






































































































































































































































































































Автор: Мейерс С.
Теги: компьютерные технологии программирование информатика
ISBN: 5-94074-033-2
Год: 2000




Текст
Наиболее
Скотт Мейерс
эффективное
использование
C++
35 новых рекомендаций но улучмояи1О
►
(ОЪ
Шобьектно-
ориентированный
е f xeldS’fli'l*.-
программирования
Addison
Wesley
More effective
35 New Ways
to Improve Your Programs
and Designs
Scott Meyers
Addison-Wesley
An imprint of Addison Wesley Longman, Inc.
Серия «Для программистов»
Наиболее
эффективное
использование
35 новых рекомендаций
по улучшению ваших
программ и проектов
Скотт Мейерс
Москва, 2000
ББК 32.973.26-018.1
М46
Мейерс С.
М46 Наиболее эффективное использование C++. 35 новых рекомендаций по
улучшению ваших программ и проектов: Пер. с англ. - М.: ДМК Пресс,
2000. - 304 с.: ил. (Серия «Для программистов»).
ISBN 5-94074-033-2
В новой книге С. Мейерса, которая является продолжением популярно-
го издания Effective C++, приводятся рекомендации по наиболее эффектив-
ному использованию конструкций языка C++. Рассматриваются правила пе-
регрузки операторов, способы приведения типов, реализация механизма
RTTI и многое другое. Даны практические советы по применению буфери-
зованного оператора new, виртуальных конструкторов, интеллектуальных
указателей, proxy-классов и двойной диспетчеризации. Особое внимание
уделяется работе с исключениями и возможностям использования кода С
в программах, написанных на C++. Подробно описаны новейшие средства
языка и показано, как с их помощью повысить производительность про-
грамм. Приложения содержат код шаблона auto_ptr и аннотированный спи-
сок литературы и Internet-ресурсов, посвященных C++.
ББК 32.973.26-018.1
The author and publisher have taken care in the preparation of this book, but make no express or
implied warranty of any kind and assume no responsibility for errors or omissions. No liability is
assumed for incidental or consequental damages in connection with or arising out of the use of the
information or programs contained herein.
All rights reserved. No part of this publication may be reproduced, stored in a retrieval system,
or transmitted, in any form, or by any means, electronic, mechanical, photocopying, recording, or
otherwise, without the prior consent of the publisher.
Права на издание книги были получены по соглашению с Pearson Education USA
и Литературным агентством Мэтлок.
Все права защищены. Любая часть этой книги не может быть воспроизведена в какой бы то
ни было форме и какими бы то ни было средствами без письменного разрешения владельцев
авторских прав.
Материал, изложенный в данной книге, многократно проверен. Но, поскольку вероятность
технических ошибок все равно существует, издательство не может гарантировать абсолютную
точность и правильность приводимых сведений. В связи с этим издательство не несет ответ-
ственности за возможные ошибки, связанные с использованием книги.
ISBN 0-201-63371-Х (англ.) Copyright © 1996 by Addison Wesley Longman, Inc.
ISBN 5-94074-033-2 (рус.) © Перевод на русский язык, оформление
ДМК Пресс, 2000
Содержание
Введение .....................................................14
Глава 1. Основы ..............................................23
Правило 1. Различайте указатели и ссылки ...................23
Правило 2. Предпочитайте приведение типов в стиле C++ ......25
Правило 3. Никогда не используйте полиморфизм в массивах ...30
Правило 4. Избегайте неоправданных конструкторов по умолчанию ... 33
Глава 2. Операторы ..............................................38
Правило 5. Опасайтесь определяемых пользователем
функций преобразования типа ................................38
Правило 6. Различайте префиксную и постфиксную формы
операторов инкремента и декремента .........................45
Правило 7. Никогда не перегружайте операторы &&, 11 и , ....48
Правило 8. Различайте значение операторов new и delete .....51
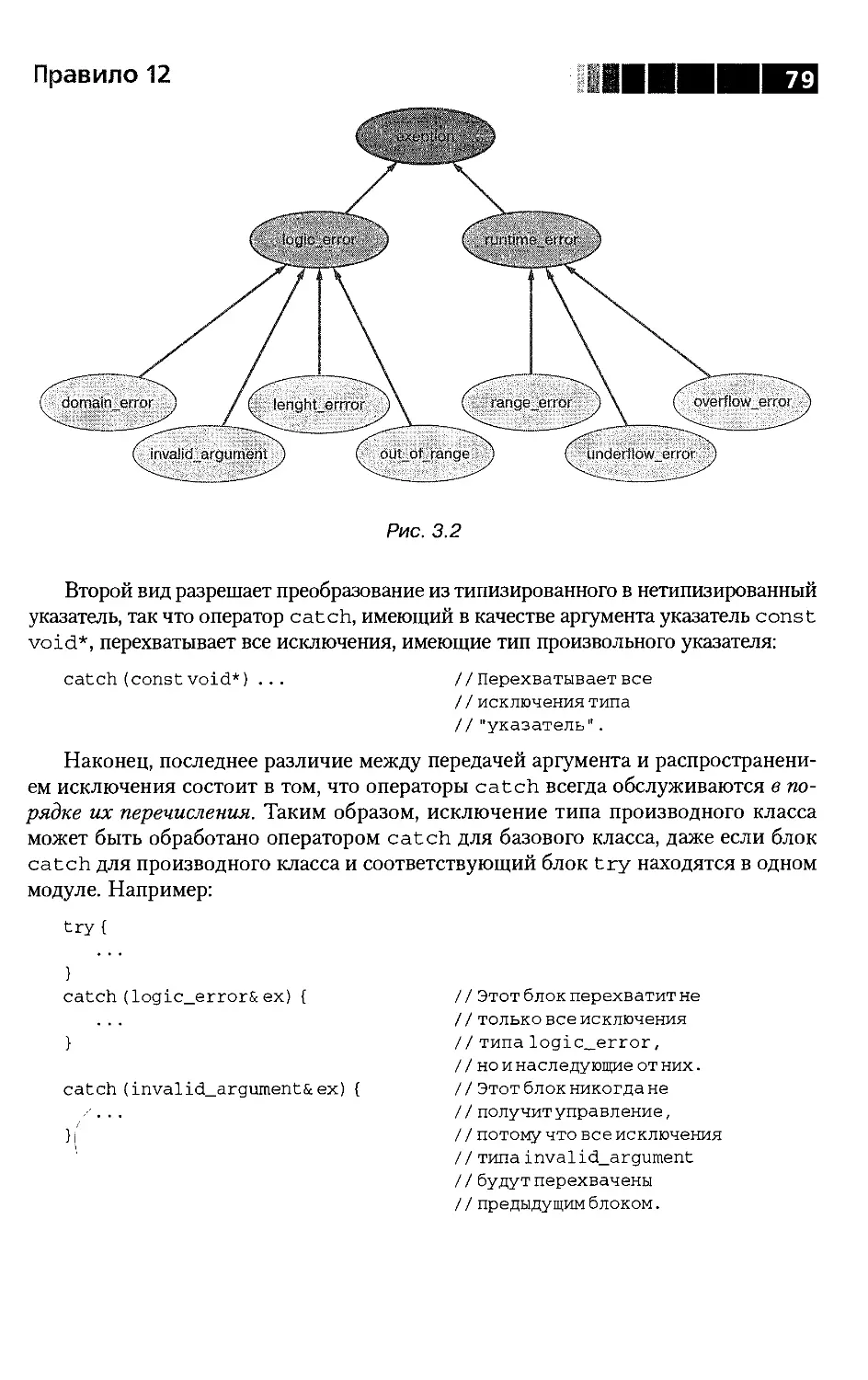
Глава 3. Исключения .............................................57
Правило 9. Чтобы избежать утечки ресурсов,
используйте деструкторы ....................................58
Правило 10. Не допускайте утечки ресурсов в конструкторах ..63
Правило 11. Не распространяйте обработку исключений
за пределы деструктора .....................................71
Правило 12. Отличайте генерацию исключения
от передачи параметра или вызова виртуальной функции .......73
Правило 13. Перехватывайте исключения, передаваемые по ссылке .80
Правило 14. Разумно используйте спецификации исключений ....84
Правило 15. Оценивайте затраты на обработку исключений .....90
Глава 4. Эффективность ..........................................94
Правило 16. Не забывайте о правиле «80-20» .................95
Правило 17. Используйте отложенные вычисления .................97
Правило 18. Снижайте затраты на ожидаемые вычисления ..........106
Правило 19. Изучите причины возникновения временных объектов 110
Правило 20. Облегчайте оптимизацию возвращаемого значения .113
Правило 21. Используйте перегрузку,
чтобы избежать неявного преобразования типов ..............116
Правило 22. По возможности применяйте оператор присваивания
вместо отдельного оператора .............................. 118
Ill Содержание
Правило 23. Используйте разные библиотеки .............. 121
Правило 24. Учитывайте затраты, связанные
с виртуальными функциями, множественным наследованием,
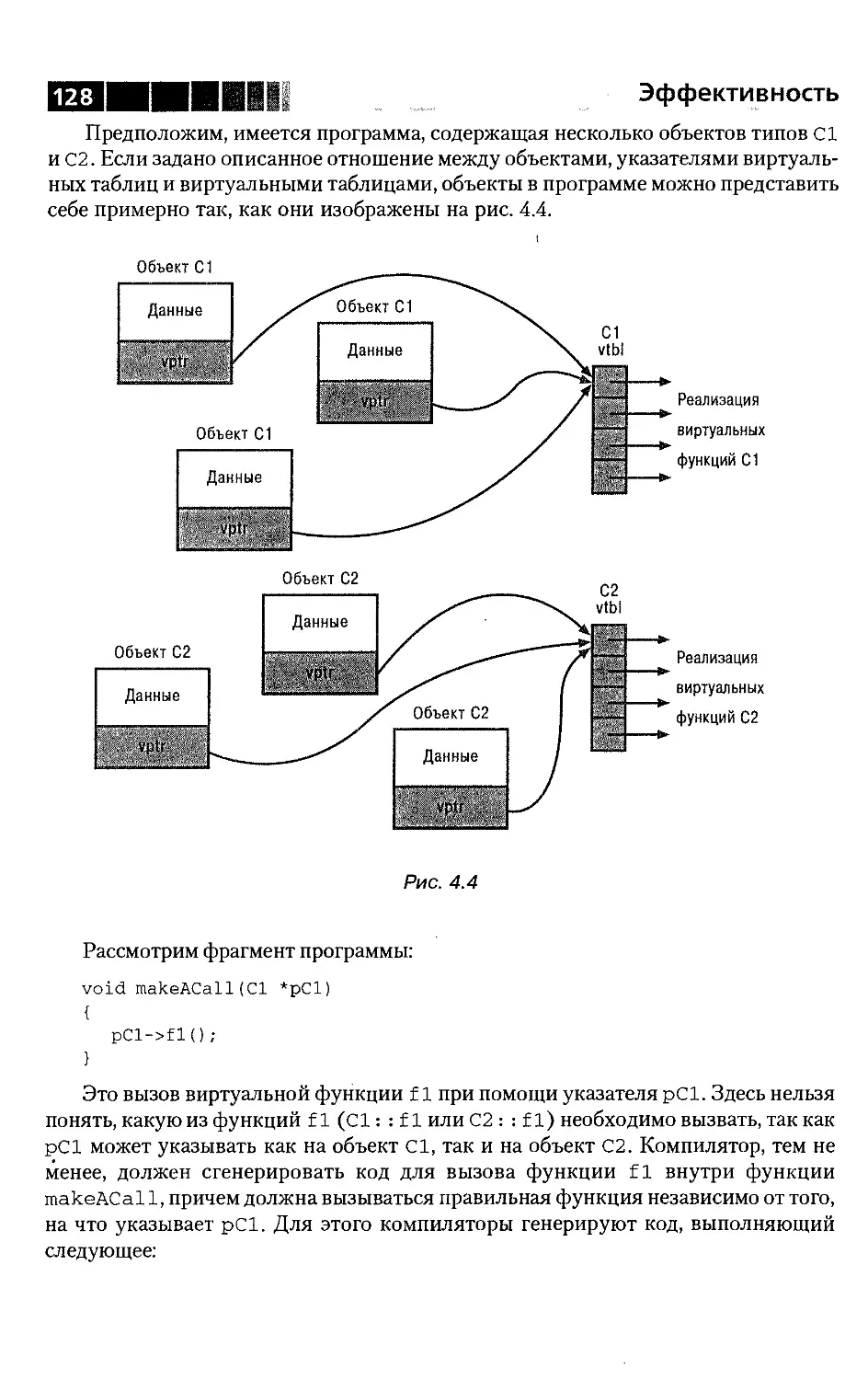
виртуальными базовыми классами и RTTI ...................124
Глава 5. Приемы ...........................................134
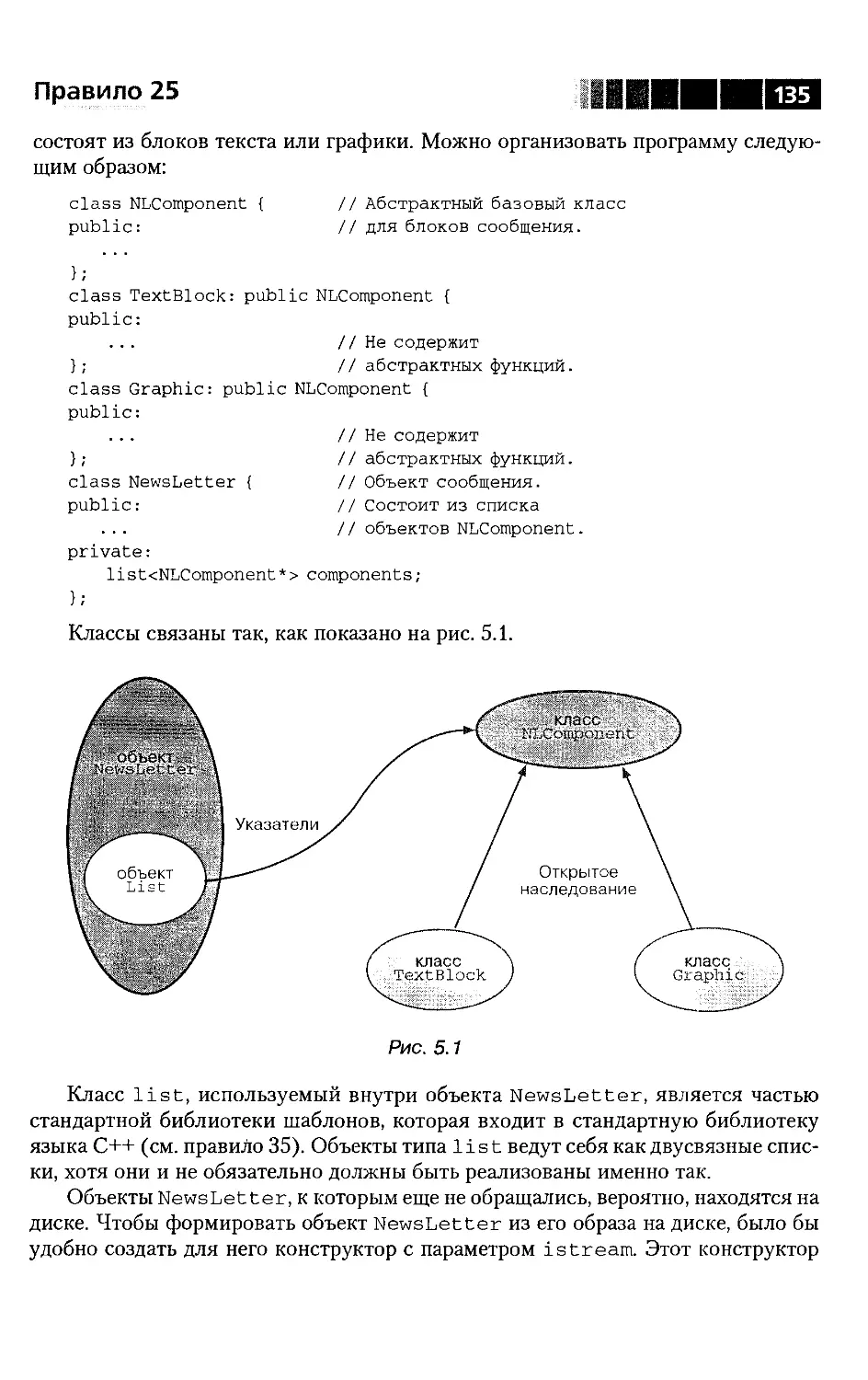
Правило 25. Делайте виртуальными конструкторы и функции,
не являющиеся членами класса ........................... 134
Правило 26. Ограничивайте число объектов в классе ...... 140
Правило 27. В зависимости от ситуации требуйте или запрещайте
размещать объекты в куче ............................... 154
Правило 28. Используйте интеллектуальные указатели ..... 167
Правило 29. Используйте подсчет ссылок ................. 190
Правило 30. Применяйте proxy-классы .....................218
Правило 31. Создавайте функций,
виртуальные по отношению более чем к одному объекту .....231
Глава 6. Разное ...........................................254
Правило 32. Программируйте, заглядывая в будущее ........254
Правило 33. Делайте нетерминальные классы абстрактными ..259
Правило 34. Умейте использовать
в одной программе С и C++ ...............................270
Правило 35. Ознакомьтесь со стандартом языка ........... 276
Приложение 1. Список рекомендуемой литературы .............284
Приложение 2. Реализация шаблона auto_ptr .................289
Это блестящая книга, проясняющая многие аспекты языка C++, начиная
с редко используемых его свойств и заканчивая разделами, которые программис-
ты считают простыми и недвусмысленными. Только глубоко понимая, каким об-
разом компилятор C++ обрабатывает исходные тексты программ, можно надеять-
ся на создание надежного программного обеспечения. Эта книга является
бесценным источником такого понимания. Прочитав книгу, я как будто вместе
с большим специалистом по C++ отредактировал огромное количество исходных
текстов и получил от него массу очень ценных наставлений.
Фред Вайлд (Fred Wild), вице-президент по технологиям,
Advantage Software Technologies
Эта книга описывает множество важных приемов, позволяющих писать эффек-
тивные программы на C++. В ней объясняется, как придумывать и реализовывать
идеи и как не попасться впросак, используя ту или иную архитектуру программы.
В книге также подробнейше рассматриваются новые свойства, недавно добавлен-
ные к C++. Любой программист, желающий использовать эти свойства, обязатель-
но захочет иметь под рукой такую книгу.
Кристофер Дж. Ван Вык (Christopher J. Van Wyk),
профессор, подразделение математики
и компьютерных наук, Университет Дрю
В пособии представлены возможности промышленного применения языка C++
в лучшем смысле этого слова. Превосходная книга для тех, кто читал предыду-
щую - «Эффективное использование C++».
Эрик Наглер (Eric Nagler), преподаватель и автор книг,
Калифорнийский университет, отделение в Санта Круз
«Наиболее эффективное использование C++» - ценное продолжение первой
книги Скотта «Эффективное использование C++». Я считаю, что каждый профес-
сиональный разработчик на C++ должен прочесть и постоянно держать в памяти
советы из этих двух книг. Все они, по моему мнению, касаются очень важных, но
плохо понимаемых аспектов языка. Я настоятельно рекомендую эту книгу, также
как и предыдущую, разработчикам, бета-тестерам и руководителям проектов; глу-
бокие знания автора и превосходный стиль изложения делают ее полезной для всех.
Стив Беркетт (Steve Burkett),
консультант по программному обеспечению
Клэнси, моему любимому внутреннему противнику, посвящается
Благодарности
В создании этой книги принимало участие множество людей. Одни предложи-
ли важные технические идеи, другие помогли подготовить ее к печати, а третьи
просто скрашивали мою жизнь, пока я работал над ней.
Часто, когда количество людей, принимавших участие в работе над книгой,
достаточно велико, появляется соблазн отказаться от перечисления участников
проекта, ограничившись стандартной фразой «Список людей, работавших над
книгой, слишком длинен, чтобы быть приведенным здесь». Я, однако, предпочи-
таю подход Джона Л. Хеннеси (John L. Hennessey) и Дэвида А. Петерсона (David
A. Patterson) - см. «Компьютерные архитектуры: численный подход», изд. Мор-
ган Кауфман (Morgan Kaufman), 1-ое издание, 1990. Один из аргументов за вклю-
чение полного списка благодарностей, приведенного ниже, - статистические дан-
ные для закона «80-20», на который я ссылаюсь в правиле 16.
Источники идей
За исключением прямого цитирования, весь текст этой книги принадлежит
мне. Тем не менее, многие описанные в ней идеи были придуманы другими.
Я всячески пытался отслеживать авторство нововведений, но мне все же при-
шлось включить информацию из источников, названия которых я уже не могу
вспомнить, в основном это сообщения из конференций Usenet comp.lang.c++
и comp.std .с++.
Многие идеи в сообществе C++ зарождаются почти одновременно и совершен-
но независимо в головах многих людей. Ниже я указываю только, где услышал ту
или иную мысль, что не всегда совпадает с тем, где она была озвучена впервые.
Брайан Керниган (Brian Kernighan) предложил использовать макроопределе-
ния для приближения к синтаксису новых операторов приведения типа, описан-
ных в правиле 2.
Предупреждение по поводу удаления массива объектов производного класса
с помощью указателя на базовый класс, изложенное в правиле 3, основано на ма-
териалах лекции Дэна Сакса (Dan Saks), прочитанной им на нескольких конфе-
ренциях и торговых выставках.
Техника использования proxy-классов из правила 5, позволяющая избежать
нежелательного вызова конструкторов с одним аргументом, основана на матери-
алах колонки Эндрю Кенига (Andrew Koenig) в журнале C++ Report за январь
1994 года.
Джеймс Канце (James Kanze) прислал сообщение в comp.lang.c++ относитель-
но реализации постфиксных декрементных и инкрементных операторов через со-
ответствующие префиксные операторы. Этот прием рассматривается в правиле 6.
Дэвид Кок (David Сок), написав мне по одному вопросу, затронутому в «Эф-
фективном использовании C++», привлек мое внимание к различию между
operator new и оператором new, положенному в основу правила 8. Даже прочитав
письмо, я не в полной мере осознал существующую разницу, но если бы не этот
первый толчок, то, скорее всего, не понимал бы ее до сих пор.
10
Ill Наиболее эффективное использование C++
Метод записи деструкторов, позволяющий избежать утечки ресурсов (см. пра-
вило 9), взят из раздела 15.3 книги Маргарет А. Эллис (Margaret A. Ellis)
и Бьерна Страуструпа (Bjarne Stroustrup) The Annotated C++ Reference Manual.
Там этот метод имеет название «Выделение ресурса - инициализация». Том Кар-
гилл (Tom Cargill) предложил перенести акцент с выделения ресурсов на их осво-
бождение.
Часть рассуждений в разделе, посвященном правилу 11, была навеяна содержи-
мым главы 4 книги Taligent’s Guide to Designing Programs, изд. Addison-Wesley, 1994.
Описание предварительного выделения памяти для класса DynArray в пра-
виле 18 основано на статье Тома Каргилла «Динамический вектор сложнее, чем
кажется», опубликованной в журнале C++ Report за июнь 1992 года. Информа-
цию о более сложной архитектуре для класса динамического массива можно най-
ти в заметке того же автора (номер C++ Report за январь 1994 года).
Правило 21 появилось благодаря докладу Брайана Кернигана «AWK для транс-
лятора C++» на конференции USENIX по C++ в 1991 году. Его идея использовать
перегруженные операторы (общим числом 67!) для выполнения арифметических
операций с операндами разных типов хотя и не была связана с проблемой, обсужда-
емой в правиле 21, но заставила меня рассмотреть множественную перегрузку опе-
раторов в качестве решения задачи по созданию временных объектов.
Мой вариант шаблона класса для подсчета объектов, рассмотренный в прави-
ле 26, основан на сообщении Джамшида Афшара (Jamshid Afshar) в конференцию
comp.lang.c++.
Идея смешанного класса, позволяющего отслеживать указатели, созданные
с помощью operator new (см. правило 27), базируется на предложении Дона
Бокса (Don Box). Стив Клемидж (Steve Clamage) придал этой идее практическое
значение, объяснив, как можно использовать dynamic_cast для нахождения
начала области памяти, занимаемой объектом.
Описание smart-указателей в правиле 28 основано: частично на заметке Сти-
вена Буроффа (Steven Buroff) и Роба Мюррея (Rob Murray) C++ Oracle в журна-
ле C++ Report за октябрь 1993 года, на классической работе Даниэла Р. Эдельсона
(Daniel R. Edelson) «Интеллектуальные (smart) указатели: интеллектуальные, но
не указатели» в материалах конференции USENIX по C++ от 1992 года, на содер-
жимом раздела 15.9.1 книги Бьерна Страуструпа «Архитектура и развитие C++»,
на докладе Грегори Колвина (Gregory Colvin) «Управление памятью в C++» на
учебном семинаре «Решения для C/C++ ‘95» и на заметке Кея Хорстманна (Сау
Horstmann) в мартовском и апрельском номерах C++ Report за 1993 год. Но кое-
что сделал и я сам.
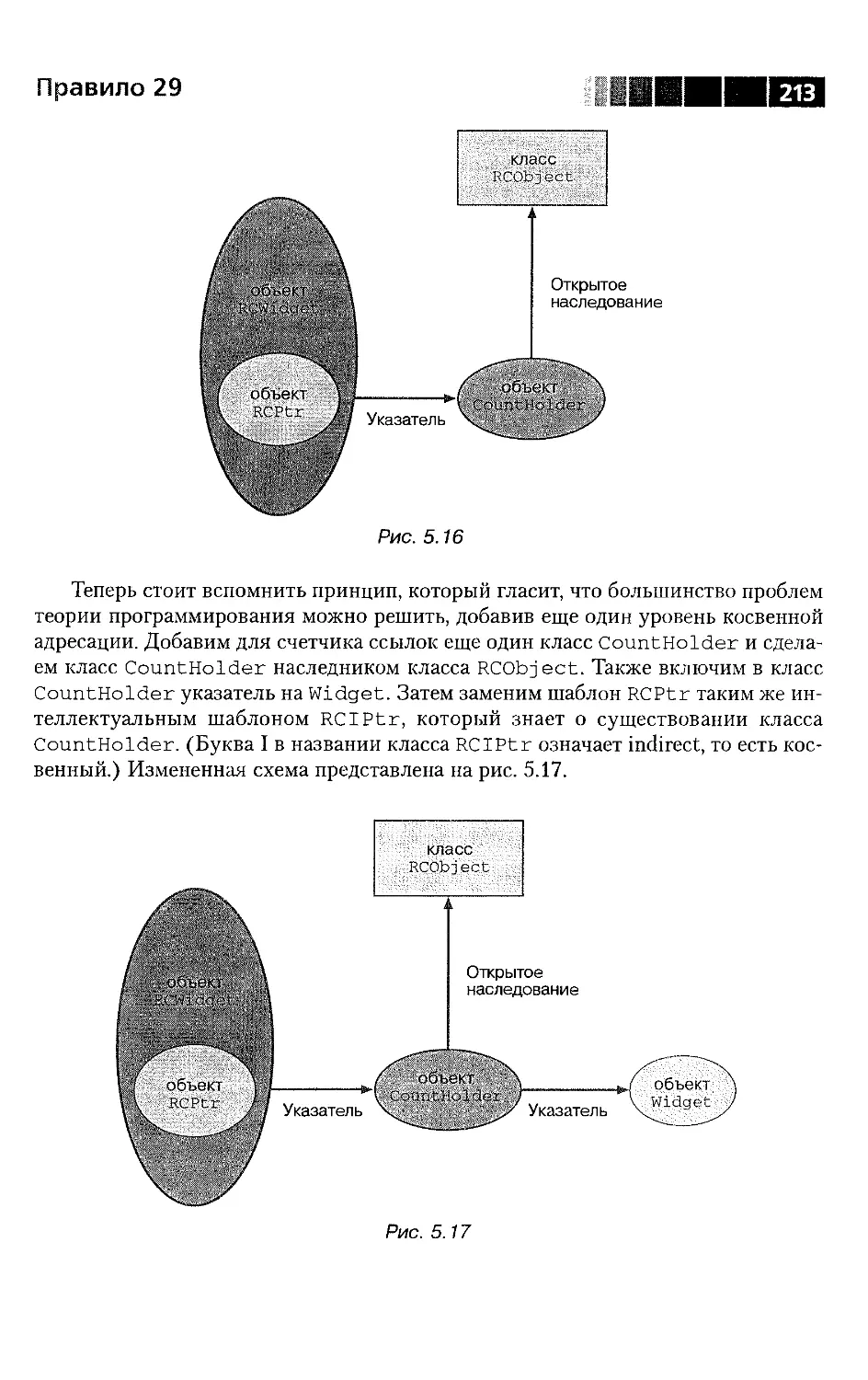
Использованный в правиле 29 метод хранения в базовом классе счетчиков
ссылок и smart-указателей для работы с этими счетчиками основан на идее Роба
Мюррея (см. разделы 6.3.2 и 7.4.2 его книги «Стратегия и тактика в C++»),
Прием, позволяющий добавлять счетчики ссылок к существующим классам,
аналогичен тому, что был предложен Кеем Хорстманном в заметке, опубликован-
ной в мартовском и апрельском номерах журнала C++ Report за 1993 год.
Источником для правила 30, касающегося контекстов lvalue, послужили
комментарии к заметке Дэна Сакса в журнале С User’s Journal (теперь C/C++
Об этой книге
him
11
User’s Journal) за январь 1993 года. Наблюдение, что методы классов, которые не
являются методами proxy-классов, не доступны при вызове по ргоху-механизму,
взято из неопубликованной работы Кея Хорстманна.
Способ, как использовать динамическую информацию о типах для того, что-
бы построить похожие на vtbl массивы указателей функций (в правиле 31),
основан на идеях Бьерна Страуструпа, выдвинутых им в сообщениях в конферен-
цию comp.lang.c++ и разделе 13.8.1 его книги «Архитектура и развитие C++».
Сведения, на базе которых появилось правило 33, частично были опублико-
ваны в моих колонках журнала C++ Report за 1994 и 1995 года. Эти колонки,
в свою очередь, включали замечания об использовании dynamic_cast для реа-
лизации виртуального оператора operators определяющего наличие аргумен-
тов некорректного типа, которые я получил от Клауса Крефта (Klaus Kreft).
Большая часть рассуждений в правиле 34 вызвана статьей Стива Клемиджа
«Связывание C++ с другими языками» в мартовском номере журнала C++ Report
за 1992 год. Мой подход к решению проблем, вызванных использованием таких
функций, как strdup, был инициирован замечаниями читателя, не сообщившего
своего имени.
Об этой книге
Просмотр черновых вариантов книги - работа неблагодарная, но жизненно
необходимая. Мне повезло, что так много людей пожелали вложить в нее свое
время и энергию. Хочу особенно поблагодарить: Джил Хатчитэл (Jill Huchital),
Тима Джонсона (Tim Johnson), Брайана Кернигана, Ерика Нагл ера и Криса Ван
Вык (Chris Van Wyk), потому что они прочли мою книгу (или ее значительную
часть) более одного раза. Кроме этих любителей неприятной работы полностью
черновик книги прочли: Катрина Эвери (Katrina Avery), Дон Бокс, Стив Буркетт
(Steve Burkett), Том Каргилл, Тони Дэвис (Tony Davis), Кэролин Даби (Carolyn
Duby), Брюс Экель (Bruce Eckel), Рид Флеминг (Read Fleming), Кей Хорстманы,
Джеймс Канце, Расс Пейли (Russ Paielly), Стив Розенталь (Steve Rosenthal), Ро-
бин Руйе (Robin Rowe), Дэн Сакс, Крис Селлз (Chris Sells), Уэбб Стейси (Webb
Stacy), Дэйв Свифт (Dave Swift), Стив Виноски (Steve Vinosky) и Фред Уайлд
(Fred Wild). Частично черновики прочли: Боб Бьючейн (Bob Beauchaine), Герд
Хойрен (Gerd Hoeren), Джефф Джексон (Jeff Jackson) и Нэнси Л. Урбано (Nancy
L. Urbano). Замечания каждого из них помогли представить материал более точ-
но и доступно.
После выхода книги я получил исправления и предложения от множества
людей. Ниже эти наблюдательные читатели перечислены в порядке получения от
них сообщений: Льюис Кида (Luis Kida), Джон Поттер (John Potter), Тим Уттор-
марк (Tim Uttormark), Майк Фелькерсон (Mike Fulkerson), Дэн Сакс, Вольфганг
Глунц (Wolfgang Glunz), Кловис Тондо (Clovis Tondo), Майкл Лофтус (Michael
Loftus), Лиз Хэнкс (Liz Hanks), Вил Эверс (Wil Evers), Стефан Кухлинз (Stefan
Kuhlins), Джим МакКракен (Jim McCracken), Элан Дучан (Alan Duchan), Джон
Джекобсма (John Jacobsma), Рамеш Нагабушнам (RameshNagabushnam), Эд Вил-
линк (Ed Willink), Кирк Свенсон (Kirk Swenson), Джек Ривз (Jack Reeves), Дуг
12
'HE Наиболее эффективное использование C++
Шмидт (Doug Schmidt), Тим Бучовски (Tim Buchowski), Пол Чисхолм (Paul
Chisholm), Эндрю Клейн (Andrew Klein), Эрик Наглер, Джеффри Смит (Jeffrey
Smith), Сэм Бент (Sam Bent), Олег Штейнбук (Oleg Shteynbuk), Антон Доблмай-
ер (Anton Doblmaier), Ульф Михаэлис (Ulf Michaelis), Секхар Муддана (Sekhar
Muddana), Майкл Бейкер (Michael Baker), Йечил Кимчи (Yechiel Kimchi), Дэвид
Папюрт (David Papurt), Йан Хаггард (Ian Haggard), Роберт Шварц (Robert
Schwartz), Дэвид Хэлпин (David Halpin), Грэхам Марк (Graham Mark), Дэвид
Баретт (David Barett), Дэмьен Канарек (Damian Kanarek), Рон Коуттс (Ron
Coutts), Ланс Витцель (Lance Whitesei), Йон Лачелт (Jon Lachelt), Шерил Фер-
гюсон (Cheryl Ferguson), Мунир Махмуд (Munir Mahmood), Клаус-Георг Адами
(Klaus-Georg Adams), Дэвди Гох (David Goh), Крис Морли (Chris Morley), Рей-
нер Баумшлагер (Rainer Baumschlager), Брайан Керниган, Чарльз Грин (Charles
Green), Марк Роджерс (Mark Rodgers), Бобби Шмидт (Bobby Schmidt), Шивара-
махришан Дж. (Sivaramakrishnan J.) и Эрик Андерсон (Eric Anderson). Их пред-
ложения позволили мне улучшить книгу, и я очень благодарен им за помощь.
При подготовке этой книги я сталкивался с множеством вопросов, связанных
с появлением стандарта ISO/ANSI для языка C++, решить которые мне помогли
Стив Клэмидж и Дэн Сакс. Они не пожалели времени, отвечая на мои беспре-
станные вопросы по электронной почте.
Джон Макс Скаллер (John Max Skaller) и Стив Рамсби (Steve Rumsby) по-
могли мне получить текст ANSI-стандарта C++ в формате HTML до его публика-
ции. Вивиан Неу (Vivian Neou) подсказала мне, что для просмотра HTML-доку-
ментов в 16-битной системе Microsoft Windows можно использовать браузер
Netscape. Я глубоко благодарен сотрудникам компании Netscape Communications
за бесплатное распространение своего браузера для этой системы.
Брайан Хоббс (Bryan Hobbs) и Хачеми Зенад (Hachemi Zenad) предоставили
мне предварительную версию компилятора MetaWare C++, что позволило прове-
рить тексты программ, приведенных в этой книге, с использованием самых новых
свойств языка. Кей Хорстманн помог мне с установкой и запуском компилятора
в чуждых для меня мирах DOS и защищенного режима DOS. Корпорация Borland
(теперь Inprise) предоставила мне последнюю бета-версию своего компилятора,
а Эрик Наглер и Крис Селлз обеспечили неоценимую помощь, проверив тексты
программ на недоступных для меня компиляторах.
Книга не могла бы появиться на свет без помощи сотрудников отдела
корпоративной и специальной литературы издательства Addison-Wesley. Я очень
обязан: Ким Доули (Kim Dawley), Лане Лэнглуа (Lana Langlois), Симоне Пэй-
мент (Simone Payment), Марти Рабинович (Marty Rabinowitz), Прадипе Сива
(Pradeepa Siva), Джону Уэйту (John Wait) и другим сотрудникам за их терпение,
поддержку и помощь в подготовке этой работы.
Крис Гузиковски (Chris Guzikovsky) помогал проектировать обложку книги,
а Тим Джонсон (Tim Johnson) уделил часть своего времени, обычно всецело по-
священного исследованиям в области низкотемпературной физики, для критиче-
ских замечаний по последним версиям этого текста.
Люди, которые мне помогали
HIMI
13
Том Каргилл благородно согласился на размещение его статьи по исключени-
ям из журнала C++ Report на сайте издательства Addison-Wesley в Internet.
Люди, которые мне помогали
Кэти Рид (Kathy Reed) ввела меня в мир программирования. Дональд Френч
(Donald French) поверил в мою способность разрабатывать и представлять учеб-
ные материалы по C++ при отсутствии у меня значительного опыта в этой обла-
сти. Он также представил меня редактору издательства Addison-Wesley Джону
Вэйту (John Wait), за что я всегда буду ему благодарен. Троица в Бивер Ридж -
Джейни Бесо (Jayni Besaw), Лорри Филдс (Lorry Fields) и Бет МакКи (Beth
McKee) позволяла мне развлечься и отдохнуть в перерывах между работой над
кнйгой.
Моя жена, Нэнси Л. Урбано, стоически перенесла все этапы подготовки кни-
ги. Сколько раз она слышала, что мы обязательно сделаем что-нибудь, после того
как книга будет опубликована! Теперь работа завершена, и я выполню все свои
обещания. Она удивительная. Я люблю ее.
И наконец, я должен вспомнить собаку Персефону, чье появление навсегда из-
менило наш мир. Без нее эта книга была бы закончена быстрее, и спал бы
я больше, но значительно меньше смеялся.
Введение
Сейчас у программистов C++ горячие денечки. Хотя коммерческие версии ком-
пиляторов языка C++ появились менее чем десять лет назад, за это время C++
стал стандартным языком для создания сложных систем почти на всех вычисли-
тельных платформах. Компании и программисты, решая серьезные задачи по раз-
работке программного обеспечения, постоянно расширяют круг пользователей
языка. Перед теми, кто пока не имел дело с C++, чаще стоит вопрос «Когда начать
использование языка?», а не «Что будет, если мы начнем применять этот язык?».
Стандартизация C++ завершена, а богатая функциональность и разнообразие те-
матик сопровождающих язык библиотек, которые включают и расширяют биб-
лиотеки С, позволяют создавать сложные, многофункциональные программы, не
теряющие при этом переносимости, а также реализовывать стандартные алгорит-
мы и структуры данных «с нуля». Компиляторы C++ продолжают совершенство-
ваться, их возможности расширяются, а качество генерируемого кода постоянно
улучшается. Среды и средства для разработки на C++ становятся все более мно-
гочисленными, мощными и полнофункциональными. Библиотеки программного
обеспечения, распространяемые на коммерческой основе, во многом устранили
саму необходимость написания исходных текстов.
По мере «взросления» языка и роста опытности его пользователей изменилась
и потребность в информации о нем. В 1990 году специалисты хотели знать, что
представляет собой язык C++. К 1992 году их интересовало, как его применять.
Сейчас программисты на C++ задают вопросы более высокого уровня. Как созда-
вать программное обеспечение с учетом его адаптации к будущим потребностям?
Как сделать программный код более эффективным, при этом не усложняя его
и сохраняя корректность работы? Как реализовать ту или иную функцию, не под-
держиваемую языком непосредственно?
В книге приводятся ответы на эти и многие похожие вопросы.
Книга показывает, как разрабатывать и внедрять более эффективное, чем то,
которое вы создавали до сих пор, программное обеспечение на языке C++: содер-
жащее меньшее количество ошибок, более надежное в экстремальных ситуациях,
более производительное, более переносимое, более полно использующее возмож-
ности языка, требующее меньших затрат при поддержке, более пригодное для
работы в системах, где задействовано несколько языков программирования, бо-
лее простое при правильном использовании, затрудняющее неправильное исполь-
зование. Короче, программное обеспечение, которое просто лучше.
Содержание этой книги разделено на 35 правил. В каждом разделе собраны
накопленные сообществом C++ сведения по какому-то определенному вопросу.
Большинство правил сформулированы как рекомендации, а объяснение, сопутству-
ющее каждому правилу, содержит информацию о том, почему эта рекомендация
Введение
ИМ!
15
имеет право на существование, что происходит, если не следовать ей, и при каких
условиях стоит все же ее нарушать.
Правила можно разбить на несколько категорий. Одни относятся к отдельным
свойствам языка, по преимуществу недавно появившимся, для которых еще не
накоплено опыта по применению. Например, правила с 9 по 15 посвящены исклю-
чениям. Другие правила объясняют, как объединить возможности языка для вы-
полнения нестандартных задач. В эту группу входят правила с 25 по 31, которые
описывают, как ограничить количество или размещение объектов, как создавать
функции, являющиеся виртуальными по отношению к объектам разных типов,
как создавать интеллектуальные указатели и т.п. Некоторые правила касаются бо-
лее сложных случаев, так, правила с 16 по 24 связаны с проблемами эффективно-
сти. Но чему бы ни было посвящено правило, вопрос обсуждается серьезно и все-
сторонне. Эта книга учит, как использовать C++ наиболее эффективно. Описание
конструкций языка, что составляет львиную долю текста других книг по C++,
здесь является вспомогательной информацией.
Поэтому, приступая к чтению данной книги, вы должны быть уже знакомы
с языком C++. Вы должны знать, что такое классы, уровни изоляции, виртуаль-
ные и невиртуальные функции и т.п., а также должны иметь представление о шаб-
лонах и исключениях. Но пусть эти требования не смущают тех, кто не является
специалистом по языку: исследуя закоулки C++, я всегда буду объяснять, как
и что происходит.
Язык C++ в этой книге
Язык C++, представленный в этой книге, соответствует документу Final Draft
International Standard (Финальный проект международного стандарта), выпущен-
ному комитетом по стандартизации ISO/ANSI в ноябре 1997 года. Поэтому неко-
торые свойства языка, представленные в книге, ваши компиляторы, возможно, еще
не поддерживают. Не волнуйтесь. Предполагается, что единственное «новое» свой-
ство, которое вам потребуется, - шаблоны, а шаблоны реализованы почти везде.
Я также использую исключения, но это использование в значительной мере огра-
ничено правилами с 9 по 15, которые как раз и посвящены исключениям. Если у вас
нет доступа к компилятору, поддерживающему исключения, ничего страшного. Это
не повлияет на вашу работу с остальными частями книги. Но правила с 9 по 15 вам
все же стоит почитать, потому что эти разделы помогут вам получить информацию,
которой вы еще не владеете, но которую должны знать.
Допускаю, что благословение комитета по стандартам для какого-либо свой-
ства языка или введение его в общепринятую практику не дает гарантии, что ваши
компиляторы поддерживают это свойство и что известные способы применимы
к существующим средам программирования. В тех случаях, когда возникает рас-
хождение между теорией (утверждено комитетом по стандартам) и практикой
(должно работать), я обсуждаю обе возможности, хотя склоняюсь к практическо-
му решению. Так как рассматриваются обе стороны вопроса, у вас будет повод
заглянуть в эту книгу всякий раз, когда ваши компиляторы на очередной шаг
приблизятся к требованиям стандарта. Она покажет вам, как использовать
16
IS Наиболее эффективное использование С++
существующие конструкции языка для реализации новых свойств, не поддержи-
ваемых пока вашими компиляторами, и даст рекомендации, как преобразовать эти
обходные пути, когда ваши компиляторы начнут поддерживать новые свойства.
Заметьте, что я ссылаюсь на ваши компиляторы - во множественном числе.
Различные компиляторы реализуют различные приближения к стандарту, поэто-
му я призываю вас вести разработку программного обеспечения с использовани-
ем как минимум двух компиляторов. Такая практика поможет вам избежать не-
нужной зависимости от нестандартных расширений языка, поддерживаемых
только одним производителем компиляторов, или отклонений от стандарта. Это
также позволит вам держаться подальше от переднего края компьютерных техно-
логий, то есть от новых свойств языка, поддерживаемых только одним произво-
дителем компиляторов. Реализация таких свойств часто имеет значительные не-
достатки (наличие ошибок, низкая производительность, а иногда и то и другое).
Кроме того, сообщество C++ еще не накопило достаточно опыта, чтобы предоста-
вить разработчикам информацию, как правильно использовать новейшие свой-
ства. Прокладывать дорогу - это здорово, но если ваша цель - создание надежно-
го кода, нащупывать путь предоставьте другим.
В книге описаны две конструкции, с которыми вы можете быть незнакомы.
Обе являются сравнительно новыми расширениями языка. Некоторые компи-
ляторы поддерживают их, но если ваши компиляторы не настолько современ-
ны, вы легко можете воспроизвести эти расширения имеющимися в наличии
средствами.
Первая конструкция - это тип bool, имеющий в качестве значений констан-
ты true и false. Даже если ваши компиляторы не поддерживают данный тип,
существуют два способа реализовать его. Один состоит в использовании глобаль-
ного оператора enum:
enum bool { false, true } ;
Такой прием позволяет перегружать функции, руководствуясь типом входяще-
го аргумента bool или int. Однако у этого способа есть недостаток: встроенные
операторы сравнения (такие как ==, <, >= и т.п.) все равно возвращают тип int.
В результате приведенный ниже код не будет работать так, как это задумывалось:
voidf(int);
void f(bool);
int x, у;
f (x<y) ;
//Вызывает f (int) , а должен
// вызывать f(bool).
Применение оператора enum может нарушить работу программы после пере-
хода на компилятор, поддерживающий тип bool.
Другой вариант состоит в том, чтобы использовать typedef для типа bool
и константы для true и false:
typedef int bool ;
const bool false = 0 ;
const bool true = 1;
17
Введение
Такой подход соответствует традиционной семантике С и C++, а поведение
программ, использующих данный прием, не изменится с переходом на компиля-
торы, обеспечивающие поддержку bool. Недостаток же этого подхода состоит
в том, что при перегрузке функций тип bool нельзя отличить от int. Оба вари-
анта неплохи. Выбирайте тот из них, который лучше всего подходит в каждом кон-
кретном случае.
Вторая новая конструкция на самом деле состоит из четырех, это операторы при-
ведения типа: static_cast,const_cast, dynamic_cast и reinterpret_cast.
Если вы не знакомы с перечисленными конструкциями, обратитесь к правилу 2, где
содержится полная информация о них. Они не только делают больше, чем операторы
приведения типов в стиле С, но и лучше выполняют все поставленные программис-
том задачи. Поэтому для приведения типов в данной книге я использовал именно их.
C++ - это не только язык. В него входит также и стандартная библиотека.
Везде, где возможно, вместо указателей char* в книге использован стандарт-
ный тип string, и я призываю вас поступать также. Применение объектов
string не создает дополнительных трудностей по сравнению со строками, об-
работка которых производится с помощью указателей char*, но значительно
облегчает управление памятью. Кроме того, когда используются объекты
string, снижается риск утечек памяти при возникновении исключений
(см. правила 9 и 10). Хорошо реализованный тип string по эффективности не
уступит своему эквиваленту char*, а, возможно, и превзойдет его (чтобы понять,
как это сделать, см. правило 29). Если стандартный тип string не реализован
в вашем компиляторе, то в нем почти наверняка реализован какой-либо класс,
подобный string. Обязательно используйте его. Это всегда предпочтительней,
чем включение в код указателей char*.
В книге при любой возможности используются структуры данных, взятые
из Standard Template Library (STL - стандартная библиотека шаблонов, см. пра-
вило 35). STL содержит битовые наборы, векторы, списки, очереди, стеки, кар-
ты, множества и т.д., и лучше иметь дело со стандартизованными объектами, чем
пытаться разработать их эквиваленты самостоятельно. В состав ваших компи-
ляторов STL может быть не включена, но благодаря компании Silicon Graphics
бесплатная копия библиотеки доступна на Web-сайте SGI STL: http://www.sgi.com/
Technology/STL/.
Если вы довольны используемой вами в настоящее время библиотекой алго-
ритмов и структур данных, то не нужно переходить на STL только потому, что она
«стандартная». Однако если вы стоите перед выбором, взять ли компонент из STL
или написать какой-либо код самому «с нуля», то вариант с STL, конечно, пред-
почтительнее. Помните о принципе повторного применения кода? STL (и осталь-
ная часть стандартной библиотеки) содержит множество модулей, которые очень
и очень стоит использовать повторно.
Соглашения и терминология
Когда в книге упоминается наследование, я всегда имею в виду открытое на-
следование. Использование закрытого наследования каждый раз оговаривается
18
[III Наиболее эффективное использование C++
специально. При изображении иерархии наследования стрелки проводятся от про-
изводных классов к базовому. Например, на рис. 1 приведена иерархия классов для
правила 31:
Эта запись обратна той, которую я использовал в первом (но не во втором)
издании книги «Эффективное использование C++». Теперь я убежден, что боль-
шинство пользователей C++ проводят стрелки наследования от производного
класса к базовому, и с удовольствием соглашаюсь с ними. На диаграммах подоб-
ного типа абстрактные классы (например, GameObj ect (Игровой объект)) закра-
шены темно-серым цветом, а конкретные классы (такие как Spaceship (Косми-
ческий корабль)) заштрихованы более светлым оттенком.
Наследование автоматически приводит к появлению указателей и ссылок
двух различных типов: статического и динамического. Статический тип указате-
ля или ссылки соответствует типу объявления. Динамический тип - типу объекта,
на который в данный момент указывает указатель или ссылка. Вот несколько
примеров, основанных на приведенных выше классах:
GameObj ect *pgo =
new Spaceship;
Asteroid *pa = newAsteroid;
pgo = pa;
GameObject& rgo = *pa;
//Статический типрдо -
//GameObj ect,динамический тип -
//Spaceship*.
// Статический тип pa - Asteroid* .
/ / Динамический тип - тоже
//Asteroid*.
//Статическийтипрдо
//не изменился (ине изменится) ,
// он по-прежнему равен
//GameObject* . Его
//динамический тип теперь -
//Asteroid*.
//Статический тип rgo -
//GameObj ect,динамический тип -
//Asteroid.
Эти примеры также демонстрируют соглашение об именах переменных, ис-
пользуемое в этой книге. Переменная рдо - это указатель на GameObject,
Введение
НИШ
19
pa - указатель на Asteroid, rgo - ссылка на Gameobject. Я часто составляю
имена переменных и ссылок подобным образом.
Два моих любимых имени для параметров - это Ihs и rhs, сокращения для
«слева» (left-hand side) и «справа» (right-hand side) соответственно. Чтобы по-
нять, что стоит за этими именами, рассмотрим класс для представления действи-
тельных чисел:
Class Rational{.....} ;
Функция для попарного сравнения объектов класса Rational может быть
объявлена следующим образом:
bool operator== (const Rational&Ihs, const Rational&rhs) ;
Такое объявление позволяет писать программы следующим образом:
Rational rl, г2 ;
if (rl == r2 ) ...
В операторе сравнения rl стоит слева от оператора == и соответствует аргу-
менту Ihs при вызове operator==, г2 расположено справа от оператора = =
и соответствует аргументу rhs.
Другие сокращения, использованные в этой книге: ctor обозначает конструк-
тор (constructor), dtor - деструктор (destructor), RTTI - динамическое
определение типов в C++ (оператор dynamic_cast - наиболее часто используе-
мый компонент этого механизма).
Если выделить память, а затем не освободить ее, то происходит утечка памяти.
Утечки могут возникать как в С, так и в C++, но в последнем они приводят к более
серьезным последствиям. Это связано с тем, что в C++ при создании объектов
автоматически вызываются конструкторы, которые могут сами выделять ресур-
сы. Посмотрите на этот пример:
class Widget {....}; //Некий класс - неважно,
/ / что он делает.
Widget *pw = new Widget; //Динамическое выделение
/ / памяти под объект Wi dge t.
... //Предположим, что область,
/ / на которую указывает pw,
/ / никогда не освобождается.
Этот код вызывает утечку памяти, потому что объект Widget, на который ука-
зывает переменная pw, никогда не будет удален. Возможна ситуация, когда кон-
структор Widget потребует выделения дополнительных ресурсов (таких как де-
скрипторы, семафоры, манипуляторы окон, блокираторы баз данных* и т.п.),
* В других книгах вы можете встретить иные варианты перевода английских понятий
window handle и database lock, поскольку в русском языке компьютерная терминология
еще недостаточно устоялась. Обычно программисты обобщенно называют эти инстру-
менты хэндлами (от англ, handle). (Прим, ред.)
20
!№ Наиболее эффективное использование C++
которые должны освобождаться при удалении объекта Widget. Если Widget не
будет удален, то доступ к этим ресурсам будет утерян так же, как и к занимаемой
ими области памяти. Чтобы подчеркнуть, что утечки памяти в C++ часто приво-
дят к утечкам других ресурсов, я буду использовать выражение «утечка ресурсов»
во всех случаях.
Примеры кода, приведенные в книге, редко включают встраиваемые функции.
Это не значит, что я их не люблю. Встраиваемые функции, безусловно, являются
важной чертой языка C++. Однако критерии для определения, должна ли
функция объявляться как встраиваемая, могут быть довольно сложными, нечетки-
ми и зависеть от платформы. В результате я избегаю использовать встраиваемые
функции, если только это не связано напрямую с обсуждаемой темой. Когда вы
встречаете в примерах невстраиваемую функцию, это не означает, что ее объявление
как inline создаст дополнительные проблемы, просто вопрос, объявлять ли функ-
цию встраиваемой или нет, не влияет на изложение темы в данном месте книги.
Некоторые свойства C++ комитет по стандартам объявил устаревшими.
В них больше нет необходимости, потому что к языку были добавлены новые свой-
ства, которые намного лучше выполняют функции прежних. В этой книге я специ-
ально обращаю внимание на устаревшие конструкции и объясняю, чем их можно
заменить. Программистам не следует работать с такими конструкциями, хотя ис-
пытывать особые угрызения совести от их использования также не стоит. Для со-
хранения обратной совместимости производители компиляторов, скорее всего, бу-
дут поддерживать устаревшие свойства еще много лет.
Клиент (или пользователь) - это кто-то (возможно, программист) или что-то
(обычно класс, функция), использующий написанный вами код. Например, вы
создали класс Date (для описания дней рождения, календарных сроков, дня вто-
рого пришествия и т.п.). Тогда всякий, обращающийся к этому классу, является
вашим клиентом. Далее, любые модули, использующие класс Date, также окажут-
ся вашими клиентами. Ради клиентов и ведется разработка! Если ваше программ-
ное обеспечение никому не требуется, зачем его создавать? Читая книгу, вы заме-
тите, что я прикладываю массу усилий, чтобы облегчить жизнь клиентам, часто за
ваш счет, поскольку хорошее программное обеспечение должно быть «клиенто-
центричным»: оно должно «вращаться» вокруг клиентов. Если это кажется вам
излишней филантропией, посмотрите на проблему с точки зрения собственных
интересов. Используете ли вы ваши классы и функции повторно? Если да, то вы -
ваш собственный клиент, и облегчая жизнь клиентам вообще, вы облегчаете ее
самому себе.
Рассуждая о шаблонах классов или функций и сгенерированных по этим шаб-
лонам объектах, я позволю себе быть несколько неряшливым и особо не подчер-
кивать разницу между шаблонами и созданными по ним объектами. Например,
если Array - это шаблон класса с параметром Т, то я могу ссылаться на шаблон-
ный класс как на Array, хотя на самом деле его правильное имя - Аг гау<Т>. Анало-
гично, если swap - шаблон функции с параметром типа Т, то имя swap (вместо
swap<T>) также может обозначать и шаблонную функцию. Разумеется, если
Введение
такая сокращенная запись может привести к недоразумению, я записываю пол-
ные имена объектов.
Принятые обозначения
Для более простого восприятия материала в книге приняты следующие услов-
ные обозначения.
Все листинги, приведенные в книге, напечатаны моноширинным шрифтом.
Имена классов, объектов, переменных, констант и т.д., встречающиеся не-
посредственно в тексте, также даны моноширинным шрифтом.
Информация, которую необходимо обязательно принять к сведению, выде-
лена курсивом.
Как сообщить об ошибках, внести предложения,
получить обновления книги
Насколько это возможно, я старался сделать книгу точной, удобной для чте-
ния и полезной, однако нет предела совершенству. Если вы обнаружите в ней ка-
кую-либо ошибку: техническую, грамматическую, опечатку, какую-нибудь - пожа-
луйста, сообщите мне об этом. Я постараюсь исправить допущенную оплошность
в последующих изданиях книги, а если вы окажетесь первым, кто сообщит об
ошибке, с удовольствием добавлю ваше имя в список благодарностей. Если у вас
появятся другие предложения по улучшению книги, также буду вам очень при-
знателен.
Я по-прежнему продолжаю собирать рекомендации по эффективному про-
граммированию на C++. Если у вас есть какие-нибудь идеи на этот счет, буду
очень благодарен, если вы поделитесь ими со мной. Шлите ваши рекомендации,
комментарии, замечания и сообщения об ошибках по адресу:
Scott Meyers
с/о Editor-in-Chief, Corporate and Professional Publishing
Addison-Wesley Publishing Company
1 Jacob Way
Reading, MA 01867
U.S.A.
Вы также можете послать сообщение электронной почты по адресу:
mec++@awl.com.
Я веду список изменений, таких как исправления ошибок, пояснения и обнов-
ления, внесенных в книгу с первого издания. Этот список, а также другие матери-
алы, связанные с данной книгой, размещен на Web-сайте издательства Addison-
Wesley по адресу: http://www.awl.com/cp/mec++.html. Он также находится на
FTP-сайте по адресу: ftp.awl.com в каталоге ср/тес++. Если у вас нет доступа
в Internet, то для получения списка изменений пошлите запрос по одному из при-
веденных выше двух адресов, и я прослежу, чтобы список был вам выслан.
22
Наиболее эффективное использование С++
В настоящее время существует также список рассылки, подписаться на кото-
рый можно, послав сообщение по адресу scott meyers-subscribe@egroups.com. Ар-
хив списка рассылки находится на странице http://www.egroups.com/messages/
scott meyers. Он предназначен для рассылки объявлений программистам, инте-
ресующимся языком C++. Объем рассылки небольшой, обычно не более двух со-
общений в месяц. Более подробные сведения о списке рассылки можно получить
на странице http://www.aristeia.com/MailingList/index.html.
Глава 1. Основы
Указатели, ссылки, приведение типов, массивы, конструкторы - это то, что состав-
ляет основу языка. Все программы на языке C++, за исключением самых простых,
используют большую часть названных понятий, а многие программы используют
их все.
Даже самые знакомые вещи иногда могут нас удивлять. Особенно это спра-
ведливо для программистов, переходящих с языка С на C++, так как концепции,
на которых базируются понятия ссылок, динамического приведения типов, кон-
структоров пр умолчанию и других, не принадлежащих языку С, обычно не все-
гда очевидны.
Эта глава объясняет разницу между указателями и ссылками и содержит со-
веты, когда следует использовать каждое из этих понятий. В ней также описан но-
вый синтаксис языка C++ для приведения типов и объясняется, чем новый стиль
превосходит заменяемый стиль языка С. Кроме того, рассматривается концепция
массивов в языке С и концепция полиморфизма в языке C++, а также говорится,
почему их никогда не стоит использовать одновременно. Наконец, в ней рассказа-
но о плюсах и минусах конструкторов по умолчанию и предложены пути для обхо-
да ограничений языка, которые требуют существования такого конструктора, даже
если это не имеет практического смысла.
Следуя советам, приведенным в нижеизложенных правилах, вы сможете со-
здавать такое программное обеспечение, где ваш замысел будет реализован ясно
и правильно.
Правило 1. Различайте указатели и ссылки
Указатель (pointer) и ссылка (reference) существенно отличаются по
внешнему виду (указатели используют операторы * (умножить) и -> (стрелка),
ссылки используют оператор . (точка)), но применяются для решения одних
и тех же задач. И указатели и ссылки позволяют неявно ссылаться на другие
объекты. Как же тогда решить, когда применять указатели, а когда ссылки?
Во-первых, запомните, что не существует нулевых ссылок. Ссылка должна все-
гда ссылаться на какой-либо объект. Если ваша переменная обеспечивает доступ
к объекту, которого может и не быть, вы должны использовать указатель, потому что
это позволит приравнять его нулю. С другой стороны, если переменная должна все-
гда ссылаться на существующий объект, то есть не должна иметь нулевого значе-
ния, то, скорее всего, лучше использовать в качестве такой переменной ссылку.
«Но подождите!», - воскликнет читатель, - «а как же будет работать следую-
щий кусок кода?»:
char *pc = 0 ;
char& rc = *pc ;
Основы
/ / Присвоить указателю значение null.
/ / Установить ссылку на содержимое
// нулевого указателя.
Надо сказать, это пример самого настоящего безобразия. Результаты работы
такой программы не определены: компиляторы могут генерировать программный
код, который будет делать все, что угодно. Если у вас возникают подобные про-
блемы, то лучше вообще отказаться от использования ссылок. В качестве другого
выхода вы можете поискать для сотрудничества программистов более высокого
класса. В дальнейшем мы не будем считаться с возможным существованием нуле-
вых ссылок.
Так как ссылка должна ссылаться на объект, C++ требует ее инициализации:
str ing& г s; / / Ошибка! Ссылки должны быть
//проинициализированы.
string s("xyzzy");
string^ rs = s; //Нормально, rs ссылается на s .
На указатели таких ограничений не налагается:
string *ps;
//Неинициализированный указатель:
//допустимо, но рискованно.
Невозможность существования нулевых ссылок подразумевает, что исполь-
зование ссылок более эффективно, чем использование указателей. Корректность
ссылки не нужно предварительно проверять:
voidprintDouble(const doubled rd)
{
cout « rd; / / Нет необходимости проверять rd;
} //она должна ссылаться на double.
Указатели же, наоборот, обычно должны проверяться на равенство нулю:
voidprintDouble (const double *pd)
{
if (pd) { //Проверка на значение null.
cout << *pd;
}
Другое важное различие между указателями и ссылками состоит в возможности
присваивать указателям различные значения для доступа к разным объектам. Ссыл-
ка же всегда указывает на один и тот же объект, заданный при ее инициализации:
string si("Nancy") ;
string s2("Clancy");
string^ rs = si;
string *ps = &sl ;
rs = s2 ;
// rs ссылается на si.
// ps указывает на si.
/ / rs все еще ссылается на si,
//но теперь si имеет значение
// "Clancy".
Правило 1
ps = &s2;
/ / ps указывает на s2 ;
// значение si не изменилось.
Вообще говоря, указатель следует использовать, если есть вероятность, что
объект, связанный с указателем, отсутствует (в этом случае ему присваивается ну-
левое значение) или периодически возникает необходимость доступа к разным
объектам (в этом случае изменяется значение указателя). Ссылку же следует ис-
пользовать, если объект, к которому необходимо обеспечить доступ, будет сущест-
вовать всегда, и не потребуется получить доступ к другому объекту с помощью
все той же ссылки.
Существует еще одна ситуация, в которой вы должны задействовать ссылки -
при реализации некоторых операторов; из них наиболее часто встречается опера-
тор [ ] (скобки). Обычно этот оператор должен вернуть некое значение, которое
затем будет использовано как принимающее в операторе присваивания:
vector<int>v(10) ; //Создаем векторцелых значений
//размерности 10;
//векторявляетсяшаблоном
//из стандартной библиотеки C++
// (см.правило 35).
v [ 5 ] =10; //Значение,возвращаемое
// оператором [ ] , является
//принимающей стороной оператора
//присваивания.
Если бы оператор [ ] возвращал указатель, то последнюю строку этого кода
надо было бы записать так:
*v[5] =10;
Но создавалось бы ложное впечатление, что v является вектором указателей.
Поэтому почти всегда желательно, чтобы оператор [ ] возвращал ссылку. (Инте-
ресное исключение из этого правила приведено в правиле 30.)
Итак, использование ссылок оправдано, когда доподлинно известно, что
объект ссылки существует, когда нет необходимости изменять значение ссылки
и при реализации операторов, в которых применение указателей нежелательно из-
за синтаксических требований. Во всех других случаях используйте указатели.
Правило 2. Предпочитайте приведение типов
в стиле C++
Рассмотрим прямое приведение типов. Это почти такой же изгой, как и опе-
ратор goto, но тем не менее оно продолжает использоваться, потому что, когда
ситуация становится «хуже некуда», может оказаться необходимым.
Приведение типов в стиле языка С не применяется так широко, как могло бы. Во-
первых, это довольно грубый инструмент, практически позволяющий привести про-
извольный тип к любому другому. Было бы неплохо более точно определять цель каж-
дого приведения. Например, существует большая разница между приведением
26
указателя на объект const к указателю на объект, не являющийся const (то есть
меняющим только атрибут const объекта), и приведением указателя на объект
базового класса к указателю на объект производного класса (то есть приведение
типа, которое полностью меняет тип указателя). Традиционное приведение типа
в стиле языка С не различает эти два случая (и неудивительно - приведение типов
в стиле языка С было разработано для С, а не для C++).
Вторая проблема с приведением типов заключается в том, что случаи его при-
менения трудно обнаружить. Синтаксически приведение типов состоит всего-на-
всего из пары скобок и идентификатора, а скобки и идентификаторы использу-
ются в C++ повсеместно. Таким образом, нелегко ответить даже на основной
вопрос: «Использует ли программа приведение типов?». Это происходит потому,
что человеческий глаз не всегда замечает код приведения типов, а такие утилиты,
как grep, не могут отличить его от других, синтаксически схожих, конструкций.
Чтобы преодолеть недостатки приведения типов в стиле языка С, в язык C++
введены четыре новых оператора приведения типов: static_cast, const_cast,
dynamic_cast и reinterpret_cast. Для большинства задач программист дол-
жен знать только, что там, где он привык писать
(type) expression
теперь следует писать
static_cast<type>(expression)
Допустим, вам необходимо привести выражение типа int к типу double,
чтобы получить число с плавающей точкой в результате вычисления целочислен-
ного выражения. Используя приведение типов в стиле языка С, это можно было
сделать следующим образом:
int firstNumber,secondNumber;
double result = ( (double) firstNumber) /secondNumber;
С новыми операторами приведения типа это делается так:
double result = static_cast<double>(firstNumber)/secondNumber;
Теперь у нас есть приведение типов, которое легко обнаружат как человечес-
кий глаз, так и программы.
Оператор static_cast обладает теми же возможностями, что и приведение ти-
пов общего назначения в стиле языка С. На него налагаются аналогичные ограниче-
ния. Например, также как и в языке С, с помощью static_cast вы не можете пре-
образовать переменную типа struct в int или переменную типа double в указатель.
Более того, с помощью оператора static_cast нельзя убрать атрибут const
в выражении, для этого служит специальный оператор const_cast.
Другие операторы приведения типов, введенные в C++, используются для бо-
лее узкого круга задач. Оператор const_cast предназначен для работы с атрибу-
тами const и volatile в выражениях. Используя оператор const_cast, вы
Правило 2
HIM!
27
подчеркиваете (как для человека, так и для компьютера), что собираетесь только из-
менить атрибут const или volatile какого-либо объекта. Это значение
оператора поддерживают и компиляторы. Если попытаться использовать опера-
тор const_cast для других задач, отличных от изменения атрибутов const или
volatile, то такое приведение типов будет отвергнуто. Вот некоторые примеры:
class Widget { ... };
class Specialwidget: public Widget { ... };
voidupdate(SpecialWidget *psw);
SpecialWidget sw; // swHe const объект,
const SpecialWidgetk csw = sw; //но csw ссылается на него,
/ / как на cons t объект.
update(&csw); //Ошибка!Нельзя передавать const
//указатель SpecialWidget*
//функции,которая принимает
//указатель SpecialWidget*.
update(const_cast<SpecialWidget*>(&csw));
//Нормально,
// атрибут const у &csw
/ / удален в результате
//преобразования типа
// (и csw и swMoryT быть изменены
// в теле функцииupdate).
update((SpecialWidget*)&csw);
/ / To же самое, но используя
/ / более трудное для обнаружения
/ / преобразование типа в стиле
/ / языка С.
Widget *pw = newSpecialWidget-;
update (pw) ; //Ошибка! pwHMeeTTnnWidget* ,
/ / а функция update принимает
// аргумент типа SpecialWidget* .
update(const_cast<SpecialWidget*>(pw));
//Ошибка!Операторconst_cast
//можно использовать только
//для изменения атрибутов
//const HnHvolatile
// и'нельзя применять для приведения
//наследования.
В настоящее время оператор const_cast чаще всего используется для изме-
нения атрибута const.
Второй специализированный оператор - dynamic_cast - для безопасного
приведения типа между уровнями иерархии наследования. Это означает, что опе-
ратор dynamic_cast позволяет приводить указатели или ссылки на объекты
базового класса к указателям или ссылкам на объекты производных или дочерних
классов таким образом, чтобы можно было определить, была ли попытка приведения
28
Mill
Основы
типа успешной*. В результате неудачной попытки возвращается нулевой указатель
(при преобразовании указателей) или возникает исключение (при преобразовании
ссылок):
Widget *pw;
update(dynamic_cast<SpecialWidget*>(pw));
//Нормально, функции update
//передаетсяуказатель
/ / на объект класса Specialwidget,
// еслирюдействительноуказывает
// на этот объект, в противном
//случае передается нулевой
//указатель.
voidupdateViaRef(SpecialWidgetkrsw);
updateViaRef(dynamic_cast<SpecialWidget&>(*pw));
/1 Нормально, передача функции
/ / updateViaRef ссылки на объект
//класса Specialwidget, еслир:-;
//действительно указывает на этот
//объект, в противномслучае
//возникает исключение.
Применение операторов dynamic_cast ограничено возможностью навигации
по иерархии наследования. Операторы нельзя использовать для приведения типов,
не имеющих виртуальных функций (см. также правило 24), или для работы
с атрибутом const:
intfirstNumber,secondNumber;
double result= dynamic_cast<double>(firstNumber)/secondNumber;
//Ошибка! int не имеет
//виртуальных функций.
const Specialwidget sw;
update(dynamic_cast<SpecialWidget*>(&sw));
//Ошибка! dynamic_cast не может
//работать с атрибутом cons t.
Если вы хотите выполнить преобразование ненаследуемых типов, то лучше
всего подойдет оператор static_cast. Чтобы удалить атрибут const, всегда
применяется оператор const_cast.
Последний из четырех новых операторов - оператор reinterpret_cast. Он
используется для приведения типов в тех случаях, когда результат приведения
почти всегда зависит от реализации. Из-за этого переносимость операторов
reinterpret_cast существенно ограничена.
Оператор dynamic_cast всегда используется для того, чтобы найти начало памяти, за-
нимаемой объектом. Подробнее об этом рассказано в правиле 27.
Правило 2
НИВ
29
Оператор reinterpret_cast обычно применяется для приведения указате-
лей на функции. Предположим, например, что у вас есть массив указателей на
функции определенного типа:
typedef void (*FuncPtr) () ;
FuncPtrfuncPtrArray[10] ;
/ / FuncPtr - это указатель на
/ / функцию, которая не имеет
/ / аргументов и возвращает
//значениеvoid.
// funcPtrArray - это массив
//из 10 указателей FuncPtr.
Предположим, что вы хотите по какой-либо причине поместить в funcPtrArray
указатель на следующую функцию:
int doSomething() ;
Вы не можете сделать это без приведения типа, потому что функция doSome-
thing имеет тип, не соответствующий типу элементов массива funcPtrArray.
Функции в funcPtrArray возвращают значение типа void, а функция do-
Something возвращает значение int:
funcPtrArray[0] =kdoSomething; //Ошибка! типы не совпадают.
Оператор reinterperet_cast позволяет подчинить работу компиляторов
вашему замыслу:
funcPtrArray[0] = //Компилируется нормально.
reinterpret_cast<FuncPtr>(&doSomething) ;
Операция преобразования указателей на функции не является переносимой
(язык C++ не гарантирует, что все указатели на функции хранятся единообраз-
но), и в некоторых случаях такая операция дает неправильный результат
(см. правило 31). Из-за этого использовать указатели на функции следует только
в самом крайнем случае.
Если ваши компиляторы не поддерживают новые виды операторов приведения
типа, вместо static_cast, const_cast и reinterpret_cast допускается ис-
пользовать традиционное приведение типа. Более того, придать синтаксису
их использования сходство с новым синтаксисом можно с помощью макро-
определений:
#definestatic_cast(TYPE, EXPR)
#defineconst_cast(TYPE, EXPR)
#definereinterpret_cast(TYPE, EXPR)
((TYPE) (EXPR))
((TYPE) (EXPR))
((TYPE) (EXPR))
Эти макроопределения допускается использовать следующим образом:
double result = static_cast(double, firstNumber)/secondNumber;
update(const_cast(SpecialWidget*, &sw) ) ;
funcPtrArray [0] =reinterpret_cast(FuncPtr, kdoSomething);
Включение в программу макроопределений не столь безопасно, как использова-
ние настоящих операторов, но они облегчат модификацию вашего кода, когда компи-
ляторы, с которыми вы работаете, начнут под держивать новые операторы.
30
III
Основы
He существует простого способа эмулировать оператор dynamic_cast, но
многие библиотеки содержат функции, выполняющие безопасные операции при-
ведения типов, использующих наследование. Если такие функции отсутствуют,
а вам просто необходимо выполнить операцию приведения типа, то и в этом слу-
чае можно обратиться к стилю языка С, но учтите, что вы не сумеете обнаружить
безуспешное приведение типов. Разумеется, в такой ситуации также допускается
создать макроопределение, похожее на оператор dynamic_cast:
#definedynamic_cast(TYPE,EXPR) ((TYPE) (EXPR))
Помните, что это лишь приблизительный аналог, который не выполняет все
функции dynamic_cast: нельзя обнаружить безуспешное преобразование типов.
Как вы, наверное, заметили, новые операторы приведения типов выглядят не-
привычно и их сложно вводить с клавиатуры. Если вы находите их вид непригляд-
ным, возможно, вас утешит информация о том, что в C++ работает и приведение
типов в стиле языка С. Однако, теряя в красоте, новые операторы делают приведе-
ние типов более ясным и распознаваемым. Программы, их использующие, проще
разбирать (как человеку, так и программным инструментам). Новые операторы
позволяют компиляторам находить ошибки приведения типов, которые в против-
ном случае остались бы не выявленными. Согласитесь, это серьезные аргументы
в пользу того, чтобы не использовать преобразование типов в стиле языка С.
Правило 3. Никогда не используйте полиморфизм
в массивах
Одна из наиболее важных черт наследования состоит в том, что, используя
указатели и ссылки на объекты производного класса, вы можете получить доступ
к объектам базового класса. Такое поведение указателей и ссылок называют поли-
морфизмом (polymorphically), - они ведут себя так, как будто принадлежат не-
скольким типам. Язык C++ теоретически позволяет управлять массивами из
объектов производного класса через указатели и ссылки на объекты базового клас-
са, но на практике это почти всегда работает не так, как хотелось бы.
Представим, например, что у вас есть класс BST (для объектов двоичного де-
рева поиска) и второй класс, BalancedBST, наследующий от BST:
class BST { ... };
classBalancedBST:publicBST {-...} ;
В реальной программе такие классы реализуются через шаблоны, но здесь это
не существенно, а синтаксис шаблонов только затрудняет чтение. Чтобы не
усложнять пример, предположим, что BST и BalancedBST содержат только пе-
ременные типа int.
Рассмотрим функцию, распечатывающую содержимое каждого объекта BST
в массиве элементов BST:
voidprintBSTArray (ostream&s, const BST array [] ,
int numEl ement s)
HIM!
31
Правило 3
{
for (int i = 0; i cnumElements; ++i) {
s << array [ i ] ; / / Предполагается, что оператор
/ / определен для объектов BST.
}
}
Этот код нормально работает, когда в качестве аргумента функции передается
массив объектов BST:
BSTBSTArray[10];
printBSTArray(cout, BSTArray,10); // Работает нормально.
Однако посмотрите, что происходит, когда вы передаете функции print-
BSTArray массив объектов типа BalancedBST:
balancedBSTbBSTArray[10];
printBSTArray(cout, bBSTArray,10); //Нормально работает?
Ваши компиляторы без проблем обработают вызов этой функции, но взгля-
ните на цикл, для которого он должен сгенерировать код:
for (int i = 0; i < numElements; ++i) {
s<<array [i] ;
}
Выражение array [ i ] на самом деле является сокращением для арифмети-
ческого выражения, вычисляющего указатель, оно эквивалентно выражению
* (array + i). Мы знаем, что array - это указатель на начало массива, но как
далеко от ячейки памяти, на которую указывает array, находится память, на ко-
торую указывает выражение array + i? Расстояние между ними определяется
выражением i * sizeof (элемент массива), потому что между array [0]
и array [ i ] как раз i элементов. Для того чтобы генерировать код, обеспечиваю-
щий корректный доступ к элементам массива, компиляторы должны знать раз-
мер каждого элемента массива. Это легко. Переменная array описана как массив
элементов типа BST, так что расстояние между указателями array и array + i
равно i * sizeof(BST).
По крайней мере, так это выглядит с точки зрения компиляторов. Но если вы
передали функции printBSTArray в качестве аргумента массив объектов типа
BalancedBST, то компиляторы скорее всего ошибаются. В этом случае они пола-
гают, что размер элемента массива равен размеру объекта BST, в действительнос-
ти же размер элемента равен размеру объекта BalancedBST. Обычно производ-
ные классы имеют большее количество членов класса, чем базовый класс, поэтому
они, как правило, превосходят базовый класс по размеру. Таким образом, следует
ожидать, что объект типа BalancedBST будет больше, чем объект типа BST. Если
это так, то выражение для вычисления указателей, созданное в теле функции
printBSTArray, будет неверным для массивов элементов типа BalancedBST,
и нельзя предсказать, что произойдет при вызове функции printBSTArray,
Основы
32
имеющей в качестве аргумента массив элементов BalancedBST. Но что бы ни слу-
чилось, вам это явно не понравится.
В другом обличье проблема возникает, если вы пытаетесь удалить массив эле-
ментов производного класса, используя указатели на базовый класс. Вот один из
способов, который вы, не подозревая подвоха, могли бы испробовать:
/ / Удаляем массив, предварительно сообщив об этом.
voiddeleteArray (ostreamk logStream, BST array [] )
{
logStream« "Удаляеммассив, расположенный по адресу"
«static_cast<void*>(array) << '\n';
delete [ ] array;
}
BalancedBST *balTreeArray = // Создаеммассивэлементов
newBalancedBST[50]; //типаBalancedBST.
deleteArray (cout, balTreeArray) ; //Сообщаем об удалении
//массива.
Вы этого не замечаете, но здесь также происходит вычисление указателей. При
удалении массива для каждого его элемента должен быть вызван деструктор
(см. правило 8). Когда компилятор обрабатывает выражение
delete [ ] array;
он создает код, который делает приблизительно следующее:
/ / Удаляем элементы в массиве *аггау в порядке, обратном
/ / порядку их создания.
for (int i = количество элементов в массиве - 1;
i >= 0 ;
—i)
{
array[i].BST::-BST; //Вызывается деструктор
} /1 для элемента array [ i ] .
Подобный цикл не работал, когда вы сами написали его, точно так же не будет
он работать и после того, как его напишет компилятор. В определении языка ска-
зано, что удаление массива элементов производного класса через указатель на
базовый класс приводит к непредсказуемому результату, но на практике это по-
чти наверняка означает печальный результат. Полиморфизм и арифметические
действия с указателями просто не сочетаются. А поскольку операции с массивами
почти всегда требуют арифметических действий с указателями, то массивы и по-
лиморфизм тоже плохо совместимы.
Заметьте, что вы вряд ли совершите ошибку по использованию полимор-
физма в массивах, если ваш конкретный (не абстрактный) класс (такой как
BalancedBST) не будет наследовать от другого конкретного класса (подобного
BST). Как объяснено в правиле 33, разработка программ, в которых конкретные
классы не наследуют один от другого, имеет много преимуществ. Советую вам
перейти к правилу 33 и прочитать все об этих преимуществах.
Правило 4
ВНМИИ11
33
Правило 4. Избегайте неоправданного использования
конструкторов по умолчанию
Default constructor (конструктор по умолчанию) - это конструктор, кото-
рый можно вызывать без аргументов. Конструкторы инициализируют объекты,
а конструкторы по умолчанию инициализируют объекты, не используя никакую
информацию из контекста, в котором создается объект. Иногда это очень ра-
зумно. Например, объекты, представляющие собой числа с известным основа-
нием можно инициализировать нулем или специальным значением «не опреде-
лено». Объекты, выполняющие функции указателей (см. правило 28), можно
инициализировать аналогичным образом. Структуры данных (связанные и ин-
дексированные списки, хэш-таблицы и т.п.) допускается создавать как пустые
контейнеры.
Но не все объекты обладают этим свойством. Для многих из них не существует
разумных способов инициализации без информации извне. Например, объект, со-
ответствующий записи в адресной книге, не имеет смысла, если отсутствует наиме-
нование записи. В некоторых компаниях каждая единица оборудования получает
корпоративный идентификационный номер, поэтому создание объекта, соответ-
ствующего единице оборудования, без указания номера также бессмысленно.
В идеале классы, объекты которых для своего создания не требуют дополни-
тельной информации, должны были бы иметь конструкторы по умолчанию,
а классы, объекты которых не могут быть созданы без дополнительной информа-
ции, — нет. К сожалению, до идеала нашему миру еще далеко, поэтому мы вынуж-
дены руководствоваться дополнительными соображениями. В частности, если
у класса отсутствует конструктор по умолчанию, то на его использование накла-
дываются определенные ограничения.
Рассмотрим класс, описывающий единицу оборудования компании, в реали-
зации которого корпоративный идентификационный номер является обязатель-
ным аргументом конструктора:
class Equipmentpiece{
public:
Equipmentpiece(intIDNumber);
};
У класса Equipment piece нет конструктора по умолчанию, поэтому его исполь-
зование в некоторых случаях вызывает сложности. Первый - это создание массивов.
Вообще говоря, не существует способов передать аргументы конструктору
элементов массива, поэтому стандартным образом создать массив элементов
Equipmentpiece невозможно:
EquipmentPiecebestPieces[10] ;
//Ошибка!Невозможно вызвать
//конструктор Equipmentpiece.
Equipmentpiece *bestPieces =
new EquipmentPiece[10] ;
/ / Ошибка! Та же проблема.
2 - 679
Основы
34
Есть три варианта, как преодолеть это ограничение. Для массивов, размещае-
мых статически, решение состоит в том, чтобы определить необходимые аргумен-
ты в момент создания массива:
int ID1, ID2, ID3, . . . , ID10;
/ / Переменные для хранения
//идентификаторов оборудования.
//Нормально, аргументы
/ / передаются
/ / в конструкторы.
EquipmentPiecebestPieces[] = {
Equipmentpiece(ID1) ,
Equipmentpiece(ID2),
EquipmentPiece(ID3),
• • t
Equipmentpiece(ID10)
};
К сожалению, этот прием не годится для динамических массивов.
Более общий подход состоит в использовании массива указателей взамен мас-
сива объектов:
typedef Equipmentpiece* PEP;
PEPbestPieces[10];
PEP *bestPieces = new PEP [10] ;
// PEP - это указатель на
//Equipmentpiece.
//Нормально,конструктор не
//вызывается.
//Тоже нормально.
Затем нужно связать каждый указатель с соответствующим объектом
EquipmentPiece:
for (int i = 0; i < 10; + + i)
bestPiece [i] = new Equipmentpiece (идентификационный номер) ;
У этого подхода есть два недостатка. Во-первых, нужно не забыть удалить все
объекты, на которые указывают элементы массива, иначе возникнет утечка памяти.
Во-вторых, общее количество использованной памяти оказывается больше, потому
что наряду с объектами Equipmentpiece нужно хранить также и указатели.
Нерационального расхода памяти можно избежать, если сначала выделить для
размещения массива область неструктурированной памяти, а затем использовать
буферизованный оператор new (см. правило 8) для создания в памяти объектов
EquipmentPiece:
// Выделяем неструктурированную область памяти, необходимую
// для размещения 10 объектов Equipmentpiece; более подробное
/ / описание функции operator new [ ] приведено в правиле 8 .
void *rawMemory =
operatornew[] (10*sizeof(Equipmentpiece));
// НастроимуказательЬезГPieces на эту область, чтобы его
/ / можно было рассматривать как массив Equipmentpiece.
Equipmentpiece *bestPieces =
35
Правило 4
static_cast<EquipmentPiece*>(rawMemory);
/ / Создадим объекты Equipmentpiece в памяти, используя
// буферизованный оператор new (см. правило 8) .
for(int i = 0;i <10; ++i)
new (bestPieces[i]) Equipmentpiece(идентификационный номер) ;
Заметьте, что все еще нужно передавать аргумент в конструктор каждого
объекта Equipment piece. Этот прием (как и использование массива указателей)
позволяет создать массив объектов без конструктора по умолчанию, но не позво-
ляет обойтись без передачи аргументов конструктору. Такого способа вообще не
существует. В противном случае сама идея назначения конструкторов, гаранти-
рующих инициализацию объектов, была бы скомпрометирована.
У использования буферизованного оператора new есть и обратная сторона.
Большинство программистов с ним вовсе не знакомо, из-за чего затруднена по-
следующая поддержка. Но главный недостаток состоит в том, что когда время
жизни объектов в массиве истечет, необходимо вручную вызывать деструкторы
этих объектов, а затем опять же вручную освободить область памяти, вызвав
operator delete [ ] (снова см. правило 8):
/ / Уничтожаем объекты в массиве best Pieces в порядке,
// обратном порядку их создания.
for (int i = 9; i >= 0; --i)
bestpieces [ i ] . --Equipmentpiece () ;
//Освободим область памяти.
' operator delete[] (rawMemory);
Если забыть о данном требовании и использовать стандартный синтаксис
удаления массива, то программа поведет себя непредсказуемо. Это вызвано тем,
что операция удаления указателя, не инициализированного с помощью оператора
new, не определена:
delete [] bestPieces; //Не определено!BestPieces
/ / не был инициализирован
// оператором new.
Более подробная информация об операторе new, буферизованном операторе new
и их взаимодействии с конструкторами и деструкторами приведена в правиле 8.
Вторая проблема с классами, не имеющими конструкторов по умолчанию, -
невозможность их использования со многими контейнерными шаблонами клас-
сов. Это связано с тем, что часто требуется иметь конструктор по умолчанию для
параметра, с помощью которого генерируется шаблон. Это требование почти все-
гда вызвано тем, что внутри шаблона создается массив элементов типа параметра
шаблона. Например, шаблон для класса Array может выглядеть примерно так:
templatecclass Т>
class Array{
public:
Array (int size) ;
2*
36
!№
Основы
private:
T*data;
);
template<class T>
Array<T>::Array(int size)
{
data = newT [size] ;
/ / Вызывает T: : T для каждого
//элемента массива.
В большинстве случаев хорошо продуманная архитектура шаблона могла бы
устранить необходимость в конструкторе по умолчанию. Например, стандартный
шаблон vector (он генерирует классы, которые ведут себя как массивы перемен-
ной длины) не требует, чтобы его параметр имел конструктор по умолчанию.
К сожалению, архитектуру большинства шаблонов можно назвать какой угодно,
только не хорошо продуманной. Из-за этого классы, не имеющие конструктора по
умолчанию, оказываются несовместимыми с большинством шаблонов. Конечно,
когда все программисты на C++ овладеют навыками корректного создания шаб-
лонов, данная проблема потеряет свое значение, но как скоро это произойдет, ос-
тается только гадать.
Последний аргумент в дилемме «создавать или не создавать конструктор по
умолчанию» связан с виртуальными базовыми классами. С такими классами, если
они не имеют конструкторов по умолчанию, очень сложно работать. Аргументы
для конструкторов виртуального базового класса должны передаваться от самого
последнего в иерархии наследующих классов. В результате виртуальный базовый
класс без конструктора по умолчанию требует, чтобы все наследующие от него
классы, независимо от глубины наследования, знали об аргументах конструктора
виртуального базового класса, понимали их назначение и обеспечивали их пере-
дачу при вызовах. Авторы производных классов не всегда помнят об этом и не
всегда оценивают по достоинству данное требование.
Из-за ограничений, налагаемых на использование классов, не имеющих кон-
структоров по умолчанию, некоторые программисты считают, что во всех классах
должны быть такие конструкторы, даже если сами конструкторы не обладают
достаточной информацией для полной инициализации объекта. Например, сто-
ронники подобной философии могли бы изменить код класса Equipmentpiece
следующим образом:
class Equipmentpiece{
public:
Equipmentpiece (int IDNumber = UNSPECIFIED) ;
private:
static const int UNSPECIFIED;
//Особое значение,
//которое задается,если
//идентификационный
// номер не был указан.
37
Правило 4
Этот код позволяет создавать объекты Equipment piece следующим образом:
Equipmentpiece е; //Теперь нормально.
Такое изменение почти всегда усложняет реализацию других членов - функций
класса, потому что нет гарантии, что поля объекта Equipment Piece были коррект-
но проинициализированы. Зная, что существование объекта Equipmentpiece
с незаполненным идентификационным номером бессмысленно, большинство чле-
нов-функций должно будет проверять, заполнено или не заполнено данное поле.
Даже если поле пусто, им нужно будет каким-то образом обработать возникшую
ситуацию. Зачастую не очень понятно, как это сделать, и многие выбирают реше-
ние, не отличающееся оригинальностью: либо генерируют исключение, либо вы-
зывают функцию, которая завершает выполнение программы. Но такое неоправ-
данное включение в класс конструктора по умолчанию явно не улучшает качество
программы.
Включение бессмысленных конструкторов по умолчанию влияет также и на
эффективность работы классов. Когда члены-функции вынуждены проверять
корректность инициализации полей, клиенты этих функций тратят на проверки
немалое время. Код, который генерируется для проверок, и код, обрабатывающий
аварийные ситуации, также увеличивает размер программ и библиотек. Подоб-
ных расходов можно избежать, если корректная инициализация полей достигает-
ся с помощью конструкторов. Но конструкторы по умолчанию часто не могут
обеспечить этого, поэтому их стоит включать в программы только по очень вес-
ким причинам. Такое ограничение, накладываемое на использование классов, га-
рантирует, что генерируемые ими объекты будут корректно инициализированы
и эффективно реализованы.
Глава 2. Операторы
К перегружаемым операторам следует относиться с уважением. Они позволяют
применять для типов, определяемых пользователем, такой же синтаксис, как и для
встроенных типов, а также обеспечивают неслыханные перспективы благодаря
функциям, стоящим за этими операторами. Но возможность заставить такие сим-
волы, как + или ==, делать все что угодно, означает также, что из-за перегружае-
мых операторов программы могут оказаться совершенно непонятными. Тем не
менее, есть много искусных программистов на C++, которые знают, как использо-
вать мощь перегружаемых операторов, не превратив программу в черный ящик.
Менее искусным, к сожалению, легко совершить ошибку. Конструкторы
с единственным аргументом и операторы неявного преобразования типа могут
доставить особенно много хлопот, поскольку их вызовы не всегда имеют соответ-
ствия в исходных текстах программ. Это ведет к появлению программ, поведение
которых понять очень трудно. Другая проблема возникает при перегрузке та-
ких операторов, как && и II, потому что переход от встроенных операторов
к функциям, написанным пользователем, приводит к незначительным изменени-
ям в семантике, и эти изменения легко проглядеть. Наконец, множество операто-
ров соотносится друг с другом по стандартным правилам, а из-за перегруженных
операторов общепринятые соотношения иногда нарушаются.
В изложенных далее правилах я попытался объяснить, когда и как использу-
ются перегруженные операторы, как они ведут себя, как должны соотноситься
друг с другом и как всем этим можно управлять. Освоив материалы данной гла-
вы, вы будете перегружать (или не перегружать) операторы с той же увереннос-
тью, что и настоящий профессионал.
Правило 5. Опасайтесь определяемых пользователем
функций преобразования типа
Язык C++ позволяет компиляторам осуществлять неявное преобразование
типов. Так же как и его предшественник, язык С, он позволяет неявное преобразо-
вание из char в int или из short в double. Вот почему можно передать функ-
ции, имеющей аргумент типа double, параметр типа short, и несмотря на это
вызов функции будет осуществлен корректно. Наиболее страшные по своим по-
следствиям преобразования в С, при которых происходит потеря информации, со-
хранились и в C++, включая преобразование из int в short и из double
в (самый распространенный вариант) char.
С такими преобразованиями ничего нельзя поделать, они встроены в язык.
Однако при добавлении собственных типов программист может лучше управлять
Правило 5
!
39
ими, выбирая, включать или нет в программу функции, которые компиляторы
потом будут использовать для неявного преобразования типов.
Существуют два типа функций, позволяющих компиляторам выполнять та-
кие преобразования: конструкторы с единственным аргументом и операторы не-
явного преобразования типов. Конструктор с единственным аргументом требует
при вызове только один аргумент. Такой конструктор может быть объявлен
с одним или несколькими параметрами при условии, что все параметры, начиная
со второго, имеют значение по умолчанию. Вот два примера:
class Name{
public:
Name(const string^ s) ;
/1 Описывает имена объектов.
/ / Преобразование string в Name.
};
class Rational {
public:
Rational (intnumerator = 0,
int denominator = 1) ;
// Класс действительных чисел.
I/Преобразует
// int в Rational.
};
Оператор неявного преобразования типа - это просто функция, являющаяся
членом класса со странным именем operator, за которым следует специфика-
ция типа. Нельзя задать тип возвращаемого значения, потому что данный тип
представляет собой просто имя функции. Например, чтобы обеспечить неявное
преобразование объектов типа Rational к типу double (что позволяет вычис-
лять арифметические выражения смешанного типа с объектами типа Rational),
можно определить класс Rational следующим образом:
class Rational {
public:
operator double()const; //Преобразует Rational
}; //ктипу double.
Эта функция будет автоматически вызываться в следующем контексте:
Rational г(1,2); // Значение г равно 1/2 .
double d= 0.5 * г; / / Преобразует г к типу
/ / double, а затем выполняет
//операцию умножения.
Приведенные фрагменты кода, вероятно, показались вам похожими на повто-
рение пройденного. Это хорошо, потому что я хочу объяснить, почему програм-
мисты обычно не хотят вводить никакие функции преобразования типа.
Главная проблема состоит в том, что появление таких функций приводит к их
вызову тогда, когда вы и не ожидаете, и не желаете этого. Результат часто
оказывается неверным, а поведение программы не поддается интуитивному ана-
лизу, и ее безумно сложно отлаживать.
40
ПИП
Операторы
Давайте сначала займемся простейшим случаем - операторами неявного пре-
образования типа. Допустим, вы хотите, чтобы класс рациональных чисел, похо-
жий на описанный выше, выводил на печать объекты Rational, как будто это
объекты одного из встроенных типов. То есть вы хотите иметь возможность вы-
полнить следующее:
Rational г (1,2 ) ;
cout« г ;
/ / Должно выводить"1/2".
Предположим далее, что вы забыли определить operator << для объекта
Rational. Вероятно, вы полагаете, что попытка вывести г на печать окончится
неудачей, ведь operator « не определен. Вы ошиблись. Ваши компиляторы, об-
рабатывая вызов функции с именем operator << и аргументом Rational, обна-
ружат, что такая функция не определена, и попытаются найти подходящую по-
следовательность операторов неявного преобразования типа, которая обеспечит
выполнение вызова. Правила подбора подходящей последовательности достаточ-
но сложны, но в этом конкретном случае компиляторы обнаружат, что вызов мож-
но выполнить, если неявно преобразовать г в double, вызвав Rational: :ope-
rator double. В результате выполнения программы, приведенной выше, значение г
будет напечатано как число с плавающей точкой, а не как действительное число.
Это вряд ли повлечет за собой катастрофические последствия, но, тем не менее,
хорошо демонстрирует, какие неприятности могут доставить операторы неявного
преобразования типа: они могут привести к вызову неверной функции (то есть не
той, которую хотел вызвать программист).
Решение проблемы состоит в замене операторов на эквивалентные функции,
не имеющие аналогов с тем же именем. Например, для приведения объекта
Rational к типу double заменим operator double на функцию с именем
asDouble:
class Rational{
public:
doubleasDouble() const;
};
/ / Приведение от типа
/ / Rational к типу double.
Такие функции-члены должны вызываться явно:
Rational г(1,2);
cout << г; //Ошибка! Оператор << для
// Rational не определен.
cout << г.asDouble() ; //Нормально, г будет
// напечатано как double .
В большинстве случаев неудобство от необходимости вызывать функции пре-
образования типов явно более чем компенсируется исчезновением нежелатель-
ных вызовов функций. Вообще говоря, чем опытнее программисты на языке C++,
тем реже они прибегают к операторам преобразования типа. Например, члены
комитета, работающие над стандартной библиотекой C++ (см. правило 35),
Правило 5
!!
принадлежат к наиболее знающим, и, вероятно, поэтому объект string, включен-
ный ими в библиотеку, не допускает неявного приведения от типа string
к char*. Вместо этого существует функция-член c_str, выполняющая данное
преобразование. Совпадение? Думаю, нет.
С неявным преобразованием, выполняемым конструктором с единственным
аргументом, бороться труднее. Более того, проблемы, создаваемые такими кон-
структорами, зачастую серьезнее, чем те, которые возникают из-за операторов не-
явного преобразования типа.
В качестве примера рассмотрим шаблон класса для массивов. Эти массивы
позволяют определять верхнюю и нижнюю границы индексов:
templatecclass Т>
class Array {
public:
Array (int lowBound, inthighBound) ;
Array(int size);
T&operator[] (intindex);
Первый конструктор позволяет клиенту задавать диапазон индексов массива,
например от 10 до 20. Так как у него два аргумента, то эта функция не может быть
использована для преобразования типа. Напротив, с помощью второго конструк-
тора допускается создавать объекты Array, указывая только количество элемен-
тов в массиве (так же, как это делается для встроенных массивов). Он может быть
использован для преобразования типов, и потому является источником постоян-
ного раздражения.
Рассмотрим реализацию сравнения объектов Array<int> и пример обработ-
ки таких объектов:
booloperator==(constArray<int>& Ihs,
const Array<int>&rhs);
Array<int>a(10);
Array<int>b(10);
for (int i = 0; i<10; ++i)
if (a==b[i]) {
11 Вместо "a"
11 должно быть " a [ i ]".
/ / Если a [ i ] и b [ i ] равны,
//выполнить какие-тодействия.
else {
выполнить другие действия, если они не равны;
Мы намеревались сравнить элементы а с соответствующими элементами Ь,
но случайно пропустили индекс при а. Конечно, хотелось бы, чтобы эта ошиб-
ка вызвала у компиляторов поток нелицеприятных комментариев, но они не бу-
дут жаловаться, поскольку встретят вызов operator== с аргументами типа
42
Операторы
Array<int> (для а) и int (для Ь). И хотя operator== с аргументами такого
типа не определен, компиляторы заметят, что они могут преобразовать int
в объект типа Arrayc int >, вызвав конструктор Array<int>, принимающий int
в качестве единственного аргумента. Именно это они и сделают, создав код, кото-
рый явно не предполагался:
for (int i = 0; i<10; + + i)
if (a ==static_cast<Array<int>>(b [ i ] ) ) ...
На каждом шаге цикла программа сравнивает содержимое а с содержимым
временного массива размерности b [ i ] (содержимое которого, скорее всего, не
определено). Эта программа не только некорректна, но и крайне неэффективна,
потому что на каждом шаге создает и удаляет временный объект Arrayc int>
(см. правило 19).
Проблем, возникающих из-за операторов неявного преобразования типа, мож-
но избежать, если просто не объявлять эти операторы, но для конструкторов
с единственным аргументом такой подход неприемлем. Данные конструкторы мо-
гут быть действительно нужны клиентам. В то же время нельзя и позволять ком-
пиляторам вызывать эти конструкторы без разбора. К счастью, существует воз-
можность удовлетворить оба требования. Есть даже два пути: простой и тот,
которым вам придется пользоваться, если ваши компиляторы пока не поддержи-
вают первый путь.
Простой вариант состоит в использовании одной из новых черт C++, а имен-
но ключевого слова explicit. Эта особенность была специально введена для ре-
шения проблемы неявного преобразования типов, и ее применение предельно об-
легчено. Если конструктор объявлен с атрибутом explicit, то компиляторам
запрещается вызывать его для неявного преобразования типа, в то время как яв-
ное преобразование разрешено:
template<class Т>
class Array {
public:
explicit Array(int size);
//Использование explicit.
};
Array<int> a(10);
Array<int> b(10);
if (a == b[i]) . . .
if (a==Array<int>(b[i] ) ) . . .
// Нормально, конструктор,
// объявленный как explicit,
/1 может быть использован
/ / для создания объектов.
/ / Также нормально.
//Ошибка!Невозможно
// неявно преобразовать int
// BArray<int>.
//Нормально, явное
//преобразование типа
//от int в Array<int>
Правило 5
43
HIM
//разрешено (хотя логика
/ / программы и выглядит
//подозрительно).
if (a==static_cast<Array<int>>(b[i])) . . .
/ / Также нормально,
/ / логика подозрительна.
if (а== (Array<int>)b[i]) . . .
//Преобразования
/ / в стиле С также разрешены,
/ / но программа
//продолжает оставаться
//подозрительной.
В примере, использующем static_cast (см. правило 2), пробел, разделяющий
два знака >, неслучаен. Если бы выражение было написано следующим образом:
if (a==static_cast<Array<int»(b[i]) ) ...
оно имело бы другой смысл. Это вызвано тем, что компиляторы C++ рассматри-
вают выражение » как единую конструкцию. Без пробела между символами >
выражение породило бы синтаксическую ошибку.
Если ваши компиляторы пока не поддерживают explicit, вам придется
освоить приемы, которые предотвращают использование конструкторов с одним
аргументом в качестве функций неявного преобразования типа. Чтобы понять эти
методы, достаточно увидеть их хотя бы один раз.
Ранее я упоминал, что правила, по которым определяется, какие последова-
тельности неявного преобразования типа корректны, а какие нет, довольно слож-
ны. Одно из этих правил состоит в том, что последовательность преобразований
не может содержать более одного преобразования, определенного пользователем
(то есть вызова конструктора с единственным аргументом или оператора неявно-
го преобразования типа).
Правильно сконструировав классы, нетрудно использовать это правило таким
образом, чтобы создание объектов было разрешено, а нежелательные неявные
преобразования типов оказались запрещены.
Снова рассмотрим шаблон Array. Допустим, требуется разработать способ,
который бы разрешал передавать конструктору целочисленный размер массива
в качестве аргумента и в то же время запрещал неявное преобразование целых чи-
сел во временный объект Array. Сначала создается новый класс Arraysize.
Объекты этого типа служат единственной цели: они описывают размерность мас-
сива, который будет создан. Затем конструктор с одним аргументом Array пере-
писывается так, чтобы принимать в качестве аргумента Arraysize, а не int. Ис-
ходный текст выглядит следующим образом:
template<class Т>
class Array {
public:
class Arraysize {
// Новый класс.
44
III
Операторы
public:
ArraySize(intnumElements) :theSize(numElements) {}
int size() const{return theSize;}
private:
int theSize;
} ;
Array(intlowBound, inthighBound);
Array(ArraySize size); // Обратите внимание на
//изменения в объявлении.
} ;
Здесь класс ArraySize размещен внутри Array, чтобы подчеркнуть, что он
всегда используется вместе с классом Array. Класс ArraySize также объявлен
как publ i с, благодаря чему доступ к нему открыт.
Посмотрим, что случится, если определить объект Array при помощи кон-
структора с единственным аргументом:
Array<int> а (10) ;
Ваши компиляторы генерируют вызов конструктора класса Array<int>, при-
нимающий int в качестве аргумента, но такого конструктора не существует. Ком-
пиляторы могут преобразовать аргумент типа int во временный объект
ArraySize, поскольку объект ArraySize - именно то, что нужно для кон-
структора Array<int>, и выполняют такие преобразования по своим обычным
правилам. Эта процедура обеспечивает успешный вызов функции и сопутствую-
щее создание объекта.
Мысль о том, что объекты Array могут быть созданы с помощью аргументов
типа int, успокаивает, но нужно еще убедиться, что запрещены нежелательные пре-
образования типа. Снова взглянем на этот код:
booloperator==(const Array<int>&Ihs, const Array<int>& rhs);
Array<int> a(10);
Array<int> b(10);
for (int i=0; i<10; + + i)
if(a==b[i])... //Вместо"а"должно
// стоять "a [i] 11 ;
/ / теперь это ошибка.
Компиляторам нужен объект типа Array<int> справа от ==, чтобы мож-
но было вызвать operator = = для объектов Array<int>, но конструктора,
принимающего единственный аргумент типа int, не существует. Компилято-
ры не могут преобразовать int во временный объект ArraySize, а затем со-
здать необходимый объект Array<int> из временного, потому что это потре-
бует вызова двух преобразований, определенных пользователем: из int
в ArraySize и из ArraySize в Array<int>. Такая последовательность
Правило 6
преобразований запрещена, поэтому при попытке выполнить сравнение ком-
пиляторы сгенерируют ошибку.
Использование класса Arraysize может показаться искусственным приемом,
но на самом деле это частный случай более универсального метода. Классы типа
Arraysize часто называют proxy-классами, потому что каждый объект такого
класса соответствует другому объекту (замещает его). Объект Arraysize дей-
ствительно замещает целое число, определяющее размерность создаваемого масси-
ва Array. Proxy-объекты предоставляют контроль над некоторыми сторонами по-
ведения программы, в данном случае неявными преобразованиями типа, что
невозможно получить другими способами, поэтому приглядитесь к ним поприс-
тальнее (см. правило 30).
Однако прежде чем обратиться к proxy-классам, еще раз обратите внимание на
следующий факт: разрешая компиляторам выполнять неявные преобразования
типа, вы почти наверняка получите больше сложностей, чем положительных ре-
зультатов, поэтому не создавайте функций преобразования типа, если не уверены
в их необходимости.
Правило 6. Различайте префиксную и постфиксную
формы операторов инкремента и декремента
Давным-давно (в конце 80-х) в далеком-далеком языке (C++ того времени) раз-
ницы между префиксными и постфиксными формами операторов + + и — не суще-
ствовало. Программистам не хватало этой возможности, и C++ был дополнен
разрешением перегружать обе формы инкрементных и декрементных операторов.
Однако при этом возникла синтаксическая проблема, связанная с тем, что ком-
пилятор различает перегруженные функции по типу передаваемых аргументов,
а префиксные и постфиксные формы инкрементных и декрементных операторов
не имеют аргументов. Чтобы преодолеть синтаксическую ловушку, было приня-
то волевое решение: постфиксные формы принимают аргумент типа int,
а компиляторы при вызове этих функций по умолчанию Подставляют 0 в качестве
аргумента:
class UPInt {
public:
UPIntk operator++ () ;
const UPInt operator++ (int) ;
UPIntkoperator--() ;
const UPIntk operator-- ( int) ;
UPIntkoperator+=(int);
// intнеограниченного размера.
//Префиксная форма ++,
//постфиксная форма ++.
//Префиксная форма — ,
//постфиксная форма -- .
/ / Оператор += для UPInt
//и int.
};
UPInt i;
+ + i ;
i + + ;
//Вызывается i .operator^ » () .
// Вызывается i . operators + (0) .
46
III
Операторы
// Вызывается i.operator--() .
//Вызывается i . operator--(0).
Это соглашение выглядит несколько странно, но вы привыкнете. Важен другой
факт: префиксные и постфиксные формы операторов возвращают значения
различного типа. В частности, префиксные формы возвращают ссылку, а постфикс-
ные формы - объект с атрибутом const. Далее я буду говорить только о префикс-
ной и постфиксной форме оператора ++, поскольку механизм работы операто-
ра — аналогичен.
Возможно, еще с тех времен, когда вы программировали на С, вы помните, что
префиксная форма инкрементного оператора иногда называлась «увеличить
и подставить», а постфиксная форма - «подставить и увеличить». Важно не за-
быть эти две фразы, потому что они почти полностью соответствуют формальной
спецификации использования префиксной и постфиксной форм:
/ / Префиксная форма: увеличить и подставить.
UPIntk UPInt::operator++ ()
{
*this += 1 ; return *this; } //Увеличить. //Подставить. //Постфиксная форма:подставить // иувеличить.
const UPInt UPInt: : operator++ (int) { UPIntoldValue= *this; ++(*this); returnoldValue; //Запомнить. //Увеличить. // Вернуть то, что //нужно подставить.
}
Обратите внимание, что постфиксный оператор не использует переданный
параметр. Это нормально. Единственное назначение параметра - обеспечить раз-
личие вызовов префиксной и постфиксной форм функций. Многие компиляторы
генерируют предупреждения, если параметры, передаваемые функции, не исполь-
зуются в ее теле. Чтобы избежать таких предупреждений, можно не указывать
имена неиспользуемых в теле функции параметров, как показано выше.
Понятно, почему постфиксная форма инкрементного оператора должна воз-
вращать объект (она возвращает сохраненное значение), но почему объект имеет
атрибут const? Представим себе, что атрибут отсутствует. Тогда следующий код
будет корректным:
UPInt i;
i + + + + ;
//Применяемпостфиксное
//увеличение дважды.
Этот код аналогичен следующему:
i.operator++(0).operator++(0);
Правило 6
47
При этом ясно, что второй вызов operator++ применяется к объекту, возвраща-
емому в результате первого вызова.
Есть две причины, по которым нужно отказаться от такой возможности. Во-
первых, она несовместима с поведением встроенных типов. При конструировании
классов существует хорошее правило: если сомневаешься, обработай аналогично
типу int, а тип int уж точно не позволяет двойное применение постфиксного
инкрементного оператора:
int i ;
i ++++;
//Ошибка!
Вторая причина состоит в том, что двойное применение постфиксного инкре-
ментного оператора почти никогда не соответствует потребностям клиента. Как
уже было отмечено выше, второй вызов operator++ изменяет значение объекта,
возвращаемого после первого вызова, а не значение исходного объекта. Таким
образом, если бы выражение
i++++;
было корректным, то значение переменной i увеличивалось бы только один раз.
Это противоречит привычной практике и может приводить к ошибкам (и для типа
int, и для типа UPInt), так что такой синтаксис лучше запретить.
Язык C++ запрещает его для типа int, но для классов, написанных пользова-
телем, программа должна делать это самостоятельно. Самый простой путь состо-
ит в том, чтобы придать значению, возвращаемому постфиксным инкрементным
оператором, атрибут const. Тогда если компиляторы видят выражение
i++++; //Эквивалентноi.operator++(0),operator++(0) .
они понимают, что объект const, возвращаемый после первого вызова, использу-
ется для повторного вызова operator++. Однако operator++ имеет атрибут
const, поэтому объекты с данным атрибутом не могут вызывать этот оператор*.
Итак, теперь вы знаете, что функции, возвращающие значение с атрибутом const,
иногда нужны, например для использования в инкрементном и декрементном опе-
раторах.
Если вы относитесь к программистам, которые заботятся об эффективности
кода, то вас, вероятно, обеспокоила реализация постфиксного инкрементного опе-
ратора. Эта функция создает временный объект для возвращаемого значения (см.
правило 19), а ее реализация, приведенная выше, создает также временный объект
(oldValue), для которого вызывается и конструктор, и деструктор. Префиксная
инкрементная функция вообще не генерирует временных объектов. Это приводит
к впечатляющему выводу: из соображений эффективности клиенты UPInt долж-
ны всегда предпочитать префиксную форму инкрементного оператора, если им
только не требуется функциональность постфиксной формы. Давайте проясним
это. Работая с пользовательскими типами, программист должен применять
К сожалению, не все компиляторы поддерживают это ограничение. Прежде чем полагать-
ся на компиляторы, протестируйте их.
48
Hr Операторы
префиксную форму при каждой возможности, потому что она обеспечивает более
эффективный код.
И еще одно замечание относительно префиксной и постфиксной форм. Если
не обращать внимания на возвращаемые значения, обе они делают одно и то же:
увеличивают значение переменной. То есть предполагается, что они делают одно
и то же. Как же обеспечить согласованность их поведения? Какую гарантию мож-
но дать, что со временем, например в результате действий различных программи-
стов, поддерживающих программное обеспечение, реализации операторов не
начнут отличаться? Это можно гарантировать, только следуя вышеописанным
принципам. В соответствии с ними постфиксная форма декрементного и инкре-
ментного операторов должна быть реализована через их префиксную форму. Тог-
да придется поддерживать только префиксную форму, потому что постфиксная
будет вести себя аналогично.
Как вы видите, легко овладеть постфиксной и префиксной формами декре-
ментного и инкрементного операторов. Если правильно задать тип возвращаемо-
го значения и реализовать постфиксную форму оператора через префиксную, то
дальше работы остается немного.
Правило 7. Никогда не перегружайте
операторы &&, || и,
Как и язык С, C++ использует оптимизированную схему оценки логических
выражений. Это означает, что вычисление выражения заканчивается, как только
установлена его истинность или ложность, даже если рассмотрены не все части
выражения. Например, в следующем случае:
char *р;
if ( (р ! = 0) && (strlen(р) >10) ) ...
не нужно волноваться по поводу вызова функции strlen с нулевым указателем,
потому что при р = 0 функция strlen попросту не будет вызвана. Аналогично,
в функции
int rangeCheck(int index)
{
if ( (index< lowerBound) I I (index>upperBound) ) . . .
}
сравнение значений index и upperBound никогда не произойдет, если значение
переменной index меньше lowerBound. .
Этот образ мышления свойственен программистам на С и C++ с незапамят-
ных времен, и они ожидают такого поведения. Более того, все написанные ими
программы рассчитаны на оптимизацию оценки логических выражений. Напри-
мер, в первом фрагменте кода, приведенном выше, существенно, чтобы функция
strlen не могла быть вызвана с нулевым аргументом, потому что, как утверждает
49
Правило 7 illM!
стандарт языка C++ (и стандарт С тоже), результат вызова функции strlen
с нулевым указателем не определен.
Язык C++ позволяет программисту модифицировать поведение операторов &&
и | I для определенных пользователем типов. Это можно сделать, перегрузив функ-
ции operator&& и operator I I как глобально, так и внутри некоторых классов.
Однако если решите пойти по этому пути, вы должны отдавать себе отчет, что ра-
дикально изменяете правила игры, поскольку оптимизирующая семантика меняет-
ся на семантику вызовов функций. Это означает, что перегруженный operator&&,
который для вас выглядит как
if (expression! && expressions) ...
для компилятора выглядит следующим образом:
if (expression!.operator&&(expressions)) ...
//operator&k является функцией-членом.
if (operator&&(expression!,expressions)) ...
//operator&k является глобальной функцией.
Семантика вызова функции имеет два чрезвычайно важных отличия от опти-
мизированной семантики оценки логического выражения. Во-первых, при вы-
зове функции вычисляются все ее аргументы, поэтому при вызове функций
operator&& и operator I I вычисляются выражения справа и слева от символа
оператора. Иными словами, этот вариант делает код менее оптимальным. Во-вто-
рых, спецификация языка не определяет порядок вычисления аргументов функ-
ции, поэтому невозможно определить, какое из двух выражений, expression!
или expression2, будет вычислено первым. Это также полностью противоречит
оптимизированной оценке логических выражений, при которой аргументы все-
гда вычисляются слева направо.
В результате при перегрузке операторов && или I I не существует способа со-
здать операторы, которые ведут себя ожидаемым и привычным образом. Поэтому
операторы && и I I вообще не следует перегружать.
Ситуация с оператором-запятая (,) выглядит аналогично, но прежде чем
рассматривать его свойства, стоит пояснить, для чего он нужен.
Оператор-запятая используется для формирования выражений, и вполне ве-
роятно, что вы встречали его в цикле for. Приведенная ниже функция, например,
почти аналогична функции из второго издания классической работы Кернигана
и Ричи (Kernighan and Ritchie) «Программирование на языке С» (The С Pro-
gramming Language, Prentice-Hall, 1988):
//Меняет порядок следования симоволов
/ / в строке s на обратный.
voidreverse(char s[])
{
for (int i=0, j=strlen(s) -1;
i , j ;
++i, --j) //Авотиоператор-запятая!
{
50
III
Операторы
int c = s[i];
s [ i ] = s [ j ] ;
s [ j ] = C;
В этом примере в заключительной части заголовка цикла i увеличивается, a j
уменьшается на 1. Здесь удобно использовать оператор-запятую, потому что
в заключительной части заголовка можно поставить только одно выражение; от-
дельные операторы, меняющие значения i и j, здесь были бы недопустимы.
Оператор-запятая подчиняется правилам, аналогичным тем, которые в языке
C++ описывают поведение операторов && и I I для встроенных типов. В выраже-
нии, содержащем запятую, сначала оценивается часть выражения слева от запя-
той, затем - справа. За значение всего выражения принимается значение части,
стоящей справа от запятой. Таким образом, в выражении в заключительной части
цикла for сначала оценивается ++i, затем --j, а результат, возвращаемый как
значение всего выражения, равен —j.
Если вы захотите написать свой собственный оператор-запятую, вам придет-
ся скопировать его поведение, описанное выше. К сожалению, это невозможно.
Если operator, не принадлежит к какому-либо классу, вы не получите га-
рантии, что левое выражение будет оценено раньше, чем правое, потому что оба
выражения будут переданы функции operator, в качестве аргументов, а поря-
док вычисления аргументов при вызове функции контролировать нельзя. Поэто-
му «внеклассовый» подход исключен.
У вас остается единственная возможность - написать operator, как член
класса. Но даже здесь нельзя быть твердо уверенным, что левый по отношению
к запятой операнд будет вычислен сначала, ведь компиляторы не обязаны обес-
печивать такой порядок. Следовательно, вы не можете перегрузить оператор-
запя- тую и гарантировать его надлежащее поведение. Поэтому перегружать его
было бы неразумно.
Наверное, вы интересуетесь, придет ли конец этому перегружаемому безумию.
В конце концов, если можно перегрузить даже оператор-запятую, неужели суще-
ствует что-то, чего перегружать нельзя? Оказывается, да. Нельзя перегружать сле-
дующие операторы:
. * : : ? :
new delete sizeof typeid
static_cast dynamic_cast const_cast reinterpret_cast
А вот эти операторы перегружать можно:
operatornew
operator delete
operatornew[] operator delete[]
+ - * / % Л & I
!=<>+=-=*= /= %=
Л= &= |= « » »= «= == ! =
<=>=&& I I ++ - , ->* ->
51
Правило 8 inn
(Об операторах new и delete, а также об operator new, operator delete,
operator new [ ] и operator delete [ ] см. правило 8).
Конечно, сама по себе возможность переопределить операторы является недоста-
точной причиной, чтобы заняться этим немедленно. Цель перегрузки операторов
состоит в том, чтобы программы было проще писать, читать и понимать,
а не поражать других знанием оператора-запятой. Не следует перегружать опера-
тор, если у вас нет для этого серьезной причины. В случае же операторов &&, I I
и , достойный повод вообще трудно найти, потому что, как бы вы ни старались,
заставить эти операторы вести себя, как положено, вам не удастся.
Правило 8. Различайте значение
операторов new и delete
Иногда кажется, что люди специально стараются затруднить понимание тер-
минов языка C++. Примером тому может служить разница между операторами
new и operator new.
В коде:
string *ps = new string ("Memory Management") ;
используется оператор new. Этот оператор является встроенным, так же как, на-
пример, sizeof, и его действие нельзя изменить. Он выполняет две функции. Во-
первых, выделяет память, достаточную для размещения объекта указанного типа.
В вышеприведенном примере это объект string. Во-вторых, вызывает конструк-
тор для инициализации объекта в выделенной памяти. Оператор new всегда вы-
полняет обе названные функции, и его поведение изменить нельзя.
Зато можно изменить способ, которым выделяется память для объекта. Для
выделения памяти оператор new вызывает специальную функцию и, чтобы изме-
нить поведение оператора, эту функцию допускается переписать или перегрузить.
Имя функции — operator new.
Функция operator new обычно объявляется следующим образом:
void* operator new(size_t size) ;
Тип возвращаемого значения — void*, потому что функция возвращает ука-
затель на неинициализированную память. (По желанию можно написать другую
версию функции operator new, записывающую в выделяемую память какое-
либо значение, но обычно никто этого не делает.) Аргумент типа size_t указы-
вает размер памяти, которую нужно выделить. Можно перегрузить функцию
operator new, добавив дополнительные аргументы, но тип первого аргумента
всегда должен быть равен size_t.
У программистов очень редко возникает необходимость вызывать функцию
operator new непосредственно, но когда это приходится делать, она вызывает-
ся, как любая другая функция:
void *rawMemory = operator new(sizeof (string) ) ;
В этом примере функция operator new вернет указатель на область памяти,
достаточно большую для хранения объекта string.
52
Hi
Операторы
Единственная задача функции operator new, так же как и оператора mallee,
состоит в выделении памяти. О конструкторах она ничего не знает. Оператор new
получит неинициализированную память, выделенную функцией operator new,
и преобразует ее в объект. При обработке строки программы типа:
string *ps = new string ("Memory Management") ;
компиляторы создадут код, похожий на:
void *memory =
operator new (sizeof(string)) ;
call string::string("MemoryManagement")
on *memory ;
string *ps =
static_cast<string*>(memory);
// Получить
// неинициализированную
/ / память для объекта
//string.
/1 Инициализировать объект
/ / в памяти,.
// Создать указатель
/ / на новый объект.
Заметьте, что на втором шаге вызывается конструктор. Использовать кон-
структор для инициализации уже выделенной памяти (включая такой ключевой
элемент, как таблица виртуальных функций объекта - см. правило 24) програм-
мисту запрещено. В этом смысле компиляторы выше простых смертных, они мо-
гут делать, что захотят. Программист же должен использовать для создания дина-
мического объекта оператор new.
Буферизованный оператор new
Иногда необходимо вызвать конструктор непосредственно. Вызов конструк-
тора для уже существующего объекта особого смысла не имеет, потому что ини-
циализировать объект по начальным данным можно только один раз. Но иногда
уже есть область выделенной памяти, и требуется создать в ней объект. Для этого
служит специальная форма функции operator new, которая называется буфери-
зованным оператором new.
В качестве примера использования данного оператора рассмотрим следу-
ющий код:
class Widget{
public:
Widget(intwidgetsize) ;
};
Widget * constructWidgetlnBuf f er (void *buf f er,
Intwidgetsize)
{
return new (buffer) Widget (widgetsize) ;
}
Эта функция возвращает указатель на объект Widget, который создается
в буфере, передаваемом функции в качестве аргумента. Данная функция может
53
Правило 8 HIM!
применяться в приложениях, которые используют разделяемую память или ввод/
вывод с отображением в память, потому что объекты в таких приложениях разме-
щаются по известным адресам памяти или тем, которые выделены при помощи спе-
циальных процедур. (Другой пример использования буферизованного оператора
new см. в правиле 4.)
Функция constructWidgetlnBuf f er возвращает значение:
new (buffer)Widget(widgetsize)
Приведенное выражение поначалу может показаться вам немного странным,
но на самом деле это просто форма оператора new с дополнительным аргументом
(buffer), который передается для неявного вызова функции operator new.
Здесь operator new помимо обязательного аргумента типа size_t принимает
дополнительный параметр типа void*, указывающий на область памяти, в кото-
рой должен разместиться создаваемый объект. Эта функция operator new пред-
ставляет собой буферизованный оператор new, и ее реализация выглядит пример-
но так:
void* operatornew(size_t, void*location)
{
return location;
}
Возможно, реализация выглядит проще, чем вы предполагали, но это все, что
должен сделать буферизованный оператор new. Действительно, основная задача
функции operator new состоит в том, чтобы найти область памяти для размеще-
ния объекта и вернуть указатель на нее. В случае буферизованного оператора new
вызывающий модуль уже знает, где должен быть расположен объект и чему дол-
жен быть равен указатель на содержащую его область памяти. Поэтому все, что
должен сделать буферизованный оператор new, - это вернуть переданный ему
указатель. (Имя неиспользованного (но обязательного) аргумента типа size_t
не указано, чтобы компиляторы не генерировали соответствующее предупрежде-
ние - см. правило 6.) Буферизованный оператор new является частью стандарт-
ной библиотеки C++. Для его использования достаточно добавить директиву
#include <new> (или, если ваши компиляторы пока не поддерживают имена
файлов заголовков нового типа, <new.h>).
Если на минуту отвлечься от буферизованного оператора new, то вы увидите,
что взаимоотношения между оператором new и функцией operator new хотя
и запутаны терминологически, по своей концепции довольно ясны.
Для создания динамического объекта нужно использовать оператор new. Он
и выделяет память, и вызывает конструктор объекта. Чтобы выделить память без
вызова конструктора, нужно включить в код функцию operator new. Если для
создания динамических объектов вам требуется какой-либо специальный ме-
ханизм выделения памяти, придется написать собственную версию функции ope-
rator new. При вызове оператора new эта функция вызывается автоматически.
Для создания объекта в области памяти, указатель на которую уже получен, сле-
дует использовать буферизованный оператор new.
54
III
Операторы
Удаление объектов и освобождение памяти
Чтобы избежать утечки ресурсов, каждый выделенный участок памяти нужно
после использования освободить. Функция operator delete соотносится со
встроенным оператором delete так же, как функция operator new с операто-
ром new. При компиляции следующего примера:
string*ps;
delete ps; // Использование оператора delete.
ваши компиляторы должны создать код не только для удаления объекта, на кото-
рый указывает переменная ps, но и для освобождения памяти, занимаемой этим
объектом.
Освобождение памяти производит функция operator delete, обычно
объявляемая так:
voidoperator delete(void *memory ToBeDeallocated) ;
Следовательно, при компиляции
delete ps;
генерируется код, который примерно соответствует следующему:
ps->~string(); //Вызов деструктора объекта.
operator delete(ps); //Освободим память,занятую
//объектом.
Отсюда следует, что если вы хотите работать только с неинициализированной
памятью, нельзя работать с операторами new и delete. Вместо этого для выделе-
ния памяти следует использовать функцию operator new, а для освобождения
памяти - функцию operator delete:
void *buffer = //Выделяемпамятьдля хранения
operatornew(50*sizeof(char)); //50 символов;
11 конструкторы не вызываем.
operatordelete(buffer); //Освобождаем память;
/ / деструкторы не вызываем.
Эти функции языка C++ эквивалентны функциям malloc и free.
Если для создания объекта в некоторой области памяти был использован бу-
феризованный оператор new, то для ее освобождения нельзя использовать опера-
тор delete. Это связано с тем, что оператор delete вызывает для освобождения
памяти функцию operator delete, но поскольку память, содержащая объект, не
была выделена в результате вызова функции operator new; буферизованный
оператор new просто вернул указатель, переданный ему в качестве аргумента. При-
чем неизвестно, откуда взялся этот указатель. Поэтому необходимо отменить дей-
ствие конструктора явным вызовом деструктора объекта:
void * mallocshared(size_t size); // Функции для выделения
void freeShared(void ‘memory); // и освобождения областей
Правило 8
Mini
55
void *sharedMemory = mallocShared(sizeof(Widget)); // разделяемой
памяти.
Widget *pw= // Как и в предыдущих примерах,
ConstructWidgetlnBuffer(sharedMemory, 10) ;
//используется буферизованный
/ / оператор new.
delete pw; //He определено! sharedMemory // создана функциейmallocShared, / / а не operator new.
pw->~Widget(); // Нормально, удаляет // o6beKTWidget, // на который указывает pw, ноне //освобождает память, занятую Widget.
freeShared(pw); //Нормально, освобождает память, на / / которую указывает pw, но не вызывает //деструктор.
Итак, чтобы предотвратить утечки памяти, неинициализированную память,
выделенную динамически (каким-либо специальным способом) и переданную бу-
феризованному оператору new, следует освобождать.
Массивы
Все рассмотренные выше примеры относились к единичным объектам. А как
насчет выделения памяти для массива? Что произойдет, например, здесь?
string *ps = new string [10] ; //Создаем массив объектов.
Оператор new остался тем же самым, но поскольку создается массив объек-
тов, его поведение слегка меняется. Во-первых, память выделяется не с использо-
ванием функции operator new, а при помощи эквивалентной функции для ра-
боты с массивами operator new[] (чаще ее называют «функция new для
массивов»). Аналогично функции operator new, функцию operator new[]
можно перегрузить. Это позволяет контролировать выделение памяти для масси-
вов таким же образом, как и для единичных объектов.
Функция operator new [ ] была добавлена в стандарт языка C++ сравнительно
недавно, и возможно, что ваши компиляторы ее не поддерживают. Тогда для выде-
ления памяти массиву, независимо от типа его элементов, будет использован гло-
бальный оператор new. Настройка механизма выделения памяти для массивов при
этом усложняется, так как требует изменений в глобальной функции operator new.
Не следует недооценивать данную задачу. По умолчанию глобальная функция
operator new отвечает за все операции выделения памяти в программе, и вмеша-
тельство в ее механизм может привести к очень серьезным последствиям. Более того,
существует только одна глобальная функция operator new «нормального» вида (то
есть имеющая единственный аргумент типа size_t), поэтому если вы перепишете
ее, ваше программное обеспечение тут же станет несовместимым с любой библиоте-
кой, использующей эту функцию. (См. также правило 27). Поэтому тем, чьи компи-
ляторы не поддерживают функцию operator new [ ], не стоит пытаться разрабаты-
вать собственные механизмы выделения памяти для массивов.
56
Второе отличие оператора new для массивов от оператора new для единичных
объектов - это количество вызываемых конструкторов. Для создания массива не-
обходимо вызвать конструктор для каждого его элемента:
string*ps= //Вызываем operatornew[] для
new string[10]; //выделения памяти,способной
/ / хранить 10 объектов типа
//string, затемвызываем
// конструктор по умолчанию для
//каждогоэлементамассива.
Аналогично, при вызове оператора delete для массива вызывается сначала де-
структор для каждого элемента массива, а затем функция operator delete [ ]
для освобождения памяти:
delete [] ps; //Вызываем деструктор str ing
/ / для каждого элемента массива,
//a затеморегабогdelete[ ]
/ / для освобождения
//памяти, занятой массивом.
Так же, как и функция operator delete, функция operator delete [ ] мо-
жет быть переопределена или перегружена. Однако на код, перегружающий эту
функцию, накладываются строгие ограничения, с которыми можно ознакомиться
в книгах по языку C++ для профессиональных программистов. (См. список на
стр. 287.)
Операторы new и delete являются встроенными и не могут быть изменены
программистом, но функции, отвечающие за выделение и освобождение памяти,
модифицировать допускается. Таким образом, можно попытаться повлиять на то,
как операторы new и delete выполняют свои функции, но что они при этом де-
лают, определяется спецификациями языка.
Глава 3. Исключения
Введение исключений в стандарт языка C++ совершенно изменило жизнь програм-
мистов, хотя, возможно, и не в лучшую сторону. Например, использование про-
стых указателей стало рискованным. Увеличилось количество потенциальных ис-
точников утечки ресурсов. Стало труднее разрабатывать конструкторы и деструк-
торы, которые бы вели себя предсказуемым образом. Приходится принимать спе-
циальные меры, чтобы программы не останавливались внезапно во время своей
работы. В целом исполняемые модули и библиотеки выросли в размерах
и потеряли в производительности.
И это только вершина айсберга. Сообщество C++ еще не знает о многих за-
труднениях, связанных с корректной разработкой программ, использующих ме-
ханизм исключений. В настоящее время не существует стандартных технологий,
применение которых обеспечивает предсказуемость и надежность обработки ис-
ключений. (Чтобы получить представление о некоторых проблемах, см. статью
Тома Каргилла, ссылка на которую приведена на стр. 285.)
Пока известно только следующее: использующие механизм исключений и при
этом корректно работающие программы появляются не случайно, а требуют тща-
тельного проектирования. Вероятность того, что не спроектированная специаль-
ным образом программа поведет себя нормально при возникновении исключения,
примерно равна вероятности того, что не предназначенная для многопоточного
исполнения программа будет работать в многопоточной реализации, то есть рав-
на нулю.
Если это так, зачем вообще использовать исключения? Программистам на
языке С было вполне достаточно кодов ошибок еще со времен изобретения С,
зачем же связываться с исключениями, если они несут столько проблем? Причи-
на все-таки есть: исключения нельзя просто проигнорировать. Если функция со-
общает о возникновении исключительной ситуации, устанавливая флаг статуса
или возвращая код ошибки, то нет никакой гарантии, что модуль, вызвавший
функцию, проверит этот флаг или код возврата. В результате работа программы
может продолжиться, невзирая на исключительную ситуацию. Если же функция
сообщает об опасной ситуации с помощью исключения, а это исключение не об-
рабатывается, выполнение программы тут же прекращается.
Такое поведение на языке С можно смоделировать, используя функции
set jmp и longjmp. Будучи перенесена в язык C++, функция longjmp приобре-
ла один очень существенный недостаток: при выравнивании стека она не вызы-
вает деструкторы локальных объектов. Но без вызова этих деструкторов боль-
шинство программ на языке C++ просто не будут работать, поэтому set jmp
и long j mp вряд ли можно использовать вместо настоящих исключений. Если вам
58
III
Исключения
нужен метод, который позволяет отследить возникновение исключительных ситу-
аций и не позволяет их игнорировать, а также гарантирует вызов локальных дест-
рукторов при просмотре стека в поисках обработчика исключительных ситуаций,
то вам просто не обойтись без исключений языка C++.
Поскольку вам предстоит еще многое узнать про обработку исключительных
ситуаций, последующие правила представляют собой далеко не полное руковод-
ство по написанию надежного программного обеспечения. Тем не менее, они со-
держат важные принципы, полезные всякому, кто хочет использовать исключе-
ния в стиле языка C++. Следуя приведенным ниже рекомендациям, вы увеличите
корректность, надежность и эффективность ваших программ, избежав многих
ловушек, которые обычно возникают при использовании исключений.
Правило 9. Чтобы избежать утечки ресурсов,
используйте деструкторы
Итак, попрощаемся с указателями, хотя, конечно, не со всеми. Однако указа-
тели, используемые, например, для доступа к локальным ресурсам, нам больше не
понадобятся. Предположим, что вы пишете программное обеспечение для орга-
низации, которая называется «Приют милых маленьких животных» и подыски-
вает новый дом для щенков и котят. Каждый день в организации создается файл,
где перечисляются все случаи передачи питомцев в хорошие руки за день, и ваша
задача - написать программу, считывающую этот файл и осуществляющую необ-
ходимую обработку данных.
Разумнее всего создать базовый класс ALA (Adorable Little Animal - милое
маленькое животное) и конкретные производные классы: Puppy для щенков
и Kitten для котят (см. рис. 3.1). Виртуальная функция process Adopt ion про-
изводит необходимую обработку данных, зависящую от вида животного:
class ALA {
public:
virtualvoidprocessAdoption() = 0;
};
class Puppy: public ALA {
public:
virtual void processAdopt ion () ;
59
Правило 9 1НПП
classKitten: publicALA {
public:
virtual voidprocessAdoptionf) ;
};
Также потребуется функция, считывающая информацию из файла и создаю-
щая, в зависимости от типа записи в нем, либо объект Puppy (щенок), либо объект
Kitten (котенок). С этой задачей отлично справится виртуальный конструктор,
функция, описанная в правиле 25. Здесь достаточно привести только ее объявление:
// Считываем информацию о животном из s, затем возвращаем
//указатель на только что созданный объект подходящего типа.
ALA * readALA( istreamk s) ;
Скорее всего, центральным местом вашей программы будет примерно та-
кая функция:
voidprocessAdoptions(istreamkdatasource)
{
while (datasource) .{ //Пока есть данные,
ALA *ра = readALA (dataSource); //считываем
11 следующую запись
/ / о животном.
pa->processAdoption() ; // Обработываем сведения
//о передаче животного,
deletepa; //Удаляемобъект,который
} //вернула функция readALA.
}
Эта функция последовательно считывает информацию из потока data-
Source и последовательно же обрабатывает каждую запись. Единственная тон-
кость состоит в том, чтобы не забыть удалять объект ра в конце каждой итерации
цикла (это необходимо, поскольку функция readALA создает при каждом вызове
новый динамический объект). В противном случае возникнет утечка ресурсов.
Теперь посмотрим, что случится, если во время выполнения функции
pa->processAdoption возникнет исключение. Функция processAdoptions
не содержит нужного обработчика, поэтому исключение распространится в мо-
дуль, вызвавший processAdoptions. В результате все операторы в теле
processAdoptions, находящиеся там после вызова pa->processAdoption, бу-
дут пропущены, и объект ра не удалится. Таким образом, утечка ресурсов будет
происходить каждый раз, когдаpa->processAdoption сгенерирует исключение.
Прекратить утечку несложно:
voidprocessAdoptions(istreamkdatasource)
{
while (datasource) {
ALA *pa = readALA(dataSource);
try {
pa->processAdoption();
}
60
catch (...) {
delete ра;
throw;
}
deleteра;
Исключения
I / Перехватываем все исключения.
//Устраняемутечкуресурсов
//при возбуждении исключения.
//Передаемисключение вызывающему
//модулю.
// Устраняемутечкуресурсов
/ / в отсутствие исключительных
//ситуаций.
}
Однако при этом текст программы засоряется блоками try и catch. Кроме
того, приходится дублировать завершающий код, общий для нормального и ава-
рийного выполнения программы. Как и при каждом дублировании, этот код не-
приятно писать и трудно поддерживать, но, что еще хуже, появляется мысль о его
ошибочности. Ведь удалять объект ра нужно независимо от того, нормальным или
аварийным путем вы покидаете функцию processAdoptions, зачем же делать
это в нескольких местах?
Повтора можно было бы избежать, если бы удалось каким-либо образом по-
местить завершающий код в деструктор локального по отношению к process-
Adoptions объекта. Локальные объекты при выходе из функции удаляются
всегда, независимо от причины выхода. (Единственное исключение из данного
правила - вызов longjmp, и именно этот недостаток longjmp является ос-
новной причиной, по которой язык C++ вообще поддерживает исключения.)
Итак, ваша задача состоит в том, чтобы перенести оператор delete из функции
process-Adopt ions в деструктор локального для функции processAdoptions
объекта.
Для решения задачи необходимо заменить указатель ра на объект, который
действует как указатель. Тогда при удалении (автоматическом) этого объекта,
похожего на указатель, можно заставить его деструктор вызвать delete. Объек-
ты, которые похожи на указатели, но таковыми не являются, называют smart-ука-
зателями (интеллектуальными указателями — подробнее о них см. в правиле 28).
В данном случае не нужен особенно «умный» указатель; требуется только похо-
жий на указатель объект, умеющий удалять объект, на который указывает, когда
покидает область видимости.
Самостоятельно создавать класс для таких объектов несложно, но в этом и нет
особой нужды. Стандартная библиотека языка C++ содержит шаблон классов
с именем auto_ptr, который делает все необходимое. Каждый класс auto_ptr
принимает указатель на динамический объект в качестве аргумента конструктора
и удаляет данный объект в деструкторе. Если ограничиться этими важными функ-
циями, то реализация auto_ptr выглядит следующим образом:
templatecclass Т>
class auto_ptr {
public:
auto_ptr(Т *р = 0) :ptr(р) {} //Сохраняемуказательptr
/ / на объект.
61
~auto_ptr() { delete ptr; } //Удаляемуказатель
//на объект.
private:
T *ptr; //Неиницализированный
/ / указатель на объект.
};
Стандартная версия класса auto_ptr выглядит гораздо более изощренно,
а приведенная усеченная реализация не годится для практического использова-
ния*. Для этого к ней следует добавить, по крайней мере, конструктор копиро-
вания, оператор присваивания и функции, эмулирующие поведение указателя
(см. правило 28). Однако основная идея ясна: если использовать объекты
auto_ptr вместо обычных указателей, то даже при возникновении исключений
не нужно будет беспокоиться о неудаленных динамических объектах. Из-за того,
что деструктору auto_ptr соответствует оператор delete для единичных
объектов, объекты auto_ptr не могут применяться вместо указателей на мас-
сивы элементов. Шаблон, выполняющий функции auto_ptr для массивов, вам
придется разработать самостоятельно. Вообще же говоря, в таких случаях более
удачным конструктивным решением является использование вместо массива
объекта типа vector.
При замене указателя на объект auto_ptr функция processAdoptions
приобретет следующий вид:
void processAdopt ions(istreams datasource)
{
while(datasource){
auto_ptr<ALA>pa(readALA(dataSource)) ;
pa->processAdoption();
}
}
Эта версия функции processAdoptions имеет два отличия от предыдущей.
Во-первых, ра объявлен как объект типа auto_ptr<ALA>, а не как указатель на
ALA*. Во-вторых, в конце тела цикла отсутствует оператор delete. Все осталь-
ное не изменилось, потому что, за исключением удаления, объекты auto_ptr ве-
дут себя как обычные указатели. Просто, не правда ли?
Идея, лежащая в основе auto_ptr - использовать объект для хранения ре-
сурсов, которые должны освобождаться автоматически, и возложить функцию
освобождения на деструктор этого объекта, - может применяться не только для
указателей. Рассмотрим функцию визуального приложения, создающую окно для
отображения некоторой информации:
/ / Эта функция может порождать утечку ресурсов
// при возбуждении исключения.
void di splayInfо(const Informations info)
{
Полная реализация почти стандартного шаблона auto-ptr приведена на стр. 289-292.
62
hbhi
Исключения
WINDOW_HANDLE w (createWindow()) ;
здесь отображаем информацию в окне с дескриптором w;
destroyWindow(w);
}
Многие оконные системы имеют интерфейс, подобный тому, что создается
с помощью языка С. Такой интерфейс использует функции типа createWindow
и releasewindow для захвата и освобождения ресурсов окна. Если исключение
возникнет в процессе отображения данных inf о в окне w, то ресурсы этого окна
будут потеряны так же, как и любые другие динамически выделяемые ресурсы.
Решение проблемы остается прежним. Надо создать класс, конструктор и де-
структор которого захватывают и освобождают необходимый ресурс:
/ / Класс для захвата и освобождения дескриптора окна.
classWindowHandle{
public:
WindowHandle(WINDOW_HANDLEhandle) :w(handle) {}
-WindowHandle() { destroyWindow(w) ; }
operator WINDOW_HANDLE() {returnw; }//См. ниже.
private:
WINDOW_HANDLEw;
//Нижеприведенные функции объявлены как private, чтобы
/ / запретить создание нескольких копий WINDOW_HANDLE.
/ / См. правило 2 8 , где описан более гибкий подход.
WindowHandle(const WindowHandlek);
WindowHandlek operator=(const WindowHandlek) ;
};
Все это очень похоже на шаблон auto_ptr, но с тем отличием, что опера-
торы присваивания и копирования явно запрещены, а для преобразования
WindowHandle в WINDOW_HANDLE определен оператор неявного преобразования
типа. Этот оператор имеет серьезное практическое значение, потому что теперь вез-
де, где раньше использовался обычный WINDOW_HANDLE, можно вместо него вклю-
чать в код WindowHandle. (Как вы помните, с операторами неявного преобразова-
ния типа нужно обращаться очень осторожно - см. правило 5.)
С помощью класса WindowHandle можно переписать функцию displayinfo
следующим образом:
// Эта функция предотвращает утечку ресурсов
// при возникновенииисключения.
voiddisplayinfo (const Informations: info)
{
WindowHandlew(createWindow()) ;
отображаем данные info в окне w;
}
Даже при возникновении исключения в теле функции display Inf о окно, со-
зданное функцией createWindow, будет удалено.
Итак, даже используя исключения, можно избежать утечек ресурсов, если сле-
довать правилу размещения ресурсов внутри объектов. Но что произойдет, если
Правило 10
63
исключение возникнет в тот момент, когда программа как раз находится
в процессе захвата ресурса, то есть внутри конструктора класса, который требует
выделения ресурсов? А что произойдет, если исключение будет возбуждено во
время автоматического освобождения таких ресурсов? Может быть, конструкто-
ры и деструкторы требуют специального обращения? Ответам на эти вопросы
посвящены правила 10 и И.
Правило 10. Не допускайте утечки ресурсов
в конструкторах
Представьте, что вы разрабатываете программу для мультимедийной адресной
книги. Наряду с обычной текстовой информацией: полным именем, адресом
и телефонным номером - книга могла бы содержать фотографии людей и образ-
цы их речи (например, в виде правильного произношения имени).
Ваша программа могла бы иметь следующий вид:
class Image { //Изображение.
public:
Image(const string^ imageDataFileName);
};
classAudioClip{ //Звуковые данные.
public:
AudioClip (const stringb audioDataFileName) ;
};
class PhoneNumber{...}; //Телефонныйномер.
class BookEntry { / / Единичная запись в адресной
public: //книге.
BookEntry(const string&name,
const string^ address = "",
const string^ imageFileName = "",
const string& audioClipFileName = "") ;
-BookEntry();
11 Эта функция добавляет
/1 телефонный номер.
voidaddPhoneNumber(const PhoneNumberk number);
private:
string theName ;
string theAddre s s ;
list<PhoneNumber> thePhones;
Image*thelmage;
AudioClip *theAudioClip;
11 Полное имя человека.
/1 Адрес.
I/Телефонные номера.
I/ Изображение.
/ /Аудиоклип.
Каждая запись BookEntry должна содержать полное имя человека. Следова-
тельно, это обязательный аргумент конструктора (см. правило 4), а все остальные
64
III
Исключения
данные - адрес человека, имена файлов, содержащих видео- и аудиоинформа-
цию - не обязательны. Обратите внимание на использование класса list для хра-
нения телефонных номеров, который является одним из контейнерных классов
стандартной библиотеки языка C++ (см. правило 35).
Простейший вариант конструктора BookEntry выглядит так:
BookEntry: :BookEntry (const string&name,
const string& address = " ”,
const string^ imageFileName = " ’,
const str ing& audioClipFileName = " “)
: theName(name),theAddress(address),
thelmage(O),theAudioClip(0)
{
if (imagefileName!= "") {
thelmage = new Image (imageFileName) ;
}
if(audioClipFileName! = "") {
theAudioClip = new AudioClip (audioClipFileName) ;
}
}
BookEntry::-BookEntry()
{
delete thelmage ;
delete theAudioClip;
}
Конструктор обнуляет указатели thelmage и theAudioClip, а затем, если
соответствующие аргументы содержат нормальные имена файлов, создает для них
реальные объекты. Деструктор удаляет эти объекты, не допуская тем самым уте-
чек памяти в объекте BookEntry. Язык C++ гарантирует безопасность удаления
нулевых указателей, поэтому деструктор BookEntry не проверяет, ссылаются ли
указатели на реальные объекты.
Пока все выглядит хорошо, и при нормальных условиях все бы прекрасно
работало, но при исключительных ситуациях появятся некоторые проблемы.
Посмотрим, что произойдет, если исключение возникнет во время выполне-
ния следующей части конструктора BookEntry:
if (audioClipFileName!="") {
theAudioClip = new AudioClip(audioClipFileName);
}
Исключение может возникнуть, например, потому что operator new (см.
правило 8) не может выделить достаточно памяти для объекта AudioClip. Оно
может также возникнуть в самом конструкторе AudioClip. Но, независимо от
причины появления, исключение, возникшее в конструкторе BookEntry, распро-
странится в точку, где создается объект BookEntry.
Итак, если исключение возникает во время создания объекта, на который
должен указывать theAudioClip (передавая управление в точку, внешнюю по
65
Правило 10 HIM
отношению к конструктору BookEntry), что удалит объект, на который уже ука-
зывает thelmage? Ответ, как кажется, очевиден - деструктор BookEntry, но это
неверно. Деструктор BookEntry не будет вызван никогда.
В языке C++ удаляются только полностью сконструированные объекты, то
есть такие, конструкторы которых уже завершили выполнение кода. Тем самым,
если объект Ь типа BookEntry создается как локальный объект:
void testBookEntryClass()
{
BookEntryb( "Addison-Wesley Publishing Company11 ,
"OneJacobWay,Reading,MA01867");
}
и в процессе создания b возникает исключение, то деструктор для объекта b не
будет вызван. Можно попытаться взять контроль в свои руки и выделить память
для b динамически, а затем, при возникновении исключения, вызывать оператор
delete:
voidtestBookEntryClass()
{
BookEntry *pb = 0 ;
try {
pb = new BookEntry b (
"Addison-Wesley Publishing Company",
"One JacobWay, Reading, MA01867 ") ;
}
catch (...) {
delete pb;
throw;
}
delete pb;
}
/ / Перехватываем все исключения.
/ / Удаляем pb при появлении
//исключения.
//Передаем обработку исключения
//вызывающему модулю.
// УдаляемрЬобычнымобразом.
Тем не менее, объект Image, созданный в конструкторе BookEntry, будет по-
терян, потому что присваивание pb произойдет не раньше, чем успешно закон-
чит работу оператор new. Если исключение возникнет внутри конструктора
BookEntry, то значение pb останется равным нулю, поэтому его удаление
в блоке catch не вызовет никаких действий. Использование вместо BookEntry*
smart-указателей, а именно класса auto_ptr<BookEntry> (см. правило 9), так-
же не даст результата, потому что присваивание pb все равно не произойдет по
той же причине.
Конечно, деструкторы для не полностью построенных объектов не вызывают-
ся в языке C++ вовсе не потому, чтобы усложнить жизнь программистам. Во мно-
гих случаях подобные действия не только не имели бы никакого смысла, но
3-679
Исключения
66
и были бы потенциально опасными. Если бы деструкторы вызывались для объек-
тов, создание которых не завершено, как деструкторы могли бы определить, что им
делать? Единственный выход состоял бы в том, чтобы снабдить объекты статусны-
ми битами, показывающими, насколько продвинулось выполнение конструктора.
Но это увеличило бы размеры объектов и замедлило выполнение конструкторов.
Примененный в языке C++ подход позволяет избежать такой дополнительной ра-
боты, но платить приходится тем, что частично сконструированные объекты не
удаляются автоматически.
Поскольку в языке C++ не освобождаются ресурсы, выделенные объектам, во
время создания которых возникают исключения, то необходимо проектировать
конструкторы так, чтобы они делали это сами. Часто бывает достаточно просто
перехватить все возможные исключения, выполнить код завершения, а затем пе-
редать исключение для дальнейшей обработки. Для объекта BookEntry это мо-
жет выглядеть следующим образом:
BookEntry: : BookEntry (const strings name,
const string^ address = ” ",
const strings imageFileName = "" ,
const strings audioClipFileName = "")
:theName(name),theAddress(address) ,
thelmage(O) , theAudioClip(0)
{
try { //Это новый блок try.
if (imageFileName! = "") {
thelmage = new Image (imageFileName) ;
}
if (audioClipFileName!="") {
theAudioClip=
new AudioClip(audioClipFileName);
}
}
catch(...){ //Перехватываем все исключения,
delete theImage; //Выполняемнеобходимые
delete theAudioClip; // операции очистки.
throw; //Вызываем исключение
/1 для дальнейшей обработки .
}
}
Не следует волноваться по поводу элементов-данных, не являющихся указа-
телями. Они инициализируются автоматически перед вызовом конструктора
класса, поэтому, когда конструктор BookEntry начинает выполняться, элементы
данных объекта theName, theAddress и thePhones уже полностью созданы.
Значит, они будут удалены одновременно с объектом типа BookEntry, которому
принадлежат, и вмешательство программиста здесь не нужно. Разумеется, если
конструкторы этих объектов вызывают функции, способные привести к исключе-
ниям, то такие конструкторы должны побеспокоиться о перехвате исключений
и выполнении операций очистки перед тем, как передать исключения далее.
Правило 10
67
Можно заметить, что код в блоке catch конструктора BookEntry почти со-
впадает с кодом в деструкторе BookEntry. Не стоит дублировать код ни в этом
месте программы, ни где бы то ни было еще, поэтому чтобы улучшить программу,
стоит поместить общий код в закрытую функцию и вызывать ее из конструктора
и деструктора:
class BookEntry {
public:
private:
//Без изменений.
voidcleanup О ; //Общие операцииочистки.
};
voidBookEntry::cleanup()
{
delete thelmage;
delete theAudioClip;
}
BookEntry: : BookEntry (const strings name,
const string^ address = "",
const string^ imageFileName = "",
const stringsaudioClipFileName = " “)
: theName(name) , theAddress(address) ,
thelmage(0),theAudioClip(0)
{
try {
... //Без изменений.
}
catch (...) {
cleanup(); //Освобождаемресурсы.
throw; //Передаемисключение
/ / для дальнейшей обработки.
}
}
BookEntry::-BookEntry()
{
cleanup();
}
Все это хорошо, но кое-какие проблемы еще остаются. Переделаем класс
BookEntry таким образом, чтобы thelmage и theAudioClip стали констант-
ными указателями:
classBookEntry {
public:
... // Как и ранее.
private:
,Image * const thelmage; // Теперь указатели имеют
AudioClip * const theAudioClip; // атрибут const.
};
3*
68
III
Исключения
Указатели данного типа необходимо инициализировать с помощью списков
инициализации в конструкторе BookEntry, потому что другого способа сделать
это для указателей с атрибутом const нет. Очень часто возникает искушение ини-
циализировать thelmage и theAudioClip следующим образом:
// Реализация, которая может привести к утечке ресурсов
/ / при возникновении исключения.
BookEntry: : BookEntry (const strings name,
const strings address = "",
const strings imageFileName= "",
const strings audioClipFileName = "")
: theName(name),theAddress(address) ,
thelmage(imageFileName ! = ""
? new Iamge (imageFi 1 eName)
' : 0) ,
theAudioClip(audioClipFileName != ""
? new AudioClip(audioClipFileName)
: 0)
{}
Но это снова приводит к начальной проблеме: если исключение возникает во
время инициализации theAudioClip, объект, на который указывает thelmage,
не будет удален никогда. Более того, нельзя решить проблему, добавив в кон-
структор блоки try и catch, потому что try и catch являются операторами,
а список инициализации элементов может включать только выражения. (В част-
ности поэтому при инициализации указателей thelmage и theAudioClip при-
шлось использовать символы ? : вместо конструкции if-then-else.)
Единственный способ выполнить код завершения перед тем, как обработка
исключения выйдет за пределы конструктора, - перехватить эти исключения.
Поэтому, если нельзя разместить блоки try и catch в списке инициализации,
значит, придется разместить их где-то еще. Например, внутри внутренних функ-
ций, возвращающих указатели, значениями которых инициализируются объекты
thelmage и theAudioClip:
class BookEntry {
public:
... //Без изменений.
private:
... // Элементы данных без изменений.
Image * initlmage (const strings imageFileName) ;
AudioClip * initAudioClip (const strings
AudioClipFileName);
} ;
BookEntry : : BookEntry (const strings name ,
const strings address = "",
const strings imageFileName = "",
const strings audioClipFileName = "")
Правило 10
II»
69
: theName(name), theAddress(address) ,
thelmage(initlmage(imageFileName)),
theAudioClip(initAudioClip(audioClipFileName))
{}
// Объект thelmage инициализируется первым, следовательно, не стоит
// волноваться об утечке ресурсов, если инициализация
/ / окончится неудачно. Поэтому данная функция
// не обрабатывает исключения.
Image * BookEntry: : initlmage (const strings imageFileName)
{
if (imageFileName != "") return new Image (imageFileName) ;
else return 0;
}
// Объект theAudioClip инициализируется вторым.
// Значит, необходимо принять меры по освобождению ресурсов,
// выделенных объекту thelmage,
// если во время инициализации
/ / theAudioClip возникнет исключение.
/ / Поэтому функция содержит блоки try и catch.
AudioClip * BookEntry::initAudioClip(const strings
AudioClipFileName)
{
try {
if (audioClipFileName != "") {
return new AudioClip (audioClipFileName) ;
}
else return 0 ;
}
catch (...) {
delete thelmage;
throw;
}
Этот фрагмент программы вполне работоспособен, и в нем даже решена глав-
ная проблема. Недостаток такого подхода состоит в том, что код, концептуально
принадлежащий конструктору, оказался разбросанным по нескольким функциям,
осложняя поддержку подобного программного обеспечения.
Более грамотно будет принять рекомендацию правила 9 и считать объекты,
на которые указывают thelmage и theAudioClip, ресурсами, управляемыми
с помощью локальных объектов. Можно использовать то обстоятельство, что
thelmage и theAudioClip являются указателями на динамически построенные
объекты и при удалении указателей также должны быть удалены. Это именно те
условия, для которых были сконструированы классы auto_ptr (см. правило 9).
Следовательно, можно заменить обычные указатели типов thelmage и the-
AudioClip на их эквиваленты типа auto_ptr:
Исключения Ц
70
III
class BookEntry {
public:
private:
// Без изменений.
const auto_ptr<Image> thelmage; //Теперь это
const auto_ptr<AudioClip> theAudioClip; //объекты
/ / типа auto_ptr.
};
Такой подход предотвращает утечку ресурсов в конструкторе BookEntry при
возникновении исключений и позволяет инициализировать объекты thelmage
и theAudioClip в списке инициализации:
BookEntry: : BookEntry (const strings name,
const strings address = "",
const strings imageFileName = "",
const strings audioClipFileName = "")
: theName(name) , theAddress(address) ,
thelmage(imageFileName ! = ""
? new Image (imageFileName)
: 0) ,
theAudioClip(audioClipFileName != ""
? new AudioClip(audioClipFileName)
: 0)
{}
Если исключение возникнет во время инициализации объекта theAudio-
Clip, то объект thelmage уже будет полностью сконструирован, а значит, и ав-
томатически удален наряду с объектами theName, theAddress и thePhones.
Более того, поскольку теперь thelmage и theAudioClip являются объектами,
они будут уничтожены в момент удаления включающего их объекта BookEntry.
Следовательно, нет необходимости вручную удалять объекты, на которые они
указывают. Это значительно упрощает деструктор BookEntry:
BookEntry::-BookEntry()
{} //Ничего не надо делать!
Таким образом, деструктор BookEntry можно вообще не создавать.
Все вышеизложенное сводится к следующему: если заменить указатели на
соответствующие объекты auto_ptr, то снижается риск утечки ресурсов при воз-
никновении исключений и исчезает необходимость освобождать ресурсы в де-
структорах. Кроме того, члены-указатели с атрибутом const обрабатываются так
же изящно, как и указатели без этого атрибута.
Обработка исключения во время функционирования конструктора может ока-
заться не простым делом, но использование объектов auto_ptr (и классов типа
auto_ptr) существенно облегчает задачу. Их применение позволяет создать про-
стой для понимания и надежный код.
71
Правило 11 ИМИ
Правило 11. Не распространяйте обработку
исключении за пределы деструктора
Деструктор может быть вызван в двух ситуациях. Во-первых, при нормальных
условиях, то есть когда объект покидает область видимости или явно вызван опе-
ратор delete. Во-вторых - когда объект удаляется механизмом обработки исклю-
чений во время выравнивания стека.
Таким образом, в момент вызова деструктора исключение уже может быть
сгенерировано, а может и не быть. К сожалению, при исполнении кода деструкто-
ра определить нельзя*. Поэтому приходится писать деструкторы, исходя из песси-
мистического предположения, что исключение уже возникло; ведь если деструктор
при уже имеющемся исключении также генерирует исключение и управление пе-
редается в вызывающий модуль, то C++ запускает функцию terminate. Действие
этой функции полностью соответствует ее имени: она завершает выполнение про-
граммы. Более того, выполнение программы заканчивается немедленно, не удаля-
ются даже локальные объекты.
Рассмотрим в качестве примера класс Session, обеспечивающий обработку
подключения к компьютерной сети, то есть событий, которые происходят между
моментом подключения и отключения. Каждый объект Session регистрирует
время своего создания и удаления:
class Session {
public:
Session();
-Session();
private:
static void logCreation (Session *objAddr) ;
static void logDestruction (Session *objAddr) ;
};
Функции logCreation и logDestruction используются для регистрации
создания и удаления объекта соответственно. Можно предположить, что деструк-
тор Session будет иметь вид:
Session::-Session()
{
logDestruction(this);
};
Посмотрите теперь, что произойдет, если функция logDestruction сгенери-
рует исключение. Оно не будет перехвачено в деструкторе Session, а передастся
В июле 1995 года комитет стандартов по C++ ISO/ANSI добавил в спецификацию языка
функцию uncaught_exception, возвращающую true, если исключение возникло, но
не было обработано.
72
Ilf
Исключения
модулю, вызвавшему деструктор. Но если сам деструктор был вызван в результате
обработки другого исключения, то функция terminate вызывается автоматичес-
ки, и ваша программа окажется полностью разрушенной.
Не думаю, чтобы вы этого хотели. Конечно, невозможность запротоколировать
уничтожение объекта Session - серьезный недостаток, и иногда он вызывает зна-
чительные неудобства, но ничего особенно ужасного в остановке программы нет.
Поэтому достаточно принять меры, чтобы исключение, возникшее в logDe-
struct! on, не покинуло тело деструктора S е s s i on. Этого можно добиться только
с помощью блоков try и catch. Первый вариант будет иметь, например, такой вид:
Session::~Session()
{
try {
logDestruction(this);
}
catch (...) {
cerr<<
"Немогу запротоколировать уничтожение объекта Session, "
« "расположенного по адресу"
«this
«".\П";
}
Однако вряд ли этот код безопаснее предыдущего варианта. Если какой-либо
вызов оператора << в блоке catch приведет к генерации исключения, оно опять
покинет деструктор, и вы снова окажетесь там, откуда начали.
Вы легко можете разместить блок try внутри блока catch, но это решение
кажется уж слишком хитроумным. Лучше не протоколировать удаление деструк-
тора Session, если функция logDestruction генерирует исключение:
Session::~Session()
{
try {
logDestruction(this) ;
}
catch (...) {}
He заметно, чтобы блок catch выполнял какие-либо действия, но видимость
часто обманчива. Данный блок не позволяет исключениям, сгенерированным
в теле logDestruction, выходить за пределы деструктора Session, а именно
это и требуется. Теперь есть уверенность, что если объект Session удаляется
в процессе выравнивания стека, функция terminate вызвана не будет.
Существует еще одна причина, по которой не стоит допускать выход исклю-
чений за пределы деструктора. Если исключение возникает в теле деструктора
и не перехвачено там же, то его выполнение останется незавершенным. (Выпол-
нение остановится в точке генерации исключения.) Незавершенный деструктор не
Правило 12
73
выполнит своих функций до конца. Взгляните, например, на измененную версию
класса Session, в которой начало сессии запускает транзакцию в базе данных,
азавершение сессии эту транзакцию закрывает:
Session::Session()
{
logCreation(this);
startTransaction();
}
Session::~Session()
{
logDestruction(this);
endTransaction();
/ / Для упрощения этот
//конструктор не
//обрабатывает исключения
//Начнемтранзакцию
//в базе данных.
//Завершимтранзакцию
/ / в базе данных.
}
В этом варианте, если функция logDestruction генерирует исключение, то
транзакция, открытая в конструкторе Session, никогда не будет завершена. Воз-
можный вариант действий - попытаться изменить порядок вызова функций
в деструкторе Session, но если исключение способно возникнуть и внутри
endTransaction, то обязательно надо использовать блоки try и catch.
Итак, есть две серьезные причины не допускать распространение исключе-
ний за пределы деструкторов. Во-первых, это предотвращает вызов функции
terminate во время процедуры выравнивания стека. Во-вторых, гарантирует, что
деструкторы полностью выполнили свои функции. Каждый из названных аргу-
ментов убедителен сам по себе, но вместе они не оставляют и тени сомнений.
Правило 12. Отличайте генерацию исключения
от передачи параметра
или вызова виртуальной функции
Объявление списка параметров функции синтаксически очень сходно с аргу-
ментом блока catch:
class Widget
void fl(Widget w) ;
voidf2(Widget&w);
voidf3(constWidgeta w);
void f 4 (Widget *pw) ;
void f 5 (const Widget *pw) ;
catch (Widget w) . . .
catch(Widget&w) . . .
catch (constWidgeta w) . . .
catch (Widget *pw) . . .
catch (const Widget *pw) . . .
/ / Некий класс; неважно,
/ / что он делает.
/ / Все эти функции имеют аргументы
//типов Widget, Widgeta
// или Widget*.
/ / Все эти catch-блоки
// перехватывают исключения типов
//Widget, Widgeta или Widget *.
74
III
Исключения
Можно было бы предположить, что передача исключения от точки throw
в точку catch происходит по механизму, в общих чертах совпадающему с меха-
низмом передачи аргумента функции из точки ее вызова в ее тело. Однако есть
и существенные отличия.
Начнем со сходства. И аргументы функций, и исключения можно передавать
тремя способами: по значению, по ссылке и при помощи указателя. Но послед-
ствия этих вариантов передачи различаются довольно серьезно. Причина в том,
что после вызова функции управление в конечном итоге вернется в вызывающий
модуль (по крайней мере, если в функции нет ошибок), но при генерации исклю-
чения управление не возвращается в модуль, содержащий оператор throw.
Рассмотрим функцию, которая и передает тип Widget в качестве параметра,
и генерирует его как исключение:
/ / Функция читает значение Widget из потока.
istreamoperator>>(istream&s, Widget&w) ;
voidpassAndThrowWidget()
{
Widget localWidget;
cin >>localwidget; //ПередаетlocalWidget в качестве
//параметра оператору >>.
throwlocalWidget; //ГенерируетlocalWidget
/ / как исключение.
}
Когда объект localWidget передается в operator», сам localWidget не
копируется. Вместо этого ссылка w в теле operator» оказывается связанной
с объектом localWidget, и все, что происходит со ссылкой w, на самом деле про-
исходит с объектом localWidget. Если же localWidget генерируется в каче-
стве исключения, то события развиваются совсем иначе. Независимо от того, пе-
рехватывается ли исключение по ссылке или по значению (оно не может
перехватываться по указателю - это привело бы к ошибке несоответствия типов),
создается копия localWidget, которая передается в качестве аргумента блоку
catch. Так и должно быть, потому что localWidget покинет область видимос-
ти, как только управление покинет функцию passAndThrowWidget, и тогда бу-
дет вызван деструктор localWidget. Если бы в блок catch передавался сам
localWidget, то catch получал бы полуразрушенный объект типа Widget или
нечто, что было когда-то объектом типа Widget. Это было бы бесполезно, и спе-
цификация C++ определяет, что объект, генерируемый в качестве исключения,
всегда копируется.
Такое копирование происходит даже тогда, когда нет опасности, что объект
может быть уничтожен. Например, если объект localWidget в функции
passAndThrowWidget объявлен с атрибутом static:
voidpassAndThrowWidget()
{
static Widget localWidget; // Теперь это статический
//объект, онбудет
Правило 12
75
/ / существовать до конца
//программы.
cin >>localwidget ;
throwlocalWidget ;
/ / Данная часть работает
//по-прежнему.
/ / По-прежнему создается
//копияlocalWidget.
}
для генерации исключения по-прежнему будет использована копия объекта
localWidget. Это означает, что даже если исключение будет перехвачено по
ссылке, блок catch сможет изменить не сам объект localWidget, а только его
копию. Такое обязательное копирование объектов-исключений поможет вам по-
нять и другое отличие между передачей параметров и генерацией исключений:
последнее обычно выполняется намного медленнее (см. правило 15).
Когда объект копируется для использования в качестве исключения, данная
операция производится с помощью конструктора копирования. Это - единствен-
ный конструктор в классе, соответствующий не динамическому, а статическому
типу объекта. Посмотрим, например, на слегка измененную версию функции
passAndThrowWidget:
class Widget{...};
class SpecialWidget: public Widget{...);
voidpassAndThrowWidget()
{
SpecialWidgetlocalSpecialWidget;
Widgets rw =localSpecialWidget;
throw rw;
/ / rw - это ссылка
/ / на объект SpecialWidget.
//Генерируется
/ / исключение типа
//Widget!
В этом примере исключение имеет тип Widget, хотя rw является ссылкой на
SpecialWidget. Так происходит потому, что статический тип rw равен Widget,
а не SpecailWidget. В действительности же rw ссылается на SpecialWidget,
однако ваши компиляторы данный факт не воспринимают, они видят только ста-
тический тип rw. Возможно, такое поведение не совпадает с желаемым, но оно со-
гласуется со всеми другими случаями копирования объектов в C++. Копирова-
ние всегда основано на статическом типе объекта (кроме метода, описанного
в правиле 25 и позволяющего осуществлять копирование на основе динамическо-
го типа объекта).
То обстоятельство, что исключения являются копиями других объектов, вли-
яет на их распространение за пределы блоков catch. Посмотрите на эти два блока
catch, которые на первый взгляд выполняют одни и те же операции:
catch (Widget&w) //Перехватываем исключение типа Widget .
{
/ / Обрабатываем исключение .
76
Исключения
throw; //Повторно генерируем исключение для
//последующей обработки.
}
catch(Widget&w) //Перехватываемисключение типа Widget.
{
... //Обрабатываемисключение.
throw w; / / Генерируем копию перехваченного
/ / исключения для последующей обработки.
}
Как видите, первый блок повторно генерирует перехваченное исключение,
а второй - создает его новую копию. Очевидно, что во втором варианте дополни-
тельная операция копирования снижает производительность программы. Но су-
ществуют ли другие различия между этими двумя подходами?
Да, существуют. Первый блок повторно генерирует перехваченное исклю-
чение независимо от его типа. В частности, если было перехвачено исключение
типа Specialwidget, то первый блок повторно сгенерирует исключение типа
SpecialWidget, хотя статический тип w и равен Widget. Это происходит пото-
му, что при повторной генерации копия не создается. Второй блок catch генери-
рует новое исключение, которое всегда будет иметь тип Widget из-за статическо-
го типа w. Вообще говоря, желательно использовать
throw;
для повторной генерации исключения, чтобы гарантировать неизменность типа.
Кроме того, это оптимальнее с точки зрения эффективности, потому что программе
не приходится создавать новый объект-исключение.
(Кстати, копия исключения является временным объектом. Как показано
в правиле 19, это позволяет компиляторам при оптимизации генерируемого кода
уклоняться от создания копий. Тем не менее, не стоит всецело полагаться на ком-
пиляторы. Исключения используются довольно редко, поэтому маловероятно, что
производители компиляторов будут прикладывать много усилий для оптимиза-
ции обработки исключений).
Рассмотрим три типа аргументов catch, с помощью которых можно перехва-
тить исключение Widget, сгенерированное функцией passAndThrowWidget:
catch (Widget w) . . .
catch(Widget&w) . . .
catch(constWidget&w) . ..
/ / Перехват исключения по значению.
/ / Перехват исключения по ссылке.
//Перехват исключения по ссылке
//на const.
Этот фрагмент демонстрирует еще одно различие между передачей парамет-
ров и распространением исключений. Генерируемый объект-исключение (который,
как пояснено выше, всегда является временным) может быть перехвачен по про-
стой ссылке, ссылку на const можно не использовать. Передача временного объек-
та по ссылке без атрибута const запрещена при вызове функции (см. правило
19) и разрешена для исключений.
Не будем пока обращать внимание на это различие и вернемся к копирова-
нию объектов-исключений. Известно, что при передаче функции аргумента по
77
Правило 12 ЕЯИИЕЫ1
значению создается копия передаваемого объекта, которая и передается функции.
То же самое происходит при передаче исключения по значению. Таким образом,
если определить аргумент catch следующим образом:
catch (Widget w) ... //Перехват по значению.
придется создавать две копии объекта-исключения: одна для временного объекта,
генерируемого для всех исключений, и вторая - для помещения этого временного
значения в w. Аналогично, при перехвате исключения по ссылке:
catch (Widget&w) //Перехватпо ссылке.
catch(const Widget&w) ... //Такжеперехватпоссылке.
придется учитывать создание копии исключения, необходимой для временного
объекта. Если же функция передается аргументу по ссылке, копирования не про-
исходит. Таким образом, при генерации исключения приходится создавать (и за-
тем удалять) на одну копию объекта-исключения больше, чем при передаче этого
объекта в качестве аргумента функции.
До сих пор не рассматривалась генерация исключения через указатель, но этот
случай эквивалентен передаче аргумента через указатель. И в том, и в другом слу-
чае передается копия указателя. Главное не использовать указатель для исключе-
ния, которое было создано как локальный объект, потому что локальный объект
будет удален, когда исключение покинет его область видимости. В этом случае
блоку catch передается указатель на уже удаленный объект. Именно для таких
ситуаций и придумано правило обязательного копирования.
То, что жизненный цикл объектов равен времени от точки вызова функции
или оператора throw до передачи аргументов или блока catch, составляет пер-
вое отличие передачи параметров от распространения исключений. Второе отли-
чие состоит в правилах сопоставления типа, которое осуществляют, с одной сто-
роны, вызывающий модуль или генератор исключения, а с другой - вызываемая
функция или перехватчик исключения. Взгляните на функцию sqrt из стандарт-
ной математической библиотеки:
double sqrt (double) ; // Функция из <cmath.h> MtM<math.h> .
Квадратный корень из целого числа можно извлечь следующим образом:
int i ;
double sqrtOfi = sqrt (i) ;
Здесь нет ничего удивительного. Язык допускает неявное преобразование из
типа int в double, поэтому при вызове функции sqrt переменная i по умолча-
нию преобразуется к типу double и результат выполнения sqrt относится к это-
му параметру double. (См. правило 5, где более полно обсуждаются операции не-
явного преобразования типа). Но, как правило, при соотнесении типа исключения
с типом аргумента catch такие преобразования не выполняются. В следующем
примере:
voidf(intvalue)
{
78
III
Исключения
try {
if (someFunction()) {
throw value;
}
catch(doubled){
//Если
// someFunction()
//возвращает true,
//генерируем
/ / исключение типа
//int.
//Здесьдолжны обрабатываться
/ / исключения типа double.
возникшее в блоке try исключение типа int никогда не будет перехвачено опера-
тором catch, который требует аргумент типа double. Этот оператор перехватыва-
ет только исключения типа double, никакие преобразования типа не производят-
ся. Следовательно, если нужно перехватить исключение типа int, то необходимо
использовать другой оператор catch (динамически включаемый), принимающий
int или int& (возможно, с атрибутами const или volatile) в качестве типа ис-
ключения.
Тем не менее, существуют два вида преобразований, которые могут применять-
ся при сопоставлении типов в операторах catch. Первый вид - это приведение
наследуемых типов. Оператору catch, перехватывающему исключения типа ба-
зового класса, разрешено перехватывать также исключения типа производного
класса. Рассмотрим, например, иерархию исключений для обработки ошибок,
определенную в стандартной библиотеке C++ (см. рис. 3.2).
Оператор catch, перехватывающий исключения типа runtime_error, мо-
жет также перехватывать исключения типа range_error, а оператор catch, пе-
рехватывающий исключения базового класса exception, - вообще любое исклю-
чение из этой иерархии.
Это правило преобразования наследуемых исключений действует по отноше-
нию к значениям, ссылкам и указателям по следующему общему принципу:
catch (runtime_error) . . .
catch(runtime_error&) ...
catch(construntime_error&) ...
catch (runtime_error*) ...
catch(const runtiem_error*) ...
/ / Также перехватывает
//исключения типа
//runtime_error,
// range_error или
//overflow_error.
/ / Также перехватывает
//исключения типа
// runtime_error*,
//range_error* или
//overflow_error*.
Правило 12
79
Рис. 3.2
Второй вид разрешает преобразование из типизированного в нетипизированный
указатель, так что оператор catch, имеющий в качестве аргумента указатель const
void*, перехватывает все исключения, имеющие тип произвольного указателя:
catch(const void*) ... //Перехватывает все
/ / исключения типа
//"указатель".
Наконец, последнее различие между передачей аргумента и распространени-
ем исключения состоит в том, что операторы catch всегда обслуживаются в по-
рядке их перечисления. Таким образом, исключение типа производного класса
может быть обработано оператором catch для базового класса, даже если блок
catch для производного класса и соответствующий блок try находятся в одном
модуле. Например:
try {
}
catch (logic_error&ex) { //Этот блок перехватит не
... // только все исключения
} //типа logic_error,
/ / но и наследующие от них.
catch (invalid_argument&ex) { //Этот блок никогда не
,- ... / / получит управление,
}| //потому что все исключения
//типаinvalid_argument
//будут перехвачены
//предыдущим блоком.
80
Ml
Исключения
Сравните это поведение с вызовом виртуальной функции. В такой ситуации
всегда вызывается функция класса, наиболее близкого к динамическому типу объек-
та, для которого вызывается функция. Можно сказать, что виртуальные функ-
ции используют алгоритм «наиболее подходящего», а исключения - алгоритм
«первого подходящего». Иногда компиляторы генерируют предупреждение, если
оператор catch для производного класса следует за таким же оператором для
базового класса (некоторые компиляторы генерируют сообщение об ошибке,
потому что ранее в C++ подобный код считался некорректным), но опасность
лучше предупреждать: избегайте описанной выше последовательности опера-
торов catch. Например, предыдущий пример может быть переработан следу-
ющим образом:
try {
}
catch (invalid_argument&ex) {
}
catch(logic_error&ex) {
}
/ / Здесь обрабатываются
/ / исключения типа
//invalid_argument.
/ / Здесь обрабатываются
// все другие исключения
//типаlogic_error.
Таким образом, между передачей объекта функции в качестве параметра или
использованием объекта для вызова виртуальной функции и генерацией объекта-
исключения существуют три принципиальных отличия. Во-первых, для объектов-
исключений всегда создаются копии; при перехвате по значению операция
копирования повторяется дважды. Для объектов, передаваемых функции в каче-
стве аргументов, операция копирования может не производиться вообще. Во-вто-
рых, для объектов, используемых в качестве исключений, существует меньше
операторов преобразования типов, чем для объектов, передаваемых функциям в ка-
честве аргументов. Наконец, в-третьих, операторы catch обслуживаются в поряд-
ке их перечисления в исходном тексте программы, выполняется же первый из них,
который может перехватить данное исключение. При вызове виртуальной функции
выбирается та из них, которая может обеспечить наилучшее совпадение с типом
объекта, даже если она не первая по порядку в исходных текстах программы.
Правило 13. Перехватывайте исключения,
передаваемые по ссылке
При создании оператора catch необходимо указать способ передачи объек-
тов исключения данному оператору. Как и при указании способов передачи па-
раметров функциям, здесь предусмотрено три варианта: по указателю, по значе-
нию или по ссылке.
Рассмотрим сначала обработку исключения по указателю. Теоретически, это
самый неэффективный способ реализации и без того медленного процесса пере-
дачи исключения из точки throw оператору catch (см. правило 15). Причина
Правило 13
в том, что генерация исключения по указателю является единственным способом
передачи информации об исключении, при котором не требуется копировать
объект (см. правило 12). Приведем пример:
class exception { . . . }
voidsomeFunction()
{
static exception ex;
throw&ex;
}
voiddoSomething ()
{
try{
someFunction ()
}
catch(exception*ex) {
}
}
/ / Из иерархии исключений
//стандартнойбиблиотеки
// C++ (см.правило 12) .
/ / Объект исключения.
//Сгенерировать в качестве
/ / исключения указатель на ех.
/ / Может генерировать исключения.
//Обнаруживает исключения;
/ / объект не копируется.
Код выглядит чисто и аккуратно, но это впечатление обманчиво. Подобная про-
грамма будет работать, только если программист сможет, сгенерировав соответству-
ющие указатели, обозначить объекты исключения таким образом, чтобы гаранти-
ровать их существование после того, как функции потеряют управление. Поскольку
глобальные и статистические объекты работают прекрасно, программисты обычно
легко забывают об этом ограничении и пишут примерно следующий код:
voidsomeFunction ()
{
exception ex // Локальный объект исключения; //он будет уничтожен, когда //программа выйдет за //область действия этой / / функции.
throw&ex; //Генерируется указатель / / на объект,который будет
} // удален.
Но это совершенно бесполезно, потому что при обработке такого исключения
оператор catch получает указатель на объект, который больше не существует.
В качестве альтернативы можно поместить указатель на новый динамичес-
кий объект:
voidsomeFunction()
{
82
throw new exception; / / Установим указатель на новый
... //динамическийобъект
// (остается лишь надеяться, clc
} //что новый оператор -
// см.правило8 -небудет cl;
//генерировать исключения! )
Это поможет в будущем избежать проблемы «Я только что обнаружил указа ри
тель на уже уничтоженный объект», но сейчас необходимо решить: стоит ли уда
лять полученный указатель? Если объект исключения был создан в куче, полу
ченный указатель лучше удалить, чтобы не допустить утечки ресурсов. В против
ном случае этот указатель следует оставить, иначе программа будет работать не
предсказуемо. Возникает вопрос: что же делать?
Четко ответить на него невозможно. Некоторые клиенты могли бы пропустит!
адрес глобального или статического объекта, другие могли бы передать адрес ис-
ключения в куче. Таким образом, перехват по указателю напоминает дилемм}
Гамлета: удалять или не удалять? Это вопрос, не имеющий однозначного ответа,
поэтому лучше в него не углубляться.
Более того, перехват исключения по указателю противоречит соглашени-
ям, принятым в данном языке программирования. Все четыре стандартных
исключения: bad_alloc (генерируется, когда operator new (см. правило 8) не
может удовлетворить запрос на выделение памяти), bad_cast (генерируется
при невозможности приведения типов посредством dynamic_cast, см. прави-
ло 2), bad_typeid (генерируется при применении dynamic_cast к нулевому
указателю и bad_exception (генерируется при неожиданных исключениях, см.
правило 14) - являются объектами, а не указателями на объекты. Поэтому их при-
дется перехватывать по значению или по ссылке.
Если программа работает со стандартными типами исключений, поиск по зна-
чению снимает вопрос об их удалении. Но поиск по значению требует, чтобы же
объекты исключения копировались дважды при каждой генерации исключения Va
(см. правило 12). При этом возникает проблема потери данных, которая заключа- но
ется в том, что объекты исключения производного класса, обрабатываемые как
исключения базового класса, теряют признаки своей «производное™». Такие «от- ва
слоенные» объекты являются объектами базового класса: в них отсутствуют за
объекты данных, определенные как элемент производного класса, и когда вирту- п<
альные функции обращаются к ним, они сами распадаются на виртуальные функ- Р'
ции базового класса. (Абсолютно то же самое происходит, когда объект передается Д
в функцию по значению.) Например, рассмотрим приложение, использующее
иерархию классов исключений, которая расширяет стандартную: n
class exception { //Как и в предыдущем примере , это
public: //стандартный класс исключений,
virtual const char * what () throw () ;
/ / Выдает краткое описание исключения
... // (см. в правиле 14 информацию
Правило 13
83
//об операторе throw()
/ / в конце объявления) .
class runtime_error:
public exception{ . . . }
class Vai idat ion_error:
/ / Также из стандартной иерархии
// исключений языка C++ .
//Этот класс добавлен
//пользователем.
public runtime_error {
public:
virtual const char * what () throw () ;
};
voidsomeFunction()
{
/ / Это переопределение функции,
/ / объявленной выше в исключении
//класса.
// Может генерировать
/ / подтверждающее исключение.
if (проверкаправильностинепрошла) {
throwvalidation_error();
}
}
voiddoSomething()
{
try{
someFunction() ;
{
cerr << ex .what () ;
}
}
//Может генерировать
//подтверждающее исключение.
// Вызываетисключение::what()
// и никогда
//Validation_error::what().
Вызываемая версия оператора what принадлежит к базовому классу, да-
же если генерируемое исключение относится к типу Validation_error и если
Validation_error переопределяет виртуальную функцию. Уверен, что подоб-
ное «расщепляющее» поведение никогда не удовлетворит вас.
Таким образом, остается перехват исключения по ссылке, который не вызы-
вает ни одной из выше обсуждавшихся проблем. В отличие от перехвата по ука-
зателю, вопрос удаления объекта теряет здесь свою актуальность, и поэтому при
перехвате исключений стандартного типа не возникает никаких трудностей. От пе-
рехвата по значению перехват по ссылке отличается тем, что не вызывает потери
данных, а объекты исключения копируются только один раз.
Если переписать последний пример, используя перехват по ссылке, то он при-
мет следующий вид:
void someFunction()
{
/ / В этой функции ничего
// не меняется.
if (проверкаправильностинепрошла) {
throwValidation_error () ;
84
Исключения
и.
}
}
voiddoSomething()
{
try{
someFunction () ; //Здесь без изменений.
}
catch(exceptions ex) { //Здесь происходит
/ / перехват по ссылке вместо
/ / перехвата по значению.
cerr«ex.what() ; //Теперь вызывает
//Validation_error::what(),
... //а не exception::what().
}
}
При этом в точке throw ничего не меняется. Единственная перемена, которая
происходит в операторе catch, состоит в добавлении амперсанда (&). Тем не ме-
нее, столь незначительная модификация программы приводит к довольно значи-
тельным различиям, так как виртуальные функции в блоке catch теперь рабо-
тают вполне предсказуемо: функции в Validation_error активизируются
в случае их переопределения в exception.
Какое счастливое совпадение! При перехвате по ссылке вы обходите сторо-
ной вопросы удаления объектов, которые в любом случае повлекут за собой про-
блемы; вы также избегаете потери данных в объектах исключения и сохраняете
возможность перехвата стандартных исключений; кроме того, вы ограничиваете
количество необходимых копий объектов исключения. Согласитесь, это убеди-
тельные аргументы, чтобы всегда перехватывать исключения по ссылке!
Правило 14. Разумно используйте спецификации
исключений
Нет смысла отрицать, что определения исключений нравятся всем. Они дела-
ют программу более понятной, потому что четко определяют, какие исключения
может генерировать функция. Иногда компиляторы обнаруживают противоречи-
вые определения исключений во время компиляции. Более того, если функция
генерирует исключение, которое отсутствует в ее спецификации исключений,
ошибка выявляется во время работы программы, и автоматически вызывается спе-
циальная функция unexpected. Таким образом, определение исключений кажет-
ся достаточно привлекательным не только для документирования программы, но
и для задания ограничений при использовании исключений.
Но красота и привлекательность обычно обманчивы. Заданное по умолчанию
поведение функции unexpected заключается в вызове функции terminate, и по
умолчанию функция terminate вызывает функцию abort. Следовательно, по
Правило 14
85
умолчанию при возникновении исключения, не входящего в спецификацию, работа
программы останавливается. Однако локальные переменные в стековых фреймах фун-
кции уничтожены не будут, так как функция abort завершает выполнение програм-
мы без проведения очистки. Следовательно, нарушение спецификации исключений
можно отнести к разряду катаклизмов, которые лучше никогда не допускать.
К сожалению, допустить ошибку, по невнимательности или незнанию напи-
сав функции, из-за которых происходит эта ужасная вещь, не составляет особого
труда. Компилирующие программы проверяют использование исключений на
согласованность со спецификациями исключений только частично. И самое пе-
чальное - стандарт языка не предусматривает (хотя компиляторы и могут вы-
вести предупреждение) проверки на вызов функции, которая могла бы нарушить
спецификацию исключений в вызывающей функции.
Рассмотрим объявление функции fl, не обладающей спецификацией исклю-
чений. Такая функция может генерировать любые исключения:
extern void fl () / / Может генерировать все что угодно.
Теперь рассмотрим функцию f 2, спецификация исключений которой опреде-
ляет, что она может вызывать исключения только типа int:
voidf2() throw(int);
В языке C++ функция fl может вызывать функцию £2, даже если функция
fl способна генерировать исключение, которое нарушает спецификацию исклю-
чений функции f2:
voidf2() throw(int)
{
f 1 () ; // Допустимо, даже если fl могла бы
//генерировать что-либо,кроме int.
)
Подобная гибкость играет существенную роль в случае, если необходимо ин-
тегрировать новый код, в котором есть спецификация исключений, с устаревшим,
не имеющим ее.
Очень важно составлять программное обеспечение таким образом, чтобы ми-
нимизировать несогласованность. Во-первых, потому что компиляторы не будут
препятствовать вызову функций, спецификации исключений в которых не согла-
сованы со спецификациями исключений в процедурах, содержащих вызовы. Вто-
рая причина кроется в том, что такие вызовы могут остановить выполнение ва-
шей программы. Для начала попробуйте не вводить спецификации исключений
в шаблоны, содержащие параметры типов. Рассмотрим шаблон, который на пер-
вый взгляд не может генерировать никаких исключений:
//Плохо разработанный шаблон без спецификаций исключений.
template<class Т>
86
Исключения
bool operator== (const T& Ihs , const T& rhs) throw ()
{
return &lhs == &rhs ;
}
Шаблон определяет функцию operator == для всех типов. Для любой пары
объектов одного и того же типа шаблон выдает true, если объекты имеют один
и тот же адрес, в противном случае он возвращает false.
Данный шаблон содержит спецификацию исключений, согласно которой функ-
ции, созданные при его помощи, не будут генерировать никаких исключений. Но
это не всегда так, потому что сохраняется возможность перегрузки operators
(адресного оператора) для некоторых типов. При этом оператор operators мо-
жет генерировать исключение при вызове из operator ==. Если возникает ис-
ключение, то произойдет нарушение спецификации, и вы все-таки попадете
в функцию unexpected.
На этом типичном примере показана общая проблема: не существует способа
узнать что-либо об исключениях, генерируемых параметрами типов шаблона.
Дело в том, что почти невозможно создать реальную спецификацию исключений
для каждого шаблона, поскольку шаблоны в любом случае как-то используют
свой параметр типа. Какой же напрашивается вывод? Нельзя смешивать шабло-
ны и спецификации исключений.
Избежать вызовов функции unexpected можно и другим способом: необхо-
димо опустить спецификацию исключений в функциях, которые вызывают функ-
ции без спецификации исключений. Это просто соображения здравого смысла, но
существует одна тонкость, которая касается разрешения пользователям регистри-
ровать функции обратного вызова:
/ / Тип указателя функции для обратного вызова оконной системы,
/ / когда в этой системе происходит событие.
typedefvoid (*CallBackPtr) (inteventXLocation,
int eventYLocation,
void*dataToPassBack);
/ / Класс оконной системы для перехода к функциям обратного вызова,
//зарегистрированным клиентами системы.
classCallBack {
public:
CallBack (CallBackPtr fPtr, void *dataToPassBack)
:func(fPtr) , data(dataToPassBack) {}
voidmakeCallBack(int eventXlocation,
int eventYLocation) const throw () ;
private:
CallBackPtr func;
Void *data;
};
//Функция,вызываемая
/ / при обратном вызове.
//Данные,передаваемые функции
//обратного вызова.
Правило 14
87
/ / Чтобы реализовать обратный вызов,
// вызываем зарегистрированную функцию
/ / с координатами события
/ / и зарегистрированные данные.
voidCallBack::makeCallBack(int eventXlocat ion,
int eventYLocation) const throw ()
{
func(eventXlocation,eventYLocation, data);
}
В данном случае вызов func в функции makeCal IBack иногда нарушает спе-
цификацию исключений из-за того, что невозможно наверняка узнать, какие ис-
ключения могут быть сгенерированы функцией func.
Проблему легко устранить, подогнав спецификацию исключений в типе
CallBackPtr*:
typedefvoid (*CallBackPtr) (inteventxLocation,
int eventYLocation,
void*dataToPassBack) throw() ;
Если задан этот тип, происходит ошибка регистрации функции callback,
и вы уже не застрахованы от генерации исключений.
// Функция обратного вызова без спецификации исключений.
voidcallBackFcnl, (inteventXLocation, inteventYLocation,
void*dataToPassBack) ;
void *callBackData;
CallBackcl(callBackFcnl,callBackData) ;
//Ошибка!CallBackFcnlможет
//генерировать исключение.
//Функция обратного вызова
// со спецификацией исключений.
voidcallBackFcn2 (inteventxLocation, inteventYLocation,
void*dataToPassBack)throw();
callBackc2(callBackFcn2,callBackData) ;
//Нормально, cal!BackFcn2имеет
//соответствующее определение ex.
Проверка спецификаций исключений при передаче указателей функции - отно-
сительно недавнее дополнение, появившееся в языке C++, так что не удивляйтесь,
* Увы, это невозможно, по крайней мере не будет переноситься. Хотя многие компиляторы
и принимают код, приведенный здесь, комитет по стандартизации по непонятной причи-
не установил, что «спецификация исключений не должна появляться в определении
типа». Если вам необходимо быстро решить эту проблему, придется создать макрос
CallBackPtr.
88
!!'
Исключения
если ваши компиляторы еще не поддерживают его. В этом случае вы сами должны
заботиться о том, чтобы не совершать подобных ошибок.
Третья методика, позволяющая избежать вызова функции unexpected, состо-
ит в обработке исключений, которые могут генерироваться «системой». Из этих
исключений чаще всего встречается bad_alloc, обычно генерируемое функциями
operator new и operator new [ ] при ошибке выделения памяти (см. прави-
ло 8). При использовании в любой функции оператора new (см. там же) будьте
готовы к тому, что в функции может возникнуть исключение bad_alloc.
Хотя профилактика обычно лучше лечения, иногда предотвратить проблему
сложнее, чем устранить ее последствия. Это значит, что в некоторых случаях спра-
виться с неожиданными исключениями проще, чем предотвратить их появление.
Например, если вы пишете программы строго с использованием специфика-
ций исключений, но вынуждены вызывать функции из библиотек, в которых не
предусмотрены такие спецификации, будет непрактично предотвращать возник-
новение неожиданных исключений, потому что для этого придется изменить код
в библиотеках.
В подобных ситуациях вы можете использовать свойство языка C++ заменять
исключения одного типа на другой. Например, предположим, что вы хотели бы
заменить все неожиданные исключения на объекты THnaUnexpectedException.
Это нетрудно сделать следующим образом:
classUnexpectedException{}; //Все объектынеожиданных
//исключений будут заменены
/ / на объекты этого типа.
voidconvertUnexpected() //Функция,которуюследует
{ //вызыватьпри генерации
throwUnexpectedException() ; //неожиданногоисключения.
}
В результате заданная по умолчанию функция unexpected будет заменяться
на функцию convertUnexpected:
set_unexpected (convertUnexpected);
После этого любое неожиданное исключение вызовет функцию convert-
Unexpected и будет заменено новым исключением типа UnexpectedExcep-
tion. Если нарушенная спецификация исключений имеет в своем составе тип
UnexpectedException, то распространение исключения будет продолжено да-
лее, как будто ничего и не произошло. (Если же спецификация исключений не со-
держит UnexpectedException, будет вызвана функция terminate, как если бы
вы не заменяли unexpected.)
Другой способ перевода неожиданных исключений в стандартный тип осно-
ван на том, что если замена функции unexpected снова генерирует текущее ис-
ключение, то оно будет замещено новым исключением стандартного типа
bad_exception. Как же это осуществить? Очень просто:
Правило 14
II»!
89
voidconvertUnexpected() //Функция, которую следует
{ / / вызвать при генерации
throw; //неожиданного исключения; просто
} / / сгенерируйте снова текущее
//исключение.
set_unexpected(convertUnexpected);
/ / Установите convertUnexpected
//для замены неожиданного
/ / исключения.
Поступив таким образом и включив bad_exception (или соответствующий
базовый класс, стандартный класс exception) во все спецификации исключе-
ний, вам больше никогда не придется беспокоиться об остановке программы
в случае возникновения неожиданного исключения. Любое случайное исключе-
ние будет заменено на bad_exception, распространяемое вместо исходного ис-
ключения.
Теперь вы понимаете, что спецификация исключений может вызвать множе-
ство неприятностей. Компиляторы осуществляют только частичную проверку их
согласованного использования, их применение в шаблонах также проблематично,
поскольку легко допустить нечаянную ошибку. По умолчанию при нарушении
спецификации исключений выполнение программы останавливается. Специфи-
кации исключений имеют еще один недостаток, который заключается в том, что
они приводят к вызову функции unexpected, даже если для работы с возник-
шим исключением уже подготовлен вызывающий оператор более высокого уров-
ня. В качестве примера рассмотрим следующую программу, которая взята без из-
менений из правила 11:
class Session {
public:
-Session();
/ / Для моделирования сеансов
//работы в сети.
private:
staticvoidlogDestruction(Session*objAddr) throw();
};
Session::~Session()
{
try{
logdestruction(this);
}
catch(...) {}
}
Деструктор Session вызывает logDestruction, чтобы зафиксировать факт
уничтожения объекта Session, но в действительности он обрабатывает любые
исключения, которые могут быть сгенерированы функцией logDestruction.
90
Исключения
IS
Тем не менее, спецификация исключений функции logDestruction утверждает,
что эта функция не должна генерировать никаких исключений. Теперь предполо-
жим, что некая функция, вызванная logDestruction, генерирует какое-либо
исключение, которое logDestruction не в состоянии перехватить. Конечно,
вероятность такого развития событий невелика, но, как вы удостоверились, совсем
несложно написать программу, ведущую к нарушению спецификации исклю-
чений. Когда непредвиденное исключение распространится на функцию
logDestruction, будет вызвана функция unexpected, что по умолчанию при-
ведет к завершению работы программы. Это корректное поведение, но разве тако-
го результата хотел добиться автор деструктора Session? Напротив, автор при-
ложил много усилий, чтобы обработать все возможные исключения, поэтому
завершение работы программы без отработки блока catch в деструкторе
Session кажется несправедливым.
Если функция logDestruction не имеет спецификации исключений, то сце-
нарий типа «я готов обрабатывать исключения, дайте мне только шанс» никогда
не возникнет. (Предотвратить это можно, например, заменив функцию unex-
pected, как было описано выше.)
Как видите, очень важно иметь точное представление о спецификациях ис-
ключений. Они обеспечивают прекрасное документирование различных видов
исключений, генерируемых функцией. Для ситуаций, в которых нарушение спе-
цификации исключений настолько «ужасно», что влечет за собой немедленное
завершение работы программы, они предлагают такое поведение по умолчанию.
Наряду с этим спецификации проверяются компиляторами только частично
и, соответственно, могут быть нарушены случайно. Более того, они могут блоки-
ровать обработку неожиданных исключений на более высоком уровне, даже если
соответствующие обработчики знают, как это сделать. При таком положении дел
спецификации исключений следует использовать разумно. Перед тем как вводить
их в функции, подумайте, будет ли их поведение в программах соответствовать
вашим планам.
Правило 15. Оценивайте затраты
на обработку исключений
При обработке исключений во время выполнения программы немало усилий ухо-
дит на то, чтобы учитывать использование системных ресурсов. В каждый момент
своего выполнения программа должна идентифицировать объекты, которые требу-
ется уничтожить при генерации исключения. Объекты должны отметить каждый вход
и выход из блока try, и для каждого блока try надо отслеживать соответствующие
операторы catch и разновидности исключений, допускающие обработку этими
операторами. Учет использования системных ресурсов обходится недешево. Так
же, как и сравнения в ходе выполнения программы, необходимые для проверки
Правило 15
I
91
спецификаций исключений на нарушения, или работа, затраченная на уничтожение
соответствующих объектов и поиск корректного оператора catch при возникно-
вении исключения. Без сомнения, обработка исключений требует серьезных зат-
рат, и вам в любом случае придется покрыть хотя бы часть из них, даже если вы
никогда не используете зарезервированные слова try, throw или catch.
Начнем с обсуждения затрат, которые возникают, даже если вы никогда не про-
изводите обработку исключений. Они включают, во-первых, пространство, ис-
пользуемое специальными структурами данных для отслеживания полностью
созданных объектов (см. правило 10), а также время, которое уходит на обнов-
ление этих структур. Конечно, такие затраты весьма невелики. Тем не менее,
программы, составленные без поддержки исключений, обычно и выполняют-
ся быстрее, и занимают меньше места, чем их аналоги, скомпилированные
с поддержкой исключений.
Теоретически, у вас нет выбора: исключения являются неотъемлемой частью
языка C++, и компиляторам так или иначе приходится их поддерживать. Вам так-
же не приходится рассчитывать на то, что производители компиляторов будут
удалять соответствующий код из программ, если вы не захотите использовать об-
работку исключений. Ведь типичные программы состоят из множества независи-
мо генерируемых объектных файлов, и если один объектный файл не применяет
исключения, вовсе не факт, что другие файлы также не делают этого.
Более того, если при создании исполняемого файла ни один из связываемых
объектных файлов не использует исключений, как быть с подключаемыми биб-
лиотеками? Если какая-либо часть программы обращается к исключениям, то
и вся остальная программа должна тоже их поддерживать. В противном случае
было бы невозможно обеспечить корректное поведение программы при обработ-
ке исключений.
С теорией мы разобрались. На практике же большинство компиляторов, под-
держивающих обработку исключений, позволяют вам самому решать, нужна ли эта
возможность в создаваемом коде. Если вы уверены, что ни одна из частей вашей
программы не содержит try, throw или catch и что ни одна из подключаемых биб-
лиотек также их не использует, то вы совершенно свободно можете компилировать
программу без под держки исключений. Это поможет сократить размер программы
и увеличить скорость ее выполнения. В будущем, когда большинство библиотек
станет применять исключения, такая стратегия потеряет свое значение. Однако на
нынешней стадии развития языка C++, если вы все же решили отказаться от исклю-
чений, компиляция программ без их поддержки является наиболее рациональной.
Эта стратегия также поможет оптимизировать обращения к библиотекам, которые
«избегают» работы с исключениями, но только в случае, если есть гарантия, что ис-
ключения, генерируемые клиентской программой, никогда не распространятся на
библиотеку. А обеспечить такую гарантию довольно трудно, потому что она запре-
щает переопределения клиентами виртуальных функций, объявленных в библиоте-
ке, и определение клиентами функций обратного вызова.
92
Исключения
Дополнительные затраты по обработке исключений связаны с выполнением
блоков try. Они возникают при каждом использовании такого блока, то есть при
каждой обработке исключений. Блоки try реализованы в различных компилято-
рах по-разному, поэтому затраты зависят еще и от компилятора. По приблизитель-
ным оценкам, использование блоков try приведет к увеличению общего объема
программы и времени ее выполнения на 5-10%. И это без учета генерации исклю-
чений; сюда входят только затраты, связанные с наличием в программе блоков try.
Следовательно, чтобы уменьшить затраты, необходимо избегать ненужных бло-
ков try.
Компиляторы обычно генерируют код для спецификаций исключений при-
мерно так же, как и для блоков try, с примерно теми же затратами. Извините, вы
полагали, что спецификация исключений - это только спецификация и не приво-
дит к генерации кода? Ну, теперь вам есть над чем подумать.
Именно затраты, связанные с генерацией исключения, и открывают суть про-
блемы. Однако это не должно вызывать значительного беспокойства, хотя бы
потому, что исключения встречаются довольно редко, так как связаны с возник-
новением исключительных событий. Как следует из правила «80-20» (см. прави-
ло 16), события такого рода почти никогда не должны оказывать значительного
влияния на работу программы в целом. Тем не менее, я предвижу ваш вопрос, на-
сколько сильный удар нанесет вам возникшее исключение. Отвечу прямо: воз-
можно, очень сильный!
По сравнению с нормальным возвратом из функции, возврат из функции при
помощи генерации исключения иногда выполняется на три порядка медленнее.
Достаточно мощный удар! Но он будет нанесен, только если возникнет исключе-
ние, а этого не должно происходить практически никогда. Поэтому не используй-
те исключения для индикации относительно обычных ситуаций, таких как завер-
шение обхода структуры данных или завершение цикла.
Но подождите! Откуда я могу обо всем этом знать? Если многие компилято-
ры сравнительно недавно начали поддерживать исключения (а это на самом деле
так); если разные компиляторы реализуют такую поддержку по-разному (и это
так); то как же я могу сделать вывод о том, что объем программы возрастет при-
мерно на 5-10%, что скорость программы понизится примерно настолько же
и что программа будет выполняться на несколько порядков медленнее при одно-
временной генерации множества исключений? Такой вывод основан на предполо-
жениях и проведенных тестах (см. правило 23). Дело в том, что большинство про-
граммистов - включая производителей компиляторов - имеют недостаточный
опыт работы с исключениями, так что хоть и известно, что с исключениями связа-
ны издержки, дать им точную оценку довольно сложно.
Какими бы не были затраты на обработку исключений, не хочется платить
больше, чем нужно. Чтобы уменьшить затраты, связанные с исключениями, по воз-
можности компилируйте программы без поддержки исключений; используйте
Правило 15
93
блоки try и спецификации исключений только там, где необходимо; и генерируй-
те исключения только в действительно исключительных случаях. Если произво-
дительность программ все равно будет слишком низкой, выполните отладку про-
грамм (см. правило 16), чтобы определить, вызвано ли это поддержкой
исключений. Если да, рассмотрите возможность перейти на другие компиляторы,
которые более эффективно реализуют обработку исключений языка C++.
Глава 4. Эффективность
Я подозреваю, что кто-то проводил секретные эксперименты по выработке услов-
ного рефлекса у разработчиков программного обеспечения на C++. Чем еще мож-
но объяснить тот факт, что при упоминании слова «эффективность» большинство
программистов начинает истекать слюной?
Но шутки в сторону. Эффективность на самом деле очень важна. Слишком
большие или слишком медленные программы не находят признания, независи-
мо от их достоинств. Так и должно быть. Ведь программы призваны помогать
нам в работе, и вряд ли кто-либо станет утверждать, что медленнее значит лучше,
что требование 32 Мб памяти вместо 16 выгоднее и что «пережевывание» 100 Мб
дискового пространства предпочтительнее, чем «поглощение» только 50. Конеч-
но, есть программы, которые имеют большой размер и используют много памяти,
так как выполняют сложные вычисления, но все же в том, что у приложения слиш-
ком «медленная поступь» или «раздутый размер», обычно виноваты плохой ди-
зайн и небрежное программирование.
Чтобы научиться создавать эффективные программы на языке C++, прежде
всего вы должны уяснить, что C++ может не иметь ничего общего с возникшими
у вас проблемами производительности. Если вы действительно хотите написать
эффективную программу на C++, то сначала должны научиться писать эффектив-
ные программы вообще. Многие программисты игнорируют эту простую истину.
Конечно, можно развертывать циклы вручную, а умножение заменить операция-
ми сдвига, но такие тонкие изменения ни к чему не приведут, если используемые
вами алгоритмы неэффективны сами по себе. Используете ли вы квадратичные
алгоритмы, когда достаточно использовать линейные? Вычисляете ли вы одно
и то же значение снова и снова? Пренебрегаете ли вы возможностью сократить
средние затраты на выполнение сложных операций? Если да, то неудивительно,
что ваши программы похожи на второсортные «приманки для туристов».
Материал данной главы рассматривает тему эффективности с двух направле-
ний. Первое из них не зависит от языка программирования, и основное внимание
уделяется моментам, общим для всех языков.
Язык C++ является очень привлекательным средством для реализации самых
смелых идей, так как сильная поддержка инкапсуляции в нем позволяет заменить
неэффективную реализацию класса улучшенными алгоритмами и структурами
данных, поддерживающих единый интерфейс.
Второе направление сконцентрировано на самом языке программирования
C++. Высокопроизводительные алгоритмы и структуры данных - это замечатель-
но, но нестабильная практика реализации может значительно снизить их эффек-
тивность. Самую коварную ошибку - создание и уничтожение слишком боль-
шого числа объектов - настолько же просто допустить, насколько распознать.
Правило 16
!
95
Излишнее создание и удаление объектов для программы подобно кровотечению,
когда драгоценное время неумолимо «истекает» при каждой операции с ненужным
объектом. Эта проблема настолько актуальна, что я вынужден посвятить четыре
отдельных раздела описанию того, откуда берутся такие объекты и как от них из-
бавиться, не нарушив корректной работы программы.
Создание слишком большого количества объектов не единственная причина,
по которой увеличивается размер программы и замедляется ее выполнение. Сре-
ди прочих «выбоин» необходимо отметить неправильный выбор библиотек и пу-
тей реализации возможностей языка. Эти проблемы также затрагиваются в насто-
ящей главе.
Изучая материал данной главы, вы ознакомитесь с некоторыми принципами,
которые способны улучшить производительность практически любого приложе-
ния. Вы узнаете, как предотвратить попадание ненужных объектов в ваши про-
граммы, а также будете иметь более четкое представление о том, как компилято-
ры ведут себя при создании исполняемых файлов.
Говорят, кто предупрежден, тот вооружен. В таком случае расценивайте сле-
дующую информацию как подготовку к битве.
Правило 16. Не забывайте о правиле «80-20»
Правило «80-20» гласит, что 80% программных ресурсов и памяти исполь-
зуется примерно 20 процентами кода программы: 80% времени уходит на выпол-
нение примерно 20% кода, 80% обращений к диску осуществляется примерно из
20% кода, 80% усилий по поддержке тратится примерно на 20% кода. Правило
«80-20» неоднократно проверялось на различных компьютерах, операционных
системах и приложениях. Это не просто запоминающаяся формула, а оценка
производительности системы, широко применяемая и имеющая солидную эм-
пирическую основу.
При рассмотрении правила «80-20» очень важно не слишком вдаваться
в цифры. Некоторые считают более точным соотношение «90-10», которое также
подтверждается экспериментально.
Независимо от точности цифр суть остается неизменной: суммарная произво-
дительность программы почти всегда определяется небольшой частью кода, ле-
жащей в ее основе.
Правило «80-20» как упрощает, так и усложняет жизнь программиста, стре-
мящегося увеличить производительность своей программы. С одной стороны,
правило «80-20» подразумевает, что большая часть создаваемого вами кода мо-
жет, честно говоря, иметь довольно среднюю производительность, поскольку
в течение 80% времени его эффективность не влияет на суммарную производи-
тельность системы, над которой вы работаете. Это, конечно же, не льстит са-
молюбию любого программиста, но должно немного охладить ваш пыл. С другой
стороны, правило подразумевает, что если возникают проблемы с произво-
дительностью, то вам предстоит хорошенько поработать, чтобы не только обна-
ружить участки неэффективного кода, но и найти способ, как их усовершенство-
вать. Обычно сложнее всего найти «узкие места». Существует два абсолютно
96
(III
Эффективность
разных подхода к данной проблеме: тот, который используется большинством про-
граммистов, и правильный.
Большинство программистов стараются просто угадать, где находятся крити-
ческие участки кода. На основе опыта, интуиции, карт Таро и спиритических се-
ансов, слухов или чего-нибудь похуже, разработчик за разработчиком торже-
ственно объявляют, что проблемы эффективного функционирования программ
восходят к сетевым задержкам, плохо настроенному распределению памяти,
к компиляторам, которые плохо выполняют оптимизацию, или к запрету «тупо-
головыми» менеджерами использовать язык ассемблера для критических внут-
ренних циклов. Подобные оценки обычно высказываются со снисходительной
усмешкой, но, как правило, и сами насмешники, и их прогнозы оказываются со-
вершенно несостоятельными.
Почти все программисты обладают отвратительной интуицией в том, что ка-
сается характеристик производительности их программ, так как эти характерис-
тики сами по себе обычно совершенно «не интуитивны». И в результате невооб-
разимые усилия тратятся на повышение эффективности тех частей программы,
которые не оказывают ощутимого влияния на ее суммарное поведение. Например,
представим, что в программу можно добавить замечательные алгоритмы и структу-
ры данных, снижающие вычислительные затраты, но, если производительность
программы ограничивается возможностями ввода-вывода, то все усилия будут по-
трачены зря. Конечно, нетрудно заменить поставляемые с компилятором библио-
теки ввода-вывода на более мощные (см. правило 23), но это не даст значитель-
ных изменений, если использующие их программы ограничены техническими
параметрами процессора.
Что же делать в случае, если ваша программа работает слишком медленно или
требует чрезмерно много памяти? Согласно правилу «80-20», совершенствование
выбранных наугад частей программы вряд ли исправит положение. Производи-
тельность программы обычно определяется не слишком явными характеристика-
ми, поэтому попытки найти наугад причину падения производительности ничем
не отличаются от простого усовершенствования произвольно выбранных частей
программы. Что же вам поможет в этом случае?
Самое эффективное средство - эмпирически, то есть при помощи отладчика,
определить те 20% программы, которые причиняют вам «головную боль». Но не
всякий отладчик подойдет для этой задачи. Вам необходим такой, чтобы непо-
средственно измерял интересующие вас ресурсы программы. Например, если про-
грамма работает слишком медленно, то необходимо использовать отладчик, кото-
рый измеряет время, затрачиваемое на выполнение ее отдельных участков. Это
позволит вам сконцентрироваться на тех местах, где усовершенствование локаль-
ной эффективности вызовет значительное улучшение суммарной работоспособ-
ности приложения.
Польза от отладчиков, определяющих, сколько раз выполняется каждый опе-
ратор, сколько раз вызывается каждая функция, скажем прямо, невелика. С точки
зрения производительности эти сведения совершенно не важны. Мало кого из
Правило 17
пользователей программ или подключаемых библиотек интересует число выпол-
ненных операторов или вызовов функций. Единственное, что имеет для них ка-
кое-либо значение, - время. Пользователи ненавидят ждать, а если ваша програм-
ма заставляет их это делать, то они ненавидят и вас.
Тем не менее, знание частоты выполнения операторов и вызова функций мо-
жет иногда пролить свет на то, как функционирует программа. Если, например,
вы создаете около сотни объектов определенного типа, вам будет небезынтерес-
но узнать, что при этом конструкторы в данном классе вызываются уже не сот-
ни, а тысячи раз. Более того, подсчет числа вызовов операторов и функций иног-
да помогает понять скрытые аспекты поведения программы. Если вы, например,
не имеете прямой возможности оценить использование динамической памяти, то
вам пригодится информация о том, как часто вызываются функции выделения
и освобождения памяти (например, операторы new, new [],delete и delete [ ] -
см. правило 8).
Конечно, даже лучшие из отладчиков являются заложниками обрабатывае-
мых данных. Не удивляйтесь, когда при обработке нетипичных входных данных
отладчик укажет, что требуется доводка части программы, попадающей в 80%,
хотя, как вы знаете, это никак не отражается на общей работе программы.
Помните, что отладчик может сообщить вам о поведении приложения во вре-
мя конкретного «прогона» (или нескольких «прогонов»), поэтому если вы отла-
живаете программу, используя нетипичные входные данные, то в итоге получите
нетипичные значения измеряемых параметров. Это, в свою очередь, приведет
к тому, что вы будете оптимизировать работу программы для нетипичного случая,
а общий эффект может быть даже отрицательным.
Лучший способ избежать таких «патологических» результатов заключается
в том, чтобы отлаживать программу, используя как можно больше различных на-
боров входных данных.
Кроме того, вы должны убедиться, что каждый набор данных типичен для
клиентов (или по крайней мере для наиболее важных из них). Типичный набор
данных обычно получить легко, потому что многие пользователи с удовольстви-
ем предоставят в ваше распоряжение свои данные для отладки. В таком случае вы
будете настраивать программное обеспечение, исходя из их потребностей, и от
этого выиграют все.
Правило 17. Используйте отложенные вычисления
С точки зрения эффективности наилучшими вычислениями являются те, ко-
торые вообще никогда не выполняются. Но зачем помещать такой код в програм-
му? А уж если по каким-либо причинам без данного кода в программе не обой-
тись, как избежать его выполнения?
Выход в том, чтобы отложить вычисления.
Помните, когда вы были еще ребенком, родители заставляли вас убирать свою
комнату? Если вы были похожи на меня в детстве, то сказали бы: «Хорошо»,
а затем быстро вернулись к тому, чем занимались до этого. Фактически, уборка
4-679
98
in
Эффективность
была бы для вас последним делом - но только до тех пор, пока вы не услышали бы,
как родители идут, чтобы посмотреть на наведенный порядок. Тогда вы бросились
бы в свою комнату и сразу же принялись за работу. Но если бы вам повезло,
и родители не стали проверять, как выполнено их поручение, то вам вообще уда-
лось бы избежать уборки комнаты.
Оказывается, тактика «задержки», которой вовсю пользуется пятилетний ре-
бенок, характерна и для программиста, работающего с C++. В информатике такая
тактика называется отложенным (буквально «ленивым») вычислением (lazy
evaluation). При использовании отложенных вычислений классы записываются
таким образом, что вычисления не производятся до тех пор, пока не потребуются
их результаты. Если результаты не потребуются никогда, то эти вычисления
никогда и не будут выполнены. Таким образом, ни пользователи вашего программ-
ного обеспечения, ни ваши родители не могли бы выбрать более мудрый путь.
Отложенное вычисление применимо для множества приложений, но в насто-
ящей главе описываются только четыре наиболее частых случая.
Подсчет ссылок
Рассмотрим следующую программу:
class String {...}; // Класс string // (стандартный тип string // может быть реализован, как описано // ниже, но это не обязательно) .
String si = "Hello"; String s2 = si; // Вызывает конструктор // копирования String.
Обычная реализация конструктора копирования String привела бы к созда-
нию объектов si и s2, каждый из которых имел бы собственную копию строки
"Hello" после инициализации s2 значением из si. Это повлекло бы за собой до-
вольно большие расходы, ведь конструктору пришлось бы скопировать значение
si, чтобы передать его s2, а это обычно требует выделения динамической памяти
при помощи оператора new (см. правило 8) и вызова функции strcpy для копи-
рования данных из si в память, выделенную для s2. Таким образом, будет произ-
водиться энергичное вычисление (eager evaluation): создание копии s 1 и помеще-
ние ее в s2 только потому, что был вызван конструктор копирования string.
Однако в данном случае не было реальной необходимости в том, чтобы в s2 нахо-
дилась копия значения, так как s2 еще совсем не использовался.
При «ленивом» подходе выполняется намного меньше работы. Вместо пере-
дачи объекту s2 копии значения si, объект s2 разделяет значение si. Достаточ-
но знать, кто и что совместно использует, и это позволит избавиться от затрат на
вызов оператора new и копирование. То, что структура данных совместно исполь-
зуется объектами si и s2, прозрачно для клиентов, и, конечно, не вносит разли-
чий в подобные операторы, поскольку они только считывают значения, а не запи-
сывают их:
99
cout « si; // Считывает значение si.
cout « si + s2; // Считывает значение si и s2.
Фактически, совместное использование значений существенно, только когда
происходит модификация той или иной строки; в этом случае важно, чтобы изме-
нения вносились только в одну строку, но не в обе. В операторе
s2.convertToUpperCase();
должно меняться только значение s2, а не значение si.
Для обработки подобных операторов нужно реализовать функцию con-
vertToUpperCase объекта String так, чтобы она копировала значение s2,
а в самой s2 до модификации делала это значение закрытым. Внутри функции
convertToUpperCase вы не можете больше придерживаться «ленивой» стра-
тегии: необходимо сделать копию значения s2 (совместно используемую) для
использования внутри s2. С другой стороны, если объект s2 никогда не изме-
няется, вам не понадобится делать закрытую копию его значения. Значение
может использоваться совместно, пока оно существует. Если вам повезет, то s2
никогда не будет изменяться, и тогда вообще не придется задавать ему собствен-
ное значение.
Более подробно о совместном использовании значений (включая весь код) рас-
сказано в правиле 29, однако, надеюсь, основная идея ясна вам уже сейчас: надо де-
лать копию чего-либо только в тот момент, когда в ней возникнет насущная необхо-
димость. Будьте ленивыми - используйте любую подходящую копию, пока это можно
делать безнаказанно (в некоторых случаях такое состояние длится бесконечно).
Как отличить считывание от записи
Изучая далее пример использования строк для подсчета ссылок, можно столк-
нуться со второй ситуацией, в которой будет полезно отложенное вычисление.
Рассмотрим следующую программу:
>
String s = "Homer's Iliad"; // Строка s содержит
// ссылку.
cout << s [3]; // Вызов operator [] для считывания s[3].
s[3]= 'х'; // Вызов operator[] для записи s[3].
Первый вызов operator [ ] соответствует считыванию части строки, второй -
выполнению записи. Ваша задача - научиться различать вызов оператора чтения
и вызов оператора записи, так как чтение строки со ссылками выполнить просто,
а для записи в такую строку может потребоваться предварительное создание но-
вой копии значения строки.
Это затрудняет реализацию. Чтобы достигнуть поставленной цели, необходи-
мо выполнять различные преобразования внутри operator [ ] (в зависимости от
того, вызывается ли он для выполнения чтения или записи). Как же определить,
был ли operator [ ] вызван в контексте чтения или записи? К сожалению, это
сделать нельзя. Но используя отложенное вычисление и proxy-классы, как
4*
100
^ин Эффективность
описано в правиле 30, вы, тем не менее, сможете отложить решение, осуществлять
ли операцию чтения или записи, пока не определите, какое действие является пра-
вильным.
Отложенная выборка
Теперь третий пример отложенного вычисления. Представьте, что у вас есть
программа, которая использует большие объекты, содержащие много полей. Эти
объекты должны существовать после завершения работы программы, поэтому они
хранятся в базе данных. Каждый объект имеет уникальный идентификатор, кото-
рый может использоваться для извлечения объекта из базы:
class LargeObject { // Большой постоянный объект.
public:
LargeObject (ObjectID id) ; // Восстановить объект с диска.
const string^ fieldlf) const; // Значение поля 1.
int field2() const; // Значение поля 2.
double field3() const; // ...
const strings field4() const;
const strings field5() const;
};
Теперь рассмотрим затраты на восстановление объекта LargeObject с диска.
void restoreAndProcessObject(ObjectID id)
{
LargeObject object (id) ; // Восстановление объекта.
}
Поскольку экземпляры объекта LargeOb j ect велики, получение всех данных
для такого объекта может оказаться достаточно сложной операцией, особенно,
если информация должна быть извлечена из удаленной базы и передана по сети.
В некоторых случаях чтение всех данных и не требуется. Например, рассмотрим
такое приложение:
void restoreAndProcessObject(ObjectID id)
{
LargeObject object(id);
if (object.fields () == 0) {
cout « "Object " « id << null field2.\n";
}
}
В этом случае требуется лишь значение f ield2, а любые попытки установить
значение других полей бесполезны.
«Ленивый» подход к описываемой проблеме заключается в том, чтобы не счи-
тывать данные с диска при создании объекта LargeOb j ect. Таким образом, вме-
сто объекта создается только его «оболочка», и данные извлекаются из базы
Правило 17
101
только тогда, когда нужно, чтобы они заняли свое место внутри объекта. Ниже
приводится один из способов реализации объектов с подкачкой страниц по тре-
бованию:
class LargeObject {
public:
LargeObject(ObjectID id) ;
const string^ fieldl() const;
int field2() const;
double field3() const;
const string^ field4() const;
private:
ObjectID oid;
mutable string *fieldlValue;
mutable int *field2Value;
mutable double *field3Value;
mutable string *field4Value;
//См. ниже
//о применении mutable.
};
LargeObject::LargeObject(Object ID id)
: oid(id), fieldlValue(0), field2Value(0), field3Value(0), ...
{}
const strings LargeObject:: fieldl () const
{
if (fieldlValue == 0) {
считать данные для поля field 1 из базы данных
и задать указатель fieldlValue на них;
}
return *fieldlValue;
}
Каждое поле объекта представлено указателем на необходимые данные, а кон-
структор LargeObject обнуляет все указатели. Такие нулевые указатели обозна-
чают поля, которые еще не были считаны из базы данных. Каждая функция-член
класса LargeObj ect должна проверить состояние указателя поля перед доступом
к данным, на которые он указывает. Если указатель нулевой, то соответствующие
данные будут считываться из базы перед выполнением любых действий над ними.
При осуществлении отложенной выборки вы сталкиваетесь со следующей
проблемой: может потребоваться инициализация нулевых указателей, чтобы они
ссылались на реальные данные из любой функции-члена, включая функции с ат-
рибутом const, подобные f ieldl. Однако компиляторы «ругаются», если вы пы-
таетесь изменить элементы данных внутри функции-члена с атрибутом const,
так что надо найти способ сказать: «Все в порядке, я знаю, что делаю». Лучший
способ для этого - объявить поля указателя как mutable, чтобы они могли изме-
няться внутри любой функции-члена, даже внутри функции-члена с атрибутом
const. Именно поэтому поля в объекте LargeObj ect были объявлены выше как
mutable.
102
III Эффективность
Ключевое слово mutable - относительно недавнее дополнение к языку C++,
так что, возможно, ваши компиляторы еще не поддерживают его. В таком случае
вам придется найти другой способ убедить компилятор позволить вам изменять
данные внутри функции-члена с атрибутом const. С одной стороны, можно ис-
пользовать стратегию псевдоуказателя this, при которой создается указатель без
атрибута const, ссылающийся на тот же самый объект, что и this. Если вы хоти-
те изменить данные, то обращаетесь к объекту через псевдоуказатель:
class LargeObject {
public:
const strings fieldl() const; // Без изменений.
private:
string *fieldlValue;
//He объявляется как mutable,
// чтобы старые компиляторы
// принимали его.
const strings LargeObject::fieldl () const
{
// Объявить указатель fakeThis, указывающий на то же, что и this,
// но не имеющий атрибута const.
LargeObject * const fakeThis =
const_cast<LargeObject* const>(this);
if (fieldlValue == 0) {
fakeThis->fieldlValue =
соответствующие данные
из базы данных;
}
return *fieldlValue;
}
// Это присваивание
// допустимо, так как то,
//на что указывает fakeThis,
//не имеет атрибута const.
Эта функция использует оператор const_cast (см. правило 2), чтобы изба-
виться от атрибута const в указателе *this. Если ваши компиляторы не поддер-
живают const_cast, вы можете использовать приведение типа языка С:
// Приведение типа языка С для эмуляции mutable.
const strings LargeObject:: f ieldl () const
{
LargeObject * const fakeThis = (LargeObject* const)this;
... / / Как и выше.
}
Рассмотрим снова указатели внутри объекта LargeObject. Скажем прямо,
утомительно было бы обнулять все указатели, а затем проверять каждый из них
перед использованием (кроме того, это может привести к ошибкам). К счастью,
такую тяжелую работу нетрудно автоматизировать с помощью smart-указателей,
Правило 17
103
о которых рассказано в правиле 28. Используя smart-указатели внутри объекта
LargeObject, вы также обнаружите, что больше не нужно объявлять указате-
ли как mutable. Увы, это только временная отсрочка, потому что необходимость
в присвоении mutable указателю возникнет снова, как только вы приметесь за
реализацию классов smart-указателей.
Отложенная оценка выражения
Заключительный пример отложенного вычисления характерен для числовых
приложений. Рассмотрим следующий код:
template<class Т>
class Matrix {...};
Matrix<int> ml(1000, 1000);
Matrix<int> m2(1000, 1000);
// Для однородных матриц.
// То же самое для матриц
// 1000 на 1000.
Matrix<int> m3 = ml + m2;
// Сложить ml и m2.
При обычной реализации operator + используется «энергичное» вычисле-
ние; в этом случае была бы высчитана и возвращена сумма ml и m2. Это достаточ-
но большой объем вычислений (1 000 000 операций сложения). Кроме того, для
хранения значений потребуется выделение памяти, что также сопряжено с опре-
деленными затратами.
Согласно стратегии отложенного вычисления, если способ реализации содер-
жит слишком много работы, она не выполняется. Вместо этого создается структура
данных внутри m3, которая указывает, что значение m3 является суммой ml и m2.
Такая структура данных состоит всего лишь из указателей на ml и m2 и перечис-
ления, указывающего, что для них должна быть выполнена операция сложения.
Конечно же, быстрее задать структуру данных, чем сложить ml и m2, и при этом
используется намного меньше памяти.
Предположим, что затем в программе перед использованием m3 выполняется
следующий код:
Matrix<int> m4(1000, 1000);
... // Присвоить m4 некоторые значения.
m3 = m4 * ml ;
Теперь можно забыть, что m3 было равно сумме ml и m2 (и таким образом
«сэкономить» затраты на вычисления), и считать с этого момента, что m3 равно
произведению т4 на ml. Но само умножение выполняться не будет. Зачем беспо-
коиться? Хорошие программисты ленивы, помните?
Этот пример выглядит достаточно надуманным, потому что ни один профес-
сионал не написал бы программу, которая вычисляла бы сумму двух матриц и не
использовала результат вычислений, но он не так гипотетичен, как кажется. Ни
один хороший программист не стал бы преднамеренно вычислять значение,
в котором нет необходимости, но при сопровождении программы нередко ее от-
дельные ветви модифицируются таким образом, что прежде полезное вычисление
104
Эффективность
становится ненужным. Чтобы уменьшить вероятность такой ситуации, надо опре-
делять объекты перед самым их использованием, но время от времени проблема
все равно будет возникать.
Если бы определение суммы матриц было единственным случаем, когда отло-
женное вычисление окупается, то едва ли стоило бы прикладывать столь значи-
тельные усилия. Чаще бывает, что нужна только часть вычисления. Например,
предположим, что матрица m3 используется после ее инициализации к сумме ml
и m2 следующим образом:
cout « m3[4]; // Вывести 4-ую строку m3.
Ясно, что нельзя отложить все вычисления - нужно определить значение в чет-
вертой строке m3. Но при этом не нужно вычислять ничего, кроме четвертой стро-
ки матрицы m3; остальная часть матрицы m3 может остаться не вычисленной до
тех пор, пока не потребуется программе. При благоприятном стечении обстоя-
тельств этого никогда не произойдет.
Какова же вероятность такой удачи? Опыт в области матричных вычислений
говорит, что преимущество на нашей стороне. Отложенное вычисление скрывает-
ся за чудом, которое называется «язык программирования APL». Этот язык был раз-
работан в 1960-ых для интерактивного использования теми, кому приходилось
выполнять матричные вычисления. Функционируя в компьютерах, имевших
меньшую вычислительную мощность, чем чипы, применяемые сегодня в микро-
волновых печах, язык APL был способен складывать, умножать и даже делить
большие матрицы, как тогда казалось, почти мгновенно! Его «изюминка» заклю-
чалась в отложенном вычислении. Этот подход был очень эффективным, так как
пользователи APL в основном складывали, умножали или делили матрицы не
потому, что им была нужна полная результирующая матрица, а потому, что требо-
валась только небольшая ее часть. Язык APL применял отложенное вычисление,
задерживая осуществление операции до тех пор, пока не было точно известно,
какая часть результирующей матрицы необходима, а затем вычислял только ее.
Это позволяло выполнять сложные вычислительные задачи в интерактивном ре-
жиме на компьютере, мощность которого была бы совершенно недостаточна для ре-
ализации, использующей «энергичное» вычисление. Сегодня компьютеры работа-
ют быстрее, но наборы данных стали больше, а пользователи менее терпеливы, так
что многие из современных библиотек матричных функций продолжают приме-
нять отложенные вычисления.
Честно говоря, лень иногда не окупается. Если m3 использовать так:
cout « m3; // Вывести всю строку m3.
то игра окончена, и придется полностью вычислять значение матрицы m3. Таким
же образом, если одна из матриц, от которых зависит m3, должна быть изменена,
потребуется выполнить действия немедленно:
m3 = ml + m2; // Помните, что m3 является
/ / суммой ml и m2 .
Правило 17
105
ml = m4;
// Теперь m3 является суммой m2
//и старого значения ml!
Здесь надо каким-то способом гарантировать, что присвоение нового значения
ml не изменяет m3. Внутри оператора присваивания Matrix <int> можно было
бы вычислить значение m3 до изменения ml, или создать копию старого значения
ml и сделать m3 зависящим от нее. В любом случае нужно обеспечить, чтобы m3
имела правильное значение после того, как матрица ml будет изменена. Другие
функции, которые могли бы изменить матрицу, следует обрабатывать аналогично.
Из-за необходимости сохранять зависимости между значениями, поддержи-
вать структуры данных, сохраняющие значения и зависимости, или и то, и дру-
гое, а также перезагружать операторы (присваивания, копирования и сложения),
отложенные вычисление требуют очень много работы. С другой стороны, они ча-
сто позволяют существенно сэкономить время и дисковое пространство при вы-
полнении программы, и во многих приложениях это с лихвой окупает усилия, ко-
торые требуются для реализации отложенных вычислений.
Резюме
Приведенные четыре примера показывают, что отложенное вычисление мо-
жет быть полезно в самых разных ситуациях: для того чтобы избежать напрас-
ного копирования объектов, отличить чтение от записи при использовании
operator [ ], не делать лишнего считывания информации из баз данных и мно-
гочисленных ненужных расчетов. Однако использование отложенного вычисле-
ния не всегда оправдано. Точно так же, как откладывание обычной уборки не спа-
сет, если родители всегда проверяют вас, отложенное вычисление не сократит
работу программы, если все вычисления необходимы. Действительно, в таком слу-
чае отложенное вычисление может даже замедлить выполнение программы и уве-
личить расход памяти, потому что вам придется не только проделывать все вычис-
ления, которых вы надеялись избежать, но и управлять сложными структурами
данных (они, собственно, и осуществляют отложенное вычисление). Отложенное
вычисление полезно только тогда, когда точно известно, что ваша программа будет
выполнять операции, без которых можно обойтись.
Заметим, что нет никаких специфических особенностей отложенного вычис-
ления в языке C++. Данная методика может применяться в любом языке програм-
мирования (хотя основные языки программирования обычно используют «энер-
гичное» вычисление), и для некоторых из них - особенно APL, части диалектов
языка Lisp и фактически всех языков, работающих с потоками данных, - эта идея
является фундаментальной. Все же, C++ больше подходит в качестве средства для
реализации пользователем отложенного вычисления. Это связано с тем, что под-
держка инкапсуляции позволяет добавлять отложенное вычисление к классу без
ведома его клиентов.
Взгляните снова на приведенные выше фрагменты кода и вы убедитесь, что
интерфейсы класса не содержат сведений о том, какое вычисление используется
классами: «энергичное» или отложенное. Следовательно, можно реализовать
класс с помощью «прямой» стратегии «энергичного» вычисления, а затем, если
106
I Эффективность i Г
во время отладки (см. правило 16) выяснится, что от способа реализации класса ; г
зависит производительность, выполнить реализацию класса на основе отложен- | <
ных вычислений. Единственным изменением, которое заметят ваши пользовате-
ли (после повторной компиляции или компоновки программы), будет улучшение j
производительности. Клиентам нравятся такие усовершенствования, и это может
заставить вас гордиться своей ленью. j
Правило 18. Снижайте затраты i
на ожидаемые вычисления
В правиле 17 я превозносил достоинства лени, откладывания дел «в долгий ящик»
и объяснил, как лень может повысить эффективность ваших программ. В этом прави- i
ле я отстаиваю совершенно иную позицию. Здесь лени нет места! Сейчас я расскажу
вам, как улучшить работу программы, заставив ее выполнять больше, чем от нее требу-
ется. Философия этого правила может быть названа «сверхэнергичным вычислени-
ем»: выполнение заданий до того, как их поручили выполнить. |
Рассмотрим, например, шаблон для классов, которые представляют большие !
наборы численных данных: ’
templatecclass NumericalType>
class DataCollection {
public:
NumericalType min() const; |
NumericalType max () const;
NumericalType avg() const ;
};
Если предположить, что функции min, max и avg возвращают текущие мини-
мальное, максимальное и среднее значения набора, то существуют три пути реа-
лизации этих функций. Используя «энергичное» вычисление, вы исследовали бы
все данные в наборе при вызове min, max или avg и вернули бы соответствующее
значение. При отложенном вычислении заставили бы функции возвращать струк-
туры данных, с помощью которых можно было бы определять соответствующее
значение, когда оно будет использоваться. Если же вы выберете «предваритель-
ное» вычисление, программа будет следить за текущими минимальным, макси-
мальным и средним значениями набора данных, чтобы при вызове функций min,
max или avg возвратить правильное значение немедленно - без вычислений. Если
бы функции min, max и avg вызывались часто, можно было бы компенсировать
затраты на слежение за соответствующими значениями данных для всех обраще-
ний к этим функциям, и средние затраты на вызов функции были бы ниже, чем
при использовании энергичного или отложенного вычисления.
Идея, лежащая в основе «сверхэнергичного» вычисления, такова: если вы
ожидаете, что вычисление будет выполняться часто, вы можете снизить средние
Правило 18
107
затраты на вызов функции, создавая свои структуры данных таким образом, чтобы
обрабатывать запросы особенно эффективно.
Один из самых простых способов добиться этого - кэшировать уже вычислен-
ные значения, которые, как вы думаете, понадобятся снова. Допустим, вы пишете
программу для предоставления информации о служащих и предполагаете, что
будет часто запрашиваться номер комнаты сотрудника. Информация о служащем
хранится в базе данных, но большинству приложений номер комнаты не нужен,
поэтому база данных не оптимизирована для его поиска. Чтобы не производить
повторный поиск в базе, вы можете написать функцию f indCubicleNumber,
которая кэширует искомые номера комнат.
Последующие запросы номера комнаты, который уже был найден, могут быть
удовлетворены обращением к кэшу вместо запроса из базы данных.
Ниже приводится один из способов реализации функции findCubicle-
Number; при этом объект тар взят из стандартной библиотеки шаблонов (Standard
Template Library - STL, см. правило 35) и используется в качестве местного кэша:
int findCubicleNumber(const strings employeeName)
{
// Определите статический объект map (имя служащего, номер комнаты) .
// Этот объект - локальный кэш данных.
typedef map<string, int> CubicleMap;
static CubicleMap cubes;
// Попытайтесь найти пункт employeeName в кэше; затем итератор STL it
// укажет на найденную ячейку, если она существует (см. подробности
// в правиле 35) .
CubicleMap::iterator it = cubes.find(employeeName);
// Значение it будет равно cubes.end(), если ячейка не найдена
// (это стандартная реакция STL). В таком случае обратитесь
//за номером комнаты, затем добавьте его в кэш.
if (it == cubes.end()) {
int cubicle =
результат поиска номера ячейки employeeName's
в базе данных;
cubes [employeeName] = cubicle; // Добавьте пару
// (employeeName,
// cubicle) в кэш.
return cubicle;
}
else {
// it указывает на корректный
// элемент кэша (имя сотрудника, номер
// комнаты). Вам нужен только второй
// компонент, то есть компонент second,
return (*it).second;
}
}
108
Эффективность
Постарайтесь не углубляться в подробности кода STL (которые будут более
ясными после того, как вы прочитаете о правиле 35). Вместо этого сконцентри-
руйтесь на общей стратегии данной функции. Она состоит в том, чтобы использо-
вать локальный кэш для замены сравнительно дорогих запросов из базы данных
дешевым поиском в структуре данных, находящейся в оперативной памяти. Если
предположение о том, что номера комнат будут запрашиваться часто, верно, то
использование кэша в функции f indCubicleNumber должно привести к сокра-
щению средних затрат на определение номера комнаты служащего.
(Один нюанс кода все же требует объяснения. Последний оператор возвраща-
ет (* it) . second вместо обычного it->second. Почему? Это связано с согла-
шениями, которым следует STL. В двух словах, итератор it является объектом,
а не указателем, поэтому нет гарантии, что оператор -> может применяться Kit*.
Спецификации STL требуют, чтобы операции “. ” и были допустимы для ите-
раторов, так что конструкция (* it) . second, будучи синтаксически громоздкой,
гарантированно работает.)
Кэширование - один из способов снизить затраты на предполагаемые вычис-
ления. Упреждающая выборка из памяти - другой. Вы можете считать упреждаю-
щую выборку вычислительным эквивалентом оптовой скидки. Контроллеры дис-
ка, например, считывают блоки или сектора данных целиком, даже если программа
запрашивает лишь небольшой объем данных. Это обусловлено тем, что машине
быстрее считать большой блок информации сразу, чем считывать два или три
маленьких блока в разное время. Кроме того, опыт показывает, что если потребо-
вались одни данные, соседние данные тоже понадобятся. Это печально известное
явление называется локальной взаимосвязанностью (данных), и проектировщи-
ки систем ориентируются на него, создавая кэш диска, памяти команд и данных
и упреждающей выборки команд.
Если вас не волнуют такие низкоуровневые вещи, как контроллеры диска или
кэш процессора, нет проблем. Все равно предварительная выборка из памяти бу-
дет вам полезна. Представьте, например, что вы хотели бы реализовать шаблон
для динамических массивов, то есть массивов, которые начинаются с одного раз-
мера и автоматически расширяются:
templatecclass Т> // Шаблон для динамических
class DynArray {...); // массивов.
DynArray<double> а; // Пока только а[0]
// является правильным
// элементом массива.
а[22] = 3.5; // Массив а автоматически
// расширяется:
// допустимые индексы 0-22.
а[32] = 0; // Массив а расширяется снова;
// теперь допустимы индексы а[0]-а[32]
В июле 1995 года комитет ISO/ANSI по стандартизации языка C++ добавил требование, согласно
которому большинство итераторов STL должны поддерживать оператор->, так что выражение it->
second должно теперь работать. Однако некоторые реализации STL не соответствуют данному
требованию, поэтому пока чаще используется конструкция (*it) .second.
109
Правило 18
Как же объект DynArray расширяется? Можно было бы просто выделить
столько дополнительной памяти, сколько необходимо, например, так:
templatecclass Т>
Т& DynArray<T>::operator!](int index)
{
if (index < 0) {
поднять исключения; // Отрицательные индексы
} // все еще недопустимы.
if (index > текущего максимального значения индекса) (
Вызов new, для того чтобы выделить достаточный объем дополнительной
памяти и тем самым сделать индекс допустимым;
}
return элемент массива с индексом index;
}
При таком подходе оператор new вызывается каждый раз, когда требуется
увеличить размер массива, но запросы new вызывают функцию operator new
(см. правило 8), а вызовы функций operator new (и operator delete) до-
статочно «дороги». Дело в том, что они обычно приводят к системным вызо-
вам, которые выполняются медленнее, чем вызовы функций внутри процесса.
Поэтому лучше сократить число системных вызовов до минимума.
Стратегия «сверхэнергичного» вычисления опирается на следующее рассуж-
дение: если необходимо увеличить размер массива для того, чтобы он соответ-
ствовал индексу i, то по принципу локальной взаимосвязанности, вероятно,
придется увеличивать его и в будущем, чтобы он соответствовал какому-либо
другому индексу, немного большему, чем i. Избежать затрат на выделение па-
мяти во время второго (ожидаемого) увеличения можно, если сразу сделать раз-
мер массива DynArray настолько большим, чтобы последующие увеличения
оказались в пределах предусмотренного диапазона. Например, можно записать
DynArray: : operator [ ] следующим образом:
template<class Т>
Т&
{
if
DynArray<T>::operator[](int index)
(index < 0) сгенерировать исключение;
if (index > текущего максимального значения индекса) {
int diff = index - текущее максимальное значение индекса;
вызов new, чтобы предоставить достаточно дополнительной памяти
и тем самым сделать index+diff действительным;
}
return элемент массива с индексом index;
}
Эта функция запрашивает вдвое больше памяти, чем необходимо при каждом
увеличении массива. Если вы снова посмотрите на предыдущий сценарий, то за-
метите, что массив DynArray должен запрашивать дополнительную память толь-
ко один раз, даже если ее логический размер увеличивается вдвое:
110
Hi
DynArray<double> a;
a [22] = 3.5;
a[32] = 0;
Эффективность
// Допустим только индекс а[0].
// Вызывается new для расширения
// хранилища а посредством
// индекса 44; логический размер а
// достигает 23.
// Логический размер а
// изменяется для учета а[32] ,
//но при этом new не вызывается.
Если придется снова увеличить размер а, то ожидаемое увеличение также будет
«недорогим», но при условии, что новый максимальный индекс не превысит 44.
Через весь этот раздел красной нитью проходит одна мысль: в большинстве слу-
чаев увеличение скорости выполнения программы может быть достигнуто ценой
увеличения расхода памяти. Отслеживание текущих минимальных, максимальных
и средних значений требует дополнительного пространства, но экономит время.
Хранение результатов в кэше использует больше памяти, но сокращает время, ре-
зультаты не вычисляются, а восстанавливаются из кэша. Упреждающая выборка
требует места для размещения данных, которые были предварительно выбраны из
памяти, но экономит время на то, чтобы получить доступ к этим данным. Эта исто-
рия столь же стара, как информатика: пространство часто приносится в жертву вре-
мени. (Однако не всегда. Использование больших объектов означает, что на стра-
нице виртуальной памяти или кэша поместится меньше объектов. В редких случаях
увеличение объектов уменьшает производительность программы, потому что воз-
растает число обращений к файлу подкачки, понижается частота успешных обра-
щений к кэшу или происходит и то, и другое. Как же выяснить, не столкнулись ли
вы с аналогичной проблемой? Используйте отладчик снова и снова (см. правило 16).)
Совет, который я предлагаю в этом разделе, таков: снижайте затраты на ожи-
даемые вычисления с помощью «сверхэнергичных» стратегий, то есть кэширова-
ния и упреждающей выборки данных. Это не противоречит использованию от-
ложенного вычисления, о котором говорилось в правиле 17. Отложенное
вычисление - это методика, предназначенная для повышения эффективности
программ при выполнении операций, результаты которых необходимы не всегда.
Сверхэнергичное вычисление повышает эффективность программ при выполне-
нии операций, результаты которых необходимы почти всегда или часто. Обе вы-
шеупомянутые методики гораздо труднее реализовать, чем обычную методику
«энергичного» вычисления, но их использование может существенно повысить
производительность программ.
Правило 19. Изучите причины возникновения
временныхобъектов
Общаясь друг с другом, программисты часто называют кратковременно необ-
ходимые переменные «временными». Например, в следующей процедуре swap:
111
Правило 19 ИШИМН
template<class Т>
void swap(T& objectl, T& objects)
{
T temp = objectl;
objectl = objects,-
objects = temp;
}
temp - временная переменная. Однако в рамках языка C++ объект temp не явля-
ется временным. Это просто локальный объект функции.
Истинные временные объекты в C++ невидимы - они не появляются в исход-
ном коде программы. Они возникают, когда создается, но не называется, стати-
ческий объект. Такие неименованные объекты обычно возникают в двух случаях:
во-первых, когда для успешного вызова функций применяются неявные преобра-
зования типов, и во-вторых, когда функции возвращают объекты. Важно пони-
мать, как и почему эти временные объекты создаются и уничтожаются, потому что
затраты на их создание и уничтожение могут оказать заметное влияние на произ-
водительность программы.
Рассмотрим вначале первый случай, когда временные объекты создаются для
успешного вызова функций. Это происходит, если тип объекта, передаваемого
функции, не совпадает с типом ее параметра. Например, проанализируем функ-
цию, которая считает число заданных символов в строке:
// Возвращает число символов ch в строке str.
size_t countchar(const strings str, char ch);
char buffer[MAX_STRING_LEN];
char c;
// Считать символ и строку, используя функцию setw, чтобы избежать
переполнения буфера при чтении строки.
cin >> с » setw(MAX_STRING_LEN) » buffer;
cout « "Обнаружено" « countchar(buffer, c)
« " символов " « c
« " в строке " « buffer « endl;
Взгляните на вызов функции countchar. Первый переданный параметр-
массив char, но соответствующий параметр функции имеет тип const strings.
Вызов может быть успешным, только если устранить несоответствие типов,
и ваши компиляторы это сделают, создавая временный объект типа string. Дан-
ный временный объект инициализируется при помощи вызова конструктора
string с параметром buffer. После этого параметр str в countchar связыва-
ется с временным объектом string. После возврата из функции countchar вре-
менный объект автоматически уничтожается.
Преобразования такого рода удобны (хотя и опасны - см. правило 5). Но
с точки зрения эффективности создание и уничтожение временного объекта
string влечет за собой ненужные расходы. Устранить их можно двумя путями.
112
Эффективность
Первый способ - изменить программу так, чтобы подобные преобразования не
могли возникать. Данная стратегия описывается в правиле 5. Альтернативный
путь - сделать так, чтобы преобразования были не нужны. Этому посвящено
правило 21.
Рассматриваемые преобразования происходят только при передаче объектов
по значению или при передаче параметра «ссылка на const». Они не возникают
при передаче объекта параметру «ссылка не на const». Проанализируем следую-
щую функцию:
void uppercasify(strings str); // Переводит все символы
//в str в верхний регистр.
В примере с подсчетом знаков массив char можно было бы успешно передать
функции countChar, но здесь попытка вызвать функцию uppercasify с масси-
вом char не удается:
char subtleBookPlug!] = "Effective C++";
uppercasify(subtleBookPlug); // Ошибка!
При этом не создается никаких временных объектов, чтобы сделать вызов
успешным. Почему?
Предположим, что временный объект создан. Тогда он был бы передан функ-
ции uppercasify, которая перевела бы все его символы в верхний регистр. Но
фактический параметр в вызове функции - subtleBookPlug - не подвергся бы
модификации; был бы изменен только временный объект string, полученный
из subtleBookPlug. Конечно, это не совпадает с замыслом программиста. Про-
граммист передавал в функцию uppercasify параметр subtleBookPlug, ожи-
дая, что переменная subtleBookPlug изменится. Неявное преобразование ти-
пов для объектов «ссылка не на const» позволило бы изменять временные
объекты, тогда как программист ожидал модификации «невременных» объектов.
Именно поэтому язык запрещает создание временных объектов для параметров
ссылки не на const. Ссылка на параметры с атрибутом const не вызывает дан-
ной проблемы, потому что такие параметры не могут быть изменены.
Временные объекты могут также создаваться, если функция возвращает
объект. Например, функция operator* должна вернуть объект, который пред-
ставляет собой сумму ее операндов. Если задан тип Number, то operator* для
этого типа объявляется примерно так:
const Number operator* (const Numbers Ihs,
const Numbers rhs);
Возвращаемое значение данной функции является временным, потому что
оно не имеет имени: это только возвращаемое функцией значение. Следователь-
но, вызов operator* каждый раз приводит к затратам на создание и удаление
такого объекта. (Объяснение того, почему возвращаемое значение является
const, вы найдете в правиле 6.)
113
Правило 20 ИМПН1
Как обычно, вам не нужны лишние затраты. Чтобы избежать их, в рассматри-
ваемом случае вы можете использовать похожую функцию, operator*=; это пре-
образование описано в правиле 22. Но для большинства функций, выдающих
объекты, не существует аналогов, то есть в принципе, концептуально, нельзя из-
бежать создания и удаления возвращаемого значения. Однако между концепцией
и действительностью лежит «сумеречная зона», называемая оптимизацией,
и иногда вы можете записывать функции, возвращающие объекты, так, что это по-
зволит вам не создавать временные объекты. Наиболее часто применяется опти-
мизация возвращаемого значения, которая обсуждается в правиле 20.
Подводя итог, можно сказать, что создание временных объектов - довольно
«дорогое» удовольствие, поэтому постарайтесь его избегать. Важнее научиться
находить места, где могут создаваться временные объекты. Когда вы видите пара-
метр типа «ссылка на const», помните, что допускается создание временного
объекта. Когда вы видите функцию, возвращающую объект, знайте, что будет со-
здан (а затем удален) временный объект. Учитесь находить такие конструкции,
и вы лучше поймете, какие ресурсы уходят на выполнение «закулисных» дей-
ствий компилятора.
Правило 20. Облегчайте оптимизацию
возвращаемого значения
Функция, которая возвращает объекты, не по вкусу ревностным поклонникам
эффективности, потому что возврат по значению, включая подразумеваемые вызо-
вы конструктора и деструктора (см. правило 19), не могут быть устранены. Пробле-
ма проста: функция либо должна вернуть объект, чтобы выполнить работу, либо нет.
Если она возвращает объект, то нет никакого способа избавиться от этого.
Рассмотрим функцию operator* для действительных чисел:
class Rational {
public:
Rational (int numerator = 0, int denominator = 1) ;
int numerator() const;
int denominator() const ;
};
// Причины постоянства (const) вызываемого
// значения указаны в правиле 6.
const Rational operator*(const Rationale Ihs,
const Rationale rhs);
Даже не глядя на код функции operator*, вы знаете, что она должна вернуть
объект, потому что возвращает произведение двух произвольных чисел. Как функ-
ция operator* может избежать создания нового объекта для хранения их произ-
ведения? Никак, поэтому она должна создавать новый объект и возвращать его.
Тем не менее, программисты C++ приложили усилия, достойные Геркулеса, что-
бы найти способ избавиться от возврата результатов по значению.
114
II!
Эффективность
Некоторые программисты возвращают указатели, что приводит к синтаксичес-
кой пародии:
// Неблагоразумный способ избежать возвращения объекта.
const Rational * operator*(const Rationale Ihs,
const Rational& rhs);
Rational a = 10;
Rational b(1, 2) ;
Rational c = * (a * b) ; // По-вашему, это естественно?
В связи с этим возникает вопрос. Должна ли вызывающая программа удалять
указатель, возвращенный функцией? Обычно отвечают «да», но это, как правило,
ведет к утечке ресурсов.
Другие разработчики возвращают ссылки, что дает в общем-то приемлемый
синтаксис:
// Опасный (и неправильный) способ избежать возвращения объекта.
const Rationale operator*(const Rationale Ihs,
const Rational& rhs) ;
Rational a = 10;
Rational b (1, 2 ) ;
Rational c = a * b; // Выглядит вполне благоразумно.
Но поведение таких функций нельзя реализовать корректно. Обычная попыт-
ка выглядит примерно так:
// Еще один опасный (и неправильный) способ избежать возвращения объекта.
const Rationale operator*(const Rational& Ihs,
const Rational& rhs)
{
Rational result(Ihs.numerator() * rhs.numerator(),
Ihs.denominator() * rhs.denominator());
return result;
}
Эта функция возвращает ссылку на объект, который больше не существует.
В частности, она возвращает ссылку на локальный объект result, но result был
автоматически удален при выходе из operator*. Возвращение ссылки на объект,
который был уничтожен, вряд ли полезно.
Поверьте, некоторые функции (operator* в том числе) все равно будут воз-
вращать объекты. Не стоит бороться с тем, чего вы не сможете победить.
Вы не получите желаемого результата, пытаясь устранить возвращение объек-
тов по значению функциями, которые требуют этого. В принципе, вас и не долж-
но волновать то, что функция возвращает объект, вам необходимо заботиться
только о затратах, которые приносит возврат объекта. Поэтому главное - найти
способ сократить затраты на возврат объектов, а не устранять сами объекты.
Если создание таких объектов не влечет никаких затрат, то не все ли равно, сколь-
ко их будет?
Правило 20
им
115
Очень часто функции, которые возвращают объекты, используются таким об-
разом, что компиляторы могут устранить затраты на создание временных объек-
тов. Тонкость заключается в том, чтобы возвращать аргументы конструктора
вместо объектов:
// Эффективный и правильный способ реализации функции,
// которая возвращает объект.
const Rational operator*(const Rational& Ihs,
const Rationale rhs)
{
return Rational(Ihs.numerator() * rhs.numerator() ,
Ihs.denominator() * rhs.denominator()) ;
}
Взгляните внимательнее на возвращаемое выражение. Оно выглядит как вы-
зов конструктора Rational, и фактически так оно и есть. Вы создаете времен-
ный объект Rational при помощи выражения:
Rational(Ihs.numerator() * rhs.numerator(),
Ihs.denominator () * rhs.denominator ()) ;
Именно этот временный объект и копируется функцией в качестве возвраща-
емого ею значения.
Кажется, что возврат аргументов конструктора вместо локальных объектов не
принесет вам много пользы, потому что вы все еще должны покрывать затраты на
создание и удаление временного объекта, появляющегося внутри функции, и вы
все еще должны покрывать затраты на создание и удаление объекта, который воз-
вращается функцией. Но вы уже получили кое-что. Правила языка C++ позволя-
ют компиляторам выполнять оптимизацию за счет удаления временных объектов.
В результате, если вы вызываете operator* в следующем контексте:
Rational а = 10;
Rational Ь(1, 2) ;
Rational с = а * Ь; // operator* вызывается здесь.
то ваши компиляторы могут устранять как временный объект внутри ope-
rator*, так и временный объект, возвращаемый operator*. Они могут созда-
вать объект, определенный выражением return в памяти, выделенной под объект с.
Если ваши компиляторы делают это, то общие затраты на образование времен-
ных объектов в результате вызова operator* сводятся к нулю. Чтобы создать
объект с, выполняется только один вызов конструктора. Кроме того, нельзя пред-
ложить ничего лучшего, потому что с - именованный объект, а именованные
объекты не могут быть удалены (см. также правило 22)*. Однако вы можете
* В июле 1996 комитет по стандартизации ISO/ANSI объявил, что как именованные, так и неимено-
ванные объекты могут быть оптимизированы при помощи оптимизации возвращаемого значения,
так что обе версии operator* (см. выше) могут теперь выдавать один и тот же (оптимизирован-
ный) объектный код.
116
^nill Эффективность
избавиться от накладных расходов, связанных с вызовом operator*, объявив
функцию как inline:
// Наиболее эффективный способ реализовать функцию,
// возвращающую объект.
inline const Rational operator*(const Rational& Ihs,
const Rational&: rhs)
{
return Rational(Ihs.numerator() * rhs.numerator(),
Ihs.denominator() * rhs.denominator()) ;
}
«Да, да», - бормочете вы, - «оптимизация, оптимизация. Какая разница, что
компиляторы могут сделать? Я хочу знать то, что они делают\ Работает ли эта
штука в реальных компиляторах?» Работает! Такая специфическая оптимиза-
ция - устранить локальный временный объект, используя точку возврата функ-
ции (и, возможно, заменяя его объектом в месте вызова функции) - хорошо
известна и широко применяется. Она даже имеет название: оптимизация воз-
вращаемого значения. Наличие особого названия для этого типа оптимизации
может объяснить, почему она так широко доступна. Программисты, ищущие ком-
пилятор C++, могут спросить продавцов, реализуется ли в нем оптимизация воз-
вращаемого значения. Если один продавец отвечает «Да», а другой спрашивает:
«Что-что реализуется?», то первый их них обладает определенным конкурентным
преимуществом. Ах, капитализм! Иногда невозможно его не любить!
Правило 21. Используйте перегрузку,
чтобы избежать неявного преобразования типов
Вот код, который выглядит совершенно правильным:
class UPInt { // Класс для целых чисел
public: // неограниченной точности.
UPInt () ;
UPInt(int value);
}
// Почему возвращаемое значение равно
// const, объясняется в правиле 6.
const UPInt operator*(const UPIntk Ihs, const UPInt& rhs) ;
UPInt upil, upi2;
UPInt upi3 = upil + upi2;
Здесь нет сюрпризов. И upil, и upi2 являются объектами типа UPInt, по-
этому их сложение просто приводит к вызову operator* для UPInt.
Рассмотрим теперь следующие операторы:
up!3 = upil + 10;
upi3 = 10 + upi2;
117
Правило 21 И1МПИ
Их выполнение также будет успешным, при этом для преобразования целого
числа 10 в тип UPInt будут созданы временные объекты (см. правило 19).
Такие преобразования обычно выполняются компиляторами автоматически,
но вряд ли вам нравится тратить дополнительные ресурсы компьютера на созда-
ние временных объектов. Так же как многие хотят получать кредиты от правитель-
ства, не возвращая их, так и большинство программистов C++ желали бы исполь-
зовать неявные преобразования типов, не неся расходов по созданию временных
объектов. Но как это сделать - ведь не существует вычислительного эквивалента
покрытия бюджетного дефицита?
Если сделать шаг назад, то обнаружится, что цель на самом деле состоит не
в преобразовании типов, а в том, чтобы можно было вызывать operator+ с аргу-
ментами типов UPInt и int. Для этого подойдет неявное преобразование типов,
но не нужно путать цели и средства. Существует другой способ успешного выпол-
нения вызовов operator* для аргументов разных типов, который устраняет не-
обходимость преобразования типов. Если вам нужно сложить объекты типа
UPInt и int, вы можете сделать это, объявив несколько функций с разными набо-
рами типов параметров:
const UPInt operator*(const UPInt& Ihs, const UPInt& rhs); const UPInt operator*(const UPIntk Ihs, int rhs); const UPInt operator*(int Ihs, const UPIntk rhs) // Сложить UPInt //и UPInt. // Сложить UPInt //и int. // Сложить int //и UPInt.
UPInt upil, upi2;
UPInt upi3 = upil + upi2; // Все в порядке, // временные объекты // для upil или upi2 //не создаются.
upi3 = upil + 10; // Все в порядке, // временные объекты // для upil или 10 //не создаются.
upi3 = 10 + upi2; // Все в порядке, // временные объекты // для 10 или upi2 //не создаются.
После выполнения перегрузки, что позволяет избежать преобразования ти-
пов, главное не увлечься и не объявить еще и функции типа:
const UPInt operator*(int Ihs, int rhs); // Ошибка!
Хотя определенная логика в этом построении есть: перегрузить все возмож-
ные комбинации operator* для типов UPInt и int. После того как заданы три
вышеприведенные функции, остается только operator*, оба аргумента которо-
го имеют тип int, поэтому-то и возникает соблазн добавить его.
118
Эффективность
'Mill
Но в языке C++ существуют свои правила игры, и согласно им один из аргу-
ментов любого перегруженного оператора должен иметь определенный пользова-
телем тип. Тип int является встроенным, поэтому нельзя перегружать оператор,
задавая только аргументы этого типа. (Если бы разрешалось изменять значение
встроенных операций, это привело бы к хаосу. К примеру, попытка перегрузки
operator* в данном случае изменила бы значение сложения двух целых чисел.)
Перегрузка функций для того, чтобы избежать создания временных объектов,
касается не только функций операторов. Например, во многих программах вам
может потребоваться сделать допустимым использование объекта string везде,
где есть char*, и наоборот. Аналогично, если вы включаете в код класс чисел (до-
пустим, класс комплексных чисел complex - см. правило 35), вам может понадо-
биться, чтобы в любом месте вместо численного объекта такого типа разрешалось
подставить число типа int или double. Этого нетрудно достичь, перегрузив все
функции с аргументами типа string, char*, complex и избежав тем самым пре-
образований типов.
Кроме того, важно не забывать о соотношении «80-20» (см. правило 16). Нет
смысла реализовать множество перегруженных функций, если это не приведет
к заметному улучшению суммарной эффективности использующих их программ.
Правило 22. По возможности применяйте оператор
присваивания вместо отдельного оператора
Большинство программистов ожидает, что если можно написать
х = х + у; х = X - у;
то можно написать и
х += у; х -= у;
Но если х и у имеют определенный пользователем тип, то нет гарантии, что
это действительно так. В языке C++ не предусмотрено связи между operator*,
operator= и operator+=, поэтому если вы хотите, чтобы все три оператора
существовали и привычно соотносились, вам придется реализовать такое поведе-
ние самостоятельно. То же самое относится к операторам -, *, / и т.д.
Хороший способ гарантировать естественное соотношение между оператором
присваивания (например, operator+=) и соответствующим отдельным операто-
ром (таким как operator*) - реализовать второй оператор через первый (см. так-
же правило 6). Сделать это достаточно легко:
class Rational {
public:
Rational& operator+=(const Rationale rhs) ;
Rational& operator—(const Rational& rhs);
};
119
// operator* реализован через operator+=.
// Почему возвращаемое значение имеет атрибут const,
// объясняется в правиле б,
//см. также предупреждение о реализации на стр. 121.
const Rational operator*(const Rationale Ihs,
const Rationale rhs)
{
return Rational(Ihs) += rhs;
}
// operator- реализован через operator—. -
const Rational operator-(const Rationale Ihs,
const Rationale rhs)
{
return Rational(Ihs) -= rhs;
}
В этом примере операторы += и -= реализованы с нуля в каком-то другом
месте, a operator* и operator- вызывают их, обеспечивая собственные фун-
кции. В таком случае необходимо поддерживать только операторы присваива-
ния. Более того, если операторы присваивания реализованы в открытом интер-
фейсе класса, то не нужно, чтобы отдельные операторы были дружественными
к классу.
Если нет причин, по которым все отдельные операторы нельзя сделать гло-
бальными, то устранить необходимость написания отдельных операторов можно
с помощью шаблонов:
template<class Т>
const Т operator* (const Т& Ihs, const Т& rhs)
{
return T(lhs) += rhs; //См. комментарии выше.
}
template<class T>
const T operator-(const T& Ihs, const T& rhs)
{
return T(lhs) -= rhs; // См. комментарии выше.
}
Тогда, если для какого-либо типа Т определен оператор присваивания, то со-
ответствующий отдельный оператор при необходимости будет генерироваться
автоматически.
Все это хорошо, но пока еще не рассматривались вопросы эффективности,
которым посвящена настоящая глава. Здесь нужно обратить внимание на три
момента. Во-первых, в общем случае операторы присваивания обычно более
эффективны, чем соответствующие версии отдельных операторов, поскольку
отдельные операторы, как правило, возвращают новый объект, и при этом так-
же создается и уничтожается временный объект (см. правила 19 и 20). Операторы
120
МИЦИ
Эффективность
же присваивания производят запись в аргумент слева, поэтому в данном случае нет
необходимости создавать временный объект для хранения возвращаемого значе-
ния оператора.
Во-вторых, создавая и отдельные операторы, и соответствующие им операто-
ры присваивания, вы позволяете клиентам ваших классов достигать компромис-
са между эффективностью и удобством. При этом пользователи могут выбирать,
писать ли код так:
Rational a, b, с, d, result;
result =a+b+c+d; // Возможно использует //3 временных объекта, по одному // для каждого вызова operator+.
или так:
result = а; //Не нужно создавать временный объект
result += b; //Не нужно создавать временный объект.
result += с; //Не нужно создавать временный объект.
result += d; //Не нужно создавать временный объект.
Первый вариант проще написать, отлаживать и поддерживать, при этом в 80%
случаев он обеспечивает приемлемую производительность (см. правило 16). Вто-
рой вариант более эффективен, и, возможно, более понятен для программистов
на языке ассемблера. Включая оба варианта, вы позволяете пользователям разра-
батывать и отлаживать код с помощью более простых отдельных операторов, со-
храняя при этом возможность их замены более эффективными операторами при-
сваивания. Более того, реализовав отдельные операторы через операторы
присваивания, вы гарантируете, что при переходе от одного варианта к другому
семантика операторов останется неизменной.
И последнее замечание об эффективности касается реализации отдельных
операторов. Снова рассмотрим реализацию operator+:
templatecclass Т>
const Т operator+ (const Т& Ihs, const T& rhs)
{ return T(lhs) += rhs; }
Выражение T (Ihs) - это вызов конструктора копирования объекта Т, созда-
ющего временный объект, значение которого равно Ihs. Затем полученный вре-
менный объект используется для вызова operator+= с параметром rhs, а резуль-
тат операции возвращается operator + *. Кажется, что этот код слишком запутан.
Может быть, лучше написать его так:
* По меньшей мере предполагается, что это так. Увы, некоторые компиляторы интерпретируют
T(lhs) как приведение типа, снимающее атрибут const с Ihs, затем складывают rhs и Ihs
и возвращают ссылку на измененный параметр Ihs! Поэтому прежде чем полагаться на описан-
ное выше поведение, протестируйте ваш компилятор.
121
Правило 23 »!
template<class Т>
const Т operator+(const Т& Ihs, const T& rhs)
{
T result(Ihs); // Скопировать Ihs в результат.
return result += rhs; // Прибавить к нему rhs и вернуть
} //в качестве результата.
Этот шаблон почти эквивалентен предыдущему, но между ними есть важное
различие. Второй шаблон содержит именованный объект result. А это означает,
что оптимизация возвращаемого значения (см. правило 20) для такой реализации
operator + до недавнего времени была невозможной (см. сноску на стр. 119). Для
первой же реализации оптимизация возвращаемого значения разрешалась всегда,
поэтому существует больше шансов, что ваш компилятор сможет сгенерировать
оптимизированный код.
Но принципы честной рекламы вынуждают меня отметить также, что выражение
return T(lhs) += rhs;
многие компиляторы рассматривают как слишком сложное для оптимизации воз-
вращаемого значения. Поэтому первая реализация может потребовать создания
одного временного объекта, так же как и при использовании именованного объек-
та result. Тем не менее, неименованные объекты всегда было проще устранять,
чем именованные, поэтому при выборе между именованным объектом и времен-
ным, возможно, будет лучше использовать второй из них. Это никогда не обой-
дется дороже, чем применение именованного объекта, а в некоторых компилято-
рах, особенно в старых, потребует даже меньше затрат.
Все рассуждения об именованных и неименованных объектах и оптимизаци-
ях компиляторов, конечно же, небезынтересны, но не стоит забывать о главном.
Операторы присваивания (такие как operator+=) обычно более эффективны,
чем соответствующие отдельные операторы (например, operator+). При разра-
ботке библиотек следует включать в нее обе версии операторов, а для выигрыша
в производительности по возможности использовать операторы присваивания
вместо соответствующих отдельных операторов.
Правило 23. Используйте разные библиотеки
Разработка библиотеки - один из примеров компромисса. В идеале, библио-
тека должна быть компактной, быстрой, мощной, гибкой, расширяемой, интуи-
тивно понятной, универсальной, легко поддерживаться, быть свободной от огра-
ничений и безошибочной. Но таких библиотек не существует. Библиотеки,
оптимизированные по скорости выполнения и размеру, обычно не переносимы на
другие компьютеры. Библиотеки с богатыми функциональными возможностями
редко бывают интуитивно понятными. Безошибочные библиотеки обладают
ограниченными возможностями. В нашем мире нельзя получить все сразу: чем-то
всегда приходится жертвовать.
Разработчики присваивают каждому из этих критериев различные приорите-
ты, принося в жертву то одно, то другое. В результате зачастую две аналогичные
122
III
Эффективность
по функциям библиотеки имеют совершенно различные характеристики произво-
дительности.
Например, рассмотрим библиотеки ввода-вывода iostream и stdio, доступ-
ные во всех компиляторах языка C++. Библиотека iostream имеет ряд преиму-
ществ перед аналогичной библиотекой языка С. Например, она является расши-
ряемой и более безопасной. Что же касается эффективности, библиотека iostream
обычно проигрывает библиотеке stdio, и исполняемые файлы, созданные при
помощи stdio, обычно имеют меньший размер и работают быстрее.
Проанализируем вначале скорость выполнения. Оценить различие в произ-
водительности между этими библиотеками можно, выполнив тесты для каждой
из них. При этом надо иметь в виду, что все тесты производительности «врут».
Сложно не только определить набор входных данных, соответствующий «типич-
ному» применению программы или библиотеки, но и выяснить, насколько «ти-
пичными» являются ваши задачи или задачи ваших пользователей. Тем не менее,
тестовые приложения могут дать некоторое понятие о сравнительной произво-
дительности различных походов к задаче, поэтому хотя и глупо полностью пола-
гаться на них, игнорировать их также неразумно.
Рассмотрим простую тестовую программу, выполняющую только основные
функции ввода-вывода. Эта программа считывает из стандартного ввода 30.000
чисел с плавающей точкой и записывает их стандартный вывод в формате с фик-
сированным числом знаков после запятой. Выбор между библиотеками iostream
и stdio осуществляется во время компиляции и зависит от переменной препро-
цессора STDIO. Если она определена, то используется библиотека stdio, в про-
тивном случае применяется библиотека io st ream.
#ifdef STDIO
#include <stdio.h>
#else
#include <iostream>
#include <iomanip>
using namespace std;
#endif
const int VALUES =30000; // Число повторений цикла.
int main()
{
double d;
for (int n = 1; n <= VALUES; ++n) {
#ifdef STDIO
scanf("%lf", &d);
printf("%10.5f", d);
#else
cin >> d;
cout « setw(10) // Задать ширину поля.
« setprecision(5) // Знаков после запятой.
« setiosflags (ios :: showpoint) // Дополнить нулями.
« setiosflags(ios::fixed) // Использовать эти значения
IIIHI
123
Правило 23
« d;
#endif
if (n % 5 == 0) {
#ifdef STDIO
printf(«\п»);
#else
cout « "\n";
#endif
}
}
return 0;
}
Когда на вход программы попадают натуральные логарифмы положительных
чисел, на ее выходе получится:
0.00000 0.69315 1.09861 1.38629 1.60944 1.79176 1.94591
2.07944 2.19722 2.30259 2.39790 2.48491 2.56495 2.63906
2.70805 2.77259 2.83321 2.89037 2.94444 2.99573 3.04452
3.09104 3.13549 3.17805 3.21888
Это по крайней мере демонстрирует, что при помощи библиотеки iostream
можно выводить числа в формате с фиксированным числом знаков после запя-
той. Конечно же, запись
cout « setw(10)
« setprecision(5)
« setiosflags(ios::showpoint)
« setiosflags(ios::fixed)
« d;
совсем не так проста, как
printf("%10.5f", d);
но operator« является расширяемым и обеспечивает безопасность при работе
с различными типами, а функция printf - нет.
Я запускал эту программу на разных компьютерах, под разными операцион-
ными системами и использовал разные компиляторы, и во всех случаях версия на
основе библиотеки stdio была быстрее. Иногда лишь немного (примерно на
20%), иногда значительно (почти на 200%), но никогда реализация на основе биб-
лиотеки iostream не могла сравниться по скорости с соответствующей реализа-
цией на основе библиотеки stdio. Кроме того, обычно размер исполняемого фай-
ла этой простой программы, скомпилированной с использованием библиотеки
stdio, был меньше (иногда намного меньше), чем размер соответствующего ис-
полняемого файла при использовании библиотеки iostream. (Для реальных
программ это различие обычно не является столь существенным.)
Степень преимущества библиотеки stdio сильно зависит от способа ее реали-
зации, поэтому в будущих версиях тестировавшихся систем или в каких-либо
124
Эффективность
других системах разница в производительности между этими двумя библиотеками
может быть пренебрежимо мала. Может существовать реализация библиотеки
iostream, которая быстрее, чем библиотека stdio, так как типы операндов в биб-
лиотеке iostream определяются во время компиляции, а функции библиотеки
stdio обычно обрабатывают строку формата во время выполнения программы.
Различие между производительностью этих двух библиотек не столь важно,
и рассматривается только в качестве примера. Основная мысль вышеизложен-
ного заключается в том, что разные библиотеки с аналогичной функционально-
стью часто обладают различной производительностью, поэтому после определе-
ния «узких» мест программы (при помощи отладчика - см. правило 16), вы
увидите, удастся ли избавиться от них, заменив одну библиотеку на другую. На-
пример, если «узким» местом программы является скорость ввода-вывода, мож-
но попробовать заменить библиотеку iostreams на stdio, если же значитель-
ная часть времени тратится на выделение и освобождение памяти, попытайтесь
использовать различные реализации operator new и operator delete (см. пра-
вило 8). Так как разные библиотеки демонстрируют различные подходы к эф-
фективности, расширяемости, переносимости, «типовой» безопасности и дру-
гим вопросам, то иногда можно повысить эффективность программного
обеспечения, использовав библиотеку, разработчики которой уделили больше
внимания вопросам производительности.
Правило 24. Учитывайте затраты, связанные
с виртуальными функциями, множественным
наследованием, виртуальными базовыми классами и RTTI
Компиляторы C++ должны реализовывать все функции языка. Детали реали-
зации, конечно же, зависят от конкретного компилятора, и разные компиляторы
по-разному реализуют те или иные свойства языка. В большинстве случаев вам
не придется заботиться об этих различиях. Но иногда реализация некоторых
свойств языка заметно влияет на размер объектов и скорость, с которой выполня-
ются функции-члены, поэтому вам важно иметь общее представление о том, что
происходит «за сценой». В качестве примера можно в первую очередь привести
виртуальные функции.
При вызове виртуальной функции выполняемый код должен соответствовать
динамическому типу объекта, для которого вызывается функция; независимо от
типа указателя или ссылки на объект. Как без лишних затрат обеспечить такое
поведение в компиляторе? Большинство реализаций используют виртуальные
таблицы (virtual table, сокращенно vtbl) и указатели на виртуальные таблицы
(virtual table pointer, сокращенно vptr).
Виртуальная таблица обычно является массивом указателей на функции.
(Некоторые компиляторы используют вместо массива разновидность связного
списка, но принцип действия остается тем же самым.) Каждый класс программы,
Правило 24
125
который объявляет или наследует виртуальные функции, имеет собственную вир-
туальную таблицу, где элементы представляют собой указатели на реализацию вир-
туальных функций для этого класса. Например, если класс определен следующим
образом:
class Cl {
public:
Cl () ;
virtual -Cl () ;
virtual void f1();
virtual int f2(char c) const;
virtual void f3(const strings s)
void f4() const;
то массив виртуальной таблицы класса Cl будет выглядеть примерно так, как
показано на рис. 4.1.
реализация С1::-С1
реализация Cl ::f1
С1
vtbl
реализация C1::f2
реализация С1 ::f3
Рис. 4.1
Обратите внимание, что в таблице отсутствуют невиртуальная функция f4
и конструктор С1. Невиртуальные функции, включая конструкторы, которые по
умолчанию являются невиртуальными, реализуются точно так же, как обычные
функции С, и имеют поэтому ту же производительность.
Если класс С2 наследует от класса С1, переопределяет некоторые из наследу-
емых виртуальных функций и добавляет еще несколько своих:
class С2: public Cl {
public:
С2 () ;
virtual ~С2 () ;
virtual void f 1 () ;
virtual void f5(char *str);
// Невиртуальная функция.
// Переопределенная функция.
// Переопределенная функция.
// Новая виртуальная функция
};
то элементы в виртуальной таблице указывают на функции, соответствующие
типу его объектов. Эти элементы включают указатели на виртуальные функции
класса С1, которые не переопределяются в классе С2 (см. рис. 4.2).
126
пни
Эффективность
C2
vtbl
реализация C2::-C2
реализация C2::f 1
реализация C1 ::f2
реализация C1::f3
реализация C2::f5
Рис. 4.2
Из этого рассуждения видно, к каким затратам может привести использование
виртуальных функций: необходимо выделить память для виртуальной таблицы
каждого класса, содержащего данные функции. Размер виртуальной таблицы клас-
са пропорционален числу объявленных в нем виртуальных функций (включая
унаследованные от базовых классов). Каждый класс должен содержать только одну
виртуальную таблицу, поэтому общий объем, занимаемый такими таблицами,
обычно незначителен, но если вы создаете большое число классов или большое
число виртуальных функций в каждом классе, то таблицы могут при этом зани-
мать достаточно много места в адресном пространстве.
Так как в программе нужна только одна копия виртуальной таблицы класса,
компилятор должен решить, куда ее удобнее поместить. Большинство программ
и библиотек создаются при помощи компоновки большого числа объектных фай-
лов, каждый из которых создается независимо. Какой из объектных файлов должен
содержать виртуальную таблицу данного класса? Можно предположить, что она
должна помещаться в объектный файл, содержащий функцию main, но многие биб-
лиотеки не включают эту функцию, кроме того, содержащий ее исходный файл
может не упоминаться во многих классах, в которых нужны виртуальные таблицы.
Как тогда компилятор узнает, какие виртуальные таблицы он должен создать?
Можно использовать различные подходы, и в связи с этим производители
разделились на два лагеря. Те из них, которые поставляют интегрированную сре-
ду, включающую и компилятор, и компоновщик, обычно создают копии виртуаль-
ной таблицы в каждом объектном файле, где она нужна. Затем компоновщик уда-
ляет дубликаты, оставляя только по одной копии каждой виртуальной таблицы
в конечном исполняемом файле или библиотеке.
Более распространенный подход состоит в использовании эвристики, чтобы
определить объектный файл, который должен содержать виртуальную таблицу для
класса. Обычно применяется такая эвристика: виртуальная таблица класса созда-
ется в объектном файле, содержащем определение (то есть тело) первой невстроен-
ной не полностью виртуальной функции класса. В этом случае виртуальная табли-
ца для приведенного класса С1 была бы помещена в объектный файл, где имеется
определение С1: : ~С1 (если эта функция не определена как inline), а виртуаль-
ная таблица для класса С 2 разместилась бы в объектном файле, содержащем опре-
деление С2 : : ~С2 (если эта функция также не была определена как inline).
Правило 24
И1М1
127
На практике такая эвристика прекрасно действует, но она может вызвать не-
приятности, если виртуальные функции объявляются как inline. Если все вир-
туальные функции в классе объявлены как встроенные, то эвристика не сработает, и
большинство основанных на ней компиляторов создадут по копии виртуальной таб-
лицы класса в каждом объектном файле, использующем ее. В больших системах это
может привести к образованию программ, содержащих сотни и тысячи копий вир-
туальной таблицы класса! Большинство компиляторов, применяющих описанную
эвристику, позволяют в какой-то степени вручную управлять созданием виртуаль-
ной таблицы, но лучшее решение в данном случае - не объявлять виртуальные
функции как inline. Кроме того, как вы впоследствии увидите, имеются причи-
ны, по которым современные компиляторы обычно игнорируют директиву inline
для виртуальных функций.
Виртуальные таблицы составляют половину механизма виртуальных функ-
ций, но сами по себе они бесполезны. Они приобретают значение, только если
существует способ определить, какая виртуальная таблица соответствует каж-
дому объекту, и это соответствие устанавливается при помощи указателя вирту-
альной таблицы.
Каждый объект, класс которого объявляет виртуальные функции, содержит
виртуальный элемент данных - указатель виртуальной таблицы, добавляемый
компилятором к объекту. Объект, имеющий виртуальные функции, схематично
изображен на рис. 4.3.
Данные
vptr
Рис. 4.3
Здесь показан указатель виртуальной таблицы в конце объекта, но следует
иметь в виду, что различные компиляторы могут размещать его по-разному.
В случае наследования указатель виртуальной таблицы часто бывает окружен эле-
ментами данных. Множественное наследование еще более усложняет эту карти-
ну, но об этом речь пойдет несколько позже. Пока просто отметим, что при исполь-
зовании виртуальных функций приходится включать еще один указатель в каждый
объект класса, который содержит такие функции.
Если объекты малы, это увеличение может оказаться существенным. Напри-
мер, если объект в среднем содержит четыре байта данных, то добавление указа-
теля виртуальной таблицы увеличит его размер вдвое (если указатель занимает
четыре байта). При ограниченном размере памяти это будет означать, что у вас
получится создать меньше объектов. Даже на системах с неограниченной памя-
тью производительность вашей программы может упасть, так как меньше объек-
тов будет помещаться в кэш или на страницу виртуальной памяти, что скорее
всего приведет к увеличению числа переключений страниц.
128
{Hi
Эффективность
Предположим, имеется программа, содержащая несколько объектов типов С1
и С2. Если задано описанное отношение между объектами, указателями виртуаль-
ных таблиц и виртуальными таблицами, объекты в программе можно представить
себе примерно так, как они изображены на рис. 4.4.
Рис. 4.4
Рассмотрим фрагмент программы:
void makeACall(Cl *рС1)
{
pCl->fl() ;
}
Это вызов виртуальной функции fl при помощи указателя рС1. Здесь нельзя
понять, какую из функций fl (Cl: : f 1 или С2 : : f 1) необходимо вызвать, так как
рС1 может указывать как на объект С1, так и на объект С2. Компилятор, тем не
менее, должен сгенерировать код для вызова функции fl внутри функции
makeACall, причем должна вызываться правильная функция независимо от того,
на что указывает рС1. Для этого компиляторы генерируют код, выполняющий
следующее:
Правило 24
1. Проследить указатель виртуальной таблицы до соответствующей виртуаль-
ной таблицы. Это простая операция, так как компиляторы знают положение указа-
теля виртуальной таблицы в объекте. (В конце концов, они сами его туда помести-
ли.) В результате ресурсы системы тратятся только на вычисление смещения (для
получения указателя виртуальной таблицы) и доступ по указателю (для получе-
ния виртуальной таблицы).
2. Найти указатель виртуальной таблицы, соответствующий вызываемой
функции (в данном примере функции fl). Это также несложно, поскольку ком-
пиляторы присваивают каждой виртуальной функции уникальный индекс в таб-
лице. Затраты на этот шаг сводятся просто к вычислению смещения в массиве
виртуальной таблицы.
3. Вызвать функцию, на которую ссылается указатель, найденный в шаге 2.
Если представить, что каждый объект имеет невидимый элемент данных vpt г
и что индекс виртуальной таблицы функции fl равен i, то оператор
pCl->fl();
будет генерировать код
(*pCl->vptr [i]) (pCl); // Вызывать функцию, на которую указывает
//
//
//
i-й элемент виртуальной таблицы,
заданной pCl->vptr; указатель рС1 передается
функции со значением this.
Данный подход почти так же эффективен, как и вызов невиртуальной функ-
ции: на большинстве компьютеров при этом выполняется всего на несколько ко-
манд больше. Виртуальные функции сами по себе обычно не влияют на произво-
дительность.
Реальные затраты на виртуальные функции во время выполнения программы
связаны с тем, что из практических соображений они не реализуются как встро-
енные. Директива inline означает «в процессе компиляции подставить вместо
вызова функции ее тело», но «виртуальная» предполагает «определить вызывае-
мую функцию во время выполнения программы». Если компилятор не знает, ка-
кая функция будет вызвана, то он не сможет сделать ее встроенной. Таким обра-
зом, надо сделать так, чтобы не реализовывать виртуальные функции как
встроенные. (Можно делать виртуальные функции встроенными при их вызове
с помощью объектов, но большинство виртуальных функций вызывается при по-
мощи указателей или ссылок на объекты, а такие вызовы не бывают встроенны-
ми. А поскольку эти вызовы общеприняты, виртуальные функции обычно не де-
лаются встроенными.)
Все сказанное до сих пор относится и к одиночному, и к множественному на-
следованию, но во втором случае картина усложняется. Нет смысла вдаваться в дета-
ли, но при множественном наследовании вычислить смещение, чтобы найти указате-
ли виртуальной таблицы в объектах, намного сложнее; в одном объекте содержится
несколько таких указателей (по одному для каждого из базовых классов); и кроме
отдельных виртуальных таблиц должны создаваться еще специальные виртуаль-
ные таблицы для базовых классов. В результате возрастают расходы памяти,
5 - 679
130
ими
Эффективность
используемой классами и объектами для виртуальных функций, и немного увели-
чивается стоимость вызова функции во время выполнения программы.
При множественном наследовании часто приходится создавать виртуальные
базовые классы. В противном случае, если производный класс имеет более одного
пути наследования от базового класса, элементы данных этого базового класса
копируются в каждый объект производного класса, по одному экземпляру для
каждого пути между производным и базовым классами. Программисты обычно
пытаются не допустить такого копирования, сделав базовые классы виртуальны-
ми. Но включение в код виртуальных базовых классов все равно приводит к до-
полнительным издержкам, поскольку их реализация часто использует указатели
на части виртуального базового класса, чтобы избежать копирования, и в объек-
тах могут храниться один или более таких указателей.
Рассмотрим следующий пример, который я называю «ужасным бриллиантом
множественного наследования» (см. рис. 4.5).
class А { ... } ;
class В: virtual public А { ... };
class С: virtual public А { ... };
class D: public В, public C { ... };
Рис. 4.5
В этом примере А является виртуальным базовым классом, так как классы В
и С виртуально наследуют от него. В некоторых компиляторах (особенно старых)
объект типа D может иметь вид, представленный на рис. 4.6.
Кажется немного странным помещать элементы данных базового класса
в конец объекта, но зачастую это делается именно так. Конечно же, в разных
реализациях память организована по-разному, поэтому предложенный рисунок
Рис. 4.6
Правило 24
131
только в общих чертах иллюстрирует то, как использование виртуальных базо-
вых классов может приводить к появлению скрытых указателей на объекты. В не-
которых реализациях добавляется меньшее число указателей, а в некоторых они
не добавляются вообще (в таком случае указатели виртуальных таблиц и вирту-
альной таблицы несут двойную нагрузку).
Если объединить этот рисунок с предыдущим, на котором было показано, как
к объектам добавляются указатели виртуальной таблицы, станет ясно, что если ба-
зовый класс А в иерархии, приведенной на станице 130, имеет виртуальные функ-
ции, то объект типа D будет устроен примерно следующим образом (см. рис. 4.7).
Данные класса В
___________vpti__________
Указатель на виртуальным
базовый класс
Данные класса С
Указатель на виртуальный
_____базовый класс_____>
Данные класса D
Данные класса А
vptr
Рис. 4.7
На рисунке закрашены части объекта, которые добавляются компилятором.
Отношение закрашенных и пустых областей определяется объемом данных
в классе. Для маленьких классов дополнительные расходы будут относительно ве-
лики. Для классов с большим объемом данных затраты окажутся менее значитель-
ными, хотя и достаточно заметными.
Странность этой схемы в том, что хотя она включает четыре класса, на ней
изображены только три указателя виртуальных таблиц. Различные реализации
могут создавать и четыре указателя виртуальных таблиц, но достаточно всего трех
(оказывается, объекты В и D могут совместно использовать один указатель),
и большинство реализаций с помощью этого добивается снижения накладных рас-
ходов, привносимых компилятором.
Итак, вы увидели, что применение виртуальных функций делает объекты
больше и мешает использованию встроенных функций, и убедились, что мно-
жественное наследование и виртуальные базовые классы также могут увели-
чивать размер объектов. Обратимся теперь к последней теме, затратам на
идентификацию типов во время выполнения программы (runtime type iden-
tification, сокращенно RTTI).
5*
132
ПИШИ
Эффективность
Идентификация типов во время выполнения программы позволяет получать
информацию об объектах и классах. При этом для хранения запрашиваемой ин-
формации нужно отвести определенное место. Информация содержится в объек-
те типа type_inf о, доступ к которому в классе можно получить при помощи опе-
ратора type id.
По логике в каждом классе должна быть только одна копия данных RTTI,
и должен существовать способ получения такой информации для каждого объек-
та. В действительности это не совсем так. В спецификации языка сказано, что га-
рантируется получение точных сведений о динамическом типе объекта, только
если этот тип содержит хотя бы одну виртуальную функцию. Данные RTTI вы-
полняют примерно ту же задачу, что и таблица виртуальных функций. Вам нужна
только одна копия информации для каждого класса, и нужно иметь способ полу-
чения соответствующей информации из любого объекта, содержащего виртуаль-
ную функцию. Параллель между RTTI и таблицами виртуальных функций не слу-
чайна: RTTI была разработана для ее реализации с помощью виртуальной таблицы
класса.
Например, индекс 0 в массиве виртуальной таблицы может содержать указа-
тель на объект type_inf о соответствующего таблице класса. Виртуальная таб-
лица класса С1 со стр. 125 имела бы тогда вид, представленный на рис. 4.8.
С1
vtbl
реализация С1 ::f1
реализация C1::f2
реализация C1::f3
Рис. 4.8
При такой реализации память будет тратиться только на добавление еще од-
ной ячейки в каждую виртуальную таблицу и выделение места для хранения од-
ного объекта type_infо для каждого класса. Так же как потери памяти на созда-
ние виртуальных таблиц вряд ли будут заметны в большинстве приложений, так
же маловероятно, что возникнут проблемы из-за размера объектов type_info.
В табл. 4.1 приведены сведения о затратах, сопровождающих использование
виртуальных функций, множественного наследования, виртуальных базовых
классов и идентификации типов.
Некоторые, увидев эту таблицу, могут ужаснуться и заявить: «Я продолжаю
писать на С!». Но помните, что каждое из описанных свойств обеспечивает какие-
то функции, которые иначе придется программировать вручную. В большинстве
случаев самостоятельная реализация оказывается менее эффективной и надежной,
чем код, созданный компилятором. Например, эмуляция вызовов виртуальных функ-
ций с помощью вложенных операторов switch или каскадирование операторов
if-then-else дает больше кода, чем вызовы виртуальных функций, и этот код
к тому же медленнее выполняется. Более того, вам придется отслеживать типы
Правило 24 illMHHKES
Таблица 4.1
Свойство Увеличивает размер объектов Увеличивает объем данных в классе Препятствует использованию встроенных функций
Виртуальные функции Да Да Да
Множественное наследование Да Да Нет
Виртуальные базовые классы Часто Иногда Нет
RTTI Нет Да Нет
объектов вручную, из-за чего объекты будут также содержать метки типов; поэтому
зачастую вы не получите никакого выигрыша даже от меньшего размера объектов.
Важно понимать, к каким затратам приводит использование виртуальных
функций, множественного наследования, виртуальных базовых классов и RTTI,
но также важно понимать, что если вам нужна функциональность этих свойств,
то вы должны так или иначе заплатить за нее. Иногда существуют разумные при-
чины для обхода предоставляемых компиляторами возможностей. Например,
скрытые указатели виртуальных таблиц и указатели на виртуальные базовые
классы могут усложнить сохранение объектов C++ в базе данных или их переда-
чу между процессами, поэтому стоит эмулировать эти свойства, чтобы было легче
выполнять подобные задачи. Но с точки зрения эффективности, запрограммиро-
вав свойства самостоятельно, вы вряд ли выиграете по сравнению с их реализаци-
ей при помощи компилятора.
Глава 5. Приемы
Большая часть книги посвящена принципам программирования. Они, конечно,
важны, но программисты не живут только принципами. Как говорилось в старом
мультсериале «Кот Феликс»: «Попадая впросак, достает он трюков рюкзак». Если
персонаж мультфильма может иметь рюкзак трюков, это могут и программисты на
C++. Считайте эту главу началом вашей коллекции нестандартных приемов.
При разработке программ на языке C++ специалисты постоянно сталкиваются
с одними и теми же проблемами. Как заставить конструкторы и функции, не явля-
ющиеся членами класса, работать подобно виртуальным функциям? Как предот-
вратить создание объектов в куче? Как, наоборот, гарантировать их создание там?
Как создавать объекты, которые автоматически выполняют какие-либо функции
при вызове других функций - членов класса? Как разные объекты могут совместно
использовать структуры данных, чтобы у клиентов при этом возникала иллюзия,
будто каждый из объектов обладает собственной копией? Как различать выполне-
ние записи и чтения в operator [ ] ? Как создать виртуальную функцию, поведе-
ние которой зависит от динамического типа нескольких объектов?
В настоящей главе, где описаны проверенные решения для задач, часто возни-
кающих перед программистами на C++, даются ответы на все эти (и многие дру-
гие) вопросы. Я называю такие решения приемами, но они также известны как
идиомы или, если изложены стилизованно, прототипы. Независимо от того, как
вы будете их называть, изложенная ниже информацию обязательно пригодится
вам в ежедневной практической работе. Эта глава должна также убедить вас, что
для языка C++ практически нет ничего невозможного.
Правило 25. Делайте виртуальными конструкторы
и функции, не являющиеся членами класса
Для начала надо пояснить, что подразумевается под термином «виртуальные
конструкторы». Виртуальные функции вызываются для выполнения операций,
привязанных к конкретному типу, если есть указатель или ссылка на объект, но не
известно, какой тип имеет объект. Конструктор же вызывается, когда объекта еще
нет, но уже в точности известно, какой тип он будет иметь. Как же тогда можно
говорить о виртуальных конструкторах?
Это легко объяснить. Хотя виртуальные конструкторы многим кажутся бессмыс-
ленными, они весьма полезны. (Если вы считаете, что бессмысленные идеи бесполез-
ны, чем вы тогда объясните успехи современной физики?) Например, предположим,
вы пишете приложение, работающее с информационными сообщениями, которые
Правило 25
!!
135
состоят из блоков текста или графики. Можно организовать программу следую-
щим образом:
class NLComponent { // Абстрактный базовый класс
public: // для блоков сообщения.
};
class TextBlock: public NLComponent {
public:
... //He содержит
}; // абстрактных функций.
class Graphic: public NLComponent {
public:
... //He содержит
}; // абстрактных функций.
class NewsLetter { // Объект сообщения,
public: // Состоит из списка
... // объектов NLComponent.
private:
list<NLComponent*> components;
};
Классы связаны так, как показано на рис. 5.1.
Рис. 5.1
Класс list, используемый внутри объекта NewsLetter, является частью
стандартной библиотеки шаблонов, которая входит в стандартную библиотеку
языка C++ (см. правило 35). Объекты типа list ведут себя как двусвязные спис-
ки, хотя они и не обязательно должны быть реализованы именно так.
Объекты NewsLetter, к которым еще не обращались, вероятно, находятся на
диске. Чтобы формировать объект NewsLetter из его образа на диске, было бы
удобно создать для него конструктор с параметром istream. Этот конструктор
шмн
Приемы
станет считывать информацию из потока после создания необходимых внутрен-
них структур данных:
class NewsLetter {
public:
NewsLetter(istream& str);
};
Псевдокод конструктора мог бы выглядеть примерно так:
NewsLetter::NewsLetter(istreamk str)
{
while (str) {
считать следующий объект из потока str;
добавить объект к списку блоков сообщения;
}
или, если поместить код для чтения из потока в отдельную функцию
readcomponent, так:
class NewsLetter {
public:
private:
// Считать данные следующего блока NLComponent из str,
// создать блок и вернуть указатель на него.
static NLComponent * readcomponent(istreamk str) ;
};
NewsLetter::NewsLetter(istreamk str)
{
while (str) {
// Добавить указатель, который вернула функция
// readcomponent в конец списка блоков; push_back -
// это функция - член списка, вставляющая элемент
//в конец списка.
components.push_back(readcomponent(str));
Рассмотрим работу функции readcomponent. Она создает новый объект,
имеющий тип TextBlock или Graphic в зависимости от считываемых данных.
Так как она создает новые объекты, то работает почти как конструктор, но по-
скольку при этом могут создаваться объекты разных типов, ее обычно называют
виртуальным конструктором. Виртуальный конструктор - это функция, которая
создает объекты разного типа в зависимости от входных данных*. Виртуальные
Строго говоря, эта функция не является конструктором, но поскольку виртуальные конструкторы
в C++ в отличие от Object Pascal или SmallTalk отсутствуют, использование данного термина при-
менительно к такого рода функциям не должно вызывать затруднений у читателя. {Прим, ped.)
Правило 25
137
конструкторы полезны в различных обстоятельствах, например при чтении дан-
ных объекта с диска (или по сети, или с накопителя на магнитной ленте и т.д.).
Широко используется также разновидность виртуального конструктора -
виртуальный конструктор копирования; он возвращает указатель на новую копию
объекта, вызывающего функцию. Из-за такого поведения виртуальные конструк-
торы копирования обычно имеют имена типа copyself, cloneSelf или просто
clone, как в следующем примере. Немного найдется функций, которые были бы
реализованы столь же просто.
class NLComponent {
public:
// Объявление виртуального конструктора копирования.
virtual NLComponent * clone() const = 0;
}; class TextBlock: public NLComponent { public: >
virtual TextBlock * clone() const // Виртуальный
{ return new TextBlock(*this) ; } // конструктор
// копирования
}; class Graphic: public NLComponent { public:
virtual Graphic * clone() const // Виртуальный
{ return new Graphic (*this) ; } // конструктор
}; // копирования
Как видите, виртуальный конструктор копирования просто вызывает реаль-
ный конструктор копирования объекта. Значение «копирования», следовательно,
одинаково в обеих функциях. Если реальный конструктор копирования выпол-
няет простое копирование, то же самое делает и виртуальный конструктор копиро-
вания. Если реальный конструктор выполняет сложное копирование, аналогично
поступает и виртуальный. Если реальный конструктор копирования осуществля-
ет какие-то особые действия, например подсчет ссылок или копирование по запи-
си (см. правило 29), то же самое делает и виртуальный конструктор. Совмести-
мость - замечательная вещь.
Обратите внимание, что приведенная выше реализация использует преимуще-
ства ослабленных ограничений на тип возвращаемого виртуальной функцией зна-
чения, которые были приняты относительно недавно. Переопределенная в произ-
водном классе виртуальная функция базового класса больше не должна объявлять
тот же самый тип возвращаемого значения. Вместо этого, если функция возвра-
щает указатель (или ссылку) на базовый класс, то функция производного класса
может возвращать указатель (или ссылку) на класс, производный от базового. Это
не приводит к появлению «дыр» в системе типов C++ и позволяет корректно
объявлять такие функции, как виртуальные конструкторы копирования. Поэто-
му виртуальный конструктор копирования clone объекта TextBlock может
138
III
Приемы
возвращать указатель TextBlock*, а виртуальный конструктор копирования
clone объекта Graphic - указатель Graphic*, хотя функция clone объекта
NLComponent возвращает указатель NLComponent*.
Существование виртуального конструктора копирования в объекте NLCom-
ponent позволяет легко реализовать конструктор копирования (обычный) для
объекта NewsLetter:
class NewsLetter {
public:
NewsLetter(const NewsLetterk rhs) ;
private:
list<NLComponent*> components;
};
NewsLetter::NewsLetter(const NewsLetterk rhs)
{
/ / Итерация по списку rhs, для копирования элемента в список
// блоков объекта используется его виртуальный конструктор
// копирования. Детали работы этого кода
// обсуждаются в правиле 35.
for (list<NLComponent*>::const_iterator it =
rhs.components.begin();
it != rhs.components.end();
++it) {
// it указывает на текущий элемент rhs . components ,
// поэтому для получения копиии вызывается
// его функция clone, и полученный дубликат добавляется
//в конец списка блоков этого объекта.
components.push_back((*it)->clone());
}
}
Если вы не знакомы со стандартной библиотекой шаблонов, этот код может
показаться вам странным, но основная его идея проста: обходится список блоков
для копируемого объекта NewsLetter, и для каждого блока вызывается его
виртуальный конструктор копирования. В данном случае вам нужен виртуаль-
ный конструктор копирования, так как список содержит указатели на объекты
NLComponent, хотя на самом деле каждый из указателей ссылается на объект типа
TextBlock или Graphic. Необходимо скопировать то, на что ссылается указа-
тель, и сделать это можно при помощи виртуального конструктора копирования.
Виртуализация функций - не членов класса
Как и конструкторы, функции - не члены класса в действительности не могут
быть виртуальными. Однако так же, как имеет смысл представлять виртуальны-
ми функции, создающие новые объекты разных типов, точно так же имеет смысл
представлять виртуальными функции - не члены класса, поведение которых зави-
сит от динамического типа их параметров. Предположим, например, что вы хотите
реализовать операторы вывода для классов TextBlock и Graphic. Очевидный
Правило 25
!
139
подход к решению подобной задачи состоит в том, чтобы сделать операторы вы-
вода виртуальными. Но оператор вывода - это operator«, а левым аргументом
данной функции является ostreamS, что не позволяет сделать его функцией -
членом класса TextBlock или Graphic.
Если попытаться обойти запрет, посмотрите, что произойдет:
class NLComponent {
public:
// Необычное объявление оператора вывода.
vitual ostream& operator«(ostream& str) const = 0;
class TextBlock,: public NLComponent {
public:
// Виртуальный оператор вывода (также не принято) .
virtual ostream& operator«(ostreamk str) const;
};
class Graphic: public NLComponent {
public:
// Виртуальный оператор вывода (также не принято) .
virtual ostream& operator«(ostream& str) const;
}; TextBlock t; Graphic g;
t « cout; // Вывести t в cout при помощи
// виртуального operator<<
// (необычный синтаксис).
g « cout; // Вывести t в cout при помощи
// виртуального operator<<
// (необычный синтаксис) .
Клиенты должны помещать объект потока справа от символа «, что противо-
речит соглашению для операторов вывода. Чтобы вернуться к обычному синтак-
сису, придется вывести operator« из классов TextBlock и Graphic, но если
делать это, нельзя будет объявлять его как виртуальный.
Альтернативный подход - объявить виртуальную функцию для вывода (на-
пример, функцию print) и определить ее в классах TextBlock и Graphic. Но
в этом случае синтаксис вывода объектов TextBlock и Graphic будет не совпа-
дать с синтаксисом остальных типов языка, использующих operator« в каче-
стве оператора вывода.
Ни одно из предложенных решений не является удовлетворительным. Вам
нужно, чтобы функция - не член класса вызывала operator«, который вел бы
себя подобно виртуальной функции, такой как print f. Обратите внимание: опи-
сание того, что нужно, очень близко к описанию того, как это можно сделать. Не-
обходимо определить обе функции operator« и print и вызвать вторую из
первой!
class NLComponent {
public:
140
паш
Приемы
virtual ostream& print(ostream& s) const = 0;
};
class TextBlock: public NLComponent {
public:
virtual ostream& print(ostream& s) const;
};
class Graphic: public NLComponent {
public:
virtual ostream& print(ostream& s) const;
};
inline
ostream& operator<<(ostream& s, const NLComponentk c)
{
return c.print(s) ;
}
Подобным образом легко создавать функции - не члены класса, действующие
как виртуальные. Вначале пишутся виртуальные функции, которые выполняют
работу, а затем функция - не член класса, всего лишь вызывающая виртуальную
функцию. Чтобы избежать расходов на вызов функции в этом синтаксическом
фокусе, нужно сделать невиртуальную функцию встроенной.
Теперь, когда вы знаете, как сделать, чтобы функции - не члены класса работа-
ли как виртуальные в случае одного аргумента, вы можете поинтересоваться, мож-
но ли сделать то же самое для нескольких аргументов. Да, но это непросто. Насколь-
ко непросто? Обратитесь к правилу 31, которое посвящено данному вопросу.
Правило 26. Ограничивайте число объектов в классе
Иногда для эффективной работы компьютера приходится ограничивать чис-
ло используемых объектов. Например, в вашей системе есть только один принтер
и вы хотите, чтобы объект принтера был единственным. Или вы можете выдать
только 16 файловых дескрипторов, поэтому вы хотите быть уверены, что суще-
ствует не больше 16 объектов файловых дескрипторов. Как можно сделать это?
Как ограничить число объектов?
Если взять за образец доказательство при помощи математической индукции,
следовало бы начать с n = 1, а затем действовать по индукции. К счастью, это не
доказательство. Более того, будет поучительным начать с п = 0, чтобы узнать, как
можно предотвратить создание экземпляров объектов?
Разрешение создания нулевого числа объектов
или одного объекта
При каждом создании экземпляра объекта будет вызван его конструктор. В этом
случае проще всего предотвратить создание объектов определенного класса, объ-
явив его конструкторы как закрытые:
141
Правило 26 f IMMIHB
class CantBelnstantiated {
private:
CantBelnstantiated();
CantBeInstantiated(const CantBelnstantiatedS);
};
Запретив при этом создание объектов, можно избирательно ослаблять
заданное ограничение. Если, например, вы хотите создать класс для принтеров,
но желаете видеть в своей системе только один принтер, можно инкапсулировать
объект принтера в функции так, чтобы все имели доступ к принтеру, но создавался
только один объект:
class PrintJob; // Предварительное объявление.
class Printer {
public:
void submitJob(const Printjobs job) ;
void reset () ;
void performSelfTest();
friend Printers thePrinter();
private:
Printer();
Printer(const Printers rhs) ;
};
Printers thePrinter()
{
static Printer p; // Единственный объект принтера,
return p;
}
Эта схема состоит из трех компонентов. Во-первых, конструкторы класса
Printer являются закрытыми. Это предотвращает создание объектов. Во-вторых,
объявляется дружественная к классу глобальная функция thePrinter. Это позво-
ляет функции thePrinter получать доступ к закрытым конструкторам. И нако-
нец, функция thePrinter содержит статический объект Printer. Это означает,
что может быть создан только один объект.
Код клиента осуществляет взаимодействие с единственным принтером систе-
мы при помощи функции thePrinter. Возвращая указатель на объект Printer,
функция thePrinter может использоваться везде, где мог бы находиться объект
Printer:
class Printjob {
public:
PrintJob(const strings whatToPrint);
};
string buffer;
// Поместить данные в буфер.
Приемы
142
thePrinter().reset() ;
thePrinter().submitJob(buffer);
Вероятно, функция thePrinter покажется вам ненужным добавлением к гло-
бальному пространству имен. Вы можете сказать: «Эта глобальная функция боль-
ше похожа на глобальную переменную, а использовать глобальные переменные
плохо, и я бы предпочел, чтобы все функции, связанные с принтером, находились
внутри класса Printer». Я не буду спорить с теми, кто считает, что это плохо.
Можно сделать функцию thePrinter статической функцией - членом класса
Printer. Это также устраняет необходимость объявления ее как friend, что
многие считают нелогичным. При использовании статической функции-члена
класс Printer примет следующий вид:
class Printer {
public:
static Printers thePrinter();
private:
Printer() ;
Printer(const Printers rhs);
};
Printers Printer::thePrinter()
{
static Printer p;
return p;
}
Клиентам придется вызывать принтер более многословно:
Printer::thePrinter().reset();
Printer::thePrinter().submitJob(buffer);
Другой подход заключается в том, чтобы переместить класс Printer и функ-
цию thePrinter из глобального в отдельное пространство имен (namespace).
Пространства имен являются сравнительно недавним дополнением языка C++.
Все, что можно объявить глобально, можно объявить и в отдельном пространстве
имен, включая классы, структуры, функции, переменные, объекты, определения
типов и т.д. Выделение в отдельное пространство имен не изменяет поведение всех
этих субстанций, но позволяет предотвратить конфликты между различными про-
странствами имен. Поместив класс Printer и функцию thePrinter в отдель-
ное пространство имен, вы можете не беспокоиться о том, что кто-либо еще выбе-
рет имена Printer и thePrinter; отдельное пространство имен предотвращает
конфликты имен.
Синтаксически пространства имен очень похожи на классы, но в них нет от-
крытых, закрытых или защищенных разделов; вся информация является откры-
той. Вы можете поместить класс Printer и функцию thePrinter в простран-
ство имен Printingstuff следующим образом:
namespace Printingstuff {
class Printer { // Этот класс находится
public: // в пространстве имен Printingstuff.
Правило 26
шив
143
void submit Job(const PrintJob& job);
void reset () ;
void performSelfTest();
friend Printers thePrinter();
private:
Printer();
Printer(const Printers rhs) ;
};
Printers thePrinterO // И эта функция тоже.
{
static Printer p;
return p;
}
} // Конец пространства имен.
Если задано пространство имен, то пользователи могут вызывать функцию
thePrinter при помощи полного имени (которое включает имя пространства
имен):
Printingstuff::thePrinter().reset();
Printingstuff::thePrinter().submitJob(buffer);
но также могут применить объявление using, чтобы записать это более компактно:
using Printingstuff::thePrinter; // Импортировать имя
// thePrinter
//из пространства имен
// Printingstuff.
thePrinterO . reset () ; // Теперь можно использовать
thePrinter().submitJob(buffer); // thePrinter
// как локальное имя.
В реализации функции thePrinter есть две тонкости, достойные отдельного
рассмотрения. Во-первых, важно, чтобы единственный объект Printer был стати-
ческим в функции, а не в классе. Объект, который является статическим в классе,
всегда создается (и уничтожается), даже если он не используется. Если же объект
является статическим в функции, то он создается при первом вызове функции,
поэтому если она вовсе не вызывается, то и объект не будет создан. (Но тогда при
каждом вызове функции придется проверять, нужно ли создавать объект.) Одно
из философских оснований, на которых был построен язык C++, - представление
о том, что не стоит платить за вещи, которые не используются, и определение та-
кого объекта, как принтер, в качестве статического в функции является одним из
способов придерживаться данного тезиса. Чтобы ваши программы были эффек-
тивными, следуйте этому принципу везде, где возможно. Если сделать объект
принтера статическим в классе, а не в функции, то обнаружится еще один недо-
статок такого подхода: не будет известно время инициализации объекта. Вы зна-
ете, что статический элемент функции инициализируется при первом вызове
функции в точке определения статического элемента. В случае определения
144
Ml
Приемы
объекта статическим в классе (или глобальным статическим, если вы додумались
сделать это) время инициализации объекта определено не столь точно. Язык C++
гарантирует порядок инициализации статических объектов в определенном
транслируемом модуле (то есть блоке исходного кода, компиляция которого дает
один объектный файл), но в спецификации языка ничего не говорится о порядке
инициализации статических объектов в различных транслируемых модулях. На
практике это вызывает бесконечные проблемы, которых нетрудно избежать,
если в данной ситуации допустимо определение статических объектов в функ-
ции. В нашем примере это возможно.
Вторая тонкость связана с взаимодействием встраивания и статических
объектов внутри функций. Посмотрите снова на код версии, в которой функция
thePrinter не является членом класса:
Printer thePrinter ()
{
static Printer р;
return р;
}
Кроме первого вызова (когда должен быть создан объект р) в этой функции
выполняется только одна строка - return р;. Если и есть функции, которые
могут быть встраиваемыми, то это, похоже, одна из них. Тем не менее, она не
объявлена как встраиваемая. Почему?
Вспомним, зачем объект объявляется как статический. Это обычно вызвано
тем, что нужна только одна копия данного объекта, не так ли? Теперь вспомним,
что означает директива inline: концептуально компиляторы должны заменять
вызов функции подстановкой ее тела. Но для функций - не членов класса значе-
ние директивы inline этим не ограничивается, потому что для них выполняется
внутренняя компоновка.
Обычно не следует беспокоиться о подобных нюансах, главное помнить: функ-
ции с внутренней компоновкой (internal linkage) могут дублироваться в програм-
ме (то есть код объекта может содержать более одной копии каждой функции
с внутренней компоновкой), и такое дублирование включает статические объек-
ты внутри функций. Что получится в результате? Если вы создаете встраиваемую
функцию - не член класса, содержащую локальный статический объект, это мо-
жет привести к созданию более одной копии статического объекта в программе!
Поэтому не создавайте встраиваемые функции - не члены класса со статически-
ми данными.*
* В июле 1996 года комитет ISO/ANSI по стандартизации изменил для встраиваемых функций
компоновку по умолчанию на внешнюю, поэтому описываемая мной проблема уже устранена, по
крайней мере на бумаге. Тем не менее, ваши компиляторы могут еще не соответствовать стандар-
ту, поэтому лучше избегать применения встраиваемых функций со статическими данными.
Правило 26
'(I
145
Но может быть, вы считаете, что создание функции, возвращающей ссылку на
скрытый объект, - это не совсем правильный способ ограничить число объектов.
Может быть, вы думаете, что лучше просто подсчитать число существующих
объектов и, если запрашивается слишком много объектов, генерировать исключе-
ние в конструкторе. Другими словами, может быть, вы считаете, что необходимо
обрабатывать создание объекта принтера так:
class Printer {
public:
class TooManyObjects{}; // Класс исключений;
// используется, если
// запрашивается слишком
// много объектов.
Printer();
-Printer () ;
private:
static size_t numObjects;
Printer(const Printers rhs);
Не больше 1 принтера,
поэтому запретить
копирование.
};
Идея заключается в том, чтобы использовать переменную NumObjects для
отслеживания числа существующих объектов Printer. Ее значение увеличива-
ется на единицу в конструкторе класса и уменьшается на единицу в его деструк-
торе. Если делается попытка создать слишком много объектов Printer, то гене-
рируется исключение типа TooManyObjects:
// Обязательное определение
// статического объекта класса.
size_t Printer::numObjects = 0;
Printer::Printer()
{
if (numObjects >= 1) {
throw TooManyObjects();
}
продолжить создание объекта;
++numObjects;
}
Printer::-Printer()
{
выполнить обычное уничтожение объекта ;
--numObjects;
}
Такой подход к ограничению числа создаваемых объектов привлекателен по
двум причинам. Во-первых, он просто реализован - несложно понять, что при
этом происходит. Во-вторых, его легко обобщить в случае, если максимально воз-
можное число объектов должно быть больше единицы.
146
Hi
Приемы
Контекст создания объектов
Однако при использовании данной стратегии возникает одна проблема.
Предположим, что имеется особый тип принтера, например цветной принтер.
Класс таких принтеров будет иметь много общего с обобщенным классом
принтера, поэтому логично выполнить наследование от него:
class ColorPrinter: public Printer {
};
Предположим теперь, что в системе есть один простой принтер и один
цветной:
Printer р;
ColorPrinter ср;
Сколько объектов Printer получится в результате этих определений объек-
тов? Два: один для р и один для части Printer в ср. Во время работы программы
при создании части базового класса в ср будет сгенерировано исключение
TooManyObj ects. Для большинства программистов это будет и нежелательным,
и неожиданным. (Если при разработке не использовать наследование конкретных
классов от других конкретных классов, эта проблема не возникает. Детали такого
подхода см. в правиле 33.)
Похожие сложности возникают, если объекты Printer находятся внутри дру-
гих объектов:
class CPFMachine { // Устройства, которые могут // копировать,
private: // печатать и отправлять факсы.
Printer p; FaxMachine f; CopyMachine c; }; CPFMachine ml ; CPFMachine m2; // Принтер. // Факс. // .Копировальный аппарат. // Нормально. // Генерирует исключение // TooManyObjects.
Проблема состоит в том, что объекты Printer могут существовать в трех раз-
личных контекстах: сами по себе, как части базового класса в производных объек-
тах и как части более крупных объектов. Наличие этих различных контекстов
значительно размывает понятие «число существующих объектов», так как ваш
взгляд на существование объекта может отличаться от точки зрения ваших ком-
пиляторов.
Часто вы заинтересованы в том, чтобы разрешить создание только отдельных
объектов, и вам нужно ограничить число только таких экземпляров объекта. Этого
легко добиться, используя исходную стратегию для класса Printer, поскольку
конструкторы класса Printer при этом являются закрытыми, а классы с закрыты-
ми конструкторами не могут быть использованы в качестве базовых классов (при
отсутствии объявлений friend) и не могут быть встроены в другие объекты.
Правило 26
ив
147
Запрет на создание производных классов от классов с закрытыми конструк-
торами приводит к общей схеме предотвращения создания производных классов,
которая не обязательно должна сочетаться с ограничением числа экземпляров
объекта. Предположим, например, что существует класс FSA для представления
конечных автоматов. (Такие машины состояний полезны во многих случаях,
включая разработку пользовательского интерфейса.) Предположим далее, вы хо-
тите, чтобы можно было создать любое число объектов FSA, но в то же время иметь
гарантию, что ни один класс не сможет наследовать от класса FSA. (Это может
потребоваться, например, для того чтобы обеспечить существование невирту-
ального деструктора в классе FSA. Как объясняется в правиле 24, классы без вир-
туальных функций дают объекты меньшего размера, чем эквивалентные классы
с виртуальными функциями.) Удовлетворить обоим критериям можно, реализо-
вав класс FSA следующим образом:
class FSA {
public:
// Псевдоконструкторы,
static FSA * makeFSAO ;
static FSA * makeFSA(const FSA& rhs) ;
private:
FSA () ;
FSA(const FSA& rhs);
};
FSA * FSA: :makeFSAO
{ return new FSA(); }
FSA * FSA: :makeFSA(const FSA& rhs)
{ return new FSA(rhs) ; }
В отличие о функции thePrinter, которая всегда возвращала ссылку на
единственный объект, каждый псевдоконструктор makeFSA возвращает указа-
тель на уникальный объект. Это позволяет создавать неограниченное число
объектов FSA.
Однако вызов в каждом псевдоконструкторе оператора new подразумевает,
что необходимо не забыть затем вызвать оператор delete, иначе возникнет утеч-
ка ресурсов. Для автоматического вызова delete при выходе из зоны видимости
можно сохранять указатель, возвращаемый функцией makeFSA в объекте
auto_ptr (см. правило 9); такие объекты автоматически удаляют то, на что они
ссылаются, когда покидают зону видимости:
// Косвенный вызов конструктора по умолчанию FSA.
auto_ptr<FSA> pfsal(FSA::makeFSAO ) ;
// Косвенный вызов конструктора копирования FSA.
auto_ptr<FSA> pfsa2(FSA::makeFSA(*pfsal));
... // Используйте pfsal и pfsa2 как обычные указатели,
// но не беспокойтесь об их удалении.
148
пш
Приемы
Разрешение создания и удаления объектов
Теперь вы знаете, как сформировать класс, разрешающий создание только од-
ного экземпляра объекта. Кроме того, вам известно: отслеживание числа объек-
тов определенного класса осложняется тем, что конструкторы объекта вызывают-
ся в трех различных контекстах, и чтобы избавиться от этой путаницы, надо
сделать конструкторы закрытыми. И еще одно, последнее замечание. Применение
функции thePrinter для инкапсуляции доступа к единственному объекту сво-
дит число объектов Printer к одному, но во время каждого запуска программы
может быть всего один объект Printer. В результате нельзя написать такой код:
создать объект pl типа Printer;
использовать pl;
уничтожить pl;
создать объект р2 типа Printer;
использовать р2;
уничтожить р2 ;
При таком подходе не существует более одного экземпляра объекта Printer
одновременно, но в разных частях программы используются различные объекты
типа Printer. Кажется неблагоразумным, что указанные в коде действия невоз-
можны, так как запрет на существование не более чем одного принтера не нару-
шается. Можно ли сделать это допустимым?
Да. Достаточно объединить код для подсчета числа объектов, который вы
использовали ранее, с только что введенными псевдоконструкторами:
class Printer {
public:
class TooManyObjects{};
// Псевдоконструктор.
static Printer * makePrinter();
-Printer();
void submitJob(const PrintJob& job) ;
void reset();
void performSelfTest();
private:
static size_t numObjects;
Printer();
Printer(const Printers rhs); // Эта функция
}; //не определяется, так как
// копирование не разрешено.
// Обязательное определение статического объекта класса.
size_t Printer::numObjects = 0;
Printer::Printer()
{
if (numObjects >= 1) {
throw TooManyObjects();
Правило 26
149
продолжить обычное создание объекта;
++numObjects ;
}
Printer * Printer::makePrinter()
{ return new Printer; }
Если требование того, что при попытке создания слишком большого числа
объектов надо генерировать исключение, кажется вам чрезвычайно строгим, вы
можете вместо этого возвращать в псевдоконструкторе нулевой указатель. Конеч-
но, тогда клиентам придется проверять указатель перед тем, как работать с ним.
Клиенты используют класс Printer так же, как и любой другой, только вме-
сто настоящего конструктора они должны вызывать псевдоконструктор:
Printer pl; // Ошибка! конструктор
//по умолчанию - закрытый.
Printer *р2 = Printer::makePrinter();// Нормально,
// косвенно вызывает
// конструктор по умолчанию.
Printer рЗ = *р2; // Ошибка! конструктор
// копирования - закрытый.
p2->performSelfTest(); // Все остальные функции
p2->reset(); // вызываются как обычно.
delete р2; // Надо, чтобы избежать
// утечки ресурсов;
//не нужно, если указатель
// р2 имеет тип auto_ptr.
Этот метод применим к любому числу объектов. Вы должны только заменить
постоянную 1 на нужное значение, а затем снять запрет на копирование объектов.
Например, следующая реализация класса Printer допускает существование до
10 объектов Printer:
class Printer {
public:
class TooManyObj ec'ts{);
// Псевдоконструкторы.
static Printer * makePrinter();
static Printer * makePrinter(const Printers rhs) ;
private:
static size_t numobjects;
static const size_t maxObjects =10; // См. ниже.
Printer();
Printer(const Printers rhs);
};
// Обязательное объявление статических объектов класса.
size_t Printer:mumObjects = 0;
150
Приемы
const size_t Printer::maxobjects;
Printer::Printer()
{
if (numObjects >= maxObjects) {
throw TooManyObjects () ;
}
}
Printer::Printer(const Printers rhs)
{
if (numobjects >= maxObjects) {
throw TooManyObjects () ;
}
}
Printer * Printer::makePrinter()
{ return new Printer; }
Printer * Printer:zmakePrinter(const Printers rhs)
{ return new Printer (rhs) ; }
He удивляйтесь, если объявление Printer: :maxObjects в определении
этого класса компиляторы не примут. В особенности если они будут сообщать об
ошибке при присвоении переменной начального значения 10. Возможность при-
сваивать начальные значения статическим элементам, объявленным как const
(целочисленных типов, например int, char, enum и т.д.) внутри определения
класса была добавлена в язык C++ сравнительно недавно, поэтому некоторые
компиляторы еще не позволяют этого. Если ваши компиляторы относятся к ним,
вы можете объявить maxobjects как счетчик в закрытом неименованном пере-
числяемом типе:
class Printer {
private:
enum { maxObjects = 10 }; //В этом классе
... // maxObjects - постоянная,
}; // равная 10.
или при помощи инициализации постоянного статического объекта как статичес-
кого элемента не const:
class Printer {
private:
static const size_t maxObjects; // He задано начальное
// значение.
};
// Это находится в отдельном файле реализации.
const size_t Printer::maxObjects = 10;
Последний способ действует так же, как и вышеприведенный исходный код,
но явное определение начального значения облегчает понимание кода другими
Правило 26
151
программистами. Если ваши компиляторы поддерживают задание начального
значения для статических const элементов в определении класса, вы должны ис-
пользовать эту возможность.
Базовый класс для подсчета объектов
У вышеописанного метода есть один негативный аспект. Если существует
множество классов, подобных классу Printer, число экземпляров которых тре-
буется ограничивать, то вам придется писать один и тот же код снова и снова для
каждого из классов. В таком «шикарном» языке, как C++, должен быть способ ав-
томатизировать этот процесс. Как же инкапсулировать понятие подсчета числа эк-
земпляров и заключить его в класс?
Это легко сделать, создав базовый класс для подсчета числа экземпляров
объекта и сделать такие классы, как Printer, его наследниками, но, оказывает-
ся, есть лучшее решение. Можно разработать способ инкапсуляции всего набо-
ра для подсчета, под которым я подразумеваю не только функции, управляю-
щие подсчетом экземпляров, но и сам алгоритм подсчета экземпляров. (Вы
увидите необходимость аналогичного приема при рассмотрении счетчика ссы-
лок в правиле 29.)
В классе Printer счетчиком является статическая переменная NumObj ects,
поэтому вам нужно поместить эту переменную в класс счетчика экземпляров. Вы
должны быть также уверены, что каждый из классов, число экземпляров которых
подсчитывается, имеет отдельный счетчик. Применение шаблона класса счетчика
позволяет автоматически создавать соответствующее число счетчиков: можно
сделать счетчик статическим элементом классов, образованных на основе этого
шаблона:
templatecclass BeingCounted>
class Counted {
public:
class TooManyObjects{}; // Для генерации исключений.
static int objectcount () { return numObjects; }
protected:
Counted();
Counted(const Counted^ rhs);
~Counted() {-numObjects; }
private:
static int numobjects;
static const size_t maxobjects;
void init() ; // Чтобы избежать дублирования
}; / / кода конструктора.
template<class BeingCounted>
Counted<BeingCounted>::Counted()
{ init(); }
templatecclass BeingCounted>
Counted<BeingCounted>::Counted (const CountedcBeingCounted>&)
{ init(); }
152
III
Приемы
template<class BeingCounted>
void Counted<BeingCounted>::init()
{
if (numObjects >= maxObjects) throw TooManyObjects();
++numObjects;
}
Классы, созданные на основе этого шаблона, предназначены для использова-
ния только в качестве базовых классов, поэтому в код включены закрытые кон-
структор и деструктор. Обратите внимание, что с помощью закрытой функции -
члена класса init удается избежать дублирования операторов в двух конструк-
торах Counted.
Теперь можно изменить класс Printer, используя шаблон Counted:
class Printer: private Counted<Printer> {
public:
// Псевдоконструкторы.
static Printer * makePrinter();
static Printer * makePrinter(const Printers rhs);
-Printer();
void submitJob(const Printjobs job);
void reset();
void performSelfTest();
using Counted<Printer>: :objectCount; // См. ниже,
using Counted<Printer>::TooManyObjects; // См. ниже.
private:
Printer();
Printer(const Printers rhs);
};
To, что класс Printer отслеживает число существующих объектов Printer
с помощью шаблона Counted, честно говоря, не касается никого, кроме автора клас-
са Printer. Такие детали реализации лучше всего делать закрытыми, и поэтому
здесь применяется закрытое наследование. Альтернативный метод - использовать
открытое наследование между Printer и Counted<Printer>, но в этом случае
вы были бы вынуждены определить в классах Counted виртуальный деструктор.
(Иначе возник бы риск неправильного поведения, если кто-либо удалил бы объект
Printer при помощи указателя Counted<Printer>*.) Как поясняется в правиле
24, наличие виртуальной функции в классе Counted практически всегда будет вли-
ять на размер и состав объектов классов, наследующих от Counted. Дополнитель-
ные расходы вам не нужны, и использование закрытого наследования позволяет
избежать этого.
Совершенно правильно, что большая часть действий класса Counted скрыта
от клиентов объекта Printer, но клиенты должны иметь способ определять чис-
ло существующих объектов Printer. Шаблон Counted включает функцию
obj ectCount, которая выдает эту информацию, однако данная функция в объекте
Правило 26
IIIMHil
153
Printer становится закрытой из-за использования закрытого наследования. До-
ступ к ней обеспечивается при помощи объявления using:
class Printer: private Counted<Printer> {
public:
using Counted<Printer>::objectcount; // Сделать эту
// функцию открытой
... // для клиентов
// Printer.
};
Это вполне допустимо, но только если ваши компиляторы поддерживают про-
странства имен. В противном случае вы можете использовать старый синтаксис
объявления доступа:
class Printer: private Counted<Printer> {
public:
Counted<Printer>::objectcount; // Сделать objectcount
// открытой в объекте
... // Printer.
};
Этот более традиционный синтаксис означает то же самое, что и объявление
using, но он обладает определенными недостатками. Класс TooManyObj ects об-
рабатывается аналогично классу Objectcount, так как клиенты объекта
Printer должны иметь доступ к TooManyObj ects, если они могут перехваты-
вать исключения данного типа.
Если класс Printer наследует от класса Counted<Printer>, он может «за-
быть» о подсчете объектов. Иногда этот класс пишется так, как будто действия по
подсчету выполняются где-то еще, а именно в классе (Counted<Printer>). Кон-
структор Printer в таком случае выглядит следующим образом:
Printer::Printer()
{
продолжить обычное создание объекта;
}
Здесь интересно не то, что вы видите, а то, чего вы не видите. Здесь нет провер-
ки числа объектов, счетчик объектов не увеличивается после завершения конструк-
тора. Все эти операции выполняются конструкторами Counted<Printer>, и так
как Counted<Printer> является базовым классом для класса Printer, то вы
знаете, что перед конструктором Printer будет всегда вызываться конструктор
Counted<Printer>. Если создается слишком много объектов, то конструктор
Counted<Printer> сгенерирует исключение, и конструктор Printer не будет
вызываться вообще. Остроумно, не так ли?
Как бы это не было остроумно, существует один недостаток, который нужно
исправить и который заключается в обязательном определении статических
154
ПИШИ
Приемы
объектов внутри класса Counted. Можно достаточно просто обойтись с перемен-
ной NumObjects, поместив в файл Counted следующий код:
templatecclass BeingCounted> // Определяет переменную
int Counted<BeingCounted>::numObjects; // numObjects
//и автоматически
// инициализирует ее нулем.
Ситуация с переменной MaxObj ects немного сложнее. Какое начальное зна-
чение вы должны присвоить этой переменной? Если вы хотите разрешить созда-
ние не более 10 принтеров, следует проинициализировать CountedcPrin-
ter>: :maxObjects значением 10. С другой стороны, если вы допускаете
существование не более 16 файловых дескрипторов, то надо проинициализиро-
вать Counted<FileDescriptor>: :maxObj ects значением 16. Что же делать?
Выбирайте самый простой путь: не делайте ничего. Не инициализируйте пе-
ременные maxObj ects. Вместо этого требуйте, чтобы соответствующую инициа-
лизацию выполняли клиенты данного класса. Автор класса Printer должен до-
бавить в файл реализации следующее:
const size_t Counted<Printer>:zmaxObjects = 10;
Аналогично, автору класса FileDescriptor необходимо добавить строку:
const size_t Counted<FileDescriptor>::maxObjects = 16;
Что произойдет, если авторы этих классов забудут определить переменную
maxObjects? Они просто получат сообщение об ошибке во время компоновки,
так как переменная maxobjects останется неопределенной. Если вы описали
данное требование для пользователей класса Counted, они вспомнят об этом
и добавят необходимую инициализацию.
Правило 27. В зависимости от ситуации требуйте
или запрещайте размещать объекты в куче
Иногда необходимо организовать работу так, чтобы объекты определенного
типа могли самоуничтожаться, то есть выполнять оператор delete this. Оче-
видно, что при этом объекты должны быть динамическими. Иногда же нужно
быть уверенными, что для определенного класса не возникнут утечки памяти, так
как все его объекты расположены не в куче. Это может потребоваться при разра-
ботке системы для промышленных применений, когда утечки памяти особенно
опасны, а размер кучи ограничен. Можно ли создать код, гарантирующий или за-
прещающий размещение объектов в куче? Во многих случаях да, но имейте в виду,
что понятие «объект находится в куче» часто трактуется по-разному.
Гарантированное размещение объектов в куче
Рассмотрим вначале запрет на создание объектов вне кучи. Чтобы ввести та-
кое ограничение, вы должны найти способ запретить клиентам создание объектов
любым способом, кроме вызова оператора new. Сделать это легко. Объекты, не
Правило 27
HIM!
155
размещаемые в куче, обычно создаются в момент их определения и автоматически
уничтожаются в конце их существования, поэтому достаточно запретить эти яв-
ные создания и уничтожения.
Простейший способ не допустить такие вызовы - объявить конструкторы и де-
структоры как закрытые, но это чрезмерное требование. Нет необходимости, чтобы
они оба были закрытыми. Лучше будет сделать деструктор закрытым, а конструк-
торы открытыми. Затем, так же как и в правиле 26, можно ввести привилегирован-
ную функцию псевдодеструктора, которая будет иметь доступ к настоящему дест-
руктору. После этого для уничтожения созданных объектов клиенты станут
вызывать псевдодеструктор.
Если, например, нужно гарантировать, чтобы объекты, представляющие чис-
ла с неограниченной точностью, создавались только в куче, можно сделать это так:
class UPNumber {
public:
UPNumber();
UPNumber(int initValue);
UPNumber(double initValue);
UPNumber(const UPNumber& rhs) ;
// Псевдодеструктор (функция-член с атрибутом const,
// так как объекты с атрибутом const могут уничтожаться) .
void destroy () const { delete this; }
private:
-UPNumber();
};
Пользователи этого класса тогда должны писать примерно следующий код:
UPNumber n; UPNumber *р = new UPNumber; // Ошибка! (Здесь разрешается, //но недопустимо, если позже // деструктор п вызывается явно) // Нормально.
delete p; // Ошибка! Попытка вызвать
// закрытый деструктор.
p->destroy(); // Нормально.
В качестве альтернативы можно объявить все конструкторы как закрытые.
Недостаток такого подхода состоит в том, что класс часто имеет несколько кон-
структоров, а автор класса должен помнить о том, чтобы объявить их все как за-
крытые. В их число может входить конструктор копирования и иногда также
конструктор по умолчанию, если эти функции будут созданы компилятором.
Функции, создаваемые компилятором, всегда являются открытыми. В результате
проще объявить закрытым только деструктор, так как он всего один в классе.
Ограничение доступа к деструктору класса или его конструкторам предотвра-
щает создание объектов не в куче. Но по причинами, изложенным в правиле 26,
это также запрещает наследование и ограничение области действия (containment):
156
nnu
class UPNumber {...};
class NonNegativeUPNumber:
public UPNumber
class Asset {
private:
UPNumber value;
Приемы
// Объявляет закрытые
// конструкторы или деструктор.
// Ошибка! Деструктор или
// конструкторы не скомпилируются.
// Ошибка! Деструктор или
// конструкторы не скомпилируются.
Ни одна из этих трудностей не является непреодолимой. Проблему наследо-
вания можно решить, сделав деструктор UPNumber закрытым (оставив конструк-
торы открытыми), и изменив классы, которые должны содержать объекты типа
UPNumber, так, чтобы они содержали вместо этого указатели на объекты
UPNumber:
class UPNumber {...};
class NonNegativeUPNumber:
public UPNumber {...};
// Объявляет закрытый деструктор.
// Теперь нормально; производные
// классы имеют доступ к закрытым
// членам класса.
class Asset {
public:
Asset(int initValue);
-Asset();
private:
UPNumber * value;
};
Asset::Asset(int initValue)
: value(new UPNumber(initValue))
( ... }
Asset::-Asset()
{ value->destroy(); }
// Нормально.
// Также нормально.
Определение, находится ли объекте куче
Если вы решите следовать описанной стратегии, то должны уточнить, что под-
разумевается под понятием «быть в куче». Если класс определен вышеуказанным
образом, то допустимо определить объект NonNegativeUPNumber, находящий-
ся не в куче.
NonNegativeUPNumber п; // Нормально.
Теперь часть UPNumber объекта п типа NonNegativeUPNumber не будет на-
ходиться в куче. Приемлемо ли это? Ответ зависит от деталей структуры и реали-
зации класса, но предположим, что это не допустимо, что все объекты типа
UPNumber - даже части базового класса в производных объектах - должны нахо-
диться в куче. Как можно наложить это ограничение?
Правило 27
«I
157
Простого способа не существует. Конструктор UPNuiaber не может определить,
вызывается ли он как часть базового класса объекта, расположенного в куче. То есть
конструктор UPnumber не определяет, что следующие контексты различны:
NonNegativeUPNumber *nl =
new NonNegativeUPNumber;
NonNegativeUPNumber n2;
//В куче.
// Не в куче.
Возможно, вы мне не верите. Возможно, думаете, что лучше «поиграть» взаи-
модействием между оператором new, operator new и конструктором, вызывае-
мым оператором new (см. правило 8). Возможно, вы думаете, что способны пере-
хитрить их, изменив класс UPNumber следующим образом:
class UPNumber {
public:
// Исключение, которое генерируется
// при создании объекта не в куче.
class HeapConstraintViolation {};
static void * operator new(size_t size);
UPNumber();
private:
static bool onTheHeap; // Флаг в конструкторах,
// определяющий, создается
... / / ли объект в куче.
};
// Обязательное определение
// статического объекта класса.
bool UPNumber::onTheHeap = false;
void *UPNumber::operator new(size_t size)
{
onTheHeap = true;
return::operator new(size) ;
}
UPNumber::UPNumber()
{
if (!onTheHeap) {
throw HeapConstraintViolation () ;
}
продолжить обычное создание объекта;
onTheHeap = false; // Сбросить флаг
} // для следующего объекта.
Здесь не происходит ничего сложного. Основная идея - воспользоваться
тем, что объект находится в куче. Для выделения неинициализированной памя-
ти применяется функция operator new, а затем вызывается конструктор для
инициализации объекта в этой памяти. В частности, operator new устанавли-
вает флаг onTheHeap равным true, и каждый из конструкторов проверяет дан-
ный флаг, чтобы определить, была ли неинициализированная память для объек-
та выделена при помощи operator new. Если нет, генерируется исключение
158
III
Приемы
типа Heapconstraintviolation. Иначе конструктор продолжает работу как
обычно, и когда завершится создание объекта, флаг onTheHeap устанавливается
равным false, что соответствует значению по умолчанию для следующего созда-
ваемого объекта.
Хотя это и хорошая идея, она не сработает. Рассмотрим возможный кли-
ентский код:
UPNumber *numberArray = new UPNumber[100];
Первая проблема заключается в том, что память для массива выделяется при
помощи operator new [ ], а не operator new, но первую функцию (если ее под-
держивают ваши компиляторы) можно написать так же просто, как и вторую.
Более проблематично, что массив numberArray содержит 100 элементов, поэто-
му конструктор будет вызван 100 раз. Однако память будет выделена всего еди-
ножды, поэтому флаг onTheHeap примет значение true только для первого из
этих 100 конструкторов. При вызове второго конструктора будет сгенерировано
исключение, и горе вам!
Даже без применения массивов работа с флагами может закончиться неуда-
чей. Рассмотрим оператор:
UPNumber *pn = new UPNumber (*new UPNumber) ;
Здесь в куче создаются два объекта класса UPNumber, и переменная рп указы-
вает на один из них; она инициализируется значением второго из объектов. Этот
код приводит к утечке ресурсов, но пока проигнорируем ее и рассмотрим, что
происходит при выполнении следующего выражения:
new UPNumber (*new UPNumber)
Оно содержит два вызова оператора new и, следовательно, два вызова
operator new, а также два вызова конструктора UPNumber (см. правило 8). Про-
граммисты обычно ожидают, что эти функции будут выполняться поэтапно:
1. Вызвать функцию operator new для первого объекта.
2. Вызвать конструктор для первого объекта.
3. Вызвать operator new для второго объекта.
4. Вызвать конструктор для второго объекта.
Но спецификация языка не гарантирует такой порядок выполнения. Некото-
рые компиляторы вместо этого генерируют вызовы функций следующим образом:
1. Вызвать функцию operator new для первого объекта.
2. Вызвать функцию operator new для второго объекта.
3. Вызвать конструктор для второго объекта.
4. Вызвать конструктор для первого объекта.
Компиляторы, которые генерируют такой код, не содержат ошибки, но при-
ем с установкой флага и operator new здесь не работает. Это связано с тем, что
флаг устанавливается на 1-ом и 2-ом шаге и сбрасывается на 3-ем шаге, поэтому
объект, создаваемый на 4-ом шаге, считает, что он находится не в куче, даже если
это и не так.
Правило 27
шт
159
Подобные затруднения не сводят на нет основную идею проверки в конструк-
торе, находится ли *this в куче. Они лишь показывают, что проверка флага,
устанавливаемого в operator new (или operator new[ ] ), является не самым
лучшим способом получения этой информации. Нужен более надежный способ.
Если вы достаточно безрассудны, то перед вами может возникнуть искуше-
ние «поиграть» с несовместимостью. Например, вы можете использовать то, что
во многих системах адресное пространство программы организовано в виде ли-
нейной последовательности адресов, и стек программы растет вниз от вершины
адресного пространства, а куча поднимается снизу (см. рис. 5.2).
Адресное
пространство
программы
(неполная
картина)
Вы можете полагать, что в системах, где память программы организована
таким образом (а это немалая часть приложений), будет удобно использовать
следующую функцию для проверки, находится ли определенный адрес в куче:
// Некорректная попытка определить,
/ / находится ли адрес в куче.
bool onHeap(const void *address)
{
char onTheStack; // Локальная стековая переменная,
return address < konTheStack;
}
Рассуждения, лежащие в основе этого подхода, достаточно интересны. Пере-
менная onTheStack является локальной переменной функции onHeap и поэто-
му находится в стеке. При вызове функции onHeap ее кадр стека (то есть ее за-
пись активации) будет помещена на вершину стека программы, и поскольку стек
в такой архитектуре растет вниз (в сторону младших адресов), то адрес перемен-
ной onTheStack должен быть меньше адреса любых других переменных или
объектов, находящихся в стеке. Если параметр address меньше, чем положение
переменной onTheStack, то он не может находиться в стеке, следовательно, он
находится в куче.
Все эти рассуждения прекрасны, но они многого не учитывают. Основная проб-
лема заключается в том, что объекты могут располагаться в трех различных облас-
тях, а не в двух. Да, объекты могут находиться в стеке и куче, но не будем забывать
160
Приемы
о статических объектах. Статические объекты - это объекты, которые инициали-
зируются при выполнении программы только один раз. Статические объекты
включают в себя не только объекты, объявленные как static, но также объекты,
объявленные в глобальном или других пространствах имен. Эти объекты должны
где-то находиться, и они находятся не в стеке и не в куче.
Где они размещаются, зависит от системы, но на многих системах, в которых
стек и куча растут навстречу друг другу, они располагаются под кучей. Преды-
дущая схема организации памяти, хотя и частично (а на некоторых системах
и полностью) соответствует действительности, все же не является универсальной.
Если включить в схему статические объекты, она примет вид, представленный
на рис. 5.3.
Адресное
пространство
программы
(полная
картина)
Рис. 5.3
Неожиданно становится очевидным, почему функция опНеар не будет рабо-
тать даже на системах, для которых предназначена: она не может различать объек-
ты в куче и статические объекты:
void allocateSomeObjects()
{
char *рс = new chat; // Объект в куче: опНеар(рс) // вернет значение true.
char с; // Объект в стеке: опНеар(&рс) //вернет значение false.
static char sc; // Статический объект: опНеар(&sc)
// вернет значение true.
}
Если вы во что бы то ни стало хотите найти способ отличать объекты в куче от
объектов в стеке, то в своем отчаянии можете пойти на сделку с дьяволом перено-
симости, но настолько ли вы безрассудны, чтобы заключить сделку, которая все
равно не гарантирует получение правильных ответов? Конечно же, нет, поэтому
Правило 27
161
вы наверняка отвергнете этот соблазнительный, но ненадежный трюк со сравне-
нием адресов.
Печальный факт состоит в том, что не только не существует переносимого
способа определить, находится ли объект в куче, не существует также и полупе-
реносимого способа, который работал бы в большинстве случаев. Если вам со-
вершенно необходимо определить, находится ли адрес в куче, придется обра-
титься к непереносимым, зависящим от реализации системным вызовам, и это
все, что можно сделать. Вам лучше попытаться изменить структуру программы,
чтобы не было столь необходимо знать, находится ли объект в куче.
От ответа на вопрос, где расположен объект, зависит, безопасно ли вызывать
для него оператор delete? Часто такое удаление принимает форму печально из-
вестного оператора delete this. Однако возможность безопасно удалить указа-
тель говорит не только о том, что он ссылается на что-то в куче, поскольку не для
любого указателя на объект в куче можно безнаказанно вызвать оператор delete.
Рассмотрим снова объект Asset, содержащий объект UPNumber:
class Asset {
private:
UPNumber value;
};
Asset *pa = new Asset;
/ -
Очевидно, что объект *pa (включая его элемент value) находится в куче. Так
же очевидно, что небезопасно вызывать оператор delete для указателя на ра->
value, так как этот указатель не был получен в результате вызова оператора new.
К счастью, легче определить, можно ли безопасно удалить указатель, чем вы-
яснить, указывает ли он на что-либо в куче, так как все, что нужно для ответа на
первый вопрос, - это набор адресов, которые были возвращены функцией
operator new. Поскольку можно написать функцию operator new самостоя-
тельно, то легко создать такой набор, например, следующим образом:
void *operator new(size_t size)
{
void *p = getMemory(size) ; // Вызвать функцию
// для выделения памяти
//и обработки событий
// нехватки памяти.
добавить р к набору выделенных адресов;
return р;
}
void operator delete(void *ptr)
{
releaseMemory(ptr); // Освободить память.
удалить ptr из набора выделенных адресов памяти;
}
bool isSafeToDelete(const void *address)
{
6 - 679
162
Приемы
вернуть результат в зависимости от того, находится ли адрес
в наборе выделенных адресов
}
Это почти так же просто, как и возвращаемое функцией значение. Функция
operator new добавляет элементы в набор выделенных адресов, функция
operator delete удаляет элементы, а функция isSaf eToDelete просматри-
вает набор, определяя, находится ли в нем заданный адрес. Если функции
operator new и operator delete являются глобальными, то эта схема будет
работать для всех типов, даже для встроенных.
На практике три вещи могут ослабить ваш энтузиазм. Первой из них являет-
ся общее крайнее нежелание определять что-либо глобально, в особенности такие
функции с предопределенным значением, как operator new и operator
delete. Зная, что существует только одно глобальное пространство имен и толь-
ко одна версия функций operator new и operator delete с «обычными» сиг-
натурами (то есть наборами типов параметров) в этом пространстве, меньше все-
го хотелось бы «захватывать» данные сигнатуры для собственного использования.
При этом код стал бы несовместимым с любым другим, где также реализованы
глобальные версии operator new и operator delete (такими являются мно-
гие объектно-ориентированные системы баз данных).
Второе соображение касается эффективности: зачем обременять все операции
выделения памяти из кучи накладными расходами на отслеживание возвращае-
мых адресов, если это не нужно?
Последнее соображение является неинтересным, но важным. Оказывается,
невозможно реализовать функцию isSaf eToDelete так, чтобы она работала во
всех случаях: объекты с несколькими или виртуальными базовыми классами име-
ют несколько адресов, поэтому нет гарантии, что адрес, переданный функции
isSaf eToDelete, тот же самый, который был возвращен функцией operator
new, даже если данный объект и размещался в куче. Дополнительные сведения по
этому вопросу см. в правиле 24 и 31.
В действительности хотелось бы обеспечить выполнение указанных функций
без сопутствующего «загрязнения» глобального пространства имен, дополнитель-
ных расходов и проблем с правильностью работы. К счастью, язык C++ позволяет
сделать в точности то, что нужно, при помощи абстрактного смешанного базового
класса (abstract mixin base class).
Абстрактный базовый класс - это класс, экземпляры которого создавать
нельзя, то есть класс, имеющий хотя бы одну абстрактную функцию*. Смешан-
ный класс - класс, обеспечивающий выполнение одной определенной функции,
разработанный так, чтобы быть совместимым с любыми другими функциями,
которые может обеспечивать наследующий класс. Такие классы почти всегда яв-
ляются абстрактными. Поэтому можно создать абстрактный смешанный базовый
класс, позволяющий производным классам определять, был ли указатель возвра-
щен функцией operator new:
В оригинале абстрактные методы названы «полностью виртуальными». (Прим, ред.)
Правило 27
HIM!
163
class HeapTracked { // Смешанный класс; отслеживает
public: // указатели, возвращаемые
// operator new.
class MissingAddress{}; // Класс исключений; см. ниже,
virtual -HeapTracked() = 0;
static void *operator new(size_t size) ;
static void operator delete(void *ptr);
bool isOnHeapO const;
private:
typedef const void* RawAddress;
static list<RawAddress> addresses;
};
Этот класс использует для отслеживания указателей, возвращаемых функ-
цией operator new, структуру list, которая является частью стандартной биб-
лиотеки C++ (см. правило 35). Данная функция выделяет память и добавляет
элементы в список; функция operator delete возвращает память и удаляет
элементы из списка; а функция isOnHeap сообщает, находится ли адрес объек-
та в списке.
Реализация класса HeapTracked проста, так для выделения и возврата памя-
ти вызываются глобальные функции operator new и operator delete, а класс
list содержит функции для вставки, удаления и поиска элементов в списке. Вот
полная реализация класса HeapTracked:
// Обязательное определение статического элемента класса.
list<RawAddress> HeapTracked::addresses;
// Деструктор класса HeapTracked абстрактный,
// чтобы сделать класс абстрактным. Но деструктор должен
// быть определен, поэтому приводится пустое определение.
HeapTracked::-HeapTracked() {}
void * HeapTracked: :operator new(size_t size)
{
void *memPtr = : :operator new(size) ; // Получить память.
addresses. push_front (memPtr); // Поместить ее адрес
//в начало списка.
return memPtr;
}
void HeapTracked::operator delete(void *ptr)
// Получить "итератор", определяющий элемент списка
//и содержащий ptr; подробности см. в правиле 35.
list<RawAddress>::iterator it =
find(addresses.begin(), addresses.end(), ptr);
if (it != addresses.end()) {
addresses.erase (it);
::operator delete(ptr);
} else {
throw MissingAddress();
}
}
// Если элемент был найден,
// удалить его, освободить
// память;
// иначе ptr не был выделен
// при помощи operator new,
// поэтому сгенерировать
// исключение.
6*
164
ПИШИ
Приемы
bool HeapTracked::isOnHeap() const
{
// Получить указатель на начало памяти,
// занятой *this; подробнее см. ниже,
const void *rawAddress = dynamic_cast<const void*>(this)
// Поиск указателя в списке адресов,
// возвращенных operator new.
list<RawAddress>::iterator it =
find(addresses.begin(), addresses.end(), rawAddress);
return it != addresses.end(); // Вернуть it, если
} // адрес был найден.
Приведенный код довольно прост, хотя если вы не знакомы с классом list
и другими компонентами стандартной библиотеки шаблонов, он может показаться
вам сложным. В правиле 35 все это объясняется подробно, хотя комментариев
в самом коде должно быть достаточно, чтобы объяснить, что происходит в примере.
Вас может поставить в тупик только следующий оператор (в функции
isOnHeap):
const void *rawAddress = dynamic_cast<const void*>(this);
Как я уже упоминал, написание глобальной функции isSafeToDelete
усложняется из-за того, что объекты с несколькими или виртуальными базовыми
классами имеют несколько адресов. Эта проблема досаждает и в функции
isOnHeap, но поскольку функция isOnHeap применяется только к объектам
HeapTracked, можно использовать особенность оператора dynamic_cast (см.
правило 2). Оператор dynamic_cast, если его просто применить к указателю на
void* (или const void*, или volatile void*, или - когда не хватает моди-
фикаторов - const volatile void*), дает указатель на начало памяти объекта,
на который он ссылается. Но оператор dynamic_cast применим только к ука-
зателям на объекты, имеющие хотя бы одну виртуальную функцию. Наша зло-
счастная функция isSafeToDelete должна была работать со всеми типами
указателей, поэтому оператор dynamic_cast не помог бы ей. Функция
isOnHeap является более избирательной (она проверяет только указатели на
объекты типа HeapTracked), поэтому в ней приведение this к const void*
при помощи оператора dynamic_cast дает указатель на начало памяти теку-
щего объекта. Это указатель, который теперь должна возвращать функция
HeapTracked: : operator new, если память для текущего объекта была перво-
начально выделена при помощи HeapTracked: : operator new. Если ваши ком-
пиляторы поддерживают оператор dynamic_cast, то предложенный метод яв-
ляется совершенно переносимым.
Имея этот класс, даже программисты на Basic могут отслеживать указатели
на объекты в куче. Для этого достаточно сделать класс наследником класса
HeapTracked. Если, например, требуется знать, является ли указатель на объект
типа Asset указателем на объект в куче, можно изменить определение класса
Asset, задав HeapTracked в качестве базового класса:
class Asset: public HeapTracked {
private:
165
Правило 27
UPNumber value;
};
Затем можно опрашивать указатели Asset* следующим образом:
void inventoryAsset (const Asset *ap)
{
if (ap->isOnHeap()) {
ар находится в куче - занести его в список
}
else {
ар не находится в куче - записать это
}
}
Недостаток смешанного класса, такого как HeapTracked, состоит в том, что
он не может использоваться со встроенными типами, поскольку типы, подобные
int и char, не способны наследовать от чего бы то ни было. Но обычно классы
вроде HeapTracked создаются благодаря возможности определить, допускается
ли выполние операции delete this, а такие операции никогда не нужно приме-
нять к встроенным типам, поскольку последние не имеют указателя this.
Запрет создания объектов в куче
На этом закончим обсуждение того, как можно определить, находится ли
объект в куче. Теперь поговорим о предотвращении создания объектов в куче. Как
обычно, имеется три случая: объекты, которые создаются непосредственно, объек-
ты, создаваемые как части базового класса в производных классах, и объекты,
встроенные в другие объекты. Рассмотрим каждый из них поочередно.
Запретить прямое создание объектов в куче легко, поскольку такие объекты
всегда создаются при помощи вызова new, и можно сделать, чтобы клиенты не
могли вызвать new. Нельзя ограничить доступность оператора new (который явля-
ется встроенным), но можно воспользоваться тем, что он всегда вызывает функ-
цию operator new (см. правило 8), а эту функцию допускается переопределить.
В частности, ее удобно объявить как private. Например, если вы хотите запре-
тить клиентам создание объектов типа UPNumber, то вот один из способов:
class UPNumber {
private:
static void *operator new(size_t size);
static void operator delete(void *ptr);
};
Пользователи могут сделать только то, что им разрешено:
UPNumber nl; static UPNumber n2; // Нормально. // Также нормально.
UPNumber *р = new UPNumber; // Ошибка! попытка вызвать // закрытую функцию operator new
166
III
Приемы
Достаточно объявить функцию operator new закрытой. Вообще кажется
странным делать operator new открытой, оставляя функцию operator delete
закрытой, поэтому если нет особой необходимости разбивать пару этих функций,
лучше всего объявлять их в одной части класса. Если вам также нужно запретить
создание в куче массивов объектов типа UPNumber, то вы также можете объявить
закрытыми функции operator new [ ] и operator delete [ ] (см. правило 8).
Интересно, что объявление функции operator new закрытой также предот-
вращает создание объектов типа UPNumber как части базового класса в производ-
ных классах. Это происходит потому, что функции operator new и operator
delete наследуются, поэтому если данные функции не объявлены открытыми
в производном классе, то класс наследует закрытые версии, объявленные в базовом
классе:
class UPNumber { ... ) ;
class NonNegativeUPNumber:
public UPNumber {
};
NonNegativeUPNumber nl;
static NonNegativeUPNumber n2;
NonNegativeUPNumber *p =
new NonNegativeUPNumber;
// Как и выше.
// Предположим, что в этом
// классе не объявляется
// функция operator new.
// Нормально.
// Также нормально.
// Ошибка! Попытка вызывать
// закрытую функцию
// operator new.
Если в производном классе объявляется собственная функция operator
new, то она будет вызываться при создании объектов производного класса в куче,
и придется найти другой способ предотвратить, попадание в кучу объектов типа
UPNumber как частей базового класса. Аналогично то, что функция operator
new класса UPNumber является закрытой, не влияет на попытки создания в куче
объектов, содержащих объекты типа UPNumber в качестве членов класса:
class Asset {
public:
Asset(int initValue);
private:
UPNumber value;
};
Asset *pa = new Asset (100) ;
// Нормально, вызывает
// Asset::operator new
// или : :operator new, а не
// UPNumber::operator new.
По сути это возвращает вас в точку, где вы находились, когда собирались гене-
рировать исключение в конструкторах UPNumber, если объект типа UPNumber
создавался в памяти, которая не находится в куче. На этот раз, конечно, хотелось
бы генерировать исключение, если данный объект находится в куче. Но так же,
как не существует переносимого способа определить, находится ли адрес в куче,
Правило 28
nun
167
нет переносимого способа определить обратное, поэтому все попытки обречены
на неудачу. Это неудивительно. В конце концов, если бы можно было определить,
что адрес находится в куче, был бы способ определить, что его там нет. Но нельзя
сделать ни того, ни, соответственно, другого.
Правило 28. Используйте
интеллектуальные указатели
Интеллектуальные указатели (smart pointers) являются объектами, которые
разработаны так, чтобы выглядеть и действовать как встроенные указатели, обес-
печивая при этом большую функциональность. Они находят множество примене-
ний, включая управление ресурсами (см. правила 9, 10, 25 и 31) и автоматизацию
программирования повторяющихся задач (см. правила 17 и 29).
Если вы используете интеллектуальные указатели вместо встроенных указа-
телей языка C++ (то есть неинтеллектуальных, или обычных указателей (dumb
pointers)), вы можете управлять следующими аспектами поведения указателей:
□ созданием и уничтожением. Вы определяете, что происходит при создании
и уничтожении интеллектуального указателя. Обычно интеллектуальным
указателям по умолчанию присваивается значение 0, чтобы не допустить
ошибок, возникающих из-за неинициализированных указателей. Некоторые
интеллектуальные указатели отвечают за удаление объекта после того, как
будет уничтожен последний указывающий на объект интеллектуальный
указатель. Это косвенно позволяет избежать утечек памяти;
□ копирование и присваивание. Вы управляете тем, что происходит при копи-
ровании или присвоении интеллектуального указателя. Для некоторых ти-
пов интеллектуальных указателей нужно, чтобы он автоматически копиро-
вал или присваивал то, на что указывает, то есть выполнял бы детальную
копию (deep сору). Для других должен копироваться или присваиваться
только сам указатель. Для третьих эти операции следует запретить. Но неза-
висимо от поведения разных типов интеллектуальных указателей их грамот-
ное использование позволяет добиться нужного функционирования про-
граммы;
□ разыменование (dereferencing). Что должно произойти, если клиент обраща-
ется к объекту, на который ссылается интеллектуальный указатель? Это ре-
шаете вы. Например, вы можете использовать интеллектуальные указатели,
чтобы реализовать стратегию отложенной выборки, описанную в правиле 17.
Интеллектуальные указатели создаются на основе шаблонов, поскольку так
же, как и встроенные указатели, они должны быть максимально типизированы;
параметр шаблона определяет тип объекта, на который он указывает. Большин-
ство шаблонов интеллектуальных указателей выглядят примерно так:
template<class Т> // Шаблон для объектов
class SmartPtr { // интеллектуальных
public: // указателей.
168
ПИШИ
Приемы
SmartPtr (Т* realPtr = 0) ;
// Создать интеллектуальный указатель
//на объект на основе
// простого указателя; неинициализированным
// указателям присваивается значение 0 (null).
SmartPtr(const SmartPtr& rhs);
// Скопировать интеллектуальныйуказатель.
-SmartPtr(); // Уничтожить интеллектуальный указатель.
// Присвоить интеллектуальный указатель.
SmartPtrk operator=(const SmartPtrk rhs);
T* operator->() const;
// Разыменовать интеллектуальный указатель,
// получив элемент, на который он указывает.
Т& operator* () const;
// Разыменовать интеллектуальный указатель.
private:
Т *pointee; // То, на что указывает
}; //интеллектуальныйуказатель.
Здесь и конструктор копирования, и оператор присваивания являются от-
крытыми. В интеллектуальных указателях, копирование и присваивание для ко-
торых запрещено, они обычно объявляются закрытыми. Два оператора разыме-
нования определяются с атрибутом const, поскольку разыменование указателя
не изменяет его (хотя и может привести к модификации того, на что он указы-
вает). И наконец, каждый интеллектуальный указатель на объект Т реализован
так, что он содержит внутри себя простой указатель на Т, который, собственно,
и ссылается на объект.
Прежде чем перейти к деталям реализации интеллектуальных указателей,
стоит обсудить, как клиенты могут их использовать. Рассмотрим распределен-
ную систему, в которой одни объекты являются локальными, а другие удален-
ными. Доступ к локальным объектам обычно выполняется быстрее и проще, чем
к удаленным, поскольку удаленный доступ может потребовать удаленного вы-
зова процедур или еще какого-либо механизма взаимодействия с удаленным
компьютером.
Программистам, пишущим код приложения, несомненно, мешает различие
в работе с локальными и удаленными объектами. Более удобно было бы, если бы
казалось, что все объекты находятся в одном месте. Применение интеллектуаль-
ных указателей в библиотеке позволяет создавать такую иллюзию:
templatecclass Т>
class DBPtr {
public:
DBPtr (T *realPtr =0) ;
DBPtr(DataBaselD id);
// Шаблон для интеллектуальных
// указателей на объекты
//в распределенной базе данных.
// Создать интеллектуальный
// указатель на объект базы данных
//на основе простого локального
// указателя на него.
// Создать интеллектуальный
Правило 28
«I
169
// указатель на объект базы данных //на основе уникального // идентификатора в базе данных. // Остальные функции // интеллектуального указателя
}; class Tuple { public: // реализуются, как изложено выше. // Класс для кортежей базы данных.
void displayEditDialog(); // Вывести диалоговое окно, // позволяющее пользователю // редактировать кортеж.
bool isValid() const; }; // Возвращается, если указатель *this // проходит проверку //на достоверность. // Шаблон класса для записи сведений //об изменении // объекта Т; подробнее см. ниже.
template<class T>
class LogEntry {
public:
LogEntry(const T& objectToBeModified);
-LogEntry();
};
void editTuple(DBPtr<Tuple>& pt)
{
LogEntry<Tuple> entry(*pt); // Сделать запись об этой
// операции редактирования.
// Подробнее см. ниже.
' II Выводить диалоговое окно
// редактирования, пока не будут
// указаны правильные значения.
do {
pt->displayEditDialog();
} while (pt->isValid() == false);
}
Кортеж (tuple), редактируемый в функции EditTuple, может быть размещен
на удаленном компьютере, но программист, который пишет функцию, не должен
беспокоиться об этом; класс интеллектуального указателя скрывает данное свой-
ство системы. С точки зрения программиста доступ ко всем кортежам осуществ-
ляется при помощи объектов, которые после объявления ведут себя в точности
как обычные указатели.
Обратите внимание на использование в функции editTuple объекта Log-
Entry. Более традиционным было бы окружить вызов функции display-
EditDialogue вызовами для начала и окончания записи. В вышеприведенном
примере запись начинается с конструктора LogEntry, а заканчивается его дест-
руктором. Как объясняется в правиле 9, обращение к объекту в начале и конце
170
Приемы
записи более надежно при генерации исключений, чем-явный вызов функций, по-
этому привыкайте использовать классы, подобные LogEntry. Кроме того, проще
создать один объект LogEntry, чем добавлять отдельные вызовы для начала и окон-
чания записи.
Создание, присваивание и уничтожение
интеллектуальных указателей
Создать интеллектуальный указатель легко: определяется объект, на который
он должен указывать (обычно при помощи аргументов конструктора интеллекту-
ального указателя), а затем находящемуся внутри интеллектуального указателя
обычному указателю присваивается значение указателя на этот объект. Если нельзя
определить исходный объект, то внутреннему указателю присваивается значение О
или сообщается об ошибке (возможно, при помощи генерации исключения).
Реализация конструктора копирования, оператора(ов) присваивания и де-
структора интеллектуального указателя несколько осложняется вопросом о вла-
дельце объекта. Если интеллектуальный указатель является владельцем объекта,
на который указывает, то он отвечает за удаление объекта после своего уничтоже-
ния. При этом предполагается, что объект, на который указывает интеллектуаль-
ный указатель, является динамическим. Такое предположение является обычным
при работе с интеллектуальными указателями. (Как убедиться в том, что это пред-
положение выполняется, см. в правиле 27.)
Рассмотрим шаблон auto_ptr из стандартной библиотеки C++. В правиле 9
объяснялось, что объект типа auto_ptr является интеллектуальным указателем
на объект в куче до тех пор, пока указатель auto_ptr не будет уничтожен. После
этого деструктор auto_ptr уничтожает объект, на который он (auto_ptr) ука-
зывал. Шаблон указателя auto_ptr может быть реализован так:
templatecclass Т>
class auto_ptr {
public:
auto_ptr(T *ptr = 0) : pointee(ptr) {}
~auto_ptr() { delete pointee; }
private:
T *pointee;
};
Такая реализация работает прекрасно, если auto_ptr является владельцем
объекта. Но что произойдет после копирования или присвоения auto_ptr?
auto_ptr<TreeNode> ptnl(new TreeNode) ;
auto_ptr<TreeNode> ptn2 = ptnl; // Вызов конструктора
// копирования.
// Что произойдет?
auto_ptr<TreeNode> ptn3 ;
ptn3 = ptn2; // Вызов operators
// Что произойдет?
Правило 28
Если вы просто скопировали внутренний обычный указатель, то в результате
два объекта auto_ptr будут указывать на один и тот же объект. Это приведет
к проблемам, поскольку деструктор каждого из объектов auto_ptr должен уда-
лить объект, на который указывает объект auto_ptr. Следовательно, вы будете
пытаться удалить объект несколько раз. Результат такого многократного удале-
ния не известен (и часто приводит к печальным последствиям).
В качестве альтернативы можно было бы создать новую копию объекта, на
который указывает auto_ptr, при помощи оператора new. У вас появится гаран-
тия, что на один объект не будет указывать несколько объектов auto_ptr, но от
этого может снизиться производительность из-за создания (и уничтожения) но-
вого объекта. Кроме того, тип создаваемого объекта не всегда будет известен, так
как объект auto_ptr<T> не обязательно должен указывать на объект типа Т; он
может указывать на объект производного от Т типа. Это противоречие нетрудно
устранить при помощи виртуальных конструкторов (см. правило 25), но их при-
менение кажется неуместным в таком универсальном классе, как auto_ptr.
Все названные проблемы исчезнут, если запретить копирование и присвоение
объектов auto_ptr, но для классов auto_ptr было принято более гибкое реше-
ние: владелец объекта изменяется при копировании или присвоении оператора
auto_ptr:
template<class Т>
class auto_ptr {
public:
auto_ptr (auto_ptr<T>& rhs) ;
auto_ptr<T>&
operator=(auto_ptr<T>& rhs) ;
// Конструктор копирования.
// Оператор
// присваивания.
};
template<class Т>
auto_ptr<T>::auto_ptr(auto_ptr<T>& rhs)
{
pointee = rhs.pointee; // Владельцем объекта *pointee
// становится указатель *this.
rhs.pointee =0; // Указатель rhs больше не владеет
} // ничем.
template<class T>
auto_ptr<T>& auto_ptr<T>: :operator=(auto_ptr<T>& rhs)
{
if (this == &rhs) // Если объект this
return *this; // присваивается сам себе,
// ничего не делать.
delete pointee; // Удалить объект.
pointee = rhs.pointee; // Владельцем объекта *pointee
rhs. pointee =0; // вместо указателя rhs
// становится *this.
return *this;
172
Приемы
ниши
Обратите внимание, что оператор присваивания должен удалять объект, вла-
дельцем которого он является, перед тем как стать владельцем нового объекта.
Если он не сможет этого сделать, то объект никогда не будет удален. Помните:
только объект auto_ptr является владельцем того, на что он указывает.
Поскольку при вызове конструктора копирования auto_ptr меняется владе-
лец объекта, то передача auto_ptr по значению часто является очень неудачной,
и вот почему:
// Эта функция часто приводит к серьезным ошибкам.
void printTreeNode(ostream& s, auto_ptr<TreeNode> p)
{ s « *p; }
int main ()
{ auto_ptr<TreeNode> ptn(new TreeNode);
printTreeNode(cout, ptn); // Передать auto_ptr по значению.
}
Во время инициализации параметра p функции printTreeNode (при помо-
щи вызова конструктора копирования auto_ptr), владельцем объекта, на кото-
рый указывает ptn, становится р. После завершения работы функции print
TreeNode указатель р выходит из области видимости, и его деструктор удаляет
то, на что р указывает (то есть то, на что раньше указывал ptn). Однако ptn боль-
ше ни на что не указывает (лежащий в его основе простой указатель равен нулю),
поэтому почти всякая попытка использовать его после вызова функции
printTreeNode даст непредсказуемые результаты. Следовательно, передача ука-
зателей auto_ptr должна осуществляться, только если вы уверены, что вам нуж-
но поменять владельца объекта на (переменный) параметр функции. Но такое
действие требуется очень редко.
Это не означает, что вы не можете передавать указатели auto_ptr в качестве
параметров. Просто передача по значению является не совсем подходящим спо-
собом для этого, в отличие от передачи по ссылке на const:
/ / Поведение этой функции намного нагляднее.
void printTreeNode(ostreamk s, const auto_ptr<TreeNode>& p)
{ s « *p; }
В приведенной функции p является ссылкой, а не объектом, поэтому для
инициализации р не вызывается конструктор. Когда этой версии функции
printTreeNode передается указатель ptn, он остается владельцем объекта,
на который указывает, и может безопасно использоваться после вызова функ-
ции printTreeNode. Таким образом, передача указателя auto_ptr как ссыл-
ки на const позволяет избежать опасностей, возникающих при передаче по
значению.
Знание процедуры смены владельца при копировании и присвоении интел-
лектуальных указателей, несомненно, полезно, но вы можете быть не менее
173
Правило 28
заинтересованы необычными объявлениями в конструкторе копирования и опе-
раторе присваивания. Такие функции обычно имеют параметры с атрибутом
const, но в данном случае это не так. В вышеприведенном коде параметры из-
меняются во время копирования или присваивания. Другими словами, объекты
auto_ptr изменяются, если они копируются или являются источником при
присваивании!
Да, именно это и происходит. Не прекрасно ли, что язык C++ настолько ги-
бок, что позволяет выполнять такие операции? Если бы требовалось, чтобы пара-
метры конструкторов копирования и операторов присваивания имели параметры
с атрибутом const, пришлось бы снимать атрибуты const или реализовывать
передачу прав владельца каким-либо другим образом. Но удобнее прямо сказать,
что вам нужно: объект должен измениться, если он копируется или является ис-
точником при присваивании. Это может показаться не очень наглядным, но это
простой и понятный способ и в данном случае правильный.
Если вас заинтересовало рассмотрение функций - членов указателя auto_ptr,
вы можете ознакомиться с его полной реализацией, которую найдете на страни-
цах 289-292. Как вы увидите, шаблон auto_ptr в стандартной библиотеке C++
имеет более гибкие конструкторы копирования и операторы присваивания, чем
описанные выше. В стандартном шаблоне auto_ptr эти функции являются шаб-
лонами функций-членов, а не просто функциями-членами. (Шаблоны функций-
-членов описываются в этом правиле позже.)
Деструктор интеллектуального указателя часто выглядит так:
templatecclass Т>
SmartPtr<T>::-SmartPtr()
{
if (*this является владельцем *pointee) {
delete pointee;
}
}
Иногда не нужно выполнять такую проверку. Например, указатель auto_ptr
всегда является владельцем того, на что он указывает. В других случаях проверка
бывает несколько более сложной. Интеллектуальный указатель, использующий
счетчик ссылок (см. правило 29) должен корректировать счетчик ссылок перед
тем, как определить, может ли он удалить то, на что указывает. Некоторые интел-
лектуальные указатели не отличаются от обычных: они не выполняют никаких
действий над объектом, на который указывают при своем уничтожении.
Реализация операторов разыменования
Обратим теперь внимание на «сердце» интеллектуальных указателей, функ-
ции operator* и operator->. Вторая функция возвращает объект, на который
ссылается указатель. В теории это просто:
templatecclass Т>
Т& SmartPtrcT>::operator*() const
174
!№
Приемы
{
выполнить обработку интеллектульного указателя;
return *pointee;
}
Во-первых, функция осуществляет необходимые вычисления для инициали-
зации pointee или какие-либо другие процедуры, обеспечивающие его правиль-
ность. Например, при использовании отложенной выборки (см. правило 17) этой
функции может потребоваться создать новый объект, на который будет указывать
pointee. Если ссылка pointee задана корректно, то функция operator* прос-
то возвращает ссылку на указываемый объект.
Обратите внимание, что возвращается ссылка. Возвращение объекта могло бы
привести к ошибке, поэтому компиляторы не допускают этого. Имейте в виду, что
ссылка pointee не обязательно должна указывать на объект типа Т; она может
указывать на объект производного от Т класса. Если бы это было так, и функция
operator* возвращала бы объект Т вместо ссылки на объект производного клас-
са, то функция возвращала бы объект неправильного типа! (Это проблема потери
данных - см. правило 13.) Виртуальные функции, которые вызываются в объек-
те, возвращаемом несчастным operator*, не вызывали бы функцию, соответ-
ствующую динамическому типу указываемого объекта. В сущности, такой интел-
лектуальный указатель не мог бы корректно поддерживать виртуальные функции,
и насколько же интеллектуальным он бы был? Кроме того, возврат ссылки более
эффективен, так как не требует создания временного объекта (см. правило 19).
Это один из тех редких случаев, когда корректность и эффективность идут рука
об руку.
Если вы из тех, кто любит беспокоиться по различным поводам, вы можете
поинтересоваться, как надо поступить, если кто-то вызовет operator* для нуле-
вого интеллектуального указателя, то есть указателя, простой указатель внутри
которого равен нулю. Расслабьтесь. Вы можете сделать все, что угодно. Результат
разыменования нулевого указателя не определен, поэтому не существует «непра-
вильного» поведения. Хотите сгенерировать исключение? Давайте, генерируйте.
Хотите вызвать функцию abort (возможно, завершив неудачей вызов assert)?
Прекрасно, вызывайте ее. Желаете обойти всю память, присвоив каждому байту
дату вашего рождения по модулю 256? Это также допустимо. В данном случае вы
совершенно свободны от ограничений языка.
Описание operator-> аналогично описанию operator*, но прежде чем
рассмотреть operator->, вспомним о необычном значении вызова этой функ-
ции. Рассмотрим снова функцию editTuple, использующую интеллектуальный
указатель на объект Tuple:
void editTuple(DBPtr<Tuple>& pt)
{
LogEntry<Tuple> entry(*pt) ;
do {
pt->displayEditDialog();
Правило 28
175
} while (pt->isValid() == false);
}
Оператор
pt->displayEditDialog();
интерпретируется компиляторами как
(pt.operator->())->displayEditDialog();
Это означает, что ко всему возвращающему operator-> допускается приме-
нить оператор выбора элемента (->). Поэтому функция operator-> может воз-
вращать только две вещи: обычный указатель на объект или другой объект интел-
лектуального указателя. В большинстве случаев вам будет нужно возвращать
обычный указатель. При этом operator-> реализуется следующим образом:
templatecclass Т>
Т* SmartPtr<T>::operator->() const
{
выполнить обработку интеллектуального указателя;
return pointee;
}
Эта конструкция будет прекрасно работать. Поскольку данная функция воз-
вращает указатель, вызовы виртуальных функций при помощи operator-> бу-
дут вести себя так, как и предполагается.
Для большинства приложений это все, что вам нужно знать об интеллекту-
альных указателях. Например, код для подсчета ссылок из правила 29 использует
не больше функций, чем было описано выше. Однако если вы хотите обогатить
свои представления об интеллектуальных указателях, вы должны больше узнать
о поведении обычных указателей и о том, когда интеллектуальные указатели мо-
гут и не могут эмулировать такое поведение. Если ваш девиз «Большинство лю-
дей останавливаются, дойдя до буквы Z, но только не я!», то следующий раздел
предназначен для вас.
Проверка равенства интеллектуальных указателей нулю
При помощи функций, которые уже были рассмотрены, вы можете создавать,
уничтожать, копировать, присваивать и разыменовывать интеллектуальные ука-
затели. Но не можете определить, равен ли интеллектуальный указатель нулю:
SmartPtr<TreeNode> ptn;
if (ptn == 0) . . .
// Ошибка!
if (ptn)
// Ошибка!
if (!ptn) . . .
/ / Ошибка!
Это серьезное ограничение.
176
Mill
Приемы
Легко было бы добавить к имеющимся классам интеллектуальных указателей
функцию-член isNull, но это не помогло бы решить проблему, которая заключа-
ется в том, что при проверке на равенство нулю интеллектуальные указатели не
ведут себя как простые указатели. Другой подход - задать оператор явного преоб-
разования, который позволяет компилироваться вышеприведенному коду прове-
рок. Обычно при этом выполняется преобразование к типу void*:
template<class Т>
class SmartPtr {
public:
operator void*();
};
SmartPtr<TreeNode> ptn;
if (ptn == 0) ...
if (ptn) ...
if (Iptn) . ..
// Возвращает 0, если
// интеллектуальный указатель
// равен null, иначе ненулевое
// значение.
// Теперь нормально.
// Также нормально.
// Нормально.
Это аналогично преобразованию для классов входных потоков и объясняет,
почему можно написать такой код:
ifstream inputFile("datafile.dat");
if (inputFile) ... // Проверка успешного открытия
// файла inputFile.
Данная функция, так же как и все функции преобразования типов, имеет один
недостаток - вызовы функций завершаются успешно, хотя большинство програм-
мистов ожидает, что они завершатся неудачей (см. правило 5). В частности, такое
преобразование позволяет сравнивать интеллектуальные указатели совершенно
различных типов:
SmartPtr<Apple> ра;
SmartPtr<Orange> ро;
if (ра == ро) . . .
// Компилируется нормально!
Даже если для типов SmartPtr<Apple> и SmartPtr<Orange> не преду-
смотрена функция operators этот код будет компилироваться без ошибок, по-
скольку интеллектуальные указатели могут быть неявно преобразованы к указа-
телям типа void*, а для встроенных указателей существует встроенная функция
сравнения. Такое поведение делает функции неявного преобразования типов до-
вольно опасными (см. правило 5). Это вариации на тему преобразования к void*.
Некоторые разработчики поддерживают возможность преобразования к const
void*, другие выбирают преобразование в тип bool. Ни одна из названных раз-
новидностей не устраняет проблему сравнений различных типов.
Правило 28
HIM!
177
Существует промежуточное решение, позволяющее использовать приемле-
мую синтаксическую форму для проверки на равенство нулю, уменьшая при этом
риск случайного сравнения интеллектуальных указателей разных типов. Оно со-
стоит в перегрузке operator! в классе интеллектуального указателя, чтобы функ-
ция operator! возвращала значение true тогда и только тогда, когда интеллек-
туальный указатель, для которого она вызывается, равен нулю.
template<class Т>
class SmartPtr {
public:
bool operator!() const; // Возвращает true тогда и только
... // тогда, когда интеллектуальный
// указатель равен null.
};
Это позволяет создавать такие клиентские программы:
SmartPtr<TreeNode> ptn;
if (!ptn) { // Нормально ;
} else { // указатель ptn равен null
} // ptn не равен null.
но не такие:
if (ptn == 0) ... // Все еще ошибка.
if (ptn) ... // Также ошибка.
Риск возникает только при таких сравнениях различных типов:
SmartPtr<Apple> ра;
SmartPtr<Orange> ро;
if (!ра == !ро) ... // Увы, компилируется.
К счастью, программисты не часто пишут подобный код. Интересно, что в биб-
лиотеке iostream кроме неявного преобразования к void* задана функция
operator!, но эти две функции обычно проверяют немного различные состояния
потока. (В стандарте библиотек языка C++ (см. правило 35) неявное преобразова-
ние к типу void* заменено неявным преобразованием к типу bool, а функция
operator bool всегда возвращает отрицание operator!.)
Преобразование интеллектуальных указателей в обычные
Иногда требуется добавить интеллектуальные указатели к приложению или
библиотеке, где уже используются обычные указатели. Например, распределен-
ная база данных может изначально не быть распределенной, так что некоторые
старые библиотечные функции могут не предназначаться для работы с интеллек-
туальными указателями:
178
Приемы
class Tuple { ... };
void normalize (Tuple *pt) ;
// Как и раньше.
// Привести указатель *pt
//к канонической форме;
// используется обычный
// указатель.
Рассмотрим, что произойдет, если вы попытаетесь вызвать функцию
normalize для интеллектуального указателя на объект Tuple:
DBPtr<Tuple> pt;
normalize(pt); //Ошибка!
Этот вызов не скомпилируется, поскольку не существует способа преобразо-
вать DBPtr<Tuple> в Tuple*. Вы можете заставить его работать, сделав следую-
щее:
normalize (&*pt) ; // Грубо, недопустимо.
но я надеюсь, вы согласитесь со мной, что это далеко не лучший вариант.
Можно сделать вызов успешным, добавив к шаблону интеллектуального ука-
зателя на Т оператор явного преобразования в обычный указатель на Т:
templatecclass Т> // Как и раньше.
class DBPtr (
public:
operator?*() { return pointee; }
};
DBPtr<Tuple> pt;
normalize(pt) ; // Теперь работает.
Добавление этой функции также устраняет проблему проверки на равенство
нулю:
if (pt == 0) ... // Нормально, преобразует
// указатель pt в Tuple*.
if (pt) ... // То же.
if (!pt) . . . // То же.
Тем не менее, у таких функций преобразования есть и недостатки. (Это почти
всегда так - см. правило 5.) Данные функции позволяют клиентам непосредствен-
но использовать в программе обычные указатели, пренебрегая интеллектуально-
стью разработанных вами объектов-указателей.
void processTuple(DBPtr<Tuple>& pt)
{
Tuple *rawTuplePtr = pt; // Преобразует DBPtr<Tuple>
// в Tuple* .
для изменения tuple используется rawTuplePtr;
}
Правило 28
179
Обычно «умное» поведение, обеспечиваемое интеллектуальным указателем,
является необходимым компонентом разработки, поэтому разрешение клиентам
использовать обычные указатели, вы, возможно, спровоцируете катастрофу. На-
пример, если интеллектуальный указатель DBPtr реализует стратегию подсче-
та ссылок, описанную в правиле 29, и вы позволите клиентам напрямую рабо-
тать с простыми указателями, это почти неизбежно вызовет ошибки, которые
нарушат структуры данных, отвечающие за подсчет ссылок.
Даже если создать оператор неявного преобразования из интеллектуального
указателя в обычный, интеллектуальные указатели и обычные не будут равно-
значны. Это связано с тем, что преобразование из интеллектуального указателя
в обычный определено пользователем, а компилятору запрещено применять бо-
лее одного такого преобразования одновременно. Например, предположим, что
имеется класс, представляющий всех клиентов, получивших доступ к опреде-
ленному кортежу:
class TupleAccessors {
public:
TupleAccessors(const Tuple *pt); // Указатель pt определяет
... // заданный кортеж.
};
Как обычно, конструктор с одним аргументом TupleAccessor также служит
оператором преобразования типа из Tuple* в TupleAccessors (см. правило 5).
Рассмотрим теперь функцию для слияния данных из двух объектов Tuple-
Accessors:
TupleAccessors merge(const TupleAccessorsk tai,
const TupleAccessors& ta2);
Поскольку указатель Tuple* может быть неявно преобразован в объект
TupleAccessors, вызов функции merge с двумя обычными указателями
Tuple* компилируется без каких-либо проблем:
Tuple *ptl, *pt2;
merge(ptl, pt2); // Нормально, оба указателя
// преобразуются
// в объекты TupleAccessors.
Соответствующий же вызов для интеллектуальных указателей DBPtr-
<Tuple> компилироваться не будет:
DBPtr<Tuple> ptl, pt2;
merge(ptl, pt2); // Ошибка! Невозможно
// преобразовать ptl
// и pt2 в объект TupleAccessors.
Это связано с тем, что преобразование DBPtr<Tuple> в объект TupleAccessors
требует вызова двух определенных пользователем преобразований (одно из
180
Приемы
DBPtr<Tuple> в Tuple* и одно из Tuple* в TupleAccessors), а такие после-
довательности преобразований в языке запрещены.
Классы интеллектуальных указателей, в которых есть функции неявного
преобразования в обычный указатель, приводят к очень неприятной ошибке.
Рассмотрим код:
DBPtr<Tuple> pt = new Tuple;
delete pt;
Такой код не должен был бы компилироваться. В конце концов, объект pt не
является указателем, и его нельзя удалить. Ведь можно удалять только указатели,
не так ли?
Да, это так. Но вы должны помнить из правила 5, что компиляторы использу-
ют неявное преобразование типов для того, чтобы по возможности сделать вызо-
вы функций успешными, а из правила 8 - что использование оператора delete
приводит к вызову двух функций (деструктора и operator delete). Компиля-
торы пытаются сделать вызов данных функций успешным, поэтому в операторе
delete они неявно преобразуют pt в Tuple*, а затем удаляют его. Это почти
наверняка приведет к остановке вашей программы.
Если интеллектуальный указатель pt является владельцем объекта, на кото-
рый он указывает, то этот объект удаляется дважды, один раз в точке вызова опе-
ратора delete, а второй - при вызове деструктора pt. Если объектом не владеет
pt, то им владеет кто-то другой. Возможно, это был тот, кто удалил pt, и тогда все
в порядке. В противном случае настоящий владелец скорее всего попытается поз-
же снова удалить объект. Первый и последний варианты означают, что объект уда-
ляется дважды, а удаление объекта более одного раза приводит к неопределенно-
му поведению.
Эта ошибка очень опасна, так как основная идея, лежащая в основе интеллек-
туальных указателей - сделать их максимально похожими на обычные указатели.
Чем ближе вы приближаетесь к этому идеалу, тем более вероятно, что клиенты
забудут о том, что они используют интеллектуальные указатели. И если это про-
изойдет, кто сможет обвинить их в вызове delete после new, ведь тем самым они
стремятся (по их мнению) избежать утечек ресурсов?
Итог всего вышесказанного достаточно прост: не создавайте операторов
неявного преобразования в обычные указатели без настоятельной необходимости.
Интеллектуальные указатели и преобразования типов
при наследовании
Предположим, что имеется открытая иерархия наследования, соответствую-
щая музыкальным носителям для бытовой аппаратуры (см. рис. 5.4).
class MusicProduct {
public:
MusicProduct(const strings title);
virtual void playO const = 0;
Правило 28
181
virtual void displayTitle () const = 0;
};
class Cassette: public MusicProduct {
public:
Cassette(const strings title);
virtual void play() const;
virtual void displayTitle () const;
};
class CD: public MusicProduct {
public:
CD(const strings title);
virtual void play() const;
virtual void displayTitle() const;
};
Предположим далее, что имеется функция, выводящая название объекта
MusicProduct, а затем проигрывающая соответствующий носитель:
void displayAndPlay (const MusicProduct* pmp, int numTimes)
{
for (int i = 1; i <= numTimes; ++i) {
pmp->displayTitle();
pmp->play();
}
}
Такую функцию можно использовать следующим образом:
Cassette *funMusic = new Cassette("Alapalooza");
CD *nightmareMusic = new CDC'Disco Hits of the 70s") ;
displayAndPlay(funMusic, 10);
displayAndPlay(nightmareMusic, 0) ;
В данном случае никаких сюрпризов нет, но посмотрим, что произойдет, если
заменить обычные указатели на их якобы «интеллектуальные» аналоги:
void displayAndPlay(const SmartPtr<MusicProduct>S pmp,
int numTimes);
Приемы
SmartPtr<Cassette> funMusic(new Cassette("Alapalooza"));
SmartPtr<CD> nightmareMusic(new CD("Disco Hits of the 70s"));
displayAndPlay(funMusic, 10); // Ошибка!
displayAndPlay(nightmareMusic, 0); //Ошибка!
Если интеллектуальные указатели так умны, почему этот код не компилируется?
Он не компилируется из-за того, что не существует преобразования из
SmartPtr<CD> или SmartPtr<Cassette> в SmartPtr<MusicProduct>. Сточ-
ки зрения компилятора, это три отдельных класса, которые не связаны друг с дру-
гом. С какой стати компиляторам думать иначе? Непохоже, что Smart Pt r<CD> или
SmartPtr<Cassette> наследуют от SmartPtr<MusicProduct>. Если данные
классы не связаны между собой отношениями наследования, едва ли можно ожи-
дать, что компиляторы будут сами по себе преобразовывать объекты одного типа
в объекты другого.
К счастью, существует простой (если дело не касается практики) способ обой-
ти это ограничение: определить в каждом классе интеллектуального указателя
оператор явного преобразования типов (см. правило 5) для каждого из других
классов интеллектуальных указателей, в которые он должен неявно конвертиро-
ваться. Например, в иерархии музыкальных носителей к классам интеллектуаль-
ных указателей Cassette и CD добавляются функции operator Smart Ptr<Mu-
sicProduct>:
class SmartPtr<Cassette> {
public:
operator SmartPtr<MusicProduct>()
{ return SmartPtr<MusicProduct>(pointee); }
private:
Cassette *pointee;
};
class SmartPtr<CD> {
public:
operator SmartPtr<MusicProduct>()
{ return SmartPtr<MusicProduct>(pointee); }
private:
CD *pointee;
};
Такой подход имеет два недостатка. Во-первых, нужно вручную перечислять
экземпляры класса SmartPtr, чтобы добавить необходимые операторы неявного
преобразования типов, но это сводит практически на нет выгоду от применения
шаблонов. Во-вторых, иногда требуется несколько таких операторов преобразова-
ния, поскольку объект может находиться в иерархии наследования достаточно глу-
боко, и нужно создать оператор преобразования для каждого базового класса, от ко-
торого объект явно или неявно наследует. (Если вы считаете, что этой проблемы
Правило 28
!!!
183
легко избежать, создав оператор неявного преобразования только для каждого из
прямых базовых классов, то вы ошибаетесь. Поскольку компиляторам запрещено
использовать более одной определенной пользователем функции преобразования
одновременно, они могут превратить интеллектуальный указатель на Т в интел-
лектуальный указатель на непрямой базовый класс Т всего за один шаг.)
Если бы можно было как-то заставить компилятор автоматически написать
функции неявного преобразования типов, то это сэкономило бы массу времени.
И такое возможно благодаря недавнему расширению языка, которое позволяет
объявлять (невиртуальные) шаблоны функций-членов (member function templates
или часто member templates). Эти шаблоны вы можете использовать для создания
таких функций преобразования типов для интеллектуальных указателей:
template<class Т>
class SmartPtr {
public:
SmartPtr(T* realPtr = 0);
// Шаблон класса
// для интеллектуальных
// указателей на объекты Т.
Т* operator->() const;
Т& operator*() const;
template<class newType> // Функция шаблона
operator SmartPtr<newType> () // для операторов неявного
{ // преобразования типов.
return SmartPtr<newType>(pointee);
}
};
Это почти волшебство, и сейчас вы узнаете, как оно происходит. (Я вскоре
приведу конкретный пример, поэтому не отчаивайтесь, если остаток параграфа
покажется вам бессмысленным набором слов. После того как вы увидите код, вам
все станет ясно, обещаю.) Предположим, компилятор располагает интеллектуаль-
ным указателем на объект Т, и он должен превратить этот объект в интеллекту-
альный указатель на базовый класс объекта Т. Компилятор проверяет, объявлен
ли искомый оператор преобразования в классе Smart Ptr<T>, но такой оператор
не объявлен. (И этого не может быть: в вышеприведенном шаблоне не объявлены
операторы преобразования.) Затем компилятор проверяет, существует ли какая-
нибудь функция-член, позволяющая выполнить требуемое преобразование. Он
находит шаблон такой функции (с формальным параметром newType), потом со-
здает экземпляр шаблона, в котором параметр newType привязан к базовому клас-
су Т, являющемуся целью преобразования. Единственный вопрос заключается в том,
будет ли код полученной функции-члена компилироваться. Для этого должна
быть допустима передача указателя (обычного) pointee конструктору интеллек-
туального указателя на базовый класс т. Указатель pointee имеет тип Т,
поэтому, конечно, разрешается его превращение в указатель на соответствующие
184
и
Приемы
базовые классы (отрытые или защищенные). Следовательно, код для оператора
преобразования типа будет компилироваться, и неявная конвертация из интел-
лектуального указателя на Т в интеллектуальный указатель на базовый класс Т
окажется успешной.
Приведем пример. Вернемся к иерархии компакт-дисков, кассет и других му-
зыкальных носителей. Как вы уже знаете, приведенный ниже код не компилиру-
ется, поскольку компиляторы не могут преобразовать интеллектуальные указате-
ли на компакт-диски или кассеты в интеллектуальные указатели на музыкальные
носители вообще:
void displayAndPlay(const SmartPtr<MusicProduct>& pmp,
int howMany);
SmartPtr<Cassette> funMusic(new Cassette("Alapalooza"));
SmartPtr<CD> nightmareMusic(new CD("Disco Hits of the 70s") ) ;
displayAndPlay(funMusic, 10); // Здесь была ошибка.
displayAndPlay(nightmareMusic, 0); // Здесь была ошибка.
Если же исправить класс интеллектуальных указателей, содержащих шаблон
функции-члена для операторов неявного преобразования типов, этот код будет
успешно компилироваться. Чтобы понять почему, рассмотрим вызов:
displayAndPlay(funMusic, 10);
Объект funMusic имеет тип SmartPtr<Cassette>. Функция же dis-
playAndPlay ожидает объект SmartPtr<MusicProduct>. Компиляторы об-
наруживают несоответствие типов и пытаются найти способ преобразования
объекта funMusic в объект SmartPtr<MusicProduct>. Они ищут в классе
SmartPtr<MusicProduct> конструктор с единственным аргументом типа
SmartPtr<Cassette> (см. правило 5), но не находят его. Затем пытаются об-
наружить в классе SmartPtr<Cassette> оператор неявного преобразования
типов, дающий класс SmartPtr<MusicProduct>, но этот поиск также закан-
чивается неудачей. Потом компиляторы ищут шаблон функции-члена, экземп-
ляр которой могут создать, и выясняют, что шаблон внутри SmartPtr
<Cassette>, если связать параметр newType с MusicProduct, генерирует
нужную функцию. Тогда они создают эту функцию, давая в результате следую-
щий код:
SmartPtr<Cassette>::operator SmartPtr<MusicProduct>()
{
return SmartPtr<MusicProduct>(pointee);
}
Будет ли этот код компилироваться? В нем не происходит ничего, кроме вы-
зова конструктора SmartPtr<MusicProduct> с аргументом pointee, поэтому
вопрос сводится к тому, можно ли создать объект Smart Pt r<MusicProduct> при
помощи указателя Cassette*. Конструктор SmartPtr<MusicProduct> ожида-
ет указатель MusicProduct*, но теперь есть твердое основание для сравнения
между двумя типами обычных указателей, и ясно, что можно подставить
Cassette* там, где ожидается MusicProduct*. Поэтому создание объекта
Правило 28
SmartPtr<MusicProduct> будет успешным, так же как и преобразование
SmartPtr<Cassette> в SmartPtr<MusicProduct>. Вуаля! Неявное преобра-
зование типов интеллектуальных указателей. Что может быть проще?
Более того, что может быть более мощным? Пусть вас не вводит в заблужде-
ние рассмотренный пример - не нужно думать, что этот метод работает только для
преобразования указателей в иерархии наследования. Он применим для любых
неявных преобразований типов указателей. Если имеется обычный указатель
типа Т1 * и другой обычный указатель типа Т2 *, то интеллектуальный указатель
на Т1 разрешается неявно преобразовать в интеллектуальный указатель на Т2
тогда и только тогда, когда можно неявно преобразовать Т1* в Т2 *.
Этот метод дает почти такое же поведение, которое вам необходимо. Предпо-
ложим, что вы добавите к иерархии MusicProduct новый класс CasSingle,
представляющий синглы на кассетах. Иерархия примет вид, изображенный
на рис. 5.5.
Рис. 5.5
Рассмотрим теперь следующий код:
templatecclass Т> // Как и выше, шаблон
class SmartPtr {...}; // функции-члена для операций
// преобразования.
void displayAndPlay(const SmartPtr<MusicProduct>& pmp,
int howMany);
void displayAndPlay(const SmartPtr<Cassette>& pc,
int howMany) ;
SmartPtr<CasSingle> dumbMusic(new CasSingle ("Achy Breaky Heart") ) ;
displayAndPlay(dumbMusic, 1); //Ошибка!
В этом примере функция displayAndPlay перегружается: в одном случае
функцией, принимающей объект Smart Ptr<MusicProduct>, а в другом - функ-
цией Smart Pt r<Cassette>. Если вы вызываете функцию displayAndPlay для
SmartPtr<CasSingle>, то ожидаете, что будет выбрана функция Smart-
Ptr<Cassette>, поскольку CasSingle прямо наследует от Cassette и только
неявно от MusicProduct. Конечно, так оно и должно быть для обычных указателей.
186
Приемы
Но, увы, наши интеллектуальные указатели не настолько умны. Они используют
функции-члены в качестве операторов преобразования, а с точки зрения компи-
ляторов C++ все вызовы функций преобразования равноценны. В результате
вызов функции displayAndPlay дает неопределенный результат, так как преоб-
разование из SmartPtr<CasSingle> в SmartPtr<Cassette> ничем не опре-
делено.
Реализация преобразования интеллектуальных указателей при помощи
шаблонов функций-членов имеет еще два недостатка. Во-первых, поддержка
шаблонов функций-членов встречается редко, поэтому данный метод не всегда
может применяться в других системах. Во-вторых, логика работы далеко не
прозрачна, и будет понятна только тем, кто хорошо знает правила соответствия
аргументов вызовов функций, функций неявного преобразования типов, неяв-
ного создания экземпляров функций из шаблонов и существования шаблонов
функций-членов. Жаль бедного программиста, который никогда не видел дан-
ный прием и которому требуется поддерживать или дополнять основанный на
нем код. Этот способ, несомненно, ловко придуман, но здесь есть опасность пе-
рехитрить самого себя.
Не будем ходить вокруг да около. В действительности вам нужно знать, мож-
но ли сделать так, чтобы классы интеллектуальных указателей вели себя подобно
обычным указателям при преобразованиях типов, основанных на наследовании.
Ответ прост: нет, нельзя. Как заметил Дэниэл Эдельсон (Daniel Edelson), интел-
лектуальные указатели интеллектуальны, но это не указатели. Лучшее, что мож-
но сделать - применять для создания функций преобразования шаблоны функций-
членов, а если возникает неоднозначность - использовать операторы приведения
типа (см. правило 2). Это не самый лучший выход, но он достаточно хорош. Кро-
ме того, необходимость иногда включать в код операторы приведения - невысо-
кая цена за сложную функциональность, которую могут обеспечивать интеллек-
туальные указатели.
Интеллектуальные указатели и атрибут const
Как вы помните, для обычных указателей атрибут const может относиться
к самому указателю; тому, на что он указывает; или и к тому, и другому:
CD goodCD("Flood"); const CD *p; // p - не-const указатель
// на const объект CD.
CD * const p = &goodCD; // p const указатель
// на не-const объект CD;
// так как р - const, нужна
// его инициализация.
const CD * const p = kgoodCD; // р - const указатель
// на const объект CD.
Естественно, вам бы хотелось, чтобы интеллектуальные указатели были столь
же гибкими. К сожалению, атрибут cons t может относиться только к указателю,
а не к объекту, на который он указывает:
187
Правило 28
const SmartPtr<CD> p =
kgoodCD;
// p - const интеллектуальный
// указатель на не-const
// объект CD.
Кажется, что это легко исправить, просто создав интеллектуальный указатель
на const объект CD:
SmartPtr<const CD> р =
kgoodCD;
// р - не-const интеллектуальный
// указатель на const объект CD.
Теперь можно создать четыре искомые комбинации атрибутов const для объ-
екта и указателя:
SmartPtr<CD> р; // He-const объект,
// He-const указатель.
SmartPtr<const CD> р; // const объект,
// не-const указатель.
const SmartPtr<CD> р = kgoodCD; // He-const объект,
// const указатель.
const SmartPtr<const CD> p = kgoodCD; // const объект,
// const указатель.
Увы, в этой бочке меда есть ложка дегтя. Если используются обычные указа-
тели, можно инициализировать const указатели при помощи не-const указате-
лей и указатели на const объекты при помощи указателей на не-const объекты;
правила присвоения не изменяются. Например:
CD *pCD = new CD("Famous Movie Themes");
const CD * pConstCD = pCD; // Нормально.
Но посмотрите, что произойдет, если сделать то же самое при помощи интел-
лектуальных указателей:
SmartPtr<CD> pCD = new CD("Famous Movie Themes");
SmartPtr<const CD> pConstCD = pCD; // Нормально ли?
Типы SmartPtr<CD> и SmartPtrcconst CD> совершенно различны. С точ-
ки зрения компиляторов они не связаны между собой, поэтому нельзя полагать,
что они совместимы по принципу присваивания. Раньше единственный способ
обеспечить совместимость заключался в создании функции для преобразования
объектов типа SmartPtrcCD> в объекты типа SmartPtrcconst CD>. Если ваш
компилятор поддерживает шаблоны функций-членов, вы можете использовать
приведенный выше метод автоматического формирования необходимых операто-
ров неявного преобразования типов. (Я уже отмечал, что этот метод успешен все-
гда, когда работает соответствующее преобразование для обычных указателей.
Преобразования, включающие const, не являются исключением из данного пра-
вила.) Если же ваш компилятор не поддерживает такие шаблоны, вам придется
пройти еще через одно испытание.
Преобразования, включающие const, - это улица с односторонним движени-
ем: можно безбоязненно переходить от не-const к const, но небезопасно от
const к не-const. Кроме того, все, что можно делать с const указателем, можно
188
Приемы
III
делать и с не-const указателем, но для не-const указателя разрешается кое-что
еще (например, присваивать ему новое значение). Аналогично все что можно сде-
лать с указателем на const, дозволяется делать и с указателем на не-const, но
с указателями на не-const можно делать и другие вещи (например, присваивать
объекту, на который указывает указатель, новое значение), которые недопустимы
для указателей на const.
Эти принципы похожи на принципы открытого наследования (см. правило
35). Разрешается преобразовывать объект производного класса в объект базового
класса, но не наоборот, и с объектом производного класса можно делать все, что
и с объектом базового класса, но обычно с объектом производного класса допус-
кается делать что-то еще. При реализации интеллектуальных указателей можно
воспользоваться этой схожестью, создав каждый интеллектуальный указатель на
класс Т при помощи открытого наследования от соответствующего интеллекту-
ального указателя на класс const-T (см. рис. 5.6).
template<class Т>
class SmartPtrToConst {
protected:
union {
const T* constPointee;
T* pointee;
};
};
template<class T>
class SmartPtr:
public SmartPtrToConst<T> {
// Интеллектуальные указатели
//на const объекты.
// Обычные функции - члены
// интеллектуального указателя.
// Для доступа
//к SmartPtrToConst.
// Для доступа к SmartPtr.
// Интеллектуальные указа-
// тели на не-const объекты.
/ Элементов данных нет.
Правило 28
189
При такой реализации интеллектуальный указатель на объект не-const-T
должен содержать обычный указатель на не-const-T, а интеллектуальный указа-
тель на const-T - обычный указатель па const-T. Можно было бы сделать это,
поместив в базовый класс обычный указатель на const-T, а в производный -
обычный указатель на не-const-T. Но получилось бы расточительно, так как
объекты SmartPtr содержали бы тогда два обычных указателя: один, унаследо-
ванный от SmartPtrToConst, а другой из самого SmartPtr.
Эту проблему нетрудно разрешить при помощи объединения (union) - старо-
го оружия языка С, которое может быть столь же полезно и в C++. Объединение
является защищенным, поэтому оба класса имеют к нему доступ, и оно содержит
оба необходимых типа обычных указателей. Объекты SmartPtrToConst<T>
используют указатель constPointee, а объекты SmartPtr<T> - указатель
pointee. Таким образом, вы имеете преимущества двух различных указателей,
отводя память только под один. (См. еще один аналогичный пример в правиле 10.)
В этом и заключается красота объединений. Конечно же, функции-члены должны
ограничиваться использованием только соответствующего указателя, но компи-
ляторы не могут наложить такое ограничение, и это делает использование объ-
единений рискованным.
При такой реализации вы получаете нужное поведение:
SmartPtr<CD> pCD = new CD("Famous Movie Themes");
SmartPtrToConst<CD> pConstCD = pCD; // Нормально.
Оценка
На этом завершается рассмотрение интеллектуальных указателей, но напо-
следок зададимся вопросом: а имеет ли смысл их использовать, в особенности, если
ваши компиляторы не поддерживают шаблоны функций-членов?
Часто интеллектуальные указатели стоят возможного риска. Например, код
для подсчета ссылок в правиле 29 благодаря их применению становится намно-
го проще. Кроме того, как показывает практика, иногда интеллектуальные ука-
затели используются ограниченно, и большинство возможных проблем (провер-
ка на равенство нулю, преобразование к обычным указателям, преобразования
типов, основанные на наследовании, и поддержка указателей на const) при
этом не возникают. В целом, конечно, реализация, понимание и поддержка ин-
теллектуальных указателей довольно сложны. Код, использующий интеллекту-
альные указатели, труднее отлаживать, чем код на основе обычных указателей.
Как бы вы ни пытались, у вас не получится разработать универсальный интел-
лектуальный указатель, который сможет заменить его обычный аналог незамет-
но для пользователя.
Тем не менее, интеллектуальные указатели позволяют выполнять в програм-
ме действия, которые было бы сложно реализовать иным способом. Если такие
указатели использовать разумно, они будут полезны каждому программисту на
языке C++.
190
Приемы
Правило 29. Используйте подсчет ссылок
Подсчет ссылок - это метод, который позволяет нескольким объектам, имею-
щим одинаковое значение, хранить его в одном и том же месте. Он обычно приме-
няется по двум причинам. Во-первых, чтобы упростить учет системных ресурсов
для объектов в куче. После выделения памяти для объекта при помощи оператора
new важно отслеживать владельца этого объекта, так как только владелец отвеча-
ет за вызов оператора delete для удаления объекта. Но владелец объекта может
меняться в процессе работы программы (например, при передаче указателей в ка-
честве параметров), поэтому отслеживание владельца объекта - достаточно слож-
ная задача. Облегчить ее выполнение можно при помощи таких классов, как
auto_ptr (см. правило 9), но практика показала, что в большинстве программ
все еще не удается правильно реализовать данный метод. Подсчет ссылок избав-
ляет программиста от необходимости отслеживать владельца объекта, поскольку
в этом случае объект сам является своим владельцем и автоматически самоунич-
тожается, если никто больше его не использует. Таким образом, подсчет ссылок
по сути является простой формой сборки мусора (garbage collection).
Подсчет ссылок применяется также из соображений здравого смысла. Если мно-
жество объектов имеют одно и то же значение, то глупо хранить несколько его копий.
Лучше совместно использовать его в нескольких объектах с тем же самым значением.
Это не только экономит память, но и ускоряет выполнение программ, так как не нуж-
но создавать и уничтожать лишние копии с одним и тем же значением.
Как и большинство простых идей, она имеет множество нюансов. В деталях
и заключена успешная реализация подсчета ссылок. Но прежде чем углубиться
в детали, нужно овладеть основами. Лучше всего начать с рассмотрения того, как
можно создать несколько объектов с одним и тем же значением. Вот один из
способов:
class String { // Стандартный тип string не
public: // обязательно должен использовать
// методы из этого правила.
String(const char *value = "");
String^ operator=(const Strings rhs) ;
private:
char *data;
};
String a, b, c, d, e;
a = b = c = d = e = "Hello";
Очевидно, что объекты a-e имеют одно и то же значение "Hello". Его пред-
ставление зависит от реализации класса String, но обычно каждый объект
String имеет собственную копию этого значения. Например, оператор присваи-
вания класса String может быть реализован так:
Strings String::operator=(const Strings rhs)
{
Правило 29
ШИ!
191
if (this == &rhs) return *this;
delete [] data;
data = new char [strlen( rhs. data) + 1];
strcpy(data, rhs.data);
return *this;
}
Если задана такая реализация, то можно представить пять объектов и их зна-
чения так, как показано на рис. 5.7.
Рис. 5.7
Избыточность такого подхода очевидна. В идеале хотелось бы, чтобы схема
программы была аналогична рис. 5.8.
В памяти хранится только одна копия значения "Hello", и его представле-
ние совместно используется объектами string, имеющим данное значение.
На практике достичь этого идеала невозможно, так как нужно отслеживать
число объектов, совместно использующих значение. Если объекту а присваивает-
ся новое значение, то вы не можете уничтожить значение "Hello", поскольку оно
все еще нужно четырем другим объектам. С другой стороны, если только один
объект имеет значение "Hello", и этот объект уходит из области видимости, то
больше ни один объект не будет обладать таким же значением, и вы должны унич-
тожить его, чтобы избежать утечки ресурсов.
Необходимость сохранять информацию о числе совместно используемых
объектов приводит к тому, что идеальная схема должна учитывать существование
счетчика ссылок (reference count) - см. рис. 5.9.
(Некоторые называют это число счетчиком использования (use count), но я к ним
не отношусь. В языке C++ достаточно стилистических особенностей, и меньше
всего он нуждается в терминологической путанице.)
192
IMMMMIU
Приемы
Реализация подсчета ссылок
Создать класс String со счетчиком ссылок несложно, но при этом требуется
учесть множество деталей, поэтому сейчас будет рассказано о реализации основ-
ных функций - членов такого класса. Но сначала важно понять, что необходимо
выделить память под каждый счетчик ссылок для всех значений String. Память
не должна находиться в объекте String, так как нужен один счетчик для каждого
значения строки, а не для каждого объекта. Это подразумевает наличие связи
между значениями и счетчиками ссылок, поэтому стоит создать класс для хране-
ния счетчиков ссылок и отслеживаемых ими значений. Назовем его stringvalue,
и поскольку весь смысл его создания заключается в том, чтобы помочь нам реали-
зовать класс String, то поместим его в закрытую область класса String. Кроме
этого, было бы удобно предоставить всем функциям - членам класса string пол-
ный доступ к структуре данных класса Stringvalue, поэтому объявим String-
Value как struct. Это полезный прием: помещение структуры в закрытую часть
класса является обычным способом обеспечить доступ к структуре членам клас-
са, закрыв его для всех остальных (конечно же, за исключением дружественных
классов).
Код мог бы выглядеть примерно так:
class String { public: // Здесь находятся функции -
// члены класса String.
private:
struct Stringvalue { . . • • }; // Содержит счетчик ссылок
// и значение строки.
Stringvalue *value; }; // Значение класса String.
Вы можете дать этому классу другое имя (например, RCString), чтобы под-
черкнуть, что он реализован с применением счетчика ссылок, но реализация класса
не должна волновать его пользователей, которых обычно интересует только откры-
тый интерфейс класса. Реализация интерфейса String со счетчиком ссылок под-
держивает те же самые операции, что и версия без него, поэтому зачем усложнять
программу, включая в имена классов, соответствующих абстрактным понятиям,
сведения об их реализации?
Правило 29
Вот код класса Stringvalue:
class String {
private:
struct Stringvalue {
int refCount;
char Mata;
Stringvalue(const char *initValue);
-Stringvalue();
};
};
String::StringValue::Stringvalue(const char *initValue)
: refCount(1)
{
data = new char [strlen(initValue) + 1] ;
strcpy(data, initValue);
}
String::StringValue::-StringValue()
{
delete [] data;
}
Только и всего, но, как вы понимаете, это совсем не полная реализация нуж-
ной функциональности. Во-первых, не реализованы ни конструктор копирования,
ни оператор присваивания, во-вторых, не обрабатывается поле ref Count. Не бес-
покойтесь - отсутствующие функции обеспечит класс String. Класс String-
Value в основном предназначен для того, чтобы связать определенное значение
со счетчиком числа объектов типа string, совместно использующих это значе-
ние. Теперь можно перейти к функциям - членам класса String. Начнем с кон-
структоров:
class String {
public:
String(const char *initValue = "") ;
String(const Strings rhs);
};
Первый конструктор реализован настолько просто, насколько возможно. Для
создания объекта Stringvalue используется передаваемая строка char*:
String::String(const char *initValue)
: value(new Stringvalue(initValue))
{}
Для следующего пользовательского кода:
String sfMore Effective C++");
получится структура данных, которая выглядит примерно так, как показано
на рис. 5.10.
7 - 679
194
Приемы
More Effective С
Рис. 5.10
Создаваемые по отдельности объекты String с одинаковым начальным зна-
чением не будут использовать структуру данных совместно, поэтому такой код:
String si("More Effective C++");
String s2("More Effective C+ + ") ;
дает структуру данных, изображенную на рис. 5.11.
Mote Ef fee tiveC
More Effective C ++ |
Рис. 5.11
Избежать такого дублирования можно, отслеживая в объекте String (или
StringValue) существующие объекты Stringvalue и создавая новые объекты
только для уникальных строк, но такое усовершенствование подсчета ссылок на-
ходится в стороне от основного пути. Поэтому я оставлю его в качестве страшно-
го и ненавистного упражнения для читателей.
Конструктор копирования класса String совсем не сложен и очень эффекти-
вен: вновь созданный объект String совместно использует тот же самый объект
StringValue, что и копируемый объект String.
String::String(const Strings rhs)
: value(rhs.value)
{
++value->refCount;
}
Следующий код:
String si("More Effective C++");
String s2 = si;
дает в результате структуру данных, показанную на рис. 5.12.
Moro Effective С *•
Рис. 5.12
Такой класс намного эффективнее, чем обычная (без подсчета ссылок) реализа-
ция класса String, поскольку при этом не нужно выделять память для второй ко-
пии значения строки, нет необходимости впоследствии освобождать память, и не
требуется копировать значение, которое будет помещено в эту память. Вместо это-
го достаточно скопировать указатель и увеличить значение счетчика ссылок на
единицу.
Правило 29
Реализация деструктора String тоже довольно проста, так как большую часть
времени он ничего не делает. Пока счетчик ссылок на объект Stringvalue не
равен нулю, по меньшей мере один объект String использует данное значение,
поэтому оно не должно быть уничтожено. Только когда уничтожаемый объект
String является единственным объектом, использующим данное значение, то
есть когда счетчик ссылок на него равен 1, деструктор string должен уничто-
жать объект StringValue:
class String {
public:
-String();
};
String::~String()
{
if (--value->refCount == 0) delete value;
}
Сравните эффективность этой функции с деструктором в реализации без
счетчика ссылок. Такая функция всегда вызывала бы оператор delete, и ее вы-
полнение почти всегда требовало бы значительных затрат. Если у различных
объектов string вдруг окажутся одинаковые значения, то приведенная реали-
зация будет просто уменьшать значение счетчика на единицу и проверять его на
равенство нулю.
Это все, что относится к созданию и уничтожению объектов String, поэтому
перейдем к оператору присваивания класса string:
class String {
public:
String^ operator=(const Strings rhs);
};
Когда пользователь пишет такой код:
si = s2; // И si, и s2 - объекты типа String.
то в результате присваивания si и s2 должны указывать на один и тот же объект
Stringvalue. Поэтому во время присваивания значение счетчика ссылок долж-
но быть увеличено на единицу. Кроме того, значение счетчика ссылок на объект
Stringvalue, на который указывал объект si до присваивания, должно умень-
шиться на единицу, поскольку s 1 уже не имеет это значение. Если объект s 1 был
единственным объектом типа String с данным значением, то оно должно быть
уничтожено. В языке C++ это выглядит примерно так:
Strings String::operator=(const Strings rhs)
{
if (value == rhs.value) { , // Если значения уже
return *this; // одинаковы, ничего не
} // делать; обычная проверка
// для значения Srhs.
7»
196
ПИ
Приемы
if (--value->refCount == 0) { delete value; ) value = rhs. value ; + +value->refCount ; // Уничтожить значение *this // если его больше никто не // использует. // Объекты *this и rhs // использует одно значение.
return *this; }
Копирование при записи
Завершая изучение строк со счетчиком ссылок, рассмотрим оператор [ ], по-
зволяющий считывать и записывать отдельные символы в строке:
class String {
public:
const char&
operator!](int index) const; // Для const String.
char& operator!](int index); // Для не-const
// объектов String.
};
Реализовать const версию функции несложно, так это просто операция чте-
ния; значение строки не может изменяться:
const char& String::operator!](int index) const
{
return value->data[index];
}
(В этой функции проверка правильности index выполняется в соответствии
с главной традицией C++, то есть не выполняется вообще. Если вам нужна про-
верка корректности параметра, вы можете легко добавить ее сами.)
Не-const версия operator [ ] - совсем другая история. Эта функция может
вызываться как для считывания символа, так и для его записи:
String s ;
cout << s[3];
s[5] = "X";
// Это чтение.
// Это запись.
Конечно, хотелось бы по-разному обрабатывать чтение и запись. Простое чте-
ние можно выполнять точно так же, как и для вышеприведенной const версии
operator [ ], но запись должна быть реализована иначе.
Когда вы изменяете значение объекта string, будьте внимательны, чтобы не
изменить значение других объектов String, совместно использующих тот же са-
мый объект Stringvalue. К несчастью, компиляторы C++ не могут сообщить
вам, запись или чтение осуществляется посредством функции operator [ ], поэтому
Правило 29
UM
197
приходится предполагать, что все вызовы не-cons t operator [ ] выполняются для
записи. (Вы можете различать запись и чтение при помощи proxy-классов, см. пра-
вило 30.)
Для безопасной реализации не-const operator [ ] надо убедиться, что ни
один из других объектов String, совместно использующих изменяемое значение
StringValue, не будет изменен при выполнении предполагаемой записи. Коро-
че говоря, вы должны быть уверены, что счетчик ссылок для соответствующего
объекта StringValue равен единице всегда, когда вы возвращаете ссылку на сим-
вол внутри объекта StringValue. Вот как это сделать:
char& String::operator[](int index)
{
// Если значение совместно используется другими
// объектами String, создать отдельную копию значения.
if (value->refCount > 1) { // Уменьшить счетчик ссылок
--value->refCount; // refCount для текущего
// значения - оно больше не
// будет использоваться.
value = // Сделать копию значения.
new StringValue(value->data);
}
// Вернуть ссылку на символ в созданном
// отдельном объекте StringValue.
return value->data[index];
}
Эта идея - совместное использование значения до тех пор, пока не нужно
будет записать что-либо в отдельную его копию, - имеет давнюю и славную ис-
торию в информатике, в особенности в операционных системах, где процессы
могут совместно использовать страницы до тех пор, пока им не потребуется
изменить данные в своей копии страницы. Описанный метод достаточно распро-
странен и называется копирование при записи (copy-on-write). Это специфическая
разновидность более общего подхода к увеличению эффективности - отложен-
ного вычисления (см. правило 17).
Указатели, ссылки и копирование при записи
Эта реализация копирования при записи почти позволяет сохранить и пра-
вильность, и эффективность. Остается одна давняя проблема. Рассмотрим следу-
ющий код:
String si = "Hello";
char *p = &sl[1];
Структура данных будет при этом выглядеть примерно так, как показано
на рис. 5.13.
Приемы
Теперь рассмотрим еще один оператор:
String s2 = si;
Конструктор копирования класса String позволяет объектам s2 и si совме-
стно использовать значение Stringvalue, поэтому полученная в результате
структура данных будет иметь вид, представленный на рис. 5.14.
Рис. 5.14
Тогда происходит следующее:
*р = "х"; // Изменяются и si, и s2 !
Конструктор копирования класса String не может обнаружить эту пробле-
му, так как нельзя узнать, существует ли указатель на объект Stringvalue со зна-
чением объекта si. И проблема не ограничивается указателями: она будет возни-
кать и в том случае, если кто-либо сохранил ссылку на результат вызова не-const
operator [] класса String.
С этой проблемой можно справиться тремя различными способами. Первый
состоит в том, чтобы игнорировать ее, сделать вид, что она не существует. Такой
подход, к несчастью, слишком часто встречается в библиотеках классов, реализу-
ющих строки с подсчетом ссылок. Если вы располагаете одной из подобных биб-
лиотек, проверьте ее, выполнив вышеприведенный пример. Если вы не уверены,
выполняется ли в классе подсчет ссылок, все равно попробуйте выполнить при-
мер. Благодаря чуду инкапсуляции может оказаться, что вы все же используете
такой тип, даже не зная об этом.
Но проблема игнорируется не во всех реализациях. Несколько более слож-
ный способ справиться с трудностями - объявить их использование недопусти-
мым. В документации таких реализаций обычно говорится примерно следующее:
«Не делайте этого, в противном случае результат будет неопределенным». Если
вы все же сделаете это, сознательно или нет, и жалуетесь на результаты, вам отве-
чают: «Мы же вас предупреждали». Такие реализации часто достаточно эффек-
тивны, но удобство их использования оставляет желать лучшего.
Правило 29
199
I
Существует и третье решение, которое состоит в устранении проблемы. Реали-
зовать его несложно, но оно иногда уменьшает степень совместного использования
значений объектами. Суть решения в следующем: к каждому объекту stringvalue
добавляется флаг, показывающий, может ли объект использоваться совместно.
Первоначально флаг устанавливается (объект может использоваться совместно),
азатем сбрасывается при вызове для представленного объектом значения не-const
operator [ ]. После того как этот флаг принимает значение false, оно остается
таким навсегда.*
Вот измененная версия Stringvalue, включающая флаг, которая определя-
ет возможность совместного использования:
class String {
private:
struct Stringvalue {
int refCount;
bool shareable; // Добавить это.
char Mata;
Stringvalue(const char *initValue);
-StringValue();
};
};
String::StringValue::StringValue(const char *initValue)
: refCount(l),
shareable(true) // И это.
{
data = new char[strlen(initValue) + 1];
strcpy(data, initValue);
}
String::StringValue::-StringValue()
{
delete [] data;
}
Как видите, здесь нужны лишь небольшие изменения: две строки, которые их
требуют, помечены комментариями. Соответственно, необходимо обновить и функ-
ции - члены класса String, чтобы учесть наличие поля shareable. Вот как это
можно сделать для конструктора копирования:
String::String(const Strings rhs)
{’
if (rhs.value->shareable) {
* Тип string в стандартной библиотеке C++ (см. правило 35) использует комбинацию второго и третьего
решений. Гарантируется, что ссылка, возвращаемая не-const operator [ ], является корректной до сле-
дующего вызова функции, который может изменить данную строку. После этого использование ссылки
(или символа, на который она указывает) дает неопределенный результат. Это позволяет восстанавли-
вать значение true для флага после каждого вызова функции, которая могла изменить строку.
200
Приемы
Hi
value = rhs.value;
++value->refCount ;
}
else {
value = new StringValue(rhs.value->data);
)
}
Все остальные функции - члены класса String должны проверять поле
shareable аналогичным образом. Единственная функция, которая будет присва-
ивать флагу shareable значение false, - это не-const версия operator[].
char& String::operator[](int index)
{
if (value->refCount >1) {
--value->refCount;
value = new StringValue(value->data);
)
value->shareable = false; // Добавить эту строку,
return value->data[index];
}
Если чтобы различать чтение и запись в operator [ ], вы используете метод
proxy-класса из правила 30, скорее всего это приводит к уменьшению числа объек-
тов StringValue, которые должны быть помечены как недоступные для сов-
местного использования.
Базовый класс для подсчета ссылок
Подсчет ссылок полезен не только для строк. Кандидатом для этой операции
является любой класс, в котором несколько объектов могут иметь общие значе-
ния. Но чтобы переписать класс для использования подсчета ссылок, требуется
приложить немало усилий, а большинство из нас и так достаточно заняты. Не
было бы лучше, если бы можно было как-то написать (а также проверить и доку-
ментировать) контекстно-независимый код для подсчета ссылок, а затем просто
включать его в классы при необходимости? Конечно, это было бы лучше. К счас-
тью, существует способ сделать это полностью или почти полностью.
Первый шаг состоит в создании базового класса RCOb j ect для объектов с под-
счетом ссылок, от которого должны наследовать все классы, собирающиеся исполь-
зовать автоматический подсчет ссылок. Класс RCObj ect инкапсулирует счетчик
ссылок, а также функции для уменьшения и увеличения этого счетчика. Он также
содержит код для уничтожения значения после того, как оно перестает быть нуж-
ным, то есть когда счетчик ссылок на него становится равным 0. И наконец, он имеет
поле, определяющее, может ли это значение использоваться совместно, и функции
для проверки и установки данного значения равным false. Нет необходимости
придавать этому полю значение true, так как по умолчанию все значения могут
использоваться совместно. Как указано выше, если объект был помечен как недо-
ступный для совместного использования, он остается таким навсегда.
Правило 29
him;
201
Определение класса RCObject выглядит следующим образом:
class RCObject {
public:
RCObject();
RCObject(const RCObject& rhs) ;
RCObjectk operator=(const RCObjectb rhs) ;
virtual ~RCObject() = 0;
void addReference();
void removeReference();
void markUnshareable();
bool isShareable() const;
bool isSharedO const;
private:
int refCount;
bool shareable;
};
Объекты RCObject могут создаваться и уничтожаться (как части базового
класса в производных классах); к ним могут добавляться новые ссылки и уда-
ляться существующие; разрешается запрашивать и устанавливать значение фла-
га, определяющего возможность их совместного использования; они также могут
сообщать, используются ли они уже совместно. Это все, что они способны пред-
ложить. Но большего от них как от класса, инкапсулирующего понятие подсчета
ссылок, и не ожидалось. Обратите внимание на виртуальный деструктор - вер-
ный знак, что класс разработан для использования в качестве базового. Кроме
того, деструктор является абстрактной функцией, а это свидетельствует, что класс
будет применяться только в качестве базового.
Код класса RCObject достаточно краток:
RCObj ect::RCObj ect()
: refCount(0), shareable(true) {}
RCObject::RCObject(const RCObjectk)
: refCount(O), shareable(true) {}
RCObjectk RCObject::operator=(const RCObject&)
{ return *this; }
RCObject::-RCObject () {} // Виртуальные деструкторы должны
// быть всегда реализованы, даже
// если они являются полностью
// виртуальными и ничего не делают
// (см. также правило 33) .
void RCObject::addReference() { ++refCount; }
void RCObject::removeReference()
{ if (--refCount == 0) delete this; }
void RCObject::markUnshareable()
{ shareable = false; }
bool RCObject::isShareable() const
{ return shareable; }
bool RCObject::isShared() const
{ return refCount > 1; }
202
Приемы
Странно, что в обоих конструкторах счетчику ref Count в конструкторе
присваивается значение 0. Интуиция подсказывает обратное. По крайней мере,
создатель нового объекта RCObject должен ссылаться на него! Оказывается,
проще сделать так, чтобы создатели объектов RCObj ect сами присваивали счет-
чику ref Count значение 1, поэтому предусмотрено такое поведение конструк-
тора в классе refCount, которое обязывает их сделать это. Как вы вскоре уви-
дите, в результате код значительно упростится.
Другая странность состоит в том, что конструктор копирования всегда при-
сваивает счетчику refCount значение 0, независимо от значения refCount в ко-
пируемом объекте RCObject. Это объясняется следующим образом: вы создаете
новый объект, представляющий значение, а на новые значения всегда ссылается
только их создатель, и они не используются совместно. И в этом случае автор
объекта отвечает за установку правильного значения счетчика refCount.
Оператор присваивания класса RCObj ect ведет себя совершенно необычно: он
не делает ничего. К счастью, маловероятно, что он будет вызываться вообще. Базо-
вый класс RCObj ect предназначен для объекта совместно используемого значения,
и в системе, основанной на подсчете ссылок, такие объекты не присваиваются друг
другу, а вместо этого выполняется присваивание для объектов, указывающих на
них. В рассматриваемом случае мы не ожидаем, что объекты StringValue будут
присваиваться друг другу, предполагается, что присваивание будет выполняться
для объектов String. При этом значение StringValue останется неизменным -
будет меняться только значение счетчика ссылок.
Тем не менее, существует вероятность, что в каком-то классе, который когда-
либо будет наследовать от класса RCObj ect, потребуется разрешить присваивание
значений, предусматривающих подсчет ссылок (см. правило 32). И в этом случае
оператор присваивания класса RCObject должен сделать то, что нужно, то есть
ничего. Чтобы понять, почему это так, представьте, будто вы хотели разрешить при-
своение между объектами StringValue. Если имеются объекты svl и sv2 типа
StringValue, что произойдет со счетчиками ссылок объектов svl и sv2?
svl = sv2; // Что произойдет со счетчиками ссылок
// объектов svl и sv2?
До присваивания несколько объектов string указывает на svl. Их число не
изменяется в результате присваивания, так как меняется только значение svl. Ана-
логично, до присваивания какое-то число объектов String указывает на sv2, и пос-
ле присваивания те же самые объекты String указывают на sv2. Счетчик ссылок
на объект sv2 также остается неизменным. Таким образом, при присваивании объ-
ектов RCObject число ссылок на эти объекты остается прежним, следовательно,
функция RCObj ect: : operator= не должна изменять счетчики ссылок. Это как
раз то, что и делает приведенная выше реализация. Интуиция подсказывает обрат-
ное? Возможно, но предложенный код все же является корректным.
Код функции RCObject: :removeReference отвечает не только за умень-
шение счетчика ссылок refCount, но и за уничтожение объекта, если новое зна-
чение счетчика refCount равно 0. Функция выполняет последнюю задачу, вызы-
вая delete this, а это безопасно, только если объект *this находится в куче
Правило 29
203
(см. правило 27). Для успешной работы данного класса вы должны спроектиро-
вать все так, чтобы объекты RCObj ect могли быть только динамическими. Обыч-
ные способы реализации этого обсуждаются в правиле 27, но есть и особые меры,
которые будут применены в рассматриваемом примере и описаны в резюме к это-
му разделу.
Чтобы воспользоваться новым базовым классом для подсчета ссылок, изме-
ним класс StringValue: он будет наследовать свойства для подсчета ссылок от
класса RCObj ect.
class String {
private:
struct StringValue: public RCObject {
char Mata;
StringValue(const char *initValue);
-StringValue();
};
};
String::StringValue::StringValue(const char *initValue)
{
data = new char[strlen(initValue) + 1] ;
strcpy(data, initValue);
}
String::StringValue::-StringValue()
{
delete [] data;
}
Эта версия класса StringValue почти идентична предыдущей. Только функ-
ции - члены класса StringValue больше не работают с полем refCount. Эти
действия теперь выполняет класс RCObj ect.
Не бледнейте, увидев, что вложенный класс (StringValue) наследует от
класса (RCObj ect), не связанного с классом (String), внутри которого он нахо-
дится. Хоть такой подход на первый взгляд кажется непонятным, все здесь совер-
шенно нормально. Вложенный класс - это такой же класс, как и любой другой,
поэтому он может наследовать от какого угодно класса. Спустя некоторое время
подобные отношения наследования будут восприниматься вами как вполне есте-
ственные.
Автоматизация работы со счетчиком ссылок
Класс RCObj ect позволяет вам размещать счетчик ссылок и предоставляет
функции - члены класса, при помощи которых можно работать со счетчиками ссы-
лок, но вызовы этих функций должны вставляться в другие классы вручную. А вы-
зов функций addReference и removeRef erence для объектов StringValue все
еще осуществляется конструктором копирования и оператором присваивания клас-
са String. Это не слишком удобно. Хотелось бы переместить и эти функции
в какой-нибудь класс, освободив авторов таких классов, как String, от всех забот
204
Приемы
по подсчету ссылок. Можно ли это сделать? Должен ли язык C++ поддерживать
повторное использование кода?
Он может и делает это. Не существует простого способа сделать так, чтобы все
операции по подсчету ссылок были выведены из прикладных классов, но есть
способ удалить большинство из них из большинства классов. (В некоторых при-
кладных классах можно удалить весь код для подсчета ссылок, но, увы, наш класс
String не является таким. Все дело портит одна функция-член, и я полагаю, что
вы не слишком удивитесь, узнав, что это наш старый враг - не-const версия
operator [ ]. Соберитесь с духом, мы в конце концов усмирим злодея.)
Обратите внимание, что каждый объект String содержит указатель на объект
Stringvalue, представляющий значение объекта String:
class String {
private:
struct StringValue: public RCObject { ... };
StringValue *value; // Значение объекта String.
};
Если с одним из ссылающихся на объект указателей происходит что-нибудь
интересное, вы должны оперировать полем refCount объекта StringValue.
«Что-нибудь интересное» включает в себя копирование, присваивание или унич-
тожение указателя. Если бы был способ сделать, чтобы сам указатель как-то обна-
руживал эти операции и автоматически выполнял необходимые действия с полем
refCount, вы могли бы быть свободны. Увы, указатели - довольно тупые созда-
ния, и вероятность того, что они обнаружат что-либо, а тем более автоматически
среагируют на найденное, очень невелика. К счастью, существует возможность
заставить их работать лучше: заменить их объектами, которые действуют, как
указатели, но делают больше, чем они.
Такие объекты называются интеллектуальными указателями, и о них подроб-
но рассказано в правиле 28. В данном случае вам нужно знать только, что объекты
интеллектуальных указателей, так же как и настоящие указатели (которые часто
называются обычными указателями), поддерживают операции выбора элемента
(->) и разыменования (*), и, как и обычные указатели, они имеют строго задан-
ный тип: нельзя сделать так, чтобы интеллектуальный указатель на объект типа Т
ссылался на объект другого типа.
Вот шаблон для объектов, которые ведут себя как интеллектуальные ука-
затели на объекты для подсчета ссылок:
// Класс шаблона для интеллектуальных указателей на объекты Т.
// Класс Т должен поддерживать интерфейс RCObject,
// обычно при помощи наследования от класса RCObject.
template<class Т>
class RCPtr {
public:
RCPtr(T* realPtr = 0) ;
Правило 29
205
RCPtr(const RCPtr& rhs);
-RCPtr();
RCPtr& operator=(const RCPtr& rhs) ;
T* operator->() const;
T& operator*() const;
private:
T *pointee;
void init();
};
//См. правило 28.
//См. правило 28.
// Обычный указатель, который
// эмулирует этот объект.
// Общий код инициализации.
Этот шаблон позволяет объектам интеллектуальных указателей управлять
тем, что происходит при их создании, присваивании и уничтожении. Когда про-
исходят такие события, объекты могут автоматически выполнять соответствую-
щие операции с полем refCount в объектах, на которые они указывают.
Например, при создании объекта RCPtr счетчик ссылок для объекта, на кото-
рый он указывает, должен быть увеличен. Нет необходимости обременять приклад-
ных разработчиков требованием вручную выполнять такие скучные операции, по-
скольку конструкторы RCPtr могут сделать это сами. Код для двух конструкторов
почти идентичен (отличаются только списки инициализации членов), поэтому
вместо того, чтобы писать их дважды, можно поместить этот код в закрытую функ-
цию - член класса init и вызвать ее из обоих конструкторов:
template<class Т>
RCPtr<T>::RCPtr(Т* realPtr): pointee(realPtr)
{
init () ;
}
template<class T>
RCPtr<T>::RCPtr(const RCPtr& rhs): pointee(rhs.pointee)
{
init();
}
template<class T>
void RCPtr<T>::init()
{
if (pointee == 0) { // Если обычный указатель равен
return; // null, то интеллектуальный
} // указатель тоже нулевой.
if (pointee->isShareable() == false) { // Если значение
pointee = new T(*pointee) ; // не может
} // использоваться совместно,
// скопировать его.
pointee->addReference(); // Теперь существует новая
} // ссылка на значение.
Размещение общего кода в отдельной функции, такой как init, кажется блес-
тящим решением, но его глянец тускнеет, если функция ведет себя некорректно,
как это происходит в данном примере.
206
МП
Приемы
Проблема заключается в следующем. Когда функция init должна создать но-
вую копию значения (так как существующая копия не может использоваться со-
вместно), она выполняет следующий код:
pointee = new T(*pointee);
Объект pointee имеет тип указателя на Т, поэтому этот оператор создает но-
вый объект Т и инициализирует его, вызывая конструктор копирования Т. Для ука-
зателя RCPtr в классе String объектом Т будет String: : StringValue, поэтому
приведенный оператор вызовет конструктор копирования для String: :String-
Value. Но вы не объявили для этого класса конструктор копирования, поэтому
он будет создан компилятором. Полученный конструктор копирования будет,
в соответствии с правилами для автоматически создаваемых конструкторов ко-
пирования языка C++, копировать только указатель data объекта StringValue,
он не будет копировать строку char*, на которую ссылается указатель data. Та-
кое поведение - бедствие почти для любого класса (а не только для класса с подсче-
том ссылок), и поэтому вам следует создавать конструктор копирования (и опера-
тор присваивания) для всех классов, содержащих указатели.
Корректность поведения шаблона RCPtr<T> зависит от того, содержит ли
класс Т конструктор копирования, создающий полностью независимую копию (то
есть выполняющий детальное копирование) значения, представляемого этим
объектом. Вы должны добавить такой конструктор в класс StringValue прежде,
чем использовать его в классе RCPtr:
class String {
private:
struct StringValue: public RCObject {
StringValue(const StringValue& rhs);
};
};
String::StringValue::StringValue(const StringValue& rhs)
{
data = new char[strlen(rhs.data) + 1] ;
strcpy(data, rhs.data);
}
Существование конструктора детального копирования не единственное тре-
бование, которое интеллектуальный указатель RCPtr<T> предъявляет к классу Т.
Кроме того, класс Т должен наследовать от класса RCOb j ect или обеспечивать ту
же функциональность. Это достаточно разумно, если принять во внимание, что
объекты RCOb j ect были разработаны для того, чтобы указывать только на объек-
ты со счетчиком ссылок. Но несмотря на его очевидность, данное требование сле-
дует документировать.
И наконец, предполагается, что RCPtr<T> указывает на объект типа т. Это так-
же кажется достаточно очевидным. В конце концов, тип pointee объявляется как
Т*. Но в действительности pointee может указывать на производный от Т класс.
Правило 29
«
207
Например, если бы имелся класс SpecialStringValue, наследующий от класса
String-. : StringValue:
class String (
private:
struct StringValue: public RCObject { ... };
struct SpecialStringValue: public StringValue { ... };
};
то в итоге мог бы получиться класс String, в котором RCPtr<StringValue>
указывал бы на объект SpecialStringValue. В таком случае хотелось бы, что-
бы эта часть функции init:
pointee = new T(*pointee); // T имеет тип StringValue,
//но pointee указывает
//на тип SpecialStringValue.
вызывала конструктор копирования класса SpecialStringValue, а не String-
Value. Это можно сделать при помощи виртуального конструктора копирования
(см. правило 25). В случае рассматриваемого класса String не предполагается,
что какие-либо классы будут наследовать от класса StringValue, поэтому этим
вопросом можно пренебречь.
После того как вы разобрались с конструкторами класса RCPtr, с остальными
функциями класса справитесь намного быстрее. Присваивание для объектов
RCPtr выполняется достаточно просто, нужно только проверить, можно ли ис-
пользовать вновь присвоенное значение совместно. К счастью, такая проверка уже
выполняется функцией init, которая была создана для конструкторов RCPtr.
Снова используем ее здесь:
template<class Т>
RCPtr<T>& RCPtr<T>::operator=(const RCPtr& rhs)
{
if (pointee != rhs.pointee) { //He выполнять // присваивание, если
// значение не меняется.
if (pointee) {
pointee->removeReference(); // Удалить
} // ссылку на текущее
// значение.
pointee = rhs.pointee; // Указывает на новое
initO ; // значение, если возможно
} // использовать его
// совместно, иначе создать
return *this; // собственную копию.
}
Деструктор устроен проще. При уничтожении объекта RCPtr он просто уда-
ляет его ссылку на объект, для которого выполняется подсчет ссылок:
208
Ml
Приемы
template<class T>
RCPtr<T>::-RCPtr()
{
if (pointee)pointee->removeReference() ;
}
Если этот интеллектуальный указатель RCPtr был последней ссылкой на
объект, то будет уничтожен объект внутри функции removeRef erence - члена
класса RCObject. Следовательно, объекты RCPtr не должны беспокоиться об
уничтожении значений, на которые они указывают.
И наконец, операторы в классе RCPtr, эмулирующие указатели, являются
частью стандартной библиотеки интеллектуальных указателей, о которой вы мо-
жете прочитать в правиле 28:
template<class Т>
Т* RCPtr<T>::operator->() const { return pointee; }
templatecclass T>
T& RCPtr<T>::operator*() const { return *pointee; }
Резюме
Теперь можно свести все части вместе и построить класс String с подсчетом
ссылок, основанный на классах RCObject и RCPtr. Надеюсь, вы не забыли, что
это и было исходной целью упражнения.
Каждая строка с подсчетом ссылок реализуется при помощи структуры
данных, схема которой представлена на рис. 5.15.
Рис. 5.15
Правило 29
209
Образующие эту структуру классы определяются так:
template<class Т> // Шаблон класса для интеллектуальных
class RCPtr { // указателей на объекты Т; класс Т
public: // должен наследовать от класса RCObject.
RCPtr(Т* realPtr = 0) ;
RCPtr(const RCPtr& rhs) ;
-RCPtr();
RCPtr& operator=(const RCPtr& rhs);
T* operator->() const;
T& operator* () const;
private:
T *pointee;
void init();
};
class RCObject { // Базовый класс для объектов
public: //со счетчиком ссылок.
void addReference();
void removeReference();
void markUnshareable();
bool isShareable() const;
bool isShared() const;
protected:
RCObject () ;
RCObject(const RCObject& rhs);
RCObject& operator=(const RCObject& rhs) ;
virtual -RCObject() = 0;
private:
int refCount;
bool shareable;
};
class String { // Класс для использования
public: // прикладными разработчиками.
String(const char *value = "");
const char& operator!](int index) const;
char& operator!](int index);
private:
// Класс для хранения строковых значений
struct StringValue: public RCObject {
char *data;
StringValue(const char *initValue);
StringValue(const StringValue& rhs);
void init(const char *initValue);
-StringValue();
};
RCPtr<StringValue> value;
};
Этот код в основном суммирует то, что было разработано ранее, поэтому здесь
для вас не должно быть сюрпризов. При внимательном рассмотрении можно увидеть,
210
МП
Приемы
что к классу String: : StringValue добавлена функция init, но как будет по-
казано дальше, она предназначена для того же, для чего и соответствующая функ-
ция в классе RCPtr: предотвращает дублирование кода в конструкторах.
Открытый интерфейс приведенного класса String значительно отличается
от того, который использовался в начале этого раздела. Где конструктор копиро-
вания? Где оператор присваивания? Где деструктор? Здесь явно что-то неладно.
Нет, все в порядке. Если вы не видите, что это так, приготовьтесь к крещению
языком C++.
Эти функции вам больше не нужны. Несомненно, копирование объектов
String допустимо, и такое копирование будет корректно обрабатывать лежащие
в их основе объекты StringValue со счетчиками ссылок, но в классе String не
написано ни одной соответствующей строчки. Причина в том, что созданный ком-
пилятором конструктор копирования String автоматически вызовет конструктор
копирования элемента RCPtr класса String, который и выполнит все необходи-
мые действия над объектом StringValue, включая и подсчет ссылок на него. Вы
не забыли, что указатель RCPtr является интеллектуальным? Он создан для обра-
ботки подсчета ссылок, и именно это и делает. Он также выполняет присваивание
и уничтожение, поэтому писать данные функции для класса String не нужно. Пер-
воначальная цель упражнения состояла в том, чтобы переместить код для подсчета
ссылок из класса String в контекстно-независимые классы, где они были бы до-
ступны для использования любым классом. Теперь это сделано (в форме классов
RCObj ect и RCPtr) и отлично работает.
Для того чтобы свести все вместе, приведем реализацию класса RCObj ect:
RCObject::RCObject()
: refCount(O), shareable(true) {}
RCObject::RCObject(const RCObjectk)
: refCount(O), shareable(true) {}
RCObject& RCObject::operator=(const RCObject&)
{ return *this; }
RCObject::-RCObject() {}
void RCObject::addReference() { ++refCount; }
void RCObject::removeReference()
{ if (-refCount == 0) delete this; }
void RCObject::markUnshareable()
{ shareable = false; }
bool RCObject::isShareable() const
{ return shareable; }
bool RCObject::isShared() const
{ return refCount > 1; }
А это реализация класса RCPtr:
template<class T>
void RCPtr<T>::init()
{
if (pointee == 0) return;
if (pointee->isShareable() == false) {
pointee = new T(*pointee);
Правило 29
!!
211
}
pointee->addReference();
}
templatecclass T>
RCPtrcT>::RCPtr(T* realPtr): pointee(realPtr)
{ init () ; }
templatecclass T>
RCPtrcT>::RCPtr(const RCPtr& rhs) : pointee(rhs.pointee)
{ init(); }
templatecclass T>
RCPtrcT>::-RCPtr()
{ if (pointee)pointee->removeReference(); }
templatecclass T>
RCPtrcT>& RCPtrcT>::operator=(const RCPtr& rhs)
{
if (pointee != rhs.pointee) {
T *oldPointee = pointee;
pointee = rhs.pointee;
init();
if (oldPointee)
oldPointee->removeReference ();
}
return *this;
}
templatecclass T>
T* RCPtrcT>::operator->() const { return pointee; }
templatecclass T>
T& RCPtrcT>::operator*() const { return *pointee; }
Реализация String: : StringValue выглядит так:
void String::StringValue::init(const char *initValue)
{
data = new char[strlen(initValue) + 1] ;
strcpyfdata, initValue);
}
String::StringValue::StringValue(const char *initValue)
{ init(initValue); }
String::StringValue::StringValue(const StringValue& rhs)
{ init(rhs.data); }
String::StringValue::-StringValue()
{ delete [] data; )
В конце концов, все пути ведут к классу String, который реализован следу-
ющим образом:
String::String(const char *initValue): value(new
StringValue(initValue)) {}
const char& String::operator[](int index) const
{ return value->data[index]; }
char& String::operator[] (int index)
212
III Приемы
{
if (value->isShared()) {
value = new StringValue(value->data);
}
value->markUnshareable();
return value->data[index];
}
Если вы сравните этот код класса string с кодом, который был разработан
при помощи обычных указателей, то будете поражены двумя вещами. Во-первых,
класс стал намного меньше, поскольку класс RCPtr принимает на себя основные
функции, которые выполнял класс String. Во-вторых, код, оставшийся в классе
String, практически не изменился: интеллектуальный указатель почти незамет-
но заменил обычный. Единственное новшество коснулось функции operator [ ],
где вызывается функция isShared вместо прямой проверки значения refCount,
а применение объекта интеллектуального указателя RCPtr устраняет необходи-
мость вручную изменять счетчик ссылок во время копирования при записи.
Все это замечательно. Кто возражает против уменьшения кода? Кто против
успешного применения инкапсуляции? Но итог скорее определяется не деталями
реализации, а тем, как новоиспеченный класс string воспринимается пользова-
телями, и именно здесь его преимущество наиболее очевидно. Если отсутствие но-
востей - хорошие новости, тогда то, что интерфейс класса String не изменился -
действительно хорошо. Вы добавили к нему подсчет ссылок и возможность поме-
чать отдельные значения строк как недоступные для совместного использования,
затем переместили подсчет ссылок в новый базовый класс, включили в код интел-
лектуальные указатели для автоматизации обработки подсчета ссылок, и при этом
ни одна строка пользовательского кода не изменилась. Конечно, было изменено
определение класса, поэтому для того, чтобы использовать строки со счетчиком
ссылок, пользователям придется снова выполнить компиляцию и компоновку, но
их капиталовложения в разработанный код остаются в целости и сохранности.
Видите? Инкапсуляция - это действительно замечательная вещь.
Добавление подсчета ссылок к существующим классам
До сих пор предполагалось, что вам доступен исходный код интересующих вас
классов. Но как быть, если нужно использовать подсчет ссылок в каком-то классе
Widget, находящемся в библиотеке, которую вы не можете изменять? Нельзя сде-
лать Widget наследником класса RCObject, поэтому недопустимо использовать
в нем интеллектуальные указатели RCPtr. Однако, слегка изменив схему, вы мо-
жете добавить подсчет ссылок к любому типу.
Во-первых, рассмотрим, как бы выглядела схема, если бы была возможность сде-
лать класс Widget наследником класса RCObj ect. В этом случае пришлось бы до-
бавить класс RCWidget, с которым работали бы пользователи, и классы RCWidget
и Widget были бы аналогичны соответственно классам String и StringValue
в рассмотренном примере. Схема такой программы приведена на рис. 5.16.
Правило 29
213
Теперь стоит вспомнить принцип, который гласит, что большинство проблем
теории программирования можно решить, добавив еще один уровень косвенной
адресации. Добавим для счетчика ссылок еще один класс CountHolder и сдела-
ем класс CountHolder наследником класса RCObject. Также включим в класс
CountHolder указатель на Widget. Затем заменим шаблон RCPtr таким же ин-
теллектуальным шаблоном RCIPtr, который знает о существовании класса
CountHolder. (Буква I в названии класса RCIPtr означает indirect, то есть кос-
венный.) Измененная схема представлена на рис. 5.17.
Рис. 5.17
214
Приемы
Так же как детали реализации класса StringValue скрыты от пользователей
класса String, класс CountHolder является одной из деталей реализации, скры-
той от пользователей класса RCWidget. Фактически, это одна из деталей реали-
зации класса RCIPtr, поэтому данный класс вложен в класс RCIPtr, реализован-
ный следующим образом:
template<class T>
class RCIPtr {
public:
RCIPtr(T* realPtr = 0) ;
RCIPtr(const RCIPtrb rhs);
-RCIPtr();
RCIPtrk operator=(const RCIPtrb rhs) ;
const T* operator->() const;
T* operator->();
const T& operator*() const;
T& operator*();
private:
struct CountHolder: public RCObject {
-CountHolder() { delete pointee; }
T *pointee;
};
CountHolder *counter;
void init () ;
void makeCopy () ;
};
template<class T>
void RCIPtr<T>::init ()
{
if
Ниже объясняется,
почему эти функции
объявлены таким
образом.
См. ниже.
(counter->isShareable() == false) {
Т *oldValue = counter->pointee;
counter = new CountHolder;
counter->pointee = new T(*oldValue);
}
counter->addReference();
}
template<class Т>
RCIPtr<T>::RCIPtr(Т* realPtr)
: counter(new CountHolder)
{
counter->pointee = realPtr;
init();
}
template<class T>
RCIPtr<T>::RCIPtr(const RCIPtrk rhs)
: counter(rhs.counter)
{ init(); }
template<class T>
RCIPtr<T>::-RCIPtr()
Правило 29
215
{ counter->removeReference(); }
templatecclass T>
RCIPtrcT>& RCIPtrcT>:: operator23 (const RCIPtrk rhs)
if (counter != rhs.counter) { counter->removeReference() ; counter = rhs.counter ; init() ; } return *this; }
template<class T> // Реализация копирования
void RCIPtrcT>::makeCopy() // для копирования
{ // при записи.
if (counter->isShared()) { T *oldValue = counter->pointee; counter->removeReference() ; counter = new CountHolder; counter->pointee = new T(*oldValue)
counter->addReference(); } } templatecclass T> // Доступ к const;
const T* RCIPtr<T>::operator->() const // копирование при
{ return counter->pointee; } // записи не нужно.
templatecclass T> // Доступ к не-const;
T* RCIPtrcT>::operator->() // нужно копирование
{ makeCopy(); return counter->pointee; } // при записи.
templatecclass T> // Доступ к const;
const T& RCIPtrcT>::operator*() const // копирование при
{ return *(counter->pointee); } // записи не нужно.
templatecclass T> // Доступ к не-const;
T& RCIPtrcT>::operator*() // нужно копирование
{ makeCopyO; return * (counter->pointee) ; } // при записи.
Класс RCIPtr имеет только два отличия от класса RCPtr. Во-первых, объек-
ты RCPtr непосредственно указывают на значения, а объекты RCIPtr указывают
на значения через промежуточные объекты CountHolder. Во-вторых, класс
RCIPtr перегружает функции operator-> и operator*, поэтому в случае
не-const доступа к указываемому объекту копирование при записи происходит
автоматически.
Если имеется класс RCIPtr, достаточно просто реализовать класс RCWidget,
поскольку каждая функция в классе RCWidget реализуется с помощью передачи
вызова через лежащий ниже класс RCIPtr объекту Widget. Например, если класс
Widget выглядит так:
class Widget {
public:
216
IE
Приемы
Widgetfint size);
Widget(const Widgets rhs);
-Widget();
Widget& operator=(const Widgets rhs) ;
void doThis () ;
int showThat() const;
};
то класс RCWidget будет определяться следующим образом:
class RCWidget {
public:
RCWidget(int size) : value(new Widget(size)) {}
void doThis() { value->doThis(); }
int showThat() const ( return value->showThat(); }
private:
RCIPtr<Widget> value;
};
Обратите внимание: конструктор RCWidget вызывает конструктор Widget
(при помощи оператора new - см. правило 8) с переданным ему аргументом; функ-
ция doThi в класса RCVii dget вызывает функцию doThi s в классе Widget; а функ-
ция RCWidget::showThat возвращает то же самое, что и ее двойник в классе
Widget. Обратите также внимание на то, что в классе RCWidget не объявлены
конструктор копирования, оператор присваивания и деструктор. Как и в случае
класса String нет необходимости писать эти функции. Благодаря поведению
класса RCIPtr версии, установленные по умолчанию, работают правильно.
Если вам кажется, что создание класса RCWidget настолько предопределено,
что его можно автоматизировать, то вы не ошиблись. Было бы несложно написать
программу, на вход которой подавался бы класс, подобный Widget, а на выходе
получался бы аналог класса RCWidget. Если вы напишете такую программу, по-
жалуйста, сообщите мне об этом.
Оценка
Давайте теперь попробуем выпутаться из деталей строк, значений, интеллек-
туальных указателей и базовых классов для подсчета ссылок. Для этого взглянем
на процесс подсчета ссылок как бы со стороны и попытаемся решить вопрос более
высокого уровня: является ли подсчет ссылок подходящим методом?
Реализация подсчета ссылок имеет свою цену. Каждое значение содержит
счетчик ссылок, и большинство операций требует проверки или изменения этого
счетчика. Поэтому для значений объектов необходимо больше памяти, и иногда
при работе с ними выполняется больше кода. Кроме этого, лежащий в основе
метода исходный код намного сложнее для класса с подсчетом ссылок, чем для
менее трудоемкой реализации. Класс строк с подсчетом ссылок обычно ни от чего
не зависит, а последняя версия нашего класса string бесполезна, если она не
основана на трех вспомогательных классах (StringValue, RCObject и RCPtr).
Но сложная схема обещает большую эффективность за счет того, что значения
Правило 29
SUMI
217
могут использоваться совместно, устраняется необходимость отслеживать вла-
дельца объекта и стимулируется повторное применение кода для подсчета ссы-
лок. Однако все четыре класса нужно написать, протестировать, документировать
и поддерживать, что, конечно, потребует больше работы, чем соответствующие
операции для одного класса. Это способен понять даже менеджер.
Подсчет ссылок - метод оптимизации, основанный на предположении, что
объекты обычно будут совместно использовать значения (см. правило 18). Если же
это предположение не подтверждается, то подсчет ссылок потребует больше памя-
ти, чем обычная реализация, и при этом будет выполняться больше кода. С другой
стороны, если объекты часто имеют общие значения, подсчет ссылок позволит
сэкономить время и память. Чем больше значения объектов и чем больше объектов
используют значения совместно, тем больше памяти вы сэкономите. Чем чаще вы-
полняется копирование и присваивание значений объектов, тем значительнее бу-
дет экономия времени. Чем больших затрат требует создание и уничтожение значе-
ния, тем больше вы сэкономите времени. Короче говоря, подсчет ссылок позволяет
повысить эффективность программы при следующих условиях:
□ немного значений совместно используется большим числом объектов. Такое
совместное использование обычно возникает при вызовах операторов присва-
ивания и конструкторов копирования. Чем больше отношение «число объек-
тов/число значений», тем лучше этот случай подходит для подсчета ссылок;
□ создание и уничтожение значений объектов требует больших затрат, или
они используют много памяти. Даже если это так, подсчет ссылок ничего
вам не дает, если значения не могут использоваться совместно нескольки-
ми объектами.
Есть только один надежный способ выяснить, удовлетворяются ли эти усло-
вия. Не стоит гадать или полагаться на программистскую интуицию (см. правило
16), лучше сразу использовать отладчик, чтобы определить, выиграет ли програм-
ма от применения подсчета ссылок. При этом вы можете определить, является ли
создание и разрушение значений «узким местом» производительности, и изме-
рить отношение «число объектов/число значений». Только такие данные позво-
лят вам выяснить, перевешивают ли преимущества подсчета ссылок (которых
множество) недостатки этого метода (которых тоже предостаточно).
Даже если удовлетворяются вышеприведенные условия, подсчет ссылок мо-
жет все же оказаться неподходящим методом. Некоторые структуры данных (на-
пример, неориентированные графы) порождают структуры, ссылающиеся сами на
себя или с кольцевой зависимостью. В таких структурах данных возникают изо-
лированные наборы объектов, которые никто не использует, и счетчики ссылок
на которые никогда не становятся равными нулю. Это связано с тем, что на каж-
дый объект в неиспользуемой структуре указывает по меньшей мере один другой
объект в той же структуре. Коммерческие схемы для сборки мусора применяют
специальные методы для поиска и устранения таких структур, но простой прием
подсчета ссылок, который рассматривался выше, нелегко расширить, чтобы вклю-
чить в него эти методы.
Приемы
Подсчет ссылок пригодится, даже если эффективность не имеет для вас ре-
шающего значения. Если вас обременяет неопределенность того, кто может уда-
лить объект, подсчет ссылок - именно тот метод, который облегчит вашу ношу.
Многие программисты преданы методу подсчета ссылок только по этой причине.
В заключение разговора о подсчете ссылок надо указать, как устранить
последний недочет. Уменьшая счетчик ссылок на объект на единицу, функция
RCObject: :removeReference проверяет, становится ли он равным 0. Если
это так, то функция removeRef erence уничтожает объект, выполняя оператор
delete this. Данная операция безопасна, только если объект был создан при
помощи вызова оператора new, поэтому нужен какой-то способ, гарантирующий,
что объекты RCObj ect создаются только так.
Здесь это делается по соглашению, класс RCOb j ect предназначен для исполь-
зования в качестве базового класса для объектов со счетчиками ссылок на значе-
ния, и на такие объекты нужно ссылаться только при помощи интеллектуальных
указателей RCPtr. Кроме того, экземпляры объектов должны создаваться только
при помощи прикладных объектов, которые представляют используемые совмест-
но значения; классы, описывающие объекты значений, не должны быть доступны
для общего использования. В рассматриваемом примере классом для объектов
значений является класс StringValue, и чтобы ограничить его использование,
он сделан закрытым элементом класса string. Только объекты String могут
создавать объекты StringValue, поэтому автор класса String должен гаранти-
ровать, что такие объекты будут создаваться при помощи оператора new.
Создание объектов RCOb j ect будет возможно только в куче. Вся ответствен-
ность за выполнение этого ограничения ложится на хорошо определенный набор
классов. Кроме того, гарантируется, что только этот набор классов способен со-
здавать объекты RCObject. Пользователи не могут случайно (или намеренно)
сформировать объекты RCObject другим образом. Право создавать объекты со
счетчиком ссылок ограничено, и оно сопровождается сопутствующей ответствен-
ностью за соблюдение правил, контролирующих создание объектов.
Правило 30. Применяйте proxy-классы
Мир многомерен, но язык C++ еще не осознал этого. По крайней мере, к тако-
му выводу подводит предложенная в языке реализация поддержки массивов.
Можно создавать двумерные, трехмерные, даже n-мерные массивы в языках
Fortran, Basic, даже в Cobol (Fortran позволяет работать только с семью измере-
ниями, но не будем придираться), а можно ли сделать это в языке C++? Только
иногда и только частично.
Например, разрешается написать:
int data[10] [20] ; // Двумерный массив 10 на 20.
Но соответствующая конструкция, использующая переменные для задания
размерности массива, недопустима:
void processinput (int diml, int dim2)
{
Правило 30
219
int data[diml][dim2];
// Ошибка! Размер массива
// должен быть известен
//во время компиляции.
Это недопустимо даже при динамическом выделении памяти:
int *data =
new int[diml][dim2];
// Ошибка!
Реализация двумерных массивов
Многомерные массивы так же полезны в C++, как и в любом другом языке,
поэтому важно найти хороший способ обеспечить их поддержку. Обычный метод
стандартен для C++: создать класс для представления нужных вам, но отсутству-
ющих в языке объектов. Следовательно, можно определить шаблон класса для
двумерных массивов:
template<class Т>
class Array2D {
public:
Array2D(int diml, int dim2);
Теперь достаточно определить нужные массивы:
Array2D<int> data(10, 20); //Нормально.
Array2D<float> *data =
new Array2D<float>(10, 20); //Нормально,
void processinput(int diml, int dim2)
{
Array2D<int> data(diml, dim2); // Нормально.
}
Использовать эти объекты массивов не совсем просто. Если следовать тради-
ционному синтаксису С и C++, то для индексирования массивов должны исполь-
зоваться квадратные скобки:
cout << data[3] [6] ;
Но как объявить в классе оператор Array 2D индексирования, который позволит
сделать это?
Первое побуждение - объявить функции operator [ ] [ ], например, так:
template<class Т>
class Array2D {
public:
// Объявления, которые не будут компилироваться.
Т& operator!][](int indexl, int index2);
const T& operator!][](int indexl, int index2) const;
220
Приемы
Но функция operator [ ] [ ] не существует, и не думайте, что ваши компиля-
торы об этом забудут. (См. в правиле 7 полный список операторов, как перегру-
жаемых, так и неперегружаемых.) Придется сделать что-то другое.
Если для вас приемлем такой синтаксис, то вы можете последовать примеру
множества языков программирования, использующих для индексации массива
круглые скобки. Для этого вам достаточно перегрузить функцию operator ():
template<class Т>
class Array2D {
public:
// Объявления, которые будут компилироваться.
Т& operator()(int indexl, int index2);
const T& operator()(int indexl, int index2) const;
};
Тогда пользователи будут использовать массивы следующим образом:
cout « data(3 , 6);
Такие массивы легко реализовать и обобщать на произвольное число измере-
ний. Недостаток этого подхода состоит в том, что объекты Ar ray 2D больше не
похожи на встроенные массивы. Фактически, доступ к элементу (3, 6) массива
data выглядит как вызов функции.
Если отказаться от мысли о том, что массивы должны быть похожи на «эмиг-
рантов» из языка Fortran, можно снова обратиться к записи оператора индекси-
рования с помощью квадратных скобок. Хотя operator [ ] [ ] и не существует, до-
пустимо написать код, который имитирует его использование:
int data[10] [20] ;
cout « data[3] [6] ; • // Нормально.
Что это дает?
Переменная data в действительности не будет двумерным массивом, а одно-
мерным из 10 элементов. Каждый из этих 10 элементов, в свою очередь, представ-
ляет собой массив из 20 элементов, поэтому выражение data [ 3 ] [ 6 ] на самом деле
означает (data [ 3 ] ) [ 6 ], то есть седьмой элемент массива, который является чет-
вертым элементом массива data. Короче говоря, значение, получаемое в результа-
те первого применения квадратных скобок, является другим массивом, поэтому вто-
рое применение скобок извлекает элемент из второстепенного массива.
Можно выполнить то же самое для класса Ar ray 2D, перегрузив функцию
operator [ ] так, чтобы она возвращала новый класс ArraylD. Затем снова пере-
грузить функцию operator [ ] в классе ArraylD, в результате чего она будет воз-
вращать элемент в исходном двумерном массиве:
template<class Т>
class Array2D {
public:
class ArraylD {
Правило 30
221
public:
Т& operator[](int index);
const T& operator[](int index) const;
};
ArraylD operatort](int index);
const ArraylD operator!](int index) const;
};
Тогда становится допустимым следующее:
Array2D<float> data(10, 20);
cout « data[3] [6] ; // Нормально.
В данном случае data [3 ] обозначает объект ArraylD, а вызов функции
operator [ ] для этого объекта соответствует запятой в записи (3 , 6) в исход-
ном двумерном массиве.
Пользователи класса Array 2D не обязательно должны знать о существовании
класса ArraylD. Объекты последнего класса представляют собой одномерные
массивы, которые не существуют с точки зрения клиентов класса Ar ray 2D.
Пользовательские приложения пишутся так, как будто они используют реальные
двумерные массивы. Пользователей не касается, что для того, чтобы удовлетво-
рить капризам языка C++, классы Ar ray 2D должны быть синтаксически совмес-
тимы с одномерными массивами.
Каждый объект ArraylD обозначает одномерный массив, отсутствующий в аб-
страктной модели, применяемой пользователями класса Array 2D. Объекты, кото-
рые обозначают другие объекты, часто называются proxy-объектами (proxy
objects), а классы, на основе которых создаются proxy-объекты, часто называются
proxy-классами (proxy classes). В этом примере ArraylD является ргоху-классом.
Экземпляры объектов этого класса соответствуют одномерным массивам, которые
теоретически не существуют. (Терминология proxy-классов и объектов не являет-
ся универсальной; иногда объекты таких классов называются заместителями
(surrogates).)
Различение записи и чтения в функции operator[]
Использование proxy-классов для реализации классов, экземпляры которых
действуют как многомерные массивы, является общепринятым, но этим воз-
можности proxy-классов не исчерпываются. Например, в правиле 5 показано,
как с помощью таких классов не допустить, чтобы конструкторы с единственным
аргументом выполняли ненужные преобразования типов. Но наиболее известным
применением proxy-классов является различение чтения и записи в функции
operator[].
Рассмотрим строковый тип с подсчетом ссылок, который поддерживает
operator [ ]. Такой тип подробно описан в предыдущем разделе. Если вы не зна-
комы с понятиями, лежащими в основе подсчета ссылок, ознакомьтесь с прави-
лом 29 сейчас.
222
ШИ
Приемы
Строковый тип, поддерживающий operator [ ], позволяет пользователям пи-
сать подобный код:
String si, s2 ;
cout «
s2[5] =
sl[3] =
si[5] ;
"X" ;
s2[8] ;
// Строковый класс;
// использование proxy-классов
//не позволяет этому классу
// соответствовать стандартному
// интерфейсу строк.
// Считать si.
// Записать s2.
// Записать si, считать s2.
Обратите внимание, что функция operator [ ] может вызываться как для чте-
ния, так и для записи символа. При чтении оператор стоит справа от оператора
присваивания, при записи - слева. Вообще говоря, использование объекта слева
от оператора присваивания (как lvalue) означает, что он может изменяться, ис-
пользование его справа (как rvalue) - что он не может быть изменен.
Так как реализация чтения, в особенности для структур данных со счетчиком
ссылок, требует намного меньших усилий, чем реализация записи, хотелось бы
различать использование функции operator [ ] слева и справа от оператора при-
сваивания. Как объясняется в правиле 29, запись объектов со счетчиком ссылок
может включать копирование всей структуры данных, а для чтения достаточно
возврата значения. К несчастью, не существует способа определить контекст вы-
зова operator [ ] внутри самой функции, то есть невозможно различить ее ис-
пользование как lvalue и rvalue.
«Постойте», - скажете вы, - «нам не нужно делать этого. Мы можем перегру-
зить функцию operator [ ], воспользовавшись тем, что она объявлена как const,
и это позволит нам различать чтение и запись». Другими словами, предлагается
решить задачу таким образом:
class String {
public:
const char& operator[](int index) const; // Для чтения.
char& operator!](int index); // Для записи.
};
Увы, это не сработает. Компиляторы делают выбор между const и не-const
функциями - членами класса на основе того, имеет ли атрибут const вызываю-
щий функцию объект. Контекст вызова функции при этом не учитывается. Сле-
довательно:
String si, s2 ;
cout « si[5] ;
s2[5] = "x";
si [3] = s2[8] ;
// Вызывает не-const operator!] ,
// так как si не-const объект.
// Также вызывает не-const
// operator!], так как s2 не-const объект.
//В обоих случаях вызывается
Правило 30
JIMI
223
// не-const operator[], так как
// и si, и s2 - не-const объекты.
В таком случае перегрузка функции operator [ ] не позволяет различать за-
пись и чтение.
В примере, иллюстрирующем правило 29, все вызовы operator [ ] выпол-
нялись для записи. На этот раз поступим иначе. Различить использование
operator [ ] слева и справа от оператора присваивания в самой функции нельзя,
но, может быть, все-таки найдется способ обойти это ограничение?
Да, невозможно определить внутри самой функции operator [ ], использу-
ется ли она в контексте lvalue или rvalue, однако ничто не мешает по-разному
обрабатывать чтение и запись, если отложить действия до тех пор, пока не будет
видно, как используется результат функции operator [ ]. Все что нужно - отсро-
чить решение о том, будет ли выполняться чтение или запись объекта, до тех пор
пока не произойдет возврат из вызова функции operator [ ]. (Это пример отло-
женной оценки - см. правило 17.)
Proxy-класс позволяет получить нужный выигрыш во времени, поскольку
функцию operator [ ] можно изменить так, чтобы она возвращала ргоху-объект
для символа строки, а не сам символ. Затем надо подождать и посмотреть, как этот
proxy-объект будет использоваться. Если он считывается, значит, вызов функции
operator [ ] следует рассматривать как чтение, если записывается - как запись.
Соответствующий код приведен ниже, но вначале поговорим, каким образом
используются proxy-объекты. С proxy-объектами можно делать три вещи:
□ создавать, то есть определять, какой символ строки они заменяют;
□ использовать в качестве цели присваивания, при этом выполняется присваи
вание символу строки, который они заменяют. В данном случае ргоху-объект
используется как lvalue;
□ использовать любым другим способом. При этом ргоху-объект выступает
как rvalue.
Вот определение для класса string с подсчетом ссылок, где распознавание
функции operator [ ] (используется ли она как lvalue или rvalue) осуществля-
ется с помощью proxy-класса:
class String { // Строки с подсчетом ссылок;
public: // подробнее см. правило 29.
class CharProxy { // Proxy-объекты для символов,
public:
CharProxy (Strings str, int index); // Создание.
CharProxyS operator=(const CharProxyS rhs);
CharProxyS operator=(char с); // Как lvalue.
operator char() const; // Как rvalue.
private:
Strings theString; // Строка, которой
// принадлежит ргоху-объект.
int charIndex; // Символ в строке, который
// заменяет ргоху-объект.
};
224
MMi
Приемы
// Продолжение класса String.
const CharProxy
operator!] (int index) const; // Для const String.
CharProxy operator!](int index); // Для не-const String.
friend class CharProxy;
private:
RCPtr<StringValue> value;
};
Кроме добавления класса CharProxy (который будет рассмотрен ниже), этот
класс String отличается от последней версии класса String из правила 29 толь-
ко тем, что обе функции operator [ ] возвращают теперь объекты CharProxy.
Но пользователи класса String могут игнорировать этот факт и писать програм-
му как обычно: будто функции operator [ ] возвращают символы (или ссылки
на символы - см. правило 1):
String si, s2 ; // Строки с подсчетом ссылок, // использующие proxy-объекты
cout « si[5]; // Допустимо и работает.
s2 [5] = "x"; // Также допустимо и работает.
sl[3] = s2[8] ; // Естественно, допустимо.
// естественно, работает.
Интересно не то, что прием работает. Интересно, как это происходит.
Рассмотрим вначале оператор
cout << si[5] ;
Выражение si [ 5 ] соответствует объекту CharProxy. Для таких объектов не
определен оператор вывода, поэтому компиляторам придется найти неявное пре-
образование типов, которое они могут применить, чтобы сделать вызов функции
operator« успешным (см. правило 5). И они находят неявное преобразование
из CharProxy в char, объявленное в классе CharProxy, и автоматически вызы-
вают этот оператор преобразования, и в результате выводится символ строки,
представленный объектом CharProxy. Это пример преобразования из Char-
Proxy в char, которое выполняется для всех объектов CharProxy, используемых
в качестве rvalue.
Использование их в качестве lvalue обрабатывается по-другому. Рассмотрим
снова оператор
s2[5] = "х";
Выражение s2 [5], как и раньше, возвращает объект CharProxy, но на этот
раз объект является целью присваивания. Какой оператор присваивания вызы-
вается при этом? Цель присваивания - объект CharProxy, поэтому вызывается
оператор присваивания класса CharProxy. Это важно, поскольку объект, при-
нимающий новое значение в операторе присваивания CharProxy, используется
как lvalue. Отсюда известно, что символ строки, замещаемый ргоху-объектом,
225
Правило 30 НИН
функционирует как lvalue, и, следовательно, надо предпринять необходимые дей-
ствия для реализации доступа к символу как к lvalue.
Аналогично, оператор
si [3] = s2[8] ;
вызывает оператор присваивания для двух объектов CharProxy, и в этом опера-
торе объект слева используется как lvalue, а объект справа - как rvalue.
Вот код для функций operator [ ] класса String:
const String::CharProxy String::operator!](int index) const
{
return CharProxy(const_cast<String&>(*this), index);
}
String::CharProxy String::operator!](int index)
{
return CharProxy(*this, index);
}
Каждая функция просто создает и возвращает proху-объект для запрашиваемо-
го символа. Над самим символом не совершается никаких действий: они отклады-
ваются до тех пор, пока не будет известно, выполняется ли его чтение или запись.
Обратите внимание, что const версия функции operator!] возвращает
const proxy-объект. Поскольку функция-член CharProxy: : operator= не объ-
явлена как const, такие proxy-объекты не могут использоваться в качестве цели
присваивания. Следовательно, ни proxy-объект, возвращаемый const версией
функции operator [ ], ни символ, который он замещает, не могут использовать-
ся в качестве lvalue. Это в точности то поведение, которое и требуется от const
версии operator [ ] в рассматриваемом примере.
Обратите внимание на использования для *this оператора const_cast (см.
правило 2) при создании объекта CharProxy, возвращаемого const operator [ ].
Это необходимо, чтобы удовлетворить ограничениям конструктора CharProxy,
который принимает только не-const объекты String. Операторы приведения
типов часто создают проблемы, но в этом случае объект CharProxy, возвращае-
мый функцией operator [ ], сам имеет атрибут const, поэтому нет опасности,
что будет изменен объект типа string, содержащий символ, на который ссыла-
ется ргоху-объект.
Каждый ргоху-объект, возвращаемый функцией operator [ ], помнит, к ка-
кой строке он относится и индекс представляемого им символа в этой строке:
String::CharProxy::CharProxy(Strings str, int index)
: theString(str), charindex(index) {}
Преобразование proxy-объекта к типу rvalue выполняется несложно - надо
просто возвратить копию символа, представленного ргоху-объектом:
String::CharProxy::operator chart) const
{
return theString.value->data[charindex];
}
8 - 679
226
Приемы
ШИНН
Если вы забыли о связи между объектом String, его элементом value и эле-
ментом data, на который он указывает, обратитесь к правилу 29. Так как эта функ-
ция возвращает символ по значению, а C++ разрешает делать это только для зна-
чений, используемых в качестве rvalue, данная функция преобразования может
использоваться только там, где допустимо использовать rvalue.
Таким образом, вы обращаетесь к реализации операторов присваивания клас-
са CharProxy, в которых символ, представленный proxy-объектом, используется
в качестве цели присваивания, то есть как lvalue. Можно реализовать обычный
оператор присваивания класса CharProxy следующим образом:
String::CharProxy&
String::CharProxy::operator=(const CharProxyk rhs)
{
// Если значение строки используется совместно несколькими
// объектами String, создать собственную копию значения.
if (theString.value->isShared()) {
theString.value = new StringValue(theString.value->data);
}
// Выполнить присваивание: присвоить значение символа,
// представленного rhs, символу, представленному *this.
theString.value->data[charindex] =
rhs.theString.value->data[rhs.charindex];
return *this;
}
Сравнивая этот код с реализацией не-const функции String: : operator [ ]
на странице 211, вы увидите, что они поразительно похожи. Этого и следовало
ожидать. В правиле 29 предполагалось, что все вызовы не-const функции
operator [ ] выполнялись для записи и обрабатывались соответственно. Здесь
же код для записи перемещен в операторы присваивания класса CharProxy,
что позволило избежать затрат на выполнение записи, если не-const функция
operator [ ] используется только как rvalue. Кстати, обратите внимание, что эта
функция требует доступа к закрытому элементу value класса String, поэтому
класс CharProxy объявлен дружественным классу String.
Второй оператор присваивания класса CharProxy почти идентичен первому:
String::CharProxy& String::CharProxy::operator=(char c)
{
if (theString.value->isShared()) {
theString.value = new StringValue(theString.value->data) ;
}
theString.value->data[charindex] = c;
return *this;
}
Как грамотный программист, вы, конечно же, чтобы избежать дублирования
кода в этих двух операторах присваивания, поместили бы его в закрытую функ-
цию - член класса CharProxy, которая вызывалась бы из обоих операторов, не
так ли?
Правило 30
«
227
Ограничения
Использование proxy-классов - удобный способ различать использование
operator [ ] в качестве lvalue и rvalue, но этот метод не лишен недостатков. Ко-
нечно, было бы великолепно, если бы proxy-объекты незаметно замещали объек-
ты, которые они представляют, однако идеала достичь нелегко. Это связано с тем,
что объекты могут использоваться как lvalue не только в операторе присваивания,
и такое использование proxy-объектов часто приводит к поведению, отличному
от поведения настоящих объектов.
Рассмотрим снова фрагмент кода из правила 29, из-за которого было принято
решение добавить к объектам StringValue флаг, указывающий на возможность
совместного использования. Если функция string::operator [ ] возвращает
CharProxy вместо chars, то следующий код не будет больше компилироваться:
String si = "Hello";
char *p = Ssl [1]; // Ошибка!
Выражение si [ 1 ] возвращает proxy-объект CharProxy, поэтому выражение
справа от знака равенства (=) будет иметь тип CharProxy*. Преобразование из
типа CharProxy* в char* не определено, из-за чего код инициализации р не бу-
дет компилироваться. Вообще, адрес proxy-объекта имеет тип, отличный от адре-
са настоящего объекта.
Чтобы устранить этот недостаток, необходимо перегрузить операторы адреса-
ции для класса CharProxy:
class String {
public:
class CharProxy {
public:
char * operators();
const char * operators() const;
};
Реализовать эти функции несложно. Функция const просто возвращает ука-
затель на const версию представленного proxy-объектом символа:
const char * String::CharProxy::operators() const
{
return S(theString.value->data[charIndex]);
}
He-const функция потребует несколько больше усилий, поскольку она воз-
вращает указатель на символ, который может быть изменен. Ее поведение анало-
гично поведению не-const версии функции String::operator [ ] в правиле 29,
и реализация также аналогична:
8’
Приемы
char * String::CharProxy::operators()
{
// Убедиться, что символ, указатель на который возвращает
// эта функция, не используется другими объектами String.
if (theString.value->isShared()) {
theString.value = new StringValue(theString.value->data);
}
//He известно, как долго указатель, возращаемый этой
// функцией, будетнужен клиентам, поэтому объект StringValue
//не может использоваться совместно.
theString.value->markUnshareable();
return &(theString.value->data[charindex]);
}
Большая часть этого кода является общей для других функций - членов клас-
са CharProxy, поэтому его следует инкапсулировать в закрытую функцию - член
класса, которую будут вызывать все остальные функции.
Второе отличие между символами char и заменяющими их объектами
CharProxy проявляется, если имеется шаблон для массивов с подсчетом ссылок,
который использует proxy-классы, чтобы различить вызов operator [ ] в каче-
стве lvalue и rvalue:
template<class Т> // Массив со счетчиком ссылок,
class Array { // использующий proxy-объекты.
public:
class Proxy {
public:
Proxy(Array<T>& array, int index);
Proxy& operator=(const T& rhs) ;
operator TO const;
};
const Proxy operator!](int index) const;
Proxy operator[](int index);
Рассмотрим, как могут использоваться эти массивы:
Array<int> intArray;
intArray[5] = 22;
intArray[5] += 5;
++intArray[5];
/ / Нормально.
/ / Ошибка!
// Ошибка!
Как и ожидалось, использование функции operator [ ] в качестве цели просто-
го присваивания завершается успехом, но если она расположена в левой части
вызова функций operator+= или operator++, код будет выполнен некоррек-
тно. Это связано с тем, что функция operator [] возвращает ргоху-объект,
а для объектов Proxy не определены операторы operator+= или operator++.
Правило 30
229
Аналогичная ситуация возникает и в случае других операторов, требующих lvalue
в качестве аргумента, включая operator* =, operator«=, operator—и т. д. Если
вы хотите, чтобы названные операторы работали с функциями operator [ ], воз-
вращающими proxy-объекты, вы должны определить каждую из этих функций для
класса Аггау<Т>::Ргоху, что потребует немалой работы. К сожалению, вам при-
дется либо выполнить ее, либо обойтись без данных операторов.
Похожая проблема возникает при вызове функций - членов класса для ре-
альных объектов через proxy-объекты. Говоря прямо, вы не можете этого сде-
лать. Например, предположим, что вы хотите работать с массивами действи-
тельных чисел, использующими подсчет ссылок. Можно было бы определить
класс Rational, а затем использовать выше приведенный шаблон Array:
class Rational {
public:
Rational (int numerator = 0, int denominator = 1) ;
int numerator() const;
int denominator() const;
};
Array<Rational> array;
Но, оказывается, использовать эти массивы нельзя:
cout << array[4].numerator(); // Ошибка!
int denom = array[22].denominator(); // Ошибка!
Проблема была предсказуема: функция operator [ ] возвращает proxy-объект
для действительного числа, а не настоящий объект Rational. Но функции-чле-
ны numerator и denominator существуют только для объектов типа Rational,
а не для соответствующих proxy-объектов. Поэтому ваши компиляторы и жалу-
ются. Чтобы proxy-объекты были более похожи на замещаемые ими объекты, вы
должны перегрузить все функции, применимые к настоящим объектам.
Другая ситуация, в которой proxy-объекты не могут заменить настоящие
объекты, возникает при передаче функциям, принимающим ссылку на не-const
объекты:
void swap(chars a, chars b);
String s = "+C+";
swap(s[0], s [ 1 ] ) ;
// Переставляет значения а и b.
// Ошибка, должно быть "C++".
// Такая перестановка исправила
//бы ошибку, но она не будет
// компилироваться..
Функция String::operator [ ] возвращает объект типа CharProxy, а функ-
ция swap требует, чтобы оба ее аргумента имели тип chars. Объект CharProxy
может быть неявно преобразован к типу char, но функции его преобразования
в тип char& не предусмотрено. Кроме того, объект типа char, в который он мо-
жет быть преобразован, нельзя связать с параметрами chars функции swap, по-
скольку данный объект - временный (это значение, возвращаемое функцией
operator char) и, как объясняется в правиле 19, существуют веские причины
Приемы
230
для того, чтобы не привязывать временные объекты к параметрам, представляю-
щими собой не-const ссылки.
И последняя ситуация, когда proxy-объекты не могут незаметно подменять
настоящие, возникает при неявном преобразовании типов. Если ргоху-объект не-
явно преобразуется в настоящий объект, который он заменяет, вызывается опреде-
ленная пользователем функция преобразования. Например, объект CharProxy
может быть преобразован в заменяемый им объект типа char при помощи вы-
зова operator char. Как объясняется в правиле 5, компиляторы используют
только одну определенную пользователем функцию преобразования при пере-
воде параметра вызова в тип параметра соответствующей функции. В результа-
те может получиться так, что вызовы функций, успешно завершающиеся при
передаче в качестве параметров настоящих объектов, будут неудачны при пе-
редаче вместо них proxy-объектов. Например, предположим, что имеется класс
TVStation (ТВ-станция) и функция watchTV (смотреть ТВ):
class TVStation {
public:
TVStation(int channel);
};
void watchTV(const TVStationk station, float hoursToWatch);
Благодаря неявному преобразованию типов из int в TVStation (см. прави-
ло 5) можно затем сделать следующее:
watchTV(10, 2.5); // Смотреть 10 канал
//в течение 2.5 часов.
Применив шаблон для массивов с подсчетом ссылок, где вызовы operator [ ]
как lvalue и rvalue различаются с помощью proxy-классов, можно было бы запи-
сать так:
Array<int> intArray;
intArray[4] =10;
watchTV(intArray[4], 2.5); //Ошибка! преобразование
//из Proxy<int> в TVStation
//не существует.
Если не забывать о проблемах, которые сопровождают неявные преобразо-
вания типов, то такое поведение не очень шокирует. Хотя лучше было бы объ-
явить конструктор класса TVStation как explicit, в этом случае компилятор
не пропустил бы даже первый вызов функции watchTV. Подробнее о неявном
преобразовании типов и влиянии на них директивы explicit см. правило 5.
Оценка
Proxy-классы позволяют добиться поведения, которое сложно или даже невоз-
можно реализовать без них. Самые распространенные примеры - использование
многомерных массивов, распознавание lvalue и rvalue и подавление неявных пре-
образований (см. правило 5).
Правило 31
В то же время proxy-классы имеют и недостатки. Будучи возвращаемыми
функцией значениями, proxy-объекты являются временными (см. правило 19),
поэтому они должны создаваться и уничтожаться. Это приводит к расходам па-
мяти и времени, которые, однако, почти всегда с лихвой компенсируются воз-
можностью отличать операции записи от операций чтения. Само существование
proxy-классов увеличивает сложность использующих их программных систем,
так как дополнительные классы усложняют, а не облегчают разработку, реализа-
цию, понимание и поддержку.
И наконец, переход от класса, который работает с настоящими объектами,
к классу, который взаимодействуют с proxy-объектами, часто изменяет семантику
класса, поскольку proxy-объекты обычно ведут себя немного иначе, чем настоящие
объекты, которые они представляют. Иногда из-за этого proxy-объекты оказывают-
ся не лучшим выбором при разработке системы, но во многих классах нет особой
необходимости делать присутствие proxy-объектов очевидным для пользователей.
Например, вряд ли пользователям понадобится получать адрес объекта Array ID
в примере двумерного массива, приведенного в начале этого раздела, и маловеро-
ятно, что объект Arrayindex (см. правило 5) будет передаваться функции, ожи-
дающей другой тип. Во многих случаях proxy-объекты могут вполне приемлемо
заменять настоящие объекты.
Правило 31. Создавайте функции, виртуальные
по отношению более чем к одному объекту
Иногда, как говорит Джаклин Сьюзан (Jacqueline Susann), одного раза недо-
статочно. Предположим, например, что вы пытаетесь занять одну из престижных
высокооплачиваемых должностей в известной компании, производящей програм-
мное обеспечение, штаб-квартира которой находится в Редмонде, штат Вашинг-
тон (я, конечно же, имею в виду Nintendo). Чтобы привлечь к себе внимание ме-
неджеров компании Nintendo, вы решаете написать видеоигру. Ее действие может
происходить в космосе, где находятся разные объекты (Game Obj ect): межпланет-
ные корабли (Space Ship), станции (Space Station) и астероиды (Asteroid).
Когда эти объекты проносятся в вашем искусственном мире, они, естествен-
но, периодически сталкиваются друг с другом. Предположим, что законы столкно-
вений таковы:
□ если корабль и космическая станция сталкиваются на малой скорости, ко-
рабль стыкуется со станцией. В противном случае корабль и станция испы-
тывают повреждения, пропорциональные скорости столкновения;
□ если сталкиваются корабль с кораблем или станция со станцией, то оба
объекта испытывают повреждения, пропорциональные скорости удара;
□ если с кораблем или станцией сталкивается небольшой астероид, то асте-
роид уничтожается. В случае большого астероида уничтожается корабль
или станция;
□ если сталкиваются два астероида, то оба разбиваются на осколки (малень-
кие астероиды), которые разлетаются во всех направлениях.
232
nil
Приемы
Эта игра может показаться довольно скучной, но она приведена здесь не для
развлечения, а чтобы рассмотреть структуру кода C++, который обрабатывает
столкновения между объектами.
Вначале отметим, что астероиды, станции и корабли имеют несколько об-
щих свойств. В частности, это движение, поэтому они все имеют свою скорость
перемещения. Будет естественно определить для этих общих свойств базовый
класс, от которого все объекты будут наследовать. На практике такой класс почти
неизменно будет абстрактным базовым классом (базовые классы вообще всегда
должны быть абстрактными - см. правило 33). Следовательно, иерархия может
выглядеть примерно так, как представлено на рис. 5.18.
class Gameobject { ... };
class Spaceship: public Gameobject { ... };
class Spacestation: public GameObject { ... };
class Asteroid: public GameObject { ... };
Теперь предположим, что вы решили написать код для проверки столкновений
объектов. Для этого пригодится, например, такая функция:
void checkForCollision(GameObjectk objectl,
GameObjectk object2)
{
if (theyJustCollided(objectl, objects)) {
processCollision(objectl, objects);
}
else {
}
}
И здесь сложность программирования этой задачи становится очевидной. Ког-
да вы вызываете функцию processcollision, вы знаете: objectl и object2
только что столкнулись, и результат столкновения зависит от того, что собой
представляют два эти объекта. Но вы не знаете, чем именно они являются, вам из-
вестно только то, что оба они имеют тип GameObj ect. Если бы обработка столкно-
вения определялась динамическим типом объекта objectl, то можно было бы
сделать функцию processcollision в классе GameObject виртуальной и вы-
зывать функцию objectl .processcollision (object2 ). Если бы на результат
Правило 31
Clin
233
влиял только динамический тип объекта object2, то это же самое можно было
бы сделать и для него. Однако все, что происходит во время столкновения, зави-
сит от динамических типов обоих объектов. Как видите, при этом недостаточно
вызова функции, которая является виртуальной только для одного объекта.
Вам необходима функция, поведение которой было бы виртуальным для бо-
лее чем одного типа объекта. В языке C++ не существует таких функций. Но вам
все равно придется реализовать требуемое поведение. Таким образом, надо найти
способ, как это сделать.
Один из вариантов заключается в том, чтобы вместо C++ выбрать какой-либо
другой язык программирования. Вы можете, например, обратиться к языку CLOS
(сокращение от Common Lisp Object System - общая система объектов Lisp). Язык
CLOS поддерживает наиболее общий объектно-ориентированный механизм вы-
зова функций - мульти-методы (multi-methods). Мульти-метод - это функция,
которая является виртуальной по отношению к произвольному числу параметров.
Более того, язык CLOS позволяет управлять разрешением вызовов перегружен-
ных мульти-методов.
Но предположим, вы должны написать код игры именно на языке C++, то
есть найти собственный способ реализовать двойную диспетчеризацию (double-
dispatching). (Этот термин возник в сообществе объектно-ориентированных про-
граммистов, которые то, что программисты C++ знают под именем виртуальной
функции, называют диспетчером сообщений. Вызов функции, виртуальной по от-
ношению к двум параметрам, называется двойной диспетчеризацией. А функция,
виртуальная по отношению к нескольким параметрам, - это, соответственно,
множественная диспетчеризация.) Существует несколько подходов к решению
поставленной задачи. Все они не лишены недостатков, но это не должно вас удив-
лять. Язык C++ не обеспечивает двойной диспетчеризации, поэтому вам придет-
ся самостоятельно выполнить ту работу, которую обычно делают за вас компиля-
торы, реализуя виртуальные функции (см. правило 24).
Использование виртуальных функций и RTTI
Виртуальные функции обеспечивают одиночную диспетчеризацию, а это
уже половина того, что требуется для решения задачи. Кроме того, и виртуаль-
ные функции создаются компиляторами, поэтому начнем с объявления в классе
GameObject виртуальной функции collide. В производных классах эта функ-
ция как обычно перегружается:
class GameObject {
public:
virtual void collide(GameObject& otherObject) = 0;
};
class Spaceship: public GameObject {
public:
virtual void collide(GameObject& otherObject);
234
МММ
Приемы
Здесь показан только производный класс Spaceship, поскольку классы
Spacestation и Asteroid устроены таким же образом.
Самый простой способ двойной диспетчеризации - эмулировать виртуальные
функции при помощи цепочек if-then-else. Вначале надо определить настоя-
щий тип объекта otherObj ect, а затем перебрать все возможные варианты:
// При столкновении с объектом неизвестного типа генерируется
// исключение типа CollisionWithUnknownObject:
class CollisionWithUnknownObject {
public:
CollisionWithUnknownObject (GameObjectk whatWeHit) ;
};
void Spaceship::collide(GameObjectk otherObject)
{
const type_info& objectType = typeid(otherObject) ;
if (objectType == typeid(Spaceship)) {
SpaceShipb ss = static_cast<SpaceShip&>(otherObject);
обработка столкновения Spaceship-Spaceship;
)
else if (objectType == typeid(SpaceStation)) {
SpaceStationb ss =
static_cast<SpaceStation&>(otherObject);
обработка столкновения Spaceship-Spacestation;
}
else if (objectType == typeid(Asteroid)) {
Asteroids a = static_cast<Asteroid&>(otherObject);
обработка столкновения SpaceShip-Asteroid;
)
else {
throw CollisionWithUnknownObject(otherObject);
}
)
Обратите внимание, что понадобилось определить тип только одного из стал-
кивающихся объектов. Второй объект - это *this, и его тип обусловлен меха-
низмом виртуальных функций. Так как мы находимся внутри функции - члена
класса Spaceship, то объект *this должен иметь тип Spaceship. Поэтому не-
обходимо определить настоящий тип только объекта otherObject.
В этом коде нет ничего сложного. Его легко написать и даже заставить рабо-
тать. Но хотя код выглядит совершенно безобидно, могут возникнуть проблемы
с RTTI (сокращение от Run Time Type Information - информация о типах в про-
цессе исполнения - механизм, позволяющий определять тип объекта во время вы-
полнения программы). Намек на реальную опасность скрыт в последнем операто-
ре else и генерируемом там исключении.
Инкапсуляция здесь не пригодится, поскольку каждая функция coll ide долж-
на знать обо всех своих родственных классах, то есть классах, наследующих от
235
Правило 31 !!
класса GameObj ect. В частности, если в игру вводится новый тип объектов -
и добавляется новый класс - придется обновить каждую RTTI цепочку i f-then-
el se программе, в которой может встречаться новый тип объекта. Если вы забу-
дете хотя бы про одну из них, в программе появится неочевидная ошибка.
И компиляторы не помогут вам ее обнаружить, поскольку не знают о том, что вы
делаете.
Такой подход к работе с типами данных имеет давнюю историю в языке С
и обычно приводит к созданию программ, которые, в сущности, невозможно под-
держивать. Улучшение подобных программ практически немыслимо. Это одна из
основных причин, из-за которых были изобретены виртуальные функции: чтобы
перенести тяжесть создания и поддержки типизированных вызовов функций с плеч
программистов на компиляторы. Но когда для реализации двойной диспетчериза-
ции используется RTTI, вы снова возвращаетесь в старые недобрые времена.
Прежние методы приводили к ошибкам в С, и они также станут причиной
проблем в C++. Поэтому в функцию collide включен заключительный опера-
тор else, который перехватывает управление при столкновении с неизвестным
объектом. Такая ситуация, в принципе, невозможна, но где были ваши принципы,
когда вы решили использовать RTTI? Существуют различные способы обработ-
ки непредвиденных столкновений, но ни один из них не является удовлетвори-
тельным. В рассмотренном случае сгенерировано исключение, но неясно, будет
ли оно лучше обработано в вызвавшей его программе, чем при помощи написан-
ного вами кода, поскольку игровой объект столкнулся с чем-то таким, о существо-
вании чего вы даже не догадывались.
Использование только виртуальных функций
Существует способ снизить вероятность ошибок, присущих реализации двой-
ной диспетчеризации при помощи RTTI, но перед тем как перейти к нему, рас-
смотрим, как можно решить данную задачу, используя только виртуальные функ-
ции. Эта стратегия начинается с той же основной структуры, что и подход RTTI.
Функция collide в классе GameObject объявляется виртуальной и переопре-
деляется в каждом из производных классов. Кроме того, функция collide пере-
гружается в каждом из классов, по одной перегрузке для каждого из производных
классов в иерархии:
class Spaceship; // Предварительное объявление.
class Spacestation;
class Asteroid;
class GameObject {
public:
virtual void collide(GameObjectk otherObject) = 0;
virtual void collide(Spaceship^ otherObject) = 0;
virtual void collide(SpaceStation& otherObject) = 0;
virtual void collide(Asteroids otherobject) = 0;
};
class Spaceship: public GameObject {
236
Приемы
public:
virtual void collide(GameObject& otherObject);
virtual void collide(Spaceships otherObject);
virtual void collide(SpaceStationS otherObject);
virtual void collide(Asteroids otherobject);
};
Основная идея заключается в том, чтобы реализовать двойную диспетчери-
зацию как две одиночных, то есть как два отдельных вызова виртуальных функ-
ций; первый определяет динамический тип первого объекта, а второй - второго
объекта. Как и в предыдущем примере, вначале вызывается виртуальная функ-
ция collide с параметром GameObj ect&. Код этой функции в данном случае по-
разительно прост:
void Spaceship::collide(GameObjectS otherobject)
{
otherobject.collide(*this);
}
На первый взгляд кажется, что это не более чем рекурсивный вызов функ-
ции collide с параметрами, заданными в обратном порядке, то есть что
otherobject становится объектом, вызывающим функцию - член класса, а объ-
ект *this - параметром функции. Но взгляните на код еще раз и вы поймете: это
не рекурсивный вызов. Как известно, компиляторы определяют, какая из набора
функций должна быть вызвана, основываясь на статическом типе передаваемых
функции аргументов. В этом случае могут быть вызваны четыре различные функ-
ции collide, но из них выбирается одна на основе статического типа *this. Что
это за статический тип? Так как вы находитесь внутри функции - члена класса
Spaceship, то объект *this должен иметь тип Spaceship. Поэтому вызывает-
ся функция collide, принимающая параметр Spaceships, а не GameObjects.
Все функции collide являются виртуальными, следовательно, при вызове
функции Spaceship: : collide выполняется подстановка вызова функции, со-
ответствующей настоящему типу объекта otherObj ect. Внутри этой реализации
функции collide известен настоящий тип обоих объектов, так как объект сле-
ва - это * thi s (и поэтому имеет тип класса, в котором реализована данная функ-
ция), а объект справа имеет тип, объявленный как тип параметра.
Все это станет для вас более ясным, когда вы увидите реализацию других
функций collide в классе Spaceship:
void Spaceship: :collide(Spaceships otherobject)
(
обработка столкновения SpaceShip-SpaceShip;
}
void Spaceship::collide(SpaceStationS otherobject)
{
обработка столкновения SpaceShip-SpaceStation;
}
Правило 31
I
237
void Spaceship::collide(Asteroids otherObject)
{
обработка столкновения SpaceShip-Asteroid;
}
Как видите, здесь нет ни RTTI, ни необходимости генерировать исключе-
ния для неизвестных типов объектов. Неизвестных типов объектов просто не
может быть - в этом и состоит особенность использования виртуальных функ-
ций. И если бы ни одна неисправимая ошибка, это было бы идеальным решением
проблемы двойной диспетчеризации.
Такая ошибка присуща и рассмотренному ранее подходу RTTI: каждый из
классов должен знать обо всех родственных классах. Код должен обновляться по
мере добавления новых классов. Однако способ обновления кода в данном слу-
чае другой. Не нужно модифицировать цепочки if - then-el se, но есть нечто
гораздо худшее: в каждое определение класса должна быть внесена новая вир-
туальная функция. Если, например, вы решите включить в код игры новый класс
Satellite (наследующий от класса GameObject), то вам придется добавить
новую функцию collide к каждому из существующих классов в программе.
Во многих случаях изменить существующие классы нельзя. Если вместо того,
чтобы писать всю видеоигру целиком, вы начали с готовой библиотеки, опреде-
ляющей прикладной интерфейс видеоигры, у вас может не быть доступа на за-
пись к классу GameObject или производным от него классам. При этом невоз-
можно добавление новых функций, независимо от того, виртуальные они или нет.
Или классы, требующие изменения, могут быть доступны физически, но не прак-
тически. Предположим, вы были-таки приняты на работу в корпорацию Nintendo
и начали работу над программами, которые используют библиотеку, содержащую
класс GameObject и другие полезные классы. Несомненно, вы не будете един-
ственным клиентом библиотеки, и руководство наверняка не будет слишком радо
тому, что при каждом добавлении нового типа к вашей программе будут переком-
пилироваться все приложения, работающие с этой библиотекой. Обычно часто
используемые библиотеки изменяются очень редко, так как стоимость переком-
пиляции всего основанного на них кода слишком велика.
Короче говоря, если вам необходимо реализовать двойную диспетчеризацию
в вашей программе, прежде всего попытайтесь изменить концепцию программы,
чтобы избежать перекомпиляции. Если же это невозможно, то подход с использо-
ванием виртуальных функций является более безопасным, чем стратегия RTTI.
Последняя ограничивает расширяемость системы, которая определяется возмож-
ностью редактировать заголовочные файлы, но, с другой стороны, не требует пе-
рекомпиляции. Однако, если методика RTTI реализована так, как показано выше,
это обычно приводит к созданию программ, которые сложно поддерживать. Вы
платите, и вы делаете выбор.
Эмуляция таблиц виртуальных функций
Ваши шансы на успех можно увеличить. Вспомните, в правиле 24 говори-
лось о том, что компиляторы обычно реализуют виртуальные функции, создавая
238
Приемы
III
массив указателей на функции (виртуальные таблицы) и затем выполняя индек-
сирование в этом массиве при вызове виртуальной функции. Использование вир-
туальной таблицы устраняет необходимость выполнять цепочки if-then-else
и позволяет компилятором генерировать один и тот же код для всех вызовов вир-
туальных функций: определить правильный индекс в виртуальной таблице, а за-
тем держа, вызвать функцию, указанную этим положением в ней.
В результате ваш RTTI-код станет более эффективным (индексирование
в массиве и вызов функции по указателю почти всегда эффективнее, чем выпол-
нение серии проверок if-then-else, и дает более компактный код), кроме этого,
RTTI используется только в одном месте: там, где инициализируется массив ука-
зателей на функции.
Итак, внесем несколько изменений в функции в иерархии GameObject:
class GameObject {
public:
virtual void collide(GameObjects otherobject) = 0;
};
class Spaceship: public GameObject {
public:
virtual void collide(GameObject& otherobject);
virtual void hitspaceship(Spaceships otherobject);
virtual void hitSpaceStation(SpaceStationS otherobject);
virtual void hitAsteroid(Asteroids otherobject);
};
void Spaceship::hitSpaceShip(Spaceships otherobject)
{
обработать столкновение SpaceShip-SpaceShip;
}
void Spaceship::hitSpaceStation(SpaceStationS otherobject)
{
обработать столкновение SpaceShip-SpaceStation;
}
void Spaceship::hitAsteroid(Asteroid& otherobject)
{
обработать столкновение SpaceShip-Asteroid;
}
Так же как и в RTTI-иерархии, рассмотренной выше, класс GameObj ect содер-
жит только одну функцию для обработки столкновений, которая выполняет пер-
вую диспетчеризацию (из двух необходимых). Так же как и в иерархии, основан-
ной на виртуальных функциях, здесь каждый тип столкновений инкапсулирован
в отдельную функцию, хотя в этом случае функции имеют различные имена, а не
одно и то же - collide. Для того чтобы отказаться от перегрузки, есть свои при-
чины, и вскоре они будут разъяснены. Пока же заметим, что вышеприведенная схе-
ма содержит все необходимое, кроме реализации функции Spaceship: : collide;
именно в ней будут вызываться различные функции hit. Как и раньше, после
Правило 31
239
успешной реализации класса Spaceship, классы Spacestation и Asteroid
можно реализовать аналогично.
В функции SpaceShiptcollide нужно каким-то образом сопоставить дина-
мическому типу параметра otherobject указатель на соответствующую функ-
цию для обработки столкновений. Простейший способ сделать это заключается
в создании ассоциативного массива, который дает указатель на соответствующую
функцию - член класса по заданному имени класса. Можно напрямую реализо-
вать функцию collide при помощи такого ассоциативного массива, но лучше
добавить промежуточную функцию lookup, принимающую объект GameObj ect
и возвращающую соответствующий указатель на функцию. То есть вы передае-
те функции lookup объект GameObj ect, и она возвращает указатель на функ-
цию - член класса, которая будет вызываться, если вы столкнетесь с чем-то типа
GameObj ect.
Функция lookup объявляется так:
class Spaceship: public GameObject {
private:
typedef void (Spaceship::*HitFunctionPtr)(GameObject&);
static HitFunctionPtr lookup(const GameObject& whatWeHit);
};
Синтаксис указателей на функции никогда не бывает особенно удобным, а для
указателей на функции - члены класса он еще хуже, чем обычно, поэтому дирек-
тивой typedef HitFunctionPtr был определен тип, который служит сокраще-
нием для указателя на функцию - член класса Spaceship, принимающую в ка-
честве параметра GameObjectS и ничего не возвращающую.
После того как получена функция lookup, реализация функции collide ста-
новится легче легкого:
void Spaceship::collide(GameObject& otherobject)
{
HitFunctionPtr hfp =
lookup(otherobject); // Найти функцию.
if (hfp) { // Если функция найдена,
(this->*hfp)(otherobject); // вызвать ее.
}
else {
throw CollisionWithUnknownObject(otherobject);
}
}
Если вы синхронизировали содержимое ассоциативного массива с иерархией
классов, производных от Gameobject, функция lookup всегда должна находить
допустимый указатель на функцию для объекта, который вы ей передаете. Но люди
всегда остаются людьми, и ошибки иногда появляются даже в очень аккуратно
написанных программных системах. Вот почему надо проверить, возвращается
ли функцией lookup корректный указатель, и сгенерировать исключение, если
происходит невозможное, в результате чего вызов функции завершается неудачей.
Приемы
Остается теперь написать функцию lookup. Если имеется ассоциативный
массив, который сопоставляет типы объектов указателям на функции - члены
соответствующих классов, сам поиск выполняется достаточно легко, но создание,
инициализация и уничтожение ассоциативного массива само по себе является
непростой задачей.
Такой массив должен создаваться и инициализироваться до того, как он будет
использоваться, и уничтожаться, когда он больше не нужен. Можно было бы со-
здавать и удалять массив вручную с помощью операторов new и delete, но это
иногда приводит к ошибкам: как гарантировать, что массив не был использован
прежде, чем вы соберетесь проинициализировать его? Лучше автоматизировать
этот процесс при помощи компилятора, объявив ассоциативный массив статичес-
ким в функции lookup. На этот раз он будет создаваться и инициализироваться
при первом вызове функции lookup и автоматически уничтожаться через, какое-
то время после выхода из функции main.
Кроме того, вы можете использовать в качестве ассоциативного массива шаб-
лон тар из стандартной библиотеки шаблонов (см. правило 35):
class Spaceship: public GameObject {
private:
typedef void (Spaceship::*HitFunctionPtr)(GameObject&);
typedef map<string, HitFunctionPtr> HitMap;
};
Spaceship::HitFunctionPtr
Spaceship:: lookup(const GameObject& whatWeHit)
{
static HitMap collisionMap;
}
Здесь collisionMap и является ассоциативным массивом. Он сопоставляет
имени класса (как объекту типа string) указатель на функцию - член класса
Spaceship. Так как выговорить map<string, HitFunctionPtr> нелегко,
было использовано определение типа. (Можете попытаться в качестве развлече-
ния переписать определение collisionMap, отказавшись от определения типов
HitMap и HitFunctionPtr. Немногие отважатся сделать это дважды.)
После создания collisionMap реализация функции lookup становится до-
статочно простой. Это связано с тем, что операция поиска непосредственно под-
держивается классом тар, и единственная переносимая функция - член клас-
са, с помощью которой можно всегда проконтролировать результат вызова typeid.
Это функция name (она, как и следовало ожидать*, возвращает имя динами-
* Оказывается, что это не столь предсказуемо. Стандарт языка C++ не определяет возвращаемое функ-
цией type_info: :name значение, и различные реализации ведут себя по-разному. (В одной из реа-
лизаций, например, функция type_info: : name возвращает class Spaceship, если задан класс
Spaceship.) Лучше было бы идентифицировать класс по адресу связанного с ним объекта type_inf о,
так как этот адрес гарантированно является уникальным. Тогда тип HitMap объявлялся бы как
map<const type_info* , HitFunctionPtr>.
Правило 31
241
ческого типа объекта). Тогда для реализации функции lookup достаточно найти
в массиве collisionMap ячейку, соответствующую динамическому типу аргу-
мента функции lookup.
Код для функции lookup довольно прост, но если вы не знакомы со стандар-
тной библиотекой шаблонов (см. правило 35), он может вызвать у вас затрудне-
ния. Не беспокойтесь. Комментарии в функции объясняют, что происходит.
Spaceship::HitFunctionPtr
Spaceship::lookup(const GameObjectk whatWeHit)
{
static HitMap collisionMap; //Вы увидите инициализацию
// collisionMap позже.
// Поиск функции обработки столкновения для типа whatWeHit.
// Возвращаемое значение - это похожий на указатель объект,
// который называется итератором (см. правило 35) .
HitMap::iterator mapEntry=
collisionMap.findftypeid(whatWeHit),name());
// mapEntry == collisionMap.end() , если поиск был неудачным;
/ / это стандартное поведение для тар.
// Снова см. правило 35.
if (mapEntry == collisionMap.end()) return 0;
// Если вы оказались здесь, поиск был успешным. mapEntry указывает
//на полную ячейку карты, состоящую из пары
// (string, HitFunctionPtr) . Вам нужна только вторая часть
// пары, поэтому она и возвращается.
return (*mapEntry).second;
}
Последний оператор в функции возвращает ( *mapEntry) . second вместо
более привычного mapEntry->second, чтобы удовлетворить капризам стандарт-
ной библиотеки шаблонов. Подробнее см. на стр. 108.
Инициализация
эмулированных таблиц виртуальных функций
Теперь настала пора инициализировать массив collisionMap. Вы, наверное,
хотели бы написать что-то вроде:
// Неправильная реализация.
Spaceship::HitFunctionPtr
Spaceship::lookup(const GameObjectk whatWeHit)
{
static HitMap collisionMap;
collisionMap["Spaceship" ] = &hitSpaceShip;
collisionMap["Spacestation" ] = &hitSpaceStation;
collisionMap["Asteroid"] = &hitAsteroid;
242
III
Приемы
Но при этом в массив collisionMap будут вставляться указатели на функ-
ции - члены класса при каждом вызове функции lookup, что крайне неэффек-
тивно. Код также не будет компилироваться, но эта проблема будет рассмотрена
чуть позже.
Сейчас нужно добиться, чтобы указатели на функции - члены класса поме-
щались в массив collisionMap только один раз, а именно при его создании. Сде-
лать это достаточно легко: просто напишите закрытую статическую функцию -
член initializeCollisionMap для создания и инициализации тар, а затем
инициализируйте массив collisionMap при помощи возвращаемого функцией
initializeCollisionMap значения:
class Spaceship: public GameObject {
private:
static HitMap initializeCollisionMap();
};
Spaceship::HitFunctionPtr
Spaceship::lookup(const GameObject& whatWeHit)
{
static HitMap collisionMap = initializeCollisionMap();
}
Но это означает, что, возможно, возникнут расходы на копирование возвращаемого
функцией initializeCollisionMap объекта map в массив collisionMap (см.
правила 19 и 20). Вы наверняка предпочли бы этого не делать. Можно было бы
обойтись без таких расходов, если бы функция initializeCollisionMap воз-
вращала указатель, но тогда пришлось бы позаботиться о том, чтобы объект тар,
на который ссылался бы данный указатель, уничтожался в соответствующее вре-
мя.
К счастью, существует способ все это сделать. Можно превратить colli s ionMap
в интеллектуальный указатель, который автоматически удаляет то, на что он ука-
зывает, при уничтожении самого указателя. Стандартная библиотека C++ как раз
для таких интеллектуальных указателей содержит шаблон auto_ptr (см. прави-
ло 9). Если определить collisionMap в функции lookup как статический интел-
лектуальный указатель типа auto_ptr, то функция initializeCollision-
Map будет возвращать указатель на инициализированный объект тар, причем без
риска утечки ресурсов; объект тар, на который указывает collisionMap, бу-
дет автоматически уничтожен одновременно с collisionMap. Таким образом:
class Spaceship: public GameObject {
private:
static HitMap * initializeCollisionMap();
};
Spaceship::HitFunctionPtr
Правило 31
243
Spaceship: : lookup(const GameObject& whatWeHit)
{
static auto_ptr<HitMap>
collisionMap(initializeCollisionMap());
}
Наиболее логичный способ реализации функции initializeCollision-
Map, казалось бы, следующий:
Spaceship::HitMap * Spaceship::initializeCollisionMap()
{
HitMap *phm = new HitMap;
(*phm)["Spaceship"] = khitSpaceShip;
(*phm)["Spacestation"] = khitSpaceStation;
(*phm)["Asteroid"] = khitAsteroid;
return phm;
}
Но, как я уже отмечал, такой код не будет компилироваться. Это связано с тем,
что HitMap объявлен как массив указателей на функции - члены класса, имею-
щие одинаковый тип аргумента, а именно GameObject. Но аргумент функции
hitSpaceShip имеет тип Spaceship, аргумент функции hitSpaceStation -
тип Spacestation, а аргумент функции hitAsteroid - тип Asteroid. И хотя
объекты Spaceship, Spacestation и Asteroid могут быть неявно преобразо-
ваны к типу GameObj ect, для указателей на функции с этими аргументами тако-
го преобразования не существует.
У вас может возникнуть искушение использовать операторы приведения ти-
пов reinterpret_cast (см. правило 2), с помощью которых обычно произво-
дят преобразования между типами указателей на функции:
// Неудачная идея. . .
Spaceship::HitMap * Spaceship::initializeCollisionMap()
{
HitMap *phm = new HitMap;
(*phm)["Spaceship"] =
reinterpret_cast<HitFunctionPtr>(khitSpaceShip);
(*phm)["Spacestation"] =
reinterpret_cast<HitFunctionPtr>(SchitSpaceStation);
(*phm)["Asteroid"] =
reinterpret_cast<HitFunctionPtr>(&hitAsteroid);
return phm;
}
Этот код будет компилироваться, но сама идея неудачна. Вы собираетесь лгать
компилятору, чего никогда нельзя делать. Неправда, что функции hi tSpaceShip,
hitSpaceStation и hitAsteroid ожидают аргумент GameObject. Функция
244
ми
Приемы
hitSpaceShip ожидает аргумент типа Spaceship, функция hitSpaceStation -
аргумент типа Spacestation, а функция hit Asteroid - аргумент типа Asteroid.
Операторы приведения типов лгут, говоря, что это не так.
Компиляторам не нравится, когда им лгут, и они часто находят способ ото-
мстить, если обнаруживают обман. Обычно они генерируют неоптимальный код
для функций, вызываемых при помощи *phm, если производные от GameObject
классы используют множественное наследование или имеют виртуальные базовые
классы. Другими словами, если бы Spacestation, Spaceship или Asteroid име-
ли другие базовые классы (кроме GameObj ect), то вы могли бы обнаружить, что
вызовы функций для обработки столкновений внутри функции collide ведут-
себя очень грубо.
Элементы данных объекта В
Виртуальный указатель
Указатель на виртуальный
базовый класс
Элементы дан;
Виртуальный указатель
Указатель на виртуальный
базовый класс
Элементы данных объекта D
Элементы данных объекта А
Виртуальный указатель
Рис. 5.19
Рассмотрим снова иерархию наследования A-B-C-D и возможный формат
объекта D, описанный в правиле 24 (см. рис. 5.19).
Адреса всех четырех частей класса в объекте D различны. Это важно, так как
хотя указатели и ссылки ведут себя по-разному (см. правило 1), компиляторы
обычно реализуют ссылки, генерируя в создаваемом коде указатели. Таким обра-
зом, передача по ссылке обычно осуществляется при помощи передачи указателя
на объект. Если по ссылке передается объект, имеющий несколько базовых клас-
сов (например, объект D), важно, чтобы компилятор передавал правильный адрес -
тот, который соответствует объявленному типу параметра вызываемой функции.
Но что, если вы солгали компиляторам и сообщили им, что ваша функция ожи-
дает параметр типа GameObj ect, хотя в действительности она ожидает объект типа
Spaceship или Spacestation? В таком случае они передадут неверный адрес
при вызове функции, что, вероятно, приведет к «кровавой бойне» во время выпол-
нения программы, а причину конфликта будет определить очень сложно. Это одна
из веских причин для того, чтобы отказаться от использования операторов при-
ведения типов.
Правило 31
шип
245
Итак, вопрос с приведением типов решен - оно не подходит. Но остается еще
одна проблема: несовпадение между типами указателей на функции, которые
должен содержать массив HitMap, и указателями на функции hitSpaceShip,
hitSpaceStation и hitAsteroid. Существует только один способ исправить
ситуацию. Надо изменить функции так, чтобы они все принимали аргументы типа
GameObject:
class GameObject { // Здесь без изменений.
public:
virtual void collide(GameObjectS otherobject) = 0;
};
class Spaceship: public GameObject {
public:
virtual void collide(GameObjectS otherobject);
// Теперь параметр всех этих функций имеет тип GameObject.
virtual void hitSpaceShip(GameObjectS spaceship);
virtual void hitSpaceStation(GameObjectk spacestation);
virtual void hitAsteroid(GameObject& asteroid);
};
Когда проблема двойной диспетчеризации решалась с помощью виртуальных
функций, вы перегружали функцию collide. Здесь же вместо этого использо-
ван ассоциативный массив указателей на функции - члены класса, поскольку тип
параметра один и тот же для всех функции hit, а значит, они должны иметь
различные имена.
Теперь можно записать функцию initializeCollisionMap так:
Spaceship::HitMap * Spaceship::initializeCollisionMap()
{
HitMap *phm = new HitMap;
(*phm) ["Spaceship"] = bhitSpaceShip;
(*phm) ["Spacestation"] = ShitSpaceStation;
(*phm)["Asteroid"] = ShitAsteroid;
return phm;
}
К сожалению, параметры функций hit теперь имеют тип GameObject вмес-
то типа производного класса, как раньше. Привести действительность в соответ-
ствие с ожиданиями можно с помощью оператора dynamic_cast (см. правило
2), примененного в каждой функции:
void Spaceship::hitSpaceShip(GameObject& spaceship)
{
Spaceships otherShip=
dynamic_cast<SpaceShip&>(spaceship);
обработать столкновение Spaceship-Spaceship;
}
void Spaceship::hitSpaceStation(GameObject& spacestation)
246
III
Приемы
{
SpaceStationb station=
dynamic_cast<SpaceStation&>(spacestation);
обработать столкновение SpaceShip-SpaceStation;
}
void Spaceship::hitAsteroid(GameObject& asteroid)
{
Asteroids theAsteroid =
dynamic_cast<Asteroid&>(asteroid);
обработать столкновение SpaceShip-Asteroid;
}
Выполнение каждого из операторов dynamic_cast вызывает генерацию ис-
ключения bad_cast, если попытка приведения типа окончилась неудачей. Но ско-
рее всего они всегда будут успешными, так как функции hi t никогда не должны
вызываться с некорректными типами параметров. Однако лучше все же перестра-
ховаться.
Использование для обработки столкновений функций,
не являющихся членами класса
Теперь вы знаете, как построить ассоциативный массив, похожий на таблицу
виртуальных функций, который позволяет реализовать вторую часть двойной дис-
петчеризации, и как инкапсулировать детали ассоциативного массива в функции
поиска. Но, поскольку этот массив содержит указатели на функции - члены клас-
са, вам все равно придется изменять определения класса, если в игру вводится
новый тип объектов GameObj ect, а это потребует обязательной перекомпиляции.
Например, если в игре появляется тип Satellite, придется добавить к классу
Spaceship объявление функции для обработки столкновений между спутника-
ми (satellites) и космическими кораблями (spaceships). Все пользователи класса
Spaceship будут вынуждены выполнить перекомпиляцию, даже если в своем ва-
рианте игры они обходятся без спутников. Именно из-за этого пришлось отказать-
ся от реализации двойной диспетчеризации, основанной только на виртуальных
функциях, хотя такое решение требовало намного меньше усилий, чем то, которое
вы только что увидели.
Перекомпиляции можно было бы избежать, если бы ассоциативный массив со-
держал указатели на функции, не являющиеся членами класса. Кроме этого, пере-
ход к функциям для обработки столкновений, не являющихся членами класса, по-
зволит решить один до сих пор не рассматривавшийся организационный вопрос:
в каком классе должно обрабатываться столкновение между объектами различных
типов? В последней из предложенных реализаций столкновение объектов 1 и 2 обра-
батывалось в классе 1-го объекта, если этот объект был левым аргументом функции
processcollision. Если же левым аргументом функции process Collision был
2-й объект, то столкновение должно было бы обрабатываться в классе для 2-го объек-
та. Целесообразно ли это? Не лучше ли сделать так, чтобы столкновения между
объектами А и в обрабатывались в каком-то нейтральном месте вне этих классов?
Правило 31
!!
247
Если вывести функции обработки столкновений из классов, то можно бу-
дет предоставить пользователям заголовочные файлы, содержащие определения
классов без функций hit или collide. Затем функция processcollision
приобретет следующую структуру:
#include "Spaceship.h"
#include "Spacestation.h"
#include "Asteroid.h"
namespace { // Неименованное пространство имен - см. ниже.
// Основные функции обработки столкновений.
void shipAsteroid(GameObject& spaceship,
GameObjectk asteroid);
void shipstation(GameObjectk spaceship,
GameObjectk spacestation);
void asteroidstation(GameObjectk asteroid,
GameObjectk spacestation);
// Вспомогательные функции обработки столкновений,
// обеспечивающие симметрию:
// меняют местами параметры и вызывают основную функцию,
void asteroidship(GameObjectk asteroid,
GameObjectk spaceship)
{ shipAsteroid(spaceship, asteroid); }
void stationship(GameObjectk spacestation,
GameObjectk spaceship)
{ shipstation(spaceship, spacestation); }
void stationAsteroid(GameObject& spacestation,
GameObjectk asteroid)
{ asteroidstation(asteroid, spacestation); }
// См. описание этих типов/функций ниже.
typedef void (*HitFunctionPtr)(GameObjectk, GameObjectk);
typedef map< pair<string,string>, HitFunctionPtr > HitMap;
pair<string,string> makeStringPair(const char *sl,
const char *s2);
HitMap * initializeCollisionMap();
HitFunctionPtr lookup(const string^ classl,
const string^ class2) ;
} // Конец пространства имен.
void processcollision(GameObject& objectl,
GameObjectb object2)
{ '
HitFunctionPtr phf = lookup(typeid(objectl).name(),
typeid(object2).name()) ;
if (phf) phf(objectl, object2);
else throw Unknowncollision(objectl, object2);
248
{Ill Приемы
Обратите внимание на неименованное пространство имен, содержащее функции
для реализации processcollision. Все, находящееся в таком неименованном
пространстве имен, будет закрытым внутри текущего модуля трансляции (по сути,
в текущем файле) - это то же самое, если бы функции были объявлены как static
для файла. Но с введением пространств имен такое объявление устарело, и вам сле-
дует привыкать использовать неименованные пространства имен, если ваши ком-
пиляторы поддерживают их.
Концептуально такая реализация очень похожа на реализацию с использовани-
ем функций - членов класса, за исключением небольших различий. Во-первых,
HitFunctionPtr теперь является указателем на функцию, не являющуюся чле-
ном класса. Во-вторых, класс исключений CollisionWithUnknownObject пере-
именован в Unknowncollision и имеет в качестве аргументов два объекта, а не
один. И наконец, функция lookup обладает двумя параметрами и выполняет обе
части двойной диспетчеризации. Это означает, что карта столкновений должна те-
перь содержать три блока данных: два имени типов и указатель HitFunctionPtr.
Но класс тар способен включать только два блока данных. Обойти возник-
шую проблему можно с помощью стандартного шаблона pair, который позволя-
ет упаковать два имени типа в один объект initializeCollisionMap. Вместе
со вспомогательной функцией makeStringPair этот объект будет выглядеть так:
/! Эта функция создает пару объектов
// pair<string, string> из двух строк char*.
// Эти пары используются позже в функции initializeCollisionMap.
// Обратите внимание,что данная функция позволяет выполнять
// оптимизацию возвращаемого значения (см. правило 20).
namespace { // Неименованное пространство имен - см. ниже.
pair<string,string> makeStringPair(const char *sl,
const char *s2)
{ return pair<string,string>(si, s2); }
} // Конец пространства имен.
namespace { // Еще одно неименованное пространство имен.
HitMap * initializeCollisionMap()
{
HitMap *phm = new HitMap;
(*phm)[makeStringPair("Spaceship", "Asteroid")] =
&shipAsteroid;
(*phm)[makeStringPair("Spaceship", "Spacestation")] =
&shipStation;
return phm;
}
} // Конец пространства имен.
Нужно изменить также функцию lookup, чтобы она работала с объектами
pair<string, string>, которые теперь включают первый компонент карты
столкновений:
Правило 31
249
namespace { // Это будет объяснено ниже.
HitFunctionPtr lookup(const strings classl,
const strings class2)
{
static auto_ptr<HitMap>
collisionMap(initializeCollisionMap());
// См. ниже описание функции make_pair.
HitMap::iterator mapEntry=
collisionMap->find(make_pair(classl, class2));
if (mapEntry == collisionMap->end()) return 0;
return (*mapEntry).second; ,
}
} // Конец пространства имен.
Это почти то же, чем вы располагали раньше. Единственное различие состоит
в использовании функции make_pair в операторе:
HitMap::iterator mapEntry=
collisionMap->find(make_pair(classl, class2));
Функция (шаблон) make_pai г введена в стандартную библиотеку только для
удобства (см. правило 35) и избавляет вас от хлопот по заданию типов при созда-
нии объекта pair. С тем же успехом можно было бы записать этот оператор сле-
дующим образом:
HitMap::iterator mapEntry=
collisionMap->find(pair<string,string>(classl, class2));
Но такая запись длиннее, и задание типов для pair является избыточным
(они совпадают с типами для classl и class2), поэтому чаще используется
форма с функцией make_pair.
Поскольку функции makeStringPair, initializeCollisionMap и lookup
были объявлены в неименованном пространстве имен, то каждая из них должна
быть реализована именно там. Вот почему эти функции реализованы в неимено-
ванном пространстве имен (в том же модуле трансляции, где находятся их объяв-
ления): компоновщик корректно свяжет их определения (то есть реализацию)
с ранее сделанными объявлениями.
Итак, цель достигнута. Если в иерархию добавляются новые под классы клас-
са GameObj ect, то существующие классы не будут нуждаться в перекомпиляции
(если они не собираются использовать новые классы). Вы избавились от нераз-
берихи, которая возникает при использовании переключателя switch, основного
на RTTI, и поддержке условных операторов if-then-else. Добавление к иерархии
новых классов требует только хорошо определенных и локализованных измене-
ний в системе: одной или двух вставок в функции initializeCollisionMap
и объявления новых функций для обработки столкновений в неименованном про-
странстве имен, связанном с реализацией функции processcollision. Чтобы
дойти до этого места, потребовалось много усилий, но, согласитесь, путешествие
того стоило.
250
(Hi
Приемы
Наследование и эмулированные таблицы виртуальных функций
Осталось устранить последнюю проблему. (Впрочем, механизм реализации
виртуальных функций настолько сложен, что практически всегда за «после-
дней» проблемой будет всплывать еще какая-нибудь.) Все что вы сделали, бу-
дет прекрасно действовать до тех, пор пока вам не понадобится разрешить при
вызове функций для обработки столкновений преобразование типов, основан-
ное на наследовании. Но предположим, что в создаваемой игре иногда требу-
ется различать военные и гражданские космические корабли. Можно было бы
модифицировать иерархию, руководствуясь правилом 33 и сделав реальные
классы Commercial Ship (Гражданский корабль) и Militaryship (Военный
корабль) наследниками нового абстрактного класса Spaceship (см. рис. 5.20).
Допустим, что гражданские и военные корабли при столкновении с чем-
либо ведут себя одинаково. Следовательно, они смогут использовать те же
функции обработки столкновений, которые применялись до добавления классов
Commercialship и Militaryship. В таком случае при столкновении, напри-
мер, объектов Militaryship и Asteroid должна вызываться функция:
void shipAsteroid(GameObject& spaceship,
GameObject& asteroid);
Но это не так. В действительности будет сгенерировано исключкние Unknown-
Col 1 i s ion. Это произойдет потому, что функция lookup должна будет найти функ-
ции, соответствующие типам с именами Militaryship и Asteroid, а в массиве
collisionMap нет таких функций. Даже если с объектом Militaryship разреша-
лось бы обращаться как с объектом Spaceship, функция lookup не может ничего
знать об этом.
Если вам нужно реализовать двойную диспетчеризацию, и при этом поддер-
живать основанное на наследовании преобразование параметров, то единственным
Правило 31
мин
251
практическим выходом будет возврат к механизму двойного вызова виртуальных
функций, который был рассмотрен ранее. Значит, вам придется примириться с необ-
ходимостью перекомпиляции при введении новых классов в иерархию наследования.
Инициализация эмулированных таблиц
виртуальных функций (повторно)
Это все, что можно сказать о двойной диспетчеризации, но неприятно закан-
чивать главу на такой грустной ноте. Поэтому вашему вниманию предлагается
набросок альтернативного подхода к инициализации массива collisionMap.
Схема программы до сих пор оставалась полностью статической. Будучи раз
зарегистрирована, функция для обработки столкновений объектов двух разных
типов остается навсегда. А что, если пользователю захочется добавлять, удалять
или изменять функции для обработки столкновений во время игры?
Чтобы сделать это, можно заключить понятие карты, хранящей функции об-
работки столкновений, в класс, где находятся функции-члены, позволяющие ди-
намически изменять содержимое карты, например:
class CollisionMap {
public:
typedef void (*HitFunctionPtr) (GameObjectk, GameObject&);
void addEntry(const string^ typel,
const stringb type2,
HitFunctionPtr collisionFunction,
bool symmetric = true); //См. ниже,
void removeEntry(const string^ typel,
const string^ type2);
HitFunctionPtr lookup(const string^ typel,
const string^ type2);
// Эта функция возвращает ссылку на одну
//и только одну карту - см. правило 26.
static CollisionMapk theCollisionMap();
private:
// Эти функции объявлены как закрытые, чтобы
// предотвратить создание нескольких карт - см. правило 26.
CollisionMap();
CollisionMap(const CollisionMapk);
};
Этот класс позволяет добавлять в карту игры новые элементы, удалять их из
нее и выполнять поиск функции обработки столкновений, связанную с опреде-
ленной парой имен типов. Он также использует методы из правила 26, чтобы со-
здавался всего один объект CollisionMap, так как в системе существует всего
одна карта. (Можно легко представить себе более сложные игры с несколькими
картами.) И наконец, она позволяет упростить добавление к карте симметричных
столкновений (то есть если столкновение объекта типа Т1 с объектом типа Т2
имеет тот же эффект, что и столкновение объекта типа Т2 с объектом типа Т1),
252
ИН»
Приемы
автоматически добавляя соответствующую ячейку карты при вызове функции
addEntry со значением необязательного параметра symmetric равным true.
Имея такой класс CollisionMap, каждый из пользователей, которому нуж-
но добавить ячейку к карте, делает это напрямую:
void shipAsteroid(GameObject& spaceship,
GameObject& asteroid);
CollisionMap::theCollisionMap(.addEntry("Spaceship",
"Asteroid",
kshipAsteroid);
void shipstation(GameObjectk spaceship,
GameObjectk spacestation);
CollisionMap::theCollisionMap().addEntry ("Spaceship",
"Spacestation",
&shipStation);
void asteroidstation(GameObject& asteroid,
GameObject& spacestation);
CollisionMap::theCollisionMap().addEntry("Asteroid",
"Spacestation",
kasteroidStation);
Нужно гарантировать, что ячейки карты будут добавлены до того, как про-
изойдут столкновения, вызывающие связанные с ними функции. Один из спо-
собов сделать это - проверять в конструкторах подклассов класса GameObj ect,
что соответствующие изображения уже были добавлены к карте при создании
каждого объекта. Но такой подход немного снизит производительность про-
граммы. В качестве альтернативы можно было бы создать класс Register-
CollisionFunction:
class RegisterCollisionFunction {
public:
RegisterCollisionFunction(
const stringb typel,
const stringb type2,
CollisionMap::HitFunctionPtr collisionFunction,
bool symmetric = true)
{
CollisionMap::theCollisionMap().addEntry(typel, type2,
collisionFunction,
symmetric);
}
};
После этого пользователи могли бы с помощью глобальных объектов данного
типа автоматически регистрировать необходимые им функции:
RegisterCollisionFunction cfl("Spaceship", "Asteroid",
&shipAsteroid);
Правило 31
пив
253
RegisterCollisionFunction cf2("Spaceship", "Spacestation",
kshipStation);
RegisterCollisionFunction cf3("Asteroid", "Spacestation",
basteroidStation);
int main(int argc, char * argv[])
{
}
Так как эти объекты создаются до вызова функции main, то функции, регист-
рируемые их конструкторами, также добавляются к карте до вызова функции
main. Если позже в игру включается новый производный класс:
class Satellite: public GameObject { ... } ;
и одна или несколько новых функций для обработки столкновений:
void satelliteship(GameObjectk satellite, GameObjectk spaceship);
void satelliteAsteroid(GameObject& satellite, GameObjectk asteroid);
то все новые функции вы сможете добавить к карте аналогичным образом, не за-
трагивая соответствующий код:
RegisterCollisionFunction cf4("Satellite", "Spaceship",
ksatelliteShip);
RegisterCollisionFunction cf5("Satellite", "Asteroid",
ksatelliteAsteroid);
Конечно, это далеко не безупречный способ реализации множественной дис-
петчеризации (такого попросту нет), но он облегчает ввод данных в основанную
на карте реализацию.
Глава 6. Разное
Эта глава содержит информацию, которую по соображениям логичной организа-
ции материала нельзя было поместить ни в одну другую. Для начала поговорим
о двух правилах объектно-ориентированной разработки программ на языке C++,
которые помогут вам создавать системы, приспосабливающиеся к изменениям.
Затем рассмотрим, как объединить в одной программе С и C++, что иногда быва-
ет просто необходимо.
И наконец, в последнем разделе книги описаны изменения в стандарте языка
C++, произошедшие со времени публикации его фактического описания. Отдель-
ное внимание уделено изменениям, которые были внесены в стандартную библио-
теку. Если вы не следите за процессом стандартизации, здесь вас ожидает несколь-
ко приятных сюрпризов.
Правило 32. Программируйте, заглядывая в будущее
Все меняется. Не всегда известно, что именно изменится, как будут осуществлять-
ся эти изменения, когда они произойдут или почему, но точно ясно: все меняется.
Хорошо написанные программы легко адаптируются к изменениям. Они вос-
принимают новые свойства, переносятся на новые платформы, подстраиваются под
новые требования, обрабатывают новые разновидности входных данных. Гибкие,
надежные и устойчивые программы не создаются случайно. Они разрабатываются
и реализуются программистами, которые приспосабливаются к сегодняшним огра-
ничениям, не забывая про нужды будущего. Программы, элегантно принимающие
изменения, пишутся профессионалами, которые умеют заглядывать в будущее.
Программировать с прицелом на будущее означает осознавать, что все меня-
ется, и быть готовым к этому. Несомненно, к библиотекам будут добавляться
новые функции, существующие функции станут снова перегружаться, и надо быть
готовым к тому, что это может привести к потенциально двусмысленным вызовам
функций. Вполне вероятно, в иерархиях появятся новые классы, а сегодняшние
производные классы могут завтра стать базовыми. Постоянно будут писаться
новые приложения, из-за чего функции будут вызываться в новом контексте,
и ваша задача - заранее побеспокоиться о корректности их выполнения.
Программисты, ответственные за поддержку ПО, обычно не являются раз-
работчиками оригинального кода, следовательно, необходимо проектировать
и реализовать программы так, чтобы облегчить их понимание, изменение и рас-
ширение другими.
Правило 32
к !!,
255
Один из способов сделать это - выражать ограничения разработки в самом
коде, а не (или не только) в комментариях или другой документации. Например,
если класс не должен иметь производных классов, не просто вставляйте коммен-
тарий в заголовочный файл класса, а предотвращайте наследование средствами
C++ (см. правило 26). Если требуется, чтобы все экземпляры класса размещались
в куче, не просто сообщайте об этом пользователям, а введите ограничение явно,
применив подход, описанный в правиле 27. Если копирование и присваивание для
класса не имеет смысла, запретите данные операции, объявив закрытыми кон-
структор копирования и оператор присваивания. C++ - это мощный, гибкий и вы-
разительный язык. Воспользуйтесь его свойствами, чтобы ввести в программы
нужные ограничения.
Поскольку все меняется, пишите классы, которые могут противостоять бес-
порядочной эволюции программного обеспечения. Избегайте делать функции
виртуальными «по требованию», то есть тогда, когда кто-то подойдет и попросит
вас сделать это. Лучше определите значение функции и целесообразность ее пере-
определения в производных классах. Если такое переопределение имеет смысл,
объявляйте ее как виртуальную, даже если пока это никому не нужно. В против-
ном случае объявите ее невиртуальной и потом не меняйте своего решения прос-
то из-за того, что кому-то так будет удобнее, не убедившись, что изменение имеет
смысл в контексте всего класса и представляемой им абстракции.
Включайте во все классы операторы присваивания и конструктор копирова-
ния, даже если «никто никогда не будет их использовать». Их невостребованность
«здесь и сейчас» не означает, что они не потребуются в будущем. Если реализо-
вать эти функции сложно, объявите их как private. Тогда никто не сможет неча-
янно вызывать функции, сгенерированные компилятором и делающие что-то не
так (что часто происходит с операторами присваивания и конструкторами копи-
рования, созданными по умолчанию).
Придерживайтесь принципа минимальной новизны, то есть старайтесь созда-
вать классы, операторы и функции, которые имеют естественный синтаксис
и наглядную семантику. Сохраняйте согласованность со встроенными типами:
если не знаете, как поступить, сделайте так же, как и для int.
Помните: все, что можно сделать, пользователи сделают обязательно. Они
будут генерировать исключения, присваивать объекты самим себе, использовать
объекты перед присваиванием им значения, присваивать объектам значения
и никогда к ним не обращаться, задавать слишком большие, слишком маленькие
и нулевые значения. В общем, все, что может откомпилироваться, наверняка бу-
дет кем-то сделано. Поэтому программируйте такие классы, с которыми легко
работать правильно и сложно - неправильно. Предполагайте, что пользователи
будут делать ошибки, и проектируйте классы так, чтобы ошибки можно было пре-
дотвращать, обнаруживать или исправлять (см., например, правило 33).
Старайтесь создавать переносимый код. Писать переносимые программы
ненамного сложнее, чем непереносимые, и разница в производительности редко
256
Разное
III
бывает достаточно существенной, чтобы оправдать применение непереносимых
конструкций (см. правило 16). Даже программы, разработанные для оборудования,
сделанного на заказ, часто потом переписываются как переносимые, так как
обычно стандартное оборудование через несколько лет достигает такого же
уровня производительности. Написание переносимых программ позволяет вам
легко переходить с одной платформы на другую, расширять пользовательскую
базу и хвастаться поддержкой открытых систем. Это тоже помогает легче на-
верстать упущенное, если вы поставили не на ту операционную систему.
Разрабатывайте код так, чтобы влияние необходимых изменений было ло-
кализовано. Инкапсулируйте все, что можно, делайте детали реализации за-
крытыми. Почаще используйте неименованные пространства имен для статичес-
ких в файле объектов и функций (см. правило 31). Пытайтесь избегать создания
виртуальных базовых классов, поскольку такие классы должны инициализиро-
ваться во всех производных от них классов - даже косвенных производных (см.
правило 4). Не применяйте без крайней нужды подход RTTI, при котором ис-
пользуются каскады операторов if-then-else (снова см. правило 31). Иногда
при каждом изменении иерархии классов придется обновлять весь набор опера-
торов, и если вы забудете хотя бы об одном из них, компиляторы не выдадут ни-
какого предупреждения.
Это призывы повторяются часто, но большинство программистов к ним не
прислушиваются. К сожалению, и многие авторы тоже. Рассмотрим следующий
совет известного эксперта по C++: «Если кто-то удаляет объект В*, который ука-
зывает на D, то вам понадобится виртуальный деструктор».
Здесь В является базовым классом, a D - производным. Другими словами,
автор предполагает, что если ваша программа выглядит, как показано ниже, то
в классе В вам не понадобится виртуальный деструктор:
class В { . . . }; // Виртуальный деструктор не нужен,
class D: public В { ... } ;
В *pb = new D;
Но ситуация меняется, если добавить оператор:
delete pb; // Теперь вам нужен виртуальный
// деструктор в классе В.
Небольшое изменение в пользовательском коде - добавление оператора
delete - приводит к необходимости изменять определение класса В, а значит, все
пользователи класса В должны будут выполнить перекомпиляцию. Если после-
довать совету процитированного автора, то добавление единственного оператора
к одной функции может потребовать обширной перекомпиляции и перекомпонов-
ки кода для всех пользователей данной библиотеки. Это какой угодно, только не
эффективный подход к разработке программ.
Другой автор пишет на ту же тему: «Если открытый базовый класс не имеет
виртуального деструктора, то ни производный класс, ни его члены не должны
иметь деструкторов».
Правило 32
I
257
Другими словами, следующий код допустим:
class string { // Из стандартной библиотеки C++.
public:
-string();
};
class В { . . . }; // Нет элементов данных с деструкторами,
// виртуальный деструктор не нужен.
но в производном от В классе ситуация меняется:
class D: public В {
string name; // теперь В должен быть виртуальным.
};
И снова небольшое изменение в способе использования класса в (в данном
случае добавление производного класса, содержащего член с деструктором) мо-
жет привести к перекомпиляции и перекомпоновке во всех клиентах. Но неболь-
шие изменения в программе должны иметь небольшое влияние на систему. Эта
разработка не проходит данный тест.
Тот же автор пишет: «Если в иерархии множественного наследования есть
деструкторы, то каждый базовый класс должен иметь виртуальный деструктор».
Обратите внимание, что во всех этих цитатах авторы говорят в настоящем
времени. Как пользователи работают с указателями сейчас? Какие члены класса
сейчас имеют деструкторы? Какие классы в иерархии сейчас имеют деструкторы?
Размышления в будущем времени ведутся совсем по-другому. Вместо того
чтобы задаваться вопросом, как класс используется сейчас, спрашивается, для
чего класс разработан? Если класс разработан с целью сделать его базовым (даже
если он сейчас и не используется в качестве такового), он должен иметь виртуаль-
ный деструктор. Такие классы корректно ведут себя и сейчас, и в будущем, и они
не влияют на других пользователей библиотеки при создании новых производ-
ных от них классов. (По меньшей мере в том, что касается их деструктора. Если
в класс нужно внести еще какие-то изменения, это может оказать влияние на дру-
гих пользователей класса.)
Коммерческая библиотека классов (созданная до введения спецификации
string в стандартную библиотеку C++) содержит класс строк без виртуального
деструктора. Как это объясняют разработчики? «Мы не сделали деструктор вир-
туальным потому, что не хотели, чтобы класс String содержал таблицу вирту-
альных функций. Мы не намерены когда-либо использовать String*, хотя знаем
о том, какие затруднения это может вызвать.»
Рассуждая так, думали ли они о будущем или только о настоящем?
Конечно же, использование таблицы виртуальных функций технически допус-
тимо (см. правило 24). Реализация большинства классов String содержит внут-
ри каждого объекта String единственный указатель char*, поэтому добавление
к каждому объекту String виртуального указателя удвоит размер объектов. Лег-
ко понять, почему разработчикам программного обеспечения хочется избежать
9 - 679
258
Разное
этого, особенно для таких часто использующихся классов, как String. Произво-
дительность подобного класса может снизиться на 20% (см. правило 16).
Но обычно память, выделенная под весь объект строки - память под сам
объект плюс динамическая память для хранения значения строки - намного боль-
ше, чем пространство, необходимое для хранения указателя char*. С этой точки
зрения накладные расходы на создание виртуального указателя не столь суще-
ственны. Тем не менее, это допустимое техническое соображение. (Комитет стан-
дартизации ISO/ANSI, похоже, тоже так думает: стандартный тип string имеет
невиртуальный деструктор.)
Меня больше беспокоит замечание разработчиков: «Мы не намерены когда-
либо использовать String*». Это может быть так, но класс String является
частью библиотеки, к которой будут обращаться тысячи программистов. Каждый
из них имеет различный опыт работы с C++, и все они делают разные вещи. Все
ли они понимают, к чему приводит отсутствие виртуального деструктора в классе
String? Знают ли они, что из-за этого создание производных от String классов
является весьма рискованным предприятием? Уверены ли разработчики класса,
что его пользователи поймут, что удаление объектов при помощи указателей
String* будет выполняться неправильно и операции RTTI над указателями
и ссылками на объекты типа String будут возвращать некорректные данные?
Легко ли использовать этот класс правильно, и сложно ли сделать что-то не так?
Разработчики должны ясно указать в документации, что класс String не
предназначен для создания производных от него классов, но вдруг программис-
ты не обратят внимания на это предупреждение или просто не будут читать до-
кументацию?
Альтернативой было бы запретить создание производных классов при помо-
щи средств языка C++. Правило 26 описывает, как можно сделать это, ограничив
создание объектов в куче и затем используя для работы с объектами в куче объек-
ты auto_ptr. Но тогда интерфейс для создания объектов String был бы непри-
вычным и неудобным, поскольку требовал бы записи:
auto_ptr<String> ps(String::makeString("Future tense C++"));
... // ps можно рассматривать как указатель
//на объект String, который не нужно удалять.
вместо:
String s("Future tense C++");
Но, возможно, уменьшение риска неправильного поведения производных клас-
сов стоило бы такого синтаксического неудобства. (Для класса String это малове-
роятно, но для других классов подобный компромисс может быть выгодным.)
Конечно же, нужно думать и о настоящем. Проектируемые вами программы
должны работать на существующих компиляторах; вы не можете ждать, пока бу-
дут реализованы последние свойства языка. Программы должны выполняться на
поддерживаемом оборудовании и на всех конфигурациях пользователей; вы не
можете заставлять пользователей выполнять обновление оборудования или опе-
рационной среды. Ваши разработки должны иметь приемлемую производительность
Правило 32
ииин
259
сейчас, обещания сделать программу более быстрой и компактной через несколь-
ко лет обычно не греют сердца потенциальных пользователей. Обычно программ-
ное обеспечение, над которым вы трудитесь, должно быть доступно «сегодня»,
что часто означает «несколько дней назад». Это важные ограничения, и игнори-
ровать их нельзя.
Вот несколько советов, которые наверняка вам пригодятся:
□ создавайте полные классы, даже если пока используются только их части.
Тогда при возникновении новых требований к классам вам с меньшей веро-
ятностью придется возвращаться к ним снова и модифицировать их;
□ разрабатывайте интерфейсы так, чтобы облегчить выполнение обычных
операций и предотвратить появление типичных ошибок. Должно быть лег-
ко использовать классы правильно, и сложно - неправильно. Запрещайте,
например, копирование и присваивание для классов, в которых эти операции
бессмысленны. Предотвращайте частичное присваивание (см. правило 33);
□ обобщайте код, если это не приводит к большим затратам. Например, если вы
пишете алгоритм для обхода дерева, подумайте, нельзя ли обобщить его так,
чтобы он мог обрабатывать все типы ориентированных графов без циклов.
Думая о будущем, вы увеличите шансы своих программ на повторное исполь-
зование, облегчите его поддержку, сделаете его более устойчивым и в то же время
изменяемым. Сегодняшние и будущие требования должны быть уравновешены. Но
слишком много программистов фокусируют свое внимание только на текущих
потребностях, и, делая это, они приносят в жертву долгосрочную жизнеспособность
разрабатываемых и реализуемых ими программ. Будьте другим. Программируйте,
заглядывая в будущее.
Правило 33. Делайте нетерминальные классы
абстрактными
Предположим, что вы работаете над программным проектом, в котором опре-
делены классы животных (Animal). При этом большинство типов животных
обрабатывается одинаково, но два класса - Li sard (ящерицы) и Chicken
(куры) - требуют специальной обра- ботки. В этом слу-
чае, очевидно, классы ящериц, кур и всех остальных жи-
CAnimalвотных должны быть связаны между собой так, как предс-
/ \ тавлено на рис. 6.1.
(^LzaicT^)(^СЬскегГ) Класс Animal включает в себя свойства, общие для
всех животных, а классы Lizard и Chicken адаптируют
Рис. 6.1 класс Animal соответственно для работы с типами «яще-
рицы» и «куры»:
Вот набросок определений для этих классов:
class Animal {
public:
Animals operator=(const Animals rhs);
9
260
Разное
};
class Lizard: public Animal {
public:
Lizards operator=(const Lizards rhs);
};
class Chicken: public Animal {
public:
Chickens operator=(const Chickens rhs) ;
};
Здесь показаны только операторы присваивания, но этого пока более чем до-
статочно. Рассмотрим следующий код:
Lizard lizl;
Lizard liz2;
Animal *pAnimall = Slizl;
Animal *pAnimal2 = Sliz2;
*pAnimall = *pAnimal2;
Здесь есть две проблемы. Во-первых, оператор присваивания, вызываемый в по-
следней строке, принадлежит классу Animal, хотя объекты имеют тип Lizard. В ре-
зультате, в объекте lizl будет изменена только часть класса Animal. Это частичное
присваивание. После присваивания члены класса Animal в объекте lizl будут иметь
значения, полученные от 1 iz2, но члены класса Lizard в, останутся без изменений.
Вторая проблема состоит в том, что программисты действительно могут пи-
сать такой код. Опытные программисты С, перешедшие на C++, довольно часто
выполняют присваивание объектам при помощи указателей. Поэтому надо сде-
лать так, чтобы присваивание выполнялось более приемлемым образом. Как го-
ворится в правиле 32, классы должно быть легко использовать правильно, и слож-
но - неправильно, а классы из вышеприведенной иерархии легко использовать
неправильно.
Один из вариантов решения проблемы - сделать операторы присваивания
виртуальными. Если бы функции Animal::operator= были виртуальными, то
присваивание привело бы к вызову оператора присваивания класса Lizard,
и такое поведение было бы корректным. Но посмотрите, что произойдет, если
объявить операторы присваивания виртуальными:
class Animal {
public:
virtual Animals operator=(const Animals rhs) ;
};
class Lizard: public Animal {
public:
virtual Lizards operator=(const Animals rhs);
Правило 33
inn:
261
};
class Chicken: public Animal {
public:
virtual Chickens operator=(const Animals rhs);
};
Благодаря относительно недавним изменениям в языке можно сделать так,
чтобы значение, возвращаемое каждым из операторов присваивания, было ссыл-
кой на корректный класс, но правила языка C++ требуют объявлять идентичные
типы параметров виртуальных функций во всех классах, в которых они объявле-
ны. Это означает, что операторы присваивания в классах Lizard и Chicken дол-
жны быть готовы принять любой тип объектов Animal в правой части присваива-
ния. Следовательно, надо учитывать, что допустим подобный код:
Lizard liz;
Chicken chick;
Animal *pAnimall = Sliz;
Animal *pAnimal2 = Schick;
*pAnimall = *pAnimal2; // Присвоить курице
// ящерицу'!
Это смешанное присваивание: слева стоит объект типа Lizard, а справа -
объект типа Chicken. Смешанные присваивания обычно не приводят к пробле-
мам в C++, потому что благодаря строгой типизации языка они оказываются
недопустимыми. Но, если оператор присваивания класса Animal стал виртуаль-
ным, появляется возможность таких смешанных операций присваивания.
Это ставит нас в сложное положение. Хотелось бы разрешить присваивание
с помощью указателей одинаковых типов, запретив при этом смешанное при-
сваивание посредством тех же самых указателей. Другими словами, разрешить:
Animal *pAnimall = Slizl;
Animal *pAnimal2 = Sliz2;
*pAnimall = *pAnimal2;
и запретить:
Animal *pAnimall = Sliz;
Animal *pAnimal2 = Schick;
// Присвоить ящерицу ящерице.
*pAnimall = *pAnimal2;
// Присвоить курицу ящерице.
Различить эти ситуации можно только во время выполнения программы, так
как иногда допустимо присваивать *pAnimall значение *pAnimal2,а иногда нет.
При этом вы вступаете в мрачный мир ошибок типа во время выполнения про-
граммы. В частности, вы должны сообщить об ошибке в функции operators
262
IS Разное
если столкнулись со смешанным присваиванием, если же типы одинаковы, надо
выполнить присваивание как обычно.
Можно использовать для реализации такого поведения оператор dynamic_cast
(см. правило 2). Вот как это делается для оператора присваивания класса Lizard:
Lizards Lizard::operator=(const Animals rhs)
{
// Убедиться, что rhs имеет тип lizard,
const Lizards rhs_liz = dynamic_cast<const Lizards>(rhs);
выполнить обычное присваивание *this значения rhs_liz;
}
Данная функция присваивает объекту *this значение rhs, только если
rhs имеет тип Lizard. Если это не так, то функция передает исключение
bad_cast, генерируемое оператором dynamic_cast при неудачной попытке
приведения типа. (На самом деле исключение имеет тип std: : bad_cast, по-
тому что компоненты стандартной библиотеки, включая генерируемые ими
исключения, находятся в пространстве имен std. Обзор стандартной библио-
теки см. в правиле 35.)
Даже если не беспокоиться об исключениях, эта функция кажется слишком
сложной и требующей больших затрат: оператор dynamic_cast должен обра-
щаться к структуре type_info, если один объект Lizard присваивается друго-
му объекту того же типа (см. правило 24):
Lizard lizl, liz2;
lizl = liz2; // Нет необходимости применять
// dynamic_cast; это присваивание
// должно быть допустимо.
Чтобы при обработке этого случая избежать чрезмерного усложнения кода
или применения оператора dynamic_cast, надо добавить к классу Lizard обыч-
ный оператор присваивания:
class Lizard: public Animal {
public:
virtual Lizards operator=(const Animals rhs) ;
Lizards operator=(const Lizards rhs); // Добавить это.
};
Lizard lizl, liz2;
lizl = liz2; // Вызов operator=
// с аргументом const izards.
Animal *pAnimall = Slizl;
Animal *pAnimal2 = Sliz2;
*pAnimall = *pAnimal2; // Вызов operator=
lie аргументом const Animals.
Правило 33
263
Фактически, если задана последняя функция operators на ее основе чрез-
вычайно просто реализовать предыдущую функцию:
Lizards Lizard::operator=(const Animals rhs)
{
return operator=(dynamic_cast<const LizardS>(rhs));
}
Эта функция пытается привести значение rhs к типу Lizard. Если такое при-
ведение успешно, вызывается обычный оператор присваивания класса. В против-
ном случае генерируется исключение bad_cast.
Честно говоря, вся эта деятельность по проверке типов во время выполнения
программы и использование операторов dynamic_cast меня беспокоит. Во-пер-
вых, некоторые компиляторы все еще не поддерживают dynamic_cast, поэтому
теоретически переносимый код, использующий их, на практике не обязательно
будет таковым. Что более важно, клиенты классов Lizard и Chicken должны
быть готовы перехватывать и обрабатывать при выполнении присваивания ис-
ключения bad_cast. Судя по моему опыту, немного найдется программистов,
которые любят писать программы подобным образом. Если же не сделать этого,
то неочевидно, выиграем ли мы что-либо по сравнению с исходной ситуацией,
когда пытались избежать частичного присваивания.
При таком неудовлетворительном положении дел с виртуальными операторами
присваивания имеет смысл перенаправить усилия и попытаться, прежде всего,
найти способ предотвратить выполнение пользователями рискованного при-
сваивания. Если такое присваивание будет отвергаться во время компиляции, вам
не придется беспокоиться о том, что оно сделает что-то не так.
Простейший способ не допустить такого присваивания - сделать функцию
operator= в классе Animal закрытой. Тогда значение «ящерицы» можно будет
присваивать ящерицам, а «куры» - курам, но частичные и смешанные присваива-
ния будут запрещены:
class Animal {
private:
Animals operator=(const Animals rhs); // Теперь эта функция
... // является закрытой.
};
class Lizard: public Animal {
public:
Lizards operator=(const Lizards rhs) ;
};
class Chicken: public Animal {
public:
Chickens operator=(const Chickens rhs) ;
};
Lizard lizl, liz2 ;
264
'Hi
Разное
lizl = liz2;
Chicken chickl, chick2;
chickl = chick2;
Animal *pAnimall = Slizl;
Animal *pAnimal2 = Schickl;
*pAnimall - *pAnimal2;
// Нормально.
// Также нормально.
// Ошибка! Попытка вызова закрытой
// функции Animal::operators
К сожалению, класс Animal является реальным, и такой подход запрещает
присваивание между объектами Animal:
Animal animall, animal2;
animall = animal2;
// Ошибка! Попытка вызова закрытой
// функции Animal::operators
Более того, это делает невозможной корректную реализацию операторов при-
сваивания классов Lizard и Chicken, поскольку операторы присваивания в про-
изводных классах отвечают за вызов операторов присваивания в своих базовых
классах:
Lizards Lizard::operator=(const Lizards rhs)
if (this == Srhs) return *this;
Animal::operator=(rhs);
// Ошибка! Попытка вызова закрытой
// функции. Но Lizard::operator=
// должен вызывать эту функцию
// для присваивания частей Animal
// в объекте *this!
Нетрудно решить последнюю проблему, объявив Animal: :operator= как
protected, но головоломка - как сделать так, чтобы можно было присваивать
объекты Animal, запретив частичное присваивание объектов Lizard и Chicken
при помощи указателей Animal, - остается нерешенной. Что делать бедному
программисту?
Проще всего устранить необходимость разрешать присваивание между объек-
тами Animal, например, сделав класс Animal абстрактным. Тогда нельзя будет
создавать экземпляры класса And mal, поэтому не нужно будет разрешать присва-
Рис. 6.2
ивание между объектами Animal. Конечно же,
это приводит к новой проблеме, так как перво-
начальная схема предполагала необходимость
создания объектов Animal. Существует простой
способ обойти данное затруднение. Вместо того
чтобы делать абстрактным сам класс Animal,
можно создать новый класс, скажем, Abstract-
Animal, состоящий из общих свойств объектов
Правило 33
265
Animal, Lizard и Chicken, и объявить абстрактным этот класс. Тогда каждый
из реальных классов будет наследовать от класса AbstractAnimal. Исправленная
иерархия показана на рис. 6.2.
А определения классов выглядят следующим образом:
class AbstractAnimal {
protected:
AbstractAnimalS operator= (const AbstractAnimalS rhs) ;
public:
virtual -AbstractAnimal () =0; // См. ниже.
};
class Animal: public AbstractAnimal {
public:
Animals operator^ (const Animals rhs) ;
};
class Lizard: public AbstractAnimal {
public:
Lizards operator=(const Lizards rhs);
};
class Chicken: public AbstractAnimal {
public:
Chickens operator=(const Chickens rhs);
};
Эта схема дает нам все, что нужно. Для классов Lizard, Chicken, Animal
разрешены однотипные присваивания; частичные и разнотипные присваивания
запрещены; и операторы присваивания в производных классах могут вызывать
операторы присваивания в базовом классе. Более того, код, написанный на осно-
ве классов Animal, Lizard или Chicken не требует изменений, поскольку эти
классы продолжают существовать и вести себя так, как они вели себя до введения
класса AbstractAnimal. Код, конечно, придется перекомпилировать, но это не
слишком большая цена за уверенность в том, что перекомпилированные присва-
ивания будут вести себя интуитивно понятно, а те, которые ведут себя неправиль-
но, не станут компилироваться.
Чтобы все это работало, класс AbstractAnimal должен быть абстрактным -
он должен содержать хотя бы одну абстрактную функцию. В большинстве случа-
ев создание подходящей функции не является проблемой, но иногда возникает
необходимость в классе типа AbstractAnimal, где, естественно, ни одна функ-
ция не может быть объявлена абстрактной. В этом случае обычно объявляется аб-
страктным деструктор, как и показано выше. Чтобы корректно поддержать поли-
морфизм при помощи указателей, базовые классы все равно должны иметь
виртуальные деструкторы, поэтому единственные затраты на «абстрагирование»
деструкторов состоят в неудобстве их реализации вне определений классов. (См.,
например, стр. 201.)
266
II
Разное
Если понятие о реализации абстрактной функции вас удивляет, вы просто
недостаточно разбираетесь в данном вопросе. Объявление функции абстрактной
не означает, что она не имеет реализации, это означает, что:
□ текущий класс является абстрактным
□ и любой наследующий от него реальный класс должен объявлять эту
функцию как «обычную» виртуальную функцию (то есть без =0).
Хотя большинство абстрактных функций никогда не реализуются, абстрак-
тные деструкторы представляют собой особый случай. Они должны быть реали-
зованы, поскольку всегда вызываются при вызове деструктора производного
класса. Кроме того, они часто выполняют полезные действия, такие как высво-
бождение ресурсов (см. правило 9) или запись сообщений в лог-файл. Хотя реа-
лизация абстрактных функций в общем случае встречается довольно редко, для
абстрактных деструкторов это не только обычно, но и обязательно.
Возможно, вы заметили, что рассказ о присваивании при помощи указателей
базового класса основан на предположении, что реальные базовые классы, такие
как Animal, содержат элементы данных. Если элементов данных нет, то пробле-
мы не существует, и будет безопаснее сделать реальный класс наследником дру-
гого реального класса без данных.
Существуют два варианта дальнейшего существования класса без данных,
который был бы реальным базовым классом: может ли он в будущем содержать
элементы данных или нет. Если да, то можно просто отложить проблему до тех
пор, пока в класс не будут добавлены элементы данных, в этом случае вы
получаете сиюминутную выгоду за счет возможных неприятностей в будущем
(см. также правило 32). С другой стороны, если базовый класс точно не будет
никогда иметь элементов данных, то похоже, что он скорее должен быть
абстрактным классом. Что толку от реального базового класса без данных?
Замена такого реального базового класса, как Animal, на абстрактный базо-
вый класс типа Abstract Animal не просто облегчает понимание поведения
operators Это также уменьшает вероятность того, что вы попытаетесь обра-
щаться с массивами полиморфно; неприятные последствия такого подхода были
рассмотрены в правиле 3. Но более важный выигрыш от использования этого
метода обнаруживается на уровне разработки, так как замена реальных базовых
классов абстрактными заставляет явно выделять полезные абстракции. То есть это
заставляет вас создавать новые абстрактные классы на основе полезных понятий,
даже если вы не осознаете их существование.
Если имеются два реальных класса С1 и С2, и вы
(ci) ( Л ) хотите, чтобы класс С2 открыто наследовал от класса
С1, вам нужно преобразовать иерархию, состоящую из
двух классов, в иерархию с тремя классами, создав
новый абстрактный класс А и сделав оба класса С1
и С2 его открытыми наследниками (см. рис. 6.3).
Данное изменение заставляет вас определить аб-
страктный базовый класс А, и это главное. Очевидно,
Правило 33
267
что классы С1 и С2 имеют что-то общее, поэтому они и связаны открытым насле-
дованием. Чтобы выполнить такое преобразование, вы должны определить, в чем
эта общность заключается. Кроме того, вы должны формализовать это «что-то»
в виде класса C++. В результате «что-то» становится не просто чем-то неопреде-
деленным, а получает статус формальной абстракции, имеющей определенные функ-
ции-члены и определенную семантику.
Но каждый класс представляет некоторый тип абстракции, поэтому не долж-
ны ли мы создавать по два класса для каждого понятия в иерархии, один абстракт-
ный (воплощающий абстрактную часть абстракции) а второй - реальный (во-
площающий часть абстракции, связанную с созданием объектов)? Нет, не
должны. Если сделать это, полученная иерархия будет содержать слишком много
классов. Такую иерархию сложно понимать, поддерживать и компилировать, что
противоречит целям объектно-ориентированного программирования.
Цель его состоит в том, чтобы определить полезные абстракции и вводить их -
и только их - в абстрактные классы. Но как выделить полезные абстракции? Кто
может знать, какие абстракции окажутся полезными в будущем? Кто может пред-
сказать, кто будет наследовать и от чего?
Я не знаю, как предсказать будущее использование иерархии наследования,
однако уверен: необходимость абстракции в одной ситуации может быть случай-
ной, но если абстракция требуется в нескольких случаях, это обычно является
значимым. Таким образом, полезные абстракции - те абстракции, которые полез-
ные в различных ситуациях. Они соответствуют классам, которые полезны как
сами по себе (то есть нужны объекты этого типа), так и для того, чтобы создавать
от них производные классы.
Это в точности соответствует выгоде от преобразования реального базового
класса в абстрактный: такое преобразование заставляет вводить новый абстракт-
ный класс, только если существующий реальный класс будет применяться в каче-
стве базового, то есть когда класс будет (повторно) использоваться в новой ситу-
ации. Как было показано, такие абстракции полезны.
Когда нужно просто ввести новое понятие, мы не можем оправдать создание
одновременно и абстрактного класса (для самого понятия) и реального класса
(для объектов, соответствующих этому понятию), но когда оно потребуется во
второй раз, оправдание налицо. Описанное преобразование просто автоматизи-
рует этот процесс и заставляет разработчиков и программистов явно представлять
полезные абстракции, даже если они еще не точно представляют, какие понятия
пригодятся в будущем. Также оказывается, что при этом гораздо проще обеспе-
чить разумное поведение операторов присваивания.
Проанализируем короткий пример. Допустим, вы разрабатываете приложение,
которое занимается переносом данных между компьютерами в локальной сети,
разбивая их на пакеты и передавая в соответствии с некоторым протоколом.
(Здесь будет рассмотрен только класс или классы для представления пакетов.)
Предположим далее, что имеется только один тип протокола передачи и только
один тип пакетов. Возможно, вы слышали о существовании других протоколов
268
и
Разное
и типов пакетов, но никогда их не поддерживали и не собираетесь делать этого
в будущем. Должны ли вы создавать абстрактные классы пакетов (для представ-
ления понятия пакета) наряду с реальными классами для пакетов, которые точно
будете использовать? Если вы сделаете это, то сможете затем добавлять новые
типы пакетов, не изменяя соответствующий базовый класс. Это избавит вас от
необходимости после добавления нового типа пакетов перекомпилировать все
использующие пакеты приложения. Но такой подход требует создания двух
классов, а сейчас вам нужен только один (для используемого типа пакетов). Стоит
ли сейчас усложнять схему с тем, чтобы разрешить будущее развитие, которое,
возможно, и не потребуется?
В данном случае не существует однозначно правильного выбора, но практика
показывает, что не получается создавать хорошие классы для понятий, которые
мы недостаточно понимаем. Если вы создадите абстрактный класс для пакетов,
насколько вероятно, что вы сделаете его таким, как нужно, в особенности, если
ваш опыт ограничивается только одним типом пакетов? Помните, что вы по-
лучите выигрыш от использования абстрактного класса для пакетов, только если
разработаете его так, чтобы будущие классы могли наследовать от него без
изменения его самого. (Если потребуется изменение абстрактного класса, то вам
придется перекомпилировать весь код, использующий пакеты, и вы ничего не
выиграете.)
Маловероятно, что вам удастся разработать удовлетворительный абстрактный
класс пакетов, если вы не слишком хорошо разбираетесь в различных типах
пакетов и ситуациях, когда они используются. В этом случае, учитывая ваш
ограниченный опыт, я бы посоветовал вам не определять абстрактный класс для
пакетов, добавив его позже, если вам потребуется выполнить наследование от
реального класса пакета.
Описанное преобразование является одним, но не единственным способом
определить необходимость абстрактных классов. Существует много других ме-
тодик выявить приемлемые кандидатуры для абстрактных классов (вы найдете
их в книгах по объектно-ориентированному анализу). Абстрактные классы мож-
но вводить не только для того, чтобы сделать реальный класс наследником дру-
гого реального класса. Но желание связать два реальных класса при помощи от-
крытого наследования обычно указывает на необходимость создания нового
абстрактного класса.
Как это часто бывает, реальность в этом случае грубо вторгается в мирное тео-
ретическое размышление. Библиотеки классов C++ от независимых производи-
телей плодятся очень быстро, и что, если вы захотите создать реальный класс,
наследующий от реального класса в библиотеке, к которой у вас есть доступ толь-
ко на чтение?
Вы не можете изменить библиотеку, добавив в нее новый абстрактный класс,
поэтому ваш выбор ограничен и непривлекателен:
□ сделать реальный класс производным от существующего реального класса
и примириться с проблемами, присущими присваиванию, которые обсуждались
Правило 33
1Ш
269
в начале этого раздела. Вы также должны остерегаться неприятностей,
связанных с массивами (см. правило 3);
□ попытаться найти абстрактный класс, который находится более высоко
в иерархии библиотеки и делает большую часть того, что вам нужно, а затем
выполнить наследование от этого класса. Конечно, подходящего класса мо-
жет и не быть, и даже если такой класс существует, вам может потребовать
ся повторить значительную часть работы, которую вы уже сделали при ре-
ализации реального класса, функциональность которого хотите расширить;
□ реализовать новый класс при помощи библиотечного класса, от которого вы
бы хотели наследовать. Например, можно включить объект библиотечного
класса в качестве элемента данных, а затем реализовать интерфейс библио-
течного класса в вашем новом классе:
class Window { // Это библиотечный класс,
public:
virtual void resize(int newWidth, int newHeight) ;
virtual void repaint() const;
int width() const;
int height() const;
};
class Specialwindow { // Это класс, который вы хотите
public: // сделать наследником класса
... // Window.
// реализация невиртуальных
функций
int width() const { return w.width(); }
int height() const { return w.height(); }
// реализация унаследованных
// виртуальных функций
virtual void resize(int newWidth, int newHeight);
virtual void repaint() const;
private:
Window w;
};
Эта стратегия требует обновлять ваш класс при каждом обновлении версии
библиотечного класса, от которого он зависит. Вы также будете вынужде-
ны отказаться от возможности переопределять объявленные в библиотеч-
ном классе виртуальные функции, так как нельзя переопределять не уна-
следованные виртуальные функции;
□ примириться с тем, что есть. Использовать реальный класс из библиотеки
и изменить программу так, чтобы этого класса было достаточно. Писать
функции - не члены класса, обеспечивающие функциональность, которую
выхотите, но не можете добавить к классу. Полученная в результате про-
грамма может быть не так эффективна, не так переносима и расширяема,
как вам бы этого хотелось, но по крайней мере работоспособна.
270
Разное
Ни один из этих вариантов не является особенно привлекательным, поэтому
вам придется выбирать наименьшее из зол. Это не слишком весело, но уж так
устроен мир. Чтобы в будущем облегчить жизнь себе (и остальным), выражайте
недовольство создателям библиотек, которые вы считаете плохо разработанны-
ми. В случае удачи (и большого числа жалоб пользователей), структура этих биб-
лиотек может со временем улучшиться.
Каким бы ни был ваш выбор, основное правило остается в силе: нетерминальные
классы должны быть абстрактными. Вы не всегда сможете следовать ему, работая
с чужими библиотеками, но в коде, которым управляете вы сами, соблюдение это-
го правила принесет вам дивиденды в виде надежности, живучести, понятности
и расширяемости ваших программ.
Правило 34. Умейте использовать
в одной программе С и C++
Проблемы, возникающие при создании программы, часть которой написана
на C++, а часть па С, во многом совпадает с трудностями, с которыми вы стал-
киваетесь, пытаясь «сшить» программу из объектных файлов, сгенерированных
несколькими компиляторами С. Не существует способа объединить такие фай-
лы, если различные компиляторы не согласуются по параметрам, зависящим от
реализации, например размеру чисел типа int и double и механизму передачи
параметров при вызове функции. Практические аспекты разработки программ
с помощью нескольких компиляторов почти полностью игнорируются при стан-
дартизации языка, поэтому единственный надежный способ проверить, можно ли
объединять в одной программе объектные файлы, созданные при помощи компи-
ляторов А и В, - получить от поставщиков А и В подтверждение, что их продук-
ты дают совместимый выход. Это верно и для программ, созданных при помощи
С и C++, поэтому перед тем, как попытаться сочетать С и C++ в одной програм-
ме, убедитесь, что ваши компиляторы С и C++ генерируют совместимые объек-
тные файлы. После этого вам нужно будет рассмотреть еще четыре аспекта: кор-
рекцию имен, инициализацию статических объектов, динамическое выделение
памяти и совместимость структур данных.
Коррекция имен
Как вы, наверное, уже знаете, коррекция имен (паше mangling) - это процесс,
во время которого компиляторы C++ дают каждой функции в программе уникаль-
ное имя. В языке С такой процесс не нужен, поскольку нельзя перегружать имена
функций, но почти любая программа C++ содержит несколько функций с одним
и тем же именем. (Рассмотрим, например, библиотеку iostream, в которой
объявляются несколько версий функций operator<< и operator».) Перегруз-
ка несовместима со многими компоновщиками, так как они обычно скептически
относятся к нескольким функциям с одним именем. Коррекция имен является
уступкой компоновщикам; в частности их требованию, чтобы все имена функций
были уникальными.
Правило 34
271
Пока вы работаете только с C++, коррекция имен вряд ли будет вас беспоко-
ить. Если имеется функция drawLine, имя которой компилятор корректирует
как xyzzy, то вы будете всегда использовать имя drawLine, и вам не будет дела
до того, что в объектных файлах она называется xyzzy.
Ситуация будет совсем другой, если функция drawLine находится в библио-
теке С. В этом случае ваш исходный файл, вероятно, будет включать заголовоч-
ный файл, содержащий такое объявление:
void drawLine (int xl, int yl, int х2 , int у2) ;
а код, как обычно, будет содержать вызовы функции drawLine. Каждый такой
вызов будет транслироваться компилятором в вызов скорректированного имени
функции, поэтому если записать следующее:
drawLine(a, b, с, d) ; // Вызов нескорректированного
// имени функции.
то объектные файлы будут содержать соответствующий вызов функции:
xyzzy(a, Ь, с, d) ; // Вызов скорректированного
/ / имени функции.
Но если drawLine является функцией С, то объектный файл (или архив, или
динамически подключаемая библиотека и т.д.) будет содержать скомпилирован-
ную версию функции drawLine с тем же именем drawLine, корректировка име-
ни не будет выполняться. Когда вы попытаетесь скомпоновать объектные файлы
вместе, то получите сообщение об ошибке, потому что компоновщик ищет функ-
цию с именем xyzzy, а такой функции не существует.
Чтобы решить проблему, вам нужен какой-то способ сообщить компилятору
C++, что не нужно выполнять корректировку определенных имен функций. Это
не нужно будет делать для функций, написанных на других языках, будь то С,
ассемблер, Fortran, Lisp, Forth или какой-то другой язык. (Включая и Cobol, но
что вам до этого?) В конце концов, если вы вызываете функцию С с именем
drawLine, она на самом деле называется drawLine, и объектный код должен со-
держать ссылку именно на это имя, а не на его откорректированную версию.
Используйте для подавления коррекции имен директиву C++ extern "С":
// Объявить функцию drawLine;
//не корректировать ее имя.
extern "С"
void drawLine (int xl, int yl, int x2 , int y2);
He попадитесь в ловушку, предположив, что если есть extern "С", то должен
быть и extern " Pascal" и extern "FORTRAN". Таких директив нет, по крайней
мере в стандарте языка. Лучше всего рассматривать директиву extern "С" не как
утверждение, что вызываемая функция написана на С, а как утверждение, что функ-
ция должна вызываться так, будто бы она была написана на С. (Технически, дирек-
тива extern "С" означает, что функция должна компоноваться принятым
272
II
Разное
в С образом, но как же именно, не слишком понятно. Тем не менее, это всегда зна-
чит, что корректировка имени функции должна подавляться.)
Например, если вам пришлось написать функцию на ассемблере, вы также
можете объявить ее при помощи директивы extern "С":
// Эта функция написна на ассемблере -
//не корректировать ее имя.
extern "С" void twiddleBits (unsigned char bits) ;
Можно даже объявлять с extern " С" функции C++. Это может быть полезно,
если вы пишете библиотеку на C++ и хотите, чтобы она была доступна пользова-
телям других языков программирования. Благодаря подавлению корректировки
имен для функций C++ программисты могут использовать естественные и нагляд-
ные имена вместо тех, которые бы автоматически создал компилятор:
// Следующая функция C++ предназначена для использования
//в других языках, поэтому ее имя не должно корректироваться.
extern "С” void simulate(int iterations);
Для многих функций корректировка имени не должна выполняться, и было бы
тяжело писать extern "С" перед каждой из них. К счастью, это не нужно. Можно
применить директиву extern "С" ко всему набору функций, просто заключив его
в фигурные скобки:
extern "С" {
// Запретить корректировку имени
// для всех этих функций.
int у2) ;
void drawLine (int xl, intyl, int х2 ,
void twiddleBits (unsigned char bits) ;
void simulate(int iterations);
}
Применение директивы extern "С" упрощает поддержку заголовочных фай-
лов, которые должны использоваться и в С, и в C++. При компиляции в C++ нуж-
но включать директиву extern " С", а при компиляции в С нет. Воспользовавшись
тем, что символ препроцессора__cplusplus определен только при компиляции
в C++, можно придать многоязычным заголовочным файлам следующую структуру:
#ifdef___cplusplus
extern "С" {
#endif
int у2);
void drawLine(int xl, int yl, int x2,
void twiddleBits (unsigned char bits) ;
void simulate(int iterations);
#ifdef___cplusplus
}
#endif
Правило 34
273
Между прочим, не существует «стандартного» алгоритма коррекции имен.
Различные компиляторы могут выполнять коррекцию имен по-разному, и они так
и делают. Это неплохо. Если бы все компиляторы выполняли коррекцию имени
одинаковым образом, сложилось бы впечатление, будто они создают совместимый
код. При существующем положении вещей, если попытаться смешать объектный
код, полученный при помощи несовместимых компиляторов C++, весьма вероят-
но, что во время компоновки у вас на экране появится сообщение об ошибке, так
как скорректированные имена функций не будут совпадать. Это будет означать,
что, вероятно, кроме рассмотренной, есть еще и другие проблемы совместимости,
и лучше обнаружить их как можно раньше.
Инициализация статических объектов
После того как вы овладели коррекцией имен, вам нужно справиться с тем,
что в C++ большая часть кода может выполняться как до, так и после вызова
функции main. В частности, конструкторы статических объектов, принадлежа-
щих классам, и объектов в глобальном и других пространствах имен обычно вы-
зываются до выполнения данной функции. Такой процесс называется инициали-
зацией статических объектов (static initialization). Это прямо противоположно
нашему обычному взгляду на программы С и C++, когда функция main рассмат-
ривается как точка входа в программу. Аналогично, деструкторы объектов, созда-
ваемые в процессе инициализации статических объектов, должны вызываться во
время уничтожения статических объектов (static destruction); этот процесс обыч-
но происходит после того, как выполнение функции main уже завершено.
Для разрешения этой дилеммы, когда с одной стороны предполагается, что
функция main должна вызываться первой, а с другой стороны - что до выполне-
ния функции main должны создаваться объекты, многие компиляторы вставля-
ют в начало функции main специально сгенерированную компилятором функ-
цию, которая и заботится об инициализации статических объектов. Аналогично,
компиляторы часто вставляют в конце функции main вызов другой специальной
функции, которая заботится об уничтожении статических объектов. Код, автома-
тически созданный для функции main, часто выглядит примерно так:
int main(int argc, char *argv[])
{
performStatidnitialization () ; // Создается // компилятором
операторы, входящие в функцию main; performStaticDestruction(); // Создается
// компилятором
)
He воспринимайте это буквально. Функции performStatidnitialization
и performStaticDestruction обычно имеют более загадочные имена, а также
могут быть встроенными, и в этом случае вы не увидите их в объектном файле.
Важно следующее: при выборе компилятором C++ такого подхода к инициализа-
ции и уничтожению статических объектов они будут создаваться и уничтожаться,
10 - 679
274
Mil
Разное
только если функция main написана на C++. Поскольку это общепринятый под-
ход к инициализации и уничтожению статических объектов, то если какая-то
часть системы написана на C++, вы должны постараться написать функцию main
также на C++.
Иногда кажется более осмысленным написать функцию main на С - скажем,
когда большая часть программы написана на С, а на C++ только вспомогательная
библиотека. Тем не менее, не исключено, что библиотека C++ содержит статичес-
кие объекты (если не сейчас, то возможно в будущем - см. правило 32), поэтому
все же лучше написать функцию main на C++. Это не означает, что вам нужно
переписывать код С. Просто переименуйте написанную на С функцию main
в realMain, а затем вызовите ее из функции main, написанной на C++.
extern "С"
int realMain(int argc, char *argv[]);
int main(int argc, char *argv[])
{
return realMain(argc, argv);
}
// Напишите эту
/ / функцию на С.
//А эту на C++.
При этом неплохо поместить перед функцией main комментарий, объясняю-
щий, что происходит.
Если вы не можете написать функцию main на C++, наверняка столкнетесь
с проблемой, поскольку нет другого переносимого способа убедиться в том, что
будут вызываться конструкторы и деструкторы статических объектов. Это не оз-
начает, что все потеряно, но вам придется больше потрудиться. Производители
компиляторов хорошо знакомы с данной проблемой, поэтому почти все из них
предоставляют какой-либо межъязыковый механизм для запуска процесса иници-
ализации и уничтожения статических объектов. За соответствующей информаци-
ей обратитесь к документации компилятора или свяжитесь с производителем.
Динамическое выделение памяти
Вопрос инициализации и уничтожения статических объектов подводит нас
к проблеме динамического выделения памяти. Здесь действует общее простое пра-
вило: части программы, написанные на C++, используют операторы new и delete
(см. правило 8), а части, написанные на С, используют функции malloc (и ее ва-
рианты) и free. Пока память, полученная при помощи new, освобождается по-
средством delete, а память, полученная при помощи malloc, освобождается
функцией free, все будет в порядке. Однако вызов функции free для указателя,
полученного при помощи new, приведет к неопределенному поведению, так же как
и удаление оператором delete указателя, полученного при помощи функции
malloc. Следовательно, нужно строго разделять использование new и delete от
malloc и free.
Иногда это легче сказать, чем выполнить. Рассмотрим скромную (но удобную)
функцию strdup, которая, не являясь стандартной ни в С, ни в C++, применяет-
ся очень широко:
Правило 34
!!
275
char * strdup(const char *ps) ; // Вернуть копию строки,
//на которую указывает ps.
Чтобы избежать утечек, память, выделенная внутри функции strdup, должна
освобождаться в функции, которая вызывала strdup. Но как это сделать? При
помощи оператора delete? Вызвав функцию free? Если вызывается функция
strdup из библиотеки С, придется выбрать второй вариант. Если функция была
написана для библиотеки C++, вероятно, первый. Следовательно, то, что нужно
сделать для функции s t гdup, меняется не только от системы к системе, но и от ком-
пилятора к компилятору. Чтобы обеспечить переносимость, старайтесь избегать
вызова функций, которые не входят в стандартную библиотеку (см. правило 35) или
не доступны в устойчивой форме на большинстве компьютерных платформ.
Совместимость структур данных
Теперь пора поговорить о передаче данных между программами С и C++.
Нельзя надеяться, что функции С будут понимать свойства функций C++, поэто-
му уровень общения между двумя языками должен быть ограничен понятиями,
которые можно выразить на С. Не существует переносимого способа передавать
процедурам, написанным на С, объекты или указатели на функции - члены клас-
са. Но язык С понимает обычные указатели, поэтому если ваши компиляторы С
и C++ дают совместимый выход, то функции в двух языках могут безопасно об-
мениваться указателями на объекты и указателями на статические функции или
функции, не являющиеся членами класса. Как и следовало ожидать, структуры
и переменные встроенных типов (например, int, char и т.д.) также могут сво-
бодно пересекать границу C/C++.
Поскольку правила, обусловливающие формат struct в C++, согласуются
с соответствующими правилами С, то можно с уверенностью предположить, что
определение структуры, которое компилируется в обоих языках, будет располо-
жено обоими компиляторами одинаковым образом. Такие структуры можно без-
опасно передавать из С в C++ и обратно. Если добавить невиртуальные функции
в версию структуры, написанную на C++, то формат структуры в памяти не дол-
жен измениться, поэтому объекты структуры (или класса), содержащие только не-
виртуальные функции, будут совместимы со своими собратьями в С, в определе-
нии структуры которых отсутствует только объявление функций - членов класса.
Но все это перестанет работать при введении виртуальных функций, поскольку
добавление к классу виртуальных функций приводит к тому, что формат объек-
тов этого типа в памяти становится другим (см. правило 24). Наследование
структуры от другой структуры (или класса) также изменяет ее формат, поэтому
структуры с базовыми структурами (или классами) являются не лучшей канди-
датурой для обмена с функциями С.
С точки зрения структуры данных все вышесказанное сводится к следующему:
можно безопасно передавать структуры данных из C++ в С и обратно, если опреде-
ление этих структур компилируется и в С, и в C++. Добавление невиртуальных
ю*
276
'ШНП1
Разное
функций-членов к C++ версии структуры, которая до этого была совместимой
с С, вероятнее всего, не повлияет на совместимость, в отличие от почти всех дру-
гих изменений.
Резюме
Если вы хотите сочетать С и C++ в одной программе, не забывайте о следую-
щих простых принципах:
□ убедитесь, что компиляторы С и C++ создают совместимые объектные файлы;
□ объявляйте функции, которые будут использоваться в обоих языках, с ди-
рективой extern "С";
□ если возможно, напишите функцию main на C++;
□ всегда используйте delete для памяти, выделенной при помощи new; все-
гда используйте free для памяти, выделенной при помощи malloc;
□ ограничьтесь передачей только структур данных, которые компилируются
в С; версии структур в C++ могут содержать также невиртуальные функци-
и-члены.
Правило 35. Ознакомьтесь со стандартом языка
С момента своей публикации в 1990 году книга The Annotated C++ Reference
Manual (Справочное руководство по C++ с комментариями) являлась исчерпы-
вающим справочником для профессиональных программистов, которым нужно
было знать, что входит в язык C++, а что нет. За время, прошедшее после выхода
ARM (часто употребляемое сокращение для справочника), комитет по стандар-
тизации ISO/ANSI внес в язык довольно много изменений, как незначительных,
так и крупных (в основном добавления). Поэтому сейчас справочник ARM уже не
может считаться исчерпывающим.
Внесенные в C++ изменения помогают писать хорошие программы. И тем, Кто
хочет быть настоящим профессионалом, необходимо знать различия текущего
стандарта C++ и его версии, описанной в ARM.
Производители программного обеспечения руководствуются стандартом
ISO/ANSI для C++ при разработке компиляторов, авторы изучают его при напи-
сании книг, а программисты ищут в нем ответы на практические вопросы. Наибо-
лее важные изменения в языке C++, введенные после выхода ARM, таковы;
□ добавлены новые свойства-. RTTI, пространства имен, тип bool, ключевые
слова mutable и explicit, возможность перегружать операторы для пе-
речислимых типов и инициализировать константные целые статические
члены класса в определении класса;
□ расширено применение шаблонов', разрешено создание шаблонов функций -
членов класса, определен стандартный синтаксис, при помощи которого
можно потребовать создания экземпляров шаблонов, в шаблонах функций
теперь разрешены аргументы без типа, и шаблоны классов сами могут ис-
пользоваться в качестве аргументов шаблонов;
Правило 35
277
□ усовершенствована обработка исключений: спецификации исключений бо-
лее строго проверяются во время компиляции, и функция unexpected
может порождать объект bad_exception;
□ изменены процедуры выделения памяти: добавлены функции operator
new [ ] и operator delete [ ], операторы new/new [ ] теперь генерируют ис-
ключение, если память не может быть выделена, и введены альтернативные
версии операторов new/new [ ], возвращающие 0 в случае неудачной попыт-
ки выделения памяти;
□ добавлены новые формы приведения типов: static_cast, dynamic_cast,
const_cast и reinterpret_cast;
□ усовершенствованы правила языка: тип значения, возвращаемого переоп-
ределенными виртуальными функциями, не должен больше в точности со-
впадать с типом переопределяемой функции, а время жизни временных
объектов определено точно.
Почти все эти изменения описаны в книге The Design and Evolution of C++
(Разработка и эволюция C++). Современные учебники по C++ (написанные пос-
ле 1994 года) также должны включать их. (Если вам попадется книга, в которой
они не описаны, откажитесь от ее покупки). Книга «Наиболее эффективное ис-
пользование C++» (которую вы держите в руках) содержит примеры практичес-
кого применения большинства из этих новых свойств. Если вас интересует ка-
кое-либо из них, поищите соответствующую запись в указателе.
Но изменения в языке C++ бледнеют по сравнению с тем, что про-
изошло со стандартной библиотекой. Кроме того, эволюция стандартной биб-
лиотеки не была отражена так же широко, как эволюция языка. Например, книга
The Design and Evolution of C++ почти не упоминает стандартную библиотеку.
Большинство книг, описывающих библиотеку, безнадежно устарели, так как она
была значительно изменена в 1994 году.
Возможности стандартной библиотеки условно делятся на следующие ос-
новные категории:
□ поддержка стандартной библиотеки С. C++ не забывает про свои корни.
Небольшая доработка привела C++ версию библиотеки С в соответствие
с более строгой проверкой типов в языке C++, но практически все, что вы
знали и любили (или ненавидели) в библиотеках С, осталось и в C++;
□ поддержка строк. Как было заявлено председателю рабочей группы стан-
дартной библиотеки C++ Майку Вайлоту (Mike Vilot), «если не появится
стандартный тип string, на улицах прольется кровь!». (Некоторые люди
бывают столь эмоциональны.) Успокойтесь и отложите топоры и дубин-
ки - стандартная библиотека C++ содержит строки;
□ поддержка локализации. В разных странах используются разные наборы
символов и соглашения при выводе даты и времени, сортировке строк,
выводе значений денежных знаков и т.д. Поддержка локализации в стан-
дартной библиотеке облегчает разработку программ, приспособленных
к тради циям той или иной культуры;
278
Разное
□ поддержка ввода/вывода. Библиотека iostream остается частью стандар-
та C++. Хотя некоторые классы и были исключены (в частности классы
iostream и f stream), а некоторые заменены (например, stringstream,
основанный на классе string, занял место устаревшего strstream, осно-
ванного на char*), главные возможности стандартных классов библиоте-
ки io st ream отражают уже существующие реализации;
□ поддержка вычислительных приложений. Комплексные числа наконец поме-
щены в стандартную библиотеку. Кроме того, библиотека теперь содержит
специальные классы массивов (valarray), ограничивающие совместное
использование. Эти массивы более подходят для эффективной оптимизации,
чем встроенные массивы, особенно в многопроцессорных архитектурах. Биб-
лиотека также предоставляет несколько полезных численных функций;
□ поддержка универсальных контейнеров и алгоритмов. В стандартной библио-
теке C++ содержится набор классов и шаблонов функций, которые известны
как стандартная библиотека шаблонов (the Standard Template Library - STL).
Стандартная библиотека шаблонов является наиболее революционной
частью библиотеки C++. Ее основные черты рассматриваются ниже.
Но прежде чем описать STL, я должен рассказать о двух характерных чертах
стандартной библиотеки C++, о которых вы должны знать.
Во-первых, почти все в библиотеке является шаблоном. В книге я говорил
о стандартном классе string, но фактически такого класса не существует.
Вместо него есть шаблон класса с именем basic_string, представляющий
последовательности символов, и этот шаблон принимает в качестве параметра
тип символов, образующий такую последовательность. Это позволяет созда-
вать строки из символов любых видов (символов двойной ширины, символов
Unicode и т.д.).
То, что мы обычно представляем себе в виде класса string, на самом деле яв-
ляется экземпляром шаблона basic_string<char>. Поскольку он часто исполь-
зуется, в стандартной библиотеке шаблонов определяется тип:
typedef basic_string<char> string;
Даже такая запись скрывает многие детали, поскольку шаблон basic_s tring
имеет три аргумента, все из которых, кроме первого, имеют значения по умолча-
нию. Для того чтобы действительно понять код типа string, нужно увидеть пол-
ное, без пропусков, объявление basic_string:
templatecclass charT,
class traits = string_char_traits<charT>,
class Allocator = allocator> >
class basic_string;
Чтобы использовать тип string, вам не обязательно понимать этот бессмыс-
ленный набор слов: хотя тип string и является определением типа для экземп-
ляра адского шаблона, он ведет себя так же, как скромный класс без шаблона, на
который он похож благодаря определению typedef. Просто сохраните в дальнем
уголке мозга запись о том, что если вам когда-либо понадобится изменить тип
Правило 35
279
символов в строках, или тонко настроить параметры символов, или управлять
выделением памяти для строк, то вы сможете сделать это при помощи шаблона
basic—string.
Подход, принятый при разработке типа string - обобщить его в шаблоне, -
повторяется во всей стандартной библиотеке C++. Потоки ввода/вывода? Они
также являются шаблонами; параметр типа определяет тип образующих потоки
символов. Комплексные числа? Тоже шаблоны; параметр типа определяет, как
должны записываться компоненты чисел. Массивы valarray? Шаблоны; пара-
метр типа определяет, что находится в каждом из массивов. И, конечно же, стан-
дартная библиотека почти полностью состоит из шаблонов. Если вы чувствуете
себя не слишком свободно при работе с шаблонами, сейчас как раз подходящее
время для того, чтобы их освоить.
Нужно знать еще, что почти все в стандартной библиотеке находится в про-
странстве имен std. Чтобы использовать что-то из стандартной библиотеки, не
задавая имя полностью, вам придется задействовать директиву using или (что
предпочтительнее) объявление using. К счастью, эти синтаксические операции
выполняются автоматически, когда вы включаете в код соответствующие заголов-
ки с помощью директивы # include.
Стандартная библиотека шаблонов
Самые значительные изменения произошли в стандартной библиотеке шаб-
лонов (Standard Template Library, сокращенно STL). (Так как почти все в библио-
теке C++ является шаблонами, название STL не слишком удачно. Но поскольку
для части библиотеки, содержащей контейнеры и алгоритмы, это название стало
уже привычным, его все и используют, не обращая внимания на то, хорошо оно
подходит или плохо.)
Вероятно, STL повлияет на развитие большинства библиотек C++, поэтому
важно, чтобы вы знали ее основы. Стандартная библиотека шаблонов базируется
на трех фундаментальных понятиях: контейнеры, итераторы и алгоритмы. Кон-
тейнеры содержат наборы объектов. Итератор - это объекты, похожие на указате-
ли и позволяющие перемещаться по контейнерам STL так же, как указатели по-
зволяют перемещаться по встроенным массивам. Алгоритмы представляют собой
функции, которые работают с контейнерами STL и используют итераторы.
Проще всего разобраться в принципе действия STL, если вспомнить главное
правило C++ (и С) для работы с массивами: указатель на массив может указы-
вать на любой элемент массива или на элемент сразу за концом массива. Если ука-
затель ссылается на элемент, расположенный сразу за концом массива, то его
можно сравнивать только с другими указателями на массив; результат его разы-
менования не определен.
Воспользовавшись этим правилом, можно написать функцию, находящую
в массиве определенное значение. Для массива целых чисел она будет выглядеть,
например, так:
int * findtint *begin, int *end, int value)
{
while (begin 1= end && *begin != value) ++begin;
280
Hi
Разное
return begin;
}
Эта функция ищет элемент со значением value в диапазоне от begin до end
(исключая end, который указываем на элемент сразу за концом массива) и воз-
вращает указатель на первый встретившийся элемента массива со значением
value; если такой элемент не будет найден, функция возвращает end.
Возврат end кажется довольно странным способом сообщить о бесплодном
поиске. Не лучше ли было бы возвращать 0 (нулевой указатель null)? Конечно,
значение null более привычно в подобной ситуации, но это не делает его «луч-
ше». Функция find должна возвращать некоторое особенное значение указате-
ля, обозначающее неудачное завершение поиска, а для такой цели указатель end
подходит ничуть не хуже, чем нулевой указатель. Кроме того, как вы вскоре уви-
дите, указатель end лучше обобщает другие типы контейнеров, чем нулевой ука-
затель.
Возможно, вам никогда и не понадобится писать функцию find, но такой под-
ход достаточно разумен и прекрасно обобщается. Если вы выполнили этот прос-
той пример, значит, уже овладели большинством идей, на которых основана биб-
лиотека STL.
Вы можете использовать функцию find так:
int values[50];
int *firstFive = findfvalues, // Поиск в диапазоне
values+50, // values[0]-values[49]
5) ; // значения 5.
if (firstFive != values+50) { // Был ли поиск успешным?
// Да.
} else { // Нет, поиск был неудачным
}
Вы также можете с помощью функции find осуществлять поиск в поддиапа-
зоне массива:
int *firstFive = find(values, // Поиск в диапазоне
values + 10, // values[0]-values[9]
5); // значения 5.
int age =36;
int *firstValue = find(values+10, // Поиск в диапазоне
values + 20, // values[10]-values[19]
age) ; // значения age.
В функции find нет ничего, что бы ограничивало ее применимость к масси-
вам целых чисел, поэтому по сути она является шаблоном:
templatecclass Т>
Т * find(T *begin, Т *end, const Т& value)
Правило 35
!
281
{
while (begin != end && *begin != value) ++begin;
return begin;
}
Обратите внимание: при преобразовании в шаблон вместо передачи value по
значению выполняется передача по ссылке на const. Это связано с тем, что те-
перь передаются произвольные типы, и поэтому приходится учитывать затраты
на передачу по значению. Для каждого передаваемого по значению параметра
приходится вызывать его конструктор и деструктор при всяком вызове функции.
Чтобы избежать этих затрат, надо использовать передачу по ссылке, исключая со-
здание и удаление объекта.
Этот шаблон достаточно хорош, но его можно еще улучшить. Посмотрите на
операции с begin и end. Из них используются только сравнение на равенство
и неравенство, разыменование, префиксный инкремент (см. правило 6) и копиро-
вание (для возвращаемого значения функции - см. правило 19). Все эти операции
можно перегрузить, поэтому зачем ограничивать функцию find работой с указате-
лями? Почему не разрешить использование не только указателей, но и любых дру-
гих объектов, поддерживающих эти операции? В результате вы освободите функ-
цию find от встроенного значения операций с указателями. Например, можно
будет определить похожий на указатель объект для связного списка, префиксный
оператор инкремента которого перемещал бы вас на следующий элемент в списке.
Эта концепция и лежит в основе итераторов STL. Итераторы - это, как уже
говорилось, похожие на указатели объекты, предназначенные для использования
с контейнерами STL. Они «близкие родственники» интеллектуальных указателей,
описанных в правиле 28, но последние обычно более «амбициозны». С технической
точки зрения и те, и другие реализуются при помощи одинаковых методов.
Рассматривая итераторы как похожие на указатели объекты, можно заменить
в функции find указатели на итераторы, переписав функцию find:
template<class Iterator, class T>
Iterator find(Iterator begin, Iterator end, const T& value)
{
while (begin != end && *begin != value) ++begin;
return begin;
}
Поздравляю! Вы только что написали часть стандартной библиотеки шабло-
нов. Она содержит десятки алгоритмов, работающих с контейнерами и итерато-
рами, и функция find является одним из них.
Контейнеры в STL имеют типы bitset, vector, list, deque, queue,
priority_queue, stack, set и map, и вы можете применять функцию find
к любому из этих типов:
list<char> charList; // Создать объект STL
// для списка символов.
// Найти положение первого символа "х" в charList.
282
Разное
II
list<char>::iterator it = find(charList.begin(),
charList.end() ,
"x") ;
«Постойте!», - кричите вы, - «Это совсем не похоже на предыдущие примеры
массивов!». Нет, они похожи; вы просто должны знать, в чем искать это сходство.
Для вызова функции find для объекта list вам нужны итераторы, указываю-
щие на первый элемент списка и на элементрасположенный сразу же за концом
списка. Без помощи со стороны класса list это было бы нелегкой задачей, так
как реализация list не известна. К счастью, класс list (как и все контейнеры
STL) должен содержать функции-члены begin и end. Эти функции-члены воз-
вращают нужные вам итераторы, которые и передаются в качестве двух первых
параметров функции find в примере.
Завершив свое выполнение, функция find возвращает объект-итератор, ука-
зывающий на найденный элемент (если он существует) или на charList. end ()
(если искомого элемента нет в списке). Поскольку вы ничего не знаете о реализа-
ции класса list, то вы ничего не знаете и о реализации итераторов в list. Как
тогда вы сможете выяснить тип объекта, возвращаемого функцией f ind? И снова
вам на помощь приходит класс list, который, как и все контейнеры STL, содер-
жит определение типа iterator, соответствующее типу итераторов в 1 i s t. Так как
объект charList является списком символов, то итераторы для такого списка
имеют тип list<char>::iterator, и именно этот тип используется в вышеприве-
денном примере. (На самом деле в каждом классе-контейнере STL определяются
два типа итераторов, iterator и const_iterator. Первый из них выступает
в качестве обычного указателя, а последний - в качестве указателя на const.)
Такой же подход может использоваться и для других контейнеров STL. Кроме
того, указатели C++ также являются итераторами STL, поэтому исходные при-
меры работы с массивами будут работать с функцией find из STL:
int values[50] ;
int *firstFive = find(values,
values+50,
5) ;
// Нормально,
// вызывает функцию
// find из STL.
Принцип организации стандартной библиотеки шаблонов очень прост. Она
представляет собой набор шаблонов классов и функций, придерживающихся ряда
соглашений. Набор классов STL содержит функции, такие как begin и end, кото-
рые возвращают объекты-итераторы определенных в классе типов. Функции ал-
горитмов STL перемещаются между наборами объектов, используя объекты ите-
раторы для наборов STL. Итераторы STL работают как указатели. Вот в сущности,
и все. Нет большой иерархии наследования, нет виртуальных функций и того
подобного. Просто несколько шаблонов классов и функций и набор соглаше-
ний, которых они придерживаются.
Правило 35
UIIB
283
Это приводит к новому откровению: стандартная библиотека шаблонов явля-
ется расширяемой. Вы можете добавлять к семейству STL свои наборы, алгорит-
мы и итераторы. До тех пор пока вы следуете соглашениям STL, стандартные на-
боры STL будут работать с вашими алгоритмами, а ваши наборы со стандартными
алгоритмами STL. Конечно, ваши шаблоны не станут частью стандартной библио-
теки C++, но они будут построены на тех же принципах, что позволит использо-
вать их повторно.
Библиотека C++ содержит намного больше возможностей, чем описано в этой
книге. Поэтому чтобы эффективно использовать ее, обратитесь к другим источ-
никам информации (их список приведен в приложении 1), где вы найдете под-
робные сведения как о библиотеке,‘гак и о соглашениях STL. Стандартная биб-
лиотека C++ намного богаче библиотеки С, и время, которое вы потратите на
ознакомление с ней, будет потрачено не напрасно. Кроме того, воплощенные в биб-
лиотеке принципы разработки - универсальность, расширяемость, эффектив-
ность, возможность настройки и повторного использования - сами по себе стоят
вашего внимания. Изучая стандартную библиотеку C++, вы не только пополните
ваши знания о готовых компонентах, которые сможете использовать в своих про-
граммах, но и поймете, как более эффективно применять C++ и разрабатывать соб-
ственные библиотеки.
Приложение 1
Список рекомендуемой литературы
Итак, ваш аппетит к информации о языке C++ остался неудовлетворенным. Уто-
лить его помогут источники, описанные в этом приложении. Конечно, характери-
стики, которые я даю книгам и журналам, субъективны, но в любом случае помо-
гут вам сориентироваться в море информации по C++.
Книги
Существуют сотни, а возможно, и тысячи книг по C++, и их число постоянно
увеличивается. Я не видел всех этих книг, а читал и того меньше, поэтому далее
следует список книг, к которым я сам обращался, когда у меня возникали вопро-
сы по разработке программ на C++. Я уверен, что есть и другие хорошие книги, но
я использую эти, и именно их могу искренне рекомендовать вам.
Начать стоит с книг, описывающих сам язык.
The Annotated C++ Reference Manual, Margaret A. Ellis and Bjarne Stroustrup
(Маргарет А. Эллис и Бьерн Страуструп. Справочное руководство по C++
с комментариями), Addison-Wesley, 1990, ISBN 0-201-51459-1.
The Design and Evolution of C++, Bjarne Stroustrup (Бьерн Страуструп. Разра-
ботка и эволюция C++), Addison-Wesley, 1994, ISBN 0-201-54330-3.
Эти книги содержат не просто описание того, что находится в языке, они так-
же приводят логическое обоснование выбора принятых решений, чего вы не най-
дете в официальных стандартах. Книга «Справочное руководство по C++ с ком-
ментариями» немного устарела (со времени ее публикации в язык были добавлены
новые возможности - см. правило 35), но до сих пор остается наилучшим руко-
водством по основным составляющим языка, включая шаблоны и исключения.
Книга «Разработка и эволюция C++» охватывает многие темы, отсутствующие
в книге «Справочное руководство по C++ с комментариями»; в ней не хватает
только описания стандартной библиотеки шаблонов (см. снова правило 35). Эти
книги являются не учебниками, а справочными руководствами, но если вы пони-
маете изложенный в них материал, вы поймете C++.
В качестве более общего справочника по языку, стандартной библиотеке и их
применению лучше всего использовать книгу, написанную основоположником C++:
The C++ Programming Language (Third Edition), Bjarne Stroustrup (Бьерн
Страуструп. Язык программирования C++ (Третье издание)). Addison-Wesley,
1997, ISBN 0-201-88954-4.
Список рекомендуемой литературы
!
285
Страуструп был тесно связан с разработкой, реализацией, применением
и стандартизацией языка с момента его возникновения, и он, возможно, знает
о языке больше, чем кто-либо еще. Его описание свойств читать нелегко, но глав-
ным образом из-за того, что оно содержит так много информации. Главы о стан-
дартной библиотеке C++ особенно полезны.
Если вы готовы перейти от изучения самого языка к его эффективному при
менению, можете обратиться к моей предыдущей книге:
Effective C++, Second Edition: 50 Specific Ways to Improve Your Programs and
Designs, Scott Meyers (Скотт Мейерс. Эффективное использование C++: 50
способов улучшить ваши программы и проекты. - ДМК, 2000.) Addison-
Wesley, 1998, ISBN 0-201-92488-9.
Эта книга аналогична той, которую вы сейчас читаете, но охватывает другие
(возможно, более фундаментальные) вопросы.
Примерно на том же уровне, как и мои книги об эффективном использовании
C++, находится и книга
C++ Strategies and Tactics, Robert Murray (Роберт Мюррей. Стратегия и так-
тика C++), Addison-Wesley, 1993, ISBN 0-201-56382-7,
но она охватывает другие темы. Книга Мюррея особенно сильна в том, что касает-
ся основ разработки шаблонов. Она также содержит главу, посвященную важной
теме миграции от С к C++. Большая часть моих рассуждений о подсчете ссылок
(см. правило 29) основана на идеях из книги «Стратегия и тактика C++».
Если вы относитесь к тем, кто предпочитает изучать программирование, чи-
тая код, то вам наверняка понравится книга
C++ Programming Style, Tom Cargill (Том Каргилл. Стиль программирования
на C++), Addison-Wesley, 1992, ISBN 0-201-56365-7.
Все главы этой книги открываются кодом C++. Затем Каргилл начинает ана-
томирование - нет, скорее вивисекцию - каждой из программ, определяя места
возможных проблем, неудачный подход к разработке, неудачную реализацию
и просто явные ошибки. Постепенно переписывая каждый пример, устраняя сла-
бые места, он в результате создает более устойчивый, легкий в поддержке, эффек-
тивный и переносимый код, который решает исходную задачу. Всем программис-
там на C++ стоило бы обратить внимание на уроки из этой книги, но особенно
важна она для тех, кто занимается проверкой кода.
В книге Каргилла не рассматриваются исключения. Этой теме посвящена его
статья
Exception Handling: A False Sense of Security (Обработка исключений: ложное
чувство безопасности) C++ Report, Volume 6, Number 9, November-December
1994, pages 21-24.
Если вы не можете достать старые выпуски журнала C++ Report, посетите
Web-сайт издательства Addison-Wesley, где она размещена по адресу http://
www.awl.com/cp/mec++.html. Если вы предпочитаете использовать FTP, то може-
те найти статью в каталоге ср/тес++ сайта ftp.awl.com.)
286
HI
Приложение 1
Тем, кто уже овладел основами C++ и готов двигаться дальше, рекомендую
познакомиться с книгой
Advanced C++: Programming Styles and Idioms, James Coplien (Джеймс Копль-
ен. Современный C++. Стили программирования и диалекты языка), Addison-
Wesley, 1992, ISBN 0-201-54855-0.
Я называю эту книгу «психоделической», так как она имеет фиолетовую об-
ложку и расширяет сознание. Копльен рассматривает и простые вопросы, но
в основном его интересует, как сделать на C++ вещи, которые кажутся невозмож-
ными. Вы хотите создавать объекты на основе других объектов? Обходить стро-
гую проверку типов? Добавить данные и функции к классам, которые выполняют
ваши программы? Копльен объяснит вам, как это сделать. В большинстве случаев
вам лучше избегать описываемых им методов, но иногда только они позволяют
решить сложную проблему, с которой вы столкнулись. Эта книга может испугать
вас или ослепить, но если вы ее прочтете, уже никогда не будете смотреть на C++
по-старому.
Если вы имеете отношение к разработке и реализации библиотек C++, с ва-
шей стороны было бы безрассудно не обратить внимания на книгу
Designing and Coding Reusable C++, Martin D. Carroll and Margaret A. Ellis
(Мартин Д. Кэрролл и Маргарет А. Эллис. Разработка и создание повторно
используемого кода на C++), Addison-Wesley, 1995, ISBN 0-201-51284-Х.
Кэрролл и Эллис анализируют множество практических аспектов разработки
и реализации библиотек, которые просто игнорируются остальными. Хорошая биб-
лиотека должна быть компактной, быстрой, расширяемой, легко обновляться, эле-
гантной при создании экземпляров шаблонов, мощной и устойчивой. Невозможно
выполнять оптимизацию по всем этим критериям, поэтому нужно выбирать комп-
ромиссные варианты, улучшающие одни стороны библиотеки за счет других. Кни-
га «Разработка и создание повторно используемого кода на C++» рассматривает эти
компромиссы и предлагает практические советы по их выполнению.
Независимо от того, для каких приложений вы пишете свои программы, вы
обязательно должны взглянуть на книгу
Scientific and Engineering C++, John J. Barton and Lee R. Nackman (Джон Дж.
Бартон и Ли К. Нэкман. C++ для ученых и инженеров), Addison-Wesley, 1994,
ISBN 0-201-53393-6.
Первая часть книги рассказывает о C++ программистам на Fortran (незавид-
ная участь в настоящее время), но вторая часть описывает методы, которые при-
годятся всем. Исчерпывающий материал по шаблонам почти революционен; воз-
можно, это самое подробное из существующих исследований, и я полагаю, что
когда вы увидите чудеса, которые можно делать при помощи шаблонов, вы не
будете больше думать о них как просто об улучшенных макрокомандах.
И наконец, возникающая в разработке объектно-ориентированного программ-
ного обеспечения дисциплина паттернов описана в книге
Design Patterns: Elements of Reusable Object-Oriented Software, Erich Gamma,
Richard Helm, Ralph Johnson, and John Vlissides (Эрих Гамма, Ричард Хелм,
Список рекомендуемой литературы
НИИ
287
Ральф Джонсон и Джон Влиссид. Паттерны разработки: элементы повторно
используемого объектно-ориентированного программного обеспечения),
Addison-Wesley, 1995, ISBN 0-201-63361-2.
Эта книга дает обзор идей, на которых основаны паттерны, но главное в ней -
каталог из 23 важнейших паттернов, полезных во многих прикладных областях.
Путешествуя по этим страницам, вы почти обязательно обнаружите паттерн, кото
рый вам пришлось бы изобретать самостоятельно, и поймете, что его дизайн
в книге превосходит подход, специально разработанный вами для такого
случая. Имена этих паттернов уже стали частью создающегося словаря объект
но-ориентированного программирования; их незнание в скором времени может
поставить под угрозу ваше взаимодействие с коллегами. Основное преимущество
данной книги заключается в том, что в ней делается акцент на разработку и реа-
лизацию программ, способных элегантно приспосабливаться к будущей эволю-
ции (см. правила 32 и 33).
Книга доступна также на компакт-диске:
Design Patterns CD: Elements of Reusable Object-Oriented Software, Erich
Gamma, Richard Helm, Ralph Johnson, and John Vlissides, Addison-Wesley, 1998,
ISBN 0-201-63498-8.
Журналы
Для настоящих программистов на C++ существует только один журнал:
C++ Report, SIGS Publications, New York, NY.
Некоторое время назад руководством журнала было принято сознательное
решение отойти от рассмотрения только C++. Большее внимание теперь уделяет-
ся вопросам программирования на уровне доменов и систем, что ценно само по
себе, но и материал по C++, хоть подчас и не столь глубокий, продолжает оста-
ваться лучшим из возможных.
Если вы чувствуете себя более уверенно в С, чем в C++, или находите матери-
ал из журнала C++ Report слишком экстремистским, чтобы его можно было ис-
пользовать, вероятно, вам больше придутся по вкусу статьи из журнала
C/C++ Users Journal, Miller Freeman, Inc., Lawrence, KS.
Как и следует из его названия, журнал публикует материалы как о С, так
и о C++. Статьи по C++ рассчитаны на менее подготовленную аудиторию, чем ста-
тьи в C++ Report. Кроме того, редакция строго контролирует авторов, поэтому
материал в журнале меньше отклоняется от основного направления. Это помога-
ет отсеивать идеи фанатиков языка, но в то же время ограничивает проявление
действительно авангардных методов.
Гоуппы новостей USENET
Языку C++ посвящены три группы новостей USENET. Группа comp.lang.c++
является универсальной, и в нее сваливается все подряд. Диапазон сообщений
простирается от подробных объяснений сложных методов программирования до
проповедей и бреда тех, кто любит и ненавидит C++, и студентов со всего мира,
288
Приложение 1
IK
которые просят помочь им сделать домашнее задание, откладываемое до тех пор,
пока не стало слишком поздно. Объем сообщений в этой группе очень велик. Если
вы не располагаете часами свободного времени, вам потребуется фильтр, чтобы
отделить зерна от плевел, причем хороший фильтр, так как мусора в конферен-
ции много.
В ноябре 1995 года была создана модерируемая версия группы comp.lang.c++.
Эта группа новостей, которая называется comp.lang,c++.moderated. также предна-
значена для общего обсуждения C++ и связанных с ним вопросов, но модераторы
стремятся удалять вопросы, относящиеся к конкретной реализации; вопросы, от-
веты на которые содержатся в списке FAQ (Frequently Asked Questions - часто
задаваемые вопросы); «флейм» и другие вещи, которые мало интересуют боль-
шинство практикующих программистов на C++.
Группа новостей comp.std.c++ имеет более узкий фокус и посвящена обсуж-
дению самого стандарта C++. Здесь много знатоков языка, но сюда имеет смысл
обратиться, если ваши сложные вопросы о C++ остаются без ответа в других до-
ступных справочниках. Эта группа также является модерируемой, поэтому отно-
шение сигнал/шум в ней достаточно высоко; здесь вы не встретите просьбы по-
мочь с домашним заданием.
Приложение 2
Реализация шаблона auto_ptr
В правилах 9, 10, 26, 31 и 32 упоминается исключительная полезность шаблона
auto_ptr. К сожалению, мало компиляторов содержат его «правильную» реали-
зацию.* В правилах 9 и 28 описано в общих чертах, как можно создать этот шаб-
лон самостоятельно, но, начиная работу над реальными проектами, лучше иметь
не просто набросок.
Ниже представлены два варианта реализации шаблона auto_ptr. Первый из
них документирует интерфейс класса и реализует все функции-члены вне опре-
деления класса. Второй реализует каждую функцию-член внутри определения
класса. Стилистически вторая реализация уступает первой, так как в ней нельзя
отделить интерфейс класса от его реализации. Но на основе шаблона auto_ptr
образуются простые классы, и из второй версии это намного очевиднее, чем из
первой.
Вот шаблон auto_ptr, интерфейс которого документирован:
template<class Т>
class auto_ptr {
public:
explicit auto_ptr(T *р = 0); // См. описание "explicit"
// в правиле 5.
template<class U> // Шаблон конструктора
auto_ptr(auto_ptr<U>& rhs) ; // копирования (см. правило 28) :
// инициализация нового
// auto_ptr при помощи
// любого совместимого
~auto_ptr(); // auto_ptr.
template<class U> // Шаблон оператора
auto_ptr<T>& // присваивания (см. правило 28)
operator=(auto_ptr<U>& rhs) ; // присвоить от любого
// совместимого auto_ptr.
T& operator*() const; // См. правило 28.
* Это связано в основном с тем, что спецификация шаблона auto_ptr менялась в течение ряда лет.
Последняя спецификация была принята только в ноябре 1997 года. Вы можете найти подробную
информацию о шаблоне auto_pt г на WWW- и FTP -сайтах этой книги (см. стр. 21-22). Обратите
внимание, что в описанной здесь реализации auto_ptr опущены некоторые детали официальной
версии, например то, что auto_ptr находится в пространстве имен std (см. правило 35) и что его
функции-члены не должны генерировать исключений.
290
III
Приложение 2
Т* operator->() const;
T* get () const;
Т* release();
void reset(Т *р = 0) ;
//См. правило 28.
// Вернуть значение текущего
// обычного указателя.
// Отказаться от обладания
// текущим обычным
// указателем и вернуть
// его значение.
// Удалить указатель,
// считая, что обладаем р.
private:
Т *pointee;
templatecclass U>
friend class auto_ptrcU>;
// Сделать все классы
// auto_ptr дружественными.
};
templatecclass T>
inline auto_ptrcT>: :auto_ptr(T *p)
: pointee(p)
{}
templatecclass T>
inline auto_ptrcT>::auto_ptr(auto_ptrcU>& rhs)
: pointee(rhs.release())
О
templatecclass T>
inline auto_ptrcT>::~auto_ptr ()
{ delete pointee; }
templatecclass T>
templatecclass U>
inline auto_ptrcT>& auto_ptrcT>::operator=(auto_ptrcU>& rhs)
{
if (this !=&rhs) reset(rhs.release());
return *this;
}
templatecclass T>
inline T& auto_ptrcT>::operator*() const
{ return *pointee; }
templatecclass T>
inline T* auto_ptrcT>::operator->() const
{ return pointee; }
templatecclass T>
inline T* auto_ptrcT>::get() const
{ return pointee; }
templatecclass T>
inline T* auto_ptrcT>::release()
{
T *oldPointee = pointee;
pointee = 0;
return oldPointee;
}
templatecclass T>
inline void auto_ptrd>: : reset (T *p)
291
Реализация шаблона auto_ptr
if (pointee != p) {
delete pointee;
pointee = p;
}
}
А вот вариант auto_ptr, в котором все функции реализованы в определе-
нии класса:
template<class Т>
class auto_ptr {
public:
explicit auto_ptr(T *p = 0): pointee(p) {}
template<class U>
auto_ptr(auto_ptr<U>& rhs): pointee(rhs.release()) {}
~auto_ptr() { delete pointee; }
template<class U>
auto_ptr<T>& operator=(auto_ptr<U>& rhs)
{
if (this !=&rhs) reset(rhs.release());
return *this;
}
T& operator*() const { return *pointee; }
T* operator-:» () const { return pointee; }
T* get() const { return pointee; }
T* release()
{
T *oldPointee = pointee;
pointee = 0;
return oldPointee;
}
void reset (T *p = 0)
{
if (pointee ! = p) {
delete pointee;
pointee = p;
}
}
private:
T *pointee;
template<class U> friend class auto_ptr<U>;
};
Если ваши компиляторы еще не поддерживают директиву explicit, вы мо-
жете определить ее при помощи директивы #def ine:
#define explicit
Это нисколько не уменьшит функциональности шаблона auto_ptr, но сде-
лает его чуть менее безопасным (подробнее об этом сказано в правиле 5).
292
III
Приложение 2
Если ваши компиляторы не поддерживают шаблоны функций-членов, вы мо-
жете использовать не входящие в шаблон auto_ptr конструктор копирования
и оператор присваивания, описанные в правиле 29. Из-за этого шаблон auto_ptr
станет менее удобным для применения, но, увы, не существует способа прибли-
зиться к поведению шаблонов функций-членов. Если шаблоны функций-членов
(или другие возможности языка) важны для вас, сообщите об этом производите-
лям программного обеспечения. Чем больше покупателей будут требовать введе-
ния новых возможностей языка, тем скорее они будут реализованы.
Алфавитный указатель
Б
Базовый класс
абстрактный 162
виртуальный 130
смешанный 162
Библиотека
iostream 122
stdio 122
Буферизованный оператор new 34
В
Виртуальная функция
эмуляция при помощи if-then-else 234
Владелец объекта 170
Вычисление
отложенное 98
энергичное 98
д
Диспетчеризация
двойная 233
множественная 233
одиночная 233
И
Идентификация типов
времени выполнения программы 132
Инициализация
статических объектов 273
Исключение
bad_alloc 82
bad cast 82
bad_exception 82
bad_typeid 82
Unexpected Exception 88
Итератор 281
К
Класс
auto_ptr 61
exception 89
proxy 45, 221
заместитель 221
Ключевое слово
explicit 42
mutable 102
Компоновка
внешняя 144
внутренняя 144
Конструктор
виртуальный 136
копирования, виртуальный 137
по умолчанию 33
с единственным аргументом 39
Копирование, детальное 206
Коррекция имен 270
Л
Логические выражения,
оптимизированная оценка 48
Локальная взаимосвязанность 108
М
Метод копирования при записи 197
инк Наиболее эффективное использование C++
О Проблема потери данных 83, 174
Объект proxy 221 typejnfo 132 неименованный 111 Оператор -- 46 &&, модификация 49 ++ 46 += 119 -= 119 [] 25, 196 ||, модификация 48 const_cast 26 dynamic_cast 27 new 51 new буферизованный 52 operator, 50 reinterpret_cast 28 sizeof 51 static_cast 26 typeid 132 запятая 49 неявного преобразования типа 39 приведения типов 26 Оптимизация возвращаемого значения 116 Оценка, отложенная 223 Пространство имен 142 неименованное 247 Псевдоуказатель 102 Р Разыменование 167 С Сборка мусора 190 Семантика вызовов функций 49 оптимизирующая 49 Ссылка 23 Статические объекты инициализация 273 уничтожение 273 Счетчик ссылок 191 Т Таблица виртуальная 124 Тип bool 16 string 17 true 16 У
П Указатель 23 smart 60
Паттерны 286 Подсчет ссылок 190 Полиморфизм 30 Правило«80-20» 95 Приведение типа const_cast 17 dynamic_cast 17 reinterpret_cast 17 static_cast 17 Присваивание смешанное 261 частичное 260 интеллектуальный 60, 167 на виртуальную таблицу 124 Уничтожение статических объектов 273 Ф Функция operator bool 177 operator delete 54 operator delete[] 56 operator new 51 operator new[] 55 operator* 173
Алфавитный указатель ! I 295
operator+ 119 operator++ 46 operator- 119 G Garbage collection 190
operator-> 173 operator« 123 1
operator^ 196 Internal linkage 144
unexpected 85 iostream 122
Ш L
Шаблон Lazy evaluation 98
auto_ptr 170 map 240 M
vector 36 Member function templates 183
функции-члена 183 Mixin base class 162 mutable 102
A N
auto ptr 61
Name mangling 270
В Namespace 142
bad alloc 82 new 51
bad cast 82 О
bad_exception 82 bad typeid 82 operator, 50
bool 16 operator« 40
C operator bool 177 operator delete 54
const_cast 17 operator delete[] 35
Copy on write 197 operator new 51
D operator&&, модификация 49 operator* 173
Deep copy 167 operator-l- 119
Default constructor 33 operator++ 46
Dereferencing 167 operator- 119
Double-dispatching 233 operator-> 173
Dumb pointer 167 operator« 123
dynamic_cast 17, 27 operator[] 196
E operator]], модификация 49
Eager evaluation 98 P
exception 89 Pointer 23
explicit 42 Polymorphically 30
!! Наиболее эффективное использование C++
Proxy class 45, 221 Proxy objects 221 R stdio 122 STL 17 string 17 Surrogate 221
Reference 23 Reference count 191 reinterpret cast 17, 28 RTTI 132, 234 Runtime type identification 132 S true 16 U unexpected 85 Unexpected Exception 88 V
sizeof 51 Smart pointer 167 Static initialization 273 static_cast 17, 26 vector 36 Virtual table 124 pointer 124
Скотт Мейерс
Наиболее эффективное использование С++
35 новых рекомендаций по улучшению
ваших программ и проектов
Главный редактор
Перевод
Научный редактор
Литературный редактор
Технический редактор
Верстка
Графика
Дизайн обложки
Захаров И. М.
Павлов Р. В.
Нилов М. В., Разоренов А. А.
Виноградова Н. В.
Прока С. В.
Тарасов С. А.
Бахарев А. А.
Антонов А. И.
ИД № 01903 от 30.05.2000
Подписано в печать 22.09.2000. Формат 70х100’/16.
Гарнитура «Петербург». Печать офсетная.
Усл. печ. л. 19. Тираж 3000 экз. Зак. № 679
Издательство «ДМК Пресс», 105023, Москва, пл. Журавлева, д. 2/8.
Отпечатано в полном соответствии
с качеством предоставленных диапозитивов
в ППП «Типография «Наука»
121099, Москва, Шубинский пер., д. 6
Ol
t (Ob
Xieidl
field 2
е field"
л field4
«Я и«прение рекомендую книгу 'Наиболее
эффективное использование C++" всем, кто
стремится овладеть C++ на среднем или бо-
лее высоком уровне».
Эксперт C/C++ User's Journal
эффективное
использование
35 новых w
рекомендаций
ло улучшению ваших
лрогромм м проектов
Скотт Мейерс
Автор книги «Наиболее эффективное
использование C++» предлагает 35 новых
способов улучшения ваших программ. Ос-
новываясь на своем многолетнем опыте,
С. Мейерс объясняет, как писать наиболее
эффективные программы: надежные, со-
вместимые, переносимые и пригодные для
повторного использования, то есть про-
граммы, безупречные во всех отношениях.
Настоящая книга описывает приемы,
которые позволяют значительно повысить
производительность программ, выбрав
оптимальное соотношение затрат време-
ни/памяти на различные операции. Здесь
вы найдете примеры обработки исключе-
ний и анализ их влияния на структуру и по-
ведение классов и функций C++, а также
варианты практического применения но-
вых возможностей языка, таких как тип
bool, ключевые слова mutable и explicit,
пространства имен, шаблоны функций-
членов, стандартная библиотека шаблонов
и многое другое.
Addison
Wesley
iiiihivii
www.dmk.ru