/































































































































































































































































Автор: Трусова Б. Г.
Теги: электротехника учебники и учебные пособия по кибернетике программирование информатика учебник для вузов издательство academia учебник по информатике
ISBN: 978-5-7695-8144-1
Год: 2012




Текст
Высшее профессиональное образование
Б а к а л а в р и ат
информатика
и программирование
Основы
информатики
Учебник
Под редакцией доктора технических наук,
профессора Б. Г. Трусова
Рекомендовано
Федеральным государственным бюджетным
образовательным учреждением высшего
профессионального образования
«Московский государственный технический
университет имени Н. Э. Баумана» в качестве
учебника для студентов высших учебных заведений,
обучающихся по направлению подготовки
«Программная инженерия»
УДК 621.391(075.8)
ББК 32.81я73
И741
Рецензент —
профессор Московского государственного технического университета
имени Н. Э. Баумана, доктор техн. наук К. А. Майков
Информатика и программирование. Основы информатики :
И741 учебник для студ. учреждений высш. проф. образования /
Н. И. Парфилова, А. В. Пруцков, А. Н. Пылькин, Б. Г. Трусов ; под
ред. Б.Г.Трусова. — М. : Издательский центр «Академия», 2012. —
256 c. — (Сер. Бакалавриат).
ISBN 978-5-7695-8144-1
Учебник создан в соответствии с Федеральным государственным образовательным стандартом по направлению подготовки 231000 «Программная
инженерия» (квалификация «бакалавр»).
Представлены разделы информатики, охватывающие основные вопросы
теории информации, перевода чисел из одной системы счисления в другую,
представления чисел и символов в памяти ЭВМ, представления и вывода знаний, функционирования аппаратного обеспечения, алгоритмизации, принципов работы различных программных продуктов, устройства вычислительных
сетей.
Для студентов учреждений высшего профессионального образования.
УДК 621.391(075.8)
ББК 32.81я73
Оригинал-макет данного издания является собственностью
Издательского центра «Академия», и его воспроизведение
любым способом без согласия правообладателя запрещается
ISBN 978-5-7695-8144-1
© Парфилова Н. И., Пруцков А. В., Пылькин А. Н.,
Трусов Б. Г., 2012
© Образовательно-издательский центр «Академия», 2012
© Оформление. Издательский центр «Академия», 2012
Список основных используемых
сокращений и обозначений
БД — база данных.
БЗ — база знаний.
ВЗУ — внешнее запоминающее устройство.
КВЗУ — контроллер внешнего запоминающего устройства.
КПВВ — контроллер порта ввода-вывода.
МП — микропроцессор.
ОЗУ — оперативное запоминающее устройство.
ОС — операционная система.
ПЗУ — постоянное запоминающее устройство.
ПО — программное обеспечение.
РГРТУ — Рязанский государственный радиотехнический
университет.
СУБД— система управления базами данных.
ЭВМ— электронно-вычислительная машина.
ЯВУ — язык высокого уровня.
ARPAnet (Advanced Research Project Agency Network) —
сеть управления перспективного планирования оборонных научно-исследовательских работ.
CD (Compact Disc) — компакт-диск.
CPU (Central Processing Unit) — центральный обрабатывающий модуль, микропроцессор.
DNS (Domain Name System) — система доменных имен.
DVD (Digital Versatile Disc) — цифровой универсальный
диск.
FAT (File Allocation Table) — таблица размещения файлов.
FTP (File Transfer Protocol) — протокол передачи файлов.
HTTP (Hypertext Transfer Protocol) — протокол передачи
гипертекста.
IMAP (Internet Message Access Protocol) — протокол доступа к интернет-сообщениям.
IP (Internet Protocol) — интернет-протокол.
NTFS (New Technology File System) — файловая система
нового типа.
3
OSI (Open System Interconnection) — взаимодействие открытых систем.
SMTP (Simple Mail Transfer Protocol) — протокол пересылки почты.
TCP (Transmission Control Protocol) — протокол управления
передачей.
URL (Uniform Resource Locator) — унифицированный
указатель ресурса.
USB (Universal Serial Bus) — универсальная последовательная шина.
WWW (World Wide Web) — Всемирная сеть.
Введение
Информационная революция второй половины ХХ в. — начала
XXI в., связанная с изобретением и развитием микропроцессорных
систем и созданием современных информационных коммуникаций,
компьютерных сетей и систем передачи данных, привела к созданию
новой отрасли — информационной индустрии, направленной на
производство технических средств и создание новых технологий производства знаний. Возникновение новой индустрии производства
знаний привело к глобальным изменениям в обществе — информатизации общества. Информатизация общества заключается в вовлечении всех его членов в общий процесс производства и реализации
знаний на базе новых компьютерных и телекоммуникационных технологий. Информатизация общества потребовала от всех его членов
определенного уровня информационной культуры, определенных
базовых знаний и умения целенаправленно использовать в своей
деятельности современные информационные технологии, технические средства и методы. Научным фундаментом процесса информатизации современного общества и развития информационной индустрии является новая научная дисциплина — информатика.
Информатика — это базовая учебная дисциплина, охватывающая
сведения о технических, программных и алгоритмических средств
организации современных информационных систем и формирующая
у обучаемого определенный кругозор, объем знаний, уровень алгоритмического мышления, а также практические навыки работы с
конкретными программными системами, необходимыми для его
дальнейшего обучения по применению информационных систем в
определенных областях человеческой деятельности.
При написании учебника авторами были поставлены две задачи.
Во-первых, дать читателю как можно более полное представление о
разделах информатики и задачах, которые решаются в каждом разделе. Во-вторых, изложить материал просто и понятно. Для этого
используются примеры, поясняющие теоретический материал.
Учебник состоит из 11 глав, каждая из которых посвящена одному
из разделов информатики.
В гл. 1 рассматривается структура информатики. Информатика
изучает процессы обработки, представления и измерения информации. Информатика связана с другими науками, например с математикой, и включает в себя ряд разделов, изучающих теорию информа-
5
ции, аппаратное и программное обеспечение ЭВМ, информационные
системы и системы искусственного интеллекта. Глава основана на
материалах работ [22, 24].
В гл. 2 рассматриваются основные понятия теории информации:
информация и данные. Несмотря на то что информация не материальна, можно измерять количество, адекватность и качество информации. Для измерения информации используются вероятностный и
объемный подходы. Вероятностный подход основан на понятии «энтропия». Объемный подход заключается в вычислении числа элементарных единиц информации (бит). Для написания главы использовались материалы работ [1, 2, 7, 15, 22, 26].
Гл. 3 посвящена информационным процессам, системам и технологиям. Информационными процессами называются любые операции с информацией: сбор, обработка, передача. Как правило, информационные процессы используются в информационных системах —
программно-аппаратных комплексах для обработки информации.
Информационные технологии — это процессы переработки исходной
информации в вид, который необходим потребителю информации.
Для получения информационного продукта применяются информационные процессы и системы. Использовались материалы работ [2,
10, 11, 24].
В гл. 4 рассматриваются системы счисления, использующиеся в
ЭВМ. Для перевода числа из одной системы счисления в другую существуют правила перевода целой и дробной частей на основе арифметических операций сложения, умножения, целочисленного деления и
получения остатка от деления. Использовалась публикация [24].
Гл. 5 посвящена представлению чисел и символов в памяти ЭВМ.
Целые и вещественные числа и символы хранятся в виде последовательностей нулей и единиц. Форматы представления данных оптимизированы для ускорения логических и арифметических операций
в ЭВМ. Использовались материалы работ [24, 38].
В гл. 6 рассмотрены логические основы построения ЭВМ. Приведены способы представления логических функций, методы перевода из одного представления в другое, методы минимизации логических функций. При написании главы использовались материалы
работ [3, 14, 34].
Гл. 7 посвящена моделям представления знаний: логическим,
фреймовым, продукционным моделям и семантическим сетям. В отличие от данных знания активны и способны порождать новые знания. Поэтому задачей модели представления является не только
хранение знаний, но и обеспечение вывода новых знаний. Для каждой модели представления знаний приводится пример логического
вывода. Данная глава основана на лекциях С. П. Хабарова [41] и других работах [4, 6, 16, 17, 18, 30, 31, 44].
В гл. 8 рассматривается аппаратное обеспечение ЭВМ, его составные части. Историю ЭВМ делят на четыре поколения. Пятое
6
поколение существует лишь в теории и реализовано частично. Основой любой ЭВМ является микропроцессор, который выполняет логические и арифметические операции и связан системной шиной с
запоминающими и периферийными устройствами. Для написания
главы использовались материалы работ [1, 22, 27, 32, 42].
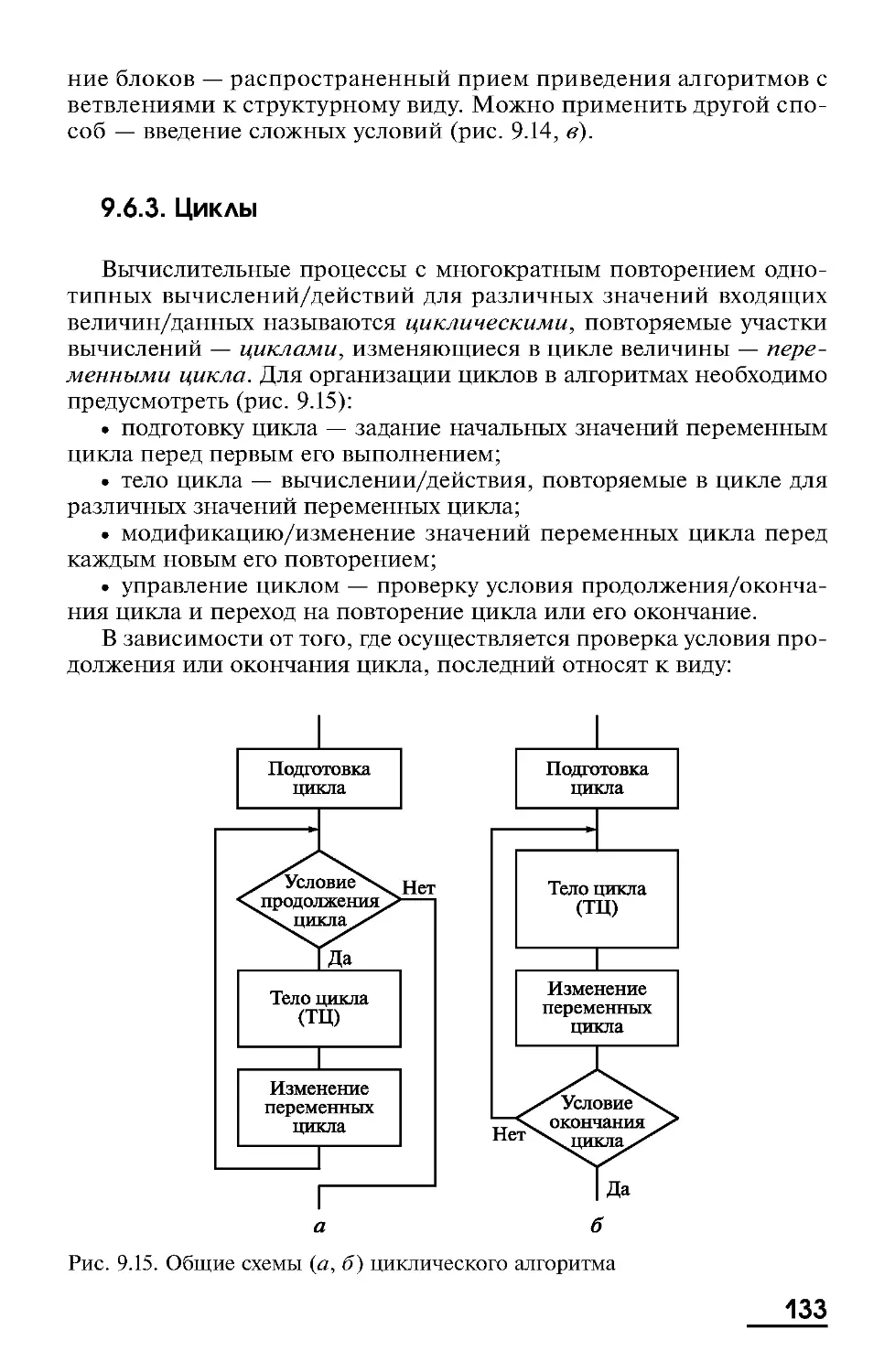
В гл. 9 рассматриваются основы алгоритмизации. Аппаратное
обеспечение ЭВМ работает под управлением различных программ.
В основе программ лежит алгоритм — последовательность действий,
необходимых для достижения результата. В этой главе рассматриваются способы записи алгоритмов в виде блок-схем, структурограмм
и словесно, основные алгоримические структуры, а также правила
разработки и описания алгоритмов решения задач.
Гл. 10 посвящена программному обеспечению ЭВМ. В главе рассматриваются различные типы программного обеспечения: операционные системы, драйверы устройств, архиваторы, базы данных.
Разделы, посвященные текстовым и табличным процессорам, подготовлены на основе лекций по дисциплине «Пакеты прикладных
программ». В основе главы лежат материалы работ [1, 5, 7, 9, 10, 11,
20, 22, 29, 32, 43].
Гл. 11 посвящена сетевым технологиям. В главе рассматриваются
устройство и принципы функционирования локальных и глобальных
сетей, основные протоколы передачи. В настоящее время большое
значение в жизни общества имеет глобальная информационная сеть
Интернет, ставшая средством для хранения и обмена информацией.
Сеть Интернет включает в себя несколько служб: электронную почту,
Всемирную сеть и службу передачи файлов, которые нашли широкое
применение. Были использованы материалы работ [1, 2, 7, 10, 11, 26].
Гл а в а 1
Информатика — наука и вид
практической деятельности
1.1. Информатика и ее структура
Информатика — это наука и вид практической деятельности,
связанные с процессами обработки информации с помощью вычис
лительной техники.
Термин «информатика» произошел от слияния двух французских
слов information (информация) и automatique (автоматика) и до
словно определял новую науку об «автоматической обработке инфор
мации». В англоязычных странах информатика называется сomputer
science (наука о компьютерной технике).
Информатика представляет собой единство разнообразных от
раслей науки, техники и производства, связанных с переработкой
информации с помощью вычислительной техники и телекоммуника
ционных средств связи в различных сферах человеческой деятель
ности.
Основная задача информатики заключается в определении общих
закономерностей процессов обработки информации: создания, пере
дачи, хранения и использования в различных сферах человеческой
деятельности. Прикладные задачи связаны с разработкой методов,
необходимых для реализации информационных процессов с исполь
зованием технических средств.
Информатика включает в себя следующие разделы.
I. Теоретическая информатика. Это часть информатики, вклю
чающая в себя ряд подразделов, тесно связанных с другой наукой —
математикой. В теории информации и кодирования изучается ин
формация как таковая, ее свойства, способы измерения количества
информации. Областью исследования теории алгоритмов и автоматов
являются методы переработки информации с помощью вычислитель
ных систем. Теория формальных языков и грамматик рассматривает
правила построения простейших языков с небольшим числом син
таксических конструкций, называемых языками программирования.
Теория принятия решений и исследования операций связана с ис
пользованием информации для принятия решений и оценки их опти
8
мальности. Теоретическая информатика использует математические
методы для общего изучения процессов обработки информации.
II. Вычислительная техника. Это раздел, включающий в себя
общие принципы построения вычислительных систем. Примером
вычислительной системы является персональный компьютер, или
ЭВМ. Этот раздел не связан с вопросами физической разработки,
реализации и производства элементов вычислительных систем. Здесь
рассматривается архитектура вычислительных систем — соглашение о составе, назначении, функциональных возможностях и принципах взаимодействия элементов внутри вычислительных систем и
вычислительной системы с другими устройствами. Примерами принципиальных, ставших классическими решений в этой области являются архитектура фон Неймана компьютеров первых поколений,
шинная архитектура ЭВМ, архитектура параллельной или многопроцессорной обработки информации.
III. Программирование. Это деятельность, направленная на разработку программного обеспечения вычислительной техники. Программирование делится на разделы, связанные с разработкой соответствующих типов программного обеспечения. Программное обеспечение, непосредственно управляющее составными частями
вычислительной техники, называется системным. Системный уровень
программного обеспечения составляют операционные системы. Служебное программное обеспечение — это архиваторы, антивирусы,
программы управления файлами и папками. Служебное программное
обеспечение предназначено для выполнения некоторых вспомогательных функций. Прикладное программное обеспечение — это
программы для решения большинства задач пользователя. Прикладное программное обеспечение включает в себя офисные, графические, справочные программы, среды разработки программ и др.
IV. Информационные системы. Это раздел информатики, связанный с решением проблем анализа потоков информации в различных сложных системах, их оптимизации, структурировании,
принципах хранения и поиска информации по запросу пользователя.
Примерами информационных систем являются информационносправочные, информационно-поисковые, глобальные системы или
сети хранения и поиска информации.
V. Искусственный интеллект. Это область информатики, в которой решаются сложнейшие проблемы, находящиеся на пересечении
с психологией, физиологией, языкознанием и другими науками.
Исторически сложились три основных направления развития систем
искусственного интеллекта. Целью работ первого направления является создание алгоритмического и программного обеспечения вычислительных машин, позволяющего решать интеллектуальные задачи не хуже человека. В рамках второго подхода объектом исследований являются структура и механизмы работы мозга человека, а
конечная цель заключается в моделировании функционирования
9
человеческого мозга. Третий подход ориентирован на создание смешанных человекомашинных или интерактивных интеллектуальных
систем, на симбиоз возможностей человеческого и искусственного
интеллектов. В данном разделе информатики решаются задачи машинного перевода, распознавания речи и рукописного текста, экспертные системы, некоторые игровые программы и др.
1.2. Информатика в обществе
В нашем информационном обществе огромную роль играют системы распространения, хранения и обработки информации. Подобно мировой системе связи возникает единая информационная
среда, которая обеспечивает любому человеку доступ ко всей необходимой для него информации. Широкое внедрение компьютеров во
все области человеческой деятельности, наряду с использованием
интеллектуальных роботов, коренным образом изменило традиционную среду обитания людей. Растет число людей, профессионально
занятых сбором, накоплением, распространением и хранением информации. Информация стала товаром, имеющим большую ценность.
Переход к информационному обществу вызывает проблемы социального, правового, технического характера. Например, применение роботов на производстве приведет к полному изменению технологии, которая в наши дни ориентирована на участие в ней человека.
Резко меняется подготовка членов нового общества к самостоятельной жизни. Уже ведутся поисковые работы в области создания новых
форм обучения, которые заменят существующие традиционные формы. Полностью меняется номенклатура профессий, специальностей
и способов организации труда.
Все эти проблемы составляют объект исследования психологов,
социологов, философов и юристов, которые работают в области информатики. Создаются автоматизированные обучающие системы
(АОС), автоматизированные рабочие места (АРМ) для специалистов
различного профиля, распределяемые банковские системы и многие
другие, чье функционирование опирается на использование всего
арсенала информатики.
1.3. Информатика в природе
Информатика в природе характеризуется изучением информационных процессов, протекающих в биологических системах, использованием накопленных знаний при организации и управлении природными системами и созданием на их основе технических систем.
10
Здесь информатика основывается на трех самостоятельных науках.
Биокибернетика — наука, которая решает проблемы, связанные
с анализом информационно-управляющих процессов, протекающих
в живых организмах, с диагностикой заболеваний и поиском путей
их лечения и созданием соответствующих систем.
Бионика — наука об использовании принципов работы живых
организмов в искусственных объектах.
Биогеоценология — наука, нацеленная на решение проблем, относящихся к системно-информационным моделям поддержания и
сохранения равновесия природных систем и поиска таких воздействий на них, которые стабилизируют разрушающие воздействия
человеческой цивилизации на биомассу Земли.
Гл а в а 2
Основы теории информации
2.1. Понятие информации
Обычно под информацией понимается совокупность сведений,
расширяющая представление об объектах и явлениях окружающей
среды, их свойствах, состоянии и взаимосвязях. Обмен информацией непрерывно происходит между людьми, между людьми и окружающим миром. Обмен информацией осуществляется посредством
сообщений.
Сообщение — это форма представления информации для ее последующей передачи в одном из следующих видов:
• числовая форма, представленная цифрами;
• текстовая форма, представленная текстами, составленными из
символов того или иного языка;
• кодовая форма, представленная кодами (например, кодами в
двоичной системе счисления, кодами для сжатия или шифрования,
кодами азбуки Морзе или азбуки для глухонемых и т. п.);
• графическая форма, представляющая изображения объектов;
• акустическая форма, представленная звуковыми сигналами;
• видеоформа, представляющая телепередачи, видео- и кинофильмы в специальном формате.
При работе с информацией всегда имеются источник и потребитель информации. При этом необходимо различать термины «информация» и «данные».
Данные — это информация, представленная в некоторой форме
(формализованном виде), что обеспечивает ее хранение, обработку
и передачу.
Пример 2.1. Конспект лектора — это данные. Читая лекцию студентам, лектор передает содержание конспекта в виде сообщения.
Студенты получают сообщение и таким образом принимают информацию, записывают ее, представляя информацию в виде данных.
Здесь лектор является источником информации, а студенты — потребителями информации.
12
Информации обладает следующими свойствами:
• запоминаемость — способность воспринять информацию и
хранить ее продолжительное время;
• передаваемость — способность информации к копированию —
восприятием ее другой системой без искажения;
• воспроизводимость — характеризует неиссякаемость информации, т. е. при копировании информация остается тождественной себе.
Свойство воспроизводимости не является базовым и тесно связано
с передаваемостью;
• преобразуемость — это способность информации менять способ
и форму своего существования.
Можно выделить три концепции информации, объясняющие ее
сущность.
П е р в а я концепция предложена американским ученым Клодом
Шенноном и отражает количественно-информационный подход.
Информация определяется как мера неопределенности события.
Количество информации зависит от вероятности ее получения. Чем
меньше вероятность получения сообщения, тем больше информации
в нем содержится. Эта концепция получила широкое распространение
в теории передачи и кодировании данных.
В т о р а я концепция рассматривает информацию как свойство
(атрибут) материи. Информация создает представление о природе,
структуре, упорядоченности и разнообразии материи. В рамках этой
концепции информация не может существовать вне материи, а значит,
она существовала и будет существовать вечно, ее можно накапливать,
хранить и перерабатывать.
Т р е т ь я концепция основана на логико-семантическом подходе,
при котором информация рассматривается как знание, которое используется для ориентировки, активного действия, управления или
самоуправления.
2.2. Непрерывная и дискретная
информация
Чтобы сообщение было передано от источника к потребителю,
необходима некоторая среда — носитель информации. Примерами
носителей информации являются воздух для передачи речи, лист
бумаги и конверт — для отсылки текста письма. Сообщение передается с помощью сигналов. Сигнал — это физический динамический
процесс, так как его параметры изменяются во времени.
Когда параметр сигнала принимает конечное число значений и
при этом все они могут быть пронумерованы, сигнал называется
дискретным. Сообщение и информация, передаваемые с помощью
13
таких сигналов, также называются дискретными. Примером дискретной информации является текстовая информация, так как количество символов (букв) конечно и их можно рассматривать как
уровни сигнала передачи сообщения.
Если параметр сигнала является непрерывной во времени функций, то сообщение и информация, передаваемая этими сигналами,
называются непрерывными.
Примером непрерывного сообщения является человеческая речь,
передаваемая звуковой волной, с меняющейся частотой, фазой и
амплитудой. Параметром сигнала в этом случае является давление,
создаваемое этой волной в точке нахождения приемника — человеческого уха.
Непрерывное сообщение может быть представлено непрерывной
функцией, заданной на некотором отрезке [а, b]. Дискретизация —
это процесс преобразования непрерывного сигнала в дискретный
сигнал с некоторой частотой.
Для этого диапазон значений функции (ось ординат) разбивается на конечное количество отрезков равной ширины. Тогда дискретное значение определяется отрезком, в который попало значение
функции, называемым шагом дискретизации. Чем меньше шаг
дискретизации, тем ближе полученный дискретный сигнал к исход
ному непрерывному сигналу, а следовательно, больше точность
дискретизации.
Пример 2.2. На метеостанции каждые полчаса происходит замер
температуры (рис. 2.1).
Рис. 2.1. Дискретизация непрерывного сообщения
Непрерывно меняющаяся температура замеряется в моменты x1,
x2,…, xn. В журнал наблюдений записывается округленное значение
температуры, являющееся дискретным значением. В данном примере получасовой промежуток является частотой дискретизации, шаг
дискретизации равен 1, так как происходит округление до целого
числа, а получасовые замеры температуры — процессом дискретизации.
14
2.3. Адекватность информации и ее формы
Важным условием практического использования информации
является ее адекватность.
Адекватность информации — это уровень соответствия образа,
созданного на основе полученной информации, реальному объекту
или явлению.
Адекватность информации выражается в трех формах:
• синтаксическая адекватность — это соответствие структуры
и формы представления информации без учета ее смысла. Информация в виде данных обычно обладает синтаксической адекватностью;
• семантическая (смысловая) адекватность — в отличие от
синтаксической адекватности учитывает смысловое содержание информации;
• прагматическая (аксиологическая, потребительская) адекватность — это соответствие ожидаемой ценности, полезности использования информации при выработке потребителем решений для
достижения своей цели.
Пример 2.3. Заказчик послал подрядчику сообщение: «Вышлите,
пожалуйста, объем выполненных работ для отчета в течение недели».
Подрядчик прислал ответ через 10 дней: «Объем выполненных работ
составил 3 млн руб.». Заказчик ожидал число (не график, не рисунок)
и получил его, следовательно, информация синтаксически адекватна.
Полученное число является объемом выполненных работ, следовательно, информация семантически адекватна. Подрядчик прислал
сообщение с опозданием, и ценность информации в нем потерялась,
так как отчет должен был быть составлен ранее, следовательно, информация прагматически неадекватна.
2.4. Синтаксическая мера информации
2.4.1. Вероятностный подход
Информация нуждается в измерении. На практике количество
информации измеряется с точки зрения синтаксической адекватности. Исторически сложились два подхода к измерению информации:
вероятностный и объемный. В 1940-х гг. К. Шеннон предложил вероятностный подход, а работы по созданию ЭВМ способствовали
развитию объемного подхода.
Рассмотрим вероятностный подход к измерению количества информации в соответствии с первой концепцией информации (см.
подразд. 2.1).
15
Пусть система α может принимать одно из N состояний в каждый
момент времени, причем каждое из состояний равновероятно. Например, в качестве системы могут выступать опыты с подбрасыванием монеты (N = 2) или бросанием игральной кости (N = 6).
Количество информации системы α вычисляется по формуле,
предложенной Р. Хартли:
H = H (α) = log 2 N =
ln N
.
ln 2
При N = 2 количество информации минимально и равно H = 1.
Поэтому в качестве единицы информации принимается количество
информации, связанное с двумя равновероятными состояниями
системы, например: «орел» — «решка», «ложь» — «истина». Такая единица количества информации называется бит.
Введем понятие вероятности. Вероятность события A — это отношение числа случаев M, благоприятствующих событию A, к общему количеству случаев N:
Р=
M
.
N
Пример 2.4. Найти вероятность выпадения числа 6 при бросании
кости.
Р е ш е н и е. Всего граней у кости N = 6. Число 6 присутствует
только на одной грани.
Следовательно, вероятность выпадения числа 6 при бросании
кости:
Р=
M 1
= .
N 6
Пример 2.5. Найти вероятность выпадения числа, большего 3,
при бросании кости.
Р е ш е н и е. Всего граней у кости N = 6. Чисел, больших 3, на
гранях кости M = 3.
16
Следовательно, вероятность выпадения числа, большего 3, при
бросании кости:
Р=
M 3 1
= = .
N 6 2
Если N состояний системы не равновероятны, т. е. система находится в i-м состоянии с вероятностью Pi и при этом все состояния
системы образуют полную группу событий, т. е. сумма вероятностей
равна 1:
N
∑ Pi = 1,
i =1
то используются следующие формулы, предложенные Шенноном.
Для определения количества информации:
• в одном (i-м) состоянии системы
Н = log 2
•
1
;
Pi
среднего количества информации во всех состояниях системы:
N
H = ∑ Pi log 2
i =1
N
1
= -∑ Pi log 2 Pi .
Pi
i =1
Из приведенных выражений следует, что количество информации
максимально, если состояния системы равновероятны.
Пример 2.6. Вычислительная система может находиться в одном
из N = 3 состояний: «включено (простой)», «вычисление», «выключено». Оператор получил сообщение о состоянии системы. Какое количество информации получил оператор? Рассмотреть два случая:
1) состояния системы равновероятны;
2) состояния системы не равновероятны; вероятность нахождения
системы в состоянии «включено (простой)» P1 = 0,3; состоянии «вычисление» P2 = 0,5; состоянии «выключено» P3 = 0,2.
Р е ш е н и е. В первом случае используем формулу Хартли:
HХ = log2N = log23 = 1,58 бит.
Во втором случае используем формулу Шеннона:
N
Н Ш = -∑ Pi log 2 Pi = -(0,3 log 2 0,3 + 0,5 log 2 0,5 + 0, 2 log 2 0, 2) =
i =1
= -(- 0,52 - 0,5 - 0, 46) = 1, 48 бит.
17
Значение количества информации, вычисленное по формуле
Хартли, больше значения, вычисленного по формуле Шеннона.
Пример 2.7. В условиях задачи из примера 2.6 определить количество информации, которое получил оператор в сообщении о состоянии «выключено», вероятность которого P3 = 0,2.
Р е ш е н и е. Используем формулу Шеннона для одного состояния:
Н = log 2
1
1
= log 2
= 2,32 бит.
Pi
0, 2
Можно сделать вывод: чем событие маловероятнее, тем больше
информации может быть получено при его возникновении.
2.4.2. Объемный подход
Объем данных V в сообщении измеряется количеством символов
(разрядов) в этом сообщении. В информатике в основном используется двоичная система счисления, т. е. все числа представляются
двумя цифрами: 0 и 1. Поэтому минимальной единицей измерения
данных является бит. Таким образом, 1 бит — это либо 0, либо 1.
Элемент, принимающий всего два значения, называется двухпозиционным и просто реализуется аппаратно: например, двумя состояниями «включено» — «выключено», «ток есть» — «ток отсутствует».
Более подробно о системах счисления будет рассказано в гл. 3.
Наряду с битом используется укрупненная единица измерения —
байт, равная 8 бит.
Пример 2.8. Сообщение в двоичной системе счисления 10010010
имеет объем данных V = 8 бит. Этот объем данных представляется
1 байтом.
Для удобства использования введены и более крупные единицы
объема данных:
1 024 байт = 1 килобайт (Кбайт);
1 024 Кбайт = 1 мегабайт (Мбайт) = 1 0242 байт = 1 048 576 байт;
1 024 Мбайт = 1 гигабайт (Гбайт) = 1 0243 байт;
1 024 Гбайт = 1 терабайт (Тбайт) = 1 024 4 байт;
1 024 Тбайт = 1 пентабайт (Пбайт) = 1 0245 байт.
18
Общий объем информации в книгах, цифровых и аналоговых носителях за всю историю человечества составляет по оценкам 1018 байт.
Зато следующие 1018 байт будут созданы в течение пяти — семи лет.
Отличие объема данных от количества информации заключается
в следующем: объем данных выражается только целыми значениями,
а количество информации — вещественными.
Формулу Хартли можно использовать для определения объема
данных. При этом результат округляется в большую сторону, так как
минимальной ячейкой памяти в ЭВМ является байт. Поэтому, заняв
только часть байта (его несколько бит), оставшаяся часть байта не
используется.
Пример 2.9. В сообщениях используются только первые шесть
букв латинского алфавита: A, B, C, D, E, F. Сколько байт необходимо для хранения сообщения «AABBCCD»?
Р е ш е н и е. Определим, сколько бит необходимо для хранения
одной буквы по формуле Хартли:
VБ = log26 = 2,58.
Результат округлим в большую сторону, следовательно:
VБ = 3 бита.
Тремя битами можно представить 8 комбинаций: 000, 001, 010, 011,
100, 101, 110, 111. Для кодирования шести букв используются первые
шесть комбинаций, а две последние комбинации не используются.
Для сообщения, состоящего из M = 7 букв, необходимо
VС = M ⋅ VБ = 7 ⋅ 3 = 21 бит = 2,625 байт.
Результат вновь округлим в большую сторону:
VС = 3 байта.
2.5. Показатели качества информации
Эффективность использования информации для принятия решений определяется показателями ее качества. Рассмотрим основные
показатели качества информации, и чем они определяются.
Репрезентативность (объективность) определяется правильностью отбора и формирования информации в целях адекватного отражения свойств объекта.
Содержательность зависит от семантической емкости, равной
отношению количества семантической информации в сообщении к
объему сообщения.
Достаточность (полнота) — это минимальный, но достаточный
для принятия правильного решения набор показателей. Как непол-
19
ная, т. е. недостаточная для принятия правильного решения, так и
избыточная информация снижает эффективность принимаемых
пользователем решений. Однако избыточная информация позволяет
восстановить частично утраченную информацию. Например, в слове
«дост*пнос*ь» потеряно 18 % букв, однако можно понять по оставшимся буквам, что это слово «доступность». Русский язык, как и
другие естественные языки, обладает большой избыточностью.
Доступность определяется степенью легкости восприятия и получения информации пользователем.
Актуальность определяется степенью соответствия информации
моменту ее использования.
Своевременность определяется поступлением информации не
позже заранее назначенного момента времени, зависящего от времени решения поставленной задачи.
Точность — это степень близости получаемой информации к
реальному состоянию объекта, процесса, явления и т. п.
Достоверность — это вероятность того, что отображаемое информацией значение параметра отличается от истинного значения
этого параметра в пределах необходимой точности.
Устойчивость — это свойство информации реагировать на изменение исходных данных, сохраняя при этом необходимую точность.
Устойчивость и репрезентативность обусловлены правильностью
выбора метода отбора и формирования информации.
Ценность определяется эффективностью принятых на основе
полученной информации решений.
Гл а в а 3
Информационные процессы, системы
и технологии
3.1. Информационные процессы
Операции над информацией называются информационными процессами. Люди обмениваются устными сообщениями, записками,
посланиями. Они передают друг другу просьбы, приказы, отчеты о
проделанной работе, описи имущества, публикуют рекламные объявления и научные статьи, хранят старые письма и документы или
долго размышляют над полученными известиями. Все это примеры
информационных процессов.
Все информационные процессы можно отнести к одному из следующих классов.
Сбор данных — это деятельность по накоплению данных с целью
обеспечения достаточной полноты. В сочетании с методами анализа
данных они порождают информацию, способную помочь в принятии
решений. Например, на основе цены товара и его аналогов, их потребительских качеств мы принимаем решение: покупать или не
покупать этот товар.
Передача данных — это процесс обмена данными. Предполагается, что существует источник информации, канал связи и потребитель информации. Между ними устанавливаются соглашения о порядке обмена данными. Такие соглашения называются протоколами
передачи данных. Например, в обычной беседе между двумя людьми
негласно принимается соглашение: не перебивать друг друга во время разговора.
Хранение данных — это поддержание данных в форме, постоянно
готовой к выдаче их потребителю. Одни и те же данные могут потребоваться потребителю многократно, поэтому существуют способы
их хранения на носителях, например на бумаге или запоминающих
устройствах, и методы их выдачи по запросу потребителя.
Обработка данных — это процесс преобразования информации
из исходной формы до получения определенного результата. Сбор,
накопление, хранение информации зачастую не являются конечной
целью информационного процесса. Нередко первичные данные ис-
21
пользуются для решения какой-либо проблемы. Данные преобразуются шаг за шагом в соответствии с алгоритмом обработки до получения выходных данных, которые после анализа пользователем
предоставляют необходимую информацию.
3.2. Информационные системы
Информационные процессы могут осуществляться в рамках информационных систем.
Информационные системы — это организованные человеком
системы сбора, хранения, обработки и выдачи информации, необходимой для принятия эффективных решений. Задачей информационных систем является удовлетворение потребностей потребителя в
информации. Потребитель должен своевременно получать информацию в требуемой форме после ее систематизации и необходимой
обработки.
Информационная система включает в себя следующие составные
части:
• информация, хранящаяся в информационной системе;
• технические средства хранения и обработки данных;
• методы и процедуры сбора и обработки информации.
Для обеспечения функционирования информационной системы
требуется квалифицированный персонал.
Информационные системы характеризуются не только структурой,
но и выполняемыми функциями. Функции информационных систем
можно подразделить на два вида:
• функции физической обработки;
• функции содержательной обработки.
Функции ф и з и ч е с к о й обработки заключаются в фиксации,
сборе, кодировании и записи данных на внешних запоминающих
устройствах (ВЗУ). Для обеспечения функций этого вида необходимо
проведение следующих мероприятий:
• исследование способов представления и хранения информации,
создание специальных языков для формального описания информации различной природы, разработка специальных приемов сжатия и
кодирования информации;
• создание сетей хранения, обработки и передачи информации, в
состав которых входят информационные банки данных, терминалы,
обрабатывающие центры и средства связи.
Функции содержательной обработки сводятся к поиску информации, документальному оформлению и размножению результатов
поиска и обработки, передаче выходной информации потребителям.
Примерами таких функций являются анализ и прогнозирование потоков разнообразной информации, перемещающихся в обществе,
аннотирование объемных документов и реферирование их.
22
Обеспечение функций этого вида требует осуществления следующих действий:
• построение различных процедур и технических средств для их
реализации, с помощью которых можно автоматизировать процесс
извлечения информации из документов, не предназначенных для
вычислительных машин, а ориентированных на восприятие их человеком;
• создание информационно-поисковых систем, способных воспринимать запросы к информационным хранилищам, сформулированные на естественном языке, а также специальных языках запросов
для систем такого типа.
По типу выполняемых задач информационные системы можно
разбить на три класса:
• учетные системы, предназначенные для контроля и выдачи
справочной информации;
• аналитические системы, предназначенные для прогнозирования,
диагностики, поддержки принятия решений;
• решающие системы, предназначенные для управления и планирования.
Классы информационных систем взаимосвязаны между собой.
Каждый предыдущий класс является исходной базой для последующего, а каждый последующий предполагает возможность решения
задач предыдущего класса. Например, аналитические системы помимо собственных задач выполняют справочные функции, а решающие системы решают задачи прогноза и контроля.
Приведенная классификация позволяет разделить информационные системы на следующие уровни:
• системы, не производящие качественного изменения информации;
• системы, анализирующие информацию;
• системы, вырабатывающие решения.
Другим критерием, который может быть положен в основу классификации информационных систем, является тип обработки информации, осуществляемой в информационной системе. По этому признаку информационные системы можно разделить на три группы:
• расчетные;
• аналитико-статистические;
• информационно-поисковые.
Автоматизированные р а с ч е т н ы е информационные системы
характеризуются небольшими объемами входной и выходной информации и значительным количеством вычислительных операций.
Автоматизированные а н а л и т и к о - с т а т и с т и ч е с к и е информационные системы предназначены для сбора и обработки статистической информации. Они характеризуются большим объемом
входной и выходной информации, а также большим количеством
арифметических и логических операций.
23
Автоматизированные и н ф о р м а ц и о н н о - п о и с к о в ы е системы используются для ввода, хранения и постоянного обновления
информации о некоторых объектах, например документах, людях,
транспортных средствах. Эти объекты непрерывно находятся в динамике, что требует постоянного обновления информации о них.
В процессе развития автоматизированных информационнопоисковых систем сформировались три вида информационного обслуживания:
1) документальное;
2) фактографическое;
3) концептографическое.
Каждому из этих видов соответствует своя информационная система, представляющая собой подсистему общей информационной
системы общества.
Система д о к у м е н т а л ь н о г о обслуживания в течение долгого
времени обеспечивала информационное обслуживание общества в
целом и различных его институтов, в том числе науки и техники.
Документальное обслуживание заключается в предоставлении
потребителям первичных документов. Потребители самостоятельно
извлекают необходимые сведения, удовлетворяя свои информационные потребности.
Документальное обслуживание потребителя осуществляется в два
этапа.
На первом этапе потребителю предоставляется перечень релевантных (соответствующих) его запросу первичных документов, т. е. документов, содержание которых имеет смысловое соответствие информационному запросу или другому тексту. Этот этап называется
библиографическим, и он аналогичен поиску книги в библиотечном
каталоге.
На втором этапе после отбора потребителем из этого перечня некоторых пертинентных документов ему предоставляют эти документы. Пертинентность — это соответствие содержания документа
информационной потребности конкретного специалиста. Этот этап
называется библиотечным обслуживанием. Он аналогичен получению книг, выбранных ранее из библиотечного каталога.
Таким образом, документальное обслуживание удовлетворяет потребность в информации опосредованно, через первичные документы.
Ф а к т о г р а ф и ч е с к о е обслуживание в отличие от документального удовлетворяет информационные потребности членов общества непосредственно, т. е. представляя им необходимые сведения:
отдельные данные и факты. Запрашиваемые потребителем сведения
извлекаются из первичных документов после определенной обработки: поиска, анализа и сравнения.
Под термином «фактографическая информация» следует понимать
сведения не только фактического характера, но и теоретического,
предположительного, оценочного характера, т. е. факты, концепции
24
и все то, что может быть объектом извлечения из текста, описания
на определенном информационном языке, хранения и поиска в той
или иной информационной системе.
Если в случае документального и фактографического обслуживания потребителю информации предоставляются документы или
сведения, извлеченные из информационного потока в «натуральном»
виде, то при к о н ц е п т о г р а ф и ч е с к о м обслуживании все эти
документы и сведения подвергаются интерпретации, оценке, обобщению со стороны информационной системы. В результате такой
интерпретации формулируется так называемая ситуативная информация, содержащая в себе оценку рассматриваемых сведений, тенденции и перспективы развития отдельных научных и технических
направлении, рекомендации. По этой причине под концептографическим обслуживанием можно также понимать формулирование и
доведение до потребителей ситуативной информации, в явном виде
не содержащейся в анализируемых источниках и полученной в результате информационно-логического и концептографического анализа некоторой совокупности документов. Другими словами, в случае
концептографического обслуживания потребителю предоставляются
не только сведения о документе или сами сведения из документа, но
и некоторая дополнительная информация, привнесенная информационной системой в процессе их интерпретации.
Для каждого из видов информационного обслуживания существует свой собственный специфичный ряд вторичных документов, на
основе которого производится обслуживание. Поэтому каждый вид
обслуживания сводится к созданию ряда вторичных документов и
предоставления их потребителю.
Разработка информационных систем на основе высокопроизводительных технических устройств и современных средств создания
программного обеспечения значительно повысила эффективность их
работы и сделала информационные системы неотъемлемой частью
жизни общества.
3.3. Информационные технологии
Информация является таким же важнейшим ресурсом современного общества, как уголь, нефть, металлы, а значит, процесс ее переработки, как и процессы переработки материальных ресурсов, можно назвать технологией.
Информационная технология — это процесс, использующий совокупность средств и методов сбора, обработки и передачи данных о
состоянии объекта, процесса или явления для получения новой информации об их состоянии. Таким образом, информационная технология — это процесс переработки первичной информации в информационный продукт.
25
Целью информационной технологии является производство информации для ее анализа человеком и принятия на его основе решения о выполнении соответствующих действий.
К техническим средствам производства информации относится
его аппаратное, программное и математическое обеспечение. С их
помощью производится переработка первичной информации в информацию нового качества.
Программное обеспечение является инструментарием информационных технологий, которое позволяет достичь поставленную
пользователем цель. В качестве инструментария можно использовать
следующие виды программных продуктов:
• текстовые процессоры и графические редакторы;
• настольные издательские системы;
• электронные таблицы;
• системы управления базами данных (СУБД);
• информационные системы функционального назначения (финансовые, бухгалтерские, для маркетинга и пр.).
Информационная технология тесно связана с информационными
системами, которые являются для нее основной средой.
Информационная технология является процессом, состоящим из
четко регламентированных правил выполнения операций, действий,
этапов разной степени сложности над данными, хранящимися в компьютерах. Основная цель информационной технологии — в результате целенаправленных действий по переработке первичной информации
получить необходимую для пользователя информацию.
Информационная система является средой, составляющими элементами которой являются компьютеры, компьютерные сети, программные продукты, базы данных (БД), обслуживающий персонал,
различного рода технические и программные средства связи и т. д.
Основная цель информационной системы — организация хранения
и передачи информации. Информационная система и обслуживающий ее персонал представляют собой человекокомпьютерную систему обработки информации.
Реализация функций информационной системы невозможна без
знания ориентированной на нее информационной технологии. Информационная технология может существовать и вне сферы информационной системы.
Таким образом, информационная технология является более емким понятием, отражающим современное представление о процессах
преобразования информации в информационном обществе. Умелое
сочетание двух информационных технологий (управленческой и
компьютерной) является залогом успешной работы информационной
системы.
Рассмотрим некоторые виды информационных технологий.
Информационная технология о б р а б о т к и д а н н ы х предназначена для решения хорошо структурированных задач, для которых
26
определены все необходимые входные данные и известны алгоритмы
и другие стандартные процедуры их обработки. Эта технология применяется для автоматизации некоторых рутинных постоянно повторяющихся несложных операций управленческого труда. Поэтому
внедрение информационных технологий и систем позволяет существенно повысить производительность труда персонала, освободить
его от рутинных операций и, возможно, привести к необходимости
сокращения численности работников.
Информационная технология обработки данных решает следующие задачи:
• обработка данных об операциях, производимых фирмой;
• создание периодических контрольных отчетов о состоянии дел
в фирме;
• получение ответов на всевозможные текущие запросы и оформление их в виде бумажных документов или отчетов.
Целью информационной технологии у п р а в л е н и я является
удовлетворение информационных потребностей всех без исключения
сотрудников фирмы, имеющих дело с принятием решений.
Эта технология ориентирована на работу в среде информационной
системы управления и используется при худшей структурированности
решаемых задач, если их сравнивать с задачами, решаемыми с помощью информационной технологии обработки данных.
Информационная технология управления идеально подходят для
удовлетворения сходных информационных потребностей работников
различных функциональных подсистем (подразделений). Поставляемая ими информация содержит сведения о прошлом, настоящем и
вероятном будущем фирмы. Эта информация имеет вид регулярных
или специальных управленческих отчетов.
Для принятия решений информация должна быть представлена
в агрегированном виде так, чтобы просматривались тенденции изменения данных, причины возникших отклонений и возможные
решения. На этом этапе решаются следующие задачи обработки
данных:
• оценка планируемого состояния объекта управления;
• оценка отклонений от планируемого состояния;
• выявление причин отклонений;
• анализ возможных решений и действий.
Главной особенностью информационной технологии п о д д е р ж к и п р и н я т и я р е ш е н и й является качественно новый метод
организации взаимодействия человека и компьютера. Выработка
решения, что является основной целью этой технологии, происходит
в результате итерационного процесса, в котором участвуют:
• система поддержки принятия решений в роли вычислительного
звена и объекта управления;
• человек как управляющее звено, задающее входные данные и
оценивающее полученный результат вычислений на компьютере.
27
Окончание итерационного процесса происходит по воле человека.
В этом случае можно говорить о способности информационной системы совместно с пользователем создавать новую информацию для
принятия решений.
Дополнительно к этой особенности информационной технологии
поддержки принятия решений можно указать еще ряд ее отличительных характеристик:
• ориентация на решение плохо структурированных (формализованных) задач;
• сочетание традиционных методов доступа и обработки компьютерных данных с возможностями математических моделей и методами решения задач на их основе:
• направленность на непрофессионального пользователя компьютера;
• высокая адаптивность, обеспечивающая возможность приспосабливаться к особенностям имеющегося технического и программного обеспечения, а также требованиям пользователя.
Гл а в а 4
Системы счисления
4.1. Непозиционная и позиционная системы
счисления
Система счисления — это соглашение о представлении чисел посредством конечной совокупности символов (цифр) A = {a0, a1, …,
an - 1}, называемой алфавитом. Каждой цифре ставится в соответствие
определенный количественный эквивалент.
Системы счисления разделяют на позиционные и непозиционные.
Рассмотрим эти системы счисления.
Непозиционная система счисления — это система, в которой
цифры не меняют своего количественного эквивалента в зависимости
от местоположения (позиции) в записи числа.
К непозиционным системам счисления относится система римских цифр, основанная на употреблении латинских букв для десятичных разрядов I = 1, X = 10, С = 100, М = 1 000 и их половин V = 5,
L = 50, D = 500.
Рассмотрим запись единиц. Числа 1 и 5 представляются соответственно цифрами I и V. Чтобы представить числа 2 или 3 необходимо
записать соответствующее число единиц: II или III. Для представления
чисел 4 или 9 к цифре V (пять) или X (десять) слева дописывается единица I: IV или IX. Для представления чисел 6, 7, 8 к цифре V справа
подписываются соответствующее число единиц: VI, VII, VIII. Аналогично записываются десятки, сотни и тысячи. Число в системе римских
чисел записывается по схеме «тысячи — сотни — десятки — единицы».
Пример 4.1. Записать число 1974 в системе римских цифр.
Р е ш е н и е. Выпишем тысячи, сотни, десятки и единицы:
1 000 — M;
900 — CM;
70 — LXX;
4 — IV.
Тогда число 1974 будет записано как MCMLXXIV. Здесь цифра M сохраняет свой количественный эквивалент 1 000 в обоих вхождениях.
29
Непозиционные системы счисления обладают следующими недостатками:
• сложность представления больших чисел (больше 10 000);
• сложность выполнения арифметических операций над числами,
записанными с помощью этих систем счисления.
Из-за перечисленных недостатков числа принято записывать с
помощью позиционных систем счисления.
Позиционная система счисления — это система, в которой количественный эквивалент цифры зависит от ее положения в числе.
Примером позиционной системы счисления является используемая
нами десятичная система счисления.
Основание позиционной системы счисления — это количество
символов в ее алфавите.
Например, в десятичной системе счисления десять цифр, поэтому
она имеет основание n = 10. Позиционная система счисления с основанием n называется n-ичной.
Далее рассматриваются только позиционные системы счисления,
поэтому слово «позиционная» опускается.
4.2. Двоичная, десятичная
и шестнадцатеричная системы счисления.
Перевод чисел в десятичную систему
счисления
Значение числа, представленного конечной дробью, в n-ичной
системе счисления:
amam–1 … a1a0,a–1a–2 … a–k,
где «,» — разделитель целой и дробной частей; ai (i = −k, m); или с
явным указанием основания системы счисления (a ma m–1 … a 1a 0,
a–1a–2 … a-k)n,
определяется по формуле
am nm + am-1nm-1 +…+ a1n1 + a0 n0 +
+a-1n-1 + a-2 n-2 +…+ a- k n- k =
m
∑ ai ni .
(4.1)
i =- k
В информатике и вычислительной технике широко используются
следующие системы счисления:
• двоичная n = 2; используемый алфавит: A = {0, 1}; например,
01110002;
30
• десятичная n = 10; используемый алфавит: A = {0, 1, 2, 3, 4, 5, 6,
7, 8, 9}; например, 10210. В дальнейшем числа без указания основания
системы счисления будем считать десятичными;
• шестнадцатеричная n = 16; используемый алфавит: A = {0, 1, 2,
3, 4, 5, 6, 7, 8, 9, A, B, C, D, E, F}; цифры A, B, C, D, E, F имеют
десятичные количественные эквиваленты 10, 11, 12, 13, 14, 15 соответственно; например, AB034D16.
Представление цифр в двоичной, десятичной и шестнадцатеричной системах счисления приведено в табл. 4.1.
Т а б л и ц а 4.1. Соответствие между цифрами двоичной, десятичной
и шестнадцатеричной систем счисления
Десятичная система
счисления
Двоичная система
счисления
Шестнадцатеричная система
счисления
0
0000
0
1
0001
1
2
0010
2
3
0011
3
4
0100
4
5
0101
5
6
0110
6
7
0111
7
8
1000
8
9
1001
9
10
1010
A
11
1011
B
12
1100
C
13
1101
D
14
1110
E
15
1111
F
31
В вычислительной технике используется двоичная система счисления, т. е. все числа и данные представляются в виде последовательности нулей и единиц (бит). Двоичная система счисления обладает
следующими преимуществами перед системами счисления с другими
основаниями:
• для реализации двоичных цифр необходимы технические устройства с двумя устойчивыми состояниями: «ток есть» — «ток отсутствует», «намагничено» — «не намагничено» и т. п., а не с десятью как в
десятичной системе счисления;
• представление информации посредством только двух состояний
надежно и помехоустойчиво;
• для выполнения арифметических операций используется простой аппарат алгебры высказываний (булевой алгебры).
В вычислительной технике процессы ввода, вывода и обработки
числовых данных связаны с преобразованием чисел из одной системы счисления в другую. Поэтому рассмотрим правила перевода чисел
одной системы счисления в систему счисления с другим основанием.
Правило 4.1 (перевод целого или дробного числа из n-й системы
счисления в десятичную). Число из n-й системы счисления в десятичную переводится с использованием формализованного представления числа (4.1).
Пример 4.2. Перевести число A50D,0B16 в десятичную систему
счисления.
Р е ш е н и е. Используем формулу (4.1):
A ⋅ 163 + 5 ⋅ 162 + 0 ⋅ 161 + D ⋅ 160 + 0 ⋅ 16–1 + B ⋅ 16–2.
Запишем вместо цифр шестнадцатеричной системы счисления их
десятичные эквиваленты и выполним операции умножения и сложения:
10 ⋅ 163 + 5 ⋅ 162 + 0 ⋅ 161 + 13 ⋅ 160 + 0 ⋅ 16–1 + 11 ⋅ 16–2 =
= 10 ⋅ 4 096 + 5 ⋅ 256 + 13 ⋅ 1 + 11 ⋅ 0,00390625 = 42 448,04296875.
Очевидно, что цифру 0 при переводе чисел можно опускать.
4.3. Перевод целых чисел из одной системы
счисления в другую
Правила перевода числа в другую, не десятичную систему счисления различаются для целых и дробных чисел.
Правило 4.2 (перевод целых чисел из десятичной системы счисления в n-ю систему счисления). Перевод целого числа X осуществляется по следующему алгоритму:
32
1) получить цифру числа n-й системы счисления как остаток
от деления числа X на основание новой системы счисления n; полученную цифру приписать слева от имеющихся цифр;
2) принять за X частное от деления числа X на основание системы счисления n;
3) выполнять шаги 1—2, пока X ≠ 0.
Пример 4.3. Перевести число 25 в двоичную систему счисления.
Р е ш е н и е. Удобно представить перевод числа в виде столбца,
каждая строка которого содержит частное и остаток от деления числа X на основание двоичной системы счисления n = 2:
В результате получим число 110012 — результат перевода числа 25
в двоичную систему счисления.
Правило 4.3 (перевод из шестнадцатеричной в двоичную систему
счисления). Каждая цифра шестнадцатеричного числа заменяется
тетрадой (четырьмя битами), являющейся представлением этой цифры в двоичной системе счисления (см. табл. 4.1).
Пример 4.4. Перевести число 3BC16 в двоичную систему счисления.
Р е ш е н и е. Цифра 316 представляется числом 00112, B16 — 10112,
C16 — 11002. Тогда результат перевода числа 3BC16 в двоичную систему счисления будет равен 0011101111002.
Правило 4.4 (перевод из двоичной в шестнадцатеричную систему
счисления). Двоичное число делится на тетрады справа налево.
Каждая тетрада заменяется соответствующей ей цифрой. Если
самая левая тетрада неполная, т. е. содержит меньше четырех
цифр, то слева от числа дописываются нули.
Пример 4.5. Перевести число 11101111002 в шестнадцатеричную
систему счисления.
Р е ш е н и е. Разделим число на тетрады и поставим в соответствие каждой тетраде шестнадцатеричную цифру. В самой левой
тетраде только две единицы, поэтому дополним ее слева двумя
нулями:
33
11
1011
1100
↓
↓
↓
0011
1011
1100
↓
↓
↓
3
B
C
В результате получаем число 3BC16. Данный пример является обратным примеру 4.4, поэтому исходные данные и результат этих двух
примеров противоположны.
С помощью шестнадцатеричной системы счисления удобно записывать значения байт, так как восемь бит записываются двумя
шестнадцатеричными цифрами. Например, число 111100012 будет записано как число F116.
4.4. Перевод дробных чисел из одной
системы счисления в другую
Если при переводе конечной дроби в другую систему счисления
получается конечная дробь, то такой перевод называется точным.
Если при переводе получается бесконечная дробь, тогда перевод называется приближенным.
Правило 4.5 (перевод дробных чисел из n-й в десятичную систему счисления). Вещественное число переводится из n-й в десятичную систему счисления с использованием формализованного представления числа (4.1).
Правило 4.6 (перевод дробных чисел с нулевой целой частью из
десятичной в n-ю систему счисления). Дробное число X, у которого
целая часть равна 0, переводится из десятичной в n-ю систему
счисления по следующему алгоритму:
1) умножить X на n;
2) получить цифру как целую часть числа X и приписать ее
справа от имеющихся цифр;
3) обнулить целую часть числа X;
4) выполнять шаги 1—3, пока X ≠ 0 (при точном переводе) или
до получения нужного количества цифр в дробной части (при приближенном переводе с заданной точностью).
Пример 4.6. Перевести число 0,6875 в двоичную систему счисления.
Р е ш е н и е. Вновь схему перевода запишем в виде столбца:
34
На последнем шаге перевода получена единица. После обнуления
целой части получим 0. Значит, перевод закончен. Результат перевода числа 0,6875 в двоичную систему счисления — число 0,10112.
Если бы нам было необходимо получить дробную часть с точностью до трех знаков, то процесс перевода был бы остановлен после
получения трех цифр в дробной части.
Правило 4.7 (перевод дробных чисел с ненулевой целой частью
из десятичной в n-ю систему счисления). При переводе дробных
чисел из десятичной в n-ю систему счисления отдельно переводятся целая и дробная части.
Пример 4.7. Перевести число 25,6875 в двоичную систему счисления.
Р е ш е н и е. Перевод целой и дробной частей был выполнен в
примерах 4.3 и 4.6. Объединим результаты перевода в одно число:
25,6875 = 11001,10112.
Десятичная система счисления может использоваться в качестве
промежуточного этапа при переводе чисел из одной системы счисления в другую. Приведенные в этой главе правила позволяют перевести числа из одной системы счисления в десятичную, а из нее — в
любую другую системы счисления.
Гл а в а 5
Представление чисел, символов,
графических и звуковых данных в ЭВМ
5.1. Представление целых чисел в ЭВМ
5.1.1. Форматы представления целых чисел
Числа в ЭВМ хранятся в соответствии с форматом. Формат — это
соглашение или правила представления числа в виде последовательности бит.
Минимальная единица хранения данных в ЭВМ — 1 байт. Существуют следующие форматы представления целых чисел: байт (полуслово), слово (включает 2 байта), двойное слово (4 байта), расширенное слово (8 байт). Биты, из которых состоят эти форматы, называются разрядами. Таким образом, в байте 8 разрядов, в слове — 16
разрядов, а в двойном слове — 32 разряда. Слева находятся старшие
разряды, а справа — младшие. Каждый из этих форматов может быть
знаковым (рис. 5.1) для представления положительных и отрицательных чисел или беззнаковым (рис. 5.2) для представления положительных чисел.
Знаковым является самый старший разряд. На рис. 5.1 знаковый
разряд обозначен символом S. Если он равен 0, то число считается
положительным, а если разряд равен 1, то число считается отрицательным.
В общем виде диапазон значений, представляемых знаковыми
форматами представления целых чисел (табл. 5.1), определяется по
формуле
Рис. 5.1. Знаковые форматы представления целых чисел
36
Рис. 5.2. Беззнаковые форматы представления целых чисел
Т а б л и ц а 5.1. Форматы представления целых чисел в ЭВМ
Формат
Число
разрядов
Диапазон (границы)
знаковый
беззнаковый
Байт
8
−128; 127
0; 255
Слово
16
−32 768; 32 767
0; 65 535
Двойное
слово
32
−2 147 483 648; 2 147 483 647
0; 4 294 967 295
−2n–1 ≤ X ≤ 2n–1 − 1;
для беззнакового формата определяется по формуле
0 ≤ X ≤ 2n − 1,
где n — число разрядов в формате.
5.1.2. Прямой и дополнительный коды
представления двоичных чисел
В прямом коде старший бит кодирует знак числа (0 — для положительного, 1 — для отрицательного), а остальные биты — модуль
числа.
Пример 5.1. Число 11 в прямом коде будет представляться как
0|1011п, а число –11 — как 1|1011п.
В дополнительном коде положительное число кодируется так же,
как и в прямом. Для представления отрицательного числа в дополнительном коде существуют два способа. При представлении чисел
в дополнительном коде используется операция инвертирования —
замена бита на противоположный, т. е. 0 на 1, а 1 на 0.
37
Правило 5.1 (поразрядное представление отрицательного числа
в дополнительном коде). Представить модуль отрицательного
числа в прямом коде и проинвертировать все разряды левее самой
младшей (правой) единицы.
Пример 5.2. Представить число −11 в дополнительном коде с помощью поразрядного представления.
Р е ш е н и е. Переведем модуль этого числа в двоичную систему:
11 = 10112, и представим его в прямом коде: 0|1011п. Самая младшая
единица — последняя, поэтому ее оставляем без изменения, а остальные разряды слева инвертируем (рис. 5.3).
Рис. 5.3. Представление числа −11 в дополнительном коде
В результате получаем 1|0101д — представление числа −11 в дополнительном коде.
Правило 5.2 (арифметическое представление отрицательного
числа в дополнительном коде). Прибавить к отрицательному числу 2 m, где m — количество разрядов в двоичном представлении или
данном формате, и полученное число перевести в двоичную систему счисления. Для байта 28 = 256, для слова 216 = 65 536, для двойного слова 232 = 4 294 967 296.
Из этих правил можно сделать вывод, что положительные числа в
случае увеличения числа разрядов дополняются слева нулями, а отрицательные — единицами.
Пример 5.3. Представить число −11 в дополнительном коде путем
арифметического представления.
Р е ш е н и е. Пусть необходимо получить m = 5 разрядов дополнительного кода. Вычислим слагаемое 2m = 25 = 32. Произведем сложение
и перевод в двоичную систему счисления:
−11 + 32 = 21 = 101012.
Полученный результат соответствует представлению числа −11 в
дополнительном коде.
Для m = 8, 28 = 256:
−11 + 256 = 245 = 111101012.
Представление числа −11 было дополнено единицами слева до 8
разрядов.
38
Возможно и обратное преобразование отрицательных чисел, записанных в дополнительном коде.
Правило 5.3 (поразрядное определение значения отрицательного
числа, записанного в дополнительном коде). Алгоритм определения
значения отрицательного числа в дополнительном коде состоит
из следующих шагов:
1) проинвертировать все разряды левее самой младшей (правой)
единицы;
2) перевести число из двоичной системы счисления в десятичную
систему по правилу 4.1;
3) умножить результат на −1.
Пример 5.4. Определить, какое десятичное число закодировано
числом 1|0101д с помощью поразрядного определения.
Р е ш е н и е. Проинвертируем разряды числа:
1010|1д → 0101|1п.
Переведем число из двоичной системы счисления в десятичную
систему счисления:
010112 = 11.
Умножим результат на −1 и получим число −11.
Правило 5.4 (арифметическое определение отрицательного числа,
записанного в дополнительном коде). Перевести двоичное число в
десятичную систему счисления и вычесть из полученного числа число 2m, где m — количество разрядов в двоичном представлении.
Пример 5.5. Определить, какое десятичное число закодировано
числом 1|0101д с помощью арифметического определения.
Р е ш е н и е. Переведем число из двоичной системы счисления в
десятичную систему счисления:
101012 = 21.
Вычтем из полученного результата перевода число 2m = 25 = 32, так
как двоичное число состоит из пяти разрядов:
21 − 32 = −11.
В результате получим десятичное число −11.
Числа в знаковых форматах записываются в дополнительном коде,
а в беззнаковых — в прямом.
Запись в дополнительном коде необходима, чтобы складывать и
вычитать положительные и отрицательные числа без преобразований.
39
Пример 5.6. Сложить 21 и −11 в двоичной системе счисления.
Р е ш е н и е. Переведем слагаемые в дополнительный код:
21 = 0|10101д; −11 = 1|10101д.
Будем использовать правила двоичной арифметики:
0 + 0 = 0;
1 + 0 = 0 + 1 = 1;
1 + 1 = 10 (с переносом единицы в следующий разряд).
Сложим два двоичных числа столбиком с учетом того, что перенос
единицы из знакового разряда игнорируется:
0101012
110101
______2
0010102 = 10.
В результате получено число 10 — сумма 21 и −11 без дополнительных преобразований.
Форматы целых чисел слово и двойное слово хранятся в памяти
ЭВМ в обратном порядке, т. е. сначала младший байт, а затем старший. Например, слово B5DE16 будет располагаться в памяти, как
показано на рис. 5.4.
Рис. 5.4. Расположение слова B5DE16 в памяти ЭВМ
Такое расположение байт удобно при операциях с числами, так
как вычисления начинаются с младших разрядов, поэтому они и располагаются сначала.
5.2. Представление вещественных чисел
в ЭВМ
Вещественные числа представляются в форме числа с плавающей
запятой (точкой) вида:
± M ⋅ n ± P,
где M — мантисса (значащая часть числа); n — основание системы
счисления; P — порядок числа.
Пример 5.7. Число 2,5 ⋅ 1018 имеет мантиссу, равную 2,5, и порядок,
равный 18.
40
Мантисса называется нормализованной, если ее абсолютное значение лежит в диапазоне:
1/n ≤ |M| < 1,
где n — основание системы счисления.
Это условие означает, что первая цифра после запятой не равна
нулю, а абсолютное значение мантиссы не превышает единицы.
Число с нормализованной мантиссой называется нормализованным.
Пример 5.8. Представить числа −245,62 и 0,00123 в форме числа
с плавающей точкой.
Р е ш е н и е. Число −245,62 можно представить в форме числа с
порядком –245,62 ⋅ 100. Мантисса этого числа не нормализована,
поэтому поделим его на 103, увеличив при этом порядок:
–0,24562 ⋅ 103.
В результате число −0,24562 ⋅ 103 нормализовано.
Число 0,00123 в форме числа с порядком 0,00123 ⋅ 100 не нормализовано, так как не нормализована мантисса. Умножим мантиссу на
102, уменьшив при этом порядок:
0,123 ⋅ 10–2.
В результате число 0,123 ⋅ 10–2 нормализовано.
В данном примере для нормализации мантиссы запятая сдвигалась
вправо или влево. Поэтому такие числа называются числами с плавающей точкой. В отличие от чисел с фиксированной точкой они
значительно ускоряют арифметические операции, при этом каждый раз
необходимо нормализовывать мантиссу чисел с плавающей точкой.
Для основанного на стандарте IEEE-754 представления вещественного числа в ЭВМ используются m + p + 1 бит, распределяемые следующим образом (рис. 5.5): 1 разряд знака мантиссы, p разрядов
порядка, m разрядов мантиссы.
Это представление называется (m, p)-форматом.
Диапазон представления чисел X (m, p)-форматом определяется
из неравенства:
2-2
p -1 + 2 - m
≤ X ≤ (1 - 2- m-1 )2-2
p -1
p -1
≈ 2-2 .
При этом порядок числа P должен удовлетворять условию −2p − 1 +
+ 1 ≤ P ≤ 2p−1 − 1.
Рис. 5.5. Структура общего формата числа с плавающей точкой
41
Т а б л и ц а 5.2. Сравнительные характеристики вещественных
форматов
Характеристика
Одинарный формат
Двойной формат
4/32
8/64
Порядок p, бит
8
11
Мантисса m, бит
23
52
Смещение порядка 2p−1 − 1
127
1 023
Количество значащих десятичных цифр мантиссы
7…8
15 … 16
Диапазон десятичных порядков
− 45 … 38
− 324 … 308
Размер, байт/бит
Для вещественных чисел в стандарте IEEE-754 используются
(23,8)- и (52,11)-форматы, называемые одинарным и двойным вещественными форматами соответственно (табл. 5.2).
Чтобы представить значение этих порядков, количество секунд, прошедших с момента образования планеты Земля, составляет всего 1018.
Правило 5.5 (перевод десятичных чисел в (m, p)-формат)). Алгоритм перевода десятичного числа X в (m, p)-формат состоит из
следующих шагов:
1) если Х = 0, то принять знаковый разряд, порядок и мантиссу
за ноль и закончить алгоритм;
2) если X > 0, то принять знаковый разряд 0, иначе принять 1.
Знаковый разряд сформирован;
3) перевести целую и дробную часть абсолютного значения
числа X в двоичную систему счисления. Если число дробное, то
получить m + 1 разрядов. Принять порядок равный нулю;
4) если X ≥ 1, то перенести запятую влево до самого старшего разряда и увеличить порядок, иначе перенести запятую вправо до первого ненулевого (единичного) разряда и уменьшить порядок;
5) если число разрядов дробной части меньше m, то дополнить
дробную часть нулями справа до m разрядов. Отбросить единицу
из целой части. Мантисса сформирована;
6) прибавить к порядку смещение 2 p−1 − 1 и перевести порядок
в двоичную систему счисления. Порядок сформирован. Код, в котором представлен порядок, называется смещенным. Смещенный
порядок упрощает сравнение, сложение и вычитание порядков при
арифметических операциях;
7) записать знаковый разряд, порядок и мантиссу в соответствующие разряды формата.
42
Пример 5.9. Представить число −25,6875 в одинарном вещественном формате.
Р е ш е н и е. В примере 4.7 был произведен перевод абсолютного
значения числа −25,6875 в двоичную систему и было получено девять
разрядов:
25,6875 = 11001,10112.
Нормализуем число, сдвинув запятую влево и повысив порядок:
1,100110112 ⋅ 24.
После отбрасывания целой части остается 23 разряда дробной части
(в соответствии с форматом (23,8)), записываемые как мантисса:
10011011000000000000000.
Порядок равен 4 (степень двойки после сдвига запятой влево).
Произведем его смещение и перевод в двоичную систему счисления:
4 + 127 = 131 = 100000112.
Число −25,6875 отрицательное, следовательно, знаковый разряд
равен 1.
Все готово для представления числа −25,6875 в одинарном вещественном формате по схеме знаковый разряд + порядок + мантисса:
1 10000011 10011011000000000000000.
Разделим это число по восемь разрядов, сформируем байты и запишем их шестнадцатеричными числами:
11000001
11001101
10000000
00000000
C1
CD
80
00
Таким образом, число −25,6875 можно записать как C1CD8000.
Как и форматы целых чисел, форматы вещественных чисел хранятся в памяти ЭВМ в обратном порядке следования байт (сначала
младшие, потом старшие).
Арифметические операции над числами с плавающей точкой осуществляются в следующем порядке.
При с л о ж е н и и (в ы ч и т а н и и) чисел с одинаковыми порядками их мантиссы складываются (вычитаются), а результату присваивается порядок, общий для исходных чисел. Если порядки исходных чисел разные, то сначала эти порядки выравниваются (число
с меньшим порядком приводится к числу с большим порядком), а
затем выполняется операция сложения (вычитания) мантисс. Если
43
при выполнении операции сложения мантисс возникает переполнение, то сумма мантисс сдвигается влево на один разряд, а порядок
суммы увеличивается на 1.
При у м н о ж е н и и чисел их мантиссы перемножаются, а порядки складываются.
При д е л е н и и чисел мантисса делимого делится на мантиссу
делителя, а для получения порядка частного из порядка делимого
вычитается порядок делителя. При этом если мантисса делимого
больше мантиссы делителя, то мантисса частного окажется больше 1
(происходит переполнение) и запятую следует сдвинуть влево, одновременно увеличив порядок частного.
5.3. Представление символов в ЭВМ
В ЭВМ каждый символ (например, буква, цифра, знак препинания) закодирован в виде беззнакового целого двоичного числа. Кодировка символов — это соглашение об однозначном соответствии
каждому символу одного беззнакового целого двоичного числа, называемого кодом символа.
Для русского алфавита существует несколько кодировок (табл. 5.3).
В кодировках 866, 1251, КОИ-8 и Unicode первые 128 символов
(цифры, заглавные и строчные латинские буквы, знаки препинания)
со значениями кодов от 0 до 127 одни и те же и определяются стандартом ASCII (American Standard Code for Information Interchange —
американский стандартный код для обмена информацией). Цифры
0, 1, …, 9 имеют соответственно коды 48, 49, …, 57; прописные латинские буквы A, B, …, Z (всего 26 букв) — коды 65, 66, …, 90; строчные
латинские буквы a, b, …, z (всего 26 букв) — коды 97, 98, …, 122.
Вторые 128 символов со значениями кодов от 128 до 255 кодировок
866, 1251, КОИ-8 содержат символы псевдографики, математические
операции и символы алфавитов, отличных от латинского. Причем
Т а б л и ц а 5.3. Кодировки букв алфавита русского языка
Операционная
система
Количество
кодируемых
символов
Размер кода
одного символа,
байт
866
MS DOS
256
1
1251 (Win-1251,
CP-1251)
Windows
256
1
Unix
256
1
Windows
65 536
2
Кодировка
КОИ-8 (КОИ-8Р)
Unicode
44
Т а б л и ц а 5.4. Значения кодов букв русского алфавита
Коды букв русского алфавита
Кодировка
А — Я (кроме Ё)
а — я (кроме ё)
Ё
ё
866
128 — 159
160 — 175 (а — п)
224 — 239 (р — я)
240
241
1251
192 — 223
224 — 255
168
184
1 040 — 1 071
1 072 — 1 103
1 025
1 105
Unicode
разные символы различных алфавитов имели один и тот же код. Например, в кодировке 1251 символ русского алфавита Б имеет тот же
код, что и символ А́ в стандартной кодировке ASCII. Такая неоднозначность вызывала проблемы с кодировкой текста. Поэтому была
предложена двухбайтовая кодировка Unicode, которая позволяет закодировать символы многих нелатинских алфавитов.
Десятичные значения кодов букв русского алфавита в кодировках
866, 1251 и Unicode приведены в табл. 5.4.
В кодировке КОИ-8 (табл. 5.5) коды букв русского алфавита упорядочены не по расположению букв в алфавите, а по соответствию
их буквам латинского алфавита. Например, коды латинских букв А,
В, С имеют соответственно десятичные значения 65, 66, 67, а русских
букв А, Б, Ц — значения 225, 226, 227.
Т а б л и ц а 5.5. Значения кодов букв русского алфавита в кодировке
КОИ-8
A
225
К
235
Х
232
а
193
к
203
х
200
Б
226
Л
236
Ц
227
б
194
л
204
ц
195
В
247
М
237
Ч
254
в
215
м
205
ч
222
Г
231
Н
238
Ш
251
г
199
н
206
ш
219
Д
228
О
239
Щ
253
д
196
о
207
щ
221
Е
229
П
240
Ъ
255
е
197
п
208
ъ
223
Е
179
Р
242
Ы
249
ё
163
р
210
ы
217
Ж
246
С
243
Ь
248
ж
214
с
211
ь
216
З
250
Т
244
Э
252
з
218
т
212
э
220
И
233
У
245
Ю
224
и
201
у
213
ю
192
Й
234
Ф
230
Я
241
й
202
ф
198
я
209
45
5.4. Представление графических и звуковых
данных в ЭВМ
Графическое изображение можно представить матрицей, состоящей из точек — пикселей (pixel — picture element). Каждая точка изображения характеризуется цветом. Растровый способ представления
графических изображений заключается в записи точек кодом соответствующего ей цвета.
Для кодирования цвета используется схема RGB. По этой схеме
каждый цвет записывается тремя составляющими основными цветами: красным (R (Red)), зеленым (G (Green)) и синим (B (Blue)). Название схемы составлено из первых букв основных цветов. Каждая
составляющая имеет максимум 256 градаций (от 0 до 255). Примеры
кодирования некоторых цветов по схеме RGB приведены в табл. 5.6.
Представление точек цветами по схеме RGB лежит в основе графического формата BitMap (битовая матрица, BMP). Данный формат
имеет две разновидности. В безпалитровом формате цвет каждой
точки изображения кодируется по схеме RGB. Палитровый формат
предполагает, что цвет каждой точки кодируется номером из палитры,
а палитра представляет собой соответствие между номером цвета и
его кодом по схеме RGB. Палитровый формат позволяет сократить
объем изображения в случае использования небольшого числа цветов.
Другие способы представления графических данных будут рассмотрены далее в подразд. 10.7.
Для представления звуковых данных используется процесс дискретизации (см. подразд. 2.2). Как и периодическое измерение температуры, звуковая волна характеризуется постоянно изменяющимся параметром — силой звуковых колебаний. Сила этих колебаний
зависит от их амплитуды. Тогда звук можно представить последовательностью дискретных численных значений его амплитуды. Такой формат
представления звука называется PCM (Pulse Code Modulation —
Т а б л и ц а 5.6. Кодирование цветов по схеме RGB
Цвет
R
G
B
Черный
0
0
0
Синий
0
0
255
Зеленый
0
255
0
Красный
255
0
0
Белый
255
255
255
46
импульсно-кодовая модуляция). Частота дискретизации измеряется
в герцах (количество замеров в секунду). Обычно используются частоты от 8 кГц до 48 кГц. Частота 48 кГц означает, что амплитуда
сигнала записывается 48 000 раз в секунду. Шаг дискретизации зависит от разрядности квантования. Например, разрядность 16 бит
означает, что сигнал имеет 216 = 65 536 возможных значений и под
хранение значения амплитуды выделяется 2 байта.
Гл а в а 6
Логические основы ЭВМ
6.1. Алгебра высказываний. Понятие,
высказывание, умозаключение
Принципы работы ЭВМ основываются на законах математической
логики, поэтому ее элементы широко используются для поиска и обработки информации и при разработке схем электронных устройств.
Математическая логика — это наука о формах и способах мышления и их математическом представлении.
Мышление основывается на понятиях, высказываниях и умозаключениях.
Понятие объединяет совокупность объектов, обладающих некоторыми существенными признаками, которые отличают их от других
объектов. Например, понятие «звезда» объединяет множество светящихся газовых шаров. Это понятие трудно спутать с таким понятием
как, например, «автомобиль». Объекты, соответствующие одному
понятию, образуют множество.
Понятие имеет две характеристики:
• содержание;
• объем.
Содержание понятия — это совокупность существенных признаков, выделяющих объекты, соответствующие данному понятию,
среди других объектов. Например, содержание понятия «человек»
можно раскрыть так: «Общественное существо, обладающее сознанием и разумом».
Объем понятия «человек» определяется численностью людей,
живущих в мире.
Высказывание (суждение, утверждение) — это повествовательное
предложение, в котором утверждаются или отрицаются свойства
реальных предметов и отношения между ними. Поэтому высказывание может быть истинным или ложным.
И с т и н н ы м называется высказывание, в котором связь понятий
правильно отражает свойства и отношения реальных вещей, например: «Москва — столица России». Истинность высказывания кодируется единицей (1) и имеет значение «истина».
48
Л о ж н ы м высказывание будет в том случае, когда оно не соответствует реальной действительности, например: «Париж — столица
США». Ложность высказывания кодируется нулем (0) и имеет значение «ложь».
Обычно высказывания обозначаются логическими переменными — заглавными латинскими буквами с индексом или без: например,
A = «Сегодня идет дождь». Логические переменные принимают только два значения: 0 и 1.
Умозаключение позволяет из известных фактов (истинных высказываний) получать новые факты. Например, из факта «Все углы
треугольника равны» следует истинность высказывания «Этот треугольник равносторонний».
Высказывания и логические операции над ними образуют алгебру
высказываний (булеву алгебру), предложенную английским математиком Джорджем Булем.
6.2. Логические операции
Основные логические операции над высказываниями, используемыми в ЭВМ, включают в себя отрицание, конъюнкцию, дизъюнкции, стрелку Пирса и штрих Шеффера. Рассмотрим эти логические
операции.
1. Отрицание –
x (обозначается также ¬ X, ∼X ).
Отрицание –
x (NOT, читается «не X») — это высказывание, которое
истинно, если X ложно, и ложно, если X истинно.
2. Конъюнкция XY (X & Y, X ∧ Y ).
Конъюнкция XY (AND, логическое умножение, «X и Y») — это
высказывание, которое истинно только в том случае, если X истинно
и Y истинно.
3. Дизъюнкция X + Y (X ∨ Y ).
Дизъюнкция X + Y (OR, логическая сумма, «X или Y или оба») —
это высказывание, которое ложно только в том случае, если X ложно
и Y ложно.
4. Стрелка Пирса X ↓ Y.
Стрелка Пирса X ↓ Y (NOR (NOT OR), ИЛИ — НЕ) — это высказывание, которое истинно только в том случае, если X ложно и Y
ложно.
5. Штрих Шеффера X | Y.
Штрих Шеффера X | Y (NAND (NOT AND), И — НЕ) — это высказывание, которое ложно только в том случае, если X истинно и Y
истинно.
Определить значения логических операций при различных сочетаниях аргументов можно из таблицы истинности (табл. 6.1)
Чтобы определить значение операции 0 + 1 в таблице истинности,
необходимо на пересечении столбца X + Y (определяет операцию) и
49
Т а б л и ц а 6.1. Таблица истинности для основных логических
операций, используемых в ЭВМ
X
Y
–
x
XY
X+Y
X↓Y
X|Y
0
0
1
0
0
1
1
0
1
1
0
1
0
1
1
0
0
0
1
0
1
1
1
0
1
1
0
0
строки, где X = 0 и Y = 1 (так, первый аргумент равен 0, а второй — 1),
найти значение 1, которое и будет являться значением операции
0 + 1.
В алгебре высказываний существуют две нормальные формы:
конъюнктивная нормальная форма (КНФ) и дизъюнктивная нормальная форма (ДНФ).
КНФ — это конъюнкция конечного числа дизъюнкций нескольких
переменных или их отрицаний (произведение сумм). Например,
формула X(Y + Z ) находится в КНФ.
ДНФ — это дизъюнкция конечного числа конъюнкций нескольких
переменных или их отрицаний (сумма произведений). Например,
формула X + YZ находится в ДНФ.
Логические операции обладают свойствами, сформулированными
в виде равносильных формул.
Снятие двойного отрицания отрицание отрицания (Закон «исключения третьего»):
X = X.
•
Коммутативность:
XY = YX;
X + Y = Y + X.
•
(6.2)
(6.3)
Ассоциативность:
(XY )Z = X(YZ );
(6.4)
(X + Y ) + Z = X + (Y + Z ).
(6.5)
•
50
(6.1)
Дистрибутивность:
X(Y + Z ) = XY + XZ.
(6.6)
X + YZ = (X + Y )(X + Z ).
(6.7)
•
Законы де Моргана:
X ⋅Y = X + Y ;
(6.8)
X + Y = X ⋅Y .
(6.9)
•
Идемпотентность:
X + X = X;
(6.10)
X ⋅ X = X.
(6.11)
•
Закон противоречия:
X ⋅ X = 0.
•
Закон «исключения третьего»:
X + X = 1.
•
(6.12)
(6.13)
Свойства констант:
X ⋅ 1 = X;
(6.14)
X ⋅ 0 = 0;
(6.15)
X + 1 = 1;
(6.16)
X + 0 = X.
(6.17)
•
Элементарные поглощения:
X + XY = X;
(6.18)
X + XY = X + Y ;
(6.19)
X(X + Y ) = X;
(6.20)
X ( X + Y ) = XY .
(6.21)
•
Преобразование стрелки Пирса:
X ↓ Y = X +Y .
•
(6.22)
Преобразование штриха Шеффера:
X Y = X ⋅Y .
(6.23)
Правило 6.1 (порядок применения формул при преобразованиях).
Перечисленные формулы рекомендуется применять в следующем
порядке:
1) преобразование стрелки Пирса (6.22) и штриха Шеффера
(6.23);
2) законы де Моргана (6.8 ), (6.9);
51
3) формулы дистрибутивности (6.6 ), (6.7);
4) элементарные поглощения (6.18 ) … (6.21).
Обычно формула приводится к ДНФ, а затем отдельные слагаемые
поглощаются.
6.3. Логические функции
6.3.1. Способы представления логических функций
Логическая функция (функция алгебры высказываний) f(X1, X2,
…, Xn) от n переменных — n-рная операция на множестве [0; 1].
В этой функции логические переменные X1, X2, …, Xn представляют
собой высказывания и принимают значения 0 или 1.
n
Существует 22 различных логических функций от n переменных.
Логические операции, рассмотренные в подразд. 6.2, можно рассматривать как логические функции от двух переменных.
Набор функций, с помощью которого можно представить (выразить) все логические функции, называется функционально-полным
или базисом. Основными базисами являются:
1) булевый базис, состоящий из конъюнкции, дизъюнкции и отрицания;
2) базис NOR, состоящий из стрелки Пирса;
3) базис NAND, включающий в себя штрих Шеффера.
Рассмотрим некоторые способы представления логических функций.
А н а л и т и ч е с к и й. Функция задается в виде алгебраического
выражения, состоящего из функций одного или нескольких базисов,
применяемых к логическим переменным.
Т а б л и ч н ы й. Функция задается в виде таблицы истинности
(соответствия), которая содержит 2n строк (по числу наборов аргументов), n столбцов по числу переменных и один столбец значений
функции. В такой таблице каждому набору аргументов соответствует
значение функции.
Ч и с л о в о й. Функция задается в виде десятичных (восьмеричных,
шестнадцатеричных) эквивалентов номеров тех наборов аргументов,
на которых функция принимает значение 1. Нумерация наборов начинается с нуля. Аналогичным образом логическая функция может
быть задана по нулевым значениям.
Пример 6.1. Функция задана аналитически:
f ( X , Y , Z ) = (Y + Z ) X (Y + Z ) + Y + Z .
Записать функцию в табличном и числовом представлениях.
52
Р е ш е н и е. Переход к другому представлению возможен и в таком
виде. Однако лучше преобразовать функцию, чтобы упростить процесс перехода к другому представлению.
Опустим отрицание до переменных по законам де Моргана (6.8),
(6.9):
f ( X , Y , Z ) = (Y + Z ) X (Y + Z ) + Y + Z = Y Z + X + Y Z + Y Z .
Сократим одинаковые слагаемые по формуле (6.10) и перегруппируем их:
f (X , Y , Z ) = Y Z + X +Y Z +Y Z = X +Y Z +Y Z .
По полученному выражению построим таблицу истинности путем
подстановки значений переменных в строке и записи значения функции в эту строку (табл. 6.2).
Чтобы представить функцию в числовом представлении, выпишем
номера наборов, на которых функция принимает значение 1: 1, 2, 4,
5, 6, 7, и номера наборов, на которых функция принимает значение
0: 0, 3.
Тогда функция f ( X , Y , Z ) = X + Y Z + Y Z имеет два числовых
представления. В первом случае перечисляются все наборы, на которых функция равна 1:
f (1, 2, 4, 5, 6, 7) = 1.
Во втором случае перечисляются все наборы, на которых функция
равна 0:
f(0, 3) = 0.
Все эти представления эквивалентны и описывают одну функцию.
Т а б л и ц а 6.2. Таблица истинности функции f ( X , Y , Z ) = X + Y Z + Y Z
Номер набора
X
Y
Z
f (X , Y , Z ) = X +Y Z +Y Z
0
0
0
0
0
1
0
0
1
1
2
0
1
0
1
3
0
1
1
0
4
1
0
0
1
5
1
0
1
1
6
1
1
0
1
7
1
1
1
1
53
Правило 6.2 (переход от табличного к аналитическому представлению функции в ДНФ). Необходимо в тех строках таблицы истинности, где функция равна 1, выписать набор переменных и
соединить их конъюнкцией. Если переменная в наборе равна 0, то
к переменной добавляется отрицание. Конъюнкции переменных
соединить дизъюнкцией.
Пример 6.2. Функция задана таблично (табл. 6.3).
Записать функцию в аналитическом представлении ДНФ и числовом представлении.
Р е ш е н и е. Выпишем те наборы переменных, на которых функция принимает значение 1, и запишем их в виде конъюнкции переменных:
–
• набор 3: X = 0, Y = 1, Z = 1 → ХYZ;
–
• набор 6: X = 1, Y = 1, Z = 0 → XYZ ;
• набор 7: X = 1, Y = 1, Z = 1 → XYZ.
Соединим полученные конъюнкции переменных дизъюнкцией и
получим аналитическое представление функции:
–
–
f(X, Y, Z ) = ХYZ + XYZ + XYZ.
Функция принимает значение 1 на наборах 3, 6, 7 и значение 0 на
наборах 0, 1, 2, 4, 5, поэтому в числовом представлении функция
будет иметь следующий вид:
f(3, 6, 7) = 1;
f (0, 1, 2, 4, 5) = 0.
Т а б л и ц а 6.3. Таблица истинности некоторой функции
54
Номер набора
X
Y
Z
f (X, Y, Z )
0
0
0
0
0
1
0
0
1
0
2
0
1
0
0
3
0
1
1
1
4
1
0
0
0
5
1
0
1
0
6
1
1
0
1
7
1
1
1
1
Правило 6.3 (переход от табличного к аналитическому представлению функции в виде КНФ). Необходимо в тех строках таблицы
истинности, где функция равна 0, выписать набор переменных и
соединить их дизъюнкцией. Если переменная в наборе равна 1, то
к переменной добавляется отрицание. Дизъюнкции переменных
соединить конъюнкцией.
Пример 6.3. Функцию, заданную таблично в примере 6.2, записать в аналитическом представлении КНФ.
Р е ш е н и е. Выпишем наборы, на которых функция принимает
значение 0, и преобразуем их в дизъюнкции переменных:
• набор 0: X = 0, Y = 0, Z = 0 → X + Y + Z;
–
• набор 1: X = 0, Y = 0, Z = 1 → X + Y + Z ;
–
• набор 2: X = 0, Y = 1, Z = 0 → X + Y + Z;
–
• набор 4: X = 1, Y = 0, Z = 0 → Х + Y + Z;
–
–
• набор 5: X = 1, Y = 0, Z = 1 → Х + Y + Z .
Запишем функцию в виде КНФ (произведения сумм):
–
–
f (X, Y, Z ) = (X + Y + Z )(X + Y + Z )(X + Y + Z ) ×
–
–
–
× (Х + Y + Z )(Х + Y + Z ).
6.3.2. Способы перевода логических функций
из одного базиса в другой
Рассмотрим способы перевода функции из одного базиса в другие.
Правило 6.4 (переход от булевого базиса к базису NOR). Алгоритм
перехода включает в себя следующие этапы.
1. Упростить функцию и преобразовать ее к произведению сумм
произведений по формуле (6.7 ), причем в каждой сумме или произведении должно быть по два аргумента. Если невозможно свести формулу, где в каждой операции по два аргумента, то использовать следующие преобразования:
X + Y + Z = (X + Y + Z )(X + Y + Z ) = ((X + Y )(X + Y ) + Z ) ×
× ((X + Y )(X + Y ) + Z ) = X + Y + X + Y + Z + X + Y + X + Y + Z ;
XYZ = ( XY + XY )Z = X + Y + X + Y + Z =
X + X +Y +Y + X + X +Y +Y + Z + Z .
55
2. Преобразовать конъюнкции по формуле
X ⋅Y = X + Y .
(6.24)
3. Преобразовать отрицание над переменными по формуле
X = X + X.
(6.25)
4. Заменить полученные операции стрелкой Пирса по формуле
X +Y = X ↓ Y .
(6.26)
Пример 6.4. Привести упрощенную функцию из примера 6.1 к
базису NOR.
Р е ш е н и е. Приведем формулу к произведению сумм по формуле (6.7):
– –
– –
–
f(X, Y, Z ) = X + YZ + Y Z = (X + YZ + Y )(X + YZ + Z ) =
–
–
–
= ((X + Y )(X + Z ) + Y )((X + Y )(X + Z ) + Z ).
Преобразуем конъюнкции:
(( X + Y )( X + Z ) + Y )(( X + Y )( X + Z ) + Z ) =
= X +Y X + Z +Y + X +Y X + Z + Z .
Преобразуем отрицания над переменными:
X +Y X + Z +Y + X +Y X + Z + Z =
= X +Y X + Z + Z +Y +Y + X +Y X + Z + Z + Z .
Заменим операции стрелкой Пирса:
X +Y X + Z + Z +Y +Y + X +Y X + Z + Z + Z =
= ((X ↓ Y )(X ↓ (Z ↓ Z )) ↓ (Y ↓ Y )) ↓ ((X ↓ Y )(X ↓ (Z ↓ Z )) ↓ Z ).
Формула приведена к базису NOR.
Правило 6.5 (переход от булевого базиса к базису NAND). Алгоритм перехода включает в себя следующие этапы.
1. Упростить функцию и преобразовать ее к сумме произведений сумм по формуле (6.7 ), причем в каждой сумме или произведении должно быть по два аргумента. Если невозможно свести
формулу, где в каждой операции по два аргумента, то использовать следующие преобразования:
X + Y + Z = ( X + Y )( X + Y ) + Z = X Y X Y Z = XX YY XX YY ZZ ;
56
XYZ = XYZ + XYZ = (XY + XY )Z + (XY + XY )Z =
= XY XY Z XY XY Z .
2. Преобразовать дизъюнкции формуле
X + Y = X ⋅Y .
(6.27)
3. Преобразовать отрицание над переменными по формуле:
X = XX .
(6.28)
4. Заменить полученные операции штрихом Шеффера по формуле:
XY = X Y .
(6.29)
Пример 6.5. Привести функцию из примера 6.2 к базису NAND.
Р е ш е н и е. Упростим выражение и приведем к виду суммы произведений:
–
–
–
–
f (X, Y, Z ) = ХYZ + XYZ + XYZ = Y(ХZ + XZ + XZ ) =
–
–
–
= Y(ХZ + X(Z + Z )) = Y(ХZ + X ) = Y(Z + X ) = YZ + YX.
Преобразуем дизъюнкции:
YZ + YX = YZYX .
Отрицания над переменными отсутствуют, поэтому приведем
операции к штриху Шеффера:
YZYX = (Y Z ) (Y X ).
Формула приведена к базису NAND.
6.3.3. Минимизация логических функций
Одна и та же функция может иметь несколько аналитических представлений. Функция называется минимальной, если ее аналитическое
представление имеет минимальное количество слагаемых и минимальное количество переменных в каждом слагаемом. Таким образом,
минимизация справедлива только для аналитического представления
логической функции в виде ДНФ.
Существует несколько методов минимизации логических функций.
Наиболее простым и эффективным является метод Блейка.
Правило 6.6 (метод Блейка). Алгоритм метода состоит из трех
этапов:
1) привести формулу к ДНФ;
57
2) для всевозможных пар слагаемых, если это возможно, применить операцию склеивания:
–
–
ХY + XZ = ХY + XZ + YZ;
3) к исходным и полученным слагаемым применить операцию
поглощения:
X + XY = X.
Пример 6.6. Минимизировать функцию из примера 6.2.
Р е ш е н и е. Исходная функция имеет вид:
–
–
f (X, Y, Z ) = ХYZ + XYZ + XYZ.
Выполним последовательно этапы метода Блейка. Применим
операцию склеивания для всевозможных пар слагаемых:
–
– –
–
– –
–
ХYZ + XYZ = ХYZ + XYZ + YZYZ = ХYZ + XYZ + 0;
–
–
ХYZ + XYZ = ХYZ + XYZ + YZ;
–
–
YZ + XYZ = YZ + XYZ + XY;
–
–
XY + ХYZ = XY + ХYZ + YZ.
В результате выполнения второго этапа получено следующее выражение:
–
–
f (X, Y, Z ) = ХYZ + XYZ + XYZ + YZ + XY.
Применим операцию поглощения:
f (X, Y, Z ) = YZ + XY.
Таким образом, функция минимизирована. Сравните полученный
результат с упрощением функции в примере 6.5, т. е. минимизация
может быть достигнута преобразованиями над функцией.
6.4. Логические элементы и логические
схемы
Основным логическим операциям, используемым в ЭВМ, соответствуют следующие логические элементы, каждый из которых
имеет два входа (слева) и один выход (справа):
Дизъюнкция
58
Конъюнкция
Стрелка Пирса Штрих Шеффера
Для отрицания отдельный элемент применяется редко, так как
отрицание (обозначается кружком) может быть помещено как на
входы:
F = AB;
так и на выходы логических элементов:
F = A + B.
Логические элементы реализуются аппаратно с помощью транзисторов, резисторов и т. п. Значению «истина» соответствует наличие
напряжения на входах и на выходах, значению «ложь» — его отсутствие.
Логические элементы соединяются между собой и подсоединяются к входам, соответствующим переменным X, Y, Z, и образуют
логическую схему. Как правило, логическая схема имеет один выход.
Пример 6.7. Построить логическую схему, реализующую упрощенную функцию из примера 6.1.
Р е ш е н и е. Каждый логический элемент имеет только два входа,
поэтому перегруппируем слагаемые:
– –
–
–
f(X, Y, Z ) = X + YZ + Y Z = (X + YZ ) + Y Z.
Запишем схему, соответствующую логической функции (рис. 6.1).
– –
Рис. 6.1. Логическая схема, соответствующая функции f(X, Y, Z ) = X + YZ + YZ
Черные точки на соединителях элементов обозначают разветвление, чтобы отличать его от наложения соединителей.
Перед построением логической схемы функцию минимизируют,
чтобы получить схему с минимальным количеством элементов.
59
Пример 6.8. Построить функцию, соответствующую схеме
Минимизировать функцию и по ней построить логическую схему.
Р е ш е н и е. Выпишем функцию, соответствующую схеме:
f ( X , Y , Z ) = ( X Y + XY )Z + X Y Z .
Минимизируем функцию по методу Блейка. Для этого приведем
ее к виду суммы произведений — раскроем скобки:
f ( X , Y , Z ) = ( X Y + XY )Z + X Y Z = X Y Z + XYZ + X Y Z .
Перейдем ко второму этапу минимизации — применим операцию
склеивания:
XYZ + X Y Z = XYZ + X Y Z + XY .
В результате второго этапа получим
f ( X , Y , Z ) = X Y Z + XYZ + X Y Z + XY .
Перейдем к третьему этапу — применим операцию поглощения:
f ( X , Y , Z ) = X Y Z + XY .
Функция минимизирована. Построим по ней логическую схему
(рис. 6.2).
–
–
Рис. 6.2. Логическая схема, соответствующая функции f(X, Y, Z ) = XYZ + XY
В результате получена логическая схема, число элементов которой
меньше, чем у исходной.
60
Количество входов логического элемента называется коэффициентом объединения (Коб). У всех рассмотренных элементов коэффициент объединения Коб = 2, но существуют элементы с коэффициентом объединения Коб = 3, 4, 8. Как правило, логические элементы не
выпускаются отдельно, а интегрированы в некоторую логическую
схему.
Для удешевления производства вместо логических элементов двух
типов И и ИЛИ используют элементы одного типа И—НЕ или
ИЛИ—НЕ. Обычно используют элементы И—НЕ.
Пример 6.9. Построить логическую схему по функции в базисе
NAND из примера 6.5.
Р е ш е н и е. Функция в базисе NAND имеет вид:
f (X, Y, Z ) = (YZ )(YX ).
Рис. 6.3. Логическая схема, соответствующая функции f(X, Y, Z ) = (YZ )(YX )
Логическая схема представлена на рис. 6.3.
Гл а в а 7
Знания. Модели представления знаний
7.1. Знания и их особенности
Знания — это форма существования и систематизации познавательной деятельности человека, то, что мы знаем после изучения. В ЭВМ
знания представляются в виде схем, формул и текста по определенным
правилам. Представлению знаний присущ пассивный аспект: книга,
таблица, память ЭВМ. В системах искусственного интеллекта подчеркивается активный аспект представления: познание должно стать
активной операцией, позволяющей не только запоминать, но и извлекать воспринятые (приобретенные, усвоенные) знания для рассуждений на их основе.
Рассмотрим особенности знаний, отличающие их от данных.
1. Внутренняя интерпретируемость. Каждая информационная
единица имеет уникальный идентификатор, который позволяет системе искусственного интеллекта найти ее, например, для ответа на
запросы, в которых этот идентификатор упомянут. Пусть имеются
следующие сведения о составе бригады цеха (табл. 7.1).
Информация о том, где хранятся сведения о фамилиях, специальностях, стаже, разрядах и окладах называется протоструктурой
информационных единиц. С помощью данной протоструктуры можно найти необходимую информационную единицу и ответить на
вопросы типа «Что системе известно о Петрове?» или «Есть ли среди
специалистов фрезеровщик?».
Т а б л и ц а 7.1. Сведения о составе бригады цеха
Фамилия
Специальность
Стаж, лет
Разряд
Оклад, руб.
Попов
Слесарь
5
1
2 000
Сидоров
Токарь
20
4
8 000
Иванов
Токарь
30
6
12 000
Петров
Фрезеровщик
25
5
10 000
62
2. Структурированность. Структура информационных единиц представляет собой рекурсивную вложенность одних информационных
единиц в другие. В данной таблице каждая строка содержит сведения об
одном из работников, а вместе эти строки определяют состав бригады.
3. Связность. Между информационными единицами установлены
связи различного типа. Отношения между информационными единицами могут быть декларативными или процедурными.
Пусть разряд определяется следующим образом. Если работник
проработал 5 лет и менее, то он имеет 1-й разряд, если 10 лет и менее —
2-й разряд и т.д. Это пример декларативного отношения «ПРИЧИНА—
СЛЕДСТВИЕ».
Пусть оклад определяется по формуле
Оклад = Разряд × Ставка (= 2000).
Расчет оклада представляет собой отношение процедурного типа
«АРГУМЕНТ — ФУНКЦИЯ».
Процедурные отношения между информационными единицами
позволяют не хранить их отдельно, а получать по мере надобности
из уже имеющихся информационных единиц.
Между информационными единицами могут устанавливаться и иные
отношения, например, определяющие порядок выбора информационных единиц из структуры или указывающие на то, что две информационные единицы несовместимы друг с другом в одном описании.
4. Семантическая метрика. Помимо отношений между информационными единицами можно установить меру близости по тематике
или проблематике. На основе этих показателей формируются классы
информационных единиц, что позволяет найти знания, близкие к
уже найденным.
5. Активность. Все операции, выполняемые ЭВМ, запускаются
командами с использованием данных, т. е. данные пассивны, а команды активны. В системах искусственного интеллекта, как и у человека, действия инициируются знаниями, имеющимися в системе.
Знания предполагают целенаправленное использование информации,
способность управлять информационными потоками для решения
определенных задач.
Все перечисленные особенности отличают знания от данных.
Однако эти особенности до сих пор не реализованы в полной мере в
существующих системах.
7.2. Модели представления знаний
Представление знаний происходит в рамках той или иной системы
представления знаний. Система представления знаний — это совокупность программных средств для хранения и обработки знаний.
Система представления знаний выполняет следующие функции:
63
• хранение знаний о предметной области в соответствии с моделью
представления знаний в базе знаний (БЗ);
• ввод новых знаний;
• проверка непротиворечивости хранимых знаний;
• удаление знаний;
• вывод новых знаний из уже имеющихся знаний;
• предоставление знаний пользователю.
Модель представления знаний — это способ записи знаний, предназначенный для отображения текущего состояния объектов некоторой предметной области и отношений между ними, а также изменение объектов и отношений.
Модель представления знаний может быть универсальной, т. е.
применимой для большинства предметных областей, или специализированной, т. е. разработанной для конкретной предметной области.
К основным универсальным моделям представления знаний относятся:
• логические модели;
• сетевые модели;
• продукционные модели;
• фреймовые модели.
Знания хранятся в БЗ в соответствии с моделью представления
знаний.
7.3. Логические модели
В основе логических моделей лежит понятие формальной теории,
задаваемой четверкой:
S = <T, F, A, R >.
Рассмотрим компоненты формальной теории:
T — множество символов теории S, называемых термами и образующих алфавит теории. Конечная последовательность символов
множества T называется выражением теории S;
F — подмножество выражений теории S, называемых формулами
теории и построенных по синтаксическим правилам. Примерами
правил могут быть правила записи формул алгебры высказываний;
A — множество формул, называемых аксиомами теории S и являющихся априорно истинными формулами;
R — конечное множество отношений между формулами, называемые правилами вывода. Правила вывода позволяют получать
новые формулы множества F за счет применения этих правил вывода к аксиомам или уже выведенным формулам.
Формальная система позволяет выводить новые правильные формулы множества F, применяя к аксиомам множества A и уже полученным формулам правила вывода множества R, т. е. выводить из
64
одних истинных высказываний новые истинные высказывания. Таким образом, в рамках формальной системы можно получить бесконечное число формул из небольшого числа исходных аксиом.
Вывод новых знаний в рамках логической модели представления
знаний заключается в получении некоторого утверждения из имеющихся аксиом и правил вывода. Если в результате вывода утверждение
получено, то оно считается истинным и является логическим следствием из аксиом.
В этом случае задачей пользователя или программиста является
описание предметной области совокупностью утверждений в виде
логических формул. Доказательство истинности утверждения осуществляется ЭВМ на основе исходных утверждений.
Наиболее простой метод логического вывода использует только
одно правило вывода и называется методом резолюции.
Метод резолюции заключается в выполнении следующих шагов:
–
1) взять отрицание формулы A и привести формулу А к КНФ;
–
2) выписать множество дизъюнктов K = {D1, …, Dn} формулы А ;
3) если в множестве существует пара дизъюнктов Di и Dj, один из
которых содержит переменную Y, а другой — отрицание переменной
–
Y , то соединить эти дизъюнкты дизъюнкцией Di + Dj и сформировать
–
новый дизъюнкт D´i + D´j, исключив переменные Y и Y ;
4) возможны три случая:
–
• если дизъюнкты Di и Dj содержат только переменные Y и Y , то
получен пустой дизъюнкт и логическое следствие верно;
• если во множестве K не существует двух дизъюнктов, для которых
применим шаг 3, то логическое следствие неверно;
• если полученный дизъюнкт не является пустым, то добавить его
к множеству K и вновь выполнить шаг 3.
Пример 7.1. Рассмотрим логический вывод знаний. Пусть для
некоторого студента справедливы три факта, являющихся аксиомами —
исходными утверждениями для логического вывода:
1) если студент болеет, то он принимает лекарства;
2) если студент не болеет, то он ходит на учебу;
3) студент не принимает лекарства.
Следует ли из этих аксиом следующее высказывание:
4) студент ходит на учебу.
Выделим в этих утверждениях простые высказывания:
A = «студент болеет»;
B = «студент принимает лекарства»;
C = «студент ходит на учебу».
Запишем утверждения с помощью этих простых высказываний с
учетом того, что конструкция «если A, то B» соответствует логической
операции импликации A → B:
1) A → B;
–
2) А → C;
65
–
3) В ;
4) C.
При преобразованиях будем использовать следующие равносильные формулы алгебры высказываний:
A = A;
A → B = A + B;
A + B = A ⋅ B,
где «+» — дизъюнкция; «⋅» — операция конъюнкции; «→» — операция
логического следствия (импликация).
Проверим, является ли высказывание 4 логическим выводом из
утверждений 1—3:
–
–
[(A → B) ⋅ (А → C ) ⋅ В ] → C.
В соответствии с методом резолюций возьмем отрицание от данного выражения и преобразуем его к КНФ:
[( A → B ) ⋅ ( A → B ) ⋅ B ] → C = ( A + B ) ⋅ ( A + C ) ⋅ B ⋅C .
Множество K включает в себя следующие дизъюнкты:
K = { A + B, A + C , B, C }.
–
Из двух дизъюнктов А + B и A + C получим новый дизъюнкт B + C,
который включается в множество K:
K = { A + B, A + C , B, C , B + C }.
–
Из двух дизъюнктов B + C и В получим новый дизъюнкт C, который также включается в множество K:
K = { A + B, A + C , B, C , B + C , C }.
–
Полученный дизъюнкт C является отрицанием дизъюнкта C , а
значит, высказывание 4 является логическим следствием из утверждений 1—3.
Помимо высказываний для представления знаний могут использоваться предикаты. В отличие от естественного языка, который очень
сложен, язык логики предикатов использует конструкции естественного языка, которые легко формализуются.
Предикат — это функция, возвращающая значения 1 («истина»)
или 0 («ложь») в зависимости от значений аргументов: например,
P(x, y) = (x > y).
В логике предикатов вводятся две операции.
66
1. Квантор существования ∃.
Выражение ∃xP(x) (читается: «существует x, для которого P(x)»)
истинно, если существует такое значение x из множества M, при
котором P(x) = 1:
∃xP(x) = P(x1) + P(x2) + …
2. Квантор общности ∀.
Выражение ∀xP(x) («для любого xP(x)») истинно, если P(x) = 1
для всех значений x из множества M:
∀xP(x) = P(x1)⋅P(x2)⋅…
Рассмотрим пример представления знаний с помощью предикатов.
Пример 7.2. Приведем структуру описания следующего объекта
с помощью логики предикатов: «Солнечная система состоит из центрального светила и девяти планет, обращающихся вокруг него».
Выражения «состоит из» и «представляет собой» используют для
того, чтобы описать структуру некоторого объекта. Описание может
быть статическим и динамическим.
В случае статического описания указывается взаимное пространственное расположение частей. В случае динамического описания —
законы их относительного перемещения в пространстве или описание
иных видов движения (их зависимости от времени).
Для нашего примера, считая для простоты, что планеты равномерно движутся по круговым орбитам, можно построить описание,
используя следующее выражение:
∀x ∃y ∀t (СОЛНЕЧНАЯ_СИСТЕМА (х, t) ≡
≡ СОСТОИТ_ИЗ(x, y, t) ⋅
⋅ ∃z0 ∃z1 … ∃z8 ∀z (((z ∈ y) → ((z = z0) + (z = z1) + … + (z = z8)) ⋅
⋅ СОЛНЦЕ(z0) ⋅ МЕРКУРИЙ(z1) ⋅ ВЕНЕРА(z2) ⋅
ЗЕМЛЯ(z3) ⋅ МАРС(z4) ⋅ ЮПИТЕР(z5) ⋅ САТУРН(z6) ⋅
⋅ УРАН(z7) ⋅ НЕПТУН(z8) ⋅
→
→
→
⋅ ∃ v0 КООРДИНАТЫ(z0, t, v0) ⋅ (v0 = 0)) ⋅
⋅
8
∏ ∃vk
k =1
(КООРДИНАТЫ (z k , t, v k ) ⋅
⋅ (ρk = ak) ⋅ (θk = bk) ⋅ (ϕk = ck ⊕ dk ⊗ t)))),
где ≡ — логическая операция эквивалентности; «⊕» — операция
арифметического сложения; «⊗» — операция арифметического умножения; t — время.
67
Для описания пространственного положения космических тел
→
определяются: v — координатный вектор в сферической системе ко→
→
ординат, v = < ρ, θ, ϕ > (соответственно, v = 0 следует понимать как
→
(ρ = 0) ⋅ (θ = 0) ⋅ (ϕ = 0), а ∃v как кортеж из трех кванторов); ak, bk, ck,
dk — числа, определяющие соответственно радиус орбиты, угол наклона орбиты, положение на орбите, период обращения.
Названия Солнца и девяти планет символизируют не только имя,
но и все существенные характеристики соответствующего объекта.
Например:
МАРС(z4) ≡ (ИМЯ (z4, МАРС) ⋅ МАССА(z4; 6,4⊗1013) ⋅
⋅ ПЕРИОД_ВРАЩЕНИЯ_ВОКРУГ_СВОЕЙ_ОСИ(z4; 24,5) ⋅
⋅ СРЕДНИЙ_ДИАМЕТР(z4, 6776)).
Общий вид такого описания можно представить схемой
∀x ∃y ∀t (А(x, t) ∼ СОСТОИТ_ИЗ(x, y, t) ⋅ S(y, t)),
где S(y, t) — описание совокупности y как статической или динамической системы пространственно организованных элементов.
Возможность получения новых знаний из уже имеющихся знаний
(аксиом) посредством логического вывода делает логические модели
представления знаний широко используемыми в системах искусственного интеллекта.
7.4. Семантические сети
Семантическая сеть — это система знаний, имеющая вид сети,
узлы которой соответствуют объектам предметной области и их свойствам, а дуги — отношениям между ними.
Представим с помощью семантической сети следующие факты:
• «Все кашалоты — киты»;
• «Моби Дик — кашалот»;
• «Киты имеют хвост».
Моби Дику посвящен одноименный роман американского писателя Г. Мелвилла.
Из данных фактов можно выделить следующие объекты, которые
будут являться узлами сети: «Моби Дик», «кашалот», «кит», «хвост».
Взаимосвязь этих объектов опишем с помощью отношений:
• «часть — целое» (IS — A) (пример: «стол» IS — A «мебель»);
• «целое — частное» (PART — OF ) (пример: «рука» PART — OF
«тело»).
Семантическая сеть, описывающая факты, представлена на рис. 7.1.
68
Рис. 7.1. Представление фактов семантической сетью
Используя отношения IS — A и PART — OF, из уже имеющихся
фактов можно вывести факты «Моби Дик — кит» и «Моби Дик имеет хвост».
Семантическая сеть представляет собой ориентированный граф с
поименованными дугами и вершинами. Вершинам графа, описывающего семантическую сеть, соответствуют:
• события представляют собой действия, происходящие в реальном мире;
• объекты представляют объекты реального мира, а также их особенности и характеристики (цвет, размер, качество), а применительно к событиям — продолжительность, время, место.
Дуги графа семантической сети отображают многообразие отношений между объектами, которые условно можно разделить на четыре класса:
• лингвистические отношения, которые, в свою очередь, подразделяются на глагольные (время, вид, род, залог, наклонение), атрибутивные (цвет, размер, форма) и падежные;
• логические отношения, используемые в алгебре высказываний:
дизъюнкция, конъюнкция, отрицание, импликация и др.;
• теоретико-множественные: отношение части целого (PART —
OF ), отношение множества и элемента (IS — A);
• квантифицированные отношения общности и существования;
они используются для представления таких утверждений как «Любой
станок надо ремонтировать», «Существует работник А, обслуживающий склад Б».
Рассмотренный ранее пример семантической сети отображал
теоретико-множественные отношения между объектами, представляющие понятия предметной области. Рассмотрим использование
семантических сетей для представления событий.
Чтобы представить некоторые знания о событиях в виде семантической сети, необходимо выделить данные события. События обычно описываются глаголом. После этого выделяются следующие объекты:
• объекты, которые являются инициаторами события;
• объекты, на которые событие воздействует;
• объекты, характеризующие свойства события.
Все связи понятий, событий и свойств с действием (глаголом) называют падежами или падежными отношениями, которые относятся
к классу лингвистических отношений (табл. 7.2).
69
Т а б л и ц а 7.2. Возможные падежи
Падеж
Значение падежа
Агент
Предмет, являющийся инициатором действия
Объект
Предмет, подвергающийся действию
Источник
Размещение предмета перед действием
Приемник
Размещение предмета после действия
Время
Момент выполнения действия
Место
Место проведения действия
Цель
Действие другого события
Введение падежей позволяет перейти от поверхностной структуры
к его смысловому содержанию.
Представим в виде семантической сети предложение: «Студент
пришел в 18.50 с работы в университет на занятие, чтобы сдать лабораторную работу в компьютерном классе».
Выделим основные события в этом предложении, соответствующие действиям:
• F1 — студент пришел;
• F2 — пришел, чтобы сдать.
Схема семантической сети представлена на рис. 7.2.
Особенность семантических сетей как модели представления знаний состоит в единстве БЗ и механизма вывода новых знаний.
Рис. 7.2. Представление знаний семантической сетью
70
Рис. 7.3. Семантическая сеть запроса «Куда пришел студент?»
Рассмотрим метод сопоставления, который заключается в выполнении следующих шагов:
1) строится семантическая сеть, соответствующая структуре запроса;
2) сеть запроса сопоставляется с семантической сетью, в результате чего отыскивается искомый узел, который и является ответом.
Запрос «Куда пришел студент?» представим в виде сети (рис. 7.3).
Сопоставление общей сети с сетью запроса начинается с поиска
вершины «пришел», имеющей дугу «агент», направленную от вершины «студент». Затем происходит переход по дуге «приемник», что
приводит к ответу «в университет на занятие».
Наряду с методом сопоставления в семантических сетях используется метод перекрестного поиска, состоящий из двух шагов:
1) поиск отношений между понятиями;
2) вершина, находящаяся на пересечении дуг, соответствующих
отношениям в запросе, является ответом на запрос.
Сеть запроса «Что сделал студент в 18.50?» представлена на рис. 7.4.
Сопоставление общей сети с сетью запроса начинается с поиска
вершины, в которую сходятся дуги «агент» и «объект». В данной семантической сети присутствует одна вершина «пришел», и она связана падежами с вершинами «студент» и «в 18.50». Поэтому вершина
«пришел» является ответом на этот запрос.
Любую семантическую сеть можно записать с помощью предикатов, т. е. преобразовать семантические сети к логической модели
представления знаний. Например, семантическую сеть, изображенную на рис. 7.1, можно описать с помощью следующих предикатов:
• является (элемент, множество);
• имеет (часть, объект),
следующим образом:
• является (кашалот, кит);
• является (Моби Дик, кашалот);
• имеет (хвост, кит).
Рис. 7.4. Семантическая сеть запроса «Что
сделал студент в 18.50?»
71
Отношение «студент — пришел» на рис. 7.2 можно описать предикатом
агент (инициатор, действие).
Другие отношения между объектами можно описать аналогичными предикатами.
Семантические сети, как модель представления знаний, имеют
следующие преимущества:
• описание объектов и событий производится на уровне, близком
к естественному языку;
• возможность объединение нескольких семантических сетей в
одну;
• возможность выделения фрагмента сети и использования ее в
качестве автономной БЗ, содержащей все необходимые объекты, события и отношения между ними;
• небольшое число типов отношений между объектами и событиями.
7.5. Продукционные модели
Эта модель называется продукционной, так как все знания представляются в виде продукций — правил вида
ЕСЛИ A, ТО B,
где A — условная часть; B — заключительная часть.
Условная часть состоит из одного или нескольких высказываний,
соединенных операциями конъюнкции. Заключение состоит из одного высказывания.
Если высказывания условной части истинны, то высказывание
заключительной части тоже считается истинным.
Правила, условная часть которых истинна на некотором этапе
логического вывода, образуют фронт готовых продукций.
Математические или программные средства, обрабатывающие
знания, представленные правилами, называются продукционными
системами или системами продукций.
Популярность продукционных моделей определяется следующими
факторами:
• простой и точный механизм использования знаний — подавляющая
часть человеческих знаний может быть записана в виде продукций;
• однородность — знания описываются по единому синтаксису;
• параллельность — одновременно могут обрабатываться несколько правил.
При большом числе продукций (более 1 000) продукционная модель имеет, по крайней мере, два недостатка:
72
усложняется проверка непротиворечивости продукций;
усложняется проверка правильности работы логического вывода.
Системы продукций состоят из двух частей:
1) БЗ, состоящая из правил;
2) блок логического вывода новых знаний из правил БЗ.
•
•
Пример 7.3. Рассмотрим функционирование системы продукций,
БЗ которой включает два правила:
правило П1
правило П2
ЕСЛИ лето = жаркое И
осадков = мало
ТО
урожай = плохой;
ЕСЛИ урожай = плохой
ТО
цены_на_продукты = растут.
В правилах использовались высказывания, представляющие названия переменных и их значения.
Рассмотрим два способа логического вывода в продукционных
моделях: прямую и обратную цепочки рассуждений. В прямой цепочке дано исходное истинное высказывание, которое служит для доказательства истинности новых высказываний. Далее производится
перебор правил. Если условная часть правила является истинной, то
и заключительная часть становится истинной.
Пусть известны два факта, т. е. эти высказывания истинны:
лето = жаркое;
осадков = мало.
Прямая цепочка рассуждений будет состоять из следующих шагов.
1. Анализируется правило П1. Его условная часть истинна, так как
оба высказывания из условной части истинны.
2. Так как условная часть правила П1 истинна, то заключительная
часть правила П1 считается истинной. Следовательно, высказывание
«урожай = плохой» является истинным.
3. Происходит переход к правилу П2 и анализируется его условная
часть. Условная часть является истинной, так как высказывание
«урожай = плохой» истинно.
4. Условная часть правила П2 является истинной, поэтому и заключительная часть этого правила является истинной. Значит, высказывание «цены_на_продукты = растут» является истинным.
В результате прямой цепочки рассуждений при условии истинности высказываний:
лето = жаркое;
осадков = мало,
были выведены следующие факты:
урожай = плохой;
цены_на_продукты = растут.
73
При обратной цепочке рассуждений анализируются заключительные части правил. Задачей обратной цепочки является доказательство
истинности высказывания. В качестве исходных данных задаются уже
известные истинные высказывания.
Пример 7.4. Пусть БЗ включает два правила и два факта, что и в
предыдущем примере. Необходимо доказать истинность высказывания «цены_на_продукты = растут».
Обратная цепочка рассуждений включает следующие шаги.
1. Производится поиск правила, в заключительной части которого находится это высказывание. Это правило П2.
2. Анализируется условная часть правила П2, состоящая из высказывания «урожай = плохой». Истинность этого высказывания неизвестна, поэтому производится поиск правила, заключительная часть
которого содержит высказывание «урожай = плохой». Это правило П1.
3. Анализируется условная часть правила П1. Она является истинной, так как оба высказывания условной части истинны. Следовательно, высказывание «урожай = плохой» является истинным.
4. Условная часть правила П2 является истинной, что доказывает
истинность высказывания «цены_на_продукты = растут».
В результате обратной цепочки рассуждений доказана истинность
высказывания «цены_на_продукты = растут».
В рассмотренном примере в БЗ находились всего два правила, но
в реальных системах продукций число правил может достигать тысячи. Поэтому возникает проблема выбора продукции, которая будет
активизирована в данной ситуации. Решение этой задачи возлагается на систему управления продукциями.
Рассмотрим несколько стратегий выбора продукций. Основная их
идея сводится к сокращению фронта готовых продукций.
1. Принцип «стопки книг». Стратегия основана на идее, что наиболее используемая продукция является наиболее полезной. Готовые
продукции образуют «стопку», в которой порядок определяется накопленной частотой использования в прошлом. На самом верху
стопки находится продукция, у которой частота использования максимальна. Этот принцип особенно хорош, когда частота использования подсчитывается с учетом некоторой ситуации, в которой ранее
исполнялась продукция, и это использование имело положительную
оценку.
2. Принцип наиболее длинного условия. Стратегия заключается в
выборе из фронта готовых продукций той, у которой стало истинным
наиболее длинное условие. Этот принцип опирается на соображении,
что частные правила, относящиеся к узкому классу ситуаций, важнее
общих правил, относящихся к широкому классу, так как первые учитывают больше информации о ситуации, чем вторые. Трудность использования данного принципа состоит в том, что необходимо за-
74
ранее упорядочить условия по вхождению друг в друга по отношению
«ЧАСТНОЕ — ОБЩЕЕ».
3. Принцип метапродукций. В систему продукций вводятся специальные метапродукции, задачей которых является организация управления в системе продукций в случае неоднозначного выбора из
фронта готовых продукций. Пример метапродукции:
ЕСЛИ (A) И (Существуют продукции, в условной части которых
есть B) ТО (продукции, в условной части которых есть C,
следует активизировать раньше, чем продукции, содержащие в
условной части B),
где A, B, C — некоторые условия.
4. Принцип «классной доски». При реализации этой стратегии
выделяется специальное рабочее поле памяти — аналог классной
доски, на которой мелом пишут объявления и стирают их по мере
необходимости. На этой «доске» выполняющиеся процессы осуществляют следующие действия:
• находят знания, инициирующие их активизацию;
• выносят информацию о своей работе, которая может оказаться
необходимой для других процессов.
5. Принцип приоритетного выбора. Стратегия связана с введением статических или динамических приоритетов для продукций. Статические приоритеты могут формироваться априорно на основании
сведений о важности продукционных правил в данной предметной
области. Эти сведения, как правило, предоставляет эксперт. Динамические приоритеты вырабатываются в процессе функционирования продукционной системы и могут отражать, например, такой
параметр, как время нахождения во фронте готовых продукций.
7.6. Фреймы
Основная идея фреймового подхода заключается в представлении
понятий или ситуаций в виде совокупности некоторых свойств и их
значений.
Фрейм можно рассматривать как фрагмент семантической сети,
предназначенный для описания объектов и всех их свойств.
Фрейм состоит из слотов. Слот соответствует некоторой характеристике объекта, представленного фреймом. Значение слота может
быть текстовым или числовым. Другие фреймы могут являться значением слота.
Для управления значением слота со слотом может быть связана
процедура. Процедура запускается при выполнении действия над
значением слота или фреймом целиком. Со слотами могут быть связаны следующие процедуры:
75
1) ЕСЛИ — ДОБАВЛЕНО: выполняется, когда новая информация
помещается в слот;
2) ЕСЛИ — УДАЛЕНО: выполняется при удалении информации
из слота;
3) ЕСЛИ — НУЖНО: выполняется, когда запрашивается информация из слота, а он пуст.
Процедуры связываются с определенным слотом или фреймом
целиком. С одним слотом могут быть связаны несколько процедур.
Рассмотрим основные особенности фреймов как модели представления знаний.
1. Базовый тип. Базовые фреймы используются для наглядного представления наиболее важных объектов предметной области. На основе
базовых фреймов строятся фреймы для новых объектов. При этом каждый дочерний фрейм содержит слот-указатель на родительский фрейм.
2. Процесс сопоставления. Во фреймовых системах осуществляется
поиск фрейма, который соответствует цели (данной ситуации), т. е. сопоставляются значения слота фрейма и значения атрибутов цели.
3. Иерархическая структура. Фреймовая система построена на
основе иерархической структуры, в которой значения атрибутов
фреймов верхнего уровня совместно используются всеми дочерними
фреймами нижних уровней. Такая структура позволяет решать следующие задачи:
• удобно систематизировать и записывать схожие объекты;
• добавлять новые объекты в соответствующие позиции иерархии;
• упростить просмотр знаний и обнаружение противоречий в
знаниях;
• сделать фреймовую систему более гибкой.
Пример 7.5. Для иллюстрации работы фреймов рассмотрим иерархию делового отчета со слотами, их значениями и связанными с
ними процедурами (рис. 7.5).
Пусть системе задан запрос: «Необходимо создать квартальный
финансовый отчет о выполнении проекта по новой технологии».
Рассмотрим ее действия по шагам.
1. На основе родительского фрейма «Финансовый отчет» создается новый фрейм «Финансовый отчет № 3». Далее все действия совершаются с этим вновь созданным фреймом. В слот «ТЕМА» записывается значение «Проект по новой технологии».
2. Запускается процедура «ЕСЛИ — ДОБАВЛЕНО», связанная со
слотом «ТЕМА», так как в слот «ТЕМА» было записано новое значение. Пусть процедура нашла руководителя этого проекта по фамилии
Иванов. Процедура вписывает его фамилию в слот «АВТОР» финансового отчета № 3. Если руководитель этого проекта не будет найден,
значение слота «АВТОР» будет наследовано от родительского фрейма
«Финансовый отчет», а именно в слот будет помещен текст «РУКОВОДИТЕЛЬ ПРОЕКТА».
76
Рис. 7.5. Иерархия делового отчета
3. Запускается процедура «ЕСЛИ — ДОБАВЛЕНО», связанная с
фреймом, так как в один из слотов было вписано новое значение.
Данная процедура составляет сообщение, чтобы отправить его Иванову, но обнаруживает отсутствие даты исполнения. Процедура
«ЕСЛИ — ДОБАВЛЕНО» передает управление процедуре «ЕСЛИ —
НУЖНО», связанной со слотом «ДАТА»
4. Запускается процедура «ЕСЛИ — НУЖНО», связанная со слотом
«ДАТА». Процедура, анализируя текущую дату (например, 12 марта
этого года), определяет, что ближайшей к ней является дата «30 марта» и вписывает ее в слот «ДАТА».
5. Процедура «ЕСЛИ — ДОБАВЛЕНО», связанная с фреймом,
обнаруживает, что отсутствует значение объема отчета. В слоте «ОБЪЕМ» нет данных, и он не связан с процедурами. В этом случае значение наследуется из одноименного слота родительского узла.
77
6. Когда все необходимые значения слотов определены, процедура составляет следующее сообщение: «Господин Иванов, пожалуйста,
подготовьте квартальный финансовый отчет по проекту новой технологии к 30 марта объемом 2 страницы».
Если в какой-то момент узел «Финансовый отчет № 3» будет удален, то система автоматически отправит АВТОРУ сообщение, что
отчет не требуется.
В общем случае фрейм представляет собой таблицу, структура и
принципы организации которой являются развитием понятия отношения в реляционной модели данных. Обобщенная структура
фрейма имеет вид таблицы (табл. 7.3).
Т а б л и ц а 7.3. Структура фрейма
ИМЯ ФРЕЙМА
Имя слота
Указатель
наследования
Указатель типа
данных
Значение
слота
Слот 1
Слот 2
………….
Слот N
Слот включает в себя следующие параметры.
Имя слота. Каждый слот должен иметь уникальное имя во фрейме, к которому он принадлежит. Имя слота в некоторых случаях
может быть служебным. Среди служебных имен могут быть следующие: имя пользователя, определяющего фрейм; дата определения или
модификации фрейма; комментарий.
Указатель наследования. Определяет, какую информацию об
атрибутах слотов во фрейме верхнего уровня наследуют слоты с теми
же именами во фрейме нижнего уровня. Типы указателей наследования:
• S (same, тот же) — слот наследуется с теми же значениями данных;
• U (unical, уникальный) — слот наследуется, но данные в каждом
фрейме могут принимать любое значение;
• I (independent, независимый) — слот не наследуется.
Указатель типа данных. Типом данных, включаемым в слот,
могут быть:
• FRAME (указатель) — указывает имя фрейма верхнего уровня;
• ATOM (переменная);
• TEXT (текстовая информация);
78
LIST (список);
LISP (присоединенная процедура).
С помощью механизма управления наследованием по отношениям IS — A осуществляются автоматический поиск и определение
значений слотов фрейма верхнего уровня и связанных процедур.
Фреймы, как и семантические сети, можно записать с помощью
предикатов. Например, предикат
•
•
значение (фрейм, слот, значение)
определяет значение слота фрейма, а предикат
функция (фрейм, слот, событие, f(x))
определяет функцию, связанную со слотом; здесь событие принимает одно из значений: ЕСЛИ — ДОБАВЛЕНО, ЕСЛИ — УДАЛЕНО
или ЕСЛИ — НУЖНО.
Фреймовая модель представления знаний эффективна для иерархического описания сложных понятий и решения задач, в которых в
зависимости от ситуации необходимо применять различные способы
вывода. В то же время во фреймовой модели затруднено управление
завершенностью и постоянством целостного образа. По этой причине существует опасность нарушения связи со связанными процедурами и проблемы зацикливания процесса вывода.
Гл а в а 8
Архитектура ЭВМ
8.1. Поколения ЭВМ
Разделение ЭВМ на поколения условно, так как поколения сменялись постепенно, поэтому временные границы между поколениями размыты. Поколения ЭВМ разделяют в зависимости от физических элементов или технологии их изготовления, используемых
при построении ЭВМ (табл. 8.1). При сравнении быстродействия
ЭВМ под операцией понимают операцию над числами с плавающей
точкой.
П е р в о е поколение ЭВМ (1951 — 1954) строилось на электронных
лампах, которые могли быстро переключаться из одного состояния в
другое. Лампы имели большие размеры, поэтому ЭВМ первого поколения, состоящие из десятков тысяч ламп, занимали целые этажи
и были энергоемки. Программы записывались в ЭВМ с помощью
установки перемычек на особом машинном коде.
В т о р о е поколение ЭВМ (1958 — 1960) строилось на транзисторах — полупроводниковых приборах, которые могли находиться в
одном из двух состояний. По сравнению с лампами транзисторы
имели малые размеры и потребляемую мощность. Увеличение производительности обеспечивалось за счет более высокой скорости
переключения и использования обрабатывающих устройств, работающих параллельно. Площадь, требующаяся для размещения ЭВМ,
уменьшилась до нескольких квадратных метров. Программы записывались на перфокарты — картонные карточки, на которых были
выбиты или не выбиты дырочки, кодирующие 0 и 1. Программирование осуществлялось на языке Ассемблер, команды которого затем
переводились в машинный код.
Т р е т ь е поколение ЭВМ (1965 — 1968) строилось на интегральных
схемах (ИС). ИС представляет собой электрическую цепь определенного функционального назначения, которая размещается на кремниевой основе. ИС содержит сотни и тысячи транзисторных элементов, что позволило уменьшить размеры, потребляемую мощность,
стоимость и увеличить надежность системы. Помимо Ассемблера
80
Т а б л и ц а 8.1. Поколения ЭВМ
Поколение
Элементная
база процессора
Максимальная
емкость ОЗУ,
байт
Максимальное
быстродействие
процесссора, оп./с
Основные языки
программирования
Управление ЭВМ
пользователем
Первое
(1951 — 1954)
Электронные
лампы
102
10 4
Машинный код
Пульт управления и
перфокарты
Второе
(1958 —1960)
Транзисторы
103
10 6
Ассемблер
Перфокарты и перфоленты
Третье
(1965 — 1968)
ИС
10 4
107
Процедурные
языки высокого
уровня (ЯВУ)
Алфавитно-цифровой
терминал
Четвертое
(1976 — 1979)
БИС
105
108
Процедурные
ЯВУ
Монохромный или
графический дисплей,
клавиатура
Четвертое
(с 1985)
СБИС
107
10 9
Процедурные
ЯВУ
Цветной графический
дисплей, клавиатура,
«мышь» и др.
Пятое
Усовершенствованные
СБИС
108
1012
Языки логического программирования
Цветной графический
дисплей и устройства
голосовой связи
81
программирование осуществлялось на языках высокого уровня (ЯВУ),
имевших большое количество операторов. Каждый оператор объединял несколько команд языка Ассемблер.
Ч е т в е р т о е поколение ЭВМ (с 1985 г. по сегодняшний день)
строилось на больших интегральных схемах (БИС). БИС содержат не
набор нескольких логических элементов, из которых строились затем
функциональные узлы компьютера, а целиком функциональные узлы.
Примером БИС является микропроцессор. БИС способствовали появлению персональных компьютеров. Увеличение количества транзисторов до миллионов привело к появлению сверхбольших ИС
(СБИС).
П я т о е поколение ЭВМ существует в теории. Основное требование к ЭВМ — машина должна сама по поставленной цели составить
план действий и выполнить его. Такой способ решения задачи называется логическим программированием. Элементная база процессора — СБИС с использованием опто- и криоэлектроники. Оптоэлектроника — раздел электроники, связанный с эффектами взаимодействия оптического излучения с электронами в веществах (главным
образом в твердых телах) и использованием этих эффектов для генерации, передачи, хранения, обработки и отображения информации.
Криоэлектроника (криогенная электроника) — область науки и
техники, занимающаяся применением явлений, имеющих место в
твердых телах при температуре ниже 120 К (криогенных температурах)
в присутствии электрических, магнитных или электромагнитных
полей (явление сверхпроводимости), для создания электронных приборов и устройств.
8.2. Структура ЭВМ
Вычислительной называется техническая система способная выполнять действия посредством арифметических и логических операций.
ЭВМ (персональный компьютер (ПК)) — это универсальная вычислительная диалоговая система, реализованная на базе микропроцессорных средств, компактных внешних запоминающих устройств,
способная выполнять последовательность операций над информацией определенной программы. В основе функционирования любой
ЭВМ лежит архитектура.
Архитектура — это наиболее общие принципы построения
ЭВМ, реализующие программное управление работой и взаимодействием основных ее функциональных узлов. В основе архитектуры
современных ЭВМ лежат принципы, предложенные американским
ученым и теоретиком вычислительной техники Джоном фон Нейманом.
Обобщенная схема ЭВМ представлена на рис. 8.1.
82
Рис. 8.1. Структура ЭВМ
ЭВМ состоит из системного блока, к которому подключаются
монитор и клавиатура. В системном блоке находятся основные компоненты ЭВМ:
• ВЗУ — внешние запоминающие устройства (жесткий диск, приводы CD/DVD/Blu-Ray, флэш-память); некоторые ВЗУ располагаются внутри системного блока и подключаются к контроллерам ВЗУ,
а некоторые — снаружи системного блока и подключаются к портам
ввода-вывода;
• ВК — видеокарта (видеоадаптер, видеоконтроллер) формирует
изображение и передает его на монитор;
• ИП — источник питания обеспечивает питание всех блоков ЭВМ
по системной шине;
• КВЗУ — контроллеры внешних запоминающих устройств управляют обменом информацией с ВЗУ;
• КК — контроллер клавиатуры содержит буфер, в который помещаются вводимые символы, и обеспечивает передачу этих символов другим компонентам;
• КПВВ — контроллеры портов ввода-вывода управляют обменом
информацией с периферийными устройствами;
• МП — микропроцессор выполняет команды программы, управляет взаимодействием всех компонент ЭВМ;
• ОЗУ — оперативное запоминающее устройство хранит исходные
данные и результаты обработки информации во время функционирования ЭВМ;
• ПЗУ — постоянное запоминающее устройство хранит программы, выполняемые во время загрузки ЭВМ;
83
• ПУ — периферийные устройства различного назначения: принтеры, сканнеры, манипулятор «мышь» и др.;
• СА — сетевой адаптер (карта) обеспечивает обмен информацией с локальными и глобальными компьютерными сетями.
К устройствам ввода информации относят клавиатуру и такие
ПУ, как сканнеры, манипуляторы типа «мышь», джойстики, а к
устройствам вывода информации — монитор и такие ПУ, как принтеры.
Современную архитектуру ЭВМ определяют следующие принципы.
1. Принцип программного управления. Обеспечивает автоматизацию процесса вычислений на ЭВМ. Согласно этому принципу для
решения каждой задачи составляется программа, которая определяет последовательность действий ЭВМ.
2. Принцип программы, сохраняемой в памяти. Согласно этому
принципу команды программы подаются, как и данные, в виде
чисел и обрабатываются так же, как и числа, а сама программа
перед выполнением загружается в ОЗУ, что ускоряет процесс ее
выполнения.
3. Принцип произвольного доступа к памяти. В соответствии с
этим принципом элементы программ и данных могут записываться
в произвольное место ОЗУ, что позволяет обратиться по любому заданному адресу (к конкретному участку памяти) без просмотра
предыдущих.
Составные части ЭВМ образуют аппаратное обеспечение ЭВМ
(hardware). Рассмотрим эти компоненты ЭВМ.
8.3. Микропроцессор
Микропроцессор (МП; CPU — Central Processing Unit (центральный обрабатывающий модуль)) — центральный блок ЭВМ, управляющий работой всех компонент ЭВМ и выполняющий операции
над информацией. Операции производятся в регистрах, составляющих микропроцессорную память.
Основные функции МП:
• выполнение команд программы, расположенной в ОЗУ; команда состоит из кода, определяющего, что эта команда делает, и операндов, над которыми эта команда осуществляется;
• управление пересылкой информации между микропроцессорной
памятью, ОЗУ и периферийными устройствами;
• обработка прерываний;
• управление компонентами ЭВМ.
Микропроцессор (рис. 8.2) состоит из следующих блоков:
• АЛУ — арифметико-логическое устройство;
84
Рис. 8.2. Структура микропроцессора
• ДБ — другие блоки (математический сопроцессор, модуль предсказания ветвлений);
• ДК — дешифратор команд;
• ИМП — интерфейс микропроцессора;
• Кэш L1 — кэш-память первого уровня;
• Кэш L2 — кэш-память второго уровня;
• МПП — микропроцессорная память;
• РОН — регистры общего назначения;
• РС — регистры смещений;
• РФ — регистр флагов;
• СР — сегментные регистры;
• УС — устройство синхронизации;
• УУ — устройство управления.
Рассмотрим назначение этих блоков МП.
Устройство управления выполняет команды, поступающие в МП
в следующей последовательности:
1) выборка из регистра-счетчика адреса ячейки ОЗУ, где хранится
очередная команда программы;
2) выборка из ячеек ОЗУ кода очередной команды и приема считанной команды в регистр команд;
3) расшифровка кода команды дешифратором команды;
4) формирование полных адресов операндов;
5) выборка операндов из ОЗУ или МПП и выполнение заданной
команды обработки этих операндов;
6) запись результатов команды в память;
7) формирование адреса следующей команды программы.
Для ускорения работы перечисленные действия выполняются
параллельно: один блок выбирает команду, второй дешифрует, третий
выполняет, образуя конвейер команд.
Команды, поступающие в УУ, временно хранятся в кэш-памяти
первого уровня, освобождая шину для выполнения других операций.
Размер кэш-памяти первого уровня 8 … 32 Кбайт.
85
Арифметико-логическое устройство выполняет все арифметические (сложение, вычитание, умножение, деление) и логические
(конъюнкция, дизъюнкция и др.) операции над целыми двоичными
числами и символьной информацией.
Устройство синхронизации определяет дискретные интервалы
времени — такты работы МП между выборками очередной команды.
Частота, с которой осуществляется выборка команд, называется
тактовой частотой.
Интерфейс МП (ИМП) предназначен для связи и согласования
МП с системной шиной ЭВМ. Принятые команды и данные временно помещаются в кэш-память второго уровня. Размер кэш-памяти
второго уровня — 256 … 2 048 Кбайт. Ранее кэш-память второго уровня размещалась на материнской плате.
Микропроцессорная память включает в себя 14 основных двухбайтовых запоминающих регистров и множество (до 256) дополнительных регистров. Регистры — это быстродействующие ячейки памяти различного размера. Основные регистры можно разделить на
4 группы.
1. Регистры общего назначения (РОН, универсальные регистры):
AX, BX, CX, DX. Можно работать с регистром целиком или отдельно
с каждой его половинкой: регистром старшего (high) байта — AH,
BH, и регистром младшего (low) байта — AL, BL, CL, DL. Например,
структура регистра AX имеет вид, показанный на рис. 8.3.
Универсальные регистры имеют свое предназначение:
• АХ — регистр-аккумулятор, с его помощью осуществляется вводвывод данных в МП, а при выполнении операций умножения и деления АХ используется для хранения первого числа, участвующего в
операции (множимого, делимого) и результата операций (произведения, частного) после ее завершения;
• ВХ нередко используется для хранения адреса базы в сегменте данных и начального адреса поля памяти при работе с
массивами;
• СХ — регистр-счетчик, используется как счетчик числа повторений при циклических операциях;
• DX — используется как расширение регистра-аккумулятора при
работе с 32-разрядными числами и при выполнении операции умножения и деления.
2. Сегментные регистры используются для хранения начальных
адресов полей памяти (сегментов), отведенных в программах для
хранения команд кода (регистр CS), данных (DS), стека (SS ), до-
Рис. 8.3. Структура регистра AX
86
полнительной области памяти данных при обмене между сегментами (ES ).
3. Регистры смещений IP, SP, ВР, SI, DI предназначены для
хранения относительных адресов ячеек памяти внутри сегментов
(смещений относительно начала сегментов).
4. Регистр флагов FL содержит одноразрядные флаги, управляющие выполнением программы в ЭВМ. Флаги принимают значения 0
или 1. Значения флагов устанавливаются независимо друг от друга.
Всего в регистре 9 флагов: 6 — статусные, отражающие результаты
операций (флаги переноса, нуля, переполнения и др.); 3 — управляющие, определяющие режим выполнения программы (флаги пошагового выполнения программы, прерываний и направления обработки данных).
МПП — это память с самым меньшим временем доступа в
ЭВМ.
Другие блоки — это блоки, ускоряющие работу МП. АЛУ производит действия только над двоичными целыми числами. Операции
над числами с плавающей точкой выполняет математический сопроцессор, освобождая МП от выполнения этих операций. Блок предсказания ветвлений программы просматривает программу на несколько шагов вперед, чтобы определить дальнейшее направление
выполнения программы. Вероятность предсказания 80 — 90 %.
Работа МП состоит в выборке очередной команды и ее выполнения. В некоторых случаях выполнение программы необходимо прервать, например в случае ошибки вычисления. Такие случаи называются прерываниями.
Выделяют два типа прерываний:
1) внутрипроцессорные прерывания, возникающие из-за непреодолимого препятствия в выполнении программы, например запись
данных в запрещенную для записи область ОЗУ или переполнение
результата при вычислениях;
2) прерывания от внешних устройств не являются фатальными
или ошибочными; прерывания второго типа возникают, когда требуется обмен данными с внешним устройством, например приводом
компакт-дисков, а он не готов.
Основными параметрами МП являются тактовая частота, разрядность и рабочее напряжение.
Тактовая частота определяет количество элементарных операций
(тактов), выполняемых МП за единицу времени. Тактовая частота современных МП измеряется в гигагерцах (1 Гц соответствует выполнению
одной операции за одну секунду, 1 ГГц = 10 9 Гц). Чем больше тактовая
частота, тем больше команд может выполнить МП и тем больше его
производительность. Первые МП, использовавшиеся в персональных
компьютерах, работали на частоте 4,77 МГц (1 МГц = 10 6 Гц). В настоящее время рабочие частоты современных МП превосходят 2 ГГц
(2011 г.).
87
Разрядность процессора показывает, сколько бит данных МП
может принять и обработать в своих регистрах за один такт. Разрядность процессора определяется разрядностью внутренней шины, т. е.
количеством проводников в шине, по которым передаются команды.
Современные МП семейства Intel имеют 64 разряда.
Рабочее напряжение процессора обеспечивается материнской
платой, поэтому разным маркам процессоров соответствуют разные
материнские платы. Рабочее напряжение процессоров не превышает
3 В. Снижение рабочего напряжения позволяет уменьшить размеры
МП, а также уменьшить тепловыделение в МП, что повышает его
производительность без угрозы перегрева.
МП все время с момента включения до момента выключения выполняет команды. Если поток команд заканчивается, например в
случае простоя ЭВМ, то МП выполняет пустую команду NOP.
8.4. Системная шина
В основе устройства ЭВМ лежит системная шина, которая служит
для обмена командами и данными между компонентами ЭВМ, расположенными на материнской плате. ПУ подключаются к шине через
контроллеры. Такая архитектура ЭВМ называется открытой, так как
легко может быть расширена за счет подключения новых устройств.
Передача информации по системной шине также осуществляется по
тактам.
Системная шина включает в себя:
• кодовую шину данных для параллельной передачи всех разрядов
числового кода (машинного слова) операнда из ОЗУ в МПП и обратно, имеет 64 разряда;
• кодовую шину адреса для параллельной передачи всех разрядов
адреса ячейки ОЗУ, имеет 32 разряда;
• кодовую шину инструкций для передачи команд (управляющих
сигналов, импульсов) во все блоки ЭВМ; простые команды кодируются одним байтом, но есть и команды, кодируемые двумя, тремя и
более байтами, имеет 32 разряда;
• шину питания для подключения блоков ЭВМ к системе энергопитания.
Системная шина обеспечивает три направления передачи информации:
1) между МП и ОЗУ;
2) между МП и контроллерами устройств;
3) между ОЗУ и внешними устройствами (ВЗУ и ПУ, в режиме
прямого доступа к памяти).
Все устройства подключаются к системной шине через контроллеры — устройства, которые обеспечивают взаимодействие внешних
устройств и системной шины.
88
Т а б л и ц а 8.2. Основные характеристики шин
Характеристика
PCI
AGP
32/32
32/32
Рабочая частота, МГц
66
133
Пропускная способность, Мбит/с
264
2112
Число подключаемых устройств, шт.
10
1
Разрядность шины данных/адреса, бит
Чтобы освободить МП от управления обменом информацией
между ОЗУ и внешними устройствами, например при чтении или
записи информации, предусмотрен режим прямого доступа в память
(DMA — Direct Memory Access).
Таким образом, МП может заниматься выполнением других команд, не отвлекаясь на копирование информации между ОЗУ и
внешними устройствами.
Характеристиками системной шины являются количество обслуживаемых ею устройств и ее пропускная способность, т. е. максимально возможная скорость передачи информации.
Пропускная способность шины зависит от следующих параметров:
• разрядность или ширина шины — количество бит, которое может
быть передано по шине одновременно (существуют 8-, 16-, 32- и
64-разрядные шины);
• тактовая частота шины — частота, с которой передаются биты
информации по шине.
Наиболее распространенные шины. PCI (Peripheral Component
Interconnect) — самая распространенная системная шина. Быстродействие шины не зависит от количества подсоединенных устройств.
Поддерживает следующие режимы:
• Plug and Play (PnP) — автоматическое определение и настройка подключенного к шине устройства;
• Bus Mastering — режим единоличного управления шиной любым
устройством, подключенным к шине, что позволяет быстро передать
данные по шине и освободить ее.
AGP (Accelerated Graphics Port) — магистраль между видеокартой
и ОЗУ. Разработана, так как параметры шины PCI не отвечают требованиям видеоадаптеров по быстродействию. Шина работает на
большей частоте, что позволяет ускорить работу графической подсистемы ЭВМ.
Параметры шин приведены в табл. 8.2.
89
8.5. Оперативное и постоянное
запоминающие устройства
Запоминающие устройства, используемые в ЭВМ, состоят из последовательности ячеек. Каждая ячейка содержит значение одного
байта и имеет собственный номер (адрес), по которому происходит
обращение к ее содержимому. Все данные в ЭВМ хранятся в двоичном
виде нулей и единиц.
Запоминающие устройства характеризуются двумя параметрами:
• объем памяти — размер в байтах, доступных для хранения информации;
• время доступа к ячейкам памяти — средний временной интервал,
в течение которого находится требуемая ячейка памяти и из нее извлекаются данные.
Оперативное запоминающее устройство (ОЗУ; RAM — Random
Access Memory) предназначено для оперативной записи, хранения и
чтения информации (программ и данных), непосредственно участвующей в информационно-вычислительном процессе, выполняемом ЭВМ в текущий период времени. После выключения питания
ЭВМ информация в ОЗУ уничтожается, поэтому она не подходит для
долговременного хранения информации. Каждая ячейка памяти
имеет свой адрес, выраженный числом. В ЭВМ на базе процессоров
Intel Pentium используется 32-разрядная адресация. Это означает, что
число независимых адресов равно 232, т. е. возможное адресное пространство составляет 4,3 Гбайт. Объем ОЗУ превышает 4 096 Мбайт
(2011 г.), время доступа 0,005 — 0,02 мкс. 1 с = 10 6 мкс.
Постоянное запоминающее устройство (ПЗУ; ROM — Read Only
Memory) хранит неизменяемую (постоянную) информацию: программы, выполняемые во время загрузки системы, и постоянные
параметры ЭВМ. В момент включения ЭВМ в его ОЗУ отсутствуют
данные, так как ОЗУ не сохраняет данные после выключения ЭВМ.
Но МП необходимы команды, в том числе и сразу после включения.
Поэтому МП обращается по специальному стартовому адресу, который ему всегда известен, за своей первой командой. Этот адрес из
ПЗУ. Основное назначение программ из ПЗУ состоит в том, чтобы проверить состав и работоспособность системы и обеспечить взаимодействие
с клавиатурой, монитором, жесткими и гибкими дисками. Обычно изменить информацию ПЗУ нельзя. Объем ПЗУ 128—256 Кбайт, время
доступа 0,035 — 0,1 мкс. Так как объем ПЗУ небольшой, но время
доступа больше, чем у ОЗУ, при запуске все содержимое ПЗУ считывается в специально выделенную область ОЗУ.
Кроме ПЗУ существует энергонезависимая память CMOS RAM
(Complementary Metal-Oxide Semiconductor RAM), в которой хранятся данные об аппаратной конфигурации ЭВМ: о подключенных к
ЭВМ устройствах и их параметры, параметры загрузки, пароль на
90
вход в систему, текущее время и дата. Питание памяти CMOS RAM
осуществляется от батарейки. Если заряд батарейки заканчивается,
то настройки, хранящиеся в памяти CMOS RAM, сбрасываются, и
ЭВМ использует настройки по умолчанию.
ПЗУ и память CMOS RAM составляют базовую систему вводавывода (BIOS — Basic Input-Output System).
8.6. Внешние запоминающие устройства
8.6.1. Общие сведения
Внешние запоминающие устройства (ВЗУ) предназначены для
долговременного хранения и транспортировки информации. ВЗУ
взаимодействуют с системной шиной через контроллеры внешних
запоминающих устройств (КВЗУ). КВЗУ обеспечивают интерфейс
ВЗУ и системной шины в режиме прямого доступа к памяти, т. е. без
участия МП.
Интерфейс — это совокупность связей с унифицированными
сигналами и аппаратуры, предназначенной для обмена данными
между устройствами вычислительной системы.
ВЗУ можно разделить по критерию транспортировки на переносные и стационарные. Переносные ВЗУ состоят из носителя, подключаемого к порту ввода-вывода (обычно USB), (флэш-память) или
носителя и привода (накопители на гибких магнитных дисках, приводы CD и DVD). В стационарных ВЗУ носитель и привод объединены в единое устройство (накопитель на жестких магнитных дисках).
Стационарные ВЗУ предназначены для хранения информации внутри
ЭВМ.
Перед первым использованием или в случае сбоев ВЗУ необходимо отформатировать — записать на носитель служебную информацию, необходимую в дальнейшем при операциях чтения-записи с
носителя.
Рассмотрим три типа ВЗУ, разделенные по критерию физической
основы или технологии производства носителя: 1) магнитные носители; 2) оптические носители; 3) флэш-память.
8.6.2. Магнитные носители
Магнитные носители основаны на свойстве материалов находиться в двух состояниях: «не намагничено» — «намагничено», кодирующие 0 и 1. По поверхности носителя перемещается головка,
которая может считывать состояние или изменять его. Запись данных на магнитный носитель осуществляется следующим образом.
91
При изменении силы тока, проходящего через головку, происходит
изменение напряженности динамического магнитного поля на поверхности магнитного носителя, и состояние ячейки меняется с
«не намагничено» на «намагничено» или наоборот. Операция считывания происходит в обратном порядке. Намагниченные частички
ферромагнитного покрытия являются причиной появления электрического тока. Электромагнитные сигналы, которые возникают
при этом, усиливаются и анализируются, и делается вывод о значении 0 или 1.
Из-за контакта головки с поверхностью носителя через некоторое
время носитель приходит в негодность.
Рассмотрим три типа магнитных носителей.
1. Накопители на жестких магнитных дисках (НЖМД; harddisk —
жесткий диск) представляют собой несколько дисков с магнитным
покрытием, нанизанные на шпиндель, в герметичном металлическом
корпусе. При вращении диска происходит быстрый доступ головки
к любой части диска.
В НЖМД может быть до десяти дисков. Их поверхность размечается дорожками (track). Каждая дорожка имеет свой номер. Дорожки
с одинаковыми номерами, расположенные одна над другой на разных
дисках, образуют цилиндр. Дорожки на диске разбиты на секторы
(нумерация начинается с единицы). Сектор занимает 571 байт. Из них
512 байт отведено для записи данных. Оставшиеся 59 байт отведены
под заголовок (префикс), определяющий начало и номер сектора, и
окончание (суффикс), где записана контрольная сумма, необходимая
для проверки целостности хранимых данных. Секторы и дорожки
формируются во время форматирования диска. Разметка секторов
зависит от типа диска. Жесткие диски устанавливаются в системном
блоке и являются основным ВЗУ ЭВМ. Объем жестких дисков превышает 1 Тбайт (2011 г.), а время доступа — 0,005 — 0,03 с.
2. Накопители на гибких магнитных дисках (НГМД; FDD —
Floppy Disk Drive) предназначены для записи информации на переносные носители — дискеты. Дискета представляет собой гибкий
диск с магнитным покрытием, помещенный в жесткий корпус со
шторкой, открываемой для доступа головки к диску, и прорезью для
защиты от записи. Как и в случае жесткого диска, поверхность гибкого диска разбивается на дорожки, которые, в свою очередь, разбиваются на секторы. Секторы и дорожки формируются во время форматирования дискеты. Дискеты могут быть двух размеров 5,25 дюймов
(133 мм; является устаревшим) и 3,5 дюймов (89 мм). Для каждого
типа дискеты нужен свой НГМД. Объем дискет — до 1,44 Мбайт,
время доступа — 0,065 — 0,1 с. В настоящее время НГМД вытеснены
флэш-памятью.
3. Дисковые массивы RAID (Redundant Array of Inexpensive Disks —
массив недорогих дисков с избыточностью) используются для хранения данных в суперкомпьютерах (мощных ЭВМ, предназначенных
92
для решения крупных вычислительных задач) и серверах (подключенных к сети ЭВМ, предоставляющих доступ к хранящимся в них
данным).
Массивы RAID — это несколько запоминающих устройств на
жестких дисках, объединенные в один большой накопитель, обслуживаемый специальным RAID-контроллером. Одна и та же информация хранится на различных жестких дисках и при потере информации на одном жестком диске восстанавливает ее с другого жесткого диска. RAID-массивы поддерживают технологию Plug and Play, т. е.
замену одного из дисков без остановки всего массива.
8.6.3. Оптические носители
Оптические носители представляют собой компакт-диски диаметром 12 см (4,72 дюйма) или мини-диски диаметром 8 см (3,15 дюйма).
Оптические носители состоят из трех слоев:
1) поликарбонатная основа (внешняя сторона диска);
2) активный (регистрирующий) слой пластика с изменяемой фазой
состояния;
3) тончайший отражающий слой (внутренняя сторона диска).
В центре компакт-диска находится круглое отверстие, надеваемое
на шпиндель привода компакт-дисков.
Запись и считывание информации на компакт-диск осуществляется головкой, которая может испускать лазерный луч. Физический
контакт между головкой и поверхностью диска отсутствует, что увеличивает срок службы компакт-диска. Фаза второго пластикового
слоя, кристаллическая или аморфная, изменяется в зависимости от
скорости остывания после разогрева поверхности лазерным лучом в
процессе записи, выполняемой в приводе. При медленном остывании
пластик переходит в кристаллическое состояние и информация стирается (записывается «0»); при быстром остывании (если разогрета
только микроскопическая точка) элемент пластика переходит в
аморфное состояние (записывается «1»). Ввиду разницы коэффициентов отражения от кристаллических и аморфных микроскопических
точек активного слоя при считывании происходит модуляция интенсивности отраженного луча, воспринимаемого головкой чтения. Поверхность диска разбита на три области. Начальная область (Lead-In)
расположена в центре диска и считывается первой. В ней записано
содержимое диска, таблица адресов всех записей, метка диска и другая служебная информация.
Средняя область содержит основную информацию и занимает
большую часть диска. Конечная область (Lead-Out) содержит метку
конца диска.
Информация на компакт-диске кодируется с большой избыточностью корректирующим кодом Рида — Соломона, обеспечивающего
93
восстановление исходной информации при невозможности ее считывания с диска.
Компакт-диск выдерживает несколько сотен циклов перезаписи.
Считывание информации осуществляется при вращении компактдиска с частотой более 10 000 об/мин.
В зависимости от возможности чтения/записи все компакт-диски
можно разделить на три типа:
1) ROM (Read Only Memory) — только для чтения; запись невозможна;
2) R (Recordable) — для однократной записи и многократного
чтения; диск может быть однажды записан; записанную информацию
изменить нельзя и она доступна только для чтения;
3) RW (ReWritable) — для многократной записи и чтения; информация на диске может быть многократно перезаписана.
Эти типы дисков отличаются материалом, из которого изготовлен
второй пластиковый слой.
Рассмотрим виды компакт-дисков CD (Compact Disc), DVD
(Digital Versatile Disc — цифровой универсальный (многосторонний)
диск) и Blu-Ray, имеющие одинаковый размер 4,72 дюйма.
Объем CD равен 650 или 700 Мбайт. Музыкальные диски относятся к CD и предназначены только для чтения с них музыки. Время
доступа к CD — 0,05 — 0,3 с.
Формат DVD являются развитием CD, объем составляет 4,7 Гбайт
за счет более плотной записи. DVD продолжают совершенствоваться.
Существует несколько конкурирующих форматов DVD: DVD-, DVD+
и DVD-RAM.
Формат Blu-Ray является дальнейшим развитием DVD и позволяет записывать 25 Гбайт информации на один слой.
Названия форматов CD и DVD в зависимости от возможности
чтения/записи представлены в табл. 8.3.
Дисковод для оптических носителей состоит из следующих частей:
• электродвигатель, который вращает диск;
• оптическая система, состоящая из лазерного излучателя, оптических линз и датчиков и предназначенная для считывания информации с поверхности диска;
Т а б л и ц а 8.3. Форматы дисков CD и DVD
Типы компакт-дисков
CD
DVD
ROM
CD-ROM
DVD-ROM
R
CD-R
DVD-R, DVD+R
RW
CD-RW
DVD-RW, DVD+RW, DVD-RAM
94
• микропроцессор, который руководит механикой привода, оптической системой и декодирует прочитанную информацию в двоичный
код.
Компакт-диск раскручивается электродвигателем. На поверхность
диска с помощью привода оптической системы фокусируется луч из
лазерного излучателя.
Луч отражается от поверхности диска и сквозь призму подается
на датчик. Световой поток превращается в электрический сигнал,
который поступает в микропроцессор, где он анализируется и превращается в двоичный код.
Для приводов оптических дисков указывается максимальная скорость чтения и записи для различных форматов дисков CD и DVD,
кратная однократной скорости для CD — 150 Кбайт/с и для DVD —
1 350 Кбайт/с. Например, скорость чтения 8x для CD означает, что
данные считываются со скоростью 1 200 Кбайт/с. Максимальная скорость чтения с дисков Blu-Ray работы составляет 12x (54 Мбайт/с).
Оптические носители могут храниться до 100 лет, но они восприимчивы к царапинам, колебаниям температуры и механическим
повреждениям.
Следует соблюдать следующие правила при работе с оптическими
носителями:
• не класть диски отражающим слоем на стол или другие поверхности;
• хранить диски в коробках, а коробки в вертикальном положении;
• для длительного хранения информации выбирать диски однократной записи (-R), а не многократной (-RW);
• подписывать диск только на внешней стороне диска;
• не наклеивать наклейки и не использовать деформированные
диски, так как это может привести к разбалансировке диска;
• не подвергать диск воздействию прямых солнечных лучей.
8.6.4. Флэш-память
Флэш-память представляет собой микросхемы памяти, заключенные в пластиковый корпус, и предназначена для долговременного
хранения информации с возможностью многократной перезаписи.
Микросхемы флэш-памяти не имеют движущихся частей. При
работе указатели в микросхеме перемещаются на начальный адрес
блока, и затем байты данных передаются в последовательном порядке. При производстве микросхем флэш-памяти используются логические элементы NAND (И — НЕ). Количество циклов перезаписи
флэш-памяти превышает 1 млн. В настоящее время размер флэшпамяти превышает 64 Гбайт (2011 г.), что позволило флэш-памяти
вытеснить дискеты. Флэш-память подключается к порту USB.
95
8.7. Видеоподсистема ЭВМ
8.7.1. Видеокарта
Видеоподсистема ЭВМ включает в себя два устройства:
1) монитор (дисплей), отображающий на своем экране текстовую
и графическую информацию;
2) видеокарта (ВК, видеоконтроллер, видеоадаптер), обеспечивающая формирование изображения, его хранение, обновление и
преобразование в сигнал, отображаемый монитором.
Видеокарта представляет собой плату, устанавливаемую в специальный слот на материнской плате или интегрированную в материнскую плату. Видеокарта содержит следующие элементы:
• графический процессор, обрабатывающий изображение и преобразующий его в сигнал для монитора;
• видеопамять, хранящую воспроизводимую на экране информацию; объем видеопамяти превышает 1 Гбайт (2011 г.);
• цифроаналоговый преобразователь (ЦАП), преобразующий цифровую информацию об изображении в аналоговый сигнал; характеристиками ЦАП являются частота преобразования и разрядность,
определяющая количество цветов, поддерживаемых видеокартой;
• видеоакселераторы; различают два типа видеоакселераторов: для
плоской (2D) и трехмерной (3D) графики. Первые эффективны для
работы с прикладными программами общего назначения, вторые
ориентированы на работу с разными мультимедийными и развлекательными программами. Видеоакселераторы позволяют производить
математические вычисления для построения трехмерных сцен на
двухмерном экране без участия МП.
8.7.2. Основные характеристики мониторов
Основными характеристиками мониторов являются размер экрана, разрешение, размер зерна и частота развертки монитора.
Размер экрана монитора задается величиной его диагонали в дюймах. Приняты следующие типоразмеры экранов: 12, 14, 15, 17, 19, 21
и 22 дюйма (1 дюйм = 2,54 см). Чем больше размер экрана монитора,
тем удобнее работать с ним.
Разрешение монитора измеряется в пикселях. Пиксель — это точка
на экране монитора. Количество точек по горизонтали и вертикали
составляют разрешение монитора. Приняты стандартные разрешения
мониторов, некоторые из которых имеют названия (табл. 8.4).
Обычно соотношение количества пикселей по горизонтали и вертикали составляет 4 : 3 (стандартные) или 16 : 9 (широкоэкранные).
Бо́льшее разрешение делает картинку на экране более четкой.
96
Т а б л и ц а 8.4. Типичные разрешения мониторов
Разрешение
Количество пикселей
Название
Соотношение сторон
640 × 480
307 200
VGA
4:3
800 × 600
480 000
SVGA
4:3
1 024 × 768
786 432
XGA
4:3
1 280 × 800
1 024 000
—
8:5
1 280 × 1024
1 310 720
SXGA
4:3
1 360 × 768
1 044 480
HD Ready
16 : 9
1 600 × 1 200
1 920 000
—
4:3
1 920 × 1 080
2 073 600
Full HD
16 : 9
1 920 × 1 200
2 304 000
—
8:5
2 560 × 1 440
3 686 400
—
16 : 9
Размер зерна (шаг точки) определяет расстояние между двумя соседними пикселями. Чем меньше размер зерна, тем выше четкость и
тем меньше устает глаз. Величина зерна современных мониторов
имеет значения от 0,25 до 0,28 мм.
Частота развертки монитора (частота регенерации) определяется
количеством обновлений изображений на экране монитора в единицу времени и измеряется в герцах. Чем больше частота, тем меньше
усталость глаз и больше времени можно работать непрерывно. Маленькая частота приводит к появлению мерцания. Современные
мониторы обеспечивают частоту развертки монитора 70 — 80 Гц.
8.7.3. Типы мониторов
Рассмотрим три типа мониторов:
1) на основе электронно-лучевой трубки;
2) жидкокристаллические;
3) плазменные.
Первый тип мониторов является аналоговым, а остальные — цифровыми.
Ко всем типам мониторов применимы перечисленные в подразд. 8.7.2
характеристики.
Электронно-лучевая трубка (ЭЛТ; CRT — Cathode Ray Tube,
катодно-лучевая трубка) представляет собой запаянную вакуумную
97
стеклянную колбу, дно (экран) которой покрыто слоем люминофора,
а в горловине установлена электронная пушка, испускающая поток
электронов.
С помощью формирующей и отклоняющей систем поток электронов направляется на нужное место экрана. Энергия, выделяемая
попадающими на люминофор электронами, заставляет его светиться.
Светящиеся точки люминофора формируют изображение, воспринимаемое визуально.
ЭЛТ-мониторы бывают монохромными или цветными. В цветном ЭЛТ-мониторе используются три электронные пушки, в отличие от одной пушки, применяемой в монохромных мониторах.
Каждая пушка отвечает за один из трех основных цветов: красный
(Red), зеленый (Green) и синий (Blue), путем смешивания которых
создаются все остальные цвета и цветовые оттенки. Поэтому цветные мониторы называют RGB-мониторами по первым буквам
основных цветов.
Недостатками ЭЛТ-мониторов являются высокое потребление
электроэнергии и вредное для здоровья человека излучение.
Для жидкокристаллических и плазменных мониторов вводятся
еще две характеристики: время отклика и контрастность. Время отклика — это минимальный временной промежуток, в течение которого пиксель может полностью поменять свой цвет — от черного к
белому и обратно (составляет 6 — 8 мс). Контрастность — это отношение яркости самого светлого и самого темного пикселя (составляет 30 000 : 1).
В жидкокристаллических мониторах (ЖК-мониторы; LCD —
Liquid Crystal Display, жидкокристаллический монитор) используется
специальная прозрачная жидкость, которая при определенных напряженностях электростатического поля кристаллизуется, при этом
изменяются ее прозрачность, коэффициенты поляризации и преломления световых лучей. Эти эффекты и используются для формирования изображения.
Конструктивно такой монитор выполнен в виде двух электропроводящих стеклянных пластин (подложка), между которыми помещается тончайший слой кристаллизующейся жидкости. Каждый элемент
экрана управляется собственным транзистором, поэтому ЖКмониторы также называют TFT-мониторами (TFT — Thin Film Transistor, тонкопленочный транзистор). В цветных мониторах каждый
элемент изображения состоит из трех отдельных пикселей (R, G и В),
покрытых тонкими светофильтрами соответствующих цветов. Поскольку ячейки сами не светятся, ЖК-монитору требуется задняя
подсветка.
Недостатками ЖК-мониторов являются ограниченность угла обзора (качество изображения зависит от того, под каким углом вы
смотрите), некачественная цветопередача, продолжительное время
отклика, неравномерная подсветка.
98
В плазменных мониторах (PDP — Plasma Display Panel) изображение формируется сопровождаемыми излучением света газовыми
разрядами в пикселях панели. Конструктивно панель состоит из трех
стеклянных пластин, на две из которых нанесены тонкие прозрачные
проводники: на одну пластину — горизонтально, на другую — вертикально.
Между ними находится третья пластина, в которой в местах пересечения проводников двух первых пластин имеются сквозные отверстия — пиксели. Эти отверстия при сборке панели заполняются
инертным газом: неоном или аргоном. При подаче высокочастотного напряжения на один из вертикально и один из горизонтально
расположенных проводников в отверстии, находящемся на их пересечении, возникает газовый разряд. Чем больше напряжение, тем
ярче светится газ.
Плазма газового разряда излучает свет в ультрафиолетовой части
спектра, который вызывает свечение частиц люминофора в диапазоне, видимом человеком. Фактически, каждый пиксель на экране работает как обычная флуоресцентная лампа (лампа дневного света).
Недостатками плазменных мониторов являются высокое энергопотребление и низкая разрешающая способность.
8.8. Контроллеры портов ввода-вывода
Контроллер порта ввода-вывода (КПВВ) обеспечивает интерфейс
между периферийным устройством, подключенным к порту КПВВ,
и системной шиной.
Порты ввода-вывода делятся на два типа в зависимости от количества бит, проходящих за один такт передачи:
• параллельные, в которых за один такт проходит несколько бит
(например, 8 или 16 бит);
• последовательные, в которых за один такт проходит один бит.
Перечислим наиболее распространенные порты ввода-вывода.
RS-232 (COM) — интерфейс обмена данными по последовательному коммуникационному порту (СОМ-порту). С помощью данного
интерфейса осуществляется работа и подключение таких устройств,
как внешний модем, мышь и т. д.
IEEE 1284 (Instute of Electrical and Electronic Engineers 1284;
LPT) — стандарт, описывающий спецификации параллельных скоростных интерфейсов SPP (Standard Parallel Port — стандартный параллельный порт), EPP (Enhanced Parallel Port — улучшенный параллельный порт), ECP (Еxtended Capabilities Port — порт с расширенными возможностями). Параллельный порт IEEE 1284 (LPT-порт)
используется для принтеров, внешних запоминающих устройств,
сканеров.
99
USB (Universal Serial Bus — универсальная последовательная
шина) — универсальный последовательный интерфейс, пришедший
на смену устаревшим портам RS-232 и IEEE 1284. Поддерживает
технологию Plug and Play с возможностью «горячей» замены, т. е.
замены устройств без необходимости выключения или перезагрузки
компьютера. Для адекватной работы интерфейса необходима операционная система, которая корректно с ним работает. Поддержка
USB введена в Microsoft Windows 2000. К портам USB можно подключить до 127 устройств. Каждое устройство, подключенное непосредственно к порту, может работать в качестве разветвителя, т. е.
можно подключать к нему другие устройства. Скорость передачи
через порт — 480 Мбит/с. Кроме данных через порт подается электропитание. В настоящее время большинство ПУ подключаются через
порт USB.
PS/2 (Personal System — персональная система) — последовательный порт, разработанный фирмой IBM в середине 1980-х гг. для
своей серии персональных компьютеров IBM PS/2. В отличие от
порта RS-232 порт PS/2 имеет более компактный разъем. Через порт
подается также электропитание. В настоящее время используется
вместе с портом USB.
IEEE 1394 (FireWire, iLink) — последовательный интерфейс, использующийся для подключения цифровых видеоустройств (видеокамер). Через порт возможна передача видеоизображения со скоростью 100 — 400 Мбит/с. Поддерживает технологию Plug and Play.
PCMCIA (Personal Computer Memory Card International Association;
PC Card) — порт, используемый в переносных компьютерах для подключения новых устройств к нему без вскрытия корпуса компьютера.
Порт имеет разрядность данных/адреса — 16/26 бит, поддерживает
автоконфигурирование, возможно подключение и отключение
устройств в процессе работы компьютера. Существует много ПУ,
разработанных для переносных компьютеров и использующих порт
PCMCIA.
8.9. Периферийные устройства
8.9.1. Клавиатура
Клавиатура — это стандартное клавишное устройство ввода,
предназначенное для ввода алфавитно-цифровых данных и команд
управления. Клавиатуры имеют по 101 — 104 клавиши, размещенные
по стандарту QWERTY (в верхнем левом углу алфавитной части
клавиатуры находятся клавиши Q, W, E, R, T, Y ).
Набор клавиш клавиатуры разбит на несколько функциональных
групп:
100
• алфавитно-цифровые клавиши (буквы и цифры) предназначены
для ввода знаковой информации и команд, которые набираются посимвольно;
• функциональные клавиши (F1 — F12); функции клавиш зависят от конкретной, работающей в данный момент времени программы;
• клавиши управления курсором подают команды на передвижение курсора по экрану монитора относительно текущего изображения
(стрелки, а также клавиши PAGE UP, PAGE DOWN, HOME, END);
курсор — экранный элемент, указывающий на место ввода знаковой
информации;
• служебные клавиши используются для разных вспомогательных
целей, таких как изменение регистра, режимов вставки, образование
сочетаний «горячих» клавиш и т. д. (SHIFT, CAPS LOCK, ENTER,
CTRL, ALT, ESC, DEL, INSERT, TAB, BACKSPACE);
• клавиши дополнительной панели дублируют действие цифровых
клавиш, клавиш управления курсором и некоторых служебных клавиш.
Клавиатура подсоединяется к системной шине через специальный
контроллер, содержащий буфер ввода, где хранятся введенные символы до тех пор, пока они не будут затребованы.
Клавиатура имеет свойство повторения знаков, используемое для
автоматизации процесса ввода. Оно состоит в том, что при продолжительном нажатии клавиши начинается автоматический ввод символа, связанного с этой клавишей.
8.9.2. Манипулятор типа «мышь»
Манипулятор типа «мышь» предназначен для быстрого доступа к
элементам интерфейса пользователя и инициирования на них событий с помощью кнопок. Обычно мышь имеет две-три кнопки.
Принцип работы мыши заключается в отслеживании перемещения
корпуса мыши по поверхности и синхронизации перемещения по
экрану монитора курсора.
Существует два типа мышей. Внутри ш а р и к о в ы х мышей находится шарик, вращающий два валика. Вращение валиков позволяет отследить перемещение мыши. В основе о п т и ч е с к и х мышей лежит светодиод, посылающий световой сигнал и считывающий
его отражение. При перемещении мыши посланный луч отражается
под другим углом, что позволяет выявить направление движения
мыши.
Все перемещения мыши и нажатия ее клавиш (клики) рассматриваются как события, анализируя которые устанавливается, состоялось
ли событие и в каком месте экрана в этот момент находится курсор
мыши.
101
Основной характеристикой мыши является разрешающая способность — насколько точно можно отследить самое мельчайшее перемещение мыши. Измеряется в точках (dot) на дюйм (dpi — dots per
inch).
Клавиатура и мышь подсоединяются к портам PS/2 или USB.
8.9.3. Принтеры
Печатающие устройства (принтеры) — это устройства вывода
данных из ЭВМ и фиксирующие их на бумаге. Основными характеристиками принтеров являются разрешающая способность, скорость
печати, объем установленной памяти и максимальный поддерживаемый формат бумаги.
Например, разрешение 1 440 dpi означает, что на длине одного
дюйма бумаги размещается 1 440 точек. Запись 720 × 360 dpi означает разрешение печати по горизонтали и вертикали соответственно.
Чем больше разрешение, тем точнее воспроизводятся детали изображения, но при этом возрастает время печати.
Единицей измерения скорости печати информации служит число
печатаемых страниц формата A4 (210 × 297 мм) в минуту (ppm —
pages per minute).
Данные с ЭВМ хранятся во встроенной памяти принтера. Далее
принтер уже самостоятельно печатает файл без участия ЭВМ. Такая
печать называется фоновой. Если данные для печати полностью не
помещаются в память принтера, ЭВМ ждет, пока принтер распечатает данные и освободит память, и вновь загружает следующий блок
данных в память принтера.
Максимальный поддерживаемый формат бумаги для большинства
принтеров A4 или A3 (297 × 420 мм).
Принтеры подключаются к ЭВМ через порты LPT или USB.
Рассмотрим три наиболее распространенных типа принтеров:
• матричные;
• струйные;
• лазерные.
В м а т р и ч н ы х принтерах печать точек осуществляется тонкими
иглами (pin).
Между бумагой и иглой находится красящая лента. При каждом
ударе иглы по ленте краска переносится на бумагу. Цвет изображения
на бумаге определяется цветом красящей ленты. Каждая игла управляется собственным электромагнитом. Печатающая головка с иглами
перемещается в горизонтальном направлении листа, и знаки в строке печатаются последовательно. Количество иголок в печатающей
головке определяет качество печати. Обычно матричные принтеры
оснащены 9, 18 или 24 иглами.
102
Достоинства матричных принтеров:
• низкая стоимость принтера и расходных материалов для него
(красящей ленты);
• низкая себестоимость копии;
• возможность одновременной печати нескольких копий с помощью копирки.
Недостатки матричных принтеров:
• невысокие качество и скорость печати;
• шум при печати.
С т р у й н ы е принтеры в печатающем узле вместо иголок имеют
тонкие трубочки — сопла, через которые на бумагу выбрасываются
мельчайшие капельки красителя (чернил) («пузырьковая» технология).
Матрица печатающей головки обычно содержит от 12 до 64 сопел (дюз).
Технически процесс распыления выглядит следующим образом.
В стенку сопла встроен электрический нагревательный элемент,
температура которого при подаче электрического импульса резко
возрастает за 5 — 10 мкс. Все чернила, находящиеся в контакте с нагревательным элементом, мгновенно испаряются, что вызывает
резкое повышение давления, под действием которого чернила выстреливаются из сопла на бумагу. Объем выстреливаемой капли не
превышает 1,5 пиколитра (1 пиколитр = 10-10 л). После «выстрела»
чернильные пары конденсируются, в сопле образуется зона пониженного давления и в него всасывается новая порция чернил. Чернила
каждого цвета находятся в своем картридже. Для создания цветного
изображения используется обычно принятая в полиграфии цветовая
схема CMYK, включающая в себя четыре базовых цвета: Cyan — циан
(оттенок голубого), Magenta — пурпурный, Yellow — желтый, blacK —
черный. Сложные цвета образуются смешением цветов CMYK. В последнее время к базовой схеме добавляют 2 — 4 цвета для повышения
правильности цветопередачи.
Основные достоинства струйных принтеров:
• высокое качество печати для принтеров с большим количеством
сопел с разрешением до 720 × 1 440 dpi; возможна печать фотографий;
• высокая скорость печати — до 10 страниц в минуту;
• бесшумность работы.
Основные недостатки струйных принтеров:
• использование хорошей бумаги, чтобы не растекались чернила;
• опасность засыхания чернил внутри сопла, что иногда приводит
к необходимости замены печатающего узла;
• высокая стоимость расходных материалов, в частности картриджей с чернилами.
В л а з е р н ы х принтерах для создания сверхтонкого светового
луча служит лазер. Лазер вычерчивает на поверхности предварительно заряженного электрически положительно светочувствительного
фотобарабана контуры невидимого точечного электронного изобра-
103
жения. На барабан наносится красящий порошок (тонер). В тех
точках барабана, на которые попал лазерный луч, меняется заряд, и
к этим местам притягиваются частицы тонера. Лист втягивается с
лотка, и ему передается электрический заряд. При наложении на
барабан лист притягивает к себе частицы тонера с барабана. Для
фиксации тонера лист снова заряжается и проходит между валами,
нагретыми до 180 °С. По окончании печати барабан разряжается,
очищается от тонера и снова используется. В результате получаются
отпечатки, не боящиеся влаги, устойчивые к истиранию и выцветанию.
Широко используются цветные лазерные принтеры. Цветная печать обеспечивается применением разноцветного тонера по цветовой
схеме CMYK. В цветном лазерном принтере находятся четыре печатных механизма, расположенные в ряд. Бумага последовательно проходит под каждым из четырех фотобарабанов, с которых на нее наносится тонер соответствующего цвета. При черно-белой печати
цветные барабаны просто приподнимаются над поверхностью бумаги и не участвуют в печати.
Достоинства лазерных принтеров:
• высокая скорость печати — от 10 до 40 и более страниц в минуту;
• скорость печати не зависит от разрешения;
• высокое качество печати (до 2 880 dpi);
• нетребовательность к качеству бумаги;
• низкая себестоимость копии (на втором месте после матричных
принтеров);
• бесшумность.
Недостатки лазерных принтеров:
• высокая цена принтеров, особенно цветных;
• невысокое качество цветных изображений, напечатанных на
цветных лазерных принтерах;
• высокое потребление электроэнергии.
8.9.4. Сканеры
Сканер — это устройство для ввода в ЭВМ информации с бумаги,
слайдов или фотопленки.
Различают планшетные и ручные сканеры.
Принцип работы п л а н ш е т н ы х сканеров заключается в следующем. Сканируемый оригинал помещается на прозрачном неподвижном стекле. Вдоль стекла передвигается сканирующий сенсор с
источником света.
Оптическая система планшетного сканера проецирует световой
поток, отражаемый от сканируемого оригинала, на сканирующий
сенсор.
104
Применяются два типа сенсоров: CCD (Charge-Coupled Device) и
CIS (Contact Image Sensor).
В ССD-сканерах используется система зеркал, установленная в
специальной каретке. Зеркала передают отраженный от оригинала
свет на параллельные линейки светочувствительных элементов (CCDматрица). Каждая линейка принимает информацию о своем цвете:
красном (Red), зеленом (Green) и синем (Blue).
В CIS-сканерах светочувствительный элемент находится в непосредственной близости от сканируемого документа, и система зеркал
не применяется. Поэтому CIS-сканеры компактнее CCD-сканеров,
однако глубина резкости и качество изображения уступают последним.
В сканирующем сенсоре уровни освещенности преобразуются в
уровни напряжения и формируется аналоговый сигнал. Затем, после
коррекции и обработки, аналоговый сигнал преобразуется в цифровой аналого-цифровым преобразователем (АЦП). Цифровой сигнал
поступает в ЭВМ, где данные, соответствующие изображению оригинала, обрабатываются и преобразовываются под управлением
драйвера сканера.
Время сканирования страницы формата A4 составляет 5 —
15 с.
В отличие от планшетного пользователь сам двигает сканирующую
головку р у ч н о г о сканера по оригиналу.
Ручные сканеры применяются в магазинах для считывания сканкодов товаров.
Основными характеристиками сканеров являются разрешающая
способность, скорость сканирования и максимальный поддерживаемый формат бумаги. Эти характеристики аналогичны характеристикам принтеров.
8.9.5. Сетевой адаптер
Для доступа ЭВМ к локальной сети используется специальная
плата — сетевой адаптер, которая выступает в качестве физического соединения ЭВМ и канала связи. Сетевой адаптер выполняет
следующие функции:
• подготовка данных, поступающих от ЭВМ, к передаче по каналу связи;
• передача данных по каналу связи;
• прием данных из канала связи и перевод их в форму, понятную
ЭВМ.
Каждый сетевой адаптер имеет уникальный физический адрес,
записанный в него на стадии производства.
105
8.9.6. Модем
Модем — это устройство, предназначенное для подсоединения
ЭВМ к обычной телефонной линии. Название происходит от сокращения двух слов: МОдуляция и ДЕМодуляция.
ЭВМ вырабатывает дискретные электрические сигналы (последовательности нулей и единиц), а по телефонным линиям информация
передается в аналоговой форме, т. е. в виде сигнала, уровень которого изменяется непрерывно, а не дискретно. Модемы выполняют
цифроаналоговое и аналого-цифровое преобразования. При передаче данных, модемы накладывают цифровые сигналы (рис. 8.4, б ),
полученные из ЭВМ, на непрерывную частоту телефонной линии
(рис. 8.4, а) (модулируют ее), а при их приеме демодулируют информацию и передают ее в цифровой форме в ЭВМ.
Модуляция колебаний — это изменение амплитуды, частоты или
фазы колебаний по определенному закону. Различают амплитудную
модуляцию (рис. 8.4, в), частотную модуляцию (рис. 8.4, г) и фазовую
модуляцию (рис. 8.4, д).
Модемы передают данные по обычным телефонным каналам со
скоростью от 300 до 56 000 бит/с. Кроме того, современные модемы
осуществляют сжатие данных перед отправлением, что сокращает
время передачи данных.
По конструктивному исполнению модемы бывают трех видов:
1) встроенные модемы интегрированы в материнскую плату;
2) внутренние модемы вставляются в системный блок ЭВМ в один
из слотов расширения материнской платы;
3) внешние модемы подключаются через один из коммуникационных портов, имеют отдельный корпус и собственный блок питания.
Рис. 8.4. Виды модуляции (а — д)
106
По аппаратной реализации модемы бывают двух типов:
• программные (software) модемы представляют собой плату,
вставляемую в слот PCI и работающую под управлением ОС Windows.
Поэтому такие модемы называют win-модемы. В программных модемах часть их функций реализована не в виде микросхем, а заменена программой, которая выполняется центральным МП ЭВМ. Такая
замена существенно удешевляет модем, но обусловливает некоторую
дополнительную нагрузку на МП;
• аппаратные (hardware) модемы реализуют все процедуры передачи и приема средствами самого модема. Поэтому такие модемы
несколько дороже, но более эффективны при работе со старыми телефонными линиями.
Факс-модемы позволяют отправлять и принимать факсимильные
сообщения (факсы) и поддерживают возможность телефонного разговора через факс-модем.
Современные цифровые модемы формально модемами не являются, так как не преобразуют цифровой сигнал в аналоговый и обратно. Они передают и принимают только цифровые сигналы.
ADSL-модемы позволяют передавать данные, используя телефонные линии. При этом остается возможность говорить параллельно по
телефону. ADSL-модемы позволяют осуществлять передачу данных
на скорости до 1 Мбит/с, а прием данных — до 7 Мбит/с.
Каждый сотовый телефон (за исключением некоторых дешевых
моделей) содержит модем для передачи данных в сетях сотовой связи.
Также такие модемы выпускаются отдельными устройствами, подключаемые к порту USB.
Таким образом, основными характеристиками модемов являются:
• скорость передачи;
• конструктивное исполнение: внутренний, внешний, встроенный;
• способ подключения к ЭВМ в случае внутреннего и внешнего
конструктивного исполнения: слот PCI, порт PCMCIA, порт USB;
• сеть или технология, по которой модем осуществляет передачу.
Гл а в а 9
Основы алгоритмизации
9.1. Понятие алгоритма
В основу работы ЭВМ положен программный принцип управления, состоящий в том, что ЭВМ выполняет действия по заранее заданной программе. Программа — это упорядоченная последовательность команд, которые понимает ЭВМ.
В основе любой программы лежит алгоритм. Алгоритм — это
полное и точное описание на некотором языке конечной последовательности правил, указывающих исполнителю действия, которые он
должен выполнить, чтобы за конечное время перейти от (варьируемых) исходных данных к искомому результату.
Термин «алгоритм» произошел от имени среднеазиатского ученого аль-Хорезми (787 — ок. 850), который описал общие правила (названные позднее алгоритмами) выполнения основных арифметических действий в десятичной системе счисления. Эти алгоритмы изучаются в начальных разделах школьной математики. К числу
алгоритмов школьного курса математики относятся также правила
решения определенных видов уравнений или неравенств, правила
построения различных геометрических фигур и т. п. Понятие «алгоритм» используется не только в математике, но и во многих областях
человеческой деятельности: например, говорят об алгоритме управления производственным процессом, алгоритме управления полетом
ракеты, алгоритме пользования бытовым прибором. Причем интуитивно под алгоритмом понимают некоторую систему правил, обладающих определенными свойствами.
Далее, изучая понятие «алгоритм», мы будем предполагать, что его
исполнителем является автоматическое устройство − ЭВМ. Это накладывает на запись алгоритма целый ряд обязательных требований.
Сформулируем эти требования в виде перечня свойств, которыми
должен обладать алгоритм, адресуемый к исполнению на ЭВМ.
1. Первым свойством алгоритма является дискретный (пошаговый)
характер определяемого им процесса. Возникающая в результате
такого разбиения запись алгоритма представляет собой упорядочен-
108
ную последовательность отдельных предписаний (директив, команд),
образующих прерывную/дискретную структуру алгоритма: только
выполнив требования одного предписания, можно приступить к исполнению следующего.
2. Исполнитель может выполнить алгоритм, если он ему понятен,
т. е. записан на понятном ему языке и содержит предписания, которые
исполнитель может выполнить. Набор действий, которые могут быть
выполнены исполнителем, называется системой команд исполнителя. Алгоритм не должен содержать описания действий, не входящих
в систему команд исполнителя, т. е. своей структурой команд и формой записи алгоритм должен быть ориентирован на конкретного
исполнителя.
3. Алгоритмы, предназначенные для исполнения техническим
устройством, не должны содержать предписаний, приводящих к неоднозначным действиям. Алгоритм рассчитан на чисто механическое
исполнение, и если применять его повторно к одним и тем же исходным данным, то всегда должен получаться один и тот же результат;
при этом и промежуточные результаты, полученные после соответствующих шагов алгоритмического процесса, тоже должны быть
одинаковыми. Это свойство определенности и однозначности — детерминированности − алгоритма позволяет использовать в качестве
исполнителя специальные машины-автоматы.
4. Основополагающим свойством алгоритма является его массовость, применимость к некоторому классу объектов, возможность
получения результата при различных исходных данных на некоторой
области допустимых значений. Например, исходными данными в
алгоритмах аль-Хорезми могут быть любые пары десятичных чисел.
Конечно, его способ не всегда самый рациональный по сравнению с
известными приемами быстрого счета. Но смысл массовости алгоритма состоит как раз в том, что он одинаково пригоден для всех случаев,
требует лишь механического выполнения цепочки простых действий
и при этом исполнителю нет нужды в затратах творческой энергии.
5. Цель выполнения алгоритма — получение конечного результата
посредством выполнения указанных преобразований над исходными
данными. В алгоритмах аль-Хорезми исходными данными и результатом являлись числа. Причем при точном исполнении всех предписаний алгоритмический процесс должен заканчиваться за конечное
число шагов. Это обязательное требование к алгоритмам — требование их результативности или конечности.
В математике известны вычислительные процедуры алгоритмического характера, не обладающие свойством конечности. Например,
процедура вычисления числа π. Однако если мы введем условие завершения вида «закончить после получения n десятичных знаков
числа π», то получим алгоритм вычисления n десятичных знаков
числа π. На этом принципе построены многие вычислительные алгоритмы.
109
6. Если алгоритм должен быть выполнен не просто за конечное
время, а за разумное конечное время, то речь идет об эффективности
алгоритма. Время выполнения алгоритма — очень важный параметр,
однако понятие эффективности алгоритма трактуется шире, включая
такие аспекты, как сложность, необходимые ресурсы, информационнопрограммное обеспечение. Эффективность алгоритма нередко
определяет возможность его практической реализации.
9.2. Алгоритмическая система
Понятие «алгоритмическая система» дает формальный ответ на
вопрос, что должно быть известно и доступно разработчикам алгоритмов. Алгоритмическая система — набор средств и понятий,
позволяющих строить некоторое множество алгоритмов для решения
определенного класса задач. Алгоритмическая система определяется
наличием четырех составляющих ее частей:
1) множеством входных объектов или исходных данных, подлежащих обработке алгоритмами данной системы;
2) множеством выходных объектов или результатов выполнения
алгоритмов данной системы;
3) системой команд исполнителя, т. е. набором тех действий, которые может выполнять исполнитель и которые мы можем описывать
в алгоритмах, что собственно является ориентацией алгоритмической
системы на конкретного исполнителя;
4) языком описания алгоритмов — языком исполнителя; язык, на
котором описан алгоритм, должен быть понятен исполнителю и не
должен включать в свой состав указания на невозможные для исполнителя действия, а также обращения к входным или выходным объектам, не принадлежащих к множеству входных или выходных объектов данной алгоритмической системы.
В качестве примера рассмотрим алгоритмическую систему, предназначенную для построения алгоритмов обработки данных — алгоритмов обработки символьных последовательностей (строк) из
ограниченного алфавита символов. Входными объектами такой системы являются строки символов конечной длины. С помощью специальных приемов можно преобразовать в строки символов практически любую информацию, в том числе формулы, таблицы, рисунки.
Результат обработки данных также представляет собой строки символов. Алгоритмические системы для обработки данных строятся на
одном и том же множестве входных и выходных объектов.
Исполнителем в современных системах обработки данных является вычислительная машина. Набор операций, выполняемых ЭВМ,
весьма ограничен, однако, комбинируя их в нужной последовательности, можно строить сложные алгоритмы решения самых различных
задач. Язык, на котором записываются алгоритмы, адресованные
110
вычислительной машине, опирается на систему команд данной ЭВМ.
Алгоритм, написанный на машинном языке, представляет собой закодированную специальным образом последовательность команд,
адресованных различным устройствам ЭВМ.
Отметим принципиальную особенность алгоритмических систем
обработки данных. В таких системах текст алгоритма также является
последовательностью символов, которую можно преобразовать в той
же алгоритмической системе. Следовательно, открывается возможность составлять алгоритмы преобразования алгоритмов, обрабатывая при этом тексты, реализующие преобразуемые алгоритмы. Это и
создает ту удивительную логическую гибкость, которая превратила
ЭВМ в принципиально новый инструмент обработки данных, обладающий колоссальными возможностями. Одним из примеров преобразования алгоритма с помощью ЭВМ из одной формы в другую
является его «трансляция» — перевод с некоторого алгоритмического языка на язык машины.
9.3. Алгоритмизация
Алгоритмизация — процесс разработки и описания алгоритма
решения какой-либо задачи.
Пусть имеется некоторая математическая задача, которая может
быть решена одним из известных математических методов. Как приступить к процессу построения алгоритма решения такой задачи?
Поскольку речь идет о разработке алгоритма для ЭВМ, то нужно
сначала проанализировать возможность его машинной реализации,
оценить ресурсы и возможности конкретной ЭВМ, имеющейся в
распоряжении (в том числе, допустимую точность вычислений, необходимый объем запоминающих устройств, быстродействие,
информационно-программное обеспечение).
Непосредственная разработка алгоритма начинается с осознания
существа поставленной задачи, с анализа того, что нам известно, что
следует получить в качестве результата, в какой форме нужно представить исходные данные и результаты вычислений. Следующая
ступень — разработка общей идеи алгоритмического процесса и анализа этой идеи. После этого можно приступить к более детальной
разработке уже задуманного конкретного алгоритма. И вот этот процесс разработки конкретного алгоритма в соответствии с определением самого понятия «алгоритм» заключается в последовательном
выполнении следующих пунктов:
• разложение всего вычислительного процесса на отдельные шаги —
возможные составные части алгоритма, что определяется внутренней
логикой самого процесса и системой команд исполнителя;
• установление взаимосвязей между отдельными шагами алгоритма и порядка их следования, приводящего от известных исходных
данных к искомому результату;
111
• полное и точное описание содержания каждого шага алгоритма
на языке выбранной алгоритмической системы;
• проверка составленного алгоритма на предмет, действительно ли
он реализует выбранный метод и приводит к искомому результату.
В результате проверки могут быть обнаружены ошибки и неточности, что вызывает необходимость доработки и коррекции алгоритма — возвращение к одному из предыдущих пунктов. Во многих
случаях разработка алгоритма включает в себя многократно повторяющуюся процедуру его проверки и коррекции.
Процедура проверки и коррекции алгоритма производится не только с целью устранения ошибок, но и с целью улучшения, т. е. оптимизации, алгоритма. При определенном методе решения задачи оптимизация проводится с целью сокращения алгоритмических действий и
упрощения по возможности самих этих действий. При этом алгоритм
должен оставаться «эквивалентным» исходному. Будем называть два
алгоритма эквивалентными если выполняются следующие условия:
1) множество допустимых исходных данных одного из них является множеством допустимых исходных данных другого; из применимости одного алгоритма к каким-либо исходным данным следует
применимость и другого алгоритма к этим данным;
2) применение этих алгоритмов к одним и тем же исходным данным дает одинаковые результаты.
Приведем пример двух эквивалентных алгоритмов. Пусть нам надо
подсчитать общую сумму чисел, приведенных в табл. 9.1.
Т а б л и ц а 9.1. Целые числа
5
1
3
8
10
9
6
1
5
10
1
1
Эквивалентными будут алгоритмы подсчета общей суммы «по
строкам»: 5 + 1 + 3 + 8 + 10 + 9 + 6 + 1 + 5 + 10 + 1 + 1 = 60, и «по столбцам»: 5 + 10 + 5 + 1 + 9 + 10 + 3 + 6 + 1 + 8 + 1 + 1 = 60. Заметим, что
для данной таблицы считать проще по столбцам.
9.4. Средства записи алгоритмов
9.4.1. Словесная запись алгоритмов
Характер языка, используемого для записи алгоритмов, определяется тем, для какого исполнителя предназначен алгоритм. Возможности исполнителя алгоритмов определяют уровень используемых
языковых средств, т. е. степень детализации и формализации пред-
112
писаний в алгоритмической записи. Если алгоритм предназначен для
исполнителя-человека, то его запись может быть не полностью формализована и детализирована, но должна оставаться понятной и
корректной. Для записи таких алгоритмов может использоваться
естественный язык. Для записи алгоритмов, предназначенных для
исполнителей-автоматов, необходимы строгая формализация средств
записи и определенная детализация алгоритмических предписаний.
В таких случаях применяют специальные формализованные языки.
Поскольку одним из пользователей языка описания алгоритмов,
так или иначе, остается человек, то, говоря об уровне языка, имеют
в виду также и уровень его доступности для человека.
К настоящему времени в информатике сложились вполне определенные традиции в представлении алгоритмов.
Самой распространенной формой представления алгоритмов,
адресуемых человеку, является обычная словесная запись. В этой
форме могут быть выражены любые алгоритмы. Но если такой алгоритм предназначен для его дальнейшей реализации на вычислительном устройстве, то принято придерживаться более формализованного способа построения фраз с тщательно отобранным набором слов.
Кроме того, необходимо указывать начало и конец алгоритма, отмечать момент ввода в вычислительное устройство значений исходных
данных и вывода/печати полученного результата. В вычислительных
алгоритмах широко используется общепринятая математическая
символика, язык формул. Вводится необходимая в вычислительной
практике операция присваивания:
у := А
(читается: «у присвоить значение А»), где у — переменная; А — некоторое выражение/формула. Следует сначала выполнить все действия, предусмотренные формулой А, а затем полученный результат
сохранить в качестве значения переменной у. Выражение А в частном
случае может быть переменной или числом. Например,
x := sinα — присвоить переменной х значение синуса;
y := x — присвоить переменной у значение переменной x;
z := 5,7 — считать значением переменной z число 5,7;
k := k + 1 — значение переменной k увеличить на единицу.
Введенные соглашения позволяют представлять словесные алгоритмы в компактной и наглядной форме.
Пример 9.1. Составим алгоритм вычисления коэффициентов
приведенного квадратного уравнения x2 + px + q = 0, корни которого
x1, x2 известны. Коэффициенты такого уравнения определяются по
формулам:
p = −(x1 + x2);
q = x1x2.
113
Предположим, что правила выполнения арифметических операций
сложения, вычитания и умножения известны исполнителю. Тогда
искомым алгоритмом будет следующая система предписаний.
Начало.
1. Ввести x1, x2.
2. p = −(x1 + x2).
3. q = x1x2.
4. Вывести p, q.
Конец.
В приведенной записи алгоритма ни в одном из предписаний нет
указания на то, к какому следующему предписанию надо перейти.
Предполагается, что в случае отсутствия специальных указаний предписания алгоритма выполняются в порядке их следования. Такое выполнение предписаний в алгоритме называется естественным ходом
выполнения алгоритма, а сам алгоритм называется линейным.
Пример 9.2. Составим алгоритм определения максимального
числа из трех чисел: z = max(a, b, c).
Р е ш е н и е. Решение задачи на ЭВМ можно получить, действуя
следующим образом. Сначала найдем наибольшее из двух чисел, например, сравнив между собой a и b. Предположим, что исполнитель
может выполнить операцию сравнения «больше». Найденное наибольшее число сохраним как значение переменной z. Далее сравним
значение переменной z с оставшимся числом c. Если с больше z, то
присвоим z новое значение — значение с, в противном случае значение z останется прежним. В результате переменная z будет равна
наибольшему из a, b, c и будет являться искомым результатом.
Изложенные рассуждения можно представить в виде следующей
словесной записи алгоритма.
Начало.
1. Ввести a, b, c.
2. Если a > b, то z := a,
иначе z := b.
3. Если c > z, то z := c.
4. Вывести z.
Конец.
Ход выполнения алгоритма зависит от результатов проверки условий а > b и c > z. Если для введенных значений a, b действительно
a > b, то выполняется операция z := a; если нет, то выполняется z := b.
Таким образом, в зависимости от результата проверки условия a > b
требуется выполнить различные действия. В алгоритме на этом шаге
предусмотрены оба возможных направления дальнейших вычислений.
При проверке условия c > z операция z := c может выполняться, если
действительно c > z, или не выполняться в противном случае.
114
Вычислительный процесс, который в зависимости от выполнения некоторых условий реализуется по одному из нескольких возможных, заранее предусмотренных направлений, называется разветвляющимся. Каждое отдельное направление называется ветвью
вычислений. Выбор той или иной ветви осуществляется при выполнении алгоритма в результате проверки этих условий и определяется свойствами исходных данных и промежуточных результатов.
При разработке алгоритма должны быть учтены все возможные
ветви вычислений.
Пример 9.3. Составим алгоритм определения остатка от деления
двух целых неотрицательных чисел А и В, где В ≠ 0. Рассматривая
деление как многократное вычитание делителя В из делимого А, получим алгоритм, состоящий из следующих шагов.
Начало.
1. Ввести A, B.
2. Если A < B, то перейти к шагу 5,
иначе перейти к шагу 3.
3. A := A − B.
4. Перейти к шагу 2.
5. ОСТ := A.
6. Вывести ОСТ.
Конец.
Шаги 2, 3, 4 записаны в алгоритме один раз, а могут выполняться
многократно. Многократно повторяемые участки вычислений образуют так называемый цикл. Вычислительный процесс, содержащий
многократные вычисления по одним и тем же математическим зависимостям, но для различных значений входящих в них переменных,
называется циклическим. Переменные, изменяющиеся в цикле, называются переменными цикла, а действия, повторяемые в цикле, —
телом цикла.
Количество повторений цикла определяется значениями переменных, входящих в условие его окончания.
Чтобы лучше понять характер циклических процессов, рассмотрим
подробнее структуру приведенного алгоритма. Первый шаг алгоритма представляет собой подготовку цикла: задание начальных значений
переменным цикла перед первым его выполнением. Тело цикла —
действия, многократно повторяемые в цикле (шаги 2, 3, 4). В каждом
конкретном случае число повторений этих действий будет различным.
Шаг 3 обеспечивает модификацию (изменение) значений переменной
цикла А, входящей в условие его окончания. Управление циклом
осуществляется на шаге 2. Проверяется условие окончание цикла
(А < В) и осуществляется либо выход из цикла, либо возврат на его
повторение. Очень важно правильно сформулировать условие окончания цикла.
115
Поняв сущность и структуру циклических алгоритмов, можно записать алгоритм более компактно.
Начало.
1. Ввести A, B.
2. Пока A ≥ B
3. ОСТ := A.
4. Вывести ОСТ.
Конец.
выполнять A := A − B.
Предписание «Пока А ≥ В выполнять А := А − В» надо понимать
следующим образом: если А больше или равно В, то выполнить операцию А := A − В и перейти опять на проверку условия А ≥ В; если А
меньше В, то перейти к выполнению следующего предписания (шаг 3),
не выполняя операцию А := A − В.
9.4.2. Схемы алгоритмов
Схема алгоритма — это графический способ его представления
с элементами словесной записи. Каждое предписание алгоритма изображается с помощью плоской геометрической фигуры — блока.
Отсюда название «блок-схема».
Переходы от предписания к предписанию изображаются линиями
связи — линиями потоков информации, а направление переходов — стрелками.
Различным по типу выполняемых действий блокам соответствуют
различные геометрические фигуры. Приняты определенные стандарты графических изображений блоков (табл. 9.2).
Т а б л и ц а 9.2. Изображение блоков в схемах алгоритмов
Наименование
символа
Обозначение и размеры
Функция
Процесс (вычислительный блок)
Выполнение операции или
группы операций, в результате
которых изменяются значение, форма представления или
расположение данных
Решение
(логический
блок)
Выбор направления выполнения алгоритма в зависимости от некоторых условий
116
Окончание табл. 9.2
Наименование
символа
Обозначение и размеры
Функция
Модификация
(заголовок
цикла)
Выполнение операций по
управлению циклом — повторением команды или
группы команд алгоритма
Пуск-останов
(начало-конец)
Начало или конец выполнения программы или подпрограммы
Предопределенный процесс
(вызов подпрограммы)
Вызов и использование
ранее созданных и отдельно
описанных алгоритмов
(подпрограмм)
Ввод-вывод
Общее обозначение ввода
или вывода данных в
алгоритме безотносительно
к внешнему устройству
Соединитель
Указание прерванной связи
между блоками в пределах
одной страницы
Межстраничный
соединитель
Указание прерванной связи
между блоками, расположенными на разных листах
Рассмотрим общие правила построения схем алгоритмов.
1. Для конкретизации содержания блока и уточнения выполняемого действия внутри блока помещаются краткие пояснения — словесные записи с элементами общепринятой математической символики (рис. 9.1, а).
2. Основное направление потока информации в схемах может не
отмечаться стрелками. Основное направление — сверху вниз и слева
направо. Если очередность выполнения блоков не соответствует этому направлению, то возможно применение стрелок (рис. 9.1, б ).
117
Рис. 9.1. Примеры изображения элементов схем алгоритмов (а — г)
3. По отношению к блоку линии могут быть входящими и выходящими. Количество входящих линий принципиально не ограничено. Количество выходящих линий регламентировано и зависит от
типа блока. Например, логический блок должен иметь не менее двух
выходящих линий, каждая из которых соответствует одному из возможных направлений вычислений. Блок модификации должен
иметь две выходящие линии, одна соответствует повторению цикла,
вторая — его окончанию.
4. Допускается разрывать линии потока информации, размещая
на обоих концах разрыва специальный символ «соединитель» (рис.
9.1, в, г). В пределах одной страницы используется символ обычного
соединителя, во внутреннем поле которого помещается маркировка
разрыва либо отдельной буквой, либо буквенно-цифровой координатой блока, к которому подходит линия потока. Если схема располагается на нескольких листах, переход линий потока с одного листа на
другой обозначается с помощью символа «межстраничный соединитель». При этом на листе с блоком-источником соединитель содержит
номер листа и координаты блока-приемника, а на листе с блокомприемником — номер листа и координаты блока-источника.
5. Нумерация блоков осуществляется либо в левом верхнем углу блока в разрыве его контура, либо рядом слева от блока (см. рис. 9.1, а).
118
Рис. 9.2. Алгоритм
вычисления коэффициентов приведенного квадратного уравнения
Рис. 9.3. Алгоритм выбора
максимального числа из
трех заданных чисел
Рис. 9.4. Алгоритм
определения остатка
от деления двух целых неотрицательных чисел
Принцип нумерации может быть различным, наиболее простой —
сквозная нумерация. Блоки начала и конца не нумеруются.
6. Для блоков приняты следующие размеры: а = 10, 15, 20 мм;
b = 1,5а. Если необходимо увеличить размер блока, то допускается
увеличение на число, кратное пяти. Необходимо выдерживать минимальное расстояние 3 мм между параллельными линиями потоков и
5 мм между остальными символами.
С помощью блок-схем можно изображать самые различные алгоритмы, например, линейной (рис. 9.2), разветвляющейся (рис. 9.3) и
циклической структур (рис. 9.4).
Пример 9.4. Рассмотрим задачу определения наибольшего общего делителя (НОД) двух целых положительных чисел M, N.
В математике известен алгоритм решения этой задачи — алгоритм
Евклида, который заключается в последовательном делении сначала
большего числа на меньшее, затем меньшего на полученный остаток,
первого остатка на второй остаток и так до тех пор, пока в остатке не
119
получится нуль. Последний по счету делитель и будет искомым результатом.
Запишем алгоритм Евклида, рассматривая деление как многократное вычитание:
1) если числа равны между собой, то взять в качестве НОД любое
из них;
2) если числа не равны между собой, то большее из чисел заменить
их разностью и вернуться к шагу 1.
Алгоритм Евклида может быть представлен следующей словесной
записью:
Начало.
1. Ввести М, N.
2. Пока М ≠ N выполнять:
если M > N, то M := M − N;
иначе N := N − M.
3. НОД := М.
4. Вывести НОД.
Конец.
Блок-схема алгоритма Евклида представлена на рис. 9.5, где блок
1 есть подготовка цикла, блок 2 — управление циклом, блоки 3, 4,
Рис. 9.5. Алгоритм Евклида
120
5 — тело цикла (разветвляющаяся структура), из них блоки 4, 5 являются блоками модификации значений переменных цикла M и N.
Блок-схемы являются исключительно простым и наглядным способом представления алгоритмов. Их очень полезно использовать при
разработке общей структуры алгоритма, чтобы отчетливо представить
себе алгоритм в целом и проследить все логические связи между его
отдельными частями, проверить все ли возможные варианты решения
поставленной задачи нашли в нем отражение.
Блок-схемы не накладывают никаких ограничений на степень
детализации в изображении алгоритма. Степень детализации определяется программистом. Однако следует помнить, что схемы общего
характера малоинформативны, а излишне подробные схемы проигрывают в наглядности. При разработке сложных алгоритмов, чтобы
понять сущность выполняемых действий и выявить основные связи,
алгоритм записывается в виде общей схемы, состоящей из крупных блоков. Блоки соответствуют основным шагам алгоритма (вводу данных, обработке,
выводу данных). Затем крупные блоки разбивают на
более мелкие, составляя более детальные схемы, позволяющие проверить их логическую правильность.
Именно так мы поступили при разработке алгоритма
Евклида, при этом использовали и словесную форму
записи, и блок-схему.
ГОСТ 19.701 — 90 (ИСО 5807-85) предусматривает использование циклической структуры общего
вида (безотносительно к типу цикла), представленной справа. Условие продолжения или окончания цикла может быть
указано как в верхнем, так и в нижнем блоке. Ее применение целесообразно только в простых алгоритмах, в более сложных она теряется в общей структуре алгоритма ввиду отсутствия явной передачи
управления.
9.4.3. Структурограммы
В практике структурного программирования для представления
алгоритмов используются также структурограммы (схемы Насси —
Шнейдермана). Этот способ позволяет изображать схему передач
управления в алгоритме не с помощью явного указания линий потоков информации, а с помощью представления вложенности
структур — функциональных блоков, которые используются для
описания выполняемых действий. Некоторые из используемых в этом
способе блоков соответствуют их изображению в схемах алгоритмов.
Для изображения алгоритмов в структурограммах используются следующие блоки.
121
1. Блок обработки (вычислений). Каждый блок является блоком
обработки. Каждый прямоугольник внутри любого блока представляет собой также блок обработки.
2. Блок следования. Этот блок объединяет ряд следующих друг за
другом процессов обработки.
3. Блок решения. Этот блок применяется для обозначения структуры ветвления. Условие располагается в верхнем треугольнике, варианты решения — по сторонам треугольника, процессы обработки —
в нижних прямоугольниках. Если блок решения является сокращенным (отсутствует одна из ветвей), то структурограмма видоизменяется
соответствующим образом.
4. Блок варианта реализует структуру многоальтернативного выбора. Варианты, которые можно сформулировать точно, размещаются слева, остальные объединяются в один, называемый выходом по
несоблюдению условий, располагаемый справа. Правую часть можно
оставить незаполненной или опустить.
5. Блок цикла с предусловием реализует циклическую структуру с
проверкой условия в начале цикла. Условие продолжения цикла размещается в верхней полосе, сливающейся с левой, указывающей
границу цикла. Данный блок может быть использован и для обозначения цикла с параметром, тогда вверху указывают закон изменения
параметра цикла.
122
6. Блок цикла с постусловие аналогичен блоку цикла с предусловием, но условие окончания цикла располагают внизу.
Каждый блок имеет форму прямоугольника и может быть вписан
в любой внутренний прямоугольник любого другого блока. Блоки
Рис. 9.6. Структурограмма алгоритма Евклида
дополняются элементами словесной записи с использованием математической символики. На рис. 9.6 приведен пример структурограммы
алгоритма Евклида.
9.5. Технология разработки алгоритмов
Опыт практической алгоритмизации и программирования привел
к формированию неких общих принципов и методов проектирования,
разработки и оформления алгоритмов.
Какими качествами должен обладать хороший алгоритм?
Прежде всего от алгоритма требуется, чтобы он правильно решал
поставленную задачу. Но не менее важно, какой ценой это достигается. Речь идет о разумности затрат на его создание. С этой точки
зрения алгоритм должен быть легким для понимания, простым для
доказательства правильности и удобным для модификации. В рамках
такой идеологии и сформировался так называемый структурный под-
123
Рис. 9.7. Базисные
управляющие
структуры
ход к конструированию и оформлению алгоритмов, позволяющий
уменьшить количество ошибок в алгоритмах, упрощающий их контроль и модификацию.
По своей сути структурный подход есть отказ от беспорядочного
стиля в алгоритмизации и программировании (в частности, отказ от
оператора goto) и определение ограниченного числа стандартных
приемов построения легко читаемых алгоритмов и программ с ясно
выраженной структурой.
Теоретическим фундаментом этого подхода является теорема о
структурировании, из которой следует, что алгоритм решения любой
практически вычислимой задачи может быть представлен с использованием трех элементарных базисных управляющих структур: структуры следования или последовательности (рис. 9.7, а); структуры
ветвления (рис. 9.7, б ); структуры цикла с предусловием (рис. 9.7, в),
где P — условие, S — оператор.
Базисный набор управляющих структур является функционально
полным, т. е. с его помощью можно создать любой сколь угодно слож-
Рис. 9.8. Дополнительные управляющие
структуры (а — в)
124
ный алгоритм. Однако для создания более компактных и наглядных
алгоритмов дополнительно используются следующие управляющие
структуры: структура сокращенного ветвления (рис. 9.8, а); структура выбора (рис. 9.8, б ); структура цикла с параметром (рис. 9.8, в);
структура цикла с постусловием (рис. 9.8, г).
В разных языках программирования реализация базовых управляющих структур может быть различной. В языке Паскаль реализованы все рассмотренные структуры.
Любой алгоритм может быть построен посредством композиции
базисных и дополнительных структур:
• их последовательным соединением − образованием последовательных конструкций;
• их вложением друг в друга − образованием вложенных конструкций.
Например, алгоритм Евклида, описанный ранее, представляет
собой комбинацию из трех управляющих структур: последовательности, цикла и ветвления (рис. 9.9).
Рис. 9.9. Алгоритм Евклида как композиция базисных структур
125
Рис. 9.10. Нисходящая схема проектирования алгоритма вычисления сложной
126
функции (а) и алгоритм вычисления сложной функции (б )
127
Каждая из структур может рассматриваться как один блок с одним
входом и одним выходом. Таким образом, мы можем ввести преобразование любой структуры в функциональный блок. Тогда всякий
алгоритм, составленный из стандартных структур, поддается последовательному преобразованию к единственному функциональному
блоку, и эта последовательность преобразований может быть использована как средство понимания алгоритма и доказательства его правильности.
Обратная последовательность преобразований может быть использована в процессе проектирования алгоритма по нисходящей
схеме с постепенным раскрытием единственного функционального блока в сложную структуру основных элементов. В области автоматизированной обработки данных такой подход называют
нисходящим проектированием или проектированием «сверху
вниз».
Разработка алгоритма по нисходящей схеме начинается с разбиения сложной исходной задачи на отдельные более простые подзадачи,
решение которых может быть представлено в общей структуре алгоритма функционально независимыми блоками. Разработку логической структуры каждого такого блока и ее модификацию можно
осуществлять независимо от остальных блоков. На первом этапе проекта раскрываются наиболее важные и существенные связи в исследуемой задаче, составляется укрупненная схема алгоритма, определяются функциональное назначение каждого блока, его входные и
выходные данные. На последующих этапах проектирования уточняется логическая структура отдельных функциональных блоков общей
схемы, строятся схемы алгоритмов, выделенных ранее подзадач. Разработка алгоритма каждой подзадачи также может осуществляться в
несколько этапов детализации. На каждом этапе проекта выполняются многократные проверки и исправления алгоритма. Подобный
подход является рациональным, позволяет значительно ускорить
процесс разработки сложных алгоритмов и в значительной мере избежать ошибочных решений.
В качестве примера рассмотрим задачу табулирования функции
одной переменной, т. е. вычисление значений функции у = f (x) для
всех значений х, изменяющихся от х 0 до хn с шагом hx, сокращенно:
x = х0(hx)хn.
Пусть
sin x, если x ≤ a;
z2 + x
, где z = cos x, если a < x < b;
y=
ln(2 + x 2 )
tg x, если x ≥ b,
где a, b, x0, hx, xn — исходные данные.
128
Процесс проектирования алгоритма табулирования функции
у = f (x) показан на рис. 9.10, а. На первом уровне детализации схема
отражает процесс табулирования функции в общем виде (блоки
1.1 — 1.5).
Далее осуществляется детализация блока 1.4 в виде последовательности блоков 2.1 — 2.3 второго уровня. Функция z = z(x), входящая в
определение исходной функции, представлена разветвляющейся структурой третьего уровня детализации (блоки 3.1 — 3.5).
Подставляя вместо функциональных блоков, подвергнутых дальнейшей детализации, соответствующие структуры, получим окончательную схему алгоритма, изображенную на рис. 9.10, б.
9.6. Структуры алгоритмов
9.6.1. Алгоритмы линейной структуры
Реализуют линейные вычислительные процессы, в которых отдельные этапы вычислений должны выполняться последовательно
друг за другом.
Линейные алгоритмы содержат только команды обработки данных.
При исполнении алгоритма команды выполняются в порядке их записи.
Линейный алгоритм вычисления коэффициентов приведенного
квадратного уравнения был рассмотрен ранее (см. рис. 9.2). Для построения таких алгоритмов используется структура следования.
9.6.2. Ветвления
Вычислительные процессы, в которых в зависимости от тех или
иных условий должны выполняться различные этапы вычислений,
называются разветвляющимися. Для построения алгоритмов, реализующих такие вычислительные процессы, необходимы специальные команды (управляющие структуры), позволяющие управлять
ходом выполнения алгоритма, а именно: осуществлять выбор одного
из нескольких возможных действий. Основной такой конструкцией
является структура простого ветвления, реализующая принятие двоичного, или дихотомического, решения. Примером алгоритма с простыми ветвлениями является рассмотренный ранее алгоритм выбора
максимального числа. Рассмотрим алгоритмы с более сложными
ветвлениями.
129
Рис. 9.11. График функции
Пример 9.5. Вычислить значение функции, график которой изображен на рис. 9.11.
Область определения функции разбивается на 4 участка, на каждом
из которых значение функции определяется по различным формулам:
- x, если x ≤ 0;
0, если 0 < x ≤ 3;
y=
x - 3, если 3 < x ≤ 5;
2, если x > 5.
Для построения схемы алгоритма решения данной задачи используем вложенную конструкцию структур ветвления (рис. 9.12). Про-
Рис. 9.12. Алгоритм вычисления значения функции по заданному графику
130
веряем заданные условия последовательно. Первым проверим условие
x ≤ 0, и если оно выполняется, то вычислим y := −x. Если первое
условие не выполняется, то, следовательно, x > 0, и надо проверить
следующее условие x ≤ 3.
Часть второго условия 0 < x можно не проверять, так как если дело
дошло до проверки этого условия, то заведомо 0 < x. Если условие
x ≤ 3 выполняется, то вычислим y := 0, иначе 3 < x, и проверяется
условие x ≤ 5, проверка 3 < x исключается. Если действительно x ≤ 5,
то вычисляем y := x − 3, а иначе 5 < x и вычисляем y := 2, исключая
проверку этого последнего условия.
Пример 9.6. Вычислить корни квадратного уравнения ax2 + bx +
+ c = 0, a ≠ 0, в области действительных чисел. В зависимости от
значения дискриминанта D = b2 − 4ac возможны три случая:
1) квадратное уравнение не имеет действительных корней, если
D < 0;
2) квадратное уравнение имеет два действительных равных корня,
если D = 0: x1 = x2 = −b/2a;
3) квадратное уравнение имеет два действительных различных
корня, если D > 0:
x1 =
-b + D
;
2a
x2 =
-b - D
.
2a
Схема алгоритма приведена на рис. 9.13. Алгоритм содержит
сложное ветвление, являющееся композицией двух простых ветвлений.
К операндам вещественного типа не следует применять операцию
отношения «=» (равно), условие может не выполняться из-за неточного представления вещественных чисел в памяти ЭВМ и неизбежных
ошибок округления при вычислениях. В алгоритме отношение D = 0
заменено отношением |D| < ε, где ε — допустимая погрешность округления.
Пример 9.7. Даны три числа а, b, с. Определить, имеется ли среди них хотя бы одна пара взаимно-обратных чисел.
Числа будут взаимно-обратными, если их произведение равно
единице. В алгоритме производятся попарные проверки данных чисел. Если искомая пара найдена, выдается ответ «Да». Если же ни
одна проверка не выявит пары взаимно-обратных чисел, выдается
ответ «Нет». Алгоритм изображен на рис. 9.14, а. Этот алгоритм верно решает задачу, но не является структурным. Алгоритм легко преобразовать к структурному виду, если продублировать блок печати
«Да» и вывести при этом найденные числа (рис. 9.14, б ). Дублирова-
131
Рис. 9.13. Алгоритм решения квадратного уравнения
Рис. 9.14. Алгоритмы поиска взаимно-обратных чисел (а — в)
132
ние блоков — распространенный прием приведения алгоритмов с
ветвлениями к структурному виду. Можно применить другой способ — введение сложных условий (рис. 9.14, в).
9.6.3. Циклы
Вычислительные процессы с многократным повторением однотипных вычислений/действий для различных значений входящих
величин/данных называются циклическими, повторяемые участки
вычислений — циклами, изменяющиеся в цикле величины — переменными цикла. Для организации циклов в алгоритмах необходимо
предусмотреть (рис. 9.15):
• подготовку цикла — задание начальных значений переменным
цикла перед первым его выполнением;
• тело цикла — вычислении/действия, повторяемые в цикле для
различных значений переменных цикла;
• модификацию/изменение значений переменных цикла перед
каждым новым его повторением;
• управление циклом — проверку условия продолжения/окончания цикла и переход на повторение цикла или его окончание.
В зависимости от того, где осуществляется проверка условия продолжения или окончания цикла, последний относят к виду:
Рис. 9.15. Общие схемы (а, б ) циклического алгоритма
133
• цикла с предусловием, когда цикл начинается с проверки условия продолжения цикла (рис. 9.15, а);
• цикла с постусловием, когда условие проверяется после выполнения тела цикла (рис. 9.15, б ).
Наиболее наглядным примером циклического вычислительного
процесса является задача табулирования функции: вычисления значений функции y = f(x) для значений аргумента x, изменяющихся от
начального x0 до конечного xn с постоянным шагом hx (рис. 9.16).
Здесь многократно повторяемые действия (тело цикла) — это вычисление значения функции f(x) для очередного значения аргумента
x и вывод полученного результата на печать; переменная цикла —
переменная x. Цикл выполняется для значений x, равных x0, x0 + hx,
x0 + 2hx, …, xn.
Для модификации переменной x в цикле ее значение надо увеличивать на значение шага: x := x + hx. Для управления циклом можно
использовать структуру цикла как с предусловием, где x < xn — условие продолжения цикла (рис. 9.16, а), так и с постусловием, где
x > xn — условие окончания цикла (рис. 9.16, б).
Алгоритмы табулирования функции с пред- и постусловием
дают, вообще говоря, одинаковый результат. Но тело цикла с
предусловием в определенной ситуации может не выполниться ни
разу, а тело цикла с постусловием обязательно выполняется хотя
бы один раз.
Рис. 9.16. Общие схемы (а, б) алгоритма табулирования функции
134
Рассмотрим случай, когда нижняя граница x0 переменной x превышает верхнюю xn. В этой ситуации цикл не должен выполняться
ни разу. Поэтому в задаче табулирования функции лучше использовать цикл с предусловием, цикл же с постусловием может дать неверный результат. Приведем пример целесообразного использования
цикла с постусловием.
Пример 9.8. Составим алгоритм вычисления суммы всех целых
чисел, вводимых с терминала до тех пор, пока не будет введен нуль.
Накопление суммы S будем осуществлять в цикле путем прибавления очередного введенного числа k к сумме всех предыдущих:
S := S + k. Перед началом цикла значение переменной S обнулим: S := 0.
Проверка условия окончания цикла возможна лишь после ввода хотя
бы одного числа, поэтому лучше использовать цикл с постусловием.
Алгоритм вычисления искомой суммы представлен на рис. 9.17.
Рис. 9.17. Алгоритм вычисления суммы вводимых чисел
Помимо циклов с пред- и постусловием принято различать циклы
с заранее неизвестным и известным числом повторений. Примером
цикла первого типа могут служить алгоритм вычисления суммы (см.
пример 9.8) и алгоритм Евклида. Примером цикла второго типа —
алгоритм табулирования функции, где число повторений цикла Nx
определяется по формуле
Nx = [(xn − x0)/hx] + 1,
где квадратные скобки [ ] означают целую часть числа.
В циклах с известным числом повторений всегда можно выделить
переменную, определяющую число повторений цикла, значение которой изменяется по заданному закону, например, от начального до
конечного с постоянным шагом. Такая переменная используется для
управления циклом: в условии окончания цикла осуществляется
сравнение текущего значения переменной с заданным порогом. Эту
переменную именуют параметром цикла, а сам цикл — циклом с
параметром.
135
Для схемного представления цикла с параметром используют
специальную управляющую структуру с блоком модификации
(рис. 9.18), где указывают закон изменения параметра цикла. Например, в задаче табулирования функции y = f(x) параметром цикла
является переменная x, закон изменения которой можно представить
в виде x = x0(hx)xn.
Рис. 9.18. Схема цикла с параметром
Схема цикла с параметром для табулирования функции одной
переменной приведена на рис. 9.18. На схеме вход 1 в блок i — первоначальный вход в цикл, вход 2 — очередное повторение цикла, выход
3 — окончание цикла.
Блок модификации включает в себя подготовку цикла (x := x0), изменение параметра цикла при его очередном повторении (x := x + hx),
управление циклом — проверку условия его продолжения (x < xn) и
переход на продолжение или окончание цикла. При этом явно выделено тело цикла.
Проверка условия x < xn проводится перед каждым, в том числе
первым, выполнением цикла, как в цикле с предусловием. И если
начальное значение параметра цикла больше конечного, то цикл не
выполняется ни разу.
Для записи цикла с параметром в языках программирования существует специальный оператор — оператор цикла с параметром.
Пример 9.9. Составим алгоритм табулирования сложной функции, приведенный на рис. 9.10, используя структуру цикла с параметром.
Алгоритм представлен на рис. 9.19. Тело цикла в этом алгоритме
представляет собой композицию двух вложенных структур ветвления
и структуры следования.
В схеме алгоритма в качестве параметра цикла может выступать
переменная любого типа.
136
Рис. 9.19. Алгоритм табулирования сложной функции
При реализации этой структуры в различных языках программирования синтаксис оператора цикла с параметром может не допускать
использование параметра цикла вещественного типа, как, например,
в языке Паскаль.
Тогда необходимо введение дополнительной переменной целого
типа, определяющей количество значений x, y и используемой в качестве параметра цикла.
Пример 9.10. Вычислить степень Y = an действительного числа a
с натуральным показателем n. Воспользоваться для вычислений следующей формулой: an = a ⋅ a… a − n раз.
Компактно произведение может быть записано в виде
n
a n = ∏ a.
i =1
137
Для вычисления Y организуем цикл с параметром i, в котором
будем накапливать искомое произведение по следующему правилу:
до начала цикла положим Y = 1, а в цикле будем домножать n раз накопленное ранее произведение на a, т. е. Y := Y · a. Алгоритм представлен на рис. 9.20.
Рис. 9.20. Алгоритм вычисления конечного произведения
Рис. 9.21. Алгоритм вычисления
конечной суммы
Пример 9.11. Вычислим сумму квадратов всех целых чисел из
заданного интервала [m, n]. В компактной форме записи:
n
S = ∑ i2.
i =m
Для вычисления указанной суммы организуем цикл с параметром,
в котором будем n раз вычислять значение очередного слагаемого
y := i2 и накапливать искомую сумму S := S + y. До начала цикла положим S := 0. Алгоритм приведен на рис. 9.21.
Пример 9.12. Определим, какое количество точек (x, y) из заданного множества x = x0 + ihx; y = y0 + ihy; i = 0, 1, …, 20 находится в
каждой из заштрихованных областей D1 и D2, включая их границы
(рис. 9.22).
Пример иллюстрирует цикл с несколькими переменными цикла.
Число анализируемых точек определяется количеством значений
переменной i. Организуем цикл с параметром i, в котором будем из-
138
Рис. 9.22. Области определения
менять значения переменных x, y и для каждой очередной пары
(x, y) проверять условия ее принадлежности к одной из заданных
областей.
Условие попадания точки (x, y) в область D1 — окружность радиусом 2 с центром в точке (5, 4): (x − 5)2 + (y − 4)2 ≤ 4.
Условие попадания точки (x, y) в область D2 — окружность радиусом 3 с центром в точке (−5, −4): (x + 5)2 + (y + 4)2 ≤ 9.
Рис. 9.23. Алгоритм подсчета числа точек, принадлежащих заданным областям
139
Для проверки условий и подсчета количества KolD1, KolD2 точек,
попавших в каждую из областей, используем структуры сокращенного ветвления. Перед циклом надо задать переменным их начальные
значения (рис. 9.23).
9.6.4. Итерационные циклы
Среди циклов с неизвестным числом повторений большое место
занимают циклы, в которых в процессе повторения тела цикла образуется последовательность значений a1, a2, …, an, …, сходящаяся к
некоторому пределу a:
lim an = a.
n→∞
Каждое новое значение an в такой последовательности является
более точным приближением к искомому результату a. Циклы, реализующие такую последовательность приближений/итераций, называют итерационными.
В итерационных циклах условие окончания цикла основывается
на свойстве безграничного приближения значений an к искомому
пределу с увеличением n. Итерационный цикл заканчивают, если для
некоторого значения n выполняется условие
|an − an–1| ≤ ε,
где ε — допустимая погрешность вычислений. При этом результат
отождествляют со значением an, т. е. считают, что an = a.
Пример 9.13. Составим алгоритм вычисления y = x с заданной
погрешностью ε, используя следующее рекуррентное соотношение:
yn = yn−1 + (x/yn−1 − yn−1)/2; y1 = x/2.
Условием окончания данного итерационного цикла будет условие
|yn − yn–1| ≤ ε. Для его проверки необходимо иметь два приближения:
текущее yn и предыдущее yn−1. Алгоритм можно упростить, если вве-
Рис. 9.24. Алгоритм вычисления квадратного корня
140
сти вспомогательную переменную d = yn − yn−1 = (x/yn−1 − yn−1)/2 и
использовать ее в условии окончания цикла: |d| ≤ ε. Для проверки
такого условия достаточно иметь лишь одно приближение, которое
обозначим через y.
Алгоритм вычисления квадратного корня представлен на рис. 9.24.
Для организации итерационного процесса использована структура
цикла с постусловием.
9.6.5. Вложенные циклы
В практике алгоритмизации нередко встречаются задачи, при
решении которых необходимо проектировать алгоритмы с несколькими циклами.
Если в теле цикла содержится один или несколько других циклов,
то такие циклы называют вложенными. Цикл, содержащий в себе
другой цикл, называют внешним. Цикл, содержащийся в теле другого цикла, называют внутренним.
Выполняются вложенные циклы следующим образом. Сначала
при фиксированных начальных значениях переменных внешнего
цикла полностью выполняется внутренний цикл и его переменные
«пробегут» все свои значения. Затем переменные внешнего цикла
примут следующие значения, и, если условие окончания внешнего
цикла не будет достигнуто, снова полностью выполняется внутренний цикл и его переменные опять «пробегут» все свои значения и
т. д. до тех пор, пока не выполнится условие окончания внешнего
цикла.
Пример 9.14. Составим алгоритм табулирования сложной функции двух переменных:
a sin x + b cos y, если x ∈(a, b) и y ∈(a, b);
z = sin x + cos y, если x ∉(a, b) и y ∉(a, b);
1 в остальных случаях
для x = x0(hx)xn и y = y0(hy)yn.
Вычисление значений функции z для всех различных пар (x, y)
необходимо организовать следующим образом. Сначала при фиксированном значении одного из аргументов, например при x = x0, вычислить значения z для всех заданных y: y0, y0 + hy, y0 + 2hy, …, yn.
Затем, изменив значение x на x0 + hx, вновь перейти к полному циклу
изменения переменной y. Данные действия повторить для всех x: x0,
x0 + hx, x0 + 2hx, …, xn.
Для записи алгоритма необходима структура вложенных циклов,
например, с параметром: внешнего — с параметром x и внутреннего — с параметром y.
141
Рис. 9.25. Алгоритм табулирования функции двух переменных
В данной задаче внешний и внутренний циклы можно поменять
местами, при этом изменится только порядок изменения аргументов.
Общее количество значений z равно Nz = NxNy, где
Nx = [(xn − x0)/hx] + 1, Ny = [(yn − y0)/hy] + 1.
Алгоритм табулирования функции, выполненный по технологии
нисходящего проектирования, представлен на рис. 9.25.
На первом этапе составлена укрупненная схема решения задачи с
выделением операции ввода исходных данных и структуры вложенных
циклов. На втором этапе раскрывается тело внутреннего цикла как
композиция структур ветвления.
Пример 9.15. Найти совершенное число в интервале [2, n]. Совершенное число равно сумме всех своих делителей, включая единицу. Например, 28 — совершенное число, так как 28 = 1 + 2 + 4 + 7 + 14.
В алгоритме для каждого целого k из заданного интервала будем
определять сумму S всех его делителей и сравнивать значения S и k.
Если они равны, то анализируемое k есть искомое совершенное число, надо его вывести и закончить поиск, в противном случае — перейти к следующему целому числу из заданного интервала.
Для реализации такого алгоритма необходима структура вложенных циклов: внешнего, для просмотра заданного интервала, и внутреннего, для вычисления суммы (рис. 9.26, а). Построенный алгоритм не является структурированным. Рассмотрим один из способов
приведения циклического алгоритма к структурному виду. Внешний
цикл имеет два условия окончания: исчерпание всех целых чисел из
заданного интервала и выполнение равенства k = S. В зависимости
от того, какое условие привело к окончанию цикла, необходимо пред-
142
принять различные действия. Объединим оба условия окончания
цикла в одно: k > n или k = S. Для принятия окончательного решения
после завершения цикла проверим, какое же условие привело к его
окончанию (рис. 9.26, б ).
Можно структурировать алгоритм иначе: в цикле с параметром k
ввести дополнительную переменную Pr, установив до цикла Pr = 0.
Как только совершенное число будет найдено, присвоить Pr значение
этого числа. Окончательное решение в этом случае принимается уже
на основании анализа признака Pr.
Структура внутреннего цикла для вычисления суммы S раскрывается на втором этапе детализации алгоритма. Поскольку все числа
делятся на единицу, то сначала устанавливается S = 1. В цикле с па-
Рис. 9.26. Алгоритм поиска (а, б) совершенного числа
143
раметром i, изменяющимся от 2 до [k/2], суммируются все делители
числа k. В интервале от [k/2] + 1 до k − 1 не может быть делителей
числа k.
9.6.6. Вспомогательные алгоритмы
При нисходящем проектировании алгоритма решения сложной
задачи исходную задачу разбивают на более простые подзадачи. Каждой такой подзадаче соответствует функционально законченная часть
алгоритма.
Если оформить эту часть алгоритма в виде самостоятельной алгоритмической единицы со своими входными и выходными данными
и таким образом, что к ней будут возможны многократные обращения
(ссылки) из основного алгоритма, то такую алгоритмическую единицу можно назвать вспомогательным или подчиненным алгоритмом
(в программировании — подпрограмма).
Если для какой-то подзадачи уже известен алгоритм ее решения,
то он может быть включен в состав вновь разрабатываемого алгоритма в качестве вспомогательного.
Если в алгоритме или в разных алгоритмах встречаются фрагменты, одинаковые по выполняемым действиям и различающиеся только значениями обрабатываемых данных, то такого рода фрагменты
могут быть оформлены в виде отдельного алгоритма. В соответствующих местах основного алгоритма будут осуществляться лишь обращения к ним. Это позволяет сократить объем и улучшить структуру
всего алгоритма в целом.
При использовании вспомогательных алгоритмов возникают вопросы их оформления (таким образом, чтобы в дальнейшем можно
было ссылаться на них из других алгоритмов) и техники включения
в основные алгоритмы в процессе исполнения последних.
В схемах алгоритмов полная формализация в оформлении подчиненных алгоритмов не производится. Однако установлены некоторые общие правила их оформления. Для подчиненного алгоритма
определяется его имя, входные и выходные данные. В блок-схеме в
блоке начала указывается имя алгоритма и имена его входных величин — исходных данных, а в блоке конца указываются имена выходных величин — результатов. Переменные, перечисленные в блоках
начала и конца, называются формальными параметрами. Их введение
необходимо для того, чтобы при многократных вызовах подчиненного алгоритма можно было задавать различные значения исходных
данных, а после его исполнения воспользоваться полученными результатами.
В качестве примера рассмотрим алгоритм вычисления степени
y := anс натуральным показателем n (см. рис. 9.20). Оформим его как
вспомогательный алгоритм. На рис. 9.27 приведена схема вспомога-
144
Рис. 9.27. Вспомогательный алгоритм вычисления
степени
тельного алгоритма: его имя — Step, его входные параметры — n, a, выходной параметр — y.
Вызов вспомогательного алгоритма (ссылка из основного алгоритма) осуществляется с
помощью специального блока (см. табл. 9.2).
В блоке вызова вспомогательного алгоритма
указываются его имя и список фактических
параметров: конкретных значений и имен исходных данных и имен вычисляемых результатов, которые должны быть подставлены
вместо формальных параметров при исполнении вспомогательного алгоритма. Количество
и порядок формальных и фактических параметров должны совпадать.
Рис. 9.28. Алгоритм вычисления степени с целым показателем
145
Далее рассмотрим алгоритм вычисления степени z = xk, x ≠ 0 с
целым показателем k, пользуясь следующим определением:
1, если k = 0;
x = x k , если k > 0;
1 / x - k , если k < 0.
k
Алгоритм вычисления z = xk построим, используя вспомогательный алгоритм Step вычисления степени с натуральным показателем.
Схема алгоритма приведена на рис. 9.28.
Ссылка на вспомогательный алгоритм Step производится дважды:
с фактическими параметрами k, x, z при k > 0 и с фактическими
параметрами −k, 1/x, z при k < 0. Исполняется вспомогательный
алгоритм Step один раз в зависимости от введенного в основной программе значения k.
После выполнения совокупности действий, предусмотренных в
Step, осуществляется возврат в основной алгоритм к блоку вывода,
следующему за блоком обращения к вспомогательному алгоритму.
Очень важно понимать суть и механизм замены формальных параметров фактическими. Формальные параметры — это переменные, формально присутствующие во вспомогательном алгоритме и
определяющие тип и место подстановки фактических параметров.
Фактические параметры — это реальные величины основного алгоритма (константы, переменные, выражения), заменяющие при
вызове вспомогательного алгоритма его формальные параметры. Над
этими величинами и производятся действия, предусмотренные командами вспомогательного алгоритма. Замена формальных параметров фактическими осуществляется по порядку их следования, число
и тип формальных и фактических параметров должны совпадать.
Гл а в а 1 0
Программное обеспечение ЭВМ
10.1. Жизненный цикл программного
продукта
Совокупность программ, процедур и правил, а также документации, связанных с функционированием системы обработки данных,
составляют программное обеспечение (ПО; software). Программное
и аппаратное обеспечение в ЭВМ работают в неразрывной связи и
взаимодействии.
ПО предназначено для решения конкретных задач. Приложение
(application) — это программная реализация решения задачи на ЭВМ.
В большинстве случаев приложения разрабатываются для последующего выхода с ним на рынок ПО. Программный продукт (ПП) — это
комплекс взаимосвязанных программ для решения определенной
проблемы (задачи) массового спроса, подготовленный к реализации
как любой вид промышленной продукции.
Жизненный цикл ПП состоит из трех стадий (рис. 10.1): разработка
ПП, эксплуатация и сопровождение, завершение жизненного цикла.
Стадия р а з р а б о т к и ПП включает в себя следующие частично
перекрывающиеся этапы.
МС — маркетинг рынка ПО и формирование требований к ПП
предназначены для изучения требований к создаваемому ПП, включающие следующие действия:
• изучение сегмента рынка ПО, где предполагается использование
разрабатываемого ПП, и анализ аналогичных ПП; определение состава и назначения функций обработки данных ПП;
• установление требований пользователя к способу взаимодействия с ПП (система меню, использование манипулятора типа
«мышь», типы подсказок, виды экранных документов и т. п.);
• определение аппаратных и программных средств, необходимых
для эксплуатации ПП.
ПС — проектирование структуры ПП связано с разработкой
структуры ПП, структуры информационной базы задачи, выбором
методов и средств создания программ — технологии программирования.
147
Рис. 10.1. Жизненный цикл программного продукта
ПР — программирование и тестирование программ являются
технической реализацией проектных решений и выполняются с помощью выбранного инструментария разработчика, включающего
языки и системы программирования. Разработка отдельных модулей
ПП ведется параллельно для сокращения продолжительности этого
этапа. Тестирование является важным этапом разработки ПП и нередко требует не меньше времени, чем программирование. Программа проверяется на устойчивость работы в случае неверных входных
данных, ошибочных действиях пользователя и сбоя аппаратного обеспечения. Тестирование разбивается на два этапа. Альфа-тестирование
осуществляется в месте его разработки, и его результатом является
стабильно работающая программа. Бета-тестирование производится
у заказчика ПП для проверки его функциональности и выявления
оставшихся ошибок. Тестирование продолжается и на этапе эксплуатации.
ДК — документирование ПП заключается в разработке необходимых сведений по установке и обеспечению надежной работы ПП,
поддержке пользователей при выполнении функций обработки системой помощи и подсказок, определении порядка взаимодействия
ПП с другими программами.
Стадия э к с п л у а т а ц и и и с о п р о в о ж д е н и я включает в
себя следующие этапы.
ВР — выпуск ПП на рынок ПО сопровождается различными
приемами маркетинга: рекламой, увеличением числа каналов реализации, скидками, службой поддержки и др. ПП может быть выпущен
на рынок как коммерческое, условно-бесплатное (shareware) или бесплатное (freeware) ПО.
Для получения копии коммерческого ПО пользователь должен
предварительно его оплатить. Условно-бесплатное ПО является ознакомительным. Пользователь может попробовать данный ПП в течение определенного периода. По истечении этого периода пользователь
должен купить ПО или отказаться от его использования. Бесплатное
ПО не имеет ограничений на использование.
148
ЭП — эксплуатация ПП идет параллельно с этапом сопровождения. При этом эксплуатация может начинаться раньше и заканчиваться позже сопровождения.
СП — сопровождение ПП заключается в поддержке работоспособности ПП, переход на его новые версии, усовершенствование, исправление обнаруженных ошибок и т. п.
Стадия з а в е р ш е н и я жизненного цикла состоит из одного
этапа.
СН — снятие ПП с продажи и отказ от сопровождения происходит,
как правило, по следующим причинам:
• появление новых технологий и устройств;
• плохие отзывы пользователей;
• смена политики разработчика этого ПП.
Длительность жизненного цикла для различных ПП различна. Для
большинства современных ПП длительность жизненного цикла составляет в среднем два-три года.
10.2. Классификация программного
обеспечения
Можно выделить следующие уровни ПО (в порядке убывания)
(рис. 10.2):
1) прикладной уровень;
2) служебный уровень;
3) системный уровень;
4) базовый уровень.
Базовый уровень отвечает за взаимодействие с аппаратными средствами и хранится в базовой системе ввода-вывода (BIOS). Программы и данные записываются в ПЗУ на этапе производства и не могут
быть изменены во время эксплуатации. ПО базового уровня выполняет следующие функции:
• тестирование оборудования после каждого включения ЭВМ,
которое состоит из инициализации системных ресурсов и регистров
микросхем, тестирования ОЗУ, инициализации контроллеров, определения и подключения ВЗУ;
• передача управления загрузчику операционной системы;
• управление электропитанием при выключении ЭВМ.
Системный уровень обеспечивает взаимодействие других программ компьютера с базовым уровнем и непосредственно с аппаратным обеспечением. Совокупность ПО системного уровня образует
ядро операционной системы (ОС) ЭВМ. Ядро ОС выполняет следующие функции:
• управление и распределение памяти ОЗУ и ВЗУ;
• управление процессами ввода-вывода;
149
Рис. 10.2. Уровни программного обеспечения
• поддержка файловой системы — упорядоченной совокупности
объектов различного типа (файлов), хранящихся в ВЗУ;
• управление устройствами через специальные программы — драйверы;
• организация взаимодействия и диспетчеризации процессов —
выполняемых в данный момент программ и задач;
• предоставление интерфейса пользователю для управления перечисленными функциями — системы окон, меню, панелей инструментов для вызова соответствующих функций.
Драйвер устройств — это программа, которая обеспечивает взаимодействие (преобразование сигналов, данных) с компонентами ЭВМ.
Почти все компоненты взаимодействуют с ОС через драйверы.
Служебный уровень автоматизирует работы по проверке и настройке компьютерной системы. Задачи, решаемые на служебном
уровне, аналогичны задачам системного уровня, однако ПО служебного уровня решает их эффективней. Таким образом, служебный
уровень дополняет системный уровень.
Типы служебных программ. 1. Диспетчеры файлов (файловые
менеджеры). Предоставляют удобные средства для выполнения большинства операций по обслуживанию файловой системы: копированию, перемещению, переименованию файлов, созданию каталогов
150
(папок), уничтожению объектов, поиску файлов и навигации в файловой системе.
2. Средства сжатия данных (архиваторы). Создают, обновляют и
обслуживают архивные файлы, предназначенные для компактного
хранения и передачи других файлов.
3. Средства диагностики. Предназначены для автоматизации процессов проверки правильности работы программного и аппаратного
обеспечения и оптимизации работы компьютерной системы.
4. Средства просмотра и воспроизведения. Служат для просмотра
текстовых файлов, графических изображений, воспроизведения звуковых или видеофайлов.
5. Средства обеспечения компьютерной безопасности. Служат для
предотвращения несанкционированного доступа к файлам для их
чтения, изменения или повреждения.
Прикладной уровень представляет собой комплекс прикладных
программ, с помощью которых выполняются конкретные задачи
(производственные, творческие, развлекательные и учебные).
Классификация прикладного ПО. 1. Офисные пакеты. Представляют собой комплексное решение задач, возникающих при документообороте в учреждениях и домашних условиях. Включают в
себя текстовый редактор для создания и обработки текстов; табличный процессор для подсчета и анализа числовых данных; систему
управления базами данных (СУБД) для хранения и обработки данных;
редактор презентаций для подготовки материалов для проведения
лекций и презентаций.
2. Графические редакторы. Предназначены для создания и обработки графических изображений и делятся на три типа: редакторы
растровой графики, редакторы векторной графики и редакторы трехмерной графики. Растровая графика состоит из массива точек разных
цветов. Векторная графика представляет собой изображение в виде
набора геометрических примитивов: точек, линий, прямоугольников,
окружностей и др. Трехмерная графика строится на основе векторной
графики, но к ней добавляются новые элементы, имитирующее третье измерение.
3. Системы автоматизированного проектирования (cad-системы).
Предназначены для автоматизации проектно-конструкторских работ
в машиностроении, приборостроении, архитектуре. Позволяют проводить математические расчеты надежности конструкций.
4. Программы для работы в локальных и глобальных сетях: браузеры, клиенты электронной почты, программы для загрузки файлов.
5. Системы автоматизированного перевода. Различают электронные
словари и программы перевода текстов на естественных языках.
6. Бухгалтерские системы. Предназначены для автоматизации
подготовки начальных бухгалтерских документов предприятия, финансовых отчетов и их учета.
7. Игровые, обучающие и справочные программы.
151
8. Инструментальные языки и системы программирования. Предназначены для разработки новых программ. Предоставляют программисту удобные средства для создания и отладки программных
средств.
Рассмотрим представителей каждого уровня ПО.
10.3. Операционные системы
10.3.1. Понятие «операционная система» и ее виды
Операционная система (ОС) представляет собой комплекс системных и служебных программных средств. С одной стороны, она
опирается на базовое ПО, входящее в его систему BIOS, с другой —
она сама является основой для ПО более высоких уровней: прикладных и большинства служебных приложений. Приложениями ОС
принято называть программы, предназначенные для работы под
управлением данной системы.
Основная функция всех ОС — посредническая. Она заключается
в обеспечении нескольких видов взаимодействия:
• взаимодействие между пользователем с одной стороны и программным и аппаратным обеспечением ЭВМ с другой стороны, называемое интерфейсом пользователя;
• взаимодействие между программным и аппаратным обеспечением, называемое аппаратно-программным интерфейсом;
• взаимодействие между программным обеспечением разного
уровня, называемое программным интерфейсом.
ОС появились и развивались в процессе совершенствования аппаратного обеспечения компьютеров, поэтому эти события исторически тесно связаны. Развитие компьютеров привело к появлению
огромного количества различных ОС, из которых далеко не все широко известны. Для одной и той же аппаратной платформы существует несколько ОС. Различия между ними рассматриваются в двух категориях: внутренние и внешние. Внутренние различия характеризуются методами реализации основных функций. Внешние различия
определяются наличием и доступностью приложений данной системы, необходимых для удовлетворения технических требований,
предъявляемых к конкретному рабочему месту.
ОС можно подразделить по типу аппаратного обеспечения, на
котором ОС работают.
Серверные ОС одновременно обслуживают множество пользователей и позволяют им делить между собой программно-аппаратные
ресурсы сервера. Серверы также предоставляют возможность работы
с печатающими устройствами, файлами или сетью Интернет. У интернетпровайдеров обычно работают несколько серверов для того, чтобы
152
поддерживать одновременный доступ к сети множества клиентов. На
серверах хранятся страницы веб-сайтов и обрабатываются входящие
запросы. Unix и специальная серверная версия ОС Windows являются примерами серверных ОС. Теперь для этой цели стала использоваться и ОС Linux.
Следующую категорию составляют ОС для персональных компьютеров. Их работа заключается в предоставлении удобного интерфейса для одного пользователя. Такие системы широко используются и
повседневной работе. Основными ОС в этой категории являются
Windows XP / Vista / 7, Apple MacOS и Linux.
Другим видом ОС являются системы реального времени. Главным
параметром таких систем является время. Например, в системах
управления производством компьютеры, работающие в режиме реального времени, собирают данные о промышленном процессе и
используют их для управления оборудованием. Такие процессы должны удовлетворять жестким временным требованиям. Если по конвейеру передвигается автомобиль, то каждое действие должно быть
осуществлено в строго определенный момент времени. Если сварочный робот сварит шов слишком рано или слишком поздно, то нанесет непоправимый вред изделию. Системы VxWorks и QNX являются ОС реального времени.
Встроенные ОС используются в смартфонах, карманных компьютерах и бытовой технике. Карманный компьютер — это маленький
компьютер, помещающийся в кармане и выполняющий небольшой
набор функции, например, телефонной книжки и блокнота. Смартфон — это мобильный телефон, обладающий многими возможностями карманного компьютера. Встроенные микропроцессорные системы, управляющие работой устройств бытовой техники, не считаются
компьютерами, но обладают теми же характеристиками, что и системы реального времени, и при этом имеют малые размер и память и
ограничения мощности, что выделяет их в отдельный класс. Примерами таких ОС являются Google Andrоid и Apple iOS.
Самые маленькие ОС работают на смарт-картах, представляющих
собой устройство размером с кредитную карту и содержащих центральный процессор. На такие ОС накладываются очень жесткие
ограничения по мощности процессора и памяти. Некоторые из них
могут управлять только одной операцией, например электронным
платежом, но другие ОС выполняют более сложные функции.
Основными функциями ОС являются:
1) распределение ресурсов ЭВМ между процессами — выделение
процессам ресурсов ЭВМ в зависимости от их приоритета;
2) поддержание файловой системы — организация хранения и
поиска программ и данных на внешних носителях;
3) обеспечение интерфейса пользователя — прием и выполнение
команд пользователя.
Рассмотрим эти функции ОС подробнее.
153
10.3.2. Распределение ресурсов ЭВМ между
процессами
После запуска программы создается соответствующий ей процесс,
которому выделяются ресурсы ЭВМ. Каждый процесс получает адресное пространство в ОЗУ, содержащее стек, регистры, счетчик команд
и другие необходимые элементы. Также ресурсами являются время
процессора и доступ к устройствам ввода-вывода.
В каждый момент времени процесс может находиться в одном из
следующих состояний:
• создание — подготовка условий для исполнения процессором;
• выполнение — непосредственное исполнение процессором;
• ожидание по причине занятости какого-либо требуемого ресурса;
• готовность — процесс не исполняется, но все необходимые для
выполнения процесса, кроме времени процессора, предоставлены;
• завершение — нормальное или аварийное окончание работы
процесса, после которого время процессора и другие ресурсы ему не
предоставляются.
Процесс могут породить ОС, пользователь или другой процесс.
ОС может выполнять несколько процессов одновременно, однако в
каждый момент времени выполняется только один процесс. Таким
образом, создается иллюзия многозадачности за счет мгновенного
перераспределения ресурсов ЭВМ, прежде всего времени процессора. Завершение процесса осуществляется ОС, другими процессами
или пользователем, например, закрывающим программу.
Специальная программа-планировщик, являющаяся частью ОС,
распределяет ресурсы ЭВМ между процессами. Таким образом, процессы конкурируют за ресурсы. Каждый процесс имеет приоритет, в
соответствии с которым он получает ресурсы ЭВМ. Наибольший
приоритет имеют компоненты ОС, наименьший — программы пользователя. Приоритет процесса зависит также от частоты запроса
процессом ресурсов. Чем более требователен процесс к ресурсам, тем
более высокий приоритет он имеет.
Пример распределения времени процессора между процессами
представлен на рис. 10.3.
Рис. 10.3. Пример распределения времени процессора между процессами
154
Рис. 10.4. Пример распределения ОЗУ и виртуальной памяти между процессами
Переключение между процессами осуществляется каждые несколько миллисекунд. Поэтому у пользователя создается впечатление
одновременной работы нескольких процессов. Однако в некоторых
случаях доступ к устройствам ввода-вывода следующего процесса
осуществляется только после того, как другой процесс освободил его:
например, распечатка документов на принтере несколькими пользователями.
Пример распределения ОЗУ между процессами представлен на
рис. 10.4.
После запуска процесса ему выделяется адресное пространство.
В памяти могут располагаться несколько процессов, причем один
процесс не имеет доступ к адресному пространству другого процесса.
Если объема ОЗУ не хватает для выполнения всех процессов, то выделяется виртуальная память на жестком диске, где хранится часть
данных процесса. Жесткий диск, на котором располагается виртуальная память, гораздо медленнее, чем ОЗУ, поэтому в виртуальной
памяти хранятся процессы, остановленные в данный момент или с
самым низким приоритетом.
В рамках одного процесса могут создаваться потоки. Потоки сообща используют ресурсы, выделяемые для процесса, прежде всего
объем ОЗУ. По существу, потоки выполняются в рамках одного процесса точно так же, как процессы выполняются на одном компьютере. Но в каждый отдельный момент выполняется один процесс и один
поток, только переключение между ними осуществляется очень быстро.
Основной причиной появления потоков является возможность
разделения функций процесса между потоками и выполнение их
параллельно. Например, некоторому процессу необходимо выполнить печать документа, однако принтер занят печатью документа
другого процесса. Если процесс однопоточный, то процесс остановится и будет ждать разрешения на печать. В случае многопоточного процесса во время простоя другой поток процесса может выполнять свои функции например, сохранить файл документа на жестком
диске.
155
Кроме этого, создание и удаление потоков осуществляется намного быстрее, чем создание и удаление процессов, что ускоряет
работу процесса в целом.
10.3.3. Поддержание файловой системы
На одном физическом жестком диске может размещаться один или
несколько логических дисков (рис. 10.5). Физический диск — это
отдельное устройство. ОС разбивает физический диск на несколько
разделов, в каждом из которых создается свой логический диск.
Каждый логический диск состоит из двух областей:
1) загрузочной области, содержащей программный код для загрузки ОС;
2) области данных, которая содержит файлы и каталоги ОС и
пользователя.
Нумерация дисков осуществляется следующим образом:
A, B — дисководы для дискет;
C, D, … — логические диски на жестких дисках, дисководах CD,
DVD или Blu-Ray и других ВЗУ.
Всем компьютерным приложениям необходимо хранить и получать
данные. Наиболее удобной для доступа к ВЗУ оказалась система, при
которой пользователь или процесс назначает для той или иной совокупности данных некоторое имя. Файл — это поименованная конечная последовательность данных на диске. Часть ОС, работающая с
файлами и обеспечивающая хранение данных на дисках и доступ к
ним, называется файловой системой.
Минимальная единица хранения на жестком диске или дискете
ОС — кластер. Файл занимает на диске один или несколько кластеров.
Месторасположение файла характеризуется двумя адресами:
1) пользовательским: имя файла — это адрес, по которому пользователь может получить доступ к совокупности данных этого файла;
2) аппаратным: номера дорожки, сектора и т. п. определяет физическое месторасположение файла на ВЗУ (см. подразд. 8.6.2).
Преобразование пользовательского адреса в аппаратный и обратно осуществляется с помощью файловой системы ОС. Таким
Рис. 10.5. Структура жесткого диска
156
образом, файловая система ОС является промежуточным звеном
между пользователем и ВЗУ.
Возможны следующие действия с файлами:
• создание — за файлом закрепляется название и выделяется место на диске;
• открытие — поиск файла на диске и выделение памяти в ОЗУ
для обмена данными с файлом;
• закрытие — сохранение текущего состояния файла после действий с ним;
• изменение — модификация содержимого файла;
• копирование и перемещение файла;
• переименование — закрепление за файлом нового имени;
• удаление — освобождение места на диске, занимаемого файлом.
На любом диске обязательно присутствует корневой каталог. Корневой каталог представляет собой совокупность записей о файлах и
других каталогах, которые он содержит (рис. 10.6). Каждая запись
содержит следующие параметры:
• имя файла;
• расширение файла;
• объем файла в байтах;
• дата и время создания файла;
• дата и время последнего открытия (доступа) файла;
• атрибуты файла: только для чтения, скрытый файл, системный
файл, архивированный файл.
Корневой каталог имеет фиксированное место на диске и размер.
Все остальные каталоги имеют такую же структуру, но могут храниться в любом месте области данных диска, как и файлы. Каталоги необходимы для упорядоченного хранения файлов. В ОС Winodows
каталоги называются папками.
В ОС Windows имя файла не может превышать 255 символов и может
содержать латинские и русские буквы, знаки пунктуации. В одном
каталоге не может находиться двух файлов с одинаковыми именами.
Рис. 10.6. Пример структуры каталогов
157
Т а б л и ц а 10.1. Основные расширения файлов ОС Windows
Тип
Назначение
EXE, COM
Исполняемые файлы — программы
DOC, RTF, TXT
Документы
LNK
Файл ярлыка
DLL, SYS
Системные файлы
BMP, JPG, GIF, PNG
Файлы изображений
MID, MP3, WAV, WMA
Звуковые файлы
ASF, AVI, MOV, MP4, MPG
Видеофайлы
Расширения файлов используются ОС, чтобы определить, какую
программу необходимо запустить для обработки файла с данным
расширением. Расширение определяет тип файла, но не тип — расширение.
Основные расширения файлов приведены в табл. 10.1.
От файловой системы требуется выполнение следующих действий:
• определение по имени файла физического расположения его
частей;
• определение наличия свободного места и выделение его для
вновь создаваемых файлов.
Скорость выполнения этих операций напрямую зависит от самой
файловой системы.
Разные файловые системы используют различные механизмы для
реализации указанных задач и имеют свои преимущества и недостатки. Файловая система FAT (File Allocation Table — таблица размещения файлов), использующихся в ОС MS-DOS и Windows, представляет собой образ носителя в миниатюре, где детализация ведется до кластерного уровня. Поэтому операция поиска физических
координат файла при его большой фрагментации будет затруднительна.
Еще хуже обстоит дело с поиском свободного места для больших
файлов. Приходится просматривать практически всю таблицу, поэтому быстродействие падает. Современная файловая система NTFS
(New Technology File System — файловая система нового типа) в ОС
Windows XP / Vista / 7 использует более компактную форму записи,
что ускоряет поиск файла. Поэтому операции с выделением места
под файл проходят быстрее. Ключевое преимущество файловой системы NTFS — возможность ограничения доступа к файлам и каталогам.
158
10.3.4. Обеспечение интерфейса пользователя
По реализации интерфейса пользователя различают интерфейс
командной строки и графический интерфейс.
Основным устройством управления в интерфейсе командной
строки является клавиатура. Управляющие команды вводят в поле
командной строки, где их можно редактировать. Исполнение команды начинается после ее подтверждения нажатием клавиши ENTER.
Интерфейс командной строки реализован в семействе ОС MS-DOS
компании Microsoft.
Графический интерфейс пользователя реализует более сложный
тип интерфейса, в котором в качестве устройства управления кроме
клавиатуры может использоваться мышь или другое устройство позиционирования. Работа с графическим интерфейсом пользователя
основана на взаимодействии активных и пассивных экранных элементов управления.
В качестве примера активного элемента управления выступает
указатель (курсор) мыши — графический объект, перемещение которого на экране синхронизировано с перемещением мыши.
В качестве пассивных элементов управления выступают графические элементы управления приложений: экранные кнопки, значки,
переключатели, флажки, раскрывающиеся списки, строки меню и
многие другие.
Характер взаимодействия между активными и пассивными элементами управления выбирает сам пользователь. В его распоряжении
приемы наведения указателя мыши на элемент управления, щелчки
кнопками мыши и другие средства.
Примером ОС с графическим интерфейсом пользователя являются ОС семейства Windows компании Microsoft и семейства MacOS
компании Apple.
Рассмотрим реализацию графического интерфейса пользователя
на примере ОС Windows XP.
ОС обеспечивает единообразный интерфейс для всех своих компонентов (составных частей): окон, меню, панелей инструментов,
через которые пользователь управляет системой.
Основным элементом, с которым работает ОС Windows, является
объект. Объекты можно классифицировать следующим образом:
• приложения — программы, файлы с расширением EXE;
• документы — файлы с текстовыми, звуковыми и графическими
данными;
• папки — каталоги на носителях данных или контейнеры, которые
могут содержать другие объекты;
• ярлыки — ссылки на объекты ОС Windows для быстрого доступа к ним;
• специальные объекты — Главное меню, Рабочий стол, Панель
управления и др.
159
Рис. 10.7. Иерархия папок ОС Windows
В ОС Windows существует следующая иерархия папок (рис. 10.7).
На ЭВМ, работающей под управлением ОС Windows, может работать несколько пользователей, для которых создаются индивидуальные элементы иерархии.
Рабочий стол появляется после запуска ОС Windows и содержит
все элементы интерфейса пользователя:
• Главное меню (меню Пуск), содержащее списки установленных
программ пользователя; документов, открытых пользователем; пункты настройки программного и аппаратного обеспечения, поиска
файлов и папок;
• Панель задач, которая отображает кнопку для каждого приложения, запущенного пользователем;
• окна приложений.
Папка Мои документы предназначена для хранения личных документов пользователя. ОС Windows создает индивидуальные папки
для каждого пользователя.
Через папку Мой Компьютер осуществляется доступ к логическим
дискам ЭВМ.
Панель управления позволяет совершать следующие действия по
управлению и настройке ЭВМ:
• установить новое программное и аппаратное обеспечение;
• настроить элементы интерфейса пользователя;
• выбрать язык;
• установить дату, время, часовой пояс.
Сетевое окружение настраивает работу компьютера в локальной
или глобальной сети, что включает в себя следующие функции:
• создание новых сетевых подключений;
• поиск ЭВМ в сети;
• навигация по доступным ресурсам сетевых ЭВМ.
В Корзину помещаются файлы и папки после удаления. Файлы и
папки удаляются из Корзины в двух случаях:
160
1) по команде пользователя;
2) по команде ОС Windows, чтобы освободить место для новых
файлов.
Навигация по иерархии папок осуществляется с помощью стандартного приложения ОС Windows Проводник.
10.3.5. Файлы конфигурации операционных систем
Windows
ОС должна хранить данные о конфигурации ЭВМ, его пользователях, установленных программах, а также о системных, сетевых и
пользовательских параметрах настройки.
Эти параметры хранятся в реестре. Реестр имеет древовидную
структуру, схожую с деревом каталогов файловой системы. Реестр
делится на разделы, аналогичные каталогам. Каждый раздел может
содержать другие разделы или параметры. Параметры могут иметь
двоичное, целое или текстовое значение.
Реестр имеет пять основных разделов.
Раздел HKEY_CURRENT_USER содержит данные настройки
пользователя, работающего в системе в настоящий момент. Здесь
хранятся ссылка на личную папку пользователя, цвета экрана и настройки панели управления. Эти данные называются профилем
пользователя.
Раздел HKEY_USERS содержит профили всех пользователей системы. Раздел HKEY_CURRENT_USER является подразделом раздела HKEY_USERS.
Раздел HKEY_LOCAL_MACHINE содержит настройки данного
компьютера: параметры установленного аппаратного (раздел Hardware) и программного (раздел Software) обеспечения, параметры запуска системы, загрузки драйверов устройств, служб ОС Windows
(раздел System).
Раздел HKEY_CLASSES_ROOT раздел является копией подраздела Software раздела HKEY_LOCAL_MACHINE. Хранящиеся здесь
сведения обеспечивают открытие необходимой программы при открытии файла с помощью проводника.
Раздел HKEY_CURRENT_CONFIG содержит сведения о текущих
настройках (профиле) оборудования, используемом компьютером
при запуске системы.
Физически разделы реестра хранятся в отдельных файлах, хранящихся в папке Windows (для ОС Windows 95/98), или в папке Windows/
system32/config (для других ОС этого семейства).
В состав ОС Windows входит программа Редактор реестра
(regedit. exe), предназначенная для просмотра и редактирования ре
естра. Для удаления устаревшей информации из реестра и поиска в
нем ошибок используются специальные служебные программы.
161
Редактирование реестра необходимо осуществлять в крайних случаях, так как удаление или изменение разделов и их параметров
может привести к сбою в работе ОС.
10.3.6. Драйверы устройств
Чтобы управлять устройствами, используются драйверы устройств —
специальные программы, которые выполняют две основные задачи:
1) перевод команд ОС в команды контроллера и обратно;
2) обмен данными между ОС и устройством через его контроллер.
Каждый контроллер устройства имеет определенное количество
регистров, предназначенных для обмена данными между ОС и устройством. Обычно ОС передает через регистры в контроллер команды
управления и данные, передаваемые в устройство, а контроллер передает ОС данные о состоянии устройства и данные, полученные от
устройства. Система команд и количество регистров для разных контроллеров различаются. Например, контроллер манипулятора типа
«мышь» обрабатывает такие параметры, как положение указателя
мыши на экране и состояние кнопок: нажата или не нажата. КПВВ
должен отслеживать состояние передачи данных через порт: данные
переданы или нет.
Драйверы разрабатываются производителем устройств и поставляются вместе с ними или доступны на веб-сайте производителя.
Периодически производители обновляют драйверы, повышая эффективность работы устройств.
10.4. Архиваторы
Одним из представителей ПО служебного уровня являются архиваторы, предназначенные для сжатия данных. Введем несколько
определений.
Сжатие данных — это процесс представления данных с более
короткой битовой последовательностью.
Степень сжатия — это отношение сжатого объема данных к их
исходному объему (объему до сжатия).
Распаковка (извлечение) — это процесс восстановления исходных
данных из их сжатого вида.
Архив — это файл, в котором хранятся папки и файлы, закодированные специальным алгоритмом сжатия данных (рис. 10.8). Архив
включает в себя следующие части:
1) словарь, содержащий информацию о структуре папок и файлов,
способе сжатия данных и информацию для распаковки данных;
162
Рис. 10.8. Пример архива
Рис. 10.9. Пример непрерывного архива
обычно занимает 32 — 512 Кбайт в зависимости от объема архива; в
большинстве случаев чем больше словарь, тем выше степень сжатия
данных;
2) область данных — данные сжатых папок и файлов;
3) информация для восстановления предназначена для восстановления архива в случае его повреждения, например при ошибке чтения
с носителя; обычно занимает 1 — 3 % от объема архива.
Непрерывный (solid) архив (рис. 10.9) — это архив, содержащий
папки и файлы, объединенные в один файл и только затем сжатые.
Непрерывный архив позволяет достичь высокой степени сжатия,
особенно если сжимаемые файлы имеют похожее содержание. Однако
увеличивается время распаковки, так как приходится анализировать
все файлы, находящиеся перед извлекаемым файлом, а в случае повреждения файла не удастся извлечь все следующие за ним файлы.
Многотомный (multivolume) архив (рис. 10.10) — это архив, разбитый на несколько файлов (тома, volume) равной длины. Многотомные архивы используются в случае, если объем архива превышает размер носителя. В этом случае архив преобразуют в многотомный
архив и записывают на несколько носителей. Один файл может находиться в нескольких томах. Многотомные архивы не допускают
изменения: в них нельзя добавлять, обновлять или удалять файлы.
Для распаковки томов необходимо, чтобы все тома находились в
одной папке. Извлечение начинается с первого тома. Если том поврежден, то файлы, находящиеся в нем, не могут быть извлечены,
однако последующие тома могут распакованы. Многотомные архивы
могут быть непрерывными.
Самораспаковывающийся (SFX, SelF-eXtracting) архив — это
архив, в начало которого добавлен код программы распаковки содержимого архива. Самораспаковывающиеся архивы имеют расширение . EXE. Самораспаковывающиеся архивы используются, если
Рис. 10.10. Пример многотомного архива
163
нет уверенности, что там, где будет распаковываться архив, есть соответствующая программа для его распаковки. Самораспаковывающиеся архивы могут быть непрерывными и многотомными. В последнем случае первый том архива будет иметь расширение . EXE.
Для работы с архивами предназначены специальные программы — архиваторы. Архиваторы позволяют сжимать и извлекать
папки и файлы из архива, создавать обычные, непрерывные, многотомные, самораспаковывающиеся архивы и их различные комбинации. Доступ к функциям архиватора осуществляется через интерфейс
пользователя архиватора или контекстное меню Проводника.
Наиболее распространенными являются архиваторы RAR и ZIP.
Форматы сжатия папок и файлов этими архиваторами несовместимы,
однако архиватор RAR поддерживает операции с архивами в формате ZIP. Файлы архивов этих архиваторов имеют расширения RAR и
ZIP соответственно.
10.5. Текстовые процессоры
10.5.1. Классификация программ для работы
с текстовыми документами
В связи с многообразием возможностей и оформления текстовых
документов пользователю предоставляется большое число программных продуктов по работе с документами. Эти программные продукты
можно разделить на три типа: текстовые редакторы, текстовые процессоры и настольные издательские системы.
Текстовые редакторы — это программы для создания и редактирования текстовых документов. Редактирование текста — это последовательность операций по изменению его внутреннего (смыслового) и внешнего (оформительского) содержания. Внутреннее редактирование текста представляет собой добавление и удаление из него
фрагментов. Внешнее редактирование заключается в изменении расположения текста на странице, формате шрифта отдельных символов,
слов или целых абзацев, вставку в текст графических объектов.
Текстовые редакторы обеспечивают базовые возможности по работе с текстовыми файлами. Текстовые редакторы позволяют выполнять следующие простые операции:
• ввод и удаление алфавитно-цифровой информации из текстового файла;
• перемещение по набранному тексту;
• открытие и сохранение текстовых файлов.
Текстовые файлы представляют собой последовательность строк,
разделенных служебными символами «перевод строки» (код символа
13) и «возврат каретки» (код символа 10).
164
Также текстовые редакторы позволяют выполнять следующие
сложные операции:
• выделение, удаление, копирование, перемещение и вставка
блоков текста — прямоугольных или строчных фрагментов текста;
• поиск фрагмента, поиск с заменой, печать документа.
Большинство текстовых редакторов ориентировано на работу с
файлами, содержащими только текст. Примерами таких файлов могут
быть тексты программ, файлы настройки, справочные файлы и др.
Текстовые процессоры — это программы, предоставляющие более
широкие возможности по редактированию текста по сравнению с
редакторами. Текстовые процессоры позволяют изменять размер, вид
и цвет шрифта, отступы абзацев, параметры страниц, вставлять в текст
таблицы, формулы, графические изображения и звуковые объекты.
Третьей группой программ для работы с текстом являются настольные издательские системы. Как и текстовые процессоры,
издательские системы позволяют набирать и форматировать документ, но используются для верстки книг и периодических изданий:
газет и журналов. При редактировании многоцветных документов
можно разделять цвет на стандартные в полиграфии цвета.
Растущие возможности текстовых процессоров постепенно приближают их к издательским системам, и такие процессоры, как Microsoft Word, в состоянии обеспечить набор и распечатку небольших
изданий.
10.5.2. Общие сведения об объектах текстового
редактора Microsoft Word
Рассмотрим принципы работы и возможности текстовых процессоров на примере текстового процессора Microsoft Word 2003 из пакета прикладных программ Microsoft Office 2003.
Элементарным объектом этого текстового процессора является
символ. Символы делятся на следующие группы:
• алфавитно-цифровые;
• знаки препинания (точка, запятая, тире, скобки, кавычки и т. д.);
• символы форматирования (конца абзаца ¶, табуляции →, пробела ⋅ и т. д.).
Для переключения между режимами отображения и скрытия символов форматирования используется сочетание клавиш CTRL +
+ SHIFT + *.
Здесь и далее названия клавиш или их сочетаний на клавиатуре
обозначаются заглавными буквами, например ENTER, CTRL + F10.
Символы составляют абзац, заканчивающийся символом конца
абзаца. Помимо символов абзацы могут составлять объекты других
типов: рисунки, формулы и т. п. Абзацы составляют текст документа
(рис. 10.11).
165
Рис. 10.11. Иерархия объектов документа текстового процессора
Microsoft Word
Рис. 10.12. Структура страницы текстового процессора Microsoft Word
Текст размещается на страницах, имеющих левое, правое, нижнее
и верхнее поля (рис. 10.12).
Для ускорения работы рекомендуется использовать не пункты
меню, а соответствующие им сочетания клавиш.
Чтобы сочетания клавиш отображались в подсказках для кнопок
панелей инструментов, необходимо выполнить следующие действия:
1) выбрать пункт меню Сервис | Настройка…;
2) выбрать вкладку Параметры;
3) установить флажок Отображать подсказки для кнопок;
4) установить флажок Включить в подсказки сочетания клавиш.
10.5.3. Элементы форматирования текстового
редактора Microsoft Word
Меню Формат | Шрифт (CTRL + D)
Здесь и далее в заголовке будет указываться пункт меню и сочетание клавиш для его быстрого вызова или вызова соответствующих
функций.
Элементы форматирования символа.
Вкладка Шрифт. Шрифт (CTRL + SHIFT + F и ESC) — чтобы
выйти из режима редактирования. Все шрифты можно разделить на
три группы:
1) классические, в которой можно выделить несколько подгрупп:
• пропорциональные с засечками (Georgia, Times New Roman);
• пропорциональные без засечек (Arial, Tahoma, Verdana);
• моноширинные, где все символы имеют одну ширину (Courier);
2) декоративные и стилизованные;
166
3) шрифты со специальными символами (Symbol, Webdings, Wingdings).
Начертание: обычный, полужирный (CTRL + B), курсив (CTRL + I).
Размер (CTRL + SHIFT + P) измеряется в пунктах (обозначается пт):
1 пункт = 1/72 дюйма ≈ 0,35 мм.
Размер изменяется от 1 до 1 638 с шагом 0,5.
Цвет символа задается выбором из палитры или заданием цвета
в цветовой модели RGB или HSL.
Подчеркивание (сплошной (CTRL + U), пунктирной или штрихпунктирной линиями) и цвет подчеркивания.
Видоизменение: зачеркнутый, надстрочный (CTRL + SHIFT + =),
подстрочный (CTRL + =), с тенью, контур, приподнятый, утопленный,
малые прописные, все прописные и скрытый.
Изменение по схеме «ВСЕ ПРОПИСНЫЕ — все строчные — Первая
прописная» осуществляется с помощью сочетания клавиш SHIFT + F3.
Чтобы изменить регистр с помощью меню необходимо выделить
текст, выбрать пункт меню Формат | Регистр и выбрать из предложенных пунктов нужный регистр текста.
Вкладка Интервал. Масштаб для увеличения или уменьшения
относительного размера символа. Допустимые значения от 1 до 600 %.
Позволяет менять размер символов относительно других.
Интервал между символами. Может быть разреженным или
уплотненным и измеряется в пунктах. Обычному соответствует интервал 0 пт.
Смещение символа вверх и вниз относительно опорной линии
строки измеряется в пунктах (рис. 10.13).
Рис. 10.13. Примеры смещений символов вверх и вниз
В отличие от надстрочного или подстрочного видоизменения размер шрифта не меняется.
Меню Формат | Абзац
Параметры форматирования абзаца.
Вкладка Общие. Выравнивание: по ширине (CTRL + J), по левому краю (CTRL + L), по правому краю (CTRL + R), по центру
(CTRL + E).
167
Рис. 10.14. Примеры отступов абзацев
Отступ всего абзаца слева и справа и первой строки. Отрицательный отступ означает выход абзаца за поля документа. Отступ или выступ первой строки не может быть отрицательным
(рис. 10.14).
Отступ слева можно устанавливать клавишей TAB. Чтобы сделать
доступной эту возможность, необходимо выполнить следующие действия:
1) выбрать пункт меню Сервис | Параметры автозамены;
2) выбрать вкладку Автоформат при вводе;
3) в группе Автоматически при вводе установить флажок Установка отступов клавишами.
Для отступа первой строки нажмите TAB в начале этой строки.
Для отступа слева всего абзаца нажмите TAB в начале любой его
строки за исключением первой строки. Для удаления отступа
первой строки или отступа слева абзаца нажмите клавишу
BACKSPACE. Размер отступа задается интервалом табуляции по
умолчанию.
Интервал до и после абзаца (в пунктах) и междустрочный интервал. Интервал — это расстояние от опорной линии одной строки до
опорной линии соседней строки (рис. 10.15).
Виды междустрочных интервалов:
• одинарный (CTRL + 1) определяется наибольшим размером
символа или объекта в данной строке;
• полуторный (CTRL + 5) и двойной (CTRL + 2) превышают одинарный интервал в 1,5 раза и 2 раза соответственно;
Рис. 10.15. Виды интервалов абзаца
168
• минимум соответствует минимальному междустрочному интервалу, который может быть установлен в данной строке; задается в
пунктах; значения, меньше размера шрифта, игнорируются;
• точно — фиксированный интервал в пунктах;
• множитель — интервал, величина которого задается относительно одинарного интервала; например, множитель 1,5 соответствует полуторному интервалу.
Вкладка Положение на странице. Включает в себя следующие
флажки.
Запрет висячих строк — запрет переноса первой и (или) последней строк абзаца на другую страницу.
Не отрывать от следующего — запрет переноса абзаца, следующего за данным абзацем, на другую страницу, например, в следующих
случаях:
• заголовок и следующий за ним текст;
• рисунок и подпись к нему;
• формула и предваряющий ее текст;
• строки таблицы.
Не разрывать абзац — поместить весь абзац на одной странице
или в одной колонке.
С новой страницы — начать абзац с новой страницы. Используется для заголовков глав, которые должны начинаться с новой страницы.
Абзац, у которого установлен флажок хотя бы в одном из трех последних свойств, помечается черным квадратиком слева от первой
строки абзаца.
Запретить автоматический перенос слов — запрет расстановки
переносов в данном абзаце; в остальном тексте переносы сохраняются.
Меню Формат | Направление текста
Существует три вида направления текста (рис. 10.16).
Можно изменять направление текста в следующих элементах:
• ячейки таблицы;
• надпись — графический элемент для вставки текста в рисунок
(см. панель инструментов Рисование).
Рис. 10.16. Виды направления текста
169
Меню Формат | Табуляция
Позиция табуляции указывает величину отступа текста или место,
с которого будет начинаться колонка текста. Чтобы вставить табуляцию в текст, нажмите клавишу TAB, в таблицу — сочетание клавиш
CTRL + TAB. Текст, набранный слева от табуляции, сжимает табуляцию (рис. 10.17).
Рис. 10.17. Табуляция
Табуляция используется в следующих случаях:
• для сдвига текста вправо от имеющегося в строке текста:
Дата
→
Подпись;
• для заполнения строки справа от текста однородными символами
(пробелами, точками, подчеркиванием и т.д.), например в оглавлении:
→
Глава 1…………………3
или для создания поля для заполнения даты:
→
→
→
"____"_____
________20__
__г.;
• для выравнивания текста справа от имеющегося в строке текста,
например в нумерованных списках для выравнивания текста после
номера:
1. → Иванов
53. → Петровский
227. → Сидоров
→
→
→
4
5
3
Параметры форматирования табуляции.
Позиции табуляции, устанавливаемые в сантиметрах. Если в
строке находится несколько табуляций, то устанавливается позиция
для каждой из них.
По умолчанию — позиция табуляции по умолчанию. Определяет
также отступ слева, устанавливаемый клавишей TAB.
Выравнивание текста, который находится справа от табуляции,
относительно позиции табуляции. Виды выравнивания:
• по левому краю — текст выравнивается своей левой границей
по позиции табуляции (рис. 10.18);
Рис. 10.18. Выравнивание табуляции по
левому краю
170
Рис. 10.19. Выравнивание табуляции
по центру
Рис. 10.20. Выравнивание табуляции
по правому краю
• по центру — текст располагается по центру относительно позиции табуляции (рис. 10.19);
• по правому краю — текст выравнивается своей правой границей
по позиции табуляции (рис. 10.20);
• по разделителю — текст располагается таким образом, чтобы
самый левый разделитель находился в позиции табуляции; для цифр
разделителем является любой нецифровой символ за исключением
пробела, для букв — только запятая (рис. 10.21);
• с чертой — в позиции табуляции устанавливается черта, а текст
располагается справа от позиции табуляции по умолчанию (рис. 10.22).
Рис. 10.21. Выравнивание табуляции
по разделителю
Рис. 10.22. Выравнивание табуляции с чертой
Заполнитель — символ (пробел, точка, минус или знак подчеркивания) для заполнения пространства, занятого знаками табуляции;
при выравнивании с чертой заполнителем является только пробел.
Чтобы установить новые параметры табуляции, нажмите кнопку
Установить, а затем кнопку Ок.
Меню Формат | Список
Список — это совокупность (последовательных или непоследовательных) абзацев, связанных одним смыслом и помеченных маркерами. Абзацы, составляющие список, называются пунктами.
Параметры форматирования списка.
Тип списка:
• маркированный — пункты помечаются маркерами, которые не
меняются от пункта к пункту:
— январь;
— февраль;
— март.
171
• нумерованный — пункты помечаются неповторяющимися маркерами:
1) понедельник;
2) вторник;
3) среда.
• многоуровневый — пункты содержат вложенные пункты разных
типов: маркированные и нумерованные в любой комбинации; возможна вложенность девяти уровней.
Вкладка Маркированный. Параметры форматирования маркированного списка (выбрать один из типов маркированных списков и
нажать кнопку Изменить…).
Знак маркера — символ или рисунок, который будет использован
в качестве маркера. Можно задать следующие параметры:
• шрифт маркера (кнопка Шрифт…) (см. раздел Меню Формат |
Шрифт);
• символ маркера (кнопка Знак…);
• графический файл с маркером (кнопка Рисунок…).
Положение маркера: отступ — расстояние от левого поля страницы до маркера. Маркер располагается справа от позиции отступа
(рис. 10.23).
Рис. 10.23. Параметры маркированного списка
Рис. 10.24. Использование позиции табуляции по умолчанию
Положение текста: табуляция после — расстояние от левого
поля страницы до первой строки пункта списка. Если отступ маркера больше позиции табуляции, то расстояние от отступа маркера до
текста равно позиции табуляции по умолчанию (рис. 10.24).
Положение текста: отступ — отступ остальных строк пункта
списка; может быть больше или меньше отступа маркера.
Вкладка Нумерованный. Параметры форматирования нумерованного списка (выбрать один из типов маркированных списков и
нажать кнопку Изменить…).
Формат номера задает схему нумерации маркера и состоит из
переменной части (цифры, буквы), определяемой типом нумерации,
и постоянной части, например слово «Глава» или точка после номе-
172
ра пункта списка. В поле Формат номера переменная часть подсвечивается серым цветом. Постоянная часть вводится в поле до или
после переменной части.
Можно изменить шрифт маркера (кнопка Шрифт…).
Нумерация определяется следующими типами (рис. 10.25):
• цифровой — пункты маркируются арабскими или римскими
цифрами;
• символьный — пункты маркируются латинскими или кириллическими, прописными или строчными буквами;
• порядковый: «1-й, 2-й, …», «один, два, …», «Первый, Второй, …».
Начать с — начальный номер пункта списка.
Положение номера на — отступ маркера от левого поля.
Положение номера определяет, каким краем будет выравниваться маркер относительно отступа маркера (по левому краю, по центру,
по правому краю) (см. виды выравнивания относительно позиции
табуляции).
Положение текста: табуляция после и Положение текста:
отступ (см. маркированные списки).
Вкладка Многоуровневый. Параметры форматирования многоуровневого списка (выбрать один из типов многоуровневого списка
и нажать кнопку Изменить…).
Уровень — задает уровень вложенности списка.
Для каждого из уровней списка можно задать следующие элементы форматирования.
Формат номера задает вид маркера нумерованного (см. нумерованные списки) или маркированного списков.
Можно изменить шрифт маркера (кнопка Шрифт…).
Нумерация — позволяет задать вид маркера маркированного или
нумерованного списков, выбрать в виде маркера рисунок или новый
символ.
Начать с (см. нумерованные списки).
Предыдущий уровень помещает в поле Формат номера маркер
одного из родительских уровней слева от позиции курсора. Позволяет создавать сложные маркеры вида «1.5.2.».
Положение номера и Положение текста (см. нумерованные
списки).
Чтобы получить доступ к следующим элементам форматирования,
нажмите кнопку Больше.
Рис. 10.25. Параметры нумерованного списка
173
Связать уровень со стилем — определяет, каким стилем будет
форматироваться уровень.
Символ после номера: табуляция, пробел или отсутствие символа.
Нумеровать заново — определяет, будут ли нумероваться пункты
вложенных уровней заново или нумерация будет продолжаться. Если
выбрана нумерация заново, то указывается, при изменении какого
пункта родительского уровня будет начинаться нумерация на данном
уровне. Не используется для пунктов самого верхнего (первого)
уровня.
Пусть необходимо составить распределение студентов двух групп
на практику на три предприятия. Студенты должны иметь номер в
списке по журналу:
Первый
уровень
Второй
уровень
Третий
уровень
1. Группа П73
1.1. ООО «СА»
1.1.1. Исаев
1.2. ОАО «ТВ»
1.2.2. Липин
2. Группа П74
2.3. ЗАО «КП»
2.3.1. Сухов
2.3.2. Мухин
Обновление нумерации происходит на третьем уровне при изменении пункта первого уровня. Следовательно, для третьего уровня
необходимо установить флажок Нумеровать заново и выбрать первый уровень, а для второго уровня снять флажок Нумеровать заново.
Чтобы изменить уровень пункта списка (кроме первого пункта),
установите курсор после маркера пункта списка или в начале любой
из строк текста пункта и нажмите клавишу TAB для увеличения уровня или сочетание клавиш SHIFT + TAB для уменьшения уровня.
Вкладка Список стилей. На вкладке можно добавить, изменить
или удалить стиль многоуровневого списка. При изменении стиля
изменяются параметры форматирования списков, помеченных этим
стилем. Чтобы добавить (изменить) стиль необходимо выполнить
следующие действия:
174
1) нажать кнопку Добавить (Изменить) на вкладке Список стилей;
2) в открывшемся окне нажать кнопку Формат;
3) в появившемся списке выбрать пункт Нумерация.
Далее можно изменять параметры форматирования многоуровневых списков (см. многоуровневые списки).
Существуют следующие правила оформления списков.
Если абзац перед списком заканчивается двоеточием, то пункты
списка оформляются следующим образом. Для нумерованного списка:
номер + закрывающаяся круглая скобка + пробел +
+ текст со строчной буквы + точка с запятой.
Последний пункт списка заканчивается точкой, а не точкой с запятой. Например:
1) чтение данных;
2) обработка данных;
3) запись данных.
Для маркированного списка:
маркер + пробел + текст со строчной буквы + точка с запятой.
Последний пункт списка также заканчивается точкой. Например:
набор текста;
редактирование текста;
печать текста.
Если абзац перед списком заканчивается точкой, то пункты списка
оформляются следующим образом. Для нумерованного списка:
•
•
•
номер + точка + пробел + текст с прописной буквы + точка.
Пример нумерованного списка.
1. Включение компьютера.
2. Обработка данных на компьютере.
3. Выключение компьютера.
Для маркированного списка схема записи пункта списка аналогична:
маркер + пробел + текст с прописной буквы + точка.
Пример маркированного списка.
Написание рукописи.
Рецензирование рукописи.
Печать книги.
Для нумерованного и маркированного списка все пункты списка
заканчиваются точкой.
•
•
•
Таблицы
Структура таблицы текстового процессора Microsoft Word представлена на рис. 10.26.
175
Рис. 10.26. Структура таблицы текстового процессора Microsoft Word
На рис. 10.26 введены следующие обозначения.
W — ширина таблицы (меню Таблица | Свойства таблицы,
вкладка Таблица). Если ширина таблицы не задана, то таблица занимает всю ширину области текста.
W1, W2, …, Wn — ширина столбцов (меню Таблица | Свойства
таблицы, вкладка Столбец).
H1, H2, …, Hm — высота строк (меню Таблица | Свойства таблицы, вкладка Строка). Ширина таблицы, столбцов и высота строк
измеряются в абсолютных (сантиметрах) или относительных (проценты) единицах. Относительные единицы используются в вебдокументах. За 100 % принимается ширина окна приложения.
R — размер интервала между ячейками (меню Таблица | Свойства
таблицы, вкладка Таблица, кнопка Параметры…, установить флажок Интервалы между ячейками и установить размер интервала).
По умолчанию равен 0 см.
L — отступ слева таблицы (меню Таблица | Свойства таблицы,
вкладка Таблица, поле Отступ слева).
Операции над таблицами. Повторять заголовок таблицы на
каждой новой странице. Существуют два способа сделать это.
С п о с о б 1. Необходимо выполнить следующие действия:
1) выделить первую строку таблицы;
2) выбрать пункт меню Таблица | Свойства таблицы;
3) выбрать вкладку Строка;
4) установить флажок Повторять как заголовок на каждой
странице.
С п о с о б 2. Необходимо выполнить следующие действия:
1) установить курсор на таблицу;
2) выбрать пункт меню Таблица | Заголовки.
Разбить таблицу на две:
176
1) установить курсор в строку, перед которой необходимо сделать
разрыв;
2) выбрать пункт меню Таблица | Разбить таблицу.
Вставить абзац перед таблицей, которая находится в начале документа (см предыдущую операцию).
Сортировка элементов таблицы требует следующих действий:
1) выбрать пункт меню Таблица | Сортировка…
2) установить, по какому столбцу (столбцам, не больше трех) будет
производиться сортировка, порядок сортировки (по возрастанию, по
убыванию);
3) нажать кнопку Ok.
Пункт меню Таблица | Сортировка… можно использовать для
сортировки абзацев.
Схема ячейки таблицы приведена на рис. 10.27.
Установка значений полей для всех ячеек таблицы требует следующих действий:
1) выбрать пункт меню Таблица | Свойства таблицы;
2) выбрать вкладку Таблица;
3) нажать кнопку Параметры…;
4) установить требуемые значения для каждого из полей.
Установка значений полей для одной ячейки таблицы требует
следующих действий:
1) установить курсор в ячейку, поля которой необходимо изменить;
2) выбрать пункт меню Таблица | Свойства таблицы;
3) выбрать вкладку Ячейка;
4) нажать кнопку Параметры…;
5) снять флажок Как во всей таблице;
6) установить требуемые значения полей.
Существует два режима приоритета размеров текста и ячейки.
1. Приоритет размера текста: размер ячейки увеличивается, если
текст туда не помещается. Используется по умолчанию. Чтобы
установить приоритет, необходимо выполнить следующие действия:
1) выбрать пункт меню Таблица | Свойства таблицы;
2) выбрать вкладку Таблица;
Рис. 10.27. Схема ячейки таблицы
177
3) нажать кнопку Параметры…;
4) в группе Параметры установить флажок Автоподбор размеров по содержимому.
2. Приоритет размера ячейки: текст сжимается, чтобы поместиться в ячейку. Чтобы установить приоритет необходимо выполнить
следующие действия:
1) выбрать пункт меню Таблица | Свойства таблицы;
2) выбрать вкладку Ячейка;
3) нажать кнопку Параметры…;
4) в группе Параметры установить флажок Вписать текст.
Если установлен приоритет размера ячейки, то приоритет размера текста игнорируется.
Стили
Стиль — это некоторый формат объекта документа. Стиль может
относиться к следующим объектам: символу (знаку), абзацу, таблице
или списку.
Стили используются для быстрого форматирования документа.
Достаточно задать стили, а затем, выделив часть документа, применить стиль к этой части.
В большинстве случаев нет необходимости специально создавать
стили. Они создаются автоматически при изменении формата объекта.
Для создания, изменения и применения стилей к тексту предназначена панель Стили и форматирование. Чтобы открыть панель, необходимо выбрать пункт меню Формат | Стили и форматирование.
Выбрав стиль и вызвав контекстное меню, можно выделить все
элементы, помеченные данным стилем, или изменить стиль. В случае
изменения стиля появляется окно Изменение стиля, в котором необходимо нажать кнопку Формат, чтобы получить доступ к изменению шрифта, абзаца, табуляции, границ, языка, нумерации и установки сочетания клавиш для данного стиля.
Стили можно копировать из одного документа в другой. Для этого необходимо выполнить следующие действия:
1) выбрать пункт меню Сервис | Шаблоны и надстройки;
2) нажать кнопку Организатор;
3) выбрать вкладку Стили.
Вкладка Стили, как и другие вкладки Автотекст, Панели, Макросы, представляет собой два списка стилей двух файлов документов
и кнопки Копировать, Удалить и Переименовать между ними.
Нажав кнопку Закрыть файл, можно выбрать файл, куда или откуда будут копироваться стили.
Чтобы скопировать стиль установите курсор на объект (символ,
абзац, список, таблицу) с нужным стилем и нажмите сочетание клавиш CTRL + SHIFT + C. Чтобы вставить стиль установите курсор на
объект, куда необходимо скопировать стиль, и нажмите сочетание
клавиш CTRL + SHIFT + V.
178
10.5.4. Примеры оформления документов
Шапки документов
Необходимо оформить служебную записку со следующей шапкой:
РГРТУ
Кафедра ЭВМ
СЛУЖЕБНАЯ ЗАПИСКА
08.06.2007 г.
Заведующему кафедрой
вычислительной и прикладной
математики, проф.
А. Н. Пылькину
Здесь РГРТУ — Рязанский государственный радиотехнический
университет.
Возможны два способа оформления шапки: с помощью табуляции
и с помощью таблицы.
С помощью т а б у л я ц и и. Левая и правая части строки разделяются табуляцией, размер которой выбирается так, чтобы элементы в
строке были разнесены к разным краям страницы. Абзац выравнивается по ширине.
РГРТУ
→
Кафедра ЭВМ
→
СЛУЖЕБНАЯ ЗАПИСКА →
08.06.2007 г.
→
Заведующему кафедрой
вычислительной и прикладной
математики, проф.
А. Н. Пылькину
С помощью т а б л и ц ы. В текст помещается таблица, состоящая
из двух столбцов и одной строки. В левую колонку заносится текст
слева и выравнивается по левому краю, а в правую колонку — текст
справа и выравнивается по правому краю. Затем границы таблицы
делаются невидимыми.
РГРТУ
Кафедра ЭВМ
СЛУЖЕБНАЯ ЗАПИСКА
08.06.2007 г.
Заведующему кафедрой
вычислительной и прикладной
математики, проф.
А. Н. Пылькину
Необходимо оформить шапку заявления:
Ректору РГРТУ
проф. Гурову В. С.
студента гр. 489
Зуева Юрия Ильича
Шапка оформляется путем установки отступа абзаца слева на заданную величину.
179
Текст документов
Необходимо оформить поле для записи личных данных с расшифровкой:
Личные данные: ________
→________________________________
(дата рождения и паспортные данные)
Сплошная линия выполняется в виде табуляции с подчеркиванием. Так выполняются все поля для подписи. Текст «(дата рождения и паспортные данные)» выполняется с отступом абзаца
влево и выравниваем посередине. Размер шрифта текста берется
60 % от исходного.
Концовки документов
Необходимо оформить концовку протокола заседания комиссии:
Председатель комиссии
Члены комиссии
А. Н. Пылькин
А. В. Пруцков
Г. В. Овечкин
О. А. Москвитина
А. В. Благодаров
Концовку также можно оформить с помощью табуляции или таблицы по тому же принципу, что и шапку.
10.5.5. Элементы документа текстового редактора
Microsoft Word
Закладки
Закладка — это часть текста документа, которой присвоено уникальное название. Название закладки можно использовать для последующих ссылок на эту часть документа. Закладки применяются в
следующих случаях:
• размещение одного и того же текста в разных частях документа;
для этого текст однажды помечается закладкой, а в остальные части
документа вставляются ссылки на закладку;
• ограничение действий служебных полей или команд текстом,
помеченным закладкой;
• быстрый переход к тексту, помеченному закладкой.
Операции с закладками. Вставка закладки:
1) выделить текст, который необходимо пометить, закладкой;
2) выбрать пункт меню Вставка | Закладка…;
180
3) в поле Имя закладки ввести название закладки: первый символ — буква, а остальные символы — буквы, цифры или знаки подчеркивания;
4) нажать кнопку Добавить.
Вставка ссылки на закладку:
1) установить курсор в ту часть документа, где необходимо вставить
ссылку на закладку;
2) выбрать пункт меню Вставка | Ссылка | Перекрестная ссылка…;
3) выбрать в раскрывающемся списке Тип ссылки пункт Закладка;
4) выбрать в списке Для какой закладки название требуемой закладки;
5) нажать кнопку Вставить.
Переход к закладке:
1) выбрать пункт меню Правка | Перейти, нажать клавишу F5
или сочетание клавиш CTRL + G;
2) выбрать в списке Объект перехода пункт Закладка;
3) выбрать в раскрывающемся списке Введите имя закладки или
ввести название закладки;
4) нажать кнопку Перейти.
Удаление закладки:
1) выбрать пункт меню Вставка | Закладка…;
2) выбрать в списке Имя закладки название удаляемой закладки;
3) нажать кнопку Удалить.
Служебные поля
Служебное поле (далее поле) — это служебная информация, помещаемая в документ. Поле имеет внутреннее и внешнее представления. Внешнее представление — это значение поля, отображаемое
в документе. Поля, которые служат для составления указателей или
форматирования текста, не имеют внешнего представления, т. е.
видны только в режиме отображения служебных символов. Внутреннее представление имеет вид:
{Имя \P1 V1 … \PN VN},
где Имя — название поля; \P1…\PN — названия необязательных параметров (ключей); V1…VN — значения соответствующих параметров.
Параметры некоторых ключей могут отсутствовать.
Например, поле вставки даты:
Внутреннее
Внешнее
представление
представление
{DATE \@ “dd. MM. yyyy”}
18.03.2007
Поле можно вставить в документ двумя способами.
181
С п о с о б 1. Вставка поля через список полей. Необходимо выполнить следующие действия:
1) выбрать пункт меню Вставка | Поле…;
2) выбрать категорию и название поля;
3) при необходимости задать параметры поля и нажать кнопку Оk.
С п о с о б 2. Ввод названия поля и его параметров непосредственно. Необходимо выполнить следующие действия:
1) нажать сочетание клавиш CTRL + F9;
2) в появившихся фигурных скобках ввести название поля и его
параметры (внутреннее представление поля);
3) нажать клавишу F9.
Некоторые поля можно вставить в документ через диалоговые
окна: например, номер текущей страницы, нумерация элементов документа (рисунков, таблиц и т. п.) и др.
Для переключения между внешним и внутренним представлениями выделенного поля следует нажать сочетание клавиш SHIFT + F9,
всех полей документа — сочетание клавиш ALT + F9.
Для редактирования параметров поля в диалоговом режиме выберите пункт контекстного меню Коды/Значения полей.
Обновление полей происходит в следующих случаях:
1) при открытии документа обновляются поля изменяемых
′ х характеристик, таких как текущие дата и время;
временны
2) при печати документа (устанавливается: меню Сервис | Параметры, вкладка Печать, установить флажок Обновлять
поля);
3) при нажатии клавиши F9 на выделенном поле.
Чтобы запретить обновление поля, необходимо его заблокировать.
Для блокировки выделенного поля нажмите сочетание клавиш CTRL +
+ F11, для разблокировки — сочетание клавиш CTRL + SHIFT + F11.
Чтобы поля выделялись в документе серым цветом, необходимо
выполнить следующие действия:
1) выбрать пункт меню Сервис | Параметры;
2) выбрать вкладку Вид;
3) выбрать в группе Показывать в списке Затенение полей пункт
Всегда.
Чтобы перемещаться от поля к полю используют клавишу F11 для
направления от начала к концу документа и сочетание клавиш SHIFT +
+ F11 для обратного направления.
Если необходимо оставить в документе только значение поля, но
не само поле, используют сочетание клавиш CTRL + SHIFT + F9.
Классификация полей. 1. Данные о документе. Для просмотра
данных без использования полей выберите пункт меню Файл | Свойства.
1.1. Общие сведения.
Author — автор документа.
Filename — имя файла документа и путь к нему.
182
LastSavedBy — имя пользователя, последним сохранившим документ.
NumPages — число страниц документа.
RevNum — номер последней редакции документа (значение поля
увеличивается на единицу при каждом сохранении документа).
1.2. Временны́е характеристики. Формат даты и времени может
быть задан в параметрах поля.
CreateDate — дата и время создания документа. Обновляется при
изменении имени документа.
Date — текущая дата (вставка поля ALT + SHIFT + D, пункт меню
Вставка | Дата и время…).
EditTime — суммарное время редактирования документа.
PrintDate — дата и время последней печати документа.
SaveDate — дата и время последнего сохранения документа.
Time — текущее время (вставка поля ALT + SHIFT + T).
2. Нумерация.
Page — номер текущей страницы документа (см. пункт меню
Вставка | Номера страниц… для вставки номера текущей страницы
в колонтитулы, для вставки в документ — ALT + SHIFT + С).
Seq — последовательная нумерация элементов документа: таблиц,
рисунков и др. (см. пункт меню Вставка | Ссылка | Название…).
Общий вид:
{Seq Идентификатор [Ключи]},
где Идентификатор — имя нумеруемых элементов («Рисунок», «Таблица»).
ListNum — вставка маркера нумерованного списка в любое место
абзаца (вставка поля ALT + CTRL + L).
Например, список следующего вида, созданный с помощью полей
ListNum.
1.
а) Текст
b) Текст
c) Текст 3
Общий вид поля:
1.
{ListNum}
{ListNum}
{ListNum}
Текст 1
Текст 2
Текст 3
{ListNum Тип \l V1 \s V2},
где Тип — тип списка ((Нет), LegalDefault, NumberDefault,
OutlineDefault); \l — уровень вложенности списка V1; \s — начальный
номер пункта списка V2.
Стиль нумерации пунктов в зависимости от типа списка и уровня
представлен в табл. 10.2.
Уровень вложенности списка поля ListNum можно изменять клавишами TAB и SHIFT + TAB.
Если перед полем ListNum находится список и если тип списка —
(Нет), то поле ListNum будет продолжать нумерацию стилем пред-
183
Т а б л и ц а 10.2. Типы списков и их уровни
Уровень
списка
Legal
Default
(Нет)
Number
Default
Outline
Default
1
1.
1.
1)
I.
2
1.1
1.1.
a)
A.
3
1.1.1
1.1.1.
i)
1.
4
(1)
1.1.1.1.
(1)
a)
5
(a)
1.1.1.1.1.
(a)
(1)
6
(i)
1.1.1.1.1.1.
(i)
(a)
7
1.
1.1.1.1.1.1.1.
1.
(i)
8
a.
1.1.1.1.1.1.1.1.
a.
(a)
9
i.
1.1.1.1.1.1.1.1.1.
i.
(i)
шествующего списка, иначе будет начата новая нумерация стилем
типа списка ListNum.
3. Указатели.
Index — вставка предметного указателя — списка понятий и терминов, встречающихся в документе, с указанием номеров страниц,
на которых они размещены (см. пункт меню Вставка | Ссылка |
Оглавление и указатели…, вкладка Указатель). Предметный указатель составляют элементы, помеченные полем XE.
TOC — вставка оглавления (см. пункт меню Вставка | Ссылка |
Оглавление и указатели…, вкладка Оглавление). Оглавление составляют элементы, имеющие стиль заголовка или помеченные полем
TC. Общий вид:
{TOC [Ключи]}.
Ключи поля TOC:
\b Закладка — создать оглавление только из текста, помеченного
указанной закладкой;
\c “Идентификатор” — создать оглавление элементов, помеченных
полем Seq с Идентификатором;
\n Уровни — запрещает вывод номеров страниц для элементов
всех (\n), одного (например, второго \n 2-2), последовательных (например, первого и второго \n 1-2) или указанных уровней (например,
первого и третьего \n 1-1 \n 3-3);
\p “Символ” — указывает символ для разделения элементов оглавления и номеров страниц. По умолчанию используется табуляция с
заполнением точками;
184
\t “Стиль,Уровень,…” — вставляет в оглавление элементы, имеющие нестандартные стили (не заголовок). Уровень указывает номер
уровня в оглавлении.
TC — определение элемента оглавления (вставка поля ALT +
+ SHIFT + O). Поле TC вставляется непосредственно перед элементом, включаемым в оглавление. Поле TC видимо только в режиме
отображения символов форматирования. Общий вид:
{TC “Текст” [Ключи]},
где Текст — текст в оглавлении для данного элемента.
XE — определение текста элемента предметного указателя (вставка поля ALT + SHIFT + X). Общий вид:
{XE “Текст” [Ключи]},
где Текст — текст, который будет использоваться в предметном указателе.
Поле XE видно только в режиме отображения символов форматирования.
Параметры страницы
Страница документа имеет следующую структуру (рис. 10.28).
Поля определяют расстояние от края страницы до основного текста и до колонтитулов.
Рис. 10.28. Структура страницы документа текстового процессора Microsoft Word
185
Рис. 10.29. Виды ориентации листа
Чтобы установить размеры полей необходимо выполнить следующие действия:
1) выбрать пункт меню Файл | Параметры страницы;
2) выбрать вкладку Поля;
3) в группе Поля установить размеры верхнего, нижнего, левого и
правого полей, поля под переплет и его положение слева или справа
от страницы;
4) выбрать вкладку Источник бумаги;
5) в группе Различать колонтитулы установить размеры от края
страницы до верхнего и нижнего колонтитулов.
Размеры задаются в сантиметрах или пунктах.
Положение переплета справа или слева устанавливается, если документ будет распечатан на одной стороне листа. Если печать будет
двухсторонняя, то на вкладке Поля в группе Страницы в раскрывающемся списке несколько страниц выбрать пункт Зеркальные
поля. При этом левое и правое поля поменяют названия на внутреннее и наружное, а переплет окажется внутри разворота.
Также на вкладке Поля задается ориентация листа: книжная или
альбомная (рис. 10.29).
В случае если в документе большинство листов имеют, например,
книжную ориентацию, а остальные — альбомную, рекомендуется
создать дополнительный документ с листами альбомной ориентации,
а в основном документе создать пустые листы книжной ориентации
вместо отсутствующих листов альбомной ориентации (рис. 10.30).
Рис. 10.30. Способ печати документов с разной ориентацией листов
186
Печать документа осуществляется в следующем порядке:
1) распечатать основной документ;
2) пустые листы основного документа с распечатанными номерами страниц вновь вставить в лоток принтера в порядке возрастания
и распечатать дополнительный документ.
Преимуществом данного способа является отсутствие проблем с
нумерацией страниц и делением документа на разделы.
Формат бумаги, на которой будет производиться редактирование
и печать документа, устанавливается на вкладке Размер бумаги в
группе Размер бумаги (пункт меню Файл | Параметры страницы).
Можно выбрать один из стандартных форматов бумаги или задать
размеры листа в сантиметрах.
Согласно ГОСТ Р 6.30 — 2003 документы изготавливают на бланках
двух стандартных размеров: А4 (210 × 297 мм) и А5 (148 × 210 мм).
Каждый лист бланка должен иметь поля не менее: левое, верхнее и
нижнее — 20 мм; правое — 10 мм.
Колонтитул представляет собой одну или несколько строк текста,
помещаемых в начало (верхний колонтитул) или в конце (нижний
колонтитул) страницы. В колонтитулах могут размещаться следующие
виды информации:
• постоянная — не изменяющаяся от страницы к странице: название, автор, дата создания и последнего изменения документа;
• переменная — имеющая разный вид на разных страницах: номер
страницы, номер и название главы.
Как правило, информация в колонтитулы вставляется с помощью
полей.
Чтобы изменить колонтитул необходимо выбрать пункт меню Вид |
Колонтитулы. В результате появится панель инструментов Колонтитулы и будут доступны для редактирования верхний и нижний
колонтитулы. Для перехода между верхним и нижним колонтитулами
используйте кнопку Верхний/нижний колонтитул на панели инструментов Колонтитулы.
Можно задать различные колонтитулы для первой страницы,
четных и нечетных страниц.
Чтобы создать колонтитул для первой (четных и нечетных) страницы необходимо выполнить следующие действия:
1) выбрать пункт меню Файл | Параметры страницы;
2) выбрать вкладку Источник бумаги;
3) в группе Различать колонтитулы установить флажок первой
страницы (четных и нечетных страниц) и нажать кнопку Ok.
Далее выбрать колонтитул и его отредактировать.
Переход между колонтитулами четных и нечетных страниц осуществляется с помощью кнопок Переход к следующему и Переход
к предыдущему на панели инструментов Колонтитулы.
Если текст разбит на разделы и необходимо, чтобы в разделе колонтитулы были такими же как и в предыдущем разделе, перейдите
187
в этот раздел и нажмите кнопку Как в предыдущем разделе на панели инструментов Колонтитулы.
Согласно ГОСТ Р 6.30 — 2003 идентификатором электронной копии документа является отметка, проставляемая в нижнем колонтитуле слева каждой страницы документа и содержащая наименование
файла на машинном носителе, дату и другие поисковые данные,
устанавливаемые в организации.
Разделы
Раздел — это часть документа, имеющая особые, отличающиеся
от других частей параметры форматирования страницы. Как отдельный раздел помечаются следующие части документа:
• колонки текста (если весь документ не разбит на колонки);
• страницы с особой нумерацией;
• страницы с особыми колонтитулами;
• страницы с особыми параметрами: полями, ориентацией листа.
Вставка разрыва раздела:
1) выбрать пункт меню Вставка | Разрыв;
2) в группе Новый раздел выбрать, где будет начинаться новый
раздел: со следующей страницы, с текущей страницы, с четной страницы, с нечетной страницы.
Чтобы наглядно посмотреть разделение документа на разделы,
необходимо выбрать пункт меню Вид | Обычный. Граница раздела
помечается горизонтальной двойной пунктирной линией.
Удаление разрыва раздела:
1) выбрать пункт меню Вид | Обычный;
2) выделить линию разрыва раздела, которого необходимо удалить;
3) нажать клавишу DEL.
В рамках раздела доступны для изменения следующие параметры:
размеры полей страницы, размер и ориентация бумаги, оформление
границ страницы, вертикальное выравнивание текста на странице
(по нижнему или верхнему краю, по высоте или по центру), колонтитулы, колонки, нумерация страниц и строк.
Чтобы установить параметры страницы для текущего раздела (всех
разделов), необходимо выполнить следующие действия:
1) выбрать пункт меню Файл | Параметры страницы;
2) установить необходимые параметры страницы;
3) выбрать вкладку Поля;
4) в группе Образец в списке Применить выбрать пункт к текущему разделу (ко всему документу) и нажать кнопку Ok.
Колонки
Текст для более компактного размещения на листе можно расположить в несколько колонок. Можно разбить текст максимум на
девять колонок, причем ширина всех колонок может быть одинаковой
188
или индивидуальной для каждой колонки. Чтобы разбить текст на
колонки, необходимо выполнить следующие действия:
1) выделить текст, который будет разбит на колонки, или пропустить этот шаг, если предполагается разбить на колонки весь текст;
2) выбрать пункт меню Формат | Колонки;
3) установить параметры колонок: число, размер, наличие или
отсутствие разделителя колонок и нажать кнопку Оk.
Текст, разделенный на колонки, помещается в отдельный раздел.
Чтобы удалить деление текста на колонки, необходимо выполнить
следующие действия:
1) установить курсор в текст, разбитый на колонки;
2) выбрать пункт меню Формат | Колонки;
3) выбрать одну колонку и нажать кнопку Оk;
4) удалить раздел, созданный для текста, разделенного на колонки
(см. п. Разделы).
10.5.6. Автоматизация работы текстового редактора
Microsoft Word
Создание макросов
Рассмотрим три способа ускорения работы текстового редактора
Microsoft Word:
1) создание макросов;
2) назначение командам сочетания клавиш;
3) назначение стилям сочетания клавиш.
Макрос — это подпрограмма, написанная на встроенном языке
программирования пакета Microsoft Office Visual Basic для приложений, выполняющая операции по форматированию и обработке документа. Макросы создаются для выполнения сложных и (или) нередко повторяемых операций.
Макрос может быть написан двумя способами:
1) непосредственно, как любая другая программа;
2) в режиме записи действий пользователя.
Чтобы записать действия пользователя в виде макроса, необходимо выполнить следующие операции:
1) продумать, какие действия необходимо выполнить, чтобы решить задачу;
2) выбрать пункт меню Сервис | Макрос | Начать запись…;
3) в окне Запись макроса задать название макроса (по умолчанию
называется Макрос 1, Макрос 2 и т. д.), назначить выполнение макроса кнопке на панели инструментов или сочетанию клавиш, задать
место хранения макроса в стандартном шаблоне Normal. dot (макрос
будет доступен для всех документов) или в текущем документе, задать
описание (краткий комментарий) макроса;
189
4) нажать кнопку Ok; в результате появится панель инструментов
Остановить запись, состоящая из двух кнопок Остановить запись
и Пауза;
5) в режиме записи сохраняются действия, выполняемые с клавиатуры; действия с документом, выполняемые мышью, совершаются, но не записываются в макрос;
6) если необходимо приостановить запись макроса, нажмите кнопку Пауза; чтобы возобновить запись, нажмите эту же кнопку;
7) чтобы закончить запись макроса, нажмите кнопку Остановить
запись.
В результате будет сгенерирована подпрограмма на языке Visual
Basic.
Чтобы просмотреть список доступных макросов, нажмите сочетание клавиш ALT + F8. В результате откроется окно Макрос, в котором можно выполнить следующие операции с макросами, нажав
на соответствующие кнопки:
• выполнить макрос;
• отладить работу макроса с помощью пошагового выполнения
его команд;
• изменить текст макроса в редакторе Visual Basic;
• создать новый макрос в редакторе Visual Basic;
• удалить макрос;
• переместить макросы из одного документа в другой с помощью
Организатора.
Назначение командам сочетания клавиш
Каждый пункт меню или кнопка на панели инструментов представляет вызов команды, записанной в виде макроса. Значительно
быстрее вызывать необходимую команду сочетанием клавиш.
Чтобы назначить команде сочетание клавиш, необходимо выполнить следующие действия:
1) выбрать пункт меню Сервис | Настройка…;
2) в окне Настройка нажать кнопку Клавиатура…;
3) в окне Настройка клавиатуры выбрать категорию и команду;
если команде назначено сочетание клавиш, то сочетание отобразится в поле Текущие сочетания;
4) установить курсор в поле Новое сочетание клавиш и нажать
желаемое сочетание клавиш; если сочетание клавиш уже используется, то под полем будет отображено текущее назначение сочетания;
5) нажать кнопку Назначить.
Категории команд включают пункты главного меню (Файл, Правка и т. д.), макросы, шрифты, автотекст, стили и символы.
Теперь по нажатию установленного сочетания клавиш будет выполняться команда.
190
Назначение стилям сочетания клавиш
Присвоение сочетания клавиш стилю позволяет быстро форматировать текст заданными стилями.
Существует два способа назначения стилям сочетания клавиш.
С п о с о б 1. Аналогичен назначению командам сочетания клавиш.
В списке категорий выбирается категория Стили, а в списке Стили —
необходимый стиль.
С п о с о б 2. Необходимо выполнить следующие действия:
1) выбрать пункт меню Формат | Стили и форматирование;
2) в открывшейся справа панели выбрать нужный стиль;
3) выбрать пункт контекстного меню Изменить… или Изменить
стиль…;
4) нажать кнопку Формат;
5) в открывшемся меню выбрать пункт Сочетание клавиш…;
6) назначить сочетание клавиш аналогично назначению сочетания
клавиш команде;
7) нажать кнопку Назначить.
Теперь по нажатию установленного сочетания клавиш выделенный
фрагмент будет отформатирован в соответствии с заданным стилем.
Слияние
Слияние используется для создания большого количества документов одинакового содержания, но с разными исходными данными.
Для слияния необходимо создать шаблон документа и базу данных
(рис. 10.31).
База данных задается в виде документа Microsoft Word или книги
Microsoft Excel и содержит данные, которые будут помещены в создаваемые по шаблону документы.
Правила оформления базы данных. 1. База данных должна
включать только таблицу, содержащую в первой строке таблицы заголовки столбцов, а в остальных строках — записи базы данных.
Заголовки столбцов будут являться названиями полей слияния.
Рис. 10.31. Схема слияния документов
191
2. Таблица должна находиться в начале документа или листа без
пустых строк перед ней.
Шаблон содержит документ, который будет создаваться для каждой
записи из базы данных.
Чтобы создать шаблон документа, необходимо выполнить следующие действия:
1) создать документ Microsoft Word (сочетание клавиш CTRL +
+ N);
2) убедиться, что файл базы данных закрыт;
3) открыть панель инструментов Слияние (выбрать пункт меню
Вид | Панели инструментов | Слияние);
4) нажать кнопку Открыть источник данных на панели инструментов Слияние и выбрать файл базы данных;
5) для каждого из полей слияния выполнить следующие действия:
• установить курсор на место, где необходимо вставить поле
слияния;
• нажать кнопку Вставить поле слияния на панели инструментов Слияние;
• выбрать поле слияния и нажать кнопку Вставить.
Чтобы выполнить слияние, необходимо открыть шаблон, нажать
кнопку Слияние в новый документ на панели инструментов Слияние
или нажать сочетание клавиш ALT + SHIFT + N.
В результате будет создан документ, состоящий из шаблонов с заполненными полями слияния из базы данных.
Путь к файлу базы данных записывается в файл шаблона. Поэтому при изменении расположения файла базы данных необходимо
вновь открыть файл базы данных.
Специальные служебные поля, используемые при слиянии.
• NEXT — перейти к следующей записи базы данных без создания
документа для текущей записи. Используется для помещения нескольких записей в текущий документ, а не в новый.
• SKIPIF — пропустить текущую запись в случае истинности
условия. Общий вид поля:
{SKIPIF Поле Оператор Значение},
где Поле — название поля слияния; Оператор — операторы сравнения, «пусто», «не пусто»; Значение — значение поля, при котором
запись должна быть пропущена.
Ключи Оператор и Значение образуют условие;
• NEXTIF — пропустить следующую за текущей запись в случае
истинности условия. Общий вид поля:
{NEXTIF Поле Оператор Значение},
где Значение — значение поля, при котором следующая запись должна быть пропущена;
192
• IF — вставка текста в зависимости от значения поля. Общий вид
поля:
{IF Поле Оператор Значение Текст1 Текст2},
где Текст1 — текст, который будет вставлен в случае истинности
условия; Текст2 — текст, который будет вставлен в случае ложности
условия;
• MERGEREC — фактический номер записи в базе данных;
• MERGESEQ — число записей, вставленных в шаблон на текущий момент. Будет отличаться от MERGEREC в случае пропуска
записей.
Чтобы вставить служебное поле в шаблон, необходимо выполнить
следующие действия:
1) нажать кнопку Добавить поле Word на панели инструментов
Слияние;
2) выбрать в списке название служебного поля;
3) при необходимости задать ключи поля.
10.6. Табличные процессоры
10.6.1. Табличные процессоры, их функции
и структура
Решение некоторых математических и экономических задач нередко сводится к обработке данных, хранящихся в прямоугольных
таблицах. Написание отдельной программы для решения каждой задачи такого типа неэффективно. Текстовые процессоры позволяют
вести и форматировать таблицы, однако они не приспособлены для
вычислений данных в них. Поэтому были разработаны программы,
называемые табличными процессорами или электронными таблицами, объединяющими в себе следующие возможности:
• создание и форматирование таблиц;
• математические вычисления табличных данных;
• представление результатов вычислений в виде таблиц, диаграмм
и графиков.
• ведение и обработка БД с реляционной моделью данных, в которой данные хранятся в виде двумерных таблиц.
Табличные процессоры используются для решения таких экономических задач, как учет объемов продаж и прибыли, контроль
численности персонала и рабочего времени, расчет налогов и заработной платы и др. Благодаря большому количеству разнообразных математических функций, табличные процессоры позволяют
решать широкий круг задач в области естественных и технических
наук.
193
Рассмотрим принципы работы и возможности табличных процессоров на примере табличного процессора Microsoft Excel 2003,
который получил наибольшее распространение. Табличный процессор Microsoft Excel 2003 входит в тот же пакет прикладных программ
Microsoft Office 2003, что и табличный процессор Microsoft Word 2003.
Предполагается, что читатель знаком с основами работы в этом табличном процессоре.
10.6.2. Общие сведения об объектах
Microsoft Excel
Файл табличного процессора Microsoft Excel имеет расширение
. xls и содержит книгу. Книга состоит из листов, а листы — из
ячеек.
Перед началом работы необходимо сделать следующие установки.
Чтобы установить стандартные для русского языка настройки,
необходимо выполнить следующие действия:
1) вызвать меню Пуск операционной системы Microsoft Windows
или нажать сочетание клавиш CTRL + ESC;
2) выбрать пункт меню Настройки | Панель управления;
3) открыть элемент Язык и региональные стандарты;
4) выбрать вкладку Региональные параметры;
5) в группе Языковые стандарты и форматы выбрать язык Русский.
Чтобы Microsoft Excel распознавал заголовки, используемые в
формулах, необходимо выполнить следующие действия:
1) выбрать пункт меню Сервис | Параметры;
2) выбрать вкладку Вычисления;
3) в группе Параметры книги установить флажок Допускать
названия диапазонов.
10.6.3. Типы адресации
в Microsoft Excel
При записи формул приходится ссылаться на ячейки, в которых
хранятся исходные значения.
Каждая ячейка имеет адрес (ссылку). Возможны следующие способы адресации ячеек.
I. Адресация одной ячейки. Ячейка на пересечении столбца А и
строки 3 имеет адрес А3. Всего на листе может быть 65 536 строк и
256 столбцов. Столбцы нумеруются A, …, Z, AA, AB, …, IV.
194
В Excel существуют следующие типы ссылок на ячейки. Отличия
типов ссылок становятся заметными при переносе или копировании
ячейки со ссылками.
1. Абсолютные ссылки. Абсолютные ссылки не меняются при
переносе или копировании ячейки со ссылками. Перед заголовком
столбца и номера строки ячейки ставится знак доллара $. Примеры
абсолютных ссылок $A$1, $B$67.
A
1
B
1
2
= $A$1 + $B$1
2
3
4
1
2
= $A$1 + $B$1
5
2. Относительные ссылки. При переносе или копировании ячейки
с относительными ссылками, ссылки меняются, сохраняя пространственное соотношение с ячейками, на которые они ссылаются. Относительная ссылка представляет адрес ячейки. Примеры относительных ссылок A2, CD45.
A
1
B
1
2
= A1 + B1
2
3
4
5
1
2
= A4 + B4
3. Смешанные ссылки. В смешанных ссылках либо перед заголовком столбца, либо номером строки ставится знак доллара. Этот
параметр не меняется при переносе или копировании ячейки со
ссылками, как абсолютная ссылка, а параметр, перед которым знак
доллара отсутствует, меняется, сохраняя пространственное соотношение, как относительная ссылка. Примеры смешанных ссылок
T$2, $AC5.
195
A
B
C
1
1
2
3
= A$1 + $B1
2
3
4
1
2
3
= B$1 + $B4
5
Задача 10.1. Формулу из ячейки B2 скопировали в ячейку C3.
Какое значение имеет формула в ячейке C3?
A
B
C
1
1
2
3
2
3
= A1 + $B$1*A$2
4
3
4
6
?
О т в е т. С3: = B2+$B$1*B$2; B2: 7; C3: 21.
Задача 10.2. В ячейке B2 вычисляется сумма двух ячеек. Формулу из ячейки B2 скопировали в ячейку C3. Зависимость между ячейками изображена на рисунке.
A
B
C
1
2
3
Какая формула записана в ячейке B2?
О т в е т. Формула в ячейке B2: =A2+$B1.
4. Трехмерные ссылки (объемные ссылки). Трехмерная ссылка
используется для ссылки на ячейку, находящуюся на другом листе, и
состоит из двух частей: названия листа и абсолютной (относительной,
смешанной) ссылки на ячейку, разделенных восклицательным знаком, например:
Лист1!B1.
196
Если название листа содержит пробелы, знаки пунктуации, то
название листа в ссылке заключается в апострофы, например:
‘Лист 1’!B1.
5. Внешние ссылки. Внешняя ссылка используется для ссылки на
ячейку в другой книге. Внешняя ссылка состоит из названия книги
в квадратных скобках и трехмерной ссылки, например:
[Книга1]Лист1!B1.
Если название книги или листа содержит пробелы, знаки пунктуации, то вся часть ссылки до восклицательного знака заключается в апострофы, например:
‘[Книга 1. xls]Лист 1’!B1.
Расширение файла книги можно не указывать. Если книга закрыта, то необходимо указать полный путь к файлу книги до квадратных
скобок с названием книги, например:
‘C:\MyDocs\[Книга 1. xls]Лист 1’!B1.
II. Адресация связных ячеек (диапазона). Диапазон определяется адресами верхней левой и нижней правой ячеек.
Например, три последовательные ячейки А1, В1, С1 можно адресовать как А1:С1.
Возможно задание диапазонов с использованием трехмерных
ссылок. Например, адресация диапазона Лист1:Лист3!B1 задает все
ячейки B1 с листа Лист1 по лист Лист3, а адресация диапазонов
Лист1:Лист3!C1:D9 задает диапазон C1:D9 на листах Лист1Лист3.
Трехмерные ссылки нельзя использовать для создания явного или
неявного пересечения диапазонов.
III. Адресация несвязных ячеек. Непоследовательные ячейки
перечисляются через точку с запятой. Например, ячейки А1, А3, В3,
С3 можно адресовать как А1; А3:С3.
10.6.4. Присвоение имен ячейкам и диапазонам
в Microsoft Excel
При записи формул удобно ссылаться на нередко используемые
ячейки не по ссылке, а по имени: например, Ставка_налога.
Существует два типа имен ячеек и диапазонов:
1) на уровне листа;
2) на уровне книги.
Чтобы присвоить имя ячейке или диапазону на уровне листа, необходимо выполнить следующие действия:
197
1) выделить ячейку или диапазон ячеек;
2) выбрать пункт меню Вставка | Имя | Присвоить;
3) в открывшемся окне Присвоение имени в поле Имя ввести имя
ячейки или диапазона, причем имя должно начинаться как трехмерная ссылка с названия листа и знака восклицания (!); первый символ
имени должен быть буквой или знаком подчеркивания, остальные
символы имени могут быть буквами, цифрами, точками или знаками
подчеркивания; регистр не учитывается;
4) в поле Формула будет записана ссылка на ячейку или диапазон;
5) нажать кнопку Добавить, чтобы ввести еще имена ячеек или
диапазонов, или кнопку Ok, чтобы закрыть окно.
Чтобы присвоить имя ячейке и диапазону на уровне книги, необходимо выполнить те же действия, но на шаге 3 при задании имени не указывать название листа.
Чтобы присвоить имя формуле или константе, необходимо выполнить те же действия, что и при задании имени на уровне книги,
но на шаге 4 в поле Формула необходимо записать формулу или
константу, например «=25%».
Присвоенные имена, именованные формулы и константы используются в формулах. При использовании имен на уровне листа на
другом листе необходимо записать название листа, знак восклицания
и имя, как в трехмерной ссылке: например, Лист1!Итог.
10.6.5. Формулы Microsoft Excel
и их отладка
В каждой ячейке, помимо значений, могут содержаться формулы.
Запись формулы начинается со знака равно (=), а далее следует арифметическое выражение или название функции. Параметры функции записываются после имени функции в скобках через точку с запятой (;).
Некоторые функции не имеют параметров. В этом случае записываются пустые скобки. Например, =ПИ(), =СЕГОДНЯ().
Формулы могут содержать следующие арифметические действия:
+ — сложение;
− — вычитание;
* — умножение;
/ — деление;
^ — возведение в степень.
В табличном процессоре Excel определены различные математические функции, некоторые из них представлены в табл. 10.3.
Эти и другие функции, их параметры и справку по ним можно
найти с помощью Мастера функций (меню Вставка | Функция).
198
Т а б л и ц а 10.3. Математические функции табличного процессора
Excel
Функция
Описание
КОРЕНЬ
Квадратный корень
ФАКТР
Факториал
СУММ
Сумма аргументов
МАКС
Максимальное значение аргументов
МИН
Минимальное значение аргументов
СРЗНАЧ
Среднее арифметическое аргументов
Пусть дано выражение
sin( x + 2)
+7
x +3
y=
,
x
x + cos 2
2
ln 1 +
x3
и значение х содержится в ячейке А1, а y — в A2, тогда соответствующая запись в ячейке A2 будет иметь вид:
= КОРЕНЬ(SIN(A1+2)/(A1+3)+7)/
/LN(ABS(1+(A1+COS(A1/2)^2)/A1^3)).
Рассмотрим вычисление сложных формул. Пусть дано выражение
x + 5, x < 0;
y = x 2 , 0 ≤ x < 2;
1
- , x ≥ 2.
x
Воспользуемся функцией ЕСЛИ:
ЕСЛИ(Условие; Значение 1; Значение 2),
где Условие — логическое выражение; Значение 1 — значение, возвращаемое в случае истинности условия; Значение 2 — значение,
возвращаемое в случае ложности условия.
Значение 1 и Значение 2 могут быть формулами. Если условие
истинно или ложно, а соответствующее значение отсутствует, то возвращается значение 0.
199
Значение х содержится в ячейке А1, а y — в A2, тогда соответствующая запись в ячейке A2 будет иметь вид
=ЕСЛИ(A1<0;A1+5;ЕСЛИ(A1<2;A1*A1;-1/A1)).
Чтобы изменить тип ссылки в формуле, необходимо выполнить
следующие действия:
1) выбрать ссылку в формуле;
2) нажимать клавишу F4 до тех пор, пока ссылка не будет иметь
нужный тип.
Формулы пересчитываются при вводе или изменении значений в
ячейках, которые участвуют в вычислениях.
Чтобы принудительно пересчитать формулы во всех открытых
книгах, нажмите клавишу F9.
Чтобы установить автоматический пересчет формул, необходимо
выполнить следующие действия:
1) выбрать пункт меню Сервис | Параметры;
2) выбрать вкладку Вычисления;
3) в группе Вычисления выбрать пункт Автоматически.
Чтобы просмотреть, какие формулы записаны в ячейках, необходимо перейти в режим проверки формул с помощью пункта меню
Сервис | Зависимости формул | Режим проверки формул или сочетания клавиш CTRL + Ё.
При вычислениях формул возможны ошибки. Условные сообщения об ошибках появляются в ячейках, где находится формула с
ошибкой (табл. 10.4).
Чтобы выявить ошибку, возникшую при вычислении формулы,
необходимо выполнить следующие действия:
Т а б л и ц а 10.4. Сообщения об ошибках
Сообщение об ошибке
Описание ошибки
#####
Столбец недостаточно широк, чтобы отображать данные в нем, или дата и время являются
отрицательными числами
#Н/Д!
Отсутствуют данные для расчетов (например,
если ячейка пуста)
#ЗНАЧ!
Использование недопустимого типа аргумента
#ДЕЛ/0!
Деление числа на 0 (нуль)
#ИМЯ?
Ошибка названия функции в формуле
#ЧИСЛО!
Неправильное числовое значение в формуле
или функции
200
1) выбрать ячейку, где содержится формула с ошибкой;
2) выбрать пункт меню Сервис | Зависимости формул | Вычислить
формулу;
3) в окне Вычисление формулы нажать кнопку Вычислить для каждой
операции формулы; вычисляемая в данный момент операция подчеркивается, а последний полученный результат выделяется курсивом;
4) повторять шаг 3 до тех пор, пока не появится сообщение об
ошибке.
Чтобы выявить ячейки, влияющие (зависимые) на значение данной ячейки, необходимо выполнить следующие действия:
1) выбрать ячейку, для которой необходимо выявить влияющие
(зависимые) ячейки;
2) выбрать пункт меню Сервис | Зависимости формул | Влияющие
ячейки (Зависимые ячейки).
В результате появятся стрелки, показывающие направления зависимостей значений ячеек. Если значение ячейки влияет (зависит)
на значение ячейки, находящейся на другом листе, то рядом со стрелкой появится условное изображение листа книги табличного процессора Microsoft Excel.
Чтобы убрать стрелки зависимостей значений, необходимо выбрать
пункт меню Сервис | Зависимости формул | Убрать все стрелки.
Существует экспоненциальный вид записи числа, используемый
в Excel. Любое число представляется в следующем виде:
ME ± P,
где М — мантисса, находящаяся в пределах [0; 10); P — десятичный
порядок.
Например, число 25 представляется, как 2,5E + 01, что означает
2,5 · 101.
10.6.6. Логические функции Microsoft Excel
В табличном процессоре Microsoft Excel существуют следующие
элементы логики высказываний:
• логические константы ЛОЖЬ и ИСТИНА, вместо которых можно использовать 0 и 1 соответственно;
• логические функции, возвращающие в качестве результата одну
из логических констант:
1) отрицание: НЕ(x);
2) конъюнкция: И(x1[; x2; …; x30]);
3) дизъюнкция: ИЛИ(x1[; x2; …; x30]).
В функциях И и ИЛИ можно использовать от 1 до 30 аргументов.
В качестве аргументов могут выступать логические константы, логические условия (например, 2 + 2 > 4) или ссылки на ячейки, где содержатся логические константы или значения.
201
Если в ячейках не содержатся логические значения, то логические
функции возвращают значение ошибки #ЗНАЧ!.
Пример 10.1. Записать в виде формулы функцию
1, x < 0, 2 ≤ x < 4;
y = 2, 0 ≤ x < 2;
3, x ≥ 4.
Запишем условия первых и вторых случаев в виде простых условий:
1) (x < 0) или ((x ≥ 2) и (x < 4));
2) (x ≥ 0) и (x < 2);
3) x ≥ 4.
Запишем условия первого случая в виде формулы, значение x находится в ячейке A1:
= ИЛИ(A1<0;И(A1>=2;A1<4)).
Запишем формулу для функции:
= ЕСЛИ(ИЛИ(A1<0;И(A1>=2;A1<4));1;ЕСЛИ(И(A1>=0;A1<2);2;3)).
10.6.7. Функции теории вероятностей
и математической статистики в Microsoft Excel
Выборочные характеристики
Дисперсия выборки из генеральной совокупности:
ДИСП(x1; x2; …; x30).
Формула вычисления выборочной дисперсии:
= n∑ x - ( ∑ x ) .
D
n(n - 1)
2
2
Дисперсия генеральной совокупности:
ДИСПРА(x1; x2; …; x30).
В отличие от функции ДИСП при вычислении значения функции
ДИСПРА предполагается, что в параметрах функции представлена
вся генеральная совокупность, а не выборка из нее.
Формула вычисления дисперсии генеральной совокупности:
D=
202
n∑ x 2 - ( ∑ x )
n2
2
.
Медиана — это число, которое является серединой упорядоченной
последовательности чисел, т. е. половина чисел имеют значения большие, чем медиана, а половина чисел — меньшие, чем медиана:
МЕДИАНА(x1; x2; …; x30).
Если количество значений четное, то функция вычисляет среднее
двух значений, находящихся в середине последовательности.
Мода — это наиболее часто встречающееся или повторяющееся
значение в последовательности чисел:
МОДА(x1; x2; …; x30).
Если несколько значений встречаются одинаковое количество раз,
то возвращается минимальное значение.
Наименьшее k-е значение из значений диапазона ячеек:
НАИМЕНЬШИЙ(диапазон; k).
Эта функция используется для определения значения, занимающего определенное относительное положение среди значений диапазона ячеек.
Минимальное значение последовательности имеет k = 1.
Если диапазон пуст или k ≤ 0 или k превышает число ячеек диапазона, то функция возвращает значение ошибки #ЧИСЛО!.
Наибольшее k-е из значений диапазона ячеек:
НАИБОЛЬШИЙ(диапазон; k).
Среднее арифметическое:
СРЗНАЧ(x1; x2; …; x30),
где x1; x2; …; x30 — числа, имена или ссылки, содержащие числа.
Ячейки, не содержащие числа, игнорируются.
Формула вычисления среднего арифметического:
X =
∑x.
n
Среднее гармоническое:
СРГАРМ(x1; x2; …; x30).
Если один из аргументов функции отрицательный, то функция
СРГАРМ возвращает значение ошибки #ЧИСЛО!.
Формула вычисления среднего гармонического:
X гарм =
n
.
1
∑x
Среднее геометрическое:
СРГЕОМ(x1; x2; …; x30).
203
Формула вычисления среднего геометрического:
X геом = n ∏ x .
Среднее доли множества данных, отбрасывая числа с экстремальными значениями:
УРЕЗСРЕДНЕЕ(диапазон; доля),
где диапазон — интервал усредняемых значений; доля — процент
значений, исключаемых из вычислений.
Например, если доля = 0,2, то отбрасываются 10 % чисел с наибольшими значениями и 10 % чисел с наименьшими значениями.
Значение параметра доля лежит в диапазоне [0; 1], иначе функция
возвращает значение ошибки #ЧИСЛО!.
УРЕЗСРЕДНЕЕ округляет в меньшую сторону количество отбрасываемых значений до ближайшего четного целого.
Комбинаторика
Количество размещений из n элементов по m — любых упорядоченных множеств из m элементов множества, состоящего из n различных элементов:
ПЕРЕСТ(n; m).
Оба аргумента усекаются до целых.
Если n или m не являются числами, то функция возвращает значение ошибки #ЗНАЧ!.
Если n ≤ 0 или m < 0 или n < m, то функция ПЕРЕСТ возвращает
значение ошибки #ЧИСЛО!.
Формула расчета размещений:
Anm =
n!
.
(n - m)!
Количество сочетаний из n элементов по m — размещений, в которых не учитывается порядок элементов:
ЧИСЛКОМБ(n; m).
Формула расчета сочетаний:
Cnm =
204
n!
.
m!(n - m)!
Законы распределения
Значение биномиального распределения (распределения Бернулли, формулы Бернулли):
БИНОМРАСП(k; n; p; признак),
где k — количество успешных испытаний; n — число независимых
испытаний; p — вероятность успеха в каждом испытании; признак —
логическое значение, определяющее форму функции.
Если параметр «признак» имеет значение ИСТИНА, то функция
возвращает интегральную функцию распределения, т. е. вероятность
того, что число успешных испытаний не более значения параметра
k. Если этот параметр имеет значение ЛОЖЬ, то возвращается функция распределения, т. е. вероятность того, что число успешных испытаний в точности равно значению параметра k.
Параметры k и n усекаются до целых.
Функция возвращает значение ошибки #ЗНАЧ!, если k, n или p
не является числом.
Функция возвращает значение ошибки #ЧИСЛО! в следующих
случаях:
1) k < 0 или k > n;
2) p < 0 или p > 1.
Формула расчета значения интегрального биномиального распределения:
k
Pn ( x ≤ k ) = ∑Cni p i (1 - p)n - 1 .
i =0
Формула расчета значения биномиального распределения:
Pn(x = k) = Сnkpk(1 – p)n – k.
Значение гипергеометрического распределения:
ГИПЕРГЕОМЕТ(m; n; M; N),
где m — число успехов в выборке; n — размер выборки; M — число
успехов в генеральной совокупности; N — размер генеральной совокупности.
Все аргументы усекаются до целых.
Если любой из аргументов не является числом, то функция возвращает значение ошибки #ЗНАЧ!.
Функция возвращает значение ошибки #ЧИСЛО! в следующих
случаях:
1) m < 0 или m > min{n, M};
2) m < min{0; n − N + M};
3) n < 0 или n > N;
4) M < 0 или M > N;
5) N < 0.
205
Формула расчета значения гипергеометрического распределения:
P=
m n- m
CM
C N -M
.
C Nn
Значение функции нормального распределения для указанного
среднего и стандартного отклонения:
НОРМРАСП(x; a; σ; признак),
где x — значение, для которого строится распределение; a — математическое ожидание нормального распределения; σ — среднее квадратическое отклонение; признак — логическое значение, определяющее
форму функции.
Если параметр «признак» имеет значение ИСТИНА, то функция
возвращает интегральную функцию распределения. Если этот аргумент имеет значение ЛОЖЬ, то возвращается функция плотности
распределения.
Функция возвращает значение ошибки #ЗНАЧ!, если a или σ не
является числом.
Функция возвращает значение ошибки #ЧИСЛО!, если σ ≤ 0.
Формула интегральной функции нормального распределения:
F ( x) =
x
1
∫
σ 2π -∞
e
-
(t -a )2
2 σ2 dt .
Формула плотности нормального распределения:
f ( x) =
1
σ 2π
e
-
( x -a )2
2 σ2 .
Если a = 0, σ = 1 и признак = ИСТИНА, то функция НОРМРАСП
возвращает стандартное нормальное распределение, т. е. НОРМСТРАСП:
НОРМСТРАСП(x),
где x — значение, для которого строится распределение.
Формула плотности стандартного нормального распределения:
ϕ( x ) =
1
-
x2
2 .
e
2π
Значение распределения Пуассона:
ПУАССОН(k; λ; признак),
где k — количество событий; λ — среднее количество событий в единицу времени; признак — логическое значение, определяющее форму возвращаемого распределения вероятностей.
206
Если параметр «признак» имеет значение ИСТИНА, то функция
возвращает интегральное распределение Пуассона, т. е. вероятность
того, что число случайных событий будет от 0 до k включительно.
Если этот аргумент имеет значение ЛОЖЬ, то возвращается функция
плотности распределения Пуассона, т. е. вероятность того, что число
событий равно k.
Параметр k усекается до целого.
Функция возвращает значение ошибки #ЗНАЧ!, если k или λ не
является числом.
Функция возвращает значение ошибки #ЧИСЛО! в следующих
случаях:
1) k ≤ 0;
2) λ ≤ 0.
Формула расчета интегрального распределения Пуассона:
λi
.
λ
i =0 i ! e
k
Pn ( x ≤ k ) = ∑
Функция плотности распределения Пуассона:
Pn ( x = k ) =
λk
.
k ! eλ
10.6.8. Финансовые функции Microsoft Excel
Основные понятия и обозначения
Для всех финансовых операций справедлив принцип временно́й
ценности денег: сегодняшние поступления ценнее будущих. Другими
словами, будущие поступления обладают меньшей ценностью по
сравнению с текущими. Из принципа временно́й ценности денег
вытекает, по крайней мере, два следствия:
1) необходимость учета фактора времени при проведении финансовых операций;
2) некорректность (с точки зрения анализа долгосрочных финансовых операций) суммирования денежных величин, относящихся к
разным периодам времени.
При количественном анализе финансовых операций не рассматривается их экономическое содержание. Порождаемые финансовыми операциями движения денежных средств можно представить в
виде численного ряда, состоящего из последовательности платежей.
Для обозначения подобного ряда в мировой практике широко используется термин «поток платежей» или «финансовый поток».
Введем следующие обозначения:
• FV — будущая стоимость финансового потока;
• PV — текущая стоимость финансового потока;
207
r — процентная ставка;
n — срок (количество периодов) проведения операции.
Текстовый процессор Microsoft Excel 2003 содержит большое число разнообразных финансовых функций.
Финансовые функции находятся в надстройке Пакет анализа,
которая входит в состав программы установки Microsoft Office. Чтобы активировать надстройку Пакет анализа, необходимо выполнить
следующие действия:
1) выбрать пункт меню Сервис | Надстройки;
2) в списке Доступные надстройки установить флажок Пакет
анализа.
Классифицируем финансовые функции. В скобках указываются
названия функций, используемые в предыдущих версиях табличного
процессора Microsoft Excel.
•
•
Функции для расчета финансовых потоков
Текущая стоимость потока PV растет и со временем достигает
уровня будущей стоимости FV. Как правило, разница между стоимостями этих потоков выражается не в абсолютных единицах: R =
= FV − PV , а в относительных единицах: r = PV/FV (рис. 10.32).
Рис. 10.32. Соотношение стоимостей потоков
1. Текущая стоимость инвестиций PV по ставке, числу периодов
выплат, периодическим выплатам и (или) выплатам в конце периода
(стоимость денег, даваемых или взятых в долг, на текущий момент;
сколько деньги стоят сейчас).
1.1. Периодические выплаты отсутствуют или одинаковы: ПС
(Приведенная Стоимость) (ПЗ).
Задача 10.3. Какая начальная сумма необходима для получения
ежегодных выплат в размере 1 000 руб. в течение 4 лет, если процентная ставка равна 10 % годовых?
Р е ш е н и е. Определим для каждой ежегодно выплачиваемой
1 000 руб. тот начальный доход, который она даст:
PV = 1 000/1,10 + 1 000/(1,10)2 + 1 000/(1,10)3 + 1 000/(1,10)4 = 3 169,87.
208
Формат функции: ПС(r; n; плт; [FV]; [тип]),
где плт — размер периодической выплаты; тип — 0, если выплата
производится в конце периода, и 1 — если в начале.
Формула для решения задачи:
=ПС(0,1; 4; 1 000) (Результат: 3 169,87).
1.2. Выплаты могут быть различными, но их периодичность сохраняется: ЧПС (Чистая Приведенная Стоимость) (НПЗ).
1.3. Выплаты и их периодичность могут быть различными:
ЧИСТНЗ.
2. Будущая стоимость инвестиций FV по ставке, числу периодов
выплат, периодическим выплатам, текущей стоимости (отдача от
текущей стоимости денег; сколько деньги будут стоить).
2.1. Периодические выплаты и ставка постоянны: БС (Будущая
Стоимость) (БЗ).
Задача 10.4. Определить будущую величину вклада в 10 000 руб.,
помещенного в банк на 3 года под 5 % годовых, если начисление процентов осуществляется:
а) раз в году; б) раз в месяц.
Р е ш е н и е. Формат функции: БС(r; n; плт; PV; [тип]).
Формулы для решения задачи:
а) =БС(0,05; 3; 0; −10 000) (Результат: 11 576,25);
б) =БС(0,05/12; 3*12; 0; −10 000) (Результат: 11 614,72).
Ставка обычно задается в виде десятичной дроби: 5 % — 0,05;
10 % — 0,1; 100 % — 1 и т. д.
Если начисление процентов осуществляется m раз в году, аргументы r и n необходимо скорректировать следующим образом:
r = r/m;
n = n×m.
Аргумент PV здесь задан в виде отрицательной величины (−10 000),
так как с точки зрения вкладчика эта операция влечет за собой отток
его денежных средств в текущем периоде с целью получения положительной величины (11 576,25) через 3 года.
Однако для банка, определяющего будущую сумму возврата средств
по данному депозиту, этот аргумент должен быть задан в виде положительной величины, так как означает поступление средств (увеличение пассивов):
=БС(0,05; 3; 0; 10 000) (Результат: -11 576,25).
Полученный при этом результат — отрицательная величина, так
как операция означает расходование средств (возврат банком денег
вкладчику).
Последний аргумент функции тип опущен, так как начисление
процентов в подобных операциях, как правило, осуществляется в
209
конце каждого периода. В противном случае функция была бы задана с указанием всех аргументов.
2.2. Периодические выплаты отсутствуют, ставка в разные периоды различна: БЗРАСПИС.
3. Определение ставки (скорости оборота средств, ставки доходности) r по числу периодов, текущей и будущей стоимостям инвестиций.
3.1. Единовременные и периодические выплаты отсутствуют или
постоянны: СТАВКА (НОРМА).
Задача 10.5. Вложение в 10 000 руб. гарантирует 15 000 руб. через
3 года. Определить скорость оборота средств.
Р е ш е н и е. Формат функции:
СТАВКА(n;плт;PV;[FV][;тип][;предположение]),
где предположение — предполагаемая величина ставки.
Формула для решения задачи:
=СТАВКА(3;;-10 000;15 000) (Результат 14 %).
Значение PV — отрицательное, так как средства изымаются у
вкладчика, а FV — положительное, так как средства возвращаются.
3.2. Выплаты могут быть различными, но их периодичность сохраняется: ВСД (Внутренняя Ставка Доходности) (ВНДОХ).
3.3. Выплаты могут быть различными, но их периодичность сохраняется, при этом деньги получены под одну ставку, затем инвестируются под другую ставку: МВСД (Модифицированная Внутренняя Ставка Доходности).
3.4. Выплаты и их периодичность могут быть различными: ЧИСТВНДОХ (Чистый Внутренний Доход).
Функции для расчета параметров кредитования
Предположим, что взята ссуда под процент.
Возвращение ссуды происходит равными выплатами P = S + D за
n равных периодов (рис. 10.33), где: S — выплата по ссуде; D — выплата по процентам.
Рис. 10.33. Параметры кредитования
210
4. Расчет показателей, связанных с кредитованием.
4.1. Размер периодической выплаты P: ПЛТ (ППЛАТ).
Задача 10.6. Определить ежегодные выплаты кредита в 1 000 руб.
на 3 года под 8 % годовых.
Р е ш е н и е. Формат функции: ПЛТ(r; n; PV; FV; тип).
Формула для решения задачи:
=ПЛТ(8 %; 3; 1 000) (Результат -388,03).
4.2. Выплата по процентам D.
4.2.1. За один период: ПРПЛТ (ПЛПРОЦ).
4.2.2. За несколько периодов: ОБЩПЛАТ.
4.3. Выплата по ссуде S.
4.3.1. За один период: ОСПЛТ (ОСНПЛАТ).
4.3.2. За несколько периодов: ОБЩДОХОД.
4.4. Число периодов выплат n: КПЕР.
Функции для расчета амортизации
Амортизационные отчисления A — процесс постепенного переноса стоимости средств труда по мере их физического и морального износа на стоимость производимых с их помощью продукции,
работ и услуг в целях накопления денежных средств для последующего полного восстановления (рис. 10.34). Амортизационные отчисления производятся по установленным нормам амортизации,
их размер устанавливается за определенный период по конкретному
виду основных фондов (группе, подгруппе) и выражаются в абсолютных (руб.) или относительных (проценты к их балансовой стоимости)
единицах.
5. Расчеты амортизации.
5.1. Метод прямолинейной амортизации (метод равномерного начисления): АПЛ (Амортизация за один Период, рассчитанная Линейно) (АМР).
Расчет равномерного или линейного уменьшения стоимости на
один и тот же процент ее первоначальной стоимости.
Рис. 10.34. Зависимость величины амортизации от времени
211
Формат функции: АПЛ(нс;ос;время),
где нс — начальная стоимость (затраты на приобретение актива);
ос — остаточная стоимость (остаточная стоимость актива); время —
количество периодов амортизации (период амортизации).
Формула функции АПЛ: (нс — ос)/время.
5.2. Метод n-кратного (двойного) учета амортизации (двойного
уменьшения остатка).
Этот метод состоит в том, что фиксированный процент снижения
стоимости имущества принимается равным удвоенному проценту
снижения при равномерной амортизации. Такое снижение будет продолжаться до конца срока амортизации, пока стоимость не достигнет
остаточной.
5.2.1. За один период: ДДОБ.
Формат функции: ДДОБ(нс; ос; время; период; [коэффициент]),
где период — период, для которого требуется вычислить амортизацию;
коэффициент — процентная ставка снижающегося остатка.
Период должен измеряться в тех же единицах, что и время.
Если коэффициент опущен, то он полагается равным 2 (метод
удвоенного процента со снижающегося остатка). Чем больше коэффициент, тем больше размер амортизационных отчислений в первый
период амортизации.
Формула функции ДДОБ:
((нс - ос) - са) × (коэффициент/время),
где са — суммарная амортизация за предшествующие периоды.
5.2.2. За несколько периодов: ПУО (Переменное Уменьшение
Остатка) (ПДОБ). Формат функции:
ПУО(нс; ос; время; нп; кп; [коэффициент]; [переключение]),
где нп, кп — начальный и конечный периоды, для которых вычисляется амортизация; переключение — логическое значение, определяющее, следует ли использовать линейную амортизацию.
Параметры нп и кп должны быть заданы в тех же единицах, что и
время.
Если параметр переключение имеет значение ЛОЖЬ или опущен,
то метод начисления линейной амортизации используется, если
амортизация больше величины, рассчитанной методом снижающегося остатка, иначе — нет.
5.3. Метод постоянного учета амортизации (метод фиксированного уменьшения остатка): ФУО (Фиксированное Уменьшение Остатка)
(ДОБ).
Метод состоит в том, что в конце каждого периода стоимость,
которую имущество имело в начале периода, снижается на одно и то
212
же фиксированное число процентов от этой стоимости. Этот метод
считается основным для расчета амортизации в США.
Формат функции: ФУО(нс; ос; время; период; [месяцы]),
где месяцы — количество месяцев в первом году эксплуатации (по
умолчанию равно 12).
Формула функции ФУО:
(нс − са) × ставка,
где ставка вычисляется по формуле
ставка = 1 − ((ос/нс) ^ (1/время)).
Для первого периода используется формула:
нс × ставка × месяцы/12,
а для последнего периода:
((нс − са) × ставка × (12 − месяцы))/12.
5.4. Метод весовых коэффициентов: АСЧ (Амортизация методом
«Суммы Чисел») (АМГД).
Реальный износ в начале срока идет быстрее, чем в конце. Поэтому разработаны методы ускоренной амортизации.
Формат функции: АСЧ(нс; ос; время; период).
Формула функции АСЧ:
(нс − ос) × (время − период + 1) × 2/(время × (время + 1)).
Рассмотрим величины амортизационных выплат и стоимости оборудования на примере следующей задачи.
Задача 10.7. Рассчитать амортизационные выплаты и стоимость
оборудования с начальной стоимостью 10 000 руб. и остаточной
стоимостью 3 000 руб. за 3 года.
Р е ш е н и е. Лист в режиме отображения значений.
213
Лист в режиме отображения значений и формул.
10.7. Графические редакторы
Основные возможности графических редакторов:
• рисование графических примитивов: точек, линий, окружностей,
прямоугольников;
• ввод текстовых надписей тем или иным шрифтом;
• увеличение, уменьшение, изменение пропорций изображения;
• операции с фрагментами — участками изображения: удаление,
копирование, перемещение;
• открытие и сохранение файлов в разных форматах.
В зависимости от принципа представления изображения различают растровую и векторную графику.
1. В растровой графике изображение описывается совокупностью
строк и столбцов, состоящих из точек (пикселей), образующих матрицу — растр (см. подразд. 5.4). Растровые изображения характеризуются следующими параметрами:
• размеры рисунка — количество пикселей в длину и ширину;
• разрешение — число точек на квадратный дюйм (dpi).
Хранение пикселей в виде трех составляющих не эффективно, так
как требует большого дискового пространства. Поэтому используют
сжатие изображений, которое заключается в представлении пикселей
меньшим количеством байт. Сжатие позволяет восстановить первоначальный рисунок без искажений. В зависимости от подхода к
сжатию различают следующие форматы хранения растровых изображений:
• хранение изображений без сжатия: BMP;
• сжатие без потерь: GIF, PNG;
• сжатие с потерями: JPG.
Сжатие с потерями означает не игнорирование отдельных пикселей, а замену их цвета на похожий, что позволяет представить изображение более компактно. Такое сжатие не позволяет восстановить
214
первоначальный рисунок, однако отличия сжатого рисунка практически незаметны.
2. В векторной графике изображения описываются с помощью
кривых линий, называемых векторами. Кривая описывается многочленом третьего порядка вида:
y = f(x) = a3x3 + a2x2 + a1x + a0,
где a0, a1, a2, a3 — коэффициенты кривой, а также параметрами,
описывающих их цвета и расположение. Например,
0 ⋅ x3 + 0 ⋅ x2 + a1x + a0 — прямая;
0 ⋅ x3 + a2 ⋅ x2 + a1x + a0 — парабола и т. д.
Форматами векторной графики являются WMF, CDR.
Сравним изображения в растровой и векторной графике (табл. 10.5).
Примером редактора растровой графики является редактор Adobe
Photoshop. Фундаментальным понятием данного редактора является
слой — часть изображения, которую можно изменять и перемещать
независимо от других частей. Слои имеют следующие параметры:
Т а б л и ц а 10.5. Сравнение растровой и векторной графики
Параметр
сравнения
Растровая графика
Векторная графика
Увеличение
изображения
Уменьшает четкость
изображения, так как
новым точкам приходится давать оттенки
средние между ближайшими точками
Не влияет на четкость
изображения, изображение масштабируется,
т. е. координаты кривых
просто пересчитываются
Уменьшение
изображения
Увеличивает четкость
изображения, но при
этом теряются мелкие
детали
Не влияет на четкость
изображения, мелкие
детали можно увеличить при просмотре без
потери качества
Размеры файла
Зависят от размера
изображения, количества
различных цветов
Зависят от количества
элементов на рисунке
Область применения
Используется для
изображений фотографического типа с
большим количеством
деталей или оттенков
Используется для
представления логотипов, схем, элементов
оформления
215
прозрачность;
цифровые эффекты: положение на изображении, длина и ширина, угол поворота, наклон;
• внутренняя и внешняя тени.
Можно менять последовательность слоев, связывать несколько
слоев в один.
Другой отличительной чертой редактора Photoshop является использование фильтров — эффектов, которые можно применить к
отдельным слоям или всему изображению: размытие и увеличение
резкости изображений, стилизация под фрески, мозаику, графику.
Редактор Photoshop является открытой программной системой, которая может быть дополнена новыми фильтрами.
Изображения со слоями хранятся в файле с расширением PSD.
Редактор Photoshop предназначен для обработки фотографических
или сходных по структуре изображений.
Самым популярным редактором векторной графики является
редактор CorelDraw, поэтому элементами изображений являются
точки и линии. Фигуры с замкнутыми контурами имеют следующие
параметры:
• координаты положения фигуры по горизонтали и вертикали;
• длина и ширина;
• цвет контура;
• заливка и ее стиль;
• наличие тени и ее параметры: величина и степень размытости.
Фигуры можно группировать, получая сложные элементы изображения.
По умолчанию изображения хранятся в файле с расширением
CDR.
Редактор CorelDraw предназначен для создания схем, архитектурных эскизов, т. е. изображений с небольшим числом используемых
цветов.
Оба редактора позволяют открывать и сохранять файлы в различных форматах. Редактор CorelDraw позволяет сохранять векторную
графику в растровых форматах.
•
•
10.8. Базы данных
10.8.1. Базы данных и их классификация
Одной из задач информационных систем является хранение данных из определенной предметной области (см. подразд. 3.2). Предметная область — это часть реального мира, объединяющая схожие
или связанные понятия. Чтобы необходимые данные можно было
легко найти и выдать пользователю в любой момент времени, данные
о предметной области должны храниться структурировано.
216
База данных (БД) — это именованная совокупность структурированных данных, относящихся к определенной предметной области.
Создание, поддержка и обеспечение доступа к БД пользователей
осуществляется с помощью специального программного инструментария — системы управления базами данных (СУБД). СУБД является частью информационной системы.
По технологии решения задач, решаемых СУБД, БД подразделяют
на два вида:
• централизованная БД хранится целиком на ВЗУ одной вычислительной системы; если система входит в состав сети, то возможен
доступ к этой БД других систем;
• распределенная БД состоит из нескольких, иногда пересекающихся или дублирующих друг друга БД, хранящихся на ВЗУ разных
узлов сети.
СУБД предоставляет доступ к данным БД двумя способами:
• локальный доступ предполагает, что СУБД обрабатывает БД,
которая хранится на ВЗУ той же ЭВМ;
• удаленный доступ — это обращение к БД, которая хранится на
одном из узлов сети; удаленный доступ может быть выполнен по
технологии файл-сервер или клиент-сервер.
Технология файл-сервер предполагает выделение одной из вычислительных систем, называемой сервером, для хранения БД. Все
остальные компьютеры сети (клиенты) исполняют роль рабочих
станций, которые копируют требуемую часть централизованной БД
в свою память, где и происходит обработка.
Технология клиент-сервер предполагает, что сервер, выделенный
для хранения централизованной БД, дополнительно производит обработку запросов клиентских рабочих станций. Клиент посылает
запрос серверу. Сервер пересылает клиенту данные, являющиеся
результатом поиска в БД по ее запросу.
10.8.2. Реляционная модель данных
Данные хранятся в БД в соответствии с моделью данных. Существуют следующие типы моделей данных: сетевая, иерархическая,
реляционная.
Рассмотрим реляционную модель данных, в которой данные хранятся в виде двумерных таблиц (рис. 10.35).
Таблицы обладают следующими свойствами:
• каждая ячейка таблицы является одним элементом данных;
• каждый столбец содержит данные одного типа (числа, текст и т.п.);
• каждый столбец имеет уникальное имя;
• таблицы организуются так, чтобы одинаковые строки отсутствовали;
• порядок следования строк и столбцов произвольный.
217
Рис. 10.35. Структура данных реляционной модели данных
Каждая таблица представляет собой отношение, описываемое
атрибутами:
СТУДЕНТ = (ФАМИЛИЯ, ИМЯ, ОТЧЕСТВО, ФАКУЛЬТЕТ).
Для идентификации записей выделяют следующие виды ключей —
полей, определяющих запись:
• первичный — однозначно определяет запись;
• вторичный — выполняет роль поисковых и группировочных
признаков и позволяет найти несколько записей.
Ключ может быть простым, если он включает одно поле, или составным, если включает два и более полей.
Если в отношении СТУДЕНТ нет однофамильцев, то первичным
будет простой ключ — поле ФАМИЛИЯ. Иначе первичным будет
составной ключ ФАМИЛИЯ + ИМЯ + ОТЧЕСТВО.
Первичный ключ должен обладать следующими свойствами:
• уникальность — не должно существовать двух или более записей,
имеющих одинаковые значения полей, входящих в первичный
ключ;
• неизбыточность — первичный ключ не должен содержать поля,
удаление которых из ключа не нарушит его уникальность.
10.8.3. Нормализация отношений
Нормализация отношений — это приведение отношений к виду,
позволяющему устранить дублирование, обеспечить непротиворечивость данных, хранимых в БД, и уменьшить трудозатраты на ведение БД.
Выделяют три нормальные формы отношений.
П е р в а я н о р м а л ь н а я ф о р м а. Отношение называется нормализованным или приведенным к первой нормальной форме, если
все его атрибуты являются простыми, т. е. не могут быть далее разделены.
218
Например, отношение
КНИГА = (АВТОР, НАЗВАНИЕ, ВЫХОДНЫЕ ДАННЫЕ)
не находится в первой нормальной форме, так как атрибут ВЫХОДНЫЕ ДАННЫЕ можно разделить на атрибуты ИЗДАТЕЛЬСТВО,
ГОД, КОЛИЧЕСТВО СТРАНИЦ.
Отношение
СТУДЕНТ = (НОМЕР, ФАМИЛИЯ, ИМЯ, ОТЧЕСТВО, ГРУППА)
находится в первой нормальной форме, где поле НОМЕР является
простым первичным ключом.
В т о р а я н о р м а л ь н а я ф о р м а. Отношение приведено ко
второй нормальной форме, если оно находится в первой нормальной
форме, и каждый неключевой атрибут функционально полно зависит
от составного ключа.
Функционально полной зависимостью неключевых атрибутов называется зависимость, при которой в записи определенному значению
ключа соответствует только одно значение неключевого поля. При
этом это поле не находится в функциональной зависимости ни от
какой части составного ключа.
Например, отношение СТУДЕНТ находится в первой и второй
нормальных формах.
Отношение
УСПЕВАЕМОСТЬ = (НОМЕР, ФАМИЛИЯ, ДИСЦИПЛИНА,
ОЦЕНКА)
находится в первой нормальной форме и имеет составной ключ НОМЕР + ДИСЦИПЛИНА. Это отношение не находится во второй
нормальной форме, так как атрибут ФАМИЛИЯ функционально зависит от поля НОМЕР составного ключа. Чтобы привести это отношение ко второй нормальной форме необходимо разбить его на
два связанных отношения:
УСПЕВАЕМОСТЬ = (НОМЕР, ДИСЦИПЛИНА, ОЦЕНКА),
СПИСОК = (НОМЕР, ФАМИЛИЯ).
Связь между отношениями осуществляется по полю НОМЕР.
Т р е т ь я н о р м а л ь н а я ф о р м а. Отношение находится в третьей
нормальной форме, если оно находится во второй нормальной форме,
и каждый неключевой атрибут не зависит от ключа транзитивно.
Транзитивная зависимость присутствует в отношении, если существует два неключевых поля, первое из которых зависит от ключа, а
второе от первого.
Например, отношение СТУДЕНТ находится в третьей нормальной
форме.
219
Отношение
ДИСЦИПЛИНА = (НАЗВАНИЕ, ЛЕКТОР, УЧ_СТЕПЕНЬ,
ГРУППА)
не находится в третьей нормальной форме, так как поле УЧ_СТЕПЕНЬ зависит от поля ЛЕКТОР, но не от составного ключа,
поэтому отношение необходимо разбить на два связанных отношения:
ДИСЦИПЛИНА = (НАЗВАНИЕ, ЛЕКТОР, ГРУППА),
ПРЕПОДАВАТЕЛЬ = (ЛЕКТОР, УЧ_СТЕПЕНЬ).
Связь между отношениями осуществляется по полю ЛЕКТОР.
10.8.4. Типы связей
Отношения могут быть связаны следующими типами связей:
• один-к-одному (1 : 1);
• один-ко-многим (1 : M);
• многие-ко-многим (M : M).
Рассмотрим сущность этих связей на примере следующих отношений. Пусть книга в библиотеке описывается отношением
КНИГА = (КНИГА_N, АВТОР_N, НАЗВАНИЕ,
ИЗДАТЕЛЬСТВО_N).
Каждая книга имеет место на полке
МЕСТО = (МЕСТО_N, КНИГА_N).
Каждая книга выпускается издательством
ИЗДАТЕЛЬСТВО = (ИЗДАТЕЛЬСТВО_N, АДРЕС).
У каждой книги есть автор
АВТОР = (АВТОР_N, ФАМИЛИЯ, ИМЯ, ОТЧЕСТВО).
Связь один-к-одному означает, что в каждый момент времени
одной записи отношения A соответствует только одна запись отношения B и наоборот. Например, каждая книга имеет одно место на
полке и на каждом месте стоит только одна книга:
КНИГА ←→ МЕСТО
Связь между отношениями осуществляется по полю КНИГА_N.
Связь один-ко-многим предполагает, что одной записи отношения
A соответствуют несколько записей отношения B, но одной записи
отношения B соответствуют только одна запись отношения A. На-
220
пример, одно издательство может издать несколько книг, но книга
издается только одним издательством:
ИЗДАТЕЛЬСТВО ←→→ КНИГА
Связь между отношениями осуществляется по полю ИЗДА
ТЕЛЬСТВО_N.
При связи многие-ко-многим одной записи отношения A соответствуют несколько записей отношения B и наоборот. Например,
один автор может написать несколько книг, и у книги может быть
несколько авторов:
КНИГА ←←→→ АВТОР
Связь между отношениями осуществляется по полю АВТОР_N.
Гл а в а 1 1
Вычислительные сети
11.1. Понятие, виды и характеристики
вычислительных сетей
Вычислительная сеть (информационно-вычислительная сеть) —
это совокупность узлов, соединенных с помощью каналов связи в
единую систему (рис. 11.1).
Узел — это любое устройство, непосредственно подключенное к
передающей среде сети. Узлами могут быть не только ЭВМ, но и
сетевые периферийные устройства, например принтеры.
Каждый узел в сети имеет минимум два адреса: физический, используемый оборудованием, и логический, используемый пользователями и приложениями.
Узлы обмениваются сообщениями. Здесь сообщение — это целостная последовательность данных, передаваемых по сети.
Отдельные части сети называются сегментами.
Передающая среда сети (канал связи) определяет, как будут передаваться сообщения по сети. Примерами передающих сред являются
радиоканалы, кабельные, спутниковые каналы.
Вычислительные сети имеют следующие характеристики.
1. Производительность — это среднее количество запросов пользователей сети, исполняемых за единицу времени. Производитель-
Рис. 11.1. Структура вычислительной сети
222
ность зависит от времени реакции системы на запрос пользователя.
Это время складывается из трех составляющих:
• времени передачи запроса от пользователя к узлу сети, ответственному за его исполнение;
• времени выполнения запроса в этом узле;
• времени передачи ответа на запрос пользователю.
2. Пропускная способность — это объем данных, передаваемых
через сеть (ее сегмент) за единицу времени (трафик).
3. Надежность — это среднее время наработки на отказ.
4. Безопасность — это способность сети обеспечить защиту информации от несанкционированного доступа.
5. Масштабируемость — это возможность расширения сети без
заметного снижения ее производительности.
6. Универсальность сети — это возможность подключения к сети
разнообразного технического оборудования и программного обеспечения от разных производителей.
Вычислительные сети используются в следующих целях:
1) предоставление доступа к программам, оборудованию и данным
для любого пользователя сети; эта цель называется совместным использованием ресурсов;
2) обеспечение высокой надежности хранения источников информации; хранение данных в нескольких местах позволяет избежать их
потерю в случае их удаления в одном из мест;
3) обработка данных, хранящихся в сети;
4) передача данных между удаленными друг от друга пользователями.
По в и д у т е х н о л о г и и п е р е д а ч и вычислительные сети
подразделяются на следующие типы:
• широковещательные сети обладают общим каналом связи, совместно используемым всеми узлами; сообщения передаются всем
узлам; примером широковещательной сети является телевидение;
• последовательные сети, в которых сообщению необходимо пройти несколько узлов, чтобы добраться до узла назначения; сообщение
передается только одному узлу; примером такой технологии передачи
является электронная почта.
Небольшие сети обычно используют широковещательную передачу, тогда как в крупных сетях применяется передача от узла к узлу.
По р а з м е р у сети можно подразделить на следующие типы:
• локальные сети — размещаются в одном здании или на территории одного предприятия; примером локальной сети является локальная сеть в учебном классе;
• региональные сети — объединяют несколько предприятий или
город; примером сетей такого типа является сеть кабельного телевидения;
• глобальные сети — охватывают значительную территорию, нередко целую страну или континент и представляют собой объедине-
223
ние сетей меньшего размера; примером глобальной сети является сеть
Интернет.
По п р и н ц и п у п о с т р о е н и я сети делятся на следующие
типы:
• одноранговые сети объединяют равноправные узлы; такие сети
объединяют не более 10 узлов;
• сети на основе выделенного сервера имеют специальный узел —
вычислительную машину (сервер), предназначенную для хранения
основных данных сети и предоставления этих данных узлам (клиентам) по запросу.
11.2. Модель взаимодействия открытых
систем
Для описания общей модели взаимодействие открытых систем
используется эталонная модель OSI (Open System Interconnection).
Модель OSI состоит из 7 уровней (от низших к высшим):
1) физический;
2) канальный;
3) сетевой;
4) транспортный;
5) сеансовый;
6) представительский;
7) прикладной.
Каждый уровень использует для передачи низшие уровни.
Взаимодействие между уровнями одного типа осуществляется по
протоколам, а между низшими и высшими — с помощью интерфейсов.
Перед отправкой по сети данные разбиваются на пакеты — группы байт фиксированной длины. Пакет последовательно проходит все
уровни от прикладного до физического (рис. 11.2). При этом на каждом уровне, кроме прикладного и представительского, к пакету добавляется служебная информация, называемая заголовком.
Рис. 11.2. Уровни модели взаимодействия открытых систем
224
Заголовок содержит информацию для адресации сообщений и для
безошибочной передачи данных по сети.
На принимающей стороне пакет проходит все уровни в обратном
порядке.
Каждый уровень анализирует пакет, отделяет заголовок своего
уровня и передает пакет на следующий уровень. На прикладном
уровне данные примут свой первоначальный вид.
Рассмотрим задачи каждого из уровней модели OSI.
1-й уровень — физический. Самый низший уровень модели OSI.
Основной задачей физического уровня является управление аппаратурой передачи данных и подключенным к ней каналом связи. На
этом уровне формируются сигналы, которые передают данные в виде
потока бит по передающей среде.
2-й уровень — канальный. На этом уровне физический канал преобразовывается в надежную линию связи, свободную от необнаруженных ошибок. Для этого формируется логический канал между
двумя узлами, соединенными физическим каналом. Данные передаются по канальному уровню в виде кадров, которые включают,
помимо данных, проверочную информацию. Проверочная информация позволяет установить, был ли передан кадр без искажений
(ошибок), и частично восстановить информацию. Если кадр не был
восстановлен, то происходит его повторная передача.
3-й уровень — сетевой. Отвечает за адресацию сообщений и перевод логических адресов в физические. Этот уровень разрешает проблемы, связанные с разными способами адресации и разными протоколами при переходе пакетов из одной сети в другую, позволяя
объединять разнородные сети.
4-й уровень — транспортный. На этом уровне данные разбиваются на пакеты. При этом гарантируется, что эти пакеты прибудут по
назначению в правильном порядке. Для этого осуществляется поиск
оптимального маршрута передачи пакетов с точки зрения загруженности сегментов сети и времени передачи данных между узлами.
Уровень управляет созданием и удалением сетевых соединений и
управляет потоком сообщений.
5-й уровень — сеансовый. Позволяет двум процессам (например,
приложениям) разных узлов устанавливать, использовать и завершать
соединение, называемое сеансом. Этот уровень управляет передачей
между двумя узлами и определяет, какая из сторон, когда и как долго
должна осуществлять передачу.
6-й уровень — представительский. На этом уровне определяется формат, используемый для обмена данными между узлами.
Уровень отвечает за преобразование, кодирование и сжатие данных.
7-й уровень — прикладной. Предоставляет доступ прикладным
процессам к сетевым службам. Этот уровень управляет общим доступом к сети.
225
11.3. Сетевые протоколы
Протоколы — это соглашение о формате и правилах передачи
данных по сети. Протоколы обладают следующими свойствами:
• протоколы работают на разных уровнях модели OSI, поэтому
функции протокола определяются уровнем, на котором он работает;
• несколько протоколов могут работать совместно, в этом случае они
образуют стек или набор протоколов разных уровней модель OSI.
Передача данных по сети разбита на несколько шагов, каждому из
которых соответствует протокол. Узел-отправитель выполняет следующие шаги:
• разбивает данные на пакеты;
• добавляет к пакетам служебную информацию: адрес получателя
и информацию для проверки правильности и восстановления в случае возникновения ошибок при передаче;
• передает пакеты в сеть через сетевой адаптер.
Узел-получатель выполняет шаги в обратной последовательности:
• принимает пакеты из сети через сетевой адаптер;
• проверяет правильность передачи данных и удаляет служебную
информацию из пакетов;
• объединяет пакеты в исходный блок данных.
11.4. Локальные сети
11.4.1. Топологии локальных вычислительных сетей
Вычислительные машины, объединенные в локальную сеть, физически могут располагаться различным образом. Однако порядок
их подсоединения к сети определяется топологией — усредненной
геометрической схемой соединений узлов сети.
Наиболее распространенными топологиями локальных сетей, в
которых передающей средой является кабель, являются кольцо, шина,
звезда.
Топология «кольцо» (рис. 11.3) предусматривает соединение узлов
сети замкнутым контуром и используется для построения сетей, за-
Рис. 11.3. Топология «кольцо»
226
Рис. 11.4. Топология «шина»
Рис. 11.5. Топология «звезда»
нимающих сравнительно небольшое пространство. Выход одного узла
сети соединяется с входом другого. Информация по кольцу передаются от узла к узлу в одном направлении. Каждый промежуточный
узел ретранслирует посланное сообщение. Принимающий узел распознает и получает только адресованное ему послание.
Последовательная организация обслуживания узлов сети снижает
ее быстродействие, а выход из строя одного из узлов приводит к нарушению функционирования кольца.
Топология «шина» (рис. 11.4) представляет собой последовательное
соединение узлов между собой. Данные распространяются по шине
в обе стороны. В каждый момент времени передачу может вести
только один узел, поэтому производительность сети зависит от количества узлов в сети. Сообщение поступает на все узлы, но принимает его только тот узел, которому оно адресовано. Узлы не перемещают сообщение, поэтому выход из строя одного узла не приводит к
нарушению функционирования сети.
Топология «звезда» (рис. 11.5) базируется на концепции центрального узла, через который вся информация ретранслирует, переключает, маршрутизирует (находит путь от источника к приемнику) информационные потоки в сети.
В качестве центрального узла выступает концентратор (хаб, hub).
Концентраторы выполняются в виде отдельных устройств с 8, 16, 24
или 48 портами, к которым подключаются ЭВМ. При получении
пакета в одном из портов концентратор широковещательно передает
его на все остальные порты. Узлы анализируют адрес получателя
пакета и, если он предназначен им, то получают его, иначе игнорируют его.
Концентраторы могут быть трех типов:
1) пассивные — только соединяющие сегменты сети;
2) активные — это пассивные концентраторы, усиливающие сигналы, увеличивая расстояние между узлами;
3) интеллектуальные — это активные концентраторы, выполняющие маршрутизацию.
227
Также центральным узлом сети может быть коммутатор (switch).
В отличие от концентратора это телекоммуникационное устройство
пересылает принятый пакет не широковещательно на все порты, а
адресату. Адресат определяется по адресу, содержащемуся в пакете.
В результате такой передачи повышается общая пропускная способность сети.
Данная топология значительно упрощает взаимодействие узлов
сети друг с другом. В то же время работоспособность локальной вычислительной сети зависит от центрального узла.
При построении локальных сетей используются данные топологии
или их сочетания.
11.4.2. Виды коммутации
Основным назначением узлов коммутации является прием, анализ,
а в сетях с маршрутизацией еще и выбор маршрута и отправка данных
по выбранному направлению.
Узлы коммутации осуществляют один из трех следующих видов
коммутации при передаче данных.
1. Коммутация каналов. Между пунктами отправления и назначения устанавливается физическое соединение путем формирования составного канала из последовательно соединенных отдельных
участков каналов связи. Такой сквозной составной канал организуется в начале сеанса связи, поддерживается в течение всего сеанса и
разрывается после окончания передачи.
П р е и м у щ е с т в а:
• возможность работы в диалоговом режиме и в режиме реального времени;
• обеспечение полной прозрачности канала.
Н е д о с т а т к и:
• создание непрерывного канала связи требует большого времени;
• канал связи монополизируется источником и приемником, что
снижает производительность сети.
Примером коммутации каналов является телефонная связь.
2. Коммутация сообщений. Данные передаются в виде сообщений разной длины. Отправитель указывает лишь адрес получателя.
Узлы коммутации анализируют адрес и текущую занятость каналов
и передают сообщение по свободному в данный момент каналу на
ближайший узел сети в сторону получателя.
П р е и м у щ е с т в а:
• увеличение производительности сети, так как после передачи
сообщения от узла к узлу канал освобождается;
• возможность выбора маршрута доставки сообщения.
Н е д о с т а т к и:
228
• увеличение времени доставки по сравнению с коммутацией
каналов;
• затруднена работа в диалоговом режиме и режиме реального
времени.
Примерами коммутации сообщений являются электронная почта
и телеконференции.
3. Коммутация пакетов. Сообщения разбиваются на несколько
пакетов стандартной длины. Пакеты могут следовать к получателю
разными путями и непосредственно перед выдачей получателю
объединяются для формирования исходных сообщений.
При передаче пакетов может создаваться виртуальный канал. Временной ресурс узла разделяется между несколькими пользователями
так, что каждому пользователю отводится постоянно множество минимальных отрезков времени и создается впечатление непрерывного
доступа.
П р е и м у щ е с т в о: наибольшая пропускная способность сети и
наименьшая задержка при передаче данных.
Н е д о с т а т о к: трудность, а иногда и невозможность его использования для систем, работающих в интерактивном режиме и в реальном масштабе времени.
Коммутация сообщений и пакетов относится к логическим видам
коммутации. При передаче данных формируется лишь логический
канал между абонентами. Каждое сообщение (пакет) имеет адресную
часть, определяющую отправителя и получателя. В соответствии с
адресом выбирается дальнейший маршрут и передается сообщение
из запоминающего устройства узла коммутации.
11.4.3. Способы адресации ЭВМ в сети
В вычислительных сетях существуют три способа адресации.
1. Аппаратные адреса представляют собой шестнадцатеричные
номера (12 цифр; например: 00-08-74-96-92-5C). Присвоение аппаратных адресов происходит автоматически: они встраиваются в аппаратуру (модемы, сетевые адаптеры и т. д.) на стадии производства
или генерируются при каждом новом запуске оборудования.
2. Числовые составные адреса, например IP-адреса (Internet
Protocol-адреса — адреса интернет-протокола). IP-адрес записывается в виде четырех десятичных чисел, разделенных точками; каждое
число лежит в диапазоне от 0 до 255. Таким образом, IP-адрес занимает 4 байта: например, 192.168.0.212.
3. Символьные адреса или имена предназначены для пользователей и несут смысловую нагрузку. Такие адреса имеют иерархическую
структуру и состоят из отдельных доменов. Домен — это условное
имя, показывающее принадлежность узлов определенной группе:
например, стране, компании или государственному учреждению.
229
Например, адрес class1. vpm. rsrea означает, что ЭВМ с этим адресом
находится в РГРТУ (. rsrea) на кафедре вычислительной и прикладной
математики (ВПМ, . vpm) в компьютерном классе 1 (class1).
Чтобы посмотреть адреса ЭВМ в ОС Windows, необходимо в командной строке набрать команду ipconfig /all.
В современных сетях для адресации используются все три способа адресации. Пользователь указывает символьный адрес, который
заменяется числовым адресом (по таблицам адресов, хранимых на
сервере имен сети). При поступлении передаваемых данных в сеть
назначения числовой адрес заменяется аппаратным.
11.4.4. Маршрутизация в вычислительных сетях
Маршрутизация необходима для обеспечения следующих характеристик:
• максимальная пропускная способность сети;
• минимальное время прохождения пакета от отправителя к получателю;
• надежность доставки и безопасность передаваемой информации.
По способу управления маршрутизацию можно подразделить на
два типа:
1) централизованная: выбор маршрута осуществляется в центре
управления сетью, а узлы коммутации реализуют поступившее решение;
2) децентрализованная: функции управления распределены между узлами коммутации.
Существуют следующие методы маршрутизации.
1. Простая маршрутизация при выборе дальнейшего пути для сообщения (пакета) учитывает лишь статическое априорное состояние
сети. Ее текущее состояние — загрузка и изменение топологии из-за
отказов — не учитывается.
2. Фиксированная маршрутизация учитывает только изменение
топологии сети. Для каждого узла назначения канал передачи выбирается по электронной таблице маршрутов (route table), определяющей кратчайшие пути и время доставки информации до пункта
назначения.
3. Адаптивная маршрутизация учитывает изменение загрузки и
изменение топологии сети. При выборе маршрута данные из таблицы
маршрутов дополняются данными о работоспособности и занятости
каналов связи, оперативной информацией о существующей очереди
пакетов на каждом канале.
Маршрутизация в сетях осуществляется специальным устройством — маршрутизатором. Маршрутизаторы — это устройства для
маршрутизации — выполняются в виде отдельных многопроцессорных
устройств или ЭВМ со специальным программным обеспечением.
230
11.5. Глобальная сеть Интернет
11.5.1. Интернет как сообщество сетей
Сеть Интернет — это глобальная сеть, соединяющая сети различного размера по всему миру. Сеть Интернет — это информационное пространство, содержащее огромное количество информации,
хранилище информационных ресурсов. Информационными ресурсами являются совокупности текстов, изображений и других данных,
а также тематические связи между ними.
В конце 1969 г. под эгидой Министерства обороны США был
создан проект ARPAnet (Advanced Research Project Agency Network —
сеть Управления перспективного планирования оборонных научноисследовательских работ), объединивший в единую вычислительную
сеть сети четырех исследовательских институтских центров по всей
территории США. В рамках этого проекта проводились исследования
в области телекоммуникаций с целью создания надежной системы,
способной передавать данные даже в случае начала ядерной войны.
Проект основывался на концепции децентрализованного управления,
так как в случае уничтожения или повреждения центра управления
происходил отказ всей сети. В 1974 г. были начаты разработки протоколов, способных обеспечить передачу данных по сетям разного
типа — TCP/IP (Transmission Control Protocol/Internet Protocol — протокол управления передачей / Интернет-протокол). В 1983 г. сеть
ARPAnet была переведена на протокол TCP/IP. После этого Министерства обороны США передало контроль над сетью Национальному научному фонду США. Началось расширение сети ARPAnet, в том
числе за пределы США. При этом фонд осуществлял борьбу с коммерциализацией сети, штрафуя тех, кто имел побочный доход в сети.
К 1995 г. сеть ARPAnet разрослась до такой степени, что Национальный научный фонд США уже не успевал отслеживать деятельность
каждого узла. Поэтому произошла передача региональным провайдерам оплаты за подсоединение многочисленных частных сетей к
национальной магистрали.
Провайдер — это организация (фирма, компания), обеспечивающая подключение пользователей к сети Интернет. Подключение
может осуществляться двумя способами:
1) по модему (телефонному, ADSL или другого типа) (см. подразд.
8.9.6);
2) прямым подключением к сети провайдера.
После того как пользователь соединился с провайдером, компьютер пользователя становится частью сети провайдера. Каждый провайдер имеет свой канал, связывающий его с более крупным провайдером. В свою очередь, сети крупных провайдеров объединены
между собой магистральными линиями.
231
11.5.2. Протоколы сети Интернет
Протоколы сети Интернет можно разделить на два типа: базовые
и прикладные. Базовые протоколы — это протоколы нижнего уровня.
Они обеспечивают физическую передачу сообщений между узлами в
сети Интернет. Примером базового протокола является протокол
ТСР/IP. Прикладные протоколы — протоколы высокого уровня. Эти
протоколы обеспечивают функционирование служб сети Интернет.
Например, протокол HTTP служит для передачи гипертекстовых документов, протокол FTP — для передачи файлов, а SMTP — для
передачи электронной почты. Базовые и прикладные протоколы находятся в такой же взаимосвязи, что и уровни модели OSI.
На нижнем уровне используются два основных протокола: IP и
TCP. Протокол TCP предназначен для управления передачей данных
в виде пакетов, регулировкой и синхронизацией передачи на разных
скоростях. Протокол IP необходим для однозначного определения
адреса получателя пакетов. Такой адрес называется IP-адресом.
Семь уровней модели OSI преобразованы в четыре уровня протоколов TCP/IP:
1) уровень межсетевого интерфейса предназначен собственно для
передачи данных по сети;
2) межсетевой уровень отвечает за маршрутизацию и доставку
пакетов;
3) транспортный уровень выполняет задачи установки и поддержания соединения между двумя узлами, отправку уведомлений о
получении данных;
4) прикладной уровень предоставляет доступ к сети приложениям.
Архитектура протоколов TCP/IP предназначена для объединения
сетей. В их качестве могут выступать локальные, национальные,
региональные и глобальные сети, каждая из которых функционирует
по своим принципам. При этом каждая сеть может принять пакет
данных и доставить его указанному узлу.
Предположим, имеется послание, отправляемое по электронной
почте. Передача почты осуществляется по прикладному протоколу
SMTP, который использует передачу по протоколам TCP/IP. По протоколу TCP данные разбиваются на небольшие пакеты фиксированной структуры и длины и маркируются так, чтобы при получении
собрать из них исходное послание.
Обычно длина одного пакета не превышает 1500 байт. Поэтому
одно электронное письмо может состоять из нескольких сотен таких
пакетов. Малая длина пакета не приводит к блокировке линии связи
и не позволяет отдельным пользователям надолго захватывать канал
связи.
К каждому полученному пакету протокола TCP протокол IP добавляет информацию, по которой можно определить адрес отправителя и получателя. Это аналогично записи адреса на конверте письма.
232
Для передачи пакета существует несколько маршрутов. Однако пакет
не всегда передается по наикратчайшему пути. На направление его
передачи влияет загруженность каналов связи, а не их протяженность.
Таким образом, более короткий маршрут может оказаться самым
долгим по времени передачи. Протокол TCP/IP гарантирует, что независимо от длины пути в результате конечного числа пересылок
TCP-пакеты достигают адресата.
Чтобы посмотреть путь пакета до узла с заданным адресом в ОС
Windows, необходимо в командной строке набрать команду tracert
<адрес узла>.
При получении пакета IP-модуль адресата извлекает пакет протокола ТСР из IP-пакета и передает его TCP-модулю. В свою очередь,
ТСР-модуль извлекает данные из TCP-пакета и собирает данные
принятых пакетов в исходное сообщение. Если пакет отсутствует или
принят с ошибками, то производится его повторная передача. Передача одного и того же пакета повторяется до тех пор, пока пакет не
будет получен в целостном виде.
Для определения ошибок в пакете используются контрольные
данные и помехоустойчивые коды, выявляющие и исправляющие
ошибки.
Полученное сообщение передается процедурам протокола SMTP,
которые далее обрабатывают это сообщение.
Таким образом, по протоколу IP данные непосредственно передаются по сети, а по протоколу ТСР обеспечивается надежная доставка данных адресату. Два узла в сети Интернет могут одновременно передавать в обе стороны по одному каналу несколько ТСР-пакетов
от различных узлов.
11.5.3. Система адресации в сети Интернет
Каждому компьютеру, подключенному к сети Интернет, присваивается числовой адрес, называемый IP-адресом.
IP-адрес используется в протоколах передачи данных. IP-адрес
содержит полную информацию, необходимую для идентификации
узла в сети.
При сеансовом подключении к сети Интернет IP-адрес выделяется компьютеру только на время этого сеанса. Такое присвоение адреса компьютеру называется динамическим распределением IP-адресов.
Динамическое распределение IP-адресов позволяет обслуживать
большое количество пользователей, имея небольшое количество IPадресов, так как один и тот же IP-адрес в разные моменты времени
может быть выделен разным пользователям.
IP-адрес состоит из четырех чисел от 0 до 255 в десятичной системе счисления, разделенных точками. IP-адрес имеет иерархическую
структуру. Например, адрес 152.207.71.12 состоит из следующих частей.
233
Первые два числа (152.207) определяют сеть, третье число (71) — подсеть, четвертое число (12) — ЭВМ в этой подсети.
Так как каждое из четырех чисел IP-адреса изменяется от 0 до 255,
то всего количество IP-адресов равно 256 4 = 4,3 млрд. Однако некоторые адреса зарезервированы, поэтому они не используются.
IP-адрес трудно запоминаем пользователем, поэтому некоторые
узлы в сети Интернет имеют символьные DNS-адреса (Domain Name
System — система доменных имен), например www. site. net. В сети
Интернет существуют специальные DNS-серверы, которые по DNSадресу выдают его IP-адрес.
DNS-адрес может иметь произвольную длину, образуется как
символьный адрес в локальной сети (см. подразд. 11.4.3) и включает
в себя несколько уровней доменов. Уровни доменов разделяются
точками. Самый правый домен — домен верхнего уровня. Чем левее
домен, тем ниже его уровень. Например, DNS-адрес rsrea. ryazan. ru
включает в себя следующие уровни:
• ru — домен Российской Федерации;
• ryazan — домен города Рязань;
• rsrea — домен РГРТУ
Во время приема запроса на перевод DNS-адрес в IP-адрес DNSсервер выполняет одно из следующих действий:
• выдает IP-адрес, если запрашиваемый DNS-адрес хранится в
его базе адресов;
• взаимодействует с другим DNS-сервером для того, чтобы найти
IP-адрес запрошенного имени в случае отсутствия DNS-адрес в его
базе; такой запрос может проходить по цепочке DNS-серверов несколько раз;
• сообщает, что такой DNS-адрес не существует.
Для ускорения работы в сети Интернет запрошенные IP-адреса
сохраняются на компьютере, чтобы не запрашивать его вновь у DNSсервера и сразу обратиться по этому адресу.
Для доступа к ресурсам, расположенным в сети Интернет, используется унифицированный указатель ресурса — URL (Uniform
Resource Locator).
Адрес URL является сетевым расширением понятия полного имени
ресурса, например, файла или приложения и пути к нему в ОС. В адресе URL, кроме имени файла и директории, где он находится, указывается сетевое имя компьютера, на котором этот ресурс расположен,
и протокол доступа к ресурсу, который можно использовать для обращения к нему.
В ЭВМ, подключенной к сети Интернет, файлы расположены в
папках с разным уровнем вложенности. Например, URL http://rsrea.
ryazan. ru/docs/prikazy/p123. htm включает в себя следующие составляющие:
• http — протокол передачи гипертекста — страниц, отформатированных в формате HTML;
234
rsrea. ryazan. ru — DNS-адрес;
docs/prikazy/ — путь к файлу;
p123. htm — название ресурса — файла в формате HTML.
Как правило, путь к ресурсу на жестком диске компьютера, подключенного к сети Интернет, отличается от адреса URL. Таким образом, адрес URL является псевдонимом пути к ресурсу. Ресурсы сети
Интернет доступны только для чтения, но не для записи.
•
•
•
11.5.4. Службы сети Интернет
Обычно сеть Интернет ассоциируется с ее основной службой
WWW. Однако служба WWW — лишь один из сервисов доступных
пользователям в сети Интернет. Службы сети Интернет представляют
собой различные способы доставки разнообразной по форме информации ее потребителям.
Рассмотрим подробнее наиболее популярные службы сети Интернет:
электронную почту, WWW и передачу файлов по протоколу FTP.
Электронная почта
Служба электронной почты (electronic mail, e-mail) появилась
раньше сети Интернет, однако она остается популярным способом
пересылки сообщений. Электронное письмо похоже на письмо, пересылаемое по обычной (традиционной) почте, но значительно превосходит его по скорости пересылки, имеет низкую стоимость пересылки и обладает большим удобством в использовании. Электронное
письмо содержит адреса электронной почты отправителя и получателя. В конверт с письмом можно вложить открытку или фотографию,
а в электронное письмо — файл любого формата: исполняемый,
графический, звуковой. Отправитель может идентифицировать себя,
поставив электронную подпись, как и подпись в обычном письме.
Электронная почта изживает традиционную почту. В настоящее время большая часть писем отправляется по электронной почте, а не по
традиционной. Ежегодно по всему миру рассылается более 800 млрд
электронных писем.
В отличие от телефонного звонка электронное письмо может быть
прочитано в удобное время для получателя время. Электронная почта
доступна, и можно легко и просто отправить письмо любому человеку даже самого высокого ранга. Служба электронной почты позволяет рассылать письма сразу большому количеству получателей и подтверждать получение письма.
Для получения адреса электронной почты необходимо выполнить
два этапа. Во-первых, выбрать почтовый сервис. Самыми популярными почтовыми сервисами являются gmail. com, mail. ru и yandex. ru.
Указанные почтовые сервисы и большинство других являются бес-
235
платными. Во-вторых, надо зарегистрироваться на почтовом сервисе,
выбрать имя для своего почтового ящика и пароль для доступа к нему
для предотвращения несанкционированного доступа к почте.
Адрес электронной почты имеет формат:
имя_пользователя @ имя_сервиса.
Например, mailbox@fastmail. net. Здесь mailbox — название почтового ящика, fastmail. net — название почтового сервиса.
Длина имени пользователя определяется почтовыми сервисами.
Обычно оно должно содержать не менее пяти-шести символов. По
имени сервиса можно определить, на каком почтовом сервисе зарегистрирован почтовый ящик.
Электронная почта построена по принципу клиент-серверной
архитектуры. Пользователь общается с клиентской программой, которая, в свою очередь, общается с сервером почтового сервиса. Одной
из популярных почтовых программ является Outlook Express фирмы
Microsoft. Некоторые почтовые программы встроены в браузер —
программу для просмотра документов во Всемирной сети (WWW),
например в браузер Opera фирмы Opera Software.
Процедуры отправки и получения почты используют разные протоколы. Для передачи писем используется протокол SMTP (Simple
Mail Transfer Protocol — протокол пересылки почты). Для приема почтовых сообщений наиболее часто используется протокол IMAP
(Internet Message Access Protocol — протокол доступа к интернетсообщениям).
Рассмотрим пример работы электронной почты. Пусть владелец
электронного ящика с адресом john@abc. net на почтовом сервисе abc.
net хочет отправить письмо владельцу почтового ящика с адресом
mary@xyz. com на сервисе xyz. com.
Сначала отправитель должен зайти на веб-сайт почтового сервиса
abc. net или запустить программу для работы с электронной почты и
ввести пароль для доступа к своему почтовому ящику. Далее отправитель должен составить текст письма, а в адресе получателя указать
адрес электронной почты mary@xyz. com.
После составления и отправления письма, почтовая программа
соединяется с почтовым сервером abc. net и передает ему письмо,
содержащее текст письма и адрес электронной почты получателя
mary@xyz. com. При отправке почты почтовая программа взаимодействует с сервером исходящей почты — SMTP-сервером.
После получения письма SMTP-сервер отправителя abc. net связывается с SMTP-сервером почтового сервиса получателя xyz. com.
Для этого ему необходимо получить IP-адрес почтового сервиса xyz.
com. Чтобы узнать этот адрес, он обращается к DNS-серверу и запрашивает IP-адрес сервера xyz. com.
DNS-сервер выдает IP-адрес, после чего SMTP-сервер abc. net
соединяется с SMTP-сервером xyz. com. Если SMTP-сервер xyz. com
236
недоступен, например, из-за сбоя или отказа оборудования на нем,
то SMTP-сервер abc. net ставит письмо в очередь для отправки. Через
каждые 10 — 15 минут сервер abc. net будет пытаться отправить письмо SMTP-серверу xyz. com. Через несколько дней, если сообщение так
и не будет отправлено, отправитель письма получит сообщение на свой
адрес электронной почты, что его письмо не может быть доставлено
по адресу mary@xyz. com с указанием причины. В данной случае причиной является отсутствие связи с почтовым сервисом xyz. com.
Как только SMTP-серверу abc. net связывается с сервером xyz.
com, он передает ему письмо. SMTP-сервер xyz. com проверяет существование адреса электронной почты mary@xyz. com и в случае
его существования помещает письмо в почтовый ящик mary, иначе
сервер abc. net получает сообщение, что ящик с таким именем не
существует. Это сообщение пересылается отправителю на адрес
john@abc. net.
После того как письмо получено сервером xyz. com, получатель —
владелец почтового ящика mary@xyz. com может прочесть его. Письма хранятся в почтовом ящике на сервере, что позволяет быстро
искать и сортирововать почтовые отправления. Для просмотра почты,
полученной в почтовый ящик, почтовая программа получателя взаимодействует с IMAP-сервером по протоколу IMAP. При взаимодействии по этому протоколу с сервера на компьютер получателя передаются заголовки писем с указанием адреса отправителя, темы
письма и его размера (в байтах или Кбайтах). Получатель может загрузить тексты писем или удалить их из почтового ящика, не загружая
их на свой компьютер.
К сожалению, служба электронной почты не всегда используется с добрыми намерениями. Настоящим бедствием пользователей
электронной почты стал спам — электронные письма рекламного
содержания.
По некоторым оценкам до 40 % всех электронных писем является спамом. Пользователям приходится тратить много времени на
фильтрацию таких писем. Также электронная почта используется для
пересылки компьютерных вирусов в виде вложений в электронное
письмо. Поэтому не открывайте вложения, о пересылки которых вы
не просили, даже если они отправлены известным вам отправителем.
Служба WWW
Всемирная сеть (WWW ) — самая популярная служба на базе сети
Интернет благодаря своей доступности, простоте и удобству использования. Всемирная сеть объединяет веб-серверы, хранящие гипертекстовые документы.
Гипертекст — это текст, отформатированный особым образом.
Гипертекст содержит ссылки на графические изображения и другие
237
гипертекстовые документы, тематически связанные с ним. Пользователь может переходить от одного документа к другому по этим
ссылкам. Такие переходы называются веб-серфингом. Идея гипертекста оказалась подходящей для объединения информации в цифровой форме, распределенной во Всемирной сети.
Так как гипертекстовые документы ссылаются не только на текст,
но и на мультимедийные ресурсы — совокупность текстовой, графической и видеоинформации, то понятие «гипертекст» было расширено до понятия гипермедия. Таким образом, гипермедия — это
способ организации мультимедийной информации на основе гипертекста.
В основе Всемирной сети, как и электронной почты, лежит
клиент-серверная архитектура. Для работы во Всемирной сети пользователю необходима специальная программа — браузер.
Браузер предназначен для решения двух основных задач:
1) запрос по требованию пользователя информационного ресурса
по его адресу URL у веб-сервера, на котором он хранится;
2) отображение содержимого запрошенного информационного
ресурса на дисплее пользователя.
Браузер повышает удобство работы во Всемирной сети, выполняя
следующие сервисные функции:
• хранение, обеспечение поиска и быстрого доступа к адресам
URL, которые пользователь посещает чаще всего;
• ведение журнала посещений информационных ресурсов;
• сохранение информационных ресурсов, которые просматривал
пользователь, на ВЗУ;
• обеспечение безопасности пользователя во время работы во
Всемирной сети.
Примерами браузеров являются Internet Explorer фирмы Microsoft,
Opera фирмы Opera Software и Mozilla Firefox, созданный независимыми разработчиками. Браузеры являются бесплатным программным
обеспечением.
Всемирная сеть — это совокупность веб-серверов, связанных
между собой. Можно выделить два типа связи:
1) физические — каналы связи, связывающие веб-серверы;
2) информационные — ссылки гипертекстового документа, находящиеся на одном веб-сервере, на информационные ресурсы на
других веб-серверах.
Веб-сервер — это совокупность аппаратного и программного обеспечения, решающая единственную основную задачу: получение
запроса пользователя на информационный ресурс, обработка и выдача его пользователю. Веб-серверы не только выдают текст и графические изображения по запросу, но и могут выполнять более сложные
операции по обработке информации: например, делать запросы к БД
и наглядно представлять результаты запроса. Прием запроса от
браузера веб-серверу и доставка информационных ресурсов осущест-
238
вляется по протоколу HTTP (Hypertext Transfer Protocol — протокол
передачи гипертекста).
Гипертекстовый документ, расположенный на одном из вебсерверов, называется веб-страницей, а совокупность страниц, объединенных общей темой и связанных ссылками друг на друга, — вебсайтами. Веб-сайты, имеющие широкую тематику, называются вебпорталами. Веб-порталы состоят из сотен тысяч страниц.
На одном веб-сервере могут располагаться один или более вебсайтов. Веб-порталы обрабатывают большое количество запросов и,
как правило, размещаются на нескольких веб-серверах по двум основным причинам:
1) равномерное распределение запросов между серверами: часть
запросов переводится с наиболее загруженных серверов на менее
загруженные;
2) хранение веб-портала на нескольких серверах более надежно,
так как выход из строя одного из веб-серверов будет компенсирован
другими серверами, и веб-портал останется доступным пользователям
Всемирной сети.
Помимо просмотра чужих веб-сайтов можно создать свой вебсайт и поместить туда информацию, которая будет интересна пользователям Всемирной сети, в виде текста, графики, звуковых и видеофайлов.
Информация, размещенная во Всемирной сети, исчисляется
огромным количеством байт. Для поиска информации во Всемирной
сети используются специальные веб-сайты — информационнопоисковые системы. Они позволяют по ключевым словам найти
информационные ресурсы, связанные с ключевыми словами. Это
может быть текст, содержащий ключевые слова, или графическое
изображение одного из ключевых слов. Примерами информационнопоисковых систем являются системы Google и Yandex.
Служба передачи файлов
Файлы большого объема можно переслать по электронной почте
или разместить на веб-сервере. Однако пересылка по электронной
почте возможно лишь нескольким получателям, а размещение файлов
на веб-сервере значительно загружает его. Чтобы сделать получение
файлов более удобным, используется протокол FTP (File Transfer
Protocol — протокол передачи файлов).
По протоколу FTP обычно передаются следующие файлы:
• программное обеспечение;
• документы большого объема;
• фото- и видеофайлы.
Для доступа к файлам необходимо использовать специальную
программу или воспользоваться браузером.
239
Файлы, расположенные на FTP-сервере, находятся в каталогах
точно так же, как в файловой системе ОС. Пользователь может получать список файлов и каталогов, расположенных на FTP-сервере,
переходить из одного каталога в другой.
Некоторые FTP-сервера предоставляют открытый доступ к файлам. В других FTP-серверах доступ к файлам может быть защищен
паролем, который задается владельцем FTP-сервера.
Список литературы
1. Бройдо В. Л. Вычислительные системы, сети и телекоммуникации /
В. Л. Бройдо, О. П. Ильина. — 4-е изд. — СПб. : Питер, 2011. — 560 с.
2. Велихов А. В. Основы информатики и компьютерной техники : учеб.
пособие / А. В. Велихов. — М. : СОЛОН-Пресс, 2003. — 544 с.
3. Гаврилов Г. П. Сборник задач по дискретной математике /
Г. П. Гаврилов, А. А. Сапоженко. — М. : Наука, 1977. — 368 с.
4. Гуц А. К. Математическая логика и теория алгоритмов : учеб. пособие /
А. К. Гуц. — Омск : Изд-во «Наследие», Диалог-Сибирь, 2003. — 108 с.
5. Дипломное проектирование по специальностям 220400 и 351400 : метод. указ. / сост. И. А. Цветков. — Рязань, Рязан. гос. радиотехн. акад. 2005. —
48 с.
6. Интеллектуальные системы поддержки принятия решений в нештатных ситуациях с использованием информации о состоянии природной среды / [В. А. Геловани, А. А. Башлыков, В. Б. Бритков, Е. Д. Вязилов]. — М. :
Эдиториал УРСС, 2001. — 384 с.
7. Информатика. Базовый курс / под ред. С. В. Симоновича. — 2-е изд. —
СПб. : Питер, 2003. — 640 с.
8. Информатика. Общий курс / [А. Н. Гуда, М. А. Бутакова, Н. М. Нечитай-
ло, А. В. Чернов] ; под ред. В. И. Колосникова. — 4-е изд. — М. : Изд.-торг.
корпорация «Дашков и К» ; Ростов н/Д. ; Наука-Спектр, 2011. — 400 с.
9. Информатика : программа, методические указания и контрольные задания / сост. И. В. Галыгина, Л. В. Галыгина. — Тамбов : Изд-во Тамб. гос.
техн. ун-та, 2004. — 48 с.
10. Информатика : учебник / под ред. Н. В. Макаровой. — 3-е изд. перераб. — М. : Финансы и статистика, 2002. — 768 с.
11. Информатика : учебник / [Б. В. Соболь, А. Б. Галин, Ю. В. Панов и
др.] — 3-е изд., перераб. и доп. — Ростов н/Д. : Феникс, 2007. — 446 с.
12. Жолков С. Ю. Математика и информатика для гуманитариев : учебник / С. Ю. Жолков. — М. : Гардарики, 2002. — 531 с.
13. Змитрович А. И. Интеллектуальные информационные системы /
А. И. Змитрович. — Минск : НТООО «ТетраСистемс», 1997. — 368 с.
14. Каймин В. А. Информатика : учебник / В. А. Каймин. — 2-е изд., перераб. и доп. — М. : ИНФРА-М, 2001. — 272 с.
15. Калинина В. Н. Математическая статистика / В. Н. Калинина,
В. Ф. Панкин. — М. : Высш. шк., 1998. — 336 с.
16. Круглов В. В. Интеллектуальные информационные системы : компьютерная поддержка систем нечеткой логики и нечеткого вывода /
В. В. Круглов, М. И. Дли. — М. : Изд-во физ.-мат. лит., 2002. — 256 с.
241
17. Левин Р. Практическое введение в технологию искусственного интеллекта и экспертных систем с иллюстрациями на Бейсике / Р. Левин,
Д. Дранг, Б. Эделсон ; пер. с англ. ; предисловие М. Л. Сальникова,
Ю. В. Сальниковой. — М. : Финансы и статистика, 1991. — 239 с.
18. Логический подход к искусственному интеллекту : от классической
логики к логическому программированию / [А. Тейз, П. Грибомон, Ж. Луи и
др.] ; пер. с франц. П. П. Пермяковой. — М. : Мир, 1990. — 432 с.
19. Максимов Н. В. Архитектура ЭВМ и вычислительных систем : учебник / Н. В. Максимов, Т. Л. Партыка, И. И. Попов. — 3-е изд., перераб и
доп. — М. : Форум, 2010. — 512 с.
20. Маликова Л. В. Практический курс по электронным таблицам MS
Excel : учеб. пособие для вузов / Л. В. Маликова, А. Н. Пылькин. — М. : Горячая линия-Телеком, 2004. — 244 с.
21. Мельников В. П. Информационные технологии : учебник /
В. П. Мельников. — М. : Издательский центр «Академия», 2008. — 432 с.
22. Могилев А. В. Информатика : учеб. пособие для студ. пед. вузов /
А. В. Могилев, Н. И. Пак, Е. К. Хеннер ; под ред. Е. К. Хеннера. — 3-е изд.,
перераб. и доп. — М. : Издательский центр «Академия», 2004. — 848 с.
23. Новичков В. С. Алгоритмизация и программирование на Турбо Паскале : учеб. пособие / В. С. Новичков, Н. И. Парфилова, А. Н Пылькин. —
М. : Горячая линия — Телеком, 2005. — 438 с.
24. Новичков В. С. Введение в информатику / В. С. Новичков,
А. Н. Пылькин ; под ред. Л. П. Коричнева. — М. : Минобразования России,
НИЦПрИС, 1998. — 112 с.
25. Новичков В. С. Основы информатики : учеб. пособие / В. С. Новичков,
А. Н. Пылькин. — Рязань : РГРТУ, 2005. — 304 с.
26. Новые информационные технологии : учеб. пособие / под ред.
В. П. Дьяконова. — М. : СОЛОН-Пресс, 2005. — 640 с.
27. Острейковский В. А. Информатика : учебник / В. А. Острейковский. —
5-е изд., стер. — М. : Высш. шк., 2009. — 511 с.
28. Пакеты программ офисного назначения : учеб. пособие /
[С. В. Назаров, Л. П. Смольников, В. А. Тафинцев и др.] ; под ред.
С. В. Назарова. — М. : Финансы и статистика, 1997. — 320 с.
29. Работа с текстовым процессором MS Word : учеб. пособие для вузов /
[Г. А. Новиков, П. А. Новиков, М. В. Орлова и др.]. — М. : Горячая линияТелеком, 2005. — 198 с.
30. Рубашкин В. Ш. Представление и анализ смысла в интеллектуальных информационных системах / В. Ш. Рубашкин. — М. : Наука, 1989. —
192 с.
31. Скрэгг Г. Семантические сети как модели памяти // Новое в зарубежной лингвистике. Вып. XII / сост. : В.А.Звегинцев ; под ред. Б.Ю.Городецкого. —
М. : Радуга, 1983. — С. 123 — 170.
32. Степанов А. Н. Информатика / А. Н. Степанов. — СПб. : Питер,
2003. — 608 с.
33. Теоретические основы информатики : учеб. пособие / [В. Л. Матросов,
В. А. Горелик, С. А. Жданов и др.]. — М. : Издательский центр «Академия»,
2009. — 352 с.
242
34. Угринович Н. Д. Информатика и информационные технологии :
учебник для 10—11 классов / Н. Д. Угринович. — М. : БИНОМ. Лаборатория
знаний, 2003. — 512 с.
35. Федотова Е. Л. Информационные технологии в науке и образовании : учеб. пособие / Е. Л. Федотова, А. А. Федотов. — М. : ИД «ФОРУМ» :
ИНФРА-М, 2011. — 336 с.
36. Фигурнов В. Э. IBM PC для пользователя / В. Э. Фигурнов. — М. :
ИНФРА-М, 1999. — 640 с.
37. Фуфаев Э. В. Пакеты прикладных программ : учеб. пособие для сред.
проф. образования / Э. В. Фуфаев, Л. И. Фуфаева. — М. : Издательский
центр «Академия», 2004. — 352 с.
38. Цветков И. Я. Представление и обработка информации в ЭВМ :
учеб. пособие / И. А. Цветков. — Рязань, Рязан. гос. радиотехн. акад., 2003. —
80 с.
39. Шафрин Ю. А. Информационные технологии / Ю. А. Шафрин. — М. :
Лаборатория Базовых Знаний, 1998. — 704 с.
40. Щикот С. Е. Комплексные тестовые упражнения по информатике /
С. Е. Щикот, С. О. Крамаров, В. В. Перепелкин. — 2-е изд., доп. — Ростов
н/Д. : Феникс, 2005. — 288 с.
41. http : //firm. trade. spb. ru. Дата просмотра 23.02.2004.
42. http : //hosting. bspu. ru/kaf/kitso/files/lec_inf. doc. Дата просмотра
27.01.2006.
43. http : //www. cfin. ru/finanalysis/inexcel/. Дата просмотра 11.06.2007.
44. http : //www. mari-el. ru/mmlab/home/AI/index. html. Дата просмотра
22.03.2008.
Оглавление
Список основных используемых сокращений и обозначений........................3
Введение.............................................................................................................5
Глава 1. Информатика — наука и вид практической
деятельности.............................................................................. 8
1.1. Информатика и ее структура...........................................................8
1.2. Информатика в обществе.............................................................. 10
1.3. Информатика в природе................................................................ 10
Глава 2. Основы теории информации.......................................... 12
2.1. Понятие информации.................................................................... 12
2.2. Непрерывная и дискретная информация..................................... 13
2.3. Адекватность информации и ее формы....................................... 15
2.4. Синтаксическая мера информации.............................................. 15
2.4.1. Вероятностный подход........................................................ 15
2.4.2. Объемный подход................................................................ 18
2.5. Показатели качества информации................................................ 19
Глава 3. Информационные процессы, системы
и технологии............................................................................ 21
3.1. Информационные процессы......................................................... 21
3.2. Информационные системы........................................................... 22
3.3. Информационные технологии...................................................... 25
Глава 4. Системы счисления............................................................. 29
4.1. Непозиционная и позиционная системы
счисления....................................................................................... 29
4.2. Двоичная, десятичная и шестнадцатеричная
системы счисления. Перевод чисел в десятичную
систему счисления......................................................................... 30
4.3. Перевод целых чисел из одной системы счисления
в другую.......................................................................................... 32
4.4. Перевод дробных чисел из одной системы счисления
в другую.......................................................................................... 34
244
Глава 5. Представление чисел, символов, графических
и звуковых данных в ЭВМ................................................... 36
5.1. Представление целых чисел в ЭВМ.............................................. 36
5.1.1. Форматы представления целых чисел................................ 36
5.1.2. Прямой и дополнительный коды представления
двоичных чисел.................................................................... 37
5.2. Представление вещественных чисел в ЭВМ................................ 40
5.3. Представление символов в ЭВМ..................................................44
5.4. Представление графических и звуковых данных
в ЭВМ............................................................................................. 46
Глава 6. Логические основы ЭВМ.................................................... 48
6.1. Алгебра высказываний. Понятие, высказывание,
умозаключение............................................................................... 48
6.2. Логические операции.................................................................... 49
6.3. Логические функции..................................................................... 52
6.3.1. Способы представления логических
функций................................................................................ 52
6.3.2. Способы перевода логических функций
из одного базиса в другой.................................................... 55
6.3.3. Минимизация логических функций................................... 57
6.4. Логические элементы и логические схемы................................... 58
Глава 7. Знания. Модели представления знаний.................... 62
7.1. Знания и их особенности............................................................... 62
7.2. Модели представления знаний...................................................... 63
7.3. Логические модели.........................................................................64
7.4. Семантические сети....................................................................... 68
7.5. Продукционные модели................................................................. 72
7.6. Фреймы........................................................................................... 75
Глава 8. Архитектура ЭВМ. ..................................................................... 80
8.1. Поколения ЭВМ............................................................................. 80
8.2. Структура ЭВМ.............................................................................. 82
8.3. Микропроцессор............................................................................ 84
8.4. Системная шина............................................................................ 88
8.5. Оперативное и постоянное запоминающие
устройства.......................................................................................90
8.6. Внешние запоминающие устройства............................................ 91
8.6.1. Общие сведения................................................................... 91
8.6.2. Магнитные носители........................................................... 91
8.6.3. Оптические носители.......................................................... 93
8.6.4. Флэш-память........................................................................ 95
245
8.7. Видеоподсистема ЭВМ.................................................................. 96
8.7.1. Видеокарта........................................................................... 96
8.7.2. Основные характеристики мониторов............................... 96
8.7.3. Типы мониторов.................................................................. 97
8.8. Контроллеры портов ввода-вывода.............................................. 99
8.9. Периферийные устройства.......................................................... 100
8.9.1. Клавиатура......................................................................... 100
8.9.2. Манипулятор типа «мышь»............................................... 101
8.9.3. Принтеры........................................................................... 102
8.9.4. Сканеры.............................................................................. 104
8.9.5. Сетевой адаптер................................................................. 105
8.9.6. Модем................................................................................. 106
Глава 9. Основы алгоритмизации................................................. 108
9.1. Понятие алгоритма....................................................................... 108
9.2. Алгоритмическая система............................................................110
9.3. Алгоритмизация............................................................................111
9.4. Средства записи алгоритмов........................................................112
9.4.1. Словесная запись алгоритмов............................................112
9.4.2. Схемы алгоритмов..............................................................116
9.4.3. Структурограммы................................................................121
9.5. Технология разработки алгоритмов............................................ 123
9.6. Структуры алгоритмов................................................................. 129
9.6.1. Алгоритмы линейной
структуры............................................................................ 129
9.6.2. Ветвления........................................................................... 129
9.6.3. Циклы................................................................................. 133
9.6.4. Итерационные циклы........................................................ 140
9.6.5. Вложенные циклы...............................................................141
9.6.6. Вспомогательные алгоритмы............................................. 144
Глава 10. Программное обеспечение ЭВМ..................................147
10.1. Жизненный цикл программного продукта............................... 147
10.2. Классификация программного обеспечения........................... 149
10.3. Операционные системы............................................................. 152
10.3.1. Понятие «операционная система»
и ее виды............................................................................. 152
10.3.2. Распределение ресурсов ЭВМ между
процессами......................................................................... 154
10.3.3. Поддержание файловой системы...................................... 156
10.3.4. Обеспечение интерфейса
пользователя....................................................................... 159
10.3.5. Файлы конфигурации операционных
систем Windows...................................................................161
10.3.6. Драйверы устройств........................................................... 162
246
10.4. Архиваторы................................................................................. 162
10.5. Текстовые процессоры............................................................... 164
10.5.1. Классификация программ для работы
с текстовыми документами............................................... 164
10.5.2. Общие сведения об объектах текстового редактора
Microsoft Word.................................................................... 165
10.5.3. Элементы форматирования текстового редактора
Microsoft Word.................................................................... 166
10.5.4. Примеры оформления документов....................................179
10.5.5. Элементы документа текстового редактора
Microsoft Word.................................................................... 180
10.5.6. Автоматизация работы текстового редактора
Microsoft Word.................................................................... 189
10.6. Табличные процессоры.............................................................. 193
10.6.1. Табличные процессоры, их функции
и структура......................................................................... 193
10.6.2. Общие сведения об объектах
Microsoft Excel.................................................................... 194
10.6.3. Типы адресации в Microsoft Excel..................................... 194
10.6.4. Присвоение имен ячейкам и диапазонам
в Microsoft Excel................................................................. 197
10.6.5. Формулы Microsoft Excel и их отладка............................. 198
10.6.6. Логические функции Microsoft Excel................................ 201
10.6.7. Функции теории вероятностей и математической
статистики в Microsoft Excel.............................................. 202
10.6.8. Финансовые функции
Microsoft Excel.................................................................... 207
10.7. Графические редакторы............................................................. 214
10.8. Базы данных............................................................................... 216
10.8.1. Базы данных и их классификация.................................... 216
10.8.2. Реляционная модель данных..............................................217
10.8.3. Нормализация отношений.................................................218
10.8.4. Типы связей........................................................................ 220
Глава 11. Вычислительные сети...................................................... 222
11.1. Понятие, виды и характеристики вычислительных
сетей............................................................................................. 222
11.2. Модель взаимодействия открытых систем................................ 224
11.3. Сетевые протоколы..................................................................... 226
11.4. Локальные сети........................................................................... 226
11.4.1. Топологии локальных вычислительных
сетей................................................................................... 226
11.4.2. Виды коммутации.............................................................. 228
11.4.3. Способы адресации ЭВМ в сети....................................... 229
11.4.4. Маршрутизация в вычислительных
сетях................................................................................... 230
247
11.5. Глобальная сеть Интернет.......................................................... 231
11.5.1. Интернет как сообщество сетей........................................ 231
11.5.2. Протоколы сети Интернет................................................. 232
11.5.3. Система адресации в сети
Интернет............................................................................. 233
11.5.4. Службы сети Интернет...................................................... 235
Список литературы........................................................................................ 241
Учебное издание
Парфилова Надежда Ивановна,
Пруцков Александр Викторович,
Пылькин Александр Николаевич,
Трусов Борис Георгиевич
Информатика и программирование
Основы информатики
Учебник
Редактор И.В.Могилевец
Технический редактор Е.Ф.Коржуева
Компьютерная верстка: О. В. Пешкетова
Корректор И. А. Ермакова
Изд. № 101115946. Подписано в печать 30.07.2012. Формат 60 × 90/16. Гарнитура «Ньютон».
Бумага офсетная № 1. Печать офсетная. Усл. печ. л. 16,0. Тираж 1 500 экз. Заказ №
ООО «Издательский центр «Академия». www.academia-moscow.ru
125252, Москва, ул. Зорге, д. 15, корп. 1, пом. 26б.
Адрес для корреспонденции: 129085, Москва, пр-т Мира, 101В, стр. 1, а/я 48.
Тел./факс: (495) 648-0507, 616-00-29.
Санитарно-эпидемиологическое заключение № РОСС RU. AE51. H 16067 от 06.03.2012.
Отпечатано с электронных носителей издательства.
ОАО «Тверской полиграфический комбинат», 170024, г. Тверь, пр-т Ленина, 5.
Телефон: (4822) 44-52-03, 44-50-34. Телефон/факс: (4822) 44-42-15.
Home page — www.tverpk.ru Электронная почта (E-mail) — sales@tverpk.ru
Г. М. АНТОНОВА, А. Ю. БАЙКОВ
СОВРЕМЕННЫЕ СРЕДСТВА ЭВМ
И ТЕЛЕКОММУНИКАЦИЙ
Объем 144 c.
В учебном пособии рассмотрены современные средства ЭВМ
и телекоммуникаций: история возникновения и общая структура
сети Интернет, общие принципы работы протоколов сети Интер
нет, технология работы с основными прикладными программами
клиентами, способы доступа к основным информационным ресур
сам, методы защиты информации, формат HTML и структура
HTML
документов.
Для студентов учреждений высшего профессионального обра
зования.
И. Ю. БАЖЕНОВА
ЯЗЫКИ ПРОГРАММИРОВАНИЯ
Объем 352 c. — (Бакалавриат).
Учебное пособие создано в соответствии с Федеральным го
сударственным образовательным стандартом по направлению
подготовки «Фундаментальная информатика и информационные
технологии» (квалификация «бакалавр»). В учебном пособии при
ведена общая характеристика языков программирования. Под
робно описаны основные структуры данных; определены простые
типы, массивы, записи и структуры; показано применение стеков,
очередей и хеш
таблиц. Рассмотрены основные конструкции язы
ков программирования, синтаксис и семантика высокоуровневых
языков программирования, включая языки С++, C#, Object Pascal
и Java. Дано понятие объектно
ориентированного программиро
вания. Раскрыты механизмы наследования, инкапсуляции и поли
морфизма. Дано описание современных интегрированных сред
разработки и библиотек классов. NET Framework, VCL и JDK.
Подробно освещается круг вопросов, связанных с сетевым про
граммированием, применением языков программирования для
разработки серверных приложений и Web
сервисов. Приведены
основы применения компонентной технологии, использования
серверов автоматизации, взаимодействия COM
компонентов с
управляемым кодом.
Для студентов учреждений высшего профессионального обра
зования.
В. Г. БАУЛА, А. Н. ТОМИЛИН, Д. Ю. ВОЛКАНОВ
АРХИТЕКТУРА ЭВМ И ОПЕРАЦИОННЫЕ СРЕДЫ
Объем 336 c. — (Бакалавриат)
Учебник создан в соответствии с Федеральным государствен
ным образовательным стандартом по направлениям подготовки
«Прикладная математика и информатика», «Фундаментальная
информатика и информационные технологии» (квалификация «ба
калавр»). Приведены необходимые сведения по основам архитек
тур ЭВМ и операционным средам. Изложены основы программи
рования на языке Ассемблер, а также способы отображения
структур данных и структур управления языка высокого уровня
(Паскаля) на язык Ассемблера.
Для студентов учреждений высшего профессионального обра
зования. Может быть использован для самостоятельного изуче
ния основ архитектуры ЭВМ и систем программирования.
Л. В. ВОРОБЬЕВ, А. В. ДАВЫДОВ, Л. П. ЩЕРБИНА
СИСТЕМЫ И СЕТИ ПЕРЕДАЧИ ИНФОРМАЦИИ
Объем 336 c.
В учебном пособии рассмотрены теория передачи информа
ции, преобразование сообщений в электрические сигналы, их
кодирование, модуляция, передача и прием; приведены качествен
ные и количественные характеристики информации; сформулиро
ваны условия согласования источников информации с каналами
связи; дана классификация сетей связи; изложены основные прин
ципы построения, морфологические и функциональные характе
ристики сетей, а также классические и телематические службы
связи, организуемые на вторичных сетях; разобраны особеннос
ти построения информационно
вычислительных и первичных се
тей связи, использующих системы передачи различного типа.
Для студентов учреждений высшего профессионального обра
зования.
О. С. ЛОГУНОВА, Е. Г. ФИЛИППОВ, В. В. ПАВЛОВ И ДР.
ПРОГРАММНЫЕ СТАТИСТИЧЕСКИЕ КОМПЛЕКСЫ
Объем 240 c.
В учебном пособии изложен теоретический и практический
материал для проведения занятий по дисциплине «Программные
статистические комплексы. Теория и практика». Данное пособие
способствует наилучшему освоению студентами практики исполь
зования новых методов обработки данных, а также решению за
дач с использованием универсального пакета STATISTICA 6.0.
Для студентов учреждений высшего профессионального обра
зования.
Г. М. СЕРГИЕВСКИЙ, Н. Г. ВОЛЧЕНКОВ
ФУНКЦИОНАЛЬНОЕ И ЛОГИЧЕСКОЕ
ПРОГРАММИРОВАНИЕ
Объем 320 c.
В учебном пособии рассмотрены основные результаты как в
теоретической части, так и в части практического применения,
накопленные к настоящему времени в области функционального
и логического программирования. Показано, что оба эти подхо
да, относящиеся к парадигме декларативного программирования,
позволяют получить новые возможности в части трансформации
и автоматического синтеза программ, доказательства свойств
программ, частичных вычислений и др. Описаны области, в кото
рых применение данных подходов имеет преимущества по срав
нению с операторным программированием. Практические аспек
ты функционального программирования изучаются на примере
языка Haskell — лучшей современной реализации функциональ
ной парадигмы. В теоретическом обосновании приведены наи
более важные (для данных целей) результаты лямбда
исчисления
и комбинаторной логики. Представлена наиболее «продвинутая»
практическая реализация идеи логического программирования:
язык Пролог. Даны его детальное описание и приемы программи
рования. Основное внимание уделено таким областям примене
ния Пролога, как программирование баз данных, синтаксичес
кий анализ, реализация переборного и эвристического поиска,
задачи искусственного интеллекта, в том числе обработки нечет
ких данных, программирование в ограничениях (Constraint Logic
Programming). Подробно описаны теоретические основы логичес
кого программирования (метод резолюций, теорема Робинсона
и др.).
Для студентов учреждений высшего профессионального обра
зования.
С. В. СИНИЦЫН, А. В. БАТАЕВ,
Н. Ю. НАЛЮТИН
ОПЕРАЦИОННЫЕ СИСТЕМЫ
Объем 304 c.
В учебнике изложены основные принципы организации совре
менных операционных систем (ОС) на примере ОС UNIX и
Windows. Рассмотрены методы и языковые средства для работы с
основными объектами, находящимися под управлением ОС: фай
лами, заданиями, пользователями, процессами. Значительное
внимание уделено вопросам обеспечения межпроцессного вза
имодействия. Текст иллюстрируется многочисленными примера
ми, содержит контрольные вопросы и задания.
Для студентов учреждений высшего профессионального обра
зования.
С. В. СИНИЦЫН, А. С. МИХАЙЛОВ, О. И. ХЛЫТЧИЕВ
ПРОГРАММИРОВАНИЕ НА ЯЗЫКЕ ВЫСОКОГО
УРОВНЯ
Объем 400 c.
В учебнике рассмотрены общие принципы высокоуровневого
программирования, непосредственным образом связанного с
изучением алгоритмов, в рамках технологического процесса. Из
лагаемый материал можно рассматривать как синтез трех аспек
тов: технологического, вычислительного и языкового. Технология
определяет этапы решения задач, отвечает на вопрос, что про
граммировать, позволяет оценивать результаты. Алгоритмизация
дает ответ на вопрос, как возможно решить поставленные зада
чи. Высокоуровневый язык обеспечивает программистов средства
ми реализации решения поставленных задач. При подготовке
учебника использован опыт передовых предприятий, занимающих
ся промышленной разработкой программного обеспечения и спе
циализирующихся на высокоточных программных системах.
Для студентов учреждений высшего профессионального обра
зования.
В. Б. УТКИН, К. В. БАЛДИН
ИНФОРМАЦИОННЫЕ СИСТЕМЫ
В ЭКОНОМИКЕ
Объем 288 c.
В учебнике содержится систематизированное изложение тео
ретических основ современных информационных систем в обла
сти экономики. Основное внимание уделено методологическим
основам применения средств автоматизации в профессиональ
ной деятельности, теории и практике моделирования экономичес
ких информационных систем, а также основам построения и ис
пользования систем искусственного интеллекта.
Для студентов учреждений высшего профессионального обра
зования.