой книги, это будет для них явным признаком того, что риск обоснован, так как на самом деле существует рынок спроса на их инструменты и большое число опытных тестировщиков, понимающих особенности методов и принципов, на которых они основаны.
Я должен сказать, чего в этой книге нет. Она не вмещает в себя огромный объем литературы по тестированию, так, например, она не заменяет мою книгу «Методы тестирования программного обеспечения», 2-е издание ([SST2 — BEIZ90]). SST2 — это всеобъемлющий (550 страниц) обзор литературы по тестированию. Эта книга предназначена для максимально широкой аудитории — от разработчиков, до тестировщиков, исследователей, студентов и аспирантов. Настоящая книга слишком мала, чтобы выполнить такую работу. Здесь не рассматриваются вопросы дизайна программ, в отличие от SST2, где они присутствуют почти в каждой главе. SST2 охватывает как структурное тестирование, так и поведенческое тестирование. Здесь же обсуждается лишь тестирование поведения. Эта книга также не может заменить работы «Тестирование программного обеспечения и обеспечение качества» [BEIZ84] или моей следующей книги «Интеграция и тестирование систем», над которой сейчас идет работа [BEIZ96]. Там речь идет о системном тестировании и тестировании интеграции систем, а обсуждаемые методы используются для создания тестов интеграции и тестов систем. В книге «Интеграция и тестирование систем» я буду считать, что вы прочитали эту книгу и знакомы с соответствующими методами.
В данной книге вы не встретите теоретических аспектов тестирования. Я не буду доказывать теорем и упомяну лишь о немногих. Эта книга для практиков. Тем не менее, вы можете быть уверены, что все, что имеет под собой прочную теоретическую базу, основано на этих теоремах. Как следствие моей попытки соответствовать теоретическим нюансам, временами текст, а особенно определения, могут показаться излишне формальными, очень похожими друг от друга и на первый взгляд не имеющими прямого отношения к вопросу. Если такое случится, то будьте уверены, что в дополнительной литературе вы найдете ответы на свои вопросы, поскольку эта книга полностью согласуется с литературой по данной тематике.
Еще несколько вещей, которые я не собираюсь здесь делать. Я не собираюсь тратить ваше время, рассуждая, насколько важны тестирование и качество. Если вы еще этого нс знаете, то вам полезнее будет подумать над этим вопросом. Также я не стану распространяться об обеспечении качества, менеджменте, организации, политике, финансах, культуре, становлении программистского эго, о том, кто должен тестировать программное обеспечение, надо ли тестировать программное обеспечение, нужны ли нам законы, обеспечивающие качество программного обеспечения, открытых системах, свободно распространяемых программных средствах, проблеме наркотиков или моральном облике современной молодежи. Все это очень интересно. Я оставляю эти темы вам для обсуждения и исследования. Если же вы хотите освоить методы поведенческого тестирования с минимумом предварительных условий и хлопот, тогда, я надеюсь, эта книга вас не разочарует.
Пропущенные модели
1. Общие положения
Этот раздел для читателей, знакомых с литературой по тестированию, в особенности читателей книги Глена Маерса «Искусство тестирования программ» [MYER79]; читателей, которые могут быть озадачены, если я не расскажу о нескольких методах поведенческого тестирования. В первую очередь о логических моделях.
Сначала я поставил себе цель уложиться в 175-страничную книгу. Этот объем вполне подходит для прочтения за один семестр. Одновременно планировалось, что эта книга заменит устаревший шедевр Маерса. Маерс уложился в 191 страницу. Когда я начал писать, для меня стало очевидно, что примеры занимают больше места, чем я предполагал. Я добавил некоторые новые технические требования, и это означало, что мне придется включить больше материала, чтобы книга была самодостаточной. Цель «175 страниц» была недостижима, и, тем не менее, мне приходилось постоянно себя ограничивать, сокращая материал.
Мои технические семинары служили обратной связью для определения тем, которые наиболее интересны людям. Я проводил их свыше 200 раз на протяжении 10 лет для тысяч тестировщиков. Участники семинара заполняли опросный лист, в котором спрашивалось, какие методы, по их мнению, могут быть полезны для них сразу же, а какие могут пригодиться в будущем (скажем через 3-5 лет). Я поддерживаю связь с бывшими студентами и организациями-заказчиками, чтобы определить, какие методы они используют при тестировании. Эта обратная связь лежит в основе данной книги.
2. Маерс. «Искусство тестирования программ»
Книга «Искусство тестирования программ» освещает вопросы тестирования так, как их понимали в 1979 году. С тех пор прошло более двух десятилетий, техноло-
2. Маерс. «Искусство тестирования программ» 15
гии тестирования развивались, и читатели не будут удивлены, обнаружив, что техника тестирования тоже изменилась. С одной стороны, сегодня мы знаем о тестировании гораздо больше. С другой стороны, создание подобного обзора потребует сейчас не одной, а целых семи книг: «Инспектирование», «Методы тестирования», «Тестирование интеграции», «Системное тестирование», «Теория тестирования», «Методы отладки», «Организация тестирования» и «Менеджмент». Моя задача существенно уже — введение в технику тестирования. Вот современное описание пяти методов, обсуждаемых Маерсом.
1. Тестирование путем покрытия логики. То, что Маерс называл «тестированием путем покрытия логики», в настоящее время называется тестированием потока управления (глава 3). Поскольку в данной книге рассматриваются не структурные методы (белого ящика), а лишь поведенческие методы (черного ящика), я остановлюсь лишь на поведенческом тестировании потока управления.
2. Разбиение по эквивалентности. Все методы тестирования, описанные в этой книге, основаны на идее разбиения набора всех возможных входных данных на классы эквивалентности (глава 3). Это означает, что все они относятся к методам тестирования путем разбиения. Маерс настоятельно советовал читателям исследовать код и спецификации, а затем на их основе осуществлять разбиение входных данных на эквивалентные классы для тестирования программы. Он также предложил для этого несколько сложных эвристических правил. Это выливается в создание специальных методов для каждой конкретной программы. Принцип, конечно, правильный и абсолютно корректный, но на практике тестировщики испытывают трудности при определении этих смутных (хоть и плодотворных) классов эквивалентности. Я расскажу вам об уже готовых методах разбиения на классы эквивалентности (или методах тестирования), что облегчает их практическое использование.
3. Анализ граничных значений. Рассуждения Маерса об анализе граничных значений являются частью более общей и более мощной методологии тестирования доменов (глава 7). Некоторые аспекты анализа граничных значений в применении к циклам будут обсуждаться в главе 4.
4. Причинно-следственные диаграммы [ELME73, MYER79]. Более подробное обсуждение вопроса, почему причинно-следственные диаграммы и связанные с ними методы не включены в данную книгу, приводится в разделе 3 «Логические модели». Такие методы трудны в практическом использовании потенциальными тестировщиками, не обладающими необходимыми знаниями, такими как булева алгебра или теория переключательных схем. Остранд [OSTR88] замечательно отозвался об этой технике: «Переводя данные спецификации в причинно-следственные диаграммы, тестировщики замещают одно сложное представление другим».
5. Предположение об ошибках. При выборе метода тестирования мы делаем ставку на определенный тип ошибок, который ожидаем обнаружить, так
16 Пропущенные модели
как предположение о типе ошибок присутствует в любом методе. Поэтому предположение об ошибках — это не какой то метод тестирования, но атрибут любого из методов. Предположение об ошибках, основанное на статистике ошибок программистов, — вполне здравая идея (посмотрите, однако, «Парадокс пестицида» в главе 1). Сегодня мы имеем подобные статистики и, опираясь на них, выбираем определенный метод тестирования. Существует также и формальная теория тестирования, основанного на ошибках, но она не вошла в эту книгу [HOWD89, MORE90].
3. Логические модели
Логические модели включают в себя причинно-следственные диаграммы [ELME73, MYER79], модели таблиц решений [BEIZ90, GOOD75] и множество других вариантов, использующихся в качестве частей различных методологий дизайна [BEND85, WEYU94B]. Это замечательные методы, однако для их разбора потребуется слишком много места. К примеру, логические модели занимают в книге «Методы тестирования программного обеспечения» 42 страницы. В данной книге из-за более современных предпосылок и примеров черновик состоял из 75 страниц. Это еще две дополнительные большие (даже слишком большие) главы, что сделает курс слишком большим для одного семестра.
Мне трудно объяснить логические модели без привлечения булевой алгебры, а ее нет смысла учить, если вы не владеете диаграммами Карно—Вейча [BEIZ90], поскольку булева алгебра почти не используется без этого важного инструмента. Я обратил внимание, что слушатели разделяются на две категории. Те, кто знаком с булевой алгеброй и картами Карно, способны овладеть этими методами самостоятельно, например, с помощью STT2. Те же, у кого нет таких знаний, не могут изучить их за четыре часа, которые я посвящаю этой теме. В итоге тестирование на основе логики всегда находится на последних местах в списке предпочтений моих студентов и спонсоров. И я частенько вообще выбрасываю эту тему из моих семинаров.
Было бы неплохо, чтобы курс по тестированию был не единственным. Вспомогательный курс, для начальных или старших курсов, когда студенты уже владеют необходимыми знаниями, мог бы включать в себя логические модели и другие модели, здесь не представленные.
4. Языковые модели
Существует большое число моделей на основе специальных языков для разработки тестов и связанных с ними инструментальных средств. Хорошим примером может служить метод разбиения по категориям Остранда [LAYC92, OSTR88] и «Т» Постона [POST94], Другие методы того же типа изложены в [BALC89, BELF76, DAVI88, КЕММ85, RICH89]. Все эти методы основаны на языке определения теста. Языки отличаются степенью формальности и выразительной силой, простираясь от самых элементарных до строгих полнофункциональных язы
4. Языковые модели 17
ков. При помощи таких языков тестировщики определяют требуемое поведение программ. Языковый процессор проверяет это определение на неоднозначности и противоречия. Другой процессор автоматически генерирует тестовые варианты (положительные и отрицательные), соответствующие данному определению при помощи большого числа формальных и эвристических методов тестирования.
Что же плохого в таком способе? Ничего. Я люблю его. Я верю, что рано или поздно тесты будут преимущественно создаваться такими вот инструментами. Однако подобные средства сложны, и их нельзя понять по-настоящему без понимания методов тестирования, на которых строятся генераторы тестов. Прочтя эту книгу, вы узнаете об этих методах.
Другая проблема является фундаментальной для любого языка программирования. Один из наиболее важных выводов, которые я сделал, наблюдая почти четыре десятилетия за развитием программного обеспечения, заключается в том, что нельзя ставить все на какой-то язык программирования, пока он популярен. Да и после потери популярности не стоит зацикливаться на нем. Люди предрекали кончину языка COBOL десятилетиями, но он, подобно бессмертному вампиру, все еще с нами. Кто мог предположить, что С вытеснит языки ассемблера, почти полностью FORTRAN и даже COBOL? Что случилось с языками PL/1 и Algol? Достоинства языков программирования слабо связаны с их популярностью. Будущее языков тестирования еще в большей степени непредсказуемо из-за относительно небольшого круга пользователей. Я надеюсь, что со временем один или два таких языка и связанные с ними генераторы тестов станут общепризнанными средствами тестирования. Тогда и наступит время написать о них, может быть, в рамках дополнительного курса.
Readme.doc
Зачем нужен Readme.doc?
Смогу ли я добиться большего успеха, чем производители фирменного программного обеспечения, попытавшись убедить вас прочесть этот раздел, прежде чем вы перейдете к следующим главам? Данный раздел — это инструкция по пользованию данной книгой. Я ничем не отличаюсь от вас. Когда мне в руки попадает новый пакет программ, я запускаю то, что мне интересно, начинаю с ним манипулировать и неизбежно захожу в тупик. Тогда я возвращаюсь назад и читаю Readme.doc, для того чтобы узнать, что же я сделал не так. Поэтому, если вы читаете этот раздел, это значит, что вы попытались прочесть главу о методах, которые, на ваш взгляд, подходят для вашей задачи, но безуспешно. Итак, давайте прочтем это прямо сейчас.
План книги
Эта книга имеет свою генеральную линию. В главе 1 подготавливается почва для дальнейшего изложения и говорится о моем видении вашей ситуации, или, иными словами, обстоятельств, в которых происходит ваше тестирование. Для некоторых из вас эти обстоятельства могут показаться идеалистическими, но на самом деле они реальны и в той или иной форме присутствуют во множестве организаций-разработчиков программного обеспечения, и это то, к чему вам надо стремиться. Сравнивая вашу ситуацию с главой 1, вы поймете, где вы находитесь и в каком направлении вам надо двигаться. Для тех, кто ориентируется в терминах, мои стандарты — пятый уровень зрелости SEI (по шкале Института программного обеспечения) и, кроме того, немного из [SCAC94].
Глава 2 необходима для понимания глав 3, 4, 5, 6, 8 и 9, глава 4 — для глав 5, 6 и 8. Вы — в большинстве своем тестировщики-практики, и я не буду осуждать вас,
План книги 19
если вы пропустите главу, которая покажется вам чересчур абстрактной или не имеющей отношения к вашей конкретной задаче. Прошу за это прощения. Глава 2 очень важна. Если вы не разберетесь в ней, то последующие главы могут быть непонятны. В лучшем случае вы не сможете извлечь из них столько пользы, как если бы вы прочитали эту главу.
Глава 2 подобна подпрограмме с нужной информацией. Вместо того чтобы снова и снова повторять основные принципы в различных контекстах для каждой главы, я опишу идеи тестирования один раз в абстрактной форме и буду ссылаться на них в дальнейшем. Если вы разберетесь в абстрактных понятиях главы 2, то в последующих главах объяснение методов будет занимать всего несколько страниц. Это сделает книгу короче и дешевле, а КПД усвоения выше.
В главах с 3 по 9 описываются конкретные методы. В каждой главе — один метод и его производные. Я постарался сделать эти главы как можно более независимыми друг от друга. Переварив главу 2, вы сможете читать остальные главы практически в любом порядке.
1—X
10-ИНСТРУМЕНТЬ1
Данная диаграмма показывает, какой материал должен быть предварительно освоен перед прочтением той или иной главы. Сплошные линии означают, что вы должны разобраться в главе, находящейся в начале стрелки, для того чтобы понять главу, па которую стрелка указывает. Прерывистые линии означают, что предварительная глава содержит определения, которые будут использоваться в последующей главе, но любом случае вы сможете понять материал без внимательного изучения предварительной главы. Прочтение главы 1 — желательно, но необязательно для понимания следующих глав. Последняя глава включает в себя
20 Readme.doc
определения из остальных глАв, и поэтому требование к предваряющим главам нежесткое.
В последней главе рассказывается об инструментальных средствах и автоматизации. И хотя методы, описываемые в этой книге, могут использоваться и безо всякой автоматизации, такое их использование будет крайне неэффективно. Я надеюсь, что вы простите мне, что я не вдаюсь в подробности при обсуждении инструментальных средств. Я не собирался делать здесь полный обзор последних коммерческих инструментов. Такую информацию можно найти в [DAIC93], [GRAH93], [SQET94] и других подобных периодических изданиях. Ситуация меняется слишком быстро, для того чтобы имело смысл печатать подобную информацию в книге.
Структура главы
Главы с 3 по 9, составляющие ядро данной книги, имеют сходную структуру, хотя порядок может меняться от главы к главе.
Обзор. Содержание главы в общих словах без использования терминов, вводимых в данной главе.
Словарь внешних терминов. Технические термины, определение которых отсутствует в данной книге, но которые вы должны знать. Англоговорящего читателя может удивить, что сюда включено так много основных компьютерных терминов. Около половины содержимого словаря внешних терминов хорошо знакомо не только профессионалу в области программного обеспечения, но и студенту. Включая сюда основные термины, я преследовал цель помочь моим многочисленным читателям, для которых английский язык не является родным. Я также надеюсь, что эти термины ощутимо облегчат перевод книги. Некоторые из внешних терминов не принципиальны для понимания книги, поскольку используются лишь в одной из нескольких иллюстраций идеи или в несущественном комментарии. Не слишком расстраивайтесь, если вы не понимаете термины, используемые в иллюстрациях, поскольку они играют вспомогательную роль в освоении методов тестирования. Все такие термины есть в алфавитном указателе, и вы можете посмотреть их применение в контексте изложения, чтобы понять, действительно ли они вам нужны для понимания темы.
Словарь внутренних терминов. Термины, определяемые в предыдущей главе.
Словарь новых определений. Определения, используемые в главе. Новые определения выделяются курсивом. Определение будет выделено курсивом еще раз, если оно дополняется или уточняется. Определения приводятся в логической последовательности, где каждое следующее определение зависит от предыдущего; их надо читать в предложенном порядке. Внимательно читайте новые определения и не двигайтесь дальше, пока их не поняли.
Конфликт словарей. Иногда вы будете находить один и тот же термин во внешнем и внутреннем словарях, а также в словаре новых определений. Когда термин появляется одновременно во внешнем и внутреннем словарях, это значит, что если вы знали его и раньше, то у вас не будет проблем с пониманием главы, одна-
Структура главы 21
ко в данном контексте определение будет более строгим, чем то, которое вы знали. Аналогично, если термин возникает во внутреннем словаре и в словаре новых определений, то в данной главе он либо уточняется, либо дополняется (переопределяется).
Термины могут выделяться в тексте курсивом (это значит, что вы, скорее всего, с ними не знакомы), при этом их определение может отсутствовать, и они не будут включены в словарь новых определений. Это означает, что этот термин ссылается на что-то, что будет определено позже. Я старался избегать таких ссылок и использовал их, только если чувствовал, что это принесет пользу. Вы, возможно, захотите заглянуть в соответствующую главу и просмотреть определение, но в любом случае можете не беспокоиться: на изучение данной главы никак не влияет понимание подобных ссылок.
Модель. Модель, на которой основан метод. Она включает то, что мы принимаем во внимание в поведении программы, что игнорируем и как мы представляем себе это поведение.
Предположение об ошибках. Любой метод тестирования основан на предположении относительно программного продукта, дизайна, пользователя, типа ошибок и возможных проявлений этих ошибок. Этот раздел поможет вам определить эффективность метода в вашем случае.
Тип приложений. Обсуждение, для каких приложений данный метод, скорее всего, будет эффективен.
Метод. Метод, что он собой представляет, как он работает и почему он работает.
Примеры. Примеры и решения технических задач — от необходимых требований до готовых тестов. Там, где это было возможно, я использовал в качестве примеров декларацию о доходах внутренней налоговой службы США. Я выбрал бланки декларации на подоходный налог, поскольку они едины для всех, содержат большое количество нетривиальной логики; они подходят для иллюстраций большинства методов черного ящика; несмотря на то, что мы затрачиваем огромные усилия, чтобы заполнить бланк декларации и разобраться в этих непостижимых формах, они, тем не менее, представляют собой вполне законченные спецификации и свободны от ошибок; и, наконец, их должен знать каждый.
Предостережения и ограничения. Что данный метод может, чего не может и ошибки какого типа он пропустит.
Автоматизация и инструментальные средства. Комментарии по поводу автоматической генерации совокупности тестовых данных и инструментальных средств, построенных на этом методе.
Резюме. Краткое содержание главы с использованием новой терминологии. При сравнении обзора и резюме становиться понятно, какие новые концепции были рассмотрены в этой главе.
Тест и упражнения. Упражнения и вопросы по итогам главы. Не прилагая усилий, вы не станете хорошо тестировать. Также вам надо знать терминологию, введенную в этой главе, если она встречается в последующих главах. Станьте сами себе ОТК. Проверьте себя. Бланки налоговой декларации являются подходящими объектами для тестирования. Проверьте сделанное, протестировав готовый пакет налоговых документов. Можете считать, что все правила налоговой службы в нем
22 Readme.doc
i
соблюдены. В том числе они проверяют, чтобы все обязательные для заполнения графы были заполнены. Если вы вводите некое значение, очевидно выходящее за указанные рамки, программа должна определить это и предупредить вас. Я должен извиниться за то, что использовал налоговые декларации за 1994 год, но если они изменятся (а это неизбежно случится), вы приобретете полезный навык в обновлении средств тестирования.
Если вы в данный момент не являетесь студентом, то с помощью этого упражнения вы дополнительно попрактикуетесь в заполнении налоговой декларации. Если же вы студент и никогда не заполняли декларацию, самое время научиться этому. Не осуждайте меня за сложность формы, обратитесь лучше с этим вопросом к своим сенаторам и конгрессменам. Кроме того, реальные проблемы, с которыми вам придется столкнуться при тестировании программ, будут гораздо более трудными.
Бланки налоговой декларации и ссылки на них
Там, где это было возможно, я иллюстрировал методы на примере формы 1040 декларации о доходах внутренней налоговой службы США и дополнений к ней за 1994 год. Копии форм, использующихся в этой книге, содержатся в приложении А. Эти формы определяют структуры, которые мы и будем тестировать. Я рассчитываю, что каждый раз, разбирая пример, вы будете сверяться с соответствующей копией формы.
Я ссылаюсь на различные строки в бланке декларации как «1040 строка 23» Если отдельно не оговаривается, отсутствие названия формы (например, бланк С) означает, что ссылка относится к форме 1040. Также для создания полезных примеров мы можем добавлять отсутствующие в настоящей форме «строки» в нашу модель. Так, например, вместо одной строки 34 могут возникнуть строки 34.1,34.2 и т. д.
Что должен знать читатель
Эта книга для людей, обладающих определенными знаниями и опытом. Одного из нижеследующего будет вполне достаточно: один год (или больше) обучения по университетской программе в области компьютерных наук или программной инженерии, два года среднего специального образования в области компьютерных наук или разработки программного обеспечения, интенсивный годовой курс обучения в сертифицированном коммерческом центре обработки данных или, что равнозначно, полный курс обучения по направлению «Программное обеспечение» в системе военного образования США, три или больше лет работы программистом. Занимаетесь ли вы программированием на данный момент — неважно. Важно, чтобы вы знали основные принципы программирования и обладали практическим навыком. Читателям с опытом прикладного тестирования, но без опыта программирования будет сложнее. Им придется потрудиться, чтобы понять и научиться применять главу 2. В словаре внешних терминов для каждой главы
Ссылки 23
приводится лексика, которую вам надо знать для освоения метода. Большинство людей склонно недооценивать собственные знания. Если вы понимаете терминологию главы, этого достаточно для ее изучения.
Не только программное обеспечение
Исходя из вышесказанного, может показаться, что эта книга адресована только разработчикам программного обеспечения и тестировщикам. Это не так. Требования к читателю достаточно скромны и являются общими при обучении науке, бизнесу, инженерному делу или бухгалтерии. «Тестирование методом черного ящика» означает, что нас не интересует, что выступает в роли программно-подобного процесса. Кроме, разумеется, программ, это могут быть химические реакции, физика электромеханических систем, таинственный ход мыслей юриста, когда он пишет налоговые законы. Все эти системы надо тестировать. Все методы, представленные в данной книге, можно применить для тестирования процессов, далеких от программирования. Если вы биохимик и хотите оптимизировать тестирование реакций, которые используете в анализе крови, эта книга будет вам полезна, поскольку маловероятно, что существует книга о тестировании химических реакций в крови. Или представьте, что наши законодатели и Конгресс захотят применить формальный анализ и методы тестирования к абсурдным налоговым законам (особенно касающимся укрывания налогов), которые они разрабатывают. Тогда они смогут использовать эту книгу, хотя вряд ли это произойдет.
Использование алфавитного указателя
Алфавитный указатель предоставляет всю информацию о термине, а также содержит раздел ссылок. Если в ссылке приводятся номера страниц, то это значит, что в данной работе на указанных страницах содержится информация по соответствующей теме. Вам это будет ясно из названия издания или из комментария, следующего за названием.
Ссылки
Исследователи вряд ли найдут в ссылках что-нибудь интересное для себя. Ссылки здесь приводятся для того, чтобы читатель мог узнать больше о теме, иногда ознакомиться с противоположной точкой зрения или удачными примерами приложений, которые он мог бы использовать как средство борьбы за внедрение данного метода в свою организацию. Я ограничил библиографию работ, которые, хотя и содержат дополнительную информацию, но не являются существенными. Также я не стал включать в список ссылок множество прекрасных работ, особенно теоретических исследований, не относящихся к теме данной книги.
Ссылки обозначаются согласно требованиям АСМ (ассоциация вычислительной техники). Первые четыре символа из имени автора, затем год публикации, и в
24 Readme.doc
конце заглавная буква, начиная с «А», если это не единственная работа автора за тот год. Так, например, [BEIZ90] — книга Бейзера, опубликованная в 1990 году, а [BEIZ91C] — третья его книга в 1991 году. Часто приводится резюме или короткий обзор, если тема не понятна из названия.
Контроль качества
Контроль качества — это ваша задача. Я ожидаю ваших комментариев, а также ваших замечаний об ошибках и недочетах, чтобы исправить их в следующих изданиях. Технологии позволяют сделать это очень просто. Пришлите мне факс или e-mail по адресам, приведенным ниже. Пожалуйста, сообщите следующую информацию о себе:
Ваше имя, место работы (компания, университет, государственное учреждение) Ваша должность
Почтовый адрес
Номер телефона, факса, e-mail
Название книги, издание
Номер страницы и комментарии или исправления
Если вы используете факс, вы можете сделать копию страницы и написать комментарий прямо на ней.
В публикациях используются номера, эквивалентные номеру версии и релиза. «Номер версии» — это то же самое, что и «номер издания», это всегда указывается в заголовке. Например, «Методы тестирования программ», издание 2-е.
Пожалуйста, посылайте ваши замечания:
Борису Бейзеру
Факс: 215-886-0144, три параллельных факса, отвечают на первый звонок
E-mail: BBEIZER@MCIMAIL.COM
Благодарности
Я написал эту книгу по настоянию Боба Постена из Programming Environments Inc при поддержке Джинджера Хостона-Ладлэма из Frontier Technologies, Эдварда Миллера из Software Research Associates, Билла Перри из Quality Assurance Institute, Ричарда Бендера из Bender Associates и еще такого огромного числа коллег по академии, что перечислить их не представляется возможным. В написании этой книги есть вклад и других людей: коллег по цеху, моих читателей, моих студентов, клиентов, приходящих на консультации, однако уже трудно сказать, кто из них и что предлагал. Вряд ли кто-нибудь из этих людей догадываются, что они являются соавторами этой книги, поскольку их участие в ее написании было по большей части неосознанным. Мотивация, сознательная или нет — тоже ценный вклад. Я также хочу поблагодарить тех, кто откликнулся на мою просьбу по Интернету о помощи в выборе темы. И, наконец, я благодарен Ли Уайту за полезную и обоснованную критику главы 7.
От издательства 25
Отказ от ответственности
Там, где было возможно в этой книге, я использовал в качестве примеров декларации о доходах внутренней налоговой службы США. Они использовались для иллюстрации проблем тестирования и не годятся для предоставления реальной информации, например как заполнять налоговую декларацию или как интерпретировать код внутренней налоговой службы США. Я по своему усмотрению сокращал или изменял формы, если это мне было надо в педагогических целях. Не используйте формы из этой книги для каких-либо реальных целей, связанных с налогами. Не представляйте эти формы, их копии или материал в них в налоговую службу. Я не несу ответственности за любое их использование, кроме как в качестве учебных пособий.
Несмотря на вышесказанное, бланки декларации, их запутанность и инструкции к ним совпадают с формами внутренней налоговой службы США. Мои кол-леги-неамериканцы говорят мне, что налоговые законы сложны во всем мире. Я за это не отвечаю. Законы и формы на самом деле дают нам нечто, за что можно быть благодарным. Если вы в состоянии заполнить налоговую декларацию в своей стране, то вы можете решить любую задачу тестирования, например тестирование программы контроля ядерного реактора.
От издательства
Ваши замечания, предложения и вопросы отправляйте по адресу электронной почты comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
Подробную информацию о наших книгах вы найдете на веб-сайте издательства http://www.piter.com.
Введение
1.1. Обзор
В этой главе вводится терминология, использующаяся в тестировании, и рассматривается тестирование как элемент процесса разработки программного обеспечения.
1.2. Основные термины
В тестировании программного обеспечения существует вполне устоявшийся словарь. Определения, данные в этой книге, широко используются, изучите их. Вы наверняка ошибетесь, если будете употреблять их в узком, а не в широком смысле.
Внешние термины: совокупность, алгоритм, анализ, бета-тестирование, ветвление, побочный продукт, вызов, вызываемый, вызывающий, параметры запроса, код, кодирование, связь, сравнивать, компилируемый сегмент, компилятор, завершенный, сложность, вычисление, последовательный, управление, аварийная ситуация, данные, база данных, порча данных, целостность данных, отлаживать, задержка, проектирование, детерминированный, среда разработки, стадия разработки, диск, документ, выполнять, эксперимент, файл, блок-схема, формальный анализ, функция, глобальные данные, аппаратные средства, гипотеза, реализуемый, независимое тестирование, инспектирование, инсталляция, взаимодействие, нажатие клавиши, ключевое слово, библиотека, макрос, сопровождение, управление, отображение, сообщение, метрика, модель, модуль, многозадачный, многопользовательский, команда объектной программы, объектно-ориентированное программирование, взаимно однозначное отображение, операционная система, выходные данные, производительность, процесс разработки программного обеспечения, обработка, программа, часть программы, оператор программы, программируемый, программист, программирование, протокол, качество, обеспечение качества, RAM (оперативная память), случайный, диапазон, надежность, ресурсы,
1.2. Основные термины 27
многократно используемый, экран, защита, набор, последовательность, совместно используемые данные, имитатор, программное обеспечение, логика программы, исходный код, область, оператор, статистический, память, управление памятью, подпрограмма, подсистема, инструмент тестирования, таблица, пропускная способность, истинностное значение, пользователь, значение, переменная.
Объект. Общий термин, включающий в себя данные и программное обеспечение.
Состояние. Набор всех значений всех объектов в данном множестве объектов в произвольный момент времени. Смысл термина «состояние» зависит от того, определяет ли он набор объектов и/или их состояний: например, состояние элемента, состояние системы, состояние объекта, начальное состояние.
Начальное состояние. Состояние объекта перед началом теста.
Конечное состояние. Состояние объекта после прохождения теста.
Ввод. Любой способ, при помощи которого данные могут быть доставлены объекту. Примеры: сохраненные данные, генерируемые данные, нажатие клавиши, сообщение.
Наблюдаемый. Любое видимое и ожидаемое изменение состояния объекта, или отсутствие изменений в состоянии объекта, если это изменение не ожидалось. Примеры: новый экран, неправильные выходные данные, неизменившийся экран.
Итог. Наблюдаемый результат теста. Примеры: изменившийся объект данных, сообщение, новый экран, изменение состояния, неизменный объект, отсутствие сообщения, пустой экран. В тестировании мы рассматриваем итог, а не вывод. Это не семантическое противоречие. То, что экран не изменился, очевидно, является итогом, но не выводом. Если вы полагаете, что все тесты должны иметь вывод, то вы упустите множество полезных тестов. Все тесты, однако, должны иметь итог.
Оракул. Любые средства, используемые для предсказания итога теста [HOWD86].
Проектирование теста. Процесс определения объекта, начального состояния и ввода, а также прогноз итога теста и/или конечного состояния для данного объекта, начального состояния или ввода.
Тестирование. Проектирование, отладка и выполнение тестов.
Подтест. Наименьшая составная часть теста, включающая в себя объект, начальное состояние, ввод и прогнозируемый итог.
Тест. Последовательность одного или более подтестов, выполняемых последовательно. Итог и/или конечное состояние одного подтеста является вводом и/ или начальным состоянием для другого. Термин «тест» обобщает, включает в себя подтесты, тесты как таковые и тестовые комплекты.
Тестовый комплект. Совокупность одного или более тестов, ориентированных на один объект с общей задачей и базой данных и используемых, как правило, совместно.
Опровергаемый. Оператор является опровергаемым, если вы можете поставить эксперимент, который либо подтвердит, либо опровергнет его истинность.
Требования. То, что объект должен выполнять и/или характеристики, которыми он должен обладать. Выбор требований относительно произволен, но они должны быть непротиворечивы, разумно полны, реализуемы и, что самое важное, опровергаемы.
28 Глава 1 • Введение
Характеристика. Желательное поведение объекта; вычисление или оценка, проводимые объектом. Требования представляют собой совокупность характеристик.
Вариант. Характеристики, представляющие собой совокупность вариантов.
Спецификация. Ясное, как правило, неполное определение требований. В качестве спецификаций могут использоваться документы, список характеристик, прототип, тестовый комплект. Спецификации обычно незакончены, поскольку многие требования часто бывают очевидны. Например: «программа не должна уничтожать или портить данные». Самая большая ошибка, которую может допустить тестировщик, — это предположить, что в спецификациях представлены все требования.
Проверка соответствия (валидация). Оценка объекта с целью продемонстрировать, что он удовлетворяет требованиям. Тестирование — это не единственный метод проверки соответствия, но в данной книге рассматривается только он [WALL94].
Искаженностъх. Оценка объекта с целью продемонстрировать, что он не удовлетворяет требованиям.
Критерии соответствия (валидации). Средства для демонстрации того, выполняются или нет требования. Например, прямое сравнение с предсказанными значениями, сравнение в пределах определенных областей значений, наблюдаемая последовательность событий.
Сравнение итогов. Предсказанный и фактический итоги теста сравниваются по определенным критериям соответствия.
Сценарий теста. Документ, программа или объект, которые для каждого теста и подтеста в тестовом комплекте определяют тестируемый объект, требование (обычно условие), начальное состояние, вводы, ожидаемый итог и критерии соответствия.
Симптом (отказ IEEE94). Наблюдаемое аномальное поведение любого объекта (не обязательного тестируемого), такое как несоответствие требованиям или возникновение незапланированных явлений.
Ошибка (сбой IEEE94). Просчет в проектировании, ведущий к возникновению симптомов у какого-либо объекта (тестируемого и не только) при прохождении этим объектом определенного теста.
Тест считается пройденным, если при корректно заданных критериях соответствия после его прохождения фактический итог совпадает с предсказанным и отсутствуют симптомы.
Тест считается не пройденным, если после его прохождения фактический итог не совпадает с предсказанным и/или присутствуют симптомы. Причиной этого может быть использование неверного объекта, неверный ввод, неверный прогнозируемый итог, неверное начальное состояние, неверные критерии соответствия, некорректное применение этих критериев, ошибка при проектировании теста,
1 Автор использует свою собственную, оригинальную терминологию. Отдавая дань классику, отметим, что более распространены следующие термины: верификация — проверка того, что программа правильно реализует определенную функцию; валидация — проверка того, что программа соответствует требованиям заказчика. — Примеч. научи, ред.
1.2. Основные термины 29
ошибка в выполнении теста, ошибка в процессе проверки соответствия и даже, каким бы это не могло показаться странным, ошибка в тестируемом объекте.
Протестирован. Объект считается (успешно) протестированным, если выполнены все запланированные тесты, без появления симптомов, это означает, что все тесты были пройдены. Если не указано обратное, «протестирован» означает — успешно протестирован.
Свободен от ошибок. Мы говорим, что объект «свободен от ошибок», если мы считаем, что вероятность появления у него симптомов или возникновения спровоцированных им симптомов у других используемых объектов достаточно мала, чтобы гарантировать успешное использование этого объекта. Идея абсолютной «свободы от ошибок» является неопровергаемой, а значит, не может быть требованием.
Случайная корректность. Успешное прохождение всех тестов еще не означает, что объект свободен от ошибок. Несмотря на то, что фактический итог совпадает с предсказанным, в программе могут быть ошибки, поскольку совпадение итогов может быть случайным. Например, если программа должна вычислять у:=хг, но ошибка в программировании приводит к тому, что вычисляется у:=2х, а входное значение х в тесте оказывается равным 2, то итог будет равен у=4, несмотря на ошибку. Про тестируемую таким образом программу говорят, что она случайно корректна.
Слепота (сокрытие, утаивание). Для любого метода тестирования (за исключением тестирования всех возможных вводов и начальных состояний) существует определенный тип ошибок, к которым он слеп. Например, множество методов слепо к случайной корректности.
Модуль. Наименьший элемент, подлежащий тестированию. Этот элемент (обычно) является продукцией одного программиста и представляет собой наименьший компилируемый сегмент программы, такой как подпрограмма. Модуль как объект тестирования обычно не включает в себя подпрограммы, вызываемые им функции, фиксированные таблицы и так далее.
Тестирование модуля. В тестировании модулей принято, что вызываемые подпрограммы и вызовы функций считаются компонентами языка (например, ключевыми словами). Вызываемые и вызывающие компоненты считаются либо работающими корректно, либо заменяются имитаторами. Тестирование модулей обычно является задачей их разработчиков.
Ошибка модуля. Ошибка, которая, скорее всего, будет выявлена при грамотном тестировании модуля.
Модуль является компонентом. Компонент представляет собой совокупность одного или более компонентов, которая может тестироваться как единое целое. Например, модуль, подпрограмма, функция, макрос, программа и подпрограммы, которые она вызывает, связанные процедуры и целые системы программного обеспечения.
Интерфейс между компонентами — любые средства, при помощи которых данные могут передаваться или совместно использоваться. Это может быть вызов подпрограммы, общий объект данных, глобальные данные, физический интерфейс, сообщение.
Тестирование интеграции-. Тесты, направленные на проверку взаимодействия и совместимости компонентов, успешно прошедших свои тесты. То есть
30 Глава 1 • Введение
компоненты А и В, которые прошли тесты компонентов, объединяются в новый компонент С = (А, В). Тестирование интеграции направлено на проверку согласованности получившейся совокупности. Интересующее нас поведение совокупности обычно исследуется с помощью интерфейса между компонентами.
Ошибка интеграции. Ошибка, которая, скорее всего, будет выявлена при грамотном тестировании интеграции.
Интеграция. Процесс тестирования интеграции, отладки интерфейса и исправления ошибок интеграции. Интеграция может изменить характер поведения и тем самым привнести новые ошибки. Интеграция обычно производится создателем компонентов, если за связываемые компоненты ответственен один человек. Зачастую ее независимо выполняет отдельный интегратор, если в создании компонентов участвовало несколько человек.
Тестирование компонента. Тестирование компонента отличается от тестирования модуля тем, что оно включает в себя тестирование вызываемых компонентов и объектов данных. Например, тестирование процедуры совместно с вызываемыми ею подпрограммами, тестирование процедуры и фиксированной таблицы данных. Разумное тестирование компонента подразумевает предварительную успешную интеграцию подчиненных компонентов и модулей и тестирование интеграции этих компонентов. В отличие от тестирования компонентов при тестировании модулей модуль когда-нибудь составит единое целое с относящимися к нему компонентами.
Ошибка компонента. Ошибка, которая, скорее всего, будет выявлена при тестировании компонента.
Системы программного обеспечения. Совокупность компонентов, такая, что определенные требования могут быть проверены, даже если некоторые компоненты отсутствуют или не подвергались тестированию.
Тестирование системы производится для проверки поведения системы, которая не может быть выполнена путем тестирования модулей, компонентов или тестирования интеграции. Например, тестирование, производительности, инсталляции, целостности данных, управления памятью, безопасности, надежности. В идеале тестирование системы предполагает, что все узлы были заранее успешно интегрированы. Тестирование системы часто осуществляется независимыми тестировщиками.
Ошибка производительности. Ошибка, главным симптомом которой является неудовлетворительная или заниженная производительность (например, низкая пропускная способность или увеличение задержки).
Ошибка безопасности. Ошибка, увеличивающая риск несанкционированного проникновения в систему, что позволит просматривать или изменять файлы, не обладая соответствующими правами.
Ошибка потери ресурсов. Ошибка, ведущая к потере динамически размещаемых ресурсов, таких как оперативная память или место на диске.
Системная ошибка. Ошибка, вероятность обнаружения которой путем тестирования модулей, компонентов или интеграции мала. Ошибка, проявляющаяся в поведении не отдельных компонентов, но системы целиком. Например, ошибка производительности, ошибка безопасности, ошибка потери ресурсов.
Модули, подпрограммы, программы, подсистемы. Приблизительные названия компонентов, расположенные по мере явного возрастания их размера.
1.3. О тестировании 31
Окружение. Совокупность аппаратных, программных средств и данных, в которых и посредством которых компоненты создаются, тестируются и используются. Сюда входят (но этим перечень не ограничивается) вызывающие и вызываемые компоненты, операционная система, аппаратные средства, компилятор, ваши средства тестирования (разумеется) и прочее, что может влиять на работу компонентов или зависеть от нее.
1.3. О тестировании
1.3.1. Тестировщик и программист
Повсюду в этой книге мы будем упоминать и противопоставлять друг другу «тестировщиков» и «программистов» так, как будто они являются разными людьми. Такое разделение может привести вас к мысли, что тестирование методом черного ящика предназначено только для независимых тестировщиков, но не для программистов. Другим ошибочным мнением является то, что я сторонник идеи, что тестирование и программирование должны выполняться различными людьми, (то есть должно проводиться независимое тестирование). Я хочу предотвратить и/или скорректировать такие ошибочные взгляды.
Говоря образно, программист должен носить две шляпы — шляпу программиста и шляпу тестировщика. Когда он выполняет тестирование, он должен надеть шляпу тестировщика и думать как тестировщик. Вот что представляет собой «тестировщик», для которого я пишу эту книгу. Итак, тестировщик может быть, а может и не быть тем же самым человеком, который пишет программы. Так как способ мышления при программировании и способ мышления при тестировании сильно отличаются, хорошая идея — просто рассказать о двух ролях, как будто бы их играют различные люди. Способ мышления в программировании известен давно и существует много книг по этой теме, поэтому не стоит специально на этом останавливаться. Способ мышления, применяемый при тестировании, возник относительно недавно, и именно поэтому эти способы сильно различаются. Методы тестирования, затрагиваемые здесь, предназначены как для независимых тестировщиков, так и для тех программистов, которые в данный момент тестируют свое или чье-либо программное обеспечение.
1.3.2. Почему мы тестируем программное обеспечение?
Для проведения тестирования программного обеспечения есть несколько весомых причин.
1. Обеспечение программистов информацией, которую они смогут использовать для предотвращения ошибок.
2. Обеспечение менеджеров информацией, которая необходима им для разумной оценки риска при использовании объекта.
3. Создание объекта, максимально свободного от ошибок.
32
Глава 1 • Введение
4. Создание проекта, поддающегося тестированию, то есть проекта, который можно легко проверить на соответствие, на искаженность и который будет легко сопровождать.
5. Проверка искаженное™ объекта с помощью как сформулированных, так и не сформулированных требований [MYER79]. Это еще называют «взломом программного обеспечения».
6. Проверить соответствие объекта (убедиться в его действенности), то есть показать, что он работает правильно.
Информация, необходимая для выполнения пункта 2, определяется степенью, до которой объект действует правильно (то есть количеством подтестов, пройденных и не пройденных), и некоторыми рамками, в пределах которых объект не может быть искажен. То есть пределом, до которого объект не взломан, и пределом, до которого он работает. Тот предел, до которого объект считается свободным от ошибок, является также границей, до которой он соответствует требованиям и не искажен. Таким образом, у нас есть три основных задачи: хорошее проектирование, искаженность, проверка соответствия.
Все, что пишут люди, содержит ошибки. Проведенное тестирование чего-либо не является эквивалентом утверждения, что это что-то свободно от ошибок. Программист не может думать обо всем — в особенности обо всех возможных взаимодействиях между различными характеристиками и между различными частями программы. Мы пытаемся взломать программу, так как только такой путь обеспечит нас уверенностью в том, что продукт готов к использованию.
Другая задача тестирования — это накопление информации для менеджмента. При наличии необходимой информации и достаточного количества тестов мы можем с достаточной уверенностью утверждать, что программа готова к использованию. В конечном счете это как раз то, за что платят тестировщикам, — помощь в создании полезной программы.
Наивысшая цель тестирования — это обеспечение качества: накопление информации, которая, вернувшись к программисту, поможет избежать ему прошлых ошибок и улучшить качество программного обеспечения в будущем.
Грязный тест (или негативный тест): тест, первичной целью которого является проверка искаженное™; то есть тест, предназначенный для того, чтобы взломать программу.
Чистый тест (или позитивный тест): тест, первичной целью которого является проверка соответствия; то есть тест, предназначенный для того, чтобы продемонстрировать корректную работу программы.
Тест является действенным, если в результате его выполнения выявляются симптомы существующих ошибок.
В спецификациях обычно указываются только те требования, которые должны быть проверены на соответствие (то есть на то, что объект должен делать), и не содержатся требования, которые должны быть проверены на искаженность (то есть на то, что объект не должен делать). Так как количество действий, которые объект должен выполнять, конечно, а количество действий, которые объект не должен выполнять, не ограничено, из общих соображений можно предположить, что
1.3. О тестировании 33
грязных тестов должно быть существенно больше, чем чистых. Так оно и есть на самом деле. В продуманных тестовых комплектах число грязных тестов относится к числу чистых как 4 : 1 или 5:1.
1.3.3. Стратегия тестирования
Стратегия тестирования, или методы тестирования — это систематические методы, используемые для отбора и/или создания тестов, которые должны быть включены в тестовый комплект. Это могут быть случайные вводы, тест, направленный на проверку моих подозрений, тест, направленный на проверку ваших подозрений, тест, направленный на проверку соответствия требованиям, тест, направленный на проверку искаженности; тесты, который мы выполняли последний раз, тесты, которые отличаются от тестов, которые мы выполняли последний раз. Мы выбираем стратегию, такую, что существуют правила, по которым мы можем определить, удовлетворяет данный тест стратегии или не удовлетворяет. В принципе, стратегия должна быть программируемой.
Стратегия является эффективной, если тесты, включенные в нее, с большой вероятностью обнаружат ошибки тестируемого объекта. Эффективность стратегии зависит от комбинации природы тестов и природы ошибок, на поиск которых эти тесты направлены. Как на войне и в бизнесе, здесь существуют эффективные и неэффективные стратегии. Более того, так как объект изменяется с целью исправления ошибок и увеличения его возможностей, типы ошибок, находимые у объекта, меняются со временем, и, следовательно, меняется эффективность стратегии. В то время как теоретически возможно, что стратегия по отношению к специфическим объектам совершенствуется во времени, на самом деле эффективность большинства стратегий со временем убывает.
Стратегия поведенческого теста основана на технических требованиях. Например: тест всех характеристик, упомянутых в спецификации, выполнение всех грязных тестов, вытекающих из требований. Тестирование, выполняемое с помощью стратегии поведенческого теста, называется поведенческим тестированием. Поведенческое тестирование называется также тестированием черного ящика. Для поведенческого тестирования также используется термин функциональное тестирование'. При поведенческом тестировании (в принципе, но не на практике) не обязательно знать, как объект сконструирован. Тема этой книги — поведенческое тестирование (тестирование черного ящика).
Стратегия структурного теста определяется структурой тестируемого объекта [BASI87, BEIZ90, NTAF88, OSTR96], Например: выполнение каждого оператора по меньшей мере один раз, выполнение каждой ветви но меньшей мере один раз, тестирование использования всех объектов данных, выполнение каждой команды
1 Термин «функциональное тестирование» обычно используется в литературе, по на практике предпочитается термин «тестирование черного ящика». Лучший и более старый термин, существующий в компьютерных науках, — «поведенческое тестирование». Проблемы с «функциональным тестированием» связаны с тем, что этот термин используется для обозначения некоторой стратегии тестирования, используемой, например, для тестирования математических функций. В этой книге три термина «функциональное тестирование», «тестирование черного ящика», «поведенческое тестирование» подменяют друг друга с доминированием термина «поведенческое тестирование».
2 Зак 770
34 Глава 1 • Введение
объектной программы, полученной при компиляции. Тестирование, выполненное с помощью стратегии структурного теста, называется также тестированием прозрачного ящика или тестированием белого ящика. Стратегия структурного теста требует полного доступа к структуре объекта — то есть к исходному коду. Эта книга только поверхностно затрагивает методы структурного тестирования.
Стратегия гибридного теста является комбинацией поведенческой и структурной стратегий [CLAR76, RICH81], Поведенческая, структурная и гибридная стратегии не противоречат друг другу, и ни про одну из них нельзя сказать, что она лучше других. Модули и низкоуровневые компоненты часто тестируются с помощью структурной стратегии. Большие компоненты и системы в основном тестируются с помощью поведенческой стратегии. Гибридная стратегия полезна на всех уровнях. Не существует лучшей стратегии, так как полезность стратегии зависит от природы тестируемого объекта, природы ошибок объекта и уровня ваших знаний.
1.3.4. Парадокс пестицида1
Большинство из нас предпочитают доделать дело до конца. Знать, что работа выполнена, выполнена правильно, и в подходящее время взять следующее задание. Тестирование программного обеспечения на это не похоже. Если вы хорошо сделали работу по выявлению ошибок и если люди из отдела обеспечения качества хорошо выполнили работу по передаче ваших исследований обратно программистам, то они, скорее всего, не повторят прошлых ошибок. Хороший программист, если у него есть время и необходимые ресурсы, обычно изучает проблемы, выявленные тестировщиками (или им самим), обобщает идеи и затем исследует свое программное обеспечение на предмет выявления и исправления в нем таких же или подобных ошибок.
Все методы тестирования имеют встроенные допущения о природе ошибок. Каждый метод тестирования нацелен на определенный набор ошибок. Если программист реагирует на результаты тестирования и информацию об ошибках сокращением и удалением этих ошибок, из этого следует, что его программа улучшается, а эффективность предыдущих тестов постепенно уменьшается. То есть ваш тест устаревает и вам приходится изучать, создавать и использовать новые тесты, основанные на новых методах отслеживания новых ошибок.
1.3.5. Природа и причины ошибок
Обратитесь к [BEIZ90] и [ANSI94] для подробного обсуждения ошибок и категорий ошибок. Главная причина, почему я использую термин «ошибка», а не официальный термин «дефект», это то, что «дефект» подразумевает, что кто-то должен нести за него ответственность. Предполагается недостаток добросовестности программиста, леность или некомпетентность. Ошибки, сделанные компетентным программистом, работающим на современном программном обеспечении, в соот-
' Это называется «парадокс пестицида» по аналогии с явлением в сельском хозяйстве, когда личинки долгоносика, приспособившись к яду, вынуждали нас создавать все более мощный яд, который! приводил к возникновению все более устойчивых к этому яду личинок, или искать принципиально иное решение.
1.3. О тестировании 35
ветствующей среде разработки программного обеспечения, не являются дефектами (надеюсь, вы не будете обвинять нас в излишней мягкости).
В хорошем, продуманном программном обеспечении источником ошибок являются сложность и ограниченная способность людей к борьбе со сложностью, а не тупость. Чем лучше программный процесс, тем менее вероятно, что ошибки, которые сохраняются в течение поведенческого тестирования, являются ошибками конкретных программистов. Большинство ошибок, которые мы находим при помощи поведенческого тестирования в хорошо разработанном, качественном программном обеспечении, являются следствием непредсказуемого взаимодействия между компонентами или между объектами, или результатом непредсказуемых побочных эффектов, вызываемых совершенно невинными, на первый взгляд, процессами.
Если ошибки, найденные в результате поведенческого тестирования, — простые и их легко распределить по категориям, это говорит о том, что неудовлетворителен технологический процесс, а не программист. Мы принимаем на веру, что программист хорбшо обучен, обладает надлежащими инструментами и компетентен1. Это называется «гипотезой компетентного программиста». Так как человек, который проводит поведенческое тестирование, не обязательно является тем же самым человеком, который пишет программное обеспечение, важно иметь в виду эту гипотезу, считая, что человеческие недостатки и неприязнь не вторгаются в процесс программирования.
Полезны три широкие категории ошибок: ошибки модулей/компонентов, ошибки интеграции и системные ошибки, названные так в соответствии с той фазой разработки, в которой, вероятнее всего, могут быть найдены ошибки.
Ошибки модулей/компонентов найти и избежать легче всего. Когда мы тестируем систему и тест выявляет ошибку, мы не можем сказать, что явилось этому причиной, — ошибка модуля, ошибка интеграции или системная ошибка. Это мы узнаем только после того, как ошибка будет устранена. Так как системное тестирование требует гораздо больших ресурсов, чем тестирование модулей/компонентов, выявление ошибок модулей, оставшихся к моменту начала системного тестирования, представляет собой напрасную трату сил. Таким образом, задачей тестирования модулей/компонентов является сокращение числа ошибок, которые переходят в последующие стадии процесса.
Ошибки интеграции более трудны для выявления и предотвращения, так как они возникают при взаимодействии между компонентами, которые являются корректными сами по себе. Взаимодействие компонентов подчиняется законам комбинаторики, что означает, что их число растет как п2 (как квадрат числа задействованных компонентов) или даже хуже (например, как п! — факториал числа компонентов). Цель тестирования интеграции — убедиться в том, что когда мы переходим к системному тестированию, некорректных взаимодействий между компонентами совсем не осталось или осталось мало.
Системное тестирование — это качественно новый уровень тестирования. Даже если все особенности были проверены при тестировании модулей/компо
1 Если некомпетентный программист нс может стать компетентным, избавьтесь от него. Если процесс содержит ошибки, исправьте его. Ни от кого нельзя ожидать продуктивности без надлежащих
инструментов.
36 Глава 1 • Введение
нентов или при тестировании интеграции, нам следует включить поведенческое тестирование как составную часть системного тестирования. При тестировании модулей/компонентов или интеграции то, что мы тестируем, имеет детерминированное поведение. При системном тестировании у пас, однако, возникают дополнительные трудности, связанные с многозадачностью. Следовательно, порядок, в котором будут возникать те или иные ситуации, уже не может быть с уверенностью предсказан. Такая неопределенность и проблема синхронизации являются богатой почвой для более сложных ошибок. Основная цель системного тестирования — убедиться в том, что в недетерминированном мире программное обеспечение ведет себя так же предсказуемо, как и в детерминированном мире.
1.3.6. Когда надо остановиться
Процесс тестирования потенциально бесконечен, как с теоретической, так и с практической точки зрения. Тем не менее, даже зная, что ошибки остались, мы должны завершить тестирование, так как если мы этого не сделаем, все усилия будут напрасны. Если у нас есть большое количество опытных данных, то можно создать статистическую модель, которая даст нам понимание того, насколько рискованно прекратить тестирование и предложить программу для коммерческого использования [HAML94, MUSA90].Ecjih вы почувствовали некоторую осторожность моей формулировки, запомните это, так как обоснованность таких моделей не очевидна и не бесспорна. Тем не менее, прогресс не стоит на месте, и большинство полезных моделей нуждаются в информации, которую мы собираем при тестировании, особенно в ходе системного тестирования, и которая является частью данных, используемых для определения момента завершения тестирования.
1.3.7. Тестирование черного ящика — это еще не все
Тестирование поведения, это еще далеко не все, что мы должны сделать. Одного тестирования мало. Если мы рассматриваем все тестирование, которое мы можем и должны провести с программой, от начала и до конца, поведенческое тестирование занимает 35-65% от общего времени1. Относительная полезность поведенческого тестирования зависит от проекта. Если в проекте все характеристики жестко запрограммированы с использованием специальной логики, то структурные методы превалируют. Когда проект основан на использовании общих алгоритмов, чье специфическое поведение определяется при помощи таблиц данных или параметров вызова, то преобладает поведенческое тестирование. Важность поведенческого тестирования подобна важности различных методов навигации. Что именно является наиболее важным, зависит от погоды, от близости берега, от того, какими приборами вы располагаете, и так далее. Нам следует прислушаться к мо-
’ В объектно-ориентированном программировании увеличивается важность поведенческого тестирования. Ясно, что методы поведенческого тестирования будут более важны для создания программного обеспечения при помощи надежной библиотеки многократно используемых объектов, чья внутренняя работа и структура сознательно от нас скрыты; ведь нам, возможно, придется проводить гораздо больше тестов, для того чтобы быть уверенными в надежност и объектов | BERA94, NORT94J.
1.3. О тестировании 37
ему любимому автору Натаниелю Боудичу [BOWD77]: «Мудрый штурман никогда не полагается только на один метод».
1.3.8. Тестирование — это еще не все
Ошибки, обнаруженные в процессе тестирования, должны нас, с одной стороны, радовать, с другой стороны — огорчать. Радовать, так как это означает, что на одну проблему стало меньше; огорчать, поскольку это указывает на несовершенство нашего процесса разработки программного обеспечения. Радовать, так как мы узнали, как усовершенствовать процесс и предотвратить подобные проблемы в будущем. Мы создаем программы около 40 лет, и наиболее важный урок, который мы усвоили, звучит следующим образом: «Делайте это как можно раньше!»
Чем раньше ошибки найдены и исправлены, тем дешевле обходится их исправление. Усилия, затрачиваемые до начала проектирования, меньше, чем усилия, затрачиваемые в течение проектирования. Усилия, затрачиваемые до начала написания кода, меньше, чем усилия, затрачиваемые после написания кода. Усилия, затрачиваемые на тестирование модулей, меньше, чем усилия, затрачиваемые на системное тестирование, которые, в свою очередь, меньше усилий, затрачиваемых после инсталляции программы. Ниже приводится несколько эффективных методик, не связанных с тестированием, приблизительно в том порядке, в котором они должны применяться.
Создание прототипа. Прототипом программы является урезанная реализация, которая имитирует то поведение программы, которое необходимо пользователю [STAK89], Цель этого — дать нечто осязаемое пользователю, чтобы он мог нам сказать, является ли полезным для него то, что мы создаем, будет ли он это впоследствии покупать. Прототип на самом деле не обязан работать и обычно не работает. Мы создаем программное обеспечение для пользователей. Привлечение их к процессу как можно раньше является эффективным подходом, позволяющим избежать грубых промахов.
Анализ требований. Требования задают содержание проектирования [ YEH R80], Если требования несовместимы, то проектирование не может быть корректным. Анализ требований означает проверку требований на логическую непротиворечивость, тестируемость, легкость реализации. Мы не можем ожидать, что пользователь обеспечит нас адекватными требованиями, так как он не умеет этого делать. Мы все были бы похожи на машину, которая, не загрязняя окружающую среду, проезжает 100 километров на литре воды, везет 12 взрослых людей и помещается на стоянке 3 х 2 м. Мы все были бы похожи на «Мерседес» по цене «Запорожца». Нашей целью как создателей программного обеспечения не является сделать невозможное и удовлетворить все капризы пользователей. Нашей целью является разработка продукта, соответствующего своей цене.
Формальный анализ [ANDE79, ВАВЕ94, HANT76, WING94]. Мы не можем тестировать все, да и нет в этом необходимости . Это особенно справедливо в случае поведенческого тестирования. Множество вещей, которые мы не можем на практике протестировать в настоящее время (и вряд ли когда-нибудь сможем), включает в себя все возможные способы взаимодействия характеристик друг с
38 Глава 1 • Введение
другом. Тестирование поведения программы при каждом возможном варианте инсталляции, является другой неосуществимой задачей. То же самое относится к взаимодействию между нашим пакетом программ и другими пакетами, проверке защищенности нашей программы, некоторым коммуникационными протоколам и множеству алгоритмов. Всякий раз, когда по ряду причин сложность тестирования увеличивается быстрее, чем сложность самого тестируемого объекта, формальный анализ, возможно, математический, является предпочтительнее тестирования. Мы, однако, нуждаемся в тестировании, чтобы убедиться, что сам наш анализ в должной мере свободен от ошибок1.
Проектирование. Хороший проект имеет мало ошибок и легко тестируется. Намного легче спроектировать что-то, что не может быть протестировано, чем что-то, поддающееся тестированию. Намного легче спроектировать что-то, что совершенно невозможно сопровождать, чем спроектировать что-то, что возможно. Самые грамотные требования сводятся на нет непродуманными проектами, проверить которые невозможно при помощи конечного числа тестов.
Формальное инспектирование [FAGA76, GILB93, WEIN90] является первичным методом предотвращения ошибок, и это неоднократно подтверждалось. Процесс разработки программного обеспечения, который не включает в себя формальное инспектирование, очевидно дефектен, и устранение ошибок в нем намного больше зависит от тестирования.
Самотестирование. Тестирование, выполняемое самими программистами, гораздо более эффективно, чем тестирование, выполняемое кем-то еще. То же самое относится к тестированию группой, производящей данное программное обеспечение. Аналогично тестирование в организации, разрабатывавшей программное обеспечение, эффективнее, чем внешнее тестирование (то есть бета-тестирование) того же самого программного обеспечения. Это не отвергает идеи, что независимое тестирование может быть действенно, так как эффективность — не единственный критерий, определяющий, кому и какое тестирование проводить.
Если независимый тестировщик повторяет тест, ранее выполненный разработчиком, или просто выполняет тестирование, которое следовало бы выполнить во время разработки, в этом случае независимое тестирование совсем не приносит никакой информации, фактически не имеет смысла. Такое тестирование (независимое повторение тестов разработчика) может быть полезно, только если разработчик некомпетентен или предумышленно делает не все корректно. А это противоречит нашей гипотезе о компетентности программиста.
Цель независимого тестирования — обеспечить различные ракурсы, следовательно, различные тесты; более того, проводить эти тесты в среде с более широкими возможностями (и поэтому более сложной и дорогой), чем это доступно разработчику. Цель самотестирования — удалить те ошибки, которые могут быть найдены
' Все, что мы делаем в процессе разработки программного обеспечения, подвержено ошибкам. Формальное (то есть математическое) доказательство корректности алгоритма точно так же уязвимо для ошибок, как любой другой процесс, выполняемый человеком. Убедиться в этом легко: достаточно вспомнить о количестве статей в математических журналах, озаглавленных: «Контрпример к теореме...».
1.4. Процесс разработки программного обеспечения 39
посредством малых затрат в простейшей детерминированной среде путем тестирования модулей/компонентов или низкоуровневого системного тестирования.
Инструменты. Мы считаем исходные синтаксические ошибки кода просто помехами, так как у нас есть инструменты (компиляторы), которые находят такие ошибки гораздо лучше, чем мы сами. В наших языках программирования и компиляторах к настоящему времени появились совершенные детекторы ошибок, автоматизировавшие то, что когда-то являлось сложной для человека задачей. Если ошибка может быть определена (и/или исправлена) автоматически, это должно быть сделано. Не пытайтесь отключать автоматизацию и инструменты, выявляющие ошибки. Исключить надо как раз подверженную ошибкам ручную обработку кода, тогда, когда доступна автоматизация. Существует все более увеличивающаяся разница между инструментами, которые в действительности используют программисты и тестировщики, и инструментами, которые разрабатывают для них исследователи. Ликвидируйте этот разрыв! Он стоит того. Это окупится. \ Мы, как тестировщики, должны всегда стремиться к тому, чтобы можно было вообще обойтись без тестирования. Это наша недостижимая цель. Тестирование является контролем качества. Обеспечение качества означает предотвращение ошибок. Всегда выгоднее предотвратить ошибки, чем их потом находить. Но эта цель недостижима, так как история показывает, что автоматизация процесса и предотвращение предыдущих ошибок являются предпосылками к встрече со все более сложными задачами, которые ставят перед нами нужды пользователей.
Наш текущий технологический процесс (каким бы несовершенным он ни был) является более совершенным, чем технологический процесс, использовавшийся всего десятилетие назад. Мы уже не программируем так, как это делали десять лет назад, но мы пишем новые программы, несущие в себе все более сложные ошибки. Наши пользователи повышают свои требования к качеству, а, следовательно, растут требования к нашим возможностям и методам тестирования.
1.4. Процесс разработки программного обеспечения
1.4.1. То, что на самом деле важно
Наиболее важные моменты, касающиеся разработки программного обеспечения, легко перечислить. Нам необходим процесс. Процесс должен быть понятен. Процессу должны следовать.
Процесс. Я убежден, что процесс используется в любом случае, поскольку даже хаос в своем роде является процессом. Наличие процесса означает, что существует возможность предсказать, что будет происходить с программным продуктом на следующем шаге. Такая предсказуемость возникает, когда появляется потребность в данном продукте, и завершается, когда продукт устаревает.
Наличие процесса еще не означает существования детально разработанной для него документации. Ряд наилучших проектов на моей памяти имели крайне ограниченный объем документации. И наоборот, когда меня спрашивают о том, что
40 Глава 1 • Введение
необходимо иметь, я ссылаюсь на подробно задокументированное описание процесса, оставшееся после одного из самых крупных провалов из тех, что мне доводилось видеть. Объем формальной документации для конкретного проекта напрямую зависит от размера этого проекта. Документы (если они читаются) — это наиболее эффективный способ донести детали проекта до человека, не разбирающегося в данном процессе и в предпосылках к проекту. Контролировать процесс, а значит обеспечить его качество обычно проще, если шаги в процессе задокументированы.
Он понятен. Если процесс непонятен тому, кто должен его понимать, то этому процессу невозможно следовать. Понимания можно добиться, читая документацию, если только людям дается время на осознание и суммирование того, что они прочли. Может в этом помочь и видео. Обучение общим методам работы с процессами лишено смысла, поскольку портят дело обычно специфические особенности, а не общие закономерности. Вам будет необходимо освоить особенности некоторого конкретного процесса.
Ему следуют. Наличие понятного процесса еще не означает, что ему будут следовать. Индикатором того, что в процессе возникли проблемы, служит возникновение расхождения между формальным процессом (то есть задокументированным процессом) и тем, что фактически делают люди. В таких случаях я встаю на сторону программистов и тестировщиков, идущих своим путем, а не тех умников, которые этот процесс придумали. Если процесс игнорируют, то это, скорее всего, потому, что он не работает, а не потому, что программисты — закостенелые ретрограды. Большинство людей, хотя и не все, если им указать более эффективный способ сделать что-либо и обеспечить инструментами и навыками, необходимыми для работы, будут следовать этому новому пути. Процессом перестают руководствоваться в случае, если он ущербен, если существуют преграды для его использования или если нс хватает необходимых ресурсов (то есть навыка, времени, инструментов).
1.4.2. Десять(16) и одна заповедь управления процессом
В таком разделе во множестве разных книг вы можете найти тщательно разработанные наборы блок-схем процедур с таинственным образом обозначенными прямоугольниками и стрелками различных видов и стилей, входящими в эти прямоугольники и выходящими из них во всех направлениях. Я не собираюсь здесь этого делать, поскольку усвоил одно еретическое правило: блок-схемы и модели процесса ничего не значат. Они ничего не значат, поскольку провал или успех процесса разработки программного обеспечения никоим образом не определяются моделью данного процесса. Культурные, этнические, прикладные и национальные особенности оказывают гораздо большее влияние на процесс, нежели грандиозные теории процессов. Утверждение «Процесс А лучше процесса Б» равносильно утверждению «Японский язык лучше тагальского». Говорить, что рецензирование предварительного проектирования должно предварять кодирование, то же самое, что говорить: «В предложении глаголы должны идти впереди существительных». Специфические особенности языка, а также порядок слов очень важны для гово
1.4. Процесс разработки программного обеспечения 41
рящего на этом языке, а также для тех, кто занимается переводами с одного языка на другой, но не они определяют способность носителя языка к общению.
Итак, мы не будем рассматривать модель водопада [ROYC70] или спиральную модель [ВОЕН86], пошаговую детализацию, нисходящую стратегию, восходящую стратегию и все такое прочее. Ниже приводятся составляющие, которые вам надо искать в любом эффективном процессе, подобно тому, как вы ищете существительные, глаголы и другие части речи в разговорном языке, но без указания, в каком порядке они должны быть скомпонованы, чтобы получился осмысленный процесс.
Дорожная карта процесса. Необходимо понимать в каждый момент времени, на какой стадии процесса находитесь вы и ваша программа. Если вы предпочитаете блок-схемы процесса — это очень хорошо, но некоторые люди отдают предпочтение комментариям и спискам. Грамотная дорожная карта процесса разбивает процесс на элементарные шаги, которые легко понять и контролировать. Она достаточно детальна, чтобы вы или кто-нибудь другой мог легко сориентироваться в ней, но эта детализация не чрезмерна и не подавляет индивидуальность и творческое начало.
Управление процессом. Управление процессом нс подразумевает жесткого соблюдения детально расписанного графика, как не означает оно и тоталитаризма и подавления индивидуальности. Управление процессом подразумевает наличие эффективных механизмов, при помощи которых все участники процесса могут получать информацию, касающуюся улучшения тех частей процесса, в которых они напрямую задействованы. Управление процессом включает в себя обратную связь, обучение и широкий круг возможностей, и направлено на создание атмосферы в коллективе, в которой люди будут стремиться улучшить себя, свой продукт и мир вокруг.
Количественные измерения и метрики. Мы имеем дело с инженерной наукой, а не с искусством, и потому объективность — требование, необходимое для управления процессом. В инженерной науке количественные измерения являются залогом объективности. В компьютерных науках количественные измерения опираются главным образом на метрики [BERL94, FENT91, GRAD87, GRAD92, MOLL93, ZUSE90, ZUSE94].
Контроль конфигурации так же стар, как Имхотеп, великий строитель пирамид. Он означает, что в любой момент времени мы можем проверить результат нашего труда (программу, требования или, скажем, тестовый комплект) и узнать: кто, что, где, когда, зачем и как. Конфигурация всего, с чем планируется дальше работать, должна контролироваться, а все, что не контролируется, просто не входит в наш продукт.
Требования. Что мы создаем? Все в курсе? Все имеют в виду одно и то же? Здесь я настаиваю на документировании, поскольку человеческая память ненадежна.
Прослеживаемость требований. Откуда взялись требования? Если, как часто бывает, требования изменяются в процессе разработки программы, на какие другие требования это повлияет? Прослеживаемость означает, что требования находят свое отражение в компонентах программного обеспечения и наоборот. Однако не требуйте и не ожидайте взаимно однозначного соответствия, так как требования и компоненты не отображаются в стиле «один к одному».
42 Глава 1 • Введение
Стратегические тонкости. Для кого разрабатывается данное программное обеспечение? Что ожидают заказчики и пользователи от программы, кроме обычной практичности? Не станет ли эта программа кошмаром для пользователя? Будет ли она вне конкуренции? Улучшит ли она нашу репутацию? Принесет ли она большой доход? Будет ли она самой быстрой? Существуют сотни таких стратегических задач, и руководство определяет относительную важность каждой из них. Без подобного руководства (желательно заданного в количественной форме) невозможно определить цели проектирования или понять, когда эти цели достигнуты.
Критерии соответствия требованиям. Как мы узнаем, что продукт удовлетворяет требованиям? Как выбрать объективные критерии соответствия требованиям так, чтобы они были связаны с каждым требованием по отдельности и со всеми вместе?
Ответственность. Кто и за что отвечает.
Критерии завершенности. Как узнать, когда данная часть программного обеспечения (ПО) будет готова к переходу на следующую стадию процесса разработки? Что является реальным, объективным признаком завершенности?
Критерий готовности. Как узнать, когда данная часть ПО будет удовлетворять условиям, необходимым для перехода к следующей стадии процесса разработки? Подобное описание вовсе не избыточно. Компонент программы может пройти через множество стадий или использоваться множеством других компонентов, каждый из которых имеет свои критерии готовности. Как правило, критерий завершенности компонента является объединением всех критериев готовности для этого компонента.
Анализ. Анализ — это инженерный процесс, при помощи которого проектирование «наполняется» требованиями (получает полные требования как входной набор данных). Он может быть полностью интуитивным или полностью формальным. Интуитивный анализ, зачастую действенный, не может, однако, быть с легкостью воспринят другими людьми, и, следовательно, какой-либо формальный, часто математический анализ необходим, даже просто для памяти.
Проектирование. Это все, что касается сути дела, не так ли? Проектирование должно предварять программирование или, по крайней мере, проводиться одновременно с ним. Инженеры, прежде чем строить, занимаются проектированием, поскольку это уменьшает риск. Проектные ошибки — это ошибки на бумаге, и обходятся они гораздо дешевле, нежели сваренная сталь или скомпилированный код.
Проверка соответствия проекта. Как нам убедиться в том, что проект будет работать, если мы раньше ничего подобного не разрабатывали? Проверка соответствия проекта — это совсем не то же самое, что проверка соответствия реализации проекта. Мосты рушатся из-за плохих, не прошедших проверки проектов, а не из-за плохих материалов и неквалифицированной рабочей силы. Чем новее проект, тем важнее его проверить перед началом конструирования. Проверка соответствия производится с помощью моделей, прототипов и инспектирования проектирования.
Программирование. Написание кода в соответствии с проектом и тестирование его с целью убедиться, что мы создали именно то, что и собирались создать.
1.5. Вопросы для самопроверки 43
Каменщик проверяет горизонтальность своей кладки с помощью уровня, а программист — с помощью тестов.
Интеграция. Единое целое по своим возможностям существенно больше, чем сумма отдельных частей. Только у тривиальных, модельных программ уровень сложности системы эквивалентен сумме уровней сложности ее составляющих. Архитектор тратит не меньше времени на придание зданию законченного вида, чем на продумывание шагов по его возведению. Об интеграции не стоит и говорить, если не существует плана интеграции и соответствующих тестов интеграции, будь то объединение двух низкоуровневых подпрограмм или нескольких сотен квазиавтономных систем.
Тестирование: Тестирование требуется везде, где работают люди. Тестирование — это основная составляющая самоуважения и гордости за свое мастерство. Механик, который не проверяет результат свой работы микрометром, или негодяй, или дурак. Программист, поиском ошибок которого занимаются впоследствии только другие люди, не уважает себя, за исключением, возможно, странной гордости за быстрое клепание огромного количества непроверенных и полных ошибок программ.
1.5. Вопросы для самопроверки
Дайте определение следующих терминов: анализ, поведенческое тестирование, тестирование черного ящика, слепота, ошибка, свободный от ошибок, вариант, чистый тест, случайная корректность, комбинаторный, гипотеза о компетентном программисте, компонент, ошибка компонента, тестирование компонента, контроль конфигурации, проверка соответствия проекта, грязный тест, эффективная стратегия, эффективный тест, критерии готовности, среда, критерии завершенности, не пройденный тест, отказ, опровергаемый, искаженность, дефект, характеристика, конечное состояние, функциональное тестирование, тестирование прозрачного ящика, гибридная стратегия, начальное состояние, ввод, интеграция, ошибка интеграции, тестирование интеграции, интерфейс, отрицательный тест, объект, наблюдаемый, оракул, итог, соответствие итогов, пройденный тест, парадокс пестицида, ошибка производительности, положительный тест, управление процессом, программирование, прототип, цель тестирования, обеспечение качества, контроль качества, требования, анализ требований, прослеживаемость требований, критерий соответствия требованиям, ошибка потери ресурсов, действенный тест, ошибка безопасности, система программного обеспечения, спецификация, состояние, структурное тестирование, подтест, симптом, система, системная ошибка, системное тестирование, тест, проектирование теста, сценарий теста, стратегия тестирования, тестовый комплект, тестируемый проект, протестированный, тестирование, методы тестирования, модуль, ошибка модуля, тестирование модуля, проверка соответствия, критерий соответствия, тестирование белого ящика.
Графы и отношения
2.1. Обзор
Графы рассматриваются как основной концептуальный инструмент тестирования.
2.2. Основные термины
Внешние термины: приложение, массив, конец стрелки, начало стрелки, банкомат, двусторонний, ветвь, ошибка, статистика ошибок, вычисление, CASE, код, данные, означать, DO...WHILE, END, динамическое связывание, время выполнения, выборка, файл, FOR...DO, функция, IF-THEN-ELSE, входное значение, инспектирование, список, цикл, меню, опция, модель, мышь, естественный язык, объектно-ориентированное программирование, путь, платежная ведомость, PRINT, вероятность, шаг обработки, программа, ветвь программы, программное управление, вход программы, выход программы, путь программы, оператор программы, программист, язык программирования, READ, RETURN, экран, программное обеспечение, спецификация, электронная таблица, оператор, метка оператора, ограничение по памяти, линейный оператор, подпрограмма, таблица, шаблон, инспектирование теста, модельная программа, транзакция, TRANSMIT, UNDO, величина, переменная, текстовой редактор.
Внутренние термины: поведенческое тестирование, ошибка, ввод, объект, действенный тест, спецификация, состояние, тестирование.
Графы — это основополагающий инструмент тестирования. Для тестирования используются масса различных моделей на основе графов, такие как граф потока управления, граф потока данных, дерево вызовов, граф конечного автомата, граф потока транзакций. Прежде всего мы обсудим абстрактные графы, чтобы ознакомиться с терминологией, которая будет полезна и неизменна при рассмотрении любых графов.
2.2. Основные термины 45
Отношения'. Определенная связь между объектами. Если А и Б — это объекты, а к — отношение, A R Б означает, что А находится в отношении & к Б. Чтобы обозначать отношения, мы будем использовать курсив, например: А связано с Б, Сэм — отец Билла, А вызывает Б, объект данных А используется для вычисления значений величин для объекта данных Б; за действием А следует действие Б. Задача тестирования состоит в том, чтобы убедиться, что все объекты имеют заданные отношения друг с другом.
Графы являются набором объектов, отношений между этими объектами и спецификаций (представленных, скажем, в виде списка), указывающих, какие объекты связаны и каким образом.
Узел. Объекты в графах называются узлами. Узлы изображаются окружностями. Задача тестирования — убедиться, что граф имеет все заданные узлы и не более того.
Имя узла. Каждый узел имеет уникальное имя. Если объекты является файлами, имена узлов могут быть именами файлов; если объекты — это программы или операторы программ, имена узлов могут быть именами программ или метками операторов соответственно. Ни свойства графа, ни свойства объектов, представленных в нем, не зависят от того, какие имена мы дадим узлам.
Вес узла. Узлы могут иметь свойства. Эти свойства называются весом узла. В этой книге в качестве веса узла мы будем использовать, например: состояние программы, значение переменной, функцию, которая' описывает, какая из нескольких величин может быть использована для вычисления чего-либо, имя другого объекта. Задача тестирования — убедиться, что узлы с заданным весом имеют ожидаемый вес.
Связь. Стрелка или линия, которая соединяет узлы, используется для иллюстрации конкретного отношения между этими узлами. Например, если суть отношения описывается как «А и Б — братья», мы соединяем А и Б линией, чтобы отметить этот факт. Если в нашей модели определено только одно отношение, мы можем не надписывать каждую связь, чтобы обозначить это отношение. Если между объектами может быть несколько отношений, мы можем помечать связи метками заданных отношений. На рисунке между узлами А и Б существуют два отношения: 0 — «А и Б — дети одних родителей» и S — «А и Б — друзья». Задача тестирования — проверить, что все связи находятся там, где и должны находиться, и что каждой связи соответствует определенное отношение.
Друзья
Дети одних
родителей
46 Глава 2 • Графы и отношения
Параллельные связи. Две или более связей между двумя узлами. Параллельные
связи используются, если между двумя узлами существуют несколько отношений.
Имя связи. Каждая связь имеет уникальное имя. Существует несколько способов обозначить связи. Мы будем часто использовать числа в качестве имен узлов, поэтому для имен связей мы будем применять строчные буквы. Другой способ дать имя связи — использовать имена соединяемых узлов. Например, связь между узлами 17 и 34 мы назовем (17, 34). Это правило не годится для графов с несколькими связями между двумя узлами. Нам не обязательно всегда указывать имя связи, в таких случаях мы его просто опускаем. Ни свойства графа, ни свойства объектов и отношений, которые этот граф представляет, не зависят от того, как мы назовем связи.
"->(17, 34)<^
17) - >(34
Вес связи. Связи могут обладать свойствами. Такие свойства называются весом связи. Простейшим возможным весом связи является факт ее существования. Примером веса связи может служить отношение или все отношения между двумя объектами. Если узлы обозначают шаги обработки, а связи показывают последовательность этих шагов, то весом связи может быть: время выполнения программы по данному пути, вероятность выполнения именно этого пути (этой последовательности), тот факт, что будет вызван определенный объект данных. Свойства модели, изображаемой графом, напрямую зависят от веса связей. Задача тестирования — убедиться, что связи с весом имеют ожидаемый вес.
Направленная связь. Направленная связь изображается стрелкой. Направленные связи используются для обозначения несимметричных отношений: отношений, существующих лишь в заданном направлении. Примеры несимметричных отношений: А отец Б, за А следует Б, Б использует А, А вызывает Б. Большинство отношений в тестировании являются несимметричными, то есть в большинстве тестовых моделей используются направленные связи. Если к — несимметричное отношение, и А & Б, из этого нс следует Б & А. Задача тестирования — убедиться, что все направленные связи имеют заданные направления.
/"~> Отец Z Лито)-------Пол
2.2. Основные термины 47
Ненаправленная связь. Связь, соответствующая симметричному отношению, то есть двустороннему отношению. Строго говоря, к — симметричное отношение, если из факта A R Б следует (в соответствии с природой отношения) Б к А. Симметричные отношения изображаются двусторонними стрелками, поэтому мы обычно опускаем стрелки на концах линий. В первом примере на рисунке две противоположно направленные стрелки могут быть заменены или двусторонней стрелкой или простой линией, поскольку отношение «дети одних родителей» симметрично. В третьем примере, напротив, несмотря на то, что существуют отношения в обоих направлениях, они различны и несимметричны. Симметричные отношения довольно редко встречаются в тестировании, вот несколько примеров таких отношений: А и Б родственники, А и Б женаты, А и Б соседи по комнате. Задача тестирования — убедиться, что все симметричные отношения на самом деле симметричны.
Дети одних родителей
,Алия
Пол
Дети одних родителей
Дети одних
родителей
Алия,
Пол г*
Брат
Сестра
Граф. Граф — это набор узлов, имен узлов, весов узлов, связей, имен связей, весов связей и отношений между узлами. Если между двумя узлами существует отношение, то между ними есть связь.
ВОПРОС: Что вы делаете, когда вам встречается граф?
ОТВЕТ: Исследую его!
Направленный граф. Граф, в котором все связи направлены. Большинство графов в тестировании — направленные. Задача тестирования — убедиться, что направления связей совпадают с заданными.
48 Глава 2 • Графы и отношения
Ненаправленный граф. Граф, в котором все связи ненаправленные. То есть ни одна связь в нем не имеет направления. Задача тестирования — убедиться, что все ненаправленные связи действительно являются двусторонними.
Входящая связь. Связь, входящая в узел. В этом случае стрелка указывает на узел.
Входной узел. Узел без входящих связей. Хотя у программы обычно есть входные точки (например, BEGIN), графы, моделирующие поведение программ, могут и не иметь входных узлов.
НАЧАЛО
Исходящая связь. Связь, выходящая из узла. В этом случае стрелка начинается на узле. Связь может быть одновременно и входящей, и исходящей. Это означает, что она начинается и заканчивается на одном и том же узле (например, цикл).
Узел ветвления. Узел с двумя или более исходящими связями. В языках программирования примерами узлов ветвления служат операторы CASE или IF-THEN-ELSE. На рисунке узел имеет три ветви. Обратите внимание, что это узел ветвления в графе, моделирующем поведение программы, в самой же программе соответствующего ветвления может и не быть.
2.2. Основные термины 49
Выходной узел. Узел без исходящих связей. На рисунках изображены выходные узлы, поскольку ни одна стрелка на них не начинается. Хотя у программы обычно есть выходные точки (например, END), графы, моделирующие поведение программ, могут и не иметь выходных узлов.
Путь. Поставьте карандаш на какой-либо узел на рисунке (например, на 14) и следуйте по стрелкам до другого узла (например, узла 17); это и есть путь от узла 14 к узлу 17. Однако если вы можете прочертить путь на графе, это не значит, что ваша программа может повторить этот путь. Путь в этом контексте не обязательно является путем в коде программы. В поведенческом тестировании мы рассматриваем пути в моделях, описывающих поведение программного обеспечения. Такие пути могут соответствовать путям в программе, а могут и не соответствовать им.
Проходимый путь. Путь в модели, для которого существует такой набор входных значений, что, используя их, программа может пройти по этому пути.
Непроходимый путь. Путь в модели, который невозможно воспроизвести в программе, какой бы набор входных значений мы ни взяли.
Путь вход—выход. Путь от входного узла к выходному узлу. Если отдельно не оговаривается, под термином «путь» подразумевается «путь вход—выход».
Сегмент пути. Обычно путь, не являющийся путем вход—выход.
Имя пути. Существует два способа назвать путь: по именам узлов вдоль этого пути или по именам связей вдоль пути. Если мы назовем путь на следующем рисунке по именам узлов, то получим: «14,99,12,17», если по именам связей, то «кгт».
50 Глава 2 • Графы и отношения
Длина пути. Существует два способа измерить длину пути. Можно воспользоваться числом узлов вдоль этого пути или количеством связей вдоль пути. В данной книге мы, как правило, будем считать связи. Предыдущий рассмотренный путь был длиной в три связи или четыре узла.
Цикл. Путь, в котором как минимум один узел встречается больше одного раза. Иначе говоря, это путь, в имени которого больше одного раза встречается имя узла (связи), в зависимости от того, как строится имя пути — перечислением узлов или перечислением связей. В примере на рисунке существует циклический путь akrmbakrmb или 7,14,99,12,17,7,14. Попробуйте найти на этом графе все циклические пути.
Нециклический путь. Путь, в котором нет циклов. Это значит, что в его имени ни разу не повторяются имена узлов (связей).
2.3. Примеры графов, используемых
в тестировании
2.3.1. Обзор
В основе всех моделей тестирования лежат графы. Они описывают определенные отношения между определенными объектами. Если вы сможете определить все объекты и отношения между ними, вы сможете составить полную картину при помощи графа. Для построения модели (графа) вам надо определить:
1. Рассматриваемые объекты (узлы).
2. Отношения, которые должны существовать между узлами.
2.3. Примеры графов, используемых в тестировании 51
3. Какие объекты связаны друг с другом (связи).
4. Свойства, которыми могут обладать связи — веса связей.
Отдельный вопрос — вдохновляет ли вас данная модель (граф) на написание действенного теста. Модель — дело вкуса. То, что нравится вам, может не нравиться мне и наоборот. Однако существуют модели, которые большинство людей считает полезными.
2.3.2. Модель потока транзакций (глава 6)
Объекты. Шаги в процедуре транзакций, такие как проверка платежной ведомости, получение денег из банкомата. Каждому шагу в процессе транзакций соответствует один узел.
Отношение. «Предшествует следующему шагу». Например, расчет жалования предшествует расчету вычитаемых налогов.
Связи. Соединяют следующие друг за другом шаги. Соответствуют отношению «предшествует» между двумя узлами.
2.3.3. Модель меню с конечным числом состояний (глава 9)
Объекты. Меню, появляющиеся в окне, например, текстового редактора. Каждому пункту меню соответствует один узел.
Отношение. «Может прямо вызвать», что означает существование пункта в меню, выбор которого влечет за собой появление нового меню. Выбранный пункт меню определяет, какое именно меню второго уровня должно появиться.
Связи. На каждый пункт в меню приходится по одной связи между узлами. Например, если меню А может (выбором соответствующих пунктов) вызвать меню Б, В, Г, то между АиБ, АиВ, АиГ существуют связи.
2.3.4. Модель потока данных (глава 5)
Объекты. Определенные объекты данных. Каждому эзсмпляру (потенциально отличимому от других величин) каждого объекта данных соответствует один узел.
Отношение, «используется для вычисления значения». В равенстве X = 2Y + Z объекты Y и Z используются для вычисления значений X.
Связи. Стрелка (связь) направлена от А к Б, если значение величины А используется для вычисления величины Б. В нашем примере стрелки направлены от Y к X и от Z к X.
52 Глава 2 • Графы и отношения
2.3.5. Модель времени выполнения
Объекты. Линейные последовательности операторов в программе.
Отношение «предшествует оператору». Например, READ filename предшествует оператору FOR....
Связи. Соединяют следующие друг за другом операторы. Соответствуют отношению «предшествует между двумя узлами». Обратите внимание, что операторы ветвления (такие как IF, CASE) имеют по одной исходящей связи на каждую ветвь.
Свойства.
1. Связей — ожидаемое время выполнения (например, в микросекундах);
2. Операторов ветвления (например, IF...THEN...ELSE, CASE) — вероятности события для каждой их ветви (исходящей связи), что программа пойдет именно по ней.
2.4. Отношения
2.4.1. Обзор
Отношения имеют определенные свойства и, следовательно, могут быть разбиты на категории. Если, глядя на отношение, вы говорите: «О, это такой-то и такой-то тип отношений», то эти ваши знания вы сможете применить в конкретных случаях. Мы не будем рассматривать все свойства всех возможных отношений. Остановимся лишь на отношениях, наиболее часто используемых при тестировании.
2.4.2. Транзитивные и нетранзитивные отношения
Отношение к транзитивно, если из А к Б и Б к В следует А к В. Например, отношение быстрее — транзитивно. Если А быстрее Б и Б быстрее В, то, следовательно, А быстрее В. Примеры транзитивных отношений: можно достичь, больше, меньше, больше или равно, меньше или равно, зависит от, подмножество, находится в проекции.
Быстрее
Быстрее
Отношение, не являющееся транзитивным, — нетранзитивно. Примеры нетранзитивных отношений: друг, сосед, лжет, связан (напрямую). К примеру, из факта, что А лжет Б, а Б лжет В не следует, что А лжет В. В принципе А мог солгать В, но это никак не следует из того, что А лгал Б, а Б лгал В. Например, мы знаем, что А вообще не разговаривал с В.
Хотя в большинстве случаев легко можно понять, являются отношения транзитивными или нет, в общем случае это не всегда так. Примером игры, построенной на транзитивности, может служить детская игра «Камень, ножницы, бумага» В этой игре ножницы режут бумагу, бумага покрывает камень, а камень тупит
2.4. Отношения 53
ножницы. Дело усложняется тем, что все три отношения (режет, покрывает, тупит) эквивалентны в данном случае отношению сильнее, чем. На неоднозначности транзитивности построено также много других детских и взрослых игр.
В наших интересах (поскольку это одна из задач тестирования) проверить, что все отношения, которые должны быть транзитивны, действительно транзитивны, и наоборот, если транзитивность не является свойством отношения, то необходимо проверить, что оно нетранзитивно. В естественных языках это бывает не всегда очевидно, поэтому спецификации могут вводить в заблуждение. Например, часто встречающееся отношение связан в естественном языке может интерпретироваться неоднозначно. Значит ли это, что из узла А можно достичь узла Б, или это значит, что А напрямую связан с Б? В первом случае отношение можно достичь должно быть транзитивно. Это значит, что если из А. можно достичь Б, а из Б можно достичь В, то из А можно достичь В. Но отношение можно достичь не обязательно транзитивно. Что, если мы добавим «прикоснувшись к руке»? Например, я могу достичь своей соседки, прикоснувшись к ее руке, а она, в свою очередь, может достичь своей соседки, прикоснувшись к ее руке, однако это не значит, что я могу достичь ее соседки, прикоснувшись к ее руке, если я, конечно, не орангутан или если мы не сидим очень близко.
Всегда обращайте внимание и проверяйте транзитивность или нетранзитив-ность всех отношений из спецификации. Кроме этого, проверяйте программиста на его понимание транзитивности или нетранзитивности. Если понятие транзитивность неоднозначно трактуется в спецификации или программистом, то у вас плодородная почва для тестирования.
2.4.3. Симметричные и несимметричные отношения
Отношение называется симметричным, если оно справедливо как в одну, так и в другую сторону. Это означает, что стрелка на графе направлена в обе стороны. Примеры: сосед, находится в браке. Отношение сосед симметрично, но не транзитивно.
В английском языке для симметричных отношениях обычно используют оборот «А и Б находятся в отношении», вместо «А относится к Б». То есть мы говорим: А и Б находятся в браке, А и Б соседи и так далее.
Отношение, не являющееся симметричным, называется несимметричным. То, что отношение не симметрично, еще не означает, что связь между парой узлов должна быть односторонней, это говорит лишь о том, что существование связи в обоих направлениях — не обязательное условие.
Симметрия — это очень важное свойство отношений, и нам следует тестировать отношения на симметричность. Например, если вы тестируете меню в продукте, управляемом через меню (то есть в продукте, работа с которым происходит посредством выбора определенных пунктов в меню), то, проверяя симметричность, вы фактически проверяете, всегда ли существует возможность возврата в предыдущее меню. Аналогично если в программе (в текстовом редакторе, или, скажем, электронной таблице) есть функция UNDO, это значит, что большинство операций симметричны, поскольку всегда можно отменить действия оператора. Однако даже
54 Глава 2 • Графы и отношения
идеальное UNDO не может быть полностью симметричным, поскольку существуют такие операции, как печать или отправить (PRINT, SEND), которые нельзя отменить.
С симметричностью, как и с транзитивностью, часто возникает путаница в спецификациях, или по вине программистов. Естественные языки, как водится, тоже усложняют нам жизнь, однако в случае симметричности проблемы возникают, поскольку (в большей йли меньшей степени) в них симметричность подразумевается, а не постулируется явно.
Всегда обращайте внимание и проверяйте симметричность или несимметричность всех отношений из спецификации. Кроме того, проверяйте программиста на его понимание симметричности или несимметричности. Если понятие «симметричность» неоднозначно трактуется в спецификации или программистом, то у вас появится плодородная почва для тестирования.
2.4.4. Рефлексивные и нерефлексивные отношения
Отношение называется рефлексивным, если каждый узел находится в этом отношении с самим собой. Это означает, что каждый узел имеет связь, ведущую обратно на него (петля). Примеры рефлексивных отношений: знаком с (поскольку, если у меня нет амнезии, я знаком сам с собой), родственник, может коснуться, связан с, равен, эквивалентен.
Если рефлексивность не выполняется для каждого узла в диаграмме, то отношение называется нерефлексивным. Следующие отношения нерефлексивные: друг (как часто можно услышать: «Он сам себе злейший враг»), выше, ниже.
Рефлексивность — это возможность остаться в исходном состоянии. Рефлексивность является важным свойством наших моделей (если она есть). Я как-то работал с неудачным текстовым редактором, в котором необходимо было что-то выбирать в каждом меню. Это можно было сделать, используя мышь (которой у меня в то время не было) или вводя ключевую букву, соответствующую первой букве в названии пункта меню. В таких случаях, если я ввожу неправильную букву, я должен остаться в том же самом меню, но самонадеянная программа вместо этого делала выбор за меня и, как правило, неверный. Используемые меню не были рефлексивными в этом странном продукте.
2.4. Отношения 55
Рефлексивность также чаще подразумевается, чем постулируется, и, следовательно, является хорошим объектом для поиска ошибок. Поскольку рефлексивность должна быть присуща каждому узлу, каждый узел должен быть проверен. Тестируйте рефлексивность по тому же принципу, что и транзитивность с симметричностью.
2.4.5. Классы эквивалентности и разбиения
Отношение эквивалентности — симметрично, транзитивно и рефлексивно. Набор объектов, удовлетворяющих отношению эквивалентности, называется классом эквивалентности. Каждый объект из этого класса называется эквивалентным (в смысле данного отношения) любому другому объекту этого класса.
Все методы, описываемые в этой книге, являются примерами тестирования путем разбиения [HAML88, OSTR88, RICH81, RICH89, WHIT94]. Эта стратегия построена на разбиении всех возможных входов на классы эквивалентности по какому-либо отношению эквивалентности. Я не буду в этой книге рассказывать, как создавать или находить подобные отношения, а познакомлю вас с набором уже готовых полезных отношений и, следовательно, полезных разбиений на классы эквивалентности.
Если у вас есть транзитивное отношение, то вы можете автоматически конвертировать его в соответствующее отношение эквивалентности и таким образом разбить множество вводов на классы эквивалентности. Однако этот метод не рассматривается в данной книге. Дополнительную информацию вы найдете в [BEIZ90], глава 12.
2.4.6. Альтернатива графам
2.4.6.1. Граф — это визуализация
Графическое представление графов, используемое в этой книге, является удобным инструментом для обучения, поскольку большинство людей находит такое визуальное представление менее абстрактным. На практике, однако, за исключением модельных задач, представленных в этой книге, графическое представление графов слишком затруднительно. Вместо того чтобы рисовать картинки и использовать шаблоны (или их программные аналоги), мы представляем графы в виде таблиц или списков. Возможно, для вас в определенных случаях эти способы представления окажутся полезны. Мне представляется правильным объяснить вам принципы их построения при первом же вашем знакомстве с графами.
2.4.6.2. Представление в виде таблиц или матриц
Графы удобно представлять в табличной или матричной форме. Обычно используется следующий порядок создания графа.
1. Нарисуйте двухмерный массив, размер которого равен числу узлов.
2. Если существует связь между узлом i и, например, j, задайте элемент [i, j] массива равным 1, в противном случае задайте его равным 0 или оставьте эту позицию пустой или же отметьте ее точкой.
56 Глава 2 • Графы и отношения
3. Если число связей между двумя узлами больше одной, значение данного элемента должно быть равно числу связей.
4. Если связи обладают весами, впишите соответствующие веса.
Обычно бывает удобно обозначать колонки и строки матрицы именами узлов. На рисунке показано подобное описание графа, внешний вид которого был приведен в начале главы.
17 34
17 . 1
34 .
На следующем рисунке представлен граф, описанный в пункте 2.2.
7 7 13 14 17 12 99 43 16
13 • • • 1 • •
14 • 1 • • 1 . •
17 1 • • • • •
12 • • 1 • 1
99 • • 1 • •
43 1 • • 1 • •
16 •
2.4.6.3. Представление в виде списка
Рассмотренные матрицы оказались по большей части пустыми. Это бывает часто, поскольку в графах число узлов, как правило, превышает число связей. Несмотря на то, что матрицы компактны, и их проще рисовать, чем графическую форму, использование такого формата часто затруднительно и приводит к ошибкам при работе с большими матрицами. Более удобная форма представления — в виде списка связей. Чем объяснять, это проще показать на примере. Вот представление в виде списка последнего графа:
7: 12: 17.16
13: 12 99: 12
14: 13. 99 43: 7
17: 7 16:
Если связи обладают весами, вы должны дополнить элементы списка соответствующими весами. К примеру, если взять имена связей в качестве их весов, то граф, изображенный на с. 50, будет представлен в следующем виде:
2.5. Основополагающие принципы тестирования 57
7: 14(a) 12: 17(m). 16(у)
14: 99(k). 13(t) 17: 7(b)
13: 12(z). 17(c) 16: 99(q). 43(h)
99: 12(r) 43: 12(х). 7(w)
Вы можете изменять этот порядок записи по своему усмотрению, добавлять
свойства, комментарии или что-то еще, чтобы список был понятным для вас и однозначно определял:
1. Начальный узел связи.
2. Конечный узел связи.
3. Все свойства связи.
4. Все свойства узла.
Для больших графов удобно записывать каждую связь на отдельной строке, оставляя место для комментариев и других аннотаций, относящихся к связям. Также может быть удобно записывать пояснения или ссылки на соответствующие параграфы так, как это сделал я:
7: 14(a) {перезапуск процесса: см. раздел 3.1.4.1.5.9}
14:99(к) {загрузка точки входа: см. раздел 3.2.4.5}
13(t) {инсталляция точки входа; см. раздел 3.3.1.7.5}
43:12(х) {устранимая ошибка; см. раздел 6.4.5}
7(w) {неустранимая ошибка: см. специальный раздел 6.4.6}
2.5. Основополагающие принципы тестирования
2.5.1. Обзор
Ниже приведены основные шаги по использованию моделей на основе графов для разработки конкретных тестов.
1. Постройте граф.
2. Определите отношения.
3. Разработайте тесты проверки узлов (тесты, подтверждающие, что все узлы на месте).
4. Разработайте тесты проверки связей (тесты, подтверждающие наличие всех заданных связей и отсутствие лишних связей).
5. Протестируйте все веса.
6. Разработайте тесты для циклов.
ВОПРОС: Что вы делаете, когда вам встречается граф?
ОТВЕТ: Исследую его!
58 Глава 2 • Графы и отношения
2.5.2. Построение графа
1. Определение узлов.
• Какие объекты (узлы) представлены на данном графе? Каждому рассматриваемому объекту соответствует один узел.
• Дайте имена узлам. Вы называете узлы по своему усмотрению, однако каждый узел должен иметь уникальное имя или идентификатор. Мне нравится использовать числа, но вы, возможно, отдадите предпочтение именам, несущим определенный смысл в контексте вашего приложения.
• Узлы могут обладать также свойствами (весами). Отметьте свойства (значения) для каждого узла.
2. Определение связей.
• Каждая связь должна начинаться и заканчиваться на узле (это может быть один и тот же узел). Поскольку довольно часто предполагается наличие входного и/или выходного узла, вам, возможно, придется добавить их в вашу модель. Если связь оборвана (то есть приходит ниоткуда или ведет в никуда), то в построении модели допущена ошибка.
• Дайте имена связям. Если между парой узлов существует больше одной связи, то разумно дать каждой связи свое уникальное имя. Если два узла может соединять только одна связь, то давать ей имя не обязательно.
• Отметьте веса каждой связи.
3. Найдите входной и выходной узлы. В графе модели не обязательно присутствуют входной и выходной узлы, но часто есть оба. Если в графе все-таки есть входной и/или выходной узлы, то, по всей видимости, они играют важную роль. Обозначьте все входные и выходные узлы соответственно. Например: 14 (ВХОД):... или 44 (ВЫХОД). Помните, что у входных узлов нет входящих связей, а у выходных нет исходящих связей.
4. Найдите все циклы. В графах моделей не обязательно присутствуют циклы, но если они есть, то они важны. Мы будем использовать специальные методы тестирования циклов, поэтому вам надо будет найти все циклы на диаграмме. Существуют способы сделать это автоматически (то есть алгоритмически), но они не описываются в этой книге, см. [ВEIZ90].
2.5.3. Определение отношений
1. Начните с написания отношений на английском языке (или на вашем родном языке).
2. Ответьте ДА или НЕТ на следующие вопросы:
• Оно рефлексивно?
2.5. Основополагающие принципы тестирования 59
• Оно симметрично?
• Оно транзитивно?
Если оно рефлексивно, то каждый узел должен иметь петлю. Если оно симметрично, то каждая связь должна быть двусторонней. Отношения на графе не обязательно должны обладать этими свойствами. Более того, они могут обладать другими свойствами, не рассматриваемыми в этой книге (см. [BEIZ90], глава 12). Какими бы ни были свойства отношений, они должны проверяться при тестировании.
2.5.4. Проверка узлов
Меньшее из всего, что вы можете сделать, — это провести достаточно тестов, для того чтобы убедиться, что все узлы именно такие, какими и должны быть. Такие тесты называются проверкой узлов. У проверки узлов, однако, есть своя градация по степени совершенства тестов. Ниже приводится список тестов (в порядке возрастания приоритета), которые надо провести, чтобы полностью выполнить проверку узлов.
1. Тесты, чтобы убедиться в наличии всех заданных узлов. Ни один узел не должен быть пропущен.
2. Тесты, чтобы убедиться в отсутствии лишних узлов (это может потребовать неограниченного числа тестов и поэтому быть неосуществимо).
3. Тесты, чтобы убедиться в корректности весов узлов, если они есть.
4. Если существуют входной и выходной узлы, то в завершение предыдущих шагов можно выбрать пути от входа до выхода и выбрать входные значения так, чтобы программа проследовала по каждому из заданных в модели путей. Обычно задают несколько таких путей от входа к выходу (тестовых вариантов).
Как уже говорилось, проверка узлов — это очень слабые тесты, на практике они оказываются настолько слабы, что фактически не используются. Все методы, излагаемые в этой книге, предполагают, что вы по меньшей мере выполнили проверку связей (см. ниже). Проверка связей, в свою очередь, подразумевает, что выполнены все тесты проверки узлов.
2.5.5. Проверка связей
Следующее по эффективности действие, которое можно сделать, — это провести достаточно тестов, для того чтобы убедиться, что все связи именно такие, какими и должны быть. Такие тесты называются проверкой связей. Ниже приводится список тестов (в порядке возрастания приоритета), которые надо провести, чтобы полностью выполнить проверку связей.
1. Тесты, чтобы убедиться в наличии всех заданных связей, — что ни одна связь не пропущена.
2. Тесты, чтобы убедиться в отсутствии лишних связей (Это может потребовать неограниченного числа тестов и поэтому быть неосуществимо).
60 Глава 2 • Графы и отношения
3. Тестирование отношений.
• Если отношение симметрично, то необходимо убедиться, что каждая связь является двусторонней: например, DO/UNDO.
• Если отношение рефлексивно, то необходимо убедиться, что каждый узел связан сам с собой: например, DO NOTHING.
• Если отношение транзитивно, то вы должны проверить его транзитивность в любой ситуации. Это делается следующим образом. Рассмотрим три объекта, А, Б и В, причем А связано с Б, а Б связано с В. То есть А к Б и Б к В. Показав (путем тестирования), что А к Б — истина и Б R В — истина, необходимо показать, что А к В тоже является истиной. Сделайте это для каждой тройки узлов, в которой выполняются данные условия.
4. Если существуют входной и выходной узлы, то шаги 1-3, как правило, завершаются подбором путей от входа к выходу, при этом выбираются такие входные параметры, с которыми программа проследует по выбранным путям. Чаще всего для теста указывают несколько путей ВХОД/ВЫХОД (тестовых вариантов). Заметим, что если вы осуществляете проверку связей, вы обычно осуществляете и проверку узлов. Тем не менее, проверка связей в большинстве случаев требует большего количества тестов, чем проверка узлов.
При тестировании черного ящика, исключая патологические случаи, если вы разрабатываете тесты проверки связей, вы вместе с тем добиваетесь и проверки узлов. Однако вы вряд ли сможете убедиться, что не существует лишних узлов и что веса узлов, если узлы обладают весами, верны. Хорошей идеей будет добавление в проверочный список инспектирования тестов и в ваш проект тестов требования проверки узлов из раздела 2.5.4.
2.5.6. Тестирование весов
Если связи имеют веса, проведите достаточное количество тестов, чтобы убедиться в правильности значения веса для каждой связи. То же самое сделайте для узлов, если они включены в модель.
2.5.7. Тестирование циклов
Мы уделяем специальное внимание тестированию циклов, так как статистика ошибок показывает, что у программистов возникают проблемы с циклами. По этой причине циклам посвящена целая глава (см. главу 4). В этом разделе излагаются лишь основы.
В нашу задачу не входит анализ кода чтобы увидеть, есть в нем циклы или нет. Мы проводим тестирование циклов, если наша модель поведения программы включает в себя циклы.
Цикл — это последовательность имен узлов, в которой как минимум одно имя узла повторяется. Если появляется другая последовательность повторяющихся имен узлов или она просто возможна, то у вас есть еще один цикл. Вы должны протестировать каждый цикл.
2.6. Резюме 61
Тестирование цикла основано на том, сколько раз вы будете выполнять этот цикл. Вы можете совсем обойти цикл, можете пройти его один раз, два раза.... Максимальное количество проходов обозначим как п. В следующем примере есть узел, который является входом в цикл (А) и два узла, которые являются выходными в цикле (X и Y).
1. Обойдем цикл: АХЕ или AXYZE. (Я буду использовать оба пути.)
2. Пройдем цикл один раз: AXYVWXE или AXYVWXYZE.
3. Пройдем цикл два раза: АХYVWXYVWXE или axywxyvwxyze.
4. Пройдем цикл обычное число раз: A(XYVW)ty₽1ca1XE.
5. Пройдем цикл максимальное число раз (n): A(XYVW)"XE и A(XYVW)nXYZE.
6. Пройдем цикл п-1 раз: A(XYVW)nlXE и A(XYVW)n !XYZE.
7. Попытаемся пройти цикл n + 1 раз: А(XYVWl^XE и A(XYVW)n4XYZE.
Рассмотрим два каких-нибудь узла в модели, скажем, А и В. Если существует путь от А к В (не обязательно прямая связь) и другой путь от В к А, и это верно для каждого А и В, то существует возможность, стартуя от любого узла, по какому-то пути прийти к любому другому узлу и вернуться назад к начальному узлу. Такие графы называются сильно связанными. Исчерпывающее тестирование цикла, как было определено, обычно является излишней тратой времени в сильно связанных графах. Очевидно, что граф с симметричными отношениями (или ненаправленный граф) является сильно связанным, так как все стрелки направлены в обе стороны. Следовательно, тестирование циклов не является эффективным для графов с симметричными отношениями.
2.6. Резюме
Вы освоили словарь и основную идею поведенческого тестирования. Может быть, материал был изложен более кратко, чем вы бы хотели. Как я уже говорил в README.DOC, эта глава — как подпрограмма, которую вы будете использовать в последующих главах при создании конкретных тестов. Рассматривайте эту главу как объект в объектно-ориентированных программах, которые вы будете создавать в последующих главах. ООП, на мой взгляд, более абстрактно, нежели эта глава. Или же рассматривайте эту главу как игру, в которой вы должны победить. Используйте следующие вопросы для оценки того, что вы вынесли из этой главы.
62 Глава 2 • Графы и отношения
2.7. Вопросы для самопроверки
1. Дайте определение: проходимый путь, несимметричное отношение, двоичное отношение, узел ветвления, оператор ветвления, дерево вызова, комментарий, граф потока управления, проверка (покрытие), оборванная связь, граф потока данных, направленный граф, направленная связь, входной узел, путь вход—выход, класс эквивалентности, отношение эквивалентности, выходной узел, граф, матрица графа, входящая связь, нетранзитивное отношение, перефлексив-ное отношение, связь, проверка связей, представление списка связей, имя связи, вес связи, цикл, нециклический путь, программа, управляемая через меню, узел, проверка узлов, имя узла, вес узла, исходящая связь, параллельные связи, стратегия тестирования путем разбиения, путь, длина пути, имя пути, сегмент пути, рефлексивное отношение, отношение, петля, соединять, сильно связанный граф, симметричные отношения, граф потока транзакций, транзитивные отношения, непроходимый путь, ненаправленный граф, ненаправленная связь.
2. Отношения могут быть: симметричными или несимметричными, рефлексивными или нерефлексивными, транзитивными или нетранзитивными. Всего насчитывается восемь различных комбинаций. В табл 2.1. приведены примеры каждого типа отношений. Придумайте еще по три примера для каждого типа. Докажите принадлежность каждого к тому или иному типу (то есть протестируйте их). Подсказка: попробуйте использовать Тезаурус Роже.
Таблица 2.1. Примеры отношений
Симметричное Рефлексивное Транзитивное Примеры
нет нет нет любит, грубит, спорит, критикует, владеет
нет нет да выше, длиннее
нет да нет знаком с
нет да да больше или равен
да нет нет двоюродные сестры, женаты, обручены
да нет да параллелен, сосед
да да нет рядом с
да да да равен
3. Определите, является ли отношение «находится в проекции» транзитивным? Придумайте ситуацию или способ освещения, при котором данное отношение нетранзитивно.
4. Рассмотрите отношение был объединен с с точки зрения его симметричности, рефлексивности, транзитивности. Приведите примеры и контрпримеры, подтверждающие ваши выводы.
5. Исследуйте следующие отношения (на предмет их симметричности, рефлексивности, транзитивности) и подтвердите свои выводы, продемонстрировав отсутствие контрпримеров: А вызывает Б, А не равно Б, А согласен с Б, А эквивалентен Б, А согласуется с Б, А совместим с Б, А несовместим с Б, А — часть Б, А — вне Б, А лучше, чем Б, А доминирует над Б, А зависит от Б.
Тестирование потока управления
3.1. Обзор
В этой главе в качестве основной модели, используемой при разработке тестов, рассматривается граф потока управления1. С помощью графа потока управления мы будем моделировать различные части формы 1040 декларации о доходах внутренней налоговой службы США (форма 1040 ВНС), сложность тестирования которой сравнима с ее собственной сложностью. В дальнейшем модель будет использована для построения набора тестов по проверке связей.
3.2. Основные термины
Внешние термины: алгебра, алгебраический, И (логическое), приложение, язык ассемблера, логическая ветвь, ошибка, оператор CASE, COBOL, код, завершать, сложность, вычисление, последовательный, ограничение, противоречие, управление, поток управления, копировать, программа для решения уравнений, ИСКЛЮЧАЮЩЕЕ ИЛИ (логическое), выполнять, выражение, крайние значения, формальная модель, оператор IF, оператор IF-THEN-ELSE, оператор, ЛОЖЬ, оператор GOTO, реализация, ВКЛЮЧАЮЩЕЕ ИЛИ (логическое), приращение, неравенство, экземпляр, прыжок, логика, логическое выражение, логическое значение, LOTUS-123, сопровождение, матрица, пропущенные требования, модель, ошибка модели, моделирование, имя, естественный язык, вложенный, НЕ
' Поток управления задает последовательность действий при выполнении программы, он соответствует цепочке операторов программы, последовательно передающих друг другу управление компьютером. — Примеч. научн.ред.
64 Глава 3 • Тестирование потока управления
(логическое), численный, оператор, ИЛИ (логическое), вставка, обработка, шаг обработки, программа, программист, программирование, псевдокод, реализм, перепрофилирование, выпуск, требования, перезапись, коммерческая презентация, предложение, система уравнений, программное обеспечение, спецификация, ошибка спецификации, электронная таблица, структурированная программа, символическая подстановка, таблица, ошибка теста, проектирование теста, тестировщик, дерево, ИСТИНА, таблица истинности, значение истинности, неструктурированное программное обеспечение, значение, версия, текстовый редактор.
Внутренние термины: проходимый путь, поведение, поведенческое тестирование, тестирование черного ящика, слеп, покрытие ветви, ошибка, случайная корректность, контроль конфигурации, покрываемые пути, входной узел, выходной узел, характеристика, граф, модель на основе графа, входящая связь, ввод, входное значение, связь, покрытие связей, вес связи, представление графа в виде списка связей, цикл, недостающая характеристика, недостающий путь, узел, имя узла, объект, оракул, итог, вывод, исходящая связь, параллельные связи, путь, сегмент пути, прототип, отношение, требование, спецификация, отрезок пути, тестовый вариант, тестовый комплект, метод тестирования, инструмент тестирования, непроходимый путь, тестирование модуля, критерий соответствия.
Логический предикат. Предложение или выражение, которое может принимать логическое значение ИСТИНА или ЛОЖЬ. Примеры: «Небо голубое», «Это утверждение ЛОЖНО», «Ваш родитель может предъявлять на вас права, поскольку вы зависите от его доходов», «Утверждается, что ваш ребенок, находится на вашем иждивении в соответствии с соглашением, принятым до 1985 года».
Предикат выбора. Выражение, которое может принимать более двух значений и служит для выбора одного из нескольких вариантов. Пример: «Отметьте только одну позицию — (1) холост, (2) женат, заполняю совместную налоговую декларацию, (3) женат, заполняем раздельные налоговые декларации, (4) глава хозяйства, (5) вдовец». Термин «предикат» часто используется для обозначения как логических предикатов, так и предикатов выбора.
Логическое И. В логических и формальных моделях «И» строго определяется, следующим образом: А & Б будет истиной в том и только в том случае, если оба, А и Б, истинны. Однако в нестрого логических и неформальных документах, таких как бланки декларации на подоходный налог, слова и фразы, подобные «еще», «также», «в дополнение к» и даже «или» могут на самом деле означать логическое И.
Логическое ИЛИ. В логических и формальных моделях «ИЛИ» всегда означает ВКЛЮЧАЮЩЕЕ ИЛИ, иначе «И/ИЛИ». Неформальное использование может быть различным и при интерпретации рекомендуется быть осторожным.
Логическое НЕ. В логических и формальных моделях вам следует заключить предложение в скобки и поставить оператор НЕ впереди, как, например, «НЕ (ваш ребенок живет с вами)» вместо «ваш ребенок НЕ живет с вами». При неформальном написании НЕ может стоять практически в любом месте в предложении, поэтому надо быть внимательным.
3.3. Отношения и модель 65
Составной предикат. Логическое выражение, включающее два или более предикатов, связанных операторами И, ИЛИ или НЕ. Примеры: (1) «Ваш ребенок НЕ живет с вами И находится на вашем иждивении в соответствии с соглашением, принятым до 1985 года», (2) «(В 1994 году вы получали оклад И/ИЛИ чаевые) И ваш оклад вместе с чаевыми НЕ превысил 60600 $ И вы НЕ получали чаевые, подлежащие налогообложению по программе социального обеспечения или страхования здоровья по старости, о которых вы НЕ сообщали своему работодателю, И вы священнослужитель, получивший разрешение ВНС НЕ платить налоги с заработков из этих источников, И вы платите налоги на индивидуальное предпринимательство с других доходов»1.
Независимые предикаты. Два или более предикатов в пути модели называются независимыми, если их значения истинности (ИСТИНА/ЛОЖЬ) формируются независимо друг от друга.
Коррелированные предикаты. Два или более предикатов в пути модели называются коррелированными, если значение истинности для одного из них определяет значения истинности для всех остальных предикатов в этом пути. Пример: путь содержит два одинаковых предиката, и значение истинности для первого из них определяет значение истинности для второго предиката на этом пути.
Комплементарные сегменты пути. Два сегмента пути, содержащие такие предикаты, что если в одном сегменте предикат принимает значение ИСТИНА, то в другом предикат получает значение ЛОЖЬ и наоборот.
3.3. Отношения и модель
3.3.1. Основы
Информация этой главы раскрывается в дополнительных источниках [ALLE72, CLAR76, EBER94, HOWD76, HOWD87, KRAU73, РЕТЕ76].
Объекты (узлы). Последовательность шагов обработки, такая, что выполнение любой части этой последовательности ведет за собой выполнение всей последовательности (если нет ошибок).
Пример: Форма 1040. Следующие строки можно моделировать одним узлом, включающим в себя строки с 7 по 14, несколькими узлами, скажем, «7-8а-8Ь, 9-10-11, 12, 13-14», или даже последовательностью из 9 отдельных узлов, по одному на каждую строку.
7. (введите) wages, salaries, tips (оклады, дополнительные доходы, чаевые).
8а. (введите) taxable Interest income (налогооблагаемый доход).
8b. (введите) tax-exempt interest income (не облагаемый налогом доход).
9. (введите) dividend income (доход по дивидендам).
10. (введите) taxable refunds, credits, or offsets of state and local income taxes (налогооблагаемые платежи, кредиты, компенсации местного подоходного налога и подоходного налога в казну штата).
’ Я не выдумал это сам. Данная спецификация — это путь выполнения в форме SE ВНС, 1994. Можете убедиться сами. Подоходный налог 101 — определенно более напряженный курс, нежели программирование 101 или тестирование 101.
3 Зак. 770
66 Глава 3 • Тестирование потока управления
11. (введите) alimony received (полученные алименты).
12. (введите) business Income or loss (доход или убыток от предпринимательской деятельности).
13. (введите) capital gain or loss (капитальные прибыль или убыток).
14. (введите) other gains or losses (другие прибыли или убытки).
Ниже приведены некоторые из возможных моделей графов для данной спецификации.
(j-8b)-------------------*^3^14)
Отношения (связи)', за ... непосредственно следует ... Если в предыдущем примере использовать один узел для каждого шага, то за узлом 9 непосредственно следует узел 10, а за узлом 10 непосредственно следует узел 11, и так далее.
Узел с предикатом. Узел с двумя или более исходящими связями, вес каждой из которых равен значению предиката. То есть ИСТИНА/ЛОЖЬ для логического предиката и по одному из нескольких вариантов для предиката выбора. Узел с предикатом выбирает один из двух или более альтернативных путей, по которым может пойти процесс.
Пример: Строки с 33b по 34 в форме 1040.
33b. Если ваши родители могут утверждать, что вы находитесь на их иждивении, отметьте графу 33b. в противном случае не отмечайте графу 33b.Граф, моделирующий это предложение, изображен на рисунке.
узел в модели
«ваши родители могут утверждать, что вы находитесь на их иждивении?»
Узел выбора. Узел с двумя или более исходящими связями, вес каждой из которых равен одному из значений величины выбора.
Пример: строка 34 в форме 1040: Введите наибольшую из ваших льгот, перечисленных в бланке А, строка 29 ИЛИ обычная льгота для вашей формы заполнения, ука
3.3. Отношения и модель 67
занная ниже. Однако, если вы отметили какую-либо графу на строке 33а или Ь. следуйте инструкциям для определения ваших стандартных льгот. Если вы отметили графу 33с, ваша стандартная льгота равна нулю, (а) холост = $3,800. (Ь) женат, заполняю совместную налоговую декларацию = $6.350, (с) вдовец = $6,350 (d) женат, заполняем раздельные налоговые декларации = $3,175, (е) глава хозяйства = $5,600. Следующий граф моделирует большую часть этого предложения. Узел 34.5 является узлом выбора.
Представление в виде списка связей более информативно и больше подходит для данного случая:
34 Стандартные льготы или детализированные льготы? 34.1 34.2 Детализированные Стандартные
34.1 GOTO Бланк А. строка 29 35
34.2 Отмечена графа 33а или ЗЗЬ? 34.3 ИСТИНА
34.4 ЛОЖЬ
34.3 GOTO Страница 22 35
34.4 Отмечена графа 33с? 34.6 ИСТИНА
34.5 ЛОЖЬ
34.5 Выберите 34.7 холост
34.8 совместная
декларация
34.8 вдовец
34.9 раздельные декларации
34.10 глава хозяйства
34.6 Льготы = $0 35
34.7 Льготы - $3.800 35
34.8 Льготы - $6.350 35
34.9 Льготы - $3.175 35
34.10 Льготы = $5600 35
35 Продолжить модель
Соединительный узел. Узел с двумя или более входящими связями. В предыдущем примере узлы 34.8, 35 были соединительными узлами.
68 Глава 3 • Тестирование потока управления
Некоторые комментарии, касающиеся данной модели.
1. Узел 34 — узел с предикатом. Обратите внимание на использование здесь союза «или». Это не логическое ИЛИ. Это способ обозначить предикат1.
2. Предикат для узла 34.2 является составным предикатом, и ИЛИ здесь имеет смысл включающего ИЛИ, поскольку можно отметить как одну графу, так и обе одновременно. Формальная запись данного предиката будет следующей: «Вы отметили графу 33а ИЛИ вы отметили графу 33b (или обе)». Этот предикат также представляет интерес из-за использования в нем слова «однако». Ключевым словом в этом случае является не «однако», а следующее за ним «если».
Вот более подробная модель для этого узла:
34.2 Отмечена графа 33а? 34.3 ИСТИНА
34.2.1 ЛОЖЬ
34.2.1 Отмечена графа 33b? 34.3 ИСТИНА
34.4 ЛОЖЬ
А вот еще более подробная модель для этого узла:
34.2 Отмечена графа 33а? 34.2.2 ИСТИНА
34.2.1 ЛОЖЬ
34.2.1 Отмечена графа 33b? 34.3 ИСТИНА
34.4 ЛОЖЬ
34.2.2 Отмечена графа 33b? 34.3 ЛОЖЬ
Эта модель лучше первоначальной, поскольку она вскрывает сложность составного предиката и мы, скорее всего, обнаружим больше ошибок с ее помощью [MYER79]. Первая улучшенная модель может быть слепа к определенному типу ошибок, так как в ней не хватает критического подхода к предикату в узле 34.2. Вторая модель более сбалансирована, и в ней делается меньше предположений о способе реализации. Поэтому, хотя она и более сложная, она лучше ищет ошибки, и я выбираю ее.
3. Предикат в строке 33с является составным предикатом: «(Вы женаты, заполняете раздельные налоговые декларации И льготы вашей супруги детализированы) ИЛИ вы иностранец с двойным гражданством». Здесь фигурирует включающее ИЛИ, поскольку вы можете быть иностранцем с двойным гражданством (что бы это ни значило) и ваша супруга может заполнять налоговую декларацию раздельно и ее льготы могут быть детализированы. Обратите внимание, что если вы не являетесь иностранцем с двойным гражданством, то должны выполняться три условия: (1) вы женаты, (2) вы заполняете налоговые декларации раздельно, (3) льготы вашей супруги детализированы.
4. Один из альтернативных пунктов в узле 34.5 скрыт под союзом «или». Это не логическое ИЛИ. Это способ обозначить параллельные связи и дополни
1 На самом деле это не узел с предикатом, а нечто иное, что будет рассмотрено в главе 6 при изучении тестирования потока транзакций. Это не настоящий предикат, поскольку вы можете выбрать оба альтернативных варианта.
3.3. Отношения и модель 69
тельные варианты выбора: «заполняю совместную налоговую декларацию» и «вдовец».
5. Узлы 34.1 и 34.3 входят в модель независимо от остальных узлов. Я мог бы включить в модель детали для них, но не стал, так как из узла 34.1 мы перенаправляемся на бланк А, который может быть описан в нескольких других разделах книги. Разумно будет строить эти модели отдельно. По той же причине я буду отдельно моделировать узел 34.3.
6. Узлы 34.1, 34.3, 34.6, 34.7, 34.8, 34.9 и 34.10 в данной модели не существенны. Я мог бы связать обработку этих узлов, со связями, исходящими из узла 34.5 и включить их в веса связей, подобно тому, как приведено ниже.
34 Стандартные или 35 Детализированные/ GOTO Бл. А Стр. 29
Детализированные льготы? 34.2 Стандартные
34.2 Отмечена графа 33а или 33b? 35 ИСТИНА/GOTO СТР. 22
34.4 ЛОЖЬ
34.4 Отмечена графа 33с? 35 ИСТИНА/ Отч.= $0
34.5 ЛОЖЬ
34.5 Выберите 35 Холост/Отч. = $3.800
35 Совместная декларация/Отч.= $6.350
35 Вдовец/0тч.= $6.350
35 Раздельные декларации/Отч.= $3.175
35 Глава хозяйства/Отч.= $5.600
35 Продолжить модель
Эта модель эквивалентна приведенной выше, но не так полезна, поскольку более трудна для восприятия и связи в ней перегружены информацией. В целях понятности лучше использовать по возможности большее количество узлов и связей.
7. В этих моделях не строится никаких предположений относительно программного обеспечения и способов их реализации. Несмотря на то, что использование оператора IF-THEN для узлов 34,34.2 и 34.4 и оператора CASE для узла 34.5 представляется очевидным, существуют пути реализации без использования операторов IF-THEN и CASE. В поведенческом тестировании нам не следует слишком глубоко погружаться в детали конкретной реализации.
3.3.2. Моделирование составных предикатов
Составные предикаты обманчивы, поскольку таят в себе подводные камни. Они также перспективны в смысле тестирования, так как программисты часто делают в них ошибки. Вы всегда можете подробно расписать составной предикат, для того чтобы вскрыть его сущность и построить его модель при помощи графа или таблицы. Ниже приводится модель на основе графа. Предположим, у вас есть составной предикат, состоящий из нескольких простых предикатов (то есть не составных), которые мы будем называть А, В, С. Например: «А&В ИЛИ С». Вы строите дерево предикатов с числом
70 Глава 3 • Тестирование потока управления
ветвей, равным числу возможных вариантов. Для двух предикатов, число ветвей будет равно четырем, для трех предикатов — будет восемь ветвей, для п простых предикатов — 2”ветвей.
На рисунке показан первый шаг. Порядок, в котором вы рассматриваете предикаты, здесь не важен. Важно, чтобы все 2П ветвей (в нашем примере восемь) были рассмотрены. Следующий шаг — собрать все исходящие связи для случая ИСТИНА в узел со значением ИСТИНА, а все связи для случая ЛОЖЬ в узел со значением ЛОЖЬ, как показано на следующем рисунке.
В итоге одиночный узел с составным предикатом «А&В ИЛИ С» заменяется на более подробную модель, на которой показаны все части предиката. Вам может показаться, что верхний узел с предикатом С избыточен, поскольку вне зависимости от его значения результат будет — ИСТИНА. Тем не менее, он здесь не лишний, поскольку все это будет так при условии отсутствия ошибок в реализации. Только путем тестирования всех восьми случаев (2" в общем случае) мы можем убедиться, что логика, вне зависимости от способов ее реализации, не содержит ошибок. Вы можете отступиться и не тестировать точно все 2" случаев. Это здорово, если не обращать внимания на то, что ваше тестирование становится слабым и вы можете пропустить больше ошибок.
Другой способ построить модель— использовать таблицу истинности (см. табл. 3.1) вместо дерева графа. Вы используете один узел для составного предиката, с условием что все варианты должны быть проверены по таблице истинности.
3.4. Методика 71
Таблица 3.1. Таблица истинности
А в с А&В ИЛИ С
ИСТИНА ИСТИНА ИСТИНА ИСТИНА
ИСТИНА ИСТИНА ложь ИСТИНА
ИСТИНА ложь ИСТИНА ИСТИНА
ИСТИНА ложь ложь ложь
ЛОЖЬ ИСТИНА ИСТИНА ИСТИНА
ЛОЖЬ ИСТИНА ложь ложь
ЛОЖЬ ложь ИСТИНА ИСТИНА
ложь ложь ложь ложь
Напоминаю, что в таблицу истинности записываются состояния простых предикатов, и просчитывается, какое из значений ЛОЖЬ или ИСТИНА будет иметь составной предикат для данной комбинации. Я использую таблицы для проверки составных предикатов, состоящих более чем из трех простых предикатов. Добавление в граф четырех узлов для составного предиката, состоящего из двух элементов, не создаст в модели слишком большой путаницы. Однако уже трехкомпонентный предикат сильно загрузит модель, а добавление четырехкомпонентного фактически нереально. Помните, что вы не можете не принимать в расчет возможность существования ошибок в вашей модели.
3.4. Методика
3.4.1. Основы
Проектирование теста и его выполнение состоит из следующих шагов:
1. Изучите и проанализируйте требования на предмет их доступной для реализации завершенности и самосогласованности. Убедитесь в том, что спецификация корректно отражает требования, внесите поправки в спецификацию, если это не так.
2. Перепишите спецификацию в виде последовательности коротких предложений. Уделите специальное внимание предикатам. Разделите сложные предикаты на эквивалентные последовательности простых предикатов. Найдите узлы выбора и выпишите их в виде простых списков. Удалите любые логические «И», которые не являются частью предикатов, вместо этого разбейте предложение на две части.
3. Однозначно пронумеруйте предложения. Впоследствии это будут имена узлов.
4. Постройте модель.
5. Проверьте модель — ваша работа так же подвержена ошибкам, как и работа программиста.
6. Выберите пути тестирования.
72 Глава 3 • Тестирование потока управления
7. Активизируйте выбранные пути тестирования. То есть выберите такие входные значения, используя которые программа, при условии отсутствия ошибок, пройдет по пути, эквивалентному тому, который вы выбрали.
8. Предскажите и запишите вероятный итог каждого теста.
9. Определите критерий (критерии) соответствия для каждого теста.
10. Выполните тест.
И. Подтвердите итог.
12. Подтвердите путь.
3.4.2. Построение модели
Как пример для иллюстрации процесса мы будем использовать строчки с 32 по 40 формы 1040 ВНС. Исходная спецификация приведена в Приложении А. Проще всего мне будет это объяснить путем последовательного построения конкретной модели, комментируя процесс по мере ее развития. Мои комментарии выделены курсивом.
Шаг 1: Проверить и обосновать требования. Вряд ли, что-то можно сделать, поскольку мы рассчитываем, что ВНС делает это за нас.
Шаг 2: Переписать спецификацию. Что касается меня, я переписываю спецификацию, используя мой собственный тип псевдокода. Использование полуформального языка (то есть псевдокода) помогает быть уверенным в однозначности при описании вещей. Хотя это похоже на программирование, это не программирование — это моделирование.
Я использую представление в виде списка, так как это легче; хотя, когда я работал, я рисовал маленькие графы для того, чтобы убедиться в корректности потоков данных для различных предикатов. Я включил мои некоторые наброски, чтобы помочь вам увидеть, как я мыслил. Несмотря на то, что построение и использование целого графа в виде рисунка чересчур громоздко, эти промежуточные наброски сегментов маленького графа помогут вам получить правильное представление о логике.
65 или старше?
32: 33а1 введите adjusted_gross_1ncome
(скорректированный_общий_доход)
33а1 33а2 положите счетчик_пометок равным нулю
Необходимо отслеживать число пометок, которые мы делаем в форме.
33а2 ЗЗаЗ если 65 или старше
Это узел с предикатом, то есть будет по крайней мере две исходящие связи.
33а4 если НЕ 65 или старше
Пропустить приращение, если менее 65.
3.4. Методика 73
ЗЗаЗ 33а4 приращение счетчика_пометок
Позднее нам будет необходимо знать общее число пометок, а этот способ моделирования не хуже любого другого.
33а4 ЗЗаб если слеп
Другой узел с предикатом.
ЗЗаб если не слеп
Пропустить приращение, если НЕ слеп.
ЗЗаб ЗЗаб приращение счетчика_пометок
Увеличение числа пометок, если слеп.
ЗЗаб 33а7если супругу 65 или он старше
Заметим, что в действительности логика здесь намного сложнее. Если бы наша модель была для всей формы 1040, то нам следовало бы учитывать корреляцию со строчками 1-5, принимая во внимание способ заполнения декларации. Только обладающие статусом (2) Женат или статусом (5) Вдова (вдовец) могли бы делать отметки в этой и следующей графе. В реальной модели вы бы предварили этот и следующий узел с предикатом другим узлом с предикатом, который спрашивает: «Женат и заполняет совместную налоговую декларацию ИЛИ вдовец с детьми на иждивении?» Если предикат является ИСТИНОЙ, вы выполняете узлы с ЗЗаб по 33а9, иначе вы переходите к узлу ЗЗаЮ. Однако для того чтобы сохранить приемлемый размер этой модели, мы не будем гнаться за реалистичностью и допустим, что этот сегмент не зависит ни от каких предыдущих сегментов и логики. Графическая реализация этой части модели приведена на рисунке.
33а8 если супругу НЕ 65 или больше
33а7 33а8 приращение счетчика_пометок
33а8 33а9 если супруг слеп
ЗЗаЮ если супруг НЕ слеп
33а9 ЗЗаЮ приращение счетчика_пометок
Узел ЗЗаЮ является излишним, так как мы изменяли счетчик пометок по мере прохождения пути; однако я предпочитаю быть уверенным, что существует по крайней мере один узел (для начала) для каждого утверждения в спецификации.
ЗЗЬЗ ЗЫ Если ваши родители могут предъявить на вас права
Узел с предикатом.
74 Глава 3 • Тестирование потока управления
33с Ваши родители не могут предъявить на вас права
ЗЗМ 33с Пометьте графу 33b
ЗЗсЗ 33с1 Женат, заполняю отдельную декларацию
Составной предикат. Если бы вы посмотрели инструкции ВНС, вы бы нашли еще больше логики в модели. Для того чтобы оставаться в разумных границах, мы проигнорируем инструкцию следовать инструкциям, но в реальных задачах у вас нет такого выбора. Для того чтобы не было скрытой сложности, я разбил предикат на составные части. Моя модель для этого раздела приведена на рис. 3.8. Возможны также и другие, эквивалентные модели.
Я тут кое-что упустил. Первое раз, когда я это делал, я забыл о возможности женатому человеку подать заявку отдельно от супруга, льготы которого не детализированы, учитывая, что я иностранец с двойным гражданством. Поэтому мне пришлось вернуться назад и добавить предикатный узел в 33с4. Здесь мне вновь помогли схемы. Эта часть модели показана на следующем рисунке.
Женат, раздельные декларации?
ЗЗсЗ Зс2 Неженат, подает декларацию отдельно 33с1 33с4 Льготы супруга не детализированы
ЗЗсЗ Льготы супруга детализированы
33с2 ЗЗсЗ Двойное гражданство.
34 Нет двойного гражданства
ЗЗсЗ 34 Пометьте графу 33с
33с4 34 Нет двойного гражданства
Это не избыточность.
ЗЗсЗ Двойное гражданство
34 34.1 Ваши льготы детализированы?
34.2 Ваши льготы не детализированы
Узел 34 — очень интересный случай. Он похож на предикатный узел, но на самом деле это не так. Это пример того, что мы называем разбиением транзакции (смотрите главу 6.). Для того чтобы следовать инструкции (смотрите дальше узел 34.13), то есть взять большую из детализированных или стандартных льгот, вы должны выполнить оба вычисления, как для стандартной льготы, так и для детализированной льготы. Фактически мы должны обрабатывать обе части парал-
3.4. Методика 75
лелъно, иначе нечего будет сравнивать в узле 34.13. Вы наверняка это делаете при заполнении своей налоговой декларации.
34.1 34.12 Используйте бланк А. строку 26
Здесь кроется еще одна целая модель.
34.2 34.3 НЕ пометили графу 33а
34.4 Пометили графу 33а
34.3 34.4 Пометили графу ЗЗЬ
34.5 НЕ пометили графу ЗЗЬ
Подождите минутку! А что насчет человека, которому 65 лет или больше, И/ИЛИ который слеп И который находится на иждивении у своих родителей или у кого-нибудь еще. Покрывает ли модель этот случай?
34.4 34.12 Стандартные льготы по инструкции
34.5 34.6 Помечена ли графа 33с?
34.7 Графа 33с не помечена
34.6 34.12 Стандартная льгота = 0
34.7 34.8 Холост
Предикат выбора.
34.9 Глава хозяйства
34.10 Женат, заполняем совместную налоговую декларацию
34.11 Женат, заполняю отдельную налоговую декларацию
34.8 34.12 Стандартная льгота = $3.800
34.9 34.12 Стандартная льгота = $5.600
34.10 34.12 Стандартная льгота = $6.350
34.11 34.12 Стандартная льгота = $3.175
Эта модель тоже может быть выражена при помощи графа на следующем рисунке.
Детализированные льготы?
Бланк А
3 Л (3z Помет. д графу ЗЗЬ? С3' Помет. д графу 33с? V Z)— »>/34J2|— НЗДЛЗ^ Помет. / л\\\ 'С ^Д34.15) [графу 33а? / / \\\ ' 1.2)—и Инструкции/ \ \\ \ L А-/. / \ \ (34.14) ш-и-^^зТд) / \ / Холостых / / \ I f / / Гзд.эУ / / \ /А / / / (35 ) 1.5)-И-Н 34.6) / / / V/ У УУ/Глава (34.10/ / \ Лк //совместная / \ Х^*134.7СГ УУ/ * —-434.11) Раздельные^4—'
76 Глава 3 • Тестирование потока управления
34.12 34.13 Пустой узел для большей ясности
34.13 34.14 Стандартные льготы больше детализированных льгот?
34.15 Стандартные льготы НЕ больше детализированных льгот?
34.14 35 Использовать стандартный список
34.15 35 Использовать детализированный список
35 36 Вычесть строку 34 из строки 32
36 36.1 Строка 32 $83.850
36.2 Строка 32 > $83.850
36.1 37 $2.450 exemptions (освобождения)
36.2 37 Согласно инструкции
37 38 Мах(0, строка_35 - строка 36)
Обозначает еще один предикат, но скрывает сегмент пути. Давайте делать правильно.
37 37.1 Строка_35 - строка_36
37.1 38 Больше нуля
37.2 Меньше или равен нулю
37.2 38 Введите ноль в строке 37
38 38.1 tax table (таблица налогов)
Выглядит привлекательно. На первый взгляд это выглядит так, как будто есть пять взаимоисключающих возможностей: (а) таблица налогов, (Ь) налоговая тарифная сетка, (с) бланк D, (d) форма 8615 или (е) форма 8814. Однако, изучая формы 8615 и 8814, я замечаю, что они могли бы представлять собой две дополнительные позиции для каждой из первых трех опций. Я пытался получить объяснения в ВПС, но не получил. Я позвонил моему бухгалтеру, и он спросил, будет ли это «специальной консультацией», но я ответил: «Не беспокойся, Чарли». Такого рода исследования вы можете проводить при создании практической модели, но в этом примере я буду рассматривать пять различных вариантов.
38 38.2 tax rate schedule (налоговая тарифная сетка)
38.3 Бланк С
38.4 Форма 8615
38.5 Форма(ы) 8814
Заметим, что может быть несколько форм 8814, но мы не говорим о том, чтобы суммировать эти формы. Такие особенности должны быть исследованы. Здесь нам следует взять вместе все формы 8814, так как они должны быть заполнены на каждого ребенка, чей интерес и дивиденды вы представляете при заполнении налоговой декларации.
38.1 39 налог в соответствии с tax table (таблицей налогов)
38.2 39 налог в соответствии с tax rate schedule (налоговой тарифной
сеткой).
38.3 39 налог в соответствии с бланком С.
38.4 39 налоги в соответствии с формой 8615
38.5 39 налоги в соответствии с формой (формами) 8814
39 39.1 дополнительные налоги в соответствии с формой 4970
39.2 НЕТ дополнительных налогов по форме 4970
39.1 39.3 заполните налоговую форму 4970
39.2 39.3 поставьте ноль для дополнительных налогов в строке 39
39.3 39.4 дополнительные налоги по форме 4972
39.5 НЕТ дополнительных налогов по форме 4972
39.4 40 Добавьте налоги из формы 4972 в строку 39
3.4. Методика 77
Я смоделировал это именно таким образом, так как из налоговых форм мне показалось, что можно облагать налогом по форме 4970 или 4972 или сразу по обеим. Такие вещи не очевидны, и вы должны их исследовать.
39.5 40 Ничего не делайте
40 41 Добавьте строки 39 и 40
Ужасно? Построение такой модели с простой на вид спецификацией стоило многих усилий. Это заняло у меня пять часов, включая время, затраченное на рисование презентабельных фрагментов графа и пояснительные комментарии, которые я бы и не делал, если бы я создавал настоящий план тестирования. Но все эти комментарии и внутренние монологи — это неплохая идея. Кто-нибудь (вроде вас), может быть, поблагодарит за это.
Исходя из опыта и практики, на построение данной модели должно затрачиваться максимум два-три часа. При большем объеме исследования это, вероятно, займет больше времени. Заметим, что мои графические модели по ходу дела становились проще. В последней модели, например, детализирован только поток управления. Это сделано преднамеренно. Вы используете графические формы для того, чтобы быть уверенным в правильности логики, однако вам также необходимо документировать детали содержания в виде списка.
По ходу дела я менял обозначения. Граф, который мы рассматривали в пункте 3.1, имеет формат имя узла/действие/значение предиката, тогда как последний формат это имя_узла/имя_узла/действие или значение предиката/коииентарии. Опираясь на последние обозначения, связи легко отметить и контролировать, но более ранние обозначения ближе к первоначальной форме изложения. При этом не имеет значения, какой формат вы используете. Выберите что-то одно, что имеет все необходимые данные и чего вы можете придерживаться.
Другая причина состоит в том, что это не программирование. Я не пытался использовать структурированное мышление, при этом мои модели полны GOTO и подобных ему вещей. В настоящее время при реализации явной логики обычно ограничиваются строго структурированными конструкциями. Я здесь предпочитаю GOTO и другие бесструктурные вещи, так как при этом не надо далеко отходить от естественного языка спецификации. Большинство естественно-языковых спецификаций бесструктурно. Если вы слишком отдаляетесь от первоначальной формулировки для принудительного использования, скажем, вложенного дерева IF-THEN-ELSE, то увеличивается вероятность ошибки моделирования, которая, в свою очередь, приводит к тестовым ошибкам или необнаруженным ошибкам программы.
3.4.3. Выбор путей тестирования
3.4.3.1 Основы
Вы ничего не выиграете, уменьшая количество тестов. Лучше использовать простые, очевидные тесты, чем выполнять работу с меньшим количеством более громоздких тестов. Предыдущий пример можно, вероятно, сжать до 10 тестов, но нам следует использовать большее их число, если при этом тестирование проходит максимально чисто и больше согласовано с требованиями.
78 Глава 3 • Тестирование потока управления
Очень часто выбор путей тестирования и их активизацию выполняют одновременно, так как корреляция предикатов может воспрепятствовать проходу программы по произвольно выбранным путям. Хотя это и хорошо на практике, дидактически это неправильно, поэтому мы сначала выберем пути тестирования, а затем, в следующем разделе, будем их активизировать.
Мы создаем путь, добавляя сегмент за сегментом, начиная с входного узла и продолжая до выходного узла. Мы выбираем наши сегменты, начиная с точек, где потоки управления расходятся из одиночного узла, и продолжаем до тех пор, пока потоки управления опять не сойдутся в один узел. Примеры: 32-33а4, 33а4-ЗЗаб, 33с-34. Поступая таким образом, мы строим путь, комбинируя ранее выбранные сегменты. Понятно, что комбинировать сегменты пути можно только в таких, одноузловых точках схождения. В каждом предикате мы выполняем ветвление, выбирая возможные значения (например, значения ИСТИНА/ЛОЖЬ), тем самым расщепляя пути, построенные до этой точки.
В узлах 32 или 33а1 нет выбора; все наши тесты должны начинаться с узлов 32,33а1.
Первым предикатом является узел 33а2. Ветвление здесь соответствует выбору из значений ИСТИНА или ЛОЖЬ, приводя к следующим двум семействам тестов:
А1: 32. 33а1. ЗЗа2(И). ЗЗаЗ. ЗЗаД
А2: 32. 33а1. ЗЗа2(Л). ЗЗаД
Следующий предикат — это узел 33а4 {слеп?). Он, очевидно, является независимым от предыдущего предиката 33а2 {65лет или старше?). Поэтому, хотя пути снова расщепляются, нет необходимости добавлять это в тесты. Для определенности зафиксируем значение предиката ИСТИНА в пути А1, а значение ЛОЖЬ — в пути А2.
АГ. 32. ЗЗаГ ЗЗа2(И). ЗЗаЗ. ЗЗаД(И). 33а5. ЗЗаб
А2: 32. 33а1. ЗЗа2(Л). ЗЗаД(Л). ЗЗаб
В узле ЗЗаб мы спрашиваем, исполнилось ли супругу 65 лет, а в 33а8 мы спрашиваем, слеп ли ваш супруг. Рассматривая эти первые четыре предиката, вы можете увидеть, что они в итоге обеспечивают 16 возможных путей прохода через этот сегмент спецификации. Мы, конечно, можем подготовить в этой точке 16 тестов, проверяющих все 16 комбинаций значений этих четырех предикатов, но это был бы плохой выбор. Тем самым мы бы пытались тестировать маловероятные ошибки. Для проверки связи от узла 32 до узла 33b требуются только два сегмента пути. Какие из них нам следует взять? Любой из двух комплементарных путей подойдет. Пути на отрезке от 32 к 33b могут привести к значениям счетчика_по-меток от нуля до четырех. Из опыта мы знаем, что программисты склонны вводить путаницу с граничными значениями (нулем или четырьмя), поэтому мы должны выделить эти варианты, следовательно, эту логику желательно проверить с помощью тестов, в которых оба — и человек, заполняющий форму, и супруг — слепы и старше 65 лет.
А1: 32. ЗЗаГ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). ЗЗаб. ЗЗаб(И). 33а7. ЗЗа8(И). 33а9.
ЗЗаЮ. 33b
А2: 32. ЗЗаГ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. 33b
3.4. Методика 79
Следующий предикат — это узел ЗЗЬ. Вначале я допустил ошибку и в результате получил проблемы с активизацией. Я не забегаю вперед, чтобы увидеть, может ли этот предикат заблокировать дальнейшие пути, завершаемые в сегменте 34-35. Вот два варианта для этого сегмента: В1: ЗЗЬ(И), ЗЗЫ, 33с и В2: ЗЗЬ(Л), 33с.
Я не знаю, какие комбинации блокируются позже, поэтому в этой точке создаю четыре варианта, комбинируя наборы А и В. Позднее мы исключим тесты, которые не выполняются. Получаем следующее семейство тестов.
В1А1: 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5. ЗЗаб(И). 33а7. ЗЗа8(И). 33а9.
ЗЗаЮ. ЗЗЬ(И). ЗЗЫ. 33с
В2АЮ 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5. ЗЗаб(И). 33а7. ЗЗа8(И). 33а9.
ЗЗаЮ. ЗЗЬ(Л). 33с
В1А2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(И). ЗЗЫ.
33с
В2А2: 32. 33а1. ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л), ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(Л). 33с
Следующий сегмент — это 33с-34. Существует пять возможных путей через этот сегмент, и все пять необходимы для покрытия связей. Пять сегментов:
СЮ ЗЗс(Л). ЗЗс2(И). ЗЗсЗ. 34
С2: ЗЗс(И). ЗЗсКИ). ЗЗсЗ. 34
СЗ: ЗЗс(И). ЗЗсКЛ). ЗЗс4(И). ЗЗсЗ. 34
С4: ЗЗс(Л). ЗЗс2(Л). 34
С5: ЗЗс(И). ЗЗсКЛ). ЗЗс4(Л). 34
Здесь целесообразна быстрая проверка. Я просмотрел четыре предиката (33с, 33с 1, 33с2 и 33с4) в предыдущем списке, чтобы быть уверенным, что каждый предикат принимает оба значения (ИСТИНА и ЛОЖЬ) в каком-нибудь сегменте теста.
С1В1А1: 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5. ЗЗаб(И). 33а7. ЗЗа8(И).
33а9. ЗЗаЮ. ЗЗЬ(И). ЗЗЫ. ЗЗс(Л). ЗЗс2(И). ЗЗсЗ. 34
С2В1А1: 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5. ЗЗаб(И). 33а7. ЗЗа8(И).
33а9. ЗЗаЮ. ЗЗЬ(И). ЗЗЫ. ЗЗс(И). ЗЗсКИ). ЗЗсЗ. 34-
СЗВ1АЮ 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5. ЗЗаб(И). 33а7. ЗЗа8(И).
33а9. ЗЗаЮ. ЗЗЬ(И). ЗЗЫ. ЗЗс(И). ЗЗсКЛ). ЗЗс4(И). ЗЗсЗ. 34
С4В1АЮ 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5. ЗЗаб(И). 33а7. ЗЗа8(И).
33а9. ЗЗаЮ. ЗЗЬ(И). ЗЗЫ. ЗЗс(Л). ЗЗс2(Л). 34
С5В1А1: 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5, ЗЗаб(И). 33а7. ЗЗа8(И).
33а9. ЗЗаЮ. ЗЗЬ(И). ЗЗЫ. ЗЗс(И). ЗЗсКЛ). ЗЗс4(Л). 34
С1В2А1: 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5, ЗЗаб(И). 33а7. ЗЗа8(И).
33а9. ЗЗаЮ. ЗЗЬ(Л). Зс(Л). ЗЗс2(И). ЗЗсЗ. 34
С2В2А1: 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5. ЗЗаб(И). 33а7. ЗЗа8(И).
33а9. ЗЗаЮ. ЗЗЬ(Л). ЗЗс(И). ЗЗсКИ). ЗЗсЗ. 34
СЗВ2АЮ 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5. ЗЗаб(И). 33а7. ЗЗа8(И).
33а9. ЗЗаЮ. ЗЗЬ(Л). ЗЗс(И). ЗЗсКЛ). ЗЗс4(И). ЗЗсЗ. 34
С4В2А1: 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5. ЗЗаб(И). 33а7. ЗЗа8(И).
33а9. ЗЗаЮ. ЗЗЬ(Л). ЗЗс(Л). ЗЗс2(Л). 34
С5В2АЮ 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5. ЗЗаб(И). 33а7. ЗЗа8(И).
33а9. ЗЗаЮ. ЗЗЬ(Л). ЗЗс(И). ЗЗсКЛ). ЗЗс4(Л). 34
С1В1А2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(И). ЗЗЫ.
ЗЗс(Л). ЗЗс2(И). ЗЗсЗ. 34
С2В1А2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(И). ЗЗЫ.
ЗЗс(И). ЗЗсКИ). ЗЗсЗ. 34
СЗВ1А2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(И). ЗЗЫ.
ЗЗс(И), ЗЗсКЛ). ЗЗс4(И). ЗЗсЗ. 34
С4В1А2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(И). ЗЗЫ.
80 Глава 3 • Тестирование потока управления
ЗЗс(Л). ЗЗс2(Л). 34
С5В1А2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(И). ЗЗМ. ЗЗс(И). ЗЗсКЛ). ЗЗс4(Л). 34
С1В2А2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(Л). ЗЗс(Л), ЗЗс2(И). ЗЗсЗ. 34
С2В2А2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(Л). ЗЗс(И). ЗЗсКИ). ЗЗсЗ. 34
СЗВ2А2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(Л). ЗЗс(И). ЗЗсКЛ). ЗЗс4(И). ЗЗсЗ. 34
С4В2А2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(Л). ЗЗс(Л). ЗЗс2(Л). 34
С5В2А2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л), ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(Л). ЗЗс(И). ЗЗсКЛ). ЗЗс4(Л). 34
Небольшая подсказка. Используйте особенности вашего текстового редактора для предотвращения ошибок. Для начала я скопировал сегменты с Cl по С5, азатем я использовал копирование и вставку для вставки предыдущих сегментов (В1А2-В2А2), перед С1-С5. Так как узел 33с не был включен в копируемый блок, мне не пришлось удалять его копии. Такой способ является простым и более надежным.
Ниже приведены восемь возможных сегментов пути от узла 34 до узла 34.12.
D1: 34(И). 34.1, 34.12
D2: 34(Л). 34.2(H). 34.4. 34.12
D3: 34(Л). 34.2СЛ). 34.3(H). 34.4. 34.12
D4: 34(Л). 34.2(Л). 34.3(Л). 34.5(H). 34.6. 34.12
D5: 34(Л). 34.2(Л). 34.3(Л). 34.5(Л). 34.7(Х0Л0СТ). 34.8. 34.12
D6: 34(Л). 34.2(Л). 34.3(Л). 34.5(Л). 34.7(ГЛАВА). 34.9, 34.12
07: 34(Л). 34.2(Л). 34.3(Л), 34.5(Л). 34.7(СОВМЕСТНО). 34.10. 34.12
08: 34(Л). 34.2(Л). 34.3(Л). 34.5(Л). 34.7(РАЗДЕЛЬНО). 34.11. 34.12
Если мы продолжим комбинирование, то у нас получится 20 вариантов, скомбинированных с восемью вариантами. То есть всего 160 вариантов для рассмотрения. Поэтому стоит исключить некоторые варианты по ходу рассмотрения. Это еще одна причина, почему активизация и выбор пути обычно выполняются вместе.
Мы исключаем пути посредством удаления комбинаций, которые не могут быть выполнены, так как предикаты блокируют друг друга. Я создал таблицу из 20 строк и 8 столбцов (табл. 3.2). Заголовками строк были сегменты cCIBlAlno С5В2А2, а заголовками столбцов — сегменты от D1 до D8.
1а. Значение ЛОЖЬ в узле 34.5 означает, что графа 33с не была помечена, поэтому путь не может пройти через узел ЗЗсЗ, соответствующий помеченной графе. Я использовал текстовый редактор, чтобы найти те сегменты, которые содержат в себе узел ЗЗсЗ. Это оказались С1, С2 и СЗ. Их нельзя скомбинировать с D5-D8, так как в этих вариантах должна быть помечена графа ЗЗсЗ. Поэтому следует вычеркнуть их из таблицы.
1Ь. Напротив, значение ИСТИНА в узле 34.5 означает, что графа 33с была помечена, поэтому путь проходил через узел ЗЗсЗ. Следовательно, D4 не комбинируется с С4 и С5.
2а. Если графа 33b помечена, логика не позволяет выбрать в узле 34.3 исходящую ветвь, соответствующую значению ЛОЖЬ. Следовательно, если выполняется узел 33bl, сегменты D4-D8 выполняться не могут. Используя
3.4. Методика 81
поиск по узлу ЗЗЬ 1 (где проверяется пометка графы ЗЗЬ), мы видим, что любой сегмент, включающий вариант В1, не может быть скомбинирован с сегментами D4-D8.
2Ь. И наоборот, если графа ЗЗЬ не помечена (вариант В2), логика не позволяет выбрать в узле 34.3 исходящую ветвь, соответствующую значению ИСТИНА, и вариант D3 не может объединяться с любыми путями, которые включают ЗЗЬ(Л). Это пути, содержащие в себе В2. Поэтому любые сегменты с В2 не комбинируются с D3.
За. Если графа 33а помечена, тогда сегменты D3-D8 можно удалить. Графа 33а помечается в узлах ЗЗаЗ, 33а5, 33а7 и 33а9. Проводя заново поиск наших сегментов, мы видим, что это любые сегменты, содержащие А1. Поэтому А1 не комбинируется с D3-D8.
Таблица 3.2. Определение графа состояний
СЕГМЕНТ D1 D2 D3 D4 D5 D6 D7 D8
С1В1А1 хххх хххх хххх хххх хххх хххх
С2В1А1 хххх хххх хххх хххх хххх хххх хххх
СЗВ1А1 хххх хххх хххх хххх хххх хххх хххх
С4В1А1 хххх хххх хххх хххх хххх хххх
С5В1А1 хххх хххх хххх хххх хххх хххх хххх
С1В2А1 хххх хххх хххх хххх хххх хххх
С2В2А1 хххх хххх хххх хххх хххх хххх хххх
СЗВ2А1 хххх хххх хххх хххх хххх хххх хххх
С4В2А1 хххх хххх хххх хххх хххх хххх
С5В2А1 хххх хххх хххх хххх хххх хххх хххх
С1В1А2 хххх хххх хххх хххх хххх хххх
С2В1А2 хххх хххх хххх хххх хххх хххх
СЗВ1А2 хххх хххх хххх хххх хххх хххх хххх
С4В1А2 хххх хххх хххх хххх хххх хххх
С5В1А2 хххх хххх хххх хххх хххх хххх хххх
С1В2А2 хххх хххх хххх хххх хххх хххх
С2В2А2 хххх хххх хххх хххх хххх хххх
СЗВ2А2 хххх хххх хххх хххх хххх хххх хххх
С4В2А2 хххх хххх хххх хххх
С5В2А2 хххх хххх хххх хххх хххх хххх хххх
ЗЬ. Наоборот, если графа 33а (А2) не помечена, то можно не учитывать D2.
4а. Если вы женаты и заполняете форму раздельно (проверяется 33с), то вы не можете заполнять форму совместно в 34.7. Следовательно, любые сегменты С1В1А1-С5В2А2, включающие ЗЗс(И), не могут комбинироваться с D7. Это все сегменты, содержащие С2, СЗ или С5.
4Ь. И наоборот, любой сегмент, содержащий С1 или С2, не может комбинироваться с D8. Так как ЗЗс(Л ) не означает заполнение раздельных деклараций и 34.7 (РАЗДЕЛЬНО) этому противоречит.
82 Глава 3 • Тестирование потока управления
5. Если вы холосты (34.7(XOJIOCT)-D5), или вы глава хозяйства (34.7 (ГЛАВА)-Эб), льготы вашего супруга не могут быть детализированы. Следовательно, сегменты с ЗЗс1(И)-С2 не могут комбинироваться с сегментами D5 или D6. Это нам ничего не дает, но, между прочим, мы уже исключили 116 вариантов из 160 возможных.
6а. Мы знаем, годами заполняя совместную налоговую декларацию, что если ваши льготы детализированы, то льготы вашего супруга должны детализироваться и наоборот. Следовательно, любые варианты с ЗЗс1(Л)-СЗ и С5 не сочетаемы с 34(H)-D1, и исключается более восьми случаев.
6Ь. Двигаясь в обратном направлении, мы можем понять, что С2 не может комбинироваться с D2-D8.
7. Если вы женаты, заполняете форму раздельно, и льготы вашего супруга не детализированы, и он не является иностранцем (С5), вы не можете быть холосты (D5) или быть главой хозяйства (D6).
Сейчас мы можем продолжить выбор путей. Рассматривая неотмеченные ячейки в таблице, видим, что для D5, D6, D7 и D8 вариантов нет. Они должны комбинироваться соответственно с С4В2А2, С4В2А2, С4В2А2 и С5В2А2.
D5C4B2A2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬСЛ).
ЗЗс(Л). ЗЗс2(Л). 34(Л). 34.2(Л). 34.3(Л). 34.5СЛ). 34.7(ХОЛОСТ).
34.8. 34.12
D6C4B2A2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(Л).
ЗЗс(Л). ЗЗс2(Л).34(Л). 34.2(Л). 34.3(Л). 34.5(Л). 34.7СГЛАВА).
34.9, 34.12
D7C4B2A2: 32. 33а1. ЗЗа2(Л). ЗЗа4(Л), ЗЗабСЛ). ЗЗа8(Л), ЗЗаЮ. ЗЗЬСЛ).
ЗЗС(Л). ЗЗс2(Л). 34СЛ). 34.2СЛ). 34.3СЛ). 34.5СЛ).
34.7(СОВМЕСТНО). 34.10, 34.12
D8C5B2A2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗабСЛ). ЗЗа8(Л). ЗЗаЮ. ЗЗЬСЛ).
ЗЗс(И). ЗЗсКЛ). ЗЗС4СЛ). 34(Л). 34.2СЛ). 34.3СЛ). 34.5СЛ).
34.7(РАЗДЕЛЬНО). 34.11. 34.12
У нас есть три варианта для D4. В данный момент я возьму вариант С1, приводящий к D4C1B2A2.
D4C1B2A2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л). ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(Л). ЗЗС(Л). ЗЗс2(И). ЗЗсЗ. 34(Л). 34.2(Л). 34.3(Л). 34.5(H), 34.6. 34.12
В этом месте мы еще должны включить Al, Bl, С2, СЗ, DI, D2 и D3. D3 может сочетаться только с комбинацией В1А2, поэтому давайте скомбинируем В1А2 с СЗ, для того чтобы получить в итоге СЗВ1А2 с D3.
D3C3B1A2: 32. ЗЗаЮ ЗЗа2(Л). ЗЗа4(Л). ЗЗаб(Л), ЗЗа8(Л). ЗЗаЮ. ЗЗЬ(И). ЗЗЫ, ЗЗс(И). ЗЗсКЛ). ЗЗс4(И), ЗЗсЗ. 34(Л). 34.2(Л), 34.3(H). 34.4. 34.12
Сейчас мы должны включить Al, С2, D1 и D2. D2 не комбинируется с С2, поэтому давайте скомбинируем ее с СЗВ2А1.
D2C3B2A1: 32. ЗЗаЮ ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). ЗЗаб. ЗЗаб(И). 33а7. ЗЗа8(И).
33а9, ЗЗаЮ. ЗЗЬ(Л). ЗЗс(И), ЗЗсКЛ). ЗЗс4(И). ЗЗсЗ. 34(Л).
34.2(H). 34.4. 34.12
3.4. Методика 83
В итоге закончим мы следующим путем:
D1C1B1A1: 32. 33а1. ЗЗа2(И). ЗЗаЗ. ЗЗа4(И). 33а5. ЗЗаб(И). 33а7. ЗЗа8(И).
33а9. ЗЗаЮ. ЗЗЬ(И). ЗЗЫ. ЗЗс(Л). ЗЗс2(И). ЗЗсЗ. 34(И). 34.1.
34.12
У нас не было вариантов для путей D5-D8. Если бы у нас были варианты, как ,и в случае D1-D4, выбор комбинаций основывался бы на нескольких критериях. Нам необходимо было бы учитывать прошлую историю ошибок, насколько трудно было анализировать комбинацию (выберите сложную комбинацию, так как если у вас есть проблемы, то они могут быть и у программиста), как много исследований мы должны были сделать для прояснения проблемы (выберите комбинацию, требующую больших исследований). Также пришлось бы опираться на интуицию и знание образа работы ответственного программиста.
В качестве упражнения закончите выбор пути от узла 34.12 к узлу 40. У нас есть восемь тестов вплоть до узла 34.12. Узел 34.13 добавит только один тест. Узел 36 не добавит никаких тестов (почему?). Узел 38 добавит два теста. Оставшиеся предикаты не нуждаются в тестировании. Таким образом, похоже, что мы можем добиться покрытия связи за 11 тестов. Так как я этого не делал, я могу ошибаться. Однако когда мы будем активизировать эти тесты, возможно, придется вернуться назад и добавить другие тесты.
На рассмотренный пример выбора пути (изложенный выше) я потратил семь часов. Может быть, я более опытен, чем вы, но мне пришлось его объяснять. Предыдущий пример не труднее, чем кажется. Вам следует его выполнить примерно за то же самое время.
3.4.4. Активизация
З.4.4.1. Основы
Активизация. Поиск входных значений, при которых (в случае отсутствия в реализации ошибок) в модели будет пройден выбранный путь.
Большая часть тех процедур, которые описывались в предыдущем разделе, являлись активизацией логики в моделях. Процедура активизации зависит от предикатов, встречающихся в рассматриваемом пути. Если предикаты в большинстве своем логические, как это было в предыдущем разделе, тогда активизация и выбор пути осуществляются одновременно. Если предикаты в большинстве своем численные (то есть алгебраические), то данные процедуры различаются, что описывается в подразделе «Алгебраическая активизация».
Знание приложения важнее знания алгоритма активизации. Знание того, что приложение будет делать в том или ином случае, существенно для определения набора путей, обеспечивающих полное покрытие, и входных значений для их активизации. Я уверен, что если бы мы были экспертами в области налогообложения, нам было бы гораздо легче найти для предыдущего примера набор путей, обеспечивающих покрытие. Прежде чем вы потратите силы и время на активизацию, запустите простейшие тесты вашей модели и убедитесь, что она обеспечивает покрытие связей. После этого у вас останется совсем немного мудреных путей, требующих для активизации применения формальных методов.
84 Глава 3 • Тестирование потока управления
Если при активизации пути возникли непреодолимые трудности, то они могут объясняться одной из следующих причин: путь непроходим, модель содержит ошибки или спецификация содержит ошибки. Проверьте эти предположения, прежде чем потратить массу времени на бесполезную работу.
3.4.4.2. Логическая активизация
Ниже приведен обзор процедур, которые мы должны сделать для выбора (и активизации) пути.
1. Разбейте модель на сегменты, начинающиеся и заканчивающиеся на одиночном узле. В примере, приведенном в разделе 3.4.3 «Выбор путей тестирования», такими сегментами были: 32-33а4, 33а4-33аб, 33аб-33а8, 33а8-ЗЗЬ, ЗЗЬ-ЗЗс, 33с-34, 34-34.12, 34.13-35, 35-37, 37-38, 39-39.3, 39.3-40.
2. Исследуйте сегменты и предикаты в них на предмет корреляции предикатов. Проводите проверку одновременно двух сегментов. Составьте список сегментов, содержащих коррелированные предикаты. Вот некоторые из таких коррелированных сегментов в примере: 32-33а4/34-34.12, 33а4-33а6/34-34.12, 33а6-33а8/34-34.12, 33a8-33al0/34-34.12, ЗЗЬ-ЗЗс/ЗЗс-34, ЗЗс-34/34-34.12.
3. Для каждого сегмента выпишите все возможные отрезки пути, на которых сегмент не содержит циклов.
4. Выберите два любых сегмента с коррелированными предикатами, даже если они не соединены напрямую, начните с тех пар сегментов, которые содержат идентичные предикаты. Вам нужна строгая корреляция. Например, сегмент, в котором задается условие, и следующий сегмент, в котором это условие проверяется. Сегмент ЗЗЬ-ЗЗс помечает графу ЗЗЬ, впоследствии это проверяется в узле 34.3 сегмента 34-34.12.
5. Исключите методом от противного непроходимые пути. Установите значение предиката в первом сегменте равным ИСТИНА и устраните все отрезки пути во втором сегменте, на которых коррелированный предикат принимает значение ЛОЖЬ. Затем положите значение первого предиката равным ЛОЖЬ и устраните все отрезки пути во втором сегменте, на которых коррелированный предикат принимает значение ИСТИНА. Будьте, однако, внимательны, так как отрицание последовательности предикатов в виде A&B&C&D... эквивалентно логической сумме отрицаний этих предикатов, то есть НЕ А ИЛИ НЕ В ИЛИ НЕ С ИЛИ НЕ D... Используйте для уверенности в верности преобразований булеву алгебру.
6. Продолжайте выполнять операции, описанные в пункте 5, объединяя сегменты и устраняя по ходу их комбинации. Таким образом, вы построите более длинные пути, содержащие коррелированные предикаты. При объединении сегментов (например, 33с-34/34-34.12) вы создаете более длинные сегменты, хотя и с меньшим числом возможных путей в каждом из них.
3.4. Методика 85
7. На данном этапе у вас уже есть набор больших сегментов, которые не коррелируют друг с другом. Это означает, что вы можете выбрать отрезки пути в каждом из сегментов, которые не зависят от других сегментов. Выберите достаточное число путей в каждом сегменте, чтобы быть уверенным, что вы обеспечили покрытие связей внутри этих сегментов.
8. Объединяйте сегменты, комбинируя пути и выбирая имеющие смысл комбинации. Обратите внимание, что число тестов при этом не должно увеличиться. Например, сегмент А содержит 6 путей, а сегмент В — 10 путей. Это означает, что пара сегментов будет содержать 10 путей, а не 60. Поскольку сегменты некоррелированные, вы можете связать любой отрезок пути в сегменте А с любым отрезком пути в сегменте В.
9. Продолжайте до тех пор, пока не получите набора путей, обеспечивающих покрытие.
10. Теперь мы можем перейти непосредственно к активизации. Следуйте вдоль пути и по достижении предиката определите входное условие, при котором предикат принимает значение ИСТИНА или ЛОЖЬ, в зависимости от требований пути. Вам, возможно, придется использовать некоторые методы из следующего раздела для осуществления этого, однако, как правило, для большинства логических предикатов и предикатов выбора, это должно быть просто, так как вы уже убедились в отсутствии противоречий на выбранном пути.
3.4.4.3. Алгебраическая активизация
Интерпретация предиката. Предикат считается интерпретированным, если он выражен через входные значения. Интерпретация предиката зависит от выбора пути. Это означает, что мы можем получить эквивалентный предикат, следуя в вычислениях по определенному пути, ведущему к этому предикату.
Примером в данном разделе служит расчет детализированных льгот в Бланке А, строке 29 (См. Приложение). Модель для этого вычисления приводится ниже. Это не полная модель — она содержит только узлы, находящиеся на пути, который мы активизируем. Переменные, начинающиеся с буквы А, относятся к бланку А или к строкам формы 1040. Переменные, начинающиеся с буквы W, относятся к процедуре расчета.
1 1.1 input AL4
1.1 1.2 input AL9
1.2 1.3 input AL14
1.3 1.4 input AL18
1.4 1.5 input AL19
1.5 1.6 input AL26
1.6 1.7 input AL27
1.7 1.8 input AL28
1.8 2 W1 = AL4 + AL9 + ALM + AL18 + AL19 + AL26 + AL27 + AL28
2 2.1 input AL13
2.1 2.2 input AL28g
2.2 3 W2= AL4 + AL13 + AL19 + AL28g
3 3.1 W3= W2-W1
86 Глава 3 • Тестирование потока управления
W3 = AL4 + AL9 +AL14 + AL18 + AL19 + AL26 + AL27 + AL28 -
(AL4 + AL13 + AL19 + AL28g)
W3 = AL8 + AL14 + AL 18 + AL26 + AL27 + AL28 - AL 13 - AL28g
W-5 rf-W3 8
IFAL9 * ALII «-АН8 ь ДЬ26 ь-АЕ-2-7 »-AE88-АШ---AL28g <-0
Второй предикат на последней не зачеркнутой строке — это интерпретированный предикат. Сначала мы подставили входные значения, а затем выразили предикат через них путем их подстановки в символьном виде.
Нетрудно заметить, что спецификация в данном случае неверна. В ней говорится: «если результат равен нулю...», а должно быть: «если результат меньше или равен нулю...»
Я зачеркнул последнюю строку, поскольку активизация у нас выполняется вдоль определенного пути. Мы будем рассматривать путь, определенный на строке 10. Продолжим модель:
3.1 4 IF AL9 + AL14 + AL18 + AL26 + AL27 + AL28 - AL13 - AL28g > О
4 5 0.8 * W3 = 0.8 * (AL9 + AL14 + AL18 + AL26 + AL27 + AL28 - AL13 -
AL28g)
5 6 input AL32
6 6.5 если раздельно
Этот путь я решил выбрать для данного теста.
6-г6—если совместно
6.5 7 Ш6= $55.900
6-6—?-----W6 $111.800
7 7.1 W7 = W5 - W6 = AL32 - 55.900
7'.1—Н).6 if-W7 < —0
8 if W7> 0: if AL32 - 55.900 > 0
8 9 W7* 0.03= AL32* 0.03-1.667.00
9---9-4 EEAL32*-».03 h667.OO-t-0.8 * (AL9 * AL14 > AL18 +-AL26-+-
AL27 । AL28--АН8----AL28g)
9.2 if AL32* 0.03 -1.667.00 > 0.8 * (AL9 + AL14 + AL18 + AL26 +
AL27 + AL28 - AL 13 - AL28g)
9.2 9.5 WL9 = 0.8 * (AL9 + AL14 + AL18 + AL26 + AL27 + AL28 - AL13 -AL28g)
9.5 10 WL10 = AL4 + AL9 + AL14 + AL18 + AL19 + AL26 + AL27 + AL28 -
0.8*(AL9 + ALM + AL18 + AL26 + AL27 + AL28 - ALII - AL28g)
Ниже приведены интерпретированные предикаты, через которые проходит этот путь:
AL9 + AL14 + AL18 + AL26 + AL27 + AL28 - AL13 - AL28g > 0
РАЗДЕЛЬНОЕ ЗАПОЛНЕНИЕ
AL32 - 55.900 > 0
Это простой случай, поскольку все три предиката полностью независимы. Но так бывает далеко не всегда. Как правило, входные значения встречаются сразу в нескольких интерпретированных предикатах. Следует отметить, что здесь указаны далеко не все существующие условия. Дополнительные условия: все входные переменные должны быть больше или равны нулю. Строго говоря, вам следует записывать такую информацию, чтобы не забыть ее на следующем шаге активизации.
3.4. Методика 87
На следующем шаге активизации мы ищем набор входных значений, удовлетворяющих всем интерпретированным предикатам на заданном пути. В последнем примере это выполняется достаточно просто.
AL9 + AL14 + AL18 + AL26 + AL27 + AL28 > AL13 + AL28g
РАЗДЕЛЬНОЕ ЗАПОЛНЕНИЕ
AL32 > 55.900
Если нам сильно не повезет, то придется решать систему уравнений для активизирующих величин. Уравнения в системе представляют собой интерпретированные предикаты. В большинстве случаев, однако, это просто вопрос правильного выбора входных значений для первого интерпретированного предиката, подстановки их в последующих предикатах и упрощения по мере продвижения. Предположим, например, что у нас есть следующий набор интерпретированных предикатов (это не относится к нашей модели) для выбранного пути:
AL9 + AL14 + AL18 + AL26 + AL27 + AL32 > AL13 + AL28
AL9 + 0.05*AL14 > AL32
AL32 > 55.900
AL14 > AL18
Обратите внимание, что я расположил неравенства так, что они направлены одинаково. Сначала установите значение любой из входных переменных таким, чтобы избавиться от одного уравнения. В данном случае это значение величины AL32, которую я положил равной $55,905. Затем подставьте это значение в другие выражения и получите следующий набор предикатов.
AL9 + AL14 + AL18 + AL26 + AL27 + 55.905 > AL13 + AL28
AL9 + 0.05*AL14 > 55.905
55.905 > 55.900
AL14 > AL18
Мы можем положить значение AL14 большим, чем AL18, например, представив его в виде AL14 = AL18+10.
AL9 + AL18 + 10 + AL18 + AL26 + AL27 + 55.905 > AL13 + AL28
AL9 + 0.05*(AL18 + 10) > 55.905
55.905 > 55.900
AL14 = AL18 + 10 > AL18
Упрощаем и группируем члены:
AL9 + 2*AL18 + AL26 + AL27 + 55.915 > AL13 + AL28
AL9 + 0.05*AL18 - 55.904.50 > 0
Складывая эти два выражения, получим:
2*AL9 + 2.05*AL18 + AL26 + AL27 +10.5 - AL13 - AL28 > 0
Мы свели все наши условия к одному выражению, слагаемые в котором можем выбирать по нашему усмотрению. После того как мы это проделали, подставляем выбранные значения в выражения для величин, от которых мы предварительно избавились (AL14, к примеру), и в результате получим набор согласованных входных значений, удовлетворяющих всем интерпретированным предикатам на заданном пути. Вот мой набор входных значений:
88 Глава 3 • Тестирование потока управления
AL9 = 10
AL18 = 15
AL26 = 30
AL27 = 40
AL13 = 5
AL28 = 10
AL14 = AL18 + 10 = 25
AL32 = 55.900
В большинстве случаев вы можете выполнить активизацию, не прибегая к формальному решению уравнений с использованием матриц и даже не подозревая о том, что можно использовать эту процедуру. Начните с простейших неравенств, где у вас есть наибольшая свобода выбора и выберите входные значения для них. Потом подставьте эти значения в другие неравенства и упростите. Используйте простейшую арифметику для исключения переменных, комбинируя выражения путем их сложения и вычитания.
Если вы не можете обойтись простейшими подстановками и упрощениями, то, прежде чем потратить время и силы на инвертирование матриц, проверьте спецификации и свои предыдущие действия. Как правило, причины, толкающие вас на инвертирование матриц, кроются в ваших предыдущих ошибках и/или в ошибках, содержащихся в спецификации.
Другой способ решения данной проблемы — поместить ваши неравенства и выражения в электронную таблицу и использовать встроенные методы решения систем уравнений для получения ответа. Например, инструменты для решения уравнений в LOTUS-123 справятся с этим превосходно. Более того, они позволяют смешивать логические и алгебраические предикаты в одном наборе неравенств.
3.4.5. Предсказание итогов
Следующим шагом в процессе проектирования теста является предсказание итогов для каждого из выбранных путей. Хотя вашим первым побуждением будет попытка сыграть роль компьютера и пройти по этим путям вручную, не спешите это делать. Во-первых, это может быть очень непростой задачей. Во-вторых, вы будете пытаться заменить собой компьютер, а в этом еще никто из людей не преуспел. Вы с большей вероятностью допустите ошибку в вашем предсказании итогов, чем программист в программе. Ниже приведено несколько более привлекательных альтернативных вариантов.
Существующие тесты. Около 80 % труда разработчиков программного обеспечения на сегодняшний день уходит на сопровождение программ. Большинство тестировщиков и программистов работает над модификацией уже существующего программного обеспечения. Это означает, что 95 процентов ваших тестов не меняется от версии к версии. Если вы будете так же тщательно контролировать конфигурацию своих тестов, как и конфигурацию программного обеспечения, то у вас будет оракул для большинства ваших тестов.
Старые программы. Серьезное обновление не всегда влечет за собой соответствующие изменения в тестовом комплекте, поэтому старые программы могут использоваться в качестве оракула. Например, старая программа была написана для
3.4. Методика 89
MS DOS. Теперь требуется перенести ее на другие платформы. Хотя подобная переделка программы может вести к полному ее переписыванию, старая программа является превосходным оракулом. Запустите на ней свои тесты для нахождения ожидаемых итогов.
Предыдущие версии. Даже если код, который вы тестируете, был переписан, как правило, для большинства путей корректные итоги могут быть получены из предыдущих версий программы. В худшем случае могут быть внесены изменения в небольшое количество путей, однако разница в итогах тестов для старой и новой версий программы легко прогнозируется. Используйте итоги, полученные для предыдущей версии, как отправную точку для поиска итогов для соответствующих путей в новой версии.
Прототипы и модельные программы. Вы можете построить прототип, достаточно подробный для того, чтобы получить с его помощью корректные итоги [STAK89], Хорошие прототипы, как правило, не лишены функциональности. Причина, по которой они не могут служить рабочей программой, кроется в том, что они или слишком медленные, или слишком большие, или просто не могут работать в заданной операционной среде.
Если у вас нет детально проработанного прототипа, вы можете получить оракула, построив модельную программу. Например, если бы мне надо было написать программу для заполнения декларации о подоходном налоге, я бы начал с того, что запрограммировал все формы в электронных таблицах, а алгебру и логику — на каком-нибудь простом языке, например, BASIC. Это не то же самое, что писать код для реального продукта, поскольку вы не забиваете себе голову вещами, о которых должен заботиться программист, такими, как доступ к структурам данных, взаимодействие с операционной системой, ввод и вывод. В большинстве стандартных программных продуктов предусмотрено много вещей, не имеющих непосредственного отношения к прикладной задаче. Я не располагаю точными цифрами, но полагаю, что менее 10 процентов программного кода имеют непосредственное отношение к прикладной задаче. Более того, эти 10 процентов кода зачастую являются наиболее простыми. Таким образом, построение модельных программ и использование их в качестве оракула не лишено смысла.
Выбор простых вариантов. Иногда существует возможность выбрать входные значения так, чтобы они, с одной стороны, активизировали нужный нам путь, а с другой — упрощали вычисления. Например, установить все входные значения, кроме нескольких, равными нулю. В примере, приведенном выше, мы могли выполнить все условия при помощи подбора значений AL9, AL18 и AL13. Остальные входные величины мы могли положить равными нулю.
Вы можете возразить, что ситуация, когда на входе может быть так много нулей маловероятна, но это плохой аргумент. В тестировании существует неписаное (и неудачное) правило, гласящее, что входные значения должны быть реалистичны. Реализм — это установка, мешающая хорошему тестированию. Реализм нужен для демонстраций, но он не является целью тестирования. Реалистичные тесты, хотя и кажутся убедительными, как правило, на поверку оказываются слабыми, поскольку именно их программист с большой вероятностью выполнит сам.
90 Глава 3 • Тестирование потока управления
Реализм не слишком хорош при поиске ошибок, а первоочередной задачей тестирования является как раз поиск ошибок, а совсем не создание иллюзии доступности для простого человека.
Если вы включили в свой допустимый набор входных значений такие маловероятные значения, как ноль, вы можете обнаружить, что предсказание итогов, интерпретация предикатов и последующая активизация становятся проще. Поскольку нереалистичные тесты, как правило, отличаются от тестов, проводимых программистами, они с большей вероятностью могут выявить ошибки.
Конечная программа. Вы можете использовать конечную программу в качестве оракула, если вы в ней уверены. Обычно проще проверить правильность итога, чем вычислять его самому, подменяя собой компьютер. Это особенно касается случаев, когда вы можете вывести на печать и проверить промежуточные значения величин. Под словом «уверены» я подразумеваю, что вы проводите анализ, подтверждающий корректность итогов. Если вы просто принимаете итоги как они есть, без проверки, вы, мягко говоря, ошибаетесь.
3.4.6. Проверка соответствия пути
Вам необходимо проверять пути из-за угрозы возникновения случайной корректности. Однако проверка пути при проведении тестирования черного ящика — непростая задача, поскольку мы имеем дело с моделями поведения. Пути в тестировании — это пути через спецификации поведения, и нет никакой уверенности (и даже необходимости), что аналогичные пути существуют в реальном программном обеспечении. Единственный способ убедиться в соответствии поведенческих путей в потоке управления, заключается в проверке корректности всех промежуточных вычислений, и особенно тех, которые обусловлены предикатами потока управления. Если подобная проверка невозможна из-за отсутствия доступных промежуточных результатов обработки, то единственный способ их получить заключается во внедрении в программу (совместно с программистами) соответствующих логических операторов для проверки тестовых условий [ANDR81, CHEN78B],
У вас нет необходимости проверять все вычисления. Найдите определение узла в начале этой главы: «один или более шагов обработки...». В большинстве приведенных моделей я, стремясь к наглядности, добавлял узлы и связи. Например, в модели на предыдущем рисунке узлы 34.1, 34.6, 34.8, 34.9, 34.10, 34.11, 34.14, и 34.15 несущественны. Граф на следующем рисунке содержит ту же самую информацию.
Любая последовательность узлов, не являющихся объединяющими узлами или предикатами (узлами выбора), может быть заменена одним узлом с одной исходящей связью. Такая сжатая модель будет проще, и ваша проверка сведется к проверке одного значения для каждой связи на выбранном пути, идентифицирующем данную связь. К примеру, можно проделать множество вычислений на пути 34.7-34.11-34.12, но все, что нам надо, это убедиться, что по данной связи проходит одно единственное значение 3,175 — льготы женатого человека, заполняющего раздельную с женой налоговую декларацию.
3.5. Рассмотрение приложения 91
Детализированные льготы? Бланк А
Л? Помет. / графу 33а? /
34.2)—и Инструкции
Помет, графу ЗЗЬ?
Помет, графу 33с?
Глава 134.10'1
Совместная
V *-,34.11, Раздельные
Давайте посмотрим теперь на проблему проверки соответствия пути в перспективе. Проверка необходима из-за угрозы возникновения случайной корректности. С другой стороны, поведенческое тестирование потока управления далеко не единственный метод, который вам придется использовать. Поэтому проверяйте в пути все, что можете проверить. То есть если промежуточные элементы обработки легко доступны и у вас есть инструменты тестирования для проверки соответствия пути, программисты будут рады сотрудничеству с вами и помогут вам, используя эту защиту от ошибок.
Другой приемлемый способ защиты от случайной корректности — это тестирование нескольких вариантов для одного и того же пути. Мы к этому придем, рассматривая в дальнейшем другие методы тестирования, и особенно тестирование доменов.
3.5. Рассмотрение приложения
3.5.1. Индикаторы приложений
Поведенческое тестирование потока управления применимо практически к любой программе и эффективно для большинства приложений. Это фундаментальный метод. Его используют обычно для тестирования относительно небольших программ или сегментов больших программ. Как будет видно из примеров, приведенных ниже, он, скорее всего, будет эффективен для индивидуальных форм ВНС, но использовать его для тестирования всего пакета налоговых документов было бы затруднительно. Эти трудности объясняются тем, что модель получается слишком громоздкой, а, следовательно, выбор пути и активизация настолько сложны, что результат не оправдывает затраченных усилий.
92 Глава 3 • Тестирование потока управления
3.5.2. Предположения об ошибках
Причиной большинства ошибок в программе могут являться ошибки потока управления, и, следовательно, возникающее при этом аномальное поведение может быть обнаружено путем тестирования потока управления. Однако основное предположение об ошибках, па поиск которых направлено тестирование потока управления, — это влияние ошибок на предикаты потока управления или то, что поток управления сам по себе неправилен. В качестве примера можно привести ошибку в вычислении элемента, который в дальнейшем будет использоваться как часть предиката потока управления, например, использование >= вместо <. Примером грубой ошибки в потоке управления является ошибочное соединение узла 34.4 с узлом 34.14 вместо 34.12. Подобные грубые ошибки в потоке управления сейчас встречаются довольно редко благодаря использованию языков структурного программирования. В старом программном обеспечении, написанном на языке COBOL, или, скажем, ассемблере, подобные ошибки встречаются значительно чаще.
Ошибки в вычислениях, не влияющие на поток управления, также можно искать с помощью рассматриваемого метода, однако для этих целей существуют лучшие методы. Тестирование доменов (см. глава 7) и тестирование потоков данных (см. глава 5) более эффективны при поиске подобных ошибок.
3.5.3. Ограничения и предостережения
Ниже приведены некоторые ограничения и предостережения.
1. Вам не имеет смысла заниматься поиском отсутствующих требований, за исключением, конечно, того случая, когда ваша модель включает в себя эти требования, а программа — нет.
2. Вероятность того, что вы обнаружите неуместные или побочные характеристики, отсутствующие в требованиях, по присутствующие в программе, мала.
3. Чем лучше программист выполнил свою работу по тестированию модуля, тем менее вероятно, что данный метод обнаружит новые ошибки, например, если именно этот метод использовался при тестировании модуля (неплохая идея).
4. У вас мало шансов найти пропущенные пути и характеристики в программе, если программа и модель, на которой основывался тест, были написаны одним человеком. Если вы программист и используете этот метод для тестирования своего собственного программного обеспечения, то неверное представление, которое привело в итоге к потере путей и характеристик в вашей программе, может остаться у вас в голове и когда вы проектируете тесты. Если тесты разрабатывает кто-то другой, вероятность одинаковых ошибок уменьшается, хотя и за счет увеличения затраченных усилий.
3.6. Резюме 93
5. Для устранения хотя и небольшой, но все же существующей угрозы возникновения случайной корректности вам надо проверить все промежуточные вычисления и значения предикатов.
6. Ваши тесты не лучше вашего оракула.
3.5.4. Автоматизация и инструментальные средства
На момент написания этой книги не существовало коммерческих инструментов, предназначенных для работы с поведенческим тестированием потока управления, однако большое количество инструментов поддерживает структурное тестирование потока управления. Вы можете использовать эти инструменты, запрограммировав ваши модели на поддерживаемых языках, таких как С, Pascal или Basic [DAIC93, GERH88, SCHI69, WARN64J. Это не будет потерей времени или избыточным программированием. Работа, затраченная на создание достаточно детальной графической модели, — это большая часть всей работы по представлению полуформальной модели в виде программы.
Причина, по которой программирование модели не является избыточным, и, конечно, отличается от программирования реального продукта, заключается в том, что вы не забиваете себе голову практическими вещами, такими как доступ к базам данных, взаимодействие с операционной системой, ввод и вывод, вопросы окружения и многим другим, порождающим реальные ошибки. В модельной программе могут отсутствовать детали, она не обязана работать на какой-то конкретной платформе, ей не обязательно быть производительной, и, что самое главное, она не должна быть интегрирована с другими частями продукта.
Как используется модель? Вовсе не для запуска тестов реальной программы. Именно программа должна быть протестирована, а не какая-то модель тестировщика. Это так! Тестирование модели отличается от тестирования реальной программы, но его тоже надо проводить. Как вы собираетесь отлаживать свои тесты? Модель надо использовать как инструмент, помогающий вам разработать набор тестов, обеспечивающих покрытие, для выбора и активизации путей, в качестве оракула для реального программного обеспечения. Если вы построили действующую модель, то вы можете применить к ней коммерческие инструменты тестирования. А это значительно упростит вашу работу.
3.6. Резюме
Поведенческое тестирование потока управления рассмотрено как фундаментальная модель тестирования черного ящика. Она является основой для всех других методов тестирования, обсуждаемых в этой книге, и впоследствии я буду считать, что вы ее усвоили.
Проектирование тестов начинается с создания поведенческой модели графа потока управления на основе документированных требований, таких как спецификация. Представление в виде списка, как правило, более удобно, чем рисунки графов, но маленькие графы помогают при проектировании модели.
94 Глава 3 • Тестирование потока управления
Составные предикаты в модели следует устранять или заменять, например, эквивалентными графами, для того чтобы не прятать реальную сложность. Вместо графа при моделировании составных предикатов, состоящих из более чем трех компонентов, используйте таблицу истинности.
Разбейте вашу модель на отрезки, которые начинаются и заканчиваются одиночным узлом, и отметьте взаимную корреляцию предикатов во всех сегментах. Постройте ваши тестовые пути, комбинируя пути в сегментах и исключая непроходимые пути. Используйте противоречия между предикатами для вычеркивания отдельных комбинаций. Маловероятно, что эта методика приведет к непроходимым путям, которые будет невозможно активизировать.
Выберите достаточное количество путей через модель, чтобы гарантировать полное покрытие связей. Не волнуйтесь, если тестов окажется слишком много. Начните с выбора очевидных путей, которые имеют прямое отношение к требованиям, и посмотрите, не можете ли вы таким способом добиться покрытия. Возможно, вы получите не самые эффективные тесты, но это политически верное решение. Расширьте эти тесты, рассмотрев столько путей, сколько надо для стопроцентной гарантии покрытия связей.
Активизируйте выбранные пути, интерпретируя предикаты вдоль пути в терминах входных величин. Интерпретированные предикаты дают набор условий или уравнений (в действительности неравенств), так что любое решение этого набора неравенств будет условием прохода но выбранному пути. Если активизация не очевидна, то перед тем, как вы потратите много времени на решение уравнений, проверьте, нет ли ошибок в спецификации или модели. Если условия все же сложны, рассмотрите вариант использования коммерческой программы, предназначенной для решения неравенств для активизации, такой как LOTUS 1-2-3. Алгебраический пакет может помочь с интерпретацией предикатов.
Не забывайте о возможности случайной корректности и сотрудничайте с программистами для получения промежуточных численных выводов, которые необходимы для проверки пути. Дайте выражениям с предикатами высокий приоритет, но не настаивайте больше чем на одном значении для каждой связи в графе.
Продумайте программирование вашей модели с помощью реального языка программирования, используйте запрограммированную модель при проектировании тестов.
3.7. Вопросы для самопроверки
1. Дайте определение следующих терминов: операция И, комплементарные сегменты пути, составной предикат, граф потока управления, коррелированные предикаты, независимые предикаты, объединяющий узел, логическая модельная программа, логический предикат, НЕ, ИЛИ, предикат, интерпретация предиката, узел с предикатом, узел выбора, предикат выбора, активизировать, простой предикат, разделение транзакций, таблица истинности.
3.7. Вопросы для самопроверки 95
Во всех следующих примерах не надо моделировать побочные формы и ведомости, определенные в инструкциях ВНС.
2. Для бланка SE, 1994 и приведенного там же графа постройте граф потока управления, используя в качестве предикатов помечаемые графы.
3. Для бланка SE, 1994 замените в построенном вами графе все единичные составные предикаты на эквивалентные последовательности простых предикатов.
4. Для бланка SE, 1994 скомпонуйте один составной предикат, определяющий все условия, при которых надо заполнять короткую форму, и все условия, при которых надо заполнять длинную форму.
5. Постройте граф-модель потокауправления для формы 1040. Рассматривайте данные, приходящие из других форм или частей в качестве входов. Для каждого варианта постройте модель, выберете пути тестирования и спроектируйте тесты, используя обеспечение покрытия узлов и обеспечение покрытия связей. Проверьте работу ваших тестов, используя в качестве оракула пакет программ для расчета налогов или модели в виде электронной таблицы. Если вы используете программу для расчета налогов, вам, возможно, придется брать входные значения из других форм. (1) строки 1-5, (2) строки 6-22, (3) строки 32-40, (4) строки 41-46, (5) строки 47-53, (6) строки 54-60, (7) строки 61-65.
6. То же, что и в задаче 5 для формы 1040, бланка SE, короткая форма, строки 1-6, но включите в модель логику для определения того, может или не может быть использована короткая форма.
7. Форма 1040, бланк на строке 10. Полная форма.
8. Форма 1040, бланк на строке 20а, social security income (доход, подлежащий налогообложению по программе социального обеспечения). Полная форма.
9. Форма 1040, бланк на строке 34, dependent deductions (льготы иждивенца). Полная форма.
10. Постройте модель для строк 1-5 формы 1040, бланк на строке 26 (1994, Бланк Self-employed health insurance deductions (Льготы для частных предпринимателей по программе страхования здоровья по старости)).
11. Найдите все пары коррелированных сегментов путей для примера в разделе 3.4.3.
12. Форма 2106, Employee business expenses (Расходы служащего по сделкам), часть II, разделы А, В, С.
13. Форма 2688, Application for Extension to File (Заявление о продлении срока), строки 1-4.
14. Форма 2210, Недоплата налогов. Включает (а) Строка 1, (Ь) часть II, (с) часть III, (d) часть IV раздела В. Представьте, что вы можете использовать короткий метод (часть III), если вы не пометили графы 1b, 1с, или
96 Глава 3 • Тестирование потока управления
Id. В любом случае выводы (если они есть) направляются на соответствующую строку формы 1040. Таким образом, вы можете не беспокоиться относительно форм 1040A, 1040NR 1041, и т. д.
15. Форма 3903, часть I, Employee Moving Expenses (Расходы на поездки служащего).
Тестирование циклов
4.1. Обзор
Тестирование цикла — это эвристический метод, который следует использовать в сочетании со многими другими методами тестирования, поскольку опыт показывает, что ошибки часто сопутствуют циклам. Методы, обсуждаемые в этой главе, применяются в тех случаях, когда имеются циклы в таких графах как: граф потока управления, граф потока транзакций, или синтаксический граф.
4.2. Основные термины
Внешние термины: приложение, массив, компоновка, группа, С, оператор BREAK, сбор/воспроизведение данных, COBOL, код, компилятор, копировать, повреждение данных, отказ, отладка, отрицательное приращение, конец файла, ввод (цикла), вычислять, выполнять, поле, файл, длина файла, FOR, GOTO, аппаратные средства, эвристический, реализация, положительное приращение, инициализировать, внутренний цикл, целочисленный, итерация, ошибка границ в памяти, объединение, модель, вложенный цикл, операционная система, внешний цикл, указатель, ошибка указателя, предусловие, процесс внутри цикла, обработка, программа, программист, программирование, язык программирования, случайный, запись, повторяющийся процесс, требование, время выполнения, поиск, программное обеспечение, сортировка, спецификация, язык структурного программирования, структурное программное обеспечение, завершать, передавать, истинное значение, значение, переменная, WHILE.
Внутренние термины: поведение, поведенческое тестирование, тестирование черного ящика, ошибка, граф потока управления, тестирование потока управления, граф, модель на основе графа, цикл, связь, логический предикат, узел, имя
4 Зак. 770
98 Глава 4 • Тестирование циклов
узла, объект, исходящая связь, путь, предикат, отношение, действенный тест, предикат-переключатель, спецификация, структура, симптом, системное тестирование, тестовый вариант, тестирование модуля.
Цикл. Повторяющийся или итерационный процесс. Та часть модели-графа, которая содержит цикл. То есть повторяющееся имя узла хотя бы на одном пути.
Число повторений цикла. Число раз, которое повторяется цикл. При выходе из цикла не спутайте это число с конечным значением переменной управления цикла, если она существует (смотри ниже). Ошибочное принятие числа повторений цикла за конечное значение переменной управления цикла — распространенный источник ошибок.
Детерминированный цикл. Цикл, число итераций которого известно до того, как начнется выполнение цикла.
Недетерминированный цикл. Цикл, число итераций которого неизвестно до того, как начнется выполнение цикла, или цикл, число итераций которого определяется или изменяется внутри цикла по ходу выполнения.
Узел управления циклом. Узел с двумя и больше исходящими связями: для одной связи цикл будет выполняться, а для другой не будет. На рисунке узел управления циклом отмечен как «20».
10
20
Узел выхода из цикла. Узел, который представляет предикат по крайней мере с одним значением, вызывающим отмену выполнения цикла. Цикл может, к несчастью, иметь более одного узла выхода. Узел 20 в только что приведенной модели — узел выхода из цикла.
Узел входа в цикл. Узел, через который происходит вход в цикл. Цикл может иметь более одного узла входа. Узел 10 на предыдущем рисунке — это узел входа в цикл.
Предикат управления циклом. Предикат в узле управления циклом, значение которого определяет, будет цикл выполняться или нет.
Переменная управления циклом. Любая переменная в предикате управления циклом, значение которой влияет на (истинное) значение предиката управления циклом — что определяет, будет цикл выполняться или нет.
Цикл с предусловием. Цикл, в котором предикат управления циклом вычисляется до того как выполняется какая-либо обработка внутри цикла. На рисунке узел управления циклом — это узел 20, а между узлами 10 и 20 нет никакой обработки. Вся обработка происходит на связи 20-10, так что это цикл с предусловием.
Обработка
Нет обработки
4.3. Отношения и модель 99
Цикл с постусловием. Цикл, в котором предикат управления циклом вычисляется после обработки. В циклах с постусловием обработка выполняется по меньшей мере один раз.
Нет обработки
Цикл со смешанной проверкой. Цикл, в котором обработка происходит и до, и после того, как вычислен предикат управления циклом1.
Обработка
Вложенные циклы. Два или более циклов — вложенные, если один полностью содержится в другом. На следующем рисунке цикл 10-20-10 является вложенным по отношению к циклу 5-25-5.
4.3. Отношения и модель
4.3.1. Основы
В этом разделе мы используем язык программирования, так что может показаться, что мы говорим о программах. Однако мы говорим не только о программах или о циклах, которые могут находиться или не находиться внутри них. Тестирование черного ящика касается поведения, а не структуры. Наши модели — это модели поведения, и соответствующие циклы могут существовать или не существовать в тестируемом программном обеспечении. Если вы будете смотреть на программное обеспечение с чересчур близкого расстояния, пытаясь разобраться, с каким видом цикла вы столкнулись, вы можете допустить ту же ошибку в своей модели, что и программист в коде.
1 Пусть вас не сбивают с толку языки программирования и семантика конструкций типа опера-юров FOR и WHILE. Почти любая комбинация детерминировапных/недетерминированных циклов с проверкой до/после/смешапной может быть создана с помощью почти любой логической структуры. Смотрите упражнения в конце главы.
100 Глава 4 • Тестирование циклов
Вы заметите, что в нижеперечисленных моделях циклов я не использую конструкции структурного программирования, такие как FOR или WHILE, а использую вместо них явные предикаты и GOTO для данных модельных циклов. Мы имеем дело с моделями, а не с кодом. Я не ратую за отбрасывание конструкций FOR и WHILE в пользу GOTO. Я не использую структурные конструкции циклов в моделях, поскольку они зависят от языка, в котором реализованы, и в некоторых случаях даже от специфического компилятора для данного языка. Это особенно справедливо для проблем с циклами со смешанной проверкой. И именно это приводит к ошибкам циклов в коде и дизайне теста.
Отношение между узлами в данных моделях — предшествует. Однако я осознанно не буду говорить ничего конкретного об оставшейся части модели. Здесь примеры будут приводиться для моделей потока управления, но тестирование цикла применяется и ко многим другим моделям (в том числе к тестированию синтаксиса), в которых, несмотря на то, что объекты и отношения различны, принципы тестирования остаются теми же.
4.3.2. Детерминированные циклы
В детерминированных циклах число повторений цикла известно до того, как будет выполняться первый оператор внутри цикла, и внутри цикла нет процесса, который вызвал бы изменение этого числа.
20 30 loop_control = 0. птах = 10
30 40 loop_process
40 30 loop_control =»< птах. loop_control = loop_control + 1
50 loop_control > птах
50 продолжить оставшуюся часть модели
Это пример цикла с постусловием. Предполагается, что переменная управления циклом loop control не меняется процессом loop process на связи 30-40. Она может использоваться процессом loop process, но этот процесс саму ее не меняет. Узел 20 — входной узел цикла. Узел 40 — выходной узел цикла и вместе с тем узел управления циклом. Несмотря на то, что я использовал простое положительное приращение (loop_control = loop control +1), можно использовать практически любую функцию, в том числе и отрицательное приращение, приращение на величину гл, или даже некоторую функцию от 1 oop_control.
Переменной управления циклом здесь является loop_control, чье максимальное значение равно 10. Однако обработка будет выполнена И раз. Ниже дан пример детерминированного цикла с предусловием.
20 30 loop_control = 1. птах = 10
30 50 loop_control > птах
40 loop_control < = птах
40 30 loop_process. loop_control - loop_control + 1
50 продолжить оставшуюся часть модели
Следующий пример — пример цикла со смешанной проверкой, поскольку обработка цикла происходит и до, и после выходного узла цикла.
20 25 loop_control = 1. птах = 10
25 30 A_processing
4.3. Отношения и модель 101
30 50 loop_control > птах
40 loop_control > птах
40 25 B_processing. loop_control = loop_control + 1
50 продолжить оставшуюся часть модели
В этой модели на каждом шаге обязательно выполняется A processing. На последнем шаге выполнения, однако, обрабатываемый объект минует B processing. Заметьте, что значение переменной управления циклом, loop control, различно для процессов А и В. Циклов со смешанной проверкой следует избегать в спецификациях, моделях и программном обеспечении, так как они уязвимы для ошибок. В языках структурного программирования смешанные циклы не могут быть созданы случайно, перед их применением программисту следует хорошенько подумать. Один из аргументов в пользу использования структурированных циклов — уход от ошибок, связанных со смешанными циклами. При построении моделей старайтесь использовать явные циклы с постусловием и предусловием, а циклы со смешанной проверкой применяйте только в тех случаях, когда они необходимы для точного моделирования требований. Если цикл со смешанной проверкой необходим, то он должен быть тщательно протестирован из-за повышенной вероятности наличия ошибок.
Поскольку в детерминированных циклах заранее известно число повторов, циклические процессы с их использованием надо конструировать во всех следующих случаях: копирование файла с известным числом записей, обработка п платежных чеков, добавление колонки чисел, заполнение массива числами, передача файла известной длины.
4.3.3. Недетерминированные циклы
Недетерминированные циклы отличаются от детерминированных тем, что количество проходов цикла неизвестно до его старта. Такое может произойти вследствие трех основных причин: это число неизвестно, обработка внутри цикла меняет переменную управления циклом (если она существует), внутри цикла обнаружено условие, вызывающее преждевременное прекращение цикла.
20 30 читать следующую запись
30 40 обработать запись
40 20 Не Конец Файла (КФ)
50 КФ
50 продолжить оставшуюся часть модели
В вышеприведенном коде мы не знаем, как много записей имеет файл, следовательно, процесс будет продолжаться, пока не будет достигнута запись КФ. Этот пример уязвим в силу нескольких причин. Если файл содержит только запись КФ, тогда эта запись будет обработана с возможными пагубными последствиями. Другое слабое место проявляется в случае, если файл не содержит записей, даже записи КФ. Если программа точно реализует данную модель, с такими файлами цикл будет выполняться бесконечно.
20 30 loop_control = 1. птах = 10
30 50 loop_control > птах
40 loop_control < = птах
102 Глава 4 • Тестирование циклов
40 45 обработка цикла
45 46 loop_control = loop_control + INT(3*RAND)
46 30 loop_control = loop_control + 1
50 продолжить оставшуюся часть модели
При обработке перехода 45-46 вышеприведенной модели из loop control каждый раз вычитается случайное число от 0 до 2. Я выбрал этот очевидный пример, но цели можно достигнуть и без использования случайных чисел. Дело в том, что мы не можем определить, когда выполнение этого цикла будет закончено, — если вообще когда-нибудь будет. Несмотря на то, что может показаться, будто конструкция детерминирована, она, тем не менее, является недетерминированной.
20 30 loop-Control = 1. птах = 10
30 50 loop_control > птах
40 loop_control < = птах
40 45 обработка цикла
45 47 значение поля = 17
46 значение поля * 17
46 30 loop_control = loop_control + 1
47 30 loop_control = птах + 1
50 продолжить оставшуюся часть модели
Несмотря на то, что вышеприведенный фрагмент имеет вид детерминированного цикла, он таким не является. Предикат в узле 45 проверяет величину определенного поля. Если эта величина равна 17, loop_control принимает значение, вызывающее прекращение выполнения цикла. Если значение поля не равно 17, цикл последовательно выполняется до значения птах. В последнем случае цикл является детерминированным. Мне не обязательно изменять переменную управления циклом, чтобы добиться этого. Например, следующий фрагмент делает то же самое без изменения переменной управления циклом.
20 30 loop_control = 1. птах = 10
30 50 loop_control > птах
40 loop_control < = птах
40 45 обработка цикла
45 50 Значение поля = 17
46 Значение поля * 17
46 30 loop_control = loop_control + 1
50 продолжить оставшуюся часть модели
Процессы с недетерминированными циклами включают: сортировку п записей, поиск файла, получение файла по каналу связи, решение системы уравнений, объединение двух файлов.
Различие между детерминированным и недетерминированным циклами чрезвычайно важно. Недетерминированные циклы, как правило, чаще содержат ошибки по сравнению с детерминированными и потому должны более тщательно тестироваться. В языках структурного программирования конструкция FOR (например, FOR I = 1 to loopmax DO ...) предназначена для детерминированных циклов. Наоборот, конструкция WHILE ... DO предназначена для недетерминированных циклов. Цикл FOR имеет явную переменную управления циклом, цикл WHILE не имеет. Поскольку циклы FOR могут быть недетерминированными, а циклы WHILE детерминированными, большинство программистов полагает, что выбор между ними — вопрос сти
4.3. Отношения и модель 103
листики. Это приводит к ошибкам, в которых недетерминированные процессы реализованы при помощи детерминированных конструкций, а детерминированные — при помощи недетерминированных. И тот, и другой случай сбивают с толку, повышают вероятность ошибки и потому перспективны для выявления.
4.3.4. Вложенные циклы
Вложенные циклы являются проблемными (то есть часто содержат ошибки). Они содержат, конечно, обычные ошибки, которые можно ожидать в единичном цикле (например, потерю первого варианта, слишком раннее прекращение, слишком позднее прекращение, бесконечное выполнение), но также и ошибки, возникающие в результате одновременного достижения условий прекращения в обоих циклах. Например, рассмотрим следующий фрагмент кода.
20 30 outer_loop_control = 1, outermax = 10
30 40 inner_loop_control = 1. innermax = 100
40 45 обработка внутреннего цикла
45 30 wner_loop_control < innermax. inner_loop_control = 1nner_loop_control + 1
50 1nner_loop_control > = Innermax
50 55 обработка внешнего цикла
55 20 outer_loop_count < outermax. outer_loop_control = outer_loop_control + 1
60 outer_loop count > = outermax
60 продолжить оставшуюся часть модели
Что здесь произойдет при outer !oop control = 10 и 1nnerloop_control = 100, а также при близких им значениях?
4.3.5. Неструктурированные (ужасные) циклы
Ужасные циклы имеют место в случаях, когда происходит прыжок (переход) из середины или прыжок в середину цикла.
На следующем рисунке представлена эта печально известная структура, поскольку в ней присутствуют оба типа переходов. Связь 30-10 является прыжком из цикла 20-30-40-20, в то время как связь 40-20 представляет собой скачок в цикл 10-20-30-10. Циклы со смешанной проверкой не слишком ужасны, поскольку в них происходит скачок из середины цикла. Другая проблема циклов со смешанной проверкой заключается в том, что входной узел цикла для первой итерации отличается от входных узлов цикла для последующих итераций.
Программисты должны стараться избегать создания ужасных циклов на языках структурного программирования, но такие циклы часто встречаются в старом
104 Глава 4 • Тестирование циклов
программном обеспечении, написанном на языке ассемблера и более старых языках программирования.
Для ужасных циклов нет хороших тестов. Как вы управитесь с ними, зависит от того, откуда они взялись. Если они следствие способа, с помощью которого вы построили модель, тогда смоделируйте ее заново, используя структурированные циклы. Ужасные циклы могут быть корректной моделью поведения приложения, особенно если, как в случае тестирования потока транзакций, вы создаете модель человеческого поведения. Например, если вы моделируете поведение человека, набирающего междугородний телефонный номер, естественно использовать цикл для набора цифр. Междугородний телефонный вызов требует набора 11 цифр. Тогда вы создаете следующий модельный цикл.
10 20 digit_count = 0. digitjnax = 11
20 30 digit_count < = digitjnax. digit_count = digit_count + 1
50 digit_count > digitjnax. выйти из цикла
30 20 набор цифры
50 продолжить дальше модель
Люди не могут и не будут вести себя структурно. Например, они могут сразу выйти из цикла, поняв, что совершили ошибку при наборе номера.
10 20 d1git_count = 0. digitjnax = 11
20 30 d1git_count < = digitjnax. digit_count = digit_count + 1
50 digit_count > digitjnax. выйти из цикла
30 40 набор цифры
40 20 цифра набрана успешно
10 цифра не набрана, трубка вешается и номер набирается заново
50 продолжить дальше модель
Если скверная структура цикла должным образом моделирует ситуацию, тогда у вас нет другого выбора, кроме как смоделировать ее именно так. Однако вы должны протестировать подобные циклы более тщательно, чем обычно, поскольку такие ситуации чаще подвержены неправильной реализации, особенно в специальных случаях, порождающих ужасные циклы.
4.4. Методы
4.4.1. Критические тестовые значения
Рассмотрим общую детерминированную модель цикла.
10 20 loop_control = startval. itermax = upperval
20 30 loop_control > itermax
40 loop_control < = itermax
30 20 loop process. loop_control = loop_control + increval
40 продолжить оставшуюся часть модели
Этот цикл определяется тремя значениями:
startval — начальное значение переменной управления циклом.
upperval — конечное значение переменной управления циклом.
4.4. Методы 105
increval — величина, на которую переменная управления циклом будет возрастать при каждом прохождении цикла.
Критические тестовые значения — комбинация величин этих трех чисел, которые, как показывает опыт, особенно часто вызывают ошибки, плюс, в добавление к ним, нормальный или типичный вариант. Мы приводим тестовые варианты в самом общем виде. Специфические особенности для разных типов циклов будут обсуждаться в последующих разделах.
Обход. Любой набор величин, вызывающий немедленный выход из цикла.
Один проход. Величины, приводящие к тому, что цикл выполняется ровно один раз.
Два прохода. Величины, приводящие к тому, что цикл выполняется ровно два раза.
Типичное число проходов. Типичное число итераций.
Максимум'. Максимальное число разрешенных итераций.
Мах + 1. На единицу больше разрешенного максимума.
Мах - 1. На единицу меньше разрешенного максимума.
Min. Заданный минимум.
Min - 1. На единицу меньше заданного минимума.
Ноль. Обсуждается ниже.
Отрицательное число проходов. Обсуждается ниже.
Заметьте, мы говорим о числе раз повторения цикла, а не о значениях переменной управления циклом (если она существует). Например, в цикле FOR I = 0 to 8 STEP 2 исходное значение переменной управления циклом I равно 0, но цикл будет выполнен не девять раз, а только пять, потому что переменная управления циклом при каждом прохождении цикла увеличивается на два.
Многие из упомянутых вариантов могут перекрываться. Например, если значение минимума равно 0, тогда имеют место следующие тождества:
Min - 1 » Отрицательное число проходов
Min = Обход
Min + 1 = Один проход
Аналогично, если значение минимума равно 1:
Min - 1 » Обход
Min = Один проход
Min + 1 = Два прохода
Вариант нуля может оказаться эквивалентным варианту обхода. Обычно вместо И только что перечисленных тестов разрабатываются только 7. Некоторые из этих вариантов, такие как обход, могут перекрываться с тестом, созданным на основе покрытия связей.
В дополнение к тестированию 11 общих ситуаций в старом программном обеспечении (например, программном обеспечении, написанном на языке ассемблер), возможно, имеет смысл протестировать особые значения числа итераций, такие как степени двойки и близкие к ним значения: 255, 256, 257, 65535, 65536 и 65537. Но не теряйте времени на особые значения, связанные с параметрами аппаратных средств, такими как байт или длина слова в таком современном языке программи
106 Глава 4 • Тестирование циклов
рования, как С — за исключением, конечно, того случая, когда вы проверяете реализацию и видите, что имеете дело с низкоуровневым программированием.
4.4.2. Детерминированные циклы
Мы обрабатываем выплату жалования. Программное обеспечение должно обрабатывать минимум одного служащего и максимум 20 000 служащих. Используя рассмотренные выше установки, мы сразу получим следующие тестовые варианты:
Обход. Нет служащих.
Один проход. Один служащий.
Два прохода. Два служащих.
Типичное число проходов. 700 служащих.
Максимум. 20 000 служащих.
Мах + 1. 20 001 служащий.
Мах - 1. 19 999 служащих.
Min. Один служащий (избыточный вариант).
Min - 1. Нет служащих (избыточный вариант).
Ноль. Нет служащих (избыточный вариант).
Отрицательное число проходов. Отрицательное число служащих?
Некоторые из этих вариантов заслуживают более подробного обсуждения.
Обход', нет служащих. Согласно требованиям, программное обеспечение не предполагает обработку этого случая. Но что оно сделает? Может ли этот вариант, хотя он и не имеет смысла, возникнуть? Скажем, пакет программ используется для создания платежных ведомостей для многих разных организаций. Он обрабатывает их по очереди (вложенный цикл с внутренним циклом для служащих и внешним циклом для организаций). Новый клиент добавляется в очередь для обработки недельной платежной ведомости, но мы пока что не получили данных сотрудников. Мы не ждем, что программное обеспечение «обработает» заработную плату для сотрудников-фантомов. И наоборот, мы не ждем, что программа начнет печатать бесконечное число чеков по $0.00 для имя. фамилия.
Мы тестируем. Нам платят не за привлекательность, не за справедливость и даже не за благоразумие. Если вообще возможно смоделировать ситуацию, мы должны сделать это и ожидать от программного обеспечения, что оно поведет себя разумно, например, скажет нам, что «название организации не будет обработано». При проведении тестирования мы подозреваем (и надеемся), что при обработке платежной ведомости какой-либо другой организации не будет учтен один из служащих или ведомость будет целиком пропущена.
Один проход', один служащий. Ищем пустой дополнительный платежный чек, продублированный платежный чек или недостаток одного чека для следующей организации.
Два прохода', два служащих. Часто действенно, в особенности для «смешанных» циклов. Ищите дублированную инициализацию циклов, потерю второго служащего, два платежных чека для второго служащего или какую-нибудь ошибку для следующей организации.
4.4. Методы 107
Типичное число проходов. Неперспективно для обнаружения ошибок, но если вы это не проделаете, то, конечно, ваше тестирование может быть подвергнуто критике. Несмотря на то, что это редко бывает эффективно для обнаружения ошибок, это политически мудро.
Максимум. Все тестовые варианты, которые ориентированы на максимумы, могут потребовать больших затрат, в особенности для вложенных циклов. Например, 20 000 служащих и 1000 организаций означают 20 000 000 платежных чеков. Даже с компьютерами это накладно. Дело не в том, что числа 20 000 и 1000 — это какие-то особенные числа, вызывающие ошибки. Дело в том, что достигнуты максимумы, вне зависимости от их значений. Если программисты предвидят возможные проблемы с тестированием, они встроят возможность изменить эти максимальные значения для тестирования, которое в большинстве случаев может быть проведено для 20 сотрудников и 10 организаций. Если возможность тестирования не была целью проектирования, у вас нет другого выбора, кроме как протестировать эти экстремальные значения, по крайней мере, один раз. Но проделайте это, скажем, для 20 000 служащих и только одной организации, и 1000 организаций, в каждой из которой всего несколько служащих.
Максимум плюс 1. Ситуация, аналогичная случаю обхода. Мы не ждем, что программа обработает больше, чем заданный максимум, но поскольку такая ситуация может случайно возникнуть, мы хотим быть уверены, что это не приведет к сбою и файлы не будут повреждены. Ищите ситуацию, когда в компании X работает 20 001 служащий, в порядке обработки компания Y следует за компанией X и первый служащий в компании Y получает платежный чек со счета компании X.
Отрицательное число проходов. Если число служащих может быть введено с клавиатуры, скажем, для того, чтобы начать обработку, тогда этот случай может быть потенциально продуктивным. Если вы можете всеми правдами или неправдами реализовать этот случай, попробуйте это сделать, и посмотрите, отклонит ли программа такое входное значение. Не обманывайте себя тем, что этот случай действительно будет отклонен только потому, что вам так сказали. Например, из-за ошибки ввода заявлено, что в компании X работает —10 служащих. Даже если этот случай, как и ожидалось, будет отклонен, то первые 10 платежных чеков для следующей в очереди организации Y могут быть не обработаны. Мы имеем дело с ошибками, которые ведут к произвольному или бессмысленному поведению. Таким образом, всегда, когда это возможно, имеет смысл использовать произвольные и бессмысленные тестовые варианты.
4.4.3. Недетерминированные циклы
Мы ищем в файле неизвестной длины специфическую запись, которая может находиться в любом месте файла или, если уж на то пошло, может вообще не содержаться в файле. Здесь мы имеем две проблемы: с размером файла и с тем местом в файле, где может быть найдена искомая запись. Два предиката управляют поведением этого цикла: предикат, управляющий получением и проверкой следующей записи, и предикат, вызывающий остановку выполнения цикла в случае, ког
108 Глава 4 • Тестирование циклов
да искомая запись найдена. Сначала мы обсудим вопрос о размере файла, а затем вопрос о месте в файле, где найдена запись.
Обход. Файл без записей. Этот вариант также является нулевым. Поскольку в файле нет записей, искомая запись не может быть найдена.
Один проход. Файл с одной записью.
1. Информация найдена: искомая запись и есть первая запись.
2. Информация не найдена: искомой записи нет в файле.
Два прохода. Файл с двумя записями.
3. Информация найдена в первой записи.
4. Информация найдена во второй записи.
5. Информация не найдена.
Типичное число проходов. Файл с 10 записями1.
Информация найдена в первой записи.
1. Информация найдена в записи 6.
2. Информация найдена в записи 9.
3. Информация найдена в записи 10.
4. Информация не найдена.
Максимум - 1. Например, мы можем положить максимальное число записей в тестируемом файле равным 50.
1. Информация найдена в записи 48.
2. Информация найдена в записи 49.
3. Информация не найдена.
Максимум. Файл, состоящий из 50 записей
1. Информация найдена в записи 49.
2. Информация найдена в записи 50.
3. Информация не найдена.
Максимум + 1. Файл, состоящий из 51 записи
Информация найдена в записи 49.
4. Информация найдена в записи 50.
5. Информация найдена в записи 51.
6. Информация не найдена.
1 Я выбрал 10 записей, поскольку теория и опыт говорят, что значения 1,2,3,4 и 5 могут приводить к различным моделям поведения. Поскольку 5 - 1 = 4 не является общим вариантом, 5 пропущено. Поскольку 6-1=5 — это первый общий вариант, 5 не является хорошим значением. Первое хорошее общее значение — это, возможно, 7. Но степени двойки и числа, близкие им (7, 8, 9), могут быть проблемными, так что 10 — это первое действительно хорошее типичное значение.
4.4. Методы 109
Вот мои аргументы в пользу тестового варианта МАХ + 1. Мы не предполагали, что программное обеспечение будет обрабатывать файлы, в которых более 51 записи. Если цикл действительно недетерминированный, тогда этот факт неизвестен нам до того, как процесс закончится. То есть длина файла становится известна только после обнаружения записи КФ (конец файла). Если это действительно так, тогда не существует способа запретить обработку файла с 51 записью. В противном случае, если чрезмерно длинный файл отвергается до того, как начнется обработка, тогда длина файла должна быть известна и цикл поиска не является по-настоящему недетерминированным. Неизвестна только точка, в которой процесс выйдет из цикла. Как много рассмотренных вариантов вы испробуете, зависит от того, что делает цикл недетерминированным.
1. Величина максимума неизвестна и не может быть найдена. В этом случае ничего не препятствует достижению максимального значения и вам обязательно следует попробовать МАХ + 1.
2. Досрочное прекращение. У нас есть однозначно детерминированный цикл, выполнение которого может быть досрочно прервано (например, оператором BREAK в языке С), но где это произойдет, неизвестно. МАХ + 1 не имеет смысла, но непременно попробуйте найти искомые данные в последней записи.
3. Обработка переменной управления. Это может происходить с детерминированными и недетерминированными циклами. Скажем, число записей было известно, и то, что мы хотели проделать, — это выборочная проверка одной из десяти записей, вместо того чтобы проверять каждую запись в файле. Это может быть реализовано увеличением переменной управления цикла на 10, но это приводит к выходу величины указателя за границу файла. Тогда нам, безусловно, следует попробовать варианты МАХ + 1.
4.4.4. Вложенные циклы
Вложенные циклы сначала должны быть протестированы как индивидуальные циклы. Задайте для внутреннего цикла типичное значение и протестируйте внешний цикл для случаев критических значений. Затем измените процедуру на противоположную, задайте для внешнего цикла типичное значение и прогоните внутренний цикл через критические тестовые варианты. Эти тесты должны выявить большинство ошибок, обычно попадающихся в одиночных, невложенных циклах.
Проблема с вложенными циклами возникает, когда два или более вложенных цикла достигают критических значений одновременно — например, нулевых, максимальных, и так далее. Вы проектируете тестовые варианты путем перебора комбинаций критических значений. Это должно привести к 64 или большему числу тестовых вариантов, если вы строго следуете этому правилу. Отступите немного от этого и протестируйте по крайней мере комбинации обход/ноль, один, два и МАХ для внутреннего цикла и обход/ноль, один, два и МАХ для внешнего цикла. Это будет 16 случаев в дополнение к тестированию одиночных циклов — всего 32 теста.
110 Глава 4 • Тестирование циклов
4.5. Рассмотрение приложения
4.5.1. Индикаторы приложений
Каждый повторяющийся (циклический) процесс требует тестирования. Каждый граф с циклами должен быть протестирован, с возможным исключением графов для автоматов с конечным числом состояний1 (глава 9), потому что в этом случае имеется слишком много циклов, и тестирования доменов (глава 7), где присутствие циклов делает метод неприменимым.
4.5.2. Предположения об ошибках
Здесь нет особо глубоких предположений; только эмпирическое наблюдение, что повторяющимся процессам трудно корректно начаться и еще более трудно правильно остановиться. Мы выполняем какие-то действия слишком много или слишком мало раз. Многие ошибки происходят также из-за того, что кто-то допускает существование определенных предусловий, хотя в действительности они не обязательны: например, что все файлы содержат хотя бы одну запись.
4.5.3. Ограничения и предостережения
Ошибки циклов обычно обнаруживаются в низкоуровневом программном обеспечении и чаще всего имеют ограниченное влияние. Симптомы, как правило, выявляются неподалеку от самой ошибки и одновременно с ней. Многие из этих ошибок будут обнаружены операционной системой или исполняемой резидентной частью компилятора, потому что они вызывают переполнение памяти, обна-ружимые ошибки указателя, чтение вне пределов файла и другую подобную чепуху. Ошибки, обнаруженные путем тестирования цикла, не очень коварны и мы хотели бы надеяться, что программисты найдут и исправят их при низкоуровневом тестировании модулей, где они часто могут быть найдены при тестировании цикла. Не ожидайте очень многого от тестирования цикла для развитого программного обеспечения.
4.5.4. Автоматизация и инструментальные средства
Специальные инструменты на самом деле не нужны. Если вы используете тестирование циклов как часть системного поведенческого тестирования, вы можете с успехом эксплуатировать систему покрытия/воспроизведения. Индивидуальные тесты циклов, особенно если они касаются файлов и вложенных циклов, могут быть трудны для реализации. Однажды реализовав и отладив типичный тестовый вариант для цикла, редактируйте его, изменяя входные значения для создания других вариантов тестирования цикла, в особенности это касается комбинированных вариантов, необходимых для вложенных циклов.
1 На самом деле любых сильно связных графов.
4.7. Вопросы для самопроверки 111
4.6. Резюме
Тестирование цикла — это эвристический метод, основанный на опыте, который программисты приобретают, сталкиваясь с ошибками в начале и конце циклов. Несмотря на то, что для пояснений в этой главе были использованы примеры с потоком управления, метод эффективен для большинства графовых моделей, имеющих циклы (исключая сильно связные графы). Необходимые для тестирования значения основаны на числе повторений цикла: 0,1, 2, MIN - 1, MIN, MIN + 1, типичное количество проходов, МАХ - 1, МАХ, и МАХ + 1, а также на комбинациях этих величин для вложенных циклов.
4.7. Вопросы для самопроверки
1. Дать определение следующих терминов: критические тестовые значения цикла, детерминированный цикл, ужасный цикл, число итераций цикла, цикл, обход цикла, узел управления циклом, предикат управления циклом, переменная управления циклом, узел входа в цикл, узел выхода из цикла, цикл со смешанной проверкой, вложенные циклы, недетерминированные циклы, цикл с проверкой до, цикл с проверкой после.
2. Рассмотрите шесть комбинаций циклов (детерминированных, недетерминированных) и (с проверкой до, после, со смешанной проверкой) в языке С. Придумайте примеры для каждой комбинации, используя следующие конструкции для создания циклов: WHILE, FOR, DO-WHILE, IF/GOTO. Если комбинация невозможна, докажите это.
3. То же, что и задание 2, но для Паскаля, с использованием FOR-TO-DOWNTO, FORDO, REPEAT-UNTIL, WHILE, и всех прочих способов создания циклов.
4. В большинстве пакетов программ для подготовки налоговых документов имеется команда для вывода форм и бланков пользователя на печать. Если каждая форма рассматривается как объект, который следует распечатать, этот циклический процесс детерминированный или недетерминированный? Обоснуйте ваш ответ. Если вы скажете ««детерминированный»», почему практичный человек может решить запрограммировать этот процесс с помощью недетерминированного цикла? Разработайте набор тестов для печати действующей декларации о доходах в вашей программе подготовки налоговых документов.
5. Классифицируйте как детерминированные или недетерминированные (по отношению к числу итераций цикла) следующие процессы: (а) проверка орфографии, (б) решение системы уравнений, (в) сортировка, (г) объединение, (д) сложение двух чисел, (е) извлечение квадратного корня, (ж) деление столбиком, (з) проведение переписи населения в Америке, (и) копирование файла, (к) копирование каталога, (л) копирование всего диска, (м) проверка диска на наличие ошибок, (н) загрузка файла, (о) подсчет числа предметов в коробке, (п) пересчет числа предметов в коробке, (р) проверка
112 Глава 4 • Тестирование циклов
ваших счетов, в предположении, что ни вы, ни банк не делали ошибок, (с) поэлементное умножение двух массивов, (т) поэлементное умножение двух матриц, (у) извлечение квадратного корня из 16-битного числа и обеспечение представления результата в виде 16-битного числа, (ф) вычисление х2 hsin-1 ABS((J 2(ABS( 17 f e Xdx)))) , где x— 16-битное число и pe-
J 0
зультат необходимо представить в виде 16-битного числа, (х) удаление п символов из конца документа начиная с последнего и в обратном порядке, (ц) добавление п символов в конец документа, (ч) удаление п символов из середины документа, когда известно, что документ содержит не меньше п символов.
6. Для каждого из детерминированных процессов из задания 5 укажите, каковы практические последствия (например, в части уязвимости, расхода оперативной памяти и дискового пространства), которые могут возникнуть в результате реализации процесса в виде недетерминированного цикла.
7. Для каждого из недетерминированных процессов из задания 5, каковы практические последствия (например, в части уязвимости, расхода оперативной памяти и дискового пространства), которые могут возникнуть в результате реализации процесса в виде детерминированного цикла?
8. Какие из процессов в задании 5 имеют вложенные циклы и какая глубина их вложения?
9. Для каждого из процессов, проанализированных вами в заданиях 5, 6, 7 и 8, создайте набор тестов циклов.
10. Смоделируйте часть 4 формы 2210 как граф потока управления с детерминированным циклом и протестируйте его соответствующим образом.
Тестирование потоков данных
5.1. Обзор
Граф потока данных является характерной особенностью многих методов проектирования программного обеспечения и с успехом используется в проектировании тестов.
5.2. Основные термины
Внешние термины: добавить запись, алиас, приложение, массив, присваивать, ошибка, С, вычисление, дерево вызовов, CASE, закрывать, код, комментарий, сравнивать, компилятор, вычисление, параллельный процесс, константа, ограничение, управление, копировать, число повторений, аварийный отказ, создавать, данные, отладочная программа, удалять, обозначать, диск, фиктивная переменная, динамический вызов, выражение, извлекать, выборка (команды или данных из памяти), поле, файл, формула, функция, глобальные данные, остановка, аппаратные средства, эвристический, иерархический, IF-THEN, IF-THEN-ELSE, сокрытие информации, инициализировать, вставлять, конкретизировать, итерировать, число повторений, переход, редактор связей, размещение, логический, цикл, сопровождение, память, адрес ячейки памяти, объединять, сообщение, перемещать, многозадачность, сеть, численный, имя объекта, объектно-ориентированное программирование, открывать, вывод, собственные данные, параллельный компьютер, раздел, PASCAL, указатель, обработка, программа, программист, программирование, язык программирования, псевдокод, ОЗУ, запись, переименовывать, повторно используемый, время выполнения, поиск, упорядочение, совместно используемые данные, побочный эффект, программное обеспечение, сортировать, исходный код, электронная таблица, оператор, хранить, структурный, символьный, синхронизация,
114 Глава 5 • Тестирование потоков данных
таблица, тестируемость, тестировщик, передавать, истинное значение, значение, переменная.
Внутренние термины: поведенческое тестирование, слепота, тестирование ветвей, случайная корректность, компонент, составной предикат, поток управления, граф потока управления, оборванная связь, детерминированный цикл, грязный тест, входной узел, выходной узел, модель с конечным числом состояний, граф, начальное состояние, входящая связь, интеграция, ввод, входной узел, покрытие связей, представление графа в виде списка связей, вес связи, цикл, тестирование цикла, модель, отрицательный тест, вложенный цикл, узел, покрытие узлов, вес узла, недетерминированный цикл, объект, оракул, итог, исходящая связь, узел выхода, путь, позитивный тест, предикат, интерпретация предиката, отношение, требование, активизировать, простой предикат, спецификация, состояние, граф потока транзакций.
Определение (объекта). Объект определяется в тех случаях, когда ему присваивается новое значение, он инициализируется, создается или конкретизируется. Не путайте имя объекта или адрес ячейки памяти, использующейся для хранения его значения, с различными возможными определениями этого объекта. Например, ячейка памяти XYZ используется для храпения переменной с именем SAM. SAM может принять несколько различных значений по ходу вычисления. Каждое из этих значений является определением SAM.
Перегрузка. Имя переменной перегружено, если оно используется для обозначения различных определений переменной по ходу выполнения программы. В программировании считается, что выгода использования перегрузки заключается в экономии памяти1, но в моделях тестирования перегрузка не дает никаких преимуществ, поскольку она только запутывает и ничего не экономит.
Логический оператор. Оператор языка программирования, включающий предикат, вычисляемый по ходу выполнения. Если предикат получает истинное значение, обработка продолжается. Если предикат получает ложное значение, происходит по крайней мере одно из следующего: управление передается обработчику логического выражения, выражение помечается как невыполненное, выполнение программы приостанавливается, управление передается отладочной программе. Логические выражения обычно проверяют соотношения между значениями переменных, такие как х > 17 или х + у = z. Выражения — мощный подсобный инструмент тестирования. В этой главе логические выражения в основном используются для проверки результатов вычислений.
Использование для вычислений. Объект используется для вычислений [RAPP82], когда он применяется для расчета значения другого объекта. Например, в выражении Y:=X + ZXhZ используются для вычисления Y, a Y — определяется. Аналогично, вХ: = X + Y, XhY используются для вычислений, и в то же время X (пере)определяется (здесь X — перегружено).
1 На самом деле при использовании оптимизирующего компилятора перегрузка не экономит память. Она, наоборот, по всей вероятности, увеличивает расход памяти и время выполнения, поскольку ограничивает свободу оптимизации и увеличивает время жизни переменных, таким образом уменьшая возможность выполнения на основе регистров. Так как время хранения переменной в памяти увеличивается, то одновременно с ростом времени выполнения увеличивается загрузка RAM.
5.2. Основные термины 115
Использование в предикате. Объект используется в предикате [RAPP82], если он применяется в предикате. В выражении IF X = Y + Z... переменные X, Y и Z использованы в предикате. В некоторых языках (например, С) объект может использоваться для вычисления и в предикате одновременно, поскольку вычисление может быть встроено в предикат. Создание моделей с одновременным использованием в предикате и для вычисления при тестировании поведения не дает никаких преимуществ, если только вы не ставите себе цель внести путаницу. Предикаты внутри утверждений не являются примерами использований в предикатах, так как утверждения обычно не влияют на ход выполнения или на конечные значения.
Использование. Объект используется, если он задействован в предикатах и/ или в вычислениях.
Входной узел. Входной узел графа потока данных, через который вводятся данные. Имя входящего в этот узел объекта обычно написано в самом узле или прямо перед узлом, но, если это особо оговорено, может быть написано над исходящей из узла связью. Примеры эквивалентных обозначений входных узлов приведены на рисунке.
Сэм, Джо »
Константы. Константы следует рассматривать как вводы и моделировать как входные узлы. Множество ошибок происходит из-за использования неправильной константы, неправильного значения константы, или изменения значения константы во время вычислений. Константы уязвимы для ошибок точно так же как и другие переменные и поэтому должны рассматриваться таким же образом.
Узел вывода. Выходной узел диаграммы потока данных — это узел, через который выводятся данные. Имя объекта, значение которого выводится, указано ря-
дом с узлом.
Сэм, Джо
Запоминающий узел. Пара узлов для одного и того же объекта данных. Узел
на диске). Узел ВЫБОРКА определяет значение переменной в памяти. Верхнее обозначение на рисунке показывает, как это обычно изображается в графах потока
116 Глава 5 • Тестирование потоков данных
данных, но обозначение в нижней части рисунка выглядит яснее. Запоминающие узлы часто сбивают с толку, поскольку при последующей обработке не сразу может быть понятно, какое именно значение переменной используется: значение, сохраненное на диске, или значение в ОЗУ, предшествующее сохранению. Например, при использовании в сетях с файлами совместного доступа они могут отличаться (и таким образом быть источником ошибок). Использование двух различных имен, скажем, значение_озу и значение_диск может помочь прояснить ситуацию.
Обрабатывающий узел. Узел с одной или более входящими связями и по крайней мере, с одной исходящей связью. Входящие связи обозначают объекты данных. Исходящая связь обозначает вычисленную функцию этих объектов данных. На рисунке общий доход — это функция трех входящих связей — wages (заработная_ плата), taxable !nterest (налогооблагаемые_проценты) и tax exempt (доход_осво-божденный_от_уплаты_налогов). Для ясности вы можете пометить обрабатывающий узел вычисляемой функцией.
5.2. Основные термины 117
Значение связи. В графах потока данных значения объектов связаны с узлами, в которых эти значения вычисляются (то есть обрабатывающими узлами). В упрощенных графах потока данных, используемых в данной книге, все исходящие из узла связи имеют одинаковые значения объектов данных. При обычном применении графов потока данных узел может быть использован для представления нескольких различных вычислений и, таким образом, может иметь несколько различных объектов, ассоциированных с исходящими связями. Обычная практика — размещение имен объектов на исходящих из таких узлов связях. При таком использовании мы неформально называем эти имена значениями исходящих связей. Подобным же образом, поскольку исходящие из одного узла связи являются входящими по отношению к следующему узлу, они называются значениями входящих связей.
Предикат выбора данных. Предикат, значение которого (например, истинное значение) используется для выбора одного из нескольких объектов данных. Например, указатель на массив выбирает объект данных в массиве, на который указывает указатель. Узел выбора данных всегда имеет предикат выбора данных.
Узел выбора данных. Узел, чьи входящие связи управляются предикатом выбора данных. Его значение (истинности или указатель) выбирает объект данных, соответствующий входящей связи. На рисунке предикат выбора данных, связанный с узлом выбора данных, выбрал объект данных VIV. Узел выбора данных вычисляет специальную функцию выбора значения входящей связи для использования в исходящей связи. Входящие связи узла выбора данных могут быть помечены условием предиката, при котором выбирается данная входящая связь.
Управляющая входящая связь. Узел выбора данных может иметь входящую связь, которая используется только в предикате выбора данных. Управляющие входящие связи принято обозначать пунктирными строками.
SAM VIV
ТОМ
-LILA
JULE
VIV -►
Управляющая переменная
118 Глава 5 • Тестирование потоков данных
В предыдущем примере выбор VIV мог быть основан на значениях всех входящих связей:
Значение_исходящей_связи: = МАКСИМУМ (значения_входящих_связей)
В этом случае управляющей входящей связи нет. И наоборот, выбор мог быть основан на значении управляющей входящей связи, которое определяет, какое значение и какой входящей связи должно быть использовано:
Значение_исходящей_связи: = ВЫБОР(УПРАВЛЯЮЩАЯ_ПЕРЕМЕННАЯ. значения_входящих_связей)
В последнем примере переменная управляющей входящей связи УПРАВЛЯЮЩАЯ^ ПЕРЕМЕННАЯ выбирает одно из значений входящих связей, как, например, в случае указателя на массив.
Граф потока данных. Граф, состоящий из входных узлов, узлов вывода, запоминающих узлов, узлов выбора данных и соответствующих связей и свойств.
5.3. Отношения и модель
5.3.1. Основы
Объекты (узлы}. Вычисляемая функция входящих связей:
7: wages (заработная_плата)
8а: taxable_interest_income (налогооблагаемый_доход_с_процентов)
8b: tax_exempt_interest_income (проценты_освобожденные_от_налога)
9: dividencMncome (доход_от_дивидендов)
10: taxable_refunds (облагаемые_налогом_платежи_по_долгам)
11: alimony_received (полученные_алимен7ы)
12: buswess_income_or_loss
(доход_или_потери_в_результате_предпринимательской_деятельности)
21: other_income (другие_доходы)
22: общий_доход : = заработная_плата + налогооблагаемый_доход_с_процентов + ... + другие_доходы.
Обратимся к форме 1040. Узлы с 7 по 21 — источники данных. Из них узлы 8а, 9, 10, 12, 13, 14, 15, 18, 19 и 21, возможно, пришли из других форм ВНС, но будут трактоваться здесь как входные данные, чтобы не усложнять пример. Строка 22 — обрабатывающий узел. Узел 22 также зависит от узлов 15b и 16b, расчетом которых мы па данный момент пренебрегаем (а вы не должны). Почти каждая строка в форме 1040 соответствует объекту данных, который вводился без предварительного расчета, пришел из другой формы или был рассчитан по ходу обработки формы 1040.
Отношение (связи). Непосредственно используется для расчета значения. В последнем примере узлы с 7: wages (заработная_плата) по 21: other !ncome (дру-гие_доходы), исключая 15а: IRA (индивидуальные_пенсионные_счета (ИПС)) и 16а: pensions (пенсии), напрямую используются для вычисления значения узла 22: total income (общий_доход). Эти значения также используются косвенным образом для вычисления значений других объектов — таких как узел 53: уоиг_ total_taxes (общая_сумма_ваших_налогов), но поскольку применение не являет
5.3. Отношения и модель 119
ся прямым, то здесь нет прямых стрелок из этих узлов к узлу 53. Однако есть потоки данных из некоторых из этих узлов, приходящие в узел 53.
Свойства узлов (веса узлов). Пометьте узлы функцией входящих связей, которую они вычисляют. Это может быть просто имя выхода функции (например, об-щий доход) или сама фактическая функция, например, формула.
Свойства связей (веса связей). Добавление весов связей не является необходимым, поскольку эта информация заложена в весах узлов. Однако поскольку графы потока данных могут быть довольно сложными, обычно исходящие связи помечаются именами представляемых ими объектов данных. Если узел представляет собой узел выбора данных, пометьте входящие связи значениями предиката выбора, соотнесенными с каждой входящей связью.
5.3.2. Аналогии с графами потока данных
В графах потока управления имеются конструкции, эквивалентные конструкциям в графах потока данных.
Простая обработка. Обычно простая обработка обозначается одиночным узлом обработки без принятия во внимание порядка обработки. Несмотря на то, что предыдущий пример для вычисления total_income (общий_доход) выглядит упорядоченным, этого упорядочения не требуется, поскольку ВНС не настаивает, чтобы мы заполняли налоговые документы, сначала указывая сумму заработка, затем налог на проценты, и так далее. Если мы пишем программу на обычном
120 Глава 5 • Тестирование потоков данных
языке программирования, тогда нам следует выбрать определенный порядок выполнения действий, но это упорядочение делается по нашему выбору и не существенно для решения задачи. В диаграммах потока данных мы не навязываем определенную последовательность, не предполагаемую требованиями.
Обозначение в виде списка связей удобнее графического представления. Комментарий, относящийся к связи, согласно нашей договоренности соответствует первому узлу из пары. Это облегчит нам задачу, поскольку нам не придется писать список узлов и затем еще и список связей. В следующем примере комментарий other_income (другие_доходы) соответствует связям, исходящим из узла 21.
21: 22: other_1ncome (другие_доходы)
11: 22: alimony_received (полученные_алименты)
15а: 15b: total_IRS_distr1bution (общее_распределение_ИПС)
15b: 22: taxable amount (налогооблагаемая_сумма) (справьтесь у вашего бухгалтера)
16а: 16b: taxable amount (налогооблагаемая_сумма) (справьтесь у другого вашего бухгалтера)
17: 22: rental_royalties (доходы_от_аренды)
18: 22: farm_1ncome_or_loss (прибыль_или_убыток_от_сельского_хозяйства)
19: 22: unemployment_compensation (пособие_по_безработице)
20а: 20b: social_security_benefit (пособие_по_социальному_обеспечению)
20b: 22: taxable_social_security_benefit (налогооблагаемые пособия_по_социальному_обеспечению)
8b: tax_exempt_1nterest_1ncome (проценты_освобожденные_от_налогов)
9: 22: dividend_1ncome (доход_от_дивидендов)
14: 22: другие_прибыли_и_убытки_из_формы_4797
10: 22: taxable_refunds (облагаемые_налогом_платежи_по_долгам)
8a: 22: taxable_1nterest (налогооблагаемые_проценты)
12: 22: bus1ness_1ncome_or_loss
(прибыль_или_убытки_от_предпринимательской_деятельности)
7: 22: wages (заработная_плата)
13: 22: capital_gains_or_loss (капитальная_прибыль_или_убытки)
22: total_1ncome (общий_доход): = wages (заработная_плата) +
taxable_1nterest_1ncome (налогооблагаемый_доход_с_процентов) + tax_exempt_interest_income (проценты_освобожденные_от_налога) + ... + other_1ncome (другие_доходы)
He так важно, как мы переставим строки в вышеприведенном графе. Связи определены, так что порядок, в котором мы расположим их на странице, не влияет на обработку или на модель. Я включил узел 8Ь, который, как кажется, никуда не ведет; ВНС желает получить эту информацию, несмотря даже на то, что она не используется в этом расчете. По-видимому, они используют ее для каких-то других расчетов.
IF-THEN-ELSE. Здесь приведена спецификация для строки 36 из формы 1040 ВНС.
36 Если значение в строке 32 (Adjusted_Gross_Income (скорректированный_общий_доход)) меньше или равно $83.850. умножить $2450 на общее число льгот, заявленных в строке бе. Если сумма в строке 32 (Adjusted_Gross_Income (скорректированный_общий_доход)) больше $83,850. смотрите инструкции (ВНС 1040) для того чтобы рассчитать облагаемую сумму.
Приводим модель псевдокода для этой операции.
36.1: 36: IF((СОД) строка_32 <= $ 83850) THEN строка_36: = число_ освобождений *
$2450 ELSE строка_36: = расчет_согласно_инструкции.
5.3. Отношения и модель 121
Ниже приводится классический граф потока управления для этой операции.
36.1: 36.2: узел предиката. СОД <= $83850
36.1: 36.3: узел предиката. СОД > $83850
36.2: 36: Строка_36: = число_ освобождений * $2450
36.3: 36: Строка_36: = расчет_согласно_инструкции
Переменная Строка_36 не перегружена. Почему? Вот граф потока данных для этой операции.
бе: 36.1: общее_число_ освобождений
kl: 36.1: значение_константы_$2450
к2: 36: значение_константы_$83850
36.1: 36: общее_число_освобождений *kl
32: 36: adjusted_gross_income (скорректированный_общий_доход)
Р23: 36: расчет_согласно_инструкции
36: ... узел_выбора_данных 36.1 IF СОД <= к2
Р23 IF СОД > к2
Меня не удовлетворяет эта модель, поскольку средства управления перемешаны с вычислением. Действительно, замысловатая модель, могла бы запутать, так что я бы добавил несколько связей, чтобы сделать ситуацию более ясной, предложив следующий граф потока данных.
бе: 36.1: total_number_of_exemptions (общее_число_освобождений)
kl: 36.1: значение_константы_$2450
36.1: 36: total jnumber_of_exempt1ons (общее_число_освобождений) * kl
Р23: 36: расчет_согласно_инструкции
к2: 36.2: значение_константы_$83850
32: 36.2: adjusted_gross_income (скорректированный_общий_доход)
36.2: 36: значение_селектора (управляющая входящая связь)
36: ... узел_выбора_данных 36.1 IF СОД <= к2 (значение_селектора =
ИСТИНА)
Р23 IF СОД > к2 (значение_селектора = ЛОЖЬ)
Вы, возможно, захотите начертить все эти графы потока данных для сравнения. Модели потоков данных могут показаться более сложными по сравнению с ранее рассматриваемыми моделями, но это не так. Они только включают больше информации, чем обычно закладывается в модель потока управления. Дополнительные детали возникают вследствие того, что каждый объект данных должен откуда-то появиться. Вот почему мы добавили два узла kl и k2, отвечающие за константы $2450 и $83850 соответственно. Мы добавили связь 32 : 36 в первую модель потока данных (связь 32 : 36.2 во вторую модель потока данных) потому что adjusted_ gross_income (скорректированный общий доход) должен откуда-то появиться. Связь бе: 36.1 для переменной total_number_of_exemptions (общее_число_освобож-дений) была добавлена по той же причине. Если мы уберем эту дополнительную информацию (уменьшив детализацию нашей модели), мы получим даже еще более простую модель (по числу узлов и связей), чем модель потока управления.
36.1: 36: total_number_of_exemptions (общее_число_освобождений) * kl
Р23: 36: расчет_согласно_инструкции
36: ... узел_выбора_данных 36.1 IF СОД <= к2
Р23 IF СОД > к2
122 Глава 5 • Тестирование потоков данных
При качественном проектировании программных средств предполагается, что значения константам kl и к2 присвоены раньше в программе или хранятся в таблице. Это намного лучше, чем многократное повторение значений $2450 и $83850 в коде программы. Это правильный подход, поскольку уменьшается вероятность ошибок, при которых якобы постоянные величины в разных местах отличаются друг от друга. Это хорошо также для сопровождения, поскольку в том случае, когда ВНС изменит ставки налогового обложения (что неминуемо когда-нибудь случится), нужно будет изменить одно значение в одном месте1. Это, конечно, правильный подход, но мы не можем быть уверены, что программист так и поступил. Но почему об этом должен заботиться тестировщик? Используя символьные константы в нашей модели, мы уменьшаем вероятность ошибок там, где мы непреднамеренно используем несколько различных значений предполагаемой константы. Хороший дизайн программного обеспечения часто также хорош и для проектирования теста.
IF-THEN. Мне не нравятся конструкции типа IF-THEN в графах потока данных, поскольку они неоднозначны, если условие не выполняется. В графах потока управления неоднозначности меньше, поскольку следующий оператор всегда подразумевается. Большинство конструкций IF-THEN лучше моделировать при помощи конструкций IF-THEN-ELSE, как в следующем примере:
IF (предикат - ИСТИНА) then х: = функция ELSE х: = пусто
Явно определяйте, что происходит с объектом данных, когда предикат не истинен. Например, постулат:
54: Удержан федеральный налог. Если вы используете форму 1099. отметьте [ГРАФА] можно представить при помощи следующего псевдокода и модели потока данных, соответственно.
54: If из_форм(ы)_1099 THEN графа: = отмечена ELSE графа: =
не_отмечена
54.1: 54: графа: = отмечена
54.2: 54: графа: = не _отмечена
F1099: 54 значение ЛОЖЬ/ИСТИНА из формы 1099
54 ... узел выбора данных: 54.1 IF F1099 = ИСТИНА
54.2 IF F1099 = ЛОЖЬ
Будьте осторожны с такими величинами, как ноль и пусто; это не одно и то же. Мы ввели два входных узла в последний пример: 54.1 графа: = отмечена и 54.2 графа: = не отмечена. В обоих случаях графа имеет реальное значение. Таким же образом значение ноль — реальное значение, в то время как пусто не имеет какого-либо значения. Это означает — не определено.
Рассмотрим оператор присваивания: IF х > 0 THEN сэм: = джо. Мы знаем, что делать с сэм, когда х > 0, но вдруг х <= 0? Есть две альтернативы: либо у переменной сэм нет значения, и она здесь же и создается, либо имеется другое, заранее
' Я начал писать эту книгу в 1992 году. Я должен был исправлять эти числа в 1993, 1994 и, наконец, еще раз в 1995 году. Однако, в отличие от вас, я не мог использовать символьную переменную для этих чисел. Было бы намного проще, если бы я мог так поступить. Если я пропустил несколько обновлений, я уверен, что вы сообщите мне об этом, — но надеюсь, что вы простите меня.
5.3. Отношения и модель 123
рассчитанное где-то в другом месте графа потока данных значение для сэм. Первый случай не представляет проблемы. Мы моделируем его так: IF х > О THEN сэм: = джо ELSE сэм:= пусто. Второй случай тоже не сложен. Он должен быть смоделирован так: IF х > О THEN сэм: = джо ELSE сэм: = старое_значение_сэм. Нам снова не нужно сомнительное IF-THEN.
Возможно, проблема возникнет, если переменная сэм определена в более чем одном месте. Какое значение нам следует использовать для случая ЛОЖЬ? Это — хороший вопрос, не имеющий простого ответа. Тут возможны варианты, поскольку в случае неоднозначности не бывает очевидного ответа. Конструкция IF-THEN однозначна в графе потока управления, потому что графы потока управления имеют подразумеваемое упорядочение (упорядоченную последовательность). Следовательно, обычно имеется подразумеваемое (предшествующее) значение для такой ситуации. В графах потока данных, в которых нет подразумеваемого упорядочения, значение становится неоднозначным. Вот почему следует избегать использования IF-THEN в подобных моделях. Но заметьте, что неоднозначность в модели увеличивает вероятность ошибок программирования.
В качестве примера использования IF-THEN рассмотрим, как бы мы могли смоделировать строки с 1-й по 5-ю в форме 1040. Здесь приведен псевдокод для этих строк.
1: IF статус налогоплательщика = холост THEN отмечена графа_1; GOTO 6а
2: IF статус налогоплательщика = женат_заполнено_совместно THEN отмечена графа_2: GOTO 6а
3: IF статус налогоплательщика = женат_заполнено_раздельно THEN отмечена графа_3; GOTO 6а 4: IF статус налогоплательщика = домовладелец THEN отмечена графа_4; GOTO 6а
5: IF статус налогоплательщика = вдовец THEN отмечена графа_5; GOTO 6а
Этот псевдокод не является неоднозначным в том случае, если мы знаем, что предшествующее состояние всех граф «не отмечена». Поскольку мы не можем быть уверены в этом в случае кода, содержащего ошибки, более предпочтительная модель могла бы выглядеть следующим образом:
1: IF статус = холост THEN графа_1; = отмечена; GOTO 6а ELSE графа_1; = не_отмечена
2; IF статус = жен_совм THEN графа_2; = отмечена; GOTO 6а ELSE графа_2; = не_отмечена
3; IF статус = жен_раздельно THEN графа_3: = отмечена: GOTO 6а ELSE графа_3; = не_отмечена
4; IF статус = домовладелец THEN графа_4: = отмечена; GOTO 6а ELSE графа_4: = не_отмечена
5: IF статус = вдовец THEN графа_5: = отмечена; GOTO 6а ELSE графа_5; = не_отмечена
Программисты могут возразить, что этот код нехорош, так как он неоправданно сложен, что само по себе делает код более уязвимым для ошибок, и, кроме того, он не структурирован. Все это правда, но ведь это не код. Это всего лишь модель, в которой мы пытаемся сделать ситуацию как можно более однозначной. Вот модель потока данных для этих действий.
0.0; . 0.1 вход_статус
0.1; графа_1: графа_1: 6; выбор; IF статус = неженат
выбрать отмечена ELSE выбрать не отмечена
124 Глава 5 • Тестирование потоков данных
графа_2: графа_2: 6: выбор: IF статус= жен_совм
графа_3: выбрать отмечена отмечена ELSE выбрать не
графа_4: графа_5: графа_3: 6: выбор: IF выбрать отмечена статус = жен_раздельно отмечена ELSE выбрать не
отмечена: графа_1: графа_2: графа_4: 6: выбор: IF выбрать отмечена выбрать отмечена статус = домовладелец отмечена ELSE выбрать не отмечена ELSE выбрать не
графа_3: графа_4: графа_5: 6: выбор: IF выбрать отмечена статус = вдовец отмечена ELSE выбрать не
графа_5: не отмечена: графа_1: графа_2: графа_3: графа_4: графа_5: 6: продолжение модели
Модель может показаться сложной, но это не так, потому что определено всего пять различных выходов (по одному на каждую графу). В тестируемом программном обеспечении, в котором реализуется этот процесс, мы должны убедиться не только в том, что правильная графа отмечена, но и в том, что все остальные графы остались неотмеченными и отмечено не больше одной графы. Заметьте, что если вход статус_налогоплателыцика не является одним из пяти правильных вариантов, тогда все графы останутся неотмеченными.
Селектор CASE. Структура Селектора CASE в графах потока данных — обобщение структуры IF-THEN-ELSE. Модель потока данных для строки 34 такова:
34.1: 34: вход $3800 (холост, deduction (возврат): = $3800)
34.2: 34: вход $5600 (домовладелец. deduction (возврат): = $5600)
34.3: 34: вход $6350 (женат совместная декларация, deduction (возврат): = $6350)
34.4: 34: вход $6350 (вдовец. deduction (возврат): = $6.350)
34.5: 34: вход $3175 (женат, заполнено раздельно, deduction (возврат): = $3175)
статус: 34: вход статус_налогоплательщика (управляющая входящая связь для
селектора 34)
34: выбор статус_налогоплательщика: холост 34.1
домовладелец 34.2
совместно 34.3 вдовец 34.4 раздельно 34.5
Строка 34 иллюстрирует работу узла CASE. Я предпочитаю использовать переменную статус налогоплателыцика для моделирования предиката выбора, потому что это тот способ, который используется в инструкциях ВНС. Обладая информацией, какая графа была отмечена в строках с 1-й по 5-ю, я бы создал в строках с 1-й по 5-ю модели переменную номер графы, значение которой устанавливалось бы
5.3. Отношения и модель 125
соответствующим той графе, которая отмечалась, и затем использовал бы значение номер_графы для управления предикатом выбора в строке 34.
Так же как и в случае конструкции IF-THEN, здесь возможна неоднозначность. Что произойдет, если ни одна из граф (строки 1-5) не будет отмечена? Что произойдет, если в строках с 1 по 5 отмечено более одной графы?
5.3.3. Короткие замечания и упрощенные методы
Не забудьте, что мы имеем дело с моделями, а не с программным обеспечением. Следовательно, закладывайте в модель как можно больше деталей из тех, что вам нужны, но не все, что вам известны. Ваши модели потока данных, используемые при разработке тестов, должны иметь различные степени детализации по аналогии с диаграммами потока данных, используемыми в проектировании. Например, имея дело с файлом, вы могли бы извлечь пользу от наличия нескольких уровней детализации (и нескольких различных моделей потока данных).
Уровень файла. Рассмотрите весь файл как один объект данных, с которым обращаются как с единым целым. Сконцентрируйтесь на операциях, которые применяются к целому файлу, и на операциях между файлами, например, открыть, закрыть, копировать, сравнить, переименовать, удалить, переместить, переслать, объединить, извлечь, создать.
Уровень записи. Тесты, которые вы проделали па уровне файла (если они успешно пройдены), гарантируют, что вы работаете с правильным файлом. Сконцентрируйтесь на получении правильной записи в модели для уровня записи. Проводимые операции аналогичны операциям на уровне файла: добавить запись, удалить запись, копировать запись, найти запись, извлечь, сравнить, переместить.
Уровень поля. Рассмотрите индивидуальные поля в записи. Здесь может быть несколько уровней. Например, одно из полей может являться массивом. Рассмотрите следующие операции: вставить поле, удалить поле, изменить значение поля, копировать значение, сосчитать число полей.
Уровень обработки. Обычно его можно совместить с уровнем поля, но это не всегда стоит делать, если операции с полями либо обработка данных достаточно сложны. Модель обработки сама по себе может быть создана на нескольких различных уровнях детализации.
Группы данных. В ряде случаев (требования приложения или способ программирования) вы, может быть, захотите сгруппировать те объекты данных, которые обрабатываются схожим образом, даже если они не связаны в контексте данного приложения. Это поможет вам создать многократно используемые модели. То есть одна и та же модель может быть использована для нескольких различных, возможно, не связанных, частей приложения. Возможность повторного использования — признак хорошего программирования и хорошего дизайна тестов.
Качественное проектирование программного обеспечения упрощает задачу моделирования, поскольку разработчики создают иерархический набор потоков данных, структура которого отражена в структуре разбиения процесса обработки.
126 Глава 5 • Тестирование потоков данных
Когда вы, как об этом говорилось выше, разделяете модель на уровни, вам, возможно, придется «создать» новые объекты данных, которых нет в спецификациях. Определите их так точно, как если бы вы занимались программированием, задайте их атрибуты, определения и так далее. После определения, такая псевдопеременная становится переменной при использовании в модели потока данных более высокого уровня.
При создании и использовании таких упрощенных методов вы не программируете и не меняете технические требования — вы закладываете фундамент, необходимый для создания высокочувствительного теста. Если приложение сложно организовано, приготовьтесь к тому, что тесты будут, подобно ему, обладать сложной структурой. Если программное обеспечение выигрывает при использовании иерархической структуры, разбиения и многократно используемых компонентов, то выиграет и тестовый комплект. Большинство методов, использование которых оправдано при проектировании программы, окупаются при разработке тестов.
Вы могли бы раскритиковать такой подход к организации разработки тестов, сказав: «Ни приложение, ни программное обеспечение не всегда бывает структурировано должным образом. Предполагая хорошую структуру тестируемой системы при проектировании тестов, вы можете упустить из виду возможность выявления ошибок, являющихся следствием плохой структуры, — например, ошибок, проистекающих из смешения уровней файла, поля, записи данных с их обработкой».
Подобный критицизм заслуживает внимания, но из того, что структура программы размыта, не следует того, что плохо структурированное тестирование будет более эффективным. Не следует доверять поимку вора вору. Необходимо работать систематично.
Как можно повысить эффективность использования скудного времени, отпущенного на проектирование тестов? Существует гораздо больше способов спроектировать программное обеспечение плохо, чем способов сделать это хорошо. Если вы решили придерживаться неструктурированного проектирования тестов в попытке найти некоторые ошибки, вы можете также ошибиться в предположениях о коде, как и при хорошо структурированном проектировании. Вы обманываете самих себя. Единственный способ сделать обоснованные допущения о коде, на которых можно основать проектирование тестов, — это посмотреть на код и построить дизайн ваших тестов в соответствии с его структурой. Но это уже нельзя назвать тестированием черного ящика.
Приняв структурированную модель, вы увеличиваете вероятность того, что ваши позитивные тесты будут обеспечивать покрытие требований. Такой набор тестов более объективен и при создании негативных тестов. Например, разделяя тесты на уровне файла и полей записи, вы можете яснее увидеть, какая имеется возможность для грязных тестов, в которых эти уровни перемешаны. Проектирование грязных тестов будет проще и потребует меньшего количества предположений об ошибках, так что работу будет проще оценить.
5.3. Отношения и модель 127
5.3.4. Упорядочение, совмещение потока управления и потока данных, циклы
5.3.4.1. Упорядочение
Ссылки на материал, описанный в этом разделе, можно встретить в [RUGG79]. Данная книга рекомендуется для дополнительного ознакомления с рассматриваемыми концепциями.
Граф потока данных содержит мало указаний о порядке обработки, продиктованном используемыми языками программирования и аппаратным обеспечением. Но некоторое упорядочение все же остается, и информация о некотором упорядочении будет уместна. Вот четыре общих вида упорядочения, которые могут встретиться в графе потока данных: удобное, но не необходимое, необходимое, синхронизация, итерирование.
Не необходимое, но удобное. У нас есть последовательность операций, которые рассчитывают значения вместе с промежуточными значениями. Вам необходимо знать adjusted gross income (скорректированный_общий_доход) (строка 31), для того чтобы рассчитать величину вашего налога, adjusted_gross_income (скоррек-тированный_общий_доход) зависит от переменной total income (общий_доход) (строка 22), которая, в свою очередь, зависит от других полей. В конечном счете эти поля зависят от входных данных. Может показаться, что подобное упорядочение необходимо, но это не так. Каждая строка в налоговой декларации может быть (теоретически) выражена прямо в виде комбинации входных данных. Так поступить допустимо, но глупо, потому что каждая строка в налоговой форме в этом случае была бы суммой множества вводимых полей. Такое упорядочение удобно, но не необходимо. Если вы уберете все подобное упорядочение из типичной диаграммы потока данных, вы получите только входные узлы и (очень сложные) выходные узлы.
Когда вы видите граф потока данных, содержащий между узлами входа и выхода еще другие узлы, проверьте эти промежуточные узлы, чтобы определить, являются ли они необходимыми или просто удобны. Можно ли упростить или систематизировать ваш граф, удалив некоторые из этих упорядочений и выразив выходы более явно через входные данные? Это диаметрально противоположно тому, что вы делали, когда изучали псевдопеременные и иерархические разбиения в разделе 5.3.3.
Необходимое. Иногда упорядочение необходимо. Вы не можете прочитать (файл, до того как он создан (несмотря на то, что это хороший тест) или закрыть неоткрытый файл. Вы должны понять, как работает приложение, чтобы узнать, является ли упорядочение в графе потока данных необходимым или нет. Не удаляйте необходимое упорядочение, потому что если вы это сделаете, вы пропустите полезные тесты и создадите бесполезные.
Синхронизация. Если имеются параллельные процессы (например, в системах с общими данными или сетевых приложениях), тогда существует необходимое упорядочение и проблема синхронизации. Например, с: = а + Ь, где а и b берутся из разных мест. Проблема синхронизации приводит к пяти дополнительным тестовым вариантам, зависящим от последовательности собы
128 Глава 5 • Тестирование потоков данных
тий (почему?), и ее мы обсудим в главе 6. Если в вашем случае таких проблем достаточно много, может оказаться, что модель потока данных не подходит для данного случая, и лучше рассмотреть модель потока управления или модель потока транзакций.
Итерирование. Если у вас есть узлы выбора, вы можете вернуть результат вычисления назад, в более раннюю точку на графе потока данных и создать цикл. Процесс повторяется до тех пор, пока (как мы надеемся) не выполнится условие прекращения. Циклы и способы их обработки в контексте модели потока данных обсуждаются в разделе 5.3.4.3.
5.3.4.2. Совмещение потока управления и потока данных
Модели потока управления и модели потока данных плохо сочетаются [KAVI87]. Каждая модель — это обособленная часть общей картины, сосредоточенная на одних аспектах проблемы и игнорирующая другие. Модель — это способ структурировать наше мышление, необходимый для получения полезных тестов. Если модель чересчур сложна, это только запутает нас. Но как мы должны обрабатывать необходимое упорядочение в рамках модели потока данных? Вот некоторые соображения.
Более одной модели. Сделайте отдельно модель потока данных и модель потока управления. Каждая приведет к различным тестам, и? как мы надеемся, при таком подходе не будет значительного перекрытия созданных тестов. Возможно, вы предпочтете в качестве альтернативы модель с конечным числом состояний (глава 9).
Поместите модель потока управления внутрь модели потока данных. У вас есть повторяющаяся процедура в модели, большей частью определяемой потоками данных. Например, вы должны найти файл, чтобы получить данные, которые затем используются в вычислении. Рассматривайте поиск файла как единичную операцию внутри модели потока данных. Для поиска файла используйте модель потока управления.
Поместите модель потока данных внутрь модели потока управления. Скажем, вы проделываете повторяющуюся обработку для каждой записи файла. Обработка моделируется при помощи графа потока данных. Расположите часть, представляемую потоками данных, внутри модели файла (либо модели потока управления или модели потока транзакций). Рассматривайте файловую часть как модель потока управления, а обработку как модель потока данных.
Когда вы проектируете тестовый вариант, никто не знает, как вы это делаете. Тестовый вариант состоит из исходных условий, вводимых данных, ожидаемых результатов. И история умалчивает (или должна умалчивать) о том, получили ли вы эти результаты, используя модель потока управления, модель потока данных или каким-то другим способом.
5.3.4.3. Циклы
Как бы вы ни моделировали проблему и какие бы ни были в ней циклы (необходимые или нет), вам следует использовать методы тестирования циклов из главы 4. К счастью, в потоковых моделях нам нечасто приходится иметь дело с циклами. Мы должны различать необходимые и несущественные циклы.
5.3. Отношения и модель 129
Причиной возникновения несущественных циклов является природа языков программирования. Если вы хотите добавить два массива, в большинстве компьютеров или языков вы, вероятно, проделаете это с помощью цикла. Цикл не необходим, потому что на параллельном компьютере вы могли бы проделать эту операцию параллельно. Большинство циклов, встречаемых нами в программном обеспечении, несущественны. Большинство детерминированных циклов не являются необходимыми.
Необходимые циклы реализуют итерационные или потенциально бесконечные процедуры. Решение уравнения с помощью итерационного процесса, такого как итерация Ньютона—Рафсона, — хороший пример. Поиск и сортировка файлов с неограниченной длиной — другие два примера. Большинство недетерминированных циклов являются необходимыми1 * * * 5.
Если у вас есть какие-нибудь необходимые (или удобные) не очень сложные циклы (то есть не вложенные, без переходов в них или из них, без большого количества управляющей логики в них), тогда простой и эффективный путь рассмотреть проблему цикла в рамках модели потока данных — это развернуть цикл.
Рассмотрим модель, приведенную на рисунке, пренебрегая пока что различиями между графами потока управления и графами потока данных. Итерационный процесс здесь зависит от входных переменных А, В и С. В ходе этого процесса происходит вычисление функции X и счетчика цикла I. Рассчитав первый результат (Xf), программа переходит к узлу ЦИКЛ, где принимается решение о том, следует ли выйти или же продолжить. Управляющий предикат может быть функцией как X, так и I, либо обоих параметров.
Нам необходимо знать исходное значение для X, потому что выполняемое в узле X вычисление зависит от предыдущего значения X. Я назвал исходное
1 Мы все знаем, что подготовка наших налоговых деклараций — повторяющаяся процедура, кото-
рая производит впечатление бесконечной (до 15 апреля). Зная особенности бюрократического мышления, я очень надеялся найти много необходимых циклов в налоговых законах. Я просмотрел все формы и инструкции (это порядка 950 страниц терминологии ВНС) в моем налоговом пакете. Я об-
наружил множество способов уйти от уплаты налогов, но не нашел ни одного необходимого цикла. Я уверен, что они там есть, но я не эксперт по налогам, так что я не смог найти пи одного. Любой читатель,
который укажет мне на необходимые циклы, чтобы использовать их в качестве примеров в последующем издании книги, получит бесплатный экземпляр этого издания.
5 Зак. 770
130 Глава 5 • Тестирование потоков данных
значение Хо. Нам также нужно исходное значение для счетчика итераций 10. Мы не знаем, действительно ли код содержит эти исходные значения в виде явно выраженных констант, но, следуя логике, полагаем, что они существуют. Опыт говорит нам, что ошибки исходных значений случаются сравнительно часто, так что это имеет смысл проверить.
Первая модель мне не нравится. Она не настолько близка к модели потока данных, насколько мне бы хотелось. Узел ЦИКЛ имеет скрытую сложность, и наиболее важный вопрос — каким образом выбраны исходные значения? Модель на следующем рисунке более ясна. Я добавил два узла выбора данных (помеченных «?»), чтобы выбрать между исходными значениями X и I. Я также ввел управляющую связь из селектора I к селектору X, чтобы показать, как программа могла бы выбирать между исходным значением Хо и последующим значением Хг Например, там мог бы находиться предикат в форме IF I = О THEN ВЫБРАТЬ X, ELSE ВЫБРАТЬ Хо. В случае реальной проблемы вам следовало бы иметь больше информации о специфике условий прекращения цикла и разместить больше этой информации внутри чисто потоковых (по данным) узлов. Например, условие прекращения цикла может быть основано на разнице между предыдущим и настоящим значениями X и сравнении ее с некоторой маленькой константой е.
Я развернул цикл дважды в следующей модели. Узел Xt производит исходное вычисление, основанное на исходных значениях Хо и 10. Узел Х2 вычисляет функцию, основанную на константах А, В и С, и использует новые значения X и I. Из-за инициализации функции ее значение для Х2, вероятно, не будет тем же самым, что и для Хг Для узла Х3, который, вероятно, имеет то же значение функции, что и Х2, цикл снова развернут.
Мы можем продолжить разворачивать цикл и получим модели для большого числа повторений (и, следовательно, с многочисленными узлами и связями). Но это не очень хорошая идея. Сколько раз нам следует разворачивать цикл? Дважды!1 Это дает вам три модели: первая остановится в узле Хр вторая остано
1 Мы должны развернуть один раз — чтобы удовлетворять требованиям методик структурного тестирования, поскольку мы хотим использовать простые пути. Второй разворот оправдан опытом и теоремой Хуанга. Смотри [BEIZ90].
5.4. Методы 131
вится в узле Х2 и третья — в узле Х3. Это три отдельных модели, позволяющие рассмотреть три случая — выход без прохождения цикла, выход после однократного прохождения цикла и выход после двукратного прохождения цикла. Если вы должны протестировать максимальное число итераций, используйте модель потока управления.
При тестировании циклов в модели потока данных мы в основном занимаемся поиском ошибок инициализации или использования неправильных значений для предварительной итерации. Например, в узле Х3 вместо использования величины Х2 программист использует величину Х( или Хо. И теория, и практика показывают, что однократное и двукратное прохождение цикла позволяют найти большинство подобных ошибок.
5.4. Методы
5.4.1. Основы
Ссылки на материал, описанный в этом разделе, можно встретить в [SNEE86, ZWEB92]. Данные книги рекомендуются для дополнительного ознакомления с рассматриваемыми концепциями.
Проектирование и выполнение тестов остаются такими же, как и для моделей потока управления, с незначительными различиями, которые вытекают из того, что мы имеем дело с графами потока данных, а не с графами потока управления. В дальнейшем я буду предполагать, что у нас нет циклов.
1. Проверьте спецификацию.
2. Идентифицируйте входные переменные, особенно константы. Дайте каждой входной переменной имя и создайте для нее входной узел.
132 Глава 5 • Тестирование потоков данных
3. Перепишите спецификацию таким образом, чтобы каждой вычисляемой функции соответствовало одно предложение.
4. Перечислите функции, начиная с тех, которые зависят только от входных переменных.
5. Перечислите функции, зависящие только от входных переменных и результатов функций, перечисленных в пункте 4.
6. Продолжайте подобным образом перечислять функции, пока не охватите их все. У вас должен получиться список, в котором наверху будут находиться функции, зависящие только от входных переменных, а далее, по мере продвижения вниз, будут находиться функции, зависящие от всё большего количества промежуточных вычислений. Заметьте, что, как правило, строгое упорядочение невозможно, но это и не нужно.
7. Проверьте промежуточные функции (в том числе функции, зависящие от входных переменных и от выходных данных других функций) и посмотрите, является ли упорядочение необходимым или просто удобным. Если оно необходимо, пометьте соответствующий узел, а также узлы, которые диктуют эту необходимость. Если упорядочение не обязательно, посмотрите, можно ли упростить модель, удаляя промежуточные узлы и выражая функцию непосредственно через входные переменные? Если вы можете удалить узлы и связи без чрезмерного усложнения вычисляемой функции, сделайте это.
8. И наоборот, возможно, вы сможете упростить модель, добавляя промежуточный узел для сложного вычисления. Однако если вы проделаете это, вы должны проверить, является ли ваше промежуточное вычисление верным. Возможно, для этого придется модифицировать исходный код и добавить оператор утверждения.
9. Теперь у вас есть набор узлов (из них каждый имеет имя) которые выражают обработку простейшим для вас способом1.
10. Имеется некое вычисление или функция, связанная с каждым узлом. Переменные в имени данной функции соответствуют узлам, с которыми связан данный узел, то есть, связям. Теперь у вас есть модель.
11. Проверьте вашу модель. Проверьте вашу работу.
Действуйте точно так же, как в случае моделей потока управления. Здесь будут некоторые отличия в деталях, которые мы рассмотрим в дальнейших разделах. Но для начала нам потребуются определения.
Подграф. Часть графа, которая соответствует правилам построения графов то есть имеющая узлы входа и выхода, не имеет оборванных связей, не имеет изолированных узлов, и так далее.
1 То, что обязательно для вас, совсем не обязательно для меня, и наоборот. Никогда не забывайте, что модели — это мысленные инструменты и что в них нет чего-либо принципиально правильного или неправильного. Они могут быть только полезными или бесполезными. Вы можете предпочесть сохранить несущественное промежуточное вычисление в модели, поскольку знаете, что это будет выгодно в другом контексте или просто потому, что люди часто склонны думать подобным образом.
5.4. Методы 133
Порожденный подграф. Подграф графа, выбранный в соответствии с определенным критерием так, что для данного критерия подграф обладает всеми свойствами полного графа для выбранных узлов и связей [WEIS81, WEIS84], Критериев много, и таким образом, существует много различных порожденных подграфов. Если, например, граф представляет собой граф потока управления и интересующий нас критерий — это поведение вдоль пути, то подграф содержит модель всего кода вдоль выбранного пути. Здесь мы в основном заинтересованы в порожденных подграфах потоков данных.
Порожденный подграф потока данных. Порожденные подграфы потоков данных выбираются по отношению к объектам данных; в нашем случае — обычно по отношению к выходному узлу. В общем случае, однако, порожденный подграф потока данных по отношению к данному объекту (узлу) — это подграф графа потока данных, содержащий все потоки данных, которые прямо или косвенно могут прийти в заданный узел, и все потоки данных, которые могут быть доступны из этого узла. Если порожденный подграф (как обычно) выбирается по отношению к выходному узлу, то в этом случае он содержит все узлы, которые могут повлиять на значение соответствующей выходной величины.
Проще говоря, вы просто отслеживаете все входящие в интересующий вас узел связи и помечаете их, затем помечаете все связи, входящие в те узлы, из которых данные связи исходят, и так далее, и то же самое проделываете для исходящих связей, вплоть до выходных узлов1.
12. Выберите «пути» тестирования. Это в действительности не пути, а порожденные подграфы.
13. Активизируйте порожденные подграфы.
14. Предскажите и запишите ожидаемые итоги.
15. Определите критерий соответствия для каждого из тестов.
16. Выполните тесты.
17. Подтвердите итоги (например, значения узла выхода).
18. Подтвердите значения в промежуточных узлах.
5.4.2. Иерархия покрытия2
Ссылки на материал, описанный в этом разделе, можно встретить в [CLAR89, RAPP82, RAPP85, SCHL70, WEIS91, WEYU90, WEYU94A]. Данные книги рекомендуются для дополнительного ознакомления с рассматриваемыми концепциями.
’ Задается транзитивным замыканием отношения «напрямую соединен с».
2 Для ортодоксов модели потоков данных, обсуждаемые в данной книге, — это интерпретации формально определенных критериев структурного тестирования для потоков данных, но вновь истолкованные в терминах поведенческого тестирования. Оправдание для такой интерпретации основано не на каком-либо глубоком теоретическом анализе, а на общем смысле и опыте. Как бы то ни было, хотя большая часть поведенческого тестирования является эвристическим и в его основе лежат факты, полученные опытным путем, подобное тестирование должно в максимальной степени соответствовать и быть основанным на более фундаментальных, основополагающих структурных методах.
134 Глава 5 • Тестирование потоков данных
Методы тестирования потоков данных более эффективны, чем методы тестирования потоков управления. Более эффективны в том смысле, что они могут обнаружить больше ошибок. Они также более эффективны с точки зрения теории, поскольку модель помогает нам создать все тесты, которые мы могли бы создать с помощью тестирования потоков управления и еще некоторые дополнительные тесты. Однако за это приходится расплачиваться. Чтобы достичь более эффективного тестирования, вам приходится проделать больше работы. Больше работы, во-первых, при проектировании тестов, а, во-вторых, при проверке результатов тестирования. Приведенные ниже методы тестирования, используемые в графах потоков данных, расположены по степени возрастания их эффективности.
Покрытие ввода/вывода. Рассмотрим каждый выходной узел отдельно (помните, что граф потока данных имеет по одному выходному узлу на каждый вывод). Для каждого выходного узла используйте набор входных значений, которые приводят к определенному значению вывода. В этой технике есть очевидное слабое место. Мы обеспечим покрытие входных и выходных узлов и, возможно, некоторых промежуточных узлов, по если среди них имеется отдельный предикат выбора, мы можем быть уверены в том, что используется только одно значение этого предиката. Другие не будут протестированы. Эта проверка слишком слаба, чтобы быть нам полезной. Она гарантирует нам только то, что программное обеспечение работает для одного набора входных данных и, очевидно, не делает ничего плохого — например, сбоя. Забудьте об этом методе.
Ввод/вывод + все предикаты. Давайте попробуем нечто посильнее. Усилим покрытие ввода/вывода, следя за тем, чтобы все предикаты (включая предикаты потока управления для циклов и другого необходимого упорядочения) были проверены для обоих значений истинности и аналогично для предикатов в операторах CASE.
Это уже лучше, но все же недостаточно хорошо. Что, если есть промежуточные вычисления, результаты которых не используются? Мы не сможем их обнаружить, не так ли? В качестве другой возможности рассмотрим следующий вариант. Мы рассчитываем величину X, но не используем ее, поскольку где-то позже на этом пути мы пересчитываем величину X без использования первого значения. В этом случае селекторы отсутствуют. Вычисление чего-либо без последующего использования полученного результата — это, скорее всего, ошибка, которая чаще всего является лишь неоправданной тратой ресурсов, но иногда может быть опасна. Тут стоит взглянуть на дело со стороны. Наша модель основана на том, что, как мы надеемся, является корректной реализацией исходных требований. Но мы же тестируем реализацию, содержащую ошибки. Следовательно, промежуточное вычисление, выход которого не используется, по всей видимости, является ошибкой, и мы должны стараться ее обнаружить.
Процитируем Раппса и Веюкера [RAPP82]: «Нельзя быть уверенным в программе, если нельзя увидеть эффект от использования величины, полученной... в ходе каждого вычисления».
Если мы просто проверили все узлы с предикатами (как потока управления, так и выбора данных), мы добились большего, чем тестирование ветвей потока управления (из-за проблемы составных предикатов), но мы не получили бы всех тех преимуществ, которые дает тестирование потоков данных.
5.4. Методы 135
Частичное покрытие узлов. Предыдущие методы обеспечивали покрытие некоторых узлов и некоторых связей, но при этом не гарантировали, что будет обеспечено покрытие всех узлов и/или всех связей. Таким образом, зная, что цель нашей стратегии, по крайней мере, обеспечить покрытие вычислительных узлов нашей модели, давайте удостоверимся, что так оно и есть на самом деле. Это называется стратегией всех определений, поскольку каждый вычислительный узел в нашей модели потока данных соответствует определению некоторой переменной. Заметьте, что это не обеспечивает покрытия связей. Таким образом, эту стратегию нельзя прямо сравнивать со стратегией ввод/вывод + предикат, описанной ранее.
Что эта стратегия значит? Мы создаем и выполняем достаточно тестов, чтобы быть уверенными в проверке каждого вычислительного узла нашей модели. Это означает, что каждая функция была выполнена хотя бы один раз и дала (по крайней мере, мы надеемся на это) правильное значение для этого случая. Заметьте, что мы отвечаем за проверку промежуточных результатов, поскольку тестирование каждого вычислительного узла подразумевает проверку вычисления, сделанного в этом узле.
Стратегия все определения (ВО) представляет определенный интерес, поскольку в ранней литературе, посвященной эвристическому тестированию потоков данных, обычно предлагался этот метод [BEND70, BEND85, HERM76]. Здесь наши методы основаны на формальной, проверенной теории [FRAN88, RAPP82]. ВО также упускает слишком многое. Например, этот метод может пропустить все узлы выбора и все циклы в модели. Этого достаточно, чтобы отказаться от такого метода. Нам нужно что-то более сильное.
Все узлы. Следующая очевидная ступень — убедиться, что мы покрываем все узлы, а не только вычислительные. Это, несомненно, более сильное утверждение, потому что мы хотим быть уверены, что в дополнение к вычислительным узлам мы обеспечиваем покрытие всех узлов выбора данных и узлов потока управления. Но это недостаточно сильно, поскольку, например, не дает гарантии, что мы проверили все варианты для предикатов выбора и потока управления. Требуется нечто еще более сильное.
Покрытие связей (все использования). Следующая логическая ступень — охват всех связей в графе потока данных. Она соответствует стратегии всех использований. Всякий раз, когда вычисление выполнено, мы будем проверять каждое использование результата этого вычисления в последующей обработке. Это, конечно, подразумевает проверку всех промежуточных вычислений, а не только конечных выводов. Но это не означает тестирования каждого возможного пути в программе. Это даже не тестирование всех возможных путей между точкой определения и местом его последующего использования.
Все использования + циклы. Существует много не охваченных здесь других стратегий тестирования потоков данных. Для того чтобы получить общее представление о них, смотрите [WEYU94A] в [MARC94]. Нам следует попытаться не допускать циклов в наших моделях потока данных, но это не всегда возможно. Если у вас есть подобные циклы, тогда разверните модель и добавьте к вашим тестовым вариантам покрытие связей развернутой модели1.
136 Глава 5 • Тестирование потоков данных
5.4.3. Построение модели
Настало время прекратить теоретизирование и начать построение модели. Давайте разработаем упрощенный вариант для строк с 54 по 60 формы 1040. Вот исходный материал, скопированный из документа ВНС с минимальными изменениями, введенными для ясности.
54: Federal Tax Withheld (Удержанный федеральный налог)
55: 1994 Estimated Tax Payment (Выплата налога со всех видов дохода в
1994) and Amount Applied from 1993 Return (Сумма, заявленная в декларации 1993)
56: Earned Income Credit (Налоговые льготы, предоставляемые получателям заработной платы)
57: Amount Paid with Form 4868 (Extension Request) (Сумма, уплаченная в соответствии с формой 4686 (Просьба о продлении))
58а: Excess Social Security and RRTA Tax Withheld (Налог на превышение социального обеспечения)
59: Другие выплаты в соответствии с формой 2439 или формой 4136
60: Общий платеж: сумма строк с 54 по 59.
Первое приближение нашей модели почти полностью совпадает со строками налоговой декларации и лишь имеет слегка более формальный вид. В глубине души я надеюсь использовать инструмент, который поможет мне проверить полноту и непротиворечивость этой спецификации, так что заблаговременная формализация — хорошая идея.
54: 60: Federal_Tax_Withheld (Удержанный_федеральный_налог)
55: 60: 1994_Estimated_Tax_Payment
(Выплата_налога_со_всех_видов_дохода_в_1994) and
Amount_Applied_from_1993_Return
(Сумма_заявленная_в_декларации_1993 )
56: 60: Earned_Income_Credit
(Налоговые_льготы_предоставляемые_получателям_заработной_платы)
57: 60: Amount_Paid_with_Form_4868 (Extension_Request)
(Сумма_уплаченная_в_соответствии_с_формой_4868 (Просьба о продлении))
58а: 60: Excess_Social_Security and RRTA_Tax_Withheld (Налог_на_превышение_социального_обеспечения)
59: 60: другие_выплаты (в соответствии с формой 2439 или формой 4136)
60: Общий Платеж: сумма строк с 54 по 59.
На самом деле это неправильно, не так ли? Строка 55 по сути является суммой двух слагаемых, строка 58а — сумма двух слагаемых, и строка 59 тоже является суммой двух слагаемых (форма 2349 и форма 4136: Налог со всех видов дохода в 1994 и Сумма, взятая из декларации 1993, соответственно). Мы создадим более детальную модель.
54: 60: Federal_Tax_Withheld (Удержанный_федеральный_налог)
55а: 55; 1994_Estimated_Tax_Payment
(Выплата_налога_со_всех_видов_дохода_в_1994)
55b: 55: Amount_Applied_from_1993_Return
1 Нам нужна одна из стратегий «всех использований», но не настолько мощная, как проверка всех путей, которая в контексте поведенческого тестирования просто неосуществима
5.4. Методы 137
(Сумма_заявленная_в_декларации_1993 )
55: 60: 55а + 55b
56: 60: Earned_Income_Credit
(Налоговые_льготы_предоставляемые_получателям_заработной_платы)
57: 60: Amount_Paid_with_Form_4868 (Extension_Request)
(Сумма_уплаченная_в_соответствии_с_формой_4868 (Просьба о продлении))
58al: 58а: Excess_Social_Security_Tax_Withheld
(Налог_на_превышение_социального_обеспечения)
58а2: 58а: Excess_RTTA_Tax_Withheld (Налог_на_превышение_РРТА)
58а: 60: 58а1 + 58а2
59а: 59: Другие_выплаты_в_соответствии с Формой 2439
59b: 59: Другие_выплаты_в_воответствии с Формой 4136
59: 60: 59а + 59b
60: Total Payments (Общие выплаты):= 54 + 55 + 56 + 57+ 58а + 59
Последняя строка мне не нравится из-за ее двусмысленного представления. Речь шла об узлах 54, 55 и так далее, или об их значениях? Будет лучше внести ясность и заменить эту строку такой:
60: Total Payments: С54 + С55 + С56 + С57 + С58а + С59
В этой модели я сделал некоторые предположения, которые могут быть, а могут и не быть верными. Во всех случаях, когда я детализировал узел (55,58а и 59), я предполагал, что входные данные могут прийти из ниоткуда, из одного или всех доступных источников. Эти узлы не являются узлами выбора данных. Узлы выбора должны иметь дело с взаимоисключающими случаями. Например, строка 38 — это узел выбора, так как в нем делается выбор между взаимоисключающими случаями. Откуда вам об этом узнать? Вы должны понять приложение и его задачи. Давайте смоделируем только одну строку 38 и то, что она за собой влечет.
38 Налог.Отметить, если из а [ ] Tax Table (Таблицы налогов), b [ ] Tax Rate Schedule (Схемы налоговых ставок), с [ ] Capital Gain Tax Worksheet (Таблицы налога на капитальную прибыль) или d [ ] Формы 8615. е. Сумма из форм(ы) 8814.
Я не являюсь специалистом по налогам, так что я должен был читать инструкции ВНС и руководство по налогам, чтобы понять, что делать с пунктом е. Пункт е должен быть добавлен в налог, несмотря на то, что в форме это не указано. Пункты а, Ь, с и d — взаимоисключающие и формируют соответствующий узел выбора. Ниже приводится модель для данного случая.
38а: 38х: часть_налога (Используйте Tax Table (Таблицу налогов))
38b: 38х: часть_налога (Используйте Tax Rate Schedule (Схему налоговых ставок))
38с: 38х: часть_налога (Используйте Capital Gain Tax Worksheet (Таблицу налога на капитальную прибыль))
38d: 38х: часть_налога (Из Формы 8615)
38х: ВЫБОР (исходя из правил 8НС) 38а
38b
38с 38d 38е: 38: Сумма_из_Форм(ы) 8814 38: С38х + С38е
138 Глава 5 • Тестирование потоков данных
5.4.4. Выбор основного порожденного подграфа
Нам надо рассмотреть несколько различных ситуаций для выбора порожденного подграфа — эквивалента путей потока управления в диаграммах потока данных. То, что мы делаем, зависит от того, что представляет собой граф потока данных.
1. Нет узлов выбора, нет узлов потока управления (и нет циклов).
2. Только потоки данных и узлы выбора.
3. Только узлы предикатов потока управления, без узлов выбора.
4. Узлы предикатов потока управления и узлы выбора.
5. Циклы.
Случай 1: Чистые потоки данных
Следующую процедуру необходимо проделать для каждого выходного узла. Выберите выходной узел. Проследуйте в обратном направлении от выходного узла ко всем соединенным с ним узлам. Проследуйте от этих узлов в обратном направлении к тем узлам, которые, в свою очередь, соединяются с ними, и так далее, пока не достигнете входных узлов (для данной модели). Теперь у вас есть порожденный граф потока данных. Символически ситуация проиллюстрирована следующим образом:
Ul, U2 и U3 — выходные переменные. А, В и С — наборы входных переменных. Средняя область содержит вычислительные узлы. U1 зависит только от входных переменных из набора A. U2 зависит как от переменных из А, так и от переменных из В, a U3 зависит только от переменных из С. У нас есть три набора тестов, соответствующих Ul, U2 и U3. Если здесь нет узлов выбора и нет узлов потока данных, вам потребуется только один тестовый вариант на одну выходную переменную. Заметьте, что каждый порожденный подграф будет содержать (возможно) различные вычислительные узлы в области ВЫЧИСЛЕНИЕ. Например, нам следует ожидать, что вычислительные узлы, относящиеся к U3, не будут перекры
5.4. Методы 139
ваться с узлами, соотносящимися с Ш и U2. Некоторая часть вычислительных узлов (но не все) будет, вероятно, использоваться как в U1, так и в U2.
Случай 2: Только потоки данных и узлы выбора
Начните, как и раньше, с порожденного подграфа для каждой выходной переменной. Однако когда вы достигнете узла выбора, вы должны включить в порожденный подграф каждый потенциально выбираемый вариант. Результатом будет нечто вроде объединенного порожденного подграфа, поскольку в данном случае имеется множество альтернативных путей. Каждый объединенный порожденный подграф приведет к получению целого набора тестовых вариантов. Рассмотрите отдельно каждый объединенный порожденный подграф.
Допустим, что в порожденном подграфе есть только один узел выбора. Выберите величину для каждого значения предиката выбора и затем исключите из порожденного подграфа все потоки данных, которые не принимают участия в определении этой величины. Если, например, в строке 38 мы выберем 38а (Использовать Тах Table (Таблицу налогов)), то нам следует исключить из порожденного подграфа потоки данных, приводящие к строке Использовать Tax Rate Schedule (Схему налоговых ставок). Использовать Capital Gain Tax Worksheet (Таблицу налога на капитальную прибыль) и Использовать форму 8615.
Порожденный подграф, основанный на U, включает в себя три вычислительные области, наборы данных А, В, С, D и узел выбора. Если мы выберем величину X, которая зависит только от наборов данных А и В, мы исключаем из порожденного подграфа наборы данных С и D и вычислительную область Y. Напротив, если мы выберем величину Y, то в этом случае исключаем набор А и вычислительную область X, поскольку входные наборы данных В, С, и D используются для вычисления Y и U по мере прохождения порожденного подграфа.
Предположим, что в порожденном подграфе имеется два или более предикатов выбора. У нас опять есть два случая: при обратном движении по потокам (от выхода к входу) они могут соответствовать или ветвлению, или слиянию потоков
140 Глава 5 • Тестирование потоков данных
данных. Сначала мы рассмотрим более простой случай, при котором в двух предикатах выбора происходит ветвление потоков. Это изображено на следующем рисунке.
U
Мы начинаем с разделения на порожденные подграфы всех выходных переменных. Так же, как и прежде, выбираем одну из переменных и определяем порожденный подграф для этой переменной. Как и раньше, первый встреченный нами предикат выбора делит граф на несколько порожденных подграфов, каждый из которых приводит к набору тестовых вариантов. На рисунке есть порожденный подграф для W, приводящий только к одному тестовому варианту, и еще один порожденный подграф для V. Следуя от V в направлении входных узлов, мы встречаем второй узел выбора, который снова порождает два варианта, приводя к порожденному подграфу для X, включающему наборы входных переменных А, В и другому набору для Y, включающему наборы входных переменных В, С и D. Помните, что узел выбора может иметь много ветвей, и вы должны разрабатывать отдельный набор тестов для каждой ветви.
И теперь рассмотрим последний случай, в котором потоки данных сливаются и следуют назад вместе. Если мы возьмем порожденный подграф V для нижнего узла выбора и проследуем по нему вверх, мы натолкнемся на другой узел выбора, приводящий к двум новым порожденным подграфам и двум тестовым вариантам, соответствующим выбору X или Y. Порожденный подграф W, однако, идет назад к тому же узлу выбора (X, Y) где снова имеется возможность выбора из двух вариантов. Приведет ли это к еще двум тестовым вариантам или только к одному?
Это зависит от того, насколько тщательно вы хотите тестировать. Если вы выберете только один вариант для W, что дает только один порожденный подграф (либо X, либо Y), тогда у вас будет один дополнительный тест. При более тщатель
5.4. Методы 141
ном (и требующем больших затрат) тестировании вам следует взять оба порожденных подграфа. В нашем примере это добавляет только один тест, но если у нас есть много узлов выбора, расположенных один за другим в каждом порожденном подграфе, разница в подходах может стать разительной. Эти два метода соответствуют применению того, что формально известно как критерий всех использований {ВИ) (берется какой-либо один порожденный подграф, который влияет на значение W) и критерий Всех путей-определение-использование (ВПОИ) (берется каждый порожденный подграф, влияющий на значение W). ВПОИ — более полный метод, чем ВИ, но требует ббльших трудозатрат. Исходя из эмпирического доказательства, приведенного в [WEYU90], вы сможете получить больше преимуществ, выбрав ВИ. Таким образом, убедитесь, что вы включили по крайней мере один порожденный подграф для каждого выхода, а не все возможные порожденные подграфы, которые появляются вследствие всех возможных комбинаций выбора в селекторах (и, как мы увидим, всех комбинаций значений для предикатов потока управления и условий циклов).
Случай 3: Предикаты потока управления без узлов выбора
Этот случай обрабатывается тем же способом, что и узлы выбора. Начиная с конца графа, от выходных переменных, создайте порожденный подграф. Правда, здесь есть отличие от предыдущего варианта. В узле выбора данных в порожденный подграф войдет только одна входящая связь. То есть каждая входящая связь создает новый порожденный подграф. В узле потока управления (например, IF-THEN-ELSE или CASE) каждая исходящая связь создает новый порожденный подграф. По этой причине, возможно, будет проще создавать порожденный подграф для потоков управления начиная от входов, а не от выходов. Однако мы имеем дело с моделя
142 Глава 5 • Тестирование потоков данных
ми потока данных, и элементы потока управления встречаются здесь (по крайней мере, на это следует надеяться) лишь случайно. Ситуация показана на следующем рисунке.
Начните создание порожденного подграфа так же, как и раньше, с выхода U (для каждого выхода). Он приводит в вычислительные области С1 и С2 и связанные с ними источники данных И и 12 (которые могут перекрываться). Продолжив создание порожденного подграфа, вы достигнете узла потока управления, который по определению означает, что за ним возможен только один из двух альтернативных вариантов. То есть вы должны выбрать либо область С1, либо область С2 (и связанные с ними потоки данных). Каждый вариант порождает один тест. Для обоих тестов нужны выходы из области В и набор данных 14. Существует хорошая практика создания порожденных подграфов:
1. Для узлов выбора потоков данных начинайте создание порожденного подграфа с входящих в узел связей.
2. Для узлов потока управления начинайте создание порожденного подграфа с исходящих из узла связей.
Выбор пути при тестировании потока управления заключается в выборе порожденного подграфа, начинающегося с узла BEGIN*. Создание порожденного подграфа при наличии потока управления в графе потока данных усложняется, поскольку в целом мы хотим создать порожденный подграф начиная с выхода. Однако присутствие узлов потока управления вынуждает нас менять направление и исключать из порожденного подграфа то, что мы могли включить в него раньше (до того как осознали, что это был узел потока управления).
Прежде чем вы станете это делать, проверьте, нужна ли вам часть модели с потоком управления. В предыдущем примере такой необходимости не было. Мы могли бы, например, заменить узел потока управления узлом выбора данных, ко-
1 Говоря формально, именно порожденный подграф определяется выбранным путем начиная от узла BEGIN и заканчивая узлом EXIT. То есть выберите путь, а затем создайте порожденный подграф, который объединяет другие порожденные подграфы, полученные для каждой активной переменной вдоль пути.
5.4. Методы 143
торый осуществлял бы выбор между выводами областей С1 и С2 и затем передавал бы их в область СЗ. Можете ли вы поступить подобным образом — зависит от приложения и от природы используемых объектов. Помните, что не важно, как именно может быть (или не может быть) запрограммировано приложение. Важно, насколько правильно модель отражает смысл требований. Вы ничего не можете сделать с основными (существенными) потоками управления и синхронизации. Вы можете лишь экспериментировать с каким-либо удобным примером. Если разумно примененный в вашей модели узел потока управления устраняет дублированные потоки данных, то это хорошо. Если он прибавляет сложности и затрудняет построение порожденного подграфа, то это плохо.
Случай 4: Смешение предикатов потока управления и узлов выбора потоков данных
Этот случай — комбинация двух предшествующих ситуаций, так что будьте аккуратны в построении ваших порожденных подграфов. Вам следует избегать смешанных моделей, поскольку в них легко запутаться. В отличие от программирования, путаница приведет не к созданию ошибки, а к бесполезной трате времени и созданию бесполезных или невыполнимых тестов.
Если у вас есть смешанная модель, как с узлами потока управления, так и с узлами выбора, вам лучше пометить узлы каждого типа, поскольку вы будете часто колебаться при построении порожденных подграфов.
Случай 5: Циклы
Модели потока данных просто неудобны для проверки циклов. Правильный подход — выполнить полную развертку однократного прохода цикла и затем ввести узел выбора данных для каждого значения. Например, если вы предпочтете три варианта, у вас получится: отсутствие прохождения цикла, однократное прохождение, двукратное прохождение и узел выбора для этих трех случаев.
5.4.5. Итоговый пример
Теперь создадим модель, которую мы можем использовать для активизации теста и для завершения этой главы. Она основана на бланке ИПС номер 1 (Форма 1040, Строка 23а/Ь). После небольшой переработки этого бланка, сделанной для того, чтобы придать ему более формальный вид, мы имеем следующую модель.
У Вас У Вашего Супруга(и)
С1: Мин ($2000. ИПС_СопСг1Ь_1994 _______ ________
(Вклад_ ИПС_в_1994))
С2: Income (Доход)
СЗ: Мин (Cl. С2) (выход) 1040 23а 1040 23Ь
Неработающий(ая) супруг(а)
С4: Мин (С2а. $2250) _______
С5: Выход_из_СЗ _______
С6: Строка_5 - Строка_4 _______
С7: Мин ($2000. 94_вклад_супр) _________
С8: Мин (Строка_6. Строка_7) (выход)
144 Глава 5 • Тестирование потоков данных
Я буду строить эту модель для случая, когда ваш супруг(а) (если он(а) есть) не работает, и вы можете (или не можете) внести взнос в ИПС за него. Полная модель (в которую включен работающий супруг) оставлена в качестве упражнения для самостоятельного выполнения. Вы можете предположить, что в этой модели некоторые из узлов и связей на самом деле не нужны, например, такие как: С 1а, СЗа, С4, С5 и С7. Я сохранил все узлы, следующие за узлом выбора, в качестве меры предосторожности и для того, чтобы быть уверенным в том, что узел выбора в этой модели явный, а не скрытый, по аналогии с формой. Строка 5 (узел 5) была сохранена, поскольку подобная строка имеется в форме ВНС, и у нас будет возможность проверить ее значение.
kl: CCla СС7 константа = $2000
BCla: CCla ВХОД ваш_взнос_в_ИПС_94
С2а: ССЗа СС4а ВХОД your_94_wages (Ваша_заработная_плата_в_1994 ??)
ВС7: СС7 ВХОД взнос_супруга_в_ИПС_94
к2: СС4а константа = $2250
CCla: Cla: Cla ССЗа ВЫБРАТЬ мин rnin(kl. BCla)
ССЗа: СЗа ВЫБРАТЬ мин mln(Cla. С2а)
СЗа: ВЫХОДа С5 ВЫХОД в Строку 23а Формы 1040
С5: С6 (замечание: спецификация ВНС неправильна. вместо "СтрокаЗ" должно быть сказано “СтрокаЗа” - подобные пустяки как раз и порождают ошибки)
СС4а: С4: С4 С6 ВЫБРАТЬ мин (С2а. к2) (замечание: в этом месте еще одна ошибка ВНС)
С6: СС8 С4-С5
СС7: С7 ВЫБРАТЬ мин (ВС7. kl)
С7: СС8 ВЫБРАТЬ мин (С6. С7)
СС8: С8 ВЫХОД в строку 23b формы 1040
Сначала мы выбираем простые порожденные подграфы. Одним из них является случай взноса в ИПС, вводимого в строку 23а формы ВНС 1040. Порожденный подграф, начинающийся от выходного узла ВЫХОДа, содержит узлы kl, BCla, CCla, С1а, ССЗа, C2a, СЗа, ВЫХОДа и соответствующие связи. Тут имеются два узла выбора (и предикаты), но только три возможности, зависящие от того, какая из следующих величин меньше: $2000, 1994 Взнос в ИПС, или заработная плата в 1994 году. В силу этого наш порожденный подграф приводит к трем тестовым вариантам, которые следует активизировать позже.
Вывод в строке 8 для супружеского взноса в ИПС более сложен из-за того, что выбор этого вывода приводит к включению в наш порожденный подграф всего графа, за исключением узла ВЫХОДа. Я буду строить свои порожденные графы методично, двигаясь от конца к началу, и буду пытаться обеспечить покрытие связей и узлов, не покрытых предыдущим тестовым вариантом. Получившиеся цепочки выглядят следующим образом.
Тест 1: С8. СС8. С6. СБ. СЗа. ССЗа. Cla. CCla. BCla. С4. СС4а. к2
Тест 2: С8. СС8. С6. С5. СЗа. ССЗа. Cla. CCla. kl. С4. СС4а. С2а
5.4. Методы 145
Тест 3: С8. СС8. С6. С5. СЗа. ССЗа. С2а. С4. СС4а
Тест 4: С8. СС8. С6. С5. СЗа. ССЗа. Cla, CCla. kl. С4. СС4а. к2
Тест 5: С8. СС8. С7. СС7. ВС7
Тест 6: С8. СС8. С7. СС7. К1
Заметьте, что я выписывал имена узлов, а не связей. В общем случае вы должны выписать все связи или ясно показать, что вы определяете набор сегментов путей через граф потока данных, которые определяют порожденный подграф. Например, более точное представление будет таким:
Тест 1: С8. СС8. С6. С5. СЗа. ССЗа. Cla. CCla. ВС1а/С6. С4. СС4а. к2
Я использовал сокращенную запись, поскольку в данном случае она недвусмысленна. В случае более сложного потокового графа она может быть неоднозначной и для точной идентификации маршрута будет недостаточно просто перечислить имена узлов.
Заметьте, что в отличие от тестирования потока управления, где мы следовали только вдоль одного набора стрелок, в данном случае, поскольку С6 содержит вычисление, затрагивающее С4 и С5, нам следует включить в порожденный подграф обе связи. Для узлов выбора, однако, в порожденный подграф включается ветвь только для выбранной входящей связи. Может быть, и есть возможность обойтись меньшим количеством тестов, но я не слишком к этому стремился. Задача заключается в том, чтобы обеспечить покрытие связей, а не минимизировать количество тестовых вариантов. Узлы выбора здесь коварны, потому что они основаны на сравнении двух величин, я имею в виду MIN (А, В). Если обе величины одинаковы, вы не знаете, какую связь следует использовать, так что это не слишком хорошая основа для тестовых вариантов (по крайней мере, для попытки обеспечить покрытие связей).
5.4.6. Активизация
Каждый тест соответствует порожденному подграфу. Если порожденные подграфы были определены корректно, тогда для активизации одного подобного порожденного подграфа достаточно задать только его входные величины. Активизация происходит по большей части так же, как это было описано для потоков управления, за исключением того случая, когда вы можете решить, что проще начать с выхода и двигаться в направлении входов. Если же в порожденном подграфе нет узлов выбора или узлов потока управления, об активизации не стоит и говорить. Любые приемлемые входные значения подойдут.
В случае существования узлов выбора или узлов потока управления следует выполнить несколько процедур.
1. Обратите внимание на минимальные и максимальные значения для каждого входа. Если значения составляют некоторое множество, запишите все значения из него.
2. Двигайтесь по всем ветвям порожденного подграфа в обратном направлении (к началу), отмечая пути, которые достигают входов без прохождения через узлы выбора (потоков данных или потоков управления). Вы можете
146 Глава 5 • Тестирование потоков данных
пока игнорировать эти части порожденного подграфа, потому что для входящих данных, скорее всего, нет ограничений.
3. Двигайтесь наверх вдоль путей, пока не достигнете узла выбора (для которого вы уже сделали выбор). Этот узел выбора — неважно является ли он узлом выбора потоков данных или потока управления — содержит предикат, значение которого вы уже определили (выбором данного порожденного подграфа). Этот предикат теперь накладывает ограничения на все входные значения, которые могут быть достигнуты при движении по порожденному подграфу из этой точки. Определите самый широкий набор входных значений, удовлетворяющих этому предикату.
4. Продолжайте обрабатывать каждый встреченный вами предикат (при движении к началу порожденного подграфа). Если в порожденном подграфе на выбранном пути имеется больше двух предикатов, следует рассматривать их условия одновременно, а каждый последующий предикат накладывает дополнительные ограничения на возможные входные значения.
Для потоков данных активизация обычно происходит проще, поскольку в этом случае существует сравнительно немного промежуточных узлов и обычно не нужно интерпретировать предикаты для того, чтобы выразить их через входные переменные. Если вы имеете дело с таким случаем, поступайте так, как если бы работали с потоками управления, учитывая, что вы имеете дело с порожденными подграфами для потоков данных, а не с отдельными путями.
Активизация предыдущего примера с бланком ИПС не так уж сложна. Ваши взносы в ИПС сравниваются с $2000, и соответственно есть два возможных варианта. Ваша заработная плата в 1994 году сравнивается с $2250 — вот еще два варианта. И, наконец, взнос в ИПС вашего супруга сравнивается с $2000. Всего мы получаем восемь возможных случаев, из них шесть должны быть осуществимы. Составляя различные комбинации входных переменных, выбирая их больше или меньше той суммы, с которой они сравниваются, получаем следующие наборы значений для активизации тестов:
Тест Ваш 1994 взнос Ваша заработная плата в 1994 Ваш 1994 взнос
Тест 1 $1900 $2251 $2060
Тест 2 $2050 $2100 $2251
Тест 3 $2100 $1950 $3500
Тест 4 $2100 $2251 $1500
Тест 5 $200 $1800 $1500
Тест 6 $200 $1800 $2500
Это не единственные значения, позволяющие обеспечить покрытие связей,
но их легко получить. Заметьте, что я не стал брать значения констант равными $2000 и $2250. Я сделал это для того, чтобы обезопасить себя от случайной корректности. Если бы я выбрал значения $2000 для взносов и $2250 для заработной платы, тогда с некоторой вероятностью могло бы случиться так, что обе связи, входящие в узлы выбора MIN (А, В), могли бы иметь одинаковые значения. В таком случае ошибка в предикате не сыграла бы никакой роли, поскольку мы бы получили $2000, невзирая на возможную некорректность алгоритма вычислений.
5.4. Методы 147
5.4.7. Предсказание итогов
Здесь не обсуждаются проблемы, касающиеся предсказания итогов, которые бы не рассматривались в главе 3. Однако вы вряд ли будете строить модельную программу на основе модели потока данных, потому что в большинстве языков программирования не слишком удобно проектировать потоки данных. Поскольку в вашей модели не должно быть очень много потоков управления, для построения оракула хорошо подойдет электронная таблица. Каждая ячейка таблицы — это явный узел, при этом она обеспечивает прямые отношения потоков данных между формулами в ячейках. Таблицы по своей природе являются удобным средством для работы с потоками, и так же, как и в случае графов потока данных, присутствие в них элементов потока управления сильно усложняет ситуацию.
5.4.8. Проверка соответствия пути
Это не проверка путей как таковая, это проверка узлов. Вы не получите большого преимущества от тестирования потоков данных и останетесь незащищенными от случайной корректности, если не будете проверять промежуточные вычисления, то есть, например, значения в узлах. Более эффективные методы тестирования подразумевают большую работу, а проверка этих промежуточных вычислений может оказаться очень трудоемкой. Таким образом, и для них вам нужен оракул.
Под «тестируемостью» здесь понимается возможность проверить промежуточные вычисления. Я не знаю, как это сделать без использования логических операторов проверки, заранее вычисленных выходных величин и символьных отладчиков.
Одним из преимуществ объектно-ориентированного программирования является то, что, наряду с надлежащим сокрытием информации, минимизирована вероятность побочных эффектов, и результатом должна быть более устойчивая работа системы. Но сокрытие информации не должно означать, что тестировщик действительно не имеет доступа к этим данным. Электрические системы в вашем автомобиле имеют разъемы, на первый взгляд не служащие никакой полезной цели. Вам они не нужны и не стоит экспериментировать с ними. Но спросите вашего механика, насколько важны эти тестовые разъемы. Подобным же образом материнская плата в вашем ПК имеет разъемы и перемычки, необходимые только для тестирования, и нужно быть смелым и глупым одновременно, чтобы играть с ними. Но для тестирования они действительно полезны.
Тестирование — законное основание для доступа к так называемым собственным данным и для снятия завесы, скрывающей информацию. Если вы тестируете ваше собственное программное обеспечение, используйте многочисленные логические операторы проверки как базовые точки тестирования. Если вы тестируете стороннее программное обеспечение, окажите на его разработчика максимально возможное давление, чтобы заставить внедрить нужные точки тестирования или логические операторы проверки.
148 Глава 5 • Тестирование потоков данных
5.5. Анализ приложений
5.5.1. Виды приложений
Приложения охватывают почти весь спектр существующего программного обеспечения, но я бы не использовал тестирование потоков данных для низкоуровневого тестирования программного обеспечения, в котором имеется много необходимых потоков управления. Наиболее естественно использовать рассматриваемый метод для следующих приложений:
1. Объектно-ориентированное программное обеспечение. ООПО — парадигма, основанная на потоках данных, вот почему графы потоков данных час-, то являются частью методологии разработки ООПО. Если вы используете для этой цели тестирование потоков данных, вы должны допускать, что объекты были должным образом протестированы на более низком уровне, так что вы можете не сомневаться в их надежности и заменить каждый из них соответствующим узлом. Далее вы концентрируетесь на том, правильные ли объекты активизируются, правильные ли сообщения проходят, и так далее.
2. Тестирование интеграции. Главная проблема с интеграцией не в том, работают ли интегрированные компоненты (это должно быть проверено в ходе тестирования модулей), а в том, правильно ли они соединены и сообщаются друг с другом. Каждый компонент моделируется узлом, а граф потока данных может быть деревом вызовов функций программы. Это замечательно, поскольку у нас есть инструменты для отображения деревьев вызовов. Печально в данном случае то, что обычного дерева вызовов будет недостаточно. Если имеются глобальные переменные, вы должны рассматривать потоки данных для них. И поскольку некоторые вызовы и межкомпонентные связи могут быть динамическими, статическое дерево вызовов, определяемое компилятором/редактором связей, не даст вам полной картины — но это будет хорошим началом работы по ее созданию.
3. Электронные таблицы. Электронные таблицы максимально адаптированы к чистому языку моделирования потока данных. Не пренебрегайте электронными таблицами, считая их лишь вспомогательным средством. Они представляют собой реальное средство программирования для людей, создающих сложные приложения для бизнеса, но имеющих мало инструментов и методов для их проверки. Однако если вы покупаете готовые электронные таблицы и планируете придать толчок вашему бизнесу с их помощью, некоторое тестирование перед их полноценным использованием будет не лишним.
5.5.2. Предположения об ошибках
Все ошибки, для поиска которых предназначено тестирование потока управления, можно найти и при помощи тестирования потоков данных, посколь
5.5. Анализ приложений 149
ку оно включает в себя тестирование потоков управления как составной элемент. Поскольку мы избегаем несущественных потоков управления в моделях потока данных, мы допускаем, что программисты умеют сами избавляться от простых ошибок потока управления. Это смещает акценты в сторону поиска ошибок данных. В моей систематике ошибок [BEIZ90] это ошибки 42хх. К подобным ошибкам относятся ошибки исходных и конечных значений, ошибки дублирования и искажения имен, перегрузка, неверный элемент, неверный тип, плохие указатели, аномалии потоков данных (например, закрытие файла до его открытия).
5.5.3. Ограничения и предостережения
1. Тестирование потоков данных не может быть лучше вашей модели. И оно не будет работать, если и вы не поработаете над несколькими типичными проблемами.
2. Вы все еще не нашли недостающие требования в спецификации.
3. Вы с большей вероятностью обнаружите неправильные характеристики программного обеспечения, если обеспечите проверку каждого вывода.
4. Тестирование потоков предпочтительнее использовать для выявления ошибок на высоких уровнях интеграции.
5. Тестирование потоков данных может потерять эффективность в том случае, если программное обеспечение и проектирование тестов выполнены одним и тем же человеком. К тестированию потоков управления это имеет меньшее отношение, поскольку принципы, лежащие в основе тестирования потоков данных и тестирования потоков управления, настолько различны, что одна только смена принципа, вероятно, приведет к новой перспективе, даже если речь идет об одном и том же человеке.
6. Вы по-прежнему можете не заметить случайную корректность, но ее вероятность легче оценить.
7. Ваши тесты не лучше, чем ваш оракул.
8. Тестирование потоков данных вряд ли вам поможет, если вы не нашли способа проверить промежуточные узлы.
5.5.4. Автоматизация и инструментальные средства
К концу 1994 года не существовало коммерческих сервисных программ, поддерживающих поведенческое тестирование потоков данных. Существует много частных программ, поддерживающих структурное тестирование потоков данных на С и Паскале [FRAN85, HARR89, HORG92, KORE85, KORE88, LASK90, OSTR91, WILS82]. Если у вас есть средство проектирования, поддерживающее диаграммы потоков данных, справьтесь у продавца, почему оно не обеспечивает автоматизацию проектирования тестов.
150 Глава 5 • Тестирование потоков данных
5.6. Резюме
Тестирование потоков данных — более эффективный метод, чем тестирование потоков управления. Он основан на определении модели потоков данных и использовании этой модели как основы для проектирования тестов. Тесты создаются путем выбора порожденных подграфов — движением от выходных узлов ко всем входным узлам порожденного подграфа. Мы определили несколько метрик покрытия, но метод всех использований, дополненный разверткой циклов (двукратной), рекомендован в качестве минимально приемлемой метрики.
5.7. Вопросы для самопроверки
1. Дайте определения следующих терминов: покрытие всех определений, покрытие всех путей определение - использование, покрытие всех узлов, покрытие всех предикатов, покрытие всех использований, логический оператор проверки условия, управляющая входящая связь, удобное упорядочение, использование в вычислениях, граф потоков данных, порожденный подграф, узел выбора данных, предикат выбора данных, определять, необходимый цикл, необходимое упорядочение, значение входящей связи, входной узел, покрытие ввода/вывода, значение связи, развертка цикла, необязательный цикл, значение исходящей связи, выходной узел, пусто, перегрузка, узел с предикатом, использование в предикате, узел обработки, псевдопеременная, запоминающий узел, подграф, использование.
2. Покажите, что строка 6 в бланке ИПС никогда не может быть отрицательной как для работающего, так и неработающего супруга(и), так что в данном случае необязательно проводить сравнение с нулем. Подсказка: операция МИН — транзитивна.
3. Переделайте Бланк ИПС, включая логические потоки и потоки данных для случаев работающего и не работающего супруга. Выберите порожденный подграф, активизируйте его и разработайте тестовые варианты.
4. Создайте модели потока данных для формы 1040. Трактуйте данные, взятые из других форм, как входные переменные. Для каждого случая спроектируйте модель, выберите порожденные подграфы и разработайте тестовые варианты, используя покрытие ввода/вывода, покрытие узлов и стратегию всех использований. Проверьте вашу работу, используя налоговый пакет или электронную таблицу в качестве оракула. Вы можете переписать налоговый пакет и взять входные значения из других форм, (а) строки 1-6, (б) строки 7-22, (в) строки 32-40, (г) строки 41-46, (д) строки 47-53, (е) строки 54-60, (ж) строки 61-65.
5. То же, что и задание 4. Форма 1040, Бланк SE, краткая форма, строки 1-6, но задействуйте логику, чтобы определить, может ли быть использована краткая форма. Используйте граф только потоков данных, затем проделайте то же самое с использованием модели графа потоков управления и покрытием
5.7. Вопросы для самопроверки 151
условий предикатов и переделайте задание, используя смесь модели потоков управления и модели потоков данных.
6. Форма 1040, бланк на строке 10. Полная форма.
7. Форма 1040, бланк на строке 22, social security income (выплаты по социальному страхованию). Полная форма.
8. Форма 1040, бланк на строке 34, dependent deductions (льготы иждивенца). Полная форма.
9. Форма 2106, только транспортные расходы. Рассмотрите случай только одного транспортного средства. Включите разделы А, В и С, но не D, и исключите строки 1-10.
10. Форма 2688, Application for Extension to File (Заявление о продлении срока). Форма целиком.
И. Форма 2210, Неполная оплата налогов, (а) только строка 1, (б) часть II, (в) часть III, (г) часть IV, раздел А, (д) часть IV, раздел В. Предположите, что вы можете использовать краткий метод (Часть III) в случае, если не сделали отметок в графах 1Ь, 1с, или Id. Во всех случаях выводы (если таковые имеются) идут в соответствующую строку Формы 1040. То есть не заботьтесь о Формах 1040А, 1040NR, 1041 и так далее.
12. Смоделируйте часть IV формы 2210 как граф потоков управления с детерминированным циклом и протестируйте его соответствующим образом.
13. Представьте форму 2210 целиком в виде графа потока данных с одним узлом для каждой из частей II, III, IVA и IVB. Моделируйте часть I по своему усмотрению, но следите за тем, чтобы высокоуровневая модель правильно определяла, когда надо использовать часть III.
14. Проделайте задание 4 для формы 3903 целиком, Employee Moving Expenses (Расходы служащего на передвижение).
Тестирование потоков транзакций
6.1. Обзор
Графы потока транзакций используют в системном тестировании приложений, работающих в режиме онлайн, и программного обеспечения для пакетной обработки. Этот граф обладает свойствами как потока управления, так и потока данных.
6.2. Основные термины
Внешние термины: поглощать, подтверждать прием, приложение, архивные данные, аудит, пакет, вызов, емкость, проверка, код, коммуникации, конкатенация (объединение), параллельный, аварийный отказ, данные, база данных, блок данных, ошибка в данных, регистрация данных, отлаживать, проектировать, драйвер устройства, диагностика, дискретный, динамический, ошибка, глобальные данные, иерархия, входящий, инициализировать, ввод, ошибка ввода, целое число, установка, интерфейс, логика, модель, неединичный вход, неединичный выход, многозадачность, сеть, операционная система, выходной, раздел, эффективность, приоритет, распределение вероятности, обработка, узел обработки, программа, программист, язык программирования, протокол, запрос, очередь, случайный, прием, запись, восстановление, сброс, ресурс, маршрутизация, сценарий, обеспечение безопасности, последовательность, сервер, имитатор, синхронный, мгновенная запись, программное обеспечение, сортировка, ключ сортировки, стек, подпрограмма, система, задача, среда тестирования, временная отметка, след, значение.
Внутренние термины: ветвление, свободный от ошибок, компонент, тестирование компонентов, составной предикат, поток управления, поток данных, на-
6.2. Основные термины 153
чальный узел, конечный узел, модель конечного числа состояний, граф, входящая связь, ввод, интеграция, промежуточный узел, связь, покрытие связей, вес связи, цикл, тестирование цикла, модельная программа, узел, покрытие узлов, итог, исходящая связь, путь, предикат, отношение, активизировать, порожденный подграф, спецификация, состояние, субмодель, системный тест, проект теста, путь теста, тестирование, критерий соответствия.
Транзакция — единичная операция по обработке данных.
Маркер транзакции — метка (например, точка), которая отображает присутствие транзакции на модельной связи.
Контрольная запись транзакции — гипотетическая или фактическая запись, которая содержит данные о транзакции. В фактической записи нет необходимости, однако во многих системах она присутствует. Там, где контекст позволяет, вместо термина «контрольная запись транзакции» будет использоваться термин «запись транзакции».
Состояние транзакции — потенциально это значения всех данных в контрольной записи транзакции или ее неявном эквиваленте. Но, как правило, состояние выражают лишь частью данных записи, зачастую целым числом.
Тип транзакции — некое обозначение, например, целое число, которое используется для идентификации транзакций различных типов.
Стартовый узел — узел в модели графа потока транзакций, в котором транзакция начинает нас интересовать. Это входной узел графа потока транзакций.
Завершающий узел — узел в модели графа потока транзакций, в котором транзакция прекращает нас интересовать. Это выходной узел графа потока транзакций.
Задача — каждая задача в графе потока транзакций представлена узлом.
Узел ветвления — узел, в котором входящая транзакция выбирает одну из нескольких альтернативных исходящих связей. Так, на рисунке входящая транзакция вышла на самую верхнюю связь.
Предикат ветвления — предикат, который управляет выбором одной из исходящих связей узла ветвления. Он может быть основан на значениях данных транзакции (то есть значениях в управляющей записи транзакции) или же на комбинации типа и состояния транзакции.
Управляющая входящая связь — по возможности не зависящая от значений в записи входящая связь, которая определяет, какая из исходящих связей узла Ветвления будет выбрана транзакцией. Узел ветвления с управляющей входящей связью подобен железнодорожной стрелке (то есть «направляет»). Для каждой управляющей входящей связи должен существовать ассоциированный с нею предикат. Управляющие входящие связи обозначены пунктирными линиями.
154 Глава б • Тестирование потоков транзакций
Узел соединения — транзакция, поступающая по любой из входящих связей узла пересечения, выйдет по единственной исходящей связи этого узла соединения. Это то же самое, что и соединительные узлы пересечения в графах потоков управления.
Узел порождения — узел, в котором входящая транзакция генерирует более чем одну исходящую транзакцию. На рисунке входящая транзакция (материнская) произвела дочернюю транзакцию. Дочерние транзакции имеют индивидуальные свойства, которые могут быть (частично) унаследованы от родительских транзакций.
Узел расщепления — узел, в котором входящая транзакция (материнская) генерирует дочерние транзакции, а сама прекращает свое существование. Дочерние транзакции не должны быть идентичными. Предполагается, что каждая из них имеет свои собственные свойства, например, тип и состояние.
Узел слияния — узел, в котором две или более входящие транзакции (родительские транзакции) сливаются в новую, выходящую дочернюю транзакцию. После узла слияния родительские транзакции перестают существовать.
@Родитель
®Родитель
Дочь
Узел поглощения — узел с входящими транзакциями, одна из которых (хищник) поглощает другие (жертвы).
6.3. Отношения и модель 155
• Хищник
Хищник
@ Жертва
Марковский узел — узел, действие которого (обработка, ветвление, порождение, расщепление и т. д.) зависит только от типа и состояния входящих транзакций, но не от пути, по которому транзакция добралась до узла.
Марковский граф потока транзакций — граф потока транзакций, все узлы которого являются марковскими.
6.3. Отношения и модель
6.3.1. Основы
Материал, рассматриваемый в этом разделе, описывался также в [MURA89, РЕТЕ81].
Объекты (узлы) — шаги процесса обработки данных посредством транзакций, например, шаги программы. Узлы представляют собой интересующие нас действия, которые трансформируют входящие транзакции и производят выходящие транзакции и/или меняют состояние входящих транзакций. Узлы могут моделировать не только программы, но и действия людей, сетевые операции и вообще все, что имеет смысл. Предполагается, что узлы имеют свою собственную модель, будь то модель потока управления, модель потока данных или какая-нибудь еще модель. Производимое обрабатывающим узлом действие зависит только от данных, содержащихся в записях входящих транзакций. Считается, что модели обработки транзакций являются марковскими.
Объекты (транзакции) — транзакция идентифицируется своей контрольной записью (фактической или гипотетической). Эта запись содержит по меньшей мере тип и состояние транзакции. Предполагается, что и все другие интересующие нас данные содержатся в записи транзакции. Интерпретация данных в записи транзакции не зависит от значений в любой другой записи транзакции.
Отношение (связи)'. «Непосредственно следует» — соединение узлов А и Б связью от А к Б, если выходящая из А транзакция обрабатывается затем узлом Б.
Вес связи — с любой связью может быть ассоциировано несколько маркеров транзакций. Каждый маркер представляет одну транзакцию.
Мы будем моделировать часть обработки формы 1040, как если бы она была сделана добропорядочным налогоплательщиком, который настаивает на том, чтобы каждая операция совершалась в том же самом порядке, в каком она появляется в форме. Внутренняя налоговая служба в США не предъявляет такого требования, и вы можете заполнять формы в том порядке, в каком это имеет смысл, но такое поведение не слишком применимо к моделированию потока транзакций. (Для этого больше подходят модели потока данных.) Заметьте, что сейчас мы моделируем не компьютер или программу, хотя и могли бы. Мы моделируем, каким
156 Глава 6 • Тестирование потоков транзакций
образом Видения Вистерия (наш субъект) заполняет декларацию о подоходном налоге.
11: 12: Предыдущий шаг в модели
12: 13: НЕ узел ветвления (имеется коммерческий доход?)
12.1: ДА
12.1: 12.2: узел порождения. 1040 продолжается
С: дочерняя транзакция, для обработки Бланка С
С: 12.2: заполненный Бланк С (узел расщепления)
С-фин: заполненный Бланк С для налоговой службы
12.2: 13: узел поглощения, данные Бланка С поглощаются 1040
13 ... узел 13 - это узел соединения
Узел 12 является узлом ветвления, так как транзакция должна либо продолжить заполнять Бланк С, либо обойти его, если нет дохода от индивидуальной трудовой деятельности. Узел 12.1 — это узел порождения, из которого начинается дочерняя транзакция для Бланка С. Предположим, что на этом уровне в узел С приходит незаполненный Бланк С, а выходит из узла С уже заполненный. Узел 12.2 представляет собой узел поглощения, потому что здесь данные Бланка С заносятся в форму 1040. Узел С — узел расщепления, так как нам необходима копия Бланка С для налоговой службы, а также для формы 1040. Наконец, узел 13 является узлом соединения, потому что форма 1040 может появиться на любой из входящих в него связей, но не на обеих.
6.3.2. Маркировки
Маркировка. Набор всех меток (и связанных с ними состояний) на всех связях в любой момент времени называется маркировкой графа потока транзакций. Для всего графа потока транзакций маркировка является тем же самым, чем является состояние для отдельной транзакции.
Очередь. Связь, которую можно маркировать более чем одной меткой, представляет собою очередь. Это может, конечно, быть и обрабатывающая очередь, но она может также представлять собой и обычную очередь из ожидающих людей.
Проследим путь следования одной транзакции через граф потока транзакций. Если бы не существовало узлов расщепления и порождения, это было бы эквивалентно маркировке пути в графе потоков управления. Но две детали делают эту простую интерпретацию маловероятной — существование очередей и узлы слияния и поглощения.
Мы можем использовать различные маркировки, определяя, какие маркеры и на каких связях появляются на каждом шагу. В нашей модели есть два вида символов: форма 1040 и Бланк С, сокращенные до «Ф1040» и «Б-С» соответственно. Если в модели есть только одна транзакция, то существуют две возможные маркировки в зависимости от того, выполняем ли мы Бланк С.
Без Бланка С:
Шаг 1: 11/12 Ф1040
Шаг 2: 12/13 Ф1040
С Бланком С;
Шаг 1: 11/12 Ф1040
6.3. Отношения и модель 157
Шаг 2: 12/12.1 Ф1040
Шаг 3: 12.1/12.2 Ф1040, 12.1/С Б-С
Шаг 4: 12.1/12.2 Ф1040. С/12.2 Б-С. С/С-фин SC-C
Шаг 5: 12.2/13 Ф1040. С/С-фин Б-С
Предположим, что дети Видении ведут свой собственный бизнес, а Видения заполняет за них налоговые декларации. Ее дети вносят данные в свои индивидуальные Бланки С, если это необходимо, а она заполнит за них всех формы 1040. Формы 1040 инициируются в узле И (только для этой подмодели). Они поступают в узел 12, который обрабатывает Видения. Она решает, необходим ли Бланк С. У Видении много других дел, поэтому она может и не принять это решение немедленно. Следовательно, на входящей связи узла 12 накапливается очередь из форм 1040. Когда у Видении появляется время, она помещает те формы 1040, которым не нужен Бланк С, в очередь к узлу 13. А для тех форм 1040, которым действительно необходим Бланк С, она берет пустой бланк С, заносит туда имя ребенка и помещает его в очередь Бланка С (12.1/С). Обработка Бланка С осуществляется детьми Видении. Заполненные Бланки С поступают в очередь к С/12.2, откуда Видения забирает их путем переноса данных в подходящую форму 1040. На связи 12.1/12.2 также накапливается очередь.
Число маркеров на любой из связей потенциально бесконечно, а, следовательно, и число потенциально разных маркировок для всего графа потенциально бесконечно. Хотя у Видении, как кажется, бесчисленное число детей, она имеет чуть ли не безграничное терпение, поэтому для нее это не проблема — но не для нас. В идеале нам следует тестировать графы потока транзакций для всех возможных пометок. Практически же это невозможно, поэтому всегда следует искать определенный компромисс.
6.3.3. Очереди
Детальное описание очередей можно встретить в [СООР81].
Все реальные очереди ограничены, то есть они имеют некий максимально возможный размер. При выходе за пределы этих размеров плохо протестированные системы могут неожиданно выйти из строя, так что стоит тестировать максимально возможный размер очереди. Если существует очередь, то должно быть и правило упорядочения — то есть правило, определяющее, в каком порядке транзакции будут поступать из очереди для обработки. Ниже приведены некоторые распространенные правила.
Правило FIFO — «первым пришел — первым вышел» («first-in, first-out»), называемое также «First-Come-First-Served» — («первым прибыл — первым обслужен»). Транзакция, которая раньше всех поступила в очередь, будет обработана раньше всех. Это самое простое правило очень распространено. Но представьте, что было бы, если бы Видения настаивала, чтобы все заполненные Бланки С возвращались к ней в том же порядке, в каком она отдавала их на обработку.
Правило LIFO — «последним пришел — первым ушел» («last-in, first-out»), называемая также LCFS «Last-Come-First-Served» — («последним пришел — первым обслужен»). Транзакция, которая позже всех поступила в очередь, будет обработана раньше всех. Подобная очередь является обрабатывающим стеком,
158 Глава 6 • Тестирование потоков транзакций
в котором входящие транзакции помещаются на вершину стека и удаляются с вершины.
Пакет. При возникновении определенных условий, таких как определенное число транзакций в очереди, или же в оговоренный момент времени обрабатываются все транзакции в очереди в пакетном режиме. При этом во время обработки новые транзакции накапливаются в новой очереди.
Случайное обслуживание. Обслуживание осуществляется случайным образом — возможно, на основе вероятностного распределения по некоторой величине в контрольной записи транзакции.
Очередь по приоритету. Каждая транзакция имеет свой приоритет. Этот приоритет может быть фиксированным или зависеть от свойств транзакции, например, от ее возраста. Каждая группа транзакций с данным приоритетом обрабатывается как отдельная очередь, причем очередь с наибольшим приоритетом обрабатывается первой. Внутри отдельной группы транзакций с данным приоритетом сервис может осуществляться по принципу FIFO, LIFO и т. д.
Множественная обработка. Для обработки очереди может использоваться один сервер {односерверная очередь) или несколько серверов {многосерверная очередь). Кроме правила упорядочения конкретной очереди, может существовать правило выбора сервера. Например, в супермаркете можно выбрать, в какую из очередей к кассам встать. В билетной кассе аэропорта, на почте, в банке нужно стоять в основной очереди и ожидать обслуживания до тех пор, пока работник учреждения не скажет «Следующий!»
Далее термин простая очередь будет использоваться для обозначения односерверной очереди без приоритета, обслуживаемой по принципу FIFO. Если правило упорядочения не оговорено, то наиболее вероятно, что это простая очередь. За ней следует очередь, обслуживаемая по принципу FIFO в зависимости от приоритета. Очередь с данным приоритетом обрабатывается по принципу FIFO, но первой обрабатывается очередь с наибольшим приоритетом, затем очередь с более низким приоритетом и т. д. Если вы имеете дело с очередью, не являющейся простой, то убедитесь, что очередность приоритетов и, если необходимо, правило выбора сервера реализованы правильно.
6.3.4. Слияние и поглощение
Существование узлов слияния и поглощения создает дополнительные проблемы при тестировании. Становятся необходимыми тесты синхронизации. Чаще всего возникают новые проблемы и вопросы, которые следует себе задать.
1. Правильные ли типы транзакций объединились?
2. В случае двух транзакций А и В, которые объединяются (или для А, поглощающей В), появляются пять дополнительных ситуаций, которые необходимо протестировать:
* А приходит, а В — никогда не приходит (А).
• В приходит, а А — никогда не приходит (В).
• А приходит раньше В (А, В).
б.З. Отношения и модель 159
« В приходит раньше А (В, А).
* Обе транзакции приходят одновременно (то есть в пределах оговоренного времени) (АВ).
3. Правилен ли тип выходящей транзакции? Для поглощения это хищник, а для объединения — дочерняя транзакция.
При тестировании необходимо рассмотреть каждый из этих случаев. Для узла слияния, имеющего три связи, потребуется протестировать 25 возможных вариантов. Для обозначения одновременных входов транзакций в узел слияния мы будем использовать совместное написание, а для раздельных — запятые. Например, (АВ, С) означает, что А и В приходят в узел одновременно, а за ними следует С. Необходимо рассмотреть 25 тестовых вариантов. Ниже следуют тестовые варианты для поглощения или слияния, в котором участвуют три транзакции.
Каждая транзакция по отдельности: (А), (В), (С).
Две транзакции за раз: (А, В), (А, С), (В, С), (В, А), (С, А), (С, В), (АВ), (АС), (СВ).
Три транзакции за раз: (А, В, С), (В, А, С), (С, А, В), (А, С, В), (В, С, А), (С, В, А), (А, ВС), (В, АС), (С, АВ), (ВС, А), (АС, В), (АВ, С), (АВС).
Число необходимых тестов быстро возрастает для узлов слияния с несколькими объединяющимися транзакциями. Проектирование тестов легко автоматизировать, но трудно заставить транзакции приходить в определенные узлы в определенном порядке. Так как слиянию и поглощению подвергаются чаще всего транзакции, которые уже прошли через какие-то операции обработки, в отличие от транзакций, пришедших извне, то выполнение этих тестов практически невозможно.
6.3.5. Циклы
С одной стороны, циклы в потоках транзакций, строго говоря, создают проблемы. А с другой стороны, они встречаются редко, и если встречаются, то они просты и встречаются нечасто. Цикл, который чаще всего можно обнаружить в потоке транзакций, — это цикл повторения обработки после обнаружения ошибки ввода данных. Так, например, банкомат дает вам три попытки ввода вашего личного идентификационного номера. Можно ожидать, что похожие циклы повторения будут встречаться в большинстве интерфейсов, таких как каналы связи с другими системами, драйверы устройств и т. д. Очереди, обслуживаемые как пакет, очевидно, содержат цикл для обработки пакетов. Сходным образом каждый узел обработки, обслуживающий очередь, работает в составе цикла для того, чтобы обрабатывать каждый последующий элемент в очереди и продолжать работу далее. Таким образом, он активируется каждый раз до тех пор, пока очередь не иссякнет. Такие циклы следует тестировать отдельно для каждого узла обработки на более низком уровне интеграции и тестирования. А это означает, что необходимо выполнять тестирование циклов различных узлов обработки транзакций в контексте компонентного тестирования этих узлов обработки.
6.3.6. Фокус и иерархические модели
Модель потока транзакций можно использовать при различных степенях детализации, вплоть до кода. Однако создавать модели потока транзакций на уровне
160 Глава б • Тестирование потоков транзакций
исходного кода — отнюдь не самая лучшая идея. Узлы на графах потока транзакций могут представлять собой не только действия программного обеспечения. Термин «обработка данных» был использован в общем смысле для обозначения любого вида работы с данными, вне зависимости от того, выполняется ли эта работа компьютером, людьми или другими системами. Модель потока транзакций обычно используется как высокоуровневая модель. Наиболее часто ее используют в системном тестировании. Корректную работу компонентов следует проверить при компонентном тестировании, обычно это делают на предшествующей стадии интеграции. Разделение сложного действия на компоненты представляется в модели потока транзакций лишь выборочно. Но при этом следует учитывать некоторые детали.
1. Компоненты модели имеют интерфейсы, через которые происходит передача данных. Обратите внимание, что глобальные данные могут соответствовать этому требованию.
2. Компоненты могут взаимодействать только через свои интерфейсы. Если есть такие компоненты, сгруппируйте их и моделируйте группу как отдельный объект.
3. Поведение компонента определяется типом и состоянием транзакции.
4. Поведение узла обработки не зависит от предыстории транзакции, если только предыстория не влияет на тип и состояние транзакции. Отдельный процесс должен быть марковским.
5. Можно проверить корректность поведения узла обработки путем проверки выходящих транзакций (или их контрольных записей) каждого процесса в модели.
6. При наличии соответствующих средств тестирования можно полностью протестировать один компонент в отдельности.
При тестировании потока транзакций первоочередное внимание следует обращать не на корректную работу отдельных процессов, а на систему в целом. Особенное внимание следует уделять корректности интерфейсов между компонентами, корректности маршрутизации транзакций между компонентами, организации и дисциплине очередей (если это не правила упорядочения FIFO), узлам слияния, поглощения, расщепления и порождения, синхронизации, одновременности, созданию и уничтожению транзакций, а также дублированию и потере транзакций.
6.4. Методика
6.4.1. Основы
Предположим, что у нас нет циклических транзакций. Если же вы встретите такие, будем надеяться, что их применение в данном случае является обоснованным, и их можно протестировать в пределах субмодели, включающей цикл. Для
6.4. Методика 161
любых циклов, которые невозможно обработать на более низком уровне, нужно будет использовать методики тестирования циклов, описанные в главе 4.
1. Проверьте спецификацию.
2. Идентифицируйте и дайте имя всем транзакциям, которые должна обработать система. У вас не должно возникнуть проблем с «нормальными» транзакциями, так как они все должны присутствовать в спецификации. Трудности обычно возникают с транзакциями, которые подразумеваются в спецификации, но не сделаны явными. Ниже приведены примеры транзакций, которые часто пропущены в спецификациях, но должны присутствовать в вашей модели.
• Подтверждения о приеме, уведомление, отрицательное квитирование.
• Специальные транзакции для установки и отладки.
• Специальные транзакции для диагностики действий.
• Транзакции, выполняющие аудит других транзакций.
• Транзакции, используемые в режиме обучения персонала.
• Транзакции инициализации или перенастройки для всех внешних интерфейсов.
• Транзакции, используемые при восстановлении системы.
• Транзакции, используемые для измерения характеристик системы.
• Транзакции, используемые для проверки обеспечения безопасности системы.
• Транзакции, используемые в протоколах, не упомянутых выше.
• Транзакции, используемые для запроса о статусе других транзакций.
• Ответы на запросы о статусе транзакций.
• Транзакции, создаваемые вашей системой для восстановления других транзакций.
• Транзакции восстановления, полученные из внешних систем.
3. Определите иерархию типов транзакций, которая включает все транзакции, описанные выше в пункте 2. Как правило, вы можете использовать ту же иерархию, что и разработчики. Такой подход делает коммуникации проще.
4. Определите состояние транзакции для каждого типа транзакции. Состояния должны соответствовать последовательности обработки, присущей типу транзакции. Если состояния представляют собой простую последовательность пунктов, например «шаг 1, шаг 2, шаг 3,... выход», то достаточно будет просто составить список. Если есть признаки более сложного поведения, то вам, вероятно, будет необходимо использовать модель с конечным числом состояний (см. главу 9).
5. Определите поведение транзакции в любой момент ее жизненного цикла. Как она порождается (или поступает в систему), как завершается (или
6 Зак. 770
162 Глава 6 • Тестирование потоков транзакций
выходит из системы), как происходит операция слияния (и с кем), как поглощается, расщепляется, порождает другую транзакцию и т. д.
6. Определите гипотетическую контрольную запись для каждого из типов транзакций. Запись должна отображать по меньшей мере тип и состояние транзакции. При этом в большинстве систем по обработке транзакций вы должны быть в состоянии использовать действительную контрольную запись транзакции, реализованную в программном обеспечении. Для внешних транзакций, — таких как, например, транзакции, обрабатываемые другими системами или людьми, — вам необходимо будет определить подходящую гипотетическую запись.
7. Идентифицируйте все очереди. Определите для каждой очереди источник (источники) появления транзакций, правило их упорядочения, приоритеты в пределах одного правила, а также применяемую обработку. Протестируйте ограничения всех очередей, которые имеют ограниченные максимально возможные размеры.
* Каким образом отдельные элементы помещаются в очередь?
» Каким образом отдельные элементы удаляются из очереди?
* Какая модель очереди используется — односерверная или многосерверная? Если многосерверная, каково правило выбора сервера?
8. Идентифицируйте компоненты обработки (это не обязательно должно быть программное обеспечение). Сгруппируйте компоненты в соответствии с принципами, описанными выше в разделе 6.3.6. Возможно, потребуется переопределить типы транзакций, выполнить слияние типов транзакций, удалить очереди и т. д., если этот этап моделирования приводит к необходимости группировки нескольких компонентов для того, чтобы удовлетворить критериям раздела 6.3.6.
9. Для каждого из определенных на предыдущем этапе компонентов решите, каким образом вы будете тестировать отдельные компоненты. По своей внутренней структуре каждый компонент может представлять собой другую — модель потока транзакций более низкого уровня или же модель иного вида.
10. Несмотря на то, что реальные компоненты не обязательно действуют подобным способом, отделите расщепления/порождения и слияния/погло-щения от связанных с ними узлов обработки путем помещения явного узла расщепления/порождения после обрабатывающего узла и явного узла сли-яния/поглощения до обрабатывающего узла.
11. После выполнения предыдущих пунктов у вас должен быть набор узлов и связей, определяющих полный набор потоков транзакций, которые необходимо протестировать.
12. Верифицируйте модель, используя модельную программу, написанную на удобном языке программирования. Это может оказаться эффективным в моделях потока транзакций, потому что они чаще всего достаточно велики.
6.4. Методика 163
Типичная система по обработке транзакций содержит много простых транзакций. Говоря «много», я подразумеваю «тысячи». Говоря «простые», я подразумеваю, что ветвления, соединения, расщепления, порождения, слияния и поглощения очень редки.
13. Определите пути прохождения ваших тестов. Вы можете использовать как отдельные пути в графе, так и порожденные подграфы. Действуйте точно так же, как и при использовании других методик.
14. Активизируйте порожденные подграфы.
15. Предскажите итоги.
16. Определите критерий соответствия.
17. Выполните тесты.
18. Подтвердите итоги.
19. Проверьте значения во всех промежуточных узлах.
6.4.2. Иерархия покрытия
Как и везде, в этой технике тестирования существует набор практических критериев покрытия, от самых простых (наименее трудоемких и неэффективных) до наиболее эффективных (основательных, но трудоемких).
1. Покрытие ввода/вывода и порождения/завершения. Проведите достаточное число тестов и убедитесь, что все старты и порождения транзакций были осуществлены и что были созданы все исходящие транзакции (в том числе порожденные в данной системе). Эти тесты могут показаться слишком слабыми, однако многие системы не проходят даже их. Рассмотрите все типы транзакций, о которых шла речь выше в разделе 6.4.1 (а также те специфические транзакции, о которых я не говорил, но которые существуют в вашем приложении). Это тот минимум, который может сделать разумный человек. Исходя из здравого смысла, это эквивалентно гарантии того, что каждая строка кода была протестирована на уровне компонентов. Если кто-то полагает, что в тестировании типа транзакций нет необходимости, то он либо уверен, что транзакция не содержит ошибок, либо считает, что она вообще не нужна. Если она не нужна, уберите ее, и у вас будет на один источник ошибок меньше. Наиболее редко используемые транзакции содержат больше всего ошибок. Дурную славу в этом отношении имеют транзакции, связанные с восстановлением.
2. Покрытие узлов. Покрытие узлов само по себе тоже не имеет смысла, поскольку оно только еще раз подтверждает выводы, сделанные при тестировании модели более низкого уровня, например, в ходе тестирования компонентов. Покрытие узлов — это все же лучше, чем ничего, так как мы убеждаемся, что все порождения, расщепления, слияния, поглощения и обработки в очереди транзакции ведут себя корректно. Этой проверки также могут не пройти многие системы.
164 Глава 6 • Тестирование потоков транзакций
3. Покрытие связей. Используя тесты, обеспечивающие покрытие связей, мы проверяем не только корректность отдельных узлов, но и их взаимодействие друг с другом. Без покрытия связей тестирование системы будет неполным. Обеспечивая покрытие связей, мы убеждаемся не только в том, что все транзакции корректно обрабатываются (покрытие узлов делает это за нас), но и в том, что на каждом шаге обрабатываются именно те транзакции, которые и должны.
4. Порожденные подграфы. Понятие порожденного подграфа в этом контексте практически полностью совпадает с аналогичным понятием для потока данных (см. главу 5). Если существуют только узлы ветвления и соединения, то порожденный подграф соответствует пути «вход - выход» в созданной модели. Если существуют узлы порождения или расщепления, то порожденный подграф получается путем следования по всем связям, исходящим из узла порождения или расщепления и дальнейшего следования по пути прохождения этих транзакций до завершающего узла. Если существуют узлы слияния или поглощения, то порожденный подграф получается при следовании вдоль входящих связей до точки, где сливающиеся транзакции (или хищник/жертва) порождаются или входят в систему. Более подробно мы будем говорить о порожденных подграфах в разделе 6.4.4.
6.4.3. Построение модели
Я бы предпочел построить модель потока транзакций для налоговой декларации, но, поскольку в процедуре заполнения налоговой декларации отсутствуют транзакции, такая модель не подходит. Возможно, лучшим выбором в данном случае будет модель потока данных. Однако для того, чтобы использовать налоговые формы в максимально возможном числе упражнений и чтобы показать вам, что почти любую модель можно использовать в любом приложении, я буду моделировать Employee Business Expense (Бизнес расходы наемного служащего), форма 2106. Я буду рассматривать каждый вход или группу входов так, как если бы они были транзакциями.
Pal: Сба Данные об основных расходах наемного служащего обрабатываются как единая транзакция, состоящая из: строки 2 (parking, tolls (парковка, подорожныйсбор)). строки 3 (travel, excluding meals and entertainment (командировочные расходы, исключая питание и развлечения)), строки 4 (other business expenses excluding meals and entertainment (другие бизнес расходы, исключая питание и развлечения)), строки 5 (meals and entertainment (питание и развлечения)). Это входящая транзакция, то есть транзакция из узла зарождения.
0т1: СИ General vehicle data (Данные об основных транспортных расходах), в том числе данные из строк 11. 12. 13. 15. 18. 19. 20 и 21. Транспортных средств может быть более одного, поэтому в этом стартовом узле может быть от 1 до п маркеров. Для каждого внесенного транспортного средства нужен один из них.
Фр1: С23 Actual expenses (Фактические расходы), в том числе введенные в строки 23. 24а. 24b и 25. Вам не нужны эти данные, если вы решили использовать стандартную плату за перевозки. Тем не менее, вы
6.4. Методика 165
можете выбрать фактические расходы. Для этого стартового узла у вас могут быть значения от нуля до п. Это число может быть меньше, чем для 0т1. но не может быть больше.
Ам1: СЗО Depreciation (Амортизация). Сюда входят данные из строк 30. 31.
33 и 36. Этот стартовый узел не может иметь больше маркеров.
чем Фр1. поскольку вам не обязательно эксплуатировать все ваши транспортные средства.
Ф1: Ф1а Стартовый узел с незаполненной формой 2106 (за исключением name, social security number, occupation (имени, номера социального страхования и рода деятельности)). Эта форма будет обработана и отослана обратно, на строку 20 бланка А. где она и возникла.
Ф1а: С1 Ф1а - узел ветвления, в нем делается выбор о будут обрабатываться транспортные расходы или не будут. (С1) здесь сответствует ветке НЕТ. Транзакции в форме 2106 могут пойти либо по этой ветке.либо по ветке Ф1д. не не по двум одновременно.
Ф1д Это ветка ДА. соответствующая наличию хотя бы одного транспортного средства.
Cl: Сба С1 - это узел соединения, в который приходит либо транзакция 2106 из узла Ф1а (нет транспортных расходов), либо из узла Т1 (транспортные расходы заполнены).
Сба: СЮ Узел поглощения, в котором погпощаются данные об основных расходах наемного служащего (Pal). Форма 2106 является хищником, a Pal - жертвой и Pal перестает существовать.
СЮ: Выход (прохождение транзакции обратно в бланк А).
Ф1д: СНа СНа - это узел порождения, где вы даете начало необходимому числу транзакций: по одной на каждое транспортное средство.
Т1 Место, в котором вы. пройдя форму 2106. ожидаете vehicle deduction (налоговых льгот на транспортное средство).
Tl: Cl Т1 - это узел поглощения, в котором налоговые льготы на транспортное средство вводятся в форму 2106.
Тсум Т1 Тсум - это узел, в котором сливаются данные обо всех транспортных средствах.
СНа: Тсум Детали, оставленные для вас в качестве упражнения (2).
Модель содержит соответствующие пояснительные примечания. СИ, СИа и СЗО — это строки во вспомогательной модели, в которой выполняется большая часть обработки данных. На уровне нашей модели мы предполагаем, что обработка выполняется корректно, и ее результат приходит в узел Тсум. Вам предлагается разработать более детальную модель этой обработки в упражнении 2. После того как вы разработаете модель потока транзакций для обработки, вы, надеюсь, согласитесь со мной, что в данном случае уместнее было бы использовать модель потока данных, или модель потока управления. Выбранный мной способ разбиения на части данной модели был удобен для меня, и он в точности повторяет структуру форм, предложенную ВНС. У вас может быть свое собственное мнение на этот счет, и оно приведет к другому, но не менее эффективному разбиению проблемы на части.
6.4.4. Выбор путей и/или порожденных подграфов тестирования
Следует рассмотреть несколько ситуаций, зависящих от того, есть ли в исследуемой модели узлы порождения/расщепления и/или слияния/поглощения. В любом случае мы предполагаем, что у нас нет циклов или что циклы могут
166 Глава 6 • Тестирование потоков транзакций
присутствовать во вспомогательных моделях. Поскольку модели потоков транзакций, как правило, состоят из множества маленьких независимых субмоделей, то, скорее всего, даже если вы решите использовать модель потока транзакций, может оказаться, что некоторые из субмоделей лучше описываются при помощи модели потока данных или модели потока управления. Ниже приведены некоторые наиболее часто встречающиеся случаи:
1. Чистая модель потока управления, есть только ветвления и соединения.
2. Узлы слияния и поглощения, нет ветвлений, нет соединений.
3. Узлы слияния и поглощения с ветвлениями и соединениями.
4. Управляющие потоки с расщеплениями и порождениями, но без слияний и поглощений.
5. Общий случай.
Случай 1: Чистая модель потока управления
Этот случай полностью идентичен случаю тестирования потока управления. Если все потоки транзакций подобны потокам управления, то лучше выбрать модель потоков управления. По сравнению с моделями потоков управления модели потоков транзакций имеют три отличия.
1. Обычно приходится рассматривать много потоков транзакций, несмотря на то, что все они относительно простые.
2. Большая вероятность существования моделей с числом входов и выходов, отличным от единицы. Транзакции могут приходить из разных источников и вследствие этого помещаться в различные очереди на обработку. Транзакции могут направляться в различные точки назначения и вследствие этого помещаться в различные выходные очереди. Нам недостаточно убедиться в корректности обработки транзакций, необходимо также проверить, что транзакции прошли правильным маршрутом. В принципе вас не должно удовлетворять простое покрытие связей, вы должны обеспечить такое покрытие для всех имеющих смысл комбинаций «вход - выход».
3. Кроме того, вам еще надо рассмотреть и проверить правила упорядочения в очередях.
Случай 2: Узлы слияния и поглощения, нет ветвления, нет соединения
Как обсуждалось в главе 5, разделе 5.4.4, это случай чистой модели потока данных. Вы можете создать порожденный подграф для каждого возможного выхода. Вы начинаете его строить из выходного узла и идете в обратном направлении к стартовым узлу(ам) для данного выхода. Включите все обратные ветвления, поскольку все они вносят свой вклад в обработку данных. В нашем примере, строя порожденный подграф, идущий назад из СЮ, мы придем в Сба. Затем мы должны включить в него связь из узла С1 (и все, что в него входит) и связь из Pal, поскольку обе связи поставляют в Сба данные, необходимые для обработки.
6.4. Методика 167
Случай 3: Узлы слияния и поглощения с ветвлением и соединением
В этом случае порождения и расщепления отсутствуют. Несколько транзакций входят в модель, и меньшее их число выходит. Остальные транзакции поглощаются в процессе прохождения модели. Этот случай идентичен случаю 3 раздела 5.4.4 главы 5. Если вы прочли эту главу, то вам надо прочесть то, что относится к данному случаю еще раз, и интерпретировать его на языке потоков транзакций. Если вы не читали про этот случай, то прочитайте, игнорируя все, что касается узлов выбора. Убедитесь, что вы, по крайней мере, охватили достаточное количество путей, чтобы обеспечить покрытие связей.
Вы создаете порожденный подграф так же, как в предыдущем случае, за исключением того, что после узлов соединения вы должны следовать по обеим входящим в этот узел соединения связям, чтобы убедиться, что вы включили в порожденный подграф все источники данных. Этот порожденный подграф определяет набор тестовых вариантов.
Рассмотрим существующие в модели узлы ветвления. Каждое значение параметра, управляющего ветвлением, определяет выбор одного из альтернативных путей. Выберите один из них. Теперь некоторые входные транзакции уже не нужны, следовательно, их можно убрать. Продолжайте этот процесс до тех пор, пока у вас не останется только один определенный путь (и соответствующие входные транзакции). Проделайте это еще раз, выбрав другую ветвь для другого варианта тестового варианта. Перебор следует продолжать до тех пор, пока вы не обеспечите покрытия связей.
Случай 4: Управляющие потоки с расщеплениями и порождениями, но без слияний и поглощений
Это достаточно простой случай. Начните с выхода и сделайте порожденный подграф для каждой транзакции, приходящей в выходные узлы. Сделайте один порожденный подграф (от выхода до всех стартовых узлов, имеющих к нему отношение) для каждой выходной транзакции. Поделите этот порожденный подграф на более мелкие части (больше тестовых вариантов), чтобы обеспечить покрытие связей для узлов ветвления.
Случай 5: Общий случай
В данном случае не существует простых рецептов. Общая идея состоит в том, чтобы сделать порожденный подграф для каждой выходной транзакции. Включите в него все входные транзакции, обеспечивающие данные. Если в каком-либо из этих порожденных подграфов существуют управляющие потоки, убедитесь, что вы разделили их и получили дополнительные тестовые варианты, гарантирующие покрытие связей в каждом из порожденных подграфов. Может показаться, что мы создаем избыточные тестовые варианты, поскольку порожденные подграфы перекрываются, — и, обеспечив покрытие связей для транзакции типа А, мы можем проделать это заново для транзакции типа В (в другом порожденном подграфе, включающем в себя некоторые ветви из предыдущего порожденного подграфа). Для мотивировки этого, казалось бы, избыточного действия достаточно
168 Глава 6 • Тестирование потоков транзакций
задать себе вопрос: «Что является целью тестирования»?» Я уже ранее говорил, что системное тестирование — это не проверка работы отдельных узлов, а проверка того, правильно ли транзакции проходят от обработки к обработке. Поскольку большая часть обработки (в случае потоков транзакций) включает в себя условные ветви, которые частично зависят от типа транзакций, то не лишним будет проверить одну и ту же логику для различных типов транзакций. По сути, такое «избыточное» покрытие связей может оказаться единственным способом проверить глубоко скрытые составные предикаты.
Используя данные выше рекомендации, мы получаем два семейства тестов.
С10/Сба/ра1. С6а/С1/Ф1а/Ф1
С10/С6а/ра1. С6а/С1/Т1/Ф1д/Ф1а/Ф1. Т1/Тсум/„.С11а...0т1/Фр1/Ам1
Это два семейства тестов, поскольку для транспортных средств возникает много тестов. И поэтому мы должны проверить вопросы синхронизации и поведение очереди.
6.4.5. Тестирование синхронизации
При слиянии двух или более транзакций или если одна поглощает другую, мы всегда должны спроектировать и провести тестирование синхронизации. В нашей модели мы можем рассмотреть в качестве примера узел Сба или узел Т1. Оба они являются узлами поглощения. Узел Сба незамысловат, и для его проверки нам необходимо пять тестов. Узел Т1 представляется более интересным и перспективным, поскольку в нем происходит слияние формы (льготы на транспортное средство), которая порождена в этой же модели. Посмотрев на эту модель, вы можете ошибочно заявить: «Мне не нужно пяти тестовых вариантов. Путь от Ф1д к Т1, очевидно, короче, чем путь, лежащий через процедуру обработки транспортного средства (от С11а до Тсум). Таким образом, я могу сделать вывод, что транзакция формы 2106 всегда приходит в узел Т1 раньше, чем данные о транспортном средстве, и ждет их там. Значит, у нас есть только 2 варианта для рассмотрения. Либо форма 2106 приходит раньше данных о транспортном средстве, либо данные о транспортном средстве отсутствуют».
Если вы и в самом деле так считаете, то делаете ошибочное допущение и попадете в ту же ловушку, что и программисты, создавшие программу, которую вы тестируете. Это всё рациональные приближения, однако природа ошибок не рациональна. К тому же обе связи, входящие в Т1, могли бы представлять собой очереди (в данном примере это не так), и правило упорядочения может вызывать любые перестановки.
Если вы не можете с уверенностью сказать, что возможен лишь один определенный порядок (например, форма 2106 приходит раньше данных о транспортном средстве), то вам будет лучше проверить все случаи. Система должна вести себя разумно для всех случаев. Я подразумеваю, что она не уничтожает, не изменяет и не теряет данные, а неполные транзакции она отвергает, уведомляя об этом пользователя или иную систему, породившую транзакцию.
Насколько глубоко мы должны проверять синхронизацию? Должны ли мы учитывать взаимодействие одного узла слияния с другим, находящимся ниже
6.4. Методика 169
в исследуемом порожденном подграфе? Гипотетически — да, но на самом деле не стоит этого делать. Число тестов растет экспоненциально, а продуктивность таких тестов синхронизации высокого порядка совсем не очевидна. Более того, проведение тестов для одного слияния уже является непростой задачей, проверка же последовательности слияний может оказаться невозможной.
А что, если один и тот же узел слияния встречается в нескольких порожденных подграфах? Следует ли повторять тесты синхронизации в каждом из них? Скорее всего, не следует, и главным образом потому, что это приведет к быстрому росту числа тестовых вариантов. Но есть и другая причина. Вы, возможно, сможете проверить эти случаи быстрее и с меньшими усилиями путем автоматической генерации соответствующим образом подобранных случайных тестовых вариантов.
6.4.6. Тестирование очереди
Проверка любой, не слишком простой очереди требует применения целой группы тестов. Где это следует делать, в системном тестировании или на более низком уровне компонентного тестирования? Если узел имеет только одну входящую связь, и у меня есть причины считать, что этой очередью управляет представляемый этим узлом компонент, то я отдаю предпочтение тестированию очереди в контексте компонентного тестирования. Если узел является узлом слияния, поглощения или соединения (несколько входящих связей), то я буду должен проверить очередь на уровне компонентов, а затем повторить эти тесты при тестировании системы. Какие именно тесты вам нужны, зависит от правила упорядочения и правила выбора сервера, если он есть. Ниже приводятся некоторые полезные виды тестов.
1. Тестирование пределов длины очереди.
* Максимальная длина очереди. Попытайтесь превысить предельно допустимое число элементов в очереди.
* Пустая очередь. Активизируйте обработку, когда в очереди ничего нет.
* Проверка циклов. Узел, обрабатывающий очередь, содержит цикл для обработки элементов очереди (особенно это касается групповых серверов). Используйте методы тестирования циклов для нескольких элементов в очереди.
* Динамические изменения длины очереди. Попытка добавить транзакцию в очередь (особенно в очередь пакетной обработки) во время проведения обработки элементов является, очевидно, необходимым тестовым вариантом. Кроме этого, попробуйте удалить элемент из очереди, пока обработчик очереди активен, если система обработки это вам позволит.
2. Тестирование сортировки и выбора. Часто правила упорядочения включают в себя процедуру сортировки. Например, правило может указывать, что в первую очередь обрабатываются наиболее старые транзакции. Это правило отличается от правила построения очереди FIFO (First in First Out — первым прибыл, первым обслужен). Очередь FIFO строится на основе положения
170 Глава 6 • Тестирование потоков транзакций
элемента в очереди. За основу в правиле «старейшая транзакция обрабатывается первой» берется отметка времени в контрольной записи транзакции. Поскольку транзакции проходят различные пути до того, как становятся в данную очередь, порядок FIFO может отличаться от порядка отметок времени. Другой пример — это очереди с приоритетом, в которых существует внутренняя сортировка по степени приоритета. Обработка должна включать в себя явную процедуру сортировки или, если очередь не слишком длинная, может осуществляться сканирование всей очереди, чтобы выбрать следующий элемент для обработки. Оба этих варианта представляют собой неявную процедуру сортировки. Сортировка всегда происходит на основе реального или скрытого ключа. Существуют элегантные способы тестирования процедур сортировки, но они лежат за рамками данной книги. Мы ограничимся некоторыми простыми, но эффективными эвристическими методами. Ниже приведено несколько случаев, которые стоит проверить.
• Правильное упорядочение.
« Все элементы имеют одинаковые ключи сортировки.
« Элементы располагаются в обратном порядке.
* Присутствует только один элемент в очереди. Проверьте все дискретные ключи сортировки (то есть приоритеты).
* Один элемент для каждого дискретного ключа сортировки.
« Для многоуровневых ключей (например, возраст внутри одного приоритета) рассмотрите комбинации приведенных выше тестов в контексте тестирования вложенных циклов.
3. Тестирование упорядочения очереди. Если в вашем случае правило упорядочения отличается от FIFO, вы должны провести тестирование упорядочения очереди, чтобы убедиться, что оно было реализовано корректно. Если это правило определяется неявной сортировкой (например, приоритетом), то используйте описанные выше тесты. За исключением этого, дать общие рекомендации довольно трудно, поскольку правила упорядочения могут быть самыми разными.
4. Тестирование приоритетов. Следует различать многоуровневые приоритеты в одной очереди и отдельную очередь для каждого приоритета. В первом случае тестирование представляет собой проверку сортировки, основанной на приоритетах. Во втором случае необходимы некоторые дополнительные тесты:
• Существует только один приоритет. Рассмотреть этот случай для каждого приоритета.
• Присутствуют все приоритеты, берется по одному элементу на каждый приоритет.
• Присутствуют все приоритеты, берется несколько элементов на каждый приоритет.
Методика 171
* Приоритеты меняются во время обработки (если это позволяет приложение). Протестируйте случаи повышения и понижения приоритета.
Очереди по приоритету заслуживают особого внимания, особенно если существуют другие ключи, используемые в других процессах. Например, пусть в одной очереди ключ определяется в области значений, а в другой очереди ключ представляет собой степень секретности. Для ключевых значений сначала обрабатываются транзакции, соответствующие наибольшим значениям, затем меньшим, и так далее. В очереди, упорядоченной по степени безопасности, первыми обрабатываются совершенно секретные транзакции, затем просто секретные, затем доверительные и так далее. Обе очереди являются очередями по приоритету, поскольку, хотя одно поле и называется «значение», а другое «степень секретности», поведение элементов в обеих очередях определяется приоритетом. О чем тогда беспокоиться? Все дело в том, что при возникновении подобной ситуации программист с большой вероятностью перепутает две очереди и использует неверный ключ. В моей практике я видел, как «конфиденциальность» путали с «безопасностью» и оба эти понятия путали с «приоритетом».
5. Тестирование правила выбора сервера. Проверяйте множественные серверы с одной очередью путем низкоуровневого компонентного тестирования. Если у вас есть несколько очередей, которые служат входными связями во множественный сервер, то правило выбора сервера должно быть проверено (или хотя бы перепроверено) при тестировании системы. Тестирование правила выбора сервера напоминает тестирование сортировки, и выполнять его надо очень тщательно при помощи следующих вариантов:
» Все элементы в одной очереди.
» Во всех очередях один элемент.
* Во всех очередях одинаковое число элементов.
6.4.7. Активизация
Проблема активизации при тестировании потоков транзакций отличается от аналогичной проблемы в методах тестирования потоков управления или потоков данных. Задача заключается не в том, чтобы найти такие транзакции, которые проследуют по выбранному пути. На самом деле суть проблемы — создать транзакции, выполняющие это условие, и ввести эти транзакции в систему. Хотя обычные транзакции, как правило, не слишком сложны, типы транзакций, представленные в разделе 6.4.1, иногда бывает просто невозможно ввести. Ниже приведены некоторые характерные проблемы и возможные способы их решения.
1. Ошибки, отрицательное квитирование и восстанавливающие транзакции из других систем. Это было моим проклятием. Вы не можете получить эти транзакции, не заставив другую систему вести себя неправильно. Вам необходима транзакция из другой системы, информирующая вас, что один из ваших блоков данных был утерян или искажен. Однако вы не можете послать ей блок данных или искаженный блок, поскольку такие ошибки могут быть об
172 Глава 6 • Тестирование потоков транзакций
наружены промежуточными системами. Вам придется заставить другую систему послать вам сообщение об ошибке, хотя на самом деле ошибки не было. Вы пытаетесь наладить сотрудничество, но в ответ вам с пафосом заявляют: «Наша система никогда не посылает сообщения об ошибках!» Вы пытаетесь как-то решить эту проблему, а заканчивается все тем, что вы объясняете разгневанному чиновнику в полосатом костюме из государственного департамента в Вашингтоне, что не собирались раздуть международный скандал1. На этот случай я не знаю приемлемого технического решения, поскольку это не техническая проблема. В крайнем случае вам придется построить имитаторы всех таких недружественных интерфейсов и протестировать все случаи, используя эти имитаторы. А потом остается только надеяться на лучшее.
2. Внутренние транзакции, связанные с восстановлением системы и нелогичными условиями. Система должна иметь защиту от аварий, таких как отказы программного или аппаратного обеспечения. Вы не сможете протестировать защитные механизмы, не создав в точности такую же ситуацию, против которой система должна себя защищать. Следует точно узнать, принимаются ли необходимые меры по защите. Вы должны сломать доктрину безопасности. Проверить, предусмотрено ли в вашем случае аварийное восстановление состояния системы и данных. Вы должны имитировать все механизмы аварий и порождаемые ими транзакции.
3. Внутренние транзакции для восстановления данных и нелогичных условий. Если система обнаруживает потерянные или дублированные транзакции, то и тестировщик должен иметь возможность терять или дублировать транзакции. Любой механизм восстановления данных рассчитан на определенный сценарий их потери или искажения. Вы должны воспроизвести каждый такой сценарий для соответствующих транзакций.
На практике задача активизации заключается в том, чтобы правильно генерировать и внедрить необходимые вам для проверки системы транзакции. Единственный разумный способ это сделать — это встроить в систему генератор транзакций на ранней стадии проектирования. Минимум действий, которые должен уметь выполнять встроенный генератор транзакций, выглядит следующим образом.
1. Создание любых заданных транзакций, как корректных, так и некорректных.
2. Размещение эти транзакций в любом месте заданной очереди.
3. Удаление выбранных транзакций из очереди.
6.4.8. Предсказание итогов
Нашей задачей при проведении тестирования не является детальная проверка данных в транзакциях. Цель системного тестирования (в контексте модели потока транзакций) заключается в проверке корректного прохождения транзакций, в том числе их порождения, завершения и так далее. Ожидаемым итогом в этом случае
1 Это реальный факт из моей практики.
6.4. Методика 173
является определение того, какие транзакции в каких очередях должны находиться до и после тестирования — предсказание конечного состояния транзакции при заданном начальном состоянии.
На практике, однако, перед тестировщиком стоит задача не предсказать итог, а проверить его. Вы должны сравнить все включенные в процесс очереди до и после проведения теста. По меньшей мере вам необходимо иметь возможность, проведя тестирование, заморозить систему, или, как альтернативный вариант, уметь делать моментальную запись всех интересующих вас очередей. Здесь подразумевается использование инструментов тестирования, и лучше всего, если они будут встроены в проект.
6.4.9. Проверка соответствия пути
На самом деле если существуют слияния или порождения, то это будет проверкой соответствия порожденного подграфа. Проблема заключается не в том, чтобы убедиться в правильности пути, а в том, чтобы найти способ встроить в систему инструменты, которые это будут делать. Существует два основных источника необходимых данных, и в обоих случаях вам, возможно, придется создавать достаточно продуманную программу, поскольку вероятность того, что в универсальных инструментах предусмотрены все возможности ваших транзакций, весьма мала.
1. Существующие записи. Системы обработки транзакций обычно включают в себя запись активности транзакций, которая требуется в различных приложениях. Например, информацию о счетах, журнал безопасности, резервные и архивные данные. Эти данные записываются в узлах, которые чаще всего и являются целью тестировщика. Например, в системах восстановления данных обычной практикой является запись состава всех активных очередей. Прежде чем вы потребуете расширить возможности регистрации данных в системе, исследуйте все журналы регистрации и записи, необходимые в приложении, и подумайте, могут ли эти данные помочь вам проверить исследуемый путь.
2. Встроенная регистрация. Обсуждаемое в предыдущем пункте дополнение данных, предоставляемых приложением, необходимо для устранения белых пятен. Постарайтесь ограничиться минимальными добавлениями, чтобы дополнительная регистрация данных не влияла существенно на поведение системы. Как правило, это вполне реально осуществить, и часто объем ресурсов, достаточный для проведения самой полной регистрации транзакций не превышает нескольких процентов от общего объема доступных ресурсов. Как правило, такие возможности регистрации должны встраиваться сразу, поскольку сделать это задним числом будет очень сложно.
3. Действия в режиме трассировки. Это наиболее приятный способ регистрации. Транзакции вполне могут запускаться в режиме трассировки. Это означает, что производится постоянная запись всех процессов, в которых участвовали эти транзакции, и всех очередей, в которых они стояли. Разумеется, такая возможность тоже должна быть встроена в систему. Вне зависимости
174 Глава 6 • Тестирование потоков транзакций
от того, насколько важен режим трассировки для тестировщика, он вполне оправданно считается отличным инструментом для отладки системы.
6.5. Рассмотрение приложений
6.5.1. Индикаторы приложений
Насколько хорошо вы сможете описать поведение системы при таком моделировании? Критериями применимости данного метода могут служить положительные ответы на приведенные ниже вопросы.
1. Выполняется ли работа дискретными единицами?
2. Распределяются ли единицы работы между обрабатывающими модулями при помощи очередей или подобных интерфейсов?
3. Существуют ли в вашем случае множественные серверы?
4. Выполняются ли ваши процессы квазипараллельно?
5. Существует ли между процессами связь в виде сообщений?
6.5.2. Предположения об ошибках
Основное предположение должно быть следующим — каждый отдельный процесс работает корректно (был проверен со всех сторон на более ранней стадии интеграции), а ошибки, которые мы ищем, возникают вследствие некорректной реализации связи между компонентами или как побочный эффект многозадачности. Типичный список предположений об ошибках включает в себя несколько стандартных пунктов.
1. Некорректные очереди. Пропуск очередей, лишние очереди, неправильные типы очередей.
2. Некорректные порождения или расщепления. Система использует порождения транзакций неправильного типа, неверный порождающий элемент, создание копий.
3. Некорректные слияния или поглощения. Неправильные слияния или поглощения, потери.
4. Ошибки маршрутизации очереди. Соединение выходов с неверными входными очередями.
5. Ошибки в правилах упорядочения. Действует неверное правило упорядочения.
6.5.3. Ограничения и предостережения
Мы предполагаем, что наш проект обладает правильным дизайном. Он имеет иерархическую структуру, в нем существует ясное разделение между обработкой
6.5. Рассмотрение приложений 175
данных и управлением очередями, транзакции однозначно делятся на типы, осуществляется явная запись управления транзакциями, и маршрутизация транзакций производится централизованно. Чем лучше проект, тем легче будет обеспечить полное покрытие при помощи тестирования потоков транзакций. Это означает, что тестировщик сможет сделать обоснованные предсказания (проведя соответствующие тесты) о пригодности программы к использованию. Предположим теперь, что у вас плохой проект. Значит ли это, что тестирование потоков транзакций будет бесполезно? Нет, оно все равно будет очень полезно. Обсуждаемые здесь тесты легко сломают программу, основанную на плохом проектировании. Единственное, что вы не сможете сделать для плохого проекта, — это статистически оправданно предсказать его пригодность к использованию.
Единственное важное ограничение для этой модели — это требование марковского поведения от каждого узла. В случае немарковского поведения у вас не будет другого выбора, кроме как тестировать каждый возможный путь для каждой возможной транзакции, поскольку поведение будет зависеть не только от данных, содержащихся в транзакции, но и от предыстории ее поведения. Такое тестирование редко осуществимо на практике. Сколько-нибудь разумное понятие покрытия бесполезно при отсутствии марковского поведения. Если у вас случай именно такого поведения и вы выполните предложенные здесь тесты, то ничего не добьетесь, кроме ошибочной уверенности. Немарковскос поведение может быть сколь угодно сложным, поэтому любое выполняемое вами покрытие охватит лишь небольшую часть возможных вариантов. Что вам следует делать при встрече с немарковским поведением?
1. Избавиться от него путем перепроектирования. В любом случае это лучший выбор. В большинстве случаев можно обойтись без немарковского поведения. Оно возникает, когда люди недостаточно хорошо разобрались в вопросе.
2. Изолировать его. Вам, возможно, придется это сделать, если ваша модель описывает поведение человека или поведение других, не контролируемых вами систем. Процедура изоляции может заключаться в наложении ограничений на действия (изменение спецификации) или выделении подобного поведения в отдельную субмодель, которую вам придется проверить очень тщательно, прежде чем вы перейдете к тестированию системы более высокого уровня.
3. Смириться с риском. Иногда это допустимо. То, что приемлемо в развлекательных программах, не может быть приемлемо в жизненно важном программном обеспечении.
6.5.4. Автоматизация и инструментальные средства
Рассмотрим отдельно автоматизацию выполнения тестов и автоматизацию их проектирования.
1. Автоматизация выполнения тестов. Необходимость автоматизации выполнения частично была рассмотрена выше в разделах 6.4.7-6.4.Э. Что ка
176 Глава 6 • Тестирование потоков транзакций
сается коммерчески доступных инструментов тестирования, то системы покрытия/воспроизведения и языки подготовки сценариев являются наиболее подходящими инструментами для автоматизации выполнения тестов. Однако в большинстве систем разработки, о которых стоило бы говорить, наличие встроенных средств тестирования — обязательное условие.
2. Автоматизация разработки тестов. Системы автоматизации могут варьироваться от тривиальных до сложнейших. Языки и системы, предназначенные для создания генераторов тестов, широко распространены (как коммерческие, так и частные). Имеет смысл потратить пять лет работы, чтобы создать специализированный генератор автоматического тестирования транзакций для проекта, разработка которого потребует 100 лет общих трудозатрат. Хотя здесь редко встречаются непреодолимые технические трудности, я допускаю, что может быть достаточно трудно убедить нужных людей, что инструменты тестирования подобного рода стоят потраченных на них времени и сил.
6.6. Резюме
Модель потока транзакций является эффективной моделью, применяемой в высокоуровневом системном тестировании большого количества систем. Моделирование начинается с идентификации интересующих нас транзакций, особенно мест, где они порождаются и завершаются и обстоятельств, при которых это происходит. Модель основана на допущении о марковском процессе1. В ней так же предполагается, что подробные модели обработки были созданы и использовались на более низком уровне компонентного тестирования, на стадии, предшествующей интеграции. Основное внимание при тестировании потоков транзакций уделяется очередям, и маршрутам транзакций в системе. Мы рассмотрели эвристическую иерархию покрытия, основанную на порожденном подграфе.
6.7. Вопросы для самопроверки
1. Дайте определение ( в контексте тестирования потоков транзакций ) следующих терминов: узел поглощения, обслуживание пакета, покрытие порож-дения/завершения, стартовый узел, ограниченная очередь, узел ветвления, предикат ветвления, управляющая входящая связь, дочерняя транзакция, узел завершения, FCFS, FIFO, узел соединения, LCFS, LIFO, покрытие связей, маркировка, марковский узел, марковский потоковый граф, узел слияния, материнская транзакция, множественный сервер, очередь, покрытие узлов, покрытие зарождения/выхода, узел зарождения, родительская
1 Иными словами полагают, что поток транзакций является марковским процессом (процессом без последействия), в котором будущее поведение транзакции зависит только от текущего состояния и не зависит от предыстории процесса. — Примеч. научи, ред.
6.7. Вопросы для самопроверки 177
транзакция, транзакция - хищник, транзакция - жертва, очередь по приоритету, тестирование приоритетов, правило упорядочения, тестирование правила упорядочения, тесты очереди, случайное обслуживание, правило выбора сервера, односерверная очередь, порожденный подграф, тестирование сортировки, узел расщепления, тесты синхронизации, задача, действия в режиме трассировки, транзакция, узел ветвления транзакции, предикат ветвления транзакции, управляющая запись транзакции, узел соединения транзакций, регистрация транзакций, тестирование выбора транзакции, состояние транзакции, маркер транзакции, тип транзакции.
2. Разработайте подробную модель части формы 2106, связанной с расходами на транспортные средства. Считайте, что число транспортных средств ограничено п. Вводя соответствующие данные для каждого транспортного средства (0т1, Фр1, Ам1, СИа) имейте в виду, что вы можете вводить фактические расходы и амортизацию, только если вы являетесь владельцем транспортного средства; однако вы не обязаны декларировать фактические расходы. Если же вы это делаете, то не обязаны декларировать амортизацию. Считайте, что вы нашли способ получить максимальные льготы (выбрав между стандартными и фактическими льготами). Введите в эту субмодель данные для всех транспортных средств и получите одно число общих льгот на транспортные средства (Тсум). Разработайте модель, выберите пути, активизируйте их, определите, что вы хотите проверить, исследуйте синхронизацию для слияния транзакций, и так далее. Проводите только чистые тесты.
3. Разработайте грязные тесты для задачи 2. Рассмотрите потерю, дублирование, искажение данных о транспортном средстве. Учтите, что вы не можете декларировать фактические расходы для одного транспортного средства, а амортизацию для другого. Все данные о транспортном средстве (0т1, Фр1, Ам 1) должны являться частью соответствующего набора для данного транспортного средства.
4. Для проверки слияния двух транзакций необходимо пять контрольных тестов, в случае трех транзакций таких тестов должно быть уже 25. Сколько тестовых вариантов потребует проверка слияния четырех транзакций? А сколько потребует слияние п транзакций?
5. Разработайте модель потока транзакций для формы 1040: (а) строки 7-22, (б) строки 23-30, (в) строки 32-40, (г) строки 41-45, (д) строки 47-53, (е) строки 45-60. В каждом случае считайте, что все входные значения вводятся в виде единой транзакции, возможно, из предыдущего блока строк. Моделируйте эти вычисления как единый элемент обработки, который не надо тестировать. Рассматривайте каждую встречающуюся форму или бланк как транзакции, которые могут порождаться и/или поглощаться как положено. Включите в модель логику для определения того, нужны или не нужны в ней данные формы. Например, в строке 14 в случае существования «дополнительных доходов» будет создана форма 4797, которая потом будет возвращена заполненной соответствующим образом и поглощена формой
178 Глава 6 • Тестирование потоков транзакций
1040, то же самое будет с W2, бланком В, бланком С, формой 3903 и так далее. Не пытайтесь моделировать эти формы. Создавайте пустые формы, как того требует логика, отправляйте их на соответствующий узел обработки форм, затем принимайте данные формы обратно в соответствующие строки формы 1040. Разработайте следующие типы тестов: покрытие узлов, покрытие связей, покрытие порождения/завершения.
6. Выполните задачу 5 в предположении, что вспомогательные формы могут быть сначала открыты, а затем оставлены незаполненными, поскольку оказалось, что в них нет необходимости.
7. Выполните еще раз задачу 5 в предположении, что различные строки могут заполняться в произвольном порядке при условии, что существуют требуемые данные (то есть вы не можете добавлять числа, пока они не введены). Разработайте необходимые тесты синхронизации, считая, что входящие формы поступают по очереди, но в произвольном порядке.
Тестирование доменов
7.1. Обзор
Тестирование доменов используется для проверки такого программного обеспечения или его частей, в которых преобладают численные вычисления. Оно является альтернативой общему эвристическому методу тестирования экстремальных значений и предельных значений входных величин.
7.2. Основные термины
Внешние термины: алгебра, неоднозначный, приложение, аппроксимировать, массив, вычислять, оператор CASE, классификация, код, коэффициент, коллинеарный, константа, несовместимый, координатные оси, компланарный, проверка соответствия данных, размерность, уравнение, эквидистантный, выражение, ЛОЖЬ, функция, иерархия, IF-THEN-ELSE, реализация, неравенство, пересекаться, линия, линейный, логика, сопровождение, означать, модель, нелинейный, численный, перекрывать, параллельный, плоскость, точка, полиномиальный, точность, обработка, программа, программист, радиус, область, округление, набор, программное обеспечение, пространство, подмножество, поверхность, символическая подстановка, система, таблица, управляемый таблицами, тестируемость, преобразование, дерево,
Внутренние термины: слепота, ошибка, случайная корректность, поток управления, поток данных, граф, ввод, связь, покрытие связей, вес связи, объект, итог, узел, покрытие узлов, вес узла, вывод, предикат, отношение, спецификация, тест, тестовый вариант, поток транзакций.
Входная переменная. Численный объект, который система получает для обработки при тестировании. В общем случае система обрабатывает п входных переменных.
180 Глава 7 • Тестирование доменов
Входной вектор. Набор значений п входных переменных, включающий одно значение для каждой переменной. В наших задачах мы будем рассматривать входной вектор так, как если бы он являлся массивом. Так же мы будем использовать эквивалентные термины: контрольный вектор, контрольная точка.
Входное пространство. Абстрактное n-мерное пространство, в котором определяется входной вектор. Наличие входных переменных подразумевает наличие п-мерного входного пространства.
Выходная переменная. В тестировании доменов означает численную переменную в тестируемой системе. В общем случае система вычисляет значения m выходных переменных.
Выходной вектор. Набор значений m выходных переменных. Как и для случая входного вектора, мы будем рассматривать выходной вектор так, как если бы он являлся массивом.
Выходное пространство, m-мерное пространство выходных векторов.
Домен. Подпространство входного пространства, в котором задается обработка, выполняемая тестируемой системой. Мы считаем, что известен способ, с помощью которого можно определить, принадлежит ли входной вектор данному домену или нет. При тестировании доменов, они задаются системой граничных неравенств (см. ниже).
Область. Подпространство выходного пространства, состоящее из значений, вычисленных тестируемой системой (выходных значений). Каждому домену соответствует своя область.
Граница домена. Способ определения домена. Обычно определение происходит в форме алгебраических неравенств. Мы будем использовать термин «граница» вместо термина «граница домена» там, где не может возникнуть неоднозначности.
Граничное неравенство. Алгебраическое выражение, содержащее входные переменные, с помощью которого можно определить, какие точки входного пространства принадлежат рассматриваемому домену. К примеру, неравенство х >= 7 означает, что для всех точек, содержащихся в данном домене, значение входной переменной х будет больше или равно семи.
Х<7 Х=7 Х>7
Граничное уравнение. Уравнение, получающееся при превращении граничного неравенства в равенство (то есть при замене символа «>=» на «=»).
Граничное множество домена. Система неравенств, совместно определяющих домен: напрцмер, х>=7, х<44 определяют домен, как диапазон чисел, лежащий между 7 и 44, причем 7 в него включается, а 44 — нет. Поскольку домены задаются соответствующими системами уравнений, мы в дальнейшем будем подразумевать под этими системами уравнений сами домены.
X = 7 X >= 7 & X < 44 X = 44
Рассматриваемый домен
7.2. Основные термины 181
Закрытые границы. Граница домена называется закрытой, если точки, лежащие на ней, включаются в рассматриваемый домен. Например, в домене х >= 7 граница закрыта, поскольку значение 7 включено в данный домен. В одномерном пространстве закрытые границы изображаются черными точками.
Открытые границы. Если граница не закрыта, то она открыта. В этом случае точки на границе не принадлежат рассматриваемому домену, они принадлежат смежному домену, если таковой существует. В предыдущем примере домен закрыт в точке х = 7 и открыт в точке х = 44, поскольку точка 44 не принадлежит этому домену. В одномерном пространстве, закрытые границы изображаются заштрихованными точками.
Закрытый домен. Домен, у которого все границы закрыты.
Открытый домен. Домен, у которого все границы открыты. Домен не обязательно должен быть открытым или закрытым. Так, например, вполне может существовать домен с одной открытой и одной закрытой границами. На рисунке рассматриваемый домен ограничен пятью неравенствами: X > О, X <= 12, 2Y <= Х+4, 2Y >= X-8, и Y > 0. В пространстве с размерностью 2 штриховка отмечает сторону, с которой домен закрыт. В предыдущем примере оси X (Y = 0) и Y(X = 0) не включены в рассматриваемый домен, а линия Х=12 и две диагональные границы — включены.
Гиперплоскость. В n-мерном пространстве линейная поверхность с размерностью меньшей, чем п называется гиперплоскостью. Например, на двумерной плоскости линия и точка являются гиперплоскостями, в одномерном пространстве точка является гиперплоскостью, в трехмерном пространстве плоскость, линия и точка — гиперплоскости. Границы доменов представляют собой гиперплоскости, как правило (но не всегда), с размерностью п-1.
Узловая точка. Точка пересечения двух или более границ доменов. В литературе ее часто называют «особая точка». В n-мерном пространстве узловую точку можно получить, решая систему из п (линейно независимых) граничных уравнений.
182 Глава 7 • Тестирование доменов
Внутренняя точка. Точка, лежащая внутри рассматриваемого домена.
Внешняя точка. Точка, лежащая вне рассматриваемого домена.
Вырожденный домен. В n-мерном пространстве домен с размерностью меньшей, чем п. Так, например, в двухмерном пространстве вырожденный домен состоит из линии или точки. В трехмерном пространстве вырожденный домен состоит из плоскости, линии или точки.
Вырожденная граница. В n-мерном пространстве граница с размерностью меньшей, чем п-1. Так, например, в трехмерном пространстве вырожденная граница домена может включать в себя линию или точку, но не плоскость. В двухмерном пространстве вырожденная граница домена состоит из точки, но не из линии.
Смежные домены. Два домена называются смежными, если у них общее граничное неравенство. Если граница рассматриваемого домена закрыта, то эта же граница смежного домена должна быть открыта, и наоборот. На рисунке рассматриваемый домен закрыт по отношению к своей верхней диагональной границе, поэтому, смежный домен над линией открыт по отношению к данной границе.
Эпсилон-окрестность (точки). Маленькая область вокруг точки радиуса е (эпсилон), где с — произвольная, но маленькая величина. На практике мы выбираем
7.2. Основные термины 183
щего для нас интерес в приложении. Иными словами, наибольшее значение е выбирается из условия, чтобы ошибка порядка е или меньше была приемлемой для данного приложения.
Точка НА. Точка, лежащая на границе домена или находящаяся так близко к границе, насколько это возможно, чтобы удовлетворять условиям, относящимся к границе1.
Точка ВНЕ [СОНЕ78] Если домен открыт по отношению к какой-либо границе, то точка ВНЕ этой границы — внутренняя точка, лежащая в непосредственной близости от границы (в пределах с-окрестности). Если домен закрыт, тогда точка ВНЕ является внешней точкой и лежит в непосредственной близости от границы снаружи. Это означает, что точка ВНЕ не удовлетворяет условиям, относящимся к границе [JENG 94]. Очевидно, у двух смежных доменов может быть одна и та же точка ВНЕ. Запомнить определение вам поможет следующий акроним: ЗВСОВИ — Закрыт ВНЕ Снаружи, Открыт ВНЕ Изнутри2.
Линейное неравенство. Неравенство вида axxx + а2х2 + а3х3 +...+апхп+...+ к >= 0, где xi — элементы входного вектора (то есть входные переменные), а1 — численные коэффициенты, а к — константа. При тестировании доменов границы часто описываются линейными неравенствами.
Линейный домен. Домен, все граничные неравенства которого линейны.
Нелинейный домен. Домен, у которого по крайней мере одно граничное неравенство не линейно.
Линейно зависимый. Два неравенства называются линейно зависимыми, если одно из них можно превратить в другое путем отбрасывания константы к и умножения всех коэффициентов а, на соответствующий множитель. Например, х + 2у >= 7 и Зх + бу < 5 линейно зависимы, поскольку, отбрасывая постоянные слагаемые и умножая первое неравенство на 3, мы получаем Зх+бу. Линейно зависимые гиперплоскости параллельны друг другу. На предыдущем рисунке диагональные границы были линейно зависимы.
Линейно независимый. Неравенства называются линейно независимыми, если они не являются зависимыми. Несколько неравенств линейно независимы, если ни одно из них не является линейно зависимым от любого другого. Границы, определяемые линейно независимыми неравенствами обязательно пересекаются.
Линейно независимые точки. Наборы точек (то есть входные векторы) vp v2, v3,..., vp линейно независимы, если уравнение с^-н c2v2 + c3v3+ ... + cpvp=0 имеет единственное решение с3 = с2 = с3 =... = ср = 0 для всех коэффициентов. Если точки не являются линейно независимыми, то они линейно зависимы, и некоторые из них можно выразить через другие.
Законченная граница. Граница, простирающаяся на +-«> по всем своим переменным. Мы будем считать границы законченными, если не оговаривается обратное. Наклоненная вверх граница на рисунке является законченной, поскольку простирается на +-оо по всем своим переменным.
1 Это может быть необходимо из-за ограничений, накладываемых компьютерным методом представления чисел [JENG 94]. К примеру, функция, определенная для целых чисел, может не иметь точных решений на границе.
2 Неплохо бы для начала запомнить акроним. — Примеч. перев.
184 Глава 7 • Тестирование доменов
Полная граница
Незаконченная граница
Сегмент границы. Часть граничного неравенства между двумя иди более доменами. Иначе говоря, один из краев домена. Как правило, граничное неравенство определяет сегменты границ для множества различных доменов.
Незаконченная граница. Граница с одним или более разрывами. Наклоненная вниз граница на рисунке выше разорвана и, следовательно, незакончена. Разрывы, если они есть, лежат между узловыми точками; это значит, что они состоят из сегментов границ.
Последовательное закрытие. Граница, для которой направление, в котором она закрыта (или открыта), сохраняется на всем ее протяжении. Мы будем в дальнейшем считать закрытие границ последовательным, если не оговаривается обратное. Граница, отмеченная как последовательная на рисунке, имеет одно и то же направление закрытия на всем своем протяжении.
Непоследовательное закрытие. Граница, для которой направление закрытия меняется по меньшей мере один раз на ее протяжении. Граница, отмеченная на рисунке как непоследовательная, закрыта. Изменения направления закрытия, если они есть, обычно происходят в узловых точках. Это означает, что в большинстве случаев направление закрытия меняется между сегментами границ.
7.3. Отношения и модель
7.3.1. Обоснование
Я изменю обычный порядок изложения и начну с обоснования необходимости тестирования доменов и его семантики, поскольку предыдущие определения мо
7.3. Отношения и модель 185
гут показаться читателю чересчур абстрактными. Тем не менее, я рассчитываю, что вы разобрались в этих определениях.
Тестирование доменов основано на простой вычислительной модели, проиллюстрированной на рис. 7.1. Тестируемая система получает входной вектор, который затем проходит через процедуру сортировки. Все входные значения, лежащие за пределами заданных допустимых значений, отбрасываются или, если это возможно, корректируются. После этого процедура сортировки (вне зависимости от того, как она реализована) определяет, какому из нескольких условий удовлетворяет входной вектор. После выбора соответствующего условия вектор поступает для обработки в соответствующий этому условию узел обработки (это осуществляется, например, при помощи гипотетического оператора CASE), где и происходит его обработка. При тестировании доменов нас интересует корректность процедуры сортировки и корректность гипотетического или реального оператора CASE, использующегося для направления входного вектора в соответствующий узел обработки, а не корректность самой обработки для каждого случая. Это разграничение впервые введено Хоуденом [HOWD76].
При тестировании доменов мы полагаем, что процедура сортировки осуществляется при помощи системы неравенств, содержащих входной вектор. Это означает, что для каждого конкретного случая существует по крайней мере одна система неравенств, которая определяет удовлетворяющий этому условию домен. Таких систем неравенств может быть больше одной, если домены задаются в несвязанных областях.
В качестве примера рассмотрим, как ВНС определил домены для подсчета ваших налогов, при условии, что вы холосты.
Домен Процедура
О < нал_доход =< $22100 налог = 0.15 х нал_доход
186 Глава 7 • Тестирование доменов
$22100 < нал_доход =< $53500 налог = $3315 + 0.28 * (нал_доход - $22100)
$53500 < нал_доход =< $115000 налог = $12107 + 0.31 * (нал_доход - $53500)
$115000 < нал_доход =< $250000 налог = $31172 + 0.36 * (нал_доход - $115000)
$250000 < нал_доход налог = $79722 + 0.396 * (нал_доход - $250000)
В приведенном примере фигурирует только одна входная переменная — нал_ доход (налогооблагаемый доход). Легко заметить, что определены пять* доменов. Первые четыре состоят из двух неравенств каждый. Для них определены верхняя и нижняя границы. У последнего домена нет верхней границы1 2. В инструкциях по заполнению декларации говорится, что если ваш доход не превышает $100000, то вы не должны использовать эти неравенства. В этом случае вам надо пользоваться налоговыми таблицами. Исследуя налоговые таблицы, можно обнаружить расхождения между ними и уравнениями. Расхождение возникает из-за того, что в таблицах приводятся верхняя и нижняя границы для каждого входа и налог рассчитывается для величины верхней и нижней границы, округленной до ближайшего доллара. Формулы же (используемые лишь для дохода, превышающего $100000) точны, и налогоплательщик может сам решать, округлять ему налог или нет.
Что же является в данном случае целью тестирования? Налоговые таблицы, так или иначе, должны применяться, и, следовательно, вам надо тестировать именно их. Если вы тестируете программу расчета налогов и используете домены, определенные при помощи уравнений в вашей модели, для тестирования табличной реализации, то можете не заметить небольших ошибок в таблице — как правило, меньших $5. Если вы тестируете таблицу, а не уравнения, вы должны в соответствии с таблицей так построить уравнения, чтобы они корректно отображали домены, приведенные в таблице.
7.3.2. Основы
Описание компонентов графа и связанных с ними отношений не столь продуктивно при тестировании доменов, как для большинства других методов; тем не менее, это позволяет понять суть метода, что необходимо при любой стратегии.
Объекты (узлы). Домены, определенные для входного вектора.
Отношение (связи). Определено отношение «смежный с». Смежный — это значит имеющий общую границу. Условимся принимать за направление связи направление неравенства. Например, если А и В — смежные домены и А является закрытым доменом, стрелку надо рисовать от А к В. Вы можете выбрать и другой способ определения направления, это не принципиально, главное, чтобы вы были последовательны в своих действиях.
Так же как для всех графических моделей, следует провести тесты, чтобы убедиться в правильности направления стрелок (вне зависимости от выбранного правила). Такая интерпретация принципа графового моделирования означает, что мы должны проверить закрытость границ всех смежных доменов (то есть
1 На самом деле — шесть. Спецификация содержит ошибку и отличается от требований. Объясните, какая ошибка допущена?
2 Поскольку максимальная сумма взимаемого с нас налога не ограничена.
7.3. Отношения и модель 187
покрытие связей). Например, каждая из констант в определениях приведенных выше доменов ($22100, $53500, $115000 и $250000) фигурирует в двух различных неравенствах и одном расчетном выражении. Ошибка, связанная с этими константами, может привести к нарушению смежности доменов. Вам придется протестировать отношения в обоих направлениях, чтобы убедиться, что ничего не пропущено и нет перекрытий доменов.
Веса связей. Неравенства, определяющие границы между доменами. Так как домены могут встречаться в нескольких неравенствах, то между двумя доменами может существовать несколько связей. Для иллюстрации этого требуется как минимум двумерное пространство. Вы можете моделировать это посредством одной связи для каждого неравенства.
Неравенство (в пространстве с размерностью два или более) может являться границей для множества доменов. Две линии, пересекающиеся на плоскости, определяют четыре области и, следовательно, четыре домена. Три неравенства на плоскости могут задать семь доменов1. Наша стратегическая задача — тестирование неравенств, а не доменов.
Веса узлов. Вычисления, соответствующие доменам. Заметим, что одному домену может соответствовать более одного вычисления. Домен может быть определен таким образом, что он будет состоять из граничащих частей, или, даже из несвязанных частей. Примером может служить следующая спецификация.
О < х =< 17 17<х = <34 34<х = <39 39<х = <44 44<х
Процесс А Процесс В Процесс С Процесс А Процесс D
Домен, соответствующий процессу А, состоит из двух несвязанных частей. Как нам его лучше исследовать? Я предпочитаю рассматривать каждую часть такого домена как самостоятельный субдомен, который обрабатывается совместно с некоторыми другими субдоменами (другими частями домена). Я придерживаюсь этого принципа, поскольку так или иначе нам все равно придется их тестировать. В дальнейшем помните, что все, сказанное о тестировании доменов, касается также и тестирования субдоменов (если они есть).
Покрытие узлов'. Для осуществления покрытия узлов вы должны сделать как минимум четыре вещи:
1. Рассмотреть по меньшей мере одну контрольную точку в каждом домене, чтобы убедиться, что с помощью оператора CASE выбран надлежащий вариант обработки, и, если сортировка проведена корректно, убедиться в правильности обработки. Это означает проведение как минимум одного теста для каждого домена. Однако один тест не может обеспечить надежную проверку процесса обработки. Обработка домена может представлять собой целую програм
1 Число доменов определяемых к-неравенствами, растет стремительно с ростом размерности пространства. (Определение возможного числа доменов представляет собой очень сложную математическую задачу, которая носит название «проблема блина» в двухмерном пространстве и «проблема апельсина» в трехмерном пространстве.)
188 Глава 7 • Тестирование доменов
му, включающую в себя поток управления, потоки данных, потоки транзакций и другие средства. Используйте для проверки соответствующую модель1.
2. Для доменов, состоящих из субдоменов (как смежных, так и не смежных), убедитесь, что все требуемые части существуют и обрабатываются в соответствии с требованиями.
3. Убедитесь, что домены не перекрываются. В одномерных и двухмерных пространствах это делается графически. В пространстве с размерностью три и более, используйте соответствующие алгебраические инструменты [WHIT95] (их описание лежит за пределами данной книги). В большинстве случаев, однако, перекрытие доменов происходит на границах.
4. Убедитесь, что входное пространство является полным. Каждый входной вектор должен быть обработан, даже если эта «обработка» означает отбраковку ввода. В одномерном и двухмерном пространстве вы можете провести эту проверку самостоятельно. В пространстве с размерностью три и более используйте соответствующие алгебраические инструменты [WHIT95] (их описание лежит за пределами данной книги). Как и в случае перекрытия, большинство подобных ошибок возникает на границах доменов.
Покрытие связей/ Ниже указано, в каком порядке следует его проводить.
1. Убедитесь, что все домены, которые должны быть смежными, на самом деле смежные, то есть имеют общее граничное неравенство.
2. Убедитесь в отсутствии лишних границ. В этом вам поможет стратегия тестирования доменов.
3. Убедитесь в корректности всех граничных неравенств. В этом заключается основная задача тестирования доменов.
В качестве примера разработки модели тестирования доменов рассмотрим вариант формы 10402, строки с 32 по 38. У меня была задача построить пример, включающий как минимум две входные переменные. Вот мой вариант спецификации для строк 32-38.
32: Adjusted Gross Income (Скорректированный_Общий_Доход Служит входом в зтом примере (СОД))
33: Без проверки, полагается равным 0
34: Стандартные отчисления В этом примере мы берем их равными $6200
35: (СОД)-$6200 Заданные вычисления
бе: Льготы Служит входом в этом примере
36: $2350 * Льготы В этом примере игнорируем верхний предел $81350
37: нал_доход = Мах (0. С35-С36) Налогооблагаемый доход. Мы будем
1 Проверка обработки может быть проведена в том числе путем тестирования домена, если, например, обработка представляет собой алгебраическое уравнение. Это можно рассматривать как проверку корректности вырожденного домена, заданного с помощью предиката равенства. [ AFIF92],
2 Этот вариант сильно искажает бланк декларации, поэтому, пожалуйста, не используйте его в целях, связанных с уплатой налогов.
7.3. Отношения и модель 189
38: Таблица расчета налогов
О < нал_доход =< $22100 $22100 < нал_доход =< $53500 $53500 < нал_доход =< $115000 $115000 < нал_доход =< $250000 $250000 < нал_доход
для всех значений использовать таблицу расчета налогов
налог = 0.15 * нал_доход налог = $3315 + 0.28 * (нал_доход - $22100) налог = $12107 + 0.31 * (нал_доход - $53500) налог = $31172 + 0.36 * (нал_доход -$115000) налог = $79722 + 0.396 * (нал_доход - $250000)
Нашей задачей является разработка модели тестирования доменов, которую мы можем использовать для проверки корректности реализации таблицы налогов. Прежде всего нам надо выразить таблицу налогов через входные переменные (СОД и Льготы). Проделайте это, заменяя входные переменные на соответствующие выражения, и затем, используя символическую подстановку, получите таблицу налогов. Я выполнил эти действия и вычеркнул несущественные для результата строки. Вот как выглядит моя перегруппированная модель:
32: СОД (Скорректированный_Общий_Доход) Вход
бе: Льготы Вход
38: Налог, рассчитанный из таблицы расчета налогов
Домен 1: налог =0.0
СОД-6200-2350 * Льготы <=0
Домен 2: налог = 0.15 * (СОД - 6200 - 2350 * Льготы)
СОД - 6200 - 2350 * Льготы > 0
СОД - 6200 - 2350 * Льготы <= 22100
Домен 3: налог = 3315 + 0.28 * ((СОД - 6200 - 2350 * Льготы) - 22100))
СОД - 6200 - 2350 * Льготы > 22100
СОД - 6200 - 2350 * Льготы <= 53500
Домен 4: налог = 12107 + 0.31 * ((СОД - 6.200 - 2.350 * Льготы) - 53500))
СОД - 6200 - 2350 * Льготы) > 53500
СОД - 6200 - 2350 * Льготы <= 115000
Домен 5: налог = 31172 + 0.36 * ((СОД - 6.200 - 2,350 * Льготы) - 115000))
СОД - 6200 - 2350 * Льготы > 115000
СОД - 6200 - 2350 * Льготы <= 250000
Домен 6: налог = 79772 + 0.396 * ((СОД - 6200 - 2350 * Льготы) - 250000)) СОД - 6200 - 2350 * Льготы > 250000
Чтобы сделать это, я использовал функцию поиска и замены в текстовом редакторе. Сначала я передвинул строку бе в начало. Затем'я удалил строки 33 и 34, поскольку в этом примере их значения считаются заданными и приведены в первоначальной модели. Далее я подставил СОД-6200 вместо С35, удалил строку 35 и упорядочил алгебраические выражения. Перед проведением подстановки я заключил выражения в скобки, чтобы избежать ошибок, таких как изменения знака из-за двойного знака «минус» и умножения выражения на константу, например, при вычислении переменной налог. Следующая подстановка была проведена для строки 36. Переменную Мах в строке 37 я удалил путем добавления другого домена, как вы можете видеть для случая отрицательного налогооблагаемого дохода. Затем я заменил переменную нал_доход и получил конечные выражения, которые и привел здесь (после небольшой перегруппировки для того, чтобы привести их
190 Глава 7 • Тестирование доменов
все к одинаковому виду). Затем я упростил алгебраические выражения для налогов и получил в результате следующую модель:
32: СОД (Скорректированный_Общий_Доход) Вход
бе: Льготы Вход
38: Налог, рассчитанный из таблицы расчета налогов
Домен 1: налог =0.0
СОД <= 6200+2350Льготы
Домен 2: налог = 0.15СОД - 352.5Льготы - 930.0
СОД > 6200 + 2350Льготы
СОД <= 28300 + 2350Льготы
Домен 3: налог = 0.28СОД - 658.ОЛьготы - 4609.0
СОД > 28300 + 2350Льготы
СОД <= 59700 + 2350 Льготы
Домен 4: налог = 0.31СОД - 728.5Льготы - 6400.0
СОД > 59700 + 2350Льготы
мС0Д<=121200+2350Льготы
Домен 5: налог = 0.36СОД - 846.ОЛьготы - 12460
СОД > 121200 + 2350Льготы
СОД <= 256200 + 2350Льготы
Домен 6: налог = 0.396 СОД - 930.6Льготы - 21683.2
СОД > 256200 + 2350Льготы
На рис. 7.2 показан возможно более наглядный способ представления этих доменов. В одномерном и двумерном пространстве будет не лишним изображать домены графически, подобно тому, как это сделал я. Границы доменов представляют собой несколько параллельных линий. Это типичные домены, встречающиеся на практике. Тем не менее, нам потребовалось выполнить алгебраические преобразования, для того чтобы упростить эти границы и выразить их через входные переменные.
Интерпретация предикатов. Символическая подстановка, проделанная выше, для того чтобы выразить домены через входные переменные, называется интерпретацией предикатов. Любое неравенство имеет вид предиката, который может принимать значение ИСТИНА или ЛОЖЬ. Предикат мы интерпретируем в терминах входных переменных.
Зачем все усложнять, интерпретируя предикаты границ доменов? Почему бы нам не работать непосредственно со строками спецификации ВНС? Дело в том, что в этом случае у вас уже не будет модели для тестирования доменов, это будет модель потока управления. Нашей же целью является проверка корректной реализации граничных предикатов (или их аналогов в коде).
Наша конечная модель является избыточной. Граничные неравенства появляются в ней дважды (по одному разу для каждого задаваемого ею домена). Эта модель неизящна, и вероятность того, что программист построит вычисления таким образом достаточно мала. Программист, проанализировав требуемые вычисления, организует их более эффективно (то есть так, чтобы их было проще сопровождать), и вместо промежуточных вычислений, заданных в спецификации, он, возможно, реализует нечто от них отличное, но, по всей вероятности, им эквивалентное. И в этом все дело. Анализ, который мы проводим для разработки тестов доменов, имеет совершенно иные задачи, в отличие от задач, стоящих перед программистом, и поэтому наши ошибки тоже, скорее всего, будут отличаться от ошибок разработчика. У нас, тестировщиков, собственные ошибки.
7.3. Отношения и модель 191
Рис. 7.2. Домены для неравенств в налоговой декларации
Основной аргумент в пользу проведения интерпретации предикатов — это обеспечение независимой проверки рациональности спецификации. Я допускаю, что спецификация содержит множество промежуточных вычислений на пути преобразования входных данных в выходные. Подобные промежуточные вычисления зачастую несущественны и являются всего лишь видением того, как должна быть запрограммирована спецификация, — что-то наши программисты могут и проигнорировать. Наша задача не ограничивается независимой проверкой работы программиста. Если проводимое нами моделирование выявляет противоречия и неопределенности в спецификации доменов (что часто и происходит), мы не зря едим свой хлеб.
Интерпретация предикатов обычно не очень сложна. В большинстве случаев вам не надо проводить ее совсем, поскольку домены изначально выражаются через входные переменные. Если вам все же приходится это делать и если ваши предикаты достаточно просты, используйте ваш текстовый редактор подобно тому, как это делал я (однако не забывайте заключать подставляемые выражения в скобки, чтобы избежать различных алгебраических ошибок при подстановке). Если текстовый редактор не справляется, используйте редактор формул. Мне хватает моего калькулятора НР-28С. Если для вас это затруднительно, используйте соответствующий математический пакет.
7.3.3. Анализ неопределенностей и противоречий
Приблизительно 30 % ошибок являются следствием некорректных требований. Цена таких ошибок высока, поскольку они проявляются лишь тогда, когда про
192 Глава 7 • Тестирование доменов
грамма начинает эксплуатироваться. Около 5 процентов ошибок происходят из-за неверного определения доменов1. Вопреки широко распространенному мифу, не существует какого-то одного превалирующего типа ошибок. Относительная частота возникновения большинства ошибок не превышает 3 процентов, то есть 5 процентов — высокий показатель и на поиск ошибок в доменах имеет смысл тратить время.
В программе необходимо исключить внутренние противоречия. Все ее функции должны быть согласованы друг с другом. Программа также не может быть неопределенной. Она всегда должна выполнять какие-либо действия над входными данными. Спецификации, однако, бывают и неопределенными и противоречивыми. Когда программист реализует такую неопределенную или внутренне противоречивую спецификацию, он или она должны сознательно или несознательно разрешать эти неопределенности и противоречия. Ошибки объясняются тем, что неопределенности и противоречия обычно не удается распознать, и тем что их разрешение обычно происходит подсознательно. Модель тестирования доменов, а также анализ, необходимый для построения этой модели, эффективны при проверке спецификаций на неопределенности и противоречия.
Неопределенность доменов. Спецификация набора доменов является неопределенной, если этот набор доменов не покрывает все входное пространство.
Противоречивость доменов. Два домена противоречивы, если они перекрываются.
Первое место, где стоит искать неопределенности и противоречия, — это границы между доменами. Рассмотрим пример:
Домен 3: СОД > 28300 + 2350Льготы
СОД <= 59700 + 2350Льготы
Домен 4: СОД >= 59700 + 2350Льготы
СОД < 121200 + 2350Лыоты
Домен 5: СОД > 121200 + 2350Льготы
СОД <= 256200 + 2350Льготы
Граница между доменами 3 и 4 противоречива, поскольку оба они одновременно закрыты на границе СОД = 59700 + 2350Льготы. Граница между доменами 4 и 5 не определена, так как входные значения для СОД = 121000 + 2350Льготы отсутствуют в спецификации.
Если у вас есть спецификация интерпретированной границы домена, вам надо проверить ее на предмет наличия неопределенностей и противоречий. Большинство из них легко могут быть выявлены при проверке. Для одной и двух входных переменных вы сможете выполнить это графически. Для трех и более входных переменных используйте соответствующие алгебраические инструменты [WHIT95].
1. Все ли входные значения в диапазоне от -<» до +°° включены? Если это не так, то существуют ли механизмы, запрещающие ввод в систему значений
1 Эта оценка занижена для современного программного обеспечения, поскольку утверждение основано на данных почти двадцатилетней давности (в 1994 году). В то время как методы компонентного тестирования совершенствовались, относительная частота возникновения ошибок в требованиях возрастала. Я не удивлюсь, если доля ошибок доменов в среднем окажется порядка 10 а для некоторых программ и всех 30 %.
Отношения и модель 193
больше верхней границы и меньше нижней? Проведите специальную проверку для нулевых значений. Спецификация в подразделе 7.3.1 не определена. Объясните, почему.
2. Последовательно ли закрытие для всех переменных и всех границ доменов в диапазоне от -<» до +°о? Если это не так, то должно быть несколько (как минимум два) неравенств, определяющих одну и ту же границу, но в различных областях входных значений, для различных направлений закрытия и включающих по меньшей мере одну переменную. Сгруппируйте эти наборы и проверьте их на предмет наложения закрытий и/или зазоров между ними. Ниже приводится пример, в котором закрытие противоречиво и не определено.
Домен 3: налог = 0.28СОД - 658.ОЛьготы - 4609.0
СОД >= 28300 + 2350Льготы. 0 < Льготы < 4
СОД > 28300 + 2350Льготы. 4 <= Льготы < 7
СОД >= 28300 + 2350Льготы. 7 < Льготы <= 10
СОД > 28300 + 2350Льготы
СОД <= 59700 + 2350Льготы
3. В одномерных и двумерных пространствах нарисуйте все заданные домены на одном рисунке, построив графически решения уравнений, определяющих границы для каждого из доменов. На следующем рисунке демонстрируется неопределенность для входных значений, меньших 7, и перекрытие доменов 1 и 2. Помните, что неопределенности и противоречия чаще всего встречаются в определении границ, поэтому вы должны быть уверены, что проверили закрытие каждой границы.
4. А как насчет пространства с размерностью три и более? В этом случае необходим алгебраический анализ, см. [WHIT95]. Вы, возможно, сможете решить задачу анализа трехмерных моделей в лоб или при помощи эвристических методов, но вряд ли вам что-нибудь сможет помочь разрешить математические аспекты данной проблемы. Созданные к 1995 году коммерческие инструменты не могут уверенно подтвердить непротиворечивость и однозначность спецификаций доменов. Организации, которым регулярно бывает нужен подобный анализ, привлекают для этих целей экспертов и разрабатывают собственное программное обеспечение.
Неоднсзначность
Х = 7Х>=7&Х<44 X = 44
Противоречие
Домен 3 X >= 50
7.3.4. Нелинейные домены
В этом разделе я поделюсь хорошими новостями, а также хорошими новостями, которые могут показаться плохими, но не для всех, и отличными новостями.
7 Зак. 770
194 Глава 7 • Тестирование доменов
1. Хорошие новости. Хорошей новостью является то, что нелинейные домены (то есть домены как минимум с одной нелинейной границей) на практике встречаются не слишком часто. Ранние исследования [СОНЕ78] выявили в коде языка COBOL около 85 процентов линейных предикатов. Мы имеем дело в основном с линейным миром.
2. Хорошие новости, которые могут показаться плохими (не обязательно). Проблему линейности в нашем случае надо рассматривать не как простую алгебраическую линейность, а в более широком смысле линейности векторных пространств. Полиномы первого порядка линейны в этом широком смысле. Поскольку любая приличная функция может быть аппроксимирована полиномами, то выбором подходящей аппроксимации можно свести задачу тестирования нелинейных доменов к задаче тестирования линейных доменов, хотя и ценой увеличения размерности. Нелинейные граничные уравнения нередко можно линеаризовать определенными преобразованиями. Это в первую очередь касается гипербол, экспоненциальных, степенных и логарифмических функций. Аппроксимация функций полиномами первого порядка встречается довольно редко, так как неэффективна с точки зрения вычислимости. Однако благодаря большой производительности современных компьютеров эта проблема стоит гораздо менее остро, чем принято считать. Выбирайте сами, чего вы хотите, вычислительной эффективности или тестируемости.
3. Отличные новости. Отличные новости [JENG94] состоят в том, что если вам нужно определить только наличие ошибки, а не описать ошибку (например, вид доменной ошибки), и при этом вы хотите исходить из рассчитываемого риска сокрытия некоторых ошибок [AFIF92], тогда проблем нелинейных границ доменов просто нет (в большинстве случаев).
7.4. Методы
7.4.1. Основы
Существует масса стратегий тестирования доменов [AFIF90, AFIF92, CLAR82, СОНЕ78, JENG94, НАОМ87, PERE85, WHIT78A, WHIT80A, WHIT85B, WHIT90, ZEIL83, ZEIL89]. Мы не будем рассматривать их все. Если вы занимались программированием, то вы, безусловно, знаете основы стратегий тестирования доменов. Если вы занимались программированием непродолжительное время, то вы использовали эвристические методы тестирования доменов. Прежде чем прейти к рассмотрению эффективных стратегий, давайте обсудим причины несовершенства эвристических стратегий.
1. Тестирование экстремальных точек. В соответствии с этой стратегией любой численный ввод должен быть протестирован в окрестности минимального и максимального значения этого ввода. Эта эвристическая стратегия имеет множество названий, таких как тестирование граничных значений [MYER79],
7.4. Методы 195
тестирование экстремальных значений и тестирование особых значений, [HOWD80]. Как подмечено Ричардсоном [RICH85] и многими другими, все эти эвристические стратегии относится к тестированию доменов. Основное отличие между формальным тестированием доменов и эвристическим тестированием доменов (общепринятым в течение десятилетий) заключается в большей эффективности первого и в том, что формальное тестирование позволяет узнать больше о найденных ошибках при помощи меньшего числа тестов.
2. Тестирование комбинаций экстремальных точек. Следующая стратегия типична и необычайно популярна (но плохо управляема). Согласно ей, необходимо проверить комбинацию экстремальных точек. Несмотря на то, что эта стратегия поддерживается коммерческими продуктами, позволяющими автоматически генерировать тесты, она в принципе ущербна, что мы и увидим в дальнейшем.
7.4.2. Недостатки комбинирования экстремальных точек
«Стратегия» комбинирования экстремальных точек, если ее можно так назвать, подразумевает существование наибольшего и наименьшего значений для каждой входной переменной. Предполагается, что все значения больше максимума и меньше минимума программа исправит или запретит. Очевидно, минимальные и максимальные значения определяют (отчасти) границы доменов, и стратегия направлена в первую очередь на тестирование границ доменов, а затем на проверку значений, лежащих чуть выше максимума и чуть ниже минимума. Это в пространстве с размерностью один. В двумерном пространстве, согласно этой стратегии, необходимо проверить комбинацию экстремальных точек. Если я условно назову четыре актуальных случая для каждой переменной соответственно «ниже», «min», «max» и «выше», то в соответствии с этой стратегией для двух переменных нам надо проверить: (нижеА, нижеВ), (нижеА, minB), ... (вышеА, вышеВ), всего 16 тестов, плюс еще один для типичных значений. Для п входных переменных число тестовых вариантов вырастет до 4n + 1.
Какой тип ошибок мы здесь рассчитываем обнаружить? Обработка, что бы она собой ни представляла, должна задавать функциональное отношение между входными переменными. Существует два варианта функциональных отношений между входными переменными: выходная функция, выраженная через эти переменные, или граница домена, выраженная через эти переменные.
1. Функция. Вычисляемая функция может быть или верной, или неверной. При тестировании комбинаций мы предполагаем отсутствие ошибок, за исключением особенных комбинаций (экстремальных случаев), поскольку для других комбинаций входных значений программа корректна. Иначе говоря, корректная обработка и обработка комбинации экстремальных значений, содержащая ошибки, соответствуют различным доменам. Если дело в этом, то нам лучше проверить границы доменов.
2. Граница домена. Входные переменные могут фигурировать в одной и той же (интерпретированной) границе домена. То есть возможны два вариан
196 Глава 7 • Тестирование доменов
та — либо входные переменные используются в описании границы, либо нет. Если нет, то они независимы. Между ними не существует функциональных отношений, мы предполагаем наличие ошибки, которая создает отношение на пустом месте. В таком случае это не ошибка, а вредительство. Если функциональное отношение существует, то его то нам и надо проверять, а тестирование ряда комбинаций критических значений не даст нам никакой информации об этом отношении.
В примере на рис. 7.3 я применил эвристическую комбинационную стратегию и получил заштрихованные точки. У нас есть три домена, границы которых изображены сплошными линиями. Только восемь контрольных точек — смежные с критическими точками, лежащими на верхней границе — могут сказать нам что-либо о корректности границ доменов. Тесты не скажут нам ничего о корректности нижней границы. Предположим, у нас есть ошибка, в результате которой реализуются два домена с границами, показанными пунктиром. Вместо трех доменов, мы получаем четыре, и кто знает, какая обработка будет им соответствовать? Тестирование комбинаций экстремальных точек не выявит эту ошибку.
Рис. 7.3. Функциональное отношение между входными переменными
Однако, может возразить предполагаемый оппонент, мы знаем, что домены существуют и что нам надо протестировать вводы в области значений Х = биУ = би их комбинации! Уже лучше, но все равно недостаточно хорошо. Эта предлагаемая поправка добавит 12 тестов, но все равно не сможет выявить ошибочное пересечение границ. В итоге мы приходим к выводу, что единственный способ протестировать функциональное отношение — это тестировать функциональное отношение. И предположение о наличии ошибки, которая создает отношение на пустом месте — плохое предположение.
Тестирование комбинаций экстремальных точек — это не лучший способ тестирования доменов в n-мерном пространстве. Он приводит к необходимости проведения массы тестов, большинство из которых бессмысленны и/или обманчивы. В преды
Методы 197
дущем примере мы провели 29 тестов, но так и не обнаружили ошибку. Правильная стратегия выявит эту ошибку всего за 4 теста. Самое плохое в рассматриваемой стратегии — это то, что число тестов растет экспоненциально с увеличением числа входных переменных. Следовательно, покрытие невозможно даже при наличии автоматизации. Для 50 входных переменных только очень небольшая часть чудовищного числа комбинаций (1.2677Е30, или 4Е19 лет тестирования при длительности теста — 1 миллисекунда) может быть проверена, и, следовательно, выбор проверяемых комбинаций будет совершенно произволен. Правильно организованное стохастическое тестирование обнаружит большее число ошибок и скажет вам больше о надежности программного обеспечения. В то же время грамотное тестирование доменов обладает существенно большими возможностями при меньших затратах.
7.4.3. Слабая стратегия 1x1, одномерное пространство
Первая стратегия (которая будет вами наиболее часто использоваться) — это слабая стратегия 1x1. Она называется «слабой», поскольку в ней предусматривается разработка всего лишь одного набора тестов для каждого граничного неравенства, вместо того, чтобы разработать подобный набор для каждого сегмента границы, а «1 х 1», так как она требует одну точку НА и одну точку ВНЕ для одного граничного неравенства.
На рис. 7.4 показаны все возможные ошибки для одномерной границы домена. В соответствии со стратегией, требуется по два теста на каждую границу (точка в одномерном пространстве) — проверка одной точки НА и одной точки ВНЕ. Я проиллюстрировал это на примере закрытой границы. Предлагаю вам в качестве упражнения самостоятельно убедиться, что стратегия работает для любой комбинации открытых и закрытых границ. Приведенные ниже случаи моделируют все возможные ошибки в одномерных границах доменов.
1. Ошибка закрытия. Граница открыта в то время, когда должна быть закрыта, и закрыта в то время, когда должна быть открыта. Тест точки ВНЕ выявит эту ошибку, поскольку ввод будет обработан как домен В, вместо того чтобы обрабатываться как домен А. Это работает, если только на границе нет случайной корректности.
2. Граница сдвинута влево. Точка ВНЕ будет обработана как домен В, вместо того чтобы обрабатываться как домен А.
3. Граница сдвинута вправо. Точка НА должна обрабатываться как домен А, но вместо этого будет обработана как домен В. Этот тест не дает информации, связана ли эта ошибка с закрытием или со сдвигом вправо, а лишь указывает на наличие ошибки.
4. Пропущенная граница. Обе точки НА и ВНЕ обрабатываются одинаково, хотя должны обрабатываться по-разному.
5. Лишняя граница. Дополнительная граница делит первоначальный домен на два домена. Наличие еще одной границы должно проявляться в видимом различии в обработке, в противном случае, мы не сможем ее обнаружить. Сравнение двух процессов обработки для точек, принадлежащих изначальной границе, должно выявить это различие.
198 Глава 7 • Тестирование доменов
Корректный домен А закрь, г
Контрольная 'гочка х точка НА
Ошибка закрытие домена В
в
Кон рольная -очка х, гонка ВНЕ
Ошибка раница сдвинута влево
Контрольная точка х точка НА
-в----------- ------ А
Ошибка, грв чина сдвинута вправо
X X fest po-nts on + off
____в _______________ sy - A
Ошибка граница nj опущена
Кон . рольная точка х
(точка НА) В А*
Контрольная точках
'точка нд) ®-------------
Ошибка: лишняя граница
Рис. 7.4. Ошибки в одномерном пространстве (закрытый домен)
Сравним эту стратегию с эвристической стратегией тестирования доменов для одномерного случая. Эвристическая стратегия предусматривает тестирование точки НА, точки ВНЕ, а также точек вблизи границы, но по другую сторону от нее («противоположность» точке ВНЕ) — то есть три теста для проверки одной границы, в то время как стратегия 1 х 1 требует лишь два теста. Неплохо. Мы уменьшили число тестов на треть и ничего при этом не потеряли; выигрыш в пространстве с большей размерностью будет гораздо более существенный.
Применим данную стратегию для случая нескольких границ. Спецификация доменов, приведенная в подразделе 7.3.1, после представления каждой границы в виде одного выражения выглядит так:
Домен нал_доход нал_доход нал_доход нал_доход нал_доход нал_доход нал_доход нал_доход нал_доход
> О
=< 22100
> 22100
=< 53500
> 53500
=< 115000
> 115000
=< 250000
> 250000
Тесты НА=0 НА=22100 НА-22-100 НА=53500 НА-53500 НА=115000 НА-115000 НА=250000 НА-250000
ВНЕ=0.00001
ВНЕ=22100.00001
ВНЕ 22100.00001
ВНЕ=53500.00001
ВНЕ-5Э500-: 00001
ВНЕ=115000.00001
BHE-H-500G. 00001
ВНЕ=250000.00001
ВНЕ -250000.00001
У нас есть пять доменов (на самом деле шесть) и пять определенных границ, которые мы проверяем при помощи 10 тестов; примитивной стратегии в то же самое время требуется 15 тестов, и при этом она не даст нам ничего нового.
7.4. Методы 199
7.4.4. Слабая стратегия 1x1, пространство с размерностью два и выше
Наша первая задача — определить, есть ли у нас ошибки, связанные с доменами. Границы, не содержащие ошибок, не требуют тестирования. Для границ, содержащих ошибки, будет полезно понять, что же неправильно в их реализации. Для этого нам необходима более сильная стратегия (N х 1, см. ниже). Для более узкой задачи (и более полезной для быстрой оценки), когда требуется определить, есть ошибки или их нет, стратегию 1x1 можно использовать в пространстве размерности два и более.
Я называю ее «слабой» стратегией 1x1, поскольку делаю следующие предположения: каждая граница простирается до ±«о, границы не содержат разрывов, и закрытие последовательно вдоль всей длины границ. Данная стратегия не ограничена требованием линейности границ или, скажем, функциями, определенными для вещественных чисел, — она применима без исключений к фактически любым доменам, которые могут определяться в программах.
Эта стратегия предусматривает тестирование одной точки НА и одной точки ВНЕ для каждого граничного неравенства, то есть тестирование двух точек, находящихся так близко друг к другу, чтобы они могли удовлетворять определению точек НА и ВНЕ. Заметим, что точка НА может и не лежать непосредственно на границе, если компьютерная или языковая система представления чисел не дает такой возможности. Точка НА всего лишь должна удовлетворять условиям границы. Такая ситуация продемонстрирована на следующем рисунке.
Правильная граница показана на нем сплошной линией. Направление ее закрытия, как обычно, отмечено штриховкой. Одна из возможных ошибочных реализаций показана пунктирной линией. Заметим, что мы не ограничены линейными границами доменов. Попробуйте изменить расположение этой кривой, и убедитесь, что в любом случае (за одним исключением, отмеченным ниже) либо точка НА будет лежать в домене В, либо точка ВНЕ будет лежать в домене А.
200 Глава 7 • Тестирование доменов
Исключение иллюстрирует данный рисунок. Ошибочная граница проходит на нем как раз между выбранными точками НА и ВНЕ. Прежде чем перейти к рассмотрению способов обнаружения данной ошибки, мы должны оценить вероятность ее возникновения. А она мала, поскольку мы имеем дело со случайными ошибками, а не с вредительством. Ошибки доменов в большинстве случаев достаточно масштабны и обладают явно выраженными симптомами. Например, возле десятичной точки пропущен коэффициент, или она поставлена не туда куда надо, пропущена или изменена константа, или даже пропущено целое выражение. В результате подобных ошибок происходит довольно существенное искажение ошибочной границы. Как мы можем от этого защититься? Выбором точек НА и ВНЕ настолько близко друг к другу, насколько это только возможно. У нас нет гарантии, что ошибочная граница не попадет в зазор между выбранными контрольными точками, но вероятность этого мала.
Но насколько действительно мала эта вероятность? Теория может дать качественную оценку [ AFIF92, JENG94]. Дженг и Ваюкер [JENG94], основываясь на теоретических исследованиях, приводят убедительные аргументы, подтверждающие, что она ничтожна. Любое тестирование характеризуется вероятностью, с которой оно пропустит серьезные ошибки. Аргументы Дженга и Ваюкера могут быть достаточно хороши для тестирования обыкновенного программного обеспечения, но для жизненно важных программ или для программ, создающих серьезные финансовые документы, может возникнуть желание избежать риска и использовать более сильные (и требующие гораздо больших затрат) методы, гарантирующие, что подобные коварные ошибки не останутся незамеченными. Давайте применим стратегию 1 х 1 к следующему примеру.
Домен 4: налог = 0.31СОД - 728.5Льготы - 6400.0
СОД > 59700 + 2350Льготы
СОД <= 121200 + 2350Льготы
Мы об этом не говорим, но число льгот (Льготы), очевидно, должно быть целочисленным и быть больше нуля. Мы начнем с выбора точки НА, поскольку это проще всего сделать. Выберете любую точку, удовлетворяющую границе домена. У нас есть две границы. Для второй границы мы имеем СОД = 121200 + 2350Льготы, поэтому, выбирая, например, значение Льготы = 5, получаем СОД = 132950. Нам надо, чтобы точка ВНЕ лежала совсем близко. В данном приложении наименьшей различимой величиной является пенни, поэтому значение, меньшее на два порядка, будет удовлетворять нашему условию. То есть получаем СОД = 132950.0001 и Льготы = 5.
Заметим, что вы вправе выбирать значение точки ВНЕ настолько близкое, насколько вам позволяет система представления чисел, чтобы не нарушались расчеты при округлении или вследствие ошибки компьютера. К примеру, вы можете выбрать значение СОД = 132950,000000000001, при условии, что ваш компьютер и/или язык поддерживают вычисления с плавающей точкой до такой значащей цифры. Это полезно, поскольку уменьшается вероятность пропустить ошибку, вкравшуюся между точек НА и ВНЕ. С другой стороны, если система представления чисел поддерживает вычисления (для последнего примера) только до десятой значащей цифры, то ваши точки НА и ВНЕ сведутся, по сути, к одной точке, и вы уже не будете использовать данную стратегию. Я предлагаю вам самим разрабо
7.4. Методы 201
тать тесты для других границ этого домена и рассчитать ожидаемые значения для спроектированных вами тестов.
7.4.5. Вырожденный случай
В n-мерном пространстве вырождение возникает, если домен определяется как область с размерностью меньшей, чем п. А и В — смежные домены и оба открыты по отношению к показанной на рисунке границе.
х. Точка ВНЕ х. для В и С
Хк | Домен В открыт
Точка ВНЕ для А и С -► Точка НА для А, В и С
Домен А открыт 4
Домен С закрыт
Линия С обозначает границу и представляет собой отдельный домен. Согласно определению, граница должна быть закрыта. Стратегия 1x1 будет здесь работать, если вы корректно интерпретируете составляющие элементы. Домен А открыт, поэтому мы берем точку НА на границе, а точку ВНЕ внутри А. Для В тоже надо выбрать точку НА, но мы можем взять ее той же самой, что и для А. Точка ВНЕ для В лежит внутри В. Как насчет С? Она закрыта, поэтому, согласно определению, точка ВНЕ должна лежать снаружи. Снаружи чего? Снаружи С и, следовательно, в обоих доменах А и В. Повторяюсь, точки могут быть общими. Таким образом, в случае вырождения нам не нужны дополнительные тесты, если мы уточним, что мы подразумеваем под «точкой ВНЕ» в данной ситуации.
7.4.6. Стратегии более высокого порядка для пространства с размерностью два и более
7.4.6.1. Для чего нужны стратегии более высокого порядка?
Существуют две причины для использования стратегий более высокого порядка. Чтобы быть уверенными, что ошибки границ различных типов не могут остаться незамеченными для выбранных точек НА и ВНЕ базовой стратегии 1 х 1 и чтобы получить информацию об ошибке, выявленной при помощи более простой стратегии. На самом деле у нас есть три причины, чтобы обсудить стратегии более высокого порядка. В дополнение к первым двум причинам мы можем использовать стратегии более высокого порядка, для того чтобы оценить их вклад в тестирование в целом.
7.4.6.2. Безопасность тестирования
Все стратегии более высокого порядка требуют большего числа контрольных точек, существенно большего. В большинстве случаев число дополнительных тестов,
202 Глава 7 • Тестирование доменов
приходящихся на одну границу, пропорционально размерности пространства. Если b — число границ, то стратегия 1x1 подразумевает проведение 2Ь тестов. Все более надежные методы требуют уже порядка Ьхп тестов, где п — размерность пространства. Это гораздо хуже, но все равно не так плохо, как в случае примитивной стратегии, основанной на комбинации экстремальных точек, которая предполагает проведение тестов.
Ситуация осложняется с ростом размерности, то есть вероятность пропустить ошибку, вкравшуюся между выбранными контрольными точками, растет с ростом размерности. Тем не менее, в 1995 году мы не располагали надежной статистикой для количественной оценки риска, а могли пользоваться лишь теоретическими исследованиями.
Афифи с соавторами [AFIF92] продемонстрировали, что для полной уверенности в отсутствии ошибок, вкравшихся между выбранными точками НА и ВНЕ, а также для проверки на наличие множества других разных ошибок доменов вам необходимо п + 2 грамотно подобранных тестов на одну границу (слабое предположение). Как минимум, одна из точек должна быть точкой НА и одна должна быть точкой ВНЕ. Особенности контрольных точек (то есть что кроется за словами «грамотно подобранный»), а также алгоритмы выбора этих точек лежат за рамками данной книги, но подробно изложены в [AFIF92].
7.4.6.3. Типы ошибок доменов
Из трех целей, преследуемых при рассмотрении стратегий более высокого порядка, вторая и третья могут быть достигнуты при исследовании стратегии N х 1 [СОНЕ78]. N х 1 — приемлемая стратегия, которую можно использовать для диагностики природы ошибок в случае, если вы определили что ваша граница содержит ошибки. Она также помогает понять суть тестирования доменов и природы ошибок в целом. И, наконец, в любой специализированной литературе, описывающей тестирование доменов, предполагается, что вы знакомы с этой стратегией.
Применение стратегии N х 1 позволяет проводить диагностику ошибок, поскольку, выбирая п точек НА, мы можем убедиться в корректности граничной гиперплоскости с размерностью п-1 в n-мерном пространстве (например, линии в двухмерном пространстве и поверхности в трехмерном пространстве).
Мы можем рассматривать возможные варианты ошибок доменов в пространстве с размерностью два и более для случая, когда все границы доменов линейны. В сущности, тестирование доменов представляет собой одну из немногих областей, где можно описать ошибки на языке математики. Данная стратегия требует наличия п точек НА и одной точки ВНЕ для n-мерного пространства.
1. Ошибка закрытия. Граница, которая должна быть открытой, реализована как закрытая, а граница, которая должна быть закрытой, реализована как открытая. Мы будем рассматривать случай закрытых границ, а анализ открытых оставим в качестве упражнения. Тестирование одиночной точки НА выявит эту ошибку, если на границе нет случайной корректности. Ошибка закрытия — это наиболее часто встречающаяся ошибка доменов.
В
7.4. Методы 203
ЕЖ ПРАВИЛЬНО А
И НЕПРАВИЛЬНО
2. Сдвиг домена «вверх» или «вниз». В одномерном пространстве эта ошибка эквивалентна сдвигу влево или вправо. Сдвиг домена возникает вследствие ошибки в постоянном слагаемом неравенства: слишком большое или слишком маленькое значение, или смена его знака. Это относится к п-мерному пространству. В отсутствии сдвига (корректная реализация) точка НА обрабатывается как домен А, а точка ВНЕ как домен В. После сдвига вверх все три точки будут обрабатываться как домен А.
ТОЧКА ВНЕ
ТОЧКИ НА ""А
ПРАВИЛЬНО
ГРАНИЦА СДВИНУТА ВВЕРХ
Я предлагаю вам самостоятельно проверить, что стратегиям х 1 вдвухмерном пространстве работает для всех видов сдвига (слишком большое, слишком маленькое значение или смена знака константы), для открытых и закрытых доменов.
Сдвиги доменов, как правило, довольно значительны. Наиболее вероятной причиной возникновения сдвига является грубая ошибка Flp2, например отсутствие десятичной точки или ее неправильное положение. Однако простая перестановка цифр в числе может привести и к небольшим сдвигам. Поэтому так важно выбирать точку ВНЕ как можно ближе к границе.
3. Поворот домена. В одномерном пространстве этому нет аналога, но эта ошибка встречается в пространстве с размерностью два и более. Поворот домена возникает вследствие какой-либо ошибки в коэффициентах тестируемого неравенства.
204 Глава 7 • Тестирование доменов
Я повернул границу домена против часовой стрелки. В отсутствие поворота точка ВНЕ обрабатывается как домен В. После поворота эта точка попадает в домен А, и, следовательно, мы получили ошибку.
Поворот домена является следствием ошибки в коэффициентах (в линейных неравенствах), и, подобно сдвигу, он скорее будет большим, нежели маленьким. И точно так же, выбирая точку ВНЕ как можно ближе к границе, мы можем повысить чувствительность к маленьким сдвигам.
4. Лишняя граница. Стратегия N х 1 применима также и для поиска лишних границ. Вместо двух доменов возникают четыре. Предположим, лишней границе соответствует некоторые различия в процессе обработки, так что мы можем отличить, скажем, домен А от домена А'.
Вч в’
ТОЧКА ВНЕ
7^7777777777777^77^^7^7/7777 I А'
ТОЧКИ НА
Сравнение двух точек НА, выбранных так, чтобы новая граница проходила между ними, выявит расхождение. Стратегия Nx 1 слепа к лишним границам, которые не приводят к изменению обработки. Однако это не смертельно, поскольку пользователь также их не заметит.
5. Пропущенная граница. Сравните любую из точек НА с точкой ВНЕ. В результате отсутствия границы домены А и В будут обрабатываться одинаково (но мы не можем сказать, будет ли это обработка соответствовать домену А или домену В).
ТОЧКИ НА
777^7777777777777777^77^7^777777 к ТОЧКА ВНЕ
7.4.6.4. Иллюстрация стратегии N х 1
Какие контрольные точки нам надо взять? Для слабой стратегии N х 1, где мы тестируем граничные уравнения, а не сегменты границ, выбирайте точки НА как можно дальше друг от друга, а точки ВНЕ посередине между ними. Вот некоторые комментарии для случая размерности большей, чем два.
1. Точки НА должны быть линейно независимы. К примеру, в трехмерном пространстве они не могут быть коллинеарными, то есть лежать на одной линии. В четырехмерном пространстве, где границы объемны, точки не могут быть компланарны. Имеет смысл выбирать точки НА рядом с узлами доменов, поскольку узловые точки доменов всегда независимы.
7.4. Методы 205
2. Точки ВНЕ надо выбирать рядом с центром тяжести точек НА. Для линий берите середину между точками НА. Для плоскостей выбирайте точку, лежащую в середине треугольника, построенного на точках НА, то есть как можно ближе к точке, равноудаленной от вершин треугольника.
Применим стратегию N х 1 для тестирования верхней границы домена 4.
Домен 4: налог = 0.31СОД - 728.5Льготы - 6400.0
СОД > 59700 + 2350Льготы
СОД <= 121200 + 2350Льготы
Число льгот (Льготы) не может быть отрицательным, поэтому мы выбираем ноль в качестве нижней границы. Здесь не задан верхний предел, но мы можем выбрать его сами, задав достаточно большое значение для уменьшения вероятности пропуска маленьких сдвигов или поворотов; например, 100. Льготы представляются целыми числами, поэтому 1 — это наименьшее значение (из тех, что мы можем выбрать), отличающееся от узловой точки. Подставляя 1 и 100, мы получаем 123550 и 356200,соответственно. Итак, мы выбрали следующие точки НА: (1, 123550) и (100, 356200). Наш следующий шаг — выбор точки ВНЕ. Для начала выберем точку на границе, посередине между двумя точками НА, то есть Льготы = 50. Подставляя это значение в уравнение границы, мы получаем 238700. Но наша точка ВНЕ должна лежать снаружи домена, в данном случае — немного выше, поэтому мы берем точку ВНЕ равной (50,238700.01). Последнее, что нам надо сделать, это подставить полученные три набора значений в уравнение для налогов, чтобы получить наш предсказанный итог. Однако будьте уверены, что вы подставляете точку ВНЕ в уравнение расчета налогов для домена 5, а не домена 4. Выполнив это, мы получаем следующие варианты теста:
Льготы СОД Налог
1 123550.00 31172.0000
50 238700.01 31172.0036
100 356200.00 31172.0000
Это не является проявлением случайной корректности, поскольку наша задача заключается не в поиске различий между точками в одном и том же домене, а в определении, не попала ли точка по ошибке в другой (например, смежный) домен. При расчете налога для точки ВНЕ в этом домене (4) получается 31172,0031 вместо 31172,0036. Налог получился один и тот же для всех трех точек, однако домены и налоговые ставки не были линейно независимы. Вообще говоря, подобная ситуация нетипична, и это подтверждает следующий пример:
Неравенство точка НА #1 (х. у) точка НА #2 (х, у) точка ВНЕ
У >= 0 0. 0.0001 0. 10 -0.0001. 5
х >= 0 0.0001. 0 10. 0 5. -0.0001
2у < х+4 2. 3 12. 8 6.999, 5.499
4у >= х-4 4. 0 20. 4 12.0001. 1.999
у <= -х+16 0. 16 16. 0 8.0001. 8.0001
Я не стану приводить результат вычисления функции в этом домене, но давайте предположим, что он у нас есть и что случайная корректность со смежным доменом отсутствует. Я проиллюстрирую процедуру на примере проектирования тестов для последней из этих границ. Нам надо выбрать точки НА как можно дальше друг от друга, имея в виду, что, используя слабую стратегию Nx 1, мы можем проверить
206 Глава 7 • Тестирование доменов
лишь границу целиком и не можем проверить отдельные сегменты данного домена. Таким образом, я могу взять любые значения на прямой, и наиболее далекими друг от друга будут точки (х = 0, у = 16) и (х = 16, у = 0). Средняя точка между ними будет равна (8,8). Поэтому для теста мы используем значения х = 8.0001 и у = 8.0001. Оси X и Y также принадлежат границам этого домена. Ошибки, связанные с координатными осями, встречаются довольно редко, но вы, возможно, все-таки захотите их протестировать. Минимальное значение у равно нулю, поэтому (0, 0.0001) и, например, (0,10) — неплохой выбор для точек НА. Тогда для точки ВНЕ получаем значение (-0.0001, 5). Следующее уравнение описывает открытую границу, и поэтому мне пришлось вычесть небольшую величину, чтобы точка ВНЕ лежала внутри. Я надеюсь, что вы нарисуете эти линии, их закрытия и тестовые точки на миллиметровой бумаге, чтобы проследить за тем, что я делал.
7.4.7. Сильное тестирование доменов
Отличие между сильным и слабым тестированием доменов заключается в том, что при слабом тестировании мы разрабатываем ряд тестов для каждого граничного неравенства, в то время как при сильном тестировании мы используем отдельный набор тестов для каждого сегмента границы'. Но это не означает использования той или иной стратегии. Ваше тестирование может быть слабым по отношению к одному набору границ и сильным по отношению к другому. Все зависит от ситуации. Используйте слабое тестирование, если для использования сильного у вас нет особых причин, подобных приведенным ниже.
1. Разрыв в граничном неравенстве. Это означает, что у вас есть три сегмента, подлежащие тестированию. Вы, разумеется, можете захотеть протестировать сегмент разрыва сам по себе, однако будет лучше, если вы протестируете обе части граничного неравенства по обе стороны от разрыва как неравенства, а не как сегменты.
2. Изменение направления закрытия в одном или более сегментах — хороший повод выбрать сильную стратегию по отношению к данному неравенству.
3. Процесс обработки построен таким образом, что некоторые контрольные точки попадают в область, которая впоследствии не обрабатывается. Предположим, у нас есть несколько доменов и любой ввод, не попадающий в эти домены, отбрасывается. Программный код проходит три ступени — проверка соответствия данных, классификация ввода, обработка. Используя слабое тестирование, вы выбираете точки, которые попадают в запрещенную область. Они отбрасываются, но тестирование логики разбиения на классы — это, собственно, не то, что вас интересует. Два набора перекрывающихся доменов — это все,
1 На самом деле мое разделение стратегий на сильные и слабые обманчиво. Подходящий набор спецификаций в случае, когда требуется «сильное» тестирование, подразумевает наличие, по меньшей мере, одного неравенства для каждой точки, в которой меняется направление закрытия границы, и/или в начале или конце каждого разрыва границы. Если вы обладаете подобной дополнительной информацией, любое ваше тестирование будет слабым — у вас нет необходимости тестировать пересечение само по себе.
7.5. Рассмотрение приложений 207
что у вас есть. Первый набор определяет границы принять/отбросить, а второй задает обработку. Подобная реализация в известном смысле избыточна, но такой подход необычайно популярен. Если вы в данном случае воспользуетесь слабой стратегией, это может ввести вас в заблуждение. Многие вводы будут отбрасываться, так как они лежат вне обрабатываемых доменов, но отбрасываются они из-за случайной корректности. Выбирая здесь слабую стратегию, вы сделаете вывод о корректности границ, задающих обработку, основываясь на данных проверки границ. Это опасное заблуждение. Сильное тестирование, вероятно, будет более безопасным. Чтобы сделать обоснованный выбор, вам придется заглянуть в программный код.
4. Вникните в стиль программирования. Если я вижу ясный, четкий, управляемый таблицами узел обработки с точно идентифицированными граничными неравенствами, и к тому же существует универсальный модуль, выполняющий классификацию, то, скорее всего, в сильном тестировании нет необходимости. Напротив, если для определения каждого домена реализован специальный код, программа полна сложных структур IF-THEN-ELSE, а граничные предикаты избыточны, то стоит использовать сильное тестирование. Если это был старый код, который раньше работал и был сохранен, то у вас, по-видимому, нет выбора, поскольку слабое тестирование может пропустить слишком много доменов, не обнаружив ошибок в их реализации, в то время как они там есть. Если у вас есть новый код, который, однако, был реализован неудачно, то я бы на вашем месте начал со слабого тестирования, так как уже оно выявит большое число ошибок. Если код был изменен в результате исправления ошибок, которые мы обнаружили при помощи слабого тестирования, то следует продолжить слабое тестирование. Однако если бы программисты сводили исправление ошибок к латанию дыр, лишь бы только это работало, я бы рекомендовал использовать сильное тестирование.
7.5. Рассмотрение приложений
7.5.1. Индикаторы приложений
Тестирование доменов не годится для тестирования систем или даже программ целиком. Никакой одиночный метод с этим не справится. Вот некоторые характерные особенности приложений, для которых применимо тестирование доменов:
1. Части спецификаций, заданные непосредственно в виде численных неравенств.
2. Сложная численная обработка с большим количеством логических условий. Например, налоговые формы, обработка платежных ведомостей, финансовые вычисления и почти все операции, выполняемые в электронных таблицах.
3. Численные вводы и сложная проверка соответствия входных данных и их классификация, даже если впоследствии отсутствует трудоемкая численная обработка.
208 Глава 7 • Тестирование доменов
4. Не ограничивайте ваше знание тестирования доменов и его применение только программным обеспечением. Мы рассматриваем тестирование черного ящика, поэтому мы делаем минимум предположений о том, что тестируется и как это реализовано. Тестирование доменов может быть действенным методом тестирования систем, которые могут содержать или не содержать программное обеспечение (что редко встречается в наши дни). Если система, вне зависимости от того, как она реализована, описывается (отчасти) алгебраическими неравенствами, то это свидетельствует о возможности применения тестирования доменов.
7.5.2. Предположения об ошибках
Ниже в порядке важности приведены ошибки, которые мы чаще всего рассчитываем обнаружить в тестируемой системе.
1. Ошибки спецификации доменов. Неопределенные домены — спецификация входного пространства неполна; противоречивые домены — перекрытие доменов, особенно для границ с направлением закрытия в обе стороны; переопределенный домен — существование домена невозможно из-за слишком большого количества неравенств; вырождение домена там, где он не нужен.
2. Ошибка границ домена. Неправильное закрытие, сдвиг, поворот, пропущенная граница, лишняя граница.
3. Ошибка обработки домена. Здесь рассматриваются корректно определенные домены, у которых, однако, обрабатывающая функция неверна. Выбор неверной функции более вероятен, чем ошибка в реализации этой функции.
4. Ошибка в узлах домена. Они проявляются только в узловых точках определяемых доменов, особенно если присутствует большое количество специальной логики.
7.5.3. Ограничения и предостережения
Применение любого метода ограничено, и тестирование доменов не исключение. Ниже приводится краткое изложение ограничений, обсуждаемых в этой главе.
1. Циклы. Мы предполагаем, что в процессе выбора доменов отсутствуют циклы. Циклы, включенные в процесс обработки домена, нам не опасны до тех пор, пока вы можете гарантировать, что обработка какого-либо домена не приведет к переходу программы на обработку другого домена. Существуют теоретические методы обработки циклов, которые могут влиять на границы, но они лежат за рамками данной книги.
2. Случайная корректность. Случайная корректность — это проблема для всех методов тестирования. Наиболее вероятной ситуацией является случайная корректность по отношению к отбрасываемым входным доменам. Это означает, что из-за случайной корректности плохие вводы отбрасываются по неверной причине.
7.7. Вопросы для самопроверки 209
3. Слепота и эпсилон. Тестирование доменов слепо к ошибкам, меньшим, чем выбранное вами е. Возможно, вам не удастся выбрать единственное значение для всего вашего тестирования. Ваша обработка может ограничивать пределы малых значений в вашей системе (например, 10’399), и выбор соответствующего е будет означать потерю значимости.
4. Сложность с выбором точки ВНЕ для закрытых доменов. Для доменов, которые граничат с доменами, отбрасываемыми на вводе, точка ВНЕ ничего вам не скажет, так как проверка соответствия ввода происходит раньше, чем выбор домена.
7.5.4. Автоматизация и инструментальные средства
К настоящему времени не существует коммерческих инструментов, обеспечивающих полноценное тестирование доменов. Некоторые автоматические генераторы тестов используют эвристическое одномерное тестирование доменов и затем создают ряд комбинаций значений экстремальных точек. Плюсом этого метода является то, что для применения стратегии 1x1 вам не нужны какие-то специальные инструменты, кроме калькулятора для элементарных вычислений и собственного желания. Вам не нужны алгебраические инструменты для проверки полноты и последовательности границ домена [WHIT95], Все инструменты, необходимые для тестирования больших размерностей, имеются в большом количестве в математических библиотеках [BISW87, KOLM88], Плохая новость состоит в том, что они практически не связаны друг с другом, что затрудняет их использование при тестировании доменов.
7.6. Резюме
Тестирование доменов представляет собой формальный, автоматизируемый метод, призванный так или иначе заменить общепринятую, но неэффективную практику тестирования экстремальных входных значений и их комбинаций. Тестирование доменов основано на формальной процедуре определения доменов как набора входных неравенств, заданных во входном пространстве. Слабая стратегия 1x1 тестирования доменов используется для адекватных неравенств, а неадекватные тестируются при помощи сильной стратегии 1x1. Стратегии более высокого порядка, такие как Nx 1 и стратегии, описанные в [AFIF92], могут помочь установить природу ошибок (например, сдвиг, поворот), если это является одной из ваших задач. Полная автоматизация проектирования тестов и их выполнение возможны при современном развитии вычислительной техники, однако поддержка этих возможностей коммерческими инструментами весьма незначительна.
7.7. Вопросы для самопроверки
1. Дайте определение следующих терминов: смежные домены, граничное уравнение, граничное неравенство, сегмент границы, центр тяжести, законченная
210 Глава 7 • Тестирование доменов
граница, закрытая граница, закрытый домен, ошибка закрытия, коллинеарный, последовательное закрытие, вырожденная граница, вырожденный домен, домен, неопределенный домен, граница домена, набор границ домена, противоречивый домен, ошибка сдвига домена, ошибка поворота домена, окрестность эпсилон, внешняя точка, гиперплоскость, незаконченная граница, непоследовательное закрытие, входное пространство, входная переменная, входной вектор, внутренняя точка, линейный домен, линейно зависимые неравенства, линейно зависимые векторы, линейно независимые векторы, линейно независимые уравнения, линейное неравенство, нелинейный домен, Nx 1, точка ВНЕ, 1x1, точка НА, открытая граница, открытый домен, выходное пространство, выходная переменная, выходной вектор, параллельный, интерпретация предиката, область, ошибка сдвига, сильное тестирование доменов, субдомен, ошибка поворота, вектор, узловая точка, тестирование домена.
2. Что является шестым доменом в примере подраздела 7.3.1?
3. Найдите неопределенность в первой спецификации подраздела 7.3.2.
4. Найдите все огрехи в последней спецификации подраздела 7.3.3.
5. В бланке SE определяются следующие домены: протестируйте их
Self_Employment Income Тариф
(Доход от частного предпринимательства)
ЧП_доход < 433.13 О
433.13 <= ЧП_доход <= 57600 0.153 * Чистый_ЧП_доход
57600 < ЧП_доход < 135000 0.029 * (Чистый_ЧП_доход -57600) + 8812.80
135000 <= Чистый ЧП_доход 11057.40
6. Продемонстрируйте, что стратегия 1x1 работает для любой комбинации открытых и закрытых границ в одномерном пространстве.
7. Начертите границы доменов, задаваемых последними неравенствами подраздела 7.4.6, и идентифицируйте все эти домены. Разработайте набор тестов, используя сильные стратегии 1x1 и Nx 1.
8. Для каждого из следующих примеров разработайте набор тестов, используя стратегии 1x1 и Nx 1. Под набором тестов подразумеваются входные значения и предсказанные итоги.
1) Вычисляемая функция: и = Зх2 + 1пу - ехр(х2 - у3) + 17.
Неравенства: -37 <= х2 + у2 - 10х - 8у <= -25, х >= 1, у >= 0.
Тесты: (х = 5, у = 8), (5, 6), (5, 2), (5, 0), (6.999, 4), (9.001, 4). Я вам дал варианты тестов, ваша задача их обосновать.
2) Вычисляемая функция: Зх + 7у - 908.7345
Неравенства: 1 <= х <= 3, 2 <= у <= 10, х2у3135 >= 30
3) Вычисляемая функция: 14х + 3.5х2 + 17
Неравенства: 0 <= 14х + 3.5х2 + 17 <= 31, 0 <= х <= 4
Синтаксическое тестирование
8.1. Обзор
Синтаксическое тестирование — это мощный метод для проверки командно-управляемого программного обеспечения и сходных приложений. Он достаточно легко осуществляется и поддерживается многими коммерческими инструментальными средствами.
8.2. Основные термины
Внешние термины: алгебра, ANSI, приложение, ASCII, булева, символ, код, команда, связь, содержание, управление, база данных, накопитель, файл, имя файла, идентичность, вход, целочисленный, непосредственное соседство, язык, уровень, логическое ИЛИ, макро, модель, MS-DOS, имя, число, операционная система, выборочно, Pascal, конвейеризация, программа, переадресация, последовательность, набор, программное обеспечение, дерево, UNIX, значение, переменная.
Внутренние термины: ошибка, чистый тест, покрытие, грязный тест, тестирование доменов, связь, покрытие связей, вес связи, цикл, тестирование цикла, узел, покрытие узлов, объект, итог, путь, отношение, спецификация, тестирование конечного автомата, система, тест.
Алфавит. Набор определенных символов, применяемых в данной задаче. Например, ASCII, иероглифы, {а, Ь, с, х, у, %, 7}. Алфавит может меняться в зависимости от приложения и даже отличаться для разных тестов. Не забывайте проверять алфавит, так как большое количество ошибок (найденных путем синтаксического тестирования) возникает из-за использования неверного алфавита, например, ASCII вместо ANSI.
212 Глава 8 • Синтаксическое тестирование
Тире. Тире между двумя элементами алфавита заменяет собой все элементы в алфавите, начинающиеся с первого и заканчивающиеся последним элементом, в предположении что естественный порядок этих символов понятен, как, например, «а-я». «1-9» означает целочисленные символы от 1 до 9, включительно.
Метасимволы (или металингвистические символы). Символы, используемые для описания языка. Используемые метасимволы включают в себя: {, }, |, [, ], (, ), *, +, <, >, ?, р, 6, а, Ф, :, :=, =, -, (запятая), (пробел) и символы, используемые в обычных текстах. Интерпретация и применение метасимволов будут обсуждаться ниже. Мы будем рассматривать слова и команды, составленные из символов, а также способы их тестирования, поэтому так важно различать тестируемые символы и символы, которые описывают тестируемые символы. Для того, чтобы описать тест, включающий символ |, обычно этот символ дублируют. То есть используют комбинацию символов «| |». Так, например, «[[» означает не два метасимвола «[», а одиночную квадратную скобку, которая фигурирует в тесте.
Нуль (X). Металингвистический символ, используемый для обозначения отсутствия символа. Не путайте X с символом пробела (о), или пустым символом (Р).
Символ пробела (а). Металингвистический символ, обозначающий знак пробела (например, в напечатанном тексте). Пробелы между словами в предложении используются для удобства чтения и не являются частью нашего описательного языка.
Пустой символ (Р). Металингвистический символ, обозначающий пустоту. Он может совпадать, а может и не совпадать с символом пробела. Типичное отличие между пустым символом и символом пробела заключается в том, что а создает видимое пространство при печати или в изображении чего-либо, в то время как Р — нет.
Строка. Последовательность, состоящая из ноля или более символов алфавита. Например, авб567хррр111, 1776,666999,{:{ |)>, —/Д\—. Строки идентифицируются при помощи букв верхнего регистра, например, А.
Набор строк. Наборы строк выделяются фигурными скобками, например, {А}. Набор, состоящий, к примеру, из нулевой строки X — {X}, обозначается просто X.
Имя строки. Другой способ обозначить строку, это заключить ее имя в угловые скобки, подобно <имя_строки>. Строковое имя также может быть именем набора строк. Например, <имя_строки_альфа>::={х,хх,ав,сде}.
Команда. Строка, используемая для управления. Команды состоят из комбинации полей, операторов, операндов и разделителей.
Командно-управляемое программное обеспечение. Программная система или ее часть, в которой основное управление происходит посредством строк, вводимых из командной строки, как, например, MS-DOS и UNIX.
Командный язык. Набор команд, используемый для управления командноуправляемым программным обеспечением. Основная задача синтаксического тестирования — проверка командных языков.
Синтаксис. Правила, определяющие, что является, а что не является правильной строкой (например, командой). Правила могут быть, а могут и не быть универсальными для всех команд, как, например, корректная форма представления чисел. Но для каждой команды в командном языке должно существовать какое-либо
8.2. Основные термины 213
правило. Синтаксическое тестирование используется для проверки, сможет ли программа распознать правильным образом составленные строки и отбросить некорректно составленные.
Строковое поле, (или просто «поле», если смысл понятен из контекста) Часть строки, которой вы даете определенное имя.
Операнд. Имя объекта, фигурирующего в командах: например, в команде DEL С: <имя файла>, объект <имя файла> является операндом. Операнды, как правило, имеют вид слов в обычном языке, таких как «имя файла» или «имя носителя».
Оператор. Специальные символы или строки, показывающие, какое действие должно быть выполнено над определенным операндом. В предыдущем примере ключевое слово DEL является оператором.
Ключевое слово. Оператор (обычно), который имеет вид обычного слова, такого как DELETE, STORE, OPEN. Несмотря на то, что ключевое слово может состоять из большого числа символов, это, тем не менее, одиночный оператор.
Разделитель. Символы алфавита, используемые для разделения отдельных операторов, операндов, и/или для обозначения конца команды. В качестве общепринятых разделителей обычно используют символы (3, а, (,), J (возврат каретки), = (перевод строки), [, ], /, \, «, » и ,.
Грамматический разбор. Процесс разбора строки, чтобы выделить в ней поля, операторы, операнды и разделители. Программа, которая это выполняет, называется синтаксический анализатор. Любые командно-управляемые системы должны иметь синтаксический анализатор, но зачастую он реализуется неявно. Главной задачей синтаксического тестирования является проверка синтаксического анализатора. Нам не обязательно знать конкретный способ проведения синтаксического анализа, чтобы тестировать анализатор.
Синтаксический анализ. Грамматический разбор в применении к одиночному полю или части команды, например, идентификация поля подстрока как строки <число>. Синтаксическое тестирование используется для проверки корректности синтаксического анализа, выполняемого программой.
Семантический анализ. Операнды имеют определенные значения. Число во введенной команде, кроме того, что оно является правильно составленной строкой, имеет еще и значение. У этого значения могут быть пределы, то есть максимум и минимум. Синтаксическое тестирование не имеет непосредственного отношения к семантическому анализу. Этот анализ лучше делать при помощи других методов, таких как тестирование доменов для численных полей.
Интерпретация команды. Предположим, что был проведен грамматический разбор команды и семантический анализ входящих в команду полей. Затем полученные данные были отправлены в программу на обработку, что означает выполнение команды. Акт выполнения команды называется интерпретацией команды.
Лексическая эквивалентность. Если вы замените буквы английского алфавита на равнозначные буквы, скажем, в кириллице, то вы создадите новый командный язык, который будет лексически эквивалентен первоначальному. DELETE С: *.*, АЕАЕТЕХ: *.*, ДЕЛЕТЕ Г: *.* и пкУ’Л X *.* лексически эквивалентны, поскольку мы всего лишь заменили алфавит. Лексическая эквивалентность может означать трансформацию строки из нескольких символов в единичный символ, как,
214 Глава 8 • Синтаксическое тестирование
например, ПЛЮС трансформируется в +. Лексическая эквивалентность может также подразумевать изменение направления чтения слева направо на направление справа налево или сверху вниз. К примеру, DELETE С: *.* может трансформироваться в *.*: 2 гг’жп. Важно понимать эту концепцию в применении к локализованным продуктам, чтобы избежать лишней траты сил на переделку тестов, в то время как проблема заключается в тривиальном изменении алфавита для лексически эквивалентного набора команд. Если два набора команд различаются только лексически, то, как правило, вы можете автоматически конвертировать тесты, написанные для одного алфавита, в тесты, написанные для другого.
Лексический анализ Операция идентификации операторов и операндов и их конвертация во внутренний язык, в котором числа, называемые маркерами, заменяют каждый оператор и операнд. Эту операцию называют также маркировкой, поскольку в результате входная строка, составленная в определенном алфавите, конвертируется в строку маркеров. Лексический анализ, обычно явный и простой, должен присутствовать в любой командно-управляемой системе. Лексически эквивалентные наборы команд маркируются в один и тот же набор маркеров. Синтаксическое тестирование используется для проверки корректности лексического анализа.
Нулевой набор. Набор Ф, не содержащий никакой (даже нулевой) строки.
Голова строки (или начало). Первый символ строки при ее проходе слева направо (в соответствующем алфавите с лексико-графическим упорядочением, разумеется).
Хвост строки (или конец). Последний символ строки при ее проходе слева направо.
Конкатенация. Если А и В строки, а С — строка, полученная в результате сцепления головы В с хвостом А, тогда говорят, что в результате конкатенации А и В получилась строка С. Конкатенация изображается путем непосредственного соседства соединяемых строк, например, АВ. К примеру, если <строка_а>: :={xxxyzz], а <строка_б>: :=<111011>, тогда результат конкатенации будет выглядеть как <стро-ка_а><строка_б>={хххугг111011]. Если {А} и {В} являются наборами строк, то {А}{В} означает конкатенацию каждой строки из {А} с каждой строкой из {В}, с сохранением порядка следования. Если {А}: :={111, 4, х], а {В}: :={/, Я], то {А]{В}: :={111/, 1Ш, 4/, 4Я, х/, х1]. Если А является строкой, то для нее выполняются равенства: ХА = АХ = А. Если А — набор строк, то Х{А} = {А}Х = {А}.
Или. Если А и В строки, то А | В (еще пишут А+В), читается «А или В», что означает либо строку А, либо В, либо обе сразу. Поскольку это определение вводится для строк, а одиночные символы можно рассматривать как строки длиной в один символ, то определение применимо так же и для одиночных символов. Или для строк аналогично логическому ИЛИ и так же подчиняется законам коммутативности и ассоциативности, то есть А | В = В | А, А | (В | С) = (А | В) | С. Очевидно, А | В | С | D... и А + В + С + D... — это то же самое, что {А, В, С, D...}.
Показатель степени. Если А — строка, то А” означает п повторений А. Например, если А: :=##$Х, то А2: :=#$Х#$Х, а А3: : = ##$Х##$Х##$Х. Согласно определению А°::= X. Краткая запись А'1’1” используется для обозначения ряда от п до m повторений строки: Так А3-6 = А31 А41 А51 А6. Если {А} — набор строк, то {А}” означает конка
8.2. Основные термины 215
тенацию наборов {А}{А}{А}...{А} ровно п-1 раз. Так {А}2 = {А}{А}, {А}3 = {А}{А}{А} и так далее.
Плюс в показателе. Если А является строкой, то А+ обозначает одно или более повторений строки А: А, АА, AAA, AAA, АААА,...., А°°. Если А : := ху, то ху, хуху, ху-хуху... По аналогии для {А}+, где {А} — набор строк имеем: {А}, {А}{А}, {А}{А}{А}...
Оператор «звезда». Если А — строка, то А* обозначает ноль или более повторений строки А: X, А, АА, ААА,... По аналогии, для {А}’, где {А} — набор строк, имеем: X, {А}, {А}{А}, {А}{А}{А}. Или {А}* = {А}+1X.. Очевидно, АА’ = А’А = А+.
Объединение. Если {А} и {В} — наборы строк, то {А} | {В} называется объединением {А} и {В}, и обозначает совокупность всех строк {А} и всех строк {В}, без повторений. Альтернативные обозначения: {А} + {В}, {A} U {В}.
Обезглавливание. Создание новой строки путем удаления ноля или большего числа символов, начиная с головы строки. Например, строка (1567x00011 была получена из строки abd567x00011 удалением первых двух символов.
Укорачивание. Создание новой строки путем удаления ноля или большего числа символов, начиная с хвоста строки. Например, строка abd567x000 была получена из строки abd567x00011 удалением последних двух символов.
Подстрока. Строка А называется подстрокой строки В, если А может быть получена из В обезглавливанием и/или укорачиванием В.
БНФ, Форма Бэкуса-Паура [ВАСК95]. Способ задания строк, использующий введенные выше операторы и обозначения с минимальными изменениями и расширением обозначений.
Отдельный металингвистический символ, означающий «определяется как». Например, <имя_строки_альфа>::=ху2<строка_бета><строка_гамма> | <дельта>. Это можно интерпретировать как «строка с именем “имя_строки_альфа” определяется как последовательность символов х, у, z в указанном порядке, за которыми следует строка с именем “строка_бета”, а за ней строка с именем “строка_гам-ма” или строка с именем “дельта”». Мы считаем, что <строка_бета>, <строка_гамма> и <дельта> имеют свои собственные определения.
Определение БНФ. Определение набора строк с использованием определений оператора, нуля, конкатенации, операции ИЛИ, показателя, плюса в показателе, оператора «звезда», нулевого набора и имени строки или имени набора строк. Определения БНФ обычно выписываются сверху вниз, однако бывает, что определения приходится передвигать, чтобы определить текущие символы алфавита. Например:
<нулевой_вход>
<нули>
<целочисленные_нули>
<десятичные_нули>
<тире>
= Х|р0'1271о0'127 | (Ра | оР)1'63 |<нули>|<тире>
= <целочисленные_нули>|<десятичные_нули>
= 0-12
= О1'12.0е'6
= -1-17
Обратите внимание, что в приведенной выше спецификации (0а | 00)1-63 отличается от (0а)1 -63 I (<т0)1 -63. В первом случае получаем {0а, а0, 0аа0, 0а0а, о0а0, ...}, в то время как второй включает в себя только {0а, 0а0а, 0а0а0а, ..., а0, о0а0, а0а0о0}. Не пытайтесь упростить данное выражение, используя обычную алгебру. Здесь тождества обычной алгебры не работают [BRZO62],
216 Глава 8 • Синтаксическое тестирование
Необязательное поле. Необязательные поля обозначают, заключая их в скобки, как, например, [<необязательное поле >]. Очевидно, что скобки служат для короткой записи показателя 0-1. То есть {^необязательное поле >] — это то же самое, что и Необязательное поле >0-1.
Одиночный произвольный символ. Обозначается как «?» и означает любой одиночный символ алфавита. Например, выражение ????abce.xxx означает, что перед abce.xxx идут четыре произвольных символа.
Произвольная последовательность символов. Обозначается как «*» и означает ввод любых разрешенных символов в заменяемое им поле. Не следует путать это с оператором «звезда». Интерпретация произвольной последовательности символов зависит от контекста и не может быть предсказанной. Так, в строке DELaC:*.exe только знание операций из MS-DOS указывает нам на то, что звездочку * надо рассматривать в данном случае как произвольную последовательность символов, заключенных между двоеточием и точкой, и что эта последовательность должна удовлетворять некоторым правилам, установленными для строк в данной позиции (например, количество символов в строке не должно превышать 8).
Произвольные последовательности символов, такие как *, которые могут обозначать неопределенное число символов или произвольные последовательности, обозначающие множественные поля или наборы строк, потенциально опасны, и их надо избегать при проектировании тестов. Они представляют опасность, поскольку их интерпретация может меняться и зависеть от контекста. По этой же причине они перспективны для поиска ошибок.
8.3. Отношения и модель
8.3.1. Основы
Преобразование БНФ-спецификации в график, представляет собой механический и поэтому автоматизируемый процесс [BRZO62], Это делается с помощью многократного применения четырех преобразований:
Серия (конкатенация). Сегменты БНФ, состоящие из <поле_а><поле_Ь>, моделируют при помощи связи, с весом <поле_а><поле_Ь>.
<Поле_а> <Поле_Ь>
Параллельное соединение (дизъюнкция). Сегменты БНФ, состоящие из <поле_а> | <поле_Ь> | <поле_с> ...<поле_п>, моделируют с помощью узла ветвления, каждая из связей которого имеет вес, равный одному из элементов (называемых дизъюнктами), далее эти связи сходятся в одном в одном связывающем узле. Мы не акцентируем внимание на узлах, изображая их окружностями в синтаксических диаграммах, так как эти узлы сами по себе не обладают важными для нас внутренними свойствами. Обычно мы используем вторую форму.
8.3. Отношения и модель 217
,— <Поле_а> -►— — <Поле_Ь> -»>— — <Поле_с>------
— <Поле_п> -»—
— <Поле d> -»—
Показатель, начинающийся не с нуля. Показатель, такой как <поле>п-т, интерпретируется как цикл, который выполняется по меньшей мере п и не больше m раз. Я сократил количество повторов цикла на 1, так как поле в цикле находится на нижней связи. Если бы я вставил это поле в верхнюю связь (эквивалентная модель), то количества повторов стали бы равны соответственно пит. Это альтернативная допустимая модель. Оператор, обозначаемый плюсом в показателе, определяет собой цикл от единицы до бесконечности.
от п-1 до т-1 раз
<Поле_в_цикле> • »
<Поле_в_цикле>-^
от п до m раз
Показатель, начинающийся от нуля. Оператор «звездочка» определяет здесь цикл от 0 до бесконечности. Есть несколько допустимых альтернативных, но эквивалентных моделей, обозначающих прохождение цикла 0 или большее количество раз. Они показаны на рисунке. Вспомните, что X — нулевая строка. Оператор «звезда» обозначает цикл от 0 до бесконечности, который можно представить также как А + [X.
Учитывая эти предварительные замечания, мы можем создать некие модели для ввода данных в различных строках формы 1040. Например, для номера социального обеспечения. Поле номера социального обеспечения состоит из трех частей по три, два и четыре символа соответственно. Между этими полями разрешен почти любой разделитель, кроме цифр. Наша спецификация в первом приближении может быть следующей:
<ном_соц_обесп>
<цифра>
<разделит>
<другие>
= <цифра>3<разделит>!п<цифра>2<разделит>,п<цифра>4
= 0|1|2|3|4[5|6|7|8|9
= Р|Х|о|<другие>
= а|Ь|с|..,А|8|С...
БНФ-форма может отличаться от этой спецификации. Вы можете ее написать с помощью различных, но эквивалентных способов. Я не указываю, сколько разделителей необходимо вводить, но я экспериментально определил, что в моих налоговых документах наличие разделителя между полями вообще не обязательно. Следовательно, я пишу X в третьей строчке. Я мог бы написать вместо <разделит>1п
218 Глава 8 • Синтаксическое тестирование
определение <разделит>0п, а затем не ставить X в третью строчку, так как <что-либо>°=Х. Я подразумеваю, что определение <другое> означает что-то еще. Однако вам стоить проверить и убедиться, что это поле включает в себя управляющие символы. Прежде чем идти дальше, убедитесь в том, что вы поняли эту спецификацию.
В моем налоговом пакете, хотя, возможно, к вашему это и не относится, очень мало ограничений, относящихся к этому полю. Мне не удалось найти верхний предел разрешенного числа входных символов. Такой предел, вероятно, существует, и любое тестирование данного программного обеспечения должно это проверять. Давайте определим верхний предел как 65 536 для каждого разделителя. Моя новая модель будет выглядеть следующим образом:
<ном_соц_обесп> : := <разделит>0'65536(<цифра><Рд3ое'""°'65536)9(<цифра>|<разделит)*
<цифра> ::= 0|1|2|3|4|5|6|7|8|9
<разделит> : := р|Х|о|<другие>
<другие> ::= а|Ь|с|..,А|В|С...
Это не спецификация для социального номера, это описание того, что допускает мой налоговый пакет. Он допускает почти все и извлекает первые девять цифр, используя их как социальный номер. Выбрав девятизначное число, он игнорирует все, что следует дальше. ВНС устанавливает более жесткие и сложные правила для корректного социального номера, так как они диктуют, где и какие цифры должны стоять, а также семантические ограничения на численные значения полей. Простая БНФ-спецификация для социального номера может иметь следующий вид:
<ном_соц_обесп>
<цифра>
<разделит>
: := <цифра>3<разделит><цифра>2<разделит><цифра>4
::= 0|1|2|3|4|5|6|7|8|9
::= о|-|/
Теперь мы можем описать нашу модель более привычным способом.
Узлы. Узлы — это точки, куда приходят входящие связи и откуда выходят исходящие. Это означает, что они являются узлами слияния или ветвления (как правило, и тем и другим). Узел ветвления заменяет оператор ИЛИ.
Отношение (связь). Здесь мы рассматриваем отношение «соединен с». Это означает, что если А соединен с В, то между А и В на графе рисуется связь.
Веса связей. Веса связей являются важной частью БНФ-спецификаций. Вес связи может представлять собой имя другой части спецификации со своим собственным графом, или сам граф. Например, для первой строки в предыдущей спецификации весами будут <разделит> и <цифра> с соответствующими показателями. Вместо этого я могу написать следующее определение:
<ном_соц_обесп> ::= <цифра>3<о|-|/><цифра>2< а|-|/ ><цифра>4
Или
<ном_соц_обесп> :: = <0]11213141516171819>3<о |-1/><011121314151617]819>2
<а|-|/><0|1|2|3|4|5|6|7|8|9>4
Показатели также включаются в веса циклов.
Как это часто бывает с подобными моделями, в первое время вам, возможно, будет удобно чертить графы в графической форме, но когда вы освоитесь с моделью, необходимость в этом отпадет. Вы будете уже работать с текстовым представлением графа. Вы неоднократно сможете убедиться на практике, что текстовое
8.4. Методы 219
представление графа может представлять собой страницу для одной единственной команды, в то время как эквивалентная графическая форма займет не одну страницу и будет больше путать, чем помогать.
8.3.2. Комментарий о трудозатратах
Не надо путать усилия, затрачиваемые на изучение БНФ-представления, с объемом работы, необходимой для тестирования реального программного обеспечения. Иногда идею довольно просто объяснить, но ее реализация требует массы усилий. Так, например, идея Великой Китайской стены сама по себе не слишком сложна. Если вы это понимаете, то, считая, что у вас есть достаточно хорошая спецификация, пускай не БНФ, но уже готовая, вы, возможно, сможете обрабатывать две типичные команды за час (например, команды MS-DOS). Если вам приходится подробно исследовать команды, чтобы определить все поля и ограничения в этих полях, то разбор одной команды может занять день или больше. Большинство примеров и упражнений в этой главе должны занимать у вас около часа или двух.
8.4. Методы
8.4.1. Основы
Кроме тестирования вводимых команд, синтаксическое тестирование применяют для решения большого количества задач, однако тестирование команд очень хорошо подходит для иллюстрации данного метода. Как обычно, мы начнем с рассмотрения спецификаций.
1. Потребуйте спецификацию команд (фактически строк), которые вы собираетесь тестировать в наиболее формальном виде. Такая информация должна существовать, иначе что же будет реализовывать программист и каким образом пользователь узнает, как ему управлять программой? Если речь идет об уже существующей системе, то вы можете найти нужную информацию в справочных файлах (подобных справке о командах в системе MS-DOS) или, на худой конец, изучить командный синтаксис экспериментально.
2. Просмотрите команды на предмет поиска в них повторяющихся частей, которые встречаются в большом количестве команд. Например, в MS-DOS 6.2 следующие поля используются в множестве команд: <адрес>, <устройство>, <каталог>, <имя_носителя>, <имя_файла>, <целочисленный>, <ВКЛЮЧИТЬ | ВЫКЛЮЧИТЬ>, <путь>, <время>. Это надо сделать, чтобы избежать повторяющихся спецификаций для общих полей. Если вы дважды определяете одну и ту же сущность, то возникает вероятность что эти две спецификации не будут идентичны и, соответственно, повышается вероятность сделать ошибку в проекте теста.
3. Ищите в командах ключевые слова. В MS-DOS каждая команда имеет ключевое слово, но в командах встречаются и другие ключевые слова, такие как AUTO, AUX, COMI, COM2, COM3, COM4, CON, LPT1, LPT2, LPT3, ON, OFF, PATH, PRN. Как и в предыдущем пункте, мы делаем это, чтобы избежать повторяющихся спецификаций и, соответственно, ошибок в тесте.
220 Глава 8 • Синтаксическое тестирование
4. Начните формирование ваших определений с ключевых слов, поскольку именно они с наибольшей вероятностью будут модифицированы при лексических изменениях (например, при переходе с английского языка на французский). Это будет простой алфавитный список.
<auto> :: = AUTO | AUTo | AUtO |.... | auto
<aux> ::= AUX|AUx|AuX|Aux|aUX|auX|aux
<последнее_ключевое_слово>
Вам, возможно, удастся сэкономить время. Вместо того чтобы выписывать все возможные комбинации букв верхнего и нижнего регистров, вам будет удобнее написать нечто вроде:
<А>::=А|а, <В>::=В|Ь
В таком случае спецификация для ключевого слова <аих> примет следующий вид:
<aux>::=<A><U><X>
Аббревиатуры команд используются во множестве систем. DELETE может быть сокращено до DEL, DELE или DELET. Тут не существует общих правил, вы должны самостоятельно решить, что в вашем случае допустимо, а что — нет.
5. Создайте БНФ-спецификацию для общих полей, таких как <носитель>.
6. Составьте список команд в порядке возрастания сложности, где сложность определяется числом полей в команде и тем, как много определений более низкого уровня вам пришлось привлечь.
7. Сгруппируйте команды. Мы не объединяем команды по принципу производимого ими действия. Это может быть хорошо для демонстраций при продаже системы, но не для ее тестирования. Группируйте их в соответствии с их характеристиками, такими как использование общих ключевых слов, использование общих определений полей, похожих структур. Например, у нас могут быть команды, имеющие одну и ту же структуру.
<ключевое_слово_команды> ::= <имя_носителя>: <путь> <разделитель> [\<swl>]
<разделитель>[\<5и2>]<возврат>
Правильный выбор групп упростит проектирование тестов и само тестирование, поможет избежать ошибок при разработке теста и сэкономит время, затрачиваемое на проектирование.
8. Для всех полей, содержание которых (например, численное, целочисленное, строковое и т. д.) может меняться, обычно существует семантическая спецификация (например, минимальное и максимальное значения). Определите все подобные семантические характеристики и решите, какой метод тестирования вы будете использовать.
9. Спроектируйте тест. Для каждой команды нужен свой набор тестов — чистых и грязных. Каждый чистый тест будет соответствовать определенному пути в синтаксическом графе этой команды. Как обычно, вы выбираете
8.4. Методы 221
путь, активизируете его, предсказываете выход, определяете критерии соответствия, убеждаетесь в правильности выхода и т. д.
Вы должны выполнить первые восемь шагов вне зависимости от того используете ли вы автоматический генератор тестов, или делаете это вручную. Первые восемь пунктов в этом списке составляют от 50 до 75 процентов всей работы, затрачиваемой на проведение синтаксического тестирования. Обратите внимание, насколько я был требователен к деталям, в частности, не пользуясь предположением о взаимозаменяемости букв верхнего и нижнего регистров. Не делайте подобных допущений, поскольку операционная система, а, следовательно, и тестируемое вами приложение различают такие вещи.
8.4.2. Иерархия покрытия
Покрытие узлов в данном случае вряд ли будет эффективным, поскольку узлы здесь не обладают интересными для нас свойствами. Однако покрытие связей нам будет необходимо. Так как мы имеем дело с циклами, мы также будем использовать тесты для циклов.
8.4.3. Чистое синтаксическое тестирование
Я считаю правильным разбить синтаксическое тестирование на две части: чистое и грязное. Чистое тестирование означает обеспечение покрытия (связей) на графе, плюс дополнительные тесты для циклов. Это легче показать, чем рассказать. На рис. 8.1 показана спецификация для строки <вещественное_число> в языке Pascal, чья БНФ задается следующим образом:
<вещественное_число> ::=<цифра>+<Х|.<цифра>+><Х|<Е|е D|d><X|+|-><цифра>+>
<цифра> ::=0|1|2|3|4|5|6|7|8|9
Здесь я привожу мой тестовый набор, обеспечивающий покрытие (исключая специальные случаи для циклов): 01,2.34,5.6Е78,9.0е+1,0.0D-000, OdO. Эти шесть тестовых вариантов (и еще фактически бесконечное число эквивалентных тестов) обеспечивают полное покрытие связей. Простейший способ убедиться в этом — это прочертить заданные пути на копии этого рисунка.
Рис. 8.1. Синтаксический граф для строки <вещественное_число>
222 Глава 8 • Синтаксическое тестирование
Наш следующий набор тестов направлен на проверку циклов. Вам надо проверить каждый цикл для следующего количества итераций: 0, 1, 2, типичного, max - 1, max и max+ 1. Мы не можем пройти цикл ноль раз, по крайней мере, в рамках чистого теста, так как это нарушило бы описанную в спецификации синтаксическую структуру. Все ли циклы были протестированы для случая 1? Если да, тогда в других тестах нет необходимости. Типичные значения различны для различных приложений, поэтому нет смысла тестировать их без знания статистики. Кстати, типичные значения обычно не особо перспективны для поиска ошибок, они нужны скорее в политических целях, чтобы убедить (без статистического подтверждения) людей в работоспособности системы.
А как насчет максимальных и близких к ним значений? В операторах + и * скрыто прямое приглашение поискать ошибки. В компьютере все числа конечны, а значит, должны быть и максимальные значения. Например, в реально существующей спецификации оговаривается, что ни одна команда или оператор не могут состоять более чем из 255 символов. Вы должны найти правило, вне зависимости от того, скрытое оно или явное, и спроектировать тесты для этих случаев. Давайте предположим, что у нас есть следующее простое правило:
<вещественное_число>:: =<цифра>ь;о<А.|.<цифра>11?><А.|<Е|eD|d><X| +1 -><цифра>ьз>
Эта спецификация может быть проверена для случаев max - 1 и мах при помощи следующих тестов: 123456789.12345678901 е 12,1234567890.123456789012е 123. Почему я комбинирую по три значения max - 1 и max в отдельных тестах? Не лучше ли будет отказаться от комбинации значений для трех полей и проверить цикл по каждому полю отдельно? Стоит задать себе вопрос, какие ошибки вы ожидаете здесь встретить. Вы ожидаете встретить ошибку такую, что программа будет работать, если два из трех ее полей превышают свои допустимые значения, и не будет работать, если все три поля меньше этих пределов. Мне кажется, что это не слишком похоже на естественную ошибку.
Какие типы ошибок мы ищем, когда проверяем операторы + и *? Было время, когда работа программного обеспечения могла нарушиться всего лишь из-за неправильной реализации предельных значений. Однако вероятность встретить подобную ошибку в современном программном обеспечении невелика. Программисты знают об этой проблеме и стараются ее избегать. Чаще всего ошибка возникает, если у двух или более программистов существуют различные нотации максимальной величины. Один программист берет предел равным 512, другой 65 536, а третий вообще считает, что 20 вполне достаточно. Ожидаемая в данном случае ошибка возникает вследствие несогласованности в нотациях вычислительно бесконечных циклов. Например, программист ограничил ввод 65 536 цифрами. В более поздней программе, обрабатывающей это число, разрешено не более 20 цифр и некорректно предполагается, что предыдущая программа тоже ограничивает свой ввод 20 цифрами.
8.4.4. Грязное синтаксическое тестирование
Используя грязное синтаксическое тестирование, мы решаем одновременно две задачи: пытаемся нарушить работу программного обеспечения, подбирая подхо
8.4. Методы 223
дящий пример отдельных синтаксических ошибок для всех команд, и добиваемся вызова всех диагностических сообщений, связанных с этой командой. Если мы хорошо справились с первым заданием, то есть шанс, что и второе задание тоже окажется выполненным, однако в любом случае это неплохо бы проверить.
Давайте сначала закончим тестирование циклов. Мы должны рассмотреть случай нулевого числа итераций для каждого цикла. Вот некоторые из моих тестов: .05, 1., 1.1 е. В случае грязного теста, я беру значения max+ 1 равными: 12345678901.1, 1.1234567890123,1.1 е1234. Обратите внимание, что в грязных тестах я делаю только по одной ошибке, а для всех остальных полей выбираются самые простые значения. К этому моменту чистые тесты должны быть уже пройдены, поэтому программа должна читать и интерпретировать все символы при условии отсутствия ошибок. Для грязных тестов ситуация иная, поскольку если, например, первое поле содержит слишком много или слишком мало цифр, то число отбрасывается и ошибочный код для второго поля уже не будет выполняться. Я хочу убедиться, что вне зависимости от способа реализации весь код будет протестирован. Если при тестировании возникает более одной ошибки, то какой бы ни была ошибка, обнаруженная первой, она инициирует запрет исполнения текущей команды, и последующий (возможно ошибочный) код не будет протестирован. Поскольку мы не можем сказать, не глядя в код программы, какое поле будет обрабатываться в первую очередь, наиболее безопасно иметь только одну ошибку в каждом поле. Существуют и другие, более веские причины иметь одновременно не более одной ошибки при проведении грязного тестирования, но их я буду обсуждать позже.
Грязное синтаксическое тестирование достаточно простой метод. Надо всего лишь соблюдать нескольких простых правил: Каждая БНФ-спецификация представляет собой дерево (на самом деле — порожденный подграф). Выполняя тестирование, мы начинаем с вершины и заканчиваем листьями — реальными символами.
Дерево поделено на уровни. На вершине дерева (например, дерева <веществен-ное число>) мы имеем несколько синтаксических элементов, определенных непосредственно, а также другие элементы, которые заданы в спецификациях на более низких уровнях дерева. Мы вносим какую-либо одну ошибку в определенное поле или откладываем определение ошибки этого поля на более низкий уровень. Мы продумываем ошибки для каждого уровня так, чтобы иметь одновременно только одну ошибку в одном поле. В каждое поле мы можем внести ошибку сразу или отложить ее внесение на более низкий уровень. Вносимые нами ошибки делятся на синтаксические или семантические.
Ниже приведена БНФ-спецификация (упрощенная для ясности) для команды COPY в MS-DOS 6.2. Оригинал фактически полностью идентичен предложенной БНФ-спецификации, за исключением небольших различий в обозначениях. Я не стал рассматривать некоторые усложняющие моменты, такие как ограничение общей длины команды, различные ограничения, накладываемые на длину строки <путь>, допустимые и обязательные типы и положения разделителей между полями и переключателями /А и /В. Я разрабатывал спецификацию последовательно сверху вниз, по одному уровню за раз, именно так, как я собираюсь строить тесты.
224 Глава 8 • Синтаксическое тестирование
Level 1: <сору> :: = COPY о [/YI/-Y](+ <источник>)1п
L2:
L2:
<источник>
<конечная_цель>
L3: <имя_носителя>
L3: <путь>
L3: <имя_файла>
L4: <имя_кат>
L4: <расш>
L5: <кат_буквы>
L5: <ф_буквы>
[о <конечная_цель>][/\/]
= [<имя_носителя>:] [<путь>][<имя_файла>]
= [<имя_носителя>:] [<путь>][<имя_файла>1
= a|b|...z|A|B|.. .Z
= (\<имя_кат >)1т\
= <ф_буквы>18[.<расш>]
= <кат_буквы>18[,<расш>]
= <ф_буквы>13
= <a|b|c - z| А|В|С - Z|0|l|2 - 9 | А | $ |
~ I ! I #1 И &| - -I {{ I }} I ((|))>
= <кат_буквы>| <0 | 'Г >
Несколько слов об уровнях. Поле <расш> возникло на уровне 4, поскольку именно столько определений мне пришлось ввести, для того чтобы дать это определение. Но в то же время это поле фигурирует в определении <имя_кат>, из чего следует, что его определение должно даваться на уровне 5. Какой из этих двух вариантов правильный? Оба. Дело в том, что это дерево определений представляет собой частично упорядоченную структуру, в то время как понятие «уровень» — строго упорядочено и неприменимо к частично упорядоченным графам, таким как наше дерево определений. Вы можете возразить, что появление одного поля в двух различных местах и в различных контекстах может стать причиной ошибки из-за различия в обработке этих двух случаев. Все правильно. В хорошем программном обеспечении такая вероятность мала, и поэтому не стоит беспокоиться по поводу одного или двух пропущенных случаев. Если же вы имеете дело с настоящей халтурой, тогда действительно это может быть хорошим тестом. При проверке недоброкачественного программного обеспечения необходимо большее число тестов для достижения полного покрытия, но оно ломается при любом систематическом тестировании.
В первом поле находится ключевое слово COPY. Если бы это была моя первая тестируемая команда, то я бы должен был начать с работы над этим ключевым словом. Все команды в MS-DOS начинаются с ключевых слов. Если распознавание ключевых слов не действует, то вряд ли какие-либо другие команды будут работать. Существует вероятность, что такое тестирование в этом проекте уже проводилось. Какие ошибки стоит внести в ключевое слово, если мы собираемся его проверить?
1. Оставить поле пустым.
2. Написать почти правильно, пропустив один символ, например, СОР.
3. Написать слишком длинно, например COPYME.
4. Взять правильное ключевое слово, но не относящееся к этой команде, например, СОМР.
Подобные ошибки вряд ли встретятся в хорошем программном обеспечении, но для недоброкачественного программного обеспечения имеет смысл попробовать проверить пункты 2 и 3. Оставшаяся часть команды должна быть свободна от ошибок, поэтому в итоге получаем следующие тесты: Т1.1.1: СОР а а:*.* и Т1.1.2: COPYME а а:*.*.
8.4. Методы 225
Несколько комментариев относительно этих двух тестов. Вы, должно быть, заметили, что я выбрал самый простой вариант, исключив максимально возможное число последующих полей. Это само по себе уменьшает вероятность отмены выполнения этой команды по какой-либо другой причине. Я также использовал оператор произвольной последовательности символов (*), поскольку подозреваю, что обработка произвольной последовательности символов является характерной чертой, общей для многих команд, и что она, возможно, использует область с путем, отличным от пути для обработки данной команды. Если я хочу избежать использования произвольной последовательности символов на этой стадии тестирования, то мне придется использовать нечто вроде имя файлаЛз! и иметь в распоряжении подобный файл, который можно будет скопировать. Теперь рассмотрим следующее поле — разделитель.
В сущности, условия при которых вам нужен или не нужен разделитель (в нашем случае о), могут быть довольно запутанными, и моя модель это не отражает. Вам не нужен разделитель, если в качестве следующего символа используется обратная косая черта, применяющаяся для переключения. Вообще существуют несколько типов разделителей. Давайте не будем столь пунктуальны и предположим, что используется только а и что он обязателен, как показано в модели. Мы получаем два следующих варианта теста: Т1.2.1: COPY а:*.* и Т1.2.2: COPY оса:*.*
Первый тест отвергается, как и должно быть, однако второй проходит гладко. В чем дело? Либо спецификация, либо модель неверна. Неверна наша модель (БНФ вариант спецификации): в ней должно быть а14, где q обозначает максимально допустимое число разделителей, равное общему числу символов в команде минус 127, то есть 118. Значит, по всей видимости нам надо проверить это при помощи грязных и чистых тестов: q = 0, грязный; Т1.2.1; q = 1, чистый; q = 117, чистый; q = 118, чистый; q = 119, грязный.
Разберемся теперь с полем переключателя. Вот несколько вариантов: неверный переключатель в этой позиции, слишком много переключений, неверны оба переключателя. Эти варианты приводят к следующему набору тестов, каждый из которых должен определить наличие ошибки.
Т1.3.1. COPY /а А:*.*
Т1.3.2. COPY //У а А:*.*
Т1.3.3. СОРУ /V а А:*.*
Т1.3.4. СОРУ /У/-У а А:*.*
Tl.3.5. COPY /Y/V а А:*.*
Tl.3.6. COPY /Y/Y/V а А:*.*
Выполняя эти тесты, я обнаружил, что не следую должным образом своей собственной модели. Корректная спецификация отличается от приведенной. Я добавлял знак + к каждому источнику, хотя он нужен только в тех случаях, когда у нас больше одного источника. Следовательно, более корректная спецификация будет выглядеть следующим образом.
<сору> ::=COPY obq [/У|/-У]<источник>(+<источник>)°'г’ [о<конечная_цель>][/У]
Какие ошибки мы можем внести в поле <источник>? Для начала обратите внимание, что поля файлов для двух источников связаны. Должен быть, как минимум,
8 Зак 770
226 Глава 8 • Синтаксическое тестирование
один источник. Поскольку в конечную цель также входит имя файла, программа не сможет правильно обработать команду, если мы опустим имя файла источника, а взамен используем имя файла конечной цели. Поэтому нам придется опустить их оба в нашем грязном тесте. Тогда у нас есть следующие варианты: нет источника (и нет конечной цели), слишком много источников, синтаксическая ошибка в источнике, семантическая ошибка в источнике, изменение положений знака +.
Tl.4.1. COPY
Tl.4.2. COPY nA:filel.txt file2.txt
Tl.4.3. COPY oA:f11el.txt ++file2.txt
Tl.4.4. COPY oA:a+b+c+d+e+f+g+h+1+...+aa... (больше максимального предела числа источников, п)
Tl.4.5. = Т2.1. Синтаксическая ошибка в спецификации источника
Т1.4.6. = Т2.2. Семантическая ошибка в спецификации источника
В Т1.4.4 я использовал очень короткие имена файлов без расширений, поскольку я хочу превысить максимально допустимое число исходных файлов в этой команде. Мне пришлось создать большое количество файлов с именами, состоящими из одного символа, затем с именами из двух символов и так далее. Выполняя этот тест, вам следует убедиться, что вы не превысили максимальную длину строки — 127 символов.
Тесты 1.4.5 и 1.4.6 фактически являются тестами следующего уровня. Я использовал систематическую схему нумерации тестов. Первая цифра обозначает уровень, вторая — тестируемое поле, а третья — способ внесения ошибки в это поле. Пропуск поля или использование слишком большого числа полей — это тесты первого уровня. Однако синтаксические и семантические ошибки в этих полях тестируются на следующем уровне.
На этом уровне также были проделаны грязные тесты для поля конечной цели и его разделителей, так как спецификации для источника и конечной цели практически полностью совпадают. Единственное, что мы можем сделать — протестировать синтаксические и семантические ошибки в спецификации целевого файла:
Т1.5.1. = Т2.3. Синтаксическая ошибка в спецификации целевого файла
II.5.2. = Т2.4. Семантическая ошибка в спецификации целевого файла
Последний полезный тест, который мы можем сделать на этом уровне — поработать с переключателями, преимущественно тем же способом, который мы использовали для первого переключателя.
Т1.6.1. COPY oA:file.txt/
Tl.6.2. COPY oA:flle.txt oV
Tl.6.3. COPY oA:file.txt//
Tl.6.4. COPY oA:file.txt/V/V
Tl.6.5. COPY oA:file.txt/Y
Аналогичной последовательности надо придерживаться и для следующего уровня исследуемого нами дерева. Семантические ошибки в поле источника означают синтаксически корректное имя файла для несуществующего файла. Поле источника на самом деле более сложно, чем показано в нашей модели. В него должно входить хотя бы одно поле с правильным именем. Это означает, что носитель и/ или путь и/или файл должны быть определены. Следовательно, более корректная спецификация будет выглядеть следующим образом:
8.4. Методы 227
(<имя носителя»:[<путь»][<имя файла»])|([<имя носителя»:]<путь>
[<имя файла»])|([<имя носителя»:][<путь»]<имя файла»
Если у вас есть один из двух компонентов, то два других не обязательны. В то же время в спецификации целевого файла все поля не обязательны. Ошибки второго уровня — это синтаксические и семантические ошибки в полях источника и целевого файла. Из-за того, что поля не обязательны, на этих уровнях встречается не так уж много синтаксических ошибок. Это означает, что нам достаточно иметь один из трех компонентов для источника. По всей видимости, единственное, что мы можем сделать на этом уровне, — поэкспериментировать с двоеточием, использовать неверный символ (;), ввести слишком много полей или вообще не указывать их. За исключением семантических ошибок (отсутствие такого источника и отсутствие такого целевого файла), все остальные тесты мы можем сделать на следующем уровне.
На уровне 3 мы экспериментируем с <имя носителя», <путь> и <имя файла». Число носителей, допустимое в MS-DOS, и, следовательно, семантика и синтаксис имени носителя зависят от версии MS-DOS. Поскольку поле <путь> не является обязательным, то единственные ошибки, которые мы можем сделать на этом уровне, это пропустить требуемый символ обратной наклонной черты в конце строки пути или ввести их слишком много. Неверный путь семантически рассматривается на следующем уровне. Я мог бы попробовать имя файла с точкой, но без расширения.
На четвертом уровне тестируются семантические и синтаксические ошибки в содержимом или в структуре имен каталогов и расширений. Здесь используется тот же набор, что и раньше. Пропустите какие-либо обязательные элементы, введите их слишком много, введите вместо них другой, неверный элемент, сделайте семантическую ошибку. Продолжайте в таком же духе, пока не дойдете до листьев дерева, то есть до того места, где вы вводите реальные символы.
Я твердо придерживался правила делать не больше одной ошибки за раз. Для этого у меня есть две причины, и обе они важны.
1. Слишком много тестов. Проверка команды MS-DOS COPY потребовала приблизительно 75-100 тестов и потребовала бы гораздо больше, если бы в основе нашего тестирования лежала реальная БНФ-спецификация со всеми своими переключателями и другими сложностями. Вне зависимости от числа тестов, проводимых вами для единичной ошибки, для двойной ошибки количество требуемых тестов придется возвести в квадрат. Коммерческие инструментальные средства [IDEI94, POST94] проделывают все это, если только у вас есть БНФ-спецификация или ее эквивалент. Эти инструменты генерируют чудовищное число грязных тестов. Для типичной системы, имеющей несколько сотен команд пользователя и оператора, вы можете с легкостью создавать около 100 000 тестов за день. Даже для автоматического выполнения это достаточно большое число. Для двойных ошибок это цифра вырастет до 10 000 000 000, а для тройных?
2. Потеря ошибок. Оказывается, что теоретически невозможно создать генератор грязных тестов, который гарантированно генерирует только грязные тесты. Специфика синтаксиса приведет к предположительно грязным тестам, которые будут легко проходиться. Система «пройдет»
228 Глава 8 • Синтаксическое тестирование
подобный тест, и вам придется проводить расследование. Если возникает слишком много ложных сигналов тревоги, то даже при наличии автоматизации польза, приносимая данным методом, сходит на нет. Если вы рассматриваете двойные ошибки, то возникает вероятность потери ошибок. Например, в выражении (x + y + (z-w) пропущена правая скобка. Если я делаю две ошибки, чтобы получить либо x + y + (z-w), либо (x + y + z- w), мы имеем в итоге две синтаксически корректные строки — ошибки были потеряны. Скобки и другие парные разделители (BEGIN-END, DO-ENDO, IF-ENDIF, PARDO-ENDPAR) могут служить простыми примерами возможности потерь ошибок. При проверке множественных ошибок стремительно растет число тестов, однако процентное соотношение ложных сигналов тревоги растет еще быстрее.
8.4.5. Предсказание итога
Предсказание итога для чистых тестов зависит от тестируемой команды и семантики. Тут не существует общих правил, и вам придется придумать их самим. Для грязных тестов предсказание итога выглядит очень просто: КОМАНДА ОТВЕРГНУТА.
8.4.6. Хорошие и плохие разновидности тестирования
Некоторые разновидности синтаксического тестирования могут облегчить вам работу, а некоторые могут, наоборот, существенно усложнить. Есть однако, и другая сторона медали. Программы, представляющие скверные разновидности, как правило, содержат наибольшее число ошибок, и, значит, синтаксическое тестирование в этом случае весьма перспективно.
1. Формальная структура. Некоторые командные языки, такие как в UNIX, имеют формальную структуру. Вместо сотен специальных команд язык имеет относительно небольшое число командных сегментов, компонуя которые при соблюдении специальных правил, можно добиться желаемого эффекта. С другой стороны, операционные системы наподобие MS-DOS, которые не обладают такой формальной структурой в полной мере, тем не менее, обладают некоторыми ее аспектами, например, возможностью конвейеризации и переадресации. Для командных языков, имеющих явную формальную структуру, обычно бывает достаточно проверить сегменты и правила их компоновки, вместо того чтобы проверять все множество возможных команд. Это особенно важно для грязного синтаксического тестирования, которое, как правило, не слишком продуктивно при проверке командных языков с формальной структурой. Если язык программирования обладает формальной структурой, то обычно не представляет труда найти полную, детальную спецификацию для всех команд, зачастую составленную в метаязыке, эквивалентном БНФ. Поэтому хотя тесты легко проектируются, они не слишком эффективны. Чистое тестирование требует, разумеется, гораздо меньших затрат.
Командные языки, не обладающие формальной структурой или со структурой, возникшей в процессе сращивания, как правило, являются хороши
8.4. Методы 229
ми объектами для грязного синтаксического тестирования (и часто полны ошибок). Наиболее печально известный пример языка такого типа — это dBASE-11/III/IV — язык программирования баз данных для PC. Макроко-мандные языки для PC часто также обладают этими неприятными особенностями. Специализированные языки, часто «проектируемые» без должного понимания, что за язык на самом деле строится, как правило, трудны для исследований, поскольку документация на команды в этих языках (и особенно на хитроумные исключения) крайне скудна. Отсутствие структуры делает затруднительным автоматизацию разработки теста, и автоматический генератор грязных тестов выдает много неверных тестовых вариантов. Несомненным плюсом таких систем, содержащих командные языки с отсутствием структуры, является простота, с которой они ломаются.
2. Точная лексическая спецификация. Существуют командные языки с точной лексической спецификацией. Ключевые слова в них четко определены и не могут соответствовать, скажем, опциям внутри команд или строкам других команд, для которых они могут показаться естественными. Спецификация языка определяет четкие правила, касающиеся преобразований алфавита и ключевых слов. Чем более ясным и логичным будет разделение между лексическими и синтаксическими аспектами, тем меньше вам придется тестировать. Полная проверка языка при помощи единого набора всеобъемлющих тестов для какой-либо одной лексической трансформации дает уверенность в надежности других лексических эквивалентов. В то же время, если существует четкая лексическая спецификация, то не составляет труда конвертировать набор чистых и грязных тестов из одной спецификации в другую. Как я уже неоднократно убеждался, качественные программы содержат меньше ошибок и их существенно легче тестировать.
Полной противоположностью чистой лексической спецификации являются языки, в которых лексические и синтаксические аспекты безнадежно перепутаны. Но хотя разработка тестов для них сложна и приходится прикладывать много усилий для исследований, их тестирование, тем не менее, приносит результаты.
3. Синтаксис, зависящий от контекста. В хороших командных языках существует четкое разделение между синтаксисом и семантикой. В плохих языках эти аспекты безнадежно перемешаны. В качестве примера рассмотрим следующую спецификацию:
<команда> ::= <ключевое_слово><разделитель1><поле1><разделитель2><поле2>
::= X ЕСЛИ <ключевое_слово> = <ключевое_слово_список_2> <разделитель2> ::= \|/|,|о|-| ЕСЛИ <поле1> = <поле1_синтаксис_1>
X ИНАЧЕ
<поле2> ::= <поле2_синтаксис_1> ЕСЛИ <поле1> = "1"
::= <поле2_синтаксис_2> ЕСЛИ <поле1> = "2"
<поле2> <поле2_синтаксис_99> ЕСЛИ <поле!> = "99"
230 Глава 8 • Синтаксическое тестирование
Командные языки с синтаксисом, зависящим от контекста, обычно не столь четкие и структурированные, как в только что приведенном примере. Основные проблемы с этими спецификациями заключаются в том, что синтаксис какого-либо поля зависит от семантики другого поля. Дело усложняется еще и тем, что синтаксис определенного поля команды может зависеть от специфической синтаксической формы и/или от значений (семантики), приведенных в последующих полях. Лучшее, что можно сделать с такими языками, — это похоронить их. Их почти невозможно использовать, невозможно поддерживать, на них очень трудно программировать, но их очень легко сломать. Как правило, в таких языках код, реализующий синтаксический анализатор, полностью скрыт и так же непоследователен, как и сам язык. Перед тестировщиками подобного мусора стоит задача убедить разработчиков, что необходимо внести изменения в этот язык. Так как исследования специфических хитросплетений — сложная задача, то нет смысла за нее браться. Такую халтуру настолько легко сломать, что вы сможете легко сделать это вручную. Это один из немногих случаев, когда тестирование заставляет меня чувствовать вину за насилие над слабым, подобно тому, что должен чувствовать взрослый, обижающий ребенка или маленькую беззащитную зверюшку.
8.5. Рассмотрение приложений
8.5.1. Индикаторы приложений
Командные языки, для которых синтаксическое тестирование эффективно, являются неотъемлемой функциональной частью большинства приложений.
1. Командно-управляемое программное обеспечение. Это наиболее очевидное приложение, и, по всей видимости, именно в него командные языки включаются чаще всего. Если система преимущественно командно-управляемая, то почти вся проверка может быть организована при помощи синтаксического тестирования. Я считаю полезным использование синтаксического тестирования в подобных случаях.
2. Программное обеспечение, управляемое при помощи меню. Широко распространенная альтернатива командно-управляемому программному обеспечению — это программное обеспечение, управляемое при помощи меню, в котором действия выполняются путем выбора определенных пунктов меню. Наиболее подходящий метод для тестирования программ, управляемых подобным образом, — это тестирование конечного автомата, рассматриваемое в главе 9. Вне зависимости, управляется программа при помощи меню или нет, всегда существуют поля с данными, и у этих полей есть определенный синтаксис, для проверки которого синтаксическое тестирование является вполне эффективным способом проверки. Делается это очень просто, поскольку дерево синтаксиса, как правило, небольшое.
3. Макроязыки. Множество коммерческих программных пакетов для PC имеет встроенный макроязык, называемый также языком сценариев. Он представляет собой язык программирования, который может использоваться
8.5. Рассмотрение приложений 231
для автоматизации повторяющихся операций. В качестве примеров можно привести командный язык пакетной обработки в MS-DOS, оболочку Norton Desktop для языка сценариев Windows, макроязыки Lotus 123 и WordPerfect, язык сценариев CrossTalk для CASL-IV. Эти языки часто реализуются в коммерческих пакетах не только для удобства пользователей, но и потому, что с их помощью удобнее всего реализовать множество сложных функций, таких как составление стандартных писем в текстовом редакторе. В идеале они являются полнофункциональными, хотя и специализированными языками программирования, имеющими формальные спецификации (зачастую эквиваленты БНФ). Некоммерческие, или узкоспециализированные1 продукты, тоже весьма часто используют макроязыки, но, как правило, они не столь явно определены или реализованы в виде коммерческого (горизонтального) пакета. Подобные языки, если они являются частью приложения, обязательно должны пройти синтаксическое тестирование.
4. Связь. Все системы связи имеют встроенный язык программирования. Это язык, описывающий формат посланий. Вы можете не догадываться о существовании подобного языка, например, в телефонии, но он есть. Телефонные коммутаторы используют особый язык для связи друг с другом. Кроме того, соответствующие локальные, междугородние и международные номера телефона имеют сильно формализованный синтаксис, называемый планом номера. Любое послание, использующееся для связи, должно иметь формат (то есть синтаксис), который должен быть проанализирован.
5. Язык запросов базы данных. Любая база данных имеет командный язык, используемый для того, чтобы определить, что надо искать и что надо из нее извлечь. Самые простые языки предлагают только один ключевой параметр. В более совершенных системах существует поиск с использованием булевой алгебры, основанный на определяемых пользователем параметрах, которые мы интерпретируем как предикаты. Подобные предикаты, очевидно, обладают формальными синтаксисом и семантикой, и, следовательно, должны быть проверены с помощью синтаксического тестирования.
6. Компиляторы и генерируемые синтаксические анализаторы. Существует один тип продуктов, в котором не стоит использовать синтаксическое тестирование и особенно грязное синтаксическое тестирование. Это современные компиляторы. Это может показаться странным и неверным, но это соответствует моей установке, гласящей, что тестировщик никогда не должен повторять тесты, выполненные ранее другими. Современные компиляторы, разумеется, имеют синтаксические анализаторы. Но эти синтаксические анализаторы генерируются полностью автоматически, с использованием генератора синтаксического анализатора, которому задается формальное описание, наподобие БНФ. Лексические анализаторы также генерируются
’ Программы, предназначенные для широкого круга пользователей, такие как текстовые редакторы, электронные таблицы и базы данных, называются горизонтальными пакетами. Пакеты, специализированные для какого-то одного рода деятельности и обеспечивающие большинство необходимых для этой деятельности функций (например, для туристических агентов, цветоводов или аптекарей), называются вертикальными пакетами.
232 Глава 8 • Синтаксическое тестирование
автоматически на основе формальных спецификаций. Наиболее известные инструменты для этих целей — это LEX и YACC [MASO90]. Несмотря на то, что первое время они в большинстве случаев использовались исключительно для генерации лексических и синтаксических анализаторов в компиляторах, сейчас они и им подобные программы все чаще используются для генерации лексических и синтаксических анализаторов в командных языках программного обеспечения. Это очень хорошо, поскольку генерируемые лексические и синтаксические анализаторы необычайно надежны. С точки зрения тестировщика применение синтаксического тестирования здесь неперспективно, поскольку даже полностью автоматизированное, оно не сможет сломать подобные лексические и синтаксические анализаторы. Прежде чем потратить массу времени и сил на синтаксическое тестирование (даже автоматизированное), оцените, что это за приложение и как оно реализовано. Если в нем используется или проектируется генератор лексического и синтаксического анализатора, то вероятность успешного применения синтаксического тестирования у вас довольно мала. Такие ошибки здесь не проходят. Единственное, что тут остается проверить, — это семантику, что, как вы видели, часто делается другими методами, такими как тестирование доменов.
8.5.2. Предположения об ошибках
Предположения об ошибках в синтаксическом тестировании удобнее всего формулировать для абстрактного синтаксического анализатора, вне зависимости от того, явный он или скрытый. Ниже приведены примеры.
1. Неполный синтаксис. Разумные с точки зрения выполняемое™ команды не принимаются, а если и принимаются, то выполняются неверно, так как синтаксический анализатор не может обработать подобную строку. Вследствие этого интерпретация команд происходит бессистемно, как правило, неверно и ведет к сбоям, или потере данных.
2. Непоследовательный синтаксис. Синтаксис, сильно зависящий от контекста, ведущий к непредсказуемому и непоследовательному синтаксическому анализу, и, как следствие, к ошибкам в интерпретации.
3. Ошибочное отклонение и ошибочное принятие. Ошибки в синтаксическом анализаторе, ведущие к отклонению корректных с точки зрения выполняемое™ команд и принятию команд, содержащих синтаксические ошибки.
4. Синтаксическое/семантическое несоответствие. Ошибки в синтаксическом анализаторе, ведущие к отклонению или некорректной модификации значений полей. Например, целые числа от 0 до 999 должны приниматься, однако реализация требует наличия ведущего ноля, в результате чего отклоняются хорошие числа, такие как 7 и 19.
5. Лексические ошибки и ошибки в алфавите. Некорректные лексические преобразования, ведущие, скажем, к интерпретации содержания полей как
8.5. Рассмотрение приложений 233
разделителей. Например, строки должны пометаться в кавычки, но не предусмотрена возможность обработки строк, содержащих кавычки, или перевод строки интерпретируется как конец поля, но невозможно ввести текст, включающий перевод строки.
8.5.3. Ограничения и предостережения
При проведении синтаксического тестирования мы сталкиваемся с двумя серьезными проблемами: психологической и методологической. Так как автоматизация проектирования достаточно проста, то после описания синтаксиса в БНФ число автоматически генерируемых тестов может измеряться сотням и тысячами. Однако в случае генерации синтаксических анализаторов эффективность таких тестов не превышает эффективность перебора всех итераций при проверке цикла. Методологический аспект заключается в существовании мнения (ничем не оправданного) об эффективности того, что я называю игрой в «Эрудита» на клавиатуре, Рахманинов-тестированием или обезьяньим тестированием. Оно представляет собой беспорядочный ввод с клавиатуры предположительно произвольных строк, до тех пор пока что-либо не сломается — этот миф обычно дополняется наличием хитрого хакера, барабанящего по кнопкам. Ранее программное обеспечение для PC, а также большинство любительских программ действительно могло быть сломано при таком тестировании, но для современного профессионального программного обеспечения такие случаи — редкость. Тем не менее, миф об эффективности деятельности хитрого хакера, творящего темные дела за клавиатурой, жив в общественном сознании и в сознании людей, несведущих в технике тестирования. Мне встречались менеджеры по разработке программного обеспечения, искренне верящие, что обезьянье тестирование — это единственное тестирование, необходимое продукту. Но что такое синтаксическое тестирование, если не полностью формализованное, научное обезьянье тестирование? В таком случае большим заблуждением будет считать, что синтаксическое тестирование недостаточно надежно.
8.5.4. Автоматизация и инструментальные средства
Возможно, наиболее привлекательная сторона синтаксического тестирования — это простота, с которой разработка теста может быть полностью автоматизирована. Возможно, из-за простоты автоматизации этот метод поддерживают коммерческие инструменты, такие как (Т) [IDEI94, POST94]. И даже в отсутствие коммерческих инструментов проектирование языка тестов, воспринимающего БНФ-спецификацию, соответствующего интерпретатора тестового языка и генератора чистых/грязных тестов не является сложной задачей. Вы определяете свой метаязык, как если бы он был обычным языком, и затем используете лексический анализатор и генератор синтаксического анализатора, наподобие LEX или YACC, чтобы они сделали ббльшую часть работы. Разумеется, вы проверяете и сам свой генератор, используя его для генерации тестов. У меня есть несколько неплохих генераторов, построенных для себя. Разработка каждого из них заняла триместр у одного хорошего (но не гениального) студента, проходящего курс обучения языку программирования, который включал в себя изучение LEX иYACC.
234 Глава 8 • Синтаксическое тестирование
Я оцениваю скорее нижний предел требуемых трудозатрат, поскольку во множестве приложений работа с коммерческими инструментами, такими как Т, усложняется тем, что вам необходимо принимать в расчет специальные входные интерфейсы, автоматизацию выполнения теста, специфику платформ и тому подобные вещи. Это особенно характерно для случаев, когда входные данные не вводятся с клавиатуры обычным способом (например, при передаче телекоммуникационных сигналов), а должны быть интегрированы глубоко внутрь приложения.
8.6. Резюме
Синтаксическое тестирование представляет собой мощное, легко автоматизируемое средство, предназначенное для тестирования лексических и синтаксических анализаторов командного процессора в командно-управляемых приложениях. Синтаксическое тестирование начинается с определения синтаксиса путем задания формального метаязыка, среди которых наиболее популярен БНФ. После задания БНФ непосредственной задачей тестировщика является генерация набора тестов, полностью покрывающих синтаксический граф. Стандартное покрытие связей мы обычно дополняем чистыми и грязными тестами для проверки показателей, особенно операторов + и *.
8.7. Вопросы для самопроверки
1. Дайте определение следующих терминов: алфавит, ассоциативный, обезглавливание, пустойсимвол, БНФ, команда, командно-управляемоепрограмм-ное обеспечение, командный язык, коммутативный, конкатенация, синтаксис, зависящий от контекста, укорачивание, тире, разделитель, дизъюнкция, потеря ошибок, показатель (метасимвол), генерируемый синтаксический анализатор, ключевое слово, LEX, лексический анализатор, лексическая эквивалентность, связи (в синтаксических графах), макроязык, программное обеспечение, управляемое через меню, метаязык, метасимвол, узел (в синтаксических графах), нулевой символ, нулевой набор, операнд, необязательное поле (обозначение в БНФ), парные разделители, параллельное преобразование, синтаксический анализатор, грамматический разбор, плюс (показатель) оператор, семантический анализ, серия преобразований, язык сценариев, символ пробела, оператор «звезда» (метасимвол), строка, поле строки, голова строки, имя строки, набор строк, хвост строки, подстрока, синтаксический анализ, синтаксис, маркер, маркировка, оператор объединения, произвольная последовательность символов, произвольный символ (одиночный), YACC.
2. Поэкспериментируйте с вашим налоговым пакетом и определите опытным путем БНФ спецификацию для следующих полей в форме 1040. После того как вы это сделаете, разработайте набор чистых и грязных тестов, обеспечивающих следующее покрытие. Окончание налогового года, имя, отчество и фамилия, полный адрес, за исключением почтового индекса, почтовый ин-
8.7. Вопросы для самопроверки 235
деке плюс маршрут доставки, поле 6с, число месяцев, которое иждивенец жил дома, поле даты в области для подписи.
3. Поэкспериментируйте с вашим налоговым пакетом и определите опытным путем БНФ спецификацию для поля социального обеспечения. Мой налоговый пакет очень нестрогий и позволяет широко варьировать синтаксис. Однако что впоследствии интерпретируется как входные данные — это отдельный вопрос. Определите синтаксис для приемлемых вводов и спроектируйте для них тесты. Затем определите полную БНФ-спецификацию, которая в том числе включает информацию о том, как должны преобразовываться различные строки для того, чтобы извлечь из них нужные числа, если это возможно. Спроектируйте чистые и грязные тесты.
4. Определите БНФ-спецификацию для целочисленных входных данных, состоящих из одной или двух цифр. Используйте только положительные числа. Включите сюда различные символы, которыми люди могут естественно заменять ноль или отсутствие вводов, например, пустой, нулевой символы, О, о, -, -0- и т. д. Затем спроектируйте набор покрывающих чистых тестов и хорошие грязные тесты для единичной ошибки.
5. Определите БНФ-спецификацию для суммы в долларах, включающую положительные и отрицательные вводы, пустые, нулевые вводы, с центами и без, с запятыми и без, и так далее, для всех способов, которыми люди могут ввести подобные данные в налоговую декларацию. Затем спроектируйте чистые тесты, обеспечивающие покрытие, и грязные тесты для единичной ошибки.
6. Определите части команд <устройство>, <путь>, <имя_файла> в MS-DOS, или эквивалентные им в вашей операционной системе. Затем спроектируйте полный набор чистых и грязных синтаксических тестов.
7. Исследуйте следующие команды MS-DOS (или аналогичные команды ввашей операционной системе) и задайте для каждой полную БНФ-спецификацию, включающую поля <устройство>, <путь> и <имя_файла>, которые вы можете считать ранее протестированными. Затем спроектируйте покрывающий набор чистых и грязных синтаксических тестов. Предусмотрите возможность использования аббревиатур, псевдонимов и различных алфавитов. Проверьте только ваши грязные тесты, испытав их. (Замечание: если вы случайно разработали чистый тест, то с последствиями его выполнения для вашей системы вы будете разбираться сами.) Команды: APPEND, ATTRIB, BUFFERS, CHDIR, COMMAND, COPY, COUNTRY, DATE, DIR, EXPAND, FC, FORMAT, KEYB, PRINT, SHARE, SORT, TIME, XCOPY.
8. Спроектируйте тесты синтаксического анализатора для старой английской валюты. Вам дается произвольное число денежных единиц, каждая из которых состоит из числа и следующего за ним символа этой единицы, например: «ЗЕ, 17s, 8р, 7S, 4hc». Синтаксический анализатор нужен для автоматического размена монет. Программа должна конвертировать входные значения и выражать сумму в терминах f, h, d, s и £. Монетная система: 2 фартинга (f) = полпенса (h), 2 полпенса = 1 пенс (d), 12 d = 1 шиллинг (s), 1 флорин (F) =
236 Глава 8 • Синтаксическое тестирование
2s, полкроны (he) = 2s6d, крона (с) = 5s, 20s ~ 1 фунт стерлингов (£), 21s = 1 гинея (G), 1 соверен (S) = 2£ 18s. Нет ничего удивительного в том, что они представляются в десятичном виде.
9. Благородному Публию Юлию Лентулу,
Трибуну, всаднику, командиру XXIII легиона
Привет вам, Публий:
Возникли вопросы для обсуждения вашей налоговой декларации за прошлый год:
1) Вы не включили XLIV талантов серебра, которые вы получили, казнив Рубидия в прошлом году.
2) Вам позволено объявлять иждивенцами всех воинов XXIII легиона, но вы не можете поступать так ни с MMCCCIX рабами ваших воинов, ни с MMMXLIV маркитантами, так как они уже фигурируют в налоговых декларациях ваших воинов...
Бедный Публий. Проблемы с налогами, возможно, возникали уже в те времена. Определите БНФ-спецификацию для положительных целых чисел в римской системе счисления. Обратите внимание: Подчеркивание1 буквы — X, L, С, D и М — означает умножение их на 1000: например, X = 10 000, L = 50 000, и так далее. Предусмотрите возможность использования букв верхнего и нижнего регистров. Включите все целые числа от 0 до 5 000 000. Затем проведите ряд тестов, обеспечивающих покрытие, а также грязные тесты. И помните, что главное — полнота, а не компактность.
1 На самом деле в римской системе счисления использовалось перечеркивание, но, откровенно говоря, это очень неудобно делать в текстовом редакторе. Я надеюсь, что приверженцы классической истории на меня не обидятся.
Тестирование систем с конечным числом состояний
9.1. Обзор
Изначально предназначенная для тестирования аппаратной логики, модель автомата с конечным числом состояний (конечного автомата) является превосходной моделью для проверки приложений, управляемых через меню. Она важна еще и потому, что получила широкое распространение для разработки объектно-ориентированных продуктов.
9.2. Основные термины
Внешние термины: приложение, поведение, начальная загрузка, ошибка, символ, закрыть файл, управление, данные, проектирование, аппаратное обеспечение, файл, функциональная клавиша, целочисленный, загрузка, логика, интеграция высокого уровня (ИВУ), меню, строка меню, отображение, память, сообщение, метод, мышь, щелчок мыши, MS-DOS, объектно-ориентированное программное обеспечение, открыть файл, операционная система, последовательный порт, программное обеспечение, подпрограмма, символьный отладчик, Windows.
Внутренние термины: поведенческое тестирование, случайная корректность, домен, тестирование домена, граф, ввод, связь, покрытие связей, список связей, вес связи, модель, узел, покрытие узлов, вес узла, пустой, вывод, путь, состояние, сильно связанные, синтаксическое тестирование, система, значение.
Состояние. Состояния изображаются узлами.
238 Глава 9 • Тестирование систем с конечным числом состояний
Имя состояния
Входное событие. Отдельное воспроизводимое событие или фиксированная последовательность определенных событий, характеризуемых вводами (или последовательностью вводов) в систему. Что конкретно означает данное событие, зависит от приложения. При рассмотрении модели с конечным числом состояний я буду использовать термин «вход» для обозначения «входного события», если при этом не будет возникать двусмысленности. В качестве примеров подобных входов можно упомянуть внешний входной сигнал, входное сообщение, символ, выбор меню, определенная последовательность команд пользователя.
Входы в моделях с конечным числом состояний используются скорее для управления, чем для ввода данных, то есть входы скорее вносят изменения в поведение системы, чем являются исходными данными для различных выводов. Это положение иллюстрируют значение целочисленного управляющего параметра, входные данные, значения которых определяют путь обработки в программе, репрезентативный ввод для каждого входного домена. Все приведенные примеры являются отдельными входными событиями.
Входное кодирование. Каждому событию может быть присвоено определенное имя или число. Это означает, что входные события могут отображаться, например, на множество целых чисел или на множество символов. Поведение системы с конечным числом состояний не меняется при изменении входного кодирования.
Входные символы. Набор отдельных имен или значений для входного кодирования.
Число входных символов. Входное кодирование задается целыми числами от 1 до, скажем, п для каждого отдельного входного события. Мы полагаем, что эти числа идут подряд, без пропусков. В большинстве моделей число входных символов мало — как правило, меньше 20. Большее число тоже может быть обработано, но не без помощи специальных инструментов.
Код состояния. Состояния можно пронумеровать. Это называется кодированием состояния. Состояния означают выполнение определенных операций. Например, у накопителя на гибких магнитных дисках могут быть следующие состояния: (1) запуск, (2) включение мотора, (3) поиск дорожки, (4) поиск сектора, (5) чтение (6) стирание, (7) выключение мотора. Мы можем обозначать эти состояния эквивалентными им номерами, например, закодировать состояния числами от 1 до 8. Поведение системы с конечным числом состояний не меняется при изменении способа кодирования состояний.
Текущее состояние. В любой момент времени система находится в определенном состоянии — в текущем.
Начальное состояние. Особое состояние системы обычно называется начальным состоянием, если оно предшествует получению какого-либо входа. Тестирование системы, не обладающей начальным состоянием, также возможно, однако это не рассматривается в данной книге.
Счетчик состояний. Гипотетический или реальный адрес ячейки памяти, содержащий код текущего состояния. Счетчик состояний часто бывает неявным.
9.2. Основные термины 239
Программный счетчик в компьютере является примером явного счетчика состояний.
Число состояний. Счетчик состояний ограничен своим максимальным значением. Если код состояний задает непрерывный диапазон, то это максимальное значение равно числу состояний. Как и в случае входных символов, число состояний в модели обычно невелико (меньше 30). Большее число может быть обработано при помощи специальных инструментов.
Автомат с конечным числом состояний (конечный автомат). Абстрактный автомат (например, программа, логическая схема, трансмиссия в автомобиле) для которого число состояний и число входных символов конечно и фиксировано. Автомат с конечным числом состояний состоит из состояний (узлов), переходов (связей), входов (весов связей) и выходов (весов связей). Автоматы с конечным числом состояний в данной книге изображаются графами состояний.
Переходы. Система реагирует на входные события, что может привести к смене состояния. Это называется переходом между состояниями, или просто переходом. Система передает сообщение другой системе. Во время передачи она находится в состоянии «передача». После завершения передачи она ожидает уведомления об успешном приеме данных. В этом случае она находится в состоянии «ожидание уведомления». Изменение состояния можно рассматривать как изменение значения счетчика состояний. Переходы на графе обозначаются связями. Если вход X инициирует переход из состояния А в состояние В, то для обозначения этого факта мы рисуем связь от А к В с весом X. В диаграмме вход X должен инициировать переход из состояния А в состояние В.
Переход в себя. Обозначает сохранение состояния. Изображается связью, выходящей из состояния и входящей в него же. Такому переходу может соответствовать определенный выход.
Кодирование выхода. Переходу может соответствовать выход. Это означает, что в результате изменения состояния инициируется выходное действие. Выходные действия также могут быть пронумерованы целыми числами. Такая нумерация называется кодированием выхода. Поведение системы с конечным числом состояний не зависит от способа кодирования выхода.
Выходное событие. В результате изменения состояния система может выдавать что-либо на выход. Это эквивалентно подаче на выход целого числа, выходного кода. Если бы мы говорили о программном обеспечении (хоть это и не обязательно), то мы могли бы сказать, что подаче на выход числа 7, например, соответствует запуск седьмой подпрограммы или передача сообщения седьмому методу объектно-ориентированной программы. Выходные события также обозначаются весами связей, причем в обозначении они следуют за символом наклонной черты. На предыдущем рисунке вход X порождает выход Y. Обратите внимание, что в модели на следующем рисунке оба входа вызывают изменение состояния (возможен переход в то же самое состояние, в данном случае «просмотр ТВ») и инициируют
240 Глава 9 • Тестирование систем с конечным числом состояний
выход (возможно, пустой, в данном случае «пропустить» для входа «кошка вошла в комнату»).
Кошка вошла
в комнату / пропустить
Пустой выход. Абстрактное пустое выходное событие. Например, событие «оставить все как есть».
Доступное состояние. Состояние В доступно из состояния А, если существует такой набор входов, что модель, находясь изначально в состоянии А, в итоге придет в состояние В. Это означает, что в графе состояний существует путь от А к В.
Недоступное состояние. Состояние недоступно из других состояний, особенно из начального состояния, если оно не является доступным. Недоступные состояния обычно означают наличие ошибки.
Сильно связанные состояния. На практике большинство состояний в автоматах с конечным числом состояний являются жестко связанными при условии отсутствия ошибок.
Изолированные состояния. Набор состояний, недоступных из начального состояния. Внутри этого набора изолированных состояний состояния могут быть, а могут и не быть сильно связанными. Их изолировала именно недоступность из начального состояния. Изолированные состояния в моделях тестирования программного обеспечения вызывают подозрения и могут содержать ошибки.
Сброс. Особый вход, приводящей к возврату системы в начальное состояние из любого другого состояния. Если любое состояние доступно из начального состояния и если существует сброс, то граф состояний сильно связан. Сброс не является обязательным требованием, однако его наличие существенно упрощает проектирование теста и тестирование. Сброс также может быть реализован как возврат к особому состоянию, не являющемуся на самом деле начальным состоянием в модели.
Набор начальных состояний. Набор состояний, обладающий следующими свойствами. Он включает в себя начальное состояние (начальные состояния). Набор начальных состояний может быть, а может и не быть сильно связанным. Если был совершен переход из состояния в этом наборе в состояние, не входящее в этот набор, то возврат в набор начальных состояний становится невозможен. Рассмотрим начальную загрузку системы. Программное обеспечение при загрузке проходит ряд шагов, каждый из которых может быть интерпретирован как состояние. После загрузки программы возврат в набор начальных состояний невозможен, поскольку вы не можете «выгрузить» программу. Загрузка системы может идти с применением нескольких наборов начальных состояний. Например, каждый набор начальных состояний включает в себя только одно состояние и пред
241
ставляет собой ступени загрузки. Тем не менее, в продуманном программном обеспечении должен быть способ возврата в начальное состояние: в операционной системе Windows это комбинация CTRL-ALT -DEL.
Рабочее состояние. Рано или поздно система пройдет начальное состояние и перейдет в сильно связанный набор рабочих состояний — область, в которой выполняется ббльшая часть тестирования.
Начальное состояние в рабочем наборе. В рабочий набор может входить состояние, которое называется «начальное состояние». Оно не является истинным начальным состоянием модели, но выполняет его функции. Например, меню, которое появляется после загрузки Windows, — это не истинное начальное состояние. Истинными являются состояния, входящие в последовательность загрузки. Однако с точки зрения выполнения операций в этой системе мы можем назвать это состояние исходным, до тех пор пока речь идет о тестировании меню. Подход, в котором ясно определяются различные наборы состояний и состояния, служащие начальными в этих наборах, представляется достаточно удобным.
Набор выходных состояний. Модель может иметь одно или два состояния, или целый набор состояний, таких, что после перехода в них возврат в набор рабочих состояний становиться невозможен. Внутри этого набора выходных состояний состояния могут быть, а могут и не быть строго связанными. Типичный пример — последовательность шагов при выходе из программы.
Полностью определенный автомат. Автомат с конечным числом состояний называется полностью определенным тогда и только тогда, когда для любой комбинации входного кода и кода состояний задан переход (возможно, назад, в то же самое состояние) и выход (возможно, пустой). Не содержащие ошибок автоматы с конечным числом состояний полностью определены. Автоматы же с ошибками могут быть, а могут и не быть полностью определены.
Программное обеспечение, управляемое при помощи меню. Программное обеспечение или разновидность программной операции, в которой основное управление осуществляется выбором соответствующих пунктов в меню.
Обход из начального состояния (или просто обход, если не возникает двусмысленности). Последовательность переходов из состояния А (например, начального состояния) в состояние В и назад в А. Если в модели есть набор начальных состояний, то подразумевается обход из состояния в этом наборе, которое проектировалось как начальное. Данный термин также используется для обозначения
242 Глава 9 • Тестирование систем с конечным числом состояний
обхода набора рабочих состояний, который стартует из начального состояния этого набора.
9.3. Отношения и модель
9.3.1. Основы
Материал, излагаемый в этом разделе, рассматривался и в [BARN72, BRZO63, CHOW78, CHOW88, MCNA60, MILL75],
Я просмотрел множество форм ВНС и инструкций в поисках примеров систем с конечным числом состояний, которые могут быть полезны для нас, но не смог найти ничего, за исключением одного, но зато вечного состояния тревоги, которую испытывает каждый из нас при упоминании о налоговой декларации. Мне придется использовать в качестве иллюстраций менее формальные примеры.
Узлы. Узлы обозначают состояния. На рисунке приведено меню для программы, управляемой с его помощью. Если выбран какой-то определенный пункт меню, то это означает, что мы находимся в соответствующем состоянии. Я настроил оболочку своей операционной системы таким образом, чтобы иметь на экране следующие пункты меню: Выход, Файл, Диск, Дерево, Вид, Настройка, Панели инструментов, Окно, Загрузить DOS, Справка.
МОЙ СОБСТВЕННЫЙ ПЛАН РАБОЧЕГО СТОЛА
Выход Файл Диск Дерево Вид Настройка Инструменты Qkho Загрузить DOS = Ctrl + D Справка
Найти | |формат| Метка |копировать| | Поиск | Запись конфиг.| DOS |Упорядочить|Редактор|Настройка| Справка J
На самом деле здесь 12, а не 10 состояний, поскольку я не включил сюда начальное состояние, то есть состояние, в котором ни один пункт меню не выбран. Я также не включил сюда выбор самой левой кнопки с чертой, управляющей меню.
Связи. Связи обозначают переходы. В данном примере существует возможность перейти из начального состояния в любое другое состояние, если выполнить соответствующее входное действие. Также возможно перейти из большинства остальных 10 состояний обратно в начальное состояние (активное меню закрывается) путем нажатия клавиши ESC или ALT. Мы остаемся в начальном состоянии, если ничего не делаем, или нажимаем на любые другие (не ESC или ALT) клавиши.
Веса связей (входные коды). В операционной системе Windows предусмотрен большой выбор возможностей для входного кодирования. Вот некоторые способы активизации меню, что означает смену состояния (появляется новое меню).
Выход Файл Дерево Вид Настройка Инструменты Окно Загрузить DOS = Ctrl + D Справка
Найти Форматировать... Копировать| | Поиск | Запись конфиг | pos |Упорядочить|Редактор|настройка| Справка
“ Метка диска...
WordPerfect - [ГЛАВА 9 - ТЕСТИРОВАНИЕ КОНЕЧНОГО ЧИСЛА СОСТОЯНИЙ]
Вставить Схема Инструменты График Таблица Окно Справка Закрыть
Выбор при помощи мыши. Поместите курсор мыши на соответствующую область в строке меню и нажмите на левую кнопку.
9.3. Отношения и модель 243
Другие указатели. Кроме мыши, можно использовать и другие устройства указания, такие как трекбол, джойстик, сенсорный экран, световое перо — все можно пересчитать по пальцам.
Комбинация ALT+Клавиша. Если вы находитесь в начальном состоянии, то можно использовать комбинацию ALT + Ключевая клавиша, где «Ключевая клавиша» — это подчеркнутая буква в названии меню, например, Вид.
Функциональные клавиши. Функциональные клавиши могут быть запрограммированы для открытия определенных меню. К примеру, F1 обычно открывает меню Справка.
Стрелки. Если в строке меню выбрано какое-нибудь меню, то вы можете перейти в соседнее меню путем нажатия на клавишу со стрелкой влево или вправо.
Перечисленные выше способы представляют собой различные варианты входного кодирования. Преобразование действий пользователя (нажатия клавиш или передвижения курсора мыши) во входной код часто осуществляется операционной системой. Если это применимо к вашему случаю, то можете не обращать на это внимания, если вы только не тестируете операционную систему. Однако если кодирование выполняет ваше приложение, то вам следовало бы его проверить. Если ваше приложение поддерживает несколько входных устройств и программа обрабатывает эти устройства напрямую, то необходимо рассматривать отдельную кодировку для каждого такого устройства и эти кодировки должны быть проверены.
В приведенном примере существует начальное состояние: состояние, в котором в строке меню не выбрано ни одного меню. Для возврата в начальное состояние из большинства меню существует несколько способов, например нажатие на клавишу ESC или ALT.
Для большинства состояний существует переход самого в себя. В начальном состоянии нажатие фактически любой обычной клавиши приводит к переходу обратно в начальное состояние. Однако обратите внимание, что когда вы находитесь в одном из открытых пунктов меню, некоторые из обычных клавиш становятся активными. Например, в моем меню Справка активны следующие подчеркнутые клавиши: Быстрая справка, Содержание, Поиск по справке, Как пользоваться справкой, Файлы Readme, £) программе. Другие буквенные клавиши вызывают переход состояния в себя, тот же эффект производит комбинация CTRL, SHIFT и обычных клавиш. Большая их часть сигнализирует, что они «не реагируют» на нажатие. Большинство клавиш действительно реагирует на нажатие, но некоторые не делают этого, что означает, что была выбрана другая кодировка выхода. Такие вещи имеет смысл проверять.
Веса связей (выходные кодировки). В этом примере производимые действия достаточно сложны. Предположим, в системе открыто меню или другое окно. Выбор какого-либо пункта может привести к целой последовательности действий. Некоторые из них работают в текущем окне, а некоторые открывают дополнительные окна.
Попробуем использовать эту концепцию в модели космического корабля Enterprise. У него есть импульсный двигатель с тремя возможными режимами: разгон (Р), нейтральное положение (П), задний ход (3). Корабль, в свою очередь, тоже имеет три состояния: движение вперед (В), остановка (О), движение назад
244 Глава 9 • Тестирование систем с конечным числом состояний
(Н). Комбинации режима работы ракетного двигателя и состояния движения корабля образуют девять состояний: РВ, РО, PH, ПВ, ПО, ПН, ЗВ, 30 и ЗН.
Согласно требованиям, предъявляемым к управлению импульсным ракетным двигателем, для того чтобы переключиться в положение «разгон» или «задний ход», вам надо пройти нейтральное положение. В нейтральном положении все двигатели выключены: Р<>П<>3. Допустимы следующие входы: р>р, з>з, п>п, р>п, п>р, п>з и з>п. Давайте теперь построим диаграмму состояний для корабля Enterprise. Наш корабль подчиняется ньютоновскому закону движения. Мы начнем с комбинации ПО, двигатели выключены и корабль стоит на месте. Если мы не будем касаться ручек управления (п>п), то ничего не произойдет и мы останемся в том же самом положении. Мы можем выбрать один из двух оставшихся вариантов: разгон вперед (п>р) или разгон назад (п>з). Между моментом времени, когда мы повернули ручку управления ракетным двигателем, и моментом, когда этот двигатель заработает, есть некая задержка. Если мы выбрали опцию разгон вперед (п > р), мы перешли в состояние РО (разгон - остановка). Аналогично если мы выберем опцию разгон назад, мы перейдем в состояние 30. В любом случае, если мы будем держать двигатель включенным (р> р), то он рано или поздно заработает и мы начнем двигаться вперед. Это переведет нас в состояние РВ (разгон - движение вперед). Если мы были в состоянии РО (разгон - остановка) и при этом выключили двигатель, то вернемся обратно в состояние ПО (нейтральное положение - остановка). Из рассмотрения верхних переходов ЗВ > 30 > ЗН и нижних переходов PH > РО > РВ следует, что если мы движемся в определенном направлении, то мы физически не можем изменить направление движения без остановки в какой-либо точке.
НАЗАД < ДВИЖЕНИЕ > ВПЕРЕД
Ниже приведены некоторые наблюдения, касающиеся модели и соответствующего ей графа.
1. Граф сильно связан, поскольку между любыми двумя состояниями существует по меньшей мере один путь. Обратите внимание на то, что эти пути не являются прямыми переходами, мы не можем перейти из одного состояния в другое, просто изменив направление движения на обратное. Например, чтобы перейти из состояния РВ в состояние ЗН, вам придется пройти следующий путь: РВ - ПВ - ЗВ - 30 - ЗН, а для перехода из ЗН в РВ: ЗН - ПН - PH - РО - РВ.
9.3. Отношения и модель 245
2. Моей задачей было моделирование двух факторов: управления режимом ракетного двигателя и направления движения корабля. Так как для каждого из них было три возможных варианта, то, комбинируя их, мы получили девять состояний. Число состояний равно произведению числа вариантов для каждого фактора. Графы состояний растут очень быстро.
3. Между входами и состояниями существует отношение. Несмотря на то, что допустимы семь входных действий, в определенном состоянии не все они разрешены. Более детальная модель (см. таблицу состояний в разделе 9.3.3 ниже) включает в себя все входы, в том числе не разрешенные. Зачем? Так как в нашем случае мы не знаем, насколько надежна система, возможно, она содержит ошибки. Предположим, например, что управление двигателем сломано и существует возможность перевода его из режима Задний ход в режим Разгон, минуя Нейтральное положение (см. проблему 2). В простейшей модели состояния и входы не зависят друг от друга, но это почти никогда не встречается на практике. Например, действия различных клавиш в модели меню явно зависят от состояния (от того, какое меню активно).
4. Модель космического корабля имеет совершенную симметрию, нечасто встречающуюся на практике. Обычно переходы соединяют состояния в системе беспорядочно.
9.3.2. Модели Мили и модели Мура
Модели с конечным числом состояний, используемые в этой книге, называются моделями Мили [MEAL55]. В моделях Мили выходы ассоциируются с переходами. Модель, альтернативная этой, называется моделью Мура [MOOR56], и в ней выходы ассоциируются с состояниями. Модель Мура можно легко получить из модели Мили, заменив каждый код выхода, ассоциированный с переходами, на соответствующее выходное состояние. Выходные состояния обычно выделяются жирной границей или двойной границей. На рисунке я заменил переход дополнительным состоянием, выходным состоянием, в котором происходит выходное действие. Обратите внимание на то, что мне также пришлось добавить фиктивный выход (пустой), чтобы показать, что переход в следующее состояние произойдет без дополнительного внешнего входа.
Причины, по которым я предпочитаю модели Мили:
1. Они содержат меньше состояний и, следовательно, проще сами по себе. Сложность модели определяется путем умножения числа входных символов на число состояний. При увеличении числа состояний вы увеличиваете размер модели и усложняете ее тестирование.
246 Глава 9 • Тестирование систем с конечным числом состояний
2. Состояния в них стабильны. Модель Мура всегда содержит изменяющиеся состояния, которые не будут терпеливо дожидаться, пока мы их проверим. Это усложняет тестирование. В модели Мили вы не меняете состояния в отсутствие входа. Справедливости ради надо отметить, что модель Мили также может содержать изменяющиеся состояния, если мы допускаем пустой вход, но в модели Мили обычно таких состояний меньше.
3. Они ближе к конечной реализации. Программисты, реализуя системы с конечным числом состояний, обычно делают это на основе моделей Мили, а не моделей Мура. Различия тестовой и проектной моделей являются источником ошибок при разработке тестов.
4. Они обеспечивают повторяемость выхода. Определенный выход (например, Открыть Файл) может соответствовать множеству различных переходов. Это могло бы потребовать отдельного состояния для каждого случая и, следовательно, привело бы к увеличению размера модели.
5. Их таблица представления проще. Представление модели с конечным числом состояний в виде таблицы проще для моделей Мили, чем для моделей Мура.
Эти две модели теоретически эквивалентны. Каждой модели Мура соответствует модель Мили и наоборот. Зачем тогда нужны эти разговоры? Согласно моим наблюдениям, в случаях, когда модели с конечным числом состояний используются в проектировании, например, при объектно-ориентированном подходе, чаще используют модель Мура, а не Мили. Вы не должны смешивать два типа моделей. Выберите один из них (я настоятельно рекомендую Мили) и придерживайтесь его.
Читатели, знакомые с графико-теоретическими моделями, обратят внимание на то, что я отдаю предпочтение моделям со взвешенными связями, а не моделям со взвешенными узлами. Модель Мура, разумеется, относится к последним, если рассматривать выходы. Модель Мура имеет определенные преимущества при описании последовательно переключающихся схем, особенно асинхронных. Обе модели были изначально созданы в рамках теории переключающихся схем и теории автоматов. Однако мы имеем дело с программным обеспечением, а не с последовательно переключающимися схемами.
В большинстве случаев доказательства теорем проще проводить для моделей со взвешенными узлами, чем со взвешенными связями, и этим объясняется превалирование первых в научных работах. Тем не менее, когда дело доходит до построения реальных инструментов, в которых графы представляются в виде списка связей, или при использовании алгоритма сокращения числа узлов (см. [BEIZ90]), модели с взвешенными связями имеют неоспоримые преимущества.
9.3.3. Таблицы переходов
Графическая форма представления моделей полезна скорее для обучения, а не как рабочий инструмент. Вы можете использовать представление в виде списка связей, так же как и для любого другого графа, и, разумеется, мы часто видим подобное представление моделей с конечным числом состояний в проектных документах. Альтернатива этому — использование табличного представления. В этом
247
случае мы могли бы начертить таблицу n х п (где п — это число состояний) и в каждую ячейку записать соответствующую ей комбинацию вход/выход. Могли бы, но не станем этого делать, поскольку такая таблица (для большей части программного обеспечения) будет почти целиком пуста. Вместо этого мы используем таблицу состояний-переходов, или коротко таблицу состояний.
В таблице состояний каждому состоянию соответствует одна строка, а каждому входу один столбец. Фактически мы можем начертить две таблицы с одинаковой разбивкой: таблицу состояний-переходов и таблицу выходов. В ячейку первой таблицы мы записываем СЛЕДУЮЩЕЕ СОСТОЯНИЕ. Во вторую таблицу мы заносим соответствующий код выхода (если он есть) для данного перехода. Иногда бывает удобно комбинировать эти две таблицы, записывая и следующее состояние и выходные данные в одну и ту же ячейку, например, в виде следующее состояние/код вы-
Таблица 9.1. Таблица состояний корабля Enterprise
Состояние 3>3 3>П п>п П>3 п>р р>р р>п з: >Р р>з
ЗН ЗН ПН
30 ЗН по
ЗВ 30 ПВ
пн ПН ЗН PH
по по 30 РО
ПВ ПВ ЗВ РВ
PH РО пн
РО РВ по
РВ РВ ПВ
Я оставил пустыми ячейки, содержащие запрещенные комбинации (состояние — вход). Они невозможны в корректно реализованной системе. В данном примере некоторые переходы запрещены в соответствии с законами физики. Другие входы, такие как з>р и р>з запрещены из-за технических ограничений, накладываемых оборудованием — системой управления двигателем. Рассмотрите, однако, вопросы 2, 3 и 4 в конце этой главы.
В этом примере я не задал выходы. Какие выходы могли бы быть в модели корабля Enterprise? Наверное, запуск топливного насоса и зажигание. Различие между разгоном вперед и задним ходом могло бы заключаться в том, какой из топливных клапанов (носовой или кормовой) открыт. Топливный насос и зажигание должны активироваться для обоих направлений двигателя. Поэтому несколько выходных функций могут соответствовать множеству различных переходов. При тестировании состояний мы основное внимание уделяем проверке состояний и переходов, а потом уж выходам. В менее фантастическом примере модели меню мы можем закрывать и открывать файлы во множестве различных пунктов меню. Безусловно, мы должны проверить открытие и закрытие файла. Но если файл открывается, как и должен, и мы в этом убедились, то у нас нет необходимости проводить тестирование открытия файла для всех случаев (то есть всех переходов), когда это открытие может случиться.
248 Глава 9 • Тестирование систем с конечным числом состояний
9.3.4. Вложенные автоматы
Обсуждаемая выше таблица достаточно сложна: она имеет 81 ячейку (девять состояний и девять входов). Пример меню на рабочем столе еще более сложен. Я насчитал 12 пунктов в строке меню и выбрал те пункты, которые могут быть активированы нажатием на обычную клавишу — 23 пункта для 26-буквенного алфавита и плюс еще девять цифр, всего — 32 входных кода. Для представления этого в виде одной таблицы нам нужна таблица 12 * 32 = 382 ячейки. Мы могли бы построить такую большую таблицу, но мы не станем этого делать. На это есть несколько причин.
1. Слишком много входов. Слишком много возможностей для ошибки при проектировании тестов.
2. Слишком много пустых ячеек. Еще больше возможностей для ошибки.
3. Слишком много запрещенных комбинаций состояние/вход.
4. Есть лучший способ.
Под лучшим способом я подразумеваю вложенные автоматы. Это то, что большинство людей делает интуитивно. Меню панели управления Windows включает в себя три пункта: Панель управления, Настройки и Справка. Мы можем построить автомат с четырьмя состояниями: по одному состоянию для каждого из трех пунктов меню и еще одно состояние, соответствующее случаю, когда ни одно меню не активно. Мы строим модель этого уровня, исследуем все способы переключения между меню, активации и деактивации меню и так далее, но ничего не делаем и не выбираем в рассматриваемых меню. Далее для каждого из трех меню мы строим отдельную модель с конечным числом состояний, которая описывает то, как данное меню работает и какие опции в нем можно выбирать. То же относится к выбору значка в начальном состоянии (ни одно меню не открыто) базовой модели.
=|________________________Control Panel___________
Settings Help
4 Ъ S
Color Fonts Ports Mouse Desktop Keyboard
О О ® a®
Printers International Date/Time 386 Enhanced Drivers Sound
Changes settings for your Microsoft Mouse
Продолжим рассмотрение нашего примера вложенной системы и исследуем меню самого верхнего уровня Настройки. Мы имеем модель со следующими опциями: Цвет, Шрифты, Порты, Мышь, Рабочий стол, Клавиатура, Принтеры, Региональные установки, Дата/Время, 386-улучшенный, Драйверы, Звук и Выход. Подчеркнутые буквы показывают, какую клавишу надо нажать, чтобы выбрать данный пункт. Итак, для обработки данного меню нам требуется другая модель. Если в этой модели мы делаем какой-либо выбор, то, как правило, активируется еще одно меню, со своими пунктами, а значит и со своей моделью и так далее.
9.3. Отношения и модель 249
Вложенные автоматы — это, по сути, единственный практический способ работы со сложными системами. Если вы исследуете стандартный проект, построенный на основе автоматов с конечным числом состояний, то увидите, что хорошие разработчики поступают точно так же. Они используют вложение своих моделей. В результате реализация проекта имеет те же самые вложения. Практика показывает, что без специальных инструментов очень трудно работать с таблицами состояний, имеющими более нескольких сотен входов. Это не очень много — всего 10 состояний и 20 входных кодов. Большие автоматы с сотнями входов постоянно используются в программном обеспечении, управляющем работой телефонных узлов, но некоторые подобные таблицы требуют сотен лет работы одного человека для создания, тестирования и отладки.
9.3.5. Улучшаем модель
Вероятность возникновения ошибок при создании модели достаточно велика. На практике модели на основе автоматов с конечным числом состояний требуют больших трудозатрат. Вы должны уметь различать ошибки модели, ошибки в тестах, основанных на этой модели, и ошибки системы. Легче избавиться от ошибок моделирования до того, как вы начали разрабатывать тест, чем потом искать их во время тестирования. Ниже описаны некоторые вещи, которые стоит поискать в моделях, и то, как их искать. Здесь нам сильно облегчает задачу то, что для таких моделей разработана теория, на основе этой теории созданы алгоритмы, и во многих случаях существуют инструментальные средства, основанные на этих алгоритмах. Однако не спешите радоваться. Данная теория выходит за рамки этой книги, а алгоритмы, если они реализованы в инструментах, почти всегда предназначены для аппаратного обеспечения и должны быть адаптированы для использования в программных моделях.
1. Завершенность и последовательность. Как много у вас входных символов? Как много состояний? Произведение этих двух чисел (называемое произведением состояние-символ) равно числу ячеек в таблице состояний. Каждой ячейке в таблице должен соответствовать один и только один переход, не больше и не меньше. Если какая-либо ячейка не заполнена, то в модели возникает неопределенность. Если для какой-либо ячейки определен более чем один переход, то возникает противоречие. Программа не может быть противоречивой или незавершенной. В любом состоянии она всегда должна выполнять какое-либо действие для любого входа, и это действие должно быть единственным. Мнимые противоречия более неприятны, так как с ними ваша система с конечным числом состояний по крайней мере в два раза больше, чем вы думаете.
2. Однозначная входная кодировка. Если входное кодирование изменяется от состояния к состоянию, то у вас либо ошибка в модели, либо ужасный проект. Это означает, что размер вашей таблицы состояний не фиксирован. На практике вы не сможете проанализировать эту ерунду.
3. Минимум автоматов. Вы создаете модель, в которой у вас есть два набора состояний с различными именами, но одинаковыми выходными действиями
250 Глава 9 • Тестирование систем с конечным числом состояний
и аналогичными переходами. Предположим, у вас есть два состояния А и В, такие, что любая входная последовательность, начинающаяся в состоянии А, выдает на выход такую же последовательность, как если бы она начиналась в состоянии В. В этом случае внешний наблюдатель не сможет отличить эти два состояния. За исключением различия имен, эти два состояния эквивалентны и могут быть объединены в одно. Аналогичные рассуждения применимы и к набору состояний. Вам следует упростить модель, объединив все эквивалентные состояния. Это можно сделать автоматически. За более подробной информацией стоит обратиться к [BEIZ90].
4. Нет сильной связи. Если в модели состояний для программного обеспечения между рабочими состояниями нет сильной связи, то либо ваша модель, либо ваш проект содержат ошибки. Что вы думаете о программе, содержащей меню, активация некоторых пунктов которого возможна только после перезапуска системы? Вы можете выявить этот момент вручную для маленьких моделей. Для больших моделей существуют специальные алгоритмы, лежащие за рамками этой книги. Также существуют алгоритмы для поиска недоступных состояний или наборов недоступных состояний. Подходящий алгоритм разбиения можно найти в [BEIZ90],
9.4. Методы
9.4.1. Основы
При проектировании тестов вам надо придерживаться принципов, описанных в предыдущих главах.
1. Идентифицируйте входы. Какие конкретно входные события вы собираетесь учесть в модели? Дайте каждому событию свое имя и опишите его. Например, конкретные входные сообщения, принадлежащие конкретным входным доменам, фиксированная последовательность входов. В модели невозможно учесть все возможные входы, поэтому используйте не слишком большое число входных событий (например, 10-20).
2. Задайте входное кодирование. Вы выбрали входное кодирование, которое будет использоваться в вашей модели. Оно может соответствовать такому же кодированию, использованному программистами, а может и не соответствовать. Не включайте в модель такие функции, которые поддерживаются программным обеспечением, но которые вы не собираетесь тестировать. К примеру, если операционная система сама конвертирует указание курсором и щелчок мышкой в выбор пункта меню, то вам не надо включать это в свою модель, считайте, что ваш вход приходит к вам уже закодированным (например, операционной системой). Вы должны проверять входное кодирование, только если оно является частью реализации программы.
3. Идентифицируйте состояние. Состояния часто создаются в виде произведения множителей. Если это так, идентифицируйте множители и имейте
9.4. Методы 251
в виду, что каждой комбинации множителей будет соответствовать свое неповторяющееся состояние и что произведение растет очень быстро и вам, возможно, будет необходимо использовать вложенные модели. Составьте список идентифицируемых состояний и дайте им имена, используя какую-либо систему. Получившиеся состояния должны исчисляться десятками, но не тысячами.
4. Задайте кодирование состояний. Если разработчики используют программную реализацию автомата с конечным числом состояний [BEIZ90], то программа может содержать процедуру кодирования текущего состояния и счетчик состояний. Если это так, то процедура кодирования состояния должна быть протестирована, однако это может представлять большую трудность в контексте чистого поведенческого тестирования. Если к программе не применялось явное проектирование с конечным числом состояний, то кодирование состояний является одной из задач вашей модели и может не содержаться в качестве составной части в программе. Тем не менее, вы должны проверить корректность кодирования в вашей модели.
5. Идентифицируйте выходные события. Только самые простые модели имеют одиночные выходные события, например, соответствующие выводу одиночного символа. Гораздо более часто выходные события состоят из последовательности действий. Идентифицируйте эти последовательности. Во вложенных моделях выходное событие представляет собой активацию модели следующего нижнего уровня в иерархии моделей. Дайте имя каждому выходному событию, вне зависимости от того, является ли это событие единичным или представляет собой последовательность действий.
6. Определите выходное кодирование. Если дизайн определяет систему с конечным числом состояний, то перед вами, возможно, встанет задача протестировать выходное кодирование, созданное программистами, и это также представляет трудность в контексте поведенческого тестирования. Тем не менее, вы должны проверить, что ваше выходное кодирование (которое в итоге является только свойством модели) на самом деле соответствует тому, что происходит в реальности.
7. Постройте таблицу состояний и таблицу выходов и уберите из них все ненужное. Это наиболее трудная часть работы, опа требует наибольших затрат времени и наиболее опасна с точки зрения возникновения ошибок.
8. Постройте тесты. Вам надо разработать три вида тестов: тесты для проверки входного кодирования, тесты для проверки выходного кодирования и тесты для проверки состояний/переходов. Первые два теста относятся только к вашей модели. Третий тест относится к программе (и вашей модели). Эти задачи и способы их решения обсуждаются ниже, в разделе 9.4.2.
9. Запустите тесты. Любое тестирование должно стартовать из начального состояния, дойти до заданного состояния, пройдя по пути через различные другие состояния, и в конце вернуться обратно в исходное состояние.
252 Глава 9 • Тестирование систем с конечным числом состояний
10. Для каждого входа проверьте переходы и выход. Это действие может быть нетривиальным. Здесь, как правило, требуется какая-либо помощь в проектировании. См. раздел 9.4.5.
Ниже приведены некоторые тесты для корабля Enterprise.
ПО > по
ПО > 30 > по
по > Р0 > по
ПО > 30 > ЗН > ПН > PH > Р0 > по
ПО > Р0 > РВ > ПВ > ЗВ > 30 > по
ПО > 30 > ЗН > ЗН > ПН > PH > Р0 > по
ПО > Р0 > РВ > РВ > ПВ > ЗВ > 30 > по
Все тесты стартуют из начального состояния ПО. Из начального состояния тесты идут в заданное состояние наикратчайшим путем и возвращаются наикратчайшим путем обратно в начальное состояние, создав, таким образом, петлю. Тесты добавляются так, чтобы обеспечить покрытие связей. Каждый следующий тест строится на основе предыдущего, более простого теста. Если вы выбрали набор обходов, обеспечивающих покрытие, то для каждого перехода у вас есть входной код. У вас также есть выходное кодирование, соответствующее всем переходам. Вы должны пройти в обратном направлении и по заданным входным кодам определить реальные входы, а по заданным выходным кодам — выходные действия, если они есть. Может показаться, что это необычайно трудоемкий процесс (и это может быть так на самом деле), однако технически он не сложен.
Эти тесты представляют собой скорее экспериментальные исследования, при этом оптимизации тестов не уделяется особого внимания. Переходя от одного теста к другому, добивайтесь минимума изменений и кладите в основу каждого следующего теста предыдущий тест, в котором вы уверены. В результате этого подхода возникнет множество на первый взгляд избыточных тестов, однако такой подход гарантированно надежен.
9.4.2. Что необходимо проверить
1. Проверьте входное кодирование. Убедитесь, что в вашей модели входное кодирование соответствует его реализации. Если они отличаются, выясните, где ошибка в модели или в программе. Способ, при помощи которого вы сможете это проверить, зависит от того, что конкретно вы кодируете. Если входы представляют собой числа, то для проверки кодирования вы, возможно, сможете использовать метод тестирования доменов. Если символьные строки — то синтаксическое тестирование или другую модель состояний. Так или иначе, вы должны подтвердить соответствие между обработкой входных событий вашей моделью и программой и объяснить все расхождения.
2. Проверьте выходное кодирование. У вас должно быть сравнительно немного выходных событий или последовательностей действий. Дайте каждой из них имя. Если закодированный выход «А» означает «открыть файл, обновить файл, закрыть файл, сообщить об исполнении», то вы должны убедиться, что все эти действия имели место, причем именно в этом порядке.
9.4. Методы 253
Вы можете исследовать промежуточные вычислительные шаги, протокол активности файла, использовать символический отладчик... Однако какой бы путь вы ни выбрали, вы должны убедиться в том, что ваши выходные коды соответствуют последовательности действий в реальной программе и объяснить все расхождения, если такое соответствие отсутствует.
3. Находитесь ли вы в начальном состоянии? Методы, обсуждаемые в этой книге, предполагают существование хотя бы одного начального состояния, а также то, что в него можно попасть. В сложных системах может быть несколько начальных состояний. Например, начальное состояние для операции, выполняемой одиночным пользователем, скорее всего, будет отличаться от начального состояния для сетевой операции. Вы не можете начать тест, пока вы не обнаружили и не исследовали начальное состояние. Сообщений программы, что вы находитесь в начальном состоянии, недостаточно. В конце концов, это может быть как раз та ошибка, которую вы ищете. Начальное состояние обладает определенными свойствами, такими как список открытых файлов, используемые ресурсы, активные программы и так далее. Проверьте это. Если ваше начальное состояние представляет собой что-нибудь вроде начальной загрузки или загрузки в память, то вы должны проверить каждое состояние и каждый переход в этом наборе состояний. Это может быть достаточно сложно, если вы не используете соответствующие инструментальные средства для вашей разработки тестов, так как подобные последовательности часто выполняются автоматически. Пошаговое отслеживание переходов необычайно полезно при тестировании.
4. Доступны ли вам все выходные состояния? Как правило, программы содержат более одного выходного состояния или набора выходных состояний. При попадании в такое состояние запускается процедура выхода из вашей модели. Наипростейший пример — состояние, в котором закрывается тестируемая программа. Однако далеко не всегда все так просто. К примеру, если я решил закрыть свой текстовый редактор, меня просят подтвердить это. Если я подтверждаю свой выбор и у меня есть какие-либо открытые файлы, которые не были предварительно сохранены, программа спросит меня, хочу ли я сохранить изменения. Это уже нетривиальный набор выходных состояний.
5. Проверьте состояния. Все ли требуемые состояния существуют? Целью обхода через выбранное состояние является проверка существования состояния и его доступности. Разумеется, вы должны иметь в распоряжении надежные средства, при помощи которых вы сможете владеть информацией о состоянии в любой момент времени. Обычно при тестировании программ такая возможность существует, особенно если есть явный счетчик состояний и если разработчики позаботились об удобстве тестирования. Если у вас нет средств для идентификации состояния, тестирование, хотя в принципе и возможно, становится гораздо более сложной задачей, и его описание лежит за рамками данной книги.
6. Нет ли лишних состояний? Это тяжело определить, как теоретически, так и практически. Однако при помощи эвристического метода, описанного
254 Глава 9 • Тестирование систем с конечным числом состояний
ниже в разделе 9.4.3, вы, скорее всего, сможете обнаружить лишние состояния, если они существуют.
7. Проверьте каждый переход. Каждому переходу соответствует потенциальный выход. Точнее говоря, существует итог каждого перехода. Переход состоит из двух вещей: нового состояния и выхода, если он есть. Если существует пустой «выход», соответствующий переходу, он также должен быть проверен. Вы задали кодирование состояний. Это означает, что у вас есть подробные характеристики, которые будут однозначно идентифицировать состояния. Проверьте каждый компонент кодирования состояния. Однако вы можете быть введены в заблуждение вероятностью существования лишних состояний, обсуждаемых в следующем разделе. Также вы должны проверить каждое выходное действие, определенное в кодировании выхода вашей модели, и особенно соответствующее пустому выходу. Убедитесь, что при пустом выходе на самом деле ничего не происходит. Если вы перешли в корректное состояние и ваши выходы (включая пустой) для этого перехода также были корректными, то с хорошей уверенностью можно сказать, что и переход был корректным.
9.4.3. Проверка лишних состояний
В конечных автоматах, например, в реализации аппаратных средств, проблема поиска лишних состояний в общем виде необычайно сложна, хорошо проработана и потому не рассматривается в данной книге. Однако в тестировании программного обеспечения мы имеем дело не с общей проблемой, а с более простыми частными случаями. Для частного случая мы делаем допущения, которые не могут быть сделаны в общем случае например, мы можем знать, в каком состоянии в данный момент находимся. В другом случае задачу упрощает природа ошибок состояний в программе.
Когда у нас в программном обеспечении есть лишние состояния, лишь в очень редких случаях их число ограничивается одним или двумя. Чаще мы сталкиваемся с удвоением числа ожидаемых состояний или даже числом состояний, превышающим ожидаемое в 1000 раз. Лишние состояния возникают из-за скрытых закономерностей в поведении систем с конечным числом состояний. Один дополнительный бит, дающий вклад в поведение состояния, удваивает общее число состояний.
На рисунке рассматривается наглядный пример. Нижний автомат с конечным числом состояний — это то, что, как мы полагаем, мы тестируем. Однако либо из-за ошибок, либо из-за неполноты модели где-то возникает иной фактор, о котором мы не догадываемся. Из-за ошибки, произошедшей во время одного из наших тестовых обходов, вместо перехода из А в В мы на самом деле переходим из А в В', в параллельное гиперпространство. К слову, в программном обеспечении мы, как правило, имеем дело не с одним гиперпространством, а с тысячами и миллионами их. Если все эти параллельные гиперпространства идентичны друг другу во всех отношениях (за исключением фактора, являющегося источником всех этих лишних состояний), то, скорее всего, мы не сможем их обнаружить при помощи конечного числа тестов. Однако в этом случае ошибка не представляет опасности.
9.4. Методы 255
Если же альтернативные системы с конечным числом состояний хоть немного отличаются друг от друга, то мы это можем обнаружить.
В чем тогда проблема? Ведь в итоге у нас есть всего лишь небольшое безобидное различие в поведении, которым можно легко пренебречь. Хороший вопрос, требующий ответа. Как я уже говорил, параллельных гиперпространств обычно не одно, а миллионы. В большинстве из них небольшие расхождения действительно безобидны, и с ними можно смириться, однако во многих гиперпространствах симптомы ошибок фатальны. Я всегда убеждался, что «безобидные» несоответствия в поведении вырастают в серьезные ошибки. Вы не сможете заставить разработчиков волноваться по поводу «безобидных» симптомов. Если вы доложите им о мерцании экрана или о том, что курсор мышки ведет себя не так, как должен, они лишь пожмут плечами. Однако если, исследуя эти изменения в поведении, вы обнаружите ошибки, ведущие к аварии, и если вы будете делать это регулярно, то вы заставите их обратить на это внимание. Ищите фатальные ошибки экспериментальным путем. Меняйте параметры (такие как длина файла, контрольные коды, опции и т. д.), которые не должны оказывать влияния на переход, и наблюдайте, не увеличится ли несоответствие в поведении. Например, уведите курсор мыши дальше или заставьте экран моргнуть два раза. Следуйте в направлениях, в которых различие в поведении растет, и вскоре вы вычислите набор обстоятельств, ведущий к фатальной ошибке. Несколько часов тестирования и внимательного наблюдения за типичным PC-приложением, — и вы будете вознаграждены сбоем в программе или разрушенной базой данных (однако убедитесь сначала, что у вас есть хорошие средства резервирования и восстановления).
Мы можем обнаружить лишние состояния в гиперпространстве, в точности повторяя каждый тест. Пройдите из начального состояния в заданное состояние и обратно (по возможности не используя команду RESET). Затем вы сравниваете все компоненты, имеющие отношение к текущему состоянию (например, открытые файлы, используемые ресурсы, состояние окна и т. д.), до прохождения теста с состоянием этих же компонентов после прохождения теста. Затем данный тест (в точности) воспроизводится, и каждый выход для каждого перехода сравнивается с предыдущим прогоном и со всеми остальными. Каждое повторение изме
256 Глава 9 • Тестирование систем с конечным числом состояний
нения в поведении записывается1. Любые отклонения в поведении, даже если они безвредные, сигнализируют о наличии лишних состояний.
Выполнение приведенных выше рекомендаций не гарантирует, что вы обнаружите лишние состояния, если таковые существуют. В общем случае подобное поведение можно распознать единственным способом, выбирая различные пути из начального состояния в заданное состояние. Повторение тестов — это не лучшее, что вы можете сделать, однако это меньшее из того, что вы обязаны сделать. Если не повторять тесты, то вероятность обнаружения ошибки мала.
Принцип точного повторения тестов не должен ограничиваться тестированием поведения систем с конечным числом состояний. Воспроизведение любого теста описанным способом является превосходной идеей, поскольку ошибки, порождающие нежелательное поведение, характерное для системы с конечным числом состояний, не могут знать, какой метод мы используем. Поэтому обязательно повторяйте свои тесты!
9.4.4. Иерархия покрытия
Как и для других методов тестирования, для систем с конечным числом состояний существует иерархия покрытия. Покрытие узлов само по себе почти ничего не может сказать. Более того, если разработчики уже провели тестирование программы на нижнем уровне (например, было выполнено тестирование модулей), то, скорее всего, это тестирование обеспечит покрытие узлов. Главный объект при тестировании систем с конечным числом состояний — это переходы. Для тестирования переходов мы сначала должны убедиться в корректности состояний (обеспечить покрытие узлов). Поэтому, как и для большинства методов тестирования, мы будем считать, что это минимум, необходимый для достижения покрытия связей (переходов). Есть ли что-нибудь еще, кроме покрытия связей? На самом деле есть еще масса различных вариантов исследования графа, но все они лежат за рамками данной книги и, что более важно, выходят за рамки интересов большинства тестировщиков, использующих этот метод.
Иерархия покрытия здесь соответствует набору все более длинных последовательностей тестов. Длина последовательности теста определяется числом переходов (или, что эквивалентно, числом входных символов). Существует целый раздел литературы, описывающей методы тестирования конечных автоматов. Я не буду останавливаться на описании этих методов (это заняло бы всю книгу), однако я могу дать некоторый обзор причин, по которым эти методы важны для нас. Мы делаем три важных предположения при использовании методов тестирования систем с конечным числом состояний для программного обеспечения.
1. Мы, как правило, знаем состояние, в котором мы находились до каждого перехода и в котором будем находиться после него. В общем случае, например, при тестировании интегральных схем у нас нет другого способа узнать это,
1 Это не так сложно, как может показаться. Мы имеем в распоряжении превосходные инструментальные средства (например, средства захвата/воспроизведения, см. главу 10) для выполнения такого сравнения.
9.4. Методы 257
кроме как путем наблюдения за поведением тестируемой системы (то есть за выходами). В некоторых случаях тестирования программного обеспечения (таких как при тестировании протоколов), при которых у вас нет информации о внутреннем состоянии (например, системы, с которой у вас установлена связь), определить внутреннее состояние тестируемой системы невозможно1. Если у вас возникли проблемы с получением информации о состоянии, то основных методов, описанных в этой книге, будет недостаточно. Лучше всего разрабатывать программное обеспечение таким образом, чтобы эта информация была доступна.
2. Выходные действия в аппаратном обеспечении в большинстве своем достаточно просты, например, подача выходного импульса на определенную ножку разъема. Однако таких переходов, которые могут вызывать возникновение подобного импульса, может быть не один и не два. В таком случае вы не сможете с легкостью определить, является ли ваш выход правильным. Это значит, что случайная корректность здесь не исключение, а правило. В программном обеспечении выходные действия сложны и часто однозначно соответствуют переходу. Из-за их сложности, зная выходное действие, легко можно определить соответствующий переход. Если они эквивалентны импульсам в линии, — например, такое может иметь место в программном обеспечении, управляющем протоколами, — тогда задача тестирования становится гораздо более сложной, и вам, возможно, не будет хватать основных методов, описанных в этой книге.
3. Рассмотрим природу интересующих нас ошибок. Мы можем искать ошибки в спецификации. Это представляется проблематичным, и для этого тестирование систем с конечным числом состояний неприменимо. Если разработчики выполнили гигантскую работу, реализуя некорректную систему с конечным числом состояний, то обнаружить это невозможно, какой бы метод тестирования вы ни использовали. Мы предполагаем, что наша модель корректна и что ошибки содержатся только в реализации этой модели. Наиболее вероятной ошибкой в программе является не некорректное состояние или неправильный переход, а крупное явление, например, целые параллельные системы с конечным числом состояний, возникающие из-за скрытых параметров состояний. В качестве простого примера можно рассмотреть программу, предназначенную делать резервные копии каждые несколько секунд, для того чтобы в случае сбоя в системе можно было восстановить информацию, используя рёЗёрбные файлы. Предположим, программа не в состоянии очистить все эти данные при нормальном выходе. Она очищает резервные файлы, но оставляет ключевой параметр состояния без изменений. При следующем старте программа пытается провести восстановление (как ей сказано), однако «требуемые» резервные файлы не су-
1 Заметим, что современные разработчики интегральных схем внедряют в свои изделия большое количество дополнительных схем, чтобы сделать эту информацию доступной для приборов, тестирующих продукцию.
9 Зак 770
258 Глава 9 • Тестирование систем с конечным числом состояний
шествуют, что ведет к аварии. Один ошибочный байт данных означает 255 альтернативных пространств, одно 32-битное слово — 4,3 миллиарда таких пространств. Если вы тщательно исследуете крошечные изменения в поведении, то можете узнать, в каком пространстве находитесь.
9.4.5. Активизация и предсказание итога
Проблемы активизации и предсказания итога при тестировании систем с конечным числом состояний как таковой не существует. «Активизация» заключается во вводе команд или входов, которые инициируют желаемый переход. Предсказание итога означает проведение выходного кодирования. Каждое из этих заданий требует существенных затрат усилий, однако они просты и для их выполнения не нужны специальные методы. Они должны быть сделаны. Наибольшая ошибка, которую тестировщик может здесь допустить, — это отнестись к этим пунктам невнимательно. Вы действительно должны определить все до мельчайших деталей. Это несложно сделать, используя соответствующие коммерческие инструментальные средства, такие как захват/воспроизведение, обсуждаемые в главе 10.
Тестирование систем с конечным числом состояний наиболее эффективно не при первоначальном тестировании программного обеспечения, а при его повторном тестировании, после внесения в него изменений в ходе сопровождения. Оно проводится с целью убедиться, что вещи, которые не должны были меняться, на самом деле остались неизменными. В таком случае предыдущий прогон теста дает нам как требуемые входы (обеспечивает активизацию), так и итоги.
9.4.6. Подсчет состояний
Наиболее важное дело тестировщика (и особенно независимого) заключается в подсчете числа состояний, числа входных кодов, а затем и их произведения состояние-символ. Программисты, которые не учитывают поведение систем с конечным числом состояний, реализуют конечные автоматы с триллионами состояний и миллиардами входных кодов. Они не могут быть протестированы должным образом ни сейчас, ни в будущем. С точки зрения тестировщика, такие ущербные программы ломаются с необычайной легкостью. Системы с конечным числом состояний, основанные всего на нескольких переменных факторах, растут очень быстро. Рассмотрите задачу 6 из упражнений в конце главы, чтобы почувствовать это самим. Одно время я заниматься разработкой логики и усвоил, что должен проводить формальный анализ любого конечного автомата, если произведение состояние-символ превышает 12, так как это число уже превышало границы моих возможностей интуитивного тестирования дизайна. Для проверки корректности конечного автомата с произведением состояние-символ порядка сотен необходимы месяцы работы, если только в состояниях и переходах не существует закономерностей. В этих случаях совершенно необходим формальный анализ (остающийся за пределами данной книги). Затраты же на автоматы с произведением порядка тысяч превышают годы или века работы одного человека — здесь ничего нельзя сделать интуитивно.
9.4. Методы 259
Из вышесказанного можно сделать вывод о том, что имеет смысл делать, а что не имеет. Предположим, вы исследовали систему и определили, что поведение системы задается пятью факторами с 7, 13, 8, 4 и 3 возможными значениями каждого из них соответственно; вы также определили, что возможные выходы (после кодирования) включают 42 отдельных действия. Произведение этих чисел дает 366 912. Как тестировщик вы должны просмотреть документацию для каждого из этих переходов. Если это невозможно, то программа не тестируема и ненадежна. Разумеется, разработчики могли бы реализовать вложенные машины, и мы надеемся, что они так и сделали. В этом случае вам надо будет протестировать шесть гораздо более простых автоматов.
Поиск значения произведения состояние-символ (для не вложенных автоматов) — это самое простое и эффективное дело, которое вы можете сделать, тестируя системы с конечным числом состояний. Сделав это на первом этапе, вы сможете узнать, может ли ваша программа быть адекватно протестирована и, следовательно, будет ли она устойчива к сбоям.
9.4.7. Средства поддержки и тестируемость
Это как раз та проблема, где программисты могут и должны отрабатывать свое жалование. Я решительно настаиваю на том, чтобы программисты использовали явные реализации конечных автоматов (то есть задаваемые таблицами), если произведение состояние-символ больше десяти. В [BEIZ90] описывается необходимый порядок работы. Если это условие выполнено, а проект тщательно проработан и легко поддается анализу (и, следовательно, вероятность ошибок в нем невелика), то следующие характеристики существенно облегчат вам тестирование.
1. Явный счетчик состояний. Существует одна заявленная переменная, или адрес ячейки памяти, которые определяют состояние в любой момент времени. Эта информация доступна и может быть записана. Текущее состояние также всегда известно.
2. Основной сброс и сброс в определенное состояние. Существует множество вариантов сброса, например, основной сброс в начальное состояние. Он, в свою очередь, может представлять собой полный сброс (все заново инициализируется), только восстановление состояния (меняется только счетчик состояний, а статус файлов и прочее остаются без изменений) или возврат в определенное состояние. Сброс может быть достаточно тщательно проработан и может иметь достаточно много параметров, точно определяющих, что именно должно быть изменено (кроме счетчика состояний). Хорошие средства сброса чрезвычайно важны в больших автоматах состояний, где для того, чтобы попасть в заданное состояние без использования механизма сброса, пришлось бы пройти через множество других состояний.
3. Пошаговое выполнение. Это означает возможность пошагового прохождения графа состояний, по одному переходу за шаг, а в случае выполнения составных выходных действий — одно выходное событие за шаг. После каждого перехода предусматривается пауза, пользуясь которой, тестировщик,
260 Глава 9 • Тестирование систем с конечным числом состояний
если тест выполняется вручную, мог бы разобраться, что произошло. Если же тест выполняется в автоматическом режиме, то специальные инструменты запишут всю необходимую информацию.
4. Трассирование переходов. Это означает запись отметки о каждом совершенном переходе. В понятие отметки входят входной код, инициировавший переход, текущее состояние, состояние после перехода, выходной код.
5. Явная таблица входного кодирования. Мы предполагаем, что существует явный механизм кодирования входа. Лучше всего, если он содержится в виде таблицы. Входное кодирование полностью отделено от последующей обработки данных.
6. Явная таблица выходного кодирования. То есть осуществлено явное кодирование выхода. Оно может представлять собой таблицу, в которой указано, какие подпрограммы надо вызывать, или определен какой-нибудь другой отдельный механизм, не являющийся частью остальной обработки.
7. Явная таблица состояний-переходов. Это означает, что реализация систем с конечным числом состояний всегда имеет явную таблицу переходов. Самое удобное в этих таблицах то, что если обнаружена ошибка перехода, то ее нахождение можно легко определить.
Эти характеристики лучше всего встраивать в модель в самом начале, так как их сложно потом модифицировать. Очевидно, для таких средств нужны специальные модели и команды управления, доступ к которым должен быть запрещен для пользователей без специального разрешения.
9.5. Рассмотрение приложений
9.5.1. Индикаторы приложений
Ниже описаны некоторые типичные ситуации, требующие использования тестирования конечных автоматов и/или приложения, в которых этот метод часто используется. Более подробно эта ситуация рассматривалась в [AVRI93, BAUE79, WILK77].
1. Программное обеспечение, управляемое при помощи меню. Разработчики коммерческих программ, управляемых при помощи меню, как правило, используют явные конечные автоматы при проектировании своих меню. В том числе они используют метод тестирования систем с конечным числом состояний для проверки корректности своих меню.
2. Объектно-ориентированное программное обеспечение. Модель с конечным числом состояний встречается в большинстве объектно-ориентированных парадигм проектирования. Корректное тестирование методов подразумевает корректное тестирование поведения состояний. В этом случае необходимость использования методов тестирования систем с конечным числом состояний очевидна.
9.5. Рассмотрение приложений 261
3. Протоколы. Обсуждение методов тестирования протоколов лежит за рамками данной книги. Этому вопросу посвящено много книг, и во всех них предполагается, что вы владеете методами тестирования систем с конечным числом состояний [CHOW88, HOLZ87, SARI87, SIDH89].
4. Драйверы устройств. Большинство устройств ведут себя как системы с конечным числом состояний, и большинство драйверов включают в себя такие системы.
5. Замена аппаратных средств. Задачи, некогда возложенные на аппаратные средства, в настоящее время все чаще решаются программным способом. Это касается не только электроники, но и механических и электромеханических устройств. В статье, приведенной в журнале Scientific America [GIBB94], предрекается использование микропроцессоров (и соответствующего программного обеспечения) в выключателях света, электробритвах (2 килобайта), автомобильных трансмиссиях (30 килобайт кода), ТВ (500 килобайт). Существенная часть поведения подобного программного обеспечения реализуется как поведение систем с конечным числом состояний.
6. Инсталляционное программное обеспечение. Программное обеспечение, предназначенное для инсталляции и конфигурации программ, часто ведет себя как система с конечным числом состояний и может эффективно тестироваться при помощи соответствующих методов.
7. Программное обеспечение для резервирования и восстановления. Программное обеспечение, задачей которого является резервирование и (особенно) восстановление, по многим признакам ведет себя подобно системе с конечным числом состояний. Мы наблюдаем рост числа двухпроцессорных файловых или сетевых серверов. Такие системы традиционно тестируются при помощи методов проверки систем с конечным числом состояний.
9.5.2. Предположения об ошибках
Предположения, которые мы можем сделать, будут относиться скорее не к природе ошибок, а к программному обеспечению, обладающему поведением системы с конечным числом состояний.
1. Специализированный конечный автомат. Программист может не догадываться, что его программа во многих случаях ведет себя как система с конечным числом состояний. Вследствие этого отсутствует должный анализ, невозможно выполнить адекватное тестирование и может быть сделано много, действительно много ошибок.
2. Ошибки кодирования. Это могут быть ошибки входного, выходного кодирования или кодирования состояний, вне зависимости от того, явное это кодирование или скрытое. Если входное кодирование реализовано в скрытом виде, то велика вероятность непоследовательного кодирования от состояния к состоянию.
262 Глава 9 • Тестирование систем с конечным числом состояний
3. Неверный выход. Это может быть ошибкой кодирования или, если выходного кодирования в явном виде не существует, то, к примеру, неверным вызовом подпрограммы.
4. Непредвиденное поведение состояния. Большое увеличение числа дополнительных состояний может быть вызвано скрытой особенностью поведения состояния.
5. Пересечение границ вложений. В реализации используются вложенные конечные автоматы, однако из-за плохого, сделанного на скорую руку проекта или ошибок в нем, границы вложений игнорируются. На следующем рисунке показана модель, состоящая из нескольких вложенных конечных автоматов. Каждая замкнутая область изображает набор состояний (например, меню). Если разрешим переход из состояния X, например, в состояние Y, то все система вложений будет нарушена, и на деле поведение в целом будет таким, как если бы вложений не было совсем. Существуют другие способы завершить подобное пересечение границ вложений, но это должно быть реализовано аккуратно. Пересечение границ вложений в примере является общей ошибкой, однако в большинстве случаев оно может быть обнаружено при помощи метода тестирования систем с конечным числом состояний. Не было ли у вас когда-нибудь такого, что вы использовали программу, управляемую при помощи меню, оказывались в пункте меню, которое не выбирали и спрашивали себя: «Как это я здесь оказался?»
9.5.3. Ограничения и предостережения
1. Большие графы состояний. Методы, описанные в данной книге, применимы к не слишком большим графам состояний (произведение состояние-символ порядка сотен). Для больших, не вложенных графов состояний, подобных тем, что используются в управлении телефонными узлами, в которых произведение состояние-символ достигает порядка тысяч или десятков тысяч, способы проверки переходов, рассматриваемые в данной книге, слишком трудоемки, даже если разработка теста и его выполнение полностью автома
9.5. Рассмотрение приложений 263
тизированы. Это не может радовать. Положительная сторона этого вопроса заключается в том, что люди, работающие с такими большими системами, обладают необходимыми инструментами и опытом, чтобы использовать более совершенные методы, чем рассматриваемые в данной книге. Если у вас нет достаточного опыта и необходимых инструментов, вам не стоит браться за тестирование таких больших конечных автоматов.
2. Вложенные модели, или вложенные системы? Чтобы модели были рациональны, необходимо использовать вложенные модели, поскольку, скажем, невложенная реализация может содержать миллиард состояний. Предположим, вы построили прекрасную вложенную модель, однако реальная программа может не являться вложенной структурой. Ваша модель охватывает лишь часть реального поведения, и покрытие связей в вашей модели никоим образом не означает покрытия связей всей системы с конечным числом состояний. Ваша модель — это всего лишь подсистема реальной системы, причем подсистема с хорошим поведением. Поэтому все ваши тесты могут успешно пройти, а программа, тем не менее, будет содержать огромное количество ошибок. Нам важно иметь в распоряжении инструменты, показывающие, какие именно реальные состояния и переходы были проверены. Такие инструменты полностью бесполезны, если только у вас конечный автомат не реализован в явном виде. В таком случае вы можете винить только себя, поскольку именно вы не выяснили, является ли реализация вложенной, как и ваша модель, или нет.
3. Отсутствие поддержки. Средства поддержки и аспекты тестируемости, описанные в разделе 9.4.7, предназначены для облегчения тестирования и повышения его эффективности. Степень этой поддержки также является мерой того, насколько сложно или просто будет проводить тестирование системы с конечным числом состояний и насколько эффективны будут тесты при поиске ошибок.
9.5.4. Автоматизация и инструментальные средства
Как всегда в разделе, описывающем автоматизацию, я могу вас порадовать и расстроить. Порадовать тем, что проблема автоматизации разработки тестов для проверки конечных автоматов исследуется уже более 30 лет, и в результате этих исследований появилось множество эффективных алгоритмов. Однако почти все подобные исследования были посвящены вопросам тестирования логики аппаратных средств, обладающих своими ограничениями и ошибками, которые отличаются от ограничений и ошибок, возникающих при тестировании программных конечных автоматов. Исключением является тестирование протоколов, для которого аппаратная модель, возможно, будет эффективна. Инструменты, в том виде, в каком они есть, обычно интегрируются в более универсальные LSI (Интеграция Высокого Уровня) системы проектирования, и, по существу, недоступны тестировщикам программного обеспечения.
На самом деле коммерческие средства поддержки разработки программноориентированных тестов существуют [POST94], но они находятся в зачаточном
264 Глава 9 • Тестирование систем с конечным числом состояний
состоянии. Большинство организаций, разрабатывающих программное обеспечение, которым приходится проводить тестирование конечных автоматов в больших объемах, разрабатывают свои инструменты [МАТТ88]. Поскольку эти инструменты дают им ощутимое преимущество, они никогда не публикуют результаты и никогда не делают эти инструменты доступными для посторонних.
9.6. Резюме
Модель конечного автомата является фундаментальной моделью тестирования, применимой к большому числу различных видов программного обеспечения. Она начинается с определения таблицы состоянийпереходов, включающей все возможные комбинации состояние-входной символ. Как правило, в большинстве моделей так же требуется входное и выходное кодирование. Обеспечение покрытия связей (переходов) является минимальной разумной целью тестирования. При использовании несложных средств поддержки, таких как явный счетчик состояний, и сброс для нахождения большинства ошибок будет достаточно простых обходов. Самое актуальное из того, что тестировщик может здесь сделать — это сосчитать произведение состояние-символ, и, исходя из этого, оценить, реально ли в данном случае выполнить тестирование. Следующее по актуальности дело, из тех, что тестировщик может сделать — это в точности повторить каждый из проводимых тестов (это относится не только к тестированию систем с конечным числом состояний, но и ко всем тестам), используя систему захват/воспроизведение. А затем необходимо исследовать даже самые тривиальные изменения в поведении для того, чтобы обнаружить скрытые ошибки в поведении систем с конечным числом состояний.
9.7. Вопросы для самопроверки
1. Дайте определение следующих терминов: полностью определенный граф состояний, текущее состояние, выходное состояние, конечный автомат (автомат с конечным числом состояний), скрытое поведение системы с конечным числом состояний, начальное состояние, набор начальных состояний, входное кодирование, входное событие, входной символ, номер входного символа, изолированное состояние, программа, управляемая через меню, вложенные системы, пустой вход, пустой выход, число состояний, выходное кодирование, входное событие, таблица выходов, доступное состояние, сброс, переход самого в себя, код состояния, стабильное состояние, счетчик состояний, произведение состояние-символ, таблица состояний, таблица состояний-переходов, сильно связанные, обход, изменяющиеся состояния, переход, недоступное состояние, рабочие состояния.
2. Переделайте модель корабля Enterprise, исходя из предположения, что три положения ручки управления двигателем находятся в вершинах треугольника, а не вдоль одной линии (поскольку это желание рулевого Клингона,
9.7. Вопросы для самопроверки 265
а Клингоны всегда добиваются того, чего хотят). Это означает, что возможны следующие дополнительные входы: р>з и з>р. Законы физики, тем не менее остаются прежними для Клингонов. Разработайте новый набор тестов.
3. (а) Добавьте в модель корабля Enterprise главный двигатель (Г). Вы можете перейти к главному двигателю из любого положения двигателя (Р, Н, 3), Однако конечный результат в любом случае будет один и тот же — движение вперед. Главный двигатель не подчиняется законам Ньютона, поэтому, если вы двигались в обратном направлении, то при включении главного двигателя вы можете перейти непосредственно к движению вперед, без промежуточной остановки. После выключения главного двигателя рычаг управления двигателем находится в положении, которое он занимал перед включением главного двигателя, но вы продолжаете двигаться вперед. Создайте модель и разработайте тесты.
(б) Задание, аналогичное 3(a), но для флагмана Клингонов Spklchutrgr Hrngrtch.
4. Компания La Forge модернизировала главный двигатель так, что теперь после его выключения он восстанавливает направление движения (вперед, назад, остановка), которое имело место перед его включением. Создайте модель и разработайте тесты.
5. Если вы работаете в оболочке операционной системы Windows, спроектируйте модель меню наивысшего уровня в этой среде, разработайте тесты и выполните их1.
6. В моем полноприводном пикапе «Тойота-Терсел» на рукоятке переключения передач нарисованы следующие передачи: R (задний ход), N (нейтральная
ющая ручка для переключения между приводом на два и на четыре колеса, педали сцепления и тормоза. Вот некоторые правила управления этой машиной2:
» Переключая передачи, вы должны пройти через нейтральную передачу, то есть реальные действия по переключению передач будут следующими: N>N, N>R, N>SL, N> 1,... R>R, ... N>2, N>3, ... R>N, ... 5>N. Переключатель режима работы трансмиссии имеет только два положения: 2ВК>4ВК и 4ВК>2ВК (ВК — ведущие колеса). Сцепление может быть включено (есть) или выключено (нет). С тормозами дело обстоит точно так же. Вы можете отпустить педаль сцепления (и включить его), если сцепления нет,
’ В формальном курсе я, как правило, использовал максимально возможное число примеров управляемых при помощи меню программ, исходя из возможностей доступных для студентов компьютеров и/или операционных систем. Однако примеры корабля Enterprise и «Тойоты» разработаны так, чтобы в них сложность моделирования возрастала постепенно.
2 Я это не выдумал. Это описание — наиболее близкое к типичному описанию 2/4 колесной трансмиссии, из тех, что я мог привести. Сейчас у меня полноприводная машина, но у нее автоматическая коробка передач. И я рад, что инженеры, разрабатывающие автоматическую трансмиссию, использовали модель конечного автомата и соответствующее тестирование.
266 Глава 9 • Тестирование систем с конечным числом состояний
и нажать на педаль (и выключить), если оно есть. То же самое относится и к тормозам.
♦ Вы можете переключиться из любой передачи (за исключением SL) на нейтральную без использования сцепления. Переключение SL>N требует сцепления.
» Вы должны использовать сцепление для переключения нейтральной передачи на любую другую.
♦ Передача SL вам доступна только в полноприводном режиме.
♦ Вы можете переключиться между режимами 2ВК>4ВК и 4ВК>2ВК, не используя сцепление, если только ваша передача отлична от SL, однако при этом вы должны стоять на месте, или двигаться вперед.
• Любое переключение передач или выбор 2/4 приводного режима можно совершить, используя или не используя сцепление, если вы стоите на месте.
« Если вы двигаетесь назад на передаче R, вы можете переключиться на первую или вторую передачу следующим образом: R>N> 1, R>N>2.
♦ Единовременное переключение между передачами переднего хода не должно быть больше, чем на две скорости в любом направлении. Это значит, что возможны следующие переходы: N> 1,1>N>2,1 >N>3, 2>N> 1, 2>N>3, 2>N>4, 3>N> 1, 3>N>2, 3>N>4, 3>N>5, 4>N>2, 4>N>3, 4>N>5 и так далее. Вы всегда можете переключить передачу на нее же саму (включая R и SL), используя сцепление или без него, если только вы не проходите через нейтральную передачу. К примеру, переключение будет 3>3, а не 3>N>3.
♦ Нельзя пытаться совершать запрещенные переключения (такие как 5>N>R), ведь не секрет, что даже лучшие трансмиссии ломаются при неправильном обращении.
• Вы можете выполнять только одно действие за раз. Это значит, что нельзя одновременно переключать скорость, режим работы трансмиссии, выжимать сцепление и тормоз или обе педали сразу.
Определите входную схему кодирования. Разработайте таблицу(ы) состояний, включающую все запрещенные переходы. Разработайте набор тестов, обеспечивающий полное покрытие. Разрабатывая тесты, руководствуйтесь общими соображениями, имея в виду, что ваши тесты могут быть потенциально опасны и/или могут иметь разрушительные последствия для машины. Ваша задача — получить достаточно небольшой набор эффективных тестов, представляющих собой обходы состояний и не разрушающих трансмиссию во время работы. Не пытайтесь разработать по настоящему минимальный набор тестов, так как это является сложной теоретической задачей. Приведенные ниже модели расположены в порядке возрастания сложности. Проработайте их.
6.1. Привод только на два колеса, нет очень низкой скорости, только три передние скорости.
9.7. Вопросы для самопроверки 267
6.2. То же, что и 6.1, но с четырьмя передачами.
6.3. То же, что и 6.1, но с пятью передачами.
6.4. Привод на два/четыре колеса, нет очень низкой скорости, только три передние скорости.
6.5. То же, что и 6.4, но с четырьмя передачами.
6.6. То же, что и 6.4, но с пятью передачами.
6.7. Привод на два/четыре колеса, есть очень низкая скорость, только три передние скорости.
6.8. То же, что и 6.7, но с четырьмя передачами.
6.9. То же, что и 6.7, но с пятью передачами.
6.10. Любое из приведенных выше заданий, но с дополнительным условием, что вы можете за один раз повышать скорость на три передачи (например, 1>N>4), а понижать только на одну (например, 4>N>3).
Подсказка. Входное кодирование не обязательно должно соответствовать единичному входному событию, но может обозначать целую последовательность событий, как, например, 4>3 обозначает 4>N, N>3. Вложенные автоматы, состояния, и/или входы вы определяете, исходя из своих соображений. Не приравнивайте G>G к G>N>G (где G — любая передача), они не эквивалентны.
Инструментальные средства и автоматизация
10.1. Обзор
В этой главе приводятся аргументы, используемые для того, чтобы убедить людей вкладывать деньги в автоматизацию инструментов тестирования. Делается обзор особенностей инструментов тестирования и дается долгосрочный прогноз будущего тестирования.
10.2. Основные термины
Внешние термины: побочный продукт, кэш-память, код, компилятор, данные, порча данных, отладочный пакет программ, функциональная надежность, редактировать, время выполнения, ЛОЖЬ, формальные методы, горячая линия, инспектирование, интерпретировать, прерывание, клавиатура, быстрый набор на клавиатуре, аппаратные средства, инициализировать, сопровождение, размещение в памяти, многозадачность, сеть, объектный код, объектно-ориентированное программирование, операционная система, оптимизирующий компилятор, бумажная лента, рабочая характеристика, пиксел, платформа, обработка побочного продукта, программа, программист, качество, случайный, остаток, экран, SMART-DRV, программное обеспечение, исходный код, упреждающее исполнение команд, оператор, текстовый редактор, пропускная способность, истина, пользователь, текстовой процессор.
Внутренние термины: все определения, все пути определение-использование, все пути, все использования, утверждение, поведенческое тестирование, ветвь, ошибка, дерево, составной предикат, компонент, поток управления, поток данных, тестирование доменов, рабочая среда, отказ, взаимодействие характеристик,
10.3. Обязательная автоматизация 269
ввод, инструментальное оснащение, тестирование интеграции, связь, модель, итог, вывод, путь, предикат, структурное тестирование, синтаксическое тестирование, система, ошибка проектирования теста, тестовый сценарий, тестировщик, тестирование модулей, проверка.
10.3. Обязательная автоматизация
Моя цель в этой главе состоит не в том, чтобы убедить вас в необходимости автоматизации тестирования, потому что если вы не верите в это, то не станете читать эту книгу. Моей целью является помочь вам четко сформулировать аргументы, используемые для доказательства важности капиталовложений в технологию тестирования гипотетической корпорации Феррингов, которые являются противниками формального тестирования, не говоря уж об инструментах автоматического тестирования. Некоторые дополнительные подробности об автоматизации тестов можно найти в [FREE88, HEND89, MILL86, NOMU87, PERE86, VOGE80].
Для меня одной из самых удручающих картин является образ человека, который вручную делает на клавиатуре то, что может быть сделано автоматически. Это и грустно, и смешно. Мы живем в пятом десятилетии от начала производства компьютеров, а некоторых из нас все еще нужно убеждать в пользе компьютеров. Автоматизация тестирования — это тот самый случай. Это забавно, так как всего век назад достиг своего совершенства паровоз. А за пятьдесят лет до этого междугородные почтовые кареты тащились упряжкой лошадей с верховым на первой лошади, который управлял всей упряжкой. По мне, так ручное тестирование — это то же самое, что всадник перед ускоряющимся локомотивом. Это опасно, унизительно и совершенно нелепо.
Если бы человеческое достоинство и оптимизация оплаты труда были бы единственным доводом в пользу автоматизации, как это было в прошлом, то аргументы по автоматизации тестирования проходили бы мимо ушей. Это не те аргументы, которые можно использовать для доказательства важности инвестиций в автоматизацию, так как бухгалтер с творческим подходом всегда сможет найти слабое место в ваших аргументах. А аргумент очень прост — ручное тестирование уже не работает. Оно никогда не работало очень хорошо, не работает сейчас и не будет работать в будущем. Ручное тестирование является самообманом. В нем понятие результата заменяется просто тяжелым трудом. И, что самое плохое, приводит к ложной уверенности в успехе. Если же вам не хватает самоуверенности, то существует гораздо более дешевый (как законный, так и незаконный) фармакологический способ ее получить.
Ручное проведение тестирования не работает. Первый миф, который должен быть рассеян, — это вера в то, что ручное выполнение тестирования работает. У нас есть превосходная статистика ошибок ручного ввода, составленная за многие дни набора на клавиатуре. Профессиональная машинистка совершает в среднем три ошибки на 1000 нажатий. Это было легко определить, так как за первоначальным вводом следовал повторный ввод с клавиатуры, во время которого второй
270 Глава 10 • Инструментальные средства и автоматизация
оператор контролировал первого. Сравнение первых действий со вторыми происходило полностью автоматически.
Обычный тест содержит 250 символов. Тестировщик, который не является оператором печатающего устройства, не обладает высокой точностью специально обученного оператора. Следовательно, нам следует ожидать, что большинство тестов, исполняемых вручную, имеют по крайней мере одну ошибку, проистекающую из неверного нажатия на клавишу. К тому же, в отличие от оператора печатающего устройства, для которого проверка была автоматизирована (более 60 лет назад), при ручном тестировании проверка выполняется визуально. А визуальная проверка является процессом даже более подверженным ошибкам, чем собственно набор. Люди даже не знают, как высока частота появления ошибок при ручном тестировании, потому что без автоматического средства выполнения невозможно записать, как много попыток выполнения теста было сделано перед тем, как тест все-таки выполнился корректно, если это произошло. По моему собственному опыту, уже 20 лет назад использование примитивных инструментов автоматического исполнения, таких как бумажная лента или телетайп, окупалось, так как ручное выполнение тестов было настолько ненадежно, что практически являлось бесполезным занятием.
Ручное тестирование приводит к ошибочной уверенности в успехе. Выполнение теста руками является делом трудным, скучным, грубым и бесчеловечным. Человеческая природа, будучи именно тем, чем она является, особенно это касается западной культуры, имеет тенденцию уравнивать усилия с результатом: «Мы так тяжело работали, у нас должно получиться хорошее тестирование!» Ошибкам не важны человеческие усилия. При тестировании поощряется обнаружение ошибок, а не усилия сами по себе. Тем не менее, большие усилия необходимо мотивировать. А основная ложная мотивация для ручного тестирования состоит в том, что это должно быть эффективно — иначе для чего бы мы так тяжело работали? Это и есть статистически не подтвержденная ложная уверенность. Ложная уверенность греет душу. Если это то, что нужно, то гораздо лучше не тестировать вовсе.
Требование надежности обуславливает использование автоматического тестирования. В течение обычного дня я выполняю более 800 000 операций с различными накопителями на магнитных дисках. В этом легко убедиться, просто использовав команду SMARTDRV/s в конце дня. В какой-нибудь из этих операций могут проскальзывать ошибки, но, к счастью, относящиеся к аппаратным средствам или операционной системе, и я их игнорирую. Я не могу вспомнить, когда я в последний раз обнаруживал искажение данных программой. У меня есть причины ожидать, что я буду использовать свою систему в течение следующих 10 лет без потерь и искажений данных. Мне хочется пожелать того же самого для остальных 100 миллионов пользователей PC. Если бы компания Microsoft хотела обеспечить гарантию статистической стабильности (с помощью теории надежности программного обеспечения), то есть чтобы никакая из их платформ никогда не допускала потерю или искажение данных в результате действий с диском, потребовалось бы 100 тестирующих машин, работающих 24 часа в сутки, выполняющих 1000 тестов в секунду, и все это примерно в течение 3 миллионов лет.
10.3. Обязательная автоматизация 271
Пользователи требуют от нас очень высокой функциональной надежности. Все статистически обоснованные методы оценки функциональной надежности программного обеспечения основаны на совершенно автоматических методах тестирования; и, как вы можете видеть, даже с такой автоматизацией все, что необходимо для пользовательской надежности, не может быть легко проверено.
Люди не могут следовать шаблонам стохастического тестирования, необходимого для обеспечения всех известных оценок надежности программного обеспечения. Так что, пока вы в своем уме, вы не будете верить случайности. Какой же вывод можно сделать о функциональной надежности программного обеспечения по результатам ручного тестирования? Да никакой! Абсолютно никакой! И еще раз никакой1. Вы не можете подтвердить качество объекта на уровне 10 у, если точность тестирования составляет 10"1.
Как часто применять тест? Неудачи при попытке обоснования использования ручного тестирования обычно основаны на грубом просчете в количестве применений тестов. Под «грубым просчетом» я подразумеваю просчет на порядок (или даже больше). Если вы полагаете, что тест должен проводиться только один раз, то использование автоматического тестирования будет трудно аргументировать. Но почему же люди недооценивают количество проходов теста? Прежде всего они не учитывают ошибки при проектировании теста. Тестировщики точно так же не защищены от ошибок, как и программисты. Если у нас есть хороший тест, т. е. тест, который обнаружил ошибки, то он должен быть запущен дюжину раз. По крайней мере три раза для отладки теста. Три раза для подтверждения того, что появились те же самые ошибки. В этом случае заново продемонстрируйте их программисту, который также захочет убедиться в том, что ошибки повторяются. Таким образом, мы получили уже около 10 запусков теста. Затем еще два или три раза тест запускает программист во время исправления ошибки. Затем для подтверждения исправлений тест еще два или три раза запускает тестировщик. Двадцать запусков — это самая низкая оценка, так как мы еще не учитываем всех менеджеров, которых необходимо убедить. Если же, как это часто случается на более поздних стадиях тестирования, ошибка уже не является простой ошибкой, которую можно объяснить одним компонентом, а проистекает из взаимодействия между компонентами, то результат можно смело увеличивать втрое. Если тестирование эффективно (то есть находит большинство ошибок), тогда средняя оценка количества повторных прогонов тестов для всех тестов (тех, которые обнаруживают ошибки, и тех, которые не обнаруживают) очень высока.
На этот счет нет надежных статистических данных, так как это не принято записывать, здесь изложен мой собственный опыт. Помимо автоматического выполнения на обычной бумажной ленте, мы использовали также майларовую перфоленту (эта лента, в 10 раз дороже обычной бумажной ленты, изнашивала ленточный перфоратор значительно быстрее), так как обыкновенная бумажная лента не могла выдержать многократные повторные прогоны. Я точно не знаю, но, вероятно, через 40 или 50 прогонов через устройство считывания с ленты обычная бумаж
1 Однако можно сделать много выводов относительно несовершенства ручного тестирования и его подверженности ошибкам.
272 Глава 10 • Инструментальные средства и автоматизация
ная лента начинает изнашиваться. Так спросите сами себя: были ли мои тестировщики попросту некомпетентны, или же из этого можно извлечь урок?
Мир технического обслуживания [PIGO94]. Современный процесс разработки программного обеспечения состоит не только из создания и тестирования нового кода, но также из поддержки существующего кода. Для большинства продуктов программного обеспечения около 80 процентов усилий тратится на техническую поддержку, как на корректирующее сопровождение, которое исправляет обнаруженные ошибки, так и на прогрессивное сопровождение, которое модернизирует и добавляет новые возможности. В течение типичного цикла сопровождения модифицируется менее 5 процентов кода. Однако это обычно приводит к необходимости комплексного регрессионного тестирования (то есть повторения наиболее важного подмножества из набора первоначальных тестов) [BURK88]. Общепризнанный опыт при проведении ручного регрессионного тестирования заключается в отказе от его использования. Одно из двух приносится в жертву — или прогрессивное тестирование (тестирование новых характеристик), или эквивалентное тестирование (тестирование неизменных характеристик), или даже оба вместе. Это опасная ситуация, так как в развивающемся продукте его сопровождение может являться причиной ошибок, количество которых сравнимо с количеством всех остальных ошибок. Программисты сопровождения защищены от ошибок не более, чем тестировщики и программисты исходного кода. Попытки провести ручное регрессионное тестирование (в действительности его не применяют) приводит к возрастанию число ошибок сопровождения до недопустимо высокого уровня.
Сколько в действительности стоит ручное тестирование? Стоимость ручного тестирования практически невозможно оценить, так как информационная инфраструктура, необходимая для проведения точных исследований, возникает только после выполнения автоматизации тестирования. Но мы можем определить общую стоимость труда, если посмотрим, сколько людей занимается тестированием. Это должно быть выполнено корректно, что практически невозможно. Вам необходимы общие данные о трудозатратах, в первую очередь включающие в себя стоимость сервиса, стоимость горячей линии и тому подобное. Если стоимость программного обеспечения определена корректно и должным образом связана с различными видами деятельности, в таком случае большинство организаций, которые проводят такую оценку впервые, будут просто потрясены реальной стоимостью ручного тестирования.
10.4. Базовый пакет инструментов
10.4.1. Основы
В этой главе я не ставил перед собой цель дать всеобъемлющий обзор инструментов тестирования. Это заняло бы всю книгу. Для обзора текущих инструментов я рекомендую [FSTC83, GRAH91, GRAH93, DAIC93, MARC94 и SQET94], Коммерческие инструменты эволюционируют так быстро, что создание хорошего
10.4. Базовый пакет инструментов 273
и всеобъемлющего руководства невозможно, за исключением разве что периодических публикаций.
Цель этой главы — рассмотреть инструменты тестирования в перспективе и обсудить важные технические особенности, на которые вам следует обращать внимание при выборе коммерческих инструментов или при их разработке. Нет инструмента, который бы точно соответствовал обсуждаемым характеристикам; любой инструмент представляет собой смесь таких характеристик.
10.4.2. Инструменты для покрытия
Эта книга посвящена поведенческому тестированию. Но в конце концов то, что мы тестируем, — это просто кусочки программы. Программы, обладающей некоей структурой. Как мы можем узнать, что наше тестирование выполнено хорошо? Здравый смысл говорит о том, что по меньшей мере каждую команду на уровне объекта следует выполнять в процессе тестирования. Поведенческое тестирование основано на модели программы, но не на самой программе, а модели могут быть ошибочными. Поэтому модель тоже необходимо проверить. Ключевой частью проверки является то, что модель должна надлежащим образом отражать поведение, заложенное в реально существующее программное обеспечение. Если мы протестировали все части нашей модели, но не протестировали весь код, значит наша модель нельзя назвать качественно разработанной.
Цель инструментов для структурного покрытия — дать нам техническое задание и количественную оценку того, какую часть программы мы фактически выполним при тестировании. Необходимо обеспечивать охват в 100 процентов. Если мы используем методы поведенческого тестирования, нам по-прежнему следует контролировать покрытие структуры, чтобы знать реальное положение дел. Каждый метод тестирования содержит в себе метрику покрытия, которая измеряет степень применимости метода. В тех случаях, когда метод имеет структурный прототип, для подтверждения реальности покрытия следует использовать соответствующий инструмент структурного покрытия. В тех случаях, когда нет очевидного структурного прототипа, вам следует записать или же определить пределы, в которых ваши тесты обеспечивают покрытие.
На данный момент существует достаточно много источников информации об инструментах для структурного покрытия различных типов. Для получения дополнительной информации по коммерческим инструментам я советую обратиться к руководствам [GRAH93, DAIC93, MARC94, SQET94].
Ниже представлены основные категории инструментов структурного покрытия.
1. Покрытие потока управления. Наименее эффективный способ — это покрытие операторов исходного кода, что является простым покрытием узлов и поэтому практически бесполезно. Однако инструменты, предлагаемые рынком, обеспечивают измерение степени покрытия операторов — источников потока управления. Этого явно недостаточно. По крайней мере, должно быть обеспечено покрытие ветвления. На практике, особенно для таких языков как С, которые поддерживают составные предикаты, давно известно, что простого покрытия ветвления (звена потока управления)
274 Глава 10 • Инструментальные средства и автоматизация
недостаточно и что каждый предикат составного предиката должен тестироваться (по крайней мере) для значения ИСТИНА или ЛОЖЬ. Большинство коммерческих инструментов обеспечивают все три метрики покрытия — операторов исходного кода, ветвлений в исходном коде и покрытие условий в исходном коде предиката.
Инструменты для покрытия потока управления действуют (как правило) посредством автоматической модификации исходного кода, добавляя технологические операторы, которые будут регистрировать пути и сегменты программы, реально работающие при проходе тестов.
Все эти инструменты обладают некоторыми потенциально важными ограничениями, о которых вам следует знать.
• Различные компиляторы. Все инструменты покрытия содержат в себе компиляторы или их эквиваленты. Так как компилятор инструмента тестирования и рабочий компилятор часто сделаны разными производителями, то их объектные коды могут различаться. Для надежности тесты, произведенные при помощи инструментов, следует повторить с реальными компиляторами для подтверждения того, что итоги полностью совпадают.
• Верхний предел объема кода. На сегодняшний день инструменты покрытия фактически ограничены объемами сегментов исходного кода в пределах от 30 000 до 50 000 строк. При возрастании размера не только время выполнения тестов становится слишком большим, но и возрастает вероятность неверно отследить выполнение каждого сегмента.
• Обработка условного ветвления. Компиляторы используют отложенное вычисление, в котором оценка предиката заканчивается при определении значения истинности предиката. Это значит, что можно попытаться покрыть все предикативные условия (ИСТИНА/ЛОЖЬ), но обычно так не делают. При современной оптимизации компиляторов, при продолжающейся оптимизации аппаратных средств и при наличии средств упреждающего исполнения команд и кэш-памяти нет гарантии, что инструмент покрытия покажет то, что происходит на самом деле. Предикаты могут быть покрыты при тестировании, но это может не дать полной картины поведения тестируемой системы. Советую быть внимательными.
« Искусственная среда тестирования. По своей природе инструменты тестирования работают в искусственной среде. При этом прерывания, многозадачность, кэширование памяти и многие другие средства операционной системы и аппаратуры либо не работают, либо работают по-другому (не так, как они это делают в действительности). Поэтому советую выполнить все тесты еще раз в реальной среде.
2. Покрытие блоков (профайлеры). Как мы можем покрыть тестами объектный код системы, состоящей из нескольких миллионов байт команд, если возможности инструментов для покрытия тестирования модулей настолько ограничены? Вы можете использовать инструменты покрытия блоков
10.4. Базовый пакет инструментов 275
или профайлеры. Профайлер не пытается интерпретировать выполняемые команды (как делает нормальный инструмент покрытия), а просто регистрирует изменение данной области памяти (выполнение команды на объектном уровне). С практической точки зрения это настолько же хорошо, как и регистрация исполнения ветвей операторов и предикатов в исходной программе. Профайлеры могут обеспечить такое покрытие данных для отдельных байтов, отдельных команд объектной программы или блоков из байтов или команд.
Покрытие объектов может быть выполнено для каждого исполнения команды, в этом случае результаты будут очень четкие, но неточные, так как система тратит большую часть времени на измерение самой себя. Такая форма называется детерминистическим покрытием. Альтернативной формой является периодическая выборка выполнения команд. Это называется статистическим покрытием. Преимуществом статистического покрытия является то, что режим тестирования реалистичен и влияние, которое оказывают инструменты покрытия, можно аналитически скорректировать. Недостатком же является то, что для получения статистически достоверного измерения надо провести тысячи повторений тестов.
3. Инструменты для покрытия потоков данных и других покрытий. Хотя тестирование потоков данных определяется здесь в контексте поведенческого тестирования, существуют соответствующие структурные концепции и связанные с ними инструменты покрытия. Уже разработаны инструменты, которые измеряют все использования, все определения, все пути определение-использование и даже все пути [FRAN85, HORG92, KORE85, OSTR91], Ни одного из них не было в свободной продаже к 1994 году. Существуют также инструменты покрытия (коммерческие) для регистрации высокоуровневого тестирования, которое не обсуждалось в этой книге, например, покрытие древовидных схем, которые необходимы при тестировании интеграции.
10.4.3. Автоматизация проведения тестирования
Автоматизации проведения тестирования следует уделить первоочередное внимание, так как даже умеренная автоматизация разработки тестов сразу же создает огромное число тестов, которые бесполезны без автоматического исполнения. Во многих системах и средствах разработки программного обеспечения есть возможность на 95 процентов или больше автоматизировать выполнение тестов. Стопроцентное автоматическое выполнение, по всей видимости, нежелательно. Это точно нежелательно, если единственная возможность это реализовать — создать сложного робота-наборщика, который будет имитировать действия пользователя с клавиатурой и мышью. Если автоматизацию проведения тестирования принять во внимание с самого начала и если это будет обязательным условием при проектировании системы, то возможна очень высокая степень автоматизации выполнения — около 99 процентов. Основной инструмент автоматизации
276 Глава 10 • Инструментальные средства и автоматизация
выполнения тестирования — это тестовый драйвер. Наиболее популярная форма тестового драйвера — это инструмент захвата/воспроизведения.
1. Наглядное, но плохое первое приближение. Наиболее общим первым приближением к автоматизации проведения тестирования является создание добавочного кода. Пишется специальная программа, в коде которой заложены все данные для тестирования, критерий соответствия и все остальное. Хорошо, но кто будет тестировать этот вновь созданный код? Должны ли мы «тестировать тестируемый код» или «тестировать тестирование тестируемого кода», и если да, то выполняет ли этот подход покрытие и как быстро? Это не лучший способ работы. Только в исключительно редких случаях оправдано создание специализированного программного обеспечения для тестирования. Как правило, универсальные инструменты тестирования, типа драйверов, в которых исходные данные теста и ожидаемый результат рассматриваются как данные, а не как программный код, удовлетворяют большинству потребностей тестировщиков.
2. Тестовый драйвер (существуют сотни доступных, коммерческих и свободно распространяемых драйверов) используется для проведения автоматического тестирования [CONK89, HOLT, 87, PANZ78]. Законченные драйверы (хотя таких драйверов на данный момент немного) должны иметь все приведенные ниже особенности. Используйте это как памятку. Существуют три определенные фазы управления тестированием: начальная установка, выполнение и постпроцессинг. Соответствующие инструменты структурного покрытия могут быть (должны быть) частью пакета.
» Фаза начальной установки. Подтвердите конфигурацию аппаратного/ программного обеспечения, ведь иначе вы не узнаете, действительно ли вы работаете в той среде, в которой собирались? Загружаются и инициализируются требуемые заранее или совместно используемые компоненты. Инициализируются другие необходимые аппаратные средства и программное обеспечение. Устанавливается доступ к требуемым структурам данных. Инициализируются инструментальные средства и инструменты покрытия.
» Фаза выполнения. Каждый тест необходимо инициализировать должным образом. Без этого инструмент тестирования не может стать средством автоматизации исполнения. Загружаются и контролируются входные данные для каждого теста. Оцениваются утверждения. Собираются выходные данные. По мере необходимости производится сброс инструментального средства для каждого теста.
« Фаза постпроцессинга. Используется подходящий критерий соответствия результатов теста. При аварии сообщается об отказах теста. С помощью интеллектуальных методов сравнения сравниваются реальные и прогнозируемые итоги (методы позволяют определять, что надо учитывать при сравнении и в какой степени). Данные о выполнении передаются в инструмент покрытия. Подтверждается правильность путей.
10.4. Базовый пакет инструментов 277
Проверяется наличие лишних и побочных результатов. При отказе теста управление передается пакету отладки.
« Захват/воспроизведение данных. Другие названия: захват/проигрыва-ние и запись/воспроизведение. На рынке коммерческие инструменты захвата и воспроизведения превалируют над другими инструментами автоматического тестирования. Я рассматриваю захват/воспроизведение данных и при автоматизации исполнения теста, и при автоматизации проектирования теста, так как он применим в обоих случаях. Захват/ воспроизведение данных является фундаментальным инструментом и наиболее популярным способом обеспечения перехода от ручного к автоматическому выполнению тестов. Инструмент захват/воспроизведение работает в двух фазах, фазе захвата и фазе воспроизведения. В фазе воспроизведения он представляет собой просто тестовый драйвер. Фаза захвата будет обсуждаться в следующем разделе, который посвящен автоматизации проектирования тестов.
10.4.4. Автоматизация проектирования тестов
Цель автоматизации проектирования тестов — уменьшение усилий, затрачиваемых на создание тестов. Связь коммерческих инструментов с различными методами, обсуждаемыми в этой книге, рассматривалась в каждой главе и не будет повторяться еще раз. Достаточно сказать, что каждый метод, обсуждаемый в этой книге, может быть дополнен соответствующими инструментами или, по крайней мере, ощутимо улучшен при их использовании.
1. Захват/воспроизведение данных. Захват/воспроизведение данных — это инструмент, автоматизирующий проектирование тестов, так как он записывает такие важные события, как вводы данных, нажатия на клавиши и так далее, а также отклик программного обеспечения (то есть выходные данные). Таким образом, он создает сценарий теста, который запускается во время фазы воспроизведения. Инструмент захват/воспроизведение может быть как простым, так и сложным, может записывать и воспроизводить все, начиная от единичного нажатия на клавишу и заканчивая пиксельным отображением экрана.
Важность метода захвата/воспроизведения в отношении данных состоит в том, что это самый легкий способ перехода от ручного тестирования к автоматическому. Захват/воспроизведение данных становится еще более мощным инструментом автоматизации проектирования, когда он используется в комбинации с текстовым редактором. Обычно если вы работаете с серией тестов, вы обнаруживаете, что большинство входных данных не меняются от теста к тесту, и только небольшое количество входных и выходных данных отличается. Таким образом, существует возможность запустить только один сложный сценарий и впоследствии создать различные варианты тестов, редактируя его. Если в процессе выполнения теста обнаруживаются ошибки, они исправляются путем редактирования. И вы можете быть уве
278 Глава 10 • Инструментальные средства и автоматизация
рены в том, что ошибки в тесте не возникнут опять при следующем запуске. Это как раз то, что не может быть выполнено, и уж тем более доказано, при тестировании вручную. Инструмент для захвата/воспроизведения данных бесполезен без возможности редактирования тестов (например, при помощи текстового редактора).
2. Мультистратегические генераторы. К 1994 году на рынке был представлен только один коммерческий мультистратегический тестовый генератор — Т [IDEI94J. В основе генераторов, рассчитанных на одну стратегию, лежат эвристическое тестирование доменов, синтаксическое тестирование, входные комбинации, случайные входные данные и другие, хорошие и не очень, существующие методы. Такие инструменты будут производиться и в дальнейшем. Сейчас, когда вы знаете основные методы поведенческого тестирования, вы можете оценить, понимают ли предполагаемые производители инструментов тестирования эти методы или же они только генерируют ни на чем не основанную эвристику.
10.4.5. Рекомендации по выбору производителя инструментов тестирования
Это не урок по оценке и выбору инструмента (может, к этой теме стоит обратиться в следующей книге?), а некоторые важные замечания, на которые следует обратить внимание при оценивании инструментов и производителей.
1. Съешьте сами то, что производите. Это я впервые услышал от Роджера Шермана из компании Microsoft. Если вы продаете еду для собак, вам не следует колебаться, перед тем как съесть миску своей собственной продукции. Вам может не понравиться вкус, но вы знаете, что это безопасно для здоровья. Спросите предполагаемого продавца инструментов, использовал ли он свой собственный продукт тестирования для себя. Если он затрудняется с ответом, уходите, так как он не доверяет своей продукции.
2. Подключение тестирующего средства. Инструменты тестирования не работают сами по себе. Инструменты тестирования встраиваются в более широкую среду разработки программного обеспечения и связанные с ней инструменты и методологии. Вам следует рассматривать не только преимущества инструментов, но также и легкость, с которой вы можете их интегрировать в вашу среду. Хорошие инструменты, которые не могут взаимодействовать с другими инструментальными средствами, встречаются довольно редко.
3. Поддержка. Не стоит ожидать бесплатной поддержки от производителей инструментов. Но вы всегда можете купить поддержку по приемлемой цене. Инструменты тестирования, подобно другим инструментам разработки программного обеспечения, могут быть довольно сложны, особенно если в основе инструмента лежит запатентованный метод. Я знал производителей замечательных инструментов, выброшенных с рынка, так как они были
10.5. Будущее тестирования 279
согласны продавать инструмент, но не поддержку, без которой инструмент просто ничто.'
10.4.6. Не обманывайте сами себя
Здесь приведена общая, но верная схема. Организация вкладывает инвестиции в инструменты тестирования. На каждом уровне организации существует стремление к качеству. Войска готовы и полны энтузиазма. Каждый разработчик и тестировщик получают лицензионную копию инструмента. Через год спросите своих сотрудников, кто все еще использует этот инструмент. Несмотря на инвестиции, первоначальный энтузиазм и все остальное, таких будет менее 5 процентов. Что же произошло? Почему это случается так часто?
Все недооценили время, которое было необходимо потратить на изучение инструментов и базовых методов, чтобы ясно понять, что данный инструмент и методы были эффективнее устаревшего ручного способа.
Вы можете изучать материал этой книги в течение одного семестра базового университетского курса или же во время интенсивного пятидневного семинара, но вы не станете экспертом, пока не выполните упражнения и реально не попрактикуетесь с материалом. Без практики методы не усвоятся и, следовательно, никогда не станут частью вашей работы. В студенческой среде это происходит автоматически, потому что упражнения и практика растягиваются на длительный период времени (а экзамены, несомненно, доказывают эффективность практики). Такие механизмы отсутствуют в обычных производственных условиях.
И управленческий аппарат, и тестировщик почему-то ждут, что они усвоят эти уроки при помощи волшебства, не тратя время на практику, и, что хуже всего, они ждут немедленного увеличения производительности. Но как же это может произойти? При реалистичном подходе на время изучения новых методов следует планировать снижение производительности и качества. За три-четыре недели напряженного труда вы освоите любой метод из этой книги, повысите с его помощью продуктивность и эффективность, а также научитесь использовать связанные с ним инструменты.
10.5. Будущее тестирования
10.5.1. Основы
Я не верю и никогда не верил в тестирование, но я не буду летать самолетом, чье программное обеспечение не протестировано должным образом. И я не противоречу сам себе. Я верю в независимое тестирование, но не в группы независимого тестирования. И опять же я не противоречу сам себе.
10.5.2. Зачем и почему я не верю в тестирование
Тестирование является нашей последней линией обороны от ошибок, но не первой или единственной. Если при тестировании обнаруживаются ошибки, то это значит,
280 Глава 10 • Инструментальные средства и автоматизация
что предыдущая стадия процесса разработки программного обеспечения неполноценна. Предотвращение ошибок дешевле, чем их обнаружение. Для того чтобы продвигать методы предотвращения ошибок и методы обнаружения первоначальных ошибок, такие как всесторонний анализ, создание прототипов, аналитические модели, формальные методы и инспектирование, мы, как тестировщики, должны стремиться поставить самих себя вне коммерции. Тестирование предназначено для обнаружения ошибок, которые остаются после выполнения предварительной работы, из-за того, что методы планирования и анализа слепы по отношению к ним. Подобно тому, как компиляторы исключают синтаксические ошибки из общего списка ошибок, будущие инструменты будут устранять текущие ошибки из сферы деятельности тестировщиков. Объектно-ориентированное программирование и эволюция операционных систем подают надежды на то, что исчезнут многие общие ошибки межкомпонентного взаимодействия. Формальные методы могут уменьшить или исключить ошибки взаимодействия характеристик. Я не думаю, что тестирование на самом деле исчезнет, так как остающиеся ошибки (после усовершенствования процесса) всегда более неуловимы и опасны. Поэтому я ожидаю, что со временем тестирование станет более технологичным, чутким и эффективным.
10.5.3. Зачем и почему я не верю в независимое тестирование
Как насчет независимого тестирования? Основная цель независимого тестирования состоит уже не в том, о чем мы думали 10 лет назад. Мы верили тогда, что независимое тестирование оправдывается его беспристрастностью: только группа независимого тестирования может быть объективна. Это плохой аргумент, которого мы не видим в других инженерных областях: «Нам нужен независимый анализ нашего строительства структурного проекта, так как мы не можем доверить проведение компетентного анализа нашим инженерам». Вот какова гнилая основа независимого тестирования!
Исторически основное оправдание существования независимого тестирования состояло не в его беспристрастности (несмотря на то, что мы это так громогласно утверждали), а в защите и выживании тестировщика. Цель существования группы независимого тестирования — защита тестировщиков. Если в организации не развита культура контроля качества, такая защита существенна. В серьезной организации, в которой контроль качества осуществляется на всех уровнях, такой довод для обоснования независимого тестирования неприменим. В этом случае можно верить в объективность разработчиков относительно оценки своей собственной работы и нет необходимости защищать тестировщиков от разработчиков. Так что же тогда является достойной причиной существования групп независимого тестирования?
1. Защита тестировщиков и обеспечение объективности. Рассмотрим это как некоторую фазу, через которую должна пройти организация для того, чтобы достичь определенного уровня качества. Это особенно важно, если требования качества диктуются свыше. Это дает надежду на прохождение этой фазы. Группа независимого тестирования может быть расформирована и
10.5. Будущее тестирования 281
направлена в разрабатывающую организацию, когда качество станет личным делом каждого.
2. Проверка конфигурации на совместимость. Продукт, который должен работать на различных платформах и во многих различных режимах, может выиграть при организации независимого тестирования. Разработчику трудно понять все нюансы программного обеспечения и все проблемы, характерные для многочисленных и сильно отличающихся друг от друга конфигураций. Группа независимого тестирования часто оказывается весьма полезна для проверки конфигурации на совместимость. Заметим, тем не менее, что такая группа использует другие тесты, отличные от тех, которые используют разработчики.
3. Тестирование рабочих характеристик и производительности. Для большинства продуктов программного обеспечения это не главная проблема, так как производительность и рабочие характеристики определяются тем, на что не влияет разработчик, например операционной системой. В тех случаях, когда рабочие характеристики и производительность системы важны, для тестирования лучше привлечь соответствующего специалиста, поскольку здесь существенную роль играет аналитическое моделирование (например, теория очередей).
4. Тестирование сети. Вообще говоря, это особый вид проблемы тестирования конфигурации. Сетевое программное обеспечение имеет свои дополнительные сложности, которые требуют знания вопросов теории сетей, особенно относящихся к протоколам. Это опять-таки повышает требования к разработчику, который должен быть не только экспертом в предметной области продукта, но и экспертом по сетям. В этом случае группы независимого тестирования могут быть полезны. Это не редкость, тестирование сети происходит на нескольких уровнях и может проводиться, хоть это и не обязательно, различными организациями. И опять, независимые тестировщики выполняют иное тестирование, нежели разработчики.
5. Локализация. Появляются различные версии продукта для различных языков или версии, которые должны удовлетворять правилам и/или требованиям, зависящим от конкретной страны или отрасли. Группа, ответственная за локализацию, может проводить и независимое тестирование.
6. Понижение риска и жизненно важное программное обеспечение. Когда ставками являются человеческие жизни и/или существует вероятность возникновения проблем с законом в случае аварии, благоразумие (а не техническая эффективность) может потребовать независимого тестирования, так как широко распространенное мнение говорит о том, что только такой способ гарантирует объективность. Это на самом деле не является ненужной тратой сил, так как уменьшение риска проблем с законом оправдывает дополнительные затраты. Однако при таком тестировании следует не просто повторять предыдущие тесты, а прилагать усилия к исследованию потенциально опасных ситуаций, не протестированных ранее.
282 Глава 10 • Инструментальные средства и автоматизация
10.5.4. Будущее тестирования
Здесь я скажу о моих надеждах по поводу тестирования.
1. Тестирование становится стандартной частью образования разработчиков программного обеспечения. Подчеркну, не кратковременным факультативным курсом, а обязательной частью образования программистов, предлагающей по крайней мере три различных области обучения. Предварительное тестирование (тестирование черного ящика), тестирование среднего уровня (интеграционное и системное тестирование) и тестирование высокого уровня (алгоритмы и теория тестирования).
2. Тестирование идет в ногу с развивающимся процессом разработки программного обеспечения и с нарастающей сложностью программного обеспечения.
3. Производство инструментов тестирования исчезает в той форме, в которой оно сейчас представлено, и занимает законное место в качестве важнейшей составляющей индустрии производства инструментов для разработки программного обеспечения.
4. Для большинства из нас тестирование перестает быть профессией, но остается неотъемлемой задачей, которую регулярно решает каждый добросовестный разработчик.
10.6. Вопросы для самопроверки
Дайте определения следующих терминов: захват/воспроизведение, проверка конфигурации на совместимость, корректирующее сопровождение, метрика покрытия, инструменты покрытия, детерминированный режим профайлера, фаза выполнения драйвера, фаза постпрограммы драйвера, фаза начальной установки драйвера, съешьте сами то, что производите, тестирование эквивалентности, отложенное вычисление, локализация, сопровождение, сетевое тестирование, профайлер, прогрессивное сопровождение, регрессионное тестирование, интеллектуальный метод сравнения, статистический режим профайлера, структурное покрытие, тестовый драйвер, тестирование производительности.
Приложение А
284 Приложение А
Форма 1040 стр.1
?> Oei^rtmert of lhe Treasury-Internal Revenue Service 1 Ю U.S. InoMdu il incomt Tax Return 1994 I I (99) R3 им *• Оф «Л w*» er tolh* fpta
F< t ti । yt ч J w 1 ; 31, 1994, Of othe уе». beginning,1994, end чд ,19
Label
Um the IRS label. Otherwise, pt**M print or type.
Campaign
Filing Status
YMrtHtMK» M Latinwm Yewlw.iW tow*? Ns.
М»хм*чк«».ккмм'»аиап«т» M LaSnae» StMUMV S*«M SwvttSr N*.
Няч.'ЧшГ un*MrandakMe.Myoutww«l> О «м.м>-ллхфп». AparlmwMM. C/tf taM^t^U»lliM.tfyOvri*w»igrMW>«Mni KMMmeWwM. &Ы» ZWCOO» For Privacy Act and sperw^,, *ked<x wn Act Notice, saemstrocl on*.
Yes No >w
Do you want S3 to gv to this fund? „ * If a joint return, odes you sporr • went $3 to go to n»s fund ?
1 II Single
2 Ц M~~r-d filing joint return (even it only one had income)
3 Married filing separate rtn. Enter spouse's SSN above & lull name here
* U H,:of hciriafx и (with qualifying person). If the Qualifying person is a chrid but not your dependent,
Cnjckonij enter lt»s child's mme her* *" ont box. b uu-!<fyrng wkkwfcr) with dependent child (yeat spouse rfied * 19
tia^J Yowsrrtf. If ycu parent (or x>meone slse) can claim yc. as »Cape, lent ‘ n his or aa«ra«w» Exemption* herlax return, do notched box 6a. But be sun to chrd ‘hi bv* on In 33t or Pv 2. -fiSUe ’ L Spo^s* ... .. . —
c Dependents: (l)n»nw ao< w *e«w> (7)0* imjw STJ-i (3) M «9» 1 «r *>*, йвоепйгО ««^u^ липы» (4) СедеОмГа гаоддоф (5>4m ic jsXjs сЫНгчпвм horn» fewhr* ЖН1 *-..>4.^,^
If more than
seevnlrt. • MntlM w*t>r**H
—
f1 tc л<С «ЙМММ t ..
d MjmvoiMaWtlwwrh»w:iue«»«»i«il»« w»i*mhM,mk aw* H*S*9w*i»«l<sh«r», дМтмОма * Total r>umbw of exemption; cte-m 4 \ *
Incom*
AttoeS Co^yjBof
If you did »l cat a
^etructrons.
7 Wages, salaries, tips. etc. Attach FornKs) W-2 .........
•a Taxable interest income. Attach Schedule 8 it over $400.
ЪТах*еха пи merest Don't inctuS on line 8a...........
UMdend income. Attach Schedule 8 if over $400..........
Taxable refunds. credits x ‘ f*iets of state and toe .< inenme taxes. ' m jny receiv' d ...............................................
Business income or (loss). Attach ScherMe C or C-EZ..............
Capital gam or (lass). If required, Attach Schedule D............
Other gp ns or (losses). Attach Form 479?........................
Encfote
U‘d not attach any ; payment w mycjr return.
Adjustments to Incom*
Jb Taxable amount. .
15b
16b
8 10 11 12 13 14
ISa Total IRA d.*triUn -w I ISal________________JbT.rxsble amount
16 a Tot pensions & a -•'*> 116*; |b Taxable amount.......
17 Renta) real estala royatta * partnerships, S eoepor Л< r. trusts, etc. Attach 8ch E 11 Farr tnrxne or t.jss). Attach Schedde F
18 Unemployment мгш J,vn 28* Fcch i MCurrty benefits. I 28a j
21 Other«пси:™ _________________________
22 Add the amounts in ths tar right column lor t,nes 7-21. This 23* Your IRA ги djdi.
b Spouse's *RA deduction................
Moving expen* . Attach Form 3903 or 3903-F One-half of sett-<arplryme^t fax Self en d he*tth insurance deduction.... fi B>n№raaHpiM4Mi*fen«io0dSVdtdud>M . Pcrwlty on early withdrawal of s»wxp Abmom iM Raxpttntr SSN
24
Caution See 50 Instructions ► 28
27
28
28
23a
23b
24
2»
26
27
28
29
30 Add im гЗа through 29. These are yew total adjustments ... *130
Adjusted Gr »ss Incom* 31 SUW»<x 1W*Hw»urM(teMfr*«»&№CNm. >®W {tw #wt МДОО «ОДдеъ? 5*« Сг«Й* > АГЖЧЛЛйГЛ . ...•131
D181
rauoi'z irnse*
Form 1040 (1994
Приложение А 285
Форма 1040 стр.2
FarrltMOn^)
Tax Computation
if you want the IRS to figure your tax, see instructions.
CrecBts
Other Taxes
Payment*
Attach Forms W-2. W-2G, and 1099-R on page 1.
Refund or Amount You Ow:
Sign
Here
Keep а соду of this return for your records.
Paid Preparer's Use Only
ГОМОН» WW
33с
v«v «ххщмйоп
fv»l>w»r» Social Securte He.
32 Amount from line 31 (adjusted gross income)
33aCkif: Г1 You were 65fokter, [j Blind; Q Spouse was 65/okksr, [ Blind
Add the number of boxes checked above and enter the total hero..... ... *• 33a
b If your parent (or someone else) can ciann you as a dependent, ck hero.... ► 33b c If you are married filing separately and your spouse itemizes deductions or you 34 Ы* V* brpir_ Standard dad stmwn bebw ftx your feme status. But И you ckd * - -
i are a duri-xtatu. alieci. w instructions and check here. Itemized tteducLons from SchedUe A, line 29, or
37
3»
4»
1 any box onttae 33a or b, see instructions to find your standard _cted. If you checked box 33c, your standard deduction ts zero.
• Smgte-$3J00 • Head of household — 55600 • Married frlmg yxrilly
nr Qualifying wrdow(er) - $6.360 • Married filing separateу - $3,175
Subtract Me 34 from line 32. ...
И In 32 is $83,850 or less, multiply $2.480 by the total no. of exemptions claimed on in бе. л In 32 is over $33,850, see the instructions for the amount to enter
Taxable income. Subfract In 36 from to 35. If In 36 rs more that to 35. enter -0-.. ..
Tax. Check if from a| J Tax Table, b<;_j Tax Rate Sche lutes, cQ Capita! Gain Tax Worksheet, or, <lQj Form 8615, Amount fromForm(s) 6814.. ►*____________________
Additional taxes. Ck if from. . af J Form 4970 bp' Form 4972
Add lines 38 and 39............................................................
43
35
36
37
38
39
40
41 <
42
43 I
44 J
<7
49
« 52
53
54
55
5»
S3
41 Credit for child and dep care exp. Attach Form 2441 42 Credit for the elderly or the disabled. Attach Sch R.
Foreign tax credit. Attach Form 1Г6. . Other credits. Check if from »j_ Form 3800 bQ Form 8396 Cj__ Form 8801 tf_ Form (spec)________________
Add line* 41 through 44 .............................
Subtract Me 45 from line 40. If line 45 is more than line 40, ante- 0-.. Self-employment tax. Attach Schedule SE-. ..........................
Alternative minimum tax. Attach Form 6251.......... .................
Recapture taxes. Ck if from аП Form 4255 bQ Form 8611 сП Form 8828 SS and Medcsra tn on to «corns rot noortof to urndoye Atart toon 4)3?
Tax on Qualified reft, ement plans, «eluding IRAt If required, art Frm 5329 Advance earned income credit payments from Form Vf-Z........
AM Im 46 • 52. Ttei в your tstsl tot.........
Fsdsrsl iroorn to wtStol L If any it from fcxm(i) 1099, dr 1994 eslirrated tax payments and amount applied from 1993 return ............................
Earned Income crodK. f! required, all Sch EIC Nontaxable earned income, amount and type ►_________________________
Amount paid with Form 4868 (extension request) Excess social security and RRTA tax withheld.... Other payments Check if from fwrn 2439 bi j Form 4136 ..............................
« • 59. These are your total, роужепц
$1 Hfn»60hfficrsthsnto*53>wto»abM53framlineS6.'n»t is th» апШум Overpad ... tt «3
Amount of line 61 you want Refunded toYou................................ ..
Amt of ki 61 you want Applied to Your 1995 Est Tax.....4 I ___________________
If to 53 Л more then In 60, subtract In 60 from tn 53. This is the Amount You Ow*.
For details on how to pay, including what to write on your ornnt, see xistructicns ..
Estimated tax penalty Also include on line 64.
Veur vomkw
Sp^ueT* Мнлакии » • jtxM «•» BOTM mud «ф.
PTtoCAW-
286 Приложение А
Форма 2106 стр.1
Form 2106 Ctewwrt в» Л» Tt»*»uw toterW IteweiM Service &T> Employee Business Expense ► Attach to Fern» 1940. ома ж ise-oiM 1994 54
Yay мм* Sectof &*ме^у Имийм« Oocupete» in wtwft ецрепме w» incumM «Untitled 1>
РвПJ . ] Employee Business Expenses «nd Reimbursements
Note: If you wen not reimbursed for any expenses tn Step t. skip Uno 7 and enter the amount from Hne6ontme&
Step 2 Enter Amounts Your Employer Gave You for Expenses Listed in Step 1
7 Enter amounts your employer gave you that were not reported to you in
box 1 of Form W-2. Include any amount reported under code V in box 13
of your Form W-2............. . ................................... 7
Step3 Figure Expenses to Deduct on Schedule A (Form 1040)
Subtract «ле 7 from line 6...........................................
Note: If both columns of Uno 8 are xera slop here, if column A is less than zero, report the amount as income on Form 1ОЛ0, line 7
In column A, enter the amount from line В 6t zero or less, enter -0-).
In column 6 multiply the amount on line 8 by 50% (.50)...........
Г ~гт
I Г
19 Add the amounts on иле 9 ot both columns and enter the total here. Also enter the tote on Schedule A (Form 1040л Km 29, (QuUn» d perform»>g artists and individuate with dteabilibes, see the rrnlrucbons for special rules on where to enter the total.).............................................................. -
СП 81 For Pa^rwortr Reduction Act Nottc», «ее Instructions,
Form 210в 0994)
Приложение А 287
Форма 2106 стр.2
Form 2156 (1994) Page 2
||-г* ч 1 Vehici* Expenses (See instructions to fmd out which sections to complete,)
Section A — General Information W Vehicle 1 ft») Vehicle 2
11 Enter the date vehicle was placed in service 11
12 Total miles vehicle was used during 1994 12 miles mi les
13 Business mites included on line 12 13 mi les miles
14 Percent of business use Dmcte line 13 by line 12 14 % X
15 Average daily round trip commuting distance 15 miles mi les
15 Commuting miles included on Urie 12 15 miles miles
17
1»
Other persona! mites. Add lines 13 end 16 ana subtract me tot* from wi« 12..........................................
Do you (or your spouse) have another vehcte available tor personal purprses?
miles
miles I l Yes I I NG
» if your enproyst provided you with a vehicle, is personal use during off duty hews permitted?... .Г] Yes 0 No Q Not applicable
20 Do you have evidence to support your deduction?..........................................................
-£]*« O*>
21 If Tas ‘ i* the evidence written?.......................................... ,........... , уе$ [")
Secti on В — Standard Mileage Rate (Use this section only if you own the vehicle ) '
22 Multiply line 13 by 29* (29). Enter the result here and on line 1. (Rural mail earners, see instructions).| 22
Section C - Actual Expenses
23 Gasoline, oil, repairs, vehicle insurance etc......................
24a Vehicle rental* .. b inclusion amount.................
c Subtract line 24b from line 24a
25
26
Value of employer-provided verecle (applies only if 100% of annual lease value was included on Form W-2 -see instructions).................
Add lines 23,24c. and 25..........
Multiply line 26 by the percentage
on line 14.......................
25
Depreciation. Enter jmotrd from line 38 below ...................
Add lines 27 and 28. Enter total he<e and on hne 1..,,..............
Section D
^>) Vehicle 2
31
Enter cost or other basis ..... Ertsr «nuitcf secton IKutertoCton
32
34
Multiply line 30 by line 14 (see instructions if you elected toe section 179 deduction)
Enter depreciation method and percentage..........
Multiply line 32 by the percentage on fine 33........................
Add lines 31 and 34...............
35
Enter the limitation amount from the tabla fn the line 36 instructions.....
Mcitipty line 36 by the percentage on line 14..........................
35
Enter smarter of line 35 or line 37.
Also enter this amount on line 28 above ........................
IM this ‘-choc < r? if -ou own the vehicle.
(b)V<toicfe2
288 Приложение А
Form 2210
OweWwwit er е* Т1 — VY :лГМПа1,ЙМ<М>**Г*С»
Форма 2210 стр.1
Underpayment of Esbnumd Tax by Individual ,, Estates and Trusts
* Sa* ш _ vto it>a*r
> Attach to Fonw 1CH8, Form КМ0А» Form 1U40HR, or Form 1041.
1994 06
Hm(t> anew» «п ш «Миш
No*»; frt moat cases, you do not need to Ate Form 2210. The IRS и*»£а л ал> penalty you ом г id send you а ЫЛ. Frk Form 2210 oriy done or more boxes in Part I apply to you H you do not need to fife Form 2210 you t't may use It to fioure your penalty. Enter the amount mm One 20orbne3t<,n ‘heponai^'tineofyx. 'return, but do not attach Form 22)b
• Reason* for Filing ~ it le, b< or c below applies to you, you may be able to lower or eliminate your г п ft But you
must check the box< apply and fite Form 2210 with your tax return. If Id below agp'ws to you, che'-ч that box and file Frrm 2210 with your tex return.
1 Check whichever boxes apply Of none app*y see the Note above):
aQ You requa il a waiver. In certam circumstances, th» IRS wt'. warn» a*l or pert of the penalty. See Waiver of PenaRy in the instructions.
r. You мм th an- ' "- xl lirmr »i mt mathoe. If yow income varied tk/ring the year, this method may reduce the amount of one bj_J or mor* required mstetenenta Sa the netruebons.
P-. You had federal ncom* tax withheld from wage* and ус и treat И a* paid for cat-mated tax purposes when It was actually wrtttwfd c[_J instead of it «*uel amount* on the payment du* dates. See th* instructions for liw 22
Yom rr“< irrd annuel payment Jew 13 below) л based on your 1993 tax and you filed or ar* filing a joint return for either 1993 or 199* di ; but not both years
Required Annual Amount
’’’W
2Enie< your 199* tex after credit»..................................
lOiher texes ... ............................................
4Add U<*m 2 and 3 ............................................
♦Earned income credit ..............................................
SCreot for federal tex pted on fuels................................
7Add -as 5 arid 6..................... .............................
•Current year tax. Subtract tew 7 from line 4 ..................
♦Multiply line 8 by 90% (.90).......................................
leWrthhr ‘-'ид taxa*. Co not include any estimated tex payment* on this tew 11 Subbed : rw 10 from Ln* в if les* than $500 step here; do Mt complete or file this form. You do not owe the penalty ........................................................... . .....................
11
12
13
12Eni*r the tex shown on your 1993 tax return (110% of that amount it the adjusted gross income shown on that return it more than $150,000, or if л err» d fling i aparately tor 199*. more than $75,000). Cautfoe: Sec frtsfrudtarw...............................................................................
13 Requited annual payment. Enter ihr amrier of an* 9 or fine 12......................................... ..........................
Hear. 4 no 10 ia equal to or more than Imo 13. stop here. you do not owe the penalty. Do nor nte Form 2210 unless you checked box Id John
«/ Short Method (CauHtrmi Road the Instructions to see if you can use the short method. If you chocked box 1b or c in _______________Parti, skip this part and go to Part IV.).... 14Enter the amount, H arty, from line 10 above.............. __________
15 Enter th* total amount it any, of estimated tax payment* you made
14Adci I no* 14 and 15 ............................................
IS
ITTotai underpayment Seryaar. Subtract tin* 16 from line 13. if zero or less, slop here; you do not owe the penalty. Do not to Form 2210 untess you checked box Id above.................................
IftMtotfoly me 17 by .06725......................................................................
!♦• tf vw amount on kne 17 was paid ewer alter 4/15/95, enter-0-.
• if the amount on ta-e 17 was paid before 4/15/95, make th* foil^wmg computation to find th* amour* Io enter on ime 19.
Amount on One 17
Number of days paid before 4/16/95
.00025
29l*Malty. Subtract line 19 frvm l^w It Epte th* result here and on Ferm К* «n* 65; Form 10*04, frw 33; Form 1M0NR.
line 66; or Form 1041, line 26. .............................
D1C1 For Paperwork Roducfki n Act NoVca, see tastructioo*.
Form 2210 (199*)
Приложение А 289
Форма 2210 стр.2
Form 2210 Л 994) ад» 2
ForiIV Regular Method (See the instructions if you are filing Form 1040NR.)
Section A — Figure Your Underpayment 3 Payment Due Dates
(a) 4/15/94 0» 6/15-94 (O 9/15/94 <*> 1/15Л6
21 Required installments. tf box 1b applies, enter the amour t 14m SctiedU* At. ’••w 2b CH alw<sr. u<il»r IM of bne 13, Form 2210. in each column 22 Estimated tax paxi and tax withheld. For column (a) only, also enter the amount from ime 22 on line 26. If line 22 is equal to or more than toe 21 for all payment periods, stop here; you do not owe the penalty. Do not rile Form 2210 unless you checked a box in Part 1 Complete toes 23 through 29 of one column before going to the next column. 23b*r smtxrl, rf wry, fijrn hm 29 cf pswoui caurr. 24 Add lines 22 and 23 25КЙ aaounts« fa»» 27 and 23 ot tte prewoa oXw» 26 Subtract line 25 from toe 24. If zero or less, enter -O-. For column (a) only, enter the amount from Ime 22. 21
22
23
24
25
27lf the amount on ime 26 is zero, subtract toe 24 from line 25. Otherwise, enter -O- 28Underpeym«nt tf line 21 is equal to or more than line 26 subtract I»nt 26 from line 2» Then go to line 23 of next column Otherwise go to toe 29 . ► 2»(\«реутпег«. tf tor & а mcr« tfto вп» Л, tubbed fee Л from Ixw a. Tten go te toe 23 of next column 27
2»
29
Section В — Figure the Penalty (Complete toes 30 through 35 of one column before going Io the next column)
April 16,1994 - June 3d, 1994 Rate Period 1 SQNumber ot days from the date shown a^ove tine 30 to the date the arrounl on line 28 was paid or 6/30/94, whichever ts earher 4/1594 6/15/94
90 Cer*
» . Number of " “ЙИГ* « ««чу.» . w. 31 1 1 Г—
July 1.1994 - September 30.1994 Rate Period 2 SZMjmber of days from the dale shown above line 32 to th Над tne “.xx." Л on jne 28 was paid or 7/30/94, wtecheww ts eartier M , Number of , в** Oh to* 3? , ™ on fine 20 x 365 к 6/30/94 6/30/94 9/1&94
Dxxr У»}» Dtya
« S >. 1
October 1.1994 - April 15.1995 Rate Periods xi: lumber of days from the date shown above toe 34 to the data the an ount on line 28 was paid or 4/15/95, whichever ts ea-^er 9/30/94 9/3194 9 36/94 1/15/95
34 й»х СУО* De* Лее-
ш: _ N-.nber ot ” “SJSST* . . 35 $ $ $ $
X Penalty Add all the amounts on lines 31, 3d, and 35 tn all coltxwis. Enter the total here and on Form 1040, toe 65; Form 104GA, line 33- Form 1040NR, Ime 66: or Form 1041, toe 26 ► 34 5
)0 Зак 770
290 Приложение А
Форма 2688
Form 2688
Оц-***** of interna ftgwwjt &»гйс»
Application for Additional Extension of Time to File U.S. individual Income Tax Return
» $M inetnrctiOM.
* Yw Musi complete aft Items that apply to you.
Your Wt name Ml LartnuM
Г» -oMteum, «юин'«Кпап*пм W 1м1пмм
Нот» «Мгм« (htfiwr. Urwt м3 «ренте»! number or ми rater). » you пм • P.O оо» «ее *»
CMS No .154М»«
1994 _____________»______________ Yaw Де gill? Я iixrty f*unrti i r
УрммеЧ fedrf .м. ж -JajTj*
ОД «ДО«0М1Ы&»
Zi?Co*
1 I request an oxtension of lima until _ _____________.19_______, to fite Form 10406Z. Form 104QA, or Form 1040 for th* calendar year
1994, or other tax year ending______________,19__________.
3 Haw you filed Form 4368 to request an extension of time to file for th»* tax year?.............................Q Yea Q Ito
if you checked Yta,’ wa will grant your extension only tor undue rwdshif Fully explain the hardsl.-p on line 3.
3 Expain Uy you "ned an extension*
if you expect to m gm or geaenteforwfclpptog transfer (GST> tent, complete few 4.
4 If у,ч or your spouse plan to fife a g»r ; xx rattan (Form 709 or 709-Л) fix 1994, generwiy due by Ycurstef.... H
April 17,1995, ace toe instrvcSons ar. j check here........................................ Spouse ]
Slgnatureand Verification
Under purwfees of j rwy I deciare that I haw exwri’twd this form; Eluding «eu-noa. ying schedules and statements, and to toe best of try knowledge and belief, И ts true, correct, and complete; and. if pm.^ed by someone othe. tntn the taxpayer that I am a nhx. red to prepare tots form.
towsnofeuear* *“ 0»W
BitneMt iwaxw ** OW •*_____________________
{»*“>$ joiner. TOTH <» anj- wa '“yuwtwHnaxn»)
SUnMwsd xn-H*w
<ew >w»»««pww * on1*______________________
Ih^^mand one rq.T^^^i^bet^wlwtoerortwf^T and will return toe cvpy.
Новее to AppMcanf — To Be Computed by the IRS
В We haw approwd )>x application. Ptease attach tn». form to your return.
We haw not approved your eppiicabon. Please rttach И »* form to your return. However, because of your reasons stated above we haw granted a ituiay grace period f.om the date sho.n i below or due cat* 4 your return, whichever is taler. This grace period is considered to be a vaixf «tension of tone fix elections ctoorwtre requ>r«ri to tie made on returns filed o*i ftrw.
[ | We haw not approved your application. After considering your reasons stated above we cannot grant your request for an extension of time to file. We are not grunting toe 10-day grace period.
___ We cermet consider your swpecanon because H wa* tiled after tn due date of your return
___ We haw not approved your nppUcat on. The maximum extension of time showed by lew *4 6 months
ZJ W*__________________________________________________________________________________________________________
N*n>
Humba* MWI «toMt <vk4u4* «ый», worn, ж *ptne.)« f PO tai numtM* itnw#• ла*лййнй Ьйг»<Н жМп»*
Cte> WM1 or e<Mt olto* Swm » Cate
If you want the copy of this form returned to you at an address other man that shown show or to an age? t acting for you, enter the name of ле agent andfor the address w tert toe cw should be sent
0181 For Pegerwom Iteductfon Act HoSce we Instructions.
Form МП 0994)
Приложение А 291
Форма 3903
Form 3903
о»е» Тпишку VWnw Hvnwwr Sew*
Н*т«<Й «ho** НЖ>
Moving Expenses
► Attach to Form 1040.
*• See separate instructions.
смей», имении
1994
________62
VwfetVI Swwte KwHmt
IStOl Moving Expenses Incurred in 1994
Caution: if you *t a member ot the armed forces» see toe instructions before completing this part
. Л
1 Enter the number cf nvles from your old home to your new workplace........... 1____________
2 Enter the number of mile» from your oM home to your old workplace 2
3 Subtract line 2 from ime 1. Enter the result but not les» than zero..........j 3 ।__________
I* few 3 at toast SO mileef
Yes * Go to line 4. Also, see Time Test in the instruction*.
Ha * You cannot deduct your moving expense* incurred in 1994. Oo not complete the rest of this part. See the Mote below И you rise incurred moving expenses before 1994.
4 Transportation and storage cf household goods and persona: effects...........................
5 Travel end lodging expenses ot moving from your old home to your new home Do not include meals.
ft Mdbr»s4and5
7 Enter the total amount your employer pari for your move (toctuding the vawe of services furnished in tend) that is not included in the wages box (box 1) of your W-2 form. Thts amount shouto be identified with coda P to box 13 of your W-2 form.
Is See 6 more than Um 71
Yes ► Go to line 8
**° * You camot deduct your moving expenses incurred to 1994. It line 6 is less than line 7, subtract line 6 from line 7 and include the result to income on Form 1040, line 7
* Subtract line 7 from Uns 6. Enter the result here and on Form 1040 line 24. This is your moving expense deduction for expert»** Incurred in 1994.......................................
Hot»’ If you incurred moving expanses before 1994 and you did not deduct those expenses on a prior year’s tax return, complete Parts II and til on радо 2 to figure toe amount, if any, you may deduct on Schedule A, itemoad Deductions.
For Paperwork Reduction Act Notice, see separate instructions.
Form ЗЮЗ 0994,
292 Приложение А
Схема налоговых ставок SE
8SE
IfepetoPMrt of >w
(99)
Self-Employment Tax
► See instruction* for Schedule SE (Form 1040). ► Attachto Form 1041
Hof’w il рта» чЛЬ »<W —jiUiywxrtt “кя-л*. (Ю iho«n on Form ГМф
Sow security umber of person with шнйпрйулмт ncome ►
OMK №>.
1994
17
Who Must File Sche&ie SE
You must fite Sclwdute SE if:
* You had ne earn ryjs from seif -employment from other than church employee income (fine 4 of Short Suf i tf*. aSE or line 4c of Lone Schedule SE) of WO or more, o'
• You had church eirvtayee income or 5108.28 or more, come from servo s you performed ** a minister or a member of e religious order Is not church employee ercuma
Hater Even if you have a tot» or о sma9 «mount of incoma from st ^-amplcymant. it may ba to your banafit to fUa ScbarMa SE and usa aitfiar ’opborW method" In Part II of Long $c -tft< SE.
Exception; if your only $e Г-атрюупип' some from eaminos as a mmtsi v. r »mber ofareligious orJer or Chrislijn Степсе practitioner, an you fifed Form 431 and received IRS approval not to be taxed on those eamings, do not file Scheduli SE. nstead, write ’Exempt—Form 436Г on Form 1040. line 47,
May I use Short Schedule SE or MUST I u«« Long Schedule SE?
Section A — Short Schedule SE. Caution: Weed above to see ifyyn can use Short ScbaOuia SE.
Nel farm profit or (toss) from Schedule F, fine 36 and farm parti im hip Schedule K-l (Form 1065), fine 15a....................... ......................................................
SJv duh Fo<m 1Ыф 1094
z
Nat profit or (loss) from Schedule C, line 31; bcttoduie >EZ. line 3; and Schedule K-1 (Form 1065). fine 15a (other than terming). Ministers and members of religious orders see instruc cns 'or amounts to report on the >ine. See rrafiruet oni, tor other income to report
3
5
6
Combine fines 1 and 2.........................................................................
Чч earning* from s<d-e,npt lymerrt. Multiply tine 3 by 92.35% (.9235). If less than $400. do no! Me
VMS schedule; you do not owe self-employment tex..............................................
Set«-e»4>»oy*ne*H tax. if the amount on line 4 is:
• $50 600 or fess, multiply line 4 by 15.3% (.>53). Enter the result here and on Form 1046, tine 47.
• More than $60.600. mu't uly line 4 by 2.9% (.029) Thur add $7,514.40 to the result. Enter the total here and bo Form luaT tine 47.
Deduction for one-half of FMr^mplm m.nt tex. Multiply line 5 by 50% (.5). .
Enter the result here and on Form 1040 line 25.......................... | 6 I____________
0181 For Paperwork Reduction Act HUtoe, see Form 1M0 instructions.
FCttAllOl iort*4*
Приложение А 293
Форма 1040 строка 10
Form 1040 State and Local Tax Refund Worksheet 1994
Line 10 * Keep tor your records
Mamefs) shown on return Social Security Nwnber
1 Enter state or local income tax refund, from Form(s) 1099-G (or similar statement)................................................................
2 Enter your total allowable itemized deductions from your 5993 Schedule A, line 26........................................................................... 2
status on your 1993 Form 1040
Single
Married filing jointly or qualifying wxfc>w(er)
Married filing separately
Married filing separately and your spouse itemized deductions
Head of household
Nate: if the filing status an your t993 Form 1040 was married filing separately and yow spouse itemized deductions m 1993, skip lines 3 through 5 and enter the amount from line 2 on line 6.
3 Enter the amount shown below for the filing status claimed on your 1993 Form 1040:
• Single, enter $3,700......................%..................
• Married filing jointly or qualifying wtdow(er), enter $6,200 ... _ .
• Married filing separately, enter $3,100 . ...................
• Head of household, enter $5,450 ............. .____________
4* Enter the number from your 1993 Form 1040. line 33a ........................ 4a
4b Multiply line 4a by $700 ($900 if your filing status was single or head of household).................................................................. 4b
5 Add lines 3 and 4b , ........................................... 5
6 Subtract line 5 from line 2. If zero or less, enter -0-.................... 6
7 Taxable refund. Enter the smaller of line 1 or line 6 txire and on form 1040, line 10........................................................................ 7
294 Приложение А
Форма 1040 строка 20
Form 1040
______Un» 20
Name(s) shewn on return
Social Security income Worksheet 1994
____________Keep for your records
Social Security Number
Taxpayer Spouse
A Enter the total amount from Box 5 of aS your Forms SSA-1099 .....
В Enter the total amount from Box 5 of aS your Forms RRB-1099 .......... ...........
1 Add amounts from line A and line 8................................................. ..........
2 Enter one-halt of line 1 ....................................................... .............
3 Add the amounts on Form 1040, lines 7.8a (before U.S. savings bond interest exclusion). 8b, 9 through 14, t Sb, 16b, 17 through 19, and line 21 ...................,
4 Foreign earned income exclusion, foreign housing exclusion, exclusion of income from U.S. possessions, or exclusions of income from Puerto Rico by bona fide residents of Puerto Rko that you claimed..........................................................
5 Add lines 2, 3, and 4 ........................................................................
6 Amount from Form 1040, lines 23 through 29. plus any write-in amounts on line 30
(other than foreign housing deduction) .............................................
7 Subtract line 6 from line 5 .......................................................
8 Enter $25,000 ($32,000 if married filing jointly; $0 if married filing separately
and you lived with your spouse at any time in 1994)............................................
9 Subtract line 8 from line 7. If zero or less, entpr -0-.......................................
tf tine 9 Is zero, stop; none of your social security benefits are taxable. Do not enter any amounts on Form 1040, lines 20a or 20b or Form I040A, lines 13a or 13b. But if you are married filing separately and you lived apart from your spouse for all of 1994, enter -0- on Form 1040. line 20b or Form 1040A, line 13b. Be sure to enter *0' to the left of Form 1040. line 20b or Form 104QA, line 13b.
If fine 9 Is more than zero, go to line 10.
10 Enter $9,000 ($12,000 if married filing jointly; $0 rt married filing separately and you lived with your spouse at any time in 1994 .......................... ,
11 Subtract line 10 from line 9. If zero or less, enter -0- ............................................
12 Enter the smaller of line 9 ot line 10...............................................................
13 Enter one-half of line 12............................................................................
14 Enter the smaller of line 2 or line 13 ................................................... ,
15 Multiply line 11 by 85% (.85) tf line 11 is zero, enter -O-.........................................
16 Add lines 14 and 15 ....................................................................................
17 Multiply bee 1 by 85% (.85).......................................................... ...............
18 Taxable social security benefits. Enter the smaller of line 16 or line 17........ ...................
♦ Enter the amount from line I on Form 1040. line 20a, or Form 1040A. line 13a. ♦ Enter the amount from line 18 on Form 1040, tine 20b or Form 1040A. line 13b.
Приложение А 295
Форма 1040 строка 26
Form 1040 Self-Employed Health Insurance Deduction Worksheet 1994 Line 26 »• Keep for your records_________
Name Social Security Number
Note: If you have more than one source of income subject to self-employment tax. or you file Form 2555.
enter your payments on the first line of this worksheet, then use the worksheet In Publication 535 to compute your deduction, end override fine 5 below,
A Enter total payments made for health insurance coverage for you, your spouse, and dependents..................................................
В Medical care insurance expense from Schedule К-1 Partnership Worksheets....
1 Total payments made for health insurance coverage for you, your spouse, and dependents...............................................................
2 Percentage used to figure the deduction...................................
3 Multiply line 1 by the percentage on line 2...............................
A _______________
fi ______________
1 ______________
2 x .25
C Net profit from your trade or business. C
0 If you are a statutory employee and are considered self-employed for the purposes of the health insurance deduction, enter your net profit from the business........... О
E Enter your wages from an S Corporation in which you are a more than 2%shareholderE
4 Net profit and any other earned income from business under which the insurance plan is established, minus any deductions you claim on Form 1040, lines 25 & 27 .. 4
5 Self-employed health Insurance deduction. Enter the smaller of line 3 «x line 4 here and on Form 1040, line 26. (Do not include this amount in figuring any medical expense deduction on Schedule A (Form 1040)). . ... 5
296 Приложение А
Форма 1040 строка 34
Standard Deduction Worksheet for Dependents 1994
iJse this worksheet only if someone can claim you as a dependent.
______________________________Keep for your records
Name(s) shown on return Social Security Number
1 Enter your earned income (defined below). If none, enter -0- 2 Mmimum amount 3 Enter the larger of fine 1 or fine 2 4 Enter on line 4 the amount shown below for your filing status: 1 2 3
•Ssngie, enter $3,800 ~~1 • Married fifing separately, enter $3.175 1 •Married filing jointiy of Qualified |— w«jow(er) enter $6,350 | ♦Head of Household, enter $5,600 5 Standard deduction. a Enter the етайег of line 3 or line 4. If under 65 and not blind, stop here and enter thrs amount on Form 1040, fine 34; or Form 1040A, fine 59. Otherwise, go to fine 5b b if 65 Pf older or blind, multiply $950 ($750 if married filing jointly or separately, or 4 5a
qualified widow(er)) by the number on Form 1040, line 33a; or Form 1040A, line 18a. 5b c Add lines 5a and 5b. Enter the total here and on Form 1040, line 34; or Form 1040A, line 19. .................................................................... 5c
Earned income includes wages. salaries, tips, professional fees, and other compensation received for personal services you performed, ft also includes any amount received as a scholarship that you must include in your income. Generally, your earned income is the total of the amounts) you reported on form 1040, Imps 7, 12. and 18, minus the amount, if any, on line 25; or on form IO4OA, line 7.
Приложение А 297
Схема налоговых ставок А строка 29
Schedule A Itemized Deductions Worksheet 1994
Line 29___________________________>- Keep t<x your records ________
Name(s) shown on return i Social Security Nurrtber
1 Add the amounts on Schedule A, tines 4, 9, 14, 18, 19, 26, 27 and 28 . . 1
2 Add the amounts on Schedule A. lines 4. 13, and 19, plus any gambling losses included on line 28 ........................................... 2
Caution: Be sure your total gambling losses are identified on me Mrscet'<’»neous tterruzed Deductions Statement.
3 Subtract line 2 from line 1. If the result Is zero, Stop Here;
enter the amount from line 1 above on Schedule A, line 29 .................... 3
4 Multiply line 3 above by 80% (.80)................... 4
5 Enter the amount from form 1040, line 32 5 ____________________
6 Enter $111,800 ($55,900 if married filing separately)...... 6
7 Subtract line 6 from line 5. К the result is zero or less, Stop Here; enter the amount from line 1 above on Schedule A. line 29.............................„............ 7 _________________
8 Multiply line 7 above by 3% (.03).......................... 8
; 9 Enter the smaller of line 4 or line 8..................................... 9
10 Total itemized deductions. Subtract line 9 from line I. Enter the result nere and on Schedule A, line 29................................... . .....10
298 Приложение А
Индивидуальные пенсионные счета
Individual Retirement Account Worksheet 1 1994
Keep for your records___________________________
Name(s) shownon return Isocial Security Number
(a) Your IRA (b) Working Spouse's IRA
1 Enter IRA contributions made for 1994, but do not enter more than $2.000 2 Enter your wages and other earned income 1
2
3 Enter the smaller of line 1 or line 2. Enter on Form 1040. line 23a or 23b ( Form 1040A, line 15a or 15b). 3
Nonworking spouse's IRA
Enter the smelter of fine 2 or $2.250
S
Enter the amount from line 3
«
Subtract line 5 from itne 4
Enter IRA contributions made for 1994 for the networking spouse but not more then $2,000
8
Enter the smelter of line 6 or line 7, Enter on Form 1040, line 23a or 23b ( Form 1040A, tine 15a or 15b).........
Список литературы
AFIF90
AFIF92
ALLE72
ANDE79
ANDR81
ANSI94
AVRI93
ВАВЕ94
ВАСК59
Afifi, Е. Н., and White, L. J. “Testing for Linear Errors in Nonlinear computer Programs.” Technical Report CES-90-03, Department of Computer Science, Case Western Reserve University, March 1990.
Afifi, E. H„ White, L. J., and Zeil, S. J. “Testing for Linear Errors in Nonlinear Computer Programs.” Proceedings of the 14th International Conference on Software Engineeing, Australia, pp. 81-91.
Alien, F. E., and Cocke, J. “Graph Theoretic Constructs for Program Control Flow Analysis.” IBM Research Report RC3923. Yorktown Heights, N Y: TJ. Watson Research Center, 1972.
Anderson, R. B. “Proving Programs Correct”. New York:
John Wiley & Sons, 1979.
Andrews, D.M., and Benson, J. P. “An Automated Program Testing Method and Its Implementation.” Fifth International Conference on Software Engineering, San Diego, CA, March 9-12, 1981. Use of assertions in testing.
ANSI/IEEE Standard PI 044-1994. “Standard Classification for Software Anomalies”. New York: American National Standards Institute, 1994.
Avritzer, Alberto, and Larson, Brian. “Load Testing Software Using Deterministic State Testing.” Proceedings of the 1993 International Symposium on Software Testing and Analysis, Cambridge, MA June 28-30, 1993. pp. 82-88.
Baber, Robert L. “Proofs of Correctness.” In MARC94, pp. 925-930.
Backus, J. “The Syntax and the Semantics of the Proposed International Algebraic Language.” Proceedings of the ACM-GAMM Conference. Paris, France: Information Processing, 1959.
300 Список литературы
BALC89 Balcer, Marc J., Hasling, William M., and Ostrand, Thomas J.
“Automatic Generation of Test Scripts from Formal Test Specifications.” Proceedings of the ACM SIGSOFT ‘89. Third Symposium on Software Testing, Analysis, and Verification. Key West, FL, December 13-15, 1989. pp. 210-218.
Automatic behavioral test generation based on the proprietary TSL specification language.
BARN72 Barnes, В. H. “A Programmer’s View of Automata.” Computing
Surveys 4 (1972): 222-239. Introduction to state graphs and related automata theory topics from a software-application perspective.
BASI87 Basili, V. R., and Selby, R.W. “Comparing the Effectiveness of
Software Testing Strategies.” IEEE Transactions on Software Engineering 13, #12 (1987): 1278-1296. A (rare) attempted controlled experiment to explore the relative effectiveness of behavioral versus structural testing, coverage metrics, professional versus student programmers.
BAUE79 Bauer, J. A., and Finger, A. B. “Test Plan Generation Using
Formal Grammars.” Fourth International Conference on Software Engineering, Munich, Germany, September 17-19, 1979. Use of state-graph model for automated test case generation. Application to telephony.
BEIZ84 Beizer, B. “Software System Testing and Quality Assurance.”
New York: Van Nostrand Reinhold, 1984. Test and QA management, integration testing, system testing. Organization of testing, behavioral testing, formal-acceptance testing, stress testing, software reliability, bug-prediction methods, software metrics, test teams, adversary teams, design reviews, walkthroughs, etc.
BEIZ90 Beizer, B. “Software Testing Techniques”, 2nd ed. New York:
Van Nostrand Reinhold, 1990. The testing book to read after this one. Structural test techniques, behavioral test techniques in more detail, interaction of software design and testability, algorithms for tool builders.
BEIZ96 Beizer, B. “Integration and System Testing (in preparation).”
Integration testing strategies, reintegration, system testing techniques. Application of test techniques to system testing. Black-Box Testing is a prerequisite.
BELF76 Belford, P. C., and Taylor, D. S. “Specification Verification —
A Key to Improving Software Reliability.” In Proceedings of the PIB Symposium on Computer Software Engineering.
New York: Polytechnic Institute of New York, 1976. Verification of specifications, use of specification languages, and related subjects.
BEND70 Bender, R. A., and Pottorff, E. L. “Basic Testing: A Data Flow
Analysis Technique”. IBM System Development Division,
Список литературы 301
BEND85
BERA94
BERL94
BISW87
ВОЕН81
ВОЕН86
BOWD77
BRIT85
BRZ062
BRZ063
BURK88
BUTL89
Poughkeepsie Laboratory, TR-00.2108, October 9, 1970. Earliest known description of data-flow testing.
Bender, R. A., and Becker, P. “Code Analysis”. Larkspur, C A: Bender and Associates, P.O. Box 849, 94939. Proprietary software development and test methodology that features use of data flow testing techniques.
Berard, Edward V. “Object Oriented Design.” In MARC94, pp. 721-729.
Berlack, H. Ronald. “Configuration Management.” In MARC94, pp. 180-206. Detailed overview of software configuration control and management practices.
Biswas, S., and Rajaraman, V. “An Algorithm to Decide Feasibility of Linear Integer Constraints Occurring in Decision Tables.” IEEE Transactions on Software Engineering SE-13, #12 (December 1987), pp. 1340-1347.
Boehm, Barry W. “Software Engineering Economics”. Englewood Cliffs, NJ: Prentice-Hall, 1981. Source book for all aspects of software economics.
Boehm, Barry W. “A Spiral Model of Software Development and Enhancements.” ACM Software Engineering Notes 11, (4), (1986), pp. 22-42.
Bowditch, N. “American Practical Navigator”, 70th ed. Washington, DC: Defense Mapping Agency Hydrographic Center, 1977. The oldest book in continuous publication except for the Bible. What our discipline should strive to be when it grows up.
Britcher, R. H., and Gafmey, J. E. “Reliable Size Estimates for Software Systems Decomposed as State Machines.” Ninth International Computer Software and Applications Conference, Chicago, IL, October 9-11, 1985. Representation of program as finite-state machine relates state-machine size to program size. Brzozowski, J. A. “A Survey of Regular Expressions and Their Application.” IRE Transactions on Electronic Computers 11 (1962), pp. 324-335. Survey of regular expression theory and relation to finite-state machines.
Brzozowski, J. A., and McCluskey, E. J., Jr. “Signal Flow Graph Techniques for Sequential Circuit State Diagrams.” IEEE Transactions on Electronic Computers 12 (1963), pp. 67-76. Basicpaper that applies flow graphs to regular expressions and state-graphs of finite-state automata.
Burke, R. @Black-Box Regression Testing — An Automated Approach.” Fifth International Conference on Testing Computer Software, Washington, DC, June 13-16, 1988.
Butler, R. W., Mejia, J. D., Brooks, P. A., and Hewson, J. E. “Automated Testing for Real-Time Systems.” Sixth International
302 Список литературы
CHEN78
CHOW78
CHOW88
CLAR76
CLAR82
CLAR89
СОНЕ78
CONK89
C00PS1
CROS92
DAIC93
Conference on Testing Computer Software, Washington, DC, May 22-25,1989.
Chen, W. T, Ho, J. P., and Wen, С. H. “Dynamic Validation of Programs Using Assertion Checking Facilities.” Second Computer Software and Applications Conference, Chicago, IL, November 1978.
Chow, T. S. “Testing Software Design Modeled by Finite State Machines.” IEEE Transactions on Software Engineering 4 (1978), pp. 78-186. Testing software modeled by state graphs with examples from telephony. Categorizes types of state-graph errors and shows relation between type of coverage and the kind of errors that can and can’t be caught.
Chow, С. H., and Lam, S. S. “Prospec: An Interactive Programming Environment for Designing and Verifying Communication Protocols.” IEEE Transactions on Software Engineering 14 (1988), pp. 327-338.
Clarke, Lori A. “A System to Generate Test Data and Symbolically Execute Programs.” IEEE Transactions on Software Engineering 2 (1976), pp. 215-222. Although aimed at structural testing, the method and tools could be applied just as easily to behavioral control flow and data flow models.
Clarke, Lori A., Hassel, J., and Richardson, D. J. “A Close Look at Domain Testing.” IEEE Transactions on Software Engineering 8 (1982), pp. 380-390. Good survey and critique; exposition of error types and what does and doesn’t work to catch them and why. Clarke, Lori A., Podgurski, Andy, Richardson, Debra J., and Zeil, Steven J. “A Formal Evaluation of Data Flow Path Selection Criteria.” IEEE Transactions on Software Engineering 15(1989), pp. 1318-1332.
Cohen, E. I. “A Finite Domain-Testing Strategy for Computer Program Testing.” Ph. D. diss., Ohio State University, June 1978. Conklin, J. “Automated Repetitive Testing.” Sixth International Conference on Testing Computer Software, Washington, DC, May 22-25, 1989.
Cooper, Robert B. “Introduction to Queuing Theory”. New York: Elsevier North Holland, 1981.
“CrossTalk Communications.” CASL Programmer Guide. Rosswell, GA: Digital Communications Associates, 1992. Daich, Greg, and Price, Gordon. “Test Preparation Execution, in Evaluation Software Technologies Report”. Software Technology Support Center, Hill AFB, Ogden, UT. Customer Service 801-777-7703. Free periodical guide to test tools and technology approved for use in U. S. government. Also, Reengineering Tools Report, Source Code Static Analysis Technologies Report, vols. 1 and 2.
Список литературы 303
DAVI88
DEON74
EBER94
ELME73
FAGA76
FENT91
FRAN85
FRAN88
FREE88
FSTC83
FUJI94
FURG89
GERH88
Davis, А. М. “A Comparison of Techniques for the Specification of External System Behavior.” Communications of the ACM 31, #9 (1988), pp. 1098-1115. Survey of state graphs, state tables, decision tables, decision trees, program design languages, Petri nets, requirement languages, and specification languages in developing requirements and tests from them.
Deo, N. “Graph Theory with Applications to Engineering and Computer Science”. Englewood Cliffs, NJ: Prentice-Hall, 1974. Ebert, Jurgen and Engels, Gregor. “Design Representations.” In MARC94, pp. 382-394. Survey of popular design models and representations, all of which can be used as a basis for test design. Elmendorf, W. R. “Cause-Effect Graphs in Functional Testing”. TR-00.2487, IBM Systems Development Division, Poughkeepsie, NY, 1973.
Fagan, M. E. “Design and Code Inspections to Reduce Errors in Program Development”. IBM Systems Journal 3 (1976) pp: 182-211. Still one of the best expositions on inspections ever written.
Fenton, Norman E. “Software Metrics: A Rigorous Approach”. London: Chapman and Hall, 1991. A rigorous but very accessible book on software metrics, suitable for a first course. Franki, P. S., Weiss, S. N. and Weyuker, EJ. “Asset — A System to Select and Evaluate Tests.” Proceedings of the IEEE Conference on Software Tools (April 1985), pp. 72-79.
Franki, P. G„ and Weyuker, E.J. “An Applicable Family of Data Flow Testing Criteria.” IEEE Transactions on Software Engineering 14, #10 (1988), pp. 1483-1498.
Freeman, P. A., and Hunt, H. S. “Software Quality Improvement Through Automated Testing.” Fifth International Conference on Testing Computer Software, Washington, DC, June 13-16, 1988. Federal Software Testing Center. “Software Tools Survey”. Office of Software Development report #OSD/FSTC-83/015, 1983.
Survey of 100 software development tools, language, source.
Fujii, Roger U. “Independent Verification and Validation.” In MARC94, pp. 568-572. What an independent test group is all about.
Furgerson, Donald F., Coutu, John P., Reinemann, Jeffrey K., and Novakovich, Michael R. “Automated Testing of a Real-Time Microprocessor Operating System.” Sixth International Conference on Testing Computer Software, Washington, DC, May 23-25, 1989. Description of application of CrossTalk CASL scripting language to test script design and to construction of a testing environment.
Gerhart, Susan L. “A Broad Spectrum Toolset for Upstream Testing, Verification, and Analysis.” Second Workshop on
304 Список литературы
GIBB94
GILB93
GOOD75
GRAD87
GRAD92
GRAH91
GRAH93
GRAH94
HAML88
HAML94
HANF70
HANT76
HARR89
Software Testing, Verification, and Analysis, Banff, Canada, July 19-21,1988.
Gibbs, Wayt. “Software’s Chronic Crisis.” Scientific American, 71, #3(1994), pp. 86-95.
Gilb, Tom, and Graham, Dorothy. “Software Inspections”. Menio Park, CA: Addison-Wesley, 1993. As good and as readable text on inspections as you’re likely to find.
Goodenough, J. B., and Gerhart, S. A. “Toward a Theory of Test Data Selection.” IEEE Transactions on Software Engineering 1 (1975), pp. 156-173. The beginning of testing theory; historical interest.
Grady, Robert B., and Caswell, D. L. “Software Metrics: Establishing a Company-Wide Program”. Englewood Cliffs, NJ; Prentice-Hall, 1987. A practical guide to implementing a total metrics program based gw expertewce \w a swppoxHvw, sophisticated, software development organization.
Grady, Robert B. “Practical Software Metrics for Project Management and Process Improvement”. Englewood Cliffs,NJ: Prentice-Hail, 1992. Vet another practical guide to metrics in an industrial setting, courtesy of Hewlett-Packard.
Graham, Dorothy R. “Software Testing Tools: A New Classification Scheme.” Journal of Software Testing, Verification, and Reliability 1, #3 (October-December 1991) pp. 17-34. An overview and rational taxonomy for test tools.
Graham, Dorothy R„ and Herzlich, Paul. “CAST Report: Computer Aided Software Testing”. London: Cambridge Market Intelligence, 1993. Periodical report on test tools for mostly European platforms.
Graham, Dorothy R. “Testing” In MARC94, pp. 1330-1353. Testing with a software development process perspective.
Hamlet, R., and Taylor, R. “Partition Testing Does Not Inspire Confidence.” Second Workshop on Software Testing, Verification, and Analysis, Banff, Canada, July 19-21, 1988.
Shows that partition testing methods cannot be used to obtain statistically meaningful software reliability measures.
Hamlet, Richard. “Random Testing.” In MARC94, pp. 970-978. Hanford, К. V. “Automatic Generation of Test Cases.” IBM System Journal 9 (1979), pp. 242-257. Use ofBNF to generate syntactically valid test cases for testing a PL/I compiler.
Hantier, S. A., and King, J. C. “An Introduction to Proving the Correctness of Programs.” ACM Computing Surveys 8, 3 (1976), pp. 331-353.
Harrold, M. J., and Sofia, M. L. “An Incremental Data Flow Testing Tool.” Sixth International Conference on Testing Computer Software, Washington, DC, May 22-25, 1989.
Список литературы 305
HEND89
HERA88
HERM76
HOLT87
HOLZ87
HORG92
HORG94
HOWD76
HOWD80
HOWD86
HOWD87
HOWD89
Henderson, В. М. “Big Brother — Automated Test Controller.” Sixth International Conference on Testing Computer Software, Washington, DC, May 22-25, 1989.
Herath, J., Yamaguchi, Y, Saito, N., and Yuba, T. “Dataflow Computing Models, Languages, and Machines for Intelligence Computations.” IEEE Transactions on Software Engineering 14, 12(1988), pp. 1805-1828. Although the paper is aimed at intelligence processing, the overview and tutorial is one of the best around.
Herman, P. M. “A Data Flow Analysis Approach to Program Testing.” Australian Computer Journal (November 1976), pp. 92-96. Earliest known published discussion of heuristic data flow testing. Holt, D. “A General Purpose Driver for UNIX.” Fourth International Conference on Testing Computer Software, Bethesda,MDJune 15-18, 1987.
Holzman, G. J. “Automated Protocol Validation in Argos: Assertion Proving and Scatter Searching.” IEEE Transactions on Software Engineering 13 (1987), pp. 683-696. Experience in automatically generated state machine-based testing cases as applied to protocol verification. Application and strategies for systems with on the order of 1024 states.
Horgan, J. R., and London, S. A. “A Dataflow Coverage Testing Tool for C.” Proceedings Symposium on Assesment of Quality Software Developement Tools. Los Alamitos, CA: IEEE CS Press, 1992, pp. 2-10. Description of the ATAC public domain C dataflow test tool.
Horgan, J. R., London, S. A., and Lyu, M. R. “Achieving Software Quality with Testing Coverage Measures.” IEEE Computer 7, #9 (Sept. 1994), pp. 60-70.
Howden, W. E. “Reliability of the Path Analysis Testing Strategy.” IEEE Transactions on Software Engineering 2 (1976), pp. 208-215. Proof that the automatic generation of a finite test set that is sufficient to test a routine is not a computable problem. Formal definition of computation error, path error, and other kinds of errors.
Howden, W. E. “An Evaluation of the Effectiveness of Symbolic
Testing.” IEEE Transactions on Software Engineering 6 (1980), pp. 162-169.
Howden, William E. “A Functional Approach to Program Testing and Analysis.” IEEE Transactions on Software Engineering 12 (1986), pp. 997-1005.
Howden, William E. “Functional Program Testing and Analysis”. New York: McGraw-Hill, 1987.
Howden, William E. “Validating Programs Without Specifications.” Proceedings of the ACM SIGSOFT ‘89, Third
306 Список литературы
IDEI94
IEEE94
JENG89
JENG94
KAVI87
КЕММ85
KOLM88
KORE85
KORE88
KRAU73
LASK90
LAYC92
LEMP89
Symposium on Software Testing, Analysis, and Verification.Key West, FL, December 13-15, 1989, pp. 2-9. Exposition of error-based testing.
IDE, Inc. “Stp/T User’s Guide”. Iselin, NJ: Interactive Development Environments, 1994.
“IEEE Software Engineering Standards”. New York: IEEE, 1994. Collection of ANSI/IEEE standards on software engineering.
Jeng, B., and Weyuker, EJ. “Some Observations on Partition Testing.” Proceedings of the ACM SIGSOFT ‘89, Third Symposium on Software Testing, Analysis, and Verification. Key West, FL, December 13-15, 1989.
Jeng, В. C., and Weyuker, E. J. “A Simplified Domain-Testing Strategy.” ACM Transactions on Software Engineering and Methodology 3 July 1994), pp. 254-270.
Kavi, К. M., Buckles, B. R, and Bhat, N. U. “Isomorphism Between Petri Nets and Dataflow Graphs.” IEEE Transactions on Software Engineering 13 (1987), pp. 1127-1134. Relation between Petri Nets and data-flow models.
Kemmerer, R. A. “Testing Formal Specifications to Detect Design Errors.” IEEE Transactions on Software Engineering 11, #1 (1985), pp. 32-43.
Kolman, B. “Introductory Linear Algebra with Applications”, 4th ed. New York: Macmillan and Company, 1988. Introductory Text used in computer sciences curricula.
Korel, Bogdan, and Laski, Janusz. “A Tool for Data Flow Oriented Program Testing.” Second Conference on Software Development Tools, Techniques, and Alternatives, San Francisco, CA, December 2-5, 1985.
Korel, Bogdan, and Laski, Janusz. “STAD — A System for Testing and Debugging: User Perspective.” Second Workshop on Software Testing, Verification, and Analysis. Banff, Canada, July 19-21, 1988, pp. 13-20.
Krause, K. W, Smith, R. W, and Goodwin, M. A. “Optimal Software Test Planning Through Automated Network Analysis.” IEEE Symposium on Computer Software Reliability, 1973.
Early example of path testing, graph models, coverage, and automated generation of paths.
Laski, J. “Data Flow Testing in STAD.” Journal for Systems and Software 12 (1990), pp. 3-14.
Laycock, Gilbert. “Formal Specification and Testing: A Case Study.” Journal of Software Testing, Verification, and Reliability 2, #1 (May 1992), pp. 7-23. Category-partition model and test generation based on the Z specification language.
Lemppenau, W. W. “Hybrid Load and Behavioral Testing of SPC-PABX Software for Analog or Digital Subscribers and
Список литературы 307
MARC94
MASO90
МАТТ88
MCNA60
MEAL55
MILL66
MILL75
MILL78
MILL86
MOLL93
MOOR56
MORE90
MURA89
MUSA90
Trunk Lines.” Sixth International Conference on Testing Computer Software, Washington, DC, May 22-25, 1989. Marciniak, John (editor-in-chief). Encyclopedia of Software Engineering. New York: John Wiley & Sons, 1994. The essential reference book that no serious software engineer or aspirant thereto should be without. Any technical term or concept used in this book that you do not know you can probably learn from MARC94. Get the CD-ROM version when it comes out.
Mason, T, and Brown, D. Lex and yacc. Sebastapol, CA: O’Reilly and Associates, 1990.
Matthews, R. S., Muralidhar, К. H., and Sparks, S. “MAP 2.1 Conformance Testing Tool.” IEEE Transactions on Software Engineering 14, #3 (1988), pp. 363-374.
McNaughton, R., and Yamada, H. “Regular Expressions and State Graphs for Automata.” IRE Transactions on Electronic Computers EC-9 (I960), pp. 39-17. Survey of the theory of regular expressions as applied to finite state automata. Proof of fundamental theorems.
Mealy, G. H. “A Method for Synthesizing Sequential Circuits.” Bell System Technical Journal 34 (1955), pp. 1045-1079.
Miller R. E. “Switching Theory”. New York: John Wiley & Sons, 1966. Basic reference on switching and automata theory.
Miller, E. E, and Melton, R. A. “Automated Generation of Test Case Data Sets.” International Conference on Reliable Software, Los Angeles, CA, April 1975.
Miller, E. E, and Howden, W. E. eds. “Tutorial: Software Testing and Validation Techniques”, 2nd ed. New York: IEEE Computer Society, 1981. A bargain resource for pre-1981 literature; huge bibliography up to and including 1981.
Miller, E. F. “Mechanizing Software Testing.” TOCG Meeting, Westlake Village, CA, April 15, 1986. San Francisco: Software Research Associates.
Moller, К. H., and Paulish, D. J. “Software Metrics”. London: Chapman and Hall, 1993. Metrics from an industrial viewpoint. Moore, E. F. “Gedanken Experiments on Sequential Machines.” In Automata Studies. Annals of Mathematical Studies #34. Princeton, NJ: Princeton University Press, 1956.
Morell, Larry J. “A Theory of Fault-Based Testing.” IEEE Transactions on Software Engineering 16, #8 (August 1990), pp. 844-857.
Murata, T. “Petri Nets: Properties, Analysis And Applications.” Proceedings of the IEEE 77, #4 (1989), pp. 541-580. In-depth tutorial, huge bibliography.
Musa, John D., lannino, Anthony, and Okumoto, Kazuhira. “Software Reliability: Professional Edition”. New York: McGraw-Hill, 1990.
308 Список литературы
MYER79
NAFT72
NOMU87
NORT94
NTAF88
ONOM87
OSTR86
OSTR88
OSTR91
OSTR94
PANZ78
PATR88
PERE85
Myers, G. J. The Art of Software Testing.
New York: John Wiley & Sons, 1979. A golden oldie.
Naftaly, S. M., and Cohen, M. C. “Test Data Generators and Debugging Systems... Workable Quality Control.” Data Processing Digest 18 (1972). Survey of automatic test data generation tools.
Nomura, T. “Use of Software Engineering Tools in Japan.” Ninth International Conference on Software Engineering, Monterey, CA, March 30 — April 2, 1987. Survey of 200 Japanese software development groups rates test tools as having the highest productivity return; ahead of a standard process, programming and design tools, and reviews.
Northrup, Linda M. “Object-Oriented Development.” In MARC94, pp. 729-737.
Ntafos, Simeon C. “A Comparison of Some Structural Testing Strategies.” IEEE Transactions on Software Engineering 14, # 6 (June 1988), pp. 868-874. Excellent survey of structural test techniques.
Onoma, A. K., Yamura, T, and Kobayashi, Y. “Practical Approaches to Domain Testing: Improvement and Generalization.” Proceedings of the Computer Software and Applications Conference, Tokyo, Japan, October 7-9, 1987, pp. 291-297.
Ostrand, T. J., Sigal, R., and Weyuker, E. “Design for a Tool to Manage Specification-Based Testing.” Workshop on Software Testing, Banff, Canada, July 15-17, 1986.
Ostrand, T. J., and Baker, M. J. “The Category-Partition Method for Specifying and Generating Functional Tests.” Communications of the ACM 31, #6 (1988), pp. 676-686.
Ostrand, Thomas J., and Weyuker, Elaine J. “Data Flow-Based Test Adequacy Analysis for Languages with Pointers.” ACM Sigsoft Symposium on Software Testing, Analysis, and Verification, October 8-10, 1991, Victoria, BC, Canada.
Ostrand, Thomas J. “Categories of Testing.” In MARC94, pp. 90-93. Overview of different types of testing and where and how used.
Panzl, D. J. “Automatic Software Test Drivers.” IEEE Computer 11(1978), pp. 44-50.
Patrick, D. P. “Certification of Automated Test Suites with Embedded Software.” National Institute for Software and Productivity Conference, Washington, DC, April 20-22, 1988. Perera, L. A., and White, L. J. “Selecting Test Data For the Domain Testing Strategy.” Technical report TR-85-5, Department of Computer Science, University of Alberta, Edmonton, Alberta, Canada, 1985.
Список литературы 309
PERE86
РЕТЕ76
РЕТЕ81
PIGO94
POST94
POWE82
RAPP82
RAPP85
RICH81
RICH85
RICH89
ROPE93
Perelmuter, I. М. “Directions of Automation in Software Testing.” Third Conference on Testing Computer Software, Washington, DC, September 29 — October 1, 1986.
Peters, L. J., and Tripp, L. L. “Software Design Representation Schemes.” PIB Symposium on Computer Software Reliability, Polytechnic Institute of New York, April 1976. Survey of software models, including HIPO charts, activity charts, structure charts, control graphs, decision tables, flowcharts, transaction diagrams, and others.
Petersen, J. L. “Petri Net Theory and the Modeling of Systems”. Englewood Cliffs, NJ: Prentice-Hall, 1981. Basic text on Petri nets.
Pigoski, Thomas M. “Maintenance.” In MARC94, pp. 619-636.
Poston, Robert M. “Test Generators.” In MARC94, pp. 1327-1330.
Powell, P. B. ed. “Software Validation, Verification, and Testing Techniques and Tool Reference Guide”. National Bureau of Standards Special Publication 500-93, 1982. Survey of testing, verification, validation, tools, and techniques with comments on effectiveness and supporting and resources needed for each.
Rapps, S., and Weyuker, E. J. “Data Flow Analysis Techniques for Test Data Selection.” Sixth International Conference on Software Engineering, Tokyo, Japan, September 13-16, Long Beach, CA: 1982, pp. 272-278.
Rapps, S., and Weyuker, E. J. “Selecting Software Test Data Using Data Flow Information.” IEEE Transactions on Software Engineering (1985), pp. 367-375.
Richardson, D. J., and Clarke, L. A. “A Partition Analysis Method to Increase Program Reliability.” Fifth International Conference on Software Engineering, San Diego, CA, March 9-12, 1981. Partition analysis testing; behavioral/structural hybrid based on domain testing.
Richardson, D. J., and Clarke, L. A. “Partition Analysis: A Method Combining Testing and Verification.” IEEE Transactions on Software Engineering 11 (1985), pp. 1477-1490. Early look at behavioral domain testing.
Richardson, Debra J., O’Malley, O. and Tittle, Cindy.
“Approaches to Specification-Based Testing.” Proceedings of the ACM SIGSOFT ‘89, Third Symposium on Software Testing, Analysis, and Verification. Key West, FL, December 13-15, New York, NY: 1989, pp. 86-96. Behavioral testing based on formal specification languages, Anna and Larch.
Roper, Marc, and Rashid, Ab Bin Ab Rahim. “Software Testing Using Analysis and Design Based Techniques.” Journal of Software Testing, Verification, and Reliability 3, #3-4
310 Список литературы
ROYC70
RUGG79
SARI87
SCAC94
SCHI69
SCHL70
SIDH89
SNEE86
SOFT88
SQET94
STAK89
THEV93
(September-December 1993), pp. 166-179. Behavioral data flow models used as a basis for test design.
Royce, W. W. “Managing the Development of Large Software Systems.” Proceedings IEEE WESCON (August 1970), pp. 1-9. Ruggiero, W., Estrin, G., Fenchel, R., Razouk, R., Schwabe, D., and Vernon, M. “Analysis of Data Flow Models Using the Sara Graph Model of Behavior.” Proceedings of the 1979 National Computer Conference. Montvale, NJ: AFIPS Press, 1979. A more elaborate data flow behavioral model than presented here. Sarikaya, Behcet, Bochmann, Gregor V., and Cerny, Eduard. “A Test Design Methodology for Protocol Testing.” IEEE Transactions on Software Engineering, SE-13, #5 (May 1987), pp. 518-531.
Scachi, Walt. “Process Maturity Models.” In MARC94, pp. 851-869.
Schiller, H. “Using MEMMAP to Measure the Extent of Program Testing.” IBM Systems Development Division, Poughkeepsie, NY, Report TR 00.1836, February 10, 1969. Description of the use of an early soft ware statement/branch coverage analyzer.
Schlender, Paul, J. “Path Analysis Techniques”. Memo, IBM System Development Division, Poughkeepsie, NY, April 27, 1970. Early discussion of data flow testing (all definitions); notes (without proof) that branch coverage is included in all definitions Sidhu, Deepinder P., and Leung, Tink-Kau. “Formal Methods for Protocol Testing: A Detailed Study.” IEEE Transactions on Software Engineering 15, #4 (April 1989), pp. 413-423. Automatic test generation for protocol testing from finite-state model.
Sneed, H. M. “Data Coverage Measurement in Program Testing.” Workshop on Software Testing, Banff, Canada, July 15-17, Washington, DC: 1986, pp. 34-40. Reports experience with use of data-flow coverage metrics; tools, comparison of effectiveness with control-flow coverage.
Software Research, Inc. “SPECTEST™ Description, METAT-EST™ Description”. San Francisco, CA: Author, 1988. Software Quality Engineering. Tools Guide. Jacksonville, FL: Author, 1994. Periodical tools guide specific to software testing. Staknis, M.E. “The Use of Software Prototypes in Software Testing.” Sixth International Conference on Testing Computer Software, Washington, DC, May 22-25, 1989.
Thevenod-Fosse, Pascale, and Waeselynck, Helene. “STATE-MATE Applied to Statistical Software Testing.” Proceedings of the 1993 International Symposium on Software Testing and Analysis. Cambridge, MA, New York, NY: ACM Press, June 28-30, 1993, pp. 99-109.
Список литературы 311
TRIP88
TSAI90
VOGE80
VOGE93
WALL94
WARN64
WEIN90
WEIS81
WEIS84
WEIS85
WEIS91
WEYU90
WEYU94
WHIT78
Tripp, Leonard L. “A Survey of Graphical Notations for Program Design — An Update.” ACM SIGSOFT, Software Engineering Notes 13, #4 (October 1988), pp. 39-44. Concise survey.
Tsai, W.T, Volovik, Dmitry, and Keefe, Thomas, F. “Automated Test Case Generation for Programs Specified by Relational Algebra Queries.” IEEE Transactions on Software Engineering 16, #3 (March 1990), pp. 316-324. Automated test generation based on domain models.
Voges, U., Gmeiner, L., and von Mayrhauser, A. A.
“Sadat — An Automated Test Tool.” IEEE Transactions on Software Engineering 6, #3 (May 1980), pp. 286-290.
Vogel, Peter A. “An Integrated General Purpose Automated Test Environment.” Proceedings of the 1993 International Symposium on Software Testing and Analysis. Cambridge, MA, June 28-30, New York, NY: ACM Press, 1993, pp. 61-69.
Wallace, Dolores R. “Verification and Validation.” In MARC94, pp.1410-1433.
Warner, C. D., Jr. “Evaluation of Program Testing”. Poughkeepsie, NY: IBM Data Systems Division Development Laboratories, TR 00.1173, July 28, 1964. Earliest known use of a hardware instruction coverage monitor: COBOL and FORTRAN source.
Weinberg, Gerald M., and Freedman, D.P. “Handbook of Walkthroughs, Inspections and Technical Reviews”.
New York: Dorset House, 1990.
Weiser, Mark D. “Program Slicing.” Proceedings of the Fifth International Conference on Software Engineering (439-449) March 1981.
Weiser, Mark D. “Program Slicing.” IEEE Transactions on Software Engineering SE-10 (1984), pp. 352-357.
Weiser, Mark D., Gannon, John D., and McMullin, Paul R. “Comparison of Structural Test Coverage Metrics.” IEEE Software (March 1985), 80-85.
Weiss, Stewart N. and Franki, Phyllis G. “Comparison of All-Uses and All-Edges: Design, Data, and Analysis.” Hunter College, New York, Dept, of Computer Science, Technical Report CS-TR 91-04.
Weyuker, Elaine. J. “The Cost of Data Flow Testing — An Empirical Study.” IEEE Transactions on Software Engineering 16 (February 1990).
Weyuker, Elaine J. “Data Flow Testing”. In MARC94, pp. 247-249. Key theoretical concepts and definitions for structural data flow testing.
White, Lee J., Cohen, E. I., and Chandrasekaran, B. “A Domain Strategy for Computer Program Testing.” Columbus, OH: Computer and Information Science Research Center, Ohio State
312 Список литературы
WHIT80
WHIT85
WHIT87
WHIT94
WHIT95
WILK77
WING94
WILS82
YERH80
YOSH87
ZEIL83
ZEIL89
ZUSE90
University, Technical Report OSU-CISRC-TR-78-4, August 1978.
White, Lee J., and Cohen, E. I. “A Domain Strategy for Computer Program Testing.” IEEE Transactions on Software Engineering 6 (1980), pp. 247-257. Use of linear predicates and associated inequalities to establish test cases, boundary choices, etc. Generalization to n-dimensional problems.
White, Lee J., and Sahay, P. N. “A Computer System for Gbnerating Test Data Using the Domain Strategy.” IEEE SOFTFAIR Conference II, San Francisco, CA, December 2-5, 1985.
White, Lee J. “Software Testing and Verification.” In Advances in Computers, vol. 26, pp. 335-391. New York: Academic Press, 1987. Superior tutorial and overview of theory.
White, Lee J., and Leung, Hareton K. N. “Integration Testing.” In MARC94, pp. 573-577.
White, Lee J. “Consistency and Completeness Checking of Domain Specifications.” 12th International Conference on Testing Computer Software. Washington, DC, June 12-15,1995. Wilkens, E. J. “Finite State Techniques in Software Engineering.” (First) Computer Software and Applications Conference, Chicago, IL, November 1977. Application of finite-state machine models to software design.
Wing, Jeannette, M. “Formal Methods.” In MARC94, pp. 504-517, p.12.
Wilson, C., and Osterweill, L. J. “A Data Flow Analysis Tool for the C Programming Language.” Sixth Computer Software and Applications Conference, Chicago, IL, November 8-12, 1982. Yeh, R. T, and Zave, P. “Specifying Software Requirements.” IEEE Proceedings 68 (1980), pp. 1077-1085. Examines specifications as a source of program bugs and suggests methodology for specification design.
Yoshizawa, Y., Kubo T, Satoh, T, Totsuka, K., Haraguchi, M., and Moriyama, H. “Test and Debugging Environment for Large Scale Operating Systems.” Eleventh International Computer Software and Applications Conference, Tokyo, Japan, October 7-9, 1987.
Zeil, S. J. “Testing for Perturbations of Program Statements.” IEEE Transactions on Software Engineering SE-9, 3 (May 1983), pp. 335-346.
Zeil, S. J. “Perturbation Techniques for Detecting Domain Errors.” IEEE Transactions on Software Engineering 15, 8 (June 1989), pp. 737-746.
Zuse, Horst. “Software Complexity. Measures and Methods”.
New York: Walter de Gruyter, 1990. Encyclopedic book on metrics.
Список литературы 313
ZUSE94 Zuse, Horst. “Complexity Metrics/Analysis.” In MARC94, pp. 131-165. Excellent survey of the theory and practice of software metrics.
ZWEB92 Zweben, Stuart H., Heym, Wayne D., and Kimmich, J. “Systematic Testing of Data Abstractions Based on Software Specifications.” Journal of Software Testing, Verification, and Reliability 1, #4 (January-March, 1992), pp. 39-55. Use of control-flow and data-flow models based on specifications and application of analogous structural test techniques. Experimental results shows relative technique strengths and effectiveness similar to that obtained for structural testing.
Алфавитный указатель
А
Активизация, 83
Алфавит, 211
Анализ, 42
Анализ требований, 37
Б
БНФ, 215
В
Валидация, 28
Вариант, 28
Ввод, 27
Веса связей, 187,218,242
Веса узлов, 187
Вес связи, 46, 155
Вес узла, 45
Вложенные циклы, 99
Внешняя точка, 182
Внутренняя точка, 182
Входная переменная, 179
Входное кодирование, 238
Входное пространство, 180
Входное событие, 238
Входной узел, 48, 115
Входной вектор, 180
Входные символы, 238
Входящая связь, 48
Вырожденная граница, 182
Вырожденный домен, 182
Выходная переменная, 180
Выходное пространство, 180
Выходное событие, 239
Выходной вектор, 180
Выходной узел, 49
Г
Гибридный тест, 34
Гиперплоскость, 181
Голова строки, 214
Грамматический разбор, 213
Граница домена, 180
Граничное множество домена, 180
Граничное неравенство, 180
Граничное уравнение, 180
Граф, 44, 47
Граф потока данных, 118
Грязный тест, 32
д
Два прохода, 105
Детерминированный цикл, 98
Длина пути, 50
Домен, 180
Дорожная карта процесса, 41
Доступное состояние, 240
3
Завершающий узел, 153
Задача, 153
Законченная граница, 183
Закрытые границы, 181
Закрытый домен, 181
Запоминающий узел, 115
Значение связи, 117
И
Изолированные состояния, 240
Или, 214
Имя пути, 49
Имя связи, 46
Имя узла, 45
Имя строки, 212
Инструменты, 39
Алфавитный указатель 315
Интеграция, 30, 43
Интерпретация команды, 213
Интерпретация предиката, 85
Интерпретация предикатов, 190
Интерфейс, 29
Искаженность, 28
Использование, 115
Использование в предикате, 115
Использование для вычислений, 114
Исходящая связь, 48
Итог, 27
К
Ключевое слово, 213
Кодирование выхода, 239
Код состояния, 238
Количественные измерения, 41
Команда, 212
Командно-управляемое ПО, 212
Командный язык, 212 Комплементарные сегменты пути, 65 Компонент, 29 Конечное состояние, 27 Конечный автомат, 239 Конкатенация, 214 Константы, 115 Контрольная запись транзакции, 153 Контроль конфигурации, 41 Коррелированныепрсдикаты, 65 Критерии завершенности, 42 Критерии соответствия, 28 Критерии соответствия требованиям, 42 Критерий всех использований, 141 Критерий готовности, 42 Критические тестовые значения, 105
Л
Лексическая эквивалентность, 213
Лексический анализ, 214
Линейное неравенство, 183
Линейно зависимый, 183
Линейно независимые точки, 183
Линейно независимый, 183
Линейный домен, 183
Логический предикат, 64
Логический оператор, 114
Логическое И, 64
Логическое ИЛИ, 64
Логическое НЕ, 64
м
Максимум, 105
Маркер транзакции, 153
Маркировка, 156
Марковский граф, 155
Марковский узел, 155
Металингвистические символы, 212
Метасимволы, 212
Методы тестирования, 33
Метрики, 41
Множественная обработка, 158
Модели Мили, 245
Модели Мура, 245
Модули, 30
Модуль, 29
н
Наблюдаемый, 27
Набор выходных состояний, 241
Набор начальных состояний, 240
Набор строк, 212
Направленная связь, 46
Направленный граф, 47 Начальное состояние, 27, 238 Негативный тест, 32 Недетерминированный цикл, 98 Недоступное состояние, 240 Независимые предикаты, 65 Незаконченная граница, 184 Нелинейный домен, 183
Ненаправленпаясвязь, 47
Ненаправленный граф, 48 Необходимые циклы, 129 Необязательное поле, 216 Неопределенность доменов, 192 Непоследовательное закрытие, 184
Непроходимый путь, 49
Нециклический путь, 50
Нулевой набор, 214
Нуль, 212
О
Обезглавливание, 215
Область, 180
Обрабатывающий узел, 116
Обход, 105
Обход из начального состояния, 241
Объединение, 215
Объект, 27, 51, 52, 65, 155, 186
Одиночный произвольный символ, 216
Один проход, 105
Окружение, 31
Операнд, 213
Оператор, 213
Операторы ветвления, 52
Оператор «звезда», 215
Определение БНФ, 215
Определение объекта, 114
Опровергаемый, 27
Оракул, 27
Ответственность, 42
Открытые границы, 181
Открытый домен, 181
316 Алфавитный указатель
Отношение, 45, 51, 52,66,155, 186, 218
несимметричное, 53
рефлексивное, 54
симметричное, 53
транзитивное, 52
Отношение эквивалентности, 55
Очередь, 156
Очередь
многосерверная, 158
односерверная, 158
Очередь по приоритету, 158
Ошибка, 28
Ошибка безопасности, 30
Ошибка интеграции, 30, 35
Ошибка компонента, 30
Ошибка модуля, 29, 35
Ошибка потери ресурсов, 30
Ошибка производительности, 30
п
Пакет, 158
Параллельные связи, 46
Перегрузка, 114
Переменная управления циклом, 98
Переход в себя, 239
Переходы, 239
Плюс в показателе, 215
Поведенческое тестирование, 12
Подграф, 132
Подпрограммы, 30
Подсистемы, 30
Подстрока, 215
Подтест, 27
Позитивный тест, 32
Показатель степени, 214
Покрытие ввода/вывода, 134
Покрытие связей, 188
Покрытие узлов, 187
Полностью определенный автомат, 241
Порожденный подграф, 133
Порожденный подграф потока данных, 133
Последовательное закрытие, 184
Правило FIFO, 157
Правило LIFO, 157
Предикат ветвления, 153
Предикат выбора, 64
Предикат управлепияциклом, 98
Предикат выбора данных, 117
Проверка связей, 59
Проверка узлов, 59
Проверка соответствия, 28
Проверка соответствия проекта, 42
Программирование, 42
Программы, 30
Проектирование, 38, 42
Проектирование теста, 27
Произвольная последовательность символов, 216
Прослеживаемость требований, 41
Протестирован, 29
Противоречивость доменов, 192
Проходимый путь, 49
Пустой выход, 240
Пустой символ, 212
Путь, 49
Путь вход — выход, 49
Р
Рабочее состояние, 241
Разделитель, 213
С
Самотестирование, 38
Сброс, 240
Свободен от ошибок, 29
Свойства, 52
Связи, 51, 52, 242
Связь, 45
Сегмент пути, 49
Сегмент границы, 184
Семантический анализ, 213
Сильно связанные состояния, 240
Символ пробела, 212
Симптом, 28
Синтаксис, 212
Синтаксический анализ, 213
Системная ошибка, 30
Системное тестирование, 35
Системы программного обеспечения, 30
Слепота, 29
Случайная корректность, 29
Случайное обслуживание, 158
Смежные домены, 182
Соединительный узел, 67
Создание прототипа, 37
Составной предикат, 65
Состояние, 27, 237
Состояние транзакции, 153
Спецификация, 28
Сравнение итогов, 28
Стартовый узел, 153
Стратегические тонкости, 42
Стратегия тестирования, 33
Строка, 212
Строковое поле, 213
Структурный тест, 33
Сценарий теста, 28
Счетчик состояний, 238
т
Текущее состояние, 238
Тест, 27
Тестирование, 27, 43
Алфавитный указатель 317
Тестирование интеграции, 29
Тестирование компонента, 30
Тестирование модуля, 29
Тестирование системы, 30
Тестовый комплект, 27
Типичное число проходов, 105
Тип транзакции, 153
Тире, 212
Транзакция, 153
Требования, 27,41
У
Ужасные циклы, 103
Узел, 45,218,242
Узел ветвления, 48, 153
Узел входа в цикл, 98
Узел выбора, 66
Узел выхода из цикла, 98
Узел поглощения, 154
Узел порождения, 154
Узел расщепления, 154
Узел слияния, 154
Узел соединения, 154
Узел с предикатом, 66
Узел управления циклом, 98
Узел выбора данных, 117
Узел вывода, 115
Узловая точка, 181
Укорачивание, 215
Управление процессом, 41
Управляющаявходящаясвязь, 117, 153
Ф
Формальное инспектирование, 38
Формальный анализ, 37
Форма Бэкуса Наура, 215
Функциональное тестирование, 12
Функциональные клавиши, 243
X
Характеристика, 28
Хвост строки, 214
ц
Цикл, 50, 60,98
Цикл со смешанной проверкой, 99
Цикл с постусловием, 99
Цикл с предусловием, 98
ч
Частичное покрытие узлов, 135
Число повторений цикла, 98
Число входных символов, 238
Число состояний, 239
Чистый тест, 32
э
Эпсилон-окрестность, 182
Борис Бейзер
Тестирование черного ящика. Технологии функционального тестирования программного обеспечения и систем
Перевел с английского А. Раздобарин
Главный редактор Заведующий редакцией Руководитель проекта Научный редактор Литературный редактор Иллюстрации Художник Корректоры Верстка
Е. Строганова И. Корнеев А. Крузенштерн
С. Орлов И. Шапошников М. Шендерова Н. Биржаков Д. Стукалин. А. Моносов К. Кузьминский
Лицензия ИД № 05784 от 07.09.01.
Подписано к печати 19.06.04. Формат 70x100/16. Усл. п. л. 25,8.
Тираж 3000. Заказ 770
ООО «Питер Принт», 196105, Санкт-Петербург, ул. Благодатная, д. 67в.
Налоговая льгота — общероссийский классификатор продукции ОК 005-93, том 2; 95 3005 — литература учебн
Отпечатано с готовых диапозитивов в ОАО «Техническая книга»
190005, Санкт-Петербург, Измайловский пр., 29
изаАтепьскпп пом ПИТЕР WWW.PITER.COM
СПЕЦИАЛИСТАМ КНИЖНОГО БИЗНЕСА!
ПРЕДСТАВИТЕЛЬСТВА ИЗДАТЕЛЬСКОГО ДОМА «ПИТЕР» предлагают эксклюзивный ассортимент компьютерной, медицинской, психологической, экономической и популярной литературы
РОССИЯ
Москва м. «Калужская», ул. Бутлерова, д. 176, офис 207, 240; тел./факс (095) 777-54-67; e-mail: sales@piter.msk.ru
Санкт-Петербург м. «Выборгская», Б. Сампсониевский пр., д. 29а; тел. (812) 103-73-73, факс (812) 103-73-83; e-mail: sales@piter.com
Воронеж ул. 25 января, д. 4; тел. (0732) 27-18-86;
e-mail: piter-vrn@vmail.ru; piterv@comch.ru
Екатеринбург ул. 8 Марта, д. 2676; тел./факс (343) 225-39-94, 225-40-20;
e-mail: piter-ural@r66.ru
Нижний Новгород ул. Премудрова, д. 31а; тел. (8312) 58-50-15, 58-50-25; e-mail: piter@infonet.nnov.ru
Новосибирск ул. Немировича-Данченко, д. 104, офис 502;
тел/факс (3832) 54-13-09, 47-92-93, 11-27-18, 11-93-18; e-mail: piter-sib@risp.ru
Ростов-на-Дону ул. Калитвинская, д. 17в; тел. (8632) 95-36-31, (8632) 95-36-32; e-mail: jupiter@rost.ru
ул. Новосадовая, д. 4; тел. (8462)37-06-07; e-mail: piter-volga@sama.ru
УКРАИНА
ул. Суздальские ряды, д. 12, офис 10-11, т. (057) 712-27-05, 712-40-88;
e-mail: piter@tender.kharkov.ua
Киев пр. Красных Казаков, д. 6, корп. 1; тел./факс (044) 490-35-68,490-35-69;
e-mail: office@piter-press.kiev.ua
БЕЛАРУСЬ
Минск ул. Бобруйская д., 21, офис 3; тел./факс (37517) 226-19-53; e-mail: piter@mail.by
МОЛДОВА
Кишинев «Ауратип-Питер»; ул. Митрополит Варлаам, 65, офис 345; тел. (3732) 22-69-52, факс (3732) 27-24-82; e-mail: lili@auratip.mldnet.com
Самара
Харьков
Ищем зарубежных партнеров или посредников, имеющих выход на зарубежный рынок.
Телефон для связи: (812) 103-73-73.
E-mail: grigorjan@piter.com
Издательский дом «Питер» приглашает к сотрудничеству авторов. Обращайтесь по телефонам: Санкт-Петербург — (812) 327-13-11, Москва - (095) 777-54-67.
Заказ книг для вузов и библиотек: (812) 103-73-73.
Специальное предложение - e-mail: kozin@piter.com
www.cnews.ru
интернет-издание о высоких технологиях
Широта охвата: В поле зрения новостного отдела CNews находятся рынки телекоммуникаций, компьютерного оборудования, программного обеспечения, электронного бизнеса, защиты информации.
Массовость: Ежедневно более 30 тыс. читателей посещают наш сайт. Ежемесячная аудитория издания - более чем 300 тыс. человек по всей России и за рубежом.
E-mail: news@cnews.ru Тел.: +7 (095) 363-11-57
□CNews Analytics
исследования и обзоры рынков ИТ www.cnews.ro/reviews
Исследования: Экспертами CNA подготовлены десятки обзоров по различным сегментам российского рынка ИТ.
Тренинги: За последний год в Школе CNews учебные курсы прошли более 900 руководителей и специалистов.
E-mail: review@rbc.ru
Тел.: +7 (095) 363-11-11
Борис Бейзер — всемирно известный консультант по проблемам разработки ПО «за плечами» которого уже сорок лет работы в IT-индустрии. Первопроходец в области тестирования, автор множества книг, посвященных данной тематике, две из которых — Software Testing Techniques и Software System Testing and Quality Assurance — долгое время считались общепризнанными стандартами.
Представляем вашему вниманию практическое, доступное руководство по современным методам тестирования черного ящика, написанное ведущим специалистом по данной проблематике.
Эту книгу ждали давно. Именно такую — практичную и понятную, освещающую основные аспекты тестирования черного ящика. Больше других ее ждали разработчики программного обеспечения, создатели больших программных систем. И вот она, наконец, вышла из-под пера Бориса Бейзера — одной из самых значительных фигур в области тестирования. Это руководство, вне всяких сомнений, станет превосходным подспорьем для независимых тестировщиков и программистов и ценным практическим пособием для студентов. Пожалуй, на сегодняшний день это единственная книга, в которой доступным языком описываются принципы поведенческого тестирования в целом и наиболее существенные современные методы тестирования черного ящика, среди которых функциональное тестирование, тестирование на соответствие заявленной спецификации. В таком руководстве не может не быть полноценных примеров, поясняющих шаг за шагом весь процесс тестирования, и они там есть.
Основные достоинства книги, которые убедят вас в том, что вы сделали правильный выбор, взяв ее с полки:
♦ исчерпывающее описание всех наиболее важных методов тестирования, включая те, которые применяются при разработке объектно-ориентированных программ;
♦ соответствие современным требованиям — с учетом последних достижений в области тестирования, позволяющих тестировщику работать, имея под рукой только калькулятор или листок бумаги;
♦ контрольные задания — вы сможете самостоятельно оценить глубину понимания материала.
Посетите наш web-магазин: www.piter.com ч
ЮПИТЕР
WWW.PITER.COM