/





























































































































































































































































































































Автор: Клейнен Дж.
Теги: теория вероятностей математическая статистика комбинаторный анализ теория графов математика высшая математика
Год: 1978




Текст
STATISTICAL TECHNIQUES
IN SIMULATION
(in two parts)
Jack P. C. Kleijnen
Katholieke Hogeschool
Tilburg, The Netherlands
Part II
Marcel Dekker, Inc. New York
Дж. Клейнен
СТАТИСТИЧЕСКИЕ МЕТОДЫ
В ИМИТАЦИОННОМ
МОДЕЛИРОВАНИИ
Выпуск 2
Перевод с английского Ю. П. АДЛЕРА,
К. Д. АРГУНОВОЙ, В. Н. ВАРЫГИНА, А. М. ТАЛАЛАЯ
Под редакцией и с предисловием
Ю. П. АДЛЕРА И В. Н. ВАРЫГИНА
¦¦¦¦¦¦¦¦¦¦
Москва «Статистика» 1978
22.1ft
К48
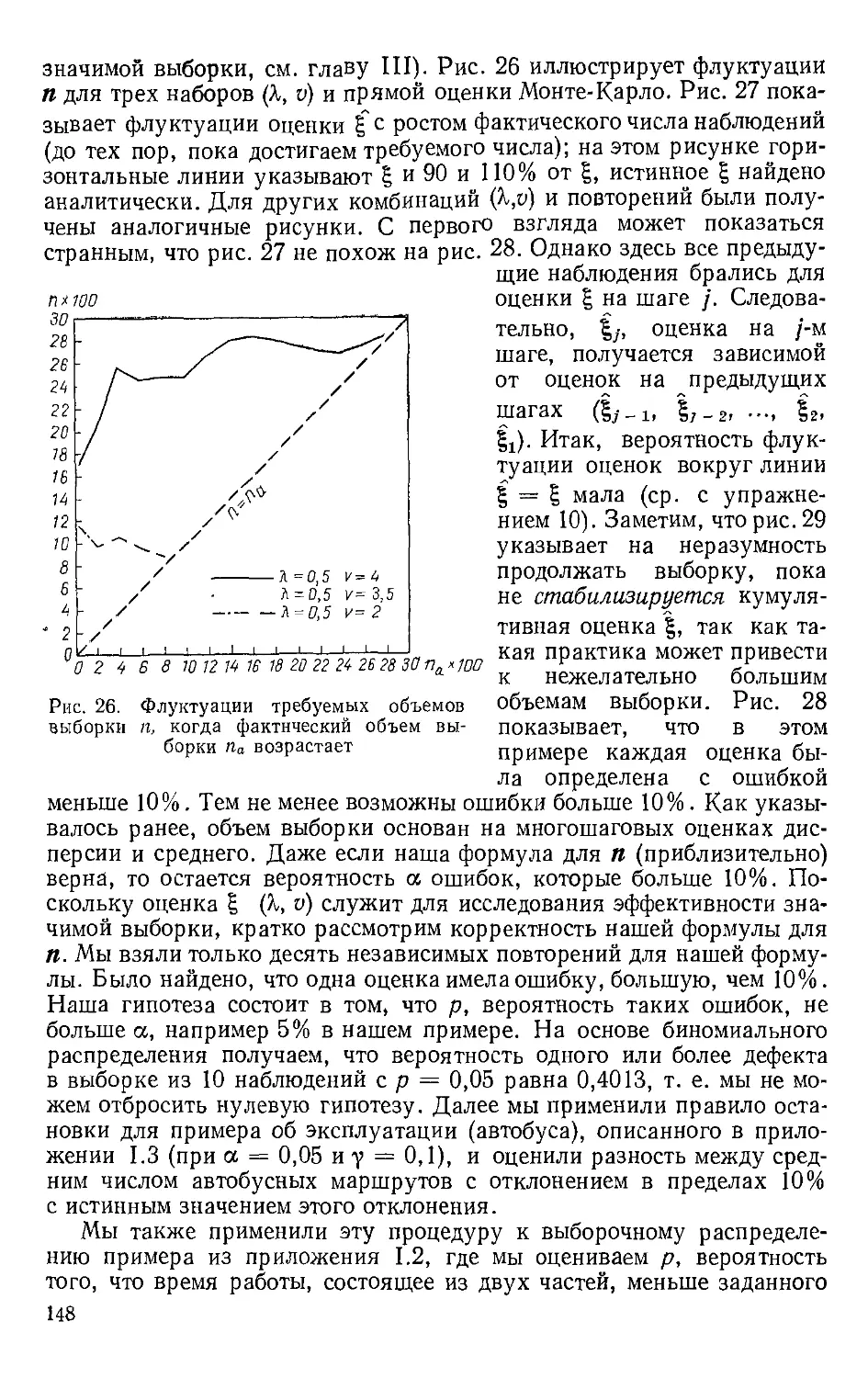
МАТЕМАТИКО-СТАТИСТИЧЕСКИЁ
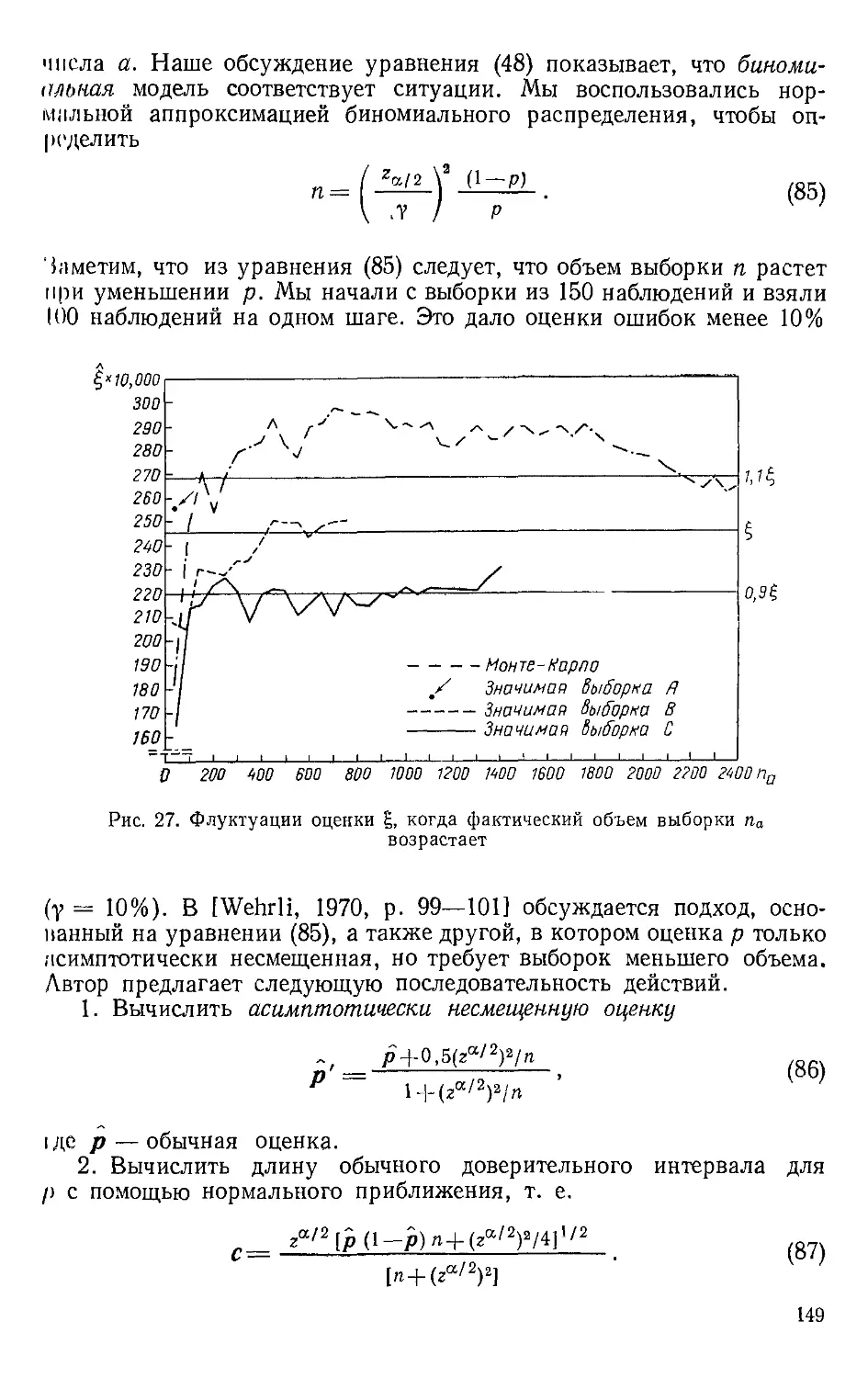
МЕТОДЫ ЗА РУБЕЖОМ
ВЫШЛИ ИЗ ПЕЧАТИ
1. Ли Ц., Джадж Д, Зельнер А.
Оценивание параметров марковских мо-
моделей по агрегированным временным
рядам.
2. Райфа Г., Шлейфер Р. При-
Прикладная теория статистических решений.
3. К л е и н е н Д ж. Статистические ме-
методы в имитационном моделировании.
Вып. 1.
¦ ГОТОВЯТСЯ К ПЕЧАТИ
1. Болч Б. У, Хуань К. Д. Мно-
Многомерные статистические методы для
экономики.
2. Б а р д Я. Нелинейное оценивание
параметров.
10805*—124
К 37—78
008@1)—78
Редколлегия: А. Г. Аганбегян, Ю. П. Ад-
Адлер, Ю. Н. Благовещенский, А. Я. Бояр-
Боярский, Н. К. Дружинин, Э. Б. Ершов,
Т В. Рябушкин, Е. М. Четыркин
Второй индекс 20204.
© 1974, Marcel Dekker, INC.
© Перевод на русский язык, предисловие, дополнительная библиография, пред-
предметный и именной указатели, «Статистика», 1978
# ПЛАНИРОВАНИЕ ИМИТАЦИОННЫХ
ЭКСПЕРИМЕНТОВ
Относительно подробный разбор всей книги содержится в преди-
предисловии к первому выпуску, так что здесь мы кратко остановимся на
содержании трех глав второго выпуска.
Закончив в последней главе первого выпуска обсуждение методов
понижения дисперсии, автор переходит в четвертой главе — первой
главе второго выпуска — к центральной теме всего повествования,
к планированию имитационных экспериментов. Эта большая глава мо-
может даже рассматриваться как самостоятельная небольшая книга по
данному вопросу. Из всего многообразия типов экспериментальных
планов автор выбрал лишь полный и дробный факторный экспери-
эксперимент да планы отсеивания. Даже процедура метода Бокса —
Уилсона и вся «техника» исследования поверхностей отклика лишь
упоминаются. А концепция D-оптимальности и некоторые другие
современные теории не фигурируют вовсе. Если рассматривать книгу
Клейнена как руководство для специалистов по моделированию,
предназначенное для первого знакомства с подходом, опирающимся
на планирование эксперимента, то подобный способ отбора материала
представляется нам вполне оправданным.
Однако при желании продвинуться дальше читатель начнет испы-
испытывать нужду в дополнительной информации, поэтому мы приводим
в конце главы краткий список работ, что позволит ему при необходи-
необходимости продвигаться в любом желаемом направлении.
Отобранный автором материал изложен обстоятельно и свежо.
Автор использует принцип: «план — под ресурсы», т. е. он устанав-
устанавливает, каким машинным временем располагает экспериментатор
и сколько длится один «прогон», а затем обсуждает возможные альтер-
альтернативы при выборе плана.
В задачах отсеивающего эксперимента обращает на себя внима-
внимание обстоятельное изложение методов последовательного отсеива-
отсеивания, которые до сих пор, насколько нам известно, описывались крат-
кратко. Упоминается одна задача отсеивания, в которой одновременно рас-
рассматривалось 100 000 факторов! Для реального эксперимента это фан-
фантастика, а в имитационном эксперименте оказывается вполне возмож-
возможным. Думается, что здесь наметилась область, которая будет стимули-
стимулировать развитие теории отсеивающих планов.
Следующая — пятая глава — трактует разнообразные и важные
вопросы определения объема выборки, причем как задачу планирова-
планирования эксперимента. Наряду с традиционными подходами используются
jOiiihlt1 подходы, сшмыпснощие выборочную процедуру с решае-
Muft 'Шдя'И'П. Л сами они разделяются на задачи множественных срав-
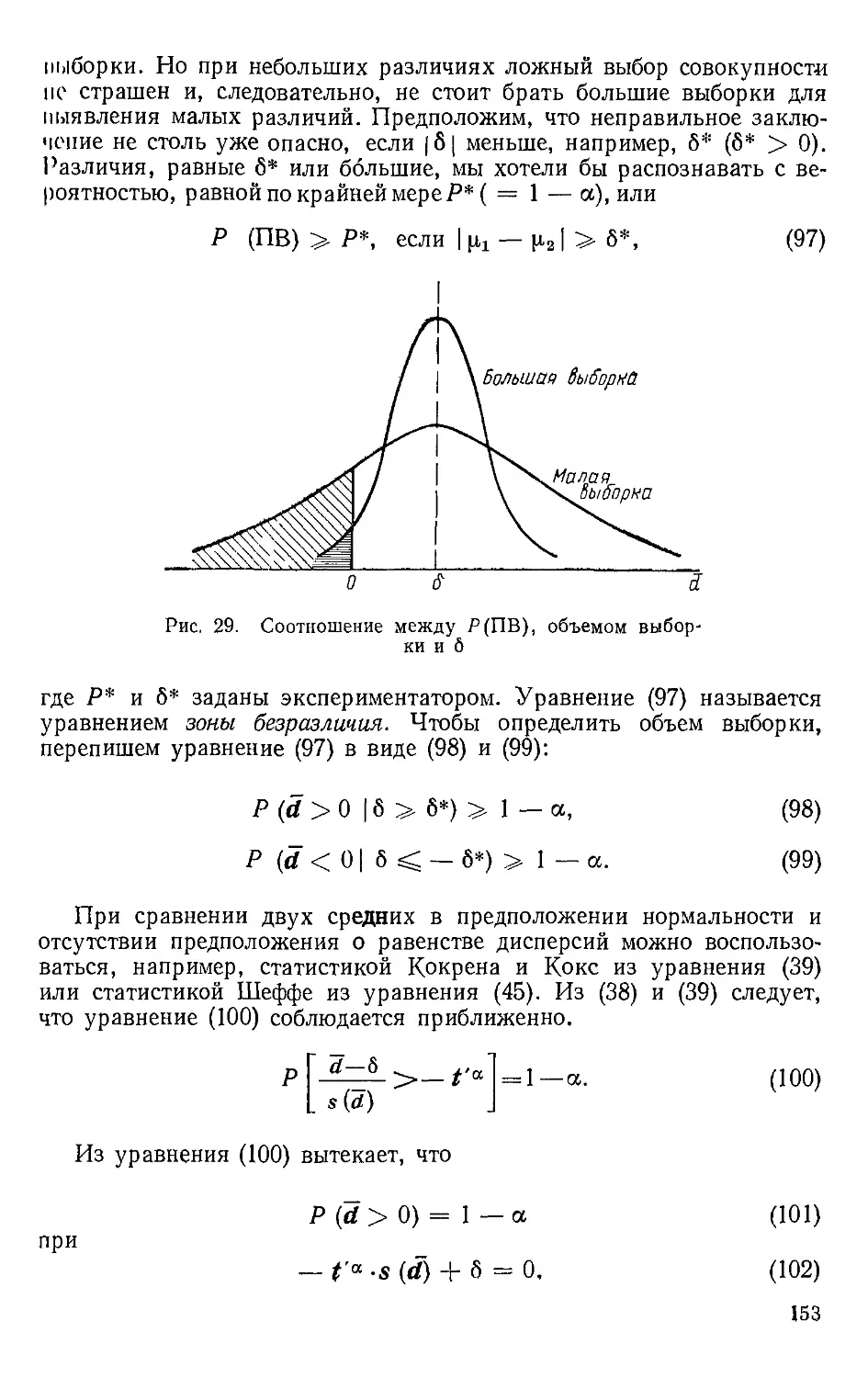
lK'iiiifi и задачи множественного ранжирования.
Б связи с таким новым подходом автор^вводит множество процедур,
известных только по журнальным публикациям. Все методы удачно,
па наш взгляд, систематизированы и постоянно сравниваются друг
с другом. Пожалуй, впервые параметрические и непараметрические
методы представлены равноправно. Но главная особенность изложе-
изложения — систематическое исследование робастности всех встречающихся
процедур. Уделяется, теперь уже традиционно, большое внимание пред-
предпосылкам, лежащим в основе каждого метода. В общем изложение
вполне соответствует тем стандартам, которые начали складываться
в последние годы в литературе по приложениям статистических ме-
методов.
Заключает книгу пример, представленный в последней — шестой
главе. Автор постарался собрать в этом примере весь арсенал средств
статистики, применяемых в имитационном моделировании, и обратить
их на исследование робастности одного из методов множественного
ранжирования — метода Бехгофера—Блюменталя. Выбор именно та-
такого примера интересен во многих отношениях, но нам представляет-
представляется наиболее примечательным то обстоятельство, что в нем отчетливо
показана роль имитационных моделей в решении «внутренних» проб-
проблем статистики, таких, например, как проблема робастности тех
или иных процедур. Имитационное моделирование уже только поэтому
заслуживало бы интенсивного развития и оправдало бы значитель-
значительные затраты сил и средств, даже если бы оно ни на что больше не было
пригодно. Как известно, это всего лишь одно из второстепенных при-
применений имитационного моделирования.
Многие и раньше подозревали, что планирование эксперимента
эффективно в задачах моделирования, в том числе и имитационного.
Теперь же появилась работа, в которой сделана попытка ответить на
«единственный» практический вопрос: что для этого надо делать?
Перевод этой книги на русский язык можно рассматривать как помощь
читателю, применяющему в своей деятельности методы моделирования
и имеющему выход на ЭВМ.
В. ВАРЫГИН, доктор технических наук
Ю. АДЛЕР, кандидат технических наук
Глшш IV ф ПЛАНИРОВАНИЕ И АНАЛИЗ
ЭКСПЕРИМЕНТОВ
»V I И1ИД1ШИЕ И РЕЗЮМЕ
И отой главе мы представим некоторые экспериментальные планы
п подробно обсудим их анализ. Конечно, существуют стандартные учеб-
учебники по планированию и анализу экспериментов, такие, как [Cochran,
<ох, J967) и [Davies, 1963]. Но эти книги пересматривались в 1957 и
1!>03 гг. соответственно и еще не содержат многих результатов, а эта
икта в основном опирается на статьи, опубликованные после 1960 г.
1чть и более новые учебники, например, [John, 1971], [Mendenhall,
1!>E8], [Peng, 1967]. Но они, как и все прочие книги, имеют общий_не-
достаток: в них не рассматривается тот вид экспериментов, который
интересует нас, а именно имитационные эксперименты. Поэтому та-
itiie книги содержат большие разделы о рандомизации, разбиении на
плоки и т. п., т. е. о методах, необходимых в силу неполной подконт-
подконтрольности условий экспериментов, характерной для промышленных
м сельскохозяйственных исследований. Из-за ограниченного объема они
но могут подробно описать еще и планы, подходящие для имитацион-
имитационного эксперимента.
Это дает нам основание заметить, что нет учебника, специально
подготовленного для исследователей, работающих в области имита-
имитационного моделирования. Поэтому мы испытывали искушение ото-
отоспать" исследователя к статьям в специальных журналах. К сожалению
существует огромная литература по планированию экспериментов; так
Горцберг и Кокс [Herzberg, Сох, 1969] приводят перечень из 800 статей,
иьтшедших до 1958 г. Следовательно, очень вероятно, что затраты вре-
времени, которое отдельный исследователь должен употребить на под-
Пор подходящих публикаций, могут стать препятствием.
Мы хотели надежно сделать для него столь сложный отбор1, для
чего отобрали подходящие публикации, систематизировали их и пред-
представили единообразно и просто.
Факторы в эксперименте бывают качественными и количественны-
количественными. Многие качественные факторы можно квантифицировать. Интел-
Интеллект, например, квантифицируется с помощью КИ (коэффициент ин-
интеллекта), дисциплина обслуживания очереди — приемом, описанным
у Миллера [Miller, 1968], а вид распределения — варьированием пара-
параметров некоторого семейства распределений. Тем'не менее, как счита-
считает Ноута [Nauta, 1967, р. 75], большинство промышленных имитацион-
имитационных моделей должно включать как минимум один качественный фак-
тор, unupiiM0|) upamuia поведения. Поэтому мы лишь кратко упомя-
упомянем так наоьшаемые методы анализа поверхности отклика, которые
приложимы лишь к случаю всех количественных факторов (правда,
в конце главы мы дадим библиографию по этой методологии). Мы со-
сосредоточимся на планах, которые можно применять, когда все факторы
качественные (или количественные) либо одни из них качественные,
а другие количественные.
Сначала мы рассмотрим общую модель с взаимодействиями, ис-
используемую в факторных планах. Дисперсионный анализ (или кратко
ANOVA) применяется при обработке результатов факторного экспе-
эксперимента. Показаны отношения между дисперсионным и регрессион-
регрессионным анализом. Обсуждаются рандомизация и разбиение на блоки
в имитации. Исследуются предпосылки ANOVA, преобразование и ко-
кодирование. Следующий параграф посвящен частному виду факторных
планов, а именно таким планам, в которых все факторы имеют только
по два значения. Приводится модель для таких «2k планов» вместе
с анализом наблюдений. Затем идет параграф, в котором говорится толь-
только о дробных репликах от полного факторного эксперимента типа 2k,
строящихся так, что вся важная информация сохраняется. Мы показы-
показываем, как можно выбрать конкретную структуру смешивания эффек-
эффектов. Мы даем планы для модели только главных эффектов, планы для
оценки главных эффектов в присутствии взаимодействий и планы для
оценки как главных эффектов, так и двухфакторных взаимодействий
(так называемые планы разрешения III, IV и V соответственно). Да-
Далее следует параграф, в котором показано, как получить независимую
оценку дисперсии ошибки опыта о2 при частичном дублировании
плана. Приводится метод переоценки эффектов с помощью дополни-
дополнительной информации от повторения плана. Вместо дублирования на-
наблюдений можно объединить суммы квадратов некоторых эффектов.
Оба метода можно сочетать с проверкой соответствия модели. Если
модель не годится, мы можем перейти к модели более высокого порядка.
Показано, что планы этой главы легко достраиваются до планов бо-
более высокого порядка (это так называемые композиционные, или по-
последовательно строящиеся, планы). Наконец, в следующем параграфе
обсуждаются планы для поиска нескольких важных факторов среди
многих мыслимых важных факторов, для так называемого отсеива-
отсеивания. Рассматривается интерпретация дробных факторных планов,
когда некоторые факторы не могут быть важными. Приводятся также
планы со случайным отбором факторных комбинаций и их анализ. Да-
Даются и так называемые сверхнасыщенные планы — систематические
(т. е. не случайные) планы с меньшим числом наблюдений, чем эффек-
эффектов. Затем мы демонстрируем несколько вариантов дробных реплик,
в которых факторы объединяются в группы для уменьшения числа фак-
факторов и наблюдений. Исследуются предпосылки таких планов группо-
группового отсеивания и устанавливается, что они не ограничительны.
Четыре типа планов группового отсеивания сравниваются между со-
собой. Глава заканчивается кратким обсуждением теории статистиче-
статистических решений и проблемы многих откликов. Приводится литература
по этим двум и по многим другим вопросам.
IV.2. ОБЩИЕ ФАКТОРНЫЕ ПЛАНЫ И ИХ АНАЛИЗ
Мы хотим рассмотреть эксперименты, в которых исследуется вли-
влияние более чем одного фактора. Традиционный метод состоял в рассмо-
рассмотрении факторов по одному, так называемый метод caeteris paribus*.
В качестве альтернативы предлагается метод факторного планиро-
планирования, т. е. метод, в котором все уровни некоторого фактора комбини-
комбинируются со всеми уровнями всех прочих факторов. Фишер [Fisher,
1966, р. 97, 100] показал, что факторные эксперименты более эффек-
эффективны, так как они дают более надежные оценки (главных) эффектов
факторов и, кроме того, позволяют оценивать взаимодействие между
факторами. (Точные определения главных эффектов и взаимодействий
мыдадим ниже2.) Примеры, показывающие различия между этими дву-
двумя методами, можно найти у Фишера [Fisher, 1966, р. 95—101] или
у Хикса [Hicks, 1966, р. 75—77]. Позднее Уэбб (Webb) построил спе-
специальные планы с одновременным варьированием одного фактора, но
признал, что «нельзя статистически доказать надежность эффектов
в этих планах» (ср. [Webb, 1968b, p. 549]). Мы отметим, что в социаль-
социальных науках факторные планы не получили широкого распространения,
поскольку в этой области трудно получить все комбинации уровней
факторов так, чтобы все сопутствующие переменные (т. е. факторы, не
включенные в эксперимент) оставались константами. Однако при моде-
моделировании социальной системы все факторы подконтрольны и их уров-
уровни можно комбинировать как угодно.
Выше мы определили факторный эксперимент как план, в котором
все уровни каждого фактора встречаются со всеми уровнями всех про-
прочих факторов. Различные уровни некоторого фактора могут соответст-
соответствовать качественным различиям (вроде разных дисциплин обслужива-
обслуживания очереди) или количественным различиям (вроде разного числа об-
обслуживающих станций). Если фактор / (/ = 1 k) имеет Lf уровней,
то общее число комбинаций уровней есть 3:
LXL.,... Lh= П Lt. A)
Значит, если у всех факторов равное число уровней, например L,
то общее число комбинаций уровней будет Lk. Левую часть выражения
A) используют также для обозначения типа факторного плана. Если,
например, имеется один фактор на двух уровнях и два фактора на
трех, то это обозначается так: план 2 X З2.
Рассмотрим пример двухфакторного эксперимента с одним фактором
на двух и одним на трех уровнях и с двумя наблюдениями в каждом
опыте. Результаты опытов приведены в табл. 1. Из этой таблицы вид-
видно, что уиг обозначает g-e. наблюдение (g = 1, 2) в ячейке i, /; в этой
ячейке фактор А имеет уровень i (i = 1, 2, 3), а фактор В — / (/ ==
* Это латинское выражение означает «при прочих равных (условиях)»,
т. е. речь идет об изменении факторов по одному, что у нас обычно называют
классическим экспериментом. — Прим. перев.
1, I'). OliiniifiMiiM магматическое ожидание yUg через r\tj. В плани-
|t()i!!iiiiin 'ла'пернмопта предполагается верной следующая модель:
Уив
+ ei]8 (i = 1 /), (/ = 1, .... J), (g = 1, 2, ...), B)
где ei]g — ошибка опыта (или шум, или флуктуация), которая пред-
предполагается независимой нормально распределенной случайной вели-
величиной со средним, равным нулю и постоянной дисперсией о2, или, ко-
коротко,
eU8 : NID @, а2). C)
Таблица 1
Пример факторного плана
Фактор А
Уровень 1
Уровень 2
Уровень 3
Фактор В
уровень 1
J'na
J'an
Ли
Узи
У312
уровень 2
J'm
J'm
У221
У222
J'321
J'322
Общее, или суммарное, среднее определяется так:
' '
и
D)
где точка означает, что мы усредняем по всем значениям с соответст-
соответствующим индексом. Если мы усредним отклик для А на уровне i со все-
всеми уровнями В, то мы получим Аи т. е.
E)
Тогда af — главный эффект фактора А на уровне i — определяется
как разность между его средним и общим средним, т. е.
ai ~ ™i — F1 == Г1г. — Ц. .• (о)
Из уравнений D)—F) следует, что среднее главного эффекта равно
нулю, так как
i=i i j I i
Главный эффект фактора В на уровне / определяется следующим обра-
образом:
af=Bj—n=2Tb# // — и.=Ti.,- — т]„ , (8)
i I
10
что
S«f=O. (9)
i
Если мы допустим, что взаимодействия нет, то получится такая мо-
модель для планирования эксперимента:
Е (уш) = г\ц = [х + at + af. A0)
Из A0) вытекает, например, что
ЧП — 4i2 — <*i — <*а UU
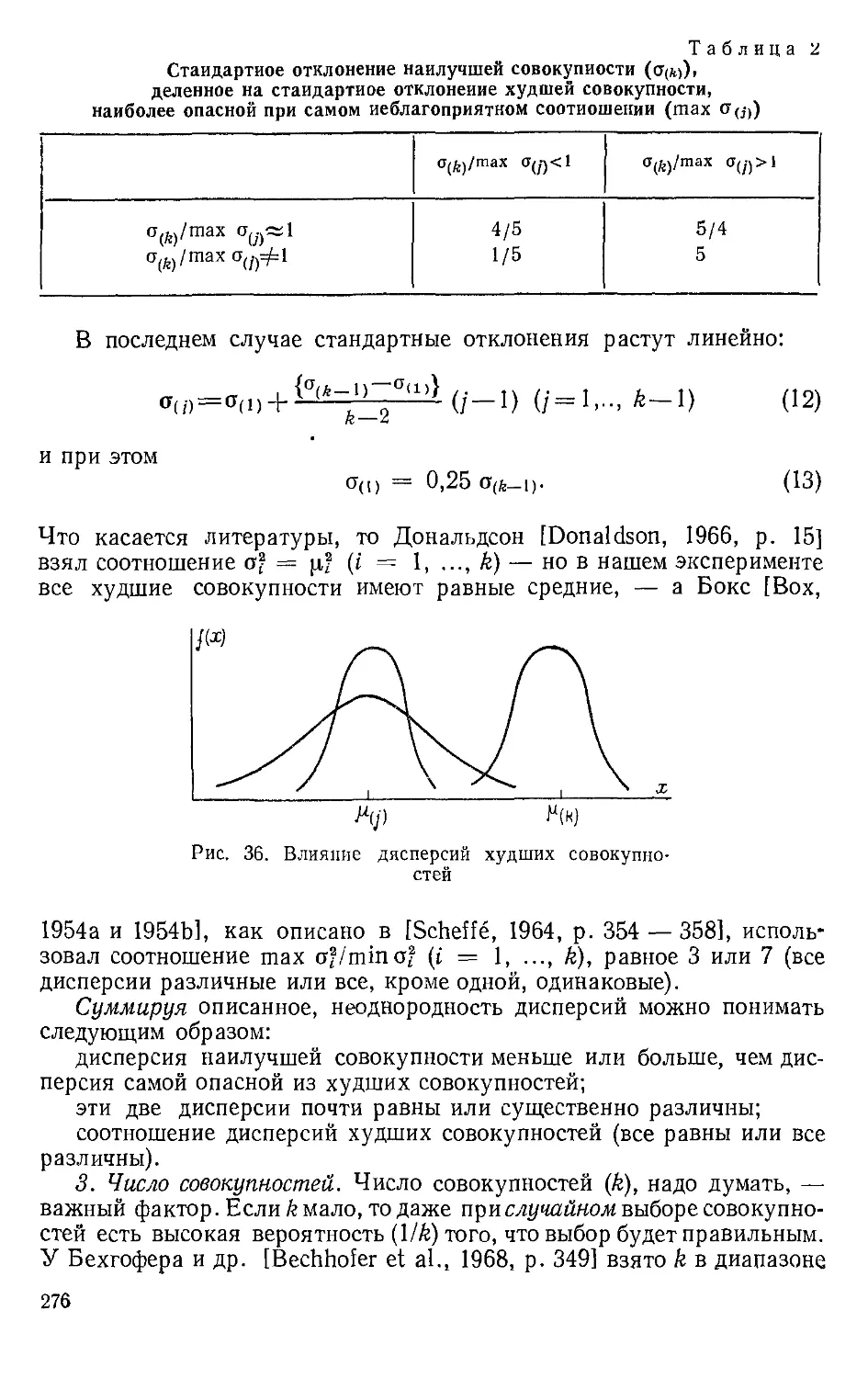
верно для есел; уровней i фактора А. Это соответствует рисунку с па-
параллельными кривыми отклика (см. рис. 20). Однако, когда есть вза-
Отнлик
v срактор В на
у*- уровне 2
ч фактор В на
црооне 1
1 2 3 Уровни
фактора Я
Рис. 20. Кривые отклика при отсут-
отсутствии взаимодействия
имодействие между факторами А и В, изменение фактора А приводит
к различным изменениям отклика на разных уровнях фактора В. Вза-
Взаимодействие для фактора А на уровне i и фактора В на уровне / опре-
определяется так:
<4jB = r\tJ — Ai—Bj+ v = r\tJ — т],. — r\.j + т]... A2)
Заметим, что, подобно тому как было для G) и (9), мы имеем а^в =
= af.B = 0. Верхний индекс обозначает факторы, участвующие во
взаимодействии, а нижний индекс — те уровни, для которых опреде-
определяется эффект. Общая модель, используемая в факторном плане с дву-
двумя факторами, такова4:
Е {уив) = I* + а* + «f + «3В A3)
л отсюда следует более частная модель A0).
Если число факторов больше двух, то мы можем обнаружить вза-
взаимодействия между двумя факторами, тремя факторами и т. д. Для
трех факторов уравнение модели факторного эксперимента выглядит
так:
= i\iih + eijug, A4)
И
-I* I <*1>\^Г-\-а)е + а?Г + а% + а7?+а?^ A5)
и
eUkg : NID @, a2). A6)
В A5) мы замечаем суммарное среднее:
главные эффекты:
22ц=Л«..-Л-, A8)
af = (//C)-1224iJft—Ц = Л.у. —П-., A9)
k
ил-Ц^Л.^-Л- - B0)
двухфакторные взаимодействия:
а«/В=Л«. —Л!.. — Л.;.+ Л..., B1)
<4С = Л|.* —Л*..—Л-* + Л..., B2)
afftC = Л.я — Л.}. — т]..л + Л- B3)
и взаимодействие трех факторов:
|Л —Ли. — Л1.ь —Л.л + Л1..+ Л.^. + Л..ь—Л...- B4)
О логических основах определения взаимодействия в трехфакторном
эксперименте можно найти у Шеффе [Scheffe, 1964, р. 119—121]. От-
Отметим, что если каждый эффект усреднить по любому из его индексов,
то получится нуль, т. е.
a<i = a? = aF = 0, B5)
АВ АВ АС АС „ВС ВС л /о(-\
щ, =<x.j =a,-. =tx.ft =a/. =<x.k =U, Bb)
ABC „ABC ABC п /о>7\
a. \k =a,.k =a//. =0. B7)
В общем случае & факторов модель включает суммарное среднее и
С* = : =& главных эффектов,
1! (к—• 1) I
С\ — : = — ~ двухфакторных взаимодействий,
2л \r—'2.) \ Z
12
k\
q\ (k-q)\
<7-факторных взаимодействий,
k\0\
/^-факторных взаимодействий.
B8)
Формальное определение ^-факторного взаимодействия приводится
у Шеффе [Scheffe, 1964, р. 124].
Наблюдения, полученные в факторном эксперименте, можно ис-
использовать для проверки значимости главных эффектов и взаимодей-
взаимодействий. Это делается с помощью хорошо известного дисперсионного ана-
анализа. Простейший случай, когда ANOVA применяется в эксперименте
с одним фактором на J уровнях и / наблюдениями на каждом уровне,
показан в табл. 2.
Таблица 2
Одиофакторный эксперимент
с / наблюдениями в ячейке
Наблюдения 1
Среднее
Уровни фактора
1 ... / ... J
Уи ••• Уи ••¦ Уи
уи ¦¦¦ Уи ¦ ¦¦ Уи
yIl ¦ ¦ ¦ yij ¦ ¦ ¦ y,j
y.j, ¦¦• y.j ¦¦¦ y.j y..
В приложении IV. 1 мы доказываем следующий хорошо известный
результат:
S2(>'^-^..J=22(>'.,—y..)a+22(j»- yj2- B9)
i i i j i i
Разложение суммы квадратов в левой части выражения B9) на
два слагаемых — основная идея дисперсионного анализа. (Если фак-
факторов будет несколько, то в правой части получится больше двух сла-
слагаемых.) Этот анализ называется дисперсионным, потому что, как
мы увидим в приложении IV. 1, каждое слагаемое в правой части (или
его обобщенный эквивалент для более чем одного фактора) приводит
к независимой оценке дисперсии ошибки а2, -если только фактор не
влияет (или для более чем одного фактора — если только главные
эффекты и взаимодействия равны нулю). Для получения этих оценок
а2 мы делим суммы квадратов на соответствующие им степени свободы
и приводим средние квадраты в табл. 3. Если же фактор влияет на
13
отклик, то ожидаемое значение «внутри уровней» остается равным
а2, тогда как средний квадрат «между уровнями» имеет (что можно по-
показать) выражение
22
i i J /
где о,- — обозначает главный эффект фактора на уровне /.
Таблица 3
Дисперсионный анализ для одного фактора с / наблюдениями в ячейке
Источник
Между уровнями
Внутри уровней
Общий, относительно
суммарного среднего
Сумма квадратов SS
Iiliiy-J-У--J
I i
22 (уи-y-jJ
i i
22 o^--*--)*
' i
Степени свободы
d!
J—l
J(I-i)
U—l
Средний квад-
квадрат MS
SS/df
SS/df
SS/df
Статистика, проверяющая влияние фактора, теперь очевидна. Если
верна гипотеза об отсутствии влияния фактора, то отношение двух
средних квадратов
MS между уровнями
MS внутри уровней
C1)
будет отношением двух независимых оценок о2, т. е. отношением двух
независимых случайных величин, имеющих ^-распределения с чис-
числом степеней свободы соответственно (/ — 1) и / (/ — 1), и это отно-
отношение имеет /^-распределение, которое табулировано. Если фактор
влияет, то C0) показывает, что числитель в C1) возрастет и ^-статисти-
^-статистика станет значимой. Поэтому большие значения F ведут к отбрасыванию
гипотезы об отсутствии влияния фактора.
ANOVA применяется и для более чем одного фактора. В этом
случае общая сумма квадратов
22- 2
-у-J
C2)
разлагается на несколько независимых сумм квадратов. Деление этих
сумм квадратов на подходящие степени свободы дает средние квадра-
квадраты— несмещенные оценки величин из соотношения C3), где С а,
14
Св, •¦¦, Cabc — известные положительные константы. В C0), на-
например, Сд = (/ — I)" / и все остальные константы отсутствуют.
главные эффекты,
двухфакторные взаимодействия,
C3)
и т. д.
При проверке того, значим ли некий конкретный эффект (главный
или взаимодействие), мы просто вычисляем отношение соответствую-
соответствующего среднего квадрата и среднего квадрата «чистой» ошибки и срав-
сравниваем это отношение с уровнем значимости из таблиц /?-распределе-
ния. Если проверка покажет, что оба фактора Л и Б не имеют глав-
главных эффектов, то мы складываем или «объединяем» их суммы квадра-
квадратов. Так как отдельные суммы квадратов независимы, их сумма снова
имеет ^-распределение с числом степеней свободы, равным сумме
индивидуальных чисел свободы. Поэтому мы делим объединенную
сумму квадратов на ее объединенные степени свободы и получаем
средний квадрат. Этот средний квадрат, деленный на средний квадрат
ошибки, имеет /^-распределение, если, конечно, гипотеза об отсутствии
главных эффектов А и В верна. Детали вычислений можно найти, ска-
скажем, у Хикса [Hicks, 1966] или Шеффе [Scheffe, 1964]. Вычислитель-
Вычислительные программы для ANOVA в факторном эксперименте есть, например,
в [Beaton, 1969],'[Bock, 1963], [Fowlkes, 1969] и [Peng, 1967, p. 219—
230]. В следующем параграфе мы приведем расчетные формулы для
тех факторных планов, которые нам интересны.
ANOVA изредка применялась в моделировании и в исследованиях
по методу Монте-Карло. Например, в имитационных экспериментах
с моделью национальной экономики Самуэльсона—Хикса (Samuel-
son—Hicks) и с моделью фирмы в [Naylor et al., 1967b; 1968] использо-
использовался план дисперсионного анализа с одним фактором на пяти уровнях.
Иенсен [Jensen, 1967] дал тщательно разработанный пример ANOVA
для эксперимента 24 в моделировании системы учета и отчетности.
В [Sasseretal., 1970] описан ANOVA для эксперимента 52 X 2 в моде-
моделировании системы управления запасами с многими потребителями 5.
В [Emshoff, Sisson, 1971, p. 211—214] обсужден эксперимент 22 с мо-
15
долью СНШ'МЫ u'Xiihmcckoi'o обслуживания; в [Sasser, 1969] и fSchink,
('hill, J00C1 использован ANOVA в монте-карловском эксперименте
Зц ио оценке работоспособности некоторых процедур регрессионного
анализа. Отметим, что в [Balderston, Hoggatt, 1962, p. 119—120]
применен непараметрический дисперсионный анализ в моделировании
рыночной деятельности.
Если фактор окажется значимым, то его уровни можно проранжи-
ровать в соответствии с их средними откликами. Для откликов от раз-
различных уровней можно построить доверительные интервалы. Обзор
этих так называемых методов множественных сравнений дан в следую-
следующей главе.
Модели, применяемые в факторных планах, можно еще предста-
представить как линейные модели обычного регрессионного анализа. Посколь-
Поскольку специалисты в социальных науках знают регрессионный анализ
лучше, чем дисперсионный, мы обсудим теперь различия между этими
методами с некоторыми подробностями. В качестве примера возьмем
двухфакторную модель для плана из табл. 1. Для простоты положим,
что нет взаимодействий и нет повторений. Из модели в уравнениях B)
и A0) следует, что
Ун = ц + of + а? + вш
у12 = ii + of + а? + е12,
C4)
у32 = |х + а? + а
ea2
или в матричных обозначениях6
где у — вектор наблюдений
C5)
C6)
X — матрица причинных или независимых («фиктивных») факторов
1 i 1 00 I 1 0
1 i 1 00 I 0 1
1 J 0 1 0 I 1 0
1 I 0 1 0 I 0 1
1 I 00 1 I 1 0
_ 1 I 0 0 1 ! 0 1
C7)
с прерывистыми линиями, разделяющими X так, что первый столбец
соответствует \i, столбцы со 2-го по 4-й — af (i = 1, 2, 3), а столб-
столбцы 5 и 6 — af (j = 1, 2), р — вектор эффектов или параметров
16
Р'=(ц, <,<«! af.af) C8)
и е — вектор «ошибок»
e' = (ellt en,..., ез2), C9)
причем е^ удовлетворяют уравнению C). Матрица X имеет неполный
ранг, так как, например, суммы столбцов 2—4 или 5 и 6 дают первый
—у
столбец. Можно показать, что ранг X равен четырем. Из G) и (9)
следуют двухсторонние условия, а именно
а? + а* + а3л = 0 D0)
а? + а| = 0. D1)
Эти два ограничения вместе с так называемыми нормальными урав-
уравнениями
X' у=Х' X р, D2)
следующими из C5), дают единственные оценки метода наименьших
квадратов (МНК-оценки); см., например, [John, 1971, р. 26—28].
В регрессионном анализе хорошо известно, что если справедливо C),
то МНК-оценки одновременно будут и оценками максимального прав-
правдоподобия, и линейными несмещенными оценками с минимальными
дисперсиями (ср. в [Johnston, 1963, р. 108—116]).
Можно посмотреть, например, в [Peng, 1967, р. 175—179], а так-
также в [Scheffe, 1964, р. 98—102], что детальная разработка D0)—D2)
дает следующие оценки, которые хорошо известны нз ANOVA (и ин-
интуитивно приемлемы):
р=у.., D3)
«t=yt.-y~ (*=1,2,3), D4)
*?=y-j~y~ (/=1,2). D5)
Теперь мы можем проверить, не равны ли нулю некоторые параметры
f>. Проверочные формулы приводятся, например, в [Johnston, 1963,
р. 115—126], [Peng, 1967, р. 173-175] и [Scheffe, 1964, р. 25—45].
Расписывание этих формул для конкретных моделей факторных пла-
планов дает известные таблицы сумм квадратов ANOVA вроде табл. 3
(ср., например, [Peng, 1967, р. 178—179]). По поводу сравнения регрес-
регрессионного и дисперсионного анализа мы отсылаем также к [Seeger
1966, р. 6—13] и [Smith, 1969].
Резюмируем: модели факторных планов — это частные случаи
общей линейной регрессионной модели. Вектор параметров fJ содер-
17
жит суммарное среднее, главные эффекты и взаимодействия; матрица
независимых переменных X состоит, как было видно, только из нулей
и единиц. (В IV.3 мы встретим несколько иную формулировку, где
X состоит только из плюс или минус единиц.) Эксперимент планиру-
планируется — это значит, что X выбирается так, чтобы оценки имели некото-
некоторые желательные свойства, к которым мы еще вернемся ниже.
Дисперсионный анализ приспособлен как к качественным, так и к
количественным факторам. Если все факторы количественны, то мы
можем использовать ANOVA для проверки, есть ли эффект некоторого
фактора без уточнения (в виде регрессионной кривой) того, как меня-
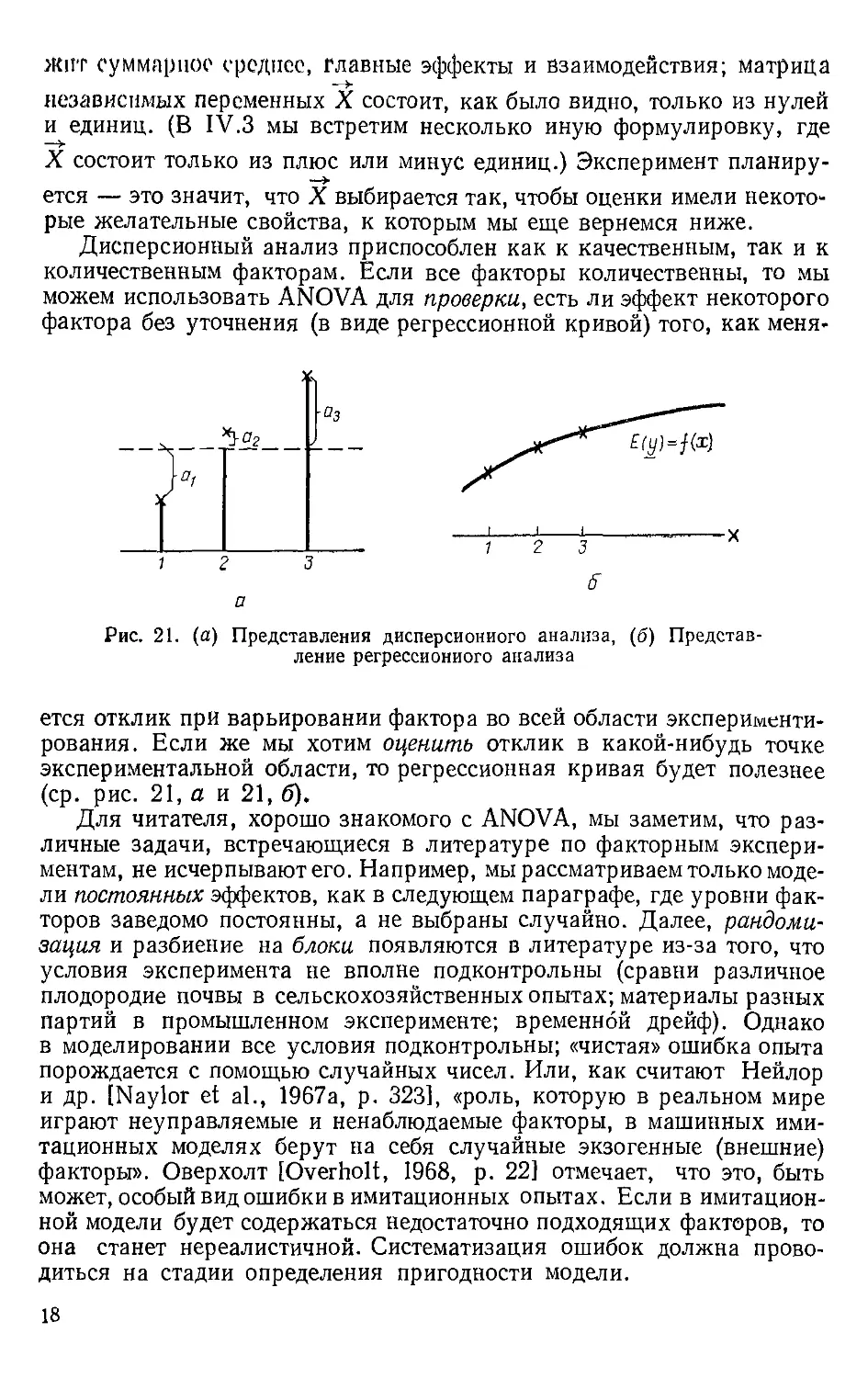
Рис. 21. (а) Представления дисперсионного анализа, (б) Представ-
Представление регрессионного анализа
ется отклик при варьировании фактора во всей области эксперименти-
экспериментирования. Если же мы хотим оценить отклик в какой-нибудь точке
экспериментальной области, то регрессионная кривая будет полезнее
(ср. рис. 21, а и 21, б).
Для читателя, хорошо знакомого с ANOVA, мы заметим, что раз-
различные задачи, встречающиеся в литературе по факторным экспери-
экспериментам, не исчерпывают его. Например, мы рассматриваем только моде-
модели постоянных эффектов, как в следующем параграфе, где уровни фак-
факторов заведомо постоянны, а не выбраны случайно. Далее, рандоми-
рандомизация и разбиение на блоки появляются в литературе из-за того, что
условия эксперимента не вполне подконтрольны (сравни различное
плодородие почвы в сельскохозяйственных опытах; материалы разных
партий в промышленном эксперименте; временной дрейф). Однако
в моделировании все условия подконтрольны; «чистая» ошибка опыта
порождается с помощью случайных чисел. Или, как считают Нейлор
и др. [Naylor et al., 1967a, p. 323], «роль, которую в реальном мире
играют неуправляемые и ненаблюдаемые факторы, в машинных ими-
имитационных моделях берут на себя случайные экзогенные (внешние)
факторы». Оверхолт [Overholt, 1968, р. 22] отмечает, что это, быть
может, особый вид ошибки в имитационных опытах. Если в имитацион-
имитационной модели будет содержаться недостаточно подходящих факторов, то
она станет нереалистичной. Систематизация ошибок должна прово-
проводиться на стадии определения пригодности модели.
18
Наличие ошибки опыта приводит к трем основным предпосылкам
ANOVA. Как мы отметили в C), при применении ANOVA к фактор-
факторным экспериментам (да и при планировании таких экспериментов)
предполагается, что ошибки распределены нормально и независимо
с постоянной дисперсией. В имитации ошибки опытов можно сделать
независимыми, применяя различные последовательности случайных чи-
чисел в разных опытах. В целом, однако, они не обязаны быть нормально
распределенными с общей дисперсией. Поэтому мы должны рассматрИ'
иать влияние ненормальности и неоднородности дисперсий в ANOVA.
Шеффе [Scheffe, 1964, р. 345, 350, 358] утверждает, что если число сте-
степеней свободы очень велико, то ненормальность не слишком влияет на
мощность /-"-критерия. Что касается неравенства дисперсий, то его
нлияние на мощность тоже мало, если равны числа наблюдений в «ячей-
«ячейках» (равны для всех комбинаций уровней факторов), но при наруше-
нарушении этого равенства влияние может стать весьма значительным. Для
малого числа степеней свободы Шеффе предлагает считать, что ненор-
ненормальность все равно не влияет на F-критерий, особенно при равном
числе наблюдений в ячейках. В случае неравных дисперсий при рав-
равном числе наблюдений, если только не ясно, что в некоторых ячейках
гшачительно большие дисперсии, стоит и в этом случае взять больше
наблюдений в этих ячейках. Позднее исследование робастности (устой-
(устойчивости) F-критерия проведено Дональдсоном [Donaldson, 1966]. Он
изучал влияние больших отклонений от предпосылок нормальности
и равенства дисперсий ошибок опытов, ограничившись случаем одно-
факторного эксперимента с равным числом наблюдений на каждом
уровне. Для этих условий он нашел вполне приемлемые влияния а- и
Р-ошибок на /^-критерий. Тем не менее Иенсен [Jensen, 1966, р. 235—
236] в своей имитационной работе проверял нормальность (по крите-
критерию Колмогорова—Смирнова) и однородность дисперсий (по критерию
БартлеттаO. Нарушение предпосылок дисперсионного анализа можно
обнаружить при анализе оцениваемых остатков и = у — у (у — это
оценочный отклик); см. [Anscombe, Tukey, 1963]. Так как в ANOVA
предполагается нормальность, мы можем использовать непараметриче-
непараметрический, или свободный от распределений, вариант. Дальнейшее развитие
такого непараметрического анализа (включая ANOVA и другие методы,
с возможным распространением на многооткликовый случай) дается
и [Puri, Sen, 1971, например, р. 103, 221, 266—277, 286—300, 331—337].
Однако, как отметил Дональдсон [Donaldson, 1966, р. 44], /^-критерий
и параметрическом дисперсионном анализе весьма нечувствителен
к ненормальности, тогда как неоднородность дисперсий нарушает
и параметрический и непараметрический варианты ANOVA.
Мы только что видели, что F-критерий не слишком чувствителен
к ненормальности и к неоднородности дисперсий. Тем не менее мы мо-
можем попытаться сделать экспериментальные данные (более) нормально
рлспределенными с общей дисперсией. Особенно благоприятные усло-
DH5I для этого возникают при моделировании систем без останова
(определенных в II.8). Такие системы мы можем моделировать непре-
непрерывно до тех пор, пока опыт для данной комбинации факторов не даст
19
постоянной дисперсии. Другой регулярный метод получения постоян-
постоянной дисперсии преобразование исходных данных. Описание подхо-
подходящих преобразований можно найти в [Mendenhall, 1968, р. 206—208],
[Peng, 1967, р. 183—185] или [Scheffe, 1964, р. 364—368]. Там можно
увидеть, что если исходная переменная у имеет среднее ц и дисперсию
а2, так что а2 можно выразить как функцию от ц,, скажем
о2 = /
D6)
то новая переменная у* будет иметь приблизительно постоянную
дисперсию, если
D7)
*/* =
Ш
Применения D6) и D7) приведены в табл. 4
Преобразование для постоянства дисперсий, если
var (y) = f (|A) при м=Я()
Таблица 4
var (ji) = f (ц)
[г (Пуассона)
(х A—ц/п) (биномиальное)
(г A — [г)//г (биномиальное)
с2[г2 (с—константа)
У*
(*>*
arcsin (уIn)'2
в радианах
arcsin (г/)^
1пг/
Приближение
var (у*)
1/4
1/D ft)
1/D ft)
С2
Мы видим, что последний случай в табл. 4 f (|л)= сг\х2 справедлив,
если отклик у есть оцениваемая дисперсия некоторой переменной
х т е
y = 8i. D8)
Шеффе [Scheffe, 1964, р. 83] доказал, что
(х = Е (у) = ? (si) =
ft—1
JV2 1_
ft
—1
D9)
E0)
ГДе ?2 — меРа эксцесса, сводящаяся к нулю, если х нормально рас-
распределен. Дополнительные ссылки о преобразованиях см. в [Andrews,
1971], [Dolby, 1963] и [Draper, Hunter, 1969].
Преобразование можно использовать и для получения более нор-
нормального распределения переменных. Так как ненормальность менее
20
важна, чем неоднородность дисперсий, преобразования чаще приме-
применяются для достижения постоянства дисперсий. (Нормальность и об-
общая дисперсия, как наблюдал Шеффе [Scheffe, 1964, р. 367], могут
при преобразовании вступать в противоречие.) Нейлор [Naylor
et al., 1968] применил логарифмическое преобразование при анализе
si, где х — моделированный национальный доход. Такое преобра-
преобразование одновременно избавило от ненормальности и от неоднородности
дисперсий. Трудная проблема может возникнуть из-за того, что пре-
преобразование меняет интерпретацию отклика; например, не ясно что
означает arcsin национального дохода? Много примеров есть у Шеффе
fScheffe, 1964, р. 366]. В эксперименте с одним фактором нет никаких
проблем, как в упомянутой выше работе Нейлор а и др. Так, если ? (.у)
не меняется от одного уровня фактора к другому, то и Е [g (у)] тоже
не меняется.
Преобразования приводят к идее кодирования натуральных пере-
переменных или факторов. Если факторы качественные,™ мы можем при-
приписать числа уровням этих факторов просто из мнемонических сооб-
соображений. Но если факторы количественные, то исходные переменные
обычно кодируются так, чтобы «нормировать» кодированные факторы,
т. е. получить переменные со средним нуль и размахом от — 1 до + 1.
Мы увидим в следующем параграфе, что такое кодирование упрощает
вычисление параметров, поскольку требует обращения лишь диаго-
диагональной матрицы; ошибки округления уменьшаются. В качестве при-
примера' влияния кодирования мы рассмотрим регрессионное уравнение
E1). (Как будет видно в IV.3, это уравнение можно представить в виде
модели дисперсионного анализа с главными эффектами рг и двухфак-
торными взаимодействиями рг7-.)
У=Ро + 2М*+ % У hjx,xj + e, E1)
t = i t=\ i=i\
где xt — нормированный фактор, полученный после кодирования ис-
исходного фактора г„ как показано в E2):
E2)
Из E1) и E2) следует, что
izi+ 2 2 VtjW + e, E3)
i ii
где
i ,p,,, E4)
E5)
E6)
21
Следои.тюлыю, voiu у стандартизованных переменных нет взаимо-
взаимодействий, т. с. $tj -- 0, то отсутствия у xt главного эффекта ф( = 0)
достаточно для того, чтобы и у исходной переменной не было глав-
главного эффекта (т. е. yt = 0). (Если же есть взаимодействие, то сказы-
сказывается влияние варьирования уровней факторов и главные эффекты
уже нельзя измерить так легко, как выше.) Заметим, что в E1) и E3)
отклик изменяется при изменении какого-либо фактора. Из E3), на-
например, следует, что при Zj = 0 (/ Ф i)
-^-Yi. E7)
d
а из E1) и E2) получается, что при Zj = 0 или, что эквивалентно,
при Xj — bj,
J J| ( 2)I=a7l. E8)
Более подробно о кодировании можно прочесть в [Mendenhall,
1968, р. 221—229, 251—257]. Отметим, что параметры регрессии —
это условные отклики (см. также [Mihram, 1972, р. 359—360]).
IV.3. ФАКТОРНЫЕ ПЛАНЫ С ФАКТОРАМИ НА ДВУХ УРОВНЯХ
Частный класс факторных планов образуют планы, в которых
каждый фактор имеет только два уровня. Поэтому если есть k факто-
факторов, то общее число комбинаций будет 2k. Такие эксперименты назы-
называются факторными экспериментами типа 2к, Один или несколько
факторов могут быть качественными; например, возможен фактор
«дисциплина обслуживания» на двух уровнях: «обслуживание в по-
порядке поступления» и «обслуживание в обратном порядке». Для коли-
количественного фактора уровни соответствуют предельным значениям,
которые допустимы для фактора в данном эксперименте.
Рассмотрим пример двухфакторного эксперимента без повторений,
показанный в табл. 5. Из B) и A3) следует такая модель:
уп = ц + а? + а? + алв + еи,
у13 = \i + а* + а| + сслв + е^
Уп = I* + < + «? + <в + е*ъ E9)
3>22 = (А + «л + а| + а*в + е22,
которую тоже можно представить в матричной форме, подобно C5)—
C9). МНК-оценки параметров модели E9) можно найти, учитывая
дополнительные условия, следующие из G), (9) и A2):
а?=-а?, F0)
*?=-*?, F1)
22
Ав —
a21 ail »
„AB nAB I r/AB\
K22 a21 \— aill-
Таблица 5
Эксперимент 23 без повторений
Фактор А
Уровень 1
Уровень 2
Фактор В
уровень 1
Уи
3>21
уровеьь 2
^12
32
Мы можем и прямо подставить F0)—F4) в E9), что даст:
А* + еп,
уи = |х — аА — ав
™
Уха = I* — <*А + otf -r- а
у21 = |х + ссА — af5
у22 = у, + аА + ав
В матричных обозначениях имеем
где
е12,
+ 1 -1 +1 -1
+ 1 -Ы -1 -1
+1 +1 +1 +1J
=(!*, аА, af,
е' = (вц, е1а, е2Ь е22).
Заметим, что столбцы X ортогональны, т. е.
F2)
F3)
F4)
F5)
F6)
F7)
F8)
F9)
G0)
G1)
где xt и Xj — любые два столбца X. Очевидно, X — невырожденная
матрица, следовательно, МНК-оценки р имеют вид:
&=(Х'Х)-*Х'3>. G2)
23
П cii.ny G1) и
*/** = # G3)
(N — число опытов (здесь N — 4)) получается, что*
(X'X) = NL G4)
Далее, h-я элемент Х'у приводится в соотношении G5) (h пробегает
значения от 1 до Я; Я — общее число параметров; в нашем примере
Я = 4).
где xgh — g-й элемент вектора xh. Подставляя G4) и G5) в G2), по-
получим
1 N
h — — V г v тел
h~~ n 2d 8hya- Gb)
Отсюда
i
fti = j* = — (Ун + 3>i2 + Уп + Уяд =У- , G7)
1
4
= -у.. + У».. G8)
Сравнивая G8) с определением а$:
<*$ =г\,. — Л... G9)
видим, что оценка этого эффекта аналогична самому эффекту. Таким
же образом мы можем показать, что МНК-оценки главного эффекта
af и взаимодействия a^f получаются просто по аналогии с их опре-
определениями в (8) и A2).
Важно отметить, что в матрице X первый столбец относится к сум-
суммарному среднему ц и содержит только единицы со знаком плюс.
Второй и третий столбцы соответствуют главным эффектам а^ и af
факторов А и В соответственно; g-й элемент (g = 1, ..., iV) такого
столбца принимает значение — 1, если соответствующий фактор на-
находится на «нижнем» уровне, и + 1, если фактор в этом опыте имеет
«верхний» уровень. (Для качественных факторов «нижний» и «верх-
«верхний» — всего лишь мнемонические символы для двух уровней.) Чет-
Четвертый столбец X представляет взаимодействие a^f; элементы этого
* / — стандартное обозначение единичной матрицы. — Прим. перга.
24
столбца суть произведения элементов второго и третьего столбцов.
Таким образом, мы можем записать регрессионную модель F6) так:
(g=l,...,N), (80)
s= I
где dgs = — 1, если фактор s находится в g-м опыте на нижнем уров-
уровне, и dkS = + 1, если этот фактор имеет верхний уровень; р0 — общее
среднее ц; CS — главный эффект s-ro фактора (т. е. Pi = ал = — ctj4
и р2 = af = — af) и р12 — взаимодействие двух факторов (р12 =
— а?? = — a^f = — afj* = a?f). Отметим, что уравнение регрес-
регрессии (80) — это полином второй степени без членов «чистых квад-
квадратов» (dJiPn) и (dg2$aJ, отсутствующих в модели ANOVA.
В плане, где все факторы имеют только по два уровня, требует-
требуется определение эффектов, несколько отличное от общего определе-
определения, данного выше. Так, «сам» главный эффект фактора А определяет-
определяется как средний отклик для верхнего уровня этого фактора минус сред-
средний отклик для нижнего уровня, т. е.
«А = Ъ. - %.• (81)
Следовательно,
«л - Оъ. — Л..) — К. — Ц.) = otf — a? = otf + a? =
= 2ал = — 2а?. (82)
Такое новое определение главного эффекта фактора в плане типа
2к соответствует удвоенному значению эффекта, определенного по-ста-
по-старому (и, быть может, с другим знаком; впрочем, знак здесь произволен,
ибо зависит от того, какой уровень мы назовем верхним, а какой —
нижним). Взаимодействие двух факторов переопределится так. Если
фактор В находится на верхнем уровне, то эффект фактора А есть
1122 — Т]12. (83)
а если В — на нижнем уровне, то эффект А есть
1121 — Ли- (84)
Поэтому если (83) и (84) различны, то имеет место взаимодействие.
Взаимодействие определяется как «средняя» разность между (83) и
(84), т. е.
«лв = -~ [AЪ-1Ъ)-A121 -Ли)]- (85)
Из A2) следует, что
Olii-t-тг)
2 (Ли —Л1-—Лч +Л-)==2 [ли — -
t 2 Л12 2 Л21+ 2 Л22 <
(86)
25
Тнк (86) вместе с F2)~ F4) показывают, что новое определение «са-
«самих» взаимодействий дает значение, вдвое отличающееся от старых,
быть может, с переменой знака.
После примера с двумя факторами рассмотрим теперь общий слу-
случай k факторов на двух уровнях. Вместо структуры 2 X 2 из табл. 5
возьмем теперь представление для k = 3, показанное в табл. 6.
В этой таблице нижние уровни факторов обозначены — 1, а их
верхние уровни + 1. Для k факторов столбец, соответствующий
s-му фактору (s = 1, ..., k), содержит сначала 2<s-!> раз — 1,
затем 2<s-!) раз + 1; 2(s-') раз — 1 и т. д. Отклик обозначается
так: если фактор Л в некотором опыте находится на верхнем уровне,
то в обозначении отклика появляется буква а, если же фактор нахо-
находится на нижнем уровне, то буква а в обозначении отсутствует. Так
же поступают и с остальными факторами.
Таблица 6
Эксперимент 22 без повторений
Комбинация
1
2
3
4
5
6
7
8
Фактор
А
I +1 + 1 +1 +
В
+ 1
+ 1
+ 1
+ 1
С
11II++++
Отклик
1
а
b
ab
с
ас
be
abc
Так, комбинация, в которой все факторы находятся на нижних уров-
уровнях, обозначается 1. Кроме того, в последнем случае обычно сочетания
букв обозначают не роль в комбинации некоторого фактора, но ком-
комбинацию саму по себе.
Аналогом (81) нового определения главного эффекта фактора
А в плане типа 2* будет
= т|г.... —
(87)
где число точек равно (k — 1). Хорошо видно, что новое определение
дает вдвое большее значение главного эффекта, чем старое. Однако
если эффекта фактора нет, то в обоих случаях получится нуль. Новое
определение представляет эффект А как разность между главными от-
откликами А на верхнем и нижнем уровнях. Следовательно, при оце-
оценивании аА мы вычитаем средний отклик фактора Л на нижнем уровне
(когда другие факторы варьируют на верхних и нижних уровнях) из
среднего отклика этого фактора на верхнем уровне. Обозначим общее
число опытов в эксперименте через N. Тогда получим N = 2k. Из спо-
способа построения плана типа 2ft видно, что в одной половине опытов
26
фактор А находится на верхнем уровне, а во второй — на нижнем
(ср. с табл. 6, где знаки фактора А чередуются). Так,
N12 N12 К '
причем индекс I относится к откликам тех комбинаций, в которых
фактор А имеет верхний уровень, а / — соответственно нижний. По-
Поэтому (88) эквивалентно следующему:
(89)
где xgl—g-a элемент столбца первого фактора (т. е. фактора А).
В общем, оценка главного эффекта фактора s есть
«s=4 2**«У* (s = l,...,ft), (90)
где xgs есть — 1, если фактор s находится на нижнем уровне в g-м
опыте, и + 1, если фактор s — на верхнем уровне. Можно показать,
что аналогично E9) — G9) оценка в (90) — это МНК-оценка главного
эффекта as фактора s. В приложении IV.2 приведен пример оценива-
оценивания взаимодействия двух факторов в плане 23. Можно доказать, что
МНК-оценка взаимодействия между факторами /, т, ..., г есть
N g = i
МНК-оценка общего среднего
N
xg0 уЙ, (92)
где
х8о = 1 (S=h ..-, #). (93)
В факторном эксперименте типа 2k есть 2k комбинаций, или «экс-
«экспериментальных точек». Каждую экспериментальную точку можно
представить как точку в ^-мерном пространстве, имеющую координа-
координаты (чь 1, ± 1, ••-, ± 1)- Если мы обозначим число комбинаций, или
«опытов» в эксперименте, через N, то можно определить так называе-
мую матрицу плана D:
D = {du}, i = 1, 2, ..., N; I = 1, 2, ..., k, (94)
где du равно — 1, если /-й фактор находится на нижнем уровне в г-й
комбинации, и т. д. После добавления столбца из плюс единиц /
27
и гич'Х cttvi()iu)B произведений исходных факторов по два, по три и т. д,
-*¦ —>¦
мы получим из матрицы D матрицу независимых переменных X.
Для fe—3 матрицы D и X приведены в табл. 7, в которой сохранены
только знаки плюс и минус без подразумеваемых единиц.
Таблица 7
Матрица плана и матрица независимых переменных
для эксперимента 23
Матрица плана D
Т
_
+
—.
+
+
—•
+
_
—
+
+
—
+
+
_
—
—
—
4-
+
+
Матрица независимых переменных X
Г
+
_]-
+
-|-
-\-
+
_
—
+
—
—
+
—
-)-
—
—
+
—
—
—
+
+
+
+
—>¦
12
+
—
i
+
—
+
It
+
—
+
—
+
—
+
2?
+
+
—
—
—
+
+
123
_
-)-
—
+
—
—
Общее среднее, главные эффекты и все взаимодействия можно оце-
—>¦
нить, перемножая соответствующий столбец матрицы X со столбцом
наблюдений у, как в (92), (91) и (90) соответственно. Очевидно, урав-
уравнение регрессии для модели ANOVA с k факторами на двух уровнях,
данное в (95), обобщает (80).
У г =
е, - |За
У 1
S=l Z=S+1
dlt
2 2
s=lz=s+l
2
(95)
где л:г; и dJS — элементы матриц X и D; / = 2k — число регрессион-
регрессионных параметров у у, эти параметры у}- обозначают общее среднее р0,
главные эффекты J3S, двухфакторные взаимодействия psz, ..., взаимо-
взаимодействие k факторов Pi2...ft, если использовать общие определения
этих эффектов в IV.2. Если же взять частные определения из этого
параграфа для экспериментов типа 2*, то у; будут обозначать полови-
половины главных эффектов и взаимодействий.
Имея оценки эффектов, можем теперь найти их дисперсии и кова-
риации. Допустим, что ошибки опытов независимы с общей дисперсией
а2. Возьмем формулу для ковариационной матрицы Qy МНК-оценок
28
in (95). Хорошо известно (см., например, [Johnston, 1963, р. ПО]),
что
й,=оЧХ'Х)-\ (96)
—>¦
где X — матрица независимых переменных. Из структуры факторного
—> —>
эксперимента видно, что столбцы хг матрицы X удовлетворяют усло-
условиям:
-> —У
х[ Xj =-0, если i Ф j,
= N, если t —/. (97)
Следовательно,
QT=-?-7. (98)
Теперь мы можем вспомнить, что главные эффекты и взаимодействия
(но не общее среднее) обычно определяют как удвоенные соответст-
иующие у). Поэтому дисперсии оценок главных эффектов и взаимодей-
взаимодействий будут 4а2/ЛГ; дисперсия оценки главного среднего останется
ог/Ы и все ковариации останутся нулями.
Теперь уже видно, как мы можем проводить гипотезу о том, что
некий эффект (главный или взаимодействие) не важен. Каждый эф-
эффект имеет одну степень свободы, поскольку у факторов по два уровня
(ср. с общими формулами для степеней свободы, например, в [Scheffe,
1964, р. 125]). Из [Hicks, 1966, р. 102, 106—107] следует, что SS, —
сумму квадратов эффекта / (/ = 1, 2, ..., 2k — 1) — можно вычислить
по общим формулам или «методом Иейтса» (Yates) для планов 2k.
Эго дает
557 = г-2*-2-(эффект;J(/=1,..., 2*—1), (99)
где г — число параллельных опытов в экспериментальных точках
(г > 1). Если г > 1, то сумма квадратов ошибок, входящая в знамена-
знаменатель /^-статистики, равна:
SSe^SSo6n,-2^SSj, A00)
причем
N (yN v Y
^?11 (N = 2*-r). A01)
? (N 2r).
i = l
Число степеней свободы для SSe есть
2fe (г — 1), A02)
iilit как на каждый опыт приходится (г— 1) степеней свободы. При
• неутствии дублирования (г = 1) в A02) получится нуль. Поэтому
имш нет независимой априорной оценки о2,то можно положить равны-
НП пулю некоторые взаимодействия и объединить их для получения
29
HiMi n\ I'i'Jiii, например, эффекты, соответствующие SSU SS2, ...
SHm, положить равными нулю, то объединенная оценка а2 будет
т
В IV.6 мы еще нерисмси к получению независимой оценки для дис-
дисперсии ошибки опыта 0IJ. Отметим, что при проверке одного эффекта
f одно!! пччкчгыосиободы можно использовать и ^-критерий (поскольку
t'\iV tb). При одновременной проверке нескольких эффектов мы
работаем с ^-статистикой. Пример мы приведем в главе VI, (89) и (92).
Теперь кратко вернемся к преимуществам факторного плана в срав-
сравнении с методом варьирования факторов по одному. Пусть мы имеем
N наблюдений. Определяя главный эффект первого фактора, возьмем
N12 опытов на нижнем и столько же на верхнем уровнях. В факторном
плане распределим N12 на нижнем уровне фактора 1 равномерно между
верхними и нижними уровнями остальных (k — 1) факторов;так же
мы поступим и с остальными N12 опытами для фактора 1. Точность
нашей оценки главного эффекта первого фактора при этом не изменит-
изменится, но факторный план допускает одновременно и оценку эффектов всех
остальных факторов.
Уравнение B8) показывает, что есть Ckq ^-факторных взаимодей-
взаимодействий (q — 2, ..., k) и С? главных эффектов; всего B* — 1) эффектов.
Таким образом, (г • 2k) опытов можно употребить для оценки этих
Bk — 1) эффектов плюс общее среднее; всего 2к оценок (ср. также с
[Hicks, 1966, р. 107]). В табл. 8 показано, как с ростом k растет число
эффектов и число опытов, потребных для их оценки.
Таблица 8
Число факторов (k) и число опытов Bк)
k
1
2
2
4
3
8
4
16
5
32
6
64
7
128
8 ...
256 ...
Однако при больших k появляются взаимодействия очень высоких
порядков. Взаимодействия высоких порядков часто предполагаются
пренебрежимыми на основе априорных соображений, предваритель-
предварительных опытов, общих соображений или по другим причинам. Пример та-
таких «других причин» мы приведем в IV.5. Там все факторы будут ко-
количественными, а взаимодействия высоких порядков соответствуют
членам высокого порядка в регрессионном полиноме; члены высокого
порядка полагаются равными нулю, поскольку считается, что полином
низкого порядка даст адекватное регрессионное уравнение. Если не-
некоторые эффекты предполагаются равными нулю, то мы не обязаны
делать наблюдения во всех 2к экспериментальных точках; часть от
этих 2* точек тоже может подойти. Дробный факторный эксперимент-
предмет обсуждения в следующем параграфе.
30
IV,1 ОСНОВЫ ДВУХУРОВНЕВЫХ ДРОБНЫХ ФАКТОРНЫХ ПЛАНОВ
В предыдущем параграфе мы показали, что с ростом числа фак-
юров число опытов растет еще быстрее, даже если все факторы варь-
варьируют только на двух уровнях. Мы также заметили, что если можно
положить некоторые эффекты равными нулю, то нужно меньше чем
21' опытов. В этом параграфе мы рассмотрим вопрос о том, какие имен-
именно наблюдения надо выбрать. Чтобы сделать такой выбор, мы должны
(мать, к каким следствиям ведет отбрасывание опытов. Мы начнем
с примера.
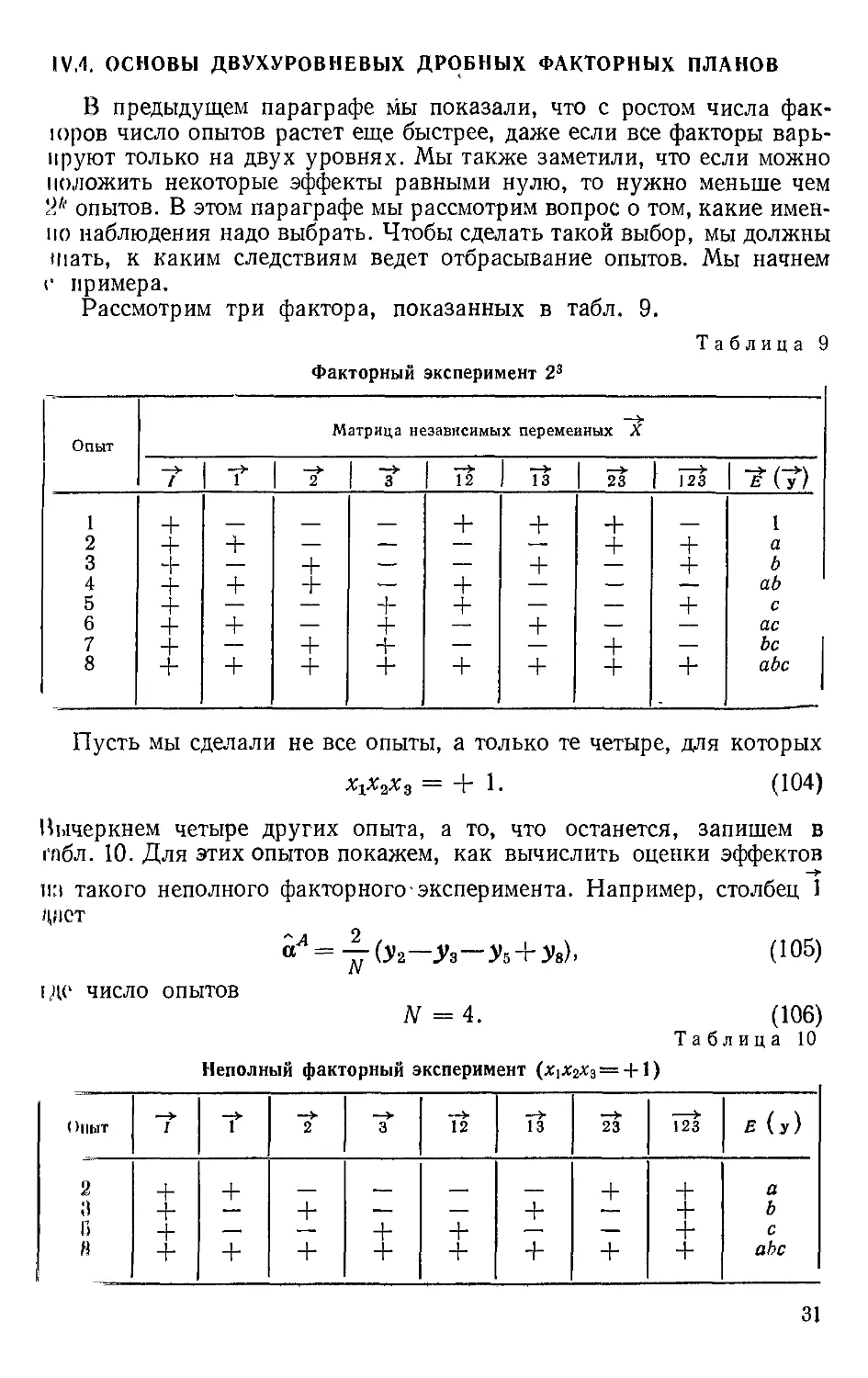
Рассмотрим три фактора, показанных в табл. 9.
Таблица 9
Факторный эксперимент 23
Опыт
1
2
3
4
5
6
7
8
Матрица независимых переменных X
+
1
+
+
_]_
[
+
г
-
—
-j-
+
t
i
—
+
~t
—
-)-
+
I?
+
—.
+
+
+
—
-j-
+
si
+
—
—
—
+
тгз
_
+
+
—
+
tan
!
a
b
ab
с
ас
be
abc
Пусть мы сделали не все опыты, а только те четыре, для которых
г„г г = 4- 1 Л04)
X 2 3 1* \ v /
Вычеркнем четыре других опыта, а то, что останется, запишем в
|'абл. 10. Для этих опытов покажем, как вычислить оценки эффектов
на такого неполного факторного-эксперимента. Например, столбец 1
дмст
A05)
N
1ДС ЧИСЛО ОПЫТОВ
N =4.
Неполный факторный эксперимент
A06)
Таблица 10
Опыт
2
а
Г)
я
+
+
+
+
—
+
~t
+
—
+
3
_
—
+
It
_
—
+
+
+
—
н-
+
—
+
Тгз
+
+
+
+
я (у)
а
b
с
abc
31
Формула A05), конечно, верна, так как фактор 1 — на нижнем уров-
уровне в опытах 3 и 5 и на верхнем — в опытах 2 и 8. Следовательно, эф-
эффект фактора А есть
a-\-abc Ь-\-с 1 , , , . „„„,
—2 ^^—(a-b-c + abc). A07)
Рассмотрим теперь столбец 23:
Как видно из последующего, A08) верно. Аналогично (83)—(85)
взаимодействие между В и С есть средняя разность эффектов В и С
на их верхних и нижних уровнях соответственно. Эффект В при С
на верхнем уровне можно измерить как abc—с; эффект В при С на
нижнем уровне — как Ь—а. Полуразность между этими эффектами
есть
^^±^ A09)
Теперь сравним A08) и A05). Так, мы видим, что получаются те же
самые значения аА и авс. Или другим путем, используя последний
столбец табл. 10, найдем
Е (у2 — Уз — Уь + У в) = а — Ь — с + abc. A10)
Правую часть (ПО) можно переписать как A11), для которого A06)
уже справедливо:
2
а—b—c-\-abc = — (—1 -\-а—b + ab—с + ас—Ьс-\-аЬс)-{-
+ — (+l+a—b—ab—c — ac-lrbc + abc). (Ill)
Наконец, с помощью (90) и (91) мы можем записать A11) так:
а — b — с + abc = а* + авс. A12)
Объединяя A12) и A10), получаем
Е (У* - У, - У, + У*) - «л + ^с. A13)
Так, из дробного факторного эксперимента в этом примере следует,
что мы имеем одни и те же значения для главного эффекта фактора А и
взаимодействия факторов В и С, фактически вычисленное значение —
сумма обоих эффектов. Это так называемые смешанные эффекты, или
эффекты, оцениваемые совместно (вместе). Конечно, если взаимодейст-
взаимодействие равно нулю, то у2 — у3 — уь + ув будет несмещенной оценкой аА.
Обобщая для плана 2k, мы получим полуреплику, отбрасывая из
таблицы полного факторного плана те строки, которые имеют знак
32
плюс для какого-нибудь эффекта (или, наоборот, которые имеют знак
минус). Напомним, что каждый эффект имеет в своем столбце равное
число плюсов и минусов. Возьмем только строки, соответствующие
иимсу плюс какого-нибудь эффекта, скажем аАВС. Таким образом,
и тлблице дробного плана в столбце эффекта аАВС получатся одни
плюсы. Следовательно, этот эффект смешан с общим средним. Это
указывается с помощью ((определяющего соотношения»
7= ABC, A14)
где I — столбец из единиц, а ABC называется генератором плана.
Г.сли же мы выберем альтернативную половину, соответствующую
знаку минус для аАВС, то мы получим
7= — А~ВС A15)
иместо A14). Это очень простой способ определения того, какие эф-
эффекты сжеошны при выборе данной реплики (части плана). Перемноже-
Перемножение букв с членами определяющего соотношения указывает эффект
смешивания, где степень буквы берется по модулю 2, т. е. если пока-
показатель степени есть с, то с по модулю 2 это:
с (mod 2) = 0, если с — четное число 0, 2, 4, 6, ...,
с (mod 2) = 1, если с — нечетное число 1, 3, 5, ... A16)
Например, в табл. 10 главный эффект А смешан, как видно из опре-
определяющего соотношения для первой реплики
7=А~ВС. A17)
Правило перемножения дает
1- 7= А ¦ (АВ~С) A18)
или
Х=А2ВС. A19)
1 То модулю 2 имеем
А= А°ВС = ВС, A20)
что совпадает с A13). Аналогично получим:
'В=АС, A21)
~С = АВ. A22)
I ели взять вторую реплику, соответствующую A15), то A17) пред-
* киштся так:
A23)
Я,к Клен ней 33
If Л И
А=—ВС, A24)
~В = — АС, A25)'
С~= — АВ. A26)
Из этих операций следует, что обычно мы используем в качестве гене-
генератора взаимодействие наивысшей степени, скажем
А$ ...К=\ 2 ... k, A27)
как средство смешивания главных эффектов с взаимодействиями (k— 1)
факторов, полагая, что эти взаимодействия высокого порядка равны
нулю в дробном факторном плане. Взаимодействия двух факторов сме-
смешиваются с взаимодействиями (k — 2) факторов и, следовательно,
уже для малых k могут рассматриваться как несмещенные оценки двух-
факторных взаимодействий.
Теперь мы рассмотрим строение матрицы плана (т. е. расположение
N экспериментальных точек в 6-мерном пространстве), для которого
генератором служит наивысшее взаимодействие. Запишем матрицу
плана полного факторного эксперимента для (k — 1) факторов. Эта
матрица с 2k~l строками и (k— 1) столбцами. Добавим столбец
взаимодействия всех факторов, т. е. столбец
1 • 2 . ГГ. ¦ (k — 1). A28)
Отождествим k-й фактор со столбцом из A28):
~k=\.2-^-(k—\) A29)
или
k . k = 1 • 2-nf- (A — 1) • k. A30)
Так как произведение столбца на себя самого дает столбец из плюс
единиц, мы получим
ft. A =7". A31)
Следовательно, из A30) получаем
7= 1 . 2- 7^ ¦ (k— 1) • k. A32)
Так мы действительно построили план, генератор которого — ^-фак-
^-факторное взаимодействие. Вторую половину полного факторного плана
2k можно получить, меняя знаки в столбце 1 • 2 • 77? - (k — 1), т. е.
k = — 1 • 2 • 77Г • Ф—1), A33)
7"= — 1 ¦ 2 -77Г ¦ (Л—1) • ?, A34)
34
Для больших k даже ПолуреплйкЗ, т. е. План с 2й-1 опытами,
пикет оказаться слишком велика и вовсе не необходима, поскольку
ЧИО1 не взаимодействия высоких порядков можно положить равными
и\ 'но. Поэтому мы можем в таком случае взять меньшую часть от
hiiмного факторного эксперимента. Реплика от полного факторного
и.сиоримента для k факторов, составляющая A/2)? часть, называет-
¦ я" планом типа 2к~Р. Возьмем для примера план с семью факто-
факторами. Полный факторный эксперимент будет включать 27 = 128 опы-
iiiii. Полуреплика имела бы генератор
/=1-2-3-4-5-6-7,
A35)
и i которого видно, что главные эффекты смешаны с взаимодействиями
инчти факторов, двухфакторные взаимодействия смешаны с пятифак-
|с||)пыми, а трехфакторные—с четырехфакторными. Если нас интере-
с v ют главные эффекты и мы полагаем, что нет никаких взаимодействий,
hi можно взять -т? реплики, т. е. принять р = 4. Поскольку 27~*
план содержит 27~4 = 23 = 8 экспериментальных точек, или опы-
iou, мы начнем с записи полного плана для трех факторов10. Затем
шождествим остальные четыре фактора с четырьмя возможными вза-
взаимодействиями первых трех факторов. Это показано в табл. 11. Итак,
пли
4 = 12, 5 = 13, б"= 23, 7= 123
7 = 124, 7 = 135, 7 = 236, Т = 1237.
Матрица плана для эксперимента 2?~4
A36)
A37)
Таблица 11
„
t-
ь
1-
1-
_
—
+
If
_
—•
j
+
-
~б=Тз
+
I
+ 1 + 1 M
~t=nt
+
+
_
1
+ 1 1+ H
Ныходит, что A37) дают генераторы 124, 135, 236 и 1237. Но если
/ 124 и /= 135, то ясно, что
= 1 = A24) A35) = I2 2345 = 2345.
A38)
35
Последов атсльно перемножая р генераторов друг на друга попарно,
по три и т. д., мы получим 2р члена, или «слов (ходов)», определяю-
определяющего соотношения. В нашем примере 27~4 имеем
7 = 124 = 135 = 236 = 1237 = (генераторы)
= 2345 = 1346*= 3~47 = 1256 = 257 =167 = (пары) A39)
= 4~56 = 1457 = 2467 = 3567 = (тройки)
= 1234567. (р-кратные)
Для определения системы смешивания какого-нибудь эффекта мы
просто умножаем на этот эффект определяющее соотношение. Это дает,
например,
1 = 24 = 35 = 1236 = 237 = 12345 = 346 = 1347 = 256 =
= 1257 = 67 = 1456 = 457 = 12467 = 13567 = 234567. A40)
Так, в нашем примере главный эффект фактора 1 не смешан с другими
главными эффектами, а смешан только с взаимодействиями.
Переменой знаков в столбцах 4, 5, 6 или 7 табл. 11 можно полу-
получить другие реплики. Меняя, например, знаки в столбце 4, получим
1 = — 12. A41)
Все 16 реплик можно построить из
~4 = ± 12, 5 = ± 13, 6 = ± 23, 7 = ± 123. A42)
Каждой из 16 комбинаций в A42) соответствует определяющее соот-
соотношение со своей системой смешивания. Та комбинация, которой со-
соответствуют все плюсы в A42), дает главные генераторы, главные оп-
определяющие соотношения и главную реплику. Все 16 возможных реп-
реплик относятся к одному «семейству». Как заметил Пенг [Peng, 1967,
р. 123—126] (см. также [John, 1971, р. 159—160]), план 2k~p
можно анализировать, как обычно, воспринимая 2&-'1-реплику как
полный факторный план, только с q (= k — р) факторами, т. е. вре-
временно пренебрегая (k — р) факторами. Оставлять надо те факторы,
которые образуют полный план 2?. Например, это видно из способа
построения табл. 11, выбросить надо факторы с 4-го по 7-й и получится
полный план для q (= k — р = 7 — 4 = 3) факторов. После анализа
плана с q факторами мы вспоминаем о смешивании. Если, например,
значима сумма квадратов для взаимодействия 23, то мы заключаем,
что значим фактор 6 в соответствии с A36). Пенг [Peng, 1967, р. 237—
247] составил программу на Фортране для анализа планов 2k~P,
приведенных в той же книге.
36
IV I» ПЛАНЫ РАЗРЕШАЮЩЕЙ СПОСОБНОСТИ III, IV И V
13окс и Хантер [Box, Hunter, 1961a, p. 319] определили следую-
пни1 типы планов:
1. Планы разрешающей способности III: ни один главный эффект
in1 смешан ни с каким другим главным эффектом, но главные эффекты
« мешаны с двухфакторными взаимодействиями, которые сами смеша-
смешаны друг с другом.
2. Планы разрешающей способности IV: ни один главный эффект
in1 смешан с другим главным эффектом или взаимодействием двух
||м к горов, но эти взаимодействия смешаны друг с другом.
3. Планы разрешающей способности V: ни один главный эффект
п и и одно взаимодействие двух факторов не смешаны с другими глав-
главными эффектами или двухфакторными взаимодействиями, но эти
miliimoдействия смешаны с взаимодействиями трех факторов.
В общем разрешающая способность плана равна наименьшему
числу символов в коде определяющего соотношения. В этом параграфе
мм подробно рассмотрим все перечисленные типы планов.
/ Планы разрешения III
Планы разрешающей способности (кратко: разрешения) III тре-
оуют только N опытов при изучении (N — 1) факторов, если только N
|.|)!1тно четырем. Для тех N (— k + 1), которые не кратны четырем,
мы получим план разрешения III из плана разрешения III для следую-
следующего N, скажем N' = k! + 1, которое уже кратно четырем, отбрасы-
iiiiii любые (k' — k) столбцов (т. е. факторов) из этого плана. Если же
N не только кратно четырем, но еще и является степенью двойки, то
планом разрешения III будет дробный факторный план, который обоз-
обозначается так: 2щ"р. Мы прежде всего рассмотрим эти планы, а за-
it'M так называемые планы Плэкета—Бермана (Plackett, Burman),
фебующие лишь, чтобы N было кратно четырем.
Если N должно быть степенью двойки, то оно принадлежит после-
•кжательности 2, 4, 8, 16, 32 и т. д. Таким образом, число исследуе-
исследуемых факторов k при N (=&+ 1) опытах будет 1, 3, 7, 15, 31 и т. д.
Плпны 2п7Р для k от 3 до 31 представлены в табл. 12. Мы видим,
шшример, из табл. 11, как строятся планы 2k~P из полных пла-
iitin для q (— k — р) факторов с приравниванием оставшихся р фак-
п)|)ов к взаимодействиям между исходными q факторами. Аналогич-
Аналогично A36)—A40) мы можем получить систему смешивания.
Раньше мы заметили, что для N, которые не кратны четырем, мы
пилучаем план разрешения III, взяв следующее подходящее значение,
i нпжем N' = k' + 1,и отбрасывая любые (&' — k) столбцов как лиш-
лишит1 из плана 2п[~р. Планы для k' уже «насыщенные», т. е. число
пиыгов N в них уже равно числу параметров (k + 1). Отсюда следует,
чш и ненасыщенных планах мы можем: A) изучить больше факторов
мри том же числе опытов; B) оценить несколько двухфакторных вза-
взаимодействий; C) оценить дисперсию ошибки опыта а2. Возьмем для
37
План 2«-i>
N
4
8
16
32
Та<
разрешающей способности
k
3
7
15
31
р
1
4
11
26
5 лица 12
III
План
23-х
27-4
215-11
231-2в
примера эксперимент с пятью факторами. Для пяти следующее число,
кратное четырем, — это восемь, значит, N' = 8. При восьми опытах
мы можем изучить семь факторов (см. возможность A)). Следова-
Следовательно, можно отбросить два фактора. Если некоторый фактор ис-
исключить из плана, то система смешивания сохраняется, за исклю-
исключением всех тех кодов, в которые входил исключенный фактор,— эти
коды исчезают. Итак, в плане 2пТ4 мы имеем определяющее соот-
соотношение A39). Если, например, отбросить факторы 3 и 5, то это соот-
соотношение сведется к
/ = 124 = 167 = 2467.
A43)
Если есть восемь опытов, а надо оценить только пять главных эф-
эффектов да общее среднее, то остается еще возможность оценки двух
взаимодействий. Из A43) видно, что шесть двухфакторных взаимодей-
взаимодействий оценить невозможно, поскольку они смешаны с главными эф-
эффектами. Это 12, 14, 24, 16, 17 и 67. Из общего числа двухфакторных
взаимодействий, равного k (k — 1)/2 = 5x4/2= 10, остается рас-
рассмотреть еще четыре взаимодействия. Это26, 27, 46 и 47. Соотношения
A43) дают 26 = 47, 27 = 46. Отсюда мы можем вместе с общим сред-
средним и главными эффектами изучить одну из следующих четырех пар
взаимодействий: B6, 27), B6, 46), D7, 27) или D7, 46). Отметим, что
—>• —>¦ —>¦ -> —*- —>
на основании A39) верно, что 3 = 26 = 47 и 5 = 27 = 46, т. е. те
двухфакторные взаимодействия, которые можно изучить, соответст-
соответствуют отброшенным главным эффектам. В общем, мы заключаем, что
можно отбросить (k' — k) факторов и получить систему смешивания,
которая более привлекательна, так как можно отбросить именно фак-
факторы 3 и 5, если взаимодействия 26 и 27 наиболее интересны среди
всех взаимодействий. Если же взаимодействия, которые можно оце-
оценить, отсутствуют, то их суммы квадратов будут несмещенными оцен-
оценками чистой дисперсии ошибки опыта а2 (ср. с возможностью C)).
Теперь мы рассмотрим планы разрешения III, в которых k факторов
изучаются в N = k -\- 1 опытах и N кратно четырем, но не обязатель-
обязательно является степенью двойки. Такие планы предложили Плэкет и
Берман [Plackett, Burman, 1946]. Если N — некоторая степень двух,
то их планы — это те же самые дробные реплики, которые мы уже
38
п(к1уждали. Плэкет и Берман [Plackett, Burman, 1946, p. 323—324]
|,|Г)улировали планы'разрешения III для N ^ 10011. Мы воспроизводим
»ш планы в табл. 13 для тех N, которые кратны четырем, но не яв-
1ИЮГСЯ степенями двойки. Работа с табл. 13 показана ниже.
1. Для N = \2 в табл. 13 видим
M;i строка использована ниже как первый столбец табл. 14. Осталь-
Остальные столбцы получаются циклическим сдвигом этого столбца на один
шик. В конце добавляется строка из минусов.
2. Для некоторых N (как N = 28) эта циклическая перестановка
исполняется с блоками. Так, если три блока (9 X 9) для N = 28 обоз-
обозначить Л, 5 и С, то получится план:
ABC
CAB
В С А
i це последняя строка состоит из одних минусов. В случаях N = 52, 76
и 100 последняя строка состоит не только из минусов, а включает
[I плюсы, и минусы, как показано в соответствующих блоках табл. 13.
1 ели N =k+ 1 не кратно четырем, мы снова берем следующее под-
>пдящее N, кратное четырем, и отбрасываем ненужные столбцы.
Интересно видеть, что в планах 2п7р каждое двухфакторное
п шимодействие полностью смешано с каким-нибудь главным эффек-
1мм, т. е. в матрице независимых переменных X у них будут одинако-
щ.ю столбцы. Но в плане Плэкета—Бермана двухфакторные взаимо-
•н'йствия не полностью смешаны с главными эффектами. Например,
и 1мбл. 14 мы можем записать столбец двухфакторного взаимодействия
1" и этот столбец не совпадет ни с каким из имеющихся от 1 до 11.
Ь i точно, 12 можно представить как линейную комбинацию одиннадцати
i ишшых эффектов и общего среднего, так же как двенадцатый вектор,
«тянутый на двенадцатимерное пространство. Поэтому оценки вза-
взаимодействий в плане Плэкета—Бермана смещены как линейные ком-
шшпции главных эффектов и общего среднего. Это приводит к тому,
чш если взаимодействия велики, то это можно установить, даже если
пещены некоторые главные эффекты.
11о в плане 2ц7Р каждое взаимодействие полностью смешано со
in him главным эффектом. Тьюки [Tukey, 1959b, p. 170—171] ввел
и пень «сокрытия» эффектов взаимодействия в планах Плэкета—
lU|iM,'iiia, дробных репликах и «случайных» планах, которые мы еще
I II i мотрим ниже. Его сравнения показали, что в этом смысле планы
Пикета—Бермана — наилучшие12. За другими типами планов раз-
г пиемия Ш мы адресуем к [John, 1971, р, 172].
39
Таблица 13
Планы Плэкета—Бермана разрешения III
N =
:12
:20
24
:28
+++ ++- Н 1- + +
38 -н—h+ H f-
40 Удвоенный план для ЛГ=2 0
44 ++—+ -+ h -H—++
+
+
+
+
+ -
_+_+ + Н h+-+- +-+ ++ Ь +
Ь+НЧ h+ I-++H Н- +-Н-
+++++-{ +Н Ь++4 Ь+Н Н-
-Ч-+++++
-Н-+ ++—++—++ —++—++++ ++++
№=55 Удвоенный план для N=28
+++-+ ++Н
+++++
«=68 +Н ь —1--
+-
N=72 +++++ ++-++ +-
+ ++ +~
N=76 + -\— Н— Н— +-
++Н—1- —f+++ ++¦
++ Ь +-Н—h +-
++-++ + + +-
-f— ++Н—I-
+
jV=80
— ++ ++ ++ — ++ ++ ++ ++
-+ + + -+ +- -) + Н + -+ -+ -+ +- +- +-
+- +- +- +-+—+-+- +- +- +- +- +- +- +- +-
++++++ ++ — ++ ++ ++ —
+ 1— + +-+-+-+ Ч Ь +- + h -+ 4 +
+ Ь+ ++-+ +-++ +++Н Н- -Н F—f— H—
«=84 ++-++ +-+ +++ -+Н
+++++
++-
+-+4—
ДГ=88 Удвоенный план для W = 44
N=92 Этот план пока не удалось получить
N=96 Удвоенный план для W=48
++++++ -н-
-н-+н—++—
-++—++—++—+ —t—++—+—1-+-+ +-+-+-+-+
++ h+—++ ++ ++++—+++H +++++
++++—-H ++ ++++—
-+—b-+
-н ++—++—
+ +-++Н—1—+—I
H—+—+—H
I + +—1—\—\—H-+-+
-++++Н ++-И
-++++++ 1-+++ ++++ ++—++++—++—
+—+-++—+ ч——i—I
+ ++ (-+++—++
Ь- +
-+-+-+—)—1—I—1 J—I—I—I—I—I—I— —f—I—|—|—|—I—|— -+--1—+-+—I—|—+ + 001=// 3
Таблица 14
План Плэкета — Бермана для 11 факторов
т
++1+++111+1
т
1++1+++111+
t
111+++I++I+
t
1+1++1+++]1
5
1 +++1++1 +11
t
+++1++1+111
t
+111+1++1++
т
+1++1+111++
л
t
V
-
То
++1+111+++1
7Т
+1+111+++1+
Резюмируем определение планов разрешения III. Даже если мы
предположим, что все взаимодействия трех и более факторов равны
нулю, мы все равно получим лишь оценки сумм или разностей главных
эффектов и некоторых двухфакторных взаимодействий 13. Однозначные
'включения возможны только в том случае, если мы потребуем равен-
и-ва нулю всех двухфакторных взаимодействий. Более точные за-
заключения возможны, если мы обратимся к планам разрешения IV.
В них уже главные эффекты не смешаны с двухфакторными взаимо-
взаимодействиями, которые смешаны между собой.
''. Планы разрешения IV
Чтобы понять построение планов с разрешающей способностью IV,
мы сначала изучим последовательное добавление новых реплик к ис-
исходной реплике 2k~p. Возьмем следующий пример плана 27~4.
Как показывает A39), главная реплика имеет генерирующее соотноше-
соотношение A44), если мы опустим взаимодействие четырех и более факторов.
/ = 124 = 135 = 236 = 347 = 257 = 167 = 456.
A44)
< Следовательно, главные эффекты смешаны с двухфакторными взаимо-
взаимодействиями, что видно из соотношений A45):
1 = 24 = 35 = 67,
2 = 14 = 36 = 57,
= 15 = 2(Г= 47 и т. д.
A45)
43
>>[ичш iiiiin Hnyi" iiciMtiiiihiunit) Ij плОлюдений yi как в A46):
idij(j=l,..,k)t A46)
i= 1
где dij — это t-й элемент /-го столбца матрицы плана D. Из смешива-
смешивания следует, что tj оценки соответствующего главного эффекта / и
плюс или минус сметанные с ним эффекты. Так, в нашем примере из
(И5) следует, что '
Е AХ) = Е (-L 2 ytdn ) = а* + а2* + а™ + а6',
а3 + а^ + а26 + сх47 и т. д. A47)
—>¦
Пусть в следующей реплике A/16) знаки столбца 1 изменены на обрат-
обратные, т. е. генераторы этой дополнительной реплики даются соотноше-
соотношением A48), а отнюдь не A36):
7= — 12^ t=—13", бГ= 23, ? = — 123 A48)
и (опуская взаимодействие четырех и более факторов) определяющие
соотношения даются A49) вместо A39):
= — 124 = — !35 = 236 = 347 = 257 = — 167 = 45б! A49>
Отсюда
Т=— 24 = —35 = — 67,
2*= — 17= 3"б = Ь% A50)
= _ 15 = 26 = 47 и т. д.
ИЛИ
Е (Ц) =ai_a24 — а35 — а67,
? (/з) - а2 — а" + а36 + а57, (J51)
? (щ = а3 - а15 + с*28 -f <*47 и т, д,
44
Объединение линейных комбинаций для обеих реплик дает, например:
= с*> и т. д.
Так, A52) показывает, что главный эффект фактора 1 и все его двух-
двухфакторные взаимодействия оцениваются без смешивания с двухфактор-
ными взаимодействиями. Обобщая, скажем, что так можно выбрать
добавляемую реплику, меняя знак в столбце некоторого фактора, ска-
скажем/, в плане 2k~p разрешения III (или выше). Тогда главный эф-
эффект фактора f и все его взаимодействия (двухфакторные) не будут сме-
смешаны с другими парными взаимодействиями. Такая вторая реплика
полезна, если из первой реплики замечено, что некоторый фактор осо-
особенно важен.
Генераторы в нашем примере, где были объединены две реплики,
можно определить следующим образом. Уравнение A37) показывает,
что генераторы главной реплики таковы:
~78 = 124" = 135 = 236 = 1237; A53)
где индекс 8 указывает, что в столбце / имеется восемь плюсов. Про-
Проведем теперь опыты с дополнительной репликой из этого семейства
планов, а именно с той репликой, в которой столбец 1 поменял знаки
на обратные. Тогда получим такие генераторы:
"/8 = _ 124 = — 135 = 236 = —1237. A54)
Поскольку в обоих случаях
/7= 2~36, A55)
мы уже имеем один генератор для объединенного плана, который есть
план 27~3 с р = 3 генераторами. Это
~11в = 236. A56)
Далее, A53) и A54) показывают, что
124*. 13?> = (— 124) • (— 135) = 2345 = Ти A57)
И
124 • 1237*= (- 124* • (-1237) - 347 = Tw A58)
45
Отсюда A56), A57) и A58) дают три генератора (определяющие соот-
соотношения, которые даны ниже). Отметим, что
A35) A237) = (— 135) (— 1237) = 257 = /16
A59)
не независимый генератор, поскольку его код можно получить из
A57) и A58): _^
27 = 2345*- 37. A60)
В общем (р —¦ 1) генератор для объединения двух реплик 2к~р из
одного семейства (и любого разрешения) получается при: A) взя-
взятии генераторов исходных реплик* со своими знаками и B) перемноже-
перемножении одинаковых исходных генераторов с разными знаками.
Мы уже показали, что если реплику с линейными контрастами 1и
как в A47), объединить с другой репликой, имеющей контрасты //-
как в A51), то получим
A61)
A62)
откуда видно, какие эффекты можно оценить в объединенной реплике.
Эти эффекты не будут смешаны, что вполне естественно, поскольку их
оценки получаются из большего числа опытов. Это две особенно по-
полезные дополняющие реплики. В первой реплике, которую мы уже
изучали, знаки столбца одного наиболее интересного фактора измене-
изменены так, чтобы эффекты, в которых участвует этот фактор, можно было
лучше изучить; во второй реплике изменяются на обратные знаки
столбцов всех факторов. Последняя реплика позволяет построить план
с разрешением IV изломана разрешения III. В качестве примера в
табл. 15 приведен план 2fif *, в котором изменены на обратные все
знаки главной реплики из табл. 11.
Таблица 15
Перемена всех знаков в главной реплике
эксперимента 27~4
Опыт
1
2
3
4
5
6
7
8
+
—
—
—
±
+
—
=
+
+
—
4=—12
_]_
-
ii-Тз
1
!
—
6^-23
1
|_
1
——
+
.
|
_|_
46
Нсли пренебречь взаимодействиями четырех и более факторов, То
ипределяющее соотношение для плана из табл. 15 имеет вид:
7 = — 124 = — 135 = — 2~36 = — 347 = — 257 =
= — 167 = — 456. A63)
Следовательно,
1 = _ 24 == — 35 = — 67,
2 = — 14 = — 36 = — 5~7 и т. д. A64)
пли
Е A[) = а1 — а24 — а35 — а07,
Е (Ц) = а2 — а14 — а36 — а57 и т. д. A65)
Вместе с главной репликой, Е (lj) для которой приведены в A47),
что дает:
?/b±iiUa. „ т. д. <166)
V 2 /
Затем мы получим группы из трех двухфакторных взаимодействий:
A67)
Так повторная реплика с обратными знаками вместе с исходной репли-
репликой 27^-4 дают план разрешения IV, а именно план 27~3. А если
мы еще поменяем знаки в столбце из единиц /8 и свяжем с этим столб-
столбцом фактор 8, то мы получим даже план разрешения IV для восьми
факторов. Такой план называют планом, дублированным наоборот*,
так как он получается расширением исходного плана таким планом,
псе знаки которого обратны знакам исходного.
Генераторы такого объединенного плана можно получить обыч-
обычным путем, как описано в A53)—A60). Так, генераторы для первой
реплики 28~5 есть
7 =~8 - 124 = 135 = 236 = 1237, A68)
* В отечественной литературе такой прием построения плана часто иазы-
(пот методом перевала. — Прим. перев.
47
i ik I li i iii\m и i шимещенин фактора 8 со столбцом из единиц;
in hi'iiiiiiiir iniopmopu мы уже получили раньше; ср., например, с
A3/). Генераторы для второй реплики 28~5 есть
7= _ 8 = — 124 = — 135 = — 236 = 1237. A69)
Так кок ио иторой реплике мы меняем знаки, то коды, состоящие из
нечетного числа факторов, получают знак минус. Из A68) и A69)
мы сразу индии, что 1237 — это генератор объединенного плана; ос-
остальные три независимых генератора 2^-* плана — это, например:
8 • 124 = (— 8) • (— 124) = 1248,
8 • Т35 = (— 8) • (— 135) = 1358, A70)
8*- 236 = (— 8) • (— 236) = 2368.
Выше было показано, что генераторами в методе перевала служат:
A) генераторы исходных реплик с четными числами факторов (в при-
примере 1237); B) генераторы исходных реплик с нечетными числами
факторов, расширенные за счет дополнительного фактора, связанного
со столбцом Т (в примере 1248, 1358, 23~68).
Вместе с методом перевала есть и второй метод построения планов
2*-р (ср. A28) — A35)). Запишем полный план для (k — р) = q фак-
факторов и сопоставим остальные р факторов с взаимодействиями между
нечетными числами C, 5, ...) из первых q факторов. Например, преды-
предыдущий план 28^4 можно построить таким образом. Запишем пол-
полный план 24. Для сравнения с методом перевала напомним, что
q (— 4) факторов могут быть: 1, 2, 3 и 8. Свяжем остальные р (= 4)
факторов так:
128 = 4, 138 = 5, 238 = 6, 123 = 7. A71)
Сравнение A71) и A70) показывает, что это тот же самый план.
Выше мы показали, как можно построить 2^-р-план из плана
2fejsYp (k = к' + 1) методом перевала. Бокс и Уилсон [Box, Wilson,
1951, p. 35] доказали следующую теорему.
«Пусть существует некоторый план для оценивания k линейных
эффектов (не обязательно дробная реплика и даже не обязательно
ортогональный план) с матрицей Dx размером N X k; допустим так-
-*¦
же, что X — соответствующая N X (k -\- 1)-матрица независимых пе-
переменных. Тогда
-1-3
4S
будет матрицей плана для оценивания линейных эффектов k + 1 фаК-
юров, правда, смещенными из-за эффектов второго порядка будут
оценки эффектов первого порядка из Dv но по этой причине оценки
->
эффектов первого порядка из D2 будут совершенно свободны от сме-
смещения».
Из этой теоремы следует, что, поскольку план Плэкета—Бермана
имеет разрешение III, из него методом перевала получается план раз-
разрешения IV. Метод перевала удваивает число опытов в плане разреше-
разрешения III, но позволяет включить еще один фактор, связывая его со
столбцом из единиц в плане разрешения III. Мы можем видеть, что план
разрешения III содержит к факторов и только N = k + 1 опытов,
если N кратно четырем. В плане с разрешением IV для k факторов чис-
число опытов будет 2k, если k кратно четырем. Это показано в табл. 16.
Таблица 16
Планы минимального объема с разрешением III и IV
для k факторов в N опытах
Разрешающая способность
Ш
k
3
7
11
15
19
N
4
8
12
16
20
Разрешающая способность
IV
к | N
4
8
12
16
20
8
16
24
32
40
Если же k не кратно четырем, то план разрешения IV мы можем
получить из следующего подходящего k. Так, например, план разреше-
разрешения IV для трех факторов может содержать восемь опытов, а для
пяти, шести или семи факторов — шестнадцать опытов. Однако Уэбб
(Webb, 1968a] предложил неортогональные планы разрешения IV
для k факторов в 2k опытах, где k не кратно четырем. Его планы тоже
основаны на методе перевала. По определению, из этих планов можно
оценить главные эффекты, не смешанные с двухфакторными взаимо-
взаимодействиями, хотя сами эти взаимодействия смешаны друг с другом.
Так как планы Уэбба не ортогональны, то оценки главных эффектов
взаимно зависимы и их дисперсии больше, чем в ортогональном плане.
В табл. 17 сведены планы Уэбба.
В этой таблице факторные комбинации в последнем столбце обозна-
обозначают то же, что и в последнем столбце табл. 6. Приводятся только пер-
первые N12 опытов, поскольку остальные опыты легко достраиваются
методом перевала. Для иллюстрации табл. 17 ниже записана полная
матрица независимых переменных с двухфакторными взаимодействия-
взаимодействиями для ft = 3 (см. табл. 18),
49
Таблица 17
Неортогональные планы Уэбба с разрешением IV,
полученные методом перевала
k
3
5
6
7
N
6
10
12
14
Дисперсия главных
эффектов
1/4 а2
1/9 а2
1/10 а2
11/100 а2
Опыты в половине плана
а, Ь, с
а, Ь, с, d, e
ab, ас, be, d, e, /
а, Ь, с, d, e, f, g
Опыт
1
2
3
4
5
6
План Уэбба для
+
+
+
А
+ 1
1
2
+i
+i
в
—1
+1
— 1
+1
1
+1
Та б л и
ца 18
трех факторов
С
—1
— 1
4-1
+ 1
+ 1
АВ
1
—1
+1
—1
—1
+1
АС
_!
+ 1
— 1
+ 1
— 1
ВС
+ 1
t
— 1
_]_1
— 1
Отметим, что в табл. 18 ортогональны любые столбцы главных эффек-
эффектов к любым взаимодействиям (двухфакторным) и общему среднему.
Никакие главные эффекты не ортогональны к любым другим глав-
главным эффектам и никакие парные взаимодействия не ортогональны к
любым другим парным взаимодействиям или к общему среднему. Так
что не все столбцы главных эффектов смешанных парных взаимодей-
взаимодействий и общее среднее ортогональны, и, ф
фектов более сложно, чем в планах 2к
как общую регрессионную модель (95), т. е.
р
, следовательно, оценивание эф-
эфк^/>. Выразим модель ANOVA
**
2 2
s=lz=s+l
2
s=l
A72)
где ро — общее среднее, ps — половина главного эффекта as фактора
s и ps2. — половина взаимодействия asz между факторами s и z; J =
= 1 +k+k (k — 1)/2 параметров. Так как есть только N (= 2k) опытов,
нельзя оценить все J параметров. В приложении IV.3 мы покажем,
что главные эффекты
РЛ1 = (Pi, Ра.
р*>
A73)
60
имеют МНК-оценки
Ьм=-^ (U'U)-i(U', — U)y, A74)
где О соответствует главным эффектам и определяется из
У = C>i. Уа. ••- Ун). A76)
Можно показать, что A74) дает несмещенные оценки парных взаимо-
взаимодействий и общего среднего. Далее мы покажем, что матрица диспер-
сий-ковариаций вектора Ьм равна:
QM=-La2(W U)-1. A77)
Двухфакторные взаимодействия нельзя определить однозначно — нет
достаточного числа наблюдений. Если некоторым взаимодействиям
приписать произвольные значения, то остальные взаимодействия мож-
можно будет оценить. Мы положим (/ — N) парных взаимодействий рав-
равными нулю, т. е. соответствующий вектор параметров, скажем C3>
будем считать нулевым:
Ьъ = О? A78)
Те взаимодействия, которые входят в рз . можно выбрать так, чтобы
остальные взаимодействия (N — k — 1) = k — 1 вместе с общим
средним из матрицы независимых переменных Х2 и вместе с матрицей
главных эффектов
_^ Г TI П
A79)
давали бы невырожденную матрицу [Хг, Х2] в сравнении с C.13)
it приложении IV.3. Общее среднее и взаимодействия, связанные с Х2,
оцениваются из
Ь2 = {Х2Х2)-1Х2. A80)
Можно легко показать, что Ь2 — несмещенная оценка, если взаимо-
взаимодействия в ра равны нулю. Далее, матрица дисперсий-ковариаций
-у
мектора Ьг имеет вид:
Q2 = a4X^X2)-1. A81)
51
Критерий Стыодспта можно применить для проверки значимости от-
отдельного параметра регрессии |3, а /-"-критерий — для проверки сов-
совместной значимости нескольких параметров смотри в [Johnston, 1963,
р. 115—135], где изложена общая теория проверки значимости пара-
параметров регрессии. Заметим, что сначала мы можем оценить главные
эффекты по A74). Затем мы можем положить равными нулю те взаимо-
взаимодействия, которые смешаны с малыми главными эффектами. Эта воз-
возможность ограничена тем, что выбор Х2 должен обеспечивать невыро-
—»¦ —>
жденность [Xlt X2].
Дальнейшее обсуждение планов разрешения IV можно найти в
[John, 1971, р. 173—174], [Marjolin, 1969] и [Srivastava, Anderson,
1970], а также в [Srivastava, Anderson, 1969]. Если в плане разрешения
IV малы все оценки линейных комбинаций двухфакторных взаимо-
взаимодействий, мы можем сделать вывод, что значимы только главные эф-
эффекты. Это заключение нельзя доказать строго, поскольку остается
возможность того, что большие взаимодействия взаимно уничтожают-
уничтожаются в линейных комбинациях. Следовательно, если мы хотим оценить
все парные взаимодействия раздельно или если некоторые линейные
комбинации парных взаимодействий, оцененных в плане разрешения
IV велики, то нам нужен план разрешения V.
3. Планы разрешения V
Планы с разрешающей способностью V дают оценки главных эф-
эффектов и парных взаимодействий, которые не смешаны с другими глав-
главными эффектами или парными взаимодействиями. Это значит, что все
коды в определяющем соотношении содержат пять или больше букв.
Эти лучшие оценки добываются за счет увеличения числа опытов.
Реплики разрешения V не существуют для двух, трех и четырех фак-
факторов. В табл. 19 показаны реплики разрешения V и выше — по Бок-
Боксу и Хантеру [Box, Hunter, 1961b, p. 450]. Продемонстрируем исполь-
использование этой таблицы на примере плана с одиннадцатью факторами.
План 211-4 содержит 27= 128 опытов. Поэтому начнем с записи пол-
полного факторного плана для семи факторов. Свяжем оставшиеся четыре
фактора, как указано в таблице, т. е.
=Ь 8 = 1237; ± 9 = 2345; ±10 = 1346; ± 11 = 1234567. A82)
Генераторы и определяющие соотношения непосредственно следуют из
A82). В табл. 19 видно, что число опытов для семи и восьми факторов
одинаково. Следовательно, в эксперименте с семью факторами имеет
смысл рассмотреть возможность включения восьмого фактора, коль
скоро это не ведет к росту числа опытов. С другой стороны, правда,
план для семи факторов имеет разрешение VII, большее чем V. Ана-
Аналогичные замечания можно сделать для планов с девятью, десятью
и одиннадцатью факторами ы. Читатель, желающий построить себе
реплику разрешения V более чем для одиннадцати факторов, должен
прочесть [Box, Hunter, 1961b, p, 455].
52
Таблица 19
Число
фикторов (k)
5
6
7
8
9а
10
11
Дробные реплики
Число
опытов (JV)
16
32
64
64
128
128
128
Степень
дробности
B-Р)
1/2
1/2
1/2
1/4
1/4
1/8
1/16
)азрешения V и
Тип плана
05- 1
AV
96-1
27- 1
о8—2
^ v
V
99—2
V i
9Ю-3
2V
oil — 4
V
выше
Оставшиеся факторы
±5=1234
±6=12345
±7=123456
±7=1234
±8=1256
±9=14578
± 10=24678
±8=1237
±9=2345
±10=1346
±8=1237
±9=2345
±10=1346
±11=1234567
а) Девять факторов в этом плане обозначены так: 1, 2, 4, 5, 6, 7, 8, 9 и 10.
Хотя планы в табл. 19 и не полные, их рассмотрение показывает, что
опытов в них больше, чем эффектов, ждущих оценки. Дэниел [Daniel,
1956, р. 92] дал табл. 20 с планами разрешения V, в которой Е —
)го мера «эффективности», определяемая отношением числа главных
)ффектов и парных взаимодействий к общему числу степеней свободы.
Л общее число степеней свободы равно числу опытов без единицы
для общего среднего, значит,
A83)
Таблица 20
с, _ k + k(k—1)/2 _
~~ N—l ~~ 2(N—1
Эффективность планов 2ур
k
5
6
7
8
9
10
11
12
13
14
15
р
1
1
1
2
2
3
4
4
5
6
7
2-Р
1/2
1/2
1/2
1/4
1/4
1/8
1/16
1/16
1/32
1/64
1/128
N
16
32
64
64
128
128
128
256
256
256
256
?
1,00
0,68
0,44
0,56
0,35
0,43
0,52
0,31
0,36
0,41
0,47
S3
Hi u hi <|'фм niiiiiiu-iii планов 2'^-р были разработаны другие
|(» ti'iititii, hiiuii.', как «сокращенные» планы Визуелла и Морби [Whith-
wi'll, Morbey, 1961], или «нерегулярные реплики», и «реплики типа
3 • 2~р»Адельмана [Addelman, 1961]. Эти специальные планы разре-
разрешения V содержат меньше опытов, чем реплики 2v~p- К сожалению,
эти преимущества реализуются в предположении, что некоторые (не
все) парные взаимодействия равны нулю, или за счет неортогональности
плана (т. е. коррелированное™ оценок эффектов). Мы находим более
привлекательными реплики, построенные позже Рехтшафнером
fRechlschaffner, 1967]. Его реплики от планов 2k насыщены, т. е. они
содержат как раз столько опытов, сколько эффектов надо оценить.
А число параметров — это одно общее среднее, k главных эффектов
и k (k — 1)/2 парных взаимодействий. Планы, построенные Рехтшаф-
Рехтшафнером, очень просты. Свяжем один «генератор» с каждым видом эф-
эффектов, как показано в табл. 21. Остальные комбинации факторов полу-
получаются перестановкой элементов каждого генератора. Для пяти фак-
факторов это показано в табл. 22.
Таблица 21
Генераторы плана для иасыщеииой реплики от 2h Рехтшафнера
Номер
I
II
III
Тип
Общее среднее
Главные эффекты
Парные взаимодействия
Генератор
(— 1 , — 1) для всех k
(—1, 1, ..., 1) для всех k
A,1, —1,...,—1) для ?>3
(—1, —1, 1) для k=3
Таблица 22
Насыщенная реплика плана 25
Опыт
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Генераюр
(-1, -1. -1, -1. -1)
(-1. 1, 1, 1, 1)
A, 1, -1, -1, -1)
.j
1
1
1
1
1
1
1
1
1
]
1
[
— 1
1
.[
Хг
— 1
1
|
1
1
1
1 •
[
— 1
— 1
1
1
1
1
1
]
—1
1
1
1
1
1
—1
1
J
1
1
—1
J
1
1
1
J
1
1
1
t
1
. 1
— 1
1
— 1
j
1
— 1
1
— 1
1
— 1
1
1
1
1
— 1
J
— 1
— 1
1
^ 1
. J
1
— 1
1
1
54
Насыщенная реплика от плана 25 в табл. 22 показывает структуру
реплик для других чисел факторов. Фактически этот план — частный
глучай, так как план Рехтшафпера для пяти факторов точно совпада-
совпадает с планом 2\f \ Но для других чисел факторов насыщенные пла-
планы дают коррелированные оценки параметров, в отличие от планов
2\Г", оценки которых полностью ортогональны. Поэтому диспер-
дисперсия отклика, усредненная по области эксперимента и приведенная на
один опыт для насыщенного плана, больше. Это видно из табл. 23,
ичятой у Рехтшафнера [Rechtshaffner, 1967, р. 573] и показывающей,
что насыщенные планы менее эффективны. Зато число опытов в них
шачительно меньше, особенно для большого числа факторов. Таким
образом ,мы считаем, что экспериментатор, желающий выбрать между
фадиционным 2у~р-планом и насыщенным планом Рехтшафиера,
должен учитывать следующее:
а. Насыщенные планы привлекательнее, если у экспериментатора
ость лишь немного машинного времени, так как они требуют значи-
значительно меньше опытов, особенно для многих факторов.
б. Меньшие дисперсии оценок отклика и параметров обеспечива-
обеспечивают более надежное оценивание, т. е. меньшую вероятность ошибок
к выводах; ошибочные выводы означают потери. Традиционные 2v~p*
Таблица 23
Сравнение насыщенных реплик и планов 2 у р
Число
факторов
(ft)
3
4
5
6
7
8
9
10
Дробность
реплики
9 — Р
в плане
1
1
1/2
1/2
1/2
1/4
1/4
1/8
2v •
8
16
16
32
64
. 64
128
128
наскщен-
ный план
7
И
16
22
29
37
46
56
Эффективность
для отклика
57,1
72,7
100,0
86,1
62,8
43,7
30,7
22,2
Эффективность для
параметров
57,1
93,5
100,0
82,6
45,1
21,2
10,4
5,6
Ei = ЕЦ В
57,1
65,5
100,0
87,0
68,5
53,6
42,6
34,5
''и1
(«усредненная» дисперсия откликов в 2у р)/Л/у
(«усредненная» дисперсия отклика в насыщенном плане)/Ns
\п) в ^v ' 'V
-Х100.
X100,
/var (?) в насыщенном плане)///5
" То же, что и ?д, но вместо |i главный эффект а1 или взаимодействие а1*.
65
ii'iriniii uiiiii (юлсе надежные оценки, даже если Мы осознаем, что эта
ьысокая надежность оплачена большим числом опытов. Когда же ма-
машинное время экспериментатора практически не ограничено, мы мо-
можем позволить себе больше наблюдений, если понимаем, что выигрыш
в надежности (который равнозначен снижению риска потерь) — это
ценность, возрастающая с ростом цены машинного времени. Точное
решение задачи понижения потерь и повышения стоимости экспери-
эксперимента можно надеяться получить методами.-статистической теории при-
принятия решений. К сожалению, такое решение невозможно, и в общем
мы можем сказать, что пока теория принятия решений обычно приво-
приводит к аналитическим формулам, которые с трудом поддаются численно-
численному решению.
Исследователь не будет нуждаться в насыщенном плане, если он
желает уменьшения дисперсий и ковариации или хочет иметь степени
свободы для оценки ошибки опыта а2. (Более того, в реальном мире
эксперименты совсем не те, что при моделировании, где требуемое
число опытов N можно получить с помощью машины и т. д.) Мы отсы-
отсылаем к [Srivastava, Chopra, 1971] за планами разрешения V, которые
не обязательно насыщены. Они табулировали планы для четырех,
пяти и шести факторов (и 11 < N < 28, 16 < N < 32, 22 < N < 40
соответственно).
В частности, более сложны в работе реплики, полученные Боксом
и Хантером [Box, Hunter, 1961a, p. 318—319, 349—350]. Они исполь-
используют «блоки» для оценки главных эффектов и всех взаимодействий
«важных» факторов, хотя можно оценить и эффекты «второстепенных»
факторов, т. е. таких, для которых предполагается, что они имеют
только главные эффекты и никаких взаимодействий. Мы не обращаем
внимания на «разбиение на блоки», так как этот метод не необходим
в имитационных опытах. Читатель, интересующийся блоками (для
элиминирования неоднородностей, встречающихся в реальном экспе-
эксперименте, или для построения специальных планов), может обратиться
к [Hicks, 1966] за определениями и к [Box, Hunter, 1961а, р. 330—
333, 345—349; 1961b, p. 452—458]. Каталог планов 2k~P (k от
5 до 16 и р от 1 до 8) вместе с их блочными конфигурациями приведен
в «Fractional Factorial Designs for Factors at Two Levels» A957). Чи-
Читатель может также пожелать свериться с [Draper, Mitchell, 1967;
1968]. Обширное обсуждение так называемых сбалансированных и ча-
частично сбалансированных планов в неполных блоках (или PBIB) есть
в [John, 1971, р. 219—328]. В имитационных экспериментах некоторые
авторы, например Нейлор и др. [Naylor et al., 1967a, p. 324], предла-
предлагают рассматривать последовательность случайных чисел как блок,
которым моделируется некоторая система с тем же самым случайным
числом. Однако нет никаких остаточных ошибок и опыты в блоке за-
зависимы, так что применение в таком плане ANOVA вызывает сомнения.
Михрам [Mihram, 1972, р. 401] предложил строить блок при генери-
генерировании наблюдений, чтобы частично использовать те же случайные
числа, т. е. использовать их только для поступлений требований, но
не для времени обслуживания. Однако использование ANOVA при
таком подходе все еще затруднено. Более того, с точки зрения плана
следует рекомендация, чтобы при сравнении нескольких систем все
случайные числа были одинаковы (см. главу III).
Если все факторы количественные, то обычно постулируется более
общая модель, которая включает не только парные взаимодействия,
но и члены полных квадратов, т. е.
s=\ s—l z = s+I s=l
Так, предполагается, что отклик можно адекватно представить регрес-
регрессионным уравнением полинома второго порядка. Быть может, понадо-
понадобится преобразование, чтобы A84) стало адекватным представлением
(ср. [Box, Tidwell, 1962]). Мы видим, что A84) это только аппроксима-
аппроксимация, поскольку мы прекрасно знаем, что программа имитационного
эксперимента — лучшая модель. Тем не менее такая модель полезна
для выявления важных факторов и их желательных уровней (ср. так-
также с [Naylor, Hunter, 1969, p. 24]). Заметим, что аппроксимацию можно
интерпретировать как разложение истинной функции в ряд Тейлора
(см., например, [Mihram, 1972,. р. 359—360]). Чисто количественные
факторы — это область методологии поверхности отклика, которую
мы кратко обсуждали в II.6. Множество планов развились из этой ме-
методологии. Здесь мы приведем только один главный план, используе-
используемый при подборе полинома второй степени, вроде A84), а именно
центральный композиционный план. Для оценки всех коэффициентов
п A84) этот план объединяет дробную реплику (или для малых k —
полный план) 2k~P с планом-«звездой» и центральными точками,
т. е. 2k~p точек единичного куба, обозначаемых (± 1, + 1, ..., ± 1),
объединяются с 2k «осевыми» точками плана-«звезды»:
(+а, 0, .... 0)
(-а, 0, .... 0)
@, +а, ..., 0)
@, -а 0)
A85)
@, 0, ..., + а)
@, 0, ..., -а)
и, скажем, п0 параллельными опытами в центральной точке @, ..., 0).
Для k = 2 центральный композиционный план показан на рис. 22.
Значение а и п0 можно выбрать так, чтобы дисперсия оценки отклика
стала постоянной на равных расстояниях от центра плана (так называе-
мяя «ротатабельность» плана) и смещение, поскольку возможны коэффи-
коэффициенты третьей степени, минимизировалось. Литературу об этих
планах, как и о многих других, связанных с анализом поверхности
отклика, мы собрали в специальной библиографии в конце этой главы.
Большинство работ по моделированию и методу Монте-Карло rie
используют результатов теории планирования эксперимента. Правда,
есть исключения, например, [Smith, 1968, р. 20, 24] приспособил планы
57
/
\
\
\
\
\
\
\
%[ ' ... и У{{\А ...У тогда как Бонини [Bonini, 1967, р. 85—96]
применил П.Ш1И 2fv 2 (разбитый на блоки); для обобщения см.
IBouitii, 19711. Игнолл [Ignall, 1972] использовал методологию ана-
анализа поверхности отклика в моделировании системы управления запа-
запасами (вместе с общими случайными числами); Бойд [Boyd, 1964, р. 74-
78] приложил ротатабельный план к моделированию компании; смо-
смотри также библиографию в конце главы (раздел Г «Приложения»);
Михрам [Mihram, 1970] обсуждал
факторное экспериментирование
в моделировании системы военных
воздушных перевозок. В [Clough
et al., 1965, p. 127], [Doornbos,
1965, p. 209] и [McQuie, 1969] ис-
использовались «смешанные» планы,
т. е. планы, в которых не все фак-
факторы имеют одинаковое число
уровней (например, некоторые
имеют по два уровня, а осталь-
остальные — по три). В [Overholt, 1970]
обсужден ряд экспериментальных
планов и методов анализа и они
использованы при моделировании
некой военной системы. Мы при-
применим план 2iV8 в монте-карлов-
ском эксперименте, описанном в
главе VI. Игнолл [Ignall, 1971] и
Рис. 22. Центральный композицией- Дже?оби "ХаРРИ™? [<1аСоЬУ>
ный план для двух факторов Harrison, 1962, р. 134] отмечают,
что при моделировании число фак-
факторов (k) можно уменьшить сре-
средствами теоретического анализа системы до экспериментирования.
В [Nolan, Sovereign, 1972] линейное программирование применено к
глобальной агрегированной модели системы и моделирование исполь-
использовано для изучения наиболее важных факторов и деталей моделей
подсистемы; в этом моделировании имел место план 23.
IV.6. ДИСПЕРСИЯ ОШИБКИ ОПЫТА, НЕАДЕКВАТНОСТЬ
И ПОСЛЕДОВАТЕЛЬНОЕ ПЛАНИРОВАНИЕ
Мы видели, что в плане 2к число опытов N = 2к используется
для оценки_общего среднего и Bk — 1) возможных эффектов (главных
и взаимодействия). При этом не остается степеней свободы для оцени-
оценивания дисперсии ошибки опыта о2. В плане 2к~Р при р > 1 общее
среднее смешано с B" — 1) эффектами в определяющем соотношении.
Остальные степени свободы используются для получения Bk~p — 1)
оценок смешанных эффектов, не входящих в определяющее соотноше-
соотношение. Опять не остается степеней свободы для оценки ошибки. Однако
оценка о2 нужна для установления доверительных интервалов разных
эффектов и проверки гипотез о них,
\<
• план 2к
О план „ звезда "
©центральные точки
Для получения оценки ошибки опыта мы Можем дублировшйь один
или несколько опытов. Правда, как отмечает Дикстра [Dykstra,
1959, р. 63], в реальном эксперименте дублирование может стать проб-
проблемой15. Зато в имитации независимое дублирование получается про-
просто переходом на новые последовательности случайных чисел. Уэбб
iWebb, 1969, р. 430] считает, что в имитационном эксперименте «нет
¦юго, что обычно понимается под ошибкой опыта». Тем не менее мы
понимаем, что в моделировании мы имеем чистую ошибку опыта,
тогда как в реальном эксперименте действуют систематические фак-
факторы, вроде временного дрейфа, которые могут сместить чистую ошиб-
ошибку. Если в экспериментальном плане мы поставим J g > 2 опытов в g-й
точке (g = 1, 2, ..., G^.N), то получим несмещенную оценку диспер-
дисперсии ошибки опыта в этой точке:
> (g = l,..., G), A86)
)
где ygj — это /-е наблюдение в точке g, a yg — среднее по наблюде-
наблюдениям в этой точке. Ясно, что оценка A86) имеет (Jg — 1) степеней
свободы. В дисперсионном анализе предполагается, что дисперсия
ошибки опыта постоянна во всех точках. Отсюда взвешенное среднее
(с весами Jg — 1), или объединенная оценка такой общей дисперсии,
есть
я og(je—i)\ у, (Jg—:
_g=i J Le=i
где G — точки, в которых дублировались опыты. Мы можем записать
A87) и как объединенный средний квадрат. По определению,
SSg=6g(Jg — l)=%{yg]—ygY A88)
dfg = (Jg - 1). A89)
Тогда A87) можно переписать так:
Число степеней свободы этой объединенной оценки равно 16:
tf»=S (^-1)=2 J8-G. A91)
g=i g=i
Таким образом, в точке g будет (Jg — 1) «дубликатов», если мы про-
пропели в ней /^ наблюдений. Тогда общее число параллельных равно ЛГ2.
Для оценки ошибки опыта не важно, как мы распределим N2 парал-
59
и 11¦ 11¦•!ч мокд> различными точками, поскольку любое распределение
даег N2 степеней свободы Мы можем, например, сделать все N2 опы-
опытов в одной точке. Но дополнительные точки можно ведь использовать
еще и для улучшения оценок эффектов. Значит, распределение опытов
шшиот па надежное п> различных оценок эффектов. Исходя из этого
,/||||цМ|)а iDykslu, 1959J предложил определенную стратегию дубли-
|)iitiiiiiini, по нюляющую увеличить надежность как оценки ошибки
О|[Ы1,|, )ак и оценок эффектов Он рассматривал только планы 2у~р
(р ^ 0) и предложил дублировать план 2k~i (q>p). Мы свели
его планы в табл. 24, где последний столбец указывает страницу из
[Dykstra, 1959]. Полноты ради упомянем, что Пейтел [Patel, 1963]
построил неполные дублирования для нерегулярных дробных планов
Адельмана [Addelman, 1961], которые требуют меньше опытов, чем
планы Дикстры. В 1960 г. Дикстра рассмотрел еще схемы дублирова-
дублирования в композиционных планах анализа поверхности отклика
Позднее Дикстра [Dykstra, 1971a, b] обсудил выбор дополнительных
экспериментальных точек, когда эти точки не обязательно дублируют
старые, а могут быть и новыми. Дополнительная точка выбирается так,
чтобы максимизировать определитель матрицы Х'Х. (Максимизация
I Х'Х | — это стандартный критерий для планов, не обязательно орто-
ортогональных; ср. [Dykstra, 1971a, р. 682—683] и [Box, Draper, 1971,
p. 732—733; 1972].) Дикстра увидел, что каждая точка-кандидат, до-
допустим х0, вносит вклад в дисперсию оценки отклика, т. е. можно
оценить var (у\х0) и выбрать ту точку, в которой дисперсия максималь-
максимальная 17. Примеры этого подхода есть в [Hebble, Mitchell, 1972]. После
получения дублирующих (или новых) точек мы должны анализировать
расширенный план. Конечно, можно взять общую программу регрес-
регрессионного анализа. Если мы отдаем предпочтение факторным структу-
структурам, то нам стоит воспользоваться специальными формулами Дик-
Дикстры [Dykstra, 1959] для планов из табл. 24. Мы предпочитаем более
простые формулы для расширенных планов, данные Боксом [Box,
1966]. Его формулы годятся для планов с частичным дублированием
Дикстры, а также и для планов с непересекающимися или частично
пересекающимися дополнительными точками (ср [Box, 1966, р. 186]).
Метод работает так. Исходный план 2k~p с Ыг = 2k~p опытами
дает независимые МНК-оценки AЪ 12, ..., 1т) (т = N± — 1) главных
эффектов и взаимодействий (ylt у2, ..., ут), где Yi может обозначать
аА, у2 — аАВ и т. д. Вторая, меньшая реплика 2k~i присоеди-
присоединяется со своими N2 = 2k-Q опытами. Из самих этих опытов про-
простая МНК-оценка L2 получается для s смешанных эффектов в линей-
линейной функции % (s <; т.):
X = 8lYl + ... + бгТг + ... + SsYs, A92)
где б — плюс или минус единицы в зависимости от системы смешива-
смешивания. МНК-оценка для % из первого эксперимента будет
Lx = 6Л + -. + бг/г + ... + 6,1,- A93)
60
Таблица 24
Некоторые дробные реплики 2 у
Число
факторов
Ф)
3
4
5
6
7
8
9
10
11
Число
опытов
в исходном
плане 2«— Р
(Wi)
8
16
16
32
64
64
128
128
128
Исходные
генераторы
—ABCDE
ABCDEF
—ABCDEFG
—ACDFH
—BDEGH
ABDEGH
—ACDEFGJ
—ABEGH
—ACFGK
ABCDFJ
—ABEFL
—BCFGK
ADEFGH
BCDEFJ
р с частичным дублированием
Число
дополнитель-
дополнительных опытов
(АЫ
4
8
8
16
16
16
16
16
16
Дополни
тельные
генераторы
—ABC
ABCD
АВ
—CDE
—ABC
—ABC
—CDE
—ABC
—CDE
—ABC
—EFG
—ADG
—ADJ
—BCF
—BDH
—ABC
—CDE
—EFG
Страница
в работе
Днкстры,
1959
64
70
70
70
71
72
72
73
74
Если Lx и L2 различаются совсем чуть-чуть, то мы соответственно
получим корректную оценку уг Фактически Бокс показал, что МНК-
оценка, основанная на обоих экспериментах, это
-L,) (I =1,2,.. , s).
A94)
I Тример применения формулы Бокса приведение приложении IV.4.
Далее Бокс вывел
Л П ГИТ Т А Г /_ i Ч —I
A95)
|де множитель в квадратных скобках указывает, что дополнительные
опыты приводят к уменьшению дисперсии (ср. с (98)). Если в К входят
и у», и у}, то
cov (уг, у}) = ±
4iV2a2
A96)
причем знак минус будет тогда, когда в A92) уг и у7 имеют одинаковые
шаки, в противном случае будет плюс. Мы можем проверять гипотезы
61
j i in и и i i|niiiiii донор игслыШе интервалы, испоЛь*
tNt = К-* A97)
[(U)]1/2
с числом степеней свободы для t тем же, что и для оценки о2, т. е.
ЛГ2 = 2*-«. Для общей проверки более чем одного эффекта мы
полагаем применить общие формулы, приведенные, например,
в [Johnston, 1963, р. 115—133] для проверок МНК-оценок; в [Dykstra,
1959, р. 65] предложен другой метод, который кажется более произ-
произвольным18.
Альтернативный, быть может, смещенный подход к оценке а2 не
требует дублирования опытов, но предполагает, что некоторые эф-
эффекты не существуют. В C3) мы видели, что ожидаемое значение сред-
среднего квадрата эффекта равно а2, если эффект равен нулю. Если же
предполагается, что не существует т эффектов, то мы можем объеди-
объединить их независимые суммы квадратов, т. е.
SS1+...+SSj+...+SSm <т>1) A98)
будет оценкой дисперсии а2 с числом степеней свободы, равным сумме
{dfx + ... + dfm). Для плана 2k~P (р > 0) отношение A98) сводит-
сводится к A03), так как dfj = 1. Остается только вопрос, как теперь вы-
выбрать эффекты, которые подходят для отношения A98). Если бы мы
дублировали опыты, то можно было бы проверить, будет ли незначим
какой-нибудь эффект, как мы показали при обсуждении C3). Если же
нет дублирования, то нельзя проверить значимость эффектов таким
образом. Поэтому Дэниел [Daniel, 1956, р. 93—95; 1959] построил
графический метод, названный «.полунормальные графики», по которо-
которому можно составить суждение о значимости эффектов. К сожалению,
как отмечает автор [Daniel, 1959, р. 338, 339], «применение полунор-
полунормальных графиков ... полностью субъективно» и только если «лишь
малая доля контрастов имеет эффекты, то можно применить такой
график, чтобы вынести суждения о фактических больших эффектах».
Бирнбаум [Birnbaum, 1959] дал более статистическую теорию метода
полунормальных графиков. Его результаты снова показали, что ме-
метод работает, только если предполагается, что имеется мало нену-
ненулевых эффектов. Поэтому вместо построения полунормальных гра-
графиков обычно априори полагают, что определенные эффекты не су-
существуют. (Напомним, что такое предположение лежит в основе
всех неполных планов.) Чаще всего приравниваются к нулю и объ-
объединяются в A98) взаимодействия высоких порядков. Когда же
оценка а2 как-то получена, мы можем проверить значимость эффек-
эффектов по /^-критерию. Если на выбранном уровне значимости эффект
окажется незначимым, то мы можем либо продолжать работать со
старой оценкой о2, либо объединить незначимый эффект со старой
оценкой (ср. [Hunter, 1959b, p. 9], а также [Cohen, 1968]. Мы от-
62
сылаем к [Holms, Berrettoni, 1969] за подходящими методами, если
объединение сумм квадратов запрещено.
Из C3) видно, что отношение A98) ведет к переоценке а2, если
объединенный эффект на самом деле не равен нулю. Это дает еще ог-
огромный шанс на то, что в дробном факторном плане а2 будет переоце-
переоценена. Если в дробном плане каждую степень свободы использовать для
оценки а2, то получится, что более чем один эффект предполагает-
предполагается равным нулю. Так, в плане разрешения IV для семи факторов мало
предположить, что равны нулю взаимодействия между факторами 1 и 4,
поскольку из A67) видно, что надо предположить то же еще и для вза-
взаимодействий факторов 3 и 6 и 5 и 7. Переоценка дисперсии ошибки
недет к таким следствиям:
1) доверительные интервалы для эффектов расширяются;
2) при проверке гипотезы о незначимости эффекта мы принимаем
се более часто, чем указывает заданный а-уровень. Это может приве-
привести к исключению фактора из дальнейшего экспериментирования,
если он ошибочно будет признан незначимым. По нашему мнению, это
меньшая неприятность, чем кажется на первый взгляд, ибо отсутствие
времени и денег, достаточных для экспериментирования, все равно
ограничивает, так что исключение фактора означает, что мы можем
уделить больше времени тем факторам, которые, по всей вероят-
вероятности, более важны19.
Можно взглянуть на объединения эффектов и с другой стороны.
При объединении эффектов мы полагаем, что они равны нулю. Это пред-
предположение означает, что в регрессионной модели будет мало параме-
параметров. Если число параметров, допустим J, меньше, чем число опытов
N, то можно найти «остаточный» средний квадрат Sr, т. е.
N ~
о _ 'V (Уг—Уу П99Ч
Off = у yl <JC/J
где yt — предсказанное значение отклика из регрессионной модели
с МНК-оценками J параметров, a yt — «истинный» отклик. В [John-
[Johnston, 1963, р. 106, 112], например, показано, что
Е (SR) = a2, B00)
соли верна модель, по которой предсказывались yi. Например, в пла-
плане 23 без дублирования можно предположить, что адекватна линейная
модель или что р12 = 013 = р23 = Р123 = 0- Отсюда в A99) мы име-
имеем ЛГ = 23 = 8, а/ = 4 (сравните: Ро, рх, р2, р3); Sr связан с
(8 - 4) = 4 степенями свободы. Заметим, что в силу ортогональности
плана мы могли бы разложить сумму квадратов в числителе A99)
на четыре независимые суммы квадратов, соответствующие р12, р13,
|liii> Pi23- Объединение эффектов подчеркивает предпосылку о том,
чю некоторые эффекты имеют определенное значение (а именно нуль),
пн'да как Sr подчеркивает предпосылку о том, что модель имеет оп-
определенный порядок (например, первый, как предполагалось). Это
приводит к проблеме проверки адекватности модели,
Пусть мы приступаем к эксперименту, полагая, что адекватна мо-
модель, содержащая только k главных эффектов, или, в терминологии
регрессионного анализа, мы имеем модель первого порядка. Если взять
насыщенный план разрешения III, то можно точно подогнать модель,
но нельзя проверить ее адекватность. Однако, если (k + 1) не кратно
четырем, план разрешения III будет не насыщенным, или, если все
же {к + 1) кратно четырем, можно взять план разрешения IV. В обоих
случаях мы сможем оценить несколько (смешанных) первых взаимодей-
взаимодействий. Далее, если одна или несколько экспериментальных точек дуб-
дублировалось, мы независимо оценим а2 и сможем проверить значимость
наших парных взаимодействий. Пусть одни взаимодействия окажут-
окажутся значимыми, а другие-—нет. Тогда может иметь смысл взять модель
со всеми взаимодействиями. Несмотря на то что некоторые взаимодей-
взаимодействия незначимы, их несмещенные МНК-оценки с минимальной дис-
дисперсией не равны нулю (хотя и малы). Так, если все факторы количест-
количественные, мы можем взять полином второго порядка (со всеми парными
взаимодействиями плюс полные квадраты) вместо модели первого по-
порядка. Сравните также с обсуждением в [Box, 1954, р. 57] и в [Hunter,
1959b, p. 9], где рассмотрена практика проверки отдельных параме-
параметров. Итак, вместо раздельной проверки эффектов мы можем получить
их общую (объединенную) сумму квадратов и сравнить ее средний
квадрат с независимой оценкой сг2.20
Если же нам не интересны частные суммы квадратов, то можно
поступить и иначе. Допустим, что N опытов включает N2 параллель-
параллельных. Тогда можно найти остаточную сумму квадратов, т. е. числитель
A99):
5«Л-2^-^J B01)
и оценку с2 из параллельных опытов о%:
G% = SSD/N2, B02)
где SSd — это числитель A90). Оценка oh, не зависит от выбора
модели, но оценка SR == SSR/(N — J) зависит от корректности
модели, дающей значение yt. Если модель верна, но обе оценки дают
(приблизительно) одно и то же значение для а2. Если же модель не
верна, то уг отклоняется от уг не только из-за ошибки опыта, но и из-за
ошибки представления. Тогда SR возрастет в сравнении с аЬ\
указывая на ошибку в выборе модели. Если мы хотим взять для срав-
сравнения SR и во F-критерий, то надо помнить, что числитель и зна-
знаменатель /^-критерия должны быть независимы. Однако SR включает
в себя и ошибку опыта, ту же, что оценивает o2D. У Менденхолла
[Mendenhall, 1968, р. 201], например, показано, как определить
сумму квадратов «неадекватности» SS[,:
SSL = SSR — SSD
64
и ее средний квадрат
MSL = SSJ(N — J — Nt). B04)
Таким образом, SSR разлагается на две независимые суммы квадра-
квадратов: SSl и SSp. Следовательно, критерий неадекватности дает
сравнение MSl/оЬ с табличным /^-отношением. Если превышен
критический уровень, то мы отбрасываем гипотезу о том, что наша мо-
модель пригодна (ср. также в [Draper, Herzberg, 1971, p. 231—232]~и в
[Hunter, 1958, p. 20—22; 1959а, p. 10, 12; 1959b, p. 9]). Приложение
метода мы покажем в главе VI.
Если мы отбрасываем гипотезу о корректности нашей модели, то
обычно переходим к модели более высокого порядка 21. Это приводит
к последовательному планированию. Мы можем начать с плана из
очень малого числа опытов. Затем мы увидим, что планы разрешения
III годятся для изучения k факторов всего в N = k + 1 опытах, если
N кратно четырем, иначе мы возьмем следующий план с Nlt кратным
четырем. Если^АГ не" кратно четырем или же если есть некоторые до-
дополнительные опыты, то мы можем проверить, адекватна ли модель
первого порядка. Для этого мы можем подсчитать некоторые суммы
квадратов взаимодействий или остаточную сумму квадратов. При на-
наличии независимой оценки а2 (из параллельных или предварительных
опытов) можно воспользоваться /^-критерием. А если взаимодействия
окажутся значимыми, то мы можем перейти к плану разрешения IV.
f" ^K счастью, мы видим, что построить план разрешения IV из плана
разрешения III не представляет никакого труда. Мы просто должны
повторить план разрешения III с обратными знаками, т. е. помимо Л^
опытов плана22 разрешения III, которые мы уже провели, мы берем еще
N± опытов. По определению, план разрешения IV дает оценки главных
эффектов, которые не смешаны с парными взаимодействиями. Поэтому
из плана разрешения IV мы можем надежно заключить, есть ли у ка-
какого-либо фактора главный эффект (при условии, что нет взаимодейст-
взаимодействий трех и более факторов; это "условие можно проверить при проверке
адекватности по плану разрешения IV). Если предположить, что те
факторы, у которых'нет главных эффектов, не имеют и взаимодействий,
то вполне возможно, что на основании плана разрешения IV мы исклю-
исключим некоторые факторы. Иметь меньше факторов это значит, что сокра-
сокращается число опытов, необходимых для эксперимента (ср. с табл. 8).
Оставшиеся факторы можно изучить в плане разрешения V.
Когда из плана разрешения IV отбрасывается один или несколько
факторов, то может случиться, что план превратится в план разреше-
разрешения V (или выше) для оставшихся факторов. Обратимся к примеру
в табл. 25. Из построения плана легко видно, что если фактор 4 незна-
незначим, то план 2IV1 превращается в полный факторный план для фак-
факторов 1, 2 и 3. (Мы еще вернемся к такому «отсеиванию» важных'среди
li факторов в IV.7.) Если с самого начала в эксперименте k факторов
и мы хотим иметь возможность реализации для них плана разрешения
V, то нужно большое внимание. Планы разрешения III и IV можно
выбрать так, чтобы они были подмножеством планов разрешения V.
>'! Дж Клеймен 8§
Дробный план 2 р
Таблица 25
+1+1+l+l
~t
!1++11++
—v
3
++++ 1 1 1 I
1=123
1++1+11+
Этого можно достигнуть для планов 2k~p, продолжая все коды в оп-
определяющем соотношении плана 2%~" из определяющих соотноше-
соотношений предыдущих планов разрешения III и IV; пример такого подхода
привел Дэниел [Daniel, 1956, р. 96—97]. Однако в табл. 20 мы видели,
что планы 2у~р не привлекательны, ибо они требуют много больше
опытов, чем число оцениваемых эффектов. Поэтому мы можем предпо-
предпочесть насыщенные планы разрешения V Уэбба. В общем его планы не
содержат предыдущих планов разрешения III и IV как подмножеств.
Все же эти планы могут быть привлекательны, поскольку из табл. 23
видно, что для больших k число дополнительных опытов здесь меньше,
чем в планах 2у~р- Отметим, что если все факторы (оставшиеся после
плана разрешения IV) количественные, то довольно просто расширить
план IV до центрального композиционного плана. Рис. 22 показы-
показывает, что такой план включает реплику 2fe-f (р > 0), к которой
добавлены осевые и центральные точки.
Вместо этого подхода, когда мы идем от плана разрешения III к
плану разрешения IV, а затем и V, мы можем продвигаться меньшими
шагами. На каждом шаге мы теперь добавим малую долю подходящих
опытов. Адельман [Addelman, 1969] систематизировал двухуровневые
дробные факторные планы от 3 до 11 факторов и всего не более чем с
256 опытами. Его дополнительные доли ограничены принадлежностью
к тому же семейству. Можно, например, на каждом шаге добавлять
27-4 = 8 опытов из 1/16 реплики, принадлежащей' семейству, ха-
характеризуемому A42). Каталог Адельмана показывает, как много
главных эффектов и парных взаимодействий можно оценить после каж-
каждого шага в предположении, что взаимодействия трех и более факторов
отсутствуют. Для демонстрации пользы метода малых шагов мы кратко
рассмотрим план 2\<Гг, который дан в A67). Если в A67) будет ве-
велик только первый контраст для парных взаимодействий, а все осталь-
остальные двухфакторные контрасты окажутся малыми, то нам может не
захотеться переходить к плану разрешения V. В этом плане можно
оценить все парные взаимодействия, мы же полагаем, что важны лишь
взаимодействия а24, а35 и а67 (пренебрегая полностью остальными
смешанными взаимодействиями, которые вычеркиваем).Для такого слу-
случая была придумана специальная процедура. Так как общие правила
66
Здесь трудно сформулировать дли каждого частного случая, мы не
будем обсуждать этих приемов, а сошлемся на [Addelman, 1969],
а также на [Daniel, 1962], [Jacoby, Harrison, 1962, p. 123—126] и
[John, 1966]. Анализ последовательно достраиваемых планов можно
вести с помощью методов, развитых Хантером [Hunter, 1964]или Бок-
Боксом [Box, 1966]. Последний метод и был представлен уравнениями
A92) —A97). Работу^ с малыми шагами можно также вести мето-
методом Дикстры [Dykstra, 1971], который мы обсуждали в связи с рас-
расширением планов (со старыми и новыми точками) для оценки ошибки
опыта и эффектов.
Одно заключительное замечание о последовательной достройке
планов. Мы видели в A52), что можно повторить план, меняя знак в
одном столбце. Таким путем можно выделить и проверить отдельный
фактор вместе со всеми его взаимодействиями.
Прежде чем перейдем к следующему классу планов, коротко рас-
рассмотрим качество этих планов. Хантер [Hunter, 1968, р.4] и Нейлор
и Хантер [Naylor, Hunter, 1969, p. 3] перечислили следующие тре-
требования к экспериментальным планам:
1) малое число опытов;
2) минимум дисперсии оценок;
3) наличие меры адекватности модели;
4) желаемая система смешивания;
5) простой счет.
К этим требованиям мы бы добавили композиционность. Относительно
утверждения 1 мы заметим, что число экспериментальных точек Nx
должно быть как минимум равно числу параметров, пусть J, подлежа-
подлежащих оценке. По поводу 2 — ковариационная матрица МНК-оценок
(с минимальной дисперсией, несмещенных) есть
а2 (Х'ХУ1 B05)
— Бокс [Box, 1952,^p. 50] показал, что диагональные элементы в B05)
минимизируются23, если
X=yV!/2"G, B06)
—> " —>
где первый столбец матрицы G состоит из единиц и, кроме того, G
ортогональна, т. е.
~G'7}=~I, B07)
a Af — число опытов (оно равно Nlt если нет дублирования). Если
N > Nt > /, то можно построить критерий для проверки неадекват-
неадекватности и удовлетворения требования 3. Желаемая система смешивания
означает, что эффекты низких порядков надо смешивать не с другими
эффектами низких порядков, а лучше смешивать их с эффектами вы-
высоких порядков. Вычисления упрощаются, если МНК-оценки в
~Ъ = (Х'ХУ^Х' у~ B08)
и в выражении B05) будут иметь диагональную матрицу (Х'Х). Тогда
обращение превращается просто в переход к обратным числам на
1* 67
-4.-4-
главной диагонали матрицы (Х'Х). Более того, исчезают машинные
ошибки округления — обычный бич программ обращения матриц.
Большинство требований точно так же подходит к нашим планам. Иной
точки зрения придерживаются Бокс и Дрейпер [Box, Draper, 1971].
Они берут в качестве критерия максимизацию определителя матрицы
—> —>
Х'Х. Они предполагают, что весьма ограничительно, будто модель
верна (т. е. без проверки существования возможных членов высокого
порядка); см. [Box, Draper, 1971, p. 733]. Если экспериментатор ап-
априори ^полагает верной линейную модель, то он может взять план,
табулированный Боксом и Дрейпером [Box, Draper, 1971, p. 736—
737] для k факторов (k = 2, ..., 7) и N = k + 1 опытов. (Для k =
= 2, 3, 7 их планы совпадают с 2А~" планами!) Мы адресуем к
[Srivastava, Chopra, 1971, p. 258—259] для знакомства с краткой дис-
дискуссией и библиографией о различных возможных критериях качест-
качества планов (таких, как, например, детерминант, след или наибольший
—>¦ -»-
корень матрицы X'X в ковариационной матрице оцениваемых эффек-
эффектов).
IV.7. ПЛАНЫ ОТСЕИВАНИЯ
Перед началом исследования~мы^можем столкнуться с многими,
например с k, факторами, которые предполагаются важными. Можно
постулировать, что на самом деле важны не все k факторов, а лишь
их малая часть, скажем k'. Мы не знаем ни того числа k', ни того,
какие k' факторов из k значимы, поэтому мы хотим отсеять (выделить)
эти факторы. Эту ситуацию обсуждали также Джекоби и Харрисон
(Jacoby, Harrison, 1962, p. 128]. Они считают, что ситуация отсеива-
отсеивания ^весьма характерна для имитационного эксперимента. Мы рас-
рассмотрим несколько типов планов отсеивания, а именно A) планы 2а~р
B) случайные планы; C) сверхнасыщенные планы; D) планы группо-
группового отсеивания.
Планы 2*-р
О применении планов 2k~P для отсеивания важных факторов
упоминается, например, в [Hunter, 1959a, р. 15] и [Box, Hunter,
1961а, р. 318, 341—344]. Для примера мы возьмем_план из табл. 25,
повторенный в табл. 26. Из структуры плана видно, что если фактор
4лне оказывает влияния, то план 2fv 1 становится полным фактор-
факторным планом для факторов 1, 2 и 3. Но если незначим и любой другой
фактор, то из таблицы видно, что получается полный план для трех
остальных. (С точностью до порядка строк, отличающегося от табл. 6.)
Этот же результат легко получить с помощью генератора для плана
24-1, а именно / = 1234. Раньше мы отмечали, что отбрасывание
фактора из плана означает, что из определяющего соотношения вычер-
вычеркиваются все коды, содержащие этот фактор (ср. с A43)). Слрдователь-
68
Таблица 26
Дробный план
+1+1+1+1
++11++1 I
X
~4=T23
1++1+11+
Но, в нашем примере вычерки-
нается генератор 1234 и ника-
ких генераторов не остается;
значит, в определяющем соот-
соотношении нет кодов и эффекты
никак не связаны; т. е. план
становится полным факторным.
1хли же несущественны не один,
а "два фактора, то план 24 пре-
превращается в полный план для
остальных двух факторов, повто-
повторенный дважды. Наконец, если
важен один фактор, то получает-
получается учетверенный полный план.
Таким образом, мы знаем, что, по определению, план разрешения
R имеет определяющее соотношение с кодами из не менее чем R сим-
символов. Так, если важны только (R — 1) факторов, то все коды в опреде-
определяющем соотношении содержат по меньшей мере один несущественный
фактор. А отбрасывание этого фактора приводит к вычеркиванию всех
кодов. Значит, в плане разрешения R вычеркиваются все коды, если
только важны (R — 1) факторов. Следовательно, план разрешения
R — это полный факторный план для (R — 1) факторов, пов-
повторенный полный план при меньшем, чем (R — 1), числе факторов,
повторенный полный план для (R — 1) факторов, если число опытов
кратно 2<я-!>. Как пример последней возможности рассмотрим
план 28~4. Например, из A70) следует, что R = IV, и, значит,
ото полный план для трех факторов. Число опытов равно 28~4 =
- 2* = 2 X 23, т. е. полный план для трех факторов удвоен. Если мы
хотим отсеять R факторов в плане разрешения R, то вычеркиваются
не все коды в определяющем соотношении. Оставшиеся коды показы-
иают, что для наших комбинаций факторов план не полон. Например,
код 1248 появляется в определяющем соотношении плана 28~4. Сле-
Следовательно, для факторов 1, 2, 4 и 8 план не полный (а дробный).
Ксли бы код 1234 не появился в определяющем соотношении, то план
для этих факторов был бы полным.
Бокс и Хантер [Box, Hunter, 1961a, p. 344—345] привели инте-
интересный пример отсеивания. Они брали план 28^4 с откликами,
приведенный в табл. 27. Оценки даны в табл. 28. Эта таблица показы-
пает, что правдоподобная интерпретация результатов эксперимента
Гйкова: есть только три важных фактора, а именно факторы 3, 5 и 8,
так как их главные эффекты и их взаимодействие можно отнести к
большим в табл. 28 (сравните числа в квадратах). Мы видели выше,
что план 2fy4—это удвоенный полный план для трех факторов. Это
показано в -табл. 29.
Если утверждение, что важны только три фактора, верно, то раз-
различие между двумя «повторами» обусловлено ошибкой опыта, а не
различиями в уровнях незначимых факторов 1, 2, 4, 6 и 7. Как отме-
69
Таблица 2?
Результаты для эксперимента'2
Опыты
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Факторы
I
__.
!
1
_
[
_J_
2
_J_
[
—
_1_
+
_j_
_]_
1
—
_J_
-i-
+
it
—
_]_
_j_
_]_
_j_
_j_
_]_
_]_
+
у
4
_
+
_|_
_.
_j_
_]_
_
—
_J_
—
—
+
у
5
_
[
_J_
+
+
—
+
_
_l_
1
_J_
_J_
_l_
_
.
+
7
[
_J_
_|_
—.
[
—
_|_
_J_
+
Отклик
60,4
66,0
62,1
63,3
82,9
75,4
82,4
73,0
68,1
61,2
71,3
59,6
67,3
75,3
66,7
77,1
Таблица 28
Отсеивание восьми факторов
2?v4
в плане
чают Бокс и Хантер [Box, Hunter, 1961a, p. 345], это можно прове-
проверить, если есть независимая подходящая оценка ошибки опыта, по-
полученная дублированием. Та-
Такую оценку можно сравнить с
оценкой, основанной на «повто-
«повторах», из табл. 29.
Обсудим теперь частные ви-
виды ситуации отсеивания. Пусть
мы обнаружили, например, k'
важных факторов среди k по-
подозреваемых, где k' много мень-
меньше, чем k, a k весьма велико,
скажем 100 или больше. Ис-
Использование плана разрешения
IV , как в табл. 27, дает число
опытов, равное 2k. Так, если
число факторов k велико, то
число опытов может оказаться
чрезмерным. Даже в планах
разрешения III число опытов
равно (k + 1) и может быть уже
велико. Следующие три типа
планов можно использовать для
решения задач с непомерным
числом опытов, обусловленным
непомерным числом факторов.
70
Эффект
1
2
3
'~4~'
5
'T
7
8 1
12+37+48+56
13-f27+|58
+46
14+28+36+57
15+|38|+26+47
16+78+34+25
17+23+68+45
18+24+|35|+67
Оценка
—1,3
-0,1
11,0
0,5
7,6
0,2
1,2
-2,4
— 1,1
1.7
0,8
-4,5
0,6
—0,3
1,2
Таблица 29
План 28-4 как дважды повторенный план для трех факторов
Опыты
1, 3
6, 8
10, 12
13, 15
2, 4
5, 7
9, 11
14, 16
Факторы
3
,
_|_
_|_
—
+
t
.
_|_
+
5
_
_|_
+
+
Отклики
60,4
75,4
61,2
67,3
66,0
82,9
68,1
75,3
62,1
73,0
59,6
66,7
63,3
82,4
71,3
77,1
Случайные планы
Обстоятельная дискуссия о случайных планах была опубликована
в журнале «Technometrics» в 1959 г. Саттерзвайт [Satterthwaite, 1959,
р. 112] определил случайные планы как планы, в которых все или не-
некоторые элементы матрицы плана выбираются с помощью случайной
выборки. Существуют разные приемы случайного выбора. Обычно
мы берем разные уровни некоторого фактора с равными вероятностями.
Однако если есть некие априорные знания о том, что некоторые уров-
уровни более обещающие, то можно воспользоваться выбором с неравны-
неравными вероятностями. Выбирать можно с возвращением или без него.
В последнем случае можно добиться,чтобы все уровни фактора появля-
появлялись в эксперименте одинаково часто. Обычно отбрасываются любые
элементы, для которых получается коэффициент корреляции между
изучаемыми факторами, который превышает допустимый предел.
Пусть, например, выборочный процесс дал коэффициент корреляции
хх и х2, который равен плюс единице. Это значит, что если в каком-
нибудь опыте хх = + 1, то и х2 = + 1, а если хг = — 1, то и ха =
"= — 1. Тогда невозможно разделить эффекты хх и х2; эти два эффекта
полностью смешаны. Известно, что и в дробном, и в полном факторном
эксперименте «коэффициент корреляции» равен нулю. Поясним, что
для неслучайных величин хх и х2 «коэффициент корреляции» опреде-
определяется так:
р = -
1'ДС
(/=1.2),
B09)
B10)
B11)
71
В планах 2k~p (p > 0) [i} = 0, так что B09) сводится к
Поскольку планы ортогональны, B12) показывает, что «коэффициент
корреляции» равен нулю. Это свойство факторных планов обеспечи-
обеспечивает независимые оценки главных эффектов. Правда, в случайных пла-
планах выборочный коэффициент корреляции г для хх и х2, определяе-
определяемый, подобно B09), как
это случайная величина, не обязательно равная нулю. Мы еще вер-
вернемся к этой корреляции при описании сверхнасыщенных планов.
Интересующихся дальнейшим обсуждением различных приемов вы-
выборки в случайных планах мы отсылаем к работам [Anscombe, 1959,
р. 195—196], [Budne, 1959a], [Jacoby, Harrison, 1962, p. 129] и
[Satterthwaite, 1959, p. 112—113]. Пример анализа работы случайного
плана дан в [Budne, 1959a]; для имитационного эксперимента случай-
случайные планы обсуждаются в fCyert, March, 1963, p. 173—178].
Привлекательная особенность случайных планов заключается в
том, что число наблюдений можно установить независимо от числа
факторов. В неслучайных планах между N и k есть математическая за-
зависимость, а именно N = 2*—р. В случайных планах такой зависи-
зависимости нет. (Конечно, с ростом отношения Nik оценки улучшаются.)
Поэтому в случайном плане можно испытать много факторов при уме-
умеренном числе опытов; N может быть даже меньше, чем k.
Относительно анализа случайных планов Саттерзвайт [Satterth-
[Satterthwaite, 1959, р. 126] заметил, что здесь не требуется никаких специ-
специальных методов, любой прием, известный для традиционных планов,
можно применить и для случайных; или «можно провести любой анализ
для любого (достаточно малого) множества факторов, игнорируя все
остальные. Игнорирование факторов равносильно созданию для ана-
анализа остаточной ошибки». Он не определил свое «достаточно малое»
подмножество. Мы можем интерпретировать его замечание следующим
образом. Саттерзвайт [Satterthwaite, 1959, р. 127] упоминал возмож-
возможность применения для анализа случайных планов методов дисперси-
дисперсионного анализа. Мы знаем, что в таком анализе число степеней свобо-
свободы не может превышать число наблюдений; следовательно, число эф-
эффектов, рассматриваемых в дисперсионном анализе, должно быть мень-
меньше числа опытов. Поэтому если число факторов в эксперименте боль-
больше числа опытов, то мы ограничиваем ANOVA «достаточно малым»
подмножеством от множества факторов.
Метод анализа, известный для традиционных планов, — это рег-
регрессионный анализ, который включает в себя дисперсионный анализ,
как мы видим в IV.2. Саттерзвайт показал, что применима и простая,
и множественная регрессия. Простая (однофакторная) регрессия оз-
72
tin чает, что в модели с несколькими факторами мы оцениваем единич-
единичный эффект, пренебрегая всеми остальными, с помощью известной фор-
формулы простой регрессии, приведенной, скажем, в [Johnston, 1963,
р. 12]. Например, в уравнении
(i=l,..., N) B14)
мы оцениваем р^ (j = 1 k) из
zJL t (xtj-Xj) (yt-y)
bj = i— ;— '-. B15)
Цели k > N, то оценок множественной регрессии не существует, но
п случайном плане оценки простой регрессии «существуют, поскольку
связаны с (ЛГ — 2) степенями свободы, и имеют конечные доверитель-
доверительные границы» tSatterthwaite, 1959, р. 135]. Заметим, что в B15) при-
причинный (объяснительный) фактор
случаен. В большинстве учебни- Т н
ков, и в частности у Джонстона
IJohnston, 1963], это не случайная
переменная. Однако у Фиша [Fisz,
1967, р. 96] берется случайная
величина лг.
Другой путь анализа — графи-
графический. Хотя эта возможность тоже
применима к традиционным пла-
плацам, ее простоту особо подчеркива- Уровни
ли авторы случайных планов. Для фактора Я
Каждого фактора ^МЫ можем] ПО- Рис. 23. Точечная диаграмма для
строить точечную диаграмму, т. е. фактора А
указать соответствие между значе-
значениями откликов на оси у и различными уровнями данного фактора на
оси х. Если фактор не имеет эффекта, то^усредненные по уровням откли-
)Ш будут совпадать для разных уровней,24. Пример точечной диаграммы
показан на рис.23 (в этом примере на'каждом уровне одинаковое число
опытов). Затем мы можем исключить (элиминировать) факторы, кото-
которые заведомо эффективны. Таков фактор Л ^""примере на рис. 23.
Для эффективного фактораЪычислим средний отклик на уровень, на-
например у?, у% и у?, и в каждом опыте, где фактор Л встречался на
уровне h (h= I, 2, 3), вычтем у% из отклика. Для таких скорректиро-
мшшых откликов^построим'теперь графики с теми факторами, которые
при первом построении не обнаружили свою значимость. Мы остано-
инмея как только исчерпаем эффективные факторы. Подробный пример
дикого графического анализа (где проверялись и взаимодействия) при-
нгдеп в iBudne, 1959b и 1959d, p. 143—154]. Очевидно, точечные диа-
ц1ПМмы могут служить первым шагом в анализе любого эксперимента,
щюиеденного как по случайному, так и по классическому плану.
73
При некоторых типах Ёопросов и откликах такой простой анализ мо-
может дать ответ без всяких дальнейших сложностей. Точечные диаграм-
диаграммы удобны также для представления результатов эксперимента «пуб-
«публике».
В дополнение к визуальной проверке точечных диаграмм Энскам-
би [Anscombe, 1959] привел некоторые критерии значимости, тоже
пригодные для отдельных факторов.
1. Критерий F дисперсионного анализа
Поскольку каждый фактор рассматривается отдельно, мы исполь-
используем формулу для /^-критерия в однофакторном дисперсионном ана-
анализе, уже приведенную выше в C1):
где фактор имеет /^уровней^с /,- наблюдениями на уровень; ytj — ис-
исходные наблюдения или наблюдения, «скорректированные» после ис-
исключения (снятия) некоторых эффективных факторов на предыдущих
шагах обработки, как описано выше. Этот критерий проверяет, равен
ли нулю Ь] из B15); сравните с нашим обсуждением отношений между
дисперсионным и регрессионным анализом.
2. критерий рандомизации Уэлча
Уэлч (Welch) не уточнил теоретическое распределение, посколь-
поскольку /^-статистика основана на нормальности. Он использовал подход,
основанный на рандомизации. Пусть мы^имеем N опытов, которые
сгруппированы соответственно J уровням определенного фактора.
Если этот фактор не эффективен, то объединение опытов по его уров-
уровням будет случайным, т. е. такое группирование можно рассматривать
как результат случайного выбора из всех возможных группирований
N опытов в группы объема Ilt /2, ..., Ij- Если теперь найти подходя-
подходящую статистику, то мы сможем построить ее распределение, а значит,
узнать, какое значение соответствует каждому возможному группи-
группированию. (Есть An(/i!/2! ••• Л/1 У1 способов группирования; по-
поскольку это перестановки критерия рандомизации, его также называ-
называют перестановочным (пермутационным) критерием.) Число различных
групп ограничено, так что распределение статистики дискретно. Ста-
Статистика Уэлча [Welch, 1938, р. 149] есть
^5 уровнями ^ s/=i s<=i (y.J-У-J . B17)
Уэлч [Welch, 1938, p. 152] получил среднее и дисперсию ?2 в предпо-
предположении об отсутствии эффекта. Для Е2 нет стандартного распределе-
распределения с табулированными критическими значениями. При поиске крити-
74
чсского, скажем 5%-ного, уровня мы находим различные возможные
значения Е2, табулируем их и вычисляем 5%-ную точку. Вместо это-
этого Энскамби [Anscombe, 1959, р. 199—200] определил ожидание и
дисперсию Е2, полученные Уэлчем [Welch) для| проверки гипотезы
о неэффективности фактора; если наблюдаемое значение Е2 значи-
значительно больше, чем, например, удвоенное или утроенное стандартное
отклонение, то Энскамби отбрасывает исходную гипотезу. Однако мы
покажем, что если не вычислять критический уровень для Е2, то мо-
можем с тем же успехом взять — /-"-критерий ANOVA (для которого
метод Уэлча подходит) или воспользоваться графическим анализом;
можем мы также применить и следующий критерий.
3. Критерий рандомизации Тьюки для фактора на двух уровнях
При двухуровневом факторе наблюдения делятся на две группы.
Тьюки [Tukey, 1959a, р. 32] потребовал: «A) подсчитать число значе-
значений в одной группе, превосходящих все значения из другой; B) под-
подсчитать число значений в другой группе, меньших, чем самое малое зна-
значение в первой, и C) сложить эти два результата (мы требуем, чтобы
ни тот ни другой результат не был равен нулю)».
В качестве примера рассмотрим рис. 23, приведенный выше, вы-
вычеркнув наблюдение, относящееся к третьему уровню. Первый шагA)
дает единицу, B) дает двойку и, следовательно, C) приводит к трем.
Если число наблюдений на каждом уровне одно и то же (это условие,
выполнение которого мы можем обеспечить в выборочной процедуре
случайных планов), то критические значения числа из C) приведены
в табл. 30 (основанной на табл. 2А из [Tukey, 1959a]). Тьюки привел
также критические значения и для групп неравного объема (в табл. 2А).
Эти критические значения лишь слегка отличны от тех, что приведены
в табл. 30. (Для 5%-ного уровня они варьируют от 7 до 11 при изме-
изменении размера группы от 1 до 10, а N меняется от 6 до более чем 86.)
Ради полноты мы отметим, что Вестлейк [Westlake, 1971] развил кри-
критерий Тьюки для частных экспериментальных ситуаций.
Таблица 30
Двухсторонние критические значения критерия Тьюки
Общее чи~ло наб-
наблюдений N
8—16
18—42
44—48
50—
Критическое значение
5%-ное
7
7
7
8
] %- ное
9
10
10
10
0,1%-ное
13
13
14
14
Мы видели, что в случайных планах число опытов N не зависит от
числа факторов k. Нет зависимости N и от числа уровней факторов. Тем
МО менее Энскамби [Anscombe, 1959, р. 200—201] указал, что нельзя
75
взять произвольное число уровней. Для усиления мощности критерия
Уэлча (который связан с /-критерием в дисперсионном анализе) он
предложил брать только два уровня, если есть уверенность в том, что
отклик линейно зависит от уровней фактора (количественного), и брать
три или четыре уровня, если отклик есть «некоторая регрессионная
кривая, описываемая полиномом низкой степени и имеющая не более
чем один максимум» (если фактор вообще имеет любой эффект). Он
также показал, что уменьшение возможности смешивания эффектов
(обусловленной неортогональностью столбцов плана) требует, чтобы
число опытов N удовлетворяло соотношению
N >„8/, B18)
где J—максимальное число уровней среди k факторов в эксперименте,
т. е.
J=max(Jh) (h=l,...,k). B19)
л
Таким образом, B18) показывает, что большое число уровней потребует
еще большего числа опытов (см. также [Budne, 1959b, p.ll]).
Заключая наше обсуждение случайных планов, мы перечислим их
преимущества по Саттерзвайту [Satterthwaite, 1959, р. 119—121] и
одновременно оценим эти, так сказать, «преимущества».
1. «Простота планирования». Однако мы думаем, что из данной гла-
главы видно, что даже непрофессиональный статистик может построить
классический план вроде плана 2*-р.
2. «Простота анализа». Тем не менее сам Саттерзвайт [Satterthwai-
[Satterthwaite, 1959, р. 126] говорит в другом месте своей работы, что большинство
методов анализа случайных планов родом из классических планов
(ср. ANOVA, регрессия, точечные диаграммы). Так что и в классичес-
классических планах существуют простые методы анализа.
3. «Обратная связь и последовательные процедуры». «Не трудно
перестраивать план случайного баланса в ходе исследования, исполь-
используя предварительный анализ ранних опытов как индикатор выбора
условий последующих экспериментов по возможности близко к облас-
области наибольшего интереса». Однако еще в IV.6 мы увидим, что класси-
классические планы тоже допускают последовательные процедуры.
4. «Число опытов». Мы рассматриваем эту характеристику как
главное преимущество случайных планов. В классических планах чис-
число опытов задается числом факторов и числом их уровней. Дробные
реплики часто смягчают этот недостаток. К сожалению, если число
уровней разных факторов различно, то планы такого рода не существу-
существуют или трудно доступны. Кроме того, даже если мы возьмем все факторы
только на двух уровнях, то классический план может оказаться слиш-
слишком велик для больших k. Так что заслуга авторов случайных планов
заключается в том, что они подчеркнули необходимость разработки
планов с умеренным числом опытов для исследования ситуаций с очень
большим числом факторов. Мы увидим, что эти работы стимулировали
разработку неслучайных планов с малым числом наблюдений для боль-
большого числа факторов,
76
5. «Эффективность». Саттерзвайт построил таблицу эффективностей
случайных планов. Однако его таблица не имеет научного оправдания,
что отмечали некоторые критики в дискуссии с ним (см. [Kempthorne,
1959, р. 161] и [Box, 1959, р. 175]). Поэтому мы не приводим таблицу
Саттерзвайта, а вместо этого обсудим результат Бокса, который срав-
сравнивал (статистическую) эффективность случайного баланса и ортого-
ортогональных планов, таких, как 2*-р. Бокс [Box, 1959, р. 175—177]
ограничил свои сравнения моделью первого порядка
yi = Po+SP;*w + ei ('=1.2 N) B20)
в предположении, что N > k. (Фактически условие N > k привело
к тому, что Бокс ограничил сравнение ситуациями, в которых невидно,
чем случайные планы более подходящи, как мы заметили в пункте D).)
В случайном плане предполагается, что каждый фактор X] имеет Lj
уровней, а каждый уровень встречается в эксперименте NIL) раз. Эф-
Эффективность измеряется так:
р __ дисперсия оценки flj- в ортогональном плане C99U
var (bj) в плане случайного баланса
В ортогональных планах можно показать, что дисперсия оценки р*7- есть
s" (Г ;v <' = 1'2-•-*>• <222>
Для случайных планов Бокс рассмотрел две альтернативы анализа,
а. Метод наименьших квадратов. Это дает
Е> = 1^ (/=1,2,..., ft). B23)
Так, особенно для больших k, неэффективность случайных планов ве-
велика, и это верно в ситуациях с большим k, где обычно рекомендуют-
рекомендуются случайные планы. (Однако мы повторяем, что Бокс полагал N > k
даже для больших k.)
б. Пофакторные точечные диаграммы. Тогда
( k r n _ -| i-i
1 н+] L i J J
что всегда меньше, чем единица, так как все члены B24) положитель-
положительны. Уравнение B24) становится наиболее простым, если все факторы
имеют только по два уровня. Тогда мы имеем
B25)
77
Так, Бокс показал, что при N > k случайные планы неэффективны,
поскольку не вес столбцы матрицы плана ортогональны.
В случае N ^ k Бокс предполагал тоже использовать систематиче-
-*-
ские, т. е. неслучайные планы. Если N ^ k, то не все столбцы в X —
матрице независимых переменных — будут взаимно ортогональны.
Рассмотрим
-> ->¦ —*
XNxik+u = (lNxi, DNxk), B26)
-*¦ ->
где /wxi—-ЛГ-мерный вектор, состоящий из плюс единиц, a D^xk—
матрица плана, так что X имеет размер N X (k + 1). В ЛГ-мерном про-
пространстве существует не более чем N ортогональных векторов. Следо-
Следовательно, если N <1 k, то не все (k + 1) столбцов X будут ортогональ-
ортогональны. Или, в более статистической терминологии, независимые оценки
k главных эффектов и общего среднего, основанные на N (=^&) наблю-
наблюдениях, приводят к тому, что число степеней свободы получается от-
отрицательным. Если все столбцы X не могут быть взаимно ортогональ-
ортогональными, то Бокс считал полезным так много ортогональности, как толь-
только возможно, во всяком случае, больше, чем та степень ортогональ-
ортогональности, которая получается в чисто случайной выборочной процедуре.
Этот намек был использован в [Booth, Сох, 1962], где исследованы
«сверхнасыщенные планы».
Сверхнасыщенные планы
Бус и Кокс рассматривали систематические двухуровневые фак-
факторные планы, в которых каждый из k факторов встречается на «ниж-
«нижнем» уровне N12 раз и на «верхнем» уровне" N12 (N четно). Предпола-
гается, что N ^ k. Ортогональность столбцов плана dh и dj влечет:
Ш] = 0(НФ!\1=1,...,к). B27)
Если N ^ k, то B27) не может удовлетворяться для всех h и /. Тем не
менее мы можем удовлетворить B27) «настолько хорошо, насколько
это возможно». Это было формализовано в [Booth, Сох, 1962, р.
489—490] с помощью минимизации
тах|ЗД-|. B28)
Если несколько планов имеют одинаковые значения в выражении B28),
то выбирается среди них такой план который содержит наименьшее
число пар столбцов, удовлетворяющих B28). Таким образом, эти ав-
авторы получили планы для различных N и k. Полученные планы табу-
табулированы в [Booth, Сох, 1962, р. 490—492] и воспроизведены в табл. 31.
Для тех значений k, которые не приведены в табл.[31, подходящие пла-
планы легко получить из планов для больших k, отбрасывая лишние по-
последние столбцы.
78
'Габлица 3i
Сверхнасыщенные планы для k факторов и Л' опытов
План I. fe=16, N=12
+ h
План II. ft = 20, JV=±= 12
- + 1 h
+ - ' + h+ + h- + - + -
-+- + + -- + + + + + + h
+ + h- + + + + + + '
+ - + + + + - + h
H 1- + + + + + + + + + + + + + -
- + + + h h + + + + + + + +
План III. fc = 24, N=\2
+ + + +- + + + h +
+ + - + h-+ + h
+ + + - + + - + + + H h
+ ++ + + -+ + - + -H + - + h-
+ + + + + — + - + h + —
- + - + + I- + + + + H + + - + - +
+ + -I h I- + + + -I + +
79
Продолжение табл. 31
План IV. ft = 24. W=18
+ -+- + - + -+- + - + -- + Н + +
- + - + - + - + - + - + — + -+-+- + h
__ I _1_ „
+ + + -+- + -I + ++++++-+-+
+ + -+ - + H + + + + + + + + + + + -
+ + + + + - + - + + h h +
+ + + + - + - + + + - + + +
+ + + + - + - + + + + - + + + +
- + + + + - + - + + + + +
+ + + + - + - + + + -I + +
План V. ft = 30, N=18
- + + + - н + — + + — + + - + - + + + +
- + - + + + + + — + + - + - + + + + -
- + + + + + - + + — + + - + - + + + + —
+ + - + + + - -i + + - + - + + + +
80
Продолжение табл. 31
План VI. А = 36, ЛГ=|8
+ + - + + + --I + -- + V + + --I
-+ + Ч 1 -I -I Н 1-- + + + Ч +
+ + + - + -I + + - + + - + - + + + -I +
+ - + + + -I + + -- + - + - + + + + + -- +
+ + + - +
+ + - + - + + -- + - + + -
-I И-- + - + + +
План VII. й = 30, W=24
h- +
- + - + Н + + — + - + — + + -:
81
Для сравнения эффективности сверхнасыщенных И случайных пла-
планов авторы сравнивали дисперсию z, где z — скалярное произведение
двух столбцов плана, т. е.
z =
(h Ф /),
B29)
Прежде чем привести результаты этих авторов, мы заметим, что мате-
математическое ожидание z в случайных планах, как, впрочем, и в сверх-
сверхнасыщенных, равно нулю. Поскольку в случайном плане каждый фак-
фактор просто независим от всех остальных, а уровни плюс и минус имеют
равные вероятности,
/=i
B30)
В сверхнасыщенном плане элементы плюс и минус не ведут себя так
просто, как в случайных планах. Тем не менее, обозначим ли мы «верх-
«верхний» уровень какого-либо фактора знаком плюс или минус — этот
выбор случаен 25. Отсюда следует, что если для табличного плана B29)
даст значение z для какой-то пары столбцов, то оно с тем же успехом
могло бы быть и —z. Следовательно, его ожидание равно нулю. Вер-
Вернемся теперь к работе [Booth, Box, 1962, p. 494], которые сосчитали
дисперсию z. Их результаты воспроизведены в табл. 32,
Таблица 32
План
Случайный
Систематический
Дисперсия z
1
13,1
7,07
— мера
II
13,1
9,68
иеортогональности
ш
13,
ю,
1
1
IV
19,1
13,6
V
19,
15,
1
3
VI
19,
17,
1
4
VII
25
11
,0
,4
Так как среднее значение z одно и то же для обоих типов планов, сверх-
сверхнасыщенные планы имеют меньший разброс, Который означает, что
большие (по модулю) значения z не встречаются. Большие значения
\z\ не желательны, поскольку неортогональность означает, что дис-
дисперсии оценок эффектов факторов велики, даже если N ^ к, случай-
случайные планы менее эффективны, чем систематические, полученные Бус
и Коксом. Если, однако, k > 36 или мы хотим сделать меньше опытов,
чем дано в табл. 31, то годятся нетабулированные планы. Мы вполне
можем построить сверхнасыщенный план с помощью итеративной ма-
машинной процедуры, как описано в [Booth, Сох, 1962, р. 492—494].
Время, потребное для записи и прогона программы генерирования
такого плана, очень легко может оказаться препятствием. Тогда, мы
можем все же использовать случайный план,
82
Это одна из ситуаций, когда привлекательны случайные планы. Сле-
Следующий иллюстрирующий пример основан на работе Саттерзвайта
fSatterthwaite, 1959, р. 114—115]. Сначала положим, что отклик ап-
аппроксимируется выражением
«=R 4- fir 4-ftr {9"M\
Возьмем факторный план 22, в котором столбцы факторов взаимно ор-
ортогональны, что видно из табл. 33.
Таблица 33
Матрица факторов в факторном
плане 22
Таблица 34
Матрица собственных независимых
факторов
Хо
+1
+1
+1
+1
7+77-
хГ
777+
xt
+1
i\
+i
(Хи Х2)
+777-
+77 +
Затем положим, что на самом деле адекватна не модель B31), а мо-
модель B32):
У = То + Ti (*Л) + Та (Xi/xJ. B32)
Тогда матрицу собственных факторов этой модели представляет табл.34
соответствующая плану 2а для исходных факторов. Из этой таблицы
видно, что не все столбцы собственных факторов ортогональны, так
что независимая оценка параметров уг и у2 невозможна.
Особенно в начальной стадии исследования адекватная модель мо-
может быть не известна полностью. Тогда преимущество ортогональности
исходных факторов может исчезнуть. (Конечно, случайный план тоже
будет не ортогональным для собственных факторов новой модели.)
Итак, в силу гибкости случайных планов они могут быть привле-
привлекательными при большом числе факторов и умеренном числе опытов,
когда есть некоторое представление о виде функции отклика, области
интереса и важных факторах. Без такой предварительной стадии не-
некоторые факторы будут произвольно отнесены к неэффективным или,
наоборот, некоторые факторы окажутся фиксированными на произ-
произвольных уровнях. (Эти произвольные уровни практически ограничи-
ограничивают выводы из эксперимента.) На следующей стадии мы можем огра-
ограничить аппроксимацию «истинной» функции отклика областью даль-
дальнейшего экспериментирования и сосредоточиться на важных факто-
факторах. Тогда мы можем взять либо «систематический ортогональный^
план для факторов, аппроксимирующих функцию отклика, либо си-
систематический сверхнасыщенный план, либо, наконец, систематический
план «группового отсеивания».
Последний класс планов мы теперь и обсудим.
83
Ллан группопшо
И nut планах It факторов объединяются в g групп, а каждая груп-
ни рассматривается как обычный фактор. Такие g групповых факторов
изучаются в систематическом плане. Постулаты группового отсеива-
отсеивания ведут к тому, что если некоторый групповой фактор незначим, то
незначимы и все исходные факторы, его образующие. Следовательно,
их можно исключить из дальнейшего исследования. Если же групповой
фактор значим, то значимы один или несколько исходных факторов.
Так что па следующем шагу все эти факторы должны сохраниться в ис-
исследовании. В двухстадийном методе g групповых факторов рассмат-
рассматриваются на первой стадии, а все исходные факторы, входящие только
в значимые группы, — на второй. Такой метод был предложен Уот-
соном (Watson) в 1961. В многостадийном групповом отсеивании груп-
группы, оказавшиеся значимыми на первой стадии (или, более обще, на
t-й стадии), перестраиваются в меньшие группы, проверяемые на сле-
следующей стадии. Такие многостадийные планы были предложены неза-
независимо Пейтелом (Patel) и Ли (Li) в 1962 г. Обсудим двух- и много-
многостадийное групповое отсеивание несколько более детально.
а. Двухстадийное групповое отсеивание
Уотсон [Watson, 1961, р. 372] ввел следующие предположения
(возможность ослабления некоторых из них обсудим ниже):
1) все факторы имеют независимо друг от друга равные априор-
априорные возможности оказаться эффективными, р (q = 1 — р);
2) эффективные факторы имеют один и тот же эффект, А > 0;
3) все они не имеют взаимодействий;
4) требуемые планы существуют;
5) направление возможных эффектов известны;
6) ошибки всех наблюдений независимы, нормально распределены
с постоянной известной дисперсией а2;
7) k = gf, где g — число групп, a / — число факторов в группе26.
В силу предположения 5 мы можем определить верхний уровень не-
некоторого фактора как уровень, дающий наивысший отклик. Тогда
верхний уровень группового фактора определится как уровень, на ко-
котором все факторы в этой группе достигли своих верхних уровней.
Вместе с предположением 3 это гарантирует невозможность взаимного
уничтожения эффектов. Так, некий групповой фактор, содержащий
один или более эффективных факторов, имеет не нулевой эффект. Мы
обсудим один пример группового отсеивания, прежде чем исследовать
эти предположения.
Пусть девять исходных факторов А, В, ..., / разбиты на три группы,
обозначенные X, Y, Z. Следовательно, каждая группа содержит три
исходных фактора. Испытание трех (групповых) факторов на их глав-
главные эффекты можно провести в четырех опытах: N± = 23. Подходя-
Подходящая реплика приведена в табл. 35. В первой строке факторы X и Y
находятся на нижних уровнях, a Z — на верхнем. Если X включает
факторы Л, В и С; Y включает D, EuF,aZ включает Н, J и /, то в пер-
84
Таблица 35
План 2 f,] для трех групповых
факторов X, Y и Z
Опыт
1
2
3
4
It
j
+ 1
j
+ 1
у"
— 1
—1
+ 1
+ 1
+1
1
+1
вом опыте исходные факторы будут иметь уровни: —1, —1, —1, —1,
—1, —1, 1, 1, 1. Пусть первая стадия показала, что эффективен толь-
только групповой фактор X. В силу предположения 6 можно применять
дисперсионный анализ, если только мы знаем независимую оценку о2.
Тогда на второй стадии мы должны исследовать только те факторы,
которые входят в X, т. е. А, В и С. Эти три фактора снова можно изу-
изучить в четырех опытах: N% = 23. Если, например, взять аналог
табл. 35, то это будут опыты с,
a, b и abc соответственно.
Уотсон [Watson, 1961, р.374]
отмечает, что мы можем эконо-
экономить опыты разумным выбором
реплик на каждой стадии и ра-
разумным выбором уровней исход-
исходных факторов, включенных в
исследование на первой стадии.
Для реплики из табл. 35 видно,
что в четвертом опыте все исход-
исходные факторы принимают свои
верхние уровни. На второй ста-
стадии мы включили комбинацию abc, т. е. комбинацию, в которой факто-
факторы Л, Б и С принимают верхние уровни. Если мы зафиксируем все мно-
множество незначимых факторов D, Е, ..., / на верхних уровнях во вто-
второй стадии, то комбинация abc совпадет с комбинацией xyz в опыте 4 из
первой стадии. Поэтому такой опыт уже был проделан. Следовательно,
изучение главных эффектов А, В и С требует только трех дополнитель-
дополнительных опытов. Мы заметим о процедуре Уотсона, что если незначимые
факторы на самом деле не важны, то их уровни несущественны. Одна-
Однако из-за ошибки опыта мы можем объявить фактор незначимым, хотя
фактически этот фактор важен. Как мы показываем в приложении
IV.5, лучше не варьировать незначимые факторы, т. е. лучше держать
множество незначимых факторов либо на нижних, либо на верхних
уровнях во всех опытах второй стадии. Благодаря этому их возможные
главные эффекты будут смешаны с общим средним. Перестройка фак-
фактора с нижнего уровня в некоторых опытах на верхний уровень
в некоторых других опытах второй стадии приведет к смешива-
смешиванию его главного эффекта с главными эффектами значимых фак-
факторов.
Теперь мы покажем, что предположения 1—7 не слишком ограничи-
ограничительны. Предположение 4 было введено для получения объемов групп,
минимизирующих число опытов на первой и второй стадиях. Это пред-
предположение означает, что на первой стадии существует план для g груп-
групповых факторов из (g + 1) опытов. Фактически мы видели, что план
разрешения III из Nt = (g -f- 1) опытов пригоден лишь в тех случаях,
когда Nx кратно четырем. Более того, это предположение означает, что
на второй стадии существует план с ЛГ2 = fs опытами, где s — число
групповых факторов, которые оказались значимыми на первой стадии.
Отсюда следует, что используется один опыт с предыдущей стадии и
что (fs + I) кратно четырем. Практически Nt и (ЛГ2 + 1) могут не быть
85
ьр.чмымп шмчнп t it [iimntMii.iii), полученные оптимальные значения
>.i.i, i..i. ij^iui к» fiMJin upuio оптимальны. Однако это не нарушает
ц]<>.m n jot крпмо чого, если (g -\- 1) и (fs + 1) не кратны четырем, то
чтит п.|0л1одсиий будет больше числа параметров и останутся степе-
степени свободы для оценки дисперсии ошибки опыта. Предположение 2
тоже необходимо для получения оптимального объема группы и, сле-
следовательно, не критично. Предположение 5, как показал Уотсон [Wat-
[Watson, 1961, р.385], можно ослабить: «Когда объем группы оптимален,
для р ^ 0,15 существует лишь вероятность 0,06 или менее встретить
два или более эффективных фактора, и нам практически не надо знать
направления всех возможных эффектов»; сравните также с нашими
замечаниями об B34) ниже. Предположение 6 нужно снова для получе-
получения оптимального плана, а также чтобы сделать возможным примене-
применение дисперсионного анализа. Мы видели выше, что ANOVA робастен
относительно ненормальности и неоднородности (гетероскедастичности)
дисперсий. Предположение 1 можно интерпретировать следующим
образом. Нам нужны некоторые априорные грубые оценки того, как
много факторов могут оказаться эффективными среди всех k факторов.
Тогда р будет равно отношению вероятного числа эффективных факто-
факторов к общему числу факторов. Это р задает оптимальный объем груп-
группы f, полученный Уотсоном [Watson, 1961, р.381]:
'•" и.^),]" • B33)
где ах—уровень значимости на первой стадии. Уравнение B33) показы-
показывает, что объем группы уменьшается с ростом р; для больших р опти-
оптимальный объем группы становится равным единице, т. е. все факторы
приходится рассматривать индивидуально. Это разумный результат, оп-
скольку большое р означает, что многие группы содержат эффективные
факторы, так что на второй стадии все или почти все исходные факторы
придется включить в рассмотрение, и метод "группирования ничего
не улучшит. Конечно, большое значение р противоречит определению
ситуации отсеивания. Если у нас нет твердой оценки р, то это будет
означать, что наше группирование вполне может оказаться не по-
тимальным. Правда, уравнение B8) для определения оптимального
объема группы — это только аппроксимация, и, следовательно,
объем группы / надо сделать целым числом /0, почти не флуктуирующим
при варьировании р (и ах). Например, если нет ошибки опыта, т. е.
аг = 0, то для 0,03 ^ р ^ 0,30 табл. 2 из Уотсона дает 6 > f0 > 3.
Если мы не положим, что все факторы имеют одну и ту же априорную
вероятность р, то мы должны будем построить классы факторов так,
чтобы каждый класс имел свою априорную вероятность. Уравнение
B33) показывает, что факторы с большими вероятностями р следует
объединять в малые группы; если р > 0,30, то мы приходим к объему
группы, равному единице, т. е. к индивидуальному изучению исход-
исходных факторов. Так, различные оценки р (которые, насколько возможно,
реалистичны) приводят к группированию в методе группового отсеи-
отсеивания. Более того, они делают группирование более гибким. Объем
86
Группы уже не константа, а переменная, и предположение ? можно без
ограничений заменить предположением
b=g1-h+gt-f, + ... + gj-h, B34)
где gj — число групп объема /; (/ = 1, ..., /). Затем число групп, рас-
рассматриваемых на первой стадии, т. е. 2g;-, можно выбрать так, чтобы
АГХ = 2gj + 1 оказалось кратным четырем, а в этом случае существует
насыщенный план (ср. [Watson, 1961, р.383—385]). Заметим, что возмо-
возможен еще вариант групп разного объема, когда нам не известны направ-
направления эффектов индивидуальных факторов (и есть основания опасать-
опасаться взаимного уничтожения разных эффектов, несмотря на замечание,
которое мы сделали о правиле вероятности такого уничтожения). На-
Наконец, в приложении IV.6 мы ослабим предположение 3 о взаимодей-
взаимодействиях. Там мы покажем, что взаимодействие двух факторов |32U, сме-
смещает оценку главного эффекта фактора р, только если факторы z, w
и р принадлежат к трем различным групповым факторам (z, w, p =
= 1, ..., k). (Эффекты чистых квадратов никогда не смещают оценок
главных эффектов.) Следовательно, если мы допустим, что двухфак-
торные взаимодействия существуют только между конкретными (свя-
(связанными) факторами, то нам следует поместить эти связанные факторы
в одну группу. Тогда их двухфакторные взаимодействия не сместят ни-
никаких главных эффектов. Мы уже показали, что если мы исследуем g
групповых факторов в плане разрешения IV, то главные эффекты не
смещаются никакими парными взаимодействиями (но, конечно, они
все же смешаны друг с другом внутри группы).
Теперь мы кратко обсудим влияние уровней значимости на первой
и второй стадиях, т. е. ах и а2, где at—вероятность ошибочного отбра-
отбрасывания гипотезы о незначимости эффекта на г-й стадии (i = 1, 2).
Если аг возрастет, мы будем объявлять многие факторные группы зна-
значимыми и это вызовет рост числа опытов на второй стадии. Если же
возрастет а2, — на N ( = Ыг + N2) это не повлияет,—то, конечно,
это значит, что многие неважные факторы будут объявлены значимыми.
Действительно оптимальный выбор можно было бы основать на стои-
стоимости, что приводит к «теории статистических решений», однако такие
расчеты не опубликованы. (Для полноты мы отметим, что Керноу
[Curnow, 1965] обнаружил в рассуждениях Уотсона не принципиаль-
принципиальную ошибку.)
б. Многостадийное групповое отсеивание
Пейтел обобщил метод Уотсона для более чем двух стадий, чтобы
добиться дальнейшего сокращения числа опытов. Он использовал
(явно или не явно) следующие предположения из предположений Уот-
Уотсона: 1, 2, 3, 4 и 5. (Предположение 4 было интерпретировано как тре-
требование равенства числа опытов на каждой стадии числу групповых
факторов на этой стадии, поскольку стадии вычисляются из первой,
когда опытов на единицу больше, чем групповых факторов.) Уотсонов-
ское предположение 6 заменено предположением об отсутствии экспе-
87
Рим* иi-i •" тип) и I in предположение 7 заменено «последователь-
ни i i ц idiuiiiH, к.iK мы увидим ниже,
Гт \ MDipiiM такой пример 2?. Пусть есть двести факторов (k = 200).
Па перкой стадии мы можем образовать десять групп, так что в каж-
каждую группу войдет по двадцать факторов (gx = 10), (/х = 20).. На вто-
второй стадии мы можем расщепить каждую группу первой i стадии на,
скажем, пять групп (g2 — 5; заметим, что g2 — это не общее число
групп па второй стадии, которое равно g-ig%). Тогда \ каждая группа
на пторой стадии будет содержать по /я = 20/5 = 4 фактора. Если мы
ПШШ'М '1'рихетадийную процедуру с числом групп, на которое расщеп-
joutoi каждая группа второй стадии, равным четырем,то?3 = /а = 4.
Отсюда k = g1g2g3 = 10x5 Х4 = 200. На каждой стадии представ-
представляют интерес только те групповые факторы, которые оказались значи-
значимыми на предыдущей стадии. Так что если на i-й стадии оказались зна-
значимыми st факторов, то на (i + 1)-й стадии мы будем изучать Si-gi+1
групповых факторов.
Пейтел [Patel, 1962, р.214] показал, что ожидаемое число опытов
на всех (п + 1) стадиях минимизируется при таком выборе числа групп,
который получается из B35) и B36):
B35)
n+i ~ p--'»¦-¦ ". B36)
Напомним, что^г не обозначает общего числа групп на стадии i, а ука-
указывает число групп, на которое расщепляется gt_v С B35) и B36)
согласуются следующие объемы групп:
Уравнение B37) показывает, что объем группы падает в геометричес-
геометрической прогрессии вместе с отношением pl/<-n+l).
\ Следующий вопрос таков: как много стадий п должна содержать
процедура? Пейтел [Patel, 1962, р.215] показал, что общее число опы-
опытов минимизируется при выборе я-стадийной процедуры вместо (п —
— 1)-стадийной, если
1 -)""". B38)
п )
Уравнение B38) дает табл. 36, которая воспроизведена по работе [Li,
1962, р.463].
Ли предложил простую многостадийную процедуру. Хотя он не
сослался на Уотсона или Пейтела, мы можем легко сравнить его пред-
предположения и результаты с тем, что сделали другие авторы. Ли [Li, 1962,'
р.456] взял эквивалент уотсоновского предположения 1, затем он ис-
использовал и предположения 3 и 4 в том смысле, что на каждой стадии
требовал равенства числа опытов и числа групповых факторов. Пред-
Положение 6 заменил требованием шалости» ошибки опыта; фактичес-
88
Оптимальное число стадий как функций
априорной вероятности р
КИ Ли пренебрег ошибкой ОПЫ- Таблица 36
та точно так же, как и Пейтел.
Вместо предположения 5, кото-
которое Уотсон взял из-за возмож-
возможности взаимного уничтожения
эффектов внутри группы, Ли
[Li, 1962, р.458] предположил,
что именно Р важных факторов
выявляются в точно Р подгруп-
подгруппах на каждой стадии28. Это
значит, что на группу прихо-
приходится не более одного важного
фактора, так что взаимное со-
сокращение невозможно. Сверх
того Ли [Li, 1962, р. 456] пред-
предположил, что эти Р «важных
факторов имеют значительно
большие эффекты, чем все не-
неважные факторы, вместе взя-
взятые». Это предположение можно
сравнить с предположением 2
Уотсона, которое устанавливает,
что важные факторы имеют эф-
фектА>0, а неважные—нулевые
эффекты; вместе с этим предпо-
предположением удовлетворяется и
требование Ли. Наконец, Ли берет многостадийный эквивалент
уотсоновского предположения 7: kt = gtft, где индекс i — номер
стадии, k% — общее число f исходных факторов, включенных в ?-ю
стадию, a ft — объем групп. Заметим, что здесь gt — общее число
групп на i-й стадии, и это определение отличается от определения
Пейтела.
Для двухстадийной процедуры он получил/х = р~1/2, что согла-
согласуется с результатами Уотсона для случая отсутствия ошибки опыта,
т. е. когда а2 = 0 в B33). Для процедуры из (п + 1) стадий можно
было бы легко показать, что Ли получил такой же оптимальный объем
группы ft, как и Пейтел29. Оптимальное число групп на i-й стадии сле-
следует непосредственно из kt = figt. Поскольку Ли предположил, что
каждый важный фактор выявляется в отдельной группе, у него общее
число групп на каждой стадии остается постоянным:
р больше чем
2,5000 Х10-1
8,7792Х1О-2
3,1675X10-2
1Д529Х10-2
4,2131x10-3
1,5423X10-3
5,6516X10-*
2,0758X10-4
7,6248X10-6
Оптимальное чис-
число стадий
1
2
3
4
5
6
7
8
9
10
g. =
B39)
Можно легко видеть, что у Ли, как и у Пейтела, получается постоянное
общее число групп на стадии. Для оптимального числа стадий Ли полу-
получил те же критические значения, что и_Пейтел.
Ли [Li, 1962, р.461] отметил, что может заслуживать внимания вы-
выбор процедуры с меньшим, чем оптимальное, числом стадий, если толь-
только увеличение общего числа опытов мало. Он показал, что доля ве-
89
i > ,< >ш ii iiiiMioi), когда выбирается (п + 1)-стадийная
ими id н-счадийной, есть
(
Nn \ п
BЩ
Мы могли бы предположить такое использование уравнения B40). Имея
р, мы определяем оптимальное число стадий п0. Положим п0 = п + 1.
Если B40) дает лишь малый отрицательный процент, то представляет
интерес использование (п0 — 1) стадий.
Теперь мы обсудим задачу оценки априорной вероятности р.
1. Ли предполагает, что все важные факторы выявляются в отдель-
отдельных группах и нет ошибки опыта. Тогда после первой стадии мы точно
знаем Р, число важных факторов, ибо
Р = %, B41)
где sx — число значимых групп на первой стадии. Поэтому после пер-
первой стадии в n-стадийной процедуре нам осталось пройти еще (п — 1)
стадию, где число факторов теперь fex = sJx и р точно известно:
р . s* — * B42)
Тогда оптимальное число групп в оставшихся (п — 1) стадиях следует
из уравнения B39), которое годится для п -\- 1-стадийной процедуры:
giz=fe1.(fri)(«-2)/Ct-D;=Sl^i/(M-n. B43)
Ли [Li, 1962, р.462—464] показал, что общее число наблюдений на всех
п стадиях лишь слегка возрастает, когда наша оценка р ошибочна.
Например, если наша начальная оценка р содержит ошибку на мно-
множитель а, т. е.
Р = а-р, B44)
а а = 2 или 0,5, то общее число наблюдений увеличивается менее чем
на' 6%.
| 2. Пусть, в противоположность Ли, мы учтем, хотя и малую ве-
вероятность того, что в одной группе может оказаться более чем один
важный фактор. Тогда мы можем применить на каждой стадии аналог
уравнения B41):
Pi = Su B45)
где Si — число значимых групп на t'-й стадии. С ростом i объем группы
уменьшается и B45) станет лучшей аппроксимацией: для групп мень-
меньшего объема меньше вероятность того, что два или больше важных фак-
фактора встретятся в одной группе. Обобщение связей различных величин,
влияющих друг на друга, показано на рис. 24. Рис. 25 показывает, как
после каждой стадии мы можем пересчитать оптимальное число ста-
90
Дий п0, объем группы f0 и общее число групп g0. При расчете Этих вели-
величин мы берем более свежую информацию о Р, но поступаем так, как
будто мы начинаем с первой стадии гс-стадийной процедуры, харак-
характеризуемой текущим Р и текущим k, которое есть число факторов пос-
после отбрасывания незначимых групп. Внимательный взгляд на блоки
8, 9 и 2 на рис. 25 обнаруживает, что на г-й стадии р оценивается по
B46), где Яг_х — число значимых факторов на предыдущей стадии:
р^-^-^тЧ—т-- <246>
i-i
Р-число Важных факторов
к-число факторов
р-Вероятность пояолений
г Важного фактора
Пггоптцмапьное число
стадий
}0-оптимальный объем
группы
пп-оптимальное число
3 групп
Рис. 24. Связи различных параметров многостадийного плана
отсеивания
группового
Истинное р на г-й стадии дается B47) (в предположении, что никакой
из р важных факторов не исключен по ошибке):
i-lfi-l
Поэтому Pi будет корректной оценкой, если Яг_1 = Р. Вероят-
Вероятность того, что последнее равенство верно, увеличивается с уменьше-
уменьшением объема групп /г_х. Чем меньше объем группы, тем меньше
вероятность того, что два или более важных фактора окажутся в од-
одной группе. Мы можем доказать, что объем группы уменьшается в ходе
процедуры, т. е. ft < /г_2. Для блока 4 на рис. 25 имеем
Используя B46), мы имеем
B48)
B49)
Поскольку (tii — 1) < tit, B49) показывает, что фактически ft <
< /г_х. Так, из рис. 25 следует, что априорная вероятность на г-й
стадии полагается равной обратному значению объема группы на пре-
предыдущей стадии. Эта процедура работает все лучше и лучше от стадии
к стадии.
91
/IU CM:
k-b0
P=PQ
щ из табл 36
или ур. B38)
р
сраВн B37)
.Выбор и проВерка д0 группы
\(ракгоро8, отбор s значийъ/х групп
Рис. 25. Блок-схема последовательно-
последовательного оценивания параметров в много-
многостадийном плане группового отсеива-
отсеивания
92
Ли [Li, 1962, р. 465—466] пока-
показал, что общее число наблюдений
не меняется, когда мы делим всю
группу к факторов на b подгрупп
так, что априорные вероятности
во всех подгруппах одинаковы
(Р/к), и применяем его процедуру
к каждой подгруппе в отдельности.
Нам следует пойти на один шаг
дальше и оценить априорную веро-
вероятность каждой группы по ее соб-
собственной оценке, если мы берем
априорную вероятность, полагая
связанные факторы объединенными
в одной подгруппе. Тогда на пер-
первой стадии, когда у нас еще нет
наблюдений, более корректно взять
наши оценки pj (/ = I, ..., b).
Завершая это обсуждение груп-
группового отсеивания, укажем наибо-
наиболее критические предпосылки об
отсутствии взаимодействий и о
знании направлений главных эф-
эффектов. Иначе говоря, групповые
факторы могут оказаться не эффек-
эффективными, тогда как фактически
эффекты будут иметь место. От-
Отбрасывание этих групповых факто-
факторов означает, что^эффекты исход-
исходных факторов в этих группах
будут Потеряны. Относительно
предположения о\знании направ-
направления главных эффектов мы пов-
повторим, что факторы с неизвестны-
неизвестными направлениями можно поло-
положить отнесенными к разным груп-
группам, состоящим из одного элемен-
элемента, или мы можем довериться
правилу вероятности встречи в
одной группе более чем двух важ-
важных факторов да еще таких про-
противоположных, что они точно со-
сократятся (или таких противопо-
противоположных эффектов с почти одина:
ковыми величинами, что ошибка
опыта и суммарный эффект несуще-
несущественных факторов маскируют
разность этих важных факторов,
имеющих Противоположные знаки). Относительно Предположения о
взаимодействиях мы повторим,^что главные эффекты не маскируются
двухфакторными взаимодействиями, если эти взаимодействия слу-
чаются только между факторами одной группы или если мы берем для
групповых факторов план разрешения IV. Мы отметим, что независимо
от Ли, Пейтела и Уотсона групповое отсеивание (или последовательное
ветвление) для имитационных экспериментов предложили Джекоби и
Харрисон [Jacoby, Harrison, 1962, p.131—133]. На каждой стадии их
процедуры каждая значимая группа разделяется точно на две под-
подгруппы (т. е. в обозначениях Пейтела, gt = 2). Из применявших груп-
групповое отсеивание в имитации мы упомянем также работы [Mihram,
1972, р.399—400] и [Nolan, Sovereign, 1972, р.684]. Близкий класс
планов для изучения BN — 1) факторов в N опытах предложен в [Ott,
Wehrfritz, 1972].
Сравнивая их планы с сверхнасыщенными и случайными планами,
мы могли бы рекомендовать первые из них, если факторов очень много.
Ли [Li, 1962, р.455] говорил о «случаях, включающих 100 000 или более
факторов». Для столь большого числа факторов нет подходящих таб-
таблиц сверхнасыщенных планов; случайные планы с умеренным числом
опытов и очень многими факторами дадут смешивание многих факторов
друг с другом.
В заключение упомянем, что Джекоби и Харрисон [Jacoby, Har-
Harrison, 1962] кратко обсуждают некоторые вариации обоих видов пла-
планов для отсеиваний. Энскамби [Anscombe, 1963] представил иной под-
подход к ситуации отсеивания. Его подход включает использование ап-
априорных распределений некоторых параметров (вроде р0, р\ и а) и
функции потерь. Мы сошлемся на [Anscombe, 1963, р.725—726]_вместо
описания тех распределений и функций, которые он использовал, так
что читатель может проверить, подходят ли эти инструменты для его
конкретных задач. Остается еще трудность, связанная с тем, что такой
анализ требует сложного численного интегрирования.
IV.8. ПРОЧИЕ ВОПРОСЫ ПЛАНИРОВАНИЯ ЭКСПЕРИМЕНТА
Выше мы, следуя Энскамби [Anscombe, 1963], упоминали иные
подходы, а именно байесовский анализ и теорию статистических реше-
решений. Функции потерь использовались также Ластом [Last, 1962] для
доказательства «правильности» оптимальных планов (вместо планов
с минимумом дисперсии или иным чисто статистическим критерием).
Задачи теории статистических решений в планировании эксперимента
обсуждались в работе [Herzberg, Сох," 1969, р.36—37], где приведено
много ссылок. К сожалению, это теоретически весьма привлекательное
направление не ведет к широко применимым простым планам.
Иной аспект планирования эксперимента — это возможность мно-
множества откликов. Как мы видели в 11.10, при выборе системы нам
нужно объединить различные аспекты («отклики») системы в функцию
критерия*. Так, функцией критерия может быть доход моделируемой
* В отечественной литературе часто гоьорят в этой связи об обобщенном
отклике, параметре оптимизации, целевой функции и т. п. — Прим. перев.
93
(>., ¦>. , ч mii|i,iniiiiiiiuou продукции или субъективно взвешен-
»¦». \ * lmiuif (малики (веса могут давать, например, управляющие);
«» И!»1мш1шоеть использовалась, например, в [Knight, Ludeman,
1%В, p. 9—14], которые построили «индекс характеристик», объеди-
объединивший различные отклики при имитационном моделировании работы
магазина, обслуживающего по предварительным заказам; в [Fromm,
1969] обсуждается «функция полезности» для выработки экономичес-
экономической политики; общее рассмотрение способов введения таких весов есть
в работе tKotler, 1970]. Отбирается тот вариант системы, который имеет
наибольшее (или наименьшее) значение критерия. И таким образом
ликвидируется проблема множественности откликов. Тем не менее
ситуации с многими откликами все же существуют. Особенно на на-
начальных стадиях исследования экспериментирование может направ-
направляться на получение обзора различных возможных вариантов системы,
причем каждый вариант связан с несколькими (быть может, противоре-
противоречивыми) откликами. Тогда мы еще не отбираем систему, а только ис-
исследуем трудный вопрос о том, как влияют разные факторы, чтобы
глубже проникнуть в суть поведения системы. Нейлор и Хантер [Nay-
lor, Hunter, 1969, р.22] пишут: «К сожалению, экспериментальных пла-
планов для экспериментов с множественным откликом фактически не су-
существует». Как исключение, мы отметим, например, планы, предло-
предложенные Дэниелом [Daniel, 1960], Дрейпером и Хантером [Draper,
Hunter, 1966], Роем и др. [Roy et al., 1971, p.113—115], но эти планы
применимы лишь в весьма специальных случаях. Поэтому планы боль-
большинства авторов построены так, что подходят только для единствен-
единственного отклика; сравните, например, [Kaczka, Kirk, 1967] или [Sasser,
1969, p. 13]. Однако даже эти случаи мы противопоставляем анализу
множественных откликов. Обычно мы стремимся использовать опре-
определенный уровень значимости а, постоянный для всех наших утверж-
утверждений относительно различных откликов. Это приводит к'многомер-
ному анализу. Обзор методов такого анализа можно найти в [Ander-
[Anderson, 1958], [Roy, 1957] и [Roy et al., 1971]; непараметрический много-
многомерный анализ излагается в [Puri, Sen, 1971]. Результаты Роя исполь-
использовались в имитационных экспериментах Дира [Dear, 1961]; Михрам
[Mihram, 1972, р. 393—397] обсудил анализ коэффициентов корреляции
для многомерных откликов. В главе V мы продолжим обсуждение спо-
способов получения совместных выводов. А в главе VI применим такой
анализ к монте-карловскому исследованию метода множественного
ранжирования. (Прочие аспекты планирования эксперимента мы упо-
упомянем еще и в следующем параграфе.)
IV.9. ЛИТЕРАТУРА
Даже эта весьма объемистая глава рисует лишь часть общей карти-
картины. Есть, например, много неполных планов для случаев, когда все
факторы варьируют более чем на двух уровнях или когда не все фак-
факторы имеют одинаковое число уровней (так называемые смешанные
планы), или для планов с неортогональными оценками эффектов и т.п.
Обзор таких планов можно найти у Адельмана [Addelman, 1963], кото-
94
рый ссылается на 48 работ. Уэбб [Webb, 1969, р.429—430; 1971] по-
построил каталог планов на двух и трех уровнях с числом опытов не бо-
более 12. Он применял подходящие методы для построения своих планов
и использовал компьютер для перебора планов — кандидатов в ката-
каталог с критерием: «усредненной» дисперсией предсказанного отклика.
Уэбб [Webb, 1969, р.430—432] провел с планом своего типа имита-
имитационный эксперимент с ракетным двигателем. Из других типов планов
и анализов перечислим: случайные эффекты (т. е. уровни фактора вы-
борочны, а не фиксированы на своих экстремальных значениях, как,
например, в случайных планах типа 2k~p), иерархические (гнездо-
(гнездовые) планы (т. е. не все уровни фактора комбинируются с уровнями
других факторов, поскольку существует некая иерархия ) и т. д. Мы
упомянем еще весьма обширную библиографию в [Herzberg,Cox,1969].
Хорошими учебниками по планированию эксперимента служат, на-
например, [Cochran, Сох, 1957], [Davies, 1963], [Hicks, 1966] и' [John,
1971].
Если экспериментатор, столкнувшись с имитационной задачей, не
сможет отдать предпочтение, например, какой-нибудь системе смеши-
смешивания или выбрать комбинацию уровней факторов для планов, подробно
рассмотренных в этой главе, то он должен посоветоваться со статисти-
статистиком-консультантом. Мы надеемся, что эта глава сделает читателя спо-
способным выбрать план эксперимента.
ПРИЛОЖЕНИЯ К ГЛАВЕ IV
ПРИЛОЖЕНИЕ IV1. ДИСПЕРСИОННЫЙ АНАЛИЗ ОДНОФАК.ТОРНОГО
ЭКСПЕРИМЕНТА
Рассмотрим однофакторный эксперимент с J уровнями и / наблю-
наблюдениями на каждом уровне, подобный тому, что приведен в табл. 2
параграфа IV.2. Пусть уц обозначает г-й отклик на /-м уровне (i =
= 1, ..., / и/ = 1, ..., /). Конечно, справедливо следующее тождест-
тождество:
ytj — y..^ (у.) —у.) + (yu — y.t), (i.i)
где
A-2)
A.3)
Возведя обе части выражения A.1) в квадрат и суммируя по i по и /,
получим
A.4)
95
II. i. ниш н if и I (Ijillli.l II A.4) СВОДИТСЯ К
-j-y..) (^yu-Iy.j) =
-/у.у) = 0. A.5)
Объединяя A.3) и A.5), получим:
-у.у. A.6)
Если справедлива гипотеза об отсутствии эффекта фактора, то все
наблюдения получаются из одной популяции. Тогда проходит хорошо
известная формула для оценки дисперсии, т. е.
-У.Г =сг2. A.7)
При этой гипотезе оценка дисперсии средних yj есть
3 У/-\) =™г(У-1)- A-8)
Объединяя A.8) с хорошо известным результатом для дисперсии сред-
среднего, а именно
имеем
ia^JL-ST <мо>
Независимо от того, верна ли предыдущая гипотеза, A.11) верно всег-
всегда:
;„) = (/ — 1)а2. A.11)
Это эквивалентно выражению
ага'СУ»--Ма =р2. A.12)
Уравнения A.7), A.10) и A.12) сведены в табл. 3 в IV.2. Мы сошлемся,
например, на Шеффе [Scheffe, 1964J для доказательства независимости
средних квадратов в уравнениях A.10) и A.12).f В'силу'их независи-
независимости мы можем использовать F-критерий, если оба средних квадрата
равны.
%
ПРИЛОЖЕНИЕ IV 2 ОЦЕНИВАНИЕ ВЗАИМОДЕЙСТВИИ В ЭКСПЕРИ-
ЭКСПЕРИМЕНТЕ 2к
В этом приложении мы покажем, как оценить взаимодействия аАВ
в эксперименте 23, обозначая xgs = —1, если фактор s принимает ниж-
нижний уровень в опытеg (g — 1, ..., N) и xgs = +1, если этот фактор на-
находится на верхнем уровне. Из B1) в IV.2 следует, что
Из-за зависимостей в B6) мы знаем, что
(ХАВ—.__(ХАВ^, аАВ = (хАВ B.2)
В эксперименте 23 мы определяем «это» взаимодействие между А и В
как плюс или минус удвоенное взаимодействие А В в общем определе-
определении, т. е.
(%ав _ 2сб^^ = 2ct^^ = 1оЛ^ = 2сс^ A 3)
22 11 21 12' V1/
По определению, мы имеем:
1122.=
112..=
2
11211 +11212+ 11221+11222
Illil + Лиг + ^121 + Л122 + Лги-Hlaia + Л221 + Лага /о
8 ¦ {
Из B.1), B.3) и B.4) следует, что
11111—11211 Tll2l+ 11221 + 11112 Tbl2-—Tll22+1i222 B 5)
Тогда оценку взаимодействия можно вычислить из
где xgl и xg2 есть g-e элементы столбцов факторов А и В в табл. 6.
ПРИЛОЖЕНИЕ IV 3 АНАЛИЗ ПЛАНОВ УЭББА
Матрица независимых переменных X в плане Уэбба для метода пе-
перевала есть
Х=\Ь' Ы], C 1)
4 Дж Клейнен ^
где//, соответствует общему среднему и представляет собой вектор раз-
размера (N12) = k, состоящий из единиц; U соответствует главным эф-
эффектам и определяется из
u , s=\,...,k, C.2)
и V соответствует двухфакторным взаимодействиям и определяется из
V = (xusxuz), и = 1, .... N12, s = 1, ..., k — 1, z = (s + 1), ..., ft.
Модель такова:
У =
C.3)
C.4)
где у — вектор с ЛГ наблюдениями; р — вектор с такими элементами:
общее среднее ро, k главных эффектов ps, а также k (k — 1)/2 двух-
факторных взаимодействий psz; е — вектор ошибок опытов30. Эквива-
Эквивалентное-выражение для C.4) есть
k k — lk
s=[ s = l z = s
В силу C.4) МНК-оценки Ь будут удовлетворять уравнению
—>->¦ —»—>¦-»•
Х'у = Х'Хб.
). C.5)
C.6)
Для & > 3 матрицу (Х'Х) нельзя обратить, поскольку она становится
вырожденной. Это квадратная матрица с 1 + k-\-k (k — 1)/2 строка-
строками и столбцами. Однако ее ранг не выше, чем УУ = 2k, что следует,
например, из Шеффе [Scheffe, 1964, р.394]:
ранг (Х"'Х) = ранг (X) < min IN, I + k + k (k~ l)/2] = 2ft. C.7)
Из определения Х в C.1) мы видим, что
~2lCh 0 2/1V
О 2U'U О
2V'l1 О 2К' F.
C.8)
Для соотношений C.6) и C.8) можно доказать, что главные эффекты,
представленные вектором $м = (Pi, ••-, Рь), оцениваются из
Ьи~ —
C.9)
98
— I
Когда (U'U) — невырожденная матрица1. Можно Показать, что ЭТИ
оценки действительно несмещенные. Далее, мы можем показать, что
матрица дисперсий-ковариаций вектора Ьм есть
QM = — a2 (Z/'T/). C.10)
Двухфакторные взаимодействия нельзя определить однозначно, по-
поскольку для этого не хватает наблюдений. Некоторым взаимодействиям
можно приписать произвольные значения и только тогда появится воз-
возможность определения оценок остальных взаимодействий. Это хорошо
известный результат в решении систем линейных уравнений, в кото-
которых число неизвестных больше, Чем число уравнений 31. Общее реше-
решение таких систем можно получить, прибегая к обобщенному обраще-
обращению, как показано в [John, 1971, р.23—26], [Rao, 1965, р.26] и [Healy,
1968а, b и с]. За полным описанием обобщенного обращения мы отсы-
отсылаем к [Rao, Mitra, 1971]. Частные решения можно получить, полагая
некоторые двухфакторные взаимодействия равными нулю. Применяя
формулы для таких решений, приведенные в [Webb, 1968a, р. 294], мы
дадим следующий метод32. Перестроим матрицу X, как показано в
C.11):
X = (Хи Х2, Х3), C.11)
где Хх относится к k главным эффектам; Х2 — к (N — k) двухфактор-
ным взаимодействиям и общему среднему (N — ранг матрицы X);
Х3 — к остальным взаимодействиям. (Всего есть k (k — 1)/2 —
— l(N — k)—1] таких взаимодействий.) Сравнивая C.11) и C.1).
получим
C.13)
где Vx — та часть V, которая сохраняет невырожденность матрицы
\Хг, Х2]. Использование результатов Уэбба дает те же решения для
главных эффектов, что мы имели в C.9). Общее среднее и взаимодей-
—>
ствия, включенные в Х2, оцениваются из
-> -*¦-*¦ -*¦-*¦
&2= (Хг^г) Х'^у. C-14)
Взаимодействие из Х3 положим равными нулю, т. е.
&з = 0. C.15)
<1* 99
Можно легко показать, что Ьг— несмещенная Оценка, если взаимодей-
взаимодействия в Рз равны нулю. Теперь матрица дисперсий и ковариации век-
вектора Ьг равна:
Qa = о2 (ХЙ,)-1. C.16)
Приложение iva. пример применения формулы бокса для
расширенных планов
Бокс [Box, 1966, р. 185] продемонстрировал работу своей формулы,
приведенной в A94), на следующем примере. Пусть мы начали с плана
2у~2, задаваемого генераторами — ACDFH и —BDEGH, и пусть
мы добавили план 28" с дополнительными генераторами —ABC
и —CDE (ср. с табл. 24). Следовательно, четыре генератора для при-
присоединенного плана 28" таковы:
—ACDFH, —BDEGH, —ABC, —CDE. D.1)
Из генераторов D.1) получаются следующие определяющие соот-
соотношения:
/ = —ACDFH = —BDEGH = —ABC = —CDE = —AGH = ...,
D.2)
где последний член получается перемножением трех предыдущих ге-
генераторов: —BDEGH, —ABC и —CDE. Из определяющего соотноше-
соотношения следует, например, что
А = — ВС = —GH, D.3)
где отброшены смешанные взаимодействия трех и более факторов. От-
Отсюда линейная функция X, определенная в A92), есть, например,
Я, = A—BC — GH. D.4)
В этом случае мы имеем:
Vi = Л, 62 = +1, у2 = ВС, б2 = -1, у3 = GH, б3 = -1. D.5)
Используя A94), получим оценку главного эффекта фактора А:
1П^ д^+Л^З V ' 64 + 48 '
= Z1+i-(L2-L1), D.6)
где/х — оценка А, основанная на первых 28~2 опытах; Z-i — оценка
[Л — ВС — ОН), где А, ВС и ОН — независимые оценки из первого
100
плана 28 ~2, а ?2 — это обычная Оценка смешанных эффектов (А —
— ВС — GH) во втором плане 28~i. Таким же образом мы имеем
ПРИЛОЖЕНИЕ IV.5. ВЫБОР УРОВНЕЙ НЕЗНАЧИМЫХ ФАКТОРОВ
В ГРУППОВОМ ОТСЕИВАНИИ
D.7)
D.8)
Рассмотрим пример из табл. 35, где три групповых фактора X, Y и
Z состоят каждый из трех исходных факторов, обозначаемых А, В, С,
D и т. д. На первом этапе значимым оказался только фактор X. Следо-
Следовательно, на второй стадии три фактора А, В и С исследуются в четы-
четырех опытах. Незначимый фактор D можно выбрать по-разному: 1) на
нижнем уровне во всех опытах; 2) на верхнем уровне во всех опытах;
3) в двух опытах на нижнем и в двух на верхнем уровне; 4) на верх-
верхнем уровне в одном опыте и на нижнем в остальных. В первом и втором
случаях главный эффект D может оказаться смешанным с общим сред-
средним; эффекты А, В и С будут оценены без смещения. В случае 3 D будет
смешан с одним из главных эффектов А, В или С, что видно из
табл. IV.5.1.
Таблица IV.5.1
Возможные задания уровней D
и получающиеся смешивания
Опыт
1
2
3
4
D смешан с
Возможные задания уровней D
(* обозначает либо +, либо —,
пустота —противоположный знак)
* -j/ *
* * *
* * *
В А С С А В
В этой таблице звездочки в первом столбце означают, что фактор
принимает в первых двух опытах либо верхний, либо нижний уровень
и соответственно противоположный уровень — в двух последних опы-
опытах. Полагая, что А, В и С расположены, как в табл. 35, видим, что
D смешан с В, еслиО соответствует звездочкам в первом столбце. В слу-
случае 4 D тоже будет нарушать главные эффекты. Пусть, для примера, D
имеет уровни +, —, —, — в опытах 1, 2, 3 и 4 соответственно. Тогда
В оценивается из
ь=
E.1)
101
где
^ = 1* — a — P + v + 0 + ei,
у2 = li + a — p — у — 6 + е2, E.2)
3>з = ц, — а+Р — Y — б + е3,
У4 = ц + а + Р + Г — б + е4.
Подставляя E.2) в E.1), получим
?(&) = р —5/2. E.3)
Таким образом, лучшая политика относительно всех факторов, ока-
оказавшихся незначимыми на предыдущей стадии, состоит в том, чтобы
держать их на одном уровне. Отсюда следует, что если такие факторы
фактически эффективны, то смещенным окажется только общее сред-
среднее, а не главные эффекты других факторов.
ПРИЛОЖЕНИЕ IV6. РОЛЬ ВЗАИМОДЕЙСТВИЙ
В ГРУППОВОМ ОТСЕИВАНИИ
Допустим, что истинная модель
? Су 0 = ft. + 2 Р/ *« + 2 2 Р* хи **' <6-1)
i=l i h
где, если все факторы количественные, мы можем разрешить / = h, т.е.
получить чистые квадратичные эффекты C7-7-. Пусть k факторов Xj объе-
объединены в g групп Хъ ..., Xg. Эти g групп проверяются в плане разре-
разрешения III. Тогда мы знаем, что
2*«=о, j=\,...,k, F.2)
и если факторы / и /' принадлежат одной группе, то
!)=#. F.3)
Если же факторы / и /' принадлежат к двум различным группам, то
«*«') = 0, F.4)
поскольку пары групповых факторов ортогональны в плане разреше-
разрешения III. Будем теперь рассматривать сумму произведений трех факто-
факторов, т. е. iliXijXij' Xij". Тогда существуют три возможности.
102
1. Факторы /, /' и /" принадлежат одной факторной группе. Тогда
(xijXtr) = +l (i = l, ..., N) F.5)
= 0, F.6)
где последнее равенство следует из F.2).
2. Факторы / и /' принадлежат одной группе, а фактор /" — дру-
другой. Тогда, как в F.5) и F.6), мы получим
F.7)
3. Все три фактора принадлежат разным факторным группам, ска-
скажем Хъ Х2 и Х3. В плане 2fn~p один групповой фактор может сме-
смешиваться с взаимодействием двух других, скажем Х3 = Х1Х2- Сле-
Следовательно,
xtr=xt,xir (i = !,...,#). F.8)
Тогда
)==ЛГ- F.9)
В обсуждении табл. 14 мы видели, что в плане Плэкета—Бермана, но не
в плане 2ff7p взаимодействие двух факторов можно выразить как
линейную комбинацию главных эффектов и общего среднего. Отсюда
столбец взаимодействия между / и / , допустим хц>, удовлетворяет
2
1 = 0
или
ХцХ1Г=^1а1хп. F.11)
(=0
Следовательно,
2 хи xir xtr=2Sfl! xn xtj"='%al^lxn хц- = Nar, F.12)
i i i=o i i
где последнее равенство следует из F.3) и F.4).
Главный эффект фактора р (р = 1, ..., k) оценивается из
откуда
N
103
Рассмотрим три слагаемых в скобках:
1) в силу F.2) первое слагаемое обращается в нуль;
2) в силу F.3) и F.4) второе слагаемое сводится к AT2SCS, где фак-
фактор s принадлежит к той же группе, что и р (или фактор р и есть сам
фактор s, если р = s);
3) в силу F.6), F.7), F.9) и F.12) последнее слагаемое сводится к
Nav?>Jlw$Zw, где факторы z,wap принадлежат трем различным груп-
группам (а множитель ар = 1 для плана 2fn~p)- Таким образом,
Отсюда если у всех факторов есть парные взаимодействия, то (смешан-
(смешанный) главный эффект каждого фактора будет смещенным. Однако если
мы допустим, что двухфакторные взаимодействия есть только между
некоторыми (связанными) факторами, то мы можем собрать эти факторы
в одну группу. Их взаимодействия не будут смешаны с главными эф-
эффектами в этой группе, но смешаются с главными эффектами факторов,
не входящих в эту группу, так как z и w в F.15) соответствуют двум
разным группам. Последнее утверждение также означает, что эффекты,
чистых квадратов C;-7- не смещают главных эффектов.
Если мы проверяем g факторных групп в плане разрешения IV, то
главные эффекты факторов'*будут ортогональны к взаимодействиям
между двумя групповыми факторами. Отсюда F.9) и F.12) заменяются
на
21xijxirxlr = 0, F.16)
а F.15) сводится к
С1 /« \ О "V1 ft /с И\
h (ap) = z ,2jps. (o-l')
s
УПРАЖНЕНИЯ
1. Экспериментатор хочет исследовать эффекты нарушения симметрии рас-
распределения случайной величины. Он предпочитает сделать фактор «симметрия»
количественным. Предложите семейство распределений, которое даст различную
симметрию при изменении его параметров.
2. В однофакторной структуре уровень / повторяется Tj раз (/ = 1, ..., J).
Каков средний квадрат ошибки? Покажите, что для постоянного числа повторе-
повторений этот средний квадрат сводится к средней оцениваемой дисперсии а2 =
= 2 WjlJ, где
3(а). Эксперимент 2'~4 с определяющим соотношением / = 1235 =
= 1246 = 2347 дал следующие отклики (каждый отклик — это среднее из 400
параллельных): 0,9975, 0,9662, 0,9937, 1,0000, 0,9987, 0,9712, 0,9925, 0,9987,
0,9512, 0,9850,0,9912,0,9837, 0,9925, 0,9987, 0, 9975, 0,9912, где у1==0,9975—
это отклик (усредненный) в опыте № 1, а опыты записаны в стандартном порядке
(т. е. в первом столбце матрицы плана знаки чередуются: Ч Ь 1 и
т. д., во втором столбце: + +— 1—Ь и т. д.); у% = 0,9662 — отклик в опы-
опыте № 2 и т. д. Определите, какие главные эффекты и двухфакторные взаимодейст-
взаимодействия не значимы на 5%-иом уровне значимости.
104
3F). Были также измерены и стандартные отклонения для 16 откликов,
которые оказались такими: 0,0018, 0,0063, 0,0028, 0,0000, 0,0013, 0,0058, 0,0030,
0,0013, 0,0074, 0,0043, 0,0033, 0,0044, 0,0030, 0,0013,^0,0052, 0,0033. Каждое
стандартное отклонение получено по 400 параллельным опытам. Предположим,
что все отклики нормально распределены с общей дисперсией (т. е. для шестнад-
шестнадцати стандартных отклонений предполагается общее среднее а). Используйте
для проверки этой гипотезы критерий согласия, если хорошее согласие дают чле-
члены порядка не выше, чем двухфакторные взаимодействия. Примечание. Числа
и этом примере получены методом Монте-Карло в эксперименте по множествен-
множественному ранжированию при р* = 0,99 из главы VI.
4. Покажите, что в неортогональных планах Уэбба разрешения IV:
а) главные эффекты §м оцениваются по A74), если матрица V не вырожде-
вырождена;
б) ковариационная матрица вектора Ьм дается A77);
в) дисперсия bi для k = 3 есть а2/4 (а какова была бы дисперсия, если ма-
матрица плана была бы ортогональна?);
г) оценки главных эффектов Ьм не смещаются общим средним и двухфак-
торными взаимодействиями.
5. Объем группы по Пейтелу на стадии i (i = 2, 3, ...) есть р~1/<п+1)
(см. B36)). Допустим, что каждый важный фактор попал в отдельную группу.
Докажите, что общее число групп на стадии I остается постоянным и равно
kpn/ш+и (см. B39)).
6. Моделируется одиоканальная система обслуживания. Исследуйте эф-
эффекты изменения среднего времени между поступлениями, среднего времени
обслуживания и двух дисциплин обслуживания: «первым пришел — первым ушел»
против «последним пришел — первым ушел».
7. Повторите упражнение 6 с общими случайными числами, с обратными
величинами и с объединением обоих методов.
8. Моделируется некоторая система (например, система хранения запасов
с многими потребителями или многоканальная система обслуживания), которая
характеризуется очень большим числом входов и параметров (ио с известным
аналитическим решением, допускающим проверку наших результатов). Отсей-
Отсейте наиболее важные факторы, применяя разные планы отсеивания.
Примечание. Множество упражнений по ANOVA можно найти в соответс-
вующих стандартных учебниках, таких, как [Cochran, Сох, 1957], [Davies,
1963], [Hicks, 1966] и [Scheffe, 1964]. Много (а именно 43) упражнений по методам
этой главы, и (или) следующей приведено в [Schmidt, Taylor, 1970, p. 558—
574] (см. также многие упражнения в [Mihram, 1972, например, р. 383—393]).
ПРИМЕЧАНИЯ
1 Мы надеемся, что наш выбор основан на полном обзоре соответствующей
литературы. Мы просмотрели раздел 9 по планированию экспериментов в «Sta-
«Statistical Theory and Method Abstracts» (с 1959 по 1972 г.), все выпуски журнала
Techno metrics (с 1959 по 1972, №3 включительно) и ссылки в других работах.
2 Джекоби и Харрисон [Jacoby, Harrison, 1962, p. 126—127] тоже обсуж-
обсуждают преимущества, которые можно извлечь из подхода, основанного на изме-
изменении одновременно только одного фактора.
3 В общепринятой терминологии планирования эксперимента число факто-
факторов обозначают буквой k.
4 Если все факторы количественные, то можно использовать более общую
модель. Мы еще вернемся к этому.
6 Для читателей знакомых с различием между фиксированными и слу-
случайными факторами, мы отметим, что в имитационном моделировании в [Sasser
ct al., 1970] «проекты» — фиксированный фактор, в то время как «начальные
условия» и «случайные числа» — это случайные факторы. Из работы [Sasser
ct al., 1970, p. 290] не ясно, анализировался ли этот эксперимент в действитель-
действительности как смешанный план.
105
' м ч ¦¦• > и > I шрп, nticiin I'l.Muii и ciiMiiiijioM ь. Транспонирование
> I1I1 | |t ( nlnflv, I'Mi'l, |i. IM| (ti'iU'iniKir критерий Бартлетта, поскольку этот
»jiiitt |nill i MimihuM »iyin*IiiH'lfJIoil it ненормальности, и предлагает свой альтер-
н 'Лишиin u|iim<|)nil.
11 Нидрибпос обсуждение подходящей аппроксимации кривой отклика только
дли имшпых эффектов дано в [Yntema, Torgerson, 1961, p. 22].
0 Например, в табл. 10 приведен план 23-1.
10 Это результаты 8 опытов для матрицы плана, имеющей только три столбца.
ц За исключением N = 92, Уэбб [Webb, 1969, р. 427] установил, что Го-
ломб и Боймерт [Golomb, Baumert, 1963] преуспели в построении матрицы
для N = 92 (см. [John, 1971, р. 184]). Однако мы покажем, что их матрица дает
столбцы плана, которые не ортогональны к единичному столбцу /в2 — общему
среднему.
12 Выше мы разъяснили утверждение Тьюки [Tukey, 1969b, p. 170]. «Если
лишь совсем мало главных эффектов действительно велики, то шанс пропустить
относительно скромные эффекты (и взаимодействия) при накоплении слабо сме-
смешанных частей главных эффектов становится пренебрежимым».
13 Напомним, что Интема и Торгерсон [Yntema, Torgerson, 1961] полага-
полагают, что будто, пренебрегая всеми взаимодействиями, можно получить достовер-
достоверные заключения.
14 План для девяти факторов можно построить из плана 211-4, а Бокс
и Хаитер [Box, Hunter, 1961b, p. 454—456] исследовали, почему снижение фа^
торов 3 и 11 ведет к предпочтительной структуре смешивания.
15 Сравните в [Dykstra, 1959, р. 63]: «способность экспериментатора к пере-
перестройке и переосмысливанию условий планирования эксперимента ведет к на-
настоящей ошибке эксперимента, в противоположность тем ошибкам, которые да-
дают параллельные наблюдения при частичной настройке факторов».
16 Бокс [Box, 1966, р. 183—186] привел пример cG= 16 и Jg— 2. Так, оче-
очевидна его ошибка, когда он полагал, что «оценка чистой ошибки в параллель-
параллельных имеет + 15 степеней свободы, имеющихся в различиях между параллельными
опытами». Фактически есть 16 степеней свободы.
17 Дисперсия var (у | х0) = а2х'о (Х'Х)'1 х0, где X включает только старые
экспериментальные точки.
** Напомним, что A96) показывает, что в общем оцениваемые эффекты кор-
коррелируют. В обычных нерасширенных планах оцениваемые эффекты независи-
независимы и можно применять хорошо известные методы дисперсионного анализа, объе-
объединяющие суммы квадратов эффектов; сравните иаш комментарий к C3).
19 В методологии поверхностей отклика иные следствия ошибочного при-
принятия гипотез об отсутствии эффекта. Мы могли бы взять в качестве уравнения
регрессии полином первой степени, хотя фактически полином более высокой сте-
степени дал бы лучшее представление. Мы ожидаем, что такое плохое описание по-
полиномом первой степени приведет лишь к тому, что для достижения оптимума
понадобится больше шагов.
20 Видно, что в плане 2«—р каждый эффект либо строго ортогонален к
другому, либо полностью с ним смешай. Следовательно, их суммы квадратов
либо независимы, либо тождественны. Однако мы видим, например в табл. 14
и 18, что в других планах бывают эффекты, которые не полностью ортогональны
ко всем остальным. Все же суммы квадратов эффектов можно определить для
любого плана (ср. с [Johnston, 1963, р. 124]), но эти суммы квадратов уже не
будут независимы (ср. еще с [Hunter, 1959а, р. 10]). -
21 Для количественных факторов есть альтернатива подбора модели низ-
низкого порядка путем преобразования факторов (ср. с [Box, Tidwell, 1962]).
22 Здесь Nt не учитывает возможности дублирования и дополнительных на-
наблюдений для остаточной суммы квадратов.
аз фактически Бокс постулирует модель первого порядка, ио его доказа-
тельство годится для любой линейной по параметрам модели, т. е. Е (у) = X р.
106
24 Бэдн [Budne , 1959d, p. 143J брал медианы вместо средних в качестве мер
«усредненного» отклика на каждом уровне, поскольку медиана нечувствительна
к крайним значениям откликов. Такое крайнее значение может оказаться оши-
ошибочным.
26 Это правило рандомизации в [Booth, Сох, 1962] явно ие сформулировано,
но это стандартная для планирования эксперимента процедура (что было под-
подтверждено частным сообщением Кокса).
26 Мы использовали наше обозначение k для числа исходных факторов вме-
вместо обозначения Уотсона. Мы берем букву / для обозиачения объема группы.
27 Мы сохраняем наши обычные обозначения. Это значит, что k и / у Пейте-
,м а соответствуют наоборот нашим / и к.
28 Мы сохраняем наши обычные обозначения. Так, по Ли надо подставить
v, р, с и si вместо наших k, р, n и /,¦ соответственно.
29 Подстановка наших обозначений р и (л + 1) вместо обозначений Ли
p/v и с, соответственно, в его формулу B6). Результат тот же, что и в нашем B37).
30 Коэффициенты Ps и psz определяются как половины главных эффектов
и двухфакториых взаимодействий из стандартного определения планов со все-
всеми факторами только на двух уровнях; сравните наш комментарий к (95).
31 Система совместна, поскольку X'X натянута на то же пространство S,
—>¦ —>¦ -*¦ -> -> ->
что и X'. Поэтому (Х'Х) Ь — это вектор в пространстве S, как и Х'у.
32 При применении формулы Уэбба мы можем взять C.8), которое показы-
показывает, что уэббовская матрица В в нашем случае есть просто нулевая матрица
Библиография по методологии исследования поверхности отклика
Здесь приводится ориентировочная библиография по методологии пове рх
ности отклика и методам поиска экстремума (максимума). Понятно, что многие
публикации могут быть отнесены к более чем одной категории. Мы будем поме-
помещать их в ту категорию, к которой они относятся в наибольшей степени. Мы от-
отметили звездочками те публикации, которые представляются наиболее подходя-
подходящими для читателей, не знакомых с основами исследования поверхностей от-
отклика.
> [После каждого раздела библиографии за разделительной чертой следуют
работы, добавленные редакторами русского перевода. Звездочки сохранены
а наиболее доступными для первого знакомства. — Прим. ред.]
БИБЛИОГРАФИЯ
Л. Общие работы
1. Andersen S. L. A959). Statistics in the strategy of chemical experimen-
experimentation. Chem. Eng. Prog. 55, 61—67.
2*. В о x Q. E. P. A954). The exploration and exploitation of response surfaces:
some general considerations and examples. Biometrics, 10, 16—60.
3. Bradley R. A. A958). Determination of optimum operating conditions by
experimental methods, Part I, mathematics and statistics fundamental to the
fitting of response surfaces. Ind. Qual. Control, 15, 16—18.
4*. Bur dick D. S. and Naylo.r Т. Н. A969). The use of response surface
methods to design computer simulation experiments with models of business
and economic systems. — In: The Design of Computer Simulation Experb
ments. (T. H. Naylor, ed.), Duke University Press, Durham, N. C.
5*. Da vies O. L. (editor) A960). The Design and Analysis of Industrial Expe-
Experiments. Hafner, New York, 495—578.
6. Draper N. R. and Herzberg A. M. A971). On lack of fit. Technomet-
rics, 13, 231—241.
107
7 DuttonJ M and Star buck W H A971) Computer Simulation of Hm
man Behavior Wiley, New York, 593 706
8-1 HerzbergA M and Cox D R A969) Recent work on the design of ex-
experiments a bibliography and review Roy Stat Soc, Ser A, 132, 29—67
9* H 111 W J and Hunter W Q A966) A review of response surface metho
dology A literature survey Technometncs, 8, 571—590
10* Hunter J S A958) Determination of optimum operating conditions by
experimental methods, Part II—1 Ind Qual Control, 15, 16—24
11* Hunter J S A959) Determination of optimum operating conditions by
experimental methods, Part II—2 Ind Qual Control, 15, 7—15
12* Hunter J S A959) Determination of optimum operating conditions,
Part II—3 Ind Qual Control, 15, 6—14
13 John P W M A971) Statistical Design and Analysis of Experiments,
MacMillan, New York, 193—218
14 MendenhallW A968) Introduction to Linear Models and the Design
and Analysis of Experiments Wadsworth, Belmont, Cal, 267—305
15 Meyer D L A963) Response surface methodology in education and psy
chology J Exp Ed , 31, 329—336
16 Meyers R H A971) Response Surface Methodology Allyn and Bacon,
Boston
17 Mihram G A A972) Simulation Statistical Foundations and Methodolo-
Methodology Academic, New York, 402—-442
18 NaylorT H A971) Computer Simulation Experiments with Models of
Economic Systems Wiley, New York, 26—28 and 165—184 Русский перевод
H e й л о р Т Машинные имитационные эксперименты с моделями экономи ¦
ческих систем М, «Мнр», 1975
19 Read D R A954) The design of chemical experiments Biometrics, 10,
1—15
20 RothP M and Stewart R A A969) Experimental studies with multip
le responses Appl Stat, 18,221—228
* Адлер Ю П, Грановский Ю В Обзор прикладных работ по планиро-
планированию эксперимента Вып 33 М , Изд во МГУ, 1972
* Адлер Ю П Введение в планирование эксперимента М, «Металлургия»,
1969
* Адлер Ю П, Маркова Е В,ГрановскийЮ В Планирование экспе
римента при поиске оптимальных условий М, «Наука», 1976 (Первое изд
1971)
* Адлер 10 П, Грановский Ю В Методология и практика планирования
эксперимента за десять лет (обзор) М, «Заводская лаборатория», 1977, т 43,
№ 10, с 1253-1259
*НалимовВВ Теория эксперимента М , «Наука», 1971
*Налимов В В, Чернова М А Статистические методы планирования
экстремальных экспериментов М, «Наука», 1965
* Налимов В В, Голикова Т И Логические основания планирования экс-
эксперимента М «Металлургия», 1976
Федоров В В Теория оптимального эксперимента М, «Наука», 1971
* Anderson V L, McLean R A Design of experiments M Dekker, Inc,
N Y, 1974
* Federer W T, Balaam L N Bibliography on experiment and treatment
design Pre 1968, Oliver and Boyd, Edinburgh, 1972
Б Планы
1 BoseRCandCarterRV A959) Complex representation in the con-
construction of rotatable designs Ann Math Stat, 30, 771—780
2 Bose R С and Draper N R A959) Second order rotatable designs in
three dimensions Ann Math Stat, 30, 1097—1112
3*. Box G E P A952) Multi factor designs of first order Biometnka, 39,
49—57
108
4 Box G E P and BehnkenD W A958) A Class of Three Leve! Second
Order Designs for Surface Fitting Technical report no 26, Statistical Tech
mques Research Group, Section of Mathematical Statistics, Department of
Mathematics Princeton University, New Jersey
5 BoxG E P and BehnkenD W A960) Simplex sum designs a class of
second order rotatable designs derivable from those of first order Ann Math
Stat, 31, 838—864
6 Box G E P and BehnkenD W A960) Some new three level designs
for the study of quantitative variables Technometncs, 2, 455—475
7' Box G E P and Draper N R A959) A basis for the selection of a res-
response surface design J Amer Stat Assoc 54, 622—654
8* В о x G E P and Draper N R A963) The choice of a second order ro-
rotatable design Biometrika, 50, 335—352
9'Box M J and Draper N R A971) Factoral designs, the X'X criterion
and some related matteis Technometncs, 13, 731—-742
10*BoxG E P andHunterJ S A957) Multi factor experimental designs
for exploring response surfaces Ann Math Stat, 28, 195—241
11 Das M N A963) On construction of second order rotatable designs through
balanced incompletely block designs with blocks of unequal size Calcutta
Stat Assoc Bull, 12, 31—46
12 Das M N and Dey A A967) Group divisible rotatable designs Ann Inst
Stat Math, 19, 331—347
13 Das M N and NarasimhamV L A962) Construction of rotatable
designs through balanced incomplete block designs Ann Math Stat, 33,
1421—1439
14 DeBaunRM A959) Response surface designs for three factors at three
levels Technometncs, 1, 1—9
15 Dey A and Nig am А К A968) Group divisible rotatable designs some
further considerations Ann Inst Stat Math, 20, 477—481
16 DoehlertD H A970) Uniform shell designs Appl Stat, 19, 231—239
17 Draper N R A960) Second order rotatable designs in four or more di
mensions Ann Math Stat, 31, 23—33
18 Draper N R and L a w г е п с e W E A965) Designs which minimize mo-
model inadequacies, cuboidal regions of interest Biometrika, 52, 111—118
19 DraperNR and Lawrence W E-(I966) The use of second order sphe-
spherical and cuboidal designs in the wrong regions Biometrika, 53, 596—599
20 Draper N R and Lawrence W E A967) Sequential designs for sphe-
spherical weight functions Technometrics, 9, 517—529
21 Draper N R and Stoneman D M A968) Response surface designs
for factors at two and three levels and at two and four levels Technomet-
Technometrics, 10, 177—179
22 DykstraO A960) Partial duplication of response surface designs Tech-
Technometrics, 2, 185—195
23 Dykstra О A971) The augmentation of experimental data to maximize
| X'X | Technometrics, 13 682—688
24 Dykstra О A971) Addendum to 'The augmentation of experimental data
to maximize |X'X|" Technometrics 13 927
25 George К С and Das M N A966) A type of central composite response
surface designs J Indian Soc Agricultural Stat, 18, 21—29
26 Hartley H О A959) Smallest composite designs for quadratic response
surfaces Biometrics, 15,611—624
27 HartleyH О and Ruud P G A969) Computer optimization of second
order response surface designs — In Statistical Computation (R С Milton
and J A Nelder, eds), Academic, New York
28 HebbleT L andMitchellT J A972) Repairing response surface de-
designs Technometrics, 14, 767—779
29 HerzbergAM A966) Cylmdncally rotatable designs Ann Math Stat,
37, 242—247
30 HerzbergAM A967) The behaviour of the variance function of the dif-
difference between two estimated responses J Roy Stat Soc. Ser B, 29, 174—
179
109
31* Hunter J S and Naylor T H A969) Experimental Design — In The
Design of Computer Simulation Expenments (T H Naylor, ed), Duke Uni
versity Press, Durham, N С
32 KarsonMJ A970) Design criterion for minimum bias estimation of res
ponse surfaces J Amer Stat Assoc 65 1565—1572
33 KarsonM J.MansonA R and Hader R J A969) Minimum bias
estimation and experimental design for response surfaces Technometrics 11,
6—17
34 Mehta J S and Das M N A968) Asymmetric rotatable designs and or
thogonal transformations Technometrics, 10, 313—322
35 Nalimov V V, Gohkova T I and Mikeshina N G A970) On
practical use of the concept of d optimahty Technometrics, 12, 799—872
36 Nigam А К and Das M N A966) On a method of construction of rota
table designs with smaller number of points controlling the number of levels
Calcutta Stat Assoc Bull , 15, 174—175
37 RechtschaffnerRL A967) Saturated fractions of 2n and 3n factorial
designs Technometrics, 9, 569—575
38 Shirafuji M A959) A two stage sequential design in response surface
analysis Bull Math Stat, 8, 115—126
39 Ihaker P J A962) Some infinite series of second order rotatable designs
J Soc Agricultural Stat, 14 110—120
40 WestlakeWJ A965) Composite designs based on irregular fractions of
factorials Biometrics, 21, 324—336
Бродский В 3 Введение в факторное планирование эксперимента М, «Нау-
«Наука» 1976
ЗедгинидЗеИ Г Планирование эксперимента для исследования многоком-
многокомпонентных смесей М, «Наука», 1976
Маркова Е В, Лисекков А Н Планирование эксперимента в условиях
неоднородностеи М , «Наука» 1973
Ф н н н и Д Введение в теорию планирования эксперимента (Пер с англ ) М ,
«Наука», 1970
Химмельблау Д Анализ процессов статистическими методами (Пер с англ )
М, «Мир», 1973
В Методы поиска максимума
1* Brooks S Н A959) A comparison of maximum seeking methods Opera-
Operations Res, 7, 430—457
2 BrooksS H and Mickey M R A961) Optimum estimation of gradient
direction in steepest ascent experiments Biometrics, 17, 48—56
3 Carpenter В H and Sweeny H С A965) Process improvement with
simplex selfdirecting evolutionary operation Chem Eng 72, 117—126
4 Chow W H A962) A note on the calculation of certain constrained maxi
ma Technometrics, 4, 135—137
5 DoerflerT E and Kern p th or n e О A963) The Compounding of Gra
dient Error in the Method of Parallel Tangents ARL 63—144, Aerospace Re-
Research Laboratores Wright Patterson Air Force Base, Ohio
6 Draper N R A963) Ridge analysis of response surfaces Technometrics, 5,
469—479
7 El dor H and Koppel L В A971) A generalized approach to the method
of steepest ascent Operations Res, 19 1613—1618
8*- Emshoff J R and Sisson R L A971) Design and Use of Computer
Simulation Models, MacMillan, New York second printing, 214—224
9 Гаг lie D J and Keen J A967) Quick ways to the top a game illustra
ting steepest ascent techniques Appl Stat, 16, 75—80
10 Glass H and Cooper L A965) Sequential search a method for solving
constrained optimization problems J ACM, 12, 71—82
11 HillJ С and Gibson J E A966) Hillclimbmg on hills with many mi
mma — In Theory of Self Adaptive Control Systems (P H Hammond, ed ),
Plenum, New York
110
12 JohnsonC H and Folks J 1 A964) A propeity of the method of
steepest ascent Ann Math Stat, 35 435—437
13 KarrH W, Luther E L, MarkowitzH M andRussellE С
A965) Simoptimization Research Phase I Report no CACI 65 P2 0 I, Conso-
Consolidated Analysis Center, Inc, Santa Monica, Calif
14 Kiefer J A953) Sequential ramimax search for a maximum Proc Amer
Math Soc , 4, 502—506
15 KreftmgJ and White R С A971) Adaptive Random Search Report
71-E-24, Department of Electrical Engineering Techmsche Hogeschool, Eind-
Eindhoven (The Netherlands)
16 LuenbergerD G A972) The gradient projection method along geode
sics Management Sci, 18, 620—631
17 Luther E L and MarkowitzH M A965)-Simoptimization Research
Phase 11 Report no CACI, 65 P2 0 1, Consolidated Analysis Center, Inc, San
ta Monica, Calif
18 Luther E L and Wright N H A965) Simoptimization Research Pha-
Phase III Report no CACI, 65 P2 0 1, Consolidated Analysis Center, Inc, Santa
Monica, Calif
19 McArthurDS A961) Strategy in research — — alternative methods for
design of experiments IRE Trans Eng Management, 1, 34—-40
20 McMurtryG J A971) Adaptive optimization in learning control — In
Pattern Recognition and Machine Learning (K S Fu, ed), Plenum,
New York
21 Mayne D Q A966) A gradient method for determining optimal control oi
nonlinear stochastic systems — In Proceedings of the Second IFAC Sympo
sium, Theory of Self Adaptive Control Systems (P H Hammond ed), Pie
num, New \ork
22 Meier R С A967) The application of optimum seeking techniques to simu
lation studies a preliminary evaluation J Financial Quant Anal, 2, 31—51
23 MeierR C.NewellW T andPazerH L A969) Simulation in Busi-
Business and Economics Prentice Hall, Englewood Cliffs, N J, second printing,
313—327
24 Molnar G A968) Self optimizing simulation — In Simulation Program
ming Languages, Proceedings IFIP working conference on simulation pro
gramming languages (J N Buxton, ed), North Holland Publishing Co,
Amsterdam
25 Pierre D A A969) Optimization Theory with Applications Wiley, New
York, 264—366
26 Schmidt J W and Taylor R E A970) Simulation and Analysis of
Industrial Systems Richard D Irwin, Inc, Homewood, 529—553
27 Spang H A A962) A review of minimization techniques for nonlinear
functions SI AM. Rev, 4, 343—365
28 SpendleyW, HextG R and Hirasworth F S A962) Sequential
application of simplex designs in optimization evolutionary operation Tech
nometncs, 4, 441—461
29 Torn A A972) Global Optimization as a Combination of Global and Local
Search — In Working papers, vol 1, Symposium Computer Simulation Ver
sus Analytical Solutions for Business and Economic Models, Graduate School
of Business Administration, Gothenburg (Sweden)
30 UmlandAWandSmithWN A959) The use of Lagrangian multip
hers with response surfaces Technometncs, 1, 289—292
31 Vajo V S A969) A Random Process for Optimization Ecom 3179, U S
Army Electronics Command, Fort Monmouth, New Jersey
32 WestlakeWJ A962) A numerical analysis problem in constrained quad-
quadratic regression analysis Technometrics, 4, 426—430
33 WethenllG В A966) Sequential Methods in Statistics Methuen, Lon
don, 144—161
34 White R С A971) A survey of random methods for parameter optimiza
tion Simulation, 17, 197—205
111
35 W 11 d с D J A964) Optimum Seeking Methods Prentice Hall, Englewood
Chfis, New Jeisey Русский перевод Уайлд Дж Методы поиска экстре-
экстремума М «Наука», 1967
36 Wolfe P A969) Convergence conditions for ascent methods SIAM Rev,
11, 226—235
37 Wolfe P A971) Convergence conditions for ascent methods II some cor-
corrections SIAM Rev, 185—188
38 ЗедгенидзеИ Г Оптимизация плотности сухой зерновой смеси мето-
методом связанного планирования эксперимента Труды Грузинского политехни
ческого института Тбилиси, 1966, №> 4, р 197—201
* Розенброк X, Сторп С Вычислительные методы для инженеров хими-
химиков М , «Мир», 1968
* Химмельблау Д Прикладное нелинейное программирование М, «Мир»,
1975
Численные методы условной оптимизации Ред Гилл Ф , Мюррей У М , «Мир»,
1977
Г Приложения
1 Boyd D F A964) The Emerging Role of Enterprise Simulation Models
Advanced Systems Development Division, IBM, Yorktown Heights, New York,
74—78
2 DavisR E.FaulkenderR W and HinesW W A969) A simulated
port facility in a theatre of operations Naval Res Logistics Quart, 16,
259—269
3 Dickey J W and Montgomery D С A970) A simulation search
technique an example application for left turn phasing Transportation Res,
4, 339—347
4 Fine Q H and MclsaacP V A966) Simulation of a timesharing sys-
system Management Sci, Appl Ser 12, 180—194
5 HoggattA С A971) On stabilizing a large microeconomic simulation
model Logistics Rev Military Logistics J, 1, 21—23 (Reprinted in Dut-
ton J M and Starbuck W H A971) Computer Simulation of Human Beha
vior Wiley, New York )
6 HogattA С and Holtbrugge В J A966) Statistical techniques for
the computer analysis of simulation models — In Studies m a Simulated
Market (L В Preston and N R Collins eds), Institute of Business and
Economic Research, University of California, Berkeley
7 Houston В F and Huffman R A A971) A technique which combines
modified pattern search methods with composite designs and polynomial con-
constraints to solve constrained optimization problems Naval Res Logistical
Quart, 18, 91—98
8 Hufschmidt M M A966) Analysis of simulation Examination of res-
response surface — In Design of Water Resource Systems (Arthur Maass et al
eds), Harvard University Press, Cambridge
9 Klin gel A R A966) Bias in PERT project completion time calculations
for a real network Management Sci, 13, 194—207
10 LuckieP T and Smith D E A968) Research applicable to problems
of intelligence, final report Report Number 4015, 11-F, HRB-Singer, Inc
State College, Репл
11 Michaels S E and Pengilly P J A963) Maximum yield for speci-
specified cost Appl Stat, 12, 189—193
12 MihramGA A971) An Efficient Procedure for Locating the Optimal Si-
mular Response University of Pennsylvania, Philadelphia
13 Smith D E A968) Sensitivity Analysis and Optimization in Computer
Simulation of Intelligence Situations, An Application of Response Surface
Methodology Report 401511-R4, HRB-Singer, Inc, State College, Penn
14 Spek P A968) Toepassing van een Oplossingsalgoritme op het Scheepsont-
werp Graduation thesis, Afdeling Algemene Wetenschappen, Technische Ho-
geschool, Delft, The Netherlands
112
lr Taraman К S and Lamer t В К A972) Application of response sur
face methodology to the selection of machining variables AI1E Trans, 4,
111—115
Ib Welch L F, Adams W E andCarmonJ L A963) Yield response
surfaces, isoquants and economic fertilizer optima for coastal Bermudagrass
Agron J 55, 63—67
Л Разные работы
1 Atkinson А С A969) Constrained maximization and the design of ex-
experiments Technometrics, 11, 616—618
2 BehnkenD W and Draper N R A972) Residuals and their variance
patterns Technometncs, 14, 101—111
3 В obis A H and Andersen L В A970) An approach for economic dis-
discrimination between alternative chemical syntheses Technometncs, 12,
439—455
4 Box G E P A954) Discussion on the symposium on interval estimation
J Roy Stat Soc, Ser B, 16, 211—212
5 Box G E P and Coutie G A A956) Application of digital computers
in the exploration of functional relationships Proc IEE, 103, Part B, Supple-
Supplement № i, 100—107
6 Box G E P and Draper N R A969) Evolutionary Operation Wiley,
New York
7 Box G E P and Hunter J S A954) A confidence region for the solu-
solution of a set of simultaneous equations with an application to experimental
design Biometnka, 41, 190—199
8 Box G E P and Hunter W G A962) A useful method for modelbuil-
ding Technometncs, 4, 301—318
9 BoxG E P and Hunter W G A965) The experimental study of phy-
physical mechanisms Technometrics, 7, 23—42
10 BoxG E P andTidwellP W A962) Transformation of the indepen-
independent variables Technometncs, 4, 531—550
H BoxG EP and YoulePV A955) The exploration and exploitation of
response surfaces, an example of the link between the fitted surface and the
basic mechanism of the system Biometrics, 11, 287—323
12 Clough D J A969) An asymptotic extreme-value sampling theory for
estimation of a global maximum Can Oper Res Soc J, 7, 102—115
13 Hill W J, Hunter W G and WichernD W (I960) A joint design
criterion for the dual problem of model discrimination and parameter estima
hon Technometrics, 10, 145—16].
14 Hoerl A E A959) Optimum solution of many variables equations Chem
Eng Prog , 55, 69—73
15 HunterW G and Kittrell J R A966) Evolutionary operation A re-
review Technometrics, 8, 289—297
16 FishmanG S and Kiviat P J A967) Digital Computer Simulation
Statistical Considerations Report no RM 5387 PR, The Rand Corporation,
Santa Monica, Calif 28—31 (Published as The statistics of discrete event
simulation, Sci Simul, 10, 185—195 A968) )
17 HeutsR M J and Rens P J A972) A Numerical Comparison Among
Some Algorithms for Unconstrained Non Linear Function Minimization Re
port EIT 34, Tilburg Institute of Economics, Department of Econometrics,
Kathoheke Hogeschool, Tilburg, The Netherlands
18 Kitagawa I A959) Successive process of statistical inferences applied to
linear regression analysis and its specializations to response surface analysis
Bull Math Stat, 8, 80—114
19 KosterHJ A970) Analyse van functies van meer dan een variabele In-
formatie, 12, 15—18
20 KruskalJ В A965) Analysis of factorial experiments by estimating mo-
monotone transformations of the data J Roy Stat Soc, Ser B, 27, 251—263
113
Ч\ М л ,i I I'll A ,111A S с go rid Л A969) L'estimation sequentiele dans les irlo
(Ides IliU'dlics Mctid, 8 553—578
22 MjiquardtDW A959) Solutions of nonlinear chemical engineering mo-
models Chem Eng Prog, 55, 65—70
23 Scheffe H A970) Multiple testing versus multiple estimation, improper
confidence sets, estimation of directions and ratios Ann Math Stat, 41, 8
24 Van der VaartH R A960) On certain types of bias in current methods
of response surface estimation Bull L Institut Inter Stat, 37, 191—203
25 Van der VaartH R A961) On certain characteristics of the distribu-
distribution of the latent roots of a symmetric random matrix under general condi-
conditions Ann Math Stat, 32, 864—873
26 VanHornR L A972) An Optimizing Tree Search Simulator —In Wor-
Working papers, vol 4, Symposium Computer Simulation Versus Analytical So-
Solutions for Business and Economic Models, Graduate School of Business Ad-
Administration, Gothenburg (Sweden)
* Горский В Г, Адлер Ю П Планирование промышленных эксперимен-
экспериментов (Модели статики) М, «Металлургия», 1974
Горский В Г, Адлер Ю П, Талалай А М Планирование промышлен
ных экспериментов (Модели динамики) М, «Металлургия», 1978,
Круг Г К, Сосулин Ю А, Фатуев В А Планирование эксперимента
в задачах идентификации и экстраполяции М , «Наука», 1977
*ХургинЯ И Да, нет или может быть М , «Наука», 1977
БИБЛИОГРАФИЯ
1 AddelmanS A961) Irregular fractions of the 2n factorial experiments
Technometncs, 3, 479—496
2 Addelman S A963) Techniques for constructing fractional replicate
plans J Amer Stat Assoc , 58, 45—71
3 Addelman S A969) Sequences of two level fractional factorial plans
Technometncs, 11, 477—509
4 Anderson TW A958) An Introduction to Multivanate Statistical Analy-
Analysis Wiley, New York Русский перевод Андерсон Т Введение в много-
многомерный статистический анализ М, Физматгиз, 1963
5 Andrews D F A971) A note on the selection of data transformations
Biometnka, 58, 249—254
6 AnscombeFJ A959) Quick analysis methods for random balance scree
mng experiments Technometncs, 1, 195—209
7 AnscombeF J A963) Bayesian inference concerning many parameters
with reference to supersaturated designs Bull Inter Stat Inst, 40, 721—733
8 AnscombeP J and Tukey J W A963) The examination and analysis
of residuals Technometrics, 5, 141—160
9 BalderstonF E and H о g g a 11 А С A962) Simulation of Market
Processes Institute of Business and Economic Research, University of Call
forma, Berkeley
10 Beaton A E A969) Algorithms for data maintenance and computation of
analysis of variance — In Statistical Computation (R С Milton and
J A Nelder, eds ), Academic, New York
11 BirnbaumA A959) On the analysis of factorial experiments without rep
hcahon Technometrics, 1, 343—359
12 Bock R D A963) Programming univanate and multivanate analysis of
^variance Technometrics, 5, 95—117
13 Bonini С Р A967) Simulation of Information and Decision Systems in
the Firm Markam Publishing Co , Chicago
14 Bonini С Р A971) Experimental design for a simulation model of the
firm — In Computer Simulation of Human Behavior (J M Dutton and
W H Starbuck, eds), Wiley, New York
15 BoothKHV and Cox D R A962) Some systematic supersaturated de-
designs Technometrics, 4, 489—495
114
16 Box G E P A952) Multi factor designs of fust order Biometnka, 39,
49—57
17 Box G E P A954) The exploration and exploitation of response surfaces,
some general considerations and examples Biometrics, 10, 16—60
18 Box G E P A959) Discussion of Ihe papers of Messrs Satterthwaite and
Budne Technometncs, 1, 174—180
19 Box G E P A966) A note on augmented designs Technometncs, 8,
184—188
20 BoxG E P and Hunter J S A961a) The 2ft-* fractional factorial de-
designs, Part I Technometncs, 3, 311—351
21 BoxG EP and Hunter J S A961b) The 2ft~* fractional factorial de-
designs, Part II Technometncs, 3, 449—458
22 Box G E P and Ti dwell P W A962) Transformation of the indepen
dent vanables Technometncs, 4, 531—550
23 Box G E P and Wilson К В A951) On the experimental attainment
oi optimum conditions J Roy Stat Soc, Ser В , 13 t—38
24 Box M J and Draper N R A971) Factorial designs, the \X'X\ criterion
and some related matters Technometncs, 13, 731—742
25 Box M J and Draper N R A972) Corrigendum factorial designs the
\X'X\ criterion and some related matters Technometncs, 14, 511
26 Bo yd D F A964) The Emerging Role of Enterprise Simulation Models
Advanced Systems Development Division IBM, Yorktown Heights, New York
27 BudneTA A959a) Random balance, Part I the missing statistical link
in fact finding techniques Ind Qual Control, 15, 5—10
28 BudneTA A959b) Random balance, Part II techniques of analysis Ind
Qual Control, lb, 11 — lb
29 BudneTA A959c) Random balance, Part III case histories Ind Qual
Control, 15, 16—19
30 Budne T A A959d) The application of random balance designs Techno-
metncs, 1, 139—155, 192—193
31 CloughD J.LevineJ B.MowbrayG and Walter J R A965)
A simulation model for subsidy policy determination in the Canadian uranium
mining industry Can Oper Res Soc J, 3, 115—128
32 CochranWGandCoxGM A957) Experimental Designs Wiley, New
York, second edition
33 Cohen A A968) A note on the admissibihty of pooling in the analysis of
variance Ann Math Stat, 39, 1744—1746
34 CurnowR N A965) A note on G S Watson's paper «A study of the
group screening method» Technometrics, 7, 444—446
35 CyertR M and Match J G A963) A Behavioral Theory of the Firm
Prentice Hall, Englewood Cliffs, New Jersey
i6 Daniel С A956) Fractional replication in industrial research — In Pro
ceedings Third Berkeley Symposium on Mathematical Statistics and Proba
bility, vol 5 (J Neyman, ed ), University of California Press, Berkeley
O Daniel С A959) Use of half normal plots in interpreting factorial two-
level experiments Technometrics, 1, 311—-341
)8 D a n i e 1 С A960) Parallel fractional replicates Technometncs, 2, 263—268
)9 Daniel С A962) Sequences of fractional replicates in the 2p~q series
J Amer Stat Soc, 57, 403—429
10 DaviesO L A963), ed The Design and Analysis of Industrial Experi-
Experiments Oliver and Boyd, London, 2nd edition
11 Dear R E A961) Multivanate Analyses of Variance and Covanance for
Simulation Studies Involving Normal Time Series, Field note 5644, Systems
Development Corporation, Santa Monica, Calif
42 Dolby J L A963) A quick method for choosing a transformation Tech
nometncs, 5, 317—327
<\l DonaldsonT S A966) Power of the F-test for Nonnormal Distributions
and Unequal Error Variances Report no RM 5072 PR, The Rand Corporation,
Santa Monica, Calif
115
U i' ,. i ii i . i* iii«Mi H|i|iniili 111 li Illiif; \iiii u'H |i.ikiii(ifliliic inel behulp
> i ! b!j (if, i Mull ll> i I'IhiI, I'i, !'0(i 212
t и i j ,mi Hi i l< f i и A M (Ml/I) OH luck of fit. Technometrics,
i ill
i. I > t t [< r , ) 1 |? iii.I || null i W (i (I9G6) Design of experiments for para-
шНм s 11111 1114111 in iiiiilliii"i|ionsc situations. Biometrika, 53, 525—533.
i, (Uii|um N \i . 11111 II и и l с r W. Q. A969). Transformations: some examples
iivhlli'il Iccliiiomctn'cs, 11,23—40.
<1(t I > г и per N R and Mitchell T. J A967). The construction of saturated
2,," » designs. Ann. Math. Stat, 38. 1110—1126.
49. Draper N. R. and Mitchell T. J. A968). Construction of the set of
256-run designs of resolution ^5 and the set of even 512-run designs of re-
resolution ^6 with special reference to the unique saturated designs. Ann.
Math. Stat, 39, 246—255.
50. Dykstra O. A959). Partial duplication of factorial experiments. Techno-
Technometrics, 1, 63—75.
51. Dykstra O. A960). Partial duplication of response surface designs. Tech-
Technometrics, 2, 185—195.
52. Dykstra О A971а). The augmentation of experimental data to maximize
\X'X\. Technometrics, 13, 682—688.
53. Dykstra O. A971b). Addendum. Technometrics, 13, 927.
54. Emshoff J. R. and Sisson R. L. A971). Design and Use of Computer
Simulation Models. MacMillan, New York, 2nd printing.
55. Fisher R. A. A966). The Design of Experiments. Oliver and Boyd, Edin-
Edinburgh, 8th edition.
56. Fisz M. A967). Probability Theory and Mathematical Statistics. Wiley, New
York, 3rd printing.
57. Fowlkes E. B. A969). Some operators for ANOVA calculations. Techno-
Technometrics, 11, 511—526.
58. Fractional Factorial Designs for Factors at Two Levels. Statistical Enginee-
Engineering Laboratory. National Bureau of Standards. Distributed by Clearinghouse,
Springfield, Virginia A957).
59. Fromm G. A969). The evaluation of economic policies. — In: The Design of
Computer Simulation Experiments, (Т. Н. Naylor, ed.), Duke University
Press, Durham, N. C.
60. Golomb S. W. and Baumert L. D. A963). The search for Hadamard
matrices. Amer. Math. Monthly, 70, 12—17.
61. Heal у M. J. R. A968a). Multiple regression with a singular matrix. Appl.
Stat, 17, 110—117.
62. H e a 1 у М. J. R. A968b). Triangular decomposition of a symmetric matrix.
Appl, Stat., 17, 195—197.
63. Heal у М. J. R. A968c). Inversion of a positive semi-definite symmetric mat-
matrix. Appl. Stat, 17, 198—199.
64. Hebble T. L. and Mitchell T. J. A972). Repairing response surface de-
designs. Technometrics, 14, 767—779.
65. Her z berg A. M and Cox D. R. A969). Recent work on the design of
experiments: a bibliography and a review. J. Roy. Stat. Soc, Ser. A, 132,
29—67.
66. Hicks С R. A966). Fundamental Concepts in the Design of Experiments.
Holt, Rinehart and Winston, New York. Русский перенод: X и к с Ч. Основ-
ные принципы планирования эксперимента. М, «Мир», 1967.
67. Н i 11 W. J. and Hunter W. G. A966). A review of response surface metho-
methodology: a literature survey. Technometrics, 8, 571—590.
68. Holms A. G. and Berrettoni J. N. A969). Chain-pooling ANOVA for
two-level factorial replication-free experiments. Technometrics, 11, 725—746.
69. Hunter J. S. A958). Determination of optimum operating conditions by
experimental methods, Part II—1. Ind. Qual. Control, 15, 16—24.
70. Hunter J. S. A959a). Determination of optimum operating conditions by
experimental methods, Part II—2. Ind. Qual. Control, 15, 7—15.
71. Hunter J. S. A959b). Determination of optimum operating conditions by
experimental methods, Part II—3. Ind. Qual. Control, 15, 6—14.
116
72 Hunter J S A964) Sequential factorial estimation Technometrics, 6,
41—55
73 Hunter J S A968) Experimental Designs in Simulation Analysis Presen
ted at the Symposium on the Design of Computer Simulation Experiments,
Duke University, Durham N С (Also published in The Design of Computer
Simulation Experiments (T H Naylor, ed ), Duke University Press, Durham,
1969)
74 Ignall E J A972) On experimental designs for computer simulation ex-
experiments Management Sci, 18, 384—388
75 JacobyJ E and Harrison S A962) Multi variable experimentation
and simulation models Naval Res Logistics Quart 9, 121—136
76 JensenRE A966) An experimental design for study of effects of accoun
ting variations in decision making J Accounting Res 4 224—238
77 JohnP W M A966) Augmenting 2™-' designs Technometrics 8, 469—
480
78 John P W M A971) Statistical Design and Analysis of Experiments
MacMillan, New York
79 Johnston J A963) Econometrics Methods McGraw Hill New York
80 KaczkaE E and Kirk R V A967) Managerial climate work groups
and organization performance Administrative Sci Quart 12 253—272
81 Kempt home О A959) Discussion of the papers of Messrs Satterthwaite
and Budne Technometrics, 1 159—166
82 Knight F D and LudemanM M A968) Computer Job Shop Simula
tion Model A Decision Tool Report no DP MS 67 100, Savannah River La
boratory E I du Pont de Nemours and Co Aiken, South Carolina
83 Ко tier P A970) A guide to gathering expert estimates Business Hon
zons, 13 79—87
84 Last К W A962) Statistical Design of Complex Experimental Programs
Part I, Optimum Experimental Designs Obtained by Minimizing a Loss Func
hon, Report no ARL 62 373, Aeronautical Research Laboratories, Wright Pat-
Patterson Air Force Base, Ohio
85 Li С H A962) A sequential method for screening experimental variables
J Amer Stat Assoc 57, 455—477
86 McQuie R A969) Experimental design and simulation in unloading ships
by helicopter Operations Res , 17, 785—799
87 Marjolin В A969) Resolution IV fractional factorial designs J Roy
Stat Soc, Ser B, 31, 514—523
88 MendenhallW A968) Introduction to Linear Models and the Design
and Analvsis of Experiments Wadsworth, Belmont, Cal
89 MihramGA A970) A cost effectiveness study for strategic airlift Trans
portation Sci, 4, 79—96
90 Mihram G A A972) Simulation Statistical Foundations and Methodolo
gy Academic, New York
91 Miller J R A968) Notes on a Simulation Investigation into the Relation
ship of Lateness to Queue Discipline and Labor Assignment Priority Rules
in a Network of Waiting Lines, Western Management Science Institute Work
shop, Graduate School of Business Administration, University of California
Los Angeles
12 Nauta F A967) Practical Problems in Digital Simulation Technical notes,
CEIR, The Hague
43 Naylor T H, Balintfy J L, Bur dick D S andChuK A967a)
Computer Simulation Techniques Wiley, New York, 2nd printing
<M Naylor T H and Hunter J S A969) Experimental Designs for Com
puter Simulation Experiments Econometric System Simulation Program Wor
king Paper № 33, Duke University Durham, N С
')'> Naylor T H.WertzK and Wonnacott T H A967b) Methods for
analyzing data from computer simulation experiments, Communications ACM,
10, 703—710
% Naylor T H, WertzK and Wonnacott T H A968) Some methods
for evaluating the effects of economic policies using simulation experiments
Rev Inter Stat Inst, 36, 184—200
117
97. N о I п л Я. L. illltl Sovereign M. G. A972). A recursive optimization and
'liuuiliilliiu upproacli to analysis with an application to transportation systems.
MiMKificnioiil Sci. Appl. Ser., 18, 676—690.
08. Oil И. Я. and Wehr fritz F. W. A972). A special screening program for
many treatments. Statistica Neerl., 26, 165—170.
99. Overholt J. L. A968). The problem of factor selection. Presented at the
Symposium on the Design of Computer Simulation Experiments, Duke Uni-
University, Durham, N. C.
100. Overholt J. L. A970). Sensitivity Tests on SLAT Computer Simulations
using Experimental Design, CNA Research Contribution, № 142, Naval War-
Warfare Analysis Group, Center for Naval Analyses, Arlington, Va.
101. Patel M. S. A962). Group-screening with more than two stages. Techno-
metrics, 4, 209—217.
102. Patel M. S. A963). Partially duplicated fractional factorial designs. Tech-
nometrics, 5, 71—83.
103. Peng К. С A967). The Design and Analysis of Scientific Experiments (An
Introduction with Some Emphasis on Computation). Addison—Wesley, Rea-
Reading, Pa.
104. Plackett R. L, and Bur man J. P. A946). The design of optimum multi-
factorial experiments. Biometrika, 33, 305—325,
105. Puri M. L. and Sen P. K. A971). Nonparametric Methods in Multivariate
Analysis. Wiley, New York.
106. Rao С R. A965). Linear Statistical Inference and Its Applications. Wiley,
New York. Русский перевод: Р а о Р. С. Линейные статистические методы
и их применение. М., «Наука», 1968.
107. Rao С. R. and Mit_raS. К. A971). Generalized Inverse of Matrices and
Its Applications. Wiley, New York.
108. Rechtschaffner R. L. A967). Saturated fractions of 2" and 3n facto-
factorial designs. Technometrics, 9, 569—-575.
109. Roy S. N. A957). Some Aspects of Multivariate Analysis. Wiley, New York.
110. RoyS. N., GnanadesikanR. and Srivastava J. N. A970). Analy-
Analysis and Design of Certain Quantitative Multiresponse Experiments. Pergamon,
Oxford.
111. Sasser W. E. A969). A Causal Relationship Between a Model's Characte-
Characteristics and the Performances of the Estimators of the Model's Parameters:
A Pilot Study, Graduate School of Business Administration, Harvard Univer-
University, Boston.
112. Sasser W. E., В ur dick D. S., Graham D. A. and Naylor Т. Н.
A970). The application of sequential sampling to simulation: an example in-
inventory model. Communications ACM, 13, 287—296.
113. Satterthwaite F. E. A959). Random balance experimentation Techno-
Technometrics, 1, 111—137, 184—192.
114. Scheffe H. A964). The Analysis of Variance. Wiley, New York, 4th prin-
printing. Русский перевод: Ш е ф ф е Г. Дисперсионный анализ. М., Физматгиз,
1963.
115. S chink W. A. and Chi u J. S. Y. A966). A simulation study of effects
of multicollinearity and autocorrelation on estimates of parameters. J. Finan-
Financial Quant. Anal., 1, 36—67.
116. Schmidt J. W. and Taylor R. E. A970). Simulation and Analysis of
Industrial Systems. Richard D. Irwin, Inc., Homewood, 111.
117. Seeger P. A966). Variance Analysis of Complete Designs. Almqvist and
Wiksell, Uppsala.
118. Smith D. E. A968). Sensitivity Analysis and Optimization in Computer
Simulation of Intelligence Situations. An Application of Response Surface Me-
Methodology, Report 4015, ll-R-4, HRB-Singer, Inc., State College, Penn.
119. S m i t.h H. A969). Regression analysis of variance. — In: The Design of Com-
Computer Simulation Experiments. (Т. Н. Naylor, ed.), Duke University Press,
Durham, N, C.
118
120. Srivastava J. N. and Anderson D. A. A969). Fractional Factorial
Designs for Estimating Main Effects Orthogonal to Two-factor Interactions:.
3" and 2mX3re Series, ARL Technical Report № 69-0123 Aerospace Research
Laboratories, Wright—Patterson Air Force Base, Ohio.
121. Srivastava J. N. and Anderson D. A. A970). Optimal fractional plans
for main effects orthogonal to two-factor interactions: 2m series. J. Amer.
Stat. Assoc, 65, 828—843.
122. Srivastava J. N. and Chopra D. V. A971). Balanced optimal 2m
fractional factorial designs of resolution V, m=s:6. Technometrics, 13, 257—
269.
123. Statistical Theory and Method Abstracts (published until 1965 as Statistical
Theory and Methods). Oliver and Boyd, Edinburgh, 1959—72.
124. Tukey J. W. A959a). A quick compact two-sample test to Duckworth's spe-
specifications. Technometrics, 1, 31—48.
125. Tukey J. W. A959b). Discussion of the papers of Messrs. Satterthwaite and
Budne. Technometrics, 1, 166—174.
126. Watson C. S. A961). A study of the group screening method. Technomet-
Technometrics, 3, 371—388.
127. Webb S. A968a). Non-orthogonal designs of even resolution. Technometrics,
10, 29—299.
128. Webb S. R. A968b). Saturated sequential factorial designs. Technometrics,
10, 535—550.
129. Webb S. A969). Interactions between the experiment designer and the com-
computer. Naval Res. Logistics Quart., 16, 423—433.
130. Webb S. R. A971). Small incomplete factorial experiment designs for two-
and three-level factors. Technometrics, 13, 243—256
131. Welch B. L. A938). On tests for homogeneity. Biometrika, 30, 149—158.
132. West lake W. J. A971). A one-sided version of the Tukey—Duckworth test.
Technometrics, 13, 901—903.
133. Whithwell J. C. and Мог bey G. K. A961). Reduced designs of resolu-
resolution five. Technometrics, 3, 459—477.
134. Yntema D. B. and Torgerson W. S. A961). Man-computer cooperation
in decisions requiring common sense. IRE Trans. Human Factors Electron.
HFE—2, 20—26.
Глава V Л ОБЪЕМ ВЫБОРКИ И НАДЕЖНОСТЬ
ВВЕДЕНИЕ И РЕЗЮМЕ
В этой главе мы рассмотрим соотношения между объемом выборки
и надежностью. Объем выборки — это число наблюдений из одной дан-
данной совокупности (или варианта системы). Надежность есть статисти-
статистическая точность выборочной оценки. Эта точность выражается, на-
например, длиной доверительного интервала и доверительной вероят-
вероятностью A —а). Сначала рассмотрим ситуацию с одной совокупностью,
а затем перейдем к общему случаю — k (>2) совокупностей. Далее мы
всегда будем различать выборки фиксированного и случайно меняю-
меняющегося объема. Для заранее установленных объемов выборок нам надо
найти надежность оценок. В обратной задаче при фиксированной же-
желаемой надежности нужно определить требуемый объем выборки.
Мы решили разделить главу на три части: часть А — надежность
для одной совокупности; часть Б—фиксированные объемы выборки
для k совокупностей: методы множественных сравнений; часть В—оп-
В—определение объема выборок для k совокупностей: методы множествен-
множественного ранжирования. В части А мы обсудим оценку дисперсии средне-
среднего отклика в имитационном опыте. Эта оценка дисперсии далее исполь-
используется в формулах для доверительных интервалов среднего значения
отклика и в формулах для объема выборки, требуемого при оценке
среднего значения с заданной надежностью. В части Б мы опишем ме-
методы множественных сравнений (ММС), с помощью которых получим
такие доверительные интервалы, например, для сравнения средних
значений k (>2) совокупностей, которые одновременно достоверны с
заданной надежностью. В этой части мы также обсудим процедуры
выбора подмножества из k совокупностей, которое, например, с задан-
заданной надежностью имеет наилучшие средние. В части В мы рассмотрим
методы множественного ранжирования (ММР), позволяющие опреде-
определить требуемое число наблюдений в каждой из k (>2) совокупностей
(для выбора наилучшей совокупности). В начале каждой части при-
приводится более развернутая аннотация. Каждая часть имеет свои биб-
библиографию и упражнения.
V.A. НАДЕЖНОСТЬ ДЛЯ ОДНОЙ СОВОКУПНОСТИ
V.A.I. Аннотация
В V.A.2 мы рассмотрим оценку дисперсии среднего отклика в ими-
имитационном опыте. Выводится центральная предельная теорема для
зависимых наблюдений стационарного процесса. Обсуждаются повтор-
120
иые и непрерывные опыты. В удлиненном опыте можно пользоваться
почти независимыми подопытами или оценивать отдельные сериальные
корреляции, или создавать независимые циклы наблюдений. Приво-
Приводится несколько дополнительных ссылок на литературу по оцениванию
дисперсии.
В V.A.3 мы приведем ряд хорошо известных результатов для до-
доверительных интервалов и критериев для среднего одной нормальной
совокупности или разности между средними двух нормальных сово-
совокупностей. Мы обсудим, например, /-критерий для одной либо двух
совокупностей с неизвестными и возможно различными дисперсиями.
Рассматриваются предположения ^-критерия и имитационное модели-
моделирование, а также биномиальное распределение и оценивание квантилей.
В V.A.4 изучается определение объема выборки. Для доверительного
интервала заданной длины обсуждается двойная выборка и (асимпто-
(асимптотически состоятельная и эффективная) последовательная выборка.
Многочисленные применения в моделировании и экспериментах Монте-
Карло показывают, что правила останова срабатывают. Мы также оп-
определим объем выборки для проверки гипотез с заданными ошибками
аир при применении двойной выборочной процедуры. В качестве аль-
альтернативы можно взять подход, основанный на селекции («зона без-
безразличия»), который отбирает с заданной надежностью уточненную
совокупность. Эвристический последовательный метод применен в ими-
имитационном эксперименте. Проверку гипотез с заданными ошибками а
и р и строго последовательной выборкой можно осуществить по кри-
критерию последовательного отношения вероятностей Вальда (Wald)
(КПОВ) (при условии, что нет мешающих параметров; следовательно,
для биномиальной совокупности существует точный КПОВ). Часть А
заканчивается приложениями, упражнениями и библиографией.
V.A.2. Оценивание дисперсии в имитационном моделировании
Как видно из II.8, для периодических систем можно увеличить
объем выборки повторением имитационных опытов, в каждом из кото-
которых получается независимая оценка отклика (например, среднее вре-
время ожидания или вероятность «большого» времени ожидания). Для
непрерывных систем мы тоже можем выделить отдельный опыт для
повторения, разделив машинное время на отрезки с учетом времени,
необходимого для завершения переходного процесса. Затем анализ
ведется традиционными статистическими методами, основанными на
независимых наблюдениях. Поскольку эти методы часто предполагают
нормальность, обсудим сначала центральную предельную теорему для
r-зависимого стационарного случая. Процесс называется стационар-
стационарным в узком смысле, если совместная функция распределения вероятно-
вероятностей наблюденийхъ х2, ¦¦¦, xt, ..., Xn во времени не есть функция вре-
времени t. Иначе говоря, эта вероятность не меняется во времени, а ос-
остается постоянной. (Это совпадает с определением установившегося
состояния, данным в 1.2 и П.4.) При такой совместной функции распре-
распределения вероятностей безусловная функция распределения вероят-
вероятности одинакова для каждого Xt. Это, в свою очередь, означает, что все
моменты для Xi не меняются во времени t. В частности, среднее значе-
значение и дисперсия, определенные в уравнениях A) и B), остаются по-
постоянными:
Е (х,) = 1* (t = 1, 2, ..., N) A)
и
var (jft) = a2. B)
Более того, .ковариация между xt и xt+s не зависит от t, но зависит
только от s — расстояния (запаздывания) между наблюдениями. Или
Е [(xt — \i)(xt+a — jx)] = cs. C)
По определению, автоковариация с запаздыванием s, деленная на
дисперсию а2, дает автокорреляцию или сериальную корреляцию
Р.~?. D)
Если постоянна не только функция распределения вероятностей,
но также первый и второй моменты в уравнениях A)—C), процесс
называется стационарным в широком смысле, или процессом со стацио-
стационарными ковариациями. Если функция распределения вероятностей
будет (многомерной) нормальной, то оба типа стационарности совпа-
совпадут. Обсуждение стационарных процессов, включая ссылки на лите-
литературу, можно найти, например, в [Fishman, 1968, р.13, 17; 1971, р.22]
и [Dear, 1961, р.9—13]. Взаимоотношения между временными рядами
и имитационным моделированием изучаются в [Mihram, 1972 р. 146—
180, 443—483].
Понятие г-зависимость означает, что Xt и xt+s автокоррелиро-
ваны только в том случае, если s ^ г. Центральная предельная теоре-
теорема для стационарной r-зависимости формулируется следующим об-
образом. Дана r-зависимая стационарная в узком смысле выборка хъ
х2, ..-, xt, ..., xn с Е (xt) = \i и существует Е (|act|3). Тогда среднее
выборки
имеет асимптотически нормальное распределение со средним ц и дис-
дисперсией, определяемой выражением
Заметим, что выражение для дисперсии не обладает асимптотическими
свойствами, хотя и выполняется для любого N. Ссылки на эту предель-
предельную теорему можно найти, например, в [Andreasson, 1971, р. 215—
223], [Fraser, 1957, р.219] и [Mihram, 1972, р.278—281]. В последней
работе обсуждаются также асимптотические распределения Вейбул-
122
ла (Weibull), применяемые к таким откликам, как минимум числа
случайных величин, в исследованиях надежности и ПЕРТ.
Для повторных опытов мы не берем дисперсию из уравнения E),
а пользуемся только свойством нормальности. Каждое повторение дает
новую последовательность
Х±, Х2, •••, Xt, •¦-, Xn
и свое среднее х. Так, если имеется п повторений, то имеется и п сред-
средних
Каждое xt независимо и предполагается удовлетворяющим приведен-
приведенной выше предельной теореме, так что каждое xt асимптотически нор-
нормально. Следовательно, к средним xt можно применить традиционный
статистический анализ. Например, A — а) — доверительные преде-
пределы для \l — даются выражением
F)
где
_ п.
jtr— "V x-ln G)
(=1
1=1
a f^!l\ есть верхний а/2-процентиль ^-критерия Стьюдента с (п—1)
степенями свободы. Заметим, что чем длиннее опыт, тем лучше выпол-
выполняется асимптотическая нормальность. Это аргумент в пользу непре-
непрерывного опыта вместо периодического с повторными экспериментами.
Далее рассмотрим непрерывные эксперименты. (Они уже кратко
обсуждались в II.9.) Конвей [Conway, 1963, р.55] отмечает, что в ка-
качестве начальных условий для опыта 2 можно воспользоваться конеч-
конечными условиями опыта 1, т. е. мы просто продолжаем имитационный
эксперимент. Преимущества этого метода заключаются в том, что пе-
переходного периода для опыта 2 или, лучше, подопыта 2 не сущест-
существует, так как мы предполагаем, что опыт 1 закончился в установившем-
установившемся состоянии. Первый метод для анализа удлиненного опыта, предло-
предложенный Конвеем (Conway, 1963, р.55—56], после отбрасывания пере-
переходной фазы заключается в следующем. Разделим остальной экспери-
эксперимент, например, на т отдельных подопытов. Обозначим средние этих
подопытов хх, х2, ..., хт-г, хт. Допустим, что мы можем выбрать
длину каждого четного подопыта так, что нечетные подопыты хх, х3, ...,
лгт_з, лгт_х (т — четное)] станут независимыми. Заметим, что
для этого каждый четный подопыт должен содержать более чем г на-
наблюдений в предположении стационарности r-зависимых случайных
123
ПС/пиши. Очевидно, что выяснение того, является ли четный подопыт
достаточно длинным, — это самостоятельная задача, обеспечивающая
независимость нечетных подопытов, хотя бы приближенную. Мы еще
вернемся к этой задаче в этом параграфе. Теперь снова можно приме-
применить традиционные методы анализа, но только к нечетным подопытам
ценой выбрасывания четных х2, xit ..., Jfm_2, xm. Казалось бы, что
не стоит генерировать т-я опыт, который выбрасывается при данном
подходе, однако он нам понадобится. Заметим далее, что этот метод
будет эффективнее, чем повторные опыты, если только переходный
период длиннее каждого четного подопыта, обеспечивающего незави-
независимость нечетных подопытов. Не будем больше задерживаться на этом
методе и перейдем к следующему, предложенному Конвеем [Conway,
1963] методу, основанному на первом. В его основе лежит оценка \х по
всем т подопытам. Кривей [Conway, 1963, р.56] показал в предполо-
предположении равенства длин четных и нечетных подопытов, что дисперсия
новой оценки меньше дисперсии оценки, основанной только на нечет-
нечетных подопытах. Это заключение интуитивно кажется правильным, так
как даже если последовательные наблюдения положительно коррели-
рованы, они содержат информацию, и кажется более эффективным
применение удлиненного опыта вместо выбрасывания всех четных по-
подопытов. Далее Конвей доказал, что опыт целиком дает более эффек-
эффективную оценку, не показав, однако, как оценить дисперсию такой
оценки. Можно, конечно, дать для этой дисперсии верхнюю границу.
Она представляет собой дисперсию оценки, основанной только на не-
нечетных опытах. Эта дисперсия просто вычисляется из независимых
нечетных опытов (или из четных подопытов, имеющих ту же длину, что
и нечетные, и, следовательно, ту же дисперсию). Недостатки этого
метода в следующем: он дает только верхнюю границу, так что надеж-
надежность остается недооцененной; мы должны найти длину подопытов,
которая обеспечивает независимость несмежных подопытов. Далее
в этом параграфе мы сосредоточимся на эффективной оценке, исполь-
использующей полный опыт (за исключением, может быть, только начальной
переходной фазы), и предложим несколько методов для получения
дисперсии этой оценки.
Подход 1. Независимые подопыты. Следуя предложению Конвея
[Conway, 1963], можно разделить полный] опыт на т подопытов. Обо-
Обозначим число индивидуальных наблюдений в одном подопыте симво-
символом а. В приложении V.A.1 выведено выражение для корреляции меж-
между двумя последовательными подопытами (9), где ps(s = 1,2, ...,а) —
корреляция между двумя индивидуальными наблюдениями со сдви-
сдвигом s; наблюдения предполагаются стационарными переменными, так
что справедливо уравнение C).
а а— 1
(9)
124
Полагаем, что сериальный коэффициент Корреляции ps положителен
и уменьшается с ростом сдвига s. Первое предположение кажется ра-
разумным для большинства моделей; второе выполняется, если нет пе-
периодичности1. Знаменатель в уравнении (9) возрастает с ростом а, так
как весовой коэффициент (а — s)la растет вместе с а, да еще знамена-
знаменатель содержит другие положительные члены. В числителе весовой
коэффициент si а уменьшается с ростом а, и это уменьшает числитель.
Этот эффект ослабляется с увеличением числа членов в числителе, но
для большого сдвига коэффициент корреляции предполагается близ-
близким к нулю. Поэтому полагаем, что если а — длина подопыта — воз-
возрастает, то корреляцией между последовательными опытами в прак-
практических целях можно пренебречь. Или, как заключают более интуи-
интуитивно авторы работы [Hauser et al., 1966, p. 81], «если интервалы до-
достаточно велики (средние подопытов или интервалов), то они будут не-
коррелированы, потому что эффекты корреляций значений, ранее встре-
встречавшихся, будут усредняться далее с большим числом значений, ко-
которые с ними не коррелируют». Поэтому если мы имеем т подопытов,
то можем построить доверительные интервалы для среднего совокуп-
совокупности с помощью уравнений F)—(8), где мы подставим п вместо т,
числа (приближенно) независимых подопытов. Эта процедура досто-
достоверна, если а столь велико, что подопыты действительно можно считать
независимыми. Способ выбора подходящего значения а был предложен
Механиком и Маккеем (Mechanic, McKay) и будет обсужден чуть поз-
позже. Заметим, что прием разделения на подопыты с интуитивно выбран-
выбранной длиной подопыта уже применялся в имитационном моделировании
несколькими экспериментаторами. Андреассон [Andreasson, 1971, р.6]
образовывал подопыты при оценке дисперсии некоторой вероятности в
моделировании телефонной станции; Адхикари [Adhikari, 1967, р.54]
применил этот же прием при моделировании системы с параллельными
каналами обслуживания. Хаузер и другие авторы [Hauser et al., 1966,
p. 83] тоже использовали подопыты при моделировании системы с об-
обратной связью. Хьюзман [Huisman, 1970] образовал 50 подопытов, со-
содержащих 50, 100, 200 и 400 индивидуальных наблюдений, соответст-
соответственно для простой задачи обслуживания (с коэффициентами использо-
использования 80 и 90%) и привел оценки сериальных корреляций средних
подопытов (см. также [Huisman, 1969]).
Задача выбора такой длины подопыта, чтобы подопыты были почти
независимы, решается этими авторами неадекватно. Механик и Мак-
кей [Mechanic, McKay, 1966] предложили итеративный способ, в ко-
котором оценивается корреляция между средними подопытов (или «пар-
«партиями» в их терминологии); подопыты увеличиваются, пока корреля-
корреляция не станет достаточно малой, что оценивается с помощью экспери-
экспериментально установленного критерия. Механик и Маккей [Mechanic,
McKay, 1966, p.24—39] применяли свой способ в некоторых задачах
массового обслуживания и получили для него ряд теоретических соот-
соотношений. Мы приводим их алгоритм в приложении V.A.2. Деррике
IDerriks, 1971] дал блок-схему процедуры Механика и Маккея; он
применяет ее к нескольким системам (простые временные ряды и си-
125
етема массового" обслуживания С известным решением; простой опер а *
тивный план цеха с неизвестным решением). Деррике нашел, что эта
процедура относительно быстрая и работает с сериальными корреля-
корреляциями, которые могут даже стать отрицательными при уменьшении до
нуля. Заметим, что Бруцелиус [Bruzelius, 1972] тоже пытался найти
подходящую длину подопыта. Он последовательно увеличивал под-
опыты и полагал, что дисперсия средних подопытов сначала возрастает,
а затем стабилизируется. Мы считаем, однако, что не доказано, будто эта
дисперсия с увеличением длины возрастает равномерно. (Эмпиричес-
(Эмпирические результаты Бруцелиуса [Bruzelius, 1972, р.25], кажется, под-
подтверждают наше утверждение.) Утверждение о стабилизации диспер-
дисперсии (субъективное) он использует без доказательства.
Подход 2. Оценивание автокорреляции. Этот альтернативный метод
не рассматривает подопыты, а оценивает корреляции или ковариации
между индивидуальными наблюдениями. Если весь опыт без учета пе-
переходной фазы содержит N индивидуальных наблюдений, то дисперсия
среднего определяется выражением E). Для оценивания этой диспер-
дисперсии в [Hauser et al., 1966, p.81] взято выражение A0), аппроксимирую-
аппроксимирующее E):
A0)
где k — максимальный сдвиг. Можно сравнить уравнение A0) с вы-
выражением2, приведенным, например, в [Blomqvist, 1967, р. 165] и
[Fishman, 1967, р. 3] для больших N, а именно2:
_| A1)
Сравнение уравнения A1) с A0) показывает, что формула, применяе-
применяемая в [Hauser et al., 1966], правильна, если N велико и если автокор-
автокорреляция становится пренебрежимой после сдвига на k.
Последнее условие не так уж важно, кроме случая, когда система
имеет периодичность. Вместо уравнения A0) можно воспользоваться
другой формулой, применяемой в [Fishman, 1967, р.З, 16—18]. С ее
помощью оценивается дисперсия среднего по выражениям A2)—A4):
var (*) = -?, A2)
где N велико и т оценивается уравнением
2 (\-s/k)dAj(\-k/N), A3)
причем
cs=N f? l(xt—x) (xt+t—x)],
s = Q,l,...,k<N. A4)
126
Сравнивая уравнения A3) и E), мы видим, что о2 и с, в уравнении
E) оцениваются величинами с0 и cs соответственно, а коэффициент
A — kIN) служит для компенсации смещения в этих оценках и берется
не N, а только k ковариаций. Мы отсылаем к [Fishman, 1967, р. 17—18]
для обсуждения выбора k. В [Mihram, 1972, р.460—467] также обсужда-
обсуждаются оценка cs и эффект элиминирования тренда на оценки. Второй под-
подход применялся авторами работ [Geisler, 1964а и b], [Hauser et al.,
1966] и [Clark et al., 1972]. Широкий эксперимент Гейзлера [Geisler,
1964b] показывает, что этот подход может дать достоверную оценку
var(jtr). (Мы дадим более детальный обзор этих результатов в V.A.4.)
Недавно Фишман [Fishman, 1971] развил вариант этого второго
подхода. Он выразил наблюдение х% временного ряда как скользяще
среднее, т. е.
Xt = V'+ fj asyt_s, A5)
s = 0
yt : NID @, a2). A6)
Для дополнительных ссылок по этому подходу можно обратиться к
[Naylor, 1971, р.252]. Однако пока не ясно, лучше ли это, чем другие
подходы, которые уже обсуждались нами (см. также [Fishman, 1972a]3).
Подход 3. Независимые циклы. 1. Кабак [Kabak, 1968] отметил,
что в одноканальной системе массового обслуживания прибытие ново-
нового заказчика в свободную систему (т. е. когда канал обслуживания не
занят) начинает новую историю, не зависящую от прошлой. Это так
называемое обновление, или регенерация, — свойство системы. В ими-
имитационном моделировании мы разделяем всю имитируемую историю на
эпохи (называемые также циклами, турами, блоками); каждая новая
эпоха начинается, когда заказчик прибывает в свободную (пустую)
систему. Кабак [Kabak, 1968] рассмотрел следующую оценку процента
необслуженных заказчиков, основанную на М циклах:
м
р=~ъ—=2
2 я* '
1
где щ — общее число заказчиков в цикле ?; п[ — общее число заказ-
заказчиков в цикле i, которые не были обслужены; pt = пУщ; gt = пг/2гаг.
Итак р — взвешенное среднее доли необслуженных заказчиков в
цикле i. Кабак показал, что оценка р асимптотически несмещенная
(иевзвешенная средняя pt будет смещенной). Заметим, что пг (и га,;) не-
независимы и одинаково распределены. Кабак оценивает дисперсию от-
отношения двух членов в уравнении A7), используя следующий резуль-
1ат, выведенный Кендэлом и Стьюартом [Kendall, Stuart, 1963, p.232]
(основанный на разложении в ряд Тейлора):
^^]x2>0). A8)
Ma M^
127
Например, в A7) роль ol играет var Bяг) = М var («,), где var (nt)
можно легко оценить, так как nt независимы.
2. Идеей независимых циклов руководствовались еще и Крейн и
Иглхарт [Crane, Iglehart, 1972a], а также Фишман [Fishman, 1972a]
независимо от работы Кабака. Они отметили, что при таком подходе
возможны решение проблемы выбора адекватных начальных условий
и определение длины переходной фазы (ср. обсуждения в II.4). Этот
подход, кроме того, позволяет проводить статистический анализ, осно-
основанный на независимых наблюдениях. Крейн и Иглхарт [Crane, Ig-
Iglehart, 1972а] рассматривают многоканальные системы. Цикл начи-
начинается, когда требование прибывает в пустую систему, когда все ка-
каналы обслуживания свободны; см. также [Fishman, 1973, р. 14], где
циклы иначе определяются. Они оценивают различные отклики
Е (w), о2 (w), P (w> a) (w обозначает установившееся время ожида-
ожидания), среднее число требований в системе и т. д. Для иллюстрации
рассмотрим следующую оценку:
м
где
"г
У1 = 2
k=i
wih—время ожидания требования k в цикле i. Чтобы сравнить этот
подход с другими, мы перепишем уравнение A9) так:
м _ n
^j}INt B0)
где Wt — среднее время ожидания в цикле t и Wj — время ожидания
м
требования / (/ — 1, ..., N = 2иг) за все время моделирования. По-
добно Кабаку они пользуются взвешенным средним средних цикла.
Как и в традиционных подходах, оценка цш есть среднее всех модели-
моделируемых требований, поэтому эта оценка имеет ту же эффективность,
что и традиционная (см. также [Crane, Iglehart, 1972а, р.30—33]).
Однако анализ fiw основан на организуемых циклах. Крейн и Иглхарт
[Crane, Iglehart, 1972b] вывели следующую формулу для A—а) дове-
доверительного интервала для отношения двух средних, скажем г] = nVm
(^2 ф 0),гпредполагая, что число наблюдений М велико, так что при-
применима центральная предельная теорема:
128
где
_ м _ м
*i= 2 хи/М, х2 = 2 x2iJM,
i=\ l=\
sl2=cov(x1,x2), s%z=var{x2),
k = (za/2J/M (z°/2 — верхняя а/2-точка в единичном стандартном
нормальном распределении),
D = (ххх2 — ks12f - 1{х2у - ks22] KxJ2 - ksn], B2)
а Хц (nx2i) независимы, причем xlt коррелируете^г. Прилагая урав-
уравнение B1) к уравнению A9), получаем xlt = yt и x2i — nt. Заметим,
что середина доверительного интервала, данная уравнением B1), есть
где правая часть — это простейшая оценка r\ = iVm^', если М стре-
стремится к бесконечности, то левая часть уравнения B3) приближается
к xjx%, поскольку k стремится к нулю. Следовательно, точечные оцен-
оценки в уравнениях A9) и A7) лишь асимптотически несмещенные. Фиш-
ман [Fishman, 1972b] получил оценку для nVm, свободную от смеще-
смещения порядка N (и доверительный интервал, как в уравнении B1))
(см. также [Fishman, 1972a]). Для простоты можно брать в левой части
уравнения B3) точечную оценку, это было показано Крейном и Иглхар-
том [Crane, Iglehart, 1972b, p.6—7]. Заметим, что Фишман [Fishman,
1972b] фактически дает (более общие) точечные оценки и доверитель-
доверительные интервалы для линейных комбинаций зависимых переменных, на-
—> —>—>•—> —> —>
пример к] = а'х/b'x, где а и 6 — векторы с известными элементами (на-
-* —>
пример, а' = A,0), см. выше), а х — вектор коррелированных пере-
переменных. Он также дал совместные доверительные интервалы для от-
откликов. (Подробнее о совместных доверительных интервалах говорит-
говорится в части Б этой главы.)
Рассмотренный подход требует многократного возвращения систе-
мьт к своему пустому состоянию, чтобы можно было получить некоторое
число независимых наблюдений. Если КПД или (интенсивность потока
требований) возрастет, то циклы становятся длиннее. Следовательно,
идет больше времени на образование М циклов; однако методы подо-
мытов и автокорреляции также требуют много наблюдений, потому
что высокий КПД вызывает сильную сериальную корреляцию. По-
Поскольку система находится в установившемся (стационарном) состоя-
состоянии, она будет возвращаться в свое пустое состояние, см. [Crane, Ig-
Iglehart, 1972а, р. 10—11].(В противном случае мы станем интересовать-
интересоваться переходными процессами и требуемым числом повторных опытов,
см. II.8.) Фишман [Fishman, 1972a и Ь; 1973] далее исследовал оцени-
!| Дж Клейнен 129
вание разных откликов в системах массового обслуживания и показал,
что многие отклики есть линейные преобразования нескольких основ-
основных откликов, так что из доверительных интервалов для основных от-
откликов следуют доверительные интервалы для откликов преобразо-
преобразованных. Заметим, что из доверительных интервалов для откликов двух
разных систем можно построить доверительный интервал для разности
двух откликов. Если
Р (хг < \ix < *2) = 1 - а B4)
и
Р (:Vi<^< 3»«) = 1 — а' B5)
то
Р(*1 — У2<Рх— \iy<x2 — уг) > 1 — 2а B6)
согласно неравенству Бонферрони (см. часть Б настоящей главы, урав-
уравнение A0)). Заметим, что из уравнения B1) мы не можем получить
var (рх—цу) = var (цх) + var (цу), так как мы не оцениваем var (ju).
(Кабак, однако, использует оценку для var (ju).)
3. В последующей статье Крейна и Иглхарта [Crane, Iglehart,
1972с] их подход обобщается для любой марковской цепи, например
для (s, 5) системы хранения запасов или ремонта. Снова система начи-
начинает работу из некоторого определенного состояния, и цикл повто-
повторяется после возвращения системы в это состояние. Например, цикл
начинается, как только запасы (х) достигают максимальной величины
5. Как мы достигли, х = S (т. е. прошлое истории несущественно для
будущей истории). Все циклы (начало в х = S) дают независимые
и идентично распределенные наблюдения. На основании свойств мар-
марковской цепи можно взять любую другую начальную точку. Эффек-
Эффективность оценки не зависит от выбора начальной точки. (Некоторые
состояния могут создавать длинные циклы, но тогда каждый цикл будет
содержать больше информации.) Для дальнейшего изучения систем
со свойством восстановления мы отсылаем к оригинальным статьям и
ссылкам в них.
Попытаемся сравнить различные оценки дисперсии среднего непре-
непрерывного опыта. При подходе 2 Хаузер и другие авторы [Hauser et al.,
1966] использовали уравнение A0). Нам же нравится уравнение A2),
так как Фишман [Fishman, 1967] учел смещение в оценках ковариаций.
Отметим, что в подходе 1 Хаузер и другие авторы [Hauser et a]., 1966,
р. 83] использовали фиксированную длину подопыта. По нашему мне-
мнению, процедура Механика и Маккея более привлекательна, так как
длина подопыта определяется итеративным путем. В [Hauser et al.,
1966, p.83] отмечено, что в примере, приведенном авторами, вариант
оценки дисперсии, основанной на подопытах, совпадает с вариантом
оценки, основанной на индивидуальных наблюдениях. Однако, как
указывают Механик и Маккей [Mechanic, McKay, 1966, p.5], оценка
индивидуальных корреляций «может быть очень громоздкой» по
объему машинного времени и памяти (ср. также с [Derriks, 1971, р.5,
22]). Хаузер и его соавторы нашли, что их процедура, основанная на
}30
нодопытах, вдвое быстрее, Чем процедура, Основанная на индивидуаль-
индивидуальных наблюдениях. Эта публикация единственная, где сравниваются
дне процедуры. В сравнении с процедурой Хаузера и его соавторов
процедура Фишмана, например, требует дополнительного времени для
определения k — сдвига, дающего некоррелированность з уравнении
(IH). Из работы [Fishman, 1967, р.18] следует, что вычисления т по-
июряются до тех пор, пока т стабилизируется. Процедура Механика
и Маккея также требует дополнительного машинного времени, так
как их итеративная процедура основана на определении подходящей
длины подопыта. Относительные достоинства обоих подходов кратко
обсуждаются в [Emshoff, Sisson, 1971, р.201—202]4.
Для относительно простых систем мы рекомендуем подход 3 (ос-
(основанный на свойстве восстановления). Для очень сложных систем
¦жепериментатор, выявив свойства марковости в своей системе, может
применять итеративную процедуру Механика и Маккея. (Повторяем,
что многие модели реальных систем — это модели с переходными со-
состояниями (процессами), когда стоит воспользоваться повторными
опытами, см. П.4. Некоторые модели имитируют, однако, относитель-
относительно несложные системы, подобные многоканальной системе массового
обслуживания, которые можно исследовать и аналитически.)
Заметим, что дисперсия среднего х возрастает по мере роста (поло-
(положительных) автокорреляционных коэффициентов (см. уравнение E)).
Хорошо известно, что в простых системах массового обслуживания
оти автокорреляции возрастают с ростом КПД (или потоков); ср. ри-
рисунки в [Blomqvist, 1971, р.221] или [Kosten, 1968]. Таблицы в [Blomq-
vist, 1967, p. 165—166; 1969, p. 132] показывают, что для систем мас-
массового обслуживания с высоким КПД нужны очень большие выборки
(из-за большой дисперсии).
В заключение кратко обсудим некоторые процедуры оценки var (x),
которые имеют ограниченное применение при моделировании сложных
систем. В [Gebhart, 1963] и [Reynolds, 1972] выведены выражения для
var (x) в^одноканальной пуассоновскои системе массового обслужива-
обслуживания. Та же формула, что и в [Gebhart, 1963], применялась в [Healy,
1964, р.12—15].Пуассоновская система с идентичными параллельными
каналами изучалась в работе [Gurtler, 1969, р.66—80]. В таких систе-
системах автокорреляция возрастает геометрически, т. е. ps = pf, так что
ilPs = pi/(l — pi) (автор описывает, как можно проверить этот гео-
i
метрический характер роста; ср. [Tintner, 1960, р.296]). Все эти под-
подходы, однако, неприменимы к сложным системам моделирования. В
I Baraldi, 1969 а и b] выведены приближенная формула для определе-
определения объема выборки в некоторых системах массового обслуживания
(пренебрегается зависимость между случайными величинами) и верх-
верхние границы некоторых оценок. Автор не оценивает var (x) по выборке,
а дает априорное значение для объема выборки. Его формула может
быть недостоверна (из-за аппроксимации) и слишком консервативна
(из-за использования верхних границ). Консервативная оценка не-
нежелательна, так как моделируемые опыты дороги, а из-за положитель-
131
Ной автокорреляции var (х) велика, так что требуется много опытов
Для получения надежных результатов. Наконец, в [Fishman, 1967,
р.2—3] и [Fishman, Kiviat, 1967, p.27] сделан упор на спектральный
анализ стационарного процесса. Но, как видно из уравнений A2)—A4),
оценки дисперсии в этих работах не используют спектр.
V.A.3. Фиксированный объем выборки и одна совокупность
В этом параграфе мы изложим некоторые хорошо известные из ма-
математической статистики результаты для определения доверительных
интервалов и обсудим критерии для среднего одной совокупности или
разности средних двух совокупностей. В последнем случае нас не ин-
интересуют два средних сами по себе, перед нами пока не стоит задача
совместного вывода (см. часть Б). Мы обсудим также оценку биномиаль-
биномиальной вероятности и квантили. На результатах этого параграфа мы будем
основываться далее при определении объема выборки.
Предположим, что мы изучаем нормально распределенную совокуп-
совокупность N (|х, о2). По п независимым наблюдениям xt (i = 1, 2, ..., п)
этой совокупности нужно сделать вывод о генеральном среднем \i.
На основании выборки мы определим среднее
х= J^Xt/n B7)
и выборочную дисперсию х (обозначенную как s2 (x) или кратко s?)
s2 (х) = si = 2 {Xi-xf/(n -1). B8)
(=1
Теперь можно образовать ^-критерий с (п — 1) степенями свободы:
^1) = -I=L = i=iJL. B9)
s (х) /Уп s (х)
Определим $1Х как верхнюю а/2-точку (симметричного) распределе-
распределения *,„_!,, т. е.
«-. )>^2i) = а/2. C0)
Тогда из уравнений B9) и C0) получаем
[LU \s(x)} = l-a. C1)
Следовательно, точечная оценка (j, есть х, а доверительный интервал
связанный с этой оценкой, есть
[x-tanL\s(x)],[x + tani2lS(x)]. C2)
132
Кроме оценки среднего, выражение C1) можно применять для провер-
проверка гипотез о среднем. Мы хотим проверить гипотезу о том, что Е (х)
равно ^0, т. е. нуль-гипотезу:
Но: ц = ц0. C3)
Ксли (л0 не содержится в интервале C2), то Но отбрасывается. Этот
путь приводит к двум источникам ошибок. Ошибка I рода, или а-ошиб-
ка, есть вероятность ошибочного отказа от Но или
Р (#0 отклоняется | (л = ц0) = а. C4)
Ошибка II рода, или р-ошибка, есть вероятность ошибочного принятия
Но, т. е.
Р (Но принимается | \i = \1г) = р. C5)
Можно фиксировать а в уравнении C4). Тогда определение \1г в аль-
альтернативной гипотезе #х : [х = цг дает конкретное р. Считая р функ-
функцией pix в уравнении C5), мы получим оперативные характеристики
критерия. Дополнение р, т. е. A — Р), называется мощностью кри-
критерия (ср. уравнения (88) — (91) далее в этом параграфе).
Теперь будем полагать, что мы изучаем две нормально распределен-
распределенные совокупности, N (jxi, of) и N (\i2, a\), и нас интересует различие
средних, скажем б. Мы можем получить независимые наблюдения Хц
(I = 1,2, ..., пх) и х2] (/ = 1, 2, ..., п2) из совокупностей 1 и 2 соответ-
соответственно. Есть несколько способов сравнить эти средние.
1. Наблюдения хх и х2 можно «спарить», т. е. xlt и x2t станут зави-
зависимыми (хотя независимость между хх и х2 останется). Например,
имеется п делянок, на каждой из которых посажены 2 вида растений,
участок i дает xxi и x2i (г= 1, ..., п). (Заметим, что приспаривании на-
наблюдений пх = п2 = п.) В имитационном моделировании и исследо-
исследованиях по методу Монте-Карло такая ситуация возникает, когда мы
пользуемся одной и той же последовательностью случайных чисел для
двух систем, так что последовательность i дает отклик xlt для системы
I и отклик x2i для системы 2. Для спаренных наблюдений мы можем
определить разность d, т. е.
dt = xlt —xu (i = 1, 2, ..., п), C6)
и проблема сведется к изучению одной совокупности со средней б =
Ну — ц,2- Проверку гипотез и оценивание можно выполнить с по-
помощью уравнения C1) при замене х на d. Отсылаем к [Fisz, 1967, р.432]
для обсуждения возможности отвергнуть гипотезу Но при применении
критерия Krf и принять Яо при применении критерия кхг и х2 в отдель-
отдельности, как в 2, к которому мы и переходим.
2. Если обе совокупности имеют одну и ту же дисперсию, а] =
о% = а2, то можно воспользоваться обычным ^-критерием. Напри-
133
Mi'|i, ни II'!'</, 1!H7, р.353) выражение в уравнении C?) распределено
мь <!('("! I "а ' 2) степенями свободы:
\t{\2)- — («f«2)
; («i-f«2—2) ,
L «i + «a J
где Л1! — выборочное среднее для совокупности 1,5? — выборочная
дисперсия для совокупности 1 и т. д., /-критерий имеет (пг + пг — 2)
степеней свободы, так как можно объединить индивидуальные суммы
квадратов.
3. Если совокупности имеют различные дисперсии (так называемая
проблема Беренса—Фишера), то применяется статистика, аналогич-
аналогичная B9), а именно
sB) [(*!/«i) +(
Эта статистика не имеет точного /-распределения, так что мы не можем
взять а/2-процентили /-распределения с (пх + п2 — 2) степенями сво-
свободы (ср. с уравнением C7)). Шеффе [Scheffe, 1970, р. 1502] предлагает
в качестве решения взять а/2-процентиль /-распределения с (min — 1)
степенями свободы, где min означает минимум пх и п2- Эта процедура
консервативна, т. е. получаются слишком большие доверительные ин-
интервалы, и в результате ошибка I рода будет меньше объявленной вели-
величины а. Кокрен и Кокс [Cochran, Сох, 1957, р.100—101] предлагают
рассматривать t' в уравнении C8) как приближенно /-распределенную
величину с верхней точкой а/2, определенной как среднее взвешенное
из /-распределения с (пх — 1) и (п2 — 1) степенями свободы и (сто-
(стохастическими) весами, зависящими от оцененных дисперсий. Или
лх/2
fa,l = "-">-' ' "аЧ-1 ^ C9)
где
Wl==jLaWa== JL. D0)
Я! rt2
Заметим, что для равных объемов выборок уравнение C9) приводит к
процедуре Шеффе (Scheffe). Уанг [Wang, 1971] показал, что вариант 3,
основанный на результатах Уэлча, дает удовлетворительные резуль-
результаты. Положим /' в уравнении C8) равным /-переменной Стьюдента
с числом степеней свободы, равным fw, где
r=«L = _»L«l.. D2)
134
I ксколько более сложные варианты 3 были исследованы в [Mehta,
Srinavasan, 1970].
4. Шеффе вывел также точную статистику (в 1943 г.; его статисти-
статистика имеется, например, у Кендэла и Стьюарта [Kendall, Stuart, 1961,
p. 144]). Пусть
t = xlt — {пМУ2 x2t (i = 1, 2 щ), D3)
а = 2 «i/"i . D4)
п предположении, что пх ^ п2. Тогда выражение в D5) есть точно t-
распределение с (n2 — 1) степенями свободы:
^Т\ D5)
(«j— и)
I Три определении х2 используются все п2 величин х2, а при определении
tti только пх величин х2 случайным образом выбираются из общего чис-
числа п2. (Из-за этой рандомизации Шеффе [Scheffe, 1970, р. 1503] не ре-
рекомендует этот подход.) Поскольку в имитационном моделировании
и в исследованиях по методу Монте-Карло все экспериментальные усло-
условия контролируются, можно просто взять первые пх наблюдений вели-
величины х2, а не делать рандомизации. Заметим, что при равных объемах
пыборок уравнение D3) сводится к уравнению C6) и подходы 1 и 4
становятся одинаковыми.
Обзоры и другие процедуры для сравнения двух выборочных сред-
средних приведены в [Csorgo, Seshadri, 1971], [Press, 1966], [Scheffe, 1970],
[Thomasse, 1972] и [Ying Yao, 1963]. Шеффе также показал, что мощ-
мощность различных критериев можно вычислить. Рассмотрим чувстви-
чувствительность ^-статистики по отношению к принятым предположениям.
Шеффе [Scheffe, 1964, р.331—369] дал обзор эффектов нарушений
независимости, нормальности и общности дисперсии. Зависимость
между наблюдениями серьезно влияет на ^-статистику. Нарушение
нормальности неважно для больших выборок; для малых выборок две
совокупности можно сравнивать, если мы берем равные выборки, пг =
- п2 = п. С помощью уравнения C7), когда дисперсии фактически
различаются, можно получить достоверные результаты при равных
объемах выборок даже для малых выборок. Можно также применять
чепараметрические критерии, например критерий знаков или ранговый
критерий Уилкоксона для парных наблюдений и ранговый критерий
Манна—Уитни для сравнения средних (см. [Keeping, 1962, р. 260—265]
или ясное изложение непараметрических методов в [Conover, 1971]).
Глубокое рассмотрение непараметрических методов (включая распро-
распространение их на случаи k > 2 совокупностей и многомерные отклики)
представлено в [Puri, Sen, 1971]. Применение непараметрических кри-
юриев в контексте имитационного моделирования дается в [Meier et
.il., 1969, p.309—311]. Робастность точечных оценок положения (без
135
соответствующих доверительных интервалов и критериев) подробно
обсуждается в [Andrews et al., 1972]. Авторы этой работы исследовали
около семидесяти различных оценок положения и нашли, что выбороч-
выборочное среднее очень чувствительно к резким выбросам; они предлагают
отбрасывать эти резко выделяющиеся наблюдения или для распределе-
распределений с большими «хвостами» использовать медиану (см. [Andrews et al.,
1972, p.237—248]). Ими также предложена альтернатива для оценки
дисперсии, которая менее чувствительна к крайним наблюдениям (см.
[Andrews et al., 1972, p.81, 160]). Мы не будем далее обсуждать непара-
непараметрические критерии, так как ^-статистика робастна и, более того, эта
статистика дает простую ясную формулу для определения объема вы-
выборки, как мы увидим в V.A.4. Последовательные варианты непара-
непараметрических критериев для определения объема выборки громоздки
(ср. [Geertsema, 1970]). В частях Б и В этой главы мы еще вернемся к
непараметрическим критериям, поскольку при множественных срав-
сравнениях и ранжировании могут употребляться статистики, чувствитель-
чувствительные к нарушению нормальности. Фишман [Fishman, 1971, р.36] пред-
предлагает два других непараметрических подхода. В первом применяется
известное неравенство Чебышева (выведенное, например, в [Fisz,
1967, р.74]), в другом — неравенство Годвина, предполагающее уни-
унимодальное распределение. К сожалению, оба подхода консервативны
и, кроме того, предполагают знание дисперсии. Посмотрим, как вы-
выполняются предположение о нормальности и другие предположения
в имитационном моделировании.
В имитационной модели предположение о нормальности можно
удовлетворить, если откликом сделать среднее значение. Предельная
теорема, сформулированная в разделе V.A.2, показывает, что даже
среднее зависимых наблюдений распределено приближенно нормально.
В любом случае предположение о нормальности не столь существен-
существенно, как мы только что видели. Более существенно предположение о
независимости. Как мы уже упоминали, чаще всего п независимых
наблюдений может быть получено повторными опытами с помощью
различных последовательностей случайных чисел. Для удлиненного
опыта (приблизительно) независимые наблюдения создаются делением
опыта на подопыты. Средние подопытов заменяют наблюдения xt (i =
= 1, 2, ..., п) по приведенной выше процедуре. Механик и Маккей
[Mechanic, McKay, 1966, p.5, 28] применили такой подход, только
вместо ^-распределения они брали нормальное, которое будет хорошим
приближением, если п > 30 (см., например, [Fisz, 1967, р. 350]). Мож-
Можно смотреть на моделирование как на длинную последовательность
сериально коррелированных наблюдений xt. Тогда предположение о не-
независимости, существенное для ^-статистики, серьезно нарушается
и нужен другой подход. Мы только что упомянули, что сериально кор-
коррелированные наблюдения xt могут дать выборку, среднее х в которой
распределено нормально (приблизительно) с ожиданием \i и диспер-
дисперсией
136
i до ps — автокорреляция со сдвигом s. Следовательно, уравнение C1)
можно заменить на
РТх — za'2 а (х) < (х < 1с + z«/2 a (IF)] = 1 — а, D7)
1ДС z°-l2 — верхняя процентная точка распределения N @,1). К Сожа-
Сожалению, мы не знаем ст(лг). Следовательно, мы оцениваем о (х) в урав-
уравнении C1) с помощью s (х) = s (х)/\/~п и корректируем оценку, заменяя
/*/2 на ^/Li). Тем же способом мы заменяем сг (х) в уравнении D7) на
сче оценку, но продолжаем применять zai2 как приближение для Р->2.
Укажем, что в уравнении D7) а (х) не равна сг (х)/Уп, но она дается
иыражением D6), где сериальные коэффициенты корреляции ps можно
оценить, применяя методы, рассмотренные в V.A.2. Как мы увидим
далее, упомянутые подходы, основанные на подопытах или уравнении
D6), дают правильные доверительные интервалы. Для третьего под-
подхода, основанного на действительно независимых циклах, мы уже ви-
видели доверительный интервал для отношения двух средних. Это отно-
отношение — несмещенная оценка среднего отклика моделируемой систе-
системы (см. уравнение B1)). Доверительный интервал основан на za/2
а силу центральной предельной теоремы. При сравнении двух систем
мы не берем ^-критерий для разностей, как это было в A)—D), но ис-
используем доверительный интервал уравнения B6), основанный на до-
доверительных интервалах уравнений B4)—B5) для средних откликов
отдельных систем. Эмпирические результаты в [Crane, Iglehart, 1972b,
p.6—7; 1972c, p. 16—21] показывают, что уравнение B1) верно.
В некоторых имитационных моделях и исследованиях по методу
Монте-Карло не выполняется предположение о биномиальном рас-
распределении. Например, бывает, что нужно оценить вероятность того,
что произойдет некоторое событие. Так, скажем, в модели отказа обо-
оборудования нужно оценить вероятность того, что оборудование прора-
проработает дольше чем с единиц времени; такие события имеют постоянную
вероятность от опыта к опыту и независимы. Следовательно, можно
воспользоваться биномиальной моделью:
Р (*, = 1) = р,
P(xt =0) = l-p(i= I, 2, ..., п), D8)
где мы положим xt = 1, если событие случается в опыте i (i = 1,2, ...,
п), и Xi = 0, если событие не происходит. Очевидно, р оценивается
выражением
; = ^ D9,
при
var (р) = р A — рIп. E0)
Доверительные интервалы для р можно построить на основании таб-
таблицы биномиального распределения или с помощью нормальной либо
137
пуассоновской аппроксимации (см., например, [Keeping, 1962, р.59,
64—68]). В [Van der Waerden, 1965, p. 291 указано, что несмещенная
оценка var (р) получается, если мы заменяем п в E0) на (п — 1), т. е.
уьг(?)=рA~р)/(п~1). E1)
Ясно, что для больших выборок это улучшение несущественно. Если
сравниваются два биномиальных распределения с вероятностями pt и
р2, то их можно оценить по уравнениям D8) и D9). Для независимых
подопытов мы имеем
var (рг — ръ) - var {px) + var (p2). E2)
Доверительные интервалы можно сконструировать в соответствии с
гипотезой о нормальности и с помощью уравненияJ52). (Нормальное
приближение выполняется лучше для разности оцениваемых вероят-
вероятностей, чем для каждой индивидуальной вероятности; см. [Scheffe,
1964, р.332],) В [Van der Waerden, 1965, р.41] отмечено, что когда
проверяется гипотеза Но : рх = р2 = р, то E2) преобразуется в
var (/>! — р2) = р A — р)(П1 + п2)/(пхп2). E3)
В уравнении E3) р можно оценить на основании {пх + п? наблюдений
из обеих совокупностей, т. е. р есть доля «успехов» в общем числе на-
наблюдений. Дополнительные замечания о биномиальных вероятностях
можно найти в [Conover, 1971, р.95—104], [Van der Waerden, 1965,
р.22—51] и [Wehrli, 1970, р.99—105].
(.^Биномиальная модель применена в [Kurlat, Springer, 1960, р.476];
в «имитационной» модели авторов этой работы изучалась надежность
противотанковых мин. (Они организовали физическую «имитацию»
вместо абстрактной модели.) В примере выборочного распределения
приложения 1.2, где мы оценили р = Р (х < а), также подходит би-
биномиальная модель. Флэгл [Flagle, 1960, р. 435—439] применил эту
модель в своей одноканальной пуассоновской системе массового обслу-
обслуживания, где оценивалась вероятность прибытия требования в пустую
систему. Однако в примере Флэгла последовательные события не не-
независимы, поэтому биномиальная модель некорректна5.
По отношению к процентилю р, Р (х < с) — р с фиксированным с,
квантиль хр определяется следующим выражением:
р (х < хр) = р. E4)
Для дискретной переменной квантиль хр определяется уравнением
Р (х < д:Р)< р и Р (х > #р)< 1 — р. E5)
Заметим, что уравнение E5) для Непрерывных переменных сводится
к уравнению E4). Ограничим наше внимание случаем непрерывных
138
переменных; случай дискретных переменных рассматривается, на-
например, в [Conover, 1971, р.31]. Примером квантиля может служить
медиана, т. е. хр для р = 0,50. Другие интересные квантили — это,
например, верхняя или нижняя 5%-ная точка распределения откли-
откликов х. Для того чтобы оценить хр, мы должны расположить наблюдения
и возрастающем порядке, например л:A) ^ л:B) ^ ... ^ хм. Упоря-
Упорядоченные наблюдения Хц) называются порядковыми статистиками.
Оцениваемый, или выборочный, квантиль равен x(pn + 1), т. е. среди п
наблюдений доля их, равная рп/п = р, принимает значение, меньшее,
чем Х(Рп + 1) (ср. с E4)). Если значение рп не целое, то его можно ок-
округлить до ближайшего меньшего целого. (Однако для выборочной ме-
медианы мы берем .*(;*), где i* = р (п + 1), если п нечетно, и lxipn) +
¦|-лГ(рп + 1)]/2, если п четно; см. [David, 1971, р.4].) Это правило
также согласуется с построением эмпирической или оцениваемой функ-
функции распределения
*,„) =-*=!, ? = 1,..., п E6)
и подходит для определения того, какое значение X(t) соответствует
р (см. упражнение 6). Таким способом мы получаем несмещенную оцен-
оценку (точку) квантиля. Применение метода «складного ножа» для несме-
несмещенной оценки можно найти в [Goodman et al., 1973].
Чтобы проверить гипотезу Но : хр = а, мы применим тот же под-
подход, что и для биномиального случая. Положим xt = 1, если х < а;
затем возьмем уравнения D9) и E0) и проверим, согласуется ли най-
найденное значение/? с р (см. также [Conover, 1971, р.104—ПО]). Этот ав-
автор далее строит следующий доверительный интервал для квантиля
Р (х(г) < хр < хм) = 1 - а, E7)
где
Ыр A — р)]»/2, E8)
Ыр{\— р)]»/2, E9)
г и s округлены до ближайшего большего целого числа. Для односто-
односторонних интервалов мы заменим а/2 на а в уравнении E8) или E9) и
исключим x(s) или х(г) в уравнении E7). Этот доверительный ин-
интервал справедлив для любого распределения при п > 20, когда при-
применима центральная предельная теорема; в противоположном случае
нужно воспользоваться биномиальными таблицами вместо таблиц
2° (см. также [Conover, 1971, р. 110—115] и [David, 1971, р. 13—15]).
Оценка квантилей — дорогостоящее дело в смысле машинного вре-
времени и памяти,так как нам нужно хранить и сортировать все п наблю-
наблюдений. Сортировка — это стандартная задача вычислительной мате-
математики; обзор различных программ сортировки содержится в [Martin,
1971). Для решения таких вычислительных задач предложены различ-
различные подходы [Goodman et al., 1973], [Lewis, 1972, p.9—10], читатель
139
может обратиться также к [Andrews etal., 1972, p. 55—56]. Заметим, что
в имитационном моделировании и исследованиях по методу Монте-
Карло проблема вычисления квантилей представляет несомненный
интерес. В исследованиях по методу Монте-Карло нас может интере-
интересовать 5%-ное критическое значение статистики х. В моделировании
может потребоваться оценка времени ожидания требований, число
которых не превышает 5% (см. например, [Frankenuysen, Schuringa,
1971, p. 2]). В [Conover, 1971, р.299] и [Holme, 1972, p.122] обсуж-
обсуждается построение доверительных интервалов для полного распределе-
распределения. Если такие интервалы построены, то сразу получаются и совмест-
совместные доверительные интервалы для всех квантилей.
V.A.4. Определение объема выборки для одной совокупности
Рассмотрим сначала оценку среднего значения \i нормально рас-
распределенной совокупности N (ц, а2), полагая а2 известной. Выбираем п
независимых наблюдений xlt ...,xnc выборочным средним х. Пусть мы
хотим оценить его с точностью, не меньшей, чем заданная. Из-за вы-
выборочных флуктуации мы никогда не можем быть на 100% уверены в
достижении этой цели, поэтому мы определим требуемую надежность
следующим образом. Мы хотели бы на 100A — а)% (т. е. на 95%)
быть уверены в том, что наша оценка х отличается от истинной не бо-
более чем на с единиц. Или
Р (\х — (X |< с) = 1 — а. F0)
Мы знаем, что среднее х независимых нормально распределенных вели-
величин xt удовлетворяет выражению
Р (\х— ц|<2а/2а(*)/}/«)= 1— а. F1)
Следовательно, чтобы уравнение F0) выполнялось, нужно соблюдение
с = 2«/2а(лг)/|/п", F2)
т. е. объем выборки п должен удовлетворять уравнению
т*(дг). F3)
В имитационном моделировании (и в большинстве других применений)
величина а2 (х) неизвестна, поэтому мы заменяем а2 (х) ее оценкой и
используем ^-статистику Стьюдента, т.е. уравнение F1) заменяем на
Я (| JF-ц | < С-\) s {x)lVn) = 1 - а. F4)
Это дает
чЦх). F5)
\ с /
140
Недостаток такого подхода вытекает непосредственно из наших пред-
предположений о стохастическом характере переменных. Уравнение F4)
ппювано на фиксированном объеме выборки п, в то время как уравне-
уравнение F5) показывает, что в действительности объем выборки'— слу-
случайная величина, так как она зависит от оценки дисперсии. Следуя
ITocher, 1963, р.113—114], будем корректировать s2 (х) в уравнении
(A5) после каждого дополнительного наблюдения. Тогда п = п дает
следующее множество событий:
2 < (*»/2/c)as5, 3 < {nj4cfsl п > ffllilcfsl, F6)
где Si (i = 2, 3, •¦-, п) есть последовательная оценка а2 после i наблю-
наблюдений. Эти оценки не независимы, поэтому трудно подсчитать вероят-
вероятность совместных событий F6), но ясно, что эта вероятность не обяза-
обязательно должна быть равна A — аN. Рассмотрим некоторые альтер-
альтернативы решения этого вопроса.
В [Anscombe, 1953, р.7—8] показано, что для больших объемов вы-
выборки последовательную процедуру оценки неизвестной о2, подобную
данной в F6), можно скорректировать простой поправкой. Поправки,
однако, столь малы, что мы бы предложили пренебречь ими. Многими
авторами было доказано, что замена неизвестной дисперсии (или дис-
дисперсии сравнения двух средних) в формуле объема выборки, основан-
основанной на известной дисперсии, ее последовательной оценки, асимптоти-
асимптотически корректна (см. [Chow, Robbins, 1965], [Starr, 1966a], [Robbins
et al., 1967] и [Srivastava, 1970]). Авторами этих работ доказано, что
эта оценка асимптотически состоятельна (т. е. доверительный интер-
интервал содержит \i с вероятностью 1 — а) и асимптотически эффективна
(т. е. математическое ожидание объема выборки равно объему выборки
с известной дисперсией). В [Starr, 1966a] изучено поведение малых вы-
выборок при данном подходе и доказано, что отклонения от заданной ве-
вероятности A — а) очень малы. Например, слегка модифицированный
вариант метода последовательных доверительных интервалов для
среднего дал в результате минимальное значение вероятности, равное
93%, при заданном 1 — а = 95% и при изменениях а/с между 0,5
и 6,75 (см. [Starr, 1966a, р.44]). Эффективность малой выборки также
высока. В [Robbins et al., 1967] приведен пример исследования Монте-
Карло поведения малых выборок при сравнении двух средних. Вновь
отклонения от A — а) оказались незначительными. (Старр [Starr,
1966b] изучил эффективность ^последовательного подхода для неко-
некоторой функции потерь; функции потерь применялись также в [Starr,
Woodroofe, 1970] для оценки дисперсии и экспоненциальных перемен-
переменных.)
При другом способе нет последовательного оценивания а2 (х),
по используется схема двойной выборки, т. е. для предварительной
выборки, состоящей из п0 наблюдений, оценивается а2 с (п0 — 1) сте-
степенями свободы, скажем s%0. Аналогично уравнению F3)
ta/2, V
^) F7)
141
l';iK 4i'(i нп mnpoii окончательной выборке имеем (п — п0) наблюдений
(п //и округляется до ближайшего большего целого числа; очевид-
очевидно, оолп п 4^ п0, -то дополнительных наблюдений не требуется). Вы-
Вычисление доверительного интервала основано на среднем по всем п
наблюдениям, но, как показывает уравнение F7), s2 вычисляется толь-
только по п0 наблюдениям. Этот хорошо известный подход был предложен
Штейном (см. [Kendall, Stuart, 1961, p.618]). Вариант этого подхода
можно найти в [Dudewicz, 1972]. Здесь вместо среднего по всем наблю-
наблюдениям берется линейная комбинация средних двух выборок, первой
и второй (ср. уравнение C8), часть В). Метод Штейна дает более высо-
высокие доверительные коэффициенты по сравнению с методом Дудевича
в случае выводов о среднем одной совокупности. В случае выводов о
разности двух средних ситуация меняется, как мы увидим далее. Но
сначала сравним процедуры последовательной и двойной выборок.
Серьезная проблема в методе Штейна — выбор объема первой вы-
выборки. Большое значение п0 снижает /™/li в уравнении F7), но мо-
может дать потерю наблюдений (когда п0 > п). Поскольку наблюдения
при моделировании дороги, мы обычно предпочитаем другую, более
эффективную, процедуру. Старр [Starr, 1966а, р. 44—47] сравнил про-
процедуру Штейна с последовательной процедурой для одной совокуп-
совокупности и нашел, что последовательный метод более эффективен (но мо-
может давать доверительные уровни меньше заданных A — а) для неко-
некоторых значений ale).
Теперь мы более подробно рассмотрим сравнение средних двух
совокупностей. В [Robbins et al., 1967] предложена последовательная
процедура, аналогичная рассмотренной последовательной процедуре
для одной совокупности (см. уравнение F6)). Так, для известных
дисперсий а\ и а\ уравнение F2) выглядит следующим образом:
+^r F8)
«1 [«2 /
Хорошо известно, что дисперсия (лгх — х2) минимальна для фикси-
фиксированного общего объема выборки п ( = пх + п2) при выполнении сле-
следу ющего соотношения:
-^=-Ei_ F9)
(см. [Dudewicz, Dalai, 1971, р.2.1] или [Tocher, 1963, р. 107, при
рг = 1]). Следовательно, значимость разности (б == |хх — \i2) ограни-
ограничивается областью (лгх — х2)±с с вероятностью по крайней мере
A — а) при минимальном общем объеме выборки, когда
G0)
а/2
«2=
142
,^ + ozf. G2)
5,1метим, что для парных наблюдений двух совокупностей применимо
уравнение F3) при а2 (х) = а\ + а|. Просто показать, что для пар-
пых наблюдений нужен меньший общий объем выборки, если сущест-
II у от положительная корреляция между хх и х2 и их дисперсии равны
Aлк оптимальное соотношение в уравнении F9) дает пх = п2, как в слу-
случае с парными наблюдениями).
Последовательный подход в случае неизвестных дисперсий, пред-
предложенный в [Robbins et al., 1967, p. 1385], состоит в следующем:
а) на каждом шаге вычисляются обычные оценки а\ и о\ по всем
наблюдениям данного шага, т. е. если было пх и п2 наблюдений, то
вычисляются
*i = 2 xu/«i, G4)
i
и si аналогично уравнению G3). По F9) возьмем следующее наблюде-
наблюдение из совокупности 1, если
-^±-< -^. G5)
П2 S2
Мели G5) не выполняется, следующее наблюдение берется из совокуп-
совокупности 2;
б) пусть ап — последовательность положительных констант, та-
такая, что
ап ->2а/2, когда п -> оо. G6)
Мы предлагаем заменить ап на а/2-процентиль ^-статистики со степе-
степенями свободы, определенными уравнением C8). Заметим, однако, что
чти числа степеней свободы могут зависеть от оценок s\ и s\ (см. урав-
уравнения C9) и D1)); тогда ап заменяем последовательностью положитель-
положительных случайных величин, которая стремится к za'2 при п -*¦ оо. Пред-
Предполагаем, что аппроксимация не нарушает достоверности этого мето-
метода. Такая последовательная процедура имеет определенные преиму-
преимущества для одной совокупности и двух совокупностей с фиксирован-
фиксированным объемом выборки (последняя обсуждалась в предыдущем парагра-
параграфе). В [Robbins et al., 1967, р. 1387]взятоа„ = z«/2[(n + 4)/(n—4)]1/2.
Авторы этой работы предлагают три различных правила остановки,
основанных на уравнениях F8)—G2). Заменяем zai2 на ап и аг и о2
на sx и s2 и останавливаем выборку, как только: 1) выполняется урав-
уравнение G2) (с указанной заменой и с заменой=на >); 2) выполняет-
143
ся уравнение F8) и 3) выполняются уравнения G0) и G1). Эти пра-
правила таковы, что общий объем выборки п будет наименьшим для пра-
правила 1 и наибольшим для правила 3. Авторы доказывают, что эти три
правила асимптотически состоятельны и эффективны. Поведение при
малых выборках, изученное в экспериментах Монте-Карло, также ока-
оказалось удовлетворительным.
Дудевич [Dudewicz, 1972] предлагает следующую процедуру двой-
двойной выборки для сравнения средних:
а) для начальной выборки объема щ (>2) из каждой совокуп-
совокупности вычисляются традиционные оценки среднего и дисперсии;
б) для следующей выборки объема (щ — п0) из совокупностей i
(f = 1, 2), где
nt = max (no+ 1, w2sf) G7)
(w2s2i округлена в большую сторону) и
w = **"' G8)
значения критической константы d*/2 табулированы Дудевичем
[Dudewicz, 1972]. Из-за ограниченной доступности исходной публи-
публикации мы приводим их в табл. 1 (заметим, что входом таблицы служит
A — а), а не а/2);
в) конструируем желаемый интервал
C*i-*s)±C G9)
где Xt — среднее по всем nt наблюдениям. Более точный интервал кон-
конструируется на основе взвешенных выборочных средних 1-го и 2-го
шага [Dudewicz, 1972, уравнение A.4)].
Сделаем несколько общих замечаний, касающихся последователь-
последовательного метода.
1. Для корректировки оценки дисперсии х можно взять известную
формулу
() ^ я_^_ (80)
»0 («D
или воспользоваться преобразованием Хелмерта (см. например, [To-
[Tocher, 1963, р. 114]), т. е.
8»(х)="у—У—, (81)
где
144
Таблица
Критическая константа dfj в двойной выборочной процедуре
(для сравнения двух средних)
\ «о
0,75
0,80
0,85
0,90
0,95
0,975
0,99
0,995
0,999
N. «о
1-аЧ
0,75
0,80
0,85
0,90
0,95
0,975
0,99
0,995
0,999
2
2,00
2,75
3,93
6,16
12,63
25,42
63,68
127,4
624
10
1,03
1,29
1,60
2,00
2,61
3,18
3,89
4,41
5,61
3
1,37
1,76
2,27
3,04
4,57
6,54
10,28
14,42
31,9
11
1,02
1,28
1,59
1,98
2,58
3,13
3,82
4,31
5,45
4
1,21
1,54
1,94
2,50
3,50
4,59
6,31
7,92
13,3
12
1,02
1,27
1,57
1,96
2,56
3,09
3,76
4,24
5,32
5
1,14
1,44
1,80
2,29
3,11
3,94
5,14
6,15
9,13
13
1,01
1,26
1,56
1,95
2,53
3,06
3,71
4,18
5,22
6
1,10
1,38
1,72
2,18
2,91
3,63
4,60
5,39
7,48
14
1,01
1,26
1,56
1,94
2,52
3,04
3,67
4,13
5,14
7
1,07
1,34
1,68
2,11
2,79
3,44
4,30
4,97
6,65
15
1,00
1,25
1,55
1,93
2,50
3,02
3,64
4,09
5,07
8
1,05
1,32
1,64
2,06
2,71
3,33
4,11
4,71
6,16
20
0,99
1,24
1,53
1,90
2,45
2,95
3,54
3,96
4,86
9
1,04
1,30
1,62
2,02
2,66
3,24
3,98
4,53
5,84
25
0,98
1,23
1,51
1,88
2,42
2,91
3,48
3,89
4,74
30
0,98
1,22
1,51
1,87
2,41
2,88
3,45
3,85
4,67
Как указывалось в 11.10, можно вычесть подходящую константу, что-
чтобы уменьшить потерю значимых цифр; выбор константы основывается
на априорной информации, результатах отладочных прогонов и т. д.
2. Можно начать с любого исходного объема выборки п0 (п0 > 2).
Увеличение предварительной выборки приводит к уменьшению эффек-
эффективности и увеличению состоятельности.
3. Вместо увеличения объема выборки на одно наблюдение с пере-
пересчетом s2 (х) и т. д. возможен многошаговый подход, где на каждом ша-
шаге добавляется^несколько наблюдений. Это повышает состоятельность
и снижает статистическую эффективность. Общая эффективность мо-
может повыситься, потому что правила остановки проверяются реже.
Наблюдения при моделировании отнимают много машинного време-
времени, и, следовательно, число наблюдений на одном шаге не должно
быть большим. Если мы сравниваем две системы, то раздельное гене-
генерирование наблюдений для систем 1 и 2 может быть громоздко. В не-
некоторых приложениях правил остановок в моделировании принят
многошаговый подход, когда число наблюдений на одном шаге
фиксировано и равно
т
S+1
- (па — nas)f @<f< 1),
(83)
145
Где tna | ^ Число наблюдений на шаге s -\- I, ns — потребное чис-
число наблюдений, вычисленное после шага s, nas — действительное чис-
число наблюдений, возможных после шага s, а / — доля. Процедура (83)
в моделировании обсуждается в [Angers et al., 1970, p.5—6] при / =
= 1/2 и в [Fishman, 1971, p.28] при / = 1/2 и 1/3. Мы еще вернемся
к применениям правил остановки в моделировании.
4. Последовательный метод для одной или двух совокупностей
пригоден также и для ненормальных распределений при больших
объемах выборки (ср. центральную предельную теорему и см. также
[Chow, Robbins, 1965, р.457], [Robbins et al., 1967, p. 1391] и [Srivas-
tava, 1970, p. 144]). В приложениях моделирования совокупности не
обязательно нормальны, поэтому результаты таких применений нуж-
нуждаются в дополнительной информации о поведении ненормальных со-
совокупностей возможно малого объема. (Как мы увидим далее, резуль-
результаты моделирования вполне хороши.) В [Geertsema, 1970] введены не-
непараметрические процедуры построения доверительного интервала
фиксированной длины для медианы одного симметричного распреде-
распределения. Процедура последовательного построения доверительного ин-
интервала основана на критерии знаков или одновыборочном критерии
Уилкоксона, точно так же, как в [Chow, Robbins, 1965]. Эти процедуры
асимптотически корректны. Их асимптотическая эффективность та же,
что и эффективность в обычной фиксированной выборке непараметри-
непараметрических критериев в сравнении с параметрическим ^-критерием. Эти
процедуры достаточно громоздки, потому что при появлении новых
наблюдений требуется переупорядочение.
Обсудим применение некоторых малораспространенных правил
остановки в моделировании и экспериментах Монте-Карло. В правилах
остановки используются формулы из V.A.3 для постоянного объема
выборки и оцениваются неизвестные параметры (последовательным,
многошаговым или двушаговым способом) без учета ошибки, вызывае-
вызываемой стохастической природой объема выборки. Примеры можно найти
в [Angers et al., 1970] и [Bruzelius, 1972], [Crane, Iglehart, 1972a, p.
12—18], [Fishman, 1971], [Flagle, 1960], [Geisler, 1964a] и [Prins,
1962]. Отклонения от заданного A — а) обсуждаются только в [Наи-
ser et al., 1966, p.82]. К счастью, эти отклонения малы, как мы видели
ранее. Другим источником ошибок в моделировании может быть на-
нарушение нормальности распределения и смещение оценки дисперсии
в удлиненном эксперименте. Как мы убедились в V.A.2, дисперсию а2
можно оценить из подопытов, индивидуальных коэффициентов авто-
автокорреляции или циклов. Первый подход был применен Механиком и
Маккеем [Mechanic,McKay, 1966, p. 34], которые нашли, что переменная
(л: — \х)/а распределена приближенно нормально в моделированных
ими системах массового обслуживания. Фишман [Fishman, 1971] оце-
оценил о2 не из подопытов, а методом скользящего среднего и подобно
Механику и Маккею не фиксировал объема выборки, а определял его
многошаговым способом с помощью (83). Он также применял критерий
относительной надежности, т. е. длина с доверительного интервала
в уравнении F0) заменялась на уц. Например, если \i надо оценить
146
с 10%-ной точностью, то y = 0,1. Следовательно, в формуле для объема
пыборки вместо уц подставляем с и, кроме того, помимо сг нужно ^ за-
заменить его оценкой. Это создает дополнительный источник ошибок.
«Относительные» доверительные интервалы не изучаются в статисти-
статистической литературе по последовательным интервалам фиксированной
длины. Фишман [Fishman, 1971, р.35] приводит результаты примене-
применений многошаговой процедуры (83) для относительных доверительных
интервалов (при у = 0,3) в случае простой системы массового обслу-
обслуживания и трех различных начальных выборок пй B50, 500 и 1000).
Иго результаты показывают, что доверительные интервалы не содер-
содержат в себе истинное среднее чаще, чем ожидаемое число а раз. (В зави-
зависимости от п0 действительное значение A — а) равно 0,73, 0,79 и 0,88
от заданного значения A — а).) Он предполагает, что отличия от за-
заданного значения A — а) частично вызываются относительным крите-
критерием уц. Для дальнейших обсуждений мы отсылаем к [Fishman, 1971].
В [Geisler, 1964a] оценивается а2 на основании автокорреляционных
коэффициентов при моделировании хранения запасов и полагается
а = 0,057 и у = 1 (т. е. истинная средняя оценивалась в пределах
100%), а объем выборки — из предварительного эксперимента по
500 наблюдениям8. Такой объем выборки брался для 25 различных си-
систем хранения запасов, каждая система повторялась 1000 раз [Geisler,
1964b, p. 710]. Часть из этих 1000 повторений, дающая оценку средне-
среднего в пределах 100%, получалась очень близкой к заданному A — а).
В [Crane, Iglehart, 1972a] применялся двушаговый подход к независи-
независимым циклам некоторой многоканальной модели массового обслужи-
обслуживания. (Фактически авторы этой работы использовали консерватив-
консервативные доверительные интервалы; позже они получили асимптотически
точные интервалы B1).) В [Angers et al., 1970] авторы тоже работали
с многошаговым правилом остановки для независимых имитационных
экспериментов. Они утверждали (без доказательства), что их «подпро-
«подпрограмма остановки широко и успешно применяется в моделировании
и хорошо работает» [Angers et al., 1970, p.7]. Мы также предпочли этот
подход в имитационном моделировании и экспериментах Монте-Кар-
Монте-Карло. Поскольку проверка правила остановок не была целью этих экс-
экспериментов, мы делали мало повторений (но получили результаты для
нескольких различных систем). Рассмотрим подробнее эти примене-
применения.
Мы применяли многошаговый подход E0 наблюдений на каждом
шаге, а = 0,05, у = 0,1 и критическую константу za/2) для оценки
интеграла методом Монте-Карло:
? (%, v) = Г — Ке-ь* dx (%, у>0). (84)
J х
V
Для обсуждения оценивания уравнения (84) методом Монте-Карло
отсылаем читателя к главе I. Мы применяли правило остановки для
нескольких комбинаций % и v в уравнении (84) и нескольких оценок по
методу Монте-Карло (а именно необработанная выборка и три оценки
147
значимой выборки, см. главу III). Рис. 26 иллюстрирует флуктуации
п для трех наборов (A, v) и прямой оценки Монте-Карло. Рис. 27 пока-
показывает флуктуации оценки Сс ростом фактического числа наблюдений
(до тех пор, пока достигаем требуемого числа); на этом рисунке гори-
горизонтальные линии указывают ? и 90 и 110% от |, истинное | найдено
аналитически. Для других комбинаций (А.,у) и повторений были полу-
получены аналогичные рисунки. С первого взгляда может показаться
странным, что рис. 27 не похож на рис. 28. Однако здесь все предыду-
предыдущие наблюдения брались для
оценки | на шаге /. Следова-
Следовательно, %], оценка на /-м
шаге, получается зависимой
от оценок на предыдущих
шагах (§;_!, \,_2, ..., §2,
li). Итак, вероятность флук-
флуктуации оценок вокруг линии
1 = 5 мала (ср. с упражне-
упражнением 10). Заметим, что рис. 29
указывает на неразумность
продолжать выборку, пока
не стабилизируется кумуля-
кумулятивная оценка \, так как та-
такая практика может привести
к нежелательно большим
Рис. 26. Флуктуации требуемых объемов
выборки п, когда фактический объем вы-
выборки па возрастает
О 2
Ю 12 14 IS 18 20 22 24 2В 28 30 п. * 100
объемам выборки. Рис. 28
показывает, что в этом
примере каждая оценка бы-
была определена с ошибкой
меньше 10%. Тем не менее возможны ошибки больше 10%. Как указы-
указывалось ранее, объем выборки основан на многошаговых оценках дис-
дисперсии и среднего. Даже если наша формула для п (приблизительно)
верна, то остается вероятность а ошибок, которые больше 10%. По-
Поскольку оценка | (к, v) служит для исследования эффективности зна-
значимой выборки, кратко рассмотрим корректность нашей формулы для
п. Мы взяли только десять независимых повторений для нашей форму-
формулы. Было найдено, что одна оценка имела ошибку, большую, чем 10%.
Наша гипотеза состоит в том, что р, вероятность таких ошибок, не
больше а, например 5% в нашем примере. На основе биномиального
распределения получаем, что вероятность одного или более дефекта
в выборке из 10 наблюдений с р = 0,05 равна 0,4013, т. е. мы не мо-
можем отбросить нулевую гипотезу. Далее мы применили правило оста-
остановки для примера об эксплуатации (автобуса), описанного в прило-
приложении 1.3 (при а = 0,05 и у = 0,1), и оценили разность между сред-
средним числом автобусных маршрутов с отклонением в пределах 10%
с истинным значением этого отклонения.
Мы также применили эту процедуру к выборочному распределе-
распределению примера из приложения 1.2, где мы оцениваем р, вероятность
того, что время работы, состоящее из двух частей, меньше заданного
148
числа а. Наше обсуждение уравнения D8) показывает, что биноми-
биномиальная ^модель соответствует ситуации. Мы воспользовались нор-
нормальной аппроксимацией биномиального распределения, чтобы оп-
определить
2а/2 \2 A-р)
п~
(85)
Ъметим, что из уравнения (85) следует, что объем выборки п растет
при уменьшении р. Мы начали с выборки из 150 наблюдений и взяли
100 наблюдений на одном шаге. Это дало оценки ошибок менее 10%
§* ю.ооо
Монте-Карло
/ Значимая Выборка Я
Значим an Выборка 8
Значимая Выборка С
0,3?,
О 200 Ш 600 800 W00 1200 М0О 1600 1800 2000 2200 2400 Па
Рис. 27. Флуктуации оценки ?, когда фактический объем выборки па
возрастает
(у = 10%). В [Wehrli, 1970, р. 99—101] обсуждается подход, осно-
панный на уравнении (85), а также другой, в котором оценка р только
асимптотически несмещенная, но требует выборок меньшего объема.
Автор предлагает следующую последовательность действий.
1. Вычислить асимптотически несмещенную оценку
(86)
|дс р — обычная оценка.
2. Вычислить длину обычного доверительного интервала для
/) с помощью нормального приближения, т. е.
(87)
149
Как tti'ii.Mi диииа С становится достаточно малой, процесс выбора
прсир.шикчп!. Таблицы Верли [Wehrli, 1970] показывают, что
ппм'М* лыборки уменьшается на 4—25% при р, изменяющемся от 0,6
до 0,9; а = 0,05 и с = 0,05. Верли не касается влияния стохасти-
стохастического характера объема выборки на оценку р.
При определении объема выборки для оценки р-го квантиля рас-
распределения х, например хр, можно взять последовательность по-
постоянных выборок для доверительных интервалов хр (см. уравнение
E7)). Продолжаем выборку до тех пор, пока интервал lx(r), x(s)] не
уменьшится до определенной длины с. Эта непараметрическая после-
последовательная процедура применяется для больших п (п > 20), так
как уравнения E8) и E9)
Л асимптотические. В [Far-
§ rell, 1966] доказано, что
последовательные вариан-
варианты правила с фиксирован-
фиксированными выборками для
W^SA"-<vvvvvw**.'vV--~ конечного п приводят к
желаемому доверительно-
доверительному интервалу. Двушаговое
па правило было предложено
Вейсом [Weiss, 1960]. Не-
Рис. 28. Осциллирующее поведение оценки достаток ДВушагового под-
подхода в том, что можно
превысить потребный об-
общий объем выборки; преимущество состоит в том, что не надо
хранить все наблюдения после добавления каждого нового наблюде-
наблюдения; практичное правило можно построить на уравнении (83) или
многошаговой процедуре с фиксированным числом дополнительных
наблюдений на каждом шаге.
Отметим, что одношаговая процедура была предложена Андер-
Андерсоном и Торберном [Anderson, Thorburn, 1972, p. 4—5, 17—18]. Од-
Однако их правило только приближенное и требует знания функции
распределения х. Часто проблема объема выборки при оценке кван-
квантилей решается с помощью непрерывной выборки, например, пока
не изменится третий знак после запятой (см. [Heuts, 1971, р. 18],
[Heuts, Rens, 1972, p. 7]. Конечно, такая «числовая точность» не га-
гарантирует статистически правильных результатов. Доверительные
интервалы для разности двух квантилей (хр — xq или хр — ур) можно
просто получить из уравнения B6); другой подход обсуждается
в [David, 1971, р. 15].
Объем выборки для сравнения двух биномиальных вероятностей
можно определить с помощью нормальной аппроксимации. В [А1-
Bayyati, 1971] дается описание другого способа решения этой задачи,
но предлагаемая процедура консервативна и, следовательно, менее
привлекательна в случае дорогостоящих имитационных экспери-
экспериментов. Рассмотрим подробнее общую проблему проверки гипотез
(в противоположность оцениванию).
150
Вместо оценивания среднего \i распределений X мы можем про*
г.г/шть нуль-гипотезу Но против альтернативной гипотезы Нг, где
H0:\i = \i0, Hi.p = цх. (88)
Хорошо известно, что для определенных значений \i0 и \1г мы можем
определить п так, чтобы не превысить заданной величины р при из-
Ш'стной дисперсии х. Предполагая pix > pi0 при одностороннем кри-
юрии, имеем:
Р(На принимается \Н1) = Р ( *~~И0
— — ^r — <2a — * ° (i = j4l =
[ а/Уп vlVn J
^- rnt (fa-~ ^o) 1 — ft /OQ\
откуда следует, что
2a (fazJiel ^=—гР (90)
a
1ГЛИ
га=Bа+2Р)» p2_ (91)
(fa—Mo)
Для обсуждения двустороннего критерия мы отсылаем, например,
к [Robbins, Starr, 1965, p. 1].
Для неизвестной дисперсии о2 мы можем заменить о2 ее оценкой,
а 2а и zP на ft и ftv, где у есть число степеней свободы оценки о2. При
заданном объеме выборки Но отклоняется, если
.*=?->*«, (92)
или в соответствии с уравнением (91)
- lSX ^(fa-Ы /ООЧ
- (93>
При выводе (93) мы не учитывали стохастического характера объема
иыборки. Точные решения даются двойной выборочной процедурой
Штейна; ср. с процедурой Дудевича [Dudewicz, 1972, р. 4], где на первом
шаге а2 оценивается по п0 наблюдениям, затем берется вторая выборка
из (п — п0) наблюдений, где п определяется из уравнения (91) подста-
подстановкой s2, t% _х и ^ _!, наконец, гипотеза Яо отклоняется, если вы-
выполняется уравнение (93) (при v = п0 — 1). В [Robbins, Starr, 1965,
151
p. !'l iI(ik,i i.iiki, 4io процедура двойной выборки не является асимп-
нн ц||(Ч'м1 дефективной, при неудачно выбранном начальном объеме
1НI(н)|)М1 ома может быть неэффективной. Авторами изучены после-
последовательные аналогии этой процедуры. (Фактически они изучали
двушаговый критерий.) Авторы нашли, что их процедура асимпто-
асимптотически корректна (т. е. ошибки аир удовлетворительны) и асимп-
асимптотически эффективна.
Для двух совокупностей с парными наблюдениями d = хх—х2
построение эксперимента точно то же, что и раньше. Для независимых
наблюдений Дудевич [Dudewicz, 1972, р. 5] предлагает метод двух
выборок, который требует табл. 1, приведенной выше, и еще одной таб-
таблицы с поиском в ней методом проб и ошибок (ее можно найти в [Du-
[Dudewicz, 1972] и [Dudewicz,, Dalai, 1971]). Чэпмен [Chapman, 1950]
предлагает двойную выборочную процедуру для проверки гипотез
об отношении двух средних. (Его таблица II расширена Дудевичем
[Dudewicz, 1972, Table II].) Однако к задаче проверки гипотез для
разности двух средних можно подойти иначе. Мы обычно сравниваем
два средних, чтобы выбрать лучшее, например наибольшее. Эта за-
задача выбора допускает формулировку на языке проверки гипотез.
Мы хотим дискриминировать три гипотезы:
Н-х : Hi < Ца, Яо : Hi = На. #i ¦ Hi > Из- (94)
Объем выборки можно задать выбором а- и р-ошибок (ср. также об-
обсуждение последовательных критериев для выбора одной из трех
гипотез в [Wetherill, 1966, р. 30—40]). Однако можно также применять
подход, соответствующий общей формулировке задачи выбора сред-
среднего из k совокупностей (k > 2). Итак, мы оцениваем \ih с помощью
выборочного среднего
xh= S Хм/in (A =1,2). (95)
i= 1
Примем в качестве совокупности с наибольшим средним ту сово-
совокупность, которая даст наибольшее выборочное среднее. Мы хотим
обеспечить некий минимум вероятности Р* или A — а) сделать пра-
правильный выбор (сокращенно ПВ), а именно
P(UR) = P[x1>'xt\\i1>\ti) или (*! < х2 | Hi < Иг)] (96)
>Р*=1—а.
Рассмотрим рис. 29, где Hi — Иг = 8 предполагается положительной;
d обозначает хх—х2. Вероятность неправильного выбора равна за-
заштрихованной площади. Эта вероятность уменьшается с ростом вы-
выборки. Но ясно, что если б мало отличается от 0, то вероятность не-
неправильного выбора остается значительной. Поэтому небольшие
различия между Hi и Нг трудно различить и нужны очень большие
152
иыборки. Но при небольших различиях ложный выбор совокупности
по страшен и, следовательно, не стоит брать большие выборки для
мыявления малых различий. Предположим, что неправильное заклю-
заключение не столь уже опасно, если |б| меньше, например, б* (б* > 0).
Различия, равные б* или большие, мы хотели бы распознавать с ве-
вероятностью, равной по крайней мере Р*( = 1 — а), или
Р (ПВ) > Р*, если | Цх — ця | > б*,
большая дыборна.
(97)
Рис, 29. Соотношение между Р(ПВ), объемом выбор-
выборки и б
где Р* и б* заданы экспериментатором. Уравнение (97) называется
уравнением зоны безразличия. Чтобы определить объем выборки,
перепишем уравнение (97) в виде (98) и (99):
Р (d>0 |б > б*) > 1 —а,
Р {d < 01 б < — б*) > 1 — а.
(98)
(99)
При сравнении двух средних в предположении нормальности и
отсутствии предположения о равенстве дисперсий можно воспользо-
воспользоваться, например, статистикой Кркрена и Кокс из уравнения C9)
или статистикой Шеффе из уравнения D5). Из C8) и C9) следует,
что уравнение A00) соблюдается приближенно.
A00)
при
Из уравнения A00) вытекает, что
Р (d > 0) = 1 — а
— t'a -s (d) + б = 0,
A01)
A02)
153
Псе можно iioK.'i'i.'vib, что A02) справедливо при
^-i)8 A03)
Здесь мы оперировали уравнениями C8) и C9) и применили следую-
следующее правило размещения выборки:
J±=JL. A04)
п2 si
Отношение A04) показывает, что мы берем больше наблюдений из
совокупности с большей дисперсией; отсюда хорошо известный факт:
для фиксированного объема выборки дисперсия (лгх — х2) минимизи-
минимизируется при п1/п2 = о^/сга; определение нужного объема выборки уп-
упрощается, если вместо отношения пх1пг = sjs^ взять отношение
пг/п2 — sl/s%. Из уравнения A03) следует, что для б = б* потребные
объемы выборок даются выражением A05):
2S* @,5,«_,+0,5^K
h E*J v ;
Если действительно б > б*, то уравнение A05) дает «сверхгарантию»,
т. е.
P(d> 0) > 1 — а. A06)
Следовательно, tin из уравнения A05) удовлетворяет (98). Аналогично
выводам A00) — (Ю6) находим, что уравнение A05) удовлетворяет
(99). Следовательно, выполняется (97), если пренебречь стохасти-
стохастическим характером ^ и л,.
Таким же образом выводим из статистики Шеффе D5) выражение
для наименьшего объема выборки пх:
-J*-')'-», A07)
1 (б*J
где
щ = хи - (njn,I'2 лг2г (г = 1, 2 пх). A08)
Заметим, что иг надо пересчитывать (старые и новые значения), когда
изменяется (%/n2); чтобы это сделать, надо знать все значения хи и
x2f, что может потребовать большой машинной памяти. Легко вывести
иное выражение для числителя s2 (и), а именно
154
> i от результат выглядит сложнее, но он дает возможность рассчитЫ-
и.пъ s2 (и) с помощью сумм, при этом не нужны старые индивидуаль-
индивидуальные значения хи и x2i (ср. наши комментарии к уравнению (80)).
11иеледовательное применение A07) происходит следующим образом.
К'ли объем выборки оказывается меньше, чем пх, то генерируется
•чцс одно дополнительное значение из совокупности с наименьшим
к'кущим объемом выборки. Если обе совокупности имеют одинаковый
к'кущий объем, то согласно условию пх ^ п2 для статистики Шеффе
п i обеих совокупностей берем по одному наблюдению.
Нами не доказано, что выше приведенная последовательная про-
процедура удовлетворяет требованию (97). Это эвристическая процедура,
основанная на том соображении, что последовательные варианты
оценочных процедур работоспособны (см. обсуждение 65)). Далее
мы приведем некоторые экспериментальные данные о применении
формул для определения объема выборки A03) и A07). Но прежде
чем приведем их, заметим, что если экспериментатор находит форму-
формулировку (97) более адекватной по сравнению с выбором, основанным
на проверке гипотез либо определении доверительных интервалов, то
он может применять методы множественного ранжирования (для
к > 2 совокупностей), о которых идет речь в части В настоящей
главы.
Мы применили уравнения A03) и A07) к моделированию хорошо
известной задачи разносчика газет, сформулированной в [Naylor
ct al., 1967, p. 177—178], следующим образом. «Разносчик газет поку-
покупает газеты по 4 цента за штуку и продает их по 10 центов. В конце
каждого дня издатель газеты оплачивает непроданные газеты по
2 цента за штуку. Ежедневная потребность (D) в газетах выражается
(дискретной) функцией вероятностей». Мы прибегнем к имитацион-
имитационной модели, чтобы оценить разницу в прибыли разносчика газет при
двух разных количествах их. Результаты моделирования исполь-
используются затем для выбора того варианта, который дает больший до-
доход10. Мы применяли правилу остановки Кокрена — Кокс и Шеффе
с тем, чтобы удовлетворить условию нормальности, и определяли одно
наблюдение как среднее из десяти отдельных наблюдений. На осно-
ьании центральной предельной теоремы можно ожидать, что средние
лучше удовлетворяют предложению нормальности. (Можно взять
также одно наблюдение вместо десяти и использовать робастность
/-статистики; статистики Кокрена — Кокс и Шеффе определены ина-
иначе, чем обычный ^-критерий.) Мы отсылаем к [Kleijnert, 1967, р. 11—
18], где представлены различные блок-схемы этой модели. Для случая
Р* — 0,95 и б* = 4 результаты приведены в табл. 2, где математические
ожидания разностей для ожидаемого дохода найдены аналитическим
способом. В табл. 2 min означает число наблюдений (т. е. средних из
десяти отдельных наблюдений), которые генерируются перед тем,
как формула для объема выборки применяется первый раз. Часть
таблицы между пунктирными горизонтальными линиями относится
к ситуациям, для которых |б| < б*. В ситуациях, где |б| > б*,
статистика Шеффе всегда обеспечивает правильный выбор, в то время
как статистика Кокрена — Кокс «ошибается» (табл. 2). Таблица
155
Таблица 2
Экспериментальные результаты применения правила остановки,
основанного на статистиках Кокрена — Кокс и Шеффе
Сравнивае-
Сравниваемое число
газет
A)
75—80
80—85
85—90
90—95
95—100
100—105
105—110
110—115
115—120
Ожидаемая
разница, 6
B)
26,80
24,00
23,20
15,20
11,60
4,00
—0,80
—2,00
—7,60
Оцененные разности, d
статистика Шеффе
min=2
повторе-
повторение 1
C)
22,00
26,19
26,29
13,74
11,67
0,36
2,55
повторе-
повторение 2
D)
29,12
20,50
27,17
14,90
13,55
6,13
—7,85
—2,81
*
статистика Кокрена —Кокс
min = 2
повторение 1
E)
25,33
27,46
19,20
38,20
4,23
0,04
—3,71
-5,23
повторение 2
F)
26,00
18,00
29,81
16,26
10,27
6,96
—3,14
—2,09
—4,41
min= 5
повторение 1
G)
25,33
24,07
23,33
13,66
13,50
3,34
—2,23
—3,25
—6,88
* Не вычислено, так как требовалось слишком много машинного времени.
действительных и желаемых объемов выборок в [Kleijnen, 1967,
р. 20] показывает, что неправильный выбор получается в случае,
когда моделирование останавливается при минимальном числе на-
наблюдений (т. е. после двух наблюдений); когда этот минимум под-
поднимается до пяти, получается правильный выбор (см. столбец 7).
Тот факт, что статистика Кокрена — Кокс работает хуже, чем ста-
статистика Шеффе, можно объяснить приближенным характером ее.
Отметим, что статистика Кокрена — Кокс требует больших выборок,
но занимает меньше времени для написания машинных программ;
детали можно найти в [Kleijnen, 1967, р. 21—22]. При |б | < б* очень
возможны неправильные выборы (ср. знаки у чисел между пунктир-
пунктирными линиями табл. 2).
Было показано, что, если нас не интересует доверительный ин-
интервал для среднего, можно определить р-ошибку и альтернативную
гипотезу (т. е. |лх), а также оценить неизвестную дисперсию по пред-
предварительной выборке (см. уравнение (91)). Вместо двойной выбороч-
выборочной процедуры Штейна можно взять выборочную процедуру с зоной
безразличия (см. уравнение (96)). Третья альтернатива — это пол-
полностью последовательная проверка гипотез с учетом стохастического
характера объема выборки. Этот подход дает полезные процедуры
при отсутствии мешающих параметров (вроде а2). Он основан на кри-
критерии последовательного отношения вероятностей (КПОВ) Вальда,
который осуществляет выбор между двумя простыми гипотезами,
Но : Э = 60 и Нх : 6 = 6ГКПОВ состоит в следующем. Произво-
156
'ШТСЯ выборка из п наблюдений xt (t = 1, 2, ..., п) с плотностью рас-
распределения / (х); тогда вероятность получения определенного набора
точений xt u есть
P=f] f(^|e = eh) A10)
при заданном параметре в, равном 6Л. Если считать наблюдения
иыборочного процесса xt случайными, то вероятность Р в уравнении
A10) будет случайной величиной. Отношение вероятностей, или от-
отношение правдоподобия, / определяется как отношение вероятностей
пыборочных наблюдений при гипотезах Н1 : G = 6Х и Яо : в = Эо
соответственно, т. е.
l=-J~- (HI)
Очевидное правило принятия решений состоит в том, чтобы продол-
продолжать выборку до тех пор, пока отношение не станет близким к едини-
единице; Нх принимается, если отношение мало. Мы хотим получить:
Р (#0 отклоняется | 60) = а, A12)
Р (#0 принимается | ©х) = р. A13)
Принимая случайный характер как наблюдений xh так и объема вы-
выборки п, Вальд показал, что уравнения A12) и A13) приближенно
реализуются, если продолжить выборку, пока не будет выполняться
условие
_^<1<±±> (ц4)
1 —а а
и принимается Но, если
либо принимается Нъ если
'>—¦ <ш>
Доказательство уравнений A14) — A16) есть, например, в [Ghosh,
Freeman, 1961, p. 38—43] и [Wetherill, 1966, p. 14—16]. Объем вы-
выборки при такой процедуре меньше, чем в случае фиксированной
выборки. (Мы не знаем ни одного исследования эффективности КПОВ
в сравнении с приближенными последовательными процедурами вы-
выбора, которые не учитывают стохастического характера объема вы-
выборки. Они применялись нами выше. Оба подхода, однако, требуют
различных формулировок задачи; ср. параметры Р* и б* и в другом
подходе— а, р, \i0 и цх.)
157
Hpnt'iti И|||1кч'гп КПОВ для среднего [А нормальной совокупности
t и nimiloft дисперсией для стандартного отклонения а нормальной
шиокушюсти (pi известно или нет), среднего X пуассоновской совокуп-
совокупности или для биномиального параметра р (см., например, [Ghosh,
Freeman, 1961, p. 44—48]). Мы считаем, что случай биномиальноге
распределения важен для моделирования и экспериментов Монте-
Карло. Ссылаясь на формулировку Уизерилла [Wetherill, 1966, р. 17],
отметим, что согласно КПОВ в этом случае следует продолжать вы-
выборку до тех пор, пока не будет выполняться
Ро / V 1-Ро
где г и s обозначают число неудачных (дефектных) и удачных выборок
соответственно, р — вероятность неудачи (In означает логарифм).
В [Corneliussen, Ladd, 1970] изучены точные статистические свойства
биномиального последовательного критерия. Уравнение A17) нашло
наибольшее число применений в области контроля качества (см.
[Wetherill, 1966, р. 27]). Этот критерий применялся также в «физи-
«физической модели» противотанковой мины [Kurlat, Springer, 1960, p. 477].
Нам неизвестны никакие применения этих результатов в моделиро-
моделировании и экспериментах Монте-Карло, хотя биномиальное распреде-
распределение может оказаться вполне реалистичным в задачах, решаемых
в таких экспериментах.
Другая практическая проблема — проверка гипотез относитель-
относительно среднего \i нормальной совокупности N (\i, а2) при неизвестной
а2. К сожалению, эта проблема не имеет удовлетворительного решения
в рамках чисто последовательной теории. Один из подходов состоит
в том, чтобы решать переформулированную задачу:
Но : ц = к,, Нх : | |х — ц0 \/а > 6lt A18)
т. е. расстояние ц относительно ц0 определяется в долях неизвестного
стандартного отклонения а и этодгюзволяет построить критерий
(см. [Wetherill, 1966, р. 46]). Однако формулировка A18) нереалистич-
нереалистична в случаях имитационного моделирования и экспериментов Монте-
Карло. В другом подходе из п0 наблюдений на основе предваритель-
предварительной выборки оценивается а2; следующие наблюдения выбираются по
одному через определенные промежутки времени до тех пор, пока
КПОВ не достигнет одной из границ. Такая процедура была развита
в [Paulson, 1964, р. 1048—1052]. В его подходе х рассчитывается по
всем п наблюдениям, а для вычисления s2 используются только первые
п0 наблюдений. Его процедура применялась при моделировании сис-
системы управления запасами [Sasser et al., 1970, p. 290, 292—294].
Отметим далее, что в последовательном ANOVA исходная гипотеза
#0 : iij = |х2 = ... = nh также переформулирована нереалистично
(см. [Ghosh, Freeman, 1961, p. 72] и [Wetherill, 1966, p. 71]). Неуди-
Неудивительно, что КПОВ^не так часто применяется как в моделировании^
исследованиях по методу Монте-Карло, так и в других областях.
Обширное изучение КПОВ в работе [Ghosh, 1970]. Упомянем также
шшгу [Fu, 1970], в которой содержится глубокое обсуждение КПОВ,
иключая модифицированные границы (ограниченные максимальным
числом наблюдений), непараметрические варианты, выбор между
более чем двумя гипотезами и т. д.
Подытоживая, можно сказать, что методы КПОВ для проверки
i ипотез более точны и эффективны, чем планы с фиксированным
объемом выборки, но обычно они неудобны для проверки гипотез
I) моделировании и методах Монте-Карло; заслуживающее внимания
исключение представляет собой биномиальный вариант КПОВ. Было
бы интересно изучить КПОВ для проверки гипотезы о ц в N (\i, а2),
когда а2 пересчитывается после каждого шага, и сравнить применение
1акого приближенного КПОВ с применением двойной выборки и ме-
юда зон безразличия. В задачах оценивания ситуация другая. Неко-
юрые авторы утверждают, что для не слишком маленьких выборок
приближенная последовательная процедура, основанная на формуле
фиксированного объема выборки, дает правильные доверительные
уровни и приближается к точной последовательной процедуре (ср,
| Johnson, 1957]).
Наконец, имеется другой тип процедур, если мы хотим найти
некоторую функцию потерь, возможно, вместе с априорным распре-
распределением для интересующих нас параметров. Можно попытаться раз-
развить подход на основе статистической теории принятия решений
В [Maurice, 1957] предложена «минимаксная» процедура для выбора
между двумя совокупностями на основе последовательной выборки
при известной общей дисперсии. В [Grundy et al., 1954, p. 318] ми-
минимизирован «средний риск» (с применением двойного выборочного
плана при известной дисперсии. В [Hayes, 1969] описан байесовский
подход с фиксированной выборкой для выбора между двумя альтер-
альтернативами при известной дисперсии; однако из этого подхода не полу-
получается простой процедуры. Детали теории принятия решений в после-
последовательной выборке можно найти в [Wetherill, 1966, р. 11—12,
85—110, 134—141, 187—189]. Для моделирования систем хранения
¦запасов в [Brenner, 1965; 1966] изучены экономичные объемы выборок,
которые, однако, слишком специфичны для всеобщего использова-
использования в моделировании. В [Naylor, 1971] дан краткий обзор различных
правил останова в моделировании, а в [Dutton, Starbuck, 1971,
р 592—593] можно найти дополнительные ссылки.
ПРИЛОЖЕНИЯ К ЧАСТИ VA
ПРИЛОЖЕНИЕ VA1 КОРРЕЛЯЦИЯ МЕЖДУ ПОСЛЕДОВАТЕЛЬНЫМИ
ОПЫТАМИ
В этом приложении мы выведем коэффициент корреляции для
средних двух последовательных подопытов или, для краткости, опы-
юв. Обозначим средние этих двух опытов хг и х2, где каждый опыт
состоит из отдельных наблюдений хи (г = 1, 2, . ., а) и хг] (/ = 1,
2, ..., а) соответственно. Из определения ковариации следует, что
159
°= t x2]) ]\ =
?= l l*it ~
~ E
а
2
= "V 2 2
0 /
(i.i)
Мы предполагаем, что хи и x2j образуют стационарные случайные
последовательности. Стационарность предполагает, что ковариации
не меняются с течением времени, но изменяются в зависимости от
«сдвига», т. е. числа периодов между двумя случайными величинами,
как мы уже видели в уравнении C). Поскольку x2i, x2i есть первое,
второе, ... наблюдение за х1а, имеем
COV (Xlt, Х
Получаем следующую таблицу.
= С(в
A-2)
Таблица V.A 1.1
Величина (а+/—i) при изменении i и / от 1 до а
)
1
2
3
(а-2)
(а-1)
а
e+i
а+1
а+2
а+3
2а—2
2а—1
2а
1
а
а+1
а+2
2а—3
2а—2
2а-1
2
а-1
а
а+1
2а—4
2а—3
2а—2
3
а—2
а—1
а
[2а—5
2а—4
2а—3
/
(а-2)
3
4
5
а
а+1
а+2
(а-1)
2
3
4
а—1
а
а+1
а
1
2
3
а—2
а—1
а
Эта таблица вместе с приведенными выше формулами дает
cov (xlt х2) = ^-[Ci + 2с2 + Зс3 +... + (а— 1) са
s=l
160
Для того чтобы определить корреляцию вместо ковариации, нам
надо знать еще дисперсию хг. С помощью уравнения E) получим
уаг^О^-Га2 +—2(a-s)cJ. A.4)
Поскольку стандартные отклонения хх и х2 равны, корреляция между
хг и х2 выражается уравнением A.5):
!, -*2/ '
„_2 ('уа i уа— 1
а-1_1
s = 1 „ PBa-s)
¦ A.5)
ПРИЛОЖЕНИЕ VA2 МЕТОД ПОДОПЫТОВ МЕХАНИКА И МАККЕЯ
Механик и Маккей [Mechanic, McKay, 1966, p. 18—23] предложи-
предложили следующий алгоритм. Пусть вся выборка состоит из N отдель-
отдельных наблюдений (xt, t = 1, .... N). Образуем подопыты, или блоки,
объемом a, b = 4а, с = 46, ..., s. Должно быть по крайней мере три
блока разного объема, и наибольший блок должен давать не менее
25 групповых средних, т. е. N/s > 25.
Для каждого блока (а, Ь, ..., s) вычислим выборочную среднюю
Xai> xbi, ¦¦¦ при ?=1, 2, ..., Nla и т. д.). Для средних х вычислим
(смещенные) оценки дисперсии общей средней х, т. е.
а2
Va=—— (a = N/a), B.1)
а
где
а2а= V (*»'-*)'. B.2)
(Заметим, что оценка VI становится менее смещенной с ростом объема
блока, так как средние блоков становятся более независимыми.)
Оценим взвешенное среднее раЬ автокорреляции блочных данных по
отношению к первым (К — 1) сдвигам (К = Ыа = 4) [Mechanic,
McKay, 1966, p. 11]. Или
к —i
~ n ^C wh Pa (fe) /n о\
Wab —л ^ «¦_ j > lz-°/
' Длс Клейнен 161
где веса равны:
wh = -^- B.4)
и ра (А) означает сериальную корреляцию сдвига k между средними
блоков объема а. Очевидно, что если средние независимы, то ра (k) = О
даже для k = 1 и р становится равным нулю. Механик и Маккей
[Mechanic, McKay, 1966, p. 12] вывели выражение для оценки раЬ, не
содержащее автокорреляционных коэффициентов!
Вычислим такие оценки для всех блоков, кроме наибольшего, т. е.
вычислим раЬ, рЬс, ..., pgr (q = r/4 = s/16). Поскольку оценка рчув-
рчувствительна к ошибкам оценивания, р оценивается по крайней мере
по 100 блокам. Доверительные интервалы, однако, вычисляются на
основе дисперсии только 25 блоков.
Будем р (кратко р) считать достаточно малым:
1) если он лежит в области 0,05 ^ р <С 0,50 и
а) не является первым р в последовательности,
б) меньше, чем предыдущий,
в) все последующие р, если они существуют, монотонно убывают
(за исключением последней цепочки, когда р может колебаться сколько
угодно, оставаясь ^ 0,05);
2) если коэффициент ^ 0,05 и все остальные р ^ 0,05. Если по-
последовательность р не удовлетворяет критериям а) или б), то общий
объем выборки N надо увеличить. И наконец, вычисляется дисперсия
следующего наибольшего блока, т. е.
B.6)
УПРАЖНЕНИЯ
1 Докажите, что дисперсия х — 2"=1JC;/yV, где xt стационарно г-за-
висимы, определяется формулой E)
2. Докажите, что уравнение A1) эквивалентно следующей формуле (взято
из [Fishman, 1967]):
var(*)= —
S=— с»
3. Если Р (jcx < \ах < х2) = 1 — а я Р (ух < \ау < у2) = 1 — а, то по-
постройте (консервативный) доверительный интервал для ^/Ца-
4. Предположим, что в — линейная функция от X, например в (к) —
= а + ЬК, и есть следующий доверительный интервал- Р [Qt < 0 (к{) < 0?] >
162
l—fti, P [03 - в A2) в4] -> 1 — а2. Докажите результа-f, полученный
[Crane, Igleliart, 1972a, p 4].
для всех А,! < К <: А2] > 1 —• ai — a2-
!иаете ли вы другой подход к проверке эффекта X на в, т. е. чувствительно-
I [И X?
5. Будет ли^в общем случае биномиальная модель соблюдаться для перио-
периодических и непрерывных систем?
6. Дана выборка из п = 5 наблюдений; наблюдения упорядочены по воз-
возрастанию дсA>, дс12), ..-, дс<5>- Вычислите медиану из порядковых статистик и
из эмпирической функции распределения; то же — для нижнего квартиля
* 10,251 •
7. Рассмотрите эксперимент Монте-Карло с некоторым методом множествен-
множественного ранжирования. Каждое повторение показывает, «работает» метод или нет
(I е. выбирается ли лучшая совокупность). Нуль-гипотеза состоит в том, что
метод «работает», т. е. Е (/>)> Р*. Определите число повторений, которое гаран-
шрует ошибку I рода не более чем в 1% случаев, а ошибка II рода не должна
мри этом превышать 10% для альтернативной гипотезы Нг : р = 0,85 (в то
премя как Р* = 0,90).
8. Докажите, что var (jCj — jc2) минимизируется лри п^/ц = aja2, когда
есть ограничение на фиксированный общий объем выборки п = пх -\- п2 и наблю-
наблюдения независимы.
9. Парные наблюдения берутся из двух совокупностей. Докажите, что тре-
требуемый объем выборки для единичных наблюдений, заданный G2), наибольший
мри а1=а2 (и парные наблюдения имеют положительную ковариацию).
10. Рассмотрите следующий тип оценки. Выбираем 50 независимых значе-
значений х и находим среднее |г. Далее берем еще 100 независимых наблюдений х
и вычисляем среднее значение |2- Продолжаем, увеличивая объем выборки до
150, 200 и т. д. Будет ли поведение оценки похоже на рис. 27 или на рис. 28?
Какова вероятность того, что все \j (j = 1, 2, ..., т) больше | (предполагается
применимость центральной предельной теоремы)?
11. Выведите потребные объемы выборок в уравнении A03), используя ста-
тстику Кокрена—Кокс для проверки гипотезы о разности двух средних.
12. Выведите для уравнения A09) альтернативное выражение статистики
Шсффе.
13. Выведите формулу для ожидаемого дохода разносчика газет, когда он
покупает с газет; сравните со столбцом 2 в табл. 2.
14. Проведите моделирование простой системы массового обслуживания:
а) оцените дисперсию среднего для опыта, используя подопыты;
б) оцените дисперсию на основании коэффициентов автокорреляции;
в) оцените эту дисперсию на основе независимых циклов;
г) определите объем выборки, необходимой для оценки установившегося
i |>еднего (х с точностью до с единиц и с вероятностью A — а);
д) повторите задачу г), но с у и вероятностью A —• а);
е) исследуйте экспериментально, состоятельна ли процедура г).
Замечание. В [Schmidt, Taylor, 1970, p. 558—574] приведено еще 43 задачи,
которые можно решить с помощью моделирования и процедур, рассмотренных
N части А настоящей главы.
ПРИМЕЧАНИЯ
1 В [Blomqvist, 1967, р. 162; 1968, р. 187] обсуждается (аналитически) одно-
ii,шальная система с дисциплиной «первый пришел — первый ушел» при экспо-
экспоненциально распределенном времени прибытия и обслуживания. Автор этой
|1,к'юты нашел, что (положительные) ковариации времени ожидания уменьшают
It 163
ся экспоненциально до нуля. В [Blomqvist, 1970, р. 121] показано, что в пере-
переходной фазе ковариации также монотонно уменьшаются до нуЛя.
2 В [Blomqvist, 1968, р 188—189, 1970, р 125] доказано, что уравнение
A1) также дает асимптотическую среднюю квадратичную ошибку (т. е может
существовать смещение в переходном состоянии) для простой системы массового
обслуживания, начинающей работу из пустого состояния
6 Этот вариант заменяет бесконечное число автокорреляций ps в A1) конеч-
конечным числом (р) параметров bs (bs соотносится с as согласно A5)) К сожалению,
остается необходимость оценки адекватности значения р
4 Краткое обсуждение различных методов определения надежности сред-
среднего моделируемого опыта содержится в [Dear, 1961, р 21—22], [Emshoff,
Sisson, 1971, р 193—195, 198—202], [Hilher, Lieberman, 1968, р 463—465] и
[Fishman, Kiviat, 1967, р 27]
6 Положим хг = 1, если требование i (i = 1, 2, , га) прибывает в пустую
систему Пусть вг обозначает время между прибытиями требований (i —• 1) и i,
Sj — время обслуживания требования г, гиг — его время ожидания Тогда
Р (хг = 1 | xl-1 = \) — Р (Sj_i < v,), в то время как Р (хг ~ 1|jc1_i = 0) =
= Р (SJ-1+ TO,_i < ¦»,)
в В [Tocher, 1963, р 114] содержится опечатка ^ статистика должна быть
в квадрате в выражениях
S? > i (U2?lt<? (i = 1, 2, )
7 В [Geisler, 1964a, p 263] автор указывает, что его подход основан на
центральной предельной теореме и неравенстве Чебышева На самом деле из
этого неравенства следовало бы, что множитель A,96) для 95%-ного интервала
должен быть равен (О.Об)"/2 = ~|/20 Но коэффициент 1,96 все же верен на
основании центральной предельной теоремы для зависимых наблюдений ста-
стационарного процесса
8 Было бы ошибочно называть эту процедуру двушаговой сло= 500, так
как 500 наблюдений имеют сериальную корреляцию E00 наблюдений были взя-
взяты потому, что они дают хорошую оценку а2, см [Geisler, 1964a, p 269])
Более того, вычисления повторялись 10 раз Средние значения для десяти повто-
повторов были затабулированы Эти средние были использованы в [Geisler, 1964b]
9 В [Dudewicz, Dalai, 1971, Sees 2, 3] доказано, что общий потребный объем
выборки для размещения A04) по сравнению с оптимальным размещением на
3% выше для crj/af, = 2 и на 27% выше для af/af, = 10
10 В действительности задачей Нейлора и его соавторов было определение
оптимального из всех возможных количеств газет Однако ее можно решить
по-другому, используя процедуру Кифера—Вольфовица или одномерный ва-
вариант методологии построения поверхности отклика (ср [Wethenll, 1966,
р 154—157])
11 Для непрерывной случайной величины в A10) Р есть не вероятность,
а совместная функция плотности распределения, вспомните, что для непрерыв-
непрерывной х вероятность х быть в точности равной х есть 0. КПОВ годится для непрерыв-
непрерывных и для дискретных переменных
БИБЛИОГРАФИЯ
1 Ad hi кап А К A967) Simulation of queuing problems Opsearch, 4,
49—60
2 AlBayyatiH A A971) A rule of thumb for determining a sample size
in comparing two populations Technometrics, 13 675—677
3 Anderson H and Thorburn D A972) Determining the daily need of
cash for a savings bank, simulation versus analytical solution — In Wor-
Working Papers, vol 2, Symposium Computer Simulation versus Analytical So-
Solutions for Business and Economic Models, Graduate School of Business Ad-
Administration, Gothenburg (Sweden)
4 Andreassonl J A971) Antithetic and Control Variate Methods for
the Estimation of Probabilities in Simulations Report NA 71 41, Department
164
of Information Processing The Royal Institute of Technology, Stockholm
(Sweden)
5 Andrews D F, BickelP J, HampelF R, HuberP J, Ro
gersW H and Tukey J W A972) Robust Estimates of Location Prin-
Princeton University Press, Princeton, New Jersey
6 Angers С GrenierC and HurtubiseF A A970) A Stopping
Rule Subroutine for Digitial Computer Simulation DREV R—629/70, Defen
ce Research Establishment Valcartier, Quebec (Canada)
7 AnscombeF J A953) Sequential estimation J Roy Stat Soc, Ser В
15, 1—29
8 Baraldi S A969a) Previsione e hmitazione degh errori statistici nelle si
mulaziom numenche su calcolatore Rivista di Ingegnena, 224—227
9 В a r a 1 d t S A969b) Previsioni teonche e misure spenmentah degh errori
statistici in certe simulazioni numenche Rmsta di Ingegnena, 395—401
10 Blomqvist N A967) The covanance function of the M/G/l queuing
system Skandmavisk Aktuanetidskrift, 50, 157—174
11 Blomqvist N A968) Estimation of waiting time parameters in GI/G/1
queuing system, Part I general results Skandinavisk Aktuanetidskrift, 51,
178—197
12 Blomqvist N A969) Estimation of waiting time parameters in GI/G/1
queuing system, Part II heavy traffic approximations Scandinavisk Aktuane-
Aktuanetidskrift, 52, 125—136
13 Blomqvist N A970) On the transient behaviour of the GI/G/1 waiting-
times Skandinavisk Aktuanetidskrift, 53, 118—129
14 Blomqvist N A971) Senestorlek vid systemsimulenng—ett exempel
Sartryck ur Statistik Tidsknft, 3, 220—225, 244
15 Brenner M E A965) A relation between decision making penalty and
simulation sample size for inventory systems Operations Res, 13, 433—-443
16 Brenner M E A966) A cost model for determining the sample size in
the simulation of inventory systems J Ind Eng, 17, 141—144
17 BruzeliusL H A972) Estimating endogeneous parameters in a dynamic
simulation model — In Working Papers, vol 1, Symposium Computer Simu
lation versus Analytical Solutions for Business and Economic Models, Gra
duate School of Business Administration, Gothenburg (Sweden)
18 Chapman D G A950) Some two sample tests Ann Math Stat, 21,
601—606
19 ChowY S and Rob bins H A965) On the asymptotic theory of fixed
width sequential confidence intervals for the mean Ann Math Stat, 36, 457—
462
20 ClarkS R.RourkeT A andWrenJ M A972) A note on the re-
producibihty of discrete—event simulation studies Infor, 10, 194—200
21 CochranWG and Cox G M A957) Experimental Designs 2nd edition,
Wiley, New York
22 ConoverW J A971) Practical Nonparametric Statistics Wiley, New
York
23 ConwayRW A963) Some tactical problems in digital simulation Mana-
Management Sci, 10, 47—61
24 CorneliussenA and Ladd D W A970) On sequential tests of the
binomial distribution Technometncs, 12, 635—646
25 CraneM A andlglehartD L A972a) A New Approach to Simula
ting Stable Stochastic Systems I—General Multi Server Queues Technical
Report, № 86—1, Control Analysis Corporation, Palo Alto, California
26 CraneM A andlglehartD L A972b) Confidence Intervals for the
Ratio of Two Means with Application to Simulations Technical Report,
№ 86—2, Control Analysis Corporation, Palo Alto, California
27 CraneM A andlglehartD L A972c) Simulating Stable Stochastic
Systems, II Markov Chains Technical Report, № 86—3, Control Analysis
Corporation, Palo Alto, California
28 CsorgoM and Seshadn V A971) Characterizations of the Behrens—
Fisher and related problems (a goodness of fit point of view) Theory Prob.
Applications, 16, 23—35
165
29 David H A A971) Order Statistics Wiley New York
30 Dear R E A961) Multnanate Analyses of Variance and Co\anance for
Simulation Studies Involving Normal Time Series, Field note 5644 System
Development Corporation, Santa Monica, California
31 DernksJ С A971) Onderzoek tav de Implementatie van de Methode
van Mechanic en McKay ш Simulatie—Techmeken Graduate thesis, tueede
studienchting, Technische Hogeschool, Delft (The Netherlands)
32 DudewiczE J A972) Statistical Inference with Unknown and Unequal
Variances Department of Statistics, The University of Rochester, Rochester,
New York
33 DudewiC7E J and Dalai S R A971) Allocation of Observations m
Ranking and Selection with Unequal Variances The University of Rochester,
Rochester, New York
34 Dutton J M and Star b иск W H A971) Computer Simulation ol
Human Behavior Wiley, New York
35 EmshoffJ R andSissonR L A971) Design and Use of Computer
Simulation Models Second printing MacMillan, New York
36 Farrell R H A966) Bounded length confidence intervals for the p pomt
of a distribution function III Ann Math Stat, 37, 586—592
37 FishmanG S A967) Digital Computer Simulation The Allocation of
Computer Time in Comparing Simulation Experiments RM 5288 1 PR, The
Rand Corporation, Santa Monica, California, Operations Res, 16, 1968, 280—
295, 1087
38 FishmanG S A968) Spectral Methods in Econometrics R 453 PR The
Rand Corporation, Santa Monica, California
39 FishmanG S A971) Estimating sample size in computing simulation
experiments Management Sci, 18,21—38
40 FishmanG S A972a) Output Analysis for Queueing Simulalions Tech
meal Report, № 56, Department of Administrative Sciences, Yale University,
New Haven, Connecticut
41 FishmanG S A972b) Estimation in Multiserver Queueing Simulations
Technical Report, № 58, Department of Administrative Sciences, Yale Univer
sity, New Haven, Connecticut
42 FishmanG S A973) Statistical Analysis of Multiserver Queueing Simu
lations Technical Report, № 64, Department of Administrative Sciences, Yale
University, New Haven, Connecticut
43 FishmanG S and Kiviat P J A967) Digital Computer Simulation
Statistical Considerations RM 5387-PR, The Rand Corporation, Santa Monica,
California
44 Fisz M A967) Probability Theory and Mathematical Statistics 3rd edi
tion, Wiley, New York
45 Flagle С D A960) Simulation techniques In Operations Research and
Systems Engineering (C D Flagle, W H Huggins and R H Roy, eds), The
John Hopkins Press, Baltimore
46 FraserD A S A957) Nonparametnc Methods in Statistics Wiley, New
York
47 Fu К S A970) Sequential Methods in Pattern Recognition and Machine
Learning Second printing, Academic, New York Русский перевод Ф у К С
Последовательные методы в распознавании образов и обучении машин М,
«Наука», 1974
48 GebhartR F A963) A limiting distribution of an estimate of mean
queue length Operations Res, 11, 1000—1003
49 GeertsemaJ С A970) Sequential confidence intervals based on rank
tests Ann Math Stat, 41, 1016—1026
50 GeislerM A A964a) The sizes of simulation samples required to com-
compute certain inventory characteristics with stated precision and confidence
Management Sci, 10, 261—286
51 GeislerM A A964b) A test of a statistical method for computing selec
ted inventory model characteristics by simulation Management Sci, 10,
709-715
166
52 Ghosh В К A970) Sequential Tests of Statistical Hypotheses Addison—
Wesley, Reading, Massachusetts
j3 Ghosh В К and Freeman H A961) Investigation of Sequential Me
thods in Design and Analysis of Experiments (Introduction to Sequential
Experimentation, Sequential Analysis of Variance), Technical Report R—11,
FEA MRS 60—7j Field Evaluation Agency, Fort Lee, Virginia
'A GoodmanA S, LewisP A W andRobbmsH E A973) Simulta
neous estimation of large numbers of extreme quantiles in simulation expe-
experiments Commun Stat In press
55 GrundyP M, Rees D H andHealyM J R A954) Decision bet-
between two alternatives—how many experiments? Biometrics, 10, 317—323
>f> Gurtler H A969) Quantitative Modelle zur Ophmierung des Schalterver-
kehrs in emem Postamt Doctoral dissertation, Wilhelms-Umversitat, Mun-
ster (Germany)
>7 Hauser N, Bansh N N andEhrenfeldS A966) Design problems
in a process control simulation J Ind Eng , 17, 79—-86
58 Hayes R H A969) The value of sample information In The Design of
Computer Simulation Experiments (T H Naylor, ed), Duke University
Press, Durham, North Carolina
)9 Heal у T L A9Ь4) On the Solution of Queueing Problems by Computer
Simulation Operations Research Memorandum Op 8—15, Operations Evalua-
Evaluation, Advanced Development Division, National Cash Register Company,
Dayton, Ohio
GO Heuts R M J A971) Parameter Estimation in the Exponential Distribu-
Distribution Confidence Intervals and a Monte Carlo Study for Some Goodness of
Fit Tests, EIT 22, Tilburg Institute of Economics, Kathoheke Hogeschool, Til-
burg (The Netherlands)
Gl Heuts R M J and Rens P J A972) A Monte Carlo Study on the Kuyper
Test Statistic for Testing Exponentiahty (Two Different Approaches), RC Re-
Report, № 13, Rekencentrum Katholieke Hogeschool, Tilburg (The Netherlands)
d2 Hi 1 her F S and Lieberman G J A968) Introduction to Operations
Research Second printing, Holden Day, San Francisco, California
03 H о 1 m e I A972) On the Construction of Confidence Bands for Distribution
Functions In Working Papers, vol 1 Symposium Computer Simulation ver-
versus Analytical Solutions for Business and Economic Models, Graduate School
of Business Administration, Gothenburg (Sweden)
G4 Huisman F A969) Statistische Aspekten van Simulatie Report, № 2,
Afdehng Werktuigbouwkunde, Technische Hogeschool Twente, Enschede (The
Netherlands)
65 Huisman F A970) Bepaling van de Deelrungrootte bij Simulatie Re-
Report, № 005, Afdehng Werktuigbouwkunde, Technische Hogeschool Twente,
Enschede (The Netherlands)
G6 Johnson N L A957) Sequentially determined confidence mtervals Bio-
metnka, 44, 279—281
(O Kabak I W A968) Stopping rules for queueing simulations Operations
Res, 16, 431—437
()8 Keeping E S A962) Introduction to Statistical Inference Van Nostrand,
Princeton, New Jersey
(.9 Kendall M G and S t u a r t A A961) The Advanced Theory of Stati
sties, vol 2 Griffin, London Русский перевод Кендалл М, Стьюарт А
Статистические выводы и связи Т 2 М , «Наука», 1970
70 Kendall M G and S t u a r t A A963) The Advanced Theory of Stati-
Statistics, vol 1, second edition, Griffin, London Русский перевод Кен
далл М, Стьюарт А Теория распределении Т 1 М, «Наука», 1966
71 KleijnenJP A967) Reliability and Simulation (Obtainable at Katholie-
Katholieke Hogeschool, Tilburg, The Netherlands)
/2 Kosten L A968) Statistische Aspecten van Simulatie Afdeling Algemene
Wetenschappen, Technische Hogeschool, Delft (The Netherlands)
! Kurlat S and Springer M A960) Sequential analysis of the reliability
of an antitank mine sjmulauon system Operations Res, 8, 473—486
167
74 Lewis P A W A972) Large—Scale Computer—Aided Statistical Mathe-
Mathematics Naval Postgraduate School, Monterey, California (To appear in Pro-
Proceedings Computer Science and Statistics 6th Annual Symposium on the In-
Inference, Western Periodical, Hollywood, California)
75 Martin W A A971) Sorting Computing Surveys, 3, 147—174
76 Maurice R A957) A minimax procedure for choosing between two popu-
populations using sequential sampling J Roy Stat Soc, Ser B, 19, 225—-261
77 Mechanic H and McKay W A966) Confidence Intervals for Averages
of Dependent Data in Simulations II Technical Report 17—202, IBM Advan-
Advanced Systems Development Division, Yorktown Heights, New York
78 MehtaJ S andSrinavasanR A970) On the Behrens—Fisher prob-
problem Biometrika, 57, 649—655
79 Meier R C, Newell W T andPazer H L A969) Simulation in
Business and Economics Prentice Hall, Englewood Cliffs, New Jersey
80 MihramG A A972) Simulation Statistical Foundations and Methodolo-
Methodology Academic, New York
81 NaylorT H A971) Computer Simulation Experiments with Models of
Economic Systems Wiley, New York Русский перевод Н е й л о р Т Ма-
Машинные имитационные эксперименты с моделями экономических систем
М «Мир» 1975
82 NaylorT H.BahntfyJ L.BurdickD S and ChuK A967)
Computer Simulation Techniques 2nd printing, Wiley, New York
83 Paulson E A964) Sequential estimation and closed sequential decision
procedures Ann Math Stat, 35, 1048—1058
84 PressSJ A966) A confidence interval comparison of two test procedures
proposed for the Behrens—Fisher problem J Amer Stat Assoc, 61, 454—
466
85 Prins H J A962) Een Monte Carlo Methode om een Integraal met Vooraf
Gegeven Nauwkeungheid te Schatten, Waarbij het Oppervlak van het Gebied,
Waarover Geintegreerd Wordt, Mede Geschat Moet Worden Report, № 9/62,
Philips' Gloeilampenfabneken N V, Nat Lab Groep Statistiek, Eindhoven
(The Netherlands)
86 PuriM L and Sen P К A971) Nonparametnc Methods in Multivanate
Analysis Wiley, New York
87 Reynolds J F A972) Asymptotic properties of mean length estimators
for finite Markov queues Opeiations Res, 20 52—57
88 Robbins H, Simons G and Starr N A967) A sequential analogue
of the Behrens—Fisher problem Ann Math Stat, 38 1384—1391
89 Robbins H and Starr N A965) Remarks on Sequential Hypothesis Te-
Testing Technical Report, № 68, Department of Statistics, University of Minne
sota, Minneapolis
90 SasserW E BurdickD S Graham D A and NaylorT H
A970) The application of sequential sampling to simulation an example in-
inventory model Communicdtions ACM, 13, 287—296
91 ScheffeH A964) The Analysis of Variance 4th printing Wiley, New
York Русский перевод Ш е ф ф е Г Дисперсионный анализ М , Физматгиз,
1963
92 ScheffeH A970) Practical solutions of the Behrens—Fisher problem
J Amer Stat Assoc 65 1501—1508
93 Schmidt J W and Taylor R E A970) Simulation and Analysis of
Industrial Systems Richard D Irwin, Inc, Homewood, Illinois
94 SrivastavaM S A970) On a sequential analogue of the Behiens—Fi-
Behiens—Fisher pmblem J Roy Stat Soc, Ser B, 32, 144—148
95 Starr N A966a) The performance of a sequential procedure for the fixed-
width interval estimation of the mean Ann Math Stat, 37, 36—50
96 Starr N A966b) On the asymptotic efficiency of a sequential procedure
for estimating the mean Ann Math Stat, 17, 1173—1185
97 Starr N and Woodroofe M A970) Further Remarks on Sequential
Estimation The Exponential Case Technical Report № 7, Department of
Statistics and Statistical Research Laboratory, The University of Michigan,
Ann Arboi
J68
'18 thomasseA H A972) Het Behrens—Fisher Probleem Scnptle о 1 v prof
dr J Hemelnjk Mathematisch Instituut, Universiteit van Amsterdam, Am
sterdam
')<) Tintner Q A960) Handbuch der Okonometne Springer Verlag, Berlin
100 Tocher К D A963) The Art of Simulation The English Universities Press
Ltd , London
11I VanderWaerdenB L A965) Mathematische Statistik Springer Ver
lag, Beilin Русский перевод Ван дер Варден Б Л Математическая ста
тистика М, ИЛ 1960 (перевод предыдущего издания)
11J V an Fr ankenhuy sen J H and S с h u r i n g a A W A971) Wachthj
den bij Lifttransport in een Hoog Kantoorgebouw Report BW 6/71, Afdeling
Mathematische Beshskunde Stichting Mathematisch Centrum, Amsterdam
103 Wang Y Y A971) Probabilities of the type I errors of the Welch tests for
the Behrens—Fisher problem J Amer Slat Assoc, 66, 605—608
104 Wehrli M A970) Zur Stichprobenreduktion bei Monte Carlo Simulationen
Unternehmensforschung 14 97—108
11M Weiss L A960) Confidence intervals of preassigned length for quantiles
of ummodal populations Naval Res Logistics Quart, 7, 251—256
106 Wet hen 11 G В A966) Sequential Methods in Satisfies Methuen London
and Wiley, New York
107 Ying Yao A963) On the Comparison of the Means of Two Populations
with Unknown Variance ARL 63—106, Aerospace Research Laboratories,
Wright—Patterson Air Force Base Ohio
Шварц Г выборочный метод М «Статистика», 1978
11олезная в контексте данной главы сводка результатов содержится в книге
Закс Л Статистическое оцениваняе М «Статистика», 1976
кория статистических решений представлена в книге Райфа Г, Шлей
фер Р Прикладная теория статистических решений М «Статистика», 1977
V Б МЕТОДЫ МНОЖЕСТВЕННЫХ СРАВНЕНИЙ
V.B.I. Вступление и краткое резюме
В V А мы обсуждали проблему Надежности суждений о среднем
одной совокупности или о разности средних двух совокупностей при
фиксированном объеме выборки. Теперь перейдем к рассмотрению
общего случая k (> 2) совокупностей В отличие от V А 4 (и далее
V В), где число наблюдений выбирается с целью получить наиболее
Iочное значение среднего с определенной, заранее заданной надеж-
надежностью, здесь мы будем рассматривать фиксированный объем выборки,
состоящей из пг наблюдений совокупности я, (t = 1, 2, , k) Такие
< итуации встречаются в моделировании и исследованиях по методу
Монте-Карло, они мало изучены Кроме того, мы не будем стремиться
к гому, чтобы получить наилучшую систему, а попытаемся определить,
пнияют ли факторы на систему, а если влияют, то как Попытаемся
Юм самым получить более глубокое представление о проблеме За-
Заме I им, что фактор или факторы предполагаются качественными, для
количественных факторов более адекватны методы регрессионного
ииализа1
В V Б 2 мы обсудим несколько принятых уровней ошибок, которые
могут встречаться в ситуациях с множественными суждениями Под-
чодящий уровень будем подбирать экспериментально. В V.B.3 будут
169
представлены параметрические и непар а" метрические методы множе-
множественных сравнений (ММС), применяемые для различных целей и
ситуаций. Обсуждаемые цели экспериментов: доверительные границы
для сравнений с эталоном (ц,г — ц0), все попарные сравнения (^г —
— цс), линейные контрасты средних B сгц,г при 2 ct = 0), линейные
функции B c^i), сами средние (ц,г), выбор подмножества, содержа-
содержащего наилучшую совокупность, или^подмножесгва, содержащего все
совокупности, лучшие по сравнению со стандартной совокупностью.
Кроме экспериментальных ситуаций с одним фактором мы будем изу-
изучать ситуации со многими факторами. В V.B.4 обсуждается эффектив-
эффективность и робастность ММС. Даются рекомендации для применения
определенных ММС в моделировании и экспериментах Монте-Карло.
В V.B.5 кратко обсуждается еще ряд ММС для упомянутых экспе-
экспериментальных ситуаций. Далее перечисляются ММС для других це-
целей и ситуаций. Читатель, интересующийся выбором метода для своей
конкретной задачи, может пропустить V.B.3 и перейти сразу к V.B.4.
V.B.2. Уровни ошибок
Рассмотрим традиционный уровень ошибки а в доверительном
интервале и проверку гипотез' относительно только одной совокуп-
совокупности. Доверительный интервал можно определить, например, в виде
«^ содержится в интервале х + ^(л-i) s (x)». В V.A.3 мы видели,
что это утверждение о доверительности легко может быть переформи-
переформировано в утверждение о значимости при проверке гипотезы Но : \х =
= |л0 (для любого pi0). Если доверительный интервал не содержит
\х0, то мы отбрасываем Но. Поскольку подход, основанный на дове-
доверительных интервалах, более общий по сравнению с подходом, ос-
основанным на проверке гипотез, мы будем пользоваться формулиров-
формулировками в терминах доверительных интервалов (оценивания). Итак, бу-
будем следовать Тьюки, который подчеркивал преимущество исполь-
использования доверительных интервалов (см., например, [Kurtz et al.,
1965, p. 148—149] или fTukey, 1953, p. 247—256]J.
Пусть S — утверждение о доверительном интервале для \х или
об уровне значимости при проверке гипотезы Н0 : \i = \i0. Исполь-
Использование уровня ошибки а означает, что вероятность того, что данный
доверительный интервал не накрывает истинного значения \i, равна
а и что если гипотеза Но верна, то вероятность того, что значимое ут-
утверждение ложно (т. е. что Но ошибочно отвергается), есть а. Заметим,
что при проверке гипотез мы должны добавлять «если Но справедли-
справедливо». В последующем обсуждении, когда будет определиться значи-
значимость суждения S, а не доверительный интервал, всегда будет пред-
предполагаться оговорка «при условии выполнения нулевой гипотезы».
Статистикам в своей деятельности приходится формулировать много
утверждений. Каждое утверждение можно рассматривать как опыт
с вероятностью успеха A — а) и с вероятностью неудачи а. Для
N экспериментов с одним утверждением в каждом среднее число не-
неверных утверждений есть aN и доля неверных экспериментов есть
aN/N ~ а.
170
Рассмотрим пример эксперимента, в котором определяются сред-
средние значения k совокупностей на основании п независимых наблюде-
наблюдений из каждой совокупности. При сравнении двух совокупностей —
I и 2 — можно применять обычную ^-статистику для вывода утвержде-
утверждения 5Х «(Х]_— (Л2 содержится в интервале (хх—х2) ± tfin-i) s (Jfi — х2)»
аналогично тому, что мы видели в разделе V.A.3. Тем же способом
можно вывести утверждение 52 о |х3 — |Л4. Вероятность [безусловная
(маргинальная)] того, что 5Х ложно, есть а; вероятность того, что 52
ложно, есть также а. Можно, однако, рассматривать оба утверждения
вместе, потому что они относятся к одному эксперименту. Пусть
St = 0 означает, что утверждение i ложно, и S, = 1 означает, что
утверждение i истинно (? = 1, 2, ...). Тогда совместная вероятность
того, что оба (независимые) утверждения истинны, есть
Р (Sx = 1 AS2= \) = P (Sx- l)P(S2 = 1) = (l — af < A - a). A)
Вообще, если есть т независимых утверждений и каждое с дове-
доверительным уровнем A — а), то (совместная) вероятность того, что
все т суждений истинны, есть
B)
i=\
где A — а)т много меньше, чем A — а), если т велико. Следователь-
Следовательно, если в нашем эксперименте много утверждений и каждое с дове-
доверительным уровнем (Г—"а), то выводы из эксперимента'могут содер-
содержать большую долю ложных утверждений!
Значение а в каждом отдельном утверждении называется удель-
удельным уровнем ошибки. Вместо выбора уровня ошибки можно выбирать
вероятность того, что заключение по эксперименту правильно, т. е.
вероятность того, что все"утверждения, касающиеся эксперимента,
истинны, или
P(Sx= 1Л52= 1Л-Л5т = 1). C)
Уровень ошибки, устанавливаемый в эксперименте, например схе,
ость вероятность того, что не все утверждения истинны; это эквивалент-
эквивалентно вероятности того, что одно или более утверждений в эксперименте
ложны:
а? = Р (Si = О V 5, = О V ... V Sm) = 0. D)
(Заметим, что А V В означает А или В или А и"В.) Если аЕ равно,
например, 10%, это значит, что в 90 из 100экспериментов все утверж-
утверждения относительно этих экспериментов верны, или, иначе, в 10 из
100 экспериментов множество совокупностей «недооценено», т. е. по
|файней мере одно утверждение в наборе утверждений об "экспери-
"эксперименте будет ложным. Вычисления просты, если все утверждения не-
(ависимы, так как можно пользоваться уравнением B). Однако,
171
/
к сожалению, утверждения часто зависимы, например (хг — х2),
(хг — х3), ..., где несколько утверждений имеют общий элемент
Существуют специальные методы вычислений в случае зависимых
утверждений. Существенный момент в концепции уровней ошибок —
не зависимость или независимость утверждений, а наличие более чем
одного (связанного) утверждения. Это означает, что уровень ошибки
меняется, если утверждения объединяются вместе; (не) зависимость
утверждений влияет на степень изменения в конечном уровне ошибки
(см. [Ryan, 1959, р. 34]).
Можно определить несколько других уровней ошибок. В [Miller,
1966, р. 5—12, 28—35, 84—85, 102—107] дается весьма полное пред-
представление об уровнях ошибок на сравнение; устанавливаемых в экс-
эксперименте; на эксперимент (в отличие от ошибок, устанавливаемых
в эксперименте) и при р-уровнях значимости Дункана или «защитных»
уровнях. В [Verhagen, 1963] предложен «предупредительный уровень».
В [Seeger, 1966, р. 134—141] обсуждается доля ложно значимых ут-
утверждений у Эклунда (Eklund). Есть много других ссылок на различ-
различные уровни ошибок3. Какой из них следует предпочесть — весьма
спорный вопрос; каждый вариант имеет своих защитников. По нашему
мнению, основными служат уровни ошибок на сравнение и устанав-
устанавливаемых в эксперименте. С помощью первого типа можно фиксиро-
фиксировать безусловную (маргинальную) вероятность истинности определен-
определенного утверждения; с помощью второго фиксируется совместная ве-
вероятность того, что все суждения, составляющие заключение по экс-
эксперименту, верны4. Уровень ошибок на сравнение хорошо известен из
традиционной теории проверки гипотез и доверительных интервалов;
ошибки, устанавливаемые в эксперименте, развиваемые с 1950-х
годов, встречаются во многих ММС. Остается только неясным, какой
тип предпочесть.
Если мы имеем одно утверждение в эксперименте с одной или двумя
совокупностями, то эти два понятия уровня ошибок совпадают. При-
Применение уровня ошибки, устанавливаемой в эксперименте, оправдано
в случае, когда заключения об эксперименте основаны на многих
суждениях. Пример заключения, основанного на многих сужде-
суждениях, может быть, скажем, таким: «|хх — [х2 содержится в интервале
/j и [д,х — |х3 в интервале /2» или (в доверительных терминах): «pix от-
отличается от |х2, но не отличается от ji3 (предположение, что 1Х не со-
содержит нуль, а /2 содержит). Взятые вместе оба суждения имеют
больше смысла. Следовательно, мы выбрали формулировку, что имен-
именно объединенные суждения дают заключение об эксперименте. Если
суждения основываются на одном эксперименте, то оправдано при-
применение традиционного уровня ошибки на сравнение. Часто, однако,
у нас есть выборка щ наблюдений из совокупности i (i = 1, ..., k)
и мы смотрим, какое из k средних отличается от других, или ищем
наибольшее среднее. В таких ситуациях суждения о сравнении k сред-
средних должны рассматриваться совместно. Статистики согласятся с тем,
что использование уровня ошибки на сравнение дает много ложных
утверждений. Если есть т суждений, то ожидаемое число ложных
172
с уждений будет am, где а — уровень ошибки на сравнение5. Даже
если статистики согласны с тем, что в такой ситуации применение
уровня ошибки на сравнение выглядит нежелательным, то, как мы
ипделн, нет согласия по поводу альтернативного уровня. Однако
ним кажется, что большинство статистиков6 предпочитают уровень
ошибки, устанавливаемой в эксперименте, так как при этом кон-
контролируется весь эксперимент со всеми нужными утвержде-
утверждениями.
Но существует плата за пользование уровнем ошибки, устанав-
устанавливаемой в эксперименте. Если мы хотим, чтобы все т суждений в экс-
эксперименте были правильными, то длины индивидуальных доверитель-
пых интервалов должны возрасти. Например, в одном из методов
оцениваемое стандартное "отклонение умножается не на t%/2> а на
(юльшую величину ^/B"!)- В терминах проверки гипотез из ММС
пмтекает, что такой критерий менее чувствителен к отклонениям от
//„ : \ix = |х2 = ... = |xft и метод становится менее мощным по срав-
сравнению с несовместным методом. В [Miller, 1966, р. 32—33] упомянуты
фи возможности для уменьшения длины интервала и увеличения
мощности критерия.
1. Увеличение уровня ошибки эксперимента аЕ- В [Dunn, 1964
р. 248], например, предложено значение [а^] брать значительно
Гюльше традиционного 0,05, и в приведенном примере автор взял
а г. = 20%. Трудность состоит в том, что для некоторых ММС пона-
понадобятся специальные таблицы, а эти таблицы существуют только для
че, равного били 1% (см., например, непараметрическую процедуру
и [Steel, 1959a]).
2. Уменьшение числа утверждений т. Число т зависит от числа
факторов и числа их уровней. Если мы имеем один фактор с k уровня-
уровнями, то хотелось бы реализовать <х,е для всех т утверждений относи-
юльно k средних. Если, однако, существует много утверждений из-за
гого, что много факторов, то мы можем определить мощность крите-
критерия, выбирая аЕ для всех суждений только относительно основных
>ффектов или всех суждений относительно одного определенного
фактора. В таком случае формируются «семейства» близких суждений
m общего множества т суждений, и внутри каждого семейства опре-
определяется уровень ошибок. Этот уровень называется уровнем ошиб-
ошибки для семейства и используется вместо уровня для всего эксперимен-
in. В V.B.3 мы вернемся к образованию семейств. Мы согласны с
I Miller, 1966, р. 34—35], что выбор семейств производится из субъек-
швных соображений. (В любом случае экспериментатор должен иметь
II виду различные уровни.)
3. Увеличение объема выборки. Зная объем выборки, можно вы-
вычислить мощность критерия. Это, однако, очень трудная проблема
(ш. [Miller, 1966, р. 102 — 107], [Hartley, 1955, р. 51—52], [Ryan,
1!M9, р. 36—37], [Scheffe, 1964, р. 71] и [Tukey, 1953]). Можно также
питаться сформировать выборку так, чтобы гарантировать правиль-
правильную ранжировку k средних, но тогда мы перейдем к методам множе-
11венного ранжирования, которые будут обсуждаться в V.B.
173
V.B.3. Методы множественных сравнений
Метод Бонферрони. Пусть имеется т суждений с уровнем ошибки
на сравнение at (I = 1, 2, .., т). Для независимых суждений можно
применить B) и D) и найти E), где последнее равенство выполняется,
если для всех суждений берется одно значение аг = а.
«я = 1 — Р (все суждения правильны) =1 — P[(SX =1 Д S2 = 1 Л
E)
Л ... Л Sm'= 1) = 1 — П A — af) = 1 — (I _ a)-.
Рис. 30. Диаграмма
Венна
Следовательно,
Р (di\Ma\Ma) = Р
Обычно, однако, утверждения, составляю-
составляющие, заключение об эксперименте, зависимы.
Тогда мы можем определить верхний пре-
предел аЕ.
Рассмотрим вначале диаграмму Венна на
рис. 30. Рисунок показывает, что вероят-
вероятности события Ах и/или А 2 удовлетворяют
условиям
Р (Аг\/А2 = Р (А,) + Р (А2) -
< Р (А,) + Р (Ла). F)
Или в общем случае
Р {АхуА%) + Р (А3) <
Р (Л3). G)
(8)
Пусть At обозначает событие, при котором суждение ложно E,- =
= 0), тогда уравнение (8) можно записать в следующем виде:
2
1= 1
(9)
Если для каждого суждения уровень ошибки на сравнение равен
аи то (9) эквивалентно A0):
«?
Щ
1=1
A0)
Это ограничение называется неравенством Бонферрони [Miller, 1966
р. 8]. (Сравните также упражнение 1.) Итак, пусть при множест-
множественном сравнении имеется т суждений, возможно, зависимых и
для каждого задан традиционный уровень ошибки сравнения'^ аг
('¦ = 1 m); тогда можно выбрать уровень ошибки эксперимента
174
ниже некоторого заданного значения, например 10%, а, так, чтобы
т
y\xt = 0,10. Применение неравенства Бонферрони в методах мно-
множественного сравнения особенно хорошо изложено в [Dunn, 1961;
1964] (см. также [Miller, 1966, р. 15—16, 67—70], [Scheffe, 1964, р. 80]
пли [Seeger, 1966, р. 123]). Рассмотрим простой пример.
Допустим имеется п нормально распределенных независимых на-
наблюдений из каждой совокупности и надо сравнить между собой все
средние. Из V.A.3 известно, что два средних |хг и \iy (i Ф V) можно
сравнить с помощью ^-критерия с числом степеней свободы B п — 2),
;i именно
(la—хг) — (jxj—(v
Г,,,_о= П1'2. A1)
2П % (S2+S2y/2 V '
Нужно сделать т ~ k (k—1)/2 таких сравнений. Следовательно,
уровень ошибки, устанавливаемый в эксперименте, не превышает,
скажем, а', если коэффициент ошибки одного сравнения а' 1т. Итак,
следующие т утверждений имеют совместный доверительный уровень
по крайней мере A — а'O:
A*1-1*1-) 6 (*!-**') ±^2т) («?+ в?'I/2/П1/2- A2)
Подчеркнем, что подход Бонферрони можно применять и к утверж-
утверждениям, не основанным на ^-статистике. Например, в [Dunn, 1964]
применен непараметрический ранговый критерий на каждое сравнение
(см. D1)).
Обсудим преимущества и недостатки подхода Бонферрони. (Глу-
(Глубокое понимание относительных возможностей этого подхода возмож-
возможно только после обсуждения других ММС (см. V.B.4).) Ограничения
подхода следующие: 1) мы должны знать, сколько суждений имеет
место (или определить их максимальное число) перед тем, как присту-
приступить к анализу результатов выборки; 2) процедура консервативна,
когда известна только верхняя граница аЕ. Первый недостаток не-
несуществен, если, например, мы имеем k совокупностей и знаем зара-
заранее, что мы хотим сравнить все k совокупностей со стандартной сово-
совокупностью (т = k) либо со всеми другими (т — k (k — 1)/2). (В ме-
методе Шеффе, как мы увидим, необходимо познакомиться с данными,
чтобы далее решить, какие именно сравнения нас интересуют.) Вто-
Второй недостаток также может быть несущественным; в [Dunn, 1961],
например, показано, что при определенных обстоятельствах этот метод
дает меньшие доверительные интервалы по сравнению с точными ММС.
Мы вернемся к эффективности различных ММС в V.B.4. Теперь рас-
рассмотрим преимущества метода Бонферрони:
1. Можно применять статистики, традиционные для немножест-
немножественных ситуаций и хорошо известные многим экспериментаторам.
2. Метод имеет более широкое применение, чем другие ММС.
Как мы увидим далее, большинство ММС требуют нормально распре-
распределенных независимых наблюдений с общей дисперсией, равным
175
числом наблюдений в совокупностях и однофакторным планом. В ме-
методе Бонферрони не нужно предположение о нормальности, так как
можно применить непараметрические статистики (или пользоваться
известной робастностью ^-статистики). Неравенство дисперсий также
не проблема, так как в V.A.3 мы предложили пересмотренные ^-ста-
^-статистики. Число наблюдений на популяцию может меняться при при-
применении некоторых традиционных параметрических и непараметри-
непараметрических критериев. Многофакторные планы также не создают проблем,
как мы убедимся позже. Наконец, отметим, что метод Бонферрони —
единственный, допускающий зависимость наблюдений (получающую-
(получающуюся в моделировании при использовании общих случайных чисел)!
Для отдельного сравнения fx; — |х,< можно применить параметри-
параметрическую и непараметрическую статистики для парных наблюдений
(dj = Xtj — Xi'j, где } — I, ..., п) с уровнем ошибки на сравнение а' 1т.
В заключение коснемся вопроса о таблицах для этого метода.
Существующие таблицы дают критические значения статистики для
традиционных уровней 10, 5, 1% и т. д. В ситуациях множественного
сравнения, однако, мы пользуемся уровнями а'1т, где а' равно,
например, 10%. Для одного сравнения широко применяется ^-ста-
^-статистика. Шеффе [Scheffe, 1964, р. 80] дает следующую аппроксима-
аппроксимацию верхней а-точки ^-статистики с v степенями свободы:
tv « 2« + fB«)8 + Z»]/ D0), A3)
где za — верхняя а-точка стандартного нормального распределения
./V @, 1). В [Dunn, 1961, р. 55] приведена таблица двустороннего кри-
критерия уровней ошибки, устанавливаемых в эксперименте, не выше 5
или 1 % и разных v и т. Эта таблица частично воспроизведена в [Mil-
[Miller, 1966, р. 238]. Другие источники определения а'//л-точки ^-рас-
^-распределения даны в [Miller, 1966, р. 70]. В непараметрических методах
можно брать нормальное распределение как асимптотическое распре-
распределение статистики. Тогда определение a'/m-точки не представляет
проблемы, так как во многих публикациях содержатся детальные таб-
таблицы для N @,1). Заметим, что другие неравенства, более строгие,
чем неравенство Бонферрони, были выведены в [Khatri, 1967], но они
применяются только к нормальным совокупностям и более громоздки.
Экспериментальные ситуации. Метод Бонферрони применяется
к любой ситуации, где имеется более одного утверждения. Для част-
частных случаев изобретены специальные ММС. В эксперименте с k со-
совокупностями (т. е. один фактор на k уровнях) могут быть различные
цели.
1. Сравнение средних цг k экспериментальных совокупностей со
средней |л0 стандартной или контрольной совокупности: (л, — ц0
(? = 1, ..., k). При моделировании такой стандартной системы можно
взять конфигурацию существующей системы, правило приоритета
в применении и т. д.
2. Сравнение всех парных сравнений: \it — \ц- (г, V = 1, ..., k;
i < t"). Если нет стандартной совокупности, то B) есть очевидное
обобщение A).
176
3. Сравнение всех контрастов между k средними. Под контрастом
понимается линейная функция k средних, например 2 ^гМ-г» где из-
псстные коэффициенты ct удовлетворяют условию 2 ci = 0. Примером
контраста служит (цг + ^2)/2 — (х3- Упомянутые сравнения |лг — М-о,
,i также |Х; — цг — частные случаи контрастов с коэффициентами
., = + 1, с0 = — 1, d> = 0 (i' ф1) и сг = + 1, с г = — 1,
(,» = 0 (i <Ц', i" Ф i, i" Ф i') соответственно. Пример контраста
и моделировании дает система массового обслуживания с тремя воз-
возможными правилами приоритета, например: а) первый пришел —
первый ушел, б) последний пришел — первый ушел, в) случайно.
Нам может, например, понадобиться изучить парные сравнения
|i, — ^2) На — М-з и М-2 — М-з плюс среднее поведение при регулярных
приоритетах в сравнении со случайным правилом приоритета, т. е.
(Hi + М-2)/2 — \iz. Другие примеры не из области моделирования
приведены в [Crouse, 1969, р. 38], [Dunn, 1964, р. 243] и [Scheffe,
1964, р. 66].
4. Сравнение всех линейных функций средних, где известные коэф-
коэффициенты Hjciji; не обязательно должны удовлетворять 2сг = 0.
11апример, если мы хотим еще изучить средние сами по себе, то когда
имеем средние |хр, мы получаем ср = 1 и ср- = 0 (р' Ф р).
Заметим, что множество суждений, удовлетворяющих A), есть
подмножество суждений типа B). Подобным же образом B) содержит-
содержится в C), в то время как C) содержится в D). Очевидно, что ММС,
пригодные для некоторого набора суждений, также пригодны и для
подмножества этого множества. Тем не менее в большинстве случаев
лучше применять процедуру, специально построенную для данной
ситуации, поскольку такая процедура может дать более короткие до-
иерительные интервалы по сравнению с более общей процедурой,
которая не сможет учесть особенностей частного случая. Имеется мно-
множество суждений, не идентичных ни одному из четырех перечислен-
перечисленных подмножеств. Например, множество суждений только о средних
¦ пдержится в D), но D) — это более общий набор. Следовательно, мы
можем применить общую процедуру (аналогичную процедуре для ли-
1н'['шых функций), но такой подход будет консервативным, т. е. он
мет слишком длинные доверительные интервалы. Мы вернемся к этой
проблеме в V.B.4.
Часто цель эксперимента — выбор наилучшей совокупности.
Имеются специальные методы для выбора подмножества, содержаще-
m лучшую совокупность с заданной вероятностью, или для выбора
подмножества, содержащего все совокупности, лучшие, чем стан-
ыртная.
Помимо различных экспериментальных целей, подобных уже пере-
шсленным, можно выделить экспериментальные планы с одним фак-
шром либо многими факторами. Мы только что обсудили однофак-
"фиые планы. В многофакторных планах цели экспериментов могут
"ьпь подобными данным выше. Например, парные сравнения между
177'
kj уровнями фактора;/ (j = 1, U, ..., J), но не парные сравнения между
уровнями фактора / и уровнями другого фактора /' (/ Ф /'). Мы те-
теперь изучим несколько ММС для различных экспериментальных
ситуаций.
Сравнения между экспериментальной и стандартной совокупностя-
совокупностями. Допустим, мы имеем пг наблюдений из экспериментальной совокуп-
совокупности i (i = 1, ..., k) и п0 наблюдений из стандартной или контроль-
контрольной совокупности. Нужно сравнить средние |лг экспериментальных
совокупностей со стандартной средней |х0. Мы изложим ММС Даннетта
для нормальных наблюдений и непараметрический ранговый метод
Стила; будут также кратко рассмотрены несколько непараметри-
непараметрических методов.
Параметрический метод Даннетта. Даннетт [Dunnett, 1955; 1964]
использует традиционные предположения ANOVA, а именно наблю-
наблюдения распределены нормально и независимы, с общей неизвестной
дисперсией а2 и средними \ij (/ = 0,1, ..., k). Эта общая дисперсия
оценивается обычной обобщенной оценкой или средней квадратичной
ошибкой:
sLslx*i>* , A4)
где v означает число степеней свободы, так что
»= 2 (>Ь~ 1). A5)
/=о
Следовательно, безусловное распределение
*' = I Г'~?\1/2 ('=1.2.-.fe) 06)
sD 1
\tli tloj
есть ^-распределение с v степенями свободы. Значения tt зависимы,
поскольку они все имеют общие члены х0 и s0. Изучив максимум8
k статистик ti, Даннетт получил следующие разультаты для равных
объемов выборок nt — п0 = п.
1. Односторонние доверительные интервалы. Данные k суждений
выполняются в уравнении A7) при установленном в эксперименте
уровне ошибки аЕ = а, критической точке d%,v, затабулированной
Даннеттом [Dunnett, 1955, р. 1117—1118] и Кришнаиэхом и Эрмитажем
[Krishnaiah, Arm it age, 1966, p. 41, 51] для а = 1 или 5% и разных к
и v. Значения d",rJ [V2) также затабулированы в [Gupta, Sobel, 1957]17;
V.l-H0>(xi-x0)-dt,osb^(i=l,...,k). A7)
Уравнение A7) показывает, что мы ищем экспериментальные средние,
превышающие контрольные. Если правая часть A7) положительна,
178
го Xt значимо больше. Если «лучшее» значение среднего — это сред-
среднее, которое меньше стандартного, то Xt значимо меньше, если
В случае, когда мы ищем не лучшие средние значения, а средние,
отличающиеся от контрольного, нужно брать следующие двусторонние
доверительные интервалы.
2. Двусторонние доверительные интервалы. Критическая кон-
константа d'kav табулирована у Даннетта [Dunnett, 1964, р. 488—489]
для k = 1 A) 12, 15, 20 и приведенных выше значений а и v:
(V-i-V-o) € fc-^
Неравенство дисперсий и объемов выборки будет обсуждаться в V.B.4.
Описание ММС Даннетта дано в [Miller, 1966, р. 76—81], где воспроиз-
воспроизведены и таблицы Даннетта.
Критерий суммы рангов Стила. Стил [Steel, 1959a] предло-
предложил непараметрический метод построения доверительных интервалов
для возможнопГсдвига расположений, т. е. все совокупности пред-
предполагаются имеющими идентичные распределения за исключением
возможных различий в средних. (Значит, дисперсии и другие моменты
равны для всех совокупностей.) Далее он предположил, что все на-
наблюдения независимы; критические константы табулированы для
равных объемов выборок. Следуя [Miller, 1966, р. 144—145], можно
описать процедуру Стила следующим образом.
Мы имеем наблюдения для контрольной совокупности (хП1, ...,
v()n) и для t-й экспериментальной совокупности (xtl, ..., xin). Наблю-
Наблюдения каждой экспериментальной совокупности объединим с на-
наблюдениями над контрольной совокупностью. Расположим получен-
полученные In наблюдений в возрастающем порядке безотносительно к их
принадлежности. Припишем ранги 1, 2, ..., 2 п упорядоченным таким
образом наблюдениям: наименьшее наблюдение получит ранг 1 и т. д.
Теперь рассмотрим только наблюдения из экспериментальной совокуп-
совокупности. Ранги этих наблюдений обозначим riu ri2, ..., rin. (Ранги
(r01, ..., ron) стандартной совокупности не используются.) Следова-
юльно, сумма рангов i экспериментальной совокупности равна гг =
- 2^i rtg, и это есть известная статистика Уилкоксона для срав-
сравнения двух совокупностей (см. например, [Conover, 1971, р. 223]
пли [Wilks, 1963, р. 460]). Для построения доверительных интервалов
и критериев, которые были бы справедливы одновременно для всех
/¦ 'разностей, нужно определить наибольшую статистику г% среди
/.' статистик, полученных по двум'выборкам (см. наше обсуждение ра-
поты Даннетта8). Обозначим г — тах;гг. Критическое значение г, ха-
характеризующее уровень ошибки эксперимента а (назовем его г™,„),
щбулировано Миллером [Miller, 1966, р. 250] для k = 2 A) 10, а = 1
179
или Ь% и п между 6 и ШО9. Любая совокупность с ранговой суммой
ft > г?, п считается сдвинутой в положительном направлении от стан-
стандарта. (Следовательно, отдельные утверждения из сложной гипоте-
гипотезы Но: |х0 = (Ах = ... = |Aft отклоняются, если тахггг > Гъ, v •) Для
двустороннего критерия могут быть значимыми как высокие, так и
низкие суммарные ранги. Поэтому статистика ранговой суммы г, за-
заменяется на r\ = max [г*, л Bя+1) —гг], где я Bя +1) — гг есть
ранговая сумма для наблюдений, которые проранжированы в обратном
порядке (ранг 1 приписывается наибольшему из наблюдений и т. д.).
Критические значения гТ'п для тахг г\ табулированы Миллером
[Miller, 1966, р. 251] для k = 2 A) 9, п = 4 A) 20, а = 1%, 5%10.
Применение этого непараметрического критерия показано у Стила
[Steel, 1959a, р. 563—564].
Если мы хотим получить доверительные интервалы вместо проверки
значимости разностей \it — jx0, то можно применить графическую
процедуру, описанную в [Miller, 1966, р. 145—146]. Однако поскольку
при моделировании и экспериментах Монте-Карло мы пользуемся
ЭВМ, проще оказывается числовая процедура, предложенная тем же
Миллером [Miller, 1966, р. 149] и основанная на работе [Lehmann, 1963].
Вычислим п2 разностей:
dgh = xis — xoh (g = 1, ...,re), (h = 1, ..., n). B0)
Расположим эти разности в возрастающем порядке, т. е.
rfA)<rfB, <...<</(„.,. B1)
Для одностороннего доверительного интервала вычислим критичес-
критическое значение at, n:
aS|e=n.+^-r?i, B2)
Тогда доверительные интервалы с уровнем ошибки, устанавливаемым
в эксперименте, определяются следующим выражением:
о
B3)
Для двусторонних доверительных интервалов заменим г?, „ на г?п
в B2) и вычислим
1 k,n { k,n)
(см. также упражнение 3).
Заметим, что, как и в других непараметрических ММС, критичес-
критические значения /•?, п выводятся из того факта, что если Но верна, то каж-
каждое возможное ранжирование {к + 1) п наблюдений равновероятно,
180
Следовательно, точные распределения статистики критерия требуют
i ромоздких преобразований выражений с факториалами. Точное рас-
распределение аппроксимируется с помощью многомерного нормального
распределения. Еще предполагается непрерывность распределений,
поэтому теоретически не может быть совпадений. В практике совпаде-
совпадения, конечно, встречаются. При моделировании и экспериментах
Монте-Карло, однако, отклики — это количественные многоразряд-
многоразрядные переменные с многими знаками после запятой, поэтому вероят-
вероятность совпадений очень мала. Если тем не менее совпадения встретят-
1Я, то можно обратиться для консультации к публикациям. Как мы
\же указывали в V.A, ранжирование наблюдений требует много
машинного времени и машинной памяти, поскольку надо хранить все
наблюдения. Обзор программ сортировки содержится в [Martin, 1971],
im также [Lewis, 1972, p. 8—9]. Примеры расхода машинного вре-
времени на оценки, основанные на ранжировании (и других правилах),
даны в [Andrews et al., 1972, p. 105].
Другие методы. Существует несколько других непараметрических
ММС, которые применяются либо там, где не годится ранговый кри-
К'рий Стила, либо там, где они «работают» лучше него. Например,
множественные критерии знаков, построенные Стилом ([Steel,
1959b], а также [Rhyne, Steel, 1965]), предполагают блочный эффект.
11о при моделировании и экспериментах Монте-Карло блочный эф-
эффект отсутствует, так как при дублировании некоторой совокупности
причиной различия служат случайные ошибки, а не систематический
прочный эффект. В [Rhyne, Steel, 1965] еще указано, что их непара-
непараметрический ММС предполагает, что совокупности имеют общую дис-
дисперсию11. В [Miller, 1966, р. 165—172] обсуждаются другие ММС,
разработанные Немени и Данн и основанные на методе ранжирования
Краскалла — Уоллиса в однофакторном плане дисперсионного ана-
шза. (Метод Краскалла — Уоллиса обсуждается в [Conover, 1971,
|) 256]. ) Как замечает Миллер, эти процедуры имеют то неприятное
t иойство, что сравнение двух совокупностей зависит от наблюдений
и i других совокупностей. Кроме того, довольно трудно применить эти
критерии для построения доверительных интервалов. В [Gabriel,
Vn, 1968, p. 309], [Peritz, 1971], [Puri, Sen, 1971, p. 244—254] пред-
покагаются другие непараметрические ранговые критерии (которые
применимы ко всем парным сравнениям); см. также [Gupta et al.,
l'O1, p. 10]. К сожалению, авторы этих работ не сравнивают свои
критерии с критерием Стила. В V.B мы обсудим несколько иных ме-
шдов для ситуаций с контрольной совокупностью, когда объем вы-
ппрки будет определяться двушаговым или последовательным путем.
Все попарные сравнения. Если нет стандартной совокупности,
in мы можем сравнить все совокупности между собой, т. е. изучить
р.пности \1г — iv (г<О'')> получающиеся в результате k (k—l)/2
п.фпых сравнений. Вначале мы рассмотрим параметрический метод
I ыоки, далее — ранговый критерий Стила и несколько других ММС.
Метод Тьюки, основанный на стьюдентизированном размахе. Ме-
1пд Тьюки основан на стьюдентизированном размахе. Этот размах
игласно [Scheffe, 1964, р. 28] определяется следующим образом.
181
Пусть Zj (/ = 1, ..., w) —w независимых наблюдений из нормального
распределения N (\i, oi). Тогда размах для Zj есть
j— min z}. B5)
Пусть si — независимая оценка ol с v степенями свободы, т. е.
vslhl есть 1%, и пусть она статистически не зависит от Rw. Тогда стью-
дентизированный размах, скажем qWi „, определяется как
Qw,v = -^- B6)
В [Miller, 1966, p. 47—48] перечислены различные публикации, со-
содержащие таблицы стьюдентизированного размаха. В [Harter, 1960a,
р. 671] указано, что некоторые публикации дают неточные критичес-
критические точки и наиболее точные таблицы можно найти, например, в [Mil-
[Miller, 1966, р. 234—237] для w от 2 до 100, у от 1 до оо и а = 5 или 1 %.
Поскольку в ММС используется и более высокий уровень а, таблица
для а = 10% есть в [Harter, 1960b].
Процедура Тьюки предполагает, что имеется по п наблюдений
в каждой из k совокупностей. Все наблюдения независимы, нор-
нормально распределены с общей дисперсией о2 и, возможно, различными
средними ц^ Тогда для данного уровня ошибки, устанавливаемого
в эксперименте а, имеют место доверительные интервалы
где s2 есть общая объединенная оценка о2, основанная на k (п — 1
степенях свободы, <$, fc(n-i) — верхняя а-точка стьюдентизирован-
стьюдентизированного размаха с параметрами k и k (п — 1).
Доказательство уравнения B7) очень простое, и мы приведем его
здесь. Положим, zt = xt— |лг, так что все zt будут иметь среднее
значение, равное 0. Все z% имеют общую дисперсию a1 In. Следователь-
Следовательно, zt—независимые наблюдения с распределением N @, asln). Объ-
Объединенная оценка их дисперсии var (z) = а2/п, с v = к (п — 1) сте-
степенями свободы, есть
<b=—- = —
Хорошо известно, что sf и хг независимы (см. [Fisz, 1967, р. 346]).
Поэтому <з% независимы от xt — \it = zlt так что, по определению,
max; zt — min; zt
Vz QkMn-i). B9)
182
11лн с вероятностью A — а) мы имеем
rriflx %i—mm 2>i ^^ cjk,k(n 1) _ y— t уоЮ)
что эквивалентно
~ для всех i, V C1)
|^гс|<1?ц(л-1)^р
\/п
и соответствии с уравнением B7).
Метод Тьюки может быть обобщен на все контрасты и все линейные
комбинации, для наблюдений с определенной структурой корреляций
или с известными (различными) дисперсионными отношениями и на
многофакторные планы дисперсионного анализа [Miller, 1966, р. 39—
42], [Scheffe, 1964, р. 73—75], [Sen, 1969], [Tukey, 1953]. Мы вернемся
к этим обобщениям, но сперва рассмотрим непараметрические методы
парных сравнений.
Ранговый критерий Стила. Пусть имеется по п наблюдений в каж-
каждой совокупности i (i = 1, ..., k). Все наблюдения независимы,
но не обязательно нормальны. Функции плотности имеют равные
ожидания возможных сдвигов. Как и в критерии Стила для сравне-
сравнений с контрольной совокупностью, мы вычисляем ранг Гц- для срав-
сравнения совокупностей i и V. (Величина V в этом случае не равна 0,
она пробегает значения от i + 1 до k.) Двусторонний критерий равен:
r'w = max [щ., п Bга + 1) — ги-Ь C2)
Ранговая статистика для ситуации множественных сравнений с за-
заданным в эксперименте уровнем ошибки есть максимум из этих
k (k — 1)/2 статистик г и-, т. е.
?r). C3)
Нуль-гипотеза о равных средних отклоняется, если г* > Гк,п (две
звездочки (**) отличают это критическое значение от Гк% в ситуации
с контрольной совокупностью). Доверительные интервалы для
|ij — \Lr можно построить на основании формул B0) — B4) с подста-
подстановкой ль*™. Миллер [Miller, 1966, р. 157, 252] протабулировал крити-
критические значения для к = 2 A) 10, п от 6 до 100 и а = 1 или 5%. При-
Применение метода показано в [Steel, 1960, р. 199—200]. Позже в [Gabriel,
Lachenbruch, 1969] указывалось, что таблицы для метода Стила очень
консервативны, особенно при больших k и малых п.
Другие непараметрические методы. Миллер [Miller, 1966,
р. 138—143, 165—172] обсуждает множественный критерий знаков при
наличии блоков и критерий типа Краскалла — Уоллиса. Как мы ви-
видели в примере с контрольной совокупностью, эти процедуры хуже,
чем ранговый критерий. Альтернативные методы, как уже отмечалось,
приведены в [Peritz, 1971] и [Puri, Sen, 1971, p. 244—254, 328—331].
183
Ё [Tobach et at., 19B7] рассмотрен частный случай, разработанный
Данн [Dunn, 1964], к которому мы еще вернемся.
Параметрический метод Габриеля для проверки гипотез на под-
мнокествах средних. Рассмотренные параметрические и непарамет-
непараметрические ММС можно применять для проверки ^гипотезы ц,г- = цу.
Габриель [Gabriel, 1964] предложил процедуру для сходной задачи.
Он проверял, однородны ли подмножества полного множества k сред-
средних. Его критерий очень близок к традиционному /^-критерию ANOVA
для проверки гипотезы Н0:\х.г = ... — \ik, т. е. однородности всего
множества. Если /-"-критерий отклоняет эту гипотезу на доверитель'
ном уровне A — а), то можно применять процедуру Габриеля для
определения подмножеств, для которых это различие значимо или
незначимо. Такой анализ подмножеств не влияет на уровень ошибки,
установленный в эксперименте а, т. е. вероятность того, что одно или
более суждений утверждают значимость различия подмножества
средних при условии, что оно в действительности однородно, остается
равной а (ср. также наше обсуждение с изложенным далее критерием
в методе Шеффе). К сожалению, эта процедура, по нашему мнению,
имеет следующий недостаток (возможно, читатель не согласится с этим).
Габриель (Gabriel, 1964, р. 463] приводит пример, где совокупности
проранжированы в порядке убывания выборочных средних:
DCBFAEHG. Далее различие между D и 0 объявлено незначимым,
а различие в большем подмножестве DCHG оказалось значимым, т. е.
включение совокупностей С и Я с выборочными средними, заключен-
заключенными между крайними членами D и G, делает различие в подмножестве
значимым. По нашему мнению, это свойство нежелательно12.
Линейные контрасты. Параметрический метод Шеффе. Линейный
контраст, скажем t^, определяется следующим выражением:
ty=2 суММ.2,...), C4)
(¦= 1
где известные коэффициенты Сц удовлетворяют условиям
2 си = 0 (/=1,2,...). C5)
Заметим, что уравнениям C4) и C5) удовлетворяют бесконечно много
преобразований. Несмещенная оценка я[^- есть
*с дисперсией
var (гЬ,) = (j^ = ^ cf/ var (лгг) = % с}¦• = о2 \^ —— C7)
T i n' T "г
Л 84
при условии, что все наблюдения х независимы с общей дисперсией о2;
число наблюдений в совокупностях может быть различным. Неизве-
Неизвестное значение о2 в C7) можно оценить с помощью обычной объеди-
объединенной оценки si, которая при подстановке ее в C7) даета^,. Предпо-
Предполагается, что наблюдения х нормально распределены; тогда вероят-
вероятность того, что все контрасты % одновременно удовлетворяют нера-
пенствам
1%-^|<5»* (/=1,2,.-). C8)
равна 1 — а, где
C9)
0 обозначает число степеней свободы оценки а2у т. е. v = 2г (щ — 1)
и однофакторном плане. Этот результат был выведен Шеффе; его дока-
(ательство можно найти в [Scheffe, 1964, р. 67—72], другое доказа-
юльство приведено в [Miller, 1966, р. 48—53, 63—66]. Вывод основан
па проекциях доверительного эллипсоида (основанного на f-статис-
шке) на оси.
Процедуру Шеффе, уравнение C8), можно применить следующим
образом. Шеффе показал, что ^-критерий ANOVA отклоняет Но : цг =
- ... = \ik тогда и только тогда, когда C8) по крайней мере для
одного контраста я[з значимо отлично от нуля. Поэтому первым шагом
при анализе результатов эксперимента может быть применение
/¦'-критерия для проверки гипотезы Но. Если ^-критерий оказывается
незначимым, то C8) не дает ни одного значимого контраста и, следо-
мательно, даже и не нужно вычислять C8I3. Если f-критерий откло-
отклоняет #0, то следующим логическим шагом будет определение того,
какой контраст вызывает это отклонение. Однако существует беско-
бесконечное множество контрастов и мы не можем вычислить все. В дей-
действительности на основании результатов эксперимента можно опре-
определить, какие контрасты представляют интерес, к ним и надо приме-
применить C8). Может случиться, что Яо отклоняется, но ни один из вы-
вычисленных контрастов не получился значимым (см. [Miller, 1966,
|i. 51]). Габриелем [Gabriel, 1964, р. 469—470] разработана процедура
для выявления значимых контрастов. Заметим, что процедура Шеффе
позволяет исследовать данные до решения вопроса о контрастах;
при подходе Бонферрони общее число сравнений надо установить до
и (учения данных. Применение процедуры Шеффе обсуждается в [Se-
[Seiner, 1966, р. 120—122].
Миллер [Miller, 1966, р. 53] показал, что метод Шеффе можно обоб-
обобщить на наблюдения с неравными дисперсиями а? или на коррелиро-
нлпные данные. К сожалению, при этом предполагаются известными
чнеперсионное отношение о\1а2г или корреляционные коэффициенты
|i,/<. Построение доверительных интервалов для C8) дается Мил-
к'ром.
Метод ранжирования Данн. Хотя для парных сравнений есть не-
1 иолько непараметрических процедур, для контрастов их не так уж
того. Укажем на методы, предлагаемые в [Crouse, 1969], [Dunn,
185
1964], [Puri, Sen, 1971, p. 236—240, 244—254]. Первые две множест-
множественные процедуры для контрастов (ММС) ограничиваются лишь срав-
сравнением средних двух подмножеств k совокупностей, т. е.
Ф, = -^ ~- (/=1.2.-). D0)
где I' пробегает значение по kx совокупностям, a i" — по k2 A ^ къ
k2 < k и kt + k2 ^ k). Тем не менее эти контрасты выдаются за един-
единственные, представляющие интерес для экспериментатора14. Такие
ММС похожи, поскольку они основаны на ранговых наблюдениях и
на асимптотическом распределении статистики критерия. Мы остано-
остановимся на методе Данн, который довольно прост и основан на неравен-
неравенстве Бонферрони; процедура заключается в следующем 15.
Установим, какие т контрастов стоит изучать. Проранжируем
Nj — 2f ny + 2/» tii» наблюдений, входящих в контрасты ср7-, от
наименьшего к наибольшему (по возрастанию). Вычислим ранговые
суммы для совокупностей г,', и г,»,. (Индекс / берется с п>) и п»„
так как ранговые суммы меняются от контраста к контрасту; для
простоты представления индекс / не берется с щ- и п,».) Вычислим
разности в средних рангах между двумя подмножествами, т. е.
Дисперсия dj есть
[ШЬ±И](^ ^) ,42)
При выводе распределения статистики критерия предполагается,
что все k функций плотности имеют одинаковые ожидания сдвигов.
Когда зерна нуль-гипотеза о равенстве средних dj, имеет место асим-
асимптотически нормальное многомерное распределение. Следовательно,
можно проверить каждое dj отдельно, используя двусторонние кри-
критические значения za/<2m> из таблицы для N @,1). Так:
1) если — ?a/<2m> < dj/cij < za/<2m>, то не отклоняется гипо-
гипотеза о равенстве средних двух подмножеств, содержащих kx и k« сово-
совокупностей некоторого контраста уу,
2) если djhj > za/t-2m), то Но отклоняется в пользу гипотезы
о том, что среднее kx совокупностей больше среднего k2 совокупностей;
3) если djhj < — 2a/'2m), то принимается гипотеза о том/^что
среднее k1 совокупностей меньше.
Применение этого критерия можно найти в [Dunn, 1964, р.243—
247]. Мы отметим, что в [Tobach, 1967] предложен вариант процеду-
процедуры Данн специально для парных сравнений.
Линейные функции. Мы уже упоминали, что линейные функции
средних, например \р} = 2гси-р1г, становятся полезными, когда мы
хотим изучить кроме контрастов в средних еще и сами средние. S-ме-
186
то!) Шеффе весьма многогранен, поскольку он применим также и
|« линейным функциям. Все, что мы должны сделать, это заменить
(Л — 1) на к в определении S из уравнений C9). Объясняется эго тем,
•по линейные функции k средних «натянуты» на пространство размер-
размерности k, тогда как линейные контрасты ограничены одним условием,
.1 именно 2гсг7(х, =- 0 [Scheffe, 1964, р. 70].
Метод Тыоки для парных сравнений можно обобщить на случай
пшейных контрастов и линейных функций средних, но эти обобщен-
обобщенные ММС в большинстве случаев дают более широкие доверитель-
доверительные интервалы, чем метод Шеффе (см.[Miller, 1966, р. 39—41,43—44]
п iScheffe, 1964, р. 74—79]). Очевидная альтернатива — применить
параметрические или непараметрические методы к линейным функциям
и следовать подходу Бонферрони. Если нас не интересуют средние
•пачения вместе с контрастами, а только сами средние, то возможно
применение методов, которые рассмотрены далее.
Только средние. Стьюдентизированный максимум модуля. Сна-
Сначала определим стьюдентизированный максимум модуля. Пусть
г} (/ = 1, ..., w) есть w независимых наблюдений из N @, ст|) и пусть
si — несмещенная оценка а\ с v степенями свободы и независимая
ччя каждого г. Тогда максимум модуля г3 есть max71 Zj | и, следова-
юльно, стьюдентизированный максимум модуля есть
max,- \zj I
=—J—l-
D3)
(Существуют лишь неполные таблицы mw v. Пиллай и Рамачандран
штабулировали верхние 5%-ные точки для w = 1 A) 8 и v между
Г> и оо, таблица приведена в [Miller, 1966, р. 239]. Несколько большее
число критических значений подсчитано в [Dunn, Massey, 1965].
Поскольку в ММС могут встречаться большие значения уровня ошиб-
ошибки эксперимента, мы представляем в табл. 1 значения, вычисленные
авторами указанной работы для 16 10 и 20%.
Таблица 1
Верхняя а-точка для стьюдеитизироваиного максимума модуля
ш
2
6
10
20
о
4
а
0.10
2,66
3,51
3,89
4,38
i 0,20
2,01
2,74
3,06
3,47
so
а
0,10
2,19
2,77
3,03
3,33
0,20
1,76
2,33
2,58
2,90
30
а
0,10
2,03
2,50
2,71
2,98
0,20
1,66
2,17
2,39
2,66
оо
а
0,10
1,95
2,38
2,56
2,79
0,20
1,62
2,09
2,29
2,54
Далее рассмотрим однофакторный план дисперсионного анализа
для k совокупностей при пг нормально распределенных наблюдениях
187
с общей дисперсией а2 и средними |л, (i = 1, , /г). Следовательно,
(лгг — |хг)У/гг — независимые наблюдения из распределения N @, а2).
Несмещенная оценка а2 есть обычная объединенная оценка si, с v =
= 2 (яг — 1) степенями свободы, которая не зависит от (л:г — ^г) х
хУ/гг. Итак,
max,|x,-n.lVn, =Wftp D4)
sD
и следующие утверждения имеют совместный доверительный уровень
A - а):
| jLt г—xl\^tnt,vSv/y'nl (i = l,..,k). D5)
Заметим, что стьюдентизированный максимум модуля можно при-
применить к любому множеству к оценок, например к k оцененным коэф-
коэффициентам регрессии р„ при условии, что оценки независимы и воз-
возможна независимая оценка их общей дисперсии. Мы еще вернемся
к этому типу применений. Возможно распространение метода и на
случай неравных дисперсий, но с известным отношением дисперсий.
Стьюдентизированный максимум модуля можно применять для линей-
линейных функций, но он дает более широкие доверительные интервалы,
чем другие параметрические процедуры (см. [Miller, 1966, р. 73] и
[Scheffe, 1964, р. 72]).
Независимые t-критерии. Если k статистик хг имеют неравные не-
неизвестные дисперсии а], то мы не сможем применить стьюдентизиро-
стьюдентизированный максимум модуля. Если же отдельные наблюдения независимы
и нормально распределены, то можно оценить а\ с помощью выражения
Причем оценки имеют ьг = пг — 1 степеней свободы и независимы от
хъ (и Xi' и sf', i' ф1). Следовательно, мы имеем такие k независимых
^-статистик, основанных на уг степенях свободы:
D7)
Итак, мы получим двусторонние доверительные границы с совмест-
совместным доверительным уровнем A — а), если выберем критические кон-
константы таким образом, что ^-статистики удовлетворяют условию
, D8)
где а, идентичны верхним критическим точкам — + — A — аI/*
^-таблицы с ьг степенями свободы. Для одинакового числа степеней
свободы vt — v эти критические точки табулированы в [Dunn, Mas-
188
scy, 1965] для некоторых значений v и k. Их значения воспроизведены
II табл. 2 для а = 10 и 20%. (Для а = 0,01; 0,025; 0,05; 0,30; 0,40 и
0,50 см. [Dunn, Massey, 1965].) Другие критические значения для раз-
пых vt и k можно вычислить на основе подробной ^-таблицы с исполь-
использованием аппроксимации для С из уравнения A3). Сравнение табл. 1
и 2 показывает, что табл. 2 дает более широкие доверительные интер-
интервалы (стандартное отклонение нельзя вывести из объединенной оценки).
Таблица 2
, 1 1 1/АI
Верхняя | ~z~Jr ~A—а) точка ^-распределения
2 2
k
2
6
10
20
V
4
а
0,10
2,75
3,91
4,54
5,52
0,20
2,08
3,09
3,64
4,47
10
а
0, 10
2,21
2,85
3,14
3,55
0,20
1,78
2,41
2,71
3,11
30
а
0,10
2,03
2,52
2,71
3,01
0,20
1,67
2,19
2,41
2,71
оо
а
0,10
1,95
2,38
2,56
2,79
0,20
1,62
2,09
2,29
2,54
Подмножество, содержащее лучшую совокупность. Мы рассмот-
рассмотрели несколько процедур, в которых средние значения сравнивались
между собой или с некоторым стандартным значением. Эти ММС дают
доверительные границы для |х, — fv или цг — [Ло с каким-то выбран-
выбранным доверительным уровнем A — а). При проверке гипотез нас ин-
интересует, отличаются ли средние и если отличаются, то в каком на-
направлении. Тогда вероятность того, что одно или более различий лож-
ложно объявлены значимыми, когда нуль-гипотеза о равных средних
справедлива, есть а. Уровень ошибки, устанавливаемый для экспе-
эксперимента, неуправляем для альтернативной гипотезы, т. е. неуправ-
неуправляема (и часто трудно вычисляема) мощность (см. [Miller, 1966,
р. 102—107]). Нередко требуется определить, какая из систем имеет
наибольшее среднее. Рассмотренные ММС можно применять для вы-
выяснения того, какая из совокупностей значимо лучше (ср., например,
уравнение A8) и другие доверительные интервалы). Если доверитель-
доверительный интервал не содержит нуля, имеет место значимое различие. Од-
Однако есть метод, приспособленный непосредственно для выбора
с некоторой заданной вероятностью подмножества из общего числа
k совокупностей, такого, что оно (это подмножество) содержит наилуч-
наилучшую совокупность (или содержит все совокупности не хуже, чем
стандартная, если есть стандартная совокупность). Или
Р (ПВ) >
D9)
где Р* — заданная вероятность и ПВ означает правильный выбор,
т. е. подмножество, содержащее лучшую совокупность. Отношение
189
D9) выполняется для всех конфигураций средних. Знак равенства
имеет место в случае, если все средние равны (ср. Но с описанными
ММС); в противном случае имеет место неравенство. Подмножество
имеет случайный объем, скажем s. Этив совокупностей в подмножестве
не проранжированы, следовательно, для выбора лучшей совокупно-
совокупности требуются дополнительные эксперименты (иначе выбор будет ос-
основан на чем-то неуловимом). Польза этого подхода в том, что после
предварительной фазы, на которой берутся п наблюдений из каждой
совокупности, можно отбросить k — s худших совокупностей.
В части В мы приведем методы множественного ранжирования, кото-
которые дают возможность определить, сколько наблюдений нужно взять
из каждой совокупности для того, чтобы выбрать лучшую совокупность
с заданным доверительным интервалом, хотял на предварительной
фазе исследования есть смысл брать фиксированные числа исходных
наблюдений из каждой совокупности. Обсуждение этого метода и
рассмотренных ММС и процедур ранжирования можно найти в [Desu,
Sobel, 1968, p. 402], [Gupta, 1965, p. 225—227], [Gupta, Santner,
1972], [Gupta, Sobel, 1958, p. 235—236] и [Miller, 1966, p. 226—229].
ц^ Если функционирование системы определяется средним значением
отклика и нас интересует система с наибольшим средним (или наимень-
наименьшим, что зависит от конкретной задачи; ср., например, высокий до-
доход или низкая цена). Другим критерием может быть дисперсия:
функционирование улучшается, если дисперсия понижается; см., на-
например, моделирование национального дохода в [Naylor et al., 1968],
где экономическая политика выбирается так, чтобы минимизировать
флуктуации национального дохода. Мы вернемся к этому.
Довольно странно, но многие учебники не содержат метода под-
подмножеств. (Даже в объемном обзоре Миллера он упоминается только
кратко.) Этот метод очень полезен на предварительной стадии, поэтому
мы предлагаем несколько процедур этого типа, а именно процедуры
для выбора лучшей совокупности и для сравнения совокупности со
стандартом при условии нормальности (параметрическая процедура)
или отсутствия нормальности (непараметрическая процедура).
Параметрический метод Гупты. Гупта [Gupta, 1965, р. 235—
236] предложил метод для нормально распределенных совокупностей
с неизвестными средними значениями \it и общей неизвестной диспер-
дисперсией а2. Мы имеем равное число (п) независимых наблюдений из каж-
каждой соковупности. Это дает выборочные средние Xi (i = 1, ..., k) и объ-
объединенную оценку si с v = k (п — 1) степенями свободы. Проце-
. дура выбирает подмножество, которое содержит совокупность с наи-
наибольшей средней с вероятностью по крайней мере Р*, Р* определяется
экспериментатором (так же, как определялось а для описанных ММС).
Совокупность i включается в подмножество, если
Xi > xmax — D sJVnl
где]*константа D зависит от k, n и Р* и табулирована в [Gupta, Sobel
1957, p. 962—964], тогда как для других k и п значения D/]/ приведе-
приведены в [Dunnett, 1955, р. 1117—1118] и [Krishnaiah, Armitage, 1966,
190
p. 41, 51P. Если мы ищем наименьшее среднее, то нужно положить
х' = — х и применить описанный выше метод х'. Доказательство ис-
использует тот факт, что Р (ПВ) достигает своего минимума, если все
средние равны; для равных средних Р (ПВ) есть довольно простой
интеграл, который приравнивается Р* и решается относительноD.
Гупта [Gupta, 1965, р. 229—232] изучал свойства процедуры та-
такого типа и обнаружил следующее:
1. Если все параметры (щ) равны, то Р (ПВ) достигает мини-
минимального значения Р*, а ожидаемый объем подмножества Е (s) —
своего максимума P*k.
2. Если \it > цг, то вероятность того, что t'-я совокупность содер-
содержится в подмножестве, не меньше, чем для совокупности V.
3. Процедура (малопривлекательная), которая гарантирует попа-
попадание наилучшей совокупности в подмножество, включает в это под-
подмножество все k совокупностей. Процедура Гупты выбирает подмно-
подмножество объема s, где s может быть меньше, чем k (т. е. 1 ^ s ^ k).
Вероятность включения лучшей совокупности в подмножество данного
объема s (s заранее неизвестно) максимизирована в процедуре Гупты.
Существуют также методы для выбора подмножества, содержаще-
содержащего наименьшую дисперсию а? для k переменных с распределениями
N (цг,°*) или наименьший масштабный коэффициент pt гамма-рас-
гамма-распределения, или наименьший биномиальный параметр pt биноми-
биномиально распределенных переменных (см. [Gupta, 1965], [Gupta, Nagel,
1971J и [Gupta, Sobel, 1960; 1962]). Вместо этих специальных про-
процедур мы можем воспользоваться уравнением E0) в надежде на то,
что такое правило будет достаточно робастным; вначале можно пре-
преобразовать исходные данные (логарифм или arcsin; см. табл. 4 в гла-
главе IV). В [Goel, 1972] рассмотрена возможность применения метода
подмножеств к распределению Пуассона. Недавно опубликован об-
обширный обзор по методу подмножеств для параметрических (нормаль-
(нормального, гамма-, биномиального, пуассоновского и отрицательного би-
биномиального распределений), непараметрических и многомерных си-
ситуаций, а также для задач теории принятия решений и байесовского
подхода [Gupta, Panchapakesan, 1972].
В [Desu, Sobel, 1968] предложен другой метод подмножеств. В от-
отличие от метода Гупты этот метод подходит, когда объем подмнооюества
не случаен, а известен заранее. В указанной работе предложена так
же общая и известная дисперсия о2 и использована «зона безразличия»,
т. е. вероятность ПВ гарантируется, если только наилучшее среднее
\x,(k) на б* единиц лучше других средних; ц^), для которых б* меньше,
нас не интересуют. Следовательно,
Р (ПВ) > Р*, если [x(ft) — ц(й_п > б*. E1)
Мы предпочитаем~метод Гупты потому, что подход, предложенный
в'[Desu, Sobel, 1968], требует знания дисперсии и задания б*. Мы упо-
упомянули здесь эту процедуру, так как ее можно применять для опреде-
определения объема выборки п в правиле Гупты. Если п мало, то s может быть
равным k, т. е. после предварительной фазы не исключается ни одна со-
191
вокупность. Следовательно, можно определить б* (или Р*), а также
предположительное значение о2 и использовать таблицу из [Desu,
Sobel, 1968, p. 404—407] для вычисления п, при котором s меньше,
чем к.
Исследование [Desu, Sobel, 1968] было продолжено в [Gupta,
Santner, 1972], где авторы показали также соотношение между методом
подмножеств (s^k или5<&) и подходом для выбора объема выборки,
который обсуждается в части В этой главы. В [Sobel, 1969] также
обобщены методы, рассмотренные в [Gupta, 1965] и [Desu, Sobe],
1968], и получен ряд правил выбора t ( > 1) лучших совокупностей
с «зоной безразличия» и без нее.
Непараметрический метод Ризви и Собела. Ризви и Собел [Rizvi,
Sobel, 1967] предложили непараметрическую процедуру для выбора
подмножества, содержащего совокупность с наибольшим значением
медианы с вероятностью, равной по крайней мере Р*. Они предпола-
предполагают только, что есть равное (нечетное) число (я) независимых наблю-
наблюдений в каждой из k совокупностей; совокупности имеют непрерывные
распределения возможно различного вида, т. е. совокупности могут
различаться не только сдвигом (ср. [Sobel, 1967, р. 1804]). Мы извлек-
извлекли из работы Ризви и Собела [Rizvi, Sobel, 1967, p. 1789], что их пра-
правило можно применять следующим образом:
1. Для каждой совокупности проранжировать наблюдения в воз-
возрастающем порядке, получим упорядоченные статистики
X(l)i < хЫг < ¦•¦ < xU)l < •¦• < x(n)i A> = 1. ¦¦¦> k).
2. Найти значение критической константы, скажем а18, в табл. 3
из [RizVi, Sobel, 1967, p. 1801—1802].
3. Для каждой совокупности определить статистику а-го порядка
x(a)i (г' ~ 1> •••> k) и найти максимум из этих значений:
[xia)i]. E2)
4. г-ю совокупность включить в подмножество, если
xMi > -*;max(a) E3)
при г = (п + 1)/2, т. е. X(T)i есть медиана выборки.
Если нас интересует наименьшая медиана, то на основании [Rizvi,
Sobel, 1967, p. 1799] правило имеет следующий вид19: t-ю совокупность
включить в подмножество, если
min(n+1-я) , E4)
где
f(n + i_0) Л, E5)
а г = (я + 1)/2, и а можно найти в табл. 3 Ризви и Собела.
192
Для больших значений />*и малых значений п известно априори,
что подмножество состоит из k совокупностей 20. Табл. 2 у Ризви и
Собела показывает, что минимальное п нужно выбрать для заданного
Р", чтобы не произошло вырождения процедуры. Аналогично тому,
как сделано у Гупты для параметрического метода, Ризви и Собел
[Rizvi, Sobel, 1967, p. 1790—1792, 1800] доказывают, что максимум
ожидаемого значения s достигается, когда все k распределений оди-
одинаковы, и это значение приблизительно равно kP*. Совокупность
с большим значением медианы имеет больше шансов быть включенной
в подмножество с наибольшей медианой Ризви и Собел [Rizvi, Sobel,
1967, p. 1792—1798] изучили асимптотическую эффективность их
правила и нашли, что для нормально распределенной совокупности
с общей известной дисперсией их правило (очевидно) неэффективно
по сравнению с параметрической процедурой Гупты, однако для экс-
экспоненциального распределения их правило эффективнее (в два раза)
Другие процедуры В [Bartlett, Govindarajulu, 1968], а также
в [Patterson, 1965] предложены непараметрические процедуры, но
они требуют от совокупностей одинаковых ожидаемых сдвигов.
В IBarlow, Gupta, 1969] и [Gupta, McDonald, 1970; 1972] обсуждаются
пепараметрические процедуры для «стохастически возрастающих»
распределений, т е. Fx (х) "> F2 (х) для всех х, если параметры G удов-
удовлетворяют 6Х < Э2 (например, нормальные распределения с цг < pi2
и общей дисперсией). В [Barlow, Gupta, 1969] авторы сравнили эф-
эффективность своей процедуры с эффективностью процедуры Ризви
и Собела. Для класса распределений, которые они изучали, не было
найдено равномерно лучшей процедуры. Метод подмножеств для
нормальных совокупностей с неравными"дисперсиями был построен
Дудевичем [Dudewicz, 1972] и Дудевичем и Далалом [Dudewicz,
Dalai, 1971]. Поскольку в нем"применяется двойная выборка, мы об-
обсудим его в части В.
Подмножество, содержащее все совокупности, которые лучше, чем
стандартная. Параметрический метод Гупты и Собела. Гупта и Со-
Собел [Gupta, Sobel, 1958] предложили метод, требующий п независимых
наблюдений в каждой из (k — 1) экспериментальных совокупностей и
одной стандартной; все совокупности должны иметь нормальное рас-
распределение и равные неизвестные дисперсии ст2 (Эти авторы также да-
дают варианты для известных, быть может, различных дисперсий of и
известного стандартного среднего ^0) Совокупность i входит в под-
подмножество, если
хг > х0 — DsjVn, E6)
где si — объединенная оценка дисперсии о2 с v = k (n — 1) степе-
степенями свободы, D — критическая константа, зависящая от Р*, k и
v и табулированная Гуптой и Собелом [Gupta, Sobel, 1957, p. 962—
964], значениеD/1/Тдается в [Dunnett, 1955, р. 1117—1118] и [Krishnai-
ah, Armitage, 1966, р 41, 51] для других значений k и v. (Значение
D содержится в столбце, соответствующем р = k— 1; критические кон-
стантьГв уравнениях E6) и E0) можно найти в тех же таблицах, еще
одним параметром будет общее число совокупностей, включая стан-
7 Дж Клейнен 193
дартную совокупность.) Заметим, что объем подмножества может при-
принимать значения от 0 до k — 1.
Уравнение A7) показывает, что Даннетт [Dunnett, 1955] счел бы,
что совокупность i лучше стандартной, если
xt > ~х0 + DsjVn, E7)
где критическая константа D выбирается так, чтобы контрольная со-
совокупность удовлетворяла E7), если бы все совокупности имели равные
средние, т. е. если бы выполнялась нуль-гипотеза. Сравнение E7) и
E6) показывает, что при подходе Даннетта гипотеза о том, что все
экспериментальные средние не лучше стандартной, отвергается толь-
только тогда, когда есть сильное свидетельство против Яо. (лгг должно
быть лучше х0 плюс коэффициент Ds,J]/~n.) При подходе Гупты и Со-
бела нет гипотезы #0, предпочитающей стандарт, поэтому больше
совокупностей входят в подмножество.
Непараметрический метод Ризви, Собела и Вудворта. В [Rizvi,
et al., 1968, p. 2076—2077] предложена процедура, аналогичная рас-
рассматриваемой в [Rizvi, Sobel, 1967] для выбора подмножества при от-
отсутствии контрольной совокупности. Существует одно, более ограни-
ограничительное, предположение, а именно предположение о стохастически
упорядоченных распределениях. Так, авторы предполагают, что г-е
распределение либо стохастически лучше стандартного [Ft (х) <
^ Fo (х) для всех х], либо хуже. (Заметим, что это ограничение менее
строгое, чем предположение о распределениях, отличающихся только
сдвигом.) Процедура работает аналогично методу Ризви — Собела:
1. Расположить наблюдения в возрастающем порядке внутри
совокупности, т. е. получить упорядоченные статистики Xj^)(j — 1,
..., п).
2. Найти критическую константу а ^иначе обозначаемую г — с)
в [Rizvi'et al., 1968, p. 2079] или [Rizvi, Sobel, 1967].
3. Отнести г-ю совокупность к подмножеству, если X(r)i >
> л:(аH, где г = (п +;1)/2.
Отметим, что шаг 3 есть «естественная» альтернатива для шагов
3 и 4 в процедуре Ризви — Собела. Возможно вырождение процедуры,
когда все экспериментальные совокупности включаются в подмноже-
подмножество. Если i-я совокупность стохастически лучше, чем / совокупность,
то она с большей вероятностью будет включена в подмножество/Если
мы хотим включить в подмножества совокупности с медианами, мень-
меньшими, чем у контрольной, то аналогично E4) включаем г-ю совокуп-
совокупность, если хм i < хы + г _ а}0.
Другие процедуры. В [Rizvi et al., 1968, p. 2086] рассматривается
процедура, основанная на ранговой статистике Стила для сравнений
экспериментальной и контрольной средних, обсуждавшихся ранее.
Эта альтернативная процедура также предполагает стохастически
упорядоченные распределения. Для этого класса распределений про-
цедура менее эффективна; она более эффективна для частного случая—
для распределений, отличающихся только сдвигом (см. [Rizvi et al.,
Щ
1968, p. 208?]). Кроме того, в указанной работе выведена асимП/ПопШ-
•к>асая процедура, основанная на выборочных средних, для стохасти-
стохастически упорядоченных распределений (при техническом условии от-
относительно дисперсии и четвертого центрального момента контроль-
контрольной совокупности). Эта процедура работает только при больших
пыборках; она может быть более или менее эффективной по сравнению
с другими непараметрическими процедурами.
Гупта и Собел [Guptas Sobel, 1958, p. 239—244] дают параметри-
параметрические процедуры для дисперсий of (или, более обобщенно, для мас-
масштабных коэффициентов гамма-распределений) и для биномиальных
параметров рг. Альтернативой может служить уравнение E6) после
преобразования (логарифмического или arcsin). Метод подмножеств
для случая стандартной совокупности также обсуждается Гуптой
|Gupta, 1965, р. 234—235, 243—244]. В [Desu, 1970] обсуждается про-
процедура для выбора подмножества, не содержащего худших совокуп-
совокупностей, но эта формулировка задачи кажется менее привлекательной.
В [Gupta, Panchapakesan, 1968; 1972] приведен список литературы по
методу подмножеств для многомерных и других ситуаций. Процедуры
для определения объема выборки в ситуациях с контрольной совокуп-
совокупностью будут обруждаться в части В этой главы.
Многофакторные планы. Введение. До сих пор мы ограничивались
рассмотрением ситуаций с одним фактором на k уровнях, например
для k различных машин или правил обслуживания очереди. Далее
рассмотрим случаи с более чем одним фактором, например имитацион-
имитационный эксперимент, в котором одним фактором служит правило обслу-
обслуживания очереди, а другим — распределение времени обслужива-
обслуживания и т. д. Для, допустим, трех факторов можно изучить основные
эффекты взаимодействия между двумя и тремя факторами; если фактор
С имеет с уровней, то мы имеем с главных эффектов фактора С, а имен-
именно aci = х\тЛ — г] ._ (i = 1, ..., с) с 2 aCi = 0 (см. главу IV). Мы можем
при желании реализовать заданную вероятность того, что все сужде-
суждения об эксперименте правильны. Для фиксированного уровня ошибки,
задаваемого в эксперименте, ценой будет широкий доверительный
интервал или малая мощность для отдельных эффектов. Следователь-
Следовательно, целесообразно использовать уровни ошибок для семейств сужде-
суждений вместо общего уровня по всему эксперименту. Если, например,
есть три фактора, каждый из которых имеет несколько уровней, то
псе суждения, касающиеся главных эффектов одного фактора, можно
считать составляющими одно семейство суждений, и мы хотели бы с до-
нерительным уровнем A — а) быть уверены в том, что все суждения
отого семейства верны. Если, однако, число .уровней факторов мало,
то можно рассматривать как одно семейство суждения, касающиеся
главных эффектов всех факторов. Следовательно, составление се-
семейств субъективно. Отметим, что уровни ошибок для разных семейств
можно сделать различными. Поэтому мы можем взять более высокий
уровень ошибки для семейства суждений о главных эффектах, а более
низкий уровень — для взаимодействий, если нас больше интересует
исследование главных эффектов. Для дальнейшего обсуждения се-
/" 195
мейств суждений мы рекомендуем [Miller, 1966, р. 10—12, 31—35],
[Kurtz et al., 1965, p. 154], [Tukey, 1953], а также V.B.2. Пример,
включающий создание семейств суждений, будет дан в главе VI. Теперь
же обсудим некоторые методы реализации уровней ошибок для се-
семейств или даже для эксперимента в опытах со многими факторами.»
Общий метод (Бонферрони). Если мы возьмем уровень ошибки
аг для t-ro суждения (i = 1, ..., т), то уровень ошибки для семейства
из т суждений не превысит 2аг согласно неравенству Бонферрони из
уравнения A0). Если семейство не слишком велико, то такойподход
очень полезен из-за простоты и гибкости (см. также наше обсуждение
процедуры Бонферрони в V.B.3). Суждения могут быть зависимыми.
Примером служит ANOVA, где каждое суждение — это /-"-критерий
для проверки значимости главных эффектов факторов А, В, ... двух-
факторных взаимодействий и т. д. Все эти /-"-критерии имеют общий
знаменатель — средний квадрат ошибки (числители будут независи-
независимыми в ортогональном плане; см. главу IV). Другой пример дает
оценки главных эффектов некоторого фактора, скажем а?, которые
отрицательно коррелированы (см. упражнение 8). Для индивидуаль-
индивидуальных наблюдений может не выполняться условие нормальности, тогда
мы применяем непараметрические методы для каждого суждения
с уровнем ошибки аг. Можно даже применять различные процедуры
для различных семейств, например, стьюдентизированный размах
Тьюки — для изучения главных эффектов и метод Шеффе — для
взаимодействий. Часть общего уровня ошибки можно использовать
для ММС Шеффе, так как его метод дает возможность сначала изучить
данные, а потом решить, какие сравнения стоит произвести («разведка
данных»). Однако, поскольку остаток а для процедуры Шеффе будет
небольшим, в результате мы получим широкие доверительные интер-
интервалы (см. [Miller, 1966, р. 62] и [Scheffe, 1964, р. 80]). В [Dunn, 1961,
р. 61—63] применен метод Бонферрони к двухфакторному плану 21.
Мы также применим этот подход к конкретному примеру в главе VI.
Множественные F-критерии. Хорошо известно, что в многофактор-
многофакторных планах ANOVA возможно изучение главных эффектов и взаимодей-
взаимодействий с помощью /^-статистик. В качестве примера рассмотрим двух-
факторный план с фактором А на а уровнях, В — на 6 уровнях и
с числом наблюдений п для каждой комбинации уровней. Для про-
проверки гипотезы о том, что фактор А не имеет главного эффекта т. е.
Н*:аА = ... = а* = 0, E8)
мы разделим средний квадрат фактора А на средний квадрат ошибки
и сравним это отношение с верхней а-точкой ^-статистики с числами
степеней свободы (а — 1) и (п — 1) ab. Для проверки гипотезы о том,
что оба фактора А и В не имеют главных эффектов, т. е.
Нл+в . ал = ... = ал = ав = ... = а? = о, E9)
мы объединим суммы квадратов А и В, вычислим их средние квадраты,
разделим на средний квадрат ошибки и сравним с верхней а-точкой
196
Я-стаТистики с Числами степеней свободы (а \- b — 2) и {п — 1) ah.
Эту процедуру можно найти в любом учебнике, описывающем ANOVA,
а также в главе IV, уравнение C3).
Мы должны понимать, что гипотеза НА+В в E9) — это простая
(составная) гипотеза. Рассмотрим теперь множественные гипотезы
НА : af = ... = а? = 0 F0)
и Нв : af = ... = af = 0 F1)
вместе с гипотезой о взаимодействиях
аАВ = аАВ = аАВ = = аАВ = q
Каждая отдельная гипотеза проверяется с помощью /^-критерия, тра-
традиционного для ANOVA. Очевидно, что уровень ошибки, устанавли-
устанавливаемый для эксперимента, т. е. вероятность ложного отклонения ги-
гипотезы, сейчас выше, чем а, где a — уровень ошибки для каждого
отдельного F-критерия. Мы можем пожелать, чтобы уровень ошибки
для всего эксперимента был ниже уровня аЕ. Тогда можно применить
неравенство Бонферрони, т. е. каждый из трех f-критериев возьмет22
a = a?/3. Другой метод основан на улучшенном неравенстве Бон-
Бонферрони, которое будет представлено далее.
Миллер [Miller, 1966, р. 101—102] доказывает следующую лемму,
которая основана на лемме, доказанной Кимболом. Пусть имеется
/г отношений Ut = VJW (i— 1, ..., k), Vt и W независимы и W при-
принимает только положительные значения. Определим константы
— оо ^ at ^ 0 и 0 ^ bt ^ оо (г = 1, ..., k). Тогда на основании
[Kimball, 1951] получается, что
k
Р (a, <Ut<bi для всех i) > f[ P (Щ <Ut< bt). F3)
i=\
Заметим, что это неравенство лучше неравенства Бонферрони, так как
к к
П (!—«*)> 1~2 а* Для0<а,<1, k>\. F4)
i=\ (=1
Улучшенное неравенство можно применить к ортогональному плану,
где главные эффекты и взаимодействия между 2, ..., k факторами
имеют независимые (или полностью смещенные) средние квадраты
MSt (или Vi в приведенной выше лемме) и используется для проверки
независимый средний квадрат ошибки MSE (или WJ3.
Изучим теперь множественные f-критерии для частного случая
планов, а именно для 2k~P планов. Из главы IV известно, что каж-
каждый эффект в 2k~p плане можно проверить отдельно с помощью
/"-критерия с одной степенью свободы в числителе и v степенями сво-
197
боды в знаменателе. (Заметим, что суждения, касающиеся эффектов
в 2"~р плане, можно классифицировать как множественные /•'-кри-
терии или как критерии для отдельных эффектов, поскольку Flt „ =
= Ц, где Ц используется в двусторонних доверительных интервалах
для одного параметра или разности двух параметров.) Поскольку,
по нашему мнению, 2к~р планы очень полезны в имитационном мо-
моделировании, мы покажем, что просто вывести критерии одновремен-
одновременно для всех эффектов этих планов. В главе IV мы видели, что главные
эффекты и взаимодействия (кроме общего среднего) 2к~р плана (р > 0)
оцениваются из
| (/ =1,-,•/). F5)
Пусть а2 — дисперсия отдельных нормально распределенных неза-
независимых наблюдений yt. Ввиду ортогональности плана все оценен-
оцененные эффекты независимы, так что
^j F6)
Следовательно, можно воспользоваться стьюдентизированным макси-
максимумом модуля для получения совместных доверительных интервалов
^(/=1,...,/). F7)
Второй метод использует максимум из J /-"-статистик; каждая Т^-ста-
тистика имеет в числителе одну степень свободы. Такой максимум
/^-статистики был вычислен в [Nair, 1948, р. 26] для а, равного 1 и
5%; еще есть таблица в [Pearson, Hartley, 1966, p. 176]. Максимум
/^-статистики и (квадрат) максимум модуля дают одно и то же значе-
значение. (Не существует равномерно лучшей статистики; мы это провери-
проверили для / = 2, 8, v = 10, оо и а = 0,05 по таблицам из [Miller, 1966,
р. 239] и [Pearson, Hartley, 1966, p. 176].) Третьей альтернативой
служит улучшенное неравенство Бонферрони F3), ранее уже рассмот-
рассмотренное для общих планов. Четвертый метод, так называемый S-метод
Шеффе для q = J, дает широкие доверительные интервалы. Этот
метод применим, поскольку, как было упомянуто в главе IV, 2к~р
планам соответствует линейная регрессионная модель
где yj = asl2. Метод Шеффе мы обсудим подробно для случая про»
извольного плана, к чему мы теперь и переходим.
Индивидуальные эффекты. Мы видели, как с помощью уравнений
E8) — F4) можно проверить, имеет ли фактор главный эффект или
198
существуют взаимодействия между факторами. Это может быть первым,
тагом анализа. Обычно более интересно найти, какие эффекты важны
и, следовательно, отклонить одну или несколько гипотез/проверяв'
мых с помощью /-"-статистик, например" гипотезу о том, что главным
эффектом А нельзя пренебречь, так как на одном из уровней А про-
произошел выброс. Для однофакторного эксперимента мы обсуждали не-
несколько методов исследования средних, контрастов средних и т. д.
Для планов с большим числом факторов полезным методом будет
неравенство Бонферрони (см., например, [Dunn, 1961]). Другой путь—
S-метод Шеффе. Уравнение C8) показывает, что его можно применить
иЛ'к однофакторному плану. Фактически метод даже еще более общ,
потому что Шеффе [Scheffe, 1964, р. 68—70] доказал, что процедура
применима к любой линейной модели вида
у = Х'р + е, F9)
где е — вектор нормально распределенных ошибок с ковариацион-
—>¦ —*-
пой матрицей а2/ (см. [Miller, 1966, р. 53], где е с ковариационной
матрицей с22 с 21 известной, а о2 неизвестной). Предположим, что мы
хотим изучить q-иерное пространство L оцениваемых функций, ге-
генерированных данным множеством независимых оцениваемых функ-
функций {tyu ..., я|5рJ4. Например, k средних в однофакторном плане дают
q = k; а в двухфакторном плане q — db, хотя число контрастов между
аЬ средними будет q = ab — 1 (минус единица означает, что существует
один контраст с 21 сь = 0). Тогда A — а) есть вероятность того, что
G0) одновременно выполняется для всехя[з в ^-мерном пространстве L.
G0)
при
S = fo Fl.Y", G1)
где v — число степеней свободы оценки с2. Для контрастов между
к средними в однофакторном плане уравнения G0) и G1) эквивалентны
уравнениям C8) и C9). Применение метода, например, в двухфактор-
двухфакторном плане будет выглядеть так. Если мы хотим исследовать главные
эффекты фактора А, то существуют главные эффекты а? = Т1г.—
-г] (i = 1, ..., а), которые удовлетворяют одному дополнитель-
дополнительному условию Eocf = 0 (см. IV.2). Следовательно, если мы хотим
построить совместные доверительные интервалы для главных эффек-
эффектов А, то мы должны положить в уравнении G1) q = а — 1. Вместо
изучения главных эффектов г]г-- — -ц мы можем рассмотреть сред-
средние в строках г]г и сравнить их друг с другом, т. е. рассмотреть кон-
фасты г]г- _ — г],--., (г < i'), и это вновь дает q = а — 1. Если же
мы также хотим получить доверительные интервалы для средних по
строкам г]г ., то q = а. Ну а если нас интересуют а главных эффектов
,1 вместе с Ь главными эффектами В, т q = а + b — 2 "'(минус 2 по-
тму, что 2af = 0 и ?af = 0). Другое интересующее нас
199
семейство — это ab взаимодействий af,B = 0 (t = 1, ..., а) вместе
с (а + Ь) дополнительными условиями; эти условия, однако, не неза-
независимы (см. упражнение 10). Следовательно, для семейства взаимо-
взаимодействий q — ab — (а + Ь — 1) = (а — 1) F — 1). Другие примеры
широкого применения метода Шеффе можно найти в [Miller, 1966,
р. 54—62] и [Scheffe, 1964, р. 104, ПО, 119, 273]. Заметим, что в [Puri,
Sen, 1971, p. 308—318, 328—331] рассматриваются непараметричес-
непараметрические асимптотические процедуры для контрастов между эффектами
в двухфакторном плане.
Метод Шеффе весьма гибок, однако он дает широкие дове-
доверительные интервалы, поэтому в частных случаях можно применять
специальные методы (см., например, уравнение F7)). К таким част-
частным случаям, например, относится ситуация, в которой мы не инте-
интересуемся главными эффектами и взаимодействиями, а изучаем средние
в ячейках и некоторые специальные функции этих средних, как мы
теперь покажем.
Индивидуальные средние ячеек. Если мы интересуемся только сред-
средними ячеек (в отличие от строк, столбцов, взаимодействий и т. д.), то
можно применять стьюдентизированный максимум модуля, поскольку
средние ячеек независимы и имеют общую дисперсию о2/п (см. урав-
уравнения D3) — D5)). Функции средних ячеек — контрасты, их можно
изучать с помощью стьюдентизированного размаха Тьюки (см. [Miller,
1966, р. 41—42] и [Konijn, 1959, р. 62, 64], где дается детальный при-
пример применения критерия Тьюки и стьюдентизированного максимума
модуля в двухфакторном плане). Сравнения между контрольной
средней (т. е. некоторой определенной ячейкой в плане) и эксперимен-
экспериментальными средними можно основать на методе Даннетта. В [Konijn,
1960, р. 16—17] также применен метод Даннетта в двухфакторном пла-
плане (см. также [Dunnett, 1964, р. 485—486]J5. Важным моментом яв-
является то, что, когда мы переходим к многофакторным планам, сред-
средние в ячейках остаются независимыми. Подходящая оценка общей
дисперсии для средних ячеек и ее степени свободы следуют из формул
ANOVA, например v = (п — 1) ab в двухфакторном плане, или если
предполагается, что нет взаимодействий и п = 1, то v = (а—1)
(Ь — 1), т. е. v — есть число степеней свободы среднего квадрата вза-
взаимодействия .
V.B.4. Эффективность и робастность ММС
в имитационном моделировании
Введение. В V.B.3 мы обсудили ряд ММС (позднее будут рассмот-
рассмотрены еще некоторые из них.) Здесь же мы изучим, какие методы и
при каких обстоятельствах применяются в моделировании. Рекомен-
Рекомендации по применению ММС в моделировании содержатся в [Conway
et al., 1959, p. 107], [Fishman, Kjviat, 1967, p. 28] и fNaylor et al.,
1967a, p. 1327]. Два метода—методы Тьюки и Даннетта—были при-
применены в [Naylor et al., 1967b, 1968] для построения совместных до-
доверительных интервалов для разностей х( —Xj и Х(—х$ в модели
200
Массового обслуживания с несколькими станциями и при моделиро-
иании национальной экономической системы. Мы не знаем других при-
примеров применения ММС при моделировании (или исследованиях Мон-
Монте-Карло). Это можно объяснить тем, что в большинстве исследований
по моделированию отсутствует формальный статистический анализ,
;i также тем, что в большинстве учебников по статистике не обсужда-
обсуждаются ММС; эти методы неизвестны большинству специалистов в обла-
области моделирования. Для выбора конкретного метода важны некоторые
факторы. (По различным подходам можно проконсультироваться
u [Gabriel, 1969а] и [O'Neill, Wetherill, 1971, p. 231—232].)
1. Цели эксперимента и планы. Мы видели, что эксперименты мо-
могут преследовать различные цели, например, такие, как сравнение
с контролем, все парные сравнения и т. д. Метод, пригодный для
некоторого множества сравнений, пригоден также и для подмножеств
этого множества, но не для больших множеств. Если мы хотим сде-
сделать все парные сравнения, то метод Даннетта не годится, а возможны
методы Тьюки и Шеффе. Выбор подмножества, содержащего наилуч-
наилучшую совокупность, представляет собой другую цель. Различаются еще
и экспериментальные планы, они, например, бывают однофакторными
или многофакторными, а число наблюдений в каждой из совокупно-
совокупностей может быть одинаковым либо различным.
2. Эффективность ММС. Эффективность можно измерять длиной
получаемых доверительных интервалов. В пункте 1 мы заметили, что
метод, пригодный для множества сравнений, можно применять и для
подмножеств. Однако ММС, специально развитые для подмножеств,
могут оказаться более эффективными, так как они учитывают особен-
особенности подмножества. Метод Тьюки для парных сравнений более эф-
эффективен, чем метод Шеффе, но менее эффективен, чем метод Даннетта
для сравнений с контрольной совокупностью; стьюдентизированный
максимум модуля для средних лучше, чем метод Шеффе (см. [Scheffe,
1964, р. 75—79]). Другой тип сравнений эффективности стоит сделать
для параметрических — непараметрических процедур. Для немно-
жественных^сравнений параметрические ММС более эффективны, если
выполняются предположения о распределениях (см. также [Conovef,
1971, р. 281]). С ростом отклонения от предполагаемого вида распреде-
распределения уменьшается эффективность параметрических ММС, и в конце
концов они вовсе перестают действовать. К сожалению, неизвестны
критические значения для отклонений. Отклонения от предполагаемых
распределений приводят нас к следующему фактору.
3. Робастность ММС. По определению, робастность метода воз-
возрастает по мере того, как уменьшается его чувствительность к на-
нарушению лежащих в его основе предположений. Обычно предполо-
предположения ММС следующие: нормальность распределения (кроме непара-
непараметрических процедур), независимость наблюдений, равные дисперсии.
(Методы также предполагают определенный план, например одно-
факторный с равными объемами выборок, и экспериментальные цели,
и частности сравнение с контрольной совокупностью, как мы видели
II пункте 1.) Робастность — очень сложная проблема, потому что су-
существует много типов и степеней отклонения от лежащих в основе ме-
201
предположений. Это объясняет, почему не исследована чувстви-
чувствительность большинства статистик ММС. Исключение составляют
F- и ^-критерии. Чувствительность этих двух статистик хорошо из-
известна, так как они широко применяются в математической статистике
и детально изучены. Они робастны при изучении средних, что мы уже
видели в IV.2. Исследований чувствительности других статистик нет,
поэтому наши рекомендации носят по необходимости интуитивный
характер. Миллер LMiller, 1966, р. 108] утверждает: «Если нужны
рискованные догадки, то можно предположить, что стьюдентизиро-
ванный размах, стьюдентизированный максимум модуля и множест-
множественные ^-критерии Даннетта более чувствительны к условиям нормаль-
нормальности, равных дисперсий и независимости, чем /^-критерий. Каждый
из них зависит от крайних значений, т. е. от наибольшей из множества
переменных, или разности между наибольшей и наименьшей во мно-
множестве. Распределение крайних значений более чувствительно к форме
«хвоста» распределения (ненормальность), наибольшей дисперсии
(гетероскедастичность), взаимозависимости между переменными (за-
(зависимость) по сравнению с распределениями суммы квадратов... Не-
робастность этих статистик, быть может, не катастрофична, но, по
всей вероятности, хуже, чем для /^-статистики». Тьюки [Tukey, 1953]
обсуждал ненормальность и гетероскедастичность. При имитацион-
имитационном моделировании и в экспериментах Монте-Карло независимые на-
наблюдения можно получить с помощью различных последовательно-
последовательностей случайных чисел. Представление о степени нарушения нормаль-
нормальности и гетероскедастичности можно получить из гистограмм, выбирая
из каждой совокупности по п наблюдений. Применяются обычные кри-
критерии нормальности и однородности дисперсий. Равные дисперсии
можно реализовать при моделировании стационарных состояний си-
систем с помощью подходящих длин опытов; преобразование наблюде-
наблюдений также Сможет дать равные дисперсии (см. главу IV, особенно
табл. 4). В случае нарушения нормальности мы все-таки можем при-
применить параметрическую процедуру, ибо она служит асимптотичес-
асимптотическим эквивалентом перестановочного критерия 27 при слабых ограни-
ограничениях на моменты распределения [Miller, 1966, р. 181].
Рассмотрим, какие ММС пригодны (эффективны или робастны)
для различных экспериментальных целей и планов.
Однофакторные планы. 1. Сравнения с контрольной совокупностью.
В V.B.3 мы рассмотрели несколько ММС, специально предложенных
для построения доверительных интервалов или проверки гипотез
относительно \it — jx0 (i = 1, ..., k). Два метода оказались наиболее
подходящими, а именно параметрический (Даннетта) и непараметри-
непараметрический (Стила). Как и во всех других ситуациях с множественным срав-
сравнением, подход Бонферрони также потенциально применим. Метод
Даннетта дает меньшие доверительные интервалы, чем методы Тьюки
и Шеффе, два последних метода предназначены для больших мно-
множеств контрастов. В общем мы отдаем предпочтение методу проверки
Стила, ибо, как утверждает Миллер [Miller, 1966, р. 146—147, 155],
«единственное условие, накладываемое на распределения, состоит
в том, что они должны иметь плотности (т. е. ни нормальность, ни
202
равные дисперсии не предполагаются)... Для нормальных или почти
нормальных распределений больше подходит ^-критерий (Даннетта'),
но ранговый критерий Стила также не плох... Для распределений
с нарушенной нормальностью ранговый критерий эффективнее,
чем ^-критерий, действительно, он много более эффективен... Отметим,
что в методе Стила доверительные интервалы средних значений в про-
противоположность критериям для медиан применимы только при жест-
жестком сдвиге распределений. Никакие искажения, кроме сдвига, не до-
допускаются» (см. также [Steel, 1959a, р. 5621). Обсуждение требования
равных дисперсий в методе Даннетта содержится в приложении.
Для тех ситуаций, когда нет подходящих таблиц (например, в слу-
случае неравных объемов выборок или для уровня ошибки в эксперимен-
эксперименте, большего, чем 5%) либо если нужны доверительные интервалы,
мы рекомендуем подход Бонферрони. Если нет сильного нарушения
нормальности (как в экспоненциальных распределениях), то для срав-
сравнения можно применять ^-статистику; в противном случае надо брать
подходящую непараметрическую статистику для каждого сравнения
(см. также наше обсуждение подхода Бонферрони в V.B.3J8.
2. Все попарные сравнения. Сравним более подробно следующие
ММС: параметрические методы Тьюки и Шеффе, непараметрические
методы Стила'и'Перица и подход Бонферрони. Ввиду того что метод
Тьюки был построен специально для некоторого множества парных
сравнений, *он "дает меньшие доверительные интервалы, чем метод
Шеффе. Преимущество процедуры Шеффе в ее робастности, так как
F-статистика нечувствительна к нарушению нормальности и гетеро-
скедастичности (см. [Scheffe, 1964, р. 75—78, 331—3641). Подход Бон-
Бонферрони, использующий отдельные ^-критерии, тоже серьезный со-
соперник: ^-статистика нечувствительна к нарушению нормальности.
А в случае неравных дисперсий мы можем применить, например,
^-критерий Кокрена — Кокс, который обсуждался в V.A.3. Когда за-
зависимы наблюдения, можно взять разности dt — x-t1— Xri (/ = 1, •¦-, п).
Если серьезно нарушается нормальность, то можно воспользо-
воспользоваться непараметрической разновидностью подхода Бонферрони.
Обладая гибкостью, подход Бонферрони вместе с тем и довольно
эффективен. Таблицы, подробно сравнивающие эффективность,
приведены в [Dunn, 1961]. Данн нашла, что если производятся
все k (k — 1)/2 парных соавнений, то метод Тьюки эффективнее #-под-
хода Бонферрони (см. [Dunn, 1961, table 6]). Эффективность подхода
Бонферрони по сравнению с методом Шеффе растет по мере того, как
число (яг) суждений становится малым по сравненикГс числом (к) со-
совокупностей; мы воспроизводим таблицу Данн в нашей'табл. 3. В край-
крайних случаях нарушения нормальности (например, экспоненциальных
распределений) непараметрический метод Стила эффективнее метода
Тьюки (см. [Miller, 1966, р. 155] nJSherman, 1965]). Миллер [Miller,
1966,"р.' 155] даже"утверждает, что критерий Стила"разумен в случае
проверки медиан (в противоположность доверительным'интервалам для
средних), когда распределения отличаются как расположением, так
и "другими параметрами (вроде дисперсий). Однако в'[Gabriel, Lach-
enbruch, 1969J утверждается, что метод Стила пригоден и для малых
203
выборок. В [Peritz, 1971] не дается таблиц для предложенного авто-
автором рангового метода, но доказано, что применимы (только) асимпто-
асимптотически %2-таблицы.
Таблица 3
Значения т, максимального числа суждений о k средних,
для которых метод Шеффе дает более длинные доверительные
интервалы, чем ^-подход Боиферрони
к
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
1-а = 0,95
о = 7
0
2
5
10
16
26
37
53
71
95
123
158
190
26x10
30x10
38x10
45X10
54X10
а = 20
0
3
7
17
33
63
ПО
189
30X10
56хЮ
89X10
14Х102
V = оо
0
3
9
24
55
129
281
614
126x10
27 ХЮ2
56хЮ2
108Х102
223 xl О2
426 XI О2
872 XI О2
182 ХЮ3
329 ХЮ3
635X103
132x10*
а = 7
0
3
6
12
20
32
49
71
100
1-ос=0,!
о = 20
0
3
10
23
46
104
19X10
38X10
9
О=оо
0
4
13
36
99
241
59X10
14 хЮ2
316x10
696x10
149ХЮ2
ЗЮхЮ2
694хЮг
150x103
312x103
66 хЮ4
12хЮ5
26X10?
6хЮ6
Резюмируем: метод Тьюки наиболее эффективен при соблюдении
всех предпосылок; метод Шеффе более робастный, чем метод Тьюки;
метод Брнферрони (параметрический и непараметрический) робаст-
робастный и часто более эффективный; применению метода Стала и Перица
препятствует отсутствие таблиц для малых п.
3. Линейные контрасты. Для линейных контрастов выбор доволь-
довольно прост: мы обсуждали только один параметрический метод Шеффе
и один непараметрический — Данн. Метод ранжирования Данн, ос-
основанный на подходе Бонферрони, мы рекомендуем только для слу-
случая резкого нарушения нормальности. В иных случаях применяем
робастный метод Шеффе или ^-подход Бонферрони с соответствующей
табл. 3.
4. Линейные функции. Как и в случае линейных контрастов, выбор
производится между методом Шеффе и подходом Бонферрони. Если
выполняются предпосылки о нормальности, независимости и общей
дисперсии, то с помощью табл. 3 можно определить, какой из методов
дает более узкие доверительные интервалы — ^-подход Бонферрони
или метод Шеффе. Если предполагаются сильные отклонения от этих
предпосылок, то возможны соответствующие модификации подхода
204
Вонферрони: параметрическая или непараметрическая немножествен-
иая — для каждой линейной функции.
5. Средние (или коэффициенты регрессии). Если выполняются
предположения о нормальности, независимости, однородности дис-
дисперсий, то более эффективным методом будет стьюдентизированный
максимум модуля. Если неизвестные дисперсии предполагаются раз-
различными, то можно применять независимые ^-статистики; ^-статистики
нечувствительны к нарушению нормальности. В случае больших
отклонений от нормальности мы должны использовать непа-
непараметрический критерий. Если средние или регрессионные коэф-
коэффициенты зависимы, то можно применять неравенство Бон-
феррони.
6. Подмножество, содержащее наилучшую совокупность. Если мы
хотим выбрать подмножество, содержащее совокупность с наибольшей
(либо наименьшей) медианой, то наиболее подходящим будет непара-
непараметрический метод Ризви и Собела, потому что он не требует соблюде-
соблюдения условий нормальности (по определению) и равных дисперсий.
Если мы думаем, что предположения о нормальности иравных дис-
дисперсиях выполняются, то более эффективным будет параметрический
метод Гупты и Собела для выбора совокупности с наибольшей средней
(равной медиане для нормальных совокупностей). Робастность по-
последней процедуры не изучена. Если систему характеризует не сред-
средняя (но, например, дисперсия или биномиальная вероятность), то
простоты ради можно применять выше указанные процедуры/быть
может, после преобразований наблюдений,^ или какой-нибудь спе-
специальный метод (ссылки на эти методы даны в V.B.3). * ^ *
7. Подмножество, содержащее все совокупности, которые лучше
стандартной. Гупта и Собел предложили метод выбора множества,
содержащего все совокупности со средними, которые в некотором от-
отношении лучше стандартной средней. Их метод требует выполнения
нормальности, независимости и общей неизвестной дисперсии. Его
робастность неизвестна. Если подозревается отклонение от нормаль-
нормальности, то можно прибегнуть к преобразованию данных. Для случаев
нарушения нормальности распределения при выборе дисперсий или
биномиальных вероятностей были изобретены специальные проце-
процедуры (см. [Gupta, Sobel, 1958, p. 239—244]). Неравенство неизвест-
неизвестных дисперсий может быть исправлено преобразованием данных либо
применением следующего эвристического подхода. Гупта и Собел
[Gupta, Sobel, 1958] предложили метод для различных, но известных
дисперсий. Можно просто заменить oj на si в формулах, где si есть
пприорная опенка, основанная на предварительной выборке или на-
наблюдениях для оценки средних |лг. Однако для случаяотклонения от
нормальности или в случае гетероскедастичности существует подхо-
подходящий метод Ризви, Собела и Вудворта.
Многофакторные планы. В планах с большим числом факторов:
I) можно применять общий критерий на каждый тип эффектов (на-
(например, ^-критерий для проверки гипотезы о том, что фактор А не
имеет главного эффекта); 2) после отклонения гипотезы 1 можно
определить, какой конкретный эффект (например, р-й главный эф*
205
фект фактора А, ар) вызывает это отклонение, 3) нас могут заинте-
заинтересовать также средние в ячейках и сравнения между ними (в отличие,
например, от средних по строкам, которые измеряют главные эффек-
эффекты).
1. Множественные F-критерии. В ортогональном плане (не обя-
обязательно в 2k~P плане) с наблюдениями, подчиняющимися нормаль-
нормальности, независимости и равенству дисперсий, можно применять улуч-
улучшенное неравенство Бонферрони. Если любое из этих четырех условий
нарушено, то числитель среднего квадратов становится зависимым29.
С отклонением от нормальности и/или гетероскедастичности наблю-
наблюдений можно все-таки применять /^-критерий для каждого типа эф-
эффектов, потому что этот критерий нечувствителен к этим двум видам
отклонений. С зависимостью между отдельными /^-статистиками справ-
справляется неравенство Бонферрони. Метод Шеффе применим в случае
линейной модели; /^-статистика, на которой основан этот метод,
нечувствительна к отклонениям от нормальности и гетероскедастич-
гетероскедастичности. Метод становится менее эффективным по мере роста размерно-
размерности q линейного пространства эффектов (см. табл. 3 с k — 1=7.
например, для q = 2, k = 3). В 2й-"~плане мы можем, кроме того,
применить стьюдентизированный максимум модуля или максимум F-
критерия при условии, что все предпосылки соблюдаются; в ином слу-
случае выбираем между подходами Бонферрони и Шеффе.
2. Индивидуальные эффекты. Можно применять ообастный метод
Шеффе или подход Бонферрони.
3. Индивидуальные средние ячейки. Средние по ячейкам в много-
многофакторных планах не вносят ничего нового по сравнению со средни-
средними в однофакторных планах, потому что средние остаются независи-
независимыми. Следовательно, можно применять те же методы, что ив случае
однофакторного плана, выбирая между методами Бонферрони, Шеф-
Шеффе, Тьюки, Даннетта, техникой стьюдентизированного максимума мо-
модуля и т. д. ^
Читатель может также познакомиться с практическими рекомен-
рекомендациями по применению различных ММС, предложенных в [Seeger,
1966, р. 142—148, 156—157]. Основной вывод автора указанной ра-
работы состоит в том, что подход Бонферрони (применяющий ^-критерий
с равными либо различными дисперсиями или какую-нибудь непара-
непараметрическую статистику) оказывается лучшим в большинстве слу-
случаев.
V.B.5. Другие методы и экспериментальные ситуации
В этом параграфе мы дадим краткое представление о других ММС
для уже упомянутых экспериментальных ситуаций и планов, а также
для других экспериментальных целей и планов (см. также [O'Neill,
Wetherill, 1971], где опубликована библиография, содержащая свыше
200 публикаций, [Conover, 1971, р. 263—292," 342—349], [Dudewicz,
1968], [Gupta, Panchapakesan, 1972] и [Tukey, 1953]).
Другие методы множественного сравнения. 1. Хорошо известен
метод Дункана для совместной проверки. Он состоит из следующих
206
'/ratios: если на каком-то этапе среднее значение (или разность Между
средними) признано значимым, то на следующем шаге число средних
уменьшается до (k — 1) и т. д. К многошаговым процедурам относятся
критерий Килза—Ньюмана и критерий наименьшего значимого раз-
различия (НЗР) Фишера. Для подхода Дункана типично использование
р-средних уровней значимости, для которых, например, уровень зна-
значимости растет с ростом объема семейства и основывается, по нашему
мнению, на весьма произвольных предположениях. Многошаговые
критерии основаны на нормальности, независимости и гомоскедастич-
ности наблюдений в однофакторном плане (за исключением критерия
Фишера, который можно применять в многофакторных планах). Эти
критерии нельзя использовать для оценивания. Критическое обсуж-
обсуждение можно найти в [Hartley, 1955, р. 57—61], [Miller, 1966, р. 24—
31, 81—94, 97—98] и [Scheffe, 1964, р. 78]; см. также [Seeger, 1966,
р. 123—127] и [Rhyne, Steel, 1965, p. 302]. Дункан, однако, имеет
своих сторонников; сравните таблицы и эксперименты Монте-Карло
для его процедуры, данные в [Harter, 1957; 1960а; 1961] и [Balaam,
1963]30.
2. В [Duncan, 1961] и [Waller, Duncan, 1969] сконструированы
ММС, основанные на функциях потерь и априорных вероятностях.
Если экспериментатору подходят типы априорной информации и функ-
функций потерь, используемых в этих ММС, то он может применить про-
простые правила и таблицы, данные в приведенных работах 31 (см. также
[Anscombe, 1965] и [Kurtz et al., 1965]). В [Deely, Gupta, 1968] выве-
выведено байесовское решение для подхода с подмножествами (см. также
[Gupta, Panchapakesan, 1972].
3. К другим смешанным ММС относятся: критерий дисперсии раз-
разброса интервалов Тьюки, быстрые методы (не применяемые в модели-
моделировании на ЭВМ), критерий Немени, основанный на ранговых стати-
статистиках Фридмана, критерий медианы Немени. Эти критерии обсуж-
обсуждаются в [Miller, 1966, р. 94—97, 172—178, 182—185], [Seeger, 1966,
р. 115—116, 132—141], [O'Neill, Wetherill, 1971, p. 224—230].
4.,В [Slivka, 1970] предложен непараметрический критерий про-
проверки медианы времени жизни (периода безотказной работы), больше
ли он для экспериментальной совокупности i (i = 1, ..., k), чем для
стандартной. Этот подход полезен для моделирования подобных си-
систем из-за экономии машинного времени 32.
Другие экспериментальные цели и планы. 1. Как указывалось
в V.B.3, целью эксперимента может быть проведение сравнений
между дисперсиями, а не средними. Мы упоминали несколько методов
для этой задачи. Добавим к этому метод, предложенный в [Ramachand-
ran, 1959b] для построения совместных доверительных границ для
всех отношений g\Ig\> (i, V = 1, ..., k, i Ф i). Альтернатива — при-
применение логарифмического преобразования и сравнение всех erf, как
если бы они были средними (см. [Scheffe, 1964, р. 83—87] и [Miller,
1966, р. 221—223]).
2. Вместо средних и дисперсий можно сравнивать целые распре-
распределения. Для одной или двух совокупностей можно применять хорошо
известный критерий %2 или критерий Колмогорова —Смирнова. Для
207
общего случая k распределений также существует решение. Одо об-
обсуждается в [Conover, 1971, р. 317—326] и [Miller, 1966, р.185—188].
3. Миллер [Miller, 1966, р. 109—128] также предлагает методы
получения совместных выводов для случая регрессионного анализа,
т. е. доверительные границы линии у = ах + Ь, справедливые для
некоторых значений х. К сожалению, большинство результатов при-
применимо только к простому случаю у = ах + Ь.
4. Миллер далее обсуждает методы для экспериментальных пла-
планов с многомерными откликами. Важно помнить, что неравенство Бон-
Бонферрони выполняется для зависимых наблюдений, и, следовательно,
оно применимо к многомерным ситуациям. Миллер [Miller, 1966,
р. 189—210] показывает, что подход Бонферрони находит широкое
применение в случае многомерных^откликов.
Мы будем применять неравенство Бонферрони к многомерным от-
откликам в главе VI. Многомерные процедуры обсуждаются в [Gabriel,
1968; 1969b], [Gabriel, Sen, 1968], [Gnanadesikan, Gupta, 1970], [Gupta,
Panchapakesan, 1969a, 1972] и [Khatrj, 1967].
5. Отклик может быть качественным. Если есть с категорий
(с > 2), то получаем мультиномиальное распределение результатов
(если с = 2, то мы имеем биномиальное распределение). Совместные
выводы для мультиномиальных совокупностей даются в [Miller, 1966,
р. 215—221] и [Gabriel, 1966]. Однако эти распределения кажутся мало-
малоприменимыми в моделировании на ЭВМ, так как машина дает только
количественные отклики. (Количественные отклики можно превра-
превратить в качественные типа «хороший» или «плохой», но это связано
с потерей информации.)
6. Упомянем в заключение о некоторых смешанных целях. В [Sen,
1969] дан метод для взаимодействий в сбалансированных неполно-
блочных планах (PBIB). В [Scheffe, 1970] обсуждаются оценки много-
многомерных отношений (в отличие от разностей). Обзор различных проце-
процедур, особенно процедур выбора подмножеств, содержится в [Gupta,
Panchapakesan, 1969b; 1972] (ср. также [Sobel, 1969]).
ПРИЛОЖЕНИЕ К ЧАСТИ V.B
ПРИЛОЖЕНИЕ V.E.I. НЕРАВНЫЕ ДИСПЕРСИИ В МЕТОДЕ ДАННЕТТА
Легко убедиться, что р«» — коэффициент корреляции между
(хг — х0) и (Xf — х0) (i Ф V) — есть константа, равная 1/2, если
справедливо уравнение
var (*,) = -i- =var (*„) = -?-(i= 1,.... k).
При равенстве дисперсий а% = af = о2 уравнение A.1) удовлетворяет-
удовлетворяется для равных объемов выборок п0 — nt = п. Таблицы Даннетта вы-
вычислены при постоянном корреляционном коэффициенте ра< = 1/233.
Если дисперсии а§ и of различаются, то можно воспользоваться таб-
таблицами Даннетта в надежде на то, что уравнение A.1) приблизитель-
приблизительно верно, так что приближенно работает и соответствующий уровень
ошибки. Либо можно выбрать объемы выборок п0 и nt таким образом,
20S
чтобы A.1) удовлетворялось. Следовательно, мы можем: 1) иснользо^
иать априорные знания о al и af; 2) произвести предварительную вы-
выборку для оценки дисперсий, но не средних (т. е. х0 и xt вычисляются
не по этой выборке); 3) произвести предварительную выборку, оце-
оценить дисперсии и выбрать число дополнительных наблюдений таким
образом, чтобы приблизительно удовлетворялось уравнение A.1);
для оценки средних берется полная выборка. Это ведет к выборкам
случайного объема, что противоречит предположению Даннетта о
фиксированных объемах. Для проверки достоверности этого эвристи-
эвристического подхода нужны дополнительные исследования.
Если дисперсии совокупностей различны, то заменим sD]/r2/n в
уравнениях A7)—A9) выражением
в то же время аппроксимируя степени свободы v в d%itl и d^v с по-
помощью подхода Кокрена—Кокс из V.A.3, т. е.
или с помощью подхода Уэлча (см. уравнение D1) из V.A). Заметим,
что для совокупностей с общей дисперсией Даннетт [Dannett, 1955,
р. 1106—1107] показал, что оптимальный объем выборки имеет по-
порядок по/п( ~ Vk, т. е. дополнительные наблюдения производятся
из контрольной совокупности, чтобы выполнить все k сравнений
Хг — х0 (см. также [Scheffe, 1964, р. 88]). Если совокупности имеют
различные дисперсии, то правило оптимального размещения нужда-
нуждается в уточнении. (Для справок рекомендуется работа [Bechhofer,
Nocturne, 1972].) Однако если дисперсии не равны, важнее удовлет-
удовлетворить основному предположению процедуры Даннетта, т. е. нужно
попытаться удовлетворить уравнению A.1). Поэтому мы и будем пы-
пытаться удовлетворить этому уравнению.
УПРАЖНЕНИЯ
1. Пусть Si = 0 означает, что суждение I ложно (» = 1, 2). Покажите,
что неравенство Бонферрони грубее для положительных (S± и S2), чем для от-
отрицательно взаимно-коррелированных величин (т. е. при положительной корре-
корреляции а.Е определенно меньше, чем 2^а;).
2. Покажите, что доверительные пределы Даннетта A7) приводят к A8).
3. Постройте двусторонние доверительные интервалы для Цг — \х0 (i — 1,...,
k), основываясь на критерии ранговых сумм Стила с применением графиче-
графического и численного методов, описанных в [Miller, 1966, р. 145, 149].Положите
jc01 = 1, JcO2 = 3; xtl = 1, xi2 = 2, xi3 = 3,5 и r*a = 11.
4. Почему ранговая статистика Данн (й,-) для проверки контрастов
(см. уравнение D1)) требует таблиц нормального распределения, а не ^-критерия?
5. Докажите, что аг в уравнении D8) есть верхняя [1/2—[—A—аI/* /2] точ-
точка ^-распределения.
209
ё. Предположим, что дли выбора наибольшего среднего применяется ММС
Даннетта. Покажите, что Р (ПВ) > 1 — а, если \xt < \х0 и Р (ПВ) < 1 — а,
если, например, ц0 = цх = ... = Цй-i — Ph — 6 (б — положительная кон-
константа).
7. В каком отношении находятся дисперсии нормальных распределений
и масштабные коэффициенты гамма-распределений?
8. Докажите, что в плане с равным числом наблюдений в ячейках оценки
главных эффектов некоторого фактора, например, af (i = 1, ..., а), имеют
ковариации (— I/a) (a2In).
9. Пусть семейство суждений состоит из суждений, относящихся к ab сред-
средним в ячейках плана с фактором Л, имеющим а уровней, и фактором В, имеющим
Ь уровней. Чему равно q в методе Шеффе, уравнение G1)? Каким будет q, если
нас интересуют только контрасты между аЬ средними?
10. Докажите, что в двухфакторном плане дополнительное условие
2?=l afbB = ° следует из 2}afjB~0 (?=1, ..., а) и 2t afP = О
(/= 1, ..., й- 1).
11. Рассмотрим совместную проверку гипотез об отсутствии эффектов в
2ft—р факторном плане. Докажите, что аналогом максимума f-критерия
служит квадрат стыодентизированного максимума модуля.
12. Докажите, что корреляция между (xt — Хо) и (Xf — х0) равна 1/2,
если oVtii = а§/«о для i = 1, ..., k (см. уравнение A.1) в приложении V.B.1).
13. Допустим, что мы имеем план с пятью факторами и 50 повторами для
каждого уровня. Мы применяем S-метод Шеффе для множественных контрас-
контрастов с а = 0,05:
а) покажите, что дополняющие величины дают более узкие ожидаемые до-
доверительные интервалы при условии, что отрицательная корреляция по абсолют-
абсолютной величине больше чем 0,03;
б) покажите, что эта отрицательная корреляция должна стать равной
— 0,30, если общее число повторов уменьшается с 250 до 24 (ср. в главе III при-
примечание 48).
14. В [Naylor et al., 1968, p. 190] дана таблица, показывающая оценивае-
оцениваемую дисперсию для каждого из 50 повторов у пяти различных стабилизирующих
стратегий в имитационной экономической модели этих авторов. Примените сле-
следующие ММС к исходным данным и их логарифмическим преобразованиям:
Даннетта, Стила, Бонферрони (предполагая, что стратегия I контрольная) и
Тьюки, Стила, Бонферрони и Шеффе для всех парных сравнений.
15. Примените методы из упражнения 14 к стационарному времени ожида-
ожидания в однокаиальной системе массового обслуживания с различными параме-
параметрами.
ПРИМЕЧАНИЯ
1 В регрессионном анализе, например, можно, предположив линейность
кривой отклика у = Ро + Pi* + и. проверить гипотезу р\ = 0.
2 Однако имеются некоторые ММС (например, множественный ранговый
критерий Дункана) для проверки значимости суждений, которые не имеют дове-
доверительного эквивалента; см. [Miller, 1966, р. 26], а также [Ryan, 1959,
р. 40—41].
3 В [Seeger, 1966, р. 117—119] обсуждаются все упомянутые типы ошибок,
за исключением предупреждающего уровня Верхагена. В [Harter, 1957] даны
таблицы, показывающие, как различаются величины некоторых типов ошибок.
Аналогичные таблицы даются в [Boardman, Moffit, 1971] и [Gabriel, 1964, p.
470—476]. Различные уровни ошибок ясно изложены в [Balaam, Federer,
1965], [Hartley, 1955, p. 47—49], [O'Neill, Wetherill, 1971, p. 220—223]. [Ryan,
1959, p. 26—40] и [Tukey, 1953]. В последней работе приведено также много при-
примеров. Далее, можно сравнить [Сох, 1965], [Dunnett, 1964, р. 483], [Konijn,
1959, р. 61], [Rhyne, Steel, 1965, p. 295], [Scheffe, 1964, p. 89] и [Seeger, 1968].
4 Краткая критика других уровней ошибок: Верхаген [Verhagen, 1963]
определяет уровень ошибок только для независимых суждений; уровень Эклун-
210
да по изложению в [Seeger, 1966, р. 134—141] становится работоспособным
только при очень грубых приближениях; как указано в [Miller, 1966, р. 31, 85],
защитный уровень Дункана в большинстве случаев достигает своего значения
при нереалистичном числе, равном оо, кроме того, он возрастает с ростом числа
совокупностей (см. также [Scheffe, 1964, р. 78]); уровень ошибок на эксперимент
не очень сильно отличается от заданного уровня ошибки, как об этом говорится
в [Hartley, 1955, р. 48], [Miller, 1966, р. 10] и [Ryan, 1959, р. 38—40]).
5 Это утверждение выполняется также для зависимых суждений (см. урав-
уравнение (9) в [Miller, 1966, р. 7]).
в См. [Сох, 1965], [Kurtz et al., 1965, p. 146—148], [Miller, 1966, p. 10]
и [Ryan, 1959, p. 35, 38].
* Следующие обозначения эквивалентны: а ? b ± с, или b — с < a < b +
+ с, или \a — b\ <C с
8 P (t; < а для всех i) = P (max ,- tt < a).
9 В [Steel, 1959a, p. 370] также дана подобная таблица. Однако таблица
Миллера использует более современное приближение, предложенное Гуптой
[Miller, 1966, р. 152].
10 В частном сообщении Миллер указал, что Стил отклоняет Яо при ма-
малых значениях min [г;, я Bя +1) — г,-], в то время как сам Миллер откло-
отклоняет #0 при больших значениях max [г,-, п Bп +1) — г,-]. Оба подхода дают
идентичные заключения, потому что max = я B я +1) — min Миллео дает
таблицы критических максимальных значений, а Стил [Steel,ч 1959а, р. 571] —
таблицы критических минимальных значений.
11 Это находится в противоречии с утверждением Снгера [Seeger, 1966,
р. 130] о том, что критерий знаков (в ситуациях многомерного сравнения) не
требует равенства дисперсий. (В частном сообщении Сигер объяснил, что он
имел в виду применение неравенства Бонферрони к одномерному критерию
знаков для двух совокупностей, что не требует общей дисперсии.) Сигер [Seeger,
1966, р. 132] далее указывает, что ранговый критерий чувствителен к неодно-
неоднородности дисперсий; это интересовало Стила [Steel, 1959a, р. 562] и Миллера
[Miller, 1966, р. 146] в отношении критериев; для построения доверительных
интервалов требуется равенство дисперсий (см. наше обсуждение робастности
различных критериев в разделе V.B.4).
12 Процедура обеспечивается неким типом транзитивности выводов; см.
[Gabriel, 1964, р. 460—462].
13 Это соотношение между ANOVA F-критерием для проверки Но : \хг =
= ... = [ik и критериями относительно отдельных контрастов выполняется
только для критериев контрастов, основанных на уравнении C8). Следователь-
Следовательно, если мы применяем, например, критерий стьюдентизированного ранга Тью-
ки к контрастам Ц; — |i^, то после незначимости F-критерия можно сделать
некоторые значимые суждения о [хг — yt,^.
11 Критерии для более общих контрастов можно основать на формуле A2)
из [Dunn, 1964].
15 Фактически Дани рассматривает два ММС: в одном проранжированы
все совокупности, в другом —• только те, которые входят в определенный кон-
контраст. Эффективность обоих методов сравнивалась для нескольких ситуаций,
и ни один из методов ие был признан лучшим [Dunn, 1964, р. 252], [Sherman,
1965]. Мы не обсуждаем первый вариант, потому что такой подход предполагает,
что совокупности не упоминаются в данном контрасте, однако годятся для
ранжирования.
16 Эти значения можно найти в табл. 1—4 [Dunn,.Massey, 19651 в столб-
столбцах, где р = 0,0, и строках, соответствующих 1 — а = 0,80 и 0,90.
17 См. в [Gupta, Sobel, 19571 столбец соответствующий нужным значени-
значениям k или р, где р равно k — 1. В [Dunnett, 19551 см. столбец, для р (= k — 1),
например для Р* = 0,95, k = 5, u= 15. Даннетт берет значение 2,36, так что
D есть (\/~2) B,36) ^ 3,33, в то время как Гупта~и Собел дают 3,34.
18 У Ризви^и Собела"а равно (г — с).
19 Уравнение F,6)~у Ричви и Собела идентично уравнению C.3). Следова-
Следовательно, уравнение F.6) или C.3) справедливо при а = г —-ев табл. 3. Поэтому
в F.3) мы имеем (г + с) = г + (г —' а) ~ %г — а = (я + 1) — о..
211
20 Критическая константа а равна 0 и хй^ становится — <х>, так назы-
называемое вырождение (см. [Rizvi, Sobel, 1967, p. 1789—1790, 1802]).
21 В [Dunn, 1961, p. 61] содержится опечатка: объединенная оценка дис-
дисперсии имеет (п — 1) ab степеней свободы вместо п (а — 1) F — 1).
32 В [Hartley, 1955, р. 50] предложена альтернативная процедура. Од-
Однако можно проверить, что эта процедура сводится к методу Бонферрони (по-
(потому что в ней используется Fa (k; v*, v) ж Fajk A; v*, v), обеспечивающее
равное число степеней свободы, как в случае 2k~P эксперимента). Эта процеду-
процедура — усовершенствованный метод Бонферрони для случая, когда могут раз-
различаться степени свободы [Hartley, 1955, р. 52—54]. В [Ramachandran, 1956a]
дано решение для проверки только двух средних квадратов. В [Gupta, 1963]
содержится таблица для max (Ft) (выведенных для различных задач), кото-
которая, на первый взгляд, выглядит полезной. Для Р (Ft < Fa Л F2 < Fa Л •¦¦
... Л Fh < Fa) =1 — а эквивалентно Р (max. Ft < Fa) =1 — а. Но, к со-
сожалению, таблицы Гупты действуют только при условии равных степеней сво-
свободы. (В примере а — 1 = 6 — 1 = (а — 1) F — 1) = (я — 1) ab.) Это усло-
условие очень ограничительно.
23 Миллер [Miller, 1966, р. 102] упоминает о другом применении, вклю-
включающем ^-статистику с независимыми числителем и общим знаменателем. По
его мнению, точные результаты выводятся с применением стьюдентизирован-
ного максимума модуля. Если щ различны или нет таблиц для стьюдентизиро-
ванного максимума модуля, то используется улучшенное неравенство Бонферро-
Бонферрони F3).
24 1b есть оцениваемая функция, если она имеет несмещенную линейную
оценку [Scheffe, 1964, р. 131.
35 В [Konijn, 1960, р. 17] также дается аппроксимация для доверительных
интервалов г\и — тI7-, где %; есть контроль, меняющийся вместе с В-столб-
цами. Простую аппроксимацию можно получить с помощью метода Бонферро-
Бонферрони, т. е. метод Даннетта применяется к каждому столбцу с а= а?/Ь.
28 Для малых п мощность критериев мала. Это менее важно, если мы хо-
хотим применить один из ММС, и только в случае сильного нарушения нормаль-
нормальности и наличия гетероскедастичности отклоняем нуль-гипотезу.
27 Перестановочный критерий приблизительно описывается следующим
образом. При наличии Яо любой набор наблюдаемых величин имеет одну и ту
же вероятность. Определим все возможные наборы; вычислим соответственные
значения некоторой выбранной статистики; найдем, какое значение превышает
долю а значений этой статистики; сравним это критическое значение со значе-
значением статистики для конкретного набора, полученного в эксперименте. О пере-
перестановочных критериях см., например, [Conover, 1971, р. 357—364] и [Miller,
1966, р. 179—182].
28 Сигер [Seeger, 1966, р. 145] дает таблицу для размеров доверительных
интервалов в методах Даннетта и Бонферрони. (Он называет метод Бонферро-
Бонферрони методом Фишера.) Для уровня ошибки, устанавливаемого в эксперименте
и равного 5% , размеры доверительных интервалов одинаковы, и, следовательно,
подход Бонферрони более привлекателен, так как он содержит меньше предпо-
предположений.
29 Рассмотрим факторный план 2k~P. Ковариация между, например,
и 2 эффектами определяется следующим выражением'
Если наблюдения уг- независимы, то это выражение сводится к
л N
1=1
212
Гели, Далее, наблюдения имеют равные дисперсии а2, то мы имеем
В ортогональном плане 2 х^ХB = 0. Для нормально распределенных наб-
'подепий из равенства ковариации нулю следует независимость [Fisz, 1967,
р 159]. Независимость оцененных эффектов означает, что их суммы квадратов
независимы (см. например, уравнение (99) в главе IV).
30 В частной беседе Габриель сообщил о неопубликованном исследовании
Монте-Карло Саубрана, в котором получились равные уровни ошибок, устанав-
устанавливаемых в эксперименте, для методов Дункана, Тьюки, Шеффе—Габриеля
и Райана (вариант Дункана). Мощности этих методов не очень различаются, но
процедура Райана оказывается лучшей. Метод Кила дает неподходящие резуль-
результаты
31 Решение Дункана дает критическую константу, которая не зависит от
числа совокупностей (k). Это приводит к высокому уровню ошибки, если k ве-
велико, но эта характеристика применяется потому, что априорная вероятность
того, что все k совокупностей идентичны, мала (см [Duncan, 1961, р. 1029—•
10301).
32 В имитационных экспериментах нет совместной обработки, прилагаемой
к экспериментальным единицам. Однако метод Сливки пригоден. Пусть есть п0
наблюдений стандартной системы. Моделирование начинается с t-й совокуп-
совокупности; моделирование заканчивается, как только время жизни этой совокуп-
совокупности станет больше, чем медиана контрольной совокупности; записывается 0.
(Так экономится машинное время, поскольку имитационный эксперимент не
доводится до разрушения системы )"Если время жизни меньше, чем медиана кон-
контрольной совокупности, тогда записывается 1
33 Даннетт fDunnett, 1964, р. 490] вывел довольно сложный корректировоч-
корректировочный множитель для предложенной им двусторонней критической константы d'
в частном случае, когда Хо имеет меньшую дисперсию, чем экспериментальные
средние Xi, дисперсии которых равны.
БИБЛИОГРАФИЯ
1 Andrews D F, BickelP J, На in pel F R, HuberP J, Ro-
Rogers W H and Tukey J W A972) Robust Estimates of Location Prin-
Princeton University Press, Princeton, N J
2 AnscombeF J A965) Comments on Kurtz—Link—Tukey—Wallace pa-
paper Technometrics, 7, 167—168
3. Balaam L N A963) Multiple comparisons — a sampling experiment.
Australian J Stat, 5, 62—84
4 Balaam L N and FedererW T. A965) Answer to query: Error rate
bases Technometrics, 7, 260—262
5 Barlow R E and Gupta S S A969) Selection procedures for restric-
restricted families of piobability distributions Ann Math Stat, 40, 905—917
6 BartlettN S and G о vi n d a r a j u 1 u Z A968) Some distribution—free
statistics and their application to the selection problem Ann Inst Stat Math,
20, 79—97
7. BechhoferR E and Nocturne D J A972). Optimal allocation of ob-
observations when comparing several Ireatments wilh a control, II: 2-sided com-
comparisons Technometrics, 14, 423—-436
8 BoardmanT J and M о f f i 11 D R A971) Graphical Monte Carlo type
I error rates for multiple comparison procedures Biometrics, 27, 738—744
9. Con over W. J. A971). Practical Nonparametric Statistics. Wiley, New
York
10 ConwayR W, Johnson В М and Maxwell W L A959). Some
problems of digital systems simulation Management Sci, 6, 92—110
213
11 Cox D R A965) A remark on multiple comparison methods Technomet-
ncs, 7, 223—224.
12 С rouse С F A969) A multiple comparison of rank procedure for a one-
oneway analysis of variance South African Stat J 3, № 1, 35—48
13 Deely J J and Gupta S S A968) On the properties of subset selec-
selection procedures Sankhya, Ser A, 30, Pt 1, 37—50
14 Desu M M A970) A selection problem 4nn Math Stat, 41, 1596—1603
15 Desu M M and Sobel M A968) A fixed subset—size approach to the
selection problem Biometrika, 55, 401—410
16 DudewiczE J A968) A Categorized Bibliography on Multiple—Decision
(Ranking and Selection) Procedures Department of Statistics, The Univer-
sitv of Rochester, New York
17 DudewiczE J A972) Statistical Inference with Unknown and Unequal
Variances Department of Statistics, The University of Rochester, New York
18 Dudewicz E J and Dalai S R A971) Allocation of Observations in
Ranking and Selection with Unequal Variances Department of Statistics, The
University of Rochester, New York
19 DuncanDB A961) Baycs rules for a common multiple comparisons pro-
problem and related Student-t problems Ann Math Stat, 32, 1013—1033
20. Dunn О J A961) Multiple comparisons among means J Amer Stat As-
soc, 56, 52—64
21. Dunn О J A964) Multiple comparisons using rank sums Technometrics,
P 241—252
22 Dunn О J and MasseyF J A965) Estimation of multiple contrasts
using t-distributions J Amer Stat Assoc, 60, 573—583
23 DunnettCW A955) A multiple comparison procedure for comparing se-
several treatments with a control J Amer Stat Assoc, 50, 1096—1121
24 DunnettCW A964) New tables for multiple comparisons with a control
Biometrics, 20 482—491
25 FishmanG S and Kiviat P J A967) Digital Computer Simulation
Statistical Considerations RM—5387—PR, The Rand Corporation, Santa Mo
nica, California
26 Fisz M A967) Probability Theoiy and Mathematical Statistics Wiley,
New York, third printing
27 Gabriel К R A964) A procedure for testing the homogeneity of all sets
of means in analysis of variance Biometrics. 20, 459—477
28 Gabriel К R A966) Simultaneous test procedures for multiple compari-
comparisons on categorical dati J Amer Stat Assoc, 61, 1081—1096
29 Gabriel К R A968) Simultaneous test procedures in rnultivariate analy-
analysis of variance Biometrika, 55, 489—504
30 Gabriel К R A969a) Simultaneous test procedures — some theory of
multiple comparisons Ann Math Stat, 40, 224—250
31 G a b r i e 1 К R A969b) Comparison of some methods of simultaneous in-
inference in MANOVA — In Multivanate Arul\sis, \ol 2 (P R Krishnaiah,
ed ), Academic New York
32 GabrielK R andLachenbruchP A A969) Non-parameiric ANOVA
in small samples A Monte Carlo study of the adequacy of the asymptotic
approximation Biometrics, 25, Pt 3, 593—596
33 Gabriel К R and Sen P К A968) Simultaneous test procedures for
one wav ANOVA and MANOVA based on rank scores Sankya, Ser A, 30,
Pt 3, 303—362
34 GnanadesikanM and Gupta S S A970) A selection procedure for
multivariate normal distributions ш terms of the geneiah/cr! variances Tech-
nometucs, 12, 103—117
35 Goel P К A972) A Note on the Non Existence oi Subset Selection Proce
dure for Poisson Populations Mimeographed ^eries № 303, Department of
Statistics, Division of Mathematical Sciences, Purdue University, Lafayette,
Indiana
36 Gupta S S A963) On a selection and rankng procedure for gamma popu-
populations Ann Inst Stat Math, 14, 199-216
214
')/ Gupta S S A965) On some multiple decision (selection and ranking)
rules Technometi ics 7 225—245
38 Gupta S S and McDonald G A970) On some classes oi selection
procedures based on ranks —• In Nonparametnc Techniques in Statistical
Inference (M L Pun, ed ), University Press, Cambridge, England
39 Gupta S S and McDonald G С A972) Some selection procedures
with applications to reliability problems — In Operations Research and Re-
Reliability (D Giouchko, ed ), Gordon and Breach, New York
40 Gupta S S and Nagel К A971) On some contributions to multiple de
cision theory — In Statistical Decision Theory and Related Topics (S S
Gupta and J Yackel, eds ), Academic, New York
41 Gupta S S, Nagel К and Panchapakesan S A971) On the Or
der Statistics from Equally Correlated Normal Random Variables Mimeogra
phed Series, № 290, Department of Statistics, Division of Mathematical Scien
ces, Purdue University, Lafayette, Indiana
42 Gupta S S and Panchapakesan A968) On a Class of Selection and
Ranking Procedures Mimeographed Series, № 171, Department of Statistics
Division oi Mathematical Sciences, Purdue University, Lafayette, Indiana
43 GuptaS S and P a n ch ap a ke sa n S A969a) Some selection and ran
king procedures for multivanate normal distributions — In Multivanate Ana-
Analysis, vol 2 (P R Knshnaiah, ed ), Academic, New York
44 GuptaS S and Panchapakesan S A969b) Selection and ranking
procedures — In The Design of Computer Simulation Experiments
(T H Naylor, ed ), Duke University Press, Durham, North Carolina
45 Gupta S S and Panchapakesan S A972) On multiple decision pro-
procedures J Math Physical Sci, 6, 1—71
46 GuptaS S andSantnerT J A972) Selection of a Restricted Subset
of Normal Populations Containing the One with the Largest Mean Mimeo
graphed Series, № 299, Department of Statistics, Division of Mathematical
Sciences, Purdue University, Lafayette, Indiana
47 GuptaS S and Sob el M A957) On a statistic uhich arises in selection
and ranking procedures Ann Math Stat, 28, 957—967
48 Gupta S S and Sobel M A958) On selecting a subset which contains
all populations better than a standard Ann Math Stat, 29, 235—244
49 Gupta S S and Sobel M A960) Selecting a subset containing the
best of several binomial populations — In Contributions to Probability and
Statistics (I Alkm, S G Ghurye, W Hoeffdmg, W G Madow and
H В Mann, eds), Stanford University Press, Stanford, California
50 Gupta S S and Sobel M A962) On selecting a subset containing the
population with the smallest variance Biometrika, 49, 495—507
51 HarterH L A957) Error rates and sample sizes for range tests in mul-
multiple comparisons Biometrics, 13, 511—536
52 HarterH L A960a) Critical values for Duncan's new multiple range test
Biometrics, 16, 671—685
53 Harter H L A960b) Tables of range and studentized range Ann Math
Stat, 31, 1122—1147
54 HarterH L A961) Corrected error rates for Duncans new multiple ran-
range test Biometrics, 17, 321—324
55 HartleyH О A955) Some recent developments in analysis of variance
Commun Pure Appl Math, 8, 47—72
56 Khatri С G A967) On certain inequalities for normal distributions and
their applications to simultaneous confidence bounds Ann Math Stat 38
1853—1867
57 Ki mb all A W A951) On dependent tests of significance in the analysis
of variance Ann Math Stat, 22, 600—602
58 Konijn H S A959) Basing decisions on an analysis of variance Austra-
Australian J Stat, 1, 57—68
59 Konijn H S A960) Multiple comparison with controls Australian J
Stat, 2, 16—18
60 Knshnaiah P R and Armitage J V A966) Tables for multivanate
t-distnbution Sankhya, Ser. B, 28, Pt 1 and 2, 31—56
215
61 Kurtz 1 E Link R I TukeyJ W and WailaceD L A965)
Shortcut multiple comparisons for balanced single and double classifications,
Part 1, results Technometncs, 7, 95—162
62 LehmannE L A963) Nonparametnc confidence intervals for a shift pa-
parameter Ann Math Stat, 34, 1507—1512
63 Lewis P A W A972) Large—Scale Computer—Aided Statistical Mathe
matics Naval Postgraduate School, Monterey, California
64 Martin W A A971) Sorting Computing Surveys, 3, 147—174
65 Miller R G A966) Simultaneous Statistical Inference McGraw Hill,
New York
66 Nair К R A948) The studentized form of the extreme mean square tests
in the analysis of variance Biometnka 35, 16—31
67 NaylorT H, Burdick D S andSasserW E A967a) Computer si
mulation experiments with economic systems The problem оГ experimental
design J Amer Stat Assoc, 62, 1315—1337
68 NaylorT H.WertzK and Wonnacott T H A967) Methods for
analyzing data from computer simulation experiments Commun ACM, 10,
703—710
69 NaylorT H, Wertz К and Wonnacott TH A967b) Methods for
evaluating the effects of economic policies using simulation experiments Rev
Inter Stat Inst, 36, 184—200
70 O'Neill R andWethenllQ В A971) The present state of multiple
comparison methods J Roy Stat Soc, Ser B, 33, 218—250 (including dis-
discussions)
71 PatteisonD W A965) A nonparametric population selection procedure
Ann Math Stat, 36, 1614—1615
72. PearsonE S and Hartley H О A966) Biometnka Tables for Stati
sticians, vol 1, Cambridge University Press, Cambridge, England, third edi
tion
73 Peritz E A971) On a statistic for rank analysis of variance J Roy Stat
Soc, Ser B, 33, 137—139
74 Pur i M L and Sen P К A971) Nonparametnc Methods in Multivanant
Analysis Wiley, New York
75 RamachandranK V A956a) On the simultaneous analysis of variance
test Ann Math Stat, 27, 521—528
76 Ramachandran К V A956b) Contributions to simultaneous confidence
interval estimation Biometrics, 12, 51—56
77 RhyneA L andSteelR G D A965) Tables for a treatments versus
control multiple comparison sign test Technometncs, 7, 293—306
78 Rizvi M H and Sobel M A967) Nonparametric procedures for selec-
selecting a subset containing the population with the largest a quantile Ann
Math Stat, 38, 1788—1803
79 RizviM H.SobelM and WoodworthG G A968) Nonparametric
ranking procedures for comparison with a control Ann Math Stat, 39,
2075—2093
80 Ryan T A A959) Multiple comparisons in psychological research Psych
Bull, 56, 26—47
81 Scheffe H A964) The Analysis of variance Wiley, New York, fourth
printing Русский перевод Шеффе Г Дисперсионный анализ М, Фнзмат-
гиз, 1963
82 Scheffe H A970) Multiple testing versus multiple estimation improper
confidence sets, estimation of directions and ratios Ann Math Stat, 4i,
1—29
83 SeegerP A966) Variance Analysis of Complete Designs Almqvist and
Wiksell, Uppsala
84 SeegerP A968) A note on a method for the analysis of significance en
masse Technometrics, 10, 586—593
85 Sen P К A969) A generalization of the T method of multiple comparisons
for interactions J Amer Stat Assoc, 64, 290—295
86 Sherman E A965) A note on multiple comparisons using rank sums
Technometrics, 7, 255—256
216
87 Shvka J A970) A one-sided nonparametnc multiple comparison control
percentile test treatments versus control Biometnka, 57, 431—438
88 Sob el M A967) Nonparametnc procedures for selecting the t populations
with the largest к quantiles Ann Math Stat, 38, 1804—1816
89 Sobel M A969) Selecting a subset containing at least one of the best
populations —In Multivanate Analysis, vol 2 (P R Knshnaiah, ed ), Aca-
Academic, New York
90 Steel R G D A959a) A multiple comparison rank sum test treatments
versus control Biometrics, 15, 560—572
91 Steel R Q D A959b) A multiple comparison sign test treatments versus
control J Amer Stat Assoc, 54, 767—775
92 Steel R G D A960) A rank sum test for comparing all pairs of treat-
treatments Technometncs, 2, 197—207
93 Tobach E, Smith M, Rose G and Richter D A967) A table
for making rank sum multiple paired comparisons Technometncs, 9, 561—
567
94 Tukey J W A953) The Problem of Multiple Comparisons, Department of
Statistics, Princeton University, Princeton, New Jersey
95 VerhagenO M W A963) The caution level in multiple tests of signi
ficance Austi ahan J Stat, 5, 41—-48
96 Waller R A and DuncanD В A969) A Bayes rule for the symmetric
multiple comparisons problem J Amer Stat Assoc, 64, 1484—1503
97 Wilks S S A963) Mathematical Statistics Wiley, New York, second prin-
printing Русский перевод У и л к с С Математическая статистика М , «Hay
ка», 1967
Гласе Дж , Стэнли Дж Статистические методы в педагогике н психологии
М , «Прогресс», 1976
Дэвид Г Метод парных сравнений М, «Статистика», 1978
VB. МЕТОДЫ МНОЖЕСТВЕННОГО РАНЖИРОВАНИЯ '
V.B.I. Введение и резюме
В этой части главы V мы изложим методы определения числа на-
наблюдений, которое следует взять в каждой из k (k > 2) совокупностей
Пг (г = 1, , k), чтобы выбрать лучшую совокупность В основном
в этой части мы предполагаем, что лучшая совокупность просто имеет
наибольшую среднюю В случае, когда нас интересует наименьшая
средняя, можно пользоваться теми же процедурами для выбора наи-
наибольшей средней, применяя их к наблюдениям, умноженным на минус
единицу В V В 5 мы кратко рассмотрим другие критерии выбора не
по средним, а, допустим, по дисперсиям для других задач, формули-
формулируемых не как выбор лучшей совокупности, а как, например, полное
ранжирование всех k совокупностей. Методы полного или частичного
ранжирования называются методами множественного ранжирования
(или ММР); в литературе их еще называют методами множественного
выбора и принятия решений. При имитационном моделировании наб-
наблюдение можно определить как один прогон данной системы, т. е. как
одну последовательность выходов системы, которые вместе дают не-
несмещенную оценку искомой характеристики системы,представляющей
интерес для экспериментатора (скажем, моделируемая история одного
месяца дает одно наблюдение дохода за месяц). Различные варианты
системы соответствуют различным совокупностям. В терминологии
217
планирования эксперимента k совокупностей можно сопоставить од-
одному фактору с k уровнями или, например, / факторам, каждый из
которых имеет kj уровней, так что k = Il[=i^. Мы предполагаем>
что не все / факторов (/ > 1) количественные. Для чисто количествен-
количественных факторов иные методы (в том числе методология поверхности от-
отклика, обсуждаемая в главах II и IV) более удобны для отыскания оп-
оптимальной комбинации уровней факторов. Мы не считаем, что при мо-
моделировании важных альтернатив системы ММР должны применяться
механически. При принятии решений помимо выхода модели руко-
руководствуются еще и другими соображениями. Тем не менее ММР дают
экспериментатору возможность определить «разумное» число наблю-
наблюдений.
Примем к сведению, что не существует книги, дающей обзор ММР
для моделирования. [Bechhofer et al., 1968] — превосходная книга,
но доступная только аспирантам и студентам-статистикам и содержа-
содержащая лишь некоторые последовательные ММР, т. е. не все последова-
последовательные и непоследовательные ММР, которые могут оказаться важны-
важными для имитационного моделирования. Надеемся, что наш обзор полу-
получился достаточно полным. Он основан на публикациях из рефератив-
реферативного журнала «Statistical Theory andMethod Abstracts» A959—1972 гг.)
и других публикациях, упомянутых в библиографических списках,
в том числе и в книгах [Bechhofer et al., 1968] с 320 ссылками и [Dude-
wicz, 1968] с 250 ссылками.
В V.B.2 мы обсудим основную концепцию ММР, а именно подход,
использующий концепцию «зоны безразличия» и эффект различных
сочетаний средних совокупностей (таких, как наименее предпочтитель-
предпочтительное, обобщенное наименее предпочтительное, с равными средними и—
новая концепция — «частично безразличные» сочетания). В V.B.3
мы представляем те из существующих методов, которые, по нашему
мнению, могут найти применение в моделировании. Эти методы класси-
классифицированы в соответствии с лежащими в их основе предположения-
предположениями: параметрические — непараметрические и «полупараметрические»
ММР, с одинаковыми распределениями или с разными, с известными
дисперсиями или с неизвестными. Мы также обсудим методы для таких
ситуаций, где существует стандартная совокупность, и для многофак-
многофакторных планов. В V.B.4 обсуждаются применения ММР в имитацион-
имитационном моделировании. Эффективность и робастность ММР сначала
изучим в общем, а затем, в V.B.3, исследуем эффективность и робаст-
робастность отдельных методов.
Вместо того чтобы полагаться на робастность существующих
методов, можно применять эвристические ММР, предлагаемые в
V.B.4. Там же'даны и практические^рекомендации для выбора соот-
соответствующего метода в" имитационном моделировании. BV.B.5 мы
упоминаем методы для ненормальных распределений (например, гам-
гамма-, биномиального), процедуры принятия решений и формулируем
другие задачи (скажем, задачу о t лучших средних). За V.B.5 следуют
приложения, простые упражнения, библиография. Читатель может про-
пропустить детальное описание в V.B.3, потому что в V.B.4 все подходя-
nine ММР разобраны и охаракгеризованы. Мы обсуждаем такое боль-
большое количество ММР потому, что они основаны на предположениях,
i оторые могут нарушаться при моделировании; следовательно, иссле-
1,()ватель должен решать, какие предположения кажутся выполнимы-
Mif и соответственно выбирать метод.
V.B.2. Подход, использующий «зоны безразличия»
Во введении было сказано, что в основном мы ограничим наше
ниимание теми ММР, цель которых — выбор наибольшей средней.
1.стественной статистикой в таком выборе будет выборочная средняя
или х, т.е. лучшей совокупностью объявляется та, выборочное сред-
среднее которой принимает наибольшее значение, скажем ЛГ[Ь]. (Обоз-
(Обозначим как X(D выборочное среднее t-й лучшей совокупности и как
«¦[,] — наибольшее выборочное среднее в выборке.) При малой вы-
оорке вероятность того, что лучшая совокупность не соответствует
лучшему среднему (лг(?!) Ф Х[щ), велика. Следовательно, мы должны
определить, сколько нужно взять наблюдений, чтобы получить пра-
иильный выбор с большой вероятностью. Если, однако, средние сово-
совокупности не очень сильно отличаются, то требуются большие выборки,
чтобы идентифицировать лучшую совокупность. (Ср. на рис. 29
is V.A.4 две совокупности.) Обычно выгодно брать много наблюдений,
чтобы выявить небольшие различия в средних. Поэтому в [Bechhofe'r,
1954] предложен так называемый подход, использующий «зоны без-
безразличия», которому с тех пор следовали многие авторы. Рассмотрим
отот подход более подробно.
Мы имеем k совокупностей П,- (t = 1, ..., k), также обозначаемых
11(г), где цA) ^ цB) <; ... <; ii(h _ 0 <; |xu); очевидно, мы не знаем,
какой совокупности соответствует \i(h). Мы хотим определить со-
совокупность с наибольшей средней. Вероятность правильного выбора
(ПВ) желательно сделать не меньше наперед заданной константы Р*.
(Эта константа должна быть больше, чем l/k, так как случайный вы-
выбор совокупности без всякой выборки гарантирует Р (ПВ) > \lk.)
Большие выборки понадобятся для выбора лучшей совокупности, если
средние совокупностей мало различаются; но потери от неправильного
выбора тоже будут небольшими. Поэтому в [Bechhofer, 1954] предложе-
предложено гарантировать ПВ с вероятностью по меньшей мере Р*, только
если лучшая (наибольшая) средняя совокупности по крайней мере на
б* (б* > 0) единиц больше следующей за ней лучшей (наибольшей)
средней:
Р (ПВ) > Р*г если б = Им - Rft _и > 6*. A)
Этот подход обсуждается в [Bechhofer, 1954, р. 23; 1958, р. 411],
более общее обсуждение дается в [Barr, Rizvi, 1966].
Теперь рассмотрим подробнее влияние различных сочетаний сред-
средних на Р (ПВ).
1. Наименее предпочтительное сочетание (НПС):
НЧ1) = ••• = Нчл-1) = Hh) — б*- B)
219
Так как наилучшее среднее на 8* единиц больше следующего за ним,
мы хотели бы гарантировать Р (ПВ) > Р*. Уравнение B) показыва-
показывает, что все" сочетания могут гарантировать^(ПВ) > Р*, потому что
лучшая совокупность только на б* единиц лучше и все остальные
(k — 1) совокупностей одинаково близки с" лучшей (см. уравнение
B.4) в приложении V.B.2). Истинное сочетание средних неизвестно
экспериментатору, однако метод должен осуществить Р (ПВ) > Р*
(обеспечить \ih — jj,^ > б*) даже в НПС3. Если \iw — Pa-i) стано-
становится больше, чем б*, и/или одна или несколько совокупностей
имеют средние меньшие, то Р (ПВ) возрастает [Bechhofer et al.,
1968, p. 5].
2. Частично безразличные сочетания (ЧБС). Рассмотрим следую-
следующий вариант:
0<I*(ft,-|i(ft-i,<6*, (За)
Нч1> = ... = Rfc-2) <Нчй-1) — б*- (Зб)
Дадим определение термина ЧБС для этого сочетания. Из определе-
определений, встречаемых в литературе, например в [Bechhofer, 1954; 1958],
может сложиться впечатление, что в варианте уравнений (За) и C6)
правильный выбор не нужен, поскольку лучшее Среднее отличается
не больше чем на б* единиц. Тем не менее две лучшие совокупности на
б* единиц превосходят остальные (k — 2) совокупностей, поэтому же-
желателен выбор Uh или П&_х. Мы утверждаем, что метод, гаранти-
гарантирующий требование уравнения A), также гарантирует и Р (ПВ),
если уравнения (За) и C6) имеют место, когда мы определим ПВ как
выбор одной из лучших совокупностей — либо Щ, либо П(&_1)( ко-
которая хуже, чем П(й), менее чем на б* единиц. Рассмотрим ситуацию
с исключением одной из двух лучших совокупностей, скажем П(й).
Тогда остается (k — 1) совокупностей с одной лучшей по крайней ме-
мере на б* единиц. Следовательно, в этой ситуации метод гарантирует
также выбор лучшей средней с вероятностью, равной по меньшей ме-
мере б*. Далее, включим совокупность, которая была удалена. Это вклю-
включение не уменьшит вероятности того, что лучшая, ранее выбранная
совокупность n(ft_i) даст большее выборочное среднее по сравнению
с другими совокупностями / (/ = 1, ..., k — 2). (Все наблюдения неза-
независимы, рост числа совокупностей от k — 1 до k не уменьшает со-
согласно правилам процедуры числа попадающих в выборку наблюде-
наблюдений.) Совокупность Пй, только что включенная нами, может быть, как
и может не быть, выбрана вместо лучшей совокупности TI^-d, но
оба выбора по определению правильны. Более формальный вывод
приведен в приложении V.B.I.
3. Обобщенное наименее предпочтительное сочетание (ОНС):
Мчи = ... = ц<ь-1) = \iih) — 8 (б > 0). D)
ОНС включает НПС; положим, б = б* в уравнении D). Далее,
условия (За) не противоречат уравнению D), но уравнение C6) проти-
противоречит (потому что б* > 0). Предположим, что уравнение D) выпол-
220
ияется при малых б, предположим даже, что 8 = 0, при этом мы имеем
сочетание равных средних (СРС):
СРС, ОНС с малым б или ЧБС приводят к неприятным следствиям для
последовательных ММР без ограничения. Такие ММР не ограничивают
число наблюдений в выборке. Поэтому получаются очень большие вы-
выборки, так как лучшая совокупность П(й) не легко идентифицируется
13-за конкуренции двух либо более совокупностей. Поэтому практич-
практичнее определить верхнюю границу для объема выборки. Такую границу
можно получить просто из имеющегося машинного времени. Можно
вычислить и объемы выборок, потребные для одношагового или дву-
шагового ММР, и использовать эти объемы, возможно, скорректиро-
скорректированные в качестве верхнего предела (ср. [Bechhofer et al., 1968, p. 227]).
Ясно, что адаптация исходного открытого метода может повлиять на
Р (ПВ), но на практике это преодолимо.
), Сторонник теории принятия решений хотел бы видеть Р (ПВ),
растущую с ростом (x(fe) — Ц(ь-1)> вместо формулировки в духе «все
или ничего» в уравнении A). Как мы только что убедились, следст-
следствием подхода, использующего «зоны безразличия», является то, что
Р (ПВ) растет по мере роста \i(k) — H(ft-i) быстрее, чем б*, но это
возрастание Р (ПВ) неуправляемо. Мы еще вернемся к выводам теории
принятия решений в V.B.5 (см. также [Bechhofer et. al., 1968, p. 253]).
V.B.3. Существующие методы
В этом параграфе мы дадим обзор тех существующих ММР, кото-
которые, по нашему мнению, могут пригодиться в имитационных экспе-
экспериментах. Поскольку наша главная забота—применимость в моде-
моделировании, будем классифицировать методы по предпосылкам, лежа-
лежащим в их основе. Все методы предполагают независимость наблюде-
наблюдений (внутри и между совокупностями). Из параметрических методов
возьмем только ММР для нормальных распределений. Мы предпола-
предполагаем, что этот тип методов наиболее широко применим в имитационном
моделировании по сравнению с другими параметрическими методами.
Нормальное распределение служит адекватной аппроксимацией мно-
многих других распределений, и отклонения между действительным не-
неизвестным распределением и нормальным предполагаются не столь
уж страшными. Мы вернемся к проблеме робастности методов в сле-
следующем параграфе. Методы, основанные на других распределениях,
кратко описаны в V.B.5. Здесь же мы изучим еще непараметрические
или «полунепараметрические» ММР. Помимо различий параметриче-
параметрические—непараметрические между распределениями могут существо-
существовать и другие различия только в расположении или как в расположе-
расположении, так и в форме. Для нормальных совокупностей последнее разли-
различие эквивалентно различию равные дисперсии — неравные дисперсии.
Другая классификация: известные дисперсии — неизвестные дис-
дисперсии. Все ММР из этого параграфа используют подход, основанный
221
на «зонах безразличия» (определен в уравнении A), либо его модифи-
модификация, используемая в [Sobel, 1967]). Для ограниченной выборки па-
параметрические методы выбирают лучшую совокупность с наибольшим
значением средней, а (полу-)непараметрические методы выбирают со-
совокупность с наибольшим рангом (или в общем случае с наибольшим
баллом) или наибольшей модой. Мы также предложим некоторые ме-
методы для ситуаций со стандартной совокупностью и обсудим много-
многосторонние классификации (планы) дисперсионного анализа.
Нормальные совокупности. Известные дисперсии. Для известных
дисперсий существуют различные ММР. Дисперсии могут различать-
различаться и могут не различаться, поэтому такие методы также применимы и к
равным известным дисперсиям. Если экспериментатор может предпо-
предположить равные, но неизвестные дисперсии а2 и, более того, опреде-
определить область безразличия б* как долю от а, скажем б* = Х*а, то он
сможет применить ММР для равных известных дисперсий. (Из урав-
уравнения F) следует п = (d/k*J, а уравнение A2) содержит б*/с = А,*.)
Этот подход, однако, не кажется привлекательным для моделирова-
моделирования. Теперь мы представим одну одновыборочную и одну последова-
последовательную процедуру.
Одновыборочный метод Бехгофера [Bechhofer, 1954]. Из изло-
изложенного следует, что процедура Бехгофера предполагает нормаль-
нормальность независимо распределенных наблюдений с известными диспер-
дисперсиями, скажем of (i = 1, ..., k). Из совокупности i выбирается щ
наблюдений так, чтобы удовлетворить уравнению A). В приложении
V.B.2 мы дали простой вывод для определения щ; наш вывод отлича-
отличается от вывода Бехгофера, но приводит к тем же результатам4. Берем
выборку объемом пи как в уравнении
п. = (Oid/6*) , F)
где б* есть константа, определенная в уравнении A), ad — критиче-
критическая константа, растущая вместе с k (больше конкурентов) и Р*. Бех-
гофер [Bechhofer, 1954, р. 30—34] составил таблицы d для k = 2 A) 10
и Р* между (примерно) Ilk и 0,9995; d есть решение уравнения B.13)
из приложения V.B.2. Есть и другие таблицы, например в [Milton,
1963], но более пространные таблицы были составлены Гуптой [Gupta,
1963а, р. 800, 810] с /г = /г + 1 и А = dlV2 кля k = 1 A) 49 и Р*,
равной 0,75, 0,90, 0,95, 0,975 и 0,99 (см. также [Gupta et al., 1971,
p. 18], где вычислено h с числом десятичных знаков, большим на еди-
единицу). Если уравнение F) не дает целого числа, то мы берем ближай-
ближайшее большее целое. При выводе уравнения F) объемы выборок долж-
должны удовлетворять пропорции
-^-=^L(l,i' = l,..,,k), G)
щ. of.
так что выборочные средние имеют равные дисперсии. Размещение вы-
выборки в уравнении G) не самое эффективное, однако оно упрощает
222
вычисление объема выборки, удовлетворяющей требуемой вероятно-
пи из уравнения A); ср. с [Bechhofer, 1954, р. 24]. В [Dudewicz,
Dalai, 1971] сравнивается обычное размещение уравнения G) с опти-
оптимальным размещением njny = оь/оу для случая k = 2 (см. также
V.A.4). Для k > 2 не существует правила оптимального размещения.
1$ указанной работе далее доказано, что (асимптотически) обычное
правило уравнения G) требует меньшего общего объема выборки по
сравнению со случаем, когда берется равное число наблюдений из каж-
каждой совокупности (удовлетворяющих также требуемой вероятности
уравнения A); просмотрите ссылки в [Dudewicz, Dalai, 1971, p. 7.2]).
Мы отметим, что несколько приближенных формул для определения
объема в одновыборочном методе (не требующих табулирования кон-
константы d) обсуждаются в [Dudewicz, Zaino, 1971]. О применении урав-
уравнения F) см. упражнение 1.
Последовательный метод Бехгофера, Кифера и Собела [Bechhofer,
Kiefer, Sobel, 1968]. В [Bechhofer et al., 1968, p. 258—259, 264—265]
дан последовательный метод, в котором на каждой стадии s (s = 1,
2, ...) берется rt наблюдений из совокупности i (i = 1, ..., k), rt—
наименьшее целое, для которого выполняется уравнение
г
(8)
1
(Отметим соответствие между уравнением (8) и его одновыборочным
аналогом — уравнением G).) Константа с2 — это общая дисперсия
xis — средних наблюдений, выбираемых на шаге s из П;, т. е.
(9)
где xisg есть g-e индивидуальное наблюдение на шаге s из Пг. После
шага т (т = 1, 2, ...) вычислим «кумулятивную» статистику:
m ri
yim-icri)-1 2 S Х"Г A0)
s=[g-l
Пусть уц]т обозначает проранжированные yim, т. е. Уц\т^---
... ^ Ушт- Тогда после каждого шага т вычисляем (k — 1) разно-
разностей:
djm = УШт — УШт (j = 1 k — 1). A1)
Эксперимент заканчивается, как только т удовлетворит уравнению
П2M:
* A2)
223
До тех пор, пока не выполняется уравнение A2), выборка про-
продолжается. Как только эксперимент останавливает совокупность с наи-
наибольшим значением у1т (или с наибольшей выборочной средней),
эта совокупность выбирается в качестве лучшей. Заметим, что с ро-
ростом 5* или уменьшением Р* уменьшается объем выборки.
Если все совокупности имеют равные известные дисперсии, напри-
например а? =ст2, то процедура упрощается, потому что на каждом шаге бе-
берется единственное наблюдение (гг = 1). Эти авторы предлагают ме-
методы и для многих других распределений, что будет видно в V.B.5.
В противоположность одновыборочной процедуре Бехгофера здесь
объем выборки неизвестен до тех пор, пока эксперимент не окончен.
Хочется иметь некоторое представление об ожидаемом объеме выборки,
чтобы планировать машинное время, потребное для эксперимента.
В [Bechhofer, 1968, р. 301—313, 364] выведено несколько асимптотиче-
асимптотических результатов для математического ожидания объема выборки
(или среднего объема выборки, СОВ).
1. Если6 б*/о близко к нулю, воспользуйтесь таблицами из
[Bechhofer et al., 1968, р 353—362], дающими оценки СОВ по методу
Монте-Карло в НПС и СРС для различных Р* и k с б*/о = 0,2, так
что оценки надо умножить на @,2а/б*J (см. [Bechhofer et al., 1968,
p. 303]). Авторы указанной работы предполагают, что 6*/cr ^ 0,2
должно быть близким к нулю, чтобы аппроксимация работала.
2. Для Р*, близкого к единице, в [Bechhofer et al., 1968, p. 306—
307] дается таблица для СОВ, однако только для НПС. Умножайте
числа из таблиц на (а/б*J. Пример есть в [Bechhofer et al., 1968,
p. 312].
3. Для НПС эти авторы построили также регрессионные уравнения
по данным из таблиц, упомянутых в A). Коэффициенты этих уравне-
уравнений даются в табл. 14.2.3 [Bechhofer et al , 1968].
Известные отношения дисперсий. Цвушаговый метод Бехгофера,
Даннетта и Собела [Bechhofer, Dunnett, Sobel, 1954]. Бехгофер,
Даннетт и Собел предложили метод для неизвестных дисперсий of, но
известных отношений аг, скажем о] = ага2 с неизвестной о2, но из-
известными целыми аг. Процедура состоит в следующем:
1. Первая выборка из t-й совокупности включает atn0 наблюде-
наблюдений; п0 может быть любым целым; практическое правило для оптималь-
оптимального выбора п0 неизвестно.
2. Вычисляем si, несмещенную оценку о2 на первом шаге:
si
[ k , aln»
= ~y — у
v ^d аг Ai
агщ
где
о- 2 (а,па-1)-л0 2 <h-k (H)
есть число степеней свободы,
224
3. Вторая выборка из Пг состоит из аг (п — п0) наблюдений, где
п = max {nj 2s§ (/z/5*J[}, A5)
перевернутые квадратные скобки ][ означают наименьшее целое чис-
число, равное рациональному числу внутри скобок или больше него, h —
критическая константа, возрастающая с Р* и k и убывающая с v.
Мы вернемся к этой константе после шага 5.
4. Вычисляем общую выборочную среднюю:
а п
V —[а »\~1 "V1 1* /1С\
лг—\и1п) 2j 'g~ (lo)
5. Выбираем совокупность с наибольшей выборочной средней.
Критическая константа h — это квантиль многомерного ^-распределе-
^-распределения (с корреляцией 1/2). Она табулирована в табл. 1а и 1Ь в [Dun-
nett, 1955, р = k — 1], в_ [Krishnaiah, Armitage, 1966, p. 41, 51, с
n — v, p = k — 1], a h~V2 даются в [Gupta, Sobel, 1957]7 О приме-
применении говорится в упражнениях 3 и 8.
Равные неизвестные дисперсии. Двушаговый метод Бехгофера,
Даннетта и Собела [Bechhofer, Dunnett, Sobel, 1954]. Случай равных
неизвестных дисперсий сводится к случаю известного отношения дис-
дисперсий, а именно й, = 1 в а,1 = ага2. Следовательно, применим метод
уравнений A3) — A6).
Последовательный метод Робинса, Собела и Старра [Robbtns,
Sobel, Starr, 1968]. Если дисперсии а? = а2 известны, то можно при-
применять одновыборочный метод Бехгофера, т. е. из уравнения F) полу-
получить, что
п = (ad/8*J, A7)
где d табулирована, например, в [Bechhofer, 1954]. Далее, в [Rob-
bins, 1968] просто оценивается общая дисперсия а2, и эта оценка под-
подставляется на каждом шаге. При этом используется хорошо известная
оценка, основанная на всех наблюдениях, возможных после шага
т (т > 2):
1 1 km/ ут г \а
S*m=- — У У Us- ^' • A8)
k (m-l) **.**. \ m )
I ^= I S — 1
Из уравнения A7) следует, что выборка заканчивается при первом т
из т, для которого выполняется уравнение A9)8:
т > (sm d/8*J. A9)
Эти авторы доказывают, что в их методе вероятность из уравнения A)
удовлетворяется асимптотически (т. е. для б* -*¦ 0 и, следовательно,
при п -*¦ оо). При малых выборках их анализ тоже дает в примерах
8 Дж Клейнец 225
удовлетворительные результаты (см. таблицу в [Robbins et al., 1968,
p. 91]). Согласно нашему замечанию в V.A для машинных применений
удобно вычислять Sm после преобразования Хелмерта для суммы квад-
квадратов:
т т— 1
2 (хи-х,У= 2«.. B0)
s=I s=l
где
if s Y
\ .,m-\), B1)
при этом новое наблюдение х дает новое значение и без пересчета ста-
старого (см., например, [Kendall, Stuart, 1963, p. 250] или [Tocher, 1963,
p. 114]).
Последовательный метод Бехгофера и Блюменталя [Bechhofer,
Blumenthal, 1962]. Альтернативная последовательная процедура была
предложена Бехгофером [Bechhofer, 1958]; позже эквивалентное, но
алгебраически более простое правило было сформулировано у Бехго-
Бехгофера и Блюменталя [Bechhofer, Blumenthal, 1962, p. 54 — 57]. Про-
Процедура состоит в следующем:
1. Пусть yim означает выборочную сумму для t-й совокупности
после шага т:
т
Уш= 2 ¦*«•• B2)
S = 1
(Ср. уравнение A0), когда о? = с2 = 1, и, следовательно, rt — 1.)
Обозначим ранжированные yim через Ущт- Пусть slm — лучшая
несмещенная оценка общей дисперсии о2, основанная на vm степенях
свободы после шага т; если нет другой информации, то подходит одно-
факторный план, где Sum идентично 8„ из уравнения A8) с vm =
= k (m — 1). Числитель si , т. е. сумму квадратов, обозначим как
2. Вычислим значение
^к1 —1)F*K
т km
3. Вычислим (k — 1) значений
г (ssVm)+Gm-2S*ymm j^-o/»
/ос \_i_/7 9fi* «
4. Вычислим значение статистики останова на m-м шаге:
zm = 2 Lym. B5)
226
5. После шага т (т :> 2) прекращаем выборку, если
zm < A - Р*)!Р*, B6)
и выбираем в качестве лучшей совокупности совокупность с наиболь-
наибольшей выборочной суммой, t/[fe]m; иначе переходим к шагу (т + 1).
В однофакторном плане без дополнительной информации (т. е.
vm — k {m — 1) ) можно подставить
Hm = (SSv ) + вт = — \ктУ yjc%~(yv. V.
21 B7)
и уравнение B4). За дополнительными замечаниями по вычислитель-
вычислительным формулам и за численным примером мы отсылаем к [Bechho-
[Bechhofer, Blumenthal, 1962]. Бехгофер [Bechhofer, 1958, p. 413 — 414]
показал, как формула для статистики останова zm упрощается с ростом
числа степеней свободы vm; если vm = оо, то zm сводится к статисти-
статистике останова в методе Бехгофер а, Кифера иСобеладля равных известных
дисперсий (ср. уравнение A2) с zm (dm) [Bechhofer, 1958, p. 414]).
Недавно Бехгофер [Bechhofer, 1970] отметил, что, хотя не было
аналитически доказано, что процедура Бехгофера — Блюменталя
гарантирует вероятность из уравнения A), он полагает, что это условие
иыполняется асимптотически при б* -> оо для фиксированного Р*.
Добавим, что в довольно обширных исследованиях по методам Монте-
Карло было установлено, что Р (ПВ) ^ Р* в НРС (см. [Bechhofer,
Blumenthal, 1962, p. 58 — 64] и наши результаты в главе VI). Бехго-
Бехгофер [Bechhofer, 1970] замечает, что в противоположность первоначаль-
первоначальным публикациям метод нельзя применять в более благоприятных со-
сочетаниях средних; фактически объем выборки при этом возрастает.
Мы вернемся к этому замечанию в V.B.4, где ММР сравниваются по
эффективности.
Последовательный метод Паульсона [Paulson, 1964a] с ограничением
и с исключением. Паульсон [Paulson, 1964a] предложил последователь-
последовательный метод, в котором совокупности исключаются в ходе эксперимента,
если они дают выборочное среднее хуже, чем лучшее среднее, по край-
крайней мере на некоторую определенную величину. Он дал метод для об-
общей неизвестной и общей известной дисперсии, но последнее предпо-
предположение не выполняется в имитационном моделировании, так что мы
предлагаем здесь только метод с общей неизвестной дисперсией9.
1. Возьмем я0 наблюдений из каждой совокупности и оценим о2
г помощью si; v — число степеней свободы. Нет простого практиче-
практического правила для эффективного выбора п0; о пробном правиле см.
I Paulson, 1964 а, р. 179]. Оценка si опирается только на эти п0 наблю-
наблюдений; наблюдения, полученные позднее, не берутся. Выборочная сум-
м,'1, однако, использует все наблюдения.
П* 227
2. Вычислим значения следующих вспомогательных переменных:
B8)
1[, C0)
где X— константа, удовлетворяющая 0<Х<6*. Первоначально
Паульсон [Paulson, 1964a, p. 177] положил К — б*/4, но позже он же
[Paulson, 1964 b, p. 1050] предложил % = 3 б*/8 как более эффектив-
эффективное значение для этого типа последовательных процедур. В [Ramberg,
1966, р. 65] исследован метод Паульсона для известной дисперсии о2
в экспериментах Монте-Карло, и автор указанной работы нашел, что
% = 0 оптимально для НПС (но не обязательно для других случаев).
W), — наибольшее целое, меньшее, чем aj%; Wx + 1 есть максималь-
максимальное число шагов, т. е. этот последовательный метод ограниченный.
3. Если п0 > W\, то мы останавливаем эксперимент и выбираем
в качестве лучшей совокупности совокупность с наибольшим выбо-
выборочным средним []
4. Если п0 ^ W\, то мы исключаем каждую совокупность /,
для которой выполняется уравнение
V хи < max / V хЛ — ак + п0 X. C1)
Если после применения правила исключения уравнения C1) остает-
остается одна совокупность, то мы останавливаем эксперимент и выбираем
эту совокупность; в ином случае мы переходим к следующему шагу
и берем одно наблюдение из каждой не исключенной до этого шага со-
совокупности.
5. В общем, после шага п0 + t (/= 1, ..., W — пй) мы исключаем
каждую совокупность /, удовлетворяющую
no+t no-\-t
2^.<max 2 xrs-ai+(no + t)%, C2)
s=l '' s= I
где максимум берется по всем совокупностям г", не исключенным пос-
после шага п0 + t — 1, и т. д. Мы приводим блок-схему процедуры на
рис. 31.
В [Hoel, Mazumdar, 1968] обобщен метод Паульсона на так назы-
называемые совокупности Куплена — Дармоса (частный класс совокуп-
совокупностей, имеющих один неизвестный параметр, например экспонен-
экспоненциальная, биномиальная, Пуассона, нормальная с известными диспер-
дисперсиями; см. [Bechhofer et al., 1968, p. 62, 251]).
Неравные и неизвестные дисперсии. Двуишговый метод Дудевича
и Далала. Дудевич и Далал [Dudewicz, Dalai, 1971, раздел 4] предло-
предложили следующий метод, в котором, правда, шаги 3 и 4 взяты из пуб-
публикации Дудевича [Dudewicz, 1972, р. 3].
228
1. Берем первую выборку по п0 наблюдений (п0 > 2) из каждой
совокупности и вычисляем выборочное среднее на первом шаге
и оценки дисперсии
— Xj0)
C3)
C4)
2. Вычислим общие объемы выборок щ для совокупности i:
nt = max \n0 + 1,
¦[]¦
C5)
Взять п0 наблюдений
и Вычисли ть
где max б'ерется по иеис
нлюченныи совокупностям
Исключить j-ю содокуп -
ность. Уменьшить к
Да
Нет
Выбрать един-
единственную ос-
оставшуюся co-
Sokl/пность
Нет
вы бра гь содокуп -
ность с наибольшей
1 х
js
взять одно наблю-
наблюдение S каждой из
остадшихся к сово-
нупностей.т\ = п+-1
Рис. 31. Последовательный метод Паульсона с ограничением и
с исключением
229
где константа ho есть решение уравнения Бехгофера для константы d,
аналога уравнения Стьюдента (ср. уравнение B.13) в приложении
V.B.2), т. е. ho есть решение уравнения
--Р*, C6)
?„„_! и /„„_! — функции распределения и плотности ^-переменной
Стьюдента с (пй — 1) степенями свободы. Константа ho табулирована
в [Dudewicz, Ramberg, 1972] для k = 2AM, Р* = 0,75 @,05) 0,95;
0,975; 0,99 и п0 = 2A) 10 E) 30. Дудевич и Далал [Dudewicz, Dalai,
1971] вычислили еще итоговое Р* для фиксированных hD = 0,0@,1M,1,
k = 2 A) 25 и гс0 = 2 A) 15 EK0. Для k > 26 Дудевич и Далал
[Dudewicz, Dalai, 1971, раздел 5] вывели формулу для нижних границ
Р (ПВ). Табл. III в [Dudewicz, Dalai, 1971] показывает, что с ростом
п0 константа hD быстро приближается к своей границе, а именно к d
Бехгофера.
3. Возьмем rtt — п0 дополнительных наблюдений из совокуп-
совокупности 1 и вычислим среднее для второго шага xtl:
4. Вычислим xt — взвешенное среднее двух выборочных сред-
средних:
C8)
где вес Ьх равен:
5. Выберем лучшую совокупность, дающую наибольшее xt.
Вариант этого метода есть в [Dudewicz, Dalai, 1971].Там вместо
3-го и 4-го шагов берется линейная комбинация nt наблюдений:
где
an =... = аг-(яг—i)) = ct,
at-l) ±[(ni-1J- (я, - 1)B| (l-(8*/hDf /sf)]l/2
(nt-l)nt V
230
В действительности любое aig, удовлетворяющее следующим ус-
условиям, будет обоснованным:
2 aig = \, аа = ...= а/По> si 2 а& = F*/М8- D2)
Наконец, эти авторы обсуждают также применение общих выборочных
средних, но они рекомендуют точную процедуру, основанную на xt.
Далее Дудевич [Dudewicz, 1972, р. 7] утверждает, что использование
выборочных средних «кажется надежным».
(Полу-) непараметрические методы. Неизвестные распределения
с общей неизвестной дисперсией. Последовательные методы А и В
Сриваставы [Srivastava, 1966]. Сривастава ввел два класса последо-
последовательных методов, в которых требование уравнения A) для вероят-
вероятности выполняется асимптотически, т. е. при б* -> 0. Для малых вы-
выборок Сривастава и Огилви [Srivastava, Ogilvie, 1968] изучили случаи,
когда Р* = 0,95 при k = 2, 4, 6, и показали аналитически, что урав-
уравнение A) выполняется. Рассмотрим методы, принадлежащие и одному
и другому классу10.
Метод А, основанный на t-распределении. Следуя [Srivastava,
1966, р. 372], а также [Srivastava, Ogilvie, 1968], мы нашли, что про-
процедуру можно изложить следующим образом:
1. На каждом шаге s берем по одному наблюдению из каждой сово-
совокупности и вычисляем si — оценку дисперсии после т шагов:
km _ 1
2 2 (xu-*iJ+i ¦ D3)
s=l J
2 2
i= 1s= 1
Член, равный 1, в квадратных скобках для непрерывных распре-
распределений можно отбросить, и уравнение D3) в этом случае сведется к
уравнению A8). В своем уравнении B.5) Сривастава [Srivastava, 1966]
дает оценку
si = (km)-1 Г j] | (xis -ъ)* + 11, D4)
но с заменой т на (т — 1) в знаменателе, как это сделано в книге
[Srivastava, Ogilvie, 1968, p. 1041], что не нарушает асимптотического
поведения.
2. Прекращаем выборку
D5)
231
и выбираем совокупность с наибольшей выборочной средней; ат —
критическая константа, определяемая из/-распределения с v~k (т — 1)
степенями свободы, скажем /„ (t), таким образом, что11
77
I
Метод В, основанный на многомерном t-распределении. Эта про-
процедура идентична А во всем, кроме критических констант. В прило-
приложении V.B.3 мы показали, что эти константы, скажем а?, можно найти
в таблицах в [Dunnett, 1955], [Krishnaiah, Armitage, 1966] или [Gupta,
Sobel, 1957]. Надо найти d' в таблице Даннетта и положить а*т = d!
либо найти q в таблице Гупты и Собела и положить а*т = qlY~2. (Ве-
(Величины d' и q меняются cv = k(rn — 1), Р* и k.I2
Неизвестные распределения с идентичными ожидаемыми располо-
расположениями. Есть ММР и для неизвестных функций распределения с
идентичными ожиданиями возможных сдвигов расположения, т. е.
хг имеют функции распределения Ft, удовлетворяющие
Ft (х) = F (*-ii,)(i = 1, .... k). D7)
К сожалению, для некоторых из этих методов характерны определен-
определенные недостатки, объясняемые далее, которые делают их менее привле-
привлекательными. Поэтому мы только кратко опишем эти ММР; для деталь-
детального изучения отсылаем к литературе.
Непараметрический метод Бехгофера и Собела [Bechhofer, SoSel,
1958]. Метод Бехгофера и Собела основан на выборе совокупности с
наибольшей вероятностью, дающей наибольшее наблюдение. Рассмот-
Рассмотрим
P( A(i, V = \,..-,Щ, D8)
так что 2^рг = 1. Затем найдем совокупность, соответствующую
/?(ft), где рA) <;...<! P(h-D ^= Pw- Совокупность, удовлетворяющая
p(ft), согласно уравнению D7) это совокупность с наибольшим парамет-
параметром положения n(fe) (см. также упражнение 4). Определим многознач-
многозначную переменную у:
yia= 1, если xis = max xt>s (s = 1,2, ...), D9)
i1
= 0 в остальных случаях.
Из уравнения D9) следует, что многозначная переменная с наибольшей
вероятностью исхода есть та переменная, которая соответствует со-
совокупности с наибольшей pt (которая, в свою очередь, соответствует
совокупности с наибольшим \it). К методам выбора многозначного со-
события с наибольшей вероятностью относятся, например, метод, пред-
232
ложенный в [Bechhofer et al., 1959], и последовательный метод, который
обсуждается в [Bechhofer, Sobel, 1956]. Дополнительные ссылки даны
в [Dudewicz, 1968] и [Gupta, Panchapakesan, 1969 а, р. 475]. К сожа-
сожалению, упомянутый подход означает, что
Р (ПВ) > Р*, если PibMh-u > e*. E°)
где 0* > 1. Правильный выбор происходит, если мы выбираем совокуп-
совокупность с наибольшей pit что эквивалентно выбору наибольшей ци но
«зона безразличия» теперь определена в терминах pt, а не ц,г. Но рц —
эмпирическая величина, значения [хг и pt как-то связаны. Аналогично
уравнению B) сочетание
Р(« = ••• = Р<ь-1) = Р(«/6* E1)
есть НПС для уравнения E0), т. е. оно минимизирует Р (ПВ), согласно
условиямP(ft)/p(ft_D > 8*. Из D7) следует, что E1)дает^(!) = ... =
= [x(ft_]) и поэтому 6* > 1, (х№) > H(ft-D- Обозначим \iw — jX(ft-i).
связанные с 0*, через бе*. Связь между 0* и бе» зависит от числа
совокупностей, формы распределений и мешающих параметров;
см. [Dudewicz, 1971, табл. 2 и 7], где перечислены бе* как функции 6* и
k для нормальных совокупностей в предположении известной общей
дисперсии а2 (или, что эквивалентно, заменены «зоны безразличия»
в уравнении A) на \iih) — |Л(&_3) >- А.*ст) и для равномерных распре-
распределений в предположении единичного размаха. Итак, если мы хотим
переформулировать исходную задачу уравнения A) на языке «зоны
безразличия», \i(h) — Ц(ь-г) > б*, то оказывается необходимым
знание формы распределения (и мешающих параметров). Но цель
метода Бехгофера и Собела — использование информации об Fi.
Методы Лемана [Lehmann, 1963] — одновыборочные, ранговые
и др. Леман предложил одновыборочный метод для «математического
ожидания баллов», например математического ожидания нормально
распределенных баллов или рангов. (Общее обсуждение ожидаемых
и случайных баллов содержится в [Bradley, 1968, р. 146 — 163] и [Со-
nover, 1971, р. 281—282, 290 — 292].) Такие методы служат для вы-
выбора совокупности, которая дает наибольшее ожидаемое значение
баллов (вместо наибольшей выборочной средней). Критерий выбора
не требует знания функции F, как в непараметрических методах. Но
тогда надо определить объем выборки п так, чтобы (асимптотически)
выполнялось условие уравнения A) для вероятности. Такая формула
для п содержит функцию плотности / (х). Следовательно, нужно иметь
представление о функции плотности переменной xt, например, что она
приблизительно нормальна с определенной дисперсией ст2. Методы Ле-
Лемана менее чувствительны к отклонениям от предполагаемого рас-
распределения по сравнению с методами для средних. К сожалению, его
процедуры требуют определения мешающих параметров, таких, как
дисперсия о2 в нормальном приближении. Другие процедуры позво-
позволяют вычислить эти параметры. Отметим, что в [Bartlett, Govindara-
julu, 1968] изучены методы для ожидаемых или случайных баллов
(см, также [Puri, Puri, 1969] и [Randies, 1970]),
233
Последовательный метод для сумм рангов Сена и Сриваставы
[Sen, Srivastava, 1972b]. Сен и Сривастава ввели несколько последо-
последовательных асимптотически корректных и эффективных методов, ос-
основанных на результатах Лемана [Lehmann, 1963] (см. [Srivastava,
Sen, 1972, а и Ь]). Эти методы требуют непрерывных распределений
только со сдвигом (и некоторых технических условий регулярности).
Для них тоже есть оценки Монте-Карло. Поскольку не найдено пра-
правила для меньшего числа наблюдений во всех случаях и все правила
удовлетворяют условию для вероятности в уравнении A), мы предло-
предложим здесь лишь правило, которое требует наименьшего машинного
времени, и, более того, не требует симметричности распределения в
отличие от других правил. Эта процедура состоит в следующем:
1. Берем предварительную выборку л0 наблюдений из каждой из k
совокупностей; п0 выбирается так, чтобы с в уравнении E2) стало по-
положительным для п = п0:
с = ть-иа (п — 1) (п/2I'2 — п, E2)
где irik-i,a определяется, например, в [Gupta, 1963, р. 810] (см. таб-
таблицу Гупты для п = k— 1 и а = 1 — Р* для тп,а — hV~2, a также
наши комментарии к уравнению F)).
2. Прекращаем выбор наблюдений из каждой совокупности, как
только объем выборки п удовлетворит уравнению
с < k~x 2 2 2 7 ( " 2б* < *и — Хц> < 26*), E3)
*= 1 /=i/'=/+1
где / — так называемая функция-индикатор, т. е. в общем:
/ (А) = 1, если условие Л верно, E4)
= 0, если А ложно.
Следовательно, в уравнении E3) /есть 1, если — 26* ^ дггу — хи> ^
< 26*, и т. д.
3. После остановки выбирается в качестве лучшей та совокупность,
которая имеет наибольшую сумму рангов гг; все совокупности проран-
жироваиы, т. е.
п п Г п k I
«, vi #¦ ХЛ V V 7 I v ~"ч> v \ /сеч
где функция-индикатор — альтернативный способ определения ранга
наблюдения Хц.
Заметим, что для последовательных ранговых методов все наблю-
наблюдения надо хранить в машинной памяти (после появления нового на-
наблюдения происходит переранжировка). Поскольку для имитационного
моделирования нужны большие выборки (как видно из части V.A
этой главы), требуется и большая машинная память. Эту проблему мож-
можно решить с помощью хранения информации не на сердечниках, а на
лентах или дисках, В моделировании время, затрачиваемое для ран-
234
жирования и переранжирования наблюдений, не столь значительно по
сравнению с тем временем, которое затрачивается на генерирование
самих наблюдений (на одно наблюдение затрачивается один имитацион-
имитационный опыт); см. также [Lewis, 1972, р. 9 — 10], [Martin, 1971] и обсуж-
обсуждение в главе V, часть А, уравнение E9).
Стохастически упорядоченные распределения. Как известно, сово-
совокупность i называется стохастически большей, чем совокупность
i'(i Ф i'), если
Ft (х) < Ff (х) для всех х. [E6)
Очевидно, что подкласс совокупностей, образуемых уравнением
E6), состоит из распределений, отличающихся только сдвигом.
Метод последовательного ранжирования с исключением Хоула
[Hoel, 1971]. Недавно Хоул предложил метод, в котором все k сово-
совокупностей (непрерывных) сравниваются друг с другом попарно, и,
как в методе Паульсона [Paulson, 1964a], совокупности могут исклю-
исключаться в ходе выборочного процесса. Правило Хоула основывается на
критерии последовательного отношения вероятностей (КПОВ), об-
обсуждавшемся в V.A.4. Переформулировка в терминах «зоны безраз-
безразличия» уравнения A) выглядит соответствующим образом, т. е.
Р (ПВ) > Р*, если |х(М/ц№ _ 1) > 9*, E7)
где 8* ^ 1. Из правой части уравнения E7) следует, что
\р (X(h) > *(ft_i>) > e*/(i + е*) E8)
(для определения 9* см. еще [Hoel, 1971, р. 637]). На основании [Hoel,
1971, р. 632, 637] мы вывели, что следующий метод применим на каждом
шаге ко всем парам совокупностей. (Когда начинается выборка, мы
имеем k (k — 1) пар, а не k (k — l)/2.)
1. Определим ранг Гц> (j) наблюдения ; из совокупности i (т. е.
Xij) при сравнении с совокупностью i' (i Ф i' и 1 ^ / ^ п). При
продолжении выборки этот ранг может измениться, поэтому мы долж-
должны в действительности определить гп> (/, п), т. е. ранг наблюдения /
в совокупности i по отношению к совокупности i' в выборке п наблю-
наблюдений из двух совокупностей.
2. Вычислим логарифм отношения правдоподобия, когда сделаны п
наблюдений из совокупностей i и г" (п = 1, 2, ...):
т° / = 1 I [^]
j^,(/»)-Km-i)n
где т0 = 1/0* и рекомендуется брать тх = A + 8*)/2; по опреде-
определению, Гц' {п + 1, п) = 2 п + 1. При вычислениях по уравнению E9)
читателю может понадобиться обратиться к [Bradley, 1967, р. 596].
236
3. Исключаем совокупность г", если для некоторого i
lu'(n) > In [( k - 1)/A - Р*)]. F0)
4. Продолжаем выборку из оставшихся совокупностей до тех пор,
пока останется только одна совокупность. Если, однако, на определен-
определенном шаге исключаются все оставшиеся совокупности, то выбираем из
них совокупность I, для которой min lu> (я) будет максимальным.
Решение достигается через конечное число шагов, так что выборки не
могут достигать «слишком» больших размеров (ср. наши комментарии
после уравнения E) в V.B.2). Тот же тип процедуры можно применить
в других задачах. Хоул [Hoel, 1971, р. 634] применил свой метод для
выбора нормально распределенной совокупности с наименьшей дис-
дисперсией. Укажем, что Фу [Fu, 1970, р. 54 — 63, 96 — 116] также об-
обсуждает применение KJTOB к задачам с k (k 2js 2) альтернативами,
возможного и для непараметрических случаев.
Неизвестные распределения. Одновыборочный непараметрический
метод Собела [Sobel, 1967]. Собел требует только непрерывности функ-
функций распределения Ft. К сожалению, чтобы получить решение, он пере-
переформулировал исходную задачу уравнения A). Он определил правиль-
правильный выбор как выбор совокупности с наибольшей медианой. (Для
симметричных распределений среднее и медиана совпадают.) Его про-
процедура выбирает совокупность с наибольшей выборочной медианой
и обеспечивает Р (ПВ)^Р* при условии выполнения определенного
отношения безразличия. К сожалению, величина этого безразличия
не естественна, это разность между двумя лучшими медианами, как мы
увидим.
Обозначим а-квантили F (х) через xa(F); это дает величину13 х,
удовлетворяющую
F (х) = а. F1)
Медиана соответствует а = 0,5 и обозначается х0 5 (F). Естественным
отношением безразличия было бы
^5(^))-\5(^-i))>6*, F2)
где F(t) обозначает функцию распределения с ?-й наименьшей медиа-
медианой. Собел использует два отношения безразличия, и оба иные, чем
в уравнении F2).
Подход 1
Р (ПВ) > Р*, если A >d*. F3)
где
d = min IFW (x) - F(k) (x)], F4)
I лежит в интервале
/ = [xo,5-e* (Fih)), Xo.s+e* (Fm)] F5
236
(ср. рис, 32). Константы P*,d* и ? * определяются экспериментатором.
(Очевидно, 1 > Р* > Ilk, d* > 0, 0 < ? * < 0,5.) Когда функции
распределения перекрываются, d убывает. Чтобы d^d* (так что
Р (ПВ) > Р*), можно уменьшить d*; таблицы Собела показывают,
что объем выборки возрастает по мере убывания d*. Другим способом
сохранения d> d* служит уменьшение ? *, так что / в уравнении F8)
уменьшается и х в уравнении F8) меньше изменяется при поиске ми-
минимума в уравнении F4); меньшие значения ? * требуют больших объе-
объемов выборки. Точные отношения между б* в уравнении F2) и новыми
константами d* и ? * неиз-
неизвестны, так что мы не можем
воспользоваться уравнением
F3) для решения первона-
первоначально сформулированной за-
задачи (модифицированной для
медиан).
Подход 2
рис 32. Формулировка задачи Собела. Под-
"д 1
р (
где
ПЕ
d'
>M?Р*
= х0
,5-6*
¦0, F6)
—
F7)
(см. рис. 33). Из рис. 33 следует, что когда распределения перекрыва-
перекрываются друг другом, d' уменьшается и может стать отрицательным
(см. пунктирное распределение F('i)), так что выполнение Р (ПВ) ^
^ Р* не гарантировано. Чтобы d' не принимало отрицательного
значения, мы должны выбрать
наименьшее ? *, но мы не зна-
знаем, каким его надо сделать.
Методы со стандартной сово-
совокупностью. Мы представим не-
несколько процедур для стандарт-
стандартной, или контрольной, совокуп-
совокупности (например, существующая
система в имитационном экспе-
эксперименте).
Метод Паульсона для выбора
лучшей средней [Paulson, 1962].
Предполагая нормальность сово-
совокупностей с общей для всех неиз-
неизвестной дисперсией а2, Паульсон построил последовательную процедуру
с исключением худших совокупностей в ходе экспериментирования.
Цель процедуры — выявление совокупностей, которые лучше, чем
стандартная, и если такие совокупности существуют, то выбор наилуч-
наилучшей среди них. Аналогично рассмотренным ММР он гарантирует
Р(ПВ)>Р*. если наилучшая экспериментальная совокупность Uih)
по крайней мере на б* лучше либо других экспериментальных сово-
0,5+ Е*
0,5-е*
/
/ \
/ 1
/
7 П^
у
у
У
— —^г"
I
|
I
I
X
й'
Рис. 33. Формулировка задачи Собела.
Подход 2
237
купностей Uu) (/ — 1, ..., k — 1), либо стандартной совокупности
По, т. е. "
Я (ПВ) > Р*, если |i№) - max (ц№ _ 1)t ц0) > б*. F8)
Особенность этой процедуры — дополнительная защита для стан-
стандартной совокупности. Стандарт выбирается с вероятностью по крайней
мере ЯЗ. даже если он так же хорош, как лучшая экспериментальная
совокупность (вместо того, чтобы быть на б* лучше), т. е. 1б
Р (ПВ) > Я5, если [л0 — \i(k) > 0. F9)
Процедура состоит в следующем:
1. Берется предварительная выборка для оценки а2. Обозначим эту
оценку si, где v — число степеней свободы. Эта выборка не использует-
используется для оценки средних в отличие от метода Паульсона [Paulson, 1964 а].
2. Вычисляются границы аи Ь:
а = l(Xa/k)-2'v — 1] у/2, G0)
b = — {[р — (к — 1) Wife]-2/" — 1}о/2, G1)
где
К = min [I, p/(aft — а)] G2)
и а = 1 _ />5, Р = 1 — Я*.
1 3. Пусть Хуз обозначает s-e наблюдение (полученное в упомяну-
упомянутой предварительной выборке) из совокупности i', которая не исклю-
исключается на шаге s (s = 1,2, ...; V == 1,..., k). На шаге s вычисляем для
каждой совокупности i':
= б* (хг, - лг0, — 6*/2)/(ЗД). G3)
4. После яг шагов (т = 1,2,...) действия таковы:
а) если
G4)
s=l
то исключаем совокупность i', если не остается ни одной эксперимен-
экспериментальной совокупности, то выбираем в качестве лучшей контрольную
совокупность;
б) если
тах( 2 *!'.)> а, G5)
'' \s = i /
то выбираем совокупность, дающую этот максимум;
в) если
6<тах 2 г1'А <а> G6)
238
to переходим к Шагу (т + 1), выбирая По одному наблюдению Из
каждой оставшейся совокупности; повторяем шаги 3 и 4.
, Паульсон [Paulson, 1962, р. 439 — 440] также изучал случай с из-
известным значением pi0 и известными (произвольными) функциями
плотности.
Непараметрический метод для выбора лучшей средней Сена и Сри-
ваставы [Sen, Srivastava, 1972 b]. Недавно Сен и Сривастава развили
четыре непараметрических метода, гарантирующие выполнение урав-
уравнений F8) и F9); см. также [Srivastava, Sen, 1972]. Они предположили
только существование сдвига (и некоторые технические условия ре-
регулярности). Их правила асимптотически корректны и эффективны,
они последовательны, но не исключают худших совокупностей. Резуль-
Результаты Монте-Карло на малых выборках показывают, что уравнения F8)
и F9) выполняются. Ни один метод во всех изученных случаях не тре-
требует меньшего числа наблюдений. Следовательно, мы предложим толь-
только правила, аналогичные уравнениям E2) — E5) (ситуация без стан-
стандартной совокупности).
1. Производим предварительную выборку п0 наблюдений из каждой
из (k + 1) совокупностей, п0 выбираем так, что с в уравнении G7)
положительно при п = п0:
с = mk_[}b (n— 1) (п/3у/2~п. G7)
Константа тк_1ъ определяется из системы шести уравнений с ше-
шестью неизвестными (mk,a, b, ти—\,ь а, ха, d):
Р ( max xt > mk Л = а (= 1 —Р*), G8а)
\\<i<k 1 ' )
Р( max xt > mh_x Л = b, G86)
P (maxjfj >xa\ = a, G8b)
mk,a = xa d (d—iy1, G8r)
ть-иь =xa (d — l)-1, G8д)
a + 6 = P (=1-PO*), G8e)
где Xt — стандартные нормальные переменные с корреляцией 1/2,
для которой Гупта [Gupta, 1963 а, р. 810] построил таблицы для
Р(тах xt > mn,a)=a. G9)
\l<i<n ) V '
Поэтому уравнения G8а), G86) и G8в) можно решить из таблиц Гуп-
ты при п = k, k — 1, 1 и а = 1 — Р*, b, a.
2. Прекращаем выборку дополнительных наблюдений из каждой
совокупности, как только п удовлетворит уравнению E3), где с в
239
уравнении E3) определяется из уравнения G7), вместо k берется k +
+ 1, i пробегает значения от 0 до k.
3. Как только выборка прекращена, выбираем стандартную сово-
совокупность, если
max (г, - г0) < A2)"'/« mk,a (ft + 1) пъ>\ (80)
где г — сумма рангов в случае k + 1 совокупностей, определенная
аналогично уравнению E5). Если уравнение (80) не выполняется, то
выбирается экспериментальная совокупность с наибольшей суммой
рангов.
Метод классификации Паульсона [Paulson, 1964 b]. Целью экспе-
экспериментатора может быть не выбор лучшей совокупности, а только
классификация совокупностей на лучшие (|хг > \i0) или худшие
(\it <; pi0). Мы встречали методы этого'сорта в части, посвященной
множественным сравнениям. Паульсон [Paulson, 1964b, p. 1052—1054]
ввел процедуру, в которой число наблюдений не фиксируется, но мо-
может быть выбрано последовательно. (Совместная) вероятность класси-
классифицировать все экспериментальные совокупности со средними \it ^
^ \х0 или Hi > \i0 -\- б* правильно по крайней мере равна Р*
(или 1—а). (Заметьте меру безразличия б*.) Он предполагает, что все
совокупности имеют нормальные распределения. Прежде всего изло-
изложим этот метод для известных, возможно, различных дисперсий
a? (i = 1, ..., k) и Go; a затем—вариант для неизвестной общей диспер-
дисперсии о2:
а) Известные дисперсии16. Пусть zis обозначает разности между
экспериментальными и контрольными наблюдениями, т. е.
я и = *is — XOs (i = 1 k; s = 1, 2, ...), (81)
так что среднее разностей после т шагов равно:
а дисперсия частных разностей есть
ah = of + a%. (83)
Вычисляем «допуски»:
di = к + {ah In (k/a)]/B %m), (84)
где % = 3 б*/8 рекомендуется Паульсоном, и затем вычисляем среднее
разностей с поправкой на «допуск»:
Щ = zin + dt, (85a)
Vi = zim — di. (856)
240
После т шагов экспериментальная совокупность i классифицируется
как худшая, если а, < б*, и как лучшая, если vt >0. На следующем
шаге берется по одному наблюдению из каждой еще не классифициро-
классифицированной совокупности и из контрольной. Эксперимент заканчивается,
когда все совокупности классифицированы.
б) Равные неизвестные дисперсии. Возьмем первую выборку из
п0 наблюдений из каждой совокупности и вычислим объединенную
оценку с v = (k + 1) (п0 — 1) степенями свободы. Продолжаем, как
и в случае а), но с заменой of,- на 2 si и In (kla) на [(k/aJ'v — 1] у/2.
Заметим, что а2г1 оценивается только из первой выборки, но средние
оцениваются на основании всех возможных наблюдений. Выбор п0
кратко обсуждается в [Paulson, 1964 b, p. 1053 — 1054].
в) Доверительные интервалы. После классификации может возник-
возникнуть дополнительное требование построить доверительные интервалы
для разностей между лучшими средними, скажем \ip, и контрольной
средней pi0 с совместным доверительным уровнем A — у) и с длиной,
не превосходящей L (L > б*). Тогда, после того, как совокупности
классифицированы с использованием (а) или (б), выборка продолжает-
продолжается для совокупностей, классифицированных как лучшие, до тех пор,
пока не станет
ирт - vpn < L (р = 1, ..., Р < ft), (86)
где для известных дисперсий ирт есть минимальное значение ир на
каждом шаге s (I ^s ^ т) при а в уравнении (84), замененной на у/2
(конструируются двусторонние интервалы с доверительным уровнем у),
а vpm есть максимум vp по всем т шагам; для неизвестных дисперсий
этот минимум или максимум берется только по шагам после предва-
предварительной выборки из пй наблюдений. Искомые доверительные интер-
интервалы раВНЫ Upm — 1>рт-
В [Tong, 1969] также дана классификационная процедура для
нормальных совокупностей с общей дисперсией о2. Автор указанной
работы вывел одновыборочную процедуру с известной о2 и двушаговую
асимптотическую последовательную процедуру для неизвестной о2.
В противоположность Паульсону он не исключает совокупностей в
ходе выборочного процесса. (См. также [Sobel, Tong, 1970].)
Метод подмножеств М. Пурии П. Пури [Puri, Puri, 1969]. М. Пури
и П. Пури дали одновыборочный метод, основанный на рангах или, в
более общем случае, баллах. Они предполагают идентичность распре-
распределений с точностью до сдвига и дают асимптотическое решение для
данного объема выборки. Их процедура выбирает подмножество, вклю-
включающее все лучшие совокупности (ць ^ \х0 -*г б*) с заданной вероят-
вероятностью Р*. Совокупность включается в это подмножество, если его
баллы выше, чем баллы контрольной совокупности. (Ср. с соответству-
соответствующими методами подмножеств в части, описывающей методы множе-
множественных сравнений.) Их решение, однако, требует знания функции
плотности; см. процедуру Лемана для выбора лучшей средней.
Метод Сриваставы [Srivastava, 1966} для правильного выбора стан-
стандарта. Сривастава предложил последовательный метод для опреде-
241
ления объема выборки, который гарантирует выполнение уравнения
F9) асимптотически для неизвестных распределений с общей неизвест-
неизвестной дисперсией. В противоположность методу Паульсона он не гаран-
гарантирует выполнения уравнения F8).
Метод Дудевича и Рамберга [Dudewicz, Ramberg, 1972] для совмест-
совместных доверительных интервалов. Дудевич и Рамберг дают двушаговый
метод для нормальных совокупностей с неравными и неизвестными
дисперсиями (см. также [Dudewicz 1972, р. 9]). Процедура полностью
аналогична процедуре в [Dudewicz, Dalai, 1971] в уравнениях C3) —
D2). Однако б* (или их символ а) здесь означает «мы должны быть
уверены, что наименьшая выборочная разность значима на уровне
а" (а = 1 — Р*). В частном сообщении Дудевич сказал, что б*
можно также интерпретировать как наименьшую разность, т. е. если
N ^ Vt — 6*» то можно быть уверенным с вероятностью Р*, что
•*"о ^ Xt (i = 1> •••¦ ^ — 0- (Заметим, что всего есть k совокупно-
совокупностей.) Можно записать (k — 1) односторонних доверительных интер-
интервалов с совместной вероятностью Р*:
Щ — i*o > (Xi - Хо) — б* (i = 1, ..., k - 1), (87)
так что можно заключить, что \it > ц0 только если xt — х0 ^ б*.
Таким способом можно выбрать подмножество совокупностей, которые
лучше, чем стандартная, но метод предложен не специально для этой
цели.
Многофакторные планы. До сих пор мы ограничивали рассмотре-
рассмотрение экспериментальных планов одним фактором, возможно, с различ-
различным числом наблюдений на уровень (см. метод Бехгофера, Кифера и
Собела). В многофакторных планах нас может заинтересовать лучший
уровень фактора Л, лучший уровень фактора Б и т. д. Если рассмат-
рассматривать только один фактор Аса уровнями, то мы будем иметь одно-
одностороннюю классификацию с k=a совокупностями. Выше обсуждаемым
способом можно определить число наблюдений, скажем пЛ, которое
гарантирует выбор лучшего уровня А, т. е. а^, при условии, что этот
уровень по крайней мере на Ьл лучше следующего за ним лучшего
уровня. Или
Р (ПВд) > Ра , если а(Аа) — а? _ {, > 8%. (88)
Число наблюдений для одного уровня фактора А надо распределить
между Ь уровнями фактора В (см. табл. 1). Если в ячейках мы имеем
равное число наблюдений пА1Ь, то (апА\Ь) наблюдений придется на
один уровень В. Можно затем проверить полученную величину Р*в
для (апл/b) наблюдений в
Р (ПВВ) > РЪ , если afb) — afb-i)> Ь% . (89)
Как показано в [Bechhofer, 1954, р. 27], еслицсредние в ячейках
имеют равные дисперсии, то вероятности в уравнениях (88) и (89)
242
независимы, так что совместная вероятность правильного выбора луч-
лучшего уровня для А и В есть произведение отдельных вероятностей
(см. также упражнение 6).
Таблица 1
Двухфакториый план
Фактор В
1
2
*
Ь
Общее число наблюдений
Фактор а
1
"л
2
пА
...
а
"л
Мы не можем быть уверенными в том, что наблюдения независимы,
так как средние в ячейках могут не иметь равных дисперсий или рас-
распределения не будут нормальны (нулевая корреляция означает незави-
независимость для нормальных распределений). В таком случае мы исполь-
используем неравенство Бонферрони для получения границ совместной
вероятности правильного выбора
если
(90)
где Pf —желаемая минимальная вероятность правильного выбора
лучшего уровня фактора / (f = 1, ..., F) и а{ — лучший уровень
фактора / и т. д. Подробно подход Бонферрони описан в V.B.3. Если
мы хотим зафиксировать минимальную величину совместной вероят-
вероятности ПВ, то нужно разделить эту минимальную величину Р* на части
Ра,Рв и т. д. и определить необходимое число наблюдений в ячейке
итеративным способом; для примера можно посмотреть [Bechhofer,
1954, р. 37 — 38].
Если факторы взаимодействуют друг с другом, то бессмысленно
искать лучшие уровни А и В. Вместо этого рассмотрим план с однофак-
торной классификацией, где k = ab уровней, и найдем лучшую ком-
комбинацию их. В эксперименте без взаимодействий наблюдения в данной
ячейке можно использовать для выводов об обоих факторах А и В,
т. е. каждое наблюдение работает дважды (см. также ¦ [Bawa, 1972]).
Заметим, что в многофакторных планах с взаимодействиями или без
243
них общая дисперсия отдельного наблюдения может быть оценена по
традиционным формулам ANOVA. О ММР в классификациях с большим
числом факторов см. также [Bechhofer, 1954, р. 25 — 29, 37 — 38;
1958, р. 414 — 417, 425 — 426].
V.B.4. Эффективность, робастность и приближенные методы
ММР в имитационном моделировании. Будем далее исследовать
применимость рассмотренных ММР в имитационных экспериментах.
Читателю очень рекомендуем вернуться к введению в V.B.4, озаглав-
озаглавленному «Эффективность и робастность ММС в имитационном модели-
моделировании». О желательности применения ММР в имитации кратко упо-
упоминали несколько авторов, а именно tConway et. al., 1959, p. 107],
[Fishman, Kiviat, 1967, p. 28], [Naylor et al., 1967 a, p. 1327]. Дейст-
Действительные применения были осуществлены Нейлором и другими ав-
авторами [Naylor et al., 1967b, 1968], которые основывались на двуша-
говой процедуре, рассмотренной в [Bechhofer et al., 1954], в моделирова-
моделировании многоканальной системы массового обслуживания и национальной
экономической системы при предположении общей неизвестной диспер-
дисперсии; первое применение предложено в [Kleijnen et al., 1972, p. 251—
253] 17. Недавно Сэссер и его соавторы [Sasser et al., 1970] применили
последовательный метод Бехгофера и Блюменталя [Bechhofer, Blumen-
thal, 1962] для определения наибольшей средней и классификационную
процедуру Паульсона [Paulson, 1964 b] в моделировании многономен-
многономенклатурной системы хранения запасов (без известного аналитического
решения) при предположении общей неизвестной дисперсии. Они также
применили эвристический вариант процедуры Бехгофера и Блюмен-
Блюменталя, к которому мы еще вернемся. Они обнаружили значительное со-
сокращение машинного времени по сравнению с непоследовательными
методами определения объема выборки. Число применений ММР в мо-
моделировании все еще значительно меньше, чем ММС.
Общие размышления об эффективности и робастности. Для выбора
конкретного метода важны несколько факторов:
1. Экспериментальная цель и план. Мы ограничили наше иссле-
исследование преимущественно процедурами для выбора лучшей средней.
Был дан краткий обзор процедур для ситуаций с контрольной совокуп-
совокупностью. Другие цели будут упомянуты в V.B.5. Однофакторные и мно-
многофакторные планы обсуждались в V.B.3.
2. Эффективность ММР. Эффективность может быть измерена
числом наблюдений, необходимых для удовлетворения требования
уравнения A). Сюда относятся следующие три дихотомии:
а) известные — неизвестные дисперсии. Если дисперсии должны
оцениваться, то объем выборки возрастает (ср. аналогично: ^-стати-
^-статистика дает более широкие доверительные интервалы, чем нормаль-
нормальная переменная);
б) последовательные — непоследовательные методы. Последователь-
Последовательные ММР требуют меньшего числа наблюдений, так как они исполь-
используют оценки неизвестных параметров. Эта экономия аналогична эко-
экономии при проверке последовательной гипотезы, основанной на КПОВ
244
(см. V.A.4). Некоторые последовательные ММР используют преиму-
преимущество наиболее предпочтительных сочетаний средних. Непосле-
Непоследовательные процедуры не могут основываться на них, так как объем
выборки определяется до того, как получены наблюдения, что не
дает возможности выявить НПС. С другой стороны, для последова-
последовательных ММР без ограничений могут понадобиться слишком большие
объемы выборок для СРС (см. также [Bechhofer et al., 1968, p. 5]);
в) параметрические — непараметрические методы. Параметри-
Параметрические методы по крайней мере так же эффективны, как и непарамет-
непараметрические, если предположение о виде распределения действительно
удовлетворяется в данном эксперименте. Если в действительности рас-
распределение отклоняется от предполагаемого, то эффективность пара-
параметрической процедуры уменьшается и может упасть до нуля. Это
приводит нас к следующему.
3. Робастность ММР. Рассмотрим следующие три предположения:
а) независимые наблюдения. Независимость есть предположение,
на котором основаны все ММР. Его нарушение приводит к серьезным
последствиям (см. [Scheffe, 1964, р. 331 — 369], где приводится общее
обсуждение предположения о зависимости, а также нормальности и по-
постоянстве дисперсий). Независимость реализуется в имитационном
моделировании генерированием каждого опыта с помощью новой по-
последовательности случайных чисел, отклик каждого опыта берется
13 качестве одного наблюдения. К сожалению, эта практика исключает
применение общих случайных чисел для увеличения надежности срав-
сравнений между системами (см. главу III);
б) нормальные распределения. Очевидно, что непараметрические
методы не используют это предположение. Некоторые методы пред-
предполагают только, что нормально распределены выборочные средние,
и это предположение выполняется на малых выборках, если откло-
отклонения от нормальности отдельных наблюдений не очень велики
(центральная предельная теорема). Есть методы, основанные на дру-
других распределениях, например гамма-распределениях для дисперсий,
биномиальных распределениях для вероятностей и т. д. Параметри-
Параметрические ММР, имеющие широкое применение в моделировании, осно-
основаны, однако, на нормальности распределения наблюдений. Если
имитируемый отклик есть среднее, то это среднее распределено асимп-
асимптотически нормально, даже если отдельные наблюдения сериально
коррелированы. (См. обсуждение центральной предельной теоремы
для стационарных r-зависимых реализаций в V.A.2.) Преобразование
наблюдений тоже можно использовать для получения нормально рас-
распределенных наблюдений (см. IV.2 и V.B.4). Позже мы вернемся к
этому предположению;
в) дисперсии. ММР, основанные на нормальности, предполагают
либо известные, но различные дисперсии, либо неизвестные дисперсии
с известными отношениями (возможно, равными единице, т. е. неиз-
неизвестную общую дисперсию). Исключение составляет метод Дудевича
и Далала. Большинство непараметрических (или полунепарамет-
рических) ММР предполагают не только равенство дисперсий, но и
идентичность распределений с точностью до сдвига. Общую дисперсию
245
можно обеспечить подходящим преобразованием наблюдений или под-
подходящей длиной опытов в моделировании стационарного состояния.
Заметим, что предположения об идентичности распределений с точ-
точностью до сдвига можно осуществить для нормальных распределений
(\i( ф jv, о\ = аУ), но не для гамма-распределений, включая эк-
экспоненциальное распределение (см. упражнение 7).
Как мы видели в V. Б. 4, F-статистика и ^-статистика довольно не-
нечувствительны к нарушению нормальности и к гетерогенности диспер-
дисперсий; множественная ^-статистика Даннетта, представляя собой эк-
экстремальную статистику, вероятно, проявит большую чувствитель-
чувствительность. Величина^ Бехгофера—тоже критическая точка экстремальной
статистики, так как она основана на уравнении (91), см. также урав-
уравнение G9):
Р (x(J) <x(k) для всех /; / = 1, ..., k — 1)
= Р (max ~Х}—~хк<Ъ). (91)
1 <Г / < k - 1
Преобразование наблюдений можно использовать для получения
приближенного нормального распределения и/или равных дисперсий.
Другой эффект преобразований, особенно важный в ММР, — изме-
изменение отношения безразличия. Рассмотрим, например, логарифмиче-
логарифмическое преобразование
zt = In xt (i = 1, ..., ft), (92)
так что
t)i ss E (zt) « In Е^(Хг) = In |xf. (93)
Следовательно, при применении методов ранжирования к преобразо-
преобразованным переменным г Р(ПВ) гарантируется (приблизительно), если
выполняется следующее отношение безразличия:
Л№) Л(ь-1) > 8* (94)
или из уравнения (93)
lWl*tt-i> > ехр (б*) = 65. (95)
Таким образом, логарифмическое преобразование полезно, если мы
хотим определить отношение безразличия в относительных разностях
(Xfftj/jxtft-D. Заметим, что в [Bechhofer et al., 1968, p. 273] изучено
влияние различных преобразований при ранжировании дисперсий
нормальных совокупностей, параметров экспоненциальных или пуас-
соновских распределений. В [Naylor et al., 19681 применено логарифм
мическое преобразование в методе Бехгофера, Даннетта и Собела при!
моделировании национальной экономики18.
В большинстве случаев мы моделируем сложные системы со сто-|
хастическим выходом, имеющим неизвестное распределение. (Если
откликом служит значение средней, то его поведение можно считать'
нормальным.) Дисперсия распределения неизвестна (как и средняя),
246
ii Дисперсии разных моделируемых систем предполагаются различ-
различными (так же как и средние, и мы хотим выбрать лучшую). Мы пред-
предполагаем, что распределения не просто идентичны с точностью до сдви-
сдвига. Следовательно, для нас приемлемы непараметрические ММР с не-
неизвестными и, возможно, различными дисперсиями. Поскольку мо-
моделирование занимает много машинного времени, методы должны быть
эффективными. Эффективность увеличивается с введением последо-
последовательных планов, извлечением выгод из НПС и исключением худших
совокупностей. (Кроме того, желательно иметь еще априорную ин-
информацию и различные типы функций потерь, хотя практических
решений пока нет; см. также V.B.5.) Исследуем, удовлетворяют ли
существующие методы требованиям робастности и эффективности,
и если нет, то как их можно перестроить, чтобы они стали удовлетво-
удовлетворять им.
Робастность и эффективность существующих методов; прибли-
приближенные методы. 1. Одновыборочный метод Бехгофера [Bechhofer, 1954\
для нормальных распределений с известными дисперсиями. Поскольку
при имитации дисперсии а\ неизвестны, их приходится получать с
помощью оценок sf вида
J (* >2 (96)
Фактически метод, предложенный в [Robbins et al., 1968] берет пра-
правило Бехгофера для замены неизвестной (и как авторы предполагают)
общей дисперсии о? = о2 оценкой; эта оценка последовательно пере-
пересматривается (см. уравнения A7) и A9)). Мы предлагаем обобщить
процедуру авторов указанной работы на случай с неравными диспер-
дисперсиями: применить правило Бехгофера в уравнении F) с заменой af
на их оценки, увеличить эффективность, перейдя к последователь-
последовательному получению оценок. Этот приближенный метод впервые был пред-
предложен в [Chambers, Jarratt, 1964], где авторы заменили неизвестные
неравные дисперсии19 оценками первого шага их двухвыборочного
метода.
Помимо предположения о известных дисперсиях при имитацион-
имитационном моделировании может нарушаться также предположение о нор-
нормальности распределений. В приложении V.B.2 приведен метод, не
требующий, чтобы наблюдения были нормальными, а удовлетворя-
удовлетворяющийся тем, что нормальны выборочные средние. В силу централь-
центральной предельной теоремы это довольно слабое предположение. (Сле-
(Следовательно, метод можно применять для ранжирования других пара-
параметров, кроме средних из нормальных совокупностей, при условии,
что средние оценки этих параметров имеют приближенно нормальные
распределения; см. также [Bechhofer, 1954, р. 29].) Заметим, что оценки
дисперсий для распределений с нарушением нормальности остаются
несмещенными.
Что касается эффективности выше рассмотренных ММР, а также
нашего приближенного варианта, то они не обладают преимуществами
247
ВПК- Таблицы в [Robbins et al., 1968, p. 91] показывают, что метод,
предложенный в этой работе, требует лишь немного больше наблю-
наблюдений, чем метод Бехгофера, даже если дисперсия неизвестна.
2. Последовательный метод Бехгофера, Кифера и Собела [Bechho-
fer, Kiefer, Sobel, 1968] для нормальных распределений с известными
дисперсиями. Как и в случае метода Бехгофера [Bechhofer, 1954],
необходимо заменить неизвестные дисперсии о? их оценками s?, если
мы хотим применить этот метод. Снова оценка aj может быть получена
из предварительной выборки или последовательно. (Мы считаем, что
последовательный подход требует меньше наблюдений, зато он слож-
сложнее, так как на каждом шаге берутся r-t наблюдений по совокупности г,
но само значение г% зависит от s\, поэтому изменение sj приводит и к
изменению r^; множитель с также должен пересчитываться на каждом
шаге.) Мы не знаем ни одного метода, близкого к тому, который был
переделан Бехгофером, Кифером и Собелом. Мы можем только сказать,
что в других ММР (во многих других типах методов, но не во всех)
подстановка оценки мешающего параметра дает удовлетворительные
результаты. Нужны дальнейшие исследования, чтобы проверить,
гарантируют ли интуитивно применяемые методы выполнение требо-
требований уравнения A).
Бехгофер, Кифер и Собел изучали, хотя и кратко, эффект откло-
отклонения распределения от предполагаемой нормальности. Они провели
эксперимент Монте-Карло с равномерными распределениями с общими
известными дисперсиями (см. [Bechhofer et al., 1968, p. 266 — 267,
348, 363]). Для k = 3, б* = 0,2 и 0,40 < Р* < 0,99 ими было найдено,
что в НПС вероятностное требование уравнения A) легко выполнялось.
Они пришли к выводу, что в общем случае их метод нечувствителен
к нарушению нормальности, так как он зависит только от различий
между суммами независимых переменных, так что применима цент-
центральная предельная теорема. В нашем эвристическом варианте ис-
используются оценки дисперсии, но они остаются несмещенными для
распределений с нарушенной нормальностью.
В [Bechhofer et al., 1968, p. 274, 289] указано, что метод этих ав-
авторов дает сверхгарантию, т. е. дает Р (ПВ), превышающую Р* даже
в случае НПС. Сверхгарантия означает, что выбирается больше на-
наблюдений, чем это строго необходимо для выполнения уравнения (IJ0.
Однако если сравнить его с одновыборочным методом Бехгофера, то
он более эффективен для Р*, больших, чем, скажем, 70% в НПС, но
не в СРС (см. [Bechhofer et al., 1968, p. 279, 281, 364]). Неэффектив-
Неэффективность в СРС возникает потому, что последовательная процедура
продолжает свой поиск лучшей совокупности даже тогда, когда ее не
существует (ср. с нашими комментариями по поводу уравнения E)).
Метод предназначается в основном для БПК, поскольку если средние
сильно различаются, то возрастает вероятность больших значений d
в уравнении A1), так что уравнение A2) удовлетворяется раньше
(см. [Bechhofer et al., 1968, p. 348]).
3. Двушаговый метод Бехгофера, Даннетта и Собела [Bechhofer,
Dunnett, Sobel, 1954] для нормальных совокупностей с известными от-
248
ношениями дисперсий. Когда отношения дисперсий аг неизвестны,
мы можем выбрать один из следующих двух подходов
1) Оценим аг с помощью s\, оценок о? Значения аг можно получить
из предварительной выборки (применяется только для оценок аг или
для того, чтобы вычислить So и хг в уравнениях A3) и A6)), можно так-
также применить последовательное оценивание (подробно см [Kleijnen,
1968, р. 12—13] или [Kleijnen, Naylor, 1969, p. 611—612) Этот
вариант нуждается в дальнейших исследованиях, чтобы выяснить,
будет ли удовлетворяться уравнение A)
2) Положим аг = 1 (t = 1, , k), т е предположим, что совокуп-
совокупности имеют общую (неизвестную) дисперсию Исходный метод годится
без модификаций Остается открытым вопрос, чувствителен ли он к
неоднородности дисперсий Критическая константа h табулирована,
например, в [Dunnett, 1955] и [Gupta, Sobel, 1957] Следовательно,
чувствительность зависит от экстремальной статистики (см примеча-
примечание 7 в этой части, примечание 8 в части V Б, а также [Gupta, Sobel,
1957, p. 957]) Миллер [Miller, 1966, р 1081 предполагает, что экстре-
экстремальная статистика более чувствительна к неоднородности дисперсий
(и нарушению нормальности), чем, например, /^-статистика
Выбор между подходами 1 и 2 можно сделать по результатам предва-
предварительной выборки В случае резкого неравенства дисперсий применяем
подход 1, в противном случае—подход 2 (Такие советы стоит давать
и для других ММР с общими дисперсиями. Надо брать больше наблю-
наблюдений из совокупностей с большими дисперсиями, только если имеет
место резкое неравенство дисперсий ) Поскольку оба подхода исполь-
используют константу h, можно предположить, что оба они более чувствитель-
чувствительны к нарушению нормальности, но, к счастью, нормальность распре-
распределений нужна только для выборочных средних, а к этим средним
можно применить центральную предельную теорему
Мы считаем, что эффективность этого метода меньше, чем метода
Бехгофера, Кифера и Собела, потому что последний полностью после-
последовательный Кроме того, метод Бехгофера, Даннетта и Собела и его
эвристический вариант не используют преимуществ БПК-
4 Последовательный метод Роббинса, Собела и Старра [Robbins,
Sobel, Starr, 1968] для нормальных распределений с общей неизвестной
дисперсией Как и в 3-м методе, здесь есть два подхода
1) Предположим, что исходный метод нечувствителен к неодно-
неоднородности дисперсий Поскольку метод использует d Бехгофера, он
зависит от экстремальной статистики, которая считается чувствитель-
чувствительной к неравенству дисперсий
2) Вслед за Роббинсом, Собелом и Старром заменим с,2 в правиле
Бехгофера на ее оценку s,2 Это дает метод 1.
Чувствительность к нарушению нормальности и эффективность обоих
вариантов обсуждаются после метода 1.
5 Последовательный метод Бехгофера и Блюменталя [Bechhofer,
Blumenthal, 1962] для нормальных распределений с общей неизвестной
дисперсией Вновь мы имеем два подхода
1) Допустим, что исходный метод нечувствителен к неоднородности
дисперсий (и нарушению нормальности) Бехгофер [Bechhofer, 1958,
249
p. 426] утверждает, что Р (ПВ) для этого метода ведет себя аналогично
мощности традиционного /-"-критерия ANOVA; он предполагает, что
метод нечувствителен к нарушению нормальности, но более чувстви-
чувствителен к неравенству дисперсий. Для обсуждения поведения F-критерия
в случае нарушения нормальности и неоднородности дисперсий мы
отсылаем к IV.2; для неравных дисперсий мы рекомендуем равные
объемы выборок за исключением случая небольшого числа наблюдений
и сильной неоднородности; для совокупностей с большими дисперсия-
дисперсиями мы рекомендуем большее число наблюдений (ср. G) и (8)). Мы также
провели исследование Монте-Карло робастности метода Бехгофера—
Блюменталя и широко обсудим эти результаты в следующей главе.
Здесь мы только заметим, что метод оказался довольно робастным;
крайняя асимметрия распределения (и большие k, скажем k > 7) при-
приводит к Р (ПВ) < Р* в НПС. Насколько мы понимаем, наш экспе-
эксперимент— это только изучение робастности ММР, и, поскольку резуль-
результаты говорят о приличной робастности метода Бехгофера — Блюмен-
Блюменталя, мы рекомендуем его для имитационного моделирования. К со-
сожалению, Бехгофер [Bechhofer, 1970] заметил недавно, что эвристи-
эвристические аргументы и эксперименты Монте-Карло указывают на неко-
некоторые нежелательные характеристики метода—возрастание объема
выборки с улучшением сочетания средних, и он не рекомендовал его
применять. (Однако можно возразить, что для больших выборок метод
приближается к методу Бехгофера, Кифера и Собела для общих из-
известных дисперсий и, следовательно, может асимптотически исполь-
использовать преимущества БПК.)
2) Исходный метод предполагает, что на каждом шаге берется по
одному наблюдению от каждой из k совокупностей с общей дисперсией.
Чтобы удовлетворить предположению общей дисперсии, мы предла-
предлагаем определить наблюдение из Пг- как среднее ri наблюдений, выбран-
выбранных из П; на данном шаге; rt удовлетворяют
— =о20'=1 k), (97)
п
где о2 — константа (ср. уравнение (8)). Поскольку средние
xis (s = 1, 2, ...) имеют общую дисперсию о2 (как и исходные средние
]xt), то можно применять к xis метод Бехгофера — Блюменталя. На сле-
следующем шаге можно заменить af в уравнении (97) оценками St, ко-
которые определены из предварительной выборки или последовательно
скорректированы. Гарантирует ли этот вариант удовлетворение урав-
уравнению A) — неизвестно. (Мы знаем только, что для больших выборок
исходная процедура приближается к методу Бехгофера, Кифера и
Собела для общих известных дисперсий, применение уравнения (97)
с заменой о? на sf приближает асимптотически этот вариант к варианту
Бехгофера, Кифера и Собела, но мы не знаем-, как он работает.) Отно-
Относительно чувствительности к нарушению нормальности см. наше об-
обсуждение подхода 1,
250
Что касается эффективности, то мы укажем эксперимент Монте-
Карло в [Bechhofer, Blumenthal, 1962, p. 58 — 64J, показывающий,
что в НПС (I) исходная процедура требует немного больше наблюде-
наблюдений, чем процедура Бехгофера, Кифера и Собела, хотя процедура Бех-
[ офера — Блюменталя требует оценки дисперсии о2; объем выборки
Оудет намного меньше, чем в методе Бехгофера [Bechhofer, 1964].
6. Последовательный метод Паульсона [Paulson, 1964a] с исклю-
исключением для нормальных совокупностей с общей неизвестной дисперсией.
Вновь при этом подходе можно генерировать наблюдения с общей дис-
дисперсией из выборочного аналога уравнения (97). Оценки s2, можно
получить из первой выборки п0 наблюдений по каждой совокупности;
>ти п0 наблюдений используются далее для оценивания \ih но а?
не пересчитываются после первого шага. Так, использование предва-
предварительной выборки может чередоваться с исходной процедурой.
(Заметим, однако, что в нашем варианте наблюдения могут иметь не-
неравные дисперсии, поскольку в уравнение (97) подставлены оценки.)
Дальнейшая адаптация происходит за счет пересчета о} и, следова-
следовательно, rt после каждого шага. Нам неизвестны исследования этого
варианта и относящихся к нему процедур, а также исследования чув-
чувствительности исходной процедуры к нарушению нормальности и не-
неравным дисперсиям. В правило исключения уравнения C2) входит эк-
экстремальная статистика глахг Bxis), так что мы предполагаем, как
и Миллер [Miller, 1966], что метод чувствителен к нарушению нормаль-
нормальности и к неоднородности дисперсий.
Эффективность результатов описана Паульсоном [Paulson, 1964a,
р. 177] и Рамбергом [Ramberg, 1966]. Результаты Монте-Карло у Пауль-
Паульсона для общей и известной дисперсии показывают, что его метод эф-
эффективнее, чем одновыборочный метод Бехгофера, как для НПС, так
идляСРС. Сочетание оказывается особенно важным для правила иск-
исключения Паульсона. Его метод использует преимущества БПК. (Ср.:
если средние больше различаются, то правило работает чаще.) Рамберг
провел эксперименты Монте-Карло для сравнения эффективности ме-
методов Бехгофера, Кифера и Собела и одновыборочного метода Бехго-
Бехгофера с общими известными дисперсиями. На основании результатов
Рамберга [Ramberg, 1966, р. 35 — 37] мы заключаем, что метод Пауль-
Паульсона требует немного больше наблюдений, чем метод Бехгофера, Ки-
Кифера и Собела в НПС и СРС^для Р* ^ 0,99; нет наилучшего метода
для всех случаев21. Важным фактором служит k, потому что чем больше
совокупностей есть, тем больше совокупностей можно исключить,
так что метод Паульсона может стать эффективным. Для подробного
ознакомления с эффективностью сравнений мы отсылаем к [Ramberg,
1966] и экспериментам Монте-Карло с методом Бехгофера, Кифера и
Собела [Bechhofer et al., 1968, p. 344—378]. Мы добавим к этому еще
табл. 2, которая сводит вместе результаты Монте-Карло из [Bechho-
[Bechhofer et al., 1968, p. 349] и [Paulson, 1964a, p. 177]. Затем,-так как оба
метода дают сверхгарантию для общих известных дисперсий, Рамберг
приспосабливает методы с меньшими Р* в правилах остановки; при-
применяемые значения Р* были основаны на оценках из экспериментов
251
Монте-Карло. Мы не знаем, существует ли сверхгарантия в методах
Паульсона и Бехгофера — Кифера — Собела в случае неизвестных и
различных дисперсий. Поэтому мы не обсуждаем подробно выбор
значения Р*, а отсылаем к [Ramberg, 1966]. При сравнении эффектив-
эффективности различных ММР нужно помнить, что метод Бехгофера — Блю-
менталя требует лишь немного больше наблюдений, чем процедура
Бехгофера — Кифера — Собела при НПС.
7. Двушаговый метод Дудевича и Далала [Dudewicz, Dalai, 1971}
для неравных и неизвестных дисперсий. Этот метод использует пред-
предположения, значительно менее ограничительные, чем приведенные
выше методы, так как дисперсии могут быть неизвестными и нерав-
неравными. Итак, неоднородность дисперсий — не проблема.
Таблица 2
Общее число наблюдений для известной дисперсии
21 б 02
2=1 и б* = 0,2
k
4
4
10
р»
0,95
0,99
0,99
[Bechhofer,
1954]
850
1442
4506
[Bechhofer Kiefer, Sobel,
1968]
CPC
1101
2122
8412
НПС
501
712
2342
[Paulson, 1964a]
CPC
755
1178
3226
НПС
443
644
1982
Мы предполагаем, что критическая константа hD имеет ту же чувст-
чувствительность к нарушению нормальности, что и константа Бехгофера d,
поскольку это—стьюдентизированный аналог <i. Хотя она и зависит от
экстремальной статистики, центральная предельная теорема позволяет
предположить, что метод довольно нечувствителен к нарушению нор-
нормальности.
Что касается эффективности, то метод не имеет преимуществ при
БПК и не исключает худших совокупностей. Дудевич [Dudewicz,
1972, р. 4] далее ссылается на [Wetherill, 1966, р. 181 — 182], где ав-
автор предполагает, что двушаговые методы могут оказаться в большин-
большинстве случаев эффективными там, где эффективны полностью последо-
последовательные планы в отличие от одношаговых планов. Однако из лите-
литературы ясно, что трудно выбрать разумный объем одношаговои вы-
выборки. Кроме того, Старр [Starr, 1966, р. 38], например, изучил близ-
близкую задачу, а именно задачу оценки единственной средней, и нашел,
что его последовательное правило «всегда более эффективно, чем дву-
шаговая выборка; различия в эффективности везде, где они значи-
значительны, если пренебречь дисперсиями, связаны с тем, что объем выбор-
выборки на первом шаге выбирается неудовлетворительно».
8. Последовательный метод Сриваставы [Srivastava, 1966] для
неизвестных распределений с общей неизвестной дисперсией. Можно
попытаться генерировать наблюдения с общей дисперсией, применяя
выборочный аналог уравнения (97). Как будет работать такая эври-
эвристическая процедура—не известно. Или можно надеяться, что исход-
252
ные процедуры А и В робастны; А основана на ^-статистике, а В —
на многомерной ^-статистике. В [Srivastava, Ogilvie, 1968] показано,
что В (грубо) на 10% более эффективно, чем Л, для нормальных рас-
распределений. Однако для имитационных экспериментов мы предпочи-
предпочитаем процедуру А, потому что А использует хорошо известную t-
статистику (более подробно об этом одностороннем t-критерии см. урав-
уравнение B.17) в [Srivastava, 1966]). Для такой ^-статистики известна
нечувствительность к нарушению нормальности и к неоднородности
дисперсии в больших выборках; в малых выборках двусторонний
^-критерий остается нечувствительным, но односторонний ^-критерий
более чувствителен (см. [Scheffe, 1964, р. 335, 346, 353]).
Эффективность методов Сриваставы асимптотически эквивалент-
эквивалентна эффективности метода Бехгофера для известных общих дисперсий,
и асимптотически он более эффективен, чем двушаговые методы Бех-
Бехгофера—Даннетта — Собела (см. [Srivastava, 1966, р. 372, 374] и
[Srivastava, Ogilvie, 1968, p. 1041]). Методы не имеют преимуществ
при БПК-
9. Мультиномиальный метод Бехгофера и Собела [Bechhofer,
Sobel, 1958] для неизвестных распределений с идентичными ожида-
ожиданиями сдвига. Этот метод не столь привлекателен потому, что исходное
отношение безразличия заменяется на p(ft)/p(ft _ х) ^0*. Соотношение
между pi(ft) — M-Cfc-i) и Pik)/P(k-i) зависит от мешающих парамет-
параметров (вроде о2 для нормальных распределений). Эти мешающие парамет-
параметры можно оценить так же, как эвристические варианты в других ММР.
Однако нужно еще определить тип функции распределения, например
нормальные распределения, а это противоречит цели непараметриче-
непараметрических процедур. Неизвестно, как работает метод, если распределения
не отличаются не только расположением, но и формой. Дудевич
[Dudewicz 1971a] показывает, что исходный метод очень неэффективен,
если выполняются предположения о распределении при определенной
параметрической процедуре.
10. Одновыборочный ранговый метод Лемана [Lehmann, 1963]
и близкие к нему методы для неизвестных распределений с идентич-
идентичными ожиданиями сдвигов. Как и в методе Бехгофера и Собела [Bech-
[Bechhofer, Sobel, 1958], в методе ранжирования Лемана и других авторов
нет полной независимости от распределения потому, что определение
объема выборки требует выявления типа распределения. Известно, что
такие методы менее чувствительны к отклонениям от таких установ-
установленных распределений, чем методы, основанные на средних. Недо-
Недостаток заключается в том, что они требуют определения значений ме-
мешающих параметров (например, а2 в нормальном распределении),
в то время как многие ММР допускают оценки этих параметров. Не-
Неизвестно, как работает метод, если распределения отличаются по фор-
форме. Интересно исследовать работу методов, когда: 1) на основе предва-
предварительной выборки или последовательно оценена форма распределе-
распределения; 2) оценены мешающие параметры; 3) взяты малые выборки; 4) рас-
распределения отличаются по форме.
В общем (исходные) методы ранжирования эффективны по срав-
сравнению с параметрическим методом Бехгофера [Bechhofer, 1954] для
253
известной общей дисперсии, т. е. для многих распределений, отлича-
отличающихся от нормального, они требуют меньшего числа наблюдений
(особенно методы с нормально распределенными баллами). Если чи-
читатель хочет ознакомиться с деталями, то он может обратиться
к [Lehmann, 1963, р. 271], [Bartlett, Govindarajulu, 1968, p. 92],
[Puri, Puri, 1969, p. 625].
11. Последовательный метод ранжирования Сена и Сриваставы
[Sen, Srivastava, 1972b] для неизвестных распределений с идентичным
ожиданием сдвига. Рассмотрим сначала эффективность этого метода.
Его нельзя применять для БПК, он не исключает худших совокуп-
совокупностей. Этот метод асимптотически эффективен, т. е. для б*, близких
к нулю, средний объем выборки (СОВ) последовательного правила
равен объему выборки в одношаговом ранговом методе Лемана для из-
известной функции плотности (см. [Srivastava, Sen, 1972]). Мы убедились,
что метод Лемана эффективнее, чем одновыборочный метод Бехгофера.
Мы также заметили, что метод Лемана робастен. К сожалению, мы не
знаем, является ли последовательный вариант Сриваставы и Сена
также нечувствительным к отклонениям от предположений для рас-
распределений с идентичными формами. Эта процедура использует кон-
константу Гупты h или d Бехгофера (т. е. экстремальные статистики), и,
следовательно, она предположительно чувствительна к неоднородности
дисперсий, или различиям в форме. Заметим, что эксперимент Монте-
Карло показывает хорошее поведение на малых выборках (предполо-
(предположение о распределении не было нарушено в этом эксперименте).
12. Последовательный ранговый метод Хоула [Hoel, 1971] с исклю-
исключением для стохастически упорядоченных распределений. Стохасти-
Стохастически упорядоченные распределения охватывают распределения, раз-
различающиеся только сдвигом, но не нормальные распределения с раз-
различными дисперсиями. Мы не знаем, чувствителен ли метод к откло-
отклонениям от предположения о стохастической упорядоченности.
Что касается эффективности, то метод является последовательным
и способным исключать худшие совокупности. Недостаток состоит
в том, что нужны довольно сложные вычисления (ср. выражение в урав-
уравнении E9)).
13. Одновыборочный непараметрический метод Собела [Sobel,
1967]. Это единственный известный нам независимый от распределения
метод. Он достоверен для (неизвестных) распределений, которые раз-
различны не только по расположению и стохастической упорядоченности.
К сожалению, формулировка задачи не та, что бывает в имитационных
приложениях.
Для методов, предполагающих существование контрольной со-
совокупности, можно сделать те же самые комментарии, что и для рас-
рассмотренных ММР. Мы добавим ряд замечаний. Методы Паульсона
[Paulson, 1962], Сена и Сриваставы [Sen, Srivastava, 1972 Ы дают сверх-
сверхгарантию для ПВ стандартной совокупности. Может случиться,
что в ней нет надобности, например, если" экспериментатора не волнует,
делает ли он ошибочный выбор 1) из-за неудачного выбора контроль-
контрольной или экспериментальной системы, хотя экспериментальная система
на самом деле лучше, или 2) из-за неправильного выбора эксперимен-
254
тальной системы, хотя контрольная система лучше (см. также [Kleijnen,
1968, р. 7] или [Kleijnen, Naylor, 1969, p. 609]). Однако по некоторым
неучтенным соображениям мы можем отказаться от существующей
системы, только если существует сильное свидетельство в пользу того,
что экспериментальная система лучше. Комментарии об эффективности
метода Паульсона есть в [Paulson, 1962] и [Roberts, 1963]. Классифи-
Классификационный метод Паульсона [Paulson, 1964 b] можно адаптировать с
помощью либо варианта с известными, быть может, различными дис-
дисперсиями, оценивающими эти дисперсии, либо его варианта для не-
неизвестных, но общих дисперсий, получаемых по гг наблюдениям на
каждом шаге.
Подводя итоги, мы видим, что осталась нерешенная проблема. Ме-
Метода, гарантирующего выполнение требования для вероятности из
уравнения A) в случае неизвестных, возможно, различных распреде-
распределений, не существует. Следовательно, мы можем либо надеяться, что
существующий метод нечувствителен к нарушениям лежащих в основе
предположений, либо надеяться, что один из эвристических вариантов
работает хорошо. Относительная эффективность метода становится
существенной, если мы считаем, что более чем один метод гарантирует
выполнение уравнения A). Для того чтобы улучшить эффективность
метода, мы можем добавить следующее эвристическое правило, на-
направленное на исключение совокупностей, которые по всей вероят-
вероятности относятся к худшим (ср. с методами Паульсона). Исключаем со-
совокупность i, если разность между лучшей выборочной средней лг[&] и
средней xt минус умноженная на с оценка стандартного отклонения
этой разности останется положительной, т. е. если
(хм -xt) - с [var (хм - лггI1/2 > 0. (98)
Мы можем выбрать, например22, с = 3. Для ознакомления с исклю-
исключением мы отсылаем к [Bechhofer et al., 1968, p. 230 — 240].
Перед тем как закончить этот параграф, мы дадим следующие ре-
рекомендации (основанные на интуиции так, что мы понимаем, что каж-
каждый^ может быть с чем-то несогласен):
,> 1. Процедура Дудевича и Далала [Dudewicz, Dalai, 1971]'кажется
лучшим выбором для гарантированного выполнения требования урав-
уравнения A) в случае, когда не применяется центральная предельная
теорема. Метод, однако, относительно неэффективен, если он не по-
последователен, не использует преимуществ БПК^и не исключает худ-
худших совокупностей.
2. Метод Бехгофера [Bechhofer, 1954] улучшен введением последо-
последовательных оценок дисперсий, чтобы удовлетворить уравнению A).
Этот вариант почти идентичен методу Роббинса—Собела—Старра для
общих неизвестных дисперсий, и этот последний метод опробован.
Предполагается, что он нечувствителен к нарушению нормальности,
поскольку центральная предельная теорема применима к выборочным
средним и оценки дисперсии остаются несмещенными. Он относительно
255
неэффективен, так как не использует преимуществ БПК и не исключает
худших совокупностей.
3. Если экспериментатор не хочет доверять предположениям, он
может применить исходный метод Бехгофера —Блюменталя [Bechho-
fer, Blumenthal, 1962], так как это единственный метод, хорошо ис-
исследованный на чувствительность к нарушению нормальности и не-
неравенству дисперсий. К сожалению, он не может использовать преиму-
преимуществ БПК и может даже потребовать больших выборок в БПК- Он
не исключает совокупностей.
4. Экспериментатор, которого интересует больше всего эффектив-
эффективность ММР (поскольку его имитационный эксперимент требует много
времени на один опыт), может выбрать метод Паульсона [Paulson,
1964а] или один из наших эвристических вариантов. Мы предполагаем,
что это наиболее эффективный метод благодаря исключению худших
совокупностей в ходе экспериментирования. Его чувствительность к
неоднородности дисперсий (или требуемого числа наблюдений rt на
каждом шаге) и нарушению нормальности неизвестна, но ею можно
пренебречь, поскольку в правиле исключения работает экстремальная
статистика. Мы бы не рекомендовали первоначальный метод Бехго-
Бехгофера, Даннетта и Собела [Bechhofer, Dunnett, Sobel, 1954] для общих
неизвестных дисперсий, потому что их критическая константа h чув-
чувствительна к неоднородности дисперсий, в то же время метод не более
эффективен, чем рекомендованные выше. Улучшенный метод Срива-
ставы [Srivastava, 1966], возможно, дает те же результаты, что и ис-
исправленный метод Бехгофера [Bechhofer, 1954]. Робастность последо-
последовательных параметрических методов (Сена, Сриваставы и Хоула) пока
неизвестна. Как бы то ни было применение одного из первоначальных
либо модифицированных ММР кажется лучшим способом, чем теку-
текущая практика определения числа опытов чисто интуитивным путем.
V.B.5. Другие распределения, решения и постановки задач
1. Другие распределения. Мы обсудили методы для выбора нор-
нормальной совокупности с лучшей средней. Как мы заметили, ММР
могут применяться и в других ситуациях, может быть, после преобра-
преобразований данных. Имеются, однако, специальные методы для других
распределений. Лучшей ссылкой служит работа [Bechhofer et al.,
1968, p. 255 — 274], где даются процедуры для выбора лучшей нор-
нормальной совокупности (средние или дисперсии в качестве критерия
выбора), экспоненциальной, гамма-, Вейбулла, биномиальной, от-
отрицательно биномиальной и пуассоновской; должны удовлетворяться
определенные отношения безразличия. (Эти отношения не всегда
соответствуют 8(ft) — ®(h-i) > 6*, но, например, удовлетворяют
F(fe) — 9(ft-i))/@(ft) fyft-i)) > -б*-) Некоторые дополнительные, хотя
и не исчерпывающие, ссылки таковы: [Taylor, David, 1962] для
биномиальных совокупностей, [Bechhofer et al., 1959], [Bechhofer,
Sobel, 1956] для мультиномиальных распределений, [Chambers, Jar-
ratt, 1964], если ст? = а (^г), например для биномиальных или пуас-
соновских распределений. Много ссылок можно найти в [Bechhofer,
1958], [Bechhofer, et al., 1968], [Dudewicz, 1968] и [O'Neill, Wethe-
rill, 1971].
2. Другие решения. Гутман [Guttman, 1963] предложил метод,
который, как и уравнение A), гарантирует Р (ПВ) > Р*, но не имеет
зон безразличия б*. Его правило основывается на методах выбора под-
подмножеств, обсуждаемых в V.B. Здесь выборка продолжается до тех
пор, пока объем подмножеств не станет равным единице. (Подмноже-
(Подмножество, однако, может оставаться большего объема, если ограничены
возможные денежные ресурсы.) Метод имеет тот недостаток, что, оста-
оставаясь только «псевдомногошаговым», он наблюдения предыдущего ша-
шага не использует на последующем шаге. Кроме того, может не оказаться
необходимых таблиц (ср. его уравнение B.5), дающее нечетные вели-
величины для Р*). Преимущество состоит в том, что эти методы выбора
подмножеств не требуют выполнения ограничительных предположений
(см. например, непараметрический метод Ризви и Собела в V.B).
Байесовский подход и подход теории статистических^ решений
для проблемы выбора можно найти, например, в [Somerville, 1954]
с продолжением в [Shirafuji, 1956] и Fairweather, 1968]; [Dunnett, 1960]
и" [Hayes, 1969]. Дополнительные ссылки есть в [Bechhofer et al.,
1968] и [Dudewicz, 1968, разделы Е и Р].
3. Другие постановки задач. Вместо выбора единственной лучшей
совокупности нас может заинтересовать выбор t лучших совокупно-
совокупностей A ^ t ^ k) с упорядочением этих совокупностей или без него
(см. [Bechhofer, 1955], [Bechhofer et al., 1954], [Bechhofer et al., 1968],
[Freeman et al., 1967] и [Puri, Puri, 1967]). Вместо выбора совокуп-
совокупности, связанной с лучшей средней, может появиться желание оценить
значение лучшей выборочной средней или, в более общем" случае,
величин параметров Q(i) (см. [Dudewicz, 1968, раздел Q; 1971b],
[Dudewicz, Dalai, 1971, раздел 6], [Dudewicz, Tong, 1971] и [Rizvi,
Saxena, 1972]). Другие задачи, относящиеся к ранжированию, это:
классификация дисперсий относительно дисперсии контрольной сово-
совокупности (см. [Paulson, 1964 b]), совместные доверительные интер-
интервалы заданной длины (см. [Healy, 1956] с применением к факторным
экспериментам), методы выбора подмножеств (см. [Barron, Gupta,
1970], [Gupta, Panchapakesan, 1969 b] для последовательных правил,
[Dudewicz, Dalai, 1971, раздел 6] или [Dudewicz, 1972, p. 7 — 8] для
двухшаговых правил). Ранжирование многомерных совокупностей
обсуждается в [Srivastava, Taneja, 1972]. Сюда относятся также работы
[Somerville, 1970] и [Zinger, 1961]. Много дополнительных ссылок
дается в [Dudewicz, 1968].
ПРИЛОЖЕНИЯ К ЧАСТИ V.B
ПРИЛОЖЕНИЕ V.B.I. ВЫБОР ОДНОЙ ИЗ ЛУЧШИХ СОВОКУПНОСТЕЙ
Для простоты в приложениях предполагается, что совокупности
обозначены так, что цх ^ ... ^ \ik, т. е. ц{ = |л(г). Сочетание
средних в этом приложении такое:
ОК |*й - 1*й_! < б* A.1а)
Дж. Клейнец
257
Hi = ... = ph-% < и-fc-i — б*. A.16)
Правильным выбором будет выбор П^ или ITft_1. Следовательно, по-
поскольку процедура выбирает совокупность с наибольшей выборочной
средней х (или какую-то другую статистику вроде ранговой суммы),
мы имеем
Р (ПВ)=Р (xk есть max) + f (Jfh-i есть max) =
= P\xh>~Xj(j=\t...t k—2) \l~
= P (xh > Jfft.i) P (xh > x} все j\xk> xk_j) +
+ P(xh.l >xk) P Cxh-i > Xj все /1 xh^ > xk). A.2)
Воспользуемся символом
P {xh > хы) = p, A.3)
так что (предполагаем для простоты непрерывные переменные)
Р (xh^>xh) = 1 - р. A.4)
Далее,
Р 1~хк > xj (/ = 1, ..., k — 2)\xh > Xfc.il
>P [^ft> ^ (/ = 1. •¦-. k - 2)], A.5
поскольку условие xh > д:^-! приводит к большим значениям jrfe
Следовательно,
Р (Ym)^pP[xh>Xj все /] + A — р) Р (xh^>Xj для всех /]. A.6
Рассмотрим ситуацию только с совокупностью 1, ..., k — 2, k, т. е
исключим совокупность k — 1. Метод гарантирует
Р (xk > Xj все /) > Р*, если ^^ — ц,А_2 > б*. A.7
Включение совокупности k — 1 не уменьшает вероятности в уравне
нии A.7), поскольку все наблюдения независимы и число наблюдени
для определения выборочных средних не уменьшается. Применени
уравнения A.7) и его аналога для xh^ дает
Р (ПВ) > рР* + A — р) Р* = Р*. A.S
258
ПРИЛОЖЕНИЕ V.B.2. ОДНОВЫБОРОЧНЫИ МЕТОД ДЛЯ ИЗВЕСТНЫХ
ДИСПЕРСИИ
Все наблюдения независимы и выборочные средниехг (i = 1, ..., k)
предполагаются нормально распределенными. (Если индивидуальные
наблюдения нормальны, то это предположение выполняется для лю-
любого объема выборки пп если же нет, то это асимптотически выполняет-
выполняется для конечных дисперсий а\ и средних \it.) Вероятность того, что на-
наибольшее выборочное среднее находится в совокупности с наибольшей
средней \Lk, равна вероятности того, что лучшая совокупность дает
выборочную среднюю xh и все другие совокупности дают выборочные
средние, меньшие, чем xh, где xh может меняться от — оо до + оо.
Или
Р (ПВ) = Г Ф (х; \xh, -^ ) -Ф (*; р1г ^-) ... Ф f x; \ih-i, -^-) dx,
jJ^ \ «fe / \ п\ } \ «ft-i I
B.1)
где ф (х; \ih, al/nh) есть функция плотности нормальной переменной
со средней \ih и дисперсией a%lnh\ Ф (х; \is, aj/n}) есть (кумулятивная)
функция распределения нормальной переменной со средним р,;- и дис-
дисперсией af/rij (I = 1, ..., k — 1). Итак, Р (ПВ) ^ Р* должно вы-
выполняться только для сочетаний, удовлетворяющих
ц, < Н - б* (/ = 1, .... k - 1). B.2)
Легко проверить, что для ? > О
ф(х; ць_6*,-^Л < Ф ( х; iift-б*- 6 , -^-] • B.3)
Следовательно, Р (ПВ) в уравнении B.1) достигает своего минимума
при выполнении B.2), если средние в сочетании
р} = iift - б*(/ = 1, ..., k - 1) B.4)
независимо от значений а;? и ol-
,')га минимальная величина Р (ПВ) равна:
«1
.h-S*tA=L\dx. B.5)
«ft-i /
I (одстановка
2 = — (l.b)
259
уравнение B.5) дает
оо
Лша = f Ф(г) • Ф (Л= + ННЩ
z, B.7)
где ф (z) обозначет функцию плотности стандартной нормальной пере-
переменной, т. е.
Ф (z) = Ф (*; 0, 1). B.8)
В уравнении B.7) мы имеем для / = 1, ..., k — 1:
i < -t^z z f fift | ? (J;) =
y
B.9)
где Ф (z) обозначает вероятность того, что стандартная нормальная
переменная z меньше, чем z. Возьмем объем выборки в соответствии с
пропорцией
— =—г (/=!,....fc-1). B.10)
Тогда уравнение B.9) становится равным
ф/_Нл._&2+-^-6*]=Ф^ + -^-в*). B.11)
Из уравнений B.9) и B.11) следует, что уравнение B.7) сводится к
~ldz. B.12J
Поскольку мы требуем Pmin ^ Р*, го мы должны решить уравнение
B.13) для d:
Р*= j 9(z)[O(Z+d)]fc-id2 B.13)
260
или
nh = (M/6*J. B.15)
Наше уравнение B.13) эквивалентно уравнению B0) из [Bechhofer,
1954] (если в его уравнении мы заменим d = V/VS/c на d, определенное
в уравнении B.14), и положим t = 1, поскольку мы ищем лучшую
совокупность). Бехгофер затабулировал значения d, удовлетворяющие
уравнению B.13). Используя эти значения, вместе с уравнениями
B.15) и B.10), мы найдем искомые величины я,- (J; = 1, ..., k — 1)
и nk.
ПРИЛОЖЕНИЕ V.B.3. КРИТИЧЕСКИЕ КОНСТАНТЫ ДЛЯ МЕТОДА В
СРИВАСТАВЫ
Сривастава [Srivastava, 1966, р. 374] определил последовательность
(ат) = (av a, ...) как ряд любых положительных констант, удовлет-
удовлетворяющих
lim am = а, C.1)
т-*оо
где а следует из
Р (/? > a V2) = 1 — Р* C.2)
или, что эквивалентно,
P{R < a~V~2) = P* C.3)
и /? определяется из
/?= max (Zj—zh), C.4)
K/<ft1
ату и г& — независимые стандартные нормальные переменные. Срива-
Сривастава упоминает, что R табулировано в [Bechhofer, 1954]. В [Srivasta-
[Srivastava, Ogilvie, 1968, p. 1043, уравнение B.6)] дается формула, которая
идентична, что можно проверить, формуле Бехгофера B0) с t = 1
и d = xV2. Поскольку для а Сриваставы мы имеем a = df]/2, берем d
из [Bechhofer, 1954]. Далее рассмотрим ат.
В [Gupta, Sobel, 1957] табулировано q, где
р (у < q) = р* C.5)
и
31 = (max Xj—x) isv, C.6)
a Xj и х — независимые нормальные переменные с общей средней
ц и общей дисперсией а2, в то время как si — независимая оценка а2.
Положим теперь Zj = (Xj — ц)/о (/ = 1, ..., р), zh = (х— \l)/o
и p = k—1. Тогда уравнение C.6) превращается в
у = a [max (zj) — zh]/sv, C.7)
K/ft1
261
где Z) и zh — независимые стандартные нормальные переменные.
Поскольку v -> оо, si стремится к а2 и, следовательно, у стремится к /?.
(Конечно, входы у Гупты и Собела для v = оо соответствуют данным
Бехгофера.) Следовательно, мы берем am = q/V2, где q (P*, k, о) с,
v = k (т — 1) табулировано в [Gupta, Sobel, 1957], [Dunnett, 1955]
и [Kjishnaiah, Armitage, 1966].
УПРАЖНЕНИЯ
1. Примените одновыборочный метод для определения объемов выборок щ,
если известны дисперсии а\ = 90, а| = 130, а§ = 191 и Р* =0,75, б*= 4
[Bechhofer, 1954, р. 37].
2. Докажите, что s% в уравнении A3) — несмещенная оценка а2 в а2 =
= а; а2.
3. В [Naylor et al., 1967b) авторы имитировали 50 опытов для каждого
из 5 вариантов системы с очередью. При условии общей дисперсии они нашли
сумму квадратов, равную 12, 715, 825. Вариант системы с лучшей средней должен
быть выбран с вероятностью по крайней мере 90%, если лучший вариант не
менее чем на 100 единиц лучше других вариантов. Примените метод Бехгофе-
Бехгофера, Даннетта и Собела [Bechhofer, Dunnett, Sobel, 1954] для определения того,
достаточно ли опытов было генерировано.
4. Определить рг = Р (jq > jc2) и р2 — Р (jc3 > xt). Пусть ху и х2 —непрерыв-
—непрерывные переменные с функциями распределения Fj (х) = F (х — |i;) и \хг > (х2.
Докажите, что р2 > pt.
5. Докажите, что «"Fx (x) > F2 (x)» верно для всех х", если закон распреде-
распределения функций нормальный с Hi < ц2 и °\ ~ а1 или экспоненциальный с
Е (Xl) < E (jc2).
6. Докажите, что в двухфакторном плане Р (ПВ) для факторов Л и В со-
соответственно независимы, если дисперсии средних в ячейках оД./л^ постоянны.
7. Пусть два параметра гамма-распределеиия обозначены pub (см. [Fisz,
1967, р. 152]). Покажите, что нельзя получить гамма-распределения, идентич-
идентичные с точностью до ожидаемого сдвига.
8. В [Naylor et al., 1968] авторы хотели выбрать экономическую полити-
политику, которая минимизирует дисперсию национального дохода, с Р (ПВ) > 90%,
если лучшая дисперсия составляет не более 90% следующей за ней лучшей дис-
дисперсии. Пусть s| обозначает выборочную дисперсию политики ? (? = 1, ..., 5)
в опыте g (g = 1, ..., 50). Каким образом, можно применить метод Бехгофе-
Бехгофера, Даннетта и Собела [Bechhofer, Dunnett, Sobel, 1954]?
9. Докажите, что s2 = 2^_j (xs — xJl(m — 1) — несмещенная оценка для
любого распределения.
10. Примените ММР для выбора системы массового обслуживания с наи-
наименьшим временем ожидания стационарного состояния для различных дисцип-
дисциплин очереди (например, «первый пришел—-первым обслужен», «первый пришел —
последним обслужен», случайное обслуживание).
Замечание. Много других потенциальных приложений ММР можно найти
в литературе, например в [Schmidt, Taylor, 1970, p. 516—575].
ПРИМЕЧАНИЯ
1 Глава V.B есть обобщение работ [Kleijnen, 1968], [Kleijnen, Naylor,
1969] и [Kleijnen et al., 1972].
2 Использование выборочного среднего для выбора совокупности с наилуч*
шими средними, конечно, эффективно во многих задачах, однако не во всех.
Например, средняя точка области изменения есть лучшая статистика для рав-
равномерных распределений (см. [Dudewicz, 1971a]). Как мы упоминали в V.A,
систематическое изучение около 70 различных оценок расположения распреде-
распределений в [Andrews et al., 1972]. Авторы этой работы нашли, что выборочное сред-
262
нее — весьма неробастная оценка. Отбрасывание резко выделяющихся наблю-
наблюдений или переход к медиане — вот простые решения в таких случаях; о более
сложных оценках см. [Andrews et al., 1972].
s Некоторые ММР, например непараметрический метод Собела [Sobel,
1968], дают минимум Р (ПВ) при наиболее предпочтительных сочетаниях, оп-
определенных аналогично уравнению B).
4 В [Bechhofer, 1954, р. 24] используются следующие более сложные форму-
формулировки. Положим, а? = ctiG2, где а^ —• неизвестные отношения дисперсий и
а2 — общая известная константа. Выберем п, так, чтобы a^ltii оказалось кон-
константой. Найдем d в таблицах и вычислим п = (ad/б*J, где а2 — константа
в a? = aja2. Положим щ = а\п (см. также уравнения B2) и A7) из [Bechhofer,
1954]).
6 В [Bechhofer et al., 1968, уравнение 12.3.7] авторы берут б* в показателе
степени, где мы используем б*/с. В их уравнении A2.6.3), однако, утверждает-
утверждается, что Р (ПВ) > Р*, если jx(fe) — H(fe_D > б*е. Следовательно, их б*с эк-
эквивалентно нашему б*. В нашем описании их процедуры мы пользуемся б* вез-
везде, как было определено в уравнении A).
8 Дисперсия а2 — это общая дисперсия. Если Дисперсии не равны, опреде-
определим наблюдение из П,- как среднее г,- наблюдений, в которых г, удовлетворяет
условию а2/гг = а2 (см. уравнение (8)). Следовательно, равные средние нужно
умножить на ги чтобы получить число индивидуальных наблюдений из П;.
7 Может возникнуть некоторая путаница с таблицами. Сначала Бехго-
фер и его соавторы [Bechhofer et al., 1954, p. 173] отсылали к [Dunnett, Sobel,
1954] для k = 3 и указывали, что нет таблиц для k > 3. Позднее Бехгофер
[Bechhofer, 1958, р. 410] стал отсылать к [Dunnett, Sobel, 1954; 1955] и упоми-
упоминать [Dunnett, 19551 и [Gupta, Sobel, 1957]. Из [Bechhofer et al., 1954, p. 1721
следует, что Р (ПВ) (б > б*) > Р [zj/s0 < h (/ = 1 k — 1)], где zj —
многомерное нормальное распределение с нулевыми средними дисперсиями а2
и коэффициентом корреляции р-., = 1/2 (у ф /'). В [Dunnett, 1955, р. 1102]
то же выражение с h = d' и k — 1 = р. В [Gupta, Sobel, 1957] исследовано
P [Zj/so < qlYi U = I- ¦¦•, k — 1)]. Последние две публикации делают работы
[Dunnett, Sobel, 1954; 1955] устаревшими. Например, для k= 5, Р* = 0,99,
v = 15 в [Dunnett, 19551 Дано 3,20, а в [Gupta, Sobel, 1957] дается q — 4,54,
так что h — 4,54/]/2 =ь 3,2. См. также обсуждение библиографии в [Gupta,
1963а, р. 806—809; 1963b, p. 835—837]. Общая библиография таблиц, относящих-
относящихся к ММР и ММС, приведена в [Dudewicz, 1968, раздел R].
8 Требование Роббинса и его соавторов [Robbins et al., 1968, p. 89], что
m должно быть нечетным целым > 5, важно только из дополнительных сооб-
соображений.
9 Мы предлагаем метод Паульсона для общего X, а ие только для специаль-
специального случая X = б*/4 из [Paulson, 1964a, р. 178—1791.
10 Мы предлагаем оба метода А и В, хотя Сривастава и Огилви показали,
что метод В требует меньше наблюдений. Метод А, однако, более робастен
(см. V.B.4).
11 Константами ат в этом классе процедур может быть любая последова-
последовательность положительных констаит, удовлетворяющих Игл ат ~ а с Ф (— а) =
= A — P*)l(k — 1), а Ф обозначает стандартную функцию нормального рас-
распределения. Следуя [Srivastava, Ogilvie, 1968, уравнение B.2)], мы определили
ат из ^-распределения. Хорошо известно, что ^-распределение приближается
к стандартному нормальному распределению с ростом v.
12 1) В [Srivastava, Ogilvie, 1968, p. 1046] нет ссылок на [Krishnaiah,
Armitage, 1966] или на работы Гупты и Собела, а упоминается только Даннетт
в их первой аппроксимации а*. Сривастава и Огилви используют этот под-
подход и для вычисления а*, но не приводят результатов а*. 2) Мы отметим сле-
следующее сходство между методами Бехгофера, Даннетта и Собела [Bechhofer,
Dunnett, Sobel, 1954], Роббинса и его соавторов [Robbins et al., 1968] и Срива-
ставы [Srivastava, 1966]. Во всех трех методах объем выборки определяется
следующим правилом: т = (ас/б*J, где с — константа, табулированная, на-
263
пример, в [Dunnett, 1955], [Bechhofer, 1954] и в таблице ^-статистики (или
стандартного нормального распределения для числа степеней свободы > 30).
В [Gupta, Sobel, 1957] выведено отношение между тремя константами, урав-
уравнение D.6) показывает отношение между d' Даинетта (=А = q/V~%) и значением
d Бехгофера; уравнение D.9) показывает отношение между h Даннетта и стан-
стандартной нормальной переменной (см. также приложение V.B.3). 3) В заключе-
заключение заметим, что Леман [Lehmann, 1963, р. 269] доказал, что для неизвестных
распределений с общей известной дисперсией в асимптотическом методе берет-
берется п — (ad/8*J точно так же, как это было в [Bechhofer, 1954]. Сравните также
наше приложение V.B.2, где требуется только асимптотическая нормальность
выборочных средних для получения тех же решений.
13 Мы предположим, что квантили единственны, т. е. что только одно зна-
значение удовлетворяет уравнению F1). Для более общих определений см. [Sobel,
1967] или уравнение E5) из V.A.
14 Уравнения F8) следуют из [Paulson, 1962, р. 437]: Р (Dj\ Rj) > \ — Р,
где Rj обозначает сочетание [р,., = (i0 (/' = 1, ..., k, но /' ф /) и \xj = р0 +
+ б*] и Dj обозначает решение, что П/ есть лучшая экспериментальная совокуп-
совокупность, которая также лучше, чем контрольная.
15 Ср. [Paulson, 1962]: Р (?>„ \ Ro) > 1 — а, где Ro обозначает ц0 = V4
(i = 1, ..., k) и Do обозначает выбор По.
18 Выполняются следующие соотношения между обозначениями Паульсо-
на и нашими обозначениями: А = б*, d — %., d + [о2/ l°S (kla)]/2dn ~ d;.
17 Нейлор и его соавторы использовали критическую константу h = 1,58,
взятую из [Dunnett, Sobel, 1954, табл. 3]. Это, однако, верно только для k = 3.
О правильном подходе см. примечание 7 и упражнение 3.
18 Нейлор и его соавторы хотели выбрать экономическую политику, кото-
которая минимизирует флуктуации в национальной экономике. Эти флуктуации
были измерены оценкой дисперсии s\ — ????! (xlt = jc/J/L99 (i = 1, ..., 5).
Укажем, что оценка s2 могла бы быть несмещенной оценкой дисперсий совокуп-
совокупностей о^, если бы Хц были независимыми наблюдениями из какой-то одной
определенной совокупности П,-. Эти авторы не учитывали смещения, вызывае-
вызываемого сериальной корреляцией и переходным состоянием, и брали Е (s^-) в каче-
качестве критерия выбора. Процедура ранжирования применялась к 2?g = ln sfgx
X fe = 1, ..., 50), что гарантирует Р (ПВ) > 90%, если лучшая дисперсия со-
составляет не более 90% следующей лучшей (см. упражнение 8).
19 В [Chambers, Jarratt, 1964] предполагаются неизвестные дисперсии а2
известными и общими функциями средних (х,-, скажем о2 = о (ц{). В [Chambers,
Jarratt, 1964, p. 51] |/"п б*/а (\хг) есть аналог Yni^*l°i B нашем приложении
V.B.2. (Значение у* у авторов указанной работы равно 1.)
20 Можно попытаться снизить сверхгарантию, используя значения Р*,
меньшие тех, которые нам действительно нужны. Решение о том, насколько их
уменьшить, принимается на основе оценок Монте-Карло сверхгарантий для дан-
данных k и Р*. Однако мы не знаем, существует ли также сверхгарантия в нашем
интуитивном варианте.
21 Рамберг предполагает, что в большинстве случаев метод Бехгофера,
Кифера и Собела работает лучше. Тем не менее мы считаем, что общее число на-
наблюдений более существенно, чем число'шагов в имитационном эксперименте,
и что Р* и k, принимающие низкие значения, 0,75 и 3 соответственно, не столь
существенны, сколь Р*, равное 0,99 (или 0,999), и &, равное 10. Далее ограничим
наши заключения СРС и НПС.
23 В [Sasser et al., 1970, p. 292] применено эвристическое правило исключе-
исключения (jc^j — ~xi) — 2 [var Ц-?])]!/2 — 2 [var (хЦ]1/2 > 0, где мы интерпре-
интерпретируем «стандартное отклонение, ассоциированное с планом h, как стандартное
отклонение средней Xi, а не индивидуального наблюдения Xi. Авторы доби-
добились значительной экономии машинного времени, когда применили это пра-
правило к моделирование системы хранения запасов (Sas$er et al., 1970, p. 295].
264
БИБЛИОГРАФИЯ
1. Andrews D. F., Bickel P. J., Hampel F. R., Hubei P. J., Ro-
Rogers W. H. and Tukey J. W. A972). Robust Estimates of Location. Prin-
Princeton University Press, Princeton, New Jersey.
2. В a r r D. R. and Rizvi M. H. A966). An introduction to ranking and selec-
selection procedures. J. Amer. Stat. Assoc, 61, 640—646,
3. Barron A. and Gupta S. S. A970). A Class of non-Eliminating Sequen-
Sequential Multiple Decision Procedures. Mimeograph Series, № 247, Department
of Statistics, Purdue University, Indiana.
4. В a r 11 e 11 N. S. and G о v i n d a r a j u 1 u Z. A968). Some distribution—free
statistics and their application to the selection problem. Ann. Inst. Stat. Math.,
20, 79—97.
5. В a w a V. S. A972). Asymptotic efficiency of one R-factor experiment rela-
relative to R one-factor experiments for selecting the best normal population.
J. Amer. Stat. Assoc, 67, 660—661.
6. В ее hh о f er R. E. A954). A single-sample multiple decision procedure for
ranking means of normal populations with known variances. Ann. Math. Stat.,
25, 16—39.
7. Bechhofer R. E. A958). A sequential multiple-decision procedure for se-
selecting the best one of several normal populations with a common unknown
variance and its use with various experimental designs. Biometrics, 14,
408—429.
8. Bech ho f e r R. E. A970). Correction note: an undesirable feature of a se-
sequential multiple-decision procedure for selecting the best one of several nor-
normal populations with a common unknown variance. Biometrics, 26, 347—349.
9. Bechhofer R. E. and Blume.nthal S. A962). A sequential multiple-de-
multiple-decision procedure for selecting the best one several normal populations with
a common unknown variance, II: Monte Carlo sampling results and new
computing formulae. Biometrics, 18, 52—67.
10. Bechhofer R. E., Dunnett С W. and Sobel M. A954). A two-sample
multiple decision procedure for ranking means of normal populations with
a common unknown variance. Biometrika, 41, 170—176.
11. Bechhofer R. E., Elmaghraby S. and Morse N. A959). A single-
sample multiple-decision procedure for selecting the multinomial event which
has the highest probability. Ann. Math. Stat., 30, 102—119.
12. Bechhofer R. E., Kiefer J. and Sobel M. A968). Sequential Identi-
Identification and Ranking Procedures. The University of Chicago Press, Chicago.
13. Bechhofer R. E. and Sobel M. A956). A sequential multiple-decision
procedure for selecting the multinomial event with the largest probability
(preliminary report). Ann. Math. Stat., 27, 861.
14. В echho f er R. E. and Sobel M. A958). Non-parametric multiple-decision
procedures for selecting the one of k populations which has the highest pro-
probability of yielding the largest observation (preliminary report). Ann. Math.
Stat., 29, 325.
15. Bradley J. V. A968). Distribution-Free Statistical Tests. Prentice-Hall,
Englewood Cliffs, New Jersey.
16. Bradley R. A. A967). Topics in rank-order statistics. — In: Proceedings
of the Fifth Berkeley Symposium on Mathematical Statistics and Probability,
vol. 1. (L. M. LeCam and J. Neyman, eds.), University of California Press,
Berkeley, 593—607.
17. Chambers M. L. and Jarratt P. A964). Use of double sampling for
selecting best population. Biometrika, 51, 49—64.
18. Con over W. J. A971). Practical Nonparametric Statistics. Wiley, New
York.
19. Con way R. W., Johnson В. М. and Maxwell W. L. A959). Some
problems of digital systems simulation. Management Sci., 6, 92—110.
20. Dudewicz E. J. A968). A Categorized Bibliography on Multiple-Decision
(Ranking and Selection) Procedures, Department of Statistics, The Univer-
University of Rochester, Rochester, New York.
21. Dudewicz E. J. A969). Estimation of Ordered Parameters. Technical Re-
265
port, Us 60, Department of Operations Research, College of Engineering, Cor-
Cornell University, Ithaca, New York.
22. Dudewicz E. J. A971a). A nonparametric selection procedure's efficiency:
largest location parameter case. J. Amer. Stat. Assoc, 66, 152—161.
23. Dudewicz E. J. A971b). Maximum likelihood estimators for ranked means.
Zeitschrift Wahrscheinlichkeitstheorie und Verwandte Gebiete, 19, 29—42.
24. Dudewicz E. J. A972). Statistical Inference with Unknown and Unequal
Variances. Department of Statistics, The University of Rochester, Rochester,
New York.
25. Dudewicz E. J. and Dalai S. R. A971). Allocation of Observations in
Ranking and Selection with Unequal Variances. Department of Statistics, The
University of Rochester, Rochester, New York.
26. Dudewicz E. J. and Ramberg J. S. A972). Multiple Comparisons with
a Control: Unknown Variances, Department of Statistics, The University of
Rochester, Rochester, New York.
27. Dudewicz E. J. and Tong Y. L. A971). Optimal confidence intervals
for the largest location parameter. — In: Statistical Decision Theory and
Related Topics. (S. S. Gupta and J. Yackel, eds.), Academic, New York.
28. Dudewicz E. J. and Zaino N. A. A971). Sample size for selection. —
In: Statistical Decision Theory and Related Topics. (S. S. Gupta and J. Yackel,
eds.), Academic, New York.
29. Dunnett C. W. A955). A multiple comparison procedure for comparing se-
several treatments with a control. J. Amer. Stat. Assoc, 50, 1096—1121.
30. Dunnett C. W. A960). On selecting the largest of к normal population
means. J. Roy. Stat. Soc, Ser. B, 22, 1—40.
31. Dunnett C. W. and Sobel M. A954). A bivariate generalization of Stu-
Student's t-distribution with tables for certain special cases. Biometrika, 41,
153—169.
32. Dunnett C. W. and Sobel M. A955). Approximations to the probability
integral and certain percentage points of a multivariate analogue of Student's
t-distribution. Biometrika, 42, 258—260.
33. Fair weather W. R. A968). Some extensions of Somerville's procedure
for ranking means of normal populations. Biometrika, 55, 411—418.
34. Fishman G. S. and Kiviat P. J. A967). Digital Computer Simulation:
Statistical Considerations, RM—5387—PR, The RAND Corporation, Santa
Monica, California. (Published as: "The statistics of discrete-event simulation.
Sci. Simulation, 10, 1968, 185—195.)
35. Fisz M. A967). Probability Theory and Mathematical Statistics. Wiley, New
York, third printing.
36. F r e e m a n H., К u z m а с к A. and Maurice R. A967). Multivariate t and
the ranking problem. Biometrika, 54, 305—308.
37. Fu K. S. A970). Sequential Methods in Pattern Recognition and Machine
Learning. Academic, New York, second printing. Русский перевод: Ф у К.
Последовательные методы в распознавании образов и обучении машин.
М., «Наука», 1974.
38. Gupta S. S. A963a). Probability integrals of multivariate normal and mul-
multivariate t. Ann. Math. Stat., 34, 792—828.
39. Gupta S. S. A963b). Bibliography on the multivariate normal integrals and
related topics. Ann. Math. Stat., 34, 829—838.
40. Gupta S. S., Na gel K. and P anchapakesan S. A971). On the Order
Statistics from Equally Correlated Normal Random Variables. Mimeographed
Series, № 290, Department of Statistics, Division of Mathematical Sciences,
Purdue University, Lafayette, Indiana.
41. Gupta S. S. and Panchapakesan S. A969a). Some selection and ran-
ranking procedures for multivariate normal populations. — In: Multivariate Ana-
Analysis, vol. 2. (P. R. Krishnaiah, ed.), Academic, New York.
42. Gupta S. S. and Panchapakesan S. A969b). Selection and ranking
procedures. In: The Design of Computer Simulation Experiments. (Т. Н. Nay-
lor, ed.), Duke University Press, Durham, North Carolina.
43. Gupta S. S. and Sobel M. A957). On a statistic which arises in selection
and ranking procedures. Ann. Math. Stat., 28, 957—967.
266
44 GuttmanI A963) A sequential procedure for the best population Sankhya,
Ser A, 25 Pt 1, 25—28
45 Hayes R H A969) The value of sample information — In The Design
of Computer Simulation Experiments (T H Naylor, ed) Duke University
Press Durham North Carolina
46 Heal у W С A956) Two sample procedures in simultaneous estimation
Ann Math Stat, 27, 687—702
47 Hoel D G A971) A method for the construction of sequential selection
procedures Ann Math Stat 42, 630—642
48 Hoel D G and Mazumdar M A968) An extension of Paulson's selec
tion procedure Ann Math Stat, 39, 2067—2074
49 KendallM О andStuart A A963) The Advanced Theory of Statistics,
vol 1 Charles Griffin, London, second edition Русский перевод Кен
далл М, Стьюарт А Теория распределений Т 1 М «Наука», 1966
50 KleijnenJPC A968) The Use of Multiple Ranking and Multiple Com
parison Piocedures in the Simulation of Business and Economic Systems
Preliminary Report, Los Angeles (Obtainable at Kathoheke Hogeschool, Til-
burg, the Netherlands )
51 KleijnenJPC and N а у 1 о г Т Н A969) The use of multiple ranking
procedures to analyze simulations of business and economic systems Pro-
Proceedings of the Business and Economic Statistics Section Annual Meeting
of the American Statistical Association, New York 605—615
52 KleijnenJ P С NeylorT H andSeaksT G A972) The use of
multiple ranking procedures to analyze simulations of management systems
a tutorial Management Sci, Appl Ser 18 245—257
53 KrishnaiahP R and ArmitageJ V A966) Tables for mulhvariate
t distribution Sankhya, Ser B, 28, Pts 1 and 2, 31—56
54 LehmannE L A963) A class of selection procedures based on rank
Mathematische Ann , 150, 268—275
55 LewisP A W A972) Large Scale Computer Aided Statistical Mathema-
Mathematics, Na\al Postgraduate School, Monterey, California
56 Martin W A A971) Sorting Computer Surveys, 3, 147—174
57 Miller R G A966) Simultaneous Statistical Inference New York
58 Milton R С A963) Tables of the Equally Correlated Multivanate Normal
Probability Integral Technical Report, № 27, Department of Statistics, Uni
versity of Minnesota, Minneapolis
59 Naylor T H, Burdick D S and SasserW E A967a) Computer
simulation experiments with economic systems the problem of experimental
design J Amer Stat Assoc, 62, 1315—1337
60 Naylor T H.WertzK and Wonnacott T H A967) Methods for
analyzing data from computer simulation experiments Comm ACM, 10,
703—710
61 NaylorT H.WertzK and Wonnacott T A968) Some methods for
evaluating the effects of economic policies using simulation experiments Rev
Inter Stat Inst 36 184—200
62 O'Neill R and Wetherill G В A971) The present state of multiple
comparison methods J Roy Stat Soc, Ser B, 33, 218—241
63 Paulson E A962) A sequential procedure for comparing several experi-
experimental categories with a standard or control Ann Math Stat, 33, 438—443
64 Paulson E A964a) A sequential procedure for selecting the population
with the largest mean from k normal populations Ann Math Stat, 35, 174—
180
65 Paulson E A964b) Sequential estimation and closed sequential decision
procedures Ann Math Stat, 35, 1048—1058
66 Pun M L and Pun P S A969) Multiple decision procedures based on
rank for certain problems in analysis of variance Ann Math Stat, 40, 619—
632
67 RambergJ S A966) A Comparison of the performance Characteristics
of Two Sequential Procedures for Ranking Means of Normal Populations.
Technical Report, № 4, Department of Industrial Engineering and Operations
Research, College of Engineering, Cornell University, Ithaca, New York.
267
68. Randies R. H. A970). Some robust selection procedures. Ann. Math. Stat.,
41, 1640—1645.
69. Rizvi M. H. and Saxena К. М. L. A972). Distribution-free interval esti-
estimation of the largest a-quantile. J. Amer. Stat. Assoc, 67, 196—198.
70. R ob bin s H., Sobel M. and Starr N. A968). A sequential procedure for
selecting the largest of к means. Ann. Math. Stat., 39, 88—92.
71. Roberts С D. A963). An asymptotically optimal sequential design for
comparing several experimental categories with a control. Ann. Math. Stat.,
34, 1486—1493.
72. S ass er W. E., Bur dick D, S., Graham D. A. and Nay lor Т. Н.
A970). The application of sequential sampling to simulation: an example in-
inventory model. Comm ACM, 13, 287—296
73. Scheffe H. A964). The Analysis of Variance. Wiley, New York. Русский
перевод: Ш е ф ф е Г. Дисперсионный анализ. М., Физматгиз, 1963.
74. Schmidt J. W. and Taylor R. E. A970). Simulation and Analysis of
Industrial Systems. Richard D. Irwin, Homewood, Illinois.
75. Sen A. K. and Srivastava M. S. A972a). On a Sequential Selection
Procedure Based on Wilcoxon Statistic. University of Connecticut / University
of Illinois at Chicago Circle.
76. Sen A and Srivastava M. S. A972b). A Monte Carlo Study of Some
Sequential Solutions to Ranking and Slippage Problems. Center for Urban
Studies, University of Illinois and University of Toronto.
77. S h i r a f u j i M. A956). Note on the determination of the replication numbers
for the slippage problem in r-way layout. Bull. Math. Stat., 7, 46—51.
78. Sobel M. A967). Nonparametric procedures for selecting the t populations
with the largest a-quantiles. Ann. Math. $tat., 38, 1804—1816.
79. Sobel M. and Tong Y. L. A970). Optimal Allocation for Partitioning a
Set of Normal Populations in Comparison with a Control. Technical Report,
№ 134, Department of Statistics, University of Minnesota, Minneapolis.
80. S om er v i 11 e P. N. A954). Some problems of optimum sampling. Biomet-
rika, 41, 420—429.
81. S om e r vi 11 e P. N. A970). Optimum sample size for a problem in choosing
the population with the largest mean. J. Amer. Stat. Assoc, 65, 763—775.
82. Srivastava M. S. A966). Some asymptotically efficient sequential proce-
procedures for ranking and slippage problems. J. Roy. Stat. Soc, Ser. B, 28,
370—380.
83. S r i v a s t a v a M. S., О g i 1 v i e J. A968). The performance of some sequen-
sequential procedures for a ranking problem. Ann. Math. Stat., 39, 1040—1047.
84. Srivastava M. S and S e n A. K. A972). A Sequential Solution of Wil-
Wilcoxon Types for a Slippage Pioblem. University of Toronto/University of
Illinois at Chicago Circle. (Center for Urban Studies, Chicago).
85. Srivastava M. S. and Taneja V. S. A972). Some Sequential Proce-
Procedures for Ranking Multivariate Normal Populations. Department of Stati-
Statistics, University of Toronto, Toronto.
86. S t a r r N. A966). The performance of a sequential procedure for the fixed-
width interval estimation of the mean. Ann. Math. Stat., 37, 36—50.
87. Statistical Theory and Method Abstracts A959—1972). (Published until 1965
as Statistical Theory and Methods.) Oliver and Boyd, Edinburgh, 1959—1972.
88. Taylor R. J., David H. A. A962). A multi-stage procedure for the selec-
selection of the best of several populations. J. Amer. Stat. Assoc, 57, 785—796.
89. Tocher K. D. A963). The Art of Simulation. The English Universities
Press, London.
90. Tong Y. L. A969). On partitioning a set normal populations by their laco-
tions with respect to a control. Ann. Math. Stat., 40, 1300—1324.
91. Wether ill G. B. A966). Sequential Methods in Statistics. Methuen, Lon-
London.
92. Zinger A. A961). Detection of best and outlying normal populations with
known variances. Biometrika, 48, 457—461.
Роббинс Г., Сигмунд Д., Ч а о И. Теория оптимальных правил остановки,
М., «Наука», 1977.
268
Глава VI ф ЭКСПЕРИМЕНТЫ МОНТЕ-КАРЛО С МЕТОДОМ
МНОЖЕСТВЕННОГО РАНЖИРОВАНИЯ
БЕХГОФЕРА —БЛЮМЕНТАЛЯ: ПРИМЕР1
VI.1. ВВЕДЕНИЕ И РЕЗЮМЕ
Эта глава преследует две цели.
1. Продемонстрировать на примере, как можно применить различ-
различные методы, обсужденные в предыдущих главах, к планированию и
анализу имитационных экспериментов и экспериментов по методу
Монте-Карло. Мы применим план 2fv3, дополняющие величины, фор-
формулы для определения объема выборки, дисперсионный и регрессион-
регрессионный анализ, совместные выводы и т. д.
2. Предметом конкретного исследования служит эксперимент по
методу Монте-Карло с методом множественного ранжирования (ММР),
разработанным Бехгофером и Блюменталем [Bechhofer, Blumenthal,
1962]. Цель эксперимента по методу Монте-Карло — исследовать
робастность этой процедуры.
В VI .2 мы коротко опишем ММР и цель эксперимента, т. е. изучение
чувствительности ММР к нарушению его предпосылок. В VI.3 мы
подробно обсудим различные факторы, которые могут влиять на эту
чувствительность. Ненормальность распределения мы определим как
фактор 1. Этот фактор описывает возможность или невозможность
для случайных величин стать меньше заданной константы (так называе-
называемый фактор «усеченное™» распределения); асимметрию и хвосты рас-
распределения мы примем фактором 2. Комбинируя факторы 1 и 2, мы
выберем четыре типа распределений (экспоненциальное, Эрланга,
взвешенную разность двух случайных величин с экспоненциальным
распределением и сумму разностей случайных величин с экспонен-
экспоненциальным распределением). Неоднородность дисперсий будет обозна-
обозначена как фактор 3. Это означает, что дисперсия наилучшей генеральной
совокупности (afk)) может быть либо больше, либо меньше дисперсии
конкурирующей худшей совокупности (при наименее благоприятной
ситуации). Фактор 4 измеряет, сильно ли различаются или не разли-
различаются вовсе эти две дисперсии. Фактор 5 показывает, являются ли
дисперсии худших генеральных совокупностей (в наименее благо-
благоприятной ситуации) равными или они все различны. Фактор 6 опреде-
определяет число совокупностей (три или семь); фактор 7 определяет расстоя-
расстояние б = б* между наилучшей и следующей за ней совокупностями в
наименее благоприятной ситуации. Фактор Р*, гарантирующий ми-
минимальное значение вероятности правильного выбора, рассматривается
269
на 22 уровнях от 0,35 до 0,99 и определяет векторы, состоящие из 22
независимых наблюдений. Все факторы, кроме Р*, будут варьировать
на минимальном числе уровней, т. е. на двух уровнях.
В VI.4 мы построим план 2iV3 для упомянутых 7 факторов. Он
позволяет при 16 комбинациях уровней факторов получить оценки
главных эффектов, не смешанные с возможными двухфакторными
взаимодействиями и оценками некоторых линейных комбинаций двух-
факторных взаимодействий.
В VI.5 будет определено число повторных реализаций так, чтобы
ошибка а была меньше 1%, а ошибка р — меньше 10% (для данных
альтернативных гипотез). Для каждой точки плана 2[у3 будет гене-
генерироваться 800 повторных реализаций.
В VI.6 рассмотрены два метода понижения дисперсии, а имен-
именно использование общих случайных чисел и дополняющих величин.
Будут фигурировать дополняющие величины, поскольку они не услож-
усложняют статистического анализа.
В VI.7 будет коротко описан тип выхода-эксперимента.
В VI.8 мы исследуем робастность ММР с помощью проверки зна-
значимости отличия оцениваемой части наблюдений от соответствующего
значения Р* в меньшую сторону.Будет использована ^-статистика Стью-
дента с уровнем ошибки для семейства гипотез. Три комбинации фак-
факторов дают значимо более низкие значения доли правильных выборов
для любого разумного уровня ошибки. Одиннадцать комбинаций дают
удовлетворительные значения этой доли наблюдений тоже для любого
разумного уровня ошибки.
В VI.9 мы рассмотрим несколько методов отыскания важных
факторов, т. е. таких факторов, которые приводят к потере работо-
работоспособности ММР. Показано, что первый метод, который использует
таблицы сопряженности признаков, неприемлем. Второй метод за-
заключается в применении биномиального критерия вероятности того,
что в отброшенных комбинациях фактор, имеющий один и тот же уро-
уровень, тем не менее не важен. Показано, что эти критерии, однако, име-
имеют малую мощность. Третий метод—это регрессионный анализ. Будут
исследованы обычные предпосылки регрессионного и дисперсионного
анализа и будет показано, почему простой метод наименьших квадратов
предпочтительнее обобщенного метода. Мы оценим коэффициенты
регрессии или «эффекты», проверим адекватность уравнения регрессии
(если Р* ^ 0,90, будет провозглашена адекватность), значимость
отличия коэффициентов регрессии от нуля (фактор 1 даст нулевой
эффект, фактор 5, может быть, тоже имеет нулевой эффект).
В VI.10 содержатся выводы и направления дальнейших исследо-
исследований. В конце главы мы даем приложения, упражнения и библиогра-
библиографию.
VI.2. ЦЕЛЬ ЭКСПЕРИМЕНТА
Во время экспериментирования с ММР Бехгофера и Блюменталя
был запланирован эксперимент с не менее чем девятью процедурами
(см. tKleijnen, 1969, р. 1—2]). Случилось так, что процедура Бехго-
270
фера и Блюменталя была первой среди тех, которые мы исследовали,
отчасти из-за того, что в то время она казалась наиболее перспектив-
перспективной. Во время экспериментирования мы обнаружили, что исследова-
исследование всех этих процедур потребовало бы слишком много машинного
времени. Генерирование данных для плана типа 2?—4, который исполь-
использовался при изучении метода Бехгофера — Блюменталя, заняло около
часа машинного времени на IBM/360—модель 75. Поэтому в данной
главе будут изложены только те результаты исследования ме-
метода Бехгофера — Блюменталя, которые имеются в настоящее
время.
Как мы видели в предыдущей главе, ММР Бехгофера — Блюмента-
Блюменталя позволяют определить, какое количество наблюдений потребно для
каждой из k совокупностей (k ^ 2), чтобы гарантировать выбор сово-
совокупности с наибольшим математическим ожиданием с заранее заданной
вероятностью Р*. Вероятность правильного выбора (ПВ) должна быть
не меньше Р*, что обеспечивает отличие математического ожидания |x(ft)
наилучшей совокупности от математического ожидания Ц(ь_и следу-
следующей за ней по убыванию совокупности не менее чем на б* (так назы-
называемый подход «зоны безразличия»). А именно
Р (ПВ) > Р*, если ц№) - ц№_1} > б*, A)
где Р* и б* устанавливаются экспериментатором. Метод Бехгофера —
Блюменталя последователен, т. е. на каждом s-м шаге (s = 1, 2, ...)
используется одно наблюдение для каждой из k совокупностей и после
каждого /я-го шага (т ^ 2) вычисляется значение статистики для оста-
останова процедуры, гт, определенной в V.B.3. Как только имеет место
неравенство zm ^ A — Р*)/Р*, отбор наблюдений прекращается
и выделяется наилучшая совокупность, которой соответствует выбор-
выборка с наибольшим выборочным средним. В методе предполагается,
что все наблюдения j«ris (i = 1, ..., k) (s = 1, 2, ...) имеют нормальное
распределение, независимы и обладают общей дисперсией а% и матема-
математическими ожиданиями \ih т. е.
хи : N (ц„ oi). B)
Мы хотим узнать, чувствителен ли метод к ненормальности рас-
распределения и неоднородности дисперсий. (Если большинство методов
гарантирует требование к вероятности A), то мы надеемся найти в сле-
следующем эксперименте такой метод, который требует наименьшего чис-
числа наблюдений из k совокупностей.) Метод может быть нечувствитель-
нечувствительным к небольшим отклонениям от нормальности и однородности диспер-
дисперсий. Поэтому мы рассмотрим и небольшие и значительные отклонения
от этих двух допущений. Более того, метод может быть робастным
(и требовать приемлемого числа наблюдений) только для определенных
значений Р*, б* и k. Так что ниже мы рассмотрим более подробно мыс-
мыслимые важные факторы.
271
Vl.3. ФАКТОРЫ В ЭКСПЕРИМЕНТЕ
1. Ненормальность. То, что нам хотелось бы исследовать, — это
отклонения от нормальности, которых можно ожидать в моделях ком-
коммерческой деятельности и моделях экономических систем. К сожале-
сожалению, видимо, нельзя узнать, какого распределения можно ожидать для
сложных имитационных моделей. Что касается литературы, то Бех-
гофер и др. [Bechhofer et al., 1968, p. 266 — 267, 348, 363] сочетали
равномерное распределение в экспериментах Монте-Карло с их ме-
методом ММР. Равномерное распределение, однако, выглядит нереали-
нереалистичным для имитационных моделей. В [Neave, Granger, 1968] взято
специальное несимметричное двумодальное распределение, получен-
полученное взвешиванием двух нормальных распределений. В этой работе
проверена робастность различных двух выборочных критериев для
проверки различия средних. У Дональдсона [Donaldson, 1966] исполь-
использованы экспоненциальное и логнормальное распределения для анализа
чувствительности ^-критерия, когда он применялся к характеристикам
обслуживания. В [Andrews et al., 1972, p. 56 — 57, 60] работает от-
отношение х/у (где х — стандартизованная нормальная случайная ве-
величина, а у — положителен и независим от х) для получения несколь-
нескольких типов симметричных распределений с удлиненными «хвостами»
(см. также [Rogers, Tukey, 1972]). Дополнительную библиографию
по изучению влияния ненормальности на различные статистические
процедуры с помощью метода Монте-Карло можно найти в [Scheffe,
1964, р. 345 — 351], [Teichroew, 1965, р. 35] и в первой главе этой
книги. Ясно, что существует только один путь, чтобы удовлетворить
требованию о нормальности распределения, но сколько угодно воз-
возможностей отклониться от этого требования. Мы покажем, как при-
принять решение об определении ненормальности.
Важной характеристикой распределения может быть «усечение»,
когда случайная величина не может принять значение, меньшее, чем
заданная константа. Гамма-распределения, например, не могут дать
значение меньше нуля. Это свойство нужно в некоторых моделях,
например в моделях массового обслуживания, где время ожидания,
которое подлежит изучению, не может быть отрицательным. След-
Следствием усечения распределения будет то, что даже малая выборка из
наихудшей генеральной совокупности не сможет иметь выборочное
среднее, меньшее, чем (нижняя) точка усечения. Вполне возможно, что
это увеличивает вероятность Р (ПВ). В других моделях, где изучается
прибыль, переменная не усечена и может изменяться в пределах от—оо
до+ сю. Поэтому мы решили использовать в качестве фактора в экспе-
экспериментах Монте-Карло усеченность или неусеченность распределений.
Вторая важная характеристика — это асимметричность и хвосты
распределений. Мы рассмотрим очень несимметричные распределения
с поднятыми хвостами и сравним их с симметричным или почти сим-
симметричным распределением, имеющим хвосты, более близкие к нор-
нормальным. Приближенной мерой приподнятости хвостов распределения
служит эксцесс у, определяемый следующим образом:
Y = о-4 Е [(х - ц)Ч - 3. C)
272
Если у > 0, то хвосты имеют тенденцию к большему подъему, чем
хвосты нормального распределения (см., например, [Scheffe, 1964,
р. 332]). (В [Kendal], Stuart, 1963, p. 86] отмечено, что эксцесс— это
лишь приближенная мера для хвостов распределения.)
Комбинируя оба названных фактора, мы решили использовать
распределения, приводимые в табл. 1, которую затем обсудим более
подробно.
Таблица 1
Типы распределений, используемых для определения ненормальности
Усеченные
Неусеченные
Асимметричные и имею-
имеющие поднятые хвосты
(Почти) симметричные
с хвостами, имеющими
малый подъем
Экспоненциальное
Эрланга с параметром
4
Взвешенная разность двух
случайных величии с экс-
экспоненциальным распределе-
распределением: хг—0,1 х2
Сумма разностей между
случайными величинами с
экспоненциальным распреде-
распределением: (*! — Х2)-\-(Х3 — ДС4)
Распределение Эрланга и экспоненциальное распределение — это
специальные случаи гамма-распределения. Гамма-распределение имеет
функцию плотности
/(*)
Г(Р)
= 0
ХР-1е-Ьх для Х>0,
для
моментом &-го порядка, определяемым следующим образом:
так что
E{x) = f и var (*)=-?
D)
E)
F)
(см. [Fisz, 1967, р. 152 — 153]). Легко показать, что в этом случае эк-
эксцесс равен 6/р. Экспоненциальное распределение получается путем
подстановки р = 1 в D). Это распределение имеет максимальную асим-
асимметрию и эксцесс, равный шести. Распределение Эрланга — это се-
семейство распределений, которые получаются, если числа р в D) —
целые числа. С ростом р распределение Эрланга приближается к нор-
нормальному распределению, что показано в [Mood, Graybill, 1963,
p. 127]. Мы решили взять р = 4, что соответствует плотности распре-
распределения, приведенной на рис. 34. Это распределение близко к симмет-
симметричному и его эксцесс равен 1,5, т. е. по сравнению с экспоненциаль-
273
ным распределением его эксцесс значительно меньше и оно лучше сог-
согласуется с нормальным. Генерирование этого распределения на ЭВМ
осуществляется просто, поскольку мы складываем четыре независимые
случайные величины, подчиняющиеся экспоненциальному распре-
распределению с параметром 6. Третий тип функции распределения в табл. 1 —
это асимметричное распределение с поднятыми хвостами, такими же,
как у экспоненциального распределения, но без усечения. Мы взяли
такую случайную величину:
х = хг — 0,1дг2,
G)
где хх и х2 — независимые случайные величины, имеющие экспонен-
экспоненциальное распределение с общим параметром 6. Можно показать, что
плотность распределения случайной величины х есть:
f(x) = 10/11 b ехр A0 bx) для х < 0,
/ (x) = 10/11 Ь ехр (—bx) для л: > 0.
(8)
Эта функция приведена на рис. 35. Если х положительно, то площадь
под кривой плотности распределения составит 10/11 площади под кри-
кривой плотности для слу-
f(x) чайной величины с экспо-
экспоненциальным распределе-
распределением, имеющим параметр
Ь. Только 1/11 площади
расположена левее точки
х = 0. Очевидно, что х
имеет очень несимметрич-
несимметричное распределение и мож-
Р=4 но показать, что его эк-
эксцесс близок к эксцессу
экспоненциального распределения случайной величины (т. е. -у—6),
но ее значения могут изменяться в пределах от— оо до-)- оо. Распреде-
Распределением четвертого типа в табл. 1 служат симметричное распределение с
менее поднятыми хвостами и без усечения. Мы взяли такую случайную
величину:
Рис. 34. Распределение Эрлапга с параметром
4
Х2)
Х8) —
(9)
где xt (i = 1, ..., 4) — независимые случайные величины с экспонен-
экспоненциальным распределением, имеющие общий параметр Ь. Легко заме-
заметить, что функция плотности распределения х в (9) симметрична. Мы
определили, что его эксцесс равен 1,5, т. е. точно совпадает с эксцес-
эксцессом распределения Эрланга с р = 4, Видно, что математическое ожи-
ожидание любого из четырех типов распределений можно легко изменить
путем добавления константы. Эта константа не влияет на дисперсию,
асимметрию или эксцесс. Отметим, что в нашем эксперименте все к
совокупностей в одной определенной комбинации факторов обладают
274
распределением одного типа (например, распределением Эрланга). Ви-
Видимо, интересно исследовать случаи, когда некоторые совокупности
имеют экспоненциальные распределения, а другие имеют распреде-
распределения Эрланга. При нашем подходе, однако, можно более эффективно
идентифицировать влияние усечения.
2. Неоднородность дисперсий. Рассмотрим влияние дисперсий на
вероятность того, что наблюдаемое значение из некоторой худшей
совокупности больше, чем наблюдаемое значение из наилучшей сово-
совокупности. Если мы используем аппроксимацию с помощью нормаль-
нормального распределения для k распределений, то эта вероятность опре-
определится следующим образом:
A0)
где индекс (/) соответствует/-Й наилучшей совокупности иг — стандар-
стандартизованная нормальная случайная величина. Так, вероятность не-
неправильного выбора увеличи-
увеличивается, если уменьшается раз-
разность |л№) — \i(j) (или увеличи-
увеличиваются дисперсии afk) и erf/)).
Если это обобщить на распре-
распределения любого типа, то можно
заключить, что вероятность
неправильного выбора растет,
если средние совокупностей
незначительно отличаются друг
от друга или если наблюдения
\ Экспоненциально
Рис. 35. Функция плотности для Xi —
0,1 Х2, когда Xi и Х2 распределены
экспоненциально
подвержены сильным колеба-
колебаниям. Мы позже вернемся к
вопросу о соотношении средних. Отметим, что мы ограничим наше
внимание наиболее неблагоприятным соотношением средних, кото-
которое было определено в V.B.2 следующим образом:
= M-(ft) —
(И)
Из A1) следует, что самая опасная из худших совокупностей та, ко-
которая имеет наибольшую дисперсию max о2 (/) (см. также рис. 36).
!</<? 1
</<- 1
Мы решили сравнить дисперсию наилучшей совокупности (a\k))
с дисперсией самой опасной из худших совокупностей (max afj)).
Один аспект этого сравнения — узнать, будет ли дисперсия afk) боль-
больше или меньше max а,2,-). Мы брали значения из табл. 22.
Другой аспект—будут ли дисперсии других (k — 2) худших со-
совокупностей равными или различными. Поэтому мы изучали два соот-
соотношения дисперсий худших совокупностей. Это
ft = ... = cxfA_2) = aBA_,) и
275
Таблица '2.
Стандартное отклонение наилучшей совокупности (ff(fc)),
деленное на стандартное отклонение худшей совокупности,
наиболее опасной при самом неблагоприятном соотношении (max a(J-))
a(fe)/max ow«l
o(fc)/maxo(/)=?l
o(fe)/max а(/)<1
4/5
1/5
a(fe)/max а(Л>1
5/4
5
В последнем случае стандартные отклонения растут линейно:
A2)
и при этом
= 0,25 О(ь_|
A3)
Что касается литературы, то Дональдсон [Donaldson, 1966, р. 15]
взял соотношение а\ = \if (i = 1, ..., к) — но в нашем эксперименте
все худшие совокупности имеют равные средние, — а Бокс [Box,
Рис. 36. Влияние дясперсий худших совокупно-
совокупностей
1954а и 1954b], как описано в [Scheffe, 1964, р. 354 — 358], исполь-
использовал соотношение max o^/minof (i = 1, ..., k), равное 3 или 7 (все
дисперсии различные или все, кроме одной, одинаковые).
Суммируя описанное, неоднородность дисперсий можно понимать
следующим образом:
дисперсия наилучшей совокупности меньше или больше, чем дис-
дисперсия самой опасной из худших совокупностей;
эти две дисперсии почти равны или существенно различны;
соотношение дисперсий худших совокупностей (все равны или все
различны).
3. Число совокупностей. Число совокупностей (k), надо думать, —
важный фактор. Если k мало, то даже при случайном выборе совокупно-
совокупностей есть высокая вероятность (\lk) того, что выбор будет правильным.
У Бехгофера и др. [Bechhofer et al., 1968, p. 349] взято k в диапазоне
276
от 2 до 25 в их экспериментах по методу Монте-Карло. Большие зна-
значения k требуют много машинного времени, поскольку число наблю-
наблюдений на одном шаге пропорционально k (берется одно наблюдение из
каждой генеральной совокупности) и число шагов тоже растет с ро-
ростом k, как и число конкурирующих совокупностей. Поэтому мы ре-
решили рассмотреть максимальное число—семь генеральных совокуп-
совокупностей. Минимальное значение k взято три (а не два, поскольку в таком
случае не нужны никакие множественные ранжирования).
4. Соотношение средних и коэффициент б*. Мы решили изучить
только наименее благоприятную ситуацию для средних, определяемую
МОИ
У-[к-П
Рис. 37. Расстояние 6 = [х^)— Ц
распределений
и размах
формулой A1). Мы предполагали, что для соотношения \i(k) —
— ц,(б_1) > б* процедура дает Р (ПВ) не менее, чем для соотношения
()
= б*
(
и (или) для jX(/')< Щь-и (/' = 1. ••-, k — 2).
Ц—О < ^* метод не позволяет получить пра-
праM() — Rft-n
Для случая (() Ц(О у р
вильного выбора. (В последующих экспериментах можно будет взять
другие соотношения средних, например, их равенство для исследо-
исследования эффекта объема выборки.)
Мы можем изучить наименее благоприятную ситуацию для разных
значений б = (х(А) — Rft-n = б*. Средние совокупностей могут
быть так близки друг другу, что существует большая вероятность то-
того, что наблюдения из наилучшей совокупности окажутся хуже, чем
наблюдения из худшей. Велико или мало б = б*, это зависит от раз-
размаха наблюдений в совокупности (см. рис. 37). Поэтому мы должны
соотносить б и размах наблюдений.
Бехгофером и др. [Bechhofer et al., 1968, p. 349, 365] изучены of =
= 1 и б = 0,15 или б = 0,20. Поскольку в этой работе использова-
277
ны главным образом нормальные распределения с б = 0,20 (и а2 —
= 1), мы применили формулу A0). Это позволило найти, что 44% на-
наблюдений из худшей совокупности больше наблюдений из лучшей со-
совокупности:
Р (*(„>*(*,) = Р {z > 0,20/1/2) = 0,44. A4)
Поэтому мы решили взять в качестве малых значений б = б*:
б=6*=0,20
в качестве больших значений б мы берем
5 = 5*:= 1,25
A6)
что соответствует 19%' вместо 44% в формуле A4). 14 и 19% —это
грубые оценки (они основаны на нормальности распределения). Так
или иначе большое значение «относительного» расстояния по сравне-
сравнению с 6, соответствующей среднему стандартному отклонению {с7№) +
+ 0(ь_1)}/2, примерно в шесть раз превышает его малое значение.
5. Гарантированная вероятность Р*. Требование к вероятности
Р* в A) — еще один фактор наряду с б = б*. У Бехгофера и др.
[Bechhofer et al., 1968, p. 349,
365] P
Таблица 3
Значения Р* в экспериментах
по методу Монте-Карло по работе
[Bechhofer et al., 1968]
Основные экспери-
эксперименты
0,35 @,05) 0,85
0,89 @,01) 0,99
Дополнительные
эксперименты
0,40 @,05) 0,85
0,991 @,001H,999
365] вероятность Р* измени^
лась, как показано в табл. 3.
В наших экспериментах в ка-
качестве низкого значения бра-
бралось Р* = 0,35 (которое выше,
чем \lk). В качестве самого
высокого значения мы взяли
Р* = 0,99. Более высокие значе-
значения потребовали бы очень боль-
большого числа наблюдений, а это в
свою очередь повлекло бы боль-
большие затраты машинного времени.
Как и Бехгофер и др. [Bechhofer
et al., 1968], мы рассмотрим Р* с числом уровней больше двух. По
мере уменьшения Р* в методе Бехгофера — Блюменталя требуется
меньшее число наблюдений. (Статистика для останова метода, zmt
сама по себе ие зависит от Р*, но отбор наблюдений прекращается, как
только выполнится неравенство гт < A — Р*IР*.) Теперь пред-
предположим, что мы решили испытать метод при Р* = 0,99 и начали
генерировать наблюдения. Тогда любой уровень Р*, меньший, чем
0,99, можно проверить за то же самое время, поскольку такой уровень
требует только части наблюдений, потребных для Р* = 0,99. Хотя
рассмотрение большего числа' уровней Р*, меньших, чем 0,99, не тре-
278
бует дополнительных наблюдений, нужны некоторые дополнительные
вычисления. Мы готовы заплатить за дополнительную информацию
некоторым увеличением счета. Более важно то, что отклики для раз-
различных уровней Р* будут зависимы. Для этих откликов частично ис-
используются те же наблюдения. Для близких уровней Р* используется
больше общих наблюдений, и поэтому отклики коррелированы силь-
сильнее. (Можно положить, что эта корреляция положительна.) Это оз-
означает, что наш эксперимент дает многомерный отклик.
Кроме фактора/3*, все факторы в эксперименте взяты на минималь-
минимальном числе уровней, т. е. на двух уровнях, для того, чтобы ограничить
число комбинаций уровней факторов. Семь двухуровневых факторов
приведены ниже.
1. Ненормальность: неусеченность или усеченность распределений.
2. Ненормальность: симметричные распределения с хвостами, близ-
близкими к хвостам нормального распределения, либо асимметричные
распределения с поднятыми хвостами.
3. Неоднородность дисперсий: отношение o(ft)/max au) меньше
единицы или больше.
4. Неоднородность дисперсий: отношение cr(ft)/max au) близко
к единице или значительно отличается от единицы.
5. Неоднородность дисперсий: все дисперсии сгB;) равны или все
различны.
6. Число совокупностей велико (k = 7) или мало (k = 3).
7. Разность между наилучшим средним и худшим средним: б =
= б* равна 1,25 {cr(ft) + сг№ _ х)}12 либо равна 1,25 {сг№) + °чь-1)}/2.
Теперь рассмотрим, как эти семь факторов, взятые вместе, задают
совокупность. Факторы 1 и 2 определяют тип распределения, используе-
используемый в экспериментах по методу Монте-Карло. Эти типы распределений
сведены в табл. 1 и имеют один независимый параметр, т. е. параметр
экспоненты Ъ. Факторы 3, 4 и 5 (совместно с фактором 6) указывают
относительные дисперсии, следуя табл. 2 и уравнениям A2) и A3).
Возьмем
max'(!(,) = 1 A7)
при всех фиксированных дисперсиях. Задание дисперсий приво-
приводит к определенным значениям экспоненциального параметра bt
(i = 1, ..., k) (ср. с F)). Эти значения bt (вместе с фиксированными
значениями параметра р) приводят к определенным значениям для
средних распределений в табл. 1. Эти значения противоречат соотно-
соотношению, определяемому седьмым фактором. Если мы положим
1*0, = 0 (i = 1, ..., k - 1), A8)
то седьмой фактор определяет
= б*, A9)
где б* следует из A5) и A6). Противоречие между средними, которые
следуют величинам р и Ъь и средними из A8) и A9) можно легко раз-
279
роиигп. добаомением подходящих констант at (i — l,...,k) к каждому
наблюдению из t-й совокупности. Эти константы не влияют на диспер»
сии, асимметрию и хвосты распределений, а только сдвигают распре-
распределения относительно исходных.
VI.4. ПЛАН ЭКСПЕРИМЕНТА
Даже если мы возьмем семь факторов из VI.3 только на двух уров-
уровнях, то все равно получим очень много комбинаций уровней всех фак-
факторов 27 = 128. Как мы установили в главе IV, можно допустить,
что эти семь факторов не имеют значимых взаимодействий, и поэтому
оценивать главные эффекты по плану 2'п4, т. е. используя только восемь
комбинаций. Мы не склонны допускать заранее, что все двухфакторные
взаимодействия равны нулю. Поэтому мы решили остановиться на
плане 2Jv3. При использовании этих шестнадцати комбинаций полу-
полученные оценки главных эффектов не смещаются возможными двухфак-
торными взаимодействиями и оценками некоторых линейных комбина-
комбинаций двухфакторных взаимодействий. Этот последний класс оценок
поможет нам проверить важность двухфакторных взаимодействий.
Возможны несколько планов типа 2|у3, каждый из которых имеет
свою схему смешивания, или структуру совместных эффектов. Таким
образом, был предложен план типа 2|у3 (см. B0) ниже), который обес-
обеспечивает несмешанность всех двухфакторных взаимодействий, включа-
включающих только четыре различных фактора (например, факторы 1, 2,
3 и 4). (Двухфакторные взаимодействия, включающие пять или
больше факторов, не могут быть несмешанными.) Мы предположим,
что первые четыре фактора, приведенные в конце VI.3, могут быть
наиболее важными, и поэтому мы решили, что двухфакторные взаимо-
взаимодействия, включающие только эти четыре фактора, не должны быть
смешаны друг с другом. Эту схему смешивания для двухфакторных
взаимодействий можно реализовать, если взять для плана такие гене-
генерирующие соотношения:
If = ll3, "б = 124, ~1 = 24. B0)
Эти генерирующие соотношения дают следующий определяющий конт» ¦
раст:
7 = 1235 = 1246 = 234~f = 3~45б" = 1457* = 1367 = 2567. B1
Этот определяющий контраст показывает, что на самом деле главны!
эффекты не смешаны с двухфакторными взаимодействиями. (Они
смешаны с трехфакторными взаимодействиями.) Двухфакторные вза*
имодействия смешаны следующим образом:
12 = 35 = 46;Тз = 25 = 67; 14 = 26 = 57; 23 = Тб = 47;
24=1б = 37;34 = 27 = 56; 17 = 45= 36. B2)
280
Схема смешивания B2) показывает, что действительно нет двухфак-
торных взаимодействий, включающих только факторы 1, 2, 3 и 4, сме-
смешанных друг с другом. Следовательно, если только первые четыре фак-
фактора имеют значимые взаимодействия, то, как следует из первых шести
равенств B2), эти взаимодействия можно оценить и они не будут сме-
смешаны друг с другом. Если, однако, факторы 5, 6 и 7 также имеют двух-
факторные взаимодействия, то они будут смещать результаты. Если
нам не повезет, то смешанные двухфакторные взаимодействия могут
даже скомпенсировать друг друга. При этом можно ошибочно решить,
что двухфакторных взаимодействий не существует.
Таблица 4
Комбина-
Комбинация
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
у
1
+
—.
.
—
—
у
2
+
1
—.
—
-)-
_]_
—
План
у
3
+
¦
—
—
_]_
_j_
[
—
07 —3
1 IV
У
4
+
[
_]_
_]_
-\-
-)-
_J_
1
—.
_
—.
—
У
5=123
+
—.
—
_I_
_J_
—
v
6= 124
+
—
|
_
_J_
1
—
v
7 = 234
+
1
—
|
[
_j_
_|_
—•
Генерирующие соотношения'B0) соответствуют плану, приведенному
в табл. 4. Для того чтобы определить план эксперимента в исходных
факторах, мы свяжем факторы 1 —7 с факторами из раздела VI.3 в том
порядке, в котором они записаны, т. е. фактор 1 — это «усечение»,
фактор 2 — симметрия и т. д. Затем мы свяжем уровни + и — факто-
факторов в табл. 4 с двумя уровнями факторов VI.3 случайным образом.
Этот случайный порядок был достигнут с помощью таблицы случайных
чисел и сравнением этих чисел с 1/2. Результаты этой процедуры
показаны в табл. 5. Совмещение табл. 4 и 5 дает план в исходных
факторах, приведенный в табл. 6, где xt (i = 1, ..., 4) обозна-
обозначают неизвестные случайные величины, имеющие экспоненциаль-
экспоненциальное распределение с параметром bt — Ь. В качестве примера
рассмотрим комбинацию 1 в табл. 6. Факторы 1 и 2 находятся на
уровне + в табл. 4. Следовательно, из табл. 5 мы должны взять
усеченное, асимметричное распределение с поднятыми хвостами.
В табл. 1 мы видим, что это распределение—экспоненциальное рас-
распределение случайной величины хх. Фактор 6 находится на уровне
га 1
Таблица 5
Случайная связь между уровнями + и — и двумя уровнями
исходных семи факторов
Фактер
Урввень—
Уровень
1. Усечение
2. Симметрия и хвосты
3. а(А)<тах о(Д
4. а,м~
с. <JA)— а(&_ |(
6. Число генеральных
совокупностей (k)
7. Расстояние 6 = 6*
Неусеченное
Симметричное и близкое
к нормальному
a(fe)<max a(/)
Усеченное
Асимметричное с подня-
поднятыми хвостами
аA)= •••=
План 2 IV
Таблица 6
в исходных факторах (х •— независимая случайная величина
с экспоненциальным распределением)
Комби-
Комбинация
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Распределение
Хг
Х\—0,1х*
Хх-\- Хаг\- хз -(- Xt
Х1—Х$-\-Хз—Xi
Хг
Хг—0,1лс2
Х\-\-Х^-\-Х^-\-Х^
Х\ **2~1 **3 Х^
X!
*!—0,U2
Х1-\-Х2-\-Хз-{-Х4,
Хх—Лг+*3—-*4
Х1
хг~ 0,1ха
JC1+JC2+JC3+JC4
k
3
7
7
3
3
7
7
3
7
3
3
7
7
3
3
7
5
5
5
5
1/5
1/5
1/5
1/5
5/4
5/4
5/4
5/4
4/5
4/5
4/5
4/5
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
1
......
1/4
1
1
1/4
1
0,85
0,85
1
0,85
1
1
0,85
1
1/4
1/4
1
1 1 1
1 1 1
0,70 0,55 0,40
0,70 0,55 0,40
0,70 0,55 0,40
0,70 0,55 0,40
1 1 1
1 1 1
a(i)
1
1
0,25
0,25
0,25
0,25
1
1
€ 7
to a!
1,25
1,25
0,20
0,20
0,20
0,20
1,25
1,25
0,20
0,20
1,25
1,25
1,25
1,25
0,20
0,20
4- в табл. 4 так, что k = 3. Факторы 3 и 4 находятся на уровнях
4-по табл. 4. Совмещение табл.5 и 2 приводит к равенству о3/тах сг(;)=5.
Поскольку в A7) мы взяли max o(j) = 1, мы знаем, что о(8) = 5.
Поскольку фактор 5 находится на уровне +, мы используем A3), чтобы
получить сгA) = 0,25. Наконец, фактор 7 находится на уровне +, по-
поэтому б ( = 6*) равно б = 1,25 {а(к) + о^.ц }/2.
VI.5. ЧИСЛО ПОВТОРНЫХ РЕАЛИЗАЦИЙ
Как мы знаем, эксперименты по методу Монте-Карло с методом
Бехгофера — Блюменталя заключаются в следующем. С помощью
вычислительной машины генерируем случайные числа xs(i = I, ...,k),
(s = 1,2, ...). К этим случайным числам мы применяем ММР. ММР
дает возможность определить, когда прекратить отбор наблюдений.
Затем ММР выбирает в качестве наилучшей совокупности ту, у ко-
которой наибольшее выборочное среднее. В эксперименте по методу Мон-
Монте-Карло мы действительно знаем, какая совокупность имеет наиболь-
наибольшее среднее. Поэтому мы можем проверить, дает ли ММР правильный
выбор. Если метод приводит к правильному выбору, то мы обозначим
это единицей, противоположный случай мы отметим нулем. Предпо-
Предположим, что мы повторяем п раз ММР к наблюдениям, которые гене-
генерируются ЭВМ. После п повторений мы оценим вероятность правиль-
правильного выбора Р (ПВ) путем отбора этих случаев в п повторных реали-
реализациях. Если ММР гарантирует требование к вероятности правиль-
правильного выбора A), то такая отобранная часть не должна быть значитель-
значительно меньше, чем Р*. Эти вычисления можно проделать для каждой из
шестнадцати комбинаций уровней факторов. Теперь введем некоторые
другие обозначения и определим, каково число повторений п на каж-
каждую комбинацию уровней факторов.
Для простоты ограничим в этом параграфе наше внимание одной
комбинацией факторов. Определим:
1)т = 0, если ММР обеспечивает неправильный выбор в г по-
повторных реализациях,
1)г = 1, если ММР обеспечивает правильный выбор в г повтор-
повторных реализациях (г = 1, ..., п), B3)
где vr имеет математическое ожидание
Е (*г) = Р (*г = 1) = ц„. B4)
Если ММР гарантирует A), то
|*„ > Р*- B5)
Оценим \iv no n повторным реализациям:
Ао= 2 Ч/ч. B6)
Допуская независимость повторных реализаций (мы далее возвра-
возвратимся к этому допущению), можно считать, что vr имеют биномиальное
распределение и
var (?„) = |х„ A — |л„)/п. B7)
Мы хотим взять столько повторных реализаций, чтобы вероятность
ошибки отвергнуть метод множественного ранжирования была мала.
28
Если мы отвергнем ММР, то в дальнейших Экспериментах ой не будет
участвовать. Другими словами, нулевая гипотеза в нашем случае —
это то, что ММР работоспособен, т. е.
Но : V» = „Ш, > Р*, B8)
где нижний индекс 0 соответствует нулевой гипотезе. Мы хотим, что-
чтобы ошибка 1-го рода или а-ошибка была мала. (См. по, поводу типов
ошибок главу V.) Гипотеза Но отвергается, если оценка |m0 находится
ниже нижнего конца доверительного интервала. Следовательно,
— р
B9)
где мы аппроксимировали биномиальное распределение нормальным
распределением стандартизованной случайной величины г. Определим
za как верхнюю а%-ную точку, т. е.
Р (z > z«) = а, C0)
или, в силу симметрии нормального распределения,
P(z< — 2а) = а. C1)
Следовательно, B9) и C1) дают
oMl - o|*D)/(o|*D - vLf. C2)
В условиях нулевой гипотезы Но величина ^г0 может превзойти Р*
так, что
о1*0 - vL > Р* - vL( >0) для о1х„ > Р* C3)
и
о^0 > Р*> 0,5, C4)
где в последнем соотношении мы допускаем, что интересующие нас
уровни Р* не меньше чем 50%. Следовательно, ошибка 1-го рода не
превосходит а, если в C2) мы заменим 0\lv на Р*, т. е.
п = B<*J Р* A — Р*)/(Р* — vLf. C5)
Из C5) следует, что если взять малое значение для vl, to это приведет
к малому числу повторных реализаций. Однако при такой малой ве-
величине vl гипотеза Но будет редко отвергаться, даже если она не-
284
верна. Рассмотрим ошибку 2-го рода, Или ^-ошибку. Определим аль*
тернативную гипотезу Нх:
Тогда имеем
C7)
По аналогии с C0) определим
Р (z > гЗ) = р. C8)
Из C7) и C8) следует, что
п = И2 iVld A - lV.v)/(vL - rf. C9)
Если мы хотим управлять как а, так и р, то мы должны удовлетворить
как уравнению C5), так и C9). Эти два уравнения дают
vL = (Р* + ^@/A ± с)> D0)
где с обозначает:
Решение уравнения D0), соответствующее знаку минус, дает величину
vL, которая не удовлетворяет неравенству:
i|iB < vL < Р*. D2)
Это неравенство должно быть удовлетворено, чтобы ошибки аир
были меньше 50%. Оставшееся решение для vl следующее:
VL==P* + c&,= l_p#+_?_ D3)
1+с 1+с 1+с
Это решение должно согласовываться с условием D2), так как это
взвешенное среднее величин Р* и 1\х1). Подстановка vL из D3) в C5) или
C9) приводит к желаемому числу повторных реализаций, обеспечи-
обеспечивающих заданные нами ошибки аир (или эквивалентные им 2а и гЗ),
уровень Р*, который нас интересует, и величину 1\iv, альтернативу
\iD, которую мы хотим определить (с вероятностью не меньше 1 — Р).
Очевидно, что эти четыре величины (а, р, Р*, 1^г„) субъективны. Мы
решили принять вероятность ошибочно отвергнуть ММР, равной толь-
только 1%, т. е. а = 0,01 или г« = 2,33, и вероятность ошибочно принять
ММР, равной 10%, т. е. р = 0,1 или гР = 1,26. Мы затем решили изу-
изучить эти комбинации величин Р* и^„^Р*), которые данывтабл.7.
285
Таблица 7
Число повторных реализаций (я) для различных значений Р*
(которое должно быть гарантировано) и |ЦВ (действительная
вероятность) при а=0,01 и Р=0,1
100 Р*
100 1(г„
100(Р*-хц„)
п
50
42
8
499
60
55
5
1251
70
65
5
1114
75
70
5
1007
80
75
5
873
85
80
5
714
90
85
5
528
95
92,5
2,5
1128
97,5
96,0
1,5
1658
99
97,5
1,5
816
99,5
98,5
1,0
1008
99,9
99,5
0,4
1651
Эта таблица показывает, как выглядят данные комбинации Р*
и 1^0, где 1ци приближается к Р* по мере роста Р*. Видимо, имеет
смысл обнаружить небольшое (по абсолютной величине) различие меж-
между Р* и x\iv, составляющее, например, 0,004, если вероятность Р*
составляет 99,9%, но не тогда, когда она равна, например, 60%. Хотя
выбранные значения а, р, Р* и гц0 субъективны, но так или иначе
они дают некоторое основание для выбора числа повторных реализаций.
Это число п определяет надежность выводов по результатам нашего
эксперимента. Вначале мы решили повторять эксперименты для каж-
каждой комбинации факторов 1000 раз. Поскольку эксперимент требует
много машинного времени, мы решили уменьшить число повторных
реализаций на 20%. Таким образом, было взято 800 повторных реа-
реализаций. Мы видим, что в большинстве экспериментов, выполненных
Бехгофером и др. [Bechhofer et al., 1968, p. 349, 365] также использо-
использовалось 800 повторных реализаций (вероятность Р* при этом изменя-
изменялась в пределах от 0,35 до 0,99) и около 200 повторных реализаций для
дополнительных экспериментов, когда Р* была равна 0,999.
Можно добавить несколько замечаний по поводу вывода о числе
повторных реализаций (см. также [Kleijnen, 1969а, р. 22 — 23]).
1. Мы использовали «.тестовый» подход (проверку гипотез), при ко-
котором ошибки аир фиксированы. Это лучше, чем подход «оценивания»,
при котором мы утверждаем, что с вероятностью, скажем, 90% оце-
оцениваемая величина Р (ПВ) лежит внутри (в 10%-ных пределах) по
отношению к истинной величине Р (ПВ), по которой мы проверяем,
работоспособен ли на самом деле ММР. Подход «оценивания» потребо-
потребовал бы только 90 повторных реализаций для Р* = 0,75 и 30 повтор-
повторных реализаций для Р* = 0,90. Если же ыы хотим оценить вероят-
вероятность неправильного выбора, то нам надо иметь 807 повторных реа-
реализаций для Р* = 0,75 и 2421 — для Р* = 0,90. Таким образом, для
величины, которая представляет интерес, а именно вероятности вер-
верного или неверного выбора, получаются совсем другие результаты
(см. упражнение 4).
2. В нашем выводе мы рассмотрели только одну комбинацию фак-
факторов и определенный уровень вероятности Р*. В действительности в
эксперименте участвуют шестнадцать комбинаций семи факторов, каж-
каждый из которых имеет два уровня, а фактор Р* имеет много уровней.
Нулевая гипотеза могла бы, например, быть определена как "\ьв > Р*
286
для любой комбинации вероятности Р* и семи двухуровневых фак-
факторов. Ошибка а могла бы теперь устанавливаться в эксперименте
(см. V.B.2). Мы не использовали такой подход, когда определяли чис-
число повторных реализаций, но далее мы возвратимся к нему, когда бу-
будем проводить анализ результатов эксперимента.
3. Мы допускали, что все повторные наблюдения независимы.
В действительности, как мы увидим в следующем разделе, повторные
наблюдения для одной определенной комбинации факторов попарно
коррелированы, при этом корреляция отрицательна, т. е.
cov (vr, vr') < 0, если г = 2 г", г' =2г" — 1,
cov (vr, vr') = 0 в других случаях. D 4
Эта корреляция уменьшает дисперсию величины ци до величины,
меньшей, чем следует из выражения B7), поэтому ошибки 1-го и 2 -го
рода будут меньше, чем те, которые были получены выше.
VI.6. МЕТОДЫ ПОНИЖЕНИЯ ДИСПЕРСИИ
Надежность результатов экспериментов по методу Монте-Карло
можно увеличить, применяя методы понижения дисперсии. В главе III
мы обсудили несколько таких методов. К сожалению, большинство
методов достаточно сложно. Для обычного применения подходят ме-
методы, использующие «общие случайные числа» и «дополнительные ве-
величины».
Метод, использующий «общие случайные числа», заключается в том,
что для r-й повторной реализации в каждой комбинации факторов ис-
используется одна и та же последовательность случайных чисел. (Дей-
(Действительно, длины последовательностей случайных чисел меняются
для разных комбинаций факторов, поэтому мы используем максималь-
максимально возможное количество общих случайных чисел.) Интуитивно ясно,
что в этом случае отклики для различных комбинаций факторов под-
подвержены одинаковым случайным колебаниям, так что эффекты фак-
факторов могут быть определены точнее. В приложении 1 дан формаль-
формальный анализ этих соображений. Этот анализ показывает, что главный
эффект, например а,- двухуровневого фактора/, оценивается следующим
образом:
«j=S хчУ*1* (/=!.-. 7), D5)
где xtj = — 1, если /-и фактор находится на уровне «минус»
в i-й комбинации факторов (< = 1, ..., 16);
хц = + 1, если /-й фактор находится на уровне «плюс» D6)
в (-й комбинации факторов,
определяется по табл. 4), a yt обозначает отклик, т. е. оцениваемую
часть цп в B6) для г-й комбинации факторов. (Мы пользуемся симво-
символами х и у в D5), поскольку эти обозначения установились в планиро-
287
и.шпп >ыiii-|iiiiviDii,i и (К'грсл'пишюм анализе; символ xtj не надо пу-
Ttii'ii с симиолом xis --• переменными, к которым применяется ММР.)
Тогда дисперсия оценки а7- будет равна:
var(a;)=-Lcr*(l-p), D7)
где р обозначает коэффициент корреляции между откликами yt и
уг{1ф1') и р > 0, поскольку в r-й реализации для r-й комбинации
и комбинации V используются одни и те же общие случайные числа.
При выводе D7) допускалось, что дисперсии и ковариации наблюде-
наблюдений yt постоянны для всех комбинаций факторов. (Это предположение
не обязательно используется ниже в этой главе.)
Метод, применяющий дополняющие величины, заключается в том,
что в повторных реализациях 1-й и 2-й, 3-й и 4-й и т. д., или в общем
случае в г — 2 г" и г'=2 г" — 1 (г" = 1, ..., я/2) пользуются их допол-
дополняющими случайными величинами. Так, первая реализация, например,
использует случайные числа гх, г2, ..., а ее повторение — A—гг),
A — г2), .... (Число случайных чисел на повтор случайно, как следует
из правила останова последовательной процедуры множественного
ранжирования; соответственно последовательности случайных чисел
не имеют постоянной длины.) Случайные числа для одной повторной
реализации должны быть независимы, как независимы наблюдения;
это основная предпосылка ММР и она не нарушается в наших экспе-
экспериментах по методу Монте-Карло. Такая предпосылка выполняется,
когда употребляются дополняющие величины (или общие случайные
числа). Дополняющие величины создают отрицательную корреляцию
между откликами повторных реализаций с номерами г — 2 г" и г' =
= 2 г"—1. Предположим, что в повторной реализации большинство
случайных чисел для лучшей совокупности мало так, что случайные
величины xis, к которым применяется ММР, например, велики. Срав-
Сравним случайные величины, имеющие экспоненциальный закон распре-
распределения, которые генерируются следующим образом:
х = — Е(хIп г. D8)
Большие значения из лучшей совокупности приводят к правильному
выбору, т. е. у = 1. В повторной реализации, где берутся дополняющие
величины, большинство больших случайных величин будет генери-
генерироваться для лучшей совокупности. (Здесь нет проблемы синхрони-
синхронизации, поскольку ММР требует, чтобы из каждой генеральной совокуп-
совокупности на каждом шаге было взято одно наблюдение.) В результате
большинство наблюдений с низкими значениями будет отбираться из
лучшей совокупности и это приведет к неверному выбору, т. е. у = 0.
Таким образом, можно ожидать, что отклики в двух таких реализа-
реализациях будут отрицательно коррелированы. (Отрицательная корреляция
на самом деле обнаружена в результатах эксперимента3. Она понижает
дисперсию среднего отклика на одну^коэдбинадию факторов4.)
Из всего этого следует, что мы можем выбирать из трех методов:
1 — общие случайные числа;
2 — дополняющие величины;
3 — совместное применение методов 1 и 2.
Как мы объясняли в главе III, последний метод C) не всегда дает
наилучшее понижение дисперсии. Мы решили не применять метод 1
или метод 3, поскольку они усложняют статистический анализ эк-
эксперимента. Эти два метода приводят к зависимости (средних) откликов
для шестнадцати комбинаций факторов. В методе 3 нет проблем такого
рода, поскольку мы имеем дело со средними откликами двух дополня-
дополняющих реализаций, т. е.
г'-ц}/2 D9)
(г"=1,..., 400) (г = 1,..., 16).
Это обеспечивает я/2 = 400 независимых наблюдений на одну комби-
комбинацию факторов. Средний отклик на комбинацию факторов, т. е. оце-
оцениваемая часть правильных выборов дается следующим выражением:
800 400 _
3»/= S «!г/800= 2 ^v/400. E0)
Величина Vir' — независимая несмещенная оценка стандартного
отклонения отклика yit т. е.
E1)
где
•N 400 _
var(»<r-)= 2 (»ir—3>i)V399. E2)
r" = i
В экспериментах Монте-Карло мы регистрируем yt, оцениваемую
часть для каждой г-й комбинации факторов, и стандартное откло-
отклонение st. Эти результаты получаются для 22 уровней вероятности Р*у
т. е. для 0,35 @,05) 0,85; 0,89 @,01) 0,99.
VI.7. РЕЗУЛЬТАТЫ ЭКСПЕРИМЕНТА
Как было упомянуто в конце предыдущего параграфа, в ММР Бех-
гофера—Блюменталя бралось 800 повторных реализаций для каждой
из 16 комбинаций семи двухуровневых факторов (план эксперимента
2iV3 приведен в табл. 4) для каждого из 22 уровней вероятности Р*
(см. табл. 8). Для каждой из этих шестнадцати комбинаций были ис-
использованы независимые случайные числа, поэтому отклики уп и
Уп' независимы для i Ф i' (I Ф V или / = /'), где t, i' = 1, ..., 16
и /, /' = 1, ..., 22. План 2iV3 позволяет оценить общее среднее (р0),
семь главных эффектов (plf ..., р7) для семи двухуровневых факторов,
названных в конце параграфа VI.3 и 7 сумм двухфакторных взаимо-
дж. Клейнен
289
Таблица 8
План и результаты эксперимента
Комбинации
факторов
1
16
Уровни Р*
1 | 22
@,35) ¦¦• @,99)
У1,1 ••• У1.22
У1в,1 ' '• У\Ъ,22
действий (Р12, ..., Рв7), смешанных по трое, как показано в B2). Как
и в главе IV, мы можем обозначить общее среднее, 7 главных эффектов
и 7 сумм троек взаимодействий символами от Yi до у1ь. Эти эффекты
можно оценить для каждого уровня Р*, поскольку отклики получа-
получаются за пренебрежимо малое машинное время для всех уровней ве-
вероятности Р*, меньших, чем самый высокий уровень. Двадцати двум
уровням Р* соответствуют, од-
однако, зависимые наблюдения
для одной комбинации факторов
в плане 2{у3, т.е. уп и )iir за-
зависимы.
Резюмируя, приведем табл. 8.
c°v (уи, Уи') = 0 для t ф С,
фОмя i = i' E3)
Знак для ковариации в E3) при
i=V априори неизвестен5. (В до-
дополнительных экспериментах, не связанных с исходным экспериментом
этой главы, ковариации в E3) удалось оценить; было найдено, что
они положительны и что они уменьшаются по мере удаления за уровни
Р* в обе стороны). Наряду с 16 независимыми векторами, каждый из
которых состоит из 22 долей наблюдений, зависимо оцениваемых и
происходящих из различных совокупностей, мы получили оценки
стандартных отклонений этих 16 X 22 долей. Оценки этих стандарт-
стандартных отклонений основаны на формуле E1). Наряду с долей правильных
выборов мы получили среднее число стадий, требуемых в ММР для до-
достижения выбора, и оценили стандартные отклонения от этого среднего
числа стадий. Эти данные, однако, еще не анализировались, посколь-
поскольку целью такого первого эксперимента было изучение робастности
ММР, а не его эффективности. Для Р* = 0,99 и всех 16 комбинаций,
если использовался план 27, были изучены два варианта исходного
ММР. В обоих вариантах ММР не использовался до тех пор, пока из
каждой генеральной совокупности не было взято пробное число на-
наблюдений (п0 > 2). Были применены два правила для определения п9
(для более детального знакомства см. [Kleijnen 1969а, р. 10— 13]).
Мы не будем обсуждать эти два варианта.
Ради полноты отметим, что мы употребили мультипликативный
генератор случайных чисел:
где
xi+i = aXi (mod m),
а = 7s,
т = 231 — 1.
E4)
E5)
E6)
Этот генератор был широко опробован Льюисом и др. [Lewis et al.r
1969], где также дана подпрограмма для ассемблера, пригодная для
IBM/360.
290
VI.8. ПРОВЕРКА РОБАСТНОСТИ ММР
Первый шаг в анализе эксперимента—проверка того, гарантирует
ли ММР требование к вероятности в формуле A), т. е. действительно
ли доля правильных выборов несущественно меньше вероятности Р*
для всех уровней и всех комбинаций факторов в плане 2Jv3. Вторым
шагом, обсуждаемым в следующем параграфе, мы займемся, только
если ММР не работает при всех обстоятельствах. На этом шаге мы зай-
займемся исследованием вопроса о том, какие факторы важны, и, следо-
следовательно, сможем объяснить, почему ММР не работает. Мы обычно
наблюдаем, что в большинстве случаев планирования экспериментов
внимание концентрируется на эффектах факторов, которые варьиру-
варьируются в эксперименте, т. е. на «относительных-» значениях откликов
или вариациях откликов, когда изменяются уровни факторов. В нашем
эксперименте, однако, нас прежде всего интересуют «абсолютные»
значения откликов и проверка неравенства Е (у) ^ Р*.
Если не использовать дополняющих величин, то каждая оценивае-
оцениваемая часть у и (i = 1, ..., 16), (/ = 1, ..., 22) должна иметь биномиаль-
биномиальное распределение. Применение дополняющих величин означает, что
отдельные независимые наблюдения у«г" (г" = 1, ..., 400) не имеют
биномиального распределения. (Они могут принимать значения 0, -я-
и 1.) В работе [Scheffe, 1964, р. 335] сделан вывод о том, что для боль-
больших выборок ^-критерий не зависит от вида распределения совокуп-
совокупности. В нашем случае п = 400, поэтому мы решили использовать
t-статистику для проверки того, будет ли доля правильных выборок
не меньшей, чем Р*. Эта статистика имеет вид:
(i = 1,..., 16) (J = 1, ...,22),
где vu — число степеней свободы ^-статистики, т. е.
vn = п — 1 = 399, E8)
поскольку каждое стандартное отклонение Sn оценивается по 400
наблюдениям. Как мы видели в V.B.2, когда используется ошибка
1-го рода а, то даже при выполнении гипотезы:
Но '¦ Е (Уи) ^ P*i Для всех i и всех U E9)
ожидаемое число случаев, когда ММР ошибочно отвергается, равно
а X 16 X 22. Так что, если мы возьмем в E7) 5%-ный уровень зна-
значимости, то можно ожидать, что более чем в 18 случаях мы признаем
значимой долю с низкой оценкой, даже если гипотеза Но в E9) верна.
Вместо задания так называемой ошибки на сравнение, которую мы
взяли равной 5% в E7), мы могли бы предпочесть установление уровня
10* 291
значимости в эксперименте. Недостаток такого пути состоит в том, что
частные проверки, подобные критерию E7), будут иметь низкие ве-
вероятности обнаружения отклонений от нуль-гипотезы. Эту низкую
мощность частных критериев можно возместить не фиксацией значи-
значимости, установленной в эксперименте, а фиксацией уровня ошибки
для семейства частных проверок (т. е. вероятности быть правильными),
которая задается на семействе утверждений. Такое семейство не со-
содержит всех возможных утверждений, а состоит из набора близких по
смыслу утверждений. Как будет видно дальше, мы применяем именно
этот подход в данной главе.
Обозначим ошибки, используемые в частных ^-критериях через ас
(«на сравнение»); мы употребляем одинаковые ас во всех тестах. Пусть
через аЕ обозначен уровень значимости в эксперименте и через а/? —
уровень значимости для семейства частных утверждений, причем каж-
каждое семейство состоит из 22 утверждений на каждую г-ю комбинацию.
Тогда имеем:
1 _ аЕ = Р Гугг > Л* — ?с SU Для всех ' и 1 I Н<^ =
= Р[уи > Р1 — t*csn Для всех ;1#о1 х —
•••х р Ьш > pt — Сс Sw для всех 1' Н°^
= (l-af)*6, ° F0)
где предпоследнее равенство выполняется, поскольку все 16 комбина-
комбинаций факторов обеспечивают независимость откликов (ср. с E3)), а
последнее равенство выполняется, поскольку мы задаем все уровни
ошибок для семейств одинаковыми и равными а/?. Из F0) следует такое
соотношение между уровнями ошибок:
aF = 1 _ A _ аЕУ<*6. F1)
Из неравенства Бонферрони, которое было введено в разделе V.B.3,
следует соотношение между а^ и ас:
ар ^ тас, F2)
где т — число утверждений на семейство.
В нашем эксперименте имеем т = 22, но мы можем также пойти на
улучшение мощности частных тестов, сокращая число уровней вероят-
вероятности Р* до 10 наибольших, например Р* = 0,90 @,01) 0,99, так чтот
становится равным 10. Равенства F1) и F2) приводят к табл. 9 и 10,
где мы фиксировали некоторые разумные значения для аЕ и aF соот-
соответственно. Напомним, что эти «объединенные» ошибки можно сделать
значительно большими, чем традиционные ошибки, например, равные
5%. Мы видим, что наш вывод, использующий независимость откликов
для 16 комбинаций факторов приводит к большим значениям ас (и, сле-
следовательно, к большей мощности) для данного значения ая, чем ис-
использование неравенства Бонферрони:
a?< 16/nac F3)
292
Например, аЕ = 0,20, т = 10 дают ошибку ас = 0,001385, из табл. 9
но по F3) ас = 0,001250.
Чтобы вычислить критические точки, соответствующие различным
ошибкам «на сравнение», мы можем воспользоваться равенством:
= zac
F4)
поскольку E8) показывает, что число степеней свободы для каждого
частного критерия равно 399. Поэтому мы можем обоснованно аппрок-
аппроксимировать ^-распределение нормальным распределением случайной
величины z; za было определено в C0) как верхнее а-значение случайной
величины, имеющей стандартизованное нормальное распределение,
для которой площадь под кривой распределения правее этой точки рав-
равна а%.
Таблица i
Уровни значимости на семейство
и на сравнение при заданных уровнях
значимости для всего эксперимента
0,20
0,10
0,05
аС
= 22
т=10
0,013850
0,006563
0,003201
0,00062955 0
0,00029832
0,00014550
,0013850
0,0006563
0, 0003201
Таблица 10
Уровень ошибки «на сравнение»
при заданных уровнях
ошибок на семейство
aF
0,20
0,10
0,05
m = 22
0,0090909
0,0045455
0,0022727
m=10
0,0200
0,0100
0,0050
Существует много таблиц для величины z; мы использовали работу
[Smirnov, 1965] для того, чтобы получить табл. 11. В этой работе та-
табулировано кумулятивное распределение Ф (z) для различных зна-
значений z 6. Если Ф (z) не совпадает точно с A — ас), то мы берем бли-
ближайшее наибольшее значение Ф (z), так что уровни ошибки в экспе-
эксперименте или на семейство не превосходят аЕ или ар. (Эту аппроксима-
аппроксимацию надо уточнять, если вычисленное значение /-статистики близко
к критическому значению.)
Таблица 11
Критические точки гас для различных значений ав и
0,20
0,10
0,05
т
3
3
3
= 22
,226
,435
,625
т =
2,
3,
3,
= 10
994
214
415
aF
0,20
0,10
0,05
«С
т=22
2,362
2,610
2,838
т
2,
2,
2,
= 10
054
327
576
293
Как мы отмечали в V.B.2, выбор типа уровня ошибки, который
стоит задавать в эксперименте,—это довольно спорный вопрос. По-
Поскольку выбор уровня ошибки «на сравнение» приводит во многих
случаях к ложным результатам, мы ее отвергли. Выбор между уров-
уровнями ошибки в эксперименте или на семейство более труден. Чтобы не
ухудшить мощность критериев, мы рекомендовали подход с заданием
уровня ошибки на семейство гипотез, где под семейством здесь пони-
понимаются все утверждения, относящиеся к одной определенной комбина-
комбинации факторов плана 2\<j3. Кроме типа уровня ошибки, мы должны задать
еще и ее значение. Определение таких значений весьма произвольно.
(Подход теории статистических решений, основанный на функциях
потерь, также произволен, поскольку трудно определить потери в на-
нашем эксперименте.) Обычно в статистике ис пользуют значение ошибки,
равное 5%, хотя берут также и значения 1 0 и 1 %. В случае одновре-
одновременных выводов можно следовать, например, [Dunn, 1964, р. 248]
и использовать большие значения ошибки, скажем 20%. Чтобы дать
возможность читателю выбрать значения для аЕ или aF, мы приводим
результаты для различных значений а?иа?. Мы сами предпочли а^ =
= 0,20 для того, чтобы не ухудшать мощностей частных критериев.
Имея полученные выше критические точки, мы сравним эти точки
со значениями ^-статистики в E7O. Из E7) и E8) следует, что доля
наблюдений значимо низка, если значение ^-статистики меньше (ал-
(алгебраически), чем — z с, где z c берем из табл. 11. Чтобы сэкономить
место, мы не перечисляем всех 16x22 значений ^-статистик, но даем
в табл. 12 наименьшие из них для каждой комбинации факторов и со-
соответствующего уровня Р*. Табл. 11 и 12 допус кают следующие выводы:
Таблица 12
Наименьшее значение ^-статистики и соответствующее
значение Р* для всех 16 комбинаций из плана 2 'у3
Комбинация
факторов
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
т =
'mtn
4,1666
—4,6875
1,3214
14,8686
2,9855
—5,2620
0,5434
4,4871
—6,1965
—2,4492
0,3636
—1,4318
—0,7169
6,6923
—2,4038
—1,9503
= 22
я*
0,99
0,98
0,99
0,50
0,75
0,35
0,98
0,97
0,93
0,80
0,99
0,99
0,98
0,99
0,99
0,35
т =
fmln
4,1666
—4,6875
1,3214
29,7692
3,7763
—3,7261
0,5434
4,4871
—6,1965
—2,3209
0,3636
—1,4318
—0,7169
6,6923
—2,4038
0,3636
= 10
Р*
0,99
0,98
0,99
0,96
0,92
0,97
0,98
0,97
0,93
0,96
0,99
0,99
0,98
0,99
0,99
0,99
294
1) опыты 2, 6, и 9 (определенные в табл. 6) дают значимо низкое
значение долей наблюдений при любых трех значениях аЕ или aF
из табл. 11;
2) в опыте 15 нуль-гипотеза отвергается при т = 10 и aF = 0,10
{и, следовательно, при aF = 0,20) или при т = 22 и aF = 0,20;
3) в опыте 10 нуль-гипотеза отвергается при а^ = 0,20 и яг = 22,
а также при aF = 0,20 и т = 10;
4) во всех остальных опытах нуль-гипотезы не отвергаются при лю-
любых значениях аЕ, aF и т из табл. 11.
Следуя пункту 1, можно заключить, что ММР не работоспособен при
любых обстоятельствах. Следуя пункту 4, мы заключим, что тем не
менее ММР гарантирует требования к вероятности во многих ситуа-
ситуациях.
Раз мы узнали, что ММР не работоспособен при всех обстоятель-
обстоятельствах, мы перейдем к следующему шагу и исследуем факторы, которые
приводят к потере работоспособности ММР. Это будет сделано в сле-
следующем параграфе.
VI.9. ОПРЕДЕЛЕНИЕ ВАЖНЫХ ФАКТОРОВ
Для определения «важных» факторов, т. е. факторов, которые при-
приводят к потере работоспособности ММР, можно рассмотреть несколько
методов. Первый метод использует таблицу сопряженности признаков
2X2 для каждого эффекта. Например, предположим, что в VI.8 мы
отвергли только комбинации 2, 6 и 9. Из табл. 4 следует, что в трех
отвергнутых комбинациях факторов 2 всегда находится на уровне+•
В табл. 13 приведен анализ данных для этого фактора.
Таблица 13
Уровни фактора в сопоставлении с принятием
или отбрасыванием для фактора 2
Уровень
фактора 2
Всего
Факторные комбинации
отвергнутые
соо со
неотвергнутые
5
8
13
Всего
8
8
16
Применив эту таблицу, можно надеяться определить, связан ли
признак «уровень второго фактора» с признаком «отвергнуть» комбина-
комбинацию факторов. (За более общим обсуждением такой «связи» мы отсылаем
читателя к работе [Kendall, Stuart, 1961, p. 536 — 591].) Основным
допущением при проверке независимости или отсутствия «связи» яв-
является то, что все индивиды (здесь все комбинации факторов), принад-
принадлежащие к одной определенной ячейке (из четырех имеющихся ячеек),
имеют одну и ту же вероятность (см. [Kendall, Stuart, 1961, p. 547]).
Но в вышеуказанной таблице комбинации 2 и 6, попадающие в одну
и ту же ячейку, имеют неодинаковую вероятность, поскольку у них
295
различны уровни других факторов (фактор 3 находится на уровне -f-
в комбинации 2 и на уровне — в комбинации 6, см. табл. 4). Поэтому
мы не проанализируем результаты с помощью таблиц сопряженности
признаков.
Второй метод заключается в использовании условных критериев.
Например, дано условие, что три комбинации факторов отвергнуты
так, как это показано в табл. 13. Какова вероятность того, что во всех
трех комбинациях фактор 2 находится на одном и том же уровне
(в табл. 13 на уровне+) при нулевой гипотезе об отсутствии эффекта
фактора 2?
Мы имеем:
Р (фактор 2 находится на уровне + в отвергнутой комбинации | Но) — Р (фак-
(фактор 2 находится на уровне — в отвергнутой комбинации | Яо) = 1/2 F5)
для ортогонального плана8. [Поэтому вероятность трех одинаковых
знаков следует из биномиального распределения с вероятностью «ус-
«успеха», равной 1/2, или
Р C одинаковых знака \Н0) = Р C плюса \ Но) + Р C минуса | Яо) = A/2K +
+ A/2K = 0,25. F6)
Так что даже при гипотезе об отсутствии влияния фактора 2 вероят-
вероятность того, что фактор 2 находится на одном и том же уровне во всех
трех отвергнутых комбинациях все-таки равна 25%. Следовательно,
нулевая гипотеза может быть отвергнута только при ошибке (на срав-
сравнение) а>25%, которая необычно высока. Таким образом, мы за-
заключаем, что для трех отвергнутых комбинаций факторов (а именно 2,
6 и 9) нет чувствительных критериев, которые могут основываться на
F5) и F6). Так, если взглянуть на табл. 14,
Таблица 14
Уровни главных эффектов и двухфакториых взаимодействий
в трех отвергнутых комбинациях
Отвергну-
Отвергнутые комбн-
2
6
9
—>—>—>—>—>—>—>¦
I 2 3 4 5 6 7
+
! ! _1_
+ + + - +
7?=
3~5=
Я
+
Тз=
25=
67
+
7t=
26=
?7
—
lt=
23=
4Т
+
+
И-
24=
37
+
_|_
—
34-
27=
+
—
77=
45 =
3?
-|_
—
то мы заметим очень большую возможность того, что эффекты 2, 6
и 26 неважны, даже тогда, когда они имеют одинаковые знаки во всех
трех отвергнутых] комбинациях. (Двухфакторное взаимодействие 26
смешано со взаимодействиями 14 и 57, но разумно допустить, что если
важны только факторы 2 и 6, то взаимодействия 14 и 57 не существу-
296
ют). В конце раздела 8 мы заключили, что при большей ошибке опыт 15„
а при еще большей ошибке и опыт 10 надо отвергнуть. Поэтому табл-
14 можно расширить, как показано в табл. 15.
Таблица 15
Уровни главных эффектов и двухфакторные взаимодействия
в пяти отвергнутых комбинациях
Отвергну-
Отвергнутые комби-
2
6
9
15
10
12 3 4 6 6 7
_ + + + __ +
_j_ _]__|_
_|_ _j_ _j_ — _|_
_j_ . _j_ _j_
- + + -- + -
U=
35=
4?
_|_
—
—
Tt=
2t=
67
_J_
_J_
—-
Й-
57
+
it-
23=
4?
+
7t=
st-
stay
+
—
—
?4=
27=
56
_
_J_
^—
VI-
71=
36
—.
+
Из F5) следует, что
P D одинаковых знакав4 отвергнутых комбинациях |Я0)=A/2L 2 = 0,125, F7)
Р C одинаковых знака в 4 отвергнутых комбинациях | Но) =
1 2 = 0,50, F8)
4!
Р D одинаковых знака в 5 отвергнутых комбинациях | Но) =
51
= ?у-[у A/2L A/2)XL2 ==ь0,3125. F9>
Из F7) и F9) видно, что табл. 15 не приводит к отбрасыванию ги-
гипотезы о том, что нет важных эффектов при разумном значении ошиб-
ошибки а. Наиболее значимый результат дает двухфакторное взаимодействие
26, смешанное с взаимодействиями 14 и 57, а это можно интерпрети-
интерпретировать как свидетельство того, что факторы 2 и 6 вносят наибольший
вклад в потерю работоспособности ММР для определенных комбина-
комбинаций факторов. Напомним, что фактор 2 обозначает ненормальность,
которая определяется асимметрией и подъемом хвостов распределений,
а фактор 6 обозначает число совокупностей (k). Второй метод не эффек-
эффективен, поскольку он не использует приемлемых комбинаций факторов,
а в отвергнутых он не учитывает величину отклонений между оценивае-
оцениваемыми долями наблюдений и требуемой вероятностью"/3*.
Третий метод хорошо известен—это дисперсионный анализ (ANOVA)
или, в более общем случае, регрессионный анализ эксперимента 2'у 3,
описанный в главе IV. Эти методы анализа используют все 16 комбина-
комбинаций факторов, взятые вместе,[с фактическими значениями оцениваемых
долей наблюдений «правильного выбора». Более того, используются еще
29?
и оцениваемые стандартные отклонения этих долей наблюдений, как
будет видно дальше. В VI.4 мы выделили общее среднее ро< семь глав-
главных эффектов от рх до C7 и 21 двухфакторное взаимодействие от C12 до
§67, смешанные в семь групп по три взаимодействия, что показано в
{22). Обозначим эти 15 коэффициентов через Yi> •••> Yi5> гДе
Yi = Po, G0)
Y2 = Pi, .... Ys = К G1)
Тв = Pl2 + Рз5 + P46. •••> Yl5 =
= Ри + Р45 + Рз6. G2)
Величины Yn •••, Y15 соответствуют пятнадцати независимым или объяс-
объяснительным переменным, которые можно обозначить хъ ..., х1&. Факторы
X] {) = 1, ..., 15) могут принимать только значения — 1 или + 1.
Для переменных х2 х8эти значения определены в табл. 4; для хд. ...,
..., х1ъ их уровни определяются перемножением соответствующих
столбцов в табл. 4 (например, для хд — перемножением столбцов 1
и 2 или 3 и 5 и т. д.); хх имеет только один уровень + 1. План экспе-
эксперимента 2iV3 обеспечивает ортогональность всех этих независимых
переменных, т. е.
2 хих,г=0, если \Ф\' (/, /' = !,..., 15). G3)
Очевидно,
2*?/ = 16, (/ = 1 15). G4)
Каждая комбинация независимых переменных х}- приводит к 22 кор-
коррелированным откликам, также называемым зависимыми или объяс-
объясняющими переменными, которые обозначаются уг (I = 1, ..., 22).
Отклики соответствуют 22 уровням вероятности Р*. Мы предполагаем,
что каждую зависимую переменную можно выразить как линейную
комбинацию 15 независимых переменных Xj плюс отклонение, шум или
ошибка е. Тогда регрессионное уравнение вида
t = l,..., 16) G5)
предполагается для каждой из 22 зависимых переменных или
н (»" = 1,..., 16), ('=1,-. 22). G6)
С первого взгляда может показаться неразумным строить уравнение
регрессии с 15 параметрами (ylt ..., Y15) только для шестнадцати на-
298
блюдений (уъ ..., у1в) в соответствии с G5). Однако нужно помнить,
что каждое значение отклика уц в действительности есть среднее,
полученное по 400 независимым наблюдениям, как показано в E0).
Соответственно мы строим уравнение регрессии с 15 параметрами для
16 X 400 = 6400 независимых наблюдений. Программа для ЭВМ была
написана так, что в качестве выходных параметров оценивались толь-
только средние значения ytl и стандартные отклонения наблюдений вц,
а не индивидуальные наблюдения. Однако при дисперсионном или ре-
регрессионном анализе нам не нужны эти индивидуальные значения для
оценки эффектов. Они требуются только при вычислении стандартных
ошибок, когда осуществляется проверка значимости эффектов, а также
при оценивании величины Эц, которая опирается на индивидуальные
наблюдения, как показано в E2). (Для исследования действительного
вида функции отклика лучше иметь множество экспериментальных то-
точек, чем повторные наблюдения в нескольких точках (см. ниже крите-
критерии для проверки адекватности).)
Сложность состоит в том, что дисперсионный анализ основан на оп-
определенных предпосылках, а именно на нормальности распределения
ошибок наблюдений е, имеющих одинаковые дисперсии и являющихся
независимыми случайными величинами, т. е. ошибки et в G5) должны
удовлетворять условию:
et : N @, а2). G7)
Более того, дисперсионный анализ (в отличие от MANOVA — много-
многомерного дисперсионного анализа) предполагает одномерный отклик.
В нашем эксперименте требование нормальности распределения не
критично, поскольку величины yi или уц основаны на большом числе
наблюдений, на 400 наблюдениях. Требование независимости наблю-
наблюдений выполняется для yt (но не для ytl, т. е. только для заданного
значения / наблюдения независимы). Требование равенства диспер-
дисперсий, как мы увидим далее, нарушено как для уи так и для ytl. Если
не брать дополняющих величин, то из биномиального распределения
следует:
var (у) = с A — с)/800, G8)
где с — вероятность «успеха», т. е. с = Р (ПВ). Если факторы экспе-
эксперимента 2iv3 влияют на вероятность Р (ПВ), то с будет меняться для
16 комбинаций факторов. (Очевидно, что с изменяется с изменением
вероятности Я*, имеющей 22 уровня: с увеличением Р* увеличивается
и с.) Это соображение надо приспособить к использованию дополняю-
дополняющих величин. Тем не менее априори ясно, что дисперсии неодинаковы.
В результате эксперимента получаются оценки, которые действитель-
действительно обладают значительной неоднородностью дисперсий. Для Р* =
= 0,99 (или / = 22) оцениваемые стандартные отклонения sH22) ле-
лежат в диапазоне от 0,0000 до 0,0074, а для Р* = 0,35 (или / = 1) —
в диапазоне между 0,0105 и 0,0160. Окончательно мы заметим, что эк-
эксперимент дает многомерный отклик (см., например, E3)).
Поскольку предпосылки о равенстве дисперсий и одномерности
отклика нарушены, мы рассмотрим возможность применения других
299
методов в отличие от простого метода наименьших квадратов для
регрессионного анализа. В дополнении 2 мы детально рассмотрим
следующие три метода:
1) обычный метод наименьших квадратов (ОМНК) для регрессион-
регрессионного анализа, используемый в традиционном дисперсионном анализе;
2) обобщенный метод наименьших квадратов (ОбМНК) для
уравнения, которое можно построить при неоднородности дис-
дисперсий;
3) обобщенный метод наименьших квадратов для системы урав-
уравнений, которая может строиться при неоднородности дисперсий и
зависимости ошибок наблюдений в 22 уравнениях регрессии.
Мы предпочитаем оценки коэффициентов регрессии уп, которые
эффективны и для которых можно проверить значимость. Оценки
эффективны, если они являются наилучшими линейными несмещенными
оценками (НЛНО). Термин «наилучшие» относится к свойству мини-
минимальности дисперсии. Оценки обобщенного МНК, будут такими оцен-
оценками (НЛНО), но они требуют знания ковариационной матрицы
ошибок наблюдений B, и 2 в B.8) и B.17) в дополнении 2). К сожа-
сожалению, нам ковариационная матрица неизвестна. Мы можем оценить
элементы этой матрицы. (Ее диагональные элементы, т. е. дисперсии,
оцениваются величинами sh; обобщенный МНК для системы урав-
уравнений также требует оценивания ковариаций; эти ковариации не оце-
оценивались в данном эксперименте, но они оценивались в дополнитель-
дополнительном эксперименте.) Замена ковариационной матрицы в обобщенном
методе ковариационной матрицей оценок позволяет получить несмещен-
несмещенные оценки ytj, но эти оценки не лучше оценок (НЛНО). Мы не знаем,
имеют ли они еще и меньшую дисперсию, чем обычные МНК-оценки
(сравните с литературой)9. Мы знаем, что МНК-оценки обладают пре-
преимуществом простоты вычислений, поскольку при ортогональной мат-
матрице независимых переменных не нужна обратная матрица. Обращение
матрицы с помощью ЭВМ может приводить к значительным ошибкам
округления. МНК-оценки остаются несмещенными, даже если ковариа-
ционная матрица не имеет диагонального вида а2/. Проверку значи-
значимости оцениваемых коэффициентов регрессии можно выполнить для
МНК-оценок с помощью хорошо известных ^-критериев дисперсионного
анализа для одного уравнения. Известно, что эти /^-критерии достаточно
нечувствительны к неоднородности дисперсий (и ненормальности рас-
распределения) особенно при большом и одинаковом числе наблюдений
на каждую точку эксперимента (ср. [Scheffe, 1964, р. 331—369]). Мы
можем справиться со случаем более чем одного уравнения, применяя
неравенство Бонферрони. (Асимптотическая проверка значимости
обобщенных МНК-оценок также возможна с помощью результатов
многомерного анализа (см. [Zellner, 1962, р. 355], где эта проверка
основана на критерии, изложенном в [Roy, 1957]). Получающиеся здесь
формулы значительно сложнее. Более того, в дополнительном экспе-
эксперименте, где оценивались ковариации, матрица оцениваемых ковариа-
ковариаций и дисперсий и даже подматрицы только для трех уровней Р*
оказались вырожденными, поэтому проверка не получалась.)
300
В приложении 2 показано, что МНК для одного уравнения приводит
к следующей формуле для оценивания коэффициентов регрессии:
S
(/=!,..., 15),
(/=!,..., 22).
G9)
Эта формула согласуется с хорошо известной формулой для оценива-
оценивания эффектов в эксперименте типа 2к~Р. (В зависимости от опре-
определения этих эффектов коэффициенты регрессии точно равны эффектам
или равны половине от этих эффектов (см. D5) или главу IV). В данном
случае мы определяем эффекты так же, как в G0) — G2).) Из G9) по-
получим оценку стандартных отклонений коэффициентов уп:
(80)
Заметим, что вместо известной формулы для планов 2k~p из формулы
(80) следует случай неравных дисперсий. Все коэффициенты регрессии
имеют одинаковые стандартные отклонения для любого заданного
уровня / вероятности Р*. Формулы G9) и (80) использованы в табл. 16.
Таблица 16
Эффекты в плане 2 7fv8 для 22 уровней вероятности Р*
р*
0,35
0,40
0,45
0,50
0,55
0,60
0,65
0,70
0,75
0,80
0,85
0,89
0,90
0,91
0,92
0,93
0,94
0,95
0,96
0,97
0,98
0,99
60,0
62,6
65,3
68,3
72,7
75,0
78,4
81,4
84,2
87,2
90,1
91,3
92,9
93,5
93,9
94,1
95,0
95,7
96,3
'97,1
97,8
98,6
Главные эффекты (Х.1000)
12 3 4 5 6 7
— 1—22 53 8 3 54 175
—2—21 49 16 10 46 156
2—24 46 21 8 41 138
1—24 40 21 8 38 124
—2—30 36 24 6 36 111
—4—27 3124 5 32 95
—6—28 30 25 5 31 79
—8—26 27 20 2 30 64
—6—26 21 17 4 26 51
—3—24 15 18—0 23 38
—2—24 9 14—123 25
—3—19 4 12—2 20 18
—3—18 3 11—2 20 15
—3—17 0 11—2 20 14
—3—17 0 10—2 19 12
—2—15—1 10—2 18 11
—1—13—2 10—3 16 9
—0—12—3 8—2 15 8
1—11—4 5—3 13 7
0—10—3 5—3 12 6
—1 —8 —4 4—2 10 4
0—4—3 3-3 7 3
Двухфакторные взаимодействия (Х1000)
12 =
35 =
46
—8
—2
3
6
13
14
15
15
14
15
12
10
9
7
8
8
9
8
7
5
4
2
13 =
25 =
67
13
15
18
17
17
21
21
17
17
15
10
8
7
5
5
4
4
3
2
1
2
—0
14 =
26 =
57
20
24
26
26
25
21
17
19
15
15
17
15
15
15
15
15
14
12
11
11
9
6
23 =
15 =
47
—21
—26
—29
—27
—30
—29
-31
—27
—24
—20
-19
—15
— 16
—14
—13
—13
-12
— 11
-10
—9
—7
—4
24 =
16 =
37
—4
—2
2
1
—3
—3
—5
—7
—6
5
2
—2
—2
—1
[
—2
—1
— 1
j
2
2
—2
34 =
27 =
56
28
27
29
31
33
30
32
29
28
26
21
17
15
14
12
10
9
8
7
6
4
3
17 =
45 =
36
—30
—26
—26
-23
— 19
-14
—9
—3
—3
1
3
6
6
6
6
6
6
6
5
4
4
3
О
О) о
о щ о
1-Я
Rlx
Шг
si§<s
<5ё»
3,4
3,4
3,5
3,5
3,4
3,4
3,2
3,1
2,9
2,7
2,5
2,2
2,1
2,1
2,0
1,9
1,8
1,7
1.6
1,4
1,3
1,0
301
При изучении табл. 16 мы можем определить величины некоторых
эффектов, которые было бы трудно найти иначе. Наряду с факторами —
непосредственным предметом изучения в нашем эксперименте (а имен-
именно факторами 1 — 5, определяющими ненормальность распределения
и неравенство дисперсий) — в плане 27~3 существуют еще два фактора
(а именно число совокупностей k — 6-й фактор и расстояние б = 6* —
7-й фактор) и также многоуровневый фактор Р*. Табл. 16 вместе с табл. 5
показывают, что «малое» число совокупностей имеет наибольший
эффект и это имеет смысл, поскольку уже при трех совокупностях даже
процедура случайного выбора дает Р (ПВ) = 1/3. Далее, при большом
расстоянии б = б* любая процедура даст в большинстве случаев пра-
правильный выбор. Наконец, с ростом Р* эффекты факторов уменьшаются.
Этому факту можно дать два объяснения. Во-первых, с ростом Р* ММР
требует больше наблюдений, поэтому выборочные средниеxt стремятся
к \ii и семь двухуровневых факторов могут стать менее важными. Во-
вторых, отклонение между оцениваемой долей ytl и минимальной ве-
вероятностью Р*, например на 0,05 , при Р* = 0,35 менее важно, чем
при Р* = 0,99. Коэффициенты регрессии объясняют абсолютные раз-
различия у— Р*, а не относительные различия, например (у — Р*I
A — Р*). Соответственно определенное значение эффекта оказывает
на высоком уровне Р* большее влияние, чем на низком уровне. (На
этом основании кажется лучшим измерять отклик не в виде уп, а в
виде (уц — Р*цI{\ — Р'й)- Другой подход, предложенный профес-
профессором Тьюки, можно основать на «логит»-преобразовании (см. [Fin-
пеу, 1952], [Kendall, Buckland, 1971]).
Нашим следующим шагом может быть проверка значимости оцени-
оцениваемых эффектов. Но сначала мы проверим, будет ли такое уравнение-
регрессии адекватным, т. е. дает ли хорошее приближение уравнение
с взаимодействиями не более чем двух факторов. Для того чтобы про-
проверить адекватность уравнения, мы предлагаем следующее (см. также
IV.6). Хорошо известно, что остаточный средний квадрат 5^ (см. [John-
[Johnston, 1963, р. 112]) имеет математическое ожидание сга, если отсутствует
ошибка, обусловленная уравнением регрессии (а ошибки удовлетво-
удовлетворяют обычным допущениям G7)). Тогда мы определим
iSR= 2 (У.!—У«J1A6—15) (/=1,..., 22), (81)
где
^ (82)
и отношение г5|/оа есть случайная величина, имеющая распределение
%2 с одной степенью свободы. Вторую оценку величины а2 в G7) можно
получить из 400 независимых наблюдений для каждой комбинации фак-
факторов, как мы определили в E1). Поскольку выражение G7) показы
вает, что все i-e комбинации факторов приводят к одной и той же эк-
302
спериментальной ошибке о2, мы можем взять среднее или объединенную
оценку, основанную на дублировании:
,sb=2 *Ь/16 (/=1 22). (83)
«= 1
В предположении G7) и строгом выполнении того, что не только yilt
но также и индивидуальные наблюдения^,, нормально распределены,
отношение iSbv/o2 есть случайная величина, имеющая распределение
X2 с числом степеней свободы v = 16 X 399 и независимая от г5^°.
Следовательно, отношение rSR и гяЬ имеет распределение Фишера при
указанных предпосылках, или
^1.»=-^ (/= 1 22), (84)
с числом степеней свободы v = 16 X 399 = 6384, так что мы можем
считать v = оо. Большие значения статистик (84) свидетельствуют о
неадекватности.
Теперь рассмотрим влияние обычных предположений G7) на провер-
проверку адекватности. Мы знаем, что требование независимости ошибок на-
наблюдений выполняется. Величины уп (и соответственно уи) в выра-
выражении для ;S# распределены приближенно нормально, поскольку каж-
каждая из них есть среднее по 400 независимым наблюдениям. Однако на-
наблюдения, на которых основаны дисперсии s«, не будут нормально рас-
распределенными. Наше обсуждение выражения G8) показало, что наблю-
наблюдения при различных комбинациях i (/=1, ..., 16) имеют разные дис-
перрии. Таким образом, нам необходимо знать, какова чувствительность
/•"-статистик в (84) к ненормальности распределения и к неоднородности
дисперсий. Мы знаем из fScheffe, 1964], что /^-статистика робастна,.
когда она применяется к проверке различия средних, и не робастна^
когда она применяется к проверке различия дисперсий. Проверка
адекватности соответствует нулевой гипотезе:
Но--Е(Уи)= I \}XU (i = l,...,16)
(/=1 22). (85)
Соответственно это будет проверкой различия средних, а не диспер-
дисперсий! Следовательно, мы можем воспользоваться проверкой с по-
помощью (84).
У нас есть 22 уравнения регрессии и наша нулевая гипотеза состоит
в том, что все эти уравнения дают хорошее приближение. Табл. 10
дает различные ошибки «на сравнение» при заданных уровнях ошибок
на семейство сравнений, равных 20, 10 и 5%, и 22 утверждениях в се-
семействе (или 10 утверждениях, если мы ограничимся десятью основ-
основными уровнями вероятности Р*). В таблицах для величины FOl, v2
Зоз-
Таблица 17
Уровень значимости F t "^ и F 7am , когда
P(FVV ^ )
а
fl,oo
с а
f7,°o
0
1,
1.
,25
32
29
0
2
1
,10
,71
,72
0
3
2
,05
,84
,01
0,
5
2
025
,02
,29
0
6
2
01
,63
,64
0,
7
2
005
,88
,90
0,001
10,8
3,47
0.
12
3
0005
,1
,72
даны уровни значимости для стандартных значений а, например 1%,
а не для значений, подобных величине 0,90909%. По табл. 17 из ра-
'боты [Dixon, Massey, 1957, p. 402] находим строку для F4- ю, которой
воспользуемся позднее. В [Dixon, Massey, 1957] приведен также спи-
список значений для а, превышающих 25%. Последний столбец табл. 18
дает наименьшее а, для которого вычисленное значение ^-статистики
для качества подгонки в (84) превосходит табличное значение Т7" «>.
Это значение а мы называем «критическим уровнем» at. Тогда имеем
(86)
Например, для Р* = 0,40 мы вычислили FliOa = 9,63, и это значе-
значение превосходит величину Т7?,» для a = 0,005, но не для a = 0,001,
так что aL = 0,005. Соответственно уровень ошибки та сравнение» «с
не меньше, чем критический уровень at, ведущий к отбрасыванию
нулевой гипотезы при
если
(87)
Из табл. 10 и 18 следует, что мы должны отвергнуть гипотезы для всех
22 уравнений регрессии, дающих хорошее приближение при любых
трех значениях B0, Ю или 5%) уровня ошибки «на семейство». Если,
однако, мы ограничим наше изучение 10 главными уровнями вероят-
вероятности Р* (т. е. Р* = 0,90 @,01) 0,99), то мы заключим, что гипотеза о
хорошем приближении должна быть отвергнута только при ошибке
«на сравнение» большей, чем 0,10. Табл. 18 показывает, что Flco
становится значимым при значении 0,25, но не при 0,10. Из последнего
столбца табл. 10 видно, что для 10 основных уровней Р* мы далеки от
того, чтобы отвергнуть гипотезу об адекватности. Поэтому мы заклю-
заключаем, что для Р* > 0,90 наши уравнения регрессии служат хорошей
аппроксимацией, но для Р* < 0,90 эти уравнения не адекватны. Со.
ответственно для Р*< 0,90 нет большого смысла исследовать оце.
ниваемые коэффициенты регрессии у/г- (Поскольку здесь получилась
неадекватность, мы предполагаем, что для Р* ^ 0,90 значимы трехфак-
304
soe
* |
+
> о о о о о о
> о о о о о о
> о о о сэ о о
т СЛ СП СЛ СЛ СЛ
NONOfONONONONOtO NONONONONOOO^-NONONONOtObG
елелелелелелелелслелелелелелъооелелелелелел
+++ + от ++++++
оо о о ос .
ооооооос _ _ .
ооооооооооооос
ел ел ел ел ел слелслслслелелслс
я
V
) ^Э ^Э Ю ND Ю Ю (О ^Э ^Э С
эюелелелелслелелос
) О О С_ _ _ .
) •— ОО О О С
1 ел ел ел ел с
Э ^Э ^Э ^Э ^Э ^Э О ^5 ^Э ^^
. _ j>oooooooow
_)ооооооооооел
тслелелелелелелелслелел
пелелелелелелел(
+++++++
c ^ ^э ^э ^э о ^ с ^ ^ ^э ^ ^э ^э ^э ^^ сэ ^э
^э ^э ^э ^э ^э о ^э о ^э ^э ^э ^э ^э ^э ^э ^э ^э ^э ^э ^э ^э ^^
ел ел ел ел слслслслслелелслелелел ел ел ел ел ел ел ел
^-елооооооооооооооооооо
ел ел ел елелелслелелелелелел ел ел ел ел ел ел
о о о
о
ел
^Э ^Э ^Э ^Э ^Э ^5 ^Э ^Э (О ^Э О ^Э ^Э ^Э ^Э ^Э ^5 ^Э ^^ ND ND ^Э
юооооооооооооооооооелелю
слелоооооооооооооооо j 1_ел
елелелелелелслелелелелелелелелел ~ г
NDi—ooND^-OOO
слослелослот—
> о о о о о
Э ^Э О ^5 ^Э ^Э <
юооооооооо
1елелелелелелелелелел
) О ОО ОО (
ел ел ел ел ел ел ел ел с
. _ _3ооооооос_
т ел ел ел ел ел ел ел ел ел ел ёл
оооооооооооооооооооооо
ел ел ел ел ел ел ел ел ел ел ел ел ел елелелелелелелелел
елелелелелел
слелелелелелелоъоелелелелелелел
ел ел
_ оооос_
ооооооооо
елелелелелелелелелелел ел с
> о о
) О О О О О О
_> о о о о о о
i ел ел ел ел ел ел ел
оооосоооомюююоооооо
ооооооо^^-слслслсл^-ооооо
en^-ooienen j i l ooooo
~ г~ елелелел е
ел ел ел ел ел ел
з о о о о с
рооооооооооооооооо
"^ ^i -* С, J ^^ Г^ с, J С, J с, J С^Ъ f**> С^Ъ С^5 С^5 С~5 ^^ ^^ с~^
1 ел ел_ел ел ел ел ел ел ел ел ел ел ел ел ел ел
ю
о»
+
to ю to ю ю to to to ю
» ov o\ Ь\ о» о\ О\ и* Од ел
-1-+-ТЧ- +Н-+
ел о ю о о с
елоелс
о о о to
ел ел ел
-1
и
1)
я
с
1
г
3
Е
CD
¦с
с
s
^*
я
Объединен-
Объединенные взаимо-
взаимодействия
Адекват-
Адекватность
'В
а
¦о
о
¦е-
а
?
Н
ш
S
J3
ш
торные взаимодействия, а главные эффекты смешаны с ними (см. B1).)
Позднее мы еще займемся проверкой значимости эффектов при Р* ^
> 0,90.
Мы хотим проверить значимость оцененных коэффициентов рег-
регрессии, т. е. проверить нулевую гипотезу:
Н0:Е (у>) = 0 0" = 1. •- 15) (Г = 13, .... 22). (88)
Для уравнения с номером V мы можем проверить (88), если предполо-
предположить, что выполняются обычные предпосылки G7). Для такого случая
мы можем использовать f-критерий или, поскольку число степеней
свободы равно единице, ^-критерий:
i'Fi.u = vt% = rSSj/t-sb, (89)
где SSj — сумма квадратов для /-го эффекта, т. е.
tSSj = 16 (Y/rJ, (90)
а величина i-sb, определяемая в (83), служит оценкой дисперсии а2
в G7) и имеет число степеней свободы v = 16 X 399 = 6384 (см. IV.3
или [Johnston, 1963, р. 135]). Критерии для эффектов \пв (88) про-
проверяют различия средних, а не различия дисперсий. Здесь — это
разности между средними значениями отклика на уровне + факто-
фактора Xj и на уровне—этого фактора (ср. G9)). Известно, что /-"-критерий,
основанный на (89), достаточно нечувствителен к неоднородности дис-
дисперсий и ненормальности распределения. Мы проверим все двухфак-
торные взаимодействия совместно, т. е.
(Г = 13, ..., 22). (91)
В (91) предполагается, что уравнения регрессии первого порядка дают
адекватную аппроксимацию. Эту гипотезу можно проверить для одного
уравнения, объединяя суммы квадратов двухфакторных взаимодейст-
взаимодействий:
15
rsD
(92)
(см. IV.2). Критический уровень величины F7 „ можно найти, исполь-
используя последнюю строку табл. 17. Критические уровни (аь) для индиви-
индивидуальных критериев (89) и объединенного критерия (92) показаны в
табл. 18. Табл. 18 можно интерпретировать следующим образом.
Как было упомянуто выше, мы ограничили наши решения десятью
уравнениями регрессии, соответствующими вероятности Р* =>
306
= 0,90 @,01) 0,99. (Ради полноты в табл. 18 также даны критические
уровни'по*формулам_(89)^*(92) для Р* < 0,90.) В последнем столбце
табл. 10 были^даньГуровни ошибок «на сравнение», которые соответ-
соответствуют уровням ошибок на семейство 0,20, 0,10 и 0,05 и, как в (88),
10 утверждениям на семейство. Из табл. 18 мы заключаем, что даже при
всех этих малых уровнях ошибок «на сравнение» все эффекты значимо
отличаются от нуля, кроме основного эффекта фактора 1 («усеченность»)
и'смешанных двухфакторных взаимодействий 16, 24 и 37. В соответ-
соответствии с условными критериями, основанными на F5), главные эффекты 2
(«асимметрия»), 6 (число совокупностей k) и их взаимодействия дают
наиболее значимые результаты (вместе со смешанными взаимодейст-
взаимодействиями 23 + 15 + 47 и, конечно, общим средним). Но также сущест-
существенно значимы факторы 7 (б = б*) и 4 (a(h)/max о^)Ф 1) (и взаимо-
взаимодействия 34 + 27 + 56 и 12 + 35 + 46). Если бы мы сделали по
табл. 18 вывод, что факторы 1, 3 и 5 несущественны (при aF < 0,01),
то мы могли бы сложить суммы квадратов для главных эффектов фак-
факторов 1, 3 и 5 с остаточной суммой квадратов. Это дало бы величину
-/^-статистики для проверки адекватности, равную 4,94 для Р* = 0,99
(при Р* = 0,99 главные эффекты 1, 3 и 5 наиболее значимы). Значение
FiiCO = 4,94 значимо при ас — 0,001. Так что отбрасывание факторов
1, 3 и 5 даст плохое приближение. Отбрасывание только факторов 1
и 5 (aF = 0,01) дает значение /^-статистики для проверки адекват-
адекватности ^3.00 — 2,86 при Р* = 0,99, и эта величина значима только при
ас = 0,05; поэтому мы можем весьма уверенно заключить, что фак-
факторы I я Ь не влияют.
Мы должны понимать, что эффекты могут значимо отличаться от
нуля, но тем не менее быть неважными. Так, если коэффициенты регрес-
регрессии отличаются от нуля, но общее среднее |30 велико (ср. «сверхгаран-
«сверхгарантию»), то существует достаточно большая возможность того, что ожи-
ожидаемая доля правильных выборов, Е (у) в G5), будет все еще не мень-
меньше, чем требуемая вероятность Р*. Мы предположили, что такое яв-
явление действительно имеет место в нашем эксперименте. Поскольку
все факторы кроме одного (или двух) дают значимые эффекты, мы мо-
можем ожидать, что почти все 16 комбинаций факторов дадут оцениваемые
доли наблюдений значимо ниже соответствующей вероятности Р*.
Действительно, мы видели в VI.8, что ММР работоспособна в большин-
большинстве случаев. Видимо, будет неправильным решить по коэффициентам
регрессии, что все факторы кроме 1-го (и 5-го) «важны». Мы полагаем,
что главным образом факторы 2-й и 6-й приводят к потере работоспо-
работоспособности ММР. Оцениваемые коэффициенты регрессии все-таки по-
полезны, поскольку они могут быть ориентиром в дальнейших исследо-
исследованиях ММР, как мы увидим в VI. 10, но сначала мы коротко обсудим
многоуровневый фактор Р*.
Этот фактор Р* проявляет свое влияние особым образом. С ро-
ростом Р* можно ожидать также роста доли правильных выборов у
даже в том случае, когда ММР не гарантирует требования к вероят-
вероятности A). С ростом Р* ММР будет требовать большего числа наблюде-
11* 307
ний, поэтому растет и вероятность Р (ПВ) = Е (у). Не имеет смысла
оценивать эффект Р*, например, следующим образом:
-Е(у)=Е(У1)-Е(у) (/ = 1 22), (93)
где у — среднее значение уг. Фактор Р* важен, если на некоторых
уровнях Р* JVLMP работоспособна, а на других уровнях она неработо-
неработоспособна, т. е. на некоторых уровнях / неравенство
Е(Уп)>Р1 (94)
выполняется, а на некоторых уровнях не выполняется. Использова-
Использование ^-критерия, как и в VI.8, показывает, что ограничение только вы-
высокими уровнями Р*, например Р* = 0,90 @,01) 0,99, приводит к
нарушению неравенства (94) так же, как и ограничение низкими уров-
уровнями (ср. табл. 12). Поскольку наиболее подходящие уровни Р*—
это высокие уровни, то мы можем в дальнейших экспериментах огра-
ограничиться только этими уровнями. (Более детальный анализ влияния
Р* можно было бы сделать, описывая уп или (уп — Р*)/A — Р*)
уравнением регрессии относительно количественной переменной Pf;
такое уравнение можно построить для каждой из шестнадцати комби-
комбинаций плана эксперимента 27 ~ 3. Если Р* не взаимодействует с 7 двух-
двухуровневыми факторами, то все уравнения регрессии имеют одинаковые
коэффициенты, за исключением общего среднего C0. При анализе таких
уравнений мы должны учитывать зависимость между наблюдениями.)
VI.10. ЗАКЛЮЧЕНИЕ И НАПРАВЛЕНИЕ ДАЛЬНЕЙШИХ ИССЛЕДОВАНИЙ
Из VI.8 мы узнали, что ММР не гарантирует требования к вероят-
дости A), поэтому некоторые факторы должны оказаться важными.
Следовательно, мы хотим узнать, для какой комбинации факторов про-
процедура неработоспособна. Анализ, проведенный в VI.9, не смог точно
выявить действительно важные факторы. С помощью регрессионного
анализа (или дисперсионного анализа) показано, что при обычных
значениях ошибок все эффекты значимо отличаются от нуля (кроме
параметров fj|_ и р\6 4- C24 + Рз?)- Но, как мы показали, некоторые
из этих эффектов могут тем не менее оказаться несущественными.
Биномиальные критерии по отвергнутым комбинациям позволили
предположить, что факторы 2 и 6 и их взаимодействия наиболее важ-
важны, но при этом не удалось сделать каких-либо определенных выводов.
Следовательно, в дальнейших экспериментах мы можем исследовать
все 2' комбинаций факторов, собрать отвергнутые комбинации и про-
308
анализировать их с помощью биномиальных критериев, как в VI.9,
надеясь при этом, что увеличенное число комбинаций ухудшит мощность
критериев. Это позволит сделать определенные выводы. Вспомним, од-
однако, что генерирование данных для 27 ~3 комбинаций занимает час
времени на IBM 360/75, поэтому дополнительный эксперимент 27 —
24 потребует более семи часов машинного времени, а это уже непозво-
непозволительно большое время. Поэтому мы можем предсказывать долю пра-
правильных выборов для каждой из 27 — 24 комбинаций. Эти предсказа-
предсказания можно основать на уравнениях регрессии из VI.9 (ср. с (82) выше).
К сожалению, как показал анализ в VI.9, двухфакторные взаимодей-
взаимодействия значимы, поэтому эксперимент 2;V3 не дает единственных оце-
оценок отдельных взаимодействий. Для Р* < 0,90 подобранные урав-
уравнения регрессии не дают хорошего приближения. Поэтому, видимо,
на следующей стадии экспериментирования целесообразно изучить
только значения Р*, для которых Р* > 0,90. Более того, мы отбро-
отбросили фактор 1, поскольку этот фактор был незначимым при любой
разумной величине ошибки. Исключение фактора 5 правильно при
aF не ниже 1 %, а это можно учесть, чтобы уменьшить машинное время
на следующей стадии. Дополнительное исключение третьего фактора,
например фактора 3, не оправдано, поскольку подобранное уравнение
регрессии в этом случае не дает хорошего приближения. Если мы вы-
выкинем меньше чем три фактора, то некоторые двухфакторные взаимо-
взаимодействия останутся смешанными, поэтому действительно нужно даль-
дальнейшее экспериментирование (если мы не упростим ситуацию, предпо-
предполагая, что некоторые двухфакторные взаимодействия равны нулю,
но это, видимо, слишком произвольное допущение). Если мы хотим,
чтобы наши выводы были обоснованы для всех значений k (число сово-
совокупностей) и всех б = б* (расстояний), то мы можем выполнить эк-
эксперименты только при неблагоприятных уровнях этих двух факторов,
т. е. при большом k (например, k = 7) и малом б = б* @,20 {o(ft) +
+ очь-ц}/2), тогда они не будут факторами в плане эксперимента.
Для выбора плана на следующей стадии мы отсылаем читателя к об-
обсуждению планов с разрешением V и насыщенных планов Рехтшаффне-
ра (Rechtschaffner) в IV.5, а затем к последовательным планам из IV.6.
Мы можем проверить, значимо ли отличается от вероятности Р* пред-
предсказанная доля, применив /-критерий с дисперсией
а2 (у) = а2 B у, Xij) = 2 & №> (95)
где последнее равенство выполняется, если оцениваемые коэффициенты
регрессии независимы (и xtl = ±1).
Наряду с вероятностью правильного выбора мы можем исследовать
требуемые объемы выборок как функцию от k, б* и Р* и исследовать
другие соотношения для математических ожиданий. Можно изучить
таким же образом другие методы ранжирования, чтобы отыскать ро-
бастную и эффективную процедуру для имитационного моделирования.
309
ПРИЛОЖЕНИЯ К ГЛАВЕ VI
ПРИЛОЖЕНИЕ VIA. ОБЩИЕ СЛУЧАЙНЫЕ ЧИСЛА И ОЦЕНИВАНИЕ
ЭФФЕКТОВ ФАКТОРОВ
Основной эффект /-го фактора, о,-, оценивается следующим образом:
^N (/=1,2,...,/), A.1)
гу = + 1, если /-Й фактор находится на верхнем уровне, и xi}- =
— — 1, если он находится на нижнем уровне в г-й комбинации фак-
факторов, a yt — отклик для t-й комбинации факторов (г = 1, ..., N)
(см. главу IV). Из A.1) следует:
A.2)
В плане эксперимента xi} = + 1 в половине всех комбинаций факторов,
a xtj = — 1 в другой половине. Следовательно,
А) ~ + 1 (ПРИ всех i и /) A.3)
SS XijXt'j = [ {N12) (-1) + {N12 -\){+\)}N = -N. A.4)
ii'
Допустим, что ковариации между откликами для разных комбинаций
одинаковы и равны у.
cov (з>г> Ус) — V (*'?=О> • A-5)
одинаковы также дисперсии откликов:
о2 Ш = о? (г = 1, .... N). A.6)
Подставим A.3) — A.6) в A.2). Тогда получим
где р — коэффициент корреляции для откликов yt и ус (г ^= t"),
Чтобы определить знак р, рассмотрим выражение:
п п \
SV .. \
=1 ,1=1 , A.8)
\ п п /
310
где ytr — отклик для r-й повторной реализации г-й комбинации фак-
факторов (т. е. yir принимает значения 0 или 1 соответственно в случае от-
отказа или успеха в работе ММР для r-й повторной реализации i-й
комбинации факторов). Тогда
cov(yhУ!')=— 2d2dcov(yirtyi'r'y ( '
r r'
где
cov (yir, yi'r') = 0 для г ф r',
> 0 для г = r'. A.10
Следовательно, cov(yi, у г) и соответственно коэффициент корреляции
р — положителен.
ПРИЛОЖЕНИЕ VI.2. ПРОСТОИ И ОБОБЩЕННЫЙ МЕТОД
НАИМЕНЬШИХ КВАДРАТОВ МНК
Поскольку требования равенства дисперсий (для каждого урав-
уравнения регрессии) и при одном уравнении регрессии нарушаются в на-
нашем эксперименте, мы рассмотрим следующие три типа оценок.
1. Простой метод наименьших квадратов для одного уравнения
регрессии, т. е. мы пренебрегаем неоднородностью дисперсий и суще-
существованием более чем одного уравнения регрессии. Тогда наилучшей
линейной несмещенной оценкой (НЛНО) будет простая, или обычная,
оценка по методу наименьших квадратов (МНК-оценка). Регрессион-
Регрессионные уравнения G6) в матричной записи имеют вид:
;—Л;1г + -С; A = 1, •••, tZ). (Z.I)
где F, -«• вектор наблюдений над зависимыми переменными, т. е,
У( = (Уи, -, УшУ, B-2)
Хг — матрица значений независимых переменных
X = {xtj} (i = 1 16), (/ = 1, .... 15), B.3)
состоящая из ортогональных столбцов, как показано в G3) (на самом
деле Хг не меняется с изменением /). Г; — вектор коэффициентов рег-
регрессии:
?г = (уи, •.., Уш), B-4)
определенный в G0) — G2); Е{ — вектор ошибок:
311
Щ = (е1г, .... em). B.5)
Из B.1) получаем МНК-оценки Гг:
fl = {XiXH-1X(fl. . B.6)
Поскольку имеют место G3) и G4), B.6) сводится к
Ул=2 *иУнИ6. B.7)
i= 1
2. Обобщенный метод наименьших квадратов для одного уравне-
уравнения регрессии, т. е. мы оцениваем коэффициенты регрессии с учетом
того, что ковариационная матрица ошибок наблюдений (для одного
-у
данного уравнения) не есть матрица га21. В нашем эксперименте эта
-*¦
ковариационная матрица 2; есть диагональная матрица:
2, = {,а„.} (I, V = 1 16), B.8)
где
гац' = 0 при i ф i',
= ;О? при i = V. B.9)
Следуя работе [Johnston, 1963, р. 183], получим НЛНО матрицы
Гг, имеющую вид:
Г? = (Х; 2Г1 X,)-1 X/ 2Г1 К,. B.10)
-у
Поскольку матрица ?г нам неизвестна, ее можно заменить в формуле
-»-
B.10) оценкой S;, которая есть диагональная матрица с элементами
на диагонали:
iot = sh, B.11)
где s2n — оценки, которые находятся так же, как в E1). Подстановка
-> _^,
матрицы S, вместо ?г в B.10) приводит к оценкам, которые уже не
обязательно будут НЛНО.
3. Обобщенный метод наименьших квадратов для системы урав-
уравнений регрессии, т. е. мы учитываем совместно и неоднородность диспер-
дисперсий, и существование более чем одного уравнения регрессии. Следуя
[Zellner, 1962], можно записать различные уравнения регрессии в еди-
единой форме B.12), что соответствует формуле B.1) для задачи с одним
уравнением регрессии:
У =ХТ + Е, B.12)
312
где Y— это вектор, образуемый 22 подвекторами или числом элемен-
элементов 22 X 16, вида
Г = (Yx, .... Г22), B.13)
X — диагональная матрица, если ее записать с помощью подматриц Хг:
-—*¦ -»¦ —»
X, 0 ...0
о % ...о
_о о ...x22j
B.14)
где 0 — матрица с числом элементов (которые сами матрицы) 16 X
-* -> -*
X 15, равных нулю (подматрицы Хг одинаковы); Г и? определяются
-у
аналогично матрице Y, т. е,
Г = A\, ..., Г22),
Е = (?1( ..., ?22/-
B,15)
B.16)
Ковариационная матрица Ё ошибок в B.16) симметрична и определена
следующим образом:
2 =
^1,2
V
^2,2
2,22
_222Д
B.17)
где матрицы Ег на диагонали сами диагональны (размером 16 X 16),
и представляют из себя ковариационные матрицы отдельных урав-
уравнений регрессии, определенных в B.8) и B.9), а внедиагональные мат-
рицы En- Aф1'), размером 16Х 16, — диагональные матрицы ковариа-
ций, как в E3). Уравнение B.12) в точности соответствует B.1), но
теперь ковариационная матрица B.17) будет матрицей оценок, полу-
полученных обобщенным методом наименьших квадратов для набора урав-
уравнений регрессии:
Г =
)-1 X'
Y.
B.18)
Поскольку матрица Е неизвестна, мы должны оценить дисперсии и ко-
вариации. Ее элементы на главной диагонали оцениваются с помощью
B.11). Элементы ковариаций не определяются по (исходному) экспе-
эксперименту, но их можно определить по ковариациям между отдельными
наблюдениями, что также позволяет оценить и дисперсии. Пусть через
1>иг' мы обозначим реализацию г' (г' = 1, ..., 2R) t-йкомбинации
313
факторов (г = 1, ..., 16) для уровня I {I = 1, ..., 22) вероятности Р*
и пусть через Ъцг (г = 1, ..., R) мы обозначим среднее двух реализа-
реализаций, для которых использованы дополняющие величины. Тогда имеем
B.19)
где можно оценить cov (vily Vu')c помощью выражения
Л ^ _ я _ _ _ _
v cov E„, »«')= 2 (««г— »ii) (»«т—Vt
1
(R-l) B.20)
при г;,; = ;угг. (Последнее равенство в B.20) может оказаться удоб-
удобным для машинных расчетов.) Мы видим, что в [Zellner, 1962, р. 350]
требуется равенство диагональных элементов в каждой диагональной
подматрице ковариационной матрицы Е в B.17) (что приводит к одно-
однородности дисперсий для одного уравнения регрессии). В этой работе
оценивались диагональные элементы каждой подматрицы по откло-
отклонениям между фактическими значениями зависимых переменных и зна-
значениями, предсказанными уравнениями регрессии, использующими
МНК-оценки. Мы же оцениваем эти элементы из повторных реализа-
реализаций для одной и той же комбинации факторов.
УПРАЖНЕНИЯ
1. Докажите, что переменная, определенная в G), имеет среднее 0,9/Ь
и дисперсию 1,01/62; определите функцию плотности распределения этой пере-
переменной.
2. Покажите, что в плане 2J^ все двухфакторные взаимодействия, вклю-
включающие только четыре различных фактора, можно сделать не смешанными.
3. Получите факторную комбинацию 6 в табл. 6.
4. Выведите формулу для числа повторных реализаций, если мы хотим
оценить Р (ПВ) с точностью 10% и доверительной вероятностью 90%.
5. Является ли правильным следующее доказательство несмещенности оце-
оценок обобщенного МНК с использованием оценки ковариационной матрицы?
Е[(Х' S-iX)-i X'S-i (X
х' (XX')-1 Е] =В.
6. Покажите, что в дисперсионном и регрессионном анализе отдельные на-
наблюдения не используются нигде, кроме вычисления стандартного отклонения.
314
7. Допустим, что в E3) cov (уи, уп,) = а1{, (независимо от номера I).
Докажите, что в МНК cov^Vjb V/j') = ац-1^ и cov (VH> Y/чО = ® ПРИ / Ф /'•
8. Каким простым способом можно уменьшить ошибки округления в ЭВМ
при оценивании коэффициентов регрессии yj{? (Указание: не использовать
исходный отклик у).
9. Показать, что в (84) выполняется равенство js|, = Q\t%lv при v = 16 X
X 399 и что г$д независима от iSR.
10. Показать, что если в эксперименте 2Г7^ не влияют три фактора, то
можно оценить все взаимодействия без дополнительных экспериментов. Как
можно интерпретировать линейную комбинацию взаимодействий 17+45+36
в табл. 18, если мы исключили влияние факторов 1, 3 и 5?
11. Почему разность р0 — Р* дает оценку снизу для «сверхгарантии»
в ММР?
ПРИМЕЧАНИЯ
1 Эта глава основана на двух предварительных отчетах [Kleijnen, 1969a;
1969b]; краткое изложение представлено в работе [Kleijnen, 1972]. Профессор
Бёрдик (D. Burdick; Университет Дьюк) дал полезные советы по планированию
эксперимента, а профессор Шорак (G. Shorack; Университет Вашингтона,
временный математический центр Амстердама) сделал замечания по анализу.
Машинное время для генерирования данных было обеспечено профессором Ней-
лором (Т. Naylor; Университет Дьюк; IBM 360/75); эти данные были проанализи-
проанализированы в Katholieke Hogeschool Tilburg (IBM 1620). Дополнительные экспери-
эксперименты были поставлены благодаря профессору Ломбаерсу (Н. Lombaers; Techni-
sche Hogeschool Delft; IBM 360/65). Программа на Фортране для генерирования
данных написана мистером Фицджеральдом (Mr. В. Fitzgerald; Университет
Дьюк).
2 Неравенство а^/тах а(^ > 1 означает, что наилучшая совокупность
обладает и наибольшим стандартным отклонением. Если бы экспериментатор
знал, что а; = a\it, то он бы использовал логарифмическое преобразование для
того, чтобы получить однородность дисперсий (см. табл. 4 в главе IV).
3 Если бы повторные реализации были независимы, то мы бы оценили дис-
дисперсию их среднего исходя из формулы для биномиального распределения
рA-рIп.
Реально оцениваемые дисперсии имеют меньшее значение.
4 Отметим, что машинное время можно также сократить с помощью стати-
статистического метода, подобного методу с использованием обратных случайных чи-
чисел, но обладающего более эффективной численной процедурой. Например, вме-
вместо логарифмического преобразования, как в D8); мы можем взять линейную
аппроксимацию для того, чтобы генерировать случайные величины, имеющие
распределение, близкое к экспоненциальному.
800 800
где сх обозначает отрицательный коэффициент корреляции между повторными
реализациями 2г" и 1г" — 1 (г" = 1 400) для уровней I и V соответственно,
а с2 обозначает положительный коэффициент корреляции между повторными реа-
реализациями г на уровнях I и V соответственно. Сравните обсуждение возможных
противоречий между методами, использующими дополняющие величины и об-
общие случайные числа в главе III.
6 Т. е. z = 0,000 @,001) 2,500 @,002) 3,400 @,005) 4,00 @,01) 6,00.
7 Значениями af-статистик были снабжены выходные данные (на перфокар-
перфокартах) плана 2Jy 3 для 22 уровней Р*, показанных в табл. 8. Эти значения яв-
являются входными данными для машинной программы анализа.
315
8 Предположим, что единственный важный фактор — это фактор 1, и'по-
и'поэтому все комбинации, имеющие фактор 1 на уровне «плюс», отвергнуты. Тогда
в восьми отвергнутых комбинациях фактор 2 находится четыре раза на уровне
«плюс» и четыре раза — на уровне «минус».
9 Литература: [Zellner, 1962 и 1963], [Zellner, Huang, 1962], [Kakwani,
1967], [Parks, 1967], [Kmenta, Gilbert, 1968], [Plasmans, 1970], [Plasmans, van
Straelen, 1970], [Rao, Mitra, 1971, p. 155—167].
10 Здесь наше представление немного отличается от обсужденного в IV.6,
где SR основана иа всех наблюдениях, включая повторные.
БИБЛИОГРАФИЯ
1. Andrews D. F., Bickel P. J., Hamp el F. R., Huber P. J., Ro-
Rogers W. H. and Tukey J. W. A972). Robust Estimates of Location. Prin-
Princeton University Press, Princeton N. J.
2. Bechhofer R. E. and В lumen thai S. A962). A sequential multiple-
decision procedure for selecting the best one of several normal populations
with a common unknown variance, II: Monte Carlo sampling results and new
computing formulae. Biometrics, 18, 52—67.
3. Bechhofer R. E., Kiefer J. and Sob el M. A968). Sequential Identifi-
Identification and Ranking Procedures. The University of Chicago Press, Chicago,
111.
4. В о x G. E. P. A954a). Some theorems on quadratic forms applied in the study
of analysis of variance problems: I. Effect of inequality of variance in the
one-way classification Ann. Math. Stat., 25, 290—302.
5. Box G. E. P. A954b). Some theorems on quadratic forms applied in the
study of analysis of variance problems: II. Effect of inequality of variance
and of correlation of errors in the two-way classification. Ann. Math. Stat.,
25. 484—498.
6. Dixon W. J. and Masse у F. J. A957). Introduction to Statistical Analy-
Analysis. 2nd ed., McGraw-Hill, New York.
7. Donaldson T. S. A966). Power of the F-test for Nonnormal Distributions
and Unequal Error Variances, RM-5072-PR, The Rand Corp., Santa Monica,
Calif.
8. D u n n 0. J. A964). Multiple comparisons using rank sums. Technometrics,
6, 241—252
9. Finney D. J. A952). Statistical Method in Biological Assay. Griffin, Lon-
London.
10. Fisz M. A967). Probability Theory and Mathematical Statistics. Wiley,
New York.
11. Johnston J. A963). Econometric Methods. McGraw-Hill, New York.
12. Kakwani N. C. A967). The unbiasedness of Zellner's seemingly unrelated
regression equations estimators. J. Amer. Stat. Assoc, 62, 141—142.
13. Kendall M. G. and Buckland W. R. A971). A Dictionary of Statistical
Terms. 3rd ed., Oliver and Boyd, Edinburgh.
14. Kendall M. G. and Stuart A. A961). The Advanced Theory of Stati-
Statistics, vol. 2, Griffin, London. Русский перевод: Кендалл М., Сть го-
ар т А. Статистические выводы и связи. Т. 2. М., «Наука», 1970.
15. Kendall M. G. and Stuart A. A963). The Advanced Theory of Stati-
Statistics, vol. 1, 2nd ed., Griffin, London. Русский перевод: Кендалл М.,
СтьюартА. Теория распределений. Т. 1. М., «Наука», 1966.
16. Kleijnen J. P. С. A969а). The Use of Multiple Ranking Procedures to
Analyze Simulations of Business and Economic Systems II: The Design of
a Monte Carlo Experiment for the Evaluation of Multiple Ranking Proce-
Procedures. Econometric System Simulation Program Working Paper, Duke Uni-
University, Durham, N. С
17. Kleijnen J. P. C. A969b). The Design and Analysis of a Monte Carlo
Experiment with a Multiple Ranking Procedure. Katholieke Hogeschool, Til-
burg (Netherlands).
316
1& Kleij nen J. Р. С. A972). The Design and Analysis of Monte Carlo Expe-
, riments: A Case Study on the Robustness of a Multiple Ranking Procedure.—
\In: Working, papers, vol. 1, Symposium Computer simulation versus analytical
solutions for business and economic models, Graduate School of Business
Administration, Gothenburg (Sweden).
19. Kmenta J. and Gilbert R. F. A968). Small sample properties of alter-
alternative estimators of seemingly unrelated regressions. J. Amer. Stat. Assoc,
63, 1180—1200.
20. Lewis P. A. W., Goodman A. S. and Miller J. M. A969). A pseudo-
pseudorandom number generator for the System/360. IBM Systems J., 8, 136—146.
21. Mood A. M. and Gray bill F. A. A963). Introduction to the Theory of
Statistics. 2nd ed., McGraw-Hill, New York.
22. Neave H. R. and Granger С W. J. A968). A Monte Carlo study com.
paring various two-sample tests for differences in mean. Technometrics, 10,
509—522.
23. Parks R. W. A967). Efficient estimation of a system of regression equa-
equations when disturbances are both serially and contemporaneously correlated.
J. Amer. Stat. Assoc, 62, 500—509.
24. Plasmans J. A970). The General Linear Seemingly Unrelated Regression
Problem, I: Models and Inference. EIT 18, Tilburg Institute of Economics,
Department of Econometrics, Tilburg (Netherlands).
25. Plasmans J. and van Straelen R. A970). The General Linear See-
Seemingly Unrelated Regression Problem, II: Feasible Statistical Estimation and
an Application. EIT 19, Tilburg Institute of Economics, Department of Eco-
Econometrics, Tilburg (Netherlands).
26. Rao С R. and Mitra S. K. A971). Generalized Inverse of Matrices and
its Applications. Wiley, New York.
26a. Rogers W. H. and Tukey J. W. A972). Understanding some long-tailed
symmetrical distributions. Stat. Neerl., 26, 211—226
27. Roy S. N. A957). Some Aspects of Multivariate Analysis. Wiley, New York.
28. Scheffe H. A964). The Analysis of Variance. Wiley, New York. Русский
перевод: Шеффе Г. Дисперсионный анализ. М., Физматгиз, 1963.
29. Большее Л. Н., Смирнов Н. В. Таблицы математической статистики.
М., «Наука», 1964.
30. Teichroew D. A965). A history of distribution sampling prior to the era
o! the computer and its relevance to simulation. J. Amer Stat. Assoc 60,
27—49.
31. Zellner A. A962). An efficient method of estimating seemingly unrelated
regressions and tests for aggregation bias. J. Amer. Stat. Assoc, 57, 348—
368.
32. Zellner A. A963). Estimators for seemingly unrelated regression equations:
some exact finite sample results. J. Amer. Stat. Assoc, 58, 977—992.
33. Zellner A. and Huang D. S. A962). Further properties of efficient esti-
estimators for seemingly unrelated regression equations. Int. Econ, Rev., 3,
300—313.
ОТВЕТЫ К УПРАЖНЕНИЯМ
Глава IV
1. Семейство распределений Эрлаига, например, экспоненциальное рас-
распределение для малых значений параметра.
ri J
2.MSE= f, ^ (ytj-y.j)*l 2,to-l).
i=l i=i
Подставить rj = r.
3. Незначимы при ошибке 5%: главный эффект фактора 1, взаимодействия
13=25=67, 24 = 16 = 37. Хорошая аппроксимация (см. также главу VI).
4. (а) Подставьте уравнения C.1) и C.8) в C.6). Столбцы 1 и т. д. до
(k + 1) приводят к ({/', — ~U'jy = 2U'd~bM.
(б) Используйте следующее: если те = Av с ковариационной матрицей 2 „,
то 2W = A2VA'. Здесь А = 0,5 (U'~U)-1 (U1, —~U').
(в) Используйте уравнение A77). Ортогональный план:
= а2/б < а2/4.
(г) bM = Ay [А определено в 4 (б)] при Е (у) = Xf>. Подставьте C.1)
для X и найдите АХ = /.
5. Общее число важных факторов s = kp. Общее число групп на i-й стадии
gts = p-lll-n+l)kp.
6-8. См. главу IV.
Глава V
Часть V.A
1. var (х) = 2B;, cov (jc^, xt,)lN и использовать уравнение C).
2. Подставить ps = p_s и р0 = 1.
/ *i И' Л2 \
З.Р —^<"?-^ < 1 >1— 2а (см. формулу B6))
4. Использовать неравенство Бонферрони, как в уравнении B6). Другой
путь: подобрать уравнение регрессии по всем наблюдениям при Ях и %г и прове-
проверить коэффициенты регрессии (см. главу IV).
5. Системы работают периодически.
6. Медиана = х^ = Х^3у Для р = 1/4, хр = х^2у
318
1/2
1/4
x x x x x
A) B) C) W E)
7. n = 528 (cm. rJiaByJVI, табл. 7).
8. Решение d [a2 (x1-x2)]/dra1=—a?/«f + a|/(n—nlJ=:0
9. (ax — a2J — 4 cov (Xi, x2) < 0, если ax = a2.
10. Рис. 27. Совместная вероятность равна @,5)"г.
П. Подставьте знаменатель уравнений C8), C9) и A04) в A02) и возведите
в квадрат.
"t _
12. Подставьте уравнение A08) в равенство 2 (иг — иJ = 2 («J) —
/
13. fx (с) = 82 DP (D= D) — 2c. P (D < c) + 6c. P (D > c).
14. См. текст V.A.
Часть V.E
1. Вычитаемый член P (Si = О Л S2 = 0) максимален при положительно
коррелированных Si и S2.
2. Возьмем х\ = — Xi, тогда (х, < \х0 эквивалентно неравенству |х(' > \х'а.
3. d,2\ = — 1. ^E) == 1> следовательно, —• 1 < (х; —• р,0 < 1.
4. Дисперсия dj точно известна (см. D2)).
5. Доля от t, равная [1 — A — aI/f&]/2, превосходит величину а,;.
6. Р (Xi — Х~о < d%iOso (YJ/n) I \xt = ц0) = 1 — а (см. A7)). Составьте
описание для альтернативной гипотезы.
7. Случайная величина s^ti/a2 имеет распределение у?; распределение у?
относится к гамма-распределениям.
8. cov (uf, a^) = cov (xlf x2) — cov (Xi., x..) —
— cov (x.., x2) + cov (x.., x..)= и т. д.
9. o = a& и q = ab—\ соответственно.
П. Уравнение F7) приводит к неравенству тах7- a2 < (m" aJ 4a2/N;
уравнение (99) в главе IV дает SSj = Na?/4.
12. Числитель выражения для р есть cov (xt —х, Гг, — 1с0) = а2 (Зс0).
Запишите знаменатель.
13. (а) 25 средних на каждый уровень с дисперсией а2 A + р)/2. Степени
свободы уменьшаются с 5 E0 —1) до 5 B5 — 1). Сравните с формулой
y1/2]
14-15. См. текст V.B.
319
Часть У.В
1. пу = 12, п2 = 17, п3 = 25.
2. ?1(s§)=y-12af1(ai«o— I) a? = ц-Ч: (a,n0— I)a2 = a2.
3. 2s2 (n/a*J = 2 E1, 901) {2, 62/A/2 • 100)}2 = 36> 50.
OO
4. p2 = 1 — P (x2 < лГх) = 1 — J1 F2 (x) /j (л) dx и F2 (x) < Fx (х) для всех x.
— OO
5. Используйте: Ft (x) = Ф [(x — щ)/а] и Fi (x) = 1 — exp [— x/? (*)].
6. Правильный выбор для фактора А в случае yj = X, -,, — х<-\. > 0
для всех у = 1, ..., а — 1; для В в случае zg = jc^.j — jc.( j > 0 для g =
= 1, ..., b — 1. Записать из cov (yj, Zg).
7. Для равных вероятностей рг = р2 = р (= 1 для экспоненциального рас-
распределения). Различные математические ожидания, если р/Ь± Ф р/Ь2. Различные
Ь приводят к различным формам.
8. Примените метод к X\g = — In s\g, где б* = — In @,9) ж 0,11.
9. Е (I2) = E (x2)lm + IE (x)]2 (m — 1I m; E (xt x). E (xt x) = m-1 X
X {[?(jc)]2 (m - 1) + E (jc2)} и т. д.
10. См. текст V. В.
Глава VI
1. Е (х) = lib — @,1) lib, var (x) = 1/62 + @,1J/62. Функцию / (х) в (8)
можно получить, используя, например, B.4.19) из [Fisz, 1967].
2. См. аналогичное уравнение B0), включающее р = 3 генератора, иден-
идентифицирующее три фактора с тремя трехфакторными взаимодействиями; три
трехфакторных взаимодействия требуют ие менее четырех различных факторов.
3. См. VI.4.
4.п = (га/2/0,1JA— Р*)/Р*.
5. Обратной матрицы (XX')-1 не существует, поскольку матрица (XX')
вырождена. \
6. См., например, в [Scheffe, 1964, р. 123] формулы для плана с тремя фак-
факторами и М повторными реализациями. Составьте формулы [Johnston, 1963,
р. 134] для регрессионного анализа.
7. 2? = Л2г/Л', где Л = (Х'Х) X' и 2у = 8,г< /.
8. Вычислите ул из (yji — PJ). Затем уОг станет равным Yoi + Р*-
9. Величина s2( = %з99а^/399 при а2 = а!-/400 независима от уц.
10. См. уравнение B0). A7 + 45 + 36) = A2з1) = B467) = четырехфак-
торному взаимодействию между оставшимися факторами.
11. Сверхгарантией служит 2^Y^л:u^ — Р*, где каждый xuj находится на
подходящем уровне, поэтому основные допущения ММР (почти) удовлетворяются.
320
ф ДОПОЛНИТЕЛЬНАЯ БИБЛИОГРАФИЯ
ПО ИМИТАЦИОННОМУ МОДЕЛИРОВАНИЮ
И НЕКОТОРЫМ СМЕЖНЫМ ВОПРОСАМ
Краткий дополнительный перечень работ, относящихся к имитационному
моделированию и связанным с ним проблемам, приводится в связи с постоянно
растущим интересом к имитационным моделям. Библиография не дублирует
ссылок, приведенных в примечаниях к отдельным главам, и не претендует на
полноту. Ее цель —• помочь читателю в отыскании работ иа русском языке для
дальнейшего чтения.
Адлер Ю. П., Губ и некий А. И., Гречко Ю. П. О плани-
планировании эксперимента при исследовании эффективности и надежности систем
человек—техника. Доклад на совещании по кибернетике. АН СССР, 1971.
Анисимов Б. В., Петров В. Я- Организация вычислительных
процессов ЦВМ. М., «Высшая школа», 1977.
Бернатович А. С. Моделирование систем с банками данных на авто-
автоматизированной имитационной модели. — «Программирование», 1978, № 2.
Бериатович А. С. Применение методов планирования экспериментов
для исследования сложных имитационных моделей. — В кн.: Электронная тех-
техника. М., изд. ЦНИИ «Электроника», 1977, вып. 1 B2).
Браун Дж. В. Методы Монте-Карло. — В кн.: Современная матема-
математика для инженеров. М., ИЛ, 1959.
Бусленко В. Н. Автоматизация имитационного моделирования слож-
сложных систем. М., «Наука», 1977.
Бусленко Н. П. Метод статистического моделирования. М., «Ста-
«Статистика», 1970.
Бусленко Н. П. Моделирование сложных систем. М., «Наука»,
1968.
Бусленко Н. П., Калашников В. В., Коваленко И. Н.
Лекции по теории сложных систем. М., «Советское радио», 1973.
Вентцель Е. С. Введение в исследование операций. М., «Советское
радио», 1964.
р? Вопросы математико-статистического анализа краткосрочных экономиче-
экономических прогнозов. М., ЦЭМИ АН СССР, 1977.
Вычисление в алгебре и теории чисел. М., «Мир», 1976.
Вычислительные методы выбора оптимальных проектных решений. Киев,
«Наукова думка», 1977.
Гаррет Р., Лондон Дж. Основы анализа операций на море. М.,
Воениздат, 1974.
Геронимус Ю. В. Имитационное моделирование. — В кн.: Эконо-
Экономико-математические методы и модели планирования и управления. М., «Зна-
«Знание», 1973.
Г и д р о в и ч С. Р., С ы р о е ж и н И. М. Игровое моделирование
экономических процессов (деловые игры). М., «Экономика», 1976.
Г о л е н к о Д. И. Статистические модели в управлении производством.
М., «Статистика», 1973.
Голенко Д. И., ЛившицС. Е., Кеслер С. Ш. Статистиче-
Статистическое моделирование в технико-экономических системах (управление разработ-
разработками). Л., изд. ЛГУ, 1977.
Трем Р. Г., Грей К. Ф. Руководство по операционным играм. М.,
«Советское радио», 1977.
321
Г р е и ь П. Статистические игры и их применение. М,, «Статистика», 1975.
Гуд Г. X., Макол Р. Э. Системотехника. М., «Советское радио»,
1962.
Дружинин В. В., Конторов Д. С. Вопросы военной системо-
системотехники. М., Воениздат, 1976.
Ермаков С. М. Метод Монте-Карло и смежные вопросы. М., «Наука»,
1975.
Зигель А., Вольф Дж. Модели группового поведения в системе
человек—-машина. М., «Мир», 1973.
К в е й д Э. Анализ сложных систем. М., «Советское радио», 1969.
Кнут Д. Искусство программирования для ЭВМ. М., «Мир», 1977, т. 2.
Кодирование и передача информации в вычислительных сетях. «Вопросы
иибериетики», вып. 28, 1977.
Кокс Д. Р., Смит У. Л. Теория очередей. М., «Мир», 1966.
К о ф м а н А., К р ю о н Р. Массовое обслуживание. М., «Мир», 1965.
Мартин Ф. Моделирование на вычислительных машинах. М., «Совет-
«Советское радио», 1972.
Мартыненко В. Ф., Попов Ю. В., Девишев Р. И. Моде-
Модели функционирования и управления аптечной сети. М., «Медицина», 1977.
Мастаченко В. Н. Надежность моделирования строительных кон-
конструкций М., Стройиздат, 1974.
Математика в социологии. М., «Мир», 1977.
Математическое моделирование в социологии. Новосибирск, «Наука», 1977.
Метод статистических испытаний (метод Монте-Карло). М., Физматгиз,
1962.
Модели и методы анализа экономических целенаправленных систем. Ново-
Новосибирск, «Наука», 1977.
Моделирование территориальных систем. Киев, «Будивельник», 1977.
Моисеев Н. Н. Математик задает вопрос. М., «Знание», 1974.
Моль А., Фукс В., Касслер М. Искусство и ЭВМ. М., «Мир»,
1975.
Нивергельт Ю., Ф а р р е р Дж., Рейнгольд Э. Машинный
подход к решению математических задач. М., «Мир», 1977.
Новиков О. А., Петухов С. И. Прикладные вопросы теории
массового обслуживания. М., «Советское радио», 1969.
Новые идеи в географии. М., «Прогресс», 1976, т. 1.
П о л л я к Ю. Г. Вероятностное моделирование на ЭВМ. М., «Советское
радио», 1971.
Руководство по научно-техническому прогнозированию. М., «Про-
«Прогресс», 1977.
С а а т и Т. Л. Математические модели конфликтных ситуаций. М., «Со-
«Советское радио», 1977.
Системы и средства автоматизации научных исследований. Тезисы докладов
V Всесоюзной конференции по планированию и автоматизации эксперимента
в научных исследованиях. М., изд. МЭИ, 1976.
Теория систем и биология. М., «Мир», 1971.
У а т т К. Экология и управление природными ресурсами. М., «Мир»,
1971.
Фогель Л., Оуэне А., Уолш М. Искусственный интеллект
И эволюционное моделирование. М., «Мир», 1969.
Холл А. Опыт методологии для системотехники. М., «Советское радио»,
1975.
Шаракшаиэ А. С, Железное И. Г. Испытания сложных си-
систем. М., «Высшая школа», 1974.
Яковлев Е. И. Машинная имитация. М., «Наука», 1975.
УКАЗАТЕЛЬ ПЕРЕВОДА ТЕРМИНОВ
Accounting system система учета и отчетности
Ad hoc method метод для данного случая (лат.); подходящий метод
Adjustment поправка
Alias смешивание эффектов; смешивание; совместные эффекты
Allowances допуски
Analysis of residuals анализ остатков
Analysis of variance for a one factor experiment дисперсионный анализ одио-
факторного эксперимента
Analytical solution аналитическое решение
Approximative procedures приближенные методы
Artifical intelligence искусственный интеллект
Association зависимость между величинами; ассоциация; объединение
Asymptotically consistent sequential sampling асимптотически состоятельная
последовательная выборка
Asymptotically officient sequential sampling асимптотически эффективная по-
последовательная выборка
Asymptotically normally distributed асимптотически нормально распределено
Asymptotic distribution of the test statistic асимптотическое распределение ста-
статистики критерия
Asymptotic effeciency асимптотическая эффективность
Asymptotic multivariate normal distribution асимптотически нормальное мно-
многомерное распределение
Augmented design расширенный план
Autocorrelated data автокоррелированные данные
Autocovariance with lag автоковариация с запаздыванием
Avereged variance of the estimated response усредненная дисперсия предска-
предсказанного отклика
«Axial» points «осевые» точки
Balanced incomplete block design сбалансированный план в неполных блоках;
сбалансированный неполноблочный план
Best linear unbiased estimators, BLUE наилучшие линейные несмещенные
оценки, НЛНО
Blocking arrangement of 2h~* designs блочная конфигурация в планах 2h~i>
Caeteris-paribus method метод прочих равных условий (л а т.)
Cancellation of effects взаимное уничтожение эффектов
«Caution level» «предупредительный уровень»
Closed sequential procedure последовательный метод с ограничением
Combination of the levels of the factors комбинация уровней факторов
Composite hypothesis составная гипотеза
Computer time машинное время
Concomitant variable сопутствующая переменная
Conditional probability условная вероятность
Confidence coefficient A—а) доверительная вероятность A—a)
Confidence level доверительный уровень; уровень значимости
Confounding of effects смешивание эффектов
Consecutive runs последовательные опыты
Contingency table таблица сопряженности признаков
323
Continued runs непрерывные опыты
Continuous system непрерывная система
Continuous variable непрерывная переменная
Control эталон [контроль]
Corrected responses скорректированные отклики
«Covariance» stationary process процесс со стационарными «ковариация4ш»
Cross-section data данные по аналогии (сравнительные)
Crude sampling необработанная [исходная] выборка
Cyclically shifting циклический сдвиг
I*
Data snooping разведка данных
Debugging runs отладочные прогоны (опыты)
Decision theory теория статистических решений
Defective sampling неудачная (дефектная) выборка
Defining relation определяющее соотношение
Degree if «concealment» степень «сокрытия»
Degree of freedom степень свободы
Dependence of events зависимые события
.Dependent observations зависимые наблюдения
Design matrix матрицы плана
Design of resolution III план разрешения III; план с разрешающей способно-
стью III
Discrimination дискриминация [гипотез!
Distribution-free ANOVA дисперсионный анализ, свободный от распределений
(иепараметрический)
Distribution-free test непараметрический критерий
Double-sampling scheme схема двойной выборки
«Dummy» variables «фиктивные» факторы
Duncan's p-level significance р-уровень значимости Дуикана
Dunkan's protection level защитный уровень Дункана
Duplication дублирование
Eigenvalue собственное значение; характеристическое число
Endogenous variables эндогенные переменные; внутренние переменные; внут-
внутрисистемные переменные
Error rate доля ошибки; коэффициент ошибки; уровень ошибки
Error sum of squares сумма квадратов ошибки
.Estimate the variance of the average response of a simulation run оценка дис-
дисперсии среднего отклика в имитационном опыте
Estimator of location оценка положения
Evoluationary model building эволюционное построение модели; адаптация
модели
Experimental error variance дисперсия ошибки опыта
Experimental objective цель эксперимента
Experimental unit экспериментальная единица; образец
Experimentwise error rate уровень ошибки, устанавливаемый в эксперименте
Explained variables объясняющие переменные (отклики)
Explanatory variables причинные факторы; объяснительные факторы
Extreme observations крайние наблюдения
Extreme statistic крайнее значение
Exogenous variables экзогенные переменные; внешние переменные
Expected range ожидаемый размах; математическое ожидание размаха
Expected value математическое ожидание; ожидаемое значение
Experimental design экспериментальный план
Exponential density function экспоненциальная- функция плотности, экспонен-
экспоненциальная плотность распределения
Factor analysis факторный анализ
Factor loadings факторные нагрузки
Family of distributions семейство распределений
Family of fractions семейство реплик
324
"milywise error rate уровень ошибки для семейства (утверждений)
sner's «least significant difference» (LSD) test критерий «наименьшего зна-
значимого различия» (НЗР) Фишера
xed effect model модель постоянных эффектов
rixed sample size фиксированный объем выборки
Fluctuating sample size случайно меняющийся объем выборки
Fold over design доел: план, дублированный наоборот; методы перевала
Form of the response function вид функции отклика
Fourth central moment четвертый центральный момент
Fractional factorial дробный факторный [эксперимент]
Fractional factorial design with all factors at two levels двухуровневый дроб-
дробный факторный план
Frequency diagram гистограмма
Fully sequential sampling строго последовательная выборка
Fully sequential testing полностью последовательная проверка {гипотез]
Gaming имитационная игра
Gap-straggler-variance test (Tukey) критерий дисперсии разброса интервалов
(Тьюки)
General experience общее соображение (основанное на опыте)
General linear regression model общая линейная регрессионная модель
General model with interactions общая модель с взаимодействиями
Generalized splitting обобщенное разбиение
Generator of design генератор плана
Godwin inequality неравенство Годвина
Grand mean общее среднее
Gupta's parametric procedure параметрический метод Гупты
Heavy tail поднятый хвост
Heterogeneity of variances неоднородность дисперсии
Heteroscedasticity гетероскедастичность; неоднородность дисперсии
Heuristic approach эвристический подход
Heuristic sequential procedure эвристический последовательный метод
Hierarchy иерархия
High-order mod-el модель высокого порядка
Histogram гистограмма
Homogeneous variances однородность дисперсий
Human thought мышление
Identity characteristic идентифицирующая характеристика
Incomplete factorial неполный факторный эксперимент; дробный факторный
эксперимент
Increasing order возрастающий порядок
Independent observations независимые наблюдения
Indicator function функция-индикатор
Information-theoric measure теоретико-информационная мера
Inner product скалярное произведение
Integral calculus интегральное исчисление
Interpolation интерполяция
Inverse function обратная функция
Irregular fraction нерегулярная реплика
Job shop scheduling календарное планирование работы цеха [производства]
Joint confidence level of A—а) совместный доверительный уровень A—га)
Joint probability function совместная функция распределения
Kurtosis эксцесс
Lack of fit неадекватность
Lag covariance ковариация с запаздыванием; ковариация с запаздывающим
аргументом
326
Large-scale simulation крупномасштабное моделирование
Layout план; методика проведения (напр., испытаний); расположение;
распределение; таблица; схема; конфигурация; структура
Limit предел
Limit theorem предельная теорема
Linear combinations of dependent variables линейные комбинации зависимых
переменных
Linear equations лииейиые уравнения
Linear model линейная модель
Linear programming линейное программирование
Linear regression линейная регрессия
Linear space of effects линейное пространство эффектов
Linear transformation линейное преобразование
Location parameter параметр положения
Logarithm of the likelihood ratio логарифм отношения правдоподобия
«Logit» transformation «логит»-преобразование
Main effect главный эффект
Maintenance техническое обслуживание
Mann—Whitney rank test ранговый критерий Манна—Уитни
Marginal probability function безусловная функция распределения компонен-
компоненты многомерного распределения; маргинальная функция распределения
Matrix of independent variables матрица независимых переменных
Matrix not of full rank матрица неполного ранга
Matrix of variance and covariance матрица дисперсий-ковариаций
Maximum likelihood estimator оценка [метода] максимального правдоподобия
Maximum seeking method метод поиска максимума
Measure for the heaviness of the tails мера приподнятости хвостов
Measure of nonorthogonality мера иеортогональности
Midpoint середина; центр; средняя точка
Minimum variance linear unbiased estimator линейная несмещенная оценка
с минимальной дисперсией
Modular design модульная конструкция
Moving average скользящее среднее
Multi-factor designs многофакториые планы
Multi-item inventory система управления запасами с многими потребителями
Multinomial distribution мультиномиальное распределение
Multinomial variable многозначная переменная
Multiple f-tests множественные F-критерии
Multiple hypotheses множественные гипотезы
Multiple regression множественная регрессия
Multiple response experiments эксперименты с множественным откликом
Multiple selection procedure метод множественного выбора
Multiple sign test множественный критерий знаков
Multistage design многостадийный план
Multi-server system многоканальная система
Multivarjate analysis многомерный анализ
Multivariate analysis of variance, MANOVA многомерный дисперсионный ана-
анализ; MANOVA
Nested design иерархический (гнездовой) план
Newspaper-boy problem задача разносчика газет
Nonlinear equation нелинейное уравнение
Nonorthogonal estimators of effects неортогональная оценка эффектов
Nonmultiple comparisons иемножественные сравнения
Nonoverlapping непересечение
Nonparametric methods непараметрические методы
Nonparametric multivariate analysis депараметрический многомерный анализ
Nonrobustness иеробастность
Non-truncated distribution неусечениое распределение
Normal equations нормальные уравнения
326
Normalization of variables нормализация факторов; нормирование факторов
Nuisance parameters мешающие параметры
Number theory теория чисел
One-dimensional variant of response surfaee methodology одиофакториый ва-
вариант методологии построения поверхности отклика
One-half fraction полУреплика
One-sided interval односторонний интервал
One-way lay-out однофакторный план [ANOVA]
Open and sequential procedure последовательный метод без ограничения
Operating characteristic операционная характеристика
Operations research исследование операций
Optimal allocation rule правило оптимального размещения
Ordered observations упорядоченные наблюдения
Order statistics порядковые статистики
Orthogonal design ортогональный план
Outlier выброс; резко выделяющееся значение
Overprotection сверхгарантия
Paired observations парные наблюдения
Pairwise comparisons парные сравнения
Parent distribution теоретическое распределение; распределение генеральной
совокупности
Partially balanced incomplete block design (PBIB) частично сбалансированный
план в неполных блоках; неполноблочиый частично сбалансированный план
Partially duplicated design план с частичным дублированием (Д и к с т р а)
Partially overlapping additional design points частично пересекающиеся точки,
дополняющие план
Per comparison error rate удельный уровень ошибки [уровень ошибки на одно
сравнение]
Permutation test критерий перестановок; перестановочный критерий; пермута-
ционный критерий
PERT ПЕРТ (сетевое планирование)
Point estimator точечная оценка
Poisson queueing system пуассоновская система массового обслуживания
Pooled estimator объединенная оценка
Population mean генеральное среднее; математическое ожидание
Power of F-test мощность F-критерия
Predetermined reliability (наперед) заданная надежность
Prior rough estimate грубая априорная оценка
Principal fraction главная реплика
Principal identifying relation главное определяющее соотношение
Process переработка; обработка (данных)
Producer производитель
Prolonged run удлиненный опыт
Property of system свойство системы
Pure error «чистая» ошибка
Pure quadratic effect эффект чистого квадрата
Qualitative factor качественный фактор
Quality control контроль качества
Quantile estimation оценивание квантиля
Quantitative factor количественный фактор
Random balance design план случайного баланса
Random effect случайный эффект
Rank sum сумма рангов
Ranking observations ранговые наблюдения
«Reduced» design «сокращенный» план (Хизуелл и Морби)
Regression analysis регрессионный анализ
Regression analysis technique процедура регрессионного анализа
327
Region of interest область интереса
Regularity conditions условия регулярности
Reject отвергать; отбрасывать
Related factors связанные факторы
Relationship отношение
Renewal обновление
Reordering переупорядочение
Repair ремонт; починка; восстановление
Repairmen system система ремонта
Replicated runs повторные опыты; параллельные опыты
Reranked переранжировка
Residual sum of squares остаточная сумма квадратов
Response curve кривая отклика
Robustness робастность; устойчивость (к нарушениям предпосылок)
Rotatability of design ротатабельность плана
Rounding error ошибка округления
Rule of thumb эмпирическое правило; эмпирический прием
Saturated design насыщенный план
Saturated fraction насыщенная реплика
Scale parameter масштабный коэффициент
Scheffe's S-technique S-метод Шеффе
Screening design отсеивающий план; план отсеивания; план отсеивающего
эксперимента
Selection criterion критерий выбора
Semidistribution-free полунепараметрический
Sequential bifurcation последовательное ветвление
Sequential probability ratio test (SPRT) критерий последовательного отноше-
отношения вероятностей (КХЮВ)
Sequential rank-sum procedure последовательный метод для сумм рангов
Sequential sampling последовательная выборка
Sequentialization of design композиционность плана; последовательная до-
страиваемость плана
Serial correlation сериальная корреляция
Serial correlation coefficient коэффициент сериальной корреляции
Service bureau бюро обслуживания
Service time время обслуживания
Set of events множество событий
Shift in location сдвиг расположений
Shortage дефицит; нехватка; недостаток; отрицательный уровень запасов
Side-condition дополнительное условие [в задачах на условный экстремум]
Significance level уровень значимости
Simple regression простая регрессия (однофакторная)
Simulation имитационное моделирование; имитация; моделирование
Simultaneous confidence intervals совместные доверительные интервалы
Simultaneous inference совместные выводы (заключения)
Single hypothesis простая гипотеза
Single composite hypothesis отдельное утверждение из сложной гипотезы
Skewness асимметрия, асимметричность
Small sample малая выборка
Sorting routine программа сортировки [данных]
Span a space of k dimensions натянуты на пространство k измерений
Spectral analysis of stationary process спектральный анализ стационарного
процесса
Spread размах; разброс; различие выборочных средних
Spread of distribution размах распределения
Standard error стандартная ошибка
Standard normal единичное (стандартное) распределение
«Star» design план-«звезда»
Static system статическая система
Stationary distribution стационарное распределение
328
Statistical accuracy статистическая точность
Statistical techniques статистические методы
Statistical test статистический критерий
Steel's rank sum test критерий суммы рангов Стила
Step шаг; ступень
Stopping rule правило останова
Stopping statistic статистика останова
Stochastically ordered distributions стохастически упорядоченные распреде-
распределения
Strictly stationary process стационарный в узком смысле процесс
Studentized maximum modulus стьюдентизированный максимум модуля
Studentized range стьюдентизированный размах
Subset подмножество
Subset containing best population подмножество, содержащее лучшую Сово-
Совокупность
Substitute подстановка
Sum of squares of effect сумма квадратов эффекта
Supersaturated designs сверхнасыщенные планы
Surface of an irregularly shaped figure площадь нерегулярной поверхности
Survival time время жизни; период безотказной работы
Symmetric long-tailed distribution симметричное распределение с длинными
хвостами
Synchronization синхронизация
System is consistent система совместна
Taylor series expansion разложение в ряд Тейлора
Testing hypotheses проверка гипотез
Test lack of fit проверка степени (не) адекватности; проверка адекватности
Third order coefficient коэффициент третьей степени; коэффициент третьего
порядка
Time series временной ряд
Time trend временной дрейф; временной тренд
Traffic intensity интенсивность потока [требований]
Transitivity транзитивность
Translation of the distributions сдвиг распределений
Trend-elimination элиминирование тренда
Trial-and-error метод проб и ошибок
Truncation усеченность; усечение
Truncation point точка усечения
t-test критерий Стьюдента; ^-критерий
Two-factor interactions двухфакторные взаимодействия
Two-sided critical value двухстороннее критическое значение
Two-stage least squares двухступенчатый метод наименьших квадратов; двух-
двухступенчатый МНК
Two-way lay-out двухфакторный план [ANOVA]
Type I error ошибка I рода
Туре II error ошибка II рода
Uncontrolled factor неуправляемый фактор
Uncontrollable variables - неуправляемые переменные
Uniform distribution равномерное распределение
Unimodal distribution унимодальное распределение
Unit cube единичный куб
Unobserved factor ненаблюдаемый фактор
Unweighted average невзвешенное среднее
Utility function функция полезности
Upper-bound верхняя граница
Upper level of a factor высший уровень фактора
Upper а/2 percentile of Student's ^-statistic верхний а/2 процентиль ^-критерия
Стьюдента
329
Variability вариабельность
Variance of the estimator of p^ дисперсия оценки р;-
Vector of effects вектор эффектов
Vector of «errors» вектор «ошибок»
Vector of observations вектор наблюдений
Vector of parameters вектор параметров
Verhagen's caution level предупреждающий уровень Верхагена
Violations of independence нарушения независимости
Wald's sequential probability ratio test (SPRT) критерий последовательного
отношения вероятностей Вальда (КПОВ)
Weibull distribution распределение Вейбулла
Weighing-coefficient весовой коэффициент; вес
Weighted average взвешенное среднее
Welch's randomization test критерий рандомизации Уэлча
Wide-sense stationary process стационарный в широком смысле процесс
Wilcoxon's one-sample test одновыборочный критерий Уилкоксона
Wilcoxon's rank test ранговый критерий Уилкоксона
2h factorial experiment факторный эксперимент [типа] 2k
3-2~* replicate реплика [типа] 3-2-"?
ИМЕННОЙ УКАЗАТЕЛЬ
Addelman S. 54, 60, 66, 94
Adhikari A. K- 125
Al-Bayyati H. A. 150
Anderson D. A. 52, 150
Anderson H. 150
Anderson T. W. 94
Andreasson I. J. 125
Andrews D. F. 20, 136, 140, 181, 262,
272
Angers С 146, 147
Anscombe F. J. 19, 72, 74, 75, 93, 141,
207
Armitage J. V. 178, 190, 193, 225, 232,
262, 263
Balaam L. N. 207, 210
Balderston F. E. 16
Baraldi S. 131
Barlow R. E. 193
Barr D. R. 219
Barron A. 257
Bartlett N. S. 193, 233, 254
Baumert L. D. 106
Bawa V. S. 243
Beaton A. E. 15
Bechhofer R. E. 209, 218, 220, 225, 226,
227, 228, 232, 233, 242—253, 255—
257, 261—264, 269, 272, 276—278
Berbettoni J. N. 63
Birnbaum N. 62
Blomqvist N. 126, 131, 163, 164
Blumenthal S. 226, 227, 249, 256, 269,
272
Boardman T. J. 210
Bonini С. Р. 58
Booth К. Н. V. 78, 82, 107
Box Q. E. P. 15, 37, 48, 52, 56, 57, 64,
69, 70, 77, 82, 106, 176
Box M. J. 60, 67, 68
Boyd D. F. 58
Bradley J. V. 233, 235
Brenner M. E. 159
Bruzelius L. H. 126, 146
Buckland W. R. 302
Budne T. A. 72, 73, 76, 107
Burdick D. S. 315
Burman J. P. 37—39
Chambers M. L. 247, 256, 264
Chapman D. Q. 152
Chiu J. S. Y. 16
Chopra D. V. 56
Chow W. H. 146
Chow Y. S. 141
Clark S. R. 127
Clough D. J. 58
Cochran W. G. 7, 95, 105, 134
Cohen A. 63
Conover W. J. 135, 138—140, 179, 181,
201, 206, 208, 212, 233
Conway R. W. 123, 200
Cox D. R. 7, 78, 82, 93, 95, 107, 210,
211
Cox Q. M. 7, 105, 134
Crane M. A. 128—130, 137, 146, 147
Crouse C. F. 177, 185
Csorgo M. 135
Curnow R. N. 87
Cyert R. M. 72
Dalai S. R. 142, 152, 164, 193, 228, 230,
242, 252, 255, 257
Daniel С 53, 62, 66, 67, 94
David H. A. 139, 150, 256
Davis R. E. 7, 95, 105
Dear R. E. 122, 164
Deely J. J. 207
Derriks J. С 125, 130
Desu M. M. 190—192, 195
Dixon W. J. 304
Dolby J. L. 20
Donaldson T. S. 19, 272, 276
Doornbos P. 58
Draper N. R. 20, 56, 60, 64, 68, 94
Dudewicz E. J. 142, 144, 151, 152, 164,
193, 206, 218, 228, 230, 231, 233, 242,
252, 253, 255, 257, 262, 263
Duncan D. B. 207, 213
Dunn O. J. 173, 175, 177, 184—188,
196, 199, 203, 211, 212, 294
Dunnett C. W. 178—190, 193, 194, 209—
211, 213, 225, 248, 249, 256, 262—
264
Dutton J. M. 159
Dykstra O. 59, 60, 62, 67, 106
Emshoff J. R. 15, 131, 164
Fairweather W. R. 257
Farrell R. H. 150
Federer W. T. 210
Finney D. J. 302
Fisher R. A. 9
331
Fishman G. S. 122, 126—132, 136, 146,
147, 164, 200, 244
Fisz M. 73, 133, 134, 136, 182, 213,
262
Flagle С D. 138, 146
Fowlkes E. B. 15
Frankenuysen 140
Fraser D. A. S. 122
Freeman H. 157, 158, 257
Fromm G. 94
Fu K. S. 159, 236
Gabriel K. R. 181, 183—185, 201, 203,
208, 210
Gebhart R. F. 131
Geertsema J. S. 136, 146
Geisler M. A. 127, 146, 147, 164
Ghosh В. К. 157—159
Gilbert R. F. 316
Gnanadesikan R. 208
Goel P. K. 190
Golomb S. W. 106
Goodman A. S. 139
Govindarajulu Z. 193, 233, 254
Granger С W. J. 272
Graybill F. A. 273
Grundy P. M. 159
Gupta S. S. 181, 190—193, 195, 205—
208, 211, 225, 232, 239, 249, 257,
262, 263, 264
Gurtler H. 131
Guttman I. 257
Harrison S. 58, 67, 68, 72, 93, 105
Harter H. L. 182, 207, 210
Hartley H. O. 173, 198, 207, 210—212
Hauser N. 125—127, 130, 146
Hayes R. H. 159, 257
Healy M. J. R. 99
Healy T. L. 131
Healy W. C. 257
Hebble T. L. 60
Herzberg A. M. 7, 64, 93, 95
Heuts R. M. J. 150
Hicks C. R. 9, 15, 29, 56, 95, 105
Hillier F. S. 164
Hoel D. G. 228, 235, 236, 254
Hoggatt A. C. 16
Holme I. 140
Holms A. G. 63
Huang D. S. 316
Huisman F. S. 125
Hunter W. G. 20, 94
Hunter J. S. 37, 52, 56, 62, 64, 67—69,
90, 94, 106
Iglehart D. L. 128—130, 137, 146, 147
Ignall E. J. 58
Jacoby J. E. 58, 67, 68, 72, 93, 105
Jarratt P. 247, 256, 264
Jensen R. E. 15, 19
John P. W. M. 7, 17, 36, 39, 52, 56,
67, 95, 99, 106
Johnson N. L. 159
Johnston J. 17, 29, 52, 62, 63, 73, 106,
302, 306
Kabak I. W. 127
Kaczka E. E. 94
Kakwani N. С 316
Keeping E. S. 135, 138
Kempthorne O. 77
Kendall M. G. 127, 135, 142, 226, 273,
295, 302
Khatri С G. 176, 208
Kiefer J. 248
Kirk R. V. 94
Kiviat P. J. 132, 164, 200, 214
Kleijnen J. P. С 155, 156, 249, 255,
262, 270, 286, 315
Kmenta J. 216
Knight F. D. 94
Konijn H. S. 200, 210, 212
Kosten L. 131
Kotler P. 94
Krishnaiah P. R. 178, 19a, 193, 225,
232, 262, 263
Kurlat S. 138, 158
Kurtz Т. Е. 170, 196, 207, 211
Lachenbruch P. A. 183, 203
Last K. W. 93
Lehmann E. L. 180, 234, 253, 254, 264
Lewis P. A. W. 139, 181, 235
Ц С. Н. 84, 88—90, 93
Ludeman M. №. 94
McDonald G. С 193
McKay W. 125, 130, 136, 146, 161, 162
McQuie R. 58
March J. G. 72
Martin W. A. 139, 181, 235
Massey F. J. 181, 188, 211, 304
Maurice R. 159
Mazumdar M. 228
Mechanic H. 125, 130, 136, 146, 161,
162
Mehta J. S. 135
Meier R. С 135
Mendenhall W. 7, 20, 21, 64
Mihram G. A. 21, 56—58, 93, 94, 105,
122, 127
Miller J. R. 7
Miller R. G. 172—176, 179—183, 185,
187, 188, 190, 196—200, 202, 203,
207—212, 249, 251
Mitchell T. J. 56, 60
'Mitra S. K. 99, 316
Moffit D. R. 210
Mood A. M. 273
Morbey G. K. 54
332
Nagel К. 191
Nair К. R. 198
Nauta F. 7
Naylor Т. Н. 15, 18, 56, 57, 67, 94, 127,
155, 200, 210, 244, 246, 249, 262
Neave H. R. 272
Nocturne D. J. 209
Nolan R. L. 58, 93
Ogilvie J. 231, 253, 261, 263
O'Neill R. 201, 206, 207, 210, 257
Ott E. R. 93
Overhdlt J. L. 18, 58
Panchapakesan S. 191, 195, 206—208,
233, 257
Parks R. W. 316
Patel M. S. 60, 84, 88, 89
Patterson D. W. 193
Paulson E. 158, 227, 228, 235, 237—
241, 244, 251, 254—257, 263, 264
Pearson E. S. 198
Peng К. С 7, 15, 17, 20, 36
Peritz E. 181, 183, 204
Plackett R. L. 37—39
Plasmans J. 316
Press S. J. 135
Prins H. J. 146
Pun M. L. 19, 94, 135, 181, 183, 186,
200, 233, 241, 254, 257
Puri P. S. 233, 241, 254, 257
Ramachandran K. V. 207, 212
Ramberg J. S. 228, 230, 242, 251, 252
Randies R. H. 233
Rao С R. 99, 316
Rechtschaffner R. L. 54, 55
Rens P. J. 150
Reynolds J. F. 131
Rhyne A. L. 181, 207, 210
Rizvi M. H. 192—194, 212, 219, 257
Robbins H. 141, 142, 143, 146, 151, 225,
226, 247, 248, 249, 255, 263
Rogers W. H. 272
Roy S. N. 94, 210, 300
Ryan T. A. 172, 173, 210, 211
Santner T. J. 190
Sasser W. E. 15, 16, 94, 158, 264
Satterthwaite F. E. 71—73, 76, 77, 83
Saxena К. М. L. 257
Scheffe H. 12, 13, 15, 17, 19, 20, 21,
29, 95, 98, 105, 106, 134, 135, 138,
173, 175—177, 181, 183, 185, 187,
188, 196, 199—201, 203, 206—212,
245, 253, 272, 273, 276, 291, 300, 303
Schink W. A. 16
Schmidt J. W. 105, 163
Schuringa A. W. 140
Seeger P. 17, 172, 175, 185, 207, 210—
212
Sen A. K. 234, 239, 254, 256
Sen P. K. 19, 94, 135, 181, 183, 200,
208
Seshadri V. 135
Sherman E. 203, 211
Shirafuji M. 257
Sisson R. L. 15, 131, 164
Slivka J. 207
Smith D. E. 17
Sobel M. 190—195, 205, 208, 211, 212,
225, 232, 233, 241, 248, 249, 253, 256,
261—264
Somerville P. N. 257
Sovereign M. G. 58, 93
Springer M. 138, 158
Srivastava J. N. 141
Srivastava M. S. 52, 56, 146, 213, 234,
239, 241, 252—254, 256, 257, 261,
263
Srinavasan R. 135
Starbuck W. H. 159
Starr N. 141, 142, 151, 225, 249, 252
Steel R. Q. D. 173, 179, 180, 183, 203,
207, 210, 211
Stuart A, 127, 135, 142, 226, 273, 295
Taneja V. S. 257
Taylor R. E. 256
Taylor R. J. 105, 163
Teichroew D. 272
Thomasse A. H. 135
Thorburn D. 150
Tidwell P. W. 57, 106
Tobach E. 184, 186
Tocher K. D. 141, 142, 144, 164, 226
Tong Y. L. 257, 341
Torgerson W. S. 106
Tukey J. W. 19, 39, 75, 106, 170, 173,
183, 196, 202, 206, 210, 272
Van der Waerden B. L. 138
Verhagen A. M. W. 172, 210
Waller R. A. 207
Wang Y. Y. 134
Watson С S. 84—87
Webb S. 9, 49, 59, 95, 99
Wehrfritz F. W. 93
Wehrli M. 138, 149, 150
Weiss L. 150
Welch B. L. 74
Welch L. F. 75
Westlake W. J. 75
Wetherill G. B. 52, 157—159, 164,- 201,
206, 207, 210, 252, 257
Whithwell J. С 54
Wilks S. S. 179
Wilson К. В. 48
Woodroofe M. 141
Ying Yao 135
Yntema D. B. 106
.Zellner A. 300, 316
Zinger A. 257
333
ОГЛАВЛЕНИЕ
Планирование имитационных экспериментов 5
Глава IV. Планирование и анализ экспериментов 7
IV. 1. Введение и резюме 7
IV.2. Общие факторные планы и их анализ 9
IV.3. Факторные планы с факторами на двух уровнях 22
, IV.4. Основы двухуровневых дробных факторных планов 31
IV.5. Планы разрешающей способности III, IV и V 37
IV.6. Дисперсия ошибки опыта, неадекватность и последовательное
планирование 58
IV.7. Планы отсеивания 68
IV.8. Прочие вопросы планирования эксперимента 93
IV.9. Литература 94
Приложения к главе IV 95
Приложение IV. 1. Дисперсионный анализ однофакторного эксперимента 95
Приложение IV.2. Оценивание взаимодействий в эксперименте 2k . . 97
Приложение IV.3. Анализ планов Уэбба 97
Приложение IV.4. Пример применения формулы Бокса для расширен-
расширенных планов 100
Приложение IV.5. Выбор уровней незначимых факторов в групповом от-
отсеивании 101
Приложение IV.6. Роль взаимодействий в групповом отсеивании . . . 102
Глава V. Объем выборки и надежность 120
V.A. Надежность для одной совокупности 120
V.A.I. Аннотация 120
V.A.2. Оценивание дисперсии в имитационном моделировании .... 121
V.A.3. Фиксированный объем выборки и одна совокупность 132
V.A.4. Определение объема выборки для одной совокупности .... 140
Приложения к части V.A 159
Приложение V.A.I. Корреляция между последовательными опытами . . 159
Приложение V.A.2. Метод подопытов Механика и Маккея 161
V.B. Методы множественных сравнений 169
V.B.I. Вступление и краткое резюме 169
V.B.2. Уровни ошибок 170
V.B.3. Методы множественных сравнений 174
V.B.4. Эффективность и робастность ММС в имитационном моделировании 200
V.B.5. Другие методы и экспериментальная ситуация 206
Приложение к части V.B 208
Приложение V.B.I. Неравные дисперсии в методе Даннета 208
V.B. Методы множественного, ранжирования 217
V.B.I. Введение и резюме 2!7
V.B.2. Подход, использующий «зоны безразличия» 2!9
V.B.3. Существующие методы 221
V.B.4. Эффективность, робастность и приближенные методы 244
V.B.5. Другие распределения, решения и постановки задач 256
Приложения к части V.B 257
Приложение V.B.I. Выбор одной из лучших совокупностей 257
334
Приложение V.B.2. Одновыборочный метод для известных днпд'ргиЛ , JTi!)
Приложение V.B.3. Критические константы для метода В ('рИПП<"Г(ШЫ . I
Глава VI. Эксперименты Монте-Карло с методом миож(Ч шчшши |Шп-
жирования Бехгофера—Блюменталя: пример , » "li'J
VI. 1. Введение и резюме "ii'i
VI.2. Цель эксперимента "<Н
VI.3. Факторы в эксперименте , , , ',v,"
VI.4. План эксперимента „ ',VU|
VI.5. Число повторных реализаций , 1«м,1
VI.6. Методы понижения дисперсии ум/
VI.7. Результаты эксперимента 2Н',\
VI.8. Проверка робастности ММР 2д\
VI.9. Определение важных факторов 2Ш)
VI. 10. Заключение и направление дальнейших исследований .... 308
Приложения к главе VI 310
Приложение VI. 1. Общие случайные числа и оценивание эффектов фак-
факторов 310
Приложение VI.2. Простой и обобщенный метод наименьших квадратов
МНК 311
Ответы к упражнениям 318
Дополнительная библиография по имитационному моделированию и неко-
некоторым смежным вопросам 321
Указатель перевода терминов 323
Именной указатель 331
Клейнен Дж.
К48 Статистические методы в имитационном моделироиапии/
Пер. с англ. Ю. П. Адлера, К. Д. Аргуновой, В. П. Вары-
пина, А. М. Талалая; Под ред. и с предисл. Ю. П. Адлера
и В. Н. Варыгина. — Вып. 2. — М.: Статистика, 1978.—
335 с, ил. — (Математико-статистические методы за рубе-
рубежом).
В пер.: 1 р. 60 к.
Работа представляет собой обзор статистических аспектов построения ими-
имитационных моделей. Второй выпуск включает гл. IV—VI. Предмет IV главы —
планирование и анализ эксперимента; предмет V главы — исследование соотно-
соотношения между объемом выборки и надежностью оценок; в гл. VI рассматриваются
способы применения ранее освещенных методов. Для чтения книги предпола-
предполагается знание основ теории вероятностей и математической статистики.
Книга предназначена для научных работников, занимающихся построением
моделей в экономике. Она может быть полезна также преподавателям статисти-
статистических дисциплин, аспирантам и студентам старших курсов вузов.
ББК 22.172
517.8
37—78
008@1)—78
• Второй индекс 20204.
Дж. Клейнеи
СТАТИСТИЧЕСКИЕ МЕТОДЫ В ИМИТАЦИОННОМ МОДЕЛИРОВАНИИ
Вып. 2
Редакторы К- М. Чижевская, Е. В. Крестьянинова
Мл. редактор О. Б. Степанченко
Техи. редактор В. А. Чуракова
Корректоры Г. А. Башарина, Я. Б. Островский, 3. С. Кандыба
Худ. редактор Т. В. Стихно
Обложка художника Т. Н. Погореловой
ИБ № 665
Сдано в набор 01.03.78. Подписано к печати 30.08.78.
Формат бумаги 60Х90'/,6. Бумага кн.-журн. Гарнитура «Литературная».
Высокая печать. Объем 21,0 печ. л. Уч.-изд. л. 24,0 Усл. п. л. 21,0.
Тираж 9000 экз. (Тематич. план 1978 г. № 37) Заказ № 130 Цена 1 р. 60 к.
Издательство «Статистика», Москва, ул. Кирова, 39.
Московская типография № 4 Союзполиграфпрома
при Государственном комитете СССР
по делам издательств, полиграфии и книжной торговли,
г. Москва, И-41, Б. Переяславская ул., 46