/


























































































































































































Автор: Зубов А.В. Зубова И.И.
Теги: общие вопросы лингвистики, литературы и филологии прикладное языкознание вычислительная (автоматическая) лингвистика лингвистика информационные технологии
ISBN: 5-7695-1531-7
Год: 2004




Текст
ВЫСШЕЕ ПРОФЕССИОНАЛЬНОЕ ОБРАЗОВАНИЕ
А.В.ЗУБОВ, И.И.ЗУБОВА
ИНФОРМАЦИОННЫЕ
ТЕХНОЛОГИИ
В ЛИНГВИСТИКЕ
Рекомендовано
Учебно-методическим объединением
по образованию в области лингвистики
в качестве учебного пособия для студентов
высших учебных заведений, обучающихся
по специальности 021800 —
Теоретическая и прикладная лингвистика
Москва
ACADEM7V
2004
УДК 800(075.8)
ББК81.1я73
3-915
Рецензенты:
кафедра теоретической и прикладной лингвистики
лингвистического факультета Московского государственного
областного университета (зав. кафедрой —
доктор филологических наук, профессор Ю. К Марчук);
кандидат филологических наук,
старший научный сотрудник И НИ ОН РАН С. Ю. Семенова
Зубов A.B.
3-915 Информационные технологии в лингвистике: Учеб.
пособие для студ. лингв, фак-тов высш. учеб. заведений / А. В.
Зубов, И.И.Зубова — М.: Издательский центр «Академия»,
2004. - 208 с.
ISBN 5-7695-1531-7
Пособие содержит как общие, так и профессиональные знания,
необходимые будущему специалисту-лингвисту. В нем рассмотрены
основные понятия современных информационных технологий, показаны
возможности их использования в проведении лингвистических
исследований, практической обработке текстов и обучении иностранным языкам
на базе персональных компьютеров. !
Для студентов лингвистических факультетов высщих учебных
заведений. Может быть полезно, аспирантам и преподавателям информатики.
УДК 800(075.8)
ББК81.1я73
© Зубов А. В., Зубова И. И., 2004
О Образовательно-издательский центр «Академия», 2004
ISBN 5-7695-1531-7 О Оформление. Издательский центр «Академия», 2004
Любимому сыну Антону, будущему
пользователю суперсовременных
информационных технологий,
посвящается
ПРЕДИСЛОВИЕ
Становление современного информационного общества
приводит к коренным изменениям во всех сферах жизни и
деятельности человека. В сознании людей все больше утверждается мысль,
что будущий стратегический потенциал общества будут
составлять не вещество и энергия, а информация и научные знания.
В недалеком будущем реально защищенным в социальном плане
может быть лишь только- широкообразованный человек,
способный гибко перестраивать направление и содержание своей
деятельности в связи со сменой технологий или требований рынка
[98, 5-7]К
В наши дни владение информационными технологиями
ставится в один ряд с такими качествами, как умение читать и
писать [193, 10]. Сегодня специалист с высшим образованием
должен свободно ориентироваться в мировом информационном
пространстве, иметь необходимые знания и навыки поиска, обработки
и хранения информации с использованием современных
информационных технологий, компьютерных систем и сетей [111, 21].
Вполне естественно, что приобретаемые в процессе изучения
информационных технологий знания, умения и навыки зависят
как от уровня обучения, так и от основной специальности
обучаемого. Для студентов, обучающихся по специальности
«Теоретическая и прикладная лингвистика», необходимы более
углубленные знания по проблемам алгоритмизации, моделированию
лингвистических задач, современным языкам программирования. Эти
знания позволят им получить четкое представление о том, как
ставится и решается лингвистическая задача с помощью
компьютера: от ее словесной формулировки к алгоритму и компьютерной
программе.
Все это позволит студентам в будущем эффективно
использовать информационные технологии для автоматического
распознавания и обработки текста и речи, статистического анализа тек-
B квадратных скобках дана ссылка на список литературы в конце книги.
Первая цифра обозначает порядковый номер книги в списке, последующие
цифры — номера страниц. Ссылка на другие книги списка литературы указана
после точки с запятой.
3
стов, моделирования в филологических исследованиях, обучения
языкам [139]. Все сказанное выше возможно без знания высшей
математики и построения сложных математических моделей.
Более того, как отметил известный специалист по автоматической
обработке текстов Терри Виноград: «ЭВМ — это языковые
машины: основа их могущества заключается в способности
манипулировать лингвистическими знаками—символами, которым
приписывается некоторый смысл» [37, Щ. Таким образом,
естественный язык занимает в информатике фактически центральное место.
Основное отличие данной книги от других книг по использо-'
ванию информационных технологий в гуманитарных науках
заключается в том, что в ней по отношению к письменному тексту
не только ставятся задачи и предлагаются методы их решения, но
и приводятся детальные процедуры их выполнения. Такой подход
позволит студенту быть готовым к практическому созданию
описанных в книге систем и разработке процедур решения
аналогичных задач.
ГЛАВА 1
ЛИНГВИСТИКА
И ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ
ЛИНГВИСТИКА: РАЗДЕЛЫ И НАПРАВЛЕНИЯ
Существует достаточно большое число определений понятия
лингвистика. В «Лингвистическом энциклопедическом словаре»
(1990) лингвистика (языкознание, языковедение) определяется
как «наука о естественном человеческом языке вообще и о всех
языках мира как индивидуальных его представителях» [115, 618].
Несколько конкретизируя приведенное выше определение,
Ю. С. Маслов пишет, что она исследует сущность и природу
языка, проблему его происхождения и общие законы его развития и
функционирования [127, 4]. Более детально задачи лингвистики
рассмотрены в упомянутом энциклопедическом словаре [115, 618—
622], а также в работе В.В.Звегинцева [60, 9—22].
Существуют многочисленные попытки выделения внутри
лингвистики отдельных ветвей или направлений [60, 3—36; 155, 5—
14; 90, 261-262; 22; 181, 5-12; 45; 189, 4-9; 49, 5-31; 48,
4-28; 143, 3-6; 124, 3-23]. В работах [60, 3-36; 189, 4-9]
четко отделяются друг от друга теоретическая и прикладная
лингвистика. Общим для перечисленных и некоторых других работ
этого периода (конец 60-х — начало 70-х годов XX века)
является твердое убеждение, что эти два направления лингвистики
взаимосвязаны и дополняют друг друга, что успешное
функционирование прикладной лингвистики возможно лишь на базе
лингвистических теорий, разработанных в рамках теоретической
лингвистики.
Некоторые из существовавших в то время и новых
зарождающихся подходов к анализу языковых явлений (машинный
перевод, автоматическая обработка речевой информации,
порождающая грамматика, дескриптивная лингвистика, математическая
лингвистика и др.) почти единогласно относились авторами к
проблемам прикладной лингвистики.
Несколько позже Р.Г.Пиотровский, четко разделяя
теоретическую и прикладную лингвистику (но не признавая последнюю
как самостоятельный раздел языкознания), выделяет
структурное и математическое языкознание, а также «новую»
лингвистику, к которой относит инженерную лингвистику [155, 5—75].
В последней он выделяет далее вычислительную лингвистику,
5
экспериментальную фонетику, лингвистическое обеспечение
систем научно-технической информации [155, 11].
Группа ученых Ленинградского университета [22, 13],
опираясь на три основных аспекта любой достаточно развитой области
знания — теорию, эксперимент, практику, — и учитывая их
диалектическую взаимосвязь в процессе познания, выделила в
языкознании три взаимосвязанных направления: теоретическую
лингвистику, экспериментальную лингвистику и прикладную
лингвистику. При этом структурную лингвистику авторы считают
симбиозом таких наук, как теоретическое языкознание,
психология, логика, семиотика, математика, математическая
лингвистика. С их точки зрения, это совокупность методов теоретической
лингвистики и математики [22, 4]. В последние годы в рамках
прикладной лингвистики выделяют также компьютерную
лингвистику [49, 9-11; 124, 23; 17].
Как видно из вышесказанного, «прикладная лингвистика» —
понятие, до сих пор не имеющее четкого определения и
конкретного конечного перечня решаемых ею задач. Тем не менее
попытки разобраться с этими проблемами были и есть.
Одно из первых определений понятия прикладная лингвистика
принадлежит В. В. Звегинцеву. Он определил ее как новую область
лингвистики, «которая осуществляет реализацию
лингвистических знаний с целью решения всякого рода практических задач»
[60, 23]. Далее, несколько детализируя сказанное, автор отмечает:
«Прикладная лингвистика представляет новый взгляд на задачи
изучения языка. Исходя из этого нового взгляда, она производит
переоценку достигнутого в науке о языке, направляет по
определенному руслу лингвистические исследования и, конечно,
комплектует собственную тематику» [60, 24].
В «Лингвистическом энциклопедическом словаре» прикладная
лингвистика определяется как «направление в языкознании,
занимающееся разработкой методов решения практических задач,
связанных с использованием языка» [115, 397]. При этом задачи
прикладной лингвистики делятся на традиционные, или «вечные»,
и «новые» [45, 126, 127]. К числу первых относят создание и
совершенствование письменности, разработку систем
транскрипции устной речи, систем транслитерации иноязычных слов,
унификацию и стандартизацию научно-технической терминологии,
создание словарей различных типов, перевод с языка на язык,
обучение языку и т.д. [115, 397; 45, 126]. К новым задачам
прикладной лингвистики относятся те, появление которых
обусловлено современной научно-технической революцией,
характеризующейся укреплением взаимосвязи общественных, естественных
и технических наук. Перечень таких задач достаточно широк [115,
397; 45, 127—132; 181]. Наиболее удачным представляется
определение прикладной лингвистики и перечня решаемых ею задач,
6
сделанное А. Е. Кибриком. По мнению автора, «прикладная
лингвистика —- раздел языкознания, в котором разрабатываются
методы решения практических задач, связанных с оптимизацией
использования языка как важнейшего средства человеческой
коммуникации» [97, 267]. Множество задач, решаемых прикладной
лингвистикой, А.Е.Кибрик выделяет с опорой на те функции
языка, которые оптимизируются задачами прикладной
лингвистики.
В частности, он выделяет следующие четыре функции [97, 262]:
1) оптимизация способов фиксации и хранения речевой
информации;
2) оптимизация способов передачи информации;
3) оптимизация интеллектуальных способностей человека,
связанных с использованием языка;
4) оптимизация использования языка как средства массовой
коммуникации.
В рамках каждого из этих разделов автор выделяет конкретные
задачи. Их также можно условно разделить на «вечные» и «новые»
(ср. с. 6). К числу задач первого типа, отмечаемых А. Е. Кибриком,
можно отнести создание алфавитов и письменностей, создание
систем транскрипции и транслитерации, задачи сурдопедагогики
и задачи использования языка в медицине, языковое
планирование, языковое строительство, нормализацию языка и т.д.
«Новые» задачи — это такие проблемы, решение которых
возможно с использованием современных информационных
технологий.
ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ И ПРИЧИНЫ,
СПОСОБСТВУЮЩИЕ ИХ ПОЯВЛЕНИЮ
До последнего времени мощь любого государства определялась
уровнем развития промышленности, новизной и эффективностью
ее технической базы. Именно с опорой на новейшее техническое
оборудование совершенствовалась технология материального
производства. Под словом технология (от греч. techne — 'искусство,
мастерство, умение' и logos — 'слово, учение') понимается
«совокупность методов обработки, изготовления, изменения
состояния, свойства, формы сырья, материала или полуфабриката,
используемых в процессе производства продукции» [205, 1338].
Такая технология была основой индустриального общества.
Семидесятые годы XX века стали периодом создания
персональных компьютеров и началом развития информационного
общества. Основное отличие этого общества от индустриального
заключается в том, что наряду с высокоэффективной технологией
материального производства все большую роль начинают играть
7
информационные технологии как совокупность законов, методов и
средств получения, хранения, передачи, распространения,
преобразования информации с помощью компьютеров.
Наряду с приведенным выше существуют и иные определения
понятия «информационные технологии» [86, 23; 235].
Появлению и бурному развитию информационных технологий
способствовали следующие достижения научно-технического
прогресса:
1) создание персональных компьютеров с большой памятью и
большой скоростью выполнения операций;
2) разработка звуковых плат, дающих возможность
воспроизводить и записывать речь, звуки и музыку в большом диапазоне
частот;
3) изобретение видеоплат, позволяющих выводить на экран
компьютеров изображение с телеэкранов и видеомагнитофонов;
4) разработка специальных (мультимедийных) компьютеров,
позволяющих воспроизводить на экране дисплеев цвет, звук,
музыку, движение;
5) создание специальных процессоров и устройств, способных
передавать информацию в сети от одного компьютера к другому;
6) разработка устройств электронной связи (модемов),
позволяющих передавать информацию на далекие расстояния (по
телефонным линиям, кабелям, радиоканалам и т.п.);
7) создание электронной оргтехники, связанной с
персональными компьютерами и позволяющей осуществлять
высокоскоростную печать документов, их копирование и размножение.
ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ В ЛИНГВИСТИКЕ
Конкретизируя определение понятия «информационные
технологий» по отношению к лингвистике, можно сказать, что
информационные технологии в лингвистике — это совокупность
законов, методов и средств получения, хранения, передачи,
распространения, преобразования информации о языке и законах
его функционирования с помощью компьютеров. Если соотнести
это определение с теми задачами, которые решает современная
прикладная лингвистика [45, 127—132; 97, 262; 181; 115, 397], то
можно отметить, что понятие «информационные технологии» в
лингвистике относится в основном к задачам прикладной
лингвистики. К их числу можно отнести:
1) создание систем искусственного интеллекта;
2) создание систем автоматического перевода;
3) создание систем автоматического аннотирования и
реферирования текстов;
4) создание систем порождения текстов;
8
5) создание систем обучения языку;
6) создание систем понимания устной речи;
7) создание систем генерации речи;
8) создание автоматизированных информационно-поисковых
систем;
9) создание систем атрибуции и дешифровки анонимных и
псевдоанонимных текстов;
10) разработка различных баз данных (словарей, карточек,
каталогов, реестров и т.п.) для гуманитарных наук;
11) разработка различного типа автоматических словарей;
12) разработка систем передачи информации в сети
Интернети т.д.
Эти комплексные задачи включают целый ряд более мелких
проблем. К их числу относится автоматизация следующих
процессов:
1) построение словарей текстов;
2) морфологический анализ слова;
3) определение значения многозначного слова;
4) синтаксический анализ предложения;
5) поиск слова в словаре;
6) порождение предложения и т.д.
Некоторые из приведенных выше задач детально
рассматриваются в данной книге.
БУДУЩЕЕ ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ
Философы, психологи и другие специалисты отмечают, что в
будущем социально защищенным может считаться лишь тот
человек, который способен гибко перестраивать направление и
содержание своей деятельности в связи со сменой технологий или
требований рынка [98, 5; 239]. Чтобы подготовить такого
человека, необходимо заменить традиционную технологию получения
новых знаний более эффективной организацией познавательной
деятельности обучаемых в ходе учебного процесса. Это можно
сделать с использованием современных информационных
технологий. Именно они могут продемонстрировать обучаемому тот факт,
что любой информационный ресурс1 представляет реальную
ценность лишь в том случае, когда к нему организован
соответствующий доступ. С их помощью будущих специалистов можно
научить правильной организации хранения информации и выбору
адекватных форм, ее представления [216, 34\. «Интеллектуальная
собственность, представленная в цифровом формате, станет
главной "валютой" XXI века» [19, 40\.
Об информационных ресурсах см. с. 156—175.
9
Технология получения и распространения новых знаний уже
сейчас неотделима от Internet. Формируется инфраструктура,
объединяющая в единое целое глобальные и местные
телекоммуникационные каналы, радио, телевидение, телефонные линии
связи (одна планета — одна сеть). Все это не просто создает
сверхинтеллект, а формирует новые измерения сознания, феномен
сверхпсихологических изменений в личности человека [19, 39; 98,
6]. Широкое распространение в недалеком будущем получат
видеоконференции и дистанционное обучение1 [19, 40; 117, 93, 94;
54; 85; 178, 103-261, 522-555].
К концу XXI века ученые изучат принципы работы мозга на
уровне отдельных нейронов и научатся обращаться с ним, как со
сложным электронным объектом [19, 41]. Это даст новый толчок
к созданию систем искусственного интеллекта, систем
автоматического порождения текстов, их перевода, реферирования и т.д.
В ближайшие годы должна найти решение проблема
распознавания и синтеза устной речи, широкое распространение получат
электронная коммерция (e-commerce) мобильная цифровая
телефонная связь, генная инженерия [19, 39, 40; 43; 117, 92, 93].
1 О дистанционном обучении, сети Интернет и видеоконференциях см. с. 142—
145, 178-189.
ГЛАВА 2
ОСНОВНЫЕ СОСТАВЛЯЮЩИЕ
ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ
СТРУКТУРА ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ
В составе современных информационных технологий можно
выделить следующие составляющие:
1) теоретические основы информационных технологий;
2) методы решения задач информационными технологиями;
3) средства решения задач, используемые в информационных
технологиях:
а) аппаратные средства;
б) программные средства.
Рассмотрим подробнее эти составляющие.
ТЕОРЕТИЧЕСКИЕ ОСНОВЫ
ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ
Теоретическую основу информационных технологий
составляют важнейшие понятия и законы информатики. В свою
очередь понятие «информатика» тесно связано с понятием
«информация».
Слово информация (от лат. informatio — 'разъяснение,
изложение') в обычном житейском понимании обозначает некоторые
сведения о внешнем и внутреннем мире, которые мы используем
для регулирования своего поведения. Более строго это понятие
раскрывается разными способами [160, 7; 202, 4, 5; 226, 13—16].
Выберем один из них, который более всего подходит к
рассматриваемым в пособии лингвистическим задачам, и определим
информацию как определенным образом связанные сведения,
данные, понятия, отраженные в нашем сознании и изменяющие наши
представления о реальном мире [226, 16].
Информация обладает разными свойствами [152, 45— 48; 226,
18—20]. Наиболее важными из них являются: ценность,
достоверность, полнота, актуальность, логичность, компактность.
Ценность информации определяется тем, насколько она важна для
достижения цели, стоящей перед ее получателем. Полнота
информации связана с тем, насколько много в ней сведений,
11
позволяющих получателю информации достичь своей цели.
Актуальность информации определяется необходимостью ее
немедленного использования для достижения какой-либо цели.
Компактность информации — способность представить ее в наиболее
сжатом виде. Понятия достоверность и логичность информации
не требуют особых пояснений.
Выделяют различные виды информации. При этом для ее
классификации по видам разработано много подходов, использующих
разнообразные признаки и особенности информации. Так, в
зависимости от того, какими органами чувств воспринимается
информация, ее делят на визуальную, аудиальную (звуковую,
фонетическую), аудиовизуальную, тактильную. По направленности
информации всем членам общества или каким-то его группам
различают информацию массовую, предназначенную для всех
членов общества, и специальную — для специалистов в
различных областях науки, техники, культуры, производства.
Специальную информацию подразделяют на научную, техническую,
производственную, эстетическую и т.п.
В каждом виде специальной информации выделяют подвиды.
Например, в зависимости от области науки и научной
информации выделяют информацию физическую, математическую,
биологическую, лингвистическую и т.д. Так, лингвистической
информацией называют множество определенным образом связанных
сведений, данных, понятий о языке и правилах его
функционирования, отраженных в нашем сознании и влияющих на наше
речевое поведение.
Слово «информатика» также не имеет единого определения.
С современной точки зрения информатика — это наука о законах
и методах получения, хранения, передачи, распространения,
преобразования и использования информации в естественных и
искусственных системах с применением компьютера.
В зависимости от вида информации выделяют различные типы
информатики. Так, различают информатику социальную,
экономическую, научную, научно-техническую, статистическую,
биологическую, медицинскую и т. п.
Наука, изучающая законы и методы организации и
переработки с помощью компьютера лингвистической информации,
называется лингвистической информатикой. Вспомнив, что понимается
под лингвистической информацией, можно сказать, что
объектом исследования лингвистической информатики будет структура
слов, словосочетаний, предложений, текстов.
Ее интересуют правила, объединяющие нижестоящие
языковые единицы в вышестоящие, правила перевода предложений и
текстов, способы построения рефератов и аннотаций, пути
обучения языкам и целый ряд других вопросов, связанных с языком
и речью.
12
МЕТОДЫ РЕШЕНИЯ ЗАДАЧ С ИСПОЛЬЗОВАНИЕМ
ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЙ
Основным методом решения различных задач
информационными технологиями является метод моделирования. Суть его
заключается в том, что для решения какой-либо задачи строится
модель некоторого объекта, явления или процесса. Этот метод
используется человеком очень давно. Существуют различные
определения понятий «модель» и «моделирование» [16, 13; 17, 22;
235, 45—53]. За основу примем следующее определение понятия
«модель» [103, 46]: модель — это формализованное описание
объекта, системы нескольких объектов, процесса или явления,
выраженное конечным набором предложений какого-либо языка,
математическими формулами, таблицами, графиками, специальными
знаками или какими-нибудь схемами.
Описание считается формализованным, если оно понятно не
только человеку, но и некоторому устройству, например
компьютеру. Предположим, архитектор, разрабатывая план какого-либо
города или поселка, строит его модель в виде таких специальных
знаков, как квадрат, прямоугольник, круг, которые обозначают
целые дома, заводы, улицы и т.п.
Модель взаимосвязи в треугольнике его сторон (катетов аиЬи
гипотенузы с) выражается формулой с2 = а2 + Ъ2.
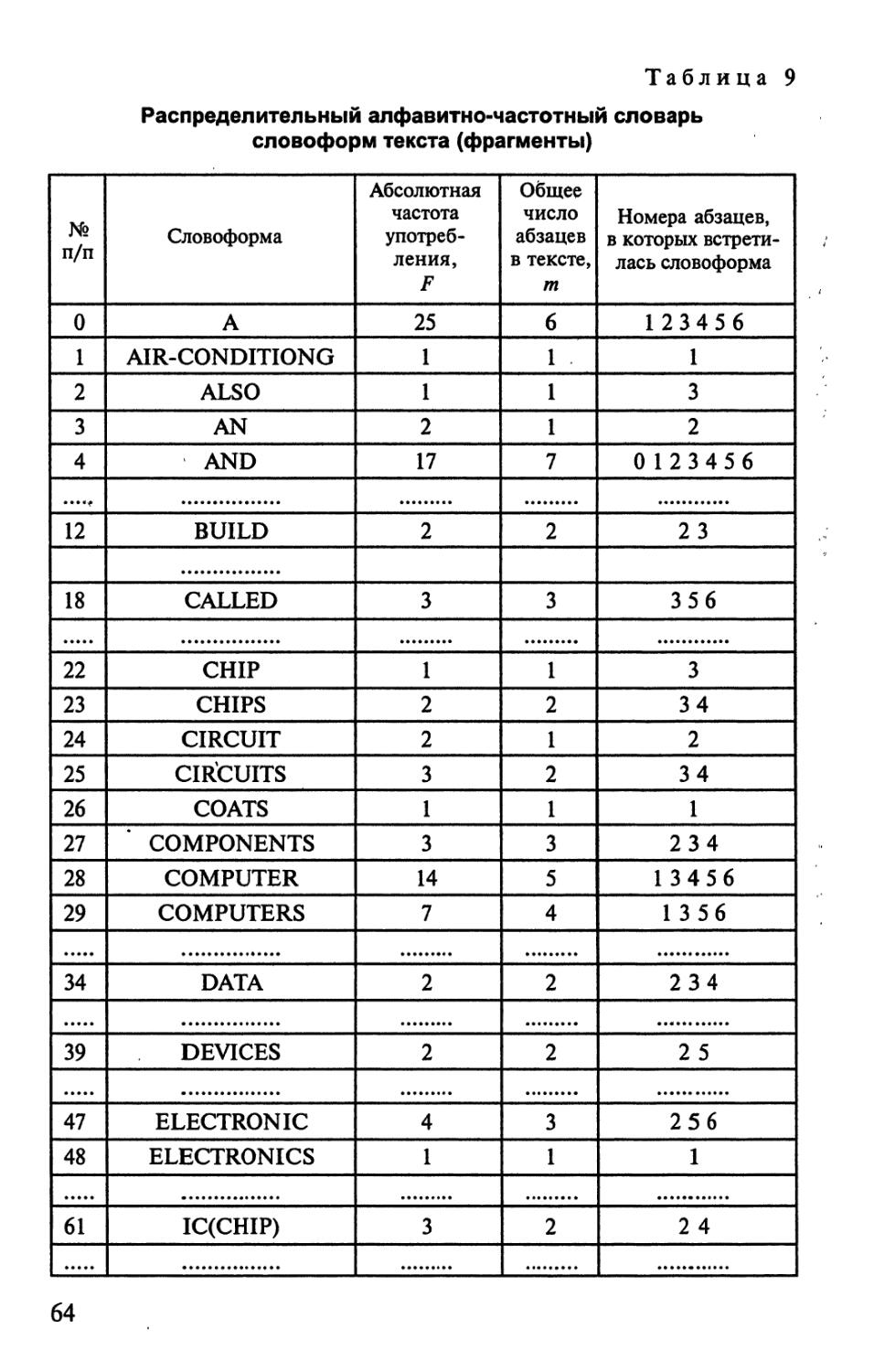
Модель распределения словоформ какого-либо текста по
частоте употребления может быть представлена в виде таблицы 1.
По отношению к моделируемому объекту, процессу или
явлению модель должна удовлетворять целому ряду свойств.
Важнейшими из них являются следующие [163, 23—28].
1. Модель выступает в качестве упрощенного аналога
изучаемого объекта (процесса, явления).
2. Модель не должна быть сложнее самого оригинала.
3. Метод изучения объекта (процесса, явления) путем его
моделирования должен быть более экономным по сравнению с
другими возможными методами изучения того же объекта.
4. Построенная модель должна быть предельно простой и
логически корректной, не содержащей противоречий.
5. Модель должна по возможности иметь общий
(универсальный) характер, позволяющий использовать ее для изучения дру-
Таблица 1
Словоформа
Информация
Компьютер
Технология
Частота
73
46
27 ,
13
гих подобных объектов (процессов, явлений). Например,
построив на материале английского текста модель его реферирования,
опирающуюся на ключевые слова текста (см. с. 56—75),
необходимо, чтобы эта модель работала и для текстов других языков.
6. Модель должна отражать наиболее существенные черты
реального объекта, процесса или явления, которые важны для
проводимого в данный момент процесса моделирования.
Существуют различные виды моделей. При использовании
информационных технологий в лингвистике выделяют следующие
типы моделей [17, 26, 27; 18; 165, 23, 24; 235, 46-53].
1. Структурные модели служат для изучения и описания
внутреннего строения некоторого объекта. Например, такая модель
строится, если необходимо изучить систему согласных какого-либо
языка или устройство речевого аппарата человека.
2. Функциональные модели позволяют изучать поведение
некоторого объекта, течение некоторого процесса или же этапы
реализации некоторого явления. Например, функциональная
модель строится, если необходимо смоделировать процесс
создания некоторого текста человеком. Такая же модель создается
для объяснения процесса перевода текста с одного языка на
другой.
3. Динамические модели создаются при необходимости найти
объяснение некоторых процессов или явлений в их временном
развитии. Так, если требуется узнать, как со временем менялось
произношение некоторого слова, строят динамическую модель
такого процесса.
Особая роль в лингвистике отводится функциональным
моделям, позволяющим раскрыть суть функционирования языка,
механизма производства и восприятия речи и текста. Нельзя
заглянуть в мозг человека и посмотреть, как в нем осуществляются
операции с буквами, звуками, словами, предложениями при
всевозможном использовании языка. Поэтому для решения таких
задач в рамках функциональных моделей выделяют воспроизводящие
инженерно-лингвистические модели (ВИЛМ). Они представляют
собой компьютерные системы, поведение которых, с одной
стороны, имитирует поведение реальных лингвистических объектов,
а с другой стороны, позволяет хотя бы частично воспроизвести
эти реальные объекты [164, 25, 26\.
Многочисленные примеры используемых в лингвистике
моделей можно найти в работах [64; 83; 84; 96; 103; 123; 156; 164;
191; 215].
Как отмечалось выше, существуют разные способы
формализованного описания объекта, процесса или явления: формулы,
таблицы, графики, схемы, наборы предложений естественного
языка и т.д. Все эти способы составляют основу алгоритмического
решения задач с помощью ПК.
14
АЛГОРИТМ И ЕГО СВОЙСТВА
Общие понятия об алгоритме
С точки зрения современной психологии задача в самом
общем понимании — это некоторая цель, поставленная в
конкретных условиях и требующая исполнения, решения [170, 39].
Примерами интеллектуальных задач являются следующие: 1) решить
полное квадратное уравнение ах2 + Ъх + с = 0; 2) составить
таблицу значений х2, х3 и 1/х величины х, меняющейся с некоторым
шагом к от некоторого начального значения п до некоторого
конечного значения т\ 3) найти среди группы русских глаголов те,
которые употреблены в инфинитиве; 4) составить реферат научного
текста; 5) перевести текст с английского языка на русский и т.д.
Чтобы решить задачу, необходимо знать ее начальные условия,
а также метод или способ ее решения. Так, чтобы решить полное
квадратное уравнение, необходимо знать конкретные значения
коэффициентов я, Ъ и с (начальные условия). В качестве метода
решения этого уравнения надо использовать правило вычисления
значений хх и х2:
-b± ylb2 - Аас
Для выделения из группы русских глаголов инфинитивных форм
необходимо, чтобы среди анализируемых глаголов были эти
инфинитивные формы (начальные условия). А способ решения
сводится к следующей проверке: оканчивается ли соответствующий
глагол на -/ш>, -«/ь, -ти. Чтобы провести такую проверку, надо
выполнить определенные действия: выделить у глагола две
последние буквы, сравнить их с окончаниями -ть, -ты, -чъ и т.д.
Чтобы перевести текст на русский язык, необходимо иметь, как
минимум, англо-русский словарь и знать английскую и русскую
грамматики, лексикологию и еще многое другое. Все это
начальные условия. В качестве метода решения этой задачи выступают те
правила перевода текстов, которым обучают в вузе.
Таким образом, метод или способ решения некоторой задачи
сводится к поиску определенных правил. Согласно «Словарю
русского языка» С.И.Ожегова правило — это предписание,
устанавливающее порядок чего-нибудь [149, 529]. Точное предписание о
выполнении в определенном порядке некоторой
последовательности действий (физических или умственных), приводящее к
решению некоторой типовой задачи, называют алгоритмом (ср. [237,
23, 24]). Например, при необходимости сварить кофе
последовательность физических действий будет такой: вскипятить нужное
15
количество воды, засыпать кофе в горячую воду (одну-две чайные
ложки на стакан воды), нагреть воду до кипения (но не
кипятить) и т.д. Определенные последовательности физических
действий выполняются человеком и при решении таких задач, как
«добраться из дома в университет», «найти в большом городе
нужный дом», «изготовить на станке какую-то деталь» и т.п. Примеры
задач, для решения которых необходимо выполнить
определенную последовательность умственных действий, приведены выше.
Слово алгоритм происходит от слова algorithmi —латинской
формы написания имени великого математика IX века аль-Хорез-
ми. Он впервые четко сформулировал правила выполнения
арифметических действий. Сейчас это понятие используется для
обозначения последовательности любых действий (арифметических,
логических, взятия логарифмов, вычисления синуса и т.п.).
Алгоритмы обладают следующими основными свойствами:
дискретностью, результативностью, массовостью,
детерминированностью и формализованностыо [237, 25, 26].
Дискретность алгоритма заключается в том, что он
разбивается на конечное число действий-шагов (предписаний, команд),
которые могут быть пронумерованы. Причем только после
выполнения одного предписания можно перейти к выполнению
другого.
Результативность алгоритма означает, что при всех
начальных условиях число шагов алгоритма конечно, и он приводит к
решению задачи.
Массовость алгоритма предполагает, что по данному
алгоритму может быть решен целый ряд типовых задач (они отличаются
лишь различными начальными условиями).
Детерминированность алгоритма заключается в том, что при
многократном решении одной и той же задачи с
одинаковыми начальными условиями всегда получается один и тот же
результат.
Формализованность алгоритма состоит в том, что тот, кто его
выполняет (человек, машина), может не вникать в смысл того,
что он делает согласно предписаниям алгоритма, и все равно
придет к верному результату.
Между задачей и ее алгоритмом соответствие неоднозначное.
Очень мало задач имеют только один алгоритм решения.
Например, задача «позвонить по междугороднему телефону» для
данного типа телефонного автомата имеет единственный алгоритм,
представленный в виде правила пользования этим телефонным
аппаратом. Большинство задач могут иметь несколько алгоритмов
решения. Так, есть несколько правил приготовления кофе,
можно различными путями добраться из дома в университет,
несколькими способами составить по тексту его реферат и т.д. В то же
время есть задачи, алгоритм решения которых до сих пор неизве-
16
стен. Так, неясно, как человек пишет стихи, повесть или научную
статью. Нет точных предписаний, как переводить текст с одного
языка на другой и т.д.
Способы записи алгоритмов
Существует несколько способов записи алгоритмов решения
задач. Наиболее известны следующие: словесный* графический и
табличный.
Словесное представление алгоритма решения задачи сводится к
тому, что составляющие алгоритм шаги (предписания)
записываются в виде слов и предложений естественного языка.
При графическом представлении алгоритма его шаги
изображаются разными геометрическими фигурами (блоками),
образующими блок-схему алгоритма. Связи между блоками обозначены
стрелками, соединяющими соответствующие фигуры. Чаще всего
в качестве таких геометрических фигур используются следующие:
1. Параллелограмм используется для обозначения действий ввода
I 7 информации в компьютер и вывода информа-
/ / ции из него.
2. Прямоугольник
используется для записи вычислительных и
некоторых других действий.
3. Ромб используется для проверки различных условий.
о
4. Овал используется для обозначения начала и конца
алгоритма.
о
5. Круг
О
служит для указания тех блоков алгоритма, на
которые передается управление от блоков
первых трех типов.
При табличном представлении алгоритма его шаги
записываются в графах специальных таблиц. Чаще всего такой способ
записи алгоритма используется для выполнения различных
вычислений по формулам.
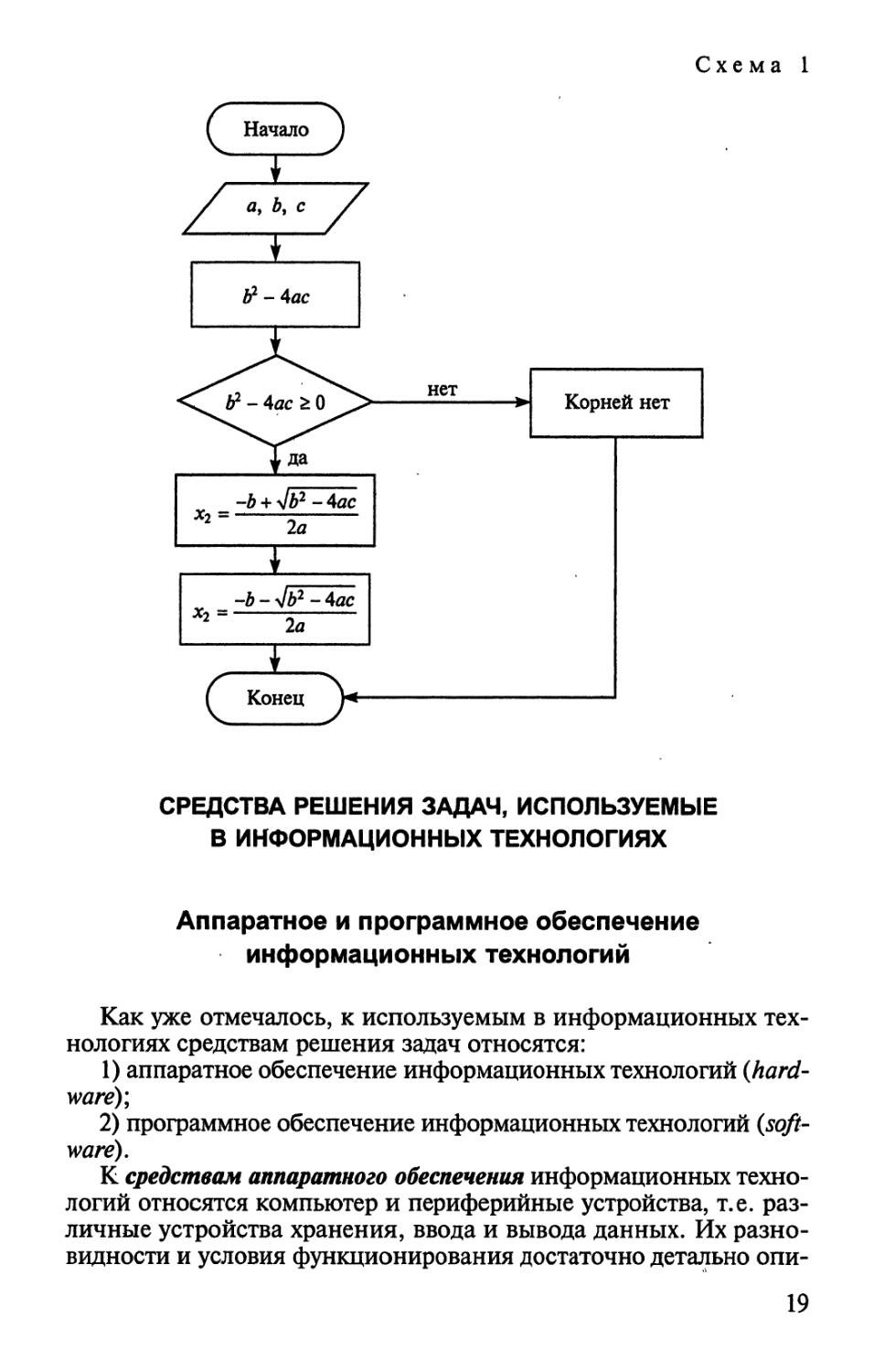
Продемонстрируем три способа записи алгоритма на
примере следующей задачи: «Решить полное квадратное уравнение
ах2+ Ьх + с = 0 (1)» (слово «решить» в данном случае означает, что
надо найти то значение х, при котором левая часть равенства
17
обращается в нуль). Как было отмечено выше, способ решения
« -Ъ ± yjb2 - Аас /ЛЧ
этой задачи определяется равенством хх 2 =— г— (2),
' 2а
где величина Ъ2 - Аас называется дискриминантом. Тогда формула
(2) может быть вычислена по следующему словесному алгоритму.
1. Присвоить коэффициентам a, b и с конкретные начальные
числовые значения.
2. Вычислить значение Ь2 - Аас,
3. Если Ь2 - Аас > О, то выполнить шаг 6. Если Ь2 - Аас < О, то
выполнить шаг 4.
4. Сделать вывод: «Уравнение корней не имеет».
5. Перейти к шагу 8.
6. Вычислить х{ =
7. Вычислить х2 =
-ь+ЛО*-
-ъ-
1а
-Jb2-
-Аас
-Аас
2а
8. Закончить работу.
Запись процесса решения этой же задачи в виде блок-схемы
(в графическом виде) может быть представлена следующим
образом (схема 1).
Наконец, алгоритм решения того же уравнения в табличной
форме может быть задан следующим образом (например, при
значениях коэффициентов: а = 1, Ъ = -7, с = 12, т.е. для уравнения
х2-7х+12 = 0) (табл. 2).
Таблица 2
а
| 1
b
-7
с
12
Ь2
49
ас
12
Аас
48
Z>2 - 4ас
1
д/£2 - 4дс
±1
2ö
2
Окончание табл. 2
-b + Vä2 - Аас
7 ■+ 1 =8
-£ - V&2 - Аас
7-1 = 6
-£ + Л2 - Аас
Х,= Та
8/2 = 4
-Ь - -Л>2 - Аас
*2 = Та
6/2 = 3
18
Схема 1
с
/
Начало
\
а, Ь, с
I
Ь2 - 4ас
)
/
х2 =
| да
-b + W-
2а
-4ас
I
х2=-
-6 - У&2 - 4дс
2ö
Г Конец \
СРЕДСТВА РЕШЕНИЯ ЗАДАЧ, ИСПОЛЬЗУЕМЫЕ
В ИНФОРМАЦИОННЫХ ТЕХНОЛОГИЯХ
Аппаратное и программное обеспечение
информационных технологий
Как уже отмечалось, к используемым в информационных
технологиях средствам решения задач относятся:
1) аппаратное обеспечение информационных технологий
(hardware);
2) программное обеспечение информационных технологий
(Software).
К средствам аппаратного обеспечения информационных
технологий относятся компьютер и периферийные устройства, т.е.
различные устройства хранения, ввода и вывода данных. Их
разновидности и условия функционирования достаточно детально опи-
19
саны в большом числе специальных изданий и учебников по
информатике [235; 87; 186; НО; 188; 259].
Как отмечалось выше, программное обеспечение (ПО)
компьютера является вторым важным средством решения задач,
используемых в информационных технологиях. Программное
обеспечение современных персональных компьютеров условно делится на
три группы: 1) системное ПО; 2) прикладное ПО; 3)
прикладные инструментальные средства.
В системном программном обеспечении (первая группа ПО), в
свою очередь, выделяют две группы программ: 1) операционные
системы и 2) дополнительные системные программы
(программы-утилиты и драйверы).
Операционная система (ОС) — это главная программа,
загружаемая в оперативную память компьютера после его включения.
Основные функции ОС сводятся к следующему:
1) управление работой персонального компьютера
(управление внутренними функциями ПК, осуществление контроля за
выполнением операций, распределение памяти и т.п.);
2) запуск на выполнение прикладных программ;
3) обеспечение пользователю удобного способа общения с
компьютером.
Современные операционные системы разрабатываются по
следующим двум направлениям [133]:
1) создание принципиально новых операционных систем,
связанных с широким использованием цифровых способов
обработки информации;
2) использование в будущих версиях операционных систем
лингвистических технологий: технологии речевого и рукописного
ввода информации, автоматического самообучения компьютерных
систем и т.д.
Результатом работ первого направления является новая
операционная система BeOS фирмы «Be». Это мультимедийная ОС,
рассчитанная на многопроцессорные компьютеры. Обработка на
таких ПК мультимедийных данных проходит значительно
быстрее, чем на компьютерах с ОС Windows NT или UNIX. Решаемая
под управлением ОС BeOS задача разбивается на множество
небольших задач, которые выполняются одновременно. В
зависимости от сложности основной задачи таких небольших задач может
насчитываться до тысячи. Данная операционная система тоже
поддерживает принцип многозадачности, т. е. с помощью ОС BeOS
можно одновременно решать несколько сложных задач. Основное
назначение такой системы — удовлетворение потребностей
разработчиков различных приложений для обработки
мультимедийных данных (видео, звука, графики, трехмерной анимации) [214].
Второе направление развития операционных систем
сформулировано в ряде публичных выступлений руководителя фирмы
20
«Microsoft» Билла Гейтса. Эта крупнейшая фирма продолжает
разрабатывать серию ОС Windows. Примерами являются ОС Windows
ХР — следующая после ОС Windows 2000 сетевая офисная
операционная система и ОС Millenium — операционная система для
домашних мультимедийных ПК, имеющая еще более
упрощенный пользовательский интерфейс и гораздо больше
возможностей по обработке мультимедийной информации, в том числе и
огромных потоков данных, поступающих из сети Интернет.
Как отмечалось выше, к системному ПО относятся и
программы-утилиты. Утилита — это программа, расширяющая
возможности операционной системы, помогающая работать с
компьютерной системой и повышающая ее эффективность. К числу таких
программ можно отнести:
1) программы-архиваторы — служат для упаковки больших
объемов информации с высоким коэффициентом сжатия;
2) программы для создания резервных копий обрабатываемой
информации — позволяют быстро копировать данные на
объемные носители информации;
3) антивирусные программы — предотвращают заражение
компьютера «вирусом» (специальной программой, уничтожающей или
искажающей информацию в памяти компьютера) и
ликвидирующие последствия такого заражения;
4) программы для диагностики компьютера — проверяют
работоспособность всех устройств компьютера и т.д.
Важным классом системных программ являются программы-
драйверы, необходимые для управления устройствами
компьютера (чаще всего устройствами ввода-вывода). Наиболее
распространены драйверы клавиатуры, мыши, принтера, сканера и т.д.
Вторую большую часть программного обеспечения
компьютера составляют программы пользователя, или прикладные
программы. С их помощью можно решать некоторые профессиональные
задачи, связанные с обработкой информации в науке,
промышленности, сельском хозяйстве, образовании, медицине, культуре
и т.д. Невозможно перечислить все программы, составляющие эту
часть ПО. В качестве отдельных примеров назовем следующие.
1. Текстовые процессоры служат для подготовки и печати
различных документов. Такие программы позволяют проводить
редактирование и форматирование текста, вставлять в текст
графические изображения, таблицы, формулы, диаграммы и т.д. Для
оформления документа они предлагают пользователю сотни
различных шрифтов. К их числу относятся, например, такие
программы, как MS Word, Corel WordPerfect, Lotus WordPro и т.д.
2. Программы автоматического преобразования графической
информации в текстовую используются для преобразования
полученного с помощью сканера графического изображения текста
в текстовый файл с целью его дальнейшей обработки соответ-
21
ствующими программами (например, текстовыми процессорами,
программами-переводчиками и т.п.). Наиболее известны
российские программы CuneiForm (фирма «Cognitive Technologies») и
FineReader (фирма «ABBYY Software House»).
3. Системы машинного перевода (МП) позволяют переводить
текст с одного языка на другой без вмешательства человека. К
наиболее известным системам МП, поддерживающим перевод с
иностранных языков на русский и обратно, относятся системы PROMT
(российская фирма «PROMT») и Socrat (российская фирма
«Арсенал»).
4. Системы автоматического аннотирования и
реферирования текста позволяют создать аннотацию и реферат
научно-технического текста без участия человека (например, программа
Аннотатор российской фирмы «MediaLingua»).
5. Настольно-издательские системы используются для создания
с помощью компьютера различных видов полиграфической
продукции. К их числу относятся, например, такие программы, как
PageMaker (американская фирма «Adobe»), Ventura (американская
фирма «Corel») и т.д.
6. Обучающие программы, например программы обучения с
помощью компьютера английскому языку English Gold и English
Platinum1 и т.д.
7. Экспертные системы широко используются как в
промышленности, например для диагностики неисправности отдельных
приборов, так и в медицине, например при определении болезни
и метода ее лечения.
8. Программы создания и обработки электронных таблиц
(табличные процессоры) позволяют обрабатывать различные
экономические и статистические данные, представленные в виде
сложных таблиц (ведомостей, статистических отчетов и т.п.). В
настоящее время наиболее известны такие программы, как MS Excel,
Lotus 1-2-3 и др.
9- Системы управления базами данных (СУБД) позволяют
осуществлять создание и модификацию больших совокупностей
структурированных определенным образом данных (баз данных), а также
поиск в них информации. Практически все современные СУБД
содержат средства для создания баз данных.
В состав прикладных инструментальных средств (третья группа
ПО) входят различные средства разработки программного
обеспечения. К ним прежде всего относятся языки и системы
программирования.
Язык программирования, или алгоритмический язык, — это
искусственный язык, используемый для представления
алгоритма решения задачи в виде, понятном компьютеру. Существуют
1 Подробнее см. с. 139—142.
22
различные подходы к классификации языков программирования.
Согласно одному из современных подходов языки
программирования делятся на следующие четыре типа: 1) языки
ассемблера; 2) языки системного уровня; 3) языки описания
сценариев; 4) языки промежуточного типа.
Языки ассемблера представляют записанные в алгоритме
действия в виде машинных кодов (например, 01 — сложить, 02 —
вычесть и т.д.).
В языках системного уровня действия алгоритма
записываются в виде отдельных английских слов или их частей. Существуют
определенные правила (синтаксис) следования таких слов друг
за другом. Подобные языки могут быть простыми и достаточно
сложными. К числу простых можно отнести практически
неиспользуемые сейчас языки программирования Algol, Fortran, Cobol,
используемые — PL/1, Quick BASIC и др. Более сложными
современными языками этого типа являются С, C++, Pascal, Turbo
Pascal, Java и т.д.
Языки описания сценариев служат для связывания готовых
программ в новые более сложные программы. В настоящее время к
ним относятся такие языки программирования, как Perl, TCL,
Visual BASIC, JavaScript, языки оболочек ОС UNIX и т.д.
К языкам промежуточного типа относится, например, язык
Lisp. Он обладает свойствами и языков программирования
системного уровня, и языков описания сценариев.
Система программирования (система разработки
приложений) — это интегрированный набор средств разработки программ,
обычно включающий язык программирования, средства
компоновки и отладки программы, а также обширную библиотеку
готовых к использованию программных модулей.
Элементы алгоритмического языка QBASIC
Язык BASIC был создан в 1965 году в США. Слово BASIC
является аббревиатурой английского словосочетания Beginner's
All-purpose Symbolic Instruction Code и переводится как
«многоцелевой язык программирования для начинающих». Позже
появились более совершенные версии этого языка. К ним
относятся GW-BASIC, Quick BASIC, QBASIC (усеченный вариант языка
Quick BASIC), Turbo BASIC, Visual BASIC и др. Каждая из версий
имеет свои особенности и специфичное применение [42; 61; 95].
Для того чтобы в полной мере проследить переход от
словесной формулировки лингвистической задачи к ее компьютерной
реализации, рассмотрим основные составляющие языка QBASIC
[61, 59—128]. К ним относятся:
1) алфавит языка QBASIC;
23
2) типы исходных данных;
3) операторы обработки исходных данных.
В алфавит языка QBASIC входят следующие знаки:
1) все прописные и строчные буквы латинского алфавита;
2) десятичные цифры от 0 до 9;
3) знаки арифметических действий (см. табл. 3);
4) знаки логических действий (см. табл. 4);
5) знаки-разделители: "." (точка), "," (запятая), ";" (точка с
запятой), ":" (двоеточие), "'" (апостроф), "(" (открывающая скоб-
ка), ")"• (закрывающая скобка), "_' (знак подчеркивания);
6) специальные знаки: "#" (знак номера), "$" (знак доллара), "&"
(коммерческое "И"), Т (восклицательный знак),"%" (знак процента).
С помощью этих знаков на языке QBASIC описываются
действия по обработке текстовых и числовых данных, т.е. создаются
программы.
Чтобы познакомиться с тем, каким образом компьютеру
передается обрабатываемая информация (каким образом она
«описывается»), необходимо знать, какие же данные машина принимает
для обработки. В основном компьютер, как и мы, люди, имеет
дело с двумя видами информации:
1) информацией, представленной буквами
(буквосочетаниями, словами, предложениями, текстами). Ее называют
символьной или строковой,
2) информацией, представленной числами. Ее называют
вещественной1.
Каждый тип информации может быть представлен в виде
констант (постоянных величин) и переменных, которые в процессе
решения задачи могут изменяться.
Строковые константы — это обычные буквы, слова,
предложения, тексты любого естественного языка, последовательности
цифр, заключаемые в кавычки. Например: «ВЕСНА», «СЕГОДНЯ
29 МАРТА 2001 ГОДА», «ПЕТРОВ И.В.», «TEXT», «FILE» и т.п.
Каждая строковая переменная имеет имя (точно так же, как
каждый человек имеет свое имя, фамилию, город — название и т.д.).
Этим именем называется некоторая область компьютерной
памяти, где будут размещаться соответствующие данные (суффикс,
слово, предложение, текст, текст с числами и т.д.). В разных
алгоритмических языках существуют свои правила записи таких имен.
В языке QBASIC для записи имени строковой переменной
используется любая латинская буква, входящая в его алфавит. Другим
знаком может быть одна из десятичных цифр от 0 до 9 и знак $.
Знак $ в имени строковой переменной должен всегда стоять на
последнем месте. Например: Х$, К2$, S9$, BUK$, STROKASи т.д.
1 Для упрощения дальнейшего изложения в понятие «вещественная»
включаются как дробные, так и целые числа.
24
Вещественные и целые константы — это привычные для
человека дробные и целые числа: 5; 2077; 0,5; 29,0995 и т.п.
Вещественная переменная, как и строковая, должна иметь свое
имя. Оно записывается точно так же, как и имя строковой
переменной, только в конце имени не ставится знак $. Так,
следующие имена X, К2, S9, BUK, STROKA служат для размещения в
них целых и дробных чисел, а не элементов текста.
Еще одной составляющей языка QBASIC являются операторы
обработки исходных данных. Оператор — это условная запись
действия, выполняемого компьютером над некоторой информацией
(данными). В самом общем виде оператор языка QBASIC
записывается так:
НС Имя оператора/содержание оператора
где НС — номер строки программы или номер оператора в
программе обработки данных, может принимать значение от 0 до
65535, не является обязательным;
имя оператора — это одно из слов или частей слов
английского языка, обозначающее то действие, которое этот оператор
выполняет;
содержание оператора — это какая-то константа или
переменная, какое-то арифметическое или логическое выражение1 или же
номер какого-либо другого оператора той же программы. Например:
20 LET Х=5 ИЛИ LET Х=5
120 LET Y=X+Z ИЛИ LETY=X+Z
1745 IF В$="ТЬ" THEN 70 ИЛИ IF В$="ТЬ" THEN 70
2014 GOTO 1775 ИЛИ GOTO 1775
225 PRINT W$ ИЛИ PRINTW$
Можно выделить пять основных групп операторов: 1)
арифметических действий; 2) логических действий; 3) управления
программой; 4) ввода и вывода информации; 5) специальных.
Простейшим из операторов является оператор присваивания,
который в общем виде записывается так:
НС 1=К
где не — номер строки программы; / — имя любой переменной,
которой присваивается значение К (вместо К может быть число,
слово, предложение, какая-то другая переменная или
арифметическое выражение).
Например:
20 1=5
В$="ВЕСНА"
Z=Y+X
арифметическое или логическое выражение — это
несколько переменных, соединенных соответственно знаками арифметических или
логических действий (см. табл. 3 и 4).
25
В первом случае переменной /приписывается значение,
равное 5, во втором — в область памяти с именем BS передается слово
ВЕСНА. В третьем случае переменной Z присваивается значение,
получаемое в результате сложения значений переменных Y и X.
Операторы арифметических действий выполняют различные
арифметические операции над переменными (табл. 3),
Таблица 3 Таблица 4
Операторы Операторы
арифметических действий логических действий
Тип арифметического
действия
Сложение
Вычитание
Умножение
Деление
Возведение в степень
Знак
действия
+
-
*
/
Л
Тип арифметического
действия
Равно
Меньше
Больше
Меньше или равно
Больше или равно
Знак
действия
=
<
>
< =
> =
Приведенные в таблице 3 знаки арифметических действий
используются при вычислении различных арифметических
выражений. Например, пусть необходимо подсчитать следующее
значение Y:
Y=X2-5X+3
для Х=5. Тогда программу решения данной задачи1 на языке
QBASIC можно записать так (см. табл. 3):
Х=5
Y=XA2-5*X+3
Сначала переменной X присваивается значение, равное 5, а
затем компьютер вычисляет значение У, подставляя везде вместо
означение 5.
В операторах логических действий выполняются следующие
логические операции (табл. 4). Примеры, иллюстрирующие
применение этих операторов, будут приведены после рассмотрения
третьей группы операторов.
Операторы управления программой. Чаще всего используются
следующие операторы управления программой.
1. Оператор безусловного перехода go го («перейти к»):
НС GO TO HCl
программа — это последовательность операторов, которая указывает
компьютеру, какие действия и в какой последовательности должны выполняться.
26
Он означает следующее: «перейти к выполнению оператора,
который имеет номер HCl». Например, оператор GO то 1200
позволяет компьютеру перейти к выполнению оператора под
номером 1200.
2. Оператор условного перехода if then («если то»):
не if условие then HCl
Этот оператор работает следующим образом: если (if)
выполнено некоторое условие, то (then) машина должна перейти к
выполнению оператора под номером HCl. Если же это условие не
выполнено, то компьютер должен выполнить тот оператор,
который стоит ниже. Например, если часть программы записана так:
40 IF В$="ТЬ" THEN 70
IF В$="ТИ" THEN 85
то оператор 40 выполняется компьютером следующим образом:
если то, что находится в строковой переменной с именем В$
совпадает (равно) с буквосочетанием ть, то компьютер должен
выполнить оператор под номером 70. Если же в В$ находятся любые
другие буквы, то компьютер будет выполнять следующий
оператор. То же самое действие будет выполнено и в случае, если
оператор if будет записан в виде:
не if условие goto HCl
Этот же оператор может быть записан и в следующей форме:
не if условие then оператор
В этом случае при выполнении условия будет выполнен
некоторый оператор, стоящий за словом then. Если же условие не
выполнено, то будет выполняться следующий в программе
оператор. Например:
IF X>0 THEN Y=Xa2+5
3. Оператор конца программы end («конец»):
НС END
Он пишется в конце всей программы и позволяет компьютеру
закончить решение задачи. Например:
Х=5
Y=XA2+5*X+3
END
Операторы ввода и вывода информации. Для решения любой
задачи необходима исходная информация, которая должна быть
введена в память компьютера с устройства ввода. Полученные в
результате решения задачи данные должны быть выведены из
компьютера на устройство вывода. Простейший способ ввода
27
информации в память машины — это использование оператора
присваивания (см. об этом операторе на с. 25). Обычно он
используется в тех случаях, когда число переменных, которым в
начале работы присваиваются (вводятся в переменные)
определенные начальные числовые или строковые значения,
невелико.
Рассмотрим, как исходная информация может быть введена в
компьютер с клавиатуры дисплея. Для ввода информации любого
типа (строковой или числовой) используется оператор ввода input
(«ввести»), который в полном виде записывается так:
НС INPUT PI, P2,...
где не, как всегда, номер оператора программы, а PI, Р2У... —
имена переменных, которым с клавиатуры передаются
исходные данные. Если вводится одно данное (одно слово, одно
число), то используется только одна переменная PL Например, в
компьютер необходимо ввести для последующего анализа
русский глагол ходить. Это действие можно записать следующим
образом:
INPUT W$
Как только компьютер встретит данный оператор, он
высветит на экране дисплея знак вопроса (?). Человек должен набрать
на клавиатуре слово ходить (при этом данное слово появляется и
на экране дисплея) и нажать на клавиатуре клавишу enter. Слово
ходить попадет в область оперативной памяти с именем WS.
В случаях, когда в машинную память вводится одно или
несколько предложений (текст), целесообразнее использовать
оператор ввода LINPUT, который записывается точно так же, как и
оператор input:
НС LINPUT-PI, P2,...
Выполняется он аналогично оператору input, но не
«отсекает» при этом пробел, который следует за последним знаком
предложения или текста (что делает оператор input). Такой пробел
необходим для опознавания конца предложения или текста.
После того как слово ходить проанализировано и компьютер,
например, принял решение, что это русский глагол в
неопределенной форме, результат надо напечатать на принтере. Для
вывода информации на принтер используется оператор print,
который записывается так:
НС PRINT Dl, D2,...
где не — номер оператора программы, а Dl, D2,... — выводимые
на печать данные. Вместо Dl, D2,... могут стоять либо имена
переменных (как в операторах ввода linput и input), либо строко-
28
вые или числовые константы. Такой строковой константой может
быть, например, фраза «ГЛАГОЛ УПОТРЕБЛЕН В
НЕОПРЕДЕЛЕННОЙ ФОРМЕ». Итак, если необходимо вывести на принтер
проанализированный глагол ходить, который находится,
например, в области памяти с именем W$, и результат проведенного
анализа в виде упомянутой выше фразы, то для этого можно
использовать следующую команду:
PRINT W$; "- ГЛАГОЛ УПОТРЕБЛЕН В НЕОПРЕДЕЛЕННОЙ ФОРМЕ"
При выполнении этого оператора на экране дисплея (на
бумаге принтера) появится следующая информация:
ХОДИТЬ - ГЛАГОЛ УПОТРЕБЛЕН В НЕОПРЕДЕЛЕННОЙ ФОРМЕ
Если сравнить* данный оператор с общим видом оператора
print, то можно заметить, что вместо D1 в операторе указана
переменная W$, а вместо D2 — приведенная выше фраза. Как
видно из результата выполнения оператора вывода, между
словом ходить и фразой на экране дисплея поставлен один знак
пробела. Если необходимо, чтобы между выводимыми данными было
более одного пробела, то между Dl, D2, ... в операторе print
надо ставить не точку с запятой, а запятую. Эти знаки называются
разделителями информации.
Рассмотрим далее некоторые из специальных операторов языка
QBASIC.
1. Оператор len (часть английского слова length — 'длина'). Он
служит для определения числа знаков (букв и т.д.) в строковых
данных. В общем виде этот оператор записывается так:
HC I=LEN (К)
где не — номер оператора программы; / —- имя переменной, в
которую будет передан результат работы оператора len, т.е. число
знаков (букв, цифр и т.п.), находящихся в обрабатываемом
данном К Вместо К может стоять имя переменной или любая
строковая константа. Последняя заключается в кавычки или апострофы.
Например, если необходимо узнать, сколько букв в слове ходить,
достаточно написать следующий оператор:
I=LEN ("ХОДИТЬ")
После выполнения этого оператора в переменной /будет
число 6 (6 букв в слове ходить). Вместо К в операторе len может
стоять переменная, в которой уже находится какое-то слово. Так,
если после ввода слово ходить оказалось в области памяти с
именем WS, то в этом случае для подсчета числа букв надо написать
оператор
I=LEN(W$)
Итог будет тот же: /=6.
29
2. Оператор instr дает возможность узнать, в каком месте
слова, словосочетания, предложения или текста находится
некоторая его часть (буква, суффикс, приставка, основа слова, слово
и т. п.). Общий вид этого оператора таков:
HC I=INSro (n, W$,'В$)
где не — номер оператора программы; / — имя переменной, в "
которую передается результат работы этого оператора, т.е. номер
первого найденного символа (буквы, цифры, знака) строки
символов, находящейся в переменной с именем W$\ п — номер по- \
зиции начала поиска в строковой переменной W$ (п принимает J
значения 1, 2, 3, 4 и т.д.); В$ — имя переменной, содержащей
искомую часть заданной строки символов (буква, суффикс и т. д.).
Например, если в переменной WS находится слово ходить
(w$="ходить") и необходимо узнать, в каком месте этого слова
находится окончание -ть (в$="ть"), то это действие на языке
QBASIC записывается следующим образом:
I=INSTR (W$, B$)
Поскольку в операторе отсутствует параметр я, то компьютер
будет проводить поиск с начала слова ходить и в итоге в
переменной /окажется число 5 (так как начало окончания -ть начинается
с 5-й позиции).
3. Оператор left$ позволяет выделить в строковом данном
(слове, словосочетании, предложении и т.п.) несколько левых
символов (букв, цифр, знаков). Например, результатом действия
B$=LEFT$ (W$, n)
при условии, что ю$=мприехать", а п=3, будет помещение в
переменную BS приставки при- (в$="при,!).
4. Оператор right$, общий вид которого выглядит следующим
образом:
HC B$=RIGHT$ (W$, n)
позволяет выделить в строке символов, содержащейся в
переменной с именем WS, определенное число (п) правых символов и
направить их в переменную с именем В$. Например, если в слове
ходить, расположенном в переменной WS (№$="ХОДИТЪ"),
необходимо выделить две последние (правые) буквы и поместить их в
область памяти с именем В$, то такое действие будет записано на
языке QBASIC в виде команды
B$=RIGHT$ (W$, 2)
5. Оператор mid$ (часть английского слова middle —-
'середина') записывается в следующем виде:
HC B$=MID$ (W$, n, k)
30
Он позволяет выделить в строковом данном, находящемся в
переменной с именем W$9 начиная с символа под номером я, К
последующих символов. Результат такого выделения записывается
в область памяти с именем В$. Например, в переменной W$
находится слово приходила (w$=" приходила"). Необходимо выделить
его часть —ход-, В данном случае оператор mid$ будет иметь вид
B$=MID$(W$, 4, 3)
т. е. компьютер поместит в переменную В$ строку из трех
последовательных символов, выделение которых из слова приходила
начнется с 4-й позиции (в $=" ход").
ГЛАВА 3
ОБЩИЕ ПРИНЦИПЫ РЕШЕНИЯ
ЛИНГВИСТИЧЕСКИХ ЗАДАЧ
МЕТОДОМ МОДЕЛИРОВАНИЯ
ОСНОВНЫЕ ЭТАПЫ РЕШЕНИЯ ЗАДАЧИ
Как было обмечено выше, основным методом решения
лингвистических задач является метод моделирования.
Моделирование — процесс творческий. И модель в любом случае отражает
наиболее важные и существенные особенности моделируемого
объекта, процесса или явления (оригинала модели).
В общем, процесс моделирования на компьютере включает
следующие этапы [165, 24— 34\:
1) постановка задачи;
2) разработка модели;
3) проведение компьютерного эксперимента;
4) анализ результатов работы компьютерной модели.
В свою очередь, каждый этап моделирования может быть
представлен в виде некоторой последовательности конкретных
действий.
Говоря о постановке задачи, выделяют следующие действия:
1) описание решаемой задачи;
2) формулирование цели моделирования;
3) анализ оригинала модели.
Описание решаемой задачи может быть представлено
словесно, в виде формулы или нескольких формул, в виде таблиц,
графиков и т. п.
Цели моделирования могут быть различными [165, 25]:
объяснение сути некоторого явления или процесса, создание объектов
с заранее заданными свойствами, определение последствий
воздействия на некоторый объект, процесс или явление, принятие
правильного решения и т.п.
При анализе оригинала модели (некоторого объекта, процесса
или явления) в нем прежде всего выделяются наиболее важные,
существенные черты и свойства. Если оригинал представляет
собой совокупность более мелких составляющих, то на этапе
анализа его расчленяют, разделяют на ряд более мелких объектов и
выявляют отношения между этими составляющими. При
компьютерном моделировании стараются выделять такие черты и
свойства оригинала, которые мог бы легко опознать компьютер. Эти
черты и свойства называют формальными.
32
На этапе непосредственной разработки модели, опираясь на
результаты детального анализа ее оригинала, создается алгоритм
решения задачи.
Проведение компьютерного эксперимента связано с созданием
на основе алгоритма компьютерной программы на каком-либо
алгоритмическом языке и отладкой этой программы
(устранением ошибок программирования).
Наконец, в процессе анализа результатов работы
компьютерной модели выявляются логические ошибки в самой
компьютерной программе и алгоритме (формуле, графике и т.п.), который
послужил основой компьютерной модели. Такие ошибки
исправляются внесением в алгоритм и программу соответствующих
изменений.
Рассмотрим подробнее эти этапы и соответствующие им
действия в процессе создания конкретных воспроизводящих
инженерно-лингвистических моделей (ВИЛМ) [162, 25—40]. Поскольку
решение лингвистических задач на ПК имеет свою специфику,
введем некоторые основные понятия, связанные с этой
процедурой. Все модели, создаваемые ниже, будут понятны, если принять
единые определения основных лингвистических единиц.
Информация поступает в компьютерную память в виде
цепочки символов, каждый из которых занимает один байт памяти.
Цепочка буквенных символов, находящаяся в тексте между
двумя знаками пробела, называется словоупотреблением.
Следовательно, компьютер читает не слово, а словоупотребление.
Словоупотребление, находящееся вне предложения или текста,
будем называть словоформой. Несколько словоформ, имеющих одно
и то же лексическое значение, образуют слово, или лексему.
Например, в тексте1
СКОРОЛ PMflETi_jBECHAi__j. ьлВЕСНОЙ-ШЕГЧЕ.,, ДЬППИТСЯц.
ПРИХОДИ^, BECHAl-j!
8 словоупотреблений. Если бы из единиц этого текста составлялся
алфавитно-частотный словарь, то в нем оказалось бы 7
словоформ. В таком словаре словоформы располагаются по алфавиту и
при каждой словоформе указывается абсолютная частота
(/^употребления словоформы (как сумма зафиксированных в тексте
соответствующих словоупотреблений):
Словоформа F
1. ВЕСНА 2
2. ВЕСНОЙ 1
3. ДЫШИТСЯ 1
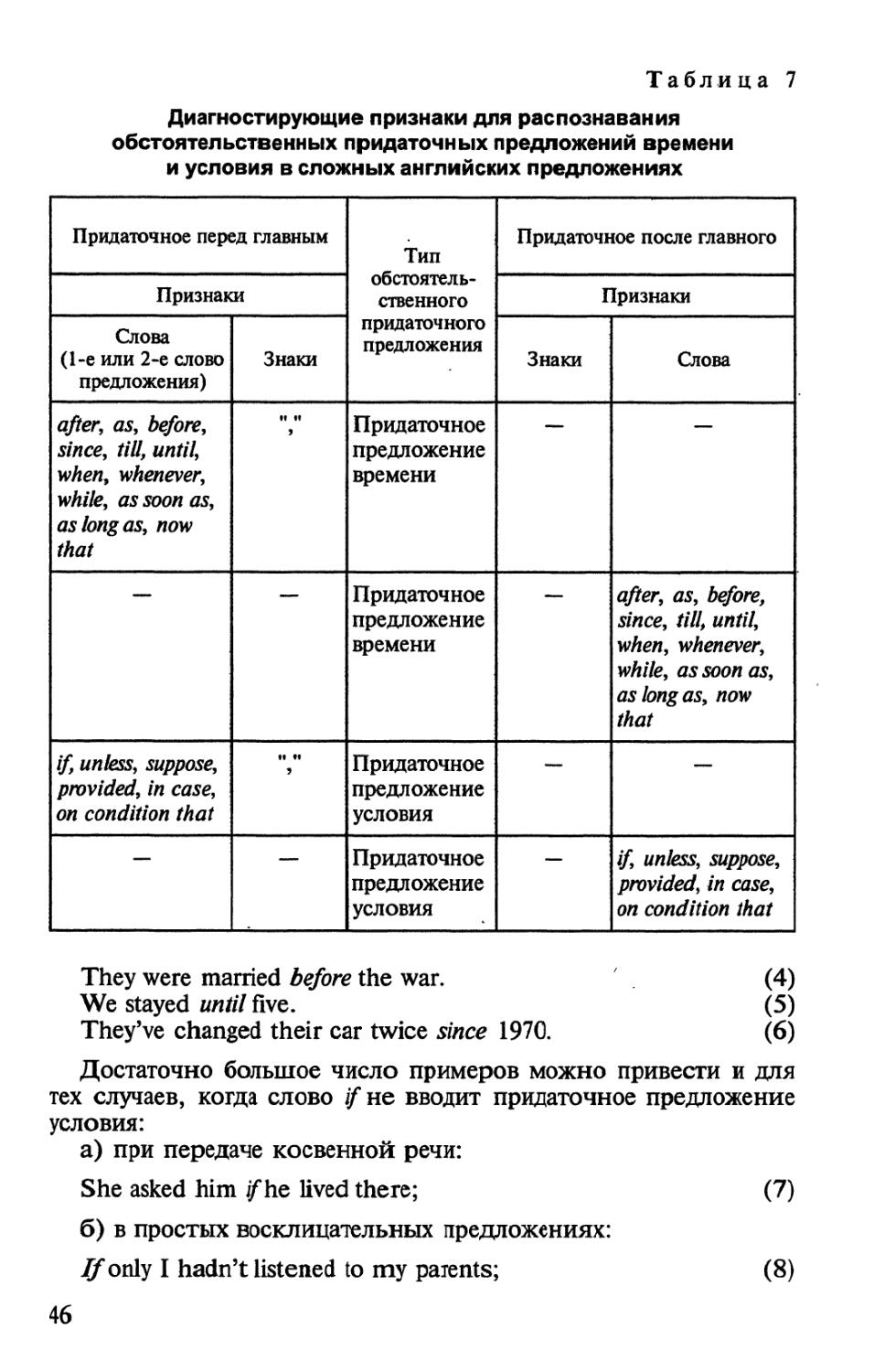
При вводе текстов в память компьютера все знаки препинания отделяются
от слов знаком пробела (i_j).
2 Зубов
33
4. ЛЕГЧЕ
5. ПРИДЕТ
6. ПРИХОДИ
7. СКОРО
1
1
1
1
Как видно, два словоупотребления весна исходного текста
(предложения) преобразуются вне его в одну словоформу весна.
Если составить из этого же текста алфавитно-частотный
словарь слов, то он будет включать 5 слов:
Слово F
1. ВЕСНА
2. ДЫШАТЬСЯ
3. ЛЕГКО
4. ПРИХОДИТЬ
5. СКОРО
3
1
1
2
1
Здесь словоформы весна и весной относятся к одному
словарному слову весна, а глаголы придет и приходи являются
словоформами лексемы приходить. Таким образом, если, например, в
лингвистической задаче сказано, что в предложении
необходимо найти слово машина, это означает, что искать в нем надо все
словоформы, относящиеся к этому слову: машина, машины,
машине, машину, машиной, машин, машинам, машинами, машинах1
(или, если это возможно, общую часть таких слов. В данном
примере это возможно, и потому для компьютерного поиска
задается слово машин).
Предложением с компьютерной точки зрения называется
цепочка словоупотреблений между двумя знаками конца
предложения (точкой, вопросительным знаком, восклицательным знаком,
многоточием). Пример такого предложения приведен выше. Текст
в компьютере — это линейная последовательность подобных
предложений.
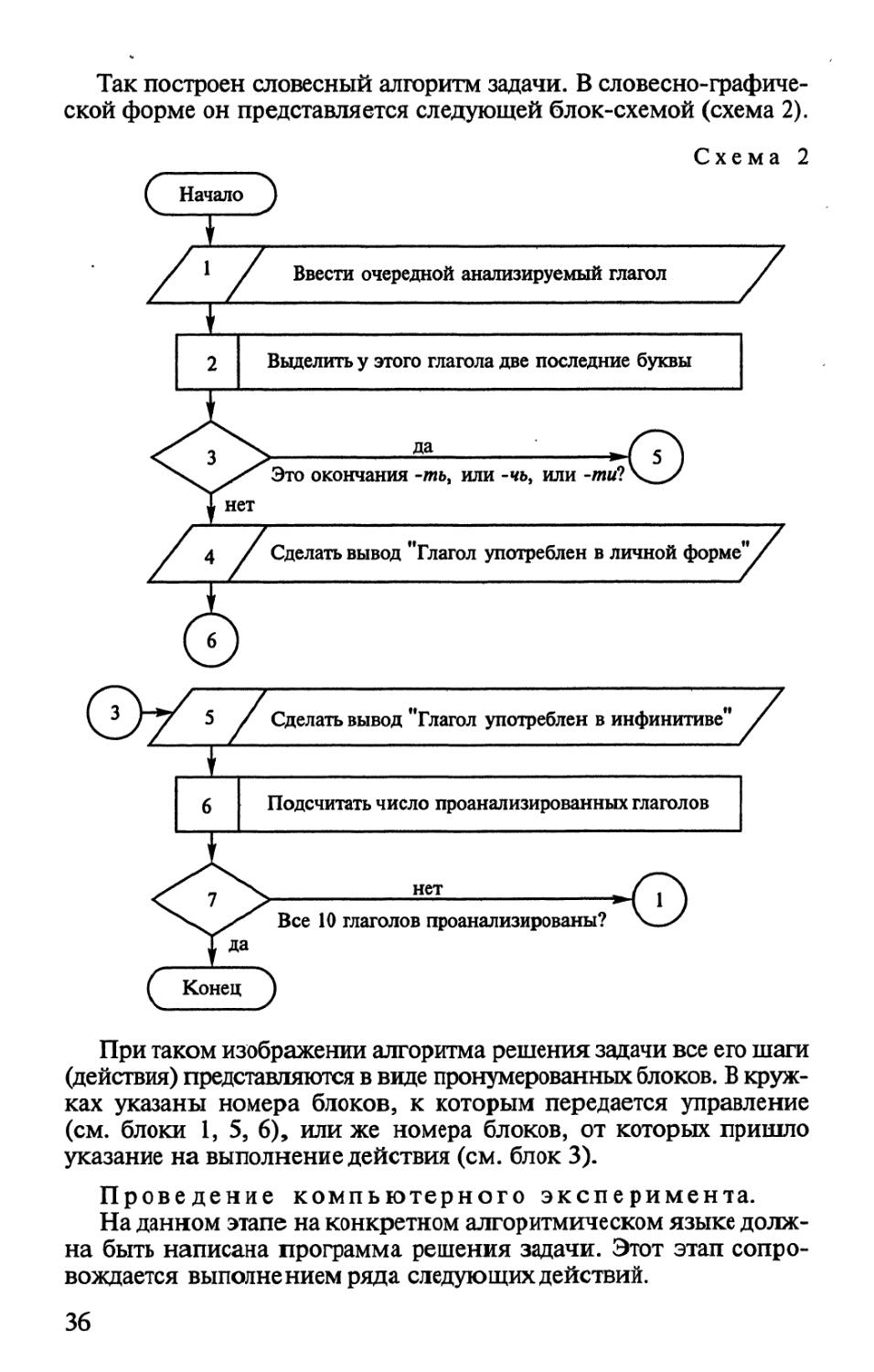
Проиллюстрируем этапы построения
инженерно-лингвистической модели на одном простейшем примере.
Постановка задачи.
Описание задачи: задана группа из 10 русских глаголов, среди
которых есть глаголы в инфинитиве без частицы -ся или -сь.
Необходимо найти в этой группе глаголы в инфинитиве и
напечатать их.
Формулирование цели процесса моделирования: создать такую
модель опознавания инфинитивной формы русского глагола, ко-
1 Вместо 12 словоформ (6 форм в единственном числе и 6 форм во
множественном) здесь приведены 9 форм, так как форма машины совпадает в род.
падеже ед. числа, им. падеже мн. числа и вин. падеже мн. числа. Форма машине
одинакова для дат. падежа ед. числа и предл. падежа ед. числа.
34
торая объясняла бы процесс выделения подобных форм и давала
бы верные результаты для любого исходного количества глаголов,
удовлетворяющих заданному описанию.
Решению каждой лингвистической задачи должен
предшествовать тщательный анализ соответствующего лингвистического
материала: конкретных букв (звуков), слов, словосочетаний,
предложений, абзацев, текстов. Для поиска наиболее важных,
существенных признаков, положенных в основу алгоритма решения
сформулированной выше задачи, необходимо изучить большое
число русских глаголов в самых разных грамматических формах и
попытаться найти какие-то черты, которые отличают глагол в
неопределенной форме от глаголов в других грамматических
формах. Причем эти признаки должны быть формальными, т. е. любой
человек, даже не знающий русского языка, ориентируясь на них,
сможет решить поставленную задачу.
Анализируя, например, слова петь, беречь, косила, переделал,
работаю, идти, пошел, толочь, бегать, пройду, читать, нести,
прочитаю, ходить, сделаю, хранить, уехать, стеречь, подарю, берегу,
играть й т.п., можно сделать вывод, что русский глагол в
инфинитиве заканчивается буквосочетаниями -ть, -чь, -ти1. Это и есть
те формальные признаки, на которые будет опираться модель.
Разработка модели.
Как было сказано выше, любая воспроизводящая инженерно-
лингвистическая модель представляется з виде
словесно-графического алгоритма, опирающегося на выделенные в процессе
анализа оригинала модели признаки. Как же отыскать в группе из
10 русских глаголов глаголы в неопределенной форме? Очевидно,
необходимо выполнить следующую цепочку «умственных»
действий:
1. Взять очередной анализируемый глагол.
2. Выделить у этого глагола две последние буквы.
3. Посмотреть, совпадают ли эти буквы с буквосочетаниями
-ть, -чь, -ти. Если да, то перейти к действию 4; если нет, то
выполнить действие 6.
4. Сделать вывод: «Данный глагол употреблен в инфинитиве».
5. Перейти к действию 7.
6. Сделать вывод: «Данный глагол употреблен в личной форме».
7. Подсчитать число проанализированных глаголов.
8. Проверить, все ли 10 глаголов проанализированы. Если нет,
то перейти к выполнению действия 1; если да, то перейти к
действию 9.
9. Закончить работу.
1 К такому же выводу можно прийти, если посмотреть соответствующие
разделы русской грамматики [194, 108, 109].
35
Так построен словесный алгоритм задачи. В
словесно-графической форме он представляется следующей блок-схемой (схема 2).
( Начало J
Схема 2
/
t
Л
♦ '
2
/ Ввести очередной анализируемый глагол
Выделить у этого глагола две последние буквы
/
да
Это окончания -тиь, или -чъ, или -ти?
0
4 / Сделать вывод "Глагол употреблен в личной форме"
5 / Сделать вывод "Глагол употреблен в инфинитиве"
Подсчитать число проанализированных глаголов
нет
Все 10 глаголов проанализированы'
-О
( Конец J
При таком изображении алгоритма решения задачи все его шаги
(действия) представляются в виде пронумерованных блоков. В
кружках указаны номера блоков, к которым передается управление
(см. блоки 1, 5, 6), или же номера блоков, от которых пришло
указание на выполнение действия (см. блок 3).
Проведение компьютерного эксперимента.
На данном этапе на конкретном алгоритмическом языке
должна быть написана программа решения задачи. Этот этап
сопровождается выполнением ряда следующих действий.
36
1. Путем анализа построенного алгоритма выделяют основные
переменные (области памяти компьютера, ср. с. 24, 25). В данном
случае ими будут:
а) место в памяти компьютера для размещения каждого
анализируемого глагола;
б) место в памяти компьютера для размещения двух последних
букв глагола;
в) место в памяти компьютера (счетчик) для размещения
числа проанализированных глаголов.
2. В зависимости от конкретного алгоритмического языка этим
переменным присваивают определенные имена. Если
использовать для программирования алгоритмический язык QBASIC, то
выделенным выше переменным можно дать следующие имена:
W$ — строковая переменная для размещения анализируемого
глагола;
В$ — строковая переменная для размещения двух последних
букв глагола;
/ — числовая переменная (счетчик) для размещения числа
проанализированных глаголов.
3. Следующий далее процесс написания компьютерной
программы заключается в замене блоков алгоритма (см. схему 2)
одним или несколькими операторами какого-либо
алгоритмического языка: Заменяя блоки операторами языка QBASIC, получаем
следующую программу, моделирующую действия человека при
определении им инфинитивной формы русского глагола (табл. 5).
Таблица 5
Номер
блока
алгоритма
п
2
3
4
5
6
7
Номер
оператора
программы
10
50
60
Оператор языка QBASIC
INPUT "ВВЕДИТЕ ОЧЕРЕДНОЙ РУССКИЙ
ГЛАГОЛ", W$
B$=RIGHT$ (W$, 2)
IF В$="ТЬ" OR В$="ЧЬ" OR В$="ТИ"
GOTO 50
PRINT W$; "- ГЛАГОЛ УПОТРЕБЛЕН В
ЛИЧНОЙ ФОРМЕ"
GOTO 60
PRINT W$; "- ГЛАГОЛ УПОТРЕБЛЕН В
ИНФИНИТИВЕ"
1=1+1
IF К=10 THEN 10
END
Пояснения
см. с. 28
см. с. 30, 31
см. с. 26,27
см. с. 28,29
см. с. 26,27
см. с. 28,29
см. с. 25,26
см. с. 26,27
см. с. 27
37
4. Отладку программы, т. е. устранение в ней различных ошибок
программирования, выполняет программист, хорошо знающий
соответствующий алгоритмический язык.
Анализ результатов работы компьютерной
программы.
Для проверки универсальности созданной ВИЛМ на вход
компьютерной программы подают разное количество различных
русских глаголов. Во всех случаях программа должна давать
правильный результат. Если относительно какого-то глагола компьютер
дал неверный ответ, то это может быть следствием следующих
причин:
1) неверно построен алгоритм;
2) сделана ошибка при программировании;
3) учтены не все формальные признаки, определяющие
русский глагол в инфинитиве.
В 1-м и 3-м случае вводятся изменения и дополнения в
алгоритм, во 2-м случае исправляются ошибки программирования.
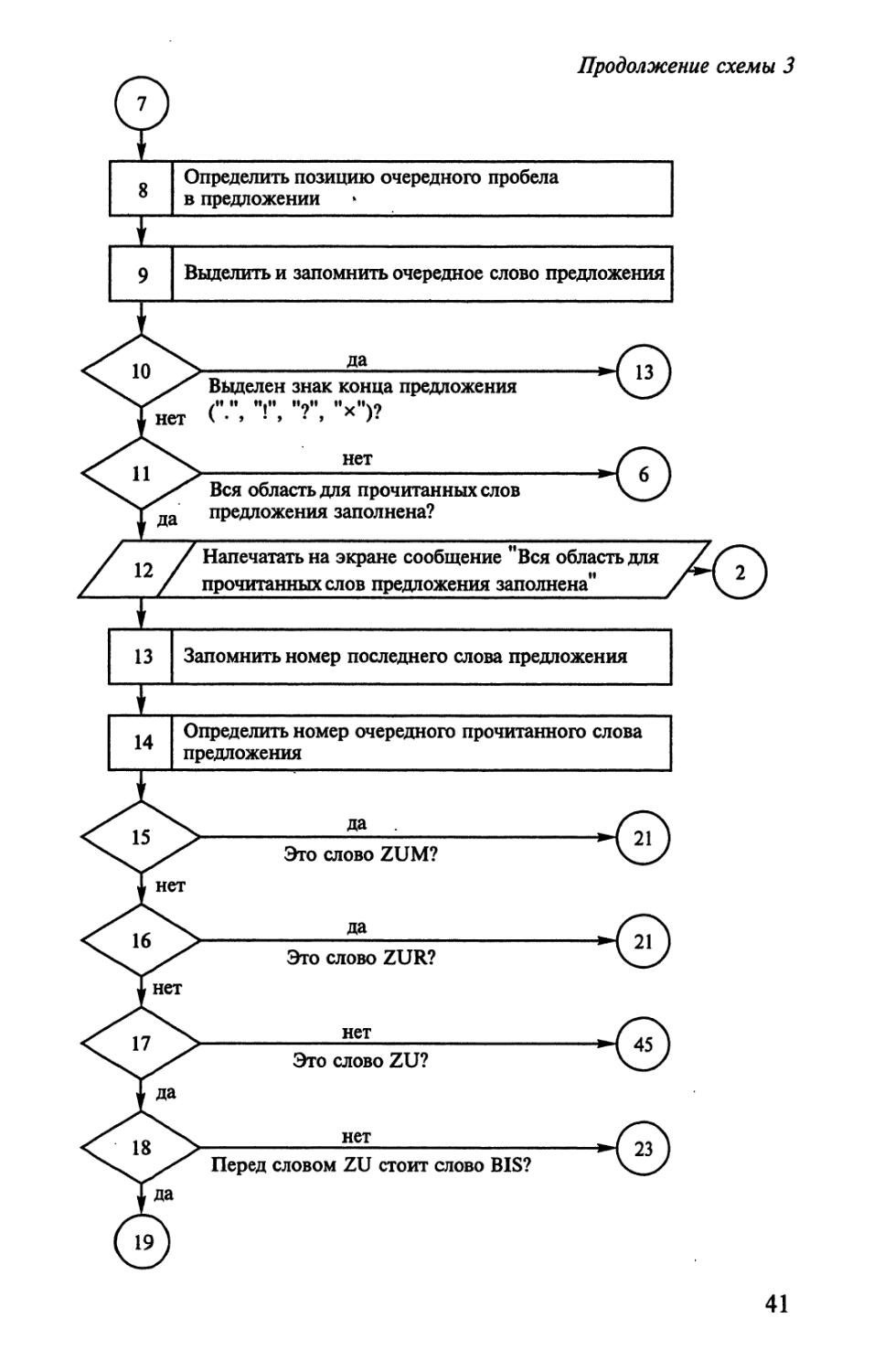
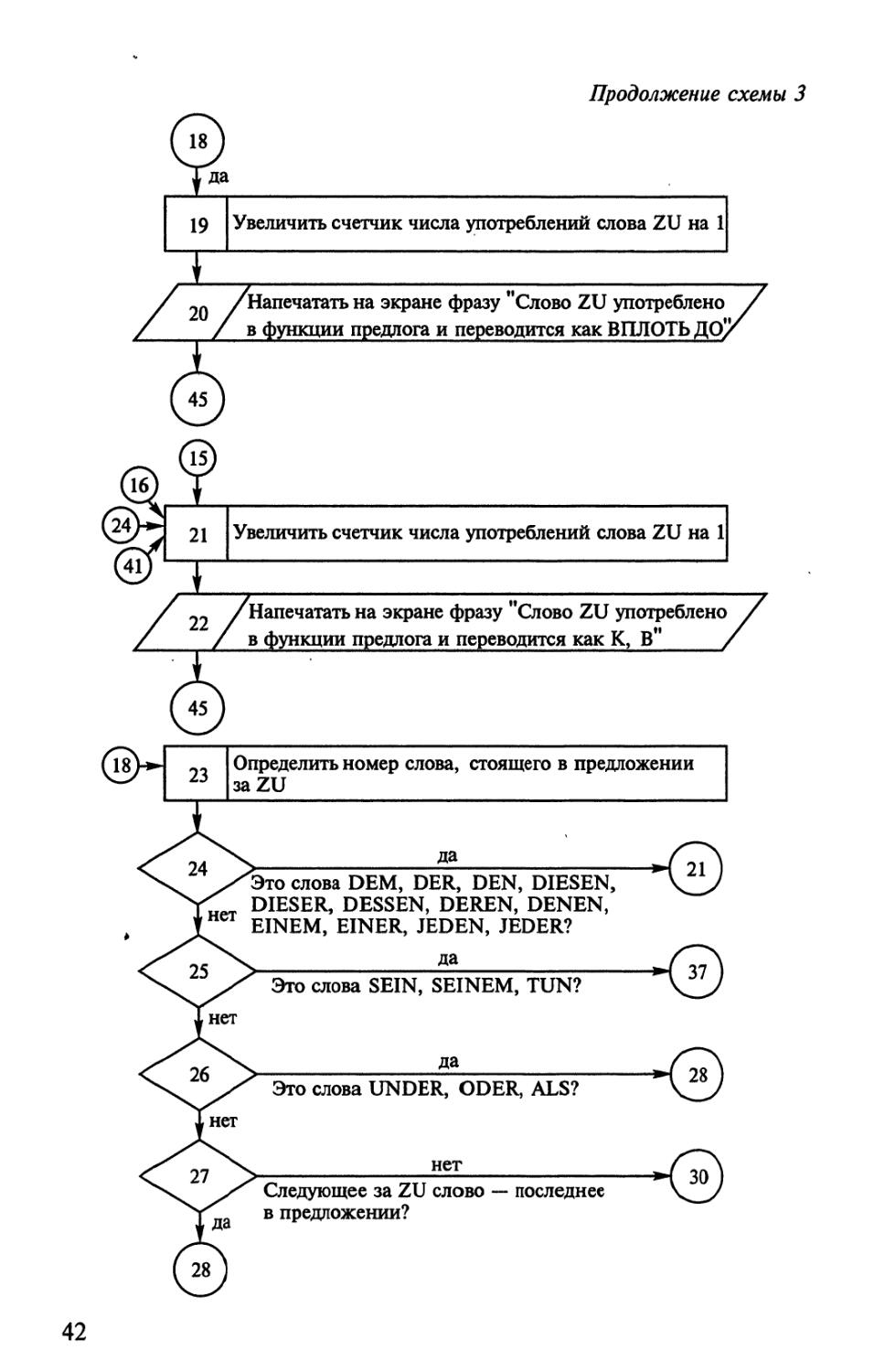
Моделирование процесса определения
лексико-грамматического значения слова zu
в немецком предложении
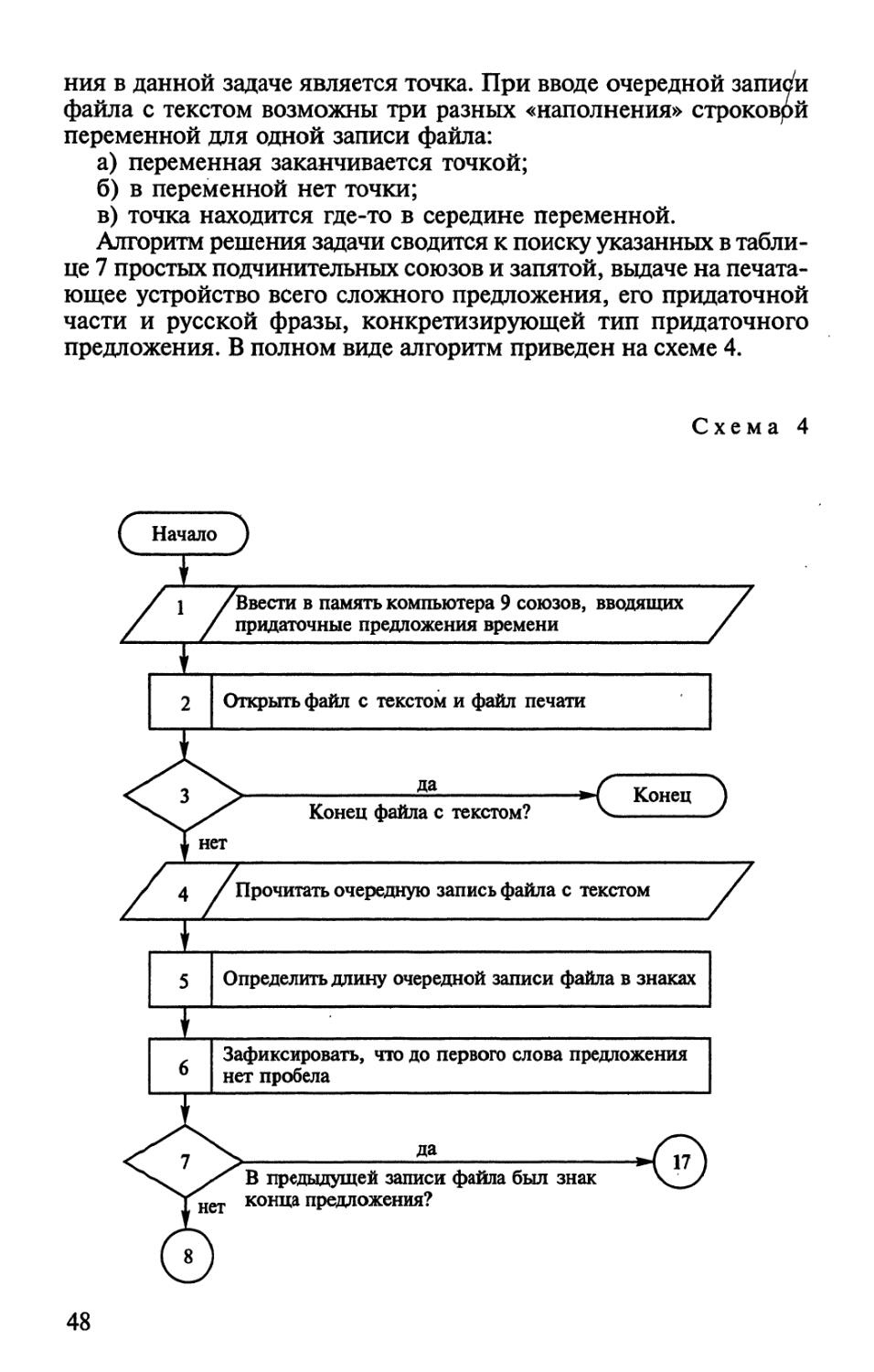
Задачи подобного рода часто встречаются в процессах
автоматического анализа текстов и при их переводе с одного языка на
другой. В обоих случаях среди нескольких лексических или
грамматических значений одного и того же слова приходится выбирать
одно единственное, специфичное для данного текста. Как
правило, это делается методом контекстологического анализа
омонимичного или полисемичного (многозначного) слова. Этот метод
хорошо описан в работах [64; 124, 138—160; 167], и суть его будет
ясна в ходе решения данной задачи.
Строго не придерживаясь изложенной выше процедуры
решения лингвистических задач, но сохраняя ее суть, представим
процесс решения этой задачи следующей последовательностью
действий.
Постановка задачи.
Описание задачи: в память компьютера с клавиатуры
поочередно вводятся любые немецкие предложения. Необходимо
составить алгоритм и программу, позволяющие определить, в какой
функции (и с каким лексическим значением) в каждом
немецком предложении употреблено слово zu (если, конечно, оно есть
в предложении).
Анализ оригинала модели: изучение употреблений слова zu в
немецких предложениях [60, 350—354], а также данные немецких
грамматик (например, [146, 357— 378\) — свидетельствует о том,
38
что слово zu употребляется в следующих пяти функциях: 1)
предлог; 2) отделяемая приставка; 3) частица при инфинитиве; 4) в
конструкции с причастием I; 5) усилительная частица. Более
детальный анализ немецких предложений позволяет построить
следующую таблицу диагаостирующих признаков (табл. 6), однозначно
определяющих функцию слова zu и его возможный перевод на
русский язык.
Таблица 6
Таблица диагностирующих признаков для распознавания
функции слова zu
Функция
в
предложении
Предлог
Отделяемая
приставка
Частица
при
инфинитиве
В
конструкции с
причастием I
Усилительная
частица
Формальные диагностирующие признаки
Левое окружение
слова
Слова
bis
—~
um
ohne
Признаки
~~
—
Формальные
выделители не
обнаружены
Перевод
слова zu
к, в
вплоть до
—~
чтобы
без того,
чтобы
который,
следует
—
Правое окружение слова
Слова
dem, den, der,
diesem, dieser,
dessen, einem,
einer, jeder,
jeden, deren,
denen
und, oder, als
sein, seinem,
tun
Признаки
Признак
имени
существительного в
немецком
языке — две
одинаковые
первые буквы
Знаки
препинания V,".",
Окончания
инфинитива:
-en, -rn, -In
Суффиксы
причастия I
и окончания
имен
существительных:
-ende, -nden,
-Inde, -nder,
-ndes, -rnde
Формальные выделители не
обнаружены
39
Разработка модели.
Алгоритм данной задачи сводится к поиску в немецком
предложении слова zu и анализу его левого и правого окружения в
соответствии с данными таблицы 6. Анализ показывает, что после
слова zu имя существительное может находиться на 1, 2 или 3-м
месте. В тех случаях, когда в немецком предложении за словом zu
идут артикли derm dem, они сливаются с zw и пишутся,
соответственно, как zur и zum. Особенностью немецкого языка является
также то, что все имена существительные пишутся с прописной
буквы. Для выделения имен существительных при вводе
предложения в компьютер первая буква таких слов удваивается.
Например, вместо слов Morgen, Zimmer, Studenten в машину вводятся
слова MMorgen, ZZimmer^ SStudenten. При подготовке немецкого текста
для обработки по данному алгоритму после последнего
предложения текста ставится знак *. Все эти особенности и учитываются
при построении алгоритма (схема 3).
Схема 3
с
Начало J
Ввести в память компьютера диагностирующие слова
и признаки
Ввести с клавиатуры очередное немецкое
предложение
да
Введен знак * ?
-( Конец J
Очистить счетчик числа употреблений слова ZU
в предложении
Зафиксировать, что до первого слова предложения
нет пробела
Запомнить номер очередного слова предложения
Определить начало очередного слова предложения
40
Продолжение схемы
Определить позицию очередного пробела
в предложении »
Выделить и запомнить очередное слово предложения
да
Выделен знак конца предложения
М И tf.lt И«« " ft.«
нет
~©
Вся область для прочитанных слов
да предложения заполнена?
О
12
Напечатать на экране сообщение Вся область для
прочитанных слов предложения заполнена"
7©
13
Запомнить номер последнего слова предложения
14
Определить номер очередного прочитанного слова
предложения
15
да
Это слово ZUM?
О
16
да
Это слово ZUR?
•©
17
нет
Это слово ZU?
в
18
нет
Перед словом ZU стоит слово BIS?
•0
да
19
Продолжение схемы 3
г да
19
Увеличить счетчик числа употреблений слова ZU на 1
20
'Напечатать на экране фразу Слово ZU употреблено
в функции предлога и переводится как ВПЛОТЬ ДО/
15)
16
®^21
Увеличить счетчик числа употреблений слова ZU на 1
22
'Напечатать на экране фразу Слово ZU употреблено
в функции предлога и переводится как К, В"
Определить номер слова, стоящего в предложении
за ZU
да
да
Это слова SEIN, SEINEM, TUN?
да
Это слова UNDER, ODER, ALS?
нет
Следующее за ZU слово — последнее
в предложении?
-©
Это слова DEM, DER, DEN, DIESEN,
нет DIESER, DESSEN, DEREN, DENEN,
He EINEM, EINER, JEDEN, JEDER?
■©
-*4 28
42
Продолжение схемы 3
28
Увеличить счетчик числа употреблений ZU на 1
/Напечатать на экране фразу Слово ZU употреблено
в функции отдельной приставки и переводится
вместе с глаголом"
<§Ч
зо
Определить длину слова, стоящего в предложении
за ZU
31
Выделить у этого слова 4 последние буквы
Это буквосочетания ENDE, NDEN
да LNDE, RNDE, NDER, NDES?
г©
Увеличить счетчик числа употреблений ZU на 1
/Напечатать на экране фразу Слово ZU употреблено
в конструкции с причастием I и переводится
КОТОРЫЙ, СЛЕДУЕТ"
®Л
35
Выделить у того же слова предложения две последние!
буквы
нет
Это буквосочетания EN, RN, LN?
37
Увеличить счетчик числа употреблений слова ZU на 1
43
Окончание схемы
37
ZНапечатать на экране фразу Слово ZU употреблено
в функции приинфинитивной частицы и не
переводится"
Определить номер очередного слова, стоящего
в предложении за ZU
40 Выделить у этого слова отдельно 1-ю и 2-ю буквы
да
Две первые буквы слова совпадают?
•©
нет
Проверены поочередно три слова
да справа от ZU?
-Н 39
43
Увеличить счетчик числа употреблений слова ZU на 1
/Напечатать на экране фразу Слово ZU употреблено
в функции усилительной частицы и переводится
какСШИШКОМ" '^
нет
Все предложения проанализированы?
да
В предложении найдено слово ZU?
-0
-0
Напечатать на экране фразу В данном предложении
нет слова ZU
Проведение компьютерного эксперимента.
Компьютерный эксперимент и анализ его результатов
описаны в [62, 66-68].
Моделирование процесса распознавания
придаточных предложений времени и условия
в английском тексте
Рассматриваемая в этом подразделе задача относится к числу
простейших задач синтаксического анализа. Она имеет
самостоятельную ценность как модель действий человека при проведении
синтаксического анализа предложения. С другой стороны,
подобные проблемы приходится решать при анализе исходного текста в
процессе его перевода на другой язык, построении компьютером
рефератов текстов, синтезе текстов ив ряде других случаев.
Примеры подобного типа задач можно найти в различных
исследованиях [123; 143; 162; 215].
Постановказадачи.
Описание задачи: на дискете или жестком диске находится
любой английский текст. Последовательно читая и анализируя
предложения этого текста, компьютер должен выделить из них и
напечатать на принтере придаточные предложения времени и
условия.
Анализ оригинала модели — основная лингвистическая
проблема, возникающая в ходе решения сформулированной задачи, —
сводится к поиску формальных признаков английских
придаточных предложений времени и условия. В наиболее
систематизированном виде признаки таких предложений изложены в
грамматиках английского языка [29, 578—637; 242, 290—293]. Их можно
представить в виде таблицы различительных (диагностирующих)
признаков (табл. 7).
Однако не все приведенные в таблице 7 слова однозначно
указывают на наличие в сложном предложении именно придаточных
предложений времени или условия. Например, подчинительный
союз as может быть частью сравнительного союза as...as в простом
предложении:
This book is as interesting as that one. (1)
Иногда союзы when и while вводят причастные обороты с
причастием I:
When crossing the street, first look to the left. (2)
While reading this book, had to use the dictionary very often. (3)
Часто слова before, till, until, since, after устанавливают связь
между двумя событиями или временами в простом предлржении:
45
Таблица 7
Диагностирующие признаки для распознавания
обстоятельственных придаточных предложений времени
и условия в сложных английских предложениях
Придаточное перед главным
Признаки
Слова
(1-е или 2-е слово
предложения)
after, as, before,
since, till, until,
\when, whenever,
while, as soon as,
as long as, now
\that
if, unless, suppose,
provided, in case,
on condition that
~~—
Знаки
>
—~
Тип
обстоятельственного
придаточного
предложения
Придаточное
предложение
времени
Придаточное
предложение
времени
Придаточное
предложение
условия
Придаточное
предложение
условия
Придаточное после главного
Признаки
Знаки
—
—*
Слова
after, as, before,
since, till, until,
when, whenever,
while, as soon as,
as long as, now
that
—
//, unless, suppose,
provided, in case,
on condition that
They were married before the war. (4)
We stayed until five. (5)
They've changed their car twice since 1970. (6)
Достаточно большое число примеров можно привести и для
тех случаев, когда слово // не вводит придаточное предложение
условия:
а) при передаче косвенной речи:
She asked him if he lived there; (7)
б) в простых восклицательных предложениях:
IforAy I hadn't listened to my parents; (8)
46
в) в некоторых типах вопросительных предложений:
Do you know if the shops are open now? (9)
Союзы as и since часто используются также для введения
придаточных предложений причины и т.д.
Более надежными признаками для выделения придаточных
предложений времени и условия являются составные союзы as
soon as, as long as, now that и in case, on condition that Можно,
конечно, попытаться найти дополнительные признаки,
отличающие придаточные предложения времени и условия, вводимые
однословными союзами, указанными в таблице 7. Например, если
when и while стоят в начале предложения и вводят причастные
обороты с причастием I [примеры (2) и (3)], то необходимо
проверить, имеет ли стоящее за ними слово признак причастия I
(окончание -ing). Проверкой конечного знака предложения на знаки
«!» и «?» можно устранить случаи, подобные приведенным в
предложениях (8) и (9).
В простых повествовательных предложениях, вводимых
однословными союзами [примеры (4), (5), (6), (7)], можно заметить,
что число слов, стоящих за соответствующим союзом, мало. Оно
в большинстве случаев значительно меньше, чем число слов в
придаточном предложении, стоящем за вводящим
подчинительным союзом. Как мы уже отмечали, компьютер мало что может
определить в тексте с вероятностью в 100 %. Поэтому любой
анализ текста проводится им с определенной степенью вероятности,
т.е. некоторое число слов, предложений и т.д. могут быть проана7
лизированы неверно. Для этого даже высчитывают специальные
коэффициенты надежности. Исходя из вышеизложенного,
несколько упростим задачу и будем считать, что если в
повествовательном предложении встречаются простые союзы after, as, before,
since, till, until, when, whenever, while9 то они вводят придаточные
предложения времени (в соответствии с табл. 7). Если же в таком
предложении встречаются простые союзы if и unless, то они
вводят придаточные предложения условия (см. табл. 7). Учет
указанных выше отличий [примеры (1)—(9) и им подобные] может быть
сделан в качестве самостоятельного задания на основе
приведенного ниже алгоритма.
Разработка модели.
Как отмечалось выше, анализируемый английский текст
должен считываться в память компьютера с дискеты или винчестера.
Особенность данной задачи заключается в том, что компьютеру
придется выделять из текста не просто отдельные слова, как это
было в предыдущей задаче (см. с. 34—38), а целые
повествовательные предложения. Чтобы выделить предложение, необходимо
знать, где оно начинается и где заканчивается. Концом предложе-
47
ния в данной задаче является точка. При вводе очередной запис/и
файла с текстом возможны три разных «наполнения» строковой
переменной для одной записи файла:
а) переменная заканчивается точкой;
б) в переменной нет точки;
в) точка находится где-то в середине переменной.
Алгоритм решения задачи сводится к поиску указанных в
таблице 7 простых подчинительных союзов и запятой, выдаче на
печатающее устройство всего сложного предложения, его придаточной
части и русской фразы, конкретизирующей тип придаточного
предложения. В полном виде алгоритм приведен на схеме 4.
Схема 4
( Начало j
1 /Ввести в память компьютера 9 союзов, вводящих
/ придаточные предложения времени
I
Открыть файл с текстом и файл печати
да
Конец файла с текстом?
*С Конец J
4 / Прочитать очередную запись файла с текстом
Определить длину очередной записи файла в знаках
Зафиксировать, что до первого слова предложения
нет пробела
да
В предыдущей записи файла был знак
'нет кога*а предложения?
•©
8
48
Продолжение схемы 4
Определить номер очередного слова записи файла
Определить начало очередного слова записи файла
10
Определить позицию пробела после очередного слова
записи файла
11
Выделить и запомнить очередное слово записи файла
Запись файла закончена?
.Д*
-©
Выделен знак конца предложения . ?
•©
Зафиксировать, что в записи файла нет знака конца
предложения
Зафиксировать, что запись файла заканчивается
знаком конца предложения
да
Выделен знак конца предложения . ?
■0
нет
Вся область памяти для прочитанных
да слов предложения заполнена?
■Ч 8
49
Продолжение схемы
18
I
Напечатать на экране дисплея фразу Вся область
для прочитанных слов предложения заполнена"
С Конец J
GH
19
Зафиксировать, что в середине записи файла есть
знак конца предложения
20
Запомнить номер последнего прочитанного слова
предложения
21
Напечатать на принтере сложное английское
предложение
Определить номер очередного прочитанного слова
предложения
да
Это союзы AFTER, AS, BEFORE,
НеТ SINCE, TILL, UNTIL, WHEN,
WHENEVER, WHILE?
-H 26
Это союз IF, UNLESS?
■©
Зафиксировать, что найден союз, вводящий
придаточное предложение условия
да
Это первое прочитанное слово
предложения?
*©
да
Это союз, вводящий придаточное
предложение условия?
Продолжение схемы
28
Напечатать на принтере фразу Придаточное
предложение времени"
Зафиксировать, что придаточное предложение
условия уже выводится на печать
30
Напечатать на принтере фразу Придаточное
предложение условия"
31
Определить начало и конец придаточного
предложения для печати
32
Напечатать на принтере найденное придаточное
предложение
Определить номер очередного за союзом
прочитанного слова предложения
нет
Это запятая ?
-©
Определить начало и конец придаточного
предложения
нет
Найден союз, вводящий придаточное
да предложение условия?
■©
Окончание схемы
Напечатать на принтере фразу Придаточное
предложение не отделено от главного запятой"
Все прочитанные слова предложения
да проанализированы?
Зд / Напечатать на экране фразу В предложении нет
придаточного времени или условия"
40
нет
В середине записи файла был знак
^да конца предложения?
<D
Проведение компьютерного эксперимента.
Компьютерный эксперимент и особенности его проведения
представлены в работе [73, 79, 80].
ГЛАВА 4
ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ
В ОБРАБОТКЕ ТЕКСТОВ
АВТОМАТИЧЕСКОЕ ЧТЕНИЕ ТЕКСТА
В наши дни для быстрого и качественного ввода текстовой
информации в компьютер широко используются сканеры. Сканер
работает по принципу фотоаппарата, позволяя ПК «увидеть» текст.
Для того чтобы «понять» его содержание, т.е. перевести
графическое (точечное) изображение символов в пригодную для
дальнейшей обработки (редактирования, реферирования, перевода
и т.д.) текстовую форму, необходима система автоматического
чтения текста или оптического распознавания символов (OCR-
система — Optical Character Recognition).,
В классическом понимании система автоматического чтения
текста — это компьютерная программа, позволяющая
преобразовать текст с бумажного носителя в электронный текстовый файл,
который может быть прочитан средствами обработки текстов.
Исходный текст должен быть вначале введен в ПК с помощью
сканера или получен на факс-модем.
История появления современных программ в области
распознавания начинается с конца 40-х годов XX века, когда ученые
многих стран стали работать над идеей обучения компьютера
умению решать разные интеллектуальные задачи. Автоматическое
чтение текста, распознавание речи, решение шахматных задач и
головоломок и даже сочинение музыки и стихотворений — вот
далеко не полный перечень идей, которые выдвигались и
разрабатывались в то время. К концу 50-х годов эти идеи оформились в
отдельную область знания — искусственный интеллект. Одной из
задач, которая вскоре выделилась в отдельное направление, была
задача распознавания образов. Идеальная компьютерная система
распознавания должна уметь формировать, анализировать и
интерпретировать любое изображение, в том числе и символьное.
В настоящее время во всем мире широко известны две OCR-
системы, созданные российскими разработчиками. Это FineReader
компании «ABBYY Software House» и CuneiForm фирмы «Congitive
Technologies». Несмотря на определенные трудности
распознавания текстов (на одной странице может встретиться до трех и
более шрифтов разного размера, стиля начертания и гарнитуры;
тексты часто бывают многоязычными, многоколоночными, включают
53
в себя таблицы, графические изображения и т.д.), возможности
систем автоматического чтения текста огромны. Рассмотрим
основные из них.
1. В процессе сканирования и распознавания текста документа
OCR-системы автоматически подбирают яркость сканирования,
фрагментируют каждую страницу, выделяя в ней области
графических иллюстраций и таблиц, распознают символы текста,
проверяют орфографию распознанных слов и показывают
окончательный результат в текстовом редакторе.
2. OCR-системы позволяют распознавать печатные символы
почти двух сотен языков.
3. Хорошо распознаются рукопечатные символы, т. е. символы,
написанные от руки печатными буквами с небольшим
интервалом между ними.
4. OCR-системы узнают все используемые в тексте документа
шрифты без предварительного обучения, хорошо воспринимают
полужирный, курсивный, слипшийся, подчеркнутый и
многоколоночный текст. Изначально в мире преобладали системы
автоматического чтения текста, требующие обучения каждому новому
шрифту (новой гарнитуре, стилю, размеру и т.д.). Такие системы
называли мультифонтовыми (от англ. font — 'шрифт').
Противоположным классом ORC-систем являются так называемые
интеллектуальные программы, именуемые еще омнифонтовыми. Их не
нужно обучать, эти программы распознают разные стилевые
начертания одной и той же буквы не потому, что их обучили
различным гарнитурам шрифтов, а потому, что они знают
топологию (правила начертания) этой буквы.
5. Системы способны самообучаться и распознавать плохо
пропечатанные символы или символы незнакомых программе языков.
6. Наряду со сплошными текстами (без таблиц и иллюстраций)
программы автоматического чтения текста хорошо распознают:
а) тексты с графикой, подписями, логотипами;
б) таблицы;
в) тексты, напечатанные на цветном (гербовом) фоне;
г) тексты разноформатных документов (например, чертежей).
7. OCR-системы поддерживают все модели сканеров и любые
графические форматы.
8. Появились и широко используются сетевые версии программ
автоматического чтения текста.
9. Программы автоматического чтения текста поддерживают
публикацию бумажных документов в глобальной сети Интернет.
В процессе распознавания и генерации HTML-страницы1 ее
оформление производится по всем правилам Web-публикации.
1 HTML (HyperText Markup Language) — язык гипертекстовой разметки
документа, см. с. 183.
54
10. Точность распознавания OCR-систем на текстах хорошего и
среднего качества достигает 97—99 %.
Развитие программ автоматического чтения текстов в
ближайшем будущем пойдет в направлении повышения точности
распознавания текстов низкого качества, выделения текстовой
информации на фоне шумов (например, распознавание номерных
знаков автомобилей), а также интеграции OCR-систем с
различными программами обработки информации (системами
машинного перевода, системами автоматического аннотирования и
реферирования текстов, электронными архивами, системами
автоматизации делопроизводства и т.д.).
АВТОМАТИЧЕСКОЕ РЕФЕРИРОВАНИЕ
И АННОТИРОВАНИЕ ТЕКСТА
Реферат и аннотация текста. Общие понятия
Рефератом будем называть связный текст, который кратко
выражает не только центральную тему или предмет какого-либо
документа, но и цель, применяемые методы, основные
результаты описанного исследования или разработки [135, 291]. Рефераты
обычно составляют к научно-техническим документам —
научным книгам, статьям, патентам на изобретение и т.п. Поэтому в
приведенном определении и говорится о «методах и основных
результатах описанного исследования или разработки». Реферат
акцентирует внимание читателя на новых сведениях и определяет
целесообразность его обращения к исходному документу. Он
помогает человеку ориентироваться в информационных потоках,
оперативно отбирать для себя наиболее ценную и полезную
информацию. Процесс составления реферата называется реферированием.
Аннотацией называют краткое изложение содержания
документа, дающее общее представление о его теме [35, 56]. Таким
образом, если реферат в краткой форме знакомит читателя с сутью
излагаемого в документе содержания (фактами, методикой,
экспериментами и т.п.), то аннотация выполняет лишь сигнальную
функцию, сообщая о том, что опубликована статья или книга на
определенную тему. Процесс составления аннотации называется
аннотированием.
Рефераты и аннотации представляют собой вторичные
документы. Первичные, или исходные, документы — это, как мы уже
отмечали, книги, статьи, патенты и т.п. В каждом вторичном
документе можно выделить два компонента информации:
1) содержательный;
2) документографический.
55
Первый компонент содержит информацию первоисточника
(о чем книга, статья). Второй компонент — это сведения о самом
первичном документе (тип документа: книга, статья и т.п.; вид:
печатный, рукописный; год издания; место издания и т.д.). В
дальнейшем речь пойдет только о первом компоненте вторичного
документа.
Научно-технический прогресс привел к появлению большого
числа публикаций (книг, статей и т.п.) по самым разным
проблемам науки, техники, образования, и специалисты не успевают
следить за новейшей литературой по своей области знания. Для
этого, как установлено, человек должен был бы прочитывать
ежедневно 1500 страниц текста на разных языках, что явно
превышает его физические возможности. Поэтому для оперативного
«поверхностного» знакомства с новейшими публикациями
используются рефераты и аннотации книг и статей, которые составляются
в специальных организациях и публикуются в реферативных
журналах (РЖ) и реферативных сборниках (PC).
Реферирование и аннотирование текста являются довольно
сложными и трудными видами интеллектуальной деятельности.
Составление человеком рефератов или аннотаций занимает много
времени. Это приводит к тому, что до ученых, педагогов,
инженеров и других специалистов новейшая информация (особенно
зарубежная) доходит очень медленно, что, в свою очередь, ведет к
повторению в разных странах и в пределах одной страны одних и
тех же исследований, более позднему применению новейших
методик, технологий, процессов. Чтобы как-то избежать этого, для
составления рефератов и аннотаций применяют современные
компьютеры. Составление реферата или аннотации текста с помощью
компьютера называется автоматическим реферированием или
аннотированием.
Формулировка задачи автоматического реферирования
и аннотирования текста
Для того чтобы дать точную формулировку задачи
автоматического реферирования и аннотирования текста, необходимо
проанализировать, как выполняет работу по составлению реферата
или аннотации человек (референт). Анализ литературы,
содержащей принципы построения человеком рефератов или аннотаций,
показывает, что при этом выделяют три этапа [114, 52—55; 35,
70-94; 23]:
1) подготовительный — референт определяет тематическую
направленность текста и пытается понять и осмыслить документ в
целом;
56
2) аналитический — референт делит текст на некоторые
фрагменты (абзацы, аспекты1 и т.п.). Каждый фрагмент внимательно
изучается, в нем выделяют основные смысловые единицы
(предложения, словосочетания, слова). Данный этап заканчивается
составлением плана будущих реферата или аннотации;
3) этап непосредственного построения реферата или
аннотации —- выделенные ранее смысловые единицы (их комбинации
или преобразования) располагаются в единый вторичный текст в
соответствии с планом реферата или аннотации.
Рассмотрим несколько подробнее отдельные моменты 2-го и
3-го этапов. В качестве основных смысловых единиц, выделяемых
из исходного текста на 2-м этапе, могут выступать: 1)'целые
ключевые предложения; 2) ключевые словосочетания и слова.
Ключевое {опорное) слово — это термин, относящийся к
основному содержанию текста и повторяющийся в нем несколько раз
(с учетом всех возможных синонимов).
Ключевое словосочетание — это сочетание слов, среди которых
есть одно или несколько ключевых.
Ключевым предложением считается предложение, содержащее
два и более ключевых слова или ключевых словосочетания.
Составление плана будущих реферата или аннотации
заключается в выделении некоторых смысловых ориентиров, которые на
3-м этапе будут развернуты более подробно. В качестве таких
ориентиров выступают:
1) основные темы и подтемы исходного текста;
2) основные аспекты исследования;
3) основные ключевые предложения, словосочетания и слова.
Выбор тех или иных ориентиров зависит от типа составляемого
реферата или аннотации. Подробнее эти вопросы рассмотрены в
работах [35; 114; 23].
Создаваемый на 3-м этапе реферат или аннотация содержат
выделенные ранее смысловые единицы. В качестве смысловых
единиц реферата могут выступать:
1) полные (без изменения) ключевые предложения исходного
текста;
2) перефразированные ключевые предложения исходного
текста;
3) предложения, составленные из ключевых слов или
словосочетаний исходного текста с помощью специальных связующих
элементов;
4) предложения, обобщающие несколько предложений
исходного текста (не обязательно ключевых).
Аспект — это один или несколько абзацев текста, в которых описывается
некоторая часть исследования — его тема, цель, используемые методы,
результаты, выводы и т.п.
57
При перефразировании применяются различные лексико-грам-
матические явления: использование синонимов, конверсивов,
замен по принципу «вид — род», «часть — целое» и т.п.
При получении новых предложений из ключевых слов и
словосочетаний исходного текста чаще всего используют различные
логико-смысловые скрепы, например, потому что, в то время
как, поэтому, вследствие и т. п.
В обобщающих предложениях исходный текст передается
совершенно другими словами. В них то же самое содержание
излагается в более кратком виде.
Смысловыми единицами аннотации могут быть:
1) ключевые слова или словосочетания исходного текста с
предшествующими им специальными фразами — реляторами
типа: «В статье рассматриваются следующие вопросы:...», «Книга
посвящена следующим проблемам: ...»и т.п.;
2) специальные предложения, содержащие оценочные
элементы: «Рассматривается важная проблема...», «Статья посвящена
актуальной теме...» и т.д.;
3) специальные предложения, содержащие клише, т. е.
специализированные словесные штампы, фиксирующие внимание
читателя на определенных аспектах содержания: «Недостаток...
заключается», «Цель публикации...», «Ставится задача...»,
«Делается попытка...» и т.д.
Следующий важный вопрос, который необходимо рассмотреть,
связан с тем, как человек выбирает из текста ключевые
предложения, словосочетания и слова. Это делается, как уже
отмечалось, на 2-м этапе общего процесса составления вторичного
документа. Читая текст повторно (первый раз он читается на
подготовительном этапе) или в третий раз, человек мысленно выделяет
в нем три типа единиц (предложений, словосочетаний, слов):
1) единицы, которые обязательно должны быть включены в
реферат или аннотацию. Такие единицы отражают новые идеи,
гипотезы, новые методы, явления, процессы, новые результаты,
т. е. все новое и оригинальное, что есть в исходном документе. Это,
по существу, и есть основные смысловые единицы текста
(ключевые предложения, словосочетания и слова);
2) единицы, которые отражают фактические данные: параметры
изделий, процессов, методов и т.д. Такие единицы не являются
принципиально новыми;
3) единицы, которые аргументируют и иллюстрируют
единицы первых двух типов.
Единицы первого уровня обязательно используются при
составлении реферата (см. с. 57). Из единиц второго уровня
используются лишь некоторые (в зависимости от типа реферата или его
потребителя). Третья группа единиц изредка переносится в
реферат в обобщенном виде.
58
Если поручить составление реферата или аннотации
компьютеру, то, очевидно, его надо научить выполнять те же действия,
которые осуществляет человек. Компьютер должен уметь:
1) находить в тексте ключевые слова, словосочетания и
предложения;
2) находить в тексте менее значимые единицы;
3) составлять из текстовых единиц двух первых типов
смысловые единицы реферата или аннотации;
4) составлять из таких единиц текст реферата или аннотации.
Говоря о двух последних «умениях» компьютера, необходимо
помнить, что почти во всех существующих системах
автоматического реферирования в качестве основных смысловых единиц
реферата выступают ключевые предложения или ключевые
словосочетания и слова исходного текста. Первые в их
последовательной совокупности (в том порядке, в котором они идут в исходном
тексте) образуют текст (квазитекст) реферата. Второй тип
смысловых единиц (ключевые словосочетания и слова) используется
компьютером для построения так называемых табличных
рефератов1.
При составлении с помощью компьютера аннотации также
используются как ключевые предложения (в том виде, что и при
составлении реферата), так и ключевые слова и словосочетания.
Последние перечисляются вслед за реляторами вида: «В статье
рассматриваются следующие вопросы:...», «Книга посвящена
следующим проблемам: ...», «Статья раскрывает следующие
понятия: ...» и т.д.
По способам выделения из исходных текстов ключевых
словосочетаний и предложений (первые два «умения» компьютера)
различают несколько методов автоматического реферирования и
аннотирования текстов. Наиболее известны следующие три
группы методов:
1) статистические;
2) позиционные;
3) логико-семантические.
Суть статистической группы методов заключается в том, что:
1) ключевыми словами считаются такие знаменательные слова
текста, которые с учетом всех синонимов встречаются в тексте
наибольшее число раз;
2) ключевым предложением считается предложение текста,
которое:
а) имеет несколько ключевых слов;
б) содержит ключевые слова на небольшом расстоянии друг
от друга.
1 Подробнее см.: 114, 71-73; 69, 110-112.
59
Принадлежность слова, словосочетания или предложения к
числу ключевых определяется специальными статистическими
коэффициентами.
В позиционных методах автоматического реферирования и
аннотирования ключевым предложением считается предложение,
входящее в заголовок, подзаголовок, начало или конец какой-то
части текста или всего текста. Такие предложения, как правило,
содержат информацию о целях, методах, выводах и результатах
исследования, описанного в первичном документе. Важность тех
или иных предложений с указанной точки зрения определяется
экспертами путем изучения семантической структуры первичных
документов определенного типа.
Логико-семантические методы опираются на исследование
структуры и семантики текстов. Существует несколько вариантов
этих методов, но цель их одна — выделить из конкретного текста
предложения с наибольшим функциональным весом. Величина эта
зависит от многих факторов: наличия в исследуемом
предложении специальных семантически значимых слов, связи этого
предложения с другими предложениями текста, синтаксического типа
самого предложения и т.д.
Формулируя задачу построения системы автоматического
аннотирования и реферирования текста, необходимо четко указать:
1) метод, который используется для выделения ключевых слов
предложения;
2) способ определения ключевых словосочетаний предложения;
3) критерий выделения ключевых предложений текста;
4) тип подготавливаемой аннотации: текстовая, в виде релято-
ра1 с последующими ключевыми словами и словосочетаниями,
или табличная;
5) тип формируемого реферата: текстовый или табличный.
Учитывая все сказанное, сформулируем задачу
автоматического реферирования и аннотирования текста следующим образом:
«На устройстве внешней памяти (например, дискете или
винчестере) находится английский научно-технический текст. Начало
каждого абзаца в нем обозначено знаком *. Используя для
выделения ключевых (опорных) слов текста один из вариантов
статистического метода, а именно коэффициент важности слова2
к - Fm
составить алгоритм, позволяющий пэлучить:
1 См. с. 58, 59.
2 В формуле для Квяж буквы означают следующее: F— частота
словоупотреблений в тексте; т — число абзацев текста, в которых встретилось слово; N —
общее число словоупотреблений в тексте; п — общее число абзацев в тексте.
60
а) аннотацию текста в виде релятора со следующими за ним
ключевыми словосочетаниями текста. Ключевым сочетанием
считается ключевое имя существительное со стоящим перед ним
определением, выраженным именем прилагательным или
причастием, не относящимся к числу общеупотребительных;
б) словесный реферат текста в виде последовательной цепочки
ключевых предложений. Ключевым предложением текста будем
считать предложение, содержащее три и более разных ключевых слова.
Аннотацию и реферат вывести на экран дисплея».
Исходным материалом для сформулированной выше задачи
автоматического аннотирования и реферирования будет служить
следующий текст:
* MICROPROCESSORS AND MINICOMPUTERS.
* THE FIRST COMPUTERS FILLED A LARGE ROOM WITH THEIR
ELECTRONICS. PHOTOGRAPHS OF EARLY COMPUTERS SHOW MEN
AND WOMEN IN BUSINESS SUITS AND LABORATORY COATS
STANDING IN THE MIDDLE OF A ROOM SURROUNDED BY A
U-SHAPED MACHINE. IN REALITY, PEOPLE OPERATING AND
DEVELOPING THE FIRST COMPUTERS DID NOT WEAR SUITS. AIR-
CONDITIONING WAS POOR AT THAT TIME AND THE COMPUTER
GOT SO HOT THAT THE COMPUTER OPERATORS DRESSED IN T-
SHIRTS AND TENNIS SHOES.
* THE DEVELOPMENT OF THE TRANSISTOR IN 1948 MADE IT
POSSIBLE TO BUILD ELECTRONIC DEVICES OF A VERY SMALL SIZE.
AN INTEGRATED CIRCUIT (IC(CHIP) FOR SHORT) WAS SOON
DEVELOPED. AN IC(CHIP) IS A LARGE NUMBER OF TRANSISTORS
AND OTHER ELECTRONIC COMPONENTS WIRED TOGETHER. THEY
FORM A SPECIAL CIRCUIT AND ARE MICROSCOPICALLY PLACED
ON A SMALL PIECE OF SILICON (OR OTHER MATERIAL) WHICH
SERVES AS SEMICONDUCTOR.
* INTEGRATED CIRCUITS, ALSO CALLED CHIPS, ARE NOW
MANUFACTURED SEPARATELY FROM COMPUTERS. THEY PROVIDE
BUILDING BLOCKS TO BUILD A COMPUTER. THE MOST
IMPORTANT OF THESE COMPUTER COMPONENTS IS THE CENTRAL
PROCESSING UNIT (CPU FOR SHORT) OR MICROPROCESSOR. IT
IS THE PART OF THE COMPUTER THAT OBEYS THE INSTRUCTIONS
OF A PROGRAM. A MICROPROCESSOR IS A SMALL UNIT CONTAINED
ON THE SEMICONDUCTOR CHIP. MICROPROCESSORS ARE USED
IN MINICOMPUTERS AND EACH OF THESE INTEGRATED CIRCUITS
IS CAPABLE OF PROCESSING 8-BIT OR 16-BIT DATA.
* SOME OTHER COMPONENTS .OF THE COMPUTER ARE
COMPUTER MEMORY CHIPS, VOICE SYNTHESIZERS THAT
PRODUCE SOUNDS SIMILAR TO HUMAN SPEECH AND EVEN
INTEGRATED CIRCUITS THAT PERMIT THE COMPUTER TO SEND
COMPUTER DATA ON A TELEPHONE LINE. IT WILL SOON BE
POSSIBLE TO MANUFACTURE A TELEVISION SET INTO ONE
IC(CHIP) SMALLER THAN A DOMINO.
61
* WITH ELECTRONIC DEVICES OF A VERY SMALL SIZE IT WAS
POSSIBLE TO DESIGN POWERFUL COMPUTERS SMALLER AND
LESS EXPENCIVE. THEY WERE CALLED MICRO(MICROCOMPU-
TER) - AND MINICOMPUTERS. TODAY A MICROCOMPUTER IS
CONSIDERED A SMALL AND RATHER SLOW COMPUTER, USUALLY
FOR INDIVIDUAL USE, 8-BIT WORDS. A MINICOMPUTER IS A SMALL
COMPUTER OF 16-BIT WORDS AND USUALLY CAPABLE OF
SUPPORTING 10 TO 40 USERS.
* A MICROCOMPUTER THAT SERVES THE COMPUTING NEEDS
OF ONE PERSON AT A TIME IS CALLED A PERSONAL COMPUTER.
TODAY A PERSONAL COMPUTER WILL FIT IN A SPACE OCCUPIES'
BY A BOX OF MATCHES. BUT THESE COMPUTERS ARE MORE
POWERFUL THAN THE EARLY ELECTRONIC COMPUTERS AND
THEY ARE MUCH EASIER TO PROGRAM THAN THE EARLIER
MACHINE. AND THERE ARE LARGE LIBRARIES OF PROGRAMS ANY
PERSON CAN BUY AND RUN ON HIS PERSONAL COMPUTER.
Принципиальный алгоритм решения задачи
Как видно из приведенной выше формулировки, решаемая
задача является сложной и состоит из нескольких простых
подзадач. Представим их в виде блоков следующего принципиального "\
алгоритма (схема 5) и рассмотрим далее более подробно.
В блоке А в память компьютера вводится находящийся на
устройстве внешней памяти файл с английским
научно-техническим текстом. Далее в блоке В формируется массив словоформ
одного абзаца текста, словоформы сортируются по алфавиту, под-
считывается частота употребления каждой словоформы в абзаце и
в специальной области компьютерной памяти создается алфавит-
но-частотный словарь одного абзаца. Подобные действия
выполняются со всеми абзацами текста.
Как было отмечено выше, началом каждого абзаца служит
знак *, а сам текст начинается с 3-й позиции первой строки абзаца.
В результате выполнения блоков An В алгоритма в специальных
областях памяти компьютера будут расположены алфавитно-час-
тотные словари словоформ всех семи абзацев текста. Так, нулевой
абзац (заглавие текста) будет представлен следующим словарем
(табл. 8).
Таблица 8
Словоформа
AND
MICROPROCESSORS
MINICOMPUTERS
Частота
1
1
1
62
Схема 5
Принципиальный алгоритм задачи автоматического реферирования
и аннотирования текста
Г Начало J
А
Ввод в память компьютера исходного текста i
♦
в
Создание алфавитно-частотных словарей абзацев
текста
1
1 q
Создание распределительного алфавитно-частотного
словаря текста
♦
D
Создание словаря потенциальных опорных
словоформ текста
i
Е
Создание словаря главных и второстепенных опорных
словоформ текста |
*
F
Выделение из текста ключевых словосочетаний для
аннотации
*
G
Выделение из текста ключевых предложений для 1
реферата
*
H
i
Печать аннотации к тексту на экране дисплея
f
I
Печать реферата текста на экране дисплея
i
С Конец J
Блок С объединяет алфавитно-частотные словари абзацев в
единый распределительный алфавитно-частотный словарь текста. При
этом каждой словоформе приписываются общая частота ее
употребления во всем тексте (F), число абзацев (т) и конкретные
номера абзацев (0, 1, 2, 3, 4, 5, 6-й), в которых встретилась эта
словоформа. Фрагментарно алфавитно-частотный словарь
словоформ всего текста представлен в таблице 9.
63
Таблица 9
Распределительный алфавитно-частотный словарь
словоформ текста (фрагменты)
№
п/п
0
1
?.
3
4
••••*
1?
18
22
23
24
25
26
27
28
29
34
39
47
48
61
Словоформа
А
AIR-CONDITIONG
ALSO
AN
AND
BUILD
CALLED
CHIP
CHIPS
CIRCUIT
CIRCUITS
COATS
COMPONENTS
COMPUTER
COMPUTERS
DATA
DEVICES
ELECTRONIC
ELECTRONICS
IC(CHIP)
Абсолютная
частота
употребления,
F
25
1
1
2
17
2
3
1
2
2
3
1
3
14
7
2
2
4
1
3
Общее
число
абзацев
в тексте,
т
6
1
1
1
7
2
3
1
2
1
2
1
3
5
4
2
2
3
1
2
Номера абзацев,
в которых
встретилась словоформа
123456
1
з 1
2
0123456
23
356
3
34
2
34
1
234
13456
1356
234
25
256
1
24
64
Продолжение табл. 9
№
п/п
66
75
76
77
78
83
84
85
86
89
90
120
121
127
130
139
140
164
168
Словоформа
INTEGRATED
MACHINE
MADE
MANUFACTURE
MANUFACTURED
MICRO(MICRO-
COMPUTER)
MICROCOMPUTER
MICROPROCESSOR
MICROPROCESSORS
MINICOMPUTER
MINICOMPUTERS
PROGRAM
PROGRAMS
SEMICONDUCTOR
SERVES
SMALL
SMALLER
TIME
TRANSISTOR
Абсолютная
частота
употребления,
F
4
2
1
1
1
1
2
3
1
1
3
2
1
2
2
6
2
2
1
Общее
число
абзацев
в тексте,
т
3
2
1
1
1
1
2
1
1
1
3
2
1
2
2
3
2
2
1
Номера абзацев,
в которых
встретилась словоформа
234
16
2
4
3
5
56
3
о
5
035
36
6
23
26
235
4.5
16
2
3 Зубов
65
Окончание табл. 9
№
п/п
169
172
173.
174
| 186
Словоформа
TRANSISTORS
USE
USED
USERS
WORDS
Абсолютная
частота
употребления,
F
1
1
1
1
2
Общее
число
абзацев
в тексте,
т
1
1
1
1
1
Номера абзацев,
в которых
встретилась словоформа
2
5
3
5
5
1 Всего словоформ: 395
Прежде чем сформулировать решаемую в блоке D подзадачу,
введем ряд уточнений. Выше, говоря о ключевых словах текста,
мы отмечали три особенности этих слов: 1) это слова-термины;
2) они должны встречаться в тексте несколько раз; 3) должны
учитываться все возможные синонимы этого термина в тексте.
Начнем с анализа третьего пункта. Просматривая исходный
текст, можно заметить в нем две пары синонимов: chip — 1С и
micro — microcomputer. В настоящее время без специальных, очень
сложных программ компьютер не может сам их обнаружить.
Большую помощь при определении синонимичности слов могут ока- .
зать словари-тезаурусы (см. с. 162,163). Поэтому при записи текста
на диск эти синонимы указывались в скобках друг за другом
IC(chip), micro(microcomputer). Далее синонимичные словоформы
объединяются в одно условное слово с суммированием частот их
употребления, объединением номеров абзацев, в которых они
использовались, и их общего числа.
Синонимичными для компьютера являются и грамматические
формы одних и тех же слов: chip и chips, circuit и circuits, small и
smaller и т.д. Найти и объединить эти словоформы компьютер
может самостоятельно, без специального предредактирования
текста человеком. В результате получается единое условное
слово, речь о котором шла выше. Говоря о второй из трех
упомянутых выше особенностей ключевых слов, условимся, что в число
потенциальных опорных словоформ текста будем включать
только те из словоформ в таблице 9, которые встретились в двух и
более абзацах (т.е. т >2).
Наконец, чтобы учесть первую особенность ключевых слов и
оставить в числе потенциальных опорных словоформ текста только
66
Таблица 10
Словоформа
COMPUTER
COMPUTERS
Частота, F
14
7
Число абзацев, т
5
4
Номера абзацев
13456
1356
Таблица 11
Словоформа
COMPUTER
COMPUTERS
Частота, F
21
0
Число абзацев, т
5
0
Номера абзацев
13456
0
термины, необходимо из представленных в таблице 9 словоформ
исключить все служебные словоформы (предлоги, частицы,
артикли, местоимения, наречия, вспомогательные глаголы,
числительные и т.д.) и словоформы с общеупотребительным значением
(coats, form, human, part и т. д.). Эти две группы словоформ
называют иногда отрицательными, запрещенными или стоп-словами.
Рассмотрим несколько подробнее действия компьютера по
объединению грамматических форм одного и того же слова. Он
последовательно анализирует все словоформы распределительного
словаря, начинающиеся с одной и той же буквы. На первом шаге
такого анализа она выделяет у второй из двух сравниваемых
словоформ одну последнюю букву и оставшуюся часть второй
словоформы сравнивает с первой словоформой. Если они совпадают,
компьютер суммирует частоты этих словоформ, устанавливает
номера абзацев, в которых встретились эти словоформы, и
определяет общее количество абзацев, в которых они использовались.
Например, анализируя словоформы, представленные в
таблице 10, компьютер обнаружит, что это словоформы одного и того
же слова. Он суммирует их частоты (F= 14 + 7 = 21), но не
суммирует значения т. Компьютер просматривает номера абзацев, в
которых встретились эти словоформы (соответственно 1, 3, 4, 5,
6-й и 1, 3, 5, 6-й), и оставляет все разные номера (4-й) и по
одному из повторяющихся номеров абзацев (1, 3, 5, 6-й).
Число выделенных таким образом номеров абзацев и
составляет величину т для единого условного слова (табл. 11)1.
В данном случае словоформа computers как бы «теряет» свою
частоту Fn число абзацев т, в которых она встретилась в тексте.
1 Запись двух и более словоформ в виде, когда F и т указываются лишь для
одной формы, а для других словоформ эти величины равны нулю, называется
условным словом. Номера абзацев в последних словоформах оставлены от
результатов предыдущих действий.
67
Таб л ица 12
Словоформа
CHIP
CHIPS
1С
MICROCOMPUTER
MICRO-
Частота, F
6
0
0
3
0
Число абзацев, т
3
0
0
2
0
Номера абзацев |
234 1
34
24
56
5
Если после отделения у 2-й словоформы одной последней
буквы совпадения словоформ не произошло, то у 2-й словоформы
выделяются две последние буквы и проводится новое сравнение
оставшейся части с 1-й словоформой. В случае их совпадения
выполняются аналогичные описанным выше действия.
Объединение данных о синонимичных словоформах
проводится с опорой на тот факт, что такие словоформы в тексте по
нашему первоначальному условию заключены в скобки и
располагаются друг за другом. Найдя основную словоформу,
компьютер объединяет ее частоту с частотой синонима, уточняет число
и конкретные номера абзацев по такому же принципу, как это
было показано для объединения грамматических форм одного и
того же слова. В итоге будут получены, например, два условных
слова (табл. 12).
И последнее, самое простое действие связано с исключением
из распределительного алфавитно-частотного словаря тех
словоформ, которые встретились лишь в одном абзаце (т.е. для них
т=1).
Исключение из распределительного словаря любой
словоформы служебного или общеупотребительного слова,
грамматической формы, синонима, словоформ, встречающихся в одном
абзаце, осуществляется в виде «сжатия» распределительного
словаря, с тем чтобы в нем не осталось ненужных словоформ. При
этом компьютер опирается на заранее заданный список
запрещенных слов1.
Итогом работы блока D является словарь потенциальных
опорных словоформ исходного текста (габл. 13).
Основным критерием для создания словаря главных и
второстепенных опорных словоформ текста {блок Е) является, как уже
было отмечено выше, коэффициент важности слова:
v —
F-m
Nn
С)
1 О запрещенных словах см. с. 67.
68
Таблица 13
Словарь потенциальных опорных словоформ исходного текста
№
п/п
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Словоформа
BUILD
CHIP
CHIPS
1С
CIRCUIT
CIRCUITS
COMPONENTS
COMPUTER
COMPUTERS
DATA
DEVICES
ELECTRONIC
ELECTRONICS
INTEGRATED
MACHINE
MANUFACTURE
MANUFACTURED
MICROCOMPUTER
MICRO
MICROPROCESSOR
MICROPROCESSORS
MINICOMPUTER
MINICOMPUTERS
PROGRAM
PROGRAMS
SEMICONDUCTOR
SERVES
Абсолютная
частота
употребления,
F
2
6
0
о
5
0
3
21
0
2
2. '
5
0
4
2
2
0
3
0
4
0
4
0
3
0
2
2
Общее
число
абзацев
в тексте,
т
2
3
0
0
3
0
3
5
0
2
2
4
0
3
2
2
0
2
0
2
0
3
0
2
0
2
2
Номера абзацев,
в которых
встретилась данная
словоформа
2 3
234
0
0
2 34 ■ ■ |
0
2 3 4
13456
0
3 4
25
1256
1
234
16
34
0
56
0
03
0
035
0
36
0
23
2 6. |
69
Окончание табл. 13
№
п/п
27
28
29
Словоформа
USE
USED
USERS
Абсолютная
частота
употребления,
F
3
0
0
Общее
число
абзацев
в тексте,
т .
2
0
0
Номера абзацев,
в которых
встретилась данная
словоформа
35
0
0.
Среди ключевых словоформ текста может быть установлена
следующая иерархия. Одни из них — главные опорные слова (ГОС) —
являются особенно важными для текста. Они встречаются с
наибольшей частотой в большом числе абзацев. Другие опорные
слова встречаются с меньшей частотой и в меньшем числе абзацев.
Их называют второстепенными опорными словами (ВОС).
Существуют разные методы определения ГОС и ВОС. Используем в
качестве критерия их различия граничные значения К1^ и К\^,
предложенные в работе [63, 16, 17\. Граничные значения этих
коэффициентов при таком подходе зависят от числа абзацев текста.
Для исследуемого текста, содержащего 7 абзацев, эти
коэффициенты могут быть вычислены, например, по следующим формулам
[63, 18, 19\:
9
N-n
^ ^важ < I?
а!±+£*ж><^-.
(2)
N-n
N-n
где N— общее число словоупотреблений текста; п — общее число
абзацев текста.
Для исследуемого текста, имеющего и = 7 абзацев и ЛГ=395
словоупотреблений, неравенства (2) преобразуются в следующие
(3, 4):
0,0032 <K^<\;
(3)
(1/395+7 -Х^<0>0°32;
0,0027<ЛГ4к < 0,0032.
(4)
70
Если для каждой словоформы, вошедшей в словарь
потенциальных опорных словоформ (см. табл. 13), вычислить по формуле
(1) коэффициент важности Къаж и сравнить его с граничными
значениями Юъаж и К2важ, то:
а) главными опорными словоформами текста будем считать
те, коэффициент важности которых удовлетворяет неравенству
0,0032<Аваж<1; (5)
б) второстепенными опорными словоформами текста будем
считать те, коэффициент важности которых удовлетворяет
неравенству
0,0027 <Аваж< 0,0032; (6)
в) если же Кваж словоформы меньше 0,0027, то эта
словоформа относится к числу прочих словоформ текста.
Результатом работы блока £ является словарь главных и
второстепенных опорных словоформ, представленный в таблице 14.
В ней коэффициенты Кваж относятся ко всей группе
синонимичных словоформ, образующих одно условное слово.
Таблица 14
Словарь главных и второстепенных опорных словоформ текста1
№
п/п
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Тип опорной
словоформы
ГОС
ГОС
ГОС
ГОС
ГОС
ГОС
ГОС
ГОС
ГОС
ГОС
ГОС
ГОС
вое
вое
вое
Словоформа
CHIP.
CHIPS
1С
CIRCUIT
CIRCUITS
COMPONENTS
COMPUTER
COMPUTERS
ELECTRONIC
ELECTRONICS
INTEGRATED
MINICOMPUTER
MINICOMPUTERS
MICROPROCESSOR
MICROPROCESSORS
Аваж
0,0065
— 1
— |
0,0054
— |
0,0033
0,0338
—
0,0072
—
0,0043
0,0028
—
0,0021
—
В памяти компьютера величины К^ для словоформ не сохраняются.
71
В общей формулировке задачи автоматического реферирования
и аннотирования (см. с. 60, 61) было сказано, что аннотация
текста должна быть выдана на экран дисплея в виде релятора со
следующими за ним ключевыми словосочетаниями текста. Причем
ключевым словосочетанием считается ключевое опорное (имя)
существительное со стоящим перед ним определением, выраженным
именем прилагательным или причастием, не относящимся к
числу общеупотребительных. При таком подходе возникает три
вопроса.
1. Какие опорные словоформы (главные, второстепенные или
же те и другие) брать в основу выделения ключевого
словосочетания?
2. Как среди опорных словоформ выделить опорные
словоформы — имена существительные?
3. Каким образом среди стоящих перед опорной словоформой
определителей найти имена прилагательные или причастия, не
относящиеся к числу общеупотребительных?
Так как аннотация — это кратчайшее изложение содержания
исходного текста (см. с. 55), то она, безусловно, должна опираться
на наиболее важные в смысловом отношении текстовые
единицы, т.е. на главные опорные словоформы. Как можно заметить из
таблицы 14, опорные словоформы текста включают несколько
имен существительных, одно имя прилагательное, одно
причастие, одно сокращение. В крупных промышленных системах
автоматического реферирования и аннотирования в компьютерной
памяти находится большой автоматический словарь, в котором
каждому слову приписаны различные лексико-грамматические
(часть речи, род, число, падеж, время и т.д.), семантические и
другие признаки. Поэтому, опираясь на такой словарь,
компьютер достаточно легко определит, к какой части речи относится
каждая опорная словоформа.
Далее необходимо заметить, что отнесение определителей к
классам имени прилагательного и причастия может быть осуществлено
по упомянутому выше автоматическому словарю. А выделение
среди имен прилагательных и причастий общеупотребительных
словоформ может быть сделано лишь путем сравнения каждого
определения со специальным списком общеупотребительных имен
прилагательных и причастий, помещенным в память компьютера.
Учитывая сказанное, подзадачу, которая должна быть решена
в блоке F, сформулируем так: «Читая последовательно все
предложения текста, выделить в них ключевые словосочетания (в
указанном выше понимании), расположить их по алфавиту и удалить
из них одинаковые».
В самом начале работы по автоматическому реферированию и
аннотированию текста в память компьютера вводится список
предлогов, артиклей, наречий, союзов, числительных, вспомогатель-
72
ных глаголов, местоимений, а также общеупотребительных имен
прилагательных и причастий. Обрабатываемый текст уже
находится в компьютерной памяти {блок А). Далее начинается
последовательное чтение отдельных предложений. В каждом прочитанном
предложении компьютер ищет опорную словоформу — имя
существительное. Если она найдена, то компьютер выделяет из
предложения словоформу, стоящую перед опорной, и сравнивает ее с
введенным ранее в память списком служебных и
общеупотребительных словоформ. Словоформу-определение, не найденную в
таком списке, компьютер объединяет со стоящим за ней
опорным именем существительным и передает полученное
словосочетание в специальную область памяти для ключевых
словосочетаний текста. В результате выполнения перечисленных действий
в компьютерной памяти окажутся следующие ключевые
словосочетания:
INTEGRATED CIRCUIT
ELECTRONIC COMPONENTS
SPECIAL CIRCUIT
INTEGRATED CIRCUITS
COMPUTER COMPONENTS
SEMICONDUCTOR CHIP
INTEGRATED CIRCUITS
MEMORY CHIPS
INTEGRATED CIRCUITS
PERSONAL COMPUTER
PERSONAL COMPUTER
ELECTRONIC COMPUTERS
PERSONALCOMPUTER
На следующем этапе работы компьютер сортирует этот список
по алфавиту:
COMPUTER COMPONENTS
ELECTRONIC COMPONENTS
ELECTRONIC COMPUTERS
INTEGRATED CIRCUIT
INTEGRATED CIRCUITS
INTEGRATED CIRCUITS
INTEGRATED CIRCUITS
MEMORY CHIPS
PERSONAL COMPUTER
PERSONAL COMPUTER
PERSONAL COMPUTER
SEMICONDUCTOR CHIP
SPECIAL CIRCUIT
И наконец, на последнем этапе компьютер исключает из
рассортированного списка ключевых словосочетаний полностью
повторяющиеся словосочетания. Если в таком списке встречаются
73
словосочетания, различающиеся лишь признаком числа имени
существительного (integrated circuit и integrated circuits), то в списке
остается словосочетание с именем существительным во
множественном числе. В итоге получается следующий список ключевых
словосочетаний текста:
COMPUTER COMPONENTS
ELECTRONIC COMPONENTS
ELECTRONIC COMPUTERS
INTEGRATED CIRCUITS
MEMORY CHIPS
PERSONAL COMPUTER
SEMICONDUCTOR CHIP
SPECIAL CIRCUIT
В общей формулировке задачи построения системы
автоматического реферирования и аннотирования (см. с. 60, 61)
отмечалось, что реферат представляет собой последовательность
ключевых предложений текста. Само же ключевое предложение было
определено как такое предложение текста, в котором содержится
три и более разных опорных слова. Поэтому подзадачу блока G
сформулируем следующим образом: «Читая последовательно все
предложения текста, выделить и запомнить те из них, в которых
содержится три и более разных главных или второстепенных
опорных слова данного текста».
Результатом работы блока G является реферат текста —
последовательность ключевых предложений, в каждом из которых
обнаружено три и более опорных словоформ текста.
В процессе выполнения блока Н на экран дисплея выводится
аннотация текста в виде полученных в блоке F ключевых
словосочетаний, перед которыми ставится фраза (релятор) «THIS TEXT
IS ABOUT:» («В ЭТОМ ТЕКСТЕ ГОВОРИТСЯ:»).
THIS TEXT IS ABOUT: COMPUTER COMPONENTS, ELECTRONIC
COMPONENTS, ELECTRONIC COMPUTERS, INTEGRATED
CIRCUITS, MEMORY CHIPS, PERSONAL COMPUTER,
SEMICONDUCTOR CHIP, SPECIAL CIRCUIT.
Выполнение блока I позволяет напечатать на экране дисплея
все ключевые предложения текста. Они и представляют собой его
реферат:
AN INTEGRATED CIRCUIT (1С FOR SHORT) WAS SOON
DEVELOPED. AN 1С IS A LARGE NUMBER OF TRANSISTORS AND
OTHER ELECTRONIC COMPONENTS WIRED TOGETHER.
INTEGRATED CIRCUITS, ALSO CALLED CHIPS, ARE NOW
MANUFACTURED SEPARATELY FROM COMPUTERS. THE MOST
IMPORTANT OF THESE COMPUTER COMPONENTS IS THE CENTRAL
PROCESSING UNIT (CPU FOR SHORT) OR MICROPROCESSOR.
MICROPROCESSORS ARE USED IN MINICOMPUTERS AND EACH
74
OF THESE INTEGRATED CIRCUIT IS CAPABLE OF PROCESSING
8-BIT OR 16-BIT DATA. SOME OTHER COMPONENTS OF A
COMPUTER ARE COMPUTER MEMORY CHIPS, VOICE
SYNTHESIZERS THAT PRODUCE SOUNDS SIMILAR TO HUMAN SPEECH
AND EVEN INTEGRATED CIRCUITS THAT PERMIT THE COMPUTER
TO SEND COMPUTER DATA ON. A TELEPHONE LINE.
С опорой на рассмотренный алгоритм выделяются
необходимые переменные и составляется программа автоматического
реферирования и аннотирования [73, 101—104].
Системы автоматического реферирования
и аннотирования текстов
Основанные на описанных выше принципах,
экспериментальные системы автоматического реферирования и аннотирования
представлены в целом ряде работ [7; 23; 134; 168; 177; 207].
Наиболее известной в наши дни промышленной системой
автоматического реферирования является система «Либретто»,
разработанная по технологии компании «МедиаЛингва» [27, 16]. Она
осуществляет автоматическое реферирование русских и
английских текстов любого объема и любой степени слолрюсти.
Исходный текст может сжиматься с необходимым пользователю
коэффициентом сжатия, а реферат выдается в виде цепочки
ключевых предложений или ключевых слов (аннотация). На западном
рынке к системам подобного типа относятся системы
автоматического реферирования «Inxight Summerizer», Prosum [135, 128,
129; 258]. Несколько упрощенный вариант реферата в виде
последовательности именных групп, выделенных с помощью
синтаксических анализаторов, могут выдать системы «Extractor» и
«TextAnalyst» [135, 129]. Последняя система создана в Москве в
инновационном центре «Микросистемы».
МАШИННЫЙ ПЕРЕВОД ТЕКСТОВ
Перевод текстов. Общие понятия
Существуют различные определения понятия перевод текстов.
В качестве рабочего определения примем следующее: «Перевод
есть вид человеческой языковой деятельности, в результате
которой некоторый текст на одном языке ставится в соответствие
тексту на другом языке, при этом обеспечивается их смысловая
эквивалентность» [123, 30]. Слово «перевод» понимают двояко: как
сам процесс перехода от текста на одном языке к этому же тексту
75
на другом языке, так и результат этого перехода, т.е. тот текст,
который получается в результате перевода.
Переводом текстов человек начал заниматься еще в античном
мире — более 20 веков назад. Одним из первых основные
принципы перевода сформулировал Марк Тулий Цицерон (106—43 гг.
до н.э.), древнеримский политический деятель, оратор и
писатель. Он переводил произведения древних греков на латинский
язык и считал, что переводить следует не слова, а мысли, не
букву, а смысл, в соответствии с условиями и духом своего языка.
Однако такой правильный взгляд на теорию перевода не
являлся общепринятым как в древние, так и в последующие
средние века (конец V—середина XVII в.). Вред научной теории
перевода принесли переводы древнееврейских религиозных текстов на
* другие языки. При этом любое отступление от оригинала
рассматривалось как ересь. Такой подход привел к возникновению и раз^
витию пословного перевода, буквализму, искажавшему смысл и
стиль текста исходного языка.
В эпоху Возрождения (XIV—XVI вв.) появились шедевры
мировой литературы: произведения Ф. Рабле, У. Шекспира, С.
Сервантеса, Ф. Петрарки, Дж. Боккаччо и целого ряда других
писателей и поэтов, что привело к резкому возрастанию количества
переводов. В это время особенно отчетливо стали осознаваться
трудности перевода художественных текстов. Как протест против
пословного, буквального перевода начинает возникать вольный
перевод, при котором на другом языке передается лишь общая
идея текста исходного языка. Такой перевод не учитывает
стилистические особенности автора исходного текста, реалии места и
времени описываемых в нем событий и многие другие
особенности переводимого произведения. В процессе вольного перевода
тексты исходного языка порой искажались до неузнаваемости.
В течение многих веков речь шла лишь о переводе
художественных текстов. И многие переводчики, литераторы, критики
сомневались, что при этом можно передать художественную ценность
оригинана. Известный лингвист Вильгельм фон Гумбольдт (1767—
1835) писал об этом так: «В сущности всякий перевод
представляется мне попыткой решить неразрешимую задачу, ибо
переводчик оказывается между Сциллой и Харибдой: либо он в ущерб
традиционным пристрастиям и языку своей нации держится
слишком близко к оригиналу, либо — напротив — приносит оригинал
в жертву особенностям своего языка и национального вкуса.
Благополучно миновать обе эти особенности не только трудно, но и
невозможно» [цит. по: 119, 8]. Как видно, В. фон Гумбольдт стоял
на позициях «непереводимости»: возможен или буквальный, или
вольный перевод. Третьего не дано.
Идеи перевода в значительной степени интересовали И. В. Гёте,
Н.В.Гоголя, А.С.Пушкина, В.Г.Белинского и других писателей,
76
поэтов, критиков, переводчиков. Их труды, а также работы их
последователей постепенно помогли подойти к созданию
истинно научных теорий перевода, утверждающих возможность
хорошего перевода текста с любого языка на другой язык. Такие
теории начали создаваться в 50—60-е годы XX века. Не
останавливаясь подробно на этом вопросе [12; 236; 105; 143; 112; 119], отметим
их одну общую особенность: данные теории опираются на метод
моделирования процесса перевода текстов человеком.
Существование нескольких современных теорий перевода
объясняется, во-первых, тем, что объект моделирования —
умственные действия человека в процессе перевода — сложен и
недоступен прямому наблюдению. Во-вторых, теории перевода решают
разные задачи, связанные с языками, психологией человека,
культурой и традициями страны исходного языка (ИЯ) и переводного
языка (ПЯ). Все эти теории (модели) гипотетичны. Степень их
«пригодности» для той или иной пары языков проверяется
практикой.
Насчитывается большое количество типов и видов переводов,
существуют различные подходы к их классификации [142, 48—
55]. Рассмотрим некоторые из них.
В зависимости от переводного материала различают:
1) перевод художественной литературы;
2) научно-технический перевод (перевод научно-технических,
военных, юридических текстов и т.д.);
3) общественно-политический перевод (перевод газет,
политических журналов и т. д.);
4) бытовой перевод (перевод текстов разговорно-бытового
характера).
По форме презентации текста перевода и текста оригинала
выделяют:
1) письменный перевод;
2) устный перевод.
По признаку основной прагматической функции перевода (с
какой целью делается перевод) различают:
1) практический перевод (в целях получения новой
технической, экономической, политической, эстетической и другой
информации);
2) учебный перевод (для обучения основам перевода);
3) экспериментальный перевод (например, для оценки
умения переводчика и качества работы);
4) эталонный перевод (как образцовый перевод, с которым
сравниваются другие переводы).
По степени механизации процесса перевода выделяют:
1) традиционный («ручной») перевод, выполняемый человеком;
2) перевод, выполняемый человеком с помощью компьютера
(например, когда в памяти электронного устройства находится
77
двуязычный словарь и компьютер по запросу пользователя ищет
переводные эквиваленты иностранных слов);
3) перевод, выполняемый компьютером с помощью человека
(например, когда компьютер по специальной программе делает
перевод, а за справками — неизвестным переводным
эквивалентом, неизвестной синтаксической структурой и т. д. — обращается
к человеку-интерредактору);
4) машинный или автоматический перевод (выполняется
компьютером без вмешательства человека).
Необходимость создания систем машинного перевода
Как было отмечено выше, машинный перевод осуществляется
компьютером самостоятельно, без вмешательства человека. Более
строго это понятие может быть определено следующим образом
[142, 80]: машинный, или автоматический перевод, (МП или АП)
(англ.: machine translation, automatic translation) — это
выполняемое компьютером действие по преобразованию текста на одном
естественном языке в текст на другом естественном языке при
сохранении эквивалентности содержания, а также результат
такого действия. Человек, как правило, в той или иной мере
участвует в подготовке машинного перевода или в его «доведении»
до удобочитаемого вида. Чаще всего до ввода в компьютер
переводимый текст специальным образом готовится человеком-предре-
дактором. Он упрощает структуру предложений, выделяет
терминологические обороты, указывает класс слов для омографичных
форм и т.д. Выданный компьютером перевод для удобства чтения
подвергается стилистической правке человеком-постредактором.
В течение последних десятилетий большое внимание во всех
странах уделяется научно-техническому переводу — основному
источнику новых научных и технических знаний. Европейское
экономическое сообщество имеет свою службу перевода,
включающую около 2 тыс. переводчиков. Они переводят в год
примерно 600000 страниц текстов с пяти языков и также не справляются
со все возрастающими потоками заказов на переводы [123, 3]. Это
приводит к тому, что до специалистов различных стран
зарубежная информация доходит с большим опозданием (порой через
5—10 лет). Единственным способом увеличения скорости
перевода является использование в переводческой деятельности
современных компьютеров, которые в миллиарды раз быстрее
человека могут выполнять необходимые для перевода логические
действия. Человек-переводчик тратит 20 % своего времени на перевод,
40 % — на поиск по словарю незнакомых слов и 40 % — на
перепечатку и оформление перевода. Компьютер же в процессе
перевода тратит 95 % времени непосредственно на перевод и 5 % на
78
пополнение словаря. Если максимальная производительность
труда переводчика составляет 4—5 авторских листов в месяц, то
такая, например, система машинного перевода, как SYSTRAN,
переводит в час до 1 млн словоупотреблений (около 120 авторских
листов). Эти количественные характеристики свидетельствуют о
преимуществе компьютерных систем. Однако качество такого
перевода значительно уступает переводу, сделанному человеком.
И тем не менее проблемами машинного перевода сейчас активно
занимаются во всех развитых странах: США, Франции, Японии,
Германии, Китае и т.д. Ежегодно по машинному переводу
проводится несколько крупных международных конференций, в разных
странах постоянно издаются журналы и книги по этой проблеме
[59]. Первый эксперимент по машинному переводу был проведен
в США в Джорджтаунском университете 7 января 1954 года. ЭВМ
перевела с русского языка на английский несколько достаточно
простых предложений по физике [204]. В России первый
машинный англо-русский перевод был выполнен в 1955 году.
Основные понятия и проблемы машинного перевода
Чтобы понять, какие проблемы стоят перед специалистами по
машинному переводу, рассмотрим, что нужно знать для того,
чтобы перевести текст с одного языка на другой. Это прежде всего:
1) язык (лексика, грамматика), с которого осуществляется
перевод; .
2) язык (лексика, грамматика), на который переводится текст;
3) предметное содержание переводимого текста (реалии места
и времени, область специальных знаний, индивидуальные
особенности переводимого автора и т.п.).
Выше было отмечено (см. с. 77), что все теории перевода
текстов построены на основе моделирования деятельности человека-
переводчика. Это в полной мере относится и к теориям
машинного перевода. Однако мало что известно о детальных процедурах
перевода текста человеком. В общем виде процесс перевода текста
состоит из следующих трех этапов [114, 59—88]:
1) постижение текста на ИЯ;
2) интерпретация текста на ИЯ;
3) перевыражение текста ИЯ и создание текста на ПЯ.
Суть постижения исходного текста заключается в понимании
того, о чем говорится в исходном тексте. При этом выделяют три
формы понимания:
а) филологическое, или дословное, понимание текста. При этом
предполагается, что человек, читающий текст, понимает
значение всех слов этого текста, смысл всех его предложений и
содержание всего текста;
79
б) стилистическое понимание — это понимание настроения
героев, их иронии, трагических и комических эффектов и т. д.;
в) понимание идейного замысла автора. Оно выражается в
осознании следующего: для чего автор писал свое произведение, что
он хотел сказать читателю, какие цели преследовались автором
при создании текста.
Переходя к характеристике интерпретации текста,
необходимо отметить, что какие бы пары языков ни использовались в
качестве исходного и переводного, в таких языках нет полного
семантического тождества: слову ИЯ, как правило,
соответствует несколько слов ПЯ; один тип предложения ИЯ может быть
передан несколькими синтаксическими структурами ПЯ; любая
связная последовательность предложений ИЯ передается
несколькими допустимыми последовательностями ПЯ. Поэтому
лингвистически тонный перевод текстов невозможен в
принципе. Возможна лишь правильная интерпретация текста на
исходном языке средствами переводного языка. При этрм переводчик
должен уметь передать объективный смысл всего произведения,
сводя к минимуму свое субъективное отношение к
описываемому в тексте.
Процесс перевыражения текста ИЯ в текст ПЯ носит
творческий характер. Переводчику надо не только заменить слова и
предложения ИЯ словами и предложениями ПЯ, но и сделать это
стилистически верно, художественно. Текст перевода должен
сохранить и предметное содержание исходного текста, и его
идейный замысел. Результатом процесса перевыражения должен стать
такой текст ПЯ, который считается явлением своей литературы,
переводного языка и в то же время сохраняет оттенок чужого
[119,7].
Перевод текстов — задача, которая до сих пор не имеет
однозначного алгоритма решения. Многие действия, которые
выполняет человек в процессе перевода текста, неясны, и это создает
огромные трудности в ходе построения алгоритмов машинного
перевода. Тем не менее большинство специалистов по переводу
отмечают, что в процессе перевода текста выполняется следующая
последовательность действий:
1) морфологический анализ каждого слова предложения ИЯ;
2) синтаксический анализ каждого предложения текста ИЯ;
3) синтаксический синтез каждого предложения ПЯ;
4) морфологический синтез каждого слова предложения ПЯ.
Человек выполняет эти действия, опираясь на знания языка
или словари. Очевидно, компьютер, осуществляющий перевод
текстов, должен уметь выполнять те же самые действия.
В процессе морфологического анализа слов предложения ИЯ
каждое слово получает наборы лексико-грамматических
признаков (часть речи, род, число, падеж, время, лицо, управление
80
и т.д.). Компьютер может сформировать такие наборы либо по
формальным признакам слов (суффиксам, окончаниям,
приставкам), либо с опорой на специальный автоматический словарь. В нем
каждой словоформе уже даны соответствующие лексико-грамма-
тические признаки, и в процессе морфологического анализа
слова компьютер берет их из словаря в готовом виде.
Синтаксический анализ предложения ПЯ сводится к поиску
основных членов предложения (группы подлежащего, группы
сказуемого и т.п.).
Синтаксический синтез предложения ПЯ заключается в
создании предложения ПЯ определенной синтаксической структуры,
определяемой правилами ПЯ и синтаксической структурой
предложения ИЯ. Чтобы компьютер мог выполнить это задание, он
должен иметь в памяти сведения о синтаксических структурах ИЯ,
ПЯ и их соответствиях друг другу.
Еще одна задача этапа синтаксического синтеза связана с
заменой слов ИЯ их переводными эквивалентами из словаря ПЯ.
Морфологический синтез каждого слова предложения ПЯ
сводится к постановке слов ПЯ в нужном числе, роде, падеже,
времени и т.д. Для этого компьютер должен владеть знаниями о лек-
сико-грамматических признаках каждого слова ПЯ, которые
берутся из упомянутого выше автоматического словаря.
Таким образом, система машинного перевода текстов,
например с английского языка на русский, должна состоять из
компонентов, показанных на схеме 6.
Назначение четырех представленных на этой схеме подсистем
ясно из вышеизложенного. Рассмотрим более подробно две
другие составляющие — англо-русский автоматический словарь и
англо-русские синтаксические соответствия.
Схема 6
ТЕКСТ
ИЯ
Англо-русский автоматический словарь
i
1
1
г
II Подсисте-
II ма
морфологического
1 анализа
1
i
i
г
Подсистема
синтаксического
анализа
j
г
Подсистема
синтаксического
синтеза
1
г
1
!
Подсистема морфо- II
логическогом
синтеза 11
Англо-русские синтаксические соответствия
ТЕКСТ
ПЯ
81
Автоматический словарь системы машинного перевода
Автоматический словарь (АС) системы МП во многом
определяет успех и эффективность этой системы. При построении таких
словарей решаются следующие задачи:
A. Определение способов представления лексических единиц
словаря ИЯ (входной словарь) и словаря ПЯ (выходной словарь).
Б. Выработка принципов отбора лексики для входного словаря.
B. Выработка принципов подбора переводных эквивалентов для
выходного словаря.
Г. Разработка способов кодирования лексико-морфологической,
синтаксической, стилистической и семантической информации.
Рассмотрим эти задачи более подробно.
А. Представление лексических единиц. Для представления
лексических единиц входного и выходного словарей чаще всего
используются два способа:
1) представление лексической единицы в виде словоформы;
2) представление лексической единицы в виде основы слова
(квазиосновы).
Когда единицами словаря являются словоформы, то в него
включаются все формы слов (все возможные формы имен
существительных, глаголов, имен прилагательных и т.д.). При этом
такие формы подаются гнездами, относящимися к одному
лексическому значению [30, 355—384]. Например, фрагмент русского
словаря, построенного по этому принципу, выглядел бы так:
БЛОК
БЛОКА
БЛОКУ
БЛОК
БЛОКОМ
БЛОКЕ
БЛОКИ
БЛОКОВ
БЛОКАМ
БЛОКИ
БЛОКАМИ
БЛОКАХ
ВКЛЮЧАТЬ
ВКЛЮЧАЮ
ВКЛЮЧАЕШЬ
ВКЛЮЧАЕТ
ВКЛЮЧАЕМ
ВКЛЮЧАЕТЕ
ВКЛЮЧАЮТ
ВКЛЮЧИЛ
ВКЛЮЧИЛА
КРАСИВЫЙ
КРАСИВОГО
КРАСИВОМУ
КРАСИВЫЙ
КРАСИВЫМ
КРАСИВОМ
ЧАСТО
ЧАЩЕ
Английский словарь, построенный по такому же принципу,
будет организован следующим образом:
BE BUILDS DEVICE
AM BUILT DEVICES
IS BUILDING EARLY
ARE CALL EARLIER
82
WAS
WERE
BEING
BEEN
BUILD
CALLS
CALLED
CALLING
COMPUTER
COMPUTERS
Если лексические единицы словаря представлены основами,
то в таком словаре группа форм, относящихся к одному
лексическому значению, представляется в виде общей основы этих слов.
Чаще всего такая основа не совпадает с основой слова,
выделяемой в традиционной (школьной) грамматике. Поэтому ее
называют квазиосновой. Приведенные ниже фрагменты словарей в виде
основ будут представлены так:
БЛОК# ...* 001 ВЕ# ... 001
ВКЛЮЧ# ... 002 BUIL# ... 002
КРАСИВ # ... 001 CALL# ... 003
ЧА # ... 003 COMPUTER # ... 001
DEVICE # ... 002
EARL# ... 001
Числа, стоящие после знака #, условно обозначают те наборы
суффиксов и окончаний, которые необходимо присоединить к
основе, чтобы получить соответствующие грамматические формы
слов. Эти числа называют типами формообразования, а сами
суффиксы и окончания — машинными окончаниями.
Каждая часть речи обладает своим набором машинных
окончаний. Это зависит от числа грамматических категорий языка,
которые характеризуют слово той или иной части речи. Так, русское
имя существительное определенного рода будет
характеризоваться числом (2 числа) и падежом (6 падежей). Всего оно будет иметь
12 грамматических форм. Русское имя прилагательное получает
свои грамматические характеристики от имени существительного.
Следовательно, у имени прилагательного определенного рода
также будет 12 форм. Более сложный набор грамматических
характеристик имеет русский глагол. Для него характерны следующие
категории: лицо, время, число, род, вид, залог, наклонение.
Естественно, что и число грамматических форм у глагола будет
значительно большим [155]. Не останавливаясь на этом достаточно
сложном вопросе, приведем в качестве примера фрагменты
таблиц типов формообразования имен существительных и личных
местоимений (табл. 15), кратких имен прилагательных (табл. 16),
имен прилагательных, причастий, притяжательных, указательных
и относительных местоимений (табл. 17), глаголов2 (табл. 18).
1 Вместо многоточия (...) в дальнейшем ставится морфологическая,
синтаксическая, лексическая и семантическая информация об основе (см. с. 87—94).
2 В таблице 18 девять типов формообразования глагола, так как будущее время
может быть образовано путем подсоединения приставки и машинного окончания
за/ую или же аналитически с помощью глагола быть (например, буду содержать).
83
Таблица 15
Фрагмент таблицы типов формообразования
имен существительных и личных местоимений
Номер типа
001
002
003
004
005
1 018
Единственное число
им. пад.
ел
я
а
ка
ы
род. пад.
а
ла
и
ы
ки
ас
дат. пад.
У
лу
и
е
ке
ам
вин. пад.
ел
ю
У
ку
ас
твор. пад.
ом
лом
ей
ой
кой
ами
предл. пад.
е
ле
и
е
ке
ас
Множественное число
им. пад.
и
лы
и
ы
ки
ы
род. пад.
ов
лов
й
—
ок
ас
дат. пад.
ам
ла
ям
ам
кам
ам
1
X
К
ю
и
лы
и
ы
ки
ас
твор. пад.
ами
лами
я ми
ами
ками
ами
предл. пад.
ах
лах
ях
ах
ках
ас
Пример
блок
узел
трукция
схема]
ботка
вы J
Таблица 16
Фрагмент таблицы типов формообразования
кратких имен прилагательных
Номер
типа
001
002
Единственное число
муж. род
ен
ок
жен. род
на
ка
сред, род
но
ко
Множественное
число
ны
ки
Пример
удобен
краток \
Более детально способы организации таких таблиц
формообразования для слов различных языков представлены в целом ряде
исследований [30; 132, 97-115; 36].
Выбор типа лексических единиц (словоформы или основы),
включаемых во входную и выходную части АС, зависит главным
образом от следующих факторов: 1) типа языка; 2) объема
проектируемого словаря; 3) назначения системы МП.
Флективные и агглютинативные языки (русский, белорусский,
немецкий, польский, казахский и т.д.) имеют большое число
форм слов. В памяти компьютера они займут очень много места.
Поэтому для таких языков машинный словарь лучше строить по
основам.
Для языков аналитического типа (английский, французский,
испанский, итальянский и т.д.) можно в качестве лексических
единиц выбрать словоформы, так как число форм слов в них
невелико.
84
s
к
Ю
H
(О
т.
и
-0 2
и
? JQ
S X
а л
ii
S О
|S
с) Л
2 =с
а л
о S
§Й
|з
о *
■&>
Ш X
Её
с *
{Е
а>
(О
а
е
о,
S
С
•ffBU
•irtfödu
•ITBU
'dosx
•ITBU
•ния
•ITBU
'XBtf
•ITBU
trod
•ffBII
•inrsdii
ITBU
doflx
•itbu
•ния
ITBU
*XBff
•ITBU
•trod
•itbu
•iflfcdu
•itbu
•doflx
•itbu
•нив
ITBU
•XBtf
•itbu
•tfod
•itbu
•irtftdii
•tfBlI
•doex
•itbu
•ния
•tmu
XBtf
ITBU
•tfod
Bimx ddKOH
f
a
ti
я
*?
ю
Н
X
ев
со
о
о
(О
а
ю
о
о
2
а
о
■8-
QQ
О
Я"
S
с
ю
(О
I-
X
ф
U
(О
а
0
Я S
& cd
8
S
Пример
врем
4>
Будущ
время
о
о
mir
а»
mod
С
S
о
оно
она
X
о
2
в
3
к
S
X
о
оно
Л
X
о
g
Л
окироват
v§
|
за/з
н
за/уе
за/ует
■ fc
за/у<
за/уете
ja
за/уеш
S
Ч
^
за/ую
s
i
о
о
о
cd
О
вал
о
ключать
<s
Н
cd
Ё
Ё
Ё
иге
ишь
S
S
>»
Я
S
о
ев
S
а
удержать
G
Ifl
Ю
>
будет/
ать
>
буде
ать
будете/
ать
> 1
будеш!
ать
ем/
гь
УДУ/
ать
ю
s
5
ало
а
s
§
85
Если строится большой по объему автоматический словарь, то
его лучше организовать по основам. При этом в машинную память
можно поместить гораздо больше лексических единиц. Если
создаваемый машинный словарь невелик, то в качестве лексической
единицы можно использовать словоформу. В таком случае
упрощается и ускоряется процедура морфологического анализа и
синтеза слов.
Если строится система МП, которая должна давать и
пословный перевод, и перевод более высокого класса — семантический
или лексико-грамматический [161, 272—292], то целесообразнее
строить автоматический словарь выходного языка в виде
словоформ. В этом случае пословный машинный перевод
психологически легче читается. Если от системы МП не требуется выдачи
пословного перевода, то словарь можно строить по основам.
Б. Выработка принципов отбора лексики для входного словаря.
После принятия решения о том, из каких лексических единиц
будет состоять входной словарь системы МП, возникает вопрос:
откуда брать эти лексические единицы? Современные компьютеры
используются только для перевода научно-технических текстов.
Множество таких текстов, относящихся к достаточно узкой
предметной области (например, «вычислительная техника», «оптика»,
«виноделие», «атомная энергетика» и т.п.), называют подъязыком.
Но и лексику, специфичную для одного подъязыка, нельзя
полностью вложить в память компьютера по следующим причинам:
1) невозможно обнаружить всю лексику, так как тексты
любого подъязыка опубликованы в разных журналах и книгах (порой и
в разных странах);
2) лексика любого подъязыка постоянно пополняется, поэтому
в любом машинном словаре будут отсутствовать новейшие термины.
В таком случае поступают следующим образом: за основу берут
опубликованный словарь соответствующего подъязыка. Так как
такие словари создаются и печатаются примерно 8—10 дет, то их
лексика в определенной степени устаревает. Чтобы внести в
машинный словарь новейшие термины, опубликованный словарь
подъязыка дополняется лексикой, полученной путем
статистического анализа текстов (журнальных статей, монографий и т.д.),
изданных в последнее время. Статистический анализ заключается
в построении по этим текстам частотно-алфавитного словаря
словоформ. Если по данному подъязыку нет опубликованного
словаря, то для его создания набирается достаточно большой объем
текстов рассматриваемой предметной области (порядка 500000
словоупотреблений) и по этим текстам строится
частотно-алфавитный словарь. Он и будет являться основой автоматического
словаря для данного подъязыка.
В. Выработка принципов подбора переводных эквивалентов для
выходного словаря. Следующая задача создания автоматического
86
словаря связана с подбором переводных эквивалентов для
выходного словаря системы МП. Если опубликован двуязычный словарь
по подъязыку (например, англо-русский словарь по
вычислительной технике), то переводные эквиваленты извлекаются из такого
двуязычного словаря. Причем выбор из большого числа
содержащихся в данном словаре переводных эквивалентов конкретных
двух-трех, включаемых в АС, проводится или с опорой на
русский частотный словарь соответствующего подъязыка (для
словаря отбираются переводные эквиваленты, которые в русском
частотном словаре имеют наибольшую частоту), или же путем
консультаций со специалистами. При отсутствии опубликованного
двуязычного словаря по конкретному подъязыку отбор
необходимых единиц в выходной словарь ПЯ проводится с помощью
специалистов, хорошо знакомых с тематикой и знающих ИЯ и ПЯ.
Г. Разработка способов кодирования информации. Лексическая
единица автоматического словаря (словоформа или основа)
вместе с набором значений ее всевозможных признаков называется
машинной словарной статьей. Для размещения набора значений
признаков лексической единицы в словарной статье выделяют
обычно четыре зоны [232]: 1) морфологических сведений; 2)
семантических сведений; 3) синтаксических сведений; 4)
лексических сведений.
В зоне морфологических сведений в самом простейшем виде
располагаются следующие признаки:
1) признак части речи, к которой относится лексическая единица;
2) морфологические признаки лексической единицы.
Зона семантических сведений должна, как минимум, включать:
1) семантический признак лексической единицы (ее
принадлежность к определенному семантическому подклассу:
«одушевленный», «физическое движение» и т.п.);
2) переводные эквиваленты иностранного слова.
К числу синтаксических признаков, включаемых в зону
синтаксических сведений лексической единицы, относится, например,
управление этой единицы (глагола, предлога).
В зоне лексических сведений минимально сообщается о:
1) стилистическом использовании лексической единицы
(является она «общеязыковой» или принадлежит к определенному
подъязыку);
2) использовании этой единицы как части фразеологизма или
устойчивого словосочетания.
Рассмотрим подробнее, как выделяются и кодируются в
словарной статье указанные признаки.
Зона морфологических сведений.
Если строится, например, система англо-русского МП, то
части речи английского и русского языков могут быть представлены
в следующем виде [30, 341; 232, 26—28; 36, 217] (табл. 19).
87
Таблица 19
Части речи, используемые в системе англо-русского перевода
Номер
части
речи
1.
2.
3.
4.
1 5-
6.
1 7-
8.
9.
10.
11.
12.
13.
1 14-
1 15.
Наименование части речи
Имя существительное
Имя прилагательное
Краткое имя прилагательное
Глагол
Причастие (русское), причастие II
Причастие I
Деепричастие
Наречие
Имя числительное
Местоимение
Предлог
Союз
Частица
Междометие
Артикль
Код
части речи
N |
А 1
Е
V J
R 1
х 1
к 1
D
В
Р
G
С
Т
м
L
Для кодирования морфологических признаков лексических
единиц, принадлежащих к одному из 15 классов, представленных в
табл. 19 (учитывая английскую и русскую грамматики),
используем специфичные наборы грамматических признаков (табл. 20).
Таблица 20
Специфичные наборы грамматических признаков
для различных частей речи
Часть речи
Имя существительное, порядковое
имя числительное, имя прилагательное,
краткое имя прилагательное
Глагол
Специфичные наборы
грамматических признаков
Род, число, падеж
Время, лицо, число, род,
вид, залог, наклонение,
переходность
88
Окончание табл. 20
Часть речи
Причастие (русское), причастие I,
причастие II
Деепричастие
Наречие
Местоимение
Артикль
Специфичные наборы
грамматических признаков
Время, число, род, вид,
залог, падеж, форма
Вид, переходность
Степень сравнения
Род, число, падеж, лицо
Тип
Для различных значений соответствующих категорий
используем данные таблиц 21—32.
Таблица 21
Род
Значение категории
Мужской
Женский
Средний
Смешанный
Код
1
2
3
4
Таблица 23
Лицо
Значение категории
Первое
Второе
Третье
Условное
Код
1
2
3
4
Таблица 25
Падеж
Значение категории
Именительный
Родительный
Дательный
Винительный
Творительный
Предложный
Код
1
2
3
4
5
6
Таблица 22
Число
Значение категории
Единственное
Множественное
Двойственное
Код
1 . .
2
■3
Таблица 24
Наклонение
Значение категории
Изъявительное
Повелительное
Сослагательное
Код
1
2
3
Таблица 26
Время
Значение категории
Настоящее
Прошедшее (перфект,
имперфект)
Будущее
Инфинитив
Будущее в прошедшем
Предпрошедшее
Код
1 '
■ 2
■з
4 '
5
6
89
Таблица 28
Ввд
Значение категории
Совершенный
Несовершенный
Код
1
2
Таблица 30
Форма
Значение категории
Полная
Краткая
Код
1
2
Таблица 32
Степень сравнения
Г Значение категории
Положительная
Сравнительная
Превосходная
Код
1 ■
2
3
Зона семантических сведений.
Следующая задача связана с выбором и кодированием
признаков, которые могут войти в зону семантических сведений. В
первую очередь это признаки семантических подклассов
знаменательных слов (имени существительного, имени прилагательного и
глагола), а также семантические группы местоимений, предлогов.
Вопрос об отнесении знаменательного слова к тому или иному
семантическому подклассу достаточно сложен. В самом общем виде
он сводится к выделению в слове определенного семантического
признака (или признаков), который является ведущим на каком-
то этапе анализа. Существуют различные подходы к выделению
таких признаков [132, 117—134; 34, 64; 249, 16—18, 50—52]. Не
останавливаясь подробно на этом вопросе, допустим для
конкретности, что строится автоматический англо-русский словарь для
перевода текстов по вычислительной технике. Тогда, например,
для имен существительных этого подъязыка можно выделить
семантические подклассы (табл. 33).
Подобные семантические подклассы выделяются для глаголов,
прилагательных, предлогов и некоторых других классов слов. Сюда,
в частности, относятся и известные типы местоимений (табл. 34).
Таблица 27
Тип
Значение категории
Определенный
Неопределенный
Код
1
2
Таблица 29
Переходность
Значение категории
Код
Переходный
Непереходный
Переходный/непереходный
Таблица 31
Залог
Значение категории
Код
Активный
Пассивный
Возвратный
Возвратный/пассивный
1
2
3
4
90
Таблица 33
Семантические подклассы имен существительных
подъязыка «вычислительная техника»
№
п/п
1
2
3
4
5
6
7
Семантический подкласс
Деталь электронных приборов
Блок или небольшая конструкция
Процесс создания электронного
прибора или устройства
Операции, выполняемые
электронным устройством
Крупное электронное устройство
Сложная электронная деталь
Информационные понятия
Код
1
2
3
4
5
6
7
Пример
лампа, переключатель \
принтер, дисплей
конструирование,
создание
инструкция, оператор
компьютер, микроЭВМ\
интегральная схема,
микропроцессор
байт, бит, данные
Таблица 34
Семантические подклассы местоимений
№
п/п
1
2
3
4
5
6 ■
7
8
9
Семантический подкласс
Личные
Указательные
Притяжательные
Возвратные
Определительные
Вопросительные
Относительные
Отрицательные
Неопределенные
Код
1
2
3
4
5
6
7
8
9
Пример
я, мы
этот, тот
мой, твой
себя
весь, другой
кто, что
кто, который
никто, ничто
кто-либо, некто
К зоне семантических сведений относятся и переводные
эквиваленты английских слов. Возможны два способа их задания в
словарной статье.
1. Русские эквиваленты указываются в машинной словарной
статье сразу за английской лексической единицей1:
1 В приводимой записи многоточие "..." замещает морфологическую,
семантическую, синтаксическую и лексическую информацию о лексической единице.
Знак * в русской основе показывает, в каком месте к основе необходимо
подсоединить определенные суффиксы и окончания, которые хранятся под номерами
(типами формообразования), приводимыми за многоточием. Соответствующее
окончание см. в таблицах 15—18.
91
BLOCKS ...# БЛОК* ...001; БЛОКИР* ... 001
CENTRAL ...# ЦЕНТРАЛЬН* ...001
2. Русские переводные эквиваленты задаются в виде числового
адреса, под которым они хранятся в памяти компьютера:
Английская часть словаря Русская часть словаря
BLOCKS ...#006; 007 006 БЛОК* ... 001
CENTRAL ...#015 007 БЛОКИР* ...001
015 ЦЕНТРАЛЬН* ...001
Зона синтаксических сведений.
Синтаксические сведения о лексической единице включают,
как минимум, управление глагола и предлога. Для этого можно
воспользоваться, например, таблицей типов управления (табл. 35).
Таблица 35
Типы управления глагола и предлога
№
п/п
1
2
3
4
5
6
7
8
9
10
11
12
13
14
Тип управления
Требует родительного падежа
Требует дательного падежа
Требует винительного падежа
Требует творительного падежа
Требует предложного падежа
Требует винительного или родительного падежа
Требует винительного или творительного падежа
Требует дательного или родительного падежа
Требует дательного или творительного надежа
Требует дательного или винительного падежа
Требует родительного или творительного падежа
Требует дательного, винительного или родительного
падежа
Требует дательного, винительного или
творительного падежа
Требует дательного, винительного, родительного
или творительного падежа
Код
2
3
4
5
6
7 ■
8
9
10
. 11
12
13
14
15
Зона лексических сведений.
Лексические сведения, как уже отмечалось, включают
некоторые стилистические признаки и указание на употребление
лексической единицы во фразеологическом или устойчивом
словосочетании. При переводе, например, английских текстов по
вычислительной технике на русский язык можно воспользоваться таблицей
стилистических признаков (табл. 36).
92
Таблица 36
Стилистические признаки слов подъязыка
«вычислительная техника»
№
п/п
1
2
Стилистический признак
Общеупотребительное слово
Слово, специфичное для подъязыка
«вычислительная техника»
Код
1
2
Употребление лексической единицы во фразеологизме можно
фиксировать двумя способами:
1) указанием в зоне лексических сведений машинной
словарной статьи части фразеологизма, в котором употребляется
лексическая единица. Например, для слова быть можно указать слово
баклуши и т.д.;
2) внесением всего фразеологизма в специальный словарь
фразеологизмов, который функционирует в системе МП наравне с
автоматическим словарем отдельных лексических единиц.
Для размещения всей указанной выше информации
разрабатывается структура машинной словарной статьи.
Продемонстрируем это на примере структуры словарной статьи для имени
существительного.
Как отмечалось выше (см. табл. 20), для русского имени
существительного специфичны следующие морфологические
признаки: часть речи, род, число, падеж. Так как для их кодирования
используется одна буква (для кода части речи) и по одной цифре
(см. табл. 19, 21—32), то всего для морфологической зоны
необходимо 4 байта1. Условимся также, что если лексическая единица
задается в виде основы (например, для русского словаря), то при
такой основе будет использован трехцифровой код, обозначающий
ее тип формообразования (см. с. 83). Для его записи в структуре
машинной словарной статьи отведем 3 байта. Для записи
семантического подкласса лексической единицы используем 1 байт, так
как таких подклассов для имени существительного было
выделено 7 (см. табл. 33). Условимся также, что адрес русского
переводного эквивалента будем записывать с помощью трехзначного числа,
т. е. ему в памяти компьютера отведем 3 байта. Синтаксических
признаков в простейшем случае имя существительное иметь не будет.
Наконец, стилистический признак, включаемый в лексическую зону
словаря, будем кодировать, используя один байт (цифра 1 или 2,
см. табл. 36), а для записи части фразеологизма в словарной статье
отведем в ней, допустим, 10 байтов. Тогда машинная словарная
1 Напомним, что 1 байт «вмещает» одну букву, один орфографический знак,
одну цифру.
93
статья для имени существительного, имени прилагательного,
порядкового числительного английского языка будет иметь
следующий вид (схема 7).
Схема 7
Структура машинной словарной статьи
для имени существительного, имени прилагательного,
порядкового имени числительного ИЯ (английского языка)
ксич. единиц*
Ч
1
s
о
сх
1
er
2
о
S
S
3
I
4
1
5
и:
ев
X
со
S
&
С
S
и
6
7
8
9
10
11
12
13
14
15
S
1 §
Си
^
16
о
§
ё
2
Ö
17
18
19]
2 1
о
5 ж
« «и
&|
о со
С К
о S
СХ
Морфологическая Лексическая информация Семантическая
И1
яфо!
эмаи
(ИЯ
информация
Например, машинная словарная статья для английского слова
chips (микросхемы) будет выглядеть так1 (ср. табл. 19, 21, 22, 25,
33, 36):
1 2 3 4 5 6 7 8 9 10 И 12 13 14 15 16 17 18 19
CHIPS/N2„2 6#0 1 6
Соответствующую русскоязычную машинную словарную статью
для указанных частей речи можно представить в виде схемы 8.
Схема 8
Структура машинной словарной статьи
для имени существительного, имени прилагательного,
порядкового числительного ПЯ (русского языка)
| Адрес перевод, эквив.
я
X
X
э
i
ä
1
s
s
сх
i
2
о
5
s
3
1
4
i
С
5
s
J
6
7
8
9
10
11
12
13
14
15
2
S
Is
IT d
1
16
s
a
с
Ё
и
17
18
X
1
С сЗ
s ex
о
2
ex
о
I9]
Морфологическая
информация
Лексическая информация
Семантическая
информация
1 Знак 7" в такой записи служит для отделения самой лексической единицы
отч информации к этой единице. Знак "_" представляет незаполненные байты,
предназначенные для записи части фразеологизма и отсутствующих признаков
рода и падежа. Если переводных эквивалентов несколько (слово многозначно),
то в такой записи указываются все их адреса.
94
Тогда русский переводной эквивалент английского слова chips
имеет в машинной памяти следующий вид:
016MHKPOCXEM*N2 2 * 2*
1516 17 18 19
6004
Здесь первые три знака (016) — адрес переводного
эквивалента, а последние три знака (004) — тип формообразования
существительного микросхемы (ср. табл. 15).
Для английского и русского глаголов машинные словарные
статьи будут представлены так, как показано на схемах 9 и 10:
* ' Схема 9
Структура машинной словарной статьи для глагола ИЯ
(английского языка)
10 11 12
23 24 25 26
«
о
К
X
§
с
U
се
о
о,
2
о
О X
0Q (U
а §
С S
8 §
3
Схема 10
Структура машинной словарной статьи для глагола ПЯ
(русского языка)
со
перевод, экви
Адрес
к
X
X
5
S
о
1
S
U'
2
о
5
К
3
я
4
S
5
I
6
1
ю
7
О
ГО
8
Я
Ä
о
Я
о
Я
9
е
о
о
X
1
10
11
S
X
о
се
а
>>
12
к
со
Я
а
В
я
J
се
со
£
о
§
1
1
23
с«
X
со
Я
а
с
Ё
S
и
24
25
1б]
Я
X
S
о
«
си
Аналогичным образом строятся машинные словарные статьи и
для слов других частей речи, указанных в таблице 19. Они
приведены на схемах 11 — 16.
95
Схема 11
Структура машинной словарной статьи для причастия I,
причастия II ИЯ
1
3 4 5 6
8 9 10 I 11
22 23 24 25
«
Я
X
cd
С*
и
1
Ä
и
2
ll
СО 0>
V CQ
С S
о«
3
Схема 12
Структура машинной словарной статьи для местоимения ИЯ
Лексич. единица
1
s
о,
1
2
о
5
S
3
1
4
I
С
5
к
6
ä
X
со
К
&
Ё
ев
(3
7
8
2
h
1
9
Схема 13
Структура машинной словарной статьи для наречия ИЯ
1
3
s
cd
К
ж
«
а
о
л
X
а>
U
s
Ö
5
и
I
cd
96
Схема 14
Структура машинной словарной
статьи для предлога ИЯ
3
ксич. ед*
1
К
1
■£
2
о>
равле)
Ä
3
изнак
сх
S
Ö
4
5
6
о
одног
нта
перев
ивале
1
Схема 15
Структура машинной словарной
статьи для союза, частицы,
междометия ИЯ
§
я
X
еди
ексич
t=5
1
. s
&
Й
У
F
2
3
2
о
11
СХ еЗ
о «
рес п
экви
3
4
Схема 16
Структура машинной словарной статьи для артикля ИЯ
Лексич.
единица
1
Часть речи
2
Тип
3
4
5
Адрес переводного эквивалента
Однако большое число слов в любом языке по своей форме
могут относиться к разным частям речи. Например, русское слово
пень может быть и именем существительным, и глаголом,
английское, слово blocks может быть существительным во
множественном числе и глаголом в 3-м лице единственного числа настоящего
времени и т. п. В таких случаях в словарной статье
соответствующего слова ИЯ (например, английского) указывается информация,
относящаяся к двум частям речи. Общая схема словарной статьи
тогда будет представлена следующим образом (схема 17).
Схема 17
Общая схема словарной статьи ИЯ системы МП
Лексич.
единица
Код
1-й части
речи
Код
2-й части
речи
Информация
1-й части
речи
Информация
2-й части
речи
Адреса
перевод.
эквив.
1-й части
речи
Адреса
перевод.
эквив.
2-й части
речи
4 Зубо»
97
Следовательно, в соответствии со схемами 7, 9, 17, а также
табл. 17—34 английское слово blocks будет закодировано
следующим образом:
BLOCKS/NV2„2. 2111.2111072 . 2#006;007
где цепочки цифр: 2 2 2 й 111.211072 2
представляют соответственно информацию имени
существительного (см. схему 7) и глагола (см. схему 9); число 006 — адрес
переводного эквивалента для blocks в функции имени
существительного; 007 — адрес переводного эквивалента того же слова в функции
глагола.
Структура машинных словарных статей для слов ПЯ
(например, русского) остается без изменения (см. с. 94, 95).
Пользуясь структурными схемами словарных статей для слов
разных частей речи и таблицами кодов морфологических,
семантических, синтаксических и лексических признаков
соответствующих лексических единиц, можно составить автоматический
двуязычный (например, англо-русский) словарь.
Система синтаксических соответствий ИЯ и ПЯ
Любые пары языков (ИЯ и ПЯ) не являются полностью и
однозначно эквивалентными как на уровне отдельных слов, так и
на уровне предложений. Выбор для предложения ИЯ
определенной синтаксической структуры в ПЯ является достаточно
сложной задачей [124, 38—46; 161, 290—292\. При этом должны быть
выполнены следующие условия.
1. Предложение ПЯ должно быть правильным с точки зрения
грамматики ПЯ.
2. Предложение ПЯ должно быть построено так, чтобы оно
теряло минимум информации, которую содержало предложение ИЯ,
3. Выбранная структура предложения ПЯ должна
употребляться в ПЯ (или в отдельном его подъязыке) чаще, чем другие
допустимые структуры, передающие смысл предложения ИЯ.
4. Предложение ПЯ должно быть по возможности ближе к
структуре предложения ИЯ, чтобы передать стилистические
особенности автора текста ИЯ.
Установление соответствий между синтаксическими
структурами ИЯ и ПЯ при машинном переводе возможно следующими
тремя способами.
1. В процессе перевода в качестве синтаксической структуры
для всех предложений ПЯ берется соответствующая
синтаксическая структура предложения ИЯ.
2. Для выяснения синтаксических соответствий структур
предложений ИЯ и ЕЯ в рамках отдельного подъязыка исследуются
98
параллельные тексты1 ИЯ и ПЯ. При таком анализе выясняется,
что некоторой структуре С! ИЯ будет соответствовать структура
Т{ ПЯ (или несколько допустимых структур), структуре С2 ИЯ —
структура Т2 ПЯ и т.д. Эти соответствия и закладываются в
компьютерную память для дальнейшей работы системы МП (см. табл. 37).
3. Синтаксические структуры для предложений ПЯ могут быть
получены и путем трансформаций синтаксических структур
предложений ИЯ.
Так, если необходимо найти все русские синтаксические
структуры, соответствующие английской синтаксической структуре
S+P+ О+АР (The workers build a nice house on the glade), то,
переставляя буквы, обозначающие члены предложения, можно
получить следующие возможные структуры2:
1.S+P + AP+0' 4.0 + AP+P+S
2.AP+S+P+0 5. 0 + AP+S+P
3. 0+S+P + AP 6. 0+Рся+£ + АРит.д.
Подставляя вместо букв русские слова, соответствующие
переводимым членам приведенного выше английского предложения,
получим следующие русские предложения:
1. Рабочие строят на поляне хороший дом.
2. На поляне рабочие строят хороший дом.
3. Хороший дом рабочие строят на поляне.
4. Хороший дом на поляне строят рабочие.
5. Хороший дом на поляне рабочие строят.
6. Хороший дом строится рабочими на поляне.
Анализируя эти предложения с точки зрения четырех
приведенных выше условий, можно отметить следующее. Структура 5
несколько необычна для русского языка. Структуры 3 и 4 более
типичны для устной разговорной речи или жанра
художественной литературы. Структуры 1 и 2 более нейтральны и вполне
возможны в публицистике (газете, журнале). Структура 6 более
типична для научного письменного текста. Такой анализ позволяет
выбрать из возможных русских структур ту единственную,
которая соответствует типу переводимого английского текста (газета,
журнал, повесть, научный текст и т.п.).
В итоге, если отбор синтаксических структур проводился
способами 2 и 3, то в машинную память системы МП вводится
таблица синтаксических соответствий ИЯ и ПЯ, подобная табл. 37.
Пользуясь такой таблицей в процессе перевода, компьютер
выбирает для каждого предложения ИЯ одну из возможных структур
1 Параллельными называются некоторый текст и его перевод на один или
несколько других языков.
2 Здесь: S — подлежащее, Р — сказуемое, О — дополнение, АР —
обстоятельство места, Рся — сказуемое, выраженное возвратной формой глагола.
99
Таблица 37
Синтаксические соответствия структур ИЯ и ПЯ
Синтаксическая
структура ИЯ
С] (например,
\S+ P+ 0 + АР)
с2
С3
Синтаксическая структура ПЯ
Ti (например,
S + Р + АР + О)
Т
(/tf> + -У + /> + О)
Тз
(0+Рся+5+^Р)
т4
т5
т6
т7
т8
Вероятность
употребления
вПЯ
0,5
0,22
0,14
0,63
0,15
0,32
0,30
0,22
Примечание
Для газеты
Для газеты
Для научного
текста
ПЯ в зависимости от вероятности употребления структуры в ПЯ
или типа переводимого текста.
Практическое построение системы англо-русского МП
Формулировка задачи. На устройстве внешней памяти
компьютера (дискете или винчестере) находится английский
научно-технический текст:
INTEGRATED CIRCUITS, ALSO CALLED CHIPS, ARE NOW
MANUFACTURED SEPARATELY FROM COMPUTERS. THEY
PROVIDE BUILDING BLOCKS TO BUILD A COMPUTER. THE
MOST IMPORTANT OF THESE COMPUTER COMPONENTS IS THE
CENTRAL PROCESSING UNIT (CPU FOR SHORT) OR
MICROPROCESSOR. IT IS THE PART OF THE COMPUTER THAT OBEYS
THE INSTRUCTIONS OF A PROGRAM. A MICROPROCESSOR IS A
SMALL UNIT CONTAINED ON THE SEMICONDUCTOR CHIP.
MICROPROCESSORS ARE USED IN MINICOMPUTERS AND EACH
OF THESE INTEGRATED CIRCUITS IS CAPABLE OF PROCESSING
8-BIT OR 16-BIT DATA.
Составить алгоритм перевода этого текста на русский язык при
следующих условиях:
1. Лексической единицей английского словаря является
словоформа.
2. Лексической единицей русского словаря является
квазиоснова.
100
3. Каждой английской лексической единице, относящейся к
определенной части речи, в автоматическом словаре
соответствует один-два русских переводных эквивалента1.
4. В машинной словарной статье лексической единицы
указываются ее морфологические, синтаксические и частично
семантические признаки.
5. Структура предложения русского языка на уровне членов
предложения соответствует структуре аналогичного английского
предложения (т.е. в системе МП отсутствует подсистема
синтаксических соответствий английского и русского языков).
Процесс создания такой системы МП является сложной
задачей. Она включает следующие процедуры:
1) создание автоматического англо-русского словаря и
разработку таблиц типов формообразования слов различных классов;
2) ввод автоматического словаря и таблиц типов
формообразования русских слов в память компьютера;
3) создание алгоритма англо-русского перевода текста;
4) написание на основе алгоритма программы машинного
англо-русского перевода.
Создание автоматического англо-русского словаря
В процессе создания англо-русского автоматического словаря
(АС) выполняются четыре конкретные задачи (А, Б, В, Г), о
которых подробно говорилось выше (см. с. 82—98). Способ
представления лексических единиц английского и русского словарей
(пункт А) отражен в самой формулировке задачи построения
системы (см. условия 1 и 2 на с. 100).
Разработка принципов подбора русских эквивалентов для
английских слов (пункт В) определен в условии 3 формулировки
задачи машинного перевода. Так как создаваемая система
перевода текста является учебной, то в качестве английской лексики
для АС взяты все словоформы, вошедшие в переводимый текст
(см. с. 100). Таким образом решена сформулированная в пункте Б
проблема отбора английской лексики для АС. Остановимся
более подробно на пункте Г — разработке способов кодирования
информации к единицам английской и русской частей
автоматического англо-русского словаря. Как отмечено в формулировке
задачи создания системы МП, в проектируемом словаре
используется морфологическая, синтаксическая и частично
семантическая информация об английских и русских лексических единицах.
В качестве морфологических признаков учитываются данные,
приведенные на с. 88, 89. Однако в целях упрощения программы
1 В качестве таких эквивалентов, как правило, берутся первые переводные
эквиваленты английского слова, зафиксированные в словарях.
101
перевода уточним число таких признаков для слов некоторых
частей речи:
1) для глагола отметим лишь четыре основных
морфологических признака: часть речи, число, лицо, время. Дополнительно
для русских глаголов введем синтаксический признак
«управление глагола»1;
2) для причастия — часть речи, число, род, падеж, вид;
3) для деепричастия и наречия — часть речи;
4) для слов остальных частей речи морфологическая
информация остается без изменения.
При кодировании английских и русских слов воспользуемся
структурами машинных словарных статей, представленных выше
(см. с. 94—97). При этом части словарных статей, не содержащие
морфологические, семантические и лексические признаки,
просто «отсекаются», и словарная статья становится короче на
величину отсутствующих признаков.
С учетом кодов морфологических и синтаксических признаков,
приведенных на с. 88—90, все слова использованного для
перевода английского текста были закодированы в соответствии с
упрощенными машинными словарными статьями. Начало такого
словаря выглядит следующим образом2:
Английская часть Русская часть
A/L2 #001 001J 000
ALSO/C #002 002 ТАКЖЕ/С 000
AND/C #003 003 И/С 000
ARE/V_2_1 ; #004, 005 004J 000
BLOCKS/NV2_ 111 #006,007 005 ЯВЛЯ*СЯ/У 5 J)09
006 БЛОК*1\[1 001
007 БЛОКИР*У 4 001
1 В отличие от описанной выше схемы кодирования управления глагола и
предлога в учебной программе МП «управление» указывается не в виде одного
двузначного кода, взятого из таблицы 35, а в виде двух однозначных кодов 2, 3, 4, 5,
6, взятых из той же таблицы. То есть если глагол требует после себя слова в
дательном или творительном падеже, то байты машинной словарной статьи для
«управления» содержат не число 10, как в таблице 35, а 35, где 3 — управление
дательным падежом, а 5 — управление творительным падежом (см. начало
таблицы 35).
2 Напомним, что информация для английских словоформ, относящихся по
форме к двум частям речи, дается в соответствии со схемой 17. Так, для слова
blocks вслед за кодами NV сначала указываются морфологические признаки для
существительного JV (первые 5 знаков), а затем для глагола V (следующие в этом
ряду 5 знаков). Если английское слово относится к одной части речи (also, and,
are и т.д.), то позиции другой отсутствующей части речи заполняются
пробелами "_". Адреса переводных эквивалентов, разделенные знаком ";", относятся к
разным частям речи, а разделенные знаком "," — к одной и той же части.речи
(например, для слова are).
102
В учебной системе МП используются те типы
формообразования имен существительных, местоимений, имен прилагательных,
причастий, кратких имен прилагательных и глаголов, которые были
разработаны нами ранее (см. с. 84, 85).
Ввод автоматического словаря и таблиц типов
формообразования русских слов в память компьютера
В промышленных системах МП словари и таблицы типов
формообразования русских слов занимают в памяти компьютера
много места. Поэтому их обычно хранят во внешней памяти (на
жестком диске). Для записи словарей и таблиц на этот носитель
информации используются специальные программы. В учебной
программе МП эта информация хранится во внутренней памяти
компьютера. Ввод автоматического англо-русского словаря и
таблиц типов формообразования производится непосредственно из
программы машинного перевода.
Алгоритм задачи перевода текста с английского языка
на русский
Как отмечалось выше, в системе МП выделяют четыре
основные подсистемы: морфологического анализа, синтаксического
анализа, синтаксического синтеза и морфологического синтеза,
каждая из которых выполняет определенную функцию. В основу
описанного ниже алгоритма перевода текста с английского языка
на русский положено условие, что каждое русское предложение
строится точно по той же схеме, что и соответствующее ему
английское предложение. Такая схема может быть задана на уровне
конкретных лексических единиц, членов предложения, частей речи
или отдельных групп слов (формальных групп), задаваемых
частями речи (табл. 38).
С точки зрения простоты выделения русских синтаксических
соответствий и последующего морфологического оформления
русских слов наиболее приемлемым является уровень формальных
групп. Это в определенной степени соответствует и тем
мыслительным операциям, которые выполняет человек в процессе
чтения текста. Как правило, он читает предложение не целиком, а по
частям. Такими частями являются определенные завершенные
цепочки слов: несколько стоящих подряд имен существительных
(например, «управление механизмами сортировки зерна»), имя
прилагательное и имя существительное, предлог, имя
прилагательное и имя существительное и т.д. Эти группы у разных
исследователей называются по-разному: синтагмами, группами,
фрагментами, формальными группами. Выделение таких групп человек
проводит с опорой на специальные граничные сигналы, в роли
103
Таблица 38
Возможные уровни синтаксических соответствий предложений
английского и русского языков1
Уровень соответствия
I Лексический
I Членов
предложения
| Частей речи
I Формальных групп
Английский язык
The workers build a nice
house on the glade.
S+P+O+AP
L+N+V+L+A+N+G+L+N
N{G+VG+N2G+PG
(L+N) + (V) + (L+A+N) +
+ (G+L + N)
Русский язык
Рабочие строят хороА
ший дом на поляне. \
S+P+O+AP
N+V+A + N+G+N
N{G+VG+N2G+PG
(N)+(V)+(A+N)+(G+N)\
которых выступают предлоги, артикли, частицы,
вспомогательные глаголы и т.д. [50; 121; 125]. В итоге, например, в английском
языке выделяют: 1) именные группы (NG); 2) предложно-имен-
ные группы (PG); 3) глагольные группы (VG); 4) наречные
группы (DG); 5) О^-группы (FG).
Описанный принцип использован в разрабатываемой учебной
системе МП. При этом отпадает необходимость проведения
синтаксического анализа английского предложения, а синтаксический
синтез сводится к замене английских слов их переводными
эквивалентами и подстановками последних в соответствующие русские
формальные группы. Тогда принципиальный алгоритм учебной
системы МП может быть представлен в виде блок-схемы (схема 18).
Рамки учебного пособия не дают возможности рассмотреть
детальные алгоритмы этих блоков. Но суть их работы можно
представить следующим образом.
В процессе морфологического анализа слов английского
предложения (блок В) и его сегментации (блок С) слова английского
предложения, прочитанные в блоке А в некоторую область памяти
компьютера, заменяются в той же области теми же словами с
информацией из английской части автоматического словаря.
При сегментации английского предложения на формальные
группы компьютер опирается на два списка служебных
слов-разделителей и признаки частей речи слов английского предложения.
К словам-разделителям относятся also, separately, or, that, and,
they, it, is, are, from, to, a, the, for, on, in1. В результате выделяются
1 Индексы частей речи взяты из таблицы 19. Формальные группы
обозначают: NG — именная группа, VG — глагольная группа, PG — предложно-имен-
ная группа. Через S, Р, О, АР обозначены соответственно подлежащее,
сказуемое, прямое дополнение и обстоятельство места.
2 Так как создаваемая программа МП является учебной, то списки
разделителей невелики, В больших системах машинного перевода такие списки могут
включать сотни единиц.
104
Схема 18
Принципиальный алгоритм учебной системы машинного перевода
А
1
Чтение очередного предложения
английского текста
г
В
Морфологический анализ слов
английского предложения
т
С
Синтаксический анализ английского
предложения: сегментация предложения на
формальные группы
i
D
Синтаксический синтез русского
предложения и поиск русских переводных
эквивалентов английских слов
т
Е
i
Морфологический синтез слов русского
предложения
Г
F
Печать русского предложения на экране
дисплея
все формальные группы очередного предложения английского
текста. При этом указываются и начала этих групп (номера слов
предложения). Так, для 1-го предложения переводного текста
нулевая формальная группа предложения начинается с нулевого слова
предложения, 1-я группа — с 3-го слова и т. д. В итоге это
предложение оказалось разделенным на следующие формальные группы.
Номер английской
формальной группы
О
1
2
3
4
5
6
Английская
формальная группа
INTEGRATED CIRCUITS,
ALSO
CALLED
CHIPS
ARE NOW MANUFACTURED
SEPARATELY
FROM COMPUTERS.
В процессе поиска русских переводных эквивалентов (блок D)
компьютер выделяет из информации для каждого слова англий-
105
ского предложения три последних или предпоследних знака,
содержащие адрес переводного эквивалента, по которому
переводные эквиваленты располагаются в русской части АС. Последние
«выстраиваются» друг за другом в некоторой области памяти В
соответствии с порядком расположения английских формальных
групп:
Русские формальные группы1
ИНТЕГРАЛЬН* СХЕМ*
А 001 N_2___004
ТАКЖЕ/
С. 000
НАЗЫВАЕМ*
R 5001
МИКРОСХЕМ*
N_2 004
ТЕПЕРЬ/ИЗГОТАВЛИВА*СЯ/
D 000 V 26009
ОТДЕЛЬНО/
в_„„ооо
ОТ/ КОМПЬЮТЕР*
G2 000 N_l 007
В процессе выбора переводных эквивалентов компьютер
анализирует, к какой части речи в конкретном предложении
относится каждое слово, и в зависимости от этого берет тот или иной
русский переводной эквивалент. Для отдельных английских слов,
относящихся к одной части речи, но имеющих несколько
переводных эквивалентов, компьютер также по контексту
определяет, какой переводной эквивалент из двух, имеющихся в словаре,
надо взять (например, для предлога from).
Морфологический синтез слов русского предложения {блок Е)
заключается в морфологическом оформлении машинными
окончаниями основ русских слов, входящих в каждую русскую
формальную группу. Для этого в общем случае необходимо знать,
каким членом предложения является каждая формальная группа.
Для уже приведенного 1-го предложения текста компьютер
делает вывод, что, учитывая достаточно строгий порядок слов в
английском предложении, выражение integrated circuits может быть
подлежащим. Значит, подлежащим оно будет и в русском
предложении.
Чтобы оформить морфологически слова, входящие в сочетание
ИНТЕГРАЛЬН* А 001 СХЕМ* N 2 004
1 Под каждой русской квазиосновой приведена ее морфологическая
информация, взятая вместе с основой из русской части словаря.
Английские формальные группы
INTEGRATED CIRCUITS
ALSO
CALLED
CHIPS
ARE NOW MANUFACTURED
SEPARATELY
FROM COMPUTERS
106
необходимо знать, в каком числе слово схем* употреблено в
предложении. Компьютер обращается к английскому слову circuits и по
относящейся к нему информации определяет, что в предложении
оно употреблено во множественном числе. Этот признак
добавляется к информации квазиосновы схем*:
СХЕМ* N22 004
Ранее было решено, что группа интегральн* схем* — это
подлежащее. Значит, квазиоснова схем* должна получить
именительный падеж:
СХЕМ* N221 004
В таблице типов формообразования имен существительных (табл.
15) в строке 004 компьютер находит машинное окончание
множественного числа именительного падежа -6/. Оно и
подсоединяется к основе схем*.
Чтобы найти машинное окончание для квазиосновы имени
прилагательного интегральн*, компьютер «отбирает» у
квазиосновы имени существительного схем* признаки рода, числа,
падежа и добавляет их к информации для имени прилагательного:
ИНТЕГРАЛЬН* А221 001
После этого по таблице типов формообразования имен
прилагательных (табл. 17) в стррке 001 компьютер найдет нужное
окончание множественного числа именительного падежа -ь/е. Его он и
подсоединит к основе интегральн*. В итоге первая формальная
группа выглядит следующим образом: интегральные схемы.
Аналогичным образом осуществляется морфологический
синтез слов всех остальных формальных групп предложения.
Переведенное предложение, оформленное по правилам
русского языка, выводится на экран дисплея в блоке F:
ИНТЕГРАЛЬНЫЕ СХЕМЫ, ТАКЖЕ НАЗЫВАЕМЫЕ
МИКРОСХЕМАМИ, ТЕПЕРЬ ИЗГОТАВЛИВАЮТСЯ ОТДЕЛЬНО ОТ
КОМПЬЮТЕРОВ.
Далее машина читает следующее английское предложение, и
весь процесс перевода повторяется. Выполненный компьютером
перевод всего английского текста на русский язык приведен ниже:
ИНТЕГРАЛЬНЫЕ СХЕМЫ, ТАКЖЕ НАЗЫВАЕМЫЕ
МИКРОСХЕМАМИ, ТЕПЕРЬ ИЗГОТАВЛИВАЮТСЯ ОТДЕЛЬНО ОТ
КОМПЬЮТЕРОВ. ОНИ ОБЕСПЕЧИВАЮТ СТРОИТЕЛЬНЫМИ
БЛОКАМИ ПРОЦЕСС СОЗДАНИЯ КОМПЬЮТЕРА. НАИБОЛЕЕ ВАЖНОЕ
ИЗ ЭТИХ КОМПЬЮТЕРНЫХ КОМПОНЕНТОВ - ЦЕНТРАЛЬНОЕ
ОБРАБАТЫВАЮЩЕЕ УСТРОЙСТВО (ЦП ДЛЯ КРАТКОСТИ) ИЛИ
МИКРОПРОЦЕССОР. ЭТО ЧАСТЬ КОМПЬЮТЕРА, ЧТО ВЫПОЛ-
107
НЯЕТ КОМАНДЫ ПРОГРАММЫ. МИКРОПРОЦЕССОР -
МАЛЕНЬКОЕ УСТРОЙСТВО, СОДЕРЖАЩЕЕСЯ НА
ПОЛУПРОВОДНИКОВОЙ МИКРОСХЕМЕ. МИКРОПРОЦЕССОРЫ ИСПОЛЬЗУЮТСЯ
В МИНИКОМПЬЮТЕРАХ, И КАЖДАЯ ИЗ ЭТИХ ИНТЕГРАЛЬНЫХ
СХЕМ СПОСОБНА К ОБРАБОТКЕ 8-БИТОВЫХ ИЛИ 16-БИТОВЫХ
ДАННЫХ.
Способы применения компьютеров
для перевода текстов
Возможны три способа использования компьютеров для
перевода текстов.
1. Перевод текста человеком с использованием компьютеров.
2. Перевод текста компьютером с помощью человека.
3. Автоматический перевод.
При первом способе текст переводит человек, а за
переводными эквивалентами слов, которые ему неизвестны, он
обращается к автоматическим (электронным) словарям. Данный
способ перевода используется сейчас достаточно широко. Для этого
разработано много больших электронных словарей, например
«Lingvo», «Контекст», «Мультилекс» и др. [20].
При втором способе человек на определенных этапах
подключается к процессу перевода текста компьютером. Возможны
три варианта подключения человека к такому процессу перевода:
1) предварительная подготовка текста;
2) определенные преобразования текста непосредственно в
процессе перевода;
3) редакторская правка текста после перевода.
При предварительной подготовке текста перед его вводом в
компьютер человек проводит целый ряд операций, например:
сложные предложения сводит к нескольким простым, в тексте
специальным образом отмечает фразеологические и идиоматические
выражения, фиксирует одно переводное значение для
многозначных слов ИЯ и т.п. Лингвист, выполняющий такую работу,
называется предредактором.
Определенные преобразования текста непосредственно в
процессе перевода осуществляет интерредактор. Он реагирует на
поступающие запросы компьютера. Такая реакция сводится к тому,
что интерредактор упрощает структуру выведенного на экран
неясного для системы МП предложения исходного языка, указывает
определенным образом синтаксическую структуру этого
предложения, отмечая в предложении не переведенные системой
терминологические или фразеологические сочетания, указывает
однозначный перевод многозначного слова, выведенного в процессе на
экран компьютера, и т.п.
108
Полную редакторскую правку переведенного автоматической
системой текста осуществляет опытный переводчик —
постредактор.
При третьем способе для полностью автоматического
перевода текстов с одного языка на другой создана серия
программ. Наиболее известными из них являются STYLUS, SOCRAT,
RETRANS, ERTRANS, PARS, MULTIS, SILOD, АСПЕРА,
PROMT [24; 118; 21; 229; 13; 14; 15]. Уже созданы и работают
версии программ перевода SOCRAT и PROMT для сети Интернет
[28]. Однако результаты применения программ полностью
автоматического перевода требуют определенной, иногда большой
работы постредакторов [126; 229; 256; 13; 15; 20].
ГЛАВА 5
ИНФОРМАЦИОННЫЕ ТЕХНОЛОГИИ
В ОБУЧЕНИИ ЯЗЫКАМ
ОБЩИЕ ПРИНЦИПЫ КОМПЬЮТЕРНОГО ОБУЧЕНИЯ ЯЗЫКАМ
Широкое использование компьютеров в различных аспектах
деятельности человека не обошло стороной проблему обучения
человека языкам. Уже сейчас создано большое число компьютерных
программ обучения иностранным языкам1 [57; 196; 228; 231; 239;
136]. Эти проблемы рассматриваются в журналах, выпускаемых по
всему миру [251; 263]. Ежегодно проблемам обучения языкам
посвящается большое число конференций [106; 136; 147; 250; 252].
Сложность задачи обучения языкам объясняется тем, что
любое обучение — задача комплексная, требующая учета данных
психологии, педагогики, методики, особых свойств изучаемого
предмета. По существу, каждая обучающая программа — это
достаточно сложная система искусственного интеллекта [72, 45—91].
За последние годы значительно изменился принцип
применения компьютерных программ для обучения иностранному языку.
Если ранее утверждалось, что наиболее эффективно они могут быть
использованы в рамках автоматизированных обучающих систем, то
с появлением компьютеров в доме обучаемых такие программы все
чаще используются индивидуально и подбираются в зависимости
от цели обучения. Однако принципы построения таких обучающих
программ в целом остались неизменными. Они реализуются путем
выполнения следующих основных задач [74,108, 109]:
1) теоретического обоснования выбираемого метода обучения;
2) создания с опорой на выбранный метод технологии обучения;
3) построения обучающей программы, реализующей
выбранную технологию обучения.
Рассмотрим процесс решения этих задач более подробно.
ТЕОРЕТИЧЕСКИЕ ОБОСНОВАНИЯ ВЫБРАННОГО МЕТОДА
ОБУЧЕНИЯ
С точки зрения принципов восприятия информации при
обучении с помощью компьютера выделяют, как правило, два тео-
1 Подробнее см. с. 138—-142.
ПО
ретических подхода: бихевиористский и
когнитивно-интеллектуальный [156, 146].
Бихевиористский подход, связанный с постулатом «чем чаще
употреблено слово, тем лучше оно запоминается», в последние
годы усовершенствовался использованием целого ряда приемов:
дедуктивного контроля ответов, созданием универсальных
банков данных об изучаемом объекте или явлении, построением
справочной информации в виде гипертекстов и т.д. В рамках такой
теории различают следующие методы автоматизированного
обучения [154, 5—15]:
1) программирование учебной деятельности обучаемого;
2) тестирование;
3) информирование.
Первый из этих методов обучения характерен тем, что
управляющие воздейстщя на обучаемого полностью определяются
обучающей программой. В такой программе каждому обучаемому в
зависимости от его уровня знаний полностью задается
последовательность учебных или контрольных заданий.
При тестировании компьютер по специальным программам
выявляет индивидуальные профессиональные и психологаческие
характеристики обучаемых и достигнутые ими уровни знаний. При
этом обучаемый лишь ощтаетщ вопросы, но оценку за знания
не получает. Этот метод достаточно часто используется при
оценке различных аспектов знания инострщяыхмижщ
(тестирование словарного запаса, способности к изучению иностранных
языков и т.п.).
Суть метода информирования заключается в том, что в память
компьютера помещаются некоторые справочно-информационные
данные (грамматический справочник, орфографический словарь,
двуязычный словарь и т.п.), которые обучаемый может
использовать при подготовке к занятиям или непосредственно в процессе
занятий. Тем не менее бихевиористский подход не может
преодолеть механистичность обучения и отсутствие развития
когнитивных способностей обучаемых [156, 146].
При когнитивно-интеллектуальном подходе у обучаемого
активизируются познавательные функции. Для успешной
реализации такого подхода в памяти компьютера создается
универсальная учебная среда, включающая различные грамматические
справочники, словари, спеллеры, другие вспомогательные материалы.
При таком подходе в принципе возможны следующие методы
автоматизированного обучения [154, 5—75]:
1) моделирование учебной среды;
2) свободное обучение.
Суть процесса моделирования учебной среды сводится к
созданию компьютерных программ, которые моделируют структуру
некоторого объекта или принципы его действия. При этом, как и при
111
бихевиористском подходе, управляющие воздействия также
полностью определяются обучающей программой. Обучаемый может
выбирать учебные задания из некоторого конечного множества
заданий, включенного в универсальную учебную среду.
Различают два типа моделей учебной среды [40; 35]:
1) модели объективного (предметного) типа;
2) модели мыслительного типа.
Модели первого типа служат для познания некоторого объекта
или приобретения навыков работы с таким объектом. Примером
такой модели является компьютерная программа, обучающая
студента работе на клавиатуре.
Модели мыслительного типа — это уже упоминавшиеся выше
воспроизводящие инженерно-лингвистические модели (см. с. 14).
Их задача — изучение некоторых процессов, явлений или же
динамического поведения некоторого объекта. Чаще всего они
используются в процессе преподавания радиотехники,
электроники, физики, биологии и других дисциплин. Широко используют*
ся подобные модели и в лингвистике [157; 145; 156; 163; 164]. \
Метод свободного обучения характерен тем, что он дает воз-^
можность самому выбрать тематику обучения и способ работы с
компьютером. Компьютер при этом не только предъявляет
обучающие кадры по указанию обучаемого, но и уточняет его действия,
предлагая обучаемому наиболее эффективный способ
использования учебного материала. При этом выделяют три вида обучения:
1) структурно-управляемое обучение;
2) обучение принятию решения;
3) генеративное обучение.
Учебный материал, используемый при структурно-управляемом
обучении, представляется в виде некоторой иерархической
структуры данных1. Для каждого структурного уровня в компьютере
заранее определены цели обучения и условия для успешного
достижения такой цели. Элементарным примером такого вида обучения
может служить задача обучения формообразованию русских
глаголов [131, 75, 16]. Здесь можно выделить четыре структурных
уровня, вводящих по принципу «от простого к сложному»
основные понятия, связанные с формообразованием русского
глагола (табл. 39).
При структурно-управляемом свободном обучении обучаемый
сам может выбирать начальный уровень обучения (в нашем
примере это может быть и 2-й, и 3-й структурные уровни). Однако
локальная цель высшего уровня должна совпадать с конечной
целью обучения по данной программе.
При обучении принятию решения учебная информация,
заложенная в компьютер, представляется в виде некоторого набора
Подробнее об иерархической структуре см. с. 149, 150.
112
Таблица 39
Номер
структурного уровня
1-й структурный
уровень
2-й структурный
уровень
3-й структурный
уровень
4-й структурный
уровень
Локальная цель
обучения
Усвоение понятий о:
1) категории числа
глагола;
2) категории лица
глагола;
3) категории вида
глагола
Усвоение понятий о:
1)
вспомогательных глаголах;
2) модальных
глаголах
Усвоение понятий о
категории времени
глагола
Усвоение понятий о
правилах
формообразования русского
глагола
Условия для достижения
локальной цели
Правильное
выполнение конкретного числа
заданий на
определение по форме глагола
его числа, лица, вида
Правильное
выполнение определенных
заданий на опознавание
в рамках предложения
вспомогательных и
модальных глаголов
Правильное
выполнение определенного
числа заданий на
определение по форме
глагола его времени
Правильное
выполнение определенного
числа заданий на
оформление основы глагола
его формообразующи-
ми элементами
специальным образом записанньвс ситуаций (например, в виде
фреймов [72, 26—31]). При таком виде свободного обучения
обучаемый, исходя из задаваемой компьютером исходной ситуации
и ориентируясь на его ответы, должен прийти к некоторой
конечной ситуации. Наиболее ярко это проявляется, например, при
построении компьютерной обучающей системы, моделирующей
действия студента-медика при постановке диагноза болезни.
Компьютер при этом выступает в качестве больного, которому
студент задает определенные вопросы.
При обучении иностранному языку этот метод также может
широко использоваться. Например, можно дать задание
компьютеру выступить в роли продавца в магазине, где обучаемый, ведя
диалог с продавцом, хочет купить некоторую вещь. При этом
обучающая программа может корректировать действия обучаемого или
после каждого его шага принятия решения, либо она может
комментировать его действия после окончательного завершения всей
программы.
113
Генеративное обучение как вид свободного обучения пока
возможно лишь теоретически. Здесь предполагается активное
взаимодействие двух моделей: постоянно изменяющейся модели
обучаемого (как следствие последовательного усвоения в
процессе обучения некоторых знаний) и модели учебного
материала. Учебный материал в данном случае представляет собой
совокупность некоторых понятий и связей между ними, которые
должен усвоить обучаемый. Обучающие воздействия
компьютера прц таком обучении не заданы заранее, а вырабатываются
обучающей программой в зависимости от степени усвоения
исходного материала обучаемым [154, 13, 14]. Таким образом,
решая задачу теоретического обоснования выбираемого метода
обучения, следует выбирать одну из описанных выше моделей
обучения.
СОЗДАНИЕ ТЕХНОЛОГИИ КОМПЬЮТЕРНОГО
ОБУЧЕНИЯ ЯЗЫКАМ
Допустим, что для создания обучающей программы выбран один
из описанных выше методов. Каждая компьютерная программа,
обучающая какому-либо аспекту языка, представляет собой
некоторую совокупность боле§лростьтх программ, связанных с
обучением простым лингайстическим понятиям или явлениям.
Обучающую программу в ее полном виде назовем
автоматизированным учебным курсом (АУК) и определим ее следующим образом:
АУК — это комплекс компьютерных программ, ншшмедшыхлга_
достижение олда&J
ние, систематизация, закрепление, применение или контроль
знаний и умений [129, 7]). Нет единой технологии создания АУК.
Разработчики выделяют при этом от 4 до 14 конкретных задач
[129; 1; 2, 16; 148]. Рассмотрим детально те из них, которые
связаны непосредственно с разработкой технологии некоторого курса
компьютерного обучения.
Наиболее приемлемым представляется выделение в процедуре
разработки компьютерной технологии обучения некоторому
курсу четырех следующих основных задач [130, 20, 21]:
1) цро.еетидрвание состава курса и его содержания;
2) методическая проработка учебного материала каждой
отдельной задачи, входящей в состав курса, и создание ее обучающего
сценария;
3)_создание обучающей программы по данной задаче и ее
экспериментальная проверка (тестирование);
4) объединение обучающйГ программ всех задач курса в
единой АУК.
Рассмотрим каждую из перечисленных задач более подробно.
114
Проектирование содержания курса и его состава
В процессе реализации первой из четырех упомянутых выше
задач проводится детальный анализ учебной программы по
конкретной дисциплине. При этом в ней выделяются разделы, темы,
проблемы и задачи, в изучении которых может быть использован
компьютер [72, 52—55].
Выделение в программе по дисциплине указанных выше
составляющих невозможно без знания возможностей компьютера
по работе с текстами. Например, в составе курса «Современный
русский литературный язык» [183] можно выделить следующие
разделы: «Фонетика»; «Графика и орфография»; «Лексика и
фразеология»; «Словообразование»; «Морфология»; «Синтаксис»;
«Основы пунктуации» (схема 19).
Схема 19
Фонетика
Графика
и
орфография
Лексика
и
фразеология
Слово-
образование
Морфология
Синтаксис
Основы
пунктуации
В то же время в программе курса «Практическая грамматика
английского языка» [184] можно выделить лишь два раздела:
«Морфология» и «Синтаксис». В практических курсах по языкам,
содержащих незначительный объем теоретического материала,
разделы могут не выделяться. Здесь выявляются более мелкие
составляющие (темы или проблемы).
Далее в составе каждого из выделенных разделов находят темы,
в изучении которых эффективную помощь может оказать
компьютер. Так, в разделе «Морфология» упомянутой программы
«Современный русский литературный язык» можно выделить следующие
темы: «Распределение слов по частям речи»; «Имя
существительное»; «Имя прилагательное»; «Имя числительное»; «Глагол»;
«Местоимение»; «Наречие»; «Категория состояния»; «Служебные слова»
(схема 20).
Распределение
слов по частям
речи
Глагол
Имя
существительное
Местоимение
Имя
прилагательное
Наречие
Категория
состояния
Схема 20
Имя
числительное
1
Служебные
слова J
Точно так же в составе разделов учебной программы
«Практическая грамматика английского языка» выделяются
конкретные темы. В «Морфологии» это: «Имя существительное»; «Гла-
115
гол»; «Имя прилагательное»; «Имя числительное»; «Слово
категории состояния»; «Наречие»; «Местоимение»; «Модальное слово»;
«Частица»; «Предлог»; «Союз»; «Междометие». В «Синтаксисе»
выделяют: «Синтаксические связи слов»; «Общие сведения о
предложении»; «Коммуникативные типы предложений»; «Простое
предложение»; «Односоставное предложение»; «Эллиптическое
предложение»; «Сложносочиненное предложение»;
«Сложноподчиненное предложение»; «Чужая речь»; «Пунктуация».
Каждая из тем, в свою очередь, представляется в виде
совокупности проблем. Например, в составе темы «Глагол»
программы «Современный русский литературный язык» можно выделить
следующие проблемы (схема 21).
Схема 21
Категории глагола,
парадигма глагольного
слова при спряжении
Категория
лица и способы
ее выражения
Категория
наклонения
Образование форм
времени
Категория
вида
Возвратные
глаголы
Причастие
Деепричастие
Одноименная тема «Глагол» учебной программы «Практическая
грамматика английского языка» включает следующие проблемы:
«Основные признаки и типы глаголов»; «Лицо и число»; «Время и
вид»; «Залог»; «Наклонение»; «Модальные глаголы»;
«Инфинитив»; «Герундий»; «Причастие I»; «Причастие II».
Наконец, каждая проблема рассматривается как совокупность
небольших конкретных задач (иногда это может быть и одна
задача). Задача может содержать как чисто теоретический материал,
так и конкретные практические задания (упражнения, вопросы).
Возможна организация задач и на смешанной основе, где
теоретические вопросы чередуются с практическими заданиями на
усвоение теоретических правил. Например, проблема «Имя
существительное» темы «Морфология» программы «Практическая
грамматика английского языка» может быть представлена в виде
следующих задач (схема 22).
Схема 22
Образование
множественного числа
английских
имен
существительных
—*»
Образование
притяжательного падежа
имен
существительных
—►
Способы
выражения
рода
английских имен
существительных
—►
Основные
функции
артикля
—>•
Особые
функции
артикля
116
Таким образом, вся программа по дисциплине представляется
в виде набора конкретных задач, которые необходимо решить с
помощью компьютера. Возможны и другие подходы к
проектированию структуры курса [1, 21—23; 2, 27—30; 54, 56—64].
Методическая проработка учебного материала
и создание обучающих сценариев
Пусть в процессе выполнения предшествующего этапа в составе
некоторого курса вщелено^пределенное число, составлю —
учебных задач, например? «образованиемножественного числа
английских имен существительных», «Образование форм
времени русского глагола» и т. п. Тогда, решая вопрос о методической
проработке учебного материала каждой учебной задачи, можно
выделить в процессе ее решения следующие конкретные задания
[130, 35]:
1., Конкретизировать тип учебной задачи.
2. Определить параметры, по которым будет
оценштться.результат обучения данной учебной задаче. ^
3. Разработать формальные проце^^ы^ценщ знаний по
данной учебной задаче.
4. Сформировать узйЕшшйели рассматриваемой учебной
задачи и представить их в формализованном виде.
5. Выработать |фитерии доспщения поставленных учебных целей.
6. Подобрать учебный материал к задаче и определить
порядок его предъявления.
7. Разработать модель действий обучаемого при решении
данной задачи и представить ее в виде обучающего сценария.
При решении учебных задач с помощью компьютера
различают достаточно большое число их типов [1, 20, 21; 206, 20, 21;
182, 4]. На наш взгляд, наиболее целесообразно выделить без
детализации следующие четыре типа учебных задач [91, 58]:
1) обучающие задачи;
2) тренирующие задачи;
3) контролирующие задачи;
4) комбинированные задачи, содержащие в себе элементы
обучения и контроля.
Таким образом, строя обучающую программу конкретной
задачи, необходимо выбрать один из этих четырех типов.
За достаточно большой период использования компьютеров в
обучении иностранным языкам выработаны определенные
параметры, с помощью которых можно оценивать результат обучения
[72, 56; 130, 28-31]:
1) общее число полученных обучаемым заданий (вопросов и
упражнений);
117
2) число верно выполненных заданий;
3) число неверно выполненных заданий;
4) время выполнения отдельного задания;
5) время выполнения всех заданий;
6) число подсказок, полученных обучаемым от обучающей
системы в ходе решения задачи;
7) типы подсказок;
8) число полученных информационных справок (число
переводов слов, выданных правил и т.д.);
9) число просьб о переформулировке задания;
10) число отказов от решения задачи;
11) типы предлагаемых справочных материалов (перевод,
правило и т.п.); ;
12) число попыток, даваемых на выполнение задания;
13) типовые ошибки обучаемого при выполнении заданий;
14) частота употребления ошибок;
15) последовательность предъявляемых заданий;
16) уровень научности предъявляемого теоретического
материала;
17) сумма баллов, полученных за все задания;
18) результирующая оценка за всю учебную задачу и т.п.
В процессе разработки обучающей программы автор
обучающего сценария учебной задачи в зависимости от своего опыта,
сложности задачи, типа используемого ПК и целого ряда других
факторов выбирает определенное число таких параметров.
Разработка формальной процедуры оценки знаний при работе
с конкретной учебной задачей, как правило, связана с
перечисленными выше параметрами. Простейший способ оценки
опирается на общепринятую пятибалльную систему. Можно оценивать
знания по абсолютному числу верно выполненных заданий:
например, если правильно выполнено 95 % и более заданий, то
система ставит обучаемому «отлично». Оценка «хорошо» ставится за
80—94% верных заданий, а «удовлетворительно» — за 50—79%
правильных ответов. Еще один способ связан с начислением
определенного числа баллов за каждое выполненное задание. Это
число может зависеть от сложности задания, количества попыток
дать правильный ответ, обращений за подсказками и
дополнительной информацией, а также целого ряда других факторов.
Итоговая оценка равна сумме баллов за все выполненные задания.
При необходимости эти условные баллы несложно перевести в
общепринятую пятибалльную систему. Знания можно оценивать в
зависимости от времени выполнения отдельных заданий и их
совокупности в целом.
При любом способе оценки знаний необходимо помнить, что
это один из важнейших этапов обучения с помощью компьютера.
К оценке знаний нужно подходить оченьхюторожно. Обучаемый
О
118
должен точно знать, как оцениваются все выполненные им
задания, за что была снижена оценка. Обычно оценка снижается в
большей степени за неправильный ответ и в меньшей степени за
подсказку, обращение за помощью и просьбу о
переформулировке задания. Обучаемый может попытаться выяснить, почему ему
была поставлена та или иная оценка и обучающая система
должна дать исчерпывающий ответ. Важно также иметь в виду тот факт,
что выставляемая компьютером оценка в конечном итоге не
должна отличаться от оценки, выставляемой за аналогичное задание
опытным преподавателем. Поэтому выбранный способ оценки
знаний в его окончательном виде принимается лишь после
экспериментальной проверки работы компьютерной программы на
контрольной группе обучаемых.
Цель обучения какой-либо учебной задаче — понятие довольно
нечеткое, допускающее различные толкования [195, 80—84; 1,
21, 22; 91, 51—53]. Чаще всего под целью обучения какой-либо
задаче принято понимать описание состояния знаний, навыков,
умений и других характеристик обучаемого, которое должно быть
достигнуто в результате работы обучаемого с соответствующей
обучающей программой [195, 81; 130, 42]. Нередко цель обучения
с помощью компьютера представляется в виде двух списков: списка
усваиваемых понятий и списка усваиваемых умений [195, 82—84].
Предполагается, что после работы с компьютерной программой
обучаемый будет знать понятия, перечисленные в первом списке,
и уметь делать то, что записано во втором списке.
При обучении некоторому явлению с помощью компьютера
критерий достижения целей обучения обычно задается в виде
некоторого числового параметра. Это может быть, например,
результирующая оценка за определенное число специальных
вопросов и упражнений, поставленная компьютером с учетом
выданных им подсказок, справок, разъяснений1. То же самое может быть
сделано путем вычисления различных коэффициентов усвоения
материала. Так, в работах [217, 37; 1, 24, 25] приводятся два таких
коэффициента:
К -Ни К -Nl
12 1У2
В первом коэффициенте Тх обозначает время, которое
затратил на выполнение некоторого задания на компьютере опытный
преподаватель, а Т2 — реальное время, потраченное на
выполнение той же задачи с помощью компьютера обучаемым.
Во втором коэффициенте N{ представляет собой число
специальных вопросов по выполняемой на компьютере задаче, на
которые обучаемый дал верные ответы. N2 соответствует общему числу
1 Подробнее об этом см. с. 126,127.
119
задаваемых обучаемому вопросов. Очевидно, в общих случаях чем
ближе коэффициент Кусъ к единице, тем лучше усвоен материал.
Подбор учебного материала к выполняемой на компьютере
задаче является одной из важнейших проблем компьютерного
обучения. В методике известны общие принципы предъявления
материала обучаемому: от известного к неизвестному, от простого
к сложному, от наиболее употребительного к редко используемому.
Каждая обучающая программа по иностранному языку должна
иметь конкретное предназначение: научить туриста, обучить
секретаря-референта, подготовить молодого человека к поступлению
в университет и т.п. Именно этот факт должен определить тот
лексический и грамматический минимум, который будет
«вложен» в программу. Он определяет, что для данной категории
обучаемых является наиболее употребительным, а что редко
используемым. Известны различные подходы к классификации заданий
по иностранному языку, предъявляемых для обучения с
помощью компьютеров [148, 41— 69; 217, 31—33; 182, - 74—76; 195,
135-140; 1, 34-39].
После отбора языковых явлений, которые будут предъявляться
обучаемому, необходимо провести их тщательный анадиз. Суть его
заключается, с одной стороны, в выявлении щийолее тпшичных
фактов, специфичных для каждого изучаемого явления, а с
другой — в фшггат^^ иглгттшч^ий из таких фактов. Для
усвоения тех и других должны быть предусмотрены специальные
теоретические и практические задания. Чтобы практические
задания для каждого обучаемого были разными и не повторялись при
повторном запуске программы, целесообразно использовать
генератор случайных чисел.
В процессе моделирования будущих действий обучаемых в ходе
решения конкретной задачи на компьютере можно использовать
два подхода:
1) эмпирический подход, предполагающий за основу таких
действий принять действия опытного преподавателя;
2) теоретический подход, когда будущие обучающие действия
определяются специальными принципами, выработанными в
процессе теоретического исследования различных методов обучения
языкам.
Результатом такого моделирования должен стать обучающий
сценарий. Обучающий сценарий — это модель процесса обучения,
опирающаяся на некоторый набор правил, упражнений и
определенный метод обучения и представленная в виде
последовательности обучающих кадров. Обычно сценарий представляется в виде
диалога обучаемого с компьютером [195, 86— 91].
Обучающий кадр — это минимальный фрагмент обучающего
сценария, несущий определенную методическую нагрузку:
информационную, контрольную, выдачи заданий, обратной связи с обу-
120
чаемым. Существуют различные подходы к классификации кадров.
В общем выделяют два типа кадров: основные и вспомогательные
[72, 61].
К числу основных обучающих кадров относятся:
1) информационные (И);
2) операционные (О);
3) обратной связи (С);
4) контрольные (К).
* Среди вспомогательных обучающих кадров будем различать:
1) информирующие (ИФ);
2) иллюстрирующие (ИЛ);
3) директивные (ДР);
4) кадры разрядки (KP);
5) результирующие (РЗ).
Последние называются вспомогательными, потому что они,
как правило, сопровождают основные кадры, определенным
образом раскрывая или уточняя их содержание.
Рассмотрим подробнее основные типы кадров.
Информационный кадр — это текст учебного материала,
предъявляемый обучаемому для усвоения определенного теоретического
понятия. Если текст информации невелик, то он может
высвечиваться на экране дисплея в полном объеме. Если же исходная
информация велика, то на экране выводится название учебника или
пособия с указанием тех страниц и параграфов, которые
необходимо проработать обучаемому, прежде чем он начнет выполнять
основные задания данной задачи.
Операционные кадры — это последовательность вопросов и
упражнений, предъявляемых обучаемому с целью формирования у
него знаний, умений и навыков по проблеме, излагаемой в
информационных кадрах/Задания должны быть четкими и
предусматривать несколько вариантов правильных ответов.
Желательно, чтобы одно и то же задание иногда формулировалось по-
разному для разнообразия процесса общения с компьютером. Как
правило, такие высказывания задаются в виде предварительно
заготовленных шаблонов с заполняемыми системой атрибутами.
Например:
«Образуйте, пожалуйста, множественное число от
существительного X».
«Поставьте, пожалуйста, глагол X в прошедшее время».
«Найдите, пожалуйста, в предложении словосочетание X,
соответствующее русскому словосочетанию Y».
В подобных высказываниях вместо X(Y) подставляется
конкретное слово, словосочетание, предложение, текст.
Кадры обратной связи служат для коррекции процесса обучения.
Их цель — указать обучаемому его ошибки, разъяснить и
подсказать правильное направление выбора ответа. Другое назначение этих
121
кадров — показать обучаемому, что компьютер хорошо
понимает каждое его действие, что машина — его верный помощник и
советник. И поэтому содержащиеся в таких кадрах разъяснения,
справки, подсказки должны быть составлены так, чтобы
заинтересовать обучаемого. Предъявляемые на экране фразы должны быть
близки к естественной беседе преподавателя и ученика. Каждый
операционный кадр должен сопровождаться кадром обратной связи.
Среди кадров обратной связи выделяют:
1) высказывания, свидетельствующие о правильном ответе
обучаемого;
2) высказывания, свидетельствующие о неправильном ответе
обучаемого.
Высказывания, свидетельствующие о правильном ответе обу-;
чаемых, должны быть краткими. В то же время они должны
содержать некоторые положительные оценивающие моменты,
способствующие стимулированию работы обучаемого с компьютером,
например:
«Верно! Молодец!»
«Ответ верен! Вы отлично поняли материал!»
«Отлично! Продолжайте в том же духе!»
Высказывания, свидетельствующие о неправильном ответе,
чаще всего выбираются системой из заранее подготовленного
списка. Они дифференцируют тип ошибки, подводят обучаемого к
правильному ответу:
«Ответ неверен. Прочитайте, пожалуйста, еще раз третий абзац
текста и дайте правильный ответ».
«Вы ошиблись! Форма множественного числа образуется с
помощью суффикса -еп. Введите ответ вновь».
«Вы допустили орфографическую ошибку. Попробуйте ответить
еще раз».
Если генерируется высказывание, свидетельствующее о
неправильном ответе, и при этом дается верный ответ, то оно может
состоять как из простого шаблона, так и из шаблона с
заполняемым атрибутом, например:
«Ответ вновь неверен. Правильный ответ — Х>.
«Вы опять ошиблись. Словосочетанию X соответствует в
русском языке словосочетание Y».
«Неверно. Это существительное не имеет формы
множественного числа». к \
Контрольные кадры служат для проверки^Достижения
обучаемым цели обучения с помощью специальных выдаваемых на
экран упражнений. Если такие упражнения выполняются обучаемым
плохо, то возможно его «доучивание». Для этого используются все
122
перечисленные типы кадров, только применяются они не к
основному изучаемому материалу, а к некоторому
дополнительному, выдаваемому по особой дополнительной программе.
Рассмотрим детальнее вспомогательные типы кадров.
Информирующие кадры сообщают обучаемому о теме и цели
занятия, дают указания об особенностях работы с данной
программой. Например, информирующий кадр может быть таким:
ПК: ОБУЧАЮЩАЯ СИСТЕМА "АОС МГЛУ" ПРИВЕТСТВУЕТ ВАС!
ВЫ ПРИСТУПАЕТЕ К ИЗУЧЕНИЮ СПОСОБОВ ОБРАЗОВАНИЯ
МНОЖЕСТВЕННОГО ЧИСЛА АНГЛИЙСКИХ ИМЕН СУЩЕСТВИТЕЛЬНЫХ.
С ВАМИ РАБОТАЕТ ОБУЧАЮЩАЯ ПРОГРАММА "PLURAL".
ЖЕЛАЕМ ВАМ БОЛЬШИХ УСПЕХОВ!
Информирующим будет и следующий кадр:
ПК: ЦЕЛЬ ДАННОГО ЗАНЯТИЯ - ИЗУЧЕНИЕ ВСЕХ ВОЗМОЖНЫХ
СПОСОБОВ ОБРАЗОВАНИЯ МНОЖЕСТВЕННОГО ЧИСЛА АНГЛИЙСКИХ
ИМЕН СУЩЕСТВИТЕЛЬНЫХ.
Иллюстрирующие кадры содержат примеры стандартных
приемов выполнения каких-либо действий (как выглядит глагол в
инфинитивной форме, как записываются имена
существительные во множественном числе, примеры подстановок слов и т.д.).
Директивные кадры служат для того, чтобы обратить внимание
обучаемого на какую-нибудь информацию или на некоторую
особенность работы с компьютером. Например:
ПК: ПЕРЕД ВВОДОМ ОТВЕТА НА РУССКОМ ЯЗЫКЕ НЕ ЗАБУДЬТЕ
НАЖАТЬ ПРАВЫЕ КЛАВИШИ [CTRL-SHIFT].
с"
ИЛИ
ПК: ПОСЛЕ НАБОРА ОТВЕТА НАЖМИТЕ КЛАВИШУ [ENTER].
Кадры разрядки — это небольшие сообщения шуточного
характера или какая-либо мультипликационная заставка. Их
назначение — снижение чувства напряженности, страха от контакта с
компьютером. Например:
ПК: БУДЬТЕ СМЕЛЕЕ! КОМПЬЮТЕР - ВАШ ДРУГ И ПОМОЩНИК.
Результирующие кадры сообщают обучаемому результат
выполненного им действия. Они обязательно должны идти после
каждого операционного кадра. Желательно, чтобы такой кадр
сопровождался кадром разрядки, например:
ПК: ВЕРНО! МОЛОДЕЦ! ВЫ ХОРОШО РАЗОБРАЛИСЬ В ИЗУЧАЕМОМ
МАТЕРИАЛЕ.
ИЛИ
ПК: НЕВЕРНО! БУДЬТЕ ВНИМАТЕЛЬНЫ! ПОСТАРАЙТЕСЬ
ПРАВИЛЬНО ВЫПОЛНИТЬ СЛЕДУЮЩЕЕ ЗАДАНИЕ.
123
Если проводится конечная оценка результатов обучения, то
возможны следующие формулировки результирующих
кадров-шаблонов с заполняемыми атрибутами:
«Вы сделали X ошибок».
«Число верных ответов — X».
«Вам было предложено ^существительных в единственном числе.
Вы сделали У ошибок. Ваша оценка — Z».
Иногда в таких высказываниях используется простейший
морфологический синтез отдельных слов. Примером может явиться
синтез слова ошибка в высказывании:
«Вы сделали ^ошиб*».
Если X принимает значение от 5 до 20, то обучающая система
должна синтезировать окончание -о/с. Если же в качестве X
подставляются числа 2, 3, 4 или 22, 23, 24, 32, 33, 34 и т.д., то слово
принимает вид ошибки. Если, наконец, число ошибок равно 1,
21, 31 и т.д., то должно быть синтезировано слово ошибку.
Аналогичный синтез проводится, например, и во фразах:
«В данном слове Xбукв*».
«В этом предложении Xслов*».
При создании обучающего сценария, как было отмечено выше,
необходимо предусмотреть несколько возможных альтернативных
синонимичных ответов компьютера обучаемому, например:
«Верно! (Правильно/Да)».
«Нет! (Неверно/Неправильно)».
Нужно заранее заготовить все наиболее вероятные неверные
ответы обучаемого на задания и в каждом таком случае
предусмотреть соответствующую подсказку. Необходимо продумать вопрос о
том, как поступить, когда обучаемый отказался от ответа на
вопрос или просит изменить формулировку задания или сложность
упражнения.
Для возможности исправления неверных ответов самим
обучаемым желательно применять наводящие фразы или подсказки, а
не ограничиваться простой констатацией ошибки. Как правило,
предусматривается возможность многократного ответа (2—4 раза)
на предъявляемые задания.
Учитывая специфику восприятия человеком визуальной
информации, необходимо не перегружать экран дисплея длинными
текстами. Фразы задания должны быть как можно короче.
Продумывая возможные ответы обучаемых, следует помнить, что при
изучении иностранных языков используются следующие типы
ответов [72, 64—66]. V
1. Выборочный числовой ответ, когда обучаемый набирает на
клавиатуре одну или несколько цифр, соответствующих номеру
(номерам) правильного ответа или условия. Например:
«Определите, в каком времени употреблен глагол-сказуемое в
следующем предложении: В ноябре выпал первый снег.
124
Ответьте, пожалуйста, цифрой:
1) настоящее;
2) прошедшее;
3) будущее».
При правильном выполнении этого задания обучаемому
достаточно набрать на клавиатуре дисплея цифру 2.
Аналогичный тип ответа может быть использован и при
выполнении следующего задания:
«Из приведенных ниже трех русских предложений укажете то,
которое является правильным переводом следующего
английского предложения: Every passing year sees an ever increasing number of
foreign guests coming to visit Belorus.
A. Каждый прошедший год показывает, как увеличивается
число иностранных гостей в Беларуси.
Б. Увеличение числа иностранных гостей в Беларуси
происходит каждый год.
B. С каждым годом все больше гостей из-за рубежа посещает
Беларусь».
Правильному ответу соответствует набор обучаемым на
клавиатуре буквы В.
2. Альтернативный ответ в виде слов да и нет (или их
иностранных аналогов), верно/неверно, верно [нет, да/верно, правильно/
нет, является/нет и т.п.
Например, такой ответ необходим при выполнении задания:
«Является ли слово плеть инфинитивом русского глагола?»
Здесь можно правильно ответить словами нет или не является
и неправильно — словами да, является1.
3. Конструируемый ответ в виде слов или частей (основ,
суффиксов, приставок и т. п.). Такой ответ, например, необходим при
выполнении следующего задания:
«Раскройте, пожалуйста, скобки в следующем предложении,
употребив глагол в соответствующей контексту видовременной
форме: Пусть только звуки музыки (нарушать) мирную тишину над
планетой!»
Ответ состоит из слова нарушают.
Ответ в виде части слова ход/ж можно продемонстрировать в
следующем задании:
«Выделите, пожалуйста, общую основу из приводимых ниже
слов: ходить, хожу, поход».
4. Ответ, конструируемый в виде предложения или фразы.
Например:
«Переведите, пожалуйста, на английский язык следующее
предложение: С каждым годом все больше гостей из-за рубежа
посещает Беларусь».
1 Как правило, выбираются наиболее короткие ответы.
125
5. Ответ, конструируемый в виде текста. Такой ответ
необходим, например, при выполнении следующего задания:
«Составьте, пожалуйста, реферат следующего текста в виде
четырех связных предложений:...».
Ответы данного типа используются при обучении
иностранным языкам с помощью компьютера достаточно редко,
поскольку такой ответ трудно проверить (например, в приведенном выше
задании трудно предвидеть, какие четыре предложения войдут в
реферат).
Примеры возможных заданий в обучающих программах по
иностранным языкам можно найти в работах [136; 145; 75; 76; 80; 81;
92; 91; 104; 174; 182].
Обучающий сценарий записывается в виде
последовательности пронумерованных кадров с указанием того, кто действует (ПК
или обучаемый). Сценарий обычно начинается с информирующих
и директивных кадров. Первые содержат название системы
обучения, фамилии авторов, назначение системы. Вторые отмечают
некоторые особенности' работы с системой. Далее обучаемому
предъявляется теоретический материал, который он должен знать
для выполнения последующих заданий.
В процессе подготовки практических заданий необходимо
предусмотреть несколько возможных правильных ответов на задаваемый
вопрос или упражнение. В хорошем обучающем сценарии обычно
предусматриваются наиболее вероятные неверные ответы
обучаемых и соответствующие им подсказки. Необходимо заранее
продумать действия компьютера в тех случаях, когда обучаемый
отказывается ответить на вопрос или просит изменить его формулировку.
В приведенном выше определении обучающего сценария
отмечается, что такой сценарий опирается на некоторый метод
обучения. Это означает, что обучающие кадры в нем должны
располагаться в соответствии с теми методами компьютерного обучения,
которые были рассмотрены ранее (см. с. 110 — 114).
Продемонстрируем процедуру построения обучающего
сценария для учебной задачи «Образование множественного числа
английских имен существительных», ориентируясь на описанные
выше конкретные задания по решению подобных задач. Будем
строить комбинированную программу обучения, способную как
обучать, так и контролировать знания. В качестве параметров,
позволяющих оценить результат обучения, выделим лишь два:
количество неверно выполненных заданий^ общее число заданий.
Примем 5-балльную систему оценки знаний по числу верно
выполненных заданий. При этом оценка «5» ставится за 95—100%
правильно выполненных заданий, оценка «4» — за 75—94% и
оценка «3» — за 50—74 % таких заданий. Если, допустим,
разрабатываемая система обучения включает 60 заданий, то оценки в этой
системе будут выставляться в соответствии с данными таблицы 40.
126
Допустим также, что для
правильного ответа обучаемому
будут данк четыре попытки. Если
обучаемый неверно ответил с
1-й или 2-й попытки, ему
дается подсказка. При третьем
неверном ответе обучаемому
предлагается прочитать правила
образования множественного числа
английского имени
существительного. А если и после этого
обучаемый дал неверный ответ,
то компьютер вйсвечивает
правильный ответ на экране
дисплея.
Теперь необходимо
тщательно проанализировать лингвистическое явление «Образование
множественного числа английских имен существительных». Изучая
соответствующую литературу по английскому языку [243, 2—4;
29, 523, 524], можно выявить, что множественное число
английских имен существительных образуется от формы единственного
числа следующими способами:
1) путем прибавления к основе единственного числа
суффикса -s. В зависимости от окончания основы этот суффикс читается
двояко:
1.1) как [z] после гласных и звонких согласных: bed — beds,
day — days.
При этом:
l.l.a) если конечной гласной -е предшествует согласная/, то
она при образовании множественного числа переходит в v: knife —
knives, wife — wives;
1.1.6) если существительное в единственном числе
оканчивается на -у с предшествующей согласной, то при образовании
множественного числа буква у меняется на букву /, после которой
следует суффикс -es [iz]: baby — babies, duty — duties;
I.I.b) если существительное в единственном числе
оканчивается на -о, то множественное число образуется путем
прибавления к форме единственного числа суффикса -es, который
произносится как [z]: photo — photoes, tomato — tomatoes, hero — heroes,
potato — potatoes.
1.2) как [s] после глухих согласных: сир — cups, hat — hats.
При этом:
1.2.a) если основа единственного числа оканчивается на
глухой согласный -th [0], то во множественном числе эта буква
читается как [о]: bath — baths, path — paths;
Таблица 40
Оценка знаний в обучающей
программе «Образование
множественного числа
английских имен
существительных»
Число правильно
выполненных
заданий
57-60
45-56
30-44
[ Менее 30
Оценка
5
4
3
2
127
1.2.6) если основа единственного числа оканчивается на
глухой согласный -/, то множественное число образуется путем
прибавления к основе суффикса -es и при этом буква/меняется на
букву v: leaf— leaves;
2) прибавлением к основе единственного числа,
оканчивающейся на -s, -ss, -х, -sh, -ch, суффикса -es, который читается как
[iz]: boss — bosses, ash — ashes;
3) путем изменения корневой гласной: man — men, tooth — teeth;
4) путем прибавления к основе единственного числа
суффикса -еп: ох— oxen;
5) без изменения формы единственного числа: sheep — sheep,
deer— deer,
6) путем различных изменений основы единственного числа
заимствованных имен существительных по правилам того языка,
из которых эти имена существительные заимствованы: datum —
data, formula —formulae, nucleus — nuclei, basis — bases, crisis — crises;
7) не имеют формы множественного числа имена
существительные, обозначающие:
а) неисчисляемые предметы — названия веществ: silver, oil, ice;
б) абстрактные понятия: love, hatred, strength;
в) ряд других понятий: money, hair,
8) не имеют формы единственного числа и употребляются
всегда только во множественном числе:
а) существительные, обозначающие многие парные предметы:
trousers, spectacles, scissors;
б) существительные, имеющие собирательное значение: clothes,
contents, sayings.
Выяснив эти правила, можно перейти к подбору учебного
материала, с которым будет иметь дело обучаемый. Допустим, опыт
обучения английскому языку позволяет включить в обучающий
сценарий следующие 60 существительных (табл. 41).
Уточним формулировки некоторых кадров будущего
обучающего сценария. Как видно из таблицы 41, одни из английских
имен существительных имеют и единственное и множественное,
другие — только единственное, третьи — только множественное
число. С учетом этого можно использовать три следующих кадра-
шаблона. (
1. Образуйте, пожалуйста, множественное число от имени
существительного X.
2. Можно ли образовать множественное число от имени
существительного X? Если да, то приведите форму множественного
числа. В противном случае ответьте словом по.
3. Употребляется ли в единственном числе английское имя
существительное XI Если да, то приведите форму единственного
128
Таблица 41
Учебный материал, включенный в обучающий сценарий
Номер
правила
Ни
U.a.
1.1.6
1.1.В
1.2
' '
1.2.а
1.2.6
2
№
п/п
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
Имена
существительные
boy—boys
club —clubs
table—tables
game—games
ball-balls
door—doors
chair—chairs
window—windows
piano —pianos
life—lives
wife—wives
knife—knives j
lady—ladies
baby—babies
duty—duties
hero—heroes
potato —potatoes
pen —pens
cup—cups
list—lists
month—months i
bath —baths
path —paths
half—halves
leaf— leaves
shelf—shelves
wolf— wolves
bus—buses
class—classes
match—matches
Номер
правила
3
4
5
6
7
8
№
п/п
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
Имена
существительные
ben — benches
man — men
foot—feet
tooth—teeth
mouse—mice
goose—geese
child—children
ox—oxen
swine—swine
sheep—sheep
deer— deer
trout— trout
crisis—crises
datum—data
basis—bases
formula—formulae
nucleus—nuclei
love—
money-
ice—
hair—
oil-
hatred—
silver—
strength—
— clothes
— contents
—saving
—spectacles
— trousers
числа этого существительного. В противном случае ответьте
словом по.
В обучающем сценарии следует чередовать эти три типа
заданий-высказываний для психологической разгрузки обучаемого.
Среди большого числа возможных формулировок кадров,
свидетельствующих о правильном ответе обучаемого, выберем
краткое высказывание: «Верно! Переходите к следующему заданию».
5 Зубо»
129
Кадры, свидетельствующие о неправильном ответе
обучаемого, представлены в таблице 42. Кадры, оценивающие результат
обучения, будут зависеть от данных таблицы 40. Занесем
соответствующие высказывания в таблице 43.
Таблица 42
Высказывания-подсказки при неправильном ответе
№
п/п
1
2
3
4
5
6
7
8
9
10
11
У
Высказывание
Вы допустили ошибку в суффиксе.
Введите ответ еще раз.
Вы допустили орфографическую
ошибку. Введите ответ вновь.
Неверно. Это существительное во
множественном числе меняет корневую
согласную/на v. Введите ответ еще раз.
Неверно. В этом имени существительном
окончанию -у предшествует согласная.
Буква у меняется на / перед суффиксом
-es. Введите ответ вновь.
Неверно. Помните о правиле изменения
корневой гласной: а -» е, о -» ее, ои -> /.
Введите ответ еще раз.
Неверно. Это имя существительное
образует форму множественного числа с
помощью суффикса -еп. Введите ответ
вновь.
Формы единственного и
множественного числа у этого имени
существительного совпадают. Введите ответ еще раз.
Вы снова ошиблись. Правильный
ответ — yzx.
Неверно. Это имя существительное не
имеет формы множественного числа.
Неверно. Это имя существительное не
имеет формы единственного^шсла.
Неверно. Прочитайте еще раз правила
образования множественного числа
имен существительных и дайте пра-
вильный ответ.
Условный код
высказывания
U1
U2
из
U4
U5
U6
U7
U8
U9
U10
Uli
НомераП
слов
заданий
в табл. 41
1-31
1—60
10-12,
24-27
13-15
32-36
37-38
39-42
48-55
56-60
1 Символы yz обозначают подразумеваемую правильную форму
множественного числа имени существительного.
130
Таблица 43
Высказывания, оценивающие результат обучения
Число
верных
ответов К
Высказывание
57-60
45-56
30-44
менее 30
Вам было предложено 60 имен существительных в
единственном числе. Вы сделали бО-А'1 ошибок. Ваша оценка —
5. До свидания, N2.
Вам было предложено 60 имен существительных в
единственном числе. Вы сделали бО-А'ошибок. Ваша оценка — 4.
До свидания, N.
Вам было предложено 60 имен существительных в
единственном числе. Вы сделали 60- К ошибок. Ваша оценка — 3.
До свидания, N.
Вам было предложено 60 имен существительных в
единственном числе. Вы сделали бО-АЪшибок. Ваша оценка — 2.
Повторите правила. До свидания, N.
Для непротиворечивого представления обучающего сценария
рассматриваемой задачи уточним количество попыток, даваемых
обучаемому для ответа. Для правил 1.1, l.l.a), 1.1.в), 1.2, 1.2.а),
1.2.6), 2, 3, 4, 5, 6 (см. табл. 41) могут быть использованы все
четыре попытки. Первая и вторая попытки могут быть связаны с
ошибками в основе и суффиксе. При этом в качестве подсказок
ввдаются высказывания U1—U6 (см. табл. 40). После третьей
неверной попытки необходимо дать обучаемому подсказку в виде
правил образования множественного числа имен
существительных (высказывание Uli). После четвертой неверной попытки
обучаемому дается правильный ответ в виде высказывания U8. Для
правил 7 и 8 (см. табл. 39) будем использовать лишь две попытки.
При 1-м неверном ответе обучаемому дается возможность
познакомиться с правилами образования множественного числа
(высказывание Uli), а при 2-м неверном ответе предлагается правильный
ответ (высказывания U8—U10).
Как отмечалось выше, порядок расположения
кадров-высказываний в обучающем сценарии определяется выбранным
методом обучения. Будем строить смешанный обучающий сценарий,
моделируя один из* возможных способов общения преподавателя
и обучаемого.
1 Символ К в приведенном ниже обучающем сценарии обозначает счетчик
числа правильных ответов обучаемых.
2 Символ N обозначает имя и фамилию обучаемого, которые он вводит
перед началом работы с системой обучения.
131
Используя информацию об общей структуре обучающего
сценария, с учетом данных таблиц 40—42 представим обучающий
сценарий задачи "Образование множественного числа английских
имен существительных" в следующем виде (табл. 44).
Таблица 44
Фрагменты обучающего сценария задачи "Образование
множественного числа английских имен существительных'
•и
Номер
кадра
Кто
действует
Содержание кадра
ПК
ПК
3
4
5
б
7
ПК
ОБ
ПК
ОБ
ПК
ОБУЧАЮЩАЯ СИСТЕМА "АОС МГЛУ" ПРИВЕТСТВУЕТ ВАС!
ВЫ ПРИСТУПАЕТЕ К ИЗУЧЕНИЮ СПОСОБОВ
ОБРАЗОВАНИЯ МНОЖЕСТВЕННОГО ЧИСЛА АНГЛИЙСКИХ ИМЕН
СУЩЕСТВИТЕЛЬНЫХ. С ВАМИ РАБОТАЕТ ОБУЧАЮЩАЯ
ПРОГРАММА "PLURAL". ЖЕЛАЕМ ВАМ БОЛЬШИХ УСПЕХОВ!
ЗАПОМНИТЕ, ЧТО ПЕРЕД НАБОРОМ НА КЛАВИАТУРЕ
РУССКИХ СЛОВ, НЕОБХОДИМО НАЖАТЬ ПРАВЫЕ
КЛАВИШИ [CTRL-SHIFT], А ПОСЛЕ НАБОРА ОТВЕТА -
КЛАВИШУ [ENTER]
ВВЕДИТЕ, ПОЖАЛУЙСТА, ВАШУ ФАМИЛИЮ, ИМЯ И
НАЖМИТЕ КЛАВИШУ [ENTER]
Набирает на клавиатуре свою фамилию, имя и
нажимает клавишу [ENTER]
ВАМ НАПОМНИТЬ ПРАВИЛА ОБРАЗОВАНИЯ
МНОЖЕСТВЕННОГО ЧИСЛА АНГЛИЙСКИХ ИМЕН СУЩЕСТВИТЕЛЬНЫХ?
ДА (НАПОМНИТЬ)2
НЕТ (НЕ НАДО)
МНОЖЕСТВЕННОЕ ЧИСЛО АНГЛИЙСКИХ ИМЕН
СУЩЕСТВИТЕЛЬНЫХ ОБРАЗУЕТСЯ СЛЕДУЮЩИМИ СПОСОБАМИ:
1. ПУТЕМ ПРИБАВЛЕНИЯ К ОСНОВЕ НАСТОЯЩЕГО
ВРЕМЕНИ СУФФИКСА -S. ЭТОТ СУФФИКС В
ЗАВИСИМОСТИ ОТ ОКОНЧАНИЯ ОСНОВЫ ЧИТАЕТСЯ ДВОЯКО:
1.1. КАК [-Z] - ПОСЛЕ ЗВОНКИХ СОГЛАСНЫХ И
ГЛАСНЫХ, НАПРИМЕР:
BED-BEDS, D&Y-DAYS
ПРИ ЭТОМ: J)
ЕСЛИ КОНЕЧНОЙ ГЛАСНОЙ Е ПРЕДШЕСТВУЕТ
СОГЛАСНАЯ F, ТО ОНА ПРИ ОБРАЗОВАНИИ
МНОЖЕСТВЕННОГО ЧИСЛА ПЕРЕХОДИТ В V, НАПРИМЕР:
LIFE-LIVES, WIFE-WIVES
► к кадру 7
к кадру 11
1 Все, что написано в сценарии большими буквами, высвечивается на
экране дисплея.
2 Выражения в скобках обозначают альтернативный допустимый ответ.
132
Продолжение табл. 44
1
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
24А
25
2
ПК
ПК
ПК
ПК
ОБ
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
3 |
(далее приводятся все правила/
рассмотренные на с. 127, 128)
ПОМНИТЕ, ПОЖАЛУЙСТА, ЧТО ПОСЛЕ НАБОРА НА
КЛАВИАТУРЕ ВАШЕГО ОТВЕТА НЕОБХОДИМО НАЖАТЬ
КЛАВИШУ [ENTER]
А ТЕПЕРЬ, ПОЗНАКОМИВШИСЬ С ПРАВИЛАМИ
ОБРАЗОВАНИЯ МНОЖЕСТВЕННОГО ЧИСЛА АНГЛИЙСКИХ ИМЕН
СУЩЕСТВИТЕЛЬНЫХ, ВЫПОЛНИТЕ, ПОЖАЛУЙСТА,
СЛЕДУЮЩИЕ ЗАДАНИЯ
(запоминает число выдаваемых заданий)
ОБРАЗУЙТЕ, ПОЖАЛУЙСТА, МНОЖЕСТВЕННОЕ ЧИСЛО
ОТ ИМЕНИ СУЩЕСТВИТЕЛЬНОГО: BOY
DAVC ~— »у» Тл >. rrrit r О С
buio ^ к кадру £.э
. (неверная основа) S ^ к кадру 13
BOY (неверный суффикс) . *■■ к кадру 22
(запоминает, что сделана очередная попытка
ответа)
(анализирует, какая попытка сделана:
1-я или 2-я ^ к кадру 15,
3-я ^ к кадру 17,
«±—я ^ к кадру .сиj
ВЫ ДОПУСТИЛИ ОРФОГРАФИЧЕСКУЮ ОШИБКУ.
ВВЕДИТЕ ОТВЕТ ВНОВЬ
(переходит к кадру 11)
НЕВЕРНО. ПРОЧИТАЙТЕ ЕЩЕ РАЗ ПРАВИЛА
ОБРАЗОВАНИЯ МНОЖЕСТВЕННОГО ЧИСЛА АНГЛИЙСКИХ ИМЕН
СУЩЕСТВИТЕЛЬНЫХ И ДАЙТЕ ПРАВИЛЬНЫЙ ОТВЕТ
(переходит к кадру 8)
(переходит к кадру 11)
ВЫ СНОВА ОШИБЛИСЬ. ПРАВИЛЬНЫЙ ОТВЕТ - BOYsl
(переходит к кадру 28)
(запоминает, что сделана очередная попытка
ответа)
(анализирует, какая попытка сделана:
1-я или 2-я *■ к кадру 24,
3-я ^ к кадру 17,
4—я ^ к кадру 20)
ВЫ ДОПУСТИЛИ ОШИБКУ В СУФФИКСЕ. ВВЕДИТЕ ОТВЕТ
ЕЩЕ РАЗ
(переходит к кадру 11)
ВЕРНО! ПЕРЕХОДИТЕ К СЛЕДУЮЩЕМУ ЗАДАНИЮ 1
133
Продолжение табл. 44
1
26
28
29
30
31
32
33
34
35
36
37
38
40
41
42
43
44
1 45
2
ПК
ПК
ОБ
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ОБ.
ПК
ПК
ПК
ПК
3
(запоминает число верных ответов в счетчике
К)
МОЖНО ЛИ ОБРАЗОВАТЬ МНОЖЕСТВЕННОЕ ЧИСЛО ОТ
ИМЕНИ СУЩЕСТВИТЕЛЬНОГО LOVE?
ЕСЛИ ДА, ТО ПРИВЕДИТЕ ФОРМУ МНОЖЕСТВЕННОГО
ЧИСЛА. В ПРОТИВНОМ СЛУЧАЕ ОТВЕТЬТЕ СЛОВОМ ю\
NO ^ к кадру 37
(иначе) ^ к кадру 30
(запоминает, что сделана очередная попытка
ответа)
(анализирует, какая попытка сделана:
ля ' ^ к кадру jz
2-я ^ к кадру 35)
НЕВЕРНО. ПРОЧИТАЙТЕ ЕЩЕ РАЗ ПРАВИЛА ОБРАЗО-т
ВАНИЯ МНОЖЕСТВЕННОГО ЧИСЛА АНГЛИЙСКИХ ИМЕН
СУЩЕСТВИТЕЛЬНЫХ И ДАЙТЕ ПРАВИЛЬНЫЙ ОТВЕТ
(переходит к кадру 8)
(переходит к кадру 28)
НЕВЕРНО! ЭТО ИМЯ СУЩЕСТВИТЕЛЬНОЕ НЕ ИМЕЕТ
ФОРМЫ МНОЖЕСТВЕННОГО ЧИСЛА
(переходит к кадру 40)
ВЕРНО! ПЕРЕХОДИТЕ К СЛЕДУЮЩЕМУ ЗАДАНИЮ
(запоминает число верных ответов)
УПОТРЕБЛЯЕТСЯ ЛИ В ЕДИНСТВЕННОМ ЧИСЛЕ
АНГЛИЙСКОЕ ИМЯ СУЩЕСТВИТЕЛЬНОЕ CLOTHES?
ЕСЛИ ДА, ТО ПРИВЕДИТЕ ФОРМУ ЕДИНСТВЕННОГО
ЧИСЛА ЭТОГО ИМЕНИ СУЩЕСТВИТЕЛЬНОГО. В
ПРОТИВНОМ СЛУЧАЕ ОТВЕТЬТЕ СЛОВОМ NO
NO у" ^ к кадру 49
/ TiTt-T ^ TT /^Ь \ ^^^^^^^^^^^^^^ т/ ту* ^ TTV4T Г Л О 1
^иначе/ ^ к кадру fiz i
(запоминает, что сделана очередная попытка
ответа)
(анализирует, какая попытка сделана:
1-я ** к кадру 44/ 1
2-я ^ к кадру 47) 1
НЕВЕРНО. ПРОЧИТАЙТЕ ЕЩЕ РАЗ ПРАВИЛА
ОБРАЗОВАНИЯ МНОЖЕСТВЕННОГО ЧИСЛА АНГЛИЙСКИХ ИМЕН
СУЩЕСТВИТЕЛЬНЫХ И ДАЙТЕ ПРАВИЛЬНЫЙ ОТВЕТ
(переходит к кадру 8)
134
Продолжение табл. 44
1 1
1 46
47
48
49
50
52
69
70
71
72
73
74
75
76
77
78
..79
80
81
2
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ОБ
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
3 "1
(переходит к кадру 40)
НЕВЕРНО! ЭТО ИМЯ СУЩЕСТВИТЕЛЬНОЕ НЕ.ИМЕЕТ
ФОРМЫ ЕДИНСТВЕННОГО ЧИСЛА
(переходит к кадру 52)
ВЕРНО! ПЕРЕХОДИТЕ К СЛЕДУЮЩЕМУ ЗАДАНИЮ
(запоминает число верных ответов в счетчике К)
ОБРАЗУЙТЕ, ПОЖАЛУЙСТА, МНОЖЕСТВЕННОЕ ЧИСЛО
ОТ ИМЕНИ СУЩЕСТВИТЕЛЬНОГО: CLUB
МОЖНО ЛИ ОБРАЗОВАТЬ МНОЖЕСТВЕННОЕ ЧИСЛО ОТ
ИМЕНИ СУЩЕСТВИТЕЛЬНОГО PEN?
ЕСЛИ ДА, ТО ПРИВЕДИТЕ ФОРМУ МНОЖЕСТВЕННОГО
ЧИСЛА, В ПРОТИВНОМ СЛУЧАЕ ОТВЕТЬТЕ СЛОВОМ NO\
DUMO ^- ТХ и<4 ТТГМГ Q С.
rciiMo ^ к кадру о о
(неверная основа) S ^ к кадру 71
PEN (неверный суффикс) ^ к кадру 80
М^*^ ^^^^^^^. »У» ТУ» ^ ТГУ\Я Г О Л -
JNU *»■ к кадру о ч
(запоминает, что сделана очередная попытка
ответа)
(анализирует, какая попытка сделана:
1~я или 2"~я ** к кадру 73,
3-я ^ к кадру 75,
4—я ^ к кадру 78)
ВЫ ДОПУСТИЛИ ОРФОГРАФИЧЕСКУЮ ОШИБКУ.
ВВЕДИТЕ ОТВЕТ ВНОВЬ
(переходит к кадру 69)
НЕВЕРНО! ПРОЧИТАЙТЕ ЕЩЕ РАЗ ПРАВИЛА
ОБРАЗОВАНИЯ МНОЖЕСТВЕННОГО ЧИСЛА АНГЛИЙСКИХ ИМЕН
СУЩЕСТВИТЕЛЬНЫХ И ДАЙТЕ ПРАВИЛЬНЫЙ ОТВЕТ
(переходит к кадру 8)
(переходит к кадру 69)
ВЫ СНОВА ОШИБЛИСЬ. ПРАВИЛЬНЫЙ ОТВЕТ - PENs\
(переходит к кадру 88)
(запоминает, что сделана очередная попытка)
(анализирует, какая попытка сделана:
1-я или 2—я ^ к кадру 82, 1
3-я ^ к кадру 75,
4—я ^ к кадру 78)
135
Окончание табл. 44
1
82
83
84
85
86
87
88
1045
1046
' 1047
1048
1049
1050
1051
1052
1053
2
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
ПК
3 |
ВЫ ДОПУСТИЛИ ОШИБКУ В СУФФИКСЕ. ВВЕДИТЕ ОТВЕТ
ЕЩЕ РАЗ
(переходит к кадру 69)
(запоминает, что сделана'очередная
попытка)
(анализирует, какая попытка сделана:
1-я ^ к кадру /Df
2-я '^ к кадру 78)
ВЕРНО! ПЕРЕХОДИТЕ К СЛЕДУЮЩЕМУ ЗАДАНИЮ
(запоминает число верных ответов)
(проверяет, сколько всего правильных
ответов дал обучаемый (счетчик числа правильных
ответов К) :
если К>56 ^' к кадру 1046,
/■> /-I ттт/r А ^ y\t ^ ^ d ~— iv» ту -^ rrv\x г 1 П/1 О 1
если 4j\i\.sDo ^ к кадру lufto,
Ä/"» TT ТУТ *3 О yV*' А Л шмшЪ. »/• ТУЗ TTT-NTr 1 П RH
если ouv»j\v.ftfi ^ к кадру iuou,
ЛЛТТ» \Г ^ "Э Л «^ ту« .. . пп. , 1 Л СО \ I
если J\<ju ^ к кадру luoz;
ВАМ БЫЛО ПРЕДЛОЖЕНО 60 ИМЕН СУЩЕСТВИТЕЛЬНЫХ
В ЕДИНСТВЕННОМ ЧИСЛЕ. ВЫ СДЕЛАЛИ 60-К
ОШИБОК. ВАША ОЦЕНКА - 5. ДО СВИДАНИЯ, N
(переходит к кадру 1053)
ВАМ БЫЛО ПРЕДЛОЖЕНО 60 ИМЕН СУЩЕСТВИТЕЛЬНЫХ
В ЕДИНСТВЕННОМ ЧИСЛЕ. ВЫ СДЕЛАЛИ 60-К
ОШИБОК. ВАША ОЦЕНКА - 4. ДО СВИДАНИЯ, N
(переходит к кадру 1053)
ВАМ БЫЛО ПРЕДЛОЖЕНО 60 ИМЕН СУЩЕСТВИТЕЛЬНЫХ
В ЕДИНСТВЕННОМ ЧИСЛЕ. ВЫ СДЕЛАЛИ 60-К
ОШИБОК. ВАША ОЦЕНКА - 3. ДО СВИДАНИЯ, N
(переходит к кадру 1053)
ВАМ БЫЛО ПРЕДЛОЖЕНО 60 ИМЕН СУЩЕСТВИТЕЛЬНЫХ
В ЕДИНСТВЕННОМ ЧИСЛЕ. ВЫ СДЕЛАЛИ 60-К
ОШИБОК. ПОВТОРИТЕ ПРАВИЛА. ДО СВИДАНИЯ, N
(прекращает работу)
Для написания по построенному сценарию обучающей
программы можно использовать две группы инструментальных средств [131,
66, 67]: 1) алгоритмические языки общего назначения; 2)
специальные авторские алгоритмические языки для обучения.
136
К числу первых относятся широко известные алгоритмические
языки PASCAL, C++, PROLOG, QBASIC и др. Авторские языки
разработаны специально для создания обучающих программ. В них
заложены возможности задания определенного числа верных и
неверных ответов, средства сбора и анализа статистических данных
об учебном процессе по каждому обучаемому и группе обучаемых.
Эти языки предусматривают возможности подключения к ПК
другого обучающего оборудования (магнитофона, слайд-проекторов
и т.п.). К числу таких языков относятся языки КУРСОР,
КОНТАКТ, ЯОК (СПОК), ДИДАКТ, NATAL-74, DECAL, PASS и т.д.
После создания обучающей программы проводится ее
тестирование на нескольких группах обучаемых. Основные цели этого
этапа сводятся к следующему [131, 51]:
1) необходимо выявить трудности предъявляемых заданий;
2) уточнить выставляемые системой оценки;
3) выявить психофизиологические особенности работы
обучаемых с созданной программой.
В процессе работы с обучающей программой для всех групп
обучаемых определяется трудность каждого задания. Это можно
сделать различными способами [131, 51, 52; 1, 41, 42]. Например,
трудность задания Тг можно определить по следующей формуле:
Ty=N{/N2, где Ni — число обучаемых, правильно выполнивших
задание; N2 — общее число выполнявших задание обучаемых. При
этом если Г3<0,5, то задание считается трудным (для группы
обучаемых с определенным уровнем знаний) и его желательно
з^енить.
Для уточнения выставляемых системой оценок с несколькими
группами обучаемых проводятся занятия по конкретной теме с
помощью компьютера и без него (по традиционной методике, с
преподавателем). Полученные от системы оценки и оценки
преподавателя сопоставляются с целью дальнейшей корректировки
методики их формального выставления компьютером (например,
уточнение диапазонов суммарных баллов, за которые
выставляются оценки «отлично», «хорошо», «удовлетворительно»).
В процессе выявления психофизиологических особенностей
работы с данной обучающей программой уточняется время
ожидания системой ответа обучаемого, расположение материала на
экране дисплея, принцип работы обучаемых за экраном (по одному
или по два) и т. п.
По результатам тестирования программы может быть изменен
используемый компьютером учебный материал, внесены
исправления в обучающий сценарий, откорректировано расположение
кадров на экране дисплея и т.д.
Определение эффективности используемой обучающей
программы является одной из самых сложных задач процесса
компьютерного обучения. Эффективность может определяться в различных
137
аспектах: дидактическом, экономическом, техническом,
эргономическом [91, 54]. При этом, как правило, на основе показателей
затраченного труда и деятельности преподавателей и обучаемых
вычисляются различные коэффициенты [2, 22, 23].
На последнем этапе обучающие программы отдельных задач
объединяются в автоматизированные учебные курсы различного
назначения. Способы их использования подробнее будут
рассмотрены в следующих трех параграфах данного учебного пособия.
ИСПОЛЬЗОВАНИЕ ПЕРСОНАЛЬНЫХ КОМПЬЮТЕРОВ
В ОБУЧЕНИИ ИНОСТРАННЫМ ЯЗЫКАМ
Способы использования компьютеров
для обучения языкам
В наши дни уже не вызывает сомнения необходимость
использования компьютеров в обучении иностранным языкам. С
информационной точки зрения искусство обучения может
рассматриваться как наиболее эффективная организация общения
обучаемых со знанием, а основная задача современного образования —
научить эти знания добывать, классифицировать и использовать в
своей повседневной жизни [141, 38].
Если рассматривать современные персональные компьютеры
не просто как средство технической поддержки учебного
процесса, а как устройство, способное выполнять педагогические
функции, несущее в себе конкретные знания и передающее эти
знания в процессе диалога с обучаемым, то можно выделить три
способа использования компьютеров в обучении [141, 38].
1. Компьютер — помощник преподавателя. В этом случае
процесс обучения строится в соответствии с традиционным
содержанием образованной методами передачи знаний от преподавателя
к обучаемым. Используемые при этом обучающие программы лишь
моделируют некоторые задачи, темы, разделы изучаемого курса и
общаются с обучаемым по достаточно жесткому сценарию. Здесь
преобладает групповой метод обучения в традиционных группах,
классах и т. п.
2. Компьютер — преподаватель. При таком способе также
моделируется традиционная методика обучения и строится жесткий
сценарий обучения. Однако соответствующие обучающие программы
направлены на обучение целому курсу (информатике,
английскому языку и т.д.). Как правило, они предназначены для
индивидуализированного обучения (чаще всего в домашних условиях).
3. Компьютер — источник знаний и «оцениватель» знаний
обучаемого. Здесь используется так называемая альтернативная пе-
138
дагогика, когда обучаемый, исходя из целей обучения и своих
возможностей, опираясь на собственный опыт и знания,
обращается к компьютеру как к носителю необходимых для него
знаний или «оценивателю» полученных обучаемым знаний [141> 38;
173, 9]. Такой подход возможен как при групповом, так и
индивидуализированном обучении в рамках дистанционного
обучения.
Методика создания компьютерных обучающих программ,
применяемых в качестве помощника преподавателя, подробно
рассмотрена выше. Издано много литературы, посвященной
проблемам использования таких программ в аудиториях, для
самостоятельной работы в классах, их эффективности, преимуществ таких
программ по сравнению с традиционным обучением и их
недостатков [75; 80; 81; 92; 104; 106; 136; 145; 147; 156; 164; 174; 178].
Особенности организации обучающих программ, используемых
двумя другими способами, требует более детального рассмотрения.
Компьютерные программы
индивидуализированного обучения языкам
Компьютерные программы индивидуализированного обучения
языкам обычно представляют собой некоторые законченные
курсы, предназначенные для начального обучения,
совершенствования языка и т.д. От программ, предназначенных для
поддержки обучения, они отличаются тем, что полностью должны
заменить преподавателя в процессе обучения языку. Данный факт
заставляет создателей таких программ формализовать
иррациональную интуитивно-творческую деятельность преподавателя,
приблизить процесс обучения с помощью подобной обучающей
программы к реальному процессу обучения с преподавателем.
Среди большого числа требований, которым должны
удовлетворять компьютерные программы индивидуализированного
обучения, наиболее важными с педагогической точки зрения
являются следующие [68; 104; 108; 111; 141; 151; 174; 190; 227].
Подобные программы должны:
1) совмещать в себе обучающую, контрольную и поисковую
функции;
2) опираться на сценарии, приближенные к обычному
традиционному обучению;
3) максимально использовать принцип наглядности и
доступности, т. е. выводить на экран компьютера не только текст, но и
звук, иллюстрации, видео и т.п.;
4) иметь средства быстрой и объективной оценки знаний
обучаемых даже в тех случаях, когда ответ обучаемого далек от
наиболее ожидаемого;
139
5) содержать возможность настройки на конкретного
обучаемого (выбор способа подачи нового материала, типа
упражнений, скорости ответа и т.п.).
Как правило, обучающие программы, используемые для
индивидуализированного обучения, реализуются в виде так
называемых мультимедийных обучающих программ. Слово
мультимедийный появилось вне связи с компьютерами в англо-русском
словаре 1969 года издания. В то время урок, проводимый прешь
давателем, назывался мультимедийным, если в нем
присутствовали и рассказ учителя, и магнитофонная запись, и кино, и
слайды, и любые средства технического обучения [239, 60]. Сегодня"
под мультимедийной обучающей программой понимается
компьютерная программа, использующая текст, звук, цвет,
графику и движение. В понятие звук входят речь, музыка, их
комбинации (музыка — речь — пение и др.), а также различные звуковые
эффекты. Графика в таких программах может быть представлена
различными рисунками, геометрическими фигурами (круг, ромб
и т.д.), символами, фотографиями и сканированными
изображениями. Движение в мультимедийных программах представляется в
виде последовательности статических элементов (кадров) и
может быть трех видов: видео (life video), квазивидео и анимация.
Видео — это последовательность черно-белых или цветных
фотографий, пропускаемая на экране компьютера со скоростью около
24 фотографий в секунду. Квазивидео — тоже последовательность
кадров, движущаяся по экрану со скоростью 6—12 фото в
секунду. Анимация — это последовательность рисованных изображений
[227, 7, 8; 151, 78— 80]. Такие программы дают возможность
активизировать различные каналы восприятия информации и
повышают степень запоминания и усвоение учебного материала [68,
165; 233].
В целом процесс создания мультимедийных обучающих
программ включает следующее этапы [227, 10; 190, 99; 239, 61]:
1) разделение всего курса, который будет предложен для
обучения, на определенное число тем и подтем;
2) отбор для каждой темы или подтемы определенного
лексического и грамматического материала;
3) создание для каждой темы или подтемы набора сценариев,
в рамках которых будут закрепляться лексический материал и
грамматические правила. Такие сценарий должны включать звук,
графику и движение;
4) подбор в соответствии со сценариями необходимых текстов,
аудио- и видеоматериалов;
5) программирование сценариев. Такая работа может выполняться
высококвалифицированными программистами на различных
языках программирования. Такое программирование можно осуществить
и с помощью специальных инструментальных систем для разра-
140
ботки и редактирования учебных программ (например, LINK WAY,
TEACHCAD, MULTIMEDIA TOOLBOOK, МАГИСТР,
СЦЕНАРИЙ, STRATUM, AUTHORWARE PROFESSIONAL и др. [151, 82]).
В целом задачи создания эффективных мультимедийных
программ для изучения иностранных языков могут успешно
решаться только крупными коллективами, содержащими в своем
составе опытных преподавателей иностранных языков, методистов,
психологов, программистов, электронщиков. К числу наиболее
известных фирм такого рода относятся американские фирмы:
«Seracuse Language System», «Compulink», «Foreign Lauguage
Software Company», «Hyper Glot», «Macmillan Heinemann» и т.д.,
российские фирмы: «Мультимедиа Технологии», «Istrasoft», «New
Media Generation», «Новый диск» и т. п.
Мультимедийную обучающую программу по иностранному
языку можно охарактеризовать следующими дидактическими
параметрами [171, 178—181]:
1) тип пользователя;
2) назначение программы;
3) количество разделов, тем и подтем в программе;
4) язык комментариев и подсказок;
5) количество единиц словаря;
6) способы представления единиц словаря;
7) логический объем курса в часах (продолжительность
последовательного прослушивания всего звукового материала
программы без повторов);
8) число иллюстраций.
Помимо этого, каждую программу можно охарактеризовать
рядом технических параметров [196, 32]:
1) объем учебного текста в Кб;
2) объем памяти в Мб, занятый звуковыми фрагментами;
3) объем видеофрагментов в Мб;
4) формат видео;
5) формат аудио;
6) формат иллюстраций.
Детально эти параметры описаны в работах [196, 32; 171].
По типу пользователей различают следующие
мультимедийные программы обучения иностранным языкам [171, 178—181]:
1) для детей; 2) для молодежи и взрослых; 3) для
бизнес-применений; 4) специализированные программы.
По назначению такие программы делят на следующие виды
[171, 178—181; 3; 89; 196; 240]: 1) для игр; 2) для начального
обучения языку; 3) для совершенствования знаний языка; 4) для
сдачи различных экзаменов; 5) для работы с деловыми текстами.
Так, для начального обучения английскому языку молодежи и
взрослых можно использовать такие мультимедийные программы,
как Bridge to English, Репетитор English, Профессор Хиггинс, Learn
141
to speak English, Everyday English in Communication, Talk to Me,
Triple Play Plus [196; 171].
Для совершенствования знания английского языка молодыми
людьми и взрослыми полезны такие программы, как [196; 171]:
Complete English, English for Communication, English Cold, English
Platinum.
Совершенствование знаний английского языка взрослыми в
области бизнеса возможно путем использования мультимедийных
программ Business English и ЕВС (English Business Contracts). Их
структура и возможности хорошо описаны в работах [3; 171].
Наконец, примером специализированных мультимедийных обучают
щих программ, ориентированных на молодежь и взрослых и
предназначенных для сдачи международного теста на владение
английским языком как иностранным (TOEFL), является программа
The Heinemann TOEFL [171].
Для того чтобы представить возможности мультимедийной
обучающей программы, рассмотрим детальнее программу English Gold.
Уже отмечалось, что она предназначена для совершенствования
знаний английского языка молодежью и взрослыми. Программа
включает пять разделов: «Фонетика», «Грамматика», «Словарь»,
«Диалоги», «Фильм» — и 144 урока. Комментарии и подсказки
оформлены на русском языке. Словарь включает 12 000 слов.
Каждая словарная единица представлена в письменном и звуковом
видах, а также в виде изображения предмета. Логический объем
звука программы составляет более 100 часов. Программа содержит
2096 иллюстраций.
Подобная характеристика других упомянутых выше
мультимедийных программ, используемых для индивидуализированного
обучения, приведена в работах [196; 178, 96—102, 420—479].
Дистанционное обучение иностранным языкам
Как было отмечено выше, способ использования компьютера
как источника знаний и «оценивателя» знаний обучаемого по
окончании процесса компьютеризированного обучения реализуется в
системе дистанционного обучения. В самом общем плане
дистанционное обучение — это обучение на расстоянии, т. е. в ситуации,
когда обучаемый отделен от преподавателя в пространстве или во
времени [173, 6\ 55]. В сознании большинства преподавателей это
понятие идентично заочному обучению. Сегодня существует
достаточно много подходов к определению данного понятия [56,
20, 21; 139, 65; 54; 85; 178, 104]. Синтезируя эти подходы, можно
предложить следующее определение понятия дистанционного
обучения: дистанционное обучение — это новая форма организации
учебного процесса, соединяющая в себе традиционные и новые
142
информационные технологии обучения, основывающаяся на
принципе самостоятельного получения знаний, предполагающая в
основном телекоммуникационный принцип доставки обучаемому
основного учебного материала и интерактивное взаимодействие
обучаемых и преподавателей как непосредственно в процессе
обучения, так и при оценке полученных ими в процессе обучения
знаний и навыков. Дистанционное обучение — основная
составляющая дистанционного образования. Последнее предполагает
также наличие определенных средств прщщ,и^
единых протоколов^т^х^^^й^тт^.соответствующего
программного обеспечения, группу административного управления
[88, 15]. .' ^^^^.^^—-~~^_~ ,.
Существуют различные подходы к классификации видов или
моделей дистанционного обучения [173, 8, 9; 56, 22; 6; 266, 33;
150, 5, 6]. Наиболее оптимальной представляется классификация,
зависящая от способов доставки обучаемым учебного материала и
принципов общения с преподавателем [173, <?, 9; 56, 20].
1. Интерактивное телевизионное обучение. В данном случае
преподаватель ведет занятие в одном из классов, где установлена
видеокамера, и весь урок по телевизионным кабелям передается в
другое здание, другой город, другую область или другое
государство. По телевизионным каналам (или пересылкой видео- и
аудиокассет) обучаемым передается также учебный материал и задания.
Проверка знаний с выдачей соответствующих дипломов и
аттестатов осуществляется при личных контактах преподавателя со
студентами. Такой способ дистанционного обучения широко
используется в настоящее время в США [56, 20]. Наиболее известным
образовательным учреждением в этом плане является Национальный
технологический университет (NTU — National Technological
University). Он является центром дистанционного образования штата
Колорадо (г. Форт-Коллин) и объединяет 40 дистанционных школ,
расположенных на его территории. Для такого обучения в США
активно используется и Система публичного телевещания (Public
Broadcasting System, PBS—TV). Учебные курсы по бизнесу,
управлению, различным областям науки передаются по четырем
образовательным каналам и доступны людям всей страны.
2. Дистанционное обучение с использованием носителей учебной
информации на компакт-дисках (CD). Для получения различных
консультаций у преподавателей широко используется глобальная
сеть Интернет. Проверка знаний и навыков в этом случае, как и в
первом виде дистанционного обучения, осуществляется при
личных контактах обучаемых с преподавателями.
3. Дистанционное обучение с широким использованием
телекоммуникационных сетей. В этом случае как передача знаний
обучаемым, так и проверка их знаний и навыков осуществляются в
интерактивном режиме работы с глобальной сетью Интернет.
143
В центре такого процесса обучения находится самостоятельная
познавательная деятельность обучаемого (учение, а не
преподавание) [173, 10]. В основном различают два варианта
взаимодействия обучаемого и обучающего центра: 1) на основе World Wide
Web (WWW) и 2) в режиме видеоконференций.
На первом этапе в группе административного управления
абитуриент оформляет определенные документы, оплачивает
обучение и получает следующую информацию [139, 68]:
1) координаты преподавателей, которые будут оказывать ему
индивидуальные интерактивные консультации через Интернет по
каждому из предметов;
2) пароль для доступа к сетевой электронной библиотеке (если
такая имеется).
На второмэтапе — этапе вступительных экзаменов —
используется специальная интерактивная подсистема тестирования
абитуриентов по различным дисциплинам, включенным в число
вступительных. Прошедшие тестирование включаются в число
обучаемых.
Третий этап — этап непосредственного обучения. Первый
шаг такого обучения связан с выбором конкретного набора
учебных дисциплин, входящих в учебный план той или иной
специальности. По каждой дисциплине обучаемый получает набор
учебно-методических материалов, выполненных в виде гипертекста1.
В процессе обучения по каждому разделу обучаемый
выполняет тест, который по электронной почте передается
прикрепленному преподавателю. При необходимости обучаемый может
получить консультации через электронную почту или сеть
Интернет в режиме on-line. После положительной оценки всех
промежуточных тестов по всем ррделам учебной дисциплины обу^
чаемый допускается к экзатушну по дисциплине. Такой экзамен
может проводиться как в письменной форме через электронную
почту, так и в устной форме в региональных учебных центрах,
где обучаемый и преподаватель встречаются лично. Выполнив
подобные процедуры по каждой дисциплине, обучаемый
получает сертификат о приобретении той или иной специальности
[90, 25; 150, 5, 6].
Эффективность дистанционного обучения во многом зависит
от структуры учебно-методических материалов по обучаемой
дисциплине. Методистами разработаны специальные положения по
созданию подобных компьютерных учебно-методических
материалов [150,12-20; 173, 9, 10; 139, 69; 108]. В работе [55, 111-123]
детально рассмотрена структура учебного материала для
дистанционного обучения иностранному языку.
1 Подробнее об этом см. с. 183.
144
Несмотря на то что в последние годы идея дистанционного
образования нашла широкую поддержку во всем мире, в ее
практической реализации имеется ряд существенных трудностей.
Наиболее принципиальная из них заключается в том, что
традиционное обучение есть передача знаний от обучающего к
обучаемому, а при дистанционном обучении происходит передача не
знаний, а информации [138, 89]. Если говорить о дистанционном
обучении иностранному языку, то целью такого обучения
является не столько знание о самом предмете, т.е. языке (языковая
компетенция), сколько выработка определенных навыков и умений
разных видов речевой деятельности на основе знаний о способе
деятельности (коммуникативная компетенция) [55, 108].
Возможности компьютера при обучении устной речи детально
исследованы в целом ряде работ Р.К.Потаповой (см., например [178,
420—479\). А то, насколько быстро и эффективно передаваемая
по телекоммуникационным каналам информация превратится в
знания, зависит от возможности обучаемого ее самостоятельно
интерпретировать. Последнее, в свою очередь, связано с
предыдущими знаниями обучаемого, его образованием, жизненным
опытом и т.д. К тому же, как отмечают психологи, информация,
представляемая на экранах компьютеров, обладает иными
свойствами, чем информация, представленная в книгах, фильмах, на
слайдах и т.п. Специалисты по дистанционному обучению
предлагают проводить исследование информационного поля каждого
обучаемого путем специального построения окружающей
обучаемого информационной среды [138, 90; 187].
Еще одна трудность связана с необходимостью организации
принципиально иной структуры учебного материала,
предъявляемого при дистанционном обучении [55, 69—90, 107—124]. На
первый план здесь выходит «самостоятельная познавательная
деятельность обучаемого (учение, а не преподавание)» [173, 10].
Следующая проблема дистанционного обучения с
максимальным использованием телекоммуникационных сетей связана с
необходимостью обладания обучаемыми навыков работы с
компьютером [173, 10]. Существует еще целый ряд проблем, достаточно
подробно рассмотренных в специальных исследованиях [56, 22;
173, 9—11; 101]. В работах [54; 85; 102; 152; 178; 180] приведены
достаточно интересные данные о ресурсах сети Интернет в
области образования США, стран Европы и России.
6 Зубов
ГЛАВА 6
БАЗЫ ДАННЫХ И ЛИНГВИСТИЧЕСКИЕ
ИНФОРМАЦИОННЫЕ РЕСУРСЫ
БАЗЫ ДАННЫХ. ОСНОВНЫЕ ПОНЯТИЯ
Существует несколько определений понятия «база данных» [86,
205; 221, 146; 235, 527, 528; 201, 18]. Наиболее широкая
трактовка этого понятия такова. База данных — это совокупность
определенным образом упорядоченных сведений о некоторых объектах.
Под объектами при этом понимаются сведения, факты, события,
процессы реальной жизни [235, 531; 234, 232]. Объект может быть
материальным (студент, летчик, пчела, товар, телевизор, город
и т.д.) и нематериальным. К числу последних относятся
различные события (поход в цирк, встреча друзей, покупка автомобиля
и т.п.), факты (конец урока, наступление лета, окончание
университета и т.д.), процессы (выплавка стали, изготовление
автомобиля, перевод текста и т.п.), числа, имена (номер зачетной
книжки, имя ребенка) и т.д.
В реальном мире каждый объект обладает определенными
свойствами. В сознании человека свойствам объекта приписываются
некоторые атрибуты (вес, скорость, длина, цвет и т.п.).
Атрибутам приписываются определенные значения: батон весит 400 г,
машина имеет скорость 90 тт/ч и т. д. В базе данных атрибуты
представляются элементами данных или просто данными, а
значениям атрибутов ставятся в соответствие значения элементов данных
или просто значения данных (данные).
Рассмотрим, например, таблицу 45, содержащую информацию,
которой можно охарактеризовать любого студента университета.
Таблица 45
Студент
Номер
зачетной
книжки
357411
358125
Ф.И.О.
студента
Арбузов А. И.
Белова Р. Г.
Пол
м
ж
Год
рождения
1983
1982
Факультет
англ.
фр.
Группа
302
201
Стипендия
500
800
146
Это одна из разновидностей баз данных. Объектом в ней
является студент. Он может быть однозначно описан атрибутами «Номер
зачетной книжки», «Ф.И.О. студента», «Пол» и т.д. Эти атрибуты
для каждого конкретного студента имеют определенные значения.
Так, для студента А. И.Арбузова атрибут «Номер зачетной
книжки» имеет значение «357411», атрибут «Пол» — «м» и т.д. В
компьютерной памяти атрибутам «Номер зачетной книжки», «Ф. И. О.
студента», «Пол» и т.д. соответствуют элементы данных или
просто данные, а значениям атрибутов «357411», «Арбузов А. И.»,
«м» и т.д. — значения элементов данных или значения данных.
Таким образом, данное — это некоторый показатель, который
характеризует заданный объект и принимает для конкретного
экземпляра объекта некоторое значение [235, 531, 532; 234, 233].
Группу данных, образующих в таблице одну строку, называют
записью об объекте или просто записью (ее также называют
кортежем или сегментом). Кортеж, содержащий п данных,
называется «-мерным кортежем или просто группой из п данных. В
таблице 43 представлен семимерный кортеж или группа данных,
состоящая из 7 элементов. Чтобы пользователь мог обратиться к
кортежу, его необходимо идентифицировать. Поэтому одно из
данных, значения которого не повторяются в базе данных, т.е.
являются уникальными для каждого экземпляра объекта, выбирается
в качестве идентификатора объекта, или первичного ключа записи.
Например, в описанном выше примере это может быть данное
«Номер зачетной книжки». По идентификатору из базы данных
можно получить все сведения о студенте.
Как видно из приведенной выше базы данных «СТУДЕНТ»,
она представляет собой набор кортежей или записей. Если таких
кортежей п (5, 6,..., 10), то соответствующая таблица будет иметь
п столбцов. Набор значений одного столбца называется полем или
доменом (в нашем примере используются поля «Пол», «Ф.И.О.
студента» и т.д.).
Если несколько записей имеют одно и то же множество
данных с однотипной информацией, то говорят, что эти записи
имеют один формат. При этом различают следующие типы данных,
используемых в базах данных [87, 215, 216; 234, 231, 232; 22, 182,
183]:
1) текстовые данные (для хранения текста ограниченного
размера);
2) числовые данные (для хранения чисел любого типа);
3) дата/время (для хранения календарных дат и текущего
времени);
4) денежные данные (для хранения денежных сумм);
5) счетчики (для хранения автоматически наращиваемых чисел);
6) логические данные (содержат одно из значений «да» или
«нет» — «true» или «false»);
147
7) поле «memo» (для хранения больших объемов текста. В этом
поле хранится не сам текст, а указатель на месторасположение
текста);
8) поле объекта «OLE» (содержит указатели на
месторасположение в структуре файла базы данных мультимедийной
информации — рисунков, звуков, фильмов и т.д.);
9) гиперссылки1 (содержат URL-адреса Web-объектов сети
Интернет).
Примеры расположения этих данных представлены в таблице 46.
/
1 № 1
п/п
1
2
3
4
Поле .
счетчика
Модель
LG520SI
LG575C
Bridge
ВМ17С
Sony
200EST |
Размер
15
15
17
17
/ J
Числовы
поля
е
^Текстовое
|поле
Шаг
маски
0,28
0,28
0,27
0,25
А
Цена
3811,50 р.
4029,00 р.
5300,00 р.
9093,00 р.
У
Т
Поле денежного
аблица 46
типа ^/
i
Наличие
да
да
да
нет
*
Ожидается
05.12.99
Поле 1
даты |
Примечание
Гарантия —
1 год
Гарантия —
1 год
Гарантия —
1 год
JT 1
S
Логическое
поле
S
Поле типа
MEMO
Множество записей одного формата называют файлом.
Множество файлов образуют базу данных [99, 80; 122, 22]. Это еще
одно рабочее определение базы данных.
Допустим теперь, что объект «студент» будет описан
данными, содержащимися в таблице 47 (в памяти ПК это будет
отдельный файл).
Таблица 47
Студент
Номер
зачетной
| книжки
357411
358125
Ф.И.О.
студента
Арбузов А. И.
Белова Р. Г.
Пол
м
ж
Год
рождения
1983
1982
Факультет
англ.
фр.
Группа
302
201
Специальность
051
054
Стипендия
С1
С2
Подробнее об этом см. с. 183.
148
Причем шифры специальностей и размеры стипендий можно
также представить в виде таблиц 48, 49 (файлов в компьютерной
базе данных).
Таблица 48
Специальность
Таблица 49
Стипендия
Шифр
051
054
Название
Английский и
немецкий языки
Французский и
немецкий языки
Код
С1
С2
Размер
500
800
Все эти три файла и составляют в совокупности
компьютерную базу данных «СТУДЕНТ».
Способы организации баз данных
В приведенном выше наиболее широком определении
понятия «база данных» отмечалось, что это совокупность
определенным образом упорядоченных сведений об объекте. Способ
взаимосвязи входящих в базу данных записей называют моделью
представления данных [86, 203—214]. До последнего времени чаще
всего использовались три способа такой взаимосвязи: 1)
иерархический; 2) сетевой; 3) реляционный [86, 209—214; 93, 203—211;
8, 39-41].
Иерархическая модель представляет взаимосвязь данных в виде
иерархического дерева, состоящего из узлов. На самом верхнем
уровне иерархии имеется только один узел — корень. Каждый узел,
кроме корня, связан с одним из узлов на более высоком уровне,
называемым исходным узлом для данного узла. Ни один элемент
Схема 23
Уровень 1 .„.. QlKooeHb
Уровень 2 .02, Ö3
Уровень 3 (5б 07 08 09 ОЮ ОН
Уровень 4 015 016
Листья
17 Ö18 Ö19
Листья
149
иерархической модели не имеет более одного исходного. Каждый
элемент может быть связан с одним или несколькими
элементами на более низком уровне. Они называются порожденными.
Элементы, расположенные в конце ветви, т.е. не имеющие
порожденных, называются листьями (схема 23).
Например, сведения о студентах нашего университета могут
быть поданы в виде иерархической модели данных (схема 24).
Студент
Схема 24
Номер
зачетной
книжки
Ф.И.О.
студента
Пол
Дата
рождения
Место
обучения
Наличие
детей
Специальность
+^^7 ^<7
Факультет
Группа
L
Код
Название
Стипендия
А
Код
Размер 1
В сетевой модели данных любое данное может быть связано с
любым другим данным. При этом, как и в иерархическом
представлении, можно использовать понятия корня, исходных и
порожденных элементов, листьев. Порожденные элементы обычно
располагаются ниже исходных. ЗДесь также можно говорить об
уровнях (схема 25).
Схема 25
Уровень 1
Уровень 2
Уровень 3
Уровень 4
Корни
8 Лист
Листья
Однако в отличие от иерархической модели в сетевой модели
у порожденного узла может быть несколько исходных узлов.
Например, пусть необходимо построить базу данных для
описания всех животных, которые находятся в зоопарке большого
города. База данных должна содержать все сведения о животных,
о тех, кто за ними ухаживает, и даже о директоре. Такую базу
данных можно было бы представить в виде сетевой модели
(схема 26).
150
Схема 26
Зоопарк
Зоопарк
Г
Номер клетки!
Директор
Адрес
Место
нахождения
Номер
смотрителя
■ I
Ф.И.О.
смотрителя
Уточняющие
данные
Кличка
животного
Вид
животного
Пол
Дата
рождения
Страна
Добавлением в определенные позиции некоторых данных
сетевое представление можно преобразовать в иерархическое (схема 27).
С х е м а 27
Зоопарк
Директор
Адрес
Номер
клетки
Место
нахождения
Номер
| смотрителя
Ф.И.О.
смотрителя
Уточняющие
данные
.♦*♦♦* ♦
Кличка
животного
Номер
смотрителя
Вид
животного
Пол
Дата
рождения
Страна
происхождения
Данные в реляционной базе данных представляются в виде
таблицы. Каждая таблица выражает отношения {relation) между
включенными в нее данными. Как отмечалось выше, таблица — это
набор кортежей (записей). Если кортежи являются я-мерными,
т.е. таблица имеет п столбцов, то отношение называется
отношением степени п. Столбец с номером у называется j-м доменом
отношения.
Рассмотрим реляционную базу данных «Поэты». Как видно из
таблицы 50, один домен может быть представлен двумя и более
данными (год = год рождения + год смерти). Данное, значение
которого идентифицирует наборы кортежей, как отмечалось выше,
называется первичным ключом записи или идентификатором
записи. В наборе кортежей «поэты» таким ключом является данное «имя».
Как будет показано ниже (см. с. 156—175), большая часть
лингвистических информационных ресурсов может быть представлена
в виде реляционных баз данных [221; 241; 51; 93]. Однако в
последние годы к этим наиболее распространенным базам данных
добавилось два новых типа [193, 18; 233, 30, 31]: 1) об^ектно-
151
Таблица 50
Поэты
Домен
Данные
Домен
Домен
Значения
данных
Имя
Петрарка
Гёте
Байрон
Тютчев
Бодлер
Купала
Страна
Италия
Германия
Англия
Россия
Франция
Беларусь
Год
рождения
1304
1749
1788
1803
1821
1882
смерти
1374
1832
1824
1873
1867
1942
ориентированные базы данных; 2) объектно-реляционные, или
гибридные, базы данных.
Появление объектно-ориентированных баз данных связано с
тем, что «большинство современных средств разработки
приложений, проектирования бизнес-процессов и моделирования
данных в той или иной мере являются объекгао-ориентированными»
[201, 18]. При этом понятие «объедет», используемое в таких базах
данных, берется в полном объеме из объектно-ориентированного
программирования. Такие объекты уже не делятся на
составляющие (элементы данных), а как единое целое характеризуются
некоторыми свойствами (атрибутами) и поведением (методами).
Таблица 51
Сравнение основных технологий баз данных
Тип БД
Реляционная
Объектно-ориентированная
Гибридная
Преимущества
Зрелая технология,
высокая скорость,
основана на стандартах
Обрабатывает
мультимедиа, совместима с
сетью Интернет
Возможность
модернизации, обеспечиваемая
производителем,
совместимость со старыми
приложениями,
использующими реляционные
БД
Недостатки
Не поддерживает
мультимедиа, не
ориентирована на сеть Интернет
Не вполне зрелая
технология, нет официально
принятого стандарта
разработки,
недостаточная устойчивость работы
Нет официально
принятого стандарта
разработки, обслуживает только
объекты,
поддерживаемые производителем,
разрозненная
архитектура
152
В гибридных базах данных объединение
объектно-ориентированных и реляционных возможностей осуществляется путем
использования специальных программных модулей, обрабатывающих
определенные типы данных- [241, 30].
Сравнение технологических характеристик современных баз
данных приведено в таблице 51 [241, 30].
Системы управления базами данных
Система управления базами данных (СУБД) — это
совокупность программных средств, позволяющих осуществлять ведение
баз данных (создание, обновление, удаление элементов данных
и т.д.) и поиск в них информации. Практически все современные
СУБД содержат средства для создания баз данных. Создавать базу
данных можно тремя способами [231, 149]:
^ 1) с помощью специальных утилит, поставляемых отдельно от
СУБД;
2) методом написания DDL-сценария (сценарий Data Definition
Language);
3) использованием специальных средств, называемых CASE-
средствами (средства Computer-Aided System Engineering). К их числу
относят программные продукты ERwin, System Architect, Power
Designer, ER/Studio и т.п. (подробнее см. [221, 149]).
С целью поиска информации и модернизации данных в СУБД
используется специальный непроцедурный язык
структурированных запросов SQL (Structured Query Language). Он является
индустриальным стандартом. Его непроцедурность означает, что на этом
языке можно указать, что нужно сделать с базой данных, но
невозможно описать алгоритм этого процесса. Язык SQL включает
группы операторов, ответственных за ведение баз данных и поиск
в них нужной информации [221, 151].
В настоящее время различают два основных типа СУБД: 1)
настольные и 2) серверные [222; 223].
Настольные СУБД, как правило, не содержат специальных
приложений и сервисов, управляющих данными. Все
взаимодействия с данными осуществляются здесь с помощью
файловых сервисов операционной системы. Обработка извлекаемой
из баз данных информации осуществляется в пользовательском
интерфейсе. Сейчас такие СУБД стали сетевыми и
многопользовательскими. Самые последние версии подобных СУБД
приобрели визуальные средства проектирования форм, отчетов и
приложений. Они дают возможность публиковать данные в сети
Интернет, позволяют обращаться к данным серверных СУБД
[222, 123—127]. Основной недостаток таких систем — снижение
производительности и появление сбоев в работе при значительном
153
увеличении объема хранимых данных и увеличении числа
пользователей.
Существует более двадцати типов настольных СУБД. По
степени сложности такие системы подразделяются на:
1) СУБД для обработки небольших объемов информации;
2) СУБД, ориентированные на конечного пользователя,
который не умеет программировать или не желает тратить на это время;
3) сложные СУБД, ориентированные на разработку
законченных приложений.
Примерами простейших СУБД для обработки небольших
объемов информации (первый тип СУБД) являются программы MS
Schedule* и MS Outlook из интегрированного пакета MS Office
разных версий фирмы «Microsoft». Сюда же можно отнести и Lotus
Organizer фирмы «Lotus». Такие программы позволяют хранить,
изменять и управлять сведениями о контактах, встречах,
событиях, собраниях, задачах. Они имитируют работу с обычной
записной книжкой, представляющей собой адресный справочник
контактных лиц, и настольным календарем, вдотором отмечается
расписание встреч и событий, список дел (шщч и проектов).
Ко второму типу настольных СУБДротносятся программы
создания и обработки электронных таблиц (табличные
процессоры), например: MS Excel, Lotus 1-2-3 фирмы «Lotus», Corel
QuattroPro фирмы «Corel». Они не только создают базы данных в
виде сложных таблиц и осуществляют в них поиск информации,
но и могут проводить в таблицах различные вычисления.
Табличные процессоры могут содержать до нескольких десятков тысяч
строк и 256 столбцов. В каждую ячейку можно поместить
значение, число, текст, диаграмму, рисунок и скрытую формулу,
выполняющую те или иные вычисления над явными данными.
Программы создания и обработки электронных таблиц часто
используются для построения таких баз данных, как перечни товаров
на складах, картотеки клиентов, вклады в банках и т.д.
Пользователи, использующие настольные СУБД третьего типа,
должны уметь программировать на специальных алгоритмических
языках, встроенных в СУБД (например, VBA — Visual Basic for
Applications, Paradox Application Language и т.д.). К числу таких
СУБД относятся Paradox, dBASE, FoxBase, FoxPro, Clipper, MS
Access и т.д.
Серверные СУБД используют архитектуру «клиент-сервер», суть
которой заключается в централизованном хранении и обработке
данных. Для этого используется так называемый сервер баз
данных, выполненный как приложение или сервис операционной
системы. Только этот сервер может манипулировать файлами базы
данных, в которых хранится информация. Серверные СУБД
обладают следующими преимуществами по сравнению с
настольными [223, 143, 144].
154
1. При выполнении запросов пользователей значительно
снижается сетевой трафик (уменьшается время обработки запросов).
2. Имеется возможность хранения бизнес-правил (например,
правил ограничений на значения данйых).
3. Предоставлена возможность управления пользовательскими
привилегиями и правами доступа к различным объектам базы
данных (например, владелец некоторого объекта может предоставить
другим пользователям право использовать его тем или иным
способом).
4. Появляется возможность резервного копирования и
архивации данных.
5. Предоставлена возможность параллельной обработки данных.
6. Обеспечена поддержка всех типов мультимедийных данных
(текст, графические изображения, рисунки, видео- и
аудиоинформация).
~ К числу наиболее известных серверных СУБД относятся
программы Oracle, Informix, Ingres, Sybase, DB2, MS SQL Server.
Подробно они рассмотрены в работе [223, 147—150].
Способы доступа к информации в базах данных
Существует несколько способов доступа к информации в
базах данных. Они могут быть разделены на две категории [224,
146, 147]:
1) способы доступа, использующие специальный прикладной
программный интерфейс API (Application Programming Interface);
2) способы, использующие универсальные механизмы
доступа к данным.
Программный интерфейс API представляет собой набо£
функций, вызываемых из клиентского приложения. Для настольных
СУБД эти функции обеспечивают чтение/запись файлов базы
данных. Для серверных СУБД интерфейс API инициирует передачу
запросов серверу баз данных и получение от него результатов
выполнения запросов (или кодов ошибок).
Универсальный механизм доступа к данным реализуется в виде
библиотек и дополнительных модулей, которые называют
драйверами или провайдерами. Библиотеки обычно содержат
некоторый стандартный набор функций. Дополнительные модули
зависят от числа СУБД и реализуют непосредственное обращение к
функциям клиентского API конкретной СУБД. Среди
универсальных механизмов доступа к базам данных наиболее
используемыми являются [224, 146]:
1) ODBC (Open Database Connectivity);
2) OLEDB (Object Linking and Embedding Database),
использующий набор СОМ-интерфейсов (Component Object Model) и даю-
155
щий возможность осуществить унифицированный доступ к
данным из разных источников;
3) ADO (ActiveX Data Objects);
4) BDE (Borland Database Engine).
Первые три механизма доступа к базам данных по существу
являются промышленными стандартами. Детально процедуры
использования универсальных механизмов доступа к базам данных по
отношению к разным СУБД описаны в работах [18; 51; 219; 224; 225].
В практической работе с базой данных применяют три основных
режима выдачи информации: 1) «on-line»; 2) «off-line»; 3) ИРИ
(избирательное распространение информации).
В режиме «on-line» вся необходимая пользователю информация
выдается мгновенно на экран ПК (она даже может быть записана
в память компьютера, если это не запрещено условиями
контракта по использованию базы данных).
В режиме «off-line» на экран выдаются только количественные
данные о результатах поиска (например* сколько книг по
грамматике английского языка найдено в базе* данных, но сами названия
книг не выдаются). Полная информация выдается пользователю
за отдельную плату в распечатанном виде позже.
В режиме ИРИ запрос пользователя помещается в
специальный каталог базы данных и автоматически обрабатывается при
каждом обновлении информации, при этом информация
передается пользователю, так же как и в режиме «off-line».
ЛИНГВИСТИЧЕСКИЕ ИНФОРМАЦИОННЫЕ РЕСУРСЫ
Основные понятия
Лингвистические информационные ресурсы — это одна из
составляющих частей информационных ресурсов. Под
информационным ресурсом понимают некоторый интеллектуальный ресурс,
результат коллективного творчества [152, 85, 86]. К пассивным
формам информационных ресурсов относят книги, журналы,
газеты, словари, энциклопедии, патенты, базы и банки данных и т.п.
Активные формы включают алгоритмы, модели, программы, базы
знаний [152, 87, 88].
Лингвистические информационные ресурсы — это множество
определенным образом организованных речевых и языковых
данных, находящихся на машинных носителях информации и
используемых в различных сферах практической деятельности
(образовании, промышленности, экономике, культуре, искусстве,
издательстве и т.п.). Термин «лингвистические ресурсы» впервые
был использован итальянским ученым Антонио Замполли в
1992 году. Он употребил его в докладе «Структура Европейского
156
агентства языковых технологий», который сделал на
конференции, посвященной проблемам создания основы для развития
индустрии европейских языков. Выбор этого термина был связан с
необходимостью выразить идею о том, что большие массивы
лингвистических данных и описаний, используемые для создания и
развития эффективных систем обработки текста и речи, играют
такую же существенную, фундаментальную роль, как и железные
дороги, автомобильные шоссе, электросети (электроэнергия),
средства коммуникации для промышленности и экономического
развития страны.
С современной точки зрения пассивные лингвистические
информационные ресурсы включают следующее множество
лингвистических данных (схема 28).
• Схема 28
Лингвистические
ресурсы
I
Письменный
лексикон
Терминологические
словари
Письменные
текстовые
массивы
I
Одноязычный
Много
язычный
Одноязычный
Много
язычный
Одноязычный
Фонетические
ресурсы
Много
язычный
В самом общем виде лингвистические ресурсы — это
своеобразные лингвистические базы данных, которые можно обновлять
(добавлять новые данные, исключать или изменять старые) и в
которых можно искать ту или иную информацию.
Лингвистические ресурсы необходимы как пользователям ПК, так и
различным компьютерным системам, связанным с обработкой текста и
речи. В частности, они используются для распознавания речи и
анонимных текстов, реферирования, аннотирования и перевода
текстов, построения диалоговых систем, автоматического
анализа текста, синтеза речи и текста и т.д. [267; 19].
Проблемам создания лингвистических ресурсов ежегодно
посвящается большое число международных и национальных
научных конференций во всем мире. Создан ряд крупных
организаций, объединяющих исследователей десятков стран,
занимающихся разработкой лингвистических ресурсов. Наиболее известными
из них являются LDC (Linguistic Data Consortium) (США), ELRA
(European Language Resources Association) и TELRI (Trans European
Language Resources Infrastucture) (Европа). Однако лингвистические
157
традиции стран — участниц этих объединений, недостаточность
финансирования, разобщенность участников приводят к тому, что
лингвистические ресурсы, созданные отдельными коллективами
одной страны, не всегда могут быть использованы в других
странах. Все это ставит перед разработчиками лингвистических
ресурсов ряд проблем, важнейшими из которых являются следующие
[246; 264; 247; 267]:
1. Разработка единых стандартов создания ресурсов.
2. Разработка способов защиты лингвистических ресурсов от
несанкционированного доступа.
3. Создание единых экспертных требований.
4. Планирование единой стратегии разработки лингвистических
ресурсов.
5. Создание многофункциональных лингвистических ресурсов
большого объема для использования в разных странах.
Письменный лексикон как простейшая составляющая
лингвистических ресурсов
Как видно из схемы 28, письменный лексикон представлен
лексическими ресурсами двух типов: 1) одноязычными и 2)
многоязычными лексиконами (словарями).
В самом общем смысле словарь — это справочная книга,
которая содержит слова (морфемы, словосочетания, идиомы и т.п.),
расположенные в определенном порядке (различном в разных типах
словарей). В нем может содержаться толкование значения
описываемых единиц, а также различная информация о них. Как видно
из этого определения, существуют различные типы словарей. Среди
них выделяют:
а) по лексикографической форме основной единицы словаря:
1) для единицы, меньшей, чем слово:
- словари корней;
- словари морфем (приставок, суффиксов, окончаний);
- словари «-буквенных сочетаний;
2) для единицы, эквивалентной слову:
- словари словоформ;
- словари слов;
3) для единицы, большей, чем слово:
- словари словосочетаний;
- фразеологические словари;
- словари цитат;
б) по специфике отбираемой лексики:
1) словари, отражающие некоторые тематические и
стилевые пласты лексики:
- терминологические словари;
158
- диалектные словари;
- словари просторечий;
- словари арго (табуированной лексики);
- словари языков писателей;
2) словари, содержащие различные разновидности слов:
- словари неологизмов;
- словари архаизмов;
- словари редких слов;
- словари сокращений;
- словари иностранных слов;
- словари имен собственных;
в) по способу описания основных единиц словаря выделяют
словари, раскрывающие отдельные аспекты таких единиц и
отношений между ними:
- этимологические словари;
- словообразовательные словари;
- грамматические словари;
- орфографические словари;
- орфоэпические словари (правила произношения);
- синонимические словари;
- антонимические словари;
- паронимические словари (содержат слова с частичным
звуковым сходством при их семантическом различии,
например: главный —- заглавный, выплата — оплата и т.д.);
- частотные словари;
- словари рифм;
- словоуказатели;
- словари созвучий;
г) по расположению материала в словарях:
- идеографические словари, содержащие не слова, а
рисунки со смыслом (например, глаз с капающей слезой
обозначает «горе»);
- аналогические словари (в них слова располагаются не
по алфавиту, а по смысловым ассоциациям — мебель:
стол, стул, кровать, диван, кресло и т.п.);
- обратные словари (в них слова располагаются по
алфавиту конечных букв);
д) по эпохе функционирования слова:
- исторические словари;
е) по назначению (адресату):
- словари трудностей какого-либо языка;
- словари ошибок;
- учебные словари.
Любой словарь может быть представлен в виде двухмерной
реляционной базы данных, где по вертикали расположены единицы
лексикона — части слов, слова, словосочетания — экземпляры
159
/
объекта «СЛОВАРЬ», а по горизонтали — их некоторые
характеристики (данные), упомянутые в приведенном выше определении
понятия «словарь» (табл. 52).
Таблица 52
Единица
лексикона
Характеристика, X
XI
...
>С2
ХЗ
Х4 -
...
Простейшей лингвистической базой данных может служить
частотно-алфавитный словарь словоформ какого-либо текста [4].
Каждый экземпляр объекта (слово) описывается в нем одним
данным — абсолютной частотой употребления слова в
некотором тексте. (
Более сложную организацию имеет словоуказатель. В нем кроме
абсолютной частоты употребления словоформы в тексте
указываются номера страниц и строк на странице, где встретилась данная
словоформа. Словоформы располагаются, как правило, по
алфавиту/Например, фрагмент словоуказателя к рассказу М.
Шолохова «Судьба человека» выглядит так, как показано в таблице 53.
Таблица 53
№
п/п
56
57
58
59
60
Частота,
F
1
2
3
1
2
еловоформа
батареей
батарей
батарея
батареями
бегает
Страница/строка
51/29
35/13
34/31
57/9
41/4
Страница/строка
51/33
35/9
55/11
Страница/строка
52/38
В других типах словарей в качестве характеристик XI, Х2, ХЗ,...
(см. табл. 52) выступают толкования слов, их грамматические или
стилистические особенности и т.д.
Еще более сложным типом словарей являются конкордансы. В них
каждая словоформа текста характеризуется не только
численными показателями (частотой, номером страницы, номером строки
и т.д.), но и некоторым контекстом, в котором она употреблена.
Как правило, этот контекст состоит из трех предложений:
предложения, в котором встретилась словоформа; предложения,
стоящего перед основным предложением, и предложения, стоящего
после него. Предполагается, что контекст такого объема является
достаточно полным и содержит внутри себя отрезок,
законченно
ный в смысловом отношении. Но возможны контексты и на
уровне отдельных слов и словосочетаний. Конкордансы — ценный
материал для научных исследований. Они помогают различать
значения слов, широко используются в качестве примеров в других
словарях (толковых, синонимических, антонимических, словарях
писателей и поэтов и т.д.).
На основе конкордансов составляются контекстологические
словари. Их теоретической основой является теория детерминант.
В соответствии с ней каждое значение (перевод) многозначного
слова определяется в контексте другими словами
(детерминантами), с которыми сочетается исходное слово. Детальные сведения
об устройстве и функционировании таких словарей приведены в
работах [123; 124].
, Если говорить об одноязычных словарях как части
лингвистических ресурсов, находящихся на машинных носителях
информации, то наибольшее их число разрабатывается в настоящее время
в рамках организации ELRA. Так, по ее URL-адресам http://www.
icp.grenet.fr/ELRA/home.html и http://www.elda.fr можно заказать
Европейский португальский лексикон (ELRA-L0033 LusoEX
European Portuguese Lexicon), содержащий 61000 основ (лемм) и
1600 соответствующих формообразующих парадигм. Там же
можно найти японский компьютерный словарь (ELRA-L0036), в
который включено 260000 японских слов, английский
компьютерный словарь (ELRA-L0037), состоящий из 190000 английских слов,
и ряд других словарей. Известны созданные на машинных
носителях французские словари общеупотребительной и
специализированной лексики [33; 92].
В многоязычных словарях дается перевод значения слова
исходного языка на один или несколько иностранных языков. В
качестве лингвистических информационных ресурсов чаще всего
используются двуязычные словари. Наиболее известными из них
являются серии электронных словарей МУЛЬТИЛЕКС, LINGVO и
КОНТЕКСТ. Все они построены на основе известных бумажных
словарей и служат для быстрого поиска переводных эквивалентов
слов, уточнения перевода, поисга синонимов и целого ряда
других операций. По указанным выше URL-адресам организация ELRA
предлагает целую серию двуязычных словарей. Например,
японско-английский словарь (ELRA-M0023), включающий 230000
японских слов с их переводами на английский язык,
англо-японский словарь, содержащий 160000 английских слов и
соответствующих японских переводных эквивалентов.
Энциклопедии — это словари, содержащие характеристики не
слова как такового, а обозначенного им предмета, факта или
явления. Термин «энциклопедия» впервые был употреблен в 1541 году
и обозначал набор систематизированных отрывков, описывающих
различные разделы человеческого знания и искусства. Описание
161
некоторого предмета или понятия в энциклопедии осуществляется
в рамках словарной статьи. Например, статья, описывающая
такой предмет, как буксир, в однотомном Советском
энциклопедическом словаре [205, 173], выглядит так:
«Буксир (от гол. boegseren — 'тянуть') — самоходное судно для
вождения (буксировки) несамоходных судов, плотов и т.п.
Подразделяются на буксировщики (для вождения судов на тросе), кан-
товщики (для швартовки судов к причалу), толкачи (для
буксировки судов толканием), спасатели (для оказания помощи судам в
открытом море и их буксировки в порт-убежище)».
Чаще всего в энциклопедиях объясняются понятия,
выражаемые именем существительным или именем собственным.
Научные понятия часто выражаются именными словосочетаниями.
В настоящее время энциклопедии являютш важным ресурсом для
создания баз знаний различных интеллектуальных задач.
Энциклопедии могут использоваться в различных компьютерных
моделях понимания текста, когда контекст не дает возможности
распознать неоднозначную ситуацию.
Существует достаточно большое число различных
энциклопедий на машинных носителях информации. Наиболее известна
среди них энциклопедия «Britannica». Она включает 82000 статей и
700 дополнительных материалов, опубликованных с 1768 года. Не
менее известны французские энциклопедии «Tons les savoire du
Monde», «Le monde sur CD-ROM», «Versailles» и др. [33]. На
русском языке изданы «Большая Энциклопедия Кирилла и Мефо-
дия» и «Иллюстрированный Энциклопедический Словарь».
Основная особенность электронных энциклопедий заключается в том,
что их статьи содержат большое число иллюстраций, видео и звук
[Ю, 44-47].
Тезаурус — принципиально иной тип словарей. В нем в явном
виде указаны семантические связи между определенной частью
его лексических единиц. Как правило, такие словари строятся
для текстов достаточно узкой проблемной области:
вычислительной техники, музыки, кораблестроения, сельского хозяйства и т.д.
При этом в простейшем случае между лексическими
единицами тезауруса могут указываться следующие типы семантических
связей [146, 22—48]: 1) синонимические; 2) антонимические;
3) родовые отношения; 4) видовые отношения, 5)
ассоциативные отношения; 6) вхождение в состав более крупной
семантической единицы; 7) состав (из более простых семантических
единиц) и т.п. Например, в «Тезаурусе по теоретической и
прикладной лингвистике» слово предложение представлено так [146,
302, 303]:
ПРЕДЛОЖЕНИЕ
Синонимы: предикативная синтагма, фраза
162
Родовое понятие: высказывание, коммуникативная единица
Видовое понятие:
- главное предложение, придаточное предложение,
вводное предложение;
- простое предложение, сложное предложение;
- повествовательное предложение, восклицательное
предложение, вопросительное предложение;
- полное предложение, неполное предложение;
- распространенное предложение, нераспространенное
предложение.
Вхождение в состав более крупной единицы: сверхфразовое
э единство, текст.
Состав (из более простых семантических единиц):
- главные члены предложения, второстепенные члены
предложения;
- синтаксическая структура, синтаксическая группа,
синтаксическая конструкция;
- знаки препинания;
- пропозиция, модальность.
Главное слово тезауруса называют дескриптором (слово
предложение), а все нижестоящие слова и словосочетания —
ключевыми словами (или словосочетаниями).
Первый тезаурус (тезаурус Роже) как средство «для
облегчения выражения мыслей и помощи при написании сочинений»
был создан в 1852 году в Англии [264]. Особенно широко
тезаурусы использовались в 70-х годах XX века, когда с целью поиска
фактических данных об оборудовании (станках, автомобилях и т. п.)
или технической литературы активно разрабатывались
информационно-поисковые системы. Особой популярностью в те годы
пользовался «Тезаурус научно-технических терминов» [238].
Находят применение тезаурусы и в наши дни. Так, в Москве в 1996 году
был создан тезаурус по маркетингу и общеязыковой тезаурус
русского языка. Он содержит 1600 дескрипторов и около 7000
распределенных по этим дескрипторам русских слов.
Терминологические словари и банки данных
Терминологическим словарем (ТС) называется словарь,
основной единицей которого является термин. Нет единого подхода к
определению этого понятия. В качестве рабочего определения
примем следующее [47, 5]: «Термин — это слово или подчинительное
словосочетание, имеющее специальное значение, выражающее и
формирующее профессиональное понятие и применяемое в
процессе познания и освоения научных и
профессионально-технических объектов и отношений между ними».
163
В число единиц терминологических словарей в настоящее
время входят и номены (номенклатурные единицы,
идентификаторы). К ним, как правило, относят географические названия
(океанов, морей, озер, гор, долин, городов, сел, полей), названия
станков, приборов, аппаратов, фирм, систем, лекарств,
медицинских препаратов и т.п. В качестве номенов выступают
отдельные слова (Кавказ), словосочетания (Северный Ледовитый океан),
буквенные символы (IBM), сочетания слов и символов (Pentium
ММХ), цифры, символы и цифры (IBM 486) и т.п. [44].
Существуют различные подходы к классификации
терминологических словарей. Так, по тематике, охватываемой лексикой
терминологического словаря, различают:
1) многоотраслевые словари, включающие термины,
относящиеся к различным научно-техническим отраслям (подъязыкам):
машиностроению, судостроению, автомобилестроению и т.п.;
2) отраслевые (тематические) цгрвари, содержащие термины,
относящиеся только к одной теме, например вычислительной
технике, оптике, органической химии и т.п.;
3) узкоотраслевые словари, содержащие термины по
отдельным разделам некоторой более широкой темы. Например,
существуют узкоотраслевые словари по принтерам (тема —
«Вычислительная техника») и т.п.
По цели и назначению различают:
1) ТС, ориентированные на специалистов;
2) учебные ТС;
3) классификаторы;
4) словари (сборники) рекомендуемых терминов;
5) терминологические стандарты и т.д.
В приведенной классификации два первых наименования не
требуют особых объяснений.
Классификатор — это словарь терминов с указанием различных
типов иерархических отношений между ними. Подобные словари
по принципу своей организации схожи со словарями-тезаурусами.
Например, в классификаторе «Республика Беларусь» можно
выделить следующие термины, которые сами являются
классификационными рубриками: «Область», «Район», «Город», «Район в
городе», «Улица» и т. п. При компьютерном использовании
классификаторов их единицы получают определенные коды (схема 29).
Терминологические стандарты содержат термины вместе с их
вариантами и рекомендациями о возможности употребления в тех
или иных видах текстов.
По числу используемых естественных языков выделяют
следующие терминологические словари:
1) одноязычные;
2) двуязычные;
3) многоязычные.
164
Схема 29
Республика Беларусь
01
Гродненская область
011
Витебская область
012
Минская область
013
г. Минск
0131
г. Борисов
0132
По способу упорядочения терминов различают следующие
терминологические словари:
1) алфавитные;
2) неалфавитные (тематические);
3) частотные.
В неалфавитных (тематических) терминологических словарях
термины расположены гнездами, т. е. сначала указывается
заглавное слово, а затем перечень относящихся к нему ключевых слов,
расположенных по алфавиту, например:
компьютер
дисплей
клавиатура
монитор
мышь
принтер
системный блок
сканер
системный блок
блок питания
винчестер
ОЗУ
плата
процессор
Многообразие терминологических словарей объясняет тот факт,
что объем информации, закладываемый в словарные статьи ТС,
сильно отличается от словаря к словарю. В общем виде каждая
статья включает термин и некоторые его характеристики
(пометы): в частотных словарях — частоты употребления терминов, в
классификаторах — коды понятий, в многоязычных словарях —
адреса переводных эквивалентов и т.д. Есть и более сложная
организация словарной статьи, типичная для многоязычных
терминологических словарей. Проблема многозначности терминов
подробно рассмотрена в работе [211].
Основными источниками для составления словарей служат
научные монографии и статьи по соответствующей проблемной
области («вычислительная техника», «сельское хозяйство» и т.п.),
соответствующие учебники и учебные пособия для вузов, рефе-
165
раты и аннотации на научные издания, описания изобретений,
патенты на изобретения, а также термины, зафиксированные в
различных энциклопедиях. Упомянутая выше международная
организация ELRA занимается созданием и терминологических
словарей. Так, в ее рамках разработан технический
терминологический словарь (ELRA-L0041), содержащий 80000 английских
терминов и 120000 их японских переводных эквивалентов.
Терминологический банк данных — это некоторое множество
терминологических словарей, относящихся к различным темам,
определенным образом характеризующим какую-либо науку,
производство или вид деятельности (медицину, образование, связь,
транспорт и т.п.). Такие банки данных используются сегодня в
основном для следующих видов работ:
1) создания новых терминологических словарей (в
лексикографических целях); (
2) перевода текстов с одного язшса на другой (как человеком,
так и с помощью компьютера);
3) создания учебников, учебных пособий, написания
диссертаций и т. п. (в исследовательских целях).
Письменные текстовые массивы
Письменный текстовый массив или корпус текстов является в
настоящее время основным понятием новрго направления в
лингвистике, называемого корпусной лингвистикой (corpus linguistics) [247].
Суть этого направления сводится к тому, что достоверные данные
о фонетической, морфологической, синтаксической и
семантической структуре языка и речи могут быть получены только из
достаточно большого массива текстов. Впервые эти идеи были
высказаны российским ученым профессором Р. Г. Пиотровским в докладе
«Статистическое исследование лексики и грамматики текста с
помощью электронно-вычислительной машины», прочитанном
в Московском государственном педагогическом институте
иностранных языков в 1965 году [166]. Дальнейшее развитие этой
идеи, ее теоретическое обоснование и успешное практическое
применение показаны в целом ряде крупных работ
Р.Г.Пиотровского и его учеников [161; 162; 255; 64; 208; 209; 210].
В сегодняшнем понимании корпус текста — это совокупность
текстов, являющаяся достаточной для обеспечения надежных
научных выводов о некотором языке, диалекте или ином другом
подмножестве языка. Такие письменные совокупности текстов
могут быть использованы для решения большого числа
лингвистических задач [247]:
1) в лексикографии и лексикологии (для составления
различных словарей, определения значений многозначных слов, выяв-
166
ления ассоциативных связей слов в тексте, выделения терминов и
терминологических словосочетаний и т. п.);
2) в грамматике (для определения частоты употребления
грамматических морфем в текстах различного типа, выявления
наиболее употребляемых типов словосочетаний и предложений,
определения значений синонимичных морфологических единиц,
частоты употребления классов слов и т.д.);
3) в лингвистике текста (для дифференциации типов текста,
создания конкордансов, выявления связи между предложениями
в абзацах и между абзацами и т.д.);
А) при автоматическом переводе текстов (для поиска
контекстов слов, имеющих несколько переводных эквивалентов, поиска
переводных эквивалентов терминологических и фразеологических
словосочетаний в параллельных текстах и т.д.);
5) в учебных целях (для выбора цитат, отдельных фрагментов
произведений, примеров, используемых в процессе создания
учебников и учебных пособий, и т.д.).
Существуют различные подходы к классификации корпусов
текстов в зависимости от типа текстов, способов их организации,
языка и т. д. С точки зрения их использования лингвистами
наиболее значимы следующие виды корпусов текстов.
1. Исследовательские — создаются с целью изучения
различных аспектов функционирования языка. Как правило, такие
корпусы текстов содержат несколько десятков миллионов
словоупотреблений.
2. Иллюстративные — служат для выделения из них
лингвистических примеров, подтверждающих те или иные языковые
(речевые, текстовые) факты, обнаруженные ранее иными
лингвистическими приемами.
3. Статические — содержат тексты какого-то небольшого
временного промежутка.
4. В динамические корпусы текстов включают письменные
источники большого временного периода. Они предназначены для
проведения различных диахронических исследований.
5. Корпусы параллельных текстов состоят из множества
текстов-оригиналов, написанных на каком-либо исходном языке, и
текстов-переводов этих исходных текстов на один или несколько
других языков. Это неоценимый материал для проведения
сравнительно-сопоставительных исследований и для обучения переводу
человека и компьютера.
Входящие в корпус тексты могут быть представлены в нем
следующим образом:
1) в виде текстового архива в исходной форме, переносимой с
письменных источников;
2) в виде банка данных, при этом тексты и их единицы
предварительно определенным образом размечаются (см. с. 173);
167
3) в виде базы данных информационно-поисковой системы,
в этом случае тексты записываются в специальном формате,
предназначенном для поиска текстов, их единиц и последующей
статистической обработки.
Важной особенностью корпуса текстов является то, что это не
просто множество случайным образом объединенных текстов того
или иного языка. При его создании возникает целый ряд проблем.
Основными из них являются следующие:
1. Что должно являться основной единицей корпуса текстов?
2. Каков должен быть объем корпуса текстов (сколько единиц
он должен содержать)?
3. Какие письменные текстовые источники должны быть
представлены в корпусе текстов и в хаком количестве?
4. Из какой исходной языковой области должны быть выбраны
тексты, включаемые в состав icppnyca?
Первые ответы на эти вопросы были даны в многочисленных
исследованиях учеников профессора Р.Г.Пиотровского в 1965—
1980 годах. Именно тогда были впервые использованы различные
статистические приемы для оценки генеральной совокупности
выборки, объема выборки, порции выборки (элементарной
выборки) и т.п. [161; 162; 208; 209; 210; 255; 64; 4].
С сегодняшней точки зрения основной единицей корпуса
текстов могут быть словоупотребления (обычно их называют
словами), основы (корни, леммы) и предложения. Объем создаваемого
корпуса текстов в принятых единицах зависит от целей создания.
Он может быть небольшим при изучении частоты употребления
букв, буквосочетаний, звуков, звукосочетаний. Гораздо большим
он должен быть при изучении лексики, морфологических
явлений. Неизмеримо большее количество единиц требуется при
изучении синтаксических или стилистических особенностей текстов.
Создаваемые сегодня корпусы текстов являются
многофункциональными (т. е. могут быть использованы для изучения различных
языковых явлений) и содержат миллионы слов, десятки тысяч
лемм, тысячи предложений. Так, в апреле 2000 года по
URL-адресам http://www.icp.grenet.fr/ELRA/home.html и http://www.elda.fr
организация ELRA предлагала корпус французских текстов
(ELRA-WOO20 PAROLE French Corpus), содержащий 20093099
слов. Она же предлагала корпус португальских текстов (ELRA-
W0024 PAROLE Portuguese Corpus), включающий 3000 000 слов.
По тому же URL-адресу можно найти португальский лексикон
(ELRA-L0033 LUSOLEX European Portuguese Lexicon),
содержащий 61000 лемм и 1600 соответствующих морфологических
парадигм.
Более трудной и менее определенной является задача
конкретизации качественного состава корпуса текстов. При ее решении
необходимо определить следующее.
168
1. Тексты каких функциональных жанров включать в корпус
текстов (художественную прозу, драму, стихи, научные тексты,
газеты, журналы, технические описания и т.д.)?
2. Тексты каких временных промежутков включать в корпус
текстов (современные, 10-летней давности, 50-летней давности,
древние и т.п.)?
3. Включать тексты только литературного языка или
диалектические источники?
При решении этой задачи разработчики корпуса текстов
обычно используют консультации специалистов по языкознанию и
;щнгвостатистике либо метод анкет. Исходя из своего опыта
исследований, специалисты определяют общий объем корпуса
текстов, время издания текстов, число текстов и размер
элементарной выборки, жанры отбираемых текстов и их количество,
число элементарных выборок из каждого жанра. Так, при создании
одного из первых корпусов текстов, корпуса Брауна (The Brown
Standard Corpus of American English), группа
консультантов-ученых определила его объем в 1000000 словоупотреблений. Было
решено, что он должен состоять из 500 текстов по 2000
словоупотреблений каждый. Тексты должны быть взяты из
произведений американских авторов, изданных в США в 1961 году. При
этом было рекомендовано отобрать 15 письменных жанров: 9 —
информативная проза и 6 — художественная проза. Из каждого
жанра было сделано от 6 до 80 элементарных выборок.
Метод анкет в сочетании с опытом специалистов был
использован при создании корпуса текстов The American Heritage
Intermediate Corpus. Специалисты, ориентируясь на заданное время
создания корпуса, определили его объем в 5000000 слов
(словоупотреблений) и рекомендовали включить в него лексику из 22
разделов (жанров) детской и юношеской литературы на английском
языке. Для конкретизации текстов в 221 школу США были
разосланы анкеты с просьбой указать, какие тексты желательно
включить в корпус. После изучения анкет был составлен список из
19000 названий книг. Из этого множества было отобрано 1045
текстов. На их основе было составлено 10000 элементарных выборок
по 500 словоупотреблений каждая.
В упомянутый выше (см. с. 168) корпус португальских текстов,
предлагаемый ELRA, вошли:
1) тексты газет (за 1996—1997 гг. 3 названия) — 65 %;
2) художественные книги (12 названий) — 20%;
3) периодические журналы (7 еженедельных изданий одного
названия) — 5%;
4) периодические журналы (8 названий) — 10%.
Последняя из четырех основных проблем, возникающих при
создании корпуса текстов, связана с определением исходного
объема языковой области, из которой должны быть сделаны выборки.
169
Она решается эмпирически, путем проведения предварительных
экспериментов [162; 4].
Как показали результаты использования корпусов текстов для
практических исследований, многие лингвистические задачи с их
помощью не могут быть решены. Так, во многих языках нельзя
установить принадлежность слова предложения к тому или иному
грамматическому классу (имени существительному, глаголу и т. п.),
что, в свою очередь, не дозволяет определить частоту
употребления грамматических классов слов, структуры предложений на
уровне классов слов (частей речи), а значит, и употребительность
таких структур. Без специальной подготовки текста не разрешимы
омография морфем и слов, полисемия и целый ряд других
важных задач. Поэтому в последние годы стали создаваться таггиро-
вапные (размеченные) корпусы текстов (от англ. tag— 'индекс,
помета'). Все слова такого корпуса получают некоторые
буквенные или цифровые индексы, которые обозначают их
грамматические, лексические, семантические или структурные признаки.
Таких индексов может быть несколько. Принципы разработки
подобных индексов (кодов) и их практического использования
впервые также были предложены Р. Г. Пиотровским и его учениками
[161; 162; 169; 4; 30; 65].
Так, в исследовании [65] показана возможность применения
таггированного текста для изучения грамматических и
ритмических особенностей текстов. В соответствии с приведенной в
работе системой кодов, например, слова предложения Этой
весной опять расцвела акация получили следующий набор индексов
(ср. [65, 35, 36]):
Этой — МЖЕТ21 весной — СЖЕТ22 опять — Н22 расцвела —
ГЖЕПЗЗ акация - СЖЕИЧ42.
Первый индекс у каждого слова указывает на класс слова (М —
местоимение, С — имя существительное, Н — наречие, Г —
глагол), второй индекс служит для обозначения рода, третий —
числа, четвертый — падежа (или времени для глагола). Первая цифра
в конце кода указывает на число слогов в слове, а вторая — на
место ударного слога.
Естественно, «приписывание» таких индексов словам текстов —
задача достаточно сложная и дорогостоящая. Для некоторых
языков с определенной долей вероятности такое приписывание
может быть сделано автоматически или полуавтоматически [239; 258;
237; 236; 240].
Существует огромное число подходов к разметке текстов и его
единиц в корпусе текстов. Для этих целей можно выделить
следующие группы признаков:
1) признаки для кодирования отдельного текста;
2) признаки для кодирования предложения;
170
3) признаки для кодирования словосочетаний;
4) признаки для кодирования слова;
5) признаки для кодирования морфемы.
К первой группе признаков относятся следующие:
1) название текста (полное и краткое);
2) фамилия, имя и отчество автора;
3) псевдоним автора (если есть);
4) дата рождения автора (и смерти, если автор умер);
5) время создания текста (или его первой публикации);
г 6) место первой публикации;
; 7) тип текста (художественный, научный и т.п.);
8) графика текста (кириллица, латиница, книжно-славянская
и т.п.);
9) наличие в тексте таблиц, графиков, рисунков;
10) указание на рецензии и критические материалы к тексту;
11) адрес места хранения текста;
12) другая информация, важная для проведения конкретных
исследований.
Для кодирования отдельных предложений текста
используются следующие лингвистические признаки:
1) тип предложения (простое или сложное);
2) тип сложного предложения;
3) вид придаточного предложения;
4) число сегментов (формальных групп: группа подлежащего,
группа сказуемого и т. п.);
5) структурная формула предложения на уровне классов слов
и/или членов предложения;
6) другая информация.
Словосочетание может получить в корпусе текстов следующие
признаки:
1) число слов в словосочетании;
2) тип (свободное, идиоматическое, Фразеологическое);
3) тип по главному слову (именное, /лагольное, предложно-
именное и т.п.);
4) тип связи между главным словом и другими словами словог
сочетания (согласование, управление, примыкание и др.);
5) другая информация.
Слово (словоупотребление) максимально может иметь
следующую информацию:
1) признак класса слова;
2) тип слова (простое, сложное, составное);
3) набор грамматических признаков;
4) семантический признак;
5) синтаксический признак;
6) стилистический признак;
7) наличие приставки;
171
8) наличие суффикса;
9) наличие окончания;
10) структурная формула слова;
11) другая информация.
Для отдельной морфемы слова возможна такая информация:
1) число букв в морфеме;
2) тип морфемы (приставка, основа/ суффикс, окончание);
3) семантический тип морфемы («отрицание»,
«уменьшительность» и т.п.);
4) другая информация.
Так как чаще всего основной единицей корпуса текстов
является словоупотребление, то весь возможный объем информации,
который может быть получен из^таггированных текстов, зависит
от того, насколько удачно пройдено кодирование каждого
отдельного словоупотребления. Пока, к сожалению, не разработаны
единые обозначения для кодирования грамматических,
семантических и стилистических признаков словоупотребления в
создаваемых корпусах текстов.
С опорой на правильно проведенное кодирование всех
словоупотреблений предложения во многих случаях может быть
проведено автоматическое таггирование самого предложения.
Особая проблема возникает при подготовке корпусов
параллельных текстов. Она заключается в установлении соответствий
между текстом оригинала и его переводами. Для решения такой
задачи используется так называемый метод автоматического
выравнивания текстов. Его суть заключается в параллельной
сегментации оригинального текста и его перевода по предложениям. При
этом могут использоваться шесть возможных соответствий между
предложениями обоих текстов.
1. Одно исходное предложение переводится одним
предложением.
2. Два исходных предложения переводятся одним
предложением.
3. Одно исходное предложение переводится двумя
предложениями.
4. Два исходных предложения переводятся двумя
предложениями, но внутренние границы этих предложений в тексте
оригинала и тексте перевода не совпадают.
5. Предложение исходного текста не переводится.
6. Предложение в тексте перевода не имеет эквивалента в
тексте оригинала.
Одна из проблем, возникающая при создании и
эффективном использовании корпусов текстов, связана с созданием
удобного для пользователя языка, позволяющего извлекать из корпуса
максимум информации. По существу задача сводится к созданию
специальной поисковой системы, способной функционировать
172
в сети Интернет. Такая система должна иметь возможность найти
все те тексты, предложения, словосочетания, слова и морфемы,
которые обладают перечисленными выше признаками.
Еще больший объем информации позволяют получить
параллельные корпусы текстов. С их помощью, дополнительно к
вышесказанному, можно:
1) автоматически строить двуязычные и многоязычные
переводные словари;
2) автоматически создавать и пополнять словари для систем
машинного перевода;
^ 3) автоматически устранять полисемию лексических единиц.
Это становится возможным в связи с тем, что компьютер может
использовать контекстное окружение многозначного слова, по
длине превышающее предложение;
4) автоматически переводить терминологические и
фразеологические единицы текста;
5) осуществлять полностью автоматический перевод в рамках
новых систем машинного перевода, называемых системами с
переводческой памятью. Суть данного подхода заключается в том,
что в памяти компьютера накапливаются корпусы исходных
текстов и их переводов, выравненных между собой на различных
уровнях.
В процессе перевода такая система пытается отыскать
переводимое предложение в массиве исходных параллельных текстов. Если
оно найдено в исходном массиве текстов-оригиналов, то система
выбирает перевод такого предложения или его части в массиве
переведенных текстов.
Фонетические лингвистические ресурсы
Как видно из общей структуры лингвистических ресурсов (см.
схему 28), их составной частью являются также фонетические
лингвистические ресурсы. При их создании возникают те же
проблемы, что и при создании письменных текстовых массивов [22].
Однако главная трудность создания фонетических лингвистических
ресурсов связана с необходимостью транскрибирования устной
речи. При этом возникают следующие проблемы:
1. Какой алгоритм использовать для транскрибирования?
2. Учитывать ли индивидуальные особенности произношения?
3. Учитывать ли весь устный текст или его фрагменты?
4. Учитывать ли диалектные варианты произношения слов?
5. Учитывать ли ударения в словах?
6. Учитывать ли просодические признаки произносимых фраз?
7. Отмечать ли слова, которые при прослушивании не
распознавались?
173
8. Отмечать ли в записи для фонетического корпуса паралинг-
вистические явления, сопутствующие речи (паузы, смех,
бормотание, кашель и т.п.)?
В настоящее время общепринято, что для создания
машиночитаемых фонетических корпусов используется транскрипция на
основе орфографического представления звуков речи с
дополнительными знаками, передающими (при необходимости)
просодические, паралингвистические и другие особенности произношения.
Несмотря на трудности создания, в мире уже существует
много достаточно представительных фонетических корпусов. Так, в
70-х годах XX века в США X. Далем и его коллегами был создан
«Корпус устной речи американского варианта английского
языка». Он включал 1000000 словоупотреблений, взятых из записей
психоаналитических сеансов. С каждойшз 15 кассет, имевшихся в
распоряжении составителей корпуса, было случайным образом
отобрано 225 записей сеансов. Они содержали речь 8 женщин и
21 мужчины из 9 городов США. Отобранные записи были
транскрибированы на основе стандартной английской орфографии.
Диалектные варианты произношения не учитывались. Нераспознанные
слова при записи обозначались буквой Z Ударения и другие
просодические характеристики речи также не учитывались. В то же время
при орфографической записи устной речи в качестве специальных
комментариев отмечались паузы, смех, вздох, кашель и другие
паралингвистические явления. Известен Международный
машиночитаемый архив современного английского языка (The International
Computer Archive of Modern English — ICAME). В последние годы
предлагается коммерческий «Корпус разговорного
профессионального американского варианта английского языка» (Corpus of Spoken
Professional Ащейсап English). Он включает 2000000 слов с
индексами части речи при каждом слове (его можно найти по URL-
адресам www.athelstan.com и www.athel.com).
Существует несколько фонетических корпусов немецкой
устной речи. Одним из первых является Фрейбургский корпус. Он
создан на базе 820 магнитофонных записей устной немецкой речи
конца 60-х — начала 70-х годов XX века во Фрейбургском
отделении Института немецкого языка. Корпус включает записи
радиопередач, а также различных конференций, заседаний и других
общественных мероприятий. Для транскрибирования было отобрано
222 текста различного объема (от 175 до 16390
словоупотреблений) общей длиной в 600000 словоупотреблений. Для
приведения записей в машиночитаемый вид была разработана
специальная система транскрипции, опирающаяся на стандартную
немецкую орфографию.
По указанным выше (см. с. 168) URL-адресам организация ELRA
предлагает и фонетические корпусы текстов. Так, норвежский
фонетический корпус (ELRA-S0O81 Norwegian Speech Dat (II)
174
FDB-1000) содержит записи телефонных разговоров 1016
носителей норвежского языка (517 мужчин и 499 женщин). Известен
датский корпус разговорной речи, содержащий 10000000 слов [262].
Фонетические корпусы текстов широко используются для
решения следующих задач:
1) сопоставительного изучения устной и письменной форм
языка;
2) изучения грамматических и лексических особенностей уст-
нойуречи;
У) исследования фонетических особенностей диалектов;
4) построения частотных списков фонем и их сочетаний;
5) изучения акустических свойств речевых единиц и их
использования в психолингвистических и лингвистических экспериментах;
6) создания компьютерных систем, распознавания и синтеза
устной речи.
ГЛАВА 7
ОСНОВЫ КОМПЬЮТЕРНЫХ ТЕЛЕКОММУНИКАЦИЙ
КОМПЬЮТЕРНЫЕ СЕТИ. ОСНОВНЫЕ ПОНЯТИЯ
Компьютерная сеть — это объединение нескольких
компьютеров таким образом, что они могут взаимодействовать друг с
другом с целью совместного использования информации и ресурсов
[203, 180]. В зависимости от объемов обрабатываемой
информации и способов соединения компьютеров в единую сеть
различают следующие их виды:
1) локальцые сети;
2) региональные сети;
3) корпоративные сети;
4) глобальные сети.
Локальные компьютерные сети служат для обработки
информации местного значения: они объединяют компьютеры в
учебных классах, одной школе, небольшой фирме или на
предприятии. Как правило, такой сетью связаны компьютеры,
находящиеся в одном здании. Для успешного функционирования локальной
сети необходимо иметь:
1) определенное число персональных компьютеров и
периферийных устройств (например, принтеров, модемов и т.д.);
2) сетевые адаптеры и сетевые кабели;
3) сетевое оборудование (концентраторы или коммутаторы);
4) сетевую операционную систему (например, UNIX, Novell
NetWare, MS Windows NT или MS Windows 2000).
Сетевой адаптер — это небольшое устройство, вставляемое в
свободное гнездо материнской платы и соединяющее данный
компьютер с помощью сетевого кабеля с сетевым адаптером другого
компьютера. В сетевом адаптере каждого компьютера зафиксирован
индивидуальный адрес компьютера в сети (МАС-адрес: Media Access
Address). Из всей передаваемой по сети информации с помощью
сетевого адаптера отбирается только та, которая направлена
компьютеру с адресом, зафиксированным в его сетевом адаптере.
В качестве сетевых кабелей используются обычные
электрические или оптоволоконные кабели. Первые, в свою очередь,
делятся на коаксиальный кабель и витую пару. Оптоволоконный кабель
и витая пара обладают очень высокой пропускной способностью
(от 10 до 100 Мб/с) [39, 46—49; 203, 181, 182; 10].
176
Концентраторы и коммутаторы являются тем центром,
который объединяет компьютеры в сеть. Они различаются способом
передачи в сеть поступающей к ним информации. Эта
информация называется трафиком (от англ. traffic — /движение; поток
сообщений в сети передачи данных'), который состоит из пакетов
данных. Концентратор позволяет легко расширять сеть, включая
в нее новые компьютеры. По существу концентраторы — это
повторители информации, которая поступает в сеть извне. Они
передают трафик всем компьютерам, не выделяя конкретный
компьютер по указанному адресу. С увеличением числа пакетов
данных происходит замедление работы в сети, так как каждый
компьютер должен проанализировать все поступающие извне
пакеты. Коммутатор в отличие от концентратора анализирует
адреса назначения каждого поступающего пакета и направляет пакет
тому компьютеру сети, который указан в адресе, Коммутаторы и
концентраторы часто используются вместе в одной и той же сети.
Концентраторы расширяют сеть, увеличивая число
подключаемых в сеть компьютеров (портов), а коммутаторы разбивают сеть
на небольшие, менее загруженные сегменты [203, 181].
Первая в мире сеть была локальной. Она была создана
Министерством обороны США в 1969 году и включала в себя четыре
компьютера. Эта сеть получила название ARPANET (Advanced
Research Projects Agency Net). В 1971 году она имела в своем
составе уже 14 компьютеров, а в 1972 году — 37 [261, 9—12].
Региональная сеть — это объединение компьютеров для
решения задач более крупного масштаба, чем в локальных сетях.
Примером таких сетей может служить сеть, объединяющая
компьютеры высших учебных заведений города или небольшого
государства (например, сеть UNIBEL в Беларуси [116]),
компьютерная сеть библиотек города, сеть, объединяющая компьютеры
всех заправочных автомобильных станций, и т.п. Компьютеры
региональной сети могут быть соединены кабелями или
телефонными линиями. Для подключения компьютеров к
телефонным линиям используются модемы. Их функция заключается в
том, чтобы преобразовать цифровые (дискретные) сигналы
компьютера в аналоговые (непрерывные), воспринимаемые
телефонными линиями, и наоборот (модуляция — демодуляция).
Конструктивно модемы бывают внешние (в виде отдельных блоков) и
внутренние (в виде дополнительной платы, устанавливаемой в
гнездо материнской платы). Основная характеристика модема —
скорость передачи данных. В настоящее время она может равняться
28880 бодам (1 бод приблизительно равен скорости в 1 бит/с),
33600 бодам, 56000 бодов и выше [39, 46]. Если модем
используется для постоянной работы в телефонной сети, то для него
отводится отдельный телефонный канал, который называется
выделенной линией.
7 Зубов
177
Еще более крупным объединением компьютеров в рамках
большой корпорации (треста, компании), предприятия которой
находятся в разных городах, является корпоративная сеть. Таким
образом можно объединить компьютеры гостиниц в разных
городах страны, компьютеры, находящиеся в филиалах какой-то
фирмы. Примером корпоративной сети может служить современная
система продаж железнодорожных и авиабилетов и т.п. Основным
средством связи компьютеров в этом случае являются
телефонные линии и оптоволоконный кабель.
Развитием корпоративных сетей стала-сеть Интернет. Ее
особенности заключаются в том, что она имеет выход в глобальную
сеть Интернет и ее ресурсы защищены от несанкционированного
доступа извне [120, 77, 12].
ГЛОБАЛЬНАЯ СЕТЬ ИНТЕРНЕТ
Общая структура Сети
Все перечисленные выше типы компьютерных сетей
объединяет принцип их работы. В таких сетях есть центральный
(главный) компьютер — сервер и рабочие станции — все другие
компьютеры сети. Обработку информации осуществляет центральный
компьютер. Выход его из строя может привести к потере
информации или к нарушению работы всей сети. Поэтому ученые
разработали способ децентрализованной обработки информации в сети
и нашли способы передачи такой информации на большие
расстояния. Эти две особенности и характеризуют глобальные сети.
Компьютеры в такой сети обычно используют телефонные и
оптоволоконные каналы связи, а также спутниковую связь.
Самой большой глобальной сетью, объединившей в единое
целое тысячи региональных и корпоративных сетей мира,
является сеть Интернет. Она возникла на основе упомянутой выше сети
ARPANET. Национальный научный фонд США в конце 1970-х
годов создал на базе ARPANET сеть NSFNET, объединившую
суперкомпьютеры нескольких крупных научных центров.
Окончательный переход к технологии современной сети Интернет
произошел в январе 1983 года, когда впервые для обмена информацией
был принят протокол1 TCP/IP [120, 12].
В 1986 году NSFNET объединила под своим началом целый
ряд региональных американских сетей, таких, как BARRNET,
SURANET, NYSERNET и т.д., и окончательно отделилась от
APRANET [120, 12]. С этого времени начинается самостоятельная
1 О типах протоколов см. с. 180.
178
история сети Интернет. В 1988 году Интернет становится
международной, так как в этом году к ней подключились такие страны,
как Канада, Дания, Финляндия, Франция, Норвегия и Швеция.
К 1997 году в глобальной сети Интернет уже работали 170 стран
[120, 72-75].
Современная сеть Интернет представляет собой объединение
крупных узлов. Каждый узел — это один или несколько мощных
компьютеров-серверов. Их называют хост-компьютерами (от англ.
host — 'хозяин'). Каждым узлом управляет отдельная
организация — провайдер (от англ. provide — 'обеспечивать'). В начале
2001 года в сети Интернет было более 5 млн хост-компьютеров.
Услугами Сети к 2002 году пользовались почти 500 млн человек, а
к 2005 году их количество возрастет до 765 млн [220, 18]. В России
к началу 2000 года насчитывалось 5,4 млн пользователей.
Для поддержания совместной работы провайдеров и отдельных
пользователей применяют два типа телекоммуникационного
программного обеспечения [235, 621]:
1) программы-серверы, которые устанавливаются на
хост-компьютерах;
2) программы-клиенты, устанавливаемые на компьютере
каждого отдельного пользователя.
Такая технология телекоммуникации в сети называется
технологией «клиент-сервер». Как видно из вышесказанного, в сеть
Интернет входят миллионы компьютеров. Они могут относиться к
разным аппаратным платформам, использовать различные
операционные системы и различные форматы данных. Чтобы такие
компьютеры могли понимать друг друга, должны быть заранее
разработаны определенные соглашения о способах формирования,
передачи и приема информации (сообщений) между сетями и
отдельными компьютерами. Такую работу выполняет
Архитектурный совет Интернет (Internet Architecture Board), являющийся
частью Общества Интернет (Internet Society). Совет занимается
организацией, управлением и другими функциями,
способствующими взаимопониманию и успешной работе Сети. В состав
Совета входят Исследовательская группа Интернет (IRTF — Internet
Research Task Force) и Инженерная группа (IETF — Internet
Engineering Task Force). Люди, работающие в составе первой
группы, заняты исследованиями, направленными на дальнейшее
развитие сети, а инженеры второй группы осуществляют ее
повседневное техническое обслуживание. Общество Интернет в целом
не является владельцем сети. Оно способствует распространению
важной информации между различными провайдерами и
привлекает исследователей для разработки стандартов сети Интернет.
Существуют организации, которые по отношению к Интернету
выполняют организаторские функции. Например, такой
организацией в Европе является RIPE (Reseaux IP Europeens) [39, 23, 24].
179
Упомянутые выше соглашения о способах формирования,
передачи и приема информации между сетями и отдельными
компьютерами называют протоколами. Протокол — это совокупность
стандартов для обмена информацией между двумя
компьютерными системами или двумя компьютерами. Основным протоколом
межсетевого обмена данными является протокол TCP/IP
(Transmission Control Protocol/Internet Protocol).
TCP-протокол управляет передачей данных. Он описывает
способ, с помощью которого два компьютера сети могут
устанавливать между собой надежный каналЬсвязи с последующим
подтверждением установленной связи.
IP-протокол описывает то, каким образом компьютер,
подключенный к сети, должен разбивать данные на пакеты для
передачи их по сети и каким образом эти пакеты должны
адресоваться, чтобы их можно было доставить по месту назначения.
Каждый компьютер в сети имеет свой индивидуальный
IP-адрес. Он обозначается 32-разрядным двоичным числом (в будущем
возможно увеличение разрядности адреса). Для удобства
пользования IP-адрес ПК переводится в десятичное число, состоящее
из 4 частей, каждая из которых представляет 8 двоичных разрядов.
Например, такой IP-адрес может выглядеть так: 128.143.7.186.
Способы использования сети Интернет
Сеть Интернет в настоящее время используется для
выполнения следующих задач:
1) обеспечения работы электронной почты;
2) поиска информационных ресурсов;
3) организации телеконференций и обмена группами новостей;
4) обмена файлами;
5) проведения видеоконференций;
6) общения пользователей друг с другом в реальном времени
и т.д.
Электронная понта (e-mail или e-pistles) — это использование
компьютерной сети для отправления и приема сообщений. Все
чаще и чаще эти цели реализуются с помощью глобальной сети
Интернет. Электронное сообщение или письмо обычно состоит из
двух частей: заголовка письма {header) и тела письма (body). В
заголовке электронного письма сообщается информация о том, кому
(поле «То») направлено письмо, от кого (поле «From») и на
какую тему (поле «Subject»). Указывается и дата отправления
сообщения (поле «Date»).
В поле «То» электронного письма указывается один или
несколько электронных адресов основных получателей сообщения.
Электронный адрес — это набор символов (латинских букв, деся-
180
тичных цифр, специальных знаков), который однозначно
определяет местонахождение почтового ящика получателя сообщения.
Ок состоит из двух частей, разделенных знаком @ {коммерческое
эт). Слева от зщка @ находится условное или реальное имя
пользователя. Справа от знака @ указываются данные, описывающие
страну, тип организации или некоторый отдел той организации,
куда передается сообщение. Иногда в этой части адреса
указывается имя провайдера, к которому подключен компьютер. Все
отдельные части информации, стоящие справа от знака @ и разделенные
знаком ".", называются доменами. Например, электронный адрес
Минского государственного лингвистического университета имеет
следующий вид: mslu@user.unibel.bv. где mslu — имя
университета, user (пользователь) — общее имя вузов, подключенных к
образовательной сети UNIBEL [116], umbel — имя провайдера, к
которому подключен сервер университета, a by — сокращенное
название Республики Беларусь (Byelorussia).
Среди доменов, расположенных в правой части электронного
адреса, существует определенная иерархия. Домен, стоящий в
конце адреса, называется доменом высшего уровня. Он
идентифицирует географический регион сети, ее тип или же тип
организации, которой направлено сообщение. Так, в США последний
домен обычно обозначает тип организации: коммерческая (.сот),
образовательная (.edu), правительственная (.gov) и т.д.
Рассмотрим еще один электронный адрес: poul@market.emerv.
com. Здесь poul — имя получателя информации, market — название
отдела этой фирмы, emery —■ название фирмы, сот— тип
организации (коммерческая).
В поле «From» электронного письма указывается электронный
адрес отправителя сообщения. Здесь же может быть указано и
обычное (не электронное) имя отправителя. Краткая формулировка темы
отсылаемого сообщений указывается в поле «Subject». Поле «Date»
содержит информацию о том, когда было отправлено сообщение.
Для автоматического преобразования доменных имен адреса
электронного сообщения в IP-адрес компьютера в сети Интернет
используется специальная программа — DNS (Domain Names
System — система доменных имен). Так, например, доменные имена
электронного адреса alexander@watt.seas.virginia.edu с помощью этой
программы будут переведены в IP-адрес 128.143.7.186.
Для возможности отправки и приема сообщений по
электронной почте необходим так называемый почтовый пакет. Обычно он
включает следующие программы1.
1. Почтовый клиент.
2. Программа почтового сервера.
1 Для более широкого использования электронной почты в почтовый пакет
иногда включается и ряд других программ.
181
3. Транспортная программа.
4. Сервер списков рассылки.
Почтовый клиент обеспечивает возможность чтения
полученного письма и написания ответа. Программа почтового сервера
управляет передачей сообщения между клиентами и сетью
Интернет. Если используется сетевая операционная система UNIX,
то в качестве почтового сервера может служить программа UUCP
(Unix-to-Unix Copy Protocol — протокол копирования между
системами UNIX). При использовании других сетевых операционных
систем в качестве почтового сервера применяется программа SMTP
(Simple Mail Transfer Protocol — протокол передачи почты) [53,
427—437\. Эта система требует наличия транспортной программы.
Такая программа доставляет сообщение почтовым серверам. В
качестве их могут выступать, например, сервер POP (Post Office
Protocol — протокол почтового центра) [53, 453—460] или
сервер IMAP (Internet Mail Access Protocol — протокол доступа к
почте Интернета). Почтовый сервер далее доставляет сообщение
конечному адресату.
Сервер списков рассылки — это программа, содержащая
данные об электронных адресах клиентов, ответы на наиболее часто
задаваемые вопросы, прайс-листы и т.п. Такой сервер
анализирует сообщения, поступающие в его адрес, и принимает решение о
том, как и что ответить. Если поступило сообщение от нового
клиента, сервер списков рассылки автоматически запоминает его
электронный адрес.
Существует достаточно много почтовых программ. Так, для
операционных систем OS/2, Мае ОС и UNIX используется
почтовая программа Eudora. Для компьютеров, работающих под
управлением ОС Windows, широко применяются почтовые
программы фирмы «Microsoft»: INTERNET MAIL, EXCHANGE И
OUTLOOK EXPRESS. Для передачи по e-mail нетекстовой информации
(аудио- и видеофайлов, мультимедийных данных) используется
стандарт MIME (Multipurpose Internet Mail Extensions).
Поиск информационных ресурсов — вторая наиболее
популярная сфера применения сети Интернет. В качестве ресурсов могут
выступать книжные фонды библиотек, хранилища словарей и
текстов, личные библиотеки и т.п. Чтобы найти
информационный ресурс, необходимо знать его адрес. Адрес ресурса в
Интернете называют URL-адресом (Uniform Resource Locator —
Унифицированный локатор ресурса). В нем указывается следующая
информация: 1) метод доступа к ресурсу; 2) сервер, к которому
необходимо обратиться; 3) местонахождение ресурса на сервере.
В общем виде URL-адрес имеет следующую структуру:
протокол'.//адрес ресурса.
Используемые в сети Интернет ресурсы чаще всего
размещаются на страницах WWW-серверов (или Web-серверов), в файло-
182
вых архивах (FTP-архивах) и в информационно-справочной
системе Gopher.
WWW(World Wide Web — Всемирная Паутина) — это
глобальная гипертекстовая система, использующая для транспортировки
информации в сети Интернет протокол HTTP (Hypertext Transfer
Protocol — протокол передачи гипертекста). Гипертекст — это
способ представления всех типов информации в виде
последовательности узлов, связанных друг с другом ассоциативной (а не
последовательной) связью и реализованной в виде гиперссылок.
Гиперссылка— выделенная в гипертексте последовательность
символов, реагирующая на щелчок мыши и отсылающая
пользователя на другой фрагмент гипертекста. Большинство документов,
хранящихся на Web-сервере, создано на языке HTML (Hypertext
Markup Language — язык гипертекстовой разметки документов).
Гипертекст позволяет просматривать свои составные части в
любой последовательности.
Web-сервер — это программа, принимающая и обрабатывающая
запросы пользователей на поиск нужной им информации. С
другой стороны, Web-сервер — это компьютер, на котором
установлена данная программа. Запросы и найденная информация
передаются по протоколу HTTP. Поэтому адрес ресурса,
находящегося на страницах Web-сервера, указывается следующим образом:
http://имя домена/каталог/файл или http://имя домена.
Например, если WWW-сервер представляет собой сервер
фирмы «Microsoft», его адрес будет таким: http://www.microsoft.com.
URL-адрес Web-сервера Минского государственного
лингвистического университета, подключенного к образовательной сети
UNIBEL, выглядит так: http://www.mslu.unibel.bv.
FTP-сервер — это компьютер, содержащий файлы данных,
передаваемых по протоколу FTP (File Transfer Protocol — протокол
передачи файлов). При установлении FTP-сеанса в сети
Интернет можно обмениваться (копировать) информацией как в
текстовом, так и в двоичном виде. URL-адрес ресурса,
находящегося, например, на FTP-сервере фирмы «Microsoft», будет, таким:
ftp://ftp.microsoft.com.
Gopher-сервер — это сервер, содержащий программы,
позволяющие найти файлы, программы или другие ресурсы на
заданную пользователем тему. URL-адрес такого сервера выглядит
следующим образом (если сервер, например, принадлежит фирме
«Microsoft»): gopher://gopher.microsoft.com.
Программы просмотра страниц Web-серверов называют Web-
браузерами {Web browsers). Используя URL-адреса ресурсов и
специальные средства (поисковые инструменты), они помогают
пользователю найти нужную ему информацию в сети Интернет.
Выделяют две группы поисковых инструментов: 1) поисковые
системы и 2) поисковые службы. В зависимости от того кто создает
183
базы данных, в которых осуществляется поиск необходимой
пользователю информации, различают поисковые системы
первого и второго рода. В поисковых системах первого рода базы данных
создаются людьми, в поисковых системах второго рода этот
процесс осуществляет компьютер.
Поисковые системы первого рода, как правило, называют ка-
талогами (предметными или тематическими — subject catalogs).
Обычно такие каталоги создаются люд[ьки в виде иерархических
деревьев, на верхнем уровне которых стоят наиболее общие
понятия: бизнес, политика, образование, спорт, культурам т.д.
Элементами нижнего уровня таких деревьев являются ссылки на
конкретные Web-страницы и серверы. Обычно поиск в предметных
каталогах осуществляется по ключевым словам [235, 648—651].
В этом случае он проводится не в содержимом Web-серверов, а в
их кратких описаниях, хранящихся в каталоге. Запрос на поиск
формируется либо в виде списка ключевых слов («information
technology», «computer linguisics» и т.п.) или же путем указания
URL-адресов документов, в которых следует проводить поиск.
Результаты поиска представляются в виде гипертекста,
содержащего в качестве гипертекстовых ссылок названия или URL-адреса
найденных документов.
По ключевым словам можно осуществлять поиск следующей
информации [253]:
1) некоторого текста или его части;
2) фактических данных (например, массу солнца или имя
президента страны);
3) картин, рисунков, кинофильмов и т.д. по их названиям;
4) технической информации (например, сведения о скорости
некоторого автомобиля);
5) биографий людей (писателей, художников и т.п.).
Примерами тематических каталогов являются Yahoo, Galaxy,
WWW Virtual Library, WebCrawler, HotBot и др. Подобная
русскоязычная система носит название «Следопыт».
Поисковые системы второго рода иногда называют
автоматическими индексами, «пауками» или «червями» (spiders, crawlers).
Они постоянно сканируют Интернет, находят в сети новые
документы и из каждого документа извлекают все содержащиеся в нем
гиперссылки, которыми пополняют свои базы данных (базы URL-
адресов). Чтобы можно было выполнять эти функции,
автоматический индекс включает в себя следующие три части: программу-
робота, которая постоянно просматривает Интернет; базу данных
(множество URL-адресов), которая собирается роботом, и
интерфейс пользователя для поиска необходимой информации в этой
базе данных. Существует большое число автоматических индексов.
Наиболее популярными являются: AltaVista, OpenText, Excite,
InfoSeek и т.д. Есть и русскоязычные автоматические индексы —
184
Rambler, Russian Express, Апорт. Сравнительный анализ работы
поисковых систем приведен в работе [176].
Еще одним типом поисковых инструментов являются
поисковые службы. Получив запрос пользователя на поиск некоторой
информации, поисковые службы одновременно обращаются к
нескольким поисковым системам и другим источникам
информации. Результаты поиска объединяются и передаются
пользователю в виде гипертекстовых страниц. К числу таких средств
поиска информационных ресурсов относятся InfoMarket, Meta-
Crawler и др. Например, последняя поисковая служба посылает
запросы одновременно восьми различным поисковым серверам:
OpenText, Lycos, WebCrawler, InfoSeek, Excite, AltaVista, Yahoo
и Galaxy.
Поиск информации с помощью различных поисковых
инструментов может осуществляться путем формирования простых и
сложных запросов. Простой запрос представляет собой слово или
словосочетание, которое иногда берется в кавычки. Сложный
запрос формируется из слов или словосочетаний, соединяемых
операторами типа AND, OR, NOT, NEAR или математическими
символами, например "*", м+", "-", "~". Иногда для тех же целей
используются специальные термины domain, host, link title и др.
Следующая задача, которая может быть выполнена в рамках
сети Интернет, связана с организацией телеконференций и
обменом новостями. До последнего времени эти возможности Сети
считались вторым по распространенности сервисом Интернета.
Различают два вида телеконференций или сетевых новостей: Usenet
News и «mailing lists» (списки рассылки).
Первый вариант программы Usenet был написан на языке С++
в университете Беркли в 1982 году. В 1986 году для сетевой системы
новостей была разработана специальная форма обмена
информацией NNTP (Network News Transfer Protocol — протокол передачи
сетевых новостей). Сейчас появились специальные средства разметки
текстовой информации (языки HTML — Hypertext Markup Language
и SGML — Standard Generalized Markup Language), которые
позволяют просматривать в телеконференциях не только текст, но и
звуковые объявления, графики, фильмы. Телеконференции Usenet
News называют также группами новостей (news groups). Таких групп
существует несколько десятков тысяч [235, 629]. Каждая группа
новостей имеет свое название и иерархическую структуру (в
группу может входить несколько подгрупп, каждая подгруппа, в свою
очередь, может состоять из других подгрупп и т.д.) Например,
подгруппа новостей, содержащая сообщения об
информационных системах WWW, входит в крупную группу «Вычислительная
техника» и имеет название comp.infosystems.www (т.е. группа
«Вычислительная техника», подгруппа «Информационные системы»,
подгруппа «WWW»). В составе подгруппы comp.infosystems.www
185
выделяют 10 более мелких подгрупп: comp.infosystems.www.misk,
comp.infosystems.www.users, comp.infosystems. www.providers и др.
Есть группы новостей, в которых обсуждаются вопросы
образования (edu.), науки (sei.), музыки (music.) и'т.п. Информация,
хранящаяся в архивах на серверах телеконференций, представляет
собой названия и описания статей, но небами статьи. При
желании пользователь может получить и полные статьи. Содержание
архивов постоянно меняется, а устаревшие статьи становятся
недоступными. Человек, который следит за обновлением архивов и
за всеми поступающими в группу сообщениями, называется
модератором, а соответствующая телеконференция — управляемой
или модерируемой. Существуют и немодерируемые конференции,
куда без цензуры может послать сбои материалы («высказаться по
теме») любой желающий. Для того чтобы послать сообщение в ту
или иную группу новостей, в почтовом клиенте необходимо
заполнить стандартные позиции [9, 74]:
1) название телеконференции (Newsgroup);
2) тема (Subject);
3) область распространения (Distribution);
4) ключевые слова (Keywords);
5) аннотация (Summary).
Как было отмечено выше, второй вид телеконференций
связан со списками рассылки. Суть этой услуги заключается в том,
что информацию по какой-то теме получает небольшой (в
отличие от Usenet News) круг пользователей, подписавшихся на
данный список рассылок. По ряду причин роль телеконференций как
информационных центров Internet сейчас утеряна.
Еще одна возможность сети Интернет — обмен файлами. Этот
способ использования Сети направлен на доступ пользователя к
различным базам данных (программам, книгам, каталогам и т.п.).
Такие базы данных называются файловыми архивами или FTP-
архивами (FTP — File Transfer Protocol — протокол обмена
данными (файлами) между компьютерами в сети Интернет).
Средства FTP дают возможность просматривать каталоги и файлы
серверов, переходить из одного каталога в другой, копировать и
обновлять файлы [235, 628]. Если говорить о программных
средствах, хранящихся в FTP-архивах, т.е. два наиболее известных
способа их получения [9, 93]:
1. «Fareware» (бесплатно). При этом пользователь получает
полную версию программы на неограниченный срок.
2. «Shareware» (частично бесплатно). При этом пользователь
получает программный продукт в виде демонстрационной версии
насовсем либо его усеченную версию на некоторый
ограниченный срок.
Поиск файлов в FTP-архивах целесообразен в тех случаях,
когда известно имя файла и путь в сети, по которому его можно
186
найти, или же используется список анонимных FTP-архивов, в
которых может быть что-либо интересующее пользователя. В тех
случаях, когда известно имя файла, где находится необходимая
пользователю информация, либо производится поиск файла по
ключевым словам, характеризующим его содержание,
применяется поисковая система Archie (Archie-серверы) [235, 628; 9, 93].
Такие серверы собирают и хранят поисковую информацию о
содержимом FTP-серверов сети Инернет. Результатом работы Archie-
сервера является адрес соответствующего FTP-сервера. Если
поиск необходимо производить не по адресу, а по содержанию,
можно использовать протокол и программы Gopher [9, 105—117].
Они обеспечивают более развитые (по сравнению с FTP)
средства поиска и извлечения информации с помощью
многоуровневых меню, справочных книг, индексных ссылок и т.д. Gopher
позволяет осуществлять также поиск графической информации и
звуковых записей [235, 628].
О некоторых лингвистических ресурсах на иностранных
языках, которые можно найти по URL-адресам организации ELRA,
было сказано выше (см. с. 161, 171, 174). Лингвистические ресурсы
в сети Интернет на французском языке хорошо представлены в
работе [33]. Большой объем информации о русских
лингвистических ресурсах можно найти по URL-адресам, приведенным в
исследовании [180].
Следующее использование глобальной сети Интернет связано
с возможностью проведения видеоконференций.
Видеоконференция — это предоставление большому количеству людей
возможности не только слышать, но и видеть друг друга в реальном
времени. Впервые система видеотелефонии Picturephone была
представлена корпорацией AT&T в 1964 году на Всемирной ярмарке.
К 1996—1997 годам завершился первый этап развития технологии
видеоконференций. В итоге видеоконференции стали стандартным
и доступным видом сервиса Интернета [185, 777, 772]. Появление
таких компьютерных систем вызвано самой жизнью и
определяется следующими принципами [175; 57; 58]:
1) психологическими особенностями восприятия информации
человеком;
2) желанием сократить расходы на организацию различных
типов встреч.
Исследования психологов показали, что при обычном
телефонном разговоре в среднем передается 11 % сообщаемой
информации (учитываются все составляющие информации:
содержательная, эмоциональная, жестовая и т.д.). Если использовать телефон
и факс, то объем информации увеличивается до 24 %. При учете в
процессе беседы мимики, жестов, другой визуальной
информации (что и происходит во время видеоконференций) общий объем
сообщаемой информации увеличивается до 60 %.
187
Известно, что успешное веденце бизнеса возможно лишь
путем постоянных контактов его участников. При этом участники
могут находиться в разных городах или разных странах, поэтому
фирмы тратят огромные деньги на командировки своих
сотрудников. Видеоконференции позволяют значительно сократить
такие расходы. То же самое можно сказать о командировках
опытных врачей в отдаленные районы страны и перевозке больных из
таких районов в центральные медицинские учреждения.
Подобные проблемы возникают при организации заочного обучения и
во многих других областях жизни общества.
Для возможности организации видеоконференций необходимы:
1) компьютеры на разных концах видеолинии;
2) специальное программное обеспечение;
3) специальное оборудование;
4) специальные каналы.
Простейшей из компьютерных программ, обеспечивающих
проведение видеоконференций, является разработанная фирмой
«Microsoft» программа NetMeeting. В последние годы появился ряд
более мощных программ, таких, как Mbone, FarSite, CU-SeeMe,
ShowMe и LiveShare. Они не только обеспечивают
аудиовизуальное общение, но и позволяют осуществлять обмен файлами,
совместную работу с разными приложениями и с так называемой
«белой доской». При этом каждый участник видеоконференции
может размещать в окне монитора текст и графическую
информацию. Все изменения, проводимые на этой «белой доске»,
становятся доступными любому участнику видеоконференций.
Не очень сложная видеосистема может включать (помимо
программного обеспечения) видеокамеру (например, USB) и
устройство видеоввода. Все вместе это стоит сейчас не более 200
долларов США [58, 48]. Однако, чтобы обеспечить видеоконферейции
высокого качества (например, для проведения консультаций во
время медицинских операций), необходимо иметь более
сложное оборудование. К числу таких систем относятся, например,
системы DiViSy-2000, PictureTelStarCost, TC2000, LC5000 и др.
Цена их в настоящее время колеблется от 1 до 60 тыс. долларов
США [175, 40— 43]. В настоящее время для организации
видеоконференций во всем мире используются канал ISDN1 и
оборудование стандарта Н.320. В простейшем варианте для этого
необходимо иметь от одного до трех каналов со скоростью передачи
данных соответственно 128—384 Кбит/с. Для передачи
видеоизображения высокого качества необходимо иметь канал с
пропускной способностью как минимум 2 Мбит/с. Сейчас все большее
1 ISDN (Integrated Services Digital Network) — это международный
телекоммуникационный стандарт для передачи аудио-, видео- и других данных по
цифровым линиям [46, 301.
188
) распространение находят пгарокополосные каналы связи стандарта
Н.323. В этом случае нужна скорость передачи данных не менее
852 Кбит/с. [58, 48, 49].
По данным фирмы «TZ Telecom», в настоящее время
видеоконференции достаточно широко используются в управлении
(50 %), в дистанционном обучении (30 %) и в телемедицине (20 %).
Однако стоят такие видеоконференции достаточно дорого — от
1 до 10 долларов США за минуту связи [58, 50].
Детально процедура использования дистанционного обучения
и видеоконференций представлена в работе Р.К.Потаповой [178,
373-416]
И наконец, последний из шести упомянутых выше способов
применения сети Интернет связан с организацией общения
пользователей в реальном времени. Примером данного способа
является IRC (Inetrnet Relay Chat) — «болтовня» в реальном времени.
При этом каждый пользователь, используя клавиатуру и монитор
своего компьютера, может стать участником дискуссии в любой
точке земного шара. После подсоединения к соответствующему
каналу можно увидеть, что выводят на экран другие участники
дискуссии, а затем вывести на экран и свое сообщение. Для этих
целей используются различные программы. Простейшей из них
является программа IRC-клиент, подробно описанная в работе
[9, 82-86].
В 1996 году появился и быстро распространился новый сервис
этого типа — ICQ (название программы является омонимом и
образовано от созвучия английских слов I seek you — 'я ищу тебя').
Программа ICQ-клиент многофункциональна и поддерживает
отправление и доставку электронных сообщений, «разговор» (chat)
в реальном времени, телефонные звонки с компьютера на
обычный телефон и, наоборот, обмен короткими текстовыми
сообщениями с мобильным телефоном и пейджером, и т.д.
ЗАКЛЮЧЕНИЕ
В данном пособии, адресованном студентам-лингвистам,
приведены основные сведения об информационных технологиях
начала XXI века. Авторы сделали попытку объединения данных о
современных подходах к общему понятию «информационные
технологии» и применении этих подходов к решению
лингвистических задач.
Типовые программы по информационным технологиям для
студентов-лингвистов [98; 111; 117; 139; 174; 187; 197; 202; 212;
216] требуют обязательного включения в соответствующие
учебники и учебные пособия основополагающих понятий, связанных
с алгоритмами, моделированием, базами данных,
телекоммуникациями. Однако специфика усвоения знаний
студентами-лингвистами и возможные способы их дальнейшего использования
заставили авторов данного учебного пособия представить
указанные выше вопросы применительно к конкретным задачам —
распознаванию значений многозначных слов, синтаксическому
анализу предложений, реферированию, аннотированию и переводу
иностранных текстов. При этом показана четкая связь между
словесной формулировкой лингвистической задачи и алгоритмом ее
решения.
Знания, которые сегодня необходимо усвоить в
филологических вузах, в большом количестве содержатся на магнитных
носителях и в сети Интернет. В пособии показано отношение между
общепринятыми понятиями «база данных», «система управления
базами данных» и современными лингвистическими
информационными ресурсами. Достаточно подробно представлены пути
поиска и извлечения таких знаний.
Отдельный раздел пособия посвящен информационным
технологиям в обучении языкам. Он как бы аккумулирует знания об
алгоритмах, моделях, лингвистических ресурсах, и, как надеются
авторы, его усвоение будет способствовать повышению
эффективности обучения языкам.
Изложение материала в пособии построено таким образом,
чтобы студент-лингвист понял, что знание компьютера, умение
общаться с ним не требует усвоения основ математики, что каждый
выпускник филологического вуза может стать основным учасг-
190
ником работ по созданию компьютерных систем обучения,
систем автоматического анализа и синтеза текстов, систем
автоматического поиска, аннотирования, реферирования и перевода
текстов.
Авторы надеются, что приведенные в пособии идеи, задачи и
предложенные способы их решения на компьютере, новейшая
обширная литература позволят студентам-лингвистам активно и
успешно включиться в процесс информатизации общества.
ЛИТЕРАТУРА
1. Автоматизированные обучающие системы на базе ЭВМ. — Минск,
1980.
2. Автоматизированные учебные курсы и пути повышения их
эффективности // Средства обучения в высшей и средней специальной
школе. — М., 1984. - Вып. 8.
3. Алексеев Г. Business English — английский для бизнесменов //
Компьютер-пресс. — 1999. — № 9. — С. 48,49.
4. Алексеев П. М. Статистическая лексикография: Учеб. пособие.—Л., 1975.
5. Андреев A.A. Введение в дистанционное обучение // Компьютеры в
учебном процессе. — 1998. — № 2. — С. 44—48.
6. Андреев A.A., Солдаткин В. И. Дистанционное обучение: сущность,
технология, организация. — М., 1999.
7. Аполлонская Т.А., Колибан В.В., Пиотровский Р.Г. и др. Машинное
реферирование французских патентных документов с помощью
фреймов // НТИ. - 1983. - № 5. - С. 23 - 29.
8. Ахаян Р., Горев А., Макашарипов С. Эффективная работа с СУБД. —
СПб., 1997.
9. Бажов В. Интернет от E-mail к WWW. — СПб., 1998.
10. Барабанов С, Коростелин А.9 Крюков С. Компьютерные сети:
вчера, сегодня, завтра // Компьютер-пресс. — 1997. — № 2. — С. 152—158;
1997. -№3.- С. 158-162.
11. Барабанов С, Коростелин А., Крюков С. Компьютерные сети: вчера,
сегодня, завтра. Технологический очерк об эволюции аппаратных средств
компьютерных сетей // Компьютер-пресс. — 1997. — № 4. — С. 29—36.
12. Бархударов Л. С. Язык и перевод. — М., 1975.
13. Белоногое Г. Г., Зеленков Ю. Г., Новоселов А. П. и др. Системы
фразеологического машинного перевода. Состояние и перспективы развития //
Научно-техническая информация. — 1998. — Срр. 2. — № 12. — С. 16—23.
14. Беляева Л. П. Практические системы машинного перевода —
теория, технология, перспективы // Структурная и прикладная
лингвистика: Межвуз. сб. - СПб., 1998. — Вып. 5. - С. 172-183.
15. БеляковМ.В., Максименко О. И. Использование систем
машинного перевода при разработке автоматизированных обучающих систем //
Компьютерная лингвистика и обучение языкам. — Минск, 2000. —
С. 160-170.
16. Бешенков CA., Лыскоеа В.Ю., Матвеева Н.В. и др. Формализация
и моделирование // Информатика и образование. — 1999. — № 5. —
С. 11-14.
192
17. Бешенков CA., Лыскова В. Ю.9 Матвеева Н. В. и др. Формализация
и моделирование // Информатика и образование. — 1999. - № 6. -
С. 22-27.
18. Бешенков С. А., Лыскова В.Ю., Матвеева КВ. и др. Формализация
и моделирование // Информатика и образование. — 1999. - № 7. -
С.25-29.
19. Бишоп Р. Куда ведет технология? // Компьютерра. — 2000. — № 15.
20. Блехман М. Машинный перевод: состояние и тенденции //
Компьютеры + Программы. — 1997. — № 5. — С. 31 — 36.
21. БлюменауД.И., Анис Т. Квазихрестоматия: из опыта создания
персональных учебных пособий на основе компьютерной технологии //
Научно-техническая информация. — 1997. — Сер. 1. — № П.— С. 1—8.
22. Богданов В. В., Бондарко Л. В., Буторов В. Д. и др. Прикладная
лингвистика и теория языка // Структурная и прикладная лингвистика: Меж-
вуз. сб. — Л., 1987. — Вып. 3. — С. 3—16.
23. Богданов В. В. Реферирование // Прикладное языкознание:
Учебник. - СПб., 1996. - С. 389-399.
24. Богданов В. «Русский офис» минус «Лексикон». Обзор домашних и
офисных программ компании «Арсеналъ» // Компьютер-пресс. — 1998. —
№1.- С 43-47.
25. Богданов В. «Русский офис» минус «Лексикон» // Компьютер-
пресс. - 1998. - № 12. - С. 12-18.
26. Богданов В. Internet: история «порока» // Компьютер-пресс. —
1999.-№2.-С. 9-14.
27. Богданов В. Программы-переводчики для Windows СЕ. Обзор
«карманных» систем перевода Pocket PROMT 1.01 и «Сократ для Windows
СЕ 1.0» // Компьютер-пресс. — 1999. — № 9. — С. 134—138.
28. Богданов В. Русские Internet переводчики // Компьютер-пресс. —
1999.-№12.-С. 62-65.
29. Бонк H.A., Котий Г. А., Лукьянова H.A. Учебник английского языка. —
Ч. 1. - М., 1982.
30. Борисевич А.Д., Гончаренко В. Ä, Гренишкина В. И. и др. Кодирование
грамматической информации в машинном словаре // Статистика
текста. — Минск, 1970. — Т. 2: Автоматическая переработка текста. —
С. 331-614.
31. Ботачков Ю. Дистанционное обучение: выгодный шанс для
корпораций // Компьютеры + Программы. — 1997. — № 7.— С. 64—69.
32. Бочкин А. И. Методика преподавания информатики. — Минск,
1998.
33. Бояркина Е. Виртуальные прогулки по французским ресурсам //
Мир Internet. — 2000. — № 4. - С. 24—27.
34. Васильев Л. М. Семантика русского глагола. — М., 1981.
35. ВейзеАА. Реферирование текста. — Минск, 1978.
36. Вертель В. А. Автоматический немецко-русский словарь для
перевода научно-технических текстов // Частные вопросы автоматического
анализа текстов. — Минск, 1972. — С. 208—278.
37. Виноград Т. Работа с естественным языком // Современный
компьютер. — М., 1986.
193
38. Вине И. Как сделать бизнес в Internet. — Киев, 1997.
39. Винховненко С. Выбираем модем // Мир Internet. — 2000. — № 4.
40. Вопросы методического обеспечения автоматизированных
обучающих систем // Обучение в высшей и средней специальной школе.
Обзорная информация. — М., 1980. — Вып. 8.
41. Все зависит от «Контекста» // Компьютер-пресс. — 2000. —№ 1. —
С. 49.
42. Гейнц-Герд P. QBASIC. Основы языка программирования. — Киев,
1992.
43. Гейтс Б. Дорога в будущее. — М., 1996.
44. ГердА. С Научно-техническая лексикография // Прикладное
языкознание: Учебник. — СПб., 1996. — С. 287—308.
45. ГердА. С. О специфике задач в прикладной лингвистике //
Структурная и прикладная лингвистика: Межвуз. сб. — СПб., 1998. — Вып. 5. —
С. 123-132.
46. Глоссарий телекоммуникационных терминов // Компьютер-
пресс. - 2000.-№ 5. - С. 28-33.
47. Головин Б. М, Кобрин Р. Ю. Лингвистические основы учения о
терминах. — М., 1987.
48. Городецкий Б. Ю. Актуальные проблемы прикладной
лингвистики // Новое в зарубежной лингвистике. — М, 1983. — Вып. XII:
Прикладная лингвистика.
49. Городецкий Б. Ю. Компьютерная лингвистика: моделирование
языкового общения // Новое в зарубежной лингвистике. Вып. XXIV.
Компьютерная лингвистика. — М., 1989. — С. 5—31.
50. Данейко М. В., Петровская В. М. Алгоритм автоматической
сегментации английского предложения // Статистика текста. — Минск, 1970. —
Т. 2: Автоматическая переработка текста.
51. Дейт КДж. Введение в системы баз данных. — Киев, 1998.
52. Деньян К. Растет популярность дистанционного обучения через
Интернет // Дистанционное образование. — 1999. — № 4. — С. 38 —
40.
53. Джамса К., Коун К. Программирование для Internet в среде
Windows. — СПб., 1996.
54. Дистанционное обучение: Учеб. пособие / Под ред. Е. С. Полат. —
М., 2001.
55. Дистанционное обучение: Учеб. пособие. — М., 1998.
56. Дмитренко В. Дистанционное образование — кому это надо? //
Компьютер-пресс. — 1999. — № 9. — С. 20—22.
57. Дубева Н. Видеоконференции для телемедицины // Сети. — 1999. —
№11.-С.44-46.
58. Евдокименко Е. Оплот ISDN // Сети. - 1999. - № 11. - С. 48—50.
59. Зайцева Н.Ю. Ранние годы машинного перевода специальных
текстов и терминологии // Вестник МГЛУ. Сер. 1. Филология. — 2000. —
№8.
60. Звегинцев В. А. Теоретическая и прикладная лингвистика. — М.,
1968.
61. Зельднер Г QuickBASIC 4.5 для носорога. — М., 1994.
194
62. Зубов А. В. Вероятностно-алгоритмическая модель порождения
текста (семантико-синтаксический аспект): Автореф. дис. ... д-ра филол.
наук. — М., 1985.
63. Зубов А. В. Проблемы порождения текста. Ч. 2.
Вероятностно-алгоритмическая модель порождения текста. — Минск, 1989.
64. Зубов А. В. Переработка текста естественного языка в системе
«человек — машина» // Статистика речи и автоматический анализ текста. —
Л., 1971. -С. 286-435.
65. Зубов A.B. Автоматический статистический анализ поэтического
текста //Актуальные проблемы квантитативной лингвистики и
автоматического анализа текста: Уч. зап. Тартуск. гос. ун-та. Труды по лингвоста-
тистике. — Тарту, 1981. — Вып. 7. — № 591. — С. 35—45.
66. Зубов AB. Статистический аспект содержания текста и его
формальное представление // Квантитативная лингвистика и
автоматический анализ текстов: Уч. зап. Тартуск. гос. ун-та. — Тарту, 1986. — № 745. *—■'
С. 75-94.
67. Зубов A.B. Системы автоматизации научных исследований в
филологии // Квантитативная лингвистика и автоматический анализ
текстов: Уч. зап. Тартуск. гос. ун-та. — Тарту, 1990. — Вып. 912. — С. 34—
54.
68. Зубов A.B. Мультимедиа технология обучения иностранным
языкам: преимущества и недостатки // Проблемы компьютерной
лингвистики. — Минск, 1997. — С. 165—171.
69. Зубов А. В., БорисевинА.Д.9 Зубова И. И. Экспертная система для
определения основного содержания текста // Инженерная лингвистика и
оптимизация преподавания языков: Тез. докл. Республ. конф. 28—30 мая
1992 г. — Самарканд, 1992.
70. Зубов А. В., Зубова И. И. Основы лингвистической информатики. Ч. 1.
Информатика и вычислительная техника. — Минск, 1991.
71. Зубов А. В., Зубова И. И. Основы лингвистической информатики. Ч. 2.
Компьютерная лингвистика. — Минск, 1992.
72. Зубов А. В., Зубова И. И. Основы лингвистической информатики. Ч. 3.
Искусственный интеллект. — Минск, 1993.
73. Зубау A.B., Зубава LI., Габк A.A. Лшгвютычная шфарматыка. —
Минск, 1995.
74. Зубов А. В., ЛихтаровинА.А. ЭВМ анализирует текст: Книга для
учителя. — Минск, 1989.
75. Зубова И. И. Коммуникация с компьютером в обучении
пониманию текста // Философия, язык, культура: Тез. докл. науч. конф. — Минск,
1992.-4.2.-С. 54-56.
76. Зубова И. И. Обучение построению прозаического текста (сказки)
с помощью компьютера // Компьютерные программы в обучении
белорусскому и иностранным языкам: Тез. докл. Республ. конф. 14—15 июня
1994 г. - Минск, 1994. - С. 27, 28.
77. Зубова И. И. Тема паремии и ее формализация в целях
порождения // Когнитивная лингвистика конца XX века: Материалы Между-
нар. науч. конф. 7—9 октября 1997 г. — Минск, 1997. — Ч. 2. — С. 155—
159.
195
78. Зубова НИ. Форматизация содержания текстов малого объема //
От слова к тексту: Материалы Междунар. науч. конф. Минск / Беларусь,
13-14 ноября 2000 г. - Минск, 2000. - Ч. 2. - С. 156-163.
79. Зубова НИ, Голубовская КВ. Специфика семантической
организации рекламных объявлений на тему «Знакомство» // Компьютерная
лингвистика и обучение языкам: Сб. науч. статей. — Минск, 2000. —
С. 105 — 117.
80. Зубова И. И, Ермолицкая Л. Г. Компьютерное обучение
коммуникативным навыкам общения на материале картин французских худолрш-
ков //Компьютерные программы в обучении белорусскому и
иностранным языкам: Тез. докл. Республ. конф. 14—15 июня 1994 г. — Минск,
1994.-С. 46-48.
81. Зубова И. И., Ермолицкая Л. Г. Лингвометодические особенности
МУЛЬТИМЕДИА обучающих программ. Французская жанровая
живопись // Новые компьютерные технологии в обучении языкам: Тез.
докл. Междунар. науч. конф. 24—25 июня 1997 г. — Минск, 1997. —
С. 61-64.
82. Зубова И. #., Иванова А. 2?., Олихвер КВ. Формализация структуры
рекламного текста и его автоматическое порождение // Проблемы
компьютерной лингвистики: Сб. науч. ст. — Минск, 1997. — С. 94— 110.
83. Зубова И. И., Михаилян A.A. Три модели порождения текста
загадки // Вестник МГЛУ. Сер. 2. Филология. — 1999. — № 5. — С. 147—166.
84. Зубова И. И., Потеснова О. В. Моделирование процесса создания
текста пословицы // Исследования молодых ученых: Сб. ст.
аспирантов. -Минск, 1999.- Ч.З.- С. 118-135.
85. Интернет в гуманитарном образовании. — М., 2001.
86. Информатика. 10— 11 класс. — СПб., 1999.
87. Информатика. Базовый курс / Под ред. С. В. Симоновича. — СПб.,
2000.
88. Кадерали Ф., Шлагетер Г. Виртуальный университет — Заочный
университет в компьютерных сетях. — Минск, 1998. — № 1. — С. 15—19.
89. Казакова О. И. Последние догоняют первых... // Мир Internet. —
1999.-№12 (39).-С. 50, 51.
90. Каймин В. А., Гаркуша В. 3. «Сетевая Тестинг-Школа» — репетитор
нового поколения для школьников и абитуриентов // Дистанционное
образование. — 1995. — № 5. — С. 23—26.
91. Карамышева Т.В. Компьютерная лингводидактика. — СПб., 2000.
92. Карамышева Т.В. Пути развития систем компьютерного обучения
языкам: письменная форма речи // Новые технологии в преподавании
иностранных языков. — СПб., 1998.
93. Каратыгин С, Тихонов А.9 Долголаптев В. Базы данных. —Т. 1. —
М., 1995.
94. Каратыгин С, Тихонов А., Долголаптев В., Ильина М, Тихонова Л.
Электронный офис. — М., 1997.
95. Кечков Ю.Л. GW-, Turbo- и Quick BASIC для IBM PC. — М.,
1992.
96. Кибрик А.Е. Модель автоматического анализа письменного текста:
на материале ограниченного военного подъязыка. — М., 1970.
196
97. Кибрик А. Е. Очерки по общим и прикладным вопросам
языкознания. — М., 2001.
98. Кинелев В. Г. Контуры системы образования XXI века //
Информатика и образование. — 2000. — № 5. — С. 2—7.
99. Кипнис В. М. Компьютер для Вас. — М., 1996.
100. Юшэнны англа-беларуска-pycici слоунж. — Минск, 1995.
101. Климов А. Дистанционному образованию — дистанционный
контроль // Компьютерра. — 1999. — № 23 (301).
102. Ковалев М. М, Ботракова С. В. Ресурсы Internet в области
образования //Информатизацияобразования. — 1999. — № 4.
103. Коверин A.A. Экспериментальная проверка лингвистических
моделей на ЭВМ. — Иркутск, 1987.
104. КдрнеевЛ.А., Пиотровский Р.Г., Бычков В. 17. Компьютер в
преподавании языков. — Новгород, 1998.
105. Комиссаров В.Н. Современное переводоведение: Курс лекций. —
М., 1999.
106. Компьютерные программы в обучении белорусскому и
иностранным языкам: Тез. докл. второй республ. конф. — Минск, 1995.
107. Кречетов Н. Постреляционная весна в мире ОСТР // Компьютер-
пресс. - 1998. - № 6. - С. 105, 106.
108. Кривошеее А. О. Методология разработки компьютерного учебного
пособия // Дистанционное образование. — 1998. — № 2. — С. 9, 10.
109. Кривошеее А. О. Электронный учебник — что это такое? //
Университетская книга. — М., 1998.
110. Кук Р. Linux идет на работу // Мир ПК. — 1998. — № 5. — С. 38—43.
111. Курбацкий А. Я, Листопад И. Я, Воротницкий Ю. Я.
Информационные технологии в системе высшего образований // Информатика и
образование. — 1999. — № 3.
112. Латышев Л. К. Теория перевода немецкого текста: Курс лекций. —
М., 1978.
113. Левый Я. Искусство перевода. — М., 1974.
114. Леонов В. П. Реферирование и аннотирование научно-технической
литературы. — Новосибирск, 1986.
115. Лингвистический энциклопедический словарь. — М., 1990 (и
последующие издания).
116. Листопад Н. И. Образовательные компьютерные сети // «Круглый
стол» по проблемам компьютерных сетей и дистанционному обучению. —
Минск, 1999.-С. 10-13.
117. Листопад Н. И. Перспективы развития информационных
технологий // Информатика и образование. — 1999. — № 4. — С. 91 — 94.
118. Лучшее на российском рынке // Компьютер-пресс. — 1999. —
№ 4. - С. 44, 45.
119. Львовская З.Д. Теоретические проблемы перевода. — М., 1985.
120. Любимов А. Стратегия персональных сетей // Компьютер-пресс. —
1997. - № 10. - С. 11-18.
121. Мануков З.Г., Зубов A.B. Автоматический синтаксический анализ
предложений при переводе немецких публицистических текстов //
Частные вопросы автоматического анализа текстов. — Минск, 1972.
197
122. Мартин Дж. Организация баз данных в вычислительных
системах. — М., 1980.
123* Марчук Ю.Н Проблемы машинного перевода. — М., 1983.
124. Марчук Ю. Н Основы компьютерной лингвистики. — М., 2000.
125. Марчук Ю. Н Опыт машинного семантико-синтаксического анализа
текста для перевода // Семантика текста и проблемы перевода. — М., 1984.
126. Марчук Ю. Н Модель «текст—текст» и переводные соответствия
в теории машинного перевода // Проблемы компьютерной
лингвистики. — Минск, 1999. — С. 21—29.
127. Маслов Ю. С. Введение в языкознание. — М., 1975.
128. Машинный фонд русского языка: идеи и суждения. — М.,
1986.
129. Методика составления обучающих курсов для АОС // Средства
обучения в высшей и средней специальной школе. Обзорная
информация. — М., 1983. — Вып. 3.
130. Методические указания по разработке и использованию
обучающих программ по иностранным языкам. Ч. 1. Анализ учебной
программы языковой дисциплины и выделение перечня учебных задач / Сост.
А. В. Зубов. — Минск, 1989.
131. Методические указания по разработке и использованию
обучающих программ по иностранным языкам. Ч. 2. Создание обучающего
сценария алгоритма и программы / Сост. Зубов А. В. — Минск, 1989.
132. Методы автоматического анализа и синтеза текста. — Минск,
1985.
133. Милн Д. Сетевые ОС: Кому принадлежит будущее // Сети и
системы связи, — 1998. — № 4. — С. 24—45.
134. Михаилян A.A. Некоторые методы автоматического анализа
естественного языка, используемые в промышленных продуктах //
Компьютерная лингвистика и обучение языку. — Минск. — С. 122—131.
135. Михайлов А К, Черный А, И., Гиляровский Р. С. Научные
коммуникации и информатика. — М., 1976.
136. Mixneei4 А. Я., Зубау А. В. Беларуская мова: камп'ютэрныя сцэнарьи
для навучання рускамо^ных. — Минск, 1999.
137. Moßi, освдта та нов1 шформащйш технологи: Miжнap. конф. 36ipKa
из доповщей та повщомлень. — Киш, 1995.
138. Мозолин В. П. О некоторых проблемах телекоммуникационного
обучения // Информатика и образование. — 2000. — № 2. — С. 89, 90.
139. Морозов К Ю. Курс информатики на филологическом факультете
педвуза // Информатика и образование. — 1999. — № 9. — С. 54—65.
140. Мухин О. К, Мыльников Л. А, Система дистанционного образования
«Виртуальная школа» // Информатика и образование. — 1999. — № 4. —
С. 65-69.
141. Наумов В. В. Разработка программных педагогических средств //
Информатика и образование. — 1999. — № 3. — С. 36—40.
142. Научно-технический перевод. — М., 1987.
143. Нелюбин Л.Л. Перевод и прикладная лингвистика. — М., 1983.
144. Нелюбин Л.Л, Компьютерная лингвистика и машинный перевод:
Метод, пособие. — М., 1991.
198
145. Нелюбин Л. Л., Куряков В. Я., Бахмутова Е. В., Пронин Е. Н.
Обучающие лингвистические автоматы в обучении языку и переводу //
Проблемы компьютерной лингвистики. — Минск, 1997. — С. 160—164.
146. Никитина СЕ. Тезаурус по теоретической и прикладной
лингвистике. — М., 1978.
147. Новые компьютерные технологии в обучении языкам: Тез. докл.
Междунар. науч. конф. Минск / Беларусь, 24—25 июня 1997 г. — Минск,
1997.
148. Носенко О. Л. ЭВМ в обучении иностранным языкам в вузе. — М.,
1988.
149. Ожегов СИ. Словарь русского языка. — М., 1973.
150. Организация системы дистанционного обучения в Хагенском
заочном университете. — Минск, 1996.
151. Осин А. В. Мультимедиа в высшем образовании // Высшее
образование в России. — 1994. — № 3. — С. 78—84.
152. Острейковский В.А. Информатика. — М., 2000.
153. Павлов В.М., Орлова О. П., Шавель Е.Е. Учебник немецкого
языка.-Л., 1971.
154. Пасжин Е. #., Мишин А. И. Автоматизированная система обучения
ЭКСТЕРН. - М., 1985.
155. Пиотровская A.A. Машинная морфология русского глагола //
Статистика речи и автоматический анализ текста. — Л., 1973. — С. 260—
277.
156. Пиотровская К. Р. Об обучающих лингвистических автоматах //
Проблемы компьютерной лингвистики. — Минск, 1997. — С. 146—
160.
157. Пиотровская K.P. Квантитативная лингвистика и компьютерное
обучение языкам // Компьютерная лингвистика и обучение языкам. —
Минск, 2000. - С. 195-217.
158. Пиотровская A.A., Пиотровский Р. Г. Математические модели
диахронии и текстообразования // Статистика речи и автоматический
анализ текста. — Л., 1974. — С. 361—400.
159. Пиотровский Р. Г. Моделирование фонологических систем и
методы их сравнения. — М.; Л., 1966.
160. Пиотровский Р. Г. Информационные измерения языка. — Л., 1968.
161. Пиотровский Р. Г. Текст, машина, человек. — Л., 1975.
162. Пиотровский Р. Г. Инженерная лингвистика и теория языка. — Л.,
1979.
163. Пиотровский Р. Г. Компьютеризация преподавания языков. — Л.,
1988.
164. Пиотровский Р. Г. Лингвистический автомат в исследовании и
непрерывном обучении. — СПб., 1999.
165. Пиотровский Р. Г. Лингвистический автомат и его речемыслитель-
ные обоснования: Учеб. пособие. — Минск, 1999.
166. Пиотровский Р. Г. Статистическое исследование лексики и
грамматики текста с помощью электронно-вычислительной машины //
Проблемы синхронного изучения грамматического строя языка: Материалы
науч. конф. — М., 1965. — С. 144-146.
199
167. Пиотровский Р. Г., Аникина Н. В., Аполлонская Т. А. и др.
Формальное распознавание смысла текста // Статистика речи и автоматический
анализ текста. — Л., 1990.
168. Пиотровский Р.Г., Беляева А.И., Попескул АН, и др. Двуязычное
аннотирование и реферирование // Автоматизация индексирования и
реферирования документов. Итоги науки и техники. Сер. Информатика. —
М., 1983. -С. 165-244.
169. Пиотровский Р. Г., Билан В. #., Боркун М. Н. и др. Методы
автоматического анализа и синтеза текстов. — Минск, 1985.
170. Платонов К. К. Краткий словарь системы психологических
понятий. — М., 1984.
171. Поваляев Е. Электронная Alma Mater // Компьютер-пресс. — 2000. —
№5.-С. 178-181.
172. Покачаева Е. Дистанционное обучение в Санкт-Петербурге //
Компьютер-пресс. — 1999. — № 1. — С. 186.
173. Полат Е. С. Некоторые концептуальные положения организации
дистанционного обучения иностранному языку на базе компьютерных
телекоммуникаций //ЯШ. — 1998. — № 5. — С. 6— 11.
174. Полилова Т.А., Пономарева В. В. Внедрение компьютерных
технологий в преподавание иностранных языков // Иностранные языки в
школе. - 1997.-№ 6. - С. 2-7.
175. Полунин А. Видеоконференции и связь в России // Сети. — 1999. —
№11.-С. 40-43.
176. Поляков В.Н., ШонинД.В. Использование лингвистических
технологий для сбора и анализа научных данных в компьютерной сети
Интернет // Обработка текста и когнитивные технологии-2. — М., 1999. —
С. 87-100.
177. ПопескуА.Н., Рахубо H.H. Автоматизированная информационно-
поисковая система для аннотирования научно-технического текста //
Частные вопросы автоматического анализа текстов. — Минск, 1972. —
С. 332-345.
178. Потапова Р. К. Новые информационные технологии и
лингвистика. — М., 2002.
179. Представление знаний в АОС // Средства обучения в высшей и
средней специальной школе. — М., 1985. — Вып. 4.
180. Приказчикова А. Помоги себе в учебе // Дистанционное
образование. - 1998. - № 6. - С. 37-42.
181. Прикладное языкознание: Учебник. — СПб., 1996.
182. Применение ЭВМ в обучении иностранным языкам: Метод,
рекомендации. — М., 1988.
183. Программы педагогических институтов. Введение в языкознание.
Современный русский литературный язык. Общее языкознание. История
лингвистических учений. Гос. экзамен по методике. Преподавание
русского языка. — М., 1980. — Сб. № 3. — С. 17—29.
184. Программы педагогических институтов. Практическая
грамматика английского языка. Практическая фонетика английского языка для
специальности № 2103 «Иностранные языки». — М., 1986. — Сб. № 13. —
С. 3-36.
200
185. Прохоров А. Сетевые видеоконференции как средство
профессионального общения // Компьютер-пресс. — 2000. — № 3.
186. Прохоров A. Windows 2000 и Millennium // Компьютер-пресс. —
2000.- №5. -С. 156-158.
187. Ракитина Е.А., Лыскова В.Ю. Информационные поля в учебной
деятельности // Информатика и образование. — 1999. — № 1.
188. РамодинД. Linux, говорящая по-русски // Мир ПК. — 2000. —
№5.-С. 36-40.
189. Раскин В. В, К теории языковых подсистем. — М., 1971.
190. Рашби Н. Обеспечение качества мультимедийных программных
комплексов // Информатика и образование. — 1998. — № 1. — С. 93 —102.
191. Ревзин И. И. Структура языка как моделирующей системы. — М.,
1978.
192. Ревзин Я.Я., Розенцвейг В. Ю. Основы общего и машинного
перевода. — М., 1964.
193. Республиканская программа «Информатизация системы
образования». Постановление Совета Министров Республики Беларусь № 29 от
29.01.1998 // Информатика и образование. — 1999. — № 3. — С. 10—14.
194. Русский язык: Пособие для поступающих в вузы. — Минск,
1990.
195. Савельев А. Я., Новиков В. А., Лобанов Ю. И. Подготовка
информации для автоматизирующих обучающих систем. — М., 1986.
196. Садоян Р. Э. О сравнении мультимедийных курсов обучения
иностранным языкам // Дистанционное образование. — 1999. — № 5. —
С. 31-36.
197. Самовольнова Л. Е. Обязательный минимум содержания
образования по информатике // Информатика и образование. — 1999. — № 7. —
С. 2-4.
198. Самовольнова Л, Е. О преподавании курса информатики в
общеобразовательной школе в 2000/01 учебном году // Информатика и
образование. — 2000. — № 5. — С. 8—10.
199. Самохин С. Что же с памятью у них стало... История памяти.
Технология недавнего прошлого и современные решения // Компьютер-
пресс. - 2000. - № 4. - С. 22-24.
200. Самсонов П. Компьютеры и дистанционное образование в США//
Компьютер-пресс. — 1999. — № 1.
201. Свинарев С. Jasmine и рынок объективных СУБД // Computerwe-
ekly. - 1998. - № 3. - С. 18-19.
202. Семенюк Э. П. Информатизация общества и развитие
методологических проблем информатики // Научно-техническая информация. —
1990. - Сер. 2.-№ 12. - С. 2-9.
203. Сергиевский М. Сети — что это такое // Компьютер-пресс. — 1999. —
№10.-С. 180-183.
204. Слокум Дж. Обзор разработок по машинному переводу: история
вопроса, современное состояние и перспективы развития // Новое в
зарубежной лингвистике. — М., 1989. — Вып. XXIV: Компьютерная
лингвистика.
205. Советский энциклопедический словарь. — М., 1986.
201
206. Средства информационной технологии в зарубежной школе /
Под ред. Е.С. Полат, А. Н. Литвинова. — М., 1988.
207. Суданова Л. Реферирование патентов и научно-технических
статей // Компьютерная лингвистика и обучение языку. — Минск, 2000. —
С. 143, 144.
208. Статистика речи.—Л., 1968.
209. Статистика текста. Автоматическая переработка текста. — Минск,
1970.-Т. 2.
210. Статистика текста: Сб. статей. — Минск, 1969. — Т. 1.
211. Татаринов В А. Теория терминоведения. Теория термина: история
и современное состояние.— М., 1996. — Т. 1.
212. Требования к уровню подготовки выпускников средней
общеобразовательной школы (136 часов) // Информатика и образование. —
1999.-№8.-С. 9-11.
213. Требования к уровню подготовки выпускников средней
общеобразовательной школы (68 часов) // Информатика и образование. —
1999.-№8.-С. 5-7.
214. Тройко О. BeOS делает следующий шаг // Hard and Soft. — 2000. —
№5.-С. 42-44.
215. Тулдава Ю.А. Проблемы и методы квантитативно-системного
исследования. — Таллин, 1987.
216. Уваров А.Ю. Три стратегии развития курса информатики //
Информатика и образование. — 2000. — № 2. — С. 27—34.
217. Учебно-методическое обеспечение автоматизированных
обучающих систем в зарубежных странах // Средства обучения в высшей и
средней специальной школе. — М., 1984. — Вып. 5.
218. Федоров А. Мультимедиа по-русски // Компьютер-пресс. — 1998. —
№5.-С.44-48.
219. Федоров А, Универсальный доступ к данным: Microsoft UDA //
Компьютер-пресс. — 1999. — № 1. — С. 144—151.
220. Федоров A. Internet в цифрах и фактах // Компьютер-пресс. —
2000.- №2. -С. 18-25.
221. Федоров А., Епифанова И. Введение в базы данных. Ч. 1 //
Компьютер-пресс. — 2000. — № 3. — С. 146—151.
222. Федоров А., Епифанова Н. Введение в базы данных. Ч. 2: Настольные
СУБД // Компьютер-пресс. — 2000. - № 4. — С. 123 —127.
223. Федоров А., Епифанова Н. Введение в базы данных. Ч. 3: Серверные
СУБД // Компьютер-пресс. — 2000. - № 5. — С. 143 —150.
224. Федоров А, Епифанова Н. Введение в базы данных. Ч. 4: Механизмы
доступа к данным. Borland Database Engine и альтернативы //
Компьютер-пресс. — 2000. — № 6. - С. 146—153.
225. Федоров А., Епифанова Н. Введение в базы данных. Ч. 5: Механизмы
доступа к данным. OLE DB и ADO // Компьютер-пресс. — 2000. — № 7. —
С. 163-168.
226. Хохлова Н.В., Устименко А. К, Петренко Б. В. Информатика. —
Минск, 1990.
227. Христочевский С. А. Мультимедиа в образовании // Компьютер-
пресс. -1996. - № 8. — С. 7-10.
202
228. Христочевский CA. Электронные мультимедийные учебники и
энциклопедии // Информатика и образование. — 2000. — № 2. — С. 70—77.
229. Хроменков П. Современные системы машинного перевода: общие
черты и различия // Компьютерная лингвистика и обучение языкам. —
Минск, 2000. - С. 154-160.
230. Цуприков С. Методология Sybase для создания и хранения витрин
данных // Компьютер-пресс. — 1999. — № 3. — С. 173—177.
231. Чернышева И. Иностранный язык для дома и офиса // Мир ПК. —
1998.-№4.-С. 158-161.
232. Чижаковский В.Л., Беляева Л.Н. Тезаурус в системах
автоматической переработки текста. — Кишинев, 1983.
233. Шампанерт, Шайдук А. Мультимедиа // Высшее образование в
России. - 1997. -№ 4. - С. 92-94.
234. Шаров Ю. Введение в базы данных. — М., 1995.
235. Шафрин Ю. Информатика. Информационные технологии. — М.,
1998.
236. Швейцер А. Ф. Перевод и лингвистика. — М., 1973.
237. Шевченко Т. Г. Теоретический и дидактический материалы по
основам алгоритмизации //Информатизация образования. — Минск,
1999. - № 3 (16).
238. Шемакин Ю.И. Тезаурус научно-технических терминов. — М.,
1972.
239. Шмелева А. Мультимедиа — урок английского языка для взрослых
и детей // Компьютер-пресс. — 1997. — № 9. — С. 60—77.
240. Шмелева A. TOEFL против TOEFL // Мир ПК. - 2000. - № 5. -
С. 128-130.
241. Эдварде Дж. Перемены на рынке СУБД ослабляют позиции
ведущих производителей // Computerweekly. — 1998. — № 24. — С. 30—31.
242. A Grammar of the English Language. — London, 1973.
243. A Practical English Grammar. — M.: Vysshajashkola, 1978.
244. Belmore N. Comparing tagging systems // Corpus-Based studies in
English. — Amsterdam; Atlanta, 1997. — P. 331 — 338.
245. Belmore N. Automated Procedures for Evaluating Tagging // First
International Conference on Language Resources and Evaluation. Proceedings. —
Granada, Spain, 28-30 May. - Granada, 1998. - Vol. 1 - P. 903-908.
246. BEN TELRI Seminar: «Corpus Linguistics: How to Extract Meaning
From Corpora». — Newsletter, 2000. — № 10.
247. Biber D., Conrad S. & Reppen R. Corpus Linguistics. Investigating language
structure and use. — Cambridge, 1998.
248. Boello (?., Lesmo L. Automatic Refinement of Linguistic Rules for
Tagging // First International Conference on Language Resources and
Evaluation. Proceedings. Granada, Spain, 28—30 May. — Granada, 1998. —
Vol. 2.-P. 923-930.
249. CALL. - Oxford, 1998.
250. CALL and the Learning Environment. 10—12 September, 1995. —
Exetur, 1995.
251. Computer Assisted Language Learning. CALL. An international
Journal. - Lisse, 1996.
203
252. Computers in the FLU Classroom. Council of Europe Workshop. —
Graz, 1996.
253. Filmon R., Репа-Mora F. Seek and You Shall Find // IEEC Internet
Computing. — 1998. — Vol. 3. — № 1.
254. First International Conference on Language Resources & Evolution.
Proceedings. Granada, Spain, 28 —30 May. — Granada, 1998.
255.Hoffmann L., Piotrovski R. G. Beiträger zur Sprachstatistik. — Leipzig,
1979.
256. Hutchins W.J. An Introduction to Machine Translation // Computational
Linguistics. — 1993. — № 2.
257. International Journal of Corpus Linguistics. — Amsterdam; Philadelphia,
1999.-Vol. 4.—№3.
258. Kupich /., Pedersan /., Chen FA. Trainable Document Summerizer. —
Tioga: Palo Alto, CA. — 1995.
259. Linux — реальная альтернатива Microsoft? // Read me. — 1997. —
№5.-С 14, 15.
260. Ousterhout K.J. Scripting higher level programming for the 21st
century // Computer. — 1998. — № 3.
261. PC Week (русское издание). — 2001. — № 31 (301).
262. Pols Louis С. W. The 10-million words spoken Dutch Corpus and its
possible use in experimental phonetics // 100 лет экспериментальной
фонетики в России: Материалы Междунар. конф. — СПб., 2001. — С. 141 —145.
263. ReCALL. - Hull, 1998.
264. Roget P.M. Roget's thesaurus of English words and phrases. —
Harmondsworth, 1978.
265. The EUROTRA Linguistic Specification // Studies in Machine
Translation and Natural Language Processing. — Brussels; Luxembourg, 1991. —
Vol.1.
266. What's the Difference? A review of Contemporary Research on the
Effectiveness of Distance Learning in Higher Education. April, 1999. —
Washington, 1999.
267. Zampolli A. Introduction of the General Chairman // First
International Conference on Language Resources & Evolution. Granada, Spain,
28-30 May. - Granada, 1998, - P. XV-XXV.
268. Zubov A. Principle of Choice of Foreign Equivalents for a Six-Language
Pocket Computer Translator // Proceedings of the Third European Seminar
«Translation Equivolence». — Italy, 16—18 October, 1997; Mannheim,
Germany, 1998. - P. 259 - 268.
ОГЛАВЛЕНИЕ
Предисловие 3
Глава 1. Лингвистика и информационные технологии 5
Лингвистика: разделы и направления 5
Информационные технологии и причины, способствующие
их появлению 7
Информационные технологии в лингвистике 8
Будущее информационных технологий 9
Г л а в а 2. Основные составляющие информационных технологий 11
Структура информационных технологий И
Теоретические основы информационных технологий 11
Методы решения задач с использованием информационных
технологий «:, 13
Алгоритм и его свойства 15
Общие понятия об алгоритме 15
Способы записи алгоритмов . 17
Средства решения задач, используемые в информационных
технологиях 19
Аппаратное и программное обеспечение информационных
технологий 19
Элементы алгоритмического языка QBASIC 23
Глава 3. Общие принципы решения лингвистических задач методом
моделирования 32
Основные этапы решения задачи 32
Моделирование процесса определения лексико-
грамматического значения слова zu в немецком предложении 38
Моделирование процесса распознавания придаточных
предложений времени и условия в английском тексте 45
Г л а в а 4. Информационные технологии в обработке текстов 53
Автоматическое чтение текста 53
Автоматическое реферирование и аннотирование текста 55
Реферат и аннотация текста. Общие понятия 55
Формулировка задачи автоматического реферирования
и аннотирования текста 56
Принципиальный алгоритм решения задачи 62
Системы автоматического реферирования и аннотирования
текстов 75
205
Машинный перевод текстов 75
Перевод текстов. Общие понятия 75
Необходимость создания систем машинного перевода 78
Основные понятия и проблемы машинного перевода 79
Автоматический словарь системы машинного перевода 82
Система синтаксических соответствий ИЯ и ПЯ 98
Практическое построение системы англо-русского МП * 100
Создание автоматического англо-русского словаря 101
Ввод автоматического словаря и таблиц типов
формообразования русских слов в память компьютера 103
Алгоритм задачи перевода текста с английского языка на
русский 103
Способы применения компьютеров для перевода текстов 108
Глава 5. Информационные технологии в обучении языкам 110
Общие принципы компьютерного обучения языкам ПО
Теоретические обоснования выбранного метода обучения ПО
Создание технологии компьютерного обучения языкам 114
Проектирование содержания курса и его состава 115
Методическая проработка учебного материала и создание
обучающих сценариев 117
Использование персональных компьютеров в обучении
иностранным языкам 138
Способы использования компьютеров для обучения языкам 138 ^
Компьютерные программы индивидуализированного обучения )
языкам 139 ^
Дистанционное обучение иностранным языкам 142
Глава 6. Базы данных и лингвистические информационные ресурсы ... 146
Базы данных. Основные понятия 146
Способы организации баз данных 149
Системы управления базами данных 153
Способы доступа к информации в базах данных 155
Лингвистические информационные ресурсы 156
Основные понятия 156
Письменный лексикон как простейшая составляющая
лингвистических ресурсов 158
Терминологические словари и банки данных 163
Письменные текстовые массивы 166
Фонетические лингвистические ресурсы 173
Глава 7. Основы компьютерных телекоммуникаций 176
Компьютерные сети. Основные понятия 176
Глобальная сеть Интернет 178
Общая структура Сети 178
Способы использования сети Интернет 180
Заключение 190
Литература 191
Учебное издание
Зубов Александр Васильевич
Зубова Ирина Ивановна
Информационные технологии в лингвистике
Учебное пособие
Редактор А. Е. Власова
Ответственный редактор Я. Я. Галкина
Технический редактор Я И. Горбачева
Компьютерная верстка: Г. Ю. Никитина
Корректоры Л. А. Богомолова, Е. Н. Кудряшова
Изд. № A-951-I. Подписано в печать 04.08.2004. Формат 60X90/16.
Гарнитура «Тайме». Печать офсетная. Бумага тип. № 2. Усл. печ. л. 13,0.
Тираж 5100 экз. Заказ № 13649
Лицензия ИД № 02025 от 13.06.2000. Издательский центр «Академия».
Санитарно-эпидемиологическое заключение № 77.99.02.953.Д.004796.07.04 от 20.07.2004.
117342, Москва, ул. Бутлерова, 17-Б, к. 328. Тел./факс: (095)334-8337, 330-1092.
Отпечатано на Саратовском полиграфическом комбинате.
410004, г. Саратов, ул. Чернышевского, 59.