/






















































































































































































































































































































































































































































































Автор: Кэрриэ Б.
Теги: качество систем и программ специализированные и управляющие электронные вычислительные машины дискретного действия информатика информационные технологии
ISBN: 5-469-01311-1
Год: 2007




Текст
СЕРИЯ
Brian Carrier
File System
Forensic
Analysis
TT
Addison-Wesley
Upper Saddle River, NJ • Boston • Indianapolis • San Francisco
New York • Toronto • Montreal • London • Munich • Paris • Madrid
Capetown • Sydney • Tokyo • Singapore • Mexico • CityMunich
Брайан Кэрриэ
КРИМИНАЛИСТИЧЕСКИЙ
АНАЛИЗ
ФАЙЛОВЫХ
СИСТЕМ
С^ППТЕР*
Москва - Санкт-Петербург - Нижний Новгород - Воронеж
Новосибирск - Ростов-на-Дону - Екатеринбург - Самара
Киев - Харьков - Минск
2007
ББК 32.973.23-018-07
УДК 004.056.57
К90
Кэрриэ Б.
К90 Криминалистический анализ файловых систем. — СПб.: Питер, 2007. —
480 с: ил.
ISBN 5-469-01311-1
Какая структура служит хранилищем всех данных, имеющихся на вашем ПК? Очевидно,
файловая система. При этом четкого понимания ее устройства нет даже у некоторых IT-
специалистов. Развернутые технические описания файловых систем встречаются крайне редко, а
популярная литература по этой теме просто отсутствует. Специалист в области информационной
безопасности Брайан Кэрриэ написал долгожданную книгу, которая необходима всем, кто хочет
понять, как работают файловые системы и как обеспечить сохранность данных.
ББК 32.973.23-018-07
УДК 004.056.57
Права на издание получены по соглашению с Addison-Wesley Longman
Все права защищены. Никакая часть данной книги не может быть воспроизведена в какой бы то ни было
форме без письменного разрешения владельцев авторских прав.
Информация, содержащаяся в данной книге, получена из источников, рассматриваемых издательством как
надежные Тем не менее, имея в виду возможные человеческие или технические ошибки, издательство не
может гарантировать абсолютную точность и полноту приводимых сведений и не несет ответственности за
возможные ошибки, связанные с использованием книги.
© 2005 Pearson Education, Inc
ISBN 0-321-26817-2 (англ ) © Перевод на русский язык, ООО «Питер Пресс», 2007
ISBN 5-469-01311-1 © Издание на русском языке, оформление, ООО «Питер Пресс», 2007
Краткое содержание
Предисловие 19
Введение 21
Благодарности, 24
Часть I. Основы 25
Глава 1. Основы цифровых расследований 26
Глава 2. Основные принципы работы компьютеров 38
Глава 3. Снятие данных с жесткого диска 63
Часть II. Анализ томов 81
Глава 4- Анализ томов 82
Глава 5. Разделы на персональных компьютерах 93
Глава 6. Разделы в серверных системах 117
Глава 7. Многодисковые тома 143
Часть III. Анализ файловых систем 163
Глава 8- Анализ файловых систем 164
Глава 9. FAT: основные концепции и анализ 198
Глава 10. Структуры данных FAT 235
Глава 11. NTFS: основные концепции 250
Глава 12. NTFS: анализ 273
Глава 13. Структуры данных NTFS 317
Глава 14. Ext2 и Ext3: концепции и анализ 352
Глава 15- Структуры данных Ext2 и Ext3 399
Глава 16- UFS1 и UFS2: концепции и анализ 422
Глава 17- Структуры данных UFS1 и UFS2 448
Приложение. The Sleuth Kit и Autopsy 469
Алфавитный указатель 476
Содержание
Предисловие 19
От издательства 20
Введение 21
Структура книги 22
Ресурсы 23
Благодарности 24
Часть I. Основы 25
Глава 1- Основы цифровых расследований 26
Цифровые расследования и улики 26
Процесс анализа места цифрового преступления 27
Фаза сохранения системы 28
Фаза поиска улик 29
Фаза реконструкции событий 29
Общие рекомендации 30
Анализ данных 31
Типы анализа 31
Необходимые и вспомогательные данные 34
Инструментарий эксперта 35
EnCase (Guidance Software) 35
Forensic Toolkit (Access Data) 36
ProDiscover (Technology Pathways) 36
SMART (ASR Data) 36
The Sleuth Kit/Autopsy 36
Итоги 37
Библиография 37
Глава 2. Основные принципы работы компьютеров 38
Организация данных 38
Двоичная, десятичная и шестнадцатеричная запись 38
Размеры данных 41
Строковые данные и кодировка символов 42
Структуры данных 44
Флаги 45
Процесс загрузки 46
Процессор и машинный код 46
Местонахождение загрузочного кода 47
Технологии жестких дисков 48
Геометрия и внутреннее устройство жесткого диска 48
Интерфейс ATA/IDE 50
Типы адресации секторов 52
BIOS и прямой доступ 57
Диски SCSI 58
Итоги 62
Библиография 62
Глава 3. Снятие данных с жесткого диска 63
Введение 63
Общая процедура снятия данных 63
Уровни снятия данных 64
Тесты программ снятия данных 64
Чтение исходных данных 65
Прямой доступ или BIOS? 65
Режимы снятия данных 66
Обработка ошибок 67
Область HPA 67
DCO 68
Аппаратная блокировка записи 68
Программная блокировка записи 70
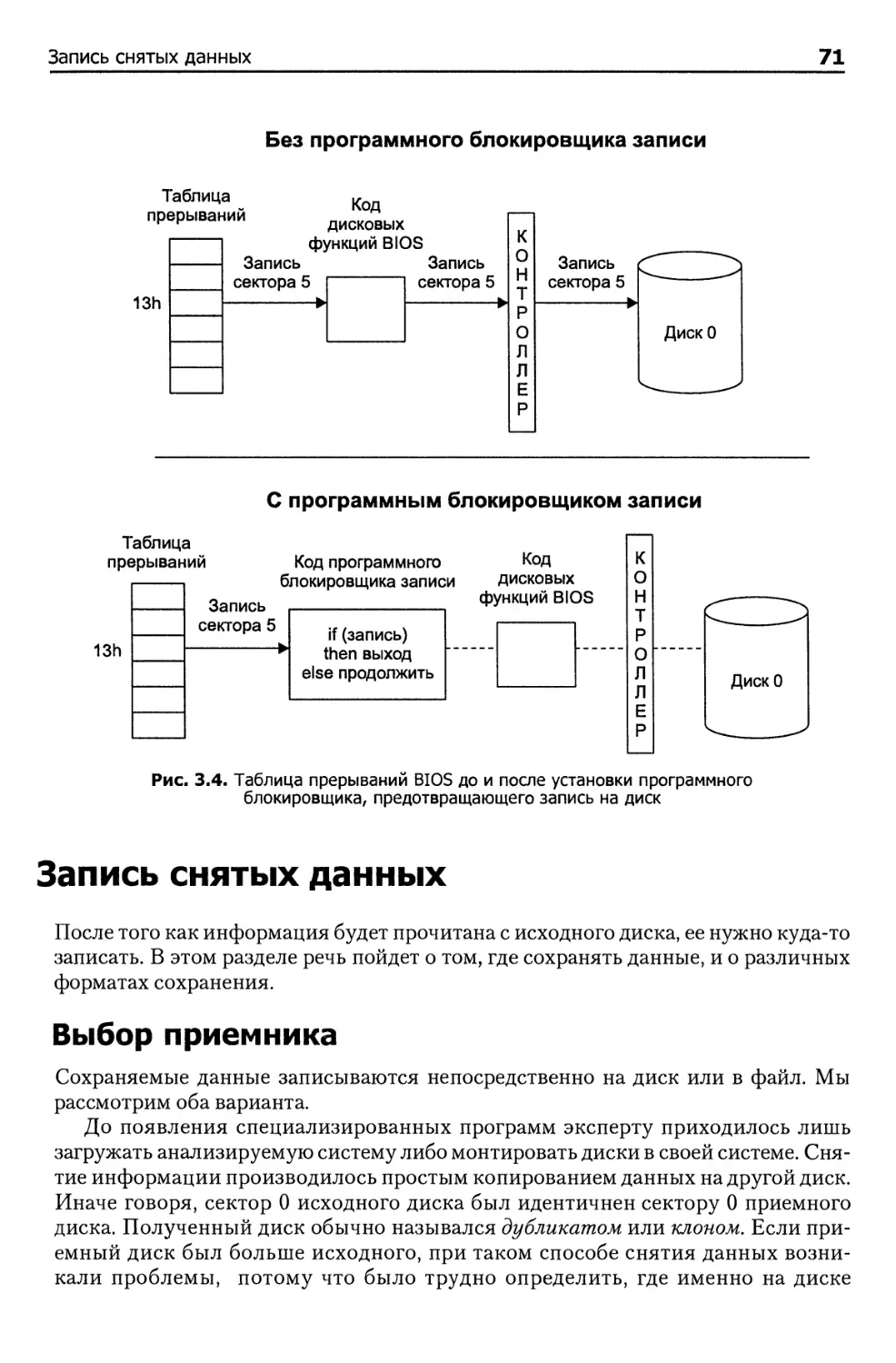
Запись снятых данных 71
Выбор приемника 71
Формат файла образа 72
Сжатие файла образа 73
Сетевое снятие данных 73
Хеширование и целостность данных 74
Практический пример с использованием dd 75
Источник 75
HPA 76
Приемник 77
Обработка ошибок 78
Криптографическое хеширование 79
Итоги 80
Библиография 80
Часть П. Анализ томов 81
Глава 4. Анализ томов 82
Введение 82
Общие положения 83
Концепция тома 83
Общая теория разделов 83
Использование томов в UNIX 84
Общая теория объединения томов 85
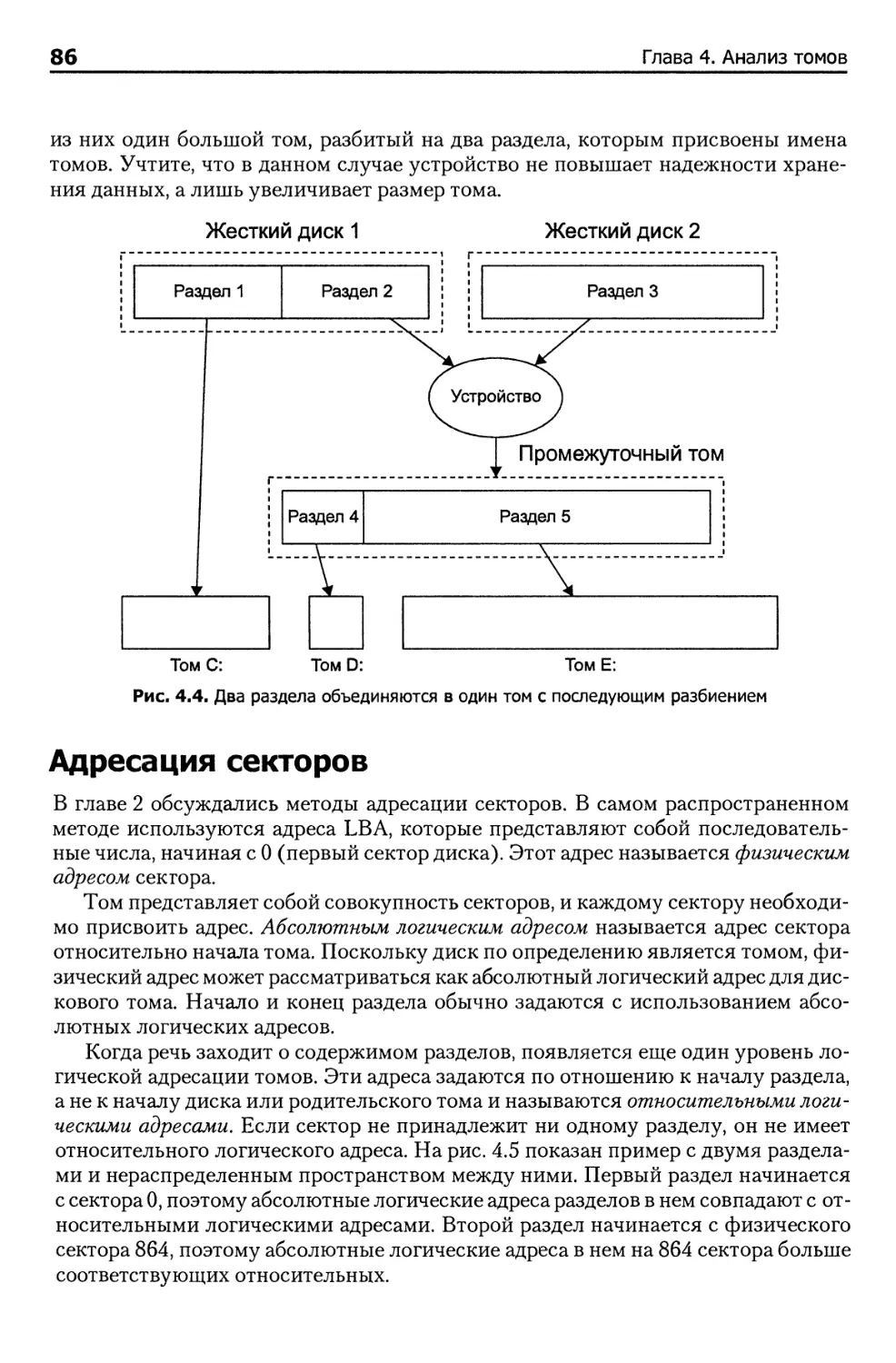
Адресация секторов 86
Основы анализа 87
Методы анализа 87
Проверка целостности 88
Получение содержимого разделов 89
Восстановление удаленных разделов 90
Итоги 92
Глава 5- Разделы на персональных компьютерах 93
Разделы в DOS 93
Общий обзор 94
Основные концепции MBR 94
Концепция расширенного раздела 95
Структуры данных 99
Факторы анализа 108
Итоги 109
Разделы Apple 109
Общий обзор 109
Структуры данных 110
Факторы анализа 113
Итоги 113
Съемные носители 114
Библиография 115
Глава 6. Разделы в серверных системах 117
Разделы BSD 117
Общий обзор 117
Структуры данных 121
Факторы анализа 127
Итоги 128
Сегменты Sun Solaris 129
Общий обзор 129
Структуры данных Sparc 130
Структуры данных i386 134
Факторы анализа 137
Итоги 137
Разделы GPT 138
Общий обзор 138
Структуры данных 139
Факторы анализа 141
Итоги 142
Библиография 142
Глава 7. Многодисковые тома 143
RAID 143
Уровни RAID 143
Аппаратная реализация RAID 146
Программная реализация RAID 147
Общие замечания по поводу анализа 150
Итоги 150
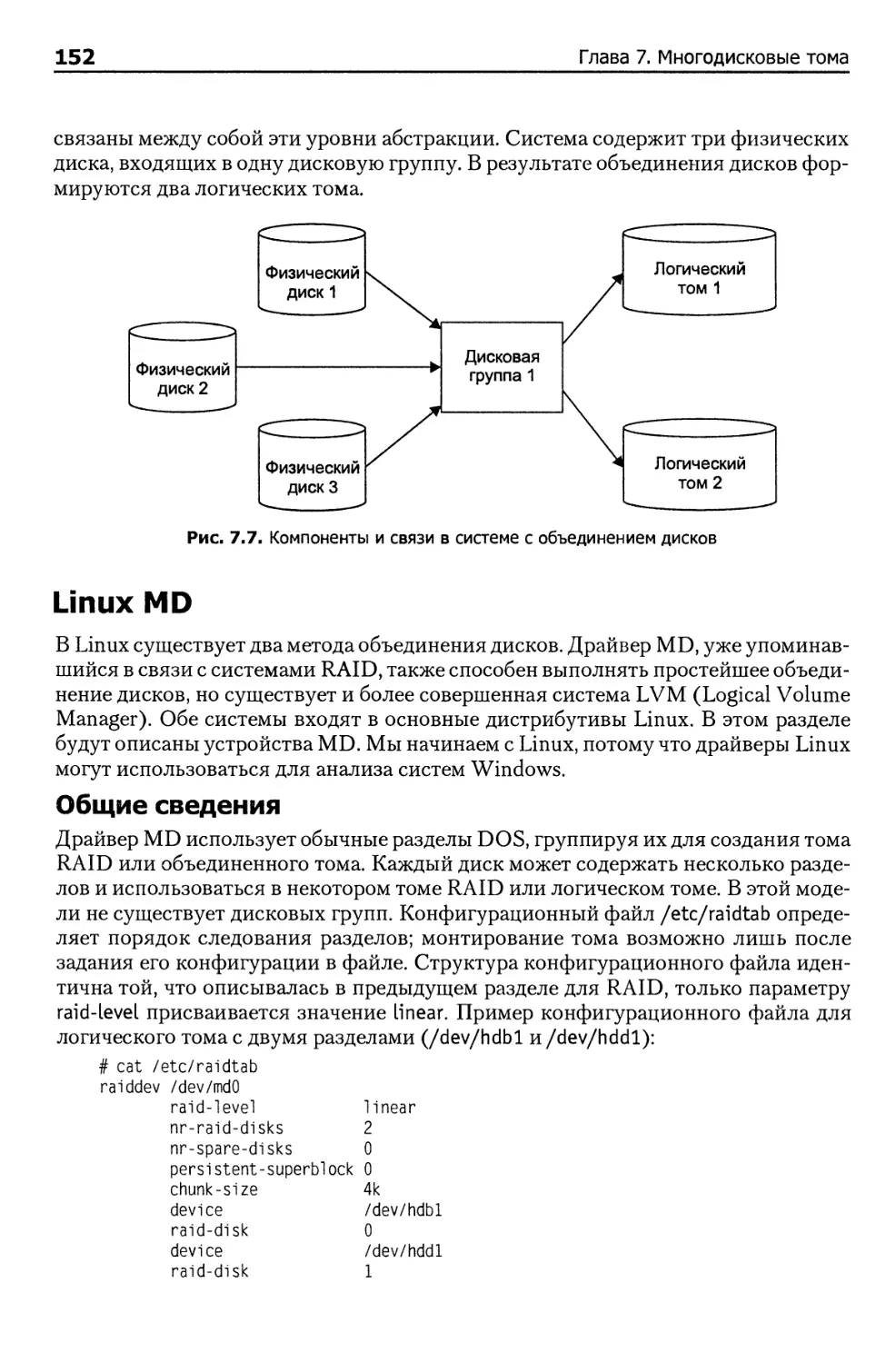
Объединение дисков 150
Общий обзор 151
Linux MD 152
Linux LVM 154
Microsoft Windows LDM 156
Библиография 162
Часть III. Анализ файловых систем 163
Глава 8- Анализ файловых систем 164
Что такое файловая система? 164
Категории данных 165
Необходимые и вспомогательные данные 166
Методы анализа и категории данных 167
Категория данных файловой системы 168
Методы анализа 168
Категория данных содержимого 169
Общие сведения 169
Методы анализа 172
Методы надежного удаления 175
Категория метаданных 176
Общая информация 176
Методы анализа 182
Категория имен файлов 187
Общие сведения 187
Методы анализа 190
Методы надежного удаления 192
Категория прикладных данных 192
Журналы файловой системы 193
Методы поиска на прикладном уровне 193
Восстановление файлов на прикладном уровне 194
Сортировка файлов по типу 195
Конкретные файловые системы 195
Итоги 196
Библиография 197
Глава 9- FAT: основные концепции и анализ 198
Введение 198
Категория файловой системы 199
Методы анализа 203
Факторы анализа 204
Сценарий анализа 204
Категория содержимого 207
Алгоритмы выделения 208
Методы анализа 209
Факторы анализа 209
Сценарий анализа 211
Категория метаданных 211
Алгоритмы выделения 216
Методы анализа 219
Факторы анализа 219
Сценарии анализа 221
Категория данных имен файлов 222
Алгоритмы выделения 224
Методы анализа 224
Факторы анализа 225
Сценарии анализа 225
Общая картина 227
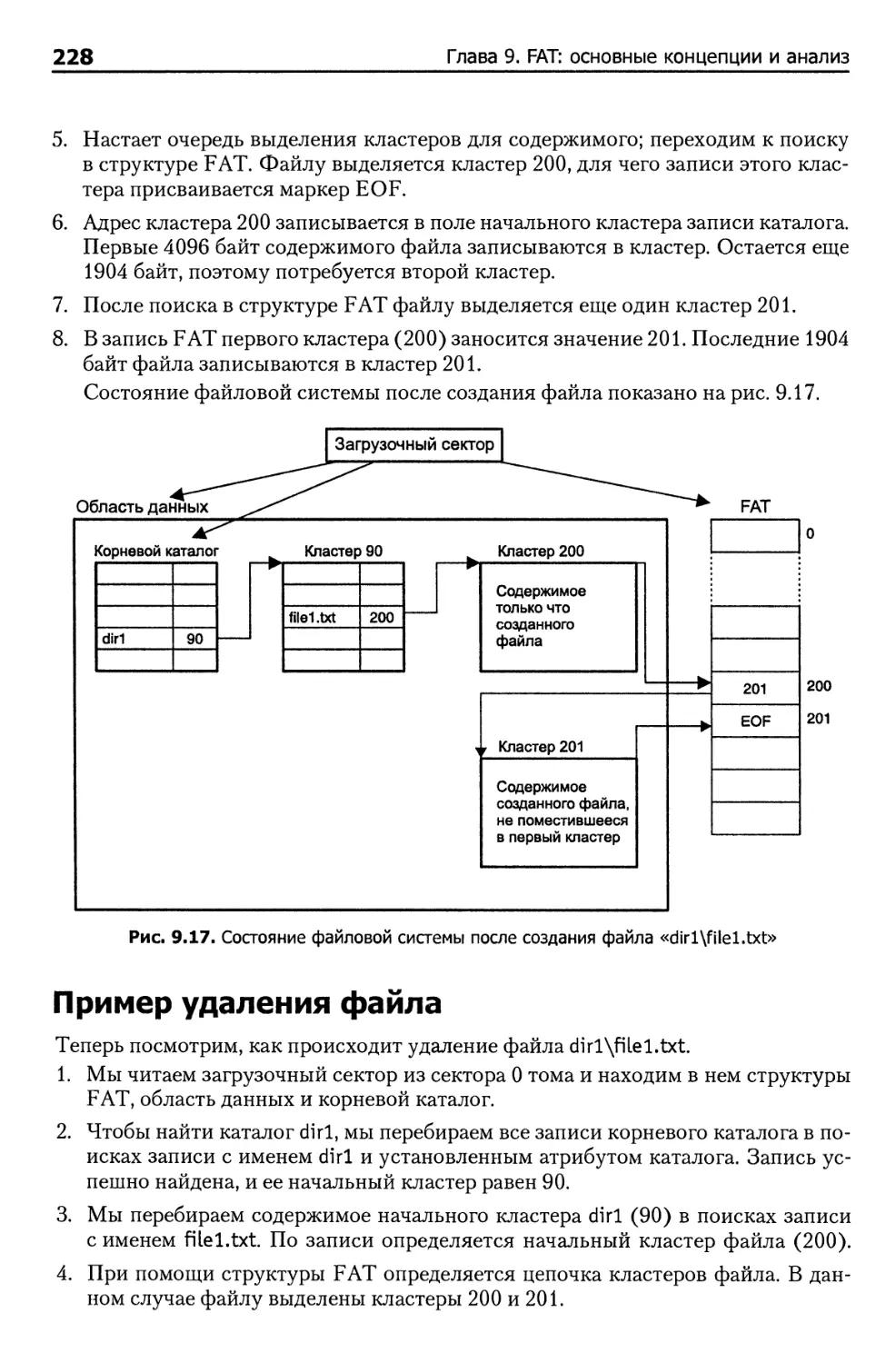
Создание файлов 227
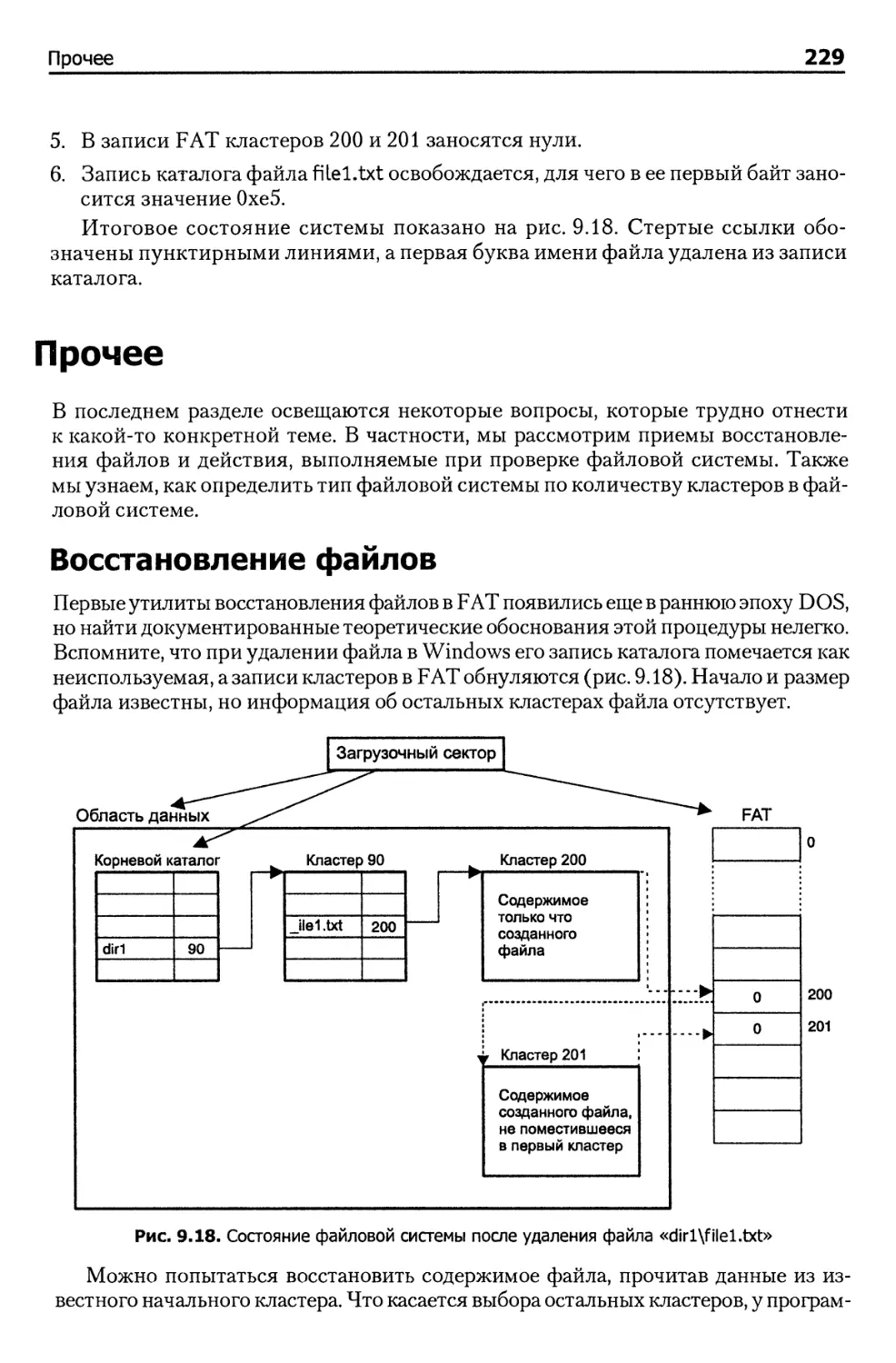
Пример удаления файла 228
Прочее 229
Восстановление файлов 229
Определение типа файловой системы 231
Проверка целостности данных 232
Итоги 233
Библиография 233
Глава 10. Структуры данных FAT 235
Загрузочный сектор 235
Структура FSINFO 239
FAT 240
Записи каталогов 241
Записи каталогов для длинных имен файлов 245
Итоги 249
Библиография 249
Глава 11. NTFS: основные концепции 250
Введение 250
Все данные — файлы 251
Концепции MFT 251
Содержимое записи MFT 252
Адреса записей MFT 253
Файлы метаданных файловой системы 254
Атрибуты записей MFT 255
Заголовки атрибутов 255
Содержимое атрибутов 256
Стандартные типы атрибутов 257
Другие концепции атрибутов , 259
Базовые записи MFT , 259
Сжатые атрибуты 260
Шифрование атрибутов 262
Индексы , 265
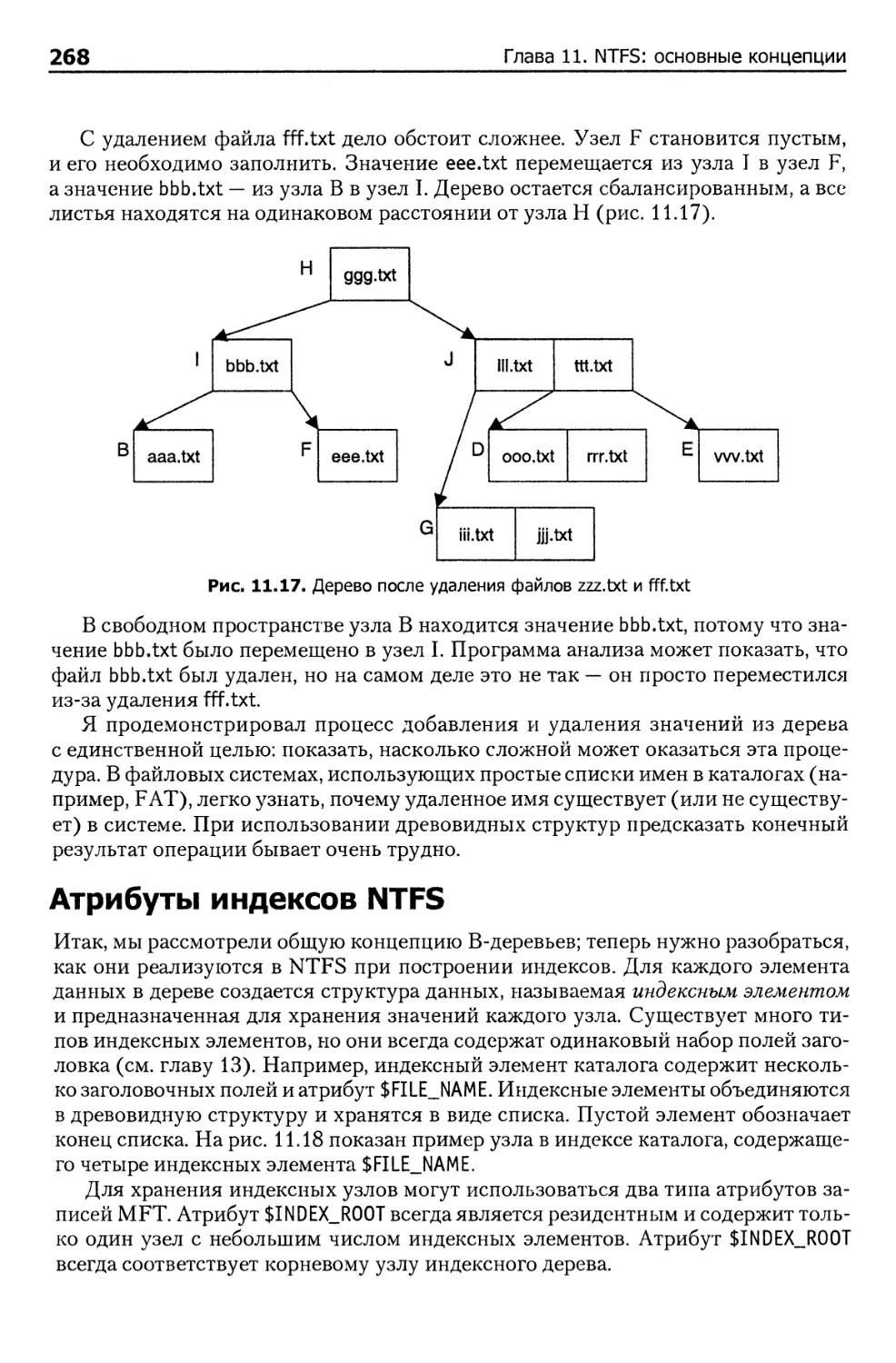
В-деревья 265
Атрибуты индексов NTFS 268
Программы анализа 270
Итоги 271
Библиография 271
Глава 12. NTFS: анализ 273
Категория данных файловой системы 273
Файл $MFT 273
Файл$МРТМ1гг 274
Файл $Boot 275
Файл $Volume 276
Oaiui$AttrDef 277
Тестовый образ 277
Методы анализа 278
Факторы анализа 278
Сценарий анализа 279
Категория данных содержимого 281
Кластеры 281
Файл $Bitmap 282
Файл $BadClus 282
Алгоритмы выделения 283
Структура файловой системы 283
Методы анализа 284
Факторы анализа 285
Сценарий анализа 285
Категория метаданных 285
Атрибут $STANDARD_INFORMATION 286
Атрибут $FILEJMAME 287
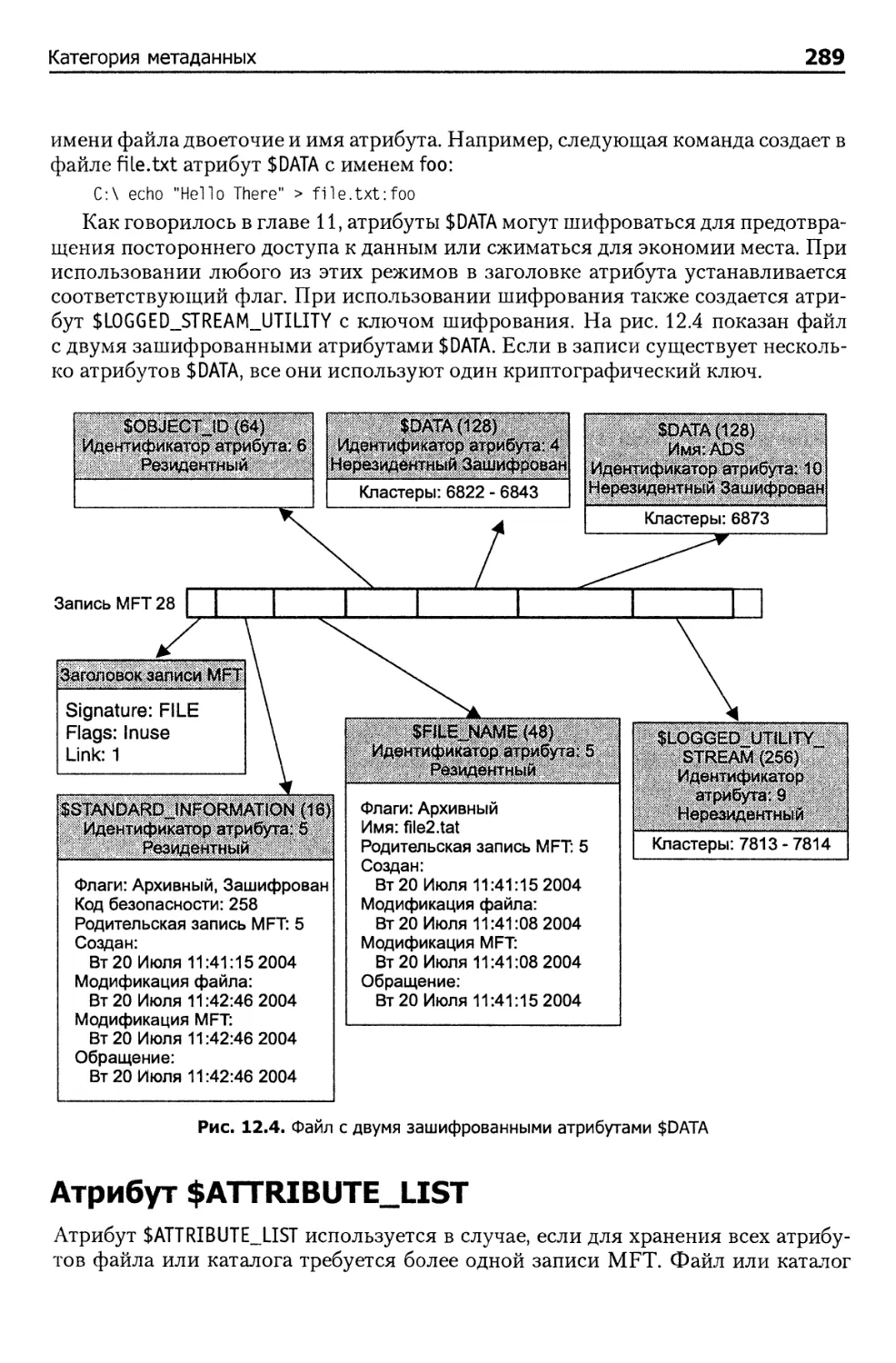
Атрибут $DATA 288
Атрибут $ATTRIBUTE_LIST 289
Атрибут $SECUFU7Y_DESCRIPTOR 291
Файл $Secure 291
Тестовый образ 292
Алгоритмы выделения 293
Методы анализа 294
Факторы анализа 296
Сценарий анализа 298
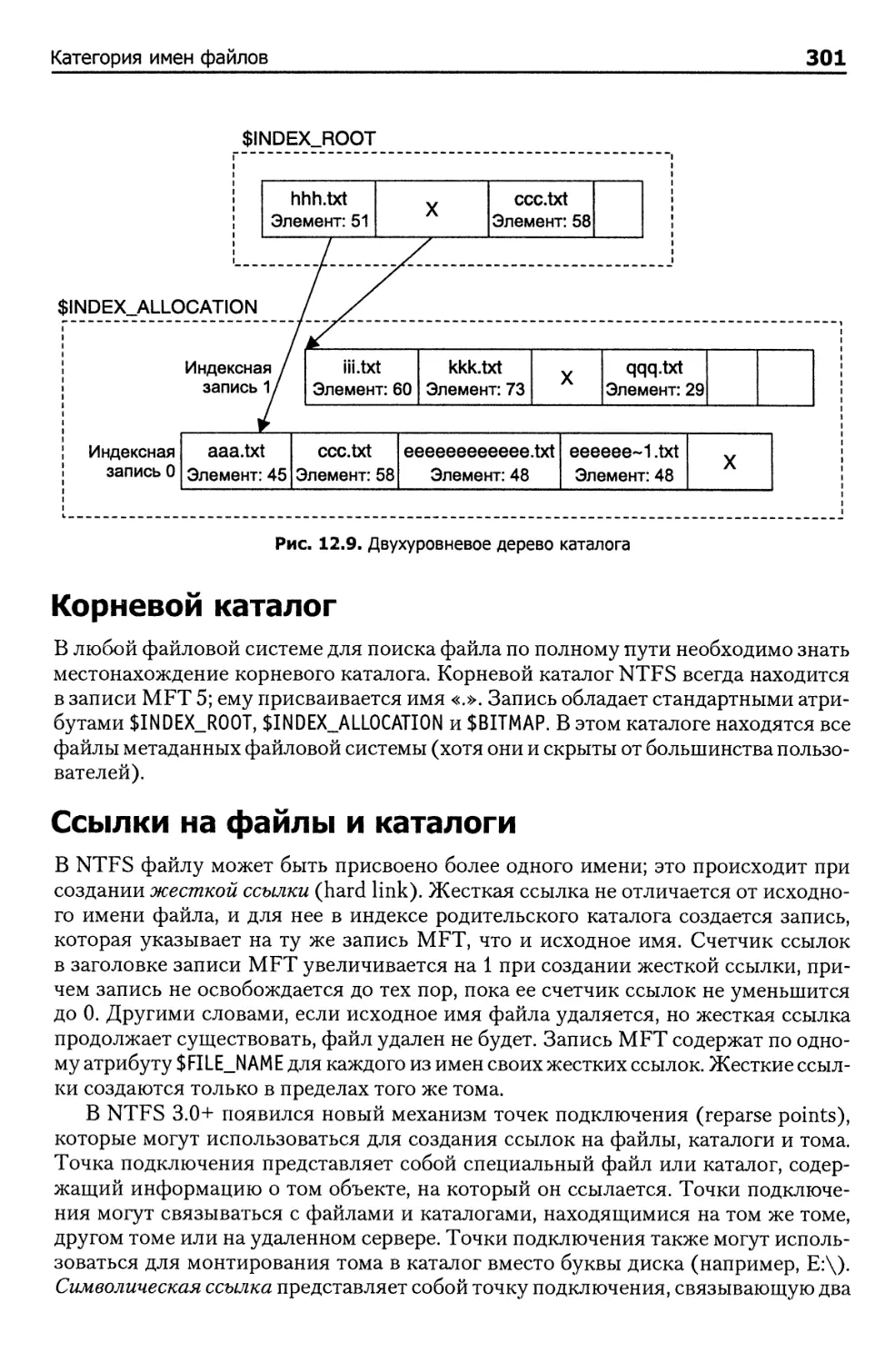
Категория имен файлов 300
Индексы каталогов 300
Корневой каталог 301
Ссылки на файлы и каталоги 301
Идентификаторы объектов 302
Алгоритмы выделения 302
Методы анализа 303
Факторы анализа 303
Сценарий анализа 304
Категория прикладных данных 306
Дисковые квоты 306
Журналы файловых систем 306
Журнал изменений 309
Общая картина 310
Создание файла 311
Пример удаления файла 312
Разное 314
Восстановление файлов 314
Проверка целостности данных 314
Итоги 315
Библиография 316
Глава 13- Структуры данных NTFS 317
Базовые концепции 317
Маркеры 317
Записи MFT (файловые записи) 318
Заголовок атрибута 320
Стандартные атрибуты файлов 324
Атрибут $STANDARD_INFORMATION 324
Атрибут $FILE_NAME 326
Атрибут $DATA 328
Атрибут $ATTRIBUTE_LIST 328
Атрибут $OBJECT_ID 330
Атрибут $REPARSE_POINT 330
Атрибуты и структуры данных индексов 331
Атрибут $INDEX_ROOT 331
Атрибут $INDEX_ALLOCATION 332
Атрибут $ВГГМАР 334
Структура данных заголовка индексного узла 334
Структура данных обобщенного индексного элемента 335
Структура данных индексного элемента каталога 336
Файлы метаданных файловой системы 339
Файл $MFT 339
Файл $Boot 339
Файл $AttrDef 341
Файл $Bitmap 342
Файл $Volume 343
Файл$ОЬ]1с1 344
Файл $Quota 345
Файл $LogFile 347
Файл $UsrJrnl 348
Итоги 351
Библиография 351
Глава 14. Ext2 и Ext3: концепции и анализ 352
Введение 352
Категория данных файловой системы 354
Общие сведения 354
Методы анализа 358
Факторы анализа 358
Сценарий анализа 359
Категория содержимого 362
Общие сведения 362
Алгоритмы выделения 363
Методы анализа 364
Факторы анализа 364
Сценарий анализа 365
Категория метаданных 365
Общие сведения 366
Алгоритмы выделения 371
Выделение индексных узлов 371
Методы анализа 373
Факторы анализа 374
Сценарий анализа 375
Категория данных имен файлов 376
Общие сведения 376
Алгоритмы выделения 380
Методы анализа 381
Факторы анализа 382
Сценарии анализа 383
Категория прикладных данных 387
Журналы файловой системы 387
Сценарий анализа 389
Общая картина 390
Пример создания файла 391
Пример удаления файла 393
Разное 395
Восстановление файлов 395
Проверка целостности данных 396
Итоги 397
Библиография 397
Глава 15- Структуры данных Ext2 и Ext3 399
Суперблок 399
Таблица дескрипторов групп 403
Битовая карта блоков 404
Индексные узлы 405
Расширенные атрибуты 409
Запись каталога 412
Символическая ссылка 414
Хеш-деревья 415
Структуры данных журнала 416
Итоги 421
Библиография 421
Глава 16. UFS1 и UFS2: концепции и анализ 422
Введение 422
Категория данных файловой системы 423
Общие сведения 423
Методы анализа 429
Факторы анализа 430
Категория содержимого 430
Общие сведения 430
Алгоритмы выделения 432
Методы анализа 433
Факторы анализа 433
Категория метаданных 434
Общие сведения 434
Алгоритмы выделения 436
Методы анализа 437
Факторы анализа 437
Категория данных имен файлов 438
Общие сведения 438
Алгоритмы выделения 439
Методы анализа 440
Факторы анализа 440
Общая картина 441
Создание файла 441
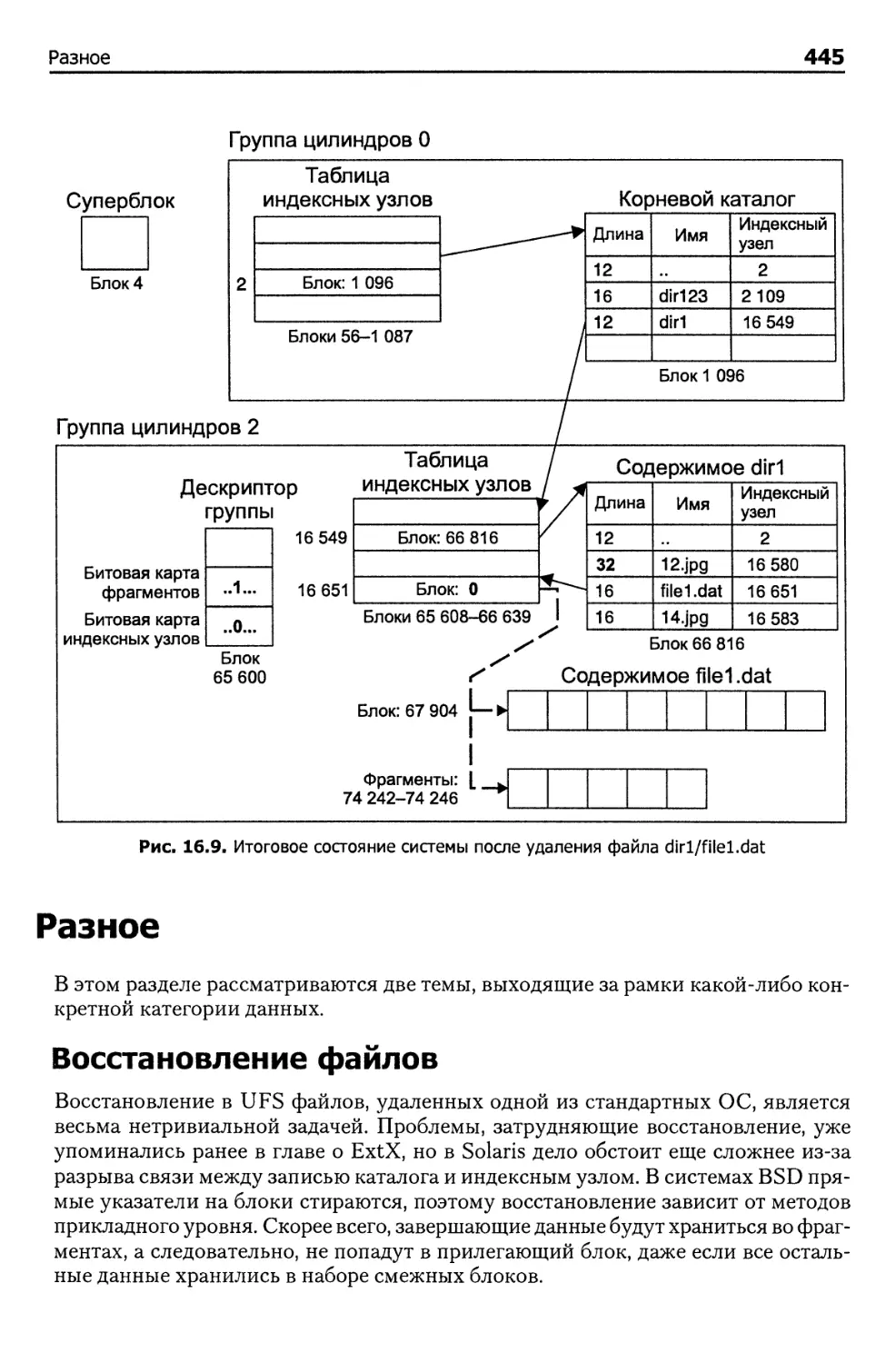
Пример удаления файла 443
Разное 445
Восстановление файлов 445
Проверка целостности данных 446
Итоги 447
Библиография 447
Глава 17. Структуры данных UFS1 и UFS2 448
Суперблок UFS1 448
Суперблок UFS2 453
Сводка групп цилиндров 456
Дескриптор группы UFS1 457
Дескриптор группы UFS2 459
Битовые карты блоков и фрагментов 460
Индексные узлы UFS1 461
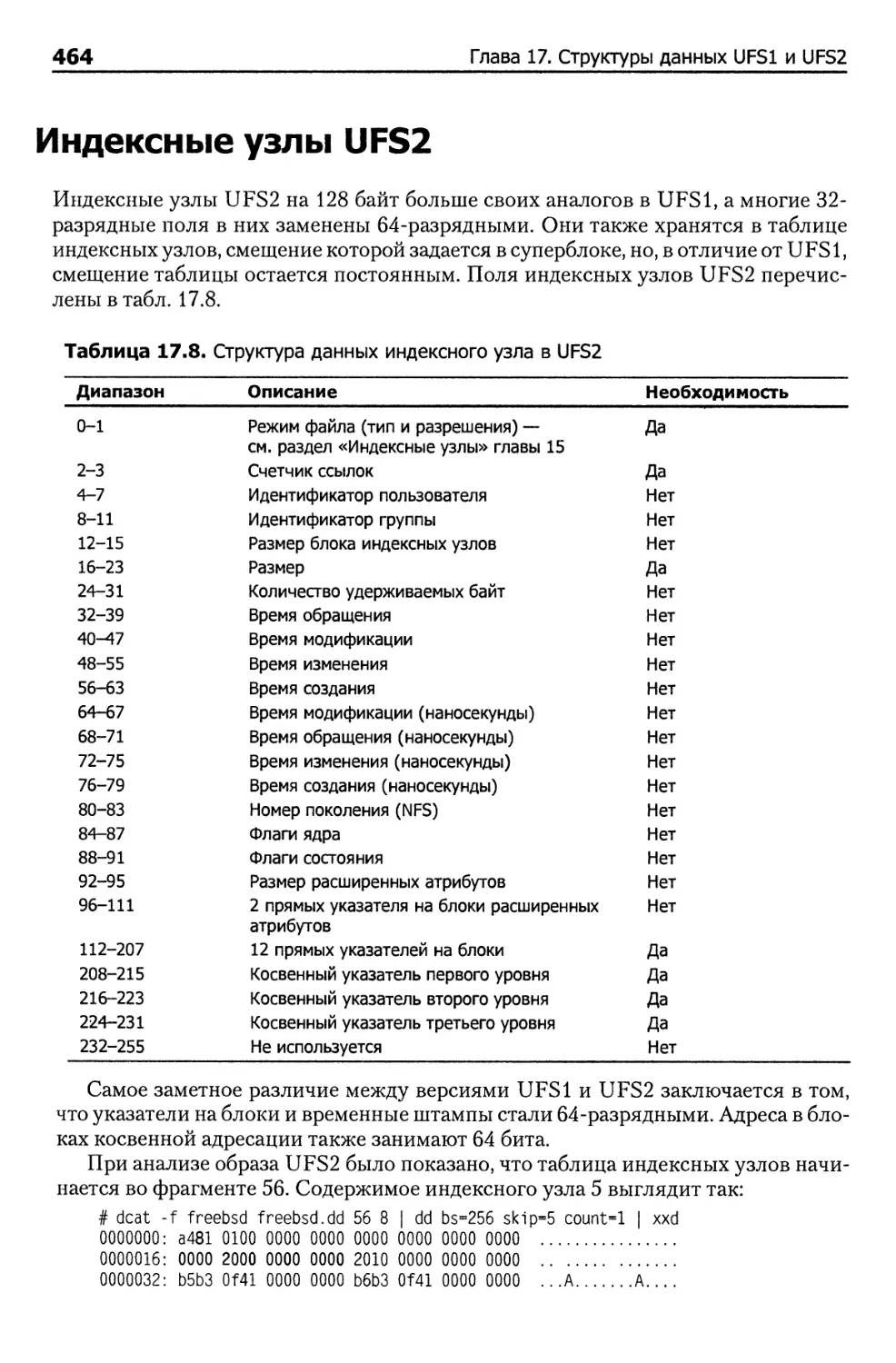
Индексные узлы UFS2 464
Расширенные атрибуты UFS2 465
Записи каталогов 466
Итоги 468
Библиография 468
Приложение. The Sleuth Kit и Autopsy 469
The Sleuth Kit 469
Программы для работы с диском 470
Программы для работы с томами 470
Программы файловой системы 470
Программы поиска 473
Autopsy 474
Режимы анализа 474
Библиография 475
Алфавитный указатель 476
Посвящаю эту книгу
моим дедушкам и бабушкам —
Генри, Габриэль, Альберту и Рите
Предисловие
Компьютерный криминологический анализ — относительно новое явление, и за
последние годы оно называлось многими терминами: «цифровая экспертиза»,
«анализ носителей информации» и т.д. Только в последнее время стало очевидно,
что цифровые устройства также могут служить ценным источником улик в ши-
широком спектре расследований. Хотя профессиональные криминалисты среди пер-
первых проявили интерес к цифровым уликам, разведка, службы информационной
безопасности и специалисты по гражданскому праву с энтузиазмом приняли этот
новый источник информации.
В 2003 г. Американское общество директоров криминологических лаборато-
лабораторий — Совет по аккредитации лабораторий (ASCLD-LAB) признал поиск циф-
цифровых улик полноценной отраслью криминологической экспертизы. Наряду с этим
признанием наблюдался рост интереса к обучению и повышению квалификации
в этой области. Для содействия разработке учебных программ была сформирова-
сформирована рабочая группа Computer Forensic Educator's Working Group (сейчас извест-
известная под названием Digital Forensics Working Group). В настоящее время свыше
30 колледжей и университетов ведут разработку научных программ в области
цифровой экспертизы, и каждый месяц их ряды пополняются.
Я имел удовольствие работать со многими органами правопорядка, учебными
учреждениями, колледжами и университетами в области разработки программ
цифровой экспертизы. Один из первых вопросов, который мне обычно задава-
задавали, — не могу ли я порекомендовать хороший учебник для их курсов. На эту тему
было написано немало книг. Одни ориентировались на отдельные аспекты рас-
расследования — такие, как методы реагирования или криминологическая экспер-
экспертиза. Другие представляли собой учебники по использованию конкретных про-
программных пакетов. Было трудно найти книгу, которая закладывала бы надежную
техническую и системную основу в области цифровой экспертизы... Так было до
настоящего времени.
В этой книге изложены основополагающие принципы анализа файловых сис-
систем. Ее материал основателен, полон и хорошо организован. Брайан Кэрриер сделал
то, что необходимо было сделать в этой области. Книга дает читателю хорошее
понимание как структур данных в разных файловых системах, так и принципов
их работы. Кэрриер написал свою книгу так, что читатель сможет использовать
то, что он знает об одной файловой системе, при изучении другой системы. Эта
книга бесценна и как учебник, и как справочник; она должна стоять на полке каж-
каждого практикующего специалиста и преподавателя в области цифровой экспер-
экспертизы. Кроме того, она содержит доступную информацию для читателей, которые
пожелают самостоятельно разобраться в таких темах, как восстановление данных.
Когда мне предложили написать это предисловие, я с радостью принял пред-
предложение! Мы с Брайаном Кэрриером знакомы уже много лет. На меня всегда про-
производило впечатление замечательное сочетание его выдающейся технической ква-
квалификации и умения понятно объяснять не только то, что знает он, но и, что еще
важнее, то, что необходимо знать читателю. Работа Брайана над Autopsy и The
Sleuth Kit (TSK) доказала его компетентность — его имя известно любому специ-
специалисту в области компьютерной экспертизы. Мне выпала честь работать с Брай-
ном в его текущей должности в Университете Пердью (Purdue), где он помогает
сделать академическому сообществу то, что однажды сделал для коммерческого
сектора: установить высокие стандарты.
Итак, я без малейших колебаний рекомендую вам эту книгу. Она поможет вам
заложить прочную основу знаний в области цифровых носителей информации.
Марк М. Поллитт (Mark M. Pollitt).
Президент Digital Evidence Professional Services, Inc.
Бывший директор программы ФБР Regional Computer Forensic Laboratory
Program.
От издательства
Ваши замечания, предложения, вопросы отправляйте по адресу электронной поч-
почты: comp@piter.com (издательство «Питер», компьютерная редакция).
Мы будем рады узнать ваше мнение!
На веб-сайте издательства — http://www.piter.com — вы найдете подробную ин-
информацию о наших книгах.
Введение
Одной из главных проблем, с которыми я сталкивался за годы разработки TSK
(The Sleuth Kit), был поиск хорошей документации по файловым системам и то-
томам (таблицы разделов, RAID и т. д.). Кроме того, мне было трудно объяснить
пользователям, почему некоторые файлы не удается восстановить или что делать
при повреждении файловой системы, — я не мог порекомендовать им хорошую
книгу. Легко найти ресурсы, описывающие файловые системы на высоком уров-
уровне, но за подробностями обычно необходимо обращаться к исходному коду. В этой
книге я постараюсь заполнить этот пробел, описать способы хранения данных на
диске, а также объяснить, где и как следует искать цифровые улики.
Круг читателей, для которых предназначена книга, делится на две группы.
К первой относятся опытные эксперты, освоившие методы цифрового расследо-
расследования на практике и обладающие опытом использования аналитических программ.
Вторую группу составляют новички, которые желают познакомиться с общей те-
теорией расследования и методами поиска цифровых улик, но еще не интересуются
учебниками по работе с конкретными программами.
Материал этой книги ценен прежде всего тем, что он направлен на обучение,
а не на освоение конкретного пакета. Возьмем какую-нибудь из более формаль-
формальных научных или инженерных дисциплин — все студенты в обязательном поряд-
порядке проходят пару семестров физики, химии или биологии. Эти курсы обязатель-
обязательны вовсе не потому, что студенты будут использовать весь усвоенный материал
на протяжении всей своей карьеры. На самом деле для выполнения многих вы-
вычислений, которые студентам приходится проводить вручную, существуют спе-
специальные программы и оборудование. Эти курсы дают студентам представление
о том, как работают соответствующие механизмы, чтобы они не ограничивались
конкретным инструментарием.
Цель этой книги — предоставить эксперту примерно такой же образователь-
образовательный материал, какой получает специалист по судебной криминалистике из на-
начального курса химии. Большинство цифровых улик находится на диске; если
эксперт будет знать, где и почему они существуют, ему будет проще давать пока-
показания. Кроме того, подобная информация поможет выявить ошибки и недочеты
в аналитических программах, потому что эксперт сможет провести проверку вы-
выходных данных.
Последние тенденции в области цифровых расследований показывают, что спе-
специалистам необходимо дополнительное обучение. К лабораториям судебной экс-
экспертизы все чаще обращаются за анализом цифровых улик, в настоящее время
идут споры относительно необходимых уровней образования и сертификации.
Многие университеты ведут курсы и даже присуждают степень магистра в области
компьютерной экспертизы. Правительственные и коммерческие лаборатории про-
проводят теоретические исследования в этой области, уделяя внимание как будущим,
так и текущим проблемам. Также появились специализированные бюллетени, в ко-
которых публикуются методики анализа и расследования. Все эти новые исследо-
исследования требуют основательной подготовки, выходящей за рамки конкретного про-
программного пакета или методики.
В этой книге я постараюсь изложить базовые концепции и теорию файловых
систем и томов, а затем применить их в контексте расследования. Для каждой
файловой системы рассматриваются методы анализа и факторы, которые должен
учитывать эксперт. Описанные сценарии закрепят навыки применения теории
на практике. Также в книге приводятся структуры данных, задействованные
в томах и файловых системах, а ручной разбор низкоуровневых образов поможет
понять, где хранятся те или иные данные. Если формальные описания структур
данных вас не интересуют, соответствующие главы можно пропустить. В книге
используются только некоммерческие программы, поэтому вы можете бесплатно
загрузить их и воспроизвести результаты в своей системе.
Структура книги
Книга делится на три части. В первой части приводится основная теория, а основ-
основной технический материал содержится во второй и третьей частях. Книга органи-
организована таким образом, чтобы изучение шло от нижних уровней абстракции к вер-
верхним. Мы начнем с общего знакомства с жесткими дисками, а затем разберемся,
как дисковое пространство организуется в разделы. После знакомства с раздела-
разделами речь пойдет о содержимом разделов, которое обычно представляет собой фай-
файловые системы.
Часть 1, «Основы», начинается с главы 1, «Основы цифровых расследований»;
в ней я излагаю свой подход к цифровым расследованиям. Будут представлены
различные фазы расследования и рекомендации, чтобы вы знали, где использу-
используются методики, описанные в книге. Впрочем, книга не требует, чтобы вы исполь-
использовали этот же подход в своей работе. Главы 2 и 3 содержат теорию и примеры
снятия данных с жесткого диска для их последующего анализа в частях 2 и 3.
Часть 2, «Анализ томов», посвящена анализу структур данных, обеспечиваю-
обеспечивающих разбиение и объединение дискового пространства в томах. В главе 4, «Ана-
«Анализ томов», приводится общий обзор методов анализа томов, а в главе 5, «Разде-
«Разделы на персональном компьютере», рассматриваются распространенные схемы
разделов DOS и Apple. Глава 6, «Разделы в серверных системах», посвящена раз-
разделам в системах BSD, Sun Solaris и Itanium. В главе 7, «Многодисковые тома»,
говорится о RAID и объединении томов.
Часть 3, «Анализ файловых систем», посвящена анализу тех структур данных
томов, которые непосредственно связаны с сохранением и загрузкой данных. В гла-
главе 8, «Анализ файловых систем», представлена общая теория анализа файловых
систем и определяется терминология для остальных глав части 3. Каждой файло-
файловой системе посвящаются как минимум две главы: в первой излагаются общие
концепции и методы расследования, а во второй приводятся структуры данных
и результаты ручного анализа дисковых образов. Вы можете сами решить, как чи-
читать эти две главы: параллельно, последовательно или вообще пропустить главу
с описаниями структур данных.
Файловые системы сильно различаются по архитектуре, поэтому при их опи-
описании используется обобщенная модель файловой системы с классификацией дан-
данных на пять категорий: данные файловой системы, содержимое, метаданные, дан-
данные имен файлов и прикладные данные. Эта обобщенная модель применяется при
описании всех файловых систем и упрощает их сравнительный анализ.
В главах 9, «FAT: основные концепции и анализ», и 10, «Структуры данных
FAT», подробно описывается файловая система FAT. Глава 11, «NTFS: основные
концепции», глава 12, «NTFS: анализ», и глава 13, «Структуры данных NTFS»,
посвящены NTFS. Затем в главах 14, «Ext2 и Ext3: концепции и анализ» и в гла-
главе 15, «Структуры данных Ext2 и Ext3», мы перейдем к файловым системам Linux
Ext2 и Ext3. Наконец, глава 16, «UFS1 и UFS2: концепции и анализ», и глава 17,
«Структуры данных UFS1 и UFS2», посвящены системам UFS1 и UFS2, встреча-
встречающимся в FreeBSD, NetBSD, OpenBSD и Sun Solaris.
После знакомства с частью 3 книги вы будете знать, где именно на диске хра-
хранятся файлы, а также разбираться в структурах, необходимых для его просмотра.
Вопросы анализа содержимого файлов в книге не рассматриваются.
Итак, вы знаете, о чем говорится в книге, теперь я скажу, чего в ней нет. Книга
останавливается на уровне файловой системы и не доходит до прикладного уров-
уровня. Следовательно, мы не будем заниматься анализом различных файловых фор-
форматов. Кроме того, здесь не рассматриваются файлы, создаваемые конкретной фай-
файловой системой или приложением. Если вас интересуют подробные инструкции
по анализу компьютера с Windows 98, который использовался для загрузки подо-
подозрительных файлов, скорее всего, книга вас разочарует. Если вы ищете руковод-
руководство по обследованию взломанных серверов Linux, вы найдете здесь ряд полез-
полезных приемов, но книга написана о другом. Все эти темы относятся к области
анализа прикладного уровня, и для их полноценного изложения потребуется от-
отдельная книга. Но если вас интересует нечто большее, чем пошаговые инструк-
инструкции, — вероятно, эта книга написана для вас.
Ресурсы
На протяжении всей книги пакет TSK (The Sleuth Kit) используется для обработ-
обработки тестовых образов дисков, чтобы материал включал как низкоуровневые, так
и отформатированные данные. Однако это вовсе не означает, что книга является
руководством по использованию TSK. Пакет TSK и Autopsy (графический ин-
интерфейс к TSK) описаны в приложении к книге. Дополнительную документацию
можно загрузить по адресу: http://www.sleuthkit.org.
URL-адреса и ссылки на другие программы приводятся по мере надобности.
Дополнительные ресурсы, ссылки и исправления размещаются на сайте книги:
http://www.digitaL-evidence.org/fsfa/.
Благодарности
Мне хотелось бы поблагодарить многих людей, помогавших мне в области циф-
цифровой экспертизы. Прежде всего я должен упомянуть тех, кто оказывал мне об-
общее содействие в течение многих лет: это Эоган Кейси (Eoghan Casey), Дэйв Дит-
Дитрих (Dave Dittrich), Дэн Фармер (Dan Farmer), Дэн Гир (Dan Geer), Дэн Калил
(Dan Kalil), Уоррен Круз (Warren Kruse), Гэри Палмер (Gary Palmer), Юджин
Спаффорд (Eugene Spafford), Ланс Спицнер (Lance Spitzner) и Витце Венема
(Wietse Venema). Я благодарен им за руководство, наставления и предоставлен-
предоставленные возможности.
Также мне хотелось бы поблагодарить Кори Альтейд (Cory Altheide), Эогана
Кейси (Eoghan Casey), Кнута Экстейна (Knuth Eckstein) и Джима Лайла (Jim Lyle)
за рецензирование книги. Хочу особо отметить Кнута, который просмотрел все
шестнадцатеричные дампы всех тестовых дисковых образов и проверил все пре-
преобразования из шестнадцатеричной системы в десятичную (и обнаружил несколь-
несколько опечаток), и Эогана, вовремя напоминавшего, когда требовались более реали-
реалистичные примеры. Кристофер Браун (Christopher Brown), Симеон Гарфинкель
(Simson Garfinkel), Кристофер Гренье (Christopher Grenier), Барри Гранди (Barry
Grundy), Горд Хама (Gord Наша), Джессе Корнблум (Jesse Kornblum), Трои Лар-
сон (Troy Larson), Марк Менц (Mark Menz), Ричард Рассон (Richard Russon)
и Крис Санфт (Chris Sanft) — все они просмотрели текст и внесли улучшения в тех
областях, в которых они особенно хорошо разбирались.
Книга появилась на свет благодаря многочисленным работникам Addison Wesley
и Pearson. Джессика Голдстейн (Jessica Goldstein) направляла мою работу и под-
подбадривала меня; Кристи Хакерд (Christy Hackerd) следила за тем, чтобы редакти-
редактирование и верстка шли гладко, а Чанда Лири-Куту (Chanda Leary-Coutu) использо-
использовала свой опыт маркетинга. Спасибо Элизе Уолтер (Elise Walter) за правку, Кристал
Андри (Christal Andry) за корректуру, Эрику Шредеру (Eric Schroeder) за состав-
составление алфавитного указателя, Джейку МакФарленду (Jake McFarland) за компь-
компьютерную верстку и Чути Празерсит (Chuti Prasersith) за дизайн обложки.
Остается поблагодарить мою семью, и особенно моего лучшего друга (и буду-
будущую супругу) Дженни, которая помогла мне сохранить душевное равновесие за
много долгих ночей и выходных, проведенных за клавиатурой (дошло до того, что
она купила мне Х-Вох, чтобы отвлечь от структур данных и уровней абстракции).
Также спасибо нашей кошке Ачу — она ежедневно напоминала мне, что игра с ре-
резинкой для волос и лазерной указкой бывает такой же занятной, как игры с еди-
единицами и нулями.
ЧАСТЬ I
Основы
Глава 1. Основы цифровых расследований 26
Глава 2. Основные принципы работы компьютеров 38
Глава 3. Снятие данных с жесткого диска 63
Основы цифровых
расследований
Полагаю, читателю, заинтересовавшемуся этой книгой, не нужно объяснять, для
чего необходимо анализировать компьютер или другое цифровое устройство, так
что я пропущу обычные цифры и статистику. Книга написана о том, как лучше
организовать цифровое расследование; она посвящена данным и способам их хра-
хранения. Инструментарий цифрового расследования стал достаточно прост в ис-
использовании, и это хорошо, потому что простота уменьшает время, необходимое
на проведение расследования. Тем не менее у нее есть pi оборотная сторона: экс-
эксперт не всегда в полной мере понимает все результаты. Это может быть опасно,
если обязан сделать заявление по поводу улик и их происхождения. Книга начи-
начинается с изложения основ расследования и компьютерных технологий, после чего
мы переходим к томам и файловым системам. Существует много способов прове-
проведения расследования; один из них описан в этой главе. Впрочем, вы не обязаны
идти по тому же пути. В этой главе я лишь показываю, какое место, на мой взгляд,
содержимое книги занимает в общей картине.
Цифровые расследования и улики
Существует огромное количество определений цифровой экспертизы и расследо-
расследований. В этом разделе я приведу те определения, которые использую лично я,
вместе с обоснованиями. Объектом цифрового расследования является некоторое
цифровое устройство, задействованное в инциденте или преступлении. Цифро-
Цифровое устройство могло использоваться при совершении физического преступле-
преступления, а могло и стать источником события, нарушившего правила или закон. При-
Приведу пример первого случая: подозреваемый собирает в Интернете информацию
для подготовки физического преступления. Среди примеров второго случая можно
выделить получение несанкционированного доступа к компьютеру, загрузку не-
незаконного материала по сети или отправку электронной почты с угрозами. После
того как факт нарушения будет выявлен, начинается расследование. Оно должно
ответить на такие вопросы: почему произошло нарушение, кто или что послужил
причиной и т. д.
Цифровым расследованием называется процесс разработки и проверки гипо-
гипотез, отвечающих на вопросы о цифровых событиях. Задача решается научным ме-
методом: эксперт строит гипотезы на основе найденных улик, а затем проверяет их
поиском дополнительных улик, которые доказывали бы несостоятельность дан-
данной гипотезы. Цифровой уликой называется цифровой объект, содержащий на-
надежную информацию, которая поддерживает или опровергает гипотезу.
Возьмем сервер, подвергшийся внешнему вторжению. Расследование начинается
с определения ответа на вопрос: когда это произошло и кто это сделал. В процессе
расследования обнаруживаются данные, которые были созданы событиями, свя-
связанными с инцидентом. Эксперт восстанавливает на сервере удаленные записи
журнала, находит программы, задействованные в атаке, и многочисленные уяз-
уязвимости, существующие на сервере. По этим и другим данными строится гипоте-
гипотеза относительно того, какая уязвимость была использована нападающим, и что он
делал потом. Позднее эксперт анализирует конфигурацию брандмауэра (firewall)
и журнала. По результатам анализа он определяет, что некоторые сценарии, сфор-
сформулированные в гипотезах, невозможны, потому что сетевой трафик соответству-
соответствующего типа не существовал, а в журнале не нашлось обязательных записей. Та-
Таким образом обнаруживаются улики, опровергающие одну или несколько гипотез.
В этой книге я использую термин «улика» в следственном контексте. Улики
имеют как юридическое, так и следственное применение. Приведенное ранее опре-
определение относилось к следственному применению улик; далеко не всегда найден-
найденные улики могут быть предъявлены в суде. Поскольку требования к юридичес-
юридической допустимости улик зависят от страны или штата, а я не обладаю юридической
подготовкой, я сосредоточу внимание на общей концепции улик, а вы можете вне-
внести поправки с учетом местного законодательства. В действительности никаких
юридических требований, относящихся именно к файловым системам, не суще-
существует, поэтому необходимую информацию можно почерпнуть из общей литера-
литературы по цифровому расследованию.
Процесс анализа места цифрового преступления
Не существует единого подхода к проведению расследований. Если спросить пя-
пятерых людей, как найти человека, который допил остатки кофе из кофейника, ве-
вероятно, вы получите пять разных ответов. Один предложит снять с кофейника
отпечатки пальцев, другой — поискать видеозаписи на камерах системы безопас-
безопасности, третий — проверить, у кого самая горячая чашка. Если нам удастся найти
нужного человека, не нарушив никаких законов, не так уж важно, какой процесс
при этом использовался, хотя некоторые способы эффективнее других.
Подход, который я использую в цифровых расследованиях, основан на процессе
анализа места физического преступления [Carrier and Spafford, 2003]. В данном слу-
случае мы имеем место цифрового преступления, к которому относится цифровое ок-
окружение, создаваемое программами и оборудованием. Процесс состоит из трех ос-
основных фаз: консервации системы, поиска улик и реконструкции событий. Эти фазы
не обязаны следовать одна за другой, а общая схема процесса показана на рис. 1.1.
Рис. 1.1. Три основные фазы анализа места цифрового преступления
Этот процесс применяется при проведении расследования как в живых, так
и в мертвых системах. Живой анализ происходит при поиске улик с использовани-
использованием операционной системы или других ресурсов анализируемого компьютера. Мер-
Мертвый анализ происходит тогда, когда вы запускаете доверенное приложение в до-
веренной операционной системе для поиска улик. При живом анализе существует
риск получения ложной информации, потому что программы могут намеренно скры-
скрывать или искажать данные. Мертвый анализ надежнее, но он возможен не всегда.
Фаза сохранения системы
В первой фазе расследования — фазе сохранения системы — эксперт пытается
законсервировать состояние места цифрового преступления. Выполняемые дей-
действия зависят от юридических, деловых или процедурных требований к рассле-
расследованию. Например, в соответствии с юридическими требованиями эксперт мо-
может быть обязан отключить систему от сети и создать полную копию всех данных.
К крайним случаям можно отнести дела, связанные с заражением вредоносными
программами; в таких ситуациях сохранение не выполняется. В большинстве рас-
расследований в корпоративных и военных средах, не передаваемых в суд, применя-
применяются методики, находящиеся где-то между этими двумя крайними точками.
Основной целью этой фазы является сведение к минимуму возможных потерь
улик в ходе расследования. Этот процесс продолжается после снятия данных из
системы, потому что данные необходимо сохранить для будущего анализа. В гла-
главе 3 рассматриваются методы создания полной копии жесткого диска, а в остав-
оставшейся части книги будут рассматриваться способы анализа данных и поиска улик.
Методы сохранения
Так как фаза сохранения системы направлена на минимизацию потерь улик, не-
необходимо ограничить количество процессов, способных записывать данные на
носители информации. При проведении мертвого анализа эксперт завершает все
процессы, отключая систему, и создает резервные копии всех данных. Как будет
показано в главе 3, для предотвращения потери улик также могут применяться
блокировщики записи.
При живом анализе следует завершить или приостановить все подозрительные
процессы. Компьютер необходимо отключить от сети (возможно, подключив сис-
систему к пустому концентратору или коммутататору, чтобы предотвратить появле-
появление в журнале сообщений о недоступности сети) или установить сетевые фильтры,
чтобы злоумышленник не мог подключиться из удаленной системы и уничтожить
данные. Важные данные копируются на случай возможной потери в процессе по-
поиска. Например, если вы собираетесь читать файлы, сохраните временные штам-
штампы всех файлов, чтобы у вас была эталонная копия времени последнего обраще-
обращения — ваши действия приведут к обновлению временных штампов.
При сохранении важных данных в процессе живого или мертвого анализа сле-
следует вычислить криптографический хеш-код; позднее он поможет доказать, что
данные не изменялись. Криптографический хеш-код (MD5, SHA-1 или SHA-256)
представляет собой очень большое число, вычисляемое по математической фор-
формуле для набора входных данных. Изменение хотя бы одного бита во входных
данных приводит к заметному изменению выходного числа; более подробную
информацию можно найти в книге «Applied Cryptography», 2nd Edition [Schneier,
1995]. Для хеширования разработаны специальные алгоритмы, при которых по-
получение одинакового результата для двух разных входных данных крайне мало-
маловероятно. Следовательно, если хеш-код важных данных остался прежним, это го-
говорит о том, что данные не подвергались модификации.
Фаза поиска улик
Позаботившись о сохранении данных, можно перейти к поиску в них улик. Вспом-
Вспомните: мы ищем данные, которые поддерживают или опровергают гипотезы о про-
произошедшем инциденте. Процесс обычно начинается с изучения стандартных мест,
зависящих от типа инцидента (если он известен). Например, если речь идет о при-
привычках по работе с браузером, следует просмотреть содержимое кэша браузера,
файл истории и закладки. Если же расследуется взлом системы Linux, стоит по-
поискать следы руткитов или новые учетные записи пользователей. С ходом рас-
расследования эксперт строит гипотезы и ищет улики, которые подтверждали бы или
опровергали их. Важно, чтобы эксперт искал и опровергающие улики, не ограни-
ограничиваясь подтверждающими.
Теория процесса поиска проста. Сначала следует определить общие характе-
характеристики искомого объекта, а затем провести поиск этого объекта в наборе дан-
данных. Например, если потребуется найти все файлы с расширением JPG, следует
просмотреть все имена файлов и выделить среди них те, которые заканчиваются
символами «JPG». Два ключевых шага — это определение того, что нужно найти,
и тех мест, где должен проводиться поиск.
Часть 2, «Анализ томов», и часть 3, «Анализ файловых систем», посвящены
поиску улик в томах и файловых системах. В сущности, главы анализа файловых
систем организованы таким образом, чтобы читатель мог сосредоточиться на кон-
конкретной категории данных, содержащей улики. В конце главы приводится сводка
популярных аналитических программ; все они позволяют просматривать, искать
и сортировать данные в подозрительных системах с целью поиска улик.
Методы поиска
Большинство улик находится в файловой системе и в файлах. Стандартная мето-
методика поиска заключается в поиске файлов по именам или шаблонам. Также часто
требуется найти файл по ключевым словам, присутствующим в их содержимом.
Возможен и вариант поиска файлов по временным данным — таким, как время
последнего обращения или записи.
Иногда поиск известных файлов проводится сравнением хеш-кодов содержимо-
содержимого файлов, вычисленных по алгоритму MD5 или SHA-1, с базой данных хеш-ко-
хеш-кодов — такой, KaKNational Software Reference Library (NSRL— http://www.nsrLnist.gov).
Базы данных хеш-кодов часто применяются при поиске заведомо хороших или
заведомо вредоносных файлов. Другой распространенный метод поиска основан
на сигнатурах, присутствующих в содержимом. По сигнатурам часто удается най-
найти все файлы заданного типа даже в том случае, если они были переименованы.
При анализе сетевого трафика возможен поиск всех пакетов, отправленных
с некоторого исходного адреса, или всех пакетов, адресованных конкретному пор-
порту. Иногда требуется найти все пакеты с заданным ключевым словом.
Фаза реконструкции событий
В последней фазе расследования на базе найденных улик определяются события,
происходившие в системе. В соответствии с нашим определением расследования
мы пытаемся найти ответы на вопросы о цифровых событиях в системе. Допустим,
в фазе поиска улик были обнаружены файлы, нарушающие корпоративную
политику или закон, но факт их обнаружения не дает никакой информации о со-
событиях. Выясняется, что один из файлов появился в результате определенного
события — загрузки по сети; также следует попытаться определить, какое прило-
приложение загрузило его. Был ли это веб-браузер или какая-то вредоносная програм-
программа? Известен ряд случаев использования вредоносных программ для защиты
при обнаружении незаконных материалов или других цифровых улик [George,
2004; Brenner, Carrier, and Henninger, 2004]. Иногда после фазы реконструкции
цифровых событий удается связать эти цифровые события с физическими.
Для реконструкции событий эксперт должен хорошо знать приложения и ОС,
установленные на компьютере, чтобы строить гипотезы на основании их воз-
возможностей. Например, цифровые события в Windows 95 отличаются от событий
Windows XP, а разные версии браузера Mozilla порождают разные события. Та-
Такой тип анализа выходит за рамки книги, но некоторые общие рекомендации мож-
можно найти в [Casey, 2004].
Общие рекомендации
Не стоит полагать, будто все расследования проводятся по одной схеме, — иногда
приходится изобретать новые процедуры. Возможно, книга покажется кому-то
излишне академичной, потому что она не ограничивается возможностями, реали-
реализованными в существующих инструментах. Некоторые методы еще не были реа-
реализованы, поэтому для поиска улик вам придется импровизировать. Приведу свой
набор общих правил, которые, как хочется верить, упростят вашу работу при раз-
разработке новых процедур.
Первое правило — сохранение исследуемой системы. Эксперт должен исклю-
исключить любые модификации данных, которые могут послужить уликами. Крайне
неприятно оказаться в суде, когда другая сторона убеждает присяжных, что вы по
неосторожности стерли улики. Решению этой задачи была посвящена первая ста-
стадия процесса расследования. Приведу несколько примеров ее реализации:
• Скопируйте важные данные, поместите оригинал в надежное место и анализи-
анализируйте копию, чтобы в случае модификации данных можно было восстановить
оригинал.
• Вычислите хеш-коды MD5 или SHA важных данных. Позднее они помогут
доказать, что данные не изменились.
• Воспользуйтесь устройством блокировки записи во время любых действий,
способных привести к записи в анализируемые данные.
• Сведите к минимуму количество файлов, создаваемых во время живого ана-
анализа, — они могут стереть улики в свободном пространстве.
• Будьте осторожны при открытии файлов во время живого анализа, поскольку
это может привести к модификации данных (таких, как время последнего об-
обращения).
Второе правило — изоляция среды анализа как от анализируемых данных, так
и от внешнего мира. Изоляция от подозрительных данных необходима, потому
что вы не знаете, что они могут сделать. Исполняемый файл из анализируемой
системы может удалить все файлы на вашем компьютере или попытаться уста-
установить связь с удаленной системой. Открытие HTML-файла в браузере может
привести к запуску сценариев и загрузке файлов с удаленного сервера. Оба вари-
варианта потенциально опасны, и от них необходимо защититься. Изоляция от подо-
подозрительных данных реализуется их просмотром в приложениях с ограниченной
функциональностью или виртуальных средах, легко воссоздаваемых в случае
уничтожения — таких, как VMWare (http://www.vmware.com).
Изоляция от внешнего мира необходима для того, чтобы предотвратить всякое
вмешательство извне и нежелательную пересылку данных. Например, как говори-
говорилось в предыдущем абзаце, даже простая загрузка HTML-страницы может приве-
привести к попытке подключения к удаленному серверу. Изоляция от внешнего мира
обычно реализуется подключением к лабораторной сети, не имеющей внешнего
выхода, или фильтрацией сетевого трафика на брандмауэре.
Следует отметить, что живой анализ затрудняет изоляцию. Система не изолиро-
изолирована от анализируемых данных по определению, потому что для анализа этих дан-
данных применяется ее же ОС, которая может содержать посторонний код. Каждое
действие выполняется с участием анализируемых данных. Кроме того, изоляция
от внешнего мира тоже усложняется, потому что для нее необходимо отключить
систему от сети, а живой анализ обычно выполняется во время активности системы.
Третье правило — проверка данных по другим независимым источникам. Тем
самым снижается риск использования ложных данных. Например, как будет по-
показано позднее, в большинстве систем временные штампы файлов легко изме-
изменить. Таким образом, если в вашем расследовании время играет важную роль, по-
постарайтесь найти записи в журналах, сетевой трафик или другие события, которые
подтверждали бы время выполнения операций с файлами.
Последнее правило — документирование всех действий. Это поможет вам оп-
определить, какой поиск еще не проводился и какие результаты были получены ра-
ранее. При проведении живого анализа или применении методов, которые могут
привести к модификации данных, очень важно документировать все происходя-
происходящее; позднее вы сможете описать, какие изменения были внесены в систему из-за
ваших действий.
Анализ данных
В предыдущем разделе я говорил, что основной задачей эксперта является поиск
цифровых улик. Это довольно общее заявление, потому что улики могут найтись
почти в любом месте. В этом разделе я намерен сузить область поиска цифровых
улик и выделить ряд положений, которые будут подробно обсуждаться позднее
в книге. Также мы обсудим, каким данным можно доверять больше других.
Типы анализа
При анализе цифровых данных эксперт ищет объекты, спроектированные чело-
человеком. Кроме того, при проектировании систем хранения данных большинства
цифровых устройств разработчики стремились добиться гибкости и масштаби-
масштабируемости, вследствие чего такие системы имеют многоуровневую структуру. Я вос-
воспользуюсь этой многоуровневой структурой для определения различных типов
анализа [Carrier, 2003a].
Если начать с нижних уровней архитектуры, мы обнаруживаем на них две не-
независимые области анализа. Первая базируется на устройствах хранения инфор-
информации, а вторая — на устройствах обмена данными. В этой книге основное внима-
внимание уделяется анализу устройств хранения информации, а еще точнее — устройств
долгосрочного хранения информации (таких, как жесткие диски). Анализ ком-
коммуникационных систем (таких, как сети IP) в книге не рассматривается, но вы
можете найти необходимую информацию в других источниках [Bejtlich, 2005;
Casey, 2004; Mandia et al., 2003].
Различные области анализа представлены на рис. 1.2. На нижнем уровне вы-
выполняется анализ физических носителей информации: жестких дисков, карт па-
памяти и дисков CD-ROM. Анализ в этой области может быть сопряжен с чтением
низкоуровневых данных с магнитной поверхности и другими методами, для ко-
которых необходима чистая комната. В книге я буду предполагать, что в вашем рас-
распоряжении имеется надежный метод чтения данных с физического носителя, а на
устройство хранения информации уже записан поток из нулей и единиц.
Рис. 1.2. Иерархия уровней анализа, основанная на архитектуре цифровых данных.
Блоки, выделенные жирными линиями, рассматриваются в книге
В дальнейшем мы будем рассматривать анализ двоичного потока информации
на физическом носителе. Структура микросхем памяти обычно определяется на
уровне процессов и выходит за рамки книги. Наше внимание будет сосредоточе-
сосредоточено на постоянных носителях — таких, как жесткие диски и карты памяти.
Как правило, устройства долгосрочного хранения информации организуются
в виде томов. Том представляет собой совокупность ячеек носителя информации,
доступных для чтения и записи со стороны приложений. Анализ томов будет под-
подробно рассматриваться в части 2 книги, а сейчас я упомяну о двух важнейших
концепциях этого уровня. Первая — это разделы (один том разбивается на не-
несколько томов меньшего объема), а вторая — сборка (объединение нескольких
томов в один большой том, на котором в дальнейшем могут создаваться разделы).
Примерами данных этой категории служат таблицы разделов DOS, разделы Apple
и массивы RAID. Некоторые носители (скажем, дискеты) не содержат данных на
этом уровне, а весь диск представляет собой один том. Анализ данных на уровне
томов позволяет определить, где находится файловая система и другие данные
и где может храниться скрытая информация.
Тома содержат разные типы данных, но самым распространенным содержи-
содержимым томов являются файловые системы. Также том может содержать базы данных
или использоваться как временное пространство подкачки (по аналогии с фай-
файлом подкачки Windows). Часть 3 посвящена файловым системам, то есть наборам
структур данных, которые позволяют приложениям создавать, читать и записы-
записывать файлы. Анализ файловых систем направлен на поиск файлов, восстановле-
восстановление удаленных файлов и поиск скрытой информации. Конечным результатом
анализа файловой системы может быть содержимое файла, фрагменты данных
и метаданные, связанные с файлами.
Рис. 1.3. Процесс анализа данных: от физического уровня к прикладному
Чтобы понять, что находится внутри файла, необходимо перейти на прикладной
уровень. Структура каждого файла определяется приложением или ОС, создавшей
файл. Например, с точки зрения файловой системы файл реестра Windows ничем
не отличается от обычной HTML-страницы — и то и другое является файлом. Тем
не менее эти файлы имеют совершенно разную структуру, а для их анализа должны
применяться разные инструменты. Анализ прикладного уровня играет очень важ-
важную роль: именно на этом уровне на основании анализа конфигурационных фай-
файлов мы определяем, какие программы выполнялись в системе, не содержит ли
скрытых данных графический файл, и т. д. В книге прикладной анализ не рас-
рассматривается — чтобы представить его на том же уровне, что и анализ томов и фай-
файловых систем, потребуется несколько отдельных книг. За дополнительной инфор-
информацией обращайтесь к общей литературе по цифровым расследованиям.
Процесс анализа представлен на рис. 1.3. На рисунке изображен диск, в ре-
результате анализа которого был получен поток байтов. Поток анализируется на
уровне томов, в результате чего формируется том. Дальнейший анализ тома на
уровне файловой системы дает файл. Наконец, файл анализируется на приклад-
прикладном уровне.
Необходимые и вспомогательные данные
Все данные в описанной схеме в той или иной степени структурированы, но не
вся структура необходима для выполнения основных функций уровня. Напри-
Например, целью уровня файловой системы является организация пустых томов для
хранения данных и их последующей выборки. Файловая система связывает имя
файла с содержимым. Следовательно, данные об имени файла и его местонахож-
местонахождении на диске являются обязательными. Так, на рис. 1.4 изображен файл с име-
именем mirade.txt и содержимым, хранящимся по адресу 345. Если имя файла или
адрес содержимого окажутся неверными или будут отсутствовать, прочитать со-
содержимое файла не удастся. Например, если в поле адреса будет храниться значе-
значение 344, то при попытке чтения будет получено постороннее содержимое.
Рис. 1.4. Чтобы система могла найти и прочитать этот файл, его имя, размер и местонахождение
содержимого должны быть точно заданы. С другой стороны, точное
значение времени последнего обращения не обязательно
На рис. 1.4 также показано, что для файла хранится время последнего обраще-
обращения. Однако этот атрибут не является необходимым для выполнения основной
функции файловой системы: даже если он будет изменен, пропадет или будет за-
задан неверно, это никак не повлияет на процесс чтения и записи содержимого.
В книге я ввожу концепцию необходимых и вспомогательных данных, пото-
потому что обязательным данным можно доверять, но о вспомогательных данных
этого сказать нельзя. Мы можем быть уверены в правильности адреса содержи-
содержимого файла, потому что в противном случае пользователь, работавший с систе-
системой, не мог бы прочитать его данные. Время последнего обращения может быть
правильным, но может и не быть. Допустим, ОС не обновила его после послед-
последнего обращения, пользователь изменил время по своему усмотрению, или внут-
внутренние часы ОС были смещены на 3 часа, и для файла было сохранено непра-
неправильное время.
Обратите внимание: то, что мы доверяем числовому значению адреса содер-
содержимого, не означает, что мы доверяем фактическому содержимому по этому ад-
адресу. Скажем, адрес в удаленном файле может быть точным, но блок данных, на
который он ссылается, может оказаться выделенным заново, а содержимое по это-
этому адресу может относиться к другому файлу. Вспомогательные данные обычно
бывают правильными, но, если они заложены в основу гипотезы об инциденте,
постарайтесь найти дополнительные источники данных для их поддержки. В ча-
частях 2 и 3 книги я буду указывать, какие данные являются необходимыми, а ка-
какие — нет.
Инструментарий эксперта
Существует множество программ, используемых аналитиками при анализе циф-
цифровых систем. Функции большинства программ такого рода в основном сосредо-
сосредоточены в фазах сохранения и поиска. В примерах, приводимых в книге, будет ис-
использоваться пакет TSK (The Sleuth Kit). Я разрабатываю этот пакет и опишу его
позднее в этом разделе. TSK распространяется бесплатно; это означает, что лю-
любой читатель может воспроизвести приведенные примеры без каких-либо допол-
дополнительных затрат.
Я не собираюсь превращать книгу в руководство по TSK, и не каждому читате-
читателю потребуются бесплатные программы на платформе UNIX. По этой причине
я привожу список самых распространенных программ анализа. Они позволят
решить большинство задач, упоминавшихся в этой главе. Краткие описания не
содержат полного списка возможностей программ и основываются на информа-
информации, размещенной на сайтах. Я лично не проверял и не пытался использовать все
их возможности, однако каждое описание было проверено разработчиками соот-
соответствующей программы.
Если вас интересует более обширный список программ, обратитесь на сайт
Кристин Сидсма (Christine Siedsma) Electronic Evidence Information (http://
www.e-evidence.info) или на сайт Якко Тунниссена (Jacco Tunnissen) Computer
Forensics, Cybercrime and Steganography (http://www.forensics.nl). Я также веду
список программ анализа с открытыми исходными кодами — как коммерчес-
коммерческих, так и некоммерческих (http://www.opensourceforensics.org). В книге приво-
приводятся теоретические обоснования того, как программы используются при ана-
анализе файловой системы, но мне кажется, что программы с открытым кодом также
пригодятся в расследовании: эксперт или доверенная сторона может прочитать
исходный код и проверить, как в программе реализована теория. Это позволит
экспертам дать более обоснованные показания относительно цифровых улик
[Carrier, 2003b].
EnCase (Guidance Software)
Несмотря на отсутствие официальных цифр, считается, что EnCase (http://www.en-
case.com) является самой распространенной программой компьютерных расследо-
расследований. EnCase работает на платформе Windows и позволяет снимать и анализи-
анализировать данные с применением локальной или сетевой версии. EnCase анализирует
различные форматы файловых систем, включая FAT, NTFS, HFS, UFS, Ext2/3,
Reiser, JFS, CD-ROM и DVD. Кроме того, EnCase поддерживает динамические
диски Microsoft Windows и AIX LVM.
EnCase выводит списки файлов и каталогов, восстанавливает удаленные фай-
файлы, проводит поиск по ключевым словам, просматривает всю графику, составляет
временные диаграммы файловых операций и идентифицирует файлы по базам
данных хеш-кодов. В пакете также реализован собственный сценарный язык EnScript,
который позволяет автоматизировать многие задачи. Дополнительные модули
обеспечивают расшифровку шифрованных файлов NTFS и монтирование анали-
анализируемых данных как локального диска.
Forensic Toolkit (Access Data)
Пакет FTK (Torensic Toolkit) работает на платформе Windows. К его функциям
относятся снятие данных и анализ дисков, файловых систем и прикладных дан-
данных (http://www.accessdata.com). FTK поддерживает файловые системы FAT, NTFS
и Ext2/3, но пакет более всего известен своими возможностями поиска и поддер-
поддержкой анализа прикладного уровня. FTK строит отсортированный индекс слов
в файловой системе, существенно ускоряющий поиск. Кроме того, FTK содержит
множество программ просмотра различных файловых форматов и поддерживает
разные форматы электронной почты.
FTK позволяет просматривать файлы и каталоги файловой системы, восста-
восстанавливать удаленные файлы, проводить поиск по ключевым словам и различным
характеристикам файлов, просматривать все графические файлы и идентифици-
идентифицировать известные файлы по базам данных хеш-кодов. Компания AccessData так-
также предлагает программы дешифрования файлов и восстановления паролей.
ProDiscover (Technology Pathways)
ProDiscover (http://www.techpathways.com) работает на платформе Windows. Эта
программа снятия данных и анализа существует как в локальной, так и в сетевой
версиях. ProDiscover умеет анализировать файловые системы FAT, NTFS, Ext2/
3 и UFS, а также динамические диски Windows. В области поиска реализованы
основные функции составления списков файлов и каталогов, восстановления уда-
удаленных файлов, поиска по ключевым словам и идентификации файлов по базам
данных хеш-кодов. Возможен вариант приобретения лицензии ProDiscover с ис-
исходными кодами, чтобы аналитик мог проверить принципы работы программы.
SMART (ASR Data)
SMART (http://www.asrdata.com) — программа снятия и анализа данных на плат-
платформе Linux. Ее разработчиком является Энди Розен (Andy Rosen), создатель
исходной версии Expert Witness (теперь эта программа называется EnCase). SMART
работает со многими файловыми системами, поддерживаемыми в Linux, и умеет
анализировать FAT, NTFS, Ext2/3, UFS, HFS+, JFS, Reiser, CD-ROM и другие
системы. При поиске улик SMART дает возможность фильтровать файлы и ката-
каталоги в образе диска, восстанавливать удаленные файлы, проводить поиск по клю-
ключевым словам, просматривать все графические файлы и идентифицировать фай-
файлы по базам данных хеш-кодов.
The Sleuth Kit/Autopsy
TSK (The Sleuth Kit) — набор программ анализа для UNIX, работающих в режиме
командной строки, a Autopsy — графический интерфейс для TSK (http://www.sl.euth-
kit.org). Инструментарий файловой системы TSK создавался на базе пакета ТСТ
(The Coroner's Tookit), авторами которого были Дэн Фармер (Dan Farmer) и Вит-
це Венема (Wietse Venema). TSK и Autopsy анализируют файловые системы
FAT, NTFS, Ext2/3 и UFS, выводят списки файлов и каталогов, восстанавливают
удаленные файлы, строят временные диаграммы файловых операций, выполня-
выполняют поиск по ключевым словам и работают с базами данных хеш-кодов.
Итоги
Не существует единственно верного подхода к проведению расследования. В этой
главе я кратко охарактеризовал тот подход, который я использую в своей работе.
Он состоит всего из трех фаз и базируется на процедуре анализа места физичес-
физического преступления. Также были представлены основные типы расследования
и приведена сводка существующих пакетов.
В следующих двух главах рассматриваются основные принципы работы ком-
компьютеров и способы снятия данных в фазе сохранения.
Библиография
• Bej tlich, Richard. The Tao of Network Security Monitoring: Beyond Intrusion Detection.
Boston: Addison Wesley, 2005.
• Brenner, Susan, Brian Carrier, and Kef Henninger. «The Trojan Defense in Cyber-
Cybercrime Cases». Santa Clara Computer and High Technology Law Journal, 21A), 2004.
• Carrier, Brian. «Defining Digital Forensic Examination and Analysis Tools Using
Abstraction Layers». InternationalJournal ofDigital Evidence, Winter 2003a. http:/
/www.ijde.org.
• Carrier, Brian. «Open Source Digital Forensic Tools: The Legal Argument». Fall
2003b. http://www.digital-evidence.org.
• Carrier, Brian, and Eugene H. Spafford. «Getting Physical with the Digital Investi-
Investigation Process». International Journal of Digital Evidence, Fall 2003. http://
www.ijde.org.
• Casey, Eoghan. Digital Evidence and Computer Clime. 2nd ed. London: Academic
Press, 2004.
• Clifford, Ralph, ed. Cybercrime: The Investigation, Prosecution, and Defense of a
Computer-Related Crime. Durham: Carolina Academic Press, 2001.
• George, Esther. «UK Computer Misuse Act — The Trojan Virus Defense».Journal
of Digital Investigation, 1B), 2004.
• The Honeynet Project. Know Your Enemy. 2nd ed. Boston: Addison-Wesley, 2004.
• Houghton Mifflin Company. The American Heritage Dictionary. 4th ed.Boston:
Houghton Mifflin, 2000.
• Mandia, Kevin, Chris Prosise, and Matt Pepe. Incident Response and Computer
Forensics. 2nd ed. Emeryville: McGraw Hill/Osborne, 2003.
• Scheier, Bruce. Applied Cryptography. 2nd ed. New York: Wiley Publishing, 1995.
Основные принципы
работы компьютеров
Данная глава посвящена низкоуровневым основам работы компьютеров. О том,
как организуется хранение данных, достаточно подробно рассказано в следую-
следующих главах, а здесь приводится вводный курс для читателей, не обладающих опы-
опытом программирования и познаниями в архитектуре операционных систем. Глава
начинается с обсуждения данных и способов их хранения на диске. В частности,
будут рассмотрены двоичное и шестнадцатеричное представление, а также пря-
прямой и обратный порядок байтов. Затем мы перейдем к процессу начальной заг-
загрузки системы и системному коду, необходимому для запуска компьютера. В конце
главы речь пойдет о жестких дисках, их геометрии, командах АТА, защищенных
областях и технологии SCSI.
Организация данных
Устройства, анализом которых мы собираемся заниматься, предназначены для
хранения цифровых данных, поэтому в этом разделе будут рассмотрены основ-
основные концепции хранения данных: двоичная и шестнадцатеричная запись, разме-
размеры данных, порядок байтов и структуры данных. Без хорошего понимания этих
концепций невозможно понять, как организуется хранение данных. Даже если
ранее вы уже занимались программированием, этот материал напомнит уже изве-
известные факты.
Двоичная, десятичная и шестнадцатеричная запись
Начнем с систем счисления. Люди привыкли работать с десятичными числами,
но компьютеры работают с двоичными данными, состоящими из нулей и единиц.
Каждая двоичная цифра (ноль или единица) называется битом; группа из 8 битов
называется байтом. Двоичные числа аналогичны десятичным, если не считать того,
что в десятичных числах используются 10 разных цифр (от 0 до 9), а в двоич-
двоичных — только две.
Прежде чем подробно заниматься двоичными числами, необходимо понять,
что такое десятичное число. Десятичное число представляет собой серию симво-
символов (цифр), при этом каждая цифра обладает некоторым значением. Для крайней
правой цифры это значение равно 1, для цифры слева от нее — 10 и т. д. Каждая
цифра обладает весовым значением, в 10 раз превышающим значение предыду-
предыдущего разряда: для второй цифры справа это значение равно 10, для третьей — 100,
для четвертой — 1000 и т. д. Для примера возьмем десятичное число 35 812. Чтобы
получить его, следует умножить цифру в каждом разряде на значение этого раз-
разряда и сложить произведения (рис. 2.1). Поскольку в данном случае десятичная
запись числа преобразуется в его десятичное значение, результат вполне законо-
закономерен. Аналогичная процедура применяется и для вычисления десятичного зна-
значения чисел, записанных в других системах счисления.
Рис. 2.1. Значение каждой цифры в десятичном числе
Крайняя правая цифра называется младшей, а крайняя левая — старшей. Так,
для числа 35 812 цифра 3 является старшей, а цифра 2 — младшей.
Теперь перейдем к двоичным числам. В каждом разряде двоичного числа на-
находится только одна из двух цифр @ и 1); при этом каждый разряд обладает деся-
десятичным значением, вдвое превышающим значение предыдущего разряда. Таким
образом, крайний правый разряд соответствует десятичному значению 1, второй
разряд справа — десятичному значению 2, третий — 4 и четвертый — 8 и т. д. Что-
Чтобы вычислить десятичное представление двоичного числа, следует просуммиро-
просуммировать весовые значения столбцов, умноженные на находящиеся в них цифры. На
рис. 2.2 показано, как двоичное число 1001 0011 переводится в десятичную систе-
систему. Из результата видно, что его десятичное значение равно 147.
В табл. 2.1 приведены десятичные значения первых 16 двоичных чисел. В ней
также указаны их шестнадцатеричные эквиваленты, о которых речь пойдет далее.
Рис. 2.2. Преобразование двоичного числа в десятичное значение
Таблица 2.1. Преобразования между двоичной, десятичной
и шестнадцатеричной системами
Двоичная запись Десятичная запись Шестнадцатеричная запись
0000 00 0
0001 01 1
0010 02 2
ООП 03 3
0100 04 4
0101 05 5
Таблица 2.1 {продолжение)
Двоичная запись Десятичная запись Шестнадцатеричная запись
ОНО 06 6
0111 07 7
1000 08 8
1001 09 9
1010 10 А
1011 11 В
1100 12 С
1101 13 D
1110 14 Е
1111 15 F
При записи шестнадцатеричных чисел используются 16 цифр (от 0 до 9, за
которыми следуют буквы от А до F). В табл. 2.1 показано соответствие между
шестнадцатеричными цифрами и десятичными числами. Шестнадцатеричная за-
запись удобна прежде всего тем, что она легко преобразуется в двоичную (и наобо-
наоборот), и часто применяется при работе с низкоуровневыми данными. Я буду снаб-
снабжать шестнадцатеричные числа префиксом Ох, чтобы отличить их от десятичных.
Необходимость в преобразовании шестнадцатеричных чисел в десятичную за-
запись возникает довольно редко, но я все же покажу, как это делается. Десятич-
Десятичные весовые коэффициенты разрядов шестнадцатеричного числа увеличивают-
увеличиваются в 16 раз. Таким образом, десятичное значение первого (крайнего правого)
разряда равно 1, второго — 16, третьего — 256 и т. д. Чтобы выполнить преобразо-
преобразование, мы просто умножаем весовые коэффициенты разрядов на соответствую-
соответствующие цифры и суммируем результаты. На рис. 2.3 показан результат преобразова-
преобразования шестнадцатеричного числа 0х8ВЕ4 в десятичную систему.
Рис. 2.3. Преобразование шестнадцатеричного числа в десятичную систему
Остается рассмотреть преобразования между шестнадцатеричной и двоичной
записью. Такие преобразования выполняются гораздо проще и сводятся к простой
подстановке. Чтобы получить двоичное представление имеющегося шестнадца-
шестнадцатеричного числа, достаточно обратиться к табл. 2.1 и заменить каждую шестнад-
цатеричную цифру эквивалентной последовательностью из 4 битов. И наоборот,
при преобразовании двоичного числа в шестнадцатеричное следует разделить чис-
число на группы по 4 бита и заменить каждую «четверку» эквивалентной шестнадца-
шестнадцатеричной цифрой. Вот и все! Преобразование двоичного числа в шестнадцате-
шестнадцатеричное и наоборот показано на рис. 2.4.
Иногда требуется определить максимальное значение, которое может быть
представлено некоторым количеством разрядов. Для этого нужно возвести коли-
чество допустимых цифр в степень, равную числу разрядов, и вычесть 1 (чтобы
учесть нулевое значение). Например, для двоичных чисел мы возводим 2 в сте-
степень, равную количеству битов, и вычитаем 1. Следовательно, наибольшее десятич-
десятичное число, которое может быть представлено 32-разрядной двоичной последова-
последовательностью:
232 - 1 = 4 294 967 295
К счастью, в большинстве системных редакторов имеется встроенный кальку-
калькулятор с возможностью преобразования между двоичной, десятичной и шестнадца-
теричной записью, поэтому запоминать все эти методы вам не придется. В книге
дисковые данные приводятся в шестнадцатеричной записи; важнейшие значения
будут приводиться как в шестнадцатеричной, так и в десятичной записи.
Рис. 2.4. Преобразование между двоичной и шестнадцатеричной записью осуществляется
простой заменой по табл. 2.1
Размеры данных
Для сохранения цифровых данных на носителе информации выделяется область
соответствующего размера. Представьте анкету, в которой символы вашего име-
имени и адреса вводятся в отдельных квадратиках: поля имени и адреса выделяются
для хранения вводимых символов. Аналогичным образом при работе с цифровы-
цифровыми данными участок диска или памяти выделяется для хранения байтов с конк-
конкретными значениями.
В общем случае байт представляет собой наименьшую область памяти, выде-
выделяемую для хранения данных. Байт позволяет представить до 256 возможных зна-
значений, поэтому для хранения больших чисел байты приходится группировать. Как
правило, на практике используются группы размером 2, 4 и 8 байт. Конкретный
способ хранения многобайтовых данных зависит от компьютера. На одних ком-
компьютерах применяется обратный порядок байтов (big-endian), при котором в пер-
первом байте на носителе хранится старший (наиболее значимый) байт хранимого
числа, а на других — прямой порядок байтов (little-endian), при котором в первом
байте хранится младший (наименее значимый) байт. Напомню, что старшим на-
называется байт с наибольшим весовым коэффициентом (крайний левый байт),
а младшим — байт с наименьшим весовым коэффициентом (крайний правый
байт).
На рис. 2.5 изображено 4-байтовое значение с прямым и обратным порядком
байтов. Для его хранения выделяется 4-байтовый блок, начинающийся с байта 80
и заканчивающийся байтом 83. При анализе содержимого диска и файловой сис-
системы необходимо учитывать порядок байтов исходной системы, в противном слу-
случае вычисленное значение окажется неверным.
В системах на базе IA32 (например, Intel Pentium) и их 64-разрядных аналогах
используется прямой порядок байтов, поэтому, если мы хотим, чтобы старший
байт оказался в крайней левой позиции, байты необходимо «переставить». На Sun
SPARC и Motorola PowerPC (например, на компьютерах Apple) применяется об-
обратный порядок байтов.
Рис. 2.5. 4-байтовое значение с прямым и обратным порядком байтов
Строковые данные и кодировка символов
В предыдущем разделе рассказывалось о том, как на компьютерах хранятся чис-
числовые данные, но мы также должны подумать о хранении строковых данных, то
есть отдельных символов и целых предложений. На практике для хранения сим-
символьных данных чаще всего применяется кодировка ASCII или Unicode. Коди-
Кодировка ASCII проще, поэтому начнем с нее. В ASCII каждый символ английского
языка обозначается числовым кодом. Например, букве А соответствует код 0x41,
а символу & — код 0x26. Наибольшее определенное значение равно 0х7Е; таким
образом, любой символ базового набора представляется одним байтом. Многие
коды соответствуют управляющим символам и не имеют печатного представле-
представления — например, звуковой сигнал 0x07. В табл. 2.2 приведены соответствия меж-
между шестнадцатеричными числами и символами ASCII. Более подробная таблица
ASCII-кодов приводится по адресу: http://www.asciitable.com/.
Таблица 2.2. Шестнадцатеричные коды символов в ASCII
OO-NULL 1—DLE 20-SPC 30-0 40-@ 50-Р 60-* 70—р
01-SOH 11-DCI 21-! 31-1 41-А 51-Q 61-a 71-q
02-STX 12-DC2 22-" 32-2 42-В 52-R 62-Ь 72-г
03-ЕТХ 13-DC3 23-# 33-3 43-С 53-S 63-с 73-S
04-ЕОТ 14-DC4 24-$ 34-4 44-D 54-Т 64-d 74-t
05-ENQ 15-NAK 25-% 35-5 45-E 55-U 65-е 75-и
Об-АСК 16-SYN 2б-& Зб-б 46-F 56-У 66-f 76-v
07-BEL 17-ETB 27-' 37-7 47-G 57-W 67-g 77-w
08-BS 18-CAN 28-( 38-8 48-H 58-X 68-h 78-x ~~
09-TAB 19-EM 29-) 39-9 49-1 59-Y 69-i 79-y
OA-LF 1A-SUB 2A-* 3A-: 4A-J 5A-Z 6A-j 7/^z
QB-BT 1B-ESC 2B-+ 3B-; 4B-K 5B-[ 6B-k 7B-{
OC-FF 1C-FS 2C-, 3O< 4C-L 5C-\ 6C-I 7C-|
QD-CR 1D-GS 2D-- 3D-= 4D-M 5D-] 6D-m 7D-}
QE-SO 1E-RS 2E-. 3E-> 4E-N 5E-A 6E-n 7E-~
QF-SI 1F-US 2F-/ 3F-? 4F-0 5F-_ 6F-0 7F-
Чтобы сохранить предложение или слово в кодировке ASCII, необходимо вы-
выделить под него область памяти, размер которой в байтах соответствует количе-
количеству символов в слове. В каждом байте хранится код одного символа. Порядок
байтов в этом случае роли не играет, потому что каждый символ представлен
отдельным 1-байтовым кодом. Таким образом, первый символ слова или пред-
предложения всегда находится на первом месте. Последовательность байтов в слове
или предложении называется строкой (string). Строки часто завершаются нуль-
символом (NULL), соответствующим коду 0x00. На рис. 2.6 показан пример стро-
строки, хранящейся в кодировке ASCII. Строка состоит из 10 символов и заверша-
завершается нуль-символом, поэтому для ее хранения выделяется 11 байт, начиная
с байта 64.
Рис. 2.6. ASCII-строка, хранящаяся в памяти, начиная с адреса 64
Кодировка ASCII проста и удобна, если ваши потребности ограничиваются
английским алфавитом. Однако для пользователей из других стран мира ее явно
недостаточно, поскольку ASCII не позволяет представлять символы национальных
алфавитов. Для решения этой проблемы была создана кодировка Unicode, в кото-
которой числовой код символа занимает более 1 байта (за подробностями обращай-
обращайтесь на сайт www.unicode.org). Версия 4.0 стандарта Unicode поддерживает более
96 000 символов, при этом для представления одного символа необходимы 4 бай-
байта (вместо 1 байта в ASCII).
Существует три варианта хранения символов Unicode. В первом варианте —
UTF-32 — каждый символ представляется 4 байтами, но при этом большая часть
памяти будет расходоваться неэффективно. Во втором варианте, UTF-16, часто
используемые символы хранятся в 2-байтовых кодах, а более редкие — в 4-байто-
4-байтовых, поэтому в среднем текст занимает меньший объем, чем в UTF-32. Третий
вариант называется UTF-8, и один символ в нем представляется 1, 2 или 4 байта-
байтами. При этом наиболее часто используемые символы кодируются всего 1 байтом.
Переменная длина кода в UTF-8 и UTF-16 несколько усложняет обработку
данных. На практике чаще используется UTF-8, поскольку в этой кодировке мень-
меньше места расходуется напрасно, a ASCII является ее подмножеством. Если строка
UTF-8 состоит только из ASCII-символов, каждый символ в ней кодируется 1 бай-
байтом, а по своему содержимому такая строка совпадает с эквивалентной ASCII-
строкой.
Структуры данных
Прежде чем переходить к особенностям хранения данных в конкретных файловых
системах, необходимо познакомиться с общими принципами организации дан-
данных. Вернемся к предыдущему примеру, в котором проводилась аналогия между
цифровыми данными и квадратиками на бумажной анкете. Когда вы заполняете
анкету, надпись перед полем указывает, что данное поле предназначено для ввода
имени или адреса. Как правило, компьютеры не снабжают данные файловых сис-
систем подобными метками. Вместо этого они просто знают, что в первых 32 байтах
записи хранится (к примеру) имя, а в следующих 32 байтах — название улицы.
Способ размещения данных в памяти определяется структурами данных. Струк-
Структура данных напоминает шаблон или карту. Она делится на поля, при этом каждое
поле обладает определенным размером и именем (хотя эта служебная информа-
информация не хранится вместе с данными). Например, структура данных может опреде-
определить, что первое поле называется number и имеет длину в 2 байта. В программе это
поле будет использоваться для хранения номера дома в адресе. Сразу же за полем
number следует поле street, длина которого равна 30 байтам. Соответствующая
структура данных показана в табл. 2.3.
Таблица 2.3. Простая структура данных для хранения номера дома и названия улицы
Диапазон байтов Описание
0-1 Номер дома B байта)
2-31 Название улицы в кодировке ASCII C0 байт)
Когда данные требуется записать на носитель информации, область памяти
для каждого компонента записи определяется по соответствующей структуре дан-
данных. Например, если требуется сохранить адрес 1 Main St., сначала адрес разби-
разбивается на составляющие: номер дома и название улицы. Число 1 записывается в
байты 0-1 выделенного блока, а строка «Main St.» — в байты 2-9 в виде ASCII-
кодов каждого символа. Остальные байты можно обнулить, так как в данном при-
примере они не используются. 32 байта, выделенные для хранения данных, могут рас-
располагаться в любом месте устройства. Смещения задаются относительно начала
выделенного блока. Не забывайте, что очередность байтов в номере дома зависит
от порядка байтов на компьютере.
При чтении данных с носителя информации мы определяем, с какого адреса
они начинаются, а затем по структуре данных узнаем смещение нужных данных.
Для примера давайте прочитаем только что записанные данные. Выходные дан-
данные утилиты, читающей физические данные с диска, выглядят так:
00000000: 0100 4d61 696е 2053 742е 0000 0000 0000 ..Main St
00000016: 0000 0000 0000 0000 0000 0000 0000 0000
00000032: 1900 536f 7574 6820 5374 2е00 0000 0000 ..South St
00000048: 0000 0000 0000 0000 0000 0000 0000 0000
Результат получен от утилиты UNIX xxd, напоминающей графический шестнад-
цатеричный редактор. В левом столбце приводится смещение в байтах, в средних
8 столбцах — 16 байт данных в шестнадцатеричной форме, а в последнем столбце —
их представление в кодировке ASCII. Символами «.» обозначается отсутствие
печатных ASCII-символов в данной позиции. Вспомните, что каждый 16-разряд-
16-разрядный символ представляет 5 бита, поэтому на один байт требуется 2 шестнадцате-
ричных символа.
Просматривая раскладку структуры данных, мы видим, что каждый адрес зани-
занимает 32 байта, поэтому первый адрес хранится в байтах 0-31. Байты 0-1 предназна-
предназначены для хранения 2-байтового номера дома, а байты 2-31 — для названия улицы.
В байтах 0-1 отображается значение 0x0100. Данные взяты из системы Intel, ис-
использующей прямой порядок байтов, поэтому 0x01 и 0x00 необходимо поменять
местами — получаем 0x0001. Преобразование к десятичному виду дает число 1.
Второе поле структуры данных занимает байты 2-31. Содержащаяся в нем
ASCII-строка не зависит от порядка байтов в системе, поэтому переставлять дан-
данные не придется. Мы можем либо преобразовать каждый байт в ASCII-эквива-
ASCII-эквивалент, либо схитрить и сразу заглянуть в нужные столбцы, чтобы найти в них на-
название «Main St.». Именно это значение было записано ранее. Из приведенного
вывода следует, что другая структура данных начинается с байта 32 и продолжа-
продолжается до байта 63. Попробуйте самостоятельно обработать ее для практики (она
соответствует адресу «25 South St.»).
Разумеется, в структурах данных файловых систем хранится совершенно иная
информация, но базовые принципы остаются прежними. Например, в первом
секторе файловой системы обычно хранится большая структура данных с десят-
десятками полей; читая ее, мы знаем, что размер файловой системы хранится в байтах
32-35. Во многих файловых системах задействовано несколько больших струк-
структур данных, используемых в разных местах.
Флаги
Прежде чем переходить к реальным структурам данных, я хотел бы обсудить еще
один тип данных — флаги. Некоторые данные всего лишь показывают, выполняет-
выполняется или не выполняется некоторое условие: скажем, является ли раздел загрузоч-
загрузочным или нет. Значения таких данных представляются одной двоичной цифрой
A или 0). Конечно, для этой информации можно выделить целый байт, в котором
сохраняется значение 0 или 1. Однако такой способ крайне неэффективен: из 8 вы-
выделенных битов реально используется всего один. Более эффективный способ
основан на упаковке нескольких двоичных условий в одно значение, каждый бит
которого соответствует некоторому признаку или условию. Такие биты часто на-
называются флагами (flags). Чтобы получить значение флага, необходимо преобра-
преобразовать число в двоичную форму и проанализировать нужный бит. Если бит ра-
равен 1, значит, флаг установлен.
Давайте рассмотрим практический пример и преобразуем структуру данных
с почтовым адресом в нечто более сложное. Исходная структура содержала два
поля данных: для номера дома и названия улицы. В новой версии в нее добавля-
добавляется необязательное 16-байтовое название города, следующее за названием ули-
улицы. Так как имя города не является обязательным, необходимо добавить флаг,
указывающий на его наличие или отсутствие. Флаг хранится в байте 31; если за-
запись содержит название города, бит 0 устанавливается (то есть 0000 0001). Если
название города присутствует, структура данных содержит 48 байт вместо 32.
Новая структура данных приведена в табл. 2.4.
Таблица 2.4. Структура данных со значением флага
Диапазон байтов Описание
0-1 Номер дома B байта)
2-30 Название улицы в кодировке ASCII B9 байт)
31-31 Флаги
32-47 Название города в кодировке ASCII A6 байт) — если флаг установлен
Пример данных, записанных на диск с использованием этой структуры:
00000000: 0100 4d61 69бе 2053 742е 0000 0000 0000 ..Main St
00000016: 0000 0000 0000 0000 0000 0000 0000 0061 а
00000032: 426f 7374 6f6e 0000 0000 0000 0000 0000 Boston
00000032: 1900 536f 7574 6820 5374 2e00 0000 0000 ..South St
00000064: 0000 0000 0000 0000 0000 0000 0000 0000
Первая строка выглядит точно так же, как в предыдущем примере. Флагу в бай-
байте 31 присвоено значение 0x61. Размер флага составляет всего 1 байт, поэтому
беспокоиться о порядке байтов не нужно. Значение необходимо преобразовать
в двоичную систему; по табл. 2.1 значения 0x6 и 0x1 заменяются двоичным значе-
значением ОНО 0001. Младший бит, то есть флаг города, установлен. В остальных би-
битах содержатся значения других флагов — скажем, признак юридического адреса.
На основании значения флага известно, что в байтах 32-47 хранится название
города («Boston»). Следующая структура данных начинается с байта 48, а ее поле
флагов хранится в байте 79. Значение равно 0x60, флаг города не установлен. Сле-
Следовательно, третья структура данных начинается с байта 80.
Флаги часто встречаются в структурах данных файловых систем. Обычно они
показывают, какие возможности активны, какие разрешения предоставлены поль-
пользователю, находится ли файловая система в «чистом» состоянии и т. д.
Процесс загрузки
В следующих главах книги речь пойдет о том, где хранятся данные на дисках и ка-
какие данные необходимы для работы компьютера. Довольно часто я буду упоми-
упоминать загрузочный код, то есть машинные команды, используемые компьютером
при запуске. В этом разделе описан процесс загрузки системы и местонахожде-
местонахождение загрузочного кода. Многие диски резервируют место для загрузочного кода,
но не используют его. Настоящий раздел поможет вам определить, какой загру-
загрузочный код используется в каждом конкретном случае.
Процессор и машинный код
Главную роль на современном компьютере играет центральный процессор (CPU,
Central Processing Unit); на некоторых компьютерах процессоров устанавливает-
устанавливается два и более процессора. В качестве примеров процессоров можно назвать Intel
Pentium и Itanium, AMD Athlon, Motorola PowerPC и Sun UltraSPARC. Сам по
себе процессор не приносит особой пользы, потому что он умеет только выпол-
выполнять полученные команды. В этом отношении он напоминает калькулятор. Как
известно, калькулятор отлично справляется с вычислениями, но при этом за ним
должен сидеть человек и вводить числа.
Процессор получает команды из памяти. Команды процессора представляют
собой машинный код, неудобный и плохо воспринимаемый человеком. Как пра-
правило, машинный код находится на два уровня ниже языков программирования
С и Perl, хорошо знакомых многим программистам. Промежуточное место зани-
занимает язык ассемблера, понятный для человека, но не слишком удобный.
Я кратко опишу структуру машинного кода, чтобы вы знали, с чем имеете дело,
обнаружив его на диске. Каждая команда машинного кода состоит из нескольких
байтов. Первая пара байтов определяет тип команды, называемый кодом опера-
операции (opcode). Например, значение 3 может обозначать операцию сложения. За
кодом операции следуют аргументы команды — скажем, аргументы команды сло-
сложения определяют два суммируемых числа.
Для данной книги более подробного описания не потребуется, но я приведу
простейший пример. Одна из машинных команд заносит числа в регистры про-
процессора. Регистрами называются ячейки, в которых процессор хранит обрабаты-
обрабатываемые данные. Ассемблерная команда MOV АН,00 заносит значение 0 в регистр
АН. Эквивалентная команда машинного кода в шестнадцатеричном виде имеет
0хВ400, где В4 — код операции MOV АН, а 00 — шестнадцатеричное число, помеща-
помещаемое в регистр. Некоторые утилиты автоматически транслируют машинный код
на ассемблер, но во многих случаях неочевидно, имеете ли вы дело с машинным
кодом или какими-то произвольными данными.
Местонахождение загрузочного кода
Итак, центральный процессор является «сердцем» компьютера, и для работы ему
необходимо передавать команды. Следовательно, для запуска компьютера некое
устройство должно поставлять процессору команды, называемые загрузочным
кодом. В большинстве систем этот процесс состоит из двух этапов: на первом эта-
этапе происходит инициализация оборудования, а на втором запускается опера-
операционная система или иное программное обеспечение. Мы кратко познакомимся
с загрузочным кодом, потому что во всех томах и файловых системах имеется спе-
специальная область для хранения загрузочного кода, причем она зачастую не ис-
используется.
При включении питания компьютер способен только прочитать команды из
специальной области памяти, как правило — из постоянной (ПЗУ). Код ПЗУ за-
заставляет систему провести проверку и настройку оборудования. После завершения
настройки процессор переходит к поиску устройства, которое может содержать
дополнительный загрузочный код. Если такое устройство найдено, то управле-
управление передается его загрузочному коду, а последний пытается найти и загрузить
операционную систему. Процесс загрузки после обнаружения загрузочного дис-
диска зависит от конкретной платформы, и более подробно рассматривается в следу-
следующих главах.
А пока для примера мы в общих чертах рассмотрим процесс загрузки системы
Microsoft Windows. При включении питания процессор читает команды из BIOS
(Basic Input/Output System) и ищет жесткие диски, дисководы CD-ROM и дру-
другие устройства, поддержка которых настроена в BIOS. После идентификации
оборудования BIOS анализирует флоппи-диски, жесткие диски и дисководы CD-
ROM в некотором заданном порядке и обращается к первому сектору за загру-
загрузочным кодом. Код первого сектора загрузочного диска заставляет процессор об-
обработать таблицу разделов и найти загрузочный раздел, в котором находится
операционная система Windows. В первом секторе раздела размещается допол-
дополнительный загрузочный код, обеспечивающий поиск и загрузку операционной
системы. На рис. 2.7 изображено взаимодействие различных компонентов в про-
процессе загрузки.
Рис. 2.7. Взаимодействие компонентов загрузочного кода в системах IA32
Если загрузочный код на диске отсутствует, BIOS не находит загрузочное ус-
устройство и выдает сообщение об ошибке. Если загрузочный код на диске не мо-
может найти загрузочный код в одном из своих разделов, он также выдает сообще-
сообщение об ошибке. Все эти компоненты загрузочного кода будут описаны в следующих
главах.
Технологии жестких дисков
В этом разделе рассматриваются основные концепции жестких дисков и различ-
различные темы, представляющие интерес с аналитической точки зрения: методы дос-
доступа, блокировка записи и возможные места хранения скрытых данных. В первом
подразделе содержится краткий обзор принципов работы диска, а два следующих
подраздела посвящены дискам AT A/IDE и SCSI соответственно.
Геометрия и внутреннее устройство жесткого диска
Начнем с внутреннего строения всех современных жестких дисков. Эта инфор-
информация полезна для понимания общих принципов хранения данных, поскольку ста-
старые файловые системы и схемы формирования разделов используют параметры
геометрии диска и другие внутренние данные, скрытые в современных дисках.
Таким образом, знание геометрии диска поможет лучше понять смысл некоторых
данных в файловой системе. Конечно, я привожу этот материал не для того, что-
чтобы вы могли самостоятельно ремонтировать жесткие диски. Моя задача — дать
концептуальное понимание их внутреннего устройства.
Жесткий диск состоит из одной или нескольких круглых пластин, располо-
расположенных друг над другом и вращающихся одновременно. На рис. 2.8 показано, как
выглядит жесткий диск изнутри. Верхняя и нижняя поверхности каждой пласти-
пластины покрыты магнитным материалом. Непосредственно после изготовления дис-
диска пластины однородны и пусты.
Рис. 2.8. Внутреннее устройство диска АТА: справа находятся пластины, а слева — рычаг
с магнитной головкой, осуществляющей чтение и запись
Внутри корпуса находится подвижный рычаг. На нем крепятся головки чте-
чтения и записи данных, находящиеся у верхней и нижней поверхностей каждой пла-
пластины. В любой момент времени только одна головка может выполнять чтение
или запись данных.
Пустые пластины размечаются операцией низкоуровневого форматирования,
создающей структуры данных дорожек и секторов. Каждая дорожка (track) пред-
представляет собой замкнутое «кольцо», проходящее по поверхности пластины. Ад-
Адреса, присваиваемые дорожкам жесткого диска, увеличиваются по направлению
от края к центру. Например, если на каждой пластине размещается по 10 000 до-
дорожек, то внешней дорожке каждой пластины присваивается адрес 0, а внутрен-
внутренней дорожке (возле центра круга) — адрес 9 999. Так как все пластины имеют
одинаковое строение, а находящимся на них дорожкам присваиваются одинако-
одинаковые адреса, совокупность всех дорожек с заданным адресом на всех пластинах
называется цилиндром. Так, цилиндр 0 состоит из дорожек 0 от нижней до верх-
верхней пластины жесткого диска. Головкам чтения/записи также присваиваются ад-
адреса, что позволяет однозначно определить, на какой пластине и с какой стороны
должна быть выполнена операция чтения или записи.
Дорожки делятся на секторы — наименьшие самостоятельно адресуемые блоки
жесткого диска, размер которых обычно составляет 512 байт. Каждому сектору
дорожки присваивается адрес, начиная с 1. Таким образом, к конкретному сектору
можно обратиться по адресу цилиндра (С), определяющему дорожку, адресу го-
головки (Н), определяющему пластину и ее поверхность, и адресу сектора (S). Схе-
Схема обращения продемонстрирована на рис. 2.9.
Рис. 2.9. Геометрия отдельной пластины с адресами дорожек (цилиндров) и секторов;
цифры не имеют даже отдаленного отношения к реальности
Как будет показано в разделе «Типы адресации секторов», схема CHS уже не
является основной схемой адресации. Вместо нее используется адресация LBA
(Logical Block Address), при которой всем секторам присваиваются последователь-
последовательные адреса. Адрес LBA никак не связан с физическим расположением сектора.
Поврежденные секторы не могут использоваться для хранения пользователь-
пользовательских данных. Раньше операционная система должна была знать о наличии по-
поврежденных секторов и не выделять их для хранения файлов. Пользователь так-
также мог вручную указать диску, какие секторы необходимо игнорировать из-за
наличия повреждений. Многие файловые системы до сих пор предоставляют воз-
возможность пометки поврежденных секторов. Впрочем, в наше время это обычно
излишне, поскольку современные диски сами выявляют плохие секторы и ото-
отображают их адреса на работоспособные секторы в другом месте диска. Пользова-
Пользователь даже не подозревает о происходящем.
Предыдущее описание геометрии диска излишне упрощено: в действительности
диски упорядочивают секторы для обеспечения оптимального быстродействия.
Это означает, что к секторам и дорожкам может применяться сдвиг, соответству-
соответствующий времени поиска и скорости диска. Впрочем, для большинства аналитиков
упрощенного описания достаточно; мало кто имеет доступ к технологически чис-
чистым помещениям и оборудованию для поиска секторов на диске.
Интерфейс ATA/IDE
Интерфейс ATA (AT Attachment) является самым распространенным интерфей-
интерфейсом жестких дисков. Диски, использующие этот интерфейс, часто называются
дисками IDE, но сокращение IDE означает «Integrated Disk Electronics» и обо-
обозначает жесткий диск со встроенной логической схемой (чего не было в старых
дисках). Интерфейс, используемый дисками «IDE», называется АТА. В этом раз-
разделе приводятся некоторые важные детали спецификации АТА, чтобы позднее
мы могли обсудить такие технологии, как аппаратная блокировка записи и защи-
защищенные области.
Спецификации АТА разрабатывались техническим комитетом Т13 (http://
www.tl3.org), входящим в Международный комитет стандартов информационных
технологий (INCITS). Окончательные версии спецификаций распространяются
за плату, но предварительные версии можно загрузить бесплатно с сайта INCITS.
Для знакомства с жесткими дисками достаточно и предварительных версий.
Диски АТА обслуживаются контроллером, который в современных системах
встраивается в материнскую плату. Контроллер передает команды одному или двум
дискам АТА по плоскому кабелю. Максимальная длина кабеля составляет 45,7 см.
Разъем кабеля имеет 40 контактов, но на новых дисках задействованы 40 допол-
дополнительных проводов, не связанных ни с какими контактами. Интерфейс показан
на рис. 2.10. Дополнительные провода предотвращают взаимные помехи между про-
проводами. На портативных компьютерах часто устанавливаются более компактные
диски с 44-контактным интерфейсом, включающим контакты для питания. Как
показано на рис. 2.11, для стыковки двух интерфейсов применяются специальные
адаптеры. Также существует 44-контактный интерфейс высокой плотности, при-
применяемый на некоторых портативных устройствах (таких, как Apple iPod).
Рис. 2.10. Диск АТА с 40-контактным разъемом, перемычками и разъемом питания
Рис. 2.11. 44-контактный АТА-диск для портативного компьютера подключается
40-контактным плоским кабелем через адаптер (я благодарен
за фото Эохану Кейси (Eoghan Casey))
Интерфейсная линия связи между контроллером и диском называется кана-
каналом. Каждый канал может обслуживать два диска, называемых «ведущим» (master)
и «ведомым» (slave), хотя ни один из дисков не управляет работой другого. Диски
ATA настраиваются на выполнение роли ведущего или ведомого при помощи фи-
физической перемычки на диске. Некоторые диски также поддерживают режим Cable
Select, в котором роль ведущего или ведомого назначается в зависимости от того,
к какому разъему плоского кабеля подключен диск. На большинстве бытовых ком-
компьютеров используются два канала и поддержка до четырех дисков AT А.
Типы адресации секторов
Для выполнения операций чтения и записи данных на диск необходима схема
адресации секторов. Как будет показано далее, одному сектору назначаются раз-
разные адреса при каждом его использовании разделом, файловой системой или фай-
файлом. В этом разделе речь пойдет о физических адресах, то есть адресах секторов по
отношению к началу физического носителя информации.
Существует два разных метода физической адресации. На старых жестких дис-
дисках используются геометрические параметры и уже упоминавшаяся схема CHS.
Упрощенный пример организации адресов цилиндров и головок показан на рис. 2.9.
Схема адресации CHS проста и удобна, но ее возможности оказались слишком
ограниченными, поэтому в наши дни она встречается редко. В исходной специ-
спецификации AT А задействован 16-разрядный номер цилиндра, 4-разрядный номер
головки и 8-разрядный номер сектора, однако в старых версиях BIOS использо-
использовался 10-разрядный номер цилиндра, 8-разрядный номер головки и 6-разрядный
номер сектора. Следовательно, для взаимодействия с жестким диском через BIOS
должен использоваться минимальный размер каждого параметра, вследствие чего
максимальный объем диска ограничивается 504 Мбайт.
Чтобы обойти это ограничение, были разработаны новые версии BIOS, транс-
транслировавшие «свои» диапазоны адресов в диапазоны адресов, соответствующие
спецификации AT А. Например, если приложение запрашивало данные из цилин-
цилиндра 8, головки 4 и сектора 32, система BIOS транслировала его и запрашивала
с диска цилиндр 26, головку 2, сектор 32. Для успешной работы трансляции сис-
система BIOS сообщала параметры геометрии диска, отличающиеся от фактических.
Процесс трансляции не работает для дисков объемом более 8,1 Гбайт.
Сейчас BIOS с трансляцией адресов встречаются относительно редко, однако
если аналитик все же столкнется с такой системой, у него возникнут проблемы.
Если извлечь диск из исходной системы и подключить его к тестовому компьюте-
компьютеру, может оказаться, что трансляция не поддерживается или работает иначе. К тому
же некоторые методы анализа выполнить не удастся из-за возврата неверных сек-
секторов. Для решения проблемы аналитик должен использовать исходную систему
или найти аналогичную систему, выполняющую ту же трансляцию. Информа-
Информацию о том, используется ли в системе трансляция адресов, можно найти в описа-
описании версии BIOS на сайте производителя или в справочном описании BIOS.
Ограничение в 8,1 Гбайт, присущее трансляции, необходимо было преодолеть,
поэтому от схемы адресации CHS пришлось отказаться. Стандартной стала схема
адресации LBA (Logical Block Addresses), в которой каждый сектор обозначается
одним числом, начиная с 0. Схема LBA поддерживается с момента выхода первой
официальной спецификации AT А. В схеме LBA приложение не обязано ничего
знать о геометрии диска; достаточно одного числа. Поддержка адресации CHS
была исключена из спецификации АТА в версии АТА-6.
К сожалению, некоторые файловые системы и другие структуры данных про-
продолжают работать со старыми адресами CHS, поэтому в книге нам неоднократ-
неоднократно потребуется преобразовывать CHS в LBA. Адрес LBA 0 соответствует адресу
CHS 0,0,1, а адрес LBA 1 соответствует адресу CHS 0,0,2. Когда все секторы до-
дорожки будут исчерпаны, используется первый сектор следующей головки того
же цилиндра, соответствующий адресу CHS 0,1,1. Представьте, что внешнее коль-
кольцо нижней пластины постепенно заполняется, после чего происходит переход
к следующей пластине, пока не будет достигнута верхняя пластина. После этого
используется второе кольцо нижней пластины. Формула преобразования выг-
выглядит так:
LBA = (((ЦИЛИНДР * головок_на_цилиндр) + ГОЛОВКА) * секторов_на_дорожку) + СЕКТОР - 1
где значения ЦИЛИНДР, ГОЛОВКА И СЕКТОР заменяются соответствую-
соответствующими компонентами CHS. Для примера возьмем диск с 16 головками на ци-
цилиндр и 63 секторами на дорожку. Адрес CHS 2,3,4 преобразуется в LBA следу-
следующим образом:
2208 - ((B * 16) + 3) * 63) + 4 - 1
Стандарты интерфейсов
В области жестких дисков встречаются многочисленные названия интерфей-
интерфейсов, способные запутать потребителя. Некоторые термины означают одно и то
же; просто комитет стандартизации выбрал один термин, а компания, выпус-
выпустившая жесткий диск, — другой. Описания неофициальных терминов вроде
«Enhanced IDE» или «Ultra ATA» приводятся на странице PC Guide «Unofficial
IDE/ATA Standards and Marketing Programs» (http://www.pcguide.com/ref/hdd/if/
ide/unstd.htm). Как правило, каждый новый стандарт обеспечивает более быст-
быстрый метод чтения или записи данных либо снимает ограничения предыдущего
стандарта.
Учтите, что спецификации АТА относятся только к жестким диска. Съемные
носители информации (такие, как CD-ROM и ZIP-диски) должны использо-
использовать особую спецификацию ATAPI (AT Attachment Packet Interface). Устрой-
Устройства AT API обычно подключаются к тем же кабелям и контроллерам, но для их
работы необходимы специальные драйверы.
Краткий перечень спецификаций, представляющих интерес для нашей темы:
• АТА-1: опубликована в 1994 году. Спецификация включает поддержку CHS
и 28-разрядных адресов LBA [T13 1994].
• АТА-3: спецификация опубликована в 1997 году, в нее были включены средства
контроля надежности pi безопасности. В частности, в АТА-3 была представле-
представлена технология SMART (Self-Monitoring Analysis and Reporting Technology),
которая пытается повысить надежность работы диска посредством отслежи-
отслеживания нескольких его частей. В этой спецификации также появились пароли
[Т13 1997].
• ATA/ATAPI-4: спецификация для съемных носителей AT API была интегри-
интегрирована в спецификацию АТА в версии АТА-4, опубликованной в 1998 году.
В ней появился 80-проводный кабель для снижения помех. В АТА-4 также до-
добавилась поддержка HPA, о которой речь пойдет далее [Т13 1998].
• ATA/ATAPI-6: в обновленной спецификации, опубликованной в 2002 году,
добавилась 48-разрядная адресация LBA, исчезла поддержка адресации CHS
и добавилась поддержка DCO [T13 2002].
• ATA/ATAPI-7: на момент написания книги спецификация оставалась в пред-
предварительной версии. В нее вошла поддержка Serial ATA (см. далее).
Команды диска
В этом разделе приводится обзор взаимодействия контроллера с жестким дис-
диском, который поможет вам лучше понять аппаратную блокировку записи и защи-
защищенные области. Материал не относится к устройствам ATAPI (скажем, диско-
дисководам CD-ROM).
Контроллер передает команды жесткому диску по плоскому кабелю. Команда
может быть принята обоими дисками, подключенными к кабелю, но одна из час-
частей команды указывает, для какого диска она предназначена: ведущего или ведо-
ведомого. Взаимодействие контроллера с жестким диском основано на записи данных
в регистры (небольшие ячейки памяти). После того как все необходимые данные
будут загружены в регистры, контроллер осуществит запись в регистр команд,
и жесткий диск выполнит команду (как при щелчке на кнопке Submit после за-
заполнения HTML-формы). Теоретически диск ничего не должен делать до момен-
момента записи в регистр команд.
Допустим, контроллер хочет прочитать сектор с диска. Для этого он должен
записать адрес сектора или количество читаемых секторов в соответствующие ре-
регистры. После того как необходимые данные будут записаны в регистры, контрол-
контроллер инициирует операцию чтения посредством записи в регистр команд.
Пароли жестких дисков
В спецификации АТА-3 появились новые средства защиты данных, в том числе
возможность назначения пароля в BIOS или прикладных программах. Если па-
парольная защита реализована, жесткому диску назначаются два пароля: пользова-
пользовательский и главный. Главный пароль нужен для того, чтобы администратор мог
получить доступ к компьютеру в случае утраты пользовательского пароля. При
использовании паролей диск может работать в двух режимах: повышенной и мак-
максимальной безопасности. В режиме повышенной безопасности блокировка с дис-
диска снимается как пользовательским, так и главным паролем. В режиме максималь-
максимальной безопасности пользовательский пароль может снять блокировку с диска, но
снятие блокировки главным паролем становится возможным только после стира-
стирания всего содержимого диска. После нескольких неудачных попыток ввода паро-
пароля диск «зависает», и систему приходится перезагружать.
Перед выполнением многих команд АТА должна быть выполнена команда
SECURITY_UNLOCK с правильным паролем. После ввода правильного пароля диск
работает обычным образом вплоть до отключения питания.
Выполнение некоторых команд АТА разрешено и с заблокированным жест-
жестким диском, поэтому при подключении к компьютеру диск может выглядеть впол-
вполне нормально. Однако при попытке прочитать данные с заблокированного диска
либо выдается сообщение об ошибке, либо запрашивается пароль. В Интернете
можно найти несколько бесплатных программ, которые сообщают, заблокирован
ли диск, и позволяют снять блокировку с вводом пароля. Для примера назову две
такие программы, atapwd и hdunlock К Пароль задается в BIOS или в специальном
приложении. Некоторые компании, специализирующиеся на восстановлении дан-
данных, умеют обходить пароль для открытия диска.
Область HPA
Защищенной областью HPA (Host Protected Area) называется специальная область
диска, предназначенная для сохранения данных и невидимая для постороннего
наблюдателя. Размер этой области задается командами АТА. Для большинства
дисков по умолчанию он равен 0.
Поддержка HPA появилась в АТА-4. Она предназначалась для того, чтобы про-
производитель компьютера мог сохранить данные, которые не терялись бы при фор-
форматировании жесткого диска пользователем и стирании его содержимого. HPA
находится в конце диска, а обращение к ее содержимому возможно лишь в ре-
результате изменения конфигурации жесткого диска.
Рассмотрим процесс резервирования HPA более подробно, на уровне команд
АТА. Некоторые из используемых команд существуют в двух версиях в зависимос-
зависимости от размера диска, но я буду приводить только одну версию. Первые две команды
возвращают максимальный номер адресуемого сектора; если возвращаемые значе-
значения различаются, значит, на диске существует область HPA. Команда READ_N ATIVE_
MAX_ADDRESS возвращает максимальный физический адрес, а команда IDENTIFY_DEVICE
возвращает количество секторов, доступных для пользователя. Следовательно,
при наличии HPA READ_NATIVE_MAX_ADDRESS вернет фактический конец диска,
тогда как IDENTIFY_DEVICE вернет конец пользовательской области (и начало
HPA). Обратите внимание: как будет показано в следующем разделе, команда
READ_NATIVE_MAX_ADDRESS не всегда возвращает последний физический адрес диска.
При создании HPA команда SET_MAX_ADDRESS задает максимальный адрес, до-
доступный для пользователя. Если потребуется отказаться от использования HPA,
команда SET_MAX_ADDRESS выполняется заново с фактическим максимальным раз-
размером диска, возвращаемым командой READ_NATIVE_MAX_ADDRESS.
Например, если объем диска составляет 20 Гбайт, READ_NATIVE_MAX_ADDRESS
возвращает количество секторов для 20 Гбайт (скажем, 41 943 040). Чтобы со-
создать защищенную область HPA объемом 1 Гбайт, следует выполнить команду
SET_MAX_ADDRESS с адресом 39 845 888. Любые попытки чтения или записи в послед-
последние 2 097 152 сектора A Гбайт) приводят к ошибке, а команда IDENTIFY_DEVICE воз-
возвращает максимальный адрес 39 845 888 (рис. 2.12). Чтобы снять защиту с HPA, сле-
следует снова выполнить команду SET_MAX_ADDRESS с полным количеством секторов.
Среди параметров команды SET_MAX_ADDRESS присутствует «бит устойчивос-
устойчивости». Если он установлен, то HPA продолжает существовать после сброса жестко-
жесткого диска или отключения питания. В спецификации АТА также присутствуют ко-
команды блокировки, которые запрещают модификацию максимального адреса до
следующего сброса. Это позволяет BIOS прочитать или записать данные в защи-
защищенную область при включении питания, задать размер защищенной области так,
1 Эти программы чаще всего встречаются на веб-сайтах, посвященных модификации игровых приста-
приставок — например, http//www.xbox-scene.com/tools/tools.php?page=harddrive.
чтобы данные оставались невидимыми для пользователя, и заблокировать область
для предотвращения ее изменений. При этом даже может использоваться пароль
(отличный от пароля для доступа к диску).
Рис. 2.12. Диск объемом 20 Гбайт с 1-гигабайтной защищенной областью HPA
Подведем итог: жесткий диск может содержать защищенную область HPA
с системными файлами или скрытой информацией (а возможно, и тем и другим).
Присутствие защищенной области выявляется сравнением результатов двух ко-
команд АТА. Для удаления защищенной области следует сбросить ограничение мак-
максимального пользовательского адреса жесткого диска, но бит устойчивости по-
позволяет внести временные изменения.
DCO
Помимо HPA для скрытия данных также может применяться механизм DCO
(Device Configuration Overlay), поддержка которого была добавлена в АТА-6. DCO
ограничивает доступ к некоторым функциям жесткого диска. В каждой специфи-
спецификации АТА указываются дополнительные возможности, реализация которых жест-
жестким диском не является обязательной. Для определения набора возможностей, фак-
фактически поддерживаемых жестким диском, используется команда IDENTIFY_DEVICE.
Под воздействием DCO команда IDENTIFY_DEVICE сообщает о том, что некоторые
поддерживаемые возможности якобы не поддерживаются, и выдает размер диска
меньше фактического.
Рассмотрим некоторые команды DCO. Команда DEVICE_CONFIGURATION_IDENTIFY
возвращает информацию о возможностях диска и его размере. Следовательно, для
обнаружения вмешательства DCO следует сравнить вывод команд DEVICЕ_СОN FI-
GURATION.IDENTIFY и IDENTIFY.DEVICE. Напомню, что команда READ_NATIVE_MAX_AD-
DRESS возвращает полный размер диска (вместе с HPA). Сравнив результат
READ_NATIVE_MAX_ADDRESS с результатом DEVICE_CONFIGURATION_IDENTIFY, можно
обнаружить присутствие секторов, скрытых DCO.
Допустим, имеется 20-гигабайтный жесткий диск, в котором механизм DCO
установил максимальный адрес 19 Гбайт. Команды READ_NATIVE_MAX_ADDRESS
и IDENTIFY_DEVICE указывают, что размер диска равен только 19 Гбайт. Если на
диске также создается HPA размером 1 Гбайт, команда IDENTIFY_DEVICE покажет,
что размер диска составляет всего 18 Гбайт (рис. 2.13).
Для создания или изменения скрытой области DCO применяется команда
DEVICE_CONFIGURATION_SET, а для ее удаления - команда DEVICE_CONFIGURATION_RE-
SET. В отличие от HPA, не существует возможности внести изменения только на
время текущего сеанса. Все изменения DCO являются устойчивыми, сохраняют-
сохраняются при сбросе и отключении питания.
Рис. 2.13. DCO создает скрытые секторы в конце диска
(помимо секторов, скрытых HPA)
Serial ATA
У устройств АТА имеются свои недостатки. Их кабели слишком велики, недоста-
недостаточно гибки, а разъемы часто оказываются совсем не там, где они нужны. Кроме
того, перемычки «ведущий/ведомый» усложняют конфигурацию жестких дисков.
Кабели и скорость передачи данных стали некоторыми причинами для разработ-
разработки интерфейса Serial ATA, включенного в спецификацию АТА-7.
Интерфейс называется «последовательным» (Serial), потому что в любой мо-
момент времени между контроллером и диском передается только один бит инфор-
информации — в отличие от 16 битов исходного интерфейса «параллельного АТА».
Разъемы Serial ATA примерно в четыре раза меньше разъемов параллельного АТА
и содержат только семь контактов. Каждое устройство Serial ATA подключается
к контроллеру напрямую, подключение «гирляндой» не поддерживается.
Интерфейс Serial ATA проектировался таким образом, чтобы после установки
нового контроллера компьютер не отличал новое устройство Serial ATA от исход-
исходных (параллельных) устройств АТА. Более того, регистры контроллера Serial ATA
создают у компьютера «иллюзию», будто он взаимодействует с параллельным дис-
диском АТА. С точки зрения компьютера каждый диск, подключенный к контролле-
контроллеру Serial ATA, работает как ведущий (master) диск на отдельном канале.
BIOS и прямой доступ
Итак, вы в общих чертах представляете, как работают жесткие диски АТА и как
осуществляется управление ими. Теперь необходимо разобраться, как с ними вза-
взаимодействуют программы, потому что это тоже может вызвать проблемы при об-
обращении к содержимому диска. Взаимодействие программ с диском может осу-
осуществляться на двух уровнях: напрямую через контроллер диска или через BIOS.
Прямой доступ к контроллеру
В предыдущем разделе было показано, что жесткий диск подключается к контрол-
контроллеру, передающему команды диску по плоскому кабелю. В одном из вариантов
чтения/записи данных программа «общается» напрямую с контроллером, кото-
который затем взаимодействует с жестким диском.
Чтобы взаимодействие было организовано подобным образом, программа дол-
должна знать способ адресации контроллера и уметь отдавать ему команды. В част-
частности, программе должен быть известен код команды для операции чтения
и режим идентификации читаемых секторов, а также способ получения у жест-
жесткого диска дополнительной информации (такой, как тип и размер).
Доступ к контроллеру через BIOS
Прямой доступ к контроллеру обеспечивает максимальную скорость чтения и за-
записи на диск, однако для него программа должна располагать подробной информа-
информацией об оборудовании. С другой стороны, одной из целей системы BIOS является
изоляция программ от технических деталей. BIOS располагает полной информа-
информацией об устройствах и предоставляет свой сервис программам, чтобы последним
было удобнее работать с оборудованием.
Как говорилось ранее в разделе «Местонахождение загрузочного кода», BIOS
используется при запуске компьютера. В процессе загрузки BIOS решает много
задач, но сейчас нас интересуют две из них. Первая — это сбор подробной инфор-
информации об установленных дисках, а вторая — заполнение таблицы прерываний,
используемой для обслуживания запросов операционной системы и прикладных
программ.
Чтобы воспользоваться сервисом жестких дисков BIOS, программа должна
загрузить необходимые данные (например, адрес и размер сектора) в регистры
процессора и выполнить команду программного прерывания 0xl3h (INT 13h). Полу-
Получив команду программного прерывания, процессор обращается к таблице преры-
прерываний и находит в ней адрес кода обработки запроса на прерывание. Как правило,
для прерывания 0x13 в таблице хранится адрес кода BIOS, который использует
имеющуюся информацию о жестких дисках для взаимодействия с контроллером.
В сущности, BIOS выполняет функции посредника между программным обеспе-
обеспечением и жестким диском.
Вообще говоря, прерывание INT 13h представляет целую категорию дисковых
функций. В эту категорию входят функции записи на диск, чтения с диска, фор-
форматирования дорожек и получения информации о диске. Исходные функции INT
13h использовали для чтения/записи адреса CHS и позволяли программам рабо-
работать с дисками объемом 8,1 Гбайт и менее. Для снятия этого ограничения в код
BIOS были добавлены новые функции, называемые «расширенными обработчи-
обработчиками INT 13h».
Расширенные обработчики INT 13h требовали нового кода BIOS и использо-
использовали 64-разрядные адреса LBA. В целях совместимости старые функции CHS были
сохранены, и для использования новых функций LBA INT 13h пришлось вносить
изменения в программное обеспечение.
Диски SCSI
В этом разделе приводится обзор технологии SCSI (Small Computer Systems Inter-
Interface), различных типов устройств и отличий от AT А. Жесткие диски SCSI не по-
получили столь широкого распространения, как жесткие диски АТА для «бытовых»
PC, но именно они применяются на большинстве серверов.
Как и в случае с АТА, существует целый ряд спецификаций SCSI, опублико-
опубликованных техническим комитетом Т10 при INCITS (http://www.tlO.org). Три основ-
основные спецификации SCSI — SCSI-1, SCSI-2 и SCSI-3 — включают несколько специ-
спецификаций более низкого уровня, но их подробное описание выходит за рамки книги.
SCSI и ATA
Между SCSI и ATA существует множество различий как на высоком, так и на
низком уровне. К наиболее очевидным различиям верхнего уровня относятся мно-
многочисленные типы разъемов. В АТА поддерживаются разъемы только с 40 и 44 кон-
контактами, но в SCSI набор форм и типов разъемов гораздо более разнообразен.
Кабели SCSI могут иметь гораздо большую длину, чем кабели АТА, и к одному
кабелю может подключаться более двух устройств. Каждому устройству, подклю-
подключенному к кабелю SCSI, присваивается уникальный числовой идентификатор, ко-
который задается при помощи перемычек на диске или специальной программы.
На многих дисках SCSI также присутствует перемычка, которая разрешает дос-
доступ к диску только для чтения; по своим функциям она напоминает блокировщик
записи АТА — внешнее устройство, блокирующее команды записи (см. главу 3).
Первое низкоуровневое различие между АТА и SCSI состоит в том, что в тех-
технологии SCSI нет контроллера. Интерфейс АТА проектировался в расчете на еди-
единый контроллер, управляющий работой одного или двух жестких дисков. Интер-
Интерфейс SCSI проектировался как шина для взаимодействия различных устройств,
круг которых не ограничивается жесткими дисками. В конфигурации SCSI плата,
подключаемая к компьютеру, не является контроллером, поскольку все устрой-
устройства на кабеле SCSI равноправны и могут обращаться с запросами друг к другу.
По аналогии с АТА, стандартный интерфейс SCSI работает в параллельном
режиме, а пересылка данных осуществляется 8- или 16-разрядными пакетами. Как
и в АТА, существует последовательная версия спецификации.
Типы SCSI
Различия в версиях SCSI сводятся к количеству одновременно пересылаемых
битов, скорости передачи (частоте сигналов в кабеле) и типам используемых сиг-
сигналов. Более старые разновидности существовали в двух версиях, нормальной
и расширенной; в нормальной версии одновременно передавалось 8 битов, а в рас-
расширенной — 16 битов. Например, устройства Ultra SCSI использовали 8-разряд-
8-разрядную пересылку, а устройства Wide Ultra SCSI — 16-разрядную. Во всех новых
системах используется 16-разрядная пересылка, и различать нормальную и рас-
расширенную версию уже не нужно.
Второе различие между версиями SCSI определяет скорость передачи сигнала
по кабелю. В табл. 2.5 приведены названия типов SCSI, частоты и скорость пере-
передачи данных для 8-разрядной нормальной и 16-разрядной расширенной шины.
Таблица 2.5. Скорость передачи данных для различных типов SCSI
Тип Частота, 8-разрядная 16-разрядная (расширенная)
МГц передача, Мбайт/с передача, Мбайт/с
SCSI(нормальная) 5 5 10
Fast SCSI 10 10 20
Ultra SCSI 20 20 40
Ultra2SCSI 40 40 80
Ultra3SCSI 80 — 160
Ultral60SCSI 80 — 160
Ultra320SCSI 160 — 320
В рамках каждого типа существуют различные способы представления дан-
данных при пересылке. Наиболее очевидным является несимметричное представле-
представление: при пересылке 1 на провод подается высокое напряжение, а при передаче
О напряжение отсутствует. При повышении скорости передачи и удлинении ка-
кабеля начинаются проблемы, потому что при высокой тактовой частоте электри-
электрический сигнал становится нестабильным, а провода начинают создавать помехи.
Второй способ передачи данных называется дифференциальным, и для пере-
пересылки каждого бита в нем задействуются два провода. При пересылке 0 на обоих
проводах напряжение отсутствует. При пересылке 1 на один провод подается по-
положительное напряжение, а на другой — отрицательное. Принимая сигналы с ка-
кабеля, устройство определяет разность между напряжениями на двух проводах.
Дифференциальный сигнал высокого напряжения (HVD, High Voltage Differential)
существовал в SCSI, начиная с первой версии, тогда как дифференциальный сиг-
сигнал низкого напряжения (LVD) появился только в Ultra2 SCSI и является основ-
основным типом сигнала для новых дисков. В табл. 2.6 показано, в каких типах SCSI
используются те или иные разновидности сигналов.
Таблица 2.6. Разновидности сигналов в разных типах SCSI
Тип сигнала Типы SCSI
SE SCSI, Fast SCSI, Ultra SCSI
HVD SCSI, Fast SCSI, Ultra SCSI, Ultra2 SCSI
LVD Ultra2 SCSI, Ultra3 SCSI, Ultral6O SCSI, Ultra320 SCSI
Ни в коем случае не путайте типы сигналов! Подключение устройств SE к ус-
устройствам HVD и некоторым устройствам LVD приведет к их повреждению. Не-
Некоторые диски LVD являются SE-совместимыми pi могут использоваться в среде
SE без повреждения, но только на тех скоростях, на которых работают устройства
SE. На устройствах SCSI присутствует условное обозначение используемого типа
сигнала (рис. 2.14).
Рис. 2.14. Условные обозначения типа сигнала на устройствах SCSI: (A) — устройства SE,
(В) — устройства LVD, (С) — SE- и LVD-совместимые устройства, (D) — устройства HVD
Типы разъемов
Существует много разновидностей разъемов SCSI, но на практике часто встреча-
встречаются лишь некоторые из них. Как правило, диски с 8-разрядной шиной использу-
используют 50-контактные разъемы, а диски с 16-разрядной шиной — 68-контактные. В на-
настоящее время наибольшее распространение получили 68-контактные адаптеры
высокой плотности, существующие в двух модификациях: нормальные и очень
высокой плотности. Нормальные разъемы получили наибольшее распространение
(рис. 2.15). 68-контактный адаптер используется для сигналов LVD и SE, но фи-
физические кабели для разных типов сигналов различаются. Внимательно проверь-
проверьте пометку на кабеле, чтобы избежать возможных проблем.
Рис. 2.15. Диск SCSI с 68-разрядным разъемом
Одну из разновидностей 68-контактных разъемов высокой плотности пред-
представляют разъемы SCA (Single Connector Attachment). Они предназначены для
объединения проводов питания с проводами данных в одном разъеме, что упро-
упрощает замену дисков на сервере. Разъем состоит из 80 контактов, среди которых
присутствуют контакты для подачи питания и настройки конфигурации диска.
На рис. 2.16 показано, как выглядит такой разъем.
Существует множество адаптеров для разных разъемов SCSI; предполагается,
что устройства SCSI обладают обратной совместимостью. Тем не менее работают
не все адаптеры и конфигурации устройств (а даже если они работают, то на ско-
скорости самого медленного из устройств). Помните, что устройства HVD не долж-
должны комбинироваться с устройствами LVD и SE без соответствующих адаптеров,
а сочетания устройств LVD и SE возможны только в том случае, если устройства
LVD способны работать в режиме SE.
Ограничения размера
Ограничения размеров, действующие для дисков АТА, не распространяются на
диски SCSI, потому что в спецификации SCSI всегда использовались 32- и 64-
разрядные адреса LBA. Тем не менее максимальный размер диска, поддерживае-
поддерживаемый BIOS (при использовании INT 13h) или файловой системой, может быть
меньше того, что поддерживается спецификацией SCSI. Данное обстоятельство
может стать ограничивающим фактором.
При работе с диском через BIOS контроллер SCSI преобразует адреса CHS
в адреса LBA. Разные контроллеры используют разные способы отображения, но
во многих случаях способ выбирается на основании геометрии, описываемой в таб-
таблице разделов. Может оказаться, что в рабочей системе аналитика установлен кон-
контроллер с другой схемой отображения адресов, поэтому обращение к диску долж-
должно осуществляться методом прямого доступа, а не через BIOS.
Итоги
В этой главе рассматривались основные принципы организации и хранения дан-
данных. Материал играет важную роль в книге, потому что мы будем рассматривать
структуры данных и методы хранения информации в разных файловых системах.
Дополнительная информация о структурах данных приводится в книгах, посвя-
посвященных языку С. Кроме того, в этой главе представлены основные технологии
жестких дисков; этот материал тоже важен, потому что именно жесткие диски
чаще всего становятся объектом анализа и экспертизы. Дополнительные све-
сведения о технологии жестких дисков можно найти на сайте PC Guide (http://
www.pcguide.com/ref/hdd/index.htm) и в официальных спецификациях АТА и SCSI.
Библиография
• Sammes, Tony, and Brian Jenkinson. Forensic Computing: A Practitioner's Guide.
New York: Springer-Verlag, 2000.
• T13. «Information Technology — AT Attachment Interface for Disk Drives», X3T10,
791D Revision 4c, 1994. http://www.tl3.org/project/d0791r4c-ATA-l.pdf.
• T13. «Information Technology — AT Attachment with Packet Interface - 6 (ATA/
ATAPI-6». 1410D Revision 3b, February 26, 2002. http://www.tl3.org/docs2002/
dl410r3b.pdf.
• T13. «Information Technology — AT Attachment with Packet Interface Extension
(ATA/ATAPI-4». 1153D Revision 18, August 19,1998. http://www.tl3.org/project/
dll53rl8-ATA-ATAPI-4.pdf.
• T13. «Information Technology - AT Attachment-3 Interface (ATA-3)», X3T13,
2008D Revision 7b, January 27, 1997. http://www.tl3.org/project/d2008r7b-ATA--
3.pdf.
Снятие данных
с жесткого диска
Основная часть материала так или иначе связана со снятием данных, находящих-
находящихся на носителе информации — а именно, на жестком диске. Анализ также может
проводиться в «живых» системах, но чаще данные копируются для проведения
стороннего анализа. Как правило, снятие данных происходит в фазе сохранения
системы и является одной из важнейших составляющих цифровой экспертизы.
Ведь если данные не будут скопированы в другую систему, они могут быть слу-
случайно утрачены, и тогда они перестанут быть уликами. Более того, если копиро-
копирование произведено некорректно, данные тоже утрачивают свою юридическую силу.
В этой главе приводится теория снятия данных, а также рассматривается конк-
конкретный пример с применением утилиты Linux dd.
Введение
Как было показано в главе 1, первой фазой цифрового анализа является сохране-
сохранение цифрового «места преступления». Обычно для сохранения системы создают-
создаются полные копии жестких дисков, которые затем доставляются в лабораторию для
проведения стороннего анализа. Эту фазу можно сравнить с процессом создания
точной копии здания, в котором было совершено реальное преступление, чтобы
следователи могли спокойно заняться поиском улик в лаборатории.
Общая процедура снятия данных
В самой общей и интуитивно понятной процедуре снятия данных один байт с ис-
исходного носителя информации (источника) копируется в приемное устройство,
после чего эта процедура многократно повторяется. Происходит примерно так,
как если бы вы при копировании документа вручную читали отдельную букву,
знак препинания или пробел из оригинала и записывали его в копию. Такой спо-
способ работает, но большинство читателей вряд ли будут им пользоваться — ведь
они могут запоминать целые слова, а копировать документ по одному или несколь-
нескольким словам гораздо эффективнее, чем по отдельным знакам. Компьютеры дей-
действуют по тому же принципу, и копирование данных из анализируемых систем
производится блоками размером от 512 до многих тысяч байтов.
Размер одного передаваемого блока обычно кратен 512 байтам, то есть разме-
размеру сектора на большинстве дисков. Если при чтении данных с анализируемого
диска происходит ошибка, большинство программ снятия данных записывает
в приемник нули.
Уровни снятия данных
В общей теории неразрушающего снятия данных сохраняется каждый байт, кото-
который может использоваться в качестве улики. Как было показано в главе 1, интер-
интерпретация данных может осуществляться на разных уровнях: например, на уровне
дисков, томов, файлов и приложений. На каждом уровне абстракции теряется
некоторая часть данных. Таким образом, снятие данных должно осуществляться
на самом низком уровне, на котором будут находиться улики. В большинстве слу-
случаев аналитик снимает содержимое каждого сектора диска; именно этот способ
будет рассматриваться в этой главе. Обратите внимание: сохраняя только содер-
содержимое секторов с данными, мы теряем информацию, которая может понадобить-
понадобиться специалистам по восстановлению данных.
Чтобы показать, почему снятие данных обычно производится на уровне диска,
рассмотрим пару примеров. Допустим, диск был клонирован на уровне тома, с соз-
созданием копии каждого сектора в каждом разделе. Такая копия позволит восста-
восстановить удаленные файлы в каждом разделе, но анализ секторов, не принадлежа-
принадлежащих ни одному из разделов, будет невозможен. Как будет показано в главе 5, на
диске с разделами DOS не используются секторы с 1 по 62, и в них могут нахо-
находиться скрытые данные. При проведении снятия на уровне тома эти скрытые дан-
данные будут потеряны.
Теперь предположим, что мы воспользовались утилитой архивации и скопи-
скопировали только существующие файлы. В этом случае станет невозможным восста-
восстановление удаленных файлов, могут стать недоступными все временные данные,
а также служебная информация, скрытая в разделах и структурах данных файло-
файловой системы. Иногда никаких других данных, кроме архива, не имеется, и анали-
аналитик должен извлечь из него максимум пользы. Скажем, в корпоративной среде
сервер перестал работать, потому что все его диски были записаны нулями, а за-
затем компьютер был перезагружен. Последний архив системы может содержать
информацию о том, кто имел доступ к системе или каким образом злоумышлен-
злоумышленник проник в нее.
В некоторых системах наше правило относительно снятия данных на минималь-
минимальном уровне, на котором мы рассчитываем найти улики, означает, что достаточно
скопировать только файлы. Допустим, вы расследуете попытку взлома сети с дей-
действующей системой обнаружения вторжений (IDS, Intrusion Detection System),
у которой имеется журнал с информацией об атаке. Если вы считаете, что данные
IDS не подвергались посторонним изменениям, то все улики существуют на фай-
файловом уровне; можно просто скопировать необходимые журналы и предпринять
необходимые шаги по их сохранению. Если есть подозрение, что данные IDS были
изменены, то информацию следует копировать на дисковом уровне для проведе-
проведения анализа всех данных.
Тесты программ снятия данных
Клонирование является критической составляющей процесса расследования,
и Национальный институт стандартов и технологий (NIST, National Institute of
Standards and Technology) провел сравнительное тестирование распространен-
распространенных программ клонирования. В рамках проекта CFTT (Computer Forensic Tool
Testing) в NIST был разработан набор требований и тестов для утилит создания
образов дисков. Результаты и спецификации приведены на веб-сайте (http://
wwwxftt.nist.gov/diskjmaging.htm).
Чтение исходных данных
В соответствии с общей теорией клонирования, описанной в предыдущем разде-
разделе, процесс состоит из двух основных частей. Сначала данные необходимо прочи-
прочитать из источника, а затем записать их в приемник. Поскольку в книге основное
внимание уделяется анализу томов и данных файловых систем, мы рассмотрим
процесс клонирования на уровне диска (поскольку именно на этом уровне хра-
хранится большинство структур данных томов). В этом разделе будут рассмотрены
вопросы, связанные с чтением диска, а в следующем речь пойдет о записи. Пред-
Предполагается, что в качестве источника используется типичная система IA32 (на-
(например, x86/i386). Мы рассмотрим различные способы обращения к данным, об-
обработку ошибок и снижение риска записи данных на исследуемый диск.
Прямой доступ или BIOS?
Как показано в главе 2, существует два способа обращения к данным на диске.
В первом способе операционная система или программа клонирования обраща-
обращается к жесткому диску напрямую; для этого программа должна обладать полной
информацией о конфигурации оборудования. Во втором способе операционная
система или программа клонирования обращается к жесткому диску через про-
прослойку BIOS (Basic Input/Output System), которой известны все подробности кон-
конфигурации. На первый взгляд особых различий не видно, и работать через BIOS
вроде бы удобнее, потому что BIOS берет на себя все аппаратные тонкости. К со-
сожалению, когда речь идет о расследовании, дело обстоит несколько сложнее.
При обращении через BIOS возникает опасность того, что BIOS вернет невер-
неверную информацию о диске. Если BIOS считает, что размер диска составляет 8 Гбайт,
тогда как фактический размер равен 12 Гбайт, функции INT 13h предоставят дос-
доступ только к первым 8 Гбайт дискового пространства. Следовательно, при клони-
клонировании диска последние 4 Гбайт не будут скопированы. Суть происходящего
продемонстрирована на рис. 3.1, где два приложения пытаются определить раз-
размер диска разными способами.
Рис. 3.1. Два приложения пытаются определить размер диска. Из-за неверной конфигурации
BIOS сообщает, что размер 12-гигабайтного диска составляет всего 8 Гбайт
Возможны различные варианты этого сценария. Первый — когда BIOS настра-
настраивается на конкретную геометрию жесткого диска, отличную от фактической.
В другом варианте программа клонирования использует устаревший метод полу-
получения размера диска. Приложение может запросить у BIOS размер диска двумя
способами. Во-первых, оно может воспользоваться исходной функцией INT 13h,
которая подвержена ограничению в 8 Гбайт и возвращает результат, используя
геометрию диска в формате CHS. Во-вторых, приложение может воспользовать-
воспользоваться расширенной функцией INT 13h, возвращающей результат в формате LBA. Так,
группа CFTT в NIST использовала 2-гигабайтный жесткий диск и компьютер, на
котором исходная и расширенная функции INT 13h возвращали разные размеры.
Результат расширенной функции был правильным, тогда как исходная функция
выдавала заниженный результат [U.S. Department of Justice, 2003].
Время от времени в один из списков рассылки, посвященных цифровой экс-
экспертизе, поступают сообщения от пользователей, клонировавших диск двумя раз-
разными программами и получивших образы разного размера. Причина обычно зак-
заключается в том, что одна программа использовала BIOS, а другая — нет. Убедитесь
в том, что вы знаете, как ваша программа обращается к диску, и в случае исполь-
использования BIOS проследите за тем, чтобы перед копированием она правильно вы-
выдавала полный размер диска. BIOS становится еще одним промежуточным зве-
звеном, повышающим вероятность внесения ошибок в итоговый образ. Если это
возможно, постарайтесь обойтись без участия BIOS.
Режимы снятия данных
Помимо способа доступа к диску аналитик также выбирает режим клонирования
данных. Мертвое снятие данных происходит тогда, когда данные из анализируе-
анализируемой системы копируются без содействия установленной на ней операционной
системы. Исторически термин «мертвое» относится не к состоянию компьютера
в целом, а только к состоянию операционной системы, поэтому при мертвом кло-
клонировании возможно использование оборудования исходного компьютера — при
условии, что загрузка производится с надежного компакт-диска или дискеты. Жи-
Живое снятие данных означает, что операционная система на анализируемом компь-
компьютере продолжает работать и используется для копирования данных.
Живое снятие данных сопряжено с определенным риском: злоумышленник мог
изменить операционную систему или другое программное обеспечение таким об-
образом, чтобы во время клонирования поставлялись неверные данные. Проведу
аналогию с реальным миром: представьте, что полиция прибывает на место пре-
преступления, на котором находятся несколько людей; нельзя исключать, что кто-то
из них причастен к преступлению. Полицейские начинают искать некую улику
и предлагают одному из незнакомцев сходить в одну из комнат и помочь им в по-
поисках. Незнакомец возвращается к полицейскому и говорит, что он ничего не на-
нашел; но можно ли ему доверять? Вполне возможно, что незнакомец является пре-
преступником, а улика находилась в комнате, но он успел уничтожить ее.
Нападающие часто устанавливают в атакуемых системах так называемые рут-
киты (rootkits), передающие пользователю ложную информацию [Skoudis & Zeltser,
2004]. Руткиты скрывают некоторые файлы в каталогах или работающие процес-
процессы. Чаще всего нападающий скрывает файлы, установленные им после взлома
системы. Также он может модифицировать операционную систему так, чтобы
в процессе она автоматически подменяла данные в некоторых секторах диска.
Полученный образ диска может не иметь отношения к происшествию из-за про-
произошедшей подмены. По возможности избегайте живого клонирования, чтобы
обеспечить надежный сбор всех улик.
Аналитики обычно загружают исследуемую систему с заведомо надежной дис-
дискеты DOS или компакт-диска Linux, конфигурация которого не предусматривает
монтирования дисков или модификации каких-либо данных. С технической точ-
точки зрения злоумышленник может изменить оборудование так, чтобы оно возвра-
возвращало ложные данные даже в надежной операционной системе, но этот вариант
гораздо менее вероятен, чем модификация операционной системы.
Обработка ошибок
В процессе чтения данных с диска программа клонирования должна обрабатывать
возникающие ошибки. Причины могут быть различными: как отказ всего диска,
так и сбои в ограниченном количестве секторов. При повреждении части секторов
клонирование возможно — но при условии, что программа обработает все ошибки.
Общепринятый способ обработки поврежденных секторов заключается в со-
сохранении адреса и записи нулей на место данных, которые не удалось прочитать.
Запись нулей сохраняет правильное местонахождение остальных данных. Если
бы поврежденные секторы просто игнорировались, то полученная копия оказа-
оказалась бы слишком маленькой, а многие аналитические программы не смогли бы
с ней работать. На рис. 3.2 показана последовательность клонируемых секторов.
Три сектора содержат ошибки, и прочитать их не удалось, поэтому в копию на их
место записываются нули.
Область HPA
При снятии данных с дисков АТА следует обращать внимание на защищенную
область HPA диска, поскольку в ней могут храниться скрытые данные. Если про-
программа снятия данных не пытается обнаружить HPA, эти данные не будут клони-
клонированы. За дополнительной информацией о HPA обращайтесь к главе 2.
Программа обнаруживает присутствие HPA, сравнивая результаты выполне-
выполнения двух команд АТА. Команда READ_NATIVE_MAX_ADDRESS возвращает общее ко-
количество секторов на диске, а команда IDENTIFY_DEVICE — количество секторов,
доступных для пользователя. Если область HPA существует, эти два числа будут
различаться.
Если у вас нет программы, которая выполняла бы необходимые команды АТА,
вероятно, вам придется сравнить количество секторов, скопированных в процессе
снятия данных, с количеством секторов, указанным на наклейке на диске. Многие
современные программы снятия данных обнаруживают присутствие HPA. Также
существуют специализированные утилиты, такие как BXDR (http://www.sanderson-
forensics.co.uk/BXDR.htm) Пола Сэндерсона (Paul Sanderson), diskstatH3 пакета The
Sleuth Kit, DRIVEID компании МуКеу Technology (http://www.mykeytechnology.com)
и hpa Дэна Mapeca (Dan Mares) (http://www.dmares.com/maresware/gk.htmSHPA).
Если на диске будет обнаружена область HPA и вы захотите получить дос-
доступ к скрытым данным, придется изменить конфигурацию диска. Чтобы уда-
удалить HPA, следует задать максимальный сектор, адресуемый пользователем,
равным максимальному сектору на диске. При этом можно использовать бит
устойчивости, чтобы изменения в конфигурации были утрачены при следующем
отключении питания жесткого диска. Выполнению команды могут помешать не-
некоторые аппаратные блокировщики записи, о которых речь пойдет далее.
Процесс удаления HPA сопряжен с изменением конфигурации диска. Суще-
Существует крайне малая вероятность того, что в контроллере диска или программе
снятия данных неверно реализован механизм изменения HPA, и попытка снятия
защиты приведет к потере данных. Следовательно, перед удалением HPA стоит
создать полный образ диска. Если в процессе удаления будут нанесены какие-
либо повреждения, у пользователя останутся исходные данные для анализа. При-
Пример диска с HPA будет рассмотрен далее в этой главе. Факт снятия HPA обяза-
обязательно должен быть отражен в ваших заметках.
DCO
При снятии данных с современных дисков АТА также следует проверить нали-
наличие области DCO (Device Configuration Overlay), из-за которой размер диска ка-
кажется меньше фактического. Область DCO в целом похожа на HPA, причем обе
области могут существовать на диске одновременно (тема DCO также обсужда-
обсуждалась в главе 2).
Присутствие DCO обнаруживается сравнением результатов двух команд АТА.
Команда READ_NATIVE_MAX_ADDRESS возвращает максимальный сектор диска, дос-
доступный для обычных команд АТА, а команда DEVICE_CONFIGURATION_IDENTIFY -
физическое количество секторов. Если результаты двух команд различаются, зна-
значит, на диске существует защищенная область DCO и ее необходимо удалить для
снятия всей информации.
Чтобы удалить область DCO, необходимо изменить конфигурацию диска ко-
командой DEVICEj:ONFIGURATION_SET или DEVICE_CONFIGURATION_RESET. Оба измене-
изменения имеют постоянный характер и не пропадают при сбросе, как это возможно
при создании областей HPA. В настоящее время лишь немногие программы спо-
способны обнаруживать и удалять DCO. Например, программа Image MASSter Solo
2 от ICS (http://www.icforensic.com) копирует секторы, скрытые в DCO. Как и в слу-
случае с HPA, самое безопасное решение заключается в полном копировании диска
с областью DCO, ее удалении и создании второй копии. Не забудьте документи-
документировать факт удаления DCO. Кроме того, проверьте, не запрещено ли удаление
DCO аппаратным блокировщиком записи.
Аппаратная блокировка записи
Одна из рекомендаций из области цифровой экспертизы, приведенных в гла-
главе 1, гласила, что исходные данные должны подвергаться как можно меньшим
изменениям. Существует множество методов снятия информации, не связан-
связанных с модификацией исходных данных, но ошибки все же случаются. Более того,
некоторые методы могут изменять исходные данные, чего нам хотелось бы из-
избежать.
Аппаратный блокировщик записи представляет собой устройство, подключен-
подключенное между компьютером и носителем информации. Такое устройство отслеживает
передаваемые команды и не позволяет компьютеру записывать данные на уст-
устройство хранения информации. Блокировщики поддерживают разные интерфей-
интерфейсы пересылки данных, в том числе ATA, SCSI, Fire Wire (IEEE 1394), USB или
Serial ATA. Они особенно важны в операционных системах, способных смонти-
смонтировать исходный диск (например, Microsoft Windows).
При обсуждении команд АТА в главе 2 говорилось о том, что диск выполняет
какие-либо действия лишь после записи в его регистр команд. Таким образом,
теоретически простейший аппаратный блокировщик записи АТА просто не дает
контроллеру записать в регистр команд никакие значения, которые могли бы при-
привести к записи информации или ее стиранию с диска. Тем не менее такое устрой-
устройство может разрешить контроллеру запись данных в другие регистры. Можно ска-
сказать, что блокировщик записи разрешает зарядить ружье, но не дает возможности
спустить курок. На рис. 3.3 показано, что команды чтения передаются диску, а ко-
команды записи — нет.
Рис. 3.3. Запрос на чтение сектора 5 передается через блокировщик записи,
но команда записи в тот же сектор блокируется на пути к диску
Устройство No Write компании MyKeyTechnologies обладает более сложной
конструкцией и выполняет функции посредника с поддержкой состояния между
контроллером и жестким диском [MyKeyTechnology, 2003]. Данные и команды
передаются жесткому диску только для заведомо безопасных команд. Аргументы
команд не записываются в регистры, если устройство NoWrite не знает, к какой
команде они относятся. Пересылка данных несколько замедляется, но зато сни-
снижается опасность записи потенциально опасных команд. Если продолжить пре-
предыдущую аналогию, такой процесс проверяет каждый патрон и разрешает заря-
заряжать ружье только холостыми.
Я уже упоминал об аппаратных блокировщиках записи в разделах, посвященных
HPA и DCO, и сейчас хочу снова вернуться к этой теме. Для удаления областей
HPA и DCO диску необходимо передать соответствующие команды. Так как вы-
выполнение этих команд приводит к изменению устройства, они должны быть оста-
остановлены аппаратным блокировщиком записи. Устройство No Write делает исклю-
исключение для команды SET_MAX и разрешает выполнять ее при сброшенном бите
устойчивости, чтобы изменения не носили постоянного характера. Все остальные
команды SET_MAX и DEVICE_CONFIGURATION блокируются. Некоторыеблокировщи-
ки записи разрешают прохождение этих команд, а другие их блокируют. На мо-
момент написания книги документация с перечислением блокируемых команд по-
почти не встречалась.
Аппаратные блокировщики записи, как и все остальные аналитические ин-
инструменты, должны проходить тщательное тестирование, и группа CFTT при
NIST опубликовала спецификацию аппаратных блокировщиков записи (http://
www.cftt.nist.gov/hardware_write_block.htm). В спецификации содержится класси-
классификация команд АТА (изменяющие, неизменяющие, конфигурационные). Со-
Согласно спецификации, устройство должно блокировать изменяющие команды
и возвращать (не обязательно) признак успеха или неудачи.
Программная блокировка записи
Кроме аппаратных блокировщиков записи также существуют программные. Одно
время инструменты цифровой экспертизы в основном работали в среде DOS и ис-
использовали метод INT 13h для обращения к диску. Для предотвращения модифи-
модификации диска во время клонирования и анализа часто использовались программные
блокировщики. В этом разделе будут описаны принципы их работы и присущие
им ограничения.
В основу работы программных блокировщиков записи заложена модифика-
модификация таблицы прерываний, используемой для поиска кода сервисных функций
BIOS. В таблице прерываний находятся записи для всех сервисных функций
BIOS, и каждая запись содержит адрес кода соответствующего обработчика.
Например, запись прерывания INT 13h указывает на код записи или чтения дан-
данных с диска.
Программный блокировщик изменяет таблицу прерываний так, чтобы в запи-
записи прерывания 0x13 хранился адрес кода блокировщика (вместо адреса кода
BIOS). Когда операционная система вызывает прерывание INT 13h, управление
передается коду блокировщика; последний анализирует запрашиваемую функцию.
На рис. 3.4 показан пример установки программного блокировщика записи и бло-
блокировки команды записи. Блокировщик записи пропускает остальные функции,
передавая запрос исходному коду BIOS INT 13h.
Программные блокировщики записи уступают аппаратным по эффективнос-
эффективности, потому что программа может обойти BIOS и произвести запись напрямую че-
через контроллер. В общем случае для ограничения доступа к устройству средства
управления должны находиться как можно ближе к устройству. Аппаратные бло-
блокировщики записи удовлетворяют этому критерию: они находятся на минималь-
минимальном расстоянии от жесткого диска и соединяются с ним плоским кабелем.
Группа CFTT при NIST разработала требования и провела тестирование про-
программных блокировщиков записи. Подробности можно найти на сайте: http://
www.cftt.nost.gov/software_write_block.htm.
Рис. 3.4. Таблица прерываний BIOS до и после установки программного
блокировщика, предотвращающего запись на диск
Запись снятых данных
После того как информация будет прочитана с исходного диска, ее нужно куда-то
записать. В этом разделе речь пойдет о том, где сохранять данные, и о различных
форматах сохранения.
Выбор приемника
Сохраняемые данные записываются непосредственно на диск или в файл. Мы
рассмотрим оба варианта.
До появления специализированных программ эксперту приходилось лишь
загружать анализируемую систему либо монтировать диски в своей системе. Сня-
Снятие информации производилось простым копированием данных на другой диск.
Иначе говоря, сектор 0 исходного диска был идентичней сектору 0 приемного
диска. Полученный диск обычно назывался дубликатом или клоном. Если при-
приемный диск был больше исходного, при таком способе снятия данных возни-
возникали проблемы, потому что было трудно определить, где именно на диске
заканчиваются скопированные данные. Как правило, перед прямым снятием дан-
данных приемный диск рекомендовалось заполнить нулями, чтобы посторонние
данные (возможно, оставшиеся от предыдущих исследований) не смешивались
сданными из анализируемой системы. Вторая потенциальная проблема со сня-
снятием данных на диск заключается в том, что некоторые операционные системы
(например, Microsoft Windows) пытаются монтировать все диски. Копия мон-
монтируется в системе, из которой снимаются данные, что может привести к из-
изменению ее содержимого. Кроме того, трудности могли возникнуть и из-за раз-
различий в геометриях исходного и приемного дисков, потому что некоторые
структуры данных описывают местонахождение данных с использованием па-
параметров геометрии диска.
В настоящее время самым распространенным способом является сохранение
данных в файле на жестком диске или на диске CD-ROM. При выводе в файл
границы данных сразу видны, а операционная система не пытается автоматичес-
автоматически монтировать диск. Такой файл часто называется образом (image). Многие про-
программы позволяют разбивать файлы образов на меньшие фрагменты, помещаю-
помещающиеся на один диск CD-ROM или DVD. Некоторые эксперты стирают диски, на
которых хранятся файлы образов, — стирание гарантирует, что данные не содер-
содержат посторонних включений от прошлых случаев.
Формат файла образа
Сохранив данные в файле, можно выбрать формат образа. Физический образ (raw
image) содержит только данные с исходного диска, что упрощает сравнение обра-
образа с исходными данными. Внедренный образ (embedded image) содержит данные
с исходного устройства и дополнительную служебную информацию: хеш-коды,
пометки даты pi времени. Некоторые программы создают физический образ и со-
сохраняют служебную информацию в отдельном файле. Напомню, что хеш-коды
(CRC, MD5 и SHA-1) используются для проверки целостности данных. Приме-
Примеры форматов образов показаны на рис. 3.5.
Рис. 3.5. Примеры образов: (А) — физический образ, (В) — внедренный образ, в котором
метаданные чередуются с физическими данными, (С) — комбинированный образ: данные
хранятся в физическом формате, а метаданные находятся в отдельном файле
В текущих реализациях многие программы клонирования используют за-
закрытые форматы внедренных образов. Примерами могут послужить программы
EnCase1 (Guidance Software) и SafeBack (NTI). Формат образов других про-
программ документирован — как, скажем, формат ProDiscover (Technology Path-
Pathway) [Technology Pathways, 2003]. Как правило, аналитические программы им-
импортируют физические образы, поэтому этот формат обеспечивает наибольшую
гибкость. Программы SMART (ASR Data) и dcfldd/dccidd снимают данные в фи-
физическом формате и создают внешний файл с дополнительной информацией.
Сжатие файла образа
Записываемые в файл данные можно сжать, чтобы они занимали меньше места.
Механизм сжатия основан на более эффективном хранении повторяющихся дан-
данных. Например, если данные содержат блок из 10 000 единиц, то после сжатия
этот блок может представляться несколькими сотнями бит вместо 10 000. Если
данные имеют полностью произвольный характер, повторений будет немного и эф-
эффективность сжатия снижается. Попытка сжатия уже сжатых данных тоже мало-
малоэффективна. Например, графика в формате JPEG уже хранится в сжатом виде,
и ее размер практически не изменится в результате повторного сжатия.
Аналитические программы, используемые для работы со сжатыми образами,
должны поддерживать соответствующий тип сжатия. Большинство общих схем
сжатия требует полной распаковки файла перед его использованием. Примерами
служат утилиты Winzip для Windows и gzip для UNIX. Специальные алгоритмы
сжатия позволяют выполнять распаковку небольшой части сжатого файла; обычно
именно такие алгоритмы применяются в программах снятия данных, чтобы избе-
избежать необходимости полной распаковки всего образа.
Преимущество сжатия состоит в том, что снятая с носителя информация со-
сохраняется в файле образа, имеющем меньший размер, хотя реальная экономия
зависит от характера данных. Впрочем, наряду с преимуществами имеется ряд
недостатков:
• Возможно, ваш выбор будет ограничен аналитическими программами, поддер-
поддерживающими данный формат.
• Снятие данных часто занимает больше времени, потому что программа долж-
должна «на ходу» сжимать обрабатываемые данные.
• Необходимость распаковки изображения при чтении данных замедляет про-
процесс анализа.
Сетевое снятие данных
Файл образа также может создаваться на удаленном компьютере. В этом случае
данные читаются с исходного диска, передаются на приемный хост по сети и за-
записываются в файл. Этот метод снятия данных особенно удобен в ситуациях, ког-
когда вы не можете получить доступ к анализируемому диску или у вас под рукой
пет необходимого адаптера или интерфейса. Многие современные программы
поддерживают сетевой режим как при мертвом, так и при живом снятии данных.
1 Спецификация формата, используемого программой Expert Witness (предшественником EnCase),
находится по адресу: http://www.asrdata.com/SMART/whitepaper.html.
Некоторые программы обеспечивают шифрование для сохранения конфиденци-
конфиденциальности данных в процессе пересылки. Здесь также может пригодиться сжатие
для уменьшения объема данных, передаваемых по медленной сети.
Хеширование и целостность данных
В главе 1 среди основополагающих концепций цифровой экспертизы называ-
называлось хеширование анализируемых данных для последующей проверки их цело-
целостности. Некоторые программы снятия данных вычисляют хеш-коды в процес-
процессе копирования данных, в других случаях приходится использовать отдельную
утилиту. Хеш-коды сохраняются либо во внедренном образе, либо во внешнем
файле, прилагаемом к физическому образу. Внедрение хеш-кодов в образ не
обеспечивает какой-либо дополнительной безопасности или проверки целост-
целостности данных.
Важно понимать, какая же функция отводится хешированию. Хеш-код, хра-
хранящийся в изображении, вовсе не гарантирует, что данные не подвергались по-
посторонним модификациям. В конце концов, если злоумышленник изменил образ,
он мог пересчитать хеш-коды, даже если они внедрены в формат образа. Напи-
Написать соответствующую программу довольно легко. Для проверки целостности
файла образа по хеш-коду потребуется криптографическая цифровая подпись
и доверенный источник. Такое решение сопряжено с основательными непроиз-
непроизводительными затратами; следовательно, гораздо проще сохранить хеш-код на но-
ноутбуке. Если кто-то захочет изменить изображение и пересчитать хеш-код, ему
придется получить доступ к вашему ноутбуку.
Хотя хеширование играет важную роль при будущих проверках целостности
образа, оно также может использоваться для демонстрации точности процесса
снятия данных и отсутствия модификаций исходных данных. Если вычислить
хеш-код диска перед снятием данных и сравнить полученное значение с хеш-
кодом физического образа, можно показать, что физический образ содержит те
же данные, что и исходный диск. В идеальном случае исходный хеш-код должен
вычисляться другой программой независимо от инструментария клонирования,
чтобы одни и те же ошибки не проявлялись в контрольных данных и в получен-
полученном образе.
Учтите, что в процессе хеширования читаются только данные, доступные
для программы. Если из-за аппаратных или программных проблем часть со-
содержимого диска окажется недоступной, хеш-код диска может совпасть с хеш-
кодом файла образа несмотря на то, что файл образа не представляет всего со-
содержимого диска. Например, если программа может прочитать только первые
8 Гбайт 12-гигабайтного диска, она вычислит хеш-код для первых 8 Гбайт, ско-
скопирует первые 8 Гбайт данных и вычислит хеш-код для 8-гигабайтного файла
образа.
Также следует подумать о периодичности вычисления хеш-кодов. Хеширо-
Хеширование чаще всего применяется для выявления изменений в блоках данных. Если
хеш-код показывает, что содержимое блока изменилось, значит, этот блок ис-
использоваться не может. Вычисление хеш-кодов для блоков меньшего размера
снижает последствия от нарушений целостности данных. Если какой-либо блок
данных не проходит проверку целостности, он исключается из дальнейшей
обработки, но остальные части образа вполне могут быть пригодными для ис-
использования.
Практический пример с использованием dd
Чтобы продемонстрировать процесс снятия данных, я опишу методику снятия
данных утилитой dd. Программа dd считается одной из самых простых и гибких
программ снятия данных, но она работает в режиме командной строки, а ее осво-
освоение несколько усложняется богатыми возможностями настройки, dd существует
во многих версиях UNIX, а также в версии для Windows1. В данном примере бу-
будет рассматриваться Linux-версия.
Фактически программа dd копирует блок данных из одного файла и записыва-
записывает его в другой файл. Она не интересуется типом копируемых данных и ничего не
знает о файловых системах и дисках — копируются только файлы.
dd читает данные по блокам; размер блока по умолчанию равен 512 байтам.
Данные читаются из входного источника, заданного флагом if=. Если флаг if= не
указан, программа получает данные из стандартного ввода, которым обычно яв-
является клавиатура. Данные записываются в выходной файл, заданный флагом of=.
При отсутствии параметра данные записываются в стандартный вывод, чаще
всего на экран. В следующем примере файл filel.dat копируется в файл file2.dat
512-байтовыми блоками:
# dd if-filel.dat of-fi1e2.dat bs=512
2+0 records in
2+0 records out
Две последние строки показывают, что два полных блока были прочитаны из
файла fUel.dat и записаны в файл file2.dat. Если при последней операции чтения и
записи использовался неполный блок, последние две строки завершались бы суф-
суффиксом + 1 вместо +0. Например, если бы файл filel.dat содержал 1500 байт вмес-
вместо 1024, результат выглядел бы так:
# dd if«filel.dat of-file2.dat bs=512
2+1 records in
2+1 records out
Обратите внимание: размер выходного файла будет составлять 1500 байт. Про-
Программа dd пытается записывать данные блоками, но если блок заполнен лишь ча-
частично, программа копирует то, что есть.
Источник
В системе Linux для каждого носителя информации и каждого раздела создает-
создается устройство, которое может использоваться в качестве входного файла. На-
Например, главный диск АТА на первом канале представлен устройством/dev/hda;
если указать это имя устройства с флагом if=, программа dd скопирует данные
с диска в файл. В Microsoft Windows для жестких дисков файлы устройств не
1 Версия Джорджа Гарнера (George Garner) находится по адресу: http://users.erols com/gmgarner/
forensics/, а версия UnxUtils — по адресу: http://unxutils.sourceforge net.
создаются но для ссылки на диск можно использовать синтаксис \\.\ — напри-
например, \\.\PhysicalDriveO.
Размер блока по умолчанию составляет 512 байт, но параметр bs= позволя-
позволяет задать произвольное значение. За одну операцию может копироваться как
1 байт, так и 1 гигабайт. Подходит любое значение, но некоторые обеспечивают
более высокое быстродействие по сравнению с остальными. Диски обычно чи-
читают данные блоками по 512 байт, но легко могут читать и больше. Слишком
малые размеры блока неэффективны, потому что они требуют более частых
обращений к диску и приводят к лишним потерям времени в процессе копиро-
копирования. Если же выбранное значение окажется слишком большим, то время бу-
будет тратиться на заполнение буфера dd перед выполнением операции копиро-
копирования. Эксперименты показали, что оптимальные значения лежат в интервале
от 2 до 8 Кбайт.
Linux работает с диском напрямую и не нуждается в услугах BIOS, поэтому
мы не рискуем получить у BIOS неверную информацию о размерах диска. Отсю-
Отсюда также следует, что в Linux невозможна программная блокировка записи, но
при желании вы можете воспользоваться аппаратным устройством.
HPA
Как упоминалось ранее, dd работает только с файлами и ничего не знает о АТА
HPA. В этом разделе будут рассмотрены некоторые способы обнаружения АТА
HPA в Linux.
В сценарии данного примера используется 57-гигабайтный диск, содержащий
120 103 200 секторов. Я поместил в сектор 15 000 строку «here i am»:
# dd itWdef/hdb bs=512 skip=15000 count-1 | xxd
1+0 records in
1+0 records out
00000000: 6865 7265 2069 2061 6d0a 0000 0000 0000 here i am
Затем в последних 120 091 200 секторах была создана область HPA. Другими
словами, на диске остались только 12 000 секторов, доступных для ОС и прило-
приложений. В этом легко убедиться, так как строка в секторе 15 000 стала недоступ-
недоступной:
# dd ifVdef/hdb bs=512 skip-15000 count=l | xxd
0+0 records in
0+0 records out
Записи не были скопированы, потому что программа не смогла прочитать дан-
данные. Возможны различные варианты обнаружения HPA в Linux. Новые версии
Linux выводят сообщения в журнале dmesg. Учтите, что размер журнала ограни-
ограничен, поэтому при выводе большого количества предупреждений или сообщений
об ошибках часть информации будет потеряна. Для нашего диска результат выг-
выглядит так:
# dmesg | less
[REMOVED]
hdb: Host Protected Area detected.
current capacity is 12000 sectors F MB)
native capacity is 120103200 sectors F1492 MB)
Впрочем, это сообщение выводится не во всех версиях Windows. Другой спо-
способ обнаружения HPA основан на использовании программы hdparm, входящей
в поставку Linux. Программа выводит информацию о жестком диске, и для полу-
получения общего количества секторов необходимо указывать флаг -I. Полученное
значение сравнивается со значением, записанным на диск или найденным на сай-
сайте фирмы-производителя. По выходным данным hdparm также можно судить о том,
поддерживает ли диск HPA (у старых дисков поддержка HPA отсутствует).
# hdparm -I /dev/hvb
[REMOVED]
CHS current addressable sectors: 11088
LBA user addressable sectors: 12000
LBA48 user addressable sectors: 12000
[REMOVED]
Commands/features:
Enabled Supported:
* Host Protected Area feature set
В наклейке на моем диске сказано, что диск содержит 120 103 200 секторов;
следовательно, многие секторы оказались недоступными для адресации. Нако-
Наконец, можно воспользоваться утилитой diskstat из пакета The Sleuth Kit. Утилита
отображает максимальный фактический адрес и максимальный адрес, доступный
для пользователя:
# diskstat /dev/hdb
Maximum Disk Sector: 120103199
Maximum User Sector: 11999
** HPA Detected (Sectors 12000 - 120103199) **
Для обращения к данным необходимо сбросить ограничения доступа. Одной
из программ, которая позволяет это сделать, является утилита setmax (http://
www.win.tue.nl/~aeb/linux/setmax.с). Мы запускаем setmax и задаем максимальное
количество секторов на диске, то есть 120 103 200 для данного примера. Утилита
изменяет конфигурацию жесткого диска, поэтому при работе с ней необходима
крайняя осторожность (в частности, следует тщательно документировать все вы-
выполняемые действия). Также учтите, что программа не поддерживает временное
изменение максимального адреса, так что вносимые изменения являются посто-
постоянными. Если вы намерены использовать подобную программу, сначала протес-
протестируйте ее на других дисках и только потом переходите к диску, который может
содержать ценную информацию:
# setmax --max 120103200 /dev/hdb
После сброса ограничений максимального адреса программа dd может ис-
использоваться для снятия информации со всего диска. Запишите размер HPA;
это позволит вам вернуть диск в исходное состояние, с которого начинался ана-
анализ данных.
Приемник
Выходные данные dd направляются либо в новый файл, либо на другое устрой-
устройство хранения информации. Например, следующие два примера выполняются
в среде Linux. Первый пример копирует в файл содержимое ведущего диска АТА
на первичном канале, а второй пример копирует содержимое того же диска на
ведомый диск АТА на втором канале:
# dd if=/dev/hda of=/mnt/hda.dd bs=2k
# dd if=/dev/hda of=/dev/hdd bs=2k
Если выходной файл не указан, данные выводятся на экран. Эта информация
может использоваться для вычисления хеш-кодов MD5, извлечения ASCII-строк
или отправки данных на удаленную систему по сети. Например, для хеширова-
хеширования диска можно воспользоваться командой md5sum из поставки Linux:
# dd if=/dev/hda bs=2k | md5sum
Передача данных на сервер также может осуществляться программой netcat
(http://www.atstake.com/research/tools/) или cryptcat (http://sf.net/projects/cryptcat).
В примере для netcat на доверенном сервере с IP-адресом 10.0.0.1 выполняется
следующая команда для открытия сетевого порта 7000 и сохранения входящих
данных в файле:
# пс -1 -р 7000 > disk.dd
Система с исходным диском загружается с надежного компакт-диска Linux.
На ней выполняется команда dd с конвейерной передачей данных программе netcat,
передающей данные серверу 10.0.0.1 на порт 7000. При отсутствии активности
подключение закрывается через три секунды:
# dd if=/dev/hda bs=2k | nc -w 3 10.0.0.1 7000
Обработка ошибок
Если во время чтения входного файла dd обнаруживает ошибку, по умолчанию
копирование данных прерывается. Если в командной строке присутствует пара-
параметр conv=noerror, программа выводит сообщение об ошибке и продолжает рабо-
работу. К сожалению, в этом случае поврежденные блоки пропускаются, образ имеет
неверный размер, а данные располагаются по искаженным адресам.
Для сохранения адресов в образе необходимо использовать флаг sync, застав-
заставляющий dd записывать данные в блочном режиме. Если данных недостаточно для
заполнения целого блока, данные дополняются нулями. Таким образом, при об-
обнаружении ошибки недействительные данные будут заменены нулями. Недостаток
такого решения заключается в том, что полученный образ всегда будет кратным
размеру блока, что может не соответствовать фактическому размеру исходного
носителя информации. Например, если я выберу размер блока равным 4 096 байт,
но размер моего (совсем крошечного) диска составляет 6 144 байта, размер файла
образа будет равен 8 192 байта вместо 6 144. Пример командной строки dd с обра-
обработкой ошибок:
# dd if=/dev/hda of=hda.dd bs=2k conv=noerror,sync
Программа dd_rescue, автором которой является Курт Гарлофф (Kurt Garloff)
(http://www.garloff.de/kurt/linux/ddrescue), похожа на исходную версию dd, но ре-
режим обработки ошибок включен в ней по умолчанию. Обнаружив ошибку, про-
программа переходит на меньший размер блока и заполняет нулями блоки, кото-
которые не удалось прочитать. Программа dd_rescue также умеет копировать данные
от конца диска к началу — автор утверждает, что это может быть полезно при на-
наличии поврежденных секторов.
Криптографическое хеширование
Как правило, для выполнения криптографического хеширования файла при
использовании dd приходится пользоваться услугами другой программы (такой,
как md5sum). Криптографический хеш-код образа вычисляется для последующей
проверки его целостности. Джессе Корнблум (Jesse Kornblum) и Рейд Литцов
(Reid Leatzow) из Центра киберпреступности Министерства обороны США
создали версию dd с хешированием копируемых данных. В настоящее время
существует две версии этой утилиты. Исходная версия dcfldd (http://source-
forge.net/projects/biatchux) вычисляет только хеш-коды по алгоритму MD5.
Новая версия dccidd (http://www.dc3.gov; также можно отправить сообщение
электронной почты по адресу: dcci@dc3.gov) умеет параллельно вычислять хеш-
коды MD5, SHA-1 и SHA-256. Переименование программы связано с реорга-
реорганизацией лаборатории.
В этих программах работают те же базовые параметры, которые описывались
ранее для dd. Кроме того, были добавлены новые параметры хеширования. Пара-
Параметр hashwindow= задает частоту вычисления хеш-кода. Если значение равно 0, то
для всего файла вычисляется один хеш-код. Если значение параметра представляет
собой число байтов, отличное от нуля, то программа вычисляет промежуточные
хеш-коды на заданном расстоянии, а затем вычисляет итоговый хеш-код. Хеш-
коды сохраняются в файле, заданном параметром hashlog=. Программа dcfLdd под-
поддерживает только алгоритм MD5, но dccidd поддерживает параметр hash= для оп-
определения алгоритма хеширования. По умолчанию выполняется параллельное
хеширование MD5 и SHA-1, но вы можете задать значение md5, shal или sha256.
Например, следующая команда создает образ жесткого диска Linux с вычисле-
вычислением хеш-кода через каждые 1 Мбайт:
# dcfldd if=/dev/hda of=/mnt/hda.dd bs=2k hashwindow=lM hashlog=/mnt/hda.hashes
Журнал хеш-кодов имеет следующий формат:
О - 1048576: 97O653da48fO47f3511196c8a23Of64c
1048576 - 2097152: b6d81b360a5672d80c27430f39153e2c
103809024 - 104857600: b6d81b360a5672d80c27430f39153e2c
104857600 - 105906176: 94al71ec3908687fdlf456087576715b
Total: 28dd34393f36958f8fc822ae39800f37c3
Строка начинается с диапазона байтов, для которого вычисляется хеш-код,
и завершается значением хеш-кода. Последнее значение представляет собой хеш-
код всего образа. Файл журнала dccidd имеет несколько иную структуру: в него
включается хеш SHA-1, а поле диапазона дополняется нулями. Приведу фраг-
фрагмент файла с окном хеширования, равным 512 байтам (хеши SHA-1 и MD5 обыч-
обычно выводятся в одной строке):
000000 - 000511: 5dbdl21cad07429edl76f7fac6al33d6
09cae0d9f2a387bb3436al5aa514bl6f9378efbf
000512 - 001023: 91cf74d0ee95d4b60197e4c0ca710be4
0f71d8729ad39ae094e235ab31a9855b2a5a5900
001024 - 001535: 8a0al0f43b2bcd9el385628f7e3a8693
641b9b828e41cd391f93b5f3bfaf2dlb7b393da0
Упоминавшаяся ранее Windows-версия dd Джорджа Гарнера также содержит
встроенную поддержку MD5. При передаче ключа -md5sum программа Гарнера
хеширует файл по алгоритму MD5. Результат хеширования сохраняется в файле
при помощи ключа -md5out
Итоги
В современных цифровых расследованиях большинство улик находится именно
на жестких дисках. Вероятно, ситуация сохранится в течение многих лет (по
крайней мере до тех пор, пока содержимое всех жестких дисков не будет шифро-
шифроваться). Снятие данных играет важную роль в процессе расследования: если оно
выполняется некорректно, вы можете лишиться данных для расследования. В этой
главе была представлена общая теория клонирования данных и рассмотрен прак-
практический пример использования dd. Программа относительно проста, но она ра-
работает в режиме командной строки, а обилие параметров может создать путаницу.
Библиография
• МуКеу Technology, Inc. «Technical White Paper: No Write Design Notes.» 2003.
https://mykeytech.com/nowritepaperl.htmL
• Skoudis, Ed, and Lenny Zeltser. Malware: Fighting Malicious Code. Upper Saddle
River: Prentice Hall, 2004.
• Technology Pathways, Inc. «ProDiscover Image File Format». 2003. https://
www.techpathways.com/uploads/P{roDiscoverImageFi leFormatv4.pdf.
• U.S. Department of Justice. «Test Results for Disc Imaging Tools: SafeBack 2.18»
NCJ 200032, June 2003. https://www.ncjrs.org/pdffilesl/nij/20032.pdf.
ЧАСТЬ II
Анализ томов
Глава 4. Анализ томов 82
Глава 5. Разделы на персональных компьютерах 93
Глава 6. Разделы в серверных системах 117
Глава 7. Многодисковые тома 143
Анализ томов
Настоящая глава открывает вторую часть книги, посвященную анализу томов.
Процесс анализа томов включает просмотр структур данных, задействованных
в определениях разделов, и сборку байтов на носителях информации для форми-
формирования томов. Тома (volumes) используются для хранения файловых систем
и других структурированных данных, которые будут описаны в третьей части кни-
книги, «Анализ файловых систем». В этой главе основные концепции анализа томов
рассматриваются с абстрактных позиций: изложенные в ней принципы примени-
применимы ко всем типам томов. Следующие три главы будут посвящены конкретным
типам разделов и систем формирования томов.
Введение
Цифровые носители информации особым образом структурируются для обеспе-
обеспечения эффективной выборки данных. Пользователи чаще всего сталкиваются
с системой томов при установке Microsoft Windows и созданием разделов на жес-
жестком диске. Процесс установки руководит действиями пользователя при созда-
создании разделов (основного и логических), и в конечном итоге на компьютере появ-
появляется список «дисков» или «томов» для хранения данных. Аналогичный процесс
происходит и при установке операционной системы UNIX. В наше время при хра-
хранении больших объемов информации все чаще применяются программы управ-
управления томами, благодаря которым несколько дисков интерпретируются как один
большой диск.
Во время цифрового следствия чаще всего снимается полный образ диска, ко-
который затем импортируется в аналитическую программу. Многие инструменты
цифровой экспертизы автоматически разбивают образ диска на разделы, но иног-
иногда у них возникают проблемы. Концепции, представленные в этой части книги,
помогут эксперту во всех подробностях понять, что делает программа и почему
при повреждении диска возникают те или иные проблемы (например, если раз-
раздел на диске был удален или модифицирован подозреваемым либо программа про-
просто не может найти раздел). Материал этой части также пригодится при анализе
содержимого секторов, не принадлежащих ни одному разделу.
Настоящая глава также содержит теоретические обоснования, краткий об-
обзор программных инструментов и разновидностей методов анализа. В следую-
следующих двух главах более подробно рассматриваются некоторые схемы разделов,
включая разделы DOS, Apple Partitions, разделы BSD и сегменты (slices) SUN.
Последняя глава посвящена распределенным дисковым томам, таким как RAID
и disk spanning.
Общие положения
Концепция тома
Многотомные системы основаны на двух основных концепциях. Первая — это
объединение нескольких томов в единое целое, а вторая — разбиение томов на
независимые разделы. Термины «раздел» (partition) и «том» (volume) часто ис-
используются как синонимы, но я буду различать эти понятия.
Томом называется совокупность адресуемых секторов, которые могут исполь-
использоваться операционной системой (ОС) или приложением для хранения данных.
Секторы тома не обязаны храниться в смежных блоках физического носителя,
хотя при использовании томов может возникнуть такое впечатление. Примером
тома, хранящегося в смежных секторах, служит жесткий диск. Том также может
представлять собой результат объединения и слияния томов меньшего размера.
Общая теория разделов
Одной из важнейших концепций систем с использованием томов является созда-
создание разделов. Разделом называется совокупность смежных секторов на диске. По
определению раздел также является томом, поэтому эти термины часто путают. Я
буду называть том, которому принадлежит раздел, родительским томом этого раз-
раздела. Разделы используются во многих ситуациях, в том числе:
• в некоторых файловых системах максимальный размер меньше размера жест-
жесткого диска;
• на многих портативных компьютерах создается специальный раздел для хра-
хранения содержимого памяти при переходе компьютера в спящий режим;
• в системах UNIX разные каталоги хранятся в разных разделах, чтобы свести
к минимуму последствия от возможной порчи файловой системы;
• в системах на базе IA-32 с несколькими операционными системами (напри-
(например, Microsoft Windows и Linux) для каждой операционной системы может
потребоваться свой раздел.
Рассмотрим систему Microsoft Windows с одним жестким диском. Том жест-
жесткого диска делится на три тома меньшего размера, в каждом из которых имеется
своя файловая система. Windows присваивает этим томам имена С, D и Е (рис. 4.1).
Каждая операционная система и аппаратная платформа обычно использует
свой метод создания разделов. Некоторые варианты реализации описаны в гла-
главах 5 и 6, но сейчас мы познакомимся с основными компонентами. Типичная си-
система разделов содержит одну или несколько таблиц, при этом каждая запись таб-
таблицы описывает один раздел. В данных записи обычно указывается начальный
сектор раздела, конечный сектор раздела (или длина) и тип раздела. На рис. 4.2
показан пример таблицы с тремя разделами.
Рис. 4.2. Таблица с информацией о начале, конце и типе каждого раздела
Система разделов предназначена для логической организации структуры тома;
следовательно, действительно необходимы только данные о начале и конце каж-
каждого раздела. Если эти данные будут повреждены или пропадут, система разделов
не сможет выполнять свои функции. Все остальные поля (например, тип и описа-
описание) несущественны и могут содержать ложную информацию.
Как правило, первый и последний секторы раздела не содержат никаких при-
признаков, по которым их можно было бы идентифицировать как граничные секто-
секторы. Ведь границы земельных участков тоже обычно не помечаются на местности.
Для определения точного положения границ необходим инспектор и документа-
документация (аналог структур данных разделов). Если структуры данных разделов отсут-
отсутствуют, границы иногда удается восстановить, если вы знаете, какая информация
хранится в разделе. Можно провести аналогию с восстановлением границ участ-
участков по особенностям местности.
Помните, что система разделов зависит от операционной системы и не имеет
отношения к типу интерфейса жесткого диска. Таким образом, система Windows
использует одну систему разделов как для дисков с интерфейсом АТА, так и для
дисков SCSI.
Использование томов в UNIX
Системы UNIX работают с томами не так, как Windows. Этот раздел предназна-
предназначен для пользователей, незнакомых с UNIX; в нем приводится краткий обзор ис-
использования томов в UNIX. За дополнительной информацией следует обратить-
обратиться к системному администратору UNIX.
В UNIX пользователь работает не с «дисками» С:, D: и т. д., а с набором ката-
каталогов, иерархия которых начинается с корневого каталога/. Подкаталоги/являют-
Подкаталоги/являются либо подкаталогами той лее файловой системы, либо точками монтирования
для новых файловых систем и томов. Например, дисководу CD-ROM в Windows
может быть присвоено обозначение Е:, но в Linux он может монтироваться под
именем /mnt/cdrom. В результате простое переключение между каталогами может
приводить к переходу с диска на диск, причем пользователь в большинстве слу-
случаев даже и не подозревает об этом. На рис. 4.3 показано, как организован доступ
к жестким дискам и компакт-дискам в Windows и UNIX.
Рис. 4.3. Точки монтирования двух томов и диска CD-ROM (A) — Microsoft Windows,
и (В) — в типичной системе UNIX
Чтобы свести к минимуму последствия от повреждения дисков, а также по-
повысить эффективность, UNIX обычно разбивает разделы каждого диска на не-
несколько томов. В томе корневого каталога (/) хранится основная информация;
отдельный том может существовать для домашних каталогов пользователей (/
home/), а приложения могут находиться в отдельном томе (/usr/). Однако все
системы уникальны, и в них могут использоваться совершенно различные схе-
схемы формирования и монтирования томов. В некоторых системах используется
один большой том для корневого каталога, а сегментирование системы отсут-
отсутствует.
Общая теория объединения томов
В крупных системах используются средства объединения томов, благодаря кото-
которым несколько дисков выглядят как один. В частности, это может делаться для
введения избыточности на случай сбоя диска. Если данные записываются на не-
несколько дисков, то в случае сбоя одного из дисков будет существовать резервная
копия. Другая возможная причина — простота добавления новых носителей. В ре-
результате объединения создается один большой том, пространство памяти которо-
которого включает пространства всех составляющих томов. Добавление новых дисков
в объединенный том не влияет на существующие данные. Эта методика будет рас-
рассматриваться в главе 7.
Рассмотрим простой пример. На рис. 4.4 изображены два тома жестких дис-
дисков, которые в сумме содержат три раздела. Разделу 1 присваивается имя тома С:,
а разделы 2 и 3 обслуживаются специальным устройством. Устройство формирует
из них один большой том, разбитый на два раздела, которым присвоены имена
томов. Учтите, что в данном случае устройство не повышает надежности хране-
хранения данных, а лишь увеличивает размер тома.
Рис. 4.4. Два раздела объединяются в один том с последующим разбиением
Адресация секторов
В главе 2 обсуждались методы адресации секторов. В самом распространенном
методе используются адреса LBA, которые представляют собой последователь-
последовательные числа, начиная с 0 (первый сектор диска). Этот адрес называется физическим
адресом сек гора.
Том представляет собой совокупность секторов, и каждому сектору необходи-
необходимо присвоить адрес. Абсолютным логическим адресом называется адрес сектора
относительно начала тома. Поскольку диск по определению является томом, фи-
физический адрес может рассматриваться как абсолютный логический адрес для дис-
дискового тома. Начало и конец раздела обычно задаются с использованием абсо-
абсолютных логических адресов.
Когда речь заходит о содержимом разделов, появляется еще один уровень ло-
логической адресации томов. Эти адреса задаются по отношению к началу раздела,
а не к началу диска или родительского тома и называются относительными логи-
логическими адресами. Если сектор не принадлежит ни одному разделу, он не имеет
относительного логического адреса. На рис. 4.5 показан пример с двумя раздела-
разделами и нераспределенным пространством между ними. Первый раздел начинается
с сектора 0, поэтому абсолютные логические адреса разделов в нем совпадают с от-
относительными логическими адресами. Второй раздел начинается с физического
сектора 864, поэтому абсолютные логические адреса в нем на 864 сектора больше
соответствующих относительных.
Рис. 4.5. Относительные логические адреса отсчитываются
от начала раздела, а абсолютные — от начала диска
Основы анализа
Задача анализа томов возникает достаточно часто, хотя это и не всегда очевидно.
Во многих случаях эксперт снимает информацию со всего жесткого диска и им-
импортирует образ в аналитическую программу для просмотра содержимого файло-
файловой системы. Чтобы определить, где начинается и заканчивается файловая систе-
система, программа должна проанализировать таблицы разделов.
У анализа структуры разделов томов имеется еще одно важное применение:
некоторые секторы, не принадлежащие ни одному разделу, могут содержать дан-
данные из предыдущей файловой системы или другую информацию, которую
подозреваемый пытается скрыть. Иногда система разделов может оказаться
поврежденной или стертой, и тогда средства автоматизированного анализа рабо-
работать не будут.
Методы анализа
Базовый принцип анализа томов прост: мы хотим найти таблицы разделов, обра-
обработать их и узнать структуру диска. Затем полученные данные передаются про-
программе анализа файловой системы, которой необходимо знать смещение разде-
разделов, или выводятся на печать, чтобы пользователь мог выбрать данные для анализа.
В некоторых случаях данные, находящиеся в разделах или в пространстве между
разделами, приходится извлекать из родительского тома (см. далее). Для анализа
данных в разделах необходимо решить, к какому типу они относятся. Чаще всего
это данные файловых систем, которые будут рассматриваться в третьей части
книги.
Чтобы проанализировать компоненты системы томов, необходимо найти и об-
обработать структуры данных с информацией об объединяемых томах и о том, как
именно это делается. Как будет показано в главе 7, существует много способов
объединения томов. Мы займемся поиском данных, не используемых в процессе
объединения и содержащих информацию от предыдущей установки или скры-
скрытую.
Проверка целостности
При анализе систем томов бывает полезно проверить каждый раздел по отношению
к другим разделам. Возможно, результат выявит другие возможные местоположе-
местоположения улик, не принадлежащих ни одному разделу. Системы разделов чаще всего не
требуют, чтобы записи хранились в отсортированном порядке, поэтому перед про-
проведением проверки вы или ваша аналитическая программа можете отсортировать
их по адресу начального или конечного сектора.
Проверки первого типа находят последний раздел и сравнивают его конечную
границу с концом родительского тома. В идеальном случае последний раздел за-
завершается в последнем секторе тома. На рис. 4.6 (А) изображена ситуация, при
которой последний раздел заканчивается перед концом тома, и на томе могут ос-
оставаться секторы со скрытыми или удаленными данными.
Проверки второго типа сравнивают начальный и конечный секторы смежных
разделов; возможны четыре варианта. В первом варианте (рис. 4.6 (В)) между дву-
двумя разделами находятся секторы, не входящие ни в один из них. Секторы, не при-
принадлежащие к разделам, могут содержать скрытую информацию, поэтому их обя-
обязательно необходимо проанализировать. Второй вариант (рис. 4.6 (С)) встречается
практически во всех системах; второ.й раздел здесь начинается сразу же после пер-
первого.
Рис. 4.6. Пять вариантов взаимного расположения разделов.
Первые три варианта допустимы, последние два — нет
Третий вариант (рис. 4.6 (D)), при котором второй раздел начинается раньше
завершения первого, в общем случае недопустим. Секторы двух разделов пере-
перекрываются, что, как правило, свидетельствует о повреждении таблицы разделов.
Чтобы определить, какие разделы допустимы (и есть ли они вообще), необходи-
необходимо проанализировать данные в каждом разделе. Четвертый вариант показан на
рис. 4.6 (Е); как правило, он тоже недопустим. Второй раздел находится внутри
первого, и для определения ошибки необходимо проанализировать содержимое
обоих разделов.
Получение содержимого разделов
Некоторые программы в качестве входных данных должны получать образы разде-
разделов. А может быть, вам потребуется извлечь данные из разделов (или промежуточно-
промежуточного пространства) в отдельный файл. В этом разделе будет показано, как произво-
производится выборка данных, а описанные методы работают во всех системах разделов.
Если структура разделов известна, выборка данных становится несложным делом.
Вы уже знаете, как это сделать при помощи программы dd, ранее описанной в главе 3.
Программа dd работает в режиме командной строки, а при вызове ей передает-
передается ряд аргументов. Для получения данных из разделов потребуются следующие
параметры:
• if — образ, из которого читаются данные;
• of — выходной файл для сохранения данных;
• bs — размер читаемого блока E12 байт по умолчанию);
• skip — количество блоков (размера bs), пропускаемых перед чтением;
• count — количество блоков (размера bs), копируемых из ввода в вывод.
Чаще всего выбирается размер блока 512 байт, совпадающий с размером сек-
сектора. По умолчанию размер блока в dd тоже равен 512 байтам, но всегда надежнее
указать его явно. Мы воспользуемся параметром skip для указания начального
сектора, в котором начинается раздел, и параметром count для указания количе-
количества секторов в разделе.
Рассмотрим пример системы разделов на базе DOS. Утилита mmls из пакета
The Sleuth Kit выводит содержимое таблицы разделов. Ее выходные данные бу-
будут более подробно описаны далее, но даже сейчас нетрудно понять, что на диске
существуют три раздела файловых систем:
# mmls -t dos diskl.dd
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0000000000 0000000001 Table #0
01: 0000000001 0000000062 0000000062 Unallocated
02: 00:00 0000000063 0001028159 0001028097 Win95 FAT32 (OxOB)
03: 0001028160 0002570399 0001542240 Unallocated
04: 00:03 0002570400 0004209029 0001638630 OpenBSD @xA6)
05: 00:01 0004209030 0006265349 0002056320 NTFS @x07)
Утилита mm Ls упорядочивает содержимое таблицы разделов по начальному сек-
сектору и выделяет секторы, не принадлежащие ни одному разделу. Первые две стро-
строки @0 и 01) описывают основную таблицу разделов и неиспользуемое простран-
пространство между таблицей разделов и первым разделом. Из листинга видно, что строка
02 определяет раздел с файловой системой FAT32, строка 04 относится к разделу
OpenBSD, а строка 05 — к разделу с файловой системой NTFS. Строка 03 обозна-
обозначает нераспределенное дисковое пространство. Графическое представление этих
данных показано на рис. 4.7.
Чтобы извлечь разделы файловых систем из образа диска, следует отметить
начальный сектор и размер каждого раздела и передать их dd:
# dd if-diskl.dd of-partl.dd bs=512 skip=63 count=1028097
# dd if-diskl.dd of=part2.dd bs=512 skip=2570400 count=1638630
# dd if=diskl.dd of=part3.dd bs=512 skip=4209030 count=2056320
Рис. 4.7. Структура образа диска из примера
Эти команды берут входные данные из файла diskl.dd и сохраняют вывод в фай-
файлах с именами parti.dd, part2.dd и part3.dd. Во всех случаях размеры копируемых
блоков составляют 512 байт. Перед извлечением первого раздела dd пропускает
64 блока, а затем копирует следующие 1 028 097 блоков. В выходных данных mm ls
мы видели, что раздел начинается с сектора 63, поэтому вроде бы пропускать нужно
только 62 блока. Однако следует вспомнить, что адресация секторов начинается
с 0, поэтому мы пропускаем 63. Расширение .dd указывает на то, что файлы содер-
содержат физические образы, созданные программой dd или ее аналогом.
Некоторые программы выводят только начальный и конечный секторы каж-
каждого раздела, а размер разделов приходится вычислять самостоятельно. Для это-
этого следует вычесть начальный сектор из конечного и прибавить 1 (вычитание оп-
определяет расстояние между двумя числами, но в нашем случае последнее число
необходимо включить в результат). Например, в предыдущем примере размер пер-
первого раздела составит
1028159 - 63 + 1 - 1028097
Чтобы понять, для чего нужно прибавлять 1, рассмотрим простой пример: раз-
раздел начинается с сектора 2 и заканчивается в секторе 4. Его размер равен 3 секто-
секторам:
4-2+1 = 3
Программа dd также может использоваться для выборки данных, находящих-
находящихся между разделами. Например, из выходных данных mm ls мы знаем, что секторы
с 1 028 160 по 2 570 399 не используются. Их содержимое извлекается командой
# dd if«diskl.dd of-unallocl.dd bs=512 skip=1028160 count=1542240
Другие низкоуровневые программы (такие, как шестнадцатеричные редакто-
редакторы) также предоставляют возможность сохранения последовательных секторов
в файлах.
Восстановление удаленных разделов
Желая помешать цифровой экспертизе, злоумышленники часто заново разбива-
разбивают диск на разделы или стирают информацию о существующих разделах. Похожая,
но более безобидная проблема возникает при восстановлении системы с повреж-
поврежденными структурами разделов. В таких ситуациях анализ заметно усложняется.
К счастью, существует несколько программ, упрощающих восстановление разде-
разделов. В этом разделе будет рассказано, как работают эти программы.
Средства восстановления разделов исходят из предположения, что в каждом
разделе находилась файловая система. Многие файловые системы начинаются со
структуры данных с постоянной сигнатурой. Например, файловая система FAT
содержит значения 0x55 и ОхАА в байтах 510 и 511 первого сектора. Программа
восстановления ищет сигнатуры и определяет по ним возможное начало раздела.
При обнаружении сигнатуры часто выполняются дополнительные проверки
с диапазонами значений, допустимых для некоторых полей структуры данных.
Например, одно из полей файловой системы FAT определяет количество секто-
секторов в кластере; значение поля представляет собой степень 2 (например, 1, 2, 4, 8,
16, 32, 64 или 128). Любое другое значение свидетельствует о том, что сектор не
является частью загрузочного сектора файловой системы FAT, хотя он и закан-
заканчивается сигнатурой 0х55АА.
Механизм поиска зависит от конкретной программы. Одни программы про-
просматривают каждый сектор и сравнивают его содержимое с известными сигнату-
сигнатурами. Другие анализируют данные только на границах цилиндров, потому что
разделы чаще всего создаются именно там. Третьи по данным служебных струк-
структур определяют размер файловой системы и переходят к ее концу, где продолжа-
продолжают поиск других известных структур данных.
Например, в системе Linux для восстановления разделов применяется програм-
программа gpart (http://www.stud.uni-hannover.de/user/76201/gpart/). Программа gpart спо-
способна идентифицировать несколько файловых систем, для чего она проверяет со-
содержимое секторов и делает выводы относительно того, какая система является
наиболее вероятной.
Ее стандартный вывод содержит слишком мало информации для наших целей,
поэтому в командную строку следует включить флаг -v. В следующем примере на
диске находится три раздела, однако таблица разделов была стерта. Программа
gpart была запущена для физического образа диска с флагом -v для определения
границ исходных секторов:
# gpart -v disk2.dd
* Warning: strange partition table magic 0x0000.
Begin scan...
Possible partition(DOS FAT). size(800mb), offset(Omb)
type: 006@x06)(Primary 'big' DOS (>32MB))
size: 800mb #sA638566) sF3-1638628)
chs: @/l/l)-A01/254/62)d @/1/1)-A01/254/62)г
hex: 00 01 01 00 06 FE 3E 65 3F 00 00 00 A6 00 19 00
Possible partition(DOS FAT). size(917mb). offset(800mb)
type: 006@x06)(Primary 'big1 DOS (>32MB))
size: 917mb #sA679604) sA638630-3518233)
chs: A02/0/1)-B18/254/62)d A02/0/1)-B18/254/62)г
hex: 00 00 01 66 06 FE 3E DA E6 00 19 00 34 AE 1С 00
Possible partitiondinux ext2). sizeE02mb). offsetA874mb)
type: 131@x83)(Linux ext2 filesystem))
size: 502mb #sA028160) sC839535-4867694)
chs: B39/0/1)-C02/254/63)d B39/0/1)-C02/254/63)r
hex: 00 00 01 EF 83 FE 7F 2E 2F 96 ЗА 00 40 ВО OF 00
Из результатов видно, что на диске, по всей вероятности, существовало два
раздела FAT и один раздел Ext2. Поле в конце строки size: показывает местона-
местонахождение раздела в секторах. Если бы флаг -v не был задан, то эта информация не
выводилась бы. Другая аналогичная утилита — TestDisk Кристофа Гренье (Christophe
Grenier) (http://www.cgsecurity.org/testdisk.html). Помните, что автоматизирован-
автоматизированное восстановление работает только при простейшем удалении или повреждении
таблицы разделов.
Итоги
Все носители информации большого объема содержат некоторую разновидность
системы томов, которая анализируется при каждом расследовании (даже если это
не очевидно). Системы томов предназначены для логической организации носи-
носителей, а системы разделов описывают начало и конец каждого раздела. В этой
главе был приведен общий обзор технологии, а в следующей главе мы подробно
рассмотрим несколько систем создания разделов и томов.
Разделы
на персональных
компьютерах
В предыдущей главе был приведен общий обзор анализа томов и показано, поче-
почему он так важен. Теперь от абстрактного обсуждения томов мы перейдем к под-
подробностям систем разделов, используемых на персональных компьютерах. В этой
главе будут рассматриваться разделы DOS, разделы Apple и съемные носители.
Для каждой системы будут описаны основные принципы работы и структуры дан-
данных. Если вас не интересуют подробности структур данных, эти описания можно
пропустить. В главе также перечислены некоторые особые обстоятельства, кото-
которые необходимо учитывать при анализе разделов в этих системах. Следующая
глава будет посвящена системам формирования разделов на серверах.
Разделы в DOS
Наибольшее распространение получила система разделов DOS. Разделы DOS в те-
течение многих лет использовались на платформе Intel IA32 (то есть i386/x86), од-
однако официальная спецификация до сих пор отсутствует. Существует много до-
документов (опубликованных как Microsoft, так и сторонними источниками), но
стандартного описания нет.
Более того, нет не только стандартного описания, но pi стандартного названия.
Компания Microsoft называет диски с подобным типом системы разделов диска-
дисками MBR (Master Boot Record) — в отличие от дисков GPT(GUID Partition Table),
используемых в системах EFI (Extensible Firmware Interface) и 64-разрядных сис-
системах на базе Intel Itanuim (IA64), о которых речь пойдет в следующей главе
[Microsoft, 2004a]. Начиная с Windows 2000, компания Microsoft также ввела раз-
различия между базовыми и динамическими дисками. Базовым может быть диск MBR
или GPT, при этом разделы диска независимы и автонохмны. Динамические дис-
диски, рассматриваемые в главе 7, могут быть дисками MBR или GPT, а их разделы
могут объединяться в один раздел большего размера. Базовые диски традицион-
традиционно ассоциируются с разделами DOS, а диски GPT еще не получили широкого рас-
распространения. Таким образом, если пользоваться современной терминологией,
в этой главе будут рассматриваться базовые диски MBR. Тем не менее в книге
для краткости будет использоваться термин «разделы DOS».
Разделы DOS применяются в Microsoft DOS, Microsoft Windows, Linux и в сис-
системах FreeBSD и OpenBSD на платформе IA32. Эта система получила наибольшее
распространение, но она же оказалась наиболее сложной. Дело в том, что система
проектировалась в 1980-х годах для малых систем, а потом постепенно адаптиро-
адаптировалась для больших современных систем. Фактически в ней задействованы два
разных метода определения разделов. Далее приводится общая характеристика
системы и ее основных структур данных, представлены программы сбора инфор-
информации о разделах на диске, а также некоторые соображения, которые должны учи-
учитываться при анализе.
Общий обзор
Здесь будут представлены основные концепции разделов DOS и системные обла-
области с загрузочным кодом, а структуры данных будут описаны далее.
Основные концепции MBR
В первом 512-байтовом секторе диска, на котором создана структура разделов
DOS, хранится основная загрузочная запись MBR (Master Boot Record). MBR
содержит загрузочный код, таблицу разделов и сигнатуру. Команды загрузочного
кода сообщают компьютеру, как обработать таблицу разделов и где находится опе-
операционная система. Таблица разделов содержит четыре записи, каждая из кото-
которых может описывать один раздел DOS. Записи состоят из следующих полей:
• начальный адрес CHS;
• конечный адрес CHS;
• начальный адрес LBA;
• конечный адрес LBA;
• количество секторов в разделе;
• тип раздела;
• флаги.
Запись таблицы описывает местонахождение раздела в адресах CHS и LBA.
Помните, что адреса CHS применимы только для дисков менее 8 Гбайт, тогда как
адреса LBA позволяют использовать диски, размер которых исчисляется в тера-
терабайтах (Тбайт).
Поле типа определяет тип данных, хранящихся в разделе: например, FAT, NTFS
или FreeBSD. Далее будет приведет более полный список. Использование поля
типа зависит от операционной системы. Скажем, Linux не обращает на него вни-
внимания — файловую систему FAT можно разместить в разделе с типом NTFS, и она
будет смонтирована как FAT. С другой стороны, Microsoft Windows учитывает
значение этого поля и не пытается смонтировать файловую систему в раздел, если
соответствующий тип раздела не поддерживается. Таким образом, если диск со-
содержит файловую систему FAT в разделе с типом файловой системы Linux, пользо-
пользователь не увидит эту файловую систему FAT в Windows. Данная особенность
иногда применяется для скрытия разделов в Windows. Например, некоторые про-
программы добавляют лишний бит к типу раздела, поддерживаемому Windows, что-
чтобы раздел не отображался при повторной загрузке системы.
Каждая запись также содержит флаг, который указывает, является ли раздел
«загрузочным». По этому флагу определяется местонахождение операционной
системы при загрузке компьютера. Используя четыре записи в MBR, можно опи-
описать простую структуру диска, содержащего не более четырех разделов. На рис. 5.1
показан пример диска с двумя разделами и MBR в первом секторе.
Рис. 5.1. Простой диск DOS с двумя разделами и MBR
Концепция расширенного раздела
MBR позволяет описать до четырех разделов. Тем не менее во многих системах
этого количества недостаточно. Допустим, имеется 12-гигабайтный диск, кото-
который пользователь хочет разделить на шесть 2-гигабайтных разделов, потому что
он использует несколько операционных систем. Описать шесть разделов при по-
помощи четырех записей невозможно.
Именно тот способ, который был выбран для решения этой проблемы, делает
разделы DOS такими сложными. Общий принцип состоит в следующем: в MBR
создается одна, две или три записи для обычных разделов, а затем формируется
«расширенный раздел», заполняющий все оставшееся место на диске. Прежде чем
двигаться дальше, стоит разобраться с некоторыми терминами. Первичным разде-
разделом файловой системы называется раздел, представленный записью в MBR и со-
содержащий файловую систему или другие структурированные данные. Первичным
расширенным разделом называется раздел, представленный записью в MBR и со-
содержащий вторичные разделы. На рис. 5.2 изображены три первичных раздела
файловой системы с одним первичным расширенным разделом.
Рис. 5.2. Диск DOS с тремя первичными разделами файловой системы
и одним первичным расширенным разделом
Чтобы понять, как устроен первичный расширенный раздел, придется забыть
практически все, о чем говорилось до настоящего момента. В MBR мы видели
централизованную таблицу с описанием нескольких разделов; теперь мы видим
связанный список разделов. Перед каждым разделом файловой системы хранит-
хранится служебная информация, описывающая этот раздел и местонахождение следу-
следующего раздела. Все разделы должны находиться в основном расширенном разде-
разделе, вот почему ему необходимо выделить максимум доступного пространства.
Вторичный раздел файловой системы, также называемый в Windows логическим
разделом, находится в границах основного расширенного раздела и содержит фай-
файловую систему или другие структурированные данные. Вторичный расширенный
раздел содержит таблицу разделов и дополнительный раздел файловой системы.
Каждый вторичный расширенный раздел представляет собой «обертку» для вто-
вторичного раздела файловой системы; он описывает местонахождение вторичного
раздела файловой системы и следующего вторичного расширенного раздела.
На рис. 5.3 показано, как работает система вторичных разделов. Вторичный
расширенный раздел 1 содержит таблицу разделов, в которой хранится информа-
информация о вторичном разделе файловой системы 1 и вторичном расширенном разделе.
Вторичный расширенный раздел 2 содержит таблицу разделов с информацией о
вторичном разделе файловой системы 2. Но в общем случае он также может со-
содержать ссылку на следующий вторичный расширенный раздел, и так далее, пока
не будет распределено все свободное дисковое пространство.
Рис. 5.3. Основной принцип и общая структура вторичных разделов
(расширенных и файловых систем)
Общая картина
Давайте объединим два метода определения разделов. Если в системе использу-
используется от одного до четырех разделов, то для их создания достаточно MBR и расши-
расширенные разделы не потребуются. Если количество разделов больше 4, в MBR со-
создается до трех первичных разделов файловой системы, а оставшееся место на
диске выделяется под первичный расширенный раздел.
В первичном расширенном разделе информация о разделах хранится в форма-
формате связанного списка. Для оптимизации схемы со связанным списком, описанной
ранее, можно отказаться от изначального создания вторичного расширенного раз-
раздела и поместить таблицу разделов в начало первичного расширенного раздела.
В этом случае таблица будет описывать одну вторичную файловую систему и один
вторичный расширенный раздел.
Рассмотрим пример. Имеется 12-гигабайтный диск, который требуется раз-
разбить на шесть 2-гигабайтных разделов. Первые три 2-гигабайтных раздела созда-
создаются в первых трех записях MBR, а оставшиеся 6 Гбайт выделяются под первич-
первичный расширенный раздел, включающий дисковое пространство от 6 до 12 Гбайт.
Остается определить еще три раздела в формате связанного списка. Мы ис-
используем таблицу разделов в первом секторе первичного расширенного раздела,
создаем вторичный раздел файловой системы в диапазоне от 6 Гбайт до 8 Гбайт
и создаем вторичный расширенный раздел в диапазоне от 8 Гбайт до 10 Гбайт.
Таблица разделов находится во вторичном расширенном разделе и содержит за-
записи вторичного раздела файловой системы в диапазоне от 8 Гбайт до 10 Гбайт и
вторичного расширенного раздела в диапазоне от 10 Гбайт до 12 Гбайт. Таблица
разделов находится в последнем вторичном расширенном разделе и содержит за-
запись последнего раздела файловой системы в диапазоне от 10 до 12 Гбайт. Схема
показана на рис. 5.4.
Рис. 5.4. Структура диска с шестью разделами файловой системы
Как утверждается в большинстве документов, расширенная таблица разделов
должна содержать не более одной записи для раздела вторичной файловой систе-
системы и одной записи для вторичного расширенного раздела. На практике многие
операционные системы не будут выдавать ошибку при использовании более двух
записей. В июле 2003 г. я опубликовал 160-мегабайтный образ диска [Carrier, 2003]
с шестью 25-мегабайтными разделами DOS в списке CFTT Yahoo! Groups (http:/
/groups.yahoo.com/group/cftt/). Образ содержал первичный расширенный раздел
с двумя записями вторичных разделов файловых систем и одной записью вто-
вторичного расширенного раздела. Одни системные программы правильно обраба-
обрабатывали запись третьего раздела, другие игнорировали его или вместо 25-мегабай-
25-мегабайтного раздела обнаруживали раздел объемом 1 Тбайт. Этот пример показывает,
что даже такая распространенная схема, как разделы DOS, может вызывать про-
проблемы у аналитических программ.
Расширенные разделы обладают специальными типами, которые используют-
используются в их записях таблиц разделов. А чтобы эта сложная схема стала еще сложнее,
существует несколько типов расширенных разделов, среди которых не различа-
различаются типы первичных и вторичных расширенных разделов. Самые распростра-
распространенные типы расширенных разделов — «расширенный раздел DOS», «расширен-
«расширенный раздел Windows 95» и «расширенный раздел Linux».
Загрузочный код
Загрузочный код диска DOS находится в первых 446 байтах первого 512-байтового
сектора, то есть в MBR. В конце сектора находится таблица разделов. Стандартный
загрузочный код Microsoft обрабатывает таблицу разделов MBR и определяет,
для какого раздела установлен флаг загрузки. Обнаружив такой раздел, загруз-
загрузчик обращается к его первому сектору и передает управление находящемуся в нем
коду. Код в начале раздела является специфическим для операционной системы.
Вирусы, внедряющиеся в загрузочный сектор, записывают себя в первые 446 байт
MBR, чтобы они выполнялись при каждой загрузке компьютера.
В наши дни компьютеры с несколькими операционными системами становят-
становятся все более распространенным явлением. Проблема решается двумя способами.
Система Windows записывает в загрузочный раздел код, который дает возмож-
возможность пользователю выбрать загружаемую операционную систему. Другими сло-
словами, сначала выполняется загрузочный код в MBR, который передает управле-
управление загрузочному коду Windows. Загрузочный код Windows дает возможность
пользователю выбрать раздел для загрузки системы.
Второй способ основан на модификации кода MBR. Новый код MBR выдает
список возможных вариантов, из которого пользователь выбирает раздел для за-
загрузки. Как правило, такое решение требует большего объема кода и использует
некоторые свободные секторы, существующие перед началом первого раздела.
Итоги
Сложность системы разделов DOS объясняется тем, что каждая таблица разделов
может содержать не более четырех записей. В других системах разделов, рассматрива-
рассматриваемых далее в этой главе, используются таблицы большего размера, поэтому такие
системы получаются более простыми. Для получения информации о структуре диска
с разделами DOS на высоком уровне необходимо выполнить следующие действия:
1. Прочитать MBR из первого сектора диска, идентифицировать и обработать
четыре записи таблицы разделов.
2. При обработке записи расширенного раздела прочитать первый сектор рас-
расширенного раздела и обработать записи его таблицы разделов так же, как это
делается для MBR.
3. При обработке записи обычного (не расширенного) раздела выводится его на-
начальный сектор и размер. Конечный сектор определяется суммированием этих
величин с вычитанием 1.
Структуры данных
От рассмотрения системы разделов DOS мы переходим к подробному описанию
структур, заложенных в основу этой системы. Если структуры данных вас не инте-
интересуют, описание можно пропустить, однако в нем встречается интересный пример
использования расширенных разделов. Материал состоит из трех подразделов
с описанием MBR, расширенных разделов и примером вывода данных для образа.
Структура данных MBR
Таблицы разделов DOS находятся в MBR и в первом секторе каждого расширен-
расширенного раздела. Во всех случаях используется одна и та же 512-байтовая структура.
Первые 446 байт зарезервированы для загрузочного кода. Код должен находить-
находиться в MBR, поскольку он используется при запуске компьютера, однако для рас-
расширенных разделов он не нужен, и на его месте могут храниться скрытые данные.
Структура MBR в табличной форме показана в табл. 5.1.
Таблица 5-1- Структуры данных в таблице разделов DOS
Диапазон байтов Описание Необходимость
0-445 Загрузочный код Нет
446-461 Запись таблицы разделов №1 (см. табл. 5.2) Да
462-477 Запись таблицы разделов №2 (см. табл. 5.2) Да
478-493 Запись таблицы разделов №3 (см. табл. 5.2) Да
494-509 Запись таблицы разделов №4 (см. табл. 5.2) Да
510-511 Сигнатура @хАА55) Нет
Таблица разделов содержит четыре 16-байтовых записи, структура которых
представлена в табл. 5.2. Адреса CHS необходимы для старых систем, в которых
они используются, но в новых системах они не нужны.
Таблица 5-2. Структура данных записи раздела DOS
Диапазон байтов Описание Необходимость
0-0 Флаг загрузочного раздела Нет
1-3 Начальный адрес CHS Да
4-4 Тип раздела (см. табл. 5.3) Нет
5-7 Конечный адрес CHS Да
8-11 Начальный адрес LBA Да
12-15 Размер в секторах Да
Флаг загрузочного раздела необходим не всегда. Стандартный загрузочный код
компьютера с единственной ОС ищет запись, у которой этот флаг равен 0x80.
Например, если на компьютере установлена Microsoft Windows, а диск разбит на
два раздела, то у раздела с операционной системой (например, C:\windows) будет
установлен флаг загрузочного раздела. С другой стороны, если загрузочный код
предлагает пользователю выбрать раздел для загрузки системы, флаг может ока-
оказаться лишним. Впрочем, некоторые загрузочные программы устанавливают его
после того, как пользователь выберет соответствующий раздел для загрузки.
Начальный и конечный адреса CHS состоят из головки (8 бит), сектора F бит)
и цилиндра A0 бит). Теоретически для каждого раздела должен быть задан только
один из двух адресов (CHS или LBA). ОС и код загрузки системы должны опреде-
определить, какие значения необходимо задать. Например, Windows 98 и ME используют
адреса CHS для разделов, находящихся в первых 7,8 Гбайт диска, a Windows 2000
и последующие системы всегда игнорируют адреса CHS [Microsoft, 2003]. Неко-
Некоторые программы создания разделов стараются задавать адреса обоих типов для
обеспечения совместимости. Использование этих полей зависит от приложения.
Поле типа раздела идентифицирует тип файловой системы, которая должна
находиться в разделе. Список наиболее распространенных типов приведен в табл. 5.3,
а более подробную информацию можно найти в документе «Partition Types»
[Brouwer, 2004].
Таблица 5.3. Некоторые типы разделов DOS
Тип Описание
0x00 Пусто
0x01 FAT12, CHS
0x04 FAT16, 16-32 Мбайт, CHS
0x05 Расширенный раздел Microsoft, CHS
0x06 FAT16, 32 Мбайт-2 Гбайт, CHS
0x07 NTFS
OxOb FAT32, CHS
ОхОс FAT32, LBA
ОхОе FAT16, 32 Мбайт-2 Гбайт, LBA
OxOf Расширенный раздел Microsoft, LBA
0x11 Скрытый раздел FAT12, CHS
0x14 Скрытый раздел FAT16, 16-32 Мбайт, CHS
0x16 Скрытый раздел FAT16, 32 Мбайт-2 Гбайт, CHS
Oxlb Скрытый раздел FAT32, CHS
Oxlc Скрытый раздел FAT32, LBA
Oxle Скрытый раздел FAT16, 32 Мбайт-2 Гбайт, LBA
0x42 Microsoft MBR, динамический диск
0x82 Solaris x86
0x82 Раздел подкачки Linux
0x84 Данные спящего режима
0x85 Расширенный раздел Linux
0x86 Набор томов NTFS
0x87 Набор томов NTFS
ОхаО Спящий режим
Oxal Спящий режим
0ха5 FreeBSD
Охаб OpenBSD
Тип Описание
0ха8 Mac OSX
0ха9 NetBSD
Oxab Mac OSX
0xb7 BSDI
0xb8 Раздел подкачки BSDI
Oxee Диск EFI GPT
Oxef Системный раздел EFI
Oxfb Файловая система Vmware
Oxfc Раздел подкачки Vmware
Обратите внимание, сколько разных типов разделов существует для файло-
файловых систем Microsoft в диапазоне от 0x01 до OxOf. Это объясняется тем, что опера-
операционные системы Microsoft используют тип раздела для определения способа
чтения и записи данных в раздел. Как говорилось в главе 2, Windows может ис-
использовать как традиционные, так и расширенные обработчики прерывания BIOS
INT13h. Расширенные обработчики INT 13h необходимы для работы с дисками
объемом более 8,1 Гбайт и применения адресации LBA (вместо CHS). Следова-
Следовательно, типы FAT16 0x04 и ОхОЕ одинаковы, но во втором случае ОС будет ис-
использовать расширенные обработчики при работе с BIOS. Аналогично, типы
ОхОВ и ОхОС представляют обычную и расширенную версии FAT32, а типы 0x05
и OxOF — обычную и расширенную версии расширенных разделов [Microsoft,
2004b]. «Скрытые» версии этих типов разделов содержат 1 вместо 0 в верхнем
полубайте, а для их создания применяются различные системные программы.
Чтобы продемонстрировать работу с MBR и таблицами разделов, мы извле-
извлечем информацию из реальной системы и разберем ее вручную. В качестве приме-
примера будем использовать компьютер с альтернативной загрузкой Windows и Linux,
на жестком диске которого находятся восемь разделов файловых систем.
Первый пример взят из первого сектора диска. Данные выводятся утилитой
xxd в Linux, но для получения информации также можно было воспользоваться
шестнадцатеричным редактором для Windows или UNIX. В Linux командная стро-
строка выглядела так:
# dd if=disk3.dd bs=512 skip=O count=l | xxd
В левом столбце выводится десятичное смещение в байтах, средние восемь стол-
столбцов содержат данные в шестнадцатеричном формате, а последний столбец — те
же данные в кодировке ASCII. Данные взяты из системы на базе IA32 с прямым
порядком байтов, при котором младшие (менее значащие) байты располагаются
по меньшим адресам, поэтому байты в средних столбцах переставляются. Содер-
Содержимое MBR выглядит так:
# dd if=disk3.dd bs=512 skip=O count=l | xxd
0000000: eb48 9010 8edO bcOO Ь0Ь8 0000 8ed8 8ec0 .H
[...]
0000384: 0048 6172 6420 4469 736b 0052 6561 6400 .Hard Disk.Read.
0000400: 2045 7272 6f72 OObb 0100 b40e cdlO асЗс Error <
0000416: 0075 f4c3 0000 0000 0000 0000 0000 0000 .u
0000432: 0000 0000 0000 0000 0000 0000 0000 0001
0000448: 0100 07fe 3f7f 3f00 0000 4160 If00 8000 ....?.?...A\ ...
0000464: 0180 83fe 3f8c 8060 lfOO cd2f 0300 0000 ....?..\ ../....
0000480: 018d 83fe 3fcc 4d90 2200 40b0 OfOO 0000 ....?.M.\@
0000496: Olcd 05fe ffff 8d40 3200 79eb 9604 55aa @2.y...U.
Первые 446 байтов содержат загрузочный код. В последних двух байтах секто-
сектора присутствует сигнатура 0хАА55 (хотя и в переставленном виде из-за порядка
байтов, используемого на данной платформе). Таблица разделов выделена жир-
жирным шрифтом и начинается со значения 0x0001 со смещением 446. Каждая стро-
строка выходных данных занимает 16 байт; каждая запись таблицы тоже занимает
16 байт. Таким образом, вторая запись начинается строкой ниже первой записи
с числа 0x8000. В табл. 5.4 приведены четыре записи таблицы разделов в описан-
описанной ранее структуре. Значения приводятся в шестнадцатеричной записи, а деся-
десятичные эквиваленты заключены в круглые скобки.
Таблица 5.4. Содержимое первичной таблицы разделов в образе диска
№ Флаг Тип Начальный сектор Размер
1 0x00 0x07 0x0000003f F3) 0x001f6041 B 056 257)
2 0x80 0x83 0x001f6080 B 056 320) 0x00032fcd B08 845)
3 0x00 0x83 0x0022904d B 265 165) 0x000fb040 A 028 160)
4 0x00 0x05 0x0032408d C 293 325) 0x0496eb79 G6 999 545)
По табл. 5.4 и типам разделов, перечисленным в табл. 5.3, можно предполо-
предположить, какие данные находятся в каждом разделе. Первый раздел должен содер-
содержать файловую систему NTFS (тип 0x07), второй и третий — файловые системы
Linux @x83), а четвертый — расширенный раздел @x05). Для второй записи ус-
установлен флаг загрузочного раздела. Присутствие расширенного раздела абсолют-
абсолютно логично, потому что ранее упоминалось о том, что на диске находятся 8 разде-
разделов. Структура диска для данной таблицы разделов показана на рис. 5.5.
Рис. 5.5. Структура диска после обработки первой таблицы
разделов данного примера (без соблюдения масштаба)
Структуры данных расширенного раздела
Ранее уже говорилось о том, что первый сектор расширенного раздела имеет ту
же структуру, что и MBR, но в расширенных разделах он используется для пост-
построения связанного списка. Записи таблицы разделов устроены несколько иначе,
потому что отсчет начальных адресов секторов ведется не от начала диска. Более
того, начальный сектор вторичного раздела файловой системы также отсчитыва-
ется не от начального сектора вторичного расширенного раздела.
Начальный адрес в записи вторичной файловой системы задается по отноше-
отношению к текущей таблице разделов — и это вполне логично, потому что вторичные
расширенные разделы служат «обертками» для разделов файловых систем. С дру-
другой стороны, начальный адрес вторичного расширенного раздела задается отно-
относительно первичного расширенного раздела.
Разберем пример, показанный на рис. 5.6. Первичный расширенный раздел на-
начинается с сектора 1000 и занимает 11 000 секторов. Его таблица разделов содержит
две записи. Первая запись описывает файловую систему FAT с начальным сектором
63, который в сумме с сектором текущей таблицы разделов дает 1063. Вторая запись
предназначена для расширенного раздела и начинается с сектора 4 000. В сумме с на-
начальным сектором первичного расширенного раздела A000) это дает сектор 5000.
Рис. 5.6. Диск с тремя вторичными расширенными разделами. Обратите внимание:
начальный сектор вторичных расширенных разделов задается по отношению
к началу первичного расширенного раздела в секторе 1000
Перейдем ко вторичному расширенному разделу (в секторе 5000). Первая за-
запись таблицы разделов описывает файловую систему NTFS с начальным секто-
сектором 63, который в сумме с адресом текущей таблицы разделов дает сектор 5063.
Вторая запись описывает расширенный раздел с начальным сектором 6500, кото-
который в сумме с сектором первичного расширенного раздела дает сектор 7500.
Давайте разберем еще один цикл, чтобы все окончательно прояснилось. Сле-
Следующий расширенный раздел начинается с сектора 7500. Первая запись файло-
файловой системы EXT3FS начинается с сектора 63, который в сумме с 7500 дает 7563.
Вторая запись описывает вторичный расширенный раздел, а ее начальное значе-
значение 9000 в сумме с 1000 дает сектор 10 000.
Вернемся к практическому примеру, в котором мы разбирали вручную табли-
таблицу разделов. Далее приводится содержимое первого сектора первичного расши-
расширенного раздела, находящегося в секторе 3 293 325:
# del if=disk3.dd bs=512 skip=O count=l | xxd
[...]
0000432: 0000 0000 0000 0000 0000 0000 0000 0001
0000448: Olcd 83fe 7fcb 3f00 0000 0082 ЗеОО 0000 ? >
0000464: 41cc 05fe bfOb 3f82 ЗеОО 40Ь0 Of00 0000 A ?.>.@
0000480: 0000 0000 0000 0000 0000 0000 0000 0000
0000496: 0000 0000 0000 0000 0000 0000 0000 55aa U.
Четыре записи таблицы разделов выделены жирным шрифтом. Мы видим,
что две последние записи не содержат данных. В табл. 5.5 представлена расшиф-
расшифровка первых двух записей таблицы разделов (нумерация разделов продолжает
табл. 5.4):
Таблица 5.5. Содержимое первичной таблицы разделов в образе диска
№ Флаг Тип Начальный сектор Размер
5 0x00 0x07 OxOOOOOO3f F3) 0x001f6041 B 056 257)
6 0x00 0x05 0x003e823f D 096 575) 0x000fb040 A 028 160)
Запись 5 помечена типом файловой системы Linux @x83); таким образом,
раздел является вторичным разделом файловой системы, а его начальный сек-
сектор задается по отношению к началу текущего расширенного раздела (сектор
3 293 325):
3 293 325 + 63 - 3 293 388
Запись 6 помечена типом расширенного раздела DOS, а начальный сектор этого
раздела задается по отношению к первичному расширенному разделу, который
является текущим:
3 293 325 + 4 096 575 = 7 389 900
Структура диска в том виде, в котором она нам известна, показана на рис. 5.7.
Прежде чем продолжить, обратите внимание на размеры двух разделов. В MBR
первичный расширенный раздел имеет размер 76 999 545 секторов. В этой таблице
размер следующего вторичного расширенного раздела составляет всего 1 028 160
секторов. Вспомните, что размер первичного расширенного раздела складывается
из размеров всех вторичных файловых систем и вторичных расширенных разде-
разделов, тогда как размер вторичного расширенного раздела складывается из размера
следующего вторичного раздела файловой системы и размера области, необходи-
необходимой для хранения таблицы разделов.
Пример можно продолжить и проанализировать следующий вторичный рас-
расширенный раздел, находящийся в секторе 7 389 900. Его содержимое представле-
представлено в табл. 5.6.
Рис. 5.7. Структура диска после обработки второй таблицы разделов (без соблюдения масштаба)
Таблица 5.6. Содержимое первой вторичной расширенной таблицы разделов
в образе диска
№ Флаг Тип Начальный сектор Размер
7 0x00 0x82 0x0000003f F3) OxOOOfbOOl (I 028 097)
8 0x00 0x05 0x004e327f E 124 735) 0x000fb040 A 028 160)
Запись 7 описывает раздел подкачки Linux; это вторичная файловая система,
а начальный адрес сектора задается по отношению к текущему расширенному раз-
разделу, то есть сектору 7 389 900:
7 389 900 + 63 = 7 389 963
Запись 8 описывает расширенный раздел файловой системы DOS, поэтому его
адрес начального сектора задается по отношению к первичному расширенному
разделу, то есть сектору 3 293 325:
3 293 325 + 5 124 735 - 8 418 060
Структура диска с информацией из этой таблицы разделов показана на рис. 5.8.
Полное содержимое таблицы разделов будет приведено далее, при рассмотрении
программ вывода содержимого таблицы разделов.
Вывод информации о разделах
Познакомившись с внутренней структурой таблицы разделов, давайте посмот-
посмотрим, как она обрабатывается некоторыми аналитическими программами. Те, кто
предпочитает обрабатывать структуры данных вручную и не пользуется вспомо-
вспомогательными программами, могут пропустить этот материал. Мы рассмотрим две
программы для Linux, но эта функция также выполняется многими Windows-про-
Windows-программами (в том числе системами экспертного анализа и шестнадцатеричными
редакторами).
Команда fdisk входит в поставку Linux и отличается от одноименной програм-
программы, поставляемой с системой Windows. Fdisk может работать с устройством Linux
или файлом образа, сгенерированным программой dd. При запуске с флагом -L
программа выводит список разделов вместо перехода в интерактивный режим
с возможностью редактирования разделов. Флаг -и означает, что информация дол-
должна выводиться в секторах (вместо цилиндров). Для диска с разделами DOS, ко-
который мы обрабатывали вручную, программа выдала следующий результат:
# fdisk -1u disk3.dd
Disk disk3.dd: 255 heads, 63 sectors, 0 cylinders
Units = sectors of 1 * 512 bytes
Device Boot Start End Blocks Id System
disk3.ddl 63 2056319 1028128+ 7 HPFS/NTFS
disk3.dd2 * 2056320 2265164 104422+ 83 Linux
disk3.dd3 2265165 3293324 514080 83 Linux
disk3.dd4 3293325 80292869 38499772+ 5 Extended
disk3.dd5 3293388 7389899 2048256 83 Linux
disk3.dd6 7389963 8418059 514048+ 82 Linux swap
disk3.dd7 8418123 9446219 514048+ 83 Linux
disk3.dd8 9446283 17639369 4096543+ 7 HPFS/NTFS
disk3.dd9 17639433 48371714 15366141 83 Linux
Рис. 5.8. Структура диска после обработки третьей таблицы разделов (без соблюдения масштаба)
Обратите внимание на некоторые обстоятельства. В выходных данных указан
только первичный расширенный раздел (disk3.dd4). Вторичный расширенный раз-
раздел, в котором находится раздел подкачки Linux, обнаружен, но информация о нем
не выводится. Такой подход приемлем в большинстве случаев, потому что для
анализа абсолютно необходимы только первичный и вторичный разделы файло-
файловых систем, но все же следует помнить, что в результатах отображаются не все
записи таблицы разделов.
Выходные данные программы mmls из пакета The Sleuth Kit выглядят несколько
иначе. В них помечаются секторы, не используемые разделами, указывается мес-
местонахождение таблиц разделов и расширенных разделов. Для диска, использо-
использованного в первом примере с fdisk, выходные данные mmls выглядят так:
# mmls -t dos disk3.dd
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0000000000 0000000001 Table #0
01: 0000000001 0000000062 0000000062 Unallocated
02: 00:00 0000000063 0002056319 0002056257 NTFS @x07)
03: 00:01 0002056320 0002265164 0000208845 Linux @x83)
04: 00:02 0002265165 0003293324 0001028160 Linux @x83)
05: 00:03 0003293325 0080292869 0076999545 DOS Extended @x05)
06: 0003293325 0003293325 0000000001 Table #1
07: 0003293326 0003293387 0000000062 Unallocated
08: 01:00 0003293388 0007389899 0004096512 Linux @x83)
09: 01:01 0007389900 0008418059 0001028160 DOS Extended @x05)
10: 0007389900 0007389900 0000000001 Table #2
11: 0007389901 0007389962 0000000062 Unallocated
12: 02:00 0007389963 0008418059 0001028097 Linux swap @x82)
13: 02:01 0008418060 0009446219 0001028160 DOS Extended @x05)
14: 0008418060 0008418060 0000000001 Table #3
15: 0008418061 0008418122 0000000062 Unallocated
16: 03:00 0008418123 0009446219 0001028097 Linux @x83)
17: 03:01 0009446220 0017639369 0008193150 DOS Extended @x05)
18: 0009446220 0009446220 0000000001 Table #4
19: 0009446221 0009446282 0000000062 Unallocated
20: 04:00 0009446283 0017639369 0008193087 NTFS @x07)
21: 04:01 0017639370 0048371714 0030732345 DOS Extended @x05)
22: 0017639370 0017639370 0000000001 Table #5
23: 0017639371 0017639432 0000000062 Unallocated
24: 05:00 0017639433 0048271714 0030732282 Linux @x83)
Строки с пометкой Unallocated обозначают пространство между разделами,
а также между концом таблицы разделов и началом первого раздела. В выходных
данных mmls указан как конечный адрес, так и результат, что упрощает их исполь-
использование для извлечения содержимого разделов программой dd.
Результаты mmls сортируются по начальному сектору раздела, поэтому пер-
первый столбец содержит только порядковый номер строки и не имеет отношения
к положению записи в таблице разделов. Во втором столбце выводится таблица
разделов и положение записи в ней. Первое число определяет таблицу @ — пер-
первичная таблица, 1 — первичная расширенная таблица), а второе определяет за-
запись в таблицу. Сортировка упрощает идентификацию секторов, не принадлежа-
принадлежащих разделам. Для примера возьмем следующий образ:
# mmls -t dos diskl.dd
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0000000000 0000000001 Table #0
01: 0000000001 0000000062 0000000062 Unallocated
02: 00:00 0000000063 0001028159 0001028097 Win95 FAT32 (OxOB)
03: 0001028160 0002570399 0001542240 Unallocated
04: 00:03 0002570400 0004209029 0001638630 OpenBSD @xA6)
05: 00:01 0004209030 0006265349 0002056320 NTFS @x07)
Из листинга видно, что раздел NTFS находится в позиции перед разделом
OpenBSD, но раздел NTFS начинается после раздела OpenBSD. Также можно за-
заметить, что запись с пометкой 00:02 отсутствует, а 1 542 240 секторов между FAT
и OpenBSD также помечены как нераспределенные.
Факторы анализа
В этом разделе упоминаются некоторые обстоятельства, которые необходимо учи-
учитывать при анализе диска с разделами DOS. Для таблицы разделов и загрузочно-
загрузочного кода обычно хватает одного сектора, но, как правило, для MBR и расширенных
разделов выделяются 63 сектора, потому что разделы должны начинаться на гра-
границе цилиндра. Следовательно, раздел 0 расширенного раздела или MBR содер-
содержит код и таблицу разделов, а секторы 1-62 могут оставаться неиспользуемыми.
В неиспользуемых секторах может храниться дополнительный загрузочный код,
но также в них могут находиться данные от предыдущей установки, нули или скры-
скрытые данные. Windows XP не стирает данные в неиспользуемых секторах при со-
создании разделов на диске.
Разделы в большинстве случаев начинаются с сектора 63, и этим обстоятель-
обстоятельством можно воспользоваться для восстановления содержимого первого раздела,
так как при отсутствии таблицы разделов средства, упоминавшиеся в главе 4, ра-
работать не будут. Попробуйте извлечь данные, начиная с сектора 63. В этом случае
в выборку будут включены другие разделы из образа, но возможно, вам удастся
определить фактический размер раздела по данным файловой систехмы. Извлече-
Извлечение раздела программой dd осуществляется так:
# dd if=disk.dd bs=512 skip=63 of=part.dd
Теоретически расширенные разделы должны содержать только две записи: для
раздела вторичной файловой системы и вторичного расширенного раздела. Боль-
Большинство программ создания разделов следуют этим правилам, но существует воз-
возможность создать третий раздел вручную. Microsoft Windows XP и Red Hat 8.0
отобразили «лишний» раздел, когда расширенный раздел содержал более двух
записей, однако ни та, ни другая ОС не позволили создать такую конфигурацию.
Протестируйте свои аналитические программы и убедитесь в том, что в подобных
«неправильных» конфигурациях они выводят информацию обо всех разделах.
Значение в поле типа раздела учитывается не всегда. Windows использует поле
для идентификации разделов для монтирования, но в таких операционных систе-
системах, как Linux, пользователь получает доступ ко всем разделам. Таким образом,
пользователь может поместить файловую систему FAT в раздел, предназначен-
предназначенный (в соответствии с типом) для хранения данных спящего режима. Эта файло-
файловая система не будет монтироваться в Windows — только в Linux.
Некоторые версии Windows создают в MBR только один первичный раздел,
а все остальные разделы создают как расширенные. Другими словами, они не со-
создают три первичных раздела, прежде чем переходить к созданию расширенных
разделов.
Если часть таблицы разделов будет повреждена, возможно, придется таблицы
расширенных разделов искать на диске. Поиск следует производить по сигнатуре
0хАА55 в двух последних байтах секторах. Обратите внимание: в файловых
системах NTFS и FAT присутствуют в той же позиции первого сектора. Чтобы
отличить таблицу разделов от загрузочного сектора файловой системы, придется
проанализировать прочее содержимое сектора. Если сектор окажется загрузоч-
загрузочным сектором файловой системы, возможно, таблица разделов находится на 63
сектора раньше него.
Итоги
В современной компьютерной аналитике чаще всего приходится иметь дело с раз-
разделами DOS. К сожалению, схема разделов DOS также оказывается самой слож-
сложной, потому что при ее исходном проектировании не учитывались масштабы со-
современных систем. К счастью, существуют системные программы для получения
информации о структуре диска, используемом и неиспользуемом пространстве.
Многие системы UNIX, работающие на IA32-совместимых платформах, исполь-
используют разделы DOS в сочетании с собственными системами разделов. Следова-
Следовательно, каждый эксперт обязан хорошо разбираться в разделах DOS.
Разделы Apple
Компьютеры с операционной системой Apple Macintosh встречаются реже, чем
компьютеры с Microsoft Windows, однако их популярность возросла с выходом
Mac OS X, операционной системы на базе UNIX. Разделы, о которых пойдет речь,
применяются на последних портативных и настольных компьютерах Apple с сис-
системой OS X, более старых системах с Macintosh 9 и даже портативных устрой-
устройствах iPod, предназначенных для воспроизведения аудио в формате МРЗ. Карты
разделов также могут использоваться в файлах образов дисков, используемых
в Macintosh при пересылке файлов. Файлы образов дисков напоминают zip-фай-
zip-файлы в Windows или tar-файлы в UNIX. Их содержимое хранится в виде файловой
системы, которая может находиться в разделе.
Архитектура системы разделов в Apple является удачным компромиссом меж-
между сложностью разделов DOS и ограниченным количеством разделов в BSD. Раз-
Раздел DOS может описывать произвольное количество разделов, а структуры дан-
данных хранятся в смежных секторах диска. Далее приводится общий обзор разделов
Apple, подробно описываются их структуры данных и способы получения под-
подробной информации.
Общий обзор
Разделы Apple описываются специальной структурой данных — картой разделов
(partition map), находящейся в начале диска. Обработка этой структуры реализо-
реализована на уровне «прошивок» (встроенного кода), поэтому карта не содержит за-
загрузочный код, как в схеме разделов DOS. Каждая запись карты разделов опреде-
определяет начальный сектор раздела, размер, тип и имя тома. Структура данных также
содержит информацию о данных, хранящихся в разделе, — в частности, местона-
местонахождение области данных и загрузочного кода.
Первая запись обычно определяет максимальный размер карты разделов. На
компьютерах Apple создаются разделы для хранения драйверов оборудования,
поэтому главный диск системы Apple содержит множество разделов с драйвера-
драйверами и другим содержимым, не имеющим прямого отношения к файловой системе.
На рис. 5.9 показан пример структуры диска Apple с тремя разделами файловой
системы и одним разделом, в котором хранится карта разделов.
Рис. 5.9. Диск Apple с одним разделом, содержащим карту разделов,
и тремя разделами файловых систем
Как будет показано далее, в системах BSD используется другая структура раз-
разделов, называемая разметкой диска. Несмотря на то что Mac OS X базируется на
ядре BSD, в этой системе используется карта разделов Apple, а не разметки диска.
Структуры данных
От знакомства с базовыми концепциями разделов Apple можно переходить к рас-
рассмотрению структур данных. Как и в случае с другими структурами данных в книге,
если этот материал не представляет для вас интереса, его можно пропустить. Здесь
также приводятся выходные данные некоторых аналитических программ на при-
примере образа диска.
Запись карты разделов
Карта разделов Apple содержит несколько 512-байтовых структур данных, каждая
из которых представляет один раздел. Карта разделов начинается со второго секто-
сектора диска и продолжается до тех пор, пока не будут описаны все разделы. Структуры
данных разделов хранятся в смежных секторах, и в каждой записи присутствует
общее количество разделов. Структура записи карты разделов показана в табл. 5.7.
Таблица 5,7- Структура данных записей разделов Apple
Диапазон байтов Описание Необходимость
0-1 Сигнатура @x504D) Нет
2-3 Зарезервировано Нет
4-7 Общее количество разделов Да
8-11 Начальный сектор раздела Да
12-15 Размер раздела в секторах Да
16-47 Имя раздела в кодировке ASCII Нет
Диапазон байтов Описание Необходимость
48-79 Тип раздела в кодировке ASCII Нет
80-83 Начальный сектор области данных в разделе Нет
84-87 Размер области данных в секторах Нет
88-91 Состояние раздела (см. табл. 5.8) Нет
92-95 Начальный сектор загрузочного кода Нет
96-99 Размер загрузочного кода в секторах Нет
100-103 Адрес кода загрузчика Нет
104-107 Зарезервировано Нет
108-111 Точка входа в загрузочный код Нет
112-115 Зарезервировано Нет
116-119 Контрольная сумма загрузочного кода Нет
120-135 Тип процессора Нет
136-511 Зарезервировано Нет
Тип раздела задается в кодировке ASCII, а не целочисленным кодом, как в дру-
других схемах. Коды состояния каждого раздела применимы как к A/UX (старая опе-
операционная система Apple), так и к современным системам Macintosh. Поле состо-
состояния содержит одно из значений, перечисленных в табл. 5.8 [Apple, 1999].
Таблица 5.8. Коды состояния разделов Apple
Тип Описание
0x00000001 Запись действительна (только A/UX)
0x00000002 Запись выделена (только A/UX)
0x00000004 Запись используется (только A/UX)
0x00000008 Запись содержит загрузочную информацию (только A/UX)
0x00000010 Запись доступна для чтения (только A/UX)
0x00000020 Запись доступна для изменения (Macintosh и A/UX)
0x00000040 Загрузочный код является позиционно-независимым (только A/UX)
0x00000100 Раздел содержит цепочечно-совместимый драйвер (только Macintosh)
0x00000200 Раздел содержит настоящий драйвер (только Macintosh)
0x00000400 Раздел содержит цепочечный драйвер (только Macintosh)
0x40000000 Автоматическое монтирование при запуске (только Macintosh)
0x80000000 Стартовый раздел (только Macintosh)
Поля области данных используются для файловых систем с областью данных,
начало которой не совпадает с началом диска. Поля загрузочного кода предназна-
предназначены для поиска загрузочного кода при запуске системы.
Чтобы идентифицировать разделы на диске Apple, программа (или человек)
читает структуру данных из второго сектора. Обработка структуры дает общее
количество разделов, после чего извлекается другая информация о разделах. Обыч-
Обычно первая запись относится к самой карте разделов. Затем читается следующий
сектор, и процесс продолжается до тех пор, пока не будут прочитаны все разделы.
Вот как выглядит содержимое первой записи карты разделов:
# dd if=mac-disk.dd bs=512 skip=l | xxd
0000000: 504d 0000 0000 000a 0000 0001 0000 003f PM ?
0000016: 4170 706с 6500 0000 0000 0000 0000 0000 Apple
0000032: 0000 0000 0000 0000 0000 0000 0000 0000
0000048: 4170 706с 655f 7061 7274 6974 696f 6e5f Apple_partition_
0000064: 6d61 7000 0000 0000 0000 0000 0000 0000 map
0000080: 0000 0000 0000 003f 0000 0000 0000 0000 ?
0000096: 0000 0000 0000 0000 0000 0000 0000 0000
На компьютерах Apple используются процессоры Motorola PowerPC, поэтому
данные на них хранятся с обратным порядком байтов. В результате отпадает не-
необходимость в перестановке байтов, как в разделах DOS. В байтах 0-1 видна сиг-
сигнатура 0x504d, а в байтах 4-7 — количество разделов, равное 10 (ОхОООООООа).
Байты 8-11 показывают, что первый сектор диска является начальным сектором
раздела, а размер раздела составляет 63 сектора @x3f). Разделу присвоено имя
«Apple», а тип раздела обозначается строкой «Apple_partition_map». Из байтов
88—91 видно, что флаги для раздела не установлены. У других записей, относя-
относящихся к конкретным разделам, заданы коды состояния.
Пример информации о разделах
Для просмотра карты разделов Apple можно воспользоваться программой mmls
из пакета The Sleuth Kit. Вот как выглядят результаты, полученные при запуске
mmls на портативном компьютере iBook с диском емкостью 20 Гбайт:
# mmls -t mac mac-disk.dd
MAC Partition Map
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0000000000 0000000001 Unallocated
01: 00 0000000001 0000000063 0000000063 Apple_partition_map
02: 0000000001 0000000010 0000000010 Table
03: 0000000011 0000000063 0000000053 Unallocated
04: 01 0000000064 0000000117 0000000054 Apple_driver43
05: 02 0000000118 0000000191 0000000074 Apple_driver44
06: 03 0000000192 0000000245 0000000054 Apple_driver_ATA
07: 04 0000000246 0000000319 0000000074 Apple_driver_ATA
08: 05 0000000320 0000000519 0000000200 AppleJWDriver
09: 06 0000000520 0000001031 0000000512 Apple_Driver_IOKit
10: 07 0000001032 0000001543 0000000512 Apple_Patches
11: 08 0000001544 0039070059 0039068516 Apple_HFS
12: 09 0039070060 0039070079 0000000020 Applejree
В этих данных строки отсортированы по начальному сектору, а второй стол-
столбец показывает, какая запись карты содержит описание раздела. В данном приме-
примере записи уже хранятся в отсортированном виде. Из строки 12 видно, что на ком-
компьютере Apple mmls выводит информацию о нераспределенных секторах. Строки
О, 2 и 3 были добавлены mmls; в них выводится информация о местонахождении
карты разделов и о свободных секторах. Перечисленные драйверы используются
системой при загрузке.
Для анализа низкоуровневого образа диска в OS X также можно запустить про-
программу pdisk с флагом -dump:
# pdisk mac_disk.dd -dump
mac-disk.dd map block size=--512
#: type name length base (size)
1: Apple_partition_map Apple 63 @ 1
2: Apple_Driver43*Macintosh 54 @ 64
3: Apple_Dnver43*Macintosh 74 @ 118
4: Apple_Driver_ATA*Macintosh 54 @ 192
5: Apple_Driver_ATA*Macintosh 74 @ 246
6: Apple_FWDriver Macintosh 200 @ 320
7: Apple_Driver_IOKit Macintosh 512 @ 520
8: Apple_Patches Patch Partition 512 @ 1032
9: Apple_HFS untitled 390668516 @ 1544 ( 18.6G)
10: Applejree 0+@ 39070060
Device block size=512. Number of Blocks=10053
DeviceType=0x0. DeviceId=0x0
Drivers-
1: @ 64 for 23. type-0xl
2: (P 118 for 36. type-Oxffff
3: @ 192 for 21. type=0x701
4: @ 246 for 34. type=0xf8ff
Как упоминалось во введении, файлы образов дисков Apple (не путайте с фай-
файлами образов, используемыми при анализе файловых систем) также могут со-
содержать карту разделов. Файл образа представляет собой архивный файл, кото-
который может содержать несколько отдельных файлов (по аналогии с zip-файлами
Windows или tar-файлами UNIX). Файл образа диска может содержать один раз-
раздел с файловой системой или же только файловую систему без разделов. Тесто-
Тестовый файл образа диска (таким файлам обычно присваивается расширение .dmg)
обладает следующей структурой:
# mmls -t mac test.dmg
MAC Partition Map
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0000000000 0000000001 Unallocated
01: 00 0000000001 0000000063 0000000063 Apple_partition_map
02: 0000000001 0000000003 0000000003 Table
03: 0000000004 0000000063 0000000060 Unallocated
04: 01 0000000064 0000020467 0000020404 Apple_HFS
05: 02 0000020468 0000020479 0000000012 Applejree
Факторы анализа
Единственная уникальная особенность разделов Apple состоит в том, что структура
данных содержит несколько неиспользуемых полей, которые могут использовать-
использоваться для сокрытия небольших объемов данных. Также данные могут скрываться
в секторах между структурой данных последнего раздела и концом пространства,
выделенного для карты разделов. Как и в любой другой схеме, имя раздела и его
тип еще ничего не гарантируют — такой раздел может содержать все, что угодно.
Итоги
Карта разделов Apple имеет довольно простую структуру, и понять ее несложно.
Структуры данных хранятся в одном месте, а максимальное количество разделов
зависит от того, каким образом производилось исходное разбиение диска. Программа
mmls позволяет легко идентифицировать местонахождение разделов Apple на дру-
других компьютерах, а в системе OS X можно воспользоваться программой pdisk.
Съемные носители
Большинство съемных носителей также содержит разделы, но на них использу-
используются те же структуры данных, что и на жестких дисках. Исключение из правила
составляют дискеты, отформатированные для системы FAT 12 в Windows и UNIX.
Они не имеют таблицы разделов, а весь жесткий диск рассматривается как один
раздел. Образ дискеты можно напрямую проанализировать как файловую систе-
систему. Некоторые портативные флеш-диски USB («брелковые диски») не имеют раз-
разделов и содержат одну файловую систему, но другие имеют разделы.
Съемные носители большей емкости (скажем, zip-диски Iomega) содержат таб-
таблицы разделов. Структура таблицы разделов на zip-диске зависит от того, был ли
диск отформатирован для Мае или для PC. Диск, отформатированный для PC,
содержит таблицу разделов DOS, и по умолчанию четвертая запись представляет
только один раздел.
Карты памяти, часто используемые в цифровых камерах, также обычно содер-
содержат таблицу разделов. Многие флэш-карты содержат файловую систему FAT,
а для их анализа можно воспользоваться обычными программами. Вот как выг-
выглядит таблица разделов на базе DOS для 128-мегабайтной карты памяти:
# mmls -t dos camera.dd
DOS Partition Table
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0000000000 0000000001 Primary Table (#0)
01: 0000000001 0000000031 0000000031 Unallocated
02: 00:00 0000000032 0000251647 0000251616 DOS FAT16 @x06)
Чтобы создать образ карты памяти, достаточно вставить ее в устройство чте-
чтения карт с интерфейсом USB или FireWire и выполнить в Linux команду dd.
С дисками CD-ROM дело обстоит сложнее из-за большого количества вари-
вариантов. Большинство компакт-дисков использует формат ISO 9660, поддерживае-
поддерживаемый многими операционными системами. Формат ISO 9660 устанавливает жест-
жесткие ограничения для имен файлов, поэтому были разработаны расширения этого
формата (такие, как Joliet и Rock Ridge), обладающие большей гибкостью. Опи-
Описание компакт-дисков усложняется тем, что один диск может содержать данные
в базовом формате ISO 9660 и в формате Joliet. А если компакт-диск является
гибридным диском Apple, он также может содержать данные в формате Apple
HFS+. Фактическое содержимое файлов хранится в одном экземпляре, но ссыл-
ссылки на эти данные присутствуют в нескольких разных местах.
У записываемых компакт-дисков (CD-R) существует понятие сеанса. Диск CD-R
может содержать один или несколько сеансов, а сама концепция сеанса была раз-
разработана для того, чтобы данные к CD-R можно было добавлять более одного раза.
При каждой записи данных на CD-R создается новый сеанс. В зависимости от
операционной системы, в которой используется диск, каждый сеанс может ото-
отображаться в виде раздела. Например, я воспользовался приложением Apple OS X
и создал компакт-диск с тремя сеансами. В системе OS X все три сеанса монтиро-
монтировались как файловые системы. При использовании диска в системе Linux после-
последний сеанс монтировался по умолчанию, но два других сеанса также можно было
смонтировать, указав их в команде mount. Для определения количества сеансов
на диске можно воспользоваться утилитой readcd (http://freshmeat.net/projects/
cdrecord/). Когда тот же диск был открыт в системе Microsoft Windows XP, сис-
система заявила, что он содержит недопустимую информацию, хотя программа
SmartProject ISO Buster (http://www.isobuster.com) увидела все три сеанса. Даже
если многосеансовый диск создавался в Windows, возможны разные варианты
поведения. Таким образом, при анализе CD-R очень важно использовать програм-
программу, позволяющую просмотреть содержимое всех сеансов, а не полагаться на стан-
стандартное поведение той платформы, на которой осуществляется анализ.
Некоторые компакт-диски также содержат разделы, специфические для «род-
«родной» операционной системы. Например, гибридные CD сочетают формат ISO
с форматом Apple — внутри сеанса используется карта разделов Apple и файло-
файловая система HFS+. К таким дискам применимы стандартные методы анализа для
платформы Apple. Например, вот как выглядит результат запуска mmls для гиб-
гибридного диска:
# mmls -t mac cd-slice.dmg
MAC Partition Map
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0000000000 0000000001 Unallocated
01: 00 0000000001 0000000002 0000000002 Apple_partition_map
02: 0000000001 0000000002 0000000002 Table
03: 0000000003 0000000103 0000000101 Unallocated
04: 01 0000000104 0000762559 0000762456 Apple_HFS
Многие загрузочные компакт-диски тоже содержат систему разделов опреде-
определенной операционной системы. Загрузочные диски Sparc Solaris содержат струк-
структуру Volume Table of Contents в томе ISO, а в начале загрузочных компакт-дисков
Intel может находиться таблица разделов DOS. Эти структуры используются после
загрузки операционной системы с компакт-диска, а код, необходимый для загруз-
загрузки системы, хранится в формате ISO.
Библиография
• Agile Risk Management, «Linux Forensics — Week 1 (Multiple Session CDRs)».
March 19, 2004, http://www.agilerm.net/linuxl.htmL
• Apple, «File Manager Reference». March 1,2004. http://developer.apple.com/documen-
tation/Carbon/Reference/FHe_Manager/index.htmL
• Apple, «Inside Macintosh: Devices». July 3,1996. http://developer.apple.com/documen-
tation/mac/Devices/Devices-2.htmL
• Apple, «The Monster Disk Driver Technote». November 22, 1999. http://devel.o-
per.apple.com/technotes/pdf/tnll89.pdf.
• Brouwer, Andries. «Minimal Partition Table Specification». September 16, 1999.
http://www.win.tue.nl/~aeb/partitions/partition_tables.html.
• Brouwer, Andries. «Partition Types». December 12, 2004. http://www.win.tue.nl/
~aeb/partitions/partition_types.html.
• Carrier, Brian. «Entended Partition Test». Digital Forensics Tool Testing Images,
July 2003. http://dftt.sourceforge.net/testl/index.htmL
• CDRoller. Reading Data CD, n.d. http://www.cdroLler.com/htm/readdata.htmL
• ECMA. «Volume and File Structure of CDROM for Information Interchange».
ISO Spec, September 1998. http://www.ecma-international.org/publications/files/
ECMA-ST/Ecma-119.pdf.
• Landis, Hale. «How it Works: Master Boot Record». May 6, 2002. http://www.ata-
atapi.com/hiwmbr.htm.
• Microsoft. «Basic Disks and Volumes Technical Reference». Windows Server 2003
Technical Reference, 2004. http://www.microsoft.com.
• Microsoft. «Managing GPT Disks in Itamium-based Computers». Windows XP
Professional Resource Kit Documentation, 2004a. http://www.microsoft.com.
• Microsoft. «MS-DOS Partitioning Summary». Microsoft Knowledge Base Article
69912, December 20, 2004b. http://support.microsoft.com/default.aspx?scid=kb;EN-
US;69912.
• Stevens, Curtis, and Stan Merkin. «El Torito: Bootable CD-ROM Format Specifica-
Specification 1.0». January 25,1999. http://www.phoenix.com/resources/specs-cdrom.pdf.
Разделы в серверных
системах
В предыдущей главе было показано, как организовано хранение информации на
персональных компьютерах. Давайте посмотрим, как происходит создание томов
на серверах. В области основных концепций эта глава совершенно не отличается
от предыдущей. Более того, я разделил их только для того, чтобы материал был
представлен по главам среднего размера, и такое разделение было ничем не хуже
других возможных (хотя ничто не мешает использовать разделы DOS и Apple на
серверах). В этой главе мы познакомимся с системами разделов FreeBSD, NetBSD
и OpenBSD; системами разделов Sun Solaris; а также разделами GPT, поддержи-
поддерживаемыми в 64-разрядных системах Intel Itanium.
Разделы BSD
Компьютерным аналитикам все чаще приходится иметь дело с серверными сис-
системами BSD UNIX — такими, как FreeBSD (http://www.freebsd.org), OpenBSD
(http://www.openbsd.org) pi NetBSD (http://www.netbsd.org). Такие системы исполь-
используют собственные схемы формирования разделов, и в этой части будут описаны
соответствующие структуры данных. На практике чаще встречается система Linux,
но она использует только разделы DOS и не имеет собственных структур данных.
Многие системы BSD работают на оборудовании IA32 (то есть x86/i386), а при
их проектировании учитывалась возможность их совместного существования на
одном диске с продуктами Microsoft. Такие системы строятся на базе разделов
DOS, упоминавшихся в предыдущей главе. Системы BSD, работающие на другом
оборудовании, по всей вероятности, не будут использовать разделы DOS, но в
книге они не рассматриваются.
Прежде чем переходить к рассмотрению темы, необходимо понять одно важ-
важное обстоятельство: во время работы операционная система может выбрать раз-
разделы, доступ к которым предоставляется пользователю. Как будет показано, опе-
операционная система FreeBSD использует системы разделов DOS и FreeBSD, тогда
как OpenBSD и NetBSD используют только систему разделов BSD. Для данного
раздела необходимо хотя бы общее понимание разделов DOS.
Общий обзор
Система разделов BSD проще системы разделов DOS, но по своим возможностям
она уступает картам разделов Apple. Необходимые данные хранятся только в од-
одном секторе, который находится в разделе DOS (рис. 6.1). Это было сделано для
того, чтобы на том же диске могла быть установлена система Windows, а пользо-
пользователь мог выбрать загружаемую операционную систему. В таблице разделов DOS
создается запись для разделов FreeBSD, OpenBSD или NetBSD — типы 0ха5, Охаб
и 0ха9 соответственно. Раздел BSD является одним из первичных разделов DOS.
Рис. 6.1. Диск с двумя разделами DOS и тремя разделами BSD внутри раздела DOS
Если бы я стремился к максимальной строгости в терминологии, стоило бы
сказать, что разделы BSD находятся внутри тома, созданного на основе раздела
DOS. Как объяснялось в главе 4, это один из примеров разбиения на разделы тома,
созданного на базе раздела.
Центральной структурой данных является разметка диска (disk label). Ее раз-
размер составляет минимум 276 байт, и она находится во втором секторе раздела BSD.
В некоторых системах, не использующих платформу IA32, она может храниться
в первом секторе со смещением. В FreeBSD, OpenBSD и NetBSD используется
одна структура данных, но с некоторыми различиями в реализации. Сейчас я из-
изложу общие положения, а конкретные подробности будут приведены далее.
Структура разметки диска содержит аппаратные спецификации диска и таб-
таблицы разделов для восьми или шестнадцати разделов BSD. В отличие от схемы
Apple, таблица разделов имеет фиксированный размер, а в отличие от разделов
DOS, существует только одна таблица разделов. Каждая запись в таблице разде-
разделов BSD содержит следующие поля:
• начальный сектор раздела BSD;
• размер раздела BSD;
• тип раздела;
• размер фрагмента файловой системы UFS;
• количество фрагментов файловой системы UFS на блок;
• количество цилиндров в группе UFS.
Адрес начального сектора отсчитывается от начала диска, а не от разметки диска
или раздела DOS. Поле типа раздела определяет тип файловой системы, которая
должна находиться в разделе BSD — например, UFS, область подкачки, FAT или
неиспользуемая область. Последние три значения используются только в том слу-
случае, если раздел содержит файловую систему UFS. Файловая система UFS опи-
описывается в главах 16 и 17.
Основные принципы схемы разделов BSD просты. Получение информации
сводится к чтению одной структуры данных и обработке списка разделов. Впро-
чем, некоторые проблемы могут возникнуть с доступом к разделам. Например,
в системе с альтернативной загрузкой аналитик должен знать, обладал ли пользо-
пользователь доступом к разделу Windows и/или к разделу BSD. В FreeBSD этот воп-
вопрос решается не так, как в OpenBSD и NetBSD. Мы разберемся, как каждая из
этих систем использует данные в разметке диска, хотя эта тема может быть отне-
отнесена к анализу уровня приложений.
FreeBSD
FreeBSD предоставляет пользователю доступ ко всем разделам DOS и BSD на
диске. В терминологии FreeBSD разделы DOS называются сегментами (slice),
а разделы BSD называются просто разделами. Следовательно, если в системе ус-
установлены Windows и FreeBSD, при работе с FreeBSD пользователь будет иметь
доступ сегментам Windows.
Структура разметки диска в FreeBSD используется для организации секторов
только в пределах раздела DOS, содержащего разделы FreeBSD. На первый взгляд
это кажется очевидным, но в действительности это одно из принципиальных раз-
различий между реализациями OpenBSD и FreeBSD. На рис. 6.2 разметка диска опи-
описывает три раздела, находящиеся в разделе DOS с типом раздела FreeBSD, но для
описания раздела с типом NTFS она не нужна.
Рис. 6.2. Диск FreeBSD с именами устройств
FreeBSD, как и прочие разновидности UNIX, связывает с каждым разделом
и сегментом специальный файл устройства. Имя этого файла задается в соответ-
соответствии с номером раздела DOS и номером раздела BSD. Первичному диску АТА
присваивается базовое имя /dev/adO. Для каждого сегмента, также называемого
разделом DOS, к базовому имени прибавляется буква «s» и номер сегмента. На-
Например, первый сегмент обозначается именем /dev/adOsl, а второй — /dev/adOs2.
На любом сегменте с типом раздела FreeBSD система ищет структуру разметки
диска. Разделам в сегменте присваиваются буквенные обозначения на основании
положения их записей в таблице разделов разметки диска. Например, если вто-
второй раздел DOS принадлежит FreeBSD, первому разделу BSD будет присвоено
имя /dev/adOs2a, а второму — /dev/adOs2b. Также иногда для разделов BSD созда-
создается вторая группа имен устройств, не включающая в себя номера сегментов. На-
Например, имя /dev/adOa может использоваться как сокращенное обозначение раз-
раздела /dev/adOs2a (если раздел FreeBSD является вторым разделом DOS).
Некоторые разделы BSD имеют особый смысл. Раздел «а» обычно выполняет
функции корневого, в нем находится загрузочный код. Раздел «Ь» обычно содер-
содержит область подкачки, раздел «с» обычно представляет весь сегмент, а начиная
с «d», разделы могут содержать произвольную информацию. Я говорю «обычно»,
потому что эти разделы создаются большинством системных программ BSD, но
пользователь может отредактировать таблицу разделов в разметке диска и изме-
изменить ее содержимое.
Итак, система FreeBSD предоставляет доступ ко всем разделам DOS и разделам
FreeBSD. В процессе полного анализа системы эксперт должен проанализировать
каждый раздел DOS и каждый раздел BSD, присутствующий в разметке диска.
NetBSD и OpenBSD
NetBSD и OpenBSD предоставляют пользователю доступ только к записям, при-
присутствующим в структуре разметки диска BSD. В отличие от разметки диска
FreeBSD, в OpenBSD и NetBSD эта структура может описывать разделы, находя-
находящиеся в любом месте диска. Иначе говоря, разметка диска может описывать раз-
разделы за пределами того раздела DOS, в котором она находится. В оставшейся ча-
части главы я буду упоминать только OpenBSD, но в действительности речь идет об
обеих системах, OpenBSD и NetBSD. Проект OpenBSD отделился от NetBSD
много лет назад.
После загрузки ядра OpenBSD разделы DOS игнорируются. Система использу-
использует их только для обнаружения начала раздела OpenBSD. Следовательно, если в си-
системе установлены как Windows, так и OpenBSD, а пользователям предоставлен
доступ к разделу FAT из OpenBSD, то раздел FAT будет присутствовать как в таб-
таблице разделов DOS, так и в разметке диска BSD. Ситуация показана на рис. 6.3
для разделов DOS, показанных на рис. 6.2. Однако на этот раз в разметке диска
потребуется дополнительная запись для обращения к разделу DOS с типом NTFS.
Рис. 6.3. Диск FreeBSD с именами устройств
Имена файлов устройств в OpenBSD похожи нате, что используются в FreeBSD.
Первичному устройству АТА назначается базовое имя /dev/wdO. Понятие «сег-
«сегментов» отсутствует, а имена разделов BSD обозначаются буквами. Следователь-
Следовательно, первому разделу BSD присваивается имя /dev/wdOa, а второму — /dev/wdOb.
Как и в FreeBSD, первый раздел обычно является корневым, а второй предназ-
предназначается для области подкачки. Третий раздел, /dev/wdOc в нашем примере, явля-
является устройством, представляющим весь диск. Вспомните, что в FreeBSD третий
раздел предназначался только для одного сегмента, или раздела, DOS.
Подведем итог: система OpenBSD предоставляет доступ только к разделам,
описанным в разметке диска OpenBSD. Анализ системы OpenBSD следует сосре-
сосредоточить на разделах, перечисленных в разметке диска.
Загрузочный код
Загрузочный код в системе BSD «окружает» структуру разметки диска, находя-
находящуюся в секторе 1 тома. В секторе 0 тома хранится загрузочный код, выполняе-
выполняемый при обнаружении загрузчиком MBR загрузочного раздела с типом BSD. Если
загрузочный код не помещается в секторе 0, он продолжается в секторе 2 и может
продолжаться до начала данных файловой системы, обычно в секторе 16.
Структуры данных
В этом разделе описываются структуры данных разметки диска BSD и приводит-
приводится пример обработки системных данных в системах FreeBSD и OpenBSD. Также
приводятся примеры результатов некоторых служебных программ.
Разметка диска
Посмотрим, как устроена структура данных, называемая разметкой диска. Если
этот материал вас не интересует, пропустите его и перейдите к примерам анализа
образов дисков. Я начну с общего описания разметки диска BSD, а затем перейду
к подробностям реализации FreeBSD и OpenBSD. В табл. 6.1 перечислены поля
этой структуры данных. Учтите, что некоторые поля могут быть не задействова-
задействованы в определении структуры диска, но при этом необходимы для выполнения
других операций.
Таблица 6.1. Структура данных разметки диска BSD
Диапазон Описание Необходимость
байтов
0-3 Сигнатура @x82564557) Нет
4-5 Тип диска Нет
6-7 Подтип диска Нет
8-23 Имя типа диска Нет
24-39 Имя идентификатора пакета Нет
40-43 Размер сектора в байтах Да
44-47 Количество секторов в дорожке Нет
48-51 Количество дорожек в цилиндре Нет
52-55 Количество цилиндров в модуле Нет
56-59 Количество секторов в цилиндре Нет
60-63 Количество секторов в модуле Нет
64-65 Количество свободных секторов в дорожке Нет
66-67 Количество свободных секторов в цилиндре Нет
68-71 Количество альтернативных цилиндров в модуле Нет
72-73 Скорость вращения диска Нет
74-75 Коэффициент чередования секторов Нет
76-77 Сдвиг дорожки Нет
78-79 Сдвиг цилиндра Нет
80-83 Время коммутации головок в микросекундах Нет
Таблица 6.1 {продолжение)
Диапазон Описание Необходимость
байтов
84-87 Время позиционирования дорожек в микросекундах Нет
88-91 Флаги Нет
92-111 Специфическая информация о диске Нет
112-131 Зарезервировано Нет
132-135 Сигнатура @x82564557) Нет
136-137 Контрольная сумма Нет
138-139 Количество разделов Да
140-143 Размер загрузочной области Нет
144-147 Максимальный размер суперблока Нет
файловой системы
148-163 Раздел BSD №1 (см. табл. 6.2) Да
164-179 Раздел BSD №2 (см. табл. 6.2) Да
180-195 Раздел BSD №3 (см. табл. 6.2) Да
196-211 Раздел BSD №4 (см. табл. 6.2) Да
212-227 Раздел BSD №5 (см. табл. 6.2) Да
228-243 Раздел BSD №6 (см. табл. 6.2) Да
244-259 Раздел BSD №7 (см. табл. 6.2) Да
260-275 Раздел BSD №8 (см. табл. 6.2) Да
276-291 Раздел BSD №9 (см. табл. 6.2) Да
292-307 Раздел BSD №10 (см. табл. 6.2) Да
308-323 Раздел BSD №11 (см. табл. 6.2) Да
324-339 Раздел BSD №12 (см. табл. 6.2) Да
340-355 Раздел BSD №13 (см. табл. 6.2) Да
356-371 Раздел BSD №14 (см. табл. 6.2) Да
372-387 Раздел BSD №15 (см. табл. 6.2) Да
388-^03 Раздел BSD №16 (см. табл. 6.2) Да
404-511 Не используется Нет
Структура 16-байтовой записи из таблицы разделов BSD приведена в табл. 6.2.
Таблица 6.2. Структура данных разметки диска BSD
Диапазон Описание Необходимость
байтов
0-3 Размер раздела BSD в секторах Да
4-7 Начальный сектор раздела BSD Да
8-11 Размер фрагмента файловой системы Нет
12-12 Тип файловой системы (см. табл. 6.3) Нет
13-13 Количество фрагментов файловой системы в блоке Нет
14-15 Количество цилиндров файловой системы в группе Нет
Поле типа определяет тип файловой системы, которая может находиться в раз-
разделе BSD. Допустимые значения перечислены в табл. 6.3.
Таблица 6.3, Типы разделов BSD
Тип Описание
0 Не используется
1 Область подкачки
2 Version 6
3 Version 7
4 System V
5 4.1BSD
6 Eighth edition
7 4.2BSD FFS (Fast File System)
8 Файловая система MSDOS D.4LFS)
9 4.4BSD LFS (Log Structured File System)
10 Используется, но имеет неизвестное или неподдерживаемое содержимое
11 OS/2 HPFS
12 CD-ROM (ISO9660)
13 Загрузчик
14 Диск vinum
Самой распространенной файловой системой для FreeBSD и OpenBSD явля-
является 4.2BSD FFS (Fast File System). Для этой системы также создается минимум
один раздел подкачки. Раздел NTFS обычно имеет тип «используется, но имеет
неизвестное содержимое».
Теперь рассмотрим пример системы, в которой установлены как FreeBSD, так
и OpenBSD. Содержимое таблицы разделов DOS выглядит так:
# mmls -t dos bsd-disk.dd
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0000000000 0000000001 Primary Table (#0)
01: 0000000001 0000000062 0000000062 Unallocated
02: 00:00 0000000063 0002056319 0002056257 Win95 FAT32 (OxOB)
03: 00:01 0002056320 0008209214 0006152895 OpenBSD @xA6)
04: 00:02 0008209215 0019999727 0011790513 FreeBSD @xA5)
Мы видим, что диск содержит раздел FAT A Гбайт), раздел OpenBSD C Гбайт)
и раздел FreeBSD F Гбайт). В каждом из разделов OpenBSD и FreeBSD находит-
находится структура разметки диска с описанием дополнительных разделов. Далее будут
описаны два раздела BSD.
Пример образа OpenBSD
Начнем с обработки разметки диска OpenBSD. Раздел начинается в секторе 2 056 320,
и разметка диска находится во втором секторе:
# dd if=bsd-disk.dd skip=2056321 bs=512 count=l | xxd
0000000: 5745 5682 0500 0000 4553 4449 2f49 4445 WEB ESDI/IDE
0000016: 2064 6973 6b00 0000 4d61 7874 6f72 2039 disk...Maxtor 9
0000032: 3130 3234 4434 2020 0002 0000 3f00 0000 1024D4 ....?...
0000048: 1000 0000 ff3f 0000 f003 0000 fO2b 3101 ? +1.
0000064: 0000 0000 0000 0000 lOOe 0100 0000 0000
[... НУЛИ ]
0000128: 0000 0000 5745 5682 Ь65е 1000 0020 0000 ....WEV..A
0000144: 0000 0100 501f 0300 8060 lfOO 0004 0000 ....P.../
0000160: 0708 1000 eO61 0900 dO7f 2200 0004 0000 a...."
0000176: 0108 1000 fO2b 3101 0000 0000 0000 0000 +1
0000192: 0000 0000 501f 0300 bOel 2b00 0004 0000 ....P _
0000208: 0708 1000 8056 0200 0001 2f00 0004 0000 V..../
0000224: 0708 1000 0000 0000 0000 0000 0000 0000
0000240: 0000 0000 3f4b ЗсОО 00f8 4000 0004 0000 ....?K<...@
0000256: 0708 1000 80a0 Of00 8057 3100 0004 0000 Wl
0000272: 0708 1000 4160 lfOO 3f00 0000 0000 0000 ....A\ .?
0000288: 0800 0000 9dae ЬЗОО 3f43 7d00 0000 0000 ?C}
0000304: OaOO 0000 0000 0000 0000 0000 0000 0000
0000320: 0000 0000 0000 0000 0000 0000 0000 0000
0000336: 0000 0000 0000 0000 0000 0000 0000 0000
0000352: 0000 0000 0000 0000 0000 0000 0000 0000
0000368: 0000 0000 0000 0000 0000 0000 0000 0000
0000384: 0000 0000 0000 0000 0000 0000 0000 0000
0000400: 0000 0000 0000 0000 0000 0000 0000 0000
[...]
В байтах 0-3 и 132-135 присутствуют сигнатуры 0x825644557. После вто-
второй сигнатуры байты 138-139 показывают, что таблица разделов содержит 16
@x0010) записей. Таблица начинается в следующей строке с байта 148, продол-
продолжается шестнадцатью 16-байтовыми структурами и завершается в позиции 403.
Записи 11-16 не используются pi содержат нули. Оставшаяся часть сектора не
используется структурой разметки диска.
В табл. 6.4 приведены основные данные шестнадцати записей таблицы разде-
разделов. Десятичные эквиваленты заключены в скобки.
Таблица 6.4. Содержимое структуры разметки диска BSD в образе диска
Начало Размер Тип
1 0x001f6080 B 056 320) 0x00031f50 B04 624) 0x07 G)
2 0x00227fd0 B 260 944) 0х000961е0 F14 880) 0x01 A)
3 0x00000000 @) 0x01312bf0 A9 999 728) 0x00 @)
4 0x002belb0 B 875 824) 0x00031f50 B04 624) 0x07 G)
5 0x002f0100C 080 448) 0x00025680 A53 216) 0x07 G)
6 0x00000000 @) 0x00000000 @) 0x00 @)
7 0x0040f800 D 257 792) 0x003c4b3f C 951 423) 0x07 G)
8 0x00315780 C 233 664) 0x000fa080 A 024 128) 0x07 G)
9 OxOOOOOO3f F3) 0x001f6041 B 056 257) 0x08 (8)
10 0x007d433f (8 209 215) 0x00b3ae9d A1 775 645) OxOa A0)
Прежде чем переходить к подробному рассмотрению разделов, необходимо по-
познакомиться со специальными разделами BSD. Первый раздел — корневой — со-
содержит загрузочный код. Второй раздел хранит область подкачки, третий пред-
представляет весь диск, а четвертый и все последующие — произвольные разделы BSD.
Образ, использованный в нашем примере, соответствует этой схеме. Первый
раздел начинается вместе с разделом DOS в секторе 2 056 320. У второго разде-
раздела поле типа равно 1, что соответствует области подкачки. Третий раздел начи-
начинается в секторе 0, а его размер соответствует размеру всего диска. Разделы 4, 5,
7 и 8 относятся к типу 4.2BSD FFS, а их начальные секторы увеличиваются
вплоть до раздела 9. Раздел 9 начинается с сектора 63, а его тип соответствует
файловой системе FAT. Он представляет раздел FAT, описанный в первой за-
записи таблицы разделов DOS, в разметке диска BSD. Раздел 10 обладает неизве-
неизвестным типом. Он представляет раздел FreeBSD, который описан третьей запи-
записью в приведенной ранее таблице разделов DOS. Так как разделу 9 соответствует
буква «i», пользователь может обращаться к разделу FAT через имя /dev/wdOi.
Как говорилось ранее, OpenBSD игнорирует содержимое таблицы разделов DOS
после загрузки.
Таблица 6.5 показывает, какие разделы будут доступны для пользователя в си-
системе OpenBSD.
Таблица 6.5. Файловые системы, доступные в системе OpenBSD
Устройство Описание Точка Начальный Конечный сектор
монтирования сектор
/dev/wdOa 4.2FFS BSD / 2 056 320 2 260 943
/dev/wdOb Подкачка - 2 260 944 2 875 823
/dev/wdOc Весь диск - 0 19 999 727
/dev/wdOd 4.2FFS BSD /tmp/ 2 875 824 3 080 447
/dev/wdOe 4.2FFS BSD /home/ 3 080 448 3 233 663
/dev/wdOg 4.2FFS BSD /var/ 4 257 792 820 921
/dev/wdOh 4.2FFS BSD /usr/ 3 233 664 4 257 791
/dev/wdOi FAT Выбирается 63 2 056 319
пользователем
/dev/wdOj Раздел FreeBSD 8 209 215 19 984 859
Раздел FreeBSD нельзя смонтировать, потому что для этого необходимо сна-
сначала прочитать разметку диска для определения местонахождения файловой си-
системы. Для просмотра тех же данных из разметки диска можно воспользоваться
утилитой mm Ls, указав в командной строке тип bsd. Смещение раздела BSD долж-
должно задаваться с ключом -о, поскольку мы работаем с образом диска.
# mmls -t bsd -о 20563210 bsd-disk.dd
BSD Disk Label
Units are in 512-byte sectors
Slot Start End Length Description
00: 02 0000000000 0019999727 0019999728 Unused @x00)
01: 08 0000000063 0002056319 0002056257 MSDOS @x08)
02: 00 0002056320 0002260943 0000204624 4.2BSD @x07)
03: 01 0002260944 0002875823 0000614880 Swap @x01)
04: 03 0002875824 0003080447 0000204624 4.2BSD @x07)
05: 04 0003080448 0003233663 0000153216 4.2BSD @x07)
06: 07 0003233664 0004257791 0001024128 4.2BSD @x07)
07: 06 0004257792 0008209214 0003951423 4.2BSD @x07)
08: 09 0008209125 0019984859 0011776454 Unknown (OxOA)
Вспомните, что программа mm Ls сортирует выходные данные по начальному
сектору раздела, поэтому раздел FAT находится в начале, хотя он и занимает
восьмую позицию в таблице разделов (позиция указывается в столбце Slot).
Пример образа FreeBSD
Теперь давайте посмотрим, как выглядит раздел BSD в образе из нашего приме-
примера. Раздел начинается с сектора 8 209 215, а разметка диска находится во втором
секторе:
# dd if=bsd-disk.dd skip=8209216 bs=512 count=l | xxd
0000000: 5745 5682 0500 0000 6164 3073 3300 0000 WEV ad0s3...
0000016: 0000 0000 0000 0000 0000 0000 0000 0000
0000032: 0000 0000 0000 0000 0002 0000 3f00 0000 ?...
0000048: 1000 0000 814d 0000 f003 0000 fO2b 3101 M +1.
0000064: 0000 0000 0000 0000 lOOe 0100 0000 0000
[... НУЛИ ]
0000128: 0000 0000 5745 5682 b9ab 0800 0020 0000 ....WEV
0000144: 0000 0000 0000 0800 3f43 7d00 0008 0000 ?C}
0000160: 0708 0880 aO73 1700 3f43 8500 0000 0000 s..?C
0000176: 0100 0000 Ые8 ЬЗОО 3f43 7d00 0000 0000 ?C
0000192: 0000 0000 0000 0800 dfb6 9c00 0008 0000
0000208: 0708 0880 0000 0800 dfb6 9c00 0008 0000
0000224: 0708 0880 1175 8400 dfb6 a400 0008 0000 u
0000240: 0708 886f 0000 0000 0000 0000 0000 0000 ...o
0000256: 0000 0000 0000 0000 0000 0000 0000 0000
0000272: 0000 0000 ebOe 4254 5801 0180 f60f 8007 BTX
0000288: 0020 0000 fa31 c08e dObc 0018 8ec0 8ed8 . ...1
0000304: 666a 0266 9dbf OOle b900 3957 f3ab 5fbe fj.f 9W.._.
0000320: e296 ac98 91e3 ldac 92ad 93ad b608 dleb
0000336: 730b 8905 8875 0288 5505 83cO 048d 7dO8 S....U..U }.
[...]
По содержимому байтов 138-139 видно, что на диске создано восемь разделов.
Записи этих разделов находятся в байтах 148-275, а их расшифровка приводится
в табл. 6.6 (десятичные эквиваленты заключены в скобки).
Таблица 6.6. Содержимое структуры разметки диска BSD в образе диска FreeBSD
Начало Размер Тип
1 0x007d433f (8 209 215) 0x00080000 E24 288) 0x07 G)
2 0x0085433f (8 733 503) Ох001773аО A 536 928) 0x01 A)
3 0x007d433f (8 209 215) ОхООЬЗе8Ы A1 790 513) 0x00 @)
4 0x009cb6df A0 270 431) 0x00080000 E24 288) 0x07 G)
5 0x00a4b6df A0 794 719) 0x00080000 E24 288) 0x07 G)
6 0x00acb6df A1 319 007) 0x00847511 (8 680 721) 0x07 G)
7 0x00000000 @) 0x00000000 @) 0x00 @)
8 0x00000000 @) 0x00000000 @) 0x00 @)
Мы видим, что начальный сектор первого раздела BSD совпадает с началь-
начальным сектором раздела DOS, в котором находится разметка диска, и этот раздел
относится к типу 4.2BSD FFS. Вторая запись определяет область подкачки,
а третья относится только к секторам раздела DOS. Записи 4, 5 и 6 определяют
разделы с файловой системой FFS. В табл. 6.7 перечислены имена устройств
и приведены данные о местонахождении каждого раздела, доступного для поль-
пользователей FreeBSD.
Таблица 6.7. Файловые системы, доступные в системе FreeBSD
Устройство Описание Точка Начальный Конечный
монтирования сектор сектор
/dev/adOsl Раздел DOS FAT Выбирается 63 2 056 319
пользователем
/dev/ad0s2 Раздел DOS OpenBSD ~ 2 056 320 8 209 214
/dev/ad0s3a 4.2FFS BSD / 8 209 215 8 733 502
/dev/ad0s3b Область подкачки - 8 733 503 1027 430
/dev/ad0s3c Весь раздел DOS FreeBSD - 8 209 215 19 999 727
/dev/ad0s3d 4.2FFS BSD /tmp 10 270 431 10 794 718
/dev/ad0s3e 4.2FFS BSD /var 10 794 719 11319 006
/dev/ad0s3f 4.2FFS BSD /usr 11319 007 19 999 727
Для просмотра содержимого разметки диска можно воспользоваться програм-
программой mm Ls из пакета The Sleuth Kit. Результат выглядит так:
# mmls -t bsd -о 82092165 bsd-disk.dd
BSD Disk Label
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0008209214 0008209215 Unallocated
01: 00 0008209215 0008733502 0000524288 4.2BSD @x07)
02: 02 0008209215 0019999727 0011790513 Unused @x00)
03: 01 0008733503 0010270430 0001536928 Swap @x01)
04: 03 0010270431 0010794718 0000524288 4.2BSD @x07)
05: 04 0010794719 0011319006 0000524288 4.2BSD @x07)
06: 05 0011319007 0019999727 0008680721 4.2BSD @x07)
Обратите внимание: пространство, выделенное под разделы FAT и OpenBSD,
помечено как «нераспределенное», поскольку для него отсутствуют записи в размет-
разметке диска. Для распределения данных по разделам необходима таблица разделов DOS.
Факторы анализа
Каждый раздел BSD в структуре разметки диска содержит поле типа, но в системах
BSD оно играет менее важную роль, чем в Microsoft Windows, так как Windows
по содержимому поля типа определяет, нужно ли присваивать разделу букву диска
или нет. В системах BSD для каждой записи в разметке диска создается устрой-
устройство, поэтому разделы могут монтироваться с любым типом. Следовательно, не-
необходимо убедиться в том, что раздел не содержит известной файловой системы,
даже если тип идентифицирует его как старый формат UNIX, поскольку раздел
может содержать другую распространенную файловую систему (например, FAT).
Максимальный размер разметки диска равен 404 байтам. Для разметок дисков,
содержащих только восемь записей, структура данных занимает всего 276 байт.
Это означает, что оставшаяся часть 512-байтового сектора может использоваться
для хранения скрытых данных (хотя и относительно небольших). Если в резуль-
результате повреждения таблицы разделов DOS определить местонахождение раздела
BSD не удается, проведите поиск сигнатуры 0x82564557. Сигнатура должна на-
находиться в байте 0 и байте 132 структуры разметки диска.
Помните, что в системе FreeBSD пользователь получает доступ как к разде-
разделам DOS, так и к разделам BSD. Таким образом, в ходе экспертизы необходимо
анализировать как разделы DOS, так и разделы BSD. Учтите, что в системе может
отсутствовать поддержка NTFS, чтобы пользователь не мог смонтировать раздел
NTFS (если он существует).
В OpenBSD пользователь имеет доступ только к разделам, перечисленным
в разметке диска. Поскольку OpenBSD игнорирует таблицу разделов DOS, мо-
может быть полезно сравнить содержимое таблицы разделов DOS с разметкой дис-
диска BSD. Проанализируйте разделы BSD и DOS, выявите возможные перекрытия
и промежутки. На рис. 6.4 показаны интересные примеры разделов BSD. Один из
разделов BSD храшггся в разделе DOS с типом NTFS. Если раздел NTFS содер-
содержит файловую систему NTFS, такая ситуация маловероятна, и ее следует проана-
проанализировать подробнее. На рисунке также показан раздел BSD, созданный в про-
пространстве, которое не было выделено разделу DOS. С точки зрения системного
администратора так поступать не рекомендуется, потому что другая программа
может выделить пространство под раздел DOS и уничтожить данные BSD, одна-
однако такая возможность существует.
Рис. 6.4. Диск с двумя разделами BSD в разделе DOS с типом OpenBSD, разделом BSD
в разделе DOS с типом NTFS и разделом BSD, не входящим в раздел DOS
Итоги
Разделы BSD описываются простой структурой данных, называемой разметкой
диска. У эксперта могут возникнуть определенные трудности с идентификацией
всех данных, доступных для пользователя в анализируемой системе. Системы
семейства BSD часто используются на серверах, которые зачастую становятся
объектами криминальных и корпоративных расследований. Если эксперт хоро-
хорошо разбирается в разделах BSD, это повысит качество расследования.
Сегменты Sun Solaris
Операционная система Solaris компании Sun Microsystems используется на боль-
больших серверах и на настольных системах. В ней применяются две разные схемы
формирования разделов, выбор зависит от размера диска и версии Solaris. В Solaris
9 появилась поддержка файловых систем, размер которых превышает 1 Тбайт,
и используются таблицы разделов EFI с 64-разрядным полем адреса [Sum, 2003].
Во всех остальных версиях Solaris используются структуры данных, напоми-
напоминающие уже описанную разметку диска BSD. Более того, главная структура дан-
данных тоже называется разметкой диска, хотя и имеет несколько иное строение.
Впрочем, этому не приходится удивляться, если учесть, что структуры различа-
различаются даже на Solaris для платформ Sparc и 1386. Ситуация дополнительно услож-
усложняется тем, что имена структур данных Solaris совпадают с именами BSD, но из-
изменяется смысл терминов. Например, в Solaris сегментом (slice) называется любой
из разделов этой системы. Для простоты я буду использовать в этом разделе тер-
термин «раздел Solaris», однако следует помнить, что в других книгах чаще встречает-
встречается официальная терминология. Мы начнем с общих характеристик архитектуры
Solaris, затем познакомимся со специфическими особенностями структур данных
Sparc и в завершение займемся спецификой структур данных i386.
Общий обзор
При установке Solaris на диске создается структура разметки диска. Ее точное
местонахождение зависит от аппаратной платформы (см. далее). Максимальное
количество разделов, описываемых разметкой диска, ограничено: для систем Sparc
оно 8, адля1386 — 16.
Описание каждого раздела на диске состоит из начального сектора, размера,
набора флагов и типа. Флаги указывают, доступен ли раздел только для чтения
и не запрещено ли его монтирование (как для областей подкачки). В других сис-
системах разделов, представленных в книге, поле типа использовалось для описания
типа файловой системы, но в Solaris оно обычно описывает точку монтирования
раздела. Например, некоторые типы обозначают разделы home, usr или var, дру-
другие — область подкачки или нераспределенное пространство. Полный список ти-
типов приведен в разделе «Структуры данных».
В Solaris используется хитроумная, но хорошо масштабируемая схема выбора
имен разделов. В среде Solaris блочные устройства находятся в каталоге/dev/dsk,
а неструктурированные устройства (raw devices) — в каталоге /dev/rdsk. В этих
каталогах разделам Solaris (или сегментам) присваиваются имена вида cWtXdYsZ
в системах Sparc и cWdYsZ в системах i386. В этом шаблоне W — номер контрол-
контроллера, X — идентификатор физической шины (SCSI ID), Y — номер диска на шине,
a Z — номер сегмента на диске. Например, если в системе Sparc имеется только
один контроллер, идентификатор SCSI ID диска равен 6, то для обращения к сег-
сегменту 5 следует использовать имя /dev/rdsk/c0t6d0s5.
В Solaris записи разделов в таблице разметки диска обычно создаются на ос-
основании точки монтирования. Это не является обязательным требованием, но
на дисках с операционной системой часто используется схема, представленная
в табл. 6.8.
Таблица 6.8. Типичная структура разметки диска
Запись Описание
0 /root/partition — операционная система и ядр
1 Область подкачки
2 Весь диск, включая разметку и все разделы
3 /export/
4 /export/swap/
5 /opt/
6 /usr/
7 /home/
На дополнительных дисках, включаемых в систему, часто создается всего один
раздел, для которого используется запись 5, 6 или 7.
Структуры данных Sparc
В системах на базе Sparc структура разметки диска создается в первом секторе
диска (сектор 0). Секторы 1-15 содержат загрузочный код системы, а в секторах
16 и далее создаются разделы для хранения файловых систем и областей подкач-
подкачки. В Solaris используется файловая система UFS; как будет показано в главе 16,
эта файловая система начинается с сектора 16. Пример строения диска Sparc по-
показан на рис. 6.5 и в табл. 6.9.
Рис. 6.5. Строение диска Sun Sparc: разметка диска и загрузочный код находятся в первом разделе
Таблица 6.9. Структура данных разметки диска Sun Sparc
Диапазон байтов Описание Необходимость
0-127 Метка в кодировке ASCII Нет
128-261 Sparc VTOC (см. табл. 6.10) Да
262-263 Пропускаемые секторы (модификация) Нет
264-265 Пропускаемые секторы (чтение) Нет
266-419 Зарезервировано Нет
420-421 Скорость диска Нет
422-423 Количество физических цилиндров Нет
424-^425 Коэффициент дублирования цилиндров Нет
426-429 Зарезервировано Нет
430-431 Коэффициент чередования Нет
432-433 Количество цилиндров данных Нет
Диапазон байтов Описание Необходимость
434-435 Количество альтернативных цилиндров Нет
436-437 Количество головок Да
438-439 Количество секторов в дорожке Да
440-443 Зарезервировано Нет
444-^51 Карта диска для раздела 1 (см. табл. 6.13) Да
452-459 Карта диска для раздела 2 (см. табл. 6.13) Да
460-467 Карта диска для раздела 3 (см. табл. 6.13) Да
468-475 Карта диска для раздела 4 (см. табл. 6.13) Да
476-483 Карта диска для раздела 5 (см. табл. 6.13) Да
484-491 Карта диска для раздела 6 (см. табл. 6.13) Да
492-499 Карта диска для раздела 7 (см. табл. 6.13) Да
500-507 Карта диска для раздела 8 (см. табл. 6.13) Да
508-509 Сигнатура (OxDABE) Нет
510-511 Контрольная сумма Нет
В байтах 128-261 находится оглавление тома (VTOC). Эта структура содер-
содержит общее количество разделов (байты 12-13), а также флаги, тип и временной
штамп для каждого раздела. Поля VTOC перечислены в табл. 6.10.
Таблица 6.10. Структура данных VTOC в разметке диска Sun Sparc
Диапазон байтов Описание Необходимость
0-3 Версия @x01) Нет
4-11 Имя тома Нет
12-13 Количество разделов Да
14-15 Тип раздела 1 (см. табл. 6.11) Нет
16-17 Флаги раздела 1 (см. табл. 6.12) Нет
18-19 Тип раздела 2 (см. табл. 6.11) Нет
20-21 Флаги раздела 2 (см. табл. 6.12) Нет
22-23 Тип раздела 3 (см. табл. 6.11) Нет
24-25 Флаги раздела 3 (см. табл. 6.12) Нет
26-27 Тип раздела 4 (см. табл. 6.11) Нет
28-29 Флаги раздела 4 (см. табл. 6.12) Нет
30-31 Тип раздела 5 (см. табл. 6.11) Нет
32-33 Флаги раздела 5 (см. табл. 6.12) Нет
34-35 Тип раздела 6 (см. табл. 6.11) Нет
36-37 Флаги раздела 6 (см. табл. 6.12) Нет
38-39 Тип раздела 7 (см. табл. 6.11) Нет
40-41 Флаги раздела 7 (см. табл. 6.12) Нет
42-43 Тип раздела 8 (см. табл. 6.11) Нет
44-45 Флаги раздела 8 (см. табл. 6.12) Нет
46-57 Загрузочная информация Нет
58-59 Зарезервировано Нет
60-63 Сигнатура @x600DDEEE) Нет
64-101 Зарезервировано Нет
102-105 Временной штамп раздела 1 Нет
Таблица 6.10 {продолжение)
Диапазон байтов Описание Необходимость
106-109 Временной штамп раздела 2 Нет
110-113 Временной штамп раздела 3 Нет
114-117 Временной штамп раздела 4 Нет
118-121 Временной штамп раздела 5 Нет
122-125 Временной штамп раздела 6 Нет
126-129 Временной штамп раздела 7 Нет
130-133 Временной штамп раздела 8 Нет
Поле типа каждого раздела VTOC указывает, для чего используется данный
раздел и где он должен монтироваться. Тем не менее при монтировании файло-
файловых систем операционная система руководствуется специальным конфигураци-
конфигурационным файлом. Таким образом, даже если раздел помечается типом /usr/, это еще
не означает, что он будет смонтирован как/usr/. В отличие от других систем, струк-
структура разметки диска Solaris не задает тип файловой системы для каждого раздела.
Допустимые значения типов разделов перечислены в табл. 6.11.
Таблица 6.11. Типы разделов Sun (для Sparc и i386)
Значение Описание Значение Описание
0 Не задано 6 Раздел /stand/
1 Раздел /boot/ 7 Раздел /var/
2 Раздел / 8 Раздел /home/
3 Раздел подкачки 9 Прочие разделы
4 Раздел /usr/ 10 Раздел cachefs
5 Весь диск
Каждый раздел также обладает полем флагов. Допустимые значения флагов пе-
перечислены в табл. 6.12 (установка хотя бы одного флага для раздела не обязательна).
Таблица 6.12. Значения флагов для разделов Sun (для Sparc и i386)
Значение Описание
1 Раздел не может монтироваться
128 Раздел доступен только для чтения
Вся эта информация полезна, но в контексте нашего обсуждения самой важ-
важной частью разметки диска является местонахождение разделов. Начальный ци-
цилиндр и размер каждого раздела хранятся в структурах карты диска, а не в VTOC.
Карта диска находится в конце структуры разметки диска, а поля ее записей пере-
перечислены в табл. 6.13.
Таблица 6,13, Структура данных карты диска Sun Sparc
Диапазон байтов Описание Необходимость
0-3 Начальный цилиндр Да
4-7 Размер Да
Однако нас интересует начальный сектор, а не цилиндр, поэтому значение при-
придется преобразовать — к счастью, это делается несложно. Вспомните, что цилиндр
X состоит из дорожек X на каждой пластине диска. Чтобы преобразовать адрес
цилиндра в адрес сектора, следует умножить адрес цилиндра на количество сек-
секторов в дорожке и количество головок (оба значения находятся в структуре раз-
разметки диска).
Для примера возьмем диск с 15 головками и 63 секторами на дорожку. Если
адрес начального цилиндра равен 1 112, вычисление дает следующий результат:
63 * 15 * 1112 - 1 050 840
Таким образом, мы должны обратиться к сектору 1 050 840 и проанализиро-
проанализировать данные при помощи программ с поддержкой схемы адресации LBA.
Давайте рассмотрим пример с реальными структурами в шестнадцатеричном
виде. Далее приводится содержимое первого сектора жесткого диска Solaris Sparc:
# dd if=sparc-disk.dd bs=512 count=l | xxd
0000000: 4d61 7874 6f72 2038 3532 3530 4136 2063 Maxtor 85250A6 с
0000016: 796c 2031 3038 3534 2061 6c74 2032 2068 yl 10854 alt 2 h
0000032: 6420 3135 2073 6563 2036 3300 0000 0000 d 15 sec 63
0000048: 0000 0000 0,000 0000 0000 0000 0000 0000
Г... НУЛИ ]
0000128: 0000 0001 0000 0000 0000 0000 0008 0002
0000144: 0000 0003 0001 0005 0000 0000 0000 0000
0000160: 0000 0007 0000 0004 0000 0008 0000 0000
0000176: 0000 0000 0000 0000 0000 0000 600d deee
[... НУЛИ ]
0000416: 0000 0000 1518 2a68 0000 0000 0000 0001 *h
0000432: 2a66 0002 OOOf 003f 0000 0000 0000 0826 *f ? &
0000448: 0020 bO6b 0000 0000 0010 0176 0000 0000 . .k v....
0000464: 009c 8286 0000 0000 0000 0000 0000 0000
0000480: 0000 0000 0000 0609 0007 cdOd 0000 1101
0000496: 005d bdd5 0000 0458 0006 3e61 dabe lffe .]....X..>a....
На платформе Sparc используется обратный порядок байтов, поэтому числа
переставлять не нужно. В первых восьми строках содержится 128-байтовая метка
в кодировке ASCII, описывающая тип жесткого диска. Таблица VTOC начинается
с позиции 128; байты 140-141 показывают, что структура содержит 8 разделов.
В байтах 142-173 перечислены типы B байта) и флаги B байта) для каждого разде-
раздела. Так, тип первого раздела содержится в байтах 142-143, и значение поля равно 2,
что соответствует разделу/. Флаги хранятся в байтах 144-145, значение поля равно
0. Байты 146-147 показывают, что второй раздел относится к типу 3 (область под-
подкачки), а поле флагов в байтах 148-149 равно 1 (раздел не монтируется).
В байтах 436-437 приводится количество головок 15 (OxOf), а в байтах 438-
439 — количество секторов на дорожку 63 @x3f)- Эти данные понадобятся для
преобразования адресов цилиндров.
Карта диска начинается с байта 444; начальный цилиндр и размер задаются 4-
байтовыми числами. У первого раздела начальный цилиндр равен 2 086 @x00000826),
а размер — 2 142 315 @x0020b06b). Вспомните, что разделу назначен тип /. На-
Начальный сектор вычисляется по следующей формуле:
15 * 63 * 2 086 - 1 971 270
Раздел находится в первой позиции таблицы, поэтому он будет считаться «сег-
«сегментом 0» диска, хотя он отдален от начала диска на многие тысячи секторов.
Описание следующего раздела хранится в байтах 452-459, с начальным цилинд-
цилиндром 0 и размером 1 048 950 @x00100176). Это пространство подкачки, соответ-
соответствующее «сегменту 1». Третья запись таблицы разделов, «сегмент 2», обычно
представляет весь диск и находится в байтах 460-467. В нашем примере ее на-
начальный цилиндр равен 0, а размер составляет 10 257 030 секторов.
Существует несколько программ, позволяющих просмотреть содержимое раз-
разметки диска Sparc, но не все они могут использоваться в процессе экспертизы.
Команды Solaris format и prvtoc работают только с устройствами, но не с файлами
образов устройств. С другой стороны, команда Linux fdisk успешно работает с об-
образами дисков Sparc. Также можно запустить программу mm Ls из пакета The Sleuth
Kit с параметром -t sun. Для образа диска из рассматриваемого примера програм-
программа mm Ls выдала следующий результат:
# mmls -t sun sparc-disk.dd
Sun VTOC
Units are in 512-byte sectors
Slot Start End Length Description
00: 01 0000000000 0001048949 0001048950 swap @x03)
01: 02 0000000000 0010257029 0010257030 backup @x05)
02: 07 0001050840 0001460024 0000409185 /home/ @x08)
03: 05 0001460025 0001971269 0000511245 /var/ @x07)
04: 00 0001971270 0004113584 0002142315 / @x02)
05: 06 0004113585 0010257029 0006143445 /usr/ @x04)
Структуры данных i386
Перед установкой Solaris в системе i386 необходимо предварительно создать один
или несколько разделов DOS. В типичной установке создается загрузочный раз-
раздел (тип раздела DOS OxBE) и раздел с файловыми системами (тип раздела DOS
0x82). Загрузочный раздел содержит загрузочный код, необходимый для запуска
системы, и файловая система как таковая в нем отсутствует. Структура разметки
диска находится во втором секторе раздела файловой системы DOS (тип 0x82)
и описывает строение разделов Sun внутри раздела DOS. Все разделы Sun долж-
должны начинаться за началом раздела DOS. На рис. 6.6 показан диск с тремя раздела-
разделами DOS; последний раздел содержит разметку диска и три раздела Sun.
Структура разметки диска занимает 512 байт, и работать с ней удобнее, чем со
Sparc-версией, потому что вся информация о разделах хранится в одном месте. Дру-
Другое преимущество 1386-версии состоит в том, что при хранении информации ис-
используется адресация LBA (а не CHS). Помимо этих различий, две структуры очень
похожи. Первые 456 байтов разметки диска называются оглавлением тома, или VTOC
(Volume Table Of Contents); здесь хранится информация о разделах, их количестве,
размере сектора и т. д. Структура данных разметки диска приведена в табл. 6.14.
Таблица 6,14. Структура данных разметки диска Sun i386
Диапазон байтов Описание Необходимость
0-11 Загрузочная информация Нет
12-15 Сигнатура @x600DDEEE) Нет
16-19 Версия Нет
Диапазон байтов Описание Необходимость
20-27 Имя тома Нет
28-29 Размер сектора Да
30-31 Количество разделов Да
32-71 Зарезервировано Нет
72-83 Раздел 1 (см. табл. 6.15) Да
84-95 Раздел 2 (см. табл. 6.15) Да
96-107 Раздел 3 (см. табл. 6.15) Да
108-119 Раздел 4 (см. табл. 6.15) Да
120-131 Раздел 5 (см. табл. 6.15) Да
132-143 Раздел 6 (см. табл. 6.15) Да
144-155 Раздел 7 (см. табл. 6.15) Да
156-167 Раздел 8 (см. табл. 6.15) Да
168-179 Раздел 9 (см. табл. 6.15) Да
180-191 Раздел 10 (см. табл. 6.15) Да
192-203 Раздел 11 (см. табл. 6.15) Да
204-215 Раздел 12 (см. табл. 6.15) Да
216-227 Раздел 13 (см. табл. 6.15) Да
228-239 Раздел 14 (см. табл. 6.15) Да
240-251 Раздел 15 (см. табл. 6.15) Да
252—263 Раздел 16 (см. табл. 6.15) Да
264-327 Временные штампы (не используется) Нет
328-^55 Метка тома Нет
456-507 Сведения об оборудовании Нет
508-509 Сигнатура (OxDABE) Нет
510-511 Контрольная сумма Нет
Рис. 6.6. Диск i386 Sun с тремя разделами DOS. Последний раздел содержит
разметку диска и три раздела Sun
Каждая из 16 записей разделов имеет структуру, показанную в табл. 6.15.
Таблица 6.15- Структура записи раздела в разметке диска Sun 1386
Диапазон байтов Описание Необходимость
0-1 Тип раздела (см. табл. 6.11) Нет
2-3 Флаг (см. табл. 6.12) Нет
4-7 Начальный сектор Да
8-11 Размер в секторах Да
В полях типа и флагов используются те же значения, которые прршодились
ранее для структур данных Sparc. Для идентификации разделов в Solaris на плат-
платформе i386 необходимо проанализировать записи разделов VTOC и определить
их структуру по начальному сектору и размеру. Начальный сектор задается по
отношению к разделу DOS (с типом 0x82). В нашем примере раздел DOS с раз-
разметкой диска начинается с сектора 22 496. Следовательно, разметка диска нахо-
находится в секторе 22 497:
# dd if=1386-disk.dd bs=512 skip=22497 | xxd
0000000: 0000 0000 0000 0000 0000 0000 eede 0d60 '
0000016: 0100 0000 0000 0000 0000 0000 0002 1000
0000032: 0000 0000 0000 0000 0000 0000 0000 0000
0000048: 0000 0000 0000 0000 0000 0000 0000 0000
0000064: 0000 0000 0000 0000 0200 0000 cOOe 1000
0000080: 0082 3e00 0300 0100 dOOb 0000 f002 1000 ..>
0000096: 0500 0000 0000 0000 309a 7001 0000 0000 0.p
0000112: 0000 0000 0000 0000 0000 0000 0000 0000
0000128: 0000 0000 0400 0000 c090 4e00 2000 faOO N. ...
0000144: 0000 0000 0000 0000 0000 0000 0800 0000
0000160: e090 4801 0041 lfOO 0100 0100 0000 0000 ..H..A
0000176: f003 0000 0900 0100 f003 0000 e007 0000
[... НУЛИ]
0000320: 0000 0000 0000 0000 4445 4641 554c 5420 DEFAULT
0000336: 6379 6c20 3233 3936 3420 616c 7420 3220 cyl 23964 alt 2
[... НУЛИ]
0000448: 0000 0000 0000 0000 0000 0000 0000 0000 ]...]..
0000464: 0200 0000 1000 0000 3f00 0000 0100 0000 ?
0000480: 0000 lOOe 0000 0000 0000 0000 0000 0000
0000496: 0000 lOOe 0000 0000 0000 0000 beda a24a ]
Данные получены в системе i386, в которой используется прямой порядок бай-
байтов. По значению со смещением 30 мы видим, что таблица содержит 16 разделов
@x10). Первая запись раздела начинается со смещением 72 и заканчивается со
смещением 83. Байты 72-73 показывают, что запись имеет тип 0x02, то есть пред-
представляет корневой раздел. Начальный сектор в байтах 76-79 равен 1 052 352
(ОхООЮОЕСО). Байты 80-83 указывают размер раздела; мы видим, что он равен
4 096 512 @х003е8200). В данной разметке используются 10 разделов, описание
последнего находится в байтах 180-191. Все временные штампы равны нулю, а имя
тома состоит из слова DEFAULT и параметров геометрии диска.
Для получения информации о местонахождении загрузочного раздела и раз-
разделов файловых систем из образа диска i386 молено воспользоваться любой про-
программой, работающей с разделами DOS. При запуске mmls для диска Solaris на
платформе i386 был получен следующий результат:
# mmls -t dos i386-disk.dd
DOS Partition Table
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0000000000 0000000001 Primary Table (#0)
01: 0000000001 0000001007 0000001007 Unallocated
02: 00:00 0000001008 0000021168 0000021168 Solaris 8 Boot (OxBE)
03: 0000022176 0000000320 0000000320 Unallocated
04: 00:01 0000022496 0024180911 0024158416 Linux swap / Solaris x86 @x82)
Напомню, что раздел типа ОхВЕ предназначен для загрузочного кода, файло-
файловая система в нем отсутствует. Файловые системы и структуры разметки диска
хранятся в разделах типа 0x82. Ту же информацию можно получить, запустив ути-
утилиту fdisk в Linux, но fdisk не включает разделы Solaris в разметку диска. Чтобы
просмотреть содержимое файловой системы, либо извлеките раздел, начиная с сек-
сектора 22 496, либо просто вызовите mmls и укажите смещение с параметром -о:
# mmls -t sun -о 22496 disk8.dd
Sun VTOC
Units are in 512-byte sectors
Slot Start End Length Description
00: 02 0000000000 0024156719 0024156720 backup @x05)
01: 08 0000000000 0000001007 0000001008 boot @x01)
02: 09 0000001008 0000003023 0000002016 alt sector @x09)
03: 01 0000003024 0001052351 0001049328 swap @x03)
04: 00 0001052352 0005148863 0004096512 / @x02)
05: 05 0005148864 0021532895 0016384032 /usr/ @x04)
06: 07 0021532896 0023581151 0002048256 /home/ @x08)
Как говорилось ранее, адреса задаются по отношению к началу раздела DOS,
поэтому при извлечении данных программой dd необходимо увеличивать адреса
всех начальных секторов на 22 496. Эксперименты показали, что при загрузке
Linux с диском Solaris i386, подключенным как один из ведомых (slave) дисков,
Linux создает устройства только для первых восьми разделов Solaris. Для всех
последующих разделов устройства не создаются.
Факторы анализа
При анализе разделов Solaris действуют те же особые соображения, что и при ана-
анализе других систем разделов. Структура разметки диска содержит неиспользуе-
неиспользуемые поля, в которых могут находиться скрытые данные (хотя объем этого скры-
скрытого пространства невелик).
Как и в других системах разделов, поле типа в описании раздела не имеет стро-
строго обязательного смысла. Даже если в структуре разметки диска сказано, что раз-
раздел является разделом /var/ или содержит область подкачки, это еще не значит,
что это действительно так. Как всегда, проведите поиск неиспользуемого простран-
пространства на диске.
Если местонахождение разметки диска неизвестно, попробуйте провести по-
поиск по сигнатурам. Сигнатура 0x600DDEEE находится внутри разметки диска,
а сигнатура OxDABE хранится в байтах 508-509.
Итоги
Системы Solaris часто встречаются в корпоративных сетях и часто становятся
объектом экспертного анализа при попытках взлома и мошенничества. В этой
части книги было показано, как организованы диски Solaris и как вывести или
извлечь соответствующую служебную информацию. Структура разметки диска
относительно проста, а для ее чтения можно воспользоваться программами fdisk и
mmls.
Разделы GPT
Системы с 64-разрядными процессорами Intel Itanium (IA64), в отличие от си-
систем IA32, не имеют BIOS. Вместо этого в них используется интерфейс EFI
(Extensible Firmware Interface). EFI (http://www.inteL.com/technology/efi) работа-
работает не только на платформе Intel, но и на других платформах — например, в систе-
системах Sun Sparc. В EFI применяется система разделов GPT(GXJID Partition Table),
поддерживающая до 128 разделов с 64-разрядной адресацией LBA. На случай сбоя
в системе хранятся резервные копии важных структур данных. На момент напи-
написания книги диски GPT применялись на мощных серверах и практически не встре-
встречались в типичных настольных системах.
Общий обзор
Диск GPT состоит из пяти основных областей (рис. 6.7). Первая — защитная об-
область MBR — начинается в первом секторе диска и содержит таблицу разделов
DOS с единственной записью. Запись представляет раздел типа ОхЕЕ, распрост-
распространяющийся на весь диск. Этот раздел существует для того, чтобы старые компь-
компьютеры распознавали диск как используемый и не пытались форматировать его.
В действительности EFI не использует разделы в традиционном смысле.
Рис. 6.7. Диск GPT состоит из пяти областей
Вторая область диска GPT начинается с сектора 1 и содержит заголовок GPT.
Заголовок определяет размер и местонахождение таблицы разделов, которое фик-
фиксируется при создании диска GPT. В системе Windows количество разделов в таб-
таблице ограничивается 128 [Microsoft, 2004]. Заголовок также содержит контроль-
контрольную сумму заголовка и таблицы разделов, что позволяет обнаруживать ошибки
и посторонние изменения.
Третья область содержит таблицу разделов. Каждая запись таблицы содержит
начальный и конечный адреса, код типа, имя, флаги атрибутов и значение GUID.
128-разрядный код GUID является уникальным для данной системы и задается
при создании таблицы разделов.
Четвертая область диска — область раздела. Она занимает наибольшее диско-
дисковое пространство и содержит секторы, распределяемые по разделам. Начальный
и конечный секторы этой области определяются в заголовке GPT. В последней
области диска хранятся резервные копии заголовка GPT и таблицы разделов. Ре-
Резервная область хранится в секторе, следующем за областью раздела.
Структуры данных
В первой области диска GPT используется стандартная таблица разделов DOS,
уже рассматривавшаяся ранее. Диск GPT с таблицей разделов DOS содержит един-
единственную запись раздела, занимающего весь диск. Пример:
# mmls -t dos gpt-disk.dd
DOS Partition Table
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0000000000 0000000001 Primary Table (#0)
01: 00:00 0000000001 0120103199 0120103199 GPT Safety Partition (OxEE)
После таблицы разделов DOS следует сектор 1 с заголовком GPT, описываю-
описывающим строение диска. Структура данных заголовка представлена в табл. 6.16.
Таблица 6.16. Структура данных заголовка GPT
Диапазон байтов Описание Необходимость
0-7 Сигнатура («EFI PART») Нет
8-11 Версия Да
12-15 Размер заголовка GPT в байтах Да
16-19 Контрольная сумма заголовка GPT (CRC32) Нет
20-23 Зарезервировано Нет
24-31 Адрес LBA текущей структуры заголовка GPT Нет
32-39 Адрес LBA другой структуры заголовка GPT Нет
40-47 Адрес LBA начала области раздела Да
48-55 Адрес LBA конца области раздела Нет
56-71 Код GUID диска Нет
72-79 Адрес LBA начала таблицы разделов Да
80-83 Количество записей в таблице разделов Да
84-87 Размер каждой записи в таблице разделов Да
88-91 Контрольная сумма таблицы разделов (CRC32) Нет
92-конец сектора Зарезервировано Нет
По этим значениям можно полностью определить структуру диска, включая
местонахождени е таблицы разделов, области разделов и резервных копий заго-
заголовка GPT и таблицы разделов.
Заголовок GPT для образа диска выглядит так:
# dd if=gpt-disk.dd bs=512 skip=l count=l | xxd
0000000: 4546 4920 5041 5254 0000 0100 5c00 0000 EFI PART...A...
0000016: 8061 аЗЬО 0000 0000 0100 0000 0000 0000 .a
0000032: lfal 2807 0000 0000 2200 0000 0000 0000 .. ( "
0000048: feaO 2807 0000 0000 7e5e 4dal 1102 5049 ..( -AM...PI
0000064: ab2a 79a6 Зеаб 3859 0200 0000 0000 0000 .*y.>.8Y
0000080: 8000 0000 8000 0000 69a5 7180 0000 0000 i.q
0000096: 0000 0000 0000 0000 0000 0000 0000 0000
Первые 8 байт содержат сигнатуру. Байты 12-15 показывают, что размер заго-
заголовка GPT составляет 96 байт @х5с). Согласно байтам 32-39, резервная копия
заголовка хранится в секторе 120 103 199 @x0728alaf). Обратите внимание: этот
же сектор был указан в качестве последнего сектора защитного раздела DOS. Бай-
Байты 40-47 показывают, что область раздела начинается с сектора 34 @x22) и завер-
завершается в секторе 120 103 166 @x0728a0fe). Из байтов 72-79 мы узнаем, что таб-
таблица разделов начинается с сектора 2, а из байтов 80-83 — что таблица содержит
128 @x80) записей. Байты 84-87 показывают, что размер каждой записи составля-
составляет 128 @x80) байт; это означает, что для хранения таблицы потребуются 32 сектора.
По информации из заголовка GPT можно вычислить начало и конец таблицы раз-
разделов, а также размер каждой записи. В табл. 6.17 перечислены поля записей таблицы.
Таблица 6-17. Структура данных записей таблицы разделов GPT
Диапазон байтов Описание Необходимость
0-15 Код GUID типа раздела Нет
16-31 Уникальный код GUID раздела Нет
32-39 Начальный адрес LBA раздела Да
40-47 Конечный адрес LBA раздела Да
48-55 Атрибуты раздела Нет
56-127 Имя раздела в Юникоде Нет
128-разрядное поле типа идентифицирует содержимое раздела. В дисках GPT
разделы используются для хранения как системной информации, так и файло-
файловых систем. Например, каждый компьютер с EFI должен содержать системный
раздел EFI с файлами, необходимыми для инициализации аппаратной и программ-
программной части системы. Значения типов назначаются фирмами-производителями; к со-
сожалению, централизованного списка в настоящее время не существует. В специ-
спецификации Intel определены типы разделов, перечисленные в табл. 6.18.
Таблица 6.18. Типы разделов GPT, определенные в спецификации Intel
GUID Описание
00000000-0000-0000-0000-0000000000 Свободная запись
C12A7328-F81F-11D2-BA4B-00A0C93EC93B Системный раздел EFI
024DEE41-33E7-lld3-9D69-0008C781F39F Раздел с таблицей разделов DOS
Компания Microsoft также определила некоторые значения типов, используе-
используемые в ее продуктах (табл. 6.19).
Таблица 6.19. Типы разделов GPT, определенные в спецификации Microsoft
GUIP Описание
E3C9E316-05BC-4DB8-817D-f92DF00215AE Зарезервированный раздел Microsoft (MRP)
EBD0A0A2-B9E5-4433-87C0-68B6B72699C7 Первичный раздел (базовый диск)
5808C8AA-7E8F-42E0-85D2-E1E90434CFB3 Раздел метаданных LDM (динамический диск)
AF9B60A0-1431-4F62-BC68-3311714A69AD Раздел данных LDM (динамический диск)
В системе Windows зарезервированный раздел используется для хранения вре-
временных файлов и данных. Первичный раздел содержит файловую систему. Пер-
Первичные разделы схожи с первичными разделами, которые мы видели при изуче-
изучении разделов DOS. Раздел метаданных LDB и раздел данных LDM используются
в динамических дисках Microsoft, о которых речь пойдет в следующей главе. Ди-
Динамические диски предназначены для объединения содержимого нескольких дис-
дисков в один том.
64-разрядное поле атрибутов разделено на три части. Установка младшего бита
означает, что функционирование системы невозможно без этого раздела. На ос-
основании этого бита система проверяет, можно ли удалить раздел. Значения битов
1-47 не определены, а биты 48-63 могут содержать произвольную информацию
для раздела данного типа. Каждый тип разделов использует эти значения по сво-
своему усмотрению.
Приведу содержимое записи таблицы разделов в простейшей системе:
# dd if=gpt-disk.dd bs=512 skip=341 dd bs=128 skip=3 count=l | xxd
0000000: 16e3 c9e3 5c0b b84d 817d f92d f002 15ae ... Л..М.}.-....
0000016: 2640 69eb 2f99 1942 afcO d673 7c0b 8ae4 &@i./..B...s|...
0000032: 2200 0000 0000 0000 0080 ЗеОО 0000 0000 " >
0000048: 0000 0000 0000 0000 0000 ffff ffff ffff
0000064: ffff ffff ffff ffff ffff ffff ffff ffff
В верхней строке (байты 0-15) мы видим код GUID типа раздела, а во второй
(байты 16-31) — код GUID самого раздела. Начальный адрес раздела хранится
в байтах 32-39; раздел начинается с сектора 32 @x0022). Конечный адрес раздела
задается байтами 40-47 и равен 4 096 000 @х003Е8000).
Пример выполнения mmls:
# mmls -t gpt gpt-disk.dd
GUID Partition Table
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0000000000 0000000001 Safety table
01: 0000000001 0000000001 0000000001 GPT Header
02: 0000000002 0000000033 0000000032 Partition Table
03: 00 0000000034 0004096000 0004095967
04: 01 0004096001 0012288000 0008192000
В конце диска находятся резервные копии заголовка GPT и таблицы разделов.
Они следуют в обратном порядке: заголовок GPT хранится в последнем секторе,
а таблица разделов — в предыдущем. В нашем примере резервный заголовок GPT
находится в секторе 120 103 199.
Факторы анализа
На момент написания книги диски GPT встречались крайне редко, и в докумен-
документации большинства системных программ ничего не говорится о поддержке GPT.
Linux позволяет разбить диск GPT на разделы для последующего применения
других программ анализа файловой системы. Пакет The Sleuth Kit тоже поддер-
поддерживает разделы GPT.
Резервная копия таблицы разделов в дисках GPT упрощает восстановле-
восстановление системы в случае повреждения исходной таблицы. Неиспользуемые байты
сектора 0, сектора 1 и всех свободных записей в таблице разделов могут ис-
использоваться для хранения скрытых данных.
Итоги
На момент написания книги разделы GPT довольно редко встречались при про-
проведении расследований и не поддерживались многими средствами экспертного
анализа. Несомненно, в будущем, с переходом многих систем на 64-разрядную
базу, ситуация изменится. Разделы GPT существенно превосходят разделы DOS
по гибкости и простоте.
Библиография
• FreeBSD Documentation Project. «FreeBSD Handbook», 2005. http://www.freebsd.org.
• Holland, Nick, ed. «OpenBSD Installation Guide». January 2005. http://www.open-
bsd.org/faq/faq4.html.
• Intel. Extensible Firmware Interface, Version 1.10, December 1, 2002. http://deve-
loper.intel.com/technology/efi/.
• Marshall Kirk McKusick, Keith Bostic, Michael Karels, John Quaterman. The Design
and Implementation of the 4.4 BSD Operating System. Boston: Addison Wesley, 2005.
• Marshall Kirk McKusick, George V. Nevile-Neil. The Design and Implementation of
the BSD Operating System. Boston: Addison Wesley, 2005.
• Mauro, Jim, and Richard McDougall. Solaris Internals: Core Kernel Architecture.
Upper Saddle River: Sun Microsystems Press, 2001.
• Microsoft. «Disk Sectors on GPT Disks». Windows XP Professional Resource Kit
Documentation, 2004. http://www.microsoft.com/resources/documentation/Windows/
XP/all/reskit/en-us/Default.aspTurU/resources/documentation/Windows/XP/aLL/reskit/
en-us/prkd_tro_zkfe.asp.
• Sun. «Solaris 9 System Administration Guide: Basic Administration. Chapter 31».
May 2002. http://docs.sun.com/db/doc/806-4073/6jd67r9fn?a=view.
• Sun. «System Administration Guide. Chapter 32: Managing Disks». April 2003.
http://docsun.cites.uiuc.edu/sun-docs/C/solaris_9/SUNWaadm/SYSADVl/pll7.htmL
• Winsor, Janice. Solaris System Administrator's Guide. 3rd edition. Palo Alto: Sun
Microsystems Press, 2000.
Многодисковые тома
На многих особо важных серверах устанавливается по несколько дисков — тем
самым повышается быстродействие, надежность и масштабируемость файловой
системы. Система объединяет диски и интерпретирует их как единое целое. В этой
главе рассматриваются системы RAID и объединенные дисковые системы. При
анализе систем с многодисковыми томами часто возникают проблемы, и далеко
не все из них были решены. В этой главе объясняются технологические основы
обеих систем томов и приводятся некоторые рекомендации по анализу и снятию
данных. Вероятно, из всех глав книги именно эта быстрее всего устареет из-за
развития новых типов носителей информации и развития новых технологий ана-
анализа. Первая половина главы посвящена системам RAID, обеспечивающим из-
избыточность при хранении данных, а вторая — объединению дисков с целью созда-
создания томов большей емкости.
RAID
Сокращение RAID происходит от слов «Redundant Arrays of Inexpensive Disks»
(«Массив недорогих дисковых накопителей с избыточностью»). Технологии RAID
обычно применяются в высокопроизводительных или особо важных системах.
Концепция RAID впервые была предложена в конце 1980-х годов с целью исполь-
использования недорогих дисков для достижения показателей быстродействия и емкос-
емкости, присущих дорогим высокопроизводительным дискам [Patterson, et al., 1988].
Основной принцип RAID —использование нескольких дисков вместо одного для
создания избыточности и ускорения работы с диском. Аппаратный контроллер
или программный драйвер осуществляют логическое объединение дисков, и ком-
компьютер видит один большой том.
Прежде системы RAID использовались только в высокопроизводительных сер-
серверах, но сейчас они все чаще встречаются в настольных системах. Так, системы
Microsoft Windows NT, 2000 и ХР позволяют реализовать некоторые уровни RAID.
Мы начнем с описания технологии, задействованной в работе с системами RAID,
а затем перейдем к вопросам снятия и анализа данных в системах RAID. При со-
создании разделов в томах RAID могут использоваться любые методы, представ-
представленные в главах 5 и 6.
Уровни RAID
Существует несколько уровней технологии RAID, обеспечивающих разный вы-
выигрыш по надежности и быстродействию. Далее мы рассмотрим шесть уровней
RAID. Томом RAID называется том, сформированный устройством или програм-
программой, обеспечивающими объединение жестких дисков.
Тома RAID уровня 0 объединяют два или более диска, с чередованием (striping)
блочных данных по дискам. При чередовании данных смежные блоки тома RAID
отображаются на блоки, находящиеся на разных дисках. Например, при двух дис-
дисках блок 0 массива RAID соответствует блоку 0 на диске 1, блок 1 — блоку 0 на
диске 2, блок 2 — блоку 1 на диске 1, блок 3 — блоку 1 на диске 2. Так, на рис. 7.1
блоки данных помечены обозначениями DO, Dl, D2 и т. д. Этот уровень RAID
используется в системах исключительно по соображениям производительности;
избыточность в нем отсутствует, потому что данные хранятся в единственном эк-
экземпляре.
Рис. 7.1. Том RAID уровня 0 с двумя дисками и чередованием данных и том RAID уровня 1
с двумя дисками и зеркальным копированием данных
В томах RAID уровня 1 используются два и более диска с зеркальным копиро-
копированием данных. Данные, записываемые на один диск, автоматически дублируют-
дублируются на другом диске; таким образом, оба диска содержат одинаковые данные. Их
содержимое может различаться в секторах, не задействованных в массиве RAID.
В случае сбоя другой диск может использоваться для восстановления данных. На-
Например, если том RAID уровня 1 содержит два диска, то блок 0 тома RAID соот-
соответствует блоку 0 на дисках 1 и 2, блок 1 тома RAID — блоку 1 на дисках 1 и 2,
и т. д. Том RAID уровня 1 также показан на рис. 7.1.
Тома RAID уровня 2 встречаются редко. В них коды с исправлением ошибок
применяются для восстановления неверных данных, прочитанных с диска. Дан-
Данные чередуются по нескольким дискам фрагментами битового уровня, а дополни-
дополнительные диски содержат контрольные данные для исправления ошибок.
Тома RAID уровня 3 состоят минимум из трех дисков, один из которых выделя-
выделяется для хранения данных контроля четности. Последний используется для вы-
выявления ошибок на двух других дисках и для восстановления содержимого в случае
сбоев. Простой, хотя и неэффективный пример контроля четности — традицион-
традиционное сложение. Если имеется два числа, 3 и 4, в сумме они дают 7. Если в какой-то
момент сумма окажется отличной от 7, значит, на диске возникла ошибка. Если
одно из значений будет потеряно, его можно будет восстановить, вычтя оставше-
оставшееся значение из 7.
В массивах RAID уровня 3 данные делятся на байтовые фрагменты и распреде-
распределяются (чередуются) по дискам данных. Диск контроля четности содержит инфор-
мацию, необходимую для восстановления данных в случае сбоя одного из дисков.
Уровень 3 отчасти напоминает уровень 0, но чередуемые данные имеют гораздо
меньший размер (байты вместо блоков), и в массиве имеется выделенный диск
контроля четности. Пример массива с двумя дисками данных и одним диском кон-
контроля четности показан на рис. 7.2.
Рис. 7.2. Том RAID уровня 3 с двумя дисками данных и одним диском контроля четности
Распространенный метод вычисления данных четности основан на операции
«исключающего ИЛИ» (XOR). Оператор XOR получает два однобитовых операн-
операнда и генерирует однобитовый результат по правилам, представленным в табл. 7.1.
Результат применения XOR к двум значениям, длина которых превышает один
бит, вычисляется независимым применением XOR к каждой паре битов.
Таблица 7.1. Правила вычисления операции XOR
Операнд 1 Операнд 2 Результат
0 0 0
0 1 1
1 0 1
JL 1 0
Оператор XOR удобен тем, что если вам известны два из трех значений, уча-
участвующих в операции, по ним можно определить третье значение. Допустим, име-
имеется три диска данных и один диск контроля четности. Диски данных содержат
числа 1011 0010, 1100 1111 и 1000 0001. Контрольная сумма этих чисел вычисля-
вычисляется следующим образом:
A011 0010 XOR 1100 1111) XOR 1000 0001
@111 1101) XOR 1000 0001
1111 1100
Байт 1111 1100 записывается на диск контроля четности. Если на втором дис-
диске произойдет сбой, хранившийся на нем байт легко восстанавливается:
1111 1100 XOR A011 0010 XOR 1000 0001)
1111 1100 XOR (ООП ООП)
1100 1111
Тома RAID уровня 4 сходны с уровнем 3, но распределение данных в них осу-
осуществляется по блокам, а не по байтам. На уровне 4 используются два и более
диска данных и выделенный диск контроля четности, поэтому его архитектура не
отличается от показанной на рис. 7.2.
Тома RAID уровня 5 сходны с уровнем 4, однако на уровне 5 нет выделенного
диска контроля четности. Все диски поочередно содержат данные и информацию
контроля четности. Например, при трех дисках блок 0 тома RAID соответствует
блоку 0 диска 1, блок 1 тома RAID — блоку 0 диска 2, а соответствующий блок
контроля четности хранится в блоке 0 диска 3. Следующий блок контроля четно-
четности соответствует блоку 1 диска 2, и в нем содержится результат выполнения опе-
операции XOR с блоками 1 дисков 1 и 3. Схема работы томов RAID уровня 5 показа-
показана на рис. 7.3.
Рис. 7.3. Том RAID уровня 5 с тремя дисками и распределенным контролем четности
Уровень 5 является одной из самых распространенных форм RAID, а для со-
создания массива необходимы как минимум три диска. Существуют и другие уров-
уровни RAID, которые встречаются реже. Они объединяют несколько уровней RAID,
что приводит к дополнительному усложнению анализа.
Аппаратная реализация RAID
Один из способов создания томов RAID основан на использовании специального
оборудования.
Общие сведения
Аппаратные реализации RAID делятся на две основные разновидности: специ-
специальные контроллеры, подключаемые к одной из шин, и устройства, подключае-
подключаемые к обычному контроллеру диска (с интерфейсом ATA, SCSI или FireWire).
В обоих случаях жесткие диски подключаются к специальному устройству, а ком-
компьютер взаимодействует с томом RAID, а не с обычными дисками. На рис. 7.4 пред-
представлены логические связи между дисками, контроллером и томом.
При использовании специального контроллера RAID компьютер проверяет
наличие контроллера во время загрузки. Во многих системах IA32 BIOS контрол-
контроллера RAID выводит сообщения на экране, а пользователь может вызвать экран
настройки контроллера и дисков. Операционной системе понадобятся драйверы
контроллера RAID. Диски, созданные одним контроллером, обычно не могут ис-
использоваться с другими контроллерами. При использовании специального уст-
устройства, подключаемого между обычным контроллером дисков и жесткими дис-
дисками, драйверы не потребуются.
Снятие данных и анализ
Аппаратные реализаций RAID весьма разнообразны, поэтому я приведу лишь неко-
некоторые общие рекомендации. Чтобы проанализировать том RAID, проще всего
снять данные с последнего тома RAID как с обычного автономного диска и восполь-
воспользоваться стандартными средствами анализа файловой системы и разделов. В од-
одном из способов анализируемая система загружается с загрузочного компакт-диска
Linux (или другой системы), содержащего драйверы контроллера RAID. Учтите,
что некоторые тома RAID очень велики, поэтому для хранения образа потребует-
потребуется большое дисковое пространство (а может быть, даже отдельный том RAID).
Загрузочные компакт-диски Linux содержат драйверы разных контроллеров
RAID, так что проверьте свой любимый дистрибутив и составьте список поддер-
поддерживаемых контроллеров. Возможно, вам придется создать собственный диск или
заготовить несколько дисков для разных случаев.
Если вы не располагаете необходимыми драйверами контроллера RAID для
снятия данных «на месте», возможно, диски и контроллер придется взять в лабора-
лабораторию. Информация о строении отдельных дисков RAID практически отсутствует,
поэтому при объединении дисков без контроллера могут возникнуть трудности.
Некоторые секторы диска могут быть не задействованы в томе RAID. В неис-
неиспользуемых секторах могут храниться скрытые данные. Таким образом, снятие
содержимого каждого диска (в дополнение к содержимому тома RAID) является
самым надежным, хотя и не всегда самым простым решением. Если раскладка дан-
данных неизвестна, с идентификацией неиспользуемых секторов диска могут воз-
возникнуть проблемы. Если возможен поиск информации по ключевым словам, про-
проведите поиск не только по тому RAID, но и по отдельным дискам.
Программная реализация RAID
Также возможна реализация томов RAID на программном уровне.
Общие сведения
При программной реализации RAID операционная система объединяет отдель-
отдельные диски при помощи специальных драйверов. В этом сценарии ОС «видит»
отдельные диски, но показывает пользователю только том RAID. Доступ к от-
отдельным дискам обычно осуществляется при помощи неструктурированных уст-
устройств UNIX или объектов устройств в Microsoft Windows. Многие современные
операционные системы обеспечивают поддержку RAID; к их числу относятся
Microsoft Windows NT, 2000 и Windows XP; Apple OS X; Linux; Sun Solaris; HP-
UX и IBM AIX. Программная реализация RAID уступает аппаратной реализации
по эффективности, потому что для вычисления битов четности и распределения
данных приходится задействовать центральный процессор. Логическая схема про-
программной реализации RAID показана на рис. 7.5.
Рис. 7.5. При программной реализации RAID ОС объединяет диски,
сохраняя доступ к каждому отдельному диску
В Windows 2000 и ХР томами RAID управляет диспетчер логических дисков,
или LDM (Logical Disk Manager). Для работы LDM диски должны быть отфор-
отформатированы как динамические; такие диски отличаются от дисков с разделами
DOS, представленных ранее в главе 5. LDM может создавать тома RAID уровней
0 (чередование), 1 (зеркальное копирование) и 5 (чередование с контролем чет-
четности), хотя поддержка RAID версий 1 и 5 доступна только в серверных версиях
Windows. Динамический диск может использоваться для нескольких томов RAID,
но это маловероятно, если система использует RAID по соображениям быстро-
быстродействия или избыточности. Вся конфигурационная информация в томах RAID
системы Windows хранится на дисках, а не в локальной системе. Диспетчер логи-
логических дисков более подробно рассматривается позднее в этой главе, когда речь
пойдет об объединении дисков.
В Linux поддержка RAID обеспечивается драйверами ядра MD (Multiple De-
Device). Диски в массивах RAID системы Linux не требуют специального форматиро-
форматирования и могут содержать обычные разделы DOS. Описание конфигурации хранит-
хранится в локальной системе в конфигурационном файле (по умолчанию /etc/raidtab).
Полученному тому RAID назначается новое устройство, и он может монтироваться
как обычный диск. Драйвер MD поддерживает RAID уровней 0 (чередование),
1 (зеркальное копирование) и 5 (чередование с контролем четности). Также
существует необязательная возможность создания «постоянного суперблока»
с размещением конфигурационной информации на диске, чтобы она могла исполь-
использоваться в других системах, кроме исходной (это упрощает анализ «на стороне»).
Снятие данных и анализ
Задачи снятия данных и анализа при программной реализации RAID решаются
почти так же, как при аппаратной реализации. При текущей технологии простей-
простейший сценарий основан на снятии данных с тома RAID для последующего приме-
применения стандартных средств анализа файловой системы. В отличие от аппаратной
реализации RAID, некоторые программы анализа позволяют объединять содер-
содержимое отдельных дисков.
Возможно, при программной реализации RAID вам не понадобится исходное
программное обеспечение для восстановления тома RAID. Например, в Linux
предусмотрена поддержка диспетчера логических дисков Windows (LDM) с воз-
возможностью правильного объединения дисков Windows. He все версии ядра Linux
поставляются с включенной поддержкой LDM, но ее можно включить при
перекомпиляции ядра. Если вы используете Microsoft Windows для создания
томов RAID, установите аппаратный блокировщик записи для предотвращения
потери данных.
Рассмотрим пример с Windows LDM в Linux. Если загрузить ядро Linux с под-
поддержкой LDM, в системе создается устройство для каждого раздела RAID. Вам
придется отредактировать файл /etc/raidtab так, чтобы он правильно описывал
конфигурацию RAID и разделы. Например, следующий конфигурационный
файл определяет Windows LDM RAID уровня 0 (чередование) с двумя раздела-
разделами (/dev/hdbl и /dev/hddl), с использованием 64-килобайтных блоков:
# cat /etc/raidtab
raiddev /dev/mdO
raid-level 0
nr-raid-disks 2
nr-spare-disks 0
persistent-superblock 0
chunk-size 64k
device /dev/hdbl
raid-disk 0
device /dev/hddl
raid-disk 1
В соответствии с этим файлом, устройство /dev/mdO может монтироваться
только для чтения, а для создания его образа можно использовать программу dd.
Процесс использования Linux с Windows LDM более подробно описан в разделе
«Объединение дисков». Аналогичный процесс используется для реализации про-
программного тома RAID средствами Linux MD в системе снятия данных. Если ско-
скопировать файл raidtab из исходной системы, его содержимое может быть взято за
основу для создания тома RAID в системе, в которой производится снятие данных.
Программы EnCase (Guidance Software) и ProDiscover (Technology Pathways)
импортируют диски из томов RAID Windows и анализируют их так, как если бы
они были отдельными томами. Такой метод анализа данных лучше работает в дол-
долгосрочной перспективе, потому что он предоставляет доступ к данным, которые
могут быть скрыты на отдельных дисках и будут пропущены, если ограничиться
снятием только одного тома RAID. Впрочем, работа с программами Linux и дру-
другими приложениями, не использующими официальную спецификацию, всегда со-
сопряжена с определенным риском — программы могут содержать ошибки, приво-
приводящие к искажению исходной версии тома RAID.
Общие замечания по поводу анализа
Анализ системы с томами RAID может оказаться сложной задачей, поскольку
такие системы встречаются не так часто и имеют разные реализации. Опробуя
разные методы снятия данных, будьте очень осторожны и следите за тем, чтобы
это не привело к модификации исходных дисков. Используйте аппаратные бло-
кировщики записи или перемычки «только для чтения» на жестких дисках для
предотвращения изменений. Также может быть полезно создать образы отдель-
отдельных дисков перед созданием образа всего тома RAID. Образы отдельных дисков
могут содержать скрытые данные, не входящие в том RAID. Случаи со скрытыми
данными RAID пока не документированы, но теоретически такая возможность
существует — все зависит от того, какая система является объектом анализа. Так-
Также нельзя исключать, что для создания тома RAID используется не весь диск.
Некоторые системы RAID ограничиваются частью жесткого диска, чтобы диск
было проще заменить в случае сбоя. Например, система может использовать только
40 Гбайт на каждом отдельном диске независимо от его фактической емкости D0
или 80 Гбайт). Неиспользуемая область может содержать данные от предыдуще-
предыдущего образа, но в ней также могут находиться скрытые данные.
Итоги
В этом разделе был приведен обзор технологии RAID. Массивы RAID широко
применяются на высокопроизводительных серверах и получают все большее рас-
распространение среди настольных систем, нуждающихся в повышенном быстродей-
быстродействии или емкости диска. Низкоуровневые подробности не рассматривались, по-
потому что они зависят от реализации, а единого стандарта пока не существует.
Дополнительная информация приводится в разделе «Объединение дисков», по-
поскольку в поддержке управления томами многих систем присутствует интегри-
интегрированная программная реализация RAID.
Ключевым фактором успешной экспертизы является опыт снятия данных
в системах RAID. Самый простой, хотя и не всегда возможный вариант — снятие
всего тома RAID «на месте» и последующий анализ с применением стандартных
средств. У такого подхода есть свои недостатки: для сохранения данных необхо-
необходим диск очень большого размера, а на отдельных дисках могут находиться дан-
данные, не входящие в итоговый том RAID. Следовательно, безопаснее также произ-
произвести снятие данных с отдельных дисков.
Объединение дисков
В результате объединения (disk spanning) несколько отдельных дисков выглядят
как один большой диск. Объединение дисков часто рассматривается вместе
с RAID, поскольку оно поддерживается многими программными решениями RAID,
однако объединение дисков не обеспечивает ни избыточности, ни повышенного
быстродействия. Оно просто формирует носители информации большего объе-
объема, а некоторые версии позволяют добавлять новые диски и динамически увели-
увеличивать размер файловой системы.
В наше время объединение дисков поддерживается многими операционными
системами. Далее будут рассмотрены программные решения в системах Microsoft
Windows и Linux. Другие системы — такие, как Sun Solaris, IBM AIX и Apple
OSX — также содержат собственные технологии объединения дисков, но здесь
они не рассматриваются. Раздел начинается с описания основных концепций
и определения общих понятий, используемых во всех реализациях. Затем мы пе-
перейдем к конкретным системам Windows и Linux. Как и в предыдущем разделе,
посвященном RAID, не надейтесь найти здесь ответы на все вопросы — хотя бы
потому, что не все ответы известны. Я всего лишь объясню, как работает объеди-
объединение дисков; возможно, это поможет вам понять, почему не существует програм-
программы, которая решала бы все ваши задачи.
Общий обзор
Объединение дисков используется примерно по тем же причинам, по которым
мы используем скоросшиватель вместо блокнота на пружинной спирали. Когда
все страницы блокнота будут исписаны, приходится покупать новый блокнот и
носить его вместе со старым. Если же кончатся страницы в скоросшивателе, вы
можете добавить в него новые страницы и даже перенести накопившиеся заметки
в папку большего размера. При использовании объединения дисковое простран-
пространство новых дисков добавляется в конец существующего пространства. На рис. 7.6
показан пример с двумя дисками, каждый из которых содержит 100 блоков дан-
данных. Блоки 0-99 хранятся на диске 1, а блоки 100-199 — на диске 2.
Рис. 7.6. Объединение дисков: 100 блоков хранятся на первом диске и еще 100 — на втором
Программная поддержка объединения дисков формирует логический том. Ло-
Логические тома состоят из нескольких физических дисков или разделов, последо-
последовательно объединяемых друг с другом. Во многих системах также существуют дис-
дисковые группы, то есть группы физических дисков; только диски, входящие в одну
группу, объединяются для создания логического тома. На рис. 7.7 показано, как
связаны между собой эти уровни абстракции. Система содержит три физических
диска, входящих в одну дисковую группу. В результате объединения дисков фор-
формируются два логических тома.
Рис. 7.7. Компоненты и связи в системе с объединением дисков
Linux MD
В Linux существует два метода объединения дисков. Драйвер MD, уже упоминав-
упоминавшийся в связи с системами RAID, также способен выполнять простейшее объеди-
объединение дисков, но существует и более совершенная система LVM (Logical Volume
Manager). Обе системы входят в основные дистрибутивы Linux. В этом разделе
будут описаны устройства MD. Мы начинаем с Linux, потому что драйверы Linux
могут использоваться для анализа систем Windows.
Общие сведения
Драйвер MD использует обычные разделы DOS, группируя их для создания тома
RAID или объединенного тома. Каждый диск может содержать несколько разде-
разделов и использоваться в некотором томе RAID или логическом томе. В этой моде-
модели не существует дисковых групп. Конфигурационный файл /etc/raidtab опреде-
определяет порядок следования разделов; монтирование тома возможно лишь после
задания его конфигурации в файле. Структура конфигурационного файла иден-
идентична той, что описывалась в предыдущем разделе для RAID, только параметру
raid-level присваивается значение linear. Пример конфигурационного файла для
логического тома с двумя разделами (/dev/hdbl и/dev/hddl):
# cat /etc/raidtab
raiddev /dev/mdO
raid-level linear
nr-raid-disks 2
nr-spare-disks 0
persistent-superblock 0
chunk-size 4k
device /dev/hdbl
raid-disk 0
device /dev/hddl
raid-disk 1
Ядро читает конфигурационный файл и создает устройство /dev/mdO, которое
может монтироваться и использоваться как отдельный том, но в действительнос-
действительности состоит из дискового пространства/dev/hdbl и /dev/hddl.
Если параметр persistent-superblock равен 0, то все данные конфигурации уст-
устройства содержатся в файле /etc/raidtab. Если он равен 1, то в конце каждого дис-
диска или раздела находятся конфигурационные данные, по которым механизм ав-
автоматической идентификации дисков Linux автоматически создает устройство
MD. Для работы процесса автоматической идентификации в Linux соответству-
соответствующий раздел DOS должен относиться к типу Oxfd. Чтобы узнать, было ли устрой-
устройство создано при загрузке, просмотрите файл журнала/var/Log/messages. Процесс
автоматической идентификации происходит при загрузке модуля ядра md.
Если диски или разделы содержат постоянный суперблок, в них создается 1024-
байтовая структура, разделенная на секции. Первая секция содержит параметры
объединенного диска или тома RAID — версии, количество дисков, время созда-
создания, идентификаторы. Вторая секция содержит общие сведения — последнее время
обновления, счетчик, состояние тома, количество работающих и сбойных дисков.
В остальных секциях хранится информация о каждом диске тома, включая ос-
основную и дополнительную версии устройства, роль устройства в томе, состояние
диска. Как будет показано в секции анализа, типичная система Linux обновляет
содержимое суперблока при загрузке, даже если том не монтируется. По содер-
содержимому суперблока ядро может узнать, что диски были отсоединены от системы
и установлены в измененном порядке.
Снятие данных и анализ
При анализе данных на томах MD лучше всего снять содержимое тома как еди-
единого диска или раздела, а затем воспользоваться стандартными средствами ана-
анализа. Проще всего это сделать при наличии постоянного суперблока; в противном
случае вам придется создать в системе снятия данных файл /etc/raidtab. Если по-
потребуется создать этот файл, попробуйте получить доступ к каталогу /etc/ на исход-
исходном диске и возьмите его за основу.
После того как конфигурационный файл будет создан, устройство MD созда-
создается командой raidstart. Команда создает в каталоге /dev/ устройство с именем,
указанным в файле. Клонирование тома осуществляется программой dd или ее
аналогом. После снятия данных необходимо выполнить команду raidstop для за-
завершения работы с устройством MD. При наличии постоянного суперблока сле-
следует помнить, что некоторые параметры обновляются при создании нового уст-
устройства командой raidstart. Заранее создайте резервные образы дисков; попробуйте
использовать блокировщики записи АТА и SCSI, если они у вас имеются.
Если для каждого раздела DOS, входящего в том, поле раздела равно Oxfd, су-
существует постоянный суперблок, а система настроена на автоматическую иден-
идентификацию устройств MD — устройство будет создано в процессе запуска. Как и
при выполнении команды raidstart, в процессе создания изменяется время после-
последнего обновления, счетчик и контрольная сумма в суперблоке. Изменения вно-
вносятся даже в том случае, если том MD не монтируется!
Если разместить диски в порядке, отличном от исходного, суперблок будет пере-
перезаписан. Это происходит даже без монтирования тома, поэтому примите меры по
сокращению изменений на каждом диске. Кроме того, у меня возникали проблемы
при загрузке, когда в системе, используемой для анализа, был установлен только
один из двух дисков. Счетчик диска увеличивался, но при следующей загрузке
с обоими дисками система Linux отказывалась создавать устройство MD из-за раз-
разных значений счетчиков.
Также оказалось, что при использовании дисков MD лучше обойтись без хра-
хранения файла raidtab. Это может быть очень опасно, потому что при отключении
системы и установке новых дисков Linux попытается обрабатывать их как часть
тома. Возможно, стоит внести изменения в сценарии отключения, чтобы они пе-
переименовывали файл raidtab — в этом случае файл не будет существовать при сле-
следующем включении питания.
Для снятия данных с томов MD можно использовать загрузочные компакт-
диски Linux. Некоторые из них обнаруживают тома MD автоматически, другие
этого не делают и требуют создать файл /etc/raidtab. Если систему можно загру-
загрузить с компакт-диска и создать устройство MD, проведите снятие данных обыч-
обычным способом. В противном случае снимите данные с каждого диска и докумен-
документируйте их местонахождение, чтобы свести к минимуму изменения дисков из-за
их установки в неверном порядке. Мне так и не удалось воссоздать том MD по
физическим образам исходных разделов и устройствам обратной связи. Это озна-
означает, что вам, возможно, придется восстановить образы на диск и извлечь данные
с дисков в лаборатории.
Linux LVM
Второй механизм объединения дисков в Linux основан на использовании LVM.
В этом разделе описывается архитектура LVM и методы снятия данных.
Общие сведения
Диспетчер логических томов (LVM) обладает более сложной архитектурой, чем
MD. В нем используются дисковые группы, которые в терминологии LVM назы-
называются группами томов. Разделам DOS, используемым в LVM, назначается тип
раздела 0х8е. Диски и разделы в группах томов делятся на физические экстен-
экстенты — равные блоки, размер которых обычно составляет несколько мегабайт. Каж-
Каждая система содержит одну или несколько групп томов, при этом каждая группа
представлена подкаталогом в каталоге /dev/.
Логический том состоит из логических экстентов, размер которых совпадает
с размером физических экстентов; между логическими и физическими экстента-
экстентами существует однозначное соответствие. На рис. 7.8 показан логический том, со-
созданный из трех наборов физических экстентов на двух физических дисках.
Логические тома создаются либо объединением физических экстентов, либо
чередованием (с объединением последовательных логических экстентов на разных
дисках). Скажем, на 2-гигабайтном томе первые 1,5 Гбайт могут размещаться на
диске 1, а последние 500 Мбайт — на диске 2. С другой стороны, на томе с чередо-
чередованием могут использоваться два диска объемом 1 Гбайт: первый мегабайт разме-
размещается на диске 1, второй — на диске 2, третий — снова на диске 1, и т. д. Логичес-
Логический том представляется файлом устройства в подкаталоге группы томов в /dev/.
Сведения о конфигурации логического тома хранятся как в локальной систе-
системе, так и на дисках. Локальная конфигурация хранится в файле /etc/Lvmtab и ка-
талоге/etc/Lvmtab.d/. Конфигурационный файл имеет двоичный формат и обнов-
обновляется утилитами LVM, такими как vgimport, vgscan и vgchange. Дисковая струк-
структура находится в начале диска и содержит информацию о диске, о группе томов,
к которой он принадлежит, и о логических томах, входящих в группу. Ни одно из
полей структуры не содержит временных штампов, поэтому структура не обнов-
обновляется при создании логического тома, как это происходит с устройствами MD.
Рис. 7.8. LVM делит физические диски на физические экстенты, отображаемые
на логические экстенты в логическом томе
Снятие данных и анализ
Анализ систем LVM открывает больше возможностей для автоматизации, чем для
устройств MD. Дальнейшее описание базируется на моем опыте работы с текущи-
текущими версиями LVM и было проверено у разработчиков LVM1. LVM содержит слу-
служебные программы vgexport и vgimport, которые должны использоваться при пе-
перемещении дисков между системами, но для снятия данных с дисков они не нужны.
Программа vgexport удаляет локальные файлы конфигурации тома и записывает
слово «-EXPORT» в имя группы томов на диске. Для проведения экспертизы при
удалении дисков из анализируемой системы этот шаг не обязателен.
Чтобы провести анализ тома LVM, следует либо удалить диски из системы и
разместить их в доверенной системе Linux, либо загрузить анализируемую сис-
систему с загрузочного компакт-диска Linux с поддержкой LVM. Как упоминалось
при обсуждении LVM, безопаснее настроить систему так, чтобы она не выпол-
выполняла автоматического монтирования и конфигурации логических томов. Вы-
Выполните команду vgscan в системе, в которой производится анализ, для прове-
проведения поиска логических томов. Команда автоматически создает файл /etc/
Lvmtab и конфигурационные файлы в каталоге/etc/Lvmtab.d/. После создания кон-
конфигурационных файлов выполните команду vgchange -а у для активизации най-
найденных томов. При работе с LVM местонахождение и конфигурация ведущих/
ведомых дисков несущественны. Содержимое активного тома копируется ко-
командой dd с устройства тома в /dev/. По моему опыту, выполнение команд vgscan
и vgchange не приводит к изменению кодов MD5 дисков. Далее приводится
последовательность команд при загрузке системы с использованием пакета
Penguin Sleuth Kit (обратите внимание: Penguin Sleuth Kit не имеет отношения
1 Переписка с Хайнцем Мауэльсхагеиом (Heinz Mauelshagen) и Э. Дж. Льюисом (A. J. Lewis), 17 нояб-
ноября 2003 г.
к аналитическому пакету The Sleuth Kit). Пакет Penguin Sleuth Kit доступен по
адресу: http://www.linux-forensics.com.
# vgscan
vgscan -- reading all physical volumes (this may take a while...)
vgscan -- found inactive volume group "vg_big2"
vgscan -- "/etc/1vmtab" and "/etc/1vrntab.d" successfully created
vgscan -- WARNING: This program does not do a VGDA backup of your volume group
Учтите, что в будущих версиях поведение LVM может измениться, поэтому
протестируйте все процедуры перед выполнением действий в реальной системе
и создайте резервные копии дисков перед объединением томов.
Microsoft Windows LDM
Компания Microsoft впервые включила поддержку объединения дисков в Windows
NT. В этом разделе описывается архитектура LDM и методы снятия данных.
Динамические диски
Диспетчер логических дисков (LDM) отвечает за управление логическими тома-
томами в Windows 2000 и ХР. LDM поддерживает простые тома (аналоги обычных
разделов), объединение дисков, RAID уровня 0 (чередование), RAID уровня 1
(зеркальное копирование) и RAID уровня 5. Технологии RAID уже упоминались
ранее в этой главе, а здесь они будут описаны более подробно.
К категории базовых относятся диски, описанные в главах 5 и 6. Базовые дис-
диски содержат таблицу разделов DOS или GPT, а каждый раздел является самосто-
самостоятельным. Базовые диски не могут использоваться в LDM. Динамический диск
содержит дополнительные структуры данных для создания разделов, пригодных
для формирования логических томов.
Динамический диск содержит две важные области. Область разделов LDM за-
занимает большую часть диска; именно в ней создаются динамические разделы. Пос-
Последний мегабайт динамического диска выделяется под базу данных LDM. База
данных содержит записи, описывающие организацию области разделов и прави-
правила создания логических томов.
В первом секторе любого динамического диска в системе IA32 находится таб-
таблица разделов DOS. Благодаря ей старые системы узнают о том, что диск исполь-
используется. Таблица содержит всего одну запись, представляющую весь диск, с типом
раздела 0x42. Область раздела LDM и база данных находятся в разделе DOS, как
показано на рис. 7.9. Для просмотра таблицы разделов можно воспользоваться
программой mmls из пакета The Sleuth Kit:
# mmls -t dos vdisk.dd
DOS Partition Table
Units are in 512-byte sectors
Slot Start End Length Description
00: 0000000000 0000000000 0000000001 Primary Table (#0)
01: 0000000001 0000000062 0000000062 Unallocated
02: 00:00 0000000063 0120101939 0120101877 Win LVM / Secure FS@x42)
В системах IA64 (Intel Itanium и т. д.) на динамических дисках создаются раз-
разделы GPT для области разделов и базы данных LDM. Для этих разделов предус-
предусмотрены специальные типы.
Рис. 7.9. Строение динамического диска в системе IA32: структуры данных LDM
находятся внутри раздела DOS
Windows поддерживает только одну дисковую группу, в которую автомати-
автоматически включаются все динамические диски. Область разделов динамического
диска разбивается на динамические разделы, а динамические разделы одного или
нескольких дисков группируются для формирования логических томов (рис. 7.10).
Очень важно различать термины, используемые компанией Microsoft для дина-
динамических дисков и разделов DOS. В схеме разделов DOS Microsoft называет ло-
логическими томами разделы, создаваемые внутри расширенных разделов, тогда как
в динамических дисках логическими томами называются все разделы, которые
могут содержать файловую систему или другие данные.
Рис. 7.10. Логический том LDM формируется из динамических разделов,
входящих в дисковую группу
База данных LDM
В базе данных LDM хранятся определения динамических разделов и правила
создания логических томов. Компания Microsoft не опубликовала точного опи-
описания строения базы данных LDM, но Интернет-группы идентифицировали не-
некоторые внутренние структуры данных (одна из групп, Linux NTFS, доступна
по адресу: http://Linux-ntfs.sourceforge.net). Из опубликованных справочных ру-
руководств Microsoft [Solomon and Russinovich, 2000] известно, что база данных
LDM состоит из четырех основных частей. Приватный заголовок сходен с загру-
загрузочным сектором файловой системы. Он описывает уникальные характеристи-
характеристики диска и логического тома. Эта структура содержит уникальный идентифика-
идентификатор диска (GUID) и имя дисковой группы. Windows содержит только одну
дисковую группу, имя которой определяется именем компьютера. Далее следу-
следует оглавление, состоящее из 16 секторов. По данным Соломона и Руссиновича,
оглавление «содержит информацию о строении базы данных», то есть о следую-
следующей части LDM.
Область базы данных содержит описания дисков, разделов, компонентов и то-
томов. Для каждого динамического диска (как DOS, так и GPT) в базе данных со-
создается запись диска. Записи разделов описывают структуру разделов на динами-
динамических дисках. Записи компонентов описывают процесс объединения разделов.
Каждая запись раздела содержит ссылку на используемую ей запись компонента.
Записи компонентов существуют для объединения, чередования и зеркального
копирования. Наконец, записи томов описывают логические тома, то есть резуль-
результат применения компонентов к разделам.
Рассмотрим пример с двумя динамическими дисками. Имеется логический том,
первая часть которого занимает 15 Мбайт на диске 1, вторая — 10 Мбайт на диске
2, а последняя часть — 20 Мбайт на диске 1 (конечно, эти цифры гораздо меньше
тех, которые используются в реальных ситуациях). Структура логического тома
показана на рис. 7.10. Программа Microsoft dmdiag (http://www.microsoft.com/
windows2000/techinfo/reskit/tooLs/existing/dmdiag-o.asp) предназначена для вывода
информации о записях в базе данных. Результат ее работы выглядит так:
Disk: Diskl rid=0.1027 updated=O.1222
assoc: diskid=6a565b54-b83a-4ebb-95eb-842ede926e88
flags:
Disk: Disk2 rid=0.1063 updated=0.1112
assoc: diskid=533fe4ab-0409-4ea6-98b3-9648bbc3bdl2
flags:
Эти две записи относятся к двум физическим дискам. Диску 1 присвоен иден-
идентификатор 0.1027, а диску 2 — идентификатор 0.1063.
Group: hashDgl rid=O.1025 update=O.1028
id: dgid=d4f40362-7794-429a-a6ad-a6dfc0553cee
diskset: id=00000000-0000-0000-0000-000000000000
copies: nconfig=all n"log-all
minors: >= 0
Запись определяет группу дисков и показывает, что имя дисковой группы оп-
определяется именем компьютера (hash).
Subdisk: Diskl-01 rid=0.1109 updated=0.1112
info: disk=0.1027 offset-0 len=30720 hidden=O
assoc: plex=0.1107 (column=0 offset-O)
Subdisk: Diskl-02 rid-0.1121 updated=0.1122
info: disk=0.1027 offset=0 len=40960 hidden=O
assoc: plex=0.1107 (column=0 offset=51200)
Эти две записи являются записями разделов для физического диска с именем
Diskl (ID:0.1027). Для обоих записей параметр plex со значением 0.1107 определяет
запись компонента, используемую для создания логического тома. Первая запись
(идентификатор 0.1109) определяет 15-мегабайтный раздел со смещением секто-
сектора 0 и размером 30 720 секторов. Вторая запись (идентификатор 0.1121) опреде-
определяет 20-мегабайтный раздел со смещением 30 720 и размером 40 960 секторов.
Subdisk: Disk2-01 rid-0.1111 updated=O.1112
info: disk=0.1063 offset-0 len=20480 hidden=O
assoc: plex=0.1107 (column=0 offset=30720)
Запись определяет раздел для динамического диска Disk2 (ID:0.1063) с иден-
идентификатором 0.1111, смещением 0 секторов и размером 20 480 секторов. Связи
между физическим диском и записями динамических разделов показаны на
рис. 7.11. Направление стрелки означает, что запись динамического раздела со-
содержит указатель на физический диск.
Plex: Volume-01 rid=0.1107 update=O.1124
type: 1ayout=CONCAT
state: state=ACTIVE
assoc: voi=0.1105
Рис. 7.12. Связи между записями базы данных LDM (указатели на другие
объекты обозначены стрелками)
Приведенный фрагмент является записью компонента объединения дисков
(CONCAT), описывающей способ создания логического тома посредством объедине-
объединения динамических разделов. Мы видим идентификатор 0.1107, который встречался
в каждой из записей разделов. Также видно, что он ассоциируется с идентифика-
идентификатором тома 0.1105, описание которого приводится далее.
Volume: Volumel rid=0.1105 update=O.1124 mountname=F:
info: len=92160 guid=e4O794dO-6e3c-4788-af3d-ff49d2ce769d
type: parttype=7 usetype=gen
state: state=ACTIVE
policies: read=SELECT
flags: writeback
База данных завершается последним фрагментом, содержащим запись логи-
логического тома. В записи указана точка монтирования F:\h длина 92 160 секторов.
Тому присвоен идентификатор 0.1105 и имя Volumel. Связи между записями по-
показаны на рис. 7.12. Учтите, что все диски группы содержат одинаковые записи
базы данных.
Итоговая организация логического тома показана на рис. 7.13. Обратите вни-
внимание: последовательность разделов в логическом томе не соблюдается.
Рис. 7.13. Диск LDM с двумя физическими дисками, тремя динамическими
разделами и одним логическим томом
База данных LDM завершается журналом транзакций, то есть протоколом из-
изменений LDM. В случае сбоя питания или отказа оборудования журнал позволя-
позволяет восстановить диск в работоспособном состоянии.
Снятие данных и анализ
Анализ любого логического тома довольно сложен, особенно при программной
реализации, а воссоздание тома в режиме «только для чтения» является отнюдь
не тривиальной задачей. Как упоминалось ранее в разделе, посвященном RAID,
анализ системы проще всего выполняется при снятии данных с логического тома
и применении стандартных средств анализа. Тем не менее в Windows это не все-
всегда возможно, потому что система пытается монтировать диски при загрузке.
Снятие смонтированной файловой системы может привести к порче образа, а мон-
монтирование способно вызвать модификацию данных. Перемещение дисковых групп
LDM между компьютерами также сопряжено с некоторым риском. В Windows
в любой момент времени поддерживается только одна дисковая группа, а дина-
динамические диски добавляются в локальную группу, если она существует [Microsoft,
2003]. Следовательно, если динамические диски из исходной системы импорти-
импортируются в систему анализа, использующую динамические диски, они будут вклю-
включены в локальную группу дисков, а ОС запишет новые данные в базу данных LDM.
Ядро Linux включает поддержку объединения дисков LDM, хотя она и не все-
всегда включается по умолчанию. Если в вашем дистрибутиве объединение дисков
отключено, возможно, вам придется перекомпилировать ядро. Если ядро поддер-
поддерживает LDM, Linux прочитает базу данных и создаст устройства для каждого ди-
динамического раздела каждого динамического диска. Например, если загрузить
Linux с двумя дисками из предыдущего примера, в системе будут созданы устрой-
устройства/dev/hdbl, /dev/hdb2 и /dev/hddl. Затем создается файл /etc/raidtab с описа-
описанием структуры, чтобы драйвер ядра MD мог создать одно устройство. Если/dev/
hdbl содержит первый раздел, /dev/hddl — второй, a/dev/hdb2 — третий, то файл
raidtab выглядит так:
raiddev /dev/mdO
raid-level linear
nr-raid-disks 3
nr-spare-disks 0
persistent-superblock 0
chunk-size 4k
device /dev/hdbl
raid-disk 0
device /dev/hddl
raid-disk 1
device /dev/hdbl
raid-disk 2
В случае «линейных» томов RAID размер фрагмента (chunk-size) задается
произвольно, но параметр должен существовать. Программы EnCase (Guidance
Software) и ProDiscover (Technology Pathways) умеют импортировать отдельные
образы из логических томов Windows и объединять их.
Если используется только объединение дисков, вы можете вручную извлечь
разделы и скомбинировать их из дисковых образов. Информацию о строении тома
можно получить при помощи программы dmdiag.exe, но программа работает толь-
только в Windows и требует, чтобы диски были смонтированы. По этой причине мы
воспользуемся другой программой из Linux. Группа Linux NTFS разработала про-
программу Idminfo (http://linux-ntfs.sourceforge.net/status.html#ldmtools), которая ана-
анализирует записи базы данных LDM динамического диска Windows и выводит
подробную информацию с ключом —dump. Программа работает с любыми неструк-
неструктурированными устройствами или дисковыми образами массива дисков, потому
что базы данных на всех дисках содержат одинаковые записи. Она выводит такую
же подробную информацию, как и dmdiag.exe, но мы сосредоточимся на информа-
информации о структуре тома из предыдущего примера:
# Idminfo --dump diskl.dd
VOLUME DEFINITIONS:
Volume Size: 0x00016800 D5 MB)
Diskl-01 VolumeOffset: 0x00000000 Offset: 0x00000000 Length: 0x00007800
Diskl-01 VolumeOffset: 0x00007800 Offset: 0x00000000 Length: 0x00005000
Diskl-02 VolumeOffset: 0x0000C800 Offset: 0x00007800 Length: 0x0000A000
Из результатов видно, что том содержит два диска и три раздела. Диск нетруд-
нетрудно воссоздать, потому что он использует объединение без разбиения данных. Ра-
Ранее из результатов выполнения mmis для образа диска мы видели, что область раз-
разделов начинается в секторе 63. Следовательно, к смещениям в выходных данных
Ldminfo необходимо прибавлять 63, потому что смещения задаются относительно
начала области разделов. Чтобы получить данные первого раздела, мы извлекаем
30 720 секторов @x7800) из области разделов первого диска:
# dd if-diskl.dd skip=63 count=30720 > span.dd
Вторая часть дискового массива является первой частью второго диска. Мы
присоединим ее содержимое к данным первого диска. Таким образом, следует из-
извлечь первые 20 480 секторов @x5000) из области разделов второго диска:
# dd if=disk2.dd skip=63 count=20480 » span.dd
Последняя часть массива находится в области разделов первого диска. Она
также будет присоединена к данным, извлеченным со второго диска. Данные начи-
начинаются с сектора 30 720 @x7800) области разделов; следовательно, нам нужен сек-
сектор 30 783 по отношению к началу диска, а его длина составляет 40 960 секторов.
# dd if-diskl.dd skip=30783 count=40960 » span.dd
Полученный образ span.dd обрабатывается как обычный образ файловой сис-
системы. Если доступна поддержка LDM уровня ядра, я рекомендую сначала опро-
опробовать этот путь, прежде чем браться за ручную обработку. Также учтите, что при
разработке многих вспомогательных драйверов сторонних разработчиков и ути-
утилит LDM подробные спецификации Microsoft отсутствовали, поэтому правиль-
правильность их работы не гарантирована.
Библиография
• Lewis, AJ. «The LVM HOWTO». The Linux Documentation Project, 2002-2004.
http://tldp.org/HOWTO/LVM-HOWTO/.
• Microsoft, «Description of Disk Groups in Windows Disk Management». Microsoft
Knowledge Base Article 222189, November 21, 2003. http://support.microsoft.com/
kb/222189.
• Microsoft. Microsoft Windows XP Professional Resource Kit Documentation, 2004.
http://www.microsoft.com/resources/documentation/Windows/XP/aU/reskit/en-us/
prork_overview.asp.
• Ostergaard, Jakob. The Software-RAID HOWTO». The Linux Documentation Pro-
Project, June 3, 2004. http://www.tldp.org/HOWTO/Software-RAID-HOWTO.html.
• Patterson, David A., Garth Gibson and Randy H.Katz. «A Case for Redundant
Arrays of Inexpensive Disks (RAID)». ACMSIGMOD International Conference on
Management of Data, June 1988.
• PC Guide. «Redundant Arrays of Inexpensive Disks». April 17,2001. http://www.pc-
guide.com/ref/hdd/perf/raid/index.htm.
• Solomon, David, and Mark Russinovich. Inside Microsoft Windows 2000. 3rd ed.
Redmond: Microsoft Press, 2000.
• Sourceforge.net. «LDM Documentation». Linux NTFS Project, 2002. http://Linux-
ntfs. sourceforge.net/ldm/index.html.
Анализ файловых
систем
Глава 8. Анализ файловых систем 164
Глава 9. FAT: основные концепции и анализ 198
Глава 10. Структуры данных FAT 235
Глава 11. NTFS: основные концепции 250
Глава 12. NTFS: анализ 273
Глава 13. Структуры данных NTFS 317
Глава 14. Ext2 и Ext3: концепции и анализ 352
Глава 15. Структуры данных Ext2 и Ext3 399
Глава 16. UFS1 и UFS2: концепции и анализ 422
Глава 17. Структуры данных UFS1 и UFS2 448
Анализ файловых
систем
В процессе анализа файловой системы эксперт изучает содержимое тома (то есть
раздела или диска) и интерпретирует его как файловую систему. Конечные ре-
результаты этого процесса могут быть представлены в разных формах — например,
составление списка файлов каталога, восстановление удаленных данных и про-
просмотр содержимого секторов. Вспомните, что анализ содержимого файлов отно-
относится к анализу прикладного уровня и не рассматривается в книге. В этой главе
будут рассмотрены общие принципы устройства файловых систем и различные
методы анализа. Тема излагается с абстрактных позиций и не сводится к тому,
как анализировать файловые системы неким конкретным инструментом. В ос-
остальных девяти главах обсуждается архитектура некоторых файловых систем и их
отличительные особенности с точки зрения цифровой экспертизы.
Что такое файловая система?
Файловые системы появились по очень простой причине: компьютерам необхо-
необходимы средства долгосрочного хранения и выборки данных. Файловые системы
предоставляют пользователям механизм хранения данных в иерархии файлов и
каталогов. Файловая система состоит из служебных и пользовательских данных,
организованных таким образом, что компьютер знает, где найти их при необходи-
необходимости. В большинстве случаев файловая система не зависит от конкретного эк-
экземпляра компьютера.
Проведем аналогию с картотекой в кабинете врача. Допустим, вымышленная
Национальная ассоциация организованного хранения документов решила, что все
истории болезни должны храниться в специальных шкафах упорядоченными по
фамилии пациента. Корешок, используемый для идентификации документа, дол-
должен быть заполнен на английском языке, а имя пациента должно указываться пос-
после фамилии. Специалист, обученный этим правилам, сможет заполнить и найти
историю болезни в любом кабинете, соблюдающем эти правила. У врача может
быть 100 пациентов и один шкаф или 100 000 пациентов и 25 шкафов. Важно лишь
то, что специалист знает, что такое шкаф, умеет открывать его и знает, как прочи-
прочитать или заполнить корешок. Если же он посетит кабинет врача, живущего по пра-
правилам Национальной ассоциации беспорядочного хранения документов, у кото-
которого все истории болезни свалены в углу, вся его подготовка окажется бесполезной,
и специалист не сможет найти необходимую информацию.
Нечто похожее происходит и в файловых системах. В них существуют конк-
конкретные процедуры и структуры данных, используемые для хранения одного файла
на дискете или сотен, а то и тысяч файлов на массивах большой емкости. Каждый
экземпляр файловой системы обладает некоторым размером, но благодаря исполь-
использованию единой базовой структуры данных этот экземпляр может быть обрабо-
обработан любым компьютером, поддерживающим данный тип файловой системы.
Некоторые данные требуют внутреннего структурирования файлов. В этом они
напоминают физические документы, которые также обычно структурируются
в виде разделов и глав. Внутреннее строение файлов зависит от приложений и вы-
выходит за рамки книги. Нас интересуют только методы и правила получения дан-
данных, находящихся внутри файла или же не принадлежащих ни одному файлу.
Категории данных
При рассмотрении различных типов файловых систем полезно иметь эталонную
модель, упрощающую сравнение разных файловых систем (скажем, FAT и Ext3).
Кроме того, наличие эталонной модели упрощает поиск доказательств. В нашей
эталонной модели будут задействованы пять категорий: данные файловой системы,
содержимого, метаданные, данные имен файлов и прикладные данные. Любая
информация файловой системы принадлежит к одной из перечисленных катего-
категорий в зависимости от того, какую роль она играет в файловой системе. Мы будем
использовать эти категории при описании файловых систем, хотя некоторые сис-
системы (а именно, FAT) не так хорошо соответствуют эталону, как другие системы.
Инструментарий The Sleuth Kit (TSK) тоже базируется на тех же категориях.
Категория данных файловой системы включает общую информацию, относя-
относящуюся к файловой системе в целом. Каждая файловая система обладает некой
общей структурой, но ее экземпляры уникальны, поскольку они обладают уни-
уникальным размером и могут оптимизироваться. Данные файловой системы указыва-
указывают, где найти некоторые структуры данных и насколько велики единицы хранения
информации. Их можно сравнить с «географической картой» файловой системы.
К категории данных содержимого относятся данные, составляющие фактичес-
фактическое содержимое файлов (которое, собственно, и является главной причиной для
создания файловых систем). Большая часть данных файловой системы относится
к этой категории, а для их хранения обычно применяются контейнеры стандарт-
стандартного размера. Название контейнеров зависит от файловой системы (например,
кластер или блоку, до описания конкретных файловых систем я буду использо-
использовать общий термин блок данных.
Категория метаданных включает данные с описаниями файлов; иначе говоря,
это данные, описывающие другие данные. В частности, к метаданным относится
информация о местонахождении содержимого файла, его размере, времени и дате
последнего чтения или записи в файл, контроле доступа и т. д. Метаданные не
включают ни фактического содержимого файла, ни его имени. Примерами струк-
структур данных этой категории являются записи каталогов FAT, записи NTFS MFT
(Master File Table), структуры i-узлов UFS и Ext3.
Категория данных имен файлов, или интерфейса с пользователем, содержит
информацию об именах, присвоенных всем файлам. В большинстве файловых
систем эти данные хранятся в каталогах в виде списка имен файлов с соответ-
соответствующими адресами метаданных. Категорию данных имен файлов можно срав-
сравнить с именем хоста в сети. Сетевые устройства взаимодействуют друг с другом
по IP-адресам, неудобным для человека. Когда пользователь вводит хостовое имя
удаленного компьютера, обмен данными становится возможным лишь после того,
как локальный компьютер преобразует имя в IP-адрес.
Категория прикладных данных содержит данные, обеспечивающие специаль-
специальные возможности. Эти данные не задействованы в процессе чтения или записи
в файл, и во многих случаях их включение в спецификацию файловой системы
не является строго обязательным. Данные включаются в спецификацию только
потому, что их реализация на уровне файловой системы (вместо обычного фай-
файла) способствует повышению эффективности. Примеры данных категории при-
приложения — статистика пользовательских квот и журналы файловой системы. Эти
данные могут быть полезны в ходе экспертизы, но, поскольку чтение и запись
файла возможны и без них, о прикладных данных забывают чаще, чем обо всех
остальных.
Отношения между пятью категориями данных показаны на рис. 8.1.
Рис. 8.1. Взаимодействие пяти категорий данных
Необходимые и вспомогательные данные
В главе 1 обсуждались различия между данными необходимыми и вспомогатель-
вспомогательными; я кратко напомню суть обсуждения. К необходимым данным файловой
системы относятся данные, без которых невозможно сохранение и выборка фай-
файлов. К такого рода данным относятся адреса, по которым хранится содержимое
файла, имя файла и указатель, связывающий имя со структурой метаданных. Вспо-
Вспомогательные данные файловой системы обеспечивают дополнительные удобства,
но для решения главной задачи — сохранения и выборки файлов — они не нуж-
нужны. В качестве примера вспомогательных данных можно назвать время последне-
последнего обращения и разрешения доступа.
Почему так важно отличать необходимые данные от вспомогательных? Пото-
Потому что необходимым данным мы просто обязаны доверять, тогда как для вспомо-
вспомогательных данных это не обязательно. Например, во всех файловых системах при-
присутствует некоторое значение, которое указывает, где хранится содержимое файла.
Оно относится к необходимым данным; ведь если это значение окажется лож-
ложным, пользователь не сможет прочитать файл. С другой стороны, информация о
времени последнего обращения или идентификаторе пользователя является вспо-
вспомогательной, потому что ее истинность не является абсолютно необходимой. Даже
если время последнего обращения к файлу не будет обновляться, это никак не
повлияет на чтение или запись в файл. Следовательно, мы должны доверять не-
необходимым данным в большей степени, чем вспомогательным, потому что они
жизненно важны для сохранения и чтения файлов.
Некоторые ОС требуют, чтобы некоторые значения обязательно задавались,
но это не означает, что эти данные являются необходимыми. К примеру, очень
строгая (и вымышленная) ОС может отказаться монтировать файловые системы
с файлами, время последнего обращения к которым относится к будущему. Дру-
Другая ОС не обратит внимания на проблемы с временем, смонтирует файловую си-
систему и сохранит в ней данные. Microsoft Windows требует, чтобы все файловые
системы FAT начинались с некоторого блока данных, хотя последний использу-
используется только в том случае, если файловая система является загрузочной. С другой
стороны, в Linux подобные требования отсутствуют.
Если рассматривать происходящее с этой точки зрения, становится очевидно,
что аналитик должен хорошо знать не только тип файловой системы, но и ОС,
записывающую данные в файловую систему. Если мы говорим о восстановлении
файлов, недостаточно узнать, как восстановить удаленный файл в файловой сис-
системе FAT, — задайтесь вопросом, как восстановить файл, удаленный Windows 98
в файловой системе FAT. Система FAT реализована во многих операционных си-
системах, и каждая из них может использовать свою методику удаления файлов.
Например, большинство ОС ограничиваются минимальным набором действий,
необходимых для удаления файла, но другие системы могут уничтожать все дан-
данные, ассоциированные с файлом. В обоих случаях конечным результатом будет
действительная файловая система FAT.
В этой книге основное внимание уделяется необходимым данным. Там, где воз-
возможно, я буду описывать информацию прикладного уровня, не являющуюся аб-
абсолютно необходимой для функционирования файловой системы. Тем не менее
очень важно, чтобы аналитик изучал и тестировал прикладные аспекты поведе-
поведения файловой системы в контексте конкретного инцидента.
Методы анализа и категории данных
В оставшейся части настоящей главы и книги пять категорий данных будут ис-
использоваться для описания методов анализа. В главе 1 было показано, что при
поиске улик аналитик определяет свойства, которыми они должны обладать, и их
вероятное местонахождение. На основании вероятного местонахождения опре-
определяется категория данных и методы анализа, которые должны быть задейство-
задействованы при поиске. Например, при поиске файлов с расширением JPG основное
внимание будет сосредоточено на методах анализа категории имен файлов. С дру-
другой стороны, при поиске файла, содержащего заранее заданное значение, будут
использованы методы анализа метаданных, поскольку адреса блоков данных от-
относятся именно к этой категории.
Во многих инструментах экспертного анализа объединяются методы анализа,
относящиеся к разным категориям, поэтому некоторые описания в книге могут
показаться искусственными. При описании методов анализа я постараюсь выде-
выделить все действия, происходящие «за кулисами», и показать, где могут произойти
сбои. Описания методов не привязаны к конкретным программам анализа. Во мно-
многих случаях для демонстрации я использую программы из пакета TSK; за допол-
дополнительной информацией обращайтесь к приложению.
Категория данных файловой системы
К категории файловой системы относятся общие данные, описывающие ее строе-
строение и местонахождение других важных данных. Чаще всего большая часть этих
данных размещается в стандартных структурах в начальных секторах файловой
системы (по аналогии с картой, висящей в вестибюле здания).
Анализ данных, относящихся к категории файловой системы, обязателен для всех
типов анализа файловых систем, потому что на этом этапе определяется местона-
местонахождение структур данных других категорий. Если какие-либо из этих данных бу-
будут повреждены или утрачены, это усложнит дополнительный анализ, потому что
вам придется искать резервные копии или догадываться, где находились значения.
Помимо общей структурной информации, в ходе анализа данных категории файло-
файловой системы также может быть получена информация о версии файловой системы;
приложении, создавшем файловую систему; дате создания и метке файловой систе-
системы. Лишь небольшая часть данных этой категории может быть просмотрена или
изменена типичным пользователем без использования шестнадцатеричного редак-
редактора. Нередко информация, не относящаяся к местонахождению структур данных,
считается несущественной, а ее значение может не соответствовать действительности.
Методы анализа
Данные этой категории обычно представляют собой одиночные самостоятельные
значения. С ними трудно сделать что-либо более содержательное, чем вывести их
для сведения аналитика или использовать в работе программы. Структурная ин-
информация может быть полезной при ручном восстановлении данных. Если вы
пытаетесь определить, на каком компьютере была создана файловая система, при-
пригодится идентификатор тома или номер версии. Структуры данных этой катего-
категории часто содержат неиспользуемые значения и свободные блоки, которые могут
использоваться для хранения небольших объемов скрытых данных. К проверке
целостности данных в этой категории можно отнести сравнение размера файло-
файловой системы с размером тома, в котором она находится. Если том имеет больший
размер, секторы после файловой системы называются резервным пространством
тома и могут использоваться для хранения скрытых данных.
В пакет TSK входит утилита fsstat, выводящая данные из категории файловой
системы. Объем выводимой информации зависит от типа файловой системы; при-
примеры будут приведены в следующих главах.
Категория данных содержимого
К категории содержимого относятся адреса ячеек носителя информации, ассоци-
ассоциированных с файлами и каталогами и предназначенных для сохранения инфор-
информации. Данные этой категории обычно делятся на группы равного размера; я буду
называть эти группы блоками данных, хотя в каждой файловой системе исполь-
используется свой термин (например, кластер или блок). Блок данных может находить-
находиться в одном из двух состояний: выделенном или свободном. Как правило, суще-
существует некоторая структура данных, в которой хранится информация о состоянии
каждого блока данных.
При создании нового или расширении существующего файла ОС ищет сво-
свободный блок данных и выделяет его файлу. Различные стратегии поиска будут
рассмотрены далее, в разделе «Стратегии выделения». Когда файл удаляется, вы-
выделенные ему блоки данных переводятся в свободное состояние и могут выде-
выделяться новым файлам. Большинство ОС не стирает содержимое блоков данных
при их переводе в свободное состояние, хотя некоторые ОС и программы «надеж-
«надежного удаления» предоставляют такую возможность.
Анализ данных содержимого проводится с целью восстановления удаленных
данных и проведения низкоуровневого поиска. Объем данных содержимого от-
относительно велик, поэтому анализ обычно проводится в автоматизированном ре-
режиме. Например, если эксперт может проанализировать содержимое 512-байто-
512-байтового сектора за 5 секунд, то при 12-часовом рабочем дне на анализ 40-гигабайтного
диска ему потребуется 388 дней.
Общие сведения
В этом разделе рассматриваются механизмы адресации блоков данных, способы
их выделения и обработки поврежденных блоков данных файловой системой.
Логические адреса файловой системы
Сектор может обладать несколькими адресами для разных уровней абстракции.
При обсуждении методов снятия данных мы видели, что каждому сектору назнача-
назначается физический адрес, отсчитываемый от начала носителя информации. В томах
секторам назначаются логические адреса томов, отсчитываемые от начала тома.
В файловых системах используются логические адреса томов, но наряду с ними
секторам назначаются логические адреса файловой системы] это связано с груп-
группировкой смежных секторов для формирования блоков данных. В большинстве
файловых систем каждому сектору тома назначается логический адрес файловой
системы. В качестве примера системы, в которой секторам не назначаются логи-
логические адреса файловой системы, молено привести систему FAT.
На рис. 8.2 показан том с 17 секторами и их логическими адресами. Внизу при-
приведены логические адреса файловой системы. Вымышленная файловая система
создает блоки данных, каждый из которых состоит из двух секторов, причем при-
присваивание адресов начинается с сектора 4. Эта очень маленькая файловая систе-
система завершается в секторе 15, а сектор 16 образует резервное пространство тома.
Рис. 8.2. Пример тома, в котором файловая система назначает адреса
группам из двух секторов, а некоторые секторы
исключаются из логической адресации
Стратегии выделения
В операционных системах используются разные стратегии выделения блоков
данных. Чаще всего ОС выделяет смежные блоки данных, но это не всегда воз-
возможно. Файл, который не состоит только из смежных блоков данных, называется
фрагментированным.
В стратегии первого доступного блока поиск начинается с первого блока дан-
данных в файловой системе. После того как первый блок будет выделен и потребует-
потребуется выделить второй блок, поиск снова начинается от начала файловой системы.
Данная стратегия часто приводит к появлению фрагментированных файлов, по-
потому что память под файл выделяется не как единое целое, а по частям. Пред-
Представьте себе театр, в котором стратегия выделения первого доступного блока ис-
используется для бронирования мест. Если группа из четырех зрителей захочет
купить билеты, кассир последовательно переберет свободные места, начиная с пер-
первого ряда. Возможно, всей четверке достанутся соседние места; а может быть, двое
будут сидеть в первом ряду, а еще двое — в последнем. Если же во время поиска
кто-то из зрителей вернет билет в кассу, третий может оказаться ближе к первому
ряду, чем первые двое. В примере на рис. 8.3 при использовании этой стратегии
следующим будет выделен блок данных 1. В операционных системах, использую-
использующих стратегию выделения первого доступного блока, удаленные данные в начале
файловой системы перезаписываются быстрее, чем при использовании других
алгоритмов. Следовательно, попытка восстановления удаленного содержимого
в конце файловой системы с большей вероятностью увенчается успехом.
Рис. 8.3. Пример выделения 8 блоков данных
В похожей стратегии поиска следующего доступного блока поиск начинается
не с начала, а с последнего выделенного блока данных. Например, после выделения
блока данных 3 на рис. 8.3 поиск начнется с блока 4, а не с 0. В нашем примере
с театром поиск продолжится не с первого ряда, а с последнего забронированного
места. Даже если во время поиска будет возвращен билет на первый ряд, он не
будет продан до того, как поиск достигнет последнего места. Такой алгоритм лучше
сбалансирован для восстановления данных, потому что блоки данных в начале фай-
файловой системы выделяются заново лишь после выделения всех блоков до ее конца.
Стратегия оптимальной подгонки ищет смежные блоки данных, объем кото-
которых позволит сохранить заданное количество данных. Такой способ хорошо ра-
работает, если количество блоков известно заранее, но при увеличении размера файла
новые блоки данных, скорее всего, будут выделены в другом месте, и файл все
равно фрагментируется. Если алгоритм не может найти смежный блок нужного
размера, он может использовать стратегию поиска первого или следующего дос-
доступного блока. Обычно именно такой алгоритм применяется при бронировании
мест в театре. Кассир перебирает пустые места, пока не найдет достаточно сосед-
соседних мест для вей группы. Скажем, если бы в примере на рис. 8.3 потребовалось
выделить два блока данных, то файл попал бы в блоки данных 4 и 5 и не был бы
разбит между блоками 1 и 4.
Каждая ОС выбирает стратегию выделения блоков данных по своему усмот-
усмотрению. В спецификациях некоторых файловых систем указано, какая стратегия
должна в них использоваться, однако обеспечить выполнение этого требования
невозможно. Проверьте реализацию файловой системы, прежде чем считать, что
она использует указанную стратегию.
Кроме проверки стратегии выделения на уровне операционной системы также
следует учитывать специфику приложения, записывающего данные. Например,
при обновлении существующих файлов некоторые приложения открывают ис-
исходный файл, обновляют его и сохраняют новые данные поверх исходных. Дру-
Другое приложение может создать копию исходного файла, обновить ее и переимено-
переименовать копию так, чтобы она перезаписала оригинал. В этом случае файл сохраняется
в новых блоках данных. Не путайте поведение приложения со стратегией выделе-
выделения, потому что ОС не заставляла приложение выделять новые блоки данных.
Поврежденные блоки данных
Во многих файловых системах предусмотрена возможность пометки поврежден-
поврежденных блоков данных. Когда-то это было необходимо, потому что старые жесткие
диски не умели обрабатывать ошибки. Операционной системе приходилось самой
выявлять поврежденные блоки данных и помечать их, чтобы они не выделялись
файлам. Современные жесткие диски обнаруживают поврежденные секторы
и подбирают им замену из числа свободных секторов, поэтому эта функциональ-
функциональность файловой системы стала излишней.
Механизм пометки поврежденных блоков данных (если он поддерживается)
позволяет легко скрывать данные. Как правило, программы проверки целостнос-
целостности диска не проверяют, действительно ли поврежден блок данных, который поме-
помечен как поврежденный. Таким образом, пользователь может вручную включить
блок данных в список поврежденных и разместить в нем свою информацию. Мно-
Многие программы снятия данных выводят список реально поврежденных секторов,
чтобы его можно было сравнить со списком помеченных секторов и выявить сек-
секторы, вручную включенные в список для хранения скрытой информации.
Методы анализа
От рассмотрения основных концепций данных содержимого мы переходим к спо-
способам их анализа. В этом разделе представлены различные методы анализа, ис-
используемые при поиске улик.
Просмотр блоков данных
Метод просмотра блоков данных применяется в тех случаях, когда эксперту изве-
известен адрес возможного местонахождения улик — например, выделенный опреде-
определенному файлу или имеющий особое значение. Скажем, во многих системах FAT32
сектор 3 не используется файловой системой и заполняется нулями, однако в нем
могут храниться скрытые данные. Просмотр содержимого сектора 3 покажет, при-
присутствуют ли в нем данные, отличные от нуля.
Принцип проведения такого рода анализа очень прост. Эксперт вводит логи-
логический адрес файловой системы, а программа вычисляет смещение в байтах или
адрес сектора для указанного блока данных. Затем программа переходит к ука-
указанной позиции и читает данные. Для примера рассмотрим файловую систему,
в которой блок данных 0 хранится со смещением 0, а размер каждого блока дан-
данных равен 2 048 байт. Смещение блока данных 10 составит 20 480 байт (рис. 8.4).
Рис. 8.4. Просмотр содержимого блоков данных 10
Данная функция выполняется многими программами, в том числе шестнадца-
теричными редакторами и средствами анализа. В частности, программа dcat из
пакета TSK позволяет просмотреть конкретный блок данных в низкоуровневом
или шестнадцатеричном формате.
Поиск в логической файловой системе
В предыдущем примере мы знали, где могут находиться улики, но не знали, какие
именно. На этот раз ситуация обратная: мы знаем содержимое улик, но не знаем,
где они находятся. При поиске в логической файловой системе каждый блок дан-
данных проверяется на присутствие некоторой фразы или значения. На рис. 8.5 каж-
каждый блок данных проверяется на присутствие строки «forensics».
Рис. 8.5. При поиске в логической файловой системе каждый блок данных
проверяется на присутствие заранее известного значения
Традиционно эта методика поиска называлась «физическим поиском», пото-
потому что в ней используется физический порядок секторов; на мой взгляд, этот тер-
термин верен только для отдельных дисков, но не для систем с объединением дисков
и массивов RAID. В таких системах порядок следования секторов не соответству-
соответствует их физическому порядку, и лучше использовать более точный термин.
К сожалению, файлы не всегда занимают смежные блоки данных, и во фраг-
ментированном файле искомое значение может оказаться разбитым на две не-
несмежных блока. В этом случае при поиске в логической файловой системе оно
обнаружено не будет. Как будет показано далее, задача решается поиском в логи-
логических файлах. Многие программы анализа позволяют выполнять поиск как по
логическим томам, так и по логическим файлам. Чтобы определить, какой режим
поиска используется вашей программой, попробуйте провести поиск по ключе-
ключевым словам в тестовых образах, размещенных на моем сайте DFTT (Digital Forensic
Tool Testing) [Carrier, 2004].
Если вернуться к аналогии из раздела «Стратегии выделения», можно сказать,
что мы пытаемся найти в театре конкретную семью. Процедура поиска в логичес-
логической файловой системе начинается с первого ряда, и проверяется каждая группа
из четырех людей, занимающих соседние места. Если семье достались несмежные
места, поиск завершится неудачей. Поиск также можно повторить для отдельно-
отдельного человека, но это может привести к ложным совпадениям из-за людей с похо-
похожей внешностью.
Состояние выделения блоков данных
Еще одна ситуация: точное местонахождение улик неизвестно, но мы знаем, что
они находятся в свободном (невыделенном) пространстве. Некоторые программы
позволяют извлечь содержимое всех свободных блоков данных файловой системы
в отдельный файл, другие проводят анализ только в пределах свободных областей.
Результат извлечения всех свободных блоков будет представлять собой низко-
низкоуровневые данные, лишенные какой-либо структуры файловой системы, поэтому
такие данные не могут обрабатываться в средствах анализа файловой системы.
На рис. 8.6 изображена битовая карта первых 12 блоков данных. В этой струк-
структуре каждый блок данных представлен одним битом. Если бит равен 1, значит,
блок данных выделен, а если 0 — свободен. Если потребуется извлечь содержи-
содержимое всех свободных блоков данных, мы извлечем блоки 2, 6, 7 и 11.
Рис. 8.6. Чтобы извлечь содержимое свободных блоков данных, мы просматриваем битовую
карту выделения и извлекаем блоки с заданным значением
Функция извлечения содержимого свободного пространства файловой систе-
системы поддерживается многими программами цифровой экспертизы, хотя опреде-
определения «свободного пространства» могут быть разными. Я заметил, что некоторые
программы считают свободными любые данные, не принадлежащие файлам, вклю-
включая данные категории файловой системы и метаданные. С другой стороны, неко-
некоторые программы восстанавливают удаленные файлы и считают их блоки дан-
данных выделенными, хотя с технической точки зрения эти блоки свободны. А вы
знаете, как ваша программа интерпретирует свободные данные?
В пакете TSK программа dls извлекает свободные данные в файл. Обнаружив
интересные данные, вы захотите узнать, в каком блоке данных файловой системы
они находились; для этой цели можно воспользоваться программой dcalc. TSK счита-
считает свободными блоки данных в категории содержимого, у которых состояние выде-
выделения помечено как свободное. Если некоторые блоки данных используются фай-
файловой системой и не имеют состояния выделения, они считаются выделенными.
Порядок выделения блоков данных
Ранее я уже упоминал некоторые стратегии, используемые ОС при выделении
блоков данных. В общем случае выбор стратегия зависит от ОС и является объек-
объектом анализа прикладного уровня. Например, Windows ME и Windows 2000 могут
использовать разные стратегии выделения блоков данных для системы FAT, но
при этом каждая из систем создает действительную файловую систему FAT.
Если относительный порядок выделения двух и более блоков данных важен,
можно попробовать определить его моделированием процедуры выделения ОС.
Это очень трудная задача, потому что сначала необходимо определить страте-
стратегию, используемую ОС, а затем исследовать все возможные сценарии, которые
могли привести к данному состоянию блоков данных. Такой метод анализа ис-
используется при реконструкции событий, которая выполняется уже после того,
как блоки будут идентифицированы как улики. Он связан с информацией при-
прикладного уровня, но его подробное рассмотрение выходит за рамки настоящей
книги.
Проверка целостности данных
Проверка целостности данных играет важную роль при анализе всех категорий
данных. Она позволяет определить, находится ли файловая система в подозри-
подозрительном состоянии. Одна из проверок целостности данных в категории содержимо-
содержимого использует информацию из категории метаданных и проверяет, что на каждый
выделенный блок данных указывает ровно одна запись метаданных. Это делается
для того, чтобы пользователь не мог вручную изменить состояние выделения бло-
блоков данных, не указав для них имени. Выделенные блоки данных, не имеющие
ассоциированной структуры метаданных, называются зависшими блоками данных.
На рис. 8.7 блоки данных 2 и 8 являются выделенными. Блок данных 2 не имеет
ассоциированной записи метаданных, поэтому он является зависшим. На блок
данных 8 ссылаются сразу две записи метаданных, что недопустимо в большин-
большинстве файловых систем.
Рис. 8.7. Проверка целостности убеждается в том, что на каждый блок данных
ссылается одна и только одна запись метаданных
В ходе другой проверки целостности данных анализируются все блоки данных,
помеченные как поврежденные. Если у вас имеется образ жесткого диска с повреж-
поврежденными секторами, многие программы снятия данных заполняют поврежденные
секторы нулями. Следовательно, любой блок данных, входящий в список повреж-
поврежденных, должен содержать нули (при условии, что программа снятия данных за-
заменяет поврежденные данные нулями). Ненулевые данные заслуживают присталь-
пристального внимания, потому что это могут быть данные, скрытые от пользователей.
Методы надежного удаления
Итак, мы разобрались с тем, как выполняется анализ данных этой категории.
Теперь давайте посмотрим, как пользователь может усложнить вашу задачу. Мно-
Многие программы надежного удаления информации, работающие в категории дан-
данных содержимого, заполняют нулями или случайными значениями все неисполь-
неиспользуемые или выделяемые файлу блоки данных.
Надежное удаление получает все более широкое распространение и становит-
становится стандартной функцией в некоторых операционных системах. Средства надеж-
надежного удаления, интегрированные в ОС, наиболее эффективны. Работа сторонних
приложений часто зависит от определенных аспектов поведения ОС, что может
повлиять на их эффективность. Скажем, много лет назад существовала програм-
программа для Linux, которая заполняла нули в блоки данных перед их освобождением,
однако ОС откладывала запись. Позднее ОС замечала, что блок данных свободен,
и вообще не записывала нули на диск. Кроме того, многие программы предпола-
предполагают, что при записи данных в существующий файл ОС будет использовать те же
блоки данных. Однако ОС также может выделить новые блоки данных, и в этом
случае содержимое файла останется на диске.
Подтвердить применение программ надежного удаления в этой категории
нелегко. Разумеется, если все свободные блоки данных содержат нули или слу-
случайные данные, логично предположить, что это работа программы надежного
удаления. Если программа записывает случайные данные или копирует содержи-
содержимое других блоков данных, без доказательств применения программы на приклад-
прикладном уровне обнаружить ее применение практически невозможно. Конечно, если
в системе найдется программа надежного удаления, вы можете определить, ис-
использовалась ли она, и проверить время последнего обращения. Если повезет, вам
также удастся найти временные копии файла.
Категория метаданных
Категория метаданных объединяет все данные с описаниями других данных. На-
Например, к ней принадлежит время последнего обращения и адреса блоков дан-
данных, выделенных файлу. Лишь немногие программы выделяют анализ метадан-
метаданных как отдельную операцию; чаще он объединяется с анализом категории имени
файла. Однако в книге я буду различать их, чтобы показать, откуда поступают
данные и почему некоторые удаленные файлы невозможно восстановить.
Многие структуры метаданных хранятся в таблицах фиксированной или ди-
динамической длины; каждой записи таблицы назначается адрес. При удалении
файла его запись метаданных переводится в свободное состояние, и ОС может
стереть часть содержащейся в ней информации.
Анализ в категории метаданных проводится с целью получения дополнитель-
дополнительной информации о конкретном файле или поиске файла, удовлетворяющего не-
некоторому критерию. Обычно в этой категории присутствует больше вспомогатель-
вспомогательных данных, чем в других категориях. Например, время последнего обращения
или записи может оказаться неточным, или ОС может не соблюдать права досту-
доступа к файлу; следовательно, эксперт не может сделать вывод относительно того,
имел ли пользователь доступ к файлу для чтения. Для поддержки заключений,
касающихся вспомогательных данных этой категории, необходимы дополнитель-
дополнительные доказательства.
Общая информация
Данный раздел посвящен основным концепциям категории метаданных. В част-
частности, мы рассмотрим новую схему адресации, резервное пространство, восста-
восстановление удаленных файлов, сжатие и шифрование.
Логическая адресация файлов
Ранее я упоминал о логических адресах файловой системы, назначаемых блокам
данных. Блок данных, выделенный файлу, также обладает логическим адресом
файла, который отсчитывается от начала файла, которому выделен данный блок.
Например, если файлу выделены два блока данных, то первому блоку назначает-
назначается логический адрес файла 0, а второму — логический адрес файла 1. Для форми-
формирования уникального логического адреса файла необходимо задействовать имя
или адрес метаданных файла. Пример показан на рис. 8.8, дополняющем преды-
предыдущий пример. На рисунке изображены два файла с пятью выделенными блока-
блоками данных. Обратите внимание: логический адрес файловой системы 1 не выде-
выделен файлу, поэтому он не имеет логического адреса файла.
Рис. 8.8. Проверка целостности убеждается в том, что на каждый блок данных
ссылается одна и только одна запись метаданных
Резервное пространство
Резервное пространство (slack space) — один из модных терминов цифровой
экспертизы, который наверняка приходилось слышать читателю. Резервное про-
пространство возникает в ситуации, когда размер файла не кратен размеру блока дан-
данных. Система обязана выделить файлу полный блок данных, даже если реально
задействована будет лишь малая его часть; неиспользуемые байты в последнем
блоке данных называются резервным пространством. Например, если размер фай-
файла составляет 100 байт, система должна выделить ему полный блок данных раз-
размером 2048 байт, а последние 1948 байт попадают в резервное пространство.
Почему резервное пространство представляет интерес для эксперта? Потому что
компьютеры «ленивы». Некоторые из них не стирают содержимое неиспользуемых
байтов, и резервное пространство содержит данные, оставшиеся от предыдущих
файлов или содержимого памяти. Вследствие архитектуры, используемой в боль-
большинстве компьютеров, в резервном пространстве имеется две интересные области.
Первая находится между концом файла и концом сектора, в котором этот файл
заканчивается. Вторая состоит из секторов, не содержащих данных файлов. На-
Наличие этих двух областей объясняется тем, что жесткие диски имеют блочную струк-
структуру, а запись в них может осуществляться только фрагментами, кратными 512 байт
(размер сектора). В предыдущем примере ОС не может записать на диск только
100 байт, она должна записать все 512 байт. По этой причине 100 байт приходится
дополнять 412 байтами данных. Представьте, что вы покупаете товар в магазине,
в котором имеются коробки только одного размера; чем меньше товар, тем больше
упаковочного материала придется положить в коробку, чтобы она была полной.
Первая область резервного пространства интересна тем, что способ заполне-
заполнения неиспользуемой части сектора определяется операционной системой. Наи-
Наиболее очевидный метод заключается в заполнении сектора нулями, что и проис-
происходит в большинстве ОС. Некоторые старые ОС (а именно, DOS и ранние версии
Windows) заполняли остаток сектора данными из памяти. Эта область резервно-
резервного пространства называлась резервом RAM [NTI, 2004], а теперь она обычно за-
заполняется нулями. Резервное пространство с содержимым памяти может содер-
содержать пароли и другие данные, не предназначенные для записи на диск.
Вторая область резервного пространства складывается из секторов, оставших-
оставшихся неиспользованными в блоке данных. Одни ОС стирают содержимое таких сек-
секторов, другие игнорируют их. Во втором случае секторы будут содержать данные
того файла, которому ранее принадлежал данный сектор.
Рассмотрим файловую систему NTFS с 2048-байтовым кластером и 512-бай-
512-байтовым сектором. Файл состоит из 612 байт, поэтому он использует весь первый
сектор и 100 байт второго сектора в кластере. Оставшиеся 412 байт второго секто-
сектора заполняются данными по усмотрению ОС. Третий и четвертый секторы ОС
может заполнить нулями, а может и оставить в них данные из удаленного файла.
Это показано на рис. 8.9: серым цветом помечено содержимое файла, а белым —
резервное пространство.
Рис. 8.9. Резервное пространство 612-байтового файла с 2048-байтовым кластером
При описании резервного пространства часто приводится аналогия с видео-
видеомагнитофоном [Kruse, 2003]. Представьте, что вы ночью записываете 60-минут-
60-минутный эпизод нового сериала. Вы смотрите записанную программу и перематывае-
перематываете ленту в начало. Позднее на ленту записывается 30-минутная программа. После
записи лента «выделяется» под 30-минутную программу, однако в конце остают-
остаются еще 30 минут от предыдущей передачи.
Все файловые системы содержат резервное пространство, потому что диско-
дисковое пространство выделяется многобайтовыми фрагментами, а не отдельными бай-
байтами. Резервное пространство представляет интерес для аналитика не из-за фай-
файловой системы, а из-за ОС и тех данных, которые она записывает. Важно заметить,
что резервное пространство относится к выделенным данным. Оно может содер-
содержать остатки ранее удаленного файла, но его память выделена некоторому файлу.
Если извлечь содержимое свободных блоков данных файловой системы, в него не
войдет содержимое резервного пространства.
Восстановление файлов по метаданным
В некоторых ситуациях улики приходится искать в удаленных файлах. Существует
два основных способа восстановления удаленных файлов: на уровне метаданных
и на прикладном уровне. Методы анализа прикладного уровня рассматриваются
в конце главы, а сейчас мы обсудим восстановление на уровне метаданных. Вос-
Восстановление по метаданным работает только в том случае, если метаданные
удаленного файла еще существуют. Если метаданные были стерты или их струк-
структура была выделена новому файлу, придется использовать методы прикладного
уровня.
После того как структура метаданных файла будет найдена, восстановление
проходит просто. Фактически оно не отличается от чтения содержимого суще-
существующего файла. В примере на рис. 8.10 (А) в записи метаданных удаленного
файла остались адреса блоков данных, что позволяет легко прочитать его содержи-
содержимое. На рис. 8.10 (В) показан пример, в котором ОС стерла адреса после удаления
файла. Практические методы восстановления будут рассмотрены далее, в главах
с описаниями конкретных файловых систем.
Рис. 8.10. Два сценария: (А) — указатели на данные не были стерты
при освобождении записи, (В) — указатели на данные потеряны
При восстановлении файлов по метаданным необходима осторожность, по-
потому что структуры метаданных и блоки данных могут быть десинхронизирова-
десинхронизированы из-за того, что блоки были выделены новым файлам. Рассмотрим пример
на рис. 8.10. Содержимое блока данных 9009 будет перезаписано, если этот блок
будет выделен записи метаданных 70 — несмотря на то, что запись 67 продолжает
ссылаться на него. При попытке восстановить содержимое метаданных 67 мы по-
получим данные из файла, использующего запись метаданных 70.
Связь между блоком данных и метаданными напоминает связь постояльца с но-
номером отеля, в котором он остановился. После того как постоялец уедет, в книгах
может остаться запись о том, что он останавливался в номере 427, однако к теку-
текущему обитателю комнаты он уже не имеет никакого отношения.
При восстановлении удаленных файлов иногда бывает трудно выявить факт
повторного выделения блока данных. Чтобы причина стала более понятной, рас-
рассмотрим серию выделений и удалений. Запись метаданных 100 выделяет блок
данных 1000 и сохраняет в нем данные. Затем файл, связанный с записью мета-
метаданных 100, удаляется; запись 100 и блок данных 1000 освобождаются. В записи
метаданных 200 создается новый файл, которому также выделяется блок данных
1000. Позднее и этот файл удаляется. Проанализировав систему, мы обнаружим
в ней две свободные записи метаданных с одинаковыми адресами блока данных
(рис. 8.11 (А)).
Даже если удастся определить, что запись 200 выделила блок данных позднее
записи 100, мы не знаем, была ли она последней в цепочке выделений. Допустим,
запись 300 выделила блок данных 1000 после того, как он был освобожден запи-
записью 200. После этого файл был удален. Возникает ситуация, показанная на рис. 8.11
(В): три свободные записи метаданных ссылаются на один адрес блока данных.
Затем в системе создается новый файл, которому выделяется запись 300 с но-
новым блоком данных 2000. Если проанализировать систему в этом состоянии, мы
не найдем никаких доказательств, что запись 300 когда-то была связана с блоком
данных 1000, хотя содержимое блока данных относится именно к записи 300. Мы
узнаем лишь то, что блок выделялся записям 100 и 200 (рис. 8.11 (С)).
Рис. 8.11. Последовательность состояний при выделении и освобождении блоков данных:
в состоянии (С) неясно, к какой записи метаданных относятся данные в блоке 1000
Этот пример показывает, что, даже если свободная структура метаданных по-
прежнему содержит адрес блока данных, очень трудно определить, относится ли
содержимое блока к этому файлу или другому, созданному после освобождения
структуры метаданных. Чтобы проверить правильность восстановления, можно
попытаться открыть файл в том приложении, в котором (по вашим предположе-
предположениям) он был создан. Если новый файл занял один из блоков удаленного файла
и записал в него свои данные, скорее всего, внутренняя структура файла будет
повреждена и открыть его не удастся.
Многие программы предоставляют функции восстановления файлов. К сожа-
сожалению, информация о процедурах, используемых для восстановления при отсут-
отсутствии метаданных, практически не публикуется, поэтому вы должны протестиро-
протестировать и сравнить программы из своего инструментария. В этом вам помогут тестовые
образы на сайте DF1\'l (Digital Forensic Tool Testing).
Сжатые и разреженные файлы
Некоторые файловые системы позволяют хранить данные в сжатом формате, что-
чтобы они занимали меньше места на диске. Сжатие файлов может происходить как
минимум на трех уровнях. На самом высоком уровне данные сжимаются в файло-
файловом формате. В качестве примера можно привести файлы JPEG: данные графичес-
графического изображения хранятся в сжатом виде, а заголовок файла — нет. На следующем
уровне внешняя программа сжимает все содержимое файла и создает новый файл1.
Перед использованием сжатый файл необходимо распаковать в другой файл.
1 Примеры внешних программ сжатия файлов — WinZip (www.winzip.com) и gzip (http://www.gnu.org/
software/gzip/gzip.html).
Последний и самый низкий уровень сжатия — сжатие данных на уровне фай-
файловой системы. В этом случае приложение, записывающее данные, не знает, что
файл будет храниться в сжатом виде. В файловых системах используются два стан-
стандартных метода сжатия. Наиболее очевидное решение — применение к блокам
данных стандартных алгоритмов сжатия, используемых для файлов. Во втором
методе файловая система не выделяет физический блок данных, который должен
быть заполнен одними нулями. Файлы, в которых пропускаются блоки данных,
заполненные одними нулями, называются разреженными файлами] пример пока-
показан на рис. 8.12. Существует несколько способов реализации разреженных фай-
файлов. Например, UFS (Unix File System) записывает 0 в поле, в котором обычно
хранится адрес блока. Ни одному файлу не может быть выделен блок 0; ОС знает,
что ноль означает блок, заполненный одними нулями.
Сжатые файлы затрудняют процесс анализа, потому что программа анализа
должна поддерживать тот же алгоритм сжатия. Кроме того, некоторые формы по-
поиска по ключевым словам и восстановления файлов теряют эффективность, по-
потому что они просматривают сжатые данные вместо исходных.
Рис. 8.12. Файл хранится в сжатом формате: блоки данных, заполненные
одними нулями, не записываются на диск
Шифрование файлов
Содержимое файла может храниться в зашифрованном виде для защиты от по-
постороннего доступа. Шифрование может выполняться приложением, создавшим
файл, внешним приложением, которое читает незашифрованный файл и создает
зашифрованный файл1, или операционной системой при создании файла. Перед
тем как записывать файл на диск, ОС шифрует его и сохраняет текст шифра в бло-
блоках данных. Информация, не относящаяся к содержимому файла (например, имя
файла и время последнего обращения), обычно не шифруется. Приложение, за-
записывающее данные, не знает, что данные хранятся в зашифрованном виде. Дру-
Другой способ шифрования содержимого файлов заключается в шифровании целого
тома2. В этом случае шифруются все данные файловой системы, не только содер-
содержимое файлов. Как правило, том с операционной системой не шифруется.
Шифрование данных создает проблемы при анализе, поскольку многие файлы
оказываются недоступными, если эксперту неизвестен ключ шифрования или
пароль. Еще хуже, если неизвестен способ шифрования. Существуют програм-
программы для подбора ключей и паролей простым перебором («атака методом грубой
силы»), но если алгоритм неизвестен, они тоже оказываются неэффективными.
Если зашифрованы только отдельные файлы и каталоги, иногда удается найти
1 Распространенные примеры — PGP (www.pgp.com) и GPG (www.gpg.org).
2 Примеры — PGP Disk (www.pgp.com), шифрованные дисковые образы Macintosh (www.apple.com)
и зашифрованные образы Linux AES.
копии незашифрованных данных во временных файлах или свободных блоках
[Casey, 2002; Wolfe, 2004].
Методы анализа
Перейдем к анализу в категории метаданных. Метаданные могут использоваться
для просмотра содержимого файлов, поиска значений и обнаружения удаленных
файлов.
Поиск метаданных
Во многих случаях анализ метаданных выполняется потому, что мы нашли имя
файла, ссылающееся на конкретную структуру метаданных, и хотим получить до-
дополнительную информацию о файле. Таким образом, нужно найти запись мета-
метаданных и обработать ее. Например, при просмотре содержимого каталога мы об-
обнаружили файл badstuff.txt и теперь хотим узнать его содержимое и дату создания.
Многие программы автоматически выполняют такого рода поиск при составле-
составлении списков имен файлов в каталогах и позволяют отсортировать результаты по
значениям метаданных.
Конкретная процедура поиска зависит от файловой системы, так как метадан-
метаданные могут храниться в разных местах. В TSK для вывода структур метаданных
используется программа istat. На рис. 8.13 изображена файловая система со струк-
структурами метаданных, обнаруженными в блоке 371. Программа читает блок данных
и выводит содержимое двух записей метаданных. Одна запись представляет уда-
удаленный файл, а другая — существующий каталог.
Рис. 8.13. Процесс просмотра содержимого записи метаданных
Просмотр логических файлов
После обнаружения метаданных можно просмотреть содержимое файла; для это-
этого следует прочитать блоки данных, выделенные файлу. Обычно это делается при
поиске улик в содержимом файла. Допустим, мы определили адрес блока данных
файла badstuff.txt и теперь хотим ознакомиться с его содержимым.
Этот процесс работает как в категории метаданных, так и в категории данных
содержимого. На рис. 8.14 перечислены блоки данных, связанные с записями
метаданных 1 и 2. Многие графические программы объединяют эту процедуру
с перечислением имен файлов. Если выбрать файл, программа переходит к поис-
поиску блоков данных, указанных в метаданных файла.
В процессе поиска необходимо помнить о резервном пространстве, потому что
последний блок данных может использоваться файлом лишь частично. Чтобы оп-
определить используемую часть последнего блока, вычислите остаток от деления
размера файла на размер каждого блока данных.
В пакете TSK для просмотра содержимого блоков данных, выделенных струк-
структуре метаданных, используется программа icat. При запуске с ключом -s выводит-
выводится информация о резервном пространстве, а с ключом -г программа пытается вос-
восстанавливать удаленные файлы.
Рис. 8.14. Объединение информации из метаданных и блоков данных
позволяет просмотреть содержимое файла
Поиск в логических файлах
Предыдущие методы подразумевают, что вам известен конкретный файл и вы
хотите просмотреть его содержимое. Нередко возникает обратная задача — найти
файл на основании его содержимого (например, найти все файлы, содержащие
слово «forensics»). В таких ситуациях применяется поиск в логических файлах.
Он основан на тех же принципах, что и просмотр логических файлов, но вместо
просмотра содержимого в файле ищется конкретное значение.
Своим названием этот метод сильно напоминает поиск в логической файло-
файловой системе. Действительно, эти методы очень похожи, только в данном случае
поиск в блоках данных производится в порядке их использования файлами, а не
в порядке их следования в томе. На рис. 8.15 изображены две записи метаданных
и выделенные им блоки данных. В данном случае поиск осуществляется в блоках
2, 3, 4 и 6 как в едином наборе. Преимущество такого вида поиска перед поиском
в логической файловой системе состоит в том, что он находит данные, фрагмен-
тированные по блокам данных или секторам. Допустим, мы ищем слово «forensics»,
которое начинается в блоке данных 4 и заканчивается в блоке 6. При поиске в ло-
логической файловой системе оно найдено не будет, потому что оно не содержится
в смежных блоках данных. Разновидностью этого вида поиска является поиск
файла с известным хеш-кодом MD5 или SHA-1.
Не забывайте, что логические адреса файлов присваиваются только выделен-
выделенным блокам данных. Это означает, что для поиска того же значения в свободных
блоках данных следует провести поиск в логическом томе. Например, поиск в ло-
логических файлах на рис. 8.15 не затронет блоки 0 и 1, поэтому необходимо прове-
провести второй поиск, который включал бы блоки 0, 1, 7, 9, 10, 11 и т. д.
Рис. 8.15. Лри поиске в логическом файле просматриваются блоки данных,
выделенные записи метаданных
Обязательно выясните, включает ли ваша программа анализа резервное про-
пространство файла при поиске в логическом файле; одни программы это делают,
другие — нет. Для этой цели можно воспользоваться поиском по ключевым сло-
словам в тестовых образах на сайте DFTT.
Анализ свободных метаданных
Если поиск проводится в содержимом удаленных файлов, не ограничивайтесь
именами удаленных файлов из содержимого каталога. Примеры будут приведе-
приведены в разделе «Категория данных имен файлов», а пока достаточно сказать, что
имя удаленного файла может быть использовано заново прежде, чем его структу-
структура метаданных. Следовательно, ваши улики могут находиться в свободной запи-
записи метаданных, однако вы не увидите их, потому что эта запись не связана с име-
именем. Многие программы анализа выводят список свободных записей метаданных
для проведения поиска или просмотра. Для получения списка свободных струк-
структур данных в TSK используется программа its.
Поиск и сортировка по атрибутам метаданных
На практике поиск файлов также нередко осуществляется по одному из их полей
метаданных. Допустим, имеется система обнаружения вторжений (IDS, Intrusion
Detection System) и вы хотите найти все файлы, созданные в течение ближайших
двух минут с момента полученного предупреждения. А может быть, вы анализи-
анализируете действия некоторого пользователя и хотите найти все файлы, в которые
ему разрешена запись. В общем случае на некоторой стадии расследования может
возникнуть необходимость в поиске значений метаданных. Некоторые примеры
будут рассмотрены в этом разделе.
Время обращения к файлу легко изменить в любой системе, но оно часто со-
содержит полезную информацию. Предположим, мы проверяем гипотезу, что зло-
злоумышленник получил доступ к компьютеру в 20:13 и установил в системе вредо-
вредоносный код; для этого можно провести поиск всех файлов, созданных между 20:13
и 8:23. Если за этот промежуток времени не будет найдено ни одного подозри-
подозрительного файла или мы найдем посторонний файл, созданный в другое время, это
означает, что неверно задано время создания файла или неверна наша гипотеза (а
возможно, и то и другое).
Если вы столкнулись с компьютером, о котором вам мало что известно, воз-
возможно, вам поможет список последних обращений и созданий файлов. Эта ин-
информация даст представление о том, как использовался компьютер в последнее
время.
Некоторые программы составляют временные диаграммы файловых операций.
Как правило, количество точек данных на диаграмме для каждого файла совпада-
совпадает с количеством временных штампов. Например, если в метаданных хранится
время последнего обращения, последней записи и последней модификации, на
диаграмме создаются три точки данных. В пакете TSK для построения времен-
временных диаграмм файловых операций используется программа mactime. Пример вы-
выходных данных mactime для каталога C:\Windows:
Wed Aug 11 2004 19:31:58 34528 .a. /system32/ntio804.sys
34392 .a. /system32/ntio412.sys
С..]
Wed Aug 11 2004 19:33:27 2048 mac /bootstat.dat
1024 mac /system32/config/default.L0G
1024 mac /system32/config/software.L0G
Wed Aug 11 2004 19:33:28 262144 ma. /system32/config/SECURITY
262144 ma. /system32/config/default
В этом списке перечислены файловые операции по секундам. В первом столбце
приводится временной штамп, во втором — размер файла, а в третьем — код опе-
операции (т — модификация содержимого, а — обращение к содержимому, с — изме-
изменение метаданных). В последнем столбце находится имя файла. Реальный вывод
содержит гораздо больше информации, но он не поместится на странице книги.
Прежде чем пытаться увязывать временные штампы и записи журналов с раз-
разных компьютеров, необходимо понять, как файловая система хранит временные
штампы. Некоторые временные штампы хранятся в формате UTC; это означает,
что для определения фактического времени необходимо знать смещение часово-
часового пояса, в котором находится компьютер. Например, если я обращаюсь к файлу
в 14:00 в Бостоне, штат Массачусетс, ОС зафиксирует, что обращение произошло
в 19:00 в формате UTC, потому что Бостон смещен на пять часов назад по отно-
отношению к времени UTC. Когда эксперт будет анализировать файл, он должен пре-
преобразовать 19:00 к местному времени. В других файловых системах время хра-
хранится с учетом местного часового пояса, и в данном примере в них будет храниться
значение 14:00. У некоторых программ также возникают проблемы с летним вре-
временем.
Еще одна стандартная задача — поиск файлов, в которые некоторому пользо-
пользователю разрешена запись. Результат поиска покажет, какие файлы могли быть
созданы подозреваемым (предполагается, что ОС соблюдает разрешения досту-
доступа, а подозреваемый не имеет прав администратора). Также возможно проведе-
проведение поиска по идентификатору владельца. Обычно такие операции используют-
используются при расследовании действий конкретного пользователя.
Если ранее мы провели поиск в логической файловой системе и обнаружили
интересные данные в одном из блоков, можно попытаться найти адрес этого бло-
блока в метаданных. Возможно, поиск покажет, какому файлу был выделен блок дан-
данных, после чего можно будет найти другие блоки данных, принадлежащие тому
же файлу. Пример показан на рис. 8.16; улики были обнаружены в блоке данных
34. Поиск в метаданных показывает, что блок был выделен структуре 107 наряду
с блоками данных 33 и 36. Если ОС не стирает адреса при удалении файлов, этот
процесс также поможет найти освободившуюся запись метаданных. Программа
ifind из пакета TSK выполнит эту работу за вас.
Рис. 8.16. Поиск в структурах метаданных позволит узнать, какой из них
был выделен заданный блок данных
Порядок выделения записей метаданных
Если потребуется узнать относительный порядок выделения двух записей, воз-
возможно, это удастся сделать с применением стратегии выделения, используемой
вашей ОС. Это сложная задача, которая к тому же сильно зависит от ОС. Записи
метаданных обычно выделяются по стратегии поиска первой доступной или сле-
следующей доступной записи. Полное описание этой методики анализа выходит за
рамки книги, поскольку она зависит от прикладного уровня.
Проверка целостности данных
Проверка целостности метаданных может выявить попытки сокрытия данных.
Также может оказаться, что образ файловой системы содержит внутренние ошиб-
ошибки, которые не позволяют получить полную информацию. Проверка целостности
может выполняться только на основе необходимых данных, в том числе адресов
блоков данных, размера и состояния выделения каждой записи метаданных.
Один из способов проверки заключается в том, чтобы проверить каждую вы-
выделенную запись и убедиться в том, что выделенные ей блоки данных действи-
действительно выделены. Также можно убедиться в том, что количество выделенных
блоков данных соответствует размеру файла. Как правило, файловые системы не
выделяют больше блоков данных, чем это необходимо. В разделе «Проверка це-
целостности данных» для категории содержимого описана проверка того, что на
каждый выделенный блок данных ссылается ровно одна выделенная запись мета-
метаданных.
Также следует проверить, что записям специальных типов файлов не выделя-
выделяются блоки данных. Например, в некоторых файловых системах создаются спе-
специальные файлы, называемые сокетами и используемые при обмена данных между
процессами. Таким файлам блоки данных не выделяются.
Еще одна проверка целостности использует информацию из категории имен
файлов и убеждается в том, что каждой выделенной записи каталога назначено
имя, которое ссылается на эту запись. Существуют проверки диапазонов дат
и других вспомогательных данных, но более точные проверки в таких случаях
обычно неприменимы.
Методы надежного удаления
Метаданные могут уничтожаться при удалении файлов, чтобы затруднить их вос-
восстановление. Время, размер и адреса блоков данных заполняются нулями или
случайными данными. Эксперт может выявить факт стирания, обнаружив обну-
обнуленные или другие недействительные записи между двумя действительными за-
записями. Более разумная программа надежного удаления заполняет структуру ме-
метаданных действительными данными, не имеющими отношения к исходному
файлу. Еще более надежная программа сдвинет оставшиеся записи, чтобы между
ними не оставалось неиспользуемых. Впрочем, на такие сдвиги уйдет очень мно-
много времени.
Категория имен файлов
К категории имен файлов относятся данные, благодаря которым пользователь
может ссылаться на файл по имени (вместо адреса его метаданных). В минималь-
минимальном варианте эта категория данных включает только имя файла и адрес его мета-
метаданных. В некоторых файловых системах к ней также причисляется информация
о типе файла или временные штампы, но такая классификация не является стан-
стандартной.
Один из важных этапов анализа имен файлов — определение местонахожде-
местонахождение корневого каталога, необходимого для поиска файла по полному имени. На-
Например, в Windows каталог С:\ является корневым каталогом диска С:. В каждой
файловой системе используется свой способ определения местонахождения кор-
корневого каталога.
Общие сведения
В этом разделе мы рассмотрим общие концепции категории имен файлов. Эта
категория относительно проста; нас интересует только метод восстановления фай-
файлов по именам.
Восстановление файлов по именам
Как было показано при описании категории метаданных, удаленные файлы мож-
можно восстановить по метаданным. При восстановлении, основанном на именах фай-
файлов, имя удаленного файла и соответствующий ему адрес метаданных использу-
используются для восстановления содержимого файла по метаданным. Иначе говоря, вся
«черная работа» выполняется на уровне метаданных, а на уровне имен файлов мы
ограничиваемся идентификацией записей метаданных, используемых для восста-
восстановления.
На рис. 8.17 показаны два имени файлов и три записи метаданных. Файл favo-
rites.txt удален, а его имя ссылается на свободную запись метаданных. Мы можем
попытаться восстановить его содержимое, используя методы восстановления по
метаданным. Обратите внимание: содержимое, связанное с записью метаданных
2, тоже можно восстановить, но его имя уже утрачено. В этом разделе рассмат-
рассматриваются некоторые проблемы, связанные с восстановлением файлов по име-
именам.
Рис. 8.17. Поиск в структурах метаданных позволит узнать, какой из них
был выделен заданный блок данных
В разделе «Восстановление файлов по метаданным» приводятся примеры того,
как повторное выделение блоков данных и их десинхронизация с метаданными
усложняют процесс восстановления. Сейчас мы рассмотрим эти примеры более
подробно и разберемся, как нарушается синхронизация имен файлов с метадан-
метаданными.
Допустим, имеется файл, в структуре имени файла которого присутствует имя
fHel.dat; структура ссылается на запись метаданных 100 (рис. 8.18 (А)). Файл был
удален, а обе структуры (имени файла и метаданных) были освобождены, однако
указатель в структуре имени файла не был стерт. Новый файл fiLe2.dat создается
в новой структуре данных, и ему заново выделяется запись метаданных 100
(рис. 8.18 (В)). Позднее файл file2.dat также был стерт, а его структуры имени
файла и метаданных освободились (рис. 8.18 (С)). Если проанализировать систе-
систему в этом состоянии, мы найдем в ней две структуры имени файла, ссылающиеся
на одну запись метаданных. Неизвестно, какому файлу принадлежит содержи-
содержимое, адрес которого хранится в записи метаданных 100— filel.dat или file2.dat
Рис. 8.18. Последовательность состояний при создании и удалении файлов: в состоянии (В)
две структуры имен файлов ссылаются на одну структуру метаданных. Невозможно
определить, к какой из них относится содержимое файла
Чтобы ситуация стала еще более запутанной, продолжим этот пример. Файл
file3.dat создается в новой записи метаданных 200 и блоке данных 1000 из преды-
предыдущего примера (рис. 8.19 (А)). Файл fHe3.dat удаляется, и структура имени фай-
файла передается файлу file4.dat (который нас не интересует). Затем создается файл
fiLe5.dat с записью метаданных 100 и блоком данных 1000 (рис. 8.19 (С)). Файл
file5.dat тоже удаляется. Наконец, создается файл file6.dat, которому повторно вы-
выделяется та же структура имени файла, что и file5.dat, но этот файл использует
новую запись метаданных 300 и новый блок данных 2000 (рис. 8.19(С)).
Рис. 8.19. Последовательность состояний при создании и удалении файлов: в состоянии (С)
нарушается синхронизация некоторых указателей
Предположим, что система анализируется в этом состоянии. Мы сталкиваем-
сталкиваемся со следующими проблемами:
• На блок данных 1000 ссылаются две записи метаданных, и мы не знаем, какая
из них была последней; также неизвестно, существовали ли другие записи ме-
метаданных, ссылавшиеся на нее с момента повторного выделения.
• На запись метаданных 100 ссылаются две структуры имен файлов, и мы не
знаем, какая из них была последней; также неизвестно, существовали ли дру-
другие записи, ссылавшиеся на нее с момента повторного выделения. В нашем
примере последним был файл file5.dat, но он более не существует.
• На запись метаданных 200 не ссылается ни одна структура имени файла, по-
поэтому мы не можем определить имя хотя бы одного файла, которому она была
выделена.
Эти проблемы могут повлиять на работу эксперта в нескольких отношениях.
Представьте программу анализа, которая читает список файлов в каталоге и вы-
выводит рядом с каждым именем соответствующие временные штампы. Информа-
Информация о времени и содержимом filel.dat и file2.dat будет неверной, потому что она
в действительности относится к файлу file5.dat, имя которого более не существу-
существует. Значения, связанные с записью метаданных 200, не будут присутствовать в
списках файлов, потому что с этой записью не связана структура имени. Именно
из-за таких ситуаций я разделил категории имен файлов и метаданных; было бы
неправильно считать, что между ними существует более тесная связь.
Итак, при анализе удаленных файлов с точки зрения имен следует помнить,
что записи метаданных и блоки данных могли быть выделены новому файлу. Так-
Также помните, что вам придется проанализировать свободные записи метаданных,
чтобы найти те из них, на которые не ссылаются структуры имен файлов.
Методы анализа
В этом разделе рассматриваются методы анализа, применимые к данным из кате-
категории имен файлов.
Получение списка имен файлов
Категория данных имен файлов предназначена для того, чтобы ассоциировать
файлы с именами. Как нетрудно предположить, одним из самых распространен-
распространенных методов анализа является получение списка файлов и каталогов. Обычно это
делается при поиске улик на основании имени, пути или расширения файла. Ког-
Когда файл будет опознан, адрес его метаданных используется для получения допол-
дополнительной информации. У этого метода есть несколько разновидностей: напри-
например, файлы можно отсортировать по расширениям, что позволяет сгруппировать
однотипные файлы.
Многие файловые системы не стирают имена удаленных файлов, поэтому
эти имена тоже будут присутствовать в списке. Впрочем, иногда адрес метадан-
метаданных стирается при удалении файла, и получить дополнительную информацию
не удастся.
Получение списка начинается с обнаружения корневого каталога файловой
системы. Обычно для этого используется процесс, который был описан ранее для
просмотра логических файлов в разделе «Категория метаданных». Строение кор-
корневого каталога хранится в записи метаданных, поэтому мы должны найти за-
запись и блоки данных, выделенные для этого каталога.
Обнаружив содержимое каталога, мы обрабатываем его, получая список файлов
и соответствующих им адресов метаданных. Если пользователь хочет просмот-
просмотреть содержимое какого-либо файла в списке, можно воспользоваться методом
просмотра логических файлов по указанному адресу метаданных. Если потребу-
потребуется вывести содержимое другого каталога, мы загружаем и обрабатываем его.
В любом случае процесс основан на просмотре логических файлов.
Эта методика поддерживается большинством программ анализа, причем мно-
многие программы объединяют информацию из категории имен файлов с информа-
информацией из категории метаданных — например, чтобы в одном представлении с име-
именами файлов выводились пометки даты и времени. На рис. 8.20 показан пример
анализа: при обработке блока данных 401 были обнаружены два имени. Нас инте-
интересует файл favorites.txt; мы видим, что его метаданные находятся в записи 3. В на-
нашей файловой системе соответствующая структура метаданных находится в бло-
блоке данных 200. Мы обрабатываем информацию из соответствующего блока данных,
получая размер и адреса содержимого этого файла.
Рис. 8.20. Чтобы получить список имен файлов, мы обрабатываем содержимое каталога
и извлекаем имена (а иногда и связанные с ним метаданные)
Данный метод анализа поддерживается многими программами. В пакете TSK
для вывода имен существующих и удаленных файлов используется программа fls.
Поиск имен файлов
Список имен файлов удобен в том случае, если вы знаете имя искомого файла, но
это не всегда так. Если полное имя файла неизвестно, можно провести поиск по
известной части. Например, мы можем знать расширение файла или его имя, но
без каталога. В результате поиска выводится список файлов, удовлетворяющих
критерию поиска. Скажем, если в ситуации на рис. 8.20 провести поиск по расши-
расширению .txt, программа просмотрит каждую запись и выведет как badstuff.txt, так
и favorites.txt. Учтите, что поиск по расширению не всегда возвращает файлы за-
заданного типа, поскольку расширение может быть изменено для скрытия файла.
Для поиска всех файлов заданного типа необходимо использовать методы при-
прикладного уровня, анализирующие строение файла.
Процесс поиска по имени сходен с процессом получения списка имен файлов.
Сначала загружается и обрабатывается содержимое каталога, затем каждая за-
запись сравнивается с заданным критерием. Если при проведении рекурсивного
поиска обнаруживается каталог, то его содержимое также участвует в поиске.
Другая разновидность поиска в этой категории — поиск имени файла, которо-
которому была выделена заданная запись метаданных. Это может быть необходимо, если
вы обнаружили улики в блоке данных, а затем нашли структуру метаданных, ко-
которой он был выделен. После обнаружения структуры метаданных среди имен
файлов ищется полное имя файла, которому был выделен блок с уликами. Задача
решается программой ffind пакета TSK.
Порядок выделения структур данных
Как уже говорилось ранее при обсуждении содержимого и метаданных, порядок
выделения структур имен файлов может использоваться для определения отно-
относительного порядка создания двух имен файлов. Метод анализа зависит от спе-
специфики ОС и выходит за рамки книги.
Проверка целостности данных
При проверке целостности данных имен файлов эксперт убеждается в том, что
все выделенные структуры имен ссылаются на выделенные структуры метадан-
метаданных. В некоторых файловых системах одному файлу может быть присвоено не-
несколько имен; как правило, эта функциональность реализуется созданием несколь-
нескольких структур имен файлов с одинаковыми адресами метаданных.
Методы надежного удаления
Программы надежного удаления в этой категории стирают имя и адрес метаданных
в структуре. Один из методов удаления может стирать поля структуры имени фай-
файла; в этом случае анализ покажет, что запись существует, но ее данные стали недей-
недействительными. Например, имя файла setuplog.txt будет заменено именем abedefgh.123.
В некоторых ОС это решение усложняется тем, что ОС помещает новое имя в ко-
конец списка, используя стратегию поиска следующей доступной структуры.
Другая методика надежного удаления имен файлов заключается в реорганиза-
реорганизации списка имен, при которой имя удаленного файла заменяется именем одного
из существующих файлов. Этот метод гораздо сложнее первого; с другой сторо-
стороны, он гораздо эффективнее в отношении сокрытия данных. Эксперт может даже
не заподозрить, что с каталогом что-то не в порядке.
Категория прикладных данных
В некоторых файловых системах хранятся данные, традиционно относящиеся
к прикладной категории. Эти данные не являются необходимыми для файловой
системы и обычно хранятся в виде специальных данных файловой системы, а не
обычных файлов, потому что такой способ более эффективен. В этом разделе рас-
рассматривается механизм журналов — один из самых распространенных механиз-
механизмов прикладной категории.
С технической точки зрения любой файл, создаваемый ОС или приложением,
может быть реализован в виде расширения файловой системы. Например, Acme
Software может решить, что ОС будет работать быстрее, если зарезервировать часть
файловой системы под адресную книгу. Вместо того чтобы хранить имена и адре-
адреса в файле, система будет сохранять их в специальном разделе тома. Возможно,
такой подход обеспечит выигрыш по эффективности, но для файловой системы
он не является обязательным.
Журналы файловой системы
Как хорошо известно любому пользователю, на компьютерах иногда происходят
сбои. Если в момент сбоя ОС записывала данные на диск или в буфере остава-
оставались несохраненные изменения, сбой может привести к нарушению целостности
системы. В системе может появиться выделенная структура метаданных с выде-
выделенными блоками данных, но ни одна структура имени файла не будет ссылаться
на эту структуру метаданных.
Для обнаружения подобных нарушений ОС запускает программу, которая скани-
сканирует файловую систему в поисках отсутствующих указателей и других признаков
повреждений. В больших файловых системах этот процесс может занять очень
много времени. Для упрощения работы программы сканирования в некоторых
файловых системах создаются журналы. Перед внесением каких-либо изменений
в метаданные файловой системы в журнале создается запись с описанием будущих
изменений. После того как изменения будут внесены, в журнале создается новая
запись с информацией об их успешном внесении. Если в системе происходит сбой,
сканирующая программа читает журнал и находит незавершенные операции. За-
Затем программа либо вносит изменения, либо возвращает их в исходное состояние.
Многие современные файловые системы поддерживают журналы, потому что
они экономят время при загрузке больших систем. Журнальные данные относят-
относятся к категории прикладных данных, потому что файловая система может функ-
функционировать и без них. Эти данные существуют лишь для того, чтобы ускорять
проверку целостности данных.
Журналы файловой системы могут пригодиться при расследованиях, хотя до
настоящего времени они еще не использовались в полной мере. В журналах содер-
содержится информация о недавно происходивших событиях файловой системы, а эта
информация может помочь при реконструкции недавнего инцидента. Большинство
программ анализа не обрабатывает содержимое журналов файловой системы. В па-
пакет TSK входят программы jls и jcat, выводящие содержимое некоторых журналов.
Методы поиска на прикладном уровне
В начале книги я упоминал о том, что в модели анализа основное внимание бу-
будет уделяться уровням томов и файловой системы. В этом разделе мы перейдем
на прикладной уровень и рассмотрим пару методов восстановления удаленных
файлов и упорядочения выделенных файлов для анализа. Эти методы не зависят
от файловой системы, поэтому в последующих главах они обсуждаться не будут.
Оба метода основаны на том факте, что многие файлы имеют четко определенный
формат и включают сигнатуру, уникальную для данного типа файла. Сигнатура
может использоваться для определения типа неизвестного файла. Команда file, при-
присутствующая во многих системах семейства UNIX, содержит базу данных сигнатур
для идентификации структуры неизвестных файлов (ftp://ftp.astron.com/pub/fiLe).
Восстановление файлов на прикладном уровне
Извлечением данных (data carving) называется процесс поиска во фрагменте дан-
данных начальной и конечной сигнатуры для известных типов файлов. В результате
строится список файлов, содержащих одну из сигнатур. Как правило, эта проце-
процедура выполняется со свободным пространством файловой системы и позволяет
аналитику восстанавливать файлы, на которые не ссылается ни одна структура
метаданных. Например, изображение в формате JPEG содержит стандартный за-
заголовок и завершитель. Если аналитику потребуется восстановить удаленные
графические изображения, он сохранит в файле содержимое свободных блоков
и запустит программу извлечения данных. Программа ищет заголовки JPEG и из-
извлекает данные, находящиеся между заголовком и завершителем.
Примером программы, выполняющей такую операцию, является программа
foremost (http://foremost.sourceforge.net), разработанная специальными агентами
Крисом Кендаллом (Kris Kendall) и Джессе Корнблумом (Jesse Kornblum) из Бюро
специальных расследований ВВС США. Программа foremost анализирует файло-
файловую систему или дисковый образ на основании содержимого конфигурационного
файла, в котором создается запись для каждой сигнатуры. В записи указывается
известное значение заголовка, максимальный размер файла, признак учета реги-
регистра символов в заголовке, типичное расширение этого типа файлов и необяза-
необязательный завершитель. Например, для файлов JPEG запись выглядит так:
jpg у 2000000 \xff\xd8 \xff\xd9
Это означает, что файл имеет типичное расширение .jpg, в его заголовке и за-
завершителе учитывается регистр символов, заголовок равен 0xffd8, а завершитель —
0xffd9. Максимальный размер файла составляет 200 000 байт, и если заголовок не
найден в пределах этого смещения, извлечение данных прерывается. В наборе дан-
данных на рис. 8.21 заголовок JPEG расположен в двух первых байтах сектора 902,
а завершитель — в середине сектора 905. Содержимое секторов 902,903,904 и в на-
начале сектора 905 извлекается как изображение JPEG.
Рис. 8.21. Блоки физических данных, анализ которых обнаруживает графическое
изображение в формате JPEG в секторах 902-905
Аналогичная программа Lazarus из пакета The Coroner's Toolkit (http://www.porcu-
pine.org/forensics/tct.htmL), автор — Дэн Фармер (Dan Farmer), просматривает
каждый сектор низкоуровневого образа и выполняет для него команду file. В ре-
результате создаются группы смежных секторов, относящихся к одному типу. Ко-
Конечный результат работы программы представляет собой список с указанием каж-
каждого сектора и его типа. Фактически программа дает возможность сортировать
данные по их содержимому. Концепция интересная, однако программа написана
на Perl и иногда работает довольно медленно.
Сортировка файлов по типу
Тип файлов может использоваться для упорядочения файлов в файловой сис-
системе. Если вы ищете файлы конкретного типа, отсортируйте их на основании
структуры содержимого. Например, для каждого файла можно выполнить ко-
команду file и сгруппировать однотипные файлы: в одну группу входит графика,
в другую — исполняемые файлы, и т. д. Такая возможность предусмотрена во мно-
многих программах анализа, но не всегда ясно, как осуществляется сортировка: по
расширению или по сигнатуре файла. Программа sorter из пакета TSK сортирует
файлы по сигнатуре.
Конкретные файловые системы
В оставшихся главах книги мы рассмотрим способы хранения данных в системах
FAT, NTFS, Ext2/Ext3 и UFS и применим к ним структуру из пяти категорий.
В табл. 8.1 приведены имена структур данных в каждой категории данных для фай-
файловых систем, описанных в книге.
Таблица 8.1. Структуры данных в файловых системах, описанных в книге
(деление по категориям)
Файловая Содержимое Метаданные Имя файла Прикладные
система данные
ExtX Суперблок, Блоки, битовая I-узлы, карта Записи Журнал
дескриптор карта блоков i-узлов, каталога
группы расширенные
атрибуты
FAT Загрузочный Кластеры, FAT Записи Записи —
сектор, каталога, FAT каталога
FSINFO
NTFS $Boot, Кластеры, $MFT, $mfTMirr, $FILE_NAME, Дисковые
$Volume, $Bitmap $STANDARD_ $IDX_ROOT, квоты,
$AttrDef INFORMATION, $IDX_ журнал,
$DATA, ALLOCATION, журнал
$ATTRIBUTE_ $BITMAP изменений
LIST, $SECURITY_
DESCRIPTOR
UFS Суперблок, Блоки, фраг- I-узлы, карта Записи —
дескриптор менты, битовая i-узлов, расши- каталога
группы карта блоков, ренные атрибуты
битовая карта
фрагментов
Существуют и другие файловые системы, которые не вошли в книгу, но могут
встретиться в вашей работе. Например, HFS+ — стандартная файловая система
компьютеров Apple. Компания Apple опубликовала структуры данных и подроб-
подробности строения файловой системы [Apple, 2004]. ReiserFS — одна из файловых
систем Linux, по умолчанию используемая некоторыми дистрибутивами (напри-
(например, SUSE [Reiser, 2003]). В стандартной документации ReiserFS приводится мало
информации о структурах данных, эти структуры документировали Флориан Бух-
гольц (Florian Bucholz) [2003] и Герсон Курц (Gerson Kurz) [2003]. Еще одна фай-
файловая система для Linux — JFS ( Journaled File System) — была разработана в IBM
(не путайте ее с файловой системой JFS, разработанной IBM для AIX). IBM до-
документировала структуру файловой системы [IBM, 2004].
Итоги
Большая часть улик в современных цифровых расследованиях получается в ре-
результате анализа файловых систем. В этой главе были представлены категории
данных, формирующие единый логический шаблон для рассмотрения конкрет-
конкретных файловых систем. Также были рассмотрены методы анализа в каждой кате-
категории данных (на достаточно формальном уровне). В табл. 8.2 представлена сводка
методов анализа для разных типов данных.
Таблица 8,2, Выбор метода поиска в зависимости от типа искомых улик
Требуется найти Категория данных Метод поиска
Файл по имени, расширению Имя файла Поиск по имени файла или вывод
или каталогу содержимого каталога
Существующий или удален- Имя файла и метаданные Поиск по атрибутам метаданных
ный файл по временным
штампам
Существующий файл по зна- Имя файла (с использова- Поиск по логическим файлам
чению, присутствующему нием метаданных и данных
в содержимом содержимого)
Существующий файл Имя файла (с использова- Поиск по логическим файлам
по хеш-коду SHA-1 нием метаданных и данных с хеш-кодами
содержимого)
Существующий файл Имя файла (с использова- Поиск по логическим файлам
или свободный блок данных нием метаданных и данных с восстановлением по метаданным
по значению, присутствую- содержимого) и поиском в логической файловой
щему в содержимом системе
Все удаленные файлы Прикладные данные и со- Восстановление на прикладном
по типу приложения держимое уровне (извлечение данных)
в свободных блоках
Свободные данные по со- Данные содержимого Поиск в логической файловой
держимому (без учета системе
типа приложения)
Библиография
• Apple. «Technical Note TNI 150-HFS Plus Volume Format». March 2004. http://
developer.apple.com/technotes/tn/tnll50.htmL
• Buchholz, Florian, «The Structure of the Reiser File System». August 17, 2003.
http://www.cerias.purdue.edu/homes/florian/reiser/reiserfs.php.
• Carrier, Brian. «Digital Forensic Tool Testing Images», 2004. http://dftt.source-
forge.net.
• Casey, Eoghan. «Practical Approaches to Recovering Encrypted Digital Evidence».
International Journal of Digital Evidence, 1 C), 2002. http://www.ijde.org.
• IBM. «Journaled File System Technology for Linux». 2004. http://www.ibm.com/
developerworks/oss/jfs/.
• Kruse, Warren. «Computer Forensics Primer». CSI 30th Annual Computer Security
Conference, November 3, 2003. http://csiannual.com/classes/jl.pdf.
• Kurz, Gerson. «ReiserFS Docs», 2003. http://p-nand-q.com/download/rfstool/rei-
serfs_docs.html.
• Reiser, Hans. «Reiser4». 2003. http://www.namesys.com.
• Wolfe, Hank. «Penetrating Encrypted Evidence». Journal of Digital Investigation,
1B), 2004.
FAT: основные
концепции и анализ
FAT (File Allocation Table) — одна из простейших файловых систем, встречаю-
встречающихся во многих операционных системах. FAT является основной файловой сис-
системой операционных систем Microsoft DOS и Windows 9х, но в NT, 2000 и ХР по
умолчанию используется система NTFS (New Technologies File System), которая
будет рассмотрена позднее. FAT поддерживается всеми версиями Windows и мно-
многими системами UNIX, и экспертам еще придется иметь с ней дело в течение не-
нескольких лет (несмотря на то, что FAT уже не является стандартной файловой
системой настольных систем Windows). FAT часто встречается в картах памяти
цифровых фотоаппаратов и «брелоковых дисках» USB. Многие пользователи зна-
знакомы с основными концепциями FAT, но не знакомы с основными «тайниками»
для скрытия данных, проблемами адресации и другими нетривиальными аспек-
аспектами. В этой главе будут представлены общие концепции и методы анализа FAT
на основе модели данных с пятью категориями. Низкоуровневые структуры дан-
данных будут описаны в главе 10. Вы можете читать эти главы параллельно, одну за
другой или пропустить описания структур данных.
Введение
Одна из причин, по которой файловая система FAT считается простой, состоит
в том, что количество структур данных в ней относительно невелико. К сожале-
сожалению, это также означает, что за прошедшие годы в нее был внесен ряд изменений
для поддержки новых возможностей (хотя эти изменения и не столь запутанны,
как в случае с разделами DOS). Файловая система FAT не лучшим образом укла-
укладывается в модель с пятью категориями, поэтому некоторые разделы выглядят
искусственно (более того, описание FAT начинает выглядеть сложнее, чем на са-
самом деле). В FAT существует две важные структуры данных (таблица размеще-
размещения файлов FAT и записи каталога), которые выполняют множество функций
и соответствуют сразу нескольким категориям модели. Отдельные компоненты
таких структур приходится рассматривать в разных разделах. Более подробные
описания приводятся в следующей главе. И все же важно рассмотреть файловую
систему FAT с применением категорий, чтобы ее было проще сравнивать с более
совершенными файловыми системами, следующими модели. FAT не содержит
никаких данных, относящихся к категории прикладных.
Основная концепция файловой системы FAT заключается в том, что каждому
файлу и каталогу выделяется структура данных, называемая записью каталога.
В этой структуре хранится имя файла, его размер, начальный адрес содержимого
файла и другие метаданные. Содержимое файлов и каталогов хранится в блоках
данных, называемых кластерами. Если файлу или каталогу выделяется более одно-
одного кластера, остальные кластеры находятся при помощи структуры данных, назы-
называемой FAT. Структура FAT используется как для идентификации следующих
кластеров в файлах, так и для определения состояния выделения кластеров. Таким
образом, она задействована как в категории содержимого, так и в категории мета-
метаданных. Существует три версии FAT: FAT12, FAT16 и FAT32. Они отличаются
друг от друга прежде всего размером записей в структуре FAT. Мы изучим связи
между структурами данных более подробно, а их общая схема показана на рис. 9.1.
Рис. 9.1. Отношения между записями каталогов, кластерами и FAT
Файловая система FAT делится на три физические области (рис. 9.2). Первая
область называется зарезервированной; в ней хранятся данные из категории файло-
файловой системы. В FAT12 и FAT16 зарезервированная область занимает всего 1 сек-
сектор, но формально ее размер определяется в загрузочном секторе. Вторая область —
область FAT — содержит основные и резервные структуры FAT. Она начинается
в секторе, следующем за зарезервированной областью, а ее размер определяется
количеством и размером структур FAT. Третья область — область данных — со-
содержит кластеры, выделяемые для хранения файлов и содержимого каталогов.
Рис. 9.2. Физическая структура файловой системы FAT
Категория файловой системы
Данные в этой категории описывают общее устройство файловой системы и исполь-
используются для поиска других важных структур данных. В этом разделе представле-
представлены общие концепции хранения данных в этой категории и способов их анализа.
Общие концепции
В файловой системе FAT данные, относящиеся к категории файловой системы,
хранятся в структуре данных загрузочного сектора. Загрузочный сектор располага-
располагается в первом секторе тома и является частью зарезервированной области фай-
файловой системы. Microsoft называет некоторые данные первого сектора блоком
параметров BIOS, или ВРВ (BIOS Parameter Block), но для простоты я буду ис-
использовать термин загрузочный сектор.
Загрузочный сектор содержит данные, принадлежащие ко всем категориям
модели, поэтому их описание откладывается до рассмотрения соответствующих
категорий. Не существует поля, которое идентифицировало бы версию файловой
системы (FAT12, FAT16 или FAT32). Тип определяется только вычислениями
с данными загрузочного сектора. Я приведу формулу в конце главы, потому что
в ней задействованы некоторые концепции, которые мы еще не рассматривали.
В FAT32 загрузочный сектор содержит дополнительные данные, в том числе
адрес резервной копии загрузочного сектора, а также основной и дополнитель-
дополнительный номера версии. Резервная копия загрузочного сектора используется при по-
повреждении версии в секторе 0; согласно документации Microsoft она всегда долж-
должна находиться в секторе 6, чтобы при повреждении стандартного экземпляра
программы могли автоматически найти ее. Структура данных загрузочного сек-
сектора рассматривается в главе 10.
Файловые системы FAT32 также содержат структуру данных FSINFO с ин-
информацией о местонахождении следующего доступного кластера и общем коли-
количестве свободных кластеров. Точность этих данных не гарантирована; они всего
лишь служат рекомендацией для операционной системы. Их структуры данных
описаны в следующей главе.
Необходимые данные загрузочного сектора
Одной из первых задач при анализе файловой системы FAT должна стать иденти-
идентификация трех физических областей. Зарезервированная область начинается в сек-
секторе 0 файловой системы, а ее размер указан в загрузочном секторе. В FAT 12/16
она обычно занимает всего 1 сектор, а в FAT32 для нее резервируются несколько
секторов.
Область FAT содержит одну или несколько структур FAT и начинается в сек-
секторе, следующем за зарезервированной областью. Ее размер вычисляется умно-
умножением количества структур FAT на размер одной структуры; оба значения хра-
хранятся в загрузочном секторе.
В области данных находятся кластеры с содержимым файлов и каталогов; она
начинается в секторе, следующем за областью FAT. Размер области данных вы-
вычисляется как разность адреса начального сектора области данных из общего ко-
количества секторов в файловой системе, указанного в загрузочном секторе. Об-
Область данных разделена на кластеры, а количество секторов в кластере указывается
в загрузочном секторе.
Структура области данных в FAT 12/16 и FAT32 несколько различается.
В FAT 12/16 начало области данных зарезервировано для корневого каталога,
а в FAT32 корневой каталог может находиться в произвольном месте области
данных (хотя обычно он все же находится в начале). Динамический размер и ме-
местонахождение корневого каталога позволяют FAT32 адаптироваться к появлению
поврежденных секторов в начале области данных и увеличивать размер каталога
до необходимого размера. Корневой каталог FAT 12/16 обладает фиксированным
размером, заданным в загрузочном секторе. Начальный адрес корневого каталога
FAT32 хранится в загрузочном секторе, а его размер определяется по структуре
FAT. На рис.9.3 показаны разные поля загрузочного сектора, используемые для
определения структуры файловых систем FAT12/16 и FAT32.
Рис. 9.3. Структура файловой системы FAT и данные загрузочного сектора,
используемые для вычисления начальных адресов и размеров
Вспомогательные данные загрузочного сектора
Помимо информации о структуре системы в загрузочном секторе хранится много
вспомогательных данных. Эти данные не являются необходимыми для сохране-
сохранения и чтения файлов, существуют исключительно для удобства и могут содер-
содержать неверную информацию. Одно из таких значений — строка из 8 символов,
называемая меткой OEM. В ней может храниться обозначение системы, создав-
создавшей экземпляр FAT, но это значение не является обязательным. Например, сис-
система Windows 95 заносит в это поле строку «MSWIN4.0», Windows 98 — строку
«MSWIN4.1», a Windows XP и 2000 — «MSDOS5.0». Я выяснил, что команда Linux
mkfs.msdos заполняет его строкой mkdosfs, некоторые флэш-диски USB записы-
записывают случайные данные, а некоторые карты памяти цифровых фотоаппаратов
используют имена, напоминающие модель камеры. Значение можно легко изме-
изменить в шестнадцатеричном редакторе, но оно поможет определить, на каком типе
компьютера была отформатирована дискета. Некоторые версии Windows требу-
требуют, чтобы значение было обязательно задано.
Файловым системам FAT назначается 4-байтовый серийный номер тома, кото-
который в соответствии со спецификацией Microsoft определяется временем создания
файловой системы с использованием текущего времени, хотя операционная систе-
система, создающая файловую систему, может задать любое значение. Тестирование по-
показало, что разные версии Windows ведут себя по-разному. Так, система Windows
98 вела себя так, как сообщает Крейг Уилсон (Craig Wilson) [Wilson, 2003]: серий-
серийный номер представлял собой результат сложения полей даты и времени в опреде-
определенном порядке. Формула приводится в разделе «Загрузочный сектор» главы 10.
В Windows XP этот алгоритм не использовался. Windows использует серийный
номер тома при работе со съемными носителями и определяет факт замены диска.
Также в загрузочном секторе присутствует поле из 8 символов, содержащее
строку «FAT12», «FAT16», «FAT32» или «FAT». Большинство систем, создаю-
создающих экземпляры FAT, корректно заполняют эту строку, но это не обязательно.
Существует только один способ определения фактического типа системы — вы-
вычисление по формуле, к которой мы придем позже. Последним идентификацион-
идентификационным маркером является 11-символьная метка тома, которую вводит пользователь
при создании файловой системы. Метка тома также хранится в корневом катало-
каталоге файловой системы. Я заметил, что при добавлении метки тома в ХР она запи-
записывается только в корневой каталог, но не в загрузочный сектор.
Загрузочный код
Загрузочный код в файловой системе FAT чередуется со структурами данных
файловой системы [Microsoft, 2003e]. В этом FAT отличается от файловых сис-
систем UNIX, где используется полностью изолированный загрузочный код. Пер-
Первые три байта загрузочного сектора содержат машинный код команды перехода,
которая заставляет процессор обойти конфигурационные данные и передать уп-
управление основному загрузочному коду. Как будет видно из структуры данных в
следующей главе, загрузочный сектор занимает 512 байт, причем байты 62-509 в
FAT12/16 и байты 90-509 в FAT32 не используются. Эти байты содержат загру-
загрузочный код, а в F AT32 дополнительный загрузочный код может находиться в сек-
секторах, следующих за загрузочным сектором.
Файловые системы FAT обычно содержат загрузочный код даже в том случае,
если они не являются загрузочными — в этом случае код выводит сообщение о том,
что для загрузки системы следует вставить другой диск. Загрузочный код FAT
получает управление от загрузочного кода MBR, находит и загружает нужные
файлы операционной системы.
Пример образа
В этом разделе я воспользуюсь данными из тестового образа FAT32. В пакет TSK
(The Sleuth Toolkit) входит программа fsstat, которая выводит большую часть дан-
данных из категории файловой системы. Пример результата, выданного программой
fsstat для тестового образа:
# fsstat -f fat fat-4.dd
FILE SYSTEM INFORMATION
File System Type: FAT
OEM Name: MSDOS5.0
Volume ID: 0x4cl94603
Volume Label (Boot Sector): NO NAME
Volume Label (Root Directory): FAT DISK
File System Type Label: FAT32
Backup Boot Sector Location: 6
FS Info Sector Location: 1
Next Free Sector (FS Info): 1778
Free Sector Count (FS Info): 203836
Sectors before file system: 100800
File System Layout (in sectors)
Total Range: 0 - 205631
* Reserved: 0 - 37
** Boot Sector: 0
** FS Info Sector: 1
** Backup Boot Sector: 6
* FAT 0: 38 - 834
* FAT 1: 835 - 1631
* Data Area: 1632 - 205631
** Cluster Area: 1632 - 205631
*** Root Directory: 1632 - 1635
CONTENT-DATA INFORMATION
Sector Size: 512
Cluster Size: 1024
Total Cluster Range: 2 - 102001
[REMOVED]
Из листинга видно, что первой копии FAT предшествуют 38 зарезервирован-
зарезервированных секторов. В зарезервированной области находится резервная копия загру-
загрузочного сектора и структура данных FSINFO. В файловой системе находится две
структуры FAT, расположенные в секторах 38-834 и 835-1631. Область данных
начинается в секторе 1632 и состоит из 1024-байтовых кластеров.
Методы анализа
Анализ категории данных файловой системы проводится для определения строе-
строения файловой системы и параметров конфигурации для применения более конк-
конкретного анализа. При этом также могут быть найдены улики, специфические для
данной ситуации. Например, вы можете узнать, какая ОС отформатировала диск,
или обнаружить на нем скрытые данные.
Для определения конфигурации файловой системы FAT необходимо найти
и обработать загрузочный сектор, структуры данных которого приведены в гла-
главе 10. Обработка загрузочного сектора упрощается тем, что он находится в пер-
первом секторе файловой системы и содержит простейшие поля. Существует две вер-
версии загрузочного сектора, причем обе хорошо документированы. На основании
данных из загрузочного сектора вычисляется местонахождение зарезервирован-
зарезервированной области, области FAT и области данных.
Структура данных FAT32 FSINFO также может предоставить некоторые све-
сведения о недавно выполненных операциях; ее местонахождение указано в загру-
загрузочном секторе. Как правило, FSINFO хранится в секторе 1 файловой системы.
В FAT32 также существуют резервные копии обеих структур данных.
Факторы анализа
Как вы убедились, данные этой категории предоставляют структурную информа-
информацию о файловой системе, причем большая часть этих данных неподконтрольна
пользователю. Следовательно, никаких сенсационных находок ожидать не стоит.
Вы не найдете значений, показывающих, где и когда была создана файловая сис-
система; впрочем, метка OEM и метка тома, хотя и относятся к вспомогательным
данным, могут предоставить некоторую полезную информацию, потому что в раз-
разных системах используются разные значения по умолчанию. Позднее мы увидим,
что в FAT существует специальный файл, имя которого совпадает с именем тома,
и этот файл может содержать время создания системы.
Существует ряд мест, не используемых файловой системой; в них могут хра-
храниться данные, скрытые от пользователя. Например, между концом загрузочного
сектора и завершающей сигнатурой хранятся свыше 450 байт данных. Windows
обычно использует это пространство для хранения загрузочного кода системы,
но в файловых системах, не являющихся загрузочными, оно не используется.
FAT32 обычно выделяет много секторов в зарезервированную область, но лишь
небольшая часть из них используется для хранения основной и резервной копий
загрузочного сектора и структуры данных FSINFO. Следовательно, эти секторы
могут содержать скрытые данные. Кроме того, в FAT32 структура FSINFO содер-
содержит сотни неиспользуемых байтов. ОС обычно стирает содержимое секторов в ре-
резервной области при создании файловой системы.
Скрытые данные также могут находиться между концом файловой системы
и концом тома. Сравните число секторов файловой системы, заданное в загрузочном
секторе, с количеством секторов тома, чтобы определить резервное пространство
тома. Учтите, что создать резервное пространство тома относительно несложно —
для этого достаточно изменить общее количество секторов в загрузочном секторе.
В файловых системах FAT32 присутствует резервная копия загрузочного секто-
сектора, которая должна находиться в секторе 6. Основная копия сравнивается с резер-
резервной для выявления расхождений. Если основная копия окажется поврежденной,
следует проанализировать резервную копию. Если пользователь изменил какие-
либо из меток или других полей основного загрузочного сектора в шестнадцате-
ричном редакторе, возможно, резервная копия будет содержать исходные данные.
Сценарий анализа
При обыске в доме подозреваемого в шкафу был найден жесткий диск. В процессе
снятия данных выяснилось, что первые 32 сектора диска повреждены и прочитать
их не удастся. Вероятно, подозреваемый положил диск в шкаф после сбоя и восполь-
воспользовался новым диском, но мы хотим проанализировать старый диск на наличие
улик. На компьютере подозреваемого установлена система Windows ME, соот-
соответственно, используется файловая система FAT. Этот сценарий показывает, как
найти файловую систему далее в том случае, если таблицы разделов не существует.
Чтобы найти начало файловой системы FAT, мы проведем поиск по сигнатурам
0x55 и ОхАА в последних двух байтах загрузочного сектора. При проведении только
одного поиска следует ожидать большого количества ложных совпадений. Если диск
заполнен случайными данными, можно ожидать, что сигнатура будет встречаться
каждые 65 536 секторов. Для уменьшения количества ложных совпадений можно
увеличить сигнатуру или использовать другие данные. Сценарий показывает, что
второй способ хорошо подходит для FAT32, потому что шаблон сигнатур хранится
в зарезервированной области файловой системы. Конечно, программы автоматизи-
автоматизированного поиска сделали бы то же самое быстрее, но мы выполним поиск вручную.
Для поиска сигнатур будет использоваться программа sigfind из пакета TSK.
Вместо нее можно воспользоваться любой другой программой с возможностью
поиска шестнадцатеричных значений. Программа sigfind выводит сектор, в кото-
котором была найдена сигнатура, и сообщает расстояние от предыдущего найденного
совпадения. Вот как выглядят ее выходные данные:
# sigfind -о 510 55АА disk-9.dd
Block size: 512 Offset: 510
Block: 63 (-)
Block: 64 (+1)
Block: 65 (+1)
Block: 69 (+4)
Block: 70 (+1)
Block: 71 (+1)
Block: 75 (+4)
Block: 128504 (+128429)
Block: 293258 (+164754)
[...]
Первый экземпляр сигнатуры найден в секторе 63; это логично, потому что
первый раздел обычно начинается в секторе 63. Мы читаем содержимое сектора
и отображаем его на структуру данных загрузочного сектора. Выясняется, что
в секторе 6 хранится резервная копия загрузочного сектора, а в секторе 1 файло-
файловой системы — структура FSINFO. Также мы узнаем, что файловая система со-
содержит 20 482 812 секторов. Структура данных FSINFO имеет такую же сигнату-
сигнатуру, как и загрузочный сектор, поэтому в секторе 64 тоже найдено совпадение.
Совпадения также обнаруживаются в секторах 69 и 70, содержащих резерв-
резервные копии загрузочного сектора и FSINFO на расстоянии шести секторов от ори-
оригинала. Блоки 65 и 71 заполнены нулями (кроме сигнатур). Совпадение в блоке
128 504 оказывается ложным; при просмотре мы видим случайные данные. Та-
Таким образом, на основании информации о расположении загрузочного сектора
и относительного местонахождения резервных копий можно сделать вывод, что
файловая система занимает на диске секторы с 63 по 20 482 874. Теперь можно
просмотреть остальные совпадения в выходных данных sigfind:
[...]
Block: 20112453 (+27031)
Block: 20482875 (+370422)
Block: 20482938 (+63)
Block: 20482939 (+1)
Block: 20482940 (+1)
Block: 20482944 (+4)
Block: 20482945 (+1)
Block: 20482946 (+1)
Block: 20482950 (+4)
Block: 20513168 (+30218)
В пропущенной части были многочисленные ложные совпадения. Мы видим,
что в секторе 20 482 875 обнаружено совпадение. Этот сектор находится за концом
предыдущей файловой системы, которая завершается в секторе 20 482 874. Одна-
Однако закономерность совпадений, начиная с сектора 20 482 875, отличается от
предыдущих: следующее совпадение найдено со смещением 63 сектора, а потом
следуют несколько близких совпадений. Просматриваем сектор 20 482 875 и вы-
выясняем, является ли совпадение ложным:
# dd if=disk-9.dd bs=512 skip=20482875 count=l | xxd
0000000: 088c 039a 5f78 7694 8f45 bf49 e396 00c0 ...._xv..E.I....
0000016: 889d ddcO 6d36 60df 485d adf7 46dl 3224 ... .m6\H]. .F.2$
0000032: 3829 95cd ad28 d2a2 dc89 f357 d921 cfde 8)...( W.!..
0000048: df8e Ifd3 303e 8619 641e 9c2f 95b4 d836 0>..d../...6
[...]
0000416: 3607 e7be 1177 db5f Ilc9 fbal c913 Ia3d 6....w._ =
0000432: da81 143d 00c7 7083 9d42 330c 0287 0001 ...-..p..B3
0000448: clff Obfe ffff 3fOO 0000 fc8a 3801 0000 ? 8...
0000464: clff 05fe ffff 3b8b 3801 7616 7102 0000 :.8.v.q...
0000480: 0000 0000 0000 0000 0000 0000 0000 0000
0000496: 0000 0000 0000 0000 0000 0000 0000 55aa U.
Совпадение легко принять за ложное, но обратите внимание на четыре завер-
завершающие строки и вспомните, о чем говорилось в главе 5 при обсуждении разде-
разделов DOS. Этот сектор содержит расширенную таблицу разделов, а таблица начи-
начинается с сектора 446. В таблицах разделов DOS используется та же сигнатура, что
и в загрузочных секторах FAT. Обработав две ненулевые записи таблицы, мы уз-
узнали бы, что раздел FAT32 находится в секторах 20 482 938-40 965 749, а расши-
расширенный раздел — в секторах 40 965 750-81 931 499. Это подтверждает результаты
sigfind: совпадение было найдено в секторе 20 482 938, а затем еще несколько со-
совпадений со смещениями 1, 6 и 7 секторов для структуры данных FSINFO и ре-
резервных копий. На рис. 9.4 показано графическое представление этого примера.
На нем изображены две файловые системы, обнаруженные нами, а также некото-
некоторые ложные совпадения и расширенные таблицы разделов.
Рис. 9.4. Результаты поиска сигнатуры загрузочного сектора FAT на диске,
не содержащем таблицы разделов
Этот пример показывает, что файловую систему FAT32 можно найти при нали-
наличии загрузочного сектора. Поиск 2-байтовой сигнатуры выдает много ложных со-
совпадений, но FAT32 несколько упрощает задачу, потому что мы ожидаем найти со-
совпадения со смещением 1,6 и 7 секторов от структуры данных FSINFO и резервных
копий. С FAT 12/16 дело обстоит сложнее; резервные структуры в этих системах
отсутствуют, но все, что потребуется, — это найти первое совпадение. Можно на-
начать поиск с сектора 63. После того как файловая система будет найдена, ее размер
используется для перехода вперед, после чего поиск продолжается. В поиске фай-
файловых систем также могут помочь структуры расширенных таблиц разделов DOS.
Категория, содержимого
К этой категории относятся данные, составляющие содержимое файла или ката-
каталога. В файловой системе FAT блоки данных называются кластерами. Кластер
(cluster) представляет собой группу смежных секторов, количество которых рав-
равно степени 2 — например, 1,2,4,8,16,32 или 64. Согласно спецификации Microsoft,
максимальный размер кластера равен 32 Кбайт. Каждому кластеру присваивает-
присваивается адрес; для первого кластера он равен 2. Другими словами, кластеров с адресами
О и 1 не существует. Все кластеры находятся в области данных файловой систе-
системы, последней из трех областей.
Поиск первого кластера
Найти первый кластер (с адресом 2) сложнее, чем кажется на первый взгляд, пото-
потому что он расположен не в начале файловой системы; кластер находится в области
данных. В зарезервированной области и области FAT, находящихся перед областью
данных, адреса кластеров не используются. Файловая система FAT дает пример
того, что не каждому логическому адресу тома соответствует логический адрес фай-
файловой системы. Как будет показано в главе 11, в NTFS ситуация изменилась — в этой
системе первый кластер также является первым кластером файловой системы.
В FAT 12/16 и FAT32 используются разные процедуры поиска адреса секто-
сектора 2. В файловой системе FAT32 кластер 2 начинается с первого сектора области
данных. Предположим, имеется файловая система с 2048-байтовыми кластерами
и областью данных, начинающейся с сектора 1224. Кластеру 2 будет соответство-
соответствовать адрес сектора 1224, а кластеру 3 — адрес сектора 1228 (рис. 9.5).
Рис. 9.5. В файловой системе FAT12/16 кластер 2 следует за корневым каталогом, а в FAT32
кластер 2 является первым сектором области данных
Адреса кластеров и секторов
Как мы только что обсуждали, адресация кластеров начинается только с области
данных. Следовательно, для адресации данных в зарезервированной области и
области FAT пришлось бы использовать либо две разные схемы адресации, либо
«наименьшее общее кратное», которым является адрес сектора (логический ад-
адрес тома). Выполнять все операции с адресами секторов достаточно удобно; именно
эта схема используется во внутренней работе всех системных программ и опера-
операционных систем, потому что им нужно знать, где находятся данные по отноше-
отношению к началу тома. Некоторые программы, в том числе пакет TSK, выводят все
адреса в виде адресов секторов, чтобы было достаточно только одной схемы адре-
адресации.
Чтобы выполнить преобразования между адресами кластеров и секторов, не-
необходимо знать адрес сектора для кластера 2 и количество секторов в кластере.
Базовая формула расчета адреса сектора для кластера С выглядит так:
(С - 2) * (кол-во секторов в кластере) + (сектор кластера 2)
Обратная формула для преобразования сектора S в кластер:
( (S - сектор кластера 2) / (кол-во секторов в кластере) ) + 2
Состояние выделения кластеров
Итак, мы знаем, как найти кластер. Теперь необходимо определить, какие класте-
кластеры выделены, а какие остаются свободными. Состояние выделения кластера оп-
определяется по структуре FAT. Обычно FAT существует в двух копиях, и первая
копия начинается после зарезервированной области файловой системы. FAT бо-
более подробно рассматривается в главе 10, но необходимую информацию я приве-
приведу здесь.
Структура FAT используется для многих целей, но базовая концепция проста:
каждый кластер файловой системы представлен одной записью. Например, за-
запись таблицы 481 соответствует кластеру 481. Каждая запись таблицы представ-
представляет собой одно число, максимальное значение которого зависит от версии FAT.
В файловых системах FAT12 используются 12-разрядные записи, в FAT16 — 16-
разрядные, а в FAT32 запись таблицы состоит из 32 разрядов (из которых исполь-
используются только 28).
Если запись таблицы равна 0, кластер не выделен файлу. Если она равна 0xff7
для FAT12, Oxfff7 для FAT16 или OxOfff fff7 для FAT32, кластер помечен как по-
поврежденный и не может выделяться файлам. Все остальные значения означают,
что кластер выделен, а их интерпретация будет рассмотрена позднее, в разделе
«Категория метаданных».
Алгоритмы выделения
При выделении кластеров ОС использует определенный алгоритм. Тестирова-
Тестирование систем Windows 98 и Windows XP показало, что в обоих случаях использовал-
использовался алгоритм поиска следующего доступного кластера. Этот алгоритм ищет первый
доступный кластер, начиная от предыдущего выделенного кластера. Предполо-
Предположим, кластер 65 выделен новому файлу, а кластер 62 свободен. Следующий поиск
начнется с кластера 66, а кластер 62 на некоторое время останется свободным (рис.
9.6). Процесс выделения кластеров зависит от многих факторов, и идентифици-
идентифицировать точный алгоритм трудно.
Чтобы найти свободный кластер для выделения файлу, ОС сканирует FAT
и ищет запись, содержащую 0. Вспомните, что в резервной области FAT32 хранится
структура данных FSINFO с номером следующего свободного кластера, которым
операционная система может руководствоваться при поиске. Если потребуется
перевести кластер в свободное состояние, система находит соответствующую за-
запись в структуре FAT и заполняет ее нулями. Большинство операционных сис-
систем не стирает содержимое кластеров при освобождении, если только эта опера-
операция не реализована как функция надежного удаления информации.
Рис. 9.6. Поиск свободного кластера начинается не от начала файловой системы,
а с последнего выделенного кластера
Методы анализа
Анализ данных в категории содержимого выполняется для нахождения конкрет-
конкретного блока данных, проверки его статуса выделения и выполнения операций с со-
содержимым. Найти конкретный блок данных в FAT сложнее, чем в других файло-
файловых системах, потому что адресация кластеров начинается не с начала файловой
системы. При обращении к блоку данных, расположенному до начала области
данных, необходимо использовать адрес сектора. Для блоков в области данных
могут использоваться как адреса секторов, так и адреса кластеров.
Состояние выделения каждого кластера определяется по записи кластера
в FAT. У свободных кластеров значение записи равно нулю, а у выделенных оно
отлично от нуля. Если потребуется извлечь содержимое всех свободных класте-
кластеров, переберите все записи FAT и извлеките каждый кластер с нулевым значени-
значением в таблице. Блоки данных, расположенные до начала области данных, в FAT не
представлены, следовательно, они не имеют формального состояния выделения,
хотя большинство таких блоков используется файловой системой. Проверьте свои
программы анализа и выясните, считают ли они свободными блоки, предшеству-
предшествующие области данных.
Факторы анализа
В процессе анализа файловой системе FAT следует изучить содержимое класте-
кластеров, помеченных как поврежденные — многие диски обрабатывают поврежден-
поврежденные секторы на аппаратном уровне, и операционная система их вообще не видит.
Поврежденные блоки данных необходимо анализировать в файловых системах
любого типа, но Microsoft сообщает, что некоторые защищенные приложения хра-
хранят информацию в кластерах FAT, помеченных как поврежденные. По этой при-
причине программа ScanDisk для Windows не проверяет, действительно ли повреж-
повреждены помеченные секторы [Microsoft, 2004b]. Некоторые версии команды format
для Windows сохраняют статус поврежденных кластеров при повторном форма-
форматировании файловой системы.
Размер области данных может оказаться некратным размеру кластера, поэто-
поэтому в конце области данных могут располагаться секторы, не принадлежащие кла-
кластеру. Такие секторы используются для скрытия информации или содержат дан-
данные, оставшиеся от предыдущей файловой системы. На рис. 9.7 показан пример
файловой системы с кластерами, состоящими из 2 секторов, и нечетным количе-
количеством секторов. Последний сектор, помеченный серым цветом, не имеет адреса
кластера.
Рис. 9.7. Последние секторы области данных не образуют полноценного кластера,
поэтому в них может храниться скрытая информация или данные
от предыдущей файловой системы
Чтобы узнать, присутствуют ли в системе неиспользуемые секторы, вычтите
адрес сектора для кластера 2 из общего количества секторов и разделите разность
на количество секторов в кластере. Если деление выполняется с остатком, значит,
неиспользуемые сектора присутствуют:
(общее количество секторов - адрес сектора для кластера 2) / (количество секторов
в кластере)
Скрытые данные также могут храниться между концом последней действи-
действительной записи основной структуры FAT и началом резервной копии или же между
концом последней записи резервной FAT и началом области данных. Чтобы вы-
вычислить объем неиспользуемого пространства, сравните размер каждой структу-
структуры FAT, указанный в загрузочном секторе, с размером, необходимым для хране-
хранения фактического количества секторов в файловой системе. Например, в файловой
системе FAT32, которую мы ранее анализировали командой fsstat, каждой копии
FAT было выделено 797 секторов. Каждая запись таблицы в файловой системе
FAT32 занимает четыре байта, следовательно, каждый 512-байтовый сектор со-
содержит 128 записей. В каждой таблице помещается
797 секторов * 128 (записей/сектор) = 102 016 записей
Из выходных данных fsstat видно, что количество кластеров равно 102 002,
следовательно, в таблице имеется 14 неиспользуемых записей, а их общий размер
составляет 64 байта.
Не каждому сектору тома ставится в соответствие адрес кластера, поэтому ре-
результаты поиска по логическому тому и логической файловой системе могут раз-
различаться. Протестируйте свои программы и определите, проводят ли они поиск
в загрузочном секторе и областях FAT. Один из простых способов — проведите
поиск строки «FAT» и посмотрите, будет ли найден загрузочный сектор (впро-
(впрочем, сначала убедитесь в том, что загрузочный сектор содержит эту строку).
Сценарий анализа
Имеется файловая система FAT 16, требуется найти первый сектор кластера 812.
У нас есть только шестнадцатеричный редактор, не имеющий специальных функ-
функций поддержки файловой системы FAT.
Первым шагом станет просмотр загрузочного сектора, расположенного в сек-
секторе 0 файловой системы. В результате обработки сектора мы узнаем, что он со-
содержит шесть зарезервированных секторов, две копии FAT и каждая копия FAT
занимает 249 секторов. Каждый кластер состоит из 32 секторов, а корневой ката-
каталог содержит 512 записей.
Теперь нужно заняться вычислениями. Первая копия FAT начинается в сек-
секторе 6 и заканчивается в секторе 254. Вторая копия FAT начинается в секторе 255
и заканчивается в секторе 503. Далее следует корневой каталог. Корневой ката-
каталог содержит 512 записей; каждая запись (как будет показано далее) занимает
32 байта, поэтому каталог располагается в секторах 504-535, а область данных
начинается в секторе 536.
Первый кластер области данных обладает адресом 2. Соответственно, иско-
искомый кластер 812 будет 810-м кластером области данных. Так как каждый кластер
занимает 32 сектора, кластер 812 смещен от начала области данных на 25 920 сек-
секторов. Наконец, мы прибавляем начальный адрес области данных и определяем,
что кластер 812 начинается в секторе 26 456 и продолжается до сектора 26 487.
Структура диска показана на рис. 9.8.
Рис. 9.8. Структура диска в примере с поиском кластера 812
Категория метаданных
К категории метаданных относятся данные, описывающие файлы или каталоги:
местонахождение содержимого, дата и время, права доступа. Эта категория дан-
данных будет использоваться для получения дополнительной информации о файле
и идентификации подозрительных файлов. В файловой системе FAT эта инфор-
информация хранится в структуре записи каталога. Структура FAT также используется
для хранения метаданных, описывающих файлы и каталоги.
Записи каталога
Записью каталога называется структура данных, создаваемая для каждого файла
и каталога. Ее размер равен 32 байтам; в структуре хранятся атрибуты файла, его
начальный кластер, дата и время. Запись каталога занимает важное место в кате-
категории метаданных и имен файлов — ведь в этой структуре содержится имя файла.
Записи каталогов могут находиться в любом месте области данных, потому что
они хранятся в кластерах, выделенных каталогам. В файловой системе FAT ката-
каталоги интерпретируются как особая разновидность файлов. Структура данных за-
записей каталогов подробно описывается в главе 10.
Каждый раз, когда в системе создается новый файл или каталог, в родительском
каталоге для него создается запись каталога. Поскольку каждая запись каталога
обладает фиксированным размером, содержимое каталога можно представить себе
как таблицу записей каталогов. В отличие от кластеров, записям каталогов не
присваиваются уникальные числовые адреса, поэтому возможен только один стан-
стандартный способ адресации каталогов: использовать полное имя файла или ката-
каталога, которому принадлежит эта запись. Мы вернемся к этой теме в разделе «Ад-
«Адреса записей каталогов».
Структура записи каталога содержит поле атрибутов. Для каждого файла мож-
можно задать значения семи атрибутов, хотя ОС (или программа анализа) могут про-
проигнорировать некоторые из них. Мы начнем с рассмотрения обязательных атри-
атрибутов — игнорировать эти атрибуты нельзя, потому что они влияют на процесс
обработки записей каталогов. Атрибут каталога используется для идентифика-
идентификации записей каталогов, относящихся к каталогам (в отличие от файлов). Класте-
Кластеры, ассоциированные с записью каталога, должны содержать новые записи ката-
каталогов. Атрибут длинного имени файла является признаком записей особого типа,
имеющих другую структуру. Эта тема подробно рассматривается в разделе «Имя
файла». Последний обязательный атрибут предназначен для хранения метки
тома] согласно спецификации, он может быть установлен только у одной записи.
Я заметил, что в Windows XP задаваемая пользователем метка тома сохраняется
именно здесь, а не в загрузочном секторе. Если ни один из этих атрибутов не уста-
установлен, значит, запись относится к обычному файлу.
Также существует четыре необязательных атрибута, которые могут устанав-
устанавливаться для каждого файла или каталога. Последствия их установки зависят от
того, насколько жестко операционная система соблюдает соответствующие пра-
правила. Атрибут доступа только для чтения должен предотвращать запись в файл,
однако эксперименты показали, что в системах Windows XP и Windows 98 в ката-
каталогах, доступных только для чтения, возможно создание новых файлов. Атрибут
скрытого файла должен исключать файлы и каталоги из выводимых списков, но
обычно их вывод включается установкой параметра конфигурации ОС. Атрибут
системного файла должен идентифицировать файл как системный, а атрибут
архивного файла обычно устанавливается Windows при создании файла или за-
записи в него. По состоянию этого атрибута программы архивации данных иденти-
идентифицируют файлы, изменившиеся с момента создания последнего архива.
В каждой записи каталога хранится три временных штампа: для создания, пос-
последнего обращения и последней модификации. У FAT есть одна странная особен-
особенность: большой разброс точности в этих значениях. Время создания не является
обязательным и измеряется с точностью до секунды; время обращения также не
обязательно и измеряется с точностью до дня; наконец, согласно спецификации
время последней модификации является обязательным и измеряется с точностью
до двух секунд. Никаких спецификаций по поводу того, при каких операциях
должно обновляться то или иное время, не существует, поэтому каждая ОС,
в которой используется FAT, реализует собственную политику обновления этих
значений. В Windows 95+ и NT+ обновляются все временные штампы, a DOS
и Windows 3.1 обновляют только время последней модификации. Время хранит-
хранится с учетом местного часового пояса; это означает, что его не нужно преобразовы-
преобразовывать в зависимости от местонахождения компьютера.
Статус выделения записи каталога определяется ее первым байтом. Для выде-
выделенной записи в первом байте хранится первый символ имени файла, а при ее
освобождении он заменяется кодом 0хе5. Именно по этой причине программы
восстановления FAT требуют ввести первую букву имени файла.
Цепочки кластеров
В записи каталога указывается начальный кластер файла, а структура FAT исполь-
используется для поиска остальных кластеров в файле. Как упоминалось ранее, для выде-
выделенных кластеров запись FAT отлична от нуля. Ненулевая запись содержит адрес
следующего кластера файла, маркер конца файла или значение, показывающее,
что кластер содержит поврежденные секторы. Чтобы найти следующий кластер
файла, достаточно найти запись кластера в FAT и определить, является ли он пос-
последним кластером в файле или за ним имеется другой кластер. Структура данных
FAT и допустимые значения более подробно рассматриваются в главе 10.
Допустим, файл хранится в секторах 40,41 и 45. Чтобы прочитать содержимое
файла, мы сначала обращаемся к полю начального кластера в записи каталога,
значение которого равно 40. По размеру файла можно определить, что файл хра-
хранится в нескольких кластерах, поэтому мы обращаемся к записи FAT кластера 40.
Запись содержит значение 41; это означает, что кластер 41 является вторым кла-
кластером в файле. Судя по размеру файла, необходим еще один кластер, поэтому мы
обращаемся к записи FAT кластера 41 и находим значение 45. Запись FAT клас-
кластера 45 содержит маркер конца файла (EOF), потому что этот кластер является
последним в файле. Последовательный список кластеров иногда называют цепоч-
цепочкой кластеров] пример показан на рис. 9.9.
Рис. 9.9. Таблица FAT с цепочкой кластеров 40-41-45
Максимальный размер файловой системы FAT зависит от размера записей
FAT. Размер записи определяет максимальный адрес следующего кластера в це-
цепочке; таким образом, адреса кластеров ограничены. В файловой системе FAT32
используются только 28 бит 32-разрядной записи, поэтому она позволяет адресовать
только 268 435 456 кластеров (на самом деле немного меньше, потому что некото-
некоторые значения зарезервированы для маркера EOF и поврежденных кластеров).
Каталоги
При создании нового каталога для него выделяется кластер, заполняемый нуля-
нулями. Поле «размер» в записи каталога не используется и всегда должно быть рав-
равно 0. Единственный способ определить размер каталога — использовать началь-
начальный кластер из записи каталога и следовать по цепочке кластеров структуры FAT
до обнаружения маркера конца файла.
Первые две записи каталога предназначены для элементов «.» и «..». Эти обо-
обозначения хорошо знакомы пользователям, работающим в режиме командной стро-
строки. Имя «.» обозначает текущий каталог, а имя «..» — родительский каталог. В дей-
действительности они представляются записями каталога с установленным атрибутом
каталога, но, похоже, система Windows не обновляет значения после их создания.
Временные штампы создания, обращения и модификации сохраняют значения,
заданные в момент создания каталога. Это поведение также может использовать-
использоваться для проверки времени создания каталога, значение которого должно совпа-
совпадать со значениями «.» и «..». Впрочем, подтвердить время последней модифика-
модификации каталога невозможно, потому что записи «.» и «..» не обновляются при каждой
модификации каталога. Ситуация показана на рис. 9.10: время создания dirl от-
отличается от времени создания записей «.» и «..». Пользователь мог сделать это
с целью маскировки своих действий, или же дата могла быть модифицирована
каким-то приложением в системе.
Рис. 9.10. Время создания записи каталога не совпадает
с временем создания записей «.» и «..»
Адреса записей каталогов
Как упоминалось ранее, существует только один стандартный способ адресации
записей каталогов: использование полного имени файла или каталога, с которым
она ассоциируется. При этом возникают минимум две проблемы, которые будут
рассмотрены в этом разделе.
Допустим, потребовалось найти все выделенные структуры каталогов. Для
этого мы начинаем поиск с корневого каталога и рекурсивно просматриваем все
выделенные каталоги. В каждом каталоге мы анализируем 32-байтовую структу-
структуру и пропускаем свободные. Адрес каждой структуры образуется из имени ката-
каталога, просматриваемого в настоящий момент, и имени файла.
Такое решение отлично работает для обычных операций с файловой систе-
системой, но аналитику нередко требуется решить обратную задачу — найти все сво-
свободные записи каталогов. Здесь возникает первая проблема. При освобождении
записи каталога первая буква имени пропадает. Если каталог содержит два фай-
файла, A-1.DAT и B-1.DAT, которые были удалены, обе записи будут содержать одинако-
одинаковое имя _-l.DAT. Таким образом, возникает конфликт уникальности имен.
Вторая проблема возникает при удалении каталога и освобождении его запи-
записи. В этом случае не остается указателя на файлы и каталоги, находившиеся в уда-
удаленном каталоге, поэтому у них не будет адреса. На рис. 9.11 (А) запись каталога
ссылается на кластер 210. Каталог удаляется, а запись каталога позднее выделя-
выделяется заново; в новом варианте она указывает на кластер 400 (рис. 9.11 (В)). Сво-
Свободные записи каталогов в кластере 210 остаются, однако их не удастся найти
простым перемещением по дереву каталогов. Но даже если эти записи будут най-
найдены, адресов у них не будет. Такие файлы называются зависшими.
Рис. 9.11. (А) — существующий каталог и его содержимое; (В) — состояние системы после
удаления каталога и повторного выделения его записи в родительском каталоге
Чтобы найти зависшие файлы, необходимо проанализировать все секторы об-
области данных. Стандартного способа не существует; один из вариантов заключа-
заключается в анализе первых 32 байтов каждого сектора (не кластера!) и их сравнении
с полями записи каталога. Если данные лежат в правильном диапазоне, обраба-
обрабатывается остаток сектора. При просмотре секторов могут обнаружиться записи
в резервном пространстве кластеров, которые были выделены другим файлам.
Другой аналогичный способ — просмотр первых 32 байтов каждого кластера для
отыскания записей «.» и «..», которые являются первыми двумя записями каждо-
каждого каталога (пример будет приведен далее). Этот способ позволяет найти только
первый кластер каталога, но не его фрагменты.
Один из способов решения подобных проблем основан на использовании дру-
другого метода адресации. Например, в TSK используется метод, который также при-
применяется в некоторых версиях UNIX; предполагается, что каждый кластер и сек-
сектор может быть выделен каталогу. Таким образом, можно представить, что каждый
сектор разделен на 32-байтовые записи, в которых могут храниться записи ката-
каталогов, а каждой записи сопоставлен уникальный адрес. Первой 32-байтовой за-
записи первого сектора ставится в соответствие адрес 0, второй — адрес 1, и т. д.
Это решение работает, но возникает небольшая проблема. Числовыми адреса-
адресами обладают все каталоги и файлы, кроме корневого каталога. Вспомните, что
местонахождение и размер корневого каталога задаются в загрузочном секторе,
а не в записи каталога. В TSK для решения этой проблемы корневому каталогу
присваивается адрес 2 (потому что именно такой способ используется в большин-
большинстве файловых систем UNIX), а первой записи первого сектора присваивается
адрес 3. На рис. 9.12 секторы 520 и 1376 представлены в расширенном виде, с по-
показом адресов содержащихся в них записей. Каждый 512-байтовый сектор вме-
вмещает 16 структур записей каталогов, поэтому в секторе 520 хранятся записи 3-18.
Рис. 9.12. Адреса, назначаемые записям каталогов, определяются сектором и
местонахождением записи внутри сектора
Пример образа
Следующий вывод istat, полученный для файла тестового образа, демонстрирует
данные, существующие для типичного файла FAT. Запись каталога для этого фай-
файла анализируется в главе 10, а здесь приводится отформатированный результат:
# istat -f fat fat-4.dd 4
Directory Entry: 4
Allocated
File Attributes: File. Archive
Size: 8689
Name: RESUME-1.RTF
Directory Entry Times:
Written: Wed Mar 24 06:26:20 2004
Accessed: Thu Apr 8 00:00:00 2004
Created: Tue Feb 10 15:49:40 2004
Sectors:
1646 1647 1648 1649 1650 1651 1652 1653
1654 1655 1656 1657 1658 1659 1660 1661
1662 1663
Файлу выделено 18 секторов, что в данной файловой системе эквивалентно
9 кластерам. В выходных данных istat приводится время и дата создания, после-
последнего обращения и модификации файла, а также атрибуты файла. Поскольку имя
файла хранится в записи каталога, для его определения достаточно одного адре-
адреса, без полного пути.
Алгоритмы выделения
В категории метаданных существует два типа данных, задействованных в проце-
процедурах выделения. Для новых файлов выделяются записи каталогов, а для суще-
существующих файлов и каталогов обновляются временные штампы. Как и в боль-
шинстве стратегий выделения, конкретное поведение зависит от ОС и не может
контролироваться структурами данных файловых систем. Прежде чем делать ка-
какие-либо предположения об алгоритмах выделения, необходимо протестировать
конкретную ОС. Я приведу свои наблюдения для Windows 98 и ХР.
Выделение записей каталогов
В Windows 98 используется стратегия выделения первой доступной записи, а по-
поиск свободных записей начинается от начала каталога. Windows XP использует
стратегию следующей доступной записи, а поиск свободных записей начинает-
начинается от последней выделенной записи. Добравшись до конца цепочки кластеров,
Windows XP заново начинает сканирование от начала каталога. Если Windows 98
или ХР не могут найти свободную запись каталога, выделяется новый кластер.
Различия между этими методами выделения записей показаны на рис. 9.13,
где запись 3 была выделена после записи 4. При выделении следующей записи
Windows 98 проводит сканирование от начала кластера и выделяет запись ката-
каталога 3. Windows XP начнет с записи 4 и выделит запись 5.
Рис. 9.13. Последней была выделена запись каталога 4. В Windows 98 следующей будет
выделена запись 3, а в Windows XP — запись 5
При переименовании файла в Windows для нового имени создается новая за-
запись, а запись старого имени освобождается. Аналогичное поведение прослежи-
прослеживается при создании нового файла или каталога в Windows командой Создать из
контекстного меню: сначала система создает запись с именем по умолчанию (ска-
(скажем, Текстовый документах!:), а затем освобождает ее при вводе пользователем на-
настоящего имени.
У Windows XP есть одна интересная особенность: при создании файла из при-
приложения Windows создаются две записи. Первая запись содержит все значения,
кроме размера и начального кластера. Эта запись освобождается, после чего со-
создается вторая запись с размером и начальным кластером. Это происходит при
сохранении файла из приложения, но не из командной строки, посредством пере-
перетаскивания или командой меню.
При удалении файла в первый байт записи каталога заносится значение 0хе5.
Windows не изменяет другие значения в записи каталога, хотя другие ОС могут
это делать. Для освобождения кластеров, выделенных файлу, в соответствующие
записи структуры FAT заносятся нули. К счастью, Windows хранит начальный
кластер цепочки в записи каталога, что дает возможность восстанавливать фай-
файлы, пока их кластеры не были выделены другим файлам.
Обновление временных штампов
Запись каталога содержит три значения времени: последнего обращения, после-
последней модификации и создания. В спецификации FAT требования к этим значениям
минимальны, но статья Microsoft Knowledge Base 299648 описывает их поведение
в Windows [Microsoft, 2003d]. Временные штампы не являются обязательными,
а их значения могут не соответствовать действительности.
Время создания задается в тот момент, когда Windows выделяет новую запись
каталога для нового файла. Последнее обстоятельство важно, потому что если ОС
выделяет новую запись каталога для существующего файла, даже если оригинал
находился на другом диске, в ней сохраняется исходное время создания. Напри-
Например, если файл был переименован или перемещен на другой каталог или диск, то
время создания оригинала копируется в новую запись. Время создания соответ-
соответствует времени выделения файлу первой записи каталога независимо от ее ис-
исходного размещения (если только файл не перемещался в новую файловую сис-
систему средствами командной строки).
Время модификации обновляется при записи в файл нового содержимого.
Время модификации отслеживается на уровне содержимого, а не на уровне запи-
записи каталога, и копируется вместе с данными. При перемещении или копировании
файлов в Windows новая запись каталога сохраняет время модификации из ис-
исходного файла. Изменение атрибутов или имени файла не приводит к обновле-
обновлению этого времени. Windows обновляет время в тот момент, когда записывает
содержимое в файл, даже если в приложении выполняется автоматическое сохра-
сохранение без реального изменения содержимого.
Подведем итог: при перемещении файла в Windows итоговый файл сохраняет
исходное время модификации с создания, за исключением копирования данных
на другой том в режиме командной строки. При копировании файла итоговый
файл сохраняет старое время модификации и получает новое время создания. Это
может выглядеть довольно странно, потому что время создания оказывается бо-
более поздним, чем время модификации. При создании новых файлов в приложе-
приложениях Windows время записи обычно оказывается более поздним, чем время со-
создания.
Время последнего обращения (а точнее, дата, поскольку значение имеет точ-
точность до суток) обновляется чаще остальных. Это происходит при каждом откры-
открытии файла. Например, если щелкнуть на файле правой кнопкой мыши для про-
просмотра его свойств, время последнего обращения обновляется. При перемещении
файла на другой том время последнего обращения для нового файла тоже обнов-
обновляется, потому что Windows читает исходное содержимое перед его записью на
новый том. С другой стороны, если перемещение происходит в пределах тома,
дата обращения не изменяется, потому что новый файл использует те же класте-
кластеры. При копировании или перемещении файла дата обращения обновляется как
в исходном, так и в итоговом файле. У этого простого правила есть единственное
исключение: в Windows XP дата обращения не обновляется при копировании
файла. С другой стороны, Windows 98 обновляет время обращения исходного
файла при создании итогового файла. Некоторые версии Windows можно настро-
настроить таким образом, чтобы время последнего обращения не обновлялось.
Что касается каталогов, я заметил, что даты задаются в момент создания ката-
каталога и в дальнейшем практически не обновляются. Даже когда для каталога выде-
выделяются новые кластеры или в каталоге появляются новые файлы, время модифи-
модификации не обновляется.
Методы анализа
Анализ в категории метаданных проводится с целью получения расширенной
информации о файле или каталоге. В FAT для этого необходимо найти конкрет-
конкретную запись каталога, обработать ее содержимое и определить, где хранится со-
содержимое файла или каталога. Поиск всех записей в FAT является сложной зада-
задачей, потому что только записи выделенных каталогов обладают полным адресом,
состоящим из пути и имени файла. Пример будет приведен в разделе «Сцена-
«Сценарии». Свободные записи могут не иметь полного адреса; вероятно, в таких ситуа-
ситуациях будет применяться схема адресации, специфическая для конкретного при-
приложения.
После того как запись каталога будет обнаружена, ее дальнейшая обработка
проходит относительно прямолинейно. Чтобы идентифицировать все кластеры,
выделенные файлу, мы берем начальный кластер из записи каталога и находим
остальные кластеры по структуре FAT.
Факторы анализа
При анализе метаданных в файловой системе FAT необходимо принять во вни-
внимание ряд особых обстоятельств. Эти обстоятельства связаны с временными штам-
штампами записей каталогов, процедурами выделения и проверками целостности дан-
данных.
Во-первых, значения времени хранятся без учета часовых поясов. Данное об-
обстоятельство работает на руку аналитику: становится неважно, на какой часовой
пояс настроена система анализа. Кроме того, исчезают трудности с летним време-
временем — вам не придется рассчитывать, нужно ли вычитать или прибавлять час в за-
зависимости от текущего месяца.
Во-вторых, согласно спецификации дата и время последнего обращения и со-
создания не являются обязательными и могут быть равны 0. Как и в большинстве
других систем, временные штампы могут быть легко изменены пользователем.
Один из документов Microsoft рекомендует разработчикам сохранять время об-
обращения к файлу перед его открытием; это позволит восстановить его, если при-
приложение не сможет прочитать файл [Microsoft, 2003a]. Для подтверждения вре-
временных штампов следует использовать дополнительные данные прикладного
уровня. Более того, на платформах Microsoft не существует единой, согласован-
согласованной процедуры обновления временных штампов.
Windows использует в качестве времени модификации последний момент из-
изменения содержимого в локальной системе. В результате копирования может
появиться файл со временем создания, соответствующим времени копирования,
и временем модификации, соответствующим последней модификации исходной
версии. Такие ситуации возникают достаточно часто и не должны рассматривать-
рассматриваться как признак постороннего вмешательства. Время модификации задается с точ-
точностью до суток, поэтому не стоит полагаться на него при реконструкции собы-
событий в системе.
Из-за специфики процедур выделения новых записей каталогов в ХР имена
удаленных файлов остаются в системе дольше, чем можно было бы ожидать, по-
потому что система не использует алгоритм поиска первой доступной записи. Впро-
Впрочем, не стоит полагать, что используемый алгоритм открывает больше возмож-
возможностей для восстановления удаленных файлов — кластеры удаленных файлов
выделяются новым файлам с такой же скоростью. Следовательно, даже если вы
видите имя файла, восстановление его содержимого может оказаться невозмож-
невозможным.
Утилита DEFRAG, входящая в поставку Windows, сжимает каталоги и удаля-
удаляет неиспользуемые записи. Кроме того, она перемещает содержимое файлов для
снижения фрагментации. В результате запуска DEFRAG записи каталогов для
удаленных файлов пропадают, а кластеры перемещаются, поэтому восстановле-
восстановление становится практически невозможным.
Содержимое резервного пространства зависит от ОС, но в системах Microsoft
Windows за последние годы оно не заполнялось случайным содержимым памяти.
Неиспользуемые секторы последнего кластера файла, выделенного в системе
Windows, обычно содержат данные предыдущего файла. Согласно спецификации
FAT, операционная система имеет полное право стереть содержимое всех секто-
секторов при выделении кластера файлу, но это делается крайне редко.
Обнаружив запись каталога, заполненную нулями, Microsoft Windows не ото-
отображает дальнейшие данные. Следовательно, при желании можно без особого тру-
труда создать каталог с несколькими файлами и использовать остальную часть про-
пространства каталога для хранения скрытых данных. Чтобы обнаружить подобные
тайники, сравните выделенный размер каталога с количеством созданных фай-
файлов. Все данные, скрытые подобным образом, должны выявляться в результате
поиска в логической файловой системе.
Собирая материал для книги, я обнаружил, что записи каталогов с установ-
установленным атрибутом метки тома обладают рядом интересных особенностей. Время
последнего обращения и создания в записях метки тома часто обнуляются, но в ка-
качестве времени последней модификации Windows обычно устанавливает теку-
текущее время при создании файловой системы. Таким образом, по этим записям мож-
можно узнать, когда была создана файловая система (хотя, конечно, это значение
можно изменить).
В Windows XP запись каталога с атрибутом метки тома может использоваться
для скрытия данных. В конце концов, это самая обычная запись каталога с полем
для хранения начального кластера цепочки. Если вручную отредактировать это
поле, занести в него адрес неиспользуемого кластера, а затем перейти к FAT
и вручную отредактировать содержимое таблицы для создания цепочки, програм-
программа ScanDisk в Windows XP не выдаст каких-либо предупреждений или ошибок.
Цепочка кластеров останется выделенной. В общем случае, если запись каталога
не ссылается на цепочку кластеров, программа ScanDisk помещает ее в каталог
потерянных кластеров. В Windows 98 программа ScanDisk обнаруживает класте-
кластеры, выделенные записям с атрибутом метки тома, и удаляет их.
Другая интересная особенность Windows XP и атрибута метки тома заключа-
заключается в том, что количество записей с этим атрибутом может быть произвольным,
и они могут располагаться в произвольных местах. Согласно спецификации, фай-
файловая система должна содержать только одну запись с этим атрибутом, находя-
находящуюся в корневом каталоге, но система не контролирует соблюдение этого тре-
требования. Таким образом, вы можете создать в разных каталогах разные записи
с атрибутом метки тома и использовать их для скрытия данных. В Windows 98
программа ScanDisk обнаруживает такие записи и оповещает пользователя. В на-
настоящее время эти действия приходится выполнять вручную, но возможно, в бу-
будущем появятся программы для их автоматизации. На сайте Д/*7 У'(Digital Forensic
Tool Testing) имеется тестовый образ для меток томов FAT [Carrier, 2004b].
Сценарии анализа
Дата создания файловой системы
Имеется файловая система FAT, содержащая незначительный набор файлов и ка-
каталогов. Возможно, дело в том, что файловая система мало использовалась, была
недавно отформатирована или в ней присутствуют скрытые данные. Чтобы про-
проверить вторую гипотезу, мы анализируем временные штампы записи каталога с ат-
атрибутом метки тома, находящейся в корневом каталоге. Программа выводит запись
каталога как обычный файл, и мы видим, что форматирование было выполнено
за две недели до снятия данных с диска. Это объясняет малое количество имен
файлов, однако в системе все равно могут присутствовать скрытые данные, а так-
также данные, оставшиеся от предыдущей файловой системы (их поиск рассматри-
рассматривается в следующем сценарии).
Поиск удаленных каталогов
Требуется восстановить удаленные каталоги в файловой системе FAT. Этот сце-
сценарий может встретиться как в обычной ситуации с поиском удаленных файлов,
так и в случае, если файловая система FAT была недавно отформатирована и мы
хотим восстановить оставшуюся информацию. В этом примере мы извлечем со-
содержимое свободного дискового пространства и проведем поиск сигнатуры запи-
записи каталога «.», начинающей содержимое каталога.
Я сделаю это с помощью TSK, но вы можете воспользоваться любой програм-
программой, которая позволяет ограничить поиск свободным пространством и искать
шестнадцатеричные сигнатуры. В TSK первая задача решается программой dls:
# dls -f fat fat-lO.dd > fat-10.dls
Поиск будет проводиться по первым четырем байтам каталога, соответствую-
соответствующим ASCII-кодам «. » (точка с тремя пробелами). В шестнадцатеричном пред-
представлении эта сигнатура имеет вид 0х2е202020. Поиск сигнатуры в свободном
пространстве осуществляется программой sigfind:
# sigfind -b 512 2е202020 fat-10.dls
Block size: 512 Offset: 0
Block: 180 (-)
Block: 2004 (+1824)
Block: 3092 (+1088)
Block: 3188 (+96)
Block: 19028 (+15840)
Просмотрим содержимое сектора 180 образа fat-10.dLs (не исходного образа
файловой системы). Оно выглядит так:
# dd if-fat-10.dls skip=180 count=l | xxd
0000000: 2e20 2020 2020 2020 2020 2010 0037 5daf . ..7].
0000016: 3c23 3c23 0000 5daf Зс23 4П9 0000 0000 <#<#..].<#0
0000032: 2e2e 2020 2020 2020 2020 2010 0037 5daf . ..7].
0000048: 3c23 3c23 0000 5daf 3c23 dcOd 0000 0000 <#<#..].<#
0000064: e549 4c45 312e 4441 5420 2020 0000 0000 .ILE1.DAT ....
0000080: 7521 7521 0000 0000 7521 5619 OOdO 0000 u!u!....u!V
Каждая запись каталога занимает 32 байта; в этом фрагменте представлены
три записи. Первые две относятся к специальным каталогам «.» и «..». Интерпре-
Интерпретация первых двух записей показывает, что запись «.» ссылается на кластер 6479
@xl94f), а запись «..» ссылается на кластер 3548 (OxOddc). Третья запись отно-
относится к файлу, который начинается с кластера 6486 @x1956) и имеет размер 53248
(OxdOOO) байт. После определения начального адреса и размера можно присту-
приступать к восстановлению файла.
Действия, выполненные в этом сценарии, показаны на рис. 9.14. Мы извлекли
содержимое свободного пространства и провели поиск кластеров, начинающихся
с записи каталога «.».
Рис. 9.14. Процесс поиска удаленных каталогов по структурам записей
Категория данных имен файлов
Обычно анализ данных в категории имен файлов связывает имя файла со струк-
структурой метаданных. В FAT адрес имени файла не отделяется от адреса метадан-
метаданных, поэтому здесь эта задача не рассматривается. Основные сведения об именах
файлов и каталогов уже приводились в разделе «Категория метаданных», потому
что имя файла используется в качестве адреса метаданных. Напомню, что струк-
структура данных записи каталога содержит имя файла по схеме 8.3, то есть имя файла
занимает 8 символов, а расширение — 3. В этом разделе основное внимание будет
уделено поддержке длинных имен файлов в FAT.
Если длина имени файла превышает восемь символов или в имени присут-
присутствуют специальные символы, в каталоге создается запись типа LFN (Long file
Name). Файлы с длинными именами также имеют нормальную запись короткого
имени SFN (Short File Name). Записи SFN необходимы из-за того, что записи LFN
не содержат ни временных штампов, ни размера, ни начального кластера — в них
хранится только имя файла. Структура данных LFN подробно рассматривается
в главе 10. При освобождении записи LFN в первый байт структуры данных за-
записывается код 0хе5.
Поле атрибутов занимает в структурах данных SFN и LFN одинаковую по-
позицию, но в записях LFN используются специальные значения атрибутов.
В остальных байтах записи хранятся 13 символов Unicode в кодировке UTF-
16, каждый символ занимает 2 байта. Если имя файла содержит более 13 сим-
символов, создаются дополнительные записи LFN. Все записи LFN в каталоге
предшествуют записи SFN и содержат контрольную сумму, которая может ис-
использоваться для связывания записей LFN с записью SFN. Записи LFN следу-
следуют в обратном порядке, так что первая часть имени файла хранится ближе все-
всего к записи SFN.
На рис. 9.15 представлен список записей каталогов в тестовом образе. В гла-
главе 10 мы займемся ручным разбором записей, а пока достаточно сказать, что в ка-
каталоге хранится информация о двух файлах, один из которых обладает длинным
именем. Записи SFN предшествуют две записи LFN, содержащие символы имени
My Long File Name.rtf в обратном порядке. Обратите внимание на совпадение конт-
контрольных сумм, вычисленных на основании SFN.
Рис. 9.15. Записи каталога из тестового образа. Каталог содержит информацию
о трех файлах; один файл обладает длинным именем, и еще один был удален
Вот какие данные были получены при запуске программы fls для этого катало-
каталога тестового образа:
# fls -f fat fat-2.dd
г/г 3: FAT DISK (Volume Label Entry)
r/r 4: RESUME-1.RTF
r/r 7: My Long File Name.rtf (MYLONG~1.RTF)
r/r * 8: _ile.txt
В третьей строке выводится длинное имя файла, а четвертая строка представ-
представляет удаленный файл. Вспомните, что адреса метаданных назначаются в зависи-
зависимости от позиции записи каталога. Промежуток между адресами RESUME-I.RTFh My
Long File Name.rtf возникает из-за записей LFN в позициях 5 и 6.
Записи LFN содержат символы Unicode, что позволяет использовать в них
международные символы (тогда как кодировка ASCII ограничивается английс-
английскими символами). До появления записей LFN международному сообществу поль-
пользователей приходилось использовать кодовые страницы для включения символов
национальных алфавитов в имена файлов. В ASCII из 256 возможных символов
задействовано только 128. Кодовые страницы используют дополнительные 128
позиций и ассоциируют их с дополнительными символами. Помимо обычных
ASCII-символов запись SFN может содержать символы из кодовой страницы.
Список кодовых страниц приводится в документации Microsoft [Microsoft, 2004a].
Алгоритмы выделения
Имена файлов хранятся в тех же структурах данных, что и метаданные, поэтому
для категории имен файлов используются те же алгоритмы выделения, что и в ка-
категории метаданных. Единственное различие заключается в том, что записи LFN
должны следовать перед записью SFN, поэтому ОС ищет промежуток, достаточ-
достаточный для сохранения всех записей. Таким образом, при использовании стратегии
поиска первой доступной записи ОС будет пропускать все записи, к которым не
примыкают другие свободные записи.
Процедура удаления уже рассматривалась в разделе «Категория метаданных» —
а именно, первый байт записи заменяется кодом 0хе5. В записи SFN это приводит
к замене первого символа имени, а в записи каталога SFN стирается ее порядко-
порядковый номер. Обычно при восстановлении удаленных файлов первый символ ко-
короткого имени приходится вводить вручную, но, если у файла также имеется длин-
длинное имя, можно воспользоваться его первым символом. При удалении каталога
содержащиеся в нем записи могут изменяться, а могут остаться в прежнем состо-
состоянии.
Методы анализа
Анализ в категории данных имен файлов выполняется с целью поиска конкрет-
конкретного имени файла. Чтобы сделать это в FAT, необходимо сначала найти корневой
каталог, причем процедура поиска зависит от версии FAT. В FAT 12/16 корневой
каталог начинается в секторе, следующем за областью FAT, а его размер задается
в загрузочном секторе. В FAT32 адрес начального кластера корневого каталога
хранится в загрузочном секторе, а его строение определяется по структуре FAT.
Обработка содержимого каталога осуществляется перебором всех 32-байто-
32-байтовых структур записей каталогов. Если у структуры установлен атрибут записи
LFN, мы сохраняем ее содержимое и переходим к следующей записи. Процесс
повторяется вплоть до обнаружения записи, не являющейся записью LFN, конт-
контрольная сумма которой совпадает с записями LFN. Состояние выделения запи-
записи проверяется по первому байту.
Вероятно, после обнаружения файла или каталога, представляющего инте-
интерес, вы захотите найти его соответствующие метаданные. Благодаря FAT это
очень легко, потому что все метаданные файла хранятся в записи каталога. Это
означает, что синхронизация метаданных, ассоциированных с именем файла, не
нарушится после удаления файла. Метаданные, ассоциированные с именем уда-
ленного файла, останутся корректными вплоть до стирания (как метаданных,
так и имени).
Факторы анализа
Поскольку имя файла и метаданные хранятся в одной структуре данных, для всех
найденных записей удаленных файлов всегда будет известно имя. При использо-
использовании LFN восстанавливается все длинное имя, хотя часть его может быть поте-
потеряна при замене первого байта кодом 0хе5.
Как показали мои эксперименты с системой Windows XP, программа ScanDisk
для файловых систем FAT не слишком придирчива. Мне удалось создать записи
LFN, не соответствующие ни одной записи SFN, и программа не посчитала это
ошибкой. Это позволило сохранить небольшой объем скрытых данных, не ото-
отображаемых при выводе содержимого каталога. В зависимости от того, как прово-
проводится поиск по ключевым словам или устроена программа анализа, данные, скры-
скрытые в записях LFN, также могут остаться необнаруженными.
Как упоминалось в разделе «Категория метаданных», злоумышленник также
может скрыть данные в конце каталога. Некоторые ОС прерывают обработку ка-
каталога после обнаружения записи, заполненной одними нулями, хотя после нуле-
нулевой записи могут следовать скрытые данные. Впрочем, другая реализация FAT
может пропустить нулевую запись и продолжить обработку до конца каталога.
Если для поиска имени файла используется механизм поиска по ключевым
словам, убедитесь в том, что вы указываете Unicode-версию длинных имен фай-
файлов. Записи SFN хранятся в ASCII, но в записях LFN используется Unicode. Так-
Также следует помнить что имя может оказаться разбитым на части в нескольких
записях LFN (см. сценарий в следующем разделе).
Сценарии анализа
Чтобы продемонстрировать некоторые методы анализа, я приведу в этом разделе
два сценария. Один посвящен поиску файла по имени, а другой — определению
относительного порядка записей каталогов.
Поиск файла по имени
Предположим, потребовалось найти в файловой системе все ссылки на файл
с именем TheStuff.dat. Нас интересуют как существующие, так и удаленные экзем-
экземпляры файла. Как это сделать, если в программе анализа поддерживается поиск
по именам файлов?
Если провести поиск по ключевому слову в файловой системе, вероятно, нам
удастся найти ссылки на искомый файл в содержимом файлов. Тем не менее сам
файл останется ненайденным, потому что его имя хранится в записи LFN, а за-
запись SFN содержит измененную версию имени. Возможны два варианта: либо
провести поиск строки «THESTUFI-1DAT» в ASCII, либо изменить критерий
поиска для длинного имени.
Чтобы найти длинную версию имени, необходимо разбить имя на фрагменты.
Каждая запись длинного имени содержит 13 символов и делится на фрагменты из
пяти, шести и двух символов. Таким образом, в Unicode наша запись длинного
имени будет разбита на фрагменты «TheSt», «uff.da» и «t». Графическое представ-
представление записей каталогов для этого файла показано на рис. 9.16.
Рис. 9.16. Поиск имени файла по ключевым словам в ASCII или Unicode
может не привести к обнаружению его записи каталога
Упорядочение записей каталогов
В процессе экспертизы системы был обнаружен каталог с множеством незакон-
незаконных графических изображений; требуется определить, как они попали в систему1.
Например, были ли они загружены по отдельности, или скопированы с компакт-
диска? Записи в этом каталоге следуют в алфавитном порядке, что немного стран-
странно, потому что Windows обычно не сортирует записи каталогов. Каталог не со-
содержит свободных записей.
Относительно каталога выдвигается ряд гипотез, в том числе:
• он был скопирован или перемещен, а новые записи создавались в алфавитном
порядке;
• каталог был создан в результате распаковки zip-файла, а программа распаков-
распаковки создала записи в алфавитном порядке;
• пользователь загружал файлы в алфавитном порядке, потому что так был от-
отсортирован список на удаленном сервере.
Чтобы проверить первую гипотезу, мы сравним время создания и последней
модификации файлов. У файлов, созданных в результате копирования, время со-
создания относится к более позднему моменту, чем время последней модификации.
В нашем случае у всех файлов время создания совпадает с временем последней
модификации, поэтому вариант с копированием выглядит маловероятным (при
условии, что временным штампам можно доверять).
Чтобы проверить гипотезу с перемещением каталога, мы создаем систему,
аналогичную исследуемой, и проводим ряд экспериментов. Мы создаем ката-
каталог с теми же именами файлов, как в проверяемом каталоге, причем файлы со-
создаются не по алфавиту. Чтобы проверить гипотезу с перемещением, мы вклю-
включаем в диспетчере файлов режим сортировки, а затем начинаем перемещать
файлы посредством перетаскивания. Записи в полученном каталоге следуют
почти в алфавитном порядке, но не совсем. Сортировка получается более стро-
строгой, чем в исходном каталоге, и все же не совсем. Эксперимент повторяется
с другими параметрами сортировки, но добиться желаемого эффекта так и не
удалось. Зато выясняется, что если бы все файлы перемещались по отдельнос-
отдельности в порядке сортировки, то содержимое нового каталога было бы отсортиро-
отсортированным.
1 Спасибо Эогану Кейси (Eoghan Casey) за основную идею этого примера.
Во втором сценарии мы проверяем, не были ли файлы созданы в результате
распаковки zip-файла. Для проведения эксперимента создается zip-файл, содер-
содержащий анализируемые файлы, после чего его содержимое распаковывается в но-
новый каталог. Выясняется, что файлы извлекаются из zip-архива в порядке их вклю-
включения в архив. Следовательно, если файлы добавлялись в архив в алфавитном
порядке, то и извлекаться они будут в том же порядке. Мы также замечаем, что у
полученных файлов время создания и модификации совпадает с исходным вре-
временем последней модификации файла. Итак, у нас нет никаких улик, которые
противоречили бы такому сценарию.
Последний сценарий — загрузка файлов в отсортированном порядке. Экспе-
Эксперимент показывает, что этот вариант возможен, но маловероятен из-за времен-
временных штампов. Время создания и модификации разных файлов иногда различает-
различается на дни и даже месяцы. Предположить, что пользователь загружал эти файлы
в отсортированном порядке в течение нескольких месяцев? Такая ситуация была
бы возможна, если бы файлы публиковались периодически, а их имена формиро-
формировались в зависимости от даты.
После проверки всех трех сценариев можно сделать вывод, что два последних
наиболее вероятны. Остается исследовать оба сценария более подробно для обна-
обнаружения доказательств (например, zip-файлов или следов продолжительной заг-
загрузки файлов). Вероятно, можно придумать и другие сценарии, которые могли
привести к данной ситуации, и проверка не исчерпывает всех возможных вариан-
вариантов. Наконец, результаты зависят от версий ОС и ZIP.
Общая картина
До настоящего момента мы подробно рассматривали организацию файловой сис-
системы FAT по категориям данных. Этот подход не всегда является наиболее есте-
естественным, поэтому напоследок я приведу примеры создания и удаления файлов.
Создание файлов
Процесс создания файла в системе FAT будет продемонстрирован на примере
dirl\filel.dat. В рассматриваемом примере каталог dirl уже существует, размер
кластера составляет 4096 байт, а размер файла — 6000 байт.
1. Мы читаем загрузочный сектор из сектора 0 тома и находим в нем структуры
FAT, область данных и корневой каталог.
2. Чтобы найти каталог dirl, мы перебираем все записи корневого каталога в по-
поисках записи с именем dirl и установленным атрибутом каталога. Запись ус-
успешно найдена, и ее начальный кластер равен 90.
3. Мы читаем содержимое начального кластера dirl (90) и последовательно пе-
перебираем все записи, хранящиеся в нем, пока не будет найдена свободная за-
запись каталога.
4. Мы находим свободную запись и переводим в выделенное состояние, записы-
записывая в нее имя filel.txt. Размер и текущее время тоже записываются в соответ-
соответствующие поля.
5. Настает очередь выделения кластеров для содержимого; переходим к поиску
в структуре FAT. Файлу выделяется кластер 200, для чего записи этого клас-
кластера присваивается маркер EOF.
6. Адрес кластера 200 записывается в поле начального кластера записи каталога.
Первые 4096 байт содержимого файла записываются в кластер. Остается еще
1904 байт, поэтому потребуется второй кластер.
7. После поиска в структуре FAT файлу выделяется еще один кластер 201.
8. В запись FAT первого кластера B00) заносится значение 201. Последние 1904
байт файла записываются в кластер 201.
Состояние файловой системы после создания файла показано на рис. 9.17.
Рис. 9.17. Состояние файловой системы после создания файла «dirl\filel.txt»
Пример удаления файла
Теперь посмотрим, как происходит удаление файла dirl\fUel.txt.
1. Мы читаем загрузочный сектор из сектора 0 тома и находим в нем структуры
FAT, область данных и корневой каталог.
2. Чтобы найти каталог dirl, мы перебираем все записи корневого каталога в по-
поисках записи с именем dirl и установленным атрибутом каталога. Запись ус-
успешно найдена, и ее начальный кластер равен 90.
3. Мы перебираем содержимое начального кластера dirl (90) в поисках записи
с именем filel.txt. По записи определяется начальный кластер файла B00).
4. При помощи структуры FAT определяется цепочка кластеров файла. В дан-
данном случае файлу выделены кластеры 200 и 201.
5. В записи FAT кластеров 200 и 201 заносятся нули.
6. Запись каталога файла filel.txt освобождается, для чего в ее первый байт зано-
заносится значение 0хе5.
Итоговое состояние системы показано на рис. 9.18. Стертые ссылки обо-
обозначены пунктирными линиями, а первая буква имени файла удалена из записи
каталога.
Прочее
В последнем разделе освещаются некоторые вопросы, которые трудно отнести
к какой-то конкретной теме. В частности, мы рассмотрим приемы восстановле-
восстановления файлов и действия, выполняемые при проверке файловой системы. Также
мы узнаем, как определить тип файловой системы по количеству кластеров в фай-
файловой системе.
Восстановление файлов
Первые утилиты восстановления файлов в FAT появились еще в раннюю эпоху DOS,
но найти документированные теоретические обоснования этой процедуры нелегко.
Вспомните, что при удалении файла в Windows его запись каталога помечается как
неиспользуемая, а записи кластеров в FAT обнуляются (рис. 9.18). Начало и размер
файла известны, но информация об остальных кластерах файла отсутствует.
Рис. 9.18. Состояние файловой системы после удаления файла «dirl\filel.txt»
Можно попытаться восстановить содержимое файла, прочитав данные из из-
известного начального кластера. Что касается выбора остальных кластеров, у програм-
мы восстановления (или специалиста) есть два метода: читать объем данных, со-
соответствующий размеру файла, не обращая внимания на состояние выделения,
или же читать данные только из свободных кластеров.
Второй метод чаще приводит к успеху, потому что он восстанавливает некото-
некоторые фрагментированные файлы. Рисунок 9.19 поясняет происходящее: на нем
показаны шесть кластеров файловой системы и три разных сценария. Размер фай-
файла составляет 7094 байт, а размер кластера — 2048 байт; следовательно, для файла
были выделены четыре кластера. Мы также знаем, что файл начинается с класте-
кластера 56. Светло-серые кластеры представляют фактическое местонахождение со-
содержимого файла в каждом сценарии.
В сценарии на рис. 9.19 (А) файл занимает четыре смежных кластера.
В этом случае в обоих вариантах правильно восстанавливаются кластеры 56-
59. На рис. 9.19 (В) файл был разделен на три фрагмента, а кластеры между фраг-
фрагментами E7 и 60) были выделены другому файлу во время восстановления. В этом
сценарии первый метод восстанавливает кластеры 56-59 и ошибочно включает
содержимое кластера 57. Второй метод правильно восстанавливает секторы 56,
58,59 и 61. На рис. 9.19 (С) показан сценарий, при котором файлу выделены те же
фрагменты, что и на рис. 9.19 (В), но кластеры между фрагментами не были выде-
выделены другим файлам на момент восстановления. В этом сценарии оба метода оши-
ошибочно восстановят кластеры 56-59, как это было сделано в предыдущем примере.
В процессе восстановления файла возможны и другие ситуации, но в них часть
файла оказывается стертой, и ни один способ уже не сможет точно восстановить
данные. Таким образом, метод 2 (с учетом состояния выделения кластеров) спо-
способен восстанавливать удаленные файлы чаще, чем метод 1. Эоган Кейси протес-
протестировал средства восстановления в программах WinHex и EnCase и выяснил, что
в WinHex версии 11.25 использовался первый метод, а в EnCase версии 4 — вто-
второй [Casey, 2004].
Рис. 9.19. Три сценария восстановления файла
И последнее замечание, относящееся к восстановлению: многокластерные ка-
каталоги обычно оказываются фрагментированными. Дело в том, что второй клас-
кластер выделяется только тогда, когда его потребуется использовать; крайне малове-
маловероятно, чтобы следующий смежный кластер оказался свободным (скорее всего,
он был выделен одному из файлов в каталоге). Таким образом, восстановление
каталогов является более сложной задачей (если только каталог не был создан
в результате копирования или файловая система недавно дефрагментировалась.
При копировании каталога, размер которого заранее известен, ему можно выде-
выделить смежные кластеры.
Если пользователь часто запускает для своей файловой системы программу
дефрагментации, это упростит восстановление файлов, удаленных с момента пос-
последней дефрагментации — большая часть файлов будет храниться в смежных сек-
секторах. С другой стороны, восстановление файлов, удаленных до дефрагментации,
становится крайне сложной задачей, поскольку дефрагментация могла привести
к перемещению кластеров.
Я создал тестовый образ для проверки средств восстановления FAT и разме-
разместил его на сайте DFTT [Carrier, 2004a]. Он содержит несколько удаленных фай-
файлов и каталогов, на которых вы можете опробовать свои средства восстановле-
восстановления.
Определение типа файловой системы
В начале главы я упоминал о том, что в файловой системе нет поля, которое иден-
идентифицировало бы ее как систему FAT12, FAT16 или FAT32. Теперь, когда чита-
читатель познакомился со всеми областями и концепциями файловой системы FAT,
мы рассмотрим методы вычисления ее типа.
«Официальный» метод определяет тип системы на основании количества кла-
кластеров в файловой системе. Чтобы получить количество кластеров, необходимо
определить количество секторов в области данных и разделить это число на коли-
количество секторов в кластере.
В FAT 12 и FAT 16 корневой каталог занимает первые секторы области дан-
данных, а кластер 2 начинается после него. В FAT32 корневой каталог имеет динами-
динамический характер, а кластер 2 находится в начале области данных. В загрузочном
секторе хранится значение, определяющее количество записей в корневом ка-
каталоге; в FAT32 оно равно 0. Чтобы вычислить количество секторов в корневом
каталоге, следует умножить количество записей на 32 байта (размер каждой за-
записи), разделить на количество байтов в секторе и округлить вверх (при необхо-
необходимости):
((К0ЛИЧЕСТВ0_ЗАПИСЕЙ * 32) + (БАЙТ_В_СЕКТОРЕ - 1)) / (БАЙТ_В_СЕКТОРЕ)
Для FAT32 результат равен 0. Чтобы определить количество секторов, зани-
занимаемых кластерами, следует взять общее количество секторов в файловой систе-
системе и вычесть из него размер зарезервированной области, размер области FAT и раз-
размер корневого каталога. Другими словами, мы вычитаем адрес сектора для кластера 2
из общего количества секторов:
ВСЕГО_СЕКТОРОВ - РАЗМЕР_ЗАРЕЗЕРВИР0ВАНН0Й_0БЛАСТИ -
KOJ1M4ECTBO_FAT * PA3MEP_FAT - РАЗМЕР_К0РНЕВ0Г0_КАТАЛ0ГА
Наконец, количество секторов в области данных делится на количество секто-
секторов в кластере. Если значение меньше 4085, значит, используется файловая сис-
система FAT12; если оно больше 4085, но меньше 65 525 — FAT16, и больше 65 525 —
FAT32. Эти значения соответствуют максимальному количеству кластеров, ко-
которые могут храниться в FAT. Вспомните, что 8 значений зарезервировано для
конца файла, 1 — для поврежденных кластеров, а записи в позициях 0 и 1 не ис-
используются.
При форматировании тома в Windows пользователю обычно предлагается
выбрать между FAT 16 и FAT32. Windows выбирает такой размер кластера, чтобы
итоговое число кластеров умещалось в предыдущем диапазоне. Например, при
форматировании системы в FAT16 могут использоваться 4-килобайтные класте-
кластеры, а в FAT32 — 2-килобайтные.
Проверка целостности данных
При анализе файловых систем бывает полезно проверять целостность данных,
чтобы выявлять поврежденные файловые системы и скрытые данные. Для загру-
загрузочного сектора и других структур данных в зарезервированной области файло-
файловой системы FAT проверка целостности должна подтвердить, что определенные
значения принадлежат положенным диапазонам, а неиспользуемые области про-
просмотреть на предмет ненулевых данных. Например, зарезервированная область
содержит немало секторов, которые не используются в некоторых файловых сис-
системах. Если в файловой системе FAT32 доступна резервная копия загрузочного
сектора, проверка целостности должна сравнить две копии и сообщить о любых
расхождениях.
Основная и резервная копии FAT также проверяются на совпадение. Следует
проверить каждую запись, помеченную как поврежденная, потому что современ-
современные жесткие диски обычно исправляют ошибки еще до того, как их заметит опе-
операционная система. Впрочем, на дискетах присутствие поврежденных секторов
вполне допустимо. В каждой копии FAT следует проверить пространство между
записью FAT последнего кластера и концом секторов, выделенных FAT, потому
что это пространство не используется файловой системой и может содержать скры-
скрытые данные. Между концом последнего кластера и концом файловой системы
может существовать пространство, не имеющее кластерного адреса.
Проверьте корневой каталог и все его подкаталоги, проверьте каждую цепоч-
цепочку кластеров в FAT и убедитесь в том, что на ее начало ссылается одна из су-
существующих записей каталогов. Также следует выполнить обратную проверку
и убедиться в том, что выделенные записи каталогов ссылаются на выделенные
кластеры. Если сразу несколько записей каталогов ссылаются на одну цепочку
кластеров, Microsoft рекомендует скопировать оба файла в новое место и удалить
оригиналы [Microsoft, 2003b]. Длина цепочки кластеров должна быть равна ко-
количеству кластеров, необходимых для хранения файла данного размера.
Записи каталогов с установленным атрибутом метки тома не должны иметь
начального кластера, и в файловой системе должна существовать только одна за-
запись метки тома. Сравните контрольные суммы записей LFN с существующей
записью SFN. Если соответствующую запись SFN найти не удалось, проанализи-
проанализируйте записи LFN. Возможно, они появились вследствие системного сбоя или
использования ОС без поддержки длинных имен файлов, но в них также могут
храниться скрытые данные. Если запись каталога содержит нулевые или случай-
случайные данные, а до и после нее находятся выделенные записи, возможно, это ре-
результат работы программы надежного удаления. Также стоит проверить, нет ли
записей каталогов после нулевой записи. Некоторые ОС не отображают записи
каталогов, следующие за нулевой записью.
Итоги
Файловые системы FAT содержат относительно немного структур данных, но со-
создают определенные трудности с восстановлением файлов и анализом временных
штампов. Структуры данных файловой системы хорошо определены в специ-
спецификации, но об алгоритмах выделения и обновлении временных штампов этого
не скажешь. Более того, файловая система FAT используется не только в Windows,
но и в других операционных системах, каждая из которых может выбрать свой
алгоритм. Всегда рекомендуется протестировать алгоритмы выделения в анализи-
анализируемых системах. Формальные описания структур данных на диске приводятся
в следующей главе (на случай, если вы не читали ее параллельно с этой главой).
Файловые системы FAT еще будут встречаться в течение нескольких ближайших
лет и хорошо подходят для «ручного» анализа. Многие шестнадцатеричные редак-
редакторы напрямую поддерживают FAT и позволяют просматривать содержимое струк-
структур данных. К сожалению, подозреваемый может воспользоваться теми же шест-
надцатеричными редакторами для модификации содержимого файловой системы.
Возможно, после чтения этой главы у вас возникли сомнения в полезности
модели с пятью категориями, но при рассмотрении других систем все встанет на
свои места.
Библиография
• Bates, Jim. «File Deletion in MS FAT Systems». September 23, 2002. http://
www.computer-investigations.com/arts/tech02.htmL
• Brouwer, Andries. «The FAT File System». September 20, 2002. http://www.win.-
tue.nL/~aeb/linux/fs/fat/fat.html.
• Carrier, Brian. «FAT Undelete Test #1». Digital Forensic Tool Testing, February
2004a. http://dftt.sourceforge.net/.
• Carrier, Brian. «FAT Volume Label Test #1». Digital Forensic Tool Testing, August
2004b. http://dftt.sourceforge.net/.
• Casey, Eoghan. «Tool Review — WinHex. Journal of Digital Investigation, 1B), 2004.
• Landis, Hale. «How It Works: DOS Floppy Disk Boot Sector». May 6,2002. http:/
/www.ata-atapi.com/hiwdos.htm.
• Microsoft. «FAT: General Overview of On-DiskForma.t».FAT32 File System Specifica-
Specification, Version 1.03. December 6,2000. http://www.microsoft.com/whdc/system/platform/
firmware/fatgen.mspx.
• Microsoft. «Last Access Date». MSDNLibrary, February 2003a. http://www.mkro-
soft.com/library/en-us/win9x/lfn_5mg.asp?frame=true.
• Microsoft. «How to Fix Cross-Linked Files». Microsoft Knowledge Base Article —
83140, May 10,2003b. http://support.mkrosoft.com/default.aspx?sdd=kb;en-us;83140.
• Microsoft. «MS-DOS FORMAT Does Not Preserve Clusters Marked Bad». Microsoft
Knowledge Base Article 103548, May 6,2003c. http://support.microsoft.com/default.aspx?-
scid=kb;en-us;103548.
• Microsoft. «Description of NTFS Date and Time Stamps for Files and Folders».
Microsoft Knowledge Base Article 299648, July 3, 2003d. http://support.mkro-
soft.com/default.aspx?scid=kb;en-us;299648.
• Microsoft. «Detailed Explanation of FAT Boot Sector». Microsoft Knowledge Base
Article Q140418, December 6, 2003e. http://support.microsoft.com/kb/ql40418.
• Microsoft. «Encodings and Code Pages». Global Development and Computing Portal,
2004a. http://www.microsoft.com/globaldev/getWR/steps/wrg_codepage.mspx.
• Microsoft. «How to Cause ScanDisk for Windows to Retest Bad Clusters». Microsoft
Knowledge Base Article 127055, December 16,2004b. http://support.microsoft.com/
default.aspx?scid=kb;en-us;127055.
• Microsoft. «Windows 2000 Server Operations Guide (Part 1).» n.d. http://www.mkro-
soft.com/resources/documentation/windows/2000/server/reskit/en-us/serverop/partl/
sopchOl.mspx.
• Wilson, Craig. «Volume Serial Numbers & Format Verification Date/Time». Digital
Detective White Paper, October 2003. http://www.digital-detective.co.uk/documents/
Volume7o20Serial7o20Numbers.pdf.
Структуры данных FAT
В предыдущей главе рассматривались основные принципы строения файловой
системы FAT и способы ее анализа. Сейчас мы займемся более подробным изуче-
изучением структур данных, заложенных в основу FAT. В этой главе мы временно за-
забудем о модели с пятью категориями и сосредоточимся на отдельных структурах
данных. Такой подход упростит понимание FAT, потому что многие структуры
данных принадлежат сразу к нескольким категориям. Предполагается, что вы уже
прочитали главу 9 или читаете ее параллельно с этой главой. Все шестнадцатерич-
ные дампы и данные, приводимые в главе, соответствуют данным, которые ана-
анализировались в главе 9 с применением инструментария TSK (The Sleuth Toolkit).
Загрузочный сектор
Загрузочный сектор находится в первом секторе файловой системы FAT и содержит
основную часть данных, относящихся к категории файловой системы. FAT 12/16
и FA32 содержат разные версии загрузочного сектора, хотя начальные 36 байт
в них совпадают. Структура данных первых 36 байтов приведена в табл. 10.1,
а структуры остальных байтов — в табл. 10.2 и 10.3.
Таблица 10-1- Структура данных первых 36 байтов загрузочного сектора FAT
Диапазон Описание Необходимость
0-2 Ассемблерная команда перехода к загрузочному коду Нет (кроме загрузочных
файловых систем)
3-10 Имя OEM в кодировке ASCII Нет
11-12 Количество байтов в секторе. Допустимые Да
значения — 512, 1024, 2048 и 4096
13-13 Количество секторов в кластере (блоке данных). Да
Допустимые значения задаются степенями 2,
но размер кластера не должен превышать 32 Кбайт
14-15 Размер зарезервированной области в секторах Да
16-16 Количество копий FAT. Обычно в системе хранятся Да
две копии, но, по документации Microsoft,
для устройств малой емкости допускается хранение
только одной копии
17-18 Максимальное количество файлов в корневом ката- Да
логе для FAT12 и FAT16. В FAT32 поле равно 0,
а в FAT16 оно обычно равно 512
продолжение &
Таблица 10.1 {продолжение)
Диапазон Описание Необходимость
19-20 16-разрядное количество секторов в файловой сие- Да
теме. Если количество секторов не может быть пред-
представлено 2-байтовой величиной, позднее в структуре
данных следует альтернативное 4-байтовое поле
(а 2-байтовое поле должно быть равно нулю)
21-21 Тип носителя. Согласно документации Microsoft, Нет
для стационарных дисков используется
значение 0xf8, а для съемных— OxfO
22-23 16-разрядный размер (в секторах) каждой копии FAT Да
в FAT12 и FAT16. В FAT32 поле равно О
24-25 Количество секторов в дорожке Нет
26-27 Количество головок Нет
28-31 Количество секторов перед началом раздела1 Нет
32-35 32-разрядное количество секторов в файловой Да
системе. Либо это поле, либо 16-разрядное
поле A9-20) должно быть равно О
1 Тестирование показало, что в файловых системах, хранящихся в расширенных разделах, Windows
задает это значение по отношению к началу расширенного раздела, а не к началу диска.
Команда в первом поле загрузочного сектора (байты 0-2) сообщает компью-
компьютеру, где находится код, необходимый для загрузки операционной системы. Если
файловая система не используется для загрузки компьютера, это значение игно-
игнорируется. DOS и Windows требуют, чтобы значение поля задавалось и для фай-
файловых систем, не являющихся загрузочными, а в других ОС (например, Linux)
такое требование отсутствует.
Тип носителя определяет, находится файловая система на стационарном или
съемном носителе, но в Microsoft Windows игнорирует это поле и использует вто-
вторую копию типа носителя, находящуюся в таблице размещения файлов [Micro-
[Microsoft, 2001]. Смысл остальных полей был описан в главе 9.
Начиная с байта 36, между структурами загрузочного сектора FAT12/FAT16
и FAT32 начинаются расхождения. В них совпадает только сигнатура 0x55 (байт
510) и ОхАА (байт 511). Обратите внимание: эта же сигнатура используется в пер-
первом секторе таблицы разделов DOS (мы еще встретимся с ней в первом секторе
NTFS). Структура остальных байтов загрузочного сектора FAT12 и FAT16 при-
приведена в табл. 10.2.
Таблица 10.2, Структура данных оставшейся части загрузочного сектора в FAT12/16
Диапазон Описание Необходимость
0-35 См. табл. 10.1 Да
36-36 Номер диска BIOS INT13H Нет
37-37 Не используется Нет
38-38 Расширенная сигнатура, которая показывает, Нет
действительны ли следующие три значения.
Сигнатура равна 0x29
Диапазон Описание Необходимость
39-42 Серийный номер тома; в некоторых версиях Windows Нет
вычисляется на основании даты и времени создания
43-53 Метка тома в кодировке ASCII. Выбирается пользова- Нет
телем при создании файловой системы
54-61 Метка типа файловой системы в кодировке ASCII Нет
Стандартные значения — «FAT», «FAT12» и «FAT16»,
но ни одно из них не является обязательным
62-509 Не используется Нет
510-511 Сигнатура @хАА55) Нет
Структура остальных байтов загрузочного сектора FAT32 приведена в табл. 10.3.
Таблица 10-3- Структура данных оставшейся части загрузочного сектора в FAT32
Диапазон Описание Необходимость
0-35 См. табл. 10.1 Да
36-39 32-разрядный размер одной копии FAT (в секторах) Да
40-41 Режим обновления нескольких структур FAT. Если Да
бит 7 равен 1, активна только одна копия FAT, индекс
которой определяется разрядами 0-3. В противном
случае все структуры FAT являются зеркальными
копиями друг друга
42-43 Основной и дополнительный номер версии Да
44-47 Кластер, в котором находится корневой каталог Да
48-49 Сектор, в котором находится структура FSINFO Нет
50-51 Сектор, в котором находится резервная копия загру- Нет
зочного сектора (по умолчанию 6)
52-63 Зарезервировано Нет
64-64 Номер диска BIOS INT13H Нет
65-65 Не используется Нет
66-66 Расширенная сигнатура, которая показывает, действи- Нет
тельны ли следующие три значения.
Сигнатура равна 0x29
67-70 Серийный номер тома; в некоторых версиях Windows Нет
вычисляется на основании даты и времени создания
71-81 Метка тома в кодировке ASCII. Выбирается пользо- Нет
вателем при создании файловой системы
82-89 Метка типа файловой системы в кодировке ASCII. Нет
Стандартное значение — «FAT32», но оно
не является обязательным
90-509 Не используется Нет
510-511 Сигнатура @хАА55) Нет
Основное различие между загрузочными секторами FAT12/16 и FAT32 со-
состоит в том, что сектор FAT32 включает дополнительные данные, которые дела-
делают файловую систему более гибкой и улучшают ее масштабируемость. Возмож-
Возможны разные стратегии обновления структур FAT и создания резервных копий
загрузочного сектора. Также существует поле версии, но, похоже, на момент на-
написания книги в продуктах Microsoft использовалась только одна версия.
Содержимое диапазона 62-509 в FAT12/16 и 90-509 в FAT32 не имеет опре-
определенного предназначения. Обычно эти байты используются для хранения загру-
загрузочного кода и сообщений об ошибках. Вот как выглядит шестнадцатеричный дамп
первого сектора файловой системы FAT32 в системе Windows XP:
# dcat -f fat-4.dd 0 | xxd
0000000: eb58 904d 5344 4f53 352e 3000 0202 2600 .X.MSDOS5.0...&.
0000016: 0200 0000 00f8 0000 3f00 4000 c089 0100 ?.@
0000032: 4023 0300 ld03 0000 0000 0000 0200 0000 @#
0000048: 0100 0600 0000 0000 0000 0000 0200 0000
0000064: 8000 2903 4619 4c4e 4f20 4e41 4d45 2020 ..).F.LNO NAME
0000080: 2020 4641 5433 3220 2020 33c9 8edl bcf4 FAT32 3
0000096: 7b8e cl8e d9bd 007c 884e 028a 5640 b408 { |.N..V@..
0000112: cdl3 7305 b9ff ff8a П66 0fb6 c640 660f ..s f...@f.
0000128: b6dl 80e2 3ff7 e286 cdcO ed06 4166 0fb7 ....? Af..
[...3
0000416: 0000 0000 0000 0000 0000 0000 OdOa 5265 Re
0000432: 6d6f 7665 2064 6973 6b73 206f 7220 6f74 move disks or ot
0000448: 6865 7220 6d65 6469 612e ffOd 0a44 6973 her media....Dis
0000464: 6b20 6572 726f 72ff OdOa 5072 6573 7320 k error...Press
0000480: 616e 7920 6b65 7920 746f 2072 6573 7461 any key to resta
0000496: 7274 OdOa 0000 0000 OOac cdb8 0000 55aa ке U.
В первой строке видна метка OEM «MSDOS5.0»; по всей вероятности, она была
сгенерирована в Windows 2000 или ХР. В системе используется прямой порядок
байтов, поэтому в числовых полях байты переставляются, а байты строковых дан-
данных следуют в обычном порядке. Из байтов 11-12 мы узнаем, что каждый сектор
занимает 512 байт @x0200), а байт 13 показывает, что размер каждого кластера
в области данных составляет 2 сектора, то есть 1024 байта. Согласно байтам 14-15,
зарезервированная область состоит из 38 @x0026) секторов, поэтому мы знаем,
что область FAT начинается в секторе 38, а согласно байту 16 в системе хранятся
две копии FAT. Байты 19-20 содержат 16-разрядный размер файловой системы;
в данном примере он равен 0. Это говорит о том, что размер определяется 32-раз-
32-разрядным полем в байтах 32-35. Из этого поля мы узнаем, что размер файловой
системы составляет 205 632 @x00032340) сектора. Байты 28-31 показывают, что
перед началом файловой системы располагаются 100 800 @x0001 89сО) секторов;
возможно, они были выделены в небольшой раздел. Например, это может быть
система с альтернативной загрузкой или раздел данных спящего режима для пор-
портативного компьютера. Для получения дополнительной информации следует про-
проанализировать таблицу разделов.
Образ относится к системе FAT32, поэтому после 36-го байта следует применять
соответствующую структуру данных. Байты 36-39 показывают, что размер каждой
копии FAT составляет 797 @x0000 031d) секторов, а поскольку мы знаем, что в си-
системе хранятся две копии FAT, общий размер области FAT составит 1594 сектора.
Байты 48-49 показывают, что информация FSINFO хранится в секторе 1, а бай-
байты 50-51 — что резервная копия загрузочного сектора находится в секторе 6.
Серийный номер тома находится в байтах 67-70, его значение равно
0х4с194603. Метка тома в байтах 71-81 представляет собой строку «NO NAME»
(с четырьмя пробелами). Позднее мы увидим, что настоящая метка хранится в
другом месте файловой системы. Метка типа хранится в байтах 82-89, в данной
системе это строка «FAT32» (плюс три пробела). Байты 90-509 файловой систе-
мой не используются, но находящиеся в них данные используются при попытке
загрузить компьютер из этой файловой системы. Байты 510 и 511 содержат сиг-
сигнатуру 0хАА55. Результат запуска утилиты fsstat из пакета TSK для этого образа
приводился в главе 9.
Как упоминалось в главе 9, некоторые версии Windows назначают серийный
номер тома на основании даты и времени создания файловой системы. Эксперимен-
Эксперименты показали, что Windows 98 поступает именно так, но Windows XP действует по
другому алгоритму. В Windows 98 вычисления разбиваются на две половины: стар-
старшие и младшие 16 бит [Wilson, 2003]. Каждое поле даты, за исключением года,
преобразуется в 1-байтовое шестнадцатеричное значение и помещается в соот-
соответствующую позицию формулы. Год представляется 2-байтовым шестнадцате-
ричным значением. Процедура показана на рис. 10.1. Старшие 16 бит образуются
сложением часов, минут и года, а младшие 16 бит — месяцев, дней, секунд и деся-
десятых долей секунд. Тестовый образ файловой системы, который мы рассматрива-
рассматривали, был создан в системе Windows XP, и в нем эти вычисления не используются.
Рис. 10.1. Процесс вычисления серийного номера тома по дате и времени создания
Структура FSINFO
Файловая система FAT32 содержит структуру данных FSINFO. Информация,
хранящаяся в этой структуре, используется операционной системой при выделе-
выделении новых кластеров. Местонахождение структуры задается в загрузочном сек-
секторе, а ее строение описано в табл. 10.4.
Таблица 10.4. Структура данных сектора FAT32 FSINFO
Диапазон Описание Необходимость
0-3 Сигнатура @x41615252) Нет
4—483 Не используется Нет
484-487 Сигнатура @x6147272) Нет
488-491 Количество свободных кластеров Нет
492-495 Следующий свободный кластер Нет
496-507 Не используется Нет
508-511 Сигнатура @хАА550000) Нет
Ни одно из этих значений не является обязательным. ОС может использовать
эти данные как дополнительную информацию, однако структура FSINFO может
и не обновляться. Далее приводится содержимое сектора 1 рассмотренной ранее
файловой системы. Смещения в байтах задаются относительно начала сектора:
# dcat -f fat fat-4.dd 1 | xxd
0000000: 5252 6141 0000 0000 0000 0000 0000 0000 RRaA
0000016: 0000 0000 0000 0000 0000 0000 0000 0000
[...]
0000464: 0000 0000 0000 0000 0000 0000 0000 0000
0000480: 0000 0000 7272 4161 Ie8e 0100 4b00 0000 ....rrAa....К...
0000496: 0000 0000 0000 0000 0000 0000 0000 55aa U.
Обратите внимание на сигнатуры в байтах 0-3, 484-487 и 508-511. Количе-
Количество свободных кластеров указывается в байтах 488-491; данная файловая систе-
система содержит 101 918 @x0001 8е1е) свободных кластеров. Следует помнить, что
значения задаются в кластерах, а не в секторах. Следующий свободный кластер
определяется байтами 492-495; в данном примере это кластер 75 @x0000 004b).
FAT
Таблица FAT, занимающая центральное место в файловой системе FAT, выпол-
выполняет две функции. Она используется для определения состояния выделения кла-
кластеров и для поиска следующего выделенного кластера файла или каталога. В этом
разделе читатель узнает, как найти FAT и как выглядит эта таблица.
Обычно в файловой системе FAT хранятся две копии FAT, но их точное коли-
количество указывается в загрузочном секторе. Первая копия FAT начинается после
зарезервированных секторов, размер которых указывается в загрузочном секторе.
Размер каждой копии FAT также хранится в загрузочном секторе. Вторая копия
FAT (если она существует) начинается в следующем секторе за первой копией.
Таблица состоит из записей одинакового размера и не содержит ни служеб-
служебных заголовков, ни завершителей. Размер каждой записи зависит от версии фай-
файловой системы. В FAT12 используются 12-разрядные, в FAT16 — 16-разрядные,
а в FAT32 — 32-разрядные записи. Адресация записей начинается с 0, и каждая
запись соответствует кластеру с тем же адресом.
Если кластер свободен, его запись равна 0. Записи выделенных кластеров
отличны от нуля и содержат адрес следующего кластера в файле или каталоге.
Если кластер завершает цепочку файла или каталога, в его записи содержится
маркер конца файла; в FAT 12 это любое значение больше 0xff8, в FAT 16 —
0xfff8, и в FAT32 - OxOfff Й№8.Если запись содержит значение Oxff7 в FAT12,
0xfff7 в FAT 16 или OxOfff fff7 в FAT32, кластер помечен как поврежденный и не
должен выделяться системой.
Вспомните, что адресация кластеров файловой системы начинается с 2. Это
означает, что записи 0 и 1 в структуре FAT не используются. Обычно в записи О
хранится копия типа носителя, а в записи 1 — статус обновления файловой систе-
системы. В загрузочном секторе также присутствует поле для хранения типа носителя,
но, как упоминалось ранее, система Windows может использовать вместо него со-
содержимое записи 0 таблицы FAT. Статус обновления может использоваться для
идентификации ошибок демонтирования файловых систем (некорректное отклю-
отключение) или аппаратных ошибок поверхности носителя. Впрочем, оба значения не
являются обязательными и могут содержать неточную информацию.
Чтобы изучить структуру FAT тестового образа, мы просмотрим содержимое
сектора 38 — первого сектора, следующего за зарезервированной областью:
# cleat -f fat fat-4.dd 38 | xxd
[...]
0000288: 4900 0000 4a00 0000 4c00 0000 0000 0000 I...J...L
0000304: 4d00 0000 ffff ffOf 4f00 0000 ffff ffOf M 0
0000320: 5100 0000 5200 0000 ffff ffOf ffff ffOf Q...R
0000336: ffff ffOf 0000 0000 0000 0000 0000 0000
0000352: 0000 0000 0000 0000 0000 0000 0000 0000
Результаты были получены в файловой системе FAT32, поэтому каждая за-
запись занимает 4 байта (два столбца), а первая из показанных записей содержит
значение 73 @x0000 0049). В структуре FAT она хранится со смещением 288 байт;
разделив это число на 4 (размер записи в байтах), мы определим, что это запись
72. Запись выделена, поскольку ее значение отлично от нуля, а следующим клас-
кластером в цепочке является кластер 73.
Записи в байтах 300-303 и 340-... равны нулю; это означает, что кластеры, со-
соответствующие этим записям, свободны. В данном примере байты 300-303 соот-
соответствуют кластеру 75, а байты 340-... — записям 85 и т. д. В разделе, посвящен-
посвященном записям каталогов, показано, как отслеживать цепочки кластеров в FAT.
Для проверки состояния выделения кластера можно воспользоваться пакетом
TSK, но при этом придется выполнять преобразования между секторами и клас-
кластерами. В файловой системе из нашего примера кластер 2 соответствует сектору
1632, и каждый кластер занимает 2 сектора. Кластер 75 преобразуется в адрес сек-
сектора по формуле
(кластер 75 - кластер 2) * 2 (секторов в кластере) + сектор 1632 * сектор 1778
Программа dstat из пакета TSK отображает состояние выделения и адрес кла-
кластера для любого сектора. Если запустить ее для сектора 1778, будет получен сле-
следующий результат:
# dstat -f fat fat-4.dd 1778
Sector: 1778
Not Allocated
Cluster: 75
Записи каталогов
В записях каталогов FAT хранятся имя и метаданные файла или каталога. Эти
записи создаются для каждого файла или каталога в системе и хранятся в класте-
кластерах, выделенных родительскому каталогу файла. Структура данных записи под-
поддерживает короткие имена по схеме 8 + 3 (8 символов имени, 3 символа расши-
расширения). Если файл имеет более сложное имя, в дополнение к обычной записи
каталога (SFN) создаются записи LFN (Long File Name). Версия записи каталога
для длинных имен будет описана в следующем разделе. В табл. 10.5 перечислены
поля, входящие в базовую структуру записи каталога.
Таблица 10.5. Структура данных базовой записи каталога FAT
Диапазон Описание Необходимость
0-0 Первый символ имени файла в кодировке ASCII Да
и состояние выделения @хе5 или 0x00, если запись
не выделена)
1-10 Символы 2-11 имени файла в кодировке ASCII Да
11-11 Атрибуты файла (см. табл. 10.6) Да
12-12 Зарезервировано Нет
13-13 Время создания (десятые доли секунды) Нет
14-15 Время создания (часы, минуты, секунды) Нет
16-17 День создания Нет
18-19 День последнего обращения Нет
20-21 Старшие 2 байта адреса первого кластера Да
@ для FAT12 и FAT16)
22-23 Время последней модификации (часы, минуты, секунды) Нет
24-25 День последней записи Нет
26-27 Младшие 2 байта адреса первого кластера Да
28-31 Размер файла @ для каталогов) Да
Первый байт структуры данных используется как признак выделения. Если
он равен 0хе5 или 0x00, значит, запись каталога свободна. В противном случае
байт содержит первый символ имени файла. Обычно имена файлов задаются
в кодировке ASCII, но они также могут содержать символы национальных алфа-
алфавитов, для чего используются кодовые страницы Microsoft [Microsoft, 2004]. Если
в этом байте имени файла содержится символ 0хе5, вместо него используется код
0x05. Если имя файла короче 8 символов, неиспользуемые байты обычно запол-
заполняются ASCII-кодом пробела 0x20.
Поле размера файла занимает 4 байта, следовательно, максимальный размер
файла равен 4 Гбайт. У каталогов поле размера равно 0, и для определения коли-
количества выделенных им кластеров следует использовать структуру FAT. Поле ат-
атрибутов содержит один или несколько флагов, перечисленных в табл. 10.6.
Таблица 10.6. Флаги поля атрибутов в записи каталога
Флаг Описание Необходимость
0000 0001 @x01) Доступ только для чтения Нет
0000 0010 @x02) Скрытый файл Нет
0000 0100 @x04) Системный файл Нет
00001000 @x08) Метка тома Да
00001111 (OxOf) Длинное имя файла Да
00010000 @x10) Каталог Да
0010 0000 @x20) Архивный файл Нет
Старшие два бита в байте атрибутов зарезервированы. Записи каталогов с ус-
установленным атрибутом длинного имени имеют другую структуру, которая бу-
будет описана в следующем разделе. Обратите внимание: атрибут длинного имени
представляет собой поразрядную комбинацию первых четырех атрибутов. Ком-
пания Microsoft выяснила, что старые ОС игнорируют записи каталогов со всеми
установленными битами и введение нового атрибута не создаст проблем.
Компонент даты во временных штампах представляет собой 16-разрядное зна-
значение, состоящее из трех частей (рис. 10.2 (А)). Младшие 5 бит определяют день
месяца (диапазон допустимых значений 1-31). Биты 5-8 определяют месяц (до-
(допустимые значения — 1-12). Биты 9-15 определяют год; их значение прибавля-
прибавляется к 1980. Диапазон допустимых значений 0-127 позволяет представлять годы
с 1980 по 2107. Преобразование даты 1 апреля 2005 года в шестнадцатеричный
формат показано на рис. 10.2 (В).
Рис. 10.2. Строение даты и преобразование 1 апреля 2005 г. в формат даты FAT
Время тоже задается 16-разрядной величиной, состоящей из трех компонентов.
Пять младших битов определяют секунды (измеряемые в 2-секундных интервалах).
Диапазон допустимых значений 0-29 позволяет представить значения из диапазо-
диапазона 0-58 с двухсекундными интервалами. Следующие 6 бит определяют минуты
(допустимые значения — 0-59). Последние 5 бит определяют часы (допустимые
значения — 0-23). Структура поля времени продемонстрирована на рис. 10.3 (А).
Пример преобразования времени 10:31:44 в формат FAT показан на рис. 10.3 (В).
К счастью, многие служебные программы преобразуют эти значения автома-
автоматически1, поэтому вам не придется заниматься этим вручную. Многие шестнадца-
теричные редакторы отображают преобразованную дату, если выделить значение
и установить соответствующие параметры. Как будет показано в дальнейших гла-
главах, этот формат хранения времени существенно отличается от других систем,
где время хранится в виде количества секунд, прошедших с некоторого момента.
Рассмотрим низкоуровневое содержимое двух записей из корневого каталога.
Местонахождение корневого каталога в файловой системе FAT32 задается в за-
загрузочном секторе:
# cleat -f fat fat-4.dd 1632 | xxd
1 Пример — «Decode from Digital Detective» (https://www.digital-detective.co.uk).
0000000: 4641 5420 4449 534b 2020 2008 0000 0000 FAT DISK
0000016: 0000 0000 0000 874d 252b 0000 0000 0000 MX+
0000032: 6245 5355 4d45 2d31 5254 4620 00a3 347e RESUME-1RTF ..4-
0000048: 4a30 8830 0000 4a33 7830 0900 П21 0000 .0.0 0...!..
Рис. 10.3. Строение времени и преобразование 10:31:44 в формат времени FAT
В первых двух строках приведена запись каталогов, поле атрибутов которой
в байте 11 содержит двоичное значение 0000 1000 @x08), что соответствует атри-
атрибуту метки тома. Мы также видим, что время и дата последней модификации со-
содержатся в байтах 22-25 строки 2. Время модификации метки тома может соот-
соответствовать времени создания файловой системы. Обратите внимание: метка тома
в загрузочном секторе содержит строку «NO NAME».
Третья и четвертая строки представляют вторую запись каталога. Нетрудно
увидеть, что она представляет файл «RESUME-1.RTF». Поле атрибутов в байте
43 содержит значение 0000 0010 @x20); установлен только бит архивного файла.
Байт 45 определяет десятые доли секунды во времени создания файла, поле рав-
равно 163 (ОхаЗ). Байты 46-47 содержат время создания 0х7е34, что соответствует
15:49:40. День создания в байтах 48-49 равен 0х304а, то есть 10 февраля 2004.
Содержимое байтов 52-53 и 58-59 показывает, что файл начинается с класте-
кластера 9 @x0000 0009), а байты 60-63 - что размер файла составляет 8689 байт @x0000
21fl). Для получения списка всех кластеров файла следует обратиться к FAT.
Кластер 9 содержит 36-байтовое смещение в структуре FAT32, тогда как ранее
мы уже определили, что основная копия FAT начинается с сектора 38. Содержи-
Содержимое этого сектора выглядит так:
# dcat -f fat fat-4.dd 38 | xxd
[...]
0000032: ffff ffOf OaOO 0000 ObOO 0000 OcOO 0000
0000048: OdOO 0000 OeOO 0000 0000 Of00 1000 0000
0000064: 1100 0000 ffff ffOf 1300 0000 1400 0000
Запись таблицы для кластера 9 находится в байтах 36-39. Значение 10 @x0000
000а) означает, что кластер 10 является следующим кластером в цепочке. Запись
кластера 10 находится в байтах 40-43, ее значение равно 11 @x0000 000b). Мы
видим, что файлу выделяется серия смежных кластеров вплоть до записи 17 (байты
68-71), содержащей маркер конца файла (OxOfff ffff)- Можно убедиться в правиль-
правильности количества кластеров, сравнив размер файла с выделенным пространством.
Файлу выделено девять 1024-байтовых кластеров; таким образом, для хранения
файла из 8 689 байт выделено 9 216 байт дискового пространства.
Теперь попробуем просмотреть те же данные с использованием TSK. Вспом-
Вспомните, что в TSK вместо адресов кластеров используются адреса секторов. Чтобы
преобразовать кластер 9 в адрес сектора, необходимо знать адрес сектора для кла-
кластера 2, который равен 1632:
(кластер 9 - кластер 2) * 2 (секторов в кластере) + сектор 1632 - сектор 1646
Программа fsstat из пакета TSK выводит содержимое структур FAT. Выходные
данные fsstat уже приводились ранее при обсуждении категории данных файло-
файловой системы, но вывод, относящийся к FAT, не был показан. Вот как он выглядит:
# fsstat -f fat fat-4.dd
С.]
1642-1645 D) -> EOF
1646-1663 A8) -> EOF
1664-1681 A8) -> EOF
[...]
В выходных данных fsstat видна цепочка кластеров файла RESUME-1.RTF, состо-
состоящая из секторов 1646-1663 и завершающаяся маркером конца файла. Размер
каждого кластера равен 2 секторам; число в круглых скобках показывает, что це-
цепочка состоит из 18 секторов.
Программа istat из пакета TSK выводит подробную информацию о записях ка-
каталогов; вывод этой программы представлен в следующем листинге. Файл RESUME-
1.RTF занимает вторую запись в корневом каталоге, и согласно принятой в TSK
схеме адресации метаданных ему соответствует адрес 4:
# istat -f fat fat-4.dd 4
Directory Entry: 4
Allocated
File Attributes: File, Archive
Size: 8689
Name: RESUME-1.RTF
Directory Entry Times:
Written: Wed Mar 24 06:26:20 2004
Accesses: Thu Apr 8 00:00:00 2004
Created: Tue Feb 10 15:49:40 2004
Sectors:
1646 1647 1648 1649 1650 1651 1652 1653
1654 1655 1656 1657 1658 1659 1660 1661
1662 1663
Записи каталогов для длинных имен файлов
Стандартные записи каталога позволяют представить файл, имя которого состоит
из 8 символов, а расширение — из 3. Если имя имеет большую длину или содержит
специальные символы, для него требуются особые записи каталогов — записи LFN
(Long File Name). Помимо всех записей LFN для файла также создается обычная
запись, причем записи LFN должны предшествовать обычной записи. Поля LFN-
версии записи каталога перечислены в табл. 10.7.
Таблица 10.7. Структура данных записи каталога LFN в FAT
Диапазон Описание Необходимость
0-0 Порядковый номер и признак выделения @хе5, Да
если запись свободна)
1-10 Имя файла, символы 1-5 (Unicode) Да
11-11 Атрибуты файла (OxOf) Да
12-12 Зарезервировано Нет
13-13 Контрольная сумма Да
14-25 Имя файла, символы 6-11 (Unicode) Да
26-27 Зарезервировано Нет
28-31 Имя файла, символы 12-13 (Unicode) Да
Поле порядкового номера содержит счетчик записей, необходимых для хране-
хранения имени файла. Первой записи соответствует порядковый номер 1. Порядковый
номер увеличивается на 1 для каждой записи LFN вплоть до последней, в кото-
которой он объединяется со значением 0x40 поразрядной операцией OR. При выпол-
выполнении этой операции результат содержит 1 во всех разрядах, в которых хотя бы
один из двух операндов содержит 1.
Записи LFN располагаются в обратном порядке перед записью короткого име-
имени файла. Следовательно, первая запись, которую вы находите в каталоге, явля-
является последней записью LFN для файла и имеет наибольший порядковый номер.
Неиспользуемые символы дополняются кодами Oxff, а имя завершается симво-
символом NULL при наличии свободного места.
Поле атрибутов записи LFN должно быть равно OxOF. Контрольная сумма вы-
вычисляется с использованием короткого имени файла и должна быть одинаковой
для всех записей LFN. Если контрольная сумма записи LFN не совпадает с конт-
контрольной суммой соответствующего короткого имени, возможно, использование
ОС без поддержки длинных имен привело к повреждению каталога. Алгоритм
вычисления контрольной суммы перебирает символы имени, на каждом шаге сдви-
сдвигает текущую контрольную сумму на один бит вправо и прибавляет ASCII-код
следующей буквы. В программном коде С это выглядит так:
с - 0;
for (i - 0; i < 11; i++) {
// Сдвиг вправо
с = ((с & 0x01) ? 0x80 : 0) + (с » 1);
// Прибавление ASCII-кода символа
с = с + shortname[i];
}
А вот как выглядят две записи LFN и одна обычная запись для файла в корне-
корневом каталоге тестового образа:
# dcat -f fat fat-4.dd 1632 | xxd
0000064: 424е 0061 006d 0065 002е 000f OOdf 7200 BN.a.m.e г.
0000080: 7400 6600 0000 ffff ffff 0000 ffff ffff t.f
0000096: 014d 0079 0020 004c 006f OOOf OOdf 6eOO .M.y. .L.o....n.
0000112: 6700 2000 4600 6900 6c00 0000 6500 2000 g. .F.i.l.e... .
0000128: 4d59 4cdf 4e47 7e31 5254 4620 ООаЗ 347е MY10nG~lRTF ..4-
0000144: 4a30 8830 0000 4a33 7830 laOO 8fl3 0000 J0.0..J3x0
Первая запись находится в первых двух строках. Байт 75 содержит код OxOf, по
которому мы узнаем, что это запись LFN. Порядковый номер хранится в байте 64,
он равен 0x42. Исключив результат операции OR с кодом 0x40 (маркер после-
последней записи LFN), мы получим 0x02; следовательно, файл представляется двумя
записями LFN. Контрольная сумма в байте 77 равна Oxdf. Позднее мы сможем
использовать это значение при проверке записи короткого имени. Первые пять
символов записи (хотя это и не первые символы имени) находятся в байтах 65-
74 и образуют строку «Name». Вторая группа символов в байтах 78-89 образует
строку «rtf». Остальные символы заполнены кодом Oxffff. Последняя группа сим-
символов в байтах 92-95 тоже содержит Oxffff. Итак, длинное имя завершается стро-
строкой «Name.rtf».
У второй записи, начинающейся с байта 96, тоже установлен атрибут LFN, а ее
порядковый номер равен 1. Контрольная сумма совпадает с контрольной суммой
первой записи, Oxdf. Запись содержит группы символов «My Lo», «ng Fil» и «е ».
Порядковый номер записи равен 1, а значит, это последняя запись LFN для дан-
данного имени. Объединяя символы двух записей, мы получаем «My Long File
Name.rtf». Короткая версия этого имени находится в третьей записи — обычной
записи каталога с именем «MYLONG~1.RTF».
Теперь можно проверить контрольную сумму, но для этого необходимо знать
ASCII-коды символов в двоичном виде. Их значения перечислены в табл. 10.8.
Таблица 10.8. ASCII-коды символов для записей LFN
из приведенного примера
Символ Шести. Двоичн.
М 0x4d 0100 1101
Y 0x59 0101 1001
L 0х4с 0100 1100
0 0x4f 0100 1111
N 0х4е 0100 1110
G 0x47 0100 0111
0х7Е 0111 1110
1 0x31 ООН 0001
R 0x52 01010010
Т 0x54 0101 0100
F 0x46 0100 ОНО
Все вычисления будут проводиться в двоичном формате, чтобы избежать по-
постоянных преобразований. На первом шаге нашей переменной check присваива-
присваивается значение первой буквы имени, «М»:
check - 0100 1101
На каждом из 10 последующих шагов мы осуществляем циклический сдвиг
текущей контрольной суммы вправо и прибавляем очередную букву. Сдвиг теку-
текущего значения и прибавление «Y»:
check - 1010 ОНО
check - 1010 ОНО + 0101 1001 - 1111 1111
Сдвиг (который ничего не изменяет, потому что значение состоит только из 1)
и прибавление «L»:
check - 1111 1111
check - 1111 1111 + 0100 1100 - 0100 1011
Сдвиг и прибавление «О»:
check - 1010 0101
check - 1010 0101 + 0100 1111 - 1111 0100
В дальнейшем строка сдвига опускается, а показывается только сложение.
Сдвиг и прибавление «N»:
check - 0111 1010 + 0100 1110 - 1100 1000
Сдвиг и прибавление «G»:
check - ОНО 0100 + 0100 0111 - 1010 1011
Сдвиг и прибавление «~»:
check - 1101 0101 + 0111 1110 - 0101 ООП
Сдвиг и прибавление «1»:
check - 1010 1001 + ООП 0001 - 1101 1010
Сдвиг и прибавление «R»:
check - ОНО 1101 + 0101 0010 = 1011 1111
Сдвиг и прибавление «Т»:
check - 1101 1111 + 0101 0100 - ООП ООП
Сдвиг и прибавление «F»:
check - 1001 1001 + 0100 ОНО - 1101 1111 - Oxdf
Вряд ли вам придется вычислять контрольные суммы вручную, но по крайней
мере теперь вы знаете, как это делается. В конечном итоге мы получаем то же
значение Oxdf, которое мы видели в каждой из записей LFN.
Для получения информации о записях каталога можно воспользоваться про-
программой fls из пакета TSK. Программа fls выводит содержимое LFN, при этом ко-
короткие имена заключаются в круглые скобки:
# fls -f fat fat-2.dd
г/г 3: FAT DISK (Volume Label Entry)
r/r 4: RESUME-1.RTF
r/r 7: My Long File Name.rtf (MYLONG~1.RTF)
r/r * 8: _ile6.txt
В первых двух строках отображается метка тома и записи каталогов с корот-
короткими именами, приводившиеся ранее в разделе «Записи каталогов». В третьей
строке показано длинное имя, которое мы недавно анализировали, а за ним сле-
следует имя удаленного файла _jle6.txt. Звездочка перед именем файла указывает на
то, что он удален, а первая буква имени отсутствует потому, что таким образом
обозначаются свободные записи. Число перед именем указывает адрес записи
каталога с дополнительной информацией.
Итоги
Файловая система FAT проста, поскольку в ней используется малое количество
структур данных. Загрузочный сектор и FAT чрезвычайно важны для автомати-
автоматизации анализа файловой системы, а записи каталога — для восстановления уда-
удаленных файлов без применения методов прикладного уровня.
Библиография
• Microsoft. «ScanDisk May Not Fix the Media Descriptor Byte». Microsoft Knowledge
Base Article 1'58869, July 28,2001. http://support.microsoft.com/default.aspx?scid=
=kb;en-us; 158869.
• Microsoft. «Encodings and Code Pages». Global Development and Computing portal,
2004. http://www.microsoft.com/globaldev/getWR/steps/wrg_codepage.mspx.
• Wilson, Craig. «Volume Serial Numbers & Format Verification Date/Time». Digital
Detective White Paper, October 2003. http://www.digital-detective.co.uk/documents/
Volume%20Serial%20Numbers.pdf.
Также см. раздел «Библиография» главы 9.
NTFS: основные
концепции
Файловая система NTFS (New Technology File System), разработанная компанией
Microsoft, является стандартной файловой системой в Microsoft Windows NT,
Windows 2000, Windows XP и Windows Server. На момент написания книги ком-
компания Microsoft прекратила продажу систем Windows 98 и ME, а место фактичес-
фактического стандарта среди новых систем потребительского уровня сейчас отводится
Windows XP. Система FAT продолжает существовать в мобильных устройствах
и портативных носителях информации, но, скорее всего, во всех расследованиях,
относящихся к Windows, вам придется иметь дело именно с NTFS. Эта система
гораздо сложнее FAT, поскольку она обладает гораздо большими возможностями
и отлично масштабируется. Из-за сложности NTFS для ее рассмотрения нам по-
потребуются три главы. Эта глава посвящена основным концепциям NTFS и их ана-
аналогам среди пяти категорий нашей модели. В главе 12 рассматривается анализ
NTFS, а модель с пятью категориями демонстрирует возможности поиска улик.
Наконец, в главе 13 описываются структуры данных, связанные с NTFS.
Введение
Основными целями при проектировании NTFS были надежность, безопасность
и поддержка носителей информации большой емкости. Масштабируемость обес-
обеспечивается применением универсальных структур данных, инкапсулирующих
другие структуры с конкретным содержимым. Внутренние структуры данных мо-
могут изменяться в соответствии с новыми требованиями, предъявляемыми к фай-
файловой системе, а универсальная «оболочка» останется неизменной.
Файловая система NTFS достаточно сложна. К сожалению, компания Microsoft
не опубликовала официальной спецификации с описанием структуры диска. Вы-
Высокоуровневое описание компонентов файловой системы найти можно, но низ-
низкоуровневая информация весьма скудна. Впрочем, другие группы опубликовали
описания дисковых структур со своей точки зрения [Linux NTFS, 2004]; эти опи-
описания включены в книгу и будут использоваться для ручного анализа диска. Од-
Однако я еще раз подчеркиваю: нет полной уверенности в том, что представленные
структуры точно отражают содержимое диска.
Система NTFS стала стандартной в семействе Windows и получает все боль-
большее распространение во многих бесплатных дистрибутивах UNIX. Из-за отсут-
отсутствия официальной спецификации и доминирующей роли одного приложения,
создающего файловую систему, довольно трудно отличить свойства, специфические
для приложения, от общих свойств файловой системы. Например, существуют
другие методы инициализации файловых систем NTFS, не используемые Micro-
Microsoft; неясно, в какой степени полученная система может считаться «действительной
файловой системой NTFS». В каждой новой версии Windows компания Microsoft
вносила изменения в файловую систему; такие различия будут особо упоминать-
упоминаться в тексте.
Все данные — файлы
Одна из важнейших концепций для понимания архитектуры NTFS гласит, что
все служебные данные хранятся в файлах. В частности, это относится к админис-
административным данным базовой файловой системы, обычно скрываемым в других фай-
файловых системах. Файлы с административными данными могут находиться в лю-
любом месте тома, как обычные файлы. Таким образом, в отличие от других файловых
систем NTFS не обладает жестко заданной структурой. Вся файловая система счи-
считается областью данных, и любой сектор может быть выделен файлу. Единствен-
Единственное фиксированное требование гласит, что первые секторы тома содержат загру-
загрузочный сектор и загрузочный код.
Концепции MFT
«Сердцем» NTFS является главная файловая таблица MFT (Master File Table),
содержащая информацию обо всех файлах и каталогах. Каждый файл и каталог
представлен как минимум одной записью таблицы, причем записи сами по себе
очень просты. Их размер составляет 1 Кбайт, но только первые 42 байта имеют
определенное предназначение. В остальных байтах хранятся атрибуты — неболь-
небольшие структуры данных, выполняющие строго специализированную функцию.
Например, один атрибут используется для хранения имени файла, а другой — для
хранения его содержимого. На рис. 11.1 показана основная структура записи MFT
с заголовком и тремя атрибутами.
Рис. 11.1. Запись MFT содержит небольшой заголовок, а остальные байты предназначены
для хранения различных атрибутов. Запись, показанная на рисунке,
содержит три атрибута
Microsoft называет каждый элемент таблицы файловой записью (file record),
но я считаю, что их проще и удобнее называть записями MFT. Каждой записи на
основании ее местонахождения в таблице присваивается адрес, начиная с 0. В на-
настоящее время размер всех записей равен 1024 байт, однако его точное значение
определяется в загрузочном секторе.
MFT, как и все структуры NTFS, представляет собой таблицу. Ситуация не-
несколько усложняется тем, что MFT содержит запись для представления себя са-
самой. Первая запись таблицы называется $MFT и задает местонахождение MFT на
диске. Фактически это единственное место, в котором указывается местонахож-
местонахождение MFT; следовательно, эту запись необходимо обработать для определения
структуры и размера MFT. Начальный адрес MFT задается в загрузочном секто-
секторе, который всегда располагается в первом секторе файловой системы. Как по-
показано на рис. 11.2, загрузочный сектор используется для поиска первой записи
MFT, которая показывает, что таблица MFT фрагментирована и занимает клас-
кластеры 32-34 и 56-58. В NTFS, как и в FAT, дисковое пространство выделяется
в виде кластеров, то есть групп смежных секторов.
Рис. 11.2. Связь загрузочного сектора с $MFT в отношении определения структуры MFT
В реализации MTFS компании Microsoft таблица MFT начинается с минималь-
минимального размера и расширяется по мере необходимости. Теоретически ОС может со-
создать фиксированное число записей при создании файловой системы, но дина-
динамическая природа реализации Microsoft позволяет легко расширить файловую
систему при добавлении дополнительного дискового пространства за счет объе-
объединения дисков. Microsoft не удаляет записи MFT после их создания.
Содержимое записи MFT
Размер каждой записи MFT определяется в загрузочном секторе, но во всех вер-
версиях Microsoft используются 1024-байтовые записи. Первые 42 байта содержат
12 полей, а остальные 982 байта не имеют фиксированной структуры и заполняют-
заполняются атрибутами. Запись MFT можно сравнить с большим сундуком для хранения
вещей. Снаружи на сундуке написаны основные сведения о владельце — имя и ад-
адрес (аналог фиксированных полей записей MFT). Сундук обычно остается пус-
пустым, но в него можно положить любой предмет, размер которого меньше размера
сундука. Записи MFT тоже не имеют фиксированной структуры и содержат ат-
атрибуты, в которых хранится конкретная информация.
В первом поле каждой записи MFT хранится сигнатура; у стандартных записей
это ASCII-строка «FILE». Если в записи обнаружена ошибка, в качестве сигнату-
сигнатуры может использоваться строка «BAAD». Поле флагов указывает, используется
ли запись и представляет ли она каталог. Состояние выделения записи MFT так-
также можно определить по атрибуту $В1ТМАР в файле $MFT (см. главу 13).
Если атрибуты не помещаются в одной записи, для файла создаются несколь-
несколько записей MFT. В этом случае первая запись называется базовой записью MFT,
а ее адрес сохраняется в одном из фиксированных полей всех остальных записей.
В главе 13 представлена структура данных записи MFT с практическим ана-
анализом тестового образа файловой системы.
Адреса записей MFT
В MFT используется последовательная 48-разрядная адресация записей, при этом
первой записи присваивается адрес 0. Максимальный адрес MFT изменяется по
мере расширения MFT и определяется делением размера $MFT на размер одной
записи. Microsoft называет этот последовательный адрес файловым номером (file
number).
Каждая запись MFT также содержит 16-разрядный порядковый номер, авто-
автоматически увеличиваемый при создании записи. Для примера рассмотрим запись
MFT 313 с порядковым номером 1. Файл, которому была выделена запись 313,
удаляется, а запись повторно выделяется новому файлу. При повторном выделе-
выделении записи присваивается новый порядковый номер 2. Адрес MFT объединяется
с порядковым номером (занимающим старшие 16 бит) и формирует 64-разряд-
64-разрядный базовый адрес файла (см. рис. 11.3).
Рис. 11.3. Базовый адрес файла образуется в результате объединения
адреса записи MFT и порядкового номера
NTFS использует базовый адрес для обращения к записям MFT, потому что
порядковый номер упрощает выявление повреждений файловой системы. Напри-
Например, если в процессе выделения структур данных для файла в системе произойдет
сбой, по порядковому номеру можно будет определить, содержит ли структура
данных адрес записи MFT, оставшийся от предыдущего файла или же являющийся
частью нового файла. Кроме того, порядковый номер можно использовать при
восстановлении удаленного содержимого. Например, если имеется свободная
структура данных с базовым адресом файла, мы можем определить, производилось
ли повторное выделение записи MFT со времени ее использования в этой струк-
структуре данных. Порядковый номер может пригодиться во время расследования, но
в этой главе для простоты я буду в основном использовать файловые номера, то
есть адреса записей MFT.
Файлы метаданных файловой системы
Поскольку каждый байт тома выделяется некоторому файлу, административные
данные файловой системы также должны храниться в файлах. Microsoft называ-
называет такие файлы файлами метаданных, но это может вызвать путаницу, поскольку
в тексте также часто упоминаются метаданные файлов. Я буду называть эти спе-
специальные файлы файлами метаданных файловой системы.
Microsoft резервирует для файлов метаданных файловой системы первые 16" за-
записей MFT1. Неиспользуемые зарезервированные записи находятся в выделен-
выделенном состоянии и содержат только базовую и общую информацию. Все файлы ме-
метаданных файловой системы отображаются в корневом каталоге, хотя обычно они
скрываются от большинства пользователей. Имена файлов метаданных файло-
файловой системы начинаются с символа «$», а первая буква является прописной. Фай-
Файлы метаданных будут рассмотрены в главе 12, а пока я ограничусь их краткой свод-
сводкой (табл. 11.1).
Таблица 11.1. Стандартные файлы метаданных файловой системы NTFS
Запись Имя файла Описание
0 $MFT Запись для самой таблицы MFT
1 $MFTMirr Содержит резервную копию первых записей MFT. См. раз-
раздел «Категория данных файловой системы» главы 12
2 $LogFile Содержит журнал транзакций метаданных. См. раздел
«Категория прикладных данных» главы 12
3 $Volume Содержит информацию о томе — метка, идентификатор
и версия. См. раздел «Категория данных файловой
системы» главы 12
4 $AttrDef Содержит информацию об атрибутах — значения
идентификатора, имена, размеры. См. раздел «Категория
данных файловой системы» главы 12
5 . Содержит корневой каталог файловой системы. См. раз-
раздел «Категория данных файловой системы» главы 12
6 $Bitmap Содержит признак выделения для каждого кластера
файловой системы. См. раздел «Категория данных
содержимого» главы 12
7 $Boot Содержит загрузочный сектор и загрузочный код
файловой системы. См. раздел «Категория данных
файловой системы» главы 12
8 $BadClus Содержит кластеры, содержащие поврежденные
секторы. См. раздел «Категория данных содержимого»
главы 12
1 В документации Microsoft говорится, что резервируются только первые 16 записей, но на практике
выделение записей пользовательским файлам и каталогам начинается с записи 24. Записи 17-23 иног-
иногда используются в тех ситуациях, когда зарезервированных записей не хватает.
Запись Имя файла Описание
9 $Secure Содержит информацию системы безопасности и управ-
управления доступом к файлам (только в Windows 2000
и Windows XP). См. раздел «Категория метаданных»
главы 12
10 $Upcase Содержит все символы Unicode в верхнем регистре
11 $Extend Каталог с файлами необязательных расширений.
Microsoft обычно не размещает файлы этого каталога
в зарезервированных записях MFT
Атрибуты записей MFT
Записи MFT обладают минимальной структурой, а большая их часть использует-
используется для хранения атрибутов — объектов, содержащих данные определенного типа.
Количество разных атрибутов велико, и каждый из них обладает собственной
внутренней структурой. Например, существуют атрибуты для имени файла, даты
и времени, и даже содержимого файла. В этом проявляется одно из отличий NTFS
от других файловых систем. Как правило, файловые системы читают и записыва-
записывают содержимое файлов, а NTFS читает и записывает атрибуты, одна из разновид-
разновидностей которых инкапсулирует содержимое файлов.
Вернемся к приведенной ранее аналогии, в которой запись MFT сравнивалась
с сундуком, а атрибуты — с коробками меньшего размера, которые кладут в сун-
сундук. Коробки могут иметь любую форму, которая лучше всего подходит для хра-
хранения объекта. Например, шляпы удобнее хранить в круглых коробках, а плака-
плакаты — в длинных тубусах.
Хотя разнотипные атрибуты рассчитаны на разные типы данных, все атрибу-
атрибуты содержат две общие части: заголовок и содержимое. На рис. 11.4 показана за-
запись MFT с четырьмя парами «заголовок/содержимое». Заголовок универсален
и стандартен для всех атрибутов. Содержимое зависит от типа атрибута и может
иметь произвольный размер.
Рис. 11.4. Пример записи MFT с заголовками и областями содержимого
Заголовки атрибутов
Заголовок определяет тип атрибута, его размер и имя. Он также содержит флаги,
указывающие на сжатие или шифрование значения. Тип атрибута представляет
собой числовой код, ассоциированный с типом хранящихся данных (см. раздел
«Стандартные типы атрибутов»). Запись MFT может содержать несколько одно-
однотипных атрибутов.
Некоторым атрибутам назначается имя, хранящееся в кодировке Unicode
UTF-16 в заголовке атрибута. Атрибуту также назначается идентификатор, кото-
который обеспечивает его уникальность в рамках записи MFT. Если запись содержит
несколько однотипных атрибутов, они различаются по значению идентификато-
идентификатора. Структура данных заголовка атрибута приведена в разделе «Заголовок атри-
атрибута» главы 13.
Содержимое атрибутов
Содержимое атрибута имеет произвольный формат и произвольный размер. На-
Например, один из атрибутов используется для хранения содержимого файла, раз-
размеры которого могут составлять несколько мегабайт или даже гигабайт. Было бы
неудобно сохранять такое количество данных в 1024-байтовых записях MFT.
Для решения этой проблемы в NTFS предусмотрена возможность хранения
содержимого атрибутов в двух местах. Содержимое резидентных атрибутов
хранится в записях MFT с заголовками. Такой способ подходит только для не-
небольших атрибутов. Содержимое нерезидентных атрибутов хранится во внеш-
внешнем кластере файловой системы. В заголовке атрибута указано, является атри-
атрибут резидентным или нерезидентным. У резидентных атрибутов содержимое
следует непосредственно за заголовком. Для нерезидентных атрибутов в заго-
заголовке содержится адрес кластера. На рис. 11.5 показана запись MFT, которая
уже приводилась ранее, но на этот раз ее третий атрибут слишком велик для
хранения в MFT, поэтому для его хранения выделяется кластер 829.
Рис. 11.5. Пример записи MFT: третий атрибут содержит слишком много данных,
поэтому он преобразуется в нерезидентный
Нерезидентные атрибуты хранятся в сериях кластеров, то есть группах смеж-
смежных кластеров. Серия определяется адресом начального кластера и длиной. На-
Например, если атрибуту были выделены кластеры 48, 49, 50,51 и 52, то серия начи-
начинается с кластера 48 и имеет длину 5. Если атрибуту также выделены кластеры 80
и 81, вторая серия начинается с кластера 80 и имеет длину 2. Третья серия может
начинаться с кластера 56 и иметь длину 4 (рис. 11.6).
В книге неоднократно подчеркивались различия между схемами адресации.
Например, мы определили логический адрес файловой системы как адрес, назнача-
назначаемый блокам данных файловой системы, а логический адрес файла •— как адрес,
задаваемый по отношению к началу файла. В NTFS эти адреса обозначаются други-
ми терминами. Логический номер кластера (LCN, Logical Cluster Number) иденти-
идентичен логическому адресу файловой системы, а виртуальный помер кластера (VCN,
Virtual Cluster Number) идентичен логическому адресу файловой системы.
Рис. 11.6. Пример списка с тремя сериями кластеров
В NTFS для описания серий нерезидентных атрибутов используются отобра-
отображения VCN/LCN. Если вернуться к предыдущему примеру, адреса VCN с адреса-
адресами 0-4 отображаются на адреса LCN 48-52, адреса VCN 5-6 — на адреса LCN 80-
41, и адреса VCN 7-10 — на адреса LCN 56-59. Структура данных списка серий
описана в разделе «Заголовки атрибутов».
Стандартные типы атрибутов
До настоящего момента мы говорили об атрибутах исключительно на общем уров-
уровне. В этом разделе приводится информация о стандартных атрибутах, многие из
которых будут подробно рассмотрены в главе 12.
Как упоминалось ранее, каждый тип атрибута представляется неким числом,
причем Microsoft сортирует атрибуты в записи по этому числу. Стандартным ат-
атрибутам присваивается значение по умолчанию, но, как будет показано позднее,
это значение можно переопределить при помощи файла метаданных файловой
системы $AttrDef. Кроме числового идентификатора каждый тип атрибута обла-
обладает именем, которое состоит только из прописных букв и начинается со знака
«$». В табл. 11.2 перечислены некоторые стандартные типы атрибутов и соответ-
соответствующие им идентификаторы. Учтите, что не все типы атрибутов и идентифика-
идентификаторы существуют для каждого файла. Помимо более подробных описаний в гла-
главе 12, структуры данных многих атрибутов приводятся в главе 13.
Таблица 11.2. Стандартные типы атрибутов в записях MFT
Идентификатор Имя Описание
типа
16 $STANDARD_INFORMATION Общая информация (флаги; время
создания, последнего обращения и мо-
модификации; владелец и идентификатор
системы безопасности)
32 $ATTRIBUTE_LIST Список других атрибутов файла
48 $FILEJMAME Имя файла в Unicode; время создания,
последнего обращения и модификации
Таблица 11.2 {продолжение)
Идентификатор Имя Описание
типа
64 $VOLUME_VERSION Информация о томе. Существует только
в версии 1.2 (Windows NT)
80 $SECURITY_DESCRIPTOR Время обращения и свойства
безопасности файла
96 $VOLUME_NAME Имя тома
112 $VOLUME_INFORMATION Версия файловой системы и другие
флаги
128 $DATA Содержимое файла
144 $INDEX_ROOT Корневой узел индексного дерева
160 $INDEX_ALLOCATION Узлы индексного дерева, корень
которого определяется атрибутом
$INDEX_ROOT
176 $ВГТМАР Битовая карта файла $MFT и его
индексов
192 $SYMBOLIC_LINK Информация о мягких ссылках.
Существует только в версии 1.2
(Windows NT)
192 $REPARSE_POINT Содержит данные точек подключения
(reparse point), выполняющих функции
мягких ссылок в версии 3.0+
(Windows 2000)
208 $EA_INFORMATION Используется для обеспечения совмес-
совместимости с приложениями OS/2 (HPFS)
224 $ЕА Используется для обеспечения совмес-
совместимости с приложениями OS/2 (HPFS)
256 $LOGGED_UTILITY_STREAM Содержит ключи и информацию о за-
зашифрованных атрибутах в версии 3.0+
(Windows 2000)
Почти все выделенные записи MFT содержат атрибуты типов $FILE_NAME
и $STANDARD_INFORMATION. Единственное исключение составляют не-базовые за-
записи MFT, о которых речь пойдет далее. Атрибут $FILE_NAME содержит имя фай-
файла, размер и временные штампы. Атрибут $STANDARD_INFORMATION содержит вре-
временные штампы, информацию о владельцах и безопасности. Последний существует
во всех файлах и каталогах, потому что содержащиеся в нем данные необходимы
для обеспечения безопасности данных и дисковых квот. В абстрактном понима-
понимании этот атрибут не содержит необходимых данных, но его присутствие необхо-
необходимо для работы механизмов файловой системы прикладного уровня. Оба атри-
атрибута всегда являются резидентными.
Каждый файл обладает атрибутом $DATA, в котором хранится содержимое файла.
Если размер содержимого достигает примерно 700 байт, он становится нерези-
нерезидентным и сохраняется во внешних кластерах. Если файл содержит более одного
атрибута $DATA, дополнительные атрибуты иногда называются альтернативными
потоками данных, или ADS (alternate data streams). Основной атрибут $DATA,
созданный при создании файла, не имеет собственного имени, но дополнительным
атрибутам $DATA должны назначаться имена. Обратите внимание: имя атрибута от-
отличается от имени типа. $DATA — это имя типа атрибута, тогда как самому атрибуту
может быть присвоено другое имя (скажем, «fred»). Некоторые программы, в том
числе входящие в пакет TSK (The Sleuth Kit), присваивают стандартному атрибу-
атрибуту $DATA имя «$Data».
Каждый каталог обладает атрибутом $INDEX_ROOT с информацией о находя-
находящихся в нем файлах и подкаталогах. При большом размере каталога информация
также хранится в атрибутах $INDEX_ALLOCATION и $В1ТМАР. Ситуация дополнитель-
дополнительно усложняется тем, что каталоги могут обладать атрибутом $DATA ломимо атри-
атрибута $INDEX_ROOT. Другими словами, в каталоге могут храниться как содержимое
файлов, так и списки его файлов и подкаталогов. В атрибуте $DATA могут нахо-
находиться любые данные, которые приложение или пользователь пожелает в нем со-
сохранить. Атрибутам $INDEX_ROOT и $INDEX_ALLOCATION для каталогов обычно при-
присваиваются имена «$130».
На рис. 11.7 показан пример записи MFT с именами и типами атрибутов. За-
Запись содержит три стандартных атрибута. В данном примере все три атрибута яв-
являются резидентными.
Рис. 11.7. Пример записи MFT с именами типов и идентификаторами атрибутов
Другие концепции атрибутов
В предыдущем разделе рассматривались базовые концепции, относящиеся ко всем
атрибутам NTFS. Этот раздел посвящен концепциям более высокого уровня. В ча-
частности, мы посмотрим, что происходит, когда файл содержит слишком много ат-
атрибутов, а также познакомимся со способами сжатия и шифрования содержимо-
содержимого атрибутов.
Базовые записи MFT
Теоретически файл может содержать до 65 536 атрибутов (из-за 16-разрядных иден-
идентификаторов), поэтому для хранения всех заголовков атрибутов одной записи MFT
может оказаться недостаточно — ведь даже у нерезидентных атрибутов заголовок
должен храниться в записи MFT. Когда с файлом ассоциируются дополнитель-
дополнительные записи MFT, исходная запись MFT называется базовой записью MFT. У не-
небазовых записей адрес базовой записи хранится в одном из полей записи MFT.
Базовая запись MFT содержит атрибут типа $ATTRIBUTE_LIST, в котором хранит-
хранится список всех атрибутов файла и адресов MFT, по которым их можно найти. Не-
Небазовые записи MFT не содержат атрибутов $FILE_NAME и $STANDARD_INFORMATION.
Атрибут $ATTRIBUTE_LIST будет рассмотрен в разделе «Категория метаданных» гла-
главы 12.
Разреженные атрибуты
Чтобы уменьшить объем места, занимаемого файлом, NTFS может сохранять зна-
значения некоторых нерезидентных атрибутов $DATA в разреженном формате. Разре-
Разреженным называется атрибут, у которого кластеры, заполненные одними нулями,
не записываются на диск. Вместо этого для нулевых кластеров создается специ-
специальная серия. Обычные серии содержат позицию начального кластера и размер,
тогда как разреженные серии содержат только размер без начального адреса. Так-
Также присутствует флаг, который указывает, что атрибут является разреженным.
Допустим, файл занимает 12 кластеров. Первые пять кластеров содержат не-
ненулевые данные, следующие три кластера заполнены одними нулями, а после-
последние четыре кластера отличны от нуля. При хранении в виде нормального атри-
атрибута для файла создается одна серия длины 12 (рис. 11.8 (А)). При хранении в виде
разреженного атрибута создаются три серии, а выделяются только девять класте-
кластеров (рис. 11.8 (В)).
Рис. 11.8. Файл из 12 кластеров: (А) — в обычном формате,
(В) — с разреженной серией из трех кластеров
Сжатые атрибуты
NTFS позволяет хранить атрибуты в сжатом виде, хотя описание алгоритма сжа-
сжатия не опубликовано. Обратите внимание: речь идет о сжатии на уровне файло-
файловой системы, а не о применении внешних приложений вроде WinZip или gzip.
Microsoft утверждает, что сжиматься могут только атрибуты $DATA и только при
хранении в нерезидентном формате. Как разреженные серии, так и сжатие дан-
данных используются в NTFS для сокращения объема расходуемого дискового про-
пространства. Флаг в заголовке атрибута указывает, что атрибут хранится в сжатом
виде, а флаги в атрибутах $STANDARD_INFORMATION и $FILE_NAME также сообщают,
что файл содержит сжатые атрибуты.
Перед сжатием содержимого атрибута данные делятся на фрагменты одинако-
одинакового размера, называемые блоками сжатия. Размер блока сжатия указывается в за-
заголовке атрибута. В каждом блоке сжатия возможна одна из трех ситуаций:
1. Все кластеры заполнены нулями. В этом случае создается серия разреженных
данных, размер которой совпадает с размером блока, а дисковое пространство
не выделяется.
2. Количество кластеров после сжатия не изменилось (то есть сжатие оказалось
малоэффективным). В этом случае блок не сжимается, а серия создается для
исходных данных.
3. Данные после сжатия занимают меньшее количество кластеров. В этом случае
данные сжимаются и сохраняются в серии на диске. После сжатой серии со-
создается разреженная серия, чтобы общая длина серии совпадала с количеством
кластеров в блоке сжатия.
В следующем простом примере продемонстрирован каждый из этих сценари-
сценариев. Предположим, размер блока сжатия равен 16 кластерам, а длина атрибута $DATA
составляет 64 сектора (рис. 11.9). Содержимое делится на четыре блока, а каждый
блок анализируется файловой системой. Первый блок сжимается до 16 класте-
кластеров, поэтому он сохраняется без сжатия. Второй блок заполнен одними нулями;
для него создается разреженная серия из 16 кластеров, но кластеры на диске не
выделяются. Третий блок сжимается до 10 кластеров; сжатые данные записыва-
записываются на диск в виде серии из 10 кластеров, к которой добавляется разреженная
серия из 6 кластеров для данных, сокращенных в результате сжатия. Последний
блок сжимается до 16 кластеров, поэтому он сохраняется без сжатия в виде серии
из 16 кластеров.
Рис. 11.9. Атрибут с двумя блоками, сохраняемыми без сжатия, одним разреженным
блоком и одним блоком, сжимаемым до 10 кластеров
Когда ОС или программа анализа читает этот атрибут, она обнаруживает уста-
установленный флаг сжатия и преобразует серии во фрагменты, размер которых соот-
соответствует размеру блока сжатия. Первая серия по длине совпадает с блоком сжа-
сжатия; следовательно, она хранится без сжатия. Вторая серия по длине совпадает
с блоком сжатия и является разреженной; это означает, что она состоит из 16 кла-
кластеров, заполненных нулями. Третья серия образует размер блока только в соче-
сочетании с четвертой; третья серия занимает только 10 кластеров и нуждается в рас-
распаковке. Последняя серия по длине тоже совпадает с блоком, а следовательно,
хранится без сжатия.
Последний пример был слишком простым, поэтому я представлю более слож-
сложный файл, показанный на рис. 11.10. Сложности объясняются тем, что исходная
структура серий не делится на блоки сжатия напрямую. Чтобы обработать этот
файл, необходимо сначала восстановить данные из шести серий, а затем разбить
их на блоки сжатия из 16 кластеров. После объединения фрагментированных се-
серий мы получим одну серию содержимого, одну разреженную серию, затем снова
содержимое и еще одну разреженную серию. Объединенные данные делятся на
блоки сжатия; мы видим, что первые два блока не содержат разреженных серий и
не сжимаются. Третий и пятый блоки содержат разреженные серии и сжимаются.
Четвертый блок хранится в разреженном виде, а соответствующие данные запол-
заполнены только нулями.
Рис. 11.10. Сжатый атрибут с сегментированными сериями, границы которых
не совпадают с границами блоков сжатия
Шифрование атрибутов
В NTFS также предусмотрена возможность шифрования содержимого атрибутов.
В этом разделе приводится обзор того, как это делается и какие данные существуют
на диске. Теоретически шифроваться могут любые атрибуты, но Windows поддер-
поддерживает шифрование только для атрибутов $DATA. Шифруется только содержимое,
но не заголовок атрибута. Для файла создается атрибут $LOGGED_UTILITY_STREAM
с ключами, необходимыми для расшифровки данных.
В Windows шифроваться могут как отдельные файлы, так и целые каталоги.
Зашифрованный каталог не содержит зашифрованных данных, но любой файл или
каталог, созданный в этом каталоге, будет зашифрован. У зашифрованных файлов
или каталогов в атрибуте $STANDARD_INFORMATION устанавливается специальный
флаг, и у каждого зашифрованного атрибута в заголовке тоже устанавливается флаг.
Основы криптографии
Прежде чем объяснять, как криптографические функции реализованы в NTFS,
я приведу краткий обзор основных концепций криптографии. Шифрованием
называется процесс, использующий криптографический алгоритм и ключ для пре-
преобразования простого текста в зашифрованные данные. Дешифрованием называ-
называется обратный процесс, использующий криптографический алгоритм и ключ для
преобразования зашифрованных данных в простой текст. Даже располагая зашиф-
зашифрованными данными, посторонний не сможет восстановить исходный текст без
ключа.
Криптографические алгоритмы делятся на две категории: симметричные
и асимметричные. Симметричные алгоритмы используют один и тот же ключ как
для шифрования, так и для расшифровки данных. Симметричное шифрование
работает очень быстро, но оно создает проблемы с передачей зашифрованных дан-
данных. Если файл зашифрован симметричным алгоритмом и мы хотим предоставить
доступ к нему многим пользователям, придется либо зашифровать файл с приме-
применением общего ключа, либо создать отдельную копию файла для каждого пользо-
пользователя и зашифровать ее с ключом, уникальным для данного пользователя. Если
использовать один ключ для всех, будет трудно лишить пользователя доступа к за-
зашифрованным данным без изменения ключа. Если шифровать файл заново для
каждого пользователя, это приведет к большим затратам времени и дискового про-
пространства.
Асимметричные алгоритмы используют один ключ для шифрования, а дру-
другой — для дешифрования. Например, ключ «spot» может использоваться для пре-
преобразования простого текста в зашифрованный, а ключ «felix» — для расшифров-
расшифровки зашифрованного текста. В самом распространенном варианте асимметричного
шифрования один из ключей делается открытым, то есть общедоступным, а дру-
другой хранится в секрете. Любой желающий может зашифровать данные с общим
ключом, но их расшифровка возможна только с закрытым (приватным) клю-
ключом. Разумеется, ключи, применяемые на практике, гораздо длиннее слов «spot»
и «felix». Как правило, длина ключей превышает 1024 бит.
Реализация в NTFS
При шифровании атрибута $DATA в NTFS применяется симметричный алгоритм
DESX. Для каждой записи MFT, содержащей шифрованные данные, генерирует-
генерируется один случайный ключ, который называется ключом шифрования файла (FEK,
File Encryption Key). Если запись содержит несколько атрибутов $DATA, все они
шифруются одним ключом FEK.
Ключ FEK хранится в зашифрованном виде в атрибуте $LOGGED_UTILITY_STREAM.
Атрибут содержит список полей расшифровки данных (DDF, Data Decryption
Fields) и полей восстановления данных (Data Recovery Fields). DDF создается для
каждого пользователя, имеющего доступ к файлу, и содержит код SID (Security
ID) пользователя, данные шифрования и ключ FEK, зашифрованный открытым
ключом пользователя. Поле восстановления данных создается для каждого мето-
метода восстановления данных и содержит ключ FEK, зашифрованный с открытым
ключом восстановления данных; он используется в тех случаях, когда админист-
администратору или другому привилегированному пользователю потребуется обратиться
к данным (рис. 11.11).
При расшифровке атрибута $DATA система обрабатывает атрибут $LOGGED_UTIL-
ITY_STREAM и находит запись DDF пользователя. Закрытый ключ пользователя
используется для дешифрования ключа FEK, а ключ FEK — для дешифрования
атрибута $DATA. Когда пользователь теряет право доступа, его ключ удаляется из
списка. Закрытый ключ пользователя хранится в реестре Windows и шифруется
симметричным алгоритмом, при этом его пароль входа в систему используется
в качестве ключа. Таким образом, для дешифрования всех зашифрованных фай-
файлов, обнаруженных в процессе расследования, необходимо знать пароль пользо-
пользователя и иметь доступ к реестру. Процесс показан на рис. 11.12.
Рис. 11.11. Процесс шифрования, начиная с содержимого файла и открытых ключей
и заканчивая шифрованным содержимым и шифрованными ключами
Рис. 11.12. Процесс дешифрования, начиная с шифрованного содержимого,
ключей и пароля и заканчивая дешифрованным содержимым
Некоторые программы способны выполнить атаку путем подбора пароля поль-
пользователя, что может использоваться для дешифрования данных. Незашифрован-
Незашифрованные копии содержимого файла также могут находиться в свободном простран-
пространстве, если шифруются только некоторые файлы и каталоги. В архитектуре NTFS
присутствует небольшой дефект: система создает временный файл с именем
EFSO.TMP, содержащий текстовую версию шифруемого файла. Завершив шифро-
шифрование исходного файла, ОС удаляет временный файл, но его содержимое не сти-
стирается. Таким образом, текстовая версия файла продолжает существовать, и его
можно восстановить, пока запись MFT не будет выделена другому файлу. Копии
незашифрованных данных также могут найтись в пространстве подкачки. Также
сообщалось, что в случае нарушения прав администратора, контроллера домена
или другой учетной записи, настроенной как агент восстановления, появляется
возможность дешифрования любых файлов, поскольку такие учетные записи об-
обладают доступом ко всем файлам [Microsoft, 1999].
Индексы
В этом разделе описаны индексные структуры данных, применяемые NTFS во мно-
многих ситуациях. Индекс в NTFS представляет собой коллекцию атрибутов, хранящихся
в отсортированном порядке. Самым распространенным примером применения
индексов можно назвать каталоги, потому что они содержат атрибуты $FILE_NAME.
До выхода NTFS версии 3.0 (входящей в поставку Windows 2000) индексным
был только атрибут $FILE_NAME, но теперь у индексов имеются и другие примене-
применения, содержащие другие атрибуты. Например, в индексах хранятся данные безо-
безопасности и определения квот. Давайте посмотрим, что собой представляет ин-
индекс и как он реализован.
В-деревья
В индексах NTFS атрибуты сортируются в виде особой разновидности деревьев,
а именно В-деревьев. Деревом называется совокупность структур данных, назы-
называемых узлами; узлы связываются между собой, начиная с корневого узла. На
рис. 11.13 (А) сверху находится узел А, связанный с узлами В и С. В свою оче-
очередь, узел В связывается с узлами D и Е. Родительским узлом называется узел, от
которого идут связи к другим узлам, а дочерним — тот узел, к которому ведет связь.
Например, узел А является родительским по отношению к узлам В и С, а после-
последние являются дочерними по отношению к А. Листом (или листовым узлом) на-
называется узел, не имеющий дочерних узлов. Так, узлы С, D и Е являются листо-
листовыми. Дерево, показанное на рисунке, называется бинарным, потому что каждый
узел имеет не более двух дочерних узлов.
Древовидные структуры упрощают поиск и сортировку данных. На рис. 11.13 (В)
показано то же дерево, что и на рис. 11.13 (А), но в нем каждому узлу присвоено
некоторое значение. Если потребовалось найти значение в дереве, сначала мы срав-
сравниваем его с корневым узлом. Если корневое значение больше, мы переходим к ле-
левому дочернему узлу, а если меньше — к правому. Допустим, потребовалось най-
найти значение 6; мы сравниваем его с корневым значение 7. Корневой узел больше,
поэтому мы переходим к левому узлу и сравниваем искомое значение со значе-
значением этого узла E). Значение узла меньше, мы переходим к правому дочернему
узлу; его значение равно 6. Таким образом, значение было найдено всего за три
сравнения. Например, значение 9 находится всего за 2 сравнения вместо 5, необ-
необходимых при хранении значений в списке.
Рис. 11.13. Примеры: (А) — дерево с пятью узлами, (В) — то же дерево после сортировки узлов
В NTFS используются В-деревья, которые напоминают бинарное дерево
с рис. 11.13, но в них каждый узел может иметь более двух дочерних узлов. Как
правило, количество дочерних узлов зависит от того, сколько значений может хра-
храниться в каждом узле. Например, в бинарном дереве в каждом узле хранилось
одно значение, поэтому количество допустимых потомков было равно двум. Если
бы в каждом узле хранилось пять значений, потомков было бы шесть. Существует
много разновидностей В-деревьев и всевозможных правил, которые здесь не бу-
будут рассматриваться — ведь этот раздел всего лишь знакомит читателя с основ-
основными концепциям В-деревьев, а не описывает процесс их создания.
На рис. 11.14 показано В-дерево, содержащее имена вместо чисел. Узел А со-
содержит три значения и имеет четыре дочерних узла. Скажем, при поиске файла
ggg.txt мы обратились бы к корневому узлу и определили, что искомое имя по
алфавиту расположено между eee.txt и LU.txt. Обращаясь к узлу С, мы находим
в нем искомое имя файла.
С добавлением и удалением узлов дело обстоит сложнее. Тем не менее это
довольно важный момент — он объясняет, почему в NTFS трудно найти имена
удаленных файлов. Предположим, что каждый узел вмещает только три имени
файлов и в узел добавляется файл jjj.txt. На первый взгляд все просто, но в дей-
действительности эта операция приводит к удалению двух и созданию пяти новых
узлов. Определив, где должен находится узел jjj.txt, мы увидим, что он должен
следовать в конце узла С, за именем iii.txt (рис. 11.15, вверху). К сожалению, это
имя станет четвертым, тогда как узел вмещает только три имени. Следовательно,
узел С разбивается надвое, имя ggg.txt смещается на один уровень вверх, и в дере-
дереве создаются узлы F и G с именами из узла С (рис. 11.15, внизу).
К сожалению, теперь выясняется, что узел А содержит четыре значения. Соот-
Соответственно, он разбивается надвое, и значение ggg.txt перемещается на уровень
выше (рис. 11.16). Добавление одного файла привело к удалению узлов А и С
и добавлению узлов F, G, H, J и J. Все данные, оставшиеся в узлах А и С от ранее
удаленных файлов, к этому моменту могут быть утрачены.
Теперь удалим файл zzz.txt. Операция исключает имя из узла Е и не требует
других изменений. В зависимости от реализации информация файла zzz.txt мо-
может оставаться в узле; возможно, ее удастся восстановить.
Рис. 11.16. Конечное состояние дерева после добавления файла jjj.txt
С удалением файла fff.txt дело обстоит сложнее. Узел F становится пустым,
и его необходимо заполнить. Значение eee.txt перемещается из узла I в узел F,
а значение bbb.txt — из узла В в узел I. Дерево остается сбалансированным, а все
листья находятся на одинаковом расстоянии от узла Н (рис. 11.17).
Рис. 11.17. Дерево после удаления файлов zzz.txt и fff.txt
В свободном пространстве узла В находится значение bbb.txt, потому что зна-
значение bbb.txt было перемещено в узел I. Программа анализа может показать, что
файл bbb.txt был удален, но на самом деле это не так — он просто переместился
из-за удаления fff.txt.
Я продемонстрировал процесс добавления и удаления значений из дерева
с единственной целью: показать, насколько сложной может оказаться эта проце-
процедура. В файловых системах, использующих простые списки имен в каталогах (на-
(например, FAT), легко узнать, почему удаленное имя существует (или не существу-
существует) в системе. При использовании древовидных структур предсказать конечный
результат операции бывает очень трудно.
Атрибуты индексов NTFS
Итак, мы рассмотрели общую концепцию В-деревьев; теперь нужно разобраться,
как они реализуются в NTFS при построении индексов. Для каждого элемента
данных в дереве создается структура данных, называемая индексным элементом
и предназначенная для хранения значений каждого узла. Существует много ти-
типов индексных элементов, но они всегда содержат одинаковый набор полей заго-
заголовка (см. главу 13). Например, индексный элемент каталога содержит несколь-
несколько заголовочных полей и атрибут $FILE_NAME. Индексные элементы объединяются
в древовидную структуру и хранятся в виде списка. Пустой элемент обозначает
конец списка. На рис. 11.18 показан пример узла в индексе каталога, содержаще-
содержащего четыре индексных элемента $FILE_NAME.
Для хранения индексных узлов могут использоваться два тина атрибутов за-
записей MFT. Атрибут $INDEX_ROOT всегда является резидентным и содержит толь-
только один узел с небольшим числом индексных элементов. Атрибут $INDEX_ROOT
всегда соответствует корневому узлу индексного дерева.
Рис. 11.18. Узел индексного дерева каталога NTFS с четырьмя индексными элементами
В больших индексах создаются нерезидентные атрибуты $INDEX_ALLOCATION,
которые не ограничиваются по количеству узлов. Содержимое этого атрибута
представляет собой большой буфер с одной или несколькими индексными запи-
записями. Индексная запись имеет статический размер (обычно 4096 байт) и содер-
содержит список индексных элементов. Каждой индексной записи присваивается ад-
адрес, начиная с 0. На рис. 11.19 показан атрибут $INDEX_ROOT с тремя индексными
элементами и нерезидентным атрибутом $INDEX_ALLOCATION; последнему был вы-
выделен кластер 713, и он использует три индексные записи.
Рис. 11.19. Каталог содержит три индексных элемента в резидентном атрибуте $INDEX_ROOT
и три индексные записи в нерезидентном атрибуте $INDEX_ALLOCATION
Атрибуту $INDEX_ALLOCATION может выделяться пространство, не используе-
используемое для хранения индексных записей. Атрибут $ BITMAP управляет состоянием
выделения индексных записей. Если в дереве потребуется создать новый узел,
$ BITMAP используется для поиска свободных индексных записей; если найти за-
запись не удалось, добавляется новое пространство. Каждому индексу присваива-
присваивается имя; это же имя должно присутствовать в заголовке атрибутов $INDEX_ROOT,
$INDEX_ALLOCATION и $В1ТМАР.
Каждый индексный элемент обладает флагом, который показывает, имеет ли он
дочерние узлы. Если такие узлы имеются, адреса их индексных записей указываются
в индексном элементе. Индексные элементы узла хранятся в отсортированном
порядке, и если искомое значение меньше значения индексного элемента, а у пос-
последнего есть дочерний узел, вы обращаетесь к дочернему узлу. Добравшись до
пустого элемента в конце списка, вы обращаетесь к его дочернему узлу.
Давайте рассмотрим несколько примеров. Для начала возьмем индекс с тремя
элементами, помещающимися в $INDEX_ROOT. В этом случае память выделяется
только для атрибута $INDEX_ROOT, который содержит три структуры данных ин-
индексных элементов и пустой элемент в конце списка (рис. 11.20 (А). Следующий
индекс содержит 15 элементов, которые не помещаются в $INDEX_ROOT, но помеща-
помещаются в атрибут $INDEX_ALLOCATION с одной индексной записью (рис. 11.20 (В)).
После заполнения всех индексных элементов в индексной записи добавляется
новый уровень, в результате создается дерево из трех узлов (рис. 11.20 (С)). Оно
содержит одно значение в корневом узле и имеет два дочерних узла. Каждый дочер-
дочерний узел находится в отдельной индексной записи одного атрибута $IN DEX_ALLOCA-
TION, а ссылки на него содержатся в элементах узла $INDEX_ROOT.
Рис. 11.20. Три сценария в индексах NTFS: (А) — небольшой индекс с тремя элементами, (В) —
индекс с двумя узлами и 15 записями, (С) — дерево из трех узлов с 25 элементами
Программы анализа
Все программы, упоминавшиеся в главе 1, поддерживают работу с образами NTFS,
но могут предоставлять различные уровни доступа к отдельным атрибутам. Для
просмотра различных атрибутов в системе Windows можно воспользоваться про-
программой nfi.exe от компании Microsoft [Microsoft, 2000]. Программа выводит со-
содержимое MFT в рабочей системе, включая имена атрибутов и адреса кластеров.
При проведении экспертизы она не принесет особой пользы, потому что система
должна быть «живой», однако программа поможет в изучении NTFS. Утилита
Марка Руссиновича (Mark Russinovich) NTFSInfo [Russinovich, 1997] выводит
аналогичную информацию.
Пакет TSK позволяет просмотреть содержимое любого атрибута. Чтобы при-
примеры двух следующих глав стали более понятными, я опишу синтаксис просмот-
просмотра различных атрибутов. Вспомните, что каждый атрибут обладает типом и каж-
каждому атрибуту в записи MFT присваивается уникальный идентификатор. При
помощи этих двух значений можно отобразить любой атрибут.
Вместо одного адреса метаданных программе icat передается адрес и тип ат-
атрибута. При наличии нескольких атрибутов такого типа к ним добавляется уни-
уникальный идентификатор. Например, чтобы просмотреть атрибут $FILE_NAME (тип
48) записи MFT 34, следует использовать запрос «34-48». Для просмотра атри-
атрибута $DATA (тип 128) запрос принимает вид «34-128». Если существуют другие
атрибуты $DATA, в запрос также включается уникальный идентификатор атри-
атрибута. Скажем, для атрибута с идентификатором 3 будет использоваться строка
«34-128-3».
Программа istat из пакета TSK выводит все атрибуты файла. Пример вывода
для атрибутов записи MFT:
[...]
Type: $STANDARD_INFORMATION A6-0) Name: N/A Resident size: 72
Type: $FILE_NAME D8-2) Name: N/A Resident size: 84
Type: $OBJECT_ID F4-8) Name: N/A Resident size: 16
Name: $DATA A28-3) Name: $Data Non-Resident, Encrypted size: 4294
94843 94844 94845 94846 94847 94848 102873 102874
102875
Name: $DATA A28-5) Name: ADS Non-Resident. Encrypted size: 4294
102879 102880 102881 102882 102883 102884 102885 102886
102887
Type: $LOGGED_UTILITY_STREAM B56-7) Name: $EFS Non-Resident size: 552
102892 102893
Итоги
Все важнейшие данные в NTFS ассоциируются с файлами или индексами. В этой
главе были рассмотрены важнейшие концепции NTFS — записи MFT, атрибуты
и индексы. На основе этих концепций мы перейдем к рассмотрению конкретных
атрибутов и категорий в главе 12.
Библиография
• Cooperstein, Jeffrey, and Richter, Jeffrey. «Keeping an Eye on Your NTFS Drives:
The Windows 2000 Change Journal Explained». Microsoft Systems Journal, Septem-
September 1999. http://www.microsoft.com/msj/0999/journaL/journal.aspx.
• Cooperstein, Jeffrey, and Richter, Jeffrey. «Keeping an Eye on Your NTFS Drives,
Part II: Building a Change Journal Application». Microsoft Systems]ournal, October
1999. http://www.microsoft.com/msj/1099/journaL2/journal2.aspx.
• Linux NTFS Project. NTFS Documentation. 1996-2004. http://linux-ntfs.source-
forge.net/ntfs/index.html.
• Microsoft. «Analysis of Reported Vulnerability in the Windows 2000 Encrypting File
System (EFS)». 1999. http://www.microsoft.com/technet/security/news/analefs.mspx.
• Microsoft. «Description of NTFS Date and Time Stamps for Files and Folders».
Microsoft Knowledge Base Article 299648, 2003. http://support.microsoft.com/
default.aspx?srid=kb;en-us;299648.
• Microsoft. «INFO: Understanding Encrypted Directories». Microsoft Knowledge
Base Article 248723, 2003. http://support.microsoft.com/default.aspx?scid=kb;en-
us;248723&sd=tech.
• Microsoft. «Overview of FAT, HPFS and NTFS File Systems». Microsoft Knowledge
Base Article 100108, 2003. http://support.microsoft.com/default.aspx?scid=kb;EN-
US;100108.
• Microsoft. «Windows NT 4.0 and Windows 2000 OEM Support Tools». February
2,2000. http://www.microsoft.com/downloads/detai4s.aspx?FamilyId=82D6AB58-890C-
405F-B532-B75lD9217CA4&displaylang=en.
• Microsoft. «Windows Server 2003 Technical Reference». Storage Technologies
Collection Section, 2004. http://www.microsoft.com/resources/documentation/Windows-
Serv/2003/aU/techref/en-us/Default.asp?url=/resources/documentation/windowsServ/
2003/all/techref/en-us/W2K3TR_ntfs/intro.asp.
• Microsoft. «Windows XP Professional Resource Kit Documentation». Chapter 13—
File Systems, 2004. http://www.microsoft.com/resources/documentation/Windows/XP/
aU/reskit/en-us/Defauit.asp?url=/resources/documentation/Windows/XP/all/reskit/en-
us/prork_overview.asp.
• Microsoft MSDN Library. «Change Journals» 2004. http://msdn.microsoft.com/
library/default.asp?url=/library/en-us/fileio/base/changejoumals.asp.
• Microsoft TechNet. «Encrypting File System in Windows XP and Windows Server
2003». 2002. http://www.microsoft.com/technet/prodtechnol/winxppro/deploy/cryptfs.-
mspx#XSLTsectionl22121120120.
• Russinovich, Mark. «Inside Encrypting File System». Part 7, Windows and .NET
Magazine Network, June 1999. http://www.winntmag.com/Articles/Print.cfm?ArticleID=5387.
• Russinovich, Mark. «Inside Encrypting File System». Part 2, Windows and .NET
Magazine Network, July 1999. http://www.winntmag.com/Articl.es/Print.cfm7Ar-
tideID=5592.
• Russinovich, Mark. «Inside Win2K NTFS». Part 1, Windows and .NET Magazine
Network, November 2000. http://www.winntmag.com/Articles/Printcfm?ArticleID=15719.
• Russinovich, Mark. «Inside Win2K NTFS». Part 2, Windows and .NET Magazine
Network, Winter 2000. http://www.winntmag.com/Articles/Printcfm?ArticleID=15900.
• Solomon, David, and Mark Russinovich. Inside Windows 2000. 3rd ed. Redmond:
Microsoft Press. 2000.
NTFS: анализ
Во второй главе, посвященной NTFS, мы приступим к обсуждению методов и раз-
различных аспектов анализа на базе модели с пятью категориями, представленной
в главе 8. NTFS сильно отличается от других файловых систем, поэтому перед
тем, как излагать этот материал, я представил важнейшие концепции NTFS в от-
отдельной главе. Если вы недостаточно хорошо разбираетесь в NTFS pi пропустили
главу 11, я рекомендую вернуться к ней. В главе 13 описываются структуры дан-
данных NTFS. Большая часть книги организована таким образом, чтобы главы с ана-
анализом файловых систем и описаниями структур данных можно было читать па-
параллельно. С NTFS это сделать сложнее, потому что в этой системе все служебные
данные ассоциируются с файлами, и было бы трудно показать файлы метаданных
в категории данных файловой системы перед рассмотрением атрибутов в катего-
категории метаданных. Соответственно, вам же будет проще, если вы прочитаете эту
главу перед тем, как браться за главу 13.
Категория данных файловой системы
Категория данных файловой системы включает данные, описывающие файловую
систему в целом, причем эти данные обычно не соответствуют конкретному поль-
пользовательскому файлу. В NTFS эти данные хранятся в файлах метаданных файловой
системы, представленных именами в корневом каталоге. За исключением загру-
загрузочного кода, эти данные могут храниться в файловой системе в любом месте диска.
У этих файлов есть одна интересная особенность: с ними, как и с обычными
файлами, могут ассоциироваться пометки даты и времени. Мои эксперименты
показали, что временные штампы соответствуют времени создания файловой си-
системы, что иногда может пригсдиться при анализе. В этом разделе рассматрива-
рассматриваются все файлы метаданных файловой системы, а в главе 13 будут подробно описа-
описаны их структуры данных.
Файл $MFT
Одним из важнейших файлов метаданных файловой системы является файл $MFT.
В нем хранится главная файловая таблица MFT (Master File Table), которая со-
содержит записи для каждого файла и каталога в системе. Следовательно, таблица
MFT необходима для поиска других файлов. Начальный адрес MFT указывается
в загрузочном секторе, о котором речь пойдет позже в этом разделе. Информация
о строении MFT берется из записи 0 самой таблицы.
Начальной записи MFT присваивается имя $MFT, а ее атрибут $DATA содержит
информацию о кластерах, используемых MFT. За информацией о записях MFT
обращайтесь к главе 11. Файл $MFT также обладает атрибутом $В1ТМАР, описыва-
описывающим состояние выделения записей MFT. Кроме того, у него имеются стандарт-
стандартные атрибуты $FILE_NAME и $STANDARD_INFORMATION (см. раздел «Категория мета-
метаданных»).
В Windows файл $MFT начинается с минимального размера и расширяется по
мере создания дополнительных файлов и каталогов. Файл $MFT может фрагмен-
тироваться, но под его расширение изначально резервируется часть дискового
пространства (см. раздел «Категория данных содержимого»).
Говоря о файлах метаданных файловой системы, я буду использовать тесто-
тестовый образ файловой системы и программу istat из пакета TSK (The Sleuth Kit).
Полный вывод istat будет приведен в конце раздела «Категория метаданных»,
а здесь приводятся только данные, относящиеся к категории файловой системы:
# istat -f ntfs ntfsl.dd 0
$STANDARD_INFORMATION Attribute Values:
Flags: Hidden, System
Owner IF: 0 Security ID: 256
Created: Thu Jun 26 10:17:57 2003
File Modified: Thu Jun 26 10:17:57 2003
MFT Modified: Thu Jun 26 10:17:57 2003
Accessed: Thu Jun 26 10:17:57 2003
[...]
Attributes:
Type: $STANDARD_INFORMATION A6-0) Name: N/A Resident size: 72
Type: $FILE_NAME D8-3) Name: N/A Resident size: 74
Type: $DATA A28-1) Name: $Data Non-Resident size: 8634368
342709 342710 342711 342712 342713 342714 342715 342716
342717 342718 342719 342720 342721 342722 342723 342724
[...]
443956 443957 443958 443959 443960 443961 443962 443963
Type: SBITMAP A76-5) Name: N/A Non-Resident size: 1056
342708 414477 414478 414479
Временные штампы $MFT обычно совпадают с моментом создания файловой
системы и не обновляются. Из листинга видно, что файл обладает атрибутами
$STANDARD_INFORMATION и $FILE_NAME, 8-мегабайтным атрибутом $DATA и атрибу-
атрибутом $В1ТМАР.
Файл $MFTMirr
В предыдущем разделе говорилось о том, что файл $MFT очень важен, так как он
используется для поиска всех остальных файлов в системе. А это означает, что
повреждение указателя в загрузочном секторе или записи $MFT приведет к пол-
полной неработоспособности файловой системы. Для решения подобных проблем
создается резервная копия важнейших записей MFT, которая может использо-
использоваться при восстановлении. Запись MFT 1 относится к файлу $MFTMirr, имеюще-
имеющему нерезидентный атрибут с резервной копией начальных записей MFT.
Атрибут $DATA файла $MFTMirr выделяет кластеры в середине файловой сис-
системы и сохраняет копии как минимум первых четырех записей MFT: для $MFT,
$MFTMirr, $LogFHe и $Volume. Если с определением структуры MFT возникают
проблемы, программа восстановления может на основании размера тома вы-
вычислить средний кластер файловой системы и прочитать резервные данные.
Каждая запись MFT обладает сигнатурой, по которой ее можно распознать как
запись MFT.
По четырем резервным записям программа восстановления определяет строе-
строение таблицы MFT и ее размер, местонахождение $LogFHe для восстановления фай-
файловой системы, а также получает информацию о версии и статусе из атрибутов
$VoLume.
Приведу пример информации о файле $MFTMirr из нашего тестового образа:
# istat -f ntfs ntfsl.dd 1
Attributes:
Type: $STANDARD_INFORMATION A6-0) Name: N/A Resident size: 72
Type: $FILE_NAME D8-2) Name: N/A Resident size: 82
Type: $DATA A28-1) Name: $Data Non-Resident size: 4096
514064 514065 014066 514067
В данном примере образ содержит 1 208 128 кластеров, а атрибут $DATA записи
$MFTMirr начинается в среднем кластере. Временные штампы не показаны, но они
совпадают с приводившимися ранее для $MFT.
Файл $Boot
Файл метаданных файловой системы $Boot находится в записи MFT 7 и содер-
содержит загрузочный сектор файловой системы. Это единственный файл метадан-
метаданных файловой системы со статическим расположением. Атрибут $DATA всегда
хранится в первом секторе файловой системы, потому что он необходим для заг-
загрузки системы. Microsoft обычно выделяет для $Boot первые 16 секторов фай-
файловой системы, но я обнаружил, что только первая половина содержит ненуле-
ненулевые данные.
Загрузочный сектор NTFS очень похож на загрузочный сектор FAT, и они об-
обладают множеством общих полей. У них даже совпадает сигнатура 0хАА55, из
чего следует, что при поиске потерянных загрузочных секторов FAT может быть
найден загрузочный сектор NTFS (и наоборот). Загрузочный сектор содержит
основные параметры файловой системы: размер кластера, количество секторов
в файловой системе, адрес начального кластера MFT, размер записи MFT. Кроме
того, в загрузочном секторе хранится серийный номер файловой системы.
Остальные секторы, выделяемые для хранения атрибута $DATA записи $Boot,
содержат загрузочный код. Загрузочный код необходим только в загрузочных
файловых системах, а его основной функцией является поиск файлов, необходи-
необходимых для загрузки операционной системы. Строение загрузочного сектора подробно
описано в главе 13.
Резервная копия загрузочного сектора хранится либо в последнем секторе тома
либо в середине тома [Microsoft, 2003]. В моих экспериментах с томами Windows
NT 4.0, 2000 и ХР резервная копия хранилась в последнем секторе. Я обнаружил,
что общее количество секторов в файловой системе было меньше общего количе-
количества секторов в томе, поэтому резервная копия загрузочного сектора не всегда
ассоциируется с конкретным файлом. Например, в используемом нами тестовом
образе файловой системы том состоит из 2 056 257 секторов, а, по данным загру-
загрузочного сектора, файловая система содержит 2 056 256 секторов. Резервная копия
загрузочного сектора хранится в последнем секторе тома, не выделенном для хра-
хранения файловой системы.
Чтобы показать, как выглядят атрибуты файла $Boot, я приведу результат за-
запуска istat для тестового образа:
# istat -f ntfs ntfsl.dd 7
Attributes:
Type: $STANDARD_INFORMATION A6-0) Name: N/A Resident size: 48
Type: $FILE_NAME D8-2) Name: N/A Resident size: 76
Type: $SECURITY_DESCRIPTOR (80-3) Name: N/A Resident size: 104
Type: $DATA A28-1) Name: $Data Non-Resident size: 8192
0 12 3 4 5 6 7
Из нижней части листинга видно, что запись содержит четыре атрибута, в том
числе 8-килобайтный атрибут $DATA, которому выделены кластеры с 0 по 7. Вре-
Временные штампы не показаны, но они совпадают с приводившимися ранее для $MFT
и $MFTMirr.
Файл $Volume
Файл метаданных файловой системы $Volume соответствует записи MFT 3. В нем
хранится метка тома и информация версии. Файл обладает двумя уникальными
атрибутами, которыми не должны обладать остальные файлы в системе. В атрибуте
$VOLUME_NAME содержится имя тома в Unicode, а атрибут $VOLUME_INFORMATION
определяет версию NTFS и состояние обновления. Кроме этих атрибутов файл
обычно обладает атрибутом $DATA, но я обнаружил, что размер этого атрибута со-
составляет 0 байт. Подробные описания атрибутов $VOLUME_NAME и $VOLUME_INFOR-
$VOLUME_INFORMATION приведены в главе 13.
С каждой новой версией Windows в файловую систему NTFS вносятся неболь-
небольшие изменения; номер текущей версии можно найти в файле $Volume. В Windows
NT 4.0 использовалась версия 1.2, в Windows 2000 — версия 3.0, а в Windows XP —
версия 3.1. Различия между версиями незначительны, и во всех версиях исполь-
используются одни и те же основные структуры данных.
Атрибуты файла $Volume для нашего тестового образа выглядят так:
# istat -f ntfs ntfsl.dd 3
Attributes:
Type: $STANDARD_INFORMATION A6-0) Name: N/A Resident size: 48
Type: $FILE_NAME D8-1) Name: N/A Resident size: 80
Type: $OBJECT_ID F4-6) Name: N/A Resident size: 16
Type: $SECURITY_DESCRIPTOR (80-2) Name: N/A Resident size: 104
Type: $VOLUME_NAME (96-4) Name: N/A Resident size: 22
Type: $VOLUME_INFORMATION A12-5) Name: N/A Resident size: 12
Type: $DATA A28-3) Name: $Data Resident size: 0
Интересующая нас информация содержится в атрибутах $VOLUME_NAME и $VOLU-
MEJNFORMATION, уникальных для этой записи MFT. Обратите внимание: атрибут
$DATA существует, но его размер равен 0. Временные штампы не показаны, но они
совпадают с приводившимися ранее для $MFT и $MFTMirr.
Файл $AttrDef
К общей категории данных файловой системы также относится файл метаданных
файловой системы $AttrDef, представленный записью MFT 4. Атрибут $DATA этого
файла определяет имена и идентификаторы типов всех атрибутов. Кстати, это один
из примеров «логического зацикливания», иногда встречающегося в NTFS: что-
чтобы узнать, какой идентификатор типа соответствует файлу $DATA, нужно сначала
как-то прочитать атрибут $DATA файла $ AttrDef. К счастью, атрибутам назначены
значения по умолчанию, приведенные в главе 11.
Файл $AttrDef позволяет файловым системам определять уникальные атрибу-
атрибуты файлов, а также переопределять идентификаторы стандартных атрибутов. Ат-
Атрибуты файла $AttrDef в нашем примере выглядят так:
# istat -f ntfs ntfsl.dd 4
Attributes:
Type: SSTANDARDJNFORMATION A6-0) Name: N/A Resident size: 48
Type: $FILE_NAME D8-2) Name: N/A Resident size: 82
Type: $SECURITY_DESCRIPTOR (80-3) Name: N/A Resident size: 104
Type: $DATA A28-4) Name: $Ddta Non-Resident size: 2560
342701 342702 342703
Обратите внимание: размер атрибута $DATA превышает 2 Кбайт. Временные
штампы не показаны, но они совпадают с приводившимися ранее для других фай-
файлов метаданных файловой системы.
Тестовый образ
Мы рассмотрели информацию о некоторых файлах нашего тестового образа, а сей-
сейчас я приведу результат запуска программы fsstat. Эти данные будут использо-
использоваться в дальнейших примерах. За информацией о том, где эти данные хранятся
на диске, обращайтесь к главе 13.
# fsstat -f ntfs ntfsl.dd
FILE SYSTEM INFORMATION
File System Type: NTFS
Volume Serial Number: 0450228450227C94
OEM Name: NTFS
Volume Name: NTFS Disk 2
Version: Windows XP
МЕТА-DATA INFORMATION
First Cluster of MFT. 342709
First Cluster of MFT Mirror: 514064
Size of MFT Entries: 1024 bytes
Size of Index Records: 4096 bytes
Range: 0 - 8431
Root Directory: 5
CONTENT-DATA INFORMATION
Sector Size: 512
Cluster Size: 1024
Total Cluster Range: 0 - 1028127
Total Sector Range: 0 - 2056255
$AttrDef Attribute Values:
$STANDARD_INFORMATION A6) Size: 48-72 Flags: Resident
$ATTRIBUTE_LIST C2) Size: No Limit Flags: Non-resident
$FILE_NAME D8) Size: 68-578 Flags: Resident. Index
$OBJECT_ID F4) Size: 0-256 Flags: Resident
$SECURITY_DESCRIPTOR (80) Size: No Limit Flags: Non-resident
$VOLUME_NAME (96) Size: 2-256 Flags: Resident
$V0LUME_INF0RMATI0N A12) Size: 12-12 Flags: Resident
$DATA A28) Size: No Limit Flags:
$INDEX_ROOT A44) Size: No Limit Flags: Resident
$INDEX_ALLOCATION A60) Size: No Limit Flags: Non-resident
$BITMAP A76) Size: No Limit Flags: Non-resident
$REPARSE_POINT (92) Size: 0-16384 Flags: Non-resident
$EA_INF0RMATI0N B08) Size: 8-8 Flags: Resident
$EA B24) Size: 0-65536 Flags:
$LOGGED_UTILITY_STREAM B56) Size: 0-65536 Flags: Non-resident
Методы анализа
Анализ данных в категории файловой системы направлен на определение конфи-
конфигурации и строения файловой системы. В NTFS первым шагом должна стать об-
обработка загрузочного сектора в первом секторе файловой системы, являющегося
частью файла $Boot. Из загрузочного сектора берутся сведения о начальном адре-
адресе MFT и размере каждой записи MFT. На основании этих сведений обрабатыва-
обрабатывается первая запись MFT, связанная с файлом $MFT. Из этой записи берется ин-
информация о местонахождении других записей MFT. Если какие-либо данные
оказались поврежденными, но размер тома известен, можно найти средний сек-
сектор файловой системы и взять из него резервную копию первых записей MFT,
хранящуюся в файле $MFTMirr.
После определения строения MFT можно переходить к поиску и обработке
файлов метаданных файловой системы $Volume и $AttrDef. Из этих файлов берет-
берется информация о версии файловой системы, метке тома и определениях специ-
специальных атрибутов.
Факторы анализа
Категория данных файловой системы почти не содержит пользовательских дан-
данных. Загрузочный сектор находится проще всего и содержит только базовую струк-
структурную информацию. Остальные данные хранятся в одной из записей MFT, но
найти ее «вручную», с помощью одного лишь шестнадцатеричного редактора, не
так уж просто. Загрузочный сектор содержит ряд значений, не используемых
NTFS, но Microsoft требует, чтобы некоторые из них были равны нулю. Я обнару-
обнаружил, что Windows XP отказывается монтировать файловые системы, у которых
эти поля содержат ненулевые значения.
Небольшой объем данных можно скрыть внутри загрузочного сектора, но боль-
больше свободного места доступно в конце файла $Boot после загрузочного кода. Я об-
обнаружил здесь несколько неиспользуемых секторов. Чтобы выявить резервное
пространство тома или неиспользуемое пространство после файловой системы,
следует сравнить количество секторов в файловой системе с размером тома. Не
забывайте, что резервная копия загрузочного сектора часто находится в секторе,
следующим за концом файловой системы, но до конца тома.
Временные штампы, ассоциированные с файлами метаданных файловой сис-
системы, обычно соответствуют времени создания файловой системы. Это обстоя-
обстоятельство может пригодиться во время расследования, если вам потребуется опре-
определить время форматирования диска. Скажем, по дате форматирования можно
определить продолжительность использования файловой системы.
Файл $MFT может иметь произвольный размер, причем в Windows этот размер
никогда не уменьшается. Конец файла может использоваться для хранения скры-
скрытых данных, однако этот способ весьма рискован, потому что данные могут быть
стерты в ходе стандартных операций. Например, пользователь может создать мно-
множество файлов, в результате чего MFT вырастет до большого размера. Если после
этого файлы будут удалены, в MFT останутся неиспользуемые записи, в которых
могут размещаться скрытые данные.
Также может быть полезно проанализировать атрибуты каждого файла мета-
метаданных файловой системы. Возможно, среди них найдутся дополнительные ат-
атрибуты, добавленные для хранения скрытых данных.
Сценарий анализа
В процессе расследования был обнаружен жесткий диск, с которого были сняты
данные. К сожалению, диск содержал большое количество поврежденных секто-
секторов, включая первый сектор (в котором находится таблица разделов) и сектор 63
(где обычно начинается первый раздел). Следовательно, мы должны выяснить,
начинается ли раздел с сектора 63, а также определить его тип и размер. Диск был
взят из системы Windows XP, и мы предполагаем, что на нем использовалась фай-
файловая система NTFS. Образ диска снят в низкоуровневом формате, а поврежден-
поврежденные секторы заполнялись нулями.
Поиск начинается с сигнатуры загрузочного сектора, то есть значения 0хАА55
в двух последних байтах секторов. Мы рассчитываем обнаружить либо первый
сектор файловой системы NTFS, либо сектор, следующий за концом файловой
системы, в котором хранится резервная копия. Для проведения поиска выбрана
утилита sigfind, хотя вместо нее можно воспользоваться любой программой с воз-
возможностью поиска по шестнадцатеричному значению.
# sigfind -о 510 -1 АА55 disk5.dd
Block size: 512 Offset: 510
Block: 210809 (-)
Block: 210810 (+1)
Block: 210811 (+1)
Block: 210812 (+1)
Block: 210813 (+1)
Block: 210814 (+1)
Block: 210815 (+1)
Block: 210816 (+1)
Block: 318170 (+107354)
Block: 339533 (+21363)
Block: 718513 (+378980)
[...]
В результате поиска обнаруживается серия очень близких совпадений, начи-
начиная с сектора 210809. Картина выглядит не так, как можно было бы ожидать при
обнаружении загрузочного сектора в начале файловой системы — далее должен
следовать загрузочный код, а не новые копии. Такая структура также не харак-
характерна и для таблиц разделов, обладающих той же сигнатурой.
Проанализируем одну из копий и посмотрим, является ли совпадение ложным:
# dd if=disk5.dd skip=210809 count=l | xxd
0000000: eb3c 904d 5357 494e 342e 3100 0208 0100 .<.MSWIN4.1
0000016: 0200 0203 51f8 0800 1100 0400 0100 0000 ....Q
0000032: 0000 0000 8000 2900 0000 004e 4f20 4e41 )....NO NA
0000048: 4d45 2020 2020 4641 5431 3220 2020 33c9 ME FAT12 3.
[...3
Содержимое сектора не характерно для файловой системы NTFS; скорее, оно
напоминает загрузочный сектор FAT12. Проверим совпадение в следующем сек-
секторе:
# dd if=disk5.dd skip=210810 count=l | xxd
0000000: eb58 904d 5357 494e 342e 3100 0202 0800 .X.MSWIN4.1
0000016: 0100 0400 00f8 0000 1100 0400 0100 0000
0000032: 0000 0200 eOlf 0000 0000 0000 0000 0000
0000048: 0100 0600 0000 0000 0000 0000 0000 0000
0000064: 8000 2900 0000 004e 4f20 4e41 4d45 2020 ..)....NO NAME
0000080: 2020 4641 5433 3220 2020 33c9 8edl bcf4 FAT32 3
C..3
Перед нами базовый шаблон загрузочного сектора файловой системы FAT32.
Совпадение в секторе 210 811 соответствует базовому шаблону структуры дан-
данных FAT FSINFO, не содержащей значений. Похоже, эти совпадения не имеют
отношения к нашему поиску загрузочного сектора NTFS; мысленно берем их на
заметку и движемся дальше.
Чтобы уменьшить число ложных совпадений, проведем поиск строки «NTFS»,
начиная с байта 3 сектора; эта строка является частью поля OEM. Сравнение ре-
результатов поиска с предыдущими совпадениями поможет сузить круг поиска для
нашей системы. Следует помнить, что строка «NTFS» не принадлежит к обяза-
обязательным значениям загрузочного сектора NTFS, поэтому ее может и не быть. В ше-
стнадцатеричном представлении строка «NTFS» имеет вид 0х4е544653; некото-
некоторые программы позволяют искать секторы, содержащие обе сигнатуры.
# sigfind -0 3 4е544653 disk5.dd
На этот раз количество совпадений оказывается гораздо меньшим. Сравнивая
результаты, мы обнаруживаем, что секторы 1 0755 545,1 075 561 и 2 056 319 при-
присутствуют в обоих результатах. Содержимое сектора 1 075 545 выглядит вроде бы
подходящим, но общее количество секторов в нем равно 0. То же происходит в сек-
секторе 1 075 561; следовательно, эти данные бесполезны. Скорее всего, они не при-
принадлежат реальной файловой системе.
Сектор 2 056 319 содержит больше ненулевых значений, чем предыдущие два
совпадения. Поле размера кластера в нем равно 1024 байт; количество секторов —
2 056 256, а начальный кластер MFT — 342 709. Если это действительно загрузоч-
загрузочный сектор, возможны два сценария. Во-первых, это может быть копия, располо-
расположенная в первом секторе файловой системы; во-вторых, это может быть копия
в секторе, следующем за концом файловой системы. Мы замечаем, что указанное
количество секторов файловой системы на 64 сектора меньше адреса, в котором
мы нашли загрузочный сектор. Следовательно, это может быть резервный загру-
загрузочный сектор файловой системы, начинающейся в секторе 63.
Для проверки этой теории обратимся к MFT. В загрузочном секторе указано,
что MFT начинается с кластера 342 709, что соответствует сектору 685 418 фай-
файловой системы и сектору 685 481 диска. Каждая запись MFT начинается с сигна-
сигнатурной строки «FILE», и мы находим сигнатуру в положенном месте:
# dd if=disk5.dd skip=685481 count=l | xxd
0000000: 4649 4c45 3000 0300 4ba7 6401 0000 0000 FILEC.K.d
[...]
Чтобы убедиться в том, что мы действительно нашли первую запись MFT, мы
возвращаемся на два сектора назад (поскольку размер каждой записи MFT равен
1024 байт) и видим, что сектор не начинается с сигнатуры «FILE»:
# dd if=disk5.dd skip=685479 count=l | xxd
0000000: ffff OOff ffff ffff ffff ffff ffff ffff
Теперь можно с уверенностью сказать, что на диске могла существовать фай-
файловая система NTFS, которая начиналась в секторе 63 и имела размер 2 056 256
секторов. Мы создаем копию дискового образа и копируем резервную копию заг-
загрузочного сектора в сектор 63. Чтобы импортировать файловую систему в обыч-
обычную программу анализа, можно либо извлечь 2 056 256 секторов из дискового об-
образа, либо создать в секторе 0 образа простейшую таблицу разделов, содержащую
раздел в секторах 63-2 056 318.
Категория данных содержимого
Кластеры
Файл NTFS представляет собой совокупность атрибутов. Атрибуты делятся на
резидентные и нерезидентные: содержимое резидентных атрибутов хранится не-
непосредственно в записи MFT, тогда как для хранения содержимого нерезидент-
нерезидентных атрибутов выделяются отдельные кластеры. Кластером называется группа
смежных секторов, количество которых равно степени 2 (то есть 1, 2, 4, 8, 16).
Каждому кластеру назначается адрес, начиная с 0. Нумерация начинается с пер-
первого кластера файловой системы, что создает гораздо меньше путаницы по срав-
сравнению со схемой нумерации FAT. Чтобы преобразовать адрес кластера в адрес
сектора, достаточно умножить его на количество секторов в кластере:
СЕКТОР = КЛАСТЕР * секторов_в_кластере
NTFS не предъявляет жестких требований к строению файловой системы.
Любой кластер может быть выделен для хранения любого файла или атрибута (за
исключением файла $Boot, который всегда начинается с первого сектора). Компа-
Компания Microsoft использует ряд общих схем устройства файловой системы; они бу-
будут рассмотрены в разделе «Алгоритм выделения». Если размер тома не кратен
размеру кластера, некоторые секторы в конце диска не будут принадлежать ни
одному кластеру. Общий размер этой зоны меньше размера кластера.
Файл $Bitmap
Состояние выделения кластера определяется при помощи файла метаданных
файловой системы, хранящегося в записи MFT 6. Атрибут $DATA этого файла
содержит один бит для каждого кластера файловой системы; например, бит О
представляет кластер 0, а бит 1 представляет кластер 1. Если бит равен 1, значит,
кластер выделен; если бит равен 0, кластер свободен. Подробное описание струк-
структуры битовой карты и анализ примера приводятся в разделе «Файл SBitmap»
главы 13.
Информация о файле $Bitmap в файловой системе нашего тестового образа
выглядит так:
# istat -f ntfs ntfsl.dd 6
Attributes:
Type: $STANDARD_INFORMATION A6-0) Name: N/A Resident size: 72
Type: $FILE_NAME D8-2) Name: N/A Resident size: 80
Type: $DATA A28-1) Name: $Data Non-Resident size: 128520
514113 514114 514115 514116 514117 514118 514119 514120
514121 514122 514123 514124 514125 514126 514127 514128
Мы видим, что файл $Bitmap обладает стандартными атрибутами файлов, а его
временные штампы совпадают с приводившимися ранее для других файлов мета-
метаданных файловой системы.
Файл $BadClus
NTFS отслеживает поврежденные кластеры, выделяя их атрибуту $DATA файла
метаданных файловой системы $ BadClus (запись MFT 8). Атрибут $DATA, которо-
которому присвоено имя $BAD, хранится в разреженном формате; когда система обнару-
обнаруживает поврежденный кластер, он добавляется в этот атрибут. Как говорилось
в главе 11, разреженный файл экономит место за счет отказа от выделения клас-
кластеров, если они заполнены нулями. Указанный размер атрибута $Bad соответствует
общему размеру файловой системы, но изначально ему не выделяется ни один
кластер. Обнаруживая поврежденные кластеры, Windows добавляет их в атрибут
$Bad, но многие жесткие диски выявляют поврежденные секторы еще до того, как
это сделает файловая система.
Информация о файле $ BadClus в файловой системе нашего тестового образа
выглядит так:
# istat -f ntfs ntfsl.dd 8
Attributes:
Type: $STANDARD_INFORMATION A6-0) Name: N/A Resident size: 72
Type: $FILE_NAME D8-3) Name: N/A Resident size: 82
Type: $DATA A28-2) Name: $Data Resident size: 0
Type: $DATA A28-1) Name: $Bad Resident size: 1052803072
Обратите внимание: файл содержит два атрибута $DATA, причем атрибут по
умолчанию ($Data) является резидентным и имеет нулевой размер. Атрибут $DATA
с именем $Bad является нерезидентным и имеет размер 1 052 803 072 байта, од-
однако адреса кластеров не показаны, потому что файловая система не содержит
поврежденных кластеров. Размер атрибута совпадает с размером файловой сис-
системы, показанным в выходных данных fsstat
Алгоритмы выделения
В этом разделе описаны мои наблюдения относительно стратегии, используе-
используемой Windows XP при выделении новых кластеров NTFS. Как и в других файло-
файловых системах, стратегия выделения зависит от конкретной ОС, и в разных реа-
реализациях NTFS могут использоваться разные стратегии. Я заметил, что Windows
ХР использует алгоритм оптимального подбора. Это означает, что данные раз-
размещаются таким образом, чтобы наиболее эффективно использовать доступное
пространство, даже если это не первый или не следующий доступный блок. Сле-
Следовательно, при небольшом объеме записываемые данные помещаются в клас-
кластеры, входящие в небольшую группу свободных кластеров — вместо большой
группы, в которой могут храниться большие файлы. Например, в сценарии, по-
показанном на рис. 12.1, для файла требуется выделить 10 кластеров. В системе
существует три группы свободных кластеров. Первая группа находится в клас-
кластерах 100-199, вторая — в кластерах 280-319, а третья — в кластерах 370-549.
Алгоритм оптимального подбора выделяет под новый файл кластеры 280-289,
потому что это наименьшая из возможных групп кластеров, в которых помес-
поместится новый файл.
Рис. 12.1. Алгоритм оптимального подбора выделяет 10 кластеров
из наименьшего возможного свободного пространства
Структура файловой системы
Файловая система NTFS не обладает жестко заданной структурой, но при форма-
форматировании файловой системы Windows соблюдает ряд общих правил. В большин-
большинстве версий NTFS структура различается, но существует целый ряд общих кон-
концепций.
К их числу относится концепция зоны MFT. Windows создает таблицу MFT
минимального размера и расширяет ее только при необходимости добавления
новых записей. Таким образом, выделение пространства за MFT для хранения
файлов создает риск фрагментации таблицы. Чтобы этого не произошло, Microsoft
резервирует часть файловой системы для MFT. Зоной MFT (MFT Zone) называ-
называется коллекция смежных кластеров, которые не используются для хранения со-
содержимого файлов или каталогов до тех пор, пока не будет заполнен весь диск.
По умолчанию Microsoft выделяет под MFT 12,5% файловой системы. После за-
заполнения всей файловой системы используется зона MFT.
Все версии NTFS и Windows выделяют первые кластеры файлу $Boot
Windows NT и 2000 размещают файлы метаданных файловой системы сразу же
после файла $Boot и в середине файловой системы. Например, если в файловой
системе используются 1-килобайтные кластеры, то первые 8 кластеров будут
выделены файлу $Boot, а кластеры файла $MFT могут начинаться с кластера 16
или 32. Следующие 12,5% файловой системы попадают в зону MFT. Средний
кластер файловой системы выделяется файлу $MFTMirr, за ним следуют осталь-
остальные файлы метаданных файловой системы — такие, как $LogFile, $Root, SBitmap
и $Upcase. Между Windows NT и 2000 обнаружилось одно различие: NT поме-
помещает файл $AttrDef в последнюю часть файловой системы, а в Windows 2000 он
размещается перед файлом $MFT.
Эксперименты показали, что Windows XP перемещает часть данных к точке,
отмечающей треть файловой системы. Так, кластеры файлов $LogFHe, $AttrDef, $MFT
и $Secure выделяются от трети пространства файловой системы. Остальные фай-
файлы метаданных файловой системы размещаются от половины файловой системы.
Только файл $Boot находится в нескольких начальных кластерах. Все кластеры
между файлами метаданных файловой системы могут выделяться пользовательским
файлам и каталогам. На рис. 12.2 показано местонахождение различных файлов
метаданных файловой системы, отформатированной в Windows 2000 или ХР.
Рис. 12.2. Структура метаданных файловой системы, отформатированной
в Windows 2000 и Windows XP
Методы анализа
Анализ данных в категории содержимого обычно сопряжен с поиском конкрет-
конкретного кластера, определением его состояния выделения и обработкой содержимо-
содержимого тем или иным способом. Найти конкретный кластер несложно, потому что пер-
первый кластер находится в начале файловой системы, а размер кластера задается
в первом секторе.
Чтобы проверить состояние выделения кластера, следует найти файл $Bitmap
и обработать его атрибут $DATA. Каждый бит этого атрибута соответствует класте-
кластеру в файловой системе.
К числу стандартных приемов анализа принадлежит извлечение всего свобод-
свободного пространства файловой системы. В NTFS эта задача решается анализом файла
$Bitmap и извлечением содержимого всех кластеров с нулевыми битами. Админи-
стративные данные файловой системы NTFS хранятся в файле, поэтому они не
будут рассматриваться как свободные данные в этом процессе.
Факторы анализа
Не существует никаких особых обстоятельств, которые необходимо было бы учи-
учитывать при анализе категории содержимого NTFS (в отличие от других файло-
файловых систем). Адресация кластеров начинается с первого кластера, поэтому необ-
необходима только одна схема адресации. Microsoft обычно выделяет под файловую
систему только реально используемое пространство, поэтому в конце файловой
системы не должно быть секторов, не обладающих адресом кластера. С другой
стороны, это означает, что после файловой системы и перед концом тома могут
храниться скрытые данные.
При проведении поиска нет различий между поиском по логическому тому
и поиском по логической файловой системе, потому что каждый сектор, использу-
используемый файловой системой, выделяется кластеру. Поскольку все данные категории
файловой системы ассоциируются с файлами, в любом конкретном случае должно
быть понятно, выделен кластер или нет. Для сравнения вспомните, что в системе
FAT многие программы расходятся в отношении того, нужно ли рассматривать
область FAT и зарезервированную область как выделенное пространство или нет.
Как и во всех современных системах, всегда проверяйте все кластеры, поме-
помеченные как поврежденные на уровне файловой системы. Как правило, диски за-
заменяют поврежденные секторы еще до того, как об их существовании станет из-
известно файловой системе.
Сценарий анализа
В этом примере мы найдем в файловой системе кластер 9 900 009. Первым шагом
должно стать определение размера кластера. Мы читаем первый сектор файло-
файловой системы и определяем, что каждый сектор занимает 512 байт, а каждый клас-
кластер состоит из 8 секторов D 096 байт).
Кластер 0 в NTFS начинается с сектора 0. Следовательно, адрес сектора иско-
искомого кластера вычисляется простым умножением адреса кластера на количество
секторов в кластере. Умножение дает результат 792 000 072. Чтобы получить сме-
смещение в байтах, достаточно умножить адрес сектора на 512; произведение равно
40 550 436 864. Сравните, сколько действий пришлось бы выполнить в FAT для
определения смещения или адреса сектора для кластера.
Категория метаданных
К категории метаданных относятся данные, описывающие файлы или каталоги. Все
метаданные хранятся в атрибутах, поэтому в этом разделе мы подробно рассмотрим
атрибуты файлов. Напомню, что типичный файл обладает атрибутами
$STANDARD_INFORMATION, $FILE_NAME и $DATA. Атрибуты каталогов и индексов рассмат-
рассматриваются в разделе «Категория имен файлов». На рис. 12.3 показан типичный файл
со стандартными атрибутами. Структуры данных атрибутов описаны в главе 13.
Рис. 12.3. Типичный файл с тремя стандартными атрибутами
Атрибут $STANDARD_INFORMATION
Атрибут $STAN DARD_IN FORMATION существует у всех файлов и каталогов; в нем хра-
хранятся основные метаданные. Именно здесь находятся основные (хотя и не един-
единственные) временные штампы, а также информация о владельце, безопасности
и квотах. Содержимое этого атрибута не является строго необходимым для хране-
хранения файлов, но многие функции прикладного уровня, предоставляемые Microsoft,
зависят от него.
По умолчанию идентификатор типа этого атрибута равен 16. Атрибут имеет ста-
статический размер, который равен 72 байтам в Windows 2000 и ХР, и 48 байтам
в Windows NT. Microsoft сортирует атрибуты в записях MFT, и этот оказывается
всегда на первом месте, потому что он обладает наименьшим идентификатором типа.
Атрибут содержит четыре временных штампа. В NTFS для представления време-
времени и дат используются 64-разрядные значения, представляющие количество сотен
наносекунд, прошедших с 1 января 1601 года в формате UTC [Microsoft, 2004]. Эта
особенность, видимо, будет особенно полезной при анализе компьютеров, использо-
использовавшихся в XVII веке. Что касается значений этого числа, то 1 января 1970 года в фор-
формате UTC соответствует 116 444 736 000 000 000 сотен наносекунд. Разумеется, я не
стану описывать методику преобразования этого времени в формат, понятный для
человека, потому что большинство калькуляторов не справляется с такими числами —
впрочем, для решения этой задачи можно воспользоваться шестнадцатеричным ре-
редактором или другой программой1. Атрибут содержит четыре временных штампа:
• время создания — время, в которое была создана файловая система;
• время последней модификации — время последнего изменения атрибутов
$DATAh$INDEX;
• время модификации MFT — время последней модификации метаданных файла.
Учтите, что это значение не отображается в Windows при просмотре свойств файла;
• время последнего обращения — время последнего обращения к содержимому
файла.
Атрибут также содержит флаг общих свойств файла (доступ только для чте-
чтения, системный или архивный). Из свойств также видно, является ли файл сжа-
сжатым, разреженным или зашифрованным. Свойства не указывают, соответствует
ли запись файлу или каталогу, но эту информацию можно получить при помощи
флагов в заголовках записей MFT.
В NTFS версий 3.0+ (Windows 2000 и ХР) этот атрибут содержит четыре до-
дополнительных значения, используемых функциональностью системы безопасно-
безопасности и прикладного уровня. Одно из новых значений определяет личность (identity)
владельца, которая соответствует владельцу файла и используется для индекси-
индексирования данных квот. Другое значение атрибута указывает, сколько байт было
добавлено в квоту пользователя из-за этого файла. Идентификатор безопасности
используется для индексирования файла $Secure и определения правил контроля
доступа, действующих в отношении файла (файл $Secure будет рассмотрен по-
позднее, в разделе «Категория метаданных»). Если в системе используется прото-
протоколирование изменений, этот атрибут содержит порядковый номер обновления
USN (Update Sequence Number) для последней записи, созданной для этого фай-
файла. Журналы изменений рассматриваются в разделе «Категория прикладных ме-
метаданных»; пока достаточно сказать, что журнал представляет собой файл с ин-
информацией об изменениях в файловой системе, который позволяет быстро найти
файлы, изменившиеся за определенный промежуток времени, вместо того, чтобы
перебирать все файлы по отдельности.
Короче говоря, этот атрибут содержит немало интересных метаданных, но ни-
никакие из них не являются необходимыми для файловой системы. В нем хранятся
основные временные штампы и некоторые идентификаторы, но ОС сама решает,
когда обновлять содержимое временных штампов и использовать ли идентифи-
идентификаторы. Обратите внимание: этот атрибут существует для всех файлов и катало-
каталогов, но в не-базовых записях MFT он может отсутствовать.
Атрибут $FILE_NAME
Запись MFT каждого файла и каталога содержит как минимум один атрибут
$FILE_NAME. Кроме того, каждый файл и каталог представлен как минимум одним
экземпляром атрибута $FILE_NAME в индексе родительского каталога, хотя эти два
экземпляра не обязательно содержат одинаковые данные. Атрибут $FILE_NAME ро-
родительского каталога будет описан позднее, в разделе «Категория имен файлов»,
а в этом разделе речь пойдет об атрибуте в записи MFT. Этот атрибут имеет иден-
идентификатор типа 48 и переменную длину, которая зависит от имени файла. Базо-
Базовая длина составляет 66 байт + имя.
Атрибут $FILE_NAME содержит имя файла в кодировке Unicode UTF-16. Имя
должно принадлежать одному из стандартных форматов, таких как формат
DOS 8.3, формат Win32 или POSIX. В Windows имена файлов обычно задаются
1 Например, Decode из пакета Digital Detective (http://www.digital-detective.co.uk).
в пространстве имен DOS 8.3, поэтому у некоторых файлов имеются атрибуты
$FILE_NAME как для реального имени, так и для DOS-версии, но это поведение
можно запретить. Каждое пространство имен устанавливает собственные огра-
ограничения относительно того, какие символы считаются допустимыми.
Атрибут $FILE_NAME содержит ссылку на родительский каталог; это одно из
самых полезных значений атрибута в записи MFT. Эта ссылка упрощает опреде-
определение полного пути для произвольной записи MFT.
Кроме того, атрибут содержит четыре временных штампа, которые ранее упо-
упоминались в разделе «Атрибут $STANDARD_INFORMATION». Как правило,
Windows не обновляет этот набор временных штампов, как и в случае с атрибу-
атрибутом $STANDARD__INFORMATION, и данные обычно относятся к моменту создания, пе-
перемещения или переименования файла.
Атрибут $FILE_NAME содержит поля для фактического и выделенного размера
файла, но эксперименты показали, что для пользовательских файлов и каталогов
в Windows эти значения равны 0. Наконец, атрибут содержит поле флагов, кото-
которые являются признаками каталогов, доступа только для чтения, системных, сжа-
сжатых, зашифрованных файлов, и т. д. Поле включает те же флаги, которые исполь-
использовались в $STANDARD_INFORMATION.
Итак, многие значения этого атрибута дублируют содержимое $STAN DA R D_I N -
FORMATION. Впрочем, есть и новые данные — имя файла и адрес родительского ка-
каталога, которые могут использоваться для определения полного пути.
Атрибут $DATA
Атрибут $DATA предназначен для хранения произвольных данных — он не имеет
фиксированного формата или заранее определенных значений. Его идентифика-
идентификатор типа атрибута равен 128, причем атрибут может иметь произвольный размер,
в том числе и 0 байт. Для каждого файла по умолчанию создается один атрибут
$DATA, которому имя не присваивается. Некоторые программы, в том числе входя-
входящие в пакет TSK (The Sleuth Kit), присваивают ему условное имя $Data. Запись
MFT может содержать дополнительные атрибуты $DATA, но этим атрибутам дол-
должны быть присвоены имена.
У дополнительных атрибутов $DATA находятся различные применения. Ска-
Скажем, в Windows пользователь может щелкнуть на файле правой кнопкой мыши
и ввести «сводку» с общей информацией о файле; эти сведения сохраняются в ат-
атрибуте $DATA. Некоторые антивирусные программы и программы резервного ко-
копирования создают атрибут $DATA для обработанных файлов. Даже каталоги мо-
могут иметь атрибут $DATA наряду со своими индексными атрибутами. Наконец,
в дополнительных атрибутах $DATA могут храниться скрытые данные. Дополни-
Дополнительные атрибуты $DATA не включаются при выводе содержимого каталога; для
работы с ними необходимы специальные программы. Многие аналитические
программы выводят содержимое дополнительных атрибутов $DATA, которые так-
также называются альтернативными потоками данных, или ADS (Alternate Data
Streams).
С точки зрения пользователя, создать ADS совсем несложно; для этого доста-
достаточно командной строки. Чтобы сохранить данные в ADS, следует поставить после
имени файла двоеточие и имя атрибута. Например, следующая команда создает в
файле file.txt атрибут $DATA с именем foo:
С:\ echo "Hello There" > file.txt:foo
Как говорилось в главе 11, атрибуты $DATA могут шифроваться для предотвра-
предотвращения постороннего доступа к данным или сжиматься для экономии места. При
использовании любого из этих режимов в заголовке атрибута устанавливается
соответствующий флаг. При использовании шифрования также создается атри-
атрибут $LOGGED_STREAM_UTILITY с ключом шифрования. На рис. 12.4 показан файл
с двумя зашифрованными атрибутами $DATA. Если в записи существует несколь-
несколько атрибутов $DATA, все они используют один криптографический ключ.
Рис. 12.4. Файл с двумя зашифрованными атрибутами $DATA
Атрибут $ATTRIBUTE_LIST
Атрибут $ATTRIBUTE_LIST используется в случае, если для хранения всех атрибу-
атрибутов файла или каталога требуется более одной записи MFT. Файл или каталог
может иметь до 65 536 атрибутов, и все атрибуты могут не поместиться в одной
записи MFT. Как минимум в записи должен храниться заголовок каждого атри-
атрибута. Содержимое может быть нерезидентным, но иногда даже для хранения заго-
заголовков требуется несколько записей MFT. Эта ситуация часто возникает при
фрагментации нерезидентных атрибутов и удлинении списков серий.
Идентификатор типа атрибута $ATTRIBUTE_LIST равен 32; это второе по величи-
величине значение. Следовательно, этот атрибут всегда будет находиться в базовой за-
записи MFT. Он содержит список всех атрибутов файла, кроме самого себя. В каж-
каждом элементе списка хранится тип атрибута и адрес записи MFT, в которой он
расположен. В заголовках не-базовых записей MFT указывается адрес базовой
записи MFT.
Ситуация усложняется тем, что в результате сильной фрагментации даже для
хранения одного списка серий может потребоваться несколько записей MFT; обыч-
обычно такое происходит только с атрибутами $DATA. В таких случаях каждая не-базо-
вая запись MFT содержит обычный атрибут $DATA, но в атрибуте указывается его
смещение в файле. Заголовок атрибута содержит поле с начальным номером вир-
виртуального кластера (VCN, Virtual Cluster Number) серии, который соответствует
логическому адресу файла. Предположим, файлу требуются две записи MFT для
хранения списка серий его атрибута $DATA. Первая запись вмещает серии первых
500 Мбайт атрибута, а вторая запись содержит остальные серии. В заголовке ат-
атрибута второй записи будет указано, что его серии начинаются с 500-мегабайтной
точки полного атрибута $DATA.
На рис. 12.5 изображена базовая запись MFT с номером 37. Базовая запись
содержит атрибуты $STANDARD_INFORMATION и $ATTRIBUTE_LIST, причем список пос-
последнего состоит из пяти элементов. Первый элемент соответствует уже обрабо-
обработанному атрибуту $STANDARD_INFORMATION. Второй элемент соответствует атри-
атрибуту $FILE_NAME, расположенному в записи 48. Третий и четвертый элементы
списка соответствуют одному атрибуту $DATA, а пятый — другому элементу $DATA.
Чтобы узнать, какому атрибуту $DATA соответствует каждая запись, достаточно
обратиться к полю идентификатора (ID). Первые 284 Мбайт первого атрибута
$DATA описываются в записи 48, а остаток атрибута — в записи 49.
Рис. 12.5. Список атрибутов из пяти элементов. Для представления файла используются
три дополнительных записи MFT, и одному из атрибутов $DATA
потребовалось две записи для его списков серий
Атрибут $SECURITY_DESCRIPTOR
Атрибут $SECURITY_DESCRIPTOR в основном встречается в файловых системах
Windows NT, потому что в NTFS версии 3.0 и далее этот атрибут сохраняется толь-
только для сохранения совместимости. В Windows дескрипторы безопасности использу-
используются для описания политики контроля доступа, действующей в отношении фай-
файла или каталога. В более старых версиях NTFS дескриптор безопасности файла
хранился в атрибуте $SECURITY_DESCRIPTOR, обладающем идентификатором типа
80. В более новых версиях NTFS дескрипторы безопасности хранятся в одном
файле, потому что многие файлы обладают одинаковым дескриптором безопаснос-
безопасности, и было бы неэффективно хранить его в одном экземпляре для каждого файла.
Файл $ Sec иге
Как упоминалось в предыдущем разделе, дескрипторы безопасности использу-
используются для определения политики контроля доступа к файлам или каталогам.
В NTFS версий 3.0+ дескрипторы безопасности хранятся в файле метаданных фай-
файловой системы $Secure, представленном записью MFT 9.
Атрибут $STANDARD_INFORMATION любого файла или каталога содержит число-
числовой код, называемый идентификатором безопасности (Security ID). Его значение
используется для индексирования файла $Secure для поиска соответствующего
дескриптора. Обратите внимание: эти 32-разрядные идентификаторы безопасно-
безопасности отличаются от идентификаторов безопасности Windows (SID), присваивае-
присваиваемых системой пользователям. Идентификаторы безопасности уникальны только
в рамках файловой системы, тогда как коды SID глобально-уникальны.
Файл $Secure содержит два индекса ($SDH и $SII) и один атрибут $DATA ($SDS).
Атрибут $DATA содержит дескрипторы безопасности, а два индекса используются
при ссылках на дескрипторы. Индекс $SII сортируется по идентификатору безо-
безопасности, хранящемуся в атрибуте $STANDARD_INFORMATION каждого файла. Ин-
Индекс $SII используется для поиска дескриптора безопасности файла при извест-
известном идентификаторе безопасности. С другой стороны, индекс $SDH сортируется
по хеш-коду дескриптора безопасности. ОС использует этот индекс, когда к фай-
файлу или каталогу применяется новый дескриптор безопасности. Если хеш-код но-
нового дескриптора найти не удается, система создает новый дескриптор и иденти-
идентификатор безопасности и включает их в оба индекса.
Приведу результат выполнения istat для файла $Secure в небольшой системе:
# istat -f ntfs ntfs2.dd 9
С.]
Attributes:
Type: $STANDARD_INFORMATION A6-0) Name: N/A Resident size: 72
Type: $FILE_NAME D8-7) Name: N/A Resident size: 80
Type: $DATA A28-8) Name: $SDS Non-Resident size: 266188
10016 10017 10018 10019 10020 10021 10022 10023
10024 10025 10026 10027 10028 10029 10030 10031
10032 10033 10034 10035 10036 10037 10038 10039
[...]
Type: $INDEX_ROOT A44-11) Name: $SDH Resident size: 56
Type: $INDEX_ROOT A44-14) Name: $SII Resident size: 56
Type: $INDEX_ALLOCATION A60-9) Name: $SDH Non-Resident size: 4096
8185 8186 8187 8188 8189 8190 8191 8192
Type: $INDEX_ALLOCATION A60-12) Name: $SII Non-Resident size: 4096
8196 8197 8198 8199 8200 8201 8202 8203
Type: $BITMAP A76-10) Name: $SDH Resident size:8
Type: $BITMAP A76-13) Name: $SDH Resident size:8
В выходных данных istat мы видим 200-килобайтный атрибут $DATA с копиями
дескрипторов безопасности и двумя индексами $SDH и $SSI.
Тестовый образ
В завершение этого раздела я приведу результат выполнения istat для типичного
файла, в данном случае это будет файл C:\boot.ini. Для простоты описания выход-
выходные данные разделены на несколько фрагментов.
# istat -f ntfs ntfsl.dd 3234
MFT Entry Header Values:
Entry: 3234 Sequence: 1
$LogFile Sequence Number: 103605752
Allocated File
Links: 1
В этой части приводятся данные заголовка записи MFT; мы видим, что его
порядковый номер равен 1, то есть это первый файл, которому выделялась данная
запись. Значение LSN (SLogFile Sequence Number) соответствует времени последне-
последнего изменения файла; это значение используется журналом файловой системы.
$STANDARD_INFORMATION Attribute Values:
Flags: Hidden. System. Not Content Indexed
Owner ID: 256 Security ID: 271
Quota Charged: 1024
Last User Journal Update Sequence Number: 4372416
Created: Thu Jun 26 10:22:46 2003
File Modified: Thu Jun 26 15:31:43 2003
MFT Modified: Tue Nov 18 11:03:53 2003
Accessed: Sat Jul 24 04:53:36 2004
В этой части приводятся данные из атрибута $STAN DARD_IN FORMATION, включая
флаги и информацию о владельце. Идентификатор безопасности используется
для поиска данных по индексу $Secure. Мы также видим порядковый номер послед-
последнего обновления журнала, который изменяется при изменении файла. Значение
используется журналом изменений (см. раздел «Категория прикладных данных»).
$FILE_NAME Attribute Values:
Flags: Archive
Name: boot.ini
Parent MFT Entry: 5 Sequence: 5
Allocated Size: 0 Actual Size: 0
Created: Thu Jun 26 10:22:46 2003
File Modified: Thu Jun 26 10:22:46 2003
MFT Modified: Thu Jun 26 10:22:46 2003
Accessed: Thu Jun 26 10:22:46 2003
В этой части выводятся данные из $FILE_NAME. Обратите внимание: времен-
временные штампы отличаются от тех, что присутствуют в $STAN DARD_IN FORMATION, а раз-
размеры равны 0. Также видно, что родительский каталог представлен записью MFT
5, что соответствует корневому каталогу.
Алгоритмы выделения
Этот раздел посвящен алгоритмам выделения метаданных. Как и остальные алго-
алгоритмы выделения, они определяются на прикладном уровне, а не на уровне фай-
файловой системы. К метаданным относятся три стратегии выделения: первые две
связаны с выделением записей MFT и атрибутов, а третья — с обновлением вре-
временных штампов.
Выделение записей MFT и атрибутов
Начнем с выделения записей MFT. Я обнаружил, что Windows выделяет записи
MFT по алгоритму поиска первой доступной записи, начиная с 24. Записи 0-15
зарезервированы, и для них установлен флаг выделения, даже если эти записи и не
используются, а записи 16-23 обычно не выделяются. Пользовательские файлы
начинаются с записи 24, а размер таблицы увеличивается по мере необходимости.
При освобождении записи никакие данные не изменяются (кроме флага, иденти-
идентифицирующего ее как используемую). Следовательно, временные штампы и спи-
список серий на этой стадии еще можно восстановить. При выделении записи ее со-
содержимое стирается, а значения, оставшиеся от предыдущего файла, пропадают.
Что касается выделения памяти для атрибутов в записях MFT, Microsoft сор-
сортирует записи по типу атрибутов и упаковывает их друг в друга. Если атрибут
$DATA в конце записи является резидентным и его размер уменьшается, то в конце
записи можно найти его старое содержимое (кроме конечного маркера Oxffffffff).
Когда из-за увеличения размеров атрибут преобразуется из резидентного в нере-
нерезидентный, содержимое записи MFT остается до тех пор, пока не будет заменено
другими атрибутами.
Обновление временных штампов
Ранее я уже говорил, что временные штампы хранятся в атрибутах $STAN DARD_IN FOR-
FORMATION и $FILE_NAME. При просмотре свойств файла в Windows отображаются дан-
данные из $STANDARD_INFORMATION, причем только три из четырех. Я опишу результа-
результаты проведенных тестов для временных штампов из $STANDARD_INFORMATION и их
обновления. Значения в $FILE_NAME обновляются при создании и перемещении
файла, но мне так и не удалось однозначно определить правила их обновления.
Обновление временных штампов NTFS в Windows производится по аналогии
с файловыми системами FAT. Время создания задается для нового файла. Если
новый файл создается «с нуля» или в результате копирования, время его созда-
создания устанавливается равным текущему времени. При перемещении файла (даже
на другой том) сохраняется время создания исходного файла.
Время последней модификации обновляется при модификации атрибута $DATA,
$INDEX_ROOT или $INDEX_ALLOCATION. При перемещении или копировании файла
его содержимое не изменяется, и новый файл сохраняет исходное время модифи-
модификации. Если файл содержит несколько атрибутов $DATA, время также обновляется
при модификации дополнительных атрибутов (то есть отличных от атрибута по
умолчанию). При изменении других атрибутов или имени файла значение долж-
должно остаться прежним.
Время модификации MFT обновляется при изменении любого атрибута; я так-
также заметил, что оно обновляется, когда приложение открывает файл, не изменяя
его содержимого. При переименовании или перемещении файла в пределах тома
значение обновляется из-за изменения атрибута $FILE_NAME. Если файл пере-
перемещается на другой том, время модификации MFT остается неизменным. Учти-
Учтите, что этот временной штамп не показывается при просмотре свойств файлов
в Windows, но многие программы анализа отображают его.
Время последнего обращения обновляется при просмотре метаданных или со-
содержимого. В частности, оно обновляется при просмотре свойств файла пользо-
пользователем и при открытии файла. При копировании или перемещении файла время
последнего обращения исходного файла обновляется из-за чтения содержимого
файла. По соображения эффективности Windows не обновляет время последнего
обращения на диске немедленно. Новая версия хранится в памяти, но ее запись
на диск может откладываться до часа. Более того, в Windows существует возмож-
возможность запретить обновление времени последнего обращения.
Итак, при создании файла «с нуля» все временные штампы $STANDARD_IN-
FORMATION и $FILE_NAME устанавливаются равными текущему времени. При копи-
копировании файла для исходной версии обновляется время последнего обращения,
а у копии — время последнего обращения и создания. Временные штампы моди-
модификации файла и MFT сохраняют исходные значения. Таким образом, время со-
создания файла может относиться к более позднему моменту, чем время последней
модификации. При перемещении файла в пределах тома изменяется время обра-
обращения и модификации MFT. Если файл перемещается на другой том, время обра-
обращения обновляется, а время модификации MFT остается прежним. При удалении
файла временные штампы по умолчанию не обновляются. В отдельных случаях
я замечал, что время последнего обращения обновилось, но мне не удалось выя-
выявить закономерность.
Каталоги ведут себя аналогичным образом. При создании или удалении фай-
файлов содержимое каталога изменяется, и время последней модификации обновля-
обновляется текущим временем. При выводе содержимого каталога обновляется время
последнего обращения. При копировании каталога обновляются все четыре вре-
временных штампа. Если каталог перемещается в границах тома, используется та же
запись MFT и обновляется только время последнего обращения и модификации
MFT. При перемещении на другой том все четыре временных штампа обновля-
обновляются текущим временем.
Методы анализа
Целью проведения анализа в категории метаданных является получение допол-
дополнительной информации о конкретном файле или каталоге. Для этого необходимо
найти запись MFT и обработать ее содержимое. Чтобы найти нужную запись MFT,
необходимо сначала найти саму таблицу MFT по начальному адресу в загрузоч-
загрузочном секторе. Первая запись MFT описывает кластерную структуру остальной таб-
таблицы. Все записи имеют одинаковый размер, поэтому найти запись с нужным
номером несложно.
После успешного поиска записи в таблице можно переходить к обработке ат-
атрибутов. Для хранения атрибутов файла или каталога может потребоваться не-
несколько записей MFT; атрибут $ATTRIBUTE_LIST также может содержать адреса
дополнительных записей. Обработка записи MFT начинается с заголовка, после
чего ищется первый атрибут. Далее мы читаем заголовок атрибута, определяем
его тип и соответствующим образом обрабатываем содержимое. Местонахожде-
Местонахождение второго атрибута определяется по длине первого атрибута. Процедура повто-
повторяется до тех пор, пока не будут обработаны все атрибуты. На рис. 12.6 приведен
пример с указанием длин атрибутов. За последним атрибутом следует маркер
Oxffffffff.
Рис. 12.6. Процесс обработки записи на примере записи MFT базового файла
(с приведенными длинами атрибутов)
Основные метаданные хранятся в атрибуте $STANDARD_INFORMATION, а содер-
содержимое файла — в атрибуте (или атрибутах) $DATA. Например, для получения вре-
временных штампов или информации о владельце файла следует обратиться к ат-
атрибуту $STANDARD_INFORMATION. За информацией о содержимом файла следует
обращаться к атрибуту $DATA. Атрибут $FILE_NAME пригодится для проверки даты
создания файла и определения родительского каталога.
Состояние выделения записи MFT определяется как флагом записи MFT, так
и битовой картой в $MFT. Содержимое атрибутов может храниться либо в записях
MFT, либо в отдельных сериях кластеров. Местонахождение резидентных атри-
атрибутов задается их размером и смещением в заголовке. Для нерезидентных атри-
атрибутов в заголовке хранится список серий, определяющий начальный кластер и ко-
количество кластеров в каждой серии.
Иногда бывает полезно провести поиск свободных записей MFT. Для этого
следует определить структуру MFT, а затем последовательно перебрать все запи-
записи. Если флаг использования записи не установлен, такая запись обрабатывается
для получения информации о файле, которому она была выделена. Атрибуты этого
файла должны оставаться в записи.
Если с поиском $MFT и $MFTMirr возникнут проблемы, можно попытаться найти
в файловой системе кластеры, начинающиеся с сигнатуры «FILE» в кодировке
ASCII. К сожалению, не существует простого способа определить, какой записи
MFT соответствует найденный блок, если таблица MFT была фрагментирована.
Факторы анализа
Любой файл или каталог может содержать дополнительные атрибуты $DATA (кро-
(кроме атрибута по умолчанию). Дополнительные атрибуты могут использоваться как
для законных целей, так и для сокрытия данных (в Windows их значения не ото-
отображаются). Некоторые тестовые образы NTFS, размещенные на сайте DFTT
(Digital Forensic Tool Testing) [Carrier, 2003], содержат записи с несколькими
атрибутами $DATA; используйте их со своими программами и проверьте, отобра-
отображаются ли значения всех атрибутов. Тестовые образы также помогут узнать, про-
просматривают ли ваши программы значения атрибутов при поиске по ключевым
словам.
Для сокрытия данных также часто применяются неиспользуемые части запи-
записей MFT и даже атрибутов. Тем не менее использование этих тайников затрудня-
затрудняется динамической природой NTFS. В первом случае добавление или изменение
атрибутов может привести к потере данных. Например, административная про-
программа может создавать дополнительные атрибуты $DATA при сканировании или
архивации файлов, и новые атрибуты будут записаны поверх скрытых данных.
В NTFS поиск свободных записей MFT является простой задачей, потому что
все данные находятся в одной таблице. В этом NTFS отличается от файловой си-
системы FAT, в которой метаданные могут находиться в любом месте файловой си-
системы. Обнаружив свободную запись MFT, мы узнаем из атрибута $FILE_NAME ее
исходное имя и адрес записи MFT. В частности, это помогает определять кон-
контекст поиска — например, отобрать все записи MFT, созданные в заданном вре-
временном промежутке. Поиск может вернуть свободные записи, и знание полного
пути принесет больше пользы, чем один адрес записи.
NTFS также упрощает восстановление содержимого, связанного с удаленны-
удаленными файлами. Если атрибут $DATA файла был резидентным, он сохраняется в запи-
записи MFT, и нам не придется беспокоиться о том, что его кластеры были выделены
другому файлу. Обнаружив запись MFT, мы найдем содержимое. К сожалению,
для данных свыше 700 байт атрибут $DATA обычно становится нерезидентным.
Размер большинства файлов, содержащих улики, оказывается больше 700 байт.
Если атрибут $DATA был нерезидентным, то, как и в любой другой файловой
системе, нужно решить проблемы с возможной десинхронизацией содержимого.
Дело в том, что кластеры могли быть выделены другому файлу. К преимуществам
NTFS следует отнести то, что местонахождение нерезидентных серий хранится
в записях NTFS и Windows не стирает эти данные при удалении файла.
Если все атрибуты файла не помещаются в одной записи MFT, восстановле-
восстановление усложняется. В этом случае необходимо проверить, не были ли другие записи
выделены повторно с момента удаления файла. Например, если для хранения ат-
атрибутов файла требовались две записи, не-базовая запись могла быть выделена
заново раньше базовой. Во многих случаях факт повторного выделения очеви-
очевиден — скажем, запись, которая раньше была не-базовой, стала базовой или содер-
содержит ссылку на другую не-базовую запись. Это может создать проблемы при опи-
описании атрибута $DATA в нескольких записях MFT. Если одна или несколько записей
были выделены для других целей, восстановить весь атрибут не удастся.
Эти три сценария показаны на рис. 12.7. В записи 90 хранится резидентный
атрибут, содержимое которого стирается при выделении записи MFT. Запись 91
содержит нерезидентный атрибут, содержимое которого можно восстановить ме-
методами прикладного уровня, если запись MFT была выделена заново до класте-
кластеров, занимаемых атрибутом. Запись 92 является базовой для записи 93, атрибут
$DATA сильно фрагментирован, а его описание присутствует в обеих записях. Если
какая-либо из этих записей будет выделена заново, восстановить атрибут $DATA
не удастся.
Рис. 12.7. Возможные способы хранения содержимого $DATA
Что касается повторного выделения записей MFT в Windows, свободные за-
записи с малыми адресами используются раньше записей с большими адресами.
Таким образом, успешное восстановление файлов с меньшими адресами MFT
менее вероятно. Если атрибут $DATA был резидентным, то повторное выделение
записи MFT приводит к потере данных. Для нерезидентных атрибутов даже пос-
после повторного выделения записи MFT еще остается вероятность восстановления
прикладными методами.
Windows заполняет неиспользуемые байты последнего сектора файла нуля-
нулями, но не стирает содержимого неиспользуемых секторов. Следовательно, в ре-
резервном пространстве за концом файла часто можно найти информацию из уда-
удаленных файлов.
Временные штампы не обновляются при удалении файла, поэтому по ним не-
невозможно определить время удаления файла. Атрибут $FILE_NAME содержит на-
набор временных штампов, которые обновляются в момент создания или переме-
перемещения файла или каталога. По ним можно выявить попытки изменения времени
создания в атрибуте $STANDARD_INFORMATION. Время хранится в формате UTC,
поэтому программа анализа должна преобразовать время к часовому поясу, в ко-
котором изначально находился компьютер. Это упростит сопоставление временных
штампов с данными журналов и других систем.
Шифрованные и сжатые атрибуты могут создать проблемы для эксперта. Если
пароль пользователя неизвестен, попробуйте поискать расшифрованные копии
зашифрованных файлов в свободном дисковом пространстве. Многие програм-
программы анализа поддерживают работу с шифрованными и сжатыми файлами. Сжа-
Сжатые файлы могут не обладать резервным пространством, и методы восстановле-
восстановления прикладного уровня не будут работать с удаленными данными, хранившимися
в сжатом формате. Также протестируйте поисковые функции вашего инструмен-
инструментария и проверьте, проводят ли они поиск внутри сжатых файлов.
Сценарий анализа
Во время исследования системы Windows 2000 обнаруживается, что один из томов
был отформатирован за день до снятия данных. Дата форматирования была опреде-
определена на основании временных штампов, связанных с файлами метаданных файло-
файловой системы. Корневой каталог файловой системы не содержит файлов и каталогов;
нам хотелось бы восстановить некоторые файлы из предыдущей файловой системы.
При форматировании файловой системы создается новая таблица MFT с ми-
минимальным количеством записей. Следовательно, записи MFT, оставшиеся от
предыдущей файловой системы, должны существовать в свободных кластерах
новой файловой системы. Если нам удастся найти эти записи, мы сможем исполь-
использовать их для восстановления исходного содержимого атрибутов.
Первым шагом должно стать извлечение содержимого свободного простран-
пространства файловой системы для проведения поиска. Если программа поиска поддер-
поддерживает режим поиска только в свободном пространстве, этот шаг не потребуется.
Для решения этой задачи мы воспользуемся программой dls из пакета TSK:
# dls -d ntfs ntfs9.dd > ntfs9.dls
Теперь можно переходить к поиску старых записей MFT. Каждая запись MFT
начинается с ASCII-сигнатуры «FILE». Для проведения поиска можно восполь-
воспользоваться стандартной утилитой типа grep или же снова прибегнуть к программе
sigfind. Мы воспользуемся sigfind, потому что эта программа позволяет отобрать
совпадения с нулевым смещением от начала сектора. Преобразование сигнатуры
«FILE» из кодировки ASCII в шестнадцатеричный формат дает 0х46494с45.
# sigfind -о 0 46494с45 ntfs9.dls
Поиск дает несколько совпадений, в том числе одно в секторе 412. Чтобы по-
показать, как обрабатываются результаты, я поэтапно опишу всю процедуру анали-
анализа. Если вас интересуют структуры данных NTFS, вернитесь к этому примеру после
чтения следующей главы. Содержимое сектора 412 выглядит так (с разбиением
структуры данных на части):
# dd if=ntfs9.dls skip=412 count=2 | xxd
0000000: 4649 4c45 3000 0300 Ь6е5 1000 0000 0000 FILEO
0000016: 0100 0100 3800 0100 0003 0000 0003 0000 ....8
0000032: 0000 0000 0000 0000 0400 0000 4800 0000 H.. .
0000048: 0500 6661 0000 0000 ..fa....
Этот фрагмент содержит заголовок записи MFT. Флаг в байтах 22-23 показы-
показывает, что запись была выделена @x0001 в прямом порядке байтов) перед форма-
форматированием, а байты 20-21 — что первый атрибут начинается со смещением 56
байт @x0038). Заголовок первого атрибута:
0000048: 1000 0000 6000 0000
0000064: 0000 0000 0000 0000 4800 0000 1800 0000 Н
[...]
0000144: Ь049 0000 0000 0000 .1
Первый атрибут относится к типу $STANDARD_INFORMATION @x0010), а его дли-
длина составляет 96 байт @x0060). Атрибут можно проанализировать на предмет со-
содержащихся в нем временных штампов. Далее мы смещаемся на 96 байт вперед,
от байта 56 к байту 152:
0000144: 3000 0000 7000 0000 0...р...
0000160: 0000 0000 0000 0200 5800 0000 1800 0100 X
0000176: 0500 0000 0000 0500 d064 f7b9 eb69 c401 d...i..
[...]
0000240: ОЬОЗ бсОО 6500 7400 7400 6500 7200 3100 ..1.e.t.t.e.r.l.
0000256: 2е00 7400 7800 7400 ..t.x.t.
Второй атрибут относится к типу $FILE_NAME @x0030), а его длина составляет
112 байт @x0070). Мы видим, что родительский каталог этого файла соответствует
записи MFT 5, то есть корневому каталогу. В атрибуте содержится имя файла
«letterl.txt». Далее мы переходим на 112 байт вперед от начального смещения 152,
к байту 264:
0000256: 4000 0000 2800 0000 @...(...
0000272: 0000 0000 0000 0300 1000 0000 1800 0000
0000288: 6dd4 12e6 d9d5 d811 a5c7 00b0 dOld e93f m ?
Третий атрибут $OBJECT_ID относится к типу $OBJECT_ID @x0040), а его длина
составляет 40 байт @x28). Следующий атрибут начинается со смещения 304:
0000304: 8000 0000 с801 0000 0000 1800 0000 0100
0000320: ае01 0000 1800 0000 4865 бсбс 6f20 4d72 Hello Mr
0000336: 204a 6f6e 6573 2c0a 5765 2073 6861 бсбс Jones..We shall
[...]
Последний атрибут относится к типу $DATA @x0080), а его длина составляет
456 байт @x01с8). Содержимое атрибута начинается с байта 328 строкой «Hello
Mr. Jones». Все содержимое файла хранится в записи MFT, поскольку атрибут
является резидентным. Если бы он был нерезидентным, нам пришлось бы обра-
обрабатывать список серий и искать кластеры в образе файловой системы. Структура
записи показана на рис. 12.8.
Рис. 12.8. Структура записи MFT, обнаруженной в свободном дисковом пространстве
В этом сценарии производился поиск следов файлов, существовавших до мо-
момента форматирования тома. Мы нашли сигнатуру «FILE», существующую в за-
записях MFT, и разобрали одну запись вручную. Структуры данных каждого атри-
атрибута подробно описаны в следующей главе.
Категория имен файлов
К категории имен файлов относятся данные, связывающие имя файла с его со-
содержимым. До настоящего момента мы рассматривали способы хранения данных
и метаданных в NTFS, но сейчас необходимо разобраться, как же имя связыва-
связывается с файлом. Для упорядочения содержимого каталогов в NTFS используются
индексы (см. главу 11). Индекс NTFS представляет собой набор структур данных,
отсортированных по некоторому ключу. Дерево содержит один или несколько
узлов, хранящихся в атрибутах $INDEX_ROOT и $INDEX_ALLOCATION. Атрибут
$INDEX_ROOT всегда определяет корневой узел дерева, a $INDEX_ALLOCATION — ин-
индексные записи, используемые для хранения других узлов. Атрибут $В1ТМАР опи-
описывает состояние выделения индексных записей. Каждый узел дерева содержит
список индексных элементов.
Индексы каталогов
KaTanorNTFS представлен обычной записью MFT, у которой установлен специаль-
специальный флаг в заголовке и в атрибутах $STANDARD_IN FORMATION и $FILE_NAME. Индексные
элементы в индексе каталога содержат адрес ссылки на файл и атрибут $FILE_NAME.
Вспомните, что атрибут $FILE_NAME содержит имя файла, временные штампы, раз-
размер и основные флаги. Windows обновляет временные штампы и размеры, чтобы
они соответствовали действительности. Если система Windows настроена на обя-
обязательное использование имени из пространства имен DOS, индекс содержит
несколько атрибутов $FILE_NAME для одного файла. Атрибутам $INDEX_ROOT, $IN-
DEX_ALLOCATION и $В1ТМАР присваивается одно имя $130. Эти структуры данных пред-
представлены в главе 11, а их формальные описания приводятся в главе 13.
На рис. 12.9 показана простая двухуровневая структура каталога, в которой
корневой узел находится в атрибуте $INDEX_ROOT, а атрибут $INDEX_ALLOCATION
содержит две индексные записи. Элементы индексной записи 0 содержат имена,
«меньшие» hhh.txt, а элементы индексной записи 1 — имена, «большие» hhh.txt
Обратите внимание: файл eeeeeeeeeeee.txt не входит в пространство имен DOS,
поэтому для него создается дополнительная запись.
При добавлении или удалении файла из каталога дерево реструктурируется
так, чтобы данные хранились в отсортированном порядке. Это может привести
к перемещению элементов в индексных записях и замене данных в удаленных фай-
файлах. У каждого узла дерева имеется поле заголовка, которое идентифицирует
последний выделенный элемент. На рис. 12.9 некоторые элементы (ccc.txt
в $INDEX_ROOT и qqq.txt в индексной записи 1) находятся в свободном простран-
пространстве. Файл qqq.txt удален, но файл ccc.txt продолжает существовать, он находится
в индексной записи 0. Чтобы понять, почему это происходит, обратитесь к разде-
разделу «Индексы» главы 11.
Рис. 12.9. Двухуровневое дерево каталога
Корневой каталог
В любой файловой системе для поиска файла по полному пути необходимо знать
местонахождение корневого каталога. Корневой каталог NTFS всегда находится
в записи MFT 5; ему присваивается имя «.». Запись обладает стандартными атри-
атрибутами $INDEX_ROOT, $INDEX_ALLOCATION и $В1ТМАР. В этом каталоге находятся все
файлы метаданных файловой системы (хотя они и скрыты от большинства пользо-
пользователей).
Ссылки на файлы и каталоги
В NTFS файлу может быть присвоено более одного имени; это происходит при
создании жесткой ссылки (hard link). Жесткая ссылка не отличается от исходно-
исходного имени файла, и для нее в индексе родительского каталога создается запись,
которая указывает на ту же запись MFT, что и исходное имя. Счетчик ссылок
в заголовке записи MFT увеличивается на 1 при создании жесткой ссылки, при-
причем запись не освобождается до тех пор, пока ее счетчик ссылок не уменьшится
до 0. Другими словами, если исходное имя файла удаляется, но жесткая ссылка
продолжает существовать, файл удален не будет. Запись MFT содержат по одно-
одному атрибуту $FILE_NAM E для каждого из имен своих жестких ссылок. Жесткие ссыл-
ссылки создаются только в пределах того же тома.
В NTFS 3.0+ появился новый механизм точек подключения (reparse points),
которые могут использоваться для создания ссылок на файлы, каталоги и тома.
Точка подключения представляет собой специальный файл или каталог, содер-
содержащий информацию о том объекте, на который он ссылается. Точки подключе-
подключения могут связываться с файлами и каталогами, находящимися на том же томе,
другом томе или на удаленном сервере. Точки подключения также могут исполь-
использоваться для монтирования тома в каталог вместо буквы диска (например, Е:\).
Символическая ссылка представляет собой точку подключения, связывающую два
файла; переход (junction) — точку подключения, связывающую два каталога; на-
наконец, точка монтирования связывает каталог с томом. Механизм Windows
Remote Storage Server использует точки подключения для описания местонахож-
местонахождения файла или каталога на сервере.
Точки подключения представляют собой специальные файлы, а в их атрибутах
$STANDARD_INFORMATION и $FILE_NAME устанавливаются соответствующие флаги.
Кроме того, они содержат атрибут $REPARSE_POINT с информацией о местонахож-
местонахождении целевого файла или каталога. Структура данных атрибута $REPARSE_POINT
обсуждается в главе 13.
В NTFS информация о точках подключения хранится в индексе из файла ме-
метаданных файловой системы \$Extend\$Reparse. Индекс сортируется по файловым
ссылкам, но не содержит сведений о местонахождении целевых файлов.
Кроме файла $Reparse, NTFS хранит информацию о точках монтирования
в атрибуте $DATA корневого каталога (запись MFT 5). Атрибут $DATA с именем
$MountMgrRemoteDatabase содержит список целевых томов, на которые ссылаются
точки подключения. Этот атрибут $DATA создается только в том случае, если в фай-
файловой системе существует точка монтирования.
Идентификаторы объектов
В NTFS версий 3.0+ существует дополнительный метод адресации файлов и ка-
каталогов (кроме стандартной адресации по именам каталогов/файлов или адресов
записей MFT). Приложение или ОС может присвоить файлу уникальный 128-
разрядный идентификатор объекта, который в дальнейшем используется для ссы-
ссылок на объект даже в случае его переименования или перемещения на другой том.
Продукты Microsoft используют идентификаторы объектов при внедрении фай-
файлов. Идентификатор может использоваться для ссылки на внедренный файл даже
после его перемещения.
У файла или каталога, которому присваивается идентификатор объекта, со-
создается атрибут $OBJECT_ID. Он содержит идентификатор объекта, а также может
содержать дополнительную информацию об исходном домене и томе, на котором
он был создан. Если потребуется найти файл по идентификатору объекта, обра-
обратитесь к индексу \$Extend\$ObjId. Индекс содержит записи для всех присвоенных
идентификаторов объектов в файловой системе.
Этот метод адресации может повлиять на работу эксперта, так как может воз-
возникнуть необходимость в поиске файла по идентификатору объекта. На момент
написания книги мне не известна ни одна программа, которая позволяла бы про-
проводить поиск файлов по идентификатору объекта.
Алгоритмы выделения
Индексы NTFS строятся на базе В-деревьев; это означает, что при выделении
структур данных не используются стратегии поиска первого или следующего до-
доступного объекта. Тем не менее возможны разные варианты реализации В-дере-
В-деревьев в контексте добавления или удаления элементов. Основной принцип заклю-
заключается в том, чтобы определить, где в дереве должен находиться файл, и попытаться
добавить его. Если узел содержит слишком много записей, он разбивается надвое
с созданием нового уровня. Процесс повторяется до тех пор, пока дерево не пе-
перейдет в допустимое состояние. При удалении файла его данные удаляются из
дерева, и происходит перемещение остальных элементов данного узла. Если узел
содержит слишком мало элементов, он пытается позаимствовать элементы из дру-
других узлов для сохранения сбалансированности дерева.
Небольшие каталоги состоят из одного узла, находящегося в атрибуте $IN-
DEX_ROOT. Если записи не помещаются в этом атрибуте, ОС перемещает их в ин-
индексную запись в атрибуте $INDEX_ALLOCATION. На этой стадии В-дерево по-пре-
по-прежнему содержит только один узел, a $INDEX_ROOT не содержит элементов, кроме
пустого элемента, ссылающегося на дочерний узел. После заполнения индексной
записи выделяется вторая запись, и атрибут $INDEX_ROOT используется в качестве
корневого узла, дочерними узлами которого являются две индексные записи.
После заполнения этих индексных записей выделяется третья, в результате чего
корневой узел будет содержать три дочерних узла.
В протестированных мной системах временные штампы и размеры в атрибуте
$FILE_NAME обновлялись с той же частотой, что и значения в атрибуте $STAN-
DARDJNFORMATION в записи MFT файла. За дополнительной информацией обра-
обращайтесь к подразделу «Алгоритмы выделения» раздела «Категория метаданных».
Методы анализа
Анализ данных в категории имен файлов проводится с целью идентификации
файлов и каталогов по именам. Процесс включает поиск каталогов, обработку их
содержимого и поиск метаданных, ассоциированных с файлом.
Как было показано в этом разделе и в предыдущей главе, анализ имен файлов
и индексов в NTFS является довольно сложным процессом. Он начинается с поиска
корневого каталога, представленного записью MFT 5. В процессе обработки ката-
каталога мы просматриваем содержимое атрибутов $INDEX_ROOT и $INDEX_ALLOCATION
и обрабатываем индексные элементы. В этих атрибутах хранятся списки, называ-
называемые индексными записями и соответствующие узлам дерева. Каждая индексная
запись содержит один или несколько индексных элементов. Индексные записи
также могут содержать свободные индексные элементы; в заголовке записи ука-
указывается, где находится последний выделенный элемент. Состояние выделения
индексных записей определяется по атрибуту $В1ТМАР каталога. Существующие
файлы могут ассоциироваться не только с выделенными, но и со свободными ин-
индексными элементами, потому что каталоги хранятся в виде В-деревьев, требую-
требующих повторной сортировки при добавлении и удалении файлов.
Имя файла также может соответствовать точке подключения — ссылке или
точке монтирования. Целевой объект точки подключения определяется в атрибу-
атрибуте $REPARSE_POINT записи MFT. Компания Microsoft определила некоторые типы
точек подключения, но возможны и другие типы, специфические для конкретных
приложений.
Факторы анализа
Имена файлов в свободных записях NTFS могут создавать путаницу. При добав-
добавлении и удалении файлов в каталогах дерево сортируется заново, элементы
перемещаются в другие узлы и в другие позиции внутри узла. Это приводит к тому,
что информация удаленных файлов оказывается в незанятом пространстве узла
дерева, а данные удаленных файлов стираются. Свободное пространство некоторых
индексов может содержать несколько копий данных одного файла. Чтобы опреде-
определить, был ли файл действительно удален, необходимо провести среди оставших-
оставшихся индексных элементов поиск копии имени файла в выделенном пространстве.
При обнаружении имени удаленного файла NTFS предоставляет ряд преиму-
преимуществ по сравнению с другими файловыми системами. Порядковый номер в ссыл-
ссылке показывает, происходило ли повторное выделение записи MFT после удале-
удаления файла. Если запись выделялась заново, скорее всего, ее данные относятся
к другому файлу. В других файловых системах нам пришлось бы гадать, сохрани-
сохранилась синхронизация или нет. Другое преимущество заключается в том, что в ин-
индексе существует атрибут $FILE_NAME с полным набором временных штампов
и флагов. Следовательно, даже если запись MFT была выделена заново, а данные
файла были стерты, базовая информация все же остается.
При поиске удаленных файлов в каталоге программа должна проверить два
возможных места. Первое — свободные области каждого узла в дереве индекса
каталога, а второе — свободные записи MFT. Если имя файла было стерто из ин-
индекса, но запись MFT еще существует, мы можем определить, что файл находил-
находился в каталоге, обратившись к адресу MFT родительского каталога в атрибуте
$FILE_NAME. Убедитесь в том, что ваша программа анализа проводит обе проверки
при поиске удаленных файлов в каталогах.
Сценарий анализа
Ваша лаборатория собирается обновить свой инструментарий анализа файловых
систем, и вам поручено протестировать новые программы. В процессе рассле-
расследования вы решаете протестировать программу Digital Investigator 4000 (DI4K),
а для подтверждения результатов воспользоваться программой FSAnalyzer 1000
(FSA1K), которая применялась до настоящего времени. На анализируемом ком-
компьютере с файловой системой NTFS найден каталог с многочисленными улика-
уликами. Сравнение содержимого каталога в двух программах выявляет ряд различий:
1. Удаленный файл aaa.txt не показывается в выходных данных DI4K, но при-
присутствует в выводе FSA1K.
2. Две программы выводят разные временные штампы файла mmm.txt. В DI4K
они относятся к более раннему моменту, чем в FSA1K.
3. Удаленный файл www.txt показывается в выходных данных DI4K, но отсут-
отсутствует в выводе FSA1K.
Для существующих файлов результаты совпадают. Чтобы разобраться в при-
причинах происходящего, мы запускаем шестнадцатеричный редактор и начинаем
разбирать индекс каталога. После ручной обработки атрибутов $INDEX_ROOT
и $INDEX_ALLOCATION выясняется, что индекс имеет структуру, показанную на
рис. 12.10 (А).
Из содержимого каталога видно, отчего возникла первая проблема. Про-
Программа FSA1K вывела файл aaa.txt как удаленный, несмотря на то, что он про-
должает существовать. Вероятно, свободная запись появилась после удаления
другого файла и перемещения элемента aaa.txt по узлу. Более новая програм-
программа DI4K нашла существующую запись aaa.txt и не стала выводить свободную
запись.
Рис. 12.10. Каталог, для которого две программы выводят разную информацию:
(А) — структура, (В) — записи MFT
Вторая проблема относится к временным штампам файла mmm.txt. Мы видим,
что индексный элемент находится в корневом узле индекса, а его метаданные хра-
хранятся в записи MFT 31, показанной на рис. 12.10 (В). Мы обрабатываем атрибут
$STANDARD_INFORMATION записи MFT 31 и находим временные штампы, выведен-
выведенные программой FSA1K. Просмотр временных штампов в атрибуте $FILE_NAME
индексного элемента обнаруживает временные штампы, выведенные в DI4K. Что-
Чтобы узнать, какая информация была более точной, мы сравниваем порядковые но-
номера индексного элемента и записи MFT. Выясняется, что у индексного элемента
порядковый номер равен 3, а у записи MFT — 4. Следовательно, запись MFT была
выделена заново после удаления файла mmm.txt, программа DI4K это заметила
и вывела данные из атрибута $FILE_NAME индексного элемента.
Третья проблема относилась к новому файлу www.txt; тем не менее в индексе
такого файла нет. Вспомните, что говорилось ранее о «зависании» удаленных
файлов NTFS, происходящем из-за перезаписи удаленных имен в индексах. Мы
ищем запись MFT для имени www.txt; для этого в логической файловой системе
проводится поиск строки «www.txt» в Unicode. В результате поиска обнаружива-
обнаруживается запись MFT 30, в которой указана запись родительского каталога 36 — за-
запись того самого каталога, который мы анализируем. Можно сделать вывод, что
новая программа DI4K не только выводит информацию о свободных элементах
в индексе, но и ищет зависшие файлы.
В отчете вы документируете все найденные различия. Ни одна программа не
выдает ложных данных, но вывод D14K был гораздо более точным.
Категория прикладных данных
К уникальным особенностям файловой системы NTFS относится поддержка мно-
многих возможностей прикладного уровня. Речь идет о возможностях, повышающих
эффективность работы операционной системы или приложений, но которые тем
не менее не обязательно включать в файловую систему. Ни одна из возможностей
прикладного уровня не является необходимой в отношении главного предназначе-
предназначения файловой системы — сохранения и загрузки файлов. Более того, пользователь
или приложение может заблокировать некоторые из возможностей прикладного
уровня. В этом разделе рассматриваются дисковые квоты, журналы файловой
системы и протоколирование изменений; соответствующие структуры данных
будут описаны в главе 13. Я буду называть данные «необходимыми», если они
критичны для работы функции прикладного уровня, а не для реализации основ-
основной функции файловой системы (сохранения-выборки данных).
Дисковые квоты
В NTFS включена поддержка квот дискового пространства. Квоты устанавливают-
устанавливаются администратором для ограничения места на диске, доступного для каждого
пользователя. Часть информации о квотах хранится в данных файловой системы,
другие данные хранятся в файлах прикладного уровня (например, в реестре Win-
Windows). В версиях NTFS, предшествовавших 3.0, запись MFT 9 представляла файл
метаданных файловой системы $Quota, но в версиях 3.0+ этот файл хранится в ка-
каталоге \$Extend, а для его представления может использоваться любая запись MFT.
В файлах $Quota для управления информацией квот используются два индек-
индекса. Первому индексу присваивается имя $0, и он связывает код SID с идентифи-
идентификатором владельца (на этот раз речь идет о «типичном» коде SID системы Windows,
а не об идентификаторе безопасности файловой системы, упоминавшемся выше).
Второй индекс с именем $Q связывает идентификатор владельца с информацией
о выделенном и расходуемом дисковом пространстве.
Факторы анализа
Данные квот не являются необходимыми, поскольку операционная система не
нуждается в них при использовании файловой системы. Например, другая ОС
может смонтировать файловую систему NTFS и не обновить квоты при создании
файла пользователем. Квоты могут пригодиться при экспертном анализе — напри-
например, по ним можно определить, кто из пользователей сохранял в системе большие
объемы данных. Например, если вы обнаружили систему с несколькими учетны-
учетными записями пользователей и большим количеством пиратских фильмов, по фай-
файлам квот можно будет определить, кто из пользователей создавал файлы. Ту же
информацию можно получить простым анализом атрибута $STANDARD_IN FORMATION
каждого файла. Система квот по умолчанию не активна, поэтому в большинстве
систем эти данные не существуют.
Журналы файловых систем
Для повышения надежности файловой системы компания Microsoft включила
в NTFS поддержку журналов. Как говорилось в главе 8, журнал файловой системы
позволяет операционной системе быстрее восстановить корректное состояние
файловой системы. Повреждения файловых систем обычно происходят при сис-
системных сбоях во время записи данных в файловую систему. В журнале хранится
информация обо всех предстоящих обновлениях метаданных, а также создаются
записи об их успешном обновлении. Если перед тем, как в журнале будет зафик-
зафиксирован факт успешного обновления, в системе произойдет сбой, ОС сможет бы-
быстро вернуть систему в предыдущее состояние.
Файл журнала NTFS представлен записью MFT 2; ему присвоено имя $ Log File.
Эта запись MFT не имеет специальных атрибутов, а содержимое журнала хра-
хранится в атрибуте $DATA. Я обнаружил, что размер файла журнала составляет око-
около 1-2 % общего размера файловой системы. О содержимом журнала известно
очень мало, хотя компания Microsoft опубликовала кое-какую высокоуровневую
информацию в своих руководствах и в книге «Inside Windows 2000».
Файл журнала делится на две основные части: область рестарта и протоколь-
протокольную область. Как показано на рис. 12.11, область рестарта содержит две копии
структуры данных, которая помогает ОС выбрать транзакции для анализа при
выполнении отката. В ней содержится указатель на последнюю заведомо успеш-
успешную транзакцию в протокольной области.
Рис. 12.11. Структура атрибута $DATA файла $LogFile, содержащего журнал NTFS
Протокольная область содержит серию записей. Каждой записи соответ-
соответствует логический порядковый номер (LSN), который представляет собой уни-
уникальное 64-разрядное значение. Номера LSN назначаются в порядке возраста-
возрастания. Протокольная область имеет конечный размер, и когда в конце файла не
остается места для создания новой записи, она помещается в начало файла.
В этой ситуации запись в конце файла журнала будет обладать большим но-
номером LSN, чем у записи в начале файла. Другими словами, номера LSN на-
назначаются записям на основании времени их создания, а не расположения
в файле. Записи, ставшие ненужными, заменяются при повторном заполнении
журнала.
Существует несколько типов записей, хотя компания Microsoft описывает толь-
только два из них. Самыми распространенными являются записи обновления, пред-
предназначенные для описания транзакций файловой системы до их выполнения. Они
же используются после выполнения транзакции файловой системы. Для многих
транзакций требуется более одной записи, потому что они разбиваются на более
мелкие операции, и каждой операции ставится в соответствие своя запись обнов-
обновления. Примеры транзакций файловой системы:
• создание файла или каталога;
• изменение содержимого файла или каталога;
• переименование файла или каталога;
• изменение любых данных, хранящихся в записи MFT файла или каталога
(идентификатор пользователя, параметры безопасности и т. д.).
Помимо номера LSN каждая запись обновления содержит два важных поля.
В первом поле хранится информация о том, что собирается сделать выполняемая
операция; оно называется полем возврата. Второе поле содержит противополож-
противоположную информацию о том, как отменить операцию. Эти записи создаются перед
выполнением транзакции файловой системы. После выполнения транзакции со-
создается еще одна запись обновления, показывающая, что транзакция была успешно
завершена. Она называется записью закрепления.
Вторая разновидность записей — записи контрольных точек. Запись конт-
контрольной точки указывает, с какой позиции журнала должна начинать ОС при
проверке файловой системы. Windows создает одну запись этого вида каждые пять
секунд, и ее номер LSN сохраняется в области рестарта журнала.
Чтобы проверить состояние файловой системы, ОС находит последнюю за-
запись контрольной точки и идентифицирует начатые транзакции. Если транзак-
транзакция успешно завершена и в журнале существует запись закрепления, ОС по со-
содержимому поля возврата убеждается в том, что данные были обновлены на диске
и не потерялись в кэше. Если транзакция не завершилась и запись закрепления
найти не удалось, ОС по содержимому поля отмены восстанавливает состояние
данных до начала транзакции.
На рис. 12.12 показан указатель из области рестарта к местонахождению
последней записи контрольной точки. Дальнейший перебор обнаруживает две
транзакции. У транзакции 1 имеется запись закрепления, поэтому система по
содержимому поля возврата проверяет правильность состояния диска. Тран-
Транзакция 2 не имеет записи закрепления, поэтому система по содержимому поля
отмены убеждается в том, что ни одно из предполагаемых изменений не суще-
существует.
Журнал не содержит пользовательских данных, которые являются нерезиден-
нерезидентными и хранятся во внешних кластерах, поэтому он не может использоваться
для восстановления файлов. В нем хранится содержимое резидентных атрибутов
для отмены недавних изменений. На момент написания книги мне неизвестна ни
одна программа анализа, которая бы умела использовать данные в файле журна-
журнала, потому что не все структуры данных документированы. Впрочем, кое-какую
информацию можно найти простым просмотром строк ASCII или Unicode в фай-
файле (см. раздел «Файл SLogFile» главы 13).
В заголовке каждой записи MFT хранится последний номер LSN для файла.
В частности, его значение приводилось в выходных данных istat в приведенных
ранее примерах. По этому значению можно определить относительный порядок
изменения двух файлов.
Рис. 12.12. Пример $LogFile с двумя транзакциями за последней записью контрольной точки.
Одна из транзакций не была закреплена
Факторы анализа
Журнал может предоставить информацию о последних изменениях в файловой
системе. Тем не менее невозможно предсказать, как долго будут существовать
файлы до их перезаписи, но самое худшее — неизвестна структура этого файла.
Следовательно, даже если вы найдете улики, возможно, их будет трудно ин-
интерпретировать. Значение LSN в заголовке записи MFT файла позволяет вос-
восстановить порядок редактирования. Чем больше число, тем позднее редактиро-
редактировался файл.
Журнал изменений
Журналом изменений называется файл, в котором регистрируются изменения
в файлах и каталогах. Он существует в NTFS версий 3.0+ и может использо-
использоваться приложениями для определения файлов, изменившихся за некоторый
промежуток времени. В общем случае для выявления изменений приложение
должно перебрать все файлы и каталоги в файловой системе и сравнить их вре-
временные штампы с пороговым значением. В больших файловых системах эта про-
процедура займет слишком много времени, но журналы изменений значительно
упрощают ее. В журналах изменений перечисляются все файлы, в которые были
внесены изменения.
В Windows любое приложение может включать и отключать механизм журнала
по своему усмотрению. По умолчанию он отключен. С журналом ассоциируется
64-разрядное число, которое изменяется при каждом включении или отключении.
При помощи этого числа приложение может определить, что из-за отключения
журнала некоторые изменения оказались потерянными. При отключении журна-
журнала Windows удаляет файл в Windows 2000 и ХР.
Журнал изменений хранится в файле \$Extend\$UsrJrnl. Обычно этому файлу
не выделяется одна из зарезервированных записей MFT, и он обладает двумя
атрибутами $DATA. Первый атрибут с именем $Мах содержит базовую информа-
информацию о журнале. Второй атрибут с именем $J содержит сам журнал в виде списка
записей переменного размера. Каждая запись содержит имя файла, время изме-
изменения и тип изменения. Длина записи зависит от длины имени файла. Каждая
запись обладает 64-разрядным порядковым номером обновления, или USN (Update
Sequence Number). Номера USN используются для индексирования записей
в журнале и хранятся в атрибуте $STANDARD_INFORMATION модифицированного
файла. USN соответствует смещению внутри журнала в байтах, что позволяет
легко найти запись по USN (потому что все записи имеют разные размеры). За-
Запись не содержит информации о том, какие данные изменились; указывается
только тип изменений.
В Windows максимальный размер журнала ограничен. Если журнал достигает
этого размера, Windows преобразует файл в разреженный и продолжает добав-
добавлять данные в конец файла. При выделении нового кластера в конце файла пер-
первый кластер удаляется и становится разреженным. Таким образом, все выглядит
так, словно файл увеличивается в размерах, но в действительности он содержит
одно и то же количество выделенных кластеров. Однако номера USN при такой
схеме всегда увеличиваются, потому что они соответствуют смещению в байтах
от начала файла.
Факторы анализа
Трудно заранее сказать, сколько информации можно извлечь из этого файла; нет
гарантии, что механизм журнала будет включен. Более того, при его отключении
Windows удаляет содержимое файла, причем отключение может производиться
любым приложением. Если все же допустить, что журнал был включен и его со-
содержимому можно доверять, содержимое журнала может пригодиться для рекон-
реконструкции недавних событий. Для файла сохраняется только время последней
модификации или создания, а журнал может содержать информацию о многих
изменениях, хотя точные описания этих изменений не будут известны.
Общая картина
После долгих описаний всевозможных структур данных и сложных взаимодей-
взаимодействий давайте рассмотрим некоторые операции, которые могут происходить при
выделении и удалении файла. Хочется верить, что это поможет собрать воедино
разрозненные фрагменты. Учтите, что порядок перечисления действий может
отличаться от того, который применяется на практике.
Создание файла
В этом примере создается файл \dirl\filel.dat; предполагается, что каталог dirl уже
существует в корневом каталоге. Размер файла составляет 4000 байт, а размер
кластера равен 2048 байт.
1. Создание файла начинается с чтения первого сектора файловой системы и об-
обработки загрузочного сектора для определения размера кластера, начального
адреса MFT и размера записи MFT.
2. Мы читаем из MFT первую запись (файл $МПГ) и обрабатываем ее для опреде-
определения структуры остальных записей MFT. Информация хранится в атрибуте
$DATA.
3. Для нового файла выделяется запись MFT. Чтобы найти неиспользуемую
запись, мы обрабатываем атрибут $В1ТМАР файла $МПГ. Первая свободная за-
запись C04) выделяется новому файлу, а соответствующий бит карты устанав-
устанавливается в 1.
4. Происходит инициализация записи MFT 304, для чего мы находим запись
в MFT и стираем ее содержимое. В записи создаются атрибуты $STAN-
DARD_INFORMATION и $FILE_NAME, а временные штампы инициализируются те-
текущим временем. В заголовке записи MFT устанавливается флаг использова-
использования.
5. Далее для файла необходимо выделить два кластера; при этом используется
атрибут $DATA файла $Bitmap, находящийся в записи MFT 6. Два смежных кла-
кластера, 692 и 693, находятся с использованием алгоритма оптимального подбо-
подбора. Соответствующие биты карты для кластеров устанавливаются равными 1.
В кластеры записывается содержимое файла, и атрибут $DATA обновляется ад-
адресами кластеров. В записи MFT обновляются временные штампы.
6. На следующем шаге создается информация об имени файла. Информация dirl
ищется в корневом каталоге, находящемся в записи MFT 5. Мы читаем атри-
атрибуты $INDEX_ROOT и $1NDEX_ALLOCATION и перемещаемся по отсортированному
дереву. После обнаружения индексного элемента dirl из него берется адрес
записи MFT 200. Обновляется время последнего обращения к каталогу.
7. Обработка атрибута $IN DEX_ROOT записи MFT 200 дает местонахождение фай-
файла filel.dat. Для файла создается новый индексный элемент, и все дерево сор-
сортируется заново. Это может привести к перемещению индексных элементов
внутри узла. У нового индексного элемента в поле базового адреса указана за-
запись MFT 304, а временные штампы и флаги заданы соответствующим обра-
образом. Для каталога обновляется время последней модификации и обращения.
8. Каждый из перечисленных этапов может сопровождаться созданием записей
в журнале файловой системы $LogFile и журнале изменений \$Extend\$UsrJrnL
Если в системе поддерживаются квоты, новый размер файла включается в квоту
пользователя в файле \$Extend\$Quota.
Связи между компонентами и итоговое состояние системы показаны на рис. 12.13.
Рис. 12.13. Состояние системы после создания файла \dirl\filel.dat
Пример удаления файла
Теперь посмотрим, что происходит при удалении файла \dirl\filel.dat
1. Удаление файла начинается с чтения первого сектора файловой системы и об-
обработки загрузочного сектора для определения размера кластера, начального
адреса MFT и размера записи MFT.
2. Мы читаем из MFT первую запись (файл $МПГ) и обрабатываем ее для определе-
определения структуры остальных записей MFT. Информация хранится в атрибуте $ DATA.
3. Далее необходимо найти каталог dirl, поэтому мы обрабатываем запись MFT
корневого каталога E) и перемещаемся по индексу в атрибутах $INDEX_ROOT
и $INDEX_ALLOCATION. Из обнаруженного элемента dirl берется адрес записи
MFT 200. Обновляется время последнего обращения к каталогу.
4. Мы обрабатываем атрибут $INDEX_ROOT записи MFT 200 и ищем в нем элемент
filel.dat. Выясняется, что адрес MFT файла соответствует записи 304.
5. Запись исключается из индекса, элементы узла перемещаются и заменяют ис-
исходный элемент. Для каталога обновляется время последней модификации
и обращения.
6. Запись MFT 304 освобождается сбросом флага использования. Также обра-
обрабатывается атрибут $DATA файла $Bitmap, и в нем обнуляется бит данной за-
записи.
7. Обрабатываются нерезидентные атрибуты записи MFT 304; соответствующие
кластеры переводятся в свободное состояние в битовой карте файла \$Bitmap.
В нашем примере освобождаются кластеры 692 и 693.
8. Каждый из перечисленных этапов может сопровождаться созданием записей
в журнале файловой системы $LogFHe и журнале изменений \$Extend\$UsrJrnl.
Если в системе поддерживаются квоты, новый размер файла вычитается из
квоты пользователя в файле \$Extend\$Quota.
Итоговое состояние показано на рис. 12.14. Обратите внимание: при удалении
файла в NTFS Windows не стирает указатели. Таким образом, связь между запи-
записью MFT и кластером сохраняется, а связь между именем файла и записью MFT
тоже продолжала бы существовать, если бы запись не была потеряна в результате
пересортировки.
Рис. 12.14. Состояние системы после удаления файла \dirl\filel.dat.
Серым цветом помечены освобождающиеся блоки
Разное
В этом разделе обсуждаются вопросы, не относящиеся к какой-либо конкретной
категории данных — восстановление удаленных файлов и проверки целостности.
Восстановление файлов
Восстановить удаленный файл в NTFS проще, чем в большинстве файловых сис-
систем. При удалении файла его имя исключается из индекса родительского катало-
каталога, освобождается его запись MFT и занимаемые им кластеры. Компонент Microsoft
не стирает содержимое указателей, хотя исключать такую возможность в буду-
будущих версиях Windows нельзя.
У NTFS есть один большой недостаток: при исключении имени файла из ин-
индекса родительского каталога индекс сортируется заново, и информация об име-
имени может быть потеряна. В этом случае имя удаленного файла пропадает из ис-
исходного каталога. Тем не менее недостаток отчасти компенсируется тем, что все
записи MFT хранятся в одной таблице, что упрощает поиск всех свободных запи-
записей. Кроме того, каждая запись содержит атрибут $FILE_NAME с базовым адресом
родительского каталога. А это означает, что при нахождении свободной записи
обычно удается определить ее полный путь, если только записи ее родительских
каталогов не были повторно выделены новым файлам или каталогам.
Другое обстоятельство, которое необходимо учитывать при восстановлении
удаленных файлов в NTFS — поиск дополнительных атрибутов $DATA. Для тести-
тестирования программ восстановления файлов в NTFS можно воспользоваться тесто-
тестовыми образами с сайта DFTT [Carrier 2004]. Образ содержит удаленные файлы
с несколькими атрибутами $DATA, на которые не ссылается ни один индексный
элемент.
Чтобы восстановить все удаленные файлы в NTFS, необходимо провести в MFT
поиск свободных записей. После обнаружения свободной записи имя определя-
определяется по атрибуту $FILE_NAME и адресу родительского каталога. Указатели на клас-
кластеры продолжают существовать, и если данные еще не были перезаписаны, их
удастся восстановить. Восстановление возможно даже при сильной фрагмента-
фрагментации файла. Если значение атрибута было резидентным, данные не будут переза-
перезаписаны вплоть до повторного выделения записи MFT. Если для хранения атри-
атрибутов файла требуется более одной записи MFT, для полного восстановления
могут потребоваться другие записи. В Windows для записей MFT используется
алгоритм выделения первой доступной записи, поэтому записи MFT с малыми
номерами выделяются чаще, чем записи с большими номерами.
При восстановлении файлов или просмотре удаленного содержимого могут
пригодиться данные журнала файловой системы или журнала изменений. Жур-
Журнал изменений не всегда активен, но в нем можно найти информацию о времени
удаления и последнего редактирования файла.
Проверка целостности данных
Проверки целостности применяются в расследованиях для идентификации по-
поврежденных образов или выявления фактов постороннего вмешательства. В этом
разделе рассматриваются некоторые проверки, выполняемые с образами файловой
системы NTFS. Первая проверка относится к загрузочному сектору. Загрузочный
сектор NTFS содержит мало данных, но компания Microsoft требует, чтобы неко-
некоторые неиспользуемые значения были обязательно равны нулю. Я обнаружил,
что после загрузочного кода в файле $Boot часто следует большое количество не-
неиспользуемых кластеров. Как и в других файловых системах, кластеры, помечен-
помеченные как поврежденные в файле $BadCLus, необходимо перепроверять, потому что
многие жесткие диски заменяют поврежденные кластеры еще до того, как они
будут распознаны файловой системой.
Файл $MFT, содержащий саму таблицу MFT, в системе Windows только уве-
увеличивается в размерах. Квалифицированный злоумышленник может попытать-
попытаться сделать эту таблицу очень большой и скрыть данные в ее конце, но он рискует
потерять данные при создании новых файлов. Первые 16 записей MFT зарезер-
зарезервированы, некоторые из них не используются в настоящее время. Зарезерви-
Зарезервированные, но неиспользуемые структуры метаданных традиционно использова-
использовались в других файловых системах для сокрытия данных; то же может произойти
в NTFS.
Каждый выделенный кластер должен входить в серию кластеров. Каждый вы-
выделенный кластер NTFS является частью файла или каталога, и проверка целост-
целостности должна подтвердить этот факт. У каждой выделенной записи МFT должны
быть установлены флаг использования и соответствующий бит атрибута $В1ТМАР.
Кроме того, у каждой выделенной записи MFT для каждого имени файла должен
существовать элемент в индексе каталога. Даже файлы метаданных файловой
системы должны быть представлены именами в своих родительских каталогах.
Количество флагов и параметров у элементов каталогов и записей MFT на-
настолько велико, что приводить список всех проверяемых флагов было бы бессмыс-
бессмысленно. Одна из трудностей при работе с NTFS заключается в том, что эта система
чрезвычайно гибка и обладает множеством параметров. Без официальной специ-
спецификации неизвестно, какие комбинации значений следует считать допустимыми,
а какие — нет.
Итоги
Вероятно, вы уже поняли, что NTFS — чрезвычайно сложная и мощная файловая
система. При рассмотрении файловой системы NTFS сложности объяснялись глав-
главным образом тем, что эта система изначально не была рассчитана на современные
объемы данных или потребности. Система NTFS сложна именно потому, что она
проектировалась с учетом современных потребностей, а также с заделом на буду-
будущее. В NTFS также реализованы многие функции прикладного уровня, что также
способствует усложнению системы.
На момент написания книги система NTFS занимала доминирующее положе-
положение в семействе Windows. Домашние пользователи устанавливают ХР и фор-
форматируют свои диски в NTFS вместо FAT. Некоторые аспекты NTFS упрощают
работу эксперта: прежде всего это простота восстановления удаленных файлов
и возможность реконструкции событий на базе журналов (если они включены).
С другой стороны, из-за общей сложности системы эксперту труднее объяснить,
где именно были найдены улики.
Библиография
• Carrier, Brian. «NTFS Keyword Search Test #1». Digital Forensic Tool Testing,
October 2003. http://dftt.sourceforge.net
• Carrier, Brian. «NTFS Undelete (and leap year) Test #1». Digital Forensic Tool
Testing, February 2003. http://dftt.sourceforge.net
• Microsoft. «Recovering NTFS Boot Sector on NTFS Partitions». Knowledge Base
Article 153973,2003. http://support.microsoft.com/default.aspx?scid=kb;EN-US;ql53973
• Microsoft MSDN Library. «FILETIME». 2004. http://msdn.microsoft.com/Library/
en-us/sysinfo/base/filetime_str.asp.
Также см. раздел «Библиография» главы 11.
Структуры данных NTFS
В третьей, и последней главе, посвященной NTFS, будут подробно описаны струк-
структуры данных этой системы. В двух предыдущих главах рассматривались основ-
основные концепции NTFS и методы анализа данных в этой системе. Во многих случа-
случаях приведенной информации оказывается вполне достаточно, но многие аналитики
желают лучше разбираться в происходящем. В этой главе сначала рассматрива-
рассматриваются структуры данных базовых элементов, а затем — структуры специализи-
специализированных атрибутов и индексов. В завершение рассматриваются файлы мета-
метаданных файловой системы. В отличие от других глав, посвященных файловым
системам, предполагается, что вы будете читать эту главу после глав 11 и 12. Пер-
Первую часть можно читать параллельно с главой 11, но для усвоения дальнейшего
материала необходимо сначала полностью прочитать главу 12 и хорошо понять
смысл различных атрибутов. Прежде чем начинать, напомню, что официально
опубликованной спецификации NTFS до сих пор нет. Описания структур дан-
данных взяты из материалов группы Linux NTFS; как вы убедитесь, они соответству-
соответствуют фактическому содержимому диска. Тем не менее нельзя исключать существо-
существования других флагов и нюансов, о существовании которых нам еще не известно.
Базовые концепции
Этот раздел посвящен основным концепциям структур данных NTFS. Сначала
мы рассмотрим некоторые особенности строения больших структур данных, по-
повышающие их надежность, а затем обсудим строение записи MFT и заголовка
атрибута.
Маркеры
Прежде чем рассматривать конкретные структуры данных NTFS, необходимо
упомянуть об особой методике хранения данных, используемой для повышения
надежности. Система NTFS включает специальные маркеры в структуры данных,
длина которых превышает один сектор. Два последних байта каждого сектора боль-
большой структуры данных заменяются специальной сигнатурой при записи структу-
структуры данных на диск. В дальнейшем сигнатура используется для проверки целост-
целостности данных — система проверяет, что у всех секторов одной структуры данных
эта сигнатура совпадает. Обратите внимание: маркеры включаются только в струк-
структуры данных, но не в секторы с содержимым файлов.
Структуры данных, использующие маркеры, содержат заголовочные поля с ука-
указанием текущей 16-разрядной сигнатуры и массива исходных значений. Когда
структура данных записывается на диск, сигнатура увеличивается на 1, два пос-
последних байта каждого сектора копируются в массив, а на их место записывется
сигнатура. При чтении структуры данных ОС убеждается в том, что два после-
последних байта каждого сектора совпадают с сигнатурой, после чего восстанавливает
исходные данные из массива. На рис. 13.1 показана структура данных с реальны-
реальными данными и версия, записываемая на диск. Во второй структуре два последних
байта каждого сектора заменены сигнатурой 0x0001.
Рис. 13.1. Структура данных, состоящая из нескольких секторов: исходные значения
и сигнатуры, записанные в два последних байта каждого сектора
Маркеры используются для выявления поврежденных секторов и структур
данных. Если в многосекторной структуре данных был успешно записан только
один сектор, его маркер будет отличаться от сигнатуры, и ОС поймет, что дан-
данные были повреждены. Первое, что необходимо сделать при рассмотрении на-
наших примеров структур файловых систем, — это заменить маркеры реальными
данными.
Записи MFT (файловые записи)
Как упоминалось в главах И и 13, главная файловая таблица MfT (Master File
Table) является основной структурой данных NTFS; в ней создается запись для
каждого файла и каталога в системе. Записи MFT имеют фиксированный размер
и содержат минимальный набор полей. В настоящее время размер записей состав-
составляет 1024 байт, но формально он определяется в загрузочном секторе. В каждой
записи MFT используются проверочные маркеры, поэтому в дисковой версии
структуры данных два последних байта каждого сектора заменяются сигнатурой
(см. предыдущий раздел). Поля записи MFT перечислены в табл. 13.1.
Таблица 13.1. Структура данных базовой записи MFT
Диапазон Описание Необходимость
0-3 Сигнатура («FILE») Нет
4-5 Смещение массива маркеров Да
6-7 Количество элементов в массиве маркеров Да
8-15 Номер LSN для $LogFile Нет
16-17 Порядковый номер Нет
18-19 Счетчик ссылок Нет
20-21 Смещение первого атрибута Да
22-23 Флаги (использования и каталога) Да
24-27 Используемый размер записи MFT Да
28-31 Выделенный размер записи MFT Да
32-39 Адрес базовой записи Нет
40-41 Идентификатор следующего атрибута Нет
42-1023 Атрибуты и маркеры Да
В качестве стандартной сигнатуры используется строка «FILE», но в записях,
в которых программа chkdsk обнаружила ошибки, также может содержаться строка
«В AAD». В следующих двух полях содержатся маркеры, а массив замененных бай-
байтов обычно хранится после байта 42. Смещения задаются по отношению к началу
записи.
Номер LSN используется в журнале файловой системы (см. раздел «Катего-
«Категория прикладных данных» главы 12). В журнале фиксируются обновления мета-
метаданных в файловой системе; эта информация ускоряет восстановление повреж-
поврежденных файловых систем.
Порядковый номер увеличивается при каждом выделении и освобождении
записи. Счетчик ссылок определяет число каталогов, содержащих записи для дан-
данной структуры MFT. Число увеличивается на 1 для каждой жесткой ссылки, со-
создаваемой для файла.
Первый атрибут файла находится по смещению, заданному относительно на-
начала файла. За первым атрибутом следуют остальные; чтобы найти их, следует
сместиться вперед на величину, указанную в поле размера в заголовке атрибута.
За последним атрибутом находится признак конца файла Oxffffffff. Если файлу
требуется более одной записи MFT, то в дополнительные записи включается ба-
базовый адрес основной записи.
Поле флагов содержит только два значения. Бит 0x01 устанавливается в том
случае, если запись используется, а бит 0x02 — если запись представляет каталог.
Давайте рассмотрим низкоуровневое содержимое записи MFT. Мы восполь-
воспользуемся программой icat из пакета TSK (The Sleuth Kit) и просмотрим атрибут $ DATA
файла $MFT, соответствующего записи 0. Чтобы задать любой атрибут в TSK, дос-
достаточно добавить идентификатор типа атрибута после адреса записи MFT. В дан-
данном случае атрибут $DATA обладает типом 128.
# icat -f ntfs ntfsl.dd 0-128 | xxd
0000000: 4649 4c45 3000 0300 4ba7 6401 0000 0000 FILEO...K.d
0000016: 0100 0100 3800 0100 Ь801 0000 0004 0000 ....8
0000032: 0000 0000 0000 0000 0600 0000 0000 0000
0000048: 5800 0000 0000 0000 1000 0000 6000 0000 X
[...]
0000496: 3101 Ь43а 0500 0000 ffff ffff 0000 5800 1..: X.
0000512: 0000 0000 0000 0000 0000 0000 0000 5800
С.]
0001008: 0000 0000 0000 0000 0000 0000 0000 5800 X.
В выходных данных используется прямой порядок байтов, поэтому байты
чисел необходимо поменять местами. Листинг начинается с сигнатуры «FILE»,
а байты 4 и 5 показывают, что массив данных, замененных маркерами, хранится
в записи MFT со смещением 48 байт @x0030). Из байтов 6-7 видно, что массив
состоит из 3 элементов. Байты 16-17 показывают, что порядковый номер запи-
записи MFT равен 1; иначе говоря, это первое использование записи. Счетчик ссы-
ссылок (байты 18-19) равен 1; это означает, что запись обладает единственным
именем. Байты 20-21 показывают, что первый атрибут начинается со смещения
56 @x0038).
Флаги в байтах 22-23 показывают, что запись используется в настоящий мо-
момент. Поле базовой записи (байты 32-39) равно 0, то есть сама запись является
базовой. Байты 40-41 показывают, что следующий идентификатор атрибута ра-
равен 6. Следовательно, мы можем предположить, что запись содержит атрибуты
с идентификаторами от 1 до 5.
С байта 48 начинается массив данных, замененных маркерами. Первые два
байта определяют сигнатуру @x0058). За ними следуют 2-байтовые группы ис-
исходных данных, которые должны быть записаны на место сигнатур. Мы обраща-
обращаемся к двум последним байтам каждого сектора (байты 510-511 и 1022-1023)
и видим, что в обоих случаях в них содержится сигнатура 0x0058. Маркеры заме-
заменяются значением 0x0000, взятым из массива. После массива с байта 56 начина-
начинается первый атрибут. Атрибуты файла завершаются на байте 504 признаком кон-
конца файла Oxffff ffff. Остальные байты записи равны 0.
Для просмотра произвольной записи MFT в TSK можно воспользоваться про-
программой dd в сочетании с icat для перехода к нужному смещению. При этом раз-
размер блока устанавливается равным 1024, то есть размеру каждой записи MFT.
Например, команда для просмотра записи 1234 выглядит так:
# icat -f ntfs ntfsl.dd 0 | dd bs-1024 skip-1234 count-1 | xxd
Заголовок атрибута
Запись MFT содержит несколько атрибутов. Все атрибуты содержат одинако-
одинаковые заголовочные структуры данных, которые будут описаны в этом разделе.
На рис. 13.2 представлена структура типичной записи MFT с заголовками. У ре-
резидентных и нерезидентных атрибутов структуры данных слегка различаются,
потому что в нерезидентных атрибутах требуется дополнительно хранить ин-
информацию о сериях.
Первые 16 байт атрибутов обоих типов совпадают. Содержащиеся в них поля
перечислены в табл. 13.2.
Рис. 13.2. Типичный файл с различными заголовками
Таблица 13.2. Структура начальных 16 байт атрибута
Диапазон Описание Необходимость
0-3 Идентификатор типа атрибута Да
4-7 Длина атрибута Да
8-8 Флаг нерезидентного атрибута Да
9-9 Длина имени Да
10-11 Смещение имени Да
12-13 Флаги Да
14-15 Идентификатор атрибута Да
Заголовок содержит базовую информацию об атрибуте, включая тип, размер
и местонахождение имени. Размер используется для поиска следующего атрибу-
атрибута в записи MFT; за последним атрибутом следует специальная последователь-
последовательность Oxffff ffff. Флаг нерезидентного атрибута устанавливается равным 1, если
атрибут является нерезидентным. Поле флагов указывает, является ли атрибут
сжатым @x00001), зашифрованным @x4000) или разреженным @x8000). Иден-
Идентификатор атрибута представляет собой число, уникальное для данного атрибута
в данной записи MFT. Смещение имени задается относительно начала атрибута.
Поля резидентного атрибута перечислены в табл. 13.3.
Таблица 13.3. Структура данных резидентного атрибута
Диапазон Описание Необходимость
0-15 Общий заголовок (см. табл. 13.2) Да
16-19 Размер содержимого Да
20-21 Смещение содержимого Да
Эти значения просто сообщают размер и местонахождение (относительно на-
начала атрибута) содержимого атрибута, также называемого потоком (stream). Рас-
Рассмотрим пример. Ранее при анализе записи MFT мы видели, что атрибуты начи-
начинаются с байта 56. Я взял атрибут в этой позиции и обнулил смещения, чтобы
было проще идентифицировать поля в заголовке атрибута.
0000000: 1000 0000 6000 0000 0000 1800 0000 0000 ....ч
0000016: 4800 0000 1800 0000 305а 7alf f63b сЗО1 Н OZz..;..
В первых четырех байтах содержится тип атрибута 16 @x10), соответствую-
соответствующий $STANDARD_INFORMATION. Байты 4-7 показывают, что размер атрибута равен
96 байтам @x60). Из байта 8 видно, что атрибут является резидентным @x00), а
из байта 9 — что ему не присвоено имя @x00). Флаги и идентификаторы в байтах
12-13 и 14-15 заполнены нулями. Байты 16-19 показывают, что длина содержи-
содержимого атрибута составляет 72 байта @x48), а байты 20-21 — что атрибут начинает-
начинается со смещением 24 байта @x18). Выполним несложную проверку: 24 байта сме-
смещения в сумме с 72 байтами длины содержимого составляют 96 байт, то есть длину
атрибута, указанную в заголовке.
У нерезидентных атрибутов структура данных устроена несколько иначе, по-
потому что для них необходима возможность описания произвольного количества
серий кластеров. Поля структуры данных нерезидентных атрибутов приведены
в табл. 13.4.
Таблица 13.4. Структура данных нерезидентного атрибута
Диапазон Описание Необходимость
0-15 Общий заголовок (см. табл. 13.2) Да
16-23 Начальный виртуальный номер кластера (VCN) Да
списка серий
24-31 Конечный номер VCN списка серий Да
32-33 Смещение списка серий Да
34-35 Размер блока сжатия Да
36-39 Не используется Нет
40-47 Выделенный размер содержимого атрибута Нет
48-55 Фактический размер содержимого атрибута Да
56-63 Инициализированный размер содержимого атрибута Нет
Вспомните, что VCN представляет собой другое название для логических ад-
адресов файлов, о которых говорилось в главе 8. Начальный и конечный номера VCN
используются в тех случаях, когда для описания одного атрибута требуется не-
несколько записей MFT. Например, если атрибут $DATA сильно фрагментирован и его
серии не помещаются в одной записи MFT, для него может быть выделена вторая
запись MFT. Вторая запись содержит атрибут $DATA с начальным номером VCN,
который следует за конечным номером VCN первой записи. Пример приводится
в разделе «$ATTRIBUTE_LIST». Поле размера блока сжатия описано в главе 11;
оно необходимо только для сжатых атрибутов.
Смещение списка серий задается относительно начала атрибута. Формат списка
серий чрезвычайно эффективен, но простотой он не отличается. Список имеет
переменную длину не менее 1 байта. Первый байт структуры данных разделен на
старшие и младшие 4 бита. Младший полубайт содержит размер (в байтах) поля
длины серии, следующего за байтом заголовка. Старший полубайт содержит раз-
размер (в байтах) поля смещения серии, следующего за полем длины. Пример пока-
показан на рис. 13.3.
Значения задаются в кластерах, а поле смещения является знаковым значе-
значением, заданным по отношению к предыдущему смещению. Например, смеще-
смещение первой серии атрибута задается по отношению к началу файловой системы,
а смещение второй серии — по отношению к предыдущему. У отрицательного чис-
числа старший бит равен 1; если вы собираетесь ввести значение на калькуляторе,
чтобы преобразовать его, прибавьте столько единиц, сколько потребуется для фор-
формирования полного 32- или 64-разрядного числа. Например, если значение равно
Oxfl, на калькуляторе вводится значение Oxfffffffl.
Рис. 13.3. Первый байт серии показывает, что поле длины занимает 1 байт,
а поле смещения — 2 байта
Чтобы просмотреть содержимое нерезидентного атрибута, давайте вернемся
к ранее проанализированной записи и перейдем к атрибуту $DATA. Содержимое
атрибута показано далее (смещения скорректированы по отношению к началу
атрибута):
0000000: 8000 0000 6000 0000 0100 4000 0000 0100 ...Г @
0000016: 0000 0000 0000 0000 ef20 0000 0000 0000
0000032: 4000 0000 0000 0000 00с0 8300 0000 0000 @
0000048: ООсО 8300 0000 0000 ООсО 8300 0000 0100
0000064: 32с0 1еЬ5 ЗаО5 2170 lblf 2290 015f 7e31 2...:.!р..и.._~1
0000080: 2076 edOO 2110 8700 00Ь0 6е82 4844 7е82 v..! n.HD~.
Первые 4 байта показывают, что атрибут относится к типу 128 @x80), а вторая
группа из 4 байт — что его общий размер равен 96 байтам @x60). Байт 8 равен 1;
это означает, что атрибут является нерезидентным. Нулевой байт 9 означает, что
длина имени атрибута равна 0; следовательно, перед нами атрибут $DATA по умол-
умолчанию, а не ADS. По нулевым флагам (байты 12-13) мы определяем, что атрибут
не зашифрован и не сжат.
Нерезидентная информация начинается с байта 16. Байты 16-23 показывают,
что начальный номер VCN для этого набора серий равен 0. Конечный номер VCN
задается байтами 24-31; в данном примере он равен 8431 @x20ef). Байты 32-33
показывают, что смещение списка серий составляет 64 байта @x0040) от начала.
Байты 40-47,48-55 и 56-63 предназначены для выделенного, фактического и ини-
инициализированного размеров содержимого; в них хранится одно и то же значение
8 634 368 байт @х0083с000).
В байте 64 начинается сам список серий. Я снова приведу соответствующий
фрагмент:
0000064: 32сО 1еЬ5 ЗаО5 2170 lblf
Вспомните, что первый байт делится на старшие и младшие 4 бита, в которых
хранится размер остальных полей. Младший полубайт байта 64 показывает, что
поле длины серии состоит из 2 байт, а старший полубайт — что поле смещения
состоит из 3 байт. Чтобы определить длину серии, мы анализируем байты 65-66
и получаем 7872 кластера (OxlecO). Следующие три байта F7-69) дают смещение
342 709 @х053аЬ5). Следовательно, первая серия начинается с кластера 342 709
и продолжается 7 872 кластера.
Структура данных следующей серии начинается после завершения текущей,
то есть с байта 70. Мы видим, что поле длины состоит из 1 байта, а поле смеще-
смещения — из 2 байт. Значение длины хранится в байте 71 и равно 112 @x70). Величи-
Величина смещения хранится в байтах 72-73 и равна 7963 (Oxlflb). Смещение является
знаковой величиной и задается по отношению к предыдущему смещению; при-
прибавляя 7963 к 342 709, мы получаем 350 672. Следовательно, вторая серия начи-
начинается с кластера 350 672 и продолжается 112 кластеров. Остаток списка серий
вы можете расшифровать самостоятельно.
Стандартные атрибуты файлов
В предыдущем разделе было показано, как происходит обработка записей MFT
и заголовков атрибутов. Каждый заголовок атрибута указывает на резидентную
или нерезидентную область дискового пространства, в которой хранится содер-
содержимое атрибута. В этом разделе объясняется, как происходит обработка калсдого
конкретного типа содержимого атрибутов.
Атрибут $STANDARD_INFORMATION
Атрибут $STANDARD_INFORMATION (идентификатор типа 16) всегда является рези-
резидентным. В нем хранятся основные метаданные файлов или каталогов. Атрибут
существует в каждом файле или каталоге; как правило, он находится в первой
позиции списка атрибутов из-за наименьшего идентификатора типа. Поля атри-
атрибута (необязательные) перечислены в табл. 13.5.
Таблица 13.5. Структура данных атрибута $STANDARD_INFORMATION
Диапазон Описание Н еобход и м ость
0-7 Время создания Нет
8-15 Время модификации файла Нет
16-23 Время модификации MFT Нет
24-31 Время обращения к файлу Нет
32-35 Флаги (см. табл. 13.6) Нет
36-39 Максимальное количество версий Нет
40-43 Номер версии Нет
44-47 Идентификатор класса Нет
48-51 Идентификатор владельца (версия 3.0+) Нет
52-55 Идентификатор безопасности (версия 3.0+) Нет
56-63 Изменение квоты (версия 3.0+) Нет
64-71 Номер USN (Update Sequence Number) Нет
Значения временных штампов задаются в сотнях наносекунд, прошедших
с 1 января 1601 г., в формате UTC. Эти поля также присутствуют и в атрибуте
$FILE_NAME, но именно этот набор штампов выводится Windows при просмотре
свойств файла и обновляется системой. Идентификаторы используются как функ-
циями прикладного уровня, так и системой безопасности. Идентификатор бе-
безопасности используется для индексирования файла $Secure; не путайте его с ко-
кодом SID системы Windows. Значения флагов перечислены в табл. 13.6.
Таблица 13.6. Флаги атрибута $STANDARD_INFORMATJON
Флаг Описание Необходимость
0x0001 Только для чтения Нет
0x0002 Скрытый файл Нет
0x0004 Системный файл Нет
0x0020 Архивный файл Нет
0x0040 Устройство Нет
0x0080 Обычный файл Нет
0x0100 Временный файл Нет
0x0200 Разреженный файл Нет
0x0400 Точка подключения Нет
0x0800 Сжатый файл Нет
0x1000 Автономный файл Нет
0x2000 Содержимое не индексируется для ускорения поиска Нет
024000 Зашифрованный файл Нет
Многие флаги совпадают с флагами системы FAT, и их описания можно найти
в соответствующем разделе. Флаги зашифрованных и разреженных атрибутов
также дублируются в заголовке атрибута, поэтому здесь я их отнес к несуществен-
несущественным. Впрочем, это спорный момент; возможно, кто-то сочтет этот флаг необходи-
необходимым, а значения в заголовке записи MFT — несущественными.
Рассмотрим пример атрибута $STANDARD_INFORMATION. Для вывода его содер-
содержимого можно воспользоваться программой icat и указать тип атрибута. В этом
случае icat автоматически скрывает стандартный заголовок и выводит только со-
содержимое. Содержимое атрибута $STANDARD_INFORMATION для файла $MFT выгля-
выглядит так:
# icat -f ntfs ntfsl.dd 0-16 | xxd
0000000: 305a 7alf f63b c301 305a 7alf f63b c301 OZz..:..OZz..;..
0000016: 305a 7alf f63b c301 305a 7alf f63b c301 OZz..;..OZz..:..
0000032: 0600 0000 0000 0000 0000 0000 0000 0000
0000048: 0600 0000 0001 0000 0000 0000 0000 0000
0000064: 0600 0000 0000 0000
В первых 8 байтах указано время создания файла; оно совпадает для всех че-
четырех временных штампов. Байты 32-35 содержат поле набора флагов 0x00000060;
в нем установлены биты скрытого и системного файла, что вполне естественно
для файла метаданных файловой системы. Байты 36-39 и 40-43 показывают, что
версии не используются, а из байтов 44-47 видно, что идентификатор класса ра-
равен 0. Идентификатор владельца (байты 48-51) равен 0, а идентификатор безо-
безопасности (байты 52-55) равен 1. Остальные значения равны 0, что вполне есте-
естественно для $MFT, потому что эта запись обычно не учитывается в пользовательских
квотах, а в большинстве систем журналы изменений по умолчанию отключены,
из-за чего номера USN не назначаются.
Атрибут $FILE_NAME
Атрибут $FILE_NAME (идентификатор типа 48) выполняет две функции. Во-пер-
Во-первых, он включается в записи MFT для хранения имени файла и информации
о родительском каталоге; во-вторых, он используется в индексах каталогов. При
использовании в записях MFT атрибут не содержит никакой необходимой ин-
информации, но в индексах эта информация присутствует.
Для стандартных файлов и каталогов этот атрибут находится на второй позиции
и всегда является резидентным. Если для хранения файла требуется несколько
записей MFT, атрибут $ATTRIBUTE_LIST будет находиться между $STANDARD_INFOR-
$STANDARD_INFORMATION и этим атрибутом. Поля атрибута $FILE_NAME перечислены в табл. 13.7.
Таблица 13.7. Структура данных атрибута $FILE_NAME
Диапазон Описание Необходимость
0-7 Базовый адрес родительского каталога Нет
8-15 Время создания файла Нет
16-23 Время модификации файла Нет
24-31 Время модификации MFT Нет
32-39 Время обращения к файлу Нет
40-47 Выделенный размер файла Нет
48-55 Реальный размер файла Нет
56-59 Флаги (см. табл. 13.6) Нет
60-63 Точка подключения Нет
64-64 Длина имени Да/Нет
65-65 Пространство имен (см. табл. 13.8) Да/Нет
66+ Имя Да/Нет
Последние три поля необходимы в тех случаях, когда атрибут используется
в индексе каталога, но не при его использовании в записи MFT для файла. В поле
флагов применяются те же значения, что и в атрибуте $STANDARD_INFORMATION
(см. ранее).
Байт пространства имен указывает, по каким правилам строится имя файла.
Допустимые значения приведены в табл. 13.8.
Таблица 13.8. Значения поля пространства имен атрибута $FILE_NAME
Код Описание
пространства
имен
0 POSIX: в имени учитывается регистр символов; допустимы любые
символы Unicode, кроме / и NULL
1 Win32: регистр символов не учитывается; допустимо большинство символов
Unicode, кроме некоторых специальных символов (/, \, :, >, < и ?)
2 DOS: регистр символов не учитывается, имена хранятся в верхнем регистре
и не могут содержать специальных символов. Имя содержит не более
8 символов, а расширение — не более трех
3 Win32 и DOS: используется в тех случаях, когда исходное имя уже принадле-
принадлежит пространству имен DOS и хранить две версии имени не нужно
Чтобы рассмотреть пример атрибута $FILE_NAME, мы снова обращаемся к запи-
записи $МПГ и указываем тип атрибута 48:
# icat -f ntfs ntfsl.dd 0-48 | xxd
0000000: 0500 0000 0000 0500 305a 7alf f63b c301 OZz..;..
0000016: 305a 7alf f63b c301 305a 7alf f63b c301 OZz..;..OZz..;..
0000032: 305a 7alf f63b c301 0040 0000 0000 0000 OZz..:...@
0000048: 0040 0000 0000 0000 0060 0000 0000 0000 .@
0000064: 0403 2400 4d00 4600 5400 ..S.M.F.T.
Первые 8 байт содержат базовый адрес файла; старшие два байта определяют
порядковый номер, а младшие шесть — запись MFT. Итак, родительский каталог
для данной записи MFT представлен записью MFT 5, а его порядковый номер
равен 5; запись соответствует корневому каталогу. В следующих 8 байтах указано
время создания файла; оно совпадает с тремя другими временными штампами
атрибута.
Байты 40-47 и 48-55 предназначены для выделенного и фактического разме-
размеров файла соответственно; в них хранится одно и то же значение 16 384 байт
@x4000). В действительности атрибут $DATA этого файла занимает 8 364 368 байт;
совершенно очевидно, что эта информация неверна. У многих файлов эти поля
заполняются нулями, но при использовании атрибута в индексе каталога они со-
содержат точную информацию.
Поле флагов (байты 56-57) содержит значение 0x0006; в нем установлены
флаги скрытого и системного файлов. Те же флаги были установлены у атрибута
$STANDARD_INFORMATION. Байт 64 показывает, что имя состоит из 4 букв, а байт
65 — что оно относится к пространству имен 3 (DOS+Win32). Имя хранится в ко-
кодировке Unicode UTF-16 и начинается с байта 66. В нашем примере это имя $MFT.
Напоследок рассмотрим файл с двумя атрибутами $FILE_NAME, поскольку
Windows требует, чтобы для каждого файла существовало DOS-имя. Файл со-
содержит атрибуты $FILE_NAME как для имени из пространства DOS, так и для име-
имени из пространства Win32. Я не стану подробно анализировать оба атрибута,
а лишь приведу выходные данные icat:
# icat -f ntfs ntfsl.dd 0-48-2 | xxd
0000000: 3920 0000 0000 0300 00b6 89a9 086a c401 9 j. .
0000016: 00b6 89a9 086a c401 00b6 89a9 086a c401 j j..
0000032: 00b6 89a9 086a c401 0000 0000 0000 0000 j
0000048: 0000 0000 0000 0000 2020 0000 0000 0000
0000064: ObOl 3500 3700 3300 3900 3800 3400 3000 ..5.7.3.9.8.4.0.
0000080: 3800 6400 3000 3100 8.d.0.1.
В байте 65 определяется пространство имен 1 (Win32). В этой записи содер-
содержится имя файла «57398408d01». Следующий атрибут $FILE_NAME обладает тем
же идентификатором типа 48, но его идентификатор атрибута равен 3:
# icat -f ntfs ntfsl.dd 0-48-3 | xxd
0000000: 3920 0000 0000 0300 00b6 89a9 086a c401 9 j. .
0000016: 00b6 89a9 086a c401 00b6 89a9 086a c401 j j..
0000032: ООЬб 89a9 086a c401 0000 0000 0000 0000 j
0000048: 0000 0000 0000 0000 2020 0000 0000 0000
0000064: 0802 3500 3700 3300 3900 3800 3400 3000 ..5.7.3.9.8.4.-.
0000080: 3100 1.
В соответствии с содержимым байта 65, атрибут относится к пространству имен
2 (DOS). Имя файла в этой записи представляет собой строку «573984-1».
Атрибут $DATA
Атрибут $DATA проще всех остальных, потому что он вообще не имеет внутренней
структуры. После заголовка следует блок низкоуровневых данных, соответству-
соответствующий содержимому файла. Атрибут соответствует идентификатору типа 128 и
не имеет ограничений на минимальный или максимальный размер. Если объем
содержимого превышает 700 байт, скорее всего, атрибут будет нерезидентным.
Для большинства файлов атрибут $DATA является последним атрибутом в записи
MFT. Учтите, что каталоги кроме своих индексных атрибутов могут обладать ат-
атрибутами $DATA.
Атрибут $ATTRIBUTE_LIST
Атрибут $ATTRIBUTE_LIST включается в записи MFT для хранения информации
о местонахождении других атрибутов. Он используется для файлов с заголовка-
заголовками атрибутов, не помещающимися в одной записи MFT, и содержит список, в ко-
котором каждый атрибут файла или каталога представлен отдельным элементом.
Атрибуту $ATTRIBUTE_LIST соответствует идентификатор типа 32, а каждый эле-
элемент списка состоит из полей, перечисленных в табл. 13.9.
Таблица 13.9. Структура элемента списка в атрибуте $FILE_NAME
Диапазон Описание Необходимость
0-3 Тип атрибута Да
4-5 Длина элемента Да
6-6 Длина имени Да
7-7 Смещение имени (относительно начала элемента) Да
8-15 Начальный номер VCN в атрибуте Да
16-23 Базовый адрес записи с атрибутом Да
24-24 Идентификатор атрибута Да
Начальный номер VCN используется в ситуациях, когда для описания одного
атрибута требуется несколько записей MFT. В таких случаях дополнительные
записи обладают ненулевыми начальными номерами VCN. Ненулевой началь-
начальный номер VCN также должен присутствовать в заголовке атрибута.
Пример файла с атрибутом $ATTRIBUTE_LIST:
# icat -f ntfs ntfsl.dd 5009-32 | xxd
0000000: 1000 0000 2000 001a 0000 0000 0000 0000
0000016: 9113 0000 0000 0800 0000 0000 0000 0000
0000032: 3000 0000 2000 001a 0000 0000 0000 0000 0
0000048: 9113 0000 0000 0800 0300 0000 0006 0000
0000064: 3000 0000 2000 001a 0000 0000 0000 0000 0
0000080: 9113 0000 0000 0800 0200 0200 502d 40bc P-@.
0000096: 8000 0000 2000 001a 0000 0000 0000 0000
0000112: 3713 0000 0000 1200 0000 0000 1000 0000 7
0000128: 8000 0000 2000 001a 2014 0000 0000 0000
0000144: adl3 0000 0000 0800 0000 0000 0000 0000
Первые 4 байта содержат тип первого элемента; он равен 16 @x10), следова-
следовательно, это атрибут $STANDARD_INFORMATION. Байты 4-5 показывают, что длина
списка равна 32 байтам @x0020), а байты 16-21 — что атрибут находится в запи-
записи MFT 5009 @x1391), которую мы рассматриваем в настоящий момент.
Следующие два элемента начинаются с байтов 32 и 64. Оба представляют ат-
атрибут $FILE_NAME с идентификатором типа 48 @x30). Оба атрибута также присут-
присутствуют в текущей записи MFT.
Первый элемент атрибута $DATA начинается с байта 96. Байты 104-111 показы-
показывают, что этот атрибут $DATA связан с номером VCN 0 атрибута, а байты 112-117 —
что атрибут находится в записи MFT 4919 @x1337). Второй элемент атрибута
$DATA начинается с байта 128. Мы видим, что они относятся к одному атрибуту
$DATA, потому что идентификатор в обоих структурах данных равен 0. Байты 136—
143 показывают, что второй элемент обладает начальным номером VCN 5152
@x1420). Другими словами, атрибут $DATA в первом элементе располагает в запи-
записи MFT местом, достаточным для описания первых 5152 кластеров. Описания
остальных серий кластеров хранятся в атрибуте $DATA записи MFT 5037 @xl3ad);
это значение мы видим в байтах 144-149.
На рис. 13.4 изображено строение этого файла. Он обладает одним атрибутом
$STANDARD_INFORMATION и двумя атрибутами $FILE_NAME в базовой записи MFT
5009, а заголовки атрибута $DATA находятся в записях 4919 и 5037.
Рис. 13.4. Структура списка атрибутов для тестового образа
В главе 12 говорилось о том, что не-базовые записи MFT не обладают стандар-
стандартными атрибутами $FILE_NAME и $STANDARD_INFORMATION. В этом легко убедиться,
просмотрев одну из записей в нашем примере. При запуске программы istat для
не-базовой записи 4919 будет получен следующий результат:
# istat -f ntfs ntfsl.dd 4919
MfT Entry Header Values:
Entry: 4919 Sequence: 18
Base File Record: 5009
SLogFile Sequence Number: 66117460
Allocated File
Links: 0
[...]
Attributes:
Type: $DATA A28-0) Name: $Data Non-Resident size: 5787792
929409 929410 929411 929412 929413 929414 929415 929416
[...]
Запись MFT содержит только один атрибут $DATA; мы видим, что в заголовке
в качестве базовой указана запись 5009. Счетчик ссылок равен 0, потому что
с записью не ассоциируются дополнительные имена.
Атрибут $OBJECT_ID
Атрибут $OBJECT_ID (идентификатор типа 64) содержит 128-разрядный глобаль-
глобальный идентификатор объекта, который может использоваться для адресации фай-
файла вместо его имени. Идентификатор объекта позволяет найти файл даже после
его переименования. Индекс \$Extend\$ObjId сортируется по идентификаторам
объектов файлов и содержит базовые адреса, по которым можно найти каждый
файл. Атрибут содержит только четыре поля, причем обычно определяется толь-
только первое из них. Поля перечислены в табл. 13.10.
Таблица 13.10. Структура элемента списка в атрибуте $OBJECT_ID
Диапазон Описание Необходимость
0-15 Идентификатор объекта Да
16-31 Исходный идентификатор тома Нет
32-47 Исходный идентификатор объекта Нет
48-63 Исходный идентификатор домена Нет
У большинства файлов, которым назначается идентификатор объекта, опре-
определяется только первое поле, а размер атрибута равен 16 байтам. Файл $Volume
часто содержит атрибут $OBJECT_ID:
# icat -f ntfs img.dd 3-64 | xxd
0000000: fe24 b024 e292 fe47 95ac e507 4bf5 6782 .$.$...G....K.g.
Атрибут $REPARSE_POINT
Атрибут $REPARSE_POINT (идентификатор типа 192) используется для файлов,
которые представляют собой точки подключения — особые объекты, предназ-
предназначенные для создания символических ссылок, переходов и точек монтирования
для томов. Microsoft определяет часть содержимого атрибута $REPARSE_POINT,
но также возможна разработка структур, специфических для конкретных
приложений. Переходы и точки подключения имеют структуру, показанную
в табл. 13.11.
Таблица 13.11. Структура данных атрибута $REPARSE_POINT
для переходов и точек монтирования
Диапазон Описание Необходимость
0-3 Флаги типа подключения Да
4-5 Размер данных подключения Да
6-7 Не используется Нет
8-9 Смещение имени целевого объекта (относительно Да
байта 16)
10-11 Длина имени целевого объекта Да
Диапазон Описание Необходимость
12-13 Смещение выводимого имени целевого объекта Да
(относительно байта 16)
14-15 Длина выводимого имени Да
Для переходов и точек монтирования в поле флагов устанавливается флаг
ОхаООООООО. Точка подключения, связанная с каталогом c:\windows, выглядит так:
# icat -f ntfs ntfs2.dd 167-192 | xxd
0000000: 0300 OOaO 2800 0000 0000 lcOO leOO 0000 .... (
0000016: 5c00 3f00 3f00 5c00 6300 ЗаОО 5c00 7700 \.?.?.\.c.:.\.w.
0000032: 6900 6e00 6400 6f00 7700 7300 0000 1200 i.n.d.o.w.s
Байты 8-9 показывают, что смещение имени целевого объекта составляет О
байт, то есть имя начинается с байта 16. Его длина указывается в байтах 10-11;
мы видим, что она составляет 28 байт (Oxlc). В Unicode имя целевого объекта
имеет вид «\??\c:\windows».
Атрибуты и структуры данных индексов
В предыдущем разделе рассматривались атрибуты и концепции, относящиеся ко
всем файлам. В этом разделе речь пойдет о структурах данных и атрибутах, спе-
специфических для индексов. Напомню, что индексы реализуются в виде структур
данных, которые представляют собой отсортированное дерево. Дерево состоит из
одного или нескольких узлов, а каждый узел содержит один или несколько ин-
индексных элементов. Корень дерева находится в атрибуте $INDEX_ROOT, а другие
узлы — в индексных записях атрибута $INDEX_ALLOCATION. Атрибут $В1ТМАР со-
содержит информацию о состоянии выделения индексных записей.
В этом разделе мы начнем с внешнего уровня и будем постепенно продвигать-
продвигаться вовнутрь.
Атрибут $INDEX_ROOT
Атрибут $INDEX_ROOT (идентификатор типа 144) всегда является резидентным.
Он всегда представляет корневой узел индексного дерева, а храниться в нем может
лишь небольшой список индексных элементов. Атрибут $INDEX_ROOT обладает 16-
разрядным заголовком, за которым следует заголовок узла и список индексных
элементов (рис. 13.5). Заголовок узла описан в разделе «Структура данных заголов-
заголовка индексного узла», а индексные элементы — в разделе «Структура данных обоб-
обобщенного индексного элемента», а этот раздел посвящен заголовку $INDEX_ROOT.
Рис. 13.5. Внутренняя структура атрибута $INDEX_ROOT:
заголовок, заголовок узла и индексные элементы
Заголовок $INDEX_ROOT начинается с байта 0 содержимого атрибута, а его поля
перечислены в табл. 13.12.
Таблица 13.12. Структура данных атрибута $INDEX_ROOT
Диапазон Описание Необходимость
0-3 Тип атрибута в индексе @, если элемент Да
не использует атрибута)
4-7 Правило сортировки Да
8-11 Размер каждой индексной записи в байтах Да
12-12 Размер каждой индексной записи в кластерах Да
13-15 Не используется Нет
16+ Заголовок узла (см. табл. 13.14) Да
Структура данных определяет тип атрибута, содержащегося в индексных эле-
элементах, способ их сортировки и размер каждой индексной записи в атрибуте
$INDEX_ALLOCATION. Значение размера в байтах 8-11 задается в байтах, а значе-
значение поля в байте 12 представляет собой либо количество кластеров, либо лога-
логарифм размера. Способ кодирования более подробно описан в разделе «Файл
$Boot». Помните, что размер индексной записи также задается в загрузочном
секторе.
Для просмотра содержимого атрибута $INDEX_ROOT можно воспользоваться
программой icat с указанием типа 144:
# icat -f ntfs ntfsl.dd 7774-144 | xxd
0000000: 3000 0000 0100 0000 0010 0000 0400 0000 0
0000016: 1000 0000 aOOO 0000 aOOO 0000 0100 0000
Байты 0-3 показывают, что атрибут в индексе относится к типу 48 @x30), что
соответствует атрибуту $FILE_NAME. Байты 8-11 показывают, что размер каждой
индексной записи равен 4096 байтам.
Атрибут $INDEX_AI_LOCATION
В больших каталогах все индексные элементы не помещаются в резидентном ат-
атрибуте $INDEX_ROOT, поэтому для их размещения необходим нерезидентный ат-
атрибут $INDEX_ALLOCATION. Атрибут $INDEX_ALLOCATION заполняется индексными
записями. Индексная запись имеет статический размер и представляет один узел
отсортированного дерева. Размер индексной записи определяется в заголовке ат-
атрибута $INDEX_ROOT и в загрузочном секторе; типичный размер равен 4096 бай-
байтам. Атрибут $INDEX_ALLOCATION обладает идентификатором типа 160 и не может
существовать без атрибута $INDEX_ROOT.
Каждая индексная запись начинается со структуры данных заголовка, за ко-
которой следует заголовок узла и список индексных элементов. Заголовок узла и ин-
индексные элементы представлены одинаковыми структурами данных, используе-
используемыми в атрибуте $INDEX_ROOT. Первая индексная запись начинается с байта О
атрибута. На рис. 13.6 показан атрибут $INDEX_ALLOCATION с двумя индексными
записями.
Поля, из которых состоит заголовок индексной записи, перечислены в табл. 13.13.
Таблица 13.13. Структура данных заголовка индексной записи
Диапазон Описание Необходимость
0-3 Сигнатура («INDX») Нет
4-5 Смещение массива с данными замены маркеров Да
6-7 Количество элементов в массиве замены маркеров Да
8-15 Номер LSN для $LogFile Нет
16-23 Номер VCN записи в полном индексном потоке Да
24+ Заголовок узла (см. табл. 13.14) Да
Рис. 13.6. Внутренняя структура атрибута $INDEX_ALLOCATION с заголовками записей,
заголовками узлов и индексными элементами
Первые четыре поля практически идентичны полям записи MFT, но отлича-
отличаются сигнатурой. Маркеры и массивы замены описаны в начале главы.
Номер VCN в байтах 16-23 определяет местонахождение записи в дереве. Ат-
Атрибут $INDEX_ALLOCATION заполнен индексными записями, которые могут следо-
следовать в произвольном порядке. Значение VCN в заголовке указывает местонахож-
местонахождение записи в буфере. Когда индексный элемент ссылается на свой дочерний
узел, он использует адрес VCN из заголовка индексной записи узла.
Вот как выглядит содержимое атрибута $1N DEX__ALLOCATION того лее каталога,
для которого мы просматривали атрибут $INDEX_ROOT:
# icat -f ntfs ntfsl.dd 7774-160 | xxd
0000000: 494e 4458 2800 0900 4760 2103 0000 0000 INDX(...GN!
0000016: 0000 0000 0000 0000 2800 0000 f808 0000 (
В первой строке видна сигнатура «INDX», а в байтах 4-5 и 6-7 содержатся
заменители маркеров. Байты 16—23 показывают, что индексная запись со-
соответствует буферу VCN 0. Заголовок узла начинается с байта 24. Атрибут
$INDEX_ALLOCATION имеет длину 8192 байта, поэтому в нем хватает места еще для
одной индексной записи, начинающейся с байта 4096:
0004096: 494е 4458 2800 0900 ed5d 2103 0000 0000 INDX(....]!
0004112: 0400 0000 0000 0000 2800 0000 6807 0000 (...h...
0004128: e80f 0000 0000 0000 ЗЬОО 0500 6900 c401 ;.. .1.. .
Байты 4112-4119 показывают, что это VCN 4 (каждый кластер в файловой
системе состоит из 1024 байт). Мы еще вернемся к этому примеру после рассмот-
рассмотрения заголовков узлов и индексных элементов.
Атрибут $В1ТМАР
В предыдущем разделе приводился атрибут $INDEX_ALLOCATION с двумя 4096-бай-
4096-байтовыми индексными записями. Может оказаться, что некоторые индексные запи-
записи не используются. Атрибут $В1ТМАР содержит информацию о том, какие индек-
индексные записи в атрибуте $1N DEX_ALLOCATION выделены для хранения данных. Как
правило, Windows выделяет индексные записи только по мере необходимости,
однако в каталоге могут появиться свободные записи — например, в результате
удаления множества файлов. Учтите, что атрибут $В1ТМАР также используется
в таблице MFT для отслеживания состояния выделения записей MFT.
Атрибут $ BITMAP (идентификатор типа 176) делится на байты; каждый байт
соответствует индексной записи. Для просмотра атрибута $В1ТМАР в предыдущем
примере можно воспользоваться программой icat:
# icat -f ntfs ntfsl.dd 7774-176 | xxd
0000000: 0300 0000 0000 0000
В байте 0 находится значение 0x03, или в двоичном представлении 0000 0011.
Следовательно, индексные записи 0 и 1 выделены для использования.
Структура данных заголовка индексного узла
До настоящего момента мы рассматривали атрибуты $INDEX_ROOT и $INDEX_AL-
LOCATION. Оба атрибута содержат заголовочные данные, за которыми следует за-
заголовок узла и список индексных элементов. В этом разделе описывается струк-
структура данных заголовка узла. Заголовок присутствует в $INDEX_ROOT и в каждой
структуре данных индексной записи; он показывает, где начинается и заканчива-
заканчивается список индексных элементов. Поля заголовка перечислены в табл. 13.14.
Таблица 13.14. Структура данных заголовка индексного узла
Диапазон Описание Необходимость
0-3 Смещение начала списка индексных элементов Да
(относительно начала заголовка узла)
4-7 Смещение конца используемой части списка Да
индексных элементов (относительно начала
заголовка узла)
8-11 Смещение конца выделенного буфера списка Да
индексных элементов (относительно начала
заголовка узла)
12-15 Флаги Нет
Индексные элементы узла $INDEX_ROOT начинаются сразу же за заголовком
узла, но индексные элементы в индексном буфере могут смещаться из-за массива
замены маркеров. При поиске данных, оставшихся от удаленных индексных эле-
элементов, мы анализируем данные между концом используемой части буфера и кон-
концом выделенного буфера.
Поле флагов содержит всего один флаг 0x01: он устанавливается в том случае,
если элементы этого списка ссылаются на дочерние узлы. Этот флаг присутству-
присутствует в каждом индексном элементе.
Давайте снова вернемся к уже рассмотренным атрибутам. Атрибут $INDEX_ROOT
содержит следующие данные:
# icat -f ntfs ntfsl.dd 7774-144 | xxd
0000000: 3000 0000 0100 0000 0010 0000 0400 0000 0
0000016: 1000 0000 aOOO 0000 aOOO 0000 0100 0000
[...]
Заголовок узла начинается с байта 16; байты 16-19 показывают, что список
начинается со смещением 16 @x10) байт, то есть с байта 32, и заканчивается со
смещением 160 (ОхаО) байт, то есть в байте 176. В этом случае выделенное и ис-
используемое пространство совпадают, потому что они относятся к атрибуту $IN-
DEX_ROOT, который является резидентным и должен занимать как можно меньше
места. В байте 28 установлен флаг 0x01, из чего следует, что у этого узла имеются
дочерние узлы (находящиеся в $INDEX_ALLOCATION).
Теперь снова рассмотрим атрибут $INDEX_ALLOCATION:
# icat -f ntfs ntfsl.dd 7774-160 | xxd
0000000: 494e 4458 2800 0900 4760 2103 0000 0000 INDXC...G4
0000016: 0000 0000 0000 0000 2800 0000 f808 0000 (
0000032: e80f 0000 0000 0000 2100 0000 0600 0000 !
[...]
Первые 24 байта принадлежат заголовку индексной записи, после которого
начинается заголовок узла. Байты 24-27 показывают, что список индексных эле-
элементов начинается со смещением 40 @x28). Не забывайте, что значение задается
относительно начала заголовка узла, поэтому к нему необходимо прибавить 24;
сумма равна 64. В данном случае список индексных элементов не следует непос-
непосредственно за заголовком списка, потому что между заголовком списка индекс-
индексных элементов и самим списком находится массив заменителей. Вспомните, что
байты 4-5 заголовка индексной записи показывают, что массив хранится со сме-
смещением 40 @x28).
Байты 28-31 показывают, что смещение конца последнего элемента равно 2296
байтам @x08f8), а байты 32-35 — что смещение конца выделенного буфера равно
4072 байтам @x0fe8). Следовательно, буфер содержит 1776 байт неиспользуемо-
неиспользуемого пространства, где могут храниться данные из файлов с именами, хранившими-
хранившимися в этих элементах. Согласно байтам 36-39, флаги равны 0, то есть узел не имеет
дочерних узлов.
Структура данных обобщенного индексного
элемента
До настоящего момента мы рассматривали общие концепции индексов NTFS, но
еще не уделили внимания индексным элементам. Структуры, о которых речь пой-
пойдет в дальнейшем, зависят от типа индекса, однако во всех индексных элементах
присутствует общая структура данных, которая будет описана в этом разделе.
В табл. 13.15 перечислены стандартные поля индексных элементов.
Таблица 13.15. Структура данных обобщенного индексного элемента
Диапазон Описание
0-7 Не определено
8-9 Длина элемента
10-11 Длина содержимого
12-15 Флаги (см. табл. 13.16)
16+ Содержимое (см. табл. 13.16)
Последние 8 байт элемента, Номер VCN дочернего узла в $INDEX_ALLOCATION
начиная с 8-байтовой границы (поле существует только при установленном флаге)
Первые 8 байт используются для хранения данных, специфических для ин-
индексного элемента. Байты 8-9 определяют размер индексного элемента, а байты
10-11 — длину содержимого индексного элемента, которое начинается с байта
16. В содержимом могут храниться любые данные. Поле флагов содержит значе-
значения, перечисленные в табл. 13.16.
Таблица 13.16. Флаги, используемые в поле флагов индексных элементов
Значение Описание
0x001 Существует дочерний узел
0x002 Последний элемент в списке
Если у индексного узла имеется дочерний узел, флаг 0x01 устанавливается,
а адрес VCN дочернего узла находится в последних 8 байтах индексного элемен-
элемента. Вспомните, что каждая индексная запись обладает номером VCN. Флаг 0x02
устанавливается для последнего элемента в списке.
Структура данных индексного элемента каталога
Индекс каталога содержит имена файлов и обладает специфической структурой
данных индексных элементов. Элементы строятся на основе базового шаблона, опи-
описанного в предыдущем разделе, и дополнительно содержат базовый адрес файла
и атрибут $FILE_NAME. Поля индексных элементов каталогов перечислены в табл. 13.17.
Таблица 13.17. Структура данных индексного элемента каталога
Диапазон Описание Необходимость
0-7 Базовый адрес MFT для имени файла Да
8-9 Длина элемента Да
10-11 Длина атрибута $FILE_NAME Нет
12-15 Флаги (см. табл. 13.16) Да
16+ Атрибут $FILE_NAME (если длина > 0) Да
Последние 8 байт элемента, Номер VCN дочернего узла в $INDEX_AL- Да
начиная с 8-байтовой LOCATION (поле существует только
границы при установленном флаге)
Базовый адрес ссылается на запись MFT, которой соответствует индексный
элемент. В индексных элементах этого типа используются стандартные флаги:
0x01 — признак наличия дочерних узлов, и 0x02 — признак последней записи
в списке.
Теперь рассмотрим остаток содержимого атрибутов $INDEX_ROOT и $INDEX_AL-
LOCATION, которые были частично проанализированы ранее. Начнем с атрибута
$INDEX_ROOT:
# icat -f ntfs ntfsl.dd 7774-144 | xxd
0000000: 3000 0000 0100 0000 0010 0000 0400 0000 0
0000016: 1000 0000 aOOO 0000 aOOO 0000 0100 0000
0000032: c51e 0000 0000 0500 7800 5a00 0100 0000 x.Z
0000048: 5ele 0000 0000 0300 eO3d ca37 5029 c401 x = .7P)..
0000064: 004c c506 0202 c401 eO9a 2a36 5029 c401 .L *6P)..
0000080: d0e4 22b5 096a c401 0004 0000 0000 0000 ..".. j
0000096: 7003 0000 0000 0000 2120 0000 0000 0000 p !
0000112: 0c02 4d00 4100 5300 5400 4500 5200 7e00 ..M.A.S.T.E.R.-.
0000128: 3100 2e00 5400 5800 5400 0000 0000 0300 1...T.X.T
0000144: 0000 0000 0000 0000 0000 0000 0000 0000
0000160: 1800 0000 0300 0000 0400 0000 0000 0000
[...]
Первые 32 байта уже обработаны; начальные 16 байт образуют заголовок $IN-
DEX_ROOT, а следующие 16 байт — заголовок узла. Байты 32-37 показывают, что
элемент относится к записи MFT 7877 @х1ес5). Байты 40-45 показывают, что
размер индексного элемента равен 120 байтам @x78), поэтому в выходных дан-
данных он завершается в байте 152. Байты 26-27 показывают, что размер атрибута
равен 90 байтам @х5а). Флаг в байте 28 сообщает о наличии дочернего узла, адрес
которого содержится в последних 8 байтах элемента, но мы уже об этом знаем
благодаря флагу в заголовке узла.
Атрибут $FILE_NAME находится в байтах 48-137, а байты 144-151 завершают
индексный элемент и содержат номер VCN дочернего узла (кластер 0). В каче-
качестве имени файла приводится строка «MASTER~1.TXT». Байты 152-175 содер-
содержат пустой индексный элемент, а флаг в байте 164 равен 3; он указывает на то, что
элемент завершает список и имеет дочерний узел. Байты 168-175 содержат адрес
дочернего узла (VCN 4). В нем находятся две индексные записи, которые мы ви-
видели в атрибуте $INDEX_ALLOCATION. Строение этого атрибута показано на рис. 13.7.
Рис. 13.7. Строение атрибута $INDEX_ROOT для рассматриваемого каталога
Процесс можно было бы повторить для каждой индексной записи в атрибуте
$INDEX_ALLOCATION. Вместо этого мы рассмотрим кое-какие интересные данные,
следующие за заголовком узла. Ранее было показано, что индексные элементы
в индексной записи 0 заканчиваются на смещении 2296, но узлу выделены еще
1776 байт, в которых может содержаться информация об удаленных именах фай-
файлов. Попробуем просмотреть неиспользуемую область и найти в ней действи-
действительные индексные элементы. Содержимое атрибута со смещением 2400 выгля-
выглядит так:
0002400: bele 0000 0000 0600 6800 5400 0000 0000 h.T
0002416: 5ele 0000 0000 0300 908b bf37 5029 c401 x 7P). .
0002432: 004c c506 0202 c401 eO9a 2a36 5029 c401 .L *6P)..
0002448: 30a7 6410 9c4a c401 003c 0000 0000 0000 O.d..J...<
0002464: 003a 0000 0000 0000 2120 0000 0000 0000 .: !
0002480: 0903 7000 7300 6100 7000 6900 2e00 6400 ..p.s.a.p.i...d.
0002496: 6c00 6c00 6500 0000 2513 0000 0000 ObOO 1.1.e...%
Индексный элемент относится к файлу в записи MFT 7870 (Oxlebe), а файл
называется psapi.dll. Вследствие природы механизма пересортировки индексов мы
не можем сказать, был ли файл удален или перемещен в другую позицию из-за
добавления или удаления файла. На этот вопрос можно ответить только после
анализа всех остальных индексных элементов. TSK отображает все элементы,
а пользователь может самостоятельно разобраться, почему элемент был освобож-
освобожден. Впрочем, программа Autopsy фильтрует вывод TSK и отображает только уни-
уникальные имена.
На рис. 13.8 показаны отношения между индексными элементами $INDEX_ROOT
и индексными записями $INDEX_ALLOCATION. Мы видим, что корневой узел индек-
индекса содержит два элемента. Любой файл с именем, меньшим MASTER~1.TXT, нахо-
находится в индексной записи с номером VCN 0, а любой файл с большим именем —
в индексной записи VCN 4. В конце индексной записи VCN 0 присутствует сво-
свободное пространство, в котором мы нашли данные файла psapi.dll. Обратите вни-
внимание на то, что это имя больше MASTER~1.TXT; вероятно, на момент его сохране-
сохранения в этом узле корневой узел содержал другой элемент.
Рис. 13.8. Строение индексных элементов в примерах
Файлы метаданных файловой системы
Познакомившись с различными атрибутами файлов и индексов, мы рассмотрим
файлы метаданных файловой системы. В основном эти файлы обладают стандар-
стандартными атрибутами, но некоторые из них имеют специфические атрибуты, кото-
которые будут описаны в последующих разделах.
Файл $MFT
Файл $МПГ представлен записью MFT 0. Он уже рассматривался в начале главы,
потому что этот файл абсолютно необходим для операций с каждым файлом
в файловой системе. Примеры выходных данных istat для файла $МПГ приводи-
приводились в главе 12. Файл обладает стандартными атрибутами, а в атрибуте $DATA со-
содержится таблица MFT.
Файл $MFT содержит только один уникальный атрибут $В1ТМАР. В нем хранит-
хранится информация о состоянии выделения записей MFT. Если бит, представляющий
запись, установлен, значит, запись выделена, а если бит равен 0 — запись свобод-
свободна. Для просмотра атрибута $ BITMAP можно воспользоваться программой icat и ука-
указать тип атрибута 176:
# icat -f ntfs ntfsl.dd 0-176 | xxd
0000000: ffff OOff ffff ffff ffff ffff ffff ffff
0000016: ffff ffff ffff ffff ffff ffff ffff ffff
Файл $Boot
Файл $Boot представлен записью MFT 7; в его атрибуте $DATA хранится содержи-
содержимое загрузочного сектора и загрузочный код. Атрибут всегда начинается с секто-
сектора 0, в котором хранится структура данных загрузочного сектора. Остальные сек-
секторы используются для хранения загрузочного кода. В табл. 13.18 перечислены
поля загрузочного сектора.
Таблица 13.18. Структура данных загрузочного сектора
Диапазон Описание Необходимость
0-2 Машинная команда перехода к загрузочному коду Нет (если файловая система
не является загрузочной)
3-10 Имя OEM Нет
11-12 Количество байт в секторе Да
13-13 Количество секторов в кластере Да
14-15 Количество зарезервированных секторов Нет
(Microsoft требует, чтобы поле было равно 0)
16-20 Не используется (Microsoft требует, чтобы поле Нет
было равно 0)
21-21 Дескриптор носителя Нет
22-23 Не используется (Microsoft требует, чтобы Нет
поле было равно 0)
24-31 Не используется (по данным Microsoft поле Нет
не проверяется) продолжение
Таблица 13.18 {продолжение)
Диапазон Описание Необходимость
32-35 Не используется (Microsoft требует, чтобы Нет
поле было равно 0)
36-39 Не используется (по данным Microsoft поле Нет
не проверяется)
40-47 Общее количество секторов в файловой системе Да
48-55 Адрес начального кластера MFT Да
56-63 Адрес начального кластера атрибута $DATA Нет
зеркальной копии MFT
64-64 Размер записи MFT (файловой записи) Да
65-67 Не используется Нет
68-68 Размер индексной записи Да
69-71 Не используется Нет
72-79 Серийный номер Нет
80-83 Не используется Нет
84-509 Загрузочный код Нет
510-511 Сигнатура @хаа55) Нет
Неиспользуемые поля соответствуют полям блокаВРВ (BIOS Parameter Block)
загрузочного сектора FAT. В документации Microsoft указано, что для монтиро-
монтирования файловой системы некоторые из этих полей должны быть обязательно рав-
равны 0, но формально эти значения не обязательны для функционирования файло-
файловой системы, и Microsoft могла не проверять эти значения. Я убедился в том, что
Windows XP отказывается монтировать диск, если содержимое этих полей от-
отлично от 0.
Среди параметров, хранящихся в загрузочном секторе, важнейшими являют-
являются размер каждого сектора и кластера. Без них поиск и идентификация данных
в файловой системе в принципе невозможны. Следующие важные параметры —
начальный адрес MFT и размер каждой записи MFT. До настоящего времени во
всех версиях Windows размер записей MFT всегда составлял 1024 байта, но это
поле существует для того, чтобы размер записи можно было легко сменить в бу-
будущем. Также обратите внимание на заданный адрес атрибута $ DATA файла $MFTMirr.
С его помощью программа восстановления информации может определить, где
находится резервная копия $МПГ.
Поля, в которых хранятся размеры записи MFT и индексных записей, имеют
специальный формат. Если значение больше 0, оно представляет количество кла-
кластеров, используемых для хранения каждой структуры данных. Если значение
меньше 0, оно представляет двоичный логарифм количества байт в каждой струк-
структуре данных. Чтобы вычислить количество байт, следует взять модуль отрица-
отрицательного числа (то есть изменить знак) и возвести число 2 в указанную степень.
Например, если значение равно -10, то размер структуры данных составит
210= 1024 байта. Этот способ применяется в тех случаях, когда размер кластера
больше одной записи MFT или индексной записи.
Рассмотрим пример содержимого загрузочного сектора. Вывод istat для файла
$Boot уже приводился в главе 12; воспользуемся программой icat для вывода ат-
атрибута $DATA (тип 128):
# icat -f ntfs ntfsl.dd 7-128 | xxd
0000000: eb52 904e 5446 5320 2020 2000 0202 0000 .R.NTFS
0000016: 0000 0000 00f8 0000 3f00 ffOO 3f00 0000 ?...?...
0000032: 0000 0000 8000 8000 4060 lfOO 0000 0000 Г
0000048: Ь53а 0500 0000 0000 10d8 0700 0000 0000 .:
0000064: 0100 0000 0400 0000 947c 2250 8422 5004 |"P."P.
0000080: 0000 0000 fa33 cO8e dObc 007c fbb8 c007 3 |....
0000096: 8ed8 e816 00b8 OOOd 8ec0 33db c606 OeOO 3
0000448: 6d70 7265 7373 6564 OOOd 0a50 7265 7373 mpressed...Press
0000464: 2043 7472 62cb 416c 742b 4465 6c20 746f Ctrl+Alt+Del to
0000480: 2072 6573 7461 7274 OdOa 0000 0000 0000 restart
0000496: 0000 0000 0000 0000 83aO Ь3с9 0000 55aa U.
В первой строке отображается имя OEM (строка «NTFS»), за которым сле-
следует несколько пробелов в кодировке ASCII @x20). Это стандартное имя, кото-
которое присваивается системой Windows. Байты 11-12 сообщают количество байт
в каждом секторе — оно равно 512 @x0200). Байт 13 показывает, что один клас-
кластер состоит из двух секторов, то есть размер кластера составляет 1024 байта.
Байты 40-47 показывают, что общее количество секторов в файловой системе
равно 2 056 256 @x001 f6040); таким образом, объем файловой системы состав-
составляет 1 Гбайт. Байты 48-55 показывают, что MFT начинается с кластера 342 709
@х00053аЬ5), а байты 56--63 — что атрибут $DATA зеркальной копии MFT начи-
начинается с кластера 514 064 @x0007d810).
Байт 64 определяет размер каждой записи MFT. Напомню, что способ кодирова-
кодирования этой величины определяется ее знаком. В данном случае значение равно 1, по-
поэтому оно определяет количество кластеров в записи MFT; следовательно, каждая
запись занимает 1024 байта. В байте 68 хранится размер каждой индексной записи
в каталоге. Значение равно 4, то есть каждая индексная запись состоит из 4 кластеров.
Байты 72-79 содержат серийный номер файловой системы; в нашем примере
он равен 0х0450228450227С94. В остальных байтах хранится загрузочный код,
а байты 510-511 содержат сигнатуру 0хАА55, которая совпадает с сигнатурой FAT.
Файл $AttrDef
Файл метаданных файловой системы $AttrDef (запись MFT 4) определяет имена
и идентификаторы атрибутов файловой системы. Атрибут $DATA этого файла пред-
представляет собой список записей, поля которых перечислены в табл. 13.19.
Таблица 13.19. Структура данных записей $AttrDef
Диапазон Описание Необходимость
0-127 Имя атрибута Да
128-131 Идентификатор типа Да
132-135 Правило отображения Нет
136-139 Правило сортировки Нет
140-143 Флаги (см. табл. 13.20) Да
144-151 Минимальный размер Нет
152-159 Максимальный размер Нет
Если размеры атрибута не ограничены, минимальный размер будет равен О,
а максимальный — Oxffffffffffffffff. Биты, устанавливаемые в поле флагов, перечис-
перечислены в табл. 13.20.
Таблица 13.20. Поле флагов в записях атрибута $AttrDef
Значение Описание
0x02 Атрибут может использоваться в индексах
0x04 Атрибут всегда является резидентным
0x08 Атрибут может быть нерезидентным
Правило сортировки используется при нахождении атрибута в индексах. Ат-
Атрибут $DATA для файла $AttrDef в нашем тестовом образе имеет следующее содер-
содержимое:
# icat -f ntfs ntfsl.dd 4-128 | xxd
0000000: 2400 5300 5400 4100 4y00 4400 4100 5200 S.S.T.A.N.D.A.R.
0000016: 4400 5f00 4900 4e00 4600 4f00 5200 4d00 D._.I.N.F.O.R.M.
0000032: 4100 5400 4900 4f00 4e00 0000 0000 0000 A.T.I.O.N
0000048: 0000 0000 0000 0000 0000 0000 0000 0000
0000064: 0000 0000 0000 0000 0000 0000 0000 0000
0000080: 0000 0000 0000 0000 0000 0000 0000 0000
0000096: 0000 0000 0000 0000 0000 0000 0000 0000
0000112: 0000 0000 0000 0000 0000 0000 0000 0000
0000128: 1000 0000 0000 0000 0000 0000 4000 0000 @.. .
0000144: 3000 0000 0000 0000 4880 0000 0000 0000 0 H
Первое определение относится к атрибуту $STANDARD_INFORMATION. Байты
128-131 определяют тип атрибута 16 @x10). Флаги в байтах 140-143 означают,
что атрибут всегда является резидентным. Согласно байтам 144-151 минималь-
минимальный размер атрибута равен 48 байтам @x30), а максимальный — 72 байтам @x48).
Файл $Bitmap
Файл $В1ТМАР, представленный записью MFT 6, содержит атрибут $DATA с ин-
информацией о состоянии выделения кластеров. Данные битовой карты делятся на
1-байтовые блоки; младший бит каждого байта соответствует кластеру, который
следует за кластером, соответствующим старшему биту предыдущего байта.
Для примера рассмотрим два байта с двоичными значениями 00000001
и 00000011. Младший бит первого байта, соответствующий кластеру 0, равен 1.
Следующие 7 бит (справа налево) равны 0, то есть кластеры 1-7 свободны. У вто-
второго байта два младших бита, соответствующих кластерам 8 и 9, равны 1. Как ви-
видите, битовая карта читается от младших бит справа налево, а после старшего бита
анализ переходит к следующему байту.
Чтобы узнать состояние выделения заданного кластера, необходимо опреде-
определить, в каком байте карты находится соответствующий бит. Для этого адрес клас-
кластера нацело делится на 9. Например, информация о кластере 5 будет храниться
в байте 0 битовой карты, а информация о кластере 18 — в байте 2. Номер бита
определяется остатком от деления. Например, при делении 5 на 8 остаток был
равен 5, а при делении 18 на 8 остаток был равен 2. На рис. 13.9 приведен нагляд-
наглядный пример вычисления бит для кластеров 5 и 74.
Рис. 13.9. Пример проверки состояния выделения для кластеров 5 и 74
Располагая информацией о строении битовой карты, возвращаемся к нашей
тестовой файловой системе. Для просмотра содержимого атрибута $DATA мы вос-
воспользуемся программой icat:
# icat -f ntfs ntfsl.dd 6-128 | xxd
0000000: ffff ffff ffff ffff ffff ff3f 0000 0000 ?. .. .
0000016: 0000 fOff ffff ffff ffff ffff ffff ffff
0000032: ffff ffff ffff ffff ffff ffff ffff ffff
0000048: ffff ffff ffff ffff 0300 0000 ffff ffff
0000064: ffff ffff ffff ffff ffff ffff ffff ffff
0000080: ffff ffff ffff ffff ffff ffff ffff ffff
Все начальные биты содержат 1; загрузочный сектор находится в первых
8 Кбайт файловой системы, поэтому вполне логично, что эти кластеры выделены.
В байте 11 мы видим значение 0x3f, или 00111И1 в двоичном представлении. Этот
байт соответствует кластерам 88-95 файловой системы. Шесть младших битов
установлены в 1; это означает, что кластеры выделены для использования. Седь-
Седьмой и восьмой биты (кластеры 94 и 95) равны 0. Следующие шесть байт заполне-
заполнены нулями, то есть кластеры этих битов свободны. Байт 18 содержит значение
OxfO, или 1111 0000 в двоичном представлении.
Файл $Volume
Файл $Volume (запись MFT 3) обладает двумя уникальными атрибутами, кото-
которые будут описаны в этом разделе.
Атрибут $VOLUME_NAME
Предполагается, что атрибут $VOLUME_NAME (идентификатор типа 96) создается
только в файле $Volume. В нем хранится имя тома в кодировке Unicode UTF-16,
и ничего более. В тестовом образе его содержимое выглядит так:
# icat -f ntfs ntfsl.dd 3-96 | xxd
0000000: 4e00 5400 4600 5300 2000 4400 6900 7300 N.T.F.S. .D.i.s.
0000016: 6b00 2000 3200 k. .2.
В данном примере файловой системе присвоено имя «NTFS Disk 2».
Атрибут $VOLUME_INFORMATION
Второй атрибут, уникальный для файла $ Volume, — $ VO LU М Е_1 N FO RM ATI О N (иден-
(идентификатор типа 112). В этом атрибуте хранится версия файловой системы.
В табл. 13.21 перечислены поля атрибута $VOLUME_INFORMATION.
Таблица 13.21. Структура данных атрибута $VOLUME_INFORMATION
Диапазон Описание Необходимость
0-7 Не используется Нет
8-8 Основная версия Да
9-9 Дополнительная версия Да
10-11 Флаги (см. табл. 13.22) Нет
В Windows NT основная версия равна 1, а дополнительная — 2. В Windows
2000 основная версия равна 3, а дополнительная — 0. В Windows XP использует-
используется основная версия 3, а дополнительная — 1. Флаги, используемые в этой струк-
структуре данных, перечислены в табл. 13.22.
Таблица 13.22. Флаги поля $VOLUME_INFORMATION
Значение Описание
0x0001 Флаг обновления
0x0002 Изменение размера $LogFile (журнал файловой системы)
0x0004 Обновление тома
0x0008 Монтирование в NT
0x0010 Удаление журнала изменений
0x0020 Восстановление идентификаторов объектов
0x8000 Изменяется chkdsk
Атрибут $VOLUME_INFORMATION в тестовой файловой системе содержал следу-
следующие данные:
# icat -f ntfs ntfsl.dd 3-112 | xxd
0000000: 0000 0000 0000 0000 0301 0000
Согласно байтам 8 и 9, файловая система обладает номером версии 3.1, что
соответствует ХР. Поле флагов заполнено нулями.
Файл $ObjId
Как было показано в главе 12, на файл можно ссылаться не только по имени, но
и по идентификатору объекта. Идентификаторы позволяют найти файл даже после
его переименования. Файл \$Extend\$ObjId содержит индекс с именем $0, связы-
связывающий идентификатор объекта файла с записью MFT. Как правило, для пред-
представления файла $ObjId не используются зарезервированные записи MFT.
Индекс содержит типичные атрибуты $INDEX_ROOT и $INDEX_ALLOCATION.
В табл. 13.23 перечислены поля элементов этого индекса.
Таблица 13.23. Структура данных индексных записей атрибута $ObjId
Диапазон Описание Необходимость
0-1 Смещение информации файла Да
2-3 Размер информации файла Да
4-7 Не используется Нет
8-9 Размер индексного элемента Да
Диапазон Описание Необходимость
10-11 Размер идентификатора объекта Да
12-15 Флаги (см. табл. 13.16) Да
16-31 Идентификатор объекта Да
32-39 Базовый адрес файла Да
40-55 Исходный идентификатор тома Нет
56-71 Исходный идентификатор объекта Нет
72-87 Исходный идентификатор домена Нет
Поле флагов содержит стандартные биты: 0x01 при наличии дочерних узлов
и 0x02 для последнего элемента в списке. Далее приводятся некоторые индекс-
индексные элементы атрибута $INDEX_ROOT (заголовок узла не показан):
0000000: 2000 3800 0000 0000 5800 1000 0000 0000 .8 X
0000016: fe24 Ь024 е292 fe47 95ac e507 4bf5 6782 .$.$...G K.g.
0000032: 0300 0000 0000 0300 0000 0000 0000 0000
0000048: 0000 0000 0000 0000 0000 0000 0000 0000
0000064: 0000 0000 0000 0000 0000 0000 0000 0000
0000080: 0000 0000 0000 0000 2000 3800 0000 0000 8
0000096: 5800 1000 0000 0000 а162 3d5e cdda d811 X b=x....
0000112: 883c OObO dOld e93f a400 0000 0000 0100 .< ?
0000128: fe24 b024 e292 fe47 95ac e507 4bf5 6782 .$.$...G....K.g.
0000144: al62 3d5e cdda d811 883c OObO dOld e93f .b=x < ?
0000160: 0000 0000 0000 0000 0000 0000 0000 0000
Байт 8 показывает, что длина элемента равна 88 байтам @x58), а в байтах 16-
31 хранится 16-байтовый идентификатор объекта. Байты 32-37 определяют
адрес записи MFT для данного идентификатора, он равен 3. Этот индексный
элемент соответствует атрибуту $OBJECT_ID, описанному в разделе «Атрибут
$OBJECT_1D». Остальные поля этого элемента равны 0, а следующий элемент
начинается с байта 88.
Файл $Quota
Файл \$Extend\$Quota используется механизмом пользовательских квот. Для него
используется обычная (не зарезервированная) запись MFT. Файл содержит два
индекса; оба используют стандартные атрибуты $INDEX_ROOT и $INDEX_ALLOCATION
для хранения своих индексных элементов. Индекс $0 связывает код SID с иден-
идентификатором владельца, а индекс $Q связывает идентификатор владельца с ин-
информацией квот. В табл. 13.24 перечислены поля индексных элементов ин-
индекса $0.
Таблица 13.24. Структура данных элементов индекса $0 файла $Quota
Диапазон Описание Необходимость
0-1 Смещение идентификатора владельца (OFF) Да
2-3 Длина идентификатора владельца Да
4-7 Не используется Нет
8-9 Размер индексного элемента Да
10-11 Размер SID(L) Да
продолжение
Таблица 13.24 {продолжение)
Диапазон Описание Необходимость
12-15 Флаги (см. табл. 13.16) Да
16-A6+L+1) SID Да
OFF+ Идентификатор владельца Да
В этих индексных элементах используются те же флаги, которые приводились
ранее для имен файлов. Флаг 0x01 является признаком наличия дочерних узлов,
а флаг 0x02 — признаком последнего элемента в списке. Если дочерний узел су-
существует, то последние 8 байт используются для хранения кода VCN дочернего
узла.
Первый индексный элемент индекса $0 выглядит так:
0000000: 1с00 0400 0000 0000 2000 0с00 0000 0000
0000016: 0101 0000 0000 0005 1200 0000 0401 0000
0000032: 1с00 0400 0000 0000 2000 0с00 0000 0000
0000048: 0101 0000 0000 0005 1300 0000 0301 0000
[...]
Байты 0-1 показывают, что идентификатор владельца хранится со смещени-
смещением 28 (Oxlc) от начала элемента, а байты 2-3 — что его длина составляет 4 байта.
Байты 8-9 показывают, что длина индексной записи равна 32 байтам @x20),
а байты 10-11 — что код SID занимает 12 байт (ОхОс). Код SID хранится в байтах
16-27, а байты 28-31 содержат идентификатор владельца 260 @x0104). Второй
элемент списка начинается с байта 32, а его идентификатор владельца находится
в байтах 60-63 и равен 259 @x0103).
Индекс $Q связывает идентификатор владельца с информацией о квотах.
В табл. 13.25 перечислены поля индексных элементов $Q.
Таблица 13.25. Структура данных элементов индекса $Q файла $Quota
Диапазон Описание Необходимость
0-1 Смещение информации квот Да
2-3 Размер информации квот Да
4-7 Не используется Нет
8-9 Размер индексного элемента Да
10-11 Размер идентификатора владельца Да
D байта)
12-15 Флаги (см. табл. 13.16) Да
16-19 Идентификатор владельца Да
20-23 Версия Нет
24-27 Флаги квот (см. табл. 13.26) Да
28-35 Байты, начисляемые пользователю Да
36-43 Время последнего начисления Нет
44-51 Мягкий порог Да
52-59 Жесткий порог Да
60-67 Время превышения Да
68-79 SID Да
В индексных элементах используются стандартные флаги: 0x01 — признак
наличия дочерних узлов, и 0x02 — признак последней записи в списке. Флаги квот
перечислены в табл. 13.26.
Таблица 13.26. Флаги квот в индексных элементах $Q
Флаг Описание
0x00000001 Используются лимиты по умолчанию
0x00000002 Достигнут лимит
0x00000004 Идентификатор удален
0x00000010 Отслеживание использования данных
0x00000020 Обеспечение правил использования данных
0x00000040 Запрос на отслеживание
0x00000080 Создание записи в журнале при достижении порога
0x00000100 Создание записи в журнале при достижении лимита
0x00000200 Устаревшая информация
0x00000400 Поврежденные данные
0x00000800 Незавершенные операции удаления
Далее приводится пример индексного элемента из тестового образа, который
уже использовался для индекса $0. Данные взяты из атрибута $INDEX_ALLOCATION,
данные заголовка удалены. Приведенная информация взята из списка элементов
и соответствует идентификатору владельца, показанному в предыдущем примере.
0000000: 1400 ЗсОО 0000 0000 5000 0400 0000 0000 ..< Р
0000016: 0301 0000 0200 0000 0100 0000 0028 0500 (..
0000032: 0000 0000 401Ь 7сЗс 7751 с401 ffff ffff ....@.|.<wQ
0000048: ffff ffff ffff ffff ffff ffff 0000 0000
0000064: 0000 0000 0101 0000 0000 0005 1300 0000
0000080: 1400 ЗсОО 0000 0000 5000 0400 0000 0000 ..< P
0000096: 0401 0000 0200 0000 0100 0000 0094 6602 f.
0000112: 0000 0000 90fe 8bdf d769 c401 ffff ffff i
0000128: ffff ffff ffff ffff ffff ffff 0000 0000
0000144: 0000 0000 0101 0000 0000 0005 1200 0000
Байты 0-1 показывают, что данные квот хранятся со смещением 20 байт @x14),
а байты 2-3 — что их объем составляет 60 байт. Байты 16-19 показывают, что
данные относятся к идентификатору владельца 259 @x0103), который соответ-
соответствует второй записи, приведенной ранее в индексе $0. Байты 24-27 содержат
флаги квот; мы видим, что для данного пользователя используются лимиты по
умолчанию. Байты 28-35 показывают, что для учетной записи данного пользова-
пользователя начислено только 337 920 байт @x052800). При желании вы можете разо-
разобрать следующую запись самостоятельно.
Файл $LogFile
Файл $LogFile (запись MFT 2) используется в качестве журнала NTFS. Он обла-
обладает стандартными файловыми атрибутами, а данные журнала хранятся в атри-
атрибуте $ DATA. К сожалению, подробная информация о структурах данных отсутствует,
но мы все же кратко познакомимся с содержимым журнала, чтобы читатель полу-
получил примерное представление о хранящихся в нем данных.
Журнал делится на страницы объемом 4096 байт. Первые две страницы пред-
предназначены для области рестарта, и в первых четырех байтах каждой страницы
хранится сигнатура «RSTR»:
# icat -f ntfs ntfsl.dd 2 | xxd | grep RSTR
0000000: 5253 5452 leOO 0900 0000 0000 0000 0000 RSTR
0004096: 5253 5452 leOO 0900 0000 0000 0000 0000 RSTR
Большинство других полей страниц заполнены нулями, а единственная строка
«NTFS» хранится в Unicode. После второй структуры данных рестарта со смеще-
смещением 8192 байта следуют записи, каждая из которых начинается с сигнатуры «RCRD»:
# icat -f ntfs ntfsl.dd 2 | xxd | grep RSTR
0008192: 5243 5244 2800 0900 0050 2500 0000 0000 RCRD(....?%
0012288: 5243 5244 2800 0900 0050 2500 0000 0000 RCRD(....?%
На первый взгляд смысл данных в записи не очевиден. Чтобы продемонстри-
продемонстрировать, что в файле журнала могут находиться резидентные атрибуты данных,
я создал файл C:\log-test.txt с ASCII-строкой «My new file, can you see it?». В фай-
файле журнала мы видим следующие данные:
2215936: 5243 5244 2800 0900 f93b 9403 0000 0000 RCRD(....;
[...]
2217312: 3801 1800 0000 0000 ес12 0000 0000 0000 8
2217328: al4d 0500 0000 0000 4d79 206e 6577 2066 .М My new f
2217344: 696c 652c 2063 616e 2079 6f75 2073 6565 lie. can you see
2217360: 2069 743f 0000 0000 0000 0000 0000 0000 it?
2217376: 0000 0000 0000 0000 0000 0000 0000 0000
2217808: 0003 0000 0094 7c22 5010 0000 004e 5446 |"P....NTF
2217824: 5320 4469 736b 2032 0043 3a5c 6c6f 672d S Disk 2.C:\log-
2217840: 7465 7374 2e74 7874 0000 1500 2e00 2e00 test.txt
2217856: 5c00 2e00 2e00 5c00 2e00 2e00 5cOO 6cOO \ \ \.l.
2217872: 6fOO 6700 2d00 7400 6500 7300 7400 2e00 o.g.-.t.e.s.t...
2217888: 7400 7800 7400 0300 4300 ЗаОО 5c00 6000 t.x.t...С.:Л. \
Мы видим в записи текст файла. Далее в записи следует имя файла и имя дис-
диска «NTFS Disk 2». После сохранения файла я модифицировал строку и добавил
в нее текст «This is my update». Эти данные встречаются позднее в файле журнала:
2248704: 5243 5244 2800 0900 f24b 9403 0000 0000 RCRDC....К
[...]
2250800: ес12 0000 0000 0000 al4d 0500 0000 0000 М
2250816: 2020 5468 6973 2069 7320 6d79 2075 7064 This is my upd
2250832: 6174 652e 0000 0000 0000 0000 0000 0000 ate
2250848: 0000 0000 0000 0000 0000 0000 0000 0000
Запись содержит только новые данные, а путь обновляемого файла в ней от-
отсутствует. Вероятно, ссылка на нее присутствует в другой записи, содержащей
имя файла.
Файл $UsrJrnl
Журнал изменений относится к категории прикладных данных. В нем фикси-
фиксируются изменения, вносимые в файлы. Имя файла журнала — \$Extend\$UsrJrnl;
информация хранится в атрибуте $DATA. Имя этого атрибута — $J. Для хранения
файла не используется зарезервированная запись MFT. Атрибут $DATA с именем
$J является разреженным и содержит список структур данных разных размеров,
называемых записями журнала изменений. Также имеется атрибут $DATA с име-
именем $Мах, содержащий информацию о максимальных пороговых значениях пользо-
пользовательского журнала.
Как упоминалось в главе 12, данные журнала не являются необходимыми для
выполнения основных функций файловой системы — хранения и выборки дан-
данных. По этой причине пометка в последнем столбце относится к необходимости
данных в контексте хранения журнала изменений. Поля структуры данных запи-
записей $J перечислены в табл. 13.27.
Таблица 13.27. Структура данных элементов индекса $J файла $UsrJrnl
Диапазон Описание Необходимость
0-3 Размер записи журнала Да
4-5 Основная версия Да
6-7 Дополнительная версия Да
8-15 Базовый адрес файла, к которому Да
относится запись
16-23 Базовый адрес родительского каталога Нет
файла, к которому относится запись
24-31 Номер USN для записи Да
32-39 Временной штамп Да
40-43 Флаги типов изменений (см. табл. 13.28) Да
44-47 Информация об источнике Нет
48-51 KoflSID Нет
52-55 Атрибуты файла Нет
56-57 Размер имени файла Да
58+ Имя файла Да
В байтах 40-43 содержится описание причины для создания записи в жур-
журнале изменений. Поле состоит из нескольких флагов, и причин для создания
записи может быть несколько. Определенные значения флагов перечислены
в табл. 13.28.
Таблица 13.28. Значения поля типа изменений в записях $J
Флаг Описание
0x00000001 Перезапись атрибута $DATA по умолчанию
0x00000002 Расширение атрибута $DATA по умолчанию
0x00000004 Усечение атрибута $DATA по умолчанию
0x00000010 Перезапись именованного атрибута $DATA
0x00000020 Расширение именованного атрибута $DATA
0x00000040 Усечение именованного атрибута $DATA
0x00000100 Создание файла или каталога
0x00000200 Удаление файла или каталога
продолжение
Таблица 13.28 {продолжение)
Флаг Описание
0x00000400 Изменение расширенных атрибутов файла
0x00000800 Изменение дескриптора безопасности
0x00001000 Переименование — запись в журнале изменений содержит старое имя
0x00002000 Переименование — запись в журнале изменений содержит новое имя
0x00004000 Изменение состояния индексирования содержимого
0x00008000 Изменение основных атрибутов файла или каталога
0x00010000 Создание или удаление жесткой ссылки
0x00020000 Изменение состояния сжатия
0x00040000 Изменение состояния шифрования
0x00080000 Изменение идентификатора объекта
0x00100000 Изменение точки подключения
0x00200000 Создание, удаление или изменение именованного атрибута $DATA
0x80000000 Закрытие файла или каталога
Источник в байтах 44-47 обычно равен 0, но в этом поле также может нахо-
находиться ненулевое значение, если запись была создана в результате действий ОС,
а не пользователя. Рассмотрим пример небольшого журнала изменений. Чтобы
найти запись MFT для журнала, мы просмотрим содержимое каталога метадан-
метаданных файловой системы \$Extend, представленного записью MFT 11:
# fls -f ntfs ntfs3.dd 11
г/г 25-144-2: $ObjId:$O
г/г 24-144-3: $Quota:$0
г/г 24-144-2: $Quota:$Q
г/г 26-144-2: $Reparse:$R
г/г 27-128-3: $UsnJrnl:$J
г/г 27-128-4: SUsnJrnl:$Max
Мы видим, что данные хранятся в записи MFT 27. Для вывода содержимого
атрибута $J используется программа icat:
# icat -f ntfs ntfs3.dd 27-128-3 | xxd
0000000: 5000 0000 0200 0000 lcOO 0000 0000 0100 P
0000016: 0500 0000 0000 0500 0000 0000 0000 0000
0000032: 3000 e2b9 eb69 c401 0001 0000 0000 0000 0....1
0000048: 0201 0000 2000 0000 1400 ЗсОО 6600 6900 <.f.i.
0000064: 6c00 6500 2d00 3000 2e00 7400 7800 7400 1.e.-.0...t.x.t.
Первые 4 байта показывают, что длина записи журнала изменений составля-
составляет 80 байт, а байты 8-13 — что запись относится к записи MFT 28 (Oxlc). Со-
Согласно байтам 24-31, номер USN записи равен 0, а байты 40-43 содержат флаги
0x00000001; это означает, что запись была создана из-за перезаписи атрибута $DATA
по умолчанию. Из последних строк листинга видно, что запись относится к фай-
файлу file-O.txt.
Атрибут $Мах содержит общую административную информацию, относящую-
относящуюся к журналу изменений. Его поля перечислены в табл. 13.29.
Таблица 13.29. Структура данных атрибута $Мах файла $UsrJrnl
Диапазон Описание Необходимость
0-7 Максимальный размер Да
8-15 Выделенный размер Да
16-23 USN ID Да
24-31 Минимальный USN Да
Вряд ли эта информация пригодится в процессе экспертизы, но для полноты
картины я все же приведу содержимое атрибута $Мах:
# icat -f ntfs ntfs3.dd 27-128-4 | xxd
0000000: 0000 8000 0000 0000 0000 1000 0000 0000
0000016: 4057 7491 eb69 c401 0000 0000 0000 0000 @Wt..i
Итоги
Многочисленные структуры данных и указатели, используемые в NTFS, услож-
усложняют любой ручной анализ. В этой главе рассматриваются некоторые известные
структуры данных. Следует подчеркнуть, что информация взята не из официаль-
официальных спецификаций, но ее надежность проверена опытом. Нельзя исключать того,
что некоторые значения или флаги еще не были идентифицированы.
Библиография
• Linux NTFS Project. NTFS Documentation, 1996-2004. http://linux-ntfs.source-
forge.net/ntfs/index.html
• Solomon, David and Mark Russinovich. Inside Windows 2000, 3rd ed. Redmond:
Microsoft Press, 2000.
Также см. раздел «Библиография» главы 11.
Ext2 и Ext3: концепции
и анализ
Файловые системы Ext2 и Ext3, которые я далее буду обозначать общим терми-
термином ExtX, используются по умолчанию во многих дистрибутивах операционной
системы Linux. Ext3 представляет собой серверную версию Ext2 с поддержкой
журналов файловой системы, но сохраняет базовую архитектуру Ext2. Системы
ExtX базируются на системе UFS (UNIX File System). Из ExtX были исключены
многие компоненты UFS, ставшие ненужными; эти системы проще понять, по-
поэтому мы начнем именно с них. В отличие от других операционных систем, Linux
поддерживает большое количество файловых систем, и для каждого дистрибути-
дистрибутива можно выбрать свою файловую систему по умолчанию. На момент написания
книги в большинстве дистрибутивов использовалась файловая система Ext3, но
файловая система Reiser тоже получила широкое распространение, а ее архитек-
архитектура не имеет ничего общего с ExtX. В этой главе рассматриваются принципы
работы ExtX, а в главе 15 будут описаны структуры данных. Эту и следующую
главы можно читать как параллельно, так и последовательно.
Введение
Архитектура ExtX позаимствована из файловой системы UFS, при проектирова-
проектировании которой основными целями были быстрота и надежность. Копии важных
структур данных дублируются в файловой системе, а все данных, ассоциирован-
ассоциированные с файлом, локализуются, чтобы свести к минимуму перемещения головок
жесткого диска во время чтения. Файловая система начинается с необязательной
зарезервированной области, а оставшаяся часть файловой системы делится на
секции, называемые группами блоков. Все группы, за исключением последней,
содержат одинаковое количество блоков, используемых для хранения имен фай-
файлов, метаданных и содержимого файлов.
Базовая информация о строении ExtX хранится в структуре данных супер-
суперблока, находящейся в начале файловой системы, Содержимое файлов хранится
в блоках, которые представляют собой группы смежных секторов. Метаданные
каждого файла и каталога хранятся в структуре данных, называемой индексным
узлом (i-узлом); эта структура обладает фиксированным размером и находится
в индексной таблице. Для каждой группы блоков существует одна индексная таб-
таблица. Имя файла хранится в структуре записи каталога, которая находится в бло-
блоках, выделенных родительскому каталогу файла. Записи каталогов представляют
собой простые структуры данных, содержащие имя файла и указатель на индекс-
ную запись файла. Отношения между записями каталогов, индексными узлами
и блоками изображены на рис. 14.1.
Рис. 14.1. Отношения между записями каталогов ExtX,
индексными узлами и блоками данных, используемыми
для хранения содержимого файлов
Системы ExtX обладают дополнительными функциями, разделенными натри
категории в зависимости от того, что должна делать операционная система, обна-
обнаружив файловую систему с функциями, которую она не поддерживает. К первой
категории относятся функции совместимости. Даже если ОС не поддерживает
какие-либо из этих функций, она все равно может смонтировать файловую систе-
систему и продолжить работу в обычном режиме. В частности, к этой категории отно-
относятся методы выделения, журналы файловой системы и расширенные атрибуты.
Также существуют несовместимые функции] столкнувшись с ними, ОС не долж-
должна монтировать файловую систему. Примером несовместимой функции является
сжатие. Наконец, функция может быть совместимой в режиме только для чтения.
Если ОС встречает одну из этих функций, которые ею не поддерживаются, фай-
файловая система должна монтироваться в режиме только для чтения. Примерами
могут послужить поддержка больших файлов и сортировка каталогов с примене-
применением В-деревьев вместо несортированных списков.
Системы ExtX содержат многочисленные экспериментальные компоненты и
функции, не реализованные в крупных дистрибутивах Linux. Кроме того, на ана-
анализируемом компьютере некоторые подсистемы могут быть не установлены.
В Linux локальный администратор может включить любые подсистемы ядра по
своему желанию, поэтому эксперт не должен делать никаких предположений от-
относительно ОС. Если вы исследуете систему Linux, которая использовалась в ка-
качестве корпоративного сервера, вероятно, она будет иметь более стандартную сбор-
сборку. С другой стороны, система Linux на настольном компьютере злоумышленника,
подозреваемого во взломе других систем, может содержать экспериментальные
подсистемы. Анализ ядра и его модификаций относится к области прикладного
анализа и выходит за рамки книги. Флаги используемых функций могут пока-
показать, что в файловой системе задействованы экспериментальные функции, не опи-
описанные в книге.
В оставшейся части главы мы рассмотрим модель данных с пятью категория-
категориями в контексте Ext2 и Ext3. В каждом разделе мы сначала обсудим основные свой-
свойства категории, а затем перейдем к подробностям их реализации в ExtX. Рассмат-
Рассматриваться будут относительно стабильные подсистемы, но помните, что к моменту
чтения книги они могут измениться или устареть.
Категория данных файловой системы
К категории данных файловой системы относится общая информация о файло-
файловой системе. В этом разделе будет рассказанр, где хранятся данные этой катего-
категории, а также будет описана методика их анализа.
Общие сведения
В ExtX для хранения данных категории файловой системы используются две
структуры: суперблок и дескриптор группы. Суперблок находится в начале фай-
файловой системы и содержит базовую информацию о размере и конфигурации. Су-
Суперблок является аналогом структур данных загрузочного сектора в файловых
системах NTFS и FAT. Как упоминалось ранее, файловая система делится на груп-
группы блоков, и с каждой группой связывается специальная структура данных, опи-
описывающая ее строение — дескриптор группы. Дескрипторы групп хранятся в таб-
таблице дескрипторов групп, которая находится в группе, следующей за суперблоком.
В файловой системе создаются резервные копии суперблока и таблицы дескрип-
дескрипторов групп, используемые в случае повреждения основной копии.
Суперблок
Суперблок начинается со смещением 1024 байта от начала файловой системы;
его размер тоже равен 1024 байтам, хотя большинство байт не используется. Струк-
Структура данных содержит только параметры конфигурации, загрузочного кода в ней
нет. Резервные копии суперблока обычно хранятся в первом блоке каждой груп-
группы блоков.
В суперблоке находятся такие базовые параметры, как размер блока, общее
количество блоков, количество блоков в группе и количество зарезервированных
блоков перед первой группой блоков. Суперблок также содержит общее количе-
количество индексных узлов и количество индексных узлов в группе блоков. Среди не-
некритичных данных суперблока стоит отметить имя тома, время последней мо-
модификации, время и путь последнего монтирования файловой системы. Также
присутствуют поля, которые указывают, является ли файловая система «чистой»,
или для нее необходимо провести проверку целостности данных. Суперблок так-
также содержит некоторые служебные данные, в том числе общее количество сво-
свободных индексных узлов и блоков. Эти данные используются при выделении но-
новых индексных узлов и блоков.
Чтобы определить строение файловой системы, сначала следует определить
ее размер на основании размера блока и количества блоков. Если полученное зна-
значение меньше размера тома, за файловой системой могут храниться скрытые дан-
данные, называемые резервным пространством тома. Первая группа блоков находит-
находится в блоке, следующем за зарезервированной областью. На рис. 14.2 показано,
какие значения используются при определении строения файловой системы. Об-
Обратите внимание: количество блоков в последней группе на рисунке не совпадает
с количеством блоков в первых четырех группах.
Суперблок определяет активные функции файловой системы. Как говорилось
в разделе «Введение», функции делятся на три категории: совместимые, несовмести-
несовместимые и совместимые только для чтения. Для простоты подробное описание каждой
функции будет приводиться в соответствующем разделе главы. Здесь я ограни-
чусь описанием только одной функции, совместимой только для чтения: так на-
называемого «разреженного суперблока». При использовании этой функции резер-
резервные копии суперблока и таблицы дескрипторов групп хранятся только в некото-
некоторых группах блоков. В тестовой файловой системе я обнаружил, что резервные
копии находятся в группах 1, 3, 5, 7 и 9, а следующие копии встретились только
в группах 25 и 27. При создании файловой системы ExtX в Linux режим разре-
разреженного суперблока включен по умолчанию. Эта функция не должна влиять на
ход расследования — разве что эксперт не должен предполагать, что каждая груп-
группа содержит зарезервированное пространство для резервной копии суперблока.
Рис. 14.2. Строение файловой системы ExtX с пятью группами блоков
В Linux метка тома в суперблоке может использоваться для идентификации
файловой системы. Например, стандартный способ ссылки на файловую систему
в Linux основан на использовании имени устройства — скажем, /dev/hda5. Также
на файловую систему можно сослаться по метке тома, а системные конфигураци-
конфигурационные файлы могут использовать метку вместо имени устройства. Например, файл
/etc/fstab в Linux содержит перечень монтируемых файловых систем; если фай-
файловой системе присвоена метка rootfs, то вместо ссылки на устройство вида/dev/
hda4 в нем может использоваться конструкция LABEL=rootfs l.
За описанием структуры данных и примером суперблока обращайтесь к сле-
следующей главе. Результат выполнения программы fsstat в файловой системе будет
приведен далее в этом разделе.
Таблица дескрипторов групп
В блоке, следующем за суперблоком, хранится таблица дескрипторов групп. В таб-
таблице хранятся структуры данных дескрипторов групп для всех групп блоков в фай-
файловой системе. Резервная копия таблицы существует в каждой группе блоков (если
только в системе не активизирована функция разреженного суперблока). Помимо
содержимого файлов, группы блоков содержат административные данные — ре-
резервные копии суперблока и таблицы дескрипторов групп, таблицы индексных
узлов, битовые карты индексных узлов и блоков. Дескриптор группы описывает
местонахождение этих данных. Базовое строение группы блоков показано на
рис. 14.3.
1 Такая конфигурация может быть удобна в обычных системах, по в системе экспертного анализа ее
применение рискованно: если метка исследуемого диска совпадает с меткой диска, используемого
при проведении анализа, то исследуемый диск будет смонтирован операционной системой. Просле-
Проследите за тем, чтобы системы анализа и снятия данных были настроены на использование имен уст-
устройств, а не меток томов.
Рис. 14.3. Строение группы блоков
Битовая карта блоков описывает состояние выделения блоков группы, а ее
начальный адрес блока задается в дескрипторе группы. Размер карты в байтах
вычисляется делением количества блоков в группе на 8. При создании файловой
системы Linux определяет количество блоков в группе равным количеству бит
в блоке. Таким образом, для хранения битовой карты блоков требуется ровно один
блок.
Битовая карта индексных узлов описывает состояние выделения индексных
узлов в группе, а ее начальный адрес блока также задается в дескрипторе группы.
Размер карты в байтах вычисляется делением количества индексных узлов в груп-
группе на 9. Как правило, количество индексных узлов в группе меньше количества
блоков, но пользователь может выбрать эти значения при создании файловой си-
системы. Наконец, начальный адрес блока таблицы индексных узлов содержится
в дескрипторе группы, а ее размер вычисляется умножением количества индекс-
индексных узлов в группе на размер каждого узла A28 байт).
В дескрипторе группы также содержится количество свободных блоков и ин-
индексных узлов в группе блоков, а в суперблоке — общее количество свободных
блоков и индексных узлов во всех группах. Структура данных дескриптора груп-
группы приведена в главе 15.
Загрузочный код
Если файловая система ExtX содержит ядро ОС, в ней может храниться загру-
загрузочный код. Все остальные файловые системы, не являющиеся загрузочными, не
содержат загрузочного кода. Если загрузочный код существует, он размещается
в 1024 байтах, предшествующих суперблоку (то есть в первых двух секторах). Заг-
Загрузочный код выполняется в результате передачи управления из кода записи MBR
(Master Boot Record) в секторе 0 диска. Как правило, загрузочный код ExtX зна-
знает, какие блоки были выделены ядру, и загружает их в память.
Во многих системах Linux загрузочный код не хранится в файловой системе
с ядром. Вместо этого в MBR находится загрузчик (boot loader), которому известно,
в каких блоках находится ядро. В этом случае ядро загружается кодом MBR, а не-
необходимость в дополнительном загрузочном коде файловой системы отпадает.
Пример образа
В этой главе рассматриваются примеры, основанные на тестовом образе файло-
файловой системы. Я приведу результат выполнения программы fsstat из пакета TSK
(The Sleuth Toolkit) для этого образа. Некоторые из представленных значений
встретятся нам в последующих примерах. Этот же образ будет использоваться
для ручного разбора в следующей главе.
# fsstat -f Iinux-ext3 ext3.dd
FILE SYSTEM INFORMATION
File System Type: Ext3
Volume Name:
Volume ID: e4636f48c4ec85946e489517a5067a07
Last Written at: Wed Aug 4 09:41:13 2004
Last Checked at: Thu Jun 12 10:35:54 2003
Last Mounted at: Wed Aug 4 09:41:13 2004
Unmounted properly
Last mounted on:
Source OS: Linux
Dynamic Structure
Compat Features: Journa.
InCompat Features: Filetype, Needs Recovery.
Read Only Compat Features: Sparse Super, Has Large Files,
Journal ID: 00
Journal Inode: 8
METADATA INFORMATION
Inode Range: 1 - 1921984
Root Directory: 2
Free Inodes: 1917115
CONTENT INFORMATION
Block Range: 0 - 3841534
Block Size: 4096
Free Blocks: 663631
BLOCK GROUP INFORMATION
Number of Block Groups: 118
Inodes per group: 16288
Blocks oer group: 32768
Group: 0:
Inode Range: 1 - 16288
Block Range: 0 - 32767
Layout:
Super Block: 0 - 0
Group Descriptor Table: 1-1
Data bitmap: 2 - 2
Inode bitmap: 3 - 3
Inode Table: 4 - 512
Data Blocks: 513 - 32767
Free Inodes: 16245 (99*)
Free Blocks: О (OX)
Total Directories: 11
Group: 1:
Inode Range: 16289 - 32576
Block Range: 32768 - 65535
В выходных данных fsstat отображаются общие параметры файловой системы
из суперблока: общее количество индексных узлов и блоков, размеры блоков и т. д.
Также приводится описание структуры каждой группы блоков. Для группы 0 оно
приведено полностью — в листинге указаны диапазоны блоков и индексных уз-
узлов. Также показаны флаги функций и временные штампы.
Методы анализа
Анализ данных категории файловой системы подразумевает обработку ключевых
структур данных для определения строения файловой системы, а эта задача на-
напрямую ведет к более сложным и полезным методам анализа. В ExtX анализ на-
начинается с поиска суперблока; сделать это нетрудно, потому что суперблок всегда
хранится со смещением 1024 байта от начала файловой системы. Когда супер-
суперблок будет обнаружен, можно переходить к его обработке. Структура суперблока
играет ключевую роль в любых расследованиях, потому что в ней хранятся сведе-
сведения о размерах и местонахождении важнейших структур данных. На случай по-
повреждения суперблока в системе должны существовать его резервные копии.
Флаги функций указывают, обладает ли файловая система уникальными возмож-
возможностями, не поддерживаемыми программой анализа или ОС. Размер файловой
системы вычисляется по размеру блока и количеству блоков в файловой системе.
В блоке, следующем за суперблоком, находится таблица дескрипторов групп.
Она содержит записи для всех групп и используется для идентификации струк-
структур данных, определяющих состояние выделения блоков и индексных узлов. Ре-
Резервные копии таблицы также находятся в каждой группе, содержащей супер-
суперблок. Используя суперблок и дескрипторы групп, можно найти все структуры
данных, используемые файлами и каталогами.
Факторы анализа
Как и во всех остальных файловых системах, в ExtX эта категория содержит важ-
важнейшую информацию, описывающую строение файловой системы. Тем не менее
в ней относительно мало пользовательских данных, содержащих доказательства
возникновения некоторых событий. Суперблок содержит большой объем неис-
неиспользуемого пространства, которое может использоваться для хранения скрытых
данных. После знакомства с главой 15 и главами, посвященными UFS, вы увиди-
увидите, что суперблок ExtX гораздо проще суперблока UFS; это обстоятельство упро-
упрощает выявление значений, используемых для сокрытия данных. 1024 байта перед
началом суперблока зарезервированы для хранения загрузочного кода; если они
не используются, в них могут храниться скрытые данные. Также стоит сравнить
размер файловой системы с размером тома — по результатам сравнения можно
узнать, нет ли неиспользуемых секторов после файловой системы.
Таблица дескрипторов групп содержит записи, эффективно использующие
выделенное пространство, однако за концом таблицы также может следовать не-
неиспользуемое пространство. Его также следует проверить (включая резервные
копии) на наличие скрытых данных.
Если суперблок поврежден или его не удается найти, проведите поиск резервных
копий. Один из способов основан на поиске сигнатуры 0xef53 в байтах 56-57.
Также можно попытаться определить границы групп блоков на основании пред-
предполагаемого размера блока и того факта, что размер группы блоков часто зависит
от количества битов в одном блоке. Следовательно, если умножить размер блока
на 9 и прибавить 1, вы получите адрес сектора с резервной копией. Например,
если в файловой системе используются 1024-байтовые блоки, а каждая группа
состоит из 8192 блоков, то резервная копия суперблока должна находиться в бло-
блоке 8192 (при отсутствии зарезервированных блоков). Резервные копии структу-
структуры данных могут использоваться для выявления изменений, вносимых вручную
в основную копию.
Сценарий анализа
Представленная для экспертизы система не содержит таблицы разделов. В гла-
главе 4 рассматривался пример использования утилиты gpart для поиска файловой
системы при отсутствии или повреждении таблицы разделов. В этом разделе мы
сделаем вручную то, что программа gpart и ее аналоги делают автоматически.
Диск предположительно использовался в системе Linux, поэтому мы будем
искать файловую систему ExtX. Вообще говоря, на компьютере также могла ис-
использоваться система Reiser или другая файловая система, поэтому поиск не дол-
должен ограничиваться только ExtX. Также следует помнить, что многие системы
Linux часто используют несколько файловых систем и разделов на одном диске.
На практике первая файловая система нередко оказывается относительно неболь-
небольшой, потому что она используется только для хранения загрузочного кода и ядра.
Суперблок ExtX обладает сигнатурой 0xef53, хранящейся в байтах 56-57. Мы
проведем поиск этого значения, чтобы найти начало файловой системы. Можно
ожидать, что в процессе поиска будет найдено много ложных совпадений, посколь-
поскольку сигнатура имеет малую длину. Для проверки истинности совпадения можно
проверить другие величины, которые должны присутствовать в суперблоке (на-
(например, можно убедиться в том, что размер блока является разумной величиной).
Также можно воспользоваться тем фактом, что в каждой группе блоков должна
храниться резервная копия, так что при обнаружении настоящего суперблока ExtX
должна быть выявлена серия совпадений, разделенных равными интервалами.
Кроме того, размер группы блоков обычно определяется на основании размера
блока, так что в случае использования стандартной процедуры создания расстоя-
расстояние между суперблоками должно быть равно 8192,16384 или 32768. Также следу-
следует учитывать, что в системе может действовать функция разреженного супербло-
суперблока; в этом случае резервная копия не будет включаться в каждую группу блоков.
Для обнаружения сигнатур можно воспользоваться любой программой с воз-
возможностью поиска шестнадцатеричных значений. Такая программа, как grep, в дан-
данном случае не подойдет, потому что она поддерживает только поиск по ASCII-
кодам. В нашем примере будет использоваться программа sigfind из пакета TSK.
Шестнадцатеричная сигнатура хранится на диске в прямом порядке байт, поэто-
поэтому необходимо либо выбрать соответствующую конфигурацию программы, либо
изменить порядок байт сигнатуры при вводе (то есть использовать последователь-
последовательность 0x53ef). Результат работы sigfind выглядит так:
# sigfind -о 56 -1 ef53 disk-8.dd
Block size: 512 Offset:56
Block: 298661 (-)
Block: 315677 (+17016)
Block: 353313 (+37636)
Block: 377550 (+24237)
Программа sigfind выводит сектор, в котором обнаружена сигнатура, и рассто-
расстояние от предыдущего совпадения. Пока расстояния не равны степеням 2, а совпа-
совпадения не удалены на одинаковые расстояния, поэтому мы их проигнорируем (ве-
(вероятно, программа автоматизированного поиска таблицы разделов провела бы
анализ их содержимого). Тем не менее позднее в выходных данных обнаружива-
обнаруживаются интересные данные:
[...]
Block: 2056322 (+274327)
Block: 2072706 (+16384)
Block: 2105474 (+32768)
Block: 2148242 (+32768)
Block: 2171010 (+32768)
Block: 2203778 (+32768)
Обратите внимание: последние четыре совпадения находятся на одинаковых
расстояниях, а предшествующее совпадение удалено от предыдущего на 16 384
сектора. Все эти расстояния достаточно характерны для групп блоков. Таким об-
образом, начальная гипотеза состоит в том, что первый суперблок находится в сек-
секторе 2 056 322, а резервные копии находятся в секторах 2 072 706, 2 105 474 и т. д.
Вероятно, группа блоков состоит из 16 384 секторов, а в системе действует режим
разреженного суперблока, поэтому резервные копии суперблока присутствуют не
во всех группах.
Чтобы проверить эту гипотезу, мы читаем 1024 байта, начиная с сектора 2 056 322,
отображаем их на структуру данных суперблока и анализируем ее различные поля.
Анализ показывает, что размер блока равен 1024 байтам, а в системе активна фун-
функция разреженного суперблока. Файловая система состоит из 104 422 блоков, по
8192 блока в группе. Следовательно, резервная копия суперблока должна быть
удалена на 16 384 сектора (потому что один блок состоит из двух секторов) — пока
все совпадает.
Последняя проверка должна определить, является ли суперблок в секторе
2 056 322 первым в файловой системе, или это одна из резервных копий. Одно из
полей суперблока идентифицирует группу блоков, к которой он принадлежит;
в нашем примере оно равно 0. У суперблока в секторе 2 072 706 это поле равно 1.
Следовательно, мы можем предположить, что файловая система начинается в сек-
секторе 2 056 320 (за 2 сектора до суперблока) и следует до сектора 2 265 164.
Возникает искушение просто сравнить разные суперблоки и найти среди них
одинаковые, чтобы сгруппировать их как резервные копии. К сожалению, такой
способ не сработает, потому что резервные копии не обновляются с той же часто-
частотой, что и основная копия. Основная копия содержит временные штампы и флаги
обновления; эти данные не обновляются в резервных копиях. Более того, одно из
полей показывает, к какой группе блоков относится суперблок, поэтому никакие
две резервные копии не будут идентичны.
Пока все было просто и логично, так как мы нашли относительно редко обнов-
обновляемый раздел /boot. Co следующей группой совпадений дело обстоит сложнее.
Обратите внимание: следующее совпадение удалено на 2 сектора от того места,
в котором, по нашим подсчетам, должна заканчиваться предыдущая файловая си-
система:
Block: 2265167 (+61389)
Block: 2265733 (+566)
Block: 2265985 (+252)
Block: 2266183 (+198)
Block: 2266357 (+174)
Block: 2266457 (+100)
[...I
На основании положения сектора 2 265 167 по отношению к концу предыду-
предыдущего раздела можно было бы предположить, что он начинает новую файловую
систему. С другой стороны, из-за разных расстояний между последующими со-
совпадениями непохоже, чтобы они были резервными копиями; программа нахо-
находит более 200 совпадений, многие из которых разделены всего 20 секторами. По-
Пожалуй, их тоже можно проигнорировать. Пропустим пару сотен совпадений:
Block: 2278273 (+2800)
Block: 2281551 (+3278)
Block: 2282617 (+1066)
Block: 2314319 (+31702)
Block: 2347087 (+32768)
Block: 2379855 (+32768)
Block: 2412623 (+32768)
Теперь мы видим равномерные интервалы, характерные для резервных копий.
Просмотр сектора 2 314 319 показывает, что это файловая система Ext3 с 1024-
байтовым размером блока и 8192 блоками в группе. Также мы видим, что копия
принадлежит к группе блоков 3. А это означает, что группа блоков началась 49 152
секторов назад, то есть в секторе 2 265 167 сразу же за концом предыдущей фай-
файловой системы.
Сотни совпадений сигнатуры объясняются тем, что копии основного супер-
суперблока присутствуют в файле журнала файловой системы, находящегося в на-
начале файловой системы. Как будет показано в конце главы, Ext3 фиксирует все
обновления суперблока, и первые две сотни совпадений соответствовали ко-
копиям, сохраненным в журнале. Этот сценарий показан на рис. 14.4. В начале
и в конце диска встречаются ложные совпадения. Многочисленные секторы
с сигнатурой также встречаются в начале второй файловой системы, где распо-
располагается журнал.
В этом сценарии местонахождение ExtX на диске определялось по сигнатуре
суперблока. Дополнительные копии суперблока в журнале файловой системы
несколько усложняют процесс поиска начала файловой системы; с другой сто-
стороны, они обеспечивают дополнительную страховку на случай серьезного сбоя
диска.
Рис. 14.4. Результаты поиска сигнатуры суперблока (с многочисленными
совпадениями в журнале файловой системы)
Категория содержимого
К этой категории относится непосредственное содержимое файлов и каталогов.
Этот раздел посвящен категории данных содержимого в ExtX и способам их ана-
анализа.
Общие сведения
В ExtX единицей данных является блок — группа смежных секторов. Блоки ExtX
можно рассматривать как аналоги кластеров в FAT и NTFS. В этом разделе рас-
рассматриваются размеры блоков и способы их адресации, а также способы провер-
проверки состояния выделения.
Блоки
Размер блока ExtX составляет 1024, 2048 или 4096 байт; его значение указано
в суперблоке. Если вы читаете эту главу параллельно с главой 15, возможно, вы
также заметили встречающиеся в тексте упоминания фрагментов. В системе UFS,
на базе которой разрабатывалась ExtX, блоки разбиваются на фрагменты. Код
ExtX для Linux не поддерживает этого деления, хотя в суперблоке присутствует
поле, в котором может храниться размер фрагмента. Так как фрагменты не под-
поддерживаются основными системами, механизмы работы с ними остаются неиз-
неизвестными; в книге предполагается, что размер фрагмента совпадает с размером
блока.
Каждому блоку присваивается адрес. Нумерация адресов начинается с 0, и блок
0 находится в первом секторе файловой системы. Каждый блок входит в опреде-
определенную группу блоков — кроме случая, когда суперблок определяет зарезервиро-
зарезервированную область в начале файловой системы. В этом случае зарезервированные
блоки не принадлежат группе, а группа 0 начинается сразу же после зарезервиро-
зарезервированных блоков. Группа, к которой относится блок, вычисляется по следующей
формуле (количество блоков в группе определяется в суперблоке):
группа - (блок - ПЕРВЫЙ_БЛОК_ДАННЫХ) / БЛОКОВ_В_ГРУППЕ
Например, если зарезервированная область отсутствует, а группа состоит из
32 768 блоков, блок 60 000 должен входить в группу 1.
Состояние выделения
Состояние выделения блока определяется по битовой карте блоков, местонахожде-
местонахождение которой задается дескриптором группы. Для хранения битовой карты выде-
выделяется полный блок, каждый бит которого представляет некоторый блок группы.
Чтобы определить, какой бит представляет заданный блок, необходимо сначала
определить адрес блока относительно начала группы. Полученный адрес может
рассматриваться как логический адрес блока в группе. Формула вычисления пер-
первого блока в группе выглядит так:
первый_блок - группа * БЛОКОВ_В_ГРУППЕ + ПЕРВЫЙ_БЛОК_ДАННЫХ
Затем адрес первого блока в группе вычитается из адреса блока. Например,
базовый адрес группы 1 в нашем примере равен 32 768, поэтому блоку 60 000
будет соответствовать смещение 27 232. Соответствующий бит находится в бай-
байте 3 404 битовой карты. Пример битовой карты ExtX приводится в следующей
главе.
Механизм создания файловых систем в Linux выбирает размер группы блоков
таким образом, чтобы битовая карта блоков помещалась в одном блоке. Следова-
Следовательно, во всех файловых системах с 4 096-байтовыми блоками по умолчанию
группа состоит из 32 768 блоков. Пользователь может переопределить эти значе-
значения при создании файловой системы, а в других приложениях могут использо-
использоваться другие алгоритмы.
В отличие от NTFS, не каждый выделенный блок принадлежит какому-либо
файлу. В системе существует множество выделенных блоков с административ-
административными данными файловой системы, которые с файлами не ассоциируются. В каче-
качестве примеров можно привести суперблоки, таблицы дескрипторов групп, бито-
битовые карты блоков и индексных узлов, а также таблицы индексных узлов.
Программа dstat из пакета TSK отображает состояние выделения блока и но-
номер группы блоков, к которой он принадлежит. Пример вывода dstat для тестово-
тестового образа:
# dstat -f Iinux-ext3 ext3.dd 14380
Block: 14380
Allocated
Group: 0
Мы видим, что блок 14 380 входит в группу блоков 0 и что он выделен.
Алгоритмы выделения
В системе Linux блоки выделяются на уровне групп, но в других ОС могут ис-
использоваться другие методы. При выделении блока индексному узлу Linux ис-
использует стратегию поиска первого доступного блока и пытается выделить блок
из той же группы, к которой принадлежит индексный узел. Это делается для того,
чтобы сократить перемещения головки диска при чтении файла. При расшире-
расширении существующих файлов Linux сначала пытается применить стратегию поиска
следующего доступного блока и ищет блоки за концом текущего файла. Одна из
совместимых функций файловой системы осуществляет предварительное выде-
выделение блоков для каталогов, чтобы они не фрагментировались при выделении
дополнительных блоков.
Если в группе не остается свободного места, используется блок из другой
группы. Учтите, что это поведение определяется на прикладном уровне и не каж-
каждая ОС следует этой методике выделения. Например, ОС может с таким же ус-
успехом игнорировать существование групп и использовать алгоритм выделения
первого доступного блока от начала файловой системы (а не от начала группы
блоков).
ExtX обычно не разрешает пользователю выделять каждый блок файловой
системы. Одно из значений суперблока указывает, сколько блоков должно быть
зарезервировано для некоторого пользователя (как правило, привилегированно-
привилегированного). Когда количество свободных блоков падает до минимального порога, обыч-
обычные пользователи не могут создавать файлы, но администратор может войти в сис-
систему для ее очистки. Впрочем, это поведение также относится к прикладному
уровню и может не поддерживаться некоторыми ОС.
При записи данных на диск Linux заполняет неиспользуемые байты нулями,
поэтому за последним блоком файла не должно оставаться никаких предыдущих
данных.
Методы анализа
При анализе категории содержимого в ExtX эксперт должен знать, как найти лю-
любой блок, прочитать его содержимое и проверит состояние выделения. Найти за-
заданный блок несложно, потому что первый блок начинается в первом секторе
файловой системы, а размер блока задается в суперблоке.
Проверка состояния выделения любого блока состоит из трех этапов. Сначала
необходимо определить, к какой группе относится блок. Затем запись этой груп-
группы ищется в таблице дескрипторов групп, и по ней определяется местонахожде-
местонахождение битовой карты блока. На последнем этапе производится обработка битовой
карты блока и анализ бита, связанного с этим блоком. Если бит установлен, зна-
значит, блок выделен для использования.
Если потребуется извлечь содержимое всех свободных блоков в файловой си-
системе, необходимо последовательно перебрать все записи в таблице дескрипто-
дескрипторов групп. Для каждой записи загружается битовая карта блока, и в ней произво-
производится поиск нулевых битов. Далее остается лишь извлечь содержимое каждого
блока, бит которого равен 0. В ExtX суперблоки, дескрипторы групп, таблицы
индексных усзлов и битовые карты относятся к выделенным данным, хотя они
и не связываются с конкретными файлами. Если в начале файловой системы при-
присутствуют зарезервированные секторы, определить состояние выделения несколь-
несколько сложнее, потому что информация о таких секторах не включается в битовую
карту. Вероятно, результат будет зависеть от конкретной программы.
Факторы анализа
В том, что касается восстановления удаленного содержимого, может пригодить-
пригодиться знание алгоритмов выделения в файловых системах ExtX. Если ОС выделяет
блоки в той же группе, в которой находится индексный узел, поиск обычно мож-
можно ограничить группой (вместо поиска по всей файловой системе). Например,
если вы ищете файл, содержащий некоторое ключевое слово, и вы знаете, к какой
группе относился этот файл, проведите поиск улик в рамках группы. Такой спо-
способ работает гораздо быстрее, чем поиски по всей файловой системе. Впрочем,
такой способ поиска не является универсальным, потому что копии файла могут
существовать в других группах, а ОС выделяет блоки не только из той группы,
к которой принадлежит индексный узел. Для определения местонахождения груп-
группы можно воспользоваться программой fsstat из пакета TSK, как это было сдела-
сделано ранее; впрочем, ту же информацию можно получить и при помощи других про-
программ.
Время существования удаленных данных в ExtX отличается от NTFS или FAT.
Если блок уже заполнен информацией, а операции с ней выполняются относи-
относительно редко, удаленные данные будут заменяться реже, чем в группах с частыми
операциями записи. В NTFS и FAT вероятность перезаписи любого кластера оди-
одинакова, тогда как в ExtX она зависит от того, в какой группе находится блок.
Сценарий анализа
В следующем сценарии требуется прочитать содержимое последнего блока фай-
файловой системы, в котором руткит хранит свой пароль (вообще говоря, мне не из-
известны руткиты, которые вели бы себя подобным образом, но это неважно). Для
решения этой задачи необходимо определить размер блока и количество блоков
в файловой системе. Оба значения хранятся в суперблоке. Трудность заключает-
заключается в том, что в нашем распоряжении имеется только шестнадцатеричный редак-
редактор, работающий с 512-байтовыми секторами.
Сначала мы читаем суперблок, находящийся в секторе 2 файловой системы.
Размер блока хранится в байтах 24-27; он равен 2. Размер блока хранится в виде
числа двоичных разрядов, на которые необходимо сдвинуть число 1024 @x0400);
в нашей файловой системе сдвиг производится на две позиции влево. Однократ-
Однократный сдвиг дает число 2048 @x0800), а повторный — число 4096 @x1000). Если вы
не поняли, что происходит, достаточно вспомнить, что число 0x4 имеет двоичное
представление 0100, а число 0x8 — двоичное представление 1000. При сдвиге
0x4000 на 1 разряд влево число 0x4 переходит в 0x8.
Затем необходимо определить последний блок файловой системы. Значение
хранится в байтах 4-7 и не требует дополнительных вычислений. Файловая сис-
система состоит из 512 064 блоков; это означает, что поиск должен производиться
вперед на 512 063 блока, а каждый блок занимает 4 096 байт, или 8 секторов. Таким
образом, в шестнадцатеричном редакторе следует просмотреть секторы с 4 096 504
по 4 096 511.
В рассмотренном сценарии был воспроизведен процесс поиска заданного бло-
блока. Многие программы анализа делают это автоматически, однако поиск блока —
достаточно стандартная задача, поэтому полезно знать, как она решается.
Категория метаданных
К категории метаданных относятся данные, описывающие файлы или каталоги.
В этом разделе рассказано, где хранятся эти данные и как производится их
анализ.
Общие сведения
В ExtX основные метаданные файлов хранятся в структурах данных индексных
узлов. Дополнительные метаданные могут храниться в расширенных атрибутах.
Обе разновидности структур данных будут описаны в этом разделе.
Индексные узлы
Все индексные узлы в ExtX имеют одинаковый размер, который может опреде-
определяться в суперблоке. Каждому файлу и каталогу выделяется один индексный узел;
адресация индексных узлов начинается с 1. Каждой группе блоков выделяется
набор индексных узлов, размер которого задается в суперблоке. Индексные узлы
каждой группы хранятся в таблице, местонахождение которой определяется в дес-
дескрипторе группы. Если адрес индексного узла известен, его группа вычисляется
по следующей формуле:
группа = (узел - 1) / УЗЛ0В_В_ГРУППЕ
Индексные узлы 1-10 обычно резервируются и должны быть выделены.
В суперблоке хранится значение первого незарезервированного индексного узла.
Из зарезервированных индексных узлов только номер 2 имеет особую функцию
и используется для представления корневого каталога. Индексный узел 1 исполь-
используется для хранения информации о поврежденных блоках, но не имеет особого
статуса с точки зрения ядра Linux. Для журнала обычно используется индексный
узел 8, но его номер может быть переопределен в суперблоке. Первый пользова-
пользовательский файл обычно создается в узле 11; этот узел часто выделяется под ката-
каталог lost+found. Этот каталог используется программами проверки целостности
файловой системы; любой индексный узел, выделенный для использования, но
не ассоциированный ни с одним именем файла, помещается в этот каталог под
новым именем.
Количество полей в каждом индексном узле является статической величиной.
Дополнительная информация сохраняется в расширенных атрибутах и косвен-
косвенных указателях, о которых речь пойдет далее в этой главе. Состояние выделения
индексного узла определяется по карте индексных узлов, местонахождение кото-
которой задается в дескрипторе группы.
Индексный узел содержит информацию о размере файла, его владельце и вре-
временных штампах. Поле размера в новых версиях ExtX является 64-разрядным, но
в старых версиях оно содержало всего 32 бита, что делало невозможной работу
с файлами, размер которых превышал 4 Гбайт. В новых версиях старшие 32 бита
размера хранятся в поле, которое ранее не использовалось. При наличии в системе
больших файлов устанавливается флаг совместимой функции только для чтения.
Для хранения информации о «владельце» используются идентификаторы поль-
пользователя и группы. В UNIX каждому пользователю присваивается идентификатор;
имя пользователя связывается с идентификатором в файле /etc/passwd. Аналогич-
Аналогично, файл /etc/groups связывает идентификатор группы с именем. Учтите, что
присутствие идентификатора пользователя в индексном узле не обязательно оз-
означает, что файл был создан именно этим пользователем. Идентификаторы пользо-
пользователя и группы в индексном узле можно в любой момент сменить командами
chown и chgrp. Также учтите, что файл /etc/passwd не обязан содержать имя пользо-
пользователя для каждого идентификатора. Стандартные системные программы просто
выводят идентификатор пользователя, если они не могут преобразовать его в имя.
Что касается временных штампов, в индексном узле хранятся времена после-
последнего обращения, модификации, изменения и удаления. Значения хранятся в виде
количества секунд, прошедших с 1 января 1970 года в формате UTC. Время пос-
последней модификации, обращения и изменения также существует в UFS; эти
величины часто обозначаются сокращением MAC. Время последнего обращения
(А-время) соответствует времени последнего обращения к содержимому файла.
Время последней модификации (М-время) соответствует последней модификации
содержимого файла, а время последнего изменения (С-время) соответствует пос-
последнему изменению метаданных файла. При создании файла все три величины
обычно устанавливаются равными текущему времени. Время удаления (D-вре-
мя) соответствует моменту удаления файла. В Linux и других системах семейства
UNIX команда touch позволяет легко присвоить файлу произвольное М- и А-вре-
А-время. Команда touch задает значения М- и А-времени, но С-время при этом обнов-
обновляется автоматически.
Тип файла хранится в поле режима, которое также содержит базовые разреше-
разрешения доступа к файлу. В UNIX существует множество типов файлов. Нормальные
файлы, создаваемые пользователем, называются обычными файлами, а каталоги,
как и следовало ожидать, называются каталогами. В остальных случаях ситуация
не столь очевидна для пользователей, не обладающих навыками работы в UNIX,
а для хранения «файлов» не выделяются блоки. Такие файлы представляют со-
собой имена, которые используются программами для обращения к аппаратным ус-
устройствам или коммуникационным каналам.
Аппаратному устройству назначается одно или несколько имен файлов, каж-
каждое из которых соответствует блочному или символьному устройству. Блочные
устройства представляют оборудование, обмен данными с которым происходит
на уровне блоков — например, жесткие диски. Как было показано в главе 2, для
получения любых данных с жесткого диска необходимо прочитать как минимум
512 байт. Если приложению достаточно прочитать менее одного сектора с блоч-
блочного устройства, то ОС читает необходимые секторы и возвращает только те дан-
данные, которые запросило приложение. С другой стороны, символьные устройства,
также называемые низкоуровневыми устройствами, не нуждаются в блочной пе-
передаче данных. В качестве примера символьного устройства можно назвать кла-
клавиатуру. Как правило, для блочного устройства также параллельно создается сим-
символьное устройство, но при попытке его использования для чтения/записи данных,
размер которых отличен от размера блока, происходит ошибка. Индексные узлы,
в которых обычно хранится информация о блоках, выделенных файлу, использу-
используются для хранения информации об идентификаторе устройства.
Еще один тип файлов предназначен для обмена данных между процессами.
Каналы FIFO, также называемые именованными каналами, обеспечивают односто-
одностороннюю передачу данных между двумя и более процессами. Процесс открывает
файл и читает данные, записанные в него другим процессом. Данные при этом
хранятся не на диске, а в памяти ядра. Если обмен данными между процессами
должен быть двусторонним, используются сокеты UNIX. Сонетом UNIX называет-
называется файл, открываемый процессами при помощи специальных функций и обеспечи-
обеспечивающий двусторонний обмен данными. Как и в случае с именованными каналами,
данные на диск не записываются. Последнюю категорию файлов составляют сим-
символические (мягкие) ссылки. Они будут более подробно рассмотрены в разделе
«Категория данных имен файлов», а пока достаточно сказать, что символические
ссылки определяют альтернативные имена для обращения к файлам или каталогам.
Помимо типа файла, в поле режима хранятся основные разрешения доступа
к файлу. Разрешения определяют возможность чтения, записи и выполнения ко-
команд для владельца, группы или всех пользователей. Например, если группе раз-
разрешено чтение файла, а остальным пользователям доступ запрещен, то прочитать
содержимое файла смогут только пользователи группы, идентификатор которой
хранится в индексном узле. Принадлежность к группе определяется по файлу
/etc/groups. Конечно, эти данные относятся к необязательным, потому что ОС мо-
может и не соблюдать установленные ограничения.
Наконец, поле режима определяет особые свойства файлов и каталогов. Если
для исполняемого файла установлен «бит устойчивости», то некоторые данные
процесса останутся в памяти после завершения процесса. Если этот бит устанав-
устанавливается для файла или каталога, то удаление содержимого каталога разрешает-
разрешается только владельцу файла. Если для исполняемого файла установлены биты SUID
(Set User ID) и SGID (Set Group ID), то процесс берет идентификаторы группы
и пользователя из файла (вместо данных пользователя, запустившего процесс).
Это позволяет непривилегированным пользователям запускать некоторые про-
программы в качестве привилегированного пользователя. Если бит SGID установ-
установлен для каталога, всем файлам в этом каталоге назначается идентификатор груп-
группы, установленный для каталога.
В каждом узле хранится счетчик ссылок; его значение равно количеству имен
файлов, ссылающихся на данный узел. Когда счетчик уменьшается до нуля
и файл не открыт ни одним процессом, индексный узел освобождается. Если
счетчик равен нулю, но файл открыт процессом, узел освобождается после его
закрытия процессом. Индексный узел также содержит счетчик поколения, ис-
используемый системой NFS (Network File System) при получении информации
о создании новых файлов. Когда индексный узел ассоциируется с новым фай-
файлом, счетчик поколения изменяется; таким образом сервер узнает о появлении
нового файла. Его можно сравнить с полем порядкового номера, которое встре-
встречалось нам в NTFS.
За описаниями структур данных и примерами индексных узлов обращайтесь
к следующей главе.
Указатели на блоки
Файловая система ExtX, как и UFS, проектировалась в расчете на эффективную
работу с небольшими файлами. По этой причине в каждом индексном узле могут
храниться адреса первых 12 блоков, выделенных файлу. Эти адреса называются
прямыми указателями. Если для хранения файла потребуется более 12 блоков,
выделяется специальный блок для хранения остальных адресов. Указатель на него
называется косвенным указателем блоков. Все адреса блоков занимают 4 байта,
а общее количество адресов в блоке зависит от размера блока. Косвенный указа-
указатель хранятся в индексных узлах.
Если файл содержит больше блоков, чем помещается в 12 прямых указателях
и в косвенном блоке, используется механизм двойной косвенной адресации. Дру-
Другими словами, индексный узел ссылается на блок, содержащий список косвенных
указателей на блоки; каждый такой указатель ссылается на блоки, содержащие
список прямых указателей. Наконец, если файлу потребуется еще больше места,
можно воспользоваться тройной косвенной адресацией: такой блок содержат на-
набор адресов блоков с двойной адресацией, которые, в свою очередь, содержат ад-
адреса блоков косвенной адресации. Графическое представление каждой из этих
структур данных показано на рис. 14.5. Каждый индексный узел содержит 12 пря-
прямых указателей, один косвенный указатель, один указатель двойной адресации
и один указатель тройной адресации.
Рис. 14.5. Примеры косвенной адресации на одном, двух и трех уровнях
В ExtX файлы могут содержать разреженные блоки. Разреженный блок созда-
создается в ситуации, когда исходный блок либо не определен, либо заполнен одними
нулями. Неопределенные блоки появляются в том случае, если программа при
создании файла потребовала, чтобы файл имел определенный размер, но не стала
записывать данные в некоторые из его частей. Вместо того чтобы заполнять блок
нулями, ОС помещает в указатель значение 0. Средства анализа и ОС должны
обрабатывать разреженные блоки так, как если бы они были заполнены нулями.
Атрибуты
Каждый индексный узел обладает некоторыми атрибутами, описанными в поле
флагов. Следует помнить, что некоторые атрибуты могут не поддерживаться те-
текущей ОС. Одни атрибуты являются экспериментальными, поддержка других
в Linux прекращена. К числу поддерживаемых относится атрибут, отменяющий
обновление А-времени файлов и каталогов. Другой атрибут используется для
пометки файлов, которые должны записываться на диск сразу же после измене-
изменения данных (без применения кэширования). Еще два атрибута относятся к об-
области безопасности; один атрибут разрешает открывать файл только в режиме
дополнения, что делает невозможным удаление данных, и еще один атрибут за-
запрещает изменение файлов (добавление или удаление данных). Наконец, один
атрибут указывает, что файл не должен сохраняться при резервном копировании
командой dump.
К числу атрибутов, которые не поддерживались большинством систем на мо-
момент написания книги, принадлежат атрибуты надежного удаления, сжатия и вос-
восстановления. При надежном удалении стирается предыдущее содержимое блоков,
связанных с файлом, а атрибут восстановления при удалении создает резервную
копию файла для восстановления в будущем. Впрочем, некоторые из этих атри-
атрибутов могут использоваться в ядрах Linux, построенных с экспериментальными
дополнениями.
Кроме перечисленных атрибутов, файл также может обладать расширенными
атрибутами. В Linux расширенные атрибуты используются только в том случае,
если файловая система была смонтирована с ключом user_xattr, а поддержка ат-
атрибутов включена в ядро (начиная с версии 2.4). Чтобы узнать, монтируется ли
файловая система по умолчанию с ключом user_xattr, следует обратиться к файлу
/etc/fstab. Если файловая система поддерживает расширенные атрибуты, в ней
должен быть установлен соответствующий флаг совместимой функции.
Расширенные атрибуты представляют собой список пар «имя-значение».
Пользователь создает произвольные пары вида «user.source=http://www.digital.evi-
dence.org» командой setfattr. В данном случае подстрока user определяет простран-
пространство имен; также существуют пространства trusted и security. Расширенные атри-
атрибуты хранятся в блоке, выделенном файлу. Если несколько файлов обладают
одинаковыми расширенными атрибутами, они совместно используют один блок.
В блоке перечислены все пары «имя-значение». Ядро Linux 2.6 требует, чтобы все
расширенные атрибуты хранились в одном блоке.
Один из вариантов использования атрибутов операционной системой — спис-
списки контроля доступа ЛCL (Access Control List). По сравнению с существующими
механизмами управления доступом ExtX списки ACL обеспечивают более совер-
совершенный метод ограничения доступа к файлам. Механизм ACL позволяет предос-
предоставить доступ к файлу конкретному кругу пользователей без использования групп
UNIX. Данные ACL хранятся в расширенном атрибуте. В системе Linux для со-
создания списка ACL используется команда setfacl, а файловая система должна быть
смонтирована с ключом acl. Структуры данных и примеры расширенных атрибу-
атрибутов приводятся в следующей главе.
Пример образа
Чтобы продемонстрировать, как выглядит служебная информация реальных фай-
файлов, я приведу выходные данные программы istat для файла из тестовой файло-
файловой системы. Анализом индексных узлов мы займемся в следующей главе, а пока
приведу отформатированный результат:
# istat -f Iinux-ext3 ext3.dd 16
inode: 16
Allocated
Group: 0
Generation Id: 199922874
uid / gid: 500 / 500
mode: -rw-r--r--
size: 10240000
num of links: 1
Inode Times:
Accessed: Fri Aug 1 06:32:13 2003
File Modified: Fri Aug 1 06:24:01 2003
Inode Modified: Fri Aug 1 06:25:58 2003
Direct Blocks:
14380 14381 14382 14383 14384 14385 14386 14387
14388 14389 14390 14391 14393 14394 14395 14396
[...]
16880 16881 16882 16883
Indirect Blocks:
14392 15417 15418 16443
Из результатов istat видно, что размер файла равен 10 Мбайт, а для хранения
информации обо всех выделенных блоках задействованы четыре косвенных ука-
указателя. Также указаны разрешения, тип файла и временные штампы MAC.
Алгоритмы выделения
В этом разделе я привожу собственные наблюдения и результаты анализа исход-
исходного кода ядра Linux в области выделения метаданных ExtX. В другой ОС или
измененном коде ядра Linux могут использоваться другие алгоритмы выделения.
Результаты были получены в стандартной системе Fedora Core 2.
Выделение индексных узлов
Когда для хранения файла или каталога требуется выделить новый индексный
узел, Linux прежде всего учитывает группу блоков, в которой должен находиться
индексный узел. Если индексный узел не относится к каталогу, Linux выделяет
его в той же группе блоков, в которой находится родительский каталог. Это дела-
делается для того, чтобы вся информация каталога находилась более или менее в од-
одной зоне. Если группа не содержит свободных индексных узлов или свободных
блоков, поиск производится в другой группе. Для выбора случайной группы Linux
использует квадратичное хеширование: этот алгоритм начинает с текущей груп-
группы блоков и последовательно прибавляет к ней степени 2 A, 2, 4, 8, 16 и т. д.).
Если в полученной таким образом группе присутствует свободный индексный
узел, он используется системой. Если алгоритм не находит группу со свободным
индексным узлом, проводится линейный поиск, начиная с текущей группы. В обо-
обоих случаях применяется поиск первого свободного индексного узла.
Если индексный узел содержит информацию о каталоге, то система пытается
поместить его в относительно редко используемую группу (чтобы обеспечить рав-
равномерное использование групп). На первой стадии поиска вычисляется среднее
количество свободных индексных узлов и свободных блоков в группах; для этого
используются значения общего количества свободных индексных узлов и бло-
блоков, хранящиеся в суперблоке. Затем Linux проводит поиск в каждой группе, на-
начиная с 0, и использует первую группу, у которой эти значения меньше средних.
Если найти группу, у которой оба параметра меньше вычисленных, не удается,
используется группа с наименьшим количеством каталогов и наибольшим коли-
количеством свободных индексных узлов. Оба значения хранятся в дескрипторах
групп.
При выделении индексного узла его содержимое стирается, а М-, А- и С-время
приводятся в соответствие с текущим временем; D-время обнуляется. Счетчик
ссылок (количество имен файлов, содержащих ссылки на данный индексный узел)
задается равным 1 для файлов. Для каталогов счетчик ссылок задается равным 2
из-за присутствия псевдоссылки «.» в данном каталоге. Linux также обновляет
поле поколения текущим значением счетчика.
При удалении файла в Linux количество ссылок на него в индексном узле
уменьшается на 1. Если счетчик ссылок уменьшается до нуля, индексная запись
освобождается. Если файл все еще открыт каким-либо процессом, он причисля-
причисляется к зависшим файлам и помещается в список, хранящийся в суперблоке. После
закрытия файла процессом или перезагрузки системы индексный узел освобож-
освобождается.
В Ext2 и Ext3 используются разные реализации удаления файлов. Ext3 обну-
обнуляет размер файла и стирает указатели на блоки в индексном узле и косвенных
блоках. С другой стороны, Ext2 не стирает эти данные, что упрощает восстанов-
восстановление. М-, А- и С-время приводятся в соответствие с моментом удаления. Если
файл был удален из-за перемещения на другой том, его А-время приводится в со-
соответствие с моментом чтения содержимого. Данное обстоятельство помогает от-
отличить удаленные файлы от перемещенных.
Обновление временных штампов
В индексных узлах ExtX хранятся четыре временных штампа, и мы должны вы-
выяснить, когда обновляются их значения. В моих экспериментах система Linux
обновляла А-время при чтении содержимого файла или каталога. Для файла это
происходило при чтении содержимого, при копировании файла и его перемеще-
перемещении на другой том. Если перемещение производится в пределах тома, то содержи-
содержимое остается на прежнем месте, поэтому временной штамп не изменяется. Для
каталогов А-время обновляется при чтении содержимого, при открытии файлов
и подкаталогов. Как будет показано позднее, содержимым блоков каталога счита-
считаются имена файлов в каталоге.
М-время соответствует моменту последней модификации; этот временной
штамп обновляется при изменении содержимого файла или каталога. Для фай-
файлов это происходит при изменении содержимого любого файла. Для каталогов
это происходит при создании или удалении находящихся в них файлов. При пе-
перемещении файла М-время приемного файла совпадает с оригиналом, потому что
содержимое файла не изменилось во время перемещения. При копировании фай-
файла М-время приемника обновляется текущим временем, потому что с точки зре-
зрения системы содержимое считается новым. Обратите внимание: если файл пере-
перемещается на сетевой диск, М-время приемного файла может быть обновлено,
потому что сетевой сервер посчитает его новым файлом.
С-время описывает момент последнего изменения индексного узла; это про-
происходит при изменении метаданных файлов или каталогов — в частности, при
создании файлов и каталогов, смене разрешений или владельца файла. При пере-
перемещении файла С-время обновляется. D-время задается только при удалении
файла и стирается при повторном выделении индексного узла. Во многих удален-
удаленных файлах М- и С-время совпадает с D-временем.
Подведем итоге: при создании файла М-, А- и С-время обновляется текущим
временем создания, D-время обнуляется, а у родительского каталога обновляется
М- и С-время. При копировании файла А-время обновляется для исходного фай-
файла и родительского каталога; у приемного файла обновляется М-, А- и С-время;
а у приемного родительского каталога обновляется М- и С-время. При перемеще-
перемещении файла у родительского каталога исходного файла обновляется М-, А- и С-
время, у родительского каталога приемного файла — М- и С-время, а приемный
файл сохраняет М- и А-время оригинала с обновлением С-времени. Если переме-
перемещение происходит в пределах тома, то для приемника используется тот же индек-
индексный узел, но при перемещении на другой том исходный индексный узел осво-
освобождается с обновлением М-, А-, С- и D-времени.
Методы анализа
Анализ в категории метаданных решает задачи поиска и обработки структур с ин-
информацией метаданных и каталогов с целью получения дополнительной инфор-
информации о файле. В ExtX эта задача сводится к поиску и обработке структур данных
индексных узлов. Чтобы найти конкретный узел, необходимо сначала определить,
к какой группе блоков он принадлежит. Затем обработка дескриптора этой груп-
группы дает таблицу индексных узлов группы. После этого остается лишь определить,
в какой записи таблицы хранится нужный индексный узел, и обработать его.
За исключением косвенных указателей и расширенных атрибутов, структура
данных индексного узла вполне самостоятельна и содержит все метаданные. Что-
Чтобы идентифицировать все блоки, выделенные файлу или каталогу, следует про-
прочитать 12 прямых указателей на блоки. Если файлу выделено большее количе-
количество блоков, далее следует обработать указатели первого, второго и третьего уровня
на блоки, в которых хранятся адреса блоков с содержимым. Если указатель блока
содержит адрес 0, файл является разреженным, а блок не выделяется на диске,
потому что его пришлось бы заполнить нулями.
Чтобы проверить состояние выделения индексного узла, следует проанали-
проанализировать битовую карту индексных узлов группы. Адрес битовой карты задается
в дескрипторе группы. Если соответствующий бит равен 1, индексный узел вы-
выделен.
Иногда требуется проанализировать свободные индексные узлы, потому что
они могут содержать информацию о времени удаления файлов. В файловой сис-
системе Ext3 имена удаленных файлов содержат ссылки на записи индексных узлов,
но в Ext2 ссылки удаляются. Впрочем, даже в Ext3 имена файлов могут быть стерты
раньше данных индексных узлов. Следовательно, в обоих случаях для сбора ин-
информации обо всех удаленных файлах необходимо проанализировать все свобод-
свободные индексные узлы. Как правило, свободный индексный узел ранее использо-
использовался, если содержащиеся в нем значения отличны от нуля.
Важная информация, связанная с файлом, также может храниться в расши-
расширенных атрибутах. Чтобы получить доступ к расширенным атрибутам, следует
взять указатель из индексного узла и обработать тот блок, на который он ссылает-
ссылается. Этот блок содержит набор пар «имя-значение», задаваемых пользователем.
Факторы анализа
Благодаря стратегиям выделения, используемым в файловых системах UFS,
в группах с малым объемом операций свободные индексные узлы могут существо-
существовать в течение более долгого времени. Значения М-, С- и D-времени также могут
показать, когда файл был удален.
В Linux и в большинстве версий UNIX пользователь может легко менять М-
и А-время файла командой touch, поэтому при оценке надежности временных
штампов существующих файлов желательно найти независимые источники ин-
информации (такие, как журналы или сетевые пакеты). Кроме того, временные штам-
штампы хранятся в формате UTC, поэтому для точного вывода значений программе
анализа должен быть известен часовой пояс, в котором находится компьютер.
Резервное пространство относится к числу функций, зависящих от операци-
операционной системы, но Linux заполняет неиспользуемые байты блоков нулями. Та-
Таким образом, данные из удаленных файлов могут существовать только в свободных
блоках. Чтобы узнать, просматривает ли ваша программа резервное пространство
файловой системы Ext3, можно воспользоваться тестовыми образами с сайта DFTT
(Digital Forensic Tool Testing).
К сожалению, данные о размере файла и выделенных блоках с большой веро-
вероятностью будут стерты из свободных индексных узлов, поэтому при восстановле-
восстановлении файлов приходится полагаться на методики прикладного уровня. Кроме того,
между блоками с содержимым файлов могут находиться блоки с косвенными ука-
указателями, поэтому программы извлечения данных по возможности не должны
включать их в итоговый файл. Обычно блоки косвенных указателей относитель-
относительно легко идентифицируются, потому что они содержат список 4-байтовых адре-
адресов с похожими или последовательно увеличивающимися значениями. В процессе
извлечения данных аналитик может воспользоваться своими знаниями о страте-
стратегии выделения — если его интересует конкретный файл или каталог, возможно,
вместо проведения анализа по всей файловой системе удастся ограничиться про-
проверкой свободных данных в отдельной группе блоков.
Если в ExtX обнаруживается удаленный файл, размеры и указатели на блоки
которого не были стерты, вам придется принять особые меры по отношению к кос-
косвенным указателям. Если они ссылаются на блоки, которые были выделены зано-
заново, вместо списка адресов блоков в них может храниться другая информация, или
адреса могут относиться к другому файлу.
Расширенные атрибуты файлов тоже должны быть включены в процесс поис-
поиска улик. Проверьте, включают ли ваши программы анализа эти данные в поиск по
ключевым словам. Расширенные атрибуты можно рассматривать как отдаленные
аналоги альтернативных потоков данных в NTFS, но их размер гораздо меньше.
Один из методов сокрытия файлов состоит в том, что процесс открывает файл
для чтения или записи, а затем удаляет имя файла. В этом случае счетчик ссылок
индексного узла равен 0, но узел не является свободным. Когда это происходит,
ядро должно включить зависший индексный узел в список, хранящийся в супер-
суперблоке, и его необходимо проанализировать в процессе расследования. В TSK для
поиска таких файлов можно воспользоваться программой fsstat.
Сценарий анализа
В процессе расследования инцидента в Linux обнаружен каталог с подозрительным
именем. Наша задача — определить, какая учетная запись пользователя исполь-
использовалась для создания находящихся в нем файлов. Идентификатор пользователя
хранится в индексном узле файла, а информация о соответствии идентификатора
и имени хранится в файле /etc/passwd.
Во время преобразования выясняется, что некоторые идентификаторы отсут-
отсутствуют в файле passwd. Это могло произойти в двух ситуациях. Первая — учетная
запись пользователя была создана во время инцидента, использована для созда-
создания файла, после чего удалена. Вторая ситуация — файлы были взяты из архи-
архивного файла (скажем, tar), и в них сохранился идентификатор пользователя с того
компьютера, на котором был создан архивный файл. В этом случае на анализиру-
анализируемом компьютере вообще не существовало пользователя с указанным идентифи-
идентификатором.
Чтобы проверить первую теорию, мы проведем поиск удаленной копии файла
паролей в свободных блоках файловой системы, содержащей каталог/etc/. В ка-
качестве критерия поиска мы скопируем строку из текущего файла. Возможно, это
позволило бы найти версию файла с новой учетной записью пользователя. Тем не
менее поиск оказался неудачным.
Для проверки второй теории мы попробуем найти в файловой системе tar-фай-
tar-файлы, в которых могли бы находиться подозрительные файлы. Описание системы,
в которой реализован второй сценарий, приводится в документе Forensic Challenge
[Honeynet Project, 2001], опубликованном Honeynet Project в 2001 г. При постро-
построении временного профиля в TSK был получен следующий результат:
[...]
Wed Nov 08 2000 08:51:56
..с -/-rwrx-xr-x 1010 users /usr/man/.Ci/ /Anap
..с -/-rwrx-xr-x 1010 users /usr/man/.Ci/bx
Wed Nov 08 2000 08:52:09
m.c 1/lrwxrwxrwx root root /.bash_history -> /dev/null
m.c 1/lrwxrwxrwx root root /root/.bash_history -> /dev/null
[...]
У двух файлов в каталоге /usr/man/.Ci зарегистрировано время изменения
08:51:56, при этом указан идентификатор пользователя 1010. Обычно программа
построения временной диаграммы преобразует идентификатор в имя пользова-
пользователя, как в двух нижних строках, где идентификатор 0 преобразован в строку root
В процессе поиска в системе обнаруживается tar-файл с подозрительным каталогом.
Идентификатор пользователя, ассоциированный с файлом, может быть сменен
командой chown; впрочем, даже если идентификатор пользователя присутствует
в файле паролей, это еще не доказывает, что файл был создан именно этим пользо-
пользователем. Если мы хотим знать, кто создал подозрительный каталог, следует про-
проанализировать разрешения родительского каталога. В данном случае родительским
каталогом является каталог /usr/local/, принадлежащий привилегированному
пользователю root; только ему разрешена запись. Такая конфигурация считается
стандартной, поэтому можно предположить, что злоумышленник не изменял раз-
разрешения после создания каталога. А это означает, что злоумышленник с большой
вероятностью получил доступ к учетной записи root.
Категория данных имен файлов
К категории имен файлов относятся структуры данных, в которых хранятся име-
имена всех файлов и каталогов. В этом разделе описано, где хранятся данные и как их
анализировать.
Общие сведения
В ExtX существует несколько способов присваивания имен файлам и каталогам;
в этом разделе будут рассмотрены три из них. В первом подразделе рассматривают-
рассматриваются записи каталогов — основные структуры данных, используемые при назначе-
назначении имен. Затем мы рассмотрим жесткие и мягкие ссылки, а также хеш-деревья.
Записи каталогов
Каталог ExtX практически ничем не отличается от обычного файла, если не счи-
считать установки специального значения типа в индексном узле. В блоках, выде-
выделенных каталогам, содержится список структур данных, называемых записями
каталогов. Запись каталога представляет собой простую структуру данных с име-
именем файла и адресом индексного узла, в котором хранятся метаданные файла.
Размер каталога соответствует количеству выделенных блоков и не связан с ко-
количеством реально существующих файлов.
Каждый каталог начинается с записей «.» и «..», обозначающих текущий и роди-
родительский каталог соответственно. За ними следуют записи всех файлов и подката-
подкаталогов в данном каталоге. Корневой каталог всегда размещается в индексном узле 2.
Запись каталога имеет динамическую длину, потому что файл может обладать
именем произвольной длины, от 1 до 255 символов. По этой причине в структуре
данных присутствует поле, определяющее длину имени и местонахождение сле-
следующей записи каталога. Длина записей округляется до числа, кратного 4. На
рис. 14.6 изображен каталог с тремя файлами. Первые две записи предназначены
для каталогов «.» и «..», а последняя запись ссылается на конец выделенного бло-
блока. Пространство за файлом c.txt не используется.
При удалении файла или каталога его имя требуется модифицировать, чтобы
ОС не пыталась выводить информацию об этом файле. ОС скрывает запись ката-
каталога, увеличивая длину предыдущей записи, чтобы она ссылалась на запись пос-
после скрываемой. Так, на рис. 14.6(В) файл b.txt был удален, а указатель в a.txt был
увеличен и переведен на c.txt. При выводе содержимого каталога запись b.txt про-
пропускается, но данные в ней еще существуют.
При создании новой записи ОС анализирует каждую существующую запись
и сравнивает ее длину с длиной имени. Кроме имени, каждая запись каталога со-
содержит 8 байт в статических полях, поэтому минимальная длина записи опреде-
определяется увеличением длины имени на 8 и округлением результата до величины,
кратной 4. Если зарезервированная длина записи превышает необходимую на ве-
величину, превышающую размер добавляемой записи, запись размещается в неис-
неиспользуемом пространстве. Для примера рассмотрим новый каталог с 4096-байто-
4096-байтовым блоком, содержащим записи «.» и «..». Параметры этих записей перечислены
в табл. 14.1.
Рис. 14.6. В записи каталога хранится имя файла и индексный узел. Кроме того, в записи
присутствует ссылка на следующую запись. Чтобы пропустить неиспользуемую
запись, достаточно увеличить указатель в предыдущей записи
Таблица 14.1. Параметры записей только что созданного каталога
Имя Длина имени Длина записи
1 12
2 4084
Последняя запись «..» обладает длиной 4084 байта, потому что она должна ука-
указывать на конец блока, хотя реально требуется всего 12 байт. Следовательно, но-
новая запись каталога будет добавлена со смещением 12 байт от начала записи «..»,
а ее длина выбирается так, чтобы она ссылалась на конец блока. Параметры запи-
записей каталога после создания нового файла приведены в табл. 14.2.
Таблица 14.2. Параметры записей после создания нового файла
Имя Длина имени Длина записи
1 12
2 12
Filel.dat 8 4072
В действительности существует две версии структур записей каталогов. В ста-
старой версии хранится только имя, адрес индексного узла и длина. В обновленной
версии один из байтов поля длины имени файла используется для хранения типа
файла (файл, каталог, символьное устройство). Позднее мы увидим, как это об-
обстоятельство может использоваться для выявления факта повторного выделения
индексного узла после удаления файла. Описания структур данных обоих типов
записей каталогов приведены в следующей главе.
Далее приводится результат выполнения f ls для одного из каталогов тестового
образа. В выходных данных присутствует один удаленный файл (он помечен пре-
префиксом *). В первом столбце отображается тип файла — сначала по данным из
записи каталога, затем по данным из индексного узла. Обратите внимание на со-
совпадение этих типов у удаленного файла; возможно, индексный узел еще не был
выделен повторно:
# fls -f Iinux-ext3 -a ext3.dd 69457
d/d 69457:
d/d 53248:
г/г 69458: acbdefg.txt
г/г * 69459: file two.dat
d/d 69460: subdirl
r/r 69461: RSTUVWXY
Ссылки и точки монтирования
В ExtX поддерживаются как жесткие, так и мягкие ссылки, при помощи которых
пользователи могут определять несколько имен для файлов и каталогов. Жесткая
ссылка представляет собой дополнительное имя для файла или каталога, принад-
принадлежащего той же файловой системе. После создания жесткой ссылки невозможно
отличить ее от исходного имени. Чтобы создать жесткую ссылку, ОС выделяет
новую запись каталога и создает в ней указатель на исходный индексный узел.
Счетчик ссылок в индексном узле увеличивается на 1, отмечая появление нового
имени. Файл будет удален лишь после удаления всех жестких ссылок на него.
Помните, что записи «.» и «..» в каждом каталоге представляют собой жесткие
ссылки на текущий и родительский каталоги. По этой причине счетчик ссылок
каталога равен как минимум 2 + количество содержащихся в нем подкаталогов.
Мягкие ссылки также определяют альтернативные имена для файлов и ката-
каталогов, но они могут выходить за пределы файловых систем. Для создания мягких
ссылок ОС использует особую разновидность файлов, называемых символичес-
символическими ссылками. Полный путь к приемному файлу или каталогу хранится либо
в блоках, выделенных файлу, либо в индексном узле, если длина пути меньше
60 символов. В следующей главе будут приведены примеры структур данных, со-
содержащих символические ссылки.
Примеры жестких и мягких ссылок показаны на рис. 14.7. Слева изображена
жесткая ссылка hardlink.txt, указывающая на файл filel.txt. Справа изображена
мягкая ссылка на тот же файл, но на этот раз в схеме появляется промежуточный
уровень. Файл softlink.txt обладает собственным индексным узлом, содержащим
путь к файлу. Обратите внимание: на рисунке (В) у обоих индексных узлов счет-
счетчик ссылок равен 1. В действительности символическая ссылка сохранит адрес
/filel.txt в индексном узле, потому что путь короче 60 символов.
Как упоминалось в главе 4, в каталогах UNIX могут храниться как файлы, так
и точки монтирования томов. Рассмотрим каталог dirl из файловой системы с име-
именем FS1. Если файловая система FS2 смонтирована в каталоге dirl, при переходе
пользователя в этот каталог и выводе его содержимого будут выведены файлы из
FS2. Даже если в FS1 каталог dirl содержит собственные файлы, при монтирова-
монтировании FS2 они отображаться не будут. На рис. 14.8 (А) каталог dirl содержит три
графических файла, но на рис. 14.8 (В) пользователь видит вместо них три файла
из корневого каталога тома FS2.
Рис. 14.8. В FS1 каталог содержит три файла, но при монтировании в нем FS2
эти три файла не видны
Для эксперта это означает, что он должен знать, где монтируются файловые
системы. Если вы ищете конкретный файл, возможно, его удастся найти лишь
после обращения к нескольким файловым системам, потому что разные каталоги
могут находиться на разных томах. Многие современные программы анализа не
отображают содержимое каталогов в точке монтирования, поэтому вам придется
самостоятельно определять, какой том здесь должен находиться. С другой сторо-
стороны, это позволяет увидеть исходное содержимое каталогов в точках монтирова-
монтирования. В одном из методов сокрытия информации файлы создаются в каталоге, в ко-
котором затем монтируется том; для случайного наблюдателя такие файлы останутся
незамеченными.
Хеш-деревья
При создании файловой системы вместо описанной реализации на базе списков
пользователь может выбрать реализацию на базе хеш-деревьев. Если файловая
система использует хеш-деревья, в суперблоке должен быть установлен блок со-
совместимой функции. Хеш-деревья также используют структуры данных записей
каталогов, но хранят их в отсортированном порядке.
Хеш-деревья ExtX сходны с В-деревьями, упоминавшимися в главе 11; за ин-
информацией о том, как деревья используются в каталоге, обращайтесь к этому раз-
разделу. Главное различие между хеш-деревьями и В-деревьями состоит в том, что
в хеш-деревьях файлы сортируются по хеш-кодам имен файлов, а не по самим
именам. В ExtX реализована экспериментальная поддержка В-деревьев, анало-
аналогичных В-деревьям NTFS, но в этой главе она не обсуждается, потому что эта воз-
возможность еще не стала стандартной.
Каталог, использующий хеш-дерево, состоит из нескольких блоков, каждый
из которых представляет один узел дерева. Каждый узел содержит файлы с хеш-
кодами, значения которых входят в заданный интервал. Первый блок дерева со-
соответствует корневому узлу с записями каталогов «.» и «..». В остальных записях
первого блока хранятся дескрипторы узлов, содержащие хеш-код и адрес блока.
По дескрипторам узлов ОС определяет блок, к которому следует обратиться за
заданным хеш-кодом.
На рис. 14.9 показан пример хеш-дерева. Первый блок содержит заголовок
и дескрипторы узлов, а второй и третий — записи каталогов для файлов. ОС, не
поддерживающая хеш-деревья, обработает записи всех блоков, не зная, что они
хранятся в отсортированном порядке.
Индексное хеш-дерево содержит до трех уровней. Структуры данных дескрип-
дескрипторов узлов и пример каталога приводятся в главе 15.
Рис. 14.9. Каталоге хеш-деревьями и двумя листовыми узлами. В дереве используются
стандартные записи каталогов, что позволяет обрабатывать его как обычный каталог
Алгоритмы выделения
При создании нового имени файла Linux использует стратегию выделения первой
доступной записи. ОС последовательно проверяет каждую запись каталога от его
начала. На основании длины имени вычисляется необходимый размер записи,
который сравнивается с зарезервированным. Если два размера не совпадают, ОС
считает, что либо запись находится в конце блока, либо длина была увеличена
для пропуска удаленной записи. В обоих случаях ОС пытается включить имя в не-
неиспользуемую область. Если не существует ни одной неиспользуемой области,
размер которой был бы достаточным для хранения имени, то имя присоединяется
в конец списка. Новые блоки выделяются по мере надобности, а их содержимое
стирается перед использованием. В Linux записи не могут пересекать границы бло-
блоков. В других ОС могут использоваться другие стратегии выделения. При исполь-
использовании хеш-деревьев файл добавляется в блок, соответствующий хеш-коду файла.
При удалении файла длина предыдущей записи увеличивается таким обра-
образом, чтобы она ссылалась на запись, следующую за удаленной. Это единственное
действие, которое переводит запись в свободное состояние. В файловой системе
Ext2 Linux стирает указатель индексного узла, в Ext3 это не делается. Переста-
Перестановка неиспользуемых записей с целью сжатия каталога не производится.
Методы анализа
Анализ данных в категории имен файлов обычно связан с выводом информации
о содержимом каталога с целью поиска конкретного файла (или файлов) по за-
заданному шаблону. Процесс начинается с поиска корневого каталога; в ExtX это
делается несложно, потому что корневой каталог всегда находится в индексном
узле 2. Каталоги в целом похожи на файлы, за исключением того, что в их индек-
индексных узлах устанавливается специальный признак типа. Обнаруженное содержи-
содержимое каталога обрабатывается как последователь структур данных записей ката-
каталогов. Если просматриваются только выделенные записи, следует обработать
текущую структуру данных каталога, сместиться вперед на ее указанный размер
и обработать следующую запись. Процесс повторяется до конца блока.
Если наряду с существующими файлами потребуется обработать свободные за-
записи, указанный размер записи игнорируется; вместо него вычисляется фактичес-
фактическая длина записи, которая и определяет величину смещения. Например, если послед-
последний символ имени находится в байте 34, то переход осуществляется к байту 36. После
перехода к границе следует отобразить содержимое на структуру данных записи
каталога и провести простейшие проверки того, могут ли данные относиться к записи
каталога. Если проверка дает положительный результат, запись обрабатывается, а
если нет — следует сместиться еще на 4 байта и проверить новую запись. Эта процеду-
процедура в конечном счете приведет к границе, указанной в предыдущей записи каталога.
На рис. 14.10 изображены две выделенные записи, между которыми находят-
находятся две свободные записи. Между записями каталогов остается неиспользуемое
пространство, поэтому найти имена простым переходом к следующей 4-байтовой
границе после каждой записи не удастся.
Рис. 14.10. Список записей каталога: две свободные записи между двумя выделенными
записями. Чтобы найти имена в свободных записях, потребуется последовательное
перемещение в неиспользуемом пространстве
Состояние выделения записи каталога определяется тем, указывает ли на нее
другая выделенная запись. Первые две записи в каждом каталоге («.» и «..») всегда
являются выделенными. Обнаружив интересующий файл, можно просмотреть его
метаданные по адресу индексного узла.
В некоторых ситуациях в файловой системе требуется провести поиск блоков,
ранее использовавшихся каталогами. Для этого следует проанализировать первые
24 байта каждого блока и определить, присутствуют ли в них записи «.» и «..». Если
записи будут обнаружены, значит, это первый блок каталога. Linux всегда выделяет
записи каталогов на границах блоков, поэтому в более общем варианте поиска началь-
начальные байты могут анализироваться на предмет любого имени файла, не только «..».
Значения указателей позволяют сделать некоторые предположения относи-
относительно порядка удаления файлов. На рис. 14.11 показаны шесть возможных ком-
комбинаций удаления трех смежных файлов. В верхней части рисунка изображено
начальное состояние с четырьмя выделенными записями каталога. Число под каж-
каждым блоком представляет «адрес» записи, введенный для удобства описания каж-
каждого сценария. Серые блоки изображают свободные записи, а числа — порядок их
удаления. Например, в сценарии (А) первым был удален файл в записи 1, а длина
записи 0 была увеличена так, чтобы она ссылалась на запись 2. Затем была удале-
удалена запись 2, а длина записи 0 была увеличена до ссылки на запись 3. Наконец,
запись 3 была удалена, а длина записи 0 была увеличена так, чтобы она ссылалась
на запись после 3. Показанное состояние (А) отличается от всех остальных воз-
возможных комбинаций последовательности удаления этих файлов.
Рис. 14.11. Шесть комбинаций относительного порядка освобождения
трех смежных записей каталога. Только последовательности
1-3-2 и 2-3-1 приводят к одному конечному состоянию
Взглянув на конечные состояния всех шести сценариев, вы увидите, что они
совпадают только в ситуациях (В) и (D). В обоих случаях можно определить, что
средний файл был удален последним. Процедура анализа описана далее в разделе
«Сценарий анализа».
Факторы анализа
В ExtX найти имена удаленных файлов несложно, а в Ext3 номер индексного узла
не стирается; возможно, это позволит получить информацию о времени удаления
файла. В Linux структура записи каталога остается в свободном состоянии до тех
пор, пока не будет создан новый файл с такой же или меньшей длиной имени.
Следовательно, записи каталогов, в которых хранились данные файлов с корот-
короткими именами, в общем случае стираются не так быстро, как записи файлов с длин-
длинными именами. В других ОС могут применяться другие методы выделения и даже
схемы сжатия каталогов для сокращения их размеров. Программа fsck для Linux
упаковывает каталоги и исключает из них неиспользуемое пространство.
При обнаружении имени удаленного файла дальнейший анализ требует осто-
осторожности. Если индексный узел файла был выделен заново, метаданные уже не
относятся к удаленному имени. Не существует простого способа определить, был
ли индексный узел выделен заново с момента удаления имени файла. В одном из
методов тип файла в записи каталога сравнивается с признаком типа в индексном
узле. Скажем, если в записи каталога указан тип каталога, а в индексном узле —
тип обычного файла, скорее всего, индексный узел был выделен заново. По этой
причине в выходные данные программы fls из пакета TSK включаются признаки
типа как из записи каталога, так и из индексного узла.
Структуры записей каталогов могут использоваться для хранения скрытых
данных. Пространство между последней записью каталога и концом блока не ис-
используется; теоретически в нем могут размещаться данные. Это особенно спра-
справедливо при использовании хеш-деревьев, потому что первый блок содержит
небольшой объем административных данных, а остальная часть не используется.
Впрочем, это довольно рискованный метод сокрытия данных, потому что ОС мо-
может стереть информацию при создании нового файла.
Сценарии анализа
В этом разделе приводятся два сценария, демонстрирующие методику использо-
использования низкоуровневой информации из записей каталогов ExtX. В первом сцена-
сценарии определяется исходное местонахождение файла, а во втором — возможный
порядок удаления файлов.
Исходное местонахождение перемещенного файла
Во время анализа системы Linux, подвергшейся взлому, обнаружен файл snif-
ferlog-l.dat, содержащий сетевые пакеты. Другие файлы каталога обладают име-
именами вида log-001.dat и не содержат сетевых данных. Содержимое каталога выг-
выглядит так:
# fls -f Iinux-ext3 ext3-8.dd 1840555
г/г 1840556: log-001.dat
г/г 1840560: log-002.dat
г/г 1840566: log-003.dat
г/г 1840569: log-004.dat
г/г 32579: snifferlog-l.dat
г/г 1840579: log-005.dat
г/г 1840585: log-006.dat
Чтобы найти исполняемый файл, который мог использоваться при создании
этого файла, мы проводим поиск полного пути к этому файлу. Исполняемые файлы
иногда содержат имена открываемых ими файлов, однако в данном случае поиск
оказался безуспешным. В конце концов, замаскировать имя открываемого файла
внутри файла программы совсем несложно. Уже собравшись перейти к другой
части системы, мы вдруг замечаем странную последовательность адресов индекс-
индексных узлов в листинге.
У родительского каталога и остальных файлов адреса индексных узлов нахо-
находятся где-то около 1 840 500, но файл snifferlog-l.dat обладает адресом 32 579. Со-
Согласно стратегии выделения, используемой в Linux, файлы обычно создаются в ин-
индексных узлах той же группы, к которой принадлежит родительский каталог.
Следовательно, либо файл snifferlog-l.dat был изначально создан в другом роди-
родительском каталоге, а потом перемещен в текущий каталог, либо он был создан
в текущем каталоге, а группа блоков была заполнена до предела.
По результатам fsstat мы определяем, что каталог журналов принадлежит
к группе блоков 113, в которой 99 % индексных узлов и 48 % блоков свободны.
Маловероятно, чтобы группа была заполнена в момент создания файла, если толь-
только с того момента не произошло массовое удаление файлов:
Group: 113:
Inode Range: 1840545 - 1856832
Block Range: 3702784 - 3735551
Free Inodes: 16271 (99*)
Free Blocks: 15728 D8*)
Более подробный анализ индексного узла snifferlog-l.dat C2 579) показывает,
что узел входит в группу блоков 2:
Group: 2:
Inode Range: 32577 - 48864
Block Range: 65536 - 98303
Free Inodes: 16268 (99*)
Free Blocks: 0 @*)
Напрашивается предположение, что файл был создан в каталоге группы бло-
блоков 2, а затем перемещен в группу блоков 113. Таким образом, мы попробуем най-
найти в группе блоков 2 каталоги, которые могли бы быть родительскими катало-
каталогами по отношению к snifferlog-l.dat В пакете TSK для решения этой задачи
используется программа Us, выводящая подробную информацию об индексных
узлах из заданного интервала. При запуске мы задаем интервал для группы бло-
блоков, в которой производится поиск, и отфильтровываем все результаты, не отно-
относящиеся к каталогам. Ключ -т преобразует данные режима в наглядный формат,
понятный для пользователя, а ключ -а ограничивает поиск используемыми ин-
индексными узлами. Утилита grep отфильтровывает все результаты, не относящие-
относящиеся к каталогам (по содержимому пятого столбца).
# ils -f Iinux-ext3 -m -a ext3-8.dd 32577-48864 | grep "Id"
<ext3-8.dd-ali ve-32577>101325771168931drwxrwxr-x14[500150010140961
<ext3-8.dd-ali ve-32655>|01326551168931drwxrwxr-x121500150010140961
<ext3-8.dd-ali ve-32660> j 01325771168771drwxr-xr-x j 2 j 500 j 50010140961
Первый столбец содержит фиктивное имя для каждой записи. Свободные за-
записи помечаются строкой «dead», а выделенные — строкой «alive». Третий столбец
содержит адрес индексного узла. Обычно результаты Us обрабатываются утили-
утилитой mactime для построения временных диаграмм, поэтому их формат не слиш-
слишком удобен для пользователя.
Для просмотра трех каталогов мы воспользуемся программой fls. Каталог в ин-
индексном узле 32577 представляется наиболее перспективным.
# fls -f Iinux-ext3 ext3-8.dd 32577
r/r 32578: only_live_twice.mp3
r/r 32582: goldfinger.mp3
r/r 32580: lic_to_kill.mp3
r/r 32581: diamonds_forever.mp3
На первый взгляд похоже на невинный каталог с музыкой из фильмов о Джейм-
Джеймсе Бонде в формате МРЗ... но обратите внимание на индексные узлы и вспомните,
что мы знаем о стратегиях выделения индексных узлов и записей каталогов. При
выделении индексных узлов используется стратегия поиска первого доступного
узла в группе блоков. Файл с содержимым сетевых пакетов находился в индекс-
индексном узле 32 579, расположенном между only_live_twice.mp3 и Iic_to_kill.mp3. Так-
Также обратите внимание, что goldfinger.mp3 обладает большим номером индексного
узла, чем остальные файлы, и находится в середине каталога. Более того, длина
имени goldfinger.mp3 равна 14 символам, а длина snifferlog-l.dat — 16 символам;
это означает, что оба файла поместились бы в записи каталога одного размера.
При анализе файлов выясняется, что файл only_live_twice.mp3 является испол-
исполняемым, а другие файлы содержат журналы сетевых пакетов в том же формате,
что и snifferlog-l.dat. Кроме того, временные штампы only_live_twice.mp3 предше-
предшествуют временным штампам snifferlog-l.dat, а временные штампы Iic_to_kill.mp3
следуют за snifferlog-l.dat.
Рис. 14.12. Файл snifferlog-l.dat перемещен из каталога в группу блоков 2
На основании собранной информации выдвигается следующая гипотеза: файл
snifferlog-l.dat был создан после файла only_live_twice.mp3, после чего был создан
файл Iic_to_kill.mp3. Через некоторое время после создания файла diamonds_for-
ever.mp3 файл snifferlog-l.dat был перемещен в каталог, находящийся в группе бло-
блоков ИЗ. После его перемещения был создан файл goldfinger.mp3, который за-
заменил запись каталога и получил следующий доступный индексный узел. М-
и С-время индексного узла 32 577 совпадают с данными файла goldfinger.mp3,
причем в обоих случаях они следуют за временными штампами файла snifferlog-
l.dat. Ситуация показана на рис. 14.12: запись каталога в группе ИЗ ссылается
на индексный блок в группе 2. Мы все еще не знаем, как произошло перемеще-
перемещение файла и всегда ли он существовал под текущим именем или ранее он был
замаскирован под МРЗ-файл. Возможно, анализ исполняемого файла прольет
свет на эти вопросы.
Порядок удаления файлов
В процессе анализа системы Linux был обнаружен каталог с именем /usr/LocaL/
.oops/. Для системы Linux такой каталог нетипичен, поэтому мы просмотрим его
содержимое. В каталоге обнаруживаются восемь удаленных файлов; все соответ-
соответствующие индексные узлы были выделены новым файлам, что основательно ус-
усложнит процесс восстановления. Впрочем, сейчас нас интересует исключительно
способ удаления файлов. В результате анализа записей каталогов были получены
значения, представленные в табл. 14.3. Имена приводятся в порядке их следова-
следования в каталоге.
Таблица 14.3. Параметры свободных записей каталогов
в рассматриваемом сценарии
Байт Имя Указанная длина Необходимая длина
12 .. 1012 12
24 config.dat 20 20
44 readme.txt 104 20
64 allfiles.tar 20 20
84 random.dat 64 20
104 mytools.zip 44 20
124 delete-files.sh 24 24
148 sniffer 876 16
164 passwords.txt 860 860
По этим данным можно сделать ряд общих наблюдений. Если указанная дли-
длина записи свободной записи каталога соответствует ее фактической длине (вы-
(вычисленной на основании имени), то следующая запись каталога была удалена после
нее. Например, запись config.dat была удалена раньше, чем readme.txt, потому что
в противном случае длина записи config.dat была бы увеличена на 20 для погло-
поглощения места, занимаемого readme.txt. Следовательно, мы знаем, что файл config.dat
был удален раньше readme.txt, allfiles.tar — раньше random.dat, a delete-files.sh —
раньше sniffer.
Также можно заметить, что файл mytools.zip был удален после delete-files.sh, но
до sniffer. Мы знаем это, потому что длина записи mytools.zip была увеличена до АА
для поглощения удаленной записи delete-files.sh. Если бы запись sniffer была уда-
удалена перед mytools.zip, то длина mytools.zip возросла бы с учетом этого факта. Так-
Также мы видим что файл passwords.txt был удален раньше sniffer, a random.dat — после
mytools.zip. Наконец, файл readme.txt был удален раньше sniffer, потому что длина
записи readme.txt указывает на sniffer.
Потратив немного времени на определение относительного порядка удалений,
мы приходим к выводу, что файлы удалялись в алфавитном порядке. Мы не зна-
знаем порядка удаления allfiles.tar, config.dat и delete-files.sh, но зато нам известно,
что они были удалены раньше других файлов, а в отсортированном списке имен
эти файлы занимают первые три места. Следовательно, эти файлы могли быть
удалены при отображении в окне отсортированного списка или же командой типа
rm *. Команда rm удаляет файлы, и мои эксперименты показали, что удаление про-
производится в алфавитном порядке. Скорее всего, файлы удалялись не один за одним,
а из сценария или окна файлового менеджера. Если бы между удалениями созда-
создавались другие файлы, интерпретировать результаты было бы намного труднее.
Категория прикладных данных
В Ext3 поддерживается только одна функция прикладного уровня — журналы
файловой системы. В Ext2 журналы отсутствуют, а другие функции прикладного
уровня (например, квоты) реализуются на основе обычных пользовательских
файлов.
Журналы файловой системы
В Ext3 реализован механизм журналов файловой системы, упоминавшийся в гла-
главе 8. В журнале файловой системы регистрируются обновления файловой систе-
системы, что позволяет ускорить ее восстановление в случае сбоя. В этом разделе опи-
описаны журналы Ext3 и способы их анализа.
Общие сведения
Журнал Ext3 обычно использует индексный узел 8, хотя его местонахождение
задается в суперблоке и находиться он может где угодно. Журнал относится к чис-
числу совместимых функций файловой системы, а при его использовании устанав-
устанавливается соответствующий флаг в суперблоке. Кроме того, в суперблоке присут-
присутствует флаг несовместимой функции для журнального устройства. При установке
этого флага файловая система использует внешний журнал, не сохраняя данные
в локальном файле. Местонахождение устройства также задается в суперблоке.
В журнале сначала регистрируются предстоящие обновления, а после их завер-
завершения также создается соответствующая запись. Журнал может работать в двух
режимах. В первом режиме в журнале регистрируются только обновления метадан-
метаданных, а во втором — все обновления, включая блоки данных. Первая версия жур-
журнала использовала второй режим, но текущая версия предоставляет возможность
выбора режима. По умолчанию регистрируются только изменения метаданных.
Журналы Ext3 ведутся на уровне блоков; это означает, что даже при изменении
одного бита индексного узла в журнале сохраняется весь блок файловой систе-
системы, в котором находится индексный узел. Также возможно ведение журналов на
уровне записей, когда в журнале сохраняются только данные индексного узла, а не
весь блок. В первом блоке журнала хранится его суперблок с общей информацией;
остальные блоки используются для хранения записей журнала. После заполне-
заполнения журнала происходит циклический возврат к началу. Размер блока журнала
должен совпадать с размером блока файловой системы.
Обновления осуществляются в виде последовательно пронумерованных транзак-
транзакций. В блоке журнала хранятся либо административные данные транзакции, либо
данные обновления файловой системы. Каждая транзакция начинается с деск-
дескриптора, содержащего порядковый номер транзакции и перечень блоков файловой
системы, обновляемых в ходе транзакции. За дескриптором следуют обновленные
блоки, описанные в дескрипторе. При записи обновления на диск создается блок
закрепления транзакции с тем же порядковым номером. За блоком закрепления
может следовать дескриптор новой транзакции. Пример показан на рис. 14.13.
Рис. 14.13. Журнал Ext3 с двумя транзакциями
Суперблок определяет местонахождение первого блока дескриптора и его по-
порядковый номер. При заполнении блока дескриптора выделяется новый блок с тем
же порядковым номером. Блок файловой системы, включенный в журнал, может
быть отменен, чтобы хранящиеся в нем изменения не применялись в процессе
восстановления. Для этой цели используется блок отмены, который содержит
порядковый номер и список отменяемых блоков. Во время восстановления все
блоки, указанные в блоке отмены, порядковые номера которых меньше порядко-
порядкового номера блока отмены, восстанавливаться не будут.
Структуры данных и пример журнала приводятся в главе 16. В пакете TSK
для вывода содержимого журнала используется программа jls. Пример ее вывода
для образа файловой системы:
# jls -f Iinux-ext3 /dev/hdb2
JBlk Description
0: Superb!ock (seq: 0)
1: Allocated Descriptor Block (seq: 295)
2: Allocated FS Block 4
3: Allocated FS Block 2
4: Allocated FS Block 14
5: Allocated FS Block 5
6: Allocated FS Block 163
7: Allocated FS Block 3
8: Allocated Commit Block (seq: 295)
9: Unallocated FS Block Unknown
В выходных данных j ls виден суперблок, дескриптор и блоки закрепления.
Транзакция 295 начинается в блоке журнала 1 и завершается в блоке 8. Также
приводятся номера блоков файловой системы, которым соответствует каждый
блок журнала. Для извлечения блоков из журнала можно воспользоваться про-
программой jcat из пакета TSK.
Методы анализа
Анализ файловой системы производится для получения дополнительной инфор-
мации о недавних событиях. Для этого достаточно найти журнал по адресу, хра-
хранящемуся в суперблоке файловой системы, и обработать суперблок журнала. В нем
хранится информация о первой действительной транзакции. После этого из деск-
дескриптора блока мы получаем информацию о том, какие блоки файловой системы
обновляются в процессе транзакции.
При поиске конкретного блока можно провести поиск среди всех дескрипто-
дескрипторов и попытаться найти дескриптор с описанием указанного блока. При поиске
ключевого слова или значения можно просмотреть весь файл, а затем вернуться
к дескриптору группы за информацией о блоке. В некоторых случаях анализ жур-
журнала упрощает восстановление файлов — для этого нужно найти блок индексной
таблицы с указателями на блоки до момента его освобождения. Иногда из журна-
журнала удается получить информацию о временных штампах; для этого нужно найти
блок с индексным узлом или другой структурой данных файловой системы, со-
содержащей соответствующие данные.
Факторы анализа
Журнал способен принести пользу в расследованиях, посвященных относитель-
относительно недавним событиям. С течением времени журнал заполняется, происходит
возврат к началу, и данные об инциденте могут оказаться стертыми. Linux начи-
начинает заполнять журнал заново с каждым монтированием файловой системы.
По умолчанию в журнале регистрируются только метаданные, поэтому вос-
восстановить удаленное содержимое файлов по журналу не удастся. Впрочем, су-
суперблок и содержимое каталогов будут храниться в журнале, поэтому теорети-
теоретически по суперблоку можно отслеживать операции создания и удаления файлов,
а по каталогам — имена файлов. Степень полезности журнала очень сильно за-
зависит от объема системной активности между инцидентом и моментом рассле-
расследования.
Сценарий анализа
В этом сценарии рассматривается система Linux, подвергшаяся внешней атаке.
Образ был создан в день взлома, поэтому журнал может содержать полезную ин-
информацию. В процессе расследования мы находим каталог с различными про-
программными средствами, использовавшимся в ходе атаки. Также обнаруживается
удаленный файл с именем passwords.txt. Все это представляет интерес, и нам хоте-
хотелось бы восстановить файл, но терпеливо отсеивать строковые данные в группах
блоков как-то не хочется. Мы обращаемся к журналу.
Известно, что удаленный файл занимал индексный узел 488 650, находящий-
находящийся в группе блоков 30. Первый индексный узел группы блоков имеет номер 488 641,
таблица индексных узлов начинается в блоке 943 044, а размер каждого блока со-
составляет 4 096 байт. Следовательно, интересующий нас индексный узел хранится
в записи 10 таблицы индексных узлов группы и соответствует первому блоку таб-
таблицы.
Мы запускаем jls для журнала и ищем сведения о блоке файловой системы
983 044:
# jls -f Iinux-ext3 ext3-8.dd 8
[...]
2293: Unallocated Descriptor Block (seq: 136723)
2294: Unallocated FS Block 983041
2295: Unallocated FS Block 1
2296: Unallocated FS Block 0
2297: Unallocated FS Block 983044
2298: Unallocated FS Block 983568
2299: Unallocated FS Block 983040
2300: Unallocated Commit Block (seq: 136723)
[...]
Журнал содержит несколько ссылок на блок 983 044; мы проанализируем раз-
различия между этими ссылками. Предыдущие записи относятся к созданию файла
в индексном узле 488 650. В листинге присутствует обновляемая таблица индек-
индексных узлов, суперблок, дескрипторы групп, родительский каталог и битовая кар-
карта блоков. Мы извлекаем таблицу индексных узлов из блока журнала 2297 и ис-
используем dd для перехода к десятому индексному узлу в таблице:
# jcat -f Iinux-ext3 ext3-8.dd 8 2297 | dd bs=128 skip=9 count=l | xxd
0000000: a481 0000 041f 0000 8880 3741 3780 3741 7A7.7A
0000016: 3780 3741 0000 0000 0000 0100 1000 0000 7.7A
0000032: 0000 0000 0000 0000 1102 OfOO 1202 OfOO
0000048: 0000 0000 0000 0000 0000 0000 0000 0000
[...]
Это те данные, которые когда-то содержались в индексном узле 488 650; раз-
размер указан в байтах 4-7 и составляет 7940 байт @xlf04). Байты 40-43 и 44-47
содержат два прямых указателя на блоки. Мы видим, что файлу выделены блоки
883 569 и 983 570. При просмотре содержимого этих блоков обнаруживается спи-
список паролей различных систем, взломанных злоумышленником.
В этом сценарии журнал помог обнаружить предыдущую копию индексного
узла. Файл был создан относительно недавно, и его индексный узел все еще хра-
хранился в журнале, несмотря на отсутствие стопроцентной уверенности в том, что
индексный узел содержал последние действительные данные по файлу, но содер-
содержимое вполне соответствовало имени файла.
Общая картина
Итак, мы рассмотрели отдельные компоненты файлов и каталогов. Давайте объе-
объединим все эти сведения в практических примерах. Сначала мы создадим, а затем
удалим файл /dirl/filel.dat. Размер файла составляет 6 000 байт, а размер блока
в файловой системе Ext3 равен 1024 байтам.
Пример создания файла
На высоком уровне процесс создания файла/dir 1/filel.dat сводится к поиску ка-
каталога dirl, созданию записи каталога, выделению индексного узла и последую-
последующему выделению блоков для содержимого файла. Точный порядок выделения
структур данных зависит от ОС; описанная далее процедура может отличаться от
той, что используется в вашей конкретной системе.
1. Создание файла начинается с чтения 1024-байтовой структуры данных супер-
суперблока, которая находится в файловой системе со смещением 1024 байта. Из
суперблока мы узнаем, что размеры блока и фрагмента равны 1024 байтам. Каж-
Каждая группа блоков состоит из 8192 блоков и 2016 индексных узлов. Зарезерви-
Зарезервированные блоки перед началом первой группы блоков отсутствуют.
2. На следующем этапе читается таблица дескрипторов групп, хранящаяся в бло-
блоках 2 и 3 файловой системы. Из таблицы берется информация о строении каж-
каждой группы блоков.
3. Далее необходимо обработать индексный узел 2, чтобы найти каталог di rl в кор-
корневом каталоге. Используя информацию о количестве индексных узлов в груп-
группе, мы определяем, что индексный узел 2 находится в группе блоков 0. Из
записи таблицы дескрипторов для группы 0 мы определяем, что таблица ин-
индексных узлов начинается в блоке 6.
4. Из блока 6 читается таблица индексных узлов, в которой обрабатывается вто-
вторая запись. Индексный узел 2 показывает, что структуры записей каталогов
для корневого каталога находятся в блоке 258.
5. Мы читаем содержимое корневого каталога из блока 258 и обрабатываем его
как список записей каталогов. В первых двух записях хранится информация о
записях «.» и «..». Последовательно перемещаясь вперед по указанным длинам
записей (удаленные файлы нас не интересуют), мы в конечном счете прихо-
приходим к записи, в которой указано имя dirl. В записи указан номер индексного
узла 5033. А-время корневого каталога обновляется временем открытия ка-
каталога.
6. Местонахождение индексного узла 5033 определяется делением числа на ко-
количество индексных узлов в группе. Так мы определяем, что узел находится
в группе блоков 2. Используя запись дескриптора для группы 2, мы определя-
определяем, что его таблица индексных узлов начинается в блоке 16 390.
7. Из блока 16 390 читается таблица индексных узлов, в которой обрабатывается
запись 1001 — относительным номером индексного узла 5 033. Содержимое
индексного узла показывает, что содержимое dirl находится в блоке 18 431.
8. Мы читаем содержимое dirl из блока 18 431 и обрабатываем его как список
записей каталогов. Нас интересует неиспользуемое пространство в каталоге.
Имя filel.dat состоит из 8 символов, поэтому для хранения записи каталога
потребуется 16 байт. Имя нового файла включается между двумя существую-
существующими именами, для каталога обновляется М- и С-время. Изменения содержи-
содержимого каталога фиксируются в журнале.
9. Для создаваемого файла необходимо выделить индексный узел, причем этот
узел должен принадлежать группе своего родительского каталога, то есть груп-
группе блоков 2. Битовая карта индексных узлов для группы 2 отыскивается в бло-
блоке 16 386 по дескриптору группы. Методом поиска первого доступного узла
мы определяем, что индексный узел 5 110 свободен. Соответствующий бит в би-
битовой карте устанавливается равным 1, счетчик свободных индексных узлов
в таблице дескрипторов уменьшается, как и счетчик свободных индексных уз-
узлов в суперблоке. Адрес индексного узла заносится в запись каталога filel.dat.
Изменения битовой карты, дескриптора группы и суперблока регистрируют-
регистрируются в журнале.
Рис. 14.14. Итоговое состояние системы после добавления файла dirl/filel.dat
10. На следующем этапе заполняется содержимое индексного узла 5110: для этого
мы находим его в таблице индексных узлов группы 2 и инициализируем
основные параметры индексного узла. Временные штампы инициализируются
текущим временем, а счетчик ссылок задается равным 1. Изменения таблицы
индексных узлов регистрируются в журнале.
11. Для хранения содержимого файла требуется выделить шесть блоков. Мы пе-
переходим к обработке битовой карты блоков, расположенной в блоке 16 385. По
алгоритму поиска первого доступного блока в группе находятся блоки 20 002-
20 003 и 20 114-20 117. Биты этих блоков в карте устанавливаются, а их адре-
адреса включаются в прямые указатели, хранящиеся в узле 5110. Счетчики сво-
свободных блоков в дескрипторе групп и суперблоке также обновляются. М-
и С-времена индексного узла обновляются в соответствии с внесенными из-
изменениями. Изменения индексного узла, дескриптора группы, суперблока и би-
битовой карты регистрируются в журнале.
12. Содержимое файла filel.dat записывается в выделенные блоки.
Итоговое состояние системы показано на рис. 14.14.
Пример удаления файла
Перейдем к процедуре удаления файла /dirl/filel.dat. Как упоминалось в преды-
предыдущем разделе, порядок освобождения структур данных зависит от ОС, и описан-
описанная далее процедура может отличаться от той, что используется в вашей конкрет-
конкретной системе.
1. Удаление файла начинается с чтения 1024-байтовой структуры данных супер-
суперблока, которая находится в файловой системе со смещением 1024 байта. Из
суперблока мы узнаем, что размеры блока и фрагмента равны 1024 байтам.
Каждая группа блоков состоит из 8192 блоков и 2016 индексных узлов. Заре-
Зарезервированные блоки перед началом первой группы блоков отсутствуют.
2. На следующем этапе читается таблица дескрипторов групп, хранящаяся в бло-
блоках 2 и 3 файловой системы. Из таблицы берется информация о строении каж-
каждой группы блоков.
3. Далее необходимо обработать индексный узел 2, чтобы найти каталог di rl в кор-
корневом каталоге. Используя информацию о количестве индексных узлов в груп-
группе, мы определяем, что индексный узел 2 находится в группе блоков 0. Из запи-
записи таблицы дескрипторов для группы 0 мы определяем, что таблица индексных
узлов начинается в блоке 6.
4. Из блока 6 читается таблица индексных узлов, в которой обрабатывается вто-
вторая запись. Индексный узел 2 показывает, что структуры записей каталогов
для корневого каталога находятся в блоке 258.
5. Мы читаем содержимое корневого каталога из блока 258 и обрабатываем его
как список записей каталогов. В первых двух записях хранится информация о
записях «.» и «..». Последовательно перемещаясь вперед по указанным длинам
записей (удаленные файлы нас не интересуют), мы в конечном счете приходим
к записи, в которой указано имя dirl. В записи указан номер индексного узла
5033. А-время корневого каталога обновляется временем открытия каталога.
6. Местонахождение индексного узла 5033 определяется делением числа на ко-
количество индексных узлов в группе. Так мы определяем, что узел находится
в группе блоков 2. Используя запись дескриптора для группы 2, мы определя-
определяем, что его таблица индексных узлов начинается в блоке 16 390.
7. Из блока 16 390 читается таблица индексных узлов, в которой обрабатывается
запись 1001 — относительным номером индексного узла 5 033. Содержимое
индексного узла показывает, что содержимое dirl находится в блоке 18 431.
8. Мы читаем содержимое dirl из блока 18 431 и обрабатываем его как список
записей каталогов. Нас интересует запись файла filel.dat. Мы находим эту за-
запись и узнаем, что ей выделен индексный узел 5110. Чтобы освободить запись
каталога, ее длина прибавляется к длине предыдущей записи каталога, отно-
относящейся к файлу 12.jpg. В результате операций обновляется М-, А- и С-время.
Изменения регистрируются в журнале.
Рис. 14.15. Итоговое состояние системы после удаления файла dirl/filel.dat
9. В результате удаления имени файла счетчик ссылок в индексном узле 5110
таблицы индексных узлов группы 2 уменьшается на 1. Значение счетчика
становится равным 0; это означает, что индексный узел необходимо освобо-
освободить. Для этого соответствующий разряд битовой карты индексных узлов об-
обнуляется, а в дескрипторе группы и суперблоке обновляются счетчики сво-
свободных индексных узлов. Изменения регистрируются в журнале.
10. Также необходимо освободить шесть блоков, выделенных для хранения со-
содержимого файла. Для каждого блока обнуляется соответствующий разряд
битовой карты и стирается указатель на блок в индексном узле. Размер фай-
файла уменьшается при каждом освобождении блока, и в конечном счете он
уменьшается до 0. М-, С- и D-время индексного узла обновляется в соответ-
соответствии с внесенными изменениями. В дескрипторе группы и суперблоке об-
обновляются счетчики свободных блоков. Изменения регистрируются в жур-
журнале.
Итоговое состояние системы показано на рис. 14.15. Жирные линии и значе-
значения представляют изменения файловой системы в результате удаления.
Разное
Этот раздел посвящен восстановлению удаленных файлов в ExtX и проверке це-
целостности файловой системы. Обе темы выходят за рамки какой-либо конкрет-
конкретной категории данных.
Восстановление файлов
В стандартных системах Linux восстановить удаленные файлы в Ext3 довольно
сложно, но в Ext2 эта задача решается проще. В Ext2 содержимое индексных уз-
узлов не стирается при удалении файла, поэтому указатели на блоки продолжают
существовать в системе. Временные штампы также обновляются при удалении
файла, и по ним можно узнать, когда произошло удаление. Тем не менее ссылка
из записи каталога на индексный узел удаляется, поэтому для восстановления
файлов придется проводить поиск в свободных индексных узлах. При просмотре
содержимого удаленных файлов Ext2 следует помнить, что блок косвенных ука-
указателей мог быть выделен заново раньше индексного узла, поэтому он может и не
содержать адреса блоков.
В Ext3 связь между именем файла и индексным узлом продолжает существо-
существовать, но указатели на блоки стираются. Для восстановления файла придется при-
применить метод извлечения данных. При извлечении содержимого конкретного
файла можно воспользоваться имеющейся информацией о группе, потому что
поиск можно ограничить блоками отдельной группы. Большинство ОС выделяет
блоки в одной группе с индексным узлом, что позволяет сосредоточить поиски
в рамках одной группы. Тем не менее формально ОС может выделять блоки где
угодно, так что может понадобиться полный поиск по всей системе.
При извлечении данных следует помнить, что данные могут чередоваться с бло-
блоками косвенных указателей. Даже в идеальной ситуации, когда удаленный файл
занимал смежную серию блоков, тринадцатый блок становится первым блоком
косвенных указателей. Местонахождение следующего блока косвенных указателей
можно вычислить на основании размера блока. Для удаленных файлов такие бло-
блоки будут заполнены одними нулями, и их следует исключить из восстановленно-
восстановленного файла.
Наконец, если файл был удален недавно, в файловой системе Ext3 можно по-
попытаться найти старую копию индексного блока в журнале. Возможно, вам удас-
удастся обнаружить копию блока индексного узла со всеми указателями на блоки дан-
данных и косвенных указателей.
Проверка целостности данных
Проверки целостности данных используются в расследованиях для выявления
недопустимых структур данных файловой системы и неиспользуемых областей,
которые могут использоваться для хранения скрытых данных. Начинать следу-
следует с категории данных файловой системы и анализа суперблока. Многие из 1024
байт суперблока не используются и могут быть задействованы для хранения
скрытых данных. Дескрипторы групп более эффективны в отношении хране-
хранения данных, а резервные копии дескрипторов групп и суперблоков могут ис-
использоваться для выявления любых изменений, вручную внесенных злоумыш-
злоумышленником.
Размер группы блоков обычно определяется количеством бит в блоке, а бито-
битовая карта блоков обычно используется полностью. С другой стороны, количество
индексных узлов обычно меньше количества блоков в группе, поэтому часть бло-
блока, выделенного под битовую карте индексных узлов, может оказаться незадей-
ствованной. У последней группы блоков битовая карта также может содержать
неиспользуемые биты.
На каждый выделенный блок должен ссылаться один и только один выделен-
выделенный индексный узел. Исключение составляют административные блоки, в кото-
которых хранится таблица дескрипторов групп, таблица индексных узлов, битовые
карты блоков и индексных узлов или суперблок.
Большая часть данных каждого индексного узла используется, и возможности
хранения скрытых данных в них ограничены, хотя в конце каждой таблицы ин-
индексных узлов могут следовать неиспользуемые байты. Все блоки, указанные в ука-
указателях выделенной индексной записи, также должны быть выделенными. Индекс-
Индексные узлы файлов специальных типов не должны ассоциироваться с выделенными
блоками. Первые 10 индексных узлов зарезервированы, но многие из них остают-
остаются неиспользованными и могут содержать скрытые данные [grugq, 2002]. Кроме
того, скрытые данные могут присутствовать в неиспользуемом пространстве рас-
расширенных атрибутов.
На все выделенные индексные узлы, кроме зарезервированных и зависших,
должно ссылаться некоторое имя файла. Зависшие файлы обязаны входить в спи-
список, хранящийся в суперблоке. Количество имен должно совпадать со счетчиком
ссылок. Если образ системы снимался во время работы, в ней могут присутст-
присутствовать зависшие файлы, открытые работающими процессами. Все выделенные
имена файлов должны указывать на выделенные записи индексных узлов. На-
Наконец, пространство в конце каталога может использоваться для хранения скры-
скрытых данных.
Итоги
Ext2 и Ext3 занимают ведущее положение среди файловых систем Linux и встре-
встречаются на многих серверах и настольных системах. Эти файловые системы осно-
основаны на простых структурах данных, но ситуация отчасти усложняется делением
пространства на группы блоков. В Ext3 восстановление файлов крайне затрудне-
затруднено стиранием указателей на блоки при удалении файла.
Возможно, самые большие проблемы с ExtX обусловлены эволюцией этих
систем. Система FAT существовала в нескольких версиях, NTFS претерпевает
изменения в каждой новой версии Windows, но у ExtX существует несколько «эк-
«экспериментальных» разновидностей, устанавливаемых или активизируемых поль-
пользователем. В этой главе технология ExtX была представлена на момент написа-
написания книги. Она может быть в любой момент дополнена новыми возможностями,
но это не означает, что эти возможности будут поддерживаться любой отдельно
взятой копией ExtX. Чтобы определить состав поддерживаемых возможностей,
необходимо проанализировать конфигурацию ядра и системы.
Библиография
• Card, Rcmy, Theodore Ts'o, and Stephen Tweedie. «Design and Implementation of
the Second Extended Filesystem». In Proceeding of the First Dutch International
Symposium on Linux, ed. Frank B. Brokken et al, Amsterdam, December 1994. http:/
/www.mit.edu/tytso/www/linux/ext2intro.htmL
• Carrier, Brian, «EXT3FS Keyword Search Test #1». Digital Forensic Tool Testing,
November 2003. http://dftt.sourceforge.net.
• Dubeau, Louis-Dominique. «Analysis of the Ext2fs Structure». The Operating System
Resource Center, 1994. http://www.nondot.org/sabre/os/files/FHeSystem/ext2fs/.
• Red Hat, Inc. Ext3 User Mailing List, n.d. https://listman. redhat.com/mailman/listinfo/
ext3-users/.
• Heavner, Scott D. Linux Disk Editor, n.d. http://lde.sourceforge.net/.
• Garfinkel, Simson, Gene Spafford, and Alan Schwartz. Practical Unix and Internet
Security. 3rd ed. Sebastopol: O'Reilly, 2003.
• Gleditsch, Arne Georg, and Per Kristjan Gjermshus. Linux Source Code, n.d. http:/
/lxr.linux.no/source/.
• grugq. «Defeating Forensic Analysis on Unix». Phrack, Issue 15, July 28,2002. http:/
/www.phrack.org/show.php?p=59&a=6.
• Honeynet Project. «The Forensic Challenge». January 15, 2001. http://www.honey-
net.org/challenge/index.htmL
• McKusick, Marshall, Keith Bostic, Michael Karels, and John Quarterman. The
Design and Implementation of the 4.4 BSD Operating System. Boston: Addison-
Wesley, 1996.
• Philips, Daniel. «A Directory Index for Ext2». Proceeding of the Usenix Fifth Annual
Linux Showcase and Conference, 2001.
• Poirier, Dave. «Second Extended File System: Internal Layout». 2002. http://
www.nongnu.org/ext2-doc/.
• Ts'o, Theodore. «E2fsprogs». Sourceforge, n.d. http://e2fsprogs.sourceforge.net/.
• Ts'o, Theodore, and Stephen Tweedie. «Planned Extensions to the Linux Ext2/
Ext3 Filesystem». Proceeding of the 2002 Usenix Technical Conference FREENIX
Track, 2002.
• Tweedie, Stephen. «EXT, Journaling Filesystem». Sourceforge, July 20, 2000. http:/
/olstrans.sourceforge.net/release/0LS2000-ext3/0LS2000-ext3.htmL
Структуры данных Ext2
иЕэЛЗ
В главе 14 были представлены основные концепции архитектуры ExtX, а в этой
главе описаны различные структуры данных, заложенные в основу ExtX. Пред-
Предполагается, что вы уже прочитали предыдущую главу или читаете ее параллельно
с этой. Если формальные описания структур данных вас не интересуют, эту главу
можно пропустить.
Суперблок
В ExtX основные данные категории файловой системы хранятся в суперблоке.
Суперблок хранится со смещением 1024 байта от начала файловой системы и за-
занимает 1024 байта. Его поля перечислены в табл. 15.1.
Таблица 15.1. Структура данных суперблока ExtX
Диапазон Описание Необходимость
0-3 Количество индексных узлов в файловой системе Да
4-7 Количество блоков в файловой системе Да
8-11 Количество блоков, резервируемых для предотвра- Нет
щения переполнения файловой системы
12-15 Количество свободных блоков Нет
16-19 Количество свободных индексных узлов Нет
20-23 Блок, с которого начинается группа блоков 0 Да
24-27 Размер блока (в формате количества разрядов Да
для сдвига величины 1024 влево)
28-31 Размер фрагмента (в формате количества разрядов Да
для сдвига величины 1024 влево)
32-35 Количество блоков в каждой группе Да
36-39 Количество фрагментов в каждой группе Да
40-43 Количество индексных узлов в каждой группе Да
44-47 Последнее время монтирования Нет
48-51 Последнее время записи Нет
52-53 Текущее количество монтирований Нет
54-55 Максимальное количество монтирований Нет
56-57 Сигнатура @xef53) Нет
58-59 Состояние файловой системы (см. табл. 15.2) Нет
Таблица 15.1 {продолжение)
Диапазон Описание Необходимость
60-61 Метод обработки ошибок (см. табл. 15.3) Нет
62-63 Дополнительная версия Нет
64-67 Время последней проверки целостности Нет
68-71 Интервал между принудительными проверками Нет
целостности
72-75 ОС, создавшая файловую систему (см. табл. 15.4) Нет
76-79 Основная версия (см. табл. 15.5) Да
80-81 UID, которому разрешено использовать зарезерви- Нет
рованные блоки
82-83 GID, которому разрешено использовать зарезерви- Нет
рованные блоки
84-87 Первый незарезервированный индексный узел Нет
в файловой системе
88-89 Размер структуры индексного узла Да
90-91 Группа блоков, в которую входит данный суперблок Нет
(для резервных копий)
92-95 Флаги совместимых функций (см. табл. 15.6) Нет
96-99 Флаги несовместимых функций (см. табл. 15.7) Да
100-103 Флаги совместимых функций только для чтения Нет
(см. табл. 15.8)
104-119 Идентификатор файловой системы Нет
120-135 Имя тома Нет
136-199 Путь последнего монтирования Нет
200-203 Битовая карта использования алгоритма Нет
204-204 Количество блоков, предварительно Нет
выделяемых файлам
205-205 Количество блоков, предварительно выделяемых Нет
каталогам
206-207 Не используется Нет
208-223 Идентификатор журнала Нет
224-227 Индексный узел журнала Нет
228-231 Журнальное устройство Нет
232-235 Начало списка зависших индексных узлов Нет
236-1023 Не используется Нет
Байты 58-59 содержат флаги состояния системы. Допустимые значения фла-
флагов приведены в табл. 15.2.
Таблица 15.2. Флаги состояния файловой системы в суперблоке
Диапазон Описание Необходимость
0x0001 Проверенная файловая система Нет
0x0002 Файловая система содержит ошибки Нет
0x0004 Обнаружены зависшие узлы Нет
Метод обработки ошибок в байтах 60-61 определяет, как должна поступать
ОС при обнаружении ошибки файловой системы. Эти значения задаются в момент
создания файловой системы. Поле содержит одно из трех значений, приведенных
в табл. 15.3.
Таблица 15.3. Значения поля метода обработки ошибок в суперблоке
Диапазон Описание Необходимость
1 Продолжение Нет
2 Перемонтирование файловой Нет
системы как доступной
только для чтения
3 Паника Нет
Поле в байтах 72-75 определяет ОС, которая могла создать файловую систе-
систему. Многие средства создания файловых систем для Linux позволяют задать зна-
значение на усмотрение пользователя. Пять определенных значений этого поля при-
приведены в табл. 15.4.
Таблица 15.4. Значения поля создателя в суперблоке
Диапазон Описание Необходимость
0 Linux Нет
1 GNU Hurd Нет
2 Masix Нет
3 FreeBSD Нет
4 Lites Нет
Для поля основной версии (байты 76-79) определены значения, перечислен-
перечисленные в табл. 15.5.
Таблица 15.5. Значения поля основной версии в суперблоке
Диапазон Описание Необходимость
0 Исходная версия Да
1 «Динамическая» версия Да
Если в поле не выставлен признак динамической версии, то содержимое су-
суперблока, начиная с байта 84, может быть неточным. Слово «динамический» в дан-
данном случае означает, что индексные узлы могут обладать динамическим разме-
размером и его точное значение задается в байтах 88-89 суперблока. Текущая версия
ядра Linux не поддерживает динамические индексные узлы, но использует дина-
динамическую версию для установки полей совместимых/несовместимых функций.
Концепция функций — совместимых, несовместимых и совместимых только
для чтения — обсуждалась в главе 14. В суперблоке для каждого типа функций
существует отдельное поле. Следует отметить, что некоторые флаги были опреде-
определены, но никогда не использовались в коде Linux. Следовательно, не все они бу-
будут встречаться в стандартной системе Linux. В табл. 15.6 перечислены флаги со-
совместимых функций, в табл. 15.7 — флаги несовместимых функций, а в табл. 15.8 —
флаги функций, совместимых только для чтения.
Таблица 15.6. Флаги поля совместимых функций в суперблоке
Флаг Описание Необходимость
0x0001 Для каталогов используется предварительное Нет
выделение блоков с целью сокращения фрагментации
0x0002 Индексные узлы серверов AFS существуют Нет
0x0004 Файловая система содержит журнал (Ext3) Нет
0x0008 Индексные узлы обладают расширенными атрибутами Нет
0x0010 Допускается изменение размеров файловой системы Нет
для больших разделов
0x0020 Каталоги используют хешированные индексы Нет
Таблица 15.7. Флаги поля несовместимых функций в суперблоке
Флаг Описание Необходимость
0x0001 Сжатие (пока не поддерживается) Да
0x0002 Записи каталогов содержат поле типа файла Да
0x00034 Файловая система нуждается в восстановлении Нет
0x0008 Файловая система использует журнальное устройство Нет
Таблица 15.8. Флаги поля совместимых функций только для чтения в суперблоке
Флаг Описание Необходимость
0x0001 Разреженные суперблоки и таблицы дескрипторов Нет
групп
0x0002 Файловая система содержит большой файл Нет
0x0004 Каталоги используют В-деревья (не реализовано) Нет
После знакомства со структурами данных и флагами можно рассмотреть ре-
реальный пример суперблока Ext3. Мы воспользуемся программой dd для извлече-
извлечения 1024 байт, начиная со смещения 1024:
# dd if=ext3.dd bs-1024 skip=l count=l | xxd
0000000: cO53 ldOO ff9d ЗаОО 4cee 0200 4708 ObOO .S :.l G...
0000016: 6745 ldOO 0000 0000 0200 0000 0200 0000 gE
0000032: 0080 0000 0080 0000 aO3f 0000 c9fd 1141 ? A
0000048: c9fd 1141 3601 2500 53ef 0100 0100 0000 ...A6.X.S
0000064: da9d e83e 004e edOO 0000 0000 0100 0000 ...>.N
0000080: 0000 0000 ObOO 0000 8000 0000 0400 0000
0000096: 0600 0000 0300 0000 077a 06a5 1795 486e z....Hn
0000112: 9485 ecc4 486f 63e4 0000 0000 0000 0000 ....Hoc
0000128: 0000 0000 0000 0000 0000 0000 0000 0000
[...]
0000224: 0800 0000 0000 0000 0000 0000 0000 0000
[...]
0001008: 0000 0000 0000 0000 0000 0000 0000 0000
Из листинга видно, что файловая система содержит 1 921 984 @x001d53c0)
индексных узла (байты 0-3) и 3 841 535 @x003a9dff) блоков (байты 4-7). Байты
20-23 показывают, что группа блоков 0 начинается с байта 0. Байты 24-27 и 28-31
содержат величину поразрядного сдвига числа 1024 @x0400) для вычисления
размеров блока и фрагмента соответственно. Оба значения равны 2; это означает,
что размеры блока и фрагмента равны 4096 @x1000) байт. Байты 32-35 показы-
показывают, что каждая группа состоит из 32 768 @x8000) блоков, а байты 40-43 — что
на группу приходится 16 288 @x3fa0) индексных узлов. Располагая этими сведе-
сведениями, мы знаем общий размер файловой системы, начальные адреса каждой груп-
группы блоков и количество индексных узлов в одной группе.
Байты 76-79 показывают, что используется динамическая версия Ext, так что
байты со смещением 84 должны содержать действительную информацию. Из бай-
байтов 88-91 можно определить, что размер каждого индексного узла равен 128 @x80)
байтам. Байты 92-95 содержат флаги совместимых функций; в этом поле уста-
установлен флаг журнала @x0004), следовательно, мы имеем дело с файловой систе-
системой Ext3. В поле флагов несовместимых функций (байты 96-99) содержится зна-
значение 0x0006; оно означает, что при следующей загрузке должно выполняться
восстановление @x004) и файловая система содержит специальные записи ката-
каталогов @x0003). Байты 100-103 содержат флаги функций, совместимых только
для чтения; значение 0x003 указывает на то, что в системе присутствуют большие
файлы @x0002) и не каждая группа блоков содержит резервную копию супер-
суперблока @x0001). Байты 224-227 показывают, что журнал находится в индексном
узле 8.
Суперблок содержит много других параметров, которые нами отдельно не рас-
рассматривались. Смысл этих параметров будет обсуждаться в соответствующих
разделах; их можно увидеть в выходных данных программы fsstat, приведенных
в главе 14.
Таблица дескрипторов групп
Таблица дескрипторов групп представляет собой список структур данных, назы-
называемых дескрипторами групп; этот список хранится в блоке файловой системы,
следующем непосредственно за суперблоком. В таблице присутствует запись для
каждой группы блоков в системе, и каждая запись содержит информацию о некото-
некоторой группе. Таблица состоит из 32-байтовых записей, представленных в табл. 15.9.
Таблица 15.9. Структура данных записи в таблице дескрипторов групп
Диапазон Описание Необходимость
0-3 Начальный адрес битовой карты блоков Да
4-7 Начальный адрес битовой карты индексных узлов Да
8-11 Начальный адрес таблицы индексных узлов Да
12-13 Количество свободных блоков в группе Нет
14-15 Количество свободных индексных узлов в группе Нет
16-17 Количество каталогов в группе Нет
18-31 Не используется Нет
Для просмотра содержимого основной таблицы дескрипторов группы мы из-
извлечем содержимое блока, следующего за суперблоком. В нашем образе блоки
занимают 4096 байт, суперблок находится в блоке 0, следовательно, таблица дескрип-
дескрипторов групп находится в блоке 1. С другой стороны, при 1024-байтовых блоках
суперблок находится в блоке 1, а таблица дескрипторов групп начинается в блоке 2.
Для извлечения содержимого таблицы используется программа dcat:
# dcat -f Iinux-ext3 ext3.dd 1 | xxd
0000000: 0200 0000 0300 0000 0400 0000 d610 7b3f {?
0000016: OaOO 0000 0000 0000 0000 0000 0000 0000
0000032: 0280 0000 0380 0000 0480 0000 0000 8e3f ?
0000048: 0100 0000 0000 0000 0000 0000 0000 0000
[...]
В листинге присутствуют данные двух дескрипторов групп. Байты 0-3 пока-
показывают, что битовая карта блоков находится в блоке 2, а байты 4-7 — что битовая
карта индексных узлов находится в блоке 3. Согласно байтам 8-11, таблица ин-
индексных узлов начинается в блоке 4. Группа в данном образе состоит из 32 768
блоков; это означает, что для хранения битовой карте блоков требуется 4096 байт,
то есть один блок. Группа содержит 16 288 индексных узлов, поэтому для карты
битовой карты индексных узлов потребуется 2036 байт. Таблица индексных узлов
содержит 16 288 записей по 128 байт каждая, итого 2 084 864 байта. При 4096-бай-
4096-байтовом размере блока таблица индексных узлов будет занимать 509 блоков с 4-го
блока по 512-й.
Запись таблицы группы 1 начинается с байта 32. Из байтов 32-35 видно, что
битовая карта блоков находится в блоке 32 770 @x8002). Это вполне логично,
потому что мы знаем, что группа 1 начинается в блоке 32 768, а в первых двух
блоках хранятся резервные копии суперблока и таблицы дескрипторов групп. Если
группа блоков не содержит резервных копий этих структур, в первом блоке груп-
группы находится битовая карта блоков.
Битовая карта блоков
Содержимое файлов и каталогов хранится в блоках; информация о состоянии
выделения каждого блока хранится в битовой карте. В каждой группе блоков хра-
хранится битовая карта содержащихся в ней блоков. Начальный адрес битовой кар-
карты находится в дескрипторе группы, а для ее хранения выделяется как минимум
один блок.
Как и остальные битовые карты, встречавшиеся в книге, битовая карта блоков
разделена на блоки. Младший бит соответствует блоку, следующему после блока,
представленного старшим байтом предыдущего байта. Иначе говоря, байты пере-
перебираются слева направо, но внутри каждого байта перебор бит осуществляется
справа налево.
При анализе содержимого дескриптора группы в тестовом образе мы видим,
что битовая карта блоков группы 0 начинается с блока 2. Для извлечения содер-
содержимого этого блока используется программа dcat (или dd):
# dcat -f Iinux-ext3 ext3.dd 2 | xxd
0000000: ffff ffff ffff ffff ffff ffff ffff ffff
[...]
0000168: ffOl fcff ffff Offe ffff ffff 03fe ffff
Строка, состоящая из одних «f», показывает, что группа блоков 0 начинается
с длинной серии выделенных блоков. В байте 1169 мы видим значение 0x01. Байт
1169 соответствует блокам 9352-9359. Значение 0x01 показывает, что блок 9352
выделен, а блоки 9353-9359 свободны.
Индексные узлы
Структура данных индексного узла предназначена для хранения метаданных
файлов и каталогов. Индексные узлы объединяются в таблицы индексных узлов,
присутствующие в каждой группе блоков. Начальный адрес таблицы индексных
узлов определяется в дескрипторе группы, а количество индексных узлов в груп-
группе задается в суперблоке.
Размер базовой структуры данных индексного блока составляет 128 байт.
В «динамических» версиях файловой системы (см. описание суперблока) индек-
индексные узлы могут иметь динамический размер, заданный в суперблоке. В текущей
версии ядра Linux возможность увеличения индексных узлов не поддерживает-
поддерживается, но первые 128 байт состоят из тех же полей, что и стандартные узлы [Ts'o and
Tweedie, 2002]. Поля базовых индексных узлов перечислены в табл. 15.10.
Таблица 15.10. Структура данных индексного узла
Диапазон Описание Необходимость
0-1 Режим доступа к файлу (тип и разрешения) — Да
см. табл. 15.11, 15.12 и 15.13
2-3 Младшие 16 бит идентификатора пользователя Нет
4-7 Младшие 32 бита размера в байтах Да
8-11 Время обращения Нет
12-15 Время изменения Нет
16-19 Время модификации Нет
20-23 Время удаления Нет
24-25 Младшие 16 бит идентификатора группы Нет
26-27 Счетчик ссылок Нет
28-31 Количество секторов Нет
32-35 Флаги (см. табл. 15.14) Нет
36-39 Не используется Нет
40-87 12 прямых указателей на блоки Да
88-91 1 косвенный указатель первого уровня Да
92-95 1 косвенный указатель второго уровня Да
96-99 1 косвенный указатель третьего уровня Да
100-103 Номер поколения (NFS) Нет
104-107 Блок расширенных атрибутов (ACL файлов) Нет
108-111 Старшие 32 бита размера / ACL каталогов Да / Нет
112-115 Адрес блока для фрагмента Нет
116-116 Индекс фрагмента в блоке Нет
Таблица 15.10 {продолжение)
Диапазон Описание Необходимость
117-117 Размер фрагмента Нет
118-119 Не используется Нет
120-121 Старшие 16 бит идентификатора пользователя Нет
122-123 Старшие 16 бит идентификатора группы Нет
124-127 Не используется Нет
Как упоминалось при описании архитектуры, размер изначально был 32-раз-
32-разрядным, но позднее был преобразован в 64-разрядное значение за счет исполь-
использования поля ACL каталогов в байтах 108-111. Если в системе присутствуют
файлы с 64-разрядным значением, в суперблоке должен быть установлен флаг
соответствующей функции, совместимой в режиме только для чтения.
16-разрядное поле режима делится на три части. В младших 9 битах содержатся
флаги разрешений, каждый бит соответствует одному разрешению. При определении
разрешений используется формат «пользователь/группа/прочие». Идентификато-
Идентификаторы пользователя и группы указаны в индексном узле, а все остальные относятся
к категории «прочих». Каждой категории могут быть предоставлены разрешения
чтения, записи или выполнения. Флаги разрешений приведены в табл. 15.11.
Таблица 15.11. Флаги разрешений в битах 0-8 поля режима
Флаг разрешения Описание
0x001 Прочие —- разрешено выполнение
0x002 Прочие — разрешена запись
0x004 Прочие — разрешено чтение
0x008 Группа —- разрешено выполнение
0x010 Группа —- разрешена запись
0x020 Группа — разрешено чтение
0x040 Пользователь — разрешено выполнение
0x080 Пользователь — разрешена запись
0x100 Пользователь — разрешено чтение
Следующие три бита предназначены для исполняемых файлов и каталогов.
При установке хотя бы одного из них изменяется поведение исполняемого файла
при запуске, или же файлы в каталогах наделяются особыми свойствами. Эти
флаги перечислены в табл. 15.12.
Таблица 15.12. Флаги битов 9-11 поля режима
Флаг Описание
0x200 Бит устойчивости
0x400 SGID (Set Group ID)
0x800 SUID (Set User ID)
За описанием этих флагов обращайтесь к разделу «Категория метаданных»
главы 14. Наконец, биты 12-15 определяют тип файла, к которому относится
данный индексный узел. Тип задается отдельным значением, а не набором фла-
флагов. Допустимые значения перечислены в табл. 15.13.
Таблица 15.13. Флаги типа для битов 12-15 поля режима
Флаг Описание
0x1000 FIFO
0x2000 Символьное устройство
0x4000 Каталог
0x6000 Блочное устройство
0x8000 Обычный файл
ОхАООО Символическая ссылка
0хС000 Сокет UNIX
Четыре временных штампа хранятся в виде количества секунд, прошедших с 1
января 1970 г. в формате UTC. Схема перестанет работать в январе 2038 года,
потому что значение представляется всего 32 битами. Поле флагов определяет
атрибуты, установленные для файла. Как было сказано в предыдущем разде-
разделе, некоторые флаги поддерживаются не всеми ОС. Значения, перечисленные
в табл. 15.14, либо описаны в электронной документации, либо используются в те-
текущей версии кода ядра.
Таблица 15.14. Флаги в поле флагов индексного узла
Флаг Описание
0x00000001 Надежное удаление (не используется)
0x00000002 Сохранение копии данных при удалении (не используется)
0x00000004 Сжатие файла (не используется)
0x00000008 Синхронные обновления — новые данные немедленно записываются на диск
0x00000010 Неизменяемый файл — модификация содержимого невозможна
0x00000020 Разрешено только присоединение данных
0x00000040 Файл не включается в результаты команды dump
0x00000080 А-время не обновляется
0x00001000 Каталог с хеш-индексированием
0x00002000 В Ext3 ведется журнал файловой системы
Рассмотрим индексную запись 16 из предыдущего образа. Прежде всего необ-
необходимо определить группу, частью которой она является. Мы знаем, что каждая
группа содержит 16 288 индексных узлов, следовательно, нам нужна группа 0.
Начальный адрес таблицы индексных узлов задается в дескрипторе группы. Ра-
Ранее мы видели, что таблица начинается в блоке 4, а каждый блок состоит из 4096
байт. Чтобы извлечь данные, мы сначала перейдем к таблице индексных узлов,
вызывая dd с размером блока 4096, а затем перейдем к узлу 16, вызывая dd с разме-
размером блока 128. Нумерация индексных узлов начинается с 1, поэтому величину
смещения нужно уменьшить на 1:
# dd if=ext3.dd bs=4096 skip=4 | dd bs=128 skip=15 count=l | xxd
0000000: a481 f401 0040 9c00 6dO9 2a3f f607 2a3f @..m.*?..*?
0000016: 8107 2a3f 0000 0000 f401 0100 404e 0000 ..*? @N..
0000032: 0000 0000 0000 0000 2с38 0000 2d38 0000 8..-8..
0000048: 2е38 0000 2f38 0000 3038 0000 3138 0000 .8../8..08..18..
0000064: 3238 0000 3338 0000 3438 0000 3538 0000 28..38..48..58..
0000080: 3638 0000 3738 0000 3838 0000 393с 0000 68..78..88..9<..
0000096: 0000 0000 Ьа94 еаОЬ 0000 0000 0000 0000
0000112: 0000 0000 0000 0000 0000 0000 0000 0000
Поле режима (байты 0-1) содержит значение 0x81а4. Биты показывают, что файл
доступен для чтения любому желающему @x004) и группе @x020), а пользователю
разрешена запись @x080) и чтение @x100). Из старших 4 битов видно, что файл
является обычным @x8000). Байты 4-7 показывают, что размер файла равен
10 240 000 байтам @х009с4000). В байтах 8-11 хранится А-время 0x3f2a096d; зна-
значение преобразуется в 1 августа 2003 г., 06:32:13 UTC. Счетчик ссылок в байтах
26-27 равен 1; это означает, что индексная запись связана с именем файла. Соглас-
Согласно байтам 32-35, специальные флаги или атрибуты для файла не устанавливались.
Байты 40-43 содержат первый прямой указатель на блок файла; в нашем при-
примере это блок 14 380 @х0000382с). В байтах 44-47 хранится второй прямой ука-
указатель на блок 14 381 @x0000382d). Байты 88-91 содержат адрес блока косвенных
указателей первого уровня, который равен 14 392 @x00003838). Аналогичный
указатель второго уровня (байты 92-95) равен 15 417 (ОхООООЗсЗЭ). Содержимое
обоих блоков представляет собой список 4-байтовых адресов. Блок указателей
первого уровня содержит список адресов, по которым хранится содержимое файла:
# dcat -f Iinux-ext3 ext3.dd 14392 | xxd
0000000: 3938 0000 3a38 0000 3b38 0000 3c38 0000 98..:8..;8..<8..
0000016: 3d38 0000 3e38 0000 3f38 0000 4038 0000 =8..>8..?8..@8..
0000032: 4138 0000 4238 0000 4338 0000 4438 0000 A8..B8..C8..D8..
[...]
Информация о состоянии выделения индексных узлов хранится в битовой
карте индексных узлов, принадлежащей той же группе, что и индексный узел.
Адрес блока битовой карты индексных узлов хранится в дескрипторе группы:
# dcat -f Iinux-ext3 ext3.dd 3 | xxd
0000000: fff7 fcff If00 0000 00c8 0000 0000 0000
Чтобы определить нужный байт, мы вычитаем 1 (с учетом первого индексного
узла группы) и делим результат на 8:
A6 - 1) / 8 = 1 остаток 7
Бит индексного узла 16 является старшим битом байта 1 @xf7); он равен 1.
Это означает, что соответствующий индексный узел выделен.
Для получения полной информации об индексных узлах можно воспользо-
воспользоваться командой istat. Далее приводится результат выполнения этой команды для
только что проанализированного узла:
# istat -f Iinux-ext3 ext3.dd 16
inode: 16
Allocated
Group: 0
Generation Id: 199922874
uid / gid: 500 / 500
mode: -rw-r--re-
-rw-r--resize: 10240000
num of links: 1
Inode Times:
Accessed: Fri Aug 1 06:32:13 2003
File Modified: Fri Aug 1 06:24:01 2003
Inode Modified: Fri Aug 1 06:25:58 2003
Direct Blocks:
14380 14381 14382 14383 14384 14385 14386 14387
14388 14389 14390 14391 14393 14394 14395 14396
16880 16881 16882 16883
Indirect Blocks:
14392 15417 15418 16443
Расширенные атрибуты
Файл или каталог может обладать расширенными атрибутами, которые представ-
представляют собой пары «имя-значение». Если файл или каталог обладает расширенны-
расширенными атрибутами, то в его индексном узле будет указан адрес, по которому эти атри-
атрибуты хранятся.
Блок расширенных атрибутов состоит из трех секций. Первые 32 байта образу-
образуют заголовок; за ним следует вторая секция, содержащая список записей имен. Третья
секция начинается с конца блока и следует по направлению к началу. В ней хранят-
хранятся значения атрибутов, причем их порядок может не совпадать с порядком следова-
следования записей имен. Структура блока расширенных атрибутов показана на рис. 15.1.
Рис. 15.1. В блоке расширенных атрибутов имена перечисляются в начале, а значения —
в конце. Новые записи создаются по направлению к середине блока
Заголовок расширенных атрибутов начинается с байта 0 блока, а его длина
равна 32 байтам. Поля заголовка перечислены в табл. 15.15.
Таблица 15.15. Структура данных заголовка расширенных атрибутов
Диапазон Описание Необходимость
0-3 Сигнатура @хЕА020000) Нет
4-7 Счетчик ссылок Нет
8-11 Количество блоков Да
12-15 Хеш-код Нет
16-31 Зарезервировано Нет
Счетчик ссылок указывает, сколько файлов с одинаковыми расширенными ат-
атрибутами совместно использует этот блок расширенных атрибутов. Linux в насто-
настоящее время не поддерживает многоблочные списки атрибутов, но в других ОС такая
возможность может быть реализована. По хеш-кодам, вычисляемому по значениям
атрибутов, ОС легко проверяет, обладают ли два файла одинаковыми атрибутами.
После заголовка начинаются записи имен. Структура каждой записи описана
в табл. 15.16.
Таблица 15.16. Структура данных записи имен блока расширенных атрибутов
Диапазон Описание Необходимость
0-0 Длина имени Да
1-1 Тип атрибута (см. табл. 15.17) Да
2-3 Смещение значения Да
4-7 Блок, содержащий значение атрибута Да
8-11 Размер значения Да
12-15 Хеш-код значения Нет
16+ Имя в кодировке ASCII Да
Смещение задается в байтах внутри заданного блока. В текущих версиях Linux
набор расширенных атрибутов может храниться только в одном блоке, а поле блока
в записи не заполняется. Поле размера содержит количество байт в значении.
Длина имени определяет длину записи, а следующая запись начинается с бли-
ближайшей 4-байтовой границы. Поле типа записи может содержать одно из шести
значений, приведенных в табл. 15.17.
Таблица 15.17. Значения поля типа в записях имен расширенных атрибутов
Значение Описание
1 Атрибут пользовательского пространства
2 POSIX ACL
3 POSIX ACL по умолчанию (только для каталогов)
4 Атрибут доверенного пространства
5 LUSTRE (в настоящее время не используется в Linux)
6 Атрибут пространства безопасности
Если атрибут относится к пользовательскому или доверенному пространству,
а также пространству безопасности, в конце блока хранится простое значение,
соответствующее данному имени. Если в поле типа указан один из типов POSIX
ACL, значение обладает собственным набором структур данных.
«Значение» атрибута POSIX ACL начинается с заголовка, за которым следует
список записей. Структура данных заголовка содержит единственное поле, пред-
представленное в табл. 15.18. Структура данных записей ACL приведена в табл. 15.19.
Таблица 15.18. Структура данных заголовка POSIX ACL
Диапазон Описание Необходимость
0-3 Версия A) Да
Таблица 15.19. Структура данных записей POSIX ACL
Диапазон Описание Необходимость
0-1 Тип (см. табл. 15.20) Да
2-3 Разрешения (см. табл. 15.21) Да
4-7 Идентификатор пользователя/группы Да
(не включается для некоторых типов)
Поле типа в записи ACL определяет тип разрешений, для которого предназна-
предназначена данная запись. Определены значения, перечисленные в табл. 15.20.
Таблица 15.20. Допустимые значения поля типа в записях POSIX ACL
Значение Описание
0x001 Пользователь — указывается в индексном узле
0x004 Группа —- указывается в индексном узле
0x20 Прочие — все остальные пользователи
0x10 Маска прав
0x02 Пользователь —- указывается в атрибуте
0x08 Группа — указывается в атрибуте
Первые три типа относятся к владельцу, группе и «прочим» пользователям,
обычно используемым в индексных узлах ExtX. Другими словами, информация
в этих записях дублирует информацию, находящуюся в индексном узле. Размер
записи, относящейся к одному из этих типов, равен всего 4 байтам, потому что
такие записи не используют поле идентификаторов в байтах 4-7. Для других ти-
типов должен быть задан идентификатор пользователя или группы, к которым от-
относятся разрешения.
Поле разрешений содержит флаги, перечисленные в табл. 15.21.
Таблица 15.21. Флаги поля разрешений в записях POSIX ACL
Флаг разрешений Описание
0x001 Выполнение
0x002 Запись
0x004 Чтение
Рассмотрим пример блока расширенных атрибутов:
# dcat -f Iinux-ext3 ext3-2.dd 1238
0000000: 0000 02ea 0100 0000 0100 0000 7447 05e8 tG. .
0000016: 0000 0000 0000 0000 0000 0000 0000 0000
0000032: 0601 сООЗ 0000 0000 1900 0000 a8e9 5147 QG
0000048: 736f 7572 6365 0000 0002 dcO3 0000 0000 source
0000064: 2400 0000 2500 adOl 0000 0000 0000 0000 %...%
[...]
0000944: 0000 0000 0000 0000 0000 0000 0000 0000
0000960: 7777 772e 6469 6769 7461 6c2d 6576 6964 www.digital-evid
0000976: 656e 6365 2e6f 7267 0000 0000 0100 0000 ence.org
0000992: 0100 0600 0200 0400 4a00 0000 0200 0600 ]
0001008: f401 0000 0400 0400 1000 0600 2000 0400
Первые 4 байта содержат сигнатуру, в байтах 4-7 находится счетчик ссылок
со значением 1, а в байтах 8-11 — количество блоков 1. Первая запись начинается
с байта 32; мы видим, что длина имени в ней равна 6. Запись относится к типу 1
(атрибут пользовательского пространства), а байты 2-3 показывают, что значение
хранится со смещением 960 (ОхОЗсО). Байты 40-43 показывают, что размер значе-
значения равен 25 байтам, а байт 48 является первым байтом имени атрибута «source».
Имя заканчивается в байте 53. Записи выравниваются по границе 4 байт, поэтому
за следующим атрибутом необходимо перейти к байту 56. Значение первого атрибута
хранится в байтах 960-94 и представляет собой строку «www.digital-evidence.org».
Блок также содержит второй атрибут для записи ACL. Он начинается в байте
988 и продолжается до байта 1023. Заголовок хранится в байтах 988-991, а первая
запись находится в байтах 992-993. Запись относится к типу 1, то есть определяет
разрешения для идентификатора пользователя, указанного в индексном узле.
Разрешения задаются в байтах 994-995; мы видим, что владелец обладает разреше-
разрешениями на чтение и запись. Вторая запись начинается с байта 996 и относится к ти-
типу 2. Она предоставляет разрешения на чтение пользователю с идентификатором
74 @х4а). При желании читатель может расшифровать остальные разрешения
самостоятельно, а я приведу результат выполнения программы istat для файла:
# istat -f Iinux-ext3 ext3-2.dd 70
С.]
Extended Attributes (Block: 1238)
user.source=www.digital-evi dence.org
POSIX Access Control List Entries:
uid: 0: Read. Write
uid: 74: Read
uid: 500: Read. Write
gid: 0: Read
mask: Read. Write
other: Read
Запись каталога
Записи каталогов используются для хранения имен файлов и каталогов. Они на-
находятся в блоках, выделенных каталогу, и содержат адреса индексных узлов, пред-
представляющих файлы и каталоги.
Существует два формата структуры записи каталога, но обе версии имеют оди-
одинаковый размер. Второй формат более эффективно использует доступное про-
пространство. Используемая версия определяется флагом несовместимой функции
в суперблоке. Исходный формат не используется по умолчанию в современных
системах; его поля перечислены в табл. 15.22.
Таблица 15.22. Структура данных исходной версии записи каталога
Диапазон Описание Необходимость
0-3 Значение индексного узла Да
4-5 Длина записи Да
Диапазон Описание Необходимость
6-7 Длина имени Да
8+ Имя в кодировке ASCII Да
Это минимальная структура данных, в которой все поля являются необходи-
необходимыми. Для каждого имени в каталоге существует одна структура, которая ссы-
ссылается на индексный узел с метаданными. Имя не завершается нуль-символом,
поэтому в записи должно присутствовать поле длины. Linux выравнивает эти
структуры данных по границам 4 байт.
Вторая версия записи каталога более эффективно использует поле длины име-
имени. Максимальное количество символов в имени файла равно 255, поэтому для
его хранения достаточно одного байта. Во второй версии записи каталога второй
байт используется для хранения типа файла (который также хранится в индекс-
индексном узле). Поля второй версии записи каталога представлены в табл. 15.23.
Таблица 15.23. Структура данных второй версии записи каталога
Диапазон Описание Необходимость
0-3 Значение индексного узла Да
4-5 Длина записи Да
6-6 Длина имени Да
7-7 Тип файла (см. табл. 15.24) Нет
8+ Имя в кодировке ASCII Да
Значение типа не является необходимым. Его допустимые значения перечис-
перечислены в табл. 15.24.
Таблица 15.24. Допустимые значения поля типа файла в записи каталога
Флаг разрешений Описание
0 Неизвестный тип
1 Обычный файл
2 Каталог
3 Символьное устройство
4 Блочное устройство
5 FIFO
6 Сокет UNIX
7 Символическая ссылка
Для просмотра низкоуровневого содержимого каталога можно воспользоваться
командой icat. В тестовом образе используются записи каталогов новой версии,
а индексный узел 69 457 соответствует каталогу:
# icat -f Iinux-ext3 ext3.dd 69457 | xxd
0000000: 510f 0100 OcOO 0102 2e00 0000 OOdO 0000 Q
0000016: OcOO 0202 2e2e 0000 520f 0100 2800 ObOl R...(...
0000032: 6162 6364 6566 672e 7478 7400 530f 0100 abcdefg.txt.S...
0000048: 1400 OcOl 6669 6c65 2074 776f 2e64 6174 ....file two.dat
0000064: 540f 0100 1000 0702 7375 6264 6972 3100 T subdirl.
0000080: 550f 0100 ЬООЗ 0801 5253 5455 5657 5859 U RSTUVWXY
0000096: 0000 0000 0000 0000 0000 0000 0000 0000
Байты 0-3 показывают, что первая запись соответствует индексному узлу
64 457 (OxOlOf5l), а байты 4-5 — что длина записи каталога равна 12 байтам (ОхОс).
По содержимому байта 6 видно, что длина имени равна всего 1 байту, а по содер-
содержимому байта 7 — что запись представляет каталог @x02). Имя, заданное в байте
8, представляет собой строку «.». Эта запись каталога представляет текущий ка-
каталог. Для проверки можно сравнить индексный узел в записи со значением, по-
полученным при выводе содержимого каталога программой icat; мы видим, что
в обоих случаях оно равно 64 457.
Чтобы найти вторую запись, следует прибавить длину первой записи к ее на-
начальному смещению; это означает, что вторая запись начинается в байте 12. Со-
Согласно содержимому байтов 16-17, длина этой записи также равна 12 байтам, и она
представляет родительский каталог «..».
Чтобы найти третью запись, мы прибавляем длину второй записи к ее началь-
начальному смещению и получаем смещение 24. Байты 28-29 показывают, что длина
записи равна 40 байтам @x28). Байт 30 показывает, что длина имени равна 11
(ОхОЬ). Имя (байты 32-47) представляет собой строку abcdefg.txt.
При переходе от начала записи в байте 24 к следующей записи мы оказываем-
оказываемся у байта 64. Так как предыдущая запись заканчивается в байте 42, между ними
остаются 20 неиспользуемых байт. В этом пространстве хранится имя удаленного
файла two.dat; до удаления эта запись начиналась с байта 42.
Если хотите, проанализируйте остальные записи самостоятельно. Далее при-
приводится результат выполнения программы fls для того же каталога:
# fls -f Iinux-ext3 -a ext3.dd 69457
d/d 69457:
d/d 53248:
г/г 69458: abcdefg.txt
г/г * 69459: file two.dat
d/d 69460: subdirl
r/r 69461: RSTUVWXY
Символическая ссылка
Символические ссылки представляют собой специальные файлы, ассоциирован-
ассоциированные с другим каталогом или файлом. «Содержимым» файла является целевой
объект ссылки, поэтому для определения символических ссылок не нужно созда-
создавать новые структуры данных. Если путь к целевому файлу или каталогу занима-
занимает менее 60 символов, он хранится в 60 байтах индексного узла, используемых
для хранения 12 прямых и 3 косвенных указателей на блоки. Если длина пути
превышает 60 байт, для его хранения выделяется отдельный блок. Размер файла
соответствует длине пути к целевому объекту.
Для просмотра символической ссылки можно воспользоваться программой icat
Программа icat выводит содержимое файла; при этом она отображает полный путь,
потому что символическая ссылка обрабатывается как обычный файл.
# fls -f Iinux-ext3 ext3-3.dd
[...]
1/1 26: filel.txt
# icat -f Iinux-ext3 ext3-3.dd 26
/di rl/di r2/di гЗ/di r4/di r5/di гб/di r7/di r8/di r9/di rlO/di rll/di rl2/di rl3/di rl4/di rl5/
filel.txt
В индексном узле указан размер 90. Согласно выходным данным fls, узел отно-
относится к типу «1», что означает «link» (то есть «ссылка»).
Хеш-деревья
Вместо хранения неупорядоченного списка записей каталогов можно отсортиро-
отсортировать некоторые записи при помощи хеш-дерева. Каждый блок каталога соответ-
соответствует узлу дерева. He-листовые узлы содержат структуры данных с указателями
на следующий уровень. В небольших каталогах дерево состоит всего из двух уров-
уровней, а первый блок является единственным узлом верхнего уровня.
Блоки, соответствующие узлам следующего уровня, задаются при помощи
структур данных, называемых дескрипторами узлов. Перед дескрипторами узлов
размещается заголовок, который начинается за записью каталога «..». Поля заго-
заголовка дескриптора узла перечислены в табл. 15.25.
Таблица 15.25. Структура данных заголовка хеш-дерева
Диапазон Описание Необходимость
0-3 Не используется Нет
4-4 Версия Да
5-5 Длина структуры Да
6-6 Уровни узлов Нет
7-7 Не используется Нет
За заголовком следует список дескрипторов узлов, идентифицирующих хеш-
коды каждого блока. В табл. 15.26 описана структура данных дескриптора
в списке.
Таблица 15.26. Структура данных дескриптора узла хеш-дерева
Диапазон Описание Необходимость
0-3 Минимальный хеш-код в узле Да
4-7 Адрес блока Да
Каждая запись содержит минимальный хеш-код и блок каталога узла. Де-
Дескриптору первого узла минимальный хеш-код не нужен, потому что он должен
быть равен 0. По этой причине 4 байта используются для другой цели — в них
хранится текущее количество дескрипторов узлов и максимальное количество дес-
дескрипторов в блоке. Таким образом, первый дескриптор узла содержит поля, пере-
перечисленные в табл. 15.27.
Таблица 15.27. Структура данных первого дескриптора узла хеш-дерева
Диапазон Описание Необходимость
0-1 Максимальное количество дескрипторов узлов Нет
2-3 Текущее количество дескрипторов узлов Да
4-7 Адрес блока первого узла Да
Оставшаяся часть блока за дескриптором последнего узла обычно содержит
данные от ранее существовавших записей каталогов.
Рассмотрим содержимое первого блока большого каталога, индексированного
с применением хеш-дерева:
# icat -f Iinux-ext3 ext3-3.dd 16
0000000: 1000 0000 0c00 0100 2eOO 0000 0200 0000
0000016: f403 0200 2e2e 0000 0000 0000 0208 0000
0000032: 7c00 0400 0100 0000 3295 6541 0400 0000 | 2.eA....
0000048: 88d5 fa92 0200 0000 86e7 50be 0300 0000 | P
0000064: 3738 3930 2e31 3233 3400 0000 1200 0000 7890.1234
В этих выходных данных байты 0-9 соответствуют записи каталога «.», а бай-
байты 12-23 — записи «..». Обратите внимание на то, что поле длины записи «..»
в байтах 16-17 равно 1012 байтам @x03f4). Оно указывает на конец 1024-байто-
1024-байтового блока.
Заголовок начинается в байте 24, первые 4 байта не используются. Байт 28
показывает, что используется хеш версии 2, а байт 29 — что структура занимает
8 байт. Дескриптор первого узла хранится в байтах 32-39. Байты 32-33 показы-
показывают, что блок может содержать до 124 @х7с) дескрипторов, но из байтов 34-35
видно, что используются только 4. Согласно байтам 36-39, первый узел хранится
в блоке 1 каталога.
Второй дескриптор узла начинается в байте 40. Мы видим, что этот узел со-
содержит файлы с хеш-кодами имени, большими 0x41659532, а имена размещаются
в блоке 4 каталога. Чтобы определить верхнюю границу хеш-кодов этого узла, мы
обращаемся к записи следующего узла, которая начинается в байте 48, и видим,
что ее хеш-код равен 0x92fad588. Запись четвертого узла начинается в байте 63.
Структуры данных журнала
В журнале регистрируются обновления метаданных, что позволяет ускорить вос-
восстановление системы после сбоев. В журнале Ext3 задействованы четыре струк-
структуры данных. Первая — суперблок журнала — находится в первом блоке. Ос-
Остальные структуры данных предназначены для блока дескрипторов, закрепления
и отмены. Каждая структура данных обладает сигнатурой, на основании которой
обычные блоки журнала отличаются от административных блоков. Данные запи-
записываются в журнал с обратным порядком байтов; в этом они отличаются от дру-
других структур данных ExtX.
Все четыре структуры данных начинаются с однотипного заголовка, описан-
описанного в табл. 15.28.
Таблица 15.28. Структура данных стандартного заголовка структур данных журнала
Диапазон Описание Необходимость
0-3 Сигнатура @хС03В3998) Да
4-7 Тип блока (см. табл. 15.29) Да
8-11 Порядковый номер Да
Тип блока является признаком, по которому различаются четыре структуры
данных. Его значения перечислены в табл. 15.29.
Таблица 15.29. Значения поля типа в заголовках журнала
Значение Описание
1 Блок дескрипторов
2 Блок закрепления
3 Суперблок, версия 1
4 Суперблок, версия 2
5 Блок отмены
По умолчанию первая версия журнала регистрирует все обновления данных,
тогда как вторая регистрирует только обновления метаданных. При помощи па-
параметра монтирования системы можно заставить вторую версию регистрировать
все обновления данных. Суперблок состоит из полей, перечисленных в табл. 15.30.
Таблица 15.30. Структуры данных суперблока журнала версии 1 и 2
Диапазон Описание Необходимость
0-11 Стандартный заголовок (см. табл. 15.28) Да
12-15 Размер журнального блока Да
16-19 Количество блоков в журнале Да
20-23 Блок, с которого начинается фактическое Да
содержимое журнала
24-27 Порядковый номер первой транзакции Да
28-31 Блок первой транзакции Да
32-35 Номер ошибки Нет
В суперблоке версии 1 используются только первые 36 байт. В суперблоке вер-
версии 2 также используются дополнительные поля, перечисленные в табл. 15.31.
Таблица 15.31. Дополнительные поля суперблока журнала версии 2
Диапазон Описание Необходимость
36-39 Совместимые функции Нет
40-43 Несовместимые функции Нет
44-47 Функции, совместимые только для чтения Нет
48-63 UUID журнала Нет
Таблица 15.31 {продолжение)
Диапазон Описание Необходимость
64-67 Количество файловых систем, исполь- Нет
зующих журнал
68-71 Местонахождение копии суперблока Нет
72-75 Максимальное количество блоков жур- Нет
нала на транзакцию
76-79 Максимальное количество системных Нет
блоков на транзакцию
80-255 Не используется Нет
256-1023 16-байтовые идентификаторы файловых Нет
систем, использующих журнал
На момент написания книги была доступна только возможность отмены. Она от-
относится к категории несовместимых функций и представляется флагом 0x00000001.
Блок дескрипторов содержит стандартную структуру данных заголовка (см.
табл. 15.28), которая занимает байты 0-11. Начиная с байта 12, следуют записи
дескрипторов, поля которых описаны в табл. 15.32.
Таблица 15.32. Структуры данных записей блоков дескрипторов журнала
Диапазон Описание Необходимость
0-3 Блок файловой системы Да
4-7 Флаги (см. табл. 15.33) Да
8-23 UUID (не существует при установленном Нет
флаге SAMEJJUID)
Каждая из этих записей определяет, какому блоку файловой системы соответ-
соответствует данный блок журнала. Например, первый блок журнала после блока деск-
дескрипторов соответствует блоку файловой системы, описанному первой записью
дескриптора. Значения поля флагов представлены в табл. 15.33.
Таблица 15.33. Значения флагов в поле дескриптора записи
Флаг Описание
0x01 Специальная обработка блока журнала
0x02 Запись содержит тот же код UUID, что и предыдущая (SAMEJJUID)
0x04 Блок удален транзакцией (в настоящее время не используется)
0x08 Последняя запись в блоке дескрипторов
Флаг специальной обработки используется в ситуациях, когда блок файловой
системы содержит четыре байта, совпадающие с сигнатурой заголовка. В таких
ситуациях содержимое четырех байтов стирается перед записью в журнал.
Блок закрепления содержит только стандартный заголовок с типом блока и по-
порядковым номером закрепляемой транзакции.
Блок отмены содержит стандартный заголовок и список блоков файловой
системы, в которых отменяются изменения. Поля блока отмены перечислены
в табл. 15.34.
Таблица 15.34. Структура блока отмены в журнале
Диапазон Описание Необходимость
0-11 Стандартный заголовок (см. табл. 15.28) Да
12-15 Размер данных в байтах Да
16-РАЗМЕР Список 4-байтовых адресов блоков фай- Да
ловой системы
Отмена применяется ко всем транзакциям, порядковый номер которых мень-
меньше либо равен порядковому номеру записи отмены.
Рассмотрим пример журнала из файловой системы. Для просмотра его содер-
содержимого можно запустить программу icat для индексного узла 8:
# icat -f Iinux-ext3 /dev/hdb2 8 | xxd
0000000: cO3b 3998 0000 0004 0000 0000 0000 0400 .;9
0000016: 0000 0400 0000 0001 0000 0126 0000 0000 &....
0000032: 0000 0000 0000 0000 0000 0000 0000 0000
0000048: a34c 4be5 c222 460b b76f d45b 518b 083c .LK.."F..o.[Q..<
0000064: 0000 0001 0000 0000 0000 0000 0000 0000
0000080: 0000 0001 0000 0000 0000 0000 0000 0000
Байты 0-3 содержат сигнатуру. Байты 4-7 показывают, что блок относится
к типу 4, то есть представляет суперблок версии 2. Согласно байтам 8-11, поряд-
порядковый номер равен 0, а байты 12-15 показывают что размер журнального блока
равен 1024 байтам @x0400). Размер журнала (байты 16-19) равен 1024 блокам,
а его записи начинаются с блока журнала 1 (байты 20-23). Чтобы идентифици-
идентифицировать первую транзакцию в журнале, мы обращаемся к байтам 24-27 — поряд-
порядковый номер транзакции равен 294 @x0126), а байты 28-31 показывают, что за-
запись находится в блоке 0. Мы уже видели, что записи журнала начинаются с блока
1. Первая транзакция находится в блоке 0, потому что файловая система была
корректно демонтирована, а все ее транзакции завершены.
После монтирования файловой системы и создания файла в корневом катало-
каталоге суперблок содержит следующую информацию:
# icat -f Iinux-ext3 /dev/hdb2 8 | xxd
0000000: cO3b 3998 0000 0004 0000 0000 0000 0400 .:9
0000016: 0000 0400 0000 0001 0000 0127 0000 0001
В отличие от предыдущего результата, порядковый номер увеличился до 295
@x0124), а соответствующий блок журнала теперь стал равным 1, потому что
в журнале появились действительные транзакции.
Перейдем к просмотру блока журнала 1. Не путайте его с блоком файловой
системы 1; речь идет о блоке внутри файла журнала. Для просмотра его содержи-
содержимого можно передать вывод icat программе dd с размером блока 1024 или же вос-
воспользоваться утилитой jcat из пакета TSK:
# jcat -f Iinux-ext3 /dev/hdb2 1 | xxd
0000000: cO3b 3998 0000 0001 0000 0127 0000 0004 .;9
0000016: 0000 0000 0000 0000 0000 0000 0000 0000
0000032: 0000 0000 0000 0002 0000 0002 0000 OOOe
0000048: 0000 0002 0000 0005 0000 0002 0000 00a3
0000064: 0000 0002 0000 0003 0000 000a 0000 0000
Поле типа (байты 4-7) показывает, что блок является блоком дескрипторов, а его
порядковый номер равен 295 @x0127). Первая запись дескриптора начинается
в байте 12 и относится к блоку 4 файловой системы. Поле флагов (байты 16-19)
равно 0; это означает, что в следующих 16 байтах существует поле UUID. Запись
показывает, что блок, следующий за блоком дескрипторов, соответствует блоку
файловой системы 4. Блок 4 содержит битовую карту индексных узлов, а его со-
содержимое было обновлено при выделении нового узла.
Вторая запись начинается с байта 36. Байты 36-39 показывают, что запись от-
относится к блоку файловой системы 2, а содержимое поля флагов равно 2; следо-
следовательно, поле UUID в записи отсутствует. Таким образом, второй блок после
блока дескрипторов относится к блоку файловой системы 2, в котором хранится
таблица дескрипторов групп. Анализируя остальные данные блока, мы видим, что
блок 14 был обновлен, потому что он находится в таблице индексных узлов и со-
содержит индексный узел, выделенный новому файлу; обновление блока 5 объяс-
объясняется тем, что этот блок содержал индексный узел корневого каталога; блок 163
был обновлен, потому что в нем хранятся записи корневого каталога; наконец,
блок 4 содержит битовую карту блоков. Если бы в журнале также регистрирова-
регистрировались обновления содержимого, то в нем появилась бы дополнительная запись для
нового содержимого файла.
Таблица дескрипторов содержит 6 записей; проверим, содержится ли в блоке
журнала 8 блок закрепления. Действительно, он здесь присутствует:
# jcat -f Iinux-ext3 /dev/hdb2 8 | xxd
0000000: cO3b 3998 0000 0002 0000 0127 0000 0000 . ;9
0000016: 0000 0000 0000 0000 0000 0000 0000 0000
Байты 4-7 показывают, что блок является блоком закрепления @x02), а бай-
байты 8-11 — что ему назначен порядковый номер 295 @x127). Наконец, из блока
дескрипторов мы узнаем, что блок журнала 6 содержит информацию о блоке фай-
файловой системы для корневого каталога. При просмотре блока 6 мы видим обнов-
обновленный блок с записью new-file.txt:
# jcat -f Iinux-ext3 /dev/hdb2 6 | xxd
0000000: 0200 0000 OcOO 0100 2e00 0000 0200 0000
0000016: OcOO 0200 2e2e 0000 ObOO 0000 e803 OcOO
0000032: 6e65 772d 6669 6c65 2e74 7874 OcOO 0000 new-file.txt....
Возможно, на основании этой информации вам удастся определить, какие фай-
файлы в последнее время создавались и удалялись в системе. Для просмотра содер-
содержимого журнала можно воспользоваться программой jls из пакета TSK. Вот как
выглядит результат для предыдущего примера:
# jls -f Iinux-ext3 /dev/hdb2
JBlk Description
0: Superblock (seq: 0)
1: Allocated Descriptor Block (seq: 295)
2: Allocated FS Block 4
3: Allocated FS Block 3
4: Allocated FS Block 14
5: Allocated FS Block 5
6: Allocated FS Block 163
7: Allocated FS Block 3
8: Allocated Commit Block (seq: 295)
9: Unallocated FS Block Unknown
Итоги
В этой главе были описаны структуры данных файловых систем Ext2 и Ext3. Коли-
Количество основных структур данных невелико, и все они имеют четкую специализа-
специализацию. Некоторые структуры данных и флаги, упоминавшиеся в главе, встречаются
только в нестандартных системах. Структуры данных ExtX отчасти напоминают
структуры UFS, которые будут рассматриваться далее, но они устроены чуть
проще.
Библиография
• Ts'o, Theodore, and Stephen Tweedie. «Planned Extensions to the Linux Ext2/
Ext3 Filesystem». Proceedings of the 2002 Usenix Technical Conference FREENIX
Track, 2002.
Также см. раздел «Библиография» главы 14.
UFS1и UFS2: концепции
и анализ
Файловая система UFS (Unix File System) существует в нескольких вариантах
и встречается во многих разновидностях UNIX, включая FreeBSD, HP-UX, NetBDS,
OpenBSD, Apple OS X и Sun Solaris. За прошедшие годы во многих ОС некоторые
структуры данных были изменены в соответствии с их потребностями, но все они
базируются на одних и тех же концепциях. В настоящее время существует две
основные модификации UFS: UFS1 и UFS2. UFS2 поддерживает диски боль-
большего объема и расширенные временные штампы. Я буду использовать термин
«UFS» для обозначения обеих систем. Эксперт может столкнуться с файловой
системой UFS при анализе систем UNIX, обычно на серверах. Поскольку ранее
мы уже подробно рассматривали системы Ext2 и Ext3, построенные на базе UFS,
эта глава не содержит пространных объяснений — предполагается, что читатель
уже понимает концепции, описанные в главе 14. В этой главе рассматриваются
концепции и методы анализа в файловой системе UFS, а в главе 17 — ее струк-
структуры данных. Эту и следующую главы можно читать как параллельно, так и пос-
последовательно.
Введение
Система UFS связана с файловой системой Berkeley FFS (Fast File System), а ее
архитектура проектировалась в расчете на быстроту и надежность. Резервные
копии важных структур данных хранятся в нескольких местах файловой систе-
системы, а данные локализуются таким образом, чтобы свести к минимуму переме-
перемещения головок жесткого диска при чтении файла. Система UFS делится на сек-
секции, называемые группами цилиндров. Размер каждой группы определяется на
основании геометрии диска. Группы цилиндров являются аналогами групп бло-
блоков ExtX.
В начале UFS находится суперблок с основной информацией о строении фай-
файловой системы. Содержимое каждого файла хранится в блоке, который представ-
представляет собой группу смежных секторов. Блоки также могут делиться на фрагменты;
фрагмент используется для хранения завершающих байтов файла (вместо выде-
выделения полного блока). Метаданные файлов и каталогов хранятся в структурах
данных, называемых индексными узлами. Имена файлов хранятся в записях ката-
каталогов, содержащихся в выделенных каталогу блоках. Запись каталога представляет
собой простейшую структуру данных с именем файла и указателем на индексный
узел. Отношения между структурами данных показаны на рис. 16.1. Каждая группа
цилиндров обладает собственной таблицей индексных узлов, битовой картой с ин-
информацией о состоянии выделения фрагментов и копией суперблока.
Рис. 16.1. Отношения между записями каталогов UFS, индексными узлами и блоками данных,
используемыми для хранения содержимого
Все разновидности UFS построены на этих базовых принципах. Очевидно, это
те же концепции, которые были описаны ранее для ExtX. Разновидности UFS
различаются способами организации структур данных и реализованными в них
дополнительными возможностями. Впрочем, по сравнению с ExtX UFS содержит
меньше экспериментальных возможностей, отражающихся на дисковых данных.
Файловая система UFS1 используется по умолчанию в OpenBSD и Solaris.
Раньше она также считалась стандартной файловой системой FreeBSD и NetBSD
до того момента, как в FreeBSD 5.0 и NetBSD 2.0 появилась UFS2. В UFS2 добав-
добавлена поддержка больших файлов и дисков, а также другие современные возмож-
возможности. На момент написания книги только FreeBSD и NetBSD поддерживали
UFS2. Apple OS X и Linux также поддерживают UFS1, но эта система в них не
является стандартной. Разновидность UFS также реализована в Solaris для под-
поддержки больших файлов и дисков. Компания Sun не опубликовала информацию
о структурах данных своей версии UFS, но программы, основанные на описаниях
структур данных от FreeBSD, успешно работают в файловой системе Solaris. Тем
не менее с необязательными данными дело может обстоять иначе.
В оставшейся части этой главы мы рассмотрим модель с пятью категориями
применительно к разновидностям UFS. В каждом разделе будут описаны основ-
основные свойства каждой категории и ее отличительные особенности в каждом вари-
варианте реализации. Я буду обозначать FreeBSD, NetBSD и OpenBSD общим терми-
термином «BSD».
Категория данных файловой системы
К категории данных файловой системы относятся общие сведения о строении
и размере компонентов файловой системы. В этом разделе описано местонахож-
местонахождение служебных данных UFS и методы их анализа.
Общие сведения
В UFS данные категории файловой системы хранятся в трех видах структур
данных: суперблоке, сводках групп цилиндров и дескрипторах групп. Суперблок
находится в начале файловой системы и содержит основную информацию
о размере и конфигурации. В суперблоке хранится ссылка на область файловой
системы, называемую сводкой групп цилиндров; в ней содержится сводная ин-
информация об использовании групп цилиндров. Каждая группа цилиндров со-
содержит структуру данных дескриптора группы с более подробной информаци-
информацией об отдельной группе. Далее все эти структуры данных будут описаны более
подробно.
Суперблок
Суперблок UFS содержит основные параметры файловой системы — такие, как
размер каждого фрагмента и количество фрагментов в каждом блоке. Кроме того,
в нем хранится размер каждой группы цилиндров и местонахождение различных
структур данных в каждой группе. На основании этой информации можно опре-
определить конфигурацию файловой системы. В суперблоке также может храниться
метка тома и время последнего монтирования файловой системы. Суперблок UFS
играет ту же роль, что и суперблок ExtX, но информация о структуре и необяза-
необязательные данные различаются.
Суперблок UFS хранится поблизости от начала файловой системы. На съем-
съемных носителях он может начинаться в первом секторе. Обычно суперблок UFS1
находится в 8, а суперблок UFS2 — в 64 килобайтах от начала файловой системы.
Также суперблок UFS2 может располагаться в 256 килобайтах от начала файло-
файловой системы, но такой вариант расположения не является стандартным. Резерв-
Резервные копии суперблока могут присутствовать во всех группах цилиндров.
В UFS1 и UFS2 используются слегка различающиеся структуры данных, но
в обеих версиях их размер превышает 1 Кбайт, а структуры содержат около 100
полей. Суперблоки UFS1 и UFS2 различаются тем, что версия UFS2 включает
64-разрядные версии полей размера и даты, которые добавляются в конец струк-
структуры данных. Неиспользуемые 32-разрядные поля игнорируются и не использу-
используются для хранения других данных.
В суперблоке также хранится другая служебная информация — например, об-
общее количество свободных индексных узлов, фрагментов и блоков. Из супербло-
суперблока можно узнать местонахождение области, называемой сводкой группы цилинд-
цилиндров. В этой области также хранится таблица с записями для всех групп цилиндров;
в записях документируется количество свободных блоков, фрагментов и индекс-
индексных узлов. Как будет показано позднее, эта информация также присутствует в де-
дескрипторе каждой группы.
Суперблок содержит информацию о геометрии диска, которая используется
для наиболее эффективной организации и оптимизации файловой системы. Мно-
Многие производные значения сохраняются отдельно, чтобы ОС не приходилось каж-
каждый раз вычислять их заново. Например, размер блока хранится как в байтах, так
и во фрагментах. Кроме того, имеется поразрядная маска и величины сдвигов для
преобразования адреса байта в адрес блока и наоборот. Теоретически достаточно
хранить только одно из этих значений, а остальные вычислять при необходимос-
необходимости. Несмотря на то что многие поля обязательными не являются, в этом разделе
основное внимание будет уделено как обязательным, так и необязательным дан-
данным, которые могут содержать улики.
Подробные описания структур данных приведены в главе 17. Суперблоки как
UFS1, так и UFS2 будут рассматриваться на примере тестовых образов файловых
систем.
Дескриптор группы цилиндров
Как упоминалось ранее, файловая система делится на группы цилиндров. Все груп-
группы (возможно, кроме последней) обладают одинаковым размером; каждая груп-
группа содержит дескриптор с описанием данной группы. Первая группа начинается
в начале файловой системы, а количество фрагментов в каждой группе задается в
суперблоке. Кроме дескриптора, каждая группа содержит таблицу индексных уз-
узлов и резервную копию суперблока.
Дескриптор группы UFS гораздо больше своего аналога в ExtX, хотя содержа-
содержащиеся в нем данные в основном не обязательны. Для хранения дескриптора груп-
группы выделяется полный блок; дескриптор состоит из набора стандартных полей
и открытой области, предназначенной для хранения различных таблиц. Стандар-
Стандартные поля содержат служебную информацию и описывают строение завершаю-
завершающей части блока. Такие служебные данные, как местонахождение последнего вы-
выделенного блока, фрагмента и индексного узла, используются для повышения
эффективности создания файлов. Также присутствует сводная информация о ко-
количестве свободных блоков, фрагментов и индексных узлов; эти параметры дол-
должны совпадать со значениями в сводке групп цилиндров. Дескриптор группы так-
также содержит время последней записи в группу (рис. 16.2).
Завершающая часть дескриптора группы содержит битовые карты индексных
узлов, блоков и фрагментов группы. В ней также хранятся таблицы, упрощающие
поиск смежных фрагментов и блоков заданного размера. Начальное местонахожде-
местонахождение каждой из этих структур данных задается в виде смещения в байтах относитель-
относительно начала дескриптора группы, а размер структуры данных обычно приходится
вычислять. Формальные описания структур данных приводятся в следующей
главе.
Рис. 16.2. Строение дескриптора группы со стандартными полями
и открытой областью, содержащей битовые карты
и другие таблицы
Как мы видели при знакомстве с ExtX, во втором блоке каждой группы всегда
хранится таблица дескрипторов групп. В UFS местонахождение дескриптора
группы, таблицы индексных узлов и резервной копии суперблока задается отдель-
отдельно для каждой файловой системы, а смещения задаются в суперблоке. Например,
таблица индексных узлов может начинаться в 32, а дескриптор группы — в 16 фраг-
фрагментах от начала. В UFS1 ситуация дополнительно усложняется тем, что смещения
дополняются базовым сдвигом, который зависит от группы цилиндров. Например,
если для таблицы индексных узлов задано смещение в 32 фрагмента, она может
быть удалена на 32 фрагмента от начала группы 0, на 64 фрагмента от начала груп-
группы 1 и на 96 фрагментов от начала группы 2. Такой разброс вносится для того, что-
чтобы сократить последствия от физических повреждений пластин на старых дисках.
Группы цилиндров называются так потому, что они выравниваются по грани-
границам цилиндров. На старых жестких дисках количество секторов в дорожке было
постоянным; это означало, что первые секторы всех групп находились на одной
пластине. Если бы не разброс административных данных, все копии суперблока
находились бы на одной пластине. На новых жестких дисках количество секто-
секторов в цилиндрах различается, поэтому такой проблемы не существует, и в UFS2
разброс административных данных уже не используется.
«Базовый» сдвиг каждой группы вычисляется на основании двух параметров
из суперблока — цикла (с) и дельты (d). Базовый сдвиг увеличивается на d для
каждой группы и возвращается к началу через с групп. Например, для каждой
группы может вноситься смещение в 32 фрагмента, которое затем будет возвра-
возвращаться к 0 после 16 групп.
На рис. 16.3 показан пример строения систем UFS1 и UFS2. В файловой сис-
системе UFS1 административные данные хранятся с циклом 3, а в UFS2 использует-
используется постоянное смещение внутри каждой группы. Фрагменты до и после админис-
административных данных могут использоваться для хранения содержимого файлов.
Рис. 16.3. UFS1 с пятью группами и разбросом административных данных; UFS2 с пятью
группами и административными данными, хранящимися с постоянным смещением
На рис. 16.4 показан пример группы. Базовый адрес удален на несколько бло-
блоков от начала группы, а резервный суперблок, дескриптор группы и таблица ин-
индексных узлов хранятся в последовательном порядке. Внутри дескриптора груп-
группы хранятся битовые карты и стандартные поля структур данных. Остальные
фрагменты предназначены для содержимого файлов и каталогов.
Рис. 16.4. Пример строения группы цилиндров в UFS1. Базовый адрес задается переменным
количеством блоков от начала группы, а битовые карты хранятся
на статическом расстоянии от базового адреса
Загрузочный код
Если файловая система UFS содержит ядро ОС, в ней также должен присут-
присутствовать загрузочный код. Он хранится в первом секторе файловой системы и
следует вплоть до суперблока или структуры данных разметки диска. Возмож-
Возможно, для полного понимания структуры UFS стоит освежить в памяти материалы
главы 6.
В BSD и Solaris используются собственные схемы создания разделов. В систе-
системах IA32 (например, x86/i386) создается один раздел, внутри которого находится
один или несколько разделов BSD. Местонахождение разделов BSD определяет-
определяется структурой разметки диска в секторе 1 раздела DOS. Загрузочный код нахо-
находится в секторе 0, а затем в секторах 2 и 5. В файловой системе UFS1 суперблок
находится в секторе 16, а в UFS2 — в секторе 128. В UFS2 загрузочный код также
занимает дополнительные секторы.
В системе i386 Solaris также создаются два раздела DOS. Один имеет неболь-
небольшие размеры и содержит только загрузочный код. Второй содержит файловую
систему, а в его секторе 0 хранится структура данных оглавления тома VTOC
(Volume Table of Contents). У дисков системы Sparc Solaris VTOC хранится в сек-
секторе 0 диска, а загрузочный код — в секторах 1-15. В новых системах Sparc Solaris
вместо VTOC может использоваться таблица разделов EFI.
В файловых системах, не содержащих загрузочного кода, секторы перед су-
суперблоком не используются. На рис. 16.5 (А) показан пример диска FreeBSD для
платформы IA32, а на рис. 16.5 (В) — пример диска Sparc Solaris.
Рис. 16.5. Примеры: (А) — система IA32 с тремя разделами DOS и двумя разделами BSD
внутри раздела FreeBSD, (В) — диск Sparc Solaris с двумя разделами Solaris
Пример образа
В завершение этого раздела я приведу результаты выполнения программы fsstat
из пакета TSK (The Sleuth Kit) для образа UFS1. Этот образ будет использоваться
как в последующих примерах этой главы, так и при ручном анализе дисковых
структур в следующей главе. В действительности выходные данные fsstat занима-
занимают гораздо больше места, потому что в них включается подробная информация
по каждой группе цилиндров; я приведу лишь самые существенные данные:
# fsstat -f openbsd openbsd.dd
FILE SYSTEM INFORMATION
File System Type: UFS 1
Last Written: Tue Aug 3 09:14:52 2004
Last Mount Point: /mnt
METADATA INFORMATION
Inode Range: 0 - 3839
Root Directory: 2
Num of Avail Inodes: 3813
Num of Directories: 4
CONTENT INFORMATION
Fragment Range: 0 - 9999
Block Size: 8192
Fragment Size: 1024
Num of Avail Full Blocks: 1022
Num of Avail Fragments: 16
CYLINDER GROUP INFORMATION
Number of Cylinder Groups: 2
Inodes per group: 1920
Fragments per group: 8064
Group 0:
Last Written: Tue Aug 3 09:14:33 2004
Inode Range: 0 - 1919
Fragment Range: 0 - 8063
Boot Block: 0 - 7
Super Block: 8 - 15
Super Block: 16 - 23
Group Desc: 24 - 31
Inode Table: 32 - 271
Data Fragments: 272 - 8063
Global Summary (from the superblock summary area):
Num of Dirs: 2
Num of Avail Blocks: 815
Num of Avail Inodes: 1912
Num of Avail Frags: 11
Local Summary (from the group descriptor):
Num of Dirs: 2
Num of Avail Blocks: 815
Num of Avail Inodes: 1912
Num of Avail Frags: 11
Last Block Allocated: 392
Last Fragment Allocated: 272
Last Inode Allocated: 7
В выходных данных fsstat приводится общая информация — размеры блока
и фрагмента, количество индексных узлов. Также в них присутствует информа-
информация по отдельным группам цилиндров, о том, какие фрагменты входят в каждую
группу и какие ресурсы были выделены последними. В выходных данных объе-
объединяются данные из суперблока, из сводки групп цилиндров и из дескрипторов
групп. Например, по адресу блока можно узнать, к какой группе он принадлежит,
а также определить местонахождение таблицы индексных узлов и дескриптора
для каждой группы. Это особенно важно для UFS1, поскольку эти администра-
административные данные хранятся с разными смещениями в группах.
Обратите внимание на присутствие двух суперблоков в первой группе. Пер-
Первая копия присутствует потому, что в секторе 16 (то есть в блоке 8 данной файло-
файловой системы) всегда присутствует суперблок. Наличие второй копии объясняет-
объясняется тем, что в каждой группе цилиндров хранится резервная копия со смещением
в 16 фрагментов.
Методы анализа
Анализ данных категории файловой системы направлен на поиск и обработку
общих сведений о файловой системе с целью применения дополнительных методов
анализа. В файловой системе UFS анализ начинается с поиска суперблока в од-
одном из стандартных мест. На основании данных суперблока определяются место-
местонахождения каждой группы цилиндров и блока данных. Резервные копии супер-
суперблока присутствуют в каждой группе цилиндров.
Чтобы найти дескриптор конкретной группы, необходимо взять смещение,
указанное в суперблоке, и прибавить его к базовому адресу группы. В UFS2 базо-
базовый адрес совпадает с началом группы, но в группах цилиндров UFS1 вносится
разброс данных. Начальный адрес дескриптора вычисляется на основании пара-
параметров (дельты и цикла), хранящихся в суперблоке. Дескриптор группы исполь-
используется при определении состояния выделения ресурсов группы.
Последняя важная структура данных хранится в области сводки групп цилин-
цилиндров. Ее адрес задается в суперблоке, и она содержит таблицу с данными об ис-
использовании каждой группы цилиндров. Сводка предназначена для получения
базовой информации о группах.
Факторы анализа
В категории данных файловой системы редко встречаются какие-либо улики.
В UFS эта категория содержит множество необязательных данных, и обнаруже-
обнаружение скрытой информации усложняется тесным переплетением обязательных и не-
необязательных данных. В конце блока, выделенного для хранения суперблока, свод-
сводки групп цилиндров или дескрипторов групп, могут находиться неиспользуемые
области. Чтобы выявить резервное пространство тома, сравните размер файло-
файловой системы с размером тома.
В суперблоке, дескрипторах групп и области присутствует разнообразная слу-
служебная информация. Если инцидент произошел совсем недавно, возможно, вам
удастся прийти к каким-либо выводам относительно того, где находились удален-
удаленные файлы или какой файл был создан последним. Хранение нескольких копий
служебных данных также позволяет сравнить их, если вы заподозрите постороннее
вмешательство. Резервные копии суперблока хранятся в каждой группе цилинд-
цилиндров, а для их поиска можно воспользоваться сигнатурой этой структуры данных.
Категория содержимого
К категории содержимого относятся данные о содержимом файлов и каталогов.
В этом разделе читатель узнает, где в UFS хранится содержимое файлов и ката-
каталогов и как осуществляется его анализ.
Общие сведения
В UFS содержимое файлов и каталогов хранится во фрагментах и блоках. Фраг-
Фрагментом называется группа смежных секторов, а блоком — группа смежных фраг-
фрагментов. Каждому фрагменту назначается адрес; нумерация адресов начинается
с 0. Адресация блоков осуществляется по первому фрагменту блока. Первый блок
и фрагмент располагаются в первом секторе файловой системы. Минимальный
размер блока UFS составляет 4096 байт, а максимальное количество фрагментов
в блоке равно 8. Пример связи между блоками и фрагментами показан на рис. 16.6:
блок 64, содержащий фрагменты 64-71, полностью выделяется файлу, а из бло-
блока 72 выделяются фрагменты 74 и 75. Остальные фрагменты блока 72 могут вы-
выделяться другим файлам.
Рис. 16.6. Два блока UFS с 8 фрагментами. Один блок выделен полностью,
в другом блоке файлу выделены только два фрагмента
Двухуровневое выделение дискового пространства (блоки и фрагменты) по-
позволяет выделять большие объемы смежных блоков без потери пространства в пос-
последнем блоке. UFS пытается свести к минимуму потери пространства в после-
последнем блоке.
Если файл может заполнить целый блок, ему выделяется полный блок. При
записи последней порции данных выделяются фрагменты, необходимые для хра-
хранения данных. Если файл увеличится в размерах и сможет заполнить целый блок,
данные будут перемещены.
Рассмотрим пример файловой системы с 8192 блоками и 1024 фрагментами.
Для хранения файла, размер которого равен 20 000 байт, потребуются 2 блока
и 4 фрагмента. Ситуация показана на рис. 16.7: два блока начинаются во фраг-
фрагментах 584 и 592. В двух блоках размещаются 16 384 байта файла, а оставшиеся
3616 байт хранятся во фрагментах 610-613. Первые два фрагмента блока исполь-
используются другим файлом.
Рис. 16.7. 20 000-байтовый файл хранится в двух 8192-байтовых блоках
и четырех 1024-байтовых фрагментах
Состояние выделения блока или фрагмента определяется по одной из двух
битовых карт. В одной карте биты соответствуют фрагментам, а в другой — бло-
блокам; вообще говоря, обе карты должны содержать практически одинаковую ин-
информацию, но битовая карта блоков позволяет быстрее находить большие смеж-
смежные блоки при создании больших файлов. Битовые карты UFS отличаются от
«обычных»: фактически в них хранится информация не о занятых, а о свободных
кластерах. Таким образом, если бит равен 1, соответствующий блок доступен, а ес-
если бит равен 0 — блок используется.
Битовые карты хранятся в упоминавшейся ранее структуре данных дескрип-
дескриптора группы цилиндров. Следовательно, перед проверкой состояния выделения
блока необходимо определить, в какой группе он находится. Впрочем, эта задача
решается легко, потому что для этого достаточно разделить адрес фрагмента на
количество фрагментов в группе цилиндров.
Чтобы определить положение нужного бита в битовой карте конкретного бло-
блока, следует вычислить начальный блок группы и вычесть это значение из адреса
блока. Пример приводился в главе 14. Блоки LJFS и битовые карты фрагментов
более подробно рассматриваются в главе 17.
Программа dstat из пакета TSK сообщает состояние выделения фрагмента UFS
и указывает, к какой группе цилиндров он принадлежит. Пример вывода для тес-
тестового образа UFS1:
# dstat -f openbsd openbsd.dd 288
Fragment: 288
Allocated
Group: 0
Алгоритмы выделения
Проектировщики UFS приложили немалые усилия к выработке стратегий выде-
выделения, обеспечивающих эффективное выделение блоков. Вероятно, аналогичные
работы проводились и для коммерческих файловых систем, но их результаты не
были опубликованы, и базовое тестирование вряд ли могло бы дать полное пред-
представление об используемых алгоритмах. В этом разделе приводится обзор доку-
документированных стратегий выделения в BSD, но за более подробной инфор-
информацией я рекомендую обратиться к книгам «Design and Implementation of the АЛ
BSD Operating System» или «Design and Implementation ol the FreeBSD Operating
System». Несмотря на наличие документированной стратегии выделения, реали-
реализации ОС не обязаны ей следовать — реализация может выбрать другую страте-
стратегию по своему усмотрению.
Первое, что учитывается при выделении блоков и фрагментов, — принадлежность
к группе цилиндров. Если ОС выделяет блоки для нового файла и в группе цилин-
цилиндров индексного узла имеются доступные блоки, то система использует блоки из
этой группы. Если при выделении блоков для существующего файла количество
блоков, принадлежащих одному файлу в рамках одной группы, может ограничи-
ограничиваться; возможно, придется выбрать другую группу цилиндров. Например, мно-
многие ОС ограничивают количество выделяемых блоков для файлов и каталогов в
одной группе на уровне 25-33 % от общего количества блоков. При достижении
порогового значения выбирается новая группа. Solaris использует аналогичную
стратегию: первые 12 блоков (прямые указатели) файлов выделяются в пределах
одной группы цилиндров, а остальные блоки выделяются в других группах.
После выбора группы цилиндров ОС выделяет блоки, руководствуясь объе-
объемом записываемых данных. Если размер файла неизвестен или файл постепенно
увеличивается, блоки выделяются последовательно с использованием стратегии
поиска следующего доступного блока. Раньше для определения оптимального
местонахождения блоков учитывалась ротационная задержка, но сейчас просто
используется следующий смежный блок. Если размер известен заранее, данные
делятся на участки; размер одного участка обычно равен 16 блокам. Для выделе-
выделения блоков в пределах участка используется стратегия поиска первого доступно-
доступного блока. Таким образом, для 8192-байтовых блоков размер каждого участка бу-
будет равен 128 Кбайт. Это значение настраивается на уровне файловой системы
и задается в суперблоке.
Для завершающей порции данных в файле вместо полного блока выделяются
фрагменты. ОС ищет серию последовательных фрагментов, размер которой до-
статочен для хранения данных. Смежные фрагменты не могут пересекать границу
блока, а информацию о наличии фрагментов нужной длины можно получить из
служебных данных файловой системы. При выделении фрагментов для последних
данных файла используется стратегия поиска первого свободного фрагмента.
Если новыми данными дополняется файл, которому уже были выделены фраг-
фрагменты, ОС пытается расширить выделенную серию фрагментов. Если расшире-
расширение невозможно, выделяется новый набор фрагментов или полный блок, а дан-
данные перемещаются. Если файл занимает 12 полных блоков, фрагменты обычно не
используются, а при расширении файла выделяются полные блоки.
В суперблоке указано, сколько свободных блоков должно оставаться в систе-
системе на любой момент времени. Свободные блоки резервируются для того, чтобы
администратор мог войти в систему и вернуть ее в нормальное состояние, однако
ОС не обязана соблюдать установленное ограничение.
Все протестированные мной системы BSD и Solaris стирали содержимое неис-
неиспользуемых секторов в фрагментах. Следовательно, в резервном пространстве
выделенных фрагментов бесполезно искать данные от удаленных файлов.
Методы анализа
Анализ данных в категории содержимого основан на поиске блока или фрагмен-
фрагмента, просмотре его содержимого и проверке состояния выделения. Для поиска дан-
данных необходимо знать адрес фрагмента или блока. Оба размера хранятся в супер-
суперблоке; поиск выполняется простым смещением от начала файловой системы до
достижения нужного адреса. Адрес блока соответствует адресу первого фрагмен-
фрагмента в блоке.
Чтобы проверить состояние выделения любого фрагмента, необходимо снача-
сначала определить группу цилиндров, к которой он принадлежит. Для этого адрес блока
делится на количество фрагментов в группе. Местонахождение дескриптора груп-
группы определяется прибавлением смещения, хранящегося в суперблоке, к базовому
адресу группы. Дескриптор группы содержит битовую карту фрагментов.
Чтобы получить содержимое всех свободных фрагментов файловой системы,
достаточно перебрать все группы и проанализировать все битовые карты фраг-
фрагментов. Фрагменты и блоки, используемые для хранения суперблоков, индекс-
индексных таблиц, дескрипторов групп и сводки групп цилиндров, считаются выделен-
выделенными, хотя они и не связываются ни с каким конкретным файлом.
Факторы анализа
Архитектура и стратегии выделения UFS предоставляют ряд преимуществ экс-
экспертам, но при этом создают и целый ряд проблем. С одной стороны, привязка
блоков к индексным узлам упрощает восстановление данных, а если удаленные
данные хранятся в редко используемых группах, они существуют дольше, чем уда-
удаленные данные в других группах. К преимуществам также можно отнести и то,
что выделение серий смежных блоков снижает фрагментацию, а это обстоятель-
обстоятельство упрощает работу программ извлечения данных.
К проблемам UFS можно отнести наличие завершающего фрагмента. «Хвост»
файла обычно оказывается в другой группе цилиндров, поскольку для его хранения
необходим лишь один фрагмент. Разброс данных усложняет их извлечение. С дру-
другой стороны, фрагменты часто позволяют восстановить больше данных, чем ExtX
со стиранием всех байтов блока. В UFS стирается только содержимое выделен-
выделенных фрагментов, так что отдельные части блока продолжают существовать и пос-
после его повторного выделения.
Восстановление очень больших файлов (скажем, вложений в сообщениях элек-
электронной почты) усложняется тем, что такой файл может занимать более 25 % объе-
объема группы цилиндров; в этом случае остаток перемещается в другую группу. Кро-
Кроме того, Solaris после выделения первых 12 блоков файла переходит к новой группе
цилиндров, что мешает работе служебных программ извлечения данных. Конеч-
Конечно, ОС, создающая файловую систему, не обязана соблюдать все правила UFS
и следовать всем стратегиям выделения.
Категория метаданных
К категории метаданных относятся данные, содержащие информацию о файлах
и каталогах. В этом разделе рассказано, где UFS хранит данные и как организует-
организуется их анализ.
Общие сведения
В UFS, как и в ExtX, метаданные файлов и каталогов хранятся в индексных уз-
узлах. UFS2 также дает возможность сохранить дополнительную информацию
о файле в расширенных атрибутах. Мы рассмотрим эти структуры данных по от-
отдельности.
Индексные узлы
Индексные узлы в UFS мало чем отличаются от своих аналогов в ExtX. Каждая
группа цилиндров содержит таблицу индексных узлов; местонахождение табли-
таблицы задается в суперблоке. В UFS1 все индексные узлы инициализируются при
создании файловой системы. В UFS2 используются динамические индексные узлы:
они инициализируются по мере надобности, а пространство таблицы индексных
узлов может использоваться для хранения содержимого файлов, если все осталь-
остальные блоки файловой системы окажутся заполненными. Для каждого файла и ка-
каталога выделяется один индексный узел, в котором хранится адрес блоков, выде-
выделенных файлу, размер файла и временные штампы.
В индексных узлах UFS хранятся 12 прямых указателей на блоки и по одному
косвенному указателю первого, второго и третьего уровня. Адрес в каждом указа-
указателе относится к полному блоку; исключение составляет последний указатель,
который может ссылаться на один или несколько фрагментов. Количество фраг-
фрагментов определяется размером файла. В UFS1 используются 32-разрядные ука-
указатели, а в UFS2 — 64-разрядные.
UFS поддерживает разреженные файлы, упоминавшиеся в главе 8. Если часть
содержимого файла не определена или весь блок заполнен нулями, ОС обычно не
выделяет блок из дискового пространства. Вместо этого в указатель заносится
значение 0, а при чтении из файла передается блок, заполненный нулями.
Типы и разрешения доступа к файлам в UFS не отличаются от используемых
в ExtX. В индексных узлах хранятся время последней модификации, обращения
и изменения, но время удаления не поддерживается. С другой стороны, в UFS2
в индексные узлы добавлено время создания. Значения временных штампов хра-
хранятся в виде количества секунд, прошедших с 12:00 1 января 1970 года в формате
UTC, а для повышения точности также хранится количество наносекунд. В UFS1
используются 32-разрядные временные штампы, а в UFS2 — 64-разрядные.
Каждому индексному узлу присваивается адрес, нумерация адресов начина-
начинается с 0. Обратите внимание: в этом отношении UFS отличается от системы ExtX,
в которой нумерация начинается с 1. Индексные узлы 0 и 1 зарезервированы, но
не задействованы ни для каких целей. Индексный узел 1 раньше содержал ин-
информацию о поврежденных блоках. Узел 2 зарезервирован для корневого катало-
каталога. Состояние выделения индексного узла определяется по битовой карте индек-
индексных узлов, хранящейся в дескрипторе группы. Чтобы определить, к какой группе
принадлежит индексный узел, следует разделить его адрес на количество индекс-
индексных узлов в группе, взятое из суперблока. Структуры данных индексных узлов
UFS1 и UFS2 подробно описаны в следующей главе.
Расширенные атрибуты
Поддержка расширенных атрибутов была реализована в UFS2. В расширенных
атрибутах хранятся дополнительные данные о файле или каталоге. Расширенный
атрибут представляет собой пару «имя-значение»; в настоящее время расширен-
расширенные атрибуты делятся на два «типа»: пользовательское и системное пространства
имен. Атрибуты пользовательского пространства имен могут быть прочитаны все-
всеми пользователями, которым разрешено чтение содержимого файла. С другой
стороны, атрибуты системного пространства имен могут читаться только приви-
привилегированными пользователями.
В индексных узлах UFS2 расширенные атрибуты представлены тремя поля-
полями. В одном поле хранится размер, а в двух других — адреса блоков, в которых
хранятся атрибуты. Блоки заполняются структурами данных переменного раз-
размера, состоящими из заголовка и значения атрибута. Пользователь назначает
атрибуты командой setextattr, а приложения читают их вызовами специальных
системных функций. Структура данных расширенных атрибутов описана в гла-
главе 17.
Тестовый образ
Далее приводятся выходные данные, полученные в результате выполнения istat
для тестового образа файловой системы. Содержимое этого индексного узла под-
подробно разбирается в главе 17, а сейчас я просто приведу вывод istat только для
того, чтобы дать представление о доступной информации:
# istat -f openbsd -z UTC openbsd.dd 3
inode: 3
Allocated
Group: 0
uid / gid: 0 / 0
mode: -rw-r-r-
size: 1274880
num of links: 1
Inode Times:
Accessed: Tue Aug 3 14:12:56 2004
File Modified: Tue Aug 3 14:13:14 2004
Inode Modified: Tue Aug 3 14:13:14 2004
Direct Blocks:
288 289 290 291 292 293 294 295
296 297 298 299 300 301 302 303
304 305 306 307 308 309 310 311
[...]
1568 1569 1570 1571 1572 1573 1574 1575
1576 1577 1578 1579 1580
Indirect Blocks:
384 385 386 387 388 389 390 391
Мы видим, что файл занимает 1 247 880 байт и для его хранения требуется
более 2 8-килобайтных блоков. В нижней части листинга перечислены все фраг-
фрагменты, выделенные для хранения файла. Ранее уже говорилось о том, что в ин-
индексном узле приводится только адрес блока, но istat приводит адреса всех фраг-
фрагментов блока. Последняя строка секции Direct Blocks показывает, что используются
только пять из восьми фрагментов блока 1576, а фрагменты 1581-1583 могут ис-
использоваться другими файлами. Также обратите внимание, что блок 384 исполь-
используется для косвенной адресации, то есть содержит указатели на другие блоки.
Алгоритмы выделения
Документированный метод выделения индексных узлов в UFS совпадает с тем,
который был описан ранее для ExtX. ОС может выбрать любой алгоритм, но на
практике индексный узел для каталога обычно выделяется в новой группе ци-
цилиндров, число каталогов в которой меньше среднего, а количество свободных
блоков — больше среднего. Индексный узел файла при наличии свободного мес-
места выделяется в той же группе цилиндров, в которой находится родительский ка-
каталог. При поиске свободных индексных узлов в группах цилиндров применяет-
применяется стратегия поиска первого доступного узла.
При выделении содержимое индексного узла стирается, а его М-, А- и С-время
(а также время создания в UFS2) задаются равными текущему времени. Счетчик
ссылок задается равным 1 для файлов и 2 для каталогов (с учетом записи «.» в ка-
каталоге).
При удалении файла системы BSD и Solaris стирают указатели на блоки в ин-
индексных узлах, очищают поля размера и режима. Следовательно, размер файла,
его тип и местонахождение содержимого восстановить не удастся. Тем не менее
содержимое блоков косвенных указателей не стирается, поэтому поиск таких бло-
блоков может оказать помощь при восстановлении. Вероятно, для поиска блоков, за-
заполненных 32- или 64-разрядными адресами, потребуется специальная програм-
программа. Обратите внимание на различия между процедурой удаления в UFS и той, что
мы видели в Linux/ExtX: в Linux поле режима не стиралось, но зато в ExtX теря-
терялось содержимое косвенных указателей.
Обновление временных штампов в OpenBSD 3, FreeBSD 5 и Sun Solaris 9 про-
производится по тем же правилам, которые были описаны в разделе ExtX для Fedora
Core 2. А именно, при создании файла все временные штампы синхронизируются
с текущим временем, а у родительского каталога обновляется М- и С-время. При
перемещении у нового файла обновляется С-время, но М- и А-время остается
прежним. При копировании файла обновляется А-время исходного файла, а у
приемного файла обновляется М-, А- и С-время. При удалении файла обновляет-
обновляется М- и С-время.
Методы анализа
Анализ в категории метаданных направлен на поиск информации о файлах для
последующей сортировки и получения дополнительной информации. Для этого
необходимо иметь возможность найти индексные узлы, проверить их состояние
выделения и обработать расширенные атрибуты (если они существуют).
Поиск индексного узла начинается с идентификации его группы; для этого
молено разделить адрес индексного узла на количество узлов в группе. Затем ин-
индексная таблица группы ищется по начальному фрагменту группы и смещению
индексной таблицы, указанному в суперблоке. В UFS1 также необходимо вычис-
вычислить дополнительное смещение разброса для группы. Наконец, индексный узел
находится в таблице вычитанием адреса индексного узла из адреса первого ин-
индексного узла в группе.
Обработка индексных узлов весьма прямолинейна. Прежде чем воспользовать-
воспользоваться данными режима и времени, необходимо сначала декодировать и обработать
эти данные. Содержимое файла ищется по адресам, хранящимся в 12 указателях
на блоки. Если файл имеет больший размер, следует прочитать отдельные блоки
и обработать их содержимое как список адресов блоков. Указатели со значением
О обозначают разреженные блоки и соответствуют блокам, заполненным нулями.
При обработке последнего указателя следует учесть размер файла. Последний блок
может быть фрагментом, и следующий фрагмент может использоваться другим
файлом.
Состояние выделения индексного узла проверяется по битовой карте индекс-
индексных узлов группы, хранящейся в дескрипторе группы. Дескриптор находится по
начальному адресу группы и смещениям в суперблоках. Если бит индексного узла
равен 1, значит, индексный узел выделен.
Иногда бывает полезно проанализировать все свободные индексные узлы, по-
потому что в них могут присутствовать временные штампы или прочая информа-
информация из удаленных файлов. Для этого в битовых картах ищутся индексные узлы,
биты которых равны 0, после чего обрабатываются узлы, отличные от нуля. Ин-
Индексные узлы, заполненные нулями, обычно ранее не использовались и находят-
находятся в инициализированном состоянии.
Расширенные атрибуты также могут содержать улики и скрытые данные, по-
поэтому их необходимо проанализировать. Для этого следует прочитать блоки, пе-
перечисленные в индексном узле, и обработать все записи в них.
Факторы анализа
Большая часть факторов анализа метаданных ExtX в полной мере применима
к UFS. В индексных узлах удаленных файлов стираются указатели на блоки, раз-
размер и режим, но UFS сохраняет состояние косвенных указателей. А это означает,
что программа восстановления может попытаться найти косвенный указатель и ре-
реконструировать файл. По М- и С-времени свободных индексных узлов иногда
удается получить информацию о времени удаления соответствующих файлов. При
извлечении данных можно воспользоваться информацией о стратегии выделения
и сосредоточить внимание на отдельной группе узлов (вместо всей файловой си-
системы).
Как было показано для ExtX, команда touch позволяет изменить М- и А-время
любого файла. Следовательно, желательно иметь в распоряжении второй источ-
источник информации с временными данными для проверки надежности временных
штампов. С-время файла обновляется при использовании команды touch. Вре-
Временные штампы хранятся в формате UTC, поэтому для правильного вывода зна-
значений программе анализа должен быть известен часовой пояс, в котором нахо-
находится компьютер.
Все протестированные мной системы BSD записывали нули на место неис-
неиспользуемых байтов в последнем фрагменте файла, также называемом резервным
пространством. Следовательно, данные из удаленных файлов можно найти толь-
только в одном месте — в свободных фрагментах. К счастью, выделяется и стирается
лишь относительно небольшое количество фрагментов. А это означает, что блок
может содержать удаленные данные во фрагментах, которые еще не были вы-
выделены повторно. Впрочем, резервное пространство может содержать скрытые дан-
данные.
Расширенные атрибуты в файловой системе UFS2 могут использоваться для
хранения небольших объемов скрытых данных. Их размер ограничивается двумя
блоками, но вы должны проверить, отображает ли программа анализа их содер-
содержимое, и включается ли оно в поиск по ключевым словам.
Скрытые данные также могут храниться в динамических таблицах индексных
узлов UFS2. ОС не инициализирует блоки записей индексных узлов в таблицах
до момента их непосредственного использования. Таким образом, данные могут
незаметно храниться в неиспользуемых областях до того момента, когда ОС их
затребует и сотрет содержимое этих областей.
Категория данных имен файлов
К категории имен файлов относятся данные, связывающие индексные узлы и про-
прочие метаданные с именами, понятными для пользователя. В этом разделе расска-
рассказывается о том, где в UFS хранятся данные и как организуется их анализ.
Общие сведения
В UFS1 и UFS2 используются те же структуры данных имен файлов, что и в ExtX,
поэтому в этом разделе я лишь в общих чертах обрисую ключевые концепции,
описанные в одноименном разделе главы 14. В структуре данных записи катало-
каталога хранится имя файла, адрес индексного узла и значение типа. Длина структуры
определяется длиной имени, максимальная длина которой равна 255 символам.
Имя хранится в кодировке ASCII и завершается нуль-символом, хотя имена ExtX
не завершаются нулями.
Структуры записей каталогов находятся в блоках, выделенных каталогам. Ка-
Каталог отличается от обычного файла лишь тем, что в поле режима для них указы-
указывается тип каталога. Первые две записи любого каталога всегда соответствуют
записям «.» и «..». В каждой записи каталога хранится длина, по которой опреде-
определяется начало следующей записи, а длина последней записи ссылается на конец
блока. При удалении файла длина предыдущей записи увеличивается таким об-
образом, чтобы она ссылалась на запись после скрываемой. За подробностями обра-
обращайтесь к главе 14. Корневой каталог всегда находится в индексном узле 2. В гла-
главе 17 приведено подробное описание структуры данных каталога и пример из
образа файловой системы. Далее приводится результат выполнения программы
fls для тестового образа файловой системы, описанного в следующей главе.
# fls -f openbsd -a openbsd.dd 1921
d/d 1921:
d/d 2:
г/г 1932: filel.txt
г/г 1933: file8.txt
г/г 1934: file7.txt
г/- * 1935: file6.txt
[...]
Строка с пометкой «*» соответствует удаленному файлу. В первом столбце
указана информация о типе файла, взятая из записи каталога и из индексного
узла. Мы видим, что UFS стирает тип файла из индексного узла, потому что у уда-
удаленного файла данные о типе в индексном узле отсутствуют.
В UFS поддерживаются как жесткие, так и мягкие ссылки, позволяющие оп-
определять дополнительные имена для файлов и каталогов. Жесткая ссылка пред-
представляет собой альтернативное имя для файла или каталога, находящегося в той
же файловой системе. При создании жесткой ссылки создается новая запись ка-
каталога, которая ссылается на индексный узел исходного файла. Счетчик ссылок
в индексном узле увеличивается, что отражает появление нового имени. Мягкие
ссылки создаются в виде символических ссылок, которые содержат путь к целе-
целевому файлу либо во фрагменте, либо в 60 байтах, обычно используемых для ука-
указателей на блоки. В UFS используются 64-разрядные указатели вместо 32-раз-
32-разрядных, поэтому пространство для хранения пути увеличивается до 120 байт.
Иллюстрации с жесткими и мягкими ссылками были приведены в главе 14.
Помните, что каталоги в UNIX используются и для хранения имен файлов,
и как точки монтирования других файловых систем. В главе 14 описана ситуа-
ситуация, при которой существующий файл становится невидимым в каталоге, потому
что там смонтирован другой том. Многие системы семейства BSD поддерживают
режим объединяющего монтирования (хотя он и не активизируется по умолча-
умолчанию), при котором содержимое каталога, используемого в качестве точки монти-
монтирования, остается видимым. ОС объединяет файлы из каталога монтирования
и корневого каталога монтируемого тома так, что они выглядят как единое целое.
Алгоритмы выделения
В BSD и Solaris для каталогов применяется стратегия выделения первой доступной
записи. ОС перебирает записи каталогов и сравнивает указанную длину записи
с фактической, то есть реально необходимой для хранения имени файла соот-
ветствующей длины. Если указанная длина больше и информация о новом файле
помещается в неиспользуемом «хвосте», запись каталогов создается в этом месте.
При выделении записи каталогов заполняются нулями. Структуры записей ката-
каталогов не пересекают границы блоков.
При удалении файла указанная длина предыдущей записи увеличивается так,
чтобы она ссылалась на начало следующей записи за удаленным файлом. В отли-
отличие от Solaris, системы BSD не стирают тип файла или поля индексного узла. Это
означает, что в BSD можно получить информацию о временных штампах для уда-
удаленного файла, но прямые указатели на блоки, скорее всего, окажутся стертыми.
Другие операционные системы могут использовать другие методы со стиранием
имени.
Методы анализа
Анализ данных в категории имен файлов направлен на получение списка файлов
и подкаталогов в заданном файле, с поиском закономерностей и конкретных имен.
Для этой цели обычно требуется сначала найти корневой каталог. Он всегда на-
находится в индексном узле 2, и это обстоятельство позволяет использовать при
поиске его содержимого приемы, описанные ранее в разделе «Категория метадан-
метаданных». После того как содержимое каталога будет найдено, оно обрабатывается
как список записей каталогов.
При обработке содержимого каталога следующая запись находится по указа-
указателю, хранящемуся в текущей записи. Поиск удаленных записей основан на про-
проверке пространства от конца имени файла в выделенной записи и до начала сле-
следующей записи. Если в этом пространстве удается обнаружить данные в формате
записи каталога, вероятно, они остались от удаленных файлов. После обнаруже-
обнаружения удаленного файла или каталога, представляющего интерес, можно получить
о нем дополнительную информацию — для этого следует определить адрес соот-
соответствующего индексного узла и обработать его. Многие программы решают эту
задачу автоматически и выводят временные штампы вместе с информацией об
имени. В главе 14 приведена иллюстрация и описан сценарий с определением
последовательности удаления файлов.
При удалении каталогов связь между индексным узлом и блоками обычно раз-
разрывается. Если потребуется найти содержимое удаленного каталога, попробуйте
найти записи «.» и «..». Записи каталогов не могут пересекать границы блоков,
поэтому каждый блок должен начинаться с новой записи.
Факторы анализа
Архитектура записей каталогов и ее реализация в большинстве систем позволяет
легко находить имена удаленных файлов, а тот факт, что поле индексного узла не
стирается в системах BSD, позволяет также найти метаданные файлов. Solaris
стирает содержимое этого поля, поэтому найти дополнительные данные не удас-
удастся. Впрочем, даже если вы обнаружите удаленную запись каталога с сохранив-
сохранившимся значением индексного узла, будет непросто определить, не соответствует
ли содержимое индексного узла прежнему файлу, или индексный узел был выде-
выделен заново, и его содержимое теперь соответствует другому файлу. Можно прове-
сти простейшую проверку и определить, свободен ли индексный узел в настоя-
настоящий момент. Если он используется, значит, индексный узел был выделен заново,
или же файл был перемещен в пределах файловой системы, и вы анализируете
его исходный индексный узел. Многие ОС стирают поле режима в индексных
узлах UFS, что не позволяет сравнить тип файла с типом, указанным в записи
каталога.
Структуры записей каталогов могут содержать скрытые данные — простран-
пространство между последней записью каталога и концом блока не используется систе-
системой. Однако эта методика сокрытия данных весьма рискованна, потому что ОС
может стереть данные при создании нового имени файла.
Общая картина
Наше знакомство с UFS завершается примерами создания и удаления файла
/dirl/filel.dat, занимающего 25 000 байт, в файловой системе UFS2.
Создание файла
На высоком уровне процесс создания файла /dir 1/filel.dat сводится к поиску ка-
каталога dirl, созданию записи каталога, выделению индексного узла и последую-
последующему выделению блоков для содержимого файла. Точный порядок выделения
структур данных зависит от ОС; описанная далее процедура может отличаться от
той, что используется в вашей конкретной системе. Для простоты в этом примере
игнорируются структуры данных со списками размеров фрагментов и кластеров.
1. Создание файла начинается с чтения суперблока, который занимает 2 Кбайт
и находится в файловой системе со смещением 64 Кбайт. Из суперблока мы
узнаем, что размер блока равен 16 Кбайт, а размер фрагмента — 2 Кбайт. Каждая
группа цилиндров содержит из 32 776 фрагментов и 8256 индексных узлов.
Мы также узнаем, что дескриптор группы хранится со смещением 40 фраг-
фрагментов, а таблица индексных узлов — со смещением 56 фрагментов в каждой
группе цилиндров.
2. Далее необходимо обработать индексный узел 2, чтобы найти каталог dirl в кор-
корневом каталоге. Используя информацию о количестве индексных узлов в груп-
группе, мы определяем, что индексный узел 2 находится в группе цилиндров 0. Сле-
Следовательно, таблица индексных узлов с информацией об узле 2 начинается
в блоке 56.
3. Из блока 56 читается таблица индексных узлов, в которой обрабатывается тре-
третья запись (первая запись соответствует индексному узлу 0). Содержимое ин-
индексного узла 2 показывает, что структуры записей каталогов для корневого
каталога находятся в блоке 1096.
4. Мы читаем содержимое корневого каталога из блока 1096 и обрабатываем его
как список записей каталогов. Последовательно перемещаясь вперед по ука-
указанным длинам записей (удаленные файлы нас не интересуют), мы в конеч-
конечном счете приходим к записи с именем dirl. В записи указан номер индексного
узла 16 549. У корневого каталога обновляется А-время.
5. Местонахождение индексного узла 16 549 определяется делением числа на
количество индексных узлов в группе. Так мы определяем, что узел находит-
находится в группе цилиндров 2. Группа 2 начинается в блоке 65 552, поэтому ее таб-
таблица индексных узлов начинается в блоке 65 608 (если бы использовалась
файловая система UFS1, нам также пришлось бы вычислить базовый адрес
для группы).
6. Из блока 65 608 читается таблица индексных узлов, в которой обрабатывается
запись 37 — относительным номером индексного узла 16 549. Содержимое ин-
индексного узла показывает, что содержимое dirl находится в блоке 66 816.
7. Мы читаем содержимое dirl из блока 66 816 и обрабатываем его как список
записей каталогов. Нас интересует неиспользуемое пространство в каталоге.
Имя filel.dat состоит из 8 символов, поэтому для хранения записи каталога
потребуется 16 байт. Имя нового файла включается между двумя существую-
существующими именами, для каталога обновляется М- и С-время. Место, отведенное
под новую запись, ранее использовалось удаленным файлом.
8. Для создаваемого файла необходимо выделить индексный узел, причем этот
узел должен входить в группу своего родительского каталога, то есть в груп-
группу 2. Чтобы найти битовую карту индексных узлов, необходимо сначала найти
дескриптор группы, удаленный на 48 фрагментов от начала группы. Выясня-
Выясняется, что дескриптор находится в блоке 65 600; из него мы узнаем, что битовая
карта индексных узлов хранится в дескрипторе со смещением 168 байт. Кроме
того, дескриптор сообщает, что последней была выделена запись индексного
узла 16 650. Проверка состояния индексного узла 16 651 показывает, что узел
свободен. Соответствующий бит в битовой карте устанавливается, номер пос-
последнего выделенного индексного узла в дескрипторе обновляется, а счетчик
свободных индексных узлов в дескрипторе группы и в сводке групп цилинд-
цилиндров уменьшается. Адрес индексного узла заносится в запись каталога filel.dat.
9. На следующем этапе мы находим в таблице индексных узлов узел 139 (отно-
(относительный адрес узла 16 651) и инициализируем его параметры. Временные
штампы инициализируются текущим временем, а счетчик ссылок задается рав-
равным 1. Также заполняются поля UID, GID и режима.
10. Размер файла равен 25 000 байт, для хранения его содержимого требуется вы-
выделить один блок и пять фрагментов. Прежде всего из дескриптора группы
определяется смещение битовой карты фрагментов, которая хранится со сме-
смещением 1200. В дескрипторе группы указан номер последнего выделенного
блока 67 896. Мы проверяем блок 67 904 по битовой карте свободных фраг-
фрагментов и определяем, что он свободен. Бит этого блока в карте обнуляется,
а счетчик свободных блоков уменьшается. Также обновляется поле указателя
на последний выделенный блок. Пять свободных фрагментов находятся по
битовой карте (или одному из служебных списков); в нашем примере это фраг-
фрагменты 74 242-74 246. Биты фрагментов обнуляются, обновляются соответству-
соответствующие служебные данные. Адрес блока и начальный фрагмент включаются в ин-
индексный узел.
11. Содержимое файла filel.dat записывается в выделенный блок и фрагменты.
Итоговое состояние системы показано на рис. 16.8.
Рис. 16.8. Итоговое состояние системы после добавления файла dirl/filel.dat
Пример удаления файла
Перейдем к процедуре удаления файла /dirl/filel.dat с использованием методов,
характерных для BSD. Как упоминалось в предыдущем разделе, порядок осво-
освобождения структур данных зависит от ОС, и описанная далее процедура может
отличаться от той, что используется в вашей конкретной системе.
1. Удаление файла начинается с чтения из суперблока структуры данных объе-
объемом 2 Кбайт, которая находится в файловой системе со смещением 64 Кбайт.
Из суперблока мы узнаем, что размер блока равен 16 Кбайт, а размер фраг-
фрагмента — 2 Кбайт. Каждая группа цилиндров состоит из 32 776 фрагментов
и 8256 индексных узлов. Мы также узнаем, что дескриптор группы хранится
со смещением 40 фрагментов, а таблица индексных узлов — со смещением
56 фрагментов в каждой группе цилиндров.
2. Далее необходимо обработать индексный узел 2, чтобы найти каталог dirl в кор-
корневом каталоге. Используя информацию о количестве индексных узлов в груп-
группе, мы определяем, что индексный узел 2 находится в группе цилиндров 0.
Следовательно, таблица индексных узлов с информацией об узле 2 начинает-
начинается в блоке 56.
3. Из блока 56 читается таблица индексных узлов, в которой обрабатывается тре-
третья запись (первая запись соответствует индексному узлу 0). Содержимое ин-
индексного узла 2 показывает, что структуры записей каталогов для корневого
каталога находятся в блоке 1096.
4. Мы читаем содержимое корневого каталога из блока 1096 и обрабатываем его
как список записей каталогов. Последовательно перемещаясь вперед по ука-
указанным длинам записей (удаленные файлы нас не интересуют), мы в конеч-
конечном счете приходим к записи с именем dirl. В записи указан номер индексного
узла 16 549. У корневого каталога обновляется А-время.
5. Местонахождение индексного узла 16 549 определяется делением числа на
количество индексных узлов в группе. Так мы определяем, что узел находится
в группе цилиндров 2. Группа 2 начинается в блоке 65 552, поэтому ее таблица
индексных узлов начинается в блоке 65 608.
6. Из блока 65 608 читается таблица индексных узлов, в которой обрабатывается
запись 37 — относительным номером индексного узла 16 549, Содержимое
индексного узла показывает, что содержимое dirl находится в блоке 66 816.
7. Мы читаем содержимое dirl из блока 66 816 и обрабатываем его как список
записей каталогов. Нас интересует запись файла filel.dat. Мы находим эту за-
запись и узнаем, что ей выделен индексный узел 16 651. Чтобы освободить за-
запись каталога, ее длина прибавляется к длине предыдущей записи каталога,
относящейся к файлу 12.jpg. В системе Solaris также пришлось бы стереть
содержимое указателя на индексный узел. Для каталога dirl обновляется М-,
А- и С-время.
8. В результате удаления имени файла счетчик ссылок в индексном узле 16 651
таблицы индексных узлов группы 2 уменьшается на 1. Значение счетчика ста-
становится равным 0; это означает, что индексный узел необходимо освободить.
Для этого соответствующий разряд битовой карты индексных узлов обнуля-
обнуляется, а в дескрипторе группы и сводке групп цилиндров обновляются счетчи-
счетчики свободных индексных узлов. В индексном узле стирается поле режима.
9. Также необходимо освободить один блок и пять фрагментов, выделенных для
хранения содержимого файла. Для каждого блока или фрагмента устанавли-
устанавливается соответствующий разряд битовой карты блоков/фрагментов и стирает-
стирается указатель на блок в индексном узле. Размер файла уменьшается при каж-
каждом освобождении блока, и в конечном счете он становится равным 0. М-
и С-время индексного узла обновляется в соответствии с внесенными измене-
изменениями. В дескрипторе группы и сводке групп цилиндров обновляются счетчи-
счетчики свободных блоков и фрагментов.
Итоговое состояние системы показано на рис. 16.9. Жирные линии и значения
представляют изменения файловой системы в результате удаления.
Рис. 16.9. Итоговое состояние системы после удаления файла dirl/filel.dat
Разное
В этом разделе рассматриваются две темы, выходящие за рамки какой-либо кон-
конкретной категории данных.
Восстановление файлов
Восстановление в UFS файлов, удаленных одной из стандартных ОС, является
весьма нетривиальной задачей. Проблемы, затрудняющие восстановление, уже
упоминались ранее в главе о ExtX, но в Solaris дело обстоит еще сложнее из-за
разрыва связи между записью каталога и индексным узлом. В системах BSD пря-
прямые указатели на блоки стираются, поэтому восстановление зависит от методов
прикладного уровня. Скорее всего, завершающие данные будут храниться во фраг-
фрагментах, а следовательно, не попадут в прилегающий блок, даже если все осталь-
остальные данные хранились в наборе смежных блоков.
Во многих системах BSD пространство выделяется 64- или 128-килобайтны-
ми участками из смежных блоков. Такая стратегия выделения может быть полез-
полезной, потому что смежные блоки обычно содержат больше данных, чем случайная
выборка со стратегией поиска первого доступного блока. С другой стороны, этот
вариант уступает стратегии оптимального подбора, при которой весь файл может
быть размещен в смежных блоках. Более того, поскольку некоторые системы ог-
ограничивают количество блоков, выделяемых файлу в одной группе, большие фай-
файлы могут оказаться фрагментированными даже в том случае, если файл сохраня-
сохраняется в смежных блоках. Solaris меняет группу цилиндров после выделения первых
12 блоков, поэтому с извлечением таких файлов могут возникнуть очень большие
проблемы. Содержимое косвенных указателей не стирается в BSD и Solaris; воз-
возможно, это поможет вам получить дополнительную информацию о восстанавли-
восстанавливаемых данных.
Проверка целостности данных
Проверки целостности данных используются в расследованиях для выявления
недопустимых структур данных файловой системы и неиспользуемых областей,
которые могут использоваться для хранения скрытых данных. Начинать следует
с категории данных файловой системы и анализа суперблока. Многие из 2048 байт
суперблока не используются и могут быть задействованы для хранения скрытых
данных. Трудно определить, какие значения не используются в конкретной ОС,
потому что многие поля суперблока содержат избыточную информацию и в со-
современных системах не являются необходимыми. Тем не менее избыточные дан-
данные могут оказаться полезными для проверки, если вы подозреваете постороннее
вмешательство. Кроме того, перед суперблоком имеются секторы, предназначен-
предназначенные для загрузочного кода и разметки диска; если файловая система не является
корневой, эти секторы не используются. Суперблоку выделяется полный блок,
и неиспользуемые фрагменты этого блока также могут использоваться для хра-
хранения скрытых данных.
Дескрипторы групп тоже могут содержать скрытые данные. Начальная часть
дескриптора структурируется, но остаток открыт, и любой желающий может этим
воспользоваться. В таких случаях эксперт обычно проверяет, где начинаются
структуры битовых карт и сколько места они реально занимают.
Проверьте каждый выделенный индексный узел и убедитесь в том, что блоки
и фрагменты, на которые он ссылается, выделены. Будьте внимательны при ана-
анализе количества фрагментов, необходимых для последней серии фрагментов. Все
выделенные блоки должны либо содержать административные структуры дан-
данных групп цилиндров, либо ссылка на них должна присутствовать в индексном
узле. В конце таблицы индексных узлов также могут присутствовать неиспользу-
неиспользуемые байты.
Каждая выделенная запись каталога должна ссылаться на выделенный индек-
индексный узел. Индексные узлы 0, 1 и 2 должны быть выделены, но с именами файлов
они не связываются, потому что эти индексные узлы зарезервированы. Простран-
Пространство в конце каталога может содержать скрытые данные, но этот способ слишком
рискован, потому что данные могут быть перезаписаны ОС.
Итоги
Файловая система UFS встречается во многих серверных средах. Она существует
уже давно, а при ее проектировании основными критериями были быстрота и эф-
эффективность, вследствие чего некоторые компоненты устроены относительно
сложно. В частности, в UFS используется ряд структур, упрощающих выделение
блоков и фрагментов; в этой главе они не рассматривались. Кроме того, супер-
суперблок содержит ряд параметров, вычисляемых по другим известным значениям,
вследствие чего суперблок и некоторые структуры данных категории файловой
системы занимают больше места, чем мы видели ранее.
Основные трудности при анализе файловой системы UFS в стандартных ОС
связаны с восстановлением удаленных файлов. Система стирает указатели на
блоки, a Solaris даже уничтожает связь между именем и индексным узлом. Сле-
Следовательно, для восстановления придется применить методы прикладного уров-
уровня, но процесс извлечения данных затрудняется стратегиями выделения блоков,
которые пытаются предотвратить выделение группы цилиндров под хранение
одного файла. Хотя структуры данных и методы удаления в файловой системе
UFS заметно отличаются от FAT и NTFS, основные методы анализа остаются
теми же.
Библиография
• FreeBSD Source Code. 2004. http://fxr.watson.org/fxr/source/.
• Garfinkel, Simson, Gene Spafford, and Alan Schwartz. Practical Unix and Internet
Security. 3rd ed. Sebastopol: O'Reilly, 2003.
• Mauro, Jim, and Richard McDougall. Solaris Internals: Core Kernel Architecture.
Upper Saddle River: Sun Microsystems Press, 2001.
• McKusick, Marshall K. «Enhancements to the Fast File System to Support Multi-
Terabyte Storage Systems». Proceedings of USENIX BSDCON '03 Conference,
September 2003.
• McKusick, Marshall, Keith Bostic, Michael Karels, and John Quarterman. The
Design and Implementation of the 4.4 BSD Operating System. Boston: Addison-
Wesley, 1996.
• McKusick, Marshall K., William N. Joy, Samuel J. Leffler, and Robert S. Fabry.
«A Fast File System for Unix». ACM Transactions on Computer Systems 2C): 181 —
197, August 1984.
• McKusick, Marshall, and Geroge Neville-Neil. The Design and Implementation of
the FreeBSD Operating System. Boston: Addison-Wesley, 2004.
• OpenBSD Source Code. 2004. http://fxr.watson.org/fxr/source/?v=OPENBSD.
• Smith, Keith A. and Margo Seltzer. «A Comparison of FFS Disk Allocation Algorithms».
Proceedings of 1996 Usenix Annual Technical Conference, 1996.
Структуры данных UFS1
HUFS2
В этой главе приведены описания структур данных файловых систем UFS1
и UFS2. Общие концепции и методы анализа UFS рассматривались в предыду-
предыдущей главе, а здесь рассматриваются структуры данных и их местонахождение в те-
тестовой файловой системе. Предполагается, что вы читаете эту главу параллельно
с предыдущей или предыдущая глава уже прочитана. Как упоминалось ранее,
структуры данных UFS иногда содержат несколько полей для хранения одного
значения в разных форматах. Скажем, размер блока хранится выраженным как во
фрагментах, так и в байтах. Благодаря наличию разных форматов ОС не прихо-
приходится каждый раз заново пересчитывать одни и те же параметры. Хотя некоторые
ОС могут требовать, чтобы в обоих полях использовались эквивалентные значе-
значения, наличие дублирующих данных не является формально необходимым. И все
же определить, какой из форматов нужно считать основным, а какой — производ-
производным, нелегко. В этой главе я обычно выделяю один из форматов как основной, но
этот выбор может не распространяться на все программы или ОС.
Суперблок UFS1
В файловой системе UFS суперблок содержит основные данные, относящиеся к ка-
категории файловой системы, но в UFS1 pi UFS2 используются разные структуры
данных. Суперблок UFS1 находится в секторе 16, а для его хранения выделяется
2048 байт, но многие из хранимых данных необязательны или заполнены нулями.
Далее я буду описывать только обязательные данные, но в следующей таблице
присутствуют все необязательные поля — хотя бы для того, чтобы дать представ-
представление о количестве необязательных данных. В таблице 17.1 перечислены поля
суперблока UFS1, используемого в FreeBSD, NetBSD pi OpenBSD.
Таблица 17.1. Структура данных суперблока UFS1
Диапазон Описание Необходимость
0-7 Не используется Нет
8-11 Смещение резервного суперблока в группах цилиндров Да
относительно «базы»
12-15 Смещение дескриптора в группах цилиндров относи- Да
тельно «базы»
16-19 Смещение таблицы индексных узлов в группах Да
цилиндров относительно «базы»
Диапазон Описание Необходимость
20-23 Смещение первого блока данных в группах цилиндров Нет
относительно «базы»
24-27 Дополнительный сдвиг (дельта) для организации Да
разброса в группах цилиндров
28-31 Маска для вычисления смещения (цикл) Да
в группах цилиндров
32-24 Время последней записи Нет
36-39 Количество фрагментов в файловой системе Да
40-43 Количество фрагментов, в которых могут храниться Нет
данные файлов
44-47 Количество групп цилиндров в файловой системе Да
48-51 Размер блока в байтах Да
52-55 Размер фрагмента в байтах Да
56-59 Размер блока во фрагментах Нет
60-63 Минимальный процент свободных блоков Нет
64-67 Продолжительность вращения до следующего блока Нет
(в миллисекундах)
68-71 Частота вращения диска Нет
72-75 Маска, используемая при вычислении адреса блока Нет
76-79 Маска, используемая при вычислении адреса Нет
фрагмента
80-83 Сдвиг, используемый при вычислении байтового Нет
адреса блока
84-87 Сдвиг, используемый при вычислении байтового Нет
адреса фрагмента
88-91 Максимальное количество выделяемых смежных Нет
блоков
92-95 Максимальное количество блоков в одной Нет
группе цилиндров
96-99 Количество бит для преобразования между адресами Нет
блока и фрагмента
100-103 Количество бит для преобразования между адресами Нет
фрагмента и сектора
104-107 Размер суперблока Нет
108-111 Смещение сводки групп цилиндров (не используется) Нет
112-115 Размер сводки групп цилиндров (не используется) Нет
116-119 Количество косвенных адресов на фрагмент Нет
120-123 Количество индексных узлов на блок в таблице Нет
индексных узлов
124-127 Количество секторов на фрагмент Нет
128-131 Метод оптимизации Нет
132-135 Количество секторов на дорожку Нет
136-139 Коэффициент чередования секторов жесткого диска Нет
140-143 Сдвиг дорожки жесткого диска Нет
144-151 Идентификатор файловой системы Нет
152-155 Адрес фрагмента для сводки групп цилиндров Нет
156-159 Размер сводки групп цилиндров в байтах Нет
160-163 Размер дескриптора группы цилиндров в байтах Нет
Таблица 17.1 {продолжение)
Диапазон Описание Необходимость
164-167 Количество дорожек в цилиндре Нет
168-171 Количество секторов в цилиндре Нет
172-175 Количество секторов в цилиндре Нет
176-179 Количество цилиндров в файловой системе Нет
180-183 Количество цилиндров в группе Нет
184-187 Количество индексных узлов в группе цилиндров Да
188-191 Количество фрагментов в группе цилиндров Да
192-195 Количество каталогов Нет
196-199 Количество свободных блоков Нет
200-203 Количество свободных индексных узлов Нет
204-207 Количество свободных фрагментов Нет
208-208 Флаг модификации суперблока Нет
209-209 Признак «чистоты» файловой системы в момент Нет
монтирования
210-210 Флаг монтирования системы в режиме «только Нет
для чтения» A, если система доступна только
для чтения)
211-211 Общие флаги (см. табл. 17.2) Нет
212-723 Последняя точка монтирования Нет
724-727 Последняя группа цилиндров, в которой проводился Нет
поиск
728-1115 Не используется Нет
1116-1195 Массив адресов индексных узлов Нет
1196-1199 Предполагаемый средний размер файла Нет
1200-1203 Предполагаемое количество файлов в каталоге Нет
1204-1311 Не используется Нет
1312-1315 Последнее время запуска fsck Нет
1316-1319 Размер массива сводки кластеров в дескрипторах групп Нет
1320-1323 Максимальная длина внутренней символической ссылки Да
1324-1327 Формат индексных узлов Да
1328-1335 Максимальный размер файла Нет
1336-1343 Маска для вычисления смещения в блоке Нет
1344-1351 Маска для вычисления смещения во фрагменте Нет
1352-1355 Состояние файловой системы Нет
1356-1359 Формат позиционных таблиц Нет
1360-1363 Количество ротационных позиций Нет
1364-1367 Заголовок списка ротационных блоков Нет
1368-1371 Блоки для каждой ротации Нет
1372-1375 Сигнатура @x011954) Да
В начале суперблока хранятся смещения, определяющие местонахождение
структур данных внутри каждой группы цилиндров. Также здесь хранятся пара-
параметры дельты и цикла, используемые для вычисления базового адреса каждой
группы цилиндров в UFS1. Стандартное общее количество блоков, фрагментов
и групп цилиндров, иногда в нескольких форматах. Количество индексных узлов
и фрагментов в группе цилиндров хранится позднее в суперблоке.
В байте 128 находится поле метода оптимизации выделения блоков. В настоя-
настоящее время для него определены два значения. Если поле равно О, ОС стремится
сэкономить время при выделении новых блоков; это может привести к неэф-
неэффективному использованию пространства и фрагментации по мере заполнения
файловой системы. Если поле равно 1, ОС стремится оптимизировать расходы
дискового пространства при выделении новых блоков и найти идеальное место-
местонахождение. С другой стороны, это может замедлить создание новых файлов. Зна-
Знание метода оптимизации может оказаться полезным во время восстановления
файлов.
Начиная с байта 208, в суперблоке расположен набор флагов. Первый флаг
устанавливается при модификации суперблока и сбрасывается при монтирова-
монтировании. Флаг в байте 209 обнуляется, если файловая система прошла проверку на
«чистоту» при монтировании. Флаг в байте 210 устанавливается равным, если
файловая система была смонтирована только для чтения. Наконец, байт 211 мо-
может содержать любые флаги из набора, представленного в табл. 17.2.
Таблица 17.2. Флаги поля общих флагов в суперблоке
Флаг Описание Необходимость
0x01 Флаг изменения — устанавливается при монтировании Нет
файловой системы
0x02 Используются мягкие зависимости Нет
0x04 При следующем монтировании требуется проверка Нет
целостности данных
0x08 Каталоги индексируются с применением хеш-дерева Нет
или В-дерева
0x10 Используются списки ACL Нет
0x20 Используется механизм TrustedBSD Mandatory Нет
Access Control
0x80 Флаги были перемещены (используется UFS2 Нет
в «старом» поле)
Поле в байтах 1234-1237 идентифицирует тип индексного узла, используемо-
используемого для хранения метаданных файла. Поле равно 2 для индексных узлов 4.4BSD
или OxOfffffff для индексных узлов 4.2BSD. Остальные данные суперблока не яв-
являются обязательными; они могут содержать, а могут и не содержать действи-
действительные данные.
Рассмотрим систему OpenBSD. Суперблок находится в секторе 16, а для его
хранения выделены 4 сектора, поэтому команда dd имеет следующий вид:
# dd if-openbsdl.dd bs=512 skip=16 count=4 | xxd
0000000: 0000 0000 0000 0000 1000 0000 1800 0000
0000016: 2000 0000 1001 0000 2000 0000 fOff ffff
0000032: dc9d 0f41 1027 0000 ff24 0000 0200 0000 ...A.'...$
0000048: 0020 0000 0004 0000 0800 0000 0500 0000
0000064: 0000 0000 ЗсОО 0000 00e0 ffff OOfc ffff ....<
0000080: OdOO 0000 OaOO 0000 0700 0000 0008 0000
0000096: 0300 0000 0100 0000 0008 0000 OOfe ffff
0000112: 0900 0000 0008 0000 4000 0000 0200 0000 @
0000128: 0000 0000 3f00 0000 0100 0000 0000 0000 ....?
0000144: 2c9d 0f41 8f5a 19a2 1001 0000 0004 0000 ...A.Z
0000160: 0008 0000 1000 0000 3f00 0000 f003 0000 ?
0000176: 1400 0000 1000 0000 8007 0000 801f 0000
0000192: 0400 0000 feO3 0000 e50e 0000 1000 0000
0000208: 0001 0000 2f6d 6e74 0000 0000 0000 0000 ..../mnt
0000224: 0000 0000 0000 0000 0000 0000 0000 0000
0000832: 0000 0000 0000 0000 0000 0000 00e6 d2dO
0000848: 0038 d3dO 003c d3dO 0100 0000 0000 0000 .8...<
0001184: 0000 0000 0000 0000 0000 0000 0040 0000 @. .
0001200: 4000 0000 0000 0000 0000 0000 0040 0000 @
0001312: 0000 0000 0700 0000 ЗсОО 0000 0200 0000 <
0001328: ff7f 0101 0840 0000 fflf 0000 0000 0000 @
0001344: ffO3 0000 0000 0000 0000 0000 0100 0000
0001360: 0100 0000 6005 0000 6205 0000 5419 0100 .... \ ..b...T...
0001376: 0000 0101 0101 0101 0101 0101 0101 0101
Рассматриваемая файловая система работает на платформе IA32, поэтому в ней
используется формат с прямым порядком байтов. Если бы файловая система от-
относилась к платформе с обратным порядком байтов (скажем, Sparc), то байты
в каждом числовом поле следовало бы переставить.
Из содержимого байтов 8-11 видно, что резервные суперблоки хранятся со
смещением 16 фрагментов @x10) от базового адреса каждой группы цилиндров.
Байты 12-15 показывают, что дескриптор группы хранится со смещением 24
фрагмента @x18) от базового адреса, а байты 16—19 — что таблица индексных уз-
узлов смещена на 32 фрагмента @x20).
Чтобы вычислить базовый адрес для группы цилиндров UFS1, следует начать
с байтов 24-27, в которых хранится дельта 32 @x20). Таким образом, в группе О
база соответствует фрагменту 0, а в группе 1 — фрагменту 32. Маска цикла в бай-
байтах 28-31 равна OxfffffffO; это означает, что в номере группы нас интересуют толь-
только 4 последних бита. Следовательно, через каждые 16 групп происходит возврат
к началу, и смещение базы снова становится равным 0. В данном примере у груп-
группы 15 смещение базы соответствует фрагменту 480, а у группы 16 оно возвраща-
возвращается к фрагменту 0.
В байтах 32-35 хранится время последней записи в виде количества секунд
с 1 января 1970 г. (GMT). Байты 36-39 показывают, что система содержит 10 000
фрагментов @x2710), а байты 44-47 — что в ней существует всего две группы
цилиндров. Размер каждого блока задается в байтах 48-51; мы видим, что он ра-
равен 8192 байтам @x2000). Размер фрагмента в байтах 52-55 равен 1024 байтам
@x0400). Для предотвращения частого деления этих двух чисел количество фраг-
фрагментов в блоке хранится в байтах 56-59; в нашем примере оно равно 8.
По содержимому байтов 104-107 мы определяем, что суперблок занимает 2048
байт @x0800). Байты 152-155 задают местонахождение сводки групп цилиндров;
в данной файловой системе она находится во фрагменте 272. Размер сводки опре-
определяется байтами 156-159 и равен 1024 байтам, или одному фрагменту. Количе-
Количество индексных узлов в группе цилиндров (байты 184-187) в этой файловой сис-
системе равно 1920 @x0780). Количество фрагментов в группе цилиндров (байты
188-191) равно 8064 (ОхШО).
Поле флагов начинается с байта 208. Его первый байт равен 0; это означает,
что суперблок был изменен после последней модификации. Согласно байту 209,
в системе используются мягкие зависимости, а флаги в байтах 210 и 211 находят-
находятся в состоянии по умолчанию. В байте 212 начинается строка последней точки
монтирования; тестовая файловая система в последний раз монтировалась в ка-
каталоге/mnt/. Остальные поля можете обработать самостоятельно. Вывод програм-
программы fsstat для этого образа ранее приводился в разделе «Категория данных файло-
файловой системы» главы 16.
Суперблок UFS2
В суперблоке UFS2 хранится та же базовая информация, что и в версии UFS1, но
из него исключены многие неиспользуемые поля, что несколько упростило струк-
структуру блока. Некоторые из сохранившихся 32-разрядных полей были заменены
64-разрядными версиями. Суперблок UFS2 обычно находится в секторе 128. Поля
версии, используемой в FreeBSD и NetBSD, перечислены в табл. 17.3.
Таблица 17.3. Структура данных суперблока UFS2
Диапазон Описание Необходимость
0-7 Не используется Нет
8-11 Смещение резервного суперблока в группах цилиндров Да
относительно «базы»
12-15 Смещение дескриптора в группах цилиндров Да
относительно «базы»
16-19 Смещение таблицы индексных узлов в группах Да
цилиндров относительно «базы»
20-23 Смещение первого блока данных в группах цилиндров Нет
относительно «базы»
24-43 Не используется Нет
44-47 Количество групп цилиндров в файловой системе Да
48-51 Размер блока в байтах Да
52-55 Размер фрагмента в байтах Да
56-59 Размер блока во фрагментах Нет
60-63 Минимальный процент свободных блоков Нет
64-71 Не используется Нет
72-75 Маска, используемая при вычислении адреса блока Нет
76-79 Маска, используемая при вычислении адреса фрагмента Нет
80-83 Сдвиг, используемый при вычислении байтового Нет
адреса блока
84-87 Сдвиг, используемый при вычислении байтового Нет
адреса фрагмента
88-91 Максимальное количество выделяемых смежных блоков Нет
92-95 Максимальное количество блоков в одной группе Нет
цилиндров
96-99 Количество бит для преобразования между адресами Нет
блока и фрагмента
100-103 Количество бит для преобразования между адресами Нет
фрагмента и сектора
Таблица 17.3 {продолжение)
Диапазон Описание Необходимость
104-107 Размер суперблока Нет
108-115 Не используется Нет
116-119 Количество косвенных адресов на фрагмент Нет
120-123 Количество индексных узлов на блок в таблице Нет
индексных узлов
124-127 Не используется Нет
128-131 Метод оптимизации Нет
132-143 Не используется Нет
144-151 Идентификатор файловой системы Нет
152-155 Не используется Нет
156-159 Размер сводки групп цилиндров в байтах Нет
160-163 Размер дескриптора группы цилиндров в байтах Нет
164-183 Не используется Нет
184-187 Количество индексных узлов в группе цилиндров Да
188-191 Количество фрагментов в группе цилиндров Да
192-207 Не используется Нет
208-208 Флаг модификации суперблока Нет
209-209 Признак «чистоты» файловой системы в момент Нет
монтирования
210-210 Флаг монтирования системы в режиме «только Нет
для чтения» A, если система доступна только
для чтения)
211-211 Не используется Нет
212-679 Последняя точка монтирования Нет
680-711 Имя тома Нет
712-719 UID системы Нет
720-723 Не используется Нет
724-727 Последняя группа цилиндров, в которой Нет
проводился поиск
728-999 Не используется Нет
1000-1007 Местонахождение суперблока Нет
1008-1015 Количество каталогов Нет
1016-1023 Количество свободных блоков Нет
1024-1031 Количество свободных индексных узлов Нет
1032-1039 Количество свободных фрагментов Нет
1040-1047 Количество свободных кластеров Нет
1048-1071 Не используется Нет
1072-1079 Время последней записи Нет
1080-1087 Количество фрагментов в файловой системе Да
1088-1095 Количество фрагментов, в которых могут храниться Нет
данные файлов
1096-1103 Адрес сводки групп цилиндров (фрагмент) Нет
1104-1111 Количество освобождаемых блоков Нет
1112-1115 Количество освобождаемых индексных узлов Нет
1116-1195 Массив адресов индексных узлов Нет
1196-1199 Предполагаемый средний размер файла Нет
Диапазон Описание Необходимость
1200-1203 Предполагаемое количество файлов в каталоге Нет
1204-1311 Не используется Нет
1312-1315 Флаги (см. табл. 17.2) Нет
1316-1319 Размер массива сводки кластеров в дескрипторах групп Нет
1320-1323 Максимальная длина внутренней символической ссылки Да
1324-1327 Формат индексных узлов Да
1328-1335 Максимальный размер файла Нет
1336-1343 Маска для вычисления смещения в блоке Нет
1344-1351 Маска для вычисления смещения во фрагменте Нет
1352-1355 Состояние файловой системы Нет
1356-1371 Не используется Нет
1372-1375 Сигнатура @x19540119) Да
Некоторые поля переместились на другие места. Из интересных изменений
можно отметить лишь то, что точка монтирования стала короче, а в суперблоке
появилось поле для имени тома. Поле флагов теперь занимает 4 байта вместо од-
одного, но в нем используются те же флаги, которые были перечислены в табл. 17.2.
Также обратите внимание на изменившуюся сигнатуру — по ней UFS1 можно
отличить от UFS2.
Далее приводится содержимое суперблока UFS2 для системы FreeBSD 5:
# dd if=freebsd5.dd skip=128 count=4 | xxd
0000000: 0000 0000 0000 0000 2800 0000 3000 0000 (.. .0...
0000016: 3800 0000 d801 0000 0000 0000 0000 0000 8
0000032: 0000 0000 0000 0000 0000 0000 0400 0000
0000048: 0040 0000 0008 0000 0800 0000 0800 0000 .@
0000064: 0000 0000 0000 0000 OOcO ffff 00f8 ffff
0000080: OeOO 0000 ObOO 0000 0800 0000 0008 0000
0000096: 0300 0000 0200 0000 0008 0000 0000 0000
0000112: 0000 0000 0008 0000 4000 0000 0000 0000 @
0000128: 0000 0000 0000 0000 0000 0000 0000 0000
0000144: adb2 Of41 fdOl 4al7 0000 0000 0008 0000 ,..A. J
0000160: 0008 0000 0000 0000 0000 0000 0003 0000
0000176: 0000 0000 0000 0000 0005 0000 b813 0000
0000192: 0000 0000 0000 0000 0000 0000 0000 0000
0000208: 0000 0080 2f6d 6e74 0000 0000 0000 0000 ..../mnt
0000672: 0000 0000 0000 0000 5546 5332 0000 0000 UFS2....
0000832: 0000 0000 0000 0000 1038 66c3 0030 66c3 8f..0f.
0000848: 0038 66c3 0000 0000 0000 0000 0040 0000 .8f @..
0000992: 0000 0000 0000 0000 0000 0100 0000 0000
0001008: 0400 0000 0000 0000 f308 0100 0000 0000
0001024: e213 0000 0000 0000 1800 0000 0000 0000
0001072: bdb4 0f41 0000 0000 c04e 0000 0040 0000 ...A N
0001088: d74b 0000 0000 0000 d800 0000 0040 0000 .K
0001184: 0000 0000 0000 0000 0000 0000 0040 0000 @. .
0001200: 4000 0000 0000 0000 0000 0000 0000 0000 @
0001312: 0000 0000 0800 0000 7800 0000 0000 0000 х
0001328: ffff 0202 1080 0000 ff3f 0000 0000 0000 ?
0001344: ffO7 0000 0000 0000 0000 0000 0000 0000
0001360: 0000 0000 0000 0000 0000 0000 1901 5419 Т.
0001376: 0000 0101 0101 0101 0101 0101 0101 0101
Из байтов 8-11, 12-15 и 16-19 видно, что суперблок хранится со смещением
40 фрагментов @x28) от начала каждой группы цилиндров, дескриптор смещен
от начала на 48 фрагментов @x30), а индексная таблица — на 56 фрагментов @x38).
Байты 44-47 показывают, что в системе существует четыре группы цилиндров.
Размер блока задается в байтах 48-51; мы видим, что он равен 16 384 байтам
@x4000). Размер фрагмента (байты 52-55) равен 2048 байтам @x0800). Байты
184-87 показывают, что группа цилиндров содержит 1280 @x0500) индексных
узлов, а байты 188-191 — что группа содержит 5048 фрагментов @х13Ь8). Общее
количество фрагментов задается в байтах 1080-1087. В тестовой файловой систе-
системе оно равно всего 20 160 байтам.
Вот как выглядит результат выполнения fsstat для образа UFS2:
# fsstat -f freebsd freebsd5.dd
FILE SYSTEM INFORMATION
File System Type: UFS 2
Last Written: Tue Aug 3 10:52:29 2004
Last Mount Point: /mnt
Volume Name: UFS2
System UID: 0
METADATA INFORMATION
Inode Range: 0 - 5119
Root Directory: 2
Num of Avail Inodes: 5090
Num of Directories: 4
CONTENT INFORMATION
Fragment Range: 0 - 20159
Block Size: 16384
Fragment Size: 2048
Num of Avail Full Blocks: 2291
Num of Avail Fragments: 24
Сводка групп цилиндров
Как в UFS1, так и в UFS2 присутствуют фрагменты, содержащие структуры дан-
данных сводки групп цилиндров. Эти структуры совпадают в обеих версиях UFS и со-
содержат статистическую информацию о каждой группе цилиндров. Структуры
образуют таблицу, каждый элемент которой соответствует одной группе. Адрес
и размер сводки задаются в суперблоке. В табл. 17.4 перечислены поля записей
таблицы.
Таблица 17.4. Структура данных записей сводки групп цилиндров
Диапазон Описание Необходимость
0-3 Количество каталогов Нет
4-7 Количество свободных блоков (полный Нет
набор фрагментов)
8-11 Количество свободных индексных узлов Нет
12-15 Количество свободных фрагментов Нет
(неполные блоки)
Как будет показано в следующем разделе, эти данные также присутствуют
в каждом дескрипторе группы цилиндров. Они используются при выделении но-
новых индексных узлов и блоков.
В тестовом образе файловой системы UFS1 сводка групп цилиндров распола-
располагалась в блоке 272 и занимала 1024 байта. Содержимое соответствующего фраг-
фрагмента выглядит так:
# dcat -f openbsd openbsd.dd 272 | xxd
0000000: 0200 0000 2fO3 0000 7807 0000 ObOO 0000 ..../...x
0000016: 0200 0000 cfOO 0000 6dO7 0000 0500 0000 m
В первой строке выводится запись группы 0. Из нее видно, что группа состоит
из двух каталогов из 815 @x032f) свободных блоков. Байты 8-11 показывают, что
в группе имеется 1912 @x0778) свободных индексных узлов, а байты 12-15 — что
в неполных блоках содержится 11 (ОхОЬ) свободных фрагментов. Вторая строка
содержит данные второй группы.
Для образов UFS программа fsstat из пакета TSK выводит информацию о груп-
группах цилиндров. Пример выходных данных fsstat для тестового образа приведен
в разделе «Категория данных файловой системы» главы 16. Выводимая в ней ин-
информация о группах цилиндров берется из суперблока, сводки групп цилиндров
и дескрипторов групп.
Дескриптор группы UFS1
Структура данных дескриптора группы содержит информацию о конфигурации
группы цилиндров. В каждой группе цилиндров создается одна структура дан-
данных. Ее смещение по отношению к базовому адресу задается в суперблоке, a UFS1
и UFS2 используют разные структуры. В этом разделе описаны структуры дан-
данных для UFS1.
Дескрипторы групп в UFS1 хранятся с разбросом, хотя расстояние от базового
адреса остается постоянным. Метод вычисления базового адреса описан в преды-
предыдущей главе и при описании суперблока в предыдущем разделе. Для хранения
дескриптора обычно выделяется полный блок, хотя и используется он лишь час-
частично. Многие поля не являются обязательными и используются только для по-
повышения эффективности выделения ресурсов.
Поля дескрипторов групп в файловой системе UFS1 перечислены в табл. 17.5.
Таблица 17.5. Структура данных дескриптора группы в UFS1
Диапазон Описание Необходимость
0-3 Не используется Нет
4-7 Сигнатура @x090255) Нет
8-11 Время последней записи Нет
12-15 Номер группы Нет
16-17 Количество цилиндров в группе Нет
18-19 Количество индексных узлов в группе Нет
20-23 Количество фрагментов в группе Нет
24-27 Количество каталогов Нет
28-31 Количество свободных блоков Нет
32-35 Количество свободных индексных узлов Нет
36-39 Количество свободных фрагментов (неполные блоки) Нет
40-43 Последний выделенный блок Нет
44-47 Последний выделенный фрагмент Нет
48-51 Последний выделенный индексный узел Нет
52-83 Сводка свободных фрагментов Нет
84-87 Количество свободных блоков в каждом цилиндре Нет
(смещение в байтах)
88-91 Таблица позиций свободных блоков (смещение в байтах) Нет
92-95 Битовая карта индексных узлов (смещение в байтах) Да
96-99 Битовая карта фрагментов (смещение в байтах) Нет
100-103 Следующее свободное пространство в дескрипторе Нет
(смещение в байтах)
104-107 Количество свободных кластеров, то есть смежных Нет
блоков (смещение в байтах)
108-111 Битовая карта блоков (смещение в байтах) Нет
112-115 Количество блоков в группе Нет
116-167 Не используется Нет
168+ Битовые карты и т. д. Да
Начиная с байта 168, в дескрипторе хранится разнообразная информация,
включающая битовые карты и таблицы. В дескрипторе группы хранятся смеще-
смещения нескольких битовых карт относительно начала блока дескрипторов группы.
В пространстве за этими полями хранится ряд других таблиц, которые в основ-
основном не содержат необходимых данных и используются для повышения эффек-
эффективности выделения новых блоков. Например, битовая карта блоков, также назы-
называемая битовой картой кластеров, представляет собой уменьшенный вариант
битовой карты фрагментов. Каждый бит в ней соответствует одному блоку. Бит
устанавливается равным 1, если все соответствующие фрагменты блока в бито-
битовой карте фрагментов равны 1.
Чтобы проанализировать дескриптор первой группы в нашей системе OpenBSD
UFS1, необходимо определить его местонахождение. Для первой группы базовое
смещение соответствует фрагменту 0. Из суперблока известно, что дескриптор
группы смещен от базы на 24 фрагмента, поэтому мы просматриваем фрагмент 24
программой dcat:
# dcat -f openbsd openbsd.dd 24
0000000: 0000 0000 5502 0900 c99d 0f41 0000 0000 ....U A....
0000016: 1000 8007 801f 0000 0200 0000 2fO3 0000 /.. .
0000032: 7807 0000 ObOO 0000 8801 0000 1001 0000 x
0000048: 0700 0000 0000 0000 0000 0000 0000 0000
0000064: 0000 0000 0100 0000 0000 0000 0000 0000
0000080: 0100 0000 a800 0000 e800 0000 0801 0000
0000096: f801 0000 8206 0000 e405 0000 0406 0000
0000112: f003 0000 0000 0000 0000 0000 0000 0000
Байты 4-7 содержат сигнатуру, а в байте 24 начинается информация о количе-
количестве свободных индексных узлов и блоков, которую мы уже видели ранее в обла-
области сводки групп цилиндров. Также здесь присутствует служебная информация
о выделении; из байтов 40-43 видно, что последний выделенный блок имел адрес
392 @x0188), а из байтов 44-47 — что последний выделенный фрагмент (непол-
(неполный блок) имел адрес 272 @x0110). Последняя выделенная запись индексного
узла указана в байтах 48-51; мы видим, что это был индексный узел 7.
Смещение битовой карты индексных узлов хранится в байтах 92-95; мы ви-
видим, что битовая карта смещена на 264 байта @x0108) от начала группы дескрип-
дескрипторов. Битовая карта фрагментов (байты 96-99) удалена на 504 байта @x0 Ш) от
начала дескриптора группы. Битовая карта блоков (байты 108-111) хранится со
смещением 1540 байт @x0604) от начала дескриптора.
Дескриптор группы UFS2
Дескриптор группы UFS2 содержит ту же базовую информацию, что и его аналог
из UFS1, но некоторые из его полей занимают больше места. Местонахождение
дескриптора относительно начала группы цилиндров хранится в суперблоке, но,
в отличие от дескрипторов UFS1, дополнительный разброс не используется. Поля
дескрипторов групп в файловой системе UFS2 перечислены в табл. 17.6.
Таблица 17.6. Структура данных дескриптора группы в UFS2
Диапазон Описание Необходимость
0-3 Не используется Нет
4-7 Сигнатура @x090255) Нет
8-11 Не используется Нет
12-15 Номер группы Нет
16-19 Не используется Нет
20-23 Количество фрагментов в группе Нет
24-27 Количество каталогов Нет
28-31 Количество свободных блоков Нет
32-35 Количество свободных индексных узлов Нет
36-39 Количество свободных фрагментов (неполные блоки) Нет
40-43 Последний выделенный блок Нет
44-47 Последний выделенный фрагмент Нет
48-51 Последний выделенный индексный узел Нет
52-83 Сводка свободных фрагментов Нет
Таблица 17.6 {продолжение)
Диапазон Описание Необходимость
84-91 Не используется Нет
92-95 Битовая карта индексных узлов (смещение в байтах) Да
96-99 Битовая карта фрагментов (смещение в байтах) Нет
100-103 Следующее свободное пространство в дескрипторе Нет
(смещение в байтах)
104-107 Количество свободных кластеров, то есть смежных Нет
блоков (смещение в байтах)
108-111 Битовая карта блоков (смещение в байтах) Нет
112-115 Количество блоков в группе Нет
116-119 Количество индексных узлов в группе Нет
120-123 Последний инициализированный индексный узел Нет
124-135 Не используется Нет
136-143 Время последней записи Нет
144-167 Не используется Нет
168+ Битовые карты и т. д. Да
В обеих версиях дескрипторов необходимая информация ограничивается сме-
смещениями битовых карт индексных узлов и фрагментов. Битовые карты находят-
находятся после байта 168, но внутри блока, выделенного дескриптору группы.
Битовые карты блоков и фрагментов
Состояние выделения блоков и фрагментов определяется по битовым картам.
В действительности информация о каждом блоке UFS хранится в двух битовых
картах: битовой карте фрагментов и битовой карте блоков. Учтите, что эти бито-
битовые карты хранят информацию в формате, обратном тому, который обычно ис-
используется на практике: их биты устанавливаются в 1 для свободных объектов,
и сбрасываются в 0 для выделенных объектов.
Начнем с битовой карты фрагментов. Для каждой группы цилиндров ведется
битовая карта фрагментов, которая хранится в дескрипторе группы. Смещение
битовой карты в байтах задается в дескрипторе, а ее размер определяется по ко-
количеству фрагментов в группе. Чтобы найти бит, представляющий конкретный
фрагмент, следует определить его адрес относительно начала группы цилиндров
вычитанием адреса первого фрагмента в группе. Скажем, если фрагмент является
50-м в группе, его состояние выделения хранится в 50-м бите, то есть втором бите
байта 6.
В рассмотренной ранее файловой системе UFS1 дескриптор группы распола-
располагался в блоке 24, а битовая карта фрагментов хранилась со смещением 504 байта.
Чтобы просмотреть ее содержимое, следует запустить dcat с параметром 8 для
просмотра всех 8 фрагментов блока:
# dcat -f openbsd openbsd.dd 24 | xxd
0000496: 0000 0000 0000 0000 0000 0000 0000 0000
0000512: 0000 0000 0000 0000 0000 0000 0000 0000
0000528: 0000 0000 0000 0000 0000 fOfe 0000 0000
0000544: 0000 0000 ffff ffff OOff 0000 0000 0000
0000560: 0000 0000 0000 0000 0000 0000 0000 0000
0000576: 0000 0000 0000 0000 0000 0000 0000 0000
Байт 504 является первым байтом в битовой карте фрагментов. Он равен 0; это
означает, что первые 8 фрагментов выделены. Свободные фрагменты отсутству-
отсутствуют вплоть до байта 538, который является байтом 34 битовой карты. Старшие
4 бита этого байта равны 1, то есть фрагменты 276-279 свободны. Данные отно-
относятся к первой группе, поэтому эти номера соответствуют их фактическим адре-
адресам; в противном случае к ним пришлось бы прибавить начальный адрес группы.
Обратите внимание: эти четыре свободных фрагмента не представляют полный
блок, поскольку каждый блок состоит из восьми фрагментов. В данном случае
первые 4 фрагмента блока выделены, а последние 4 — нет.
Байты 548-551 описывают серию из 32 смежных невыделенных фрагментов.
Байт 548 соответствует байту 44 битовой карты, поэтому первый бит относится
к фрагменту 352.
Битовая карта фрагментов малоэффективна при выделении отдельных бло-
блоков или больших групп смежных блоков, поэтому наряду с ней существует бито-
битовая карта блоков. Она дублирует информацию, находящуюся в битовой карте
фрагментов, но каждый бит в ней обозначает целый блок, поэтому адресация бло-
блоков должна производиться иначе. Блоки нумеруются последовательными числа-
числами — например, если один блок состоит из 8 фрагментов, вместо блоков 0, 8, 16,
24 и т. д. будут использоваться номера 0,1, 2,3 и т. д. Чтобы вычислить адрес бло-
блока, достаточно разделить адрес фрагмента на количество фрагментов в блоке. Если
соответствующий бит равен 1, блок свободен для выделения.
Как было показано ранее, в системе UFS1 битовая карта блоков хранится в дес-
дескрипторе группы со смещением 1540:
# dcat -f openbsd openbsd.dd 24 8 | xxd
0001536: 0100 0000 0000 0000 OOfO 0200 0000 0000
0001552: 0000 0000 0000 0000 0000 0000 cOff ffff
0001568: ffff ffff ffff ffff ffff ffff ffff ffff
[...]
Мы видим, что байт 1540 равен 0, после чего установленные биты появляются
только в байте 1545, в котором установлены 4 старших бита. Этот байт является
5-м байтом битовой карты; его биты соответствуют относительным блокам 40-47,
а биты относительных блоков 44-47 установлены равными 1. Преобразовав эти
адреса в адреса фрагментов, мы получим фрагменты 352-383, которые мы видели
в битовой карте фрагментов как набор свободных смежных фрагментов.
Индексные узлы UFS1
В структурах данных индексных узлов хранятся метаданные, описывающие фай-
файлы и каталоги. И снова в UFS1 и UFS2 используются разные структуры данных,
поскольку поля UFS2 имеют больший размер. Индексные узлы делятся между
группами цилиндров; количество индексных узлов в одной группе указывается
в суперблоке. Каждая группа цилиндров обладает собственной таблицей индекс-
индексных узлов, ее смещение также задается в суперблоке. В UFS1 величина начально-
начального сдвига таблицы индексных узлов изменяется в зависимости от группы цилин-
цилиндров (разброс), но в UFS2 индексные таблицы всегда располагаются с одинаковым
смещением относительно начала группы.
Длина индексных узлов UFS1 составляет 128 байт, а их поля перечислены
в табл. 17.7.
Таблица 17.7. Структура данных индексного узла в UFS1
Диапазон Описание Необходимость
0-1 Режим файла (тип и разрешения) — см. раздел
«Индексные узлы» главы 15 Да
2-3 Счетчик ссылок Да
4-7 Не используется Нет
8-15 Размер Да
16-19 Время обращения Нет
20-23 Время обращения (наносекунды) Нет
24-27 Время модификации Нет
28-31 Время модификации (наносекунды) Нет
32-35 Время изменения Нет
36-39 Время изменения (наносекунды) Нет
40-87 12 прямых указателей на блоки Да
88-91 Косвенный указатель 1 уровня Да
92-95 Косвенный указатель второго уровня Да
96-99 Косвенный указатель третьего уровня Да
100-103 Флаги состояния Нет
104-107 Количество блоков Нет
108-111 Номер поколения (NFS) Нет
112-115 Идентификатор пользователя Нет
116-119 Идентификатор группы Нет
120-127 Не используется Нет
Поле режима содержит те же значения, что и в ExtX. Счетчик ссылок выпол-
выполняет те же функции и увеличивается с созданием каждого имени файла, ссылаю-
ссылающегося на индексный узел. За подробностями обращайтесь к главе 15.
Рассмотрим индексный узел из образа UFS1. В начале главы уже говорилось
о том, что таблица индексных узлов смещена на 32 фрагмента от базового адреса
группы, а так как речь идет о группе 0, мы знаем, что таблица находится во фраг-
фрагменте 32. Первым используемым индексным узлом файловой системы является
узел 3, поэтому мы извлекаем его содержимое с помощью dcat и dd:
# dcat -f openbsd openbsd.dd 32 | dd bs=128 skip=3 count=l | xxd
0000000: a481 0100 0000 0000 0074 1300 0000 0000 t
0000016: 689d 0f41 8033 023b 7a9d 0f41 0057 a616 h..A.3.;zt.A.W..
0000032: 7a9d 0f41 0057 a616 2001 0000 2801 0000 Z..A.W (...
0000048: 3001 0000 3801 0000 4001 0000 4801 0000 0...8...@...H...
0000064: 5001 0000 5801 0000 9001 0000 9801 0000 P...X
0000080: aOOl 0000 a801 0000 8001 0000 0000 0000
0000096: 0000 0000 0000 0000 d009 0000 5ade 19ac Z...
0000112: 0000 0000 0000 0000 0000 0000 0000 0000
Первые 4 байта определяют режим; пример разбора для UFS2 уже приводился
ранее в разделе «Индексные узлы» главы 15, поэтому сейчас мы его рассматри-
рассматривать не будем. Биты 12-15 содержат значение 8 — это признак обычного файла.
Размер (байты 8-15) составляет 1 274 880 байт @x00137400). А-время задается
в байтах 16-19. После преобразования в обычный формат мы получаем 14:12:56,
3 августа 2004 г. по UTC.
Адрес первого блока в байтах 40-43 равен 288 @x0120). Второй блок обладает
адресом 296 @x0128). Эти блоки являются смежными, так как в файловой системе
один блок состоит из 8 фрагментов. В байтах 88-91 содержится косвенный указа-
указатель на блок, содержащий указатели на блоки; в нашем примере это блок 384.
Программа istat выводит для этого файла следующий результат:
# istat -f openbsd -z UTC openbsd.dd 3
inode: 3
Allocated
Group: 0
uid / gid: 0 / 0
mode: -rw-r--r--
size: 1274880
num of links: 1
Inode Times:
Accessed: Tue Aug 3 14:12:56 2004
File Modified: Tue Aug 3 14:13:14 2004
Inode Modified: Tue Aug 3 14:13:14 2004
Direct Blocks:
288 289 290 291 292 293 294 295
296 297 298 299 300 301 301 303
304 305 306 307 308 309 310 311
[...]
1568 1569 1570 1571 1572 1573 1574 1575
1576 1577 1578 1579 1580
Indirect Blocks:
384 385 386 387 388 389 390 391
В выходных данных istat перечисляются все выделенные фрагменты; в после-
последней строке указано всего пять фрагментов.
Информация о состоянии выделения индексного узла хранится в битовой карте
индексных узлов. Для каждой группы цилиндров ведется битовая карта индекс-
индексных узлов, которая хранится в дескрипторе группы. При рассмотрении дескрип-
дескриптора группы UFS1 было показано, что таблица индексных узлов начинается со
смещения 264. Мы можем просмотреть ее содержимое:
# dcat -f openbsd openbsd.dd 24 8 | xxd
0000256: 3f00 3f00 3f00 3f00 ffOO 0000 0000 0000 ?.?.?.?
0000272: 0000 0000 0000 0000 0000 0000 0000 0000
Байт 264 равен Oxff; это означает, что индексные узлы 0-7 выделены (содер-
(содержимое узла 3 было проанализировано ранее). Индексные узлы 8 и далее в этой
группе цилиндров свободны.
Индексные узлы UFS2
Индексные узлы UFS2 на 128 байт больше своих аналогов в UFS1, а многие 32-
разрядные поля в них заменены 64-разрядными. Они также хранятся в таблице
индексных узлов, смещение которой задается в суперблоке, но, в отличие от UFS1,
смещение таблицы остается постоянным. Поля индексных узлов UFS2 перечис-
перечислены в табл. 17.8.
Таблица 17.8. Структура данных индексного узла в UFS2
Диапазон Описание Необходимость
0-1 Режим файла (тип и разрешения) — Да
см. раздел «Индексные узлы» главы 15
2-3 Счетчик ссылок Да
4-7 Идентификатор пользователя Нет
8-11 Идентификатор группы Нет
12-15 Размер блока индексных узлов Нет
16-23 Размер Да
24-31 Количество удерживаемых байт Нет
32-39 Время обращения Нет
40-47 Время модификации Нет
48-55 Время изменения Нет
56-63 Время создания Нет
64-67 Время модификации (наносекунды) Нет
68-71 Время обращения (наносекунды) Нет
72-75 Время изменения (наносекунды) Нет
76-79 Время создания (наносекунды) Нет
80-83 Номер поколения (NFS) Нет
84-87 Флаги ядра Нет
88-91 Флаги состояния Нет
92-95 Размер расширенных атрибутов Нет
96-111 2 прямых указателя на блоки расширенных Нет
атрибутов
112-207 12 прямых указателей на блоки Да
208-215 Косвенный указатель первого уровня Да
216-223 Косвенный указатель второго уровня Да
224-231 Косвенный указатель третьего уровня Да
232-255 Не используется Нет
Самое заметное различие между версиями UFS1 и UFS2 заключается в том,
что указатели на блоки и временные штампы стали 64-разрядными. Адреса в бло-
блоках косвенной адресации также занимают 64 бита.
При анализе образа UFS2 было показано, что таблица индексных узлов начи-
начинается во фрагменте 56. Содержимое индексного узла 5 выглядит так:
# dcat -f freebsd freebsd.dd 56 8 | dd bs=256 skip=5 count=l | xxd
0000000: a481 0100 0000 0000 0000 0000 0000 0000
0000016: 0000 2000 0000 0000 2010 0000 0000 0000
0000032: Ь5ЬЗ 0f41 0000 0000 ЬбЬЗ 0f41 0000 0000 ...A A....
0000048: ЬбЬЗ 0f41 0000 0000 Ь5ЬЗ 0f41 0000 0000 ...А А....
0000064: 0000 0000 0000 0000 0000 0000 0000 0000
0000080: life 8458 0000 0000 0000 0000 0000 0000 ...X
0000096: 0000 0000 0000 0000 0000 0000 0000 0000
0000112: е800 0000 0000 0000 fOOO 0000 0000 0000
0000128: f800 0000 0000 0000 0001 0000 0000 0000
0000144: 0801 0000 0000 0000 1001 0000 0000 0000
0000160: 1801 0000 0000 0000 2001 0000 0000 0000
0000176: 5801 0000 0000 0000 6001 0000 0000 0000 X N
0000192: 6801 0000 0000 0000 7001 0000 0000 0000 h p
0000208: 4801 0000 0000 0000 7001 0000 0000 0000 H
0000224: 0000 0000 0000 0000 0000 0000 0000 0000
0000240: 0000 0000 0000 0000 0000 0000 0000 0000
В байтах О-1 отображается режим; значение 8 является признаком обычного фай-
файла. Байты 16-23 показывают, что размер файла равен 2 097 152 байтам @x00200000).
В байтах 32-39 хранится 8-байтовое А-время, которое после преобразования при-
принимает вид 15:48:05, 3 августа 2004 г. по UTC.
Байты 112-119 содержат первый прямой указатель на блок файла. В данном
примере это блок 232 @хе8). Второй указатель ссылается на блок 240 (OxfO); в те-
тестовом образе размер блока равен 8 фрагментам. Байты 208-215 содержат пер-
первый косвенный указатель 328 @x0148).
Вывод istat для этого индексного узла выглядит так:
# istat -f freebsd -z UTC freebsd.dd 5
inode: 5
Allocated
Group: 0
uid / gid: 0 / 0
mode: -rw-r--r--
size: 2097152
num of links: 1
Inode Times:
Accessed: Tue Aug 3 15:48:05 2004
File Modified: Tue Aug 3 15:48:06 2004
Inode Modified: Tue Aug 3 15:48:06 2004
Direct Blocks:
232 233 234 235 236 237 238 239
240 241 242 243 244 245 246 247
[...]
1296 1297 1298 1299 1300 1301 1302 1303
Indirect Blocks:
328 329 330 331 332 333 334 335
Расширенные атрибуты UFS2
Файлы и каталоги UFS2 также могут обладать расширенными атрибутами — па-
парами «имя-значение», заданными пользователем или системой. Расширенные ат-
атрибуты хранятся в обычных блоках данных, адреса которых задаются в индекс-
индексном узле. Каждый блок содержит список структур данных переменной длины,
поля которых перечислены в табл. 17.9.
Таблица 17.9. Структура данных записи расширенного атрибута в UFS2
Диапазон Описание Необходимость
0-3 Длина записи Да
4-4 Пространство имен (см. табл. 17.10) Нет
5-5 Дополнение содержимого Да
6-6 Длина имени Да
7-G+длина имени) Имя Да
(После имени, с выравни- Значение Да
ванием по границе 8 байт)
Имя дополняется таким образом, чтобы значение начиналось с границы 8 байт.
Значение также дополняется, чтобы следующая запись была выровнена по 8-бай-
8-байтовой границе. Величина выравнивания имени вычисляется по длине имени, а ве-
величина выравнивания значения задается в байте 5. Поле пространства имен со-
содержит одно из значений, представленных в табл. 17.10.
Таблица 17.10. Значения поля пространства имен в расширенных атрибутах
Значение Описание
1 Пользовательское пространство имен
2 Системное пространство имен
Содержимое блока расширенных атрибутов с двумя атрибутами выглядит
так:
0000000: 3000 0000 0107 0673 6f75 7263 6500 0000 0 source...
0000016: 7777 7777 2е64 6967 6974 616с 2d65 7669 wwww.digital-evi
0000032: 6465 6e63 652e 6f72 6700 0000 0000 0000 dence.org
0000048: 2000 0000 0104 0464 6174 6500 0000 0000 date
0000064: 4175 6720 3132 2c20 3230 3034 0000 0000 Aug 12. 2004....
0000080: 0000 0000 0000 0000 0000 0000 0000 0000
Байты 0-3 показывают, что длина записи равна 48 байтам @x30). Простран-
Пространство имен в байте 4 равно 1; следовательно, атрибут является пользовательским.
В содержимом присутствуют 7 байт дополнения, длина имени равна б байтам,
а имя атрибута представляет собой строку «source». Имя заканчивается в байте
12, а ближайшая 8-байтовая граница находится в байте 16. Чтобы определить завер-
завершающий адрес значения, следует вычесть из длины записи начальный байт и длину
дополнения D8-16-7=25). Значением атрибута является строка «www.digital-
evidence.org».
Записи каталогов
Структуры данных записей каталогов предназначены для хранения имен файлов
и каталогов. Они хранятся в блоках, выделенных каталогам. Каждая структура
данных содержит имя файла и адрес индексного узла с метаданными. Поля запи-
записей каталогов в UFS1 и UFS2 представлены в табл. 17.11.
Таблица 17.11. Структура данных записей каталогов UFS1 и UFS2
Диапазон Описание Необходимость
0-3 Индексный узел Да
4-5 Длина записи каталога Да
6-6 Длина имени Да
7-7 Тип файла (см. табл. 17.12) Нет
8+ Имя в кодировке ASCII Да
Допустимые значения поля типа файла перечислены в табл. 17.12.
Таблица 17.12. Значения поля типа в записи каталога
Значение Описание
0 Неизвестный тип
1 FIFO
2 Символьное устройство
4 Каталог
6 Блочное устройство
8 Обычный файл
10 Символическая ссылка
12 Сокет
14 Дубликат
Разные типы файлов, кроме последнего, были описаны в главе 15. Последний
тип используется в том случае, если файловая система монтировалась в режиме
объединения, вследствие чего появляются два файла с одинаковыми именами.
Для одного из файлов устанавливается флаг дубликата, и ОС не отображает его
по запросу пользователя.
Поле длины записи каталога используется для поиска следующей выделен-
выделенной записи, а поле длины имени — для определения конца имени и фактической
длины записи. За информацией об освобождении и выделении записей каталогов
обращайтесь к разделу «Категория данных имен файлов» главы 14.
Содержимое каталога UFS1 в тестовой файловой системе выглядит так:
# icat -f openbsd openbsd.dd 1921 | xxd
0000000: 8107 0000 OcOO 0102 2e00 0000 0200 0000
0000016: OcOO 0402 2e2e 0000 8cO7 0000 1400 0809
0000032: 6669 6c65 312e 7478 7400 93e7 8dO7 0000 filel.txt
0000048: 1400 0809 6669 6c65 382e 7478 7400 93e7 file8.txt...
0000064: 8eO7 0000 2800 0809 6669 6c65 372e 7478 ....(...file7.tx
0000080: 7400 93e7 8fO7 0000 1400 0809 6669 6c65 t file
0000096: 362e 7478 7400 93e7 9007 0000 1400 0809 6.txt
0000112: 6669 6c65 352e 7478 7400 93e7 9107 0000 file5.txt
0000128: 2800 0809 6669 6c65 342e 7478 7400 93e7 (...file4.txt...
0000144: 9207 0000 1400 0809 6669 6c65 372e 7478 file7.tx
Содержимое каталогов подробно рассматривалось в главе 15, поэтому сейчас
я ограничусь краткими пояснениями. Первые четыре байта описывают индексный
узел записи «.»; как видно из листинга, это индексный узел 1921 @x0781). Байты
24-27 содержат номер индексного узла для первой записи файла filel.txt; это ин-
индексный узел 1932 @х078с). Байты 68-69 содержат поле длины для файла file7.txt
Его длина составляет 40 байт @x28), хотя имя занимает всего 9 байт. Следующая
запись (для файла file6.txt) была удалена, а поле длины файла file7.txt ссылается
на запись после file6.txt.
Выходные данные fls для этого каталога выглядят так:
# fls -f openbsd -a openbsd.dd 1921
d/d 1921:
d/d 2:
r/r 1932: filel.txt
r/r 1933: file8.txt
r/r 1934: file7.txt
r/- * 1935: file6.txt
r/r 1936: file5.txt
r/r 1937: file4.txt
r/- * 1938: file3.txt
r/r 1939: file2.txt
r7- * 1940: filelO.txt
r/r 1941: file9.txt
Итоги
В этой главе были описаны структуры данных файловых систем UFS1 и UFS2.
По сравнению со своими аналогами из ExtX они обычно занимают больше места
и содержат больше необязательных данных; с другой стороны, эти данные повы-
повышают эффективность повседневной работы файловой системы.
Библиография
См. раздел «Библиография» главы 16.
Приложение
The Sleuth Kit и Autopsy
TSK (The Sleuth Kit) и Autopsy Forensic Browser — программы с открытыми ис-
исходными кодами на базе UNIX, опубликованные мной (в исходной версии) в на-
начале 2001 г. Пакет TSK содержит свыше 20 программ, работающих в режиме ко-
командной строки и предназначенных для анализа образов дисков и файловых
систем на предмет поиска улик. Для упрощения анализа можно воспользоваться
Autopsy Forensic Browser. Autopsy предоставляет удобный графический интер-
интерфейс к утилитам TSK.
В этом приложении TSK и Autopsy будут рассмотрены более подробно. Пакет
TSK используется во многих примерах книги, но только здесь я рассказываю о том,
как им пользоваться. Как Autopsy, так и TSK можно загрузить по адресу: http://
www.sleuthkit.org.
На сайте также имеется информация о списках рассылки для пользователей
пакета и разработчиков. В частности, вы найдете на нем выпуски бюллетеня
«Sleuth Kit Informer» со статьями об использовании TSK, Autopsy и других ана-
аналитических программ с исходными текстами.
The Sleuth Kit
TSK содержит свыше 20 программ командной строки, разделенных на несколь-
несколько групп: программы для работы с дисками, программы для работы с томами,
программы файловой системы и поиска. Программы файловой системы допол-
дополнительно делятся в соответствии с категориями данных, описанными в главе 8.
Имя каждой программы состоит из двух частей: первая часть определяет груп-
группу, а вторая — выполняемую функцию. Например, программа fls относится к ка-
категории имен файлов (f) и предназначена для вывода информации (ls, то есть
«листинг»), а программа istat относится к категории метаданных (i) и выводит
статистику (stat).
В этом разделе кратко представлен обзор всех программ TSK. На момент на-
написания книги пакет существовал в версии 1.73, но на будущее был запланирован
выход версии 2.00 с большими изменениями. В описания эти изменения не вклю-
включены, но к тому времени, когда вы будете читать книгу, версия 2.00 уже появится.
Мы начнем с нижнего уровня и будем постепенно продвигаться наверх. Многие
параметры командной строки в тексте не описаны — дополнительную информа-
информацию можно найти в электронной документации или на сайте.
Программы для работы с диском
Пакет TSK содержит всего одну программу для работы с диском — diskstat В на-
настоящее время diskstat работает только в Linux и выдает статистику о жестких
дисках АТА. Пример использования diskstat встречается в главе 3, где мы искали
защищенные области HPA (Host Protected Area) перед снятием данных с диска.
Программа выводит информацию о количестве секторов — как общем, так и дос-
доступном для пользователя, а также сообщает о существовании HPA. См. раздел
«Практический пример с использованием dd».
Программы для работы с томами
Содержимое диска делится на тома. В TSK входит программа mm ls, выводящая
информацию о строении тома. Примеры ее использования встречаются в главах 5
и 6; в настоящее время mmls поддерживает разделы DOS (dos), Apple (mac), BSD
(bsd), Sun (sun) и GPT (gpt). Тип таблицы разделов указывается в командной стро-
строке с параметром -t, за которым следует тип, указанный выше в круглых скобках.
Выходные данные mmls сортируются по начальному адресу раздела независи-
независимо от его местонахождения в таблице. Из них также можно узнать, какие секторы
тома не были выделены разделам. За примерами обращайтесь к описаниям конк-
конкретных типов разделов в главах 5 и 6.
Программы файловой системы
Большинство томов содержит файловые системы, поэтому пакет TSK в основ-
основном работает именно на этом уровне. Программы файловой системы TSK со-
созданы на основе утилит пакета The Coroner's Toolkit (TCT), авторами которого
являются Дэн Фармер (Dan Farmer) и Витце Венема (Wietse Venema). В нас-
настоящее время эта группа включает 13 программ файловой системы, разделен-
разделенных на 5 категорий. Пока в качестве входных данных программам должен пе-
передаваться низкоуровневый образ раздела, но версия 2.00 будет поддерживать
образы дисков.
Программы файловой системы поддерживают форматы Ext2/3 (Iinux-ext2, linux-
ext3), FAT (fat, fat!2, fat!6, fat32), NTFS (ntfs) и UFS1/2 (freebsd, netbsd, openbsd,
solans). Тип файловой системы указывается в командной строке с параметром -f,
за которым следует тип, указанный выше в круглых скобках.
Категория данных файловой системы
К этой категории относятся данные, описывающие общее строение и основные
параметры файловой системы. Программа fsstat выводит информацию, прочитан-
прочитанную из загрузочного сектора, суперблока или другой структуры, специфической
для конкретной файловой системы. Тип данных в результатах fsstat зависит от
файловой системы. Примеры приводятся в главах 9, 12, 14 и 16.
Категория содержимого
К категории содержимого относятся данные, хранящиеся в файлах и каталогах.
Как правило, они представляют собой блоки данных одинакового размера, выде-
ляемые файлам и каталогам. Имена всех программ TSK в этой категории начина-
начинаются с префикса d.
Программа dls выводит содержимое блоков данных; по умолчанию выводится
содержимое всех свободных блоков. Параметр -е позволяет вывести все блоки
данных — того же результата можно добиться, запустив для образа программу dd.
Параметр -I выводит информацию о состоянии выделения (вместо вывода самого
содержимого). Например, следующая команда выводит информацию о состоя-
состоянии выделения всех блоков данных в образе NTFS:
# dls -f ntfs -e -1 ntfs-10.dd
addr|al1oc
01 a
l|a
[...]
13423|a
134241 f
Символ «а» после адреса означает, что блок данных выделен, a «f» — что он
свободен. Следующая команда извлекает все свободное пространство образа
NTFS:
# dls -f ntfs ntfs-10.dd > ntfs-10.dls
Полученный файл не структурирован, потому что он просто содержит случай-
случайные блоки данных из файловой системы. Если при поиске в этом файле будут
обнаружены улики, программа dcalc поможет найти их источник. Dcalc вычисляет
адрес исходного блока данных по адресу блока из неструктурированных данных.
Например, если файловая система состоит из 4096-байтовых кластеров и в 123-м
кластере неструктурированного файла были обнаружены улики, достаточно за-
запустить dcalc с параметром -и и номером 123:
# dcalc -f ntfs -u 123 ntfs-lO.dd
15945
Программа dstat позволяет проверить состояние выделения конкретной еди-
единицы данных. Кроме того, dstat выводит информацию о группах цилиндров и бло-
блоках в файловых системах UFS и Ext2/3:
# dstat -f Iinux-ext3 ext3-5.dd 23456
Категория метаданных
К категории метаданных относятся данные, описывающие файлы: адреса блоков
данных, выделенных файлу, размер файла и временные штампы. Состав данных
этой категории зависит от типа файловой системы. В пакете TSK к этой катего-
категории относятся 4 программы, имена которых начинаются с префикса i.
Для получения подробной информации о конкретной записи метаданных мож-
можно воспользоваться программой istat. В ее результатах указываются размеры, вре-
временные штампы и разрешения; кроме того, будут приведены адреса всех выде-
выделенных единиц данных. Для образов NTFS istat выводит все атрибуты файла.
Примеры встречаются в главах 9, 12, 14 и 16.
Информация по нескольким структурам метаданных выводится программой
iLs. По умолчанию iLs ограничивается выводом информации о свободных запи-
записях, но программу также можно запустить с ключом -е для получения полной
информация. Вывод информации о свободных метаданных особенно полезен при
поиске записей удаленных файлов, если запись имени была выделена другому
файлу.
# ils -f ntfs -e ntfslO.dd
О|а|0|0|1089795287|1089795287|1089795287|100555|1|24755200|0|0
1|а|0|0|1089795287|1089795287|1089795287|100555|1|4096|0|0
255|а|256|0|998568000|1100132856|1089795731|100777|1|15360|0|0
256|f|256|0|1100132871|1100132871|1100132871|100777|1|256|0|0
Выходные данные ils форматируются с расчетом на автоматизированную об-
обработку; они часто используются с программой mactime для построения времен-
временных диаграмм. После обнаружения блока данных с интересными уликами можно
провести поиск всех записей метаданных, запустив программу ifind с параметром
-d. Если же потребуется найти запись метаданных; на которую ссылается некото-
некоторое имя файла, можно запустить программу ifind с флагом -п. Так, в следующем
примере выясняется, что кластер NTFS 3456 был выделен атрибуту $DATA записи
MFT с номером 18080:
# ifind -f ntfs -d 3456 ntfslO.dd
18080-128-3
Наконец, программа icat позволяет просмотреть содержимое любого файла по
адресу его метаданных (вместо имени файла). Например, такая возможность может
оказаться полезной для поиска свободных файлов, на метаданные которых не ссы-
ссылается ни одна запись имени. В частности, эта команда использовалась в главе,
посвященной NTFS, потому что в этой системе все данные хранятся в файлах:
# icat -f ntfs ntfslO.dd 18080
Категория имен файлов
К категории имен файлов относятся данные, связывающие имя файла с записью
метаданных. В большинстве файловых систем имя отделяется от метаданных и
хранится в блоках данных, выделенных каталогам. В пакет TSK входят две про-
программы, работающие на уровне имен файлов; имена обеих программ начинаются
с префикса f.
Программа fls перечисляет имена файлов в заданном каталоге. Она получает
адрес метаданных каталога в качестве аргумента и выводит списки как выделен-
выделенных, так и свободных имен. С ключом -г программа выполняет рекурсивную об-
обработку подкаталогов, а с ключом -I проводит поиск в метаданных и выводит вре-
временные штампы с именами файлов. Соответствующие примеры встречались во
всех предыдущих главах. Например, в следующем образе Ext3 индексный узел
69457 представляет каталог, содержащий удаленный файл two.dat:
# fls -f Iinux-ext3 -a ext3.dd 69457
г/г 69458: acbdefg.txt
г/г * 69459: file two.dat
d/d 69460: subdirl
г/г 69461: RSTUVWXY
Чтобы знать, какое имя файла соответствует некоторому адресу метаданных,
можно воспользоваться программой ffind. Пример:
# ffind -f Iinux-ext3 ext3.dd 69458
/dirl/abcdefg.txt
Категория прикладных данных
К категории прикладных относятся данные, включаемые в файловую систему для
повышения эффективности. В TSK на уровне прикладных данных работают всего
две программы; обе предназначены для работы с журналом в Ext3. В журнале ре-
регистрируются предстоящие обновления метаданных; такая информация ускоря-
ускоряет восстановление системы после сбоя. Журналы обсуждались в главах 8 и 14.
Программа]'ls выводит содержимое журнала и показывает, какие блоки фай-
файловой системы хранятся в блоках журнала. Содержимое отдельного блока жур-
журнала просматривается программой jcat. Пример:
# jls -f Iinux-ext3 ext3-6.dd
JBlk Description
0: Superblock (seq: 0)
1: Unallocated Descriptor Block (seq: 41012)
2: Unallocated FS Block 98313
3: Unallocated FS Block 1376258
[...]
Если вас заинтересовала запись некоторого блока файловой системы (напри-
(например, 98 313), просмотрите содержимое блока журнала 2 командой jcat:
# jcat -f Iinux-ext3 ext3-6.dd 2
Прочие
Некоторые программы TSK объединяют данные из разных категорий для полу-
получения вывода, отсортированного в другом порядке. Первая программа, mactime,
получает временные данные от fls и i Ls и строит по ним временные диаграммы
файловых операций. Каждая строка вывода соответствует обращению к файлу
или его изменению (см. главу 8). Далее приводится пример временной диаграм-
диаграммы (данные отформатированы по ширине страницы):
Wed Aug 11 2004 19:31:58 34528 .a. /system32/ntio804.sys
35392 .a. /system32/ntio412.sys
Wed Aug 11 2004 19:33:27 2048 mac /bootstat.dat
1024 mac /system32/config/default.L0G
1024 mac /system32/config/software.L0G
Wed Aug 11 2004 19:33:28 262144 ma. /system32/config/SECURITY
262144 ma. /system32/config/default
Программы поиска
Последнюю из основных категорий программ TSK составляют программы поис-
поиска. В версии 2.00 их круг будет расширен. Из текущей версии к этой категории
относится программа sigfind, предназначенная для поиска двоичных сигнатур.
В частности, она использовалась в ряде сценариев части III книги.
Пол Беккер (Paul Bakker) работал над включением в TSK и Autopsy индексиро-
индексированного поиска; эта возможность войдет в версию 2.00 (http://www.brainspark.nl/).
Процесс индексирования строит для образа дерево, ускоряющее поиск конкрет-
конкретных строк. Более подробное описание можно найти в бюллетене «The Sleuth Kit
Informer, Issue 16» [Bakker, 2004]
Autopsy
Теоретически весь процесс анализа может выполняться в режиме командной стро-
строки, но это неудобно. Оболочка Autopsy разрабатывалась для автоматизации про-
процесса расследования при использовании TSK, но она не ограничивает возможно-
возможности эксперта. Ничто не мешает использовать командную строку, когда потребуется
сделать что-то, выходящее за рамки графического интерфейса.
Autopsy работает на базе HTML. Фактически это веб-сервер, который умеет
запускать программы из пакета TSK и обрабатывать их вывод. Autopsy ничего не
знает о файловых системах и дисках, это область TSK. Autopsy может использо-
использоваться как при «живом», так и при «мертвом» анализе систем.
При «мертвом» анализе Autopsy позволяет использовать несколько хостов,
каждый из которых обладает собственным часовым поясом и базой данных хеш-
кодов. Все действия регистрируются в журнале, благодаря чему эксперт может
отслеживать ход анализа и делать заметки о найденных уликах. В Autopsy ис-
используется протокол HTTP, что позволяет подключаться к интерфейсу с любого
компьютера. При запуске Autopsy следует указать IP-адрес своего компьютера,
после чего к нему можно будет подключаться по сети. В частности, это позволяет
создать централизованное хранилище образов.
При «живом» анализе Autopsy и TSK записываются на компакт-диск. Диск
размещается в системе UNIX, на которой, как предполагается, произошел индци-
дент; после этого вы можете анализировать содержимое файловой системы, под-
подключаясь к Autopsy с портативного или настольного компьютера. Применение
Autopsy и TSK при «живом» анализе обладает рядом преимуществ — в частности,
они показывают файлы, скрываемые большинством руткитов (rootkits) и не из-
изменяют А-время файлов и каталогов при просмотре их содержимого. Как и во
всех разновидностях «живого» анализа, процесс зависит от данных, полученных
от ОС, однако последняя может и солгать, если она была модифицирована зло-
злоумышленником.
Режимы анализа
Autopsy поддерживает несколько режимов анализа, соответствующих структуре
пакета TSK. В режиме анализа файлов (File Analysis) эксперт просматривает спис-
списки файлов и каталогов, а также содержимое отдельных файлов. В режиме мета-
метаданных (Metadata) отображаются все метаданные, связанные с конкретной запи-
записью, и все блоки данных, выделенные файлам. Режим блоков данных (Data Unit)
позволяет просмотреть содержимое любого блока данных файловой системы (как
в шестнадцатеричном редакторе), а в режиме поиска по ключевым словам (Keyword
Search) возможен поиск по ASCII-кодам и строкам Unicode. В последнем режиме
поиск осуществляется по логическим томам, а не по логическим файлам. За до-
дополнительной информацией о типах поиска обращайтесь к главе 8.
Autopsy также дает возможность сортировать файлы по типу и строить HTML-
страницы с миниатюрами всех графических файлов. Предусмотрена возможность
построения временных диаграмм файловых операций и создания заметок при
обнаружении улик. По этим заметкам вам будет проще вернуться к тому месту,
где была обнаружена улика. Наконец, подсистема отслеживания событий позво-
позволяет создавать заметки па основании временных штампов, полученных при ис-
исследовании улик, с последующей сортировкой данных. Например, можно создать
заметки для времени создания файлов улик и оповещений системы IDS (Intrusion
Detection System). Отсортированные заметки принесут пользу в фазе реконст-
реконструкции событий.
Примерный вид окна Autopsy в режиме анализа файлов показан на рис. П.1.
Рис. П.1. Вид окна Autopsy в режиме анализа файлов
Библиография
• Bakker, Paul. «Search Tools, Indexed Searching in Forensic Images». Sleuth Kit
Informe7'#\6, September 2004. http://www.sleuthkit.org/informer/sleuthkit-informer-
16.html#search.
Алфавитный указатель
Символы А
$ AttrDef, файл, 257, 341 ADS (альтернативные потоки
$ATTRIBUTE_LIST, атрибут, 257, 289 данных), 258, 289
SBadClus, файл, 254, 282 ASCII, 42
SBITMAP, атрибут, 253, 334 АТА, диски, 48
SBitmap, файл, 282, 342 АТА-3, безопасность, 53
SBoot, файл, 254 AT API, интерфейс, 53
SDATA, атрибут, 257 Autopsy, 36, 474
$ЕА, атрибут, 257 g
$ЕА INFORMATION, атрибут, 257 _ ._
фи - , , „ ос. J В-деревья, 265
SExtend, файл, 254 вю£ 4? ^
SFILE NAME, атрибут, 257 _>„ /ot^c r» *. r>i i \ олл
SINDEX ALLOCATION, ?™ <?™S Parameter B1°ck)' 2°°
атрибут, 257, 303 BMJ, И«
$INDEX_ROOT, атрибут, 257, 303 BXDR' программа, 68
SLogFile, файл, 254 С
$LOGGED_UTILITY_STREAM, CD R 114
атрибут, 257 " '
$MFT, файл, 253 ^t,1' D4' DD-0
SMftMirr, файл, 254, 274 CHS'адреса'52
$OBJECT_ID, атрибут, 299 D
SObjId, файл, 344 D-время, 367
SQuota, файл, 306, 345 DC0 (Device Configuration Overlay), 68
SReparse, файл, 302 dd> программа, 75
$REPARSE_POINT, атрибут, 257 DEFRAG, программа, 220
SSecure, файл, 254, 291 DEVICE_CONFIGURATION_IDENTIFY,
$SECURITY_DESCRIPTOR, команда, 56
атрибут, 257, 291 DFTT, сайт, 221
SSTANDARDJNFORMATION, diskstat, программа, 68
атрибут, 257 DRIVEID, программа, 68
SSYMBOLICJLINK, атрибут, 257
SUpcase, файл, 254 E
SUsrJrnl, файл, 348 EnCase,35, 149
SVolume, файл, 254, 276, 343 EOF, маркеры (FAT), 213
SVOLUMEJNFORMATION, ExtX, 352, 399
атрибут, 257 ACL, 370
$VOLUME_NAME, атрибут, 257 блоки> 352) Зб2, 399
$VOLUME_VERSION, атрибут, 257 суперблок, 399
F R
FAT RAID, 143
FSINFO, структура данных, 200 оборудование, 143
загрузочный сектор, 232 уровни, 143
категория имен файлов, 222 READ_NATIVE_MAX_ADDRESS,
категория метаданных, 211 команда, 55
категория содержимого, 207 g
проверка целостности, 232
FAT12 200 240 SCA (Single Connector Attachment), 61
FAT16,200, 240 SCSI, 48, 58
FAT32 200 240 SECURITYJJNLOCK, команда, 54
FEK (File Encryption Key), 263 SGrID;368
FIFO 367 sigfind, программа, 205, 221
FireWire 146 SMART, технология, 53
FreeBSD SUID>368
разделы, 120 T
FSINFO, структура данных, 203 TSK 35 165 469
H diskstat, программа, 68
HPA (Host Protected Area), 68 siSfind' пР0ГРамма>205- 279
hpa, программа, 68 U
I UFS,352, 399
IDS (Intrusion Detection System), 64 блоки, 422
. . . фрагменты, 422
istat, программа ttcvt/tt л *. с хт и \ о<л
FAT 91 fi (Update Sequence Number), 310
NTFS, 271 V-W
L VCN (Virtual Cluster Number), 257, 290
LBA (Logical Block Address), 50 W^tlZ\ r
т/-XT/т • i/-1 ^ xt l. ч on DEFRAG, программа, 220
LCN (Logical Cluster Number), 257 тэдтп \ar
LFN (Long File Name), 223 '
M-N A
аугтг-г/ауг 4. T7-1 T-i 1 ч on алгоритмы выделения
MFT (Master File Table), 251 FAT 208 224 302
NIST(National Institute of Standards хтттг'с oo'o '
& Technology), 64, 66 N[tb> i83
NTFS, 198, 235, 250, 273, 317 альтернативные потоки
MFT 259 данных (ADS), 258, 289
' о-л анализ
анализ, 270 £xtX 35g
категория данных файловой „ А ^ ' п
системы, 273, 317 Ь\1,Л)9
категория имен файлов, 300 NTFS, 279
категория метаданных, 285 Solans, 137
файлы метаданных, 339 UFS) 429
NTFSInfo, программа, 270 живой, 27
мертвый, 27
О томов, 82
OpenBSD, 117, 143 асимметричное шифрование, 263
атрибуты жесткие диски (продолжение)
SATTRIBUTEJLIST, 257, 289 SCSI, 58
SBITMAP, 253, 334 адреса секторов, 52
$DATA, 257, 288 геометрия, 48
$ЕА, 257 жесткие диски, 48
$EA_INFORMATION, 257 жесткие ссылки, 301
$FILE_NAME, 257 живое снятие данных, 66
$INDEX_ALLOCATION, 257, 303 журнал файловой системы
$INDEX_ROOT, 257, 303 NTFS, 306
$LOGGED_UTILITY_STREAM, 257
$OBJECT_ID, 302 3
$REPARSE_POINT, 257 загрузочные диски, 46
$SECURITY_DESCRIPTOR, 257, 291 загрузочный сектор
$STANDARD_INFORMATION, 257 FAT, 200
SSYMBOLICJLINK, 257 NTFS, 275
$VOLUME_INFORMATION, 257 загрузчик, 356
$VOLUME_NAME, 257 записи каталогов
$VOLUME_VERSION, 257 FAT, 198, 212, 235
_ защита данных, 68
b
IT
базовые записи MFT, 259
блокировщики записи каталоги
аппаратные, 68 UNIX, 376
программные, 70 атрибут, 212
— хеш-деревья, 379
категория имен файлов
восстановление файлов FAT 222
FAT>224 NTFS, 300
N 1 го, о 14 категория метаданных
Г FAT, 211
, ч /Q NTFS, 285
геометрия (жесткого диска), 48
4 ' категория содержимого
Д FAT, 207
данные кластеры
вспомогательные, 34 FAT, 207
необходимые, 34 NTFS, 280
копирование, 63 кодировка, 42
скрытые, 64 контроллеры, 51
снятие, 63 корневой каталог
двоичные числа, 38 FAT, 200
дисковые квоты (NTFS), 306 NTFS, 298
дорожки, 49 криптографические хеш-коды, 79
криптография (NTFS), 262
Ж
м
жесткие диски
АТА, интерфейс, 51 машинный код, 47
DCO, 56 мертвое снятие данных, 66
HPA, 55 монтирование, 35
П тома (продолжение)
переходы, 302 определение, 83
проверка целостности данных, 232 сборка, 82
процессор, центральный, 46 точка монтирования, 302
прямой доступ к диску, 57 у
Р улики
разделы поиск, 29
Apple, 109 цифровые, 26
BSD, 117, 143 ф
DOS, 93
EFI 129 файлы
GPT 138 SAttrDef, 254, 341
VTOC 131 SBadClus, 254, 282
восстановление, 90 SBitmap, 282
создание, 82 $Boot, 254
разреженные атрибуты, 260 SExtend, 254
редактор. См. AppBrowser SLogFile, 254
руткиты,66 $MFT,253
SMftMirr, 254, 274
С SQuota, 306
секторы SReparse, 302
адресация, 52, 83 SSecure, 254, 291
жесткие диски, 49 SUpcase, 254
символические ссылки, 301 SUsrJrnl, 348
симметричное шифрование, 263 SVolume, 254, 276
снятие данных, 63 физические адреса, 52
dd, программа, 75 фрагментация, 170, 433
живое, 66
мертвое, 66
сетевое, 73 хеш-деревья, 379
суперблок хеш-коды, 28
ExtX, 354, 399 хеш-коды, 74
UFS1,448 u
UFS2,453 Ч
цепочки кластеров, 213
цилиндры, 49
тома
RAID, 144 Ш
логические, 151 шифрование атрибутов, 262
Брайан Кэрриэ
Криминалистический анализ файловых систем
Заведующий редакцией А. Кривцов
Ведущий редактор А. Пасечник
Литературный редактор А. Пасечник
Технический редактор Л. Родионова
Художник Л. Адуевска;
Корректоры Н. Рощина, И. Тимофеева
Верстка Л. Родионова
Подписано в печать 26.09.06. Формат 70x100/16. Усл. п. л. 38,7. Тираж 2000. Заказ 698
ООО «Питер Пресс», 198206, Санкт-Петербург, Петергофское шоссе, д. 73, лит. А29..
Налоговая льгота — общероссийский классификатор продукции ОК 005-93, том 2; 95 3005 — литература учебная.
Отпечатано с готовых диапозитивов в ОАО «Техническая книга»
190005, Санкт-Петербург, Измайловский пр., 29