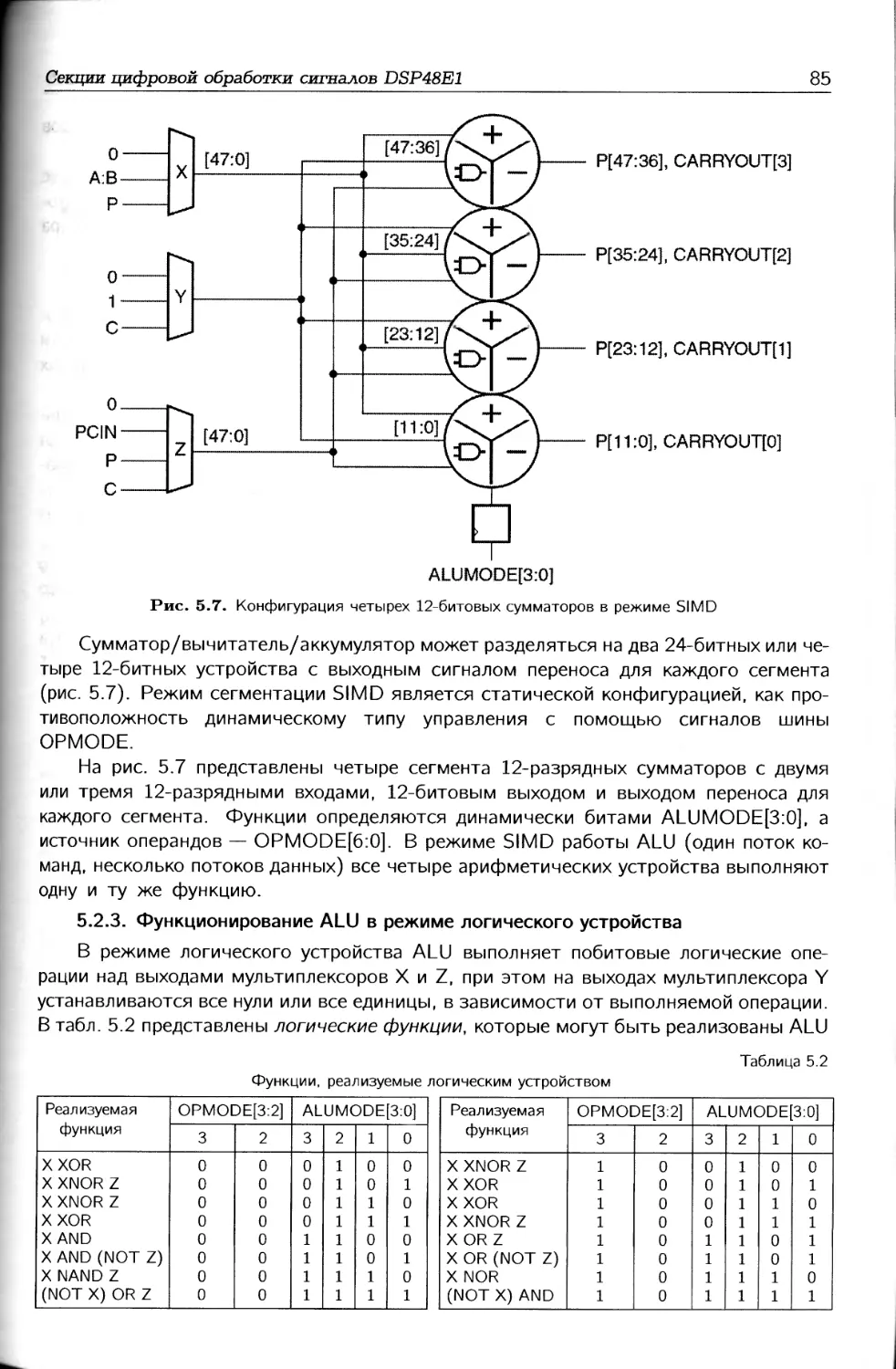
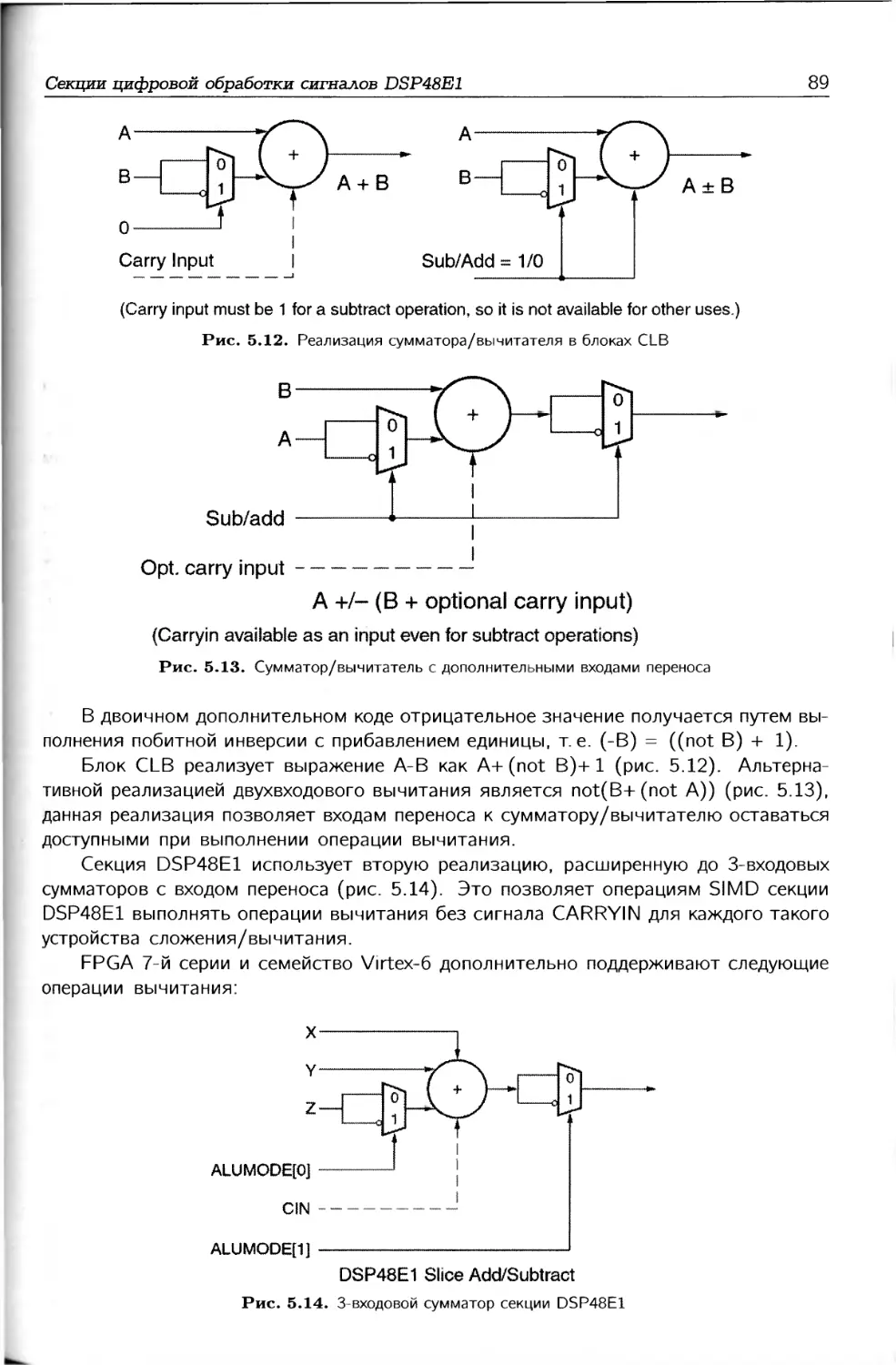
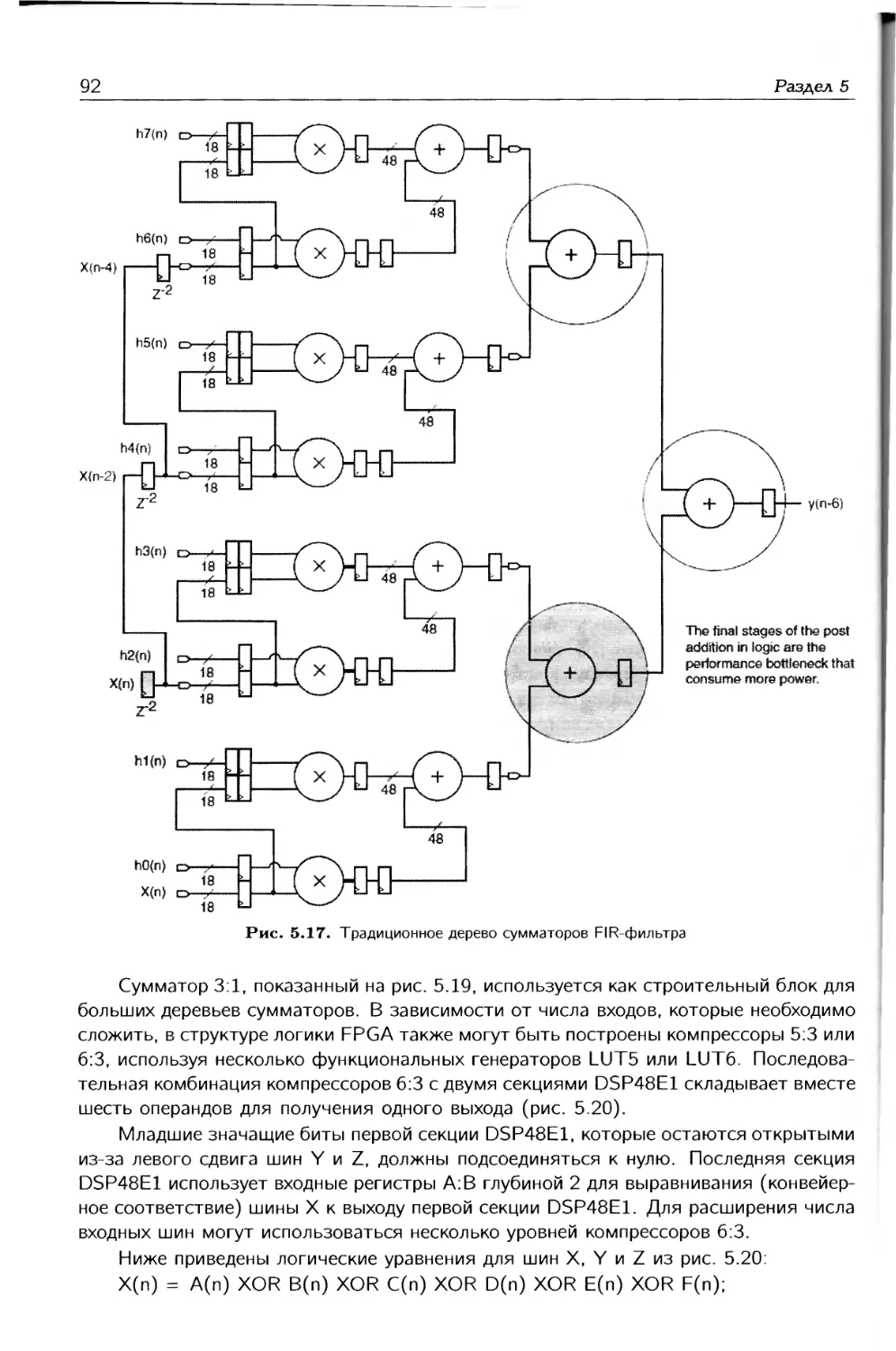
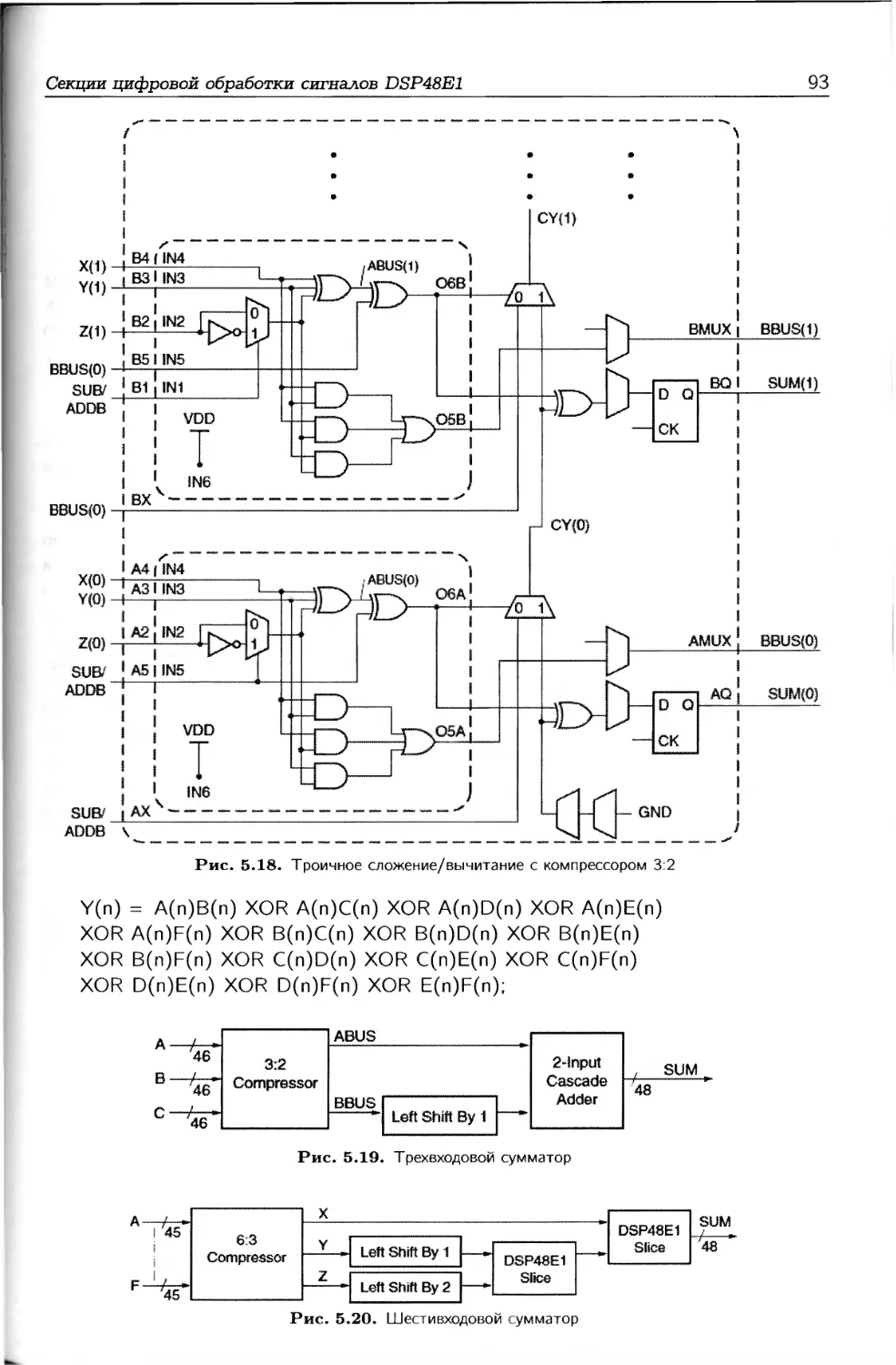
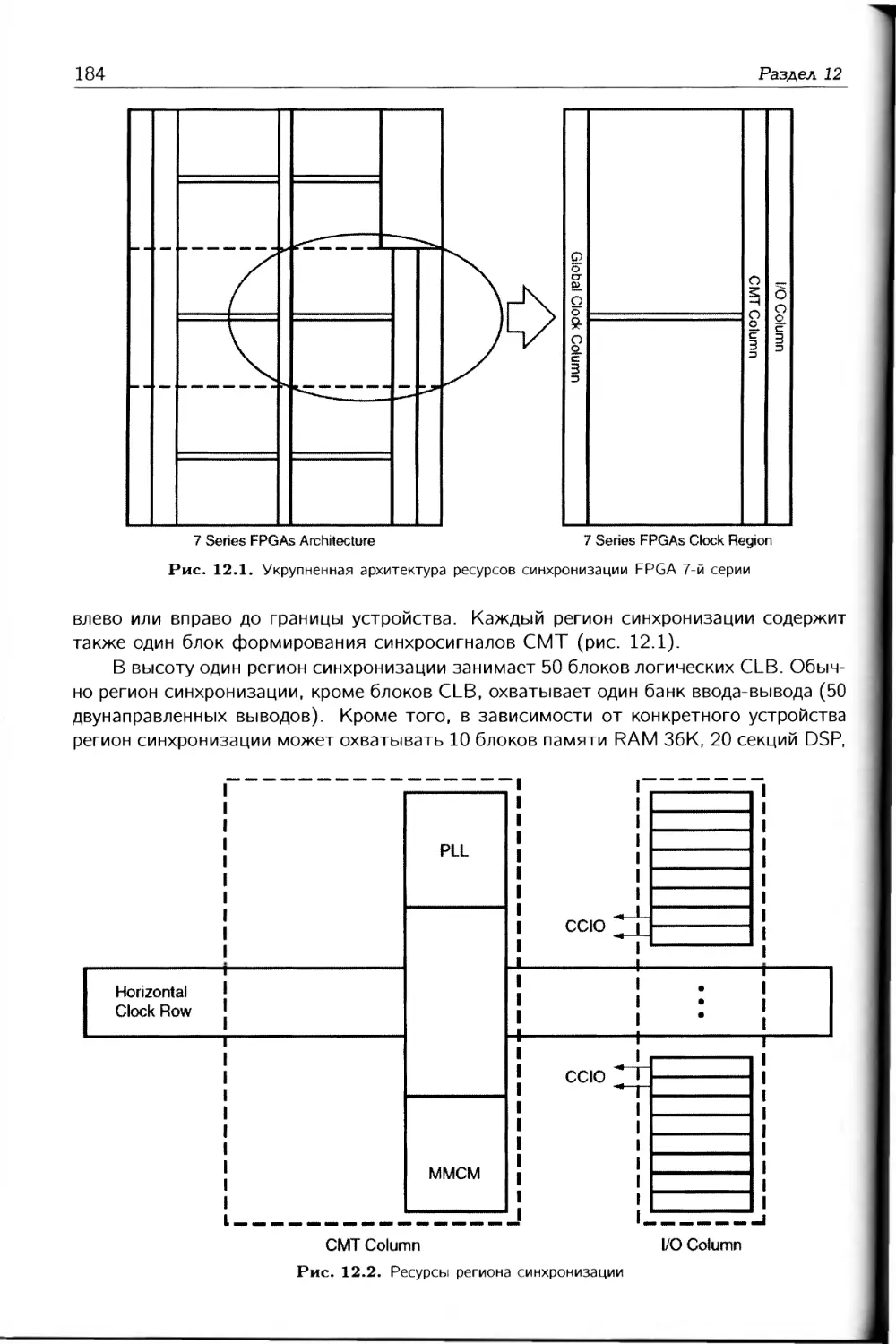
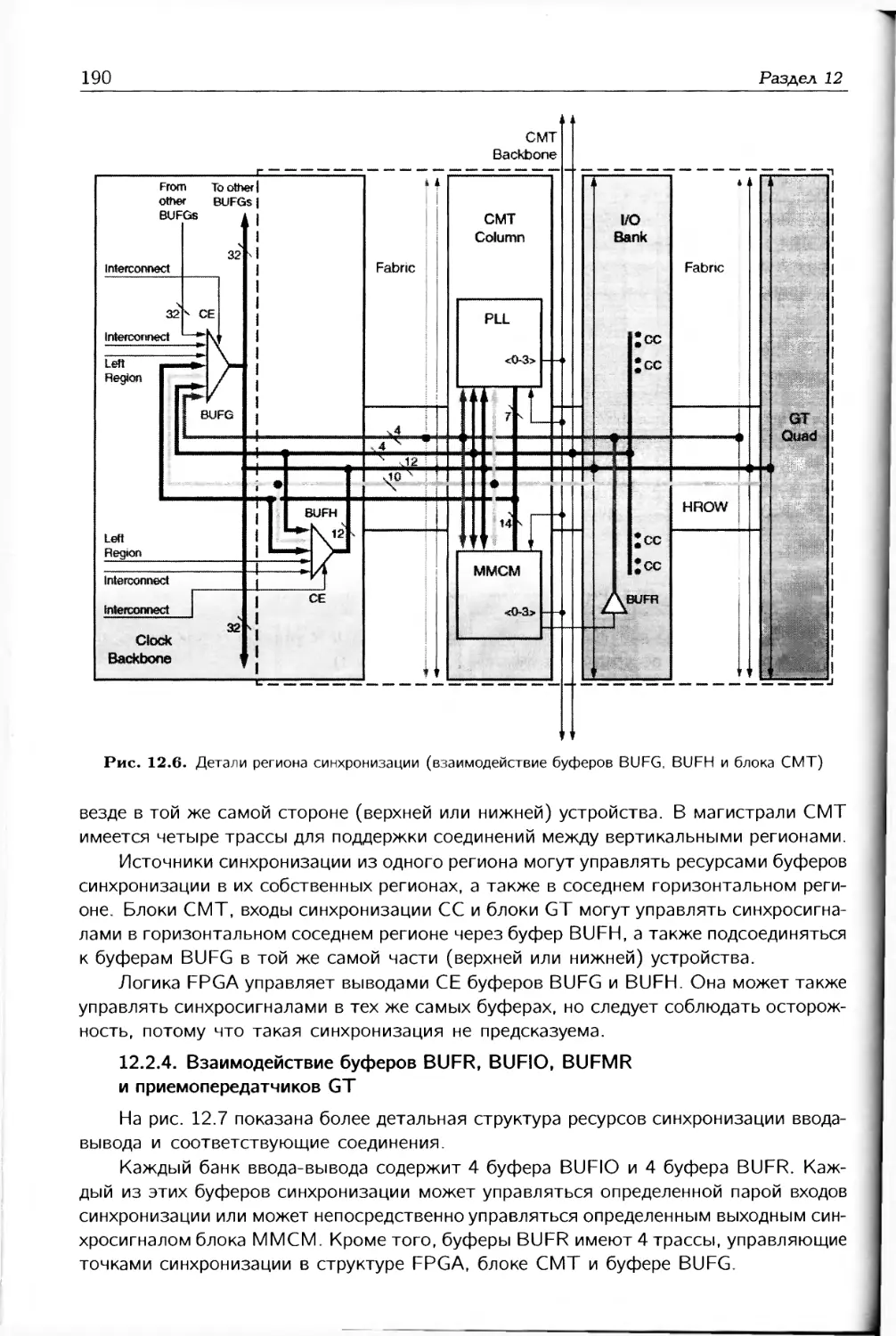
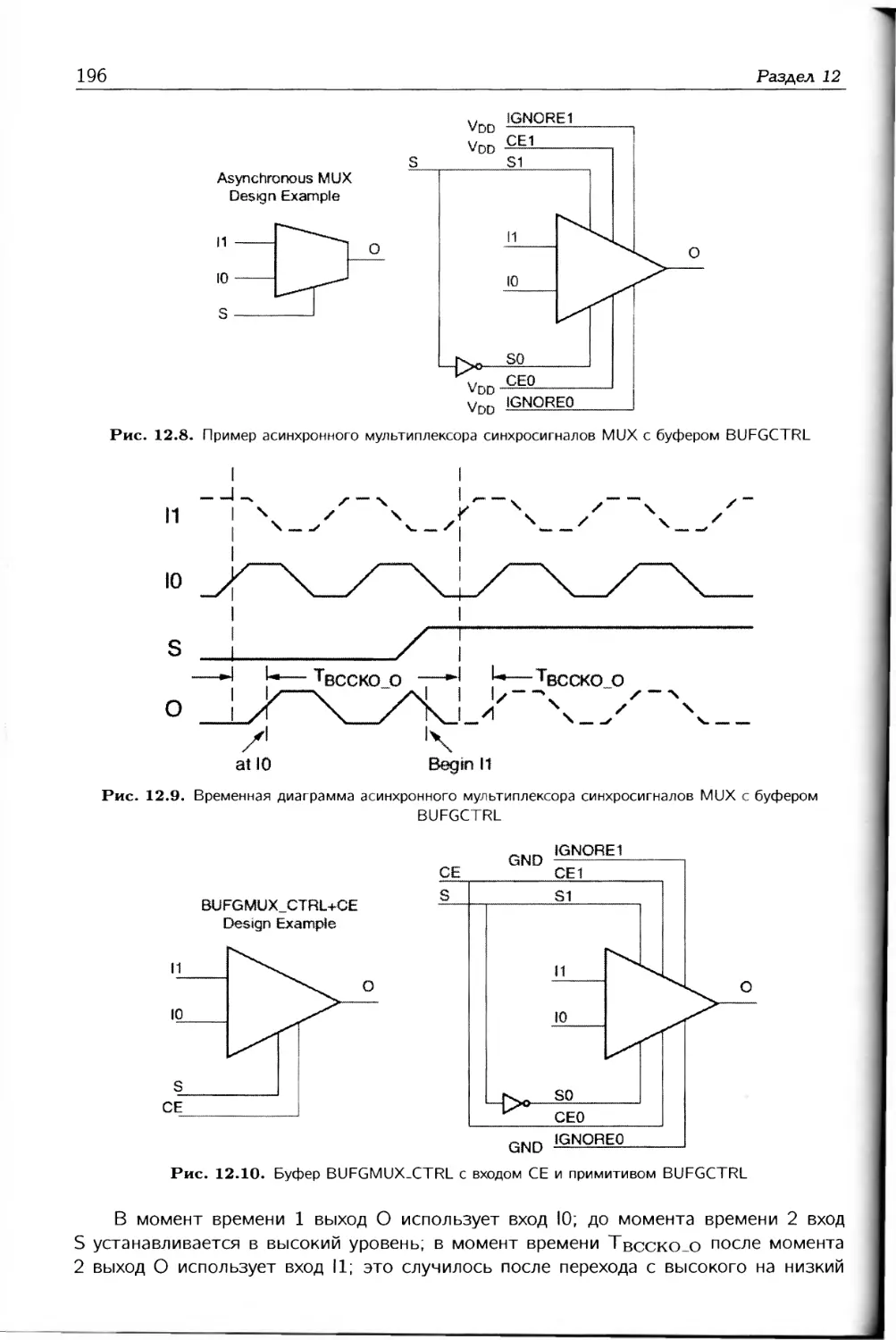
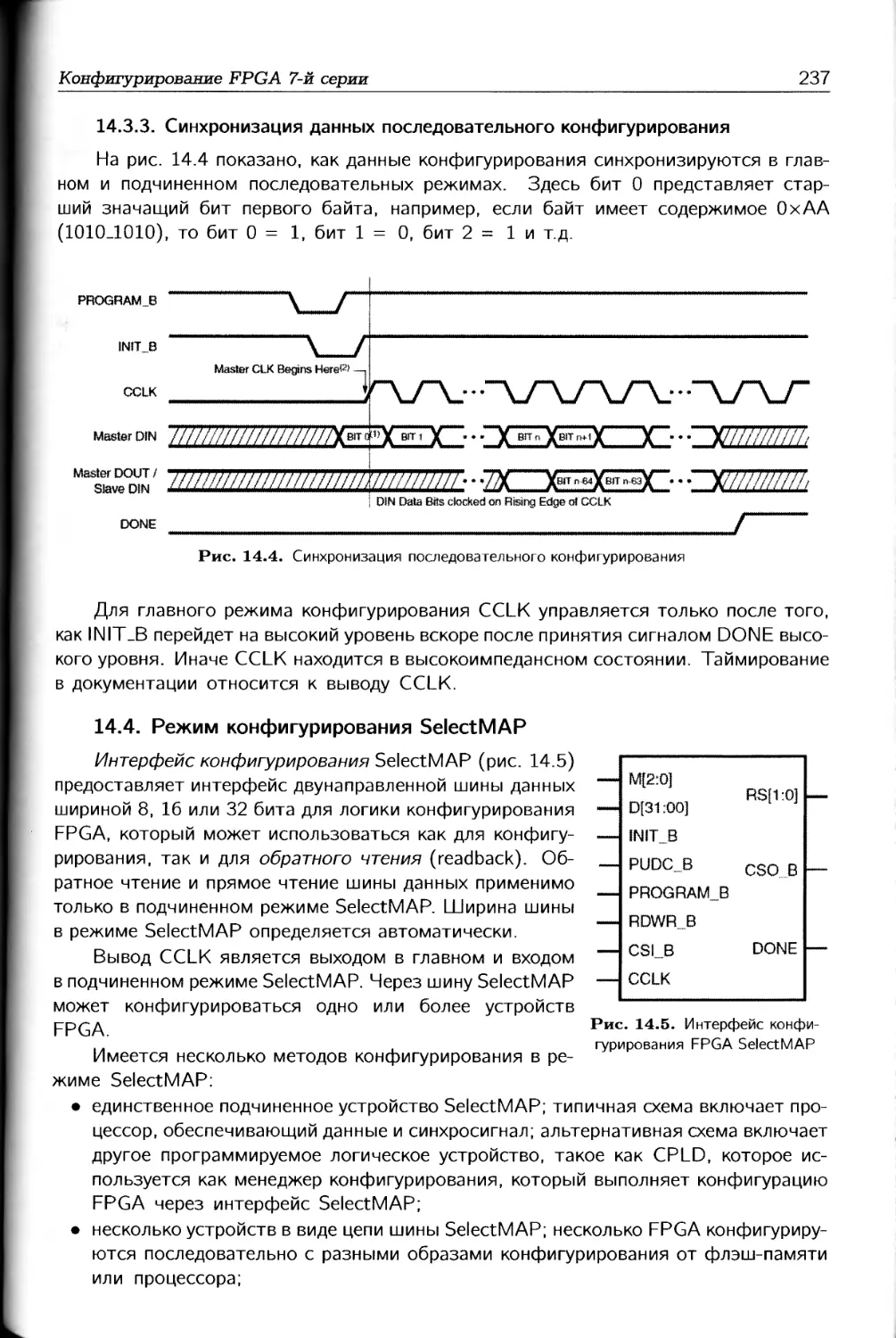
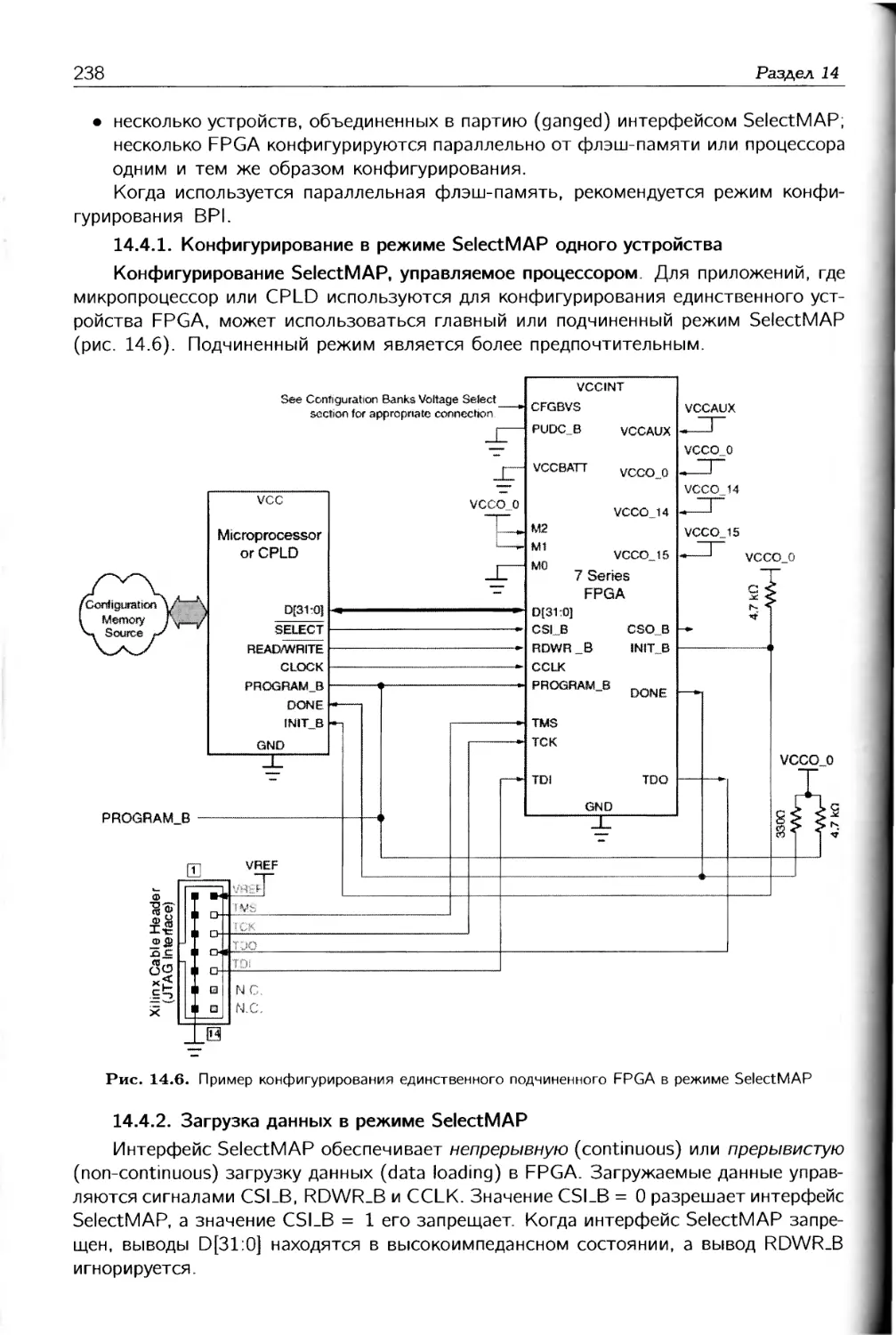
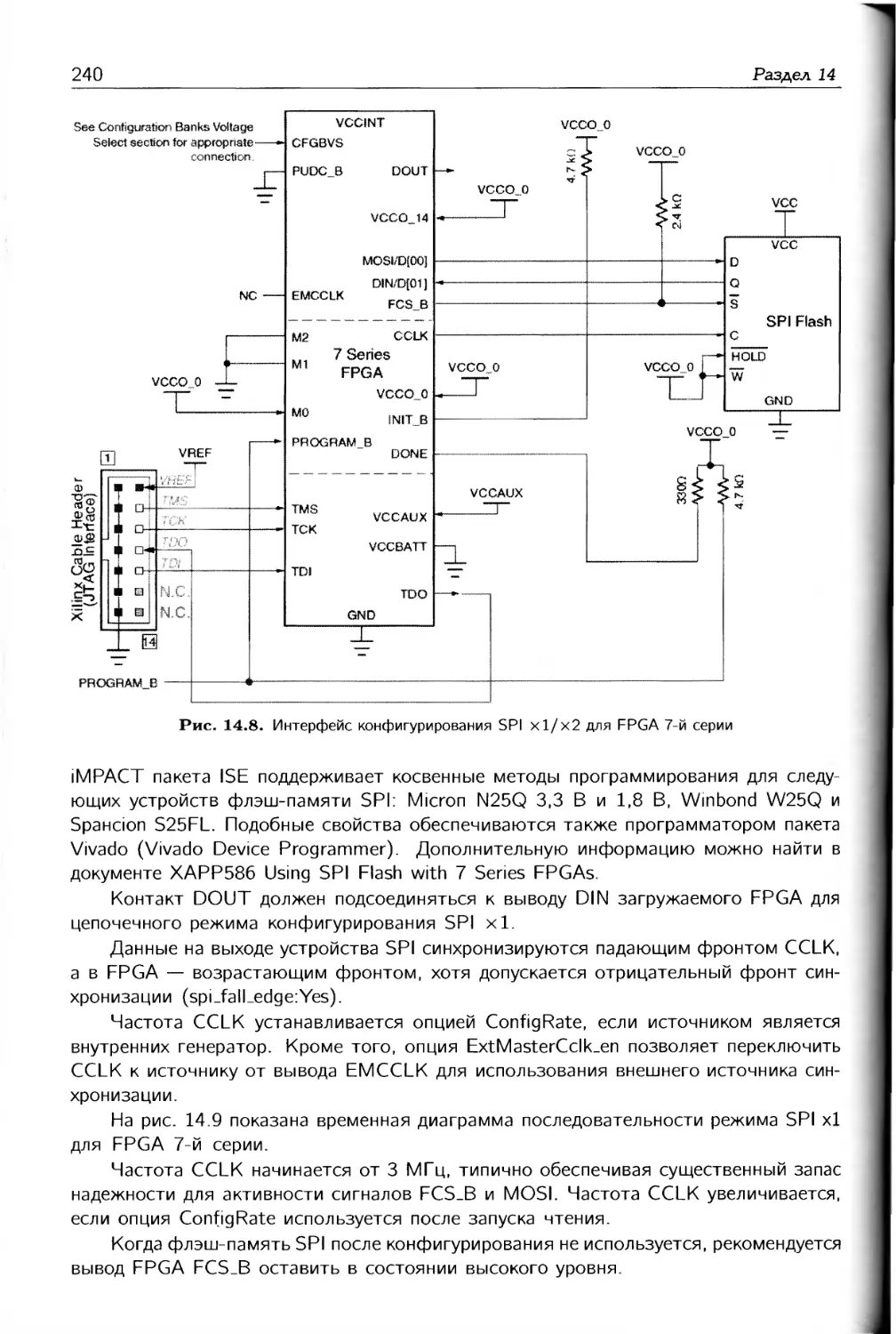
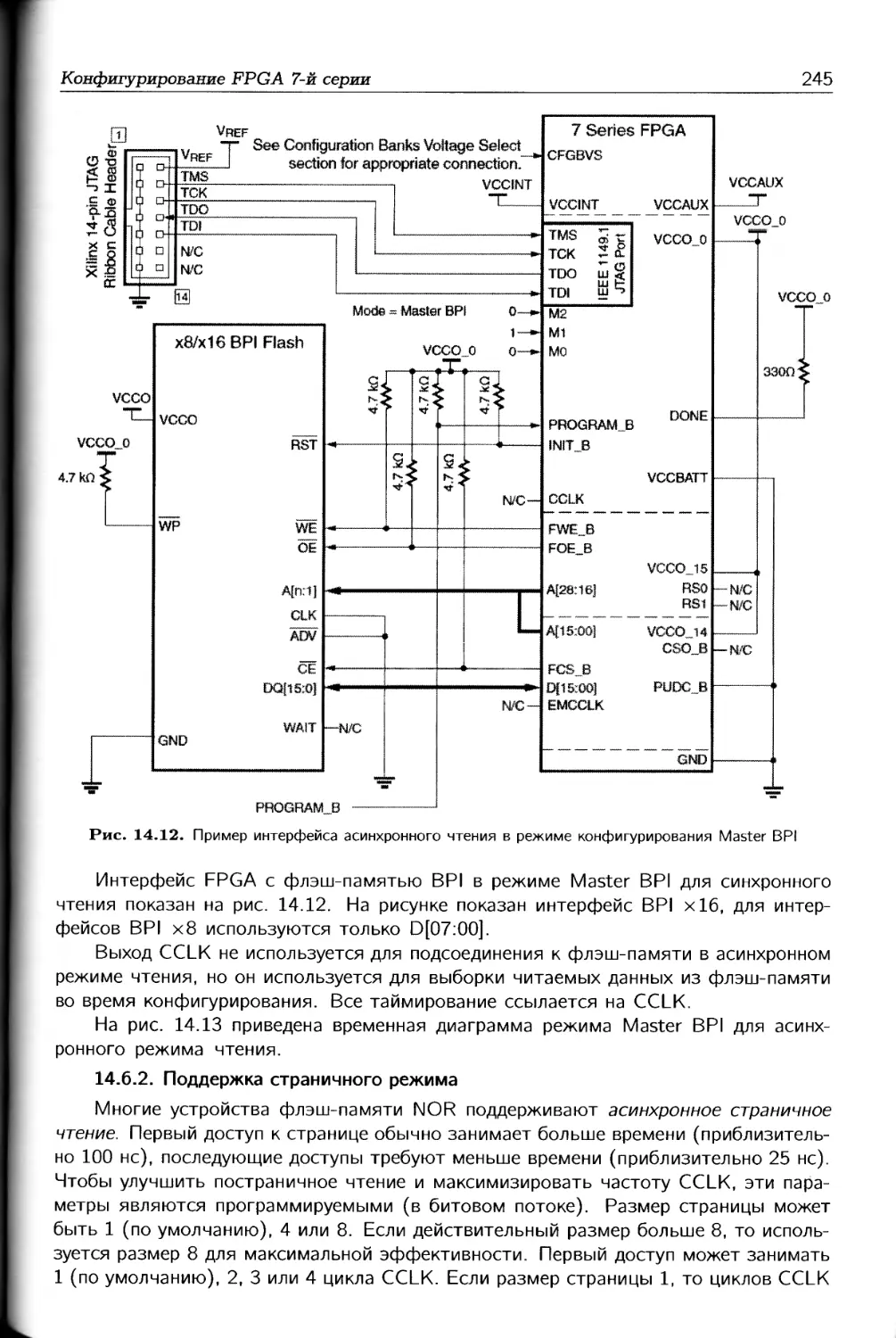
/




























































































































































































































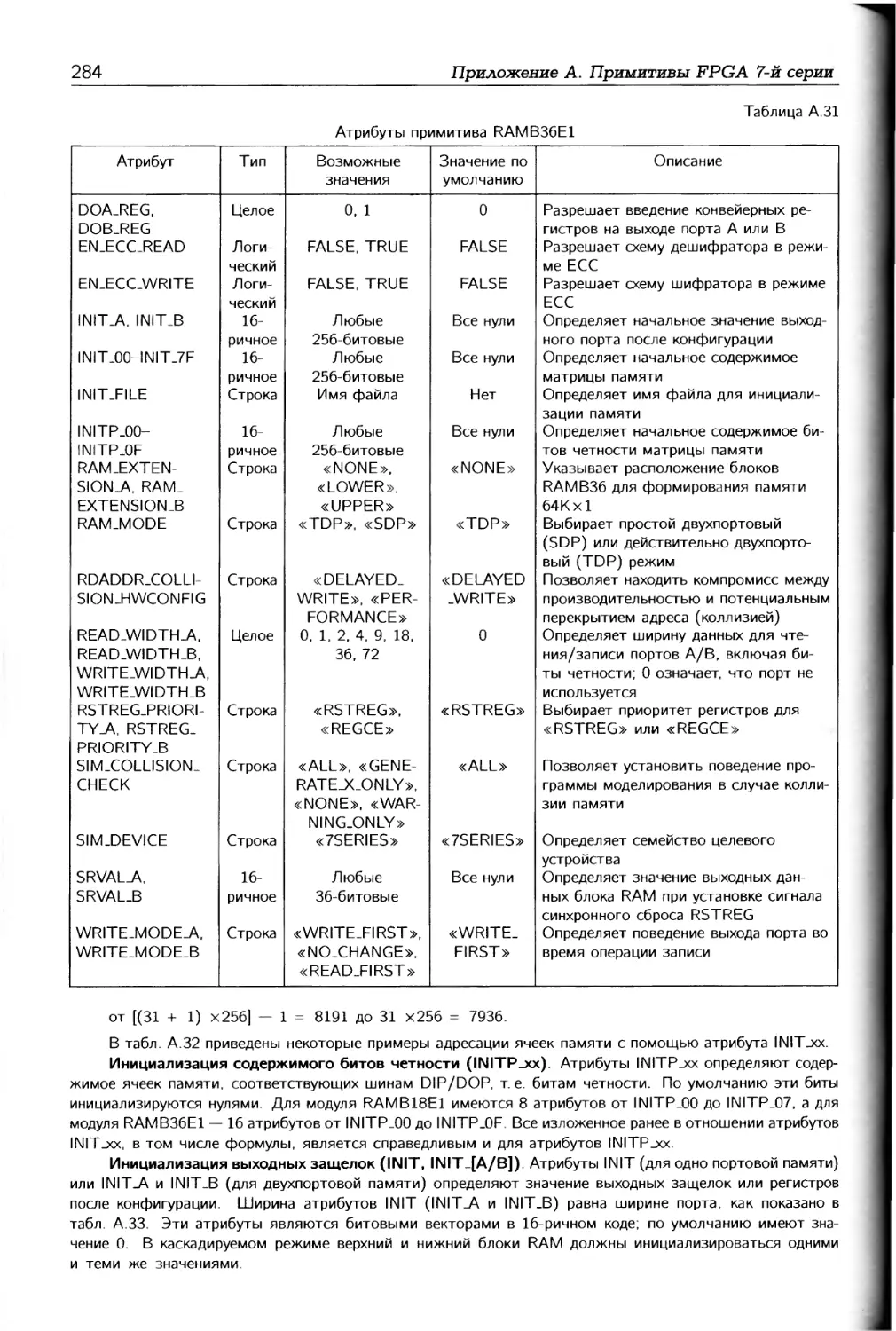
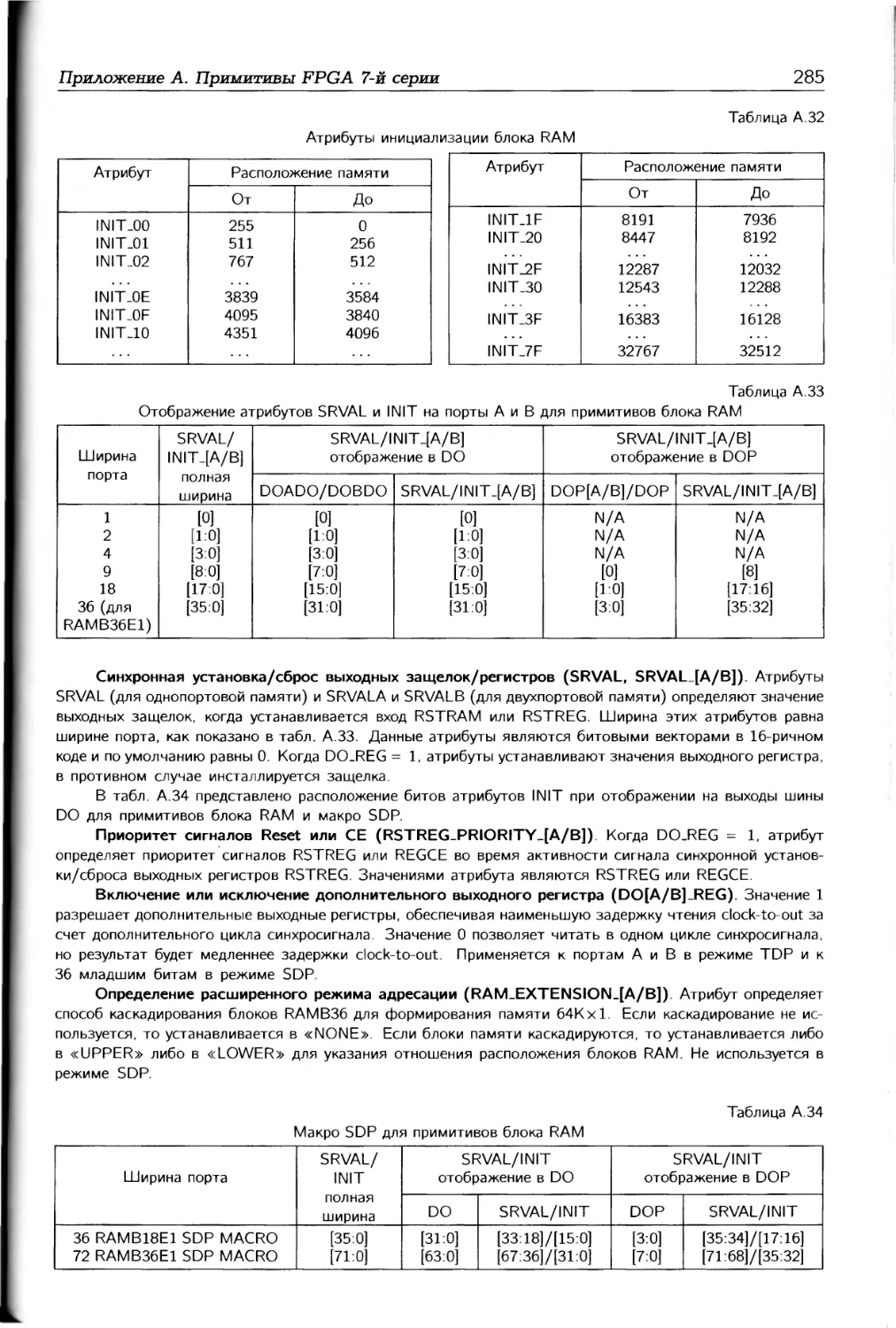

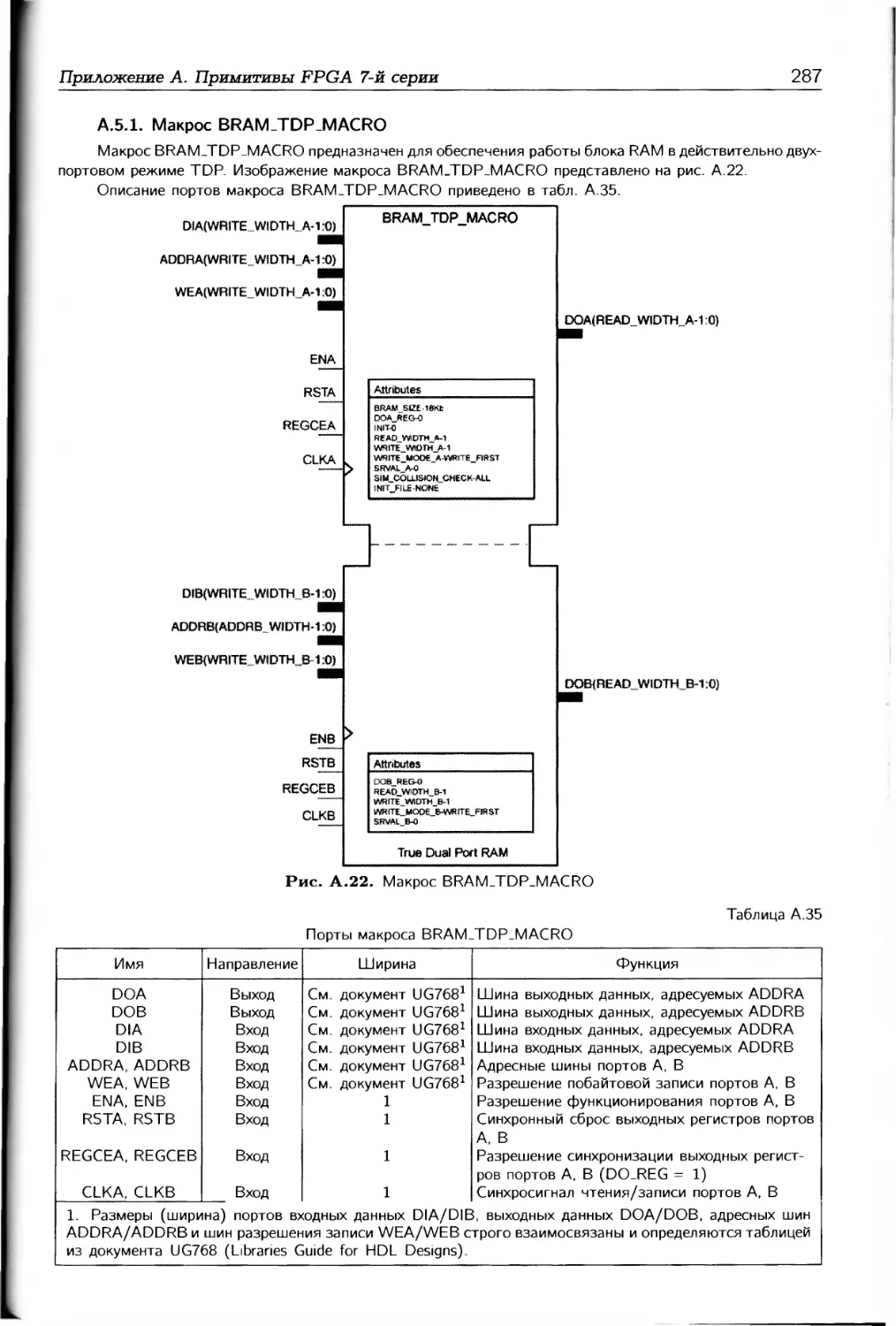

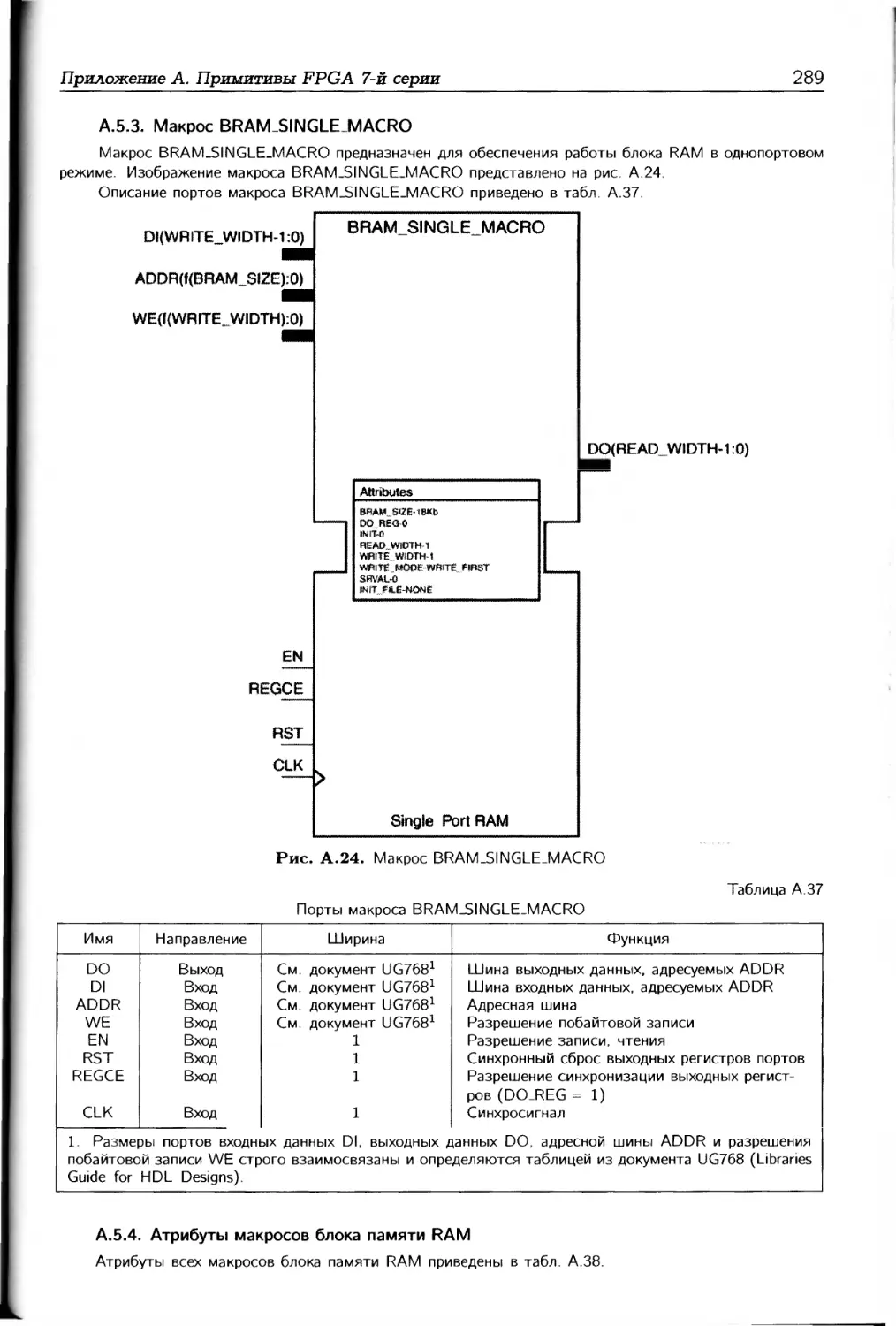















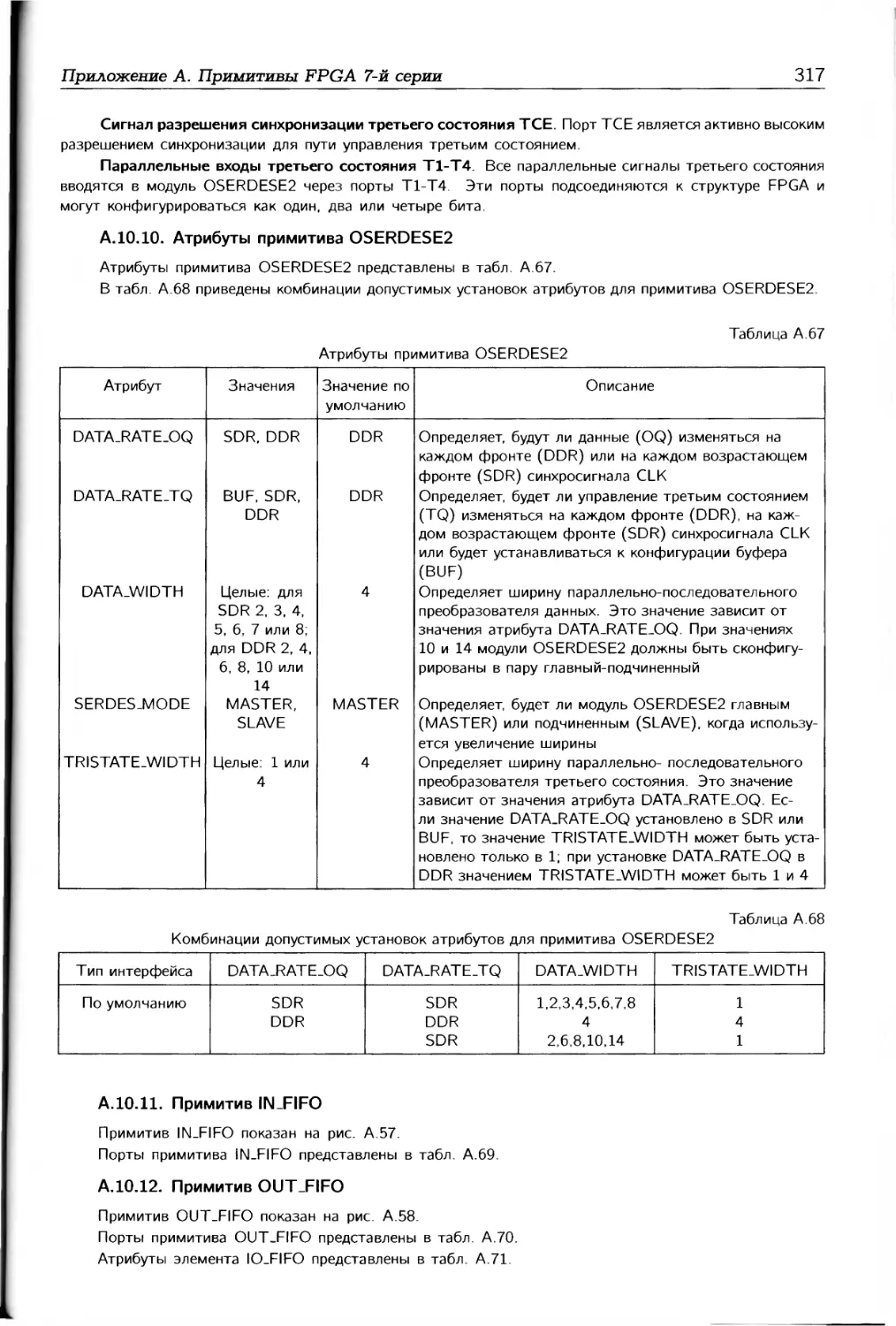
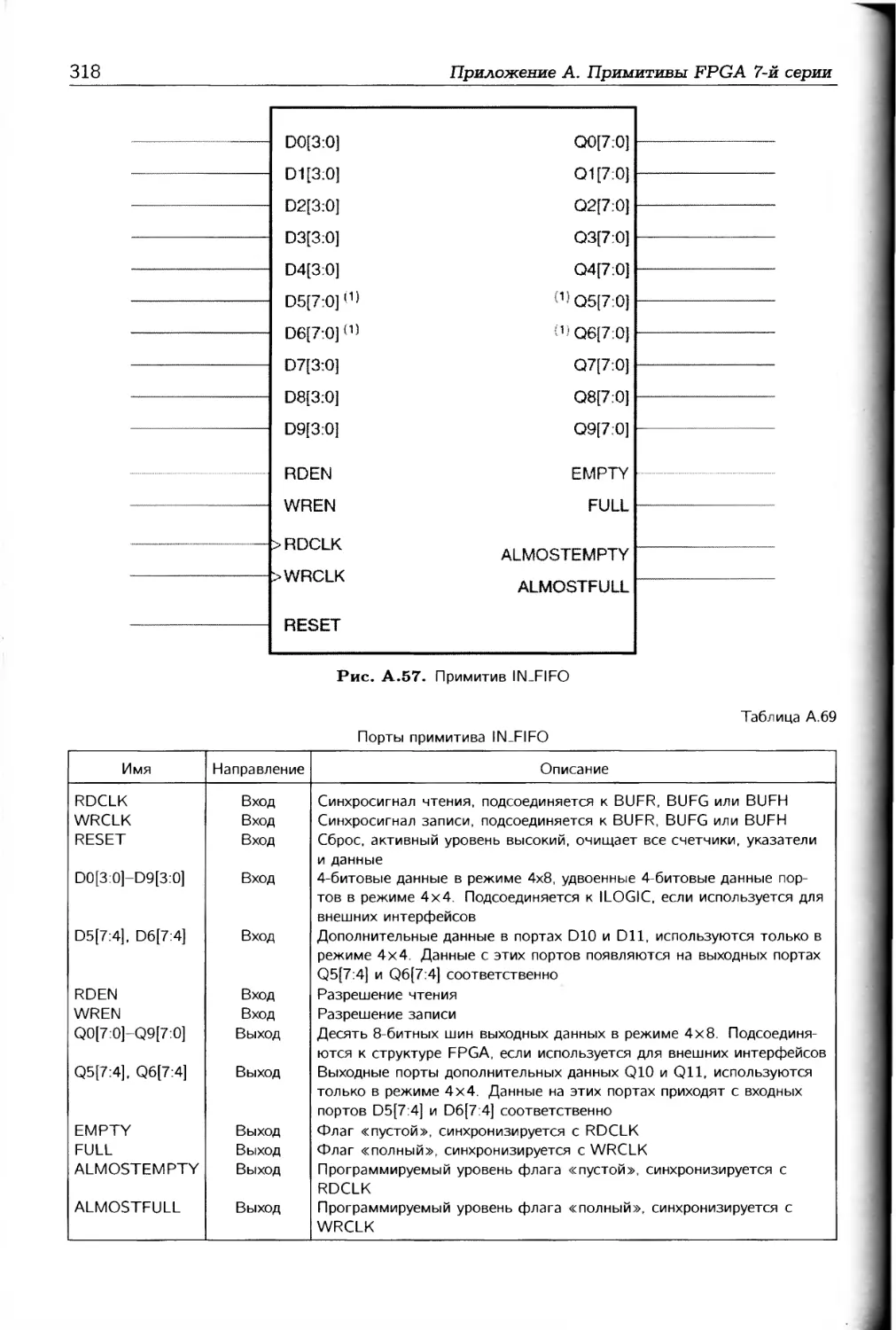

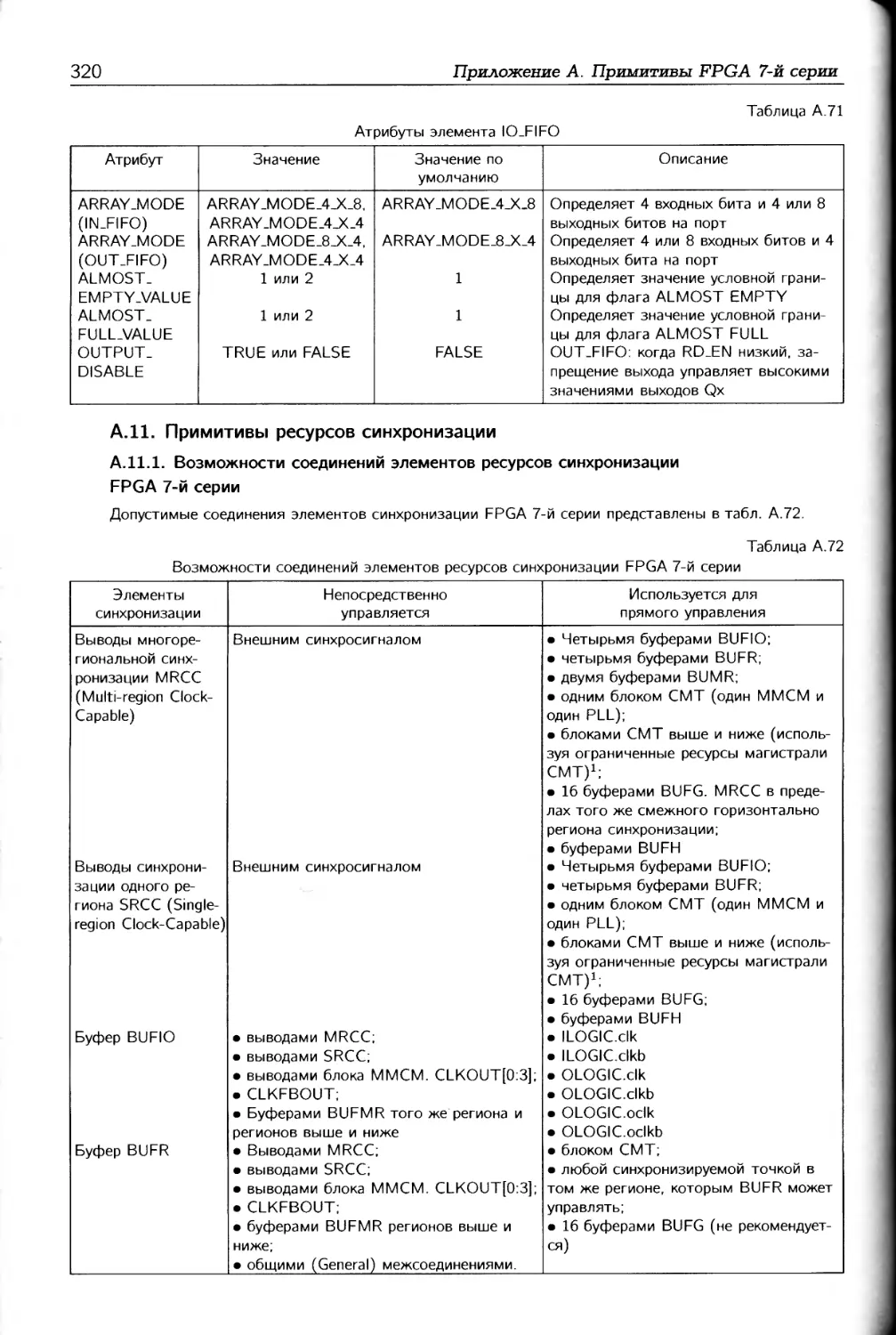



















































Автор: Соловьев В.В.
Теги: компьютерные технологии полупроводниковые устройства программирование
ISBN: 978-5-9912-0500-9
Год: 2016




Текст
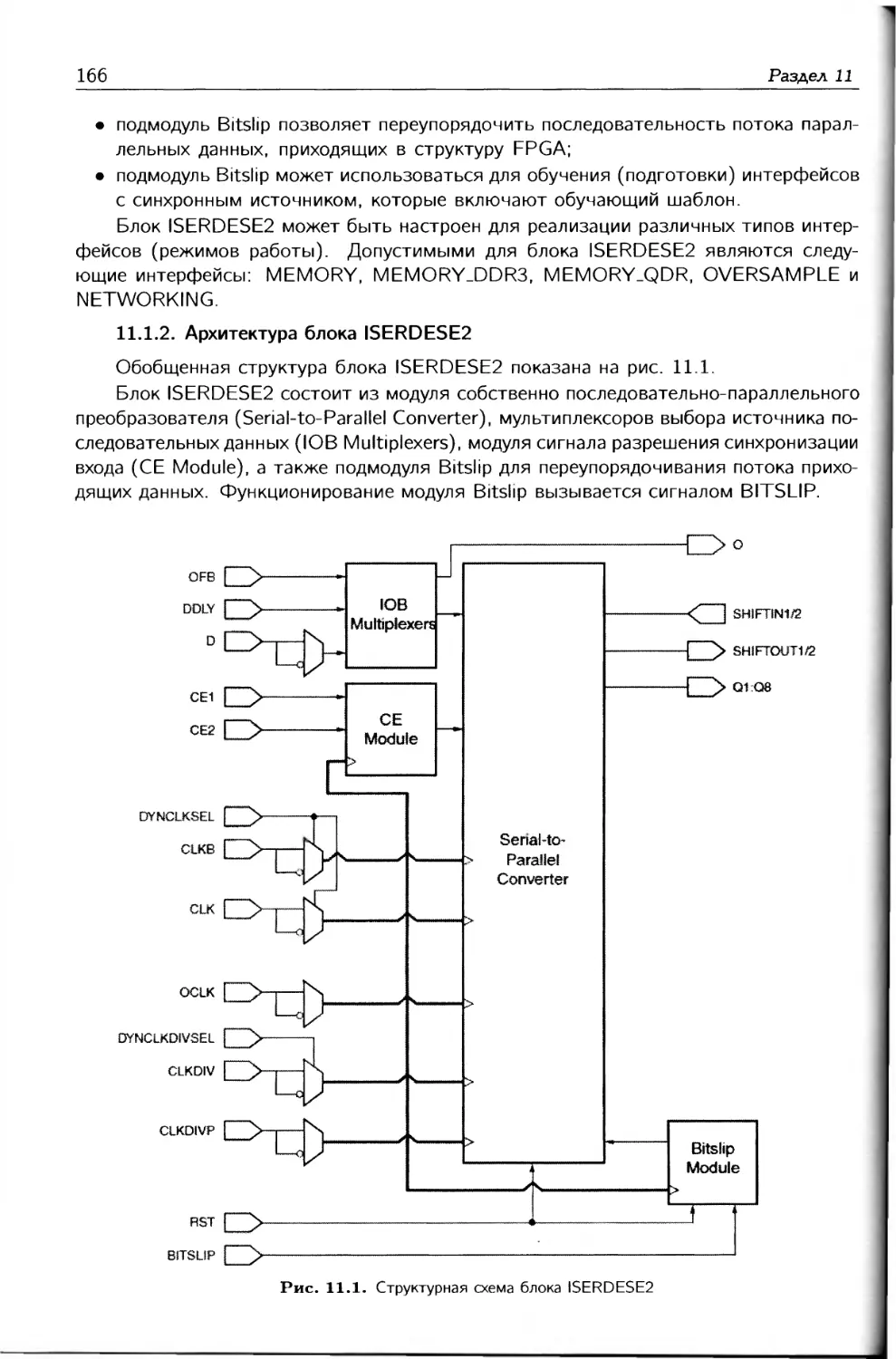
CPLD и FPGA 7-й серии
Соловьев В. В.
Архитектуры ПЛИС
Соловьев В. В.
Архитектуры ПЛИС
фирмы XILINX:
CPLD и FPGA 7-й серии
Москва
Горячая линия - Телеком
2016
УДК 681.3
ББК 32.852.3
С60
Рецензенты: ведущий инженер-конструктор ООО «Регула» (г. Минск) А. А. Козин,
канд. техн, наук, гл. инженер проекта ООО «Сенсор-М» (г. Минск) В. А. Радишевский
Соловьев В. В.
С60 Архитектуры ПЛИС фирмы Xilinx: CPLD и FPGA 7-й серии. - М.: Горячая линия -
Телеком, 2016. - 392 с.: ил.
ISBN 978-5-9912-0500-9.
Рассмотрены архитектуры программируемых логических интегральных схем
(ПЛИС) фирмы Xilinx. Приведена краткая классификация ПЛИС, дано введение в техно-
логии проектирования на основе ПЛИС, описаны архитектуры CPLD и подробно рассмот-
рены архитектуры FPGA 7-й серии. В частности, внутренняя логика FPGA: конфигури-
руемые логические блоки, распределенная память, сдвиговые регистры, мультиплексоры
и логика переноса; блоки цифровой обработки сигналов; блоки памяти RAM; режим па-
мяти FIFO; блок встроенной коррекции ошибок при записи и чтения памяти. Кроме того,
подробно рассмотрена система ввода-вывода, ресурсы синхронизации и вопросы конфи-
гурирования FPGA. В приложениях дано описание примитивов и макросов, а также вре-
менных моделей элементов архитектуры FPGA. Большинство глав заканчивается особен-
ностями применения соответствующих функциональных блоков, что значительно упро-
щает практическое использование компонентов архитектуры FPGA.
Для инженеров-практиков, разработчиков электронных систем на основе ПЛИС,
студентов и преподавателей, может быть полезна аспирантам и научным работникам,
а также менеджерам, специалистам по продаже ПЛИС.
ББК 32.852.3
Адрес издательства в Интернет WWW.TECHBOOK.ru
Справочное издание
Соловьев Валерий Васильевич
Архитектуры ПЛИС фирмы Xilinx: CPLD и FPGA 7-й серии
Редактор Ю. Н. Чернышов
Компьютерная верстка Ю. Н. Чернышова
Обложка художника О. Г. Карповой
Подписано в печать 01.11.2015. Формат 70х100/16. Усл. печ. л. 31,85.
Тираж 300 экз. (1-й завод 100 экз.) Изд. № 150500
ООО «Научно-техническое издательство «Горячая линия-Телеком»
ISBN 978-5-9912-0500-9
© В. В. Соловьев, 2016
© Издательство «Горячая линия-Телеком», 2016
Предисловие
Моей жене, детям и внукам.
В настоящее время программируемые логические интегральные схемы (ПЛИС)
широко используются в качестве элементной базы при разработке различных элек-
тронных проектов. Однако с расширением области использования и возрастанием
ответственности решаемых с помощью электроники задач также увеличивается слож-
ность проектов, реализуемых на ПЛИС. Для решения указанных проблем производи-
тели ПЛИС и средств проектирования на их основе предлагают ряд новых технологий
проектирования на ПЛИС. К таким технологиям, в частности, относится использова-
ние языков высокого уровня для описания проектов электронной аппаратуры (вместо
традиционных графических редакторов), применение всех архитектурных возможнос-
тей, которые предоставляют современные ПЛИС, и др. Таким образом, данная книга
посвящена одной из технологий проектирования на основе ПЛИС: рассмотрению ар-
хитектур CPLD и FPGA 7-й серии фирмы Xilinx.
Несколько десятилетий назад ПЛИС выпускали практически все известные про-
изводители микросхем. К настоящему времени число производителей ПЛИС несколь-
ко сократилось. Наиболее известными фирмами-производителями ПЛИС являют-
ся Altera и Xilinx, которые вместе занимают около 70 % мирового рынка. Кроме
того, ПЛИС производят такие фирмы, как Achronix, Atmel, Lattice Semiconductor,
MicroSemi (Actel), Tabula и др. ПЛИС фирмы Xilinx отличает большая функциональ-
ная мощность (несколько миллионов логических элементов), возможность использо-
вания логических элементов в качестве памяти (в дополнение к встроенным блокам
памяти), большое количество блоков цифровой обработки сигналов, большое число
триггеров (способствующих конвейерной обработке данных). Благодаря этим качест-
вам ПЛИС фирмы Xilinx получили широкое распространение среди разработчиков
электронной аппаратуры.
Архитектура FPGA 7-й серии фирмы Xilinx (по утверждению фирмы Xilinx) во-
брала в себя все лучшее, что до этого времени было разработано в области совер-
шенствования архитектур ПЛИС, причем не только фирмой Xilinx, но и другими про-
изводителями Поэтому архитектура FPGA 7-й серии стала базовой архитектурой для
следующих поколений FPGA: UltraScale. Микросхемы систем на одном кристалле SoC
фирмы Xilinx также строятся на основе архитектур FPGA 7-й серии.
В настоящей книге информация из технической документации систематизирована
таким образом, чтобы можно было изучать архитектуру современных ПЛИС фирмы
Xilinx: от общих свойств до конкретных деталей. Отметим, что степень детализации
информации является достаточной для возможности практического использования
каждого компонента архитектуры. Книга содержит большой объем справочной ин-
формации. Чтобы не отвлекать внимание читателя, большинство справочной инфор-
мации вынесено в приложения.
Первая глава является введением в проблематику современных ПЛИС. Приво-
дится краткая классификация ПЛИС согласно их историческому развитию, дается
4
Предисловие
введение в технологии проектирования на основе ПЛИС, приводится характеристика
программируемых микросхем фирмы Xilinx, а также описываются основные свойства
FPGA 7-й серии.
Вторая и третья главы посвящены FPGA фирмы Xilinx, а именно семействам
XC9500XL и CoolRunnerlL В электронных проектах CPLD часто устанавливаются на
плату вместе с FPGA, их основной функцией является управление порядком пода-
чи напряжений питания для всей системы, а также конфигурированием и инициа-
лизацией FPGA.
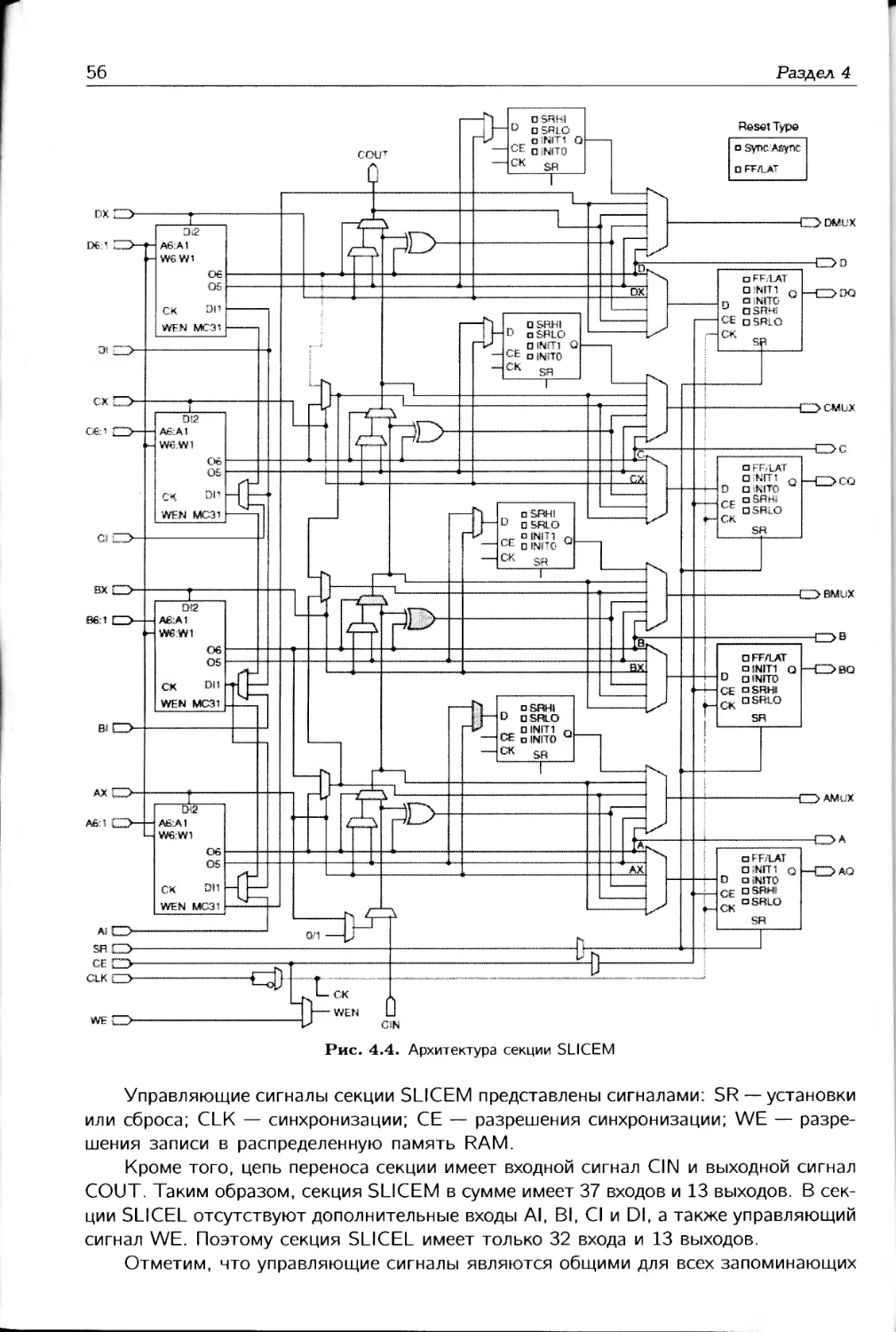
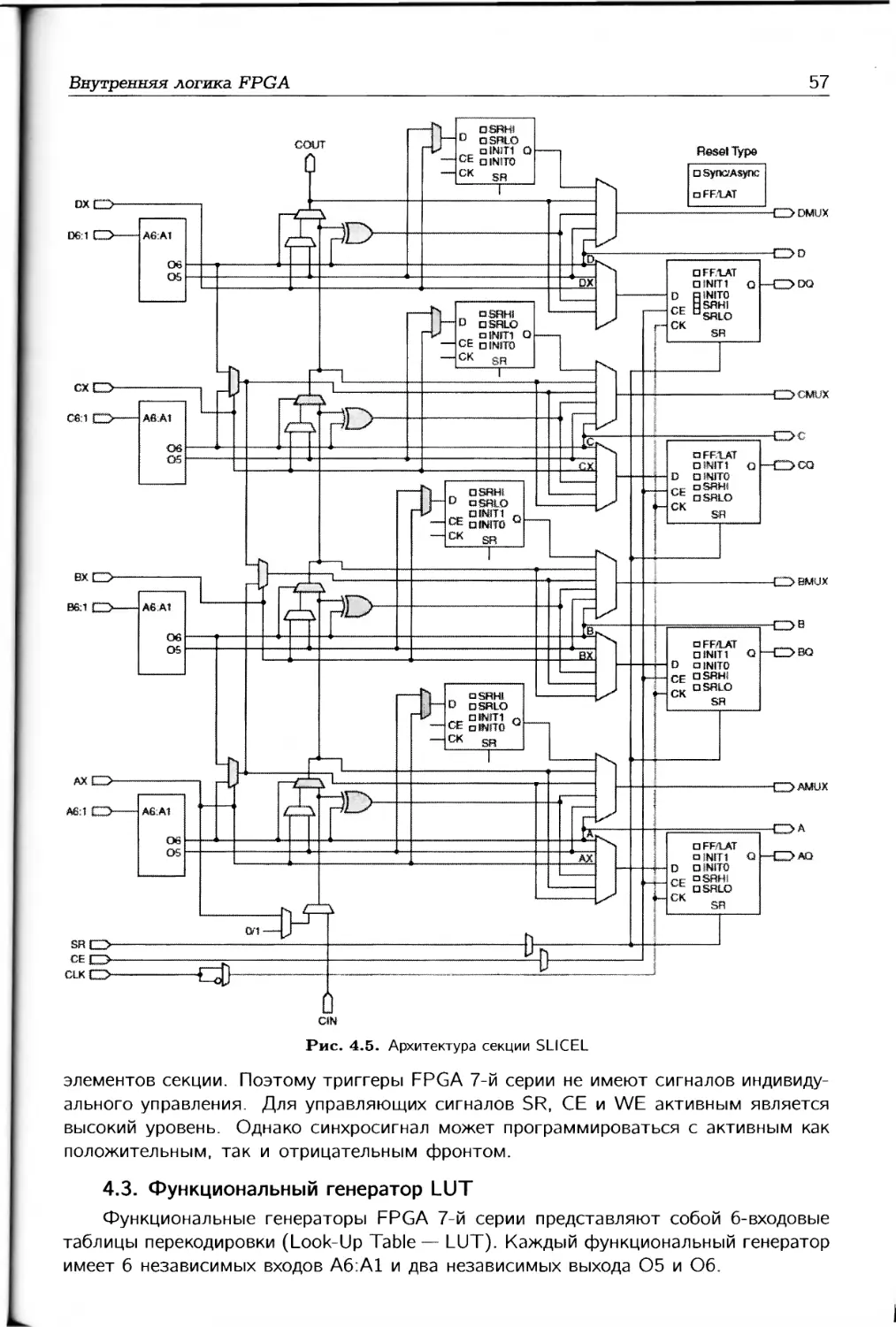
В четвертой главе описывается архитектура внутренней логики FPGA 7-й серии:
конфигурируемые логическое блоки CLB, секции, функциональные генераторы LUT,
распределенная память RAM и ROM, сдвиговые регистры, мультиплексоры, а также
логика переноса. Отметим, что четвертая и все последующие главы заканчиваются
особенностями применения соответствующих функциональных блоков.
Практически ни один современный проект на ПЛИС не обходится без решения
задач цифровой обработки сигналов (ЦОС). Поэтому пятая глава посвящена секции
цифровой обработки сигналов DSP48E1. Здесь рассматривается общая архитектура
секции DSP48E1, а также такие элементы, как арифметическо-логическое устройст-
во, детектор шаблона, логика обнаружения переполнения и потери значимости, другие
функциональные возможности секции DSP48E1. Особое внимание уделено особен-
ностям применения секции DSP48E1.
Редко какой из современных проектов обходится без использования памяти.
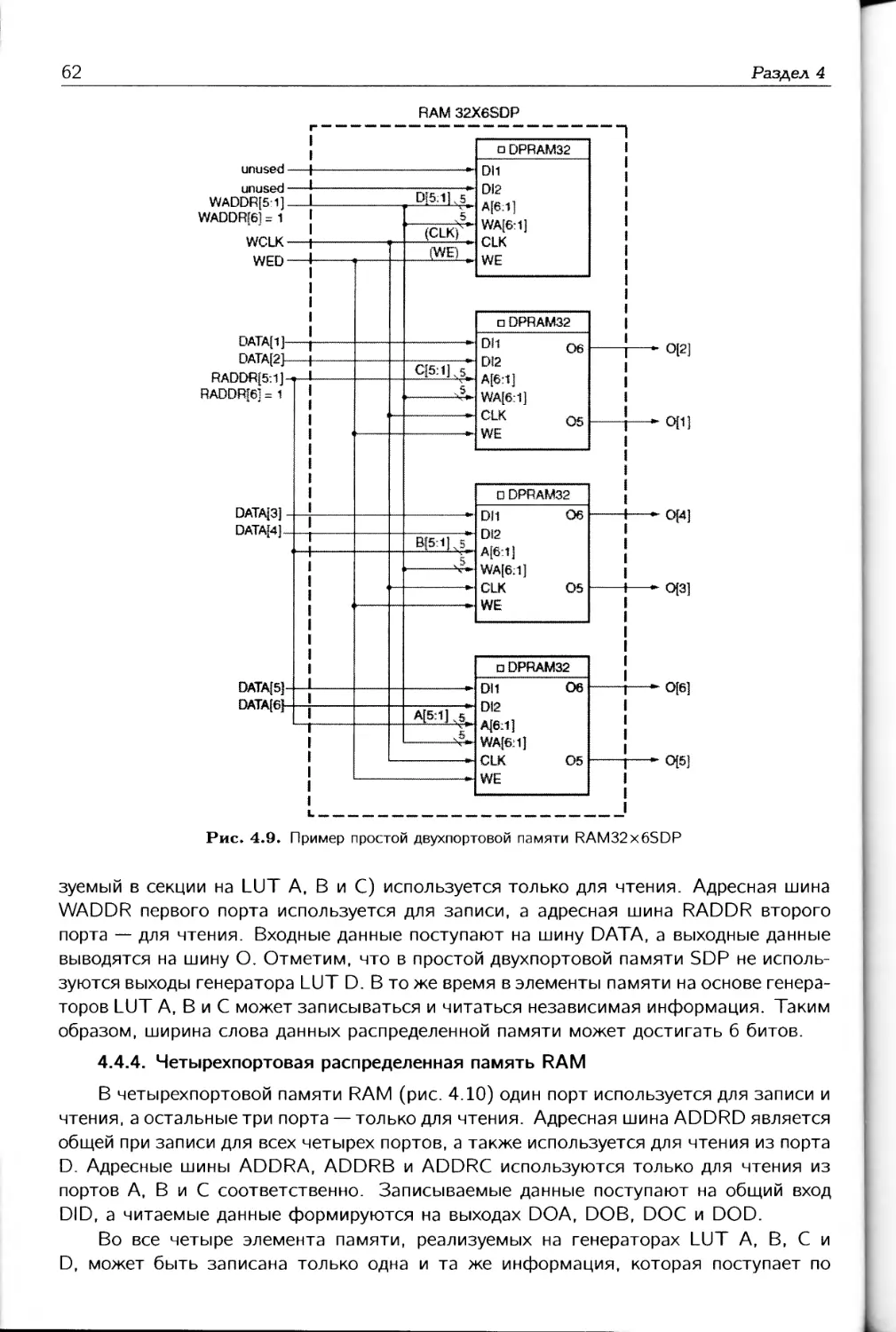
Шестая глава посвящена встроенным блокам памяти RAM. Рассматривается архи-
тектура блоков RAM, режимы функционирования, а также особенности применения,
в частности, каскадирование блоков RAM, побайтная запись в память, использова-
ние конвейерных регистров.
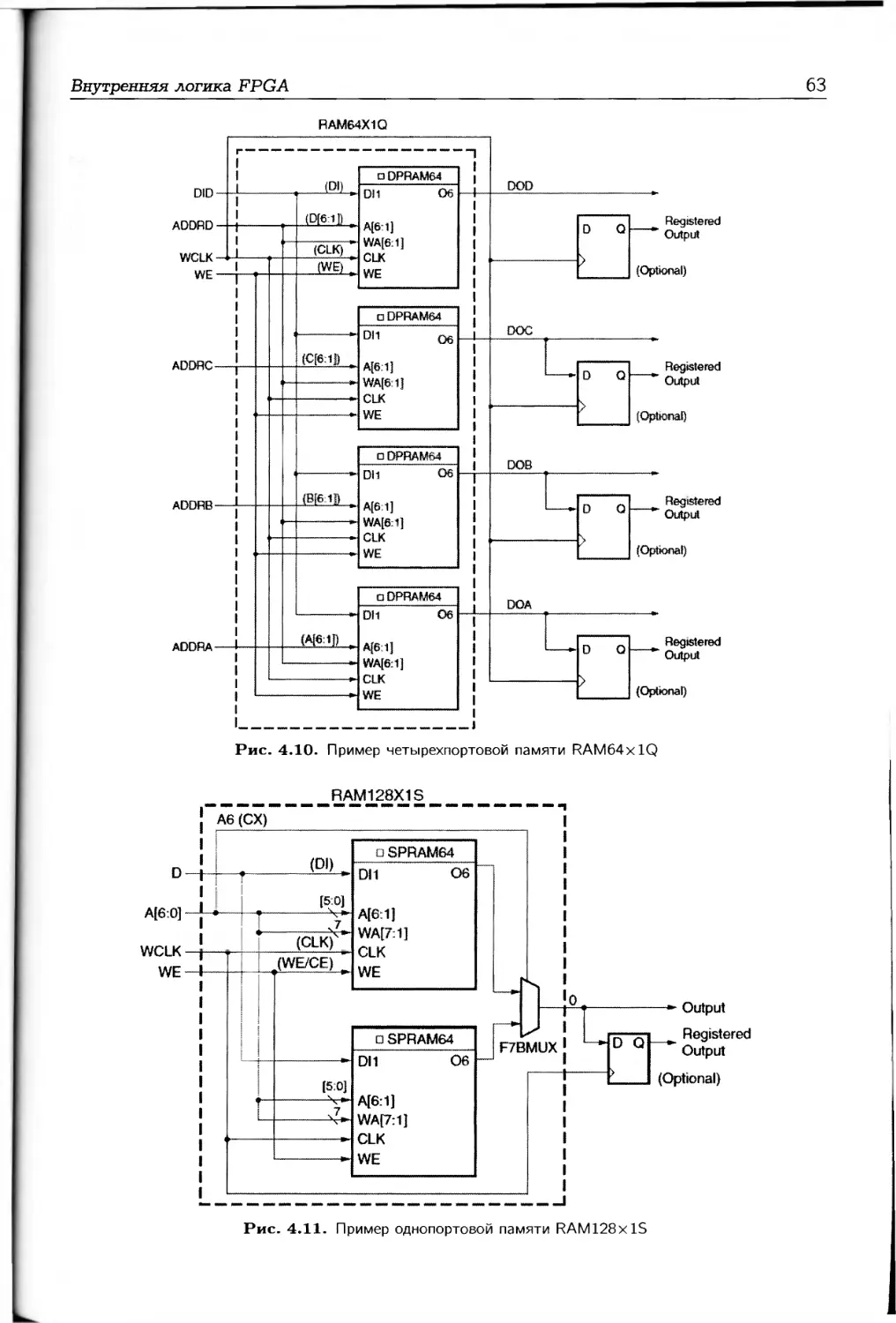
Блоки памяти RAM FPGA 7-й серии могут также функционировать в режиме
памяти типа FIFO. Седьмая глава посвящена рассмотрению свойств памяти FIFO:
описывается общая архитектура памяти FIFO, рассматриваются режимы функциони-
рования, а также особенности применения памяти FIFO.
Блоки памяти FPGA 7-й серии как в режиме RAM, так и в режиме FIFO позво-
ляют использовать механизм коррекции ошибок при записи и чтении данных. Для
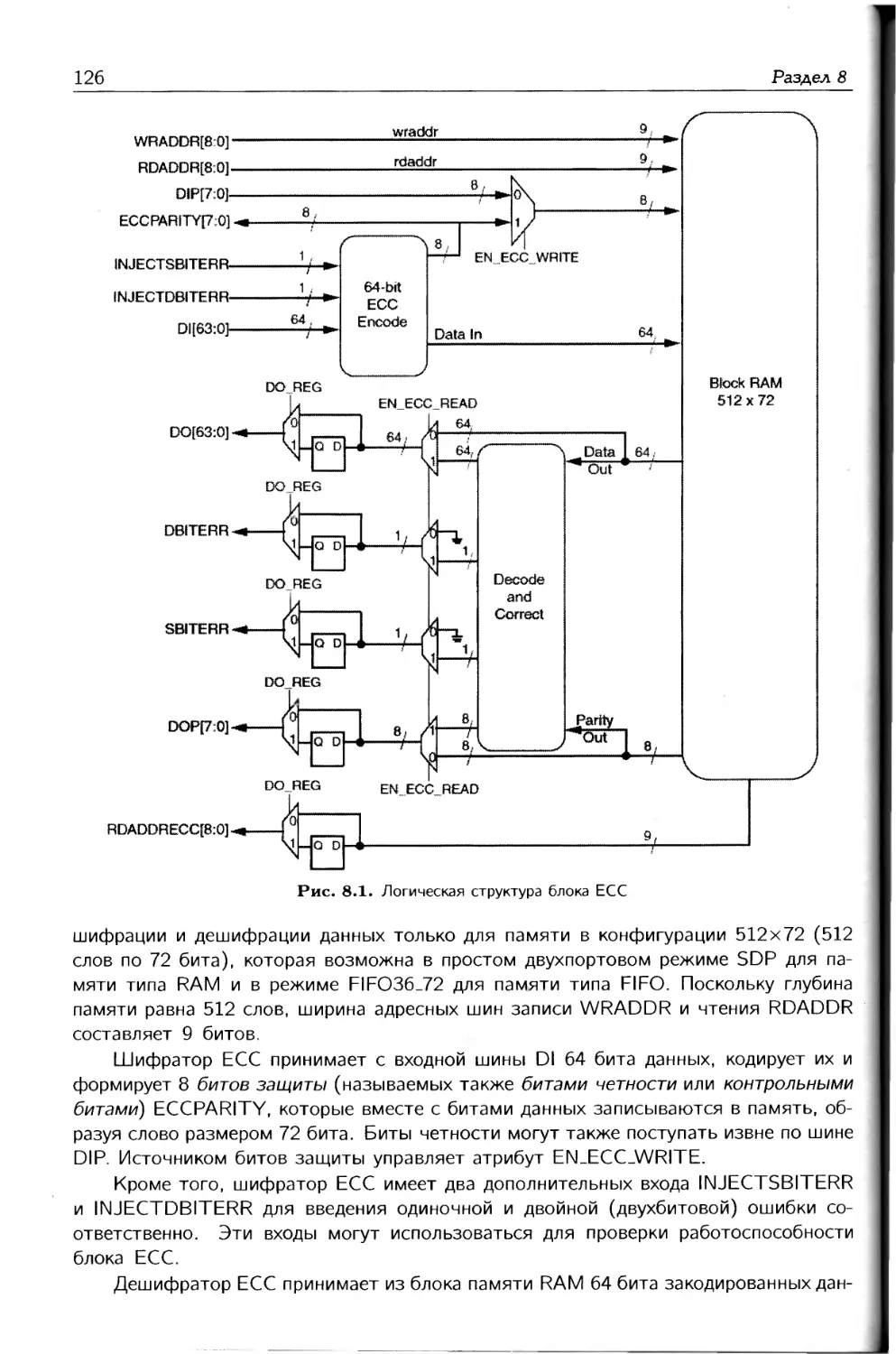
этого служит блок встроенной коррекции ошибок ЕСС. В восьмой главе описывается
архитектура, функционирование и особенности применения блока ЕСС.
В FPGA 7-й серии кардинальному усовершенствованию подверглись архитекту-
ры элементов ввода-вывода. Это связано с необходимостью поддержки современных
стандартов передачи данных, в частности дифференциальных стандартов, а также
с необходимостью упрощения использования микросхем ПЛИС на системной плате.
Поэтому в FPGA 7-й серии совокупность всех элементов ввода-вывода названа сис-
темой ввода-вывода SelectlO. В книге системе SelectIO посвящены девятая, десятая
и одиннадцатая главы.
В девятой главе описывается общая концепция системы ввода-вывода FPGA 7-
й серии, приводится архитектура блоков ввода-вывода, рассматривается механизм
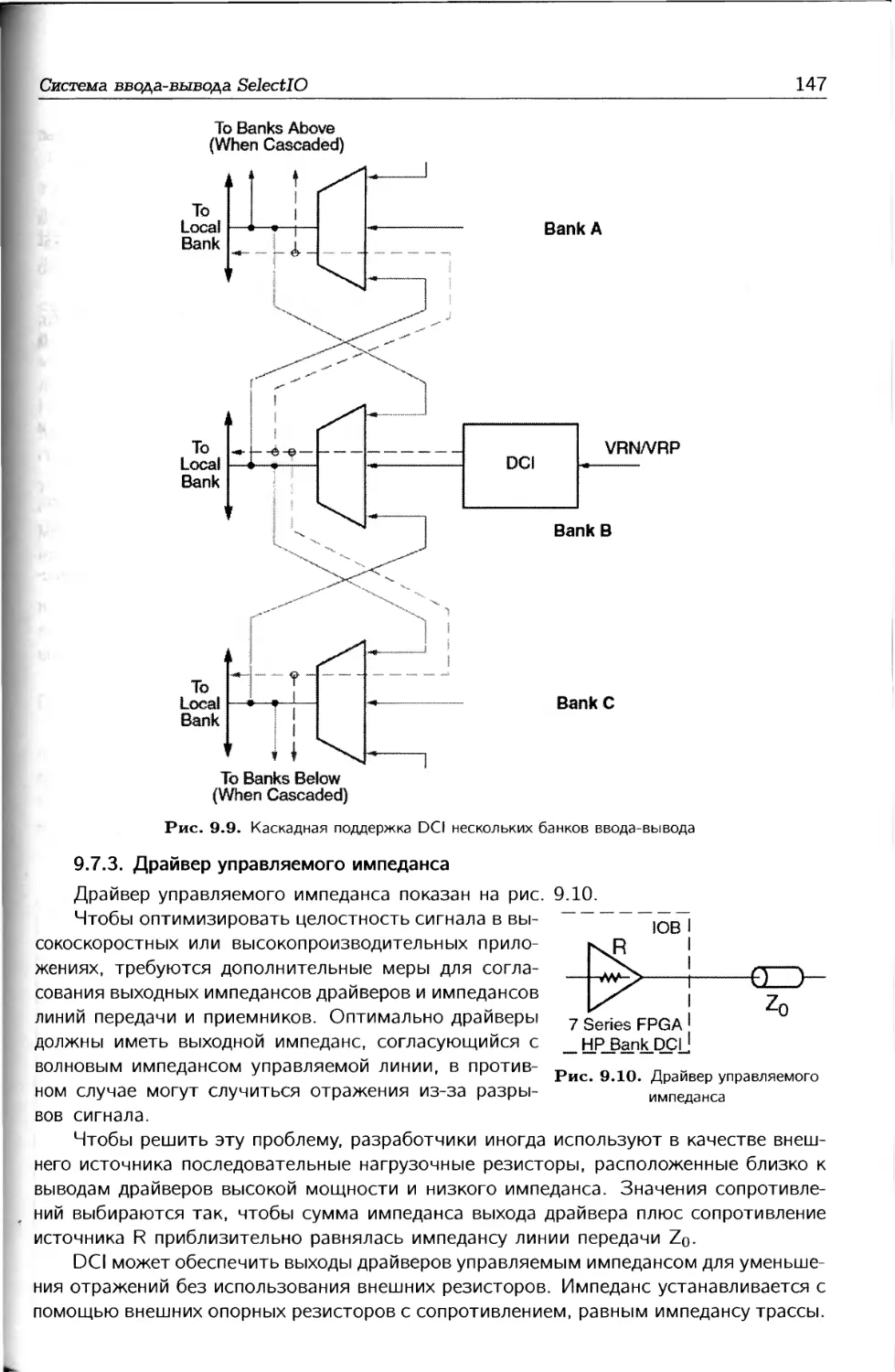
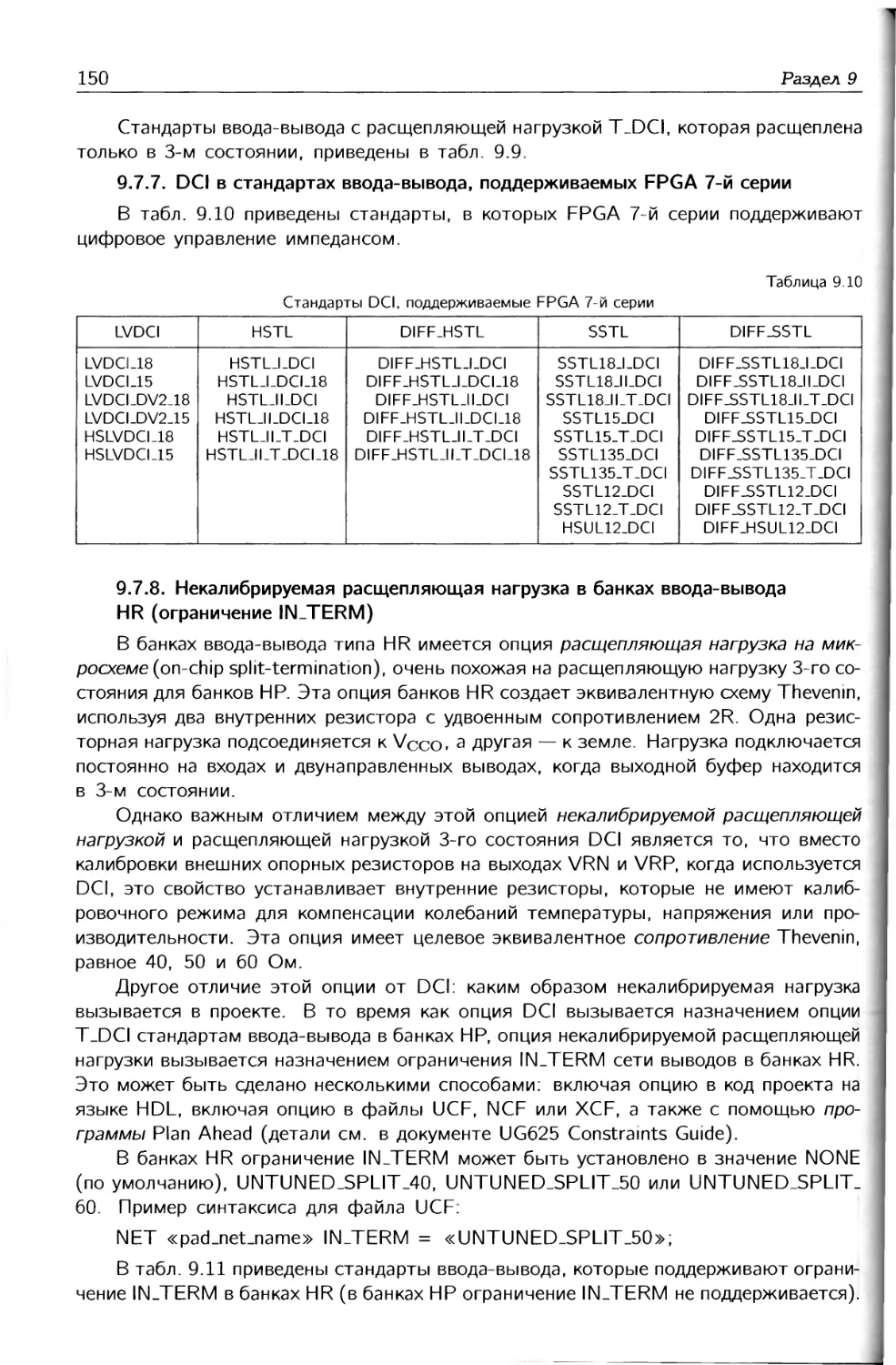
цифрового управления импедансом DCI, а также отмечаются особенности применения
ресурсов системы ввода-вы вода.
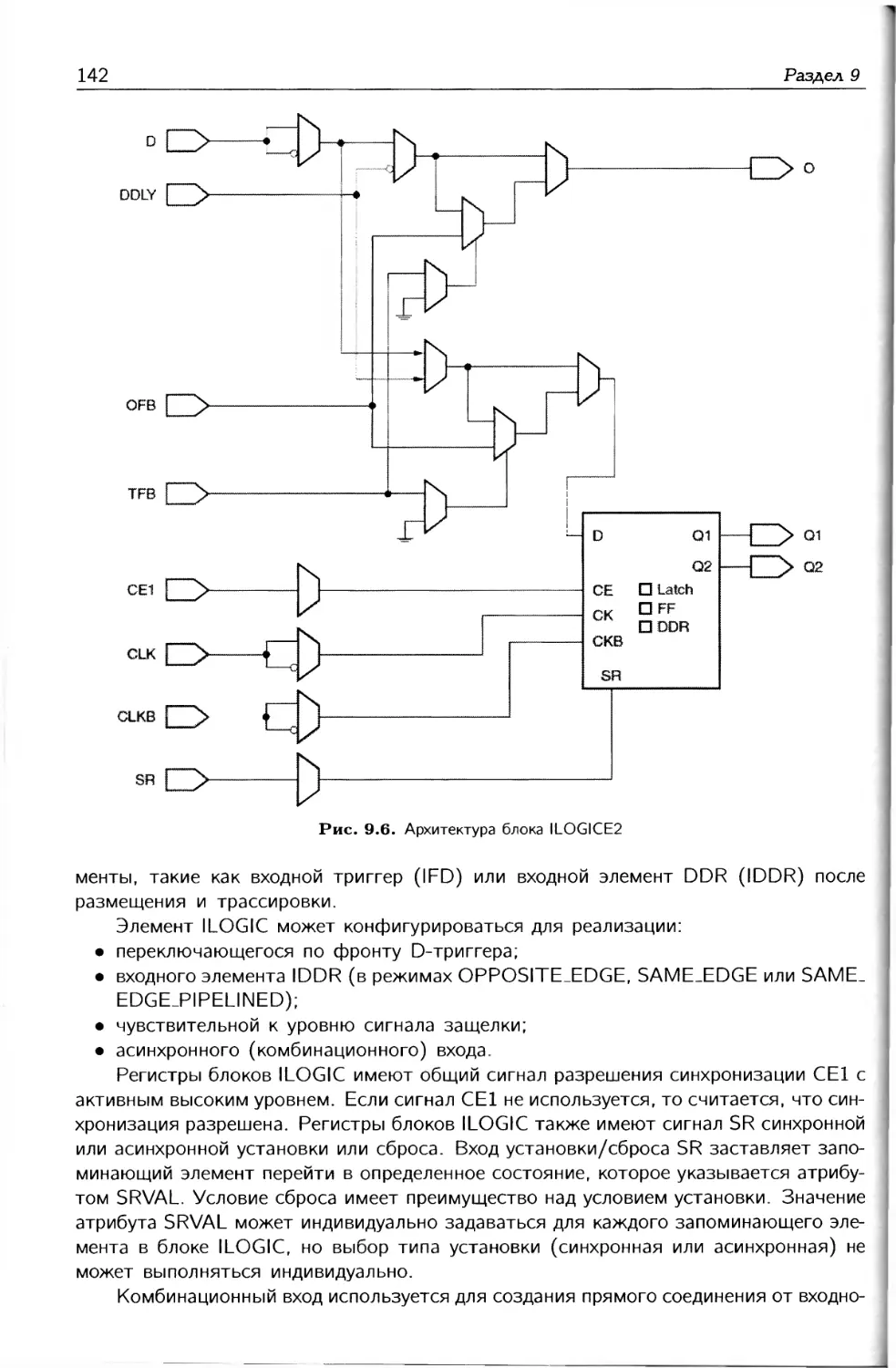
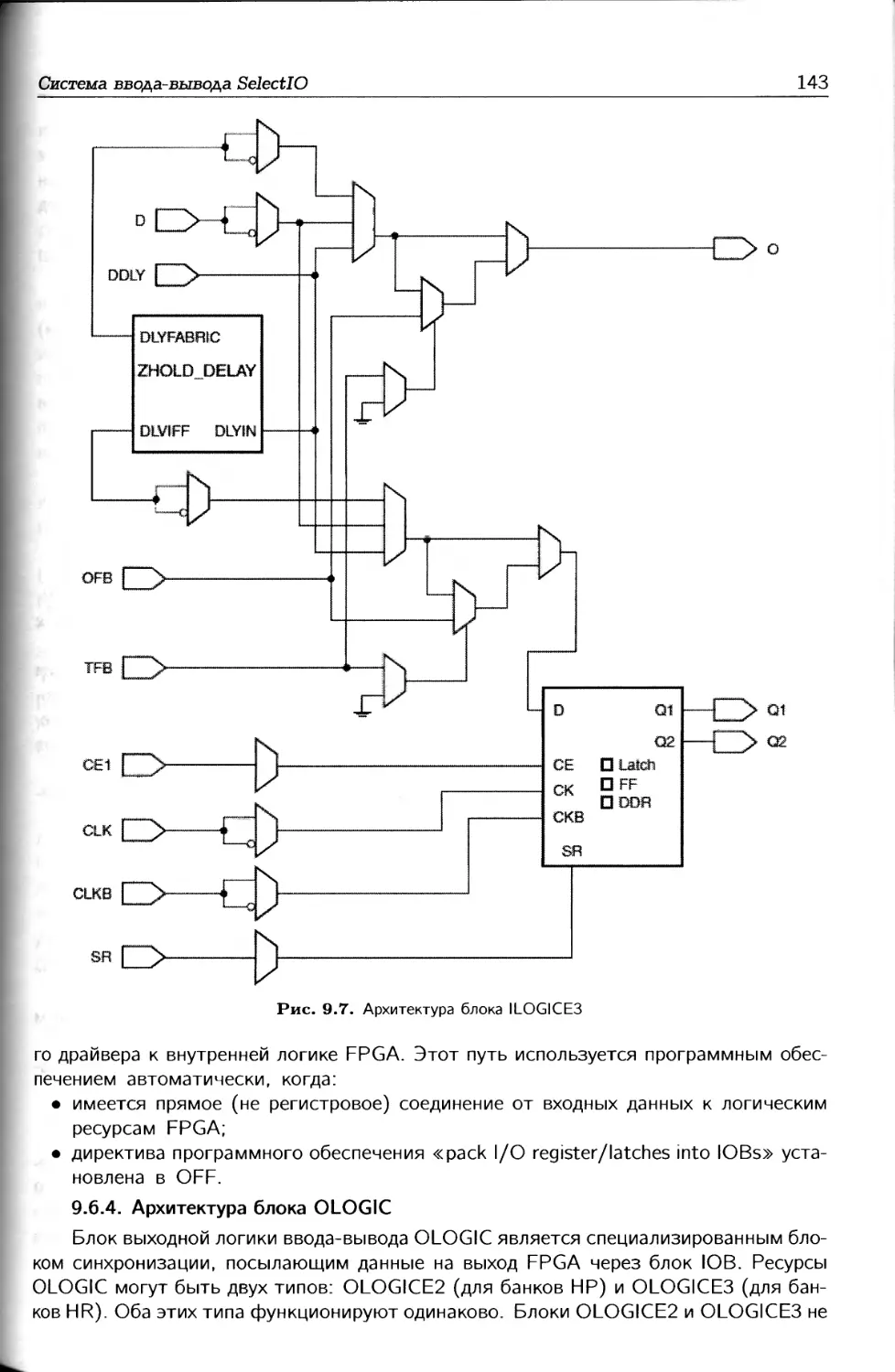
Десятая глава посвящена логическим ресурсам ввода-вывода, к которым отно-
сятся входная IDELAY и выходная ODELAY задержки, а также блоки входной ILOGIC
и выходной OLOGIC логики. Элементы IDELAY и ODELAY обеспечивают управляе-
мую программируемую величину задержки для входных и выходных данных. Основной
Предисловие
5
функцией блоков входной и выходной логики является поддержка регистров передачи
данных с удвоенной скоростью.
В одиннадцатой главе рассматриваются расширенные логические ресурсы ввода-
вывода. К последним относятся последовательно-параллельный ISERDESE2 и парал-
лельно-последовательный OSERDESE2 преобразователи, подмодуль BITSLIP и па-
мять FIFO ввода-вывода. Расширенные логические ресурсы могут использоваться для
высокоскоростной последовательной передачи данных между микросхемами FPGA,
расположенными на одной печатной плате.
Ресурсы синхронизации FPGA 7-й серии описываются в двенадцатой главе. Здесь
рассматривается общая архитектура ресурсов синхронизации, специализированные
входы синхронизации, ресурсы глобальной и региональной синхронизации. Ресурсы
синхронизации в FPGA 7-й серии управляются буферами синхронизации и блоками
формирования синхросигналов СМТ. Особенности использования буферов синхро-
низации также рассматриваются в двенадцатой главе.
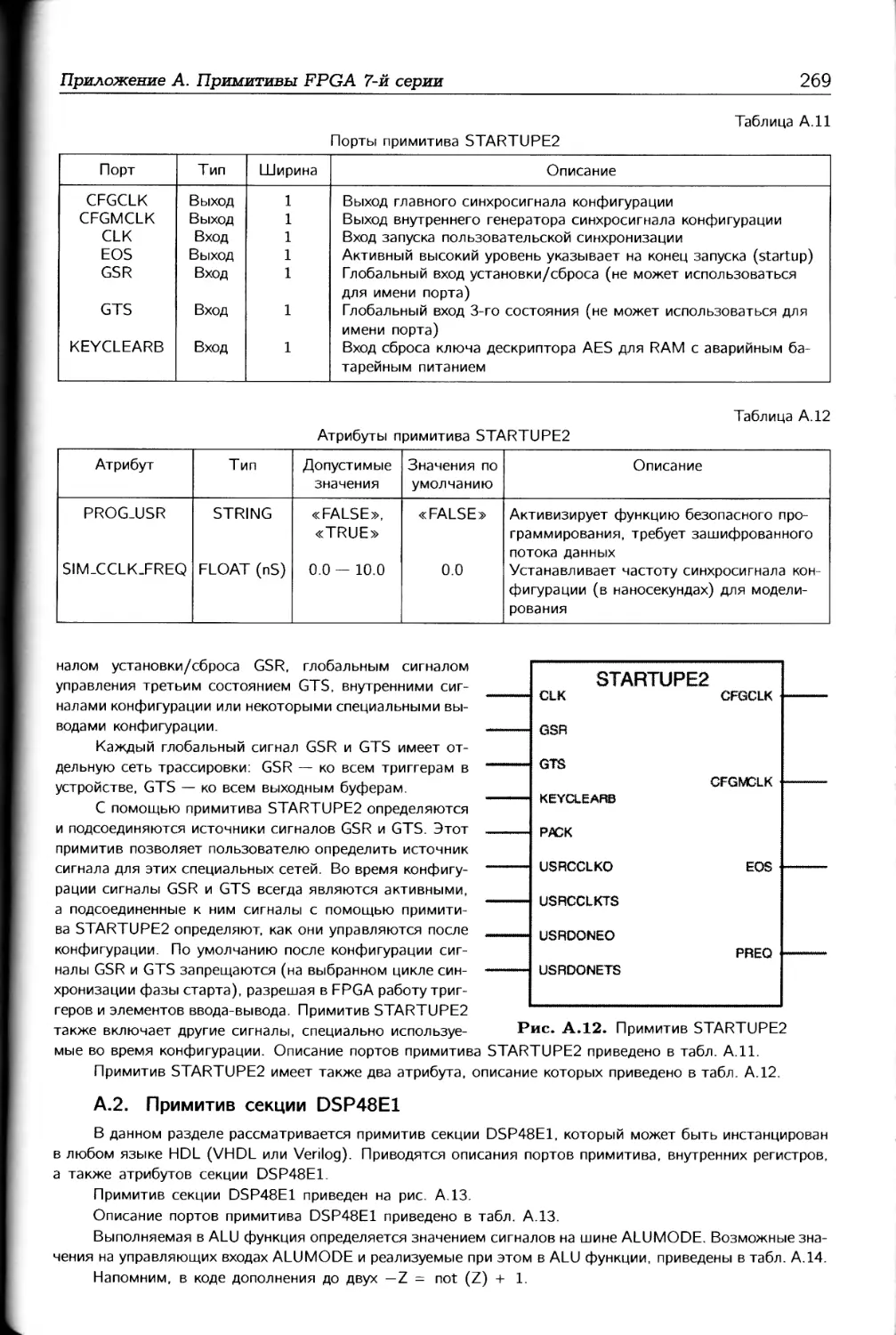
Тринадцатая глава посвящена блока формирования синхросигналов СМТ. Каж-
дый блок СМТ содержит два блока: ММСМ и PLL. Блок PEL реализует некоторое
подмножество функций блока ММСМ, поэтому в данной главе в основном рассмат-
риваются свойства блока ММСМ. Блок ММСМ в FPGA 7-й серии предоставляет
широкие возможности по формированию внутренних синхросигналов на основе внеш-
него опорного синхросигнала. При этом возможны целочисленное и дробное деление
частоты, фильтрация флуктуаций, статический и динамический фазовый сдвиг, пе-
реключение опорных синхросигналов и др.
В четырнадцатой главе рассматриваются вопросы конфигурирования FPGA 7-й
серии, без которого не обходится ни один проект на ПЛИС. FPGA 7-й серии пре-
доставляют большое разнообразие способов конфигурирования. При этом возмож-
ны главные и подчиненные режимы, простые базовые решения, конфигурирование с
низкой стоимостью и высоким быстродействием, конфигурирование от специальных
ППЗУ фирмы Xilinx или от промышленных ППЗУ по стандартным интерфейсам, а
также конфигурирование по JTAG-стандарту.
Отметим, что каждая глава заканчивается выводами, где в сжатой форме пред-
ставлена основная информация, излагаемая в данной главе. В некоторых случаях
для быстрого изучения вопроса читатель может сразу обратиться к выводам в конце
главы, а затем уточнить детали из содержания главы и приложений.
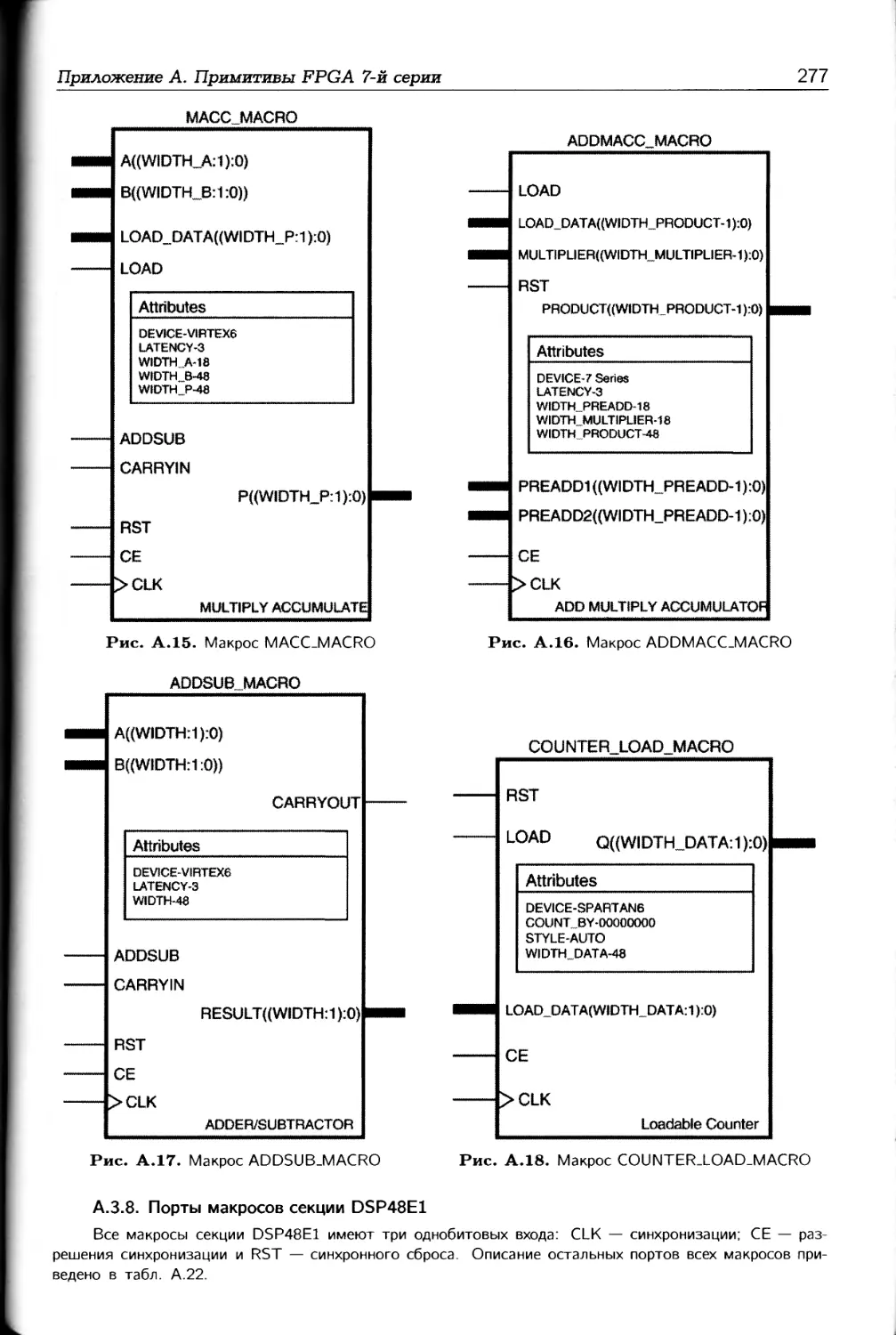
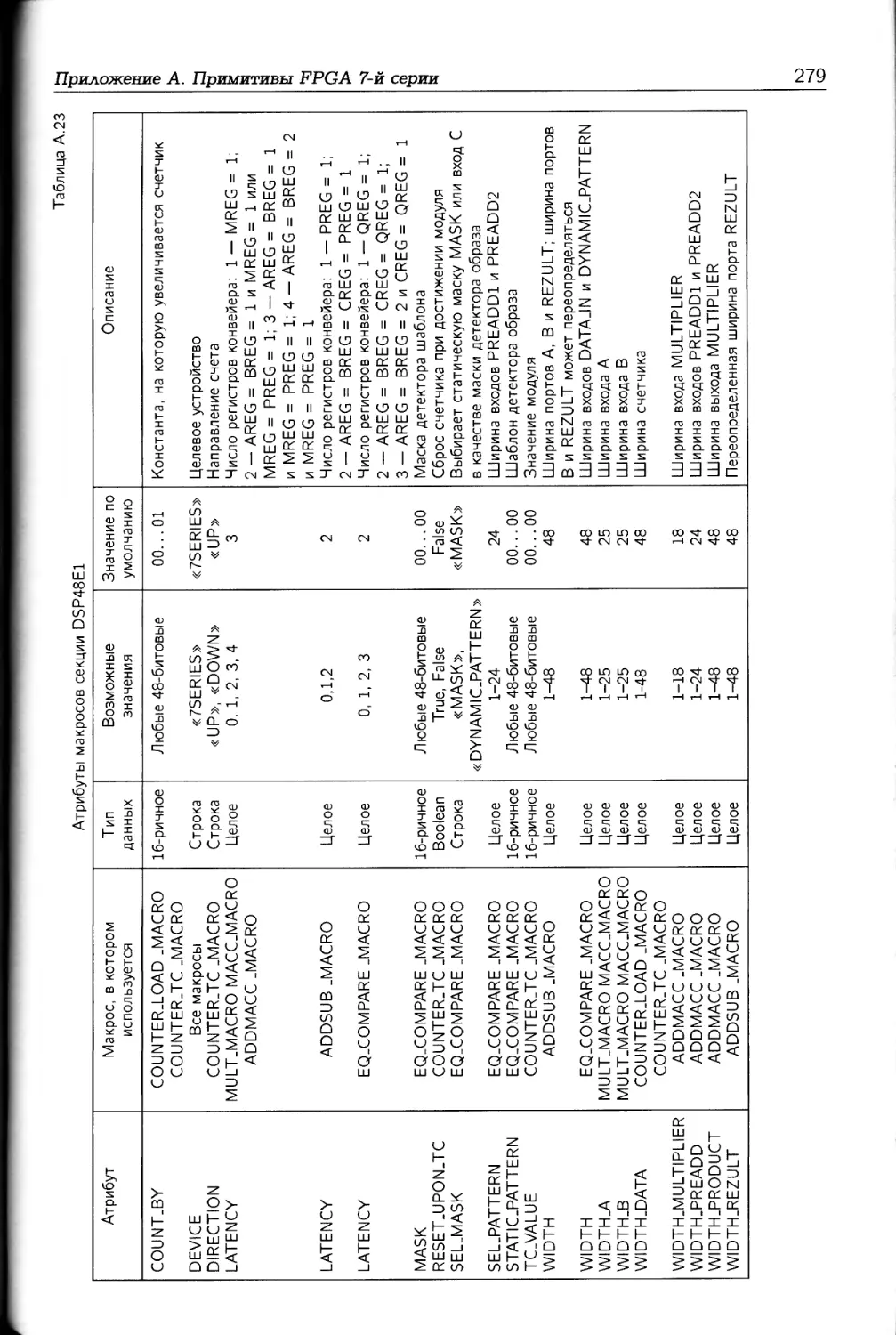
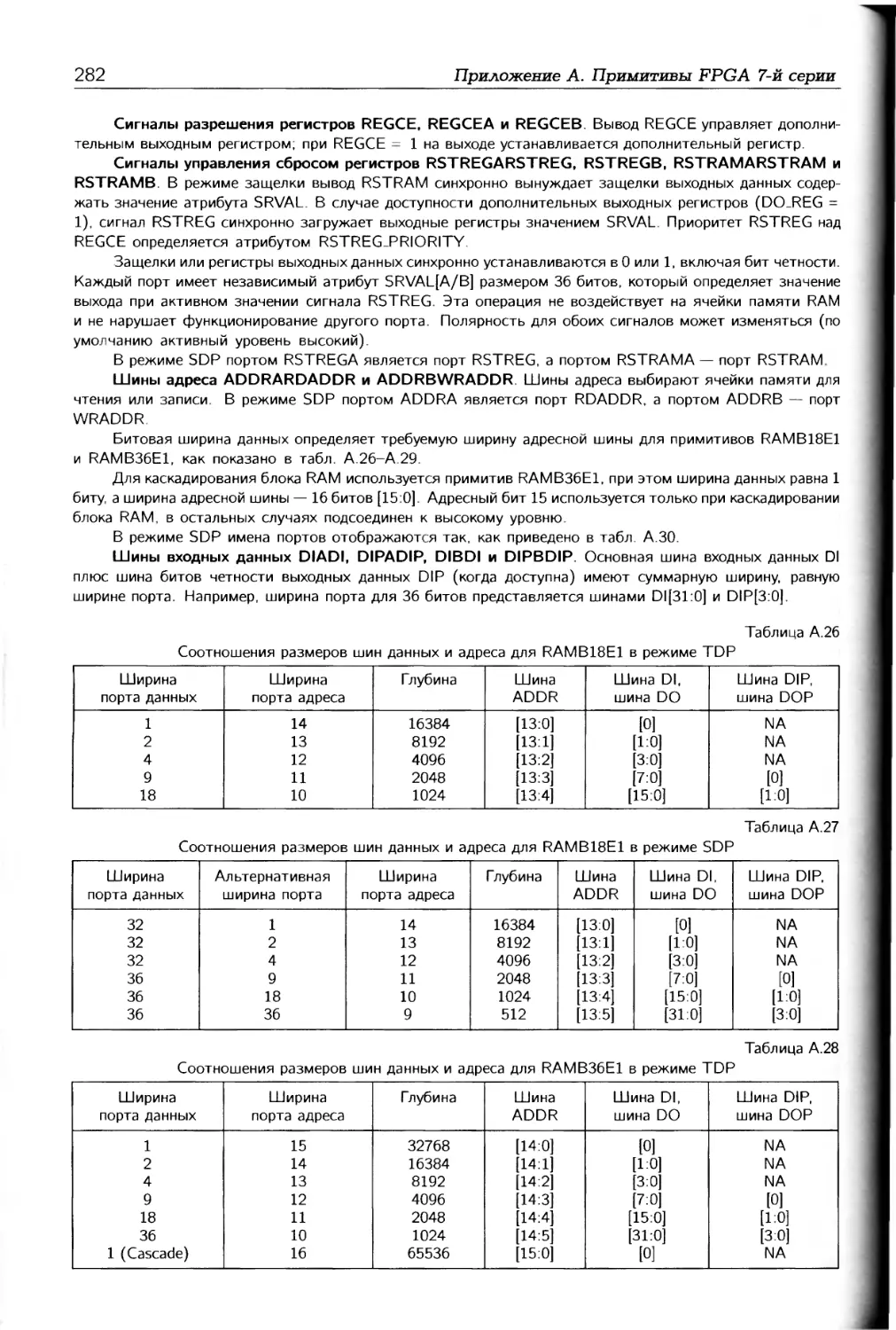
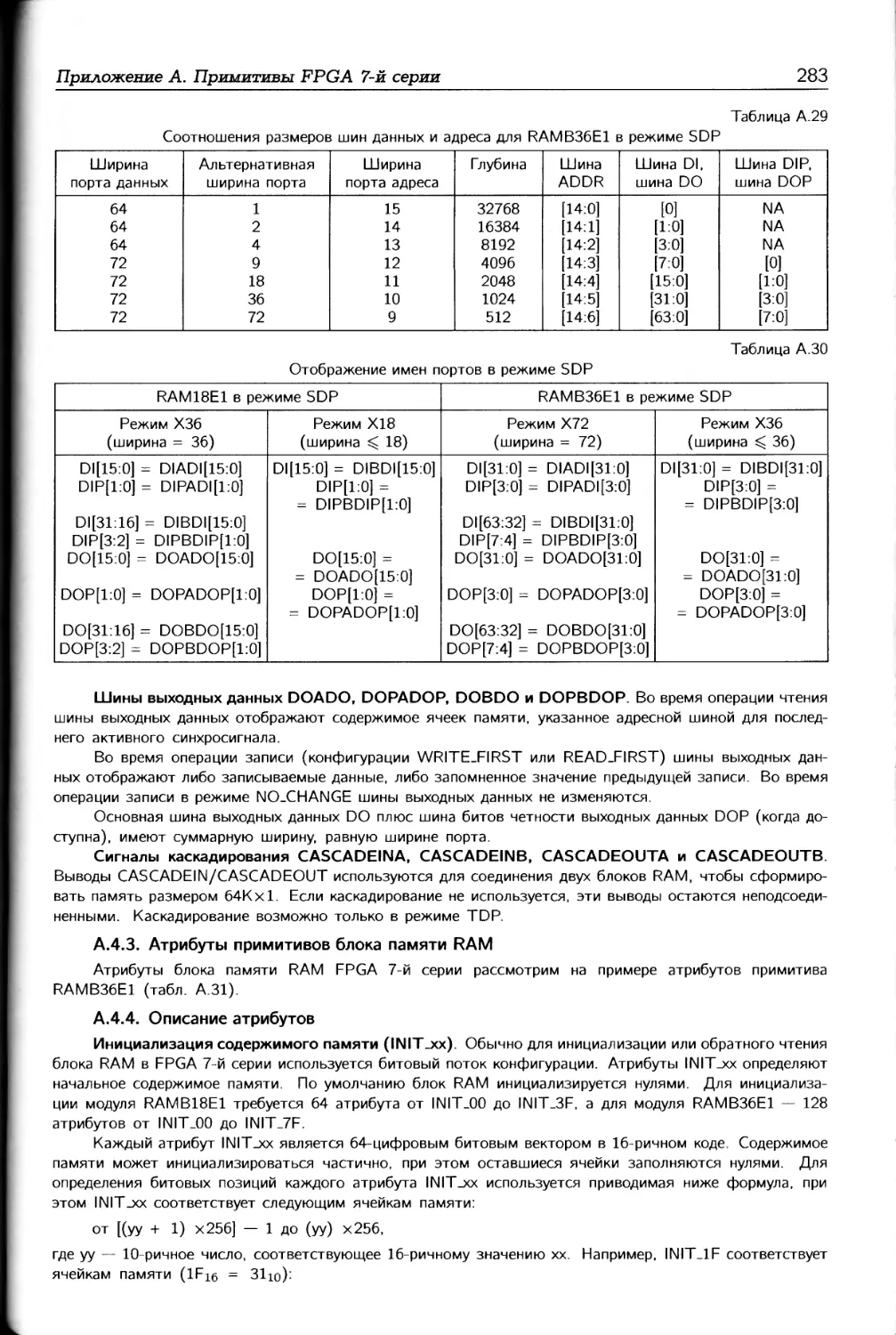
В приложении А в основном описываются примитивы и макросы, которые могут
использоваться при разработке проектов на FPGA 7-й серии. Приложение Б содержит
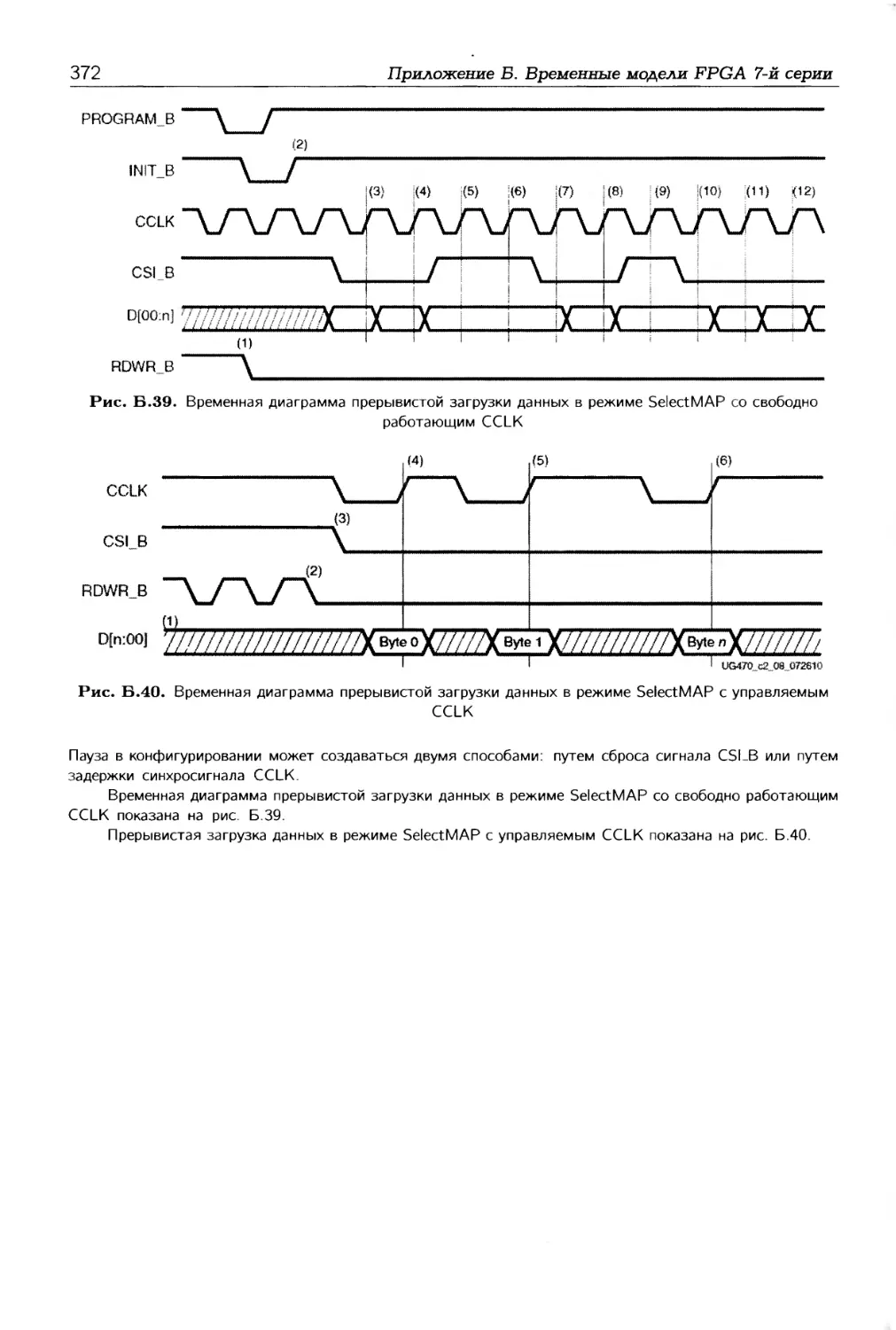
описание временных моделей элементов архитектуры FPGA 7-й серии.
В списке основной литературы приводятся ссылки на техническую документацию,
которая непосредственно использовалась при написании данной книги. Дополнитель-
ная литература включает отдельные документы, которые упоминались в тексте книги
для уточнения конкретных деталей. Список литературы, относящейся к данной теме,
включает ранее изданные книги по архитектурам ПЛИС, а также некоторые книги и
статьи, которые не потеряли актуальность и могут быть полезны в вопросах проек-
тирования на основе ПЛИС.
Книга предназначена прежде всего для разработчиков электронных систем на
основе ПЛИС. Инженеры-практики, которые впервые приступают к проектированию
на ПЛИС фирмы Xilinx, найдут в книге много технической информации: от описания
общей архитектуры до конкретных рекомендаций по практическому использованию.
Инженеры, которые имеют опыт разработки проектов на ПЛИС других производи-
телей, найдут в книге много интересной информации, которая может вызвать у них
6
Предисловие
желание проектировать на ПЛИС фирмы Xilinx. Инженеры, уже проектирующие на
ПЛИС фирмы Xilinx, также могут узнать из книги много новой информации, которая
по каким-либо причинам была упущена из их поля зрения.
Книга также предназначена для студентов и преподавателей технических универ-
ситетов соответствующих специальностей. К сожалению, в настоящее время отсутст-
вуют отечественные учебные пособия по архитектурам современных ПЛИС. Поэтому
преподаватели найдут в книге много полезной информации для подготовки лекций,
практических и лабораторных занятий, а студенты — ответы на поставленные во-
просы.
Книга может быть также полезна аспирантам и научным работникам как источник
информации об архитектурных возможностях современных ПЛИС. Последние могут
быть использованы при разработке новых методик, методов и алгоритмов проекти-
рования на основе ПЛИС.
Книга, безусловна, будет весьма полезна менеджерам, специалистам по продаже
ПЛИС фирмы Xilinx и средств проектирования на их основе, поскольку менеджеры
в первую очередь должны хорошо знать все архитектурные свойства и возможности
каждого семейства ПЛИС, чтобы грамотно их предложить потенциальным клиентам.
Работа выполнена при частичной финансовой поддержке Белостокского техно-
логического университета (Республика Польша), грант S/WI/1/2013.
1 Программируемые логические интегральные схемы
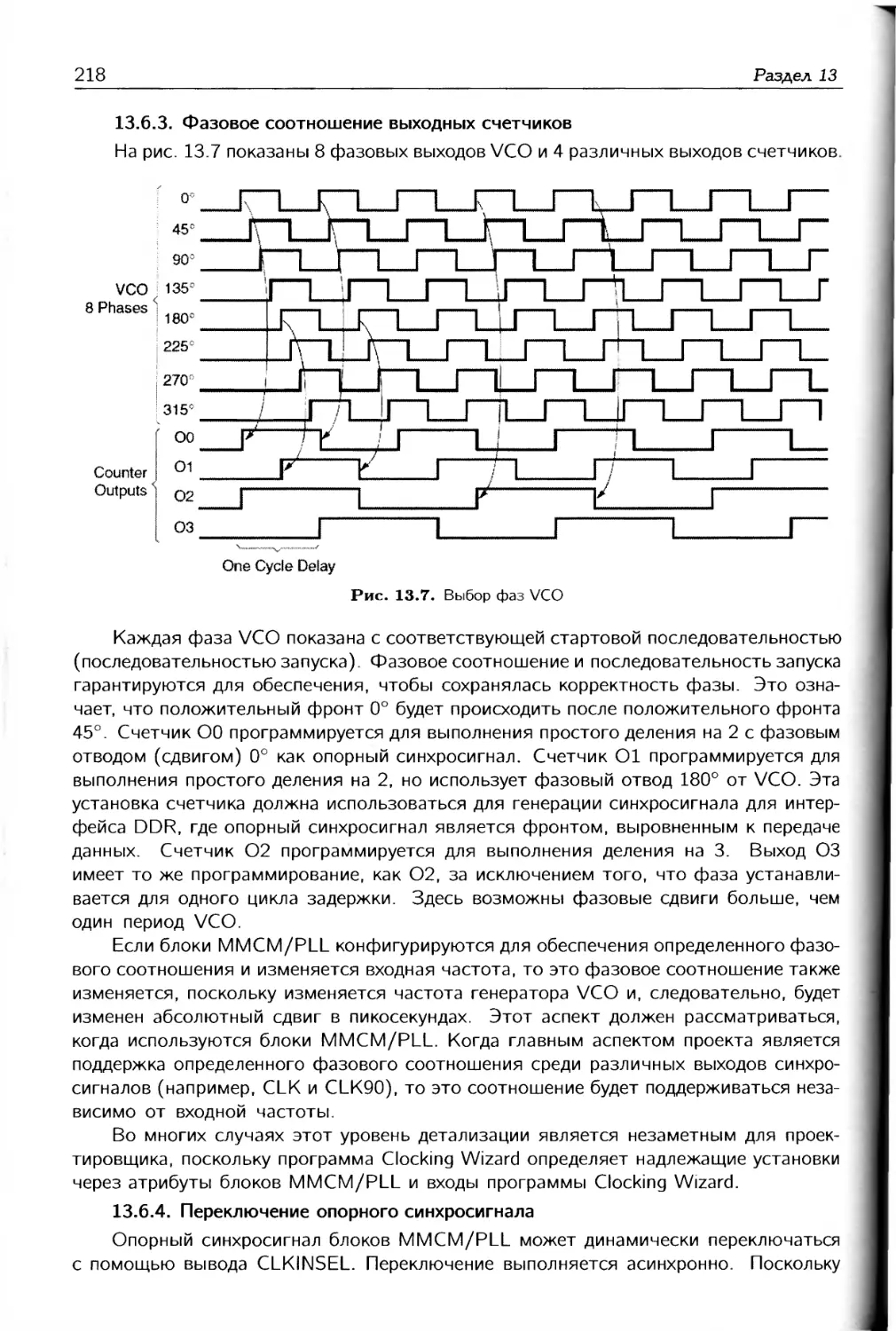
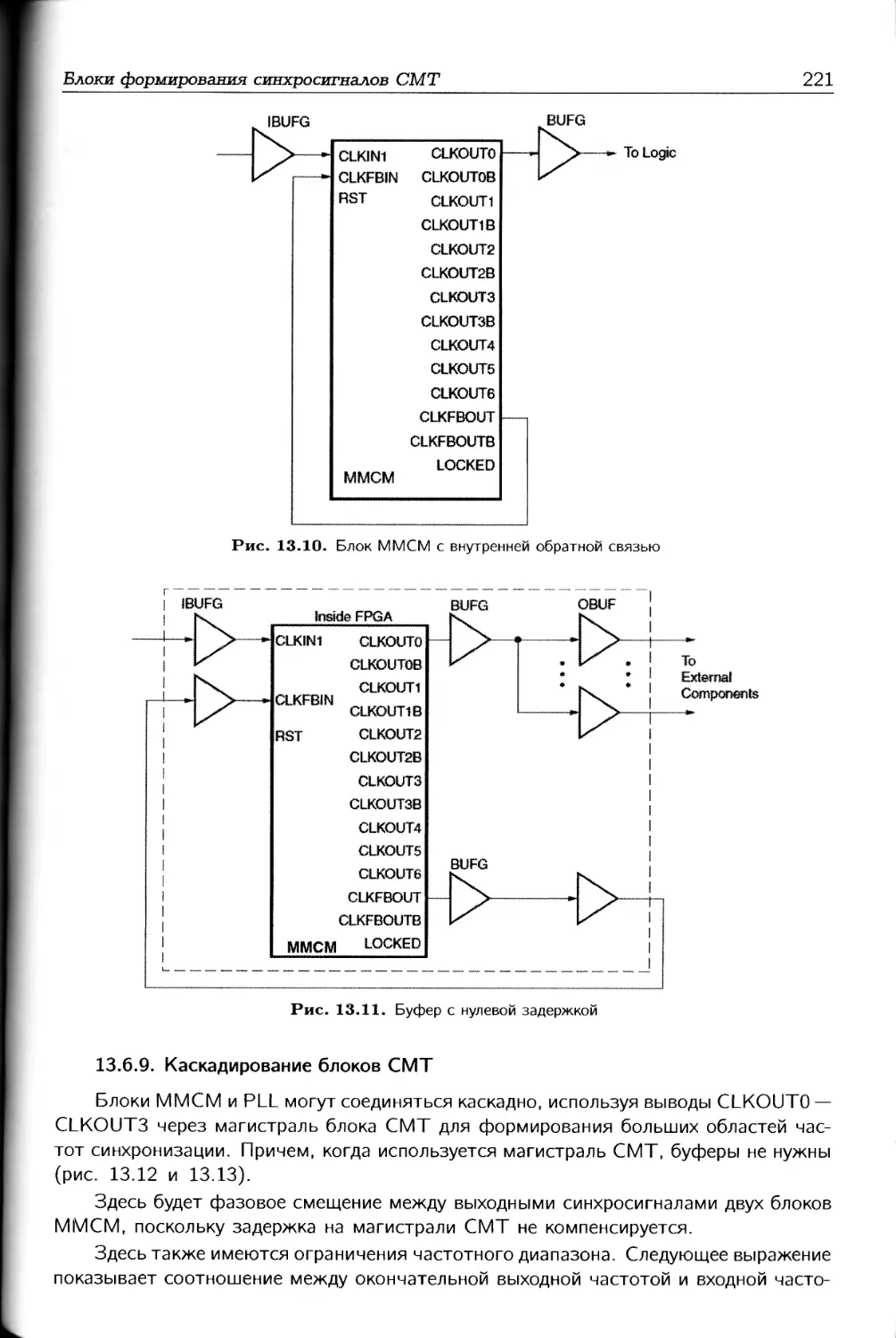
1.1. Введение в программируемые логические интегральные схемы
Понятие программируемые логические интегральные схемы (ПЛИС) с течением
времени менялось, и в настоящее время этот термин не совсем точно отражает опре-
деляемый предмет. Попытаемся разобраться, что такое ПЛИС.
1.1.1. Что такое ПЛИС?
Прежде всего, под ПЛИС понимаются микросхемы большой и сверхбольшой сте-
пени интеграции, которые пользователь может сам программировать.
Способы программирования могут быть самые разные: с помощью специального
оборудования (программаторов), с помощью кабеля от персонального компьютера, от
микропроцессора или от постоянного запоминающего устройства (ПЗУ), находящихся
на одной плате с ПЛИС и др. Главное, что пользователь (разработчик) может купить
готовую ПЛИС и сам ее запрограммировать в домашних (лабораторных) условиях.
При этом ему не надо обращаться к услугам производителей ПЛИС, как в случае за-
казных специализированных микросхем (Application Specific Integrated Circuit — ASIC).
Программирование ПЛИС заключается в изменении своей внутренней архитекту-
ры для выполнение определенных функций. Например, стандартные логические мик-
росхемы выполняют заранее определенные при их изготовлении функции, а ПЛИС
может выполнять те функции, которые для нее определит пользователь. Производи-
тели выпускают ПЛИС незапрограммированными, т. е. исходная ПЛИС не выполняет
никаких функций.
Если после программирования и выключения питания ПЛИС сохраняет свою
внутреннюю структуру и может выполнять заданные функции при каждом следую-
щем включении питания, говорят о программировании ПЛИС. Такие ПЛИС также
называют энергонезависимыми. Энергонезависимая ПЛИС может вначале програм-
мироваться с помощью программатора, а затем устанавливаться на плату, и может
программироваться уже после установки на плату. В последнем случае говорят о
программировании в системе (In-System Programmable — ISP).
Если после программирования и выключения питания ПЛИС не сохраняет свою
внутреннюю структуру (т. е. является энергозависимой) и при следующем включе-
нии питания ее необходимо настраивать заново, говорят о конфигурировании ПЛИС.
Конфигурирование ПЛИС всегда выполняется после установки ПЛИС на плате. Со-
временные ПЛИС допускают десятки тысяч перепрограммирований и неограниченное
число раз конфигурирований.
1.1.2. Чем ПЛИС отличаются от микроконтроллеров?
Это один из ключевых вопросов, который разделил армию разработчиков элек-
троники на поклонников ПЛИС и приверженцев микроконтроллеров.
По способу использования микроконтроллеры и ПЛИС мало чем отличаются друг
от друга: и те и другие перед применением необходимо программировать (конфигу-
рировать). Главное отличие микроконтроллеров от ПЛИС: при программировании
8
Раздел 1
микроконтроллер не изменяет свою архитектуру. При программировании микрокон-
троллера в его память записывается программа (и, возможно, данные), которая за-
тем выполняется процессором микроконтроллера. Сама архитектура микроконтрол-
лера (процессор, порты ввода-вывода, периферийные устройства и соединения между
ними) остаются низменными. В отличие от микроконтроллеров ПЛИС при програм-
мировании изменяет свою внутреннюю архитектуру. Благодаря этому архитектуру
ПЛИС можно настроить на выполнение конкретных функций и задач.
При обработке данных микроконтроллер последовательно выполняет команды за-
писанной в память программы, причем выполнение одной команды может занимать
несколько циклов процессора. ПЛИС в одном временном цикле параллельно обра-
батывает некоторую порцию данных, поступающих на все входы ПЛИС. Поскольку
ПЛИС имеют существенно больше внешних выводов, чем микроконтроллер, то при
использовании ПЛИС значительно (на порядки, т. е. в 10...100 раз) возрастает ско-
рость обработки данных.
Кроме того, каждый внешний вывод ПЛИС, за исключением небольшого коли-
чества специализированных (dedicated) выводов, является двунаправленным выводом
общего назначения. Поэтому пользователю ПЛИС, в отличие от микроконтроллеров,
предоставляются практически неограниченные возможности по определению ширины
и расположению внешних шин и сигналов, подсоединяемых к ПЛИС.
Что использовать в конкретном проекте, ПЛИС или микроконтроллер, во многом
зависит от предыдущего опыта разработчика, имеющихся средств проектирования и
особенностей проекта. Обычно функционально сложные и быстродействующие про-
екты реализуются на ПЛИС, а простые и не требующие высокого быстродействия —
на микроконтроллерах.
1.1.3. Программируемые логические матрицы
Исторически первыми ПЛИС принято считать программируемые логические мат-
рицы (ПЛМ — Programmable Logic Arrays — PLA). Хотя справедливости ради следует
заметить, что первыми микросхемами, которые пользователь мог запрограммиро-
вать на выполнение определенных функций, являются программируемые постоянные
запоминающие устройства (ППЗУ — Programmable Read Only Memory — PROM).
- программируемое соединение
Рис. 1.1. Обобщенная структура ПЛМ
ПЛМ начали выпускать промышленно-
стью с 1971 года, и они получили доста-
точно широкое распространение среди раз-
работчиков цифровой аппаратуры, в первую
очередь, в качестве замены элементов ма-
лой и средней степени интеграции. Обоб-
щенная структура ПЛМ показана на рис. 1.1.
Архитектура ПЛМ имеет п парафазных вхо-
дов и m выходов.
Основу архитектуры ПЛМ составляют
две программируемые матрицы: матрица
AND (И) и матрица OR (ИЛИ). Выходы мат-
рицы AND непосредственно соединены с
входами матрицы OR и образуют промежу-
точные шины (product terms) ПЛМ. В соответствии с названием матрица AND позво-
ляет на каждом из своих выходах реализовать логическую функцию AND (конъюнк-
цию), а матрица ИЛИ — логическую функцию OR (дизъюнкцию).
Программируемые логические интегральные схемы
9
Поэтому на ПЛМ очень легко реализуются системы булевых функций (СБФ),
представленные в дизъюнктивной нормальной форме (ДНФ). Фактически, архитек-
тура ПЛМ повторяет табличное представление СБФ, при этом на матрице AND реали-
зуются отдельные элементарные конъюнкции, а на матрице OR — логическая сумма
этих конъюнкций.
1.1.4. Программируемые логические устройства (PLD)
Развитие архитектуры ПЛМ шло по пути усложнения выходных буферов. В вы-
ходные буферы стали устанавливать триггеры для реализации регистров и последо-
вательных устройств, начали вводить внутренние обратные связи между выходными
буферами и входами ПЛМ для реализации конечных автоматов. Усовершенствован-
ные таким образом выходные буферы стали называть выходными макроячейками или
просто макроячейками (macrocells).
Однако трудности вызывало програм-
мирование двух матриц AND и OR, програм-
мируемые элементы которых технологичес-
ки сильно различались между собой. По-
этому было предложено программирование
матрицы OR сделать фиксированным
(рис. 1.2). Так появилась архитектура про-
граммируемых матриц логики (Programm-
able Array Logic — PAL).
Фиксированная настройка в PAL мат-
рицы OR позволила реализовать ее в ви-
де отдельных многовходовых вентилей OR,
а сами вентили OR включить в выходные
макроячейки PAL. Существенным недостат-
ком PAL, по сравнению с ПЛМ, является
ограничение на число промежуточных шин,
подсоединяемых к одному выходу. Одна-
ко в большинстве случаев, как показывает
практическое использование, это ограниче-
ние не критично. Поэтому именно архитек-
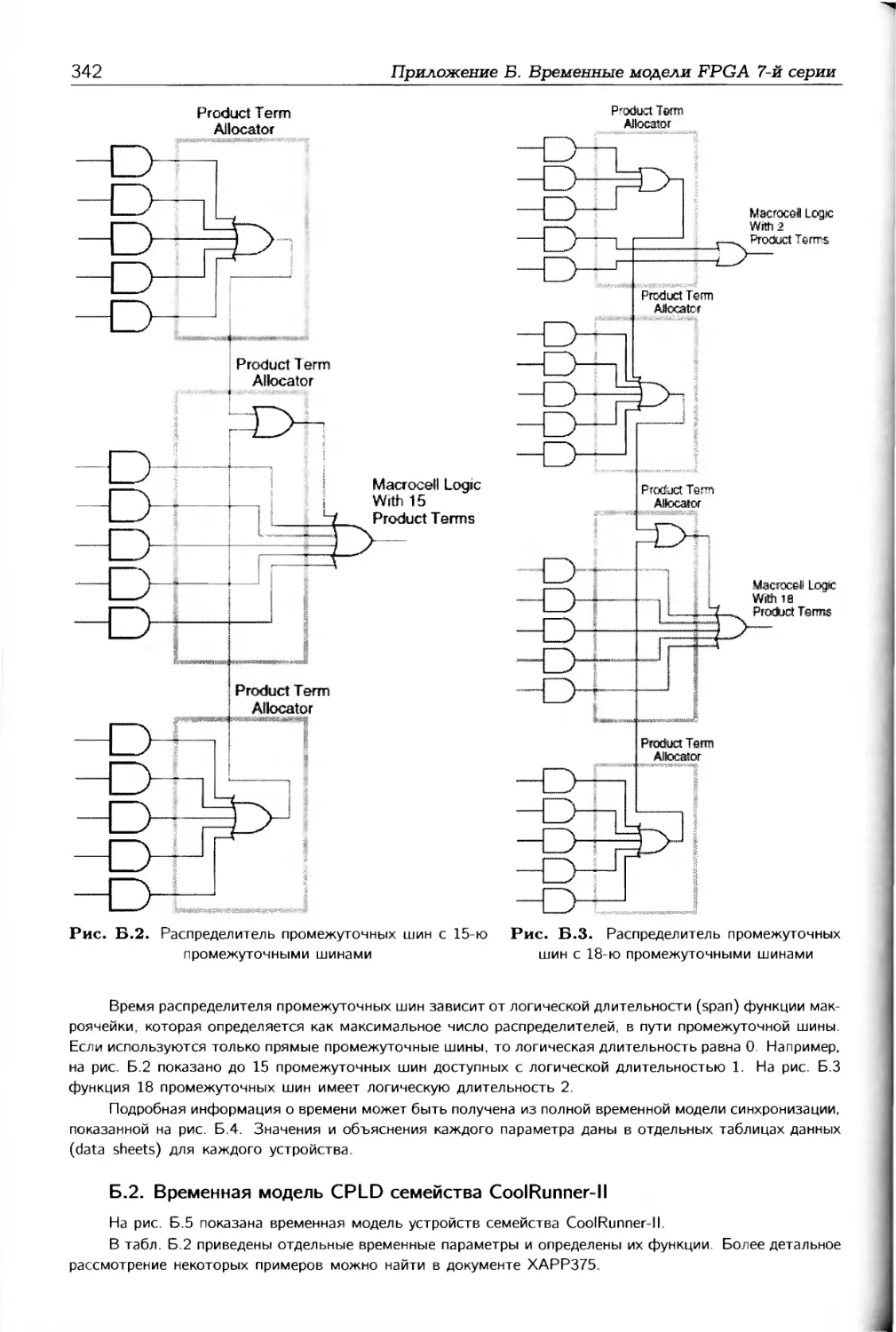
тура PAL благодаря простоте программиро-
вания получила наибольшее распростране-
ние.
В зависимости от того, какая из мат-
риц (AND или OR) программируется, а ка-
кая имеет фиксированную настройку, про-
граммируемые пользователем микросхемы
стали делить на три класса ПЛМ, PAL и
ППЗУ в ПЛМ программируются обе матри-
цы; в PAL программируется матрица AND, а
матрица OR имеет фиксированную настрой-
ку, в ППЗУ программируется матрица OR,
а матрица AND настроена на выполнение
функций полного дешифратора (рис. 1.3).
Все эти три класса микросхем стали назы-
OR
1 Ф ф
Ч>—
Ч>—О
-0—0
О—О
«»—о
0—0
зе-
1 2 ... m
—- программируемое соединение
—з|е— - фиксированное соединение
Ч)—О
•О—о
-0—0-
чз—о
О-Чн
о—о-
О-
Ч>—О-
о—о
о—о
о—о
о—о
о—о
о—о
•о—о
Ч >—{>
Рис. 1.2. Обобщенная структура PAL
ч >- - програм м ируемое соединение
OR
1 ... m
Рис. 1.3. Обобщенная структура ППЗУ
вать программируемыми логическими устройствами (ПЛУ — Programmable Logic De-
vices — PLD).
10
Раздел 1
Рис. 1.4. Структура универсальной PAL
В литературе прошлого века можно также встретить относящиеся к PLD аббре-
виатуры GAL (Generic Array Logic) и PLS (Programmable Logic Sequencer). GAL —
это PAL с расширенными возможностями программирования выходных макроячеек,
a PLS представляет собой ПЛМ с триггерами в выходных буферах (макроячейках) и
внутренними обратными связями.
В практике наибольшее распространение (и используются по настоящее время)
получили универсальные PAL, обобщенная структура которых показана на рис. 1.4, а
архитектура выходных макроячеек — на рис. 1.5.
Обобщенная структура универсальных PAL включает программируемую матрицу
AND, п парафазных входов, d «чистых» специализированных входов и di специали-
зированных входов, которые могут использоваться как обычные логические входы.
Имеется также два типа выходных макроячеек: m макроячеек МС с одной обратной
связью и m2 макроячеек MCF с двумя обратными связями. Кроме того, в некото-
рых универсальных PAL к различным макроячейкам подсоединяется различное число
промежуточных шин.
На рис. 1.5 показана типичная архитектура макроячейки универсальной PAL с
одной обратной связью. Здесь вентиль XOR служит для программирования логичес-
кого уровня (высокого или низкого) выходной функции, мультиплексор МХ1 — для
Рис. 1.5. Архитектура макроячейки универсальной PAL
Программируемые логические интегральные схемы 11
программирования типа выхода (регистрового или комбинационного), МХ2 — для
определения точки подключения обратной связи. В макроячейках с двумя обратными
связями мультиплексор МХ2 отсутствует.
1.1.5. Сложные программируемые логические устройства (CPLD)
Несмотря на большие функциональные возможности, при построении цифровых
систем на плату приходилось устанавливать несколько PLD. Однако с увеличением
степени интеграции появилась возможность на одном кристалле реализовать несколь-
ко PLD. Такие устройства получили название сложных программируемых логических
устройств (Complex Programmable Logic Devices — CPLD).
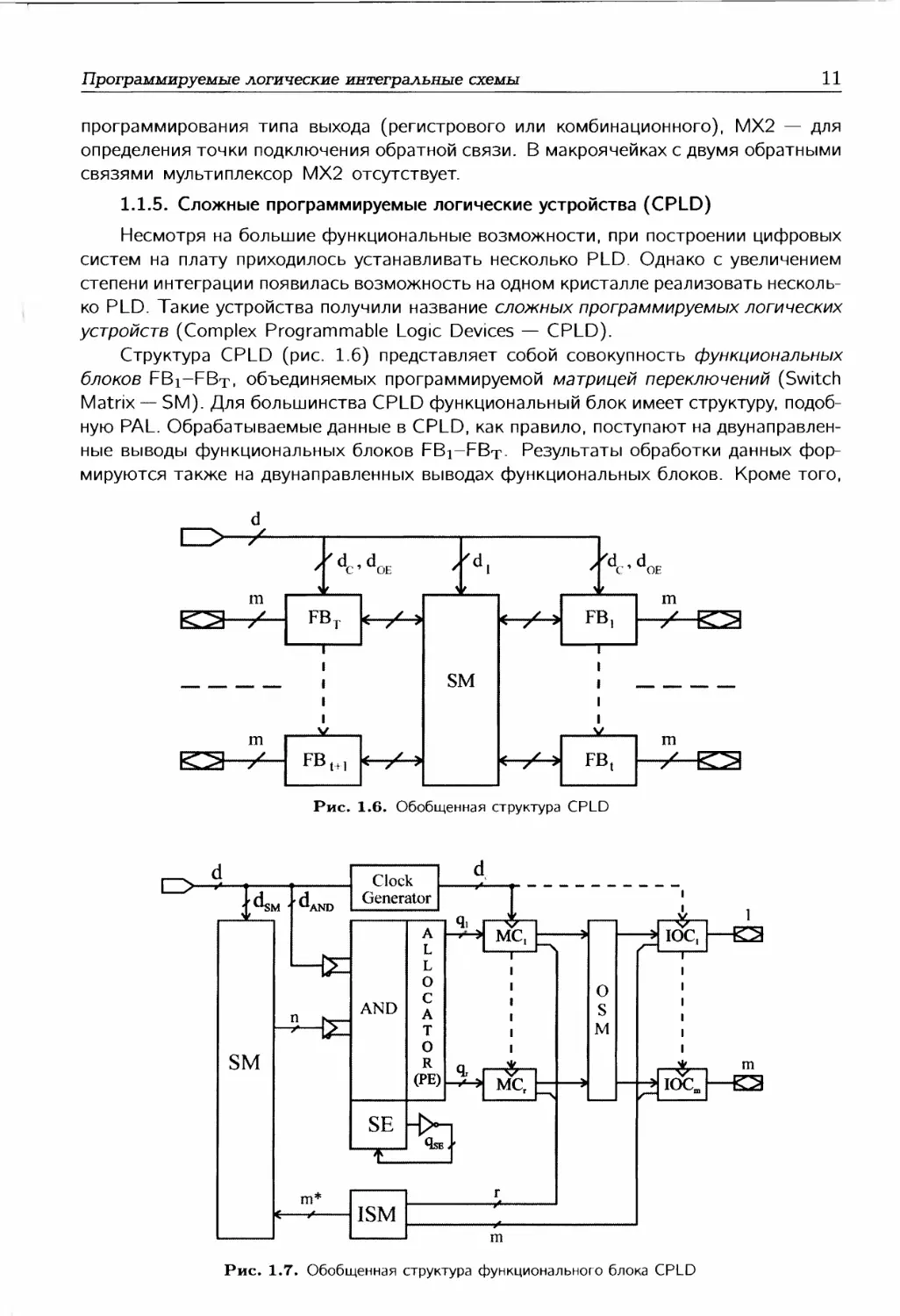
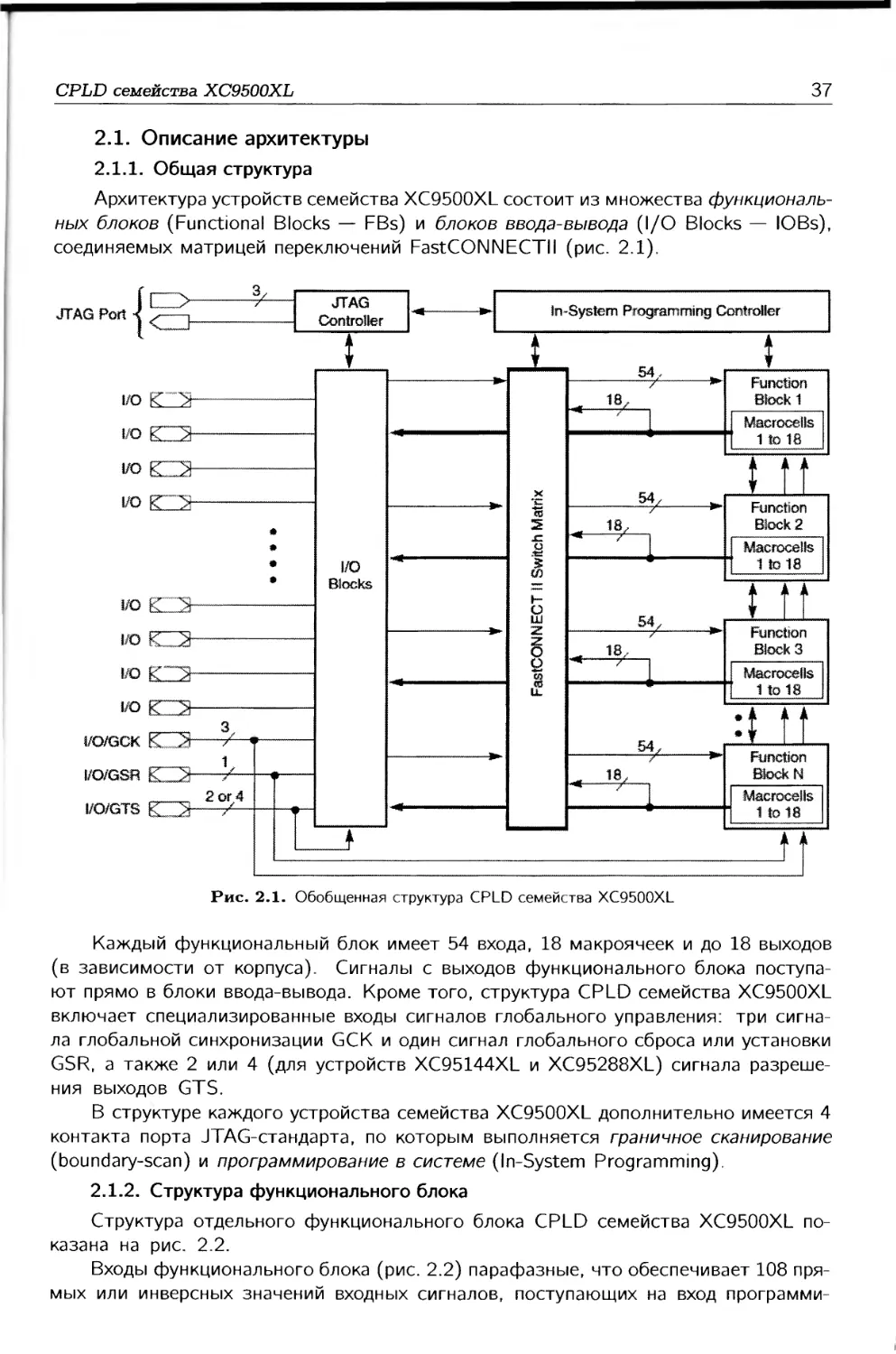
Структура CPLD (рис. 1.6) представляет собой совокупность функциональных
блоков FBx-FBt, объединяемых программируемой матрицей переключений (Switch
Matrix — SM). Для большинства CPLD функциональный блок имеет структуру, подоб-
ную PAL. Обрабатываемые данные в CPLD, как правило, поступают на двунаправлен-
ные выводы функциональных блоков FBj-FBt- Результаты обработки данных фор-
мируются также на двунаправленных выводах функциональных блоков. Кроме того,
Рис. 1.7. Обобщенная структура функционального блока CPLD
12
Раздел 1
CPLD имеет d специализированных (dedicated) входов, de из которых могут исполь-
зоваться для синхронизации триггеров, doE — для управления третьим состоянием
выходных буферов, a dj могут использоваться как обычные логические выводы.
Обобщенная структура функционального блока CPLD показана на рис. 1.7. Она
включает программируемую матрицу AND, г макроячеек MCi,...,MCr и m внешних вы-
водов, управляемых ячейками ввода-вывода IOC1,...,IOCm. Промежуточные шины от
матрицы AND к макроячейкам подключаются с помощью распределителя (allocator)
промежуточных шин. Некоторые CPLD имеют общий расширитель (Shared Expander —
SE) промежуточных шин, в этом случае распределитель промежуточных шин назы-
вают параллельным расширителем (Parallel Expander — РЕ) промежуточных шин.
1.1.6. Программируемые пользователем вентильные матрицы (FPGA)
Заметим, что основными преобразователями информации в архитектурах PLD и
CPLD являются программируемые матрицы AND и OR. Параллельно с развитием ар-
хитектур PLD/CPLD также развивался другой класс программируемых пользователем
микросхем, которые получили название программируемые пользователем вентильные
матрицы (Field Programmable Gate Arrays — FPGAs).
Основными преобразователями информации в FPGA являются функциональные
генераторы типа LUT (Look Up Table)*. Функциональный генератор LUT представ-
ляет собой небольшое ОЗУ с одним выходом. В зависимости от записанной в ОЗУ
информации она может реализовать любую булеву функцию, аргументы которой по-
ступают на адресные входы ОЗУ. Таким образом, LUT представляет собой функци-
ональный генератор, который может реализовать любую булеву функцию от неболь-
шого числа аргументов (обычно 4-6).
Отметим, что ранее встречались FPGA, в которых в качестве функциональных ге-
нераторов использовались мультиплексоры. При этом аргументы реализуемой функ-
ции подавались на управляющие входы мультиплексоров.
В FPGA функциональные генераторы LUT вместе с окаймляющими их мультип-
лексорами и триггерами называются логическими элементами или логическими ячей-
LUT также называют таблицей поиска или таблицей перекодировки
Программируемые логические интегральные схемы
13
ками (Logic Cells). Традиционно FPGA реализуется в виде матрицы логических эле-
ментов, между которыми находится программируемое поле межсоединений (рис. 1.8),
а по краям располагаются блоки ввода-вывода (Input-Output Block — IOB).
Кроме основных компонентов для логического преобразования сигналов, архи-
тектуры CPLD и FPGA также содержат целый ряд вспомогательных компонентов,
таких как:
• периферийная шина для передачи сигналов управления элементами ввода/вы-
вода;
• специализированные (dedicated) входы и связанные с ними деревья трассировки
глобальных сигналов (синхронизации, разрешения выходных буферов, установки
или сброса триггеров);
• генераторы синхросигналов;
• специализированные выводы для программирования (конфигурирования);
• схемы граничного сканирования JTAG и др.
1.1.7. Системы на одном кристалле (SoC)
Очевидно, что ресурсов одной CPLD или FPGA недостаточно для построения
всей цифровой системы. С увеличением степени интеграции появилась возможность
на одном кристалле располагать такие компоненты системы, как процессор, память,
периферийные устройства, а также CPLD или FPGA (рис. 1.9). Такие микросхемы
получили название система на кристалле (СнК — System On Chip — SoC), иногда
встречается аббревиатура SOPC (System On one Programmable Chip).
Отличительной чертой SoC является
наличие в архитектуре процессора, в ка-
честве которого часто выступает микро-
контроллер, а также область программи-
руемой логики (FPGA/CPLD) для быст-
рого выполнения специальных функций.
Именно наличие области FPGA/CPLD в
архитектуре SoC отличает микросхемы
SoC от однокристальных компьютеров.
Термин ПЛИС обозначает все виды
программируемых пользователем логиче-
ских микросхем, т. е. PLD, CPLD, FPGA
и SoC (SOPC). Отметим, что многие со-
временные FPGA и SoC позволяют работать не только с логическими (принимаю-
щими два уровня напряжений, обозначающих логические 0 и 1), но и с аналоговыми
сигналами. Поэтому, как было сказано ранее, термин программируемые логические
интегральные схемы не совсем точно отражает объекты, которые он обозначает.
1.1.8. Применение CPLD, FPGA и SoC
Современные проекты обычно реализуются в виде сложных электронных систем,
при этом на плате могут устанавливаться различные классы микросхем: процессоры,
микроконтроллеры, программируемая логика (CPLD, FPGA и SoC), память, анало-
говые микросхемы, контроллеры периферийных устройств и др. Отсюда возникает
вопрос: какое место в электронных системах занимают компоненты программиру-
емой логики?
В настоящее время используются все три типа программируемой логики: CPLD,
FPGA и SoC.
CPLD в электронных системах используется:
Микроконтроллер/
микропроцессор
Память
Ввод/вывод
Другие
модули
Программируемая
область со
структурой
FPGA/CPLD
Рис. 1.9. Обобщенная структура SoC
14
Раздел 1
• для управления порядком подачи напряжений на микросхемы системы;
• управления конфигурированием FPGA и других конфигурируемых компонентов
системы;
• преобразования уровней напряжений сигналов для частей системы, работающих
с сигналами с различными уровнями напряжения;
• реализации сложных и быстрых конечных автоматов (контроллеров).
FPGA в электронных системах используется:
• для реализации электронных систем малой и средней сложности;
• в качестве сопроцессоров для высокопроизводительной обработки информации и
реализации специальных функций, например, при цифровой обработке сигналов.
SoC в электронных системах используется:
• для реализации всей электронной системы или некоторых ее частей на одной
микросхеме.
Кроме того, FPGA часто применяются в качестве прототипа (макета) специали-
зированных микросхем ASIC. При этом проект вначале реализуется на FPGA, прове-
ряются основные концепции и идеи, заложенные в проект, а затем проект переносится
на ASIC. Использование FPGA в качестве прототипа ASIC позволяет значительно со-
кратить время и стоимость разработки проекта.
1.1.9. Технологии проектирования на основе ПЛИС
Появление ПЛИС изменило традиционное проектирования цифровых систем.
Вместо долгой и утомительной процедуры разработки принципиальной схемы про-
екта, а также выполнения всех последующих действий (отладки, проектирования пе-
чатной платы и др.), стало возможным описать функции проекта на языке проекти-
рования и выполнить программирование ПЛИС.
В общем случае проектирование на основе ПЛИС представляет собой новую идео-
логию проектирования электронных систем, когда один разработчик может в домаш-
них условиях создать сложную электронную систему. Но не все так просто. Для
создания электронной системы проектировщик должен обладать целым рядом опре-
деленных знаний и навыков, которые называются технологиями проектирования на
основе ПЛИС. К таким технологиям относятся:
• архитектуры ПЛИС;
• языки проектирования;
• программные и аппаратные средства автоматизированного проектирования;
• блоки интеллектуальной собственности (IP-ядра) и проектирование на основе IP-
ядер;
• методологии проектирования на основе ПЛИС;
• цифровая обработка сигналов;
• проектирование со встроенными микропроцессорами;
• проектирование интерфейсов;
• отладка проектов;
• проектирование печатных плат для проектов на ПЛИС;
• обеспечение целостности сигналов;
• энергосбережение;
• конфигурирование ПЛИС;
• динамическое и частичное реконфигурирование ПЛИС;
• защита проекта и др.
Программируемые логические интегральные схемы
15
Архитектуры ПЛИС. Разработчик электронных систем на основе ПЛИС обязан
очень хорошо знать архитектуру используемой микросхемы. Это очевидно. Разра-
ботчик также должен знать все архитектуры ПЛИС, выпускаемые данным произ-
водителем, чтобы выбрать наиболее подходящую микросхему. Желательно также
знать архитектуры ПЛИС других производителей, чтобы сравнивать их возможности
с требованиями проекта и, может быть, перейти к проектированию на ПЛИС дру-
гого производителя.
Хорошее знание архитектуры ПЛИС позволяет:
• разрабатывать эффективные проекты, которые в наибольшей степени использу-
ют имеющиеся архитектурные возможности ПЛИС;
• не тратить время на разработку функциональных блоков, которые включаются
в проект установкой одной опции (автор неоднократно наблюдал такие ситуации
у начинающих разработчиков);
• разрабатывать проекты с минимальной потребляемой мощностью, максималь-
ным быстродействием, минимальной стоимостью и за короткий промежуток вре-
мени.
Языки проектирования. Фактически, использование языков описания аппара-
туры — это новая технология проектирования цифровых систем, кардинально от-
личающаяся от различных схемотехнических подходов, связанных с использованием
графических редакторов. Современные языки проектирования позволяют не только
описывать структуру и поведение устройства, но также подготавливать последова-
тельность тестовых векторов для анализа, выполнять проверку результатов модели-
рования, эмулировать внешнюю среду проекта, различными способами отображать
результаты моделирования и др.
Другими словами, язык проектирования — это мощный инструмент, использу-
емый на многих этапах представления проекта: от системного уровня до уровня
отдельных транзисторов, и на многих этапах разработки проекта: от логического
синтеза до функционального и временного моделирования.
Наиболее широко используемыми языками проектирования в настоящее время
являются Verilog [1] и VHDL, на системном уровне используются языки SystemVerilog,
SystemC, C/C++ и др.
Средства автоматизированного проектирования. Разработка современной элек-
тронной системы невозможна без использования средств автоматизированного про-
ектирования, которые делятся на программные и аппаратные. Программные средства
проектирования, как правило, обеспечивают:
• ввод проекта (текстовый, графический, смешанный);
• библиотеку примитивов и стандартных функциональных блоков;
• компиляцию проекта (нахождение ошибок, формирование базы данных и машин-
ного представления проекта);
• функциональное и временное моделирование;
• отображение проекта на структуру конкретной ПЛИС;
• программирование (конфигурирование) ПЛИС.
Кроме того, современные средства проектирования предоставляют целый ряд
дополнительных программ для:
• цифровой обработки сигналов;
• проектирования на основе 1Р-ядер;
• оценки и оптимизации потребляемой мощности;
• высокоуровневого проектирования;
• проектирования на основе встроенных процессоров;
16
Раздел 1
• интеграции отдельных частей цифровой системы в одно целое;
• разработки проектов на основе SoC и др.
Аппаратные средства проектирования. Все аппаратные средства проектирования
на ПЛИС можно разделить на следующие категории:
• программаторы;
• кабели для программирования ПЛИС в системе (на плате) или для конфигури-
рования ПЛИС;
• учебные платы;
• макетные платы;
• комплекты разработчиков (development kits).
Как было сказано ранее, программаторы — это специальные устройства для про-
граммирования ПЛИС и конфигурационных ППЗУ. Конфигурационные ППЗУ служат
источником данных в режимах конфигурирования, когда ПЛИС выступает в качестве
главного (управляющего) устройства. В этом случае ПЛИС автоматически сама себя
конфигурирует, загружая данные из ППЗУ, при каждом включении питания.
Кабели для программирования используются при конфигурировании или про-
граммировании ПЛИС в системе от персонального компьютера.
Учебные платы используются при обучении студентов различным вопросам про-
ектирования электронных систем на основе ПЛИС. Обычно учебные платы содержат
кнопочные переключатели для подачи входных сигналов, светодиоды для отобра-
жения состояний выходных сигналов, семисегментные дисплеи, дисплеи типа LCD,
контроллеры стандартных интерфейсов (VGA, PS/2, RS-232, USB, 12С), гнезда для
подключения внешней памяти, дополнительные разъемы для внешних выводов и др.
ПЛИС на учебных платах обычно конфигурируются от персонального компьютера с
помощью кабеля для программирования.
Макетные платы — это более сложные устройства по сравнению с учебными пла-
тами. Они предназначены для физической отладки проектов на ПЛИС конкретного
семейства. Часто макетные платы ориентированы на определенную область приме-
нения: цифровая обработка сигналов, проектирование со встроенными микропроцес-
сорами, проектирование систем телекоммуникации и др.
Комплекты разработчиков представляют собой полный набор программных и ап-
паратных средств, достаточных для разработки электронной системы на ПЛИС опре-
деленного семейства. Комплекты разработчиков также ориентированы на определен-
ную область применения. Комплект разработчика обычно включает: программное
средство проектирования, макетную плату, библиотеку IP-ядер, кабели для конфи-
гурирования и др.
Блоки интеллектуальной собственности (IP-ядра). Чтобы два раза «не изобре-
тать велосипед», были придуманы блоки интеллектуальной собственности (Intellectual
Property — IP), или просто IP-ядра. IP-ядро представляет собой некоторый ранее
разработанный отлаженный и сертифицированный проект, который предлагается для
использования как составная часть в других проектах. Из IP-ядер формируются биб-
лиотеки, которые постоянно пополняются. В базовую комплектацию промышленных
программных средств проектирования может входить часть этих библиотек.
За дополнительную плату можно приобрести библиотеки IP-ядер таких компо-
нентов, как основные арифметические блоки, приемопередатчики, контроллеры ин-
терфейсов протоколов, контроллеры памяти, микропроцессоры, блоки DSP, а также
библиотеки IP-ядер для решения задач проектирования из очень широкой области
использования: обработка звука, обработка видеоинформации и изображений, авто-
мобильная электроника, основная логика, интерфейсные шины и ввод-вывод, сети и
Программируемые логические интегральные схемы
17
телекоммуникация, цифровая обработка сигналов, математика, интерфейсы памяти,
сетевые базы данных и др.
Библиотеки IP-ядер предлагают уже готовые проекты в таких областях, как мо-
дуляция и демодуляция сигналов; коррекция ошибок; видео и обработка изображений;
беспроводная связь; широковещательная передача; промышленность; робототехника;
медицина; космос и оборона; автомобильная техника и др.
Кроме того, промышленные программные проекты автоматизированного проек-
тирования предоставляют специальные средства проектирования на основе 1Р-ядер,
а также генераторы 1Р-ядер.
Методологии проектирования на основе ПЛИС. Среди всего разнообразия мето-
дологий проектирования кратко рассмотрим только модульное, пошаговое и вирту-
альное проектирование, которые используются при разработке электронных систем
на ПЛИС.
Технологические и архитектурные особенности ПЛИС позволили предложить но-
вые методологии проектирования: модульное и пошаговое проектирование. Архитек-
тура современных FPGA часто строится в виде столбцов различного типа. Каждый
тип столбцов состоит из функциональных блоков определенного вида: логических,
цифровой обработки сигналов, ввода-вывода, памяти и др.
При модульном проектировании каждая часть модуля проекта может разрабаты-
ваться независимыми группами инженеров. В последующем разработанный модуль
размещается в одном или нескольких соседних столбцах ПЛИС, причем никакая дру-
гая логика в эти столбцы размещена быть не может. Несмотря на некоторую избыточ-
ность по стоимости модульного проектирования, гарантируется сохранение основных
параметров каждого модуля независимо от их расположения в ПЛИС.
Пошаговое проектирование разрешает модифицировать любой столбец ПЛИС на
уровне регистровых передач. При этом в столбец может быть добавлена некоторая
логика, что запрещено при модульном проектировании. Сочетание модульного и по-
шагового проектирования обеспечивает достаточно хорошие результаты.
Виртуальное проектирование позволяет значительно сократить время разработки
проекта. На уровне регистровых передач схема проекта, как правило, имеет иерар-
хическое представление. Однако средства размещения и трассировки ПЛИС преоб-
разуют его в плоское или одноуровневое представление. В результате, если произ-
вести незначительные изменения в одном из блоков на уровне регистровых передач и
пересинтезировать только этот блок, все равно будет выполнен повторный синтез
всего устройства.
Концепция виртуального макетирования ПЛИС позволяет выполнять планиро-
вание компоновки кристалла и осуществлять предварительный временной анализ до
выполнения этапов размещения и разводки. Данный подход позволяет также выпол-
нять синтез, размещение и разводку индивидуально для каждого блока устройства. В
результате значительно сокращается время разработки устройства.
Цифровая обработка сигналов (digital signal processing — DSP). Цифровая об-
работка сигналов является неотъемлемой частью современных электронных систем
на ПЛИС. Технология проектирования на ПЛИС DSP-приложений поддерживается
на разных уровнях:
• архитектуры FPGA включают специальные DSP-блоки для высокой скорости вы-
полнения операций цифровой обработки сигналов;
• промышленные программные пакеты включают специальные программные сред-
ства (редактор DSP, генератор DSP);
18
Раздел 1
• библиотека IP-ядер содержит широкий набор элементов для реализации как от-
дельных DSP-приложений (фильтры, аналогоцифровые и цифро-аналоговые пре-
образователи, вычислители тригонометрических функций, модули быстрого пре-
образования Фурье и др.), так и уже готовые проекты, требующие минимальной
адаптации.
Все программные средства проектирования DSP-приложений, как правило, рабо-
тают совместно с пакетом MATLAB/Simulink. В электронных системах FPGA часто
выступают в качестве DSP-процессоров и по своей производительности часто пре-
восходят стандартные DSP-процессоры.
Проектирование со встроенными микропроцессорами. Современные ПЛИС мо-
гут содержать микропроцессоры (или микроконтроллеры). Имеется два способа ре-
ализации микропроцессоров в ПЛИС: аппаратный и программный. При аппаратной
реализации микропроцессора часть кристалла изначально отводится под микропро-
цессор, а оставшаяся часть — под ПЛИС. В таком случае микросхема ПЛИС называ-
ется системой на кристалле (System on Chip — SoC). При программной реализации
микропроцессора часть кристалла ПЛИС конфигурируется для реализации функций
м и кроп роцессора.
Имеется два способа аппаратной реализации микропроцессора в ПЛИС. В первом
из них микропроцессор реализуется в виде отдельной полосы (решение фирмы Altera),
содержащей процессорное ядро, ОЗУ, элементы ввода-вывода и другие процессорные
устройства. Эта процессорная полоса может реализовываться на одном кристалле
ПЛИС или на отдельном кристалле, который объединяется с ПЛИС в одном корпусе.
Во втором способе микропроцессор реализуется непосредственно в структуре ПЛИС
(решение фирмы Xilinx).
Имеется также два способа программной реализации микропроцессора. В первом
(soft) микропроцессор описывается на уровне RTL и реализуется на ПЛИС вместе с
остальной логикой проекта. Во втором случае (firm) микропроцессорное ядро реали-
зуется в виде уже размещенных и разведенных конфигурируемых блоков, такая реа-
лизация называется микропрограммной. Программная реализация микропроцессора
медленнее аппаратной. Преимуществом программной реализации микропроцессора
является то, что микропроцессор может быть реализован на любой FPGA, которая
располагает достаточным количеством ресурсов. Кроме того, на одной ПЛИС может
быть реализовано несколько микропроцессорных ядер и таким образом может быть
построена мультипроцессорная система.
Кроме рассмотренных подходов реализации микропроцессоров, предлагаемых
производителями ПЛИС, любые микропроцессоры и микроконтроллеры могут быть
реализованы на ПЛИС программно с помощью соответствующих 1Р-ядер.
Проектирование интерфейсов. Данную технологию можно разделить на три час-
ти: приемопередатчики, интерфейсы внешней памяти и интерфейсы стандартных
протоколов.
Приемопередатчики представляют собой высокоскоростные последовательные
соединения типа точка-точка, используемые для соединения различных микросхем
на одной плате. Для реализации таких соединений используются дифференциаль-
ные пары (differential pairs). Имеется много различных стандартов, поддерживаемых
приемопередатчиками: Fibre Channel (оптический кабель), InifiniBond, PCI Express,
RapidlO, SkyRoil, 10G Ethernet и др.
Важными параметрами, которыми характеризуются приемопередатчики, являют-
ся: восстановление синхронизации (clock data recovery— CDR); глазковая диаграмма
или глазковая маска; окно достоверности данных. Приемопередатчики, реализуемые
Программируемые логические интегральные схемы
19
в ПЛИС, часто позволяют конфигурировать некоторые свои параметры. Наиболее
часто конфигурируются следующие параметры приемопередатчиков:
• определение разделителей;
• амплитуда выходного сигнала;
• согласующие резисторы выходных буферов;
• внесение предискажений;
• реализация компенсации.
При проектировании микропроцессорных и встроенных систем на ПЛИС часто
объема памяти внутренних (встроенных) блоков ПЛИС бывает недостаточно. В этом
случае используются внешние микросхемы памяти, для которых на ПЛИС необходимо
предусмотреть соответствующие интерфейсы. Современные ПЛИС поддерживают
интерфейсы со следующими типами памяти: DDR4, DDR3 SDRAM, DDR2 SDRAM,
LPDDR3, LPDDR2, RLDRAMII, RLDRAMIII, QRDII SRAM, QRDII+SRAM.
Реализация интерфейсов внешней памяти поддерживается усовершенствованной
архитектурой ПЛИС, специальным программным обеспечением (настраиваемыми
функциями, генератором интерфейса памяти), эталонными проектами, демонстра-
ционными платами и моделями для компьютерного моделирования.
ПЛИС также поддерживают ряд интерфейсов стандартных протоколов, среди ко-
торых особое место занимает стандарт шины PCI Express. Протокол PCI Express,
называемый также PCIe, является последовательным интерфейсом общего назначе-
ния, который может использоваться в устройствах связи, во встроенных системах,
в серверах, мобильных и настольных приложениях, системах хранения данных и др.
Протокол PCI Express может также использоваться в качестве интерфейса перифе-
рийных устройств, интерфейса от микросхемы к микросхеме и моста к другим стан-
дартам, таким как 1394b, USB2.0, InfiniBand™ и Ethernet.
Интерфейсы стандартных протоколов в ПЛИС поддерживаются настраиваемыми
IP-ядрами, макетными платами и эталонными примерами.
Отладка проектов. Главной проблемой при отладке систем на ПЛИС является
то, что отсутствует возможность установить пробник внутри ПЛИС. Имеется мно-
го различных подходов к решению данной проблемы. Одним из них является метод
граничного сканирования (boundary scan), суть которого заключается в том, что все
триггеры устройства последовательно соединяются в одну цепочку, в результате обра-
зуется один большой сдвиговый регистр. Значение этого сдвигового регистра может
последовательно выводиться на внешние контакты, например, по JTAG-формату. Од-
нако с увеличением размера ПЛИС данный подход становится весьма трудоемким и
мало пригодным для практического использования.
Для отладки проектов на современных ПЛИС используют специальные програм-
мные средства, называемые логическими анализаторами. Логический анализатор
позволяет исследовать поведение внутренних сигналов во время работы проекта на
ПЛИС без использования внешних выводов. Другими словами, логический анализа-
тор помогает отлаживать проект на ПЛИС, зондируя состояние внутренних сигналов
в проекте без использования внешнего оборудования.
Данные, полученные с помощью логического анализатора, могут храниться в
памяти ПЛИС, а также в определенные моменты времени выводиться на внешние
интерфейсы.
Проектирование печатных плат для проектов на ПЛИС. Значительное увеличение
быстродействия и числа выводов ПЛИС привело к возникновению ряда проблем у
разработчиков печатных плат.
20
Раздел 1
Увеличение быстродействия микросхем непосредственно связано с увеличением
крутизны фронтов сигналов, которая, в свою очередь, приводит к увеличению уров-
ня шума и перекрестных помех. В связи с этим при разработке плат необходимо
применять дополнительные меры по анализу искажений сигналов и их устранению.
Современные стандарты высокоскоростных интерфейсов ввода-вывода требуют
строго определенных значений волнового сопротивления подключаемых проводников.
ПЛИС позволяют конфигурировать внутренние согласующие резисторы для удовлет-
ворения требованиям различным стандартам. Более того, многие ПЛИС поддержива-
ют опцию цифрового управления импедансом (digitally controlled impedance — DCI),
которая позволяет автоматически выполнять согласование значения волнового со-
противления в зависимости от изменений температуры и напряжения питания.
В ряде случаев многие проблемы передачи сигналов на печатной плате могут
быть решены путем отказа от передачи параллельных данных и перехода на высо-
коскоростную последовательную передачу данных, например, с помощью реализован-
ных в ПЛИС универсальных асинхронных приемопередатчиков (universal asynchronous
receiver/traHcmitter — UART).
Еще одна проблема печатных плат при использовании ПЛИС — это пиковые зна-
чения тока напряжения питания при включении системы. Для решения этой проблемы
часто на плату системы устанавливается CPLD, которая управляет порядком подачи
напряжений питания на все FPGA и SoC, расположенные на плате.
Обеспечение целостности сигналов. Понятие целостности сигналов включает в
себя ряд различных аспектов, таких как изменение формы сигнала при его прохож-
дении через проводник, отражение сигнала от конца несогласованного проводника,
а также перекрестные помехи. Все эти явления присущи как сигналам внутри крис-
талла, так и сигналам на плате. Проблемы целостности сигналов внутри кристалла
уже решены производителями ПЛИС, в то время как на плате эти проблемы должен
решать пользователь.
Когда сигнал в одном из соседних проводников переходит с одного логического
уровня на другой, то он провоцирует кратковременную импульсную помеху в дру-
гом проводнике. При этом первый проводник называется «агрессором», а второй —
«жертвой». Такого рода помехи также называются перекрестными, поскольку «жерт-
ва» также может оказывать воздействие на «агрессора». Перекрестные помехи
провоцируют возникновение шумов и задержку сигналов. Кроме того, проводников-
агрессоров может быть несколько. Точный анализ современных схем требует, чтобы
влияние каждого проводника-агрессора было проанализировано и учтено индивиду-
ально.
Перекрестные помехи на платах также называются коммутационными шумами.
В качестве обратной цепи для коммутационных шумов служит «земля». Когда не-
сколько сигнальных цепей используют одну и ту же цепь обратной связи (т. е. цепь
земли), то коммутационные шумы проходят по общей цепи и называются шумами
общего провода. Для уменьшения влияния шумов общего провода сигнальные цепи
должны, по возможности, иметь различные общие провода. Поэтому микросхемы
ПЛИС имеют множество выводов цепей земли и питания, которые стараются рав-
номерно распределить на корпусе микросхемы. При монтаже микросхемы ПЛИС на
плате все выводы земли и питания должны быть подсоединены — это способствует
уменьшению шумов общего провода.
С возрастанием скорости передачи сигналов обостряются проблемы целостности
сигналов. Одним из путей решения этих проблем является использование дифферен-
циальных пар вместо отдельных проводников. Отметим, что буферы ввода-вывода
Программируемые логические интегральные схемы
21
ПЛИС поддерживают большое число стандартов с дифференциальными выводами.
Второй способ — использование внутренних согласующих резисторов вместо внеш-
них резисторов. Большинство ПЛИС также позволяют конфигурировать внутренние
согласующие резисторы.
Энергосбережение. Энергосбережение представляет собой серьезную проблему,
которая должна решаться на всех уровнях проектирования системы на ПЛИС. Про-
изводители ПЛИС предоставляют ряд технологий (методов) для снижения энергос-
бережения, а также программные средства для оценки энергопотребления проекта.
Энергосбережение ПЛИС поддерживается:
• многочисленными опциями для снижения потребляемой мощности в различных
элементах архитектуры ПЛИС;
• анализатором потребляемой мощности;
• опцией снижения потребляемой мощности в программных средствах автомати-
зированного проектирования.
Конфигурирование ПЛИС. Чтобы разработать эффективную электронную систе-
му на ПЛИС, важно рассмотреть, какой режим конфигурирования ПЛИС лучше всего
соответствует требованиям системы.
В общем случае современные ПЛИС допускают 5 режимов конфигурирования:
• последовательная загрузка, ПЛИС в режиме ведущий (master);
• последовательная загрузка, ПЛИС в режиме ведомый (slave);
• параллельная загрузка, ПЛИС в режиме ведущий (master);
• параллельная загрузка, ПЛИС в режиме ведомый (slave);
• последовательная загрузка через JTAG-порт.
При выборе режима конфигурирования необходимо рассмотреть следующие во-
просы:
• где будут храниться конфигурационные данные;
• время конфигурирования (время готовности системы к работе после включе-
ния питания);
• стоимость схемы конфигурирования;
• предусматривается ли в будущем изменение конфигурационных данных;
• предусматривается ли удаленное обновление системы и др.
Каждый режим конфигурирования использует определенные контакты ПЛИС и
может временно использовать другие многофункциональные контакты только во вре-
мя конфигурирования. Когда конфигурирование заканчивается, эти многофункцио-
нальные контакты становятся доступными для общего использования. Режим конфи-
гурирования может также установить ограничения напряжения для некоторых банков
ввода-вывода ПЛИС.
Динамическая и частичная реконфигурация ПЛИС. Под динамической реконфи-
гурацией понимается конфигурация ПЛИС «на лету», т. е. во время работы системы.
В принципе, любую ПЛИС можно переконфигурировать во время работы системы,
вот только будет ли после этого система работать. При динамической реконфигура-
ции ПЛИС возникает ряд вопросов:
• как отключить выводы ПЛИС во время конфигурации;
• как сократить время конфигурации;
• как сохранить содержимое регистров, установленных до конфигурации;
• как сохранить работоспособность системы во время конфигурации ПЛИС и др.
Первый вопрос самый простой — для большинства ПЛИС сигнальные выводы
во время конфигурации автоматически переводятся в высокоимпедансное состояние.
Время конфигурации ПЛИС можно сократить путем увеличения ширины шины, по
22
Раздел 1
которой передаются конфигурационные данные. Традиционные ПЛИС не позволяют
положительно ответить на два последних вопроса. Однако ПЛИС от фирмы Atmel
позволяют решить эти проблемы.
До недавнего времени необходимость внесения даже небольших изменений в кон-
фигурацию ПЛИС требовало переконфигурирования всего устройства. Последние по-
коления ПЛИС допускают частичную реконфигурацию устройства. При этом значи-
тельно уменьшается время реконфигурации.
Защита проекта. Поскольку большинство ПЛИС конфигурируются всякий раз
при включении питания, в этот момент возможен несанкционированный доступ к
данным конфигурирования. Большинство средств защиты проектов на ПЛИС под-
держивают следующие возможности:
• встроенное дешифрование по стандарту (AES) с поддержкой 256-разрядного клю-
ча, алгоритм безопасности проекта промышленного стандарта (FIPS 197 Certi-
fied);
• энергозависимая и энергонезависимая программная поддержка ключа;
• ограничение доступных инструкций стандарта JTAG во время включения питания
в безопасном режиме;
• поддержка аутентификация POF и защита от атаки по сторонним каналам;
• отключение всех инструкций JTAG от момента включения питания, до момента,
пока устройство не инициализировано.
В мире известно около двух десятков фирм — разработчиков и производителей
ПЛИС. Одним из таких производителей является фирма Xilinx, занимающая 30...40 %
всего мирового объема производства ПЛИС.
Данная книга посвящена рассмотрению архитектур ПЛИС фирмы Xilinx, т. е. пер-
вой из технологий проектирования на основе ПЛИС.
1.2. ПЛИС фирмы Xilinx
1.2.1. Историческая справка
Первые ПЛИС фирмы Xilinx по архитектуре FPGA начали производиться в сере-
дине 80-х годов прошлого столетия. Изобретателями FPGA фирмы Xilinx считаются
Росс Фримен (Ross Freemen) и Бернард Вондершмитт (Bernard Vonderschmitt). До
появления FPGA фирмы Xilinx уже были известны и широко использовались PLD со
структурой PAL. Однако сложные системы строились на основе заказных микросхем
ASIC и полузаказных микросхем вентильных матриц. Отсюда возник естественный
вопрос: а нельзя ли соединить возможность программирования микросхем пользо-
вателем с мощностью заказных ASIC. Эту проблему решила фирма Xilinx, предло-
жив программируемые пользователем вентильные матрицы (Field Programmable Gate
Arrays — FPGA).
Первые FPGA изготавливались по CMOS-технологии, а для хранения информа-
ции использовалось энергозависимое статическое ОЗУ (SRAM). FPGA фирмы Xilinx
организованы в виде массива логических элементов (Logic Element) или логических
ячеек (Logic Cell), состоящих из функциональных генераторов LUT, представляющих
собой таблицу перекодировки (Look-Up Table — LUT), мультиплексоров и триггеров.
Логические элементы в FPGA фирмы Xilinx группируются в виде конфигурируемых
логических блоков (Configurable Logic Blocks — CLB).
В настоящее время фирма Xilinx производит такие классы микросхем програм-
мируемой логики, как CPLD, FPGA и SoC.
Программируемые логические интегральные схемы
23
1.2.2. CPLD фирмы Xilinx
Фирмой Xilinx выпускается две серии ПЛИС с архитектурой CPLD: XC9500XL и
CoolRunner-IL CPLD фирмы Xilinx строятся на основе популярной архитектуры PAL:
программируемая матрица AND и фиксированная матрица OR. Оособенностями
CPLD фирмы Xilinx являются:
• высокая производительность (задержка сигналов от входа до выхода — до 5 нс);
• возможность перепрограммирования в системе (не менее 10 000 циклов запись/
стирание);
• программируемый режим пониженной потребляемой мощности для каждой мак-
роячейки;
• расширенная возможность защиты запрограммированной информации от копи-
рования;
• мощный выход (24 мА);
• малая статическая потребляемая мощность;
• широкий выбор корпусов упаковки;
• простота использования.
Семейство XC9500XL разрабатывалось для тесного взаимодействия с FPGA се-
мейств Virtex, Spartan и XC4000XL, позволяя системным проектировщикам оптималь-
но разделять логику между быстрыми интерфейсными схемами, какими являются
CPLD, и устройствами с высокой логической плотностью, т. е. FPGA. Параметры
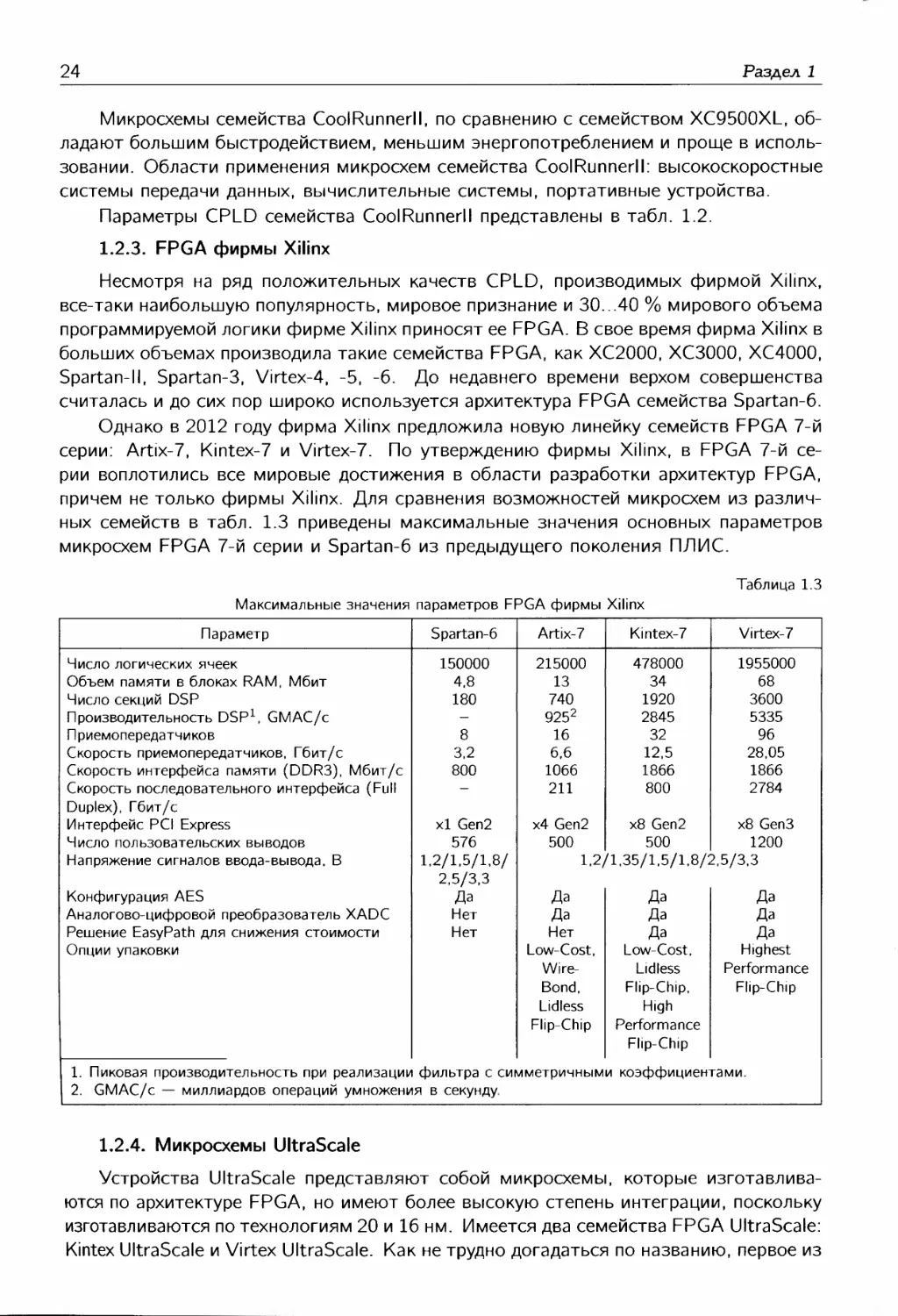
CPLD семейства XC9500XL представлены в табл. 1.1.
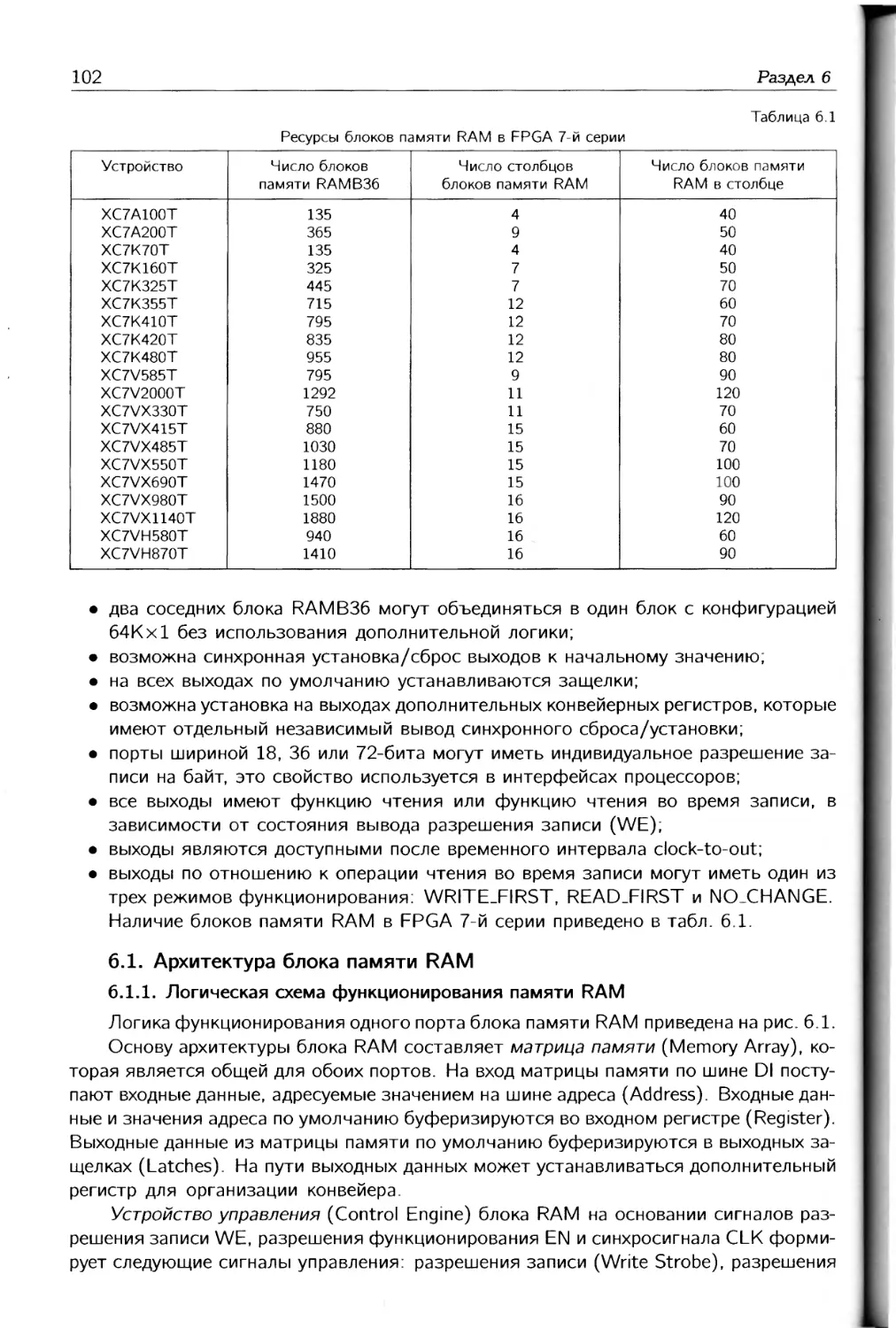
Таблица 1.1
Параметры CPLD семейства XC9500XL
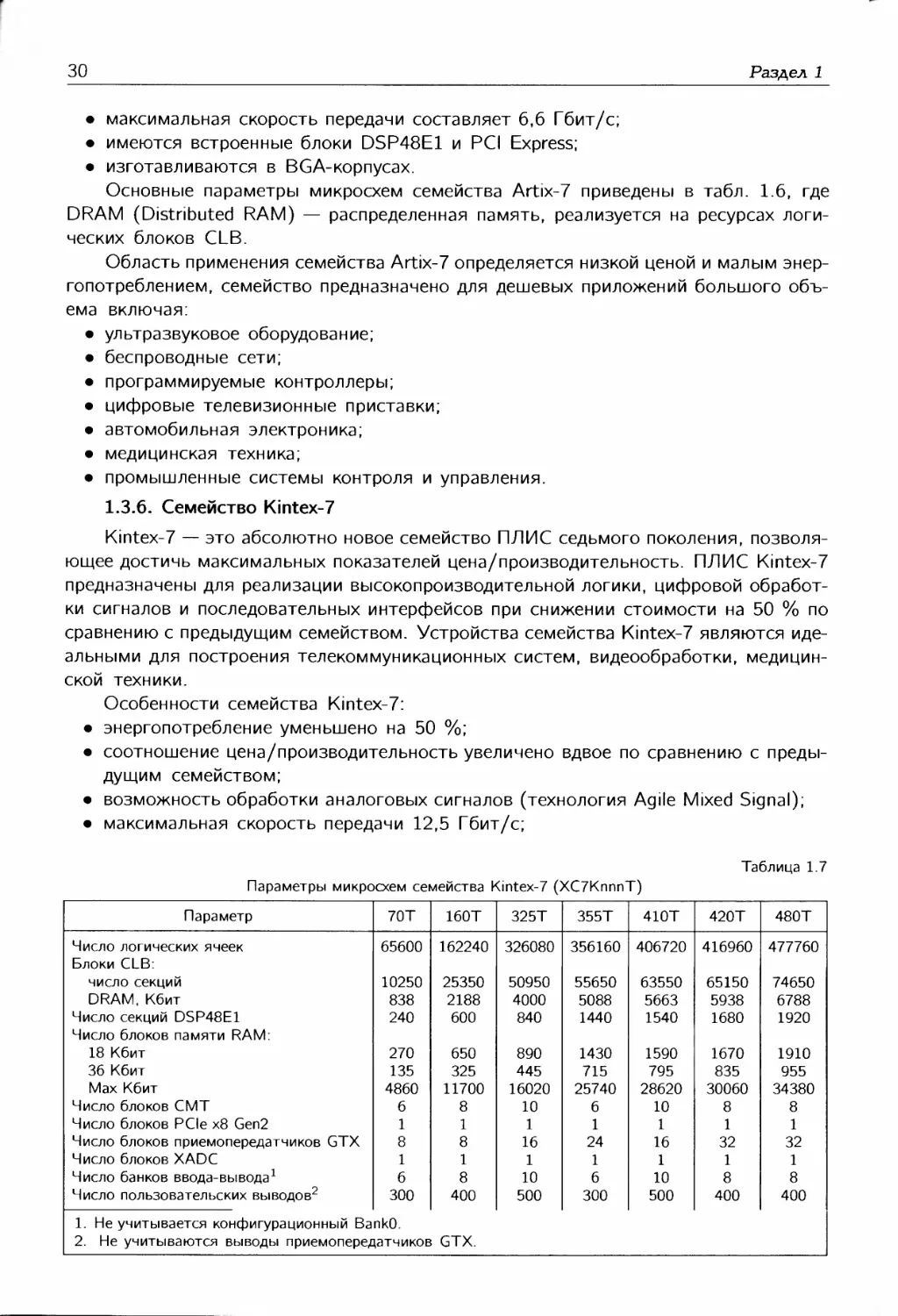
Параметр XC9536XL XC9572XL XC95144XL XC95288XL
Число системных вентилей Число макроячеек Максимальное число термов, подсоединяемых к одной макроячейке Число глобальных синхросигналов Чисор локальных синхросигналов функционального блока Число пользовательских выводов Уровни входных сигналов, В Уровни выходных сигналов, В Задержка на комбинационной части, нс Максимальная частота функционирования, МГц 800 36 90 3 18 36 2,5/3,3/5 2,5/33 5 178 1600 72 90 3 18 72 2,5/3,3/5 2,5/3,3 5 178 3200 144 90 3 18 117 2,5/3,3/5 2,5/3,3 5 178 6400 288 90 3 18 192 2.5/3.3/5 2,5/3,3 6 208
Таблица 1.2
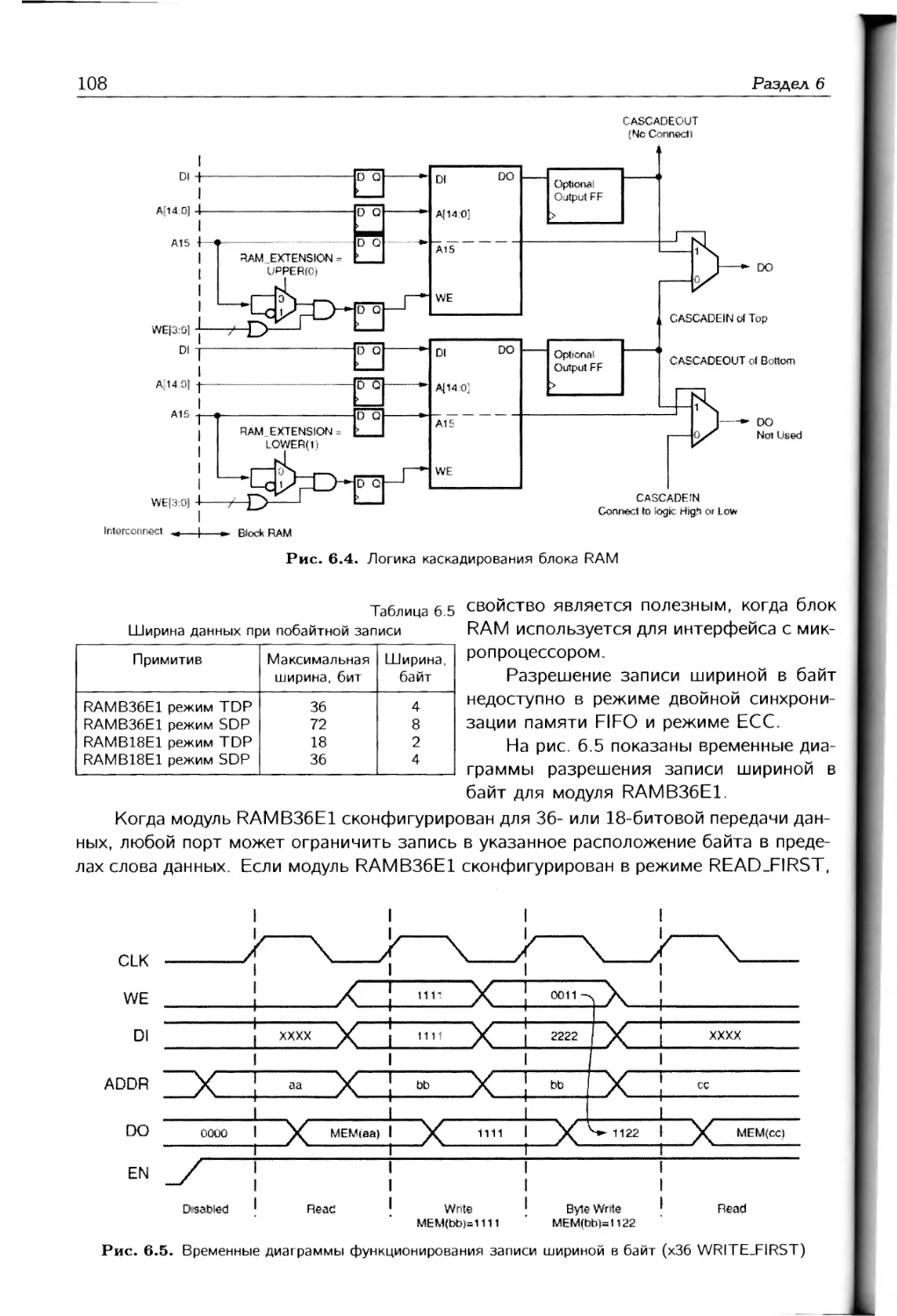
Параметры CPLD семейства CoolRunnerll
Параметр ХС2С32А ХС2С64А ХС2С128 ХС2С256 ХС2С384 ХС2С512
Число системных вентилей 750 1500 3000 6000 9000 12000
Число макроячеек 32 64 128 256 384 512
Число пользовательских выводов 33 64 100 184 240 270
Задержка на комбинационной 3,8 4,6 5,7 5,7 7,1 7,1
части, нс Максимальная частота функцио- нирования, МГ ц 323 263 244 256 217 179
Число блоков ввода-вывода 2 2 2 2 4 4
Делитель синхросигнала (Clock — — X X X X
Devider) Управление энергопотреблением (DataGATE) — — X X X X
24
Раздел 1
Микросхемы семейства CoolRunnerll, по сравнению с семейством XC9500XL, об-
ладают большим быстродействием, меньшим энергопотреблением и проще в исполь-
зовании. Области применения микросхем семейства CoolRunnerll: высокоскоростные
системы передачи данных, вычислительные системы, портативные устройства.
Параметры CPLD семейства CoolRunnerll представлены в табл. 1.2.
1.2.3. FPGA фирмы Xilinx
Несмотря на ряд положительных качеств CPLD, производимых фирмой Xilinx,
все-таки наибольшую популярность, мировое признание и 30...40 % мирового объема
программируемой логики фирме Xilinx приносят ее FPGA. В свое время фирма Xilinx в
больших объемах производила такие семейства FPGA, как ХС2000, ХС3000, ХС4000,
Spartan-Il, Spartan-3, Virtex-4, -5, -6. До недавнего времени верхом совершенства
считалась и до сих пор широко используется архитектура FPGA семейства Spartan-6.
Однако в 2012 году фирма Xilinx предложила новую линейку семейств FPGA 7-й
серии: Artix-7, Kintex-7 и Virtex-7. По утверждению фирмы Xilinx, в FPGA 7-й се-
рии воплотились все мировые достижения в области разработки архитектур FPGA,
причем не только фирмы Xilinx. Для сравнения возможностей микросхем из различ-
ных семейств в табл. 1.3 приведены максимальные значения основных параметров
микросхем FPGA 7-й серии и Spartan-б из предыдущего поколения ПЛИС.
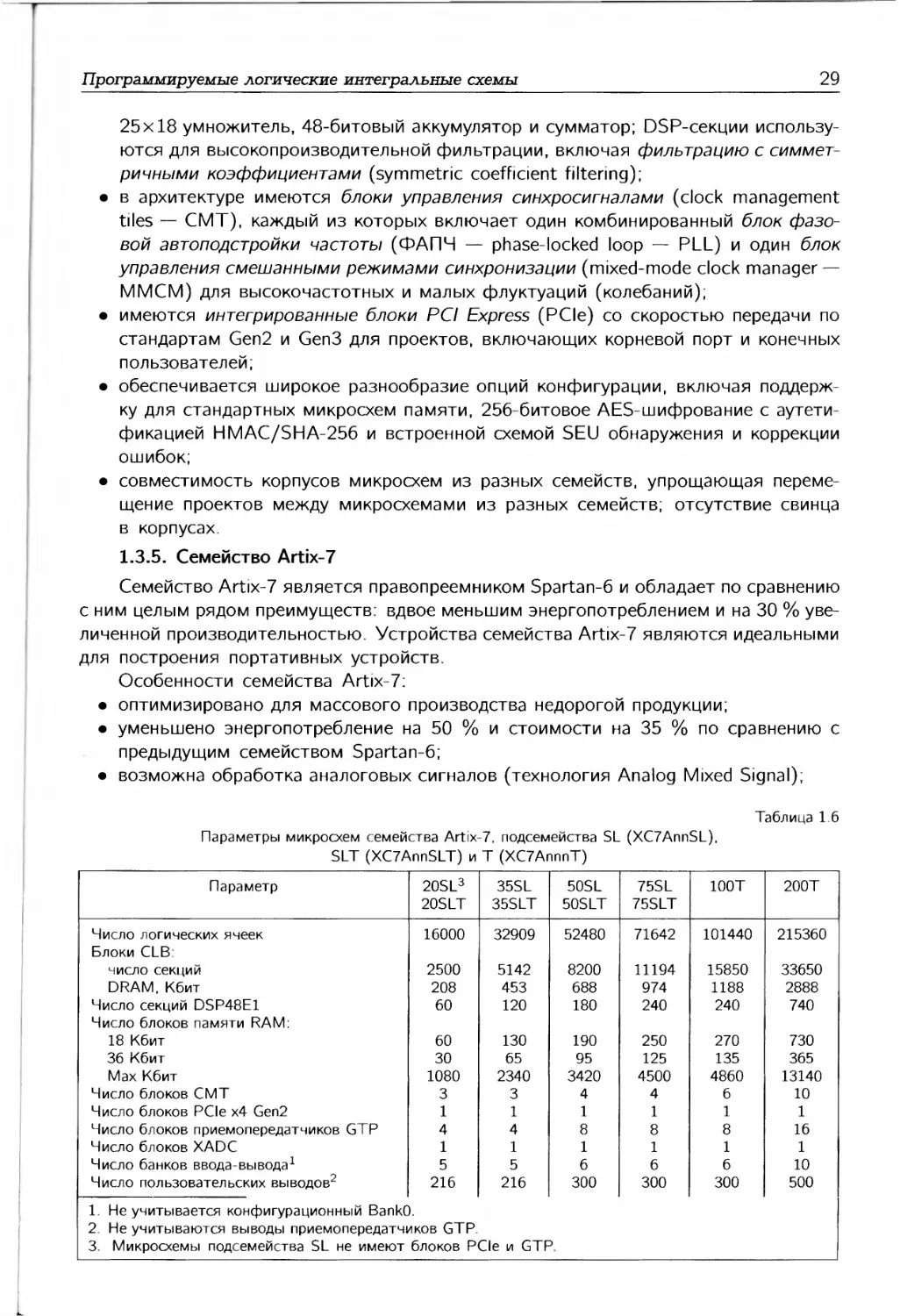
Таблица 1.3
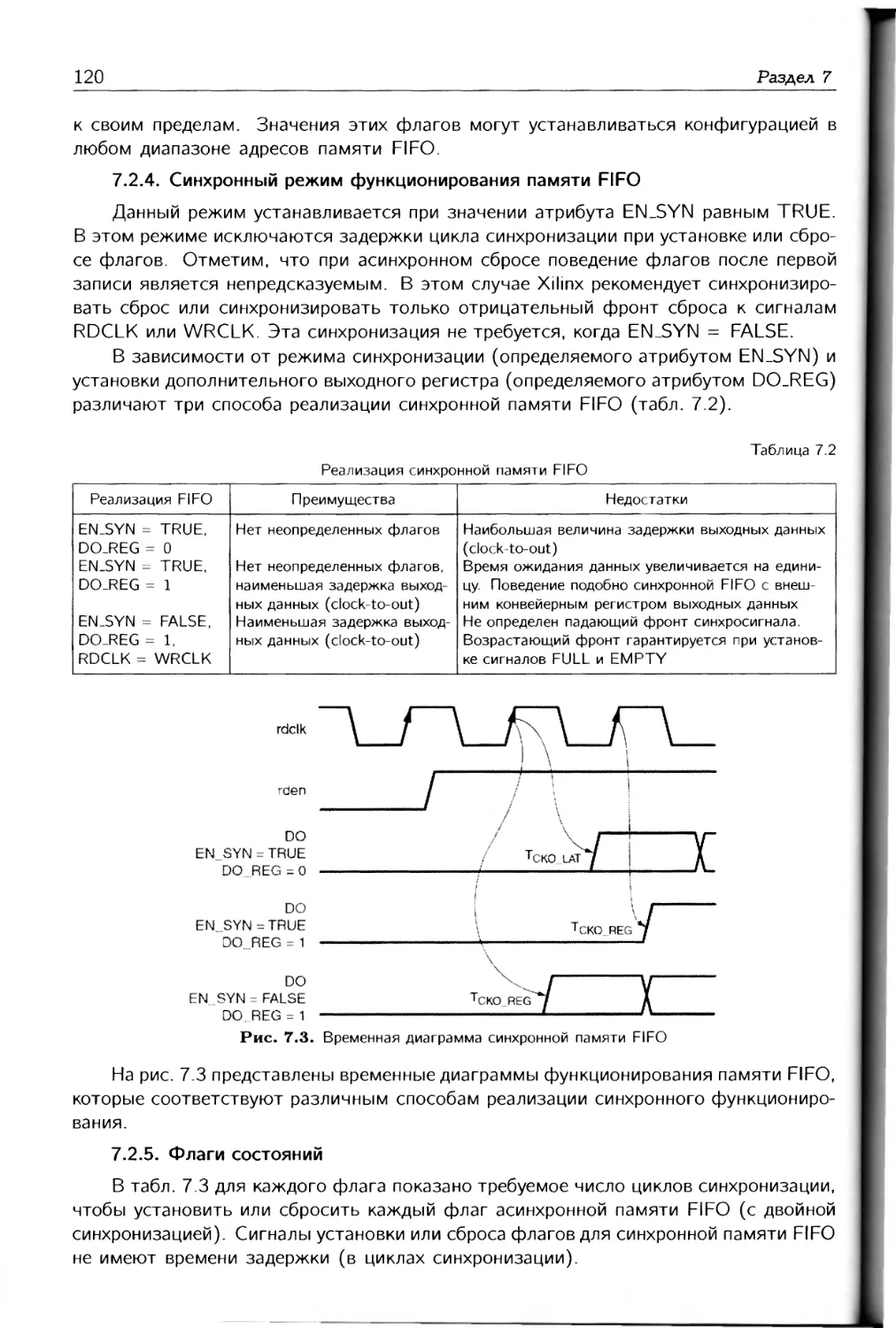
Максимальные значения параметров FPGA фирмы Xilinx
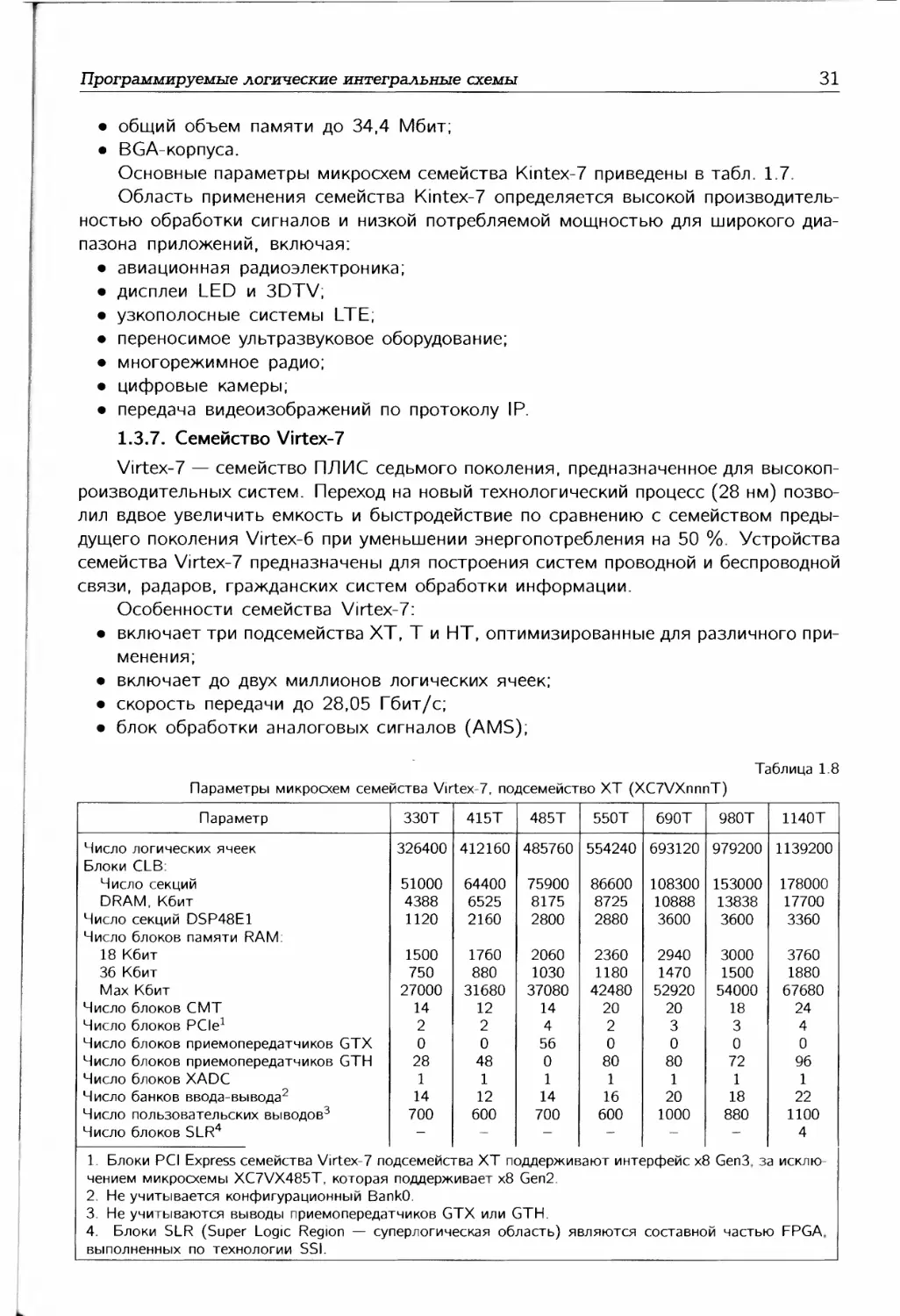
Параметр Spartan-6 Artix-7 Kintex-7 Virtex-7
Число логических ячеек Объем памяти в блоках RAM, Мбит Число секций DSP Производительность DSP1, GMAC/c Приемопередатчиков Скорость приемопередатчиков, Гбит/с Скорость интерфейса памяти (DDR3), Мбит/с Скорость последовательного интерфейса (Full Duplex), Гбит/с Интерфейс PCI Express Число пользовательских выводов Напряжение сигналов ввода-вывода, В Конфигурация AES Аналогово-цифровой преобразователь XADC Решение EasyPath для снижения стоимости Опции упаковки 1. Пиковая производительность при реализации 2. GMAC/c — миллиардов операций умножени 150000 4,8 180 8 3,2 800 xl Gen2 576 1,2/1,5/1,8/ 2,5/3,3 Да Нет Нет фильтра с сиг я в секунду. 215000 13 740 9252 16 6,6 1066 211 х4 Gen 2 500 1.2/ Да Да Нет Low-Cost, Wire- Bond, Lidless Flip-Chip иметричным 478000 34 1920 2845 32 12,5 1866 800 x8 Gen 2 500 '1,35/1,5/1,8/; Да Да Да Low-Cost, Lidless Flip-Chip, High Performance Flip-Chip и коэффициен 1955000 68 3600 5335 96 28,05 1866 2784 x8 Gen3 1200 >.5/3,3 Да Да Да Highest Performance Flip-Chip гами.
1.2.4. Микросхемы UltraScale
Устройства UltraScale представляют собой микросхемы, которые изготавлива-
ются по архитектуре FPGA, но имеют более высокую степень интеграции, поскольку
изготавливаются по технологиям 20 и 16 нм. Имеется два семейства FPGA UltraScale:
Kintex UltraScale и Virtex UltraScale. Как не трудно догадаться по названию, первое из
Программируемые логические интегральные схемы
25
Таблица 1.4
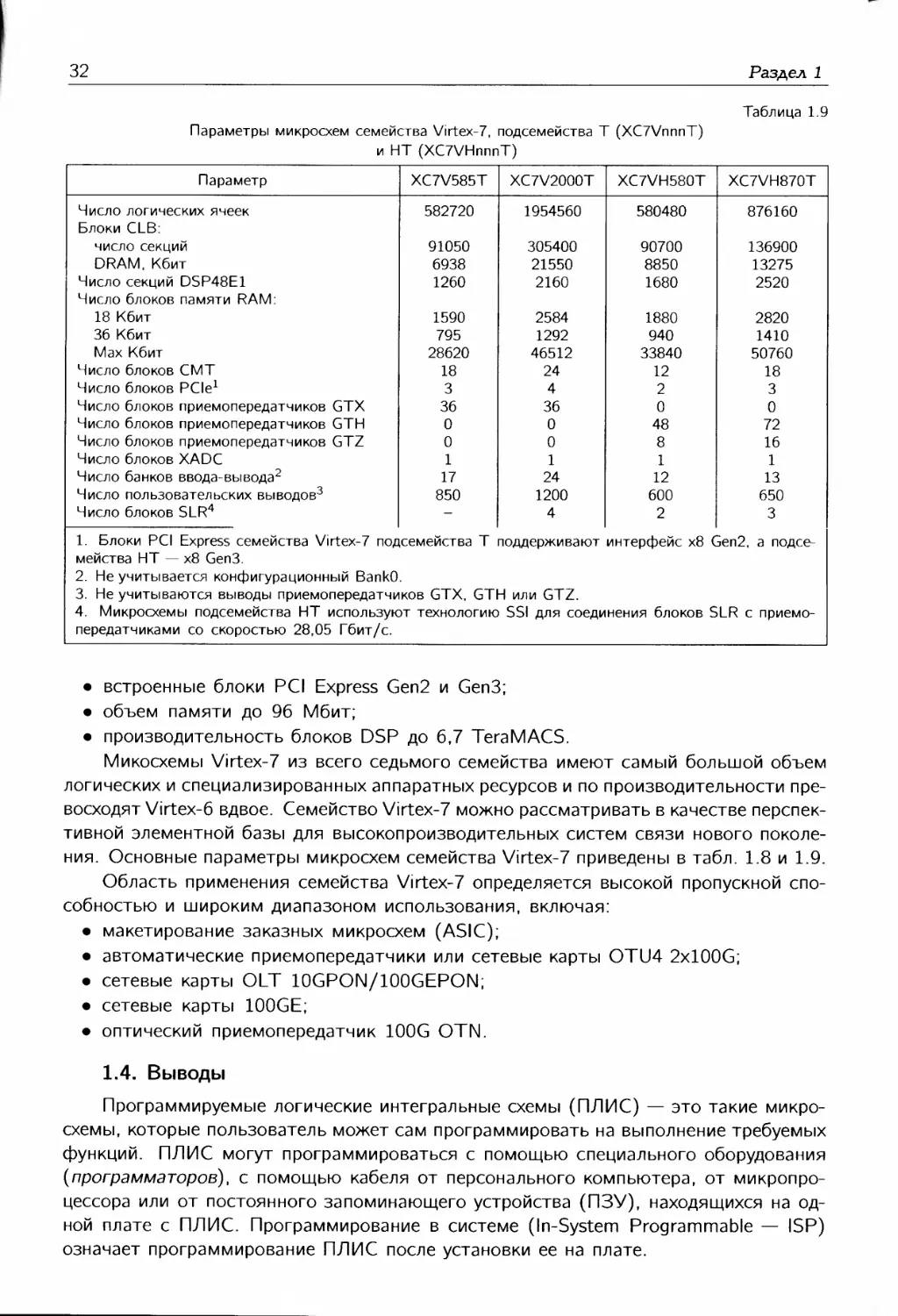
Максимальные параметры FPGA UltraScale
Параметр Kintex UltraScale Virtex UltraScale
Число логических ячеек Объем памяти блоков RAM, Мбит Число секций DSP Производительность DSP Число приемопередатчиков Скорость приемопередатчиков, Гбит/с Общая полоса пропускания, Гбит/с Интерфейс памяти (DDR3) Интерфейс PCI Express Поддержка смешанных сигналов Число двунаправленных выводов Напряжение двунаправленных выводов, В 1160880 76 5520 8180 GMACs 64 16,3 2086 2400 х8 Gen 3 Системный монитор 832 1,0...3,3 4407480 132,9 2880 4268 GMACs 120 32,75 5886 2400 x8 Gen 3 Системный монитор 1456 1,0...3,3
этих семейств основано на архитектуре Kintex-7, а второе — на Virtex-7. Отличают-
ся эти семейства только параметрами, максимальные значения которых приведены
в табл. 1.4.
В FPGA UltraScale применяются передовые технологии ASIC, используется син-
хронизация, подобная ASIC, усовершенствованы межсоединения и, самое главное,
FPGA UltraScale относятся к микросхемам, изготавливаемым по технологии 3D.
Основные особенности архитектуры FPGA UltraScale:
• быстродействующая память;
• усовершенствована архитектура блоков DSP;
• повышена пропускная способность внутри кристалла и оптимизирован интерфейс
микросхем памяти 3D;
• увеличена пропускная способность ввода-вывода и памяти, включая поддержку
памяти следующего поколения;
• возможно управление питанием со значительным объемом помех;
• применяется система безопасности проекта следующего поколения.
1.2.5. Микросхемы SoC
На основе FPGA 7-й серии фирмой Xilinx производятся микросхемы семейства
Zynq 7000, которые относятся к классу систем на кристалле SoC. В устройствах Zynq
7000 процессорное ядро реализовано аппаратно. Основные параметры процессора в
микросхемах SoC семейства Zynq 7000 приведены ниже.
Процессор...............................................
Чисор выводов процессорной системы......................
Сопроцессор для операций с плавающей точкой.............
Частота.................................................
Кэш L1..................................................
Кэш L2..................................................
Dual ARM Cortex-A9 MPCore
130
NEON&Single
800 МГц
32 Кбит команд и 32 Кбит данных
512 Кбит
Встроенная память.....................................
Поддерживаемая внешняя память.........................
Поддерживаемая внешняя статическая память.............
Каналы DMA............................................
Выводов периферийных устройств в статической памяти..
Периферийные устройства..............................
256 Кбит
DDR3, DDR2, LPDDR2
2xQuard-SPI, NAND, NOR
8 (4 для FPGA)
54
2xUSB2.0w/DMA, 2xTri-ModeGigabit
Ethernet w/DMA, 2xSD/SDIO w/DMA,
2xUART, 2xCAN 2,0 B, 2xl2C, 2xSPI,
4x32bGPIO
Программируемая часть микросхем Zynq 7000 строится на основе FPGA семейств
Artix-7 и Kintex-7. Параметры FPGA в составе семейства Zynq 7000 представлены
в табл. 1.5.
1
26
Раздел 1
Таблица 1.5
Параметры FPGA в составе семейства Zynq 7000
Параметр XC72010 ХС72020 ХС72030 ХС72040
Семейство ПЛИС Artix-7 Artix-7 Kintex-7 Kintex-7
Число логических ячеек (К) 28 85 125 235
Число LUT (К) 17.6 53,2 78,6 147,4
Число триггеров, тыс. 35,2 106,4 157,2 294,8
Число блоков памяти по 36 Кбит 60 140 265 465
Число секций DSP (18x25) 80 220 400 760
Число блоков PCI Express (Gen 2) — — 4 8
Число выводов на 3,3 В 100 200 100 200
Число приемопередатчиков на 10.3G — — 4 12
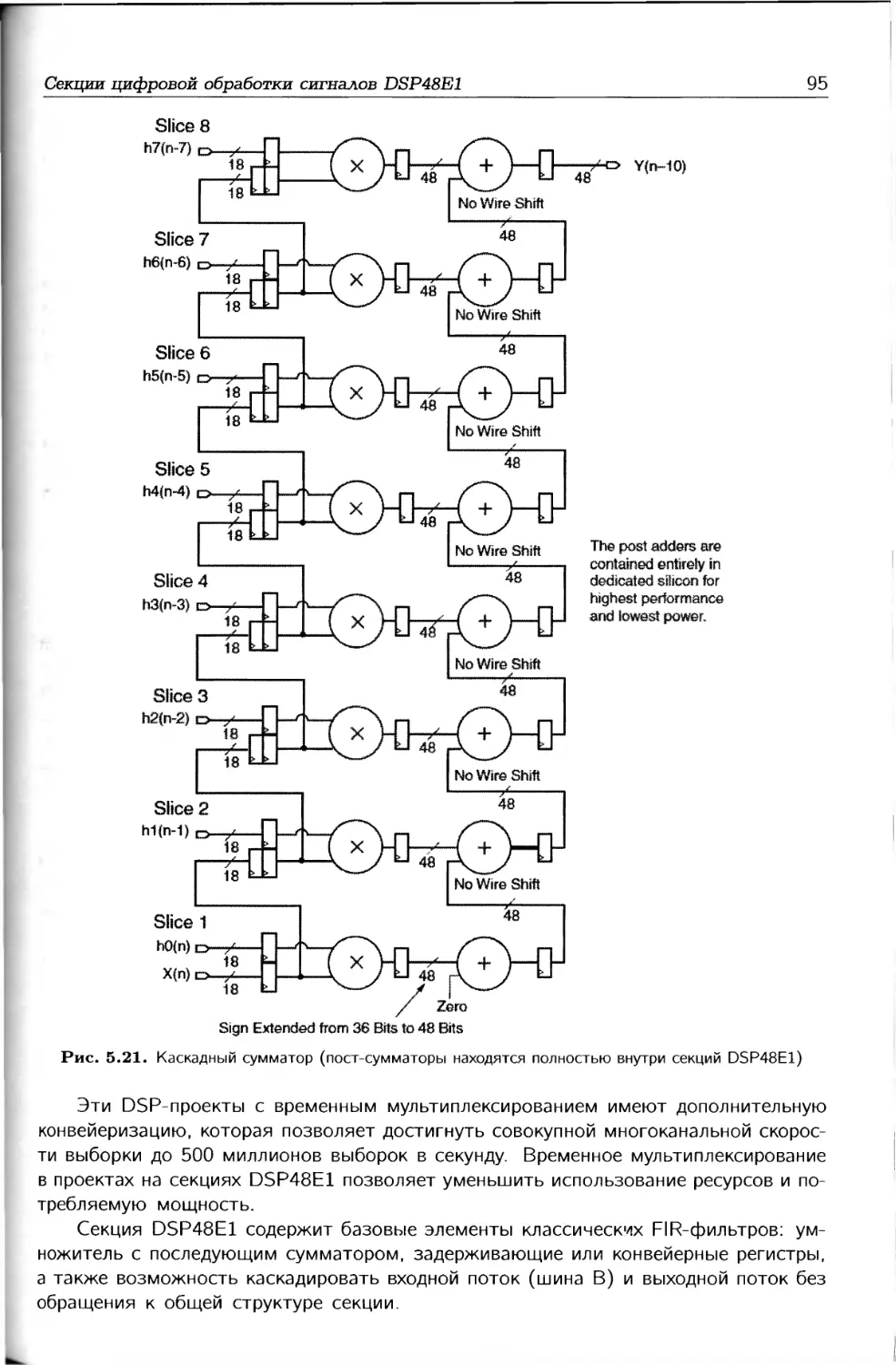
Число выводов на 1,8 В — — 150 150
1.2.6. Переход от ПЛИС к ASIC
В случае больших объемов производства для снижения стоимости ПЛИС мо-
гут программироваться на заводе во время их изготовления. С этой целью фирмы,
производители ПЛИС, предлагают микросхемы ASIC, которые по всем своим харак-
теристикам совпадают с соответствующими микросхемами ПЛИС.
Фирма Xilinx производит микросхемы ASIC серии EasyPath-7, EasyPath-6 и Easy-
Path, которые соответствуют микросхемам ПЛИС серии Virtex/Kintex-7, Virtex-6 и
Virtex соответственно.
1.3. Основные свойства FPGA 7-й серии фирмы Xilinx
1.3.1. Семейства микросхем FPGA 7-й серии
FPGA 7-й серии фирмы Xilinx объединяет три семейства FPGA (Artix-7, Kintex-7 и
Virtex-7), которые охватывают широкий спектр системных требований: от микросхем
малой стоимости для изделий массового производства — до ультравысокой степе-
ни интеграции для высокопроизводительных систем цифровой обработки сигналов с
высокой пропускной способностью.
FPGA 7-й серии фирмы Xilinx включает следующие семейства:
• Artix-7 — оптимизировано для наименьшей стоимости и энергопотребления, име-
ет малые габариты и рассчитано на использование в изделиях массового про-
изводства;
• Kintex-7 — совершенно новое семейство FPGA, оптимизировано для наилучшего
соотношения цена/производительность, по которому в 2 раза превосходит все
предыдущие семейства;
• Virtex-7 — оптимизировано для наивысшей степени производительности; допуска-
ет 2-х кратное увеличение производительности благодаря применению технологии
стековых кремниевых межсоединений (stacked silicon interconnect — SSI).
FPGA 7-й серии изготавливаются по 28-нанометровой технологии high-k metal
gate (HKMG), которую отличает высокая производительность и малое энергопотреб-
ление (low-power — HPL). FPGA 7-й серии представляют собой альтернативу заказ-
ным специализированным микросхемам (ASIC) и специализированным процессорам
ASSP.
Все микросхемы 7-й серии имеют общую архитектуру, организованную в виде
столбцов функциональных блоков одного типа. Данная архитектура основана на опти-
мизированных функциональных блоках четвертого поколения Advanced Silicon Modular
Block (ASMBL) и позволяет сократить время разработки и внедрения системы, а
также увеличивает мобильность проектов.
Программируемые логические интегральные схемы
27
1.3.2. Архитектура ASMBL
В основе всех FPGA 7-й серии положена архитектура ASMBL (Advanced Silicon
Modular Block — оптимизированный кремниевый модульный блок), показанная на
рис. 1.10.
Feature Options
Column
Based
ASMBL
Architecture
GlU Global Clock
P О High-performance I/O
R О High-range I/O
I EO Hard IP
S HI Mixed Signal
TO Transceivers
L Ш Logic (sliced
E □ Logic (SLICEM)
D@ DSP
MO Memory
CO Clock Management Tile
Рис. 1.10. Элементы технологии ASMBL FPGA фирмы Xilinx
Applications
Domain C
Applications
В архитектуре ASMBL функциональные блоки различного назначения (логичес-
кие, памяти, цифровой обработки сигналов, ввода-вывода, обработки аналоговых
сигналов, управления синхронизацией, приемопередатчиков и др.) располагаются
на кристалле в виде столбцов (по высоте кристалла). Каждый столбец состоит из
функциональных блоков одного типа. Между столбцами функциональных блоков на-
ходятся ресурсы межсоединений.
В зависимости от области (domain) применения (бытовая электроника, цифровая
обработка сигналов или телекоммуникация) микросхемы FPGA 7-й серии могут вклю-
чать различные типы столбцов функциональных блоков с необходимой комбинацией
свойств. Таким образом образуются семейства и подсемейства FPGA 7-й серии.
Особенности архитектуры ASMBL:
• устранение геометрических ограничений расположения, таких как зависимости
между количеством элементов ввода-вывода и размером матрицы структуры;
• улучшение распределения цепей питания и земли, позволяя цепям питания и зем-
ли размещаться на кристалле где угодно;
• возможность аппаратным IP-блокам (блокам интеллектуальной собственности)
масштабироваться независимо друг от друга и окружающих ресурсов.
1.3.3. Технология SSI
Новая технология стековых кремниевых межсоединений (Stacked Silicon Intercon-
nect — SSI) фирмы Xilinx позволяет вводить в архитектуру FPGA следующий струк-
турный уровень, благодаря чему могут создаваться FPGA очень высокой плотности и
производительности. Для этого площадь кристалла разделяется на множество супер-
логических регионов (Super Logic Regions — SLR), которые объединяются с помощью
супердлинных линий (Super Long Line — SSL) (рис. 1.11). Таких пассивных соединений
в FPGA, по которым сигналы передаются с очень высокой скоростью (с задержкой
около 1 нс), может быть более 10000.
Технология SSI применяется только в FPGA семейства Virtex-7. Имеется два
типа областей SLR, используемых в семействе Virtex-7: с повышенным количеством
28
Раздел 1
внутренней логики, используются в подсемействе Т, и с большим количеством блоков
DSP, RAM и приемопередатчиков, используются в подсемействах XT и НТ.
1.3.4. Свойства FPGA 7-й серии
Основные свойства FPGA 7-й серии:
• напряжение питания ядра 1,0 В с возможностью снижения до 0,9 В;
• архитектура основана на технологии 6-входовых функциональных генераторах
LUT (Look-Up Table), с возможностью конфигурирования как распределенная
память RAM (Distributed RAM — DRAM);
• включают двухпортовые блоки памяти RAM на 36 Кбит с встроенной логикой
для организации памяти типа FIFO для буферизации данных на кристалле;
• в архитектуре реализована высокопроизводительная технология ввода-вывода Se-
lectlO для поддержки интерфейсов к внешней памяти DDR3 со скоростью пере-
дачи данных до 1,866 Мбит/с;
• включают высокопроизводительные последовательные интерфейсы с встроенны-
ми приемопередатчиками, которые позволяют передавать данные со скоростью
от 600 Мбит/с до 28,05 Гбит/с, обеспечивая специальный режим малого энер-
гопотребления, оптимизированный для реализации интерфейса между микросхе-
мами на плате (chip-to-chip);
• имеется пользовательский конфигурируемый аналоговый интерфейс (configurable
analog interface — XADC), соединяющий двойные 12-битовые lMSPS-скоростные
аналого-цифровые преобразователи с температурными и электрическими (напря-
жения) датчиками на кристалле;
• имеются DSP-секции, каждая из которых содержит предварительный сумматор,
Программируемые логические интегральные схемы
29
25x18 умножитель, 48-битовый аккумулятор и сумматор; DSP-секции использу-
ются для высокопроизводительной фильтрации, включая фильтрацию с симмет-
ричными коэффициентами (symmetric coefficient filtering);
• в архитектуре имеются блоки управления синхросигналами (clock management
tiles — СМТ), каждый из которых включает один комбинированный блок фазо-
вой автоподстройки частоты (ФАПЧ — phase-locked loop — PLL) и один блок
управления смешанными режимами синхронизации (mixed-mode clock manager —
ММСМ) для высокочастотных и малых флуктуаций (колебаний);
• имеются интегрированные блоки PC! Express (PCIe) со скоростью передачи по
стандартам Gen2 и Gen3 для проектов, включающих корневой порт и конечных
пользователей;
• обеспечивается широкое разнообразие опций конфигурации, включая поддерж-
ку для стандартных микросхем памяти, 256-битовое AES-шифрование с аутети-
фикацией HMAC/SHA-256 и встроенной схемой SEU обнаружения и коррекции
ошибок;
• совместимость корпусов микросхем из разных семейств, упрощающая переме-
щение проектов между микросхемами из разных семейств; отсутствие свинца
в корпусах.
1.3.5. Семейство Artix-7
Семейство Artix-7 является правопреемником Spartan-б и обладает по сравнению
с ним целым рядом преимуществ: вдвое меньшим энергопотреблением и на 30 % уве-
личенной производительностью. Устройства семейства Artix-7 являются идеальными
для построения портативных устройств.
Особенности семейства Artix-7:
• оптимизировано для массового производства недорогой продукции;
• уменьшено энергопотребление на 50 % и стоимости на 35 % по сравнению с
предыдущим семейством Spartan-6;
• возможна обработка аналоговых сигналов (технология Analog Mixed Signal);
Таблица 1.6
Параметры микросхем семейства Artix-7, подсемейства SL (XC7AnnSL),
SLT (XC7AnnSLT) и Т (ХС7АпппТ)
Параметр 20SL3 20SLT 35SL 35SLT 50SL 50SLT 75SL 75SLT 100Т 200Т
Число логических ячеек 16000 32909 52480 71642 101440 215360
Блоки CLB:
число секций 2500 5142 8200 11194 15850 33650
DRAM, Кбит 208 453 688 974 1188 2888
Число секций DSP48E1 60 120 180 240 240 740
Число блоков памяти RAM:
18 Кбит 60 130 190 250 270 730
36 Кбит 30 65 95 125 135 365
Мах Кбит 1080 2340 3420 4500 4860 13140
Число блоков СМТ 3 3 4 4 6 10
Число блоков PCIe х4 Gen2 1 1 1 1 1 1
Число блоков приемопередатчиков GTP 4 4 8 8 8 16
Число блоков XADC 1 1 1 1 1 1
Число банков ввода-вы вода1 5 5 6 6 6 10
Число пользовательских выводов2 216 216 300 300 300 500
1. Не учитывается конфигурационный BankO.
2. Не учитываются выводы приемопередатчиков GTP
3. Микросхемы подсемейства SL не имеют блоков PCIe и GTP.
30
Раздел 1
• максимальная скорость передачи составляет 6,6 Гбит/с;
• имеются встроенные блоки DSP48E1 и PCI Express;
• изготавливаются в BGA-корпусах.
Основные параметры микросхем семейства Artix-7 приведены в табл. 1.6, где
DRAM (Distributed RAM) — распределенная память, реализуется на ресурсах логи-
ческих блоков СЕВ.
Область применения семейства Artix-7 определяется низкой ценой и малым энер-
гопотреблением, семейство предназначено для дешевых приложений большого объ-
ема включая:
• ультразвуковое оборудование;
• беспроводные сети;
• программируемые контроллеры;
• цифровые телевизионные приставки;
• автомобильная электроника;
• медицинская техника;
• промышленные системы контроля и управления.
1.3.6. Семейство Kintex-7
Kintex-7 — это абсолютно новое семейство ПЛИС седьмого поколения, позволя-
ющее достичь максимальных показателей цена/производительность. ПЛИС Kintex-7
предназначены для реализации высокопроизводительной логики, цифровой обработ-
ки сигналов и последовательных интерфейсов при снижении стоимости на 50 % по
сравнению с предыдущим семейством. Устройства семейства Kintex-7 являются иде-
альными для построения телекоммуникационных систем, видеообработки, медицин-
ской техники.
Особенности семейства Kintex-7:
• энергопотребление уменьшено на 50 %;
• соотношение цена/производительность увеличено вдвое по сравнению с преды-
дущим семейством;
• возможность обработки аналоговых сигналов (технология Agile Mixed Signal);
• максимальная скорость передачи 12,5 Гбит/с;
Таблица 1.7
Параметры микросхем семейства Kintex-7 (XC7KnnnT)
Параметр 70Т 160Т 325Т 355Т 410Т 420Т 480Т
Число логических ячеек 65600 162240 326080 356160 406720 416960 477760
Блоки CLB:
число секций 10250 25350 50950 55650 63550 65150 74650
DRAM, Кбит 838 2188 4000 5088 5663 5938 6788
Число секций DSP48E1 240 600 840 1440 1540 1680 1920
Число блоков памяти RAM:
18 Кбит 270 650 890 1430 1590 1670 1910
36 Кбит 135 325 445 715 795 835 955
Мах Кбит 4860 11700 16020 25740 28620 30060 34380
Число блоков СМТ 6 8 10 6 10 8 8
Число блоков PCIe х8 Gen2 1 1 1 1 1 1 1
Число блоков приемопередатчиков GTX 8 8 16 24 16 32 32
Число блоков XADC 1 1 1 1 1 1 1
Число банков ввода-вывода1 6 8 10 6 10 8 8
Число пользовательских выводов2 300 400 500 300 500 400 400
1. Не учитывается конфигурационный BankO.
2. Не учитываются выводы приемопередатчиков GTX.
Программируемые логические интегральные схемы
31
• общий объем памяти до 34,4 Мбит;
• BGA-корпуса.
Основные параметры микросхем семейства Kintex-7 приведены в табл. 1.7.
Область применения семейства Kintex-7 определяется высокой производитель-
ностью обработки сигналов и низкой потребляемой мощностью для широкого диа-
пазона приложений, включая:
• авиационная радиоэлектроника;
• дисплеи LED и 3DTV;
• узкополосные системы LTE;
• переносимое ультразвуковое оборудование;
• многорежимное радио;
• цифровые камеры;
• передача видеоизображений по протоколу IP.
1.3.7. Семейство Virtex-7
Virtex-7 — семейство ПЛИС седьмого поколения, предназначенное для высокоп-
роизводительных систем. Переход на новый технологический процесс (28 нм) позво-
лил вдвое увеличить емкость и быстродействие по сравнению с семейством преды-
дущего поколения Virtex-б при уменьшении энергопотребления на 50 %. Устройства
семейства Virtex-7 предназначены для построения систем проводной и беспроводной
связи, радаров, гражданских систем обработки информации.
Особенности семейства Virtex-7:
• включает три подсемейства XT, Т и НТ, оптимизированные для различного при-
менения;
• включает до двух миллионов логических ячеек;
• скорость передачи до 28,05 Гбит/с;
• блок обработки аналоговых сигналов (AMS);
Таблица 1.8
Параметры микросхем семейства Virtex-7, подсемейство XT (XC7VXnnnT)
Параметр ЗЗОТ 415Т 485Т 550Т 690Т 980Т 1140Т
Число логических ячеек Блоки CLB: Число секций DRAM, Кбит Число секций DSP48E1 Число блоков памяти RAM: 18 Кбит 36 Кбит Мах Кбит Число блоков СМТ Число блоков PCIe1 Число блоков приемопередатчиков GTX Число блоков приемопередатчиков GTH Число блоков XADC Число банков ввода-вывода2 Число пользовательских выводов3 Число блоков SLR4 1. Блоки PCI Express семейства Virtex-7 пс чением микросхемы XC7VX485T, которая 2. Не учитывается конфигурационный Ваг 3. Не учитываются выводы приемопереда’ 4. Блоки SLR (Super Logic Region — су выполненных по технологии SSL 326400 51000 4388 1120 1500 750 27000 14 2 0 28 1 14 700 >дсемейс поддерж ikO. гчиков G перлогич 412160 64400 6525 2160 1760 880 31680 12 2 0 48 1 12 600 гва XT пс ивает х8 ТХ или ( еская об 485760 75900 8175 2800 2060 1030 37080 14 4 56 0 1 14 700 эддержиЕ Gen2. ЗТН. ласть) Я1 554240 86600 8725 2880 2360 1180 42480 20 2 0 80 1 16 600 >ают инте зляются 693120 108300 10888 3600 2940 1470 52920 20 3 0 80 1 20 1000 ?рфейс х? составнс 979200 153000 13838 3600 3000 1500 54000 18 3 0 72 1 18 880 5 Gen3, з й частьн 1139200 178000 17700 3360 3760 1880 67680 24 4 0 96 1 22 1100 4 а исклю- э FPGA,
32
Раздел 1
Таблица 1.9
Параметры микросхем семейства Virtex-7, подсемейства Т (XC7VnnnT)
и НТ (XC7VHnnnT)
Параметр XC7V585T XC7V2000T XC7VH580T XC7VH870T
Число логических ячеек Блоки CLB: 582720 1954560 580480 876160
число секций 91050 305400 90700 136900
DRAM, Кбит 6938 21550 8850 13275
Число секций DSP48E1 Число блоков памяти RAM: 1260 2160 1680 2520
18 Кбит 1590 2584 1880 2820
36 Кбит 795 1292 940 1410
Мах Кбит 28620 46512 33840 50760
Число блоков СМТ 18 24 12 18
Число блоков PCIe1 3 4 2 3
Число блоков приемопередатчиков GTX 36 36 0 0
Число блоков приемопередатчиков GTH 0 0 48 72
Число блоков приемопередатчиков GTZ 0 0 8 16
Число блоков XADC 1 1 1 1
Число банков ввода-вывода2 17 24 12 13
Число пользовательских выводов3 850 1200 600 650
Число блоков SLR4 — 4 2 3
1. Блоки PCI Express семейства Virtex-7 подсемейства Т поддерживают мейства НТ — х8 Gen3. 2. Не учитывается конфигурационный BankO. 3. Не учитываются выводы приемопередатчиков GTX, GTH или GTZ. интерфейс х8 Gen2, а подсе-
4. Микросхемы подсемейства НТ используют технологию передатчиками со скоростью 28,05 Гбит/с. SSI для соединения блоков SLR с приемо-
• встроенные блоки PCI Express Gen2 и Gen3;
• объем памяти до 96 Мбит;
• производительность блоков DSP до 6,7 TeraMACS.
Микосхемы Virtex-7 из всего седьмого семейства имеют самый большой объем
логических и специализированных аппаратных ресурсов и по производительности пре-
восходят Virtex-6 вдвое. Семейство Virtex-7 можно рассматривать в качестве перспек-
тивной элементной базы для высокопроизводительных систем связи нового поколе-
ния. Основные параметры микросхем семейства Virtex-7 приведены в табл. 1.8 и 1.9.
Область применения семейства Virtex-7 определяется высокой пропускной спо-
собностью и широким диапазоном использования, включая:
• макетирование заказных микросхем (ASIC);
• автоматические приемопередатчики или сетевые карты OTU4 2xl00G;
• сетевые карты OLT 10GPON/100GEPON;
• сетевые карты 100GE;
• оптический приемопередатчик 100G OTN.
1.4. Выводы
Программируемые логические интегральные схемы (ПЛИС) — это такие микро-
схемы, которые пользователь может сам программировать на выполнение требуемых
функций. ПЛИС могут программироваться с помощью специального оборудования
(программаторов), с помощью кабеля от персонального компьютера, от микропро-
цессора или от постоянного запоминающего устройства (ПЗУ), находящихся на од-
ной плате с ПЛИС. Программирование в системе (In-System Programmable — ISP)
означает программирование ПЛИС после установки ее на плате.
Программируемые логические интегральные схемы
33
Если после выключения питания ПЛИС не сохраняет свою внутреннюю структу-
ру и при следующем включении питания ее необходимо настраивать заново, говорят
о конфигурировании ПЛИС. Большинство современных CPLD программируются, а
FPGA — конфигурируются. Современные ПЛИС допускают десятки тысяч перепро-
граммирований и неограниченное число раз конфигурирований.
Главное отличие микроконтроллеров от ПЛИС: при программировании микрокон-
троллер не изменяет свою архитектуру, а ПЛИС изменяет свою внутреннюю структуру
для выполнения заданных функций.
Исторически первыми ПЛИС принято считать программируемые логические мат-
рицы (ПЛМ — Programmable Logic Arrays — PLA). Основу архитектуры ПЛМ состав-
ляют две программируемые матрицы: матрица AND (И) и матрица OR (ИЛИ).
В зависимости от того, какая из матриц AND или OR программируется, про-
граммируемые логические устройства (ПЛУ — Programmable Logic Devices — PLDs)
делятся на три класса (ПЛМ, PAL и ППЗУ): в ПЛМ программируются обе матрицы;
в PAL программируется матрица AND, а матрица OR имеет фиксированную настрой-
ку, в ППЗУ программируется матрица OR, а матрица AND настроена на выполнение
функций полного дешифратора.
Структура CPLD (Complex Programmable Logic Devices) представляет собой со-
вокупность функциональных блоков, объединяемых программируемой матрицей пе-
реключений. Для большинства CPLD функциональный блок имеет структуру, по-
добную PAL.
Программируемые пользователем вентильные матрицы (Field Programmable Gate
Arrays — FPGAs) представляют собой совокупность функциональных генераторов ти-
па LUT (Look Up Table), которые позволяют реализовать любую булеву функцию от
небольшого числа аргументов (обычно 4-6).
Структура системы на кристалле (СнК — System On Chip — SoC) включает та-
кие компоненты, как процессор, память, периферийные устройства, а также область
программируемой логики: CPLD или FPGA.
Проектирование на ПЛИС представляет собой новую концепцию проектирова-
ния электронных систем, основу которой составляют технологии проектирования на
ПЛИС. К основным технологиям проектирования на ПЛИС относятся: архитектуры
ПЛИС, языки проектирования, программные и аппаратные средства автоматизиро-
ванного проектирования, блоки интеллектуальной собственности (IP-ядра) и проекти-
рование на основе IP-ядер, методологии проектирования на основе ПЛИС, цифровая
обработка сигналов, проектирование со встроенными микропроцессорами, проекти-
рование интерфейсов, отладка проектов, проектирование печатных плат для проектов
на ПЛИС, обеспечение целостности сигналов, энергосбережение, конфигурирование
ПЛИС, динамическое и частичное реконфигурирование ПЛИС, защита проекта и др.
Первые ПЛИС фирмы Xilinx по архитектуре FPGA начали производиться в се-
редине 80-х годов прошлого столетия. FPGA фирмы Xilinx организованы в виде
массива логических элементов (Logic Element), состоящих из функциональных ге-
нераторов LUT, мультиплексоров и триггеров. Логические элементы в FPGA фирмы
Xilinx группируются в виде конфигурируемых логических блоков (Configurable Logic
Blocks — CLB).
В настоящее время фирма Xilinx производит такие классы микросхем програм-
мируемой логики, как CPLD, FPGA и SoC.
Фирмой Xilinx выпускается две серии ПЛИС с архитектурой CPLD: XC9500XL и
CoolRunner-ll. Отличительными особенностями CPLD фирмы Xilinx являются: высо-
кая производительность, возможность перепрограммирования в системе, программи-
34
Раздел 1
руемый режим пониженной потребляемой мощности, мощный выход (24 мА), малая
статическая потребляемая мощность, простота использования.
Микросхемы семейства CoolRunnerll, по сравнению с семейством XC9500XL, об-
ладают большим быстродействием, меньшим энергопотреблением и проще в исполь-
зовании.
Семейство XC9500XL разрабатывалось для тесного взаимодействия с FPGA се-
мейств Virtex, Spartan и XC4000XL, позволяя оптимально разделять логику между
быстрыми интерфейсными схемами, какими являются CPLD, и устройствами с вы-
сокой логической плотностью, т. е. FPGA. Области применения микросхем семейства
CoolRunnerll: высокоскоростные системы передачи данных, вычислительные систе-
мы, портативные устройства.
В 2012 году фирма Xilinx предложила новую линейку семейств FPGA 7-й серии.
По утверждению фирмы Xilinx в FPGA 7-й серии воплотились все мировые достижения
в области разработки архитектур FPGA.
Устройства UltraScale представляют собой микросхемы, которые изготавлива-
ются по архитектуре FPGA, но имеют более высокую степень интеграции, поскольку
изготавливаются по технологиям 3D с проектными нормативами в 20 и 16 нм.
На основе FPGA 7-й серии фирмой Xilinx производятся микросхемы SoC семейст-
ва Zynq 7000, в которых процессорное ядро реализовано аппаратно.
Фирма Xilinx также производит микросхемы ASIC серии EasyPath-7, EasyPath-6 и
EasyPath, которые соответствуют микросхемам ПЛИС серии Virtex/К intex-7, Virtex-6
и Virtex соответственно и могут использоваться для снижения стоимости, поскольку
могут программироваться на заводе во время их изготовления.
Серия 7 FPGA фирмы Xilinx включает следующие семейства: Artix-7 — оптими-
зировано для наименьшей стоимости и энергопотребления, имеет малые габариты
и рассчитано на использование в изделиях массового производства; Kintex-7 — со-
вершенно новое семейство FPGA, оптимизировано для наилучшего соотношения це-
на/производительность, по которому в 2 раза превосходит все предыдущие семейства;
Virtex-7 — оптимизировано для наивысшей степени производительности; допускает 2-
кратное увеличение производительности благодаря применению технологии стековых
кремниевых межсоединений (stacked silicon interconnect — SSI).
Все микросхемы 7-й серии имеют общую архитектуру, организованную в виде
столбцов функциональных блоков одного типа. Данная архитектура получила назва-
ние оптимизированный кремниевый модульный блок (Advanced Silicon Modular Block —
ASMBL). Кроме того, технология SSI фирмы Xilinx, используемая в некоторых микро-
схемах семейства Virtex-7, позволяет вводить в архитектуру FPGA следующий струк-
турный уровень, благодаря чему могут создаваться FPGA очень высокой плотности
и производительности.
Семейство Artix-7 является правопреемником Spartan-б и обладает по сравнению
с ним целым рядом преимуществ: вдвое меньшим энергопотреблением и на 30 % уве-
личенной производительностью. Устройства семейства Artix-7 являются идеальными
для построения портативных устройств.
Kintex-7 — это абсолютно новое семейство ПЛИС седьмого поколения позволя-
ющее достичь максимальных показателей цена/производительность. ПЛИС Kintex-7
предназначены для реализации высокопроизводительной логики, цифровой обработ-
ки сигналов и последовательных интерфейсов при снижении стоимости на 50 % по
сравнению с предыдущим семейством. Устройства семейства Kintex-7 являются иде-
альными для построения телекоммуникационных систем, видео обработки, медицин-
ской техники.
Программируемые логические интегральные схемы
35
Virtex-7 — семейство ПЛИС седьмого поколения предназначенное для высокопро-
изводительных систем. Переход на новый технологический процесс (28 нм) позволил
вдвое увеличить емкость и быстродействие по сравнению с семейством предыдущего
поколения Virtex-б при уменьшении энергопотребления на 50 %. Устройства семейст-
ва Virtex-7 предназначены для построения систем проводной и беспроводной связи,
радаров, гражданских систем обработки информации.
2 CPLD семейства XC9500XL
Изначально семейство XC9500XL разрабатывалось для тесного взаимодействия
с FPGA семейств Virtex, Spartan и XC4000XL, позволяя оптимально разделять логику
между быстрыми интерфейсными схемами, какими являются CPLD, и устройствами
с высокой логической плотностью, т. е. FPGA. CPLD также очень эффективны при
реализации конечных автоматов и быстрых контроллеров. Подробные параметры
для каждой микросхемы CPLD семейства XC9500XL приведены в табл. 1.1. Здесь
отметим только основные технические параметры CPLD семейства XC9500XL:
• предназначены для использования в системах с напряжением питания 3,3 В;
• изготавливаются по 0.35 микронной технологии FastFLASH CMOS;
• задержка прохождения сигнала с входа на выход — 5 нс;
• максимальная частота функционирования — 208 МГц;
• используемые типы корпусов: VQFP, TQFP, CSP;
• программирование в системе (In-System Programmable — ISP);
• 54 входа на каждый функциональный блок;
• глобальных синхросигналов — 3;
• локальных синхросигналов функционального блока — 18;
• максимальное число термов, подсоединяемых к одной макроячейке — 90.
Кроме того, CPLD семейства XC9500XL обладают следующими свойствами:
• индивидуальное управление сигналами разрешения выхода (output enable — ОЕ);
• петля гистерезиса (input hysteresis) на всех пользовательских входах;
• схемы удержания шины (bus-hold) на всех пользовательских входах;
• возможность программного подсоединения неиспользуемых выводов к «земле»
для уменьшения системного шума;
• поддержка горячей вставки (hot-plugging);
• поддержка стандарта граничного сканирования IEEE 1149.1 (JTAG);
• быстрое параллельное программирование;
• управление скоростью нарастания сигнала (slew rate) для каждого выхода;
• расширенные возможности защиты информации от считывания;
• до 10000 циклов перепрограммирования;
• до 20 лет хранение запрограммированной информации.
Областью использования CPLD семейства XC9500XL является замена в старых
проектах множества микросхем малой и средней степени интеграции (в частности, се-
рии 7400) одной микросхемой, что приводит к увеличению быстродействия, снижению
энергопотребления и удобству использования проектируемой аппаратуры. Поскольку
CPLD энергонезависимы и готовы к работе сразу после включения питания (с неболь-
шой задержкой), то микросхемы CPLD часто используются в электронных системах
как стартовые контроллеры, которые управляют порядком включения напряжений
питания, конфигурированием и инициализацией микросхем на плате.
CPLD семейства XC9500XL
37
2.1. Описание архитектуры
2.1.1. Общая структура
Архитектура устройств семейства XC9500XL состоит из множества функциональ-
ных блоков (Functional Blocks — FBs) и блоков ввода-вывода (I/O Blocks — lOBs),
соединяемых матрицей переключений FastCONNECTII (рис. 2.1).
Рис. 2.1. Обобщенная структура CPLD семейства XC9500XL
Каждый функциональный блок имеет 54 входа, 18 макроячеек и до 18 выходов
(в зависимости от корпуса). Сигналы с выходов функционального блока поступа-
ют прямо в блоки ввода-вывода. Кроме того, структура CPLD семейства XC9500XL
включает специализированные входы сигналов глобального управления: три сигна-
ла глобальной синхронизации GCK и один сигнал глобального сброса или установки
GSR, а также 2 или 4 (для устройств XC95144XL и XC95288XL) сигнала разреше-
ния выходов GTS.
В структуре каждого устройства семейства XC9500XL дополнительно имеется 4
контакта порта JTAG-стандарта, по которым выполняется граничное сканирование
(boundary-scan) и программирование в системе (In-System Programming).
2.1.2. Структура функционального блока
Структура отдельного функционального блока CPLD семейства XC9500XL по-
казана на рис. 2.2.
Входы функционального блока (рис. 2.2) парафазные, что обеспечивает 108 пря-
мых или инверсных значений входных сигналов, поступающих на вход программи-
38
Раздел 2
Global Global
Set/Reset Clocks
Рис. 2.2. Структура функционального блока CPLD семейства XC9500XL
OUT
То FastCONNECT II
Switch Matrix
► To I/O Blocks
PTOE
руемой матрицы AND. Выходы матрицы AND называются промежуточными шина-
ми (product terms). Матрица AND на своих выходах позволяет формировать до 90
логических произведений входных сигналов. Распределитель промежуточных шин
(Product Term Allocator) назначает промежуточные шины макроячейкам функцио-
нального блока. При этом к каждой макроячейке могут быть подсоединены все 90
промежуточных шин.
Отметим, что не все макроячейки функционального блока имеют прямую связь с
блоками ввода-вывода, однако выходы всех макроячеек имеют связь с входом матри-
цы переключений FastCONNECTIL Макроячейки, выходы которых не имеют прямой
связи с блоками ввода-вывода, называются скрытыми (buried).
2.1.3. Архитектура макроячеек
Архитектура макроячеек CPLD семейства XC9500XL (рис. 2.3) имеет типичную
архитектуру PAL (Programmable Array Logic), которая включает многовходовой вен-
тиль OR, вентиль XOR, D- или Т-триггер, мультиплексор обхода триггера, а так-
же мультиплексоры выбора сигналов управления триггером и второго входа венти-
ля XOR.
Каждая макроячейка может управляться одним глобальным сигналом сброса/
установки GSR, тремя глобальными сигналами синхронизации GCK, а также сигнала-
ми индивидуального управления (которые формируются на отдельных промежуточ-
ных шинах): синхронизации Clock, установки Set, сброса Reset и разрешения синхро-
низации Clock Enable. Мультиплексор обхода триггера позволяет на выходе макроя-
чейки реализовать комбинационную или регистровую функцию.
В общем случае макроячейка имеет два выхода: один соединяется с блоком
ввода-вывода, а другой поступает на вход матрицы переключений FastCONNECTIL
Скрытые макроячейки имеют только один выход, который соединяется с входом мат-
рицы FastCONNECTIL Кроме того, каждая макроячейка одну промежуточную шину
может использовать для индивидуального управления выходным буфером соответ-
ствующего блока ввода-вывода. Взаимодействие выходов функциональных блоков
(макроячеек), блоков ввода-вывода и матрицы переключений показано на рис. 2.4.
CPLD семейства XC9500XL
39
Рис. 2.3. Архитектура макроячеек CPLD семейства XC9500XL
Рис. 2.4. Передача сигналов между матрицей переключений, функциональными блоками и блоками
ввода-вывода
40
Раздел 2
2.1.4. Архитектура блока ввода-вывода
Каждый блок ввода-вывода (рис. 2.5) включает входной буфер, выходной буфер
(драйвер) и мультиплексор выбора сигнала разрешения выхода. Значение выходно-
го сигнала в блок ввода-вывода поступает с выхода соответствующей этому блоку
макроячейки. Основу архитектуры блока ввода-вывода составляет буфер с тремя со-
стояниями. Третье состояние этого буфера может управляться глобально с помощью
сигналов GTS или управляться индивидуально от промежуточной шины РТОЕ соот-
ветствующей макроячейки. Каждый блок ввода-вывода имеет отдельную обратную
связь с матрицей переключений, которая используется для приема значений вход-
ных сигналов.
Входной буфер блока ввода-вывода совместим с сигналами стандарта TTL на
5,0 В и стандарта CMOS на 5,0, 3,3 и 2,5 В. Входной буфер использует внутрен-
нее напряжение питания Vccint на 3,3 В для уверенности, что пороги напряжений
входных сигналов являются постоянными и не изменяются с изменением напряжения
питания блока ввода-вывода Vccio- Каждый входной буфер обеспечивает входной
гистерезис на 50 mV для уменьшения системного шума.
То other
Macrecells
Рис. 2.5. Архитектура блока ввода-вывода
CPLD семейства XC9500XL
41
Рис. 2.6. Совмещение систем с разными уровнями напряжения сигналов с помощью CPLD семейства
XC9500XL
Напряжение питания Vccio на 3,3 В и 2,5 В выходного драйвера обеспечивает
стандарт сигналов CMOS на 3,3 В (5,0 В стандарта TTL) и 2,5 В соответственно.
На рис. 2.6 показаны напряжения питания выводов CPLD семейства XC9500XL для
сопряжения систем с разными уровнями сигналов.
2.2. Архитектурные особенности CPLD семейства XC9500XL
использоваться как источник сигнала
2.2.1. Архитектурные свойства буферов ввода-вывода
Каждый блок ввода-вывода имеет три индивидуально программируемых архи-
тектурных свойства:
• управление скоростью возрастания сигнала (Slew Rate Control);
• программируемое подсоединение к земле (User-Programmable Ground);
• удержание (захват) шины (Bus-Hold).
Уменьшение скорости возрастания сигнала может использоваться для уменьше-
ния системного шума для сигналов, не влияющих на производительность системы.
Неиспользуемые выводы микросхемы могут путем программирования CPLD подсое-
диняться к «земле» с целью уменьшения потребляемой мощности и снижения сис-
темного шума. Кроме того, эти выводы мог}
с низким логическим уровнем.
Каждый блок ввода-вывода также пре-
доставляет схему удержания (захвата) ши-
ны (рис. 2.7), называемую «хранителем»
(keeper), которая является активной в режи-
ме пользовательского функционирования.
Свойство удержания шины исключает
необходимость подсоединять неиспользуе-
мые выводы к высокому или низкому уров-
ню для удержания последнего состояния
входа до тех пор, пока не будет установлено
следующее действительное значение. Ког-
да устройство функционирует не в пользо-
вательском режиме, схема удержания шины
эквивалентна подтягивающему резистору на
стирания (erased), в режиме программирования, в режиме граничного сканирования
JTAG INTEST, а также во время инициализации при включении питания.
Set to PIN
during valid user
operation Drrve t0
Рис. 2.7. Схема удержания значения шины
50 кОм. Это происходит в состоянии
42
Раздел 2
Отметим, что к любому выводу может подсоединяться внешний подтягивающий к
«земле» резистор на 1 кОм для переопределения сопротивления внутреннего резис-
тора Rbh. например для установки значений выводов в низкий уровень при вклю-
чении питания.
2.2.2. Безопасность проекта
Устройства XC9500XL предоставляют функции защиты данных программирова-
ния от несанкционированного чтения, стирания или перепрограммирования. Биты
защиты чтения могут быть установлены пользователем для предохранения внутрен-
него шаблона (образа) программирования от чтения или копирования. Когда биты
защиты чтения установлены, они запрещают будущие операции программирования,
но разрешают стирание устройства. Стирание устройства является единственным
способом сбросить бит защиты чтения.
Биты защиты записи обеспечивают дополнительную защиту против случайно-
го стирания или перепрограммирования устройства, когда выводы JTAG подвержены
шуму, например при включении питания системы. Будучи установленной, деактивиза-
ция защиты записи может быть выполнена, когда необходимо перепрограммировать
устройство с допустимым шаблоном с помощью специальной последовательности ко-
манд протокола JTAG (табл. 2.1).
Таблица 2.1
Опции защиты данных
Защита записи Защита чтения
По умолчанию Установлена
По умолчанию Установлена Чтение разрешено. Программирование и стирание разрешены Чтение разрешено. Программирование и стирание разрешены Чтение запрещено. Программирование и стирание разрешены Чтение запрещено. Программирование и стирание запрещены
2.2.3. Режим пониженного энергопотребления
В устройствах XC9500XL предоставляется режим пониженного энергопотребле-
ния (Low Power), который может быть установлен для каждой макроячейки индивиду-
ально или сразу для всех макроячеек устройства. Режим пониженного энергопотреб-
ления вводит дополнительную задержку tbp для сигналов комбинационной логики,
а также увеличивает время установки (setup) для триггеров. Рекомендация Xilinx:
макроячейки, сигналы которых переключаются с периодом 50 нс и более, должны
программироваться в режиме пониженного энергопотребления.
2.3. Выводы
Семейство XC9500XL разрабатывалось для тесного взаимодействия с FPGA се-
мейств Virtex, Spartan и XC4000XL, позволяя оптимально разделять логику между
быстрыми CPLD и FPGA с высокой логической плотностью. CPLD также очень эф-
фективны при реализации конечных автоматов и быстрых контроллеров.
Поскольку CPLD программируются и готовы к работе сразу после включения
питания (с небольшой задержкой), то микросхемы CPLD часто используются в элек-
тронных системах как стартовые контроллеры, которые управляют порядком включе-
ния напряжений питания, конфигурированием и инициализацией микросхем на плате.
CPLD семейства XC9500XL
43
Архитектура устройств семейства XC9500XL состоит из множества функциональ-
ных блоков (Functional Blocks — FBs) и блоков ввода-вывода (I/O Blocks — lOBs), со-
единяемых матрицей переключений FastCONNECTIL Кроме того, структура CPLD се-
мейства XC9500XL включает специализированные входы сигналов глобального управ-
ления: три сигнала глобальной синхронизации GCK и один сигнал глобального сброса
или установки GSR, а также 2 или 4 сигнала разрешения выходов GTS.
Функциональный блок имеет 52 парафазных входа. Это позволяет на вход мат-
рицы AND подавать до 108 прямых или инверсных значений входных сигналов. Мат-
рица AND на своих выходах (промежуточных шинах) позволяет формировать до 90
логических произведений входных сигналов.
Архитектура макроячеек CPLD семейства XC9500XL имеет типичную архитектуру
PAL, которая включает многовходовой вентиль OR, вентиль XOR, D- или Т-триггер,
мультиплексор обхода триггера, а также мультиплексоры выбора сигналов управления
триггером и второго входа вентиля XOR.
К одной макроячейке могут быть подсоединено до 90 промежуточных шин.
Каждая макроячейка может управляться одним глобальным сигналом сброса/
установки GSR, тремя глобальными сигналами синхронизации GCK, а также сигнала-
ми индивидуального управления: синхронизации Clock, установки Set, сброса Reset и
разрешения синхронизации Clock Enable. Мультиплексор обхода триггера позволяет
на выходе макроячейки реализовать комбинационную или регистровую функцию.
Блок ввода-вывода включает входной буфер, выходной буфер (драйвер) и муль-
типлексор выбора сигнала разрешения выхода. Каждый блок ввода-вывода имеет три
индивидуально программируемых архитектурных свойства:
• управление скоростью возрастания сигнала (Slew Rate Control);
• программируемое подсоединение к земле (User-Programmable Ground);
• удержание (захват) шины (Bus-Hold).
Устройства XC9500XL предоставляют функции защиты данных программирова-
ния от несанкционированного чтения, стирания или перепрограммирования. Для это-
го служат биты защиты чтения и биты защиты записи.
В устройствах XC9500XL предоставляется режим пониженного энергопотребле-
ния (Low Power), который может быть установлен для каждой макроячейки индиви-
дуально или сразу для всех макроячеек устройства.
3 CPLD семейства CoolRunnerll
Микросхемы семейства CoolRunnerll, по сравнению с семейством XC9500XL, об-
ладают большим быстродействием, меньшим энергопотреблением и проще в исполь-
зовании. Области применения микросхем семейства CoolRunnerll: высокоскоростные
системы передачи данных, вычислительные системы, портативные устройства. Пара-
метры микросхем CPLD семейства CoolRunnerll были приведены в табл. 1.2. Здесь
перечислим только основные технические параметры CPLD семейства CoolRunnerll:
• предназначены для использования в системах с напряжением питания 1,8 В;
• изготавливаются по 0,18 микронной технологии CMOS;
• минимальная задержка прохождения сигнала с входа на выход — 3,8 нс;
• максимальная частота функционирования — 323 МГц;
• используемые типы корпусов: VQFP, TQFP, PQFP, QFN, CSP BGA, FineLine BGA;
• 40 входов на каждый функциональный блок;
• максимальное число промежуточных шин, подсоединяемых к одной макроячей-
ке — 56;
• число глобальных синхросигналов — 3;
• число локальных синхросигналов функционального блока — 16;
• уровни входных и выходных сигналов (вольт) — 1.5/1.8/2.5/3.3;
Кроме того, CPLD семейства CoolRunnerll обладают следующими свойствами:
• программирование в системе (In-System Programmable — ISP) по стандарту IEEE
1532 (JTAG);
• индивидуальное управление сигналами разрешения выхода (output enable — ОЕ);
• возможность установки триггеров Шмита на пользовательских входах;
• все выводы общего назначения имеют на входах схемы удержания шины (bus-
hold);
• поддержка горячей вставки (hot-plugging);
• поддержка граничного сканирования (Boundary Scan Test — BST) по стандарту
IEEE 1149.1 (JTAG);
• расширенные возможности защиты информации от считывания (Design Security);
• до 1000 циклов перепрограммирования;
• до 20 лет хранение запрограммированной информации;
• выводы объединены в банки ввода-вывода (I/O Banks);
• управление энергопотреблением осуществляется с помощью отдельного сигна-
ла (DataGATE);
• гибкость режимов синхронизации:
• переключение по двум фронтам синхросигнала (DualEDGE);
• наличие делителя частоты синхросигнала (Clock Divider) с коэффициентами 2,
4, 6, 8, 10, 12, 14, 16;
• режим пониженного энергопотребления CoolCLOCK;
• дополнительные опции глобальных сигналов для управления макроячейками:
• доступно 3 глобальных сигнала с выбором фронта для каждой макроячейки;
• возможно 3 глобальных сигнала разрешения выхода (output enable — ОЕ);
CPLD семейства CoolRunnerll
45
• доступны глобальные сигналы установки и сброса триггера для каждой макро-
ячейки;
• возможность формирования на промежуточных шинах локальных (индивидуаль-
ных) сигналов синхронизации, разрешения выходов, установки/сброса для управ-
ления функциональным блоком (макроячейкой);
• опция открытый сток (open-drain) выходов для реализации проводного OR и
управления светодиодами LED;
• слабое подтягивание (weak pull-up) отдельных выводов;
• программирование подсоединения к «земле» неиспользованных выводов;
• поддержка стандартов LVTTL, LVCMOS33, 25, 18, 15;
• поддержка стандартов STTL2_1, STTL3.1 и HSTL.1 для микросхем с числом
макроячеек 128 и выше;
• реконфигурирование «на лету» (On-The-Fly reconfiguration — OTF).
3.1. Описание архитектуры
3.1.1. Общая структура
Обобщенная структура CPLD CoolRunnerll приведена на рис. 3.1. Она состо-
ит из функциональных блоков (Functional Block — FB) и блоков ввода-вывода (I/O
Blocks — lOBs), которые соединяются глобальной матрицей переключений Advanced
Interconnect Matrix (AIM). Каждый функциональный блок содержит 16 макроячеек.
Архитектура CPLD CoolRunnerll также содержит периферийную шину (из 16 линий),
по которой к блокам ввода-вывода передаются сигналы управления и синхрониза-
ции. Кроме того, все блоки ввода-вывода последовательно соединяются цепью BSC
(Boundary Scan Control) для граничного сканирования и программирования в системе
(In-System Programming — ISP) по протоколу стандарта JTAG.
BSC Path
Рис. 3.1. Обобщенная структура CPLD CoolRunnerll
3.1.2. Структура функционального блока
Функциональный блок CPLD семейства CoolRunnerll (рис. 3.2) имеет 40 пара-
фазных входов (по которым из матрицы переключений может поступать 80 значений
46
Раздел 3
Global Global
SeVReset Clocks
Рис. 3.2. Структура функционального
блока CPLD семейства CoolRunnerll
сигналов), программируемую матрицу AND и
16 макроячеек. Функциональные блоки CPLD
семейства CoolRunner-ll строятся на основе ар-
хитектуры программируемых логических мат-
риц (ПЛМ — PLA), т. е. любая промежуточ-
ная шина может быть подсоединена к любой
макроячейке, а также допускается одновремен-
ное подключение одной промежуточной шины
к разным макроячейкам. Один функциональ-
ный блок имеет 56 промежуточных шин, 4 из
которых могут использоваться для формиро-
вания локальных сигналов управления.
3.1.3. Архитектура макроячеек
Архитектура макроячейки CPLD семейст-
ва CoolRunnerll приведена на рис. 3.3. Она
включает многовходовой вентиль OR, вентиль
XOR, триггер, мультиплексор обхода триггера,
а также мультиплексоры выбора сигналов
управления триггером.
Триггер макроячейки может программи-
роваться как D или Т триггер, защелка или в режиме DualEDGE. Кроме того, вход
триггера имеет прямую связь с соответствующим блоком ввода-вывода. Благодаря
этому триггер может использоваться в качестве входного буфера.
Каждая макроячейка CPLD семейства CoolRunnerll имеет 3 выхода: один соеди-
нен с соответствующим блоком ввода-вывода, а два (регистровый и комбинацион-
ный) — с матрицей переключений AIM.
Рис. 3.3. Архитектура макроячеек CPLD семейства CoolRunnerll
CPLD семейства CoolRunnerll
47
3.1.4. Архитектура блока ввода-вывода
Архитектура блока ввода-вывода CPLD семейства CoolRunnerll приведена на
рис. 3.4. Она включает входной и выходной буферы, мультиплексор выбора сигна-
лов управления выходным буфером, мультиплексор выбора входного сигнала, схемы
удержания шины и буфер опорного напряжения. Значение выходного сигнала в блок
ввода-вывода поступает с выхода соответствующей макроячейки. Третье состояние
выходного буфера может управляться глобальными сигналами GTS [0:3], локальным
сигналом СТЕ и индивидуальным сигналом РТВ. Кроме того, выходной буфер мо-
жет программироваться для уменьшения скорости возрастания сигнала, в режиме
открытый сток (Open Drain), захвата шины (Bus-Hold) и с подтягиванием к напря-
жению питания.
Available on 128 Macrocell Devices and Larger
То Macrocell
Direct Input
Enabled
GTE
PTB
GTS[0:3J
CGND
Open Drain
Disabled
From Macrocell
Global termination
Pulhjp/Bus-Hold
Рис. 3.4. Архитектура блока ввода-вывода CPLD семейства CoolRunnerll
Когда блок ввода-вывода конфигурируется как вход, для снижения шума в цепь
входного сигнала может включаться триггер Шмитта с петлей гистерезиса на 500mV.
Каждый вход может подсоединяться к матрице переключений AIM, а также непо-
средственно ко входу триггера соответствующей макроячейки.
Стандарты, поддерживаемые блоками ввода-вывода CPLD семейства CoolRun-
nerll приведены в табл. 3.1.
Таблица 3.1
Стандарты ввода-вывода
Стандарт Vccio> В Vrff. В Поддержка триггера Шмита
LVTTL 3,3 — Дополнительно
LVCMOS33 3,3 — Дополнительно
LVCMOS25 2,5 — Дополнительно
LVCMOS18 1,8 — Дополнительно
LVCMOS15 1.5 — Не поддерживается
HSTL-1 1.5 0,75 Не поддерживается
SSTL2-1 2,5 1,25 Не поддерживается
SSTL3-1 3.3 1,5 Не поддерживается
Некоторые стандарты требуют подачи в блоки ввода-вывода опорного напряже-
ния Vref- Для приема значения опорного напряжения может использоваться любой
вывод общего назначения устройства CPLD семейства CoolRunnerll (детали см. в
документе ХАРР382 CoolRunner-ll I/O Characteristics).
48
Раздел 3
3.2. Архитектурные особенности CPLD семейства CoolRunnerll
3.2.1. Режим снижения энергопотребления DataGATE
Режим снижения энергопотребления DataGATE позволяет для указанных выво-
дов с помощью перемычек (assertion rail) блокировать поступление значений входных
сигналов (рис. 3.5).
При этом во внутреннюю логику CPLD (матрицу AIM) будут поступать последние
значения сигналов, хранящиеся в защелках. Каждому входному контакту, который ис-
пользует режим DataGATE, должен быть назначен атрибут DATA.GATE. Для управ-
ления режимом DataGATE используется отдельный сигнал. Сигнал, управляющий
перемычками DataGATE, может поступать от внешнего вывода или формироваться
во внутренней логике. В последнем случае значение сигнала формируется как выход
комбинационной схемы, счетчика или конечного автомата. Если сигнал поступает с
внешнего вывода, то этот вывод должен иметь атрибут BUFG = DATA.GATE. Сигнал
разрешения режима DataGATE является отдельным выделенным выводом DGE/I/O
для каждого корпуса устройств семейства CoolRunnerll.
3.2.2. Режим делителя частоты синхросигнала ClockDivider
Режим делителя частоты синхросигнала ClockDivider позволяет делить частоту
синхросигнала, который поступает на глобальный вывод GCK2, с коэффициентами 2,
4, 6, 8, 10, 12, 14, 16. Схема делителя синхросигнала (рис. 3.6) имеет управляющий
сигнал CDRST для гарантии, что паразитные сигналы не могут пройти по глобальным
цепям синхросигнала.
При установке сигнала CDRST выход делителя недоступен после текущего цик-
ла. При сбросе сигнала CDRST выход делителя становится активным после первого
фронта на выводе GCK2. Использование режима ClockDivider возможно из языков
проектирования VHDL, Verilog и ABEL (см. документ ХАРР378 Using CoolRunner-
ll Advanced Features).
CPLD семейства CoolRunnerll
49
Рис. 3.6. Схема делителя синхросигнала для входа GCK2
3.2.3. Режим функционирования с удвоенной частотой синхросигнала
DualEDGE
Опция DualEDGE включает режим функционирования с удвоенной частотой син-
хросигнала Dual Edge Triggered (DET), который позволяет триггеру каждой макроя-
чейки функционировать с удвоенной частотой входного синхросигнала, т. е. переклю-
чаться на каждом фронте синхросигнала (рис. 3.7).
Рис. 3.7. Цепь синхросигнала макроячейки с установленной опцией DualEDGE
Режим DET используется в синхронных интерфейсах памяти и при передаче дан-
ных с удвоенной скоростью. Режим DET может быть установлен в языках проектиро-
вания или в графическом редакторе для любой ячейки во всех устройствах семейства
CoolRunnerll.
3.2.4. Режим совмещения схемы делителя синхросигнала с удвоенной
частотой синхросигнала CoolCLOCK
Режим совмещения схемы делителя синхросигнала с удвоенной частотой син-
хросигнала CoolCLOCK обеспечивает совмещение схемы делителя синхросигнала с
режимом DualEDGE с целью дальнейшего снижения энергопотребления (рис. 3.8).
Режим CoolCLOCK доступен для микросхем с числом макроячеек 128 и более.
3.2.5. Защита проекта
Опция Design Security служит для защиты микросхемы от считывания информа-
ции о программировании. Проекты могут защищаться во время программирования
для предотвращения случайного или несанкционированного считывания путем обрат-
ного чтения (readback). При использовании данного свойства в микросхеме обеспе-
чивается 4 независимых уровня защиты, чем обеспечивается предотвращение любого
электрического или визуального обнаружения образа конфигурации. Биты безопас-
ности могут быть изменены только путем перепрограммирования всей микросхемы
(см. документ WP170 CoolRunner-ll CPLDs in Secure Applications).
50
Раздел 3
Рис. 3.8. Опция CoolCLOCK, созданная объединением опций ClockDivider и DualEDGE
3.2.6. Режим реконфигурации «на лету» On-The-Fly reconfiguration
Режим реконфигурации «на лету» On-The-Fly reconfiguration (OTF) позволяет
перепрограммировать некоторую энергонезависимую часть микросхемы, в то время
как другой образ используется в настоящее время. Во время замены образа выводы
переводятся в третье состояние со слабым подтягиванием к напряжению Vccio- В за-
висимости от размеров микросхемы время реконфигурации «на лету» составляет от
50 до 300 мкс (см. документ ХАРР388 On the Fly Reconfiguration with CoolRunner-
ll CPLDs).
3.3. Программирование CPLD
Программирование CPLD фирмы Xilinx рассмотрим на примере программирова-
ния устройств семейства XC9500XL. CPLD семейства XC9500XL могут программи-
роваться автономно или в составе системы (рис. 3.9). Автономное программирова-
ние устройств XC9500XL выполняется с помощью программатора фирмы Xilinx HW-
130 или аналогичного программатора других производителей, после чего микросхема
CPLD устанавливаться на плату.
В системе (In-System Programming) CPLD семейства XC9500XL могут програм-
мироваться вместе с другими микросхемами (например, микроконтроллером или дру-
гой CPLD) от системного компьютера с помощью четырех выводов JTAG-стандарта.
Для этого может использоваться кабель фирмы Xilinx или аналогичный кабель других
производителей. Во время программирования в системе все выводы переводятся в
третье состояние и подтягиваются к верхнему уровню схемой захвата шины.
Устройства XC9500XL допускают 10000 циклов программирования в системе и
обеспечивают сохранение информации в течение 20 лет.
CPLD семейства CoolRunnerll
51
Рис. 3.9. Программирование CPLD семейства XC9500XL системного компьютера по JTAG-стандарту
3.4. Выводы
Микросхемы семейства CoolRunnerll, по сравнению с семейством XC9500XL, об-
ладают большим быстродействием, меньшим энергопотреблением и проще в исполь-
зовании.
Области применения микросхем семейства CoolRunnerll: высокоскоростные сис-
темы передачи данных, вычислительные системы, портативные устройства.
Структура CPLD CoolRunnerll состоит из функциональных блоков и блоков ввода-
вывода, которые соединяются глобальной матрицей переключений Advanced Intercon-
nect Matrix (AIM). Каждый функциональный блок содержит 16 макроячеек. Архи-
тектура CPLD CoolRunnerll также содержит периферийную шину (из 16 линий), по
которой к блокам ввода-вывода передаются сигналы управления и синхронизации.
Функциональный блок CPLD семейства CoolRunnerll имеет 40 парафазных вхо-
дов, по которым из матрицы переключений в программируемую матрицу AND может
поступать 80 значений сигналов.
Один функциональный блок имеет 56 промежуточных шин, 4 из которых могут
использоваться для формирования локальных сигналов управления.
Архитектура макроячейки CPLD семейства CoolRunnerll включает многовходовой
вентиль OR, вентиль XOR, триггер, мультиплексор обхода триггера, а также мульти-
плексоры выбора сигналов управления триггером.
Триггер макроячейки может программироваться как D- или Т-триггер, защел-
ка или в режиме DualEDGE. Вход триггера имеет прямую связь с соответствующим
блоком ввода-вывода, благодаря чему триггер может использоваться в качестве вход-
ного буфера.
Каждая макроячейка CPLD семейства CoolRunnerll имеет 3 выхода: один соеди-
нен с соответствующим блоком ввода-вывода, а два (регистровый и комбинацион-
ный) — с матрицей переключений AIM.
Третье состояние выходного буфера может управляться глобальными сигналами
GTS [0:3], локальным сигналом СТЕ и индивидуальным сигналом РТВ.
Кроме того, выходной буфер может программироваться для уменьшения ско-
рости возрастания сигнала, в режиме открытый сток (Open Drain), захвата шины
(Bus-Hold) и с подтягиванием к напряжению питания.
52
Раздел 3
Архитектурные особенности CPLD семейства CoolRunnerll:
• режим снижения энергопотребления DataGATE позволяет для указанных выводов
с помощью перемычек блокировать поступление значений входных сигналов;
• режим делителя частоты синхросигнала ClockDivider позволяет делить частоту
синхросигнала, который поступает на глобальный вывод GCK2, с коэффициен-
тами 2, 4, 6, 8, 10, 12, 14, 16;
• опция DualEDGE включает режим функционирования с удвоенной частотой син-
хросигнала Dual Edge Triggered (DET), который позволяет триггеру каждой мак-
роячейки функционировать с удвоенной частотой входного синхросигнала;
• режим совмещения схемы делителя синхросигнала с удвоенной частотой синхро-
сигнала CoolCLOCK обеспечивает совмещение схемы делителя синхросигнала с
режимом DualEDGE с целью дальнейшего снижения энергопотребления;
• опция Design Security служит для защиты микросхемы от считывания информа-
ции о программировании, обеспечивает до четырех уровней защиты;
• режим реконфигурации «на лету» On-The-Fly reconfiguration (OTF) позволяет
перепрограммировать некоторую энергонезависимую часть микросхемы, в то вре-
мя как в настоящее время используется другой образ внутренней конфигурации.
Микросхемы CPLD фирмы Xilinx могут программироваться автономно или в сис-
теме. Автономное программирование устройств XC9500XL выполняется с помощью
программатора фирмы Xilinx HW-130 или аналогичного программатора других про-
изводителей, после чего микросхема CPLD устанавливаться на плату.
В системе CPLD фирмы Xilinx могут программироваться вместе с другими мик-
росхемами (например, микроконтроллером или другой CPLD) от системного компью-
тера с помощью четырех выводов JTAG-стандарта.
Устройства CPLD фирмы Xilinx допускают 10000 циклов программирования в
системе и обеспечивают сохранение информации в течение 20 лет.
4 Внутренняя логика FPGA: конфигурируемые
логические блоки CLB, секции, функциональные
генераторы LUT
Внутренняя логика FPGA 7-й серии состоит из столбцов конфигурируемых логи-
ческих блоков CLB (Configurable Logic Block). В общем случае программные средства
синтеза позволяют реализовать проект на внутренней логике FPGA без вмешательст-
ва пользователя. Однако знание внутренней структуры и архитектурных возмож-
ностей блоков CLB позволит разработчику значительно повысить эффективность
проекта.
В данной главе рассматривается общая структура блоков CLB, архитектура сек-
ций и их отдельные компоненты, а также различные архитектурные возможности
внутренней логики: генератор LUT, распределенная память RAM и ROM, сдвиговые
регистры, мультиплексоры и логика переноса. Кроме того, в приложении А пред-
ставлены примитивы внутренней логики и рассмотрены вопросы эффективного ис-
пользования отдельных компонентов. В приложении Б приведены временные модели
функционирования элементов внутренней логики.
4.1. Конфигурируемые логические блоки CLB
Каждый блок CLB состоит из двух секций Slice(l) и Slice(O), причем на кристалле
секция Slice(l) расположена в правом верхнем углу блока CLB, а секция Slice(O) — в
левом нижнем углу (рис. 4.1). Для подключения CLB к общим ресурсам трассировки
FPGA служит матрица переключений (Switch Matrix).
Блоки CLB в FPGA 7-й серии организованы в виде столбцов. Для реализации
арифметических переносов все секции в пределах одного столбца соединяются вер-
тикально с помощью цепей переноса (рис. 4.2).
В общем случае блоки CLB в FPGA располагаются в виде регулярной матрицы
(рис. 4.3). Между строками и столбцами блоков CLB находятся каналы межсоедине-
соит соит соит соит
Рис. 4.1. Расположение секций в блоках CLB
Рис. 4.2. Цепи переноса в столбце блоков CLB
54
Раздел 4
ний, которые являются ресурсами общей трассировки кристалла (interconnect routing
resources). Межсоединения (interconnect) также используются для передачи сигна-
лов между функциональными блоками FPGA, такими как: блоки ввода-вывода ЮВ,
секции цифровой обработки сигналов DSP, блоки памяти RAM и др.
Отметим, что секции одного блока CLB не имеют никаких соединений между
собой. Возможна только передача сигналов по цепям переноса соседним секциям,
расположенным выше данного блока CLB, а также прием сигналов по цепям переноса
от соседних секций, расположенных ниже данного блока CLB. При необходимости пе-
редачи сигналов между секциями в пределах одного блока CLB задействуются ресурсы
матрицы переключений, а при передаче сигналов между блоками CLB задействуются
ресурсы межсоединений.
Каждая секция блока CLB, в свою очередь, содержит четыре 6-входовых функ-
циональных генератора LUT и 8 триггеров (по два на каждый LUT).
Секции делятся на два типа: SLICEL и SLICEM. Секции типа SLICEM обладают
дополнительными архитектурными возможностями, которые позволяют им конфигу-
рироваться как блок распределенной памяти RAM на 256 битов или сдвиговый регистр
SRL на 128 битов. Один блок CLB может содержать либо две секции SLICEL, либо
одну секцию SLICEL и одну секцию SLICEM. Общие ресурсы одного блока CLB:
Ресурс Количество
Число секций........................................2
Число LUT...........................................8
Число триггеров.....................................16
Число цепей переноса................................2
Объем распределенной памяти RAM..................... 256 битов
Сдвиговый регистр...................................128 битов
Внутренняя логика FPGA
55
Таблица 4.1
Ресурсы блоков CLB для FPGA семейства Artrix-7
Параметр 7А35Т 7А50Т 7А75Т 7А100Т 7А200Т
Число секций 52 815 118 1585 3365
Число SLICEL 36 575 8232 111 221
исло SLICEM 16 24 3568 475 1155
Число 6-входовых LUT 208 326 472 634 1346
Объем распределенной памяти, Кбит 400 600 892 1188 2888
Сдвиговый регистр, Кбит 200 300 446 594 1444
Число триггеров 416 652 944 1268 2692
Таблица 4.2
Ресурсы блоков CLB для FPGA семейства Kintex-7
Параметр 7К70Т 7К160Т 7К325Т 7К355Т 7К410Т 7К420Т 7К480Т
Число секций 1025 2535 5095 5565 6355 6515 7465
Число SLICEL 69 166 3495 353 409 414 475
Число SLICEM 335 875 16 2035 2265 2375 2715
Число 6-входовых LUT 41 1014 2038 2226 2542 2606 2986
Объем распределенной памяти, Кбит 838 2188 4 5088 5663 5938 6788
Сдвиговый регистр, Кбит 419 1094 2 2544 2831 2969 3394
Число триггеров 82 2028 4076 4452 5084 5212 5972
Таблица 4.3
Ресурсы блоков CLB для FPGA семейства Virtex-7
Параметр 7V585T 7V2000T 7VX ЗЗОТ 7VX 415Т 7VX 485Т 7VX 550Т 7VX 690Т 7VX 980Т 7VX 1140Т 7VH 580Т
Число секций 9105 3054 51 644 759 866 1083 153 178 907
Число SLICEL 633 2192 3345 383 432 517 6475 9765 1072 553
Число SLICEM 2775 862 1755 261 327 349 4355 5535 708 354
Число 6-входовых LUT 3642 1221600 204 2576 3036 3464 4332 612 712 3628
Объем распределенной памяти, Кбит 6938 2155 4388 6525 8175 8725 10888 13838 177 885
Сдвиговый регистр, Кбит 3469 10775 2194 3263 4088 4363 5444 6919 885 4425
Число триггеров 7284 2443200 408 5152 6072 6928 8664 1224000 1424000 7256
Параметры ресурсов блоков CLB для семейств Artrix-7, Kintex-7 и Virtex-7 при-
ведены в табл. 4.1-4.3 соответственно.
4.2. Секции блоков CLB
Как было отмечено ранее, блоки CLB могут содержать секции двух типов:
SLICEM (рис. 4.4) и SLICEL (рис. 4.5).
Архитектура секции SLICEM включает четыре 6-входовых функциональных гене-
ратора LUT (А, В, С, D), цепь переноса, 4 вентиля XOR, 4 выходных запоминающих
элемента, 4 дополнительных триггера, схемы BYPASS обхода генераторов LUT, муль-
типлексоры конфигурации для выбора сигналов, а также мультиплексоры F7AMUX,
F7BMUX и F8MUX (на рис. 4.4 и рис. 4.5 не показаны).
Основными входами данных являются шины А[6:1], В[6:1], С[6:1] и D[6:l], зна-
чения сигналов с которых поступают на входы соответствующих функциональных
генераторов LUT. Для обхода функциональных генераторов по схеме BYPASS служат
входы АХ, ВХ, СХ и DX. Кроме того, для реализации сдвиговых регистров служат
дополнительные входы Al, Bl, CI и DL
Каждая секция имеет 4 комбинационных выхода А, В, С и D, 4 регистровых
выхода AQ, BQ, CQ и DQ с выходных запоминающих элементов, а также 4 выхода
AMUX, BMUX, CMUX и DMUX с выходов одноименных мультиплексоров.
56
Раздел 4
Reset Type
о sync Async
соит
SR
□ FF/LAT
ODMUX
r> W6W1
05
DH
CK
WEN MO-
SR
OS
DP
Dlt
CK
W£:W1
Dll
CK
О SRHI
0 SRLO
OINIT1 Q
О INITO
O8MUX
BX
СИ2
□ FF/LAT
□ iNITO
о SRLO
SR
CK
WEN
CE
CK
Рис. 4.4. Архитектура секции SLICEM
OSRHI
a SRLO
oimti a
GE □ INITO
GE
CK
□ FF/LAT
□ INIT1
a INITO
□ SRHI
□ SRLO
012
A8:A1
W6.W1
WEN MC31
012
A6LA1
W6:W1
06
OS
WEN MC31
OS
WEN MC31
□ SRHI
□ SRLO
a INIT1
0 INITO
SR
о SRHI
Q SRLO
□ INIT1
□ INITO
SR
CE
CK
D
CE
GK
DrF/LAT
CBNITt
□ iKT*C
a SRHi
□ SRLO
SR
OFF/LAT
□ INITD
□ SRH
□ SRLO
SR
Управляющие сигналы секции SLICEM представлены сигналами: SR — установки
или сброса; CLK — синхронизации; СЕ — разрешения синхронизации; WE — разре-
шения записи в распределенную память RAM.
Кроме того, цепь переноса секции имеет входной сигнал CIN и выходной сигнал
COUT. Таким образом, секция SLICEM в сумме имеет 37 входов и 13 выходов. В сек-
ции SLICEL отсутствуют дополнительные входы Al, Bl, CI и DI, а также управляющий
сигнал WE. Поэтому секция SLICEL имеет только 32 входа и 13 выходов.
Отметим, что управляющие сигналы являются общими для всех запоминающих
Внутренняя логика FPGA
57
CIN
Рис. 4.5. Архитектура секции SLICEL
элементов секции. Поэтому триггеры FPGA 7-й серии не имеют сигналов индивиду-
ального управления. Для управляющих сигналов SR, СЕ и WE активным является
высокий уровень. Однако синхросигнал может программироваться с активным как
положительным, так и отрицательным фронтом.
4.3. Функциональный генератор LUT
Функциональные генераторы FPGA 7-й серии представляют собой б-входовые
таблицы перекодировки (Look-Up Table— LUT). Каждый функциональный генератор
имеет 6 независимых входов А6:А1 и два независимых выхода 05 и Об.
58
Раздел 4
Функциональные генераторы секций SLICEM (см. рис. 4.4) дополнительно име-
ют входы Dll, DI2, входы W6:W1 (которые используются как адрес записи в па-
мять), входы управляющих сигналов: синхронизации СК и разрешения записи WEN,
а также выход МС31.
Функциональный генератор LUT может реализовать:
• одну функцию от 6 аргументов (на выходе Об) или
• две функции от 5 общих аргументов (на выходах 05 и Об) или
• две функции от 3 и 2 (или меньше) разных аргументов (на выходах 05 и Об).
Задержка сигналов в LUT не зависит от реализуемой функции. Сигналы от функ-
циональных генераторов могут поступать:
• на выход секции (через выходы А, В, С и D для выхода Об или через выходы
мультиплексоров AMUX, BMUX, CMUX и DMUX для выхода 05);
• на вход отдельного вентиля XOR с выхода Об;
• в цепь логики переноса с выхода 05;
• на управляющий вход мультиплексора логики переноса с выхода Об;
• на вход D запоминающих элементов;
• на вход широких мультиплексоров F7AMUX или F7BMUX с выхода Об.
Для реализации функции от семи аргументов используются мультиплексоры
F7AMUX (при объединении выходов функциональных генераторов А и В) и F7BMUX
(при объединении выходов функциональных генераторов С и D). Для реализации
функции от 8 аргументов дополнительно используется мультиплексор F8MUX, кото-
рый объединяет выходы мультиплексоров F7AMUX и F7BMUX. Таким образом, одна
секция может реализовать:
• одну функцию от 8 аргументов;
• две функции от 7 аргументов;
• четыре функции от 6 аргументов;
• восемь функций от 5 попарно общих аргументов;
• четыре функции от 3 (или меньше) и четыре функции от 2 (или меньше) разных
аргументов.
Для реализации функций с числом аргументов больше 8 используется несколько
секций и ресурсы межсоединений.
4 .3.1. Запоминающие элементы
Каждая секция имеет 4 основных (выходных) запоминающих элемента и 4 до-
полнительных триггера (рис. 4.6). Выходные запоминающие элементы могут кон-
фигурироваться либо как D-триггеры, либо как защелки (прозрачные D-триггеры).
В последнем случае защелка передает сигнал при низком уровне сигнала синхрониза-
ции CLK. Дополнительные триггеры могут конфигурироваться только как триггеры.
Вход D основных запоминающих элементов может управляться непосредственно
выходами LUT Об или 05 через мультиплексоры AFFMUX, BFFMUX, CFFMUX или
DFFMUX, или входами секций BYPASS, обходя функциональные генераторы через
вход АХ, ВХ, СХ или DX. Вход D дополнительных триггеров может управляться вы-
ходом LUT 05 или входами секции BYPASS через вход АХ, ВХ, СХ или DX. Когда 4
основных запоминающих элемента конфигурируются как защелки, 4 дополнительных
запоминающих элемента использоваться не могут.
Сигналы с выходов основных запоминающих элементов поступают на выходы
секции AQ, BQ, CQ и DQ, а дополнительных триггеров — на выходы секции AMUX,
BMUX, CMUX и DMUX.
Внутренняя логика FPGA
59
Рис. 4.6. Варианты конфигурации запоминающих элементов: 4 триггера и 4 триггера/защелки
4 .3.2. Сигналы управления запоминающих элементов
Каждая секция имеет следующие сигналы управления запоминающими элемен-
тами: синхронизации CLK, разрешения синхронизации СЕ и установки/сброса SR.
Активным для сигналов СЕ и SR является высокий уровень, а сигнал синхрони-
зации CLK может инвертироваться. Поэтому в проекте инвертор на линии сигнала
синхронизации всегда реализуется внутри секции (поглощается секцией).
Сигналы управления являются общими для всех запоминающих элементов в дан-
ной секции, т. е. запоминающие элементы FPGA 7-й серии не имеют сигналов индиви-
дуального управления. Поэтому если в проекте требуется индивидуальное управление
триггерами, они будут размещены в разных секциях и может случиться ситуация,
когда оставшиеся ресурсы этих секций будут использованы не полностью.
Замечание. В проектах на FPGA 7-й серии следует избегать индивидуального
управления запоминающими элементами.
С другой стороны, все запоминающие элементы имеют опции индивидуальной
инициализации:
SRLOW — сброс по сигналу SR, по умолчанию устанавливает INIT0;
SRHIGH — установка по сигналу SR, по умолчанию устанавливает INIT1;
INIT0 — асинхронный сброс по включению питания или глобальная установ-
ка/сброс;
INIT1 — асинхронная установка по включению питания или глобальная установ-
ка/сброс;
60
Раздел 4
SRTYPE — тип управления по сигналу SR: синхронный (SYNC) или асинхрон-
ный (ASINC).
Атрибуты SRLOW и SRHIGH могут устанавливаться индивидуально для каждого
запоминающего элемента, однако выбор типа управления SRTYPE по сигналу SR не
может устанавливаться индивидуально. Значения этих опций можно определить при
описании проекта на языках проектирования HDL (VHDL или Verilog).
Кроме того, основные запоминающие элементы имеют дополнительную опцию
FF/LAT, с помощью которой они могут конфигурироваться как D-триггеры или как
защелки.
Отметим также, что все запоминающие элементы FPGA 7-й серии имеют только
один управляющий вход SR для синхронной или асинхронной установки или сброса.
Это означает, что управление триггерами с помощью двух различных сигналов (один
установки, а другой сброса) потребует использования дополнительной логики.
Замечание. В проектах на FPGA 7-й серии следует избегать управления тригге-
рами с помощью двух различных сигналов: установки и сброса.
4.4. Распределенная память RAM
Функциональные генераторы LUT в секциях типа SLICEM могут использовать-
ся как элементы памяти RAM. Такая память называется распределенной памятью
(имеется в виду, что такая память распределена по блокам CLB во внутренней логике
FPGA), в отличие от памяти RAM, реализуемой в блоках RAM. Обычно распреде-
ленная память используется для реализации элементов памяти небольшого размера
(при наличии достаточного количества логических ресурсов), чтобы сохранить ре-
сурсы блоков RAM.
Как правило, операции записи в распределенную память являются синхронными
(управляемые синхросигналом СК и сигналом разрешения записи WEN генератора
LUT), а операции чтения — асинхронными. При необходимости операция чтения
также может быть реализована как синхронная. Для этого на выход памяти уста-
навливается дополнительный триггер той же самой секции. Используя этот триггер,
производительность распределенной памяти RAM увеличивается благодаря уменьше-
нию значения задержки триггера clock-to-out. Однако добавляется дополнительное
время ожидания синхросигнала.
Таблица 4.5
Конфигурации распределенной RAM
RAM Число LUT Примитив
32x15 1 RAM32X1S
32xlD 1 RAM32X1D
32x2Q 4 RAM32M
32X6SDP 4 RAM32M
64x15 1 RAM64X1S
64X1D 2 RAM64X1D
64X1Q 4 RAM64M
64X3SDP 4 RAM64M
128x15 2 RAM128X1S
128xlD 4 RAM128X1D
256x15 4 RAM256X1S
Элементы распределенной памяти совмест-
но используют один и тот же вход синхрониза-
ции. Для выполнения операции записи вход раз-
решения записи WEN (управляемый выводом СЕ
или WE секции SLICEM), должен быть установ-
лен в высокое значение. С помощью элементов
распределенной памяти может быть реализова-
на:
• однопортовая память RAM (S);
• двухпортовая память RAM (D);
• простая двухпортовая память RAM (SDP);
• четырехпортовая память RAM (Q).
Возможные конфигурации распределенной памяти, реализуемые на одной секции
и используемые при этом примитивы, приведены в табл. 4.5.
4.4.1. Однопортовая распределенная память RAM
Однопортовая распределенная память RAM (рис. 4.7) имеет одну общую адрес-
ную шину А, которая используется как для чтения, так и для записи, однобитовые
Внутренняя логика FPGA
61
RAM64X1S
D
А[5:0}
WCLK
WE
Рис. 4.7. Пример однопортовой памяти RAM64X1S
порты входа данных D и выхода данных О (который может запоминаться в триггере), а
также управляющие сигналы: синхронизации записи WCLK и разрешения записи WE.
4.4.2. Двух-портовая распределенная память RAM
В двухпортовой распределенной памяти RAM (рис. 4.8), в отличие от однопор-
товой, имеется две адресные шины А и DPRA, а также два выхода SPO и DPO.
Адресная шина А используется для чтения данных из первого порта на выход SPO,
а адресная шина DPRA используется для чтения данных из второго порта на выход
SPO. Для записи в оба порта совместно используется адресная шина А. Вход данных
D и сигналы управления WCLK и WE являются общими для обоих портов. В два
блока двухпортовой памяти может быть записана только одинаковая информация,
при этом используется вход данных D, один порт с адресной шиной А и управляющие
сигналы WCLK и WE. Чтение информации из двухпортовой памяти может осущест-
вляться по двум независимым портам: один порт с выходом SPO адресуется шиной
А, а другой порт с выходом DPO адресуется шиной DPRA.
RAM64X1D
Рис. 4.8. Пример двухпортовой памяти RAM64X1D
4.4.3. Простая двухпортовая распределенная память RAM
В простой двухпортовой распределенной памяти RAM (рис. 4.9) один порт (реа-
лизуемый в секции на LUT D) используется только для записи, а второй порт (реали-
62
Раздел 4
Рис. 4.9. Пример простой двухпортовой памяти RAM32x6SDP
зуемый в секции на LUT А, В и С) используется только для чтения. Адресная шина
WADDR первого порта используется для записи, а адресная шина RADDR второго
порта — для чтения. Входные данные поступают на шину DATA, а выходные данные
выводятся на шину О. Отметим, что в простой двухпортовой памяти SDP не исполь-
зуются выходы генератора LUT D. В то же время в элементы памяти на основе генера-
торов LUT А, В и С может записываться и читаться независимая информация. Таким
образом, ширина слова данных распределенной памяти может достигать 6 битов.
4.4.4. Четырехпортовая распределенная память RAM
В четырехпортовой памяти RAM (рис. 4.10) один порт используется для записи и
чтения, а остальные три порта — только для чтения. Адресная шина ADDRD является
общей при записи для всех четырех портов, а также используется для чтения из порта
D. Адресные шины ADDRA, ADDRB и ADDRC используются только для чтения из
портов А, В и С соответственно. Записываемые данные поступают на общий вход
DID, а читаемые данные формируются на выходах DOA, DOB, DOC и DOD.
Во все четыре элемента памяти, реализуемых на генераторах LUT А, В, С и
D, может быть записана только одна и та же информация, которая поступает по
Внутренняя логика FPGA
63
Рис. 4.10. Пример четырехпортовой памяти RAM64xlQ
RAM128X1S
Рис. 4.11. Пример однопортовой памяти RAM128X1S
64
Раздел 4
входу DID и адресуется шиной ADDRD. Чтение информации осуществляется по че-
тырем независимым портам на выходы DOA, DOB, DOC и DOD, которая адресуется
четырьмя независимыми адресными шинами ADDRA, ADDRB, ADDRC и ADDRD
соответственно.
Для реализации распределенной памяти RAM с глубиной больше 64 требуется
использование мультиплексоров F7AMUX, F7BMUX и F8MUX, например, как для па-
мяти RAM128xlS (рис. 4.11).
4.4.5. Другие конфигурации распределенной памяти, реализуемые
в одной секции
Четыре примитива RAM64X1S (см. рис. 4.7) могут занимать одну секцию SLI-
CEM, совместно используя управляющие сигналы, а также адресную шину А; такая
конфигурация эквивалентна однопортовой памяти RAM64x4S.
Подобным образом, два примитива RAM64X1D (см. рис. 4.8) могут занимать
одну секцию SLICEM, совместно используя управляющие сигналы, а также адресную
шину А; такая конфигурация эквивалентна двухпортовой памяти RAM64x2D.
Аналогично, два примитива RAM128X1S (см. рис. 4.11) могут занимать одну
секцию SLICEM, совместно используя управляющие сигналы, а также адресную шину
А; такая конфигурация эквивалентна двухпортовой памяти RAM128x2S.
Конфигурации распределенной памяти RAM с размерами больше, чем в рассмот-
ренных конфигурациях, для своей реализации требуют более одной секции SLICEM и
строятся с использованием дополнительной логики.
4.4.6. Функционирование распределенной памяти RAM
Операция записи в распределенную память всегда является синхронной, управ-
ляется фронтом синхросигнала и разрешена при высоком уровне на линии WE (раз-
решения записи). При выполнении операции записи значение выхода D загружается
в ячейку памяти, расположенную по адресу А.
В общем случае операция чтения из распределенной памяти является асинхрон-
ной. Адрес А определяет выход О для однопортового режима или выход SPO для
двухпортового режима, а адрес DPRA определяет выход DPO для двухпортового ре-
жима. В каждый момент времени новый адрес применяется к адресным выводам,
значение адресуемой ячейки памяти становится доступным на выходе после времени
задержки доступа к LUT. Эта операция не зависит от сигнала синхронизации.
Отметим, что имеется возможность устанавливать триггеры на выходах памяти,
которые управляются тем же синхросигналом, что и операция чтения. В этом случае
операция чтения становится синхронной.
Таким образом, распределенная память предназначена для реализации в проекте
элементов памяти небольшого размера с целью экономии ресурсов блоков памяти
RAM. Распределенная память может функционировать в следующих режимах:
• однопортовая RAM32xlS, RAM64xlS, RAM128xlS и RAM256xlS;
• двухпортовая RAM32xlD, RAM64xlD и RAM128xlD;
• простая двухпортовая RAM32x6SDP и RAM64x3SDP;
• четырехпортовая RAM32x2Q и RAM64xlQ.
Дополнительно в одной секции могут быть реализованы следующие конфигура-
ции распределенной памяти: RAM64x4S, RAM64x2D и RAM128x2S.
Операция записи распределенной памяти всегда синхронная (управляется сигна-
лами WCLK и WE), а операция чтения может быть как асинхронной (по умолчанию),
так и синхронной (управляется сигналом WCLK). Сигнал синхронизации может ин-
вертироваться.
Внутренняя логика FPGA
65
4.5. Распределенная память ROM
Функциональные генераторы LUT обо-
их типов секций SLICEM и SLICEL могут
также реализовать распределенную память
типа ROM (Real Only Memory). Возмож-
ные конфигурации памяти ROM и требуе-
мое для их реализации число LUT приведе-
ны в табл. 4.6.
Таблица 4.6
Конфигурации распределенной памяти ROM
Конфигурация ROM Число LUT
ROM32X1 1
ROM64X1 1
ROM 128x1 2
ROM256X1 4
4.6. Сдвиговые регистры, реализуемые в секциях SLICEM
Каждый функциональный генератор LUT секции SLICEM может использоваться
как 32-битовый сдвиговый регистр. В этом режиме функционирования генератора
LUT входом данных сдвигового регистра является вывод DI1, а выходом данных —
вывод МС31 (рис. 4.4). Каждый LUT может задерживать данные от одного до 32
циклов синхронизации.
Выводы DI1 и МС31 могут последовательно соединяться для создания больших
сдвиговых регистров. В одной секции SLICEM может быть реализован сдвиговый
регистр до 128 битов. Возможно также объединение сдвиговых регистров нескольких
секций, однако при этом задействуются ресурсы матрицы переключений.
Сдвиговые регистры могут использоваться при реализации:
• задержек, времени ожидания;
• синхронной памяти типа FIFO (first-in, first-out);
• ассоциативной памяти САМ (content addressable memory).
Условное обозначение сдвигового регистра, соответствующего примитиву
SRLC32E и реализуемого на одном LUT, приведено на рис. 4.12.
Последовательный поток данных поступает на вход сдвигового регистра DI1 с
входа D или с выхода МС31 предыдущего LUT. Сдвигаемые данные появляются на
выходе Q31 (МС31 LUT). Адресная шина А[4:0] (А[б:2] LUT) показывает номер бита,
значение которого выводится на выход Q (Об LUT). Значение выхода дополнительно
может запоминаться в триггере. Операция сдвига является синхронной и управляется
сигналом синхронизации CLK и разрешения синхронизации СЕ.
Логика работы сдвигового регистра показана на рис. 4.13.
Рис. 4.12. Условное обозначение сдвигового регистра SRLC32E
66
Раздел 4
SHIFTOUT(Q31)
Рис. 4.13. Структурная схема сдвигового регистра SRLC32E
Сдвиговый регистр SRLC32E имеет фиксированную длину 32 бита и выполня-
ет сдвиг данных на каждом такте синхросигнала. Значение каждого бита сдвигового
регистра может быть передано на выход Q с помощью мультиплексора MUX, управля-
емого адресной шиной А. Это архитектурное свойство позволяет строить сдвиговые
регистры малого размера, например на 15 битов. Если адрес на шине А не изменя-
ется, то операция чтения является статической, а если адрес на шине А изменяется,
то операция чтения является динамической.
Отметим, что в сдвиговых регистрах SRL не поддерживаются операции установки
и сброса, а также параллельная загрузка данных.
Соединенные в цепь сдвиговые регистры и мультиплексоры F7AMUX, F7BMUX и
F8MUX позволяют реализовать в одной секции SLICEM сдвиговый регистр до 128
битов (рис. 4.14).
Возможно также создание сдвиговых регистров с числом битов более 128, однако
при этом будут задействоваться дополнительные ресурсы FPGA. Отметим, что при
установке на выходе сдвигового регистра дополнительного триггера длина сдвигового
регистра увеличивается на единицу.
Отметим некоторые свойства сдвиговых регистров, реализуемых в секциях
SLICEM:
• один функциональный генератор LUT позволяет реализовать сдвиговый регистр
длиной до 32 битов;
• одна секция позволяет реализовать сдвиговый регистр длиной до 128 битов;
• при установке на выход триггера длина сдвигового регистра увеличивается на
единицу;
• выходной бит Q (размер сдвигового регистра) определяется значением на ад-
ресной шине А;
• выход Q31 всегда содержит значение последнего бита сдвигового регистра;
• операция чтения сдвигового регистра может быть динамической, при изменении
значений на адресной шине А, или статической, при постоянном значении на
адресной шине А;
• сдвиговые регистры секций SLICEM не поддерживают операции установки или
сброса, а также параллельную загрузку данных;
• операция сдвига требует одного фронта синхросигнала;
• выход Q31 изменяется синхронно после каждой операции сдвига;
Внутренняя логика FPGA
67
SHIFTIN (D)
A[6:0]
CLK
WE
Рис. 4.14. 128-битовый сдвиговый регистр, реализуемый в одной секции SLICEM
• операции чтения динамической длины являются асинхронными;
• операции чтения статической длины являются синхронными;
• вход данных имеет временной параметр setup-to-clock (время установки после
прихода фронта синхросигнала).
4.7. Мультиплексоры
Функциональные генераторы LUT секций обоих типов SLICEM и SLICEL могут
конфигурироваться для реализации мультиплексоров. При этом возможны следу-
ющие конфигурации:
• мультиплексоры 4:1, используя один LUT, четыре мультиплексора 4:1 на секцию;
• мультиплексоры 8:1, используя два LUT, два мультиплексора 8:1 на секцию;
• мультиплексоры 16:1, используя четыре LUT, один мультиплексор 16:1 на секцию.
В структурах мультиплексоров 8:1 используются специальные мультиплексоры
F7AMUX и F7BMUX, а в мультиплексорах 16:1 дополнительно используется специ-
альный мультиплексор F8MUX (рис. 4.15).
Отметим, что хотя выходы мультиплексоров являются комбинационными, они
могут буферизироваться в запоминающих элементах блока CLB. Возможно также
создание мультиплексоров шире, чем 16 входов, в нескольких секциях CLB. Однако
при этом используются дополнительные ресурсы FPGA.
68
Раздел 4
SLICE
SELD(1:0], DATA D [3:0]
Input (1)
SEL C(1:0]. DATA C [3:0]
Input (1)
SELF7(1)
CLK
SEL В [1:0]. DATA В [3:0]
Input (2)
SELA [1:0], DATA A [3:0]
Input (2)
SELF7(2)
8:1 MUX
Output (1)
Registered
Output
8:1 MUX
Output (2)
Registered
Output
Рис. 4.15. Реализация мультиплексора MUX 16:1 в одной секции
4.8. Логика переноса
В дополнение к функциональным генераторам, каждая секция содержит спе-
циальную схему, называемую логикой переноса (Carry Logic), которая показана на
рис. 4.16.
В основном, схема логики переноса предназначена для реализации последова-
тельных сумматоров (вычитателей) с очень малым временем переноса (заема) меж-
ду разрядами. Данная схема может также использоваться при построении других
функциональных узлов, таких как умножители, счетчики, компараторы, декодеры ад-
реса, а также широкие (с большим числом аргументов) логические функции, осо-
бенно AND и OR.
Схема логики переноса (рис. 4.16) включает четыре мультиплексора MUXCY и че-
тыре вентиля XOR. На входы S0-S3 поступают сигналы распространения (propagate)
переноса, формируемые на выходах Об функциональных генераторов LUT. На входы
DI0-DI3 поступают сигналы генерации (generate) переноса, которые формируются
на выходах 05 функциональных генераторов LUT (при создании умножителей) или
поступают с входов секции АХ, ВХ, СХ и DX схемы обхода BYPASS (при создании
сумматоров или вычитателей). Выходы 00-03 содержат значение суммы, а выходы
СОО-СОЗ — значения переноса для каждого разряда. На выходах суммы дополни-
тельно могут устанавливаться триггеры (при создании аккумуляторов).
На вход CIN поступает значение переноса от схемы переноса предыдущей секции,
а выход COUT передает сигнал схеме переноса следующей секции. Кроме того, име-
Внутренняя логика FPGA
69
06 From LUTB 1 >
05 From LUTB
BX
COUT (То Next Slice)
Об From LUTD CD-
05 From LUTD CD—ft
DXED--U
06 From LUTC CD-
05 From LUTC CD—ft
cxcd^-V
06 From LUTA I >-
05 From LUTA Q—ft
AXED-fU
П Carry Chain Block
T (CARRY4)
-------CD DMUX/DQ*
-------CDDMUX
cTol—CD DQ
>___(Optional)
-------CD CMUX/CCT
-----CDCMUX
D~o]—CD CO
>. (Optional)
-----DBMUW
_____CDBMUX
d“q]—CD BQ
>____(Optional)
--------CD AMUX/AQ’
---------CDAMUX
D~Q|—CD AO
I____(Optional)
* Can be used rf
unregistereckregistered
outputs are free.
CIN (From Previous Slice)
Рис. 4.16. Схема логики переноса
ется вход CYINIT, на котором может быть значение (0 или 1) начального переноса
в цепи, а также от входа секции АХ, динамическое значение первого переноса (при
создании сум матора/вы читателя).
Входы CIN и выходы COUT могут последовательно соединяться для построения
больших цепей переноса. Длина цепи переноса ограничивается только высотой столб-
ца секций в архитектуре ASMBL. Заметим, что цепи переноса не могут пересекать гра-
ницы суперлогических областей SLR в устройствах, использующих технологию SSL
4.9. Особенности применения внутренней логики
4.9.1. Общие рекомендации для эффективного использования
блоков CLB
Для эффективного и наиболее полного использования архитектурных возмож-
ностей внутренней логики FPGA 7-й серии, необходимо придерживаться рассматри-
ваемых ниже правил.
В отношении использования ресурсов блоков CLB. При написании кода проек-
та придерживайтесь универсального стиля описания языков проектирования VHDL
или Verilog, это позволит средствам синтеза оптимально выбирать имеющиеся ре-
сурсы блоков CLB.
70
Раздел 4
Инстанцирование (создание экземпляров) примитивов отдельных ресурсов бло-
ков CLB следует использовать только в случае необходимости удовлетворения опре-
деленным требованиям по стоимости и производительности; дело в том, что средства
синтеза автоматически создают необходимые примитивы на основании кода проекта.
Для проверки эффективности реализации проекта сравнивайте полученные ре-
зультаты с предполагаемым количеством секций.
В случае недостатка ресурсов в целевом устройстве следует определить, какой
фактор является ограничивающим, и рассмотреть возможности использования аль-
тернативных ресурсов, например:
• перемещение регистров в блоки сдвиговых регистров SRL или в распределен-
ную память RAM;
• перемещение распределенной памяти RAM в блоки памяти RAM;
• перемещение общей логики блоков CLB в секции цифровой обработки сигна-
лов DSP.
В случае, когда проект переносится из одного семейства FPGA (CPLD) в другое,
удалите из него все инстанцирования, а также любые ограничения на отображение
(mapping) и план кристалла (floorplanning) (детали см. в документе UG429 7 Series
FPGAs Migration Methodology Guide).
При написании кода проекта на языках VHDL и Verilog придерживайтесь реко-
мендаций фирмы Xilinx, которые изложены в руководстве по технологии синтеза XST
(см. документ UG687 XST User Guide for Virtex-6, Spartan-6, and 7 Series Devices).
В отношении конвейеризации. Особенностью архитектуры FPGA 7-й серии явля-
ется большое количество триггеров (по два на каждый LUT). Для их эффективного
использования и повышения производительности проекта старайтесь широко исполь-
зовать конвейеризацию при проектировании последовательных схем.
В отношении сигналов управления. FPGA 7-й серии располагают относительно
ограниченными ресурсами для реализации сигналов управления. Поэтому:
• используйте управляющие сигналы только тогда, когда они необходимы;
• избегайте использования глобального сигнала сброса и минимизируйте исполь-
зование локальных сигналов сброса;
• для управляющих сигналов в качестве активного используйте высокий уровень,
поскольку использование низкого уровня в качестве активного требует задейст-
вования дополнительных логических ресурсов;
• избегайте использование для одного и того же триггера двух управляющих сиг-
налов (установки и сброса); дело в том, что все триггеры РРСА7-й серии имеют
только один вход управления SR, который может использоваться либо для уста-
новки, либо для сброса, а применение двух различных управляющих сигналов
установки и сброса требует задействования дополнительных логических ресурсов;
• избегайте использования управляющих сигналов для сдвиговых регистров и эле-
ментов памяти небольшого размера; это позволит вместо ресурсов блоков памя-
ти RAM использовать ресурсы блоков CLB.
В отношении используемых средств автоматизации проектирования. Программ-
ные средства проектирования, в случае их правильного использования, предоставля-
ют пользователю широкие возможности для оптимизации проекта. Поэтому:
• для автоматического улучшения производительности проекта используйте вре-
менные ограничения проекта;
• производительность проекта также можно улучшить за счет большего времени
работы программных средств проектирования путем установки соответствующих
опций.
Внутренняя логика FPGA
71
4.9.2. Использование защелок в качестве логических вентилей
Поскольку функция защелки является чувствительной к уровню сигнала, она
может использоваться как эквивалент логического вентиля. Для определения этой
функции служат примитивы AND2B1L (2-входовой вентиль AND с одним инверсным
входом) и OR2L (2-входовой вентиль OR), как показано на рис. 4.17.
Реализация вентиля OR2L показана на рис. 4.18.
Рис. 4.17. Примитивы
AND2B1L и OR2L
Рис. 4.18. Реализация вентиля OR2L (Q = D или SRI)
Использование вентилей AND2B1L и OR2L сохраняет ресурсы генераторов LUT.
Вентили допускают инициализацию к известному состоянию при включении пита-
ния и при активизации сигнала глобальной установки/сброса GSB (Global Set/Reset).
Используя эти примитивы, можно сократить число логических уровней и увеличить
плотность логики устройства. Однако, поскольку требуются статические входы для
синхросигнала и разрешения синхронизации, использование примитивов AND2B1L и
OR2L может создать проблемы упаковки регистров в секции, запрещая использова-
ние остальных регистров и защелок данной секции.
4.9.3. Использование схемы логического переноса
Схема специального логического переноса в блоках CLB улучшает производи-
тельность арифметических функций, таких как сумматоры, счетчики и компараторы.
Проекты, которые включают подобные узлы, автоматически задействуют логику пе-
реноса. Более сложные функции, включающие умножители, могут реализовываться,
используя отдельную секцию DSP48E1.
Выбор между применением схемы логики переноса блока CLB и секцией DSP48E1
зависит от приложения. Малые арифметические функции могут быть реализованы
быстрее и с меньшим энергопотреблением путем использования логического перено-
са блока CLB, по сравнению с секцией DSP48E1. Когда ресурсы секции DSP48E1
полностью израсходованы, секции CLB и логический перенос обеспечивают эффек-
тивную альтернативу.
Для более сложных функций логику переноса можно ввести с помощью макро-
сов, разработанных для FPGA 7-й серии. Универсальные макросы (unimacros) вклю-
чают сумматоры, счетчики, компараторы, умножители и умножители-аккумуляторы.
Универсальные макросы используют секцию DSP48E1. Программа CORE Generator
позволяет реализовать большинство из этих функций, при этом пользователь мо-
жет выбирать, где будут реализованы функции: в логике переноса CLB или в сек-
ции DSP48E1.
72
Раздел 4
4.9.4. Реализация синхронных сдвиговых регистров
В общем случае выход Q сдвиговых регистров, реализуемых в секциях блоков
CLB, является асинхронным, т. е. его значение устанавливается асинхронно в зависи-
мости от значения на адресной шине, в то время как операции записи и сдвига яв-
ляются синхронными. Для реализации полностью синхронного сдвигового регистра
можно использовать дополнительный триггер секции, как показано на рис. 4.19. При
этом сдвиговый регистр и триггер должны использовать один и тот же синхросигнал.
Synchronous
Output
Поскольку триггер может рассматриваться в качестве последнего триггера в це-
почке сдвигового регистра, адрес выбираемого бита должен указывать на требуемую
длину минус единица.
4.9.5. Реализация больших сдвиговых регистров
При необходимости построения больших сдвиговых регистров можно несколько
примитивов SRLC32E последовательно соединить в одну цепочку. Для этого выход
Q31 некоторого примитива SRLC32E соединяется с входом D следующего в цепочке
примитива. При этом адресовать следует только последний примитив в цепочке.
оит
(72-bit SRL)
OUT
(72-bit SRL)
Рис. 4.20. Пример реализации сдвигового регистра на 72 бита с асинхронным и синхронным выводом
Внутренняя логика FPGA
73
Пусть, например, необходимо построить сдвиговый регистр на 72 бита. Для этого
можно использовать три примитива SRLC32E, первые два дают длину сдвигового
регистра 64 бита (32 + 32), а на адресный вход третьего регистра подается значение
ООНI2 = 710 (32 + 32 + 8 = 72) (напомним, что адресное значение 0 соответствует
сдвиговому регистру длиной в 1 бит).
Если необходимо построить синхронный сдвиговый регистр на 72 бита, то адре-
суемое значение для третьего примитива следует уменьшить на единицу (рис. 4.20).
4.9.6. Использование распределенной памяти
В общем случае распределенная память блоков СЕВ предназначена для реализа-
ции памяти небольшого размера с целью сохранения ресурсов блоков памяти RAM.
В проекте распределенная память может вводиться с помощью инстанции (созда-
ния экземпляров примитивов распределенной памяти) или с помощью программы
CORE Generator.
Что использовать, распределенную память блоков СЕВ или память блоков RAM,
зависит от имеющихся ресурсов, а также требований по производительности и энер-
гопотреблению. Распределенная память обычно имеет меньшую задержку clock-out,
меньше потребляет энергии и имеет меньше ограничений по размещению, чем блок
RAM.
Поэтому можно предложить следующие рекомендации по использованию рас-
пределенной памяти:
• если объем памяти не превышает 64 бита и имеются свободные ресурсы блоков
CLB, всегда используйте распределенную память;
• для памяти от 64 до 128 битов, если имеется дефицит блоков RAM, используйте
распределенную память;
• если ширина слова данных больше 16 битов, используйте блок RAM;
• если необходимо уменьшить энергопотребление и повысить производительность,
используйте распределенную память.
4.9.7. Использование глобальных управляющих сигналов GSR и GTS
В дополнение к общецелевым межсоединениям, FPGA 7-й серии имеют два гло-
бальных сигнала логического управления: GSR для глобальной установки/сброса всех
регистров и триггеров в состояние инициализации и GTS для глобального асинхрон-
ного перевода всех выводов в высокоимпедансное состояние. Сигналы GSR и GTS
имеют высокий уровень активности.
Каждый из глобальных управляющих сигналов GSR и GTS имеет собственную
сеть межсоединений, которая отделена от ресурсов общецелевых межсоединений.
Эти сигналы используются во время конфигурации FPGA.
Если в проекте необходим общий сигнал сброса или установки всех триггеров
устройства, с этой целью можно использовать сигнал GSR. То же относится и к
сигналу GTS: если в проекте необходимо все выводы перевести в третье состояние,
для этого можно использовать сигнал GTS. Напомним, что источники сигналов GSR
и GTS определяются с помощью примитива STARTUPE2.
4.9.8. Оптимизация ресурсов межсоединений
Межсоединения (interconnect) являются программируемой трассировкой сигна-
лов внутри FPGA между входами и выходами функциональных элементов, таких как
секции IOB, CLB, DSP и блоки RAM. Межсоединения для оптимизации соединений
разделены на сегменты. Средство Place and Route (PAR) пакета ISE использует мат-
рицу межсоединений для обеспечения оптимальной системной производительности и
быстрого времени компиляции.
74
Раздел 4
Большинство свойств межсоединений являются недоступными для разработчи-
ков FPGA. Обычно межсоединения реализуются программным обеспечением автома-
тически на основании ограничений на производительность проекта. Из всех возмож-
ностей межсоединений доступными пользователю являются:
• использование глобальных управляющих сигналов GSR и GTS с помощью при-
митива STARTUPE2;
• выбор ресурсов трассировки синхросигналов путем использования буферов син-
хросигналов (см. документ UG472 7 Series FPGAs Clocking Resources User Guide).
В случае неудовлетворительного решения задач трассировки межсоединений воз-
можны три подхода для решения данных проблем:
• выполнение временного анализа и временных характеристик;
• использование копирования источника сигнала сети;
• изменение плана кристалла.
Временный анализ межсоединений позволяет определить тип межсоединения,
расстояние, требуемое для проведения в устройстве, и число матриц переключений,
чтобы добавить задержку на матрице переключений к общей задержке. Большинство
временных проблем решаются путем проверки задержек блоков и определяя влияние
использования меньшего числа уровней или более быстрых путей. Если задержки
межсоединений кажутся слишком большими, увеличиваются усилия по реализации
уровней или выполняются итерации по улучшению производительности.
Сети с критическим временем или сети, которые загружены в большей степени,
часто могут улучшаться путем дублирования источника сигнала сети. Конфигурация
двойных 5-входовых LUT в одной секции упрощает дублирование логики. Дублиро-
вание логики во многих секциях дает программному обеспечению больше гибкости
для размещения независимых источников.
Путем создания плана кристалла (floorplanning), пользователь может определить
ограничения на размещение компонентов проекта. Планирование размещения может
быть выполнено либо до, либо после автоматического размещения и трассировки.
Однако автоматическое размещение и трассировку всегда рекомендуется выполнять
первыми, до определения пользовательского плана кристалла. Средства проектиро-
вания Xilinx позволяют отображать размещение компонентов проекта в графическом
виде. Это помогает проектировщику выбрать между RTL-кодированием (синтезом) и
реализацией с широким исследованием проекта с помощью аналитических функций.
4.9.9. Особенности применения устройств, использующих технологию SSI
Как было отмечено ранее, некоторые устройства семейства Virtex-7 используют
технологию стековых кремниевых межсоединений (stacked silicon interconnect — SSI).
Эти устройства предоставляют уникальный дополнительный тип ресурсов межсоеди-
нений, названных супердлинными линиями (super long line — SLL). Эти специальные
ресурсы трассировки могут трактоваться подобно другим ресурсам трассировки, по-
скольку они являются обширными (более 10000) и быстрыми (задержка сигналов
около 1 нс). Ресурсы SLL обеспечивают соединения между суперлогическими реги-
онами (super logic region — SLR).
Объединение нескольких регионов SLR эффективно увеличивает высоту столб-
цов архитектуры ASMBL и увеличивает возможности устройства. Программное обес-
печение позволяет использовать преимущества этой конфигурации, а пользователи
могут применить планирование кристалла для размещения логики в регионах SLR и
между регионами SLR.
Внутренняя логика FPGA
75
Однако распространение логического переноса ограничивается пределами одного
региона SLR и не передается по линиям SLL. Такие же правила каскадирования рас-
пространяются и на другие блоки: RAM, DSP и DCL Границы регионов SLR контроли-
руются средствами планирования кристалла и указываются во временных рапортах.
Проекты, реализуемые на устройствах с технологией SSI, требуют один экзем-
пляр примитива STARTUPE2. В этом случае источник для сигналов GSR и GTS
будет распространяться через границы региона SLR ко всем элементам устройства.
Для получения дополнительной информации об устройствах, использующих техно-
логию SSI, см. документы: DS180 7 Series FPGAs Overview, WP380 Xilinx Stacked
Silicon Interconnect Technology Delivers Breakthrough FPGA Capacity, Bandwidth, and
Power Efficiency.
4.10. Выводы
Внутренняя логика FPGA 7-й серии состоит из столбцов конфигурируемых ло-
гических блоков CLB (Configurable Logic Block). Блоки CLB в FPGA располагаются
в виде регулярной матрицы. Между строками и столбцами блоков CLB находятся
ресурсы общей трассировки кристалла (межсоединения).
Каждый блок CLB состоит из двух секций Slice(l) и Slice(O). Для подключения
CLB к общим ресурсам трассировки FPGA служит матрица переключений (Switch
Matrix). Секции в пределах одного столбца соединяются вертикально с помощью
цепей переноса.
Секции одного блока CLB не имеют прямых соединений между собой. Возможна
только передача сигналов по цепям переноса соседним секциям, расположенным вы-
ше. При необходимости передачи сигналов между секциями в пределах одного блока
CLB задействуются ресурсы матрицы переключений, а при передаче сигналов между
блоками CLB задействуются ресурсы межсоединений.
Каждая секция блока CLB содержит четыре 6-входовых функциональных гене-
ратора LUT и 8 триггеров. Секции делятся на два типа: SLICEL и SLICEM. Секции
типа SLICEM обладают дополнительными архитектурными возможностями, которые
позволяют им конфигурироваться как блок распределенной памяти RAM на 256 битов
или сдвиговый регистр SRL на 128 битов. Один блок CLB может содержать либо две
секции SLICEL, либо одну секцию SLICEL и одну секцию SLICEM.
Архитектура секции SLICEM включает четыре 6-входовых функциональных гене-
ратора LUT (А, В, С, D), цепь переноса, 4 вентиля XOR, 4 выходных запоминающих
элемента, 4 дополнительных триггера, схемы BYPASS обхода генераторов LUT, муль-
типлексоры конфигурации для выбора сигналов, а также мультиплексоры F7AMUX,
F7BMUX и F8MUX.
Управляющие сигналы секции SLICEM представлены сигналами: SR — установки
или сброса; CLK — синхронизации; СЕ — разрешения синхронизации; WE — разреше-
ния записи в распределенную память RAM. Управляющие сигналы являются общими
для всех запоминающих элементов секции. Поэтому триггеры FPGA 7-й серии не
имеют сигналов индивидуального управления. Для управляющих сигналов SR, СЕ и
WE активным является высокий уровень. Синхросигнал может программироваться с
активным как возрастающим, так и падающим фронтом.
Секция SLICEM суммарно имеет 37 входов и 13 выходов. В секции SLICEL от-
сутствуют дополнительные входы Al, Bl, CI и DI, а также управляющий сигнал WE.
Поэтому секция SLICEL имеет 32 входа и 13 выходов.
Каждый функциональный генератор имеет 6 независимых входов А6:А1 и два
независимых выхода 05 и Об. Функциональные генераторы секций SLICEM дополни-
76
Раздел 4
тельно имеют входы Dll, DI2, входы W6-W1, которые используются как адрес записи
в память, управляющие сигналы синхронизации СК и разрешения записи WEN, а
также выход МС31.
Функциональный генератор LUT может реализовать:
• одну функцию от 6 аргументов (на выходе Об) или
• две функции от 5 общих аргументов (на выходах 05 и Об) или
• две функции от 3 и 2 (или меньше) разных аргументов (на выходах 05 и Об).
Для реализации функции от семи аргументов используются мультиплексоры
F7AMUX и F7BMUX, а для реализации функции от 8 аргументов дополнительно ис-
пользуется мультиплексор F8MUX.
Одна секция может реализовать:
• одну функцию от 8 аргументов;
• две функции от 7 аргументов;
• четыре функции от 6 аргументов;
• восемь функций от 5 попарно общих аргументов;
• четыре функции от 3 (или меньше) и четыре функции от 2 (или меньше) разных
аргументов.
Для реализации функций с числом аргументов больше 8 используется несколько
секций и ресурсы межсоединений.
Каждая секция имеет 4 основных (выходных) запоминающих элемента и 4 до-
полнительных триггера. Выходные запоминающие элементы могут конфигурировать-
ся либо как D-триггеры, либо как защелки. Защелка передает сигнал при низком
уровне сигнала синхронизации CLK. Дополнительные триггеры могут конфигуриро-
ваться только как триггеры.
Каждая секция имеет следующие сигналы управления запоминающими элемен-
тами: синхронизации CLK, разрешения синхронизации СЕ и установки/сброса SR.
Сигналы управления являются общими для всех запоминающих элементов в дан-
ной секции. Поэтому в проектах на FPGA 7-й серии следует избегать индивидуального
управления запоминающими элементами.
Все запоминающие элементы имеют опции индивидуальной инициализации.
Поскольку в качестве запоминающих элементов в FPGA 7-й серии используют-
ся D-триггеры или защелки, следует избегать использование триггеров другого типа
(Т, RS, JK).
Запоминающие элементы FPGA 7-й серии имеют только один управляющий вход
SR для синхронной или асинхронной установки или сброса. Поэтому в проектах на
FPGA 7-й серии следует избегать управления триггерами с помощью двух различных
сигналов: установки и сброса.
Функциональные генераторы LUT в секциях типа SLICEM могут использоваться
как распределенная память RAM. Распределенная память предназначена для реали-
зации в проекте элементов памяти небольшого размера с целью экономии ресурсов
блоков памяти RAM.
Операция записи в распределенную память является синхронной, а операция чте-
ния — асинхронной. При необходимости операция чтения также может быть реали-
зована как синхронная.
С помощью элементов распределенной памяти может быть реализована: одно-
портовая память RAM (S); двухпортовая память RAM (D); простая двухпортовая па-
мять RAM (SDP); четырехпортовая память RAM (Q). Распределенная память может
функционировать в следующих режимах:
• однопортовая RAM32xlS, RAM64xlS, RAM128xlS и RAM256xlS;
Внутренняя логика FPGA
77
• двухпортовая RAM32xlD, RAM64xlD и RAM128xlD;
• простая двухпортовая RAM32x6SDP и RAM64x3SDP;
• четырехпортовая RAM32x2Q и RAM64xlQ.
Дополнительно в одной секции могут быть реализованы следующие конфигура-
ции распределенной памяти: RAM64x4S, RAM64x2D и RAM128x2S.
В два блока двухпортовой распределенной памяти может быть записана только
одинаковая информация, однако чтение из памяти осуществляется по двум незави-
симым портам, аналогично для четырехпортовой распределенной памяти.
Функциональные генераторы LUT обоих типов секций SLICEM и SLICEL мо-
гут также реализовать память типа ROM. Возможные конфигурации памяти ROM:
ROM32xl, ROM64xl, ROM128xl и ROM256xl.
Каждый функциональный генератор LUT секции SLICEM может использоваться
как 32-битовый сдвиговый регистр SRL. В этом режиме входом данных сдвигового
регистра является вывод DI1, а выходом данных — вывод МС31.
Выводы DI1 и МС31 могут последовательно соединяться для создания больших
сдвиговых регистров. В одной секции SLICEM может быть реализован сдвиговый
регистр до 128 битов. Возможно также объединение сдвиговых регистров нескольких
секций, однако при этом задействуются ресурсы матрицы переключений.
Сдвиговые регистры могут использоваться при реализации: задержек, времени
ожидания; синхронной памяти типа FIFO (first-in, first-out); ассоциативной памяти
САМ (content addressable memory).
Значение каждого бита сдвигового регистра может быть передано на выход Q с
помощью мультиплексора, управляемого адресной шиной А. Это позволяет строить
сдвиговые регистры любого размера. В сдвиговых регистрах SRL не поддерживаются
операции установки и сброса, а также параллельная загрузка данных.
Перед использованием сдвиговых регистров, реализуемых в секциях внутренней
логики, следует ознакомиться с их отличительными свойствами (см. подраздел 4.6.2).
Функциональные генераторы LUT могут конфигурироваться для реализации
мультиплексоров, при этом мультиплексор 4:1 реализуется на одном LUT, 8:1 — на
двух LUT и 16:1 — на четырех LUT. В структурах мультиплексоров 8:1 используются
специальные мультиплексоры F7AMUX и F7BMUX, а в мультиплексорах 16:1 допол-
нительно используется специальный мультиплексор F8MUX.
При реализации мультиплексоров с числом входов более 16 задействуются до-
полнительные логические ресурсы FPGA.
Каждая секция содержит специальную схему, называемую логикой переноса. Схе-
ма логики переноса предназначена для реализации последовательных сумматоров
(вычитателей) с очень малым временем переноса (заема) между разрядами. Дан-
ная схема может также использоваться при построении таких функциональных узлов,
как умножители, счетчики, компараторы, декодеры адреса и широкие (с большим
числом аргументов) логические функции, особенно AND и OR.
Входы CIN и выходы COUT могут последовательно соединяться для построе-
ния больших цепей переноса. Длина цепи переноса ограничивается только высотой
столбца секций в архитектуре ASMBL. Цепи переноса не могут пересекать границы
суперлогических областей SLR в устройствах, использующих технологию SSL
5 Секции цифровой обработки сигналов DSP48E1
Кроме блоков CLB, в FPGA 7-й серии информация также преобразуется в секци-
ях цифровой обработки сигналов (ЦОС — Digital Signal Processing — DSP) DSP48E1.
Секции DSP48E1 в приложениях ЦОС обеспечивают лучшую гибкость и использо-
вание ресурсов, повышают эффективность приложений, уменьшают потребляемую
мощность и увеличивают максимальную частоту функционирования. Высокая произ-
водительность FPGA 7-й серии позволяет реализовать множество медленных опера-
ций в одной секции DSP48E1, используя методы временного мультиплексирования.
Секции DSP могут использоваться для реализации цифровых фильтров, быстро-
го преобразования Фурье (FFT), арифметических вычислений (сложение, вычитание,
умножение, деление), операций с плавающей точкой, счетчиков и мультиплексоров
широких шин.
Каждая секция DSP48E1 включает: предварительный сумматор (pre-adder), ум-
ножитель с накоплением (МАСС — Multiplier Accumulator), арифметическо-логическое
устройство (ALU), детектор шаблона (pattern detector). Кроме того, секции DSP48E1
поддерживают реализацию архитектуры с одним потоком команд и несколькими по-
токами данных (single instruction/multiple date — SIMD).
Дополнительно секции DSP48E1 поддерживают много независимых функций: ум-
ножение, умножение с накоплением (МАСС), умножение со сложением, 3-входовое
сложение, побитовые логические функции, циклический сдвиг, компаратор абсолют-
ных величин, обнаружение переполнения и потерю значимости, а также счетчик на
большое число битов.
Секции DSP48E1 позволяют с малым энергопотреблением и высокой произво-
дительностью реализовать параллельные и конвейерные алгоритмы цифровой обра-
ботки сигналов, которые используют много умножителей и аккумуляторов. Секции
DSP48E1 также улучшают скорость и эффективность многих приложений вне цифро-
вой обработки сигналов, такие как широкие динамические шинные преобразователи,
генераторы адреса памяти и отображаемые на память регистры ввода-вывода.
Рис. 5.1. Плитка из двух секций DSP48E1
и относительные размеры плитки
Архитектура секций DSP48E1 также под-
держивает каскадирование множества секций
для формирования широких математических
функций, фильтров ЦОС и сложной арифмети-
ки без использования общей логики FPGA.
Две секции DSP48E1 и специальные (ло-
кальные) межсоединения формируют плитку
(tile) DSP48E1 (рис. 5.1). В столбце DSP плит-
ки располагаются вертикально. Высота одной
плитки DSP48E1 соответствует пяти конфигу-
рируемым логическим блокам CLB или одному
блоку RAM на 18 Кбит.
Устройства FPGA 7-й серии могут содержать от 3 до 20 столбцов DSP или от
240 до 3600 секций DSP48E1, обеспечивая производительность от десятков до тысяч
Секции цифровой обработки сигналов DSP48E1
79
Таблица 5.1
Число секций DSP48E1 в устройствах FPGA 7-й серии
Микросхема Число секций DSP48E1 Число столбцов секций DSP48E1 Число секций DSP48E1 в столбце
7А100Т 240 3 80
7А200Т 740 9 10
7К70 240 3 80
7К160Т 600 6 100
7К325Т 840 6 140
7К355Т 1,440 12 120
7К410Т 1,540 11 140
7К420Т 1,680 12 16
7К480Т 1,920 12 160
7V585T 1,260 7 180
7V2000 2,160 9 24
7VX330 1,120 8 140
7VX415 2,160 18 120
7VX485 2,800 20 140
7VX550 2,880 18 20
7VX690 3,600 18 20
7VX980 3,600 20 18
7VX1140T 3,360 14 24
7VH580 1,680 14 12
7VH870 2,520 14 18
GMAC/c (гига операций умножения с накоплением в секунду). Число секций DSP48E1
для устройств FPGA 7-й серии приведено в табл. 5.1.
5.1. Архитектура секции DSP48E1
Общая архитектура секции DSP48E1 приведена на рис. 5.2.
Архитектура портов А и D приведена на рис. 5.3, а порта В — на рис. 5.4.
Основными преобразователями информации секции DSP48E1 (см. рис. 5.2) явля-
ются предварительный сумматор (pre-adder), умножитель MULT 25x18 и 48-разрядое
арифметическо-логическое устройство ALU.
CARRYCASCOUT’
Рис. 5.2. Архитектура секции DSP48E1
80
Раздел 5
Входные данные в секцию DSP48E1 поступают по четырем шинам: 30-битовой А,
18-битовой В, 48-битовой С и 25-битовой D. Шины А и D могут использовать пред-
варительный сумматор, который расположен во входном порту шин А и D (рис. 5.3).
Шина В также имеет входной порт, показанный на рис. 5.4. Во входных портах шин
А и В имеются двойные регистры А1 и А2 для шины А, а также В1 и В2 для шины В.
Эти регистры используются при конвейерной обработке данных. Шины А и В образу-
ют внутреннюю 48-разрядную шину А:В, при этом шина А представляет 30 старших
разрядов, а шина В — 18 младших разрядов.
Порты А и D с предварительным сумматором, а также порт В управляются 5-
битовой входной шиной INMODE. Шина С является независимым (от шин А, В и D)
входом данных и не имеет входного порта, а только один входной регистр С.
Умножитель MULT принимает в качестве аргумента 25 битов от входного порта
шин А и D, а также 18 битов от входного порта В, выполняет умножение и записывает
результат в регистр М.
Следующий уровень архитектуры составляют мультиплексоры X, У и Z. Они по-
зволяют выбирать аргументы для 48-разрядного арифметическо-логического устрой-
ства.
Входами мультиплексора X являются: внутренняя шина А:В, выход регистра ум-
ножителя М и цепь обратной связи от выходного регистра Р. Входами мультиплексора
У являются: выход регистра умножителя М и выход регистра С независимой входной
шины С. Входами мультиплексора Z являются: выход регистра С, цепь обратной свя-
Секции цифровой обработки сигналов DSP48E1
81
зи от выходного регистра Р и шина каскадирования PCIN. Входы обратной связи и
шины каскадирования мультиплексора Z могут дополнительно сдвигаться вправо на
17 битов для возможности реализации более широкого умножения.
Выбор необходимого входа для каждого мультиплексора X, У и Z обеспечивает
7-разрядная управляющая шина OPMODE.
ALU получает аргументы с выходов мультиплексоров X, Y и Z, а также сигнал
переноса CIN. Сигнал переноса выбирается с помощью мультиплексора, входами кото-
рою являются входной сигнал CARRYIN и каскадный перенос CARRYCASCIN. Выбор
сигнала переноса осуществляется с помощью управляющего сигнала CARRYINSEL
Код операции, выполняемой ALU, определяется 4-битовой шиной ALUMODE. Резуль-
тат, полученный в ALU, запоминается в выходном 48-битовом регистре Р. В выходных
регистрах также запоминаются 4-битовые сигналы переноса CARRYOUT и каскади-
рования CARRYCASCOUT.
Кроме основных логических преобразователей, секция DSP48E1 содержит детек-
тор шаблона (pattern detector), выходами которого являются сигналы PATTERN DE-
TECT и PATTERNBDETECT.
Для построения широких (т. е. большого размера) функциональных узлов пре-
дусмотрено каскадное соединение секций DSP48E1 снизу вверх, в пределах одного
столбца DSP-блоков. Данные от предыдущей секции поступают на входы ACIN и
BCIN, а к следующей секции передаются по шинам ACOUT и BCOUT. Результаты
вычислений от предыдущей секции поступают на входы PCIN, а к следующей секции
передаются по шинам PCOUT. Аналогично передается сигнал переноса: поступает
на вход CARRYCASCIN, передается с выхода CARRYCASCOUT. Кроме того, имеют-
ся специальные каскадные сигналы MULTSIGNIN и MULTSIGNOUT, которые управ-
ляются шиной OPMODE и предназначены для поддержки 96-битового расширения
умножения с накоплением.
Отметим некоторые архитектурные особенности секций DSP48E1.
Двухуровневые каскадные регистры входов А и В предназначены для поддержки
конвейерной обработки данных.
Вход С является независимым, т. е. имеет собственный синхросигнал и управ-
ляющий сигнал сброса.
Выбор аргументов ALU может выполняться динамически с помощью мультип-
лексоров X, Y, Z и управляющей шины OPMODE.
При конвейерной обработке данных благодаря управляющей шине INMODE воз-
можно динамическое переключение между операциями умножения (А*В) и деления
(А:В).
Для трехвходовых сумматоров или вычитателей возможен режим с одним пото-
ком команд и несколькими потоками данных SIMD:
• двойной 24-битовый сумматор/вычитатель/аккумулятор SIMD с двумя отдель-
ными сигналами CARRYOUT;
• учетверенный 12-битовый сумматор/вычитатель/аккумулятор SIMD с четырьмя
отдельными сигналами CARRYOUT.
ALU, кроме операций сложения и вычитания, позволяет выполнять побитовые
логические операции AND, OR, NOT, NAND, NOR, XOR и XNOR от двух 48-битовых
аргументов. Выполняемая операция может динамически указываться с помощью ши-
ны ALUMODE.
Детектор шаблона позволяет:
• определять переполнение и потерю значимости;
• выполнять сходящееся (конвергентное) округление;
82
Раздел 5
• определять шаблон конечной величины и на его основании формировать сигнал
автоматического сброса.
ALU, выходная шина Р и шина переноса CARRYOUT, кроме 48-битового сумма-
тора, также поддерживают 24- и 12-битовые сумматоры.
Дополнительный 17-битовый сдвиг вправо предназначен для возможности реа-
лизации более широкого умножителя.
Сигнал CIN входного переноса для ALU может поступать с входа CARRYIN,
при этом возможна его буферизация в триггере, а также от предыдущей секции
CARRYCASCIN. Допускается динамический выбор сигнала переноса с помощью ши-
ны CARRYINSEL.
Сигналы выходного переноса формируются как для каждого 12-битового сумма-
тора на 4-битовой шине CARRYOUT, так и для 48-битового сумматора на выходе
CARRYCASCOUT. Выходные переносы шины CARRYOUT используются в режиме
работы с одним потоком команд и несколькими потоками данных SIMD. Кроме то-
го, сигналы каскадирования CARRYCASCOUT и MULTSIGNOUT используются при
реализации умножителя с накоплением МАСС на 96 битов.
Все входы данных, а также выходы предварительного сумматора, умножителя и
ALU имеют дополнительные регистры для поддержки конвейерной обработки данных.
С этой же целью дополнительные регистры имеют все управляющие сигналы, а также
шины OPMODE, ALUMODE и CARRYINSEL. Отметим, что максимальная произво-
дительность секции DSP48E1 достигается только при конвейерной обработке данных.
Для увеличения гибкости использования секция DSP48E1 имеет независимые
сигналы разрешения синхронизации и сброса. Для уменьшения потребляемой мощ-
ности, когда умножитель не используется, атрибут USEJMULT позволяет выключать
внутреннюю логику умножителя.
5.2. Функционирование секции DSP48E1
Математическая часть секции DSP48E1 (рис. 5.5) состоит из 25-битового пред-
варительного сумматора, умножителя на 25x18 битов в двоичном дополнительном
коде, за которым следуют три 48-битовые мультиплексоры каналов передачи данных с
выходами X, Y и Z. Затем следует арифмерическо-логическоеустройство (ALU), кото-
рое может выполнять функции 3-входового сумматора/вычитателя или 2-входового
логического устройства. При функционировании ALU в режиме 2-входового логи-
ческого устройства умножитель использоваться не может. Таким образом, секция
DSP48E1 имеет три активных элемента преобразования данных: предварительный
сумматор, умножитель и арифметическо-логическое устройство.
Кроме того, имеется детектор шаблона и возможность проводного сдвига вправо
на 17 разрядов данных, поступающих с выхода Р на вход мультиплексора Z.
Секция DSP48E1 имеет четыре входные шины А, В, С и D, по которым могут
поступать входные данные. Входные данные на шинах А и В могут дополнительно
запоминаться в двухуровневых регистрах один или два раза для помощи при создании
конвейерных структур (см. рис. 5.3 и рис. 5.4). Другие входные данные и сигналы
управления дополнительно могут запоминаться в регистрах один раз. Напомним,
что максимальная частота функционирования секций DSP48E1 может достигаться
только при использовании конвейерных регистров.
Предварительный сумматор позволяет выполнять сложение или вычитание зна-
чений входов А и D до поступления данных на умножитель. Дополнительно пред
сумматор может обходиться потоком данных от входа D, делая D отдельным вход-
ным путем данных для умножителя. Когда путь D не используется, выход конвейера
Секции цифровой обработки сигналов DSP48E1
83
Рис. 5.5. Упрощенная схема функционирования секции DSP48E1
А до поступления в мультиплексор может инвертироваться. Имеется до 10 режимов
функционирования предсумматора, делая этот блок очень гибким для использования
в различных приложениях.
Функционирование секции DSP48E1 с использованием предварительного сумма-
тора можно описать следующим выражением:
Р = С ± (В х (D ± А) + CIN), (5.1)
где Р — значение, формируемое в выходном регистре ALU. Отметим, что урав-
нение (5.1) является особенно полезным при реализации симметричных фильтров
(symmetrical filters).
На второй стадии вычислений арифметическо-логическое устройство ALU в ре-
жиме сумматора/вычитателя реализует следующую функцию:
Р= (Z±(X+ Y+ CIN)) или Р = (-Z + (Х+ Y+ CIN) - 1). (5.2)
Уравнение (5.2) выражает общую функцию, реализуемую сумматором/вычита-
телем над выходами мультиплексоров X, Y, Z и сигналом CIN. Типичным использова-
нием секции DSP48E1 является случай, когда входы А и В умножаются, а результат
добавляется или вычитается из регистра С.
Умножитель секции DSP48E1 является асимметричным (аргументы имеют раз-
личный размер), он умножает 25- и 18-битовые числа в двоичном дополнительном
коде и производит два 43-битовых частичных произведения (partial products). Эти
два частичных произведения дают 86-битовый результат (рис. 5.6). До подачи на
вход сумматора/вычитателя два 43-разрядных частичных произведения знаково рас-
ширяются до 48 разрядов.
Для достижения больших произведений поддерживается каскадирование умножи-
телей с 17-битовым правым сдвигом. Правый сдвиг используется для выравнивания
вправо частичных произведений на заданное число битов. Этот каскадный путь по-
84
Раздел 5
Partial Product 1
Partial Product 2
Optional
MREG
Рис. 5.6. Умножитель чисел в двоичном дополнительном коде с дополнительным регистром MREG
дается на мультиплексор Z, который подсоединяется к сумматору/вычитателю со-
седней секции DSP.
Умножитель может эмулировать беззнаковую математику путем установки стар-
шего значащего бита операнда в 0. Дополнительный конвейерный регистр MREG на
выходе умножителя обеспечивает увеличение производительности за счет увеличе-
ния задержки на такт синхросигнала.
Когда умножитель не используется, ALU может реализовать 2-входовые пораз-
рядные логические функции AND, OR, NOT, NAND, NOR, XOR и XNOR. Входами
этих функций являются шины А:В, С, Р или PCIN, выбранные с помощью мульти-
плексоров X и Z, при этом на выходе мультиплексора У устанавливаются либо все 1,
либо все 0, в зависимости от выполняемой операции.
Выход ALU также питает логику детектора шаблона. Детектор шаблона позво-
ляет секции DSP48E1 поддерживать сходящееся (конвергентное) округление, автома-
тический сброс счетчика, когда значение счета было достигнуто, а также переполне-
ние, потерю значимости и насыщенность в аккумуляторах. Совместно с логическим
устройством, детектор шаблона, может расширяться для выполнения 48-битового
динамического сравнения двух 48-битовых полей. Это включает такие функции как
А: В NAND С == 0 или А:В (поразрядная логика) С == Pattern.
Функциями ALU управляют комбинации сигналов OPMODE, ALUMODE, CAR-
RYINSEL и CARRYIN.
5.2.1. Функционирование ALU в режиме сумматора/вычитателя
В режиме сумматора/вычитателя ALU может функционировать как один 48-би-
товый сумматор/вычитатель, два 24-битовых сумматора/вычитателя или четыре
12-битовых сумматора/вычитателя.
Входы данных в сумматор/вычитатель выбираются сигналами OPMODE и CAR-
RYINSEL. Сигналы ALUMODE выбирают функцию, реализуемую в сумматоре/вычи-
тателе. Таким образом, вместе сигналы OPMODE, CARRYINSEL и ALUMODE опре-
деляют функционирование суммирующего/вычитающего/логического устройства.
Когда ALU используется как логическое устройство, умножитель использоваться не
должен.
Биты OPMODE определяют разделение функций на части. Выполняемая опе-
рация (сложение или вычитание) определяется состоянием управляющего сигнала
ALUMODE.
5.2.2. Режим один поток команд, несколько потоков данных (SIMD)
При функционировании ALU в режиме сумматора/вычитателя 48-битовый сум-
матор/вычитатель/аккумулятор может разделяться на небольшие сегменты данных,
где блокируется распространение внутренних переносов для обеспечения независи-
мости функционирования всех сегментов.
Секции цифровой обработки сигналов DSP48E1
85
ALUMODE[3:0]
Р[47:36], CARRYOUT[3]
Р[35:24], CARRYOUT[2]
Р[23:12], CARRYOUT[1]
Р[11:0], CARRYOUT[0]
Рис. 5.7. Конфигурация четырех 12-битовых сумматоров в режиме SIMD
Сумматор/вычитатель/аккумулятор может разделяться на два 24-битных или че-
тыре 12-битных устройства с выходным сигналом переноса для каждого сегмента
(рис. 5.7). Режим сегментации SIMD является статической конфигурацией, как про-
тивоположность динамическому типу управления с помощью сигналов шины
OPMODE.
На рис. 5.7 представлены четыре сегмента 12-разрядных сумматоров с двумя
или тремя 12-разрядными входами, 12-битовым выходом и выходом переноса для
каждого сегмента. Функции определяются динамически битами ALUMODE[3:0], а
источник операндов — OPMODE[6:0]. В режиме SIMD работы ALU (один поток ко-
манд, несколько потоков данных) все четыре арифметических устройства выполняют
одну и ту же функцию.
5.2.3. Функционирование ALU в режиме логического устройства
В режиме логического устройства ALU выполняет побитовые логические опе-
рации над выходами мультиплексоров X и Z, при этом на выходах мультиплексора Y
устанавливаются все нули или все единицы, в зависимости от выполняемой операции
В табл. 5.2 представлены логические функции, которые могут быть реализованы ALU
Таблица 5.2
Функции, реализуемые логическим устройством
Реализуемая функция OPMODE[3:2] ALUMODE[3:0] Реализуемая функция OPMODE[3:2] ALUMODE 3:0]
3 2 3 2 1 0 3 2 3 2 1 0
XXOR 0 0 0 1 0 0 X XNOR Z 1 0 0 1 0 0
X XNOR Z 0 0 0 1 0 1 XXOR 1 0 0 1 0 1
X XNOR Z 0 0 0 1 1 0 X XOR 1 0 0 1 1 0
X XOR 0 0 0 1 1 1 X XNOR Z 1 0 0 1 1 1
X AND 0 0 1 1 0 0 X OR Z 1 0 1 1 0 1
X AND (NOT Z) 0 0 1 1 0 1 X OR (NOT Z) 1 0 1 1 0 1
X NAND Z 0 0 1 1 1 0 X NOR 1 0 1 1 1 0
(NOT X) OR Z 0 0 1 1 1 1 (NOT X) AND 1 0 1 1 1 1
86
Раздел 5
в режиме логического устройства, в зависимости от установки управляющих сигналов
OPMODE и ALUMODE.
Установка OPMODE[3:2] в «00» выбирает по умолчанию значение 0 на выходе
мультиплексора У; установка OPMODE[3:2] в «10» выбирает «все единицы» на выхо-
де мультиплексора Y. Значение битов OPMODE[1:0] выбирает выход мультиплексора
X, а значение битов OPMODE[6:4] выбирает выход мультиплексора Z.
5.2.4. Детектор шаблона
Детектор шаблона представляет собой устройство проверки на равенство выхо-
да ALU. Однако использование детектора шаблона приводит к снижению скорости
функционирования секции DSP48E1 из-за дополнительной логики на пути выходных
данных (рис. 5.8).
Схема детектора шаблона включает мультиплексор выбора шаблона, два муль-
типлексора выбора маски, схему сравнения и выходные триггеры. Маска используется
для маскирования определенных битов в шаблоне. В отдельных ячейках памяти хра-
нятся 48-битовые значения шаблона и маски, значения которых с помощью соответ-
ствующих атрибутов могут устанавливаться пользователем. Стандартным значением
шаблона является 48‘Ь0000... 0, а маски — 48‘ЬООП... 1.
Значения шаблона и маски могут также поступать с выхода регистра отдельного
входа С. Дополнительно маска с входа С может инвертироваться и сдвигаться вправо
на один или два разряда.
Схема сравнения формирует два выходных сигнала PATTERNDETECT (PD) и
PATTERN BDETECT (PBD), а также два внутренних сигнал PATTERN DETECT PAST
и PATTERNBDETECTPAST.
Детектор шаблона позволяет:
• обнаруживать образец, при этом может дополнительно использоваться маска;
• сравнивать образец динамического входа С с результатом А*В;
• обнаруживать переполнение/потерю значимости/насыщение в битах старше би-
та Р[46];
SEL MASK
I. Denotes an infernal signal
Рис. 5.8. Логика детектора шаблона
Секции цифровой обработки сигналов DSP48E1
87
• вычислять логические функции А:В == С, А.В OR С = = О, А:В AND С= = 1,
А:В {функция}С == 0;
• автоматически сбрасывать 48-разрядный счетчик при обнаружении конца счета;
• обнаруживать средние точки для операций округления.
В проектах детектор шаблона может также использоваться и для других целей:
• дублировать вывод (например, знаковый бит), чтобы уменьшить разветвление
выхода и таким образом увеличить скорость;
• реализовать встроенный конвертер на одном бите (например, для знакового би-
та), исключая необходимость выполнять это в логике FPGA;
• проверять отдельные биты в арифметике с плавающей точкой, управлять специ-
альными случаями, контролировать выходы секции DSP48E1;
• устанавливать флаг, если встретится определенное условие или если определен-
ное условие больше не выполняется.
5.2.5. Логика переполнения и потери значимости
Аккумулятор должен иметь, по крайней мере, один защитный (guard) бит. Когда
детектор шаблона устанавливается для обнаружения шаблона равного ООО. ..Ос мас-
кой 00111... 1 (установки по умолчанию) секция DSP48E1 указывает флагами пере-
полнение сверх 00111... 1 или потерю значимости сверх 11000... 0. Для возможности
использования логики детектора шаблона атрибут USE_PATTERN_DETECT устанав-
ливается в PATDET. Эта реализация переполнения/потери значимости использует
избыточный знаковый бит и сокращает ширину выхода до 47 битов (рис. 5.9).
Путем установки маски в другие значения, подобные 0000111... 1, может изме-
няться битовое значение P[N], от которого обнаруживается переполнение. Эта логика
поддерживает диапазон чисел до 2N — 1 (отрицательных до —2N) в двоичном допол-
нительном коде, где N — число единиц в поле маски.
Работу логики переполнения и потери значимости рассмотрим для примера, когда
N = 2. В этом случае допустимыми значениями являются числа от 22 — 1 до —22 или
от 3 до —4, а в качестве маски используется значение 0... 011. Случаи переполнения и
потери значимости для нашего примера показаны на рис. 5.10 и 5.11 соответственно.
Выход PD устанавливается в 1, если Р == pattern или mask; выход PBD уста-
навливается в 1, если Р == patternb или mask. Когда выход PD переходит с 1 в 0,
устанавливается флаг переполнения; когда выход PBD переходит с 1 в 0, устанавли-
вается флаг потери значимости.
PATTERNDETECTPASP1>
PATTTERNBDETECT
PATTTERNDETECT
Overflow
PATTERNBDETECTPAST{1)
PATTERNBDETECT
PATTERNDETECT
Underflow
Notes:
1. Denotes an internal signal
PATTERN = 48'500000000...
MASK = 48 ' 500111111...
Рис. 5.9. Логика переполнения или потери значимости
88
Раздел 5
"X X X х X * * X х Хо ооооХо . 0001X0 . ооюХо .0011X0 0100Х"
PD Caused by Overflow /---------------------
....................*.I High to Low
Overflow/ \_
Рис. 5.10. Условие переполнения
“X * X x x x < x XO- OOOO^1-1111)G~^OX1 iioiX~i . 1100X1 ioio~X'
PBD Caused by Underflow
High to Low
Underflow
Рис. 5.11. Условие потери значимости
5.2.6. Другие функциональные возможности
Высший уровень функций цифровой обработки сигналов в FPGA 7-й серии под-
держивается путем каскадированием отдельных секций DSP48E1 в столбце DSP-
блоков. Возможности каскадирования обеспечивают два канала передачи данных
(ACOUT и BCOUT) и выходы секции DSP48E1 (PCOUT, MULTSIGNOUT и CARRY-
CASCOUT). Для каскадного объединения секций в пределах одного столбца DSP-
блоков служит внутренняя 48-разрядная шина PCOUT/PCIN.
Возможности каскадирования обеспечивают высокопроизводительную реализа-
цию функций цифровых фильтров. Например, проект фильтра с импульсной харак-
теристикой конечной длины (FIR-фильтр) может использовать каскадные входы для
ранжирования серий выборок входных данных, а каскадные выходы — для ранжиро-
вания серий частичных выходных результатов.
Для арифметики повышенной точности секция DSP48E1 обеспечивает провод-
ной сдвиг вправо на 17 разрядов. Благодаря этому частичное произведение от одной
секции DSP48E1 может быть выровнено по правому краю и добавлено к следующему
частичному произведению, вычисленному в соседней секции DSP48E1. Применяя по-
добную методику, секции DSP48E1 могут использоваться для построения больших
умножителей.
Кроме того, пропускную способность улучшает программируемая конвейерная
обработка входных операндов, промежуточные произведения и выходы аккумулятора.
Для объединения нескольких столбцов DSP-блоков необходимо использовать до-
полнительные ресурсы FPGA.
5.3. Особенности применения
В приложении А приведено описание примитива и макросов секции DSP48E1.
Для лучшего понимания материала, представленного в данном разделе, читателю
желательно ознакомиться с примитивом секции DSP48E1 из приложения А.
5.3.1. Реализация операции вычитания
Секция DSP48E1 и структура цепи переноса блока CLB используют различные
способы реализации операций вычитания. При выполнении операции вычитания в
блоках CLB необходимо на вход переноса подать 1. Стандартная операция вычита-
ния со значением ALUMODE = ООН в секции DSP48E1 не требует, чтобы вывод
CARRYIN был установлен в 1.
Секции цифровой обработки сигналов DSP48E1
89
Sub/Add = 1/0
(Carry input must be 1 for a subtract operation, so it is not available for other uses.)
Рис. 5.12. Реализация сумматора/вычитателя в блоках CLB
Sub/add-------------*-----------------------
Opt. carry input--------------------
A +/- (B + optional carry input)
(Carryin available as an input even for subtract operations)
Рис. 5.13. Сумматор/вычитатель с дополнительными входами переноса
В двоичном дополнительном коде отрицательное значение получается путем вы-
полнения побитной инверсии с прибавлением единицы, т. е. (-В) = ((not В) + 1).
Блок CLB реализует выражение A-В как A+(not В)+ 1 (рис. 5.12). Альтерна-
тивной реализацией двухвходового вычитания является not(B+(not А)) (рис. 5.13),
данная реализация позволяет входам переноса к сумматору/вычитателю оставаться
доступными при выполнении операции вычитания.
Секция DSP48E1 использует вторую реализацию, расширенную до 3-входовых
сумматоров с входом переноса (рис. 5.14). Это позволяет операциям SIMD секции
DSP48E1 выполнять операции вычитания без сигнала CARRYIN для каждого такого
устройства сложения/вычитания.
FPGA 7-й серии и семейство Virtex-б дополнительно поддерживают следующие
операции вычитания:
DSP48E1 Slice Add/Subtract
Рис. 5.14. 3-входовой сумматор секции DSP48E1
90
Раздел 5
Two CARRYOUT bits are produced in the
hardware and are labeled as MULTSIGNOUT
and CARRYCASCOUT in the simulation model
One Bit Carry Out to Fabric
CARRYOUT[3]
P[47:0]
Рис. 5.15. Трехвходовой сумматор
• ALUMODE = 0001 реализует функцию (—Z+(Х+Y+CIN) —1); для большинства
использований CIN устанавливается в 1 для подавления —1;
• ALUMODE = 0010 реализует функцию — (Z+X+Y+CIN) —1; эта инверсия выхо-
да Р каскадируется с другими секциями для реализации вычитания в двоичном
дополнительном коде.
Для операций сложения сигналы CARRYOUT[3] и CARRYCASCOUT являются
одинаковыми, но отличаются при указании заема в операциях вычитания. CARRY-
OUT[3] соответствует общепринятому соглашению для структурных вычитаний, что
позволяет функции сложения/вычитания непосредственно использовать вывод CAR-
RYOUT^] для расширения двухвходовых операций вычитания. Однако сигнал CAR-
RYCASCOUT учитывает способ вычитания, используемый в секции DSP, и является
идеальным при каскадировании с другими секциями DSP.
5.3.2. Сигналы MULTSIGNOUT и CARRYCASCOUT
Сигнал CARRYOUT[3] не должен использоваться для нескольких операций ум-
ножения, потому что умножитель генерирует две частичные суммы, которые затем
суммируются в ALU.
Трехвходовые операции сложения при цифровой обработке сигналов (включая
умножение-сложение и умножение с накоплением) для обеспечения полной точности
производят два бита переноса: MULTSIGNOUT и CARRYCASCOUT (рис. 5.15).
Сигналы MULTSIGNOUT и CARRYCASCOUT служат как два бита переноса для
операций МАСС-EXTEND. Если MULTSIGNOUT является битом знака умножителя,
a CARRYCASCOUT является каскадируемым битом переноса, результатом является
абстракция модели программы Unisim.
Сигналы MULTSIGNOUT и CARRYCASCOUT в модели симуляции не соответст-
вуют аппаратуре, но биты выхода Р выполняют согласование для поддержки функций,
таких как МАСС-EXTEND. Например, трассировка CARRYCASCOUT к логике FPGA
путем использования всех нулей в верхней секции DSP не выполняет согласование
CARRYOUT[3] младшей секции DSP. Аналогично, сигнал MULTSIGNOUT, выводи-
мый в структуру FPGA, действительно не является знаком результата умножения.
Сигналы MULTSIGNOUT и CARRYCASCOUT позволяют строить высокоточные
функции умножения с запоминанием (МАСС-EXTEND), такие как 25x18 аккумулиру-
ющие умножения до 96 битов,работающие на максимальной частоте секции DSP48E1.
Они также необходимы для установки OPMODEREG и CARRYINSEL в 1, когда стро-
ятся большие аккумуляторы, такие как 96-битовый умножитель с накоплением.
При функционировании только сумматора/вычитателя аппаратные и программ-
ные значения сигнала CARRYOUT[3] совпадают. Однако аппаратные и программные
значения сигнала CARRYCASCOUT совпадают, когда ALUMODE - 0000, и инвер-
тируются, когда ALUMODE = ООН. Это несоответствие происходит из-за того, что
Секции цифровой обработки сигналов DSP48E1
91
Рис. 5.16. Программная и аппаратная модели МАСС (частичные суммы от функционирования
умножителя складываются вместе в ALU)
секция DSP48E1 выполняет операцию вычитания, используя алгоритм, отличный от
логики FPGA. Поэтому секция DSP48E1 требует инвертирования CARRYOUT, в от-
личие от логики FPGA.
MULTSIGNOUT является неверным только при функционировании сумматора.
При функционировании умножителя с накоплением МАСС значение сигнала CAR-
RYOUT[3] является неверным. Аппаратные и программные значения сигналов CAR-
RYCASCOUT и MULTSIGNOUT не совпадают из-за разногласий моделирования.
Программная модель симулятора является абстракцией аппаратной модели. Пред-
ставления программного обеспечения сигналов CARRYCASCOUT и MULTSIGNOUT
логически не эквивалентны аппаратным сигналам CARRYCASCOUT и MULTSIGN-
OUT. Логически эквиваленты только аппаратный и программный результаты на вы-
ходе Р (рис. 5.16).
5.3.3. Реализация FIR-фильтров в виде дерева сумматоров
В обычных прямых формах FIR-фильтров входной поток выборок поступает на
один вход умножителей секции DSP48E1, а коэффициенты поступают на другой вход
умножителей. Для объединения выходов нескольких умножителей используется де-
рево сумматоров (рис. 5.17).
Заключительные стадии последующего суммирования в логике FPGA являются
узким местом производительности, которое потребляет много мощности. Глубина
дерева сумматоров вычисляется как функция Iog2 Т, где Т — число ответвлений (taps)
фильтра. Использование структуры дерева сумматоров на рис. 5.17 может также
увеличить стоимость, логические ресурсы и потребляемую мощность.
Блоки CLB FPGA 7-й серии позволяют использовать функциональные генера-
торы LUT6 и цепи переноса в одной и той же секции для построения эффективных
троичных сумматоров. Генератор LUT6 в блоке CLB функционирует как двойной
генератор LUT5. Функциональный генератор LUT5 может использоваться как ком-
прессор 3:2 для сложения трех входных значений с целью получения двух выходных
значений (рис. 5.18).
Двойной генератор LUT5, сконфигурированный как компрессор 3:2, в комбина-
ции с 2-входовым сумматором каскадного переноса складывает три N-разрядных чис-
ла для получения одного (N+2)-битового выхода (рис. 5.19) путем вертикального
соединения требуемого числа секций.
92
Раздел 5
Рис. 5.17. Традиционное дерево сумматоров FIR-фильтра
Сумматор 3:1, показанный на рис. 5.19, используется как строительный блок для
больших деревьев сумматоров. В зависимости от числа входов, которые необходимо
сложить, в структуре логики FPGA также могут быть построены компрессоры 5:3 или
6:3, используя несколько функциональных генераторов LUT5 или LUT6. Последова-
тельная комбинация компрессоров 6:3 с двумя секциями DSP48E1 складывает вместе
шесть операндов для получения одного выхода (рис. 5.20).
Младшие значащие биты первой секции DSP48E1, которые остаются открытыми
из-за левого сдвига шин У и Z, должны подсоединяться к нулю. Последняя секция
DSP48E1 использует входные регистры А:В глубиной 2 для выравнивания (конвейер-
ное соответствие) шины X к выходу первой секции DSP48E1. Для расширения числа
входных шин могут использоваться несколько уровней компрессоров 6:3.
Ниже приведены логические уравнения для шин X, Y и Z из рис. 5.20:
Х(п) = А(п) XOR B(n) XOR C(n) XOR D(n) XOR E(n) XOR F(n);
Секции цифровой обработки сигналов DSP48E1
93
I RY
BBUS(O)
SUB/ I AX
ADDB \
Z(1)4M2
j B41IN4
|B3»IN3
Y(1) ---F—
BBUS(O)^B5I1N5
SUB/ ! 81 | INI
ADDB
О6В
BMUX I BBUS(1)
VDD
O5B
IN6
VDD
O5A
IN6
GND
AMUX; BBUS(O)
BQ I SUM(1)
• ABUS(O)
O6A1
AQ । SUM(O)
Рис. 5.18. Троичное сложение/вычитание с компрессором 3:2
CY(1)
CY(O)
D Q
—|CK
U4HN4
АЗ IIN3
Y(O) ~4
Z(0) -f
SUB/ JA5IIN5
ADDB
D Q
CK
Y(n) = A(n)B(n) XOR A(n)C(n) XOR A(n)D(n) XOR A(n)E(n)
XOR A(n)F(n) XOR B(n)C(n) XOR B(n)D(n) XOR B(n)E(n)
XOR B(n)F(n) XOR C(n)D(n) XOR C(n)E(n) XOR C(n)F(n)
XOR D(n)E(n) XOR D(n)F(n) XOR E(n)F(n);
Рис. 5.19. Трехвходовой сумматор
Рис. 5.20. Шести входовой сумматор
94
Раздел 5
Z(n) = A(n)B(n)C(n)D(n) OR A(n)B(n)C(n)E(n) OR A(n)B(n)C(n)F(n)
OR A(n)B(n)D(n)E(n) OR A(n)B(n)D(n)F(n) OR A(n)B(n)E(n)F(n)
OR A(n)C(n)D(n)E(n) OR A(n)C(n)D(n)F(n) OR A(n)C(n)E(n)F(n)
OR A(n)D(n)E(n)F(n) OR B(n)C(n)D(n)E(n) OR B(n)C(n)D(n)F(n)
OR B(n)C(n)E(n)F(n) OR B(n)D(n)E(n)F(n) OR C(n)D(n)E(n)F(n).
Элементы компрессора и каскадного сумматора могут располагаться подобно де-
реву для построения больших сумматоров. Последняя стадия суммирования должна
реализовываться в секции DSP48E1. При необходимости могут добавляться конвей-
ерные регистры для удовлетворения временным требованиям проекта. Отметим, что
дерево сумматоров может иметь большую площадь и/или потребляемую мощность,
чем каскад сумматоров.
5.3.4. Реализация FIR-фильтров в виде каскада сумматоров
Каскадная реализация сумматоров FIR-фильтров использует каскадный путь
внутри секции DSP48E1, при этом задействуется минимальное количество ресурсов
FPGA. Данный подход включает вычисление совокупного результата путем прираще-
ния значения, используя каскадный путь (рис. 5.21).
В случае реализации FIR-фильтра в виде каскада сумматоров для достижения
корректного результата важно найти баланс между задержкой входной выборки и
коэффициентами FIR-фильтра. Отметим, что коэффициенты могут чередоваться во
времени (волновые коэффициенты).
Использование каскадных путей для реализации сумматоров существенно улуч-
шает потребляемую мощность и скорость. Максимальное число каскадов в пути огра-
ничивается только общим числом секции DSP48E1 в одном столбце кристалла.
Высота столбцов в различных семействах FPGA 7-й серии может отличаться
и должна рассматриваться при перенесении проектов между устройствами. Охват
столбцов становится возможным, беря выход шины Р от вершины одного столбца
DSP и добавляя структуру конвейерных регистров к маршруту этой шины к порту
С нижней секции DSP48E1 соседнего столбца DSP. Также необходимо выполнять
выравнивание входных операндов для охвата нескольких столбцов DSP.
5.3.5. Применение предварительного сумматора
Возможности предварительного сумматора секции DSP48E1 могут использовать-
ся в таких приложениях, как беспроводная связь (например, в алгоритмах Long-Term
Evolution), универсальная фильтрация (FIR и IIR-фильтры), обработка изображения
(например, альфа-смешивание) и др. На рис. 5.22 показано, как предсумматор может
использоваться в проекте 8-отводного систолического симметричного FIR-фильтра.
5.3.6. Временное мультиплексирование секции DSP48E1
Высокоскоростные математические элементы в секции DSP48E1 дают возмож-
ность проектировщикам использовать временное мультиплексирование в DSP-проек-
тах. Временное мультиплексирование является процессом реализации более чем од-
ной функции внутри одной секции DSP48E1 в различные моменты времени. Вре-
менное мультиплексирование легко выполняется для проектов с низкой скоростью
выборки. Следующее неравенство определяет число функций N, которые могут вы-
полняться в одной секции DSP48E1:
N X Fchannal
F dice?
где Fchannai — частота канала; Fciice — максимальная частота функционирования сек-
ции DSP48E1.
Секции цифровой обработки сигналов DSP48E1
95
Slice 8
Y(n-10)
Slice 5
No Wire Shift
The post adders are
contained entirely in
dedicated silicon for
highest performance
and lowest power.
No Wire Shift
No Wire Shift
---------------
48
Slice 3
h2(n-2) "
18 r-*.
----
18 bk
No Wire Shift
Slice 1
hO(n) 0—7^“
18
Х(п) о—7^.
18
Sign Extended from 36 Bits to 48 Bits
Рис. 5.21. Каскадный сумматор (пост-сумматоры находятся полностью внутри секций DSP48E1)
Эти DSP-проекты с временным мультиплексированием имеют дополнительную
конвейеризацию, которая позволяет достигнуть совокупной многоканальной скорос-
ти выборки до 500 миллионов выборок в секунду. Временное мультиплексирование
в проектах на секциях DSP48E1 позволяет уменьшить использование ресурсов и по-
требляемую мощность.
Секция DSP48E1 содержит базовые элементы классических FIR-фильтров: ум-
ножитель с последующим сумматором, задерживающие или конвейерные регистры,
а также возможность каскадировать входной поток (шина В) и выходной поток без
обращения к общей структуре секции.
96
Раздел 5
Рис. 5.22. 8-отводной систолический симметричный FIR-фильтр
Многоканальная фильтрация может рассматриваться как одноканальные филь-
тры с временным мультиплексированием. В сценарии типичной многоканальной
фильтрации несколько входных каналов фильтруются, используя отдельные цифро-
вые фильтры для каждого канала. Благодаря высокой производительности секций
DSP48E1 в FPGA 7-й серии единственный цифровой фильтр может использоваться
для фильтрации восьми входных каналов путем синхронизации одного фильтра с 8-
кратной частотой синхросигнала. Такая реализация использует 1/8 общих ресурсов
FPGA, по сравнению с реализацией каждого канала отдельно.
5.3.7. Применение отображаемых на память регистров ввода-вывода
Чтобы использовать секции DSP48E1 как отображаемые на память регистры
ввода-вывода, пользователь должен широковещательно передать для использования
шину записываемых данных ко всем секциям DSP48E1. Для возможности произволь-
ного чтения необходим широкий мультиплексор. Уменьшение нагрузки трассировки
может выполняться путем конфигурирования дополнительных секций DSP48E1 как
мультиплексор широкой шины.
Для загрузки соответствующих выходных регистров DSP значениями от шины за-
писываемых данных необходим декодер адреса. Декодер адреса реализуется в струк-
туре логики FPGA с целью индивидуального управления разрешением синхронизации
регистров PREG.
5.3.8. Рекомендации по повышению производительности и уменьшению
потребляемой мощности
Для повышения производительности. Для того чтобы получить максимальную
производительность секций DSP48E1 в FPGA 7-й серии, желательно использовать
все конвейерные стадии в пределах секции. С этой целью проект нуждается в полной
конвейеризации.
Для проектов, основанных на умножителях, требуется три стадии конвейера. Для
проектов, не основанных на умножителях, должны быть использованы две стадии
Секции цифровой обработки сигналов DSP48E1
97
конвейера. Если в проекте важна задержка сигналов и могут использоваться только
один или два регистра в секции DSP48E1, позволяйте использовать регистр М.
Для минимизации потребляемой мощности. Функции, реализованные в секции
DSP48E1, потребляют меньше мощности, чем реализованные в структуре FPGA. Ис-
пользование каскадных путей в пределах секции DSP48E1 вместо трассировки в струк-
туре FPGA уменьшает энергопотребление. Умножитель с включенным регистром М
использует меньше мощности, чем без использования регистра М. Для операндов
меньше 25x18 можно сократить мощность структуры FPGA, помещая операнды в
старшие значащие биты и заполняя нулями младшие значащие биты. Если умножи-
тель не используется, атрибут USE_MULT должен быть установлен в NONE.
5.3.9. Рекомендации по применению секций DSP48E1
При описании DSP-проектов на языке HDL (hardware description language), таких
как Verilog или VHDL, используйте знаковые величины.
Как в секции DSP48E1, так и в структуре проекта используйте конвейер для
повышения производительности и снижения энергопотребления.
Для запоминания коэффициентов фильтров используйте защелки сдвиговых ре-
гистров (SRL) в блоках CLB, распределенную память RAM и/или блоки памяти RAM.
Рассмотрите возможность использования в проекте временного мультиплекси-
рования.
Небольшие умножители (например, 4x4), а также небольшие сумматоры и счет-
чики реализуйте, используя функциональные генераторы LUT и цепи переноса бло-
ков CLB.
Если проект имеет большое число операций сложения или счетчиков, восполь-
зуйтесь преимуществом режима SIMD для реализации функционирования в секции
DSP48E1. Когда для функций в режиме SIMD входные регистры также помещаются
в секцию DSP48E1, наблюдается двухкратное уменьшение стоимости и потребляемой
мощности, по сравнению с использованием блоков CLB и ресурсов межсоединений.
Когда реализуются функции с малым числом битов,входные операнды всегда рас-
ширяйте знаково. Для минимизации потребляемой мощности операнды помещайте в
старшие значащие биты, а младшие биты обнуляйте.
Когда каскадируются различные секции DSP48E1, должны быть согласованы ста-
дии конвейера различных путей сигналов.
При реализации в секции DSP48E1 счетчика по возрастанию на одну единицу
следует использовать вход CARRYIN; а для счетчиков, увеличивающихся на N или
переменное число битов, можно использовать входы С или внутреннюю шину А:В.
Счетчик секции DSP48E1 может использоваться для реализации логики управ-
ления, которая работает с максимальной скоростью.
Сдвиговые регистры SRL16 или SRL32 в блоках CLB и блоки RAM должны ис-
пользоваться для запоминания коэффициентов фильтра или действовать как файл
регистров или элементы памяти совместно с секцией DSP48E1. Поразрядная пе-
редача входных битов (4 бита на межсоединение) спроектирована для соответствия
передачи CLB- и RAM-блоков.
Конвейерные регистры должны использоваться на выходах блоков сдвиговых ре-
гистров SRL16 или RAM до подсоединения к входам секции DSP48E1. Это обес-
печивает лучшую производительность входных операндов, поступающих в секцию
DSP48E1.
Блоки RAM могут использоваться как быстрые конечные автоматы для логичес-
кого управления DSP-проектов.
98
Раздел 5
Для аппаратного ускорения процессорных функций секция DSP48E1 может ис-
пользоваться совместно с процессором, например MicroBlaze или PicoBlaze.
5.4. Выводы
Секции цифровой обработки сигналов DSP48E1 FPGA 7-й серии обеспечивают
лучшую гибкость, улучшают использование ресурсов, повышают эффективность при-
ложений, уменьшают потребляемую мощность и увеличивают максимальную частоту
функционирования. Высокая производительность FPGA 7-й серии позволяет исполь-
зовать методы временного мультиплексирования путем реализации нескольких мед-
ленных операций в одной секции DSP48E1.
Секции DSP могут использоваться для реализации цифровых фильтров, быстро-
го преобразования Фурье, арифметических вычислений (сложение, вычитание, умно-
жение, деление), операций с плавающей точкой, счетчиков и мультиплексоров шин.
Каждая секция DSP48E1 включает: предварительный сумматор, умножитель с
накопителем, арифметическо-логическое устройство и детектор шаблона. Кроме то-
го, секции DSP48E1 поддерживают реализацию архитектуры с одним потоком команд
и несколькими потоками данных SIMD для параллельной реализации нескольких опе-
раций.
С помощью секции DSP48E1 можно реализовать много независимых функций:
умножение, умножение с накоплением (МАСС), умножение со сложением, 3-входовое
сложение, побитовые логические функции, циклический сдвиг, компаратор абсолют-
ных величин, обнаружение переполнения и потерю значимости, а также счетчик на
большое число битов.
Секции DSP48E1 позволяют с малым энергопотреблением и высокой произво-
дительностью реализовать параллельные и конвейерные алгоритмы цифровой обра-
ботки сигналов, которые используют много умножителей и аккумуляторов. Секции
DSP48E1 также улучшают скорость и эффективность многих приложений вне цифро-
вой обработки сигналов, такие как широкие динамические шинные преобразователи,
генераторы адреса памяти и отображаемые на память регистры ввода-вывода.
Архитектура секций DSP48E1 также поддерживает каскадное соединение мно-
жества секций для формирования широких математических функций, фильтров ЦОС
и сложной арифметики без использования общей логики FPGA.
Устройства FPGA 7-й серии могут содержать от 3 до 20 столбцов DSP или от
240 до 3600 секций DSP48E1.
Основными преобразователями информации секции DSP48E1 являются 25-бито-
вый предварительный сумматор, умножитель на 25x18 битов и 48-битовое арифме-
тическо-логическое устройство.
Входные данные в секцию DSP48E1 поступают по четырем шинам: 30-битовой
А, 18-битовой В, 48-битовой С и 25-битовой D. Шины А и D могут использовать
предварительный сумматор, который расположен во входном порту шин А и D. Во
входных портах шин А и В имеются двойные регистры, которые используются при
конвейерной обработке данных. Шины А и В образуют внутреннюю 48-разрядную
шину А:В. Шина С является независимым (от шин А, В и D) входом данных и не
имеет входного порта, а только один входной регистр С.
Умножитель MULT принимает в качестве аргумента 25 битов от входного порта
шин А и D, а также 18 битов от входного порта В, выполняет умножение и результат
записывает в регистр М.
Секции цифровой обработки сигналов DSP48E1
99
Следующий уровень архитектуры составляют мультиплексоры X, У и Z. Они по-
зволяют выбирать аргументы для 48-разрядного арифметическо-логического устрой-
ства.
ALU получает аргументы с выходов мультиплексоров X, Y и Z, а также сигнал
переноса CIN. Результат, полученный в ALU, запоминается в выходном 48-битовом
регистре Р.
Кроме основных логических преобразователей, секция DSP48E1 содержит де-
тектор шаблона (pattern detector).
Архитектурные особенности секций DSP48E1:
• выбор аргументов ALU выполняеться динамически с помощью мультиплексоров
X, Y, Z и управляющей шины OPMODE;
• при конвейерной обработке данных благодаря управляющей шине INMODE воз-
можно динамическое переключение между операциями (А*В) и деления (А:В);
• режим с одним потоком команд и несколькими потоками данных SIMD позволяет
реализовать двойной 24-битовый и учетверенный 12-битовый сумматор/вычита-
тель/аккумулятор;
• ALU, кроме сложения и вычитания, позволяет выполнять побитовые логические
операции AND, OR, NOT, NAND, NOR, XOR и XNOR от двух 48-битовых ар-
гументов, выполняемая операция может динамически указываться с помощью
шины ALUMODE.
Детектор шаблона позволяет:
• определять переполнение и потерю значимости;
• выполнять сходящееся (конвергентное) округление;
• определять шаблон конечной величины и на его основании формировать сигнал
автоматического сброса.
Дополнительный 17-битовый сдвиг вправо предназначен для возможности реа-
лизации более широкого умножителя.
Максимальная производительность секции DSP48E1 достигается только при кон-
вейерной обработке данных.
Для уменьшения потребляемой мощности, когда умножитель не используется,
атрибут USE_MULT позволяет выключать внутреннюю логику умножителя.
Имеется до 10 режимов функционирования предсумматора, делая этот блок
очень гибким для использования в различных приложениях.
Типичным использованием секции DSP48E1 является случай, когда входы А и В
умножаются, а результат добавляется или вычитается из регистра С.
Умножитель секции DSP48E1 является асимметричным, он умножает 25- и 18-
битовые числа в двоичном дополнительном коде и производит два 43-битовых час-
тичных произведения. До подачи на вход ALU 43-битовые частичные произведения
знаково расширяются до 48 разрядов.
В режиме сумматора/вычитателя ALU может функционировать как один 48-
битовый сумматор/вычитатель, два 24-битовых сумматора/вычитателя или четыре
12-битовых сумматора/вычитателя.
Когда умножитель не используется, ALU может реализовать 2-входовые пораз-
рядные логические функции AND, OR, NOT, NAND, NOR, XOR и XNOR.
Детектор шаблона позволяет выполнять сходящееся (конвергентное) округление,
автоматический сброс счетчика по модулю, динамическое сравнение двух 48-битовых
полей, а также определять переполнение, потерю значимости и насыщение в акку-
муляторах.
100
Раздел 5
Дополнительные функциональные свойства обеспечивает возможность каскади-
рования отдельных секций DSP48E1 в пределах столбца DSP-блоков.
Возможности каскадирования обеспечивают высокопроизводительную реализа-
цию функций цифровых фильтров. Например, FIR-фильтр может использовать кас-
кадные входы для ранжирования серий выборок входных данных, а каскадные выхо-
ды — для ранжирования серий частичных выходных результатов.
6 Блоки памяти RAM
Блоки встроенной памяти RAM в FPGA 7-й серии имеют достаточно широкую
область использования. Главной функцией блоков памяти RAM, безусловно, являет-
ся запоминание, хранение и буферизация данных. Кроме того, блоки памяти RAM
могут использоваться в качестве FIFO-буферов (памяти типа FIFO), высокопроизво-
дительных конечных автоматов, больших функциональных генераторов LUT, памяти
типа ROM, а также больших сдвиговых регистров. Важным свойством блоков RAM
FPGA 7-й серии является поддержка кода с исправлением ошибок (error-correcting
code — ЕСС).
С помощью генератора блоков памяти CORE Generator фирмы Xilinx на блоках
RAM легко реализуются двух и однопортовые модули RAM, модули ROM, синхронная
память FIFO, а также преобразователи широких слов данных.
В данной главе рассматриваются только возможности блоков памяти FPGA 7-й
серии при их функционировании в режиме памяти типа RAM. Использование блоков
памяти в режиме памяти типа FIFO будет рассмотрено в главе 7, а функциониро-
вание памяти RAM и FIFO в режиме исправляющего ошибки кодирования описы-
вается в главе 8.
Блок RAM в FPGA 7-серии запоминает до 36 килобит (Кбит) данных и может
конфигурироваться либо как два независимых блока памяти RAMB18 размером 18
Кбит, либо как один блок памяти RAMB36 размером 36 Кбит. Блоки памяти RAM
FPGA 7-й серии, когда они используются в качестве памяти типа RAM, имеют три
основных режима функционирования:
• действительно двухпортовый (true dual-port — TDP) режим;
• простой двухпортовый (simple dual-port — SDP) режим;
• однопортовый (single port) режим.
Каждый блок RAMB36 в простом двухпортовом режиме может иметь следующую
конфигурацию: 64Кх1 (когда каскадируется с соседним блоком RAMB36), 32Кх1,
16Кх2, 8Кх4, 4Кх9, 2Кх18, 1Кх36 или 512x72. Каждый блок RAMB18 может
иметь следующую конфигурацию: 16Кх1, 8Кх2, 4Кх4, 2Кх9, 1Кх18 или 512x36.
Два порта являются симметричными и полностью независимыми, совместно ис-
пользуя только записанные в память данные. Каждый порт может иметь одну из до-
пустимых конфигураций, независимую от конфигурации другого порта. Кроме того,
для каждого порта ширина порта чтения может отличаться от ширины порта записи.
Содержимое памяти может инициализироваться или создаваться битовым пото-
ком при конфигурации FPGA.
Основные свойства блоков памяти RAM:
• операции чтения и записи являются синхронными;
• для операции чтения и записи требуется один фронт синхросигнала;
• простой двухпортовый режим SDP позволяет удваивать ширину данных до 72
битов для блока RAMB36 и до 36 битов для блока RAM В18;
• режим SDP поддерживает различную ширину данных для операций записи и чте-
ния;
102
Раздел 6
Таблица 6.1
Ресурсы блоков памяти RAM в FPGA 7-й серии
Устройство Число блоков памяти RAMB36 Число столбцов блоков памяти RAM Число блоков памяти RAM в столбце
ХС7А100Т 135 4 40
ХС7А200Т 365 9 50
ХС7К70Т 135 4 40
ХС7К160Т 325 7 50
ХС7К325Т 445 7 70
ХС7К355Т 715 12 60
ХС7К410Т 795 12 70
ХС7К420Т 835 12 80
ХС7К480Т 955 12 80
XC7V585T 795 9 90
XC7V2000T 1292 11 120
XC7VX330T 750 11 70
XC7VX415T 880 15 60
XC7VX485T 1030 15 70
XC7VX550T 1180 15 100
XC7VX690T 1470 15 100
XC7VX980T 1500 16 90
XC7VX1140T 1880 16 120
XC7VH580T 940 16 60
XC7VH870T 1410 16 90
• два соседних блока RAMB36 могут объединяться в один блок с конфигурацией
64Кх1 без использования дополнительной логики;
• возможна синхронная установка/сброс выходов к начальному значению;
• на всех выходах по умолчанию устанавливаются защелки;
• возможна установка на выходах дополнительных конвейерных регистров, которые
имеют отдельный независимый вывод синхронного сброса/установки;
• порты шириной 18, 36 или 72-бита могут иметь индивидуальное разрешение за-
писи на байт, это свойство используется в интерфейсах процессоров;
• все выходы имеют функцию чтения или функцию чтения во время записи, в
зависимости от состояния вывода разрешения записи (WE);
• выходы являются доступными после временного интервала clock-to-out;
• выходы по отношению к операции чтения во время записи могут иметь один из
трех режимов функционирования: WRITE-FIRST, READ-FIRST и NO-CHANGE.
Наличие блоков памяти RAM в FPGA 7-й серии приведено в табл. 6.1.
6.1. Архитектура блока памяти RAM
6.1.1. Логическая схема функционирования памяти RAM
Логика функционирования одного порта блока памяти RAM приведена на рис. 6.1.
Основу архитектуры блока RAM составляет матрица памяти (Memory Array), ко-
торая является общей для обоих портов. На вход матрицы памяти по шине DI посту-
пают входные данные, адресуемые значением на шине адреса (Address). Входные дан-
ные и значения адреса по умолчанию буферизируются во входном регистре (Register).
Выходные данные из матрицы памяти по умолчанию буферизируются в выходных за-
щелках (Latches). На пути выходных данных может устанавливаться дополнительный
регистр для организации конвейера.
Устройство управления (Control Engine) блока RAM на основании сигналов раз-
решения записи WE, разрешения функционирования EN и синхросигнала CLK форми-
рует следующие сигналы управления: разрешения записи (Write Strobe), разрешения
Блоки памяти RAM
103
CLK
Рис. 6.1. Логическая схема блока RAM (показан один порт)
чтения (Read Strobe) и разрешения запоминания в выходных защелках (Latch Enable).
Сигнал синхронизации CLK, который может инвертироваться, используется также для
синхронизации входного и дополнительного выходного регистров.
Таким образом, операции записи и чтения всегда являются синхронными, вход-
ные данные и адрес буферизируются в регистрах, а выходные данные могут буфери-
зироваться как в защелках, так и в дополнительном конвейерном регистре.
6.1.2. Потоки данных в блоке памяти RAM
В общем случае блок памяти RAM можно представить так, как показано на
рис. 6.2.
Каждый блок RAMB36 имеет одну общую
матрицу памяти на ЗбКбит и два независимых
порта А и В. Аналогично, блок RAMB18 имеет
матрицу памяти на 18Кбит и два независимых
порта А и В. Каждый порт имеет свои собст-
венные выводы для адреса (ADDR), входных
(DI) и выходных (DO) данных, синхросигнала
(CLK), разрешения функционирования (EN) и
разрешения записи (WE). Кроме того, каждый
порт имеет независимые сигналы управления
регистрами и защелками: синхронной установ-
ки/сброса выходных защелок (RSTRAM), син-
хронной установки/сброса выходного регистра
(RSTREG) и разрешения синхронизации выход-
ного регистра (REGCE).
В дополнение к основным данным, шири-
ной в 32 бита, каждый порт имеет 4 бита чет-
ности (Parity Bits), которые могут совмещаться
с основными битами, образуя слова шириной
в 36 битов. Биты четности имеют отдельные
входные (DIP) и выходные (DOP) шины.
Для возможности объединения соседних
32
4
“T*
16,
t*
4,
CASCADEOUTA CASCADEOUTB
I 36-Kbit Block RAM |
DIA
DIPA
ADDRA Port A
WEA
ENA
---► RSTREGA
- RSTRAMA
------->CLKA
*(regcea 36 Kb
Memory
Array
DOA
DOPA
32
32
16.
4Z
DIB
DIPB --------
ADDRB
WEB
ENB Port В
RSTREGB
RSTRAMB
> CLKB
REGCEB
DOB
DOPB
32,
"""7*"
cascadeina cascadeinb
блоков памяти RAM с целью построения бло-
ка размером 64Кх1 бит служат входы (CAS-
CADEIN) и выходы (CASCADEOUT) каскадирования.
Рис. 6.2. Потоки данных в двухпортовом
блоке RAMB36
Описание портов блока памяти RAMB36 приведено в табл. 6.2.
104
Раздел 6
Таблица 6.2
Порты двухпортового блока RAMB36
Имя порта1 Описание
DI[A/B] DIP[A/B] ADDR[A/B] WE[A/B] EN[A/B] RSTREG[A/B] RSTRAM[A/B] CLK[A/B] DOJA/B]1 DOP[A/B] REGCE[A/B] CASCADEIN[A/B] CASCADEOUT[A/B] 1. Имена портов при Шина входных данных Шина битов четности входных данных; может использоваться как дополнитель- ные входы данных Шина адреса Разрешение записи каждого байта Разрешение функционирования, когда вывод неактивный, никакие данные не записываются в блок RAM, а выходная шина остается в предыдущем состоянии Синхронная установка/сброс выходных регистров (при DO-REG =1); атрибут RSTREG-PRIORITY определяет приоритет над сигна- лом REGCE Синхронная установка/сброс защелок выходных данных Вход синхросигнала Шина выходных данных Шина битов четности выходных данных; может использоваться как дополни- тельные выходы данных Разрешение синхронизации выходных регистров Вход каскадирования для режима 64Кх1 Выход каскадирования для режима 64Кх1 митивов блоков RAM могут отличаться от имен функций портов.
6.2. Функционирование блока памяти RAM
6.2.1. Режимы функционирования блока памяти RAM
Как было отмечено ранее, блок памяти RAM FPGA 7-й серии может функцио-
нировать в трех основных режимах:
• действительно двухпортовом режиме TDP;
• простом двухпортовом режиме SDP;
• однопортовом режиме.
Структура блока RAM на рис. 6.2 как раз соответствует действительно двухпорто-
вому режиму TDP. Простой двухпортовый режим SDP расширяет возможности блока
RAM и будет рассмотрен ниже. Однопортовый режим блока RAM легко вводится с
помощью макроса BRAM_SINGLE_ MACRO.
Отметим некоторые особенности режимов функционирования памяти RAM:
• TDP имеет отдельные синхросигналы CLKA и CLKB для каждого порта А и В;
• SDP имеет отдельные синхросигналы WRCLK и RDCLK для операций записи
и чтения;
• TDP имеет отдельные адресные шины ADDRA и ADDRB для портов А и В,
которые являются общими для операций записи и чтения;
• SDP имеет отдельные адресные шины WRADDR и RDADDR для операций за-
писи и чтения;
• SDP имеет большую ширину порта данных: 64 и 72 бита;
• режимы записи WRITE-FIRST, READ-FIRST и NO-CHANGE возможны только
для однопортовой памяти.
6.2.2. Операции чтения и записи
Чтение. Операция чтения использует один фронт синхросигнала. Адрес чтения
запоминается в регистре порта чтения, и ранее запомненные данные загружаются
в выходные защелки после времени доступа к памяти RAM. В случае использова-
ния выходных регистров время чтения увеличивается на один дополнительный цикл
синхросигнала.
Блоки памяти RAM
105
Запись. Операция записи также является операцией одного фронта синхроим-
пульса. Адрес записи запоминается в регистре порта записи, а вход данных запо-
минается в памяти.
Имеется три режима записи, определяющие поведение данных на выходной шине
после прихода фронта синхроимпульса: WRITE-FIRST, READ-FIRST и NO-CHANGE.
Режим записи определяется во время конфигурации с помощью атрибута WRITE-
MODE. Атрибут режима записи может устанавливаться индивидуально для каждого
порта. Умалчиваемым режимом является WRITE-FIRST. Режим WRITE-FIRST вы-
водит недавно записанные данные на выходную шину. Режим READ-FIRST выводит
на выходную шину ранее запомненные в памяти данные, в то время как новые дан-
ные записываются в память. Режим NO.CHANGE поддерживает выход в состоянии,
сгенерированном предыдущей операцией чтения.
Режим NO.CHANGE является наиболее эффективным по энергопотреблению.
Этот режим невозможен в режиме SDP.
6.2.3. Синхронное и асинхронное тактирование
Блоки RAM в FPGA 7-й серии являются действительно двухпортовыми памятя-
ми RAM, где два порта одновременно могут иметь доступ к одной ячейке памяти.
Однако в таких ситуациях пользователь должен соблюдать определенные ограниче-
ния. Здесь возможны две принципиально разные ситуации: либо два порта имеют
общий синхросигнал (синхронное тактирование— synchronous clocking), либо частота
синхронизации и фаза синхросигнала являются различными для двух портов (асин-
хронное тактирование — asynchronous clocking).
Асинхронное тактирование является наиболее общим случаем, где активные
фронты обоих синхросигналов не появляются одновременно. В этом случае нет вре-
менных ограничений, когда оба порта выполняют операцию чтение. Однако когда
один порт выполняет операцию записи, другой порт не должен иметь доступ для чте-
ния или записи к той же самой ячейке памяти.
Следует избегать режима READ-FIRST в действительно асинхронных приложе-
ниях, потому что здесь нет гарантии, что в обоих режимах TDP и SDP будут читаться
старые данные. Если это условие нарушается, то средства моделирования констати-
руют ошибку, а результат операций чтения или записи является непредсказуемым.
Если выполняется операция чтения и записи, то операция записи записывает дейст-
вительные данные в адресуемую ячейку памяти. Когда асинхронные синхросигналы
могут вызывать одновременные операции чтения или записи по одному и тому же
адресу, рекомендуемым режимом является режим WRITE-FIRST.
Синхронное тактирование является специальным случаем, когда оба входа син-
хронизации управляются одним и тем же синхросигналом. При этом нет временных
ограничений, когда оба порта выполняют операцию чтения. Когда один порт выпол-
няет операцию записи, другой порт не должен писать в ту же самую ячейку памяти,
за исключением случая, когда оба порта пишут идентичные данные. Когда один порт
выполняет операцию записи, запись выполняется успешно; другой порт может надеж-
но читать данные из той же самой ячейки памяти, если записывающий порт имеет
режим READ-FIRST. Шина DATA-OUT на обоих портах отображает ранее запомнен-
ные данные. Если записывающий порт имеет режим WRITE.FIRST или NO.CHANGE,
то данные выхода DATA-OUT порта чтения могут быть недостоверными; установки
режимов порта чтения не влияют на это функционирование.
106
Раздел 6
6.2.4. Дополнительные выходные регистры для конвейерных приложений
Дополнительные (конвейерные) выходные регистры улучшают производитель-
ность проекта путем исключения задержек трассировки к триггерам логических бло-
ков CLB для конвейерных операций. Конвейерные выходные регистры имеют незави-
симые входы синхронной установки/сброса и разрешения синхронизации (на рис. 6.1
не показаны). В результате конвейерные регистры позволяют задерживать выходные
данные независимо от функционирования входного регистра.
6.2.5. Независимая ширина данных портов чтения и записи
Каждый порт блока RAM может управлять шириной данных и глубиной адреса (с
точки зрения отношения). Действительный двухпортовый блок памяти RAM в FPGA
7-серии расширяет это свойство на операции чтения и записи, где каждый индивиду-
альный порт может быть сконфигурирован с различной шириной данных. Например,
порт А может иметь 36-битовую ширину для чтения и 9-битовую ширину для записи, а
порт В может иметь 18-битовую ширину для чтения и 36-битовую ширину для записи.
Если ширина порта чтения отличается от ширины порта записи и конфигуриру-
ется в режиме WRITE_FIRST, то выход DO показывает действительно новые данные
для всех доступных байтов записи. Порт DO выводит оригинальные данные, запом-
ненные в памяти для всех недоступных байт.
Независимый выбор ширины портов чтения и записи увеличивает эффектив-
ность реализации в блоке RAM ассоциативной памяти типа САМ (content addressable
memory — память, адресуемая по содержимому).
Имеется два примитива блока RAM: RAMB36E1 и RAMB18E1. Атрибут RAM_
MODE определяет режим функционирования блока RAM: либо простой двухпортовый
режим SDP, либо действительно двухпортовый режим TDP.
Когда используются примитивы блока RAM, возможны различные варианты ши-
рины портов чтения и записи; биты четности доступны только для портов с шириной
х9, х18 и х36. Если ширина чтения равна xl, х2 или х4, то эффективная ширина
записи равна xl, х2, х4, х8, х16 или х32. Аналогично, когда ширина записи равна
xl, х2 или х4, то фактическая доступная ширина чтения равна xl, х2, х4, х8, х16
или х32 даже при том, что атрибуты примитива установлены в значение 1, 2, 4, 9,
18 и 36 соответственно.
В табл. 6.3 представлены некоторые возможные сценарии различной ширины
портов чтения и записи в случае использования бита четности.
Таблица 6.3
Сценарии использования бита четности
Примитив Установки Эффективная ширина чтения Эффективная ширина записи
Ширина чтения Ширина записи
RAMB18E1 1, 2 или 4 9 или 18 Как установлено 8 или 16
RAMB18E1 9 или 18 1, 2 или 4 8 или 16 Как установлено
RAMB18E1 1, 2 или 4 1, 2 или 4 Как установлено Как установлено
RAMB18E1 9 или 18 9 или 18 Как установлено Как установлено
RAMB36E1 1, 2 или 4 9, 18 или 36 Как установлено 8, 16 или 32
RAMB36E1 9, 18 или 36 1, 2 или 4 8, 16 или 32 Как установлено
RAMB36E1 1, 2 или 4 1, 2 или 4 Как установлено Как установлено
RAMB36E1 9, 18 или 36 9, 18 или 36 Как установлено Как установлено
Не используйте ше или равна 9 бит четности, когда ширина одного порта меньше 9, а ширина другого порта боль-
Блоки памяти RAM
107
6.2.6. Простой двухпортовый режим SDP
Каждый блок RAMB18 или RAMB36 может быть сконфигурирован в режиме
простой двухпортовой памяти RAM. В этом режиме ширина порта RAM удваивается
до 36 бит для блока RAMB18 и до 72 битов для блока RAMB36. В простом двухпор-
товом режиме SDP независимые операции чтения и записи могут происходить однов-
ременно, где порт А рассматривается как порт чтения, а порт В — как порт записи.
Когда порты чтения и записи одновременно обращаются к одной и той же ячейке
памяти, такая ситуация трактуется как конфликт, аналогичный конфликту портов в
действительно двухпортовом режиме TDP. В режиме SDP поддерживаются только
два режима на выходной шине: READ-FIRST и WRITE-FIRST.
На рис. 6.3 показан простой двухпортовый поток данных для модуля RAMB36
в режиме SDP.
Описание портов модуля RAMB36 в простом двухпортовом режиме SDP при-
ведены в табл. 6.4.
36 Kb Memory Array
64 DI DO DIP OOP RDADDR ECCPARITY RDCLK SBITERR RDEN DBITERR REGCE SSR WE WRADDR WRCLK WREN
8 8y
8,
15
8 /
15,
инп.иуб iii.iui
Рис 6.3. Модуль RAMB36 в прос-
том двухпортовом режиме SDP
Таблица 6.4
Функции портов в простом двухпортовом режиме SDP
Имя порта Описание
DO DOP DI DIP RDADDR RDCLK RDEN REGCE SBITER DBITER ECCPARITY SSR WE WRADDR WRCLK WREN Шина выходных данных Шина битов четности выходных данных Шина входных данных Шина битов четности входных данных Шина адреса читаемых данных Синхросигнал читаемых данных Разрешение порта чтения Разрешение синхронизации выходного регистра Бит состояния одиночной ошибки Бит состояния двойной ошибки Шина выходного шифратора ЕСС Синхронная установка или сброс выходных ре- гистров или защелок Разрешение записи каждого байта Шина адреса записываемых данных Синхросигнал записываемых данных Разрешение порта записи
6.2.7. Каскадирование блока RAM
В FPGA 7-й серии два соседних модуля RAMB36 можно объединять в один блок
размером 64Кх1 без использования локальных соединений или дополнительных ло-
гических ресурсов. Данное свойство доступно в режиме 64Кх1 (рис. 6.4).
Вывод А15 в примитиве RAMB36E1 может использоваться только для каскади-
рования; во всех других случаях вывод А15 должен оставаться неподсоединенным
или в высоком состоянии.
6.2.8. Побайтовая запись данных
Это свойство дает возможность записывать 8 битов (один байт) входных данных.
В примитиве RAMB36E1 действительно двухпортовой памяти RAM (режим TDP)
имеется 4 независимых входа разрешения записи шириной в байт. В простом двух-
портовом режиме SDP примитив RAMB36E1 имеет 8 таких входов.
Каждый вход разрешения записи шириной в байт соответствует одному байту
входных данных и одному биту четности. Все входы разрешения записи шириной
в байт могут управляться во всех конфигурациях ширины данных (табл. 6.5). Это
108
Раздел 6
CASCADEOUT
(No Connect!
Interconnect Block RAM
Рис. 6.4. Логика каскадирования блока RAM
Таблица 6.5
Ширина данных при побайтной записи
Примитив Максимальная ширина, бит Ширина, байт
RAMB36E1 режим TDP 36 4
RAMB36E1 режим SDP 72 8
RAMB18E1 режим TDP 18 2
RAMB18E1 режим SDP 36 4
свойство является полезным, когда блок
RAM используется для интерфейса с мик-
ропроцессором.
Разрешение записи шириной в байт
недоступно в режиме двойной синхрони-
зации памяти FIFO и режиме ЕСС.
На рис. 6.5 показаны временные диа-
граммы разрешения записи шириной в
байт для модуля RAMB36E1.
Когда модуль RAMB36E1 сконфигурирован для 36- или 18-битовой передачи дан-
ных, любой порт может ограничить запись в указанное расположение байта в преде-
лах слова данных. Если модуль RAMB36E1 сконфигурирован в режиме READ.FIRST,
Рис. 6.5. Временные диаграммы функционирования записи шириной в байт (хЗб WRITE-FIRST)
Блоки памяти RAM
109
шина DO показывает предыдущее содержимое всего адресуемого слова. В режиме
WRITE-FIRST шина DO показывает комбинацию недавно записанных разрешенных
байт и начальное содержимое незаписанных байт.
6.2.9. Режим кодирования с исправлением ошибок ЕСС
Оба типа памяти (RAM и FIFO) в блоке RAM размером 36 Кбит поддержива-
ют режим 64-битовой реализации кода коррекции ошибок (Error Correction Code —
ЕСС). Этот код используется для обнаружения одиночных и двойных битовых оши-
бок при считывании данных в блоке RAM. Одиночные ошибки затем корректируются
в выходных данных. Более подробно использование кода коррекции ошибок рассмат-
ривается в главе 8.
6.2.10. Минимизация потребляемой мощности
Для уменьшения энергопотребления FPGA 7-й серии выключают неиспользуемые
блоки RAM, начиная с размера 18 Кбит. Доступ к неиспользуемым блокам RAM
запрещается путем отключения внутреннего функционирования.
6.2.11. Некоторые архитектурные особенности
Инвертирование управляющих выводов. Для каждого порта управляющие сиг-
налы CLK, EN, RSTREG и RSTRAM имеют опцию индивидуального инвертирования.
В отношении сигнала синхронизации это означает, какой фронт является активным:
положительный или отрицательный.
Сигнал глобальной установки или сброса GSR. В FPGA 7-й серии сигнал глобаль-
ной установки или сброса GSR является глобальным асинхронным сигналом, который
активизируется в конце конфигурирования устройства. Сигнал GSR может также в
любое время вернуть устройства 7-й серии в начальное состояние. Сигнал GSR иници-
ализирует выходные защелки в значение INIT (простой двойной порт) или в значения
INIT-A и INIT-В (действительный двойной порт).
Сигнал GSR не воздействует на внутреннее содержимое памяти. В примити-
вах блока RAM (на функциональном уровне) отсутствует вывод, соответствующий
сигналу GSR.
Неиспользуемые входы. Неиспользуемые входы данных должны быть подсоеди-
нены к низкому уровню. Неиспользуемые адресные входы должны быть подсоединены
к высокому уровню.
Отображение адресов блока RAM. Каждый порт обращается к одному и тому же
множеству ячеек памяти количеством 18432 (RAMB18E1) или 36864 (RAMB36E1),
используя
Таблица 6.6
Отображение адресов порта
Ши- рина порта Расположе- ние битов четности Расположение данных
1 N/A 31 30 29 28 27 26 25 24 23 22 21 20 19 18 17 16 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
2 15 14 13 12 11 10 9 8 7 6 5 4 3 2 1 0
4 7 6 5 4 3 2 1 0
8+1 3 2 1 0 3 2 1 0
16+2 1 0 1 0
32+4 0 0
110
Раздел 6
соответствующую схему адресации. Физическое расположение ячеек памяти RAM
зависит от ширины слова данных и определяется по следующим формулам:
START = ADDR х Width;
END = ((ADDR + 1) х Width) - 1,
где START — начальный адрес записываемых данных; END — конечный адрес;
ADDR — значение на адресной шине; Width — ширина шины данных.
В табл. 6.6 показано отображение младших адресов для различной ширины пор-
та данных.
6.3. Особенности применения блоков памяти RAM
Для использования блоков памяти RAM в FPGA 7-й серии имеется два примитива
RAMB18E1 и RAMB36E1, описание которых приведено в приложении А. Другие биб-
лиотечные примитивы и макросы строятся на основе этих примитивов. Для наиболее
часто используемых режимов работы созданы макросы памяти RAM, описание кото-
рых также приведено в приложении А. Эти макросы находятся в библиотеке UniMacro
программных средств синтеза фирмы Xilinx и могут быть инстанцированы в языках
VHDL и Verilog (детали см. в документе UG768 Xilinx 7 Series FPGA and Zynq-7000
All Programmable SoC Libraries Guide for HDL Designs).
6.3.1. Ограничения на расположение блоков RAM
Экземпляры блоков RAM могут иметь присоединенное свойство (параметр) LOC,
чтобы ограничить их размещение. Свойства LOC имеют следующую форму:
LOC = RAMB36_X#Y#,
где # — некоторое десятичное число. Например, RAMB36-X0Y0 означает левый верх-
ний блок RAM в устройстве. Если модуль RAMB36E1 размещается по расположению
RAMB36_X#Y#, то для памяти FIFO нельзя указать FIFO36_X#Y#, потому что они
совместно используют одно и то же местоположение.
Два модуля RAMB18E1 могут размещаться в том же самом месте RAMB36E1,
например:
inst «my_raml8_2» LOC = RAMB36_X0Y0;
inst «my_raml8_l» LOC = RAMB36_X0Y0.
Кроме того, один модуль FIFO18 и один модуль RAM 18 могут размещаться в
том же самом месте RAMB36E1, например:
inst «my_raml8» LOC = RAMB36-X0Y0;
inst «my_fifol8» LOC = RAMB36JX0Y0.
6.3.2. Инициализация блока RAM в языках VHDL и Verilog
В языках VHDL и Verilog атрибуты и содержимое блока RAM могут быть иници-
ализированы при создании экземпляра блока памяти в коде проекта (для синтеза и
симуляции) путем использования карт генерации (generic maps) — для языка VHDL —
или путем определения параметров (defparams) — для языка Verilog.
6.3.3. Дополнительные выходные регистры
Дополнительные выходные регистры могут использоваться в порте А или В.
Установка дополнительного выходного регистра выполняется путем использования
атрибута DO[A/B]_REG. Выходные регистры имеют независимые сигналы разреше-
ния синхронизации REGCE[A/B]. Когда используются дополнительные выходные ре-
гистры порта [А/В], с помощью атрибута SRVAL и активизации выводов синхронной
Блоки памяти RAM
111
установки или сброса (RSTREG и RSTRAM) на выходах порта [A/В] можно устано-
вить определенные значения.
6.3.4. Независимые размеры порта чтения и записи
Для того чтобы определить различные размеры портов в двухпортовом режи-
ме блока RAM, пользователь должен использовать атрибуты READ_WIDTH_[A/B] и
WRITE_WIDTH_[A/B]. При этом необходимо соблюдаться следующие правила:
• проектирование однопортового блока RAM требует установки двух размеров пор-
тов: один для записи и один для чтения (т. е. READ_WIDTH_A и WRITE.
WIDTH-A);
• проектирование двухпортового блока RAM требует установки всех размеров пор-
тов;
• если размеры двух портов записи или двух портов чтения установлены в 0, средст-
ва проектирования не реализуют проект;
• в простом двухпортовом режиме SDP одна сторона портов фиксируется, а вторая
сторона может иметь переменную ширину;
• примитив RAMB18E1 имеет ширину порта до 36 битов, a RAMB36E1 — до 72
битов.
6.3.5. Правила проектирования отображения портов для примитивов
RAMB18E1 и RAMB36E1
Блоки RAM FPGA 7-й серии могут конфигурироваться с переменными размерами
и шириной портов. В зависимости от конфигурации, некоторые выводы данных и ад-
реса могут не использоваться (см. описание примитивов блока RAM в приложении А).
Здесь приведем некоторые правила при определении соединений портов блока RAM:
• в модуле RAMB36E1, если размер шины DI[A/B] меньше 32, остальные входные
выводы шины DI подсоединяются к логическому нулю;
• если размер шины DIP[A/B] меньше 4, остальные входные выводы шины DIP
[A/В] подсоединяются к логическому нулю;
• если шина DIP не используется, она может оставаться неподсоединенной;
• выводы DO[A/B] должны быть шириной 32 бита, однако действительные данные
находятся на выводах от (DO_BIT_WIDTH — 1) до 0;
• выводы DOP[A/B] должны быть шириной 4 бита, однако действительные дан-
ные находятся на выводах от (DOP_BIT_WIDTH — 1) до 0; если шина DOP не
используется, ее выводы могут оставаться неподсоединенными;
• выводы ADDR[A/B] должны быть шириной 16 битов, однако действительные
адреса для некаскадируемого блока RAM находятся от вывода 14 до 15 (шири-
на адреса); оставшиеся выводы, включая вывод 15, должны подсоединяться к
высокому уровню.
6.3.6. Каскадирование блоков RAM
Для использования функции каскадирование блока RAM должны быть инстанци-
рованы два примитива RAMB36E1, причем экземпляры примитива RAMB36E1 долж-
ны быть соседними (рис. 6.6).
Затем следуйте следующим правилам:
• установите атрибуты RAM_EXTENSION_A и RAM_EXTENSION_B для одного при-
митива RAMB36E1 в значение UPPER, а для другого — в LOWER;
• подсоедините порты CASCADEINA и CASCADEINB верхнего RAMB36E1 к портам
CASCADEOUTA и CASCADEOUTB нижнего RAMB36E;
112
Раздел 6
Upper
RAMB36E1
CASCADEINA CASCADEINB
CASCADEOUTA CASCADEOUTB
Lower
RAMB36E1
Рис. 6.6. Каскадирование
двух модулей RAMB36E1
• порты CASCADEIN нижнего RAMB36E1 под-
соедините к логическому нулю или единице;
• порты выходных данных нижнего RAMB36E1
не используются; эти выводы остаются не-
подсоединенными;
• выводы ADDR[A/B] должны иметь ширину
16 битов; порты чтения и записи — ширину
1 бит;
• может использоваться дополнительный вы-
ходной регистр путем установки значения ат-
рибута DO.REG = 1.
6.3.7. Возможность побайтной записи
Правила при использовании побайтной записи:
• в режиме хЗб выводы WE[3:0] подсоединяются к четырем входам пользовате-
ля UWE;
• в режиме х18 выводы WE[0] и WE[2] подсоединяются к пользовательскому сиг-
налу UWE[0], а выводы WE[1] и WE[3] — к UWE[1];
• в режимах х9, х4, х2, xl все выводы WE[3:0] подсоединяются к пользователь-
скому UWE;
• в простом двухпортовом режиме х72 выводы WE[7:0] подсоединяются к восьми
пользовательским входам.
6.3.8. Создание больших структур RAM
Столбцы блоков RAM имеют специальную трассировку (в дополнение к каска-
дированию 64Кх1) для создания более широкой или более глубокой памяти с мини-
мальной задержкой трассировки.
Для создания большой памяти из блоков меньшего размера используется про-
грамма CORE Generator фирмы Xilinx, которая предоставляет удобный пользователь-
ский интерфейс. Результаты работы программы могут использоваться в языках
VHDL или Verilog.
6.3.9. Блок RAM в регистровом режиме RSTREG
Сигнал RSTREG в регистровом режиме может использоваться для управления
выходным регистром как действительно конвейерным регистром независимо от бло-
ка RAM (рис. 6.7).
В этом режиме блок RAM может читаться и записываться независимо от сигна-
лов управления регистра (разрешения синхронизации REGCE и синхронной установ-
ки/сброса RSTREG). В регистровом режиме сигнал RSTREG устанавливает выход DO
Block RAM RAMEN RSTRAM DBRAM Output Register n nn
-т UI .ттп-п.гег РМ - г
DQTRAM
ПО 1 П/лМ ►
REGCE
RSTREG
Рис. 6.7. Блок RAM RSTREG в регистровом режиме
Блоки памяти RAM
113
CLK REGCLK
RAMEN
RSTRAM
DBRAM
REGCE
RSTREG
DO
Рис. 6.8. Операция сброса блока RAM в режиме RSTREG
Рис. 6.9. Операция сброса блока RAM в режиме RSTCE
Рис. 6.10. Операция сброса блока RAM в режиме защелки
в значение SRVAL и данные могут читаться из блока RAM на шину DBRAM. Данные
на шине DBRAM могут синхронизироваться с помощью сигналов управления регистра
для синхронного формирования данных на выходной шине DO. Временные диаграммы
на рис. 6.8-6.10 показывают различные случаи функционирования в режиме RSTREG.
Временные параметры блока RAM и временная модель представлены в прило-
жении Б.
6.4. Выводы
Блоки памяти RAM в FPGA 7-й серии, кроме выполнения функций запомина-
ния, хранения и буферизации данных, могут использоваться в качестве памяти типа
FIFO, высокопроизводительных конечных автоматов, больших функциональных гене-
раторов LUT, памяти типа ROM, а также больших сдвиговых регистров. Важным
свойством блоков RAM FPGA 7-й серии является поддержка кода с исправлением
ошибок ЕСС.
На блоках RAM FPGA 7-й серии легко реализуются двух и однопортовые моду-
ли RAM, модули ROM, синхронная память FIFO, а также преобразователи широких
слов данных.
114
Раздел 6
Один блок RAM FPGA 7-серии запоминает до 36 килобит (Кбит) данных и мо-
жет конфигурироваться либо как два независимых блока памяти RAMB18 размером
18 Кбит, либо как один блок памяти RAMB36 размером 36 Кбит. Блоки памяти RAM
имеют три основных режима функционирования: действительно двухпортовый режим
TDP, простой двухпортовый режим SDP и однопортовый режим.
Каждый блок RAMB36 в простом двухпортовом режиме SDP может иметь сле-
дующую конфигурацию: 64Кх1 (когда каскадируется с соседним блоком RAMB36),
32Кх1, 16Кх2, 8Кх4, 4Кх9, 2Кх18, 1Кх36 или 512x72. Каждый блок RAMB18
может иметь следующую конфигурацию: 16Кх1, 8Кх2, 4Кх4, 2Кх9, 1Кх18 или
512x36.
Два порта являются симметричными и полностью независимыми, совместно ис-
пользуя только записанные в память данные. Каждый порт может иметь одну из до-
пустимых конфигураций, независимую от конфигурации другого порта. Кроме того,
для каждого порта ширина порта чтения может отличаться от ширины порта записи.
Содержимое памяти может инициализироваться или создаваться битовым пото-
ком при конфигурации FPGA.
Основу архитектуры блока RAM FPGA 7-й серии составляет матрица памяти
(Memory Array), которая является общей для обоих портов. Операции записи и чтения
всегда являются синхронными, входные данные и адрес буферизируются в регистрах,
а выходные данные могут буферизироваться как в защелках, так и в дополнительном
конвейерном регистре.
Каждый блок RAMB36 имеет одну общую матрицу памяти на 36 Кбит и два неза-
висимых порта А и В. Аналогично, блок RAMB18 имеет матрицу памяти на 18 Кбит
и два независимых порта А и В. Каждый порт имеет свои собственные выводы для
адреса (ADDR), входных (DI) и выходных (DO) данных, синхросигнала (CLK), разре-
шения функционирования (EN) и разрешения записи (WE). Кроме того, каждый порт
имеет независимые сигналы управления регистрами и защелками: синхронной уста-
новки/сброса выходных защелок (RSTRAM), синхронной установки/сброса выходно-
го регистра (RSTREG) и разрешения синхронизации выходного регистра (REGCE).
Кроме того, каждый порт имеет 4 бита четности, которые могут совмещаться
с основными битами, образуя слова шириной в 36 битов. Биты четности имеют
отдельные входные (DIP) и выходные (DOP) шины.
Для возможности объединения соседних блоков памяти RAM с целью построения
блока размером 64Кх1 бит служат входы (CASCADEIN) и выходы (CASCADEOUT)
каскадирования.
Особенности режимов функционирования памяти RAM:
• TDP имеет отдельные синхросигналы CLKA и CLKB для каждого порта А и В;
• SDP имеет отдельные синхросигналы WRCLK и RDCLK для операций записи
и чтения;
• TDP имеет отдельные адресные шины ADDRA и ADDRB для портов А и В,
которые являются общими для операций записи и чтения;
• SDP имеет отдельные адресные шины WRADDR и RDADDR для операций за-
писи и чтения;
• SDP имеет большую ширину порта данных: 64 и 72 бита;
• режимы записи WRITE-FIRST, READ-FIRST и NO-CHANGE возможны только
для однопортовой памяти.
Однопортовый режим блока RAM вводится с помощью макроса BRAM_SINGLE_
MACRO.
Блоки памяти RAM
115
Имеется три режима записи, определяющие поведение данных на выходной шине
после прихода фронта синхроимпульса: WRITE-FIRST, READ-FIRST и NO-CHANGE.
Режим записи определяется во время конфигурации с помощью атрибута WRITE-
MODE, который может устанавливаться индивидуально для каждого порта.
Режим WRITE-FIRST (режим по умолчанию) выводит недавно записанные дан-
ные на выходную шину. Режим READ-FIRST выводит на выходную шину ранее за-
помненные в памяти данные, в то время как новые данные записываются в память.
Режим NO.CHANGE поддерживает выход в состоянии, сгенерированном предыдущей
операцией чтения.
Режим NO.CHANGE является наиболее эффективным по энергопотреблению.
Этот режим записи невозможен в режиме функционирования SDP.
В асинхронных приложениях, когда оба порта тактируются различными синхро-
сигналами, следует избегать режима READ-FIRST, рекомендуемым режимом явля-
ется режим WRITE-FIRST.
В синхронных приложениях оба входа синхронизации управляются одним и тем
же синхросигналом. При этом нет временных ограничений на операции чтения обоих
портов. Однако когда один порт выполняет операцию записи, другой порт не должен
писать в ту же самую ячейку памяти, за исключением случая, когда оба порта пишут
идентичные данные. Когда один порт в режиме READ-FIRST выполняет операцию
записи, другой порт может надежно читать данные из той же самой ячейки памяти.
Если записывающий порт имеет режим WRITE.FIRST или NO-CHANGE, то данные
на порте чтения могут быть недостоверными; установки режимов на порте чтения
не влияют на это функционирование.
Дополнительные (конвейерные) выходные регистры улучшают производитель-
ность проекта путем исключения задержек трассировки к триггерам логических бло-
ков CLB для конвейерных операций.
Каждый порт блока RAM может независимо управлять шириной данных и глуби-
ной адреса. Это свойство расширяется на операции чтения и записи. Например, порт
А может иметь 36-битовую ширину для чтения и 9-битовую ширину для записи, а порт
В может иметь 18-битовую ширину для чтения и 36-битовую ширину для записи.
Независимый выбор ширины портов чтения и записи увеличивает эффективность
реализации в блоке RAM ассоциативной (адресуемой по содержимому) памяти типа
САМ (content addressable memory).
В простом двухпортовом режиме SDP ширина порта RAM удваивается до 36 би-
тов для блока RAMB18 и до 72 битов для блока RAMB36. В режиме SDP независимые
операции чтения и записи могут происходить одновременно, где порт А рассматрива-
ется как порт чтения, а порт В — как порт записи.
Когда порты чтения и записи одновременно обращаются к одной и той же ячейке
памяти, такая ситуация трактуется как конфликт, аналогичный конфликту портов в
действительно двухпортовом режиме TDP. В режиме SDP поддерживаются только
два режима на выходной шине: READ-FIRST и WRITE.FIRST.
В FPGA 7-й серии два соседних модуля RAMB36 можно каскадно объединять в
один блок размером 64Кх1 без использования локальных соединений или дополни-
тельных логических ресурсов.
Свойство побайтовой записи данных позволяет записывать каждый байт вход-
ных данных. Для этого примитив RAMB36E1 имеет 4 независимых входа разрешения
побайтовой записи в режиме TDP и 8 — в режиме SDP. Каждый вход разрешения
записи шириной в байт соответствует одному байту входных данных и одному би-
116
Раздел 6
ту четности. Это свойство является полезным, когда блок RAM используется для
интерфейса с микропроцессором.
В FPGA 7-й серии сигнал глобальной установки или сброса GSR является гло-
бальным асинхронным сигналом, который активизируется в конце конфигурирования
устройства. Сигнал GSR также может в любое время вернуть защелки устройства 7-й
серии в начальное значение INIT. Сигнал GSR не воздействует на внутреннее содер-
жимое памяти и отсутствует в примитивах памяти.
Неиспользуемые входы данных блока RAM должны быть подсоединены к ниж-
нему уровню. Неиспользуемые адресные входы должны быть подсоединены к вы-
сокому уровню.
Для использования блоков памяти RAM в FPGA 7-й серии имеется два примитива
RAMB18E1 и RAMB36E1, другие библиотечные примитивы и макросы строятся на
основе этих примитивов.
Для создания большой памяти из блоков меньшего размера используется про-
грамма CORE Generator фирмы Xilinx. Результаты работы программы могут исполь-
зоваться в языках VHDL или Verilog.
В регистровом режиме сигнал RSTREG может использоваться для управления
выходным регистром как конвейерным регистром независимо от блока RAM. В этом
режиме блок RAM может читаться и записываться независимо от сигналов управ-
ления выходного регистра.
7 Память типа FIFO
Вторым типом памяти, который поддерживают блоки RAM FPGA 7-й серии, яв-
ляется память типа FIFO (first in, first out — первым вошел, первым вышел). Па-
мять FIFO в блоках RAM реализуется без использования дополнительной логики
блоков CLB.
Подобно памяти RAM, память FIFO реализуется либо в виде блока FIFO36 объ-
емом ЗбКбит, либо в виде блока FIFO18 объемом 18 Кбит. Для блоков FIFO18 поддер-
живаются конфигурации 4Кх4, 2Кх9, 1Кх18 и 512x36, а для блоков FIFO36 поддер-
живаются конфигурации 8Кх4, 4Кх9, 2Кх18,1Кх36 и 512x72. Порт А блока RAM
используется как порт чтения памяти FIFO, а порт В — как порт записи памяти FIFO.
Операции чтения и записи памяти FIFO являются синхронными и могут иметь
общую или независимую синхронизацию. В первом случае память FIFO называет-
ся синхронной, а во втором — с двойной синхронизацией или асинхронной. Данные
читаются из памяти FIFO на возрастающем фронте синхросигнала чтения, а записы-
ваются в память FIFO на возрастающем фронте синхросигнала записи.
Возможные конфигурации блоков
памяти FIFO приведены в табл. 7.1.
В памяти FIFO допускается также
различная ширина портов чтения и за-
писи, однако при реализации этого ре-
жима используется логика блоков CLB.
Для памяти FIFO FPGA 7-й серии
имеется два режима чтения первого
Таблица 7.1
Конфигурация памяти FIFO
FIFO18 FIFO36
4К записей по 4 бита 2К записей по 9 битов 1К записей по 18 битов 512 записей по 36 битов 8К записей по 4 бита 4К записей по 9 битов 2К записей по 18 битов 1К записей по 36 битов 512 записей по 72 бита
слова, записанного в пустую память FIFO: стандартный и FWFT (first-word fall-
through — первое слово выпадает). В режиме FWFT количество записей в табл. 7.1
увеличивается на 1.
7.1. Архитектура памяти FIFO
Логическая структура памяти типа FIFO FPGA 7-й серии, показана на рис. 7.1.
Основу памяти FIFO составляет блок памяти RAM (Block RAM). Записываемые
данные на вход блока RAM поступают с входных шин DIN/DINP. Прочитанные данные
из блока RAM выводятся на выходные шины DO/DOP. Адреса записи (waddr) и чте-
ния (raddr) данных образуются с помощью блоков формирования указателя записи
Write Pointer и указателя чтения Read Pointer. Эти блоки также формируют внешние
сигналы WRCOUNT и RDCOUNT для указания значений счетчиков записи и чтения.
Устройство управления (Status Flag Logic) на основании внешних (по отношении
к памяти FIFO) сигналов синхронизации операций записи WRCLK и чтения RDCLK,
разрешения чтения WREN и разрешения записи RDEN, а также сигнала сброса RST
формирует три внутренних сигнала управления блоком RAM: разрешения записи в
память mem_wen, разрешения чтения из памяти mem.ren, а также разрешение выхо-
да ое. Кроме того, устройство управления формирует следующие флаги состояния:
FULL — полный, EMPTY — пустой, ALMOSTFULL — почти полный, ALMOSTEMP-
TY — почти пустой, RDERR — ошибка чтения и WRERR — ошибка записи.
118
Раздел 7
WRCOUNT
DIN/DINP
WRCLK
WREN
RST
RDCOUNT
DO/DOP
RDCLK
RDEN
Рис. 7.1. Структура логики функционирования памяти FIFO
7.2. Функционирование памяти FIFO
Как было указано ранее, в FPGA 7-й серии предусмотрено два режима функциони-
рования памяти FIFO: синхронный и с двойной синхронизацией (асинхронный). Режи-
мы функционирования памяти FIFO определяются атрибутом EN-SYN, который мо-
жет быть установлении в значение TRUE для синхронного режима функционирования
и в значение FALSE для режима функционирования с двойной синхронизацией. Отме-
тим, что на функционирование памяти FIFO может влиять введение дополнительных
(конвейерных) выходных регистров путем установки атрибута DO-REG в значение 1.
Кроме того, имеется два режима чтения первого слова, записанного в пустую
память FIFO: стандартный и FWFT. К особенностям функционирования памяти FIFO
FPGA 7-й серии можно также отнести применение сигнала сброса RST. В данном
разделе эти вопросы рассматриваются более подробно.
7.2.1. Режимы функционирования: стандартный и FWFT
Имеется два режима чтения первого слова, записанного в пустую память FIFO:
стандартный режим и режим FWFT. В стандартном режиме первое слово, записан-
ное в пустую память FIFO, появляется на выходе DO после того, как пользователь
активизировал сигнал RDEN; т. е. пользователь должен прочитать данные из FIFO. В
режиме FWFT первое слово, записанное в пустую память FIFO, автоматически по-
является на выходе DO без активизации пользователем сигнала RDEN; следующий
активный сигнал RDEN затем прочитает очередное слово данных на выход DO.
Стандартный режим и режим FWFT отличаются только чтением первого запи-
санного слова в пустую память FIFO. В остальном функционирование памяти FIFO в
обоих режимах совпадает. Отметим также, что режим FWFT поддерживается только
для памяти FIFO с двойной синхронизацией.
На рис. 7.2 показано различие между стандартным режимом и режимом FWFT.
Память типа FIFO
119
RDCLK
ADEN
EMPTY
DO (Standard)
DO (FWFT)
Рис. 7.2. Временная диаграмма цикла чтения в стандартном режиме и режиме FWFT
7.2.2. Начало функционирования памяти FIFO (сигнал сброса RST)
Для работы памяти FIFO в FPGA 7-й серии требуется сигнал сброса RST. После
включения питания сигнал RST должен быть установлен в течение 5 циклов опера-
ций чтения и записи для сброса всех счетчиков и инициализации флагов. Сигнал
RST не очищает блок памяти RAM и выходной регистр. Когда сигнал RST устанав-
ливается, сигналы EMPTY и ALMOSTEMPTY равны 1, a FULL и ALMOSTFULL —
0. Установка и удержание сигнала RST в течение 5 циклов синхросигналов чтения
и записи необходима для уверенности в том, что все внутренние состояния сбрасы-
ваются в корректные значения. В течение сброса сигналы RDEN и WREN должны
иметь низкий уровень.
7.2.3. Режим двойной синхронизации памяти FIFO
Память FIFO имеет отдельные сигналы синхронизации для операций чтения и
записи. Синхросигналы могут быть одинаковыми в случае синхронной памяти FIFO
или различными по частоте и фазе в случае асинхронной (с двойной синхронизацией)
памяти FIFO. Такая гибкость синхронизации позволяет избегать проблемы неодно-
значности, сбоев или метастабильности. Режим двойной синхронизации памяти FIFO
устанавливается путем определения значения атрибута EN.SYN равным FALSE.
При операции записи слово данных, доступное на входе DI, записывается в па-
мять FIFO каждый раз, когда сигнал WREN удерживается в активном состоянии в
течение времени установки до появления возрастающего фронта на выводе WRCLK.
При операции чтения формирование следующего слова данных на выходе DO осу-
ществляется всякий раз, когда сигнал RDEN удерживается в активном состоянии в
течение времени установки до возрастающего фронта на выводе RDCLK.
Поток данных управляется автоматически. Пользователю нет необходимости
беспокоиться о формировании последовательности адресов для блока RAM. При этом
также формируются сигналы WRCOUNT и RDCOUNT, которые могут использовать-
ся в различных приложениях.
Пользователь должен контролировать флаги FULL и EMPTY и останавливать
запись, когда сигнал FULL находится в высоком состоянии, а также останавливать
чтение, когда сигнал EMPTY находится в высоком состоянии. Если эти правила на-
рушаются, активное значение сигнала WREN при высоком значении FULL устанавли-
вает флаг ошибки WRERR, а активное значение сигнала RDEN при высоком значении
EMPTY устанавливает флаг ошибки RDERR. Однако, несмотря на нарушения, содер-
жимое памяти FIFO сохраняется и адресные счетчики остаются верными.
Кроме того, во время функционирования памяти FIFO формируются программи-
руемые флаги Almost Full (почти полный) и Almost Empty (почти пустой), чтобы дать
пользователю возможность раннего обнаружения, когда память FIFO приближается
120
Раздел 7
к своим пределам. Значения этих флагов могут устанавливаться конфигурацией в
любом диапазоне адресов памяти FIFO.
7.2.4. Синхронный режим функционирования памяти FIFO
Данный режим устанавливается при значении атрибута EN_SYN равным TRUE.
В этом режиме исключаются задержки цикла синхронизации при установке или сбро-
се флагов. Отметим, что при асинхронном сбросе поведение флагов после первой
записи является непредсказуемым. В этом случае Xilinx рекомендует синхронизиро-
вать сброс или синхронизировать только отрицательный фронт сброса к сигналам
RDCLK или WRCLK. Эта синхронизация не требуется, когда EN_SYN = FALSE.
В зависимости от режима синхронизации (определяемого атрибутом EN.SYN) и
установки дополнительного выходного регистра (определяемого атрибутом DO.REG)
различают три способа реализации синхронной памяти FIFO (табл. 7.2).
Таблица 7.2
Реализация синхронной памяти FIFO
Реализация FIFO Преимущества Недостатки
EN_SYN = TRUE, DO-REG = 0 EN.SYN = TRUE, DO_REG = 1 EN.SYN = FALSE, DO-REG = 1, RDCLK = WRCLK Нет неопределенных флагов Нет неопределенных флагов, наименьшая задержка выход- ных данных (clock-to-out) Наименьшая задержка выход- ных данных (clock-to-out) Наибольшая величина задержки выходных данных (clock-to-out) Время ожидания данных увеличивается на едини- цу. Поведение подобно синхронной FIFO с внеш- ним конвейерным регистром выходных данных Не определен падающий фронт синхросигнала. Возрастающий фронт гарантируется при установ- ке сигналов FULL и EMPTY
rdclk
rden
DO
ENSYN zz TRUE
DO REG = 0
DO
EN.SYN = TRUE
DO„REG = 1
DO
EN SYN - FALSE
DO.REG = 1
Рис. 7.3. Временная диаграмма синхронной памяти FIFO
На рис. 7.3 представлены временные диаграммы функционирования памяти FIFO,
которые соответствуют различным способам реализации синхронного функциониро-
вания.
7.2.5. Флаги состояний
В табл. 7.3 для каждого флага показано требуемое число циклов синхронизации,
чтобы установить или сбросить каждый флаг асинхронной памяти FIFO (с двойной
синхронизацией). Сигналы установки или сброса флагов для синхронной памяти FIFO
не имеют времени задержки (в циклах синхронизации).
Память типа FIFO
121
Таблица 7.3
Время задержки установки и сброса флагов асинхронной памяти FIFO
Флаг состояния Время задержки в циклах синхронизации
Установка Сброс
Стандартный FWFT Стандартный FWFT
Пустой 0 0 3 4
Полный 0 0 3 3
Почти пустой 1 1 4 4
Почти полный 1 1 4 4
Ошибка чтения 0 0 0 0
Ошибка записи 0 0 0 0
Для реализации в блоках RAM памяти типа FIFO имеется два примитива:
FIFO36E1 и FIFO18E1, описание которых приводится в приложении А.
7.2.6. Диапазоны смещения флагов «почти полный» и «почти пустой»
Смещения «почти полный» и «почти пустой» обычно устанавливается в малое
значение, меньше 10. Большинство приложений используют флаг «почти полный»
для прекращения записи в память FIFO. Однако чтобы прочитать все записи из па-
мяти FIFO, следует пользоваться флагом EMPTY.
Установки «почти полный» и «почти пустой» могут также использоваться в
неостанавливаемых приложениях передачи пакетов данных для указания, что весь
пакет данных может записываться или читаться.
При установке диапазонов смещения в средствах проектирования используется
16- ричная нотация. Когда частота RDCLK отличается от частоты WRCLK, необходи-
мо определить значение дополнительного ограничения ALMOST_FULL_OFFSET. Ког-
да частоты RDCLK и WRCLK значительно отличаются друг от друга, то для приме-
нения параметра ALMOST_FULL_OFFSET следует устанавливать максимальные зна-
чения. В этом случае для вычисления максимального значения ALMOST-FULL-OFF-
SET используется следующее выражение:
max ALMOST_FULL_OFFSET =
= FIFO.DEPTM - int(4 xWRCLK_FREQ/RDCLK_FREQ) + 6,
где FIFO.DEPTM — глубина памяти FIFO; WRCLK.FREQ и RDCLK-FREQ — частота
записи и чтения памяти FIFO. Например, пусть используется память FIFO с глубиной
4К; WRCK = 500 МГц и RDCLK = 8 МГц, тогда ALMOST_FULL_OFFSET = 4096 -
- int (4x500/8) + 6 = 3840.
В приложении Б рассматриваются временные параметры памяти FIFO, а также
типичные примеры функционирования памяти FIFO во времени. Последнее необхо-
димо для лучшего понимания деталей функционирования памяти FIFO и корректного
ее использования.
7.3. Применение памяти FIFO
В данном разделе рассматриваются возможности построения больших блоков
памяти FIFO, которые могут строиться путем:
• каскадирования для образования большей глубины памяти;
• параллельного соединения для образования большей ширины слова.
7.3.1. Каскадирование памяти FIFO для увеличения глубины
На рис. 7.4 показано каскадное соединение нескольких модулей памяти FIFO для
увеличения глубины памяти. Первые N — 1 модулей FIFO следует установить в режи-
122
Раздел 7
Рис. 7.4. Каскадное соединение нескольких модулей FIFO для увеличения глубины
ме FWFT и использовать дополнительную логику для соединения их вместе. Защел-
ка данных этого проекта является суммой индивидуальных защелок модулей FIFO.
Максимальная частота ограничивается длиной пути обратной связи. Вентили NOR
реализуются логикой блоков CLB. При этом:
• если WRCLK > RDCLK, то INTCLK = WRCLK;
• если WRCLK RDCLK, то INTCLK - RDCLK;
• сигнал почни пустой ALMOSTEMPTY устанавливается в последнем модуле FIFO;
• сигнал почти полный ALMOSTFULL устанавливается в первом модуле FIFO.
7.3.2. Параллельное соединение модулей FIFO для увеличения ширины
слова данных
На рис. 7.5 показано параллельное соединение модулей FIFO. Для реализации вен-
тилей AND и OR используется логика блоков CLB. Все сигналы FULL должны быть
соединены вместе с помощью вентилей OR для формирования общего сигнала FULL,
аналогично все сигналы EMPTY должны быть соединены вместе с помощью вентилей
OR для формирования общего сигнала EMPTY. Максимальная частота ограничива-
ется логикой вентилей в цепи обратной связи.
512 х 144 FIFO
Рис. 7.5. Пример параллельного соединения FIFO для увеличения ширины слова данных
Память типа FIFO
123
7.3.3. Допустимые комбинации блоков памяти RAM и FIFO
В одном примитиве RAMB36 могут быть одновременно реализованы модули RAM
и FIFO (рис. 7.6).
RAMB18E1
TDP or
SDP Mode
RAMB18E1
TDP or
SDP Mode
RAMB18E1
TDP or
SDP Mode
FIFO18E1
FIFO18 Mode
RAMB18E1
TDP or
SDP Mode
FIFO18E1
FIFO18J36 Mode
Рис. 7.6. Допустимые комбинации блоков памяти RAM и FIFO
7.4. Выводы
Память FIFO в блоках RAM реализуется без использования дополнительной ло-
гики блоков CLB.
Память FIFO реализуется либо в виде блока FIFO36 объемом 36 Кбит, либо в виде
блока FIFO18 объемом 18 Кбит. Для блоков FIFO18 поддерживаются конфигурации
4Кх4, 2Кх9, 1Кх18 и 512 х36, а для блоков FIFO36 поддерживаются конфигурации
8Кх4, 4Кх9, 2Кх18, 1Кх36 и 512x72. Порт А блока RAM используется как порт
чтения, а порт В — как порт записи памяти FIFO.
Операции чтения и записи памяти FIFO являются синхронными и могут иметь
общую или независимую синхронизацию. В первом случае память FIFO называется
синхронной, а во втором — с двойной синхронизацией или асинхронной. Режимы
функционирования памяти FIFO определяются атрибутом EN_SYN (TRUE для синх-
ронного, FALSE для асинхронного режима функционирования).
Данные читаются из памяти FIFO на возрастающем фронте синхросигнала чте-
ния, а записываются в память FIFO на возрастающем фронте синхросигнала записи.
В памяти FIFO допускается различная ширина портов чтения и записи, однако
при реализации этого режима используется логика блоков CLB.
Для памяти FIFO FPGA 7-й серии имеется два режима чтения первого слова,
записанного в пустую память FIFO: стандартный и FWFT (первое слово выпадает).
В режиме FWFT количество записей увеличивается на 1.
Основу памяти FIFO составляет блок памяти RAM. Адреса записи и чтения дан-
ных образуются с помощью блоков формирования указателя записи и указателя чте-
ния. Эти блоки также формируют внешние сигналы WRCOUNT и RDCOUNT для
указания значений счетчиков записи и чтения.
Устройство управления на основании внешних сигналов синхронизации операций
записи WRCLK и чтения RDCLK, разрешения чтения WREN и разрешения записи
RDEN формирует три внутренних сигнала управления блоком RAM: разрешения за-
писи в память mem.wen, разрешения чтения из памяти mem_ren, а также разрешение
выхода ое. Кроме того, устройство управления формирует флаги состояния: FULL —
полный, EMPTY — пустой, ALMOSTFULL — почти полный, ALMOSTEMPTY — поч-
ти пустой, RDERR — ошибка чтения и WRERR — ошибка записи.
На функционирование памяти FIFO может влиять введение дополнительных кон-
вейерных выходных регистров путем установки атрибута DO.REG = 1.
124
Раздел 7
В стандартном режиме первое слово, записанное в пустую память FIFO, появля-
ется на выходе DO после того, как пользователь активизировал сигнал RDEN; т. е.
пользователь должен прочитать данные из FIFO. В режиме FWFT первое слово, за-
писанное в пустую память FIFO, автоматически появляется на выходе DO без ак-
тивизации пользователем сигнала RDEN; следующий активный сигнал RDEN затем
прочитает очередное слово данных на выход DO.
Стандартный режим и режим FWFT отличаются только чтением первого запи-
санного слова в пустую память FIFO. В остальном функционирование памяти FIFO
в обоих режимах совпадает.
Режим FWFT поддерживается только для памяти FIFO с двойной синхрони-
зацией.
Для корректного функционирования памяти FIFO требуется после включения пи-
тания установить сигнал сброса RST в течение 5 циклов операций чтения и записи
для сброса всех счетчиков и инициализации флагов. Сигнал RST не очищает блок
памяти RAM и выходной регистр. В течение сброса сигналы RDEN и WREN должны
иметь низкий уровень.
В асинхронном режиме входное слово данных записывается в память FIFO каж-
дый раз, когда сигнал WREN удерживается в активном состоянии в течение времени
установки до возрастающего фронта синхросигнала WRCLK. Формирование следую-
щего выходного слова данных осуществляется всякий раз, когда сигнал RDEN удержи-
вается в активном состоянии в течение времени установки до возрастающего фронта
синхросигнала RDCLK.
Значения указателей записи и чтения формируются автоматически. При этом
также образуются сигналы WRCOUNT и RDCOUNT, которые могут использоваться
в различных приложениях.
Пользователь должен контролировать флаги FULL и EMPTY и останавливать за-
пись, когда сигнал FULL находится в высоком состоянии, или останавливать чтение,
когда сигнал EMPTY находится в высоком состоянии. Если эти правила нарушаются,
устанавливается флаг ошибки записи WRERR или чтения RDERR. Однако содержи-
мое памяти FIFO сохраняется и адресные счетчики остаются верными.
Во время функционирования памяти FIFO также формируются программируемые
флаги почти полный Almost Full и почти пустой Almost Empty. Значения этих флагов
могут устанавливаться конфигурированием в любом диапазоне адресов памяти FIFO.
В синхронном режиме (EN.SYN = TRUE) исключаются задержки цикла синхро-
низации при установке или сбросе флагов (при асинхронном сбросе поведение флагов
после первой записи является непредсказуемым).
В зависимости от режима синхронизации (определяемого атрибутом EN.SYN) и
установки дополнительного выходного регистра (определяемого атрибутом DO.REG),
различают три способа реализации синхронной памяти FIFO (табл. 7.2).
Для реализации в блоках RAM памяти типа FIFO имеется два примитива:
FIFO36E1 и FIFO18E1.
Большие блоки памяти FIFO могут строиться путем каскадирования для образо-
вания большей глубины памяти или путем параллельного соединения для образования
большей ширины слова. При этом используется логика блоков CLB.
8 Встроенная коррекция ошибок блоков памяти
Блоки памяти RAM FPGA 7-й серии при записи и чтении данных поддерживают
встроенную коррекцию ошибок с помощью кода Хэмминга. Реализация встроенной
коррекции ошибок осуществляется в блоке коррекции ошибок ЕСС (Error Correction
Coding), который имеется в каждом блоке RAM FPGA 7-й серии. Опция конфигурации
блока ЕСС доступна в блоках памяти ЗбКбит для типов памяти RAM и FIFO.
Для использования коррекции ошибок примитив RAMB36E1 должен конфигури-
роваться как память RAM 512x64 в простом двухпортовом режиме SDP, при этом
для кодирования используется 8 битов в 72-битовом слове данных. Коррекция ошибок
выполняется с помощью восьми битов защиты (ECCPARITY), которые генерируются
во время каждой операции записи и запоминаются в памяти вместе с 64-битовыми
данными. Эти биты ECCPARITY используются во время каждой операции чтения
для коррекции любой единичной ошибки или обнаружения любой двойной ошибки
(без коррекции).
Во время каждой операции чтения 72 бита (64 бита данных и 8 битов четности)
читаются из памяти и поступают в дешифратор ЕСС. Дешифратор ЕСС формирует
два выхода состояний (SBITERR и DBITERR), которые используются для определе-
ния трех возможных результатов чтения:
• нет ошибок (SBITERR = DBITERR = 0);
• скорректирована единичная ошибка (SBITERR = 1);
• обнаружена двойная ошибка (DBITERR = 1).
В стандартном режиме функционирования блока ЕСС операция чтения не кор-
ректирует ошибку в матрице памяти, она только представляет скорректированные
данные на выходе DO.
Для увеличения частоты Fmax возможна установка дополнительных регистров,
управляемых атрибутом DO.REG, на выходах данных DO, а также на выходах сиг-
налов SBITERR и DBITERR.
Кроме того, примитив RAMB36E1 имеет свойство вводить ошибки для проверки
функционирования блока ЕСС. При этом примитив RAMB36E1 имеет возможность
прочитать обратно адрес, где были запомнены текущие данные выхода чтения. Это
свойство позволяет поддерживать восстановление битовой ошибки или аннулировать
адрес слова памяти с ошибочной записью для будущего доступа.
Примитив FIFO36E1 поддерживает стандартный режим ЕСС и также имеет свой-
ство введения ошибки. Память FIFO36E1 не поддерживает режим ЕСС «только шиф-
ратор» и не выводит адрес прочитанных данных.
Блок RAM ЕСС поддерживает режимы READ-FIRST и WRITE-FIRST в идентич-
ном виде для режима SDP.
8.1. Архитектура блока ЕСС
Логическая структура блока внутренней коррекции ошибок ЕСС показана на
рис. 8.1. Основу блока ЕСС составляют 64-битовые шифратор ЕСС (ЕСС Encoder)
и дешифратор ЕСС (Decoder end Correct). Блок ЕСС выполняет свои функции по
126
Раздел 8
WRADDR[8:0]
wraddr
9
RDADDR[8:0]
rdaddr
9,
DIP[7:0]-
ECCPARITYp:O]
8,
8
INJECTSBITERR.
INJECTDBITERR-
DI[63:0}
64,
---
DO.REG
EN.„ECC.„ WRITE
DO[63:0]-<
DO_REG
DBITERR-*
DO.REG
SBITERR<<<
DO_REG
DOP[7:0]
Q D
DO-REG
RDADDRECC[8:0]
QI
— Q D
64-bit
ECC
Encode
Data In
64
Block RAM
512 x 72
EN_ECC_READ
64
64;
8
8.
EN-ECC-READ
Decode
and
Correct
Out
Parity
*Out
64;
...Л
8
1 ,
1
0
1
0
Q D
J — Q D
Q D
4
9;
Рис. 8.1. Логическая структура блока ЕСС
шифрации и дешифрации данных только для памяти в конфигурации 512x72 (512
слов по 72 бита), которая возможна в простом двухпортовом режиме SDP для па-
мяти типа RAM и в режиме FIFO36.72 для памяти типа FIFO. Поскольку глубина
памяти равна 512 слов, ширина адресных шин записи WRADDR и чтения RDADDR
составляет 9 битов.
Шифратор ЕСС принимает с входной шины DI 64 бита данных, кодирует их и
формирует 8 битов защиты (называемых также битами четности или контрольными
битами) ECCPARITY, которые вместе с битами данных записываются в память, об-
разуя слово размером 72 бита. Биты четности могут также поступать извне по шине
DIP. Источником битов защиты управляет атрибут EN_ECC_WRITE.
Кроме того, шифратор ЕСС имеет два дополнительных входа INJECTSBITERR
и INJECTDBITERR для введения одиночной и двойной (двухбитовой) ошибки со-
ответственно. Эти входы могут использоваться для проверки работоспособности
блока ЕСС.
Дешифратор ЕСС принимает из блока памяти RAM 64 бита закодированных дан-
Встроенная коррекция ошибок блоков памяти
127
ных и 8 битов защиты (четности), на основании которых формирует и выводит на
выходную шину DO корректные данные, а на шину DOP — биты четности. Если при
записи в блок памяти RAM произошла одиночная ошибка, то дешифратор ее испра-
вит и установит флаг SBITERR. В случае двойной ошибки устанавливается только
флаг DBITERR. Адрес ячейки памяти, считываемой в настоящее время, выводится
на выход RDADDRECC. С помощью этих данных можно узнать адрес ячейки памя-
ти, где произошла ошибка, и принять соответствующие меры: либо аннулировать
считанные данные, либо адрес ячейки с ошибочными данными исключить из даль-
нейшего использования.
На всех выводах блока RAM, работающего в режиме встроенной коррекции оши-
бок, могут устанавливаться дополнительные (конвейерные) регистры. При этом до-
полнительные регистры устанавливаются на выходные шины данных DO и DOP, на
шину адреса RDADDRECC, а также на выходы сигналов SBITERR и DBITERR. Уста-
новкой дополнительных регистров управляет атрибут DO-REG.
Путь выходных данных DO и битов четности DOP может обходить дешифра-
тор ЕСС. Для этого служат соответствующие мультиплексоры, которые управляются
атрибутом EN_ECC_READ.
8.2. Функционирование блока ЕСС
Имеются три основных режима функционирования блока коррекции ошибок ЕСС:
• стандартный, когда одновременно используются шифратор и дешифратор ЕСС;
• «только шифратор», когда используется только шифратор ЕСС;
• «только дешифратор», когда используется только дешифратор ЕСС
В стандартном режиме функционирования блока ЕСС (EN_ECC_READ = TRUE
и EN_ECC_WRITE = TRUE) доступны как шифратор, так и дешифратор. Во время
записи в память запоминаются 64-битовые данные и сгенерированные блоком ЕСС 8
битов четности. Внешние биты четности игнорируются. Во время чтения на выход
выводятся 72-битовые дешифрованные данные.
Чтобы использовать блок ЕСС в режиме «только дешифратор», следует устано-
вить EN_ECC_WRITE = FALSE и EN_ECC_READ = TRUE.
Шифратор может использоваться двумя путями:
• в стандартном режиме ЕСС при установке EN_ECC_WRITE = TRUE и EN_ECC_
READ = TRUE; в этом режиме контроль по четности блоком ЕСС не поддер-
живается;
• в режиме только шифратор при установке EN_ECC_WRITE = TRUE и EN_ECC_
READ = FALSE; в этом режиме контроль по четности поддерживается блоком
ЕСС.
Отметим некоторые особенности функционирования блока RAM при использо-
вании режима коррекции ошибок:
• в простом двухпортовом режиме SDP порты блока RAM имеют независимые ад-
реса, синхросигналы и входы разрешения, один порт является выделенным пор-
том записи, а другой — выделенным портом чтения;
• выход DO представляет прочитанные данные после коррекции;
• выход DO остается доступным до следующей активной операции чтения;
• допускается одновременная шифрация и дешифрация данных для различных ад-
ресов записи/чтения; однако запрещается одновременная дешифрация и шифра-
ция данных по одному и тому же адресу записи/чтения;
• в конфигурации ЕСС блок RAM может иметь режимы READ_FIRST и WRITE-
FIRST.
128
Раздел 8
Кроме того, в простом двухпортовом режиме SDP примитива RAMB36E1 шиф-
ратор и дешифратор могут быть отдельно доступны для внешнего использования.
Чтобы использовать шифратор отдельно, данные должны быть направлены через
порт DI, и должен выбираться выходной порт ECCPARITY. Чтобы использовать от-
дельно дешифратор, шифратор запрещается, данные записываются в блок RAM, а
скорректированные данные и биты состояния считываются на выход блока RAM (см.
атрибуты блока RAMB36E1 в приложении А).
Для использования блока коррекции ошибок ЕСС в случае памяти RAM приме-
няется примитив RAMB36E1 в режиме SDP (поскольку блок коррекции ошибок ЕСС
применим только в этом режиме). Аналогично, для использования блока коррекции
ошибок ЕСС в случае памяти FIFO применяется примитив FIFO36E1 (поскольку блок
коррекции ошибок ЕСС применим только в режиме FIFO36-72). Описание указан-
ных примитивов в случае использования блока коррекции ошибок ЕСС приведено
в приложении А.
8.3. Применение блока ЕСС
Как было сказано ранее, имеется 3 режима функционирования блока ЕСС:
• стандартный;
• «только шифратор»;
• «только дешифратор».
8.3.1. Стандартный режим ЕСС
В стандартном режиме в блоке ЕСС используются как шифратор, так и дешиф-
ратор. Различные режимы функционирования блока ЕСС доступны как в памяти
RAM, так и в памяти FIFO. Адресные входы WRADDR и RDADDR блока RAM ус-
танавливаются пользователем. Адресные входы WRADDR и RDADDR блока FIFO
генерируются внутренне от счетчиков записи и чтения.
Для функционирования блока ЕСС в стандартном режиме, необходимо устано-
вить следующие значения атрибутов:
EN_ECC_READ - TRUE;
EN_ECC_WRITE = TRUE.
Запись в стандартном режиме ЕСС. Как показано на рис. 8.2, в момент времени
T1W значение шины DI[63:0] = А записывается в ячейку памяти а. Соответствую-
щие 8 битов контрольных разрядов (четности) РА внутренне генерируются в ЕСС,
добавляются к 64 битам данных и записываются в память. Сразу после записи зна-
чения контрольных разрядов РА появляются на выходе ECCPARITY[7:0]. Поскольку
контрольные биты ЕСС генерируются внутренне, выводы DIP[7:0] не используются.
В стандартном режиме ЕСС четность (parity) ЕСС не поддерживается.
Аналогично, в моменты времени T2W и T3W на шине DI[63:0] устанавливаются
значения В и С, которые вместе с соответствующими контрольными битами РВ и
PC записываются в ячейки памяти b и с. Значения РВ и PC появляются на выходе
ECCPARITY[7:0] вскоре после моментов времени T2W и T3W.
Чтение в режиме стандартного ЕСС. Как показано на рис. 8.3, в момент времени
T1R 72-битовое содержимое памяти, состоящее из 64 битов данных слова А и 8
битов четности РА читается из ячейки памяти а и внутренне дешифруется. Если
нет ошибки, оригинальные данные и значение контрольных битов выводятся на шины
DO[63:0] и DOP[7:0]. Если произошла ошибка либо в данных, либо в битах четности,
сигнал SBITERR устанавливается в 1. Если имеется двойная ошибка в данных и в
битах четности, ошибка не корректируется. Выводятся оригинальные данные и биты
Встроенная коррекция ошибок блоков памяти
129
WRCLK
WREN
WRADDR(8:01
DI[63:0J
DIP(7;0]
(Decode Only Mode)
ECCPARITY(7;O)
Рис. 8.2. Операция записи блока ЕСС
четности, а сигнал DBITERR устанавливается в 1. Если атрибут DO.REG = 0, то
DO[63:0] = А и DOP[7:0] = РА сразу после момент времени T1R.
Аналогично, в моменты времени T2R и T3R содержимое памяти из адресуемых
ячеек b и с читается, дешифруется и выводится на шины DO[63:0] и DOP[7:0]. Если
обнаруживается одиночная или двойная ошибка в слове А, выводы SBITERR/DBIT-
ERR могут переключаться после момента времени T1R.
На рис. 8.4 показана одиночная ошибка (SBITERR), обнаруженная в наборе дан-
ных А в режиме защелки после фронта синхросигнала T1R, а двойная ошибка (DBIT-
ERR) обнаружена в данных В в режиме защелки после фронта синхросигнала T2R.
Если атрибут DO.REG = 1, то DO[63:0] = А и DOP[7:0] = РА сразу после T2R.
RDCLK
RDEN
RDADDR[8:0]
DO[63:01
(Latch Mode)
DOP[7:0]
(Latch Mode)
SBITERR
(Latch Mode)
DBITERR
(Latch Mode)
ECCRDADDR
(Latch Mode)
DO[63:OJ
(Register Mode)
DOP(7:0]
(Register Mode)
SBITERR
(Register Mode)
DBITERR
(Register Mode)
ECCRDADDR
(Register Mode)
T1R
T2R
T3R
T4R
1 у Single Bft|Error ’ \
—*4 1 1 TRCKOmEdc„SBITERR (Latch Mode il 1 j J Double Bit ^rror \ j
1 1 TRCKO_ECp„DBITERR (Latch Mode) |
n ' XX h i XX ~ • a । A. b A c A
w т l-*~ TRCKO RokoOR ECC I i у;... j ™ i _
1, XX ЖШ A iX В IX c
H-TRCKO__DO (Register Mode)
I
; _2_—К 1 I | Single Bit Error ] К 1
1 trcko.„ECC„SbIterr (Register Mode) j । | । J" Double BlF Error” p \
c
-*-TRCKO„ECC„ DBlTfeRR (Register Mode)
a |
b*-TRCKO_RD^DDRECC..REG
Рис. 8.3. Операция чтения блока ЕСС
130
Раздел 8
Write
Cycle
Read
Cycle
Write
Cycle
Read
Cycle
WRCLK
DIN
WREN
WRADDR
INJSBITERR
INJDBITERR
RDCLK
RDADDR
RDEN
DOUT
SBITERR
DBITERR
•hock di ecc
TRCKO_DO_REG
^«CKO..SB!T..ECC
TRCKO Э6Г.ЕСС
SBITERR Corrected Data -
DBITERR Not Corrected Data
Рис. 8.5. Введение одной двухбитовой ошибки в регистровом режиме
'ROCK INJERR ECC
TRCKO RDADDR E€C. REG
Аналогично, в моменты времени T3R и T4R содержимое памяти из адресуемых
ячеек Ьис читается, дешифруется и выводится на шины DO[63:0] и DOP[7:0]. Могут
также переключаться выводы SBITERR/DBITERR после момента времени T2R, если
одиночная или двойная ошибка обнаруживается в наборе А.
На рис. 8.5 показана одиночная ошибка (SBITERR), обнаруженная в наборе дан-
ных А в регистровом режиме после фронта синхросигнала T2R, а двойная ошибка
(DBITERR) обнаружена в данных В в регистровом режиме защелки после фронта
синхросигнала T3R.
8.3.2. Режим ЕСС «только шифратор»
Для функционирования блока ЕСС в режиме «только шифратор», необходимо
установить следующие значения атрибутов:
EN_ECC_READ = FALSE;
Встроенная коррекция ошибок блоков памяти
131
EN_ECC_WRITE = TRUE.
Запись в режиме ЕСС «только шифратор». В момент времени T1W (см. рис. 8.2)
значение А шины DI[63:0] записывается в ячейку памяти а; блоком ЕСС внутренне ге-
нерируются соответствующие 8 битам четности РА, добавляются к 64 битам данных
и записываются в память. Сразу после записи значения битов четности РА появляют-
ся на выходе ECCPARITY[7:0]. Поскольку четность генерируются внутренне, выводы
DIP[7:0] не используются.
Аналогично, в моменты времени T2W и T3W значения шины В и С DI[63:0]
вместе с соответствующими им битами четности РВ и PC записываются в ячей-
ки памяти b и с. Значения РВ и PC появляются на выходе ECCPARITY[7:0] сразу
после T2W и T3W.
Чтение в режиме ЕСС «только шифратор». Чтение в режиме ЕСС «только
шифратор» совпадает с нормальным чтением блока RAM: 64-битовые данные по-
являются на выходе DO[63:0] и 8 битов четности появляются на выходе DOP[7:0].
Коррекция одиночных ошибок никогда не происходит и флаги ошибок SBITERR и
DBITERR никогда не устанавливаются.
8.3.3. Режим ЕСС «только дешифратор»
Для функционирования блока ЕСС в режиме «только дешифратор», необходимо
установить следующие значения атрибутов:
EN_ECC_READ = TRUE;
EN_ECC_WRITE = FALSE.
В этом режиме доступен только дешифратор ЕСС, а шифратор запрещен. Режим
«только дешифратор» используется для введения одиночной или двойной ошибки
для тестирования функциональности дешифратора ЕСС. При этом биты четности
должны питаться извне, используя выводы DIP[7:0].
8.3.4. Использование режима «только дешифратор» для введения
одиночной ошибки
В моменты времени T1W, T2W и T3W (см. рис. 8.2) на шине DI[63:0] устанав-
ливаются значения А, В и С с одиночной ошибкой, а шина DIP[7:0] имеет значения
РА, РВ и PC, соответствующие битам четности, сгенерированных ЕСС, для значений
А, В и С, записанных в ячейки памяти а, b и с.
В моменты времени T1R, T2R и T3R (см. рис. 8.3) содержимое ячеек памяти а,
b и с читается на выход и корректируется, как необходимо.
Режим защелки: DO[63:0] = А, В, С; DOP[7:0] = РА, РВ, PC сразу после мо-
ментов времени T1R, T2R и T3R.
Регистровый режим: DO[63:0] = А, В, С; DOP[7:0] = РА, РВ, PC сразу после
моментов времени T2R, T3R и T4R.
Линии SBITERR устанавливаются в 1 с соответствующими данными на шинах
DO/DOP.
Дешифратор ЕСС также корректирует одиночную ошибку в битах четности.
8.3.5. Использование режима «только дешифратор» для введения
двойной ошибки
В моменты времени T1W, T2W и T3W (см. рис. 8.2) значения на шине DI[63:0]
равны А, В и С с двойной ошибкой, а на шине DIP[7:0] устанавливаются значения
РА, РВ и PC, соответствующие битам четности блока ЕСС для значений А, В и С,
записанных в ячейки памяти а, b и с.
132
Раздел 8
В моменты времени T1R, T2R и T3R оригинальное содержимое ячеек памяти а,
b и с читается на выход и обнаруживается двойная ошибка.
Режим защелки: DO[63:0] = А, В, С с двойной ошибкой; DOP[7:0] = РА, РВ,
PC сразу после моментов времени T1R, T2R и T3R.
Регистровый режим: DO[63:0] = А, В, С с двойной ошибкой; DOP[7:0] = РА,
РВ, PC сразу после моментов времени T2R, T3R и T4R.
Линии SBITERR устанавливаются в 1 с соответствующими данными на шинах
DO/DOP.
Дешифратор ЕСС обнаруживает двойную ошибку в битах четности, а также оди-
ночную ошибку в битах данных и одиночную ошибку в соответствующих битах чет-
ности.
(Информацию о временных параметрах функционирования блока ЕСС см. в до-
кументе UG 473 7 Series FPGAs Memory Resources. User Guide.)
8.4. Выводы
Реализация встроенной коррекции ошибок при записи и чтении данных осущест-
вляется в блоке коррекции ошибок ЕСС. Опция конфигурации блока ЕСС доступна в
блоках памяти ЗбКбит для типов памяти RAM и FIFO.
Для использования коррекции ошибок примитив RAMB36E1 должен конфигури-
роваться как память RAM 512x64 в простом двухпортовом режиме SDP, при этом для
кодирования используется 8 битов в 72-битовом слове данных.
Коррекция ошибок выполняется с помощью восьми битов защиты ECCPARITY,
которые генерируются во время каждой операции записи и запоминаются в памяти
вместе с 64-битовыми данными. Биты ECCPARITY используются во время каждой
операции чтения для коррекции любой единичной ошибки или обнаружения любой
двойной ошибки.
Во время каждой операции чтения 64 бита данных и 8 битов четности читаются
из памяти и поступают в дешифратор ЕСС. Дешифратор ЕСС формирует два вы-
хода состояний SBITERR и DBITERR, которые используются для определения трех
возможных результатов чтения:
• нет ошибок (SBITERR = DBITERR = 0);
• скорректирована единичная ошибка (SBITERR = 1);
• обнаружена двойная ошибка (DBITERR = 1).
Примитив RAMB36E1 позволяет вводить ошибки для проверки функционирова-
ния блока ЕСС, а также прочитать обратно адрес, где были запомнены данные. Это
свойство позволяет аннулировать адрес слова памяти с ошибочной записью для бу-
дущего доступа.
Примитив FIFO36E1 поддерживает стандартный режим ЕСС и также имеет свой-
ство введения ошибки. Память FIFO36E1 не поддерживает режим ЕСС «только шиф-
ратор» и не выводит адрес прочитанных данных.
Основу блока ЕСС составляют 64-битовые шифратор ЕСС и дешифратор ЕСС
Блок ЕСС выполняет функции по шифрации и дешифрации данных только для памяти
в конфигурации 512x72 в простом двухпортовом режиме SDP для памяти RAM и
в режиме FIFO36.72 для памяти FIFO. Ширина адресных шин записи WRADDR и
чтения RDADDR составляет 9 битов.
Шифратор ЕСС принимает с входной шины DI 64 бита данных, кодирует их и
формирует 8 битов защиты (четности) ECCPARITY, которые вместе с битами дан-
ных записываются в память, образуя слово размером 72 бита. Биты четности могут
Встроенная коррекция ошибок блоков памяти
133
также поступать извне по шине DIP. Источником битов защиты управляет атрибут
EN_ECC_WRITE.
Для проверки работоспособности блока ЕСС шифратор имеет два дополнитель-
ных входа INJECTSBITERR и INJECTDBITERR для введения одиночной и двойной
ошибки соответственно.
Дешифратор ЕСС принимает из блока памяти RAM 64 бита закодированных дан-
ных и 8 битов защиты (четности), на основании которых формирует и выводит на
выходную шину DO корректные данные, а на шину DOP — биты четности.
Если при записи в блок памяти RAM произошла одиночная ошибка, то дешиф-
ратор ее исправит и установит флаг SBITERR. В случае двойной ошибки устанавли-
вается только флаг DBITERR.
Адрес ячейки памяти, считываемой в настоящее время, выводится на выход
RDADDRECC.
Имеется три основных режима функционирования блока коррекции ошибок ЕСС:
• стандартный, когда одновременно используются шифратор и дешифратор ЕСС;
• «только шифратор», когда используется только шифратор ЕСС;
• «только дешифратор», когда используется только дешифратор ЕСС.
В простом двухпортовом режиме SDP примитива RAMB36E1 шифратор и де-
шифратор могут быть отдельно доступны для внешнего использования.
9 Система ввода-вывода SelectIO
Система ввода-вывода в FPGA 7-й серии носит название система SelectIO. Ре-
сурсы системы SelectIO разделяют на три части:
• ресурсы ввода-вывода общего назначения;
• логические ресурсы ввода-вывода;
• расширенные логические ресурсы ввода-вывода.
Ресурсы ввода-вывода общего назначения реализуются с помощью широкого на-
бора примитивов, которые поддерживают большинство ассиметричных (single-ended)
и дифференциальных differential) стандартов. Важную роль в ресурсах ввода-вывода
общего назначения играет цифровое управление импедансом (Digitally-Controlled Im-
pedance — DCI).
Логические ресурсы системы SelectIO представлены модулями I LOGIC и OLOGIC,
а также модулями IDELAY и ODELAY. Модули ILOGIC и OLOGIC обеспечивают пе-
редачу данных с удвоенной скоростью (double-date-rate — DDR) по отношению к син-
хросигналу. Модули IDELAY и ODELAY обеспечивают введение программируемой
задержки в пути сигналов данных и синхронизации.
Расширенные логические ресурсы системы SelectIO обеспечиваются модулями
ISERDES и OSERDES, которые представляют собой соответственно последователь-
но-параллельный и параллельно-последовательный преобразователи. Модули ISER-
DES и OSERDES поддерживают широкий набор сетевых интерфейсов.
В данной главе рассматриваются ресурсы ввода-вывода общего назначения. Ло-
гические ресурсы системы SelectIO описываются в главе 10, а расширенные логичес-
кие ресурсы — в главе 11.
9.1. Банки ввода-вывода
Ресурсы системы ввода-вывода SelectIO представлены в виде банков. В архитек-
туре FPGA 7-й серии банки организуются в виде столбцов, которые могут распола-
гаться как по краям кристалла, так и внутри него, что обеспечивает кратчайшие пути
трассировки сигналов из внутренней логики FPGA к внешним выводам.
FPGA 7-й серии предлагают банки ввода-вывода двух типов: высокопроизводи-
тельные (high-performance — HP) и широкого диапазона (high-range — HR). Банки HP
разработаны с целью удовлетворения требований производительности быстродейст-
вующей памяти и других интерфейсов между микросхемами с напряжением до 1,8 В.
Банки HR разработаны для поддержки широкого диапазона стандартов ввода-вывода
с напряжением до 3,3 В. Свойства банков типа HP и HR приведены в табл. 9.1.
Каждый банк ввода-вы вода содержит 50 выводов. Число банков зависит от раз-
мера устройства и корпуса устройства. На рис. 9.1 показан пример расположения
банков ввода-вывода для микросхемы ХС7К325Т.
(Информацию о банках ввода-вывода каждого устройства можно найти в до-
кументе UG475 7 Series FPGAs Packaging and Pinout Product Specifications. User
Guide.)
Система ввода-вывода SelectIO
135
—
Bank 18 HR 50 I/O
Bank 17 HR 50 I/O
Bank 16 HR 50 I/O
Bank 15 HR 50 I/O
Bank 14 HR 50 I/O Bank 34 HP 501/0
Bank 13 HR 501/0 Bank 33 HP 50 I/O
Bank 12 1 ю Г1Г1 501/0 Bank 32 HP 501/0
Рис. 9.1. Банки микросхемы
ХС7К325Т
Таблица 9 1
Поддержка свойств ввода-вывода банками HP и HR
Свойство HP HR
Стандарты ввода-вывода 3,3 В1 — 4-
Стандарты ввода-вывода 2,5 В1 — 4-
Стандарты ввода-вывода 1,8 В1 + 4-
Стандарты ввода-вывода 1,5 В1 4- 4-
Стандарты ввода-вы вода 1.35V1 4- 4-
Стандарты ввода-вывода 12 В1 4- 4-
Стандарты LVDS2 + 4-
Выходной ток 24 мА для LVCMOS18 и LVTTL — 4-
Цепь питания Vccauxjo 4- —
Цифровое управление импедансом (DCI) и каска- дирование DCI (Digitally-controlled impedance) 4- —
Внутреннее напряжение VREF 4- 4-
Внутренняя дифференциальная нагрузка (DIFF.TERM) 4- 4-
IDELAY 4- 4-
ODELAY 4- —
IDELAYCTRL 4- 4-
ISERDES 4- 4-
OSERDES 4- 4-
ZHOLD-DELAY — 4-
1 He все стандарты ввода-вывода поддерживаются в обоих банках (см. документ UG471).
2. Хотя LVDS рассматривается как 2.5-вольтный стандарт, он под- держивается в обоих банках.
9.2. Ресурсы системы ввода-вывода в семействах FPGA 7-й серии
Ресурсы ввода-вывода в семействах FPGA 7-й серии распределены достаточно
неравномерно. Так, устройства семейства Artix-7 имеют только банки ввода-вывода
широкого диапазона типа HR (табл. 9.2).
В семействе Kintex-7 большинство устройств включают как банки широкого диа-
пазона типа HR, так и высокопроизводительные банки типа HP (табл. 9.3).
Большинство устройств семейства Virtex-7 имеют только высокопроизводитель-
ные банки типа HP, за исключением двух устройств XC7V585T и XC7VX330T в кор-
пусе FFG1761 (табл. 9.4 и табл. 9.5).
Таблица 9.2
Максимальное число двунаправленных выводов для устройств Artix-7
Тип корпуса Тип банка XC7A 35T XC7A 50T XC7A 75T XC7A 100T XC7A 200T
CPG236 HR 106 106
CSG324 HR 210 210 210 210
CSG325 HR 150 150
FTG256 HR 170 170 170 170
SBG484 HR 285
FGG484 HR 250 250 285 285
FBG484 HR 285
FGG676 HR 300 300
FBG676 HR 400
FFG1156 HR 500
136
Раздел 9
Таблица 9.3
Максимальное число двунаправленных выводов для устройств Kintex-7
Тип Тип XC7K XC7K XC7K XC7K XC7K XC7K XC7K
корпуса банка 70T 160T 325T 355T 410T 420T 480T
FBG484 HR 185 185
HP 100 100
FBG676 HR 200 250 250 250
HP 100 150 150 150
FFG676 HR 250 250 250
HP 150 150 150
FBG900 HR 350 350
HP 150 150
FFG900 HR 350 350
HP 150 150
FFG901 HR 300 380 380
HP 0 0 0
FFG1156 HR 400 400
HP 0 0
Таблица 9.4
Максимальное число двунаправленных выводов для устройств Virtex-7
Тип Тип XC7V XC7V XC7V XC7V XC7V XC7V XC7V XC7V XC7V
корпуса банка 585T 200T X330T X415T X485T X550T X690T X980T X1140T
FFG1157 HP 600 600 600 600 600
FFG1761 HR 100 50 0 0
HP 750 650 700 850
FHG1761 HP 850
FLG1925 HP 1200
FFG1158 HP 350 350 350 350
FFG1926 HP 720 720
FLG1926 HP 720
FFG1927 HP 600 600 600 600
FFG1928 HP 480
FLG1028 HP 480
FFG1930 HP 700 1000 900
FLG1930 HP 1100
Таблица 9.5
Максимальное число двунаправленных выводов семейства Virtex-7 для подсемейства НТ
Тип корпуса Тип банка XC7VH580T XC7VH870T
FLG1155 HP 400
HCG1155 HP 400
FLG1931 HP 600
HCL1931 HP 600
FLG1932 HP 300
HCL1932 HP 300
На основании наличия ресурсов ввода-вывода, которое выражается в типах име-
ющихся банков ввода-вывода, можно сделать следующие выводы: семейство Artix-7
предназначено для использования в приложениях общего назначения; Kintex-7 — как в
приложениях общего назначения, так и в системах высокопроизводительной передачи
данных; Virtex-7 — в системах высокопроизводительной передачи данных.
9.3. Основные свойства ресурсов ввода-вывода общего назначения
Все FPGA 7-й серии имеют конфигурируемые драйверы SelectIO и приемники
(ресиверы), поддерживающие широкое разнообразие стандартных интерфейсов. Ро-
бастный (устойчивый к грубым внешним воздействиям) набор свойств включает:
Система ввода-вывода SelectIO
137
• программируемое управление выходной мощностью;
• управление скоростью возрастания сигнала на выходах микросхемы;
• цифровое управление импедансом DCI;
• возможность генерирования внутреннего опорного напряжения (INTERNAL.
VREF).
Замечание. Банки HR не поддерживают свойство DCL
За некоторыми исключениями, каждый банк ввода-вывода содержит 50 выводов
SelectIO. Только два вывода с каждого конца каждого банка могут использоваться с
ассиметричными (single-ended) стандартами ввода-вывода. Оставшиеся 48 выводов
могут использоваться либо с ассиметричными, либо с дифференциальными стандар-
тами, используя два вывода, сгруппированные вместе как пара P/N (positive/negati-
ve — положительный/отрицательный).
Ресурс каждого вывода SelectIO содержит вход, выход и драйверы (буферы) с
тремя состояниями.
Выводы SelectIO могут конфигурироваться для:
• ассиметричных стандартов (LVCMOS, LVTTL, HSTL, PCI и SSTL);
• дифференциальных стандартов (LVDS, Mini.LVDS, RSDS, PPDS, BLVDS, диф-
ференциальные HSTL и SSTL).
Отметим некоторые новые свойства системы ввода-вывода, которые отсутство-
вали в предыдущих семействах FPGA фирмы Xilinx:
• два типа банков ввода-вывода HR и HP, причем каждый тип поддерживает неко-
торые уникальные свойства и стандарты ввода-вывода;
• новый интерфейс памяти связал стандарты ввода-вывода SSTL и HSTL, которые
теперь поддерживают атрибут SLEW и можно выбирать между граничными ско-
ростями FAST и SLOW (по умолчанию значение атрибута SLEW равно SLOW);
чтобы сохранить скорости возрастания, как в предыдущих семействах, новые про-
екты требуют установку атрибута SLEW в значении FAST (в табл. 1-56 документа
UG471 указано какие стандарты поддерживают атрибут SLEW);
• схема калибровки DCI в FPGA 7-й серии улучшает точность внутреннего сопро-
тивления нагрузки, однако значения резисторов внешней точности отличаются
для стандартов DCI, сейчас внешние резисторы выбираются для удвоенного со-
противления Thevenin, тогда как в Virtex-б и предыдущих семействах они равня-
лись сопротивлению Thevenin;
• предлагаются дополнительные проектные примитивы логики ввода-вывода с но-
выми свойствами и функциями.
9.4. Напряжения питания элементов ввода-вывода
Различные элементы системы SelectIO могут требовать четыре типа напряжений:
Vcco. Vref. Vccaux и Vccaux_io-
Напряжение Vcco- Напряжение Vcco является первичным напряжением пита-
ния схемы ввода-вывода. В табл. 1-55 документа UG471 представлены требования
к Vcco для каждого поддерживаемого стандарта ввода-вывода: входных, выходных,
а также дополнительных внутренних схем дифференциальной нагрузки. Все выводы
Vcco Для данного банка ввода-вывода должны подсоединяться к одному и тому же
внешнему напряжению питания на плате и все выводы данного банка должны исполь-
зовать один и тот же уровень Vcco- Напряжение Vcco. которое должно назначаться
данному банку ввода-вывода, должно быть согласовано с требованиями стандартов
ввода-вывода. Неправильно выбранное напряжение Vcco может привести к потере
функциональности или повреждению устройства.
138
Раздел 9
Напряжение Vref Ассиметричные (single-ended) стандарты ввода-вывода с диф-
ференциальным входным буфером требуют входное опорное напряжение Vref- Ког-
да банку ввода-вывода требуется опорное напряжение Vref. должны использоваться
два многофункциональных вывода банка как входы напряжения Vref- Отметим, что
FPGA 7-серии с помощью ограничения INTERNAL.VREF дополнительно могут ис-
пользовать внутренне опорное напряжение.
Напряжение Vccaux- Глобальная вспомогательная цепь питания Vccaux пре-
имущественно используется для обеспечения питанием свойств логики межсоедине-
ний различных блоков внутри FPGA 7-серии. В банках ввода-вывода напряжение
Vccaux используется для питания схем входных буферов для некоторых стандар-
тов ввода-вывода. Это включает все ассиметричные стандарты ввода-вывода ниже
1,8 В, а также некоторые стандарты 2,5 В (только для банков HR). Дополнительно
цепь Vccaux обеспечивает питание к схемам дифференциальных входных буферов.
Требования напряжений питания, включая последовательность включения и выклю-
чения, смотри в документе UG475 «7 Series FPGA Data Sheets».
Напряжение Vccaux_io- Вспомогательная цепь питания Vccaux_io представле-
на только в банках HP и обеспечивает питанием схемы ввода-вывода. Документация
FPGA семейств Kintex-7 и Virtex-7 содержит таблицу с заголовком «Maximum Physical
Interface (PHY) Rate for Memory Interfaces» (максимальная скорость физического ин-
терфейса для интерфейсов памяти), которая дает рекомендации для Vccaux_io- Эта
таблица указывает, какие выводы Vccaux_io могут питаться напряжением 1,8 В (по
умолчанию) или дополнительно 2,0 В для наивысшей производительности определен-
ных типов интерфейсов памяти (см. документ UG471). Имеется проектное ограниче-
ние для цепей ввода-вывода и примитивов, называемое VCCAUXJO, которое должно
определяться в проекте, если выводы Vccaux_io Для любых банков установлены в
2,0 В.
9.5. Стандарты ввода-вывода, поддерживаемые FPGA 7-серии
Стандарты ввода-вывода, поддерживаемые FPGA 7-й серии, приведены в
табл. 9.6.
Таблица 9.6
Стандарты ввода-вывода FPGA 7-й серии
Стандарт Тип банка Описание
LVTTL (Low Voltage TTL) HR Стандарт EIA/JESD общего назначения для 3,3-вольтных приложений, который использует ассиметричный входной буфер CMOS и двухтакт- ный (push-pull) выходной буфер; доступен в банках HR
LVCMOS (Low Voltage CMOS) HR. HP Широко используемый переключательный стандарт, реализованный в CMOS-транзисторах. В FPGA 7-й серии поддерживаются стандарты LVCMOS12, LVCMOS15, LVCMOS18, LVCMOS25 и LVCMOS33
LVDCI (Low Voltage Digi- tally Controlled Impedance) HP Низковольтный стандарт с цифровым управлением импедансом. Под- держиваются стандарты LVDCL15 и LVDCL18
LVDCLDV2 HP Низковольтный стандарт с цифровым управлением импедансом и с по- ловинным импедансом нагрузки источника. Поддерживаются стандар- ты LVDCLDV2JL5 и LVDCLDV2JL8
HSLVDCI (High- Speed LVDCI) HP Высокоскоростной стандарт LVDCI, предназначен для использования в двунаправленных каналах. Выходной драйвер идентичен LVDCI, в то время как вход идентичен HSTL и SSTL Используя вход с опорным напряжением Vref. этот стандарт позволяет увеличить чувствитель- ность входа приемника, который затем использует ассиметричный при- емник типа LVCMOS
Система ввода-вывода SelectIO
139
Окончание табл. 9.6
Стандарт Тип банка Описание
HSTL (High- Speed Transceiver Logic) SSTL (Stub- Series Terminated Logic) HSUL-12 (High- Speed Untermi- nated Logic) MOBILE-DDR (Low Power DDR) LVDS и LVDS.25 (Low Voltage Differential Sig- naling) RSDS (Reduced Swing Differential Signaling) Mini-LVDS PPDS (Point-to- Point Differential Signaling) TMDS (Transi- tion Minimized Differential Sig- naling) HR, HP HR, HP HR, HP HR HR, HP HR HR HR HR Стандарт высокоскоростной трансиверной логики. HSTL является об- щецелевым стандартом высокоскоростной шины; имеет 4 варианта (класса). Для поддержки синхронизации высокоскоростных интерфей- сов памяти также доступны дифференциальные версии. FPGA 7-й се- рии поддерживают class-1 для 1,2-вольтной версии HSTL в банках HP, class-1 и class-11 для 1,5- и 1,8-вольтных версий, включая дифференци- альные версии. Дифференциальные версии стандарта требуют входной буфер дифференциального усилителя и двухтактный выходной буфер. Банки HP также поддерживают версии DCI (детали смотри в докумен- те UG471) SSTL для 1,8, 1,5 и 1,35 В являются стандартом ввода-вывода для общецелевых шин памяти. FPGA 7-й серии поддерживают стандарты SSTL как для ассиметричных, так и для дифференциальных сигналов Дифференциальные версии используют истинно дифференциальный усилитель входного буфера и комплементарные двухтактные выход- ные буферы. T_DCI (DCI с 3-м состоянием) версии этого стандарта предпочтительны для реализации интерфейсов памяти в банках HP, а использование атрибута IN-TERM (некалибрируемая внутренняя на- грузка) рекомендуется для банков HR Стандарт HSUL-12 предназначен для шин памяти LPDDR2. FPGA 7-й серии поддерживают этот стандарт для ассиметричной и дифферен- циальной версий. Данный стандарт требует дифференциальный усили- тель во входном буфере и двухтактный выходной буфер Предназначен для шин памяти LPDDR и MOBILE-DDR. Стандарт MOBILE-DDR является 1,8-вольтным ассиметричным стандартом ввода-вывода, который исключает необходимость в напряжениях Vref и Vtt- FPGA 7-й серии поддерживает этот стандарт для ассиметрич- ных сигналов и дифференциальных выходов. Дифференциальные выхо- ды управляют выводами CK/CK# Низковольтная дифференциальная сигнализация (L.VDS) является важ- ным высокоскоростным интерфейсом во многих системных приложе- ниях. L.VDS доступен в банках HP, требует напряжения Vcco = 1,8 В. LVDS.25 доступен только в банках HR, требует напряжения Vcco = 2,5 В Этот стандарт подобен LVDS, который использует дифференциальные сигналы. Он имеет реализацию подобную LVDS-25 и предназначен для приложений «от точки к точке» (point-to-point) Mini-LVDS является дифференциальным стандартом ввода-вывода, ко- торый служит интерфейсом между функцией управления синхронизаци- ей и исходным драйвером LCD. Входы Mini-LVDS требуют параллель- ных нагрузочных резисторов либо используя резистор на печатной пла- те, либо используя атрибут DIFF.TERM FPGA 7-й серии. Требуется напряжение Vcco = 2,5 В PPDS является дифференциальным стандартом ввода-вывода для драйверов строк и столбцов интерфейса LCD следующего поколе- ния. Входы PPDS требуют параллельных нагрузочных резисторов либо используя резистор на печатной плате, либо используя атрибут DIFF.TERM FPGA 7-й серии. Требуется напряжение Vcco = 2,5 В TMDS является дифференциальным стандартом ввода-вывода для пе- редачи высокоскоростных последовательных данных, используя видео- интерфейсы DVI и HDML TMDS требует на выходах внешних подтяги- вающих резисторов на 50 Ом, Vcco - 8,3 В
9.6. Архитектура блоков ввода-вывода
9.6.1. Обобщенная структура ввода-вывода
Структура ввода-вывода для банка HP показана на рис. 9.2, а для банка HR —
на рис. 9.3.
140
Раздел 9
Рис. 9.2. Структура ввода-вы вода банка HP
Рис. 9.3. Структура ввода-вывода банка HR
Структура ввода-вывода банка HP на рис. 9.2 включает контактные площад-
ки выводов (PAD), буфер ввода-вывода (IOB — input-output buffer), блоки входной
(IDELAY) и выходной (ODELAY) задержки, а также входной (ILOGIC) и выходной
(OLOGIC) логические блоки. В структурах ввода-вывода банков HP используются
логические блоки ILOGICE2, а в банках HR — ILOGICE3 (отличие блоков ILOGICE2
и ILOGICE3 будет отмечено в разделе 9.2.3).
Отметим, что в структуре ввода-вывода банка HR (рис. 9.3) отсутствует блок вы-
ходной задержки. Схемы логических блоков ILOGIC и OLOGIC могут также конфигу-
рироваться как последовательно-параллельные преобразователи ISERDES и OSER-
DES соответственно.
9.6.2. Архитектура буферов ввода-вывода
На рис. 9.4 показана архитектура буфера ввода-вывода и его подсоединение к
контактной площадке для банка HP в случае ассиметричного вывода, а на рис. 9.5 —
в случае дифференциального (обычного) вывода.
В архитектуре ассиметричного буфера (рис. 9.4) отсутствуют соединения для
создания дифференциальных выходных сигналов DIFFO-OUT и CLOUT. Поэтому ас-
симетричные буферы не могут использоваться для реализации дифференциальных
стандартов. В то время как обычные (не ассиметричные или дифференциальные)
т
о
DCITERMDISABLE
DIFFIJN
IBUFDISABLE
Рис. 9.4. Структура ассиметричного буфера ввода-вывода банка HP
Система ввода-вывода SelectIO
141
DCITERMDISABLE
IBUFDISABLE
Рис. 9.5. Структура обычного (дифференциального) буфера ввода-вывода ЮВ банка HP
буферы ввода-вывода могут использоваться для реализации как ассиметричных, так
и дифференциальных стандартов.
Каждая архитектура буферов ввода-вывода (ассиметричных и обычных) вклю-
чает входной и выходной буферы, соединенные с контактной площадкой внешнего
вывода PAD, пути входных и выходных данных, а также сигналы управления буфе-
рами. Сигнал IBUFDISABLE позволяет запрещать входной буфер для уменьшения
потребляемой мощности в момент времени, когда буфер не используется. Сигнал
DCITERMDISABLE может использоваться для запрещения дополнительного свойст-
ва DCI расщепления нагрузки.
Архитектуры буферов ввода-вы вода для банков HR отличается только тем, что
в них отсутствует управляющий сигнал DCITERMDISABLE, поскольку банки HR не
обладают свойством цифрового управления импедансом DCL
При реализации примитивов для дифференциальных стандартов архитектуры бу-
феров ввода-вывода объединяются в пары.
9.6.3. Архитектура блока ILOGIC
Блок входной логики ILOGIC содержит синхронные элементы памяти для захва-
та данных, которые приходят в FPGA через буфер IOB. Блоки ILOGICE2 (рис. 9.6)
используются в банках HP, а блоки ILOGICE3 (рис. 9.7) — в банках HR. Эти бло-
ки функционируют идентично, за исключением следующего: блок ILOGICE3 имеет
элемент нулевой задержки удержания (zero hold delay — ZHOLD), а блок ILOGICE2
не имеет элемента ZHOLD.
Мультиплексоры блока ILOGIC позволяют:
• инвертировать сигналы: D, DDLY, CLK, CLKB;
• направлять каждый из сигналов D, DDLY и UFB либо на комбинационный выход
О, либо на вход триггера D.
Элемент задержки ZHOLD на D-входе запоминающего элемента устраняет любое
время удержания от контакта к контакту. Задержка ZHOLD автоматически согласует-
ся с внутренней задержкой распространения синхросигнала и гарантирует, что время
задержки от контакта к контакту равно нулю.
Элементы ILOGICE2 и ILOGICE3 не являются примитивами в том смысле, что
они не могут быть инстанцированы. Они содержат создаваемые пользователем эле-
142
Раздел 9
Рис. 9.6. Архитектура блока ILOGICE2
менты, такие как входной триггер (IFD) или входной элемент DDR (IDDR) после
размещения и трассировки.
Элемент ILOGIC может конфигурироваться для реализации:
• переключающегося по фронту D-триггера;
• входного элемента IDDR (в режимах OPPOSITE-EDGE, SAME-EDGE или SAME-
EDGE-PIPELINED);
• чувствительной к уровню сигнала защелки;
• асинхронного (комбинационного) входа.
Регистры блоков ILOGIC имеют общий сигнал разрешения синхронизации СЕ1 с
активным высоким уровнем. Если сигнал СЕ1 не используется, то считается, что син-
хронизация разрешена. Регистры блоков ILOGIC также имеют сигнал SR синхронной
или асинхронной установки или сброса. Вход установки/сброса SR заставляет запо-
минающий элемент перейти в определенное состояние, которое указывается атрибу-
том SRVAL. Условие сброса имеет преимущество над условием установки. Значение
атрибута SRVAL может индивидуально задаваться для каждого запоминающего эле-
мента в блоке ILOGIC, но выбор типа установки (синхронная или асинхронная) не
может выполняться индивидуально.
Комбинационный вход используется для создания прямого соединения от входно-
Система ввода-вывода SelectIO
143
Рис. 9.7. Архитектура блока ILOGICE3
го драйвера к внутренней логике FPGA. Этот путь используется программным обес-
печением автоматически, когда:
• имеется прямое (не регистровое) соединение от входных данных к логическим
ресурсам FPGA;
• директива программного обеспечения «pack I/O register/latches into lOBs» уста-
новлена в OFF.
9.6.4. Архитектура блока О LOGIC
Блок выходной логики ввода-вывода OLOGIC является специализированным бло-
ком синхронизации, посылающим данные на выход FPGA через блок ЮВ. Ресурсы
OLOGIC могут быть двух типов: OLOGICE2 (для банков HP) и OLOGICE3 (для бан-
ков HR). Оба этих типа функционируют одинаково. Блоки OLOGICE2 и OLOGICE3 не
144
Раздел 9
являются примитивами, т. е. они не могут быть инстанцированы (созданы их экзем-
пляры). Однако после размещения и трассировки они содержат инстанцированные
пользователем выходной триггер (OFD) или выходной элемент DDR (ODDR).
Блок OLOGIC (рис. 9.8) содержит два главных блока: один для конфигурации
пути выходных данных, а другой для конфигурации пути сигнала управления 3-м со-
стоянием. Эти два блока имеют общий синхросигнал CLK, но разные сигналы разре-
шения синхронизации: ОСЕ и ТСЕ. Оба блока имеют асинхронную или синхронную
установку или сброс (сигнал SR) управляемую атрибутом SRVAL.
Путь выходных данных и путь сигнала управления 3-м состоянием могут незави-
симо конфигурироваться для реализации:
• переключающегося по фронту D-триггера;
• выходного элемента ODDR (в режимах OPPOSITE-EDGE или SAME-EDGE);
• чувствительной к уровню сигнала защелки;
• асинхронного (комбинационного) выхода.
Комбинационные выходные пути создают прямое соединение от логики FPGA к
выходному драйверу или управлению выходным драйвером. Эти пути программным
обеспечением используются автоматически, когда:
• имеется прямое (не регистровое) соединение от логических ресурсов к выходным
данным или управлению 3-м состоянием;
• директива программного обеспечения «pack I/O register/latches into lOBs» уста-
новлена в OFF.
9.7. Цифровое управление импедансом (DCI)
С увеличением размеров и быстродействия FPGA разработка и изготовление пе-
чатных плат становится все более трудным процессом. С приближением к граничным
условиям быстродействия проблемой становится поддержка целостности сигналов
(signal integrity). Во избежание отражений (reflections) или звона (ringing) сигналов
печатная плата должна иметь согласованные значения сопротивления нагрузки.
Для согласования импедансов приемников и передатчиков (драйверов) сигналов
с импедансом трассировки традиционно в линии трасс добавляются резисторы. Од-
Система ввода-вывода SelectIO
145
нако, с увеличением количества выводов устройства, добавление резисторов близко
к выводам устройства увеличивает площадь платы и количество компонентов, а в
некоторых случаях может быть физически невозможно. Для решения этих проблем и
достижения лучшей целостности сигналов фирма Xilinx разработала технологию циф-
рового управления импедансом (digitally controlled impedance — DCI). Отметим, что
цифровое управление импедансом возможно только в банках ввода-вывода типа HP.
В зависимости от стандартов ввода-вы вода DCI может управлять либо выход-
ным импедансом драйвера, либо добавлять параллельное оконечное сопротивление
(концевик) в драйвер и/или приемник с целью точного соответствия характеристик
импеданса линии передачи. DCI активно корректирует эти импедансы внутри блока
ввода-вывода для калибровки к значению внешних резисторов, размещенных на вы-
водах VRN и VRP. Это компенсирует изменения в импедансе ввода-вывода, а также
позволяет постоянно корректировать импедансы для компенсации изменений колеба-
ний температуры и напряжения питания.
В стандартах ввода-вывода с управляющими импедансом драйверами DCI управ-
ляет импедансом драйвера либо для согласования двух опорных резисторов, либо (в
некоторых стандартах) для согласования половины значения опорных резисторов.
В стандартах ввода-вы вода с управляемой параллельной оконечной нагрузкой
DCI обеспечивает параллельную оконечную нагрузку как для передатчиков, так и для
приемников. Это избавляет от необходимости установки нагрузочных резисторов на
плате, кроме того, упрощается трассировка платы, уменьшается количество компо-
нент и улучшается целостность сигнала благодаря устранению тупикового отражения.
Тупиковое отражение (stub reflection) происходит тогда, когда нагрузочные резисторы
расположены слишком далеко от конца линии передачи. С использованием DCI на-
грузочные резисторы максимально приближены к выходному драйверу или входному
буферу, устраняя таким образом тупиковые отражения.
9.7.1. Реализация DCI в FPGA 7-й серии
DCI в каждом банке ввода-вывода использует два многоцелевых опорных (эта-
лонных) вывода для управления импедансом драйверов или значением параллельной
нагрузки для всех двунаправленных выводов этого банка. Опорный вывод N (VRN)
должен подтягиваться к напряжению Vcco с помощью опорного резистора, а опор-
ный вывод Р (VRP) должен подтягиваться к земле с помощью другого опорного ре-
зистора. Значение каждого опорного резистора должно быть равно либо волновому
импедансу трасс печатной платы, либо удвоенному этому значению.
Для того чтобы реализовать DCI в проекте, необходимо:
• назначить один из DCI-стандартов ввода-вывода банку ввода-вывода типа HP
(см. табл. 9.7 и 9.8);
• соединить многофункциональный вывод VRN с уточняющим резистором, подсо-
единенным к цепи питания Vcco данного банка;
• соединить многофункциональный вывод VRP с уточняющим резистором, подсо-
единенным к земле.
В каждом банке используется только одно множество резисторов VRN и VRP,
поэтому все DCI-стандарты в пределах каждого банка имеют возможность совмест-
но использовать одинаковые внешние эталонные значения. Если несколько банков
ввода-вывода в данном столбце банков ввода-вывода используют DCI и эти банки ис-
пользуют одинаковые значения резисторов VRN/VRP, то внутренние узлы VRN и VRP
могут каскадироваться. Эта опция называется каскадированием DCI. Если стандарты
ввода-вывода DCI не используются в банке, выводы VRN и VRP доступны как обычные
146
Раздел 9
выводы. Детальное описание выводов VRN и VRP для устройств FPGA 7-й серии при-
ведено в документе UG475 7 Series FPGAs Packaging and Pinout. Product Specification.
DCI корректирует импеданс ввода-вывода путем выборочного переключения тран-
зисторов в схеме ввода-вывода. Импеданс корректируется для соответствия внешним
опорным резисторам. Корректировка (калибровка) запускается во время включения
устройства. По умолчанию вывод DONE не переходит в высокое состояние до тех
пор, пока не завершится первая часть процесса корректировки импеданса.
Калибровка DCI может сбрасываться путем инстанцирования (создания экзем-
пляра) примитива DCIRESET. Переключение входа RST в примитиве DCIRESET во
время функционирования устройства сбрасывает состояние конечного автомата DCI
и перезапускает калибровочный процесс. Все выводы, использующие DCI, будут недо-
ступны до тех пор, пока установлен выход LOCKED примитива DCIRESET. Эта функ-
ция является полезной в приложениях, где значительны изменения температуры или
напряжения питания при включении питания устройства и при нормальном функци-
онировании устройства.
В управляемых импедансом выходных драйверах импеданс может корректиро-
ваться либо для соответствия опорным резисторам, либо половине значения опор-
ных резисторов. Для нагрузки на микросхеме нагрузка всегда корректируется для
соответствия опорным резисторам.
В стандартах ввода-вывода, которые поддерживают DCI-управляемый импедан-
сом драйвер, DCI может конфигурировать выходы драйверов следующих типов:
• управляемый драйвер импеданса;
• управляемый драйвер импеданса с половиной импеданса.
Для стандартов ввода-вывода, которые поддерживают параллельную нагрузку,
DCI создает эквивалент Thevenin или сопротивление расщепленной нагрузки для по-
ловины уровня напряжения Vcco/2.
Соглашение о наименовании стандартов ввода-вывода добавляет:
• DCI в название стандарта ввода-вывода, если резисторы расщепления нагрузки
могут быть представлены в схеме ввода-вывода;
• T.DCI в название стандарта ввода-вывода, если резисторы расщепления нагрузки
присутствуют только тогда, когда выходной буфер находится в 3-м состоянии.
Для управления функционированием DCI служат опции Match-cycle и DCIUpdate-
Mode, а также примитив DCIRESET (детали см. в документах UG470 7 Series FPGAs
Configuration. User Guide, UG628 Command Line Tools. User Guide, UG768 Xilinx 7
Series FPGA and Zynq-7000 All Programmable SoC Libraries Guide for HDL Designs и
UG471 7 Series FPGAs SelectIO Resources. User Guide).
9.7.2. Каскадирование DCI
FPGA 7-й серии имеют опцию, которая позволяет банкам ввода-вывода HP, ис-
пользующих стандарты ввода-вывода DCI, получать значение импеданса DCI от дру-
гих банков HP. Управление импедансом DCI в каскадируемых банках приходит от
главного банка ввода-вывода.
Для каскадирования DCI один (главный) банк ввода-вывода должен иметь свои
выводы VRN/VRP подсоединенными к внешним опорным резисторам. Другие банки
ввода-вывода в том же самом столбце банков ввода-вывода (подчиненные банки)
могут использовать стандарты DCI с тем же самым импедансом как главной банк, не
подсоединяя выводы VRN/VRP подчиненных банков к внешним резисторам (рис. 9.9)
(детали см. в документе UG471 7 Series FPGAs SelectIO Resources. User Guide).
На рис. 9.9 показана каскадная поддержка нескольких банков. Здесь банк В яв-
ляется главным банком, а банки А и С рассматриваются как подчиненные банки.
Система ввода-вывода SelectIO
147
То Banks Above
(When Cascaded)
(When Cascaded)
Рис. 9.9. Каскадная поддержка DCI нескольких банков ввода-вывода
9.7.3. Драйвер управляемого импеданса
Драйвер управляемого импеданса показан на рис.
Чтобы оптимизировать целостность сигнала в вы-
сокоскоростных или высокопроизводительных прило-
жениях, требуются дополнительные меры для согла-
сования выходных импедансов драйверов и импедансов
линий передачи и приемников. Оптимально драйверы
должны иметь выходной импеданс, согласующийся с
волновым импедансом управляемой линии, в против-
ном случае могут случиться отражения из-за разры-
вов сигнала.
Чтобы решить эту проблему, разработчики иногда
него источника последовательные нагрузочные резисторы, расположенные близко к
выводам драйверов высокой мощности и низкого импеданса. Значения сопротивле-
ний выбираются так, чтобы сумма импеданса выхода драйвера плюс сопротивление
источника R приблизительно равнялась импедансу линии передачи Zq.
DCI может обеспечить выходы драйверов управляемым импедансом для уменьше-
ния отражений без использования внешних резисторов. Импеданс устанавливается с
помощью внешних опорных резисторов с сопротивлением, равным импедансу трассы.
9.10.
Рис. 9.10. Драйвер управляемого
импеданса
используют в качестве внеш-
148
Раздел 9
Драйвером управляемого импеданса поддерживаются следующие стандарты:
LVDCL15, LVDCL18, HSLVDCL15, HSLVDCL18, HSUL_12_DCI и DIFF_HSUL_12_DCL
9.7.4. Драйвер управляемого импеданса с половинным импедансом
Рис. 9.11. Драйвер управляемого
импеданса с половинным импедансом
Драйвер управляемого импеданса с половинным
импедансом (рис. 9.11) поддерживается стандарта-
ми LVDCLDV2-15 и LVDCLDV2.18. Это свойство
позволяет уменьшить энергопотребление.
Для того чтобы соответствовать импедансу Zo,
сопротивление резистора R должно быть равным
2Z0.
9.7.5. Расщепление нагрузки DCI
Некоторые стандарты ввода-вывода (HSTL и
SSTL) требуют входной нагрузочный регистр, подсоединенный к напряжению Vtt.
равному Vcco/2 (рис. 9.12).
Схемы разделяемой нагрузки DCI создают эквивалентную схему Thevenin, ис-
пользуя два резистора с двойной величиной сопротивления (2R): один подсоединяет-
ся к Vcco. з другой — к земле (рис. 9.13).
Стандарты ввода-вывода, поддерживающие разделяемую нагрузку DCI, приве-
дены в табл. 9.7.
Рис. 9.12. Входная нагрузка к Vcco/2 без DCI
Рис. 9.13. Входная нагрузка к Vcco/2. использу-
ющая расщепление нагрузки DCI
Таблица 9.7
Стандарты ввода-вывода, поддерживающие разделяемую нагрузку DCI
HSTL DIFF.HSTL SSTL DIFFJSSTL
HSTL-LDCI HSTLJ-DCL18 HSTLJLDCI HSTLJLDCL18 HSTLJLT.DCI HSTLJLT.DCL18 DIFF_HSTLJ_DCI DIFF_HSTLJ_DCL18 DIFF_HSTL_ILDCI DIFF-HSTLJLDCL18 DIFF_HSTLJI_T_DCI DIFF_HSTLJI_T_DCL18 SSTL18J-DCI SSTL18JLDCI SSTL18_ILT_DCI SSTL15-DCI SSTL15_T_DCI SSTL135-DCI SSTL135_T_DCI SSTL12-DCI SSTL12_T_DCI DIFRSSTL18J-DCI DIFF_SSTL18_II_DCI DIFF_SSTL18JLT_DCI DIFF_SSTL15_DCI DIFF_SSTL15_T_DCI DIFF_SSTL135_DCI DIFF_SSTL135_T_DCI DIFF_SSTL12_DCI DIFRSSTL12_T_DCI
Система ввода-вывода SelectIO
149
7 Serie5FPCiAHP Bank pci i
Рис. 9.14. Драйвер с нагруз-
9.7.6. DCI и третье состояние (T.DCI)
Версии драйверов класса I (class-1) стандартов SSTL и HSTL поддерживаются
только для однонаправленной сигнализации. Они могут назначаться либо к входам,
либо к выходам (но не к двунаправленным выводам). Версии DCI стандартов SSTL и
HSTL класса I имеют внутренние расщепляющие нагрузочные регистры, представ-
ленные на входах.
Версии драйверов класса II (class-ll) стандартов
SSTL и HSTL поддерживаются для двунаправленной
и однонаправленной сигнализации. В проекте они
могут назначаться входам, выходам или двунаправ-
ленным выводам. Версии DCI стандартов SSTL и
HSTL класса II позволяют иметь внутренние расщеп-
ляющие нагрузочные резисторы (рис. 9.14).
Когда расщепляющая нагрузка присутствует при
управлении, DCI управляет только импедансом на-
грузки, но не драйвером. Однако многие приложения
могут извлечь выгоду от отключения расщепляющих
нагрузочных резисторов.
Стандарты T.DCI могут назначаться только дву-
направленным выводам. Для однонаправленных
входных выводов может назначаться версия DCI стандарта. Для однонаправленных
выходных выводов может назначаться либо версия с DCI, либо версия без DCI.
В табл. 9.8 представлены стандарты, в которых всегда присутствуют резисторы
DCI расщепления нагрузки.
Стандарты DCI с третьим состоянием (TJDCI) были разработаны, чтобы удов-
летворить следующим требованиям: выходные нагрузочные резисторы расщепления
выключаются, когда вывод функционирует в качестве выхода, и включаются, когда
вывод функционирует в качестве входа, находится в 3-м состоянии или в состоя-
нии ожидания.
кой к Vcco/2, использую-
щий расщепляющую нагрузку
Таблица 9.8
Стандарты ввода-вывода с всегда присутствующим расщеплением нагрузки DCI
HSTL DIFF.HSTL SSTL DIFF_SSTL
HSTL.I.DCI1 HSTL.LDCI.181 HSTL.ILDCI HSTLJLDCI.18 DIFF.HSTLJ.DCI1 DIFF_HSTLJ.DCI.181 DIFF_HSTL.II.DCI DIFF_HSTL.II_DCI.18 SSTL18.I.DCI1 SSTL18JI.DCI SSTL15.DCI1 SSTL135.DCI1 SSTL12.DCI1 DIFF.SSTL18J-DCI1 DIFF.SSTL18JLDCI DIFF.SSTL15.DCI1 DIFF.SSTL135.DCI1 DIFF_SSTL12.DC!1
1. Версии стандартов HSTL и SSTL не класса II имеют только резисторы DCI расщепления нагрузки,
представленные на входах, но не на выходах. Для этих стандартов запрещены назначения двунаправ-
ленных выводов.
Таблица 9.9
Стандарты ввода-вывода с расщепляемой нагрузкой DCI только для 3-го состояния
HSTL & DIFF.HSTL SSTL DIFF.SSTL
HSTLJLT-DCI SSTL18JLT-DCI DIFF_SSTL18JLT_DCI
HSTLJLT-DCL18 SSTL15_T_DCI DIFF_SSTL15_T_DCI
DIFF.HSTL_ILT_DCI SSTL135_T_DCI DIFF_SSTL135_T_DCI
DIFF_HSTLJLT_DCL18 SSTL12_T_DCI DIFF_SSTL12_T_DCI
Стандарты T_DCI могут назначаться только двунаправленным выводам.
150
Раздел 9
Стандарты ввода-вывода с расщепляющей нагрузкой T.DCI, которая расщеплена
только в 3-м состоянии, приведены в табл. 9.9.
9.7.7. DCI в стандартах ввода-вывода, поддерживаемых FPGA 7-й серии
В табл. 9.10 приведены стандарты, в которых FPGA 7-й серии поддерживают
цифровое управление импедансом.
Таблица 9.10
Стандарты DCI, поддерживаемые FPGA 7-й серии
LVDCI HSTL DIFF.HSTL SSTL DIFF-SSTL
LVDCL18 LVDCL15 LVDCLDV2-18 LVDCLDV2JL5 HSLVDCL18 HSLVDCL15 HSTLJ.DCI HSTLJ-DCL18 HSTLJLDCI HSTLJLDCL18 HSTLJLT-DCI HSTLJLTJDCL18 DIFF_HSTL_LDCI DIFF_HSTLJ_DCL18 DIFF_HSTL_ILDCI DIFF_HSTL_ILDCL18 DIFF_HSTL_ILT_DCI DIFF_HSTL_ILT_DCL18 SSTL18J-DCI SSTL18JLDCI SSTL18JLT-DCI SSTL15.DCI SSTL15_T_DCI SSTL135JDCI SSTL135_T_DCI SSTL12JDCI SSTL12_T_DCI HSUL12JDCI DIFF_SSTL18J_DCI DIFF_SSTL18JI_DCI DIFF_SSTL18_ILT_DCI DIFF_SSTL15_DCI DIFF_SSTL15_T_DCI DIFF_SSTL135_DCI DIFF_SSTL135_T_DCI DIFF_SSTL12_DCI DIFF_SSTL12_T_DCI DIFF_HSUL12_DCI
9.7.8. Некалибрируемая расщепляющая нагрузка в банках ввода-вывода
HR (ограничение IN.TERM)
В банках ввода-вывода типа HR имеется опция расщепляющая нагрузка на мик-
росхеме (on-chip split-termination), очень похожая на расщепляющую нагрузку 3-го со-
стояния для банков HP. Эта опция банков HR создает эквивалентную схему Thevenin,
используя два внутренних резистора с удвоенным сопротивлением 2R. Одна резис-
торная нагрузка подсоединяется к Vcco. а другая — к земле. Нагрузка подключается
постоянно на входах и двунаправленных выводах, когда выходной буфер находится
в 3-м состоянии.
Однако важным отличием между этой опцией некалибрируемой расщепляющей
нагрузкой и расщепляющей нагрузкой 3-го состояния DCI является то, что вместо
калибровки внешних опорных резисторов на выходах VRN и VRP, когда используется
DCI, это свойство устанавливает внутренние резисторы, которые не имеют калиб-
ровочного режима для компенсации колебаний температуры, напряжения или про-
изводительности. Эта опция имеет целевое эквивалентное сопротивление Thevenin,
равное 40, 50 и 60 Ом.
Другое отличие этой опции от DCI: каким образом некалибрируемая нагрузка
вызывается в проекте. В то время как опция DCI вызывается назначением опции
Т-DCI стандартам ввода-вывода в банках HP, опция некалибрируемой расщепляющей
нагрузки вызывается назначением ограничения IN.TERM сети выводов в банках HR.
Это может быть сделано несколькими способами: включая опцию в код проекта на
языке HDL, включая опцию в файлы UCF, NCF или XCF, а также с помощью про-
граммы Plan Ahead (детали см. в документе UG625 Constraints Guide).
В банках HR ограничение IN.TERM может быть установлено в значение NONE
(по умолчанию), UNTUNED.SPLIT.40, UNTUNED.SPLIT.50 или UNTUNED.SPLIT.
60. Пример синтаксиса для файла UCF:
NET «pad.net.name» IN.TERM = «UNTUNED.SPLIT.50»;
В табл. 9.11 приведены стандарты ввода-вывода, которые поддерживают ограни-
чение IN.TERM в банках HR (в банках HP ограничение IN.TERM не поддерживается).
Система ввода-вывода SelectIO
151
Таблица 9.11
Стандарты, поддерживающие ограничение IN.TERM
HSTL & SSTL DIFF-HSTL SSTL SSTL DIFF_SSTL
HSTLJ HSTLJI HSTLJ-18 HSTLJL18 SSTL18J SSTL18JI DIFF-HSTLJ DIFF-HSTLJI DIFF_HSTLJ_18 DIFF-HSTLJL18 DIFF_SSTL18J DIFF-SSTL18JI SSTL15.R SSTL15 SSTL135.R SSTL135 DIFF_SSTL15_R DIFF.SSTL15 DIFF_SSTL135_R DIFF.SSTL135
Библиотека фирмы Xilinx включает широкий набор примитивов ввода-вывода,
поддерживающих различные стандарты ввода-вывода. Описание примитивов ввода-
вывода приведено в приложении А.
Доступ к свойствам ресурсов ввода-вывода в FPGA 7-й серии осуществляется с
помощью механизма атрибутов. Атрибуты могут определяться в языках HDL (Verilog
или VHDL) при создании экземпляра примитива ввода-вывода. Кроме атрибутов,
блоки ввода-вывода могут также управляться с помощью ограничений, которые опре-
деляются в файле ограничений UCF. Описание атрибутов и ограничений примитивов
ввода-вывода также приведено в приложении А.
9.8. Применение ресурсов системы ввода-вывода
9.8.1. Правила совмещения стандартов в одном банке ввода-вывода
Необходимо придерживаться следующих правил при объединении (совмещении)
различных входных, выходных и двунаправленных стандартов в одном и том же банке:
• в одном банке ввода-вывода можно совмещать выходные стандарты только с
одним и тем же выходным напряжением выходов Vcco;
• в одном банке ввода-вывода можно совмещать входные стандарты только с оди-
наковыми напряжениями Vcco и Vref;
• в одном банке ввода-вывода можно совмещать входные и выходные стандарты
с одинаковым напряжением Vcco;
• двунаправленные стандарты можно совмещать с входными и выходными стан-
дартами, если они удовлетворяют первым трем правилам;
• в стандартах с DCI только одно значение сопротивления нагрузки (управляемое
импедансом выходного драйвера или расщепляемой нагрузкой) может использо-
ваться в одном НР-банке.
Значения напряжений Vcco и Vref для каждого из поддерживаемых стандартов
ввода-вывода приведены в табл. 1-55 документа UG471.
Значения атрибутов DRIVE, SLEW, доступности двунаправленных буферов, ти-
пов нагрузки DCI для всех поддерживаемых стандартов ввода-вывода приведены в
табл. 1-56 документа UG471.
9.8.2. Одновременно переключающиеся выходы (SSO)
Из-за явления индуктивности каждый корпус (часть корпуса) поддерживает толь-
ко ограниченное количество одновременно переключающихся выходов (simultaneous
switching outputs — SSOs). Программа прогнозирования SSN в пакете Plan Ahead
обеспечивает анализ уровня шума на каждом выходе проекта на основе информации
о контакте (жертве), а также информации о других контактах (агрессорах). Програм-
ма SSN принимает во внимание расположение контактов, стандарты ввода-вывода,
скорости нарастания сигналов, используемые нагрузки и предоставляет значение за-
паса помехоустойчивости (noise margin) для каждого вывода на основе его характе-
ристик. Запас помехоустойчивости не включает характеристики системного уровня,
152
Раздел 9
такие как перекрестные помехи трассировки платы или отражение из-за разрыва им-
педанса платы.
Дребезг (bounce) земли или питания происходит тогда, когда большое количест-
во вводов одновременно переключаются в том же направлении. Все транзисторы вы-
ходных драйверов проводят ток к общей цепи питания. В результате кумулятивный
ток переходного процесса вызывает разность потенциалов по индуктивности, кото-
рая существует между внутренними и внешними уровнями земли или внутренними
и внешними уровнями Vcco- Индуктивность связывается с соединительными про-
водами, выводной рамкой корпуса, трассировкой кристалла, трассировкой корпуса и
индуктивностью шаровых контактов. Любое вызванное SSO напряжение воздейст-
вует на допустимые пределы внутреннего шума переключения и, в конечном счете,
на качество сигнала.
Результаты работы программы SSN предполагают, что FPGA распаивается на пе-
чатной плате и плата использует методы надежного проектирования (sound design).
Значение допустимых пределов шума не применяется к FPGA, смонтированных в гнез-
дах (сонетах — socket) из-за дополнительной индуктивности шаров BGA, вводимой
сонетом.
9.8.3. Планирование выводов для уменьшения влияния SSO
Следует отделять мощные и/или одновременно переключающиеся выводы (SSO-
выводы) от чувствительных входов и выходов, особенно асинхронных входов. Мощ-
ные выводы имеются в стандартах HSTL и SSTL класса II, вариантах PCI, LVCMOS
или LVTTL с мощностью выше 8 мА. Чувствительные входы и выходы могут иметь
малые пределы шума и являются высокоскоростными сигналами или сигналами, где
амплитуда уменьшается параллельно нагрузке приемника.
Поскольку локализованный шум SSO в FPGA 7-й серии основывается на близости
сигналов друг к другу, важно попытаться разделить сигналы на основе позиции ша-
ров припоя корпуса. Дальнейшее снижение шума, вызванного SSO, возможно путем
равномерного распределения выводов вместо концентрации в одном месте. В пре-
делах одного банка выводы SSO должны быть равномерно распределены по всему
банку. Если можно использовать многократные банки, то выводы SSO должны быть
равномерно распределены по нескольким банкам.
Программа Plan Ahead в пакете ISE может помочь в планировании расположения
чувствительных контактов и контактов SSO (детали см. в документе UG471 7 Series
FPGAs SelectIO Resources).
9.8.4. Рекомендации для корректного использования DCI в FPGA
7-й серии
Ниже приводятся некоторые рекомендации, позволяющие упростить практичес-
кое использование цифрового управления импедансом DCL
Выводы Vcco должны соединяться с надлежащим напряжением Vcco. основан-
ном на атрибутах IOSTANDARD в этом же банке ввода-вывода.
Должны использоваться корректные (правильные) буферы ввода-вывода DCI ли-
бо с помощью атрибутов IOSTANDARD, либо с помощью инстанций (создания эк-
земпляров) в коде языка HDL.
Стандарты DCI требуют подсоединения внешних опорных резисторов для много-
целевых выводов VRN и VRP. Эти выводы не могут использоваться как общецелевые
двунаправленные выводы в банке ввода-вывода, использующем DCI, или в главном
банке ввода-вывода, когда каскадируется DCL Вывод VRN должен подтягиваться к
напряжению Vcco с помощью своего опорного резистора, аналогично вывод VRP
Система ввода-вывода SelectIO
153
Таблица 9.12
Стандарты ввода-вывода с входами DCI, которые не требуют опорных резисторов
LVDCI LVDCLDV2 HSLVDCI HSUL
LVDCL18 LVDCLDV2-18 HSLVDCL18 HSUL.12-DCI
LVDCL15 LVDCLDV2.15 HSLVDCL15 DCI_HSUL_12_DCI
должен подтягиваться к земле с помощью своего опорного резистора. Исключе-
ние составляет случай, когда DCI каскадируется в подчиненные банки ввода-вывода.
Стандарты ввода-вывода, DCI-входы которых не требуют опорных резисторов, пред-
ставлены в табл. 9.12.
Значение внешних опорных резисторов должно выбираться так, чтобы дать тре-
буемый импеданс выходному драйверу или импеданс расщепляемой нагрузке. На-
пример, когда используется стандарт LVDCL15 для достижения импеданса выход-
ного драйвера 50 Ом, значение внешних опорных резисторов, используемых на вы-
водах VRN и VRP, должно быть 50 Ом (каждый). Когда используется стандарт
SSTL15_T_DCI для достижения 50 Ом эквивалентной нагрузки Thevenin (R) к Vcco/2,
каждый внешний опорный резистор должен иметь значение 100 Ом (2R).
Правила DCI для банков ввода-вывода:
• напряжение Vref должно быть совместимым для всех входов в одном и том же
банке ввода-вывода, когда используется каскадирование DCI;
• напряжение Vcco должно быть совместимым для всех входов и выходов в одном
и том же банке ввода-вывода;
• разделяемая нагрузка, управляемая драйвером импеданса и нагрузка, управля-
емая драйвером импеданса с половинным импедансом, могут сосуществовать в
одном и том же банке.
Примеры практического использования DCI можно найти в документе UG471 7
Series FPGAs SelectIO Resources.
9.8.5. Руководство для выводов VRN и VRP при перемещении проектов
с FPGA предыдущих семейств на FPGA 7-й серии
Предыдущие семейства FPGA фирмы Xilinx, обладающие свойством DCI, исполь-
зовали схему для калибровки импеданса разделяемой нагрузки, немного отличающу-
юся от внешних опорных резисторов, размещаемых на выводах VRN и VRP. Значе-
ния резисторов соответствовали целевому Thevenin-эквивалентному импедансу R. DCI
семейства Virtex-б калибрует каждый участок схемы расщепленной нагрузки к удво-
енным значениям внешних резисторов. Например, в устройствах Virtex-б с целью
параллельной нагрузки в 50 Ом к VCC/2 требуются внешние резисторы на 50 Ом
для выходов VRN и VRP.
В FPGA 7-й серии значения резисторов соответствуют каждому участку схемы
расщепленной нагрузки 2R. DCI FPGA 7-й серии калибрует каждый участок схемы
расщепленной нагрузки, чтобы быть непосредственно равным значениям внешних ре-
зисторов. Например, в FPGA 7-й серии с целью параллельной нагрузки в 50 Ом к
Vcco/2 требуются внешние резисторы на 100 ом для выходов VRN и VRP. Это особен-
но важно для рассмотрения, когда выбираются значения VRN и VRP, которые будут
использоваться в том же самом банке ввода-вывода (или в нескольких каскадируемых
банках DCI) как для стандартов DCI управляющих импедансом, так и для стандартов
DCI с расщепляемой нагрузкой. Например, при переносе проекта с устройств Virtex-
6 на FPGA 7-й серии для стандарта HSTLJ_DCI_18 необходимо величину внешних
резисторов изменить с 50 Ом на 100 Ом.
154
Раздел 9
9.8.6. Рекомендации по использованию каскадирования DCI
В заключение приведем некоторые рекомендации по использованию каскадиро-
вания DCI:
• каскадирование DCI возможно только через столбец банков ввода-вывода ти-
па HP;
• главный и подчиненный банки должны находиться в одном и том же столбце
банков ввода-вывода HP и могут охватывать весь столбец;
• каскадирование не может пересекать границы вставок больших устройств се-
мейства Virtex-7, соответствующих технологии SSI (детали смотри в документе
UG475 7 Series FPGAs Packaging and Pinout. Product Specification);
• главный и подчиненный банки должны иметь одинаковое напряжение Vcco и
Vref (если используются);
• банки ввода-вы вода в одном и том же столбце банков HP, которые не используют
DCI (проходящий через банк), не должны согласовываться с правилами напря-
жений Vcco и Vref Для объединения установок DCI;
• правила банковской совместимости DCI должны удовлетворяться через все глав-
ные и подчиненные банки (например, только один стандарт ввода-вывода DCI,
использующий единственный тип нагрузки, разрешается через все главные и
подчиненные банки);
• для того чтобы расположить банки ввода-вы вода, которые находятся в одном и
том же столбце, обратитесь к рисункам «Die Level Bank Numbering Overview»
документа UG475 7 Series FPGAs Packaging and Pinout. Product Specification.
9.9. Выводы
Система ввода-вывода FPGA 7-й серии носит название система SelectIO. Ресурсы
системы SelectIO делятся на три части:
• ресурсы ввода-вывода общего назначения;
• логические ресурсы ввода-вывода;
• расширенные логические ресурсы ввода-вывода.
Ресурсы ввода-вывода общего назначения реализуются с помощью широкого на-
бора примитивов, которые поддерживают большинство ассиметричных и дифферен-
циальных стандартов. Важную роль в ресурсах ввода-вывода общего назначения иг-
рает цифровое управление импедансом DCL
Логические ресурсы представлены модулями ILOGIC и OLOGIC, а также моду-
лями IDELAY и ODELAY. Модули ILOGIC и OLOGIC обеспечивают передачу дан-
ных с удвоенной скоростью DDR по отношению к синхросигналу. Модули IDELAY
и ODELAY обеспечивают введение программируемой задержки в пути сигналов дан-
ных и синхронизации.
Расширенные логические ресурсы представлены модулями ISERDES и OSERDES,
которые представляют собой соответственно последовательно-параллельный и парал-
лельно-последовательный преобразователи. Модули ISERDES и OSERDES поддер-
живают широкий набор сетевых интерфейсов.
Ресурсы системы ввода-вывода SelectIO представлены в виде банков. Каждый
банк ввода-вывода содержит 50 выводов. Число банков зависит от размера устройст-
ва и корпуса устройства. В архитектуре FPGA 7-й серии банки организуются в виде
столбцов, которые могут располагаться как по краям кристалла, так и внутри него.
FPGA 7-й серии предлагают банки ввода-вывода двух типов: высокопроизводи-
тельные HP и широкого диапазона HR. Банки HP разработаны с целью удовлетво-
Система ввода-вывода SelectIO
155
рения требований производительности быстродействующей памяти и других интер-
фейсов между микросхемами с напряжением до 1,8 В. Банки HR разработаны для
поддержки широкого диапазона стандартов ввода-вывода с напряжением до 3,3 В.
На основании наличия ресурсов ввода-вывода, которое выражается в типах име-
ющихся банков ввода-вывода, можно сделать следующие выводы: семейство Artix-7
предназначено для использования в приложениях общего назначения; Kintex-7 — как в
приложениях общего назначения, так и в системах высокопроизводительной передачи
данных; Virtex-7 — в системах высокопроизводительной передачи данных.
Основные свойства ресурсов ввода-вывода общего назначения:
• программируемое управление выходной мощностью;
• управление скоростью возрастания сигнала на выходах микросхемы;
• цифровое управление импедансом DCI;
• возможность генерирования внутреннего опорного напряжения.
Банки HR не поддерживают свойство DCL
Два вывода с каждого конца банка могут использоваться с ассиметричными
(single-ended) стандартами ввода-вывода. Оставшиеся 48 выводов могут использо-
ваться либо с ассиметричными, либо с дифференциальными стандартами. В послед-
нем случае два вывода группируются вместе как пара Р/N. Ресурс каждого вывода
содержит вход, выход и драйверы (буферы) с тремя состояниями.
Выводы FPGA 7-й серии могут конфигурироваться для:
• ассиметричных стандартов (LVCMOS, LVTTL, HSTL, PCI и SSTL);
• дифференциальных стандартов (LVDS, Mini_LVDS, RSDS, PPDS, BLVDS, диф-
ференциальные HSTL и SSTL).
Различные элементы системы SelectIO могут требовать четыре типа напряжений:
Vcco- Vref- Vccaux и Vccaux_io-
Напряжение Vcco является первичным напряжением питания схемы ввода-выво-
да. Все выводы Vcco для данного банка ввода-вывода должны подсоединяться к
одному и тому же источнику напряжения питания, и все выводы данного банка долж-
ны использовать один и тот же уровень Vcco- Напряжение Vcco- которое должно
назначаться данному банку ввода-вывода, должно быть согласовано с требованиями
стандартов ввода-вывода. Неправильно выбранное напряжение Vcco может привести
к потере функциональности или повреждению устройства.
Опорное напряжение Vref требуется для ассиметричных (single-ended) стандар-
тов ввода-вывода с дифференциальным входным буфером. Для этого используются
два многофункциональных вывода банка как входы напряжения Vref- Отметим, что
FPGA 7-серии с помощью ограничения INTERNAL.VREF могут использовать внут-
ренне опорное напряжение.
Напряжение Vccaux используется для питания схем входных буферов для неко-
торых стандартов ввода-вывода. Это включает все ассиметричные стандарты ввода-
вывода ниже 1,8 В, а также некоторые стандарты 2,5 В (только для банков HR). До-
полнительно цепь Vccaux обеспечивает питание к схемам дифференциальных вход-
ных буферов.
Вспомогательная цепь питания Vccaux_io представлена только в банках HP и
обеспечивает питанием схемы ввода-вывода.
Структура ввода-вывода включает контактные площадки выводов PAD, буфер
ввода-вывода ЮВ, блоки входной IDELAY и выходной ODELAY задержки, а также
входной ILOGIC и выходной OLOGIC логические блоки. В структурах ввода-вывода
банков HP используются логические блоки ILOGICE2, а в банках HR — ILOGICE3.
В структуре ввода-вывода банка HR отсутствует блок выходной задержки.
156
Раздел 9
Схемы логических блоков ILOGIC и OLOGIC могут конфигурироваться как после-
довательно-параллельные преобразователи ISERDES и OSERDES соответственно.
Архитектура буферов ввода-вывода ЮВ включает входной и выходной буферы,
соединенные с контактной площадкой внешнего вывода PAD, пути входных и выход-
ных данных, а также сигналы управления буферами. Сигнал IBUFDISABLE позволяет
запрещать входной буфер для уменьшения потребляемой мощности в момент време-
ни, когда буфер не используется. Сигнал DCITERMDISABLE может использоваться
для запрещения дополнительного свойства DCI расщепления нагрузки.
В архитектуре буферов ввода-вывода банков HR отсутствует управляющий сигнал
DCITERMDISABLE, поскольку банки HR не обладают свойством цифрового управ-
ления импедансом DCL
Блок ILOGIC содержит синхронные элементы памяти для захвата входных дан-
ных. Блоки ILOGICE2 используются в банках HP, а блоки ILOGICE3 — в банках HR.
Блок ILOGICE2 не имеет элемента нулевой задержки удержания ZHOLD.
Элемент задержки ZHOLD на D-входе запоминающего элемента устраняет любое
время удержания от контакта к контакту. Задержка ZHOLD автоматически согласует-
ся с внутренней задержкой распространения синхросигнала и гарантирует, что время
задержки от контакта к контакту равно нулю.
Элемент ILOGIC может конфигурироваться для реализации:
• D-триггера;
• входного элемента IDDR;
• защелки;
• асинхронного (комбинационного) входа.
Блок OLOGIC содержит два главных блока: один для конфигурации пути выход-
ных данных, а другой для конфигурации пути сигнала управления 3-м состоянием.
Эти два блока имеют общий синхросигнал CLK, но разные сигналы разрешения син-
хронизации: ОСЕ и ТСЕ. Оба блока имеют асинхронную или синхронную установку
или сброс (сигнал SR) управляемую атрибутом SRVAL.
Путь выходных данных и путь сигнала управления 3-м состоянием могут незави-
симо конфигурироваться для реализации:
• D-триггера;
• выходного элемента ODDR;
• защелки;
• асинхронного (комбинационного) выхода.
Цифровое управление импедансом DCI возможно только в банках ввода-вывода
типа HP. DCI может управлять либо выходным импедансом драйвера, либо добавлять
параллельное оконечное сопротивление (концевик) в драйвер и/или приемник с целью
точного соответствия значения импеданса линии передачи. DCI активно корректиру-
ет эти импедансы внутри блока ввода-вывода для калибровки к значению внешних
резисторов на выводах VRN и VRP. Это компенсирует изменения в импедансе ввода-
вывода, а также позволяет постоянно корректировать импедансы для компенсации
изменений колебаний температуры и напряжения питания.
В стандартах ввода-вывода с управляющими импедансом драйверами DCI управ-
ляет импедансом драйвера либо для согласования двух опорных резисторов, либо для
согласования половины значения опорных резисторов.
В стандартах ввода-вывода с управляемой параллельной оконечной нагрузкой DCI
обеспечивает параллельную оконечную нагрузку как для передатчиков, так и для при-
емников. Это избавляет от необходимости установки нагрузочных резисторов на пла-
те и улучшается целостность сигналов благодаря устранению тупикового отражения.
Система ввода-вывода SelectIO
157
DCI в каждом банке ввода-вывода использует два многоцелевых опорных вывода.
Вывод N (VRN) должен подтягиваться к напряжению Vcco с помощью одного опор-
ного резистора, а вывод Р (VRP) должен подтягиваться к земле с помощью другого
опорного резистора. Значение каждого опорного резистора должно быть равно либо
характеристике импеданса трасс печатной платы, либо удвоенному этому значению.
Если несколько банков ввода-вывода в данном столбце банков ввода-вывода ис-
пользуют DCI и эти банки используют одинаковые значения резисторов VRN/VRP,
то внутренние узлы VRN и VRP могут каскадироваться. Эта опция называется кас-
кадированием DCI.
DCI корректирует импеданс для соответствия внешним опорным резисторам.
Корректировка (калибровка) запускается автоматически во время включения устрой-
ства. По умолчанию вывод DONE не переходит в высокое состояние до тех пор, пока
не завершится первая часть процесса корректировки импеданса.
Версии DCI стандартов SSTL и HSTL позволяют иметь внутренние расщепля-
ющие нагрузочные резисторы. Стандарты DCI с третьим состоянием (T.DCI) были
разработаны, чтобы удовлетворить следующим требованиям: выходные нагрузочные
резисторы расщепления выключаются, когда вывод функционирует в качестве вы-
хода, и включаются, когда вывод функционирует в качестве входа, находится в 3-м
состоянии или в состоянии ожидания.
В банках ввода-вывода типа HR имеется опция некалибрируемой расщепляющей
нагрузки, очень похожая на расщепляющую нагрузку 3-го состояния для банков HP.
Эта опция банков HR создает эквивалентную схему Thevenin, используя два внутрен-
них резистора с удвоенным сопротивлением 2R. Одна резисторная нагрузка к Vcco.
а другая — к земле.
При разработке проекта необходимо придерживаться правил совмещения стан-
дартов в одном банке ввода-вы вода.
Из-за явления индуктивности каждый корпус FPGA поддерживает только ограни-
ченное количество одновременно переключающихся выходов. Программа прогнози-
рования SSN пакета Plan Ahead обеспечивает анализ уровня шума на каждом выходе
проекта на основе информации о контакте (жертве), а также информации о других
контактах (агрессорах). Программа SSN принимает во внимание расположение кон-
тактов, стандарты ввода-вывода, скорости нарастания сигналов, используемые на-
грузки и предоставляет значение запаса помехоустойчивости для каждого вывода.
10 Логические ресурсы ввода-вывода
К логическим ресурсам блоков ввода-вывода FPGA 7-й серии относятся:
• элементы входной (IDELAY) и выходной (ODELAY) задержки;
• блоки входной (ILOGIC) и выходной (OLOGIC) логики;
• расширенные ресурсы ввода-вывода: блоки последовательно-параллельных пере-
датчиков (ISERDES) и приемников (OSERDES).
Элементы I DELAY и ODELAY обеспечивают управляемую задержку для входных
и выходных данных. Основной функцией блоков входной ILOGIC и выходной OLOGIC
логики является поддержка регистров передачи данных с удвоенной скоростью (double
data rate — DDR). В данной главе рассматриваются элементы входной и выходной за-
держки, а также ресурсы блоков входной и выходной логики для передачи данных с
удвоенной скоростью. Возможности расширенных ресурсов ввода-вывода рассмат-
риваются в главе 11.
К основным свойствам логических ресурсов ввода-вывода FPGA 7-й серии от-
носятся:
• поддержка комбинационных и регистровых входов и выходов;
• управление 3-м состоянием комбинационного регистрового выхода;
• поддержка входов и выходов с двойной скоростью передачи данных DDR;
• управление 3-м состоянием выхода DDR;
• поддержка регулируемой (управляемой) входной I DELAY и выходной ODELAY
задержки;
• поддержка режима DDR-выхода SAME-EDGE;
• поддержка режимов DDR-входа SAME-EDGE и SAME-EDGE -PIPELINED.
10.1. Входная задержка I DELAY
Рис. 10.1. Структура модуля задержки
IDELAY/ODELAY
В общем случае структуру модуля задерж-
ки IDELAY (ODELAY) можно представить в виде
последовательной цепочки элементов задержки с
отводами ТарО, Tapi...Тар31 (рис. 10.1).
Каждый элемент задержки вносит в переда-
ваемый сигнал задержку величиной Т =
= Tidelayresolution- Отводы ТарО, Tapi,...,
Тар31 являются входами мультиплексора MUX
32:1. Управляющие входы мультиплексора соеди-
нены с 5-битовым регистром CNTVALUE. В за-
висимости от значения, записанного в регистре
CNTVALUE, соответствующий отвод в цепочке
элементов задержки будет соединен с выходом
модуля задержки. Таким образом, величина за-
держки определяется 5-битовым целым числом
от 0 до 31, записанным в регистре CNTVALUE
Значение регистра CNTVALUE может оставаться
Логические ресурсы ввода-вывода
159
неизменным, инкрементироваться, декрементироваться, загружаться с входов
CNTVALUEIN или загружаться значением конвейерного регистра. Отметим, что под-
ключение выхода мультиплексора к соответствующему отводу в цепочке элементов
задержки не вносит искажений в передаваемый сигнал.
10.1.1. Примитив IDELAYE2
Входная задержка в проектах на FPGA 7-й серии реализуется с помощью прими-
тива IDELAYE2. Этот примитив может подсоединяться к блокам ILOGICE2/ISERD-
ESE2 или ILOGICE3/ISERDESE2 (см. рис. 9.2 и рис. 9.3 главы 9). Описание прими-
тива IDELAYE2 приведено в приложении А. Здесь рассматриваются только основные
свойства примитива IDELAYE2.
Как было указано выше, примитив IDELAYE2 представляет собой 31-отводный
циклический примитив задержки с калибровочными отводами для уточнения разре-
шающей способности. Он может применяться к комбинационному или регистровому
входному пути, а также может быть доступен из логики FPGA.
Примитив IDELAYE2 позволяет входным сигналам задерживаться на шинах вход-
ных выводов, при этом разрешающая способность величины задержки непрерывно
калибруется путем использования опорного синхросигнала примитива IDELAYCTRL.
Примитив IDELAYE2 имеет два отдельных входа данных: IDATAIN (от входно-
го буфера IBUF) и DATAIN (от внутренней логики FPGA). Отличие между входами
IDATAIN и DATAIN заключается в том, что данные с входа IDATAIN могут поступать
как в блок ILOGIC, так и во внутреннюю логику FPGA, а данные с входа DATAIN
могут поступать только во внутреннюю логику FPGA.
Примитив IDELAYE2 имеет также два выхода: однобитовый DATAOUT (задер-
жанные данные) и CNTVALUEOUT[4:0] (5-битовое значение задержки для монито-
ринга величины задержки). Кроме того, примитив IDELAYE2 имеет конвейерный
регистр, который управляется сигналами С, REGRST, LD и LDPIPEEN.
Примитив IDELAYE2 имеет 4 режима работы FIXED, VARIABLE, VAR.LOAD и
VAR_LOAD_PIPE, которые определяются атрибутом IDELAY_TYPE. В режиме FIXED
задержка имеет фиксированное значение (определяется атрибутом IDELAY-VALUE)
и не может быть изменена. В режиме VARIABLE задержка может увеличиваться или
уменьшаться в каждом цикле синхросигнала С на величину Tidelayresolution- Ре-
жим VAR.LOAD подобен режиму VARIABLE, но значение задержки дополнительно
может динамически загружаться с выводов CNTVALUEIN. Режим VAR_LOAD_PIPE
аналогичен режиму VAR.LOAD, только задержка динамически загружается не с вы-
водов CNTVALUEIN, а с выходов конвейерного регистра.
Величина задержки определяется целым числом от 0 до 31 условных единиц
(taps). В свою очередь, величина условной единицы задержки (tap) определяется
атрибутом REFCLK.FREQUENCY.
Программируемая задержка повторяет в примитиве IDELAYE2 полный цикл. Ког-
да достигается последнее значение задержки (что соответствует отводу Тар31), функ-
ция последовательной инкрементации будет возвращена к значению 0. Аналогичные
правила применяются к функциям декрементации: декрементация нуля возвращает
величину задержки к 31.
Функционирование конвейерного регистра в режиме VAR.LOAD.PIPE особенно
полезно в проектах с шинной структурой. Индивидуальные задержки могут загру-
жаться конвейерно, одно значение задержки в один момент времени, используя вход
LDPIPEEN, а затем все задержки корректируются к их новым значениям в один и тот
же момент времени, используя вход LD.
160
Раздел 10
Временные параметры и функционирование во времени примитива IDELAYE2
приведено в приложении Б.
10.1.2. Элемент IDELAYCTRL
Когда создаются экземпляры примитивов IDELAYE2 или ODELAYE2, также со-
здается экземпляр примитива IDELAYCTRL. Модуль IDELAYCTRL непрерывно ка-
либрует индивидуальные значения задержки (IDELAY/ODELAY) в данном регионе
для уменьшения воздействия изменений температуры, напряжения и функционирова-
ния. Модуль IDELAYCTRL для калибровки использует определяемый пользователем
опорный синхросигнал REFCLK.
Модули IDELAYCTRL имеются в каждом столбце блоков ввода-вывода, в каж-
дом регионе синхросигнала. Модуль IDELAYCTRL калибрует все модули IDELAYE2 и
ODELAYE2 в пределах своего региона синхронизации (более подробную информацию
см. в документе UG472 7 Series FPGAs Clocking Resources. User Guide).
Больше информации по размещению и блокированию модулей IDELAYCTRL
можно найти в руководстве по ограничениям (документ UG625 Constraints Guide).
Описание примитива IDELAYCTRL приводится в приложении А, а временная мо-
дель — в приложении Б.
10.2. Выходная задержка ODELAY
Каждый банк ввода-вывода типа HP содержит элемент программируемой вы-
ходной задержки, называемой ODELAY. Напомним, что элемент ODELAY отсутст-
вует в банках ввода-вывода типа HR. В проектах элемент ODELAY создается с по-
мощью примитива ODELAYE2. Примитив ODELAYE2 может подсоединяться к бло-
кам OLOGICE2/OSERDESE2. Аналогично примитиву IDELAYE2, примитив ODE-
LAYE2 является 31-отводным циклическим примитивом задержки с калибрируемой
разрешающей способностью задержки сигнала. Примитив ODELAYE2 может при-
меняться в комбинационных или регистровых выходных путях, а также может быть
доступен непосредственно из логики FPGA. Разрешающая способность задержки сиг-
нала изменяется путем выбора опорного синхросигнала IDELAYCTRL из области,
определенной в документе «7 Series FPGA Date Sheets».
Примитив ODELAYE2 во многом подобен примитиву IDELAYE2. Отличие заклю-
чается в том, что примитив ODELAYE2 имеет только один вход данных ODATAIN,
на который данные поступают от блока OLOGICE2/OSERDESE2. Однако примитив
ODELAYE2 имеет дополнительный вход синхросигнала CLKIN от буферов синхрони-
зации BUFIO, BUFG или BUFR. Синхросигнал поступает обратно в логику FPGA через
порт DATAOUT с задержкой, устанавливаемой атрибутом ODELAY-VALUE. Описа-
ние примитива приведено в приложении А.
Режимы функционирования примитива ODELAYE2 полностью совпадают с ре-
жимами функционирования примитива IDELAYE2. Временные параметры и функци-
онирование во времени примитива ODELAYE2 также полностью совпадают с при-
митивом IDELAYE2.
10.3. Вход IDDR блока ILOGIC
Архитектура и основные функции блока ILOGIC были рассмотрены в подразделе
9.2.3. В данном разделе рассматриваются ресурсы блока ILOGIC при реализации
входа с удвоенной скоростью передачи данных IDDR (input double data rate).
FPGA 7-й серии имеют специальные регистры в блоках ILOGIC для реализации
входных регистров DDR (double-data-rate). Это свойство используется путем созда-
Логические ресурсы ввода-вывода
161
ния экземпляра примитива IDDR. Все синхросигналы, питающие структуру ввода-
вывода, полностью мультиплексируются, т. е. синхросигнал не разделяется между
блоками ILOGIC и OLOGIC.
Примитив IDDR имеет один вход данных D и два выхода данных Q1 и Q2. Данные
тактируются синхросигналом С, который разрешается управляющим сигналом СЕ.
Примитив IDDR поддерживает три режима функционирования: OPPOSITE-EDGE,
SAME-EDGE и SAME_EDGE_PIPELINED. Описание примитива IDDR приведено в при-
ложении А.
Режим функционирования OPPOSITE-EDGE. Режим функционирования OPPO-
SITE-EDGE — это традиционное решение DDR, когда на вход D данные поступают
с удвоенной скоростью; во внутреннюю логику FPGA данные поступают через выход
Q1 по возрастающему фронту синхросигнала, а через выход Q2 — по падающему
фронту синхросигнала (рис. 10.2).
Режим функционирования SAME-EDGE. В режиме функционирования SAME-
EDGE данные во внутреннюю логику FPGA поступают через два выхода Q1 и Q2
по одному и тому же возрастающему фронту синхросигнала (рис. 10.3).
С
СЕ
D
Q1
। । । । ।
Рис. 10.3. Временная диаграмма примитива IDDR в режиме SAME-EDGE
РОА D1A D2A D3A Р4А Р5А D6A Р7А Р8А Р9А Р10А D11A Р12А Р13А
РОА । | D2A | | ОДА | | D6A | | D8A } | D10A
Рис. 10.4. Временная диаграмма примитива IDDR в режиме SAME_EDGE_PIPELINED
162
Раздел 10
Режим функционирования SAME_EDGE_PIPELINED. В режиме функционирова-
ния SAME_EDGE_PIPELINED, в отличие от SAME-EDGE, пара данных не отделяется
одним циклом синхросигнала; однако требуется дополнительный цикл задержки на
выходе Q1 (рис. 10.4).
Временные параметры и функционирование во времени блока ILOGIC приведены
в приложении Б.
10.4. Выход ODDR блока OLOGIC
Архитектура и основные функции блока OLOGIC были рассмотрены в подразде-
ле 9.2.4. В данном разделе рассматриваются логические ресурсы блока OLOGIC при
реализации выхода с удвоенной скоростью передачи данных ODDR (output double
data rate).
FPGA 7-й серии в блоке OLOGIC имеют специальные регистры для реализации
регистров выхода DDR. Это свойство становится доступным после инстанции при-
митива ODDR. Когда используется блок OLOGIC, выход DDR мультиплексируется
автоматически. Отметим, что отсутствует ручное (пользовательское) управление
выбором мультиплексора.
Примитив ODDR имеет два входа данных D1 и D2, один выход данных Q и
один вход синхросигнала С, который разрешается управляющим сигналом СЕ. Дан-
ные падающего фронта локально синхронизируются инвертированной версией вход-
ного синхросигнала. Все синхросигналы, питаемые в структуре ввода-вывода, пол-
ностью мультиплексируются, т. е. нет синхросигналов, совместно используемых бло-
ками ILOGIC и OLOGIC.
Примитив ODDR поддерживает режимы функционирования OPPOSITE-EDGE и
SAME-EDGE. Режим SAME-EDGE позволяет разработчикам представлять оба входа
данных в примитив ODDR на возрастающем фронте синхросигнала ODDR, сохраняя
ресурсы блоков CLB и синхронизации и увеличивая производительность. Этот режим
реализуется путем использования атрибута DDR_CLK_EDGE. Он также поддержива-
ется для управления 3-м состоянием.
Режим OPPOSITE-EDGE. В этом режиме (рис. 10.5) оба фронта синхросигнала
CLK используются для захвата данных от логики FPGA с двойной пропускной спо-
собностью. Оба выхода подключаются к входу данных или к входу управления 3-м
состоянием блока ЮВ.
Режим SAME-EDGE. В этом режиме (рис. 10.6) данные могут представлять-
ся в блок ЮВ на том же самом фронте синхросигнала. Представление данных в
блок ЮВ на одном и том же фронте синхросигнала позволяет избежать нарушений
времени установки и позволяет пользователю реализовать высокую частоту DDR с
CLK—1 I—I I—I I—I I—
°СЕ-П I i \
D1 I ! D1A I ;Р1В I ]Р1С I 1 D1D |~
----1—।------ -; -г_—г-1-——'} । уу
I---------------------------I-I-I_____
OQ I |Р1А|Р2А|В1В|Р2В|Р1С|Р2С|Р1Р|
Рис. 10.5. Временная диаграмма функционирования ODDR в режиме OPPOSITE_EDGE
Логические ресурсы ввода-вывода
163
CLK 1 I
I
ОСЕ |
с>1 2] D1A | D1B | D1C I D1D
D2 | D2A | Р2В | D2C | {D2D |
1111
OQ D1A D2A D1B D2B D1C D2C D1D
Рис. 10.6. Временная диаграмма функционирования ODDR в режиме SAME-EDGE
минимальной задержкой от регистра к регистру, по сравнению с использованием ре-
гистров блока CLB.
Передача синхросигнала. ODDR может передавать копию синхросигнала на вы-
ход. Это является полезным для распространения синхросигнала и данных DDR с
одинаковыми задержками, а также для генерации множественных синхросигналов, где
каждое множество синхросигналов имеет уникальный драйвер синхронизации. Это
выполняется путем подключения входа D1 примитива ODDR к высокому уровню, а
D2 — к низкому. Xilinx рекомендует использовать эту схему для передачи синхросиг-
налов от логики FPGA к выходным контактам.
Описание примитива ODDR приведено в приложении А, а временные параметры
и функционирование во времени приведены в приложении Б.
10.5. Выводы
К логическим ресурсам блоков ввода-вывода FPGA 7-й серии относятся: элемен-
ты входной IDELAY и выходной ODELAY задержки, а также блоки входной ILOGIC
и выходной OLOGIC логики,
Элементы IDELAY и ODELAY обеспечивают управляемую задержку для входных
и выходных данных. Основной функцией блоков входной ILOGIC и выходной OLOGIC
логики является поддержка регистров передачи данных с удвоенной скоростью (double
data rate — DDR).
Структуру модуля задержки IDELAY (ODELAY) можно представить в виде после-
довательной цепочки элементов задержки с отводами ТарО, Tapi.Тар31.
Величина задержки определяется 5-битовым целым числом от 0 до 31, записан-
ным в регистре CNTVALUE. Значение регистра CNTVALUE может оставаться неиз-
менным, инкрементироваться, декрементироваться, загружаться с входов CNTVA-
LUEIN или загружаться значением конвейерного регистра.
Задержка не вносит искажений в передаваемый сигнал.
Примитив IDELAYE2 представляет собой 31-отводный циклический примитив за-
держки с калибровочными отводами для уточнения разрешающей способности. Он
может применяться к комбинационному или регистровому входному пути, а также
может быть доступен из логики FPGA.
Разрешающая способность величины задержки непрерывно калибруется путем
использования опорного синхросигнала примитива IDELAYCTRL.
Примитив IDELAYE2 имеет 4 режима работы: FIXED, VARIABLE, VAR.LOAD и
VAR-LOAD.PIPE, которые определяются атрибутом IDELAY.TYPE.
164
Раздел 10
Величина задержки определяется целым числом от 0 до 31 условных единиц
(taps). В свою очередь, величина условной единицы задержки (tap) определяется
атрибутом REFCLK-FREQUENCY.
Когда создаются экземпляры примитивов IDELAYE2 или ODELAYE2, также со-
здается экземпляр примитива IDELAYCTRL. Модуль IDELAYCTRL непрерывно калиб-
рует индивидуальные значения задержки (IDELAY/ODELAY) в данном регионе для
уменьшения воздействия изменений температуры, напряжения и функционирования,
при этом используется определяемый пользователем опорный синхросигнал REFCLK.
Каждый банк ввода-вывода типа HP содержит элемент программируемой выход-
ной задержки, называемой ODELAY (элемент ODELAY отсутствует в банках ввода-
вывода типа HR).
Примитив ODELAYE2 во многом подобен примитиву IDELAYE2. Отличие заклю-
чается в том, что примитив ODELAYE2 имеет только один вход данных ODATAIN, на
который данные поступают от блока OLOGICE2/OSERDESE2.
Однако примитив ODELAYE2 имеет дополнительный вход синхросигнала CLKIN.
Синхросигнал поступает обратно в логику FPGA через порт DATAOUT с задержкой,
устанавливаемой атрибутом ODELAY_VALUE.
Режимы функционирования примитива ODELAYE2 полностью совпадают с ре-
жимами функционирования примитива IDELAYE2.
FPGA 7-й серии имеют специальные регистры в блоках ILOGIC для реализации
входных регистров DDR (double-data-rate). Это свойство используется путем созда-
ния экземпляра примитива IDDR.
Примитив IDDR имеет один вход данных D и два выхода данных Q1 и Q2. Данные
тактируются синхросигналом С, который разрешается управляющим сигналом СЕ.
Примитив IDDR поддерживает 3 режима функционирования: OPPOSITE-EDGE,
SAME-EDGE и SAME_EDGE_PIPELINED.
Режим функционирования OPPOSITE-EDGE — это традиционное решение DDR,
когда на вход D данные поступают с удвоенной скоростью; во внутреннюю логику
FPGA данные поступают через выход Q1 по возрастающему фронту синхросигнала,
а через выход Q2 — по падающему фронту синхросигнала.
В режиме функционирования SAME-EDGE данные во внутреннюю логику FPGA
поступают через два выхода Q1 и Q2 по одному и тому же возрастающему фрон-
ту синхросигнала.
В режиме функционирования SAME_EDGE_PIPELINED, в отличие от SAME-
EDGE, пара данных не отделяется одним циклом синхросигнала; однако требуется
дополнительный цикл задержки на выходе Q1.
FPGA 7-й серии в блоке OLOGIC имеют специальные регистры для реализации
регистров выхода DDR. Это свойство становится доступным после инстанции при-
митива ODDR.
Примитив ODDR имеет два входа данных D1 и D2, один выход данных Q и один
вход синхросигнала С, который разрешается управляющим сигналом СЕ.
Примитив ODDR поддерживает режимы функционирования OPPOSITE-EDGE и
SAME-EDGE. В режиме OPPOSITE-EDGE оба фронта синхросигнала CLK исполь-
зуются для захвата данных от логики FPGA с двойной пропускной способностью.
В режиме SAME-EDGE данные могут представляться в блок IOB на том же самом
фронте синхросигнала.
ODDR может также передавать на выход копию синхросигнала.
11 Расширенные логические ресурсы ввода-вывода
В данной главе рассматриваются входные последовательно-параллельные преоб-
разователи ISERDESE2 и выходные параллельно-последовательные преобразователи
OSERDESE2 FPGA 7-й серии, которые поддерживают очень быстрые скорости пе-
редачи данных, позволяя внутренней логике работать в 8 раз медленнее, чем ввод-
вывод. Подмодуль Bitslip блока позволяет переупорядочивать данные с помощью
обучающего шаблона (training pattern).
Одной из областей применения блоков ISERDESE2 и OSERDESE2 является пере-
дача данных между двумя FPGA, расположенными на одной плате. При этом можно
не использовать никаких стандартов последовательной передачи данных и сэкономить
ресурсы FPGA. Кроме того, на основе блоков ISERDESE2 и OSERDESE2 пользова-
тель может разрабатывать собственные протоколы высокоскоростной последователь-
ной передачи данных, например, для повышения уровня безопасности проекта.
В данной главе также рассматривается память FIFO ввода-вывода.
11.1. Последовательно-параллельный преобразователь
ISERDRSE2
11.1.1. Основные свойства
Блок ISERDESE2 в FPGA 7-й серии представляет собой последовательно-парал-
лельный преобразователь с определенными логическими свойствами и специфичес-
кой синхронизацией, спроектированный для упрощения реализации высокоскоростных
приложений с синхронным источником данных. Блок ISERDESE2 позволяет упрос-
тить синхронизацию при проектировании в структуре FPGA преобразователей из по-
следовательной формы в какую-либо другую форму (deserializers), в данном случае —
в параллельную.
Основные свойства блока ISERDESE2:
• блок ISERDESE2 представляет собой последовательно-параллельный преобразо-
ватель, который реализует высокоскоростную передачу данных без требования к
структуре FPGA соответствовать частоте входных данных;
• поддерживает режим передачи данных как с базовой скоростью (single date rate —
SDR), так и с удвоенной скоростью (double date rate — DDR);
• в режиме SDR последовательно-параллельный преобразователь создает слово
шириной 2, 3, 4, 5, 6, 7 или 8 битов;
• в режиме DDR последовательно-параллельный преобразователь создает слово
шириной 4, б или 8 битов, когда используется один блок ISERDESE2, и 10 или
14 битов, когда используются два каскадированных блока ISERDESE2;
• имеет специализированную поддержку интерфейсов памяти, основанных на стро-
бировании, в виде специальной схемы (включая входной вывод OCLK) для управ-
ления пересекающихся областей синхронизации строба в FPGA, что способствует
высокой производительности и упрощает реализацию;
• имеет специализированную поддержку сетевых интерфейсов, в том числе DDR3,
QDR и асинхронных интерфейсов;
166
Раздел 11
• подмодуль Bitslip позволяет переупорядочить последовательность потока парал-
лельных данных, приходящих в структуру FPGA;
• подмодуль Bitslip может использоваться для обучения (подготовки) интерфейсов
с синхронным источником, которые включают обучающий шаблон.
Блок ISERDESE2 может быть настроен для реализации различных типов интер-
фейсов (режимов работы). Допустимыми для блока ISERDESE2 являются следу-
ющие интерфейсы; MEMORY, MEMORY.DDR3, MEMORY.QDR, OVERSAMPLE и
NETWORKING.
11.1.2. Архитектура блока ISERDESE2
Обобщенная структура блока ISERDESE2 показана на рис. 11.1.
Блок ISERDESE2 состоит из модуля собственно последовательно-параллельного
преобразователя (Serial-to-Parallel Converter), мультиплексоров выбора источника по-
следовательных данных (ЮВ Multiplexers), модуля сигнала разрешения синхронизации
входа (СЕ Module), а также подмодуля Bitslip для переупорядочивания потока прихо-
дящих данных. Функционирование модуля Bitslip вызывается сигналом BITSLIP.
OFB
DDLY
D
СЕ1
СЕ2
DYNCLKSEL
CLKB
CLK
OCLK
DYNCLKDIVSEL
CLKDIV
CLKDIVP
RST
BITSLIP
Рис. 11.1. Структурная схема блока ISERDESE2
Расширенные логические ресурсы ввода-вывода
167
СЕ1
RST
CLKDIV
СЕ2
RST
CLKDIV
Рис. 11.2. Модуль разрешения синхронизации входа
Модуль сигнала разрешения синхронизации входа. Структура модуля сигнала
разрешения синхронизации входа показана на рис. 11.2.
Данный модуль состоит из двух входных триггеров и мультиплексора для выбо-
ра сигнала разрешения входа ICE. На вход одного триггера поступает сигнал разре-
шения СЕ1, а на вход другого — СЕ2. В качестве сигнала разрешения входа ICE
мультиплексор позволяет выбрать сигнал СЕ1, а также один из выходных сигналов
триггеров CE1R или CE2R. Управляется мультиплексор атрибутом NUM_CE и разде-
ленным сигналом синхронизации CLKDIV.
Сигнал ICE управляет входами разрешения синхронизации регистров FFO, FF1,
FF2 и FF3, как показано на рис. 11.3. Остальные регистры на рис. 11.3 не имеют
входов разрешения синхронизации.
Модуль разрешения синхронизации функционирует как последовательно-парал-
лельный преобразователь 2:1, синхронизируется сигналом CLKDIV. Модуль разре-
шения синхронизации является особенно необходимым для двунаправленных интер-
Рис. 11.3.
к OCLK)
от CLK
168
Раздел 11
Таблица 11.1
Рис. 11.4. Соединение модулей OSERDESE2 и разрешения синхронизации активизирует-
ISERDESE2 через порт OFB ся и Qga сигнала и СЕ2 ЯВЛЯЮТСЯ
доступными. Когда NUM_CE = 1, доступен только сигнал СЕ1, который функциони-
рует как обычный сигнал разрешения синхронизации.
Выходы О и Q[l:8]. Блок ISERDESE2 имеет два выхода: комбинационный О и
регистровый 8-битовый Q[l:8].
Входы D и DDLY. Выводы D и DDLY являются специализированными входа-
ми в блок ISERDESE2. Вход D является прямым соединением с буфером IOB. Вход
DDLY является прямым соединением с элементом задержки IDELAYE2. Это позволя-
ет пользователю иметь либо задержанную, либо незадержанную версию входных дан-
ных к регистровому (Q1-Q8) или комбинационному (О) выходу. Атрибут IOBDELAY
определяет соединения с модулем ISERDESE2. В табл. 11.1 показаны результаты
каждой установки атрибута IOBDELAY, когда подсоединяются оба входа: D и DDLY.
Порт обратной связи OFB. Порт OFB в модулях ISERDESE2 и OSERDESE2 мо-
жет использоваться для передачи данных, передаваемых на OSERDESE2, обратно к
ISERDESE2 (рис. 11.4). Это свойство разрешено, когда атрибут OFBJJSED = TRUE.
Для того чтобы обратная связь давала корректные данные, модули OSERDESE2 и
ISERDESE2 должны иметь одинаковые установки атрибутов скорости данных DATA.
RATE и ширины данных DATA.WIDTH.
Динамическая инверсия синхросигналов. Входы DYNCLKSEL и DYNCLKDIVSEL
позволяют динамически инвертировать синхросигналы блока ISERDESE2. Они ис-
пользуется совместно с атрибутами DYN_CLK_SEL_EN и DYN_CLKDIV_SEL_E. Дан-
ная операция поддерживается в режимах MEMORY-QDR и MEMORY-DDR3. Однако
динамическая инверсия синхросигналов является асинхронной операцией, поэтому ее
применение может привести к неверному функционированию блока ISERDESE2. Для
правильной работы блока ISERDESE2 после динамической инверсии синхросигналов
он должен быть сброшен.
Синхросигнал OCLK. Синхросигнал OCLK используется только тогда, когда ат-
рибут INTERFACE-TYPE установлен в значение MEMORY. Синхросигнал OCLK ис-
пользуется для передачи данных (основанных на стробе данных памяти) на область
(домен) синхронизации свободного доступа. OCLK является синхросигналом FPGA
свободного доступа, функционирует на той же самой частоте, как строб на входе
CLK. Доменная передача от CLK к OCLK показана в схеме на рис. 11.3. Синхрониза-
ция доменной передачи устанавливается пользователем путем корректировки задерж-
ки стробирующего сигнала к входу CLK (т. е. используя элемент IDELAY). Примеры
установки синхронизации этих доменных передач приводятся в генераторе интерфейса
Расширенные логические ресурсы ввода-вывода
169
Рис. 11.5. Ориентация битов на выходах Q1-Q8 портов примитива ISERDESE2
памяти MIG (Memory Interface Generator). При установке атрибута INTERFACE-TYPE
в значение NETWORKING этот порт не используется.
Задержки примитива ISERDESE2. При интерфейсе типа MEMORY задержка че-
рез стадию OCLK составляет один цикл синхросигнала CLKDIV.
Общая задержка через блок ISERDESE2 зависит от состояния фазы между син-
хросигналом CLK и синхросигналом OCLK.
Когда типом интерфейса является NETWORKING, задержка равна двум циклам
синхросигнала CLKDIV. Дополнительный цикл задержки синхросигнала CLKDIV в се-
тевом режиме (по сравнению с режимом памяти) происходит из-за подмодуля Bitslip.
Задержка в режимах MEMORY-QDR и MEMORY-DDR3 составляет два цикла
синхросигнала CLKDIV.
Порядок битов при передаче данных между блоками OSERDESE2 и ISERDESE2.
Обычно при передаче данных между различными FPGA блоки OSERDESE2 и ISERD-
ESE2 взаимодействуют между собой. Биты на входах OSERDESE2 имеют обратный
порядок на выходах блока ISERDESE2 (рис. 11.5).
Выводы SHIFTIN1/2 и SHIFTOUT1/2. Входы SHIFTIN1/2 и выходы SHIFTOUT
1/2 являются входами и выходами переноса для расширения блока ISERDESE2 до
размера 1:10 или 1:14.
Примитив блока ISERDESE2 описан в приложении А.
11.1.3. Методы синхронизации блока ISERDESE2
Методы синхронизации или типы интерфейсов блока ISERDESE2, фактически,
являются режимами его работы, которые определяют не только способ синхрониза-
ции, но и внутреннюю структуру блока ISERDESE2. Методы синхронизации блока
ISERDESE2 строго определяются типом интерфейса. В связи с этим для каждого
синхросигнала (CLK, CLKDIV и OCLK) в каждом типе интерфейса строго определе-
ны источники сигналов.
Тип интерфейса NETWORKING. В процессе последовательно-параллельного пре-
образования важным пунктом является соотношение сигналов CLK и CLKDIV. В иде-
але сигналы CLK и CLKDIV должны быть выровнены по фазе в пределах некоторого
допуска. В FPGA имеется несколько способов расположения синхронизации для удов-
летворения требованиям фазового соотношения сигналов CLK и CLKDIV.
170
Раздел 11
ISERDESE2
Clock
Input
BUFIO
CLK
Рис. 11.6. Выравнивание синхрониза-
ции, используя буферы BUFIO и BUFR
BUFR (-Х)
CLKDIV
Номинально входы CLK и CLKDIV долж-
ны быть выровнены по фазе. Например, если
сигналы CLK и CLKDIV были инвертированы
разработчиком на входах блока ISERDESE2
(рис. 11.6), то хотя расположение синхрониза-
ции является допустимой конфигурацией бу-
феров BUFIO/BUFR, синхросигналы все еще
не совпадают по фазе. Это также запрещает
использование динамического выбора инверсии с помощью сигналов DYNCLKINVSEL
и DYNCLKDIVINVSEL.
Допустимыми способами выравнивания синхронизации для блока ISERDESE2,
использующего сетевой тип интерфейса NETWORKING, являются следующие:
• CLK управляется BUFIO, CLKDIV управляется BUFR (см. рис. 11.6);
• CLK управляется ММСМ или PLL, CLKDIV управляется CLKOUT[0:6] того же
самого ММСМ или PLL;
• CLK управляется BUFG, CLKDIV управляется другим BUFG.
Когда используется блок ММСМ для управления сигналами CLK и CLKDIV, ти-
пы буферов, снабжающие ISERDESE2, не могут смешиваться. Например, если CLK
управляется буфером BUFG, то CLKDIV тоже должен управляться буфером BUFG.
В то же время блок ММСМ может управляться блоком ISERDESE2 через буферы
BUFIO и BUFR.
Тип интерфейса MEMORY. Значением типа интерфейса по умолчанию является
MEMORY. Внутренние соединения блока ISERDESE2 в режиме MEMORY показа-
ны на рис. 11.3.
Допустимыми способами выравнивания синхронизации для блока ISERDESE2,
использующего интерфейс MEMORY, являются следующие:
• CLK управляется BUFIO, OCLK управляется BUFIO, CLKDIV управляется BUFR;
• CLK управляется ММСМ или PLL, OCLK управляется ММСМ, CLKDIV управля-
ется CLKOUT[0:6] того же самого ММСМ или PLL;
• CLK управляется BUFG, CLKDIV управляется другим BUFG.
Входы OCLK и CLKDIV должны быть номинально выровнены по фазе. Никакое
фазовое соотношение между CLK и OCLK не допускается. Калибровка должна быть
выполнена для надежной передачи данных от CLK к домену OCLK.
Тип интерфейса MEMORY-QDR. Режим MEMORY.QDR имеет сложную струк-
туру синхронизации, как результат требований памяти QDR. Эта установка атри-
бута INTERFACE-TYPE поддерживается только когда используется программа MIG
(Memory Interface Generator — генератор интерфейса памяти).
Тип интерфейса OVERSAMPLE. Режим OVERSAMPLE используется для захвата
двух фаз данных DDR. На рис. 11.7 более детально показано логическое представ-
ление примитива ISERDESE2 и то, как данные захватываются на возрастающем и
падающем фронтах CLK и OCLK.
Между сигналами CLK и OCLK должен быть фазовый сдвиг на 90°, поскольку
данные захватываются как синхросигналом CLK, так и OCLK, но выход ISERDESE2
синхронизируется на домен CLK. В этом режиме синхросигнал CLKDIV не исполь-
зуется.
Допустимыми способами выравнивания синхронизации для типа интерфейса
OVERSAMPLE являются:
Расширенные логические ресурсы ввода-вывода
171
Sample 1
Sample 2
Sample 3
Sample 4
SHIFTOUT1
SHIFTOUT2
О
Рис. 11.7. Логический вид примитива ISERDESE2 в режиме OVERSAMPLE
• CLK и CLKB управляются BUFIO; OCLKB управляется BUFIO, который являет-
ся фазой, сдвинутой на 90°; два буфера BUFIO управляются от одного блока
ММСМ;
• CLK и CLKB управляются BUFG; OCLKB управляется BUFG, который является
фазой, сдвинутой на 90°; буферы BUFG управляются от одного блока ММСМ.
Тип интерфейса MEMORY.DDR3. Режим MEMORY-DDR3 имеет сложную
структуру синхронизации, как результат требований пакета DDR3. Эта установка
атрибута INTERFACE-TYPE поддерживается только когда используется генератор
интерфейса памяти MIG.
11.1.4. Расширение ширины слова блока ISERDESE2
Два модуля ISERDESE2 могут использоваться для построения последовательно-
параллельного преобразователя размером больше, чем 1:8. Соединяя порты SHIFT-
OUT главного (master) модуля ISERDESE2 с портами подчиненного (slave) модуля
ISERDESE2 (рис. 11.8), последовательно-параллельный преобразователь может быть
расширен до размера 1:10 или 1:14 (только в режиме DDR).
Для дифференциального входа главный модуль ISERDESE2 должен быть на по-
ложительной стороне (вывод _Р) дифференциальной входной пары. Когда вход не
172
Раздел 11
Рис. 11.8. Структурная схема расширения ширины слова последовательно-параллельного
преобразователя для конфигурации 1:14
является дифференциальным, то входной буфер, ассоциирующийся с подчиненным
модулем ISERDESE2, является недоступным и каскадирование не используется.
При использовании расширения ширины слова последовательно-параллельного
преобразователя следует пользоваться следующими рекомендациями:
• главный и подчиненный модули ISERDESE2 должны быть соседними блоками;
оба модуля должны конфигурироваться в режиме NETWORKING, поскольку в
режиме MEMORY каскадирование невозможно;
• установите атрибут SERDES.MODE в значение MASTER для главного модуля
ISERDESE2 и в значение SLAVE для подчиненного модуля;
• подсоедините порты SHIFTIN подчиненного модуля к портам SHIFTOUT глав-
ного модуля;
• в подчиненном модуле в качестве выходов используйте порты Q3-Q8;
• применяйте атрибут DATA.WIDTH к обоим модулям: главному и подчиненному.
Временные параметры и функционирование во времени блока ISERDESE2 при-
ведены в приложении Б.
11.2. Подмодуль BITSLIP
Все блоки ISERDESE2 в FPGA 7-й серии содержат подмодуль Bitslip. Этот под-
модуль используется с целью выравнивания слов в приложениях сетевого типа с синх-
ронным источником. Подмодуль Bitslip в блоке ISERDESE2 переупорядочивает парал-
лельные данные, позволяя каждой комбинации повторяющегося последовательного
шаблона, полученного преобразователем, быть представленным в структуру FPGA.
Этот повторяющейся последовательный шаблон традиционно называется обуча-
ющим шаблоном (training pattern) или преамбулой (преамбулы поддерживаются мно-
гими сетевыми и телекоммуникационными стандартами). В некоторых интерфейсах
это может быть медленный предшествующий синхросигнал, который может рассмат-
риваться как повторяющаяся комбинация двоичных разрядов.
Расширенные логические ресурсы ввода-вывода
173
Bitslip Operation in SDR Mode
Bitslip Operations Executed Output Pattern (8:1)
Initial 10010011
1 00100111
2 01001110
3 10011100
4 00111001
5 01110010
6 11100100
у 11001001
Bitslip Operation in DDR Mode
Bitslip Operations Executed Output Pattern (8:1)
Initial 00100111
1 10010011
2 10011100
3 01001110
4 01110010
5 00111001
6 11001001
7 11100100
Рис. 11.9. Примеры функционирования Bitslip
При установке входа BITSLIP блока ISERDESE2, последовательный поток прихо-
дящих данных на параллельной стороне переупорядочивается. Эта операция повто-
ряется до тех пор, пока требуемая преамбула не появится на выходах ISERDESE2.
Таблицы на рис. 11.9 показывают эффекты функционирования Bitslip в режимах
SDR и DDR. Бит 8 входа ISERDESE2 является первым принятым битом. В данном
примере ширина данных равна 8. Функционирование подмодуля Bitslip является син-
хронным по отношению к синхросигналу CLKDIV. В режиме SDR каждая операция
Bitslip заставляет выходной шаблон сдвигаться влево на единицу. В режиме DDR
каждая операция Bitslip заставляет выходной шаблон чередоваться между сдвигом
вправо на 1 и сдвигом влево на 3. В этом примере на восьмой операции подмодуля
Bitslip выходной шаблон возвращается к начальному шаблону. Это предполагает, что
последовательные данные являются восьмью битами повторяющегося образца.
Может показаться, что bitslip является операцией циклического сдвига, одна-
ко это не так. Функционирование bitslip добавляет один бит к потоку входных дан-
ных и теряет n-й бит во входном потоке данных. Это заставляет функционирование
на повторяющихся шаблонах проявляться подобно функционированию циклическо-
го сдвига.
Подмодуль Bitslip доступен только в режиме NETWORKING, во всех других режи-
мах он запрещен. Для того чтобы вызвать функционирование Bitslip, порт BITSLIP
должен быть установлен в высокое значение на один цикл синхросигнала CLKDIV.
Bitslip не может устанавливаться для двух последовательных циклов CLKDIV. Bitslip
должен быть аннулирован по крайней мере на один цикл CLKDIV между двумя уста-
новками Bitslip.
В обоих режимах SDR и DDR общая задержка от момента, когда модуль ISER-
DESE2 захватывает установленный вход Bitslip, до момента, когда выходы Q1-Q8
модуля ISERDESE2 «битового проскальзывания» выбираются в логику FPGA синх-
росигналом CLKDIV, равна двум циклам CLKDIV.
С точки зрения приложений одна команда Bitslip должна быть дана только для
одного цикла CLKDIV. Логика пользователя должна ждать, по крайней мере, два
цикла в режиме SDR или три цикла в режиме DDR, прежде чем проанализировать
полученный шаблон данных и потенциально выдать другую команду Bitslip.
Временная модель подмодуля Bitslip приведена в приложении Б.
174
Раздел 11
11.3. Параллельно-последовательный преобразователь
OSERDESE2
Блок OSERDESE2 является специализированным параллельно-последователь-
ным преобразователем со специфической синхронизацией и логическими ресурса-
ми, спроектированными для упрощения реализации высокоскоростных интерфейсов
с синхронным источником. Каждый модуль OSERDESE2 включает специализирован-
ный преобразователь для данных и преобразователь для сигналов управления треть-
им состоянием. Как преобразователи данных, так и преобразователь 3-го состояния
могут конфигурироваться в режимах SDR и DDR. Преобразование данных может вы-
полняться в соотношении до 8:1, а также 10:1 и 14:1 (если используется расширение
ширины слова блока OSERDESE2). Преобразование 3-го состояния может быть вы-
полнено в соотношении до 4:1. Последнее является спецификой режима DDR3 для
поддержки высокоскоростных интерфейсов памяти.
11.3.1. Архитектура блока 0SERDESE2
Структурная схема блока OSERDESE2 показана на рис. 11.10.
Блок OSERDESE2 состоит из двух модулей: параллельно-последовательного пре-
образователя данных (Data Parallel-to-Serial Convert) и параллельно- последователь-
ного преобразователя третьего состояния (3-State Parallel-to- Serial Convert). Оба
модуля имеют одни и те же сигналы управления (CLK, CLKDIV, RST), однако разные
входные и выходные порты.
Параллельно-последовательный преобразователь данных. Параллельно-последо-
вательный преобразователь данных блока OSERDESE2 принимает от двух до восьми
параллельных данных от структуры FPGA (до 14 битов при использовании расшире-
ния ширины слова), преобразует данные и передает их в блок ЮВ через выход OQ.
Параллельные данные преобразуются от наименьшего номера вывода к наибольше-
Рис. 11.10. Структурная схема блока OSERDESE2
Расширенные логические ресурсы ввода-вывода
175
му (т. е. данные на входе D1 являются первым битом, переданным на выход OQ).
Параллельно-последовательный преобразователь данных функционирует в двух ре-
жимах: с базовой (SDR) и удвоенной (DDR) скоростью передачи данных.
Для преобразования данных блок OSERDESE2 использует два синхросигнала:
CLK и CLKDIV. CLK является высокоскоростным последовательным синхросигналом,
CLKDIV является разделенным параллельным синхросигналом. Синхросигналы CLK и
CLKDIV должны быть выровнены по фазе (детали см. в подразделе 11.4.3 «Методы
синхронизации блока OSERDESE2»).
Перед использованием к блоку OSERDESE2 должен быть применен сброс. Блок
OSERDESE2 содержит внутренний счетчик, который управляет потоком данных. От-
казанное в синхронизации с CLKDIV аннулирование сброса приведет к неопределен-
ному значению выхода.
Параллельно-последовательное преобразование третьего состояния. В дополне-
ние к параллельно-последовательному преобразователю данных, модуль OSERDESE2
содержит параллельно-последовательный преобразователь для управления 3-м состо-
янием блока ЮВ. В отличие от преобразования данных, преобразователь третьего
состояния может преобразовывать только до четырех бит параллельных сигналов
третьего состояния. Преобразователь третьего состояния не может каскадироваться.
Обратная связь выхода. Вывод OFB модуля OSERDESE2 имеет две функции:
• как путь обратной связи к выводу OFB модуля ISERDESE2;
• как соединение с блоком ODELAYE2 для реализации задержки выходного сигнала
модуля OSERDESE2 в блоке ODELAYE2.
Описание примитива OSERDESE2 приведено в приложении А.
11.3.2. Методы синхронизации блока OSERDESE2
Фазовое соотношение сигналов CLK и CLKDIV является важным в процессе
параллельно-последовательного преобразования. В идеале CLK и CLKDIV являются
выровненными по фазе в пределах определенного допуска. Допустимыми способами
выравнивания синхронизации для модуля OSERDESE2 являются:
• CLK управляется буфером BUFIO, CLKDIV управляется буфером BUFR;
• CLK и CLKDIV управляются шиной CLKOUT[0:6] того же самого блока ММСМ
или PLL;
• CLK и CLKDIV управляются двумя буферами BUFG.
Когда для управления сигналов CLK и CLKDIV модуля OSERDESE2 использует-
ся блок ММСМ, типы буферов, снабжающие модуль OSERDESE2, не могут смеши-
ваться. Например, если CLK управляется буфером BUFG, то CLKDIV также должен
управляться буфером BUFG.
11.3.3. Расширение ширины слова блока OSERDESE2
В каждой плитке (tile) ввода-вывода имеется два модуля OSERDESE2: один глав-
ный, другой подчиненный. Соединяя порты SHIFTIN главного модуля OSERDESE2 с
портами SHIFTOUT подчиненного модуля OSERDESE2, параллельно-последователь-
ный преобразователь может расширяться до соотношений 10:1 и 14:1 (только для
режима DDR). Для дифференциального выхода главный модуль OSERDESE2 дол-
жен быть на положительной стороне (вывод _Р) дифференциальной выходной пары.
Когда выход не является дифференциальным, выходной буфер, ассоциирующийся с
подчиненным OSERDESE2, недоступен и увеличение ширины невозможно.
Расширение ширины также не может использоваться, когда применяются компле-
ментарные ассиметричные стандарты (т. е. DIFF.HSTL и DIFF-SSTL). В этом случае
176
Раздел 11
оба блока OLOGICE2/3 в плитке ввода-вывода используются комплементарными ас-
симетричными стандартами для передачи двух комплементарных сигналов, приводя
к недоступности блоков OLOGICE2/3 для целей расширения ширины.
На рис. 11.11 показана структура параллельно-последовательного преобразова-
теля 10:1. Порты D3-D4 используются для последних двух битов параллельного ин-
терфейса на подчиненном модуле OSERDESE2.
Правила для увеличения ширины битов параллельно-последовательного преоб-
разователя:
• оба модуля должны быть соседними в паре главный-подчиненный;
• установите атрибут SERDES.MODE в значение MASTER для главного модуля и
в значение SLAVE для подчиненного модуля;
• подсоедините порты SHIFTIN главного модуля к портам SHIFTOUT подчинен-
ного модуля;
• в подчиненном модуле можно использовать только входные порты с D3-D4 для
ширины 10 и D3-D8 для ширины 14;
• атрибут DATA-WIDTH для обоих модулей должен иметь одинаковое значение;
• установите атрибут INTERFACE-TYPE в значение DEFAULT.
11.3.4. Задержки блока OSERDESE2
Задержки сигналов от входа до выхода блоков OSERDESE2 зависят от атрибу-
тов DATA-RATE и DATA-WIDTH. Задержка определяется как период времени между
следующими двумя событиями:
1) когда данные на возрастающем фронте синхросигналов CLKDIV поступят на
входы D1-D8 блока OSERDESE2;
2) когда первый бит последовательного потока появится на выходе OQ.
В табл. 11.2 приведены различные значения задержек блока OSERDESE2.
Временные параметры и функционирование во времени блока OSERDESE2 при-
ведены в приложении Б.
Расширенные логические ресурсы ввода-вывода
177
Таблица 11.2
Задержки блока OSERDESE2
DATA.RATE DATA-WIDTH Задержка
SDR 2:1 1 цикл CLK
3:1 2 цикла CLK
4:1 3 цикла CLK
5:1 4 цикла CLK
6:1 5 циклов CLK
7:1 6 циклов CLK
8:1 7 циклов CLK
DATA.RATE DATA.WIDTH Задержка
DDR 4.1 2 цикла CLK
6:1 3 цикла CLK
8:1 4 цикла CLK
10:1 5 циклов CLK
14:1 7 циклов CLK
11.4. Память FIFO ввода-вывода
FPGA 7-й серии имеют небольшие элементы IN.FIFO и OUT.FIFO, называемые
совместно IO.FIFO, которые расположены в каждом банке ввода-вывода. Хотя эти
элементы специально спроектированы для приложений памяти, они являются доступ-
ными как общие ресурсы. Для общего использования все входы и выходы трассируют-
ся через межсоединения. Наиболее популярным способом использования элементов
Ю-FIFO является интерфейс с внешними компонентами как расширение IOLOGIC
(т.е. ISERDES или IDDR и OSERDES или ODDR). Поскольку это общие возмож-
ности межсоединений, элементы IO.FIFO могут также служить как дополнительные
ресурсы структуры FPGA.
Каждый банк ввода-вывода содержит четыре элемента IO.FIFO, с одним элемен-
том IO.FIFO на группу байта. Группа байта (byte group) определяется как группа из
12 двусторонних выводов банка. Элементы IO.FIFO физически выровнены к группе
байта. Это выравнивание приводит к лучшей производительности, когда элементы
IO.FIFO используются для интерфейса к таким компонентам межсоединений ввода-
вывода, как входы и выходы элементов SERDES. Однако, несмотря на их расположе-
ние, элементы IO.FIFO могут также являться интерфейсом к ресурсам в структуре
FPGA и другим банкам ввода-вывода (см. документ UG475 7 Series FPGAs Packaging
and Pinout. Product Specification). Этот раздел посвящен использованию элемента
IO.FIFO как интерфейса с компонентами межсоединений ввода-вывода.
Для внешних данных, приходящих в FPGA, элемент IN.FIFO может соединять-
ся с ILOGIC (т.е. ISERDESE2, IDDR или IBUF) для получения входных данных и
передачи их на структуру FPGA. Для данных, следующих на выход FPGA, элемент
OUT.FIFO может соединяться с OLOGIC (т.е. OSERDESE2, ODDR или OBUF) для
передачи данных от структуры FPGA и посылке их через элемент OUT.FIFO в бу-
феры ввода-вы вода IOB.
Элемент IN.FIFO получает 4-разрядные данные от блока ILOGIC, в то время как
сторона структуры FPGA читает любые 4- или 8-битовые данные из массива. Элемент
OUT.FIFO получает 4- или 8-битовые данные от структуры FPGA, в то время как блок
OLOGIC считывает 4-разрядные данные из массива.
Каждый элемент IO.FIFO имеет 768-битовую запоминающую матрицу и может
быть расположен как двенадцать групп 4-разрядных данных или десять групп 8-раз-
рядных данных. Элемент IO.FIFO имеет глубину на девять записей памяти FIFO,
включая входные и выходные регистры. Типичное использование IO.FIFO: буфер
для параллельного интерфейса ввода-вывода пересекающегося между двумя домена-
ми частот (например, область буфера BUFR к или от области буферов BUFG или
BUFH) или последовательно-параллельный/параллельно-последовательный преобра-
зователь 2:1 для разъединения физического интерфейса (Physical Interface — PHY)
от структуры FPGA, чтобы ослабить требования к производительности структуры.
178
Раздел 11
WREN
WRCLK
Write Clock Domain Read Clock Domain
8 Clock Cycles । 8 Clock Cycles
ALMOSTFULL I ALMOSTEMPTY
RDEN
RDCLK
Рис. 11.12. Архитектура верхнего уровня элемента IO.FIFO
Элементы IO.FIFO являются более мелкими версиями регулярных блоков FIFO
и имеют подобную функциональность. Основная цель элементов IO-FIFO состоит в
том, чтобы поддерживать функции передачи данных ввода-вывода. Они не предназна-
чены для замены встроенных блоков FIFO или FIFO, основанных на LUT. Элементы
IO-FIFO поддерживают стандартную логику флагов, синхросигналы и управляющие
сигналы. Элементы IO-FIFO могут работать в двух режимах: 4x4 режима (1:1) или
4 х 8/8 х 4 режима (1:2/2:1).
Архитектура элемента IO.FIFO показана на рис. 11.12. Элемент IO.FIFO име-
ет входной регистр, ядро FIFO с глубиной записи 7 и выходной регистр. Входной и
выходной регистры являются неотъемлемой частью элемента IO.FIFO, которые обес-
печивают восемь мест для хранения 8 записей элемента IO-FIFO.
11.4.1. Элемент IN.FIFO
Элемент IN.FIFO физически выравнивается к группе байта ввода-вывода для оп-
тимизации производительности. Глубина в 8 записей элемента IN.FIFO поддерживает
передачу данных, используя два режима работы: 4x4 и 4x8. Оба режима поддержи-
вают флаги FULL, EMPTY, ALMOSTFULL и ALMOSTEMPTY.
Режим 4x4. Этот режим конфигурирует FIFO, чтобы иметь 12 входов данных
(D) шириной 4 бита и 12 выходов данных (Q) шириной 4 бита. Порты D0[3:0]—
D9[3:0] отображаются на порты Q0[3:0]—Q9[3:0]. Порты D5[7:4] и D6[7:4] являются
двумя дополнительными входами данных портов D10[3:0] и Dll[3:0], которые ото-
бражаются на выходы Q5[7:4] и Q6[7:4] дополнительных выходных портов Q10 [3:0]
и Qll[3:0]. Другие порты Qn[7:4] не используются. В табл. 11.3 показаны детали
функционирования режима 4x4.
Режим 4x8. Этот режим конфигурирует FIFO, чтобы иметь 10 4-разрядных вхо-
дов данных (D) и 10 8-разрядных выходов данных (Q). В режиме 4x8 4-разрядные
входные данные демультиплексируются для формирования 8-разрядных выходных дан-
ных. Режим 4x8 обычно используется, когда частота выходного синхросигнала боль-
ше, чем половина входной тактовой частоты, и таким образом, выходные данные
Расширенные логические ресурсы ввода-вывода
179
Таблица 11.3
Отображение входов и выходов данных элемента IN.FIFO
в режиме 4x4
Отображение He используется
D10[3:0] D0[3:0] -> Q0[3:0] Dl[3:0] -> Ql[3:0] D2[3:0] -> Q2[3:0] D3[3:0] -> Q3[3:0] D4[3:0] Q4[3:0] D5[3:0] Q5[3:0] D6[3:0] Q6[3:0] D7[3:0] -> Q7[3:0] D8[3:0] Q8[3:0] D9[3:0] -> Q9[3:0] является D5[7:4] —> Q5[7:4) Q0[7:4] Ql[7:4] Q2[7:4] Q3[7:4] Q4[7:4] Q5[7:4] Q6[7:4] Q7[7:4] Q8[7:4] Q9[7:4]
Dll [3:0] является D6[7:4] —> Q6[7:4]
Таблица 114
Отображение входов и выходов данных
элемента IN.FIFO в режиме 4x8
Отображение
D0[3:0] Q0[7:0]
Dl[3:0] -»• Ql[7:0]
D2[3:0] -> Q2[7:0]
D3[3:0] -> Q3[7:0]
D4[3:0] -» Q4[7:0]
D5[3:0] -» Q5[7:0]
D6[3:0] -» Q6[7:0]
D7[3:0] -» Q7[7:0]
D8[3:0] -> Q8[7:0]
D9[3:0] -> Q9[7:0]
имеют удвоенную ширину входных данных. Отображения входов и выходов в режиме
4x8 приведены в табл. 11.4.
Примитив элемента IN-FIFO приведен в приложении А.
11.4.2. Элемент OUT-FIFO
Элемент OUT.FIFO располагается рядом с соответствующим элементом IN-FIFO
и физически выравнивается к байтовой группе ввода-вывода для оптимизации про-
изводительности. Элемент OUT.FIFO имеет глубину 8 записей и поддерживает пе-
редачу данных в двух форматах 4x4 и 8x4.
Режим 4x4. Этот режим конфигурирует FIFO, чтобы иметь 12 4-битовых входов
данных (D) и 12 4-битовых выходов данных (Q). Порты D0[3:0]—D9[3:0] отображают-
ся на порты Q0[3:0]—Q9[3:0]. Порты D5[7:4] и D6[7:4] являются двумя дополнитель-
ными входными портами, которые обслуживаются как порты D10[3:0] и Dll[3:0] и
отображаются на выходные порты Q5[7:4] и Q6[7:4]. Другие порты В[7:4] не исполь-
зуются. В табл. 11.5 показано детальное отображение портов в режиме 4x4. Оба
режима поддерживают флаги FULL, EMPTY, ALMOSTFULL и ALMOSTEMPTY.
Режим 8x4. Этот режим конфигурирует FIFO, чтобы иметь 10 8-битовых входов
данных (D) и 10 4-битовых выходов данных (Q). В режиме 4x8 мультиплексор 2:1 в
выходном пути данных преобразует 8-битовые входные данные в 4-битовые выходные
данные. Режим 8x4 обычно используется, когда частота выходного синхросигнала в
два раза больше частоты входного синхросигнала и, таким образом, выходные данные
Таблица 11.5
Отображение входов и выходов данных элемента OUT_FIFO
в режиме 4x4
Отображение He используется
D10[3:0] D0[3:0] -» Q0[3:0] l[3:0] -> QI [3:0] D2[3:0] -» Q2[3:0] D3[3:0] -» Q3[3:0] D4[3:0] -> Q4[3:0] D5[3:0] -> Q5[3:0] D6[3:0] -> Q6[3:0] D7[3:0] -» Q7[3:0] D8[3:0] Q8[3:0] D9[3:0] -> Q9[3:0] является D5[7:4] —> Q5[7:4] Q0[7:4] QI [7:4] Q2[7:4] Q3[7:4] Q4[7:4] Q7[7:4] Q8[7:4] Q9[7:4]
Dll[3:0] является D6[7:4] —> Q6[7:4]
Таблица 11.6
Отображение входов и выходов данных
элемента OUT_FIFO в режиме 4x4
Отображение
D0[7:0] - -> Q0[3:0]
Dl[7:0] - -> Ql[3:0]
D2[7:0] - -> Q2[3:0]
D3[7:0] - -> Q3[3:0]
D4[7:0] - э Q4[3:0]
D5[7:0] - -> Q5[3:0]
D6[7:0] - -> Q6[3:0]
D7[7:0] - э Q7[3:0]
D8[7:0] - э Q8[3:0]
D9[7:0] - э Q9[3:0]
180
Раздел 11
являются половинной ширины входных данных. В табл. 11.6 показано детальное
отображение портов в режиме 8x4.
Примитив элемента OUT-FIFO приведен в приложении А.
11.4.3. Перезагрузка элемента IN.FIFO
Элемент IO.FIFO имеет единственный асинхронный сброс, который внутренне ре-
синхронизируется областями синхронизации как для чтения, так и для записи. Чтобы
гарантировать правильный сброс, RESET должен быть установлен в высокий уро-
вень в течение, по крайней мере, четырех циклов, либо RDCLK, либо WRCLK (какой
медленнее) до записи в IO.FIFO. Сигналы RDEN и WREN должны удерживаться на
низком уровне, пока RESET устанавливается.
Элемент IO.FIFO должен удерживаться в состоянии сброса до тех пор, пока синх-
росигналы либо записи, либо чтения устанавливаются и стабилизируются. Аналогич-
но, если после конфигурации синхросигналы чтения или записи все еще не пригодны,
элемент IO.FIFO должен быть сброшен (как описано выше) после того, как синхро-
сигналы будут сформированы.
11.4.4. Флаги элемента IO.FIFO
Флаг FULL, когда установлен в высокий уровень, сигнализирует, что ядро FIFO
и входной регистр оба полные. Состояние выходного регистра игнорируется.
Флаг EMPTY указывает на состояние данных в выходном регистре. Когда флаг
EMPTY установлен в высокий уровень, данные в выходном регистре недействительны.
Флаги ALMOSTEMPTY и ALMOSTFULL предоставляют раннюю индикацию,
что элемент IO.FIFO является приближающимся к своим пределам. Эти флаги мо-
гут конфигурироваться для установки в один или два цикла перед тем, как IO.FIFO
достигнет своего полного или пустого состояния. Значение 1 указывает, что оста-
лось только одно слово для чтения или записи. Значение 2 указывает, что осталось
только два слова для чтения или записи.
Флаги ALMOSTEMPTY и ALMOSTFULL необязательно перекрываются с флага-
ми FULL и EMPTY. Можно иметь установленный ALMOSTEMPTY и аннулированный
EMPTY перед установкой EMPTY. Это произойдет, если WRCLK будет более чем в
два раза быстрее, чем RDCLK.
11.5. Выводы
К расширенным логическим ресурсам ввода-вывода FPGA 7-й серии относят-
ся входные последовательно-параллельные преобразователи ISERDESE2 и выходные
параллельно-последовательные преобразователи OSERDESE2.
Одной из областей применения блоков ISERDESE2 и OSERDESE2 является высо-
коскоростная передача данных между двумя FPGA, расположенными на одной плате.
Блок ISERDESE2 представляет собой последовательно-параллельный преобразо-
ватель с определенными логическими свойствами и специфической синхронизацией,
спроектированный для упрощения реализации высокоскоростных приложений с син-
хронным источником данных.
Блок ISERDESE2 может быть настроен для реализации следующих типов интер-
фейсов (режимов работы): MEMORY (по умолчанию), MEMORY.DDR3, MEMORY.
QDR, OVERSAMPLE и NETWORKING.
Блок ISERDESE2 состоит из модуля собственно последовательно-параллельного
преобразователя, мультиплексоров выбора источника последовательных данных, мо-
дуля сигнала разрешения синхронизации входа, а также подмодуля Bitslip для пере-
упорядочивания потока приходящих данных.
Расширенные логические ресурсы ввода-вывода
181
Модуль разрешения синхронизации функционирует как последовательно-парал-
лельный преобразователь 2:1, синхронизируется сигналом CLKDIV. Данный модуль
необходим для двунаправленных интерфейсов памяти, когда блок ISERDESE2 конфи-
гурируется для преобразователя 1:4 в режиме DDR.
Порт OFB в модулях ISERDESE2 и OSERDESE2 может использоваться для пе-
редачи данных, передаваемых на OSERDESE2, обратно к ISERDESE2.
При передаче данных между различными FPGA блоки OSERDESE2 и ISERDESE2
взаимодействуют между собой, при этом биты на входах OSERDESE2 имеют обрат-
ный порядок на выходах блока ISERDESE2.
Методы синхронизации или типы интерфейсов блока ISERDESE2, фактически,
являются режимами его работы, которые определяют не только способ синхрониза-
ции, но и внутреннюю структуру блока ISERDESE2.
Режим MEMORY-QDR имеет сложную структуру синхронизации, как результат
требований памяти QDR. Этот режим поддерживается только когда используется
программа MIG (генератор интерфейса памяти).
Режим OVERSAMPLE используется для захвата двух фаз данных DDR.
Режим MEMORY-DDR3 имеет сложную структуру синхронизации, как результат
требований пакета DDR3. Этот режим поддерживается только когда используется
генератор интерфейса памяти MIG.
Два модуля ISERDESE2 могут использоваться для построения последовательно-
параллельного преобразователя размером до 1:10 или 1:14 (только в режиме DDR).
Подмодуль Bitslip используется для выравнивания слов в приложениях сетевого
типа с синхронным источником. Подмодуль Bitslip переупорядочивает параллельные
данные, позволяя каждой комбинации повторяющегося обучающего шаблона, полу-
ченного преобразователем, быть представленным в структуру FPGA.
При установке входа BITSLIP блока ISERDESE2, последовательный поток прихо-
дящих данных на параллельной стороне переупорядочивается. Эта операция повто-
ряется до тех пор, пока требуемая преамбула не появится на выходах ISERDESE2.
Подмодуль Bitslip доступен только в режиме NETWORKING, во всех других ре-
жимах он запрещен.
Блок OSERDESE2 является специализированным параллельно-последователь-
ным преобразователем для упрощения реализации высокоскоростных интерфейсов
с синхронным источником. Каждый модуль OSERDESE2 включает специализирован-
ный преобразователь данных и преобразователь сигналов управления третьим состо-
янием. Оба преобразователя могут конфигурироваться в режимах SDR и DDR.
Преобразование данных может выполняться в соотношении до 8:1, а также 10:1 и
14:1 (если используется расширение ширины слова блока OSERDESE2). Преобразо-
вание 3-го состояния может быть выполнено в соотношении до 4:1. Последнее являет-
ся спецификой режима DDR3 для поддержки высокоскоростных интерфейсов памяти.
Блок OSERDESE2 состоит из двух модулей: параллельно-последовательного пре-
образователя данных и параллельно-последовательного преобразователя третьего со-
стояния. Оба модуля имеют одни и те же сигналы управления (CLK, CLKDIV, RST),
однако разные входные и выходные порты.
Параллельно-последовательный преобразователь данных функционирует в двух
режимах: с базовой (SDR) и удвоенной (DDR) скоростью передачи данных.
Для преобразования данных блок OSERDESE2 использует два синхросигнала:
CLK и CLKDIV. CLK является высокоскоростным последовательным синхросигналом,
CLKDIV является разделенным параллельным синхросигналом. Синхросигналы CLK
и CLKDIV должны быть выровнены по фазе.
182
Раздел 11
Перед использованием к блоку OSERDESE2 должен быть применен сброс для
инициализации внутреннего счетчика, который управляет потоком данных.
Преобразователь третьего состояния может преобразовывать только до четырех
битов параллельных сигналов третьего состояния. Преобразователь третьего состо-
яния не может каскадироваться.
Вывод OFB модуля OSERDESE2 имеет две функции: как путь обратной связи к
выводу OFB модуля ISERDESE2; как соединение с блоком ODELAYE2 для реализации
задержки выходного сигнала модуля OSERDESE2 в блоке ODELAYE2.
FPGA 7-й серии имеют небольшие элементы памяти FIFO ввода-вывода IN.FIFO
и OUT.FIFO (IO.FIFO), которые расположены в каждом банке ввода-вывода.
Наиболее общим способом использования элементов IO.FIFO является интер-
фейс с внешними компонентами как расширение IOLOGIC (т.е. ISERDES или IDDR
и OSERDES или ODDR). Элементы IO.FIFO могут также использоваться внутрен-
ней логикой FPGA.
Каждый банк ввода-вывода содержит четыре элемента IO.FIFO, с одним эле-
ментом IO.FIFO на группу байта. Группа байта (byte group) определяется как груп-
па из 12 двусторонних выводов банка. Элементы IO.FIFO физически выровнены к
группе байта.
Элемент IN.FIFO может соединяться с блоком ILOGIC (т.е. ISERDESE2, IDDR
или IBUF) для получения входных данных и передачи их на структуру FPGA. Эле-
мент OUT.FIFO может соединяться с OLOGIC (т.е. OSERDESE2, ODDR или OBUF)
для передачи данных от структуры FPGA и посылке их через элемент OUT.FIFO в
буферы ввода-вывода ЮВ.
Элемент IO.FIFO имеет входной регистр, ядро FIFO с глубиной записи 7 и выход-
ной регистр. Входной и выходной регистры являются неотъемлемой частью элемента
IO.FIFO. Таким образом, элемент IO.FIFO имеет глубину на девять записей памяти
FIFO (включая входные и выходные регистры).
Типичное использование IO.FIFO: буфер для параллельного интерфейса ввода-
вывода пересекающегося между двумя доменами частот или последовательно-парал-
лельный/параллельно-последовательный преобразователь 2:1 для разъединения фи-
зического интерфейса от структуры FPGA, чтобы ослабить требования к произво-
дительности структуры.
Глубина в 8 записей элемента IN.FIFO поддерживает передачу данных, используя
два режима работы: 4x4 и 4x8. Оба режима поддерживают флаги FULL, EMPTY,
ALMOSTFULL и ALMOSTEMPTY.
Элемент OUT.FIFO располагается рядом с соответствующим элементом IN.FIFO
и физически выравнивается к байтовой группе ввода-вывода для оптимизации про-
изводительности. Элемент OUT.FIFO имеет глубину 8 записей и поддерживает пере-
дачу данных в двух форматах: 4x4 и 8x4. Оба режима поддерживают флаги FULL,
EMPTY, ALMOSTFULL и ALMOSTEMPTY.
12 Ресурсы синхронизации FPGA 7-й серии
Проектирование подсистемы синхронизации играет важную роль в разработке
цифровой системы. Подсистема синхронизации непосредственно влияет на произво-
дительность проекта, на потребляемую мощность и, в итоге, на стоимость. Сложные
цифровые системы отличает необходимость наличия нескольких источников синхро-
сигналов для управления различными частями проекта (логикой, памятью, вводом-
выводом, последовательными интерфейсами данных, контроллерами стандартных
протоколов и др.). Проблема усугубляется очень жесткими системными требова-
ниями на временные параметры каждого управляющего синхросигнала, такие как:
• частота синхронизации;
• параметры скважности (длительность высокого и низкого уровней в пределах
такта);
• величина фазового сдвига относительно опорного или иного синхросигнала и др.
К самим синхросигналам также предъявляются очень жесткие требования к их
качеству. Синхросигналы современных цифровых систем должны отличаться:
• малым перекосом (фазовым сдвигом) при доставке синхросигнала к различным
входам синхронизации компонентов проекта (точкам синхронизации проекта);
• уменьшенной флуктуацией (дрожанием фронтов);
• отсутствием помех (glitch), кратковременных импульсов, которые могут возни-
кать во время функционирования системы и др.
Ресурсы синхронизации FPGA 7-й серии представляют собой достаточно разви-
тую иерархическую структуру, содержащую различные компоненты, которая на основе
внешних опорных (эталонных) синхросигналов позволяет сформировать необходимые
сигналы синхронизации для управления цифровой системой.
12.1. Введение в ресурсы синхронизации FPGA 7-й серии
Ресурсы синхронизации FPGA 7-й серии включают глобальные и региональные
ресурсы, а также блоки формирования синхросигналов (блоки управления синхрони-
зацией — Clock Management Tiles — CMTs). Каждый блок СМТ в свою очередь
включает один блок управления синхронизацией смешанного режима (mixed-mode
clock manager — ММСМ) и один блок фазовой автоподстройки частоты (phase-locked
loop — PLL).
С точки зрения системы синхронизации каждое устройство FPGA 7-й серии де-
лится на регионы синхронизации. Число регионов синхронизации зависит от размеров
устройства и в FPGA 7-й серии может изменяться от 4 для малых устройств до 24 для
больших устройств. Регион синхронизации охватывает все синхронизируемые элемен-
ты в некоторой области FPGA: блоки CLB, блоки ввода-вывода, приемопередатчики
GT, блоки DSP, блоки памяти RAM, блоки СМТ и др.
В центре каждой FPGA 7-й серии проходит вертикальный канал глобальной син-
хронизации (Global Clock Column), который делит устройство на левую и правую сто-
рону. Регион синхронизации распространяется от канала глобальной синхронизации
184
Раздел 12
Рис. 12.1. Укрупненная архитектура ресурсов синхронизации FPGA 7-й серии
влево или вправо до границы устройства. Каждый регион синхронизации содержит
также один блок формирования синхросигналов СМТ (рис. 12.1).
В высоту один регион синхронизации занимает 50 блоков логических CLB. Обыч-
но регион синхронизации, кроме блоков CLB, охватывает один банк ввода-вывода (50
двунаправленных выводов). Кроме того, в зависимости от конкретного устройства
регион синхронизации может охватывать 10 блоков памяти RAM 36К, 20 секций DSP,
СМТ Column
I/O Column
Рис. 12.2. Ресурсы региона синхронизации
Ресурсы синхронизации FPGA 7-й серии
185
4 (один квадрант) последовательных приемопередатчиков GT, а также половину стол-
бца интегрированного блока для PCI Express.
В центре каждого региона синхронизации проходит горизонтальный канал синхро-
низации (horizontal clock row — HROW). Блоки CLB располагаются по 25 блоков CLB
вверх и 25 блоков CLB вниз от канала HROW. Внешние синхросигналы в FPGA 7-й
серии могут поступать только на специальные выводы синхронизации (clock-capable
input-output — ССЮ), называемые в дальнейшем просто СС-входы. Каждый банк
ввода-вывода содержит 4 таких вывода: два выше и два ниже горизонтального ка-
нала синхронизации HROW (рис. 12.2).
12.1.1. Ресурсы трассировки синхронизации
Ресурсы трассировки синхронизации в FPGA 7-й серии представляют собой ие-
рархическую структуру, которая состоит из:
• линий канала глобальной синхронизации;
• линий горизонтальных каналов синхронизации;
• деревьев региональной синхронизации;
• деревьев синхронизации ввода-вывода.
Каждое устройство FPGA 7-й серии содержит 32 линии глобальной синхрониза-
ции, которые образуют в центре устройства магистраль глобальной синхронизации
(Global Clocking Backbone)*. В регионы синхронизации глобальные синхросигналы
поступают по линиям горизонтального канала HROW, который содержит 12 линий.
К конкретной точке в регионе синхронизации глобальные синхросигналы поступают
по деревьям региональной синхронизации, а к компонентам ввода-вывода — по де-
ревьям синхронизации ввода-вывода.
Все линии глобального и горизонтального каналов синхронизации, а также де-
ревья региональной синхронизации и синхронизации ввода-вывода управляются со-
ответствующими буферами.
Отметим, что по линиям синхронизации FPGA 7-й серии, кроме синхросигналов,
могут передаваться сигналы управления установки или сброса SR (set/reset), а также
разрешения синхронизации СЕ (clock enable).
12.1.2. Буферы синхронизации
Важную роль в системе синхронизации FPGA 7-й серии играют буферы синх-
ронизации. Дело в том, что компонентами синхронизации пользователь управляет
через примитивы буферов синхронизации. Но каждый буфер синхронизации имеет
конкретное физическое местоположение в системе синхронизации. Отсюда следуют
очень жесткие ограничения на входные сигналы примитивов буферов синхронизации
и ограничения на элементы, которыми может управлять каждый буфер.
Для управления ресурсами трассировки синхронизации служат следующие бу-
феры:
• глобальные BUFG (BUFGCTRL);
• горизонтальные BUFH/BUFHCE;
• региональные BUFR;
• ввода-вывода BUFIO;
• многорегиональные BUFMR.
Глобальные буферы синхронизации. Буферы глобальных синхросигналов
(BUFGCTRL или просто BUFG) управляют линиями глобальных синхросигналов и
На рис. 12.1 магистраль глобальной синхронизации названа каналом глобальной синх-
ронизации (Global Clock Column).
186
Раздел 12
должны использоваться для доступа к глобальным линиям синхронизации. Каждый
регион синхронизации может поддерживать до 12 этих глобальных линий синхрони-
зации, используя 12 линий горизонтального канала.
Глобальные буферы синхронизации BUFG:
• могут использоваться как схема стробирования синхронизации для разрешения
или запрещения синхросигналов, которые охватывают несколько регионов син-
хронизации;
• могут использоваться как свободные от помех (glitch) мультиплексоры для вы-
бора между двумя источниками синхросигналов или отключения на расстоянии
от неисправного источника синхросигнала;
• могут управляться блоками СЫТ для устранения задержки распространения син-
хросигнала или корректировки задержки синхросигнала по отношению к другому
синхросигналу.
Горизонтальные буферы синхронизации. Горизонтальный буфер синхронизации
BUFH/BUFHCE обеспечивает доступ к линиям глобальной синхронизации в одном
регионе синхронизации через горизонтальный канал синхронизации HROW. Он может
также использоваться как схема стробирования синхросигналов (BUFHCE) для одного
региона синхронизации. Каждый регион синхронизации может поддерживать до 12
синхросигналов, используя 12 горизонтальных линий синхронизации.
Региональные буферы синхронизации. Региональный буфер синхронизации
BUFR управляет деревом региональной синхронизации, которое управляет всеми на-
значениями синхронизации в том же регионе синхронизации и может программиро-
ваться для деления приходящей тактовой частоты.
Буферы синхронизации ввода-вывода. Буфер синхронизации ввода-вы вода
BUFIO управляет деревом синхронизации ввода-вывода, обеспечивая доступ к синхро-
низации всех последовательных ресурсов ввода-вывода в том же банке ввода-вывода.
Совместно с программируемым параллельно-последовательным/последователь-
но-параллельным преобразователем (serializer/deserializer) в блоке ввода-вывода IOB
буферы синхронизации BUFIO и BUFR позволяют системам с синхронными источ-
никами пересекать области синхронизации без использования дополнительных ло-
гических ресурсов.
Многорегиональные буферы синхронизации. Многорегиональные буферы синх-
ронизации BUFMR позволяют региональным синхросигналам и синхросигналам вво-
да-вывода охватывать вертикально до трех соседних регионов синхронизации.
В одном регионе синхронизации или банке ввода-вывода может поддерживать-
ся до четырех уникальных синхросигналов ввода-вывода и до четырех уникальных
региональных синхросигналов.
Ресурсы трассировки высокопроизводительных синхросигналов (High-performan-
ce clocks) подсоединяют определенные выходы блоков СМТ к внешним выводам с
очень малой флуктуацией и минимальным искажением скважности.
12.1.3. Блоки формирования синхросигналов СМТ
Каждый регион синхронизации в FPGA 7-й серии содержит блок формирования
синхросигналов СМТ (называемый также блоком управления синхронизацией), кото-
рый, в свою очередь, содержит один блок управления синхронизацией смешанного
режима (mixed-mode clock manager — ММСМ) и один блок фазовой автоподстройки
частоты (phase-locked loop — PEL).
Блоки ММСМ и PLL служат как синтезаторы частоты для широкого диапазо-
на частот, фильтры флуктуации (jitter) для внешних и внутренних синхросигналов
Ресурсы синхронизации FPGA 7-й серии
187
а также устраняют перекос (deskew) синхросигналов. Блок PLL включает подмно-
жество функций блока ММСМ. Блоки ММСМ и PLL могут использовать эталонные
(опорные) синхросигналы, которые поступают от внешних выводов.
Блоки ММСМ имеют широкие возможности по сдвигу фазы в каждом направ-
лении и могут использоваться в динамическом режиме сдвига фазы. Блоки ММСМ
также имеют дробный (fractional) счетчик либо в цепи обратной связи, либо в выход-
ном пути, который обеспечивает большую гранулярность (степень детализации) для
возможностей синтеза частоты. Программа (мастер синхронизации) LogiCORE IP
служит для упрощения использования блоков ММСМ и PLL при создании сети синх-
ронизации в проектах FPGA 7-й серии. Мастер синхронизации выбирает подходящие
ресурсы блока СМТ и оптимально конфигурирует ресурсы СМТ и соответствующие
ресурсы трассировки синхронизации.
12.2. Архитектура ресурсов синхронизации FPGA 7-й серии
12.2.1. Обобщенная архитектура системы синхронизации
На рис. 12.3 показан верхний уровень архитектуры ресурсов синхронизации FPGA
7-й серии.
Центральные вертикальные линии синхронизации образуют магистраль синхро-
низации (Clock Backbone) и делят устройство на левый и правый регионы синхрони-
зации. Горизонтальная центральная линия (Horizontal Central Line) делит устройство
на верхнюю и нижнюю части. Ресурсы магистрали синхронизации зеркально отра-
жаются на обе стороны горизонтальных соседних регионов, расширяя ресурсы гло-
Clocking
Center
188
Раздел 12
бальной синхронизации на соседний горизонтальный регион. Верхнюю и нижнюю
части устройства отделяет два множества глобальных буферов синхронизации BUFG:
16 буферов для верхней части устройства и 16 буферов для нижней части устройст-
ва. Буферы BUFG не принадлежат регионам синхронизации и могут достигать любой
синхронизируемой точки в устройстве. Все горизонтальные ресурсы синхронизации
находятся в центре регионального горизонтального канала синхронизации HROW.
Вертикальные (не региональные) ресурсы синхронизации содержатся в магистрали
синхронизации (Clock Backbone) или в магистрали блока СМТ (СМТ Backbone).
12.2.2. Архитектура региона синхронизации
На рис. 12.4 показаны ресурсы региона синхронизации и их основные соединения.
Буфер глобальной синхронизации BUFG может управлять синхронизируемыми
элементами в каждом регионе через канал HROW, даже если он физически здесь не
расположен. Буферы горизонтальной синхронизации BUFH через канал HROW управ-
ляют каждой синхронизируемой точкой в регионе. Буферы BUFG и BUFH совместно
используют линии трассировки в канале HROW.
Буферы ввода-вывода BUFIO и буферы региональной синхронизации BUFR рас-
полагаются внутри банков ввода-вывода. Буфер BUFIO управляет только ресурсами
Рис. 12.4. Основной вид региона синхронизации
Ресурсы синхронизации FPGA 7-й серии
189
То Bank Above
Four BUROs
To Bank Below
Рис. 12.5. Регион синхронизации на правой стороне устройства
синхронизации ввода-вывода, в то время как буфер BUFR управляет как ресурсами
ввода-вывода так и ресурсами структуры FPGA (Fabric).
Буфер BUFMR обеспечивает многорегиональные соединения в виде цепочки бу-
феров BUFIO и BUFR. Входы синхронизации (clock-capable inputs — СС-входы) под-
соединяют внешние синхросигналы к ресурсам синхронизации в устройстве. Опре-
деленные ресурсы могут подсоединяться к регионам выше и ниже через магистраль
блока СМТ (СМТ Backbone).
На рис. 12.5 показан более детальный вид ресурсов синхронизации в регионе
синхронизации на правой стороне устройства.
12.2.3. Взаимодействие буферов BUFG, BUFH и блока СМТ
На рис. 12.6 показана детальная структура соединений глобального буфера BUFG
и регионального буфера BUFH, блока СМТ и входов синхронизации, а также число
доступных ресурсов в регионе (здесь показана правая сторона региона).
Любые 4 входа синхронизации СС могут управлять компонентами PLL/ММСМ в
блоке СМТ и буфером BUFH. Буферы BUFG и BUFH совместно используют 12 линий
в канале HROW и могут управлять всеми точками синхронизации в регионе. Буферы
BUFG могут также управлять буферами BUFH. Это позволяет с помощью сигналов
разрешения синхронизации (clock enables - СЕ) буферов BUFHCE в одном регионе
использовать различные глобальные сигналы синхронизации.
Квадрант приемопередатчиков GT (GT Quad) в магистрали синхронизации имеет
10 специализированных трасс для управления блоком СМТ и буферами синхрониза-
ции. Буферы BUFR, расположенные в банке ввода-вывода, имеют 4 трассы, управ-
ляющие точками синхронизации в структуре FPGA, блоке СМТ и буфере BUFG.
Блоки СМТ могут, с некоторыми ограничениями, управлять другими блоками
СМТ в соседних регионах через магистраль СМТ (СМТ Backbone). Аналогично,
входы синхронизации СС могут, с теми же самыми ограничениями, управлять блоками
СМТ в соседних регионах. Входы синхронизации СС могут управлять буферами BUFG
190
Раздел 12
Рис. 12.6. Детали региона синхронизации (взаимодействие буферов BUFG, BUFH и блока СМТ)
везде в той же самой стороне (верхней или нижней) устройства. В магистрали СМТ
имеется четыре трассы для поддержки соединений между вертикальными регионами.
Источники синхронизации из одного региона могут управлять ресурсами буферов
синхронизации в их собственных регионах, а также в соседнем горизонтальном реги-
оне. Блоки СМТ, входы синхронизации СС и блоки GT могут управлять синхросигна-
лами в горизонтальном соседнем регионе через буфер BUFH, а также подсоединяться
к буферам BUFG в той же самой части (верхней или нижней) устройства.
Логика FPGA управляет выводами СЕ буферов BUFG и BUFH. Она может также
управлять синхросигналами в тех же самых буферах, но следует соблюдать осторож-
ность, потому что такая синхронизация не предсказуема.
12.2.4. Взаимодействие буферов BUFR, BUFIO, BUFMR
и приемопередатчиков GT
На рис. 12.7 показана более детальная структура ресурсов синхронизации ввода-
вывода и соответствующие соединения.
Каждый банк ввода-вывода содержит 4 буфера BUFIO и 4 буфера BUFR. Каж-
дый из этих буферов синхронизации может управляться определенной парой входов
синхронизации или может непосредственно управляться определенным выходным син-
хросигналом блока ММСМ. Кроме того, буферы BUFR имеют 4 трассы, управляющие
точками синхронизации в структуре FPGA, блоке СМТ и буфере BUFG.
Ресурсы синхронизации FPGA 7-й серии
191
BUFG.' 1 1 1 1 | Clock | Backbone 1 1 1 1 1 1 1 1 1 Гч 1 1^ жВ: 1 mm 1 1 1 1 1 1 1 1 1 1 1 1
i I
Fabric
СМТ
Column
PLl
j i
Fabric s
SRCC
Pair
MRCC
Pair
вино
bufmr |
bufmr
М ЙЙЙЯЬ-
MW жУя8*Е5аг^*Ч
<Q>
<1>
<2>
<3>
MRCC
Pair
SRCC
Pair
CMT
Backbone
Рис. 12.7. Детали региона синхронизации с буферами BUFR, BUFMR и BUFIO
Две пары входов синхронизации, называемые MRCC, поддерживают схему много-
региональной синхронизации. Пара выводов MRCC может управлять определенным
буфером BUFMR, который поочередно может управлять буферами BUFIO и BUFR
в том же самом и соседнем регионах, способствуя многорегиональным интерфей-
сам. Аналогично, квадрант приемопередатчиков GT также может управлять буфе-
рами BUFMR.
Выходы ММСМ[3:0] блока ММСМ имеют специализированный высокопроизводи-
тельный дифференциальный путь к буферам BUFR и BUFIO. Это свойство также от-
носится к высокопроизводительным синхросигналам (high-performance clock — НРС).
12.2.5. Архитектурные особенности отдельных семейств и устройств
FPGA 7-й серии
Хотя все FPGA 7-й серии построены по единой архитектуре, однако имеются
некоторые архитектурные отличия между семействами и устройствами в пределах
одного семейства. Каждая FPGA 7-й серии имеет минимум один полный столбец
ввода-вывода на левой стороне устройства. Блок GT может быть любым из после-
довательных приемопередатчиков, поддерживаемых FPGA 7-й серии (GTP, GTX или
GTH). Устройства с блоками GT либо имеют смешанный столбец блоков GT и бло-
ков ввода-вывода на правой стороне устройства (некоторые устройства семейств Kin-
192
Раздел 12
tex-7 и Artix-7), либо имеют полный столбец блоков GT с правой стороны (некото-
рые устройства семейств Kintex-7 и Vitrex-7) и полный столбец блоков ввода-вывода
с правой стороны устройства. Другие устройства семейства Vitrex-7 имеют полные
столбцы GT на правой и левой сторонах с полными столбцами блоков ввода-вывода
также на правой и левой сторонах. Устройство Artix-7 200Т имеет приемопередатчики
GTP вверху и внизу рядом со столбцом синхронизации.
Следовательно, не все регионы синхронизации содержат все блоки, показанные
на предыдущих рисунках (детали можно найти в документе UG475 7 Series FPGAs
Packaging and Pinout. Product Specification и приложении В документа UG472 7 Series
FPGAs Clocking Resources. User Guide).
12.2.6. Возможности соединения элементов синхронизации FPGA
7-й серии
Как можно заметить из предыдущего рассмотрения архитектуры ресурсов синх-
ронизации FPGA 7-й серии, соединение элементов синхронизации между собой пред-
ставляет непростую задачу. Для этого необходимо точно знать, что можно подсоеди-
нять к входам и выходам каждого элемента синхронизации. Для облегчения решения
указанной задачи в табл. А.72 приложения А суммируются возможности соединения
элементов синхронизации FPGA 7-й серии.
12.3. Входы синхронизации (СС-входы)
Внешние пользовательские синхросигналы подаются на FPGA по дифференци-
альным парам выводов синхронизации, называемых входами с возможностью син-
хронизации (clock-capable — СС) или просто СС-входами. СС-входы обеспечивают
специализированный высокоскоростной доступ к внутренним глобальным и регио-
нальным ресурсам синхронизации. СС-входы используют специальную трассировку
и должны использоваться в качестве входов синхронизации для гарантии временных
параметров и различных свойств сигналов синхронизации.
Отметим, что в FPGA 7-й серии запрещено использование для синхронизации
выводов общего назначения. Из 50 двунаправленных выводов каждого банка ввода-
вывода 4 пары выводов являются СС-входами (т. е. всего 8 выводов).
Свойства С С-входа:
• может подсоединяться к дифференциальному (differential) или асимметричному
(single-ehded) синхросигналу на печатной плате;
• может конфигурироваться для любых стандартов ввода-вывода, включая диф-
ференциальные стандарты;
• имеет главный или положительный (P-side) и подчиненный или отрицательный
(N-side) выводы.
В паре СС-входа асимметричные входы синхросигналов должны назначаться
главному выводу Р. Если асимметричный синхросигнал подсоединяется к Р-выводу
дифференциальной пары, то N-вывод не может использоваться как другой асиммет-
ричный вывод синхросигнала — он может использоваться только как двунаправлен-
ный вывод общего назначения (см. документ UG475 7 Series FPGAs Packaging and
Pinout. Product Specification).
В каждом банке ввода-вывода СС-входы организованы как две пары MRCC и две
пары SRCC. Пары SRCC имеют доступ к единственному региону синхронизации и
глобальному дереву синхронизации, а также до трех блоков СМТ. Пары SRCC мо-
гут управлять:
• линиями региональной синхронизации (буферы BUFR, BUFH, BUFIO) в пределах
того же региона синхронизации;
Ресурсы синхронизации FPGA 7-й серии
193
• блоками СМТ в том же регионе и соседних регионах синхронизации;
• линиями глобальной синхронизации (буфер BUFG) в той же (верхней или нижней)
половине устройства.
Пары MRCC имеют доступ к нескольким регионам синхронизации и глобальному
дереву синхронизации. Пары MRCC функционирует так же, как пары SRCC, и могут
дополнительно управлять буферами многорегиональной синхронизации BUFMR для
доступа к многим (до трех) регионам синхронизации.
Если СС-входы не используются как синхросигналы, то они могут применяться
как обычные двунаправленные входы, при этом они могут конфигурироваться как
любой асимметричный или дифференциальный стандарт ввода-вывода.
1 2.3.1. Подсоединение СС-входов к блокам СМТ
СС-входы могут подсоединяться к блоку СМТ в том же регионе синхронизации
и, с некоторыми ограничениями, к блокам СМТ в регионах выше и ниже данного.
Один СС-вход синхронизации может управлять несколькими (до трех) блоками
СМТ. В этом случае один блок СМТ должен быть расположен в том же самом регионе
синхронизации, что и СС-вход, а другие блоки СМТ должны находиться в соседних
регионах выше и ниже. Ресурсы, используемые в блоках СМТ, должны быть иден-
тичными для этой конфигурации для того, чтобы быть автоматически размещен-
ными без ограничения CLOCK_DEDICATED_ROUTE. Если требуется смесь блоков
ММСМ/PLL, они должны размещаться в том же блоке СМТ первыми.
Если необходимо управлять блоком СМТ от СС-входа, который не находится в
том же регионе синхронизации, и нет блока ММСМ/PLL в том же регионе, в котором
находится СС-вход, то должен быть установлен атрибут CLOCK_DEDICATED_ROUTE
= BACKBONE. В этом случае блок ММСМ или PLL не выравнивает должным образом
выходы к входному синхросигналу.
Имеются также определенные ограничения специализированных ресурсов для
управления блоками СМТ в смежных регионах синхронизации. Некоторые IP-ядра
Xilinx используют эти ресурсы, делая их недоступными для других использований,
что может приводить к нетрассируемым проектам. Если специальные трассировки к
смежным регионам синхронизации недоступны, установка атрибута CLOCK-DEDICA-
TED-ROUTE в значение FALSE позволяет использовать локальную логику межсо-
единений.
1 2.3.2. Правила размещения СС-входов
В табл. А.73 приложения А приведены правила размещения для СС-входов, кото-
рые необходимо соблюдать при ручном размещении элементов синхронизации. Вы-
полнение этих правил дает гарантию, что СС-входы имеют доступ к требуемой внут-
ренней сети синхронизации.
Двумя главными соображениями при ручном выборе выводов для СС-входов в
усовершенствовании создаваемого начального проекта являются:
• убедитесь, что СС-вход может подсоединяться к требуемому ресурсу синхрони-
зации;
• убедитесь, что требуемые ресурсы синхронизации доступны и уже не использу-
ются другой частью проекта.
Лучший способ избежать конфликтов при построении системы синхронизации —
это использование средств автоматизированного проектирования. Необходимо также
быть внимательным при переносе проекта из одного устройства в другое устройство
или из одного корпуса в другой корпус.
194
Раздел 12
12.4. Ресурсы глобальной синхронизации
Глобальные синхросигналы являются отдельными сетями внутренних соединений
специально спроектированными для возможности достижения сигналов от всех вхо-
дов синхронизации к различным ресурсам в структуре FPGA. Эти сети проектируются
так, чтобы иметь наименьший перекос и наименьшую скважность распространения,
наименьшую мощность и улучшенную устойчивость к флуктуациям, а также для под-
держки очень высокой частоты сигналов.
Понимание путей сигналов для глобальных синхросигналов расширяет понимание
различных ресурсов глобальной синхронизации. Ресурсы глобальной синхронизации
включают следующие компоненты:
• сети и деревья глобальной синхронизации;
• регионы синхронизации;
• буферы глобальных синхросигналов.
Сети и деревья глобальной синхронизации. В FPGA 7-й серии деревья глобаль-
ной синхронизации спроектированы для функционирования с малым перекосом и ма-
лым энергопотреблением. Любая неиспользуемая ветвь сети отсоединяется. Деревья
глобальной синхронизации могут также использоваться для управления логическими
ресурсами, такими как сброс или разрешение синхронизации.
Например, в блоках CLB глобальные линии синхронизации, кроме выводов CLB,
могут также управлять выводами сброса/установки SR и разрешения синхронизации
СЕ. Данное свойство можно использовать в приложениях, требующих сигналы с очень
быстрым соединением или с большим коэффициентом расширения по выходу.
Регионы синхронизации как ресурсы глобальной синхронизации. В FPGA 7-й
серии улучшено распределение глобальной синхронизации путем использования реги-
онов синхронизации. Каждый регион синхронизации может иметь до 12 глобальных
областей (доменов) синхронизации. Эти 12 глобальных синхросигналов могут управ-
ляться любой комбинацией из 32 глобальных буферов синхронизации.
Регион синхронизации (50 блоков CLB) является границей дерева синхронизации.
12.4.1. Буферы глобальной синхронизации
В каждой FPGA 7-й серии имеется 32 буфера глобальной синхронизации. СС-
вход может прямо подсоединяться к любому глобальному буферу в данной половине
устройства.
Глобальные буферы синхронизации позволяют различным источникам синхро-
сигналов или обычных сигналов иметь доступ к глобальным деревьям синхронизации
и сетям. Источниками сигналов для буферов глобальных синхросигналов могут быть:
• СС-выходы;
• блок формирования синхросигналов СМТ, управляющий буферами BUFG в той
же самой половине устройства;
• выходы соседних глобальных буферов синхронизации BUFG;
• логика FPGA;
• региональные буферы синхронизации BUFH;
• гигабитные приемопередатчики GT.
Блоки СМТ в верхней (нижней) половине устройства могут управлять только
буферами BUFR в верхней (нижней) половине устройства. Аналогично, только буфе-
ры BUFG в данной половине устройства могут использоваться как обратная связь к
блокам СМТ в данной половине устройства.
СС-входы FPGA 7-й серии могут управлять глобальными буферами синхрони-
зации BUFG косвенно через вертикальную сеть синхронизации, которая находится
Ресурсы синхронизации FPGA 7-й серии
195
в столбце магистрали синхронизации. 32 буфера BUFG организованы в 2 группы
по 16 буферов в верхней и нижней частях устройства. Любые ресурсы (например,
приемопередатчик GTX), прямо подсоединяемые к буферам BUFG, имеют верхнее
или нижнее ограничение. Например, каждый блок ММСМ в верхней (нижней) части
устройства может управлять только 16-ю буферами BUFG, расположенными в этой
верхней (нижней) части устройства. Все глобальные буферы синхронизации BUFG
могут управлять всеми регионами синхронизации устройства. Однако только 12 раз-
личных синхросигналов могут использоваться в одном регионе синхронизации.
Буферы глобальной синхронизации спроектированы таким образом, чтобы кон-
фигурироваться как синхронные или асинхронные мультиплексоры 2:1 с двумя вхо-
дами синхронизации. Имеется специализированный путь (ресурсы трассировки) для
каскадирования буферов BUFG, чтобы допустить более двух выборов входных син-
хросигналов. Выводы управления FPGA 7-й серии обеспечивают широкий диапазон
функциональности и устойчивое переключение входов.
12.4.2. Примитивы буферов глобальной синхронизации
В табл. 12.1 приведены примитивы буферов глобальной синхронизации. Все при-
митивы формируются путем настройки буфера BUFGCTRL.
Таблица 12.1
Примитивы буферов глобальных синхросигналов
Примитив Входы Выходы Сигналы управления
BUFGCTRL 10, 11 О CEO, СЕ1, IGNOREO, IGNORE1, SO, S1
BUFG 1 О —
BUFGCE 1 О СЕ
BUFGCE-l 1 О СЕ
BUFGMUX 10, 11 О S
BUFGMUX-l 10, 11 О S
BUFGMUX_CTRL 10, 11 О S
Более детальное описание примитивов глобальной синхронизации приведено в
приложении А.
12.4.3. Дополнительные модели использования буфера BUFGCTRL
Асинхронный мультиплексор синхросигналов. В некоторых случаях приложение
требует немедленного переключения между входами синхронизации или обхода фрон-
та чувствительности буфера BUFGCTRL. Например, когда один из входов синхрониза-
ции долго не переключается. В этом случае используется асинхронный мультиплексор
синхросигналов MUX. На рис. 12.8 показан пример проекта асинхронного мультиплек-
сора синхросигналов с буфером BUFGCTRL, а на рис. 12.9 — временная диаграмма.
Пояснения к рис. 12.9:
• активный синхросигнал поступает от 10;
• S активизируется высоким уровнем;
• выход Clock немедленно переключается к II;
• когда сигнал Ignore устанавливается в высокий уровень, отключается защита от
помех.
Буфер BUFGMUX-CTRL с разрешением синхронизации. Буфер BUFGMUX.
CTRL с конфигурацией разрешения синхронизации примитива BUFGCTRL позволяет
пользователю выбирать между входами приходящих синхросигналов. Если необходи-
мо, используется разрешение синхронизации для запрещения выхода. На рис. 12.10
показан пример проекта, а на рис. 12.11 — его временная диаграмма.
196
Раздел 12
Asynchronous MUX
Design Example
Рис. 12.8. Пример асинхронного мультиплексора синхросигналов MUX с буфером BUFGCTRL
at 10 Begin 11
Рис. 12.9. Временная диаграмма асинхронного мультиплексора синхросигналов MUX с буфером
BUFGCTRL
BUFGMUX_CTRL+CE
Design Example
Рис. 12.10. Буфер BUFGMUX.CTRL с входом СЕ и примитивом BUFGCTRL
В момент времени 1 выход О использует вход 10; до момента времени 2 вход
S устанавливается в высокий уровень; в момент времени Твсско.о после момента
2 выход О использует вход II; это случилось после перехода с высокого на низкий
Ресурсы синхронизации FPGA 7-й серии
197
Рис. 12.11. Временная диаграмма буфера BUFGMUX.CTRL с входом СЕ и примитивом BUFGCTRL
уровень входа 10, следующего за окончанием перехода с высокого на низкий уровень
входа II; в момент времени Твссск.се до события 3 вход СЕ принимает низкий уро-
вень; чтобы избежать помех (glitches) на выходе, выход синхросигнала переключается
на низкий уровень и сохраняет это значение до тех пор, пока не завершится переход
с высокого на низкий уровень входа II.
12.5. Ресурсы региональной синхронизации
Сети региональных синхросигналов являются независимыми сетями глобальной
сети синхронизации. Область (домен) регионального сигнала синхронизации (BUFR)
ограничивается одним регионом синхронизации, один сигнал синхронизации ввода-
вывода управляет одним банком ввода-вывода. Эти сети особенно эффективны для
проектов интерфейсов с синхронными источниками.
Ресурсы региональной синхронизации включают:
• СС-входы;
• региональные сети синхронизации;
• буферы синхронизации ввода-вывода BUFIO;
• региональные буферы синхронизации BUFR;
• многорегиональные буферы синхронизации BUFMR или BUFMRCE;
• буферы горизонтальной синхронизации BUFH, BUFHCE;
• синхросигналы высокой производительности НРС (High-Performance Clocks).
СС-входы как ресурсы региональной синхронизации. Каждый регион имеет 4 па-
ры СС-входов на один банк ввода-вывода. Пары СС-входов являются специализиро-
ванными парами ввода-вывода в выбранном месте со специальными аппаратными со-
единениями к ближайшим региональным ресурсам синхронизации и другим ресурсам
синхронизации. В каждом банке имеется 4 специализированных места для СС-входов.
СС-пара, когда используется как вход синхронизации, может управлять буферами
BUFIO, BUFMR и BUFR. Каждый столбец ввода-вывода поддерживает региональный
буфер синхронизации BUFR. Каждое устройство имеет 2 столбца ввода-вывода.
СС-входы могут управлять любым буфером BUFR в регионе, но только опреде-
ленные СС-входы могут управлять определенными буферами BUFIO, а вход MRCC
может управлять буферами BUFMR в отношении 1:1. Это значит, что СС-вход имеет
только одно соединение: либо к буферу BUFIO, либо к буферу BUFMR.
Региональные сети синхронизации. В дополнение к глобальным деревьям и сетям
синхронизации, FPGA 7-й серии содержат региональные деревья и сети синхрониза-
ции. Региональные деревья синхронизации также спроектированы с целью малого
198
Раздел 12
перекоса сигналов и малого энергопотребления. Неиспользуемые ветви деревьев от-
соединяются. Региональные деревья синхронизации могут также управлять загрузкой
регистров или разветвлением по выходам, когда исчерпаны все логические ресурсы.
Региональные сети синхронизации ограничены одним регионом синхронизации.
На один регион синхронизации приходится 4 независимые региональные сети синхро-
низации. Для доступа к региональной сети необходимо создать экземпляр буфера
BUFR.
12.5.1. Буферы синхронизации ввода-вывода BUFIO
Буфер синхронизации ввода-вывода BUFIO управляет специализированной сетью
синхронизации в пределах банка ввода-вывода, независимо от глобальных ресурсов
синхронизации. Поэтому буфер BUFIO идеально подходит для приема данных, синх-
ронизируемых источником. В регионе синхронизации (в банке ввода-вывода) имеется
четыре буфера BUFIO.
Каждый буфер BUFIO может управлять единственной сетью синхронизации вво-
да-вывода в данном регионе или банке ввода-вывода. Однако буфер BUFIO не может
управлять логическими ресурсами (блоками CLB, RAM, DSP и др.), так как сеть
синхронизации ввода-вывода охватывает только столбец ввода-вывода в регионе.
Буферы BUFIO могут управляться:
• выводами SRCC и MRCC в данном регионе;
• выводами MRCC соседнего региона используя буфер BUFMR;
• выходами синхронизации 0-3 блока ММСМ, управляя высокоскоростными синх-
росигналами НРС в том же регионе синхронизации;
• общими внутренними соединениями.
Описание примитива буфера BUFIO приведено в приложении А.
12.5.2. Буфер региональной синхронизации BUFR
Буфер BUFR является другим буфером региональной синхронизации. Буфе-
ры BUFR управляют синхросигналами в специализированной сети синхронизации в
пределах региона, независимо от дерева глобальной синхронизации. Каждый буфер
BUFR может управлять 4 региональными сетями синхронизации в данном регионе.
В отличие от буферов BUFIO, буферы BUFR могут управлять логикой ввода-вывода
и логическими ресурсами (блоками CLB, RAM, DSP и др.).
Буферы региональной синхронизации BUFR могут управлять СС-входами, ло-
кальными межсоединениями, высокопроизводительными сигналами НРС (CLKOUTO-
CLKOUT3) блоков ММСМ или буферами BUFMR в данном и соседнем регионе. Бу-
феры BUFR могут также прямо управлять входами синхронизации блока ММСМ и
буферами BUFG.
Кроме того, буферы BUFR способны генерировать разделенные выходы синхрни-
зации по отношению к входу синхросигнала. Значение делителя равно целому числу
от 1 до 8 (атрибут BUFR-DMDE). Буферы BUFR являются идеальными для синхро-
низируемых источником приложений, требующих пересечения области синхронизации
или последовательно-параллельного преобразования.
Буферы BUFR могут управляться:
• выводами SRCC и MRCC в данном регионе;
• выводами MRCC соседнего региона используя буфер BUFMR;
• выходами синхронизации 0-3 блока ММСМ, управляя высокоскоростными синх-
росигналами НРС в том же регионе синхронизации;
• выходами синхронизации 0-3 блока ММСМ;
• общими внутренними соединениями.
Ресурсы синхронизации FPGA 7-й серии
199
Каждый столбец ввода-вывода поддерживает региональные буферы синхрониза-
ции. В устройстве имеется два столбца ввода-вывода.
Описание примитива буфера BUFR приведено в приложении А.
12.5.3. Модели использования буферов BUFIO и BUFR
Буфер BUFIO идеально подходит для приема данных, синхронизируемых источ-
ником. Буфер BUFR является идеальным для приложений с синхронными источ-
никами, требующих пересечения области синхронизации или для последовательно-
параллельного преобразования. В отличие от буферов BUFIO, буферы BUFR могут
синхронизировать как ресурсы блоков ввода-вывода ЮВ, так и ресурсы логики FPGA.
На рис. 12.12 показан пример использования буферов BUFIO и BUFR.
FPGA logic
resources
Рис. 12.12. Использование буферов BUFIO и BUFR для управления логическими ресурсами
12.5.4. Многорегиональный буфер синхронизации BUFMR/BUFMRCE
Буфер BUFMR заменяет многорегиональную (многобанковую) поддержку для
буферов BUFR и BUFIO, доступных в предыдущих архитектурах семейства Virtex.
В одном банке ввода-вывода имеется 2 буфера BUFMR. Каждый буфер BUFMR мо-
жет управляться одним специализированным выводом MRCC данного банка. Выводы
MRCC обозначаются с аббревиатурой MRCC в имени вывода как для Р, так и для N
выводов пары выводов (например, IO_L12P_T1_MRCC_12 или IO_L12N_T1_MRCC_12).
Буферы BUFMR управляют буферами BUFIO и/или BUFR в данном регионе/бан-
ке и в регионе/банке выше и ниже. Примитивы BUFR и BUFIO должны быть ин-
станцированы отдельно.
Когда используются делители буфера BUFR (не обход буфера), буфер BUFMR
должен запрещаться путем сброса вывода СЕ, должен сбрасываться буфер BUFR
(установкой сигнала CLR), а затем должен устанавливаться сигнал СЕ. Эта после-
довательность операций дает уверенность, что все выходные синхросигналы буферов
BUFR выровнены по фазе. Если делители в буферах BUFR не используются, то то-
пология схемы требует только использования буфера BUFMR.
Входы буфера BUFMR подключаются к:
200
Раздел 12
• выводам MRCC в том же самом банке;
• синхросигналам блока GT в том же самом регионе.
Описание примитивов буфера BUFMR приведено в приложении А.
12.5.5. Буферы горизонтальной синхронизации BUFH и BUFHCE
Буфер горизонтальной синхронизации BUFH управляет горизонтальной сердце-
виной дерева глобальной синхронизации в единственном регионе. Описание прими-
тивов буфера BUFH приведено в приложении А.
Каждый регион имеет 12 доступных буферов BUFH. Каждый буфер BUFHCE
имеет вывод СЕ, который позволяет динамически отключать синхросигналы.
Буфер BUFH может управляться:
• выходами блоков ММСМ данного региона;
• выходами буферов BUFG;
• выходными синхросигналами блоков GT в том же самом или горизонтальном
соседнем регионе синхронизации;
• локальными внутренними соединениями;
• СС-входами от каждой, левой или правой, сторон банков ввода-вывода в том же
самом горизонтальном соседнем регионе или банке.
Для того чтобы использовать буфер BUFH, логика должна располагаться в двух
соседних друг к другу горизонтальных регионах, как показано на рис. 12.13.
Рис. 12.13. Пример использования горизонтального буфера синхронизации
Вывод СЕ может полностью выключать синхросигналы для сохранения мощнос-
ти. Потребляемая мощность и флуктуация в буфере BUFH меньше, по сравнению с
буфером BUFG, управляющим двумя соседними регионами.
12.5.6. Выбор буфера синхросигнала
FPGA 7-й серии предлагают разнообразные ресурсы для трассировки сигналов
синхронизации цифровых систем: различные типы буферов, входных выводов синх-
росигналов, средств соединения/маршрутизации др. Выбирая надлежащие ресурсы
синхронизации можно улучшить возможности трассировки, производительности и ис-
пользование общих ресурсов FPGA. В некоторых приложениях и проектах планирова-
ние размещения (floor planning) или другие типы ручного управления могут улучшить
общую производительность.
Буфер глобальных синхросигналов BUFGCTRL (чаще обозначаемый BUFG) яв-
ляется общим ресурсом трассировки синхросигнала. Это действительно глобальные
Ресурсы синхронизации FPGA 7-й серии
201
синхросигналы, которые могут подсоединяться к любой синхронизируемой точке в
устройстве. Однако в некоторых случаях для улучшения производительности, функ-
циональности или по причине доступности ресурса более выгодно использовать аль-
тернативные буферы синхронизации.
Буфер BUFG лучше применять, когда:
• проекты или части проекта имеют глобальную область действия через большие
площади устройства и локализация функций невозможна;
• каскадируются аппаратные функциональные блоки, такие как блоки RAM, DSP
или интегрированные IP-ядра, которые охватывают несколько регионов синхро-
низации, или необходимо выполнить соединения к блокам CLB, которые не яв-
ляются ближайшими;
• переключая синхронные или асинхронные синхросигналы, приложения в состоя-
нии переключить далеко от остановленного синхросигнала или выбрать синхро-
сигнал с другой частотой (с целью уменьшения энергопотребления);
• возможности сигналов разрешения синхронизации (СЕ) могут использоваться
для уменьшения энергопотребления в периоды бездействия; однако в большинст-
ве случаев возможности СЕ не должны использоваться для моделирования истин-
ной логической функции СЕ в элементах синхронизации из-за временных огра-
ничений (задержка сигнала СЕ);
• функция СЕ может использоваться для синхронной инициализации элементов
синхронизации после запуска устройства.
Главной целью объединения буферов BUFR и BUFIO является поддержка ин-
терфейсов с синхронными источниками. Буфер BUFIO синхронизирует высокоско-
ростную часть блока SelectIO, а буфер BUFR синхронизирует сторону параллельно-
последовательного/последовательно-параллельного преобразователя с низкой ско-
ростью.
Для интерфейсов, которые требуют больше логики и/или контактов ввода-выво-
да, чем доступно в одном регионе синхронизации или банке ввода-вывода, использу-
ется буфер BUFMR (BUFMRCE) для расширения функциональности синхросигнала
в регионы синхронизации выше и ниже.
Буфер BUFR может использоваться в качестве простого делителя синхросигнала
в приложениях, которые требуют деления синхросигнала, не связанного с синхрон-
ным источником, и когда не может использоваться блок MMCM/PLL или недоступна
функция деления частоты. В этих случаях особое внимание должно быть уделено
на тактирование и перекос сигналов, так как это не основная цель буфера BUFR
(см. документ UG471).
Буфер горизонтальной синхронизации BUFH (BUFHCE) является строго реги-
ональным ресурсом и не может охватывать регионы синхронизации выше и ниже.
В отличие от буфера BUFR, буфер BUFH не может делить синхросигнал.
Свойства буфера BUFH:
• подобен глобальному ресурсу синхронизации, только на региональной основе,
охватывающей два горизонтальных региона;
• может обслуживать обратную связь к блоку MMCM/PLL и компенсировать за-
держку инвертирования синхросигнала;
• является предпочтительным ресурсом синхронизации, когда интерфейс или об-
лако логики может быть локализовано к одному региону синхронизации или двум
горизонтальным соседним регионам;
202
Раздел 12
• имеет вывод разрешения синхронизации (BUFHCE), который может использо-
ваться для уменьшения динамической потребляемой мощности, когда либо логи-
ка, либо интерфейс и связанная с ним логика, не активны;
• свойство разрешения синхронизации может обеспечивать стробирование синхро-
сигнала на основе синхронизации от цикла к циклу;
• подобно глобальному дереву синхронизации, буфер BUFH может подсоединяться
к не синхронизируемым ресурсам в блоках CLB (разрешения или сброса), но с
лучшими характеристиками перекоса;
• может использоваться для синхронного запуска синхронизируемых элементов в
регионе синхронизации.
Ограничения на выбор ресурсов синхронизации для устройств с технологией сте-
ковых кремниевых соединений SSI можно найти в документе UG872 Large FPGA
Methodology Guide. Including Stacked Silicon Interconnect (SSI).
12.5.7. Синхросигналы высокой производительности (НРС)
Каждый банк ввода-вывода FPGA 7-й серии содержат 4 синхросигнала высокой
производительности (High-Performance Clock — НРС). Эти синхросигналы являются
прямыми короткими дифференциальными соединениями к буферам BUFIO и BUFR в
банке ввода-вывода. Следовательно, эти синхросигналы обеспечивают очень низкую
флуктуацию и минимальное искажение скважности.
Синхросигналы НРС подсоединяются к буферам BUFIO и BUFR и управляют
логикой ввода-вывода. Управляются сигналы НРС выходами CLKOUT[3:0] блоков
ММСМ. Поскольку столбец блоков СМТ в FPGA располагается возле столбца блоков
ввода-вывода, сигналы НРС прямо управляют ресурсами банка ввода-вывода, распо-
ложенного рядом с блоком СМТ.
12.5.8. Стробирование синхросигналов для сохранения мощности
Архитектура синхронизации FPGA 7-й серии может использоваться для стробиро-
вания синхросигналов с целью снижения энергопотребления. Большинство проектов
содержат несколько неиспользуемых буферов BUFGCE или BUFHCE.
Синхросигнал может управлять входами буферов BUFGCE или BUFHCE, выход
буфера BUFGCE может управлять различными регионами логики, а буфер BUFHCE
может управлять единственным регионом. Например, если вся логика, которая долж-
на всегда работать, ограничивается несколькими регионами синхронизации, то выход
буфера BUFGCE может управлять этими регионами. Или, если буфер BUFHCE управ-
ляет интерфейсом, который размещается в единственном регионе, то этот интерфейс
может быть выключен при отсутствии передачи (приема). Переключение выводов
разрешения буферов BUFGCE или BUFHCE предоставляет простые способы мини-
мизации динамической потребляемой мощности.
Для сохранения энергопотребления можно использовать программные средства
Xilinx Power Estimator (ХРЕ) или Xilinx Power Analyzer (XPower).
Детали использования многорегиональной синхронизации можно найти в доку-
менте UG472 7 Series FPGAs Clocking Resources. User Guide.
12.6. Выводы
Ресурсы синхронизации FPGA 7-й серии включают глобальные и региональные
ресурсы, а также блоки формирования синхросигналов (блоки управления синхрони-
зацией) СМТ. Каждый блок СМТ включает один блок управления синхронизацией
смешанного режима ММСМ и один блок фазовой автоподстройки частоты PLL.
Ресурсы синхронизации FPGA 7-й серии
203
Каждое устройство FPGA 7-й серии делится на регионы синхронизации. Число
регионов синхронизации зависит от размеров устройства и может изменяться от 4 до
24. Регион синхронизации охватывает все синхронизируемые элементы в некоторой
области FPGA: логические блоки CLB, блоки ввода-вывода, приемопередатчики GT,
блоки DSP, блоки памяти RAM, блоки СМТ и др.
Каждый регион синхронизации содержит один блок формирования синхросигна-
лов СМТ. Обычно регион синхронизации, кроме блоков CLB, охватывает один банк
ввода-вывода (50 двунаправленных выводов).
В центре каждой FPGA 7-й серии проходит вертикальный канал (магистраль)
глобальной синхронизации, который содержит 32 линий и делит устройство на левую
и правую сторону. Регион синхронизации распространяется от канала глобальной
синхронизации влево или вправо до границы устройства.
В высоту один регион синхронизации занимает 50 блоков логических CLB.
В центре каждого региона синхронизации проходит горизонтальный канал син-
хронизации HROW, который содержит 12 линий. Блоки CLB располагаются по 25
блоков CLB вверх и 25 блоков CLB вниз от канала HROW.
Внешние синхросигналы могут поступать только на специальные выводы синхро-
низации, называемые СС-входами. Один банк ввода-вывода содержит 4 таких вывода:
два выше и два ниже горизонтального канала синхронизации HROW.
Ресурсы трассировки синхронизации в FPGA 7-й серии представляют собой ие-
рархическую структуру, которая состоит из:
• линий канала глобальной синхронизации (32 линии);
• линий горизонтальных каналов синхронизации (12 линий);
• деревьев региональной синхронизации;
• деревьев синхронизации ввода-вывода.
В регионы синхронизации глобальные синхросигналы поступают по линиям гори-
зонтального канала HROW. К конкретной точке в регионе синхронизации глобальные
синхросигналы поступают по деревьям региональной синхронизации, а к компонентам
ввода-вывода — по деревьям синхронизации ввода-вывода.
Все линии глобального и горизонтального каналов синхронизации, а также де-
ревья региональной синхронизации и синхронизации ввода-вывода управляются со-
ответствующими буферами.
По линиям синхронизации, кроме синхросигналов, могут передаваться сигналы
управления установки/сброса SR, а также разрешения синхронизации СЕ.
Для управления ресурсами трассировки синхронизации служат следующие бу-
феры: глобальные BUFG (BUFGCTRL); горизонтальные BUFH/BUFHCE; региональ-
ные BUFR; ввода-вывода BUFIO; многорегиональные BUFMR. Каждый буфер имеет
конкретное физическое местоположение в системе синхронизации. Отсюда следуют
очень жесткие ограничения на входные сигналы примитивов буферов и ограничения
на элементы, которыми может управлять каждый буфер.
Горизонтальный буфер синхронизации BUFH обеспечивает доступ к линиям гло-
бальной синхронизации в одном регионе синхронизации через горизонтальный канал
синхронизации HROW. Он может также использоваться как схема стробирования син-
хросигналов (BUFHCE) для одного региона синхронизации. Каждый регион синхро-
низации может поддерживать до 12 синхросигналов, используя 12 горизонтальных
линий синхронизации.
Региональный буфер синхронизации BUFR управляет деревом региональной син-
хронизации, которое управляет всеми назначениями синхронизации в том же реги-
204
Раздел 12
оне синхронизации и может программироваться для деления приходящей тактовой
частоты.
Буфер синхронизации ввода-вывода BUFIO управляет деревом синхронизации
ввода-вывода, обеспечивая доступ к синхронизации всех последовательных ресурсов
ввода-вы вода в том же банке ввода-вы вода.
Совместно с программируемым параллельно-последовательным/последователь-
но-параллельным преобразователем (serializer/deserializer) в блоке ввода-вывода IOB
буферы синхронизации BUFIO и BUFR позволяют системам с синхронными источ-
никами пересекать области синхронизации без использования дополнительных ло-
гических ресурсов.
Многорегиональные буферы синхронизации BUFMR позволяют региональным
синхросигналам и синхросигналам ввода-вывода охватывать вертикально до трех со-
седних регионов синхронизации.
В одном регионе синхронизации или банке вода-вывода может поддерживаться
до четырех уникальных синхросигналов ввода-вывода и до четырех уникальных ре-
гиональных синхросигналов.
Ресурсы трассировки высокопроизводительных синхросигналов НРС подсоединя-
ют определенные выходы блоков СМТ к внешним выводам с очень малой флуктуацией
и минимальным искажением скважности.
Блоки ММСМ и PLL служат как синтезаторы частоты для широкого диапазо-
на частот, фильтры флуктуации для внешних и внутренних синхросигналов, а также
устраняют перекос синхросигналов. Блок PLL включает подмножество функций бло-
ка ММСМ.
Горизонтальная центральная линия делит устройство на верхнюю и нижнюю час-
ти. Верхнюю и нижнюю части устройства отделяет два множества глобальных бу-
феров синхронизации BUFG: 16 буферов для верхней части устройства и 16 буферов
для нижней части устройства.
Буфер глобальной синхронизации BUFG может управлять синхронизируемыми
элементами в каждом регионе через канал HROW. Буферы горизонтальной синхро-
низации BUFH через канал HROW управляют каждой синхронизируемой точкой в
регионе. Буферы BUFG и BUFH совместно используют 12 линий канала HROW.
Буферы BUFG могут также управлять буферами BUFH. Это позволяет с по-
мощью сигналов разрешения синхронизации буферов BUFHCE в одном регионе ис-
пользовать различные глобальные сигналы синхронизации.
Каждый банк ввода-вывода содержит 4 буфера BUFIO и 4 буфера BUFR. Буфер
BUFIO управляет только ресурсами синхронизации ввода-вывода, в то время как бу-
фер BUFR управляет как ресурсами ввода-вывода так и ресурсами структуры FPGA.
Каждый из этих буферов синхронизации может управляться определенной парой вхо-
дов синхронизации или может непосредственно управляться определенным выходным
синхросигналом блока ММСМ. Буферы BUFR имеют 4 трассы, управляющие точками
синхронизации в структуре FPGA, блоке СМТ и буфере BUFG.
Буфер BUFMR обеспечивает многорегиональные соединения в виде цепочки бу-
феров BUFIO и BUFR.
Входы синхронизации (СС-входы) подсоединяют внешние синхросигналы к ресур-
сам синхронизации в устройстве. Любые 4 входа синхронизации СС могут управлять
компонентами PLL/ММСМ в блоке СМТ и буфером BUFH. Входы синхронизации
СС могут управлять буферами BUFG везде в той же самой стороне (верхней или
нижней) устройства.
Ресурсы синхронизации FPGA 7-й серии
205
Блоки СМТ могут управлять другими блоками СМТ в соседних регионах через
магистраль СМТ (СМТ Backbone). В магистрали СМТ имеется четыре трассы для
поддержки соединений между вертикальными регионами.
Источники синхронизации из одного региона могут управлять ресурсами буферов
синхронизации в их собственных регионах, а также в соседнем горизонтальном реги-
оне. Блоки СМТ, входы синхронизации СС и блоки GT могут управлять синхросигна-
лами в горизонтальном соседнем регионе через буфер BUFH, а также подсоединяться
к буферам BUFG в той же самой части (верхней или нижней) устройства.
Логика FPGA управляет выводами СЕ буферов BUFG и BUFH. Она может также
управлять синхросигналами в тех же самых буферах, но следует соблюдать осторож-
ность, потому что такая синхронизация не предсказуема.
Две пары входов синхронизации, называемые MRCC, поддерживают схему мно-
горегиональной синхронизации. Пара выводов MRCC может управлять определенным
буфером BUFMR, который поочередно может управлять буферами BUFIO и BUFR в
том же самом и соседнем регионах, способствуя многорегиональным интерфейсам.
В FPGA 7-й серии запрещено использование для синхронизации выводов общего
назначения.
В каждом банке ввода-вывода СС-входы организованы как две пары MRCC и две
пары SRCC. Пары SRCC имеют доступ к единственному региону синхронизации и
глобальному дереву синхронизации, а также до трех блоков СМТ.
Пары MRCC функционирует так же, как пары SRCC и могут дополнительно управ-
лять буферами многорегиональной синхронизации BUFMR для доступа к нескольким
(до трех) регионам синхронизации.
Если СС-входы не используются как синхросигналы, то они могут применяться
как обычные двунаправленные входы, при этом они могут конфигурироваться как
любой асимметричный или дифференциальный стандарт ввода-вывода.
СС-вход синхронизации может управлять несколькими (до трех) блоками СМТ.
В этом случае один блок СМТ должен быть расположен в том же самом регионе
синхронизации, что и СС-вход, а другие блоки СМТ должны находиться в соседних
регионах выше и ниже.
Лучший способ избежать конфликтов при построении системы синхронизации —
это использование средств автоматизированного проектирования.
Ресурсы глобальной синхронизации включают сети и деревья глобальной синх-
ронизации, регионы синхронизации и буферы глобальных синхросигналов.
Деревья глобальной синхронизации спроектированы для функционирования с ма-
лым перекосом и малым энергопотреблением. Любая неиспользуемая ветвь сети
отсоединяется.
Каждый регион синхронизации может иметь до 12 глобальных областей (доме-
нов) синхронизации. Эти 12 глобальных синхросигналов могут управляться любой
комбинацией из 32 глобальных буферов синхронизации. Регион синхронизации яв-
ляется границей дерева синхронизации.
В каждой FPGA 7-й серии имеется 32 буфера глобальной синхронизации BUFG.
СС-вход может прямо подсоединяться к любому глобальному буферу в данной поло-
вине устройства. Эти 32 буфера BUFG организованы в 2 группы по 16 буферов в
верхней и нижней частях устройства.
Буферы глобальной синхронизации могут конфигурироваться как синхронные или
асинхронные мультиплексоры 2:1 с двумя входами синхронизации. Кроме того, име-
ется отдельные ресурсы трассировки для возможности выбора более чем из двух
входных синхросигналов.
206
Раздел 12
Все примитивы буферов глобальных синхронизации образуются путем настрой-
ки буфера BUFGCTRL.
Сети региональных синхросигналов являются независимыми сетями глобальной
сети синхронизации. Область (домен) регионального сигнала синхронизации (BUFR)
ограничивается одним регионом синхронизации. На один регион синхронизации при-
ходится 4 независимые региональные сети синхронизации. Для доступа к региональ-
ной сети необходимо создать экземпляр буфера BUFR.
СС-вход имеет только одно соединение: либо к буферу BUFIO, либо к буферу
BUFMR.
Буфер ввода-вывода BUFIO управляет специализированной сетью синхрониза-
ции в пределах банка ввода-вывода, независимо от глобальных ресурсов синхрони-
зации. В регионе синхронизации (в банке ввода-вывода) имеется четыре буфера
BUFIO. Буфер BUFIO не может управлять логическими ресурсами: блоками CLB,
RAM, DSP и др.
Буферы региональной синхронизации BUFR могут управлять СС-входами, ло-
кальными межсоединениями, высокопроизводительными сигналами НРС (CLKOUTO-
CLKOUT3) блоков ММСМ или буферами BUFMR в данном и соседнем регионе; вхо-
дами синхронизации блока ММСМ и буферами BUFG. Каждый буфер BUFR может
управлять 4 региональными сетями синхронизации в данном регионе.
Кроме того, буферы BUFR могут выполнять функции делителя частоты. Значе-
ние делителя равно целому числу от 1 до 8 (атрибут BUFR-DMDE).
Главной целью объединения буферов BUFR и BUFIO является поддержка ин-
терфейсов с синхронными источниками. Буфер BUFIO синхронизирует высокоско-
ростную часть ввода-вывода, а буфер BUFR синхронизирует сторону параллельно-
последовательного/последовательно-параллельного преобразователя с низкой ско-
ростью.
В одном банке ввода-вывода имеется 2 буфера многорегиональной синхрониза-
ции BUFMR. Каждый буфер BUFMR может управляться одним специализированным
выводом MRCC данного банка.
Буферы BUFMR управляют буферами BUFIO и/или BUFR в данном регионе/бан-
ке и в регионе/банке выше и ниже.
Буфер горизонтальной синхронизации BUFH управляет горизонтальной сердце-
виной дерева глобальной синхронизации в единственном регионе. Каждый регион
имеет 12 буферов BUFH. Чтобы использовать буфер BUFH, логика должна рас-
полагаться в двух соседних друг к другу горизонтальных регионах. Буфер BUFH
(BUFHCE) является строго региональным ресурсом и не может охватывать регионы
синхронизации выше и ниже.
Каждый банк ввода-вывода FPGA 7-й серии содержат 4 синхросигнала высокой
производительности НРС. Эти синхросигналы являются прямыми короткими диф-
ференциальными соединениями от выходов CLKOUT[3:0] блоков ММСМ к буферам
BUFIO и BUFR, они обеспечивают очень малую флуктуацию и минимальное искаже-
ние скважности, они управляют логикой ввода-вывода.
13 Блоки формирования синхросигналов СМТ
13.1. Общее описание блока СМТ
В FPGA 7-й серии блок управления синхронизацией (clock management tile —
СМТ) включает блок управления синхронизацией смешанного режима (mixed-mode
clock manager — ММСМ) и блок фазовой автоподстройки частоты (ФАПЧ — phase-
locked loop — PLL). Блок PLL реализует подмножество функций блока ММСМ. Ма-
гистраль блока СМТ (СМТ backbone) может использоваться для каскадного соеди-
нения блоков СМТ. Однако при каскадном соединении блоков СМТ имеются опреде-
ленные ограничения на размещение, расстояние и ресурсы соединения.
Каждый регион синхронизации включает один блок СМТ, поэтому FPGA 7-й се-
рии могут содержать от 4 до 24 блоков СМТ. На рис. 13.1 показана обобщенная
структура блока СМТ.
Входные (опорные) синхросигналы в блок СМТ могут поступать от буферов
BUFR, IBUFG (т.е. от СС-входов), BUFG, приемопередатчиков или от внутренней
логики, а сформированные синхросигналы могут подаваться на входы буферов BUFG
или BUFH.
BUFG
BUFH
BUFG
BUFH
Рис. 13.1. Структурная схема блока СМТ
208
Раздел 13
Отметим основные возможности блоков СМТ FPGA 7-й серии. Число выход-
ных счетчиков (делителей) блока ММСМ равно 8, некоторые из них могут управлять
инвертированием синхросигнала (т. е. выполнять фазовый сдвиг на 180°). Для об-
ратной совместимости с цифровым контроллером синхросигнала DCM (Digital Clock
Manager), 9 независимых выходов могут выбираться для отображения выходов DCM
прямо в блок ММСМ.
Блок ММСМ обладает широкими возможностями сдвига фазы синхросигнала в
каждом направлении и может использоваться в динамическом фазово-сдвиговом ре-
жиме. Разрешающая способность фазового сдвига зависит от частоты управляемого
напряжением генератора VCO (Voltage Controlled Osillator). При синтезе частоты син-
хронизации широкие возможности предоставляет дробное (фракционное — fractional)
функциональное деление с приращением 1/8 (0,125) для сигналов CLKFBOUT и
CLKOUTO.
Блоки ММСМ имеют также дополнительные возможности по расширению спек-
тра (spread spectrum). Если свойства расширения спектра не используются, то рас-
ширенный спектр на внешнем входном синхросигнале не будет фильтроваться и ис-
кажения пройдут на выходной синхросигнал.
13.2. Архитектура блоков ММСМ и PLL
Блоки ММСМ и PLL могут служить как синтезаторы частоты в широком диапа-
зоне частот, как фильтры флуктуаций для каждого внешнего или внутреннего синхро-
сигнала, а также как фильтры перекосов синхросигналов. Архитектура блока ММСМ
показана на рис. 13.2, а блока PLL — на рис. 13.3.
Архитектура блоков ММСМ/PLL включает:
• мультиплексор выбора опорного синхросигнала (CLKIN1 или CLKIN2);
• мультиплексор выбора синхросигнала обратной связи (CLKB или CLKBOUT);
• программируемый счетчик D, который выполняет функцию делителя входной
частоты;
General
Routing
CLKIN1
CLKIN2
CLKFB
LF
Lock
8-phase taps + 1 variable phase tap
OO
O1
02
03
05
06
M
VCO
Fractional Divide >
04
CLKOUTO
CLKOUTOB
CLK0UT1
CLK0UT1B
----- CLK0UT2
>— CLK0UT2B
(Fractional Divide) >
CLK0UT3
CLKOUT3B
* CLKOUT4
CLK0UT5
CLK0UT6
CLKFBOUT
CLKFBOUTB
Рис. 13.2. Структурная схема блока ММСМ
Блоки формирования синхросигналов СМТ
209
Рис. 13.3. Структурная схема блока PLL
• фазово-частотный детектор PFD (phase-frequency detector);
• накопитель заряда СР (charge pump);
• контурный фильтр LF (loop filter);
• управляемый напряжением генератор VCO;
• выходные счетчики О (6 для ММСМ и 5 для PLL);
• счетчик М управления сигналом обратной связи;
• схему Lock Detect для обнаружения фазового и частотного выравнивания опор-
ного синхросигнала и синхросигнала обратной связи.
В дополнение к выходным счетчикам целочисленного деления, блоки ММСМ до-
полнительно предоставляют фракционный (дробный, или уточняющий) счетчик для
выходов CLKOUTO и CLKFBOUT. Блоки ММСМ также позволяют инвертировать
выходы счетчиков 00-03 и счетчика М.
Входные мультиплексоры выбирают опорные синхросигналы или синхросигналы
обратной связи от следующих элементов: IBUFG, BUFG, BUFR, BUFH, GT (только
CLKIN) или от внутренней логики (не рекомендуется). Каждый вход синхросигнала
имеет программируемый счетчик (делитель) D.
Фазово-частотный детектор PFD сравнивает фазу и частоту возрастающих
фронтов как входного (опорного) синхросигнала так и синхросигнала обратной связи.
Детектор PFD используется для генерации сигнала, пропорционального фазе и час-
тоте между двумя синхросигналами. Этот сигнал управляет накопителем заряда СР
и контурным фильтром LF для генерации опорного напряжения для генератора VCO.
Детектор PFD выдает высокий или низкий сигнал элементам СР и LF, чтобы опреде-
лить, должен ли генератор VCO работать с более высокой или более низкой частотой.
Когда генератор VCO работает на слишком высокой частоте, детектор PFD по-
нижает сигнал, вызывая уменьшение управляющего напряжения для снижения час-
тоты функционирования VCO. Когда генератор VCO работает на слишком низкой
частоте, детектор PFD повышает сигнал, вызывая увеличение напряжения для уве-
личения частоты функционирования VCO. Генератор VCO производит 8 выходных
210
Раздел 13
фаз и одну переменную фазу для тонкого фазового сдвига. Каждая выходная фа-
за может выбираться в качестве опорного синхросигнала для выходных счетчиков О
(см. рис. 13.2 и 13.3). Каждый счетчик может независимо программироваться для
заданного пользователем режима.
Кроме того, предоставляется специальный счетчик М. Этот счетчик управля-
ет синхросигналом обратной связи блоков ММСМ и PLL, позволяя синтезировать
широкий диапазон частот.
По сравнению с блоком PLL, блок ММСМ дополнительно поддерживает следу-
ющие свойства:
• направление синхросигналов высокой производительности НРС к буферу BUFR
или BUFIO, используя выводы CLKOUT[0:3];
• инвертирование выходов синхросигналов CLKOUT[0:3]B;
• дополнительный выход CLKOUT6;
• выход CLKOUT4.CASCADE;
• дробное деление для CLKOUT_DIVIDE_F;
• дробное умножение для CLKFBOUT_MULT_F;
• тонкий (fine) фазовый сдвиг;
• динамический фазовый сдвиг.
Использование в проектах блока ММСМ осуществляется с помощью примитивов
MMCME2.BASE и MMCME2-ADV, а блока PLL — с помощью примитивов PLLE2-
BASE и PLLE2-ADV. Описание примитивов блоков ММСМ и PLL приведено в при-
ложении А.
13.3. Функционирование блоков ММСМ и PLL
Все излагаемое в данном разделе относится к блокам ММСМ, однако эти же
подходы практически без изменений могут использоваться и для блоков PLL. Бло-
ки ММСМ и PLL FPGA 7-й серии являются блоками смешанных сигналов, спроек-
тированными для поддержки свободных от перекоса сетей синхронизации, синтеза
частоты и уменьшения флуктуации.
13.3.1. Определение частоты генератора VCO и частоты выходных
синхросигналов
Частота Fvco функционирования управляемого напряжением генератора VCO
и частота функционирования каждого выхода Роит могут определяться из следу-
ющих выражений:
_ _ М М
Fvco = Fclkin х тт'- Роит = Fclkin х ———,
D D х О
где М, D и О — счетчики, показанные на рис. 13.2. Значение М соответствует уста-
новке атрибута CLKFBOUT_MULT_F, значение D — атрибута DIVCLKJDMDE и О —
атрибута CLKOUT_DIVIDE.
Семь счетчиков О могут программироваться независимо. Например, ОО может
программироваться для деления на два, а О1 — для деления на три. Единствен-
ным ограничением является то, что частота Русо функционирования VCO должна
быть такой же самой для всех выходных счетчиков, поскольку VCO управляет всеми
выходными счетчиками.
13.3.2. Устранение перекоса сети синхросигнала
Во многих случаях в сети синхросигналов задержка не желательна, поэтому раз-
работчики используют блоки ММСМ и PLL для компенсации задержки сети синх-
росигнала.
Блоки формирования синхросигналов СМТ
211
Выход синхросигнала CLKFBOUT, соответствующий опорной частоте синхросиг-
нала CLKIN, подсоединяется к буферу BUFG в той же половине устройства и возвра-
щается обратно к контакту обратной связи CLKFBIN блока ММСМ/PLL. Оставшиеся
выходы могут использоваться, чтобы разделить синхросигнал для дополнительно син-
тезируемых частот. В этом случае все выходные синхросигналы имеют определенную
фазу (фазовый сдвиг) относительно входного опорного синхросигнала CLKIN. Выхо-
ды CLKOUTO-CLKOUT3 в каждом блоке ММСМ или PLL могут использоваться для
каскадного соединения с другими блоками ММСМ/PLL. Однако на выходных синхро-
сигналах между каскадными блоками ММСМ/PLL появляется фазовое смещение.
13.3.3. Синтез частоты путем использования только целочисленного
делителя
Блоки ММСМ и PLL могут также использоваться для синтеза единственной час-
тоты. В таком применении блоки ММСМ/PLL не используются для устранения пе-
рекоса сети синхросигнала, а скорее для генерации выходной тактовой частоты для
других блоков. В этом режиме используются внутренние пути обратных связей блоков
ММСМ/PLL, благодаря чему минимизируется флуктуация.
На рис. 13.4 показан блок ММСМ, сконфигурированный как синтезатор частоты.
33 MHz
Reference
Clock
Processor
Gasket
CLB/Fabric
Memory Interface
66 MHz Interface
33 MHz Interface
not used
Рис. 13.4. Блок ММСМ как синтезатор частоты
В этом примере опорная частота синхросигнала равна 33 МГц, которая поступает
с кварцевого генератора или выхода другого ММСМ. Установка значения 32 на счет-
чике М заставляет генератор VCO сформировать частоту 1056 МГц (33 МГцх32).
Выходы блока ММСМ для данного примера запрограммированы на следующие часто-
ты: 528 МГц — синхросигнал процессора; 264 МГц — промежуточный синхросигнал;
176 МГц — синхросигнал межсоединений; 132 МГц — синхросигнал интерфейса памя-
ти; а также синхросигналы интерфейсов с частотами 66 и 33 МГц. В этом примере
не требуются фазовые соотношения между опорным синхросигналом и выходными
синхросигналами, но требуются отношения между выходными синхросигналами.
13.3.4. Синтез частоты путем использования дробных делителей в блоке
ММСМ
FPGA 7-й серии поддерживают дробные (не целочисленные) делители на вы-
ходном пути CLKOUTO. Разрешение дробных делителей с градацией 1/8 или 0,125
эффективно увеличивает число синтезируемых частот с коэффициентом 8.
Например, если частота CLKIN равна 100МГц и значение делителя М установ-
лено в 8, тогда частота генератора VCO составляет 800МГц. Выход CLKOUTO мо-
212
Раздел 13
жет использоваться для дальнейшего дробного деления частоты 800 МГц (т. е. если
CLKOUTO-DMDE = 2,5, то на выходе получим частоту 320 МГц).
Когда используется дробный делитель, скважность не программируется для вы-
ходов, используемых в дробном режиме.
13.3.5. Фильтр флуктуаций
Блоки ММСМ/PLL уменьшают флуктуации* (дрожание, джиттер — jitter), свой-
ственные опорному синхросигналу. Блок ММСМ и PLL может быть инстанцирован как
автономная функция просто для поддержки фильтрующей флуктуации от внешнего
синхросигнала до того, как он будет управлять другим блоком. При использовании
блока ММСМ/PLL в качестве фильтра флуктуаций обычно принимается, что блок
ММСМ/PLL будет действовать как буфер и будет регенерировать входную частоту
на выходе (например, Fin = 100 МГц и Fout = 100 МГц).
В общем, фильтрация больших флуктуаций возможна путем установки в бло-
ке ММСМ атрибута BANDWIDTH (полоса пропускания) в значение Low. Однако
установка атрибута BANDWIDTH в значение Low может привести к увеличению ста-
тического смещения фазы в блоке ММСМ.
13.3.6. Ограничения для блоков MMCM/PLL
Главными ограничениями являются: диапазон функционирования генератора
VCO; входная частота; программируемость скважности и фазового сдвига. Кроме
того, имеются ограничения подсоединения к другим элементам синхронизации (кон-
такты, блоки GT, буферы синхронизации), как представлено в приложении В доку-
мента UG472 7 Series FPGAs Clocking Resources. User Guide.
Каскадирование блоков MMCM/PLL может выполняться только для соседних
блоков СМТ.
Диапазон функционирования генератора VCO. Максимальные и минимальные
частоты функционирования генератора VCO определяются в электрических специ-
фикациях документов «7 Series FPGA Data Sheets» на сайте фирмы Xilinx. Эти зна-
чения могут также узнать в спецификациях скорости.
Минимальная и максимальная входная частота. Минимальная и максимальная
входная частота CLKIN определяется в электрических спецификациях документов «7
Series FPGA Data Sheets» на сайте фирмы Xilinx.
Программирование скважности синхросигнала. Только дискретные значения
скважности являются возможными для данной частоты функционирования VCO.
В зависимости от значения атрибута CLKOUTJDIVIDE, минимальный и максималь-
ный диапазон возможен с размером шага, который также зависит от значения атрибу-
та CLKOUT- DIVIDE. Программа Clocking Wizard предоставляет возможные значения
для данного CLKOUTJDIVIDE.
Вопросы, связанные с фазовым сдвигом и соответствующие ограничения рас-
сматриваются в следующем разделе.
13.4. Фазовый сдвиг
Во многих случаях необходим фазовый сдвиг между синхросигналами. Блок
ММСМ имеет много опций для реализации фазового сдвига. Блок PLL также имеет
базовое свойство для статического фазового сдвига. Статический фазовый сдвиг мо-
жет достигаться путем выбора одной из восьми выходных фаз VCO с дополнительным
* Флуктуация (джиттер —jitter) — отклонение периодичности опорного синхросигнала от
заданного значения; флуктуация может касаться частоты, амплитуды и фазового сдвига.
Блоки формирования синхросигналов СМТ
213
тонким фазовым сдвигом, возможным в выходных счетчиках CLKOUT, зависящих от
значения деления CLKOUT. В FPGA 7-й серии также имеется возможность интерпо-
ляции фазового сдвига как в фиксированном, так и в динамическом режиме. Возмож-
ности фазового сдвига блока ММСМ являются очень мощными, которые могу вести к
сложным сценариям. Используя программу Clocking Wizard, допустимые значения фа-
зового сдвига, в основном, определяются в установках конфигурации блока ММСМ.
13.4.1. Режим статического фазового сдвига
Разрешение статического фазового сдвига (static phase shift — SPS) в единицах
измерения времени определяется как:
1 D
SPS = ———period или ———period,
8Fvco 8MFiNp
где Fvco — частота генератора VCO; М — значение счетчика М; Fin — частота
опорного синхросигнала; period — длительность такта синхросигнала.
Поскольку генератор VCO может обеспечить восемь фазовых сдвигов синхросиг-
налов, по 45° каждый, обеспечиваются установки для сдвига на 0°, 45°, 90°, 135°,
180°, 225°, 270° и 315°. Наивысшая частота генератора VCO возможна для наимень-
шего разрешения фазового сдвига. Поскольку генератор VCO имеет однозначный
диапазон функционирования, является возможным ограничить период использова-
ния разрешения фазового сдвига от 1/8Fvcomin до 1/8FVcomax-
Каждый выходной счетчик программируется индивидуально, позволяя каждому
выходу иметь дополнительное разрешение фазового сдвига в градусах на основе фазы
выбранного VCO и значения деления счетчика CLKOUT. Степень детализации значе-
ния фазового сдвига CLKOUT может вычисляться как величина 45°/CLKOUT_DIVI-
DE. Максимальный диапазон фазового сдвига также определяется величиной
CLKOUT-DIVIDE. Максимальный фазовый сдвиг равняется 360°, когда CLKOUT.
DIVIDE 64. Когда CLKOUT.DIVIDE > 64, максимальный фазовый сдвиг
MaxPhaseShift = ^'^'КОи~т~ bi VI DE Х ) + х PhaseShiftValue)
где MaxPhaseShift — максимальный фазовый сдвиг; PhaseShiftValue — значение фа-
зового сдвига; CLKOUT.DIVIDE — значение атрибута CLKOUT.DIVIDE.
Имеется возможность сдвинуть фазу синхросигнала обратной связи CLKFBOUT.
В этом случае все выходные синхросигналы CLKOUT негативно фазово сдвигаются
по отношению к CLKIN.
Два дробных счетчика (CLKFBOUT и CLKOUT0) также имеют возможность ста-
тического фазового сдвига. Шаг фазового сдвига определяется как
8 х fractional.divide.value fractional-divide.value’
где fractional-divide.value — дробный делитель.
Например, если дробный делитель равен 2,125, то шаг статического фазового
сдвига равен 360/(2,125x8) = 21,176 градусов.
13.4.2. Интерполяция тонкого фазового сдвига в блоке ММСМ для
фиксированного или динамического режима
Режим интерполированного тонкого фазового сдвига (Interpolated fine phase shift
- IFPS) имеет линейное/ступенчатое (linear) поведение сдвига независимо от величи-
ны атрибута CLKOUT.DIVIDE и разрешения фазового сдвига, а зависит только от
214
Раздел 13
частоты генератора VCO. В этом режиме выходные сигналы могут быть повернуты
циклически на 360° с линейным приращением l/(56Fvco)- Например, если VCO ра-
ботает на частоте 600 МГц, то фазовое разрешение равно приблизительно 30 пс и
на частоте 1,6 ГГц равно приблизительно 11 пс.
Значение фазового сдвига может программироваться во время конфигурации как
установка фиксированного значения или динамически инкрементироваться/ декре-
ментироваться под управлением приложения после конфигурации.
Динамический фазовый сдвиг управляется интерфейсом PS примитива
MMCME2JXDV. Этот фазово-сдвиговый режим одинаково влияет на все выходные
синхросигналы CLKOUT, которые выбираются для этого режима установкой атрибу-
та USE_FINE.PS в значение TRUE.
Несмотря на режим (фиксированный или динамический) интерполированного
тонкого фазового сдвига, входной синхросигнал всегда должен подсоединяться к вхо-
ду PSCLK блока ММСМ.
Каждый индивидуальный счетчик CLKOUT может независимо либо выбирать
интерполированный фазовый сдвиг (ранее описанный режим статического фазового
сдвига), либо не выбирать ничего. Дробное деление запрещено в фиксированном или
динамическом интерполированном тонком фазово-сдвиговом режиме. Фиксирован-
ный или динамический фазовый сдвиг пути обратной связи будет результатом в от-
рицательном фазовом сдвиге всех выходных синхросигналов по отношению к CLKIN.
Динамический фазово-сдвиговый интерфейс не может использоваться, когда фазово-
сдвиговый режим является фиксированным.
13.4.3. Интерфейс динамического фазового сдвига в блоке ММСМ
Примитив MMCME2.ADV обеспечивает три входа PSEN, PSINCDEC, PSCLK и
один выход PSDONE для динамического тонкого фазового сдвига. Каждый CLKOUT
и делитель CLKFBOUT могут индивидуально выбираться для фазового сдвига. Ат-
рибуты CLKOUT[0:6]_USE_FINE_PS и CLKFBOUT_USE_FINE_PS выбирают выходные
синхросигналы, которые будут динамически фазово сдвигаться. Величина динами-
ческого фазового сдвига является общей для всех выбранных выходных сигналов.
Разнообразие фазового сдвига управляется портами PSEN, PSINCDEC, PSCLK
и PSDONE (рис. 13.5).
После автоматической подстройки частоты блока ММСМ, начальная фаза опре-
деляется атрибутом CLKOUT-PHASE. Обычно начальная фаза сдвига не выбирает-
ся. Фаза выходного сигнала ММСМ инкрементируется/декрементируется согласно
взаимодействию PSEN, PSINCDEC, PSCLK и PSDONE от начального или ранее вы-
полненного динамического сдвига фазы. PSEN, PSINCDEC и PSDONE являются
синхронными к PSCLK.
_ __ __ „„„ 1L „
psclk гц|тгшгшш1г1ш1лллк
PSEN
PSDONE
psincdec
Рис. 13.5. Временная диаграмма фазового сдвига
Блоки формирования синхросигналов СМТ
215
Когда PSEN устанавливается для одного периода синхросигнала PSCLK, иници-
ируется инкрементация/декрементация фазового сдвига. Когда PSINCDEC находит-
ся в высоком уровне, инициируется инкрементация, а когда PSINCDEC находится в
низком уровне, инициируется декрементация. Каждая инкрементация добавляет к
сдвигу фазы выходов синхронизации ММСМ 1/56 периода частоты генератора VCO.
Аналогично, каждая декрементация уменьшает сдвиг фазы на 1/56 периода часто-
ты генератора VCO. Вход PSEN должен быть активным для одного периода синх-
росигнала PSCLK.
Когда фазовый сдвиг заканчивается, выход PSDONE устанавливается в высо-
кий уровень точно на один период синхросигнала. Число циклов PSCLK является
детерминированным и всегда равняется 12 циклам PSCLK.
После инициирования фазового сдвига путем установки PSEN и завершения фа-
зового сдвига, сигнализируемого PSDONE, выходные синхросигналы ММСМ посте-
пенно дрейфуют от их исходного фазового сдвига до инкрементированного/ декре-
ментированного фазового сдвига в линейном виде. Окончание инкрементации или
декрементации указывается установкой PSDONE в высокий уровень. После высоко-
го импульса на выводе PSDONE может быть инициализирована другая инкремента-
ция/декрементация. Здесь нет максимального фазового сдвига или его переполнения.
Полный период синхронизации (360 градусов) может всегда быть фазой, сдвинутой
независимо от частоты. Когда обнаруживается конец периода, фазовый сдвиг прос-
то циклически повторяется.
13.4.4. Каскадирование счетчика ММСМ
Делитель CLKOUT6 (счетчик) может каскадироваться с делителем CLKOUT4.
Это обеспечивает возможность иметь выходной делитель больше, чем 128. CLKOUT6
просто питает вход делителя CLKOUT4. Имеется статическое фазовое смещение
между выходом каскадированного делителя и всеми другими выходными делителями.
13.5. Программирование MMCM/PLL
В этом разделе рассматриваются вопросы программирования блока MMCM/PLL
на основе определенных проектных требований. Проект может реализовываться дву-
мя способами: прямо через интерфейс программы Clocking Wizard или через инстан-
цию блока MMCM/PLL. Независимо от выбранного метода, для программирования
блока MMCM/PLL необходима следующая информация:
• период опорного синхросигнала;
• частоты выходных синхросигналов (до 7 максимум);
• скважность выходного синхросигнала (по умолчанию 50 %);
• фазовый сдвиг выходного синхросигнала в числе градусов по отношению к на-
чальной фазе 0 синхросигнала;
• желаемая полоса пропускания блока MMCM/PLL (по умолчанию равна OPTI-
MIZED и полоса пропускания выбирается в программе);
• режим компенсации (автоматически устанавливается программой);
• флуктуация опорного синхросигнала определяться в терминах единичного интер-
вала Ul (unit interval), например в процентах периода опорного синхросигнала.
13.5.1. Определение входной частоты
Первым шагом является определение входной частоты. Это позволяет всем воз-
можным выходным частотам определяться путем использования минимальных и мак-
симальных входных частот для определения диапазона счетчика D, диапазон функ-
ционирования генератора VCO для определения диапазона счетчика М и диапазона
216
Раздел 13
выходного счетчика. Здесь могут быть очень большие числа частот. Когда исполь-
зуются целочисленные деления, в худшем случае здесь может быть 106x64x136 -
= 868363 возможных комбинаций. В действительности общее число различных час-
тот является меньше, поскольку полный диапазон счетчиков М и D не может быть
реализован и здесь имеется перекрытие между различными установками.
В качестве примера рассмотрим Fin = Ю0 МГц. Если минимальная частота
фозово-частотного детектора PFD равна 10 МГц, то D может изменяться только
от 1 до 10:
• при D = 1 счетчик М может иметь значения только от 4 до 16;
• при D = 2 счетчик М может иметь значения только от 8 до 32;
• при D = 4 счетчик М может иметь значения только от 16 до 64.
Кроме того, D - 1, М = 4 является подмножеством D = 2, М = 8; D = 4,
М = 16 и D = 8, М = 32, позволяя этим случаям пропускаться. Для этого слу-
чая рассматривается только D = 1, 3, 5, 6, 7 и 9, поскольку все другие значения
D являются подмножествами этих случаев. Это значительно уменьшает число воз-
можных выходных частот.
Выходные частоты выбираются последовательно. Желаемая выходная частота
должна быть проверена по возможным выходным сгенерированным частотам. Как
только первая выходная частота определена, на значения М и D может быть наложе-
но дополнительное ограничение. Это может далее ограничить возможные выходные
частоты для второй выходной частоты. Продолжайте этот процесс, пока не будут
выбраны все выходные частоты. Ограничения, использованные для определения раз-
решенных значений М и D, показаны в следующих выражениях:
Dmin = roundup-———; (13.1)
TPFDMAX
Dmax = rounddown ^IN—; (13.2)
fpFDMIN
Mmin = roundup^V<tQMIN x DMin; (13.3)
•IN
Mmax = round DOWN fvcf)MAX x DMax, (13.4)
•IN
где roundup(x) — наименьшее целое, большее или равное х; rounddown(x) — наиболь-
шее целое, меньшее или равное х; fiN — входная частота; Ipdfmax и Ipdfmin —
максимальная и минимальная частота детектора PDF; fvcoMAX и fvcoMiN — макси-
мальная и минимальная частота генератора VCO.
13.5.2. Определение значений М и D
Определение входной частоты может дать несколько возможных значений М и
D. Следующим шагом является определение оптимальных значений М и D. Первым
определяется начальное значение М. Оно основывается на целевой частоте VCO,
идеальной частоте функционирования для VCO:
.. Dmin х fvcoMAX
Mideal = -------7-------. (13.5)
tin
Цель нахождения значения М заключается в точке идеального функционирования ге-
нератора VCO. Минимальное значение D используется для начала процесса. Целью
является сделать значения D и М как можно меньше при сохранении как можно вы-
сокой частоты /vco-
Блоки формирования синхросигналов СМТ
217
13.6. Использование блоков ММСМ и PLL
Примеры в этом разделе показаны для блоков ММСМ, однако, они могут также
применяться к блокам PLL. Есть несколько методов для проектирования с блоком
ММСМ и/или PLL. Программа Clocking Wizard пакета ISE может помочь при генера-
ции различных параметров блоков ММСМ и PLL. Кроме того, блок ММСМ можно
инстанцировать вручную как компонент. Это также возможно для блока ММСМ, ко-
торый будет объединен с ядром IP. В этом случае блоком ММСМ управляет ядро IP.
13.6.1. Входные сигналы синхронизации блока ММСМ
Для блока ММСМ возможны следующие источники синхронизации:
• IBUFG — буфер СС-входа этого же региона; ММСМ будет компенсировать за-
держку этого пути;
• BUFGCTRL или BUFG — буферы внутреннего глобального синхросигнала;
ММСМ не будет компенсировать задержку этого пути;
• IBUF — обычный входной буфер; не рекомендуется, потому что входной буфер
может использовать общую трассировку; блоки MMCM/PLL не компенсируют
задержку этих путей;
• BUFR — входной буфер регионального синхросигнала; блоки MMCM/PLL не ком-
пенсируют задержку этих путей.
Таким образом, блок ММСМ компенсирует задержку входного синхросигнала
только от буферов IBUFG (например, от СС-входов).
13.6.2. Управление счетчиком
Выходные счетчики блоков MMCM/PLL обеспечивают широкое разнообразие
синхросигналов, использующих комбинацию атрибутов DIVIDE, DUTY-CYCLE и РНА-
Рис. 13.6. Примеры синтеза синхросигналов выходных счетчиков
218
Раздел 13
13.6.3. Фазовое соотношение выходных счетчиков
На рис. 13.7 показаны 8 фазовых выходов VCO и 4 различных выходов счетчиков.
One Cycle Delay
Рис. 13.7. Выбор фаз VCO
Каждая фаза VCO показана с соответствующей стартовой последовательностью
(последовательностью запуска). Фазовое соотношение и последовательность запуска
гарантируются для обеспечения, чтобы сохранялась корректность фазы. Это озна-
чает, что положительный фронт 0° будет происходить после положительного фронта
45°. Счетчик ОО программируется для выполнения простого деления на 2 с фазовым
отводом (сдвигом) 0° как опорный синхросигнал. Счетчик О1 программируется для
выполнения простого деления на 2, но использует фазовый отвод 180° от VCO. Эта
установка счетчика должна использоваться для генерации синхросигнала для интер-
фейса DDR, где опорный синхросигнал является фронтом, выровненным к передаче
данных. Счетчик 02 программируется для выполнения деления на 3. Выход ОЗ
имеет то же программирование, как 02, за исключением того, что фаза устанавли-
вается для одного цикла задержки. Здесь возможны фазовые сдвиги больше, чем
один период VCO.
Если блоки ММСМ/PLL конфигурируются для обеспечения определенного фазо-
вого соотношения и изменяется входная частота, то это фазовое соотношение также
изменяется, поскольку изменяется частота генератора VCO и, следовательно, будет
изменен абсолютный сдвиг в пикосекундах. Этот аспект должен рассматриваться,
когда используются блоки ММСМ/PLL Когда главным аспектом проекта является
поддержка определенного фазового соотношения среди различных выходов синхро-
сигналов (например, CLK и CLK90), то это соотношение будет поддерживаться неза-
висимо от входной частоты.
Во многих случаях этот уровень детализации является незаметным для проек-
тировщика, поскольку программа Clocking Wizard определяет надлежащие установки
через атрибуты блоков ММСМ/PLL и входы программы Clocking Wizard.
13.6.4. Переключение опорного синхросигнала
Опорный синхросигнал блоков ММСМ/PLL может динамически переключаться
с помощью вывода CLKINSEL. Переключение выполняется асинхронно. Поскольку
Блоки формирования синхросигналов СМТ
219
синхросигнал переключается, блок MMCM/PLL, вероятно, теряет сигнал LOCKED
и автоматически настраивает частоту на новый синхросигнал. Следовательно, при
переключении опорного синхросигнала блок MMCM/PLL должен быть сброшен.
13.6.5. Потеря входного синхросигнала или синхросигнала обратной
связи
Когда входной синхросигнал или синхросигнал обратной связи теряется, устанав-
ливается состояние сигнала CLKINSTOPPED или CLKFBSTOPPED. Блок ММСМ ан-
нулирует сигнал LOCKED. После возврата синхросигнала аннулируется сигнал CLKIN-
STOPPED и должен быть применен сигнал RESET.
13.6.6. Устранение перекоса сети синхронизации
Устранение перекоса сети синхросигналов — один из наиболее частых случаев
использования блока ММСМ (рис. 13.8 и 13.9). В результате фронты синхросигналов
в точках 2, 3 и 5 приходят почти одновременно.
Выход синхросигнала от одного счетчика CLKOUT используется для управления
логикой в пределах структуры FPGA и/или блоков ввода-вывода. Счетчики обрат-
ной связи используются для контроля точного фазового соотношения между вход-
ным синхросигналом и выходным синхросигналом (например, если требуется фазовый
сдвиг на 90°). Соответствующие временные диаграммы синхросигналов показывают-
ся правильно для случая, когда входной и выходной синхросигналы выровнены по
фазе. Конфигурация на рис. 13.8 является более гибкой, но требует двух глобаль-
ных сетей синхронизации.
Имеются определенные ограничения при реализации обратной связи. Для обес-
печения сигнала обратной связи может использоваться выход CLKFBOUT. Когда
блок ММСМ одновременно управляет буферами BUFG и BUFH, только один из бу-
феров синхросигнала, который также используется в цепи обратной связи, является
свободным от перекоса. Главное ограничение: обе входные частоты к детектору PFD
должны быть идентичными. Поэтому должно выполняться следующее соотношение:
fiN _ г _ fvco
”d~ " fFB " у ’
IBUFG
CLKIN1
CLKFBIN
RST
CLKOUTO
CLKOUTOB
CLKOUT1
CLKOUT1B
CLKOUT2
CLKOUT2B
CLKOUT3
CLKOUT3B
CLKOUT4
CLKOUT5
CLKOUT6
CLKFBOUT
To Logic
CLKFBOUTB
MMCM
LOCKED
Рис. 13.8. Устранение перекоса глобальной сети синхронизации путем использования двух буферов
BUFG
220
Раздел 13
IBUFG
CLKIN1
CLKFBIN
RST
CLKOUTO
CLKOUTOB
CLKOUT1
CLKOUT1B
CLKOUT2
CLKOUT2B
CLKOUT3
CLKOUT3B
CLKOUT4
CLKOUT5
CLKOUT6
CLKFBOUT
CLKFBOUTB
MMCM
LOCKED
To Logic
Рис. 13.9. Устранение перекоса горизонтальной сети синхронизации путем использования двух
буферов BUFH
где fiN — частота входного синхросигнала; fpB — частота синхросигнала обратной
связи; fvco — частота генератора VCO.
Например, если fiN = 166 МГц, D = 1, М = 6 и О = 2, то частота fvco гене-
ратора VCO будет равна 996 МГц, а частота выходного синхросигнала — 498 МГц.
Поскольку значение М в цепи обратной связи равно 6, обе входные частоты в де-
текторе PFD равны 166 МГц.
Рассмотрим второй, более сложный пример. Пусть входная частота fiN равна
66,66 МГц, D = 2, М = 30 и О = 4. В этом случае частота fvco равна 1000 МГц, а
частота выхода CLKOUT — 250 МГц. Следовательно, частота обратной связи fpB в
детекторе PFD равна 1000/30 « 33,33 МГц, что совпадает с частотой 66,66 МГц/2
входного синхросигнала fm в детекторе PFD.
13.6.7. Блок ММСМ с внутренней обратной связью
Обратная связь в блоке ММСМ может быть внутренней, когда ММСМ использу-
ется как синтезатор или фильтр флуктуации и здесь не требуется фазовое соотноше-
ние между входным и выходным синхросигналом блока ММСМ. Производительность
блока ММСМ увеличивается, потому что синхросигнал обратной связи не подвергнут
шуму на токе питания ядра, поскольку синхросигнал никогда не приходит через блок,
питаемый током. Однако шум, представленный на сигнале CKIN и буфере BUFG, все
еще будет присутствовать (рис. 13.10).
13.6.8. Буфер с нулевой задержкой
Блок ММСМ можно также использовать для создания буфера синхросигнала
с нулевой задержкой. Буфер с нулевой задержкой применяется в ситуации, когда
необходимо единственный синхросигнал подключить ко многим точкам синхронизации
с малым перекосом между ними (рис. 13.11).
Здесь сигнал обратной связи обходит микросхему и проектируется трасса обрат-
ной связи на плате, чтобы соответствовать трассировке к внешним компонентам. В
данной конфигурации принято, чтобы фронты синхросигналов выравнивались на вхо-
де FPGA и входе внешнего компонента. Буферы входных синхросигналов CLKIN и
CLKFBIN должны быть в том же самом банке ввода-вывода.
Блоки формирования синхросигналов СМТ
221
CLKIN1
CLKFBIN
RST
ММСМ
CLKOUTO
CLKOUTOB
CLKOUT1
То Logic
CLKOUT1B
CLKOUT2
CLKOUT2B
CLKOUT3
CLKOUT3B
CLKOUT4
CLKOUT5
CLKOUT6
CLKFBOUT
CLKFBOUTB
LOCKED
Рис. 13.10. Блок ММСМ с внутренней обратной связью
Inside FPGA
CLKIN1
CLKFBIN
RST
CLKOUTO
CLKOUTOB
CLKOUT1
CLKOUTlB
CLKOUT2
CLKOUT2B
CLKOUT3
CLKOUT3B
CLKOUT4
CLKOUT5
CLKOUT6
CLKFBOUT
CLKFBOUTB
MMCM locked
To
External
Components
Рис. 13.11. Буфер с нулевой задержкой
13.6.9. Каскадирование блоков СМТ
Блоки ММСМ и PLL могут соединяться каскадно, используя выводы CLKOUTO —
CLKOUT3 через магистраль блока СМТ для формирования больших областей час-
тот синхронизации. Причем, когда используется магистраль СМТ, буферы не нужны
(рис. 13.12 и 13.13).
Здесь будет фазовое смещение между выходными синхросигналами двух блоков
ММСМ, поскольку задержка на магистрали СМТ не компенсируется.
Здесь также имеются ограничения частотного диапазона. Следующее выражение
показывает соотношение между окончательной выходной частотой и входной часто-
222
Раздел 13
IBUFG
MMCM
CLKIN1
CLKFBIN
RST
CLKOUTO
CLKOUT1B
CLKOUT2
CLKOUT2B
CLKOUT3
CLKOUT3B
CLKOUT4
CLKOUT5
CLKOUT6
CLKFBOUT
CLKFBOUTB
LOCKED
BUFG
CLKOUTOB
CLKOUT1
To Logic
CLKIN1
CLKFBIN
RST
MMCM
CLKOUTOB
CLKOUT1
CLKOUT1B
CLKOUT2
CLKOUT2B
CLKOUT3
CLKOUT3B
CLKOUT4
CLKOUT5
CLKOUT6
CLKFBOUT
CLKFBOUTB
LOCKED
CLKOUTO
Рис. 13.12. Каскадное соединение двух блоков ММСМ без выравнивания синхросигнала
той и установками счетчика для двух блоков ММСМ (рис. 13.12 и 13.13):
f(DUTMMCM2 = foUTMMCMl
Мммсм2
DmMCM2 X 0мМСМ2
f. Mmmcmi х Мммсм2
DmMCMI X OmMCMI DmMCM2 X 0мМСМ2 ’
где fouTMMCMi и 1оитммсм2 — частота синхросигнала на выходе блоков ММСМ1 и
ММСМ2; Mmmcmi и Мммсм2 — значение счетчиков М блоков ММСМ1 и ММСМ2;
Dmmcmi и Dmmcm2 — значение счетчиков D блоков ММСМ1 и ММСМ2; Ommcmi и
0ммсм2 — значение счетчиков О блоков ММСМ1 и ММСМ2; — частота опор-
ного синхросигнала.
Фазовое соотношение между выходным синхросигналом второго ММСМ и вход-
ным синхросигналом не определяется, а дополнительное фазовое смещение добавля-
ется между двумя блоками ММСМ, потому что не компенсируется соединение ма-
гистрали.
Рис. 13.13. Каскадное соединение двух блоков ММСМ с самым близким выравниванием
синхросигнала
Блоки формирования синхросигналов СМТ
223
Для того чтобы каскадно соединить блоки ММСМ, следует подсоединить вы-
ход первого ММСМ к входу CLKIN второго ММСМ. Таким способом обеспечивается
наименьшая флуктуация устройств. Использование каскадирования делает недоступ-
ными инверсные выходы CLKOUTxB.
13.6.10. Генерация широкополосных синхросигналов
Гоперация широкополосных синхросигналов (Spread-spectrum clock generation —
SSCG) широко используется производителями электронных устройств для уменьше-
ния спектральной плотности электромагнитных помех (electromagnetic interferences —
EMI), генерируемых этими устройствами. Производители должны быть уверены, что
уровни электромагнитной энергии не влияют на функционирование ближайших элек-
тронных устройств. Например, ясность телефонного разговора не должна ухудшать-
ся, когда телефон расположен рядом с видеодисплеем. Аналогично, дисплей не дол-
жен подвергаться помехам, когда используется телефон.
Для управления шумом или электромагнитными помехами, которые вызваны эти-
ми нарушениями, используются правила электромагнитной совместимости (Electro-
magnetic Compatibility— ЕМС). Типичными решениями для удовлетворения требова-
ниям электромагнитной совместимости является включение дополнительного дорого-
го экранирования, ферритовых сердечников или дроссельных катушек. Эти решения
могут неблагоприятно повлиять на стоимость конечного продукта, усложняя трасси-
ровку печатной платы, приводя к более длинному циклу разработки продукта.
Генерация широкополосных синхросигналов SSCG распространяет электромаг-
нитную энергию по большой полосе частот для эффективного уменьшения электри-
ческой и магнитной напряженности поля, измеряемой в узком окне частоты. Пиковая
электромагнитная энергия на любой одной частоте уменьшается путем модуляции
выхода генератора SSCG.
Примитив ММСМЕ2 может генерировать широкополосный синхросигнал из стан-
дартной фиксированной частоты генератора, когда опция SS_EN устанавливается в
TRUE (рис. 13.14).
В примитиве ММСМЕ2 частота VCO модулируется на выходах CLKFBOUT и
CLKOUT[6:4, 1, 0]. Выходы синхросигналов CLKOUT[3:2] используются для управ-
ления периодом модуляции и не доступны для общего использования.
Другие примеры использования генератора широкополосных синхросигналов
SSCG можно найти в документе UG472 7 Series FPGAs Clocking Resources User Guide.
Рис. 13.14. Центрально расширенная модуляция
224
Раздел 13
13.6.11. Пример использования блока ММСМ
Пусть установлены следующие значения атрибутов:
CLKOUTO-PHASE = 0; CLKOUTO_DUTY_CYCLE = 0,5; CLKOUTO.DMDE = 2;
CLKOUTl.PHASE = 90; CLKOUT1_DUTY_CYCLE = 0,5; CLKOUT1_DIVIDE = 2;
CLKOUT2_PHASE = 0; CLKOUT2_DUTY_CYCLE = 0,25; CLKOUT2.DMDE = 4;
CLKOUT3-PHASE = 90; CLKOUT3_DUTY_CYCLE = 0,5; CLKOUT3.DIVIDE = 8;
CLKOUT4-PHASE = 0; CLKOUT4_DUTY_CYCLE = 0,5; CLKOUT4-DIVIDE = 8;
CLKOUT5.PHASE - 135; CLKOUT5_DUTY_CYCLE = 0,5; CLKOUT5-DIVIDE = 8;
CLKFBOUT.PHASE = 0; CLKFBOUT_MULT_F = 8; DIVCLK.DIVIDE = 1;
CLKIN1_PERIOD = 10.0.
Временные диаграммы сформированных синхросигналов для данного примера
показаны на рис. 13.15.
Для использования порта динамической реконфигурации (Dynamic Reconfigura-
tion Port — DRP) обратитесь к документу ХАРР888 «ММСМ and PLL Dynamic Reconfi-
guration».
13.7. Выводы
Блок управления синхронизацией (clock management tile — СМТ) включает блок
управления синхронизацией смешанного режима (mixed-mode clock manager —
ММСМ) и блок фазовой автоподстройки частоты (ФАПЧ — phase-locked loop — PLL).
Блок PLL реализует подмножество функций блока ММСМ. Магистраль блока СМТ
(СМТ backbone) может использоваться для каскадного соединения блоков СМТ.
Каждый регион синхронизации включает один блок СМТ, поэтому FPGA 7-й се-
рии могут содержать от 4 до 24 блоков СМТ.
Входные (опорные) синхросигналы в блок СМТ могут поступать от буферов
BUFR, от СС-входов, буферов BUFG, приемопередатчиков или от внутренней логики,
а сформированные синхросигналы могут подаваться на входы буферов BUFG или
BUFH.
Число выходных счетчиков (делителей) блока ММСМ равно 8, некоторые из них
могут управлять инвертированием синхросигнала (выполнять фазовый сдвиг на 180°).
Для обратной совместимости с цифровым контроллером синхросигнала DCM (Digital
Блоки формирования синхросигналов СМТ
225
Clock Manager), 9 независимых выходов могут выбираться для отображения выходов
DCM прямо в блок ММСМ.
Блок ММСМ обладает широкими возможностями сдвига фазы синхросигнала в
каждом направлении и может использоваться в динамическом фазово-сдвиговом ре-
жиме. Разрешающая способность фазового сдвига зависит от частоты управляемого
напряжением генератора VCO. Имеется также дробное деление с приращением 1/8
(0,125) для сигналов CLKFBOUT и CLKOUTO.
Блоки ММСМ имеют также дополнительные возможности по расширению спек-
тра (spread spectrum).
Таким образом, блоки ММСМ и PLL могут служить как синтезаторы частоты
в широком диапазоне частот, как фильтры флуктуаций для каждого внешнего или
внутреннего синхросигнала, а также как фильтры перекосов синхросигналов.
Использование в проектах блока ММСМ осуществляется с помощью примитивов
MMCME2-BASE и MMCME2-ADV, а блока PLL — с помощью примитивов PLLE2.
BASE и PLLE2-ADV.
Разработчики часто используют блоки ММСМ и PLL для компенсации задерж-
ки сети синхросигнала.
Блоки ММСМ и PLL могут также использоваться для синтеза частоты. В таком
применении блоки MMCM/PLL не используются для устранения перекоса сети син-
хросигнала, а для генерации выходной тактовой частоты для других блоков. В этом
режиме используются внутренние пути обратных связей блоков MMCM/PLL, благо-
даря чему минимизируется флуктуация.
Блоки ММСМ поддерживают дробные (не целочисленные) делители с градацией
1/8 или 0,125 на выходном пути CLKOUTO. При использовании дробного делителя
скважность не программируется.
При использовании блока MMCM/PLL в качестве фильтра флуктуаций, блок
MMCM/PLL рассматривается как буфер, который генерирует на выходе входную час-
тоту.
Блок ММСМ имеет много опций для реализации фазового сдвига. Блок PLL
имеет базовое свойство для статического фазового сдвига.
Статический фазовый сдвиг может достигаться путем выбора одной из восьми
выходных фаз VCO с дополнительным тонким фазовым сдвигом, возможным в вы-
ходных счетчиках CLKOUT.
Для определения фазового сдвига как в фиксированном, так и в динамическом
режиме, блоков MMCM/PLL служит программа Clocking Wizard.
В режиме статического фазового сдвига каждый выходной счетчик программи-
руется индивидуально, позволяя каждому выходу иметь дополнительное разрешение
фазового сдвига в градусах на основе фазы выбранного VCO и значения деления
счетчика CLKOUT.
Режим интерполированного тонкого фазового сдвига IFPS имеет линейное по-
ведение сдвига независимо от величины атрибута CLKOUT-DIVIDE и разрешения
фазового сдвига, а зависит только от частоты генератора VCO. В этом режиме вы-
ходные сигналы могут быть повернуты циклически на 360° с линейным приращением
l/(56Fvco)-
Примитив MMCME2-ADV обеспечивает три входа PSEN, PSINCDEC, PSCLK и
один выход PSDONE для динамического тонкого фазового сдвига.
Фаза выходного сигнала ММСМ при динамическом фазовом сдвиге инкремен-
тируется/декрементируется согласно взаимодействию PSEN, PSINCDEC, PSCLK и
PSDONE от начального или ранее выполненного динамического сдвига фазы.
226
Раздел 13
Каждая инкрементация (декрементация) добавляет (отнимает) к сдвигу фазы
выходов синхронизации ММСМ 1/56 периода частоты генератора VCO.
После инициирования фазового сдвига путем установки PSEN и завершения фа-
зового сдвига, сигнализируемого PSDONE, выходные синхросигналы ММСМ посте-
пенно дрейфуют от их исходного фазового сдвига до инкрементированного/ декре-
ментированного фазового сдвига в линейном виде. Окончание инкрементации или
декрементации указывается установкой PSDONE в высокий уровень.
Счетчик (делитель) CLKOUT6 может каскадироваться с счетчиком CLKOUT4
для реализации делителя больше, чем 128.
Программирование блока ММСМ/PLL может осуществляться двумя способами:
с помощью программы Clocking Wizard или путем инстанции блока ММСМ/PLL. Для
программирования блока ММСМ/PLL необходима следующая информация:
• период опорного синхросигнала;
• частоты выходных синхросигналов (до 7 максимум);
• скважность выходного синхросигнала (по умолчанию 50 %);
• фазовый сдвиг выходного синхросигнала в числе градусов по отношению к на-
чальной фазе синхросигнала 0;
• желаемая полоса пропускания блока MMCM/PLL;
• режим компенсации;
• флуктуация опорного синхросигнала, определяемая в терминах единичного ин-
тервала Ul (unit interval), например в процентах периода опорного синхросигнала.
Определение входной частоты позволяет определять все возможные выходные
частоты путем использования минимальных и максимальных входных частот для
определения диапазона счетчика D, а также диапазон функционирования генерато-
ра VCO для определения диапазона счетчика М и диапазона выходных счетчиков.
Формулы (3.1)-(3.4) определяют ограничения на значения счетчиков D и М.
Подходящих значений счетчиков D и М может быть выбрано достаточно много.
При нахождении значений D и М необходимо стремиться выбрать значения D и М как
можно меньше при сохранении как можно высокой частоты fvco- Первым находится
значение М по формуле (3.5).
Блок ММСМ компенсирует задержку входного синхросигнала только от буфе-
ров IBUFG.
Если блоки ММСМ/PLL конфигурируются для обеспечения определенного фазо-
вого соотношения и изменяется входная частота, то это фазовое соотношение также
изменяется, поскольку изменяется частота генератора VCO и, следовательно, будет
изменен абсолютный сдвиг в пикосекундах.
Когда главным аспектом проекта является поддержка определенного фазового
соотношения среди различных выходных синхросигналов (например, CLK и CLK90),
то это соотношение будет поддерживаться независимо от входной частоты.
При переключении опорного синхросигнала блок ММСМ/PLL должен быть сбро-
шен.
Когда входной синхросигнал или синхросигнал обратной связи теряется, должен
быть применен сигнал сброса RESET.
Блоки ММСМ часто применяются для устранения перекоса сети синхросигналов,
при этом могут использоваться либо два буфера BUFG, либо два буфера BUFH.
Когда блок ММСМ используется как синтезатор или фильтр флуктуации, за-
действуется внутренняя обратная связь блока ММСМ, при этом не требуется фазовое
соотношение между входным и выходным синхросигналом блока ММСМ.
Блоки формирования синхросигналов СМТ
227
Блок ММСМ можно использовать для создания буфера синхросигнала с нулевой
задержкой, который применяется в ситуации, когда необходимо единственный синхро-
сигнал подключить ко многим точкам синхронизации с малым перекосом между ними.
Для формирования больших областей синхронизации блоки ММСМ и PLL могут
соединяться каскадно через магистраль блока СМТ, используя выводы CLKOUTO —
CLKOUT3.
Примитив ММСМЕ2 может генерировать синхросигнал расширенного спектра из
стандартной фиксированной частоты. Генерация расширенного спектра синхросигна-
ла SSCG распространяет электромагнитную энергию по большой полосе частот для
эффективного уменьшения электрической и магнитной напряженности поля. Пико-
вая электромагнитная энергия на любой одной частоте уменьшается путем модуляции
выхода SSCG.
14 Конфигурирование FPGA 7-й серии
14.1. Основы конфигурирования
14.1.1. Режимы конфигурирования
Устройства FPGA 7-й серии конфигурируются путем загрузки конфигурацион-
ных данных, которые представляются в виде последовательного битового потока
(bitstream). FPGA могут загружать себя из внешнего устройства энергонезависи-
мой памяти типа ППЗУ (PROM) или они могут быть сконфигурированы внешним
интеллектуальным источником, таким как микропроцессор, процессор DSP, микро-
контроллер, компьютер PC или тестер печатных плат. В любом случае, есть два об-
щих канала передачи данных конфигурирования. Первым является последовательный
канал передачи данных, который используется для минимизации внешних контактов
FPGA. Вторым каналом является 8-, 16- или 32-разрядный параллельный канал пе-
редачи данных, используемый для более высокой производительности или доступа
к интерфейсам памяти промышленного стандарта. Параллельный канал также иде-
ально подходит для внешних источников данных, таких как процессоры или х8- или
х16-параллельная флэш-память.
FPGA фирмы Xilinx могут перепрограммироваться в системе неограниченное ко-
личество раз.
Поскольку данные конфигурирования FPGA фирмы Xilinx сохраняются в защел-
ках конфигурирования типа CMOS (CMOS configuration latches— CCL), после выклю-
чения питания они должны быть реконфигурированы. Битовый поток загружается в
устройство через специальные выводы конфигурирования.
FPGA 7-й серии имеют следующие режимы конфигурирования:
• главный последовательный режим конфигурирования Master-Serial;
• подчиненный последовательный режим конфигурирования Slave-Serial;
• главный параллельный режим конфигурирования SelectMAP (х8и х1б);
• подчиненный параллельный режим конфигурирования SelectMAP (х8, х16 и
х32);
• режим конфигурирования JTAG или режим граничного сканирования (boundary-
scan);
• главный режим конфигурирования последовательного периферийного интерфей-
са (Serial Peripheral Interface — SPI) флэш-памяти (xl, x2, x4);
• главный режим конфигурирования побайтного периферийного интерфейса (Byte
Peripheral Interface — BPI) флэш-памяти, использующий параллельную флэш-
память NOR (х8 и х16).
Определенный режим конфигурирования выбирается путем установки необхо-
димого уровня на специальных входных выводах выбора режима конфигурирования
М[2:0]. На выводах режима М[2:0] должны быть установлены постоянные уровни на-
пряжения либо через подтягивающие или понижающие резисторы (^ 1 кОм), либо
прямо подсоединяя к земле или напряжению Vcco_o- Выводы режима не должны
переключаться во время и после конфигурирования.
Конфигурирование FPGA 7-й серии
229
Термины главный (Master) и подчиненный (Slave) относятся к направлению син-
хросигнала конфигурирования (configuration clock — CCLK). В основных режимах
конфигурирования FPGA 7-й серии управляют синхросигналом CCLK от внутрен-
него генератора. Чтобы выбрать желаемую частоту, используется опция битового
потока -g ConfigRate. Раздел BitGen документа UG628 Command Line Tools User
Guide предоставляет больше информации для средства проектирования ISE. Раздел
Device Configuration Bitstream Settings документа UG908 Vivado Design Suite User Guide
Programming and Debugging — для пакета Vivado.
После конфигурирования CCLK выключается, если только не выбирается опция
сохранения состояния (persist option) или не используется режим обнаружения оди-
ночной ошибки SEU (Single Event Upsets). Вывод CCLK является выводом с третьим
состоянием и слабо подтягивается вверх. В подчиненных режимах конфигурирования
вывод CCLK является входом.
Интерфейс конфигурирования JTAG всегда доступен независимо от установок
выводов режима.
Чтобы сделать эффективную систему, важно рассмотреть, какой режим конфи-
гурирования FPGA лучше всего соответствует требования системы. Каждый режим
конфигурирования использует выделенные контакты FPGA и может временно исполь-
зовать другие многофункциональные контакты только во время конфигурирования.
Когда конфигурирование заканчивается, эти многофункциональные контакты стано-
вятся доступными для общего использования. Режим конфигурирования может так-
же устанавливать ограничения на значения напряжений для некоторых банков ввода-
вывода FPGA. Доступны несколько различных опций конфигурирования, эти опции
достаточно гибки, поэтому для каждой системы можно найти оптимальное решение.
При выборе лучшей опции конфигурирования необходимо рассмотреть следующие
вопросы: время полной установки, а также скорость, стоимость и сложность кон-
фигурирования.
14.1.2. Длина конфигурационного битового потока
Проекты на FPGA заканчиваются в образе конфигурационной последовательнос-
ти, называемой битовым потоком (bitstream). Потоки битов загружаются через ин-
терфейс конфигурирования, чтобы сконфигурировать FPGA в соответствии с функ-
циями проекта. Конфигурационная последовательность для каждого типа конфи-
гурирования FPGA имеет фиксированную длину. В табл. 14.1 приведены размеры
битового потока и другая специфичная информация для устройств FPGA 7-й серии.
14.1.3. Главные и подчиненные режимы
Самозагружающиеся режимы конфигурирования FPGA, в общем случае назы-
ваемые главными режимами (Master), доступны как с последовательным, так и с
параллельным каналом передачи данных. Главные режимы эффективно используют
различные типы энергонезависимой памяти, чтобы сохранить конфигурационную ин-
формацию в FPGA. В главном режиме конфигурационная последовательность FPGA
обычно находится на той же плате во внешней к FPGA энергонезависимой памяти. В
главном режиме FPGA управляет процессом конфигурирования. Для этого FPGA ге-
нерирует синхросигнал конфигурирования во внутреннем генераторе, который управ-
ляет логикой конфигурирования и может наблюдаться на выходном контакте CCLK.
Управляемые внешне подчиненные режимы конфигурирования FPGA, в общем
называемые подчиненными режимами (Slave), также доступны как с последователь-
ным так и с параллельным каналом передачи данных. В режиме Slave внешний «ин-
теллектуальный агент», такой как процессор, микроконтроллер, процессор DSP или
230
Раздел 14
Таблица 14.1
Длина битового потока для устройств FPGA 7-й серии
Устройство Длина конфигурационной последовательности, бит Минимальный размер конфигурационной флэш-памяти, Мбит Длина команды JTAG, бит
Семейство Artix-7
7А35Т 17 536096 32 6
7А50Т 17 536096 32 6
7А75Т 30 606 304 32 6
7А100Т 30 606 304 32 6
7А200Т 77 845 216 128 6
( Семейство Kintex-7
7К70Т 24 090 592 32 6
7К160Т 53 540 576 64 6
7К325Т 91548 896 128 6
7К355Т 112414 688 128 6
7К410Т 127 023328 128 6
7К420Т 149880 032 256 6
7К480Т 149880 032 256 6
Семейство Virtex-7
7V585T 161398 880 256 6
7V2000T 447 337 216 512 24
7VX330T 111238 240 128 6
7VX415T 137 934 560 256 6
7VX485T 162 187488 256 6
7VX550T 229878496 256 6
7VX690T 229878 496 256 6
7VX980T 282 521312 512 6
7VX1140T 385127 680 512 24
7VH580T 195 663008 256 22
7VH870T 294006 336 512 38
Serial
Byte-Wide
Processor,
Microcontroller
7 Series FPGA
СГГО1Л1 ПЛПГЛ DIN
CLOCK
CCLK
(a) Slave Serial Mode
JTAG Tester,
Processor,
Microcontroller
7 Series FPGA
(b) JTAG Mode
Processor,
Microcontroller 7 Series FPGA
[7:0] DATA [15:0] [31:0] SELECT READ/WRITE CLOCK 8. 16, 32 [7:0] D[15:0] [31:0] CSI....B RDWR_B CCLK
(c) Slave SelectMAP Mode
Рис. 14.1. Починенные режимы конфигурирования
тестер загружает образ конфигурирования в FPGA, как показано на рис. 14.1. Пре-
имущество подчиненных режимов конфигурирования состоит в том, что конфигу-
рационная последовательность FPGA может находиться, практически, где угодно в
системе: во флэш-памяти, на плате, вместе с кодом главного процессора, на жест-
Конфигурирование FPGA 7-й серии
231
ком диске, а также конфигурирование может произойти по какому-либо сетевому или
другому типу соединения.
Режим Slave Serial чрезвычайно прост, состоит только из синхросигнала и входа
последовательных данных. Режим JTAG также является простым последовательным
режимом конфигурирования, популярным для анализа прототипа и широко исполь-
зуется для теста платы. Режим Slave SelectMAP является простым х8-, х16- или
х32-битовым периферийным интерфейсом процессора, который включает вход сиг-
нала выбора кристалла CSLB и вход управления чтением-записью RDWR.B.
14.1.4. Соединение JTAG
Четырех контактный интерфейс JTAG широко распространен в аппаратуре от-
ладки для тестирования плат. Кабель программирования Xilinx для FPGA 7-й се-
рии использует интерфейс JTAG для загрузки в FPGA прототипа и отладки проекта.
Независимо от режима конфигурирования для облегчения отладки в конечный про-
ект, используемый в приложении, лучше также включить интерфейс конфигуриро-
вания JTAG.
14.1.5. Базовое конфигурационное решение
В базовом конфигурационном решении FPGA при включении питания автома-
тически получает свою конфигурационную последовательность от устройства флэш-
памяти. Для этого у FPGA есть последовательный периферийный интерфейс (serial
peripheral interface — SPI), через который FPGA может считать конфигурационную
последовательность из стандартного устройства флэш-памяти SPL
Программа iMPACT пакета ISE может программировать выбранную флэш-память
SPI. Для этого программа iMPACT соединяется с FPGA через его стандартный интер-
фейс JTAG и через FPGA может косвенно программировать флэш-память SPI (см.
документ ХАРР586 Using SPI Flash with 7 Series FPGAs). Подобная возможность
также имеется в пакете Vivado.
14.1.6. Конфигурационные решения низкой стоимости
Опция с самой низкой ценой варьируется в зависимости от определенного при-
ложения.
Если имеется запасная энергонезависимая память, уже доступная в системе, об-
раз потока битов может быть сохранен в системной памяти. Образ FPGA может даже
быть сохранен на жестком диске или загружен удаленно по сетевому соединению. Для
этого следует рассмотреть один из следующих режимов конфигурирования: Master
BPI Mode и Slave Serial Mode или JTAG Configuration Mode и Boundary-Scan.
Если для приложения уже требуется энергонезависимая память, можно объеди-
нить память для приложения и для конфигурирования. Например, конфигурационная
последовательность FPGA может быть сохранена с любым кодом системного про-
цессора. Если процессор — это встроенный в FPGA процессор MicroBlaze, данные
конфигурирования FPGA и код процессора MicroBlaze могут совместно использовать
одно и то же устройство энергонезависимой памяти.
14.1.7. Конфигурационные решения высокой скорости
Некоторые приложения требуют, чтобы логика была функциональной за короткий
промежуток времени от начала конфигурирования. Определенные режимы и методы
конфигурирования FPGA выполняются быстрее, чем другие. Время конфигурирова-
ния включает время инициализации плюс время конфигурирования. Время конфигу-
рирования зависит от размера устройства и скорости логики конфигурирования.
232
Раздел 14
При той же тактовой частоте параллельные режимы конфигурирования быстрее,
чем последовательные режимы, потому что они программируют 8, 16 или 32 бита
за один промежуток времени.
Конфигурирование одной FPGA всегда быстрее, чем конфигурирование несколь-
ких FPGA в конфигурационной цепи. В проекте с несколькими FPGA, где критична
скорость конфигурирования, каждая FPGA должна конфигурироваться отдельно и
параллельно.
В главных режимах FPGA внутренне генерирует синхросигнал конфигурирования
и выводит его на выход CCLK. По умолчанию частота CCLK начинается на низкой
частоте, но опции битового потока могут либо увеличить внутренне сгенерированную
частоту CCLK, либо переключить источник CCLK на источник внешнего синхросиг-
нала от вывода EMCCLK. Максимальная частота CCLK зависит от спецификаций
чтения для присоединенной энергонезависимой памяти: более быстрая память раз-
решает более быструю конфигурацию. При использовании внутреннего генератора
для источника CCLK выходная частота может меняться в зависимости от процесса
обработки данных, напряжения или температуры.
Опция генератора тактовых импульсов EMCCLK разрешает внешний точный ис-
точник синхросигнала для оптимальной производительности конфигурирования. Оп-
ция EMCCLK позволяет более точные допуски и более быстрые синхросигналы.
14.1.8. Защита битового потока от несанкционированного копирования
Во время включения питания битовый поток определяет функциональность
FPGA. Это дает возможность сторонним лицам получить конфигурационную после-
довательность и создать несанкционированную копию проекта.
Как и для процессоров, имеется много методов для защиты битового потока
FPGA и любого встроенного в FPGA ядра интеллектуальной собственности (intellec-
tual property — IP). Самые мощные методы защиты — это AES с ключом SRAM с ава-
рийным батарейным питанием или AES с ключом eFUSE. Идентификация устройства
с помощью универсального идентификатора устройства (device DNA) является треть-
им методом, который использует более низкий уровень безопасности. Кроме того,
устройства FPGA 7-й серии также имеют реализованный аппаратно усовершенство-
ванный стандарт шифрования (Advanced Encryption Standard — AES), чтобы обеспе-
чить высокую степень безопасности проекта.
14.1.9. Загрузка нескольких FPGA с помощью одной конфигурационной
последовательности
Обычно в системе имеется один образ битового потока конфигурирования на
одну FPGA. Несколько различных образов битовых потоков FPGA могут совместно
использовать единственную флэш-память конфигурирования, увеличив цепь конфи-
гурирования. Однако если в приложении все FPGA имеют тот же номер партии и
используют ту же конфигурационную последовательность, требуется только один об-
раз битового потока. Альтернативное решение, названное спаренной «ganged» или
поперечной «broad-side» конфигурацией, загружает несколько подобных FPGA одним
и тем же потоком битов. Спаренное или поперечное конфигурирование поддержива-
ется только в подчиненных последовательных режимах или подчиненных режимах
SelectMAP.
14.1.10. Оценка факторов конфигурирования
Много факторов определяют, какое конфигурационное решение оптимально для
конкретной системы. Имеется также большое число деталей, которые должны учи-
тываться при выборе способа конфигурирования. Отметим, что к выбору способа
Конфигурирование FPGA 7-й серии
233
конфигурирования нужно отнестись очень серьезно, чтобы не создать проблемы поз-
же, во время проектирования.
Разработчики должны понимать различие между специализированными вывода-
ми конфигурирования и выводами, допускающими повторное использование после
конфигурирования.
Другими проблемами, которые необходимо рассмотреть, являются форматы
файла «Data File» данных и размеры битового потока. Размер битового потока непо-
средственно зависит от размеров устройства, а также имеется несколько форматов,
в которых может быть создан битовый поток.
Процесс конфигурирования FPGA включает несколько шагов. Каждый шаг часто
состоит из последовательности событий. Например, первый шаг — это последова-
тельность включения питания для многих источников питания. Чтобы определить
полное время конфигурирования, разработчик должен учитывать вклад каждого ша-
га. Инструменты пакета Vivado обеспечивают команду TCL calc_config_time, которая
может использоваться для оценки времени конфигурирования. Можно также исполь-
зовать справку help calc_config_time для получения информации о времени конфи-
гурирования.
14.1.11. Отладка конфигурирования
Перед отладкой всего проекта создайте и протестируйте простой проект, ис-
пользуя битовый поток тестового примера (например, счетчик с выходами LED).
Этот простой тестовый проект помогает устранять любые потенциальные пробле-
мы с параметрами настройки битового потока или интерфейсами платы. Попробуйте
сконфигурировать FPGA, используя другой метод, например конфигурирование че-
рез JTAG, вместо конфигурирования от флэш-памяти, чтобы определить, имеются
ли проблемы для данного режима конфигурирования. Дополнительным ресурсом яв-
ляется центр решений проблем конфигурирования фирмы Xilinx (Xilinx Configuration
Solution Center).
В данном тестовом примере два сигнала конфигурирования, INIT.B и DONE,
должны быть подсоединены к драйверам LED. Изменение сигнала INIT.B от низко-
го до высокого уровня указывает завершение инициализации при включении питания.
Падение сигнала INIT.B во время конфигурирования может указать ошибку контроль-
ной суммы CRC в битовом потоке. Рекомендации для конфигурирования и других вы-
водов находятся в документе ХМР277 «7 Series Schematic Design Checklist». Если кон-
фигурирование не завершилось должным образом, регистр состояния предоставляет
важную информацию о том, какие ошибки вызвали отказ. Режимы readback/verify
стандарта JTAG могут определить, были ли данные конфигурирования правильно за-
гружены в устройство.
Модель симуляции конфигурирования (SIM-CONFIG) позволяет моделировать
поддерживаемые интерфейсы конфигурирования. Эта модель позволяет выяснить,
как конфигурируемые устройства реагируют на воздействия в интерфейсе конфигури-
рования (для получения дополнительной информации см. документ UG626 Synthesis
and Simulation Design Guide).
14.2. Интерфейсы конфигурирования
14.2.1. Интерфейсы и режимы конфигурирования
Устройства FPGA 7-й серии имеют пять интерфейсов конфигурирования. Каж-
дый интерфейс конфигурирования соответствует одному или более режимам конфи-
гурирования и ширине шины данных, как приведено в табл. 14.2. Для получения
234
Раздел 14
Таблица 14.2
Режимы конфигурирования FPGA 7-й серии
Режим конфигурирования M[2:0] Ширина шины данных Направление CCLK
Master Serial 000 x 1 Выход
Master SPI 001 xl, x2, x4 Выход
Master BPI 010 x8. X16 Выход
Master SelectMAP 100 x8, X16 Выход
JTAG 101 x 1 Не применим
Slave SelectMAP 110 x8, X16, x32 Вход
Slave Serial (по умолчанию) 111 xl Вход
подробной информации о интерфейсе и синхронизации обратитесь к соответствую-
щей документации конкретного устройства FPGA 7-й серии 7 (data sheet).
14.2.2. Выводы конфигурирования
В устройствах FPGA 7-й серии у каждого режима конфигурирования есть соот-
ветствующий набор интерфейсных выводов, которые охватывают один или несколько
банков ввода-вывода. Банк 0 содержит специальные выводы конфигурирования и
всегда является частью каждого интерфейса конфигурирования. Банк 14 и Банк 15
содержат многофункциональные выводы, которые используются в определенных ре-
жимах конфигурирования. Таблицы данных (data sheet) FPGA 7-й серии определяют
характеристики переключения для выводов конфигурирования в банках, работающих
с напряжением 3,3, 2,5, 1,8 или 1,5 В.
Весь интерфейс JTAG и выделенные контакты конфигурирования расположе-
ны в отдельном, специализированном банке 0 со специальным напряжением питания
(Vcco_o)- Многофункциональные контакты расположены в банках 14 и 15.
Специальные входные контакты конфигурирования функционируют с напряже-
нием Vcco_o уровня LVCMOS (LVCMOS18, LVCMOS25 или LVCMOS33), имеют ток
12 мА и быструю скорость нарастания (slew rate) во время конфигурирования.
Для режимов, которые используют многофункциональный ввод-вывод, соответ-
ствующий напряжениям VCCO.14 или VCCO.15, многофункциональные контакты
должны быть соединены с надлежащим напряжением для соответствия стандарту
ввода-вывода конфигурирования устройства.
Многофункциональные контакты также соответствуют стандарту LVCMOS, име-
ют ток 12 мА и быструю скорость нарастания во время конфигурирования. Если
используется опция Persist, многофункциональный ввод-вывод для выбранного ре-
жима конфигурирования остается активным после конфигурирования, со стандарт-
ным вводом-выводом, установленным к значению по умолчанию общего назначения
LVCMOS, током на 12 мА и медленной скоростью нарастания.
Названия конкретных выводов каждого режима конфигурирования и их распо-
ложение в банках ввода-вывода можно найти в документе UG470 7 Series FPGAs
Configuration. User Guide. Описание выводов конфигурирования для FPGA 7-й се-
рии приведено в приложении А.
14.2.3. Выбор напряжения банков конфигурирования
Напряжение конфигурирования в различных банках определяется с помощью ло-
гического контакта CFGBVS, значение которого выбирается между VCCO.O и GND.
Когда контакт CFGBVS в высоком уровне, конфигурирование и ввод-вывод JTAG в
банке 0 поддерживает функционирование на напряжениях 3,3 В или 2,5 В во время
и после конфигурирования. Когда контакт CFGBVS в низком уровне, ввод-вывод в
Конфигурирование FPGA 7-й серии
235
банке 0 поддерживает функционирование на напряжениях 1,8 В или 1,5 В. Конфигу-
рирование не поддерживается при напряжении 1,2 В.
CFGBVS так же управляет допуском по напряжению в банках 14 и 15, но только
во время конфигурирования. Когда CFGBVS в высоком уровне, ввод-вывод конфигу-
рирования в банках 14 и 15 поддерживает функционирование при напряжениях 3,3 В
или 2,5 В во время конфигурирования. Когда контакт CFGBVS в низком уровне,
ввод-вывод конфигурирования в банках 14 и 15 поддерживает функционирование при
напряжениях 1,8 В или 1,5 В во время конфигурирования.
Напомним, контакт CFGBVS не доступен для устройств Virtex-7 НТ. Устройства
Virtex-7 НТ поддерживают функционирование только при напряжении 1,8 В.
14.2.4. Установка опций конфигурирования в пакете Vivado
Выбор напряжения конфигурирования может быть поручен пакету Vivado, путем
установки свойства config.voltage или cfgbvs. Кроме того, свойство config_mode мо-
жет быть определено так, чтобы инструменты распознали, какие используются кон-
такты конфигурирования. Инструменты Vivado обеспечивают предупреждения, если
есть какие-либо конфликты между параметрами настройки контакта конфигурирова-
ния, такими как IOSTANDARD на многофункциональном контакте конфигурирования,
который конфликтует с напряжением конфигурирования. Эти свойства могут быть
установлены в диалоговом окне конфигурирования Vivado (Редактирование устано-
вок устройства «Edit Device Settings») или посредством команд Tel (см. документ
UG912 Vivado Design Suite Properties Reference Guide, для получения дополнительной
информации о синтаксисе Tel, а также см. документ UG899 Vivado Design Suite User
Guide I/O and Clock Planning, где приведены примеры того, как инструменты Vivado
используют эти опции).
14.2.5. Опция внешнего главного синхросигнала конфигурирования
EMCCLK
По умолчанию главные режимы конфигурирования используют внутренний ис-
точник синхросигнала CCLK. Однако для приложений, где сокращение времени кон-
фигурирования критически важно, должен использоваться внешний главный синхро-
сигнал конфигурирования EMCCLK. Синхросигнал EMCCLK позволяет использовать
более точный источник внешнего синхросигнала, чем внутренний синхросигнал FPGA
с допуском на отклонение частоты главного синхросигнала CCLK (Fmccktol)- На-
пример, когда главный CCLK имеет максимальную частоту 100 МГц, 50%-ный допуск
означает, что установка ConfigRate не может быть быст-
рее, чем 66 МГц. Однако источник внешнего таймера мо-
жет быть применен со скоростью 100 МГц так как у него
есть допуск 200 ppm в минуту или меньше (100.2 МГц, мак-
симум). В главном режиме FPGA 7-й серии поддерживают
возможность динамично переключиться на источник внеш-
него таймера EMCCLK (детали см. в документе UG470 7
Series FPGAs Configuration User Guide).
14.3. Последовательный режим
конфигурирования
В последовательных режимах FPGA конфигурируется
путем загрузки одного бита за один цикл синхросигнала
CCLK. Вывод CCLK является выходом в главном режиме
и входом в подчиненных режимах. На рис. 14.2 показан основной интерфейс после-
довательной конфигурирования FPGA 7-й серии.
М[2:0]
DOUT
DIN
INITJB
PUDC__B
PROGRAM В
DONE
CCLK
. 14.2. Интерфейс по-
довательной конфигу-
>вания FPGA 7-й серии
236
Раздел 14
14.3.1 . Подчиненный последовательный режим конфигурирования
Обычно подчиненное последовательное конфигурирование (Slave-Serial) исполь-
зуется для устройств в последовательной цепи или когда конфигурируется единст-
венное устройство от микропроцессора или CPLD (рис. 14.3). Подчиненные режимы
конфигурирования подобны главным режимам, за исключением направления синхро-
сигнала CCLK. CCLK должен управляться от внешнего источника синхросигнала.
Рис. 14.3. Пример конфигурирования в подчиненном последовательном режиме
14.3.2 . Главный последовательный режим конфигурирования
Главный последовательный режим конфигурирования (Master-Serial) подобен
подчиненному режиму последовательного конфигурирования, за исключением того,
что синхросигнал CCLK генерируется FPGA. В этом случае вывод CCLK является
выходом.
Для FPGA 7-й серии режим Master SPI является доминирующим режимом конфи-
гурирования для конфигурирования с малым количеством выводов из флэш-памяти
последовательного типа.
Конфигурирование FPGA 7-й серии
237
14.3.3 . Синхронизация данных последовательного конфигурирования
На рис. 14.4 показано, как данные конфигурирования синхронизируются в глав-
ном и подчиненном последовательных режимах. Здесь бит 0 представляет стар-
ший значащий бит первого байта, например, если байт имеет содержимое ОхАА
(1010-1010), то бит 0=1, бит 1=0, бит 2 = 1 и т.д.
Рис. 14.4. Синхронизация последовательного конфигурирования
Для главного режима конфигурирования CCLK управляется только после того,
как INIT-B перейдет на высокий уровень вскоре после принятия сигналом DONE высо-
кого уровня. Иначе CCLK находится в высокоимпедансном состоянии. Таймирование
в документации относится к выводу CCLK.
14.4. Режим конфигурирования SelectMAP
Интерфейс конфигурирования SelectMAP (рис. 14.5)
предоставляет интерфейс двунаправленной шины данных
шириной 8, 16 или 32 бита для логики конфигурирования
FPGA, который может использоваться как для конфигу-
рирования, так и для обратного чтения (readback). Об-
ратное чтение и прямое чтение шины данных применимо
только в подчиненном режиме SelectMAP. Ширина шины
в режиме SelectMAP определяется автоматически.
Вывод CCLK является выходом в главном и входом
в подчиненном режиме SelectMAP. Через шину SelectMAP
может конфигурироваться одно или более устройств
FPGA.
Имеется несколько методов конфигурирования в ре-
жиме SelectMAP:
М[2:0]
D[31:00] INITJ3 PUDC.B RS[1:0] CSOJB
PROGRAM_B
RDWFLB
CSLB DONE
CCLK
Рис. 14.5. Интерфейс конфи-
гурирования FPGA SelectMAP
• единственное подчиненное устройство SelectMAP; типичная схема включает про-
цессор, обеспечивающий данные и синхросигнал; альтернативная схема включает
другое программируемое логическое устройство, такое как CPLD, которое ис-
пользуется как менеджер конфигурирования, который выполняет конфигурацию
FPGA через интерфейс SelectMAP;
• несколько устройств в виде цепи шины SelectMAP; несколько FPGA конфигуриру-
ются последовательно с разными образами конфигурирования от флэш-памяти
или процессора;
238
Раздел 14
• несколько устройств, объединенных в партию (ganged) интерфейсом SelectMAP;
несколько FPGA конфигурируются параллельно от флэш-памяти или процессора
одним и тем же образом конфигурирования.
Когда используется параллельная флэш-память, рекомендуется режим конфи-
гурирования BPI.
14.4.1. Конфигурирование в режиме SelectMAP одного устройства
Конфигурирование SelectMAP, управляемое процессором. Для приложений, где
микропроцессор или CPLD используются для конфигурирования единственного уст-
ройства FPGA, может использоваться главный или подчиненный режим SelectMAP
(рис. 14.6). Подчиненный режим является более предпочтительным.
See Configuration Banks Voltage Select
section for appropriate connection.
VCCINT
CFGBVS VCCAUX
PUDC-B VCCAUX VCCBATT vcco_o VCCO J 4 М2 •
VCCO_Q
VCCO„14 VCCO_15
Ml 1 VCCO„15 MO
7 Series
FPGA
Memory
Source
vcc
VCCCLO
vcco_o
D{31:0]
SELECT
DONE
GND
VCCO_0
TDI
TOO
GND
PROGRAM_B
TMS
TCK
CSO„B
IN1T„B
Microprocessor
or CPLD
D(31:0]
CSIJB
RDWR _B
CCLK
PROGRAM.B
READ/WRITE
CLOCK
PROGRAM_B
DONE
INITB
Ф
Xtr
Бс
og
Configuration
TO
NC
Рис. 14.6. Пример конфигурирования единственного подчиненного FPGA в режиме SelectMAP
VREF
14.4.2. Загрузка данных в режиме SelectMAP
Интерфейс SelectMAP обеспечивает непрерывную (continuous) или прерывистую
(non-continuous) загрузку данных (data loading) в FPGA. Загружаемые данные управ-
ляются сигналами CSLB, RDWR.B и CCLK. Значение CSLB = 0 разрешает интерфейс
SelectMAP, а значение CSLB = 1 его запрещает. Когда интерфейс SelectMAP запре-
щен, выводы D[31:0] находятся в высокоимпедансном состоянии, а вывод RDWRJ3
игнорируется.
Конфигурирование FPGA 7-й серии
239
Кргда RDWR.B = 0, контакты данных являются входами (данные записываются
в FPGA), когда RDWR.B = 1, контакты данных являются выходами (данные читают-
ся из FPGA). Для конфигурирования в режиме SelectMAP значение RDWR.B долж-
но быть установлено для записи (RDWR.B = 0), а для обратного чтения значение
RDWR.B должно быть установлено в 1 с одновременной установкой сигнала CSLB.
Изменение значения входа RDWR.B с низкого уровня на высокий при низком
значении входа CSI.B вызывает аварийное состояние ABORT и конфигурация дву-
направленных выводов асинхронно изменяется с входов на выходы. Аналогично, из-
менение значения входа RDWR.B с высокого уровня на низкий при низком значении
входа CSI.B вызывает изменение конфигурации двунаправленных выводов асинхрон-
но с выходов на входы, а состояние ABORT переходит в состояние обратного чтения.
Если обратное чтение не требуется, RDWR.B может подсоединяться к земле.
При RDWR.B = 1 и установленном CSI.B FPGA управляет данными SelectMAP
без отношения к CCLK.
Все действия на шине данных SelectMAP тактируются сигналом CCLK. Когда
RDWR.B = 0 для записи, FPGA захватывает выводы данных SelectMAP на возраста-
ющем фронте CCLK. Когда RDWR.B = 1 для управления чтением, FPGA обновляет
данные на выводах данных SelectMAP на возрастающем фронте CCLK. В подчинен-
ном режиме SelectMAP конфигурирование может приостанавливаться путем оста-
новки сигнала CCLK.
Временные диаграммы непрерывной и прерывистой загрузки данных в режиме
SelectMAP приведены в приложении Б.
14.5. Режим конфигурирования Master SPI
Для FPGA 7-й серии режим конфигурирования Master SPI позволяет исполь-
зовать для запоминания битового потока устройства флэш-памяти индустриального
стандарта SPI с малым количеством выводов. Для чтения битового потока FPGA
поддерживает четырехконтактный интерфейс флэш-устройств SPI.
Режим конфигурирования Master SPI FPGA 7-й се-
рии (рис. 14.7) дополнительно может читать из уст-
ройств SPI, которые поддерживают операции быстро-
го чтения выходов х2 и х4. Эти режимы выходов
пропорционально быстрее, чем стандартный 1-битовый
интерфейс SPL Кроме того, режим синхронизации на
отрицательном фронте делает возможным лучшее ис-
пользование каждого периода синхросигнала и допуска-
ет высокую скорость синхронизации. Также поддержи-
вается 32-битовая адресация устройств флэш-памяти
SPI с объемом свыше 128 Мбит.
М[2:0] DOO.MOSI ММММЯ
D01JDIN FCS„B МММ.
INIT„B DONE
•ммм. PROGRAMME
****** PUDCLB
****** EMCCLK CCLK МШМ1*
На рис. 14.8 показаны соединения ДЛЯ конфигури- Рис. 14.7. Интерфейс конфи-
рования SPI с шириной данных х1 или х2. Эти соеди- гурирования SPI FPGA 7-й серии
нения являются одинаковыми, потому что режим х2 использует контакт DOO.MOSI
как двухцелевой двунаправленный вывод данных. Режим конфигурирования с цепоч-
ным соединением возможен только в режиме SPI 1х.
Программное средство IMPACT фирмы Xilinx обеспечивает возможность про-
граммировать последовательную флэш-память SPI, используя косвенные методы про-
граммирования. Этот подход загружает новый проект FPGA во флэш-память SPI пу-
тем передачи данных от программы IMPACT через FPGA 7-й серии к флэш-памяти
SPI. Во время этой операции предыдущее содержимое памяти теряется. Программа
240
Раздел 14
VCCO-O
0)
"S®
a? 8
Ф52
VREF
X
PROGRAMS
6Q
NC
See Configuration Banks Voltage
Select section for appropriate
connection
VCCINT CFGBVS PUDC_B DOUT VCCO„14 MOSi/DfOO] DIN/D(01] EMCCLK FCS_B М2 CCLK . 7 Series FPGA vcco_o M0 INIT_B PROGRAM.B DONE ™S VCCAUX TCK VCCBATT TDI TDO GND
vcco„o
vcco_o
VCCO-O
CM
vcco_o VCCO-O t —
D
Q
s
vcc
vcc
SPI Flash
c
HOLD
GND
VCCAUX
VCCO 0
Рис. 14.8. Интерфейс конфигурирования SPI xl/x2 для FPGA 7-й серии
iMPACT пакета ISE поддерживает косвенные методы программирования для следу-
ющих устройств флэш-памяти SPI: Micron N25Q 3,3 В и 1,8 В, Winbond W25Q и
SpaHcion S25FL. Подобные свойства обеспечиваются также программатором пакета
Vivado (Vivado Device Programmer). Дополнительную информацию можно найти в
документе ХАРР586 Using SPI Flash with 7 Series FPGAs.
Контакт DOUT должен подсоединяться к выводу DIN загружаемого FPGA для
цепочечного режима конфигурирования SPI xl.
Данные на выходе устройства SPI синхронизируются падающим фронтом CCLK,
а в FPGA — возрастающим фронтом, хотя допускается отрицательный фронт син-
хронизации (spi_fall_edge:Yes).
Частота CCLK устанавливается опцией ConfigRate, если источником является
внутренних генератор. Кроме того, опция ExtMasterCclk.en позволяет переключить
CCLK к источнику от вывода EMCCLK для использования внешнего источника син-
хронизации.
На рис. 14.9 показана временная диаграмма последовательности режима SPI xl
для FPGA 7-й серии.
Частота CCLK начинается от 3 МГц, типично обеспечивая существенный запас
надежности для активности сигналов FCS-В и MOSL Частота CCLK увеличивается,
если опция ConfigRate используется после запуска чтения.
Когда флэш-память SPI после конфигурирования не используется, рекомендуется
вывод FPGA FCS.B оставить в состоянии высокого уровня.
Конфигурирование FPGA 7-й серии
241
PROGRAM В
INIT В
Рис. 14.9. Временная диаграмма последовательности режима SPI х1 для FPGA 7-й серии
Таблица 14.3
Команды чтения памяти SPI
Команда SPI Код операции
Быстрое чтение х1 ОВ
Быстрое чтение двойного выхода ЗВ
Быстрое чтение учетверенного выхода 6В
Быстрое чтение, 32-битовый адрес ОС
Быстрое чтение двойного выхода, 32-битовый адрес ЗС
Быстрое чтение учетверенного выхода, 32-битовый адрес 6С
14.5.1. Команды чтения в режимах Master SPI Dual (х2) и Quad (х4)
Режим конфигурирования Master SPI поддерживает быстрые операции чтения
Dual и Quad. Вначале FPGA передает код операции Fast Read (OBh) к флэш-памяти
SPI, затем читает информацию в команде для изменения ширины данных в каждой
части битового потока. Затем FPGA вы-
дает новую команду чтения для быст-
рой операции чтения Dual или Quad к
устройству SPI и начинает читать соот-
ветствующую ширину данных.
Чтобы в программе разрешить этот
режим конфигурирования, используется
опция spi_buswidth, чтобы вставить соот-
ветствующие команды битового потока.
В табл. 14.3 представлены коды опера-
ций чтения памяти SPI, поддерживаемые
FPGA 7-й серии.
14.5.2. Память SPI свыше 128 Мбит
Флэш-память SPI объемом более 128 Мбит требуют адрес шириной более 24 би-
тов, который является стандартом для устройств SPI. Производители флэш-памяти
SPI используют различные методы для поддержания 32-битовой адресации. Реше-
ния, поддерживаемые в FPGA 7-й серии, используют специальные команды для 32-
битовой адресации (см. табл. 14.3). Для генерации битового потока, который может
адресовать объем памяти свыше 128 МВ, используется опция spi_32bit_addr.
14.5.3. Временная диаграмма конфигурирования SPI
Устройства флэш-памяти SPI синхронизируют выходные данные на падающем
фронте, а по умолчанию FPGA 7-й серии синхронизируют входные данные на возрас-
тающем фронте. Эти результаты в отстающей половине цикла ограничивают макси-
мальную скорость синхронизации конфигурационного решения (рис. 14.10).
Для того чтобы улучшить использование периода синхронизации, FPGA 7-й серии
могут модифицироваться для синхронизации входных данных на падающем фронте.
242
Раздел 14
CCLK
MISO[3:0]
(from SPI flash)
SPI flash FPGA FPGA
CLK-to-data data-to-CLK data
valid time setup time hold time
Рис. 14.10. Базовая временная диаграмма конфигурирования SPI
Когда конфигурирование стартует, FPGA синхронизирует входные данные на возрас-
тающем фронте. Это продолжается до тех пор, пока FPGA читает команду в ранней
части битового потока, который указывает ей изменить синхронизацию по падающе-
му фронту. Это выполняется до команды переключиться к внешней синхронизации
или до команды изменить главную частоту синхронизации. Функционирование синх-
ронизации по падающему фронту разрешается установкой опции spi_fall_edge.
14.5.4. Определение максимальной частоты синхросигнала
конфигурирования
В режиме Master SPI синхросигнал конфигурирования предоставляет FPGA. Час-
тота синхросигнала главной FPGA устанавливается с помощью опции ConfigRate.
Опция ConfigRate устанавливает номинальную частоты синхросигнала конфигури-
рования.
Установка ConfigRate может увеличиваться для более быстрого времени кон-
фигурирования, если удовлетворяются временные требования, обсуждаемые в этой
главе. Когда определяется значение установки ConfigRate, должны рассматриваться
следующие временные параметры:
• номинальная частота главного CCLK FPGA (ConfigRate);
• допуск частоты главного CCLK FPGA (Fmccktol);
• синхросигнал SPI к выходу (на выходе) (Tspitco);
• время установки данных FPGA (Tspidcc)-
Для максимальной производительности FPGA необходимо использовать режим
падающего фронта синхросигнала чтобы сделать улучшение каждого периода синх-
росигнала. Здесь предполагается, что разрешена опция spi_ falLedge.
Синхросигнал конфигурирования главной FPGA имеет допуск TMCCKTOL. Из-
за допуска главного синхросигнала конфигурирования опция ConfigRate должна из-
меняться так, что период для наихудшего случая (самого быстрого) главной частоты
CCLK был больше, чем сумма времени действительного адреса FPGA, синхросигнала
SPI к выходу и времени установки FPGA, как показано в (2.1):
1
ConfigRate
х (1 + FMCCKTOLmax) > Tspitco + Tspidcc-
Широкий допуск частоты синхросигнала конфигурирования главной FPGA явля-
ется существенным фактором в этом вычислении и если требуются максимальные
скорости конфигурирования, рекомендуется использовать внешний синхросигнал для
минимизации влияния этой переменной. Эти требования соединяются с выводом
EMCCLK и в битовом потоке разрешается опция ExtMasterClk.en.
Конфигурирование FPGA 7-й серии
243
14.5.5. Особенности при включении питания
При включении питания FPGA автоматически начинает свою процедуру конфи-
гурирования. Когда FPGA находится в режиме конфигурирования Master Serial SPI,
FPGA устанавливает FCS_B в низкий уровень для выбора флэш-памяти SPI и управля-
ет командой чтения их флэш-памяти SPI. Флэш-память SPI должна быть включена
и готова принять команду до того, как FPGA переведет FCSJ3 в низкий уровень и
пошлет команду чтения.
Поскольку FPGA и флэш-память SPI могут подключаться к различным шинам
питания или потому что FPGA и флэш-память SPI могут отвечать в разное вре-
мя вдоль ската (ramp) совместно используемого источника питания, важно особое
внимание к последовательности включения питания FPGA и флэш-памяти SPI или
скатам включения питания.
Следующий метод проектирования системы может гарантировать, что флэш-
память SPI готова получать команды, прежде чем FPGA запустит свою процедуру
конфигурирования:
• управляйте последовательностью источников питания, таким образом, чтобы
флэш-память SPI была включена и готова к асинхронному чтению, прежде чем
FPGA начнет свою процедуру конфигурирования.
• содержите контакт FPGA IN 1Т_В от момента включения питания на низком уров-
не, чтобы задержать запуск процедуры конфигурирования FPGA, установите вы-
вод INIT-B в высокий уровень только после того, как флэш-память SPI станет
готова получать команды.
14.6. Интерфейс конфигурирования в режиме Master BPI
Режим конфигурирования Master BPI (рис. 14.11)
позволяет использовать для запоминания конфигураци-
онной последовательности стандартные параллельные
устройства флэш-памяти NOR (BPI). Для считывания
запомненных данных FPGA 7-й серии поддерживают пря-
мое соединение адреса, данных и сигналов управления
флэш-памяти BPI.
В режиме Master BPI требуются некоторые выво-
ды из банка 15. Устройства 7А35Т и 7А50Т семейства
Artix-7 в корпусе CPG23 не содержат банка 15, поэтому
они не поддерживают режим Master BPI.
FPGA 7-й серии в режиме Master BPI предоставля-
ют два режима чтения из флэш- памяти BPI: синхрон-
ный и асинхронный. Самое быстрое время конфигуриро-
М[2:01 A[28:00]
D[15:00] CSO„B
INITB RS[1:0]
PUDCJ3 CCLK
PROGRAMME FCSJB
EMCCLK FOE... В —
FWE....B
DONE МММ.
ADV_B —
Рис. 14.11. Интерфейс кон-
фигурирования в режиме Master
BPI
вания, по сравнению с другими режимами конфигурирования, может быть достигнуто
при чтении из флэш-памяти в режиме Master BPI в синхронном режиме с использо-
ванием внешнего синхросигнала. Кроме того, для флэш-памяти большого объема
шина адреса может содержать до 29 линий.
По умолчанию FPGA 7-й серии используют асинхронный режим чтения из памя-
ти BPI. FPGA управляет адресной шиной от заданного начального адреса, а флэш-
память BPI посылает обратно битовый поток данных. По умолчанию начальным
адресом является адрес 0. Начальный адрес может явно задаваться в процедуре ре-
конфигурирования MultiBoot. В асинхронном режиме поддерживаемая ширина шины
х8 и х16 определяется автоматически.
244
Раздел 14
Таблица 14.4
Поддерживаемые параллельные семейства флэш-памяти NOR
Производитель Семейство Объем Режимы чтения
Micron P33 (Axcell™) 64 Мбит — 1 Гбит Синхронный, асинхронный
Micron P30 (StrataFlash™, Axcell) 64 Мбит — 1 Гбит Синхронный, асинхронный
Micron M29EW 64 Мбит — 1 Гбит Асинхронный
Micron G18F 128 Мбит - 1 Гбит Синхронный, асинхронный
SpaHcion S29GLxxxP 128 Мбит - 1 Гбит Асинхронный
SpaHcion S29GLxxxS 128 Мбит - 1 Гбит Асинхронный
FPGA 7-й серии в режиме Master BPI могут дополнительно читать битовый поток
из выбранного устройства BPI, которое поддерживает пакетный синхронный режим
чтения. Устройства BPI, которые поддерживают синхронный режим чтения, защел-
кивают передаваемый от FPGA начальный адрес во внутреннем адресном счетчике.
Затем подается синхросигнал, выходы флэш-памяти выводят данные от ячейки сле-
дующего последовательного адреса на свою шину данных в течение каждого периода
синхросигнала. В синхронном режиме чтения устройство BPI может поставлять дан-
ные во много раз быстрее, чем через асинхронный интерфейс.
Программа iMPACT предоставляет возможность программировать параллель-
ную флэш- память NOR, используя косвенный метод программирования. Этот ме-
тод загружает новый проект FPGA, который обеспечивает соединение от программы
iMPACT через FPGA 7-й серии к флэш-памяти BPI. Подобные возможности предо-
ставляет программатор пакета Vivado. Во встроенных системах, таких как интерфейс
PCIe, отсутствует соединение JTAG. Вместо этого может использоваться программи-
рование в системе через интерфейс PCIe.
В табл. 14.4 приведены семейства флэш-памяти NOR, которые могут использо-
ваться для конфигурирования FPGA 7-й серии.
14.6.1. Поддержка режима асинхронного чтения
В режиме конфигурирования Master BPI FPGA 7-й серии для чтения битово-
го потока по умолчанию используют режим асинхронного чтения флэш-памяти BPI.
После включения питания, когда вывод INIT.B принимает высокий уровень, выбира-
ются выводы выбора режима М [2:0]. В это время контакты выбора режима должны
быть определены на допустимых логических уровнях (для режима конфигурирования
Master BPI М[2:0] = 010). Контакт PUDC.B должен остаться на постоянном логи-
ческом уровне всюду при конфигурирования FPGA.
После того, как определен режим конфигурирования Master BPI, FPGA устанав-
ливает значения управляющих сигналов флэш-памяти (FWE.B в высокий, FOE.B в
низкий и FCS.B в низкий уровень). Несмотря на то что вывод CCLK не соединен с
устройством флэш-памяти BPI для асинхронного режима чтения флэш-памяти BPI,
адрес на выходах FPGA устанавливается после нарастающего фронта CCLK, а дан-
ные выбираются на следующем нарастающем фронте CCLK. Временные параметры,
связанные с BPI, используют вывод CCLK в качестве эталона. В режиме Master BPI
адрес начинается с 0 и последовательно увеличивается на 1, пока не установится вы-
вод DONE. Если адрес достигает максимального значения (29’hlFFFFFFF), а конфи-
гурирование не выполнено (не устанавливается вывод DONE), в регистре состояния
устанавливается флаг ошибки, и запускается нейтрализация реконфигурирования. В
FPGA 7-й серии режим BPI также поддерживает асинхронный постраничный режим
чтения, чтобы позволить увеличить частоту CCLK.
Конфигурирование FPGA 7-й серии
245
11
CD T5
$
,C ф
x
X
TDI
N/C
NO
TCK
TDO
14
7 Series FPGA
CFGBVS
vcco
VCCO
VCCOJ)
4.7 кП
WP
Mode ® Master BPI
x8/x16 BPI Flash
VCCO 0
Vref
*T“ See Configuration Banks Voltage Select
.......I section for appropriate connection.1
TMS....VCCINT
VCCINT
RST
CCLK
A(28:16|
CE
Ж
WAIT
—N/C
TMS
TCK
TDO
TDI
PROGRAMS
INITJB
FWE„B
FOE„B
М2
M1
MO
WE
OE
A[n:1]
CLK
AW
N/C-—
VCCAUX
VCCO_0
GND
PROGRAM JB
Рис. 14.12. Пример интерфейса асинхронного чтения в режиме конфигурирования Master BPI
e
ш <
й^
DONE
VCCAUX
VCCO_0
VCCOJ)
VCCBATT
VCCOJ 5
RS1
-N/C
-N/C
A[15:00]
FCS.B
PUDC В
EMCCLK
VCCO„14 ----
CSO„B — N/C
GND
Интерфейс FPGA с флэш-памятью BPI в режиме Master BPI для синхронного
чтения показан на рис. 14.12. На рисунке показан интерфейс BPI х1б, для интер-
фейсов BPI х8 используются только D[07:00],
Выход CCLK не используется для подсоединения к флэш-памяти в асинхронном
режиме чтения, но он используется для выборки читаемых данных из флэш-памяти
во время конфигурирования. Все таймирование ссылается на CCLK.
На рис. 14.13 приведена временная диаграмма режима Master BPI для асинх-
ронного режима чтения.
14.6.2. Поддержка страничного режима
Многие устройства флэш-памяти NOR поддерживают асинхронное страничное
чтение. Первый доступ к странице обычно занимает больше времени (приблизитель-
но 100 нс), последующие доступы требуют меньше времени (приблизительно 25 нс).
Чтобы улучшить постраничное чтение и максимизировать частоту CCLK, эти пара-
метры являются программируемыми (в битовом потоке). Размер страницы может
быть 1 (по умолчанию), 4 или 8. Если действительный размер больше 8, то исполь-
зуется размер 8 для максимальной эффективности. Первый доступ может занимать
1 (по умолчанию), 2, 3 или 4 цикла CCLK. Если размер страницы 1, то циклов CCLK
246
Раздел 14
М [ 2:0] Q1O (Binary) ~ Master BPi______________________________________________________________________________________________________________
PROGRAM_B V “ Г
ini г в _~ТГ\ / TZT
мм ММ ММ ММ ММ ММ «Я» ММ ММ ММ «М» ЯММММММЯМММММММММММММММММММ1ММММММММЙММММЯМММММММММЯаММММММММММММММММММММММММММЯМММММ|МЙМММММММММММММММММММЯМЯМММММММММММММММММММММММММММММММММ»
FWE В 1
FOE__B ~0 7
FCS_B 0 \ t
................ WHW ИМ.И » hWiMiM.M.M.MMI MUI М1МММИМММ1МММН^*ММк МММММММШМММ /М» ММ -МММ ^мммммммммм -ММММММММММЙММ
А[п:ОО] ___________________________________________________X АО )СаПС _ ZX^DCZZ
DONE I
Рис. 14.13. Временная диаграмма режима Master BPI для асинхронного режима чтения
Рис. 14.14. Пример временной диаграммы BPI при поддержке страничного режима
для первого доступа должно быть 1. На рис. 14.14 показана временная диаграмма
BPI при размере страницы равном 4 и первом доступе CCLK равном 2. Ширина шины
данных для примера на рис. 14.14 может быть х8 (п = 7) или х15 (п = 15).
14.6.3. Поддержка режима синхронного чтения
Режим конфигурирования FPGA 7-й серии Master BPI с синхронным чтением
является самой быстрой прямой опцией конфигурирования флэш-памяти.
Режим синхронного чтения Master BPI (рис. 14.15) поддерживает семейства уст-
ройств флэш-памяти из табл. 14.4 с синхронной поддержкой. FPGA запускается в
асинхронном режиме чтения, и заголовок потока битов определяет, продолжается ли
режим чтения асинхронно или режим чтения переключается на более быстрый синх-
ронный режим. Команды потока битов инициируют переключатель от асинхронного
чтения на синхронное чтение, если установлена опция BPI_sync_mode.
Конфигурирование FPGA 7-й серии
247
|i
Ф
Vref
tr
c
М/С
N/C
TCK
TDO
TDI
7 Series FPGA
CFGBVS
14
VCCO
VCCOJ)
4.7 kO
VCCO
WP
GND
VrefT See Configuration Banks Voltage Select
—I section tor appropriate connection.
VCCINT
Mode = Master BPI
VCCO 0
CLK
CE
DQ[15:0]
Micron
PC28FxxxP30T
WE
ОЁ
adv
VCCINT
CCLK
N/C—
WAIT —N/C
FWE..B
FOE,„B
ADVJB
A[28:16J
RST
A[n:1}
VCCAUX
TMS тек ТОО TDI IEEE 1149.1 JTAG Port
М2
М1
МО
VCCOJ)
PROGRAMJB
INITJB
VCCAUX
VCCOJ)
VCCOJ)
DONE
VCCBATT
VCCOJ 5
asoL-n/c
RS1 — N/C
A[15:00]
PUDC В
FCS„B
D[15W]
EMCCLK
VCCOJ 4 ---
CSO_B — H/C
GND
Я
PROGRAMJB
Рис. 14.15. Пример интерфейса конфигурирования синхронного чтения в режиме Master BPI
Имеется два доступных параметров настройки для опции: Typel или Туре2.
Typel используется, чтобы установить синхронную флэш-память семейства G18F и
биты задержки, а Туре2 используется, чтобы установить семейство РЗО.
Переключение к синхронному режиму выполняется контроллером FPGA, кото-
рый делает асинхронную запись в регистр конфигурирования флэш-памяти BPI, что-
бы установить устройство в синхронный режим и инициировать конфигурационную
последовательность. Чтобы поддерживать синхронный режим чтения, вывод FPGA
CCLK соединен с устройством флэш-памяти BPI, и сигнал FPGA ADV.B должен быть
соединен с сигналом ADV флэш-памяти Micron.
Синхронная установка битов регистра конфигурирования флэш-памяти BPI яв-
ляется энергозависимым и очищается в момент выключения питания или когда сброс
посылается к флэш-памяти BPI устройством FPGA, переводя INIT.B на низкий уро-
вень.
Режим синхронного чтения требует несколько дополнительных соединений, по
сравнению с режимом асинхронного чтения. Вывод CCLK устройства FPGA дол-
жен подсоединяться к сигналу CLK флэш-памяти, а вывод ADV_B FPGA — к ADV
флэш-памяти. Пример на рис. 14.15 поддерживает FPGA, которая первоначально
включается в асинхронном режиме и затем переключается к синхронному режиму.
Синхронным режимом чтения поддерживается только ширина данных х1б, по-
казанная на рис. 14.15.
248
Раздел 14
14.6.4. Определение максимальной частоты синхросигнала
конфигурирования
В режиме Master BPI синхросигнал конфигурирования предоставляет FPGA. Час-
тота синхросигнала конфигурирования главной FPGA устанавливается опцией Config-
Rate. Опция ConfigRate устанавливает номинальную частоту синхросигнала конфи-
гурирования. Установка ConfigRate по умолчанию рекомендуется для асинхронного
режима чтения BPI. Это умалчиваемое значение устанавливает номинальную часто-
ту главного CCLK равным 3 МГц, которая удовлетворяет временным требованиям
для ведущих семейств флэш-памяти BPI. Установка опции ConfigRate может уве-
личиваться для более быстрого времени конфигурирования, если удовлетворяются
временные требования, обсуждаемые в этом подразделе. Когда определяется значе-
ние установки ConfigRate для асинхронного режима чтения, должны рассматриваться
следующие параметры:
• номинальная частота главного CCLK FPGA (ConfigRate);
• допуск частоты главного CCLK FPGA (Fmccktol);
• время установки достоверного значения на выходах ADDR[28:0] после возраста-
ющего фронта CCLK (Tbpicco);
• время от адресации флэш-памяти BPI к достоверному значению на выходе (время
доступа) (ТАсс);
• время установки данных FPGA (Tbpidcc)-
Главный синхросигнал конфигурирования FPGA имеет допуск. Из-за допуска
главного синхросигнала конфигурирования (Тмссктоь), опция ConfigRate должна
проверяться так, чтобы период для наихудшего случая (самого быстрого) частоты
главного CCLK был больше чем сумма времени установки адреса FPGA, времени
доступа к флэш-памяти BPI и времени установки FPGA:
1
ConfigRate
х (1 + FMCCKTOLmax) Tbpicco + Тдсс + Tbpidcc-
14.6.5. Особенности последовательности включения питания
При включении питания FPGA автоматически запускает свою процедуру конфи-
гурирования. Когда FPGA находится в режиме конфигурирования Master BPI, FPGA
переводит FCS.B на низкий уровень и управляет последовательностью адресов, чтобы
считать конфигурационную последовательность из флэш-памяти BPI. Флэш- память
BPI должна быть готова к асинхронному чтению, прежде чем FPGA будет управлять
низким уровнем FCS.B и выводить первый адрес, чтобы гарантировать, что флэш-
память BPI может вывести сохраненную конфигурационную последовательность.
Один из этих подходов проектирования системы может гарантировать, что флэш-
память BPI готова к асинхронным чтениям, прежде чем FPGA запустит свою проце-
дуру конфигурирования:
• управляйте последовательностью источников питания, таким образом, что флэш-
память BPI обязательно будет включена и готова к асинхронному чтению, прежде
чем FPGA начнет свою процедуру конфигурирования.
• удерживайте контакт FPGA INIT.B на низком уровне от момента включения пита-
ния, чтобы задержать запуск процедуры конфигурирования FPGA и переводите
контакт INIT.B на высокий уровень только после того, как флэш-память BPI
станет готовой к асинхронному чтению.
Конфигурирование FPGA 7-й серии
249
14.7. Граничное сканирование и JTAG конфигурирование
FPGA 7-й серии поддерживают стандарт IEEE 1149.1, определяя архитектуру гра-
ничного сканирования и порт доступа для тестирования (Test Access Port — ТАР).
Эти стандарты гарантируют целостность на уровне плат отдельных компонентов и
соединений между ними. В дополнение к тестированию связи, архитектура гранич-
ного сканирования предлагает гибкость для определяемых пользователем инструкций
конфигурирования и верификации, которые добавляют возможность загрузки данных
конфигурирования непосредственно в FPGA. Порт доступа для тестирования и архи-
тектура граничного сканирования обычно упоминаются совместно как JTAG (JTAG-
стандарт, JTAG-порт).
Устройства FPGA 7-й серии полностью совместимы с JTAG-стандартом (IEEE
Std. 1149.1). Архитектура JTAG-стандарта (рис. 14.16) включает все обязатель-
ные элементы, определенные в стандарте IEEE 1149.1. Эти элементы включают
порт ТАР, контроллер ТАР, регистр команд (lHetruction register), декодер команд
(instruction decoder), регистр границы (Boundary register) и регистр обхода (Bypass
register). FPGA 7-й серии также поддерживают 32-разрядный регистр идентификации
устройства (Device Identification register) и регистр конфигурирования (Configuration
register).
тек ►
TDI >
IEEE Std 1149.1 Compliant Device
TAP State Machine
I/O I/O I/O
>TDO
Рис. 14.16. Типичная архитектура JTAG
14.7.1. Контроллер TAP и архитектура JTAG
Порт FPGA ТАР содержит четыре обязательных специальных контакта, как опре-
делено в табл. 14.5 и показано на рис. 14.16. Три входных контакта TDI, ТСК и TMS,
250
Раздел 14
Таблица 14.5
Выводы контроллера ТАР
Вывод Описание
TDI Вход данных тестирования. Этот контакт — последовательный ввод ко всем регистрам ко- манд JTAG и регистрам данных. Состояние контроллера ТАР и текущей команды определяет регистр, который питается контактом TDI. Данные на входе TDI записываются в регистры JTAG на нарастающем фронте ТСК
TDO Выход данных тестирования. Этот контакт — последовательный выход для всех регистров ко- манд JTAG и регистров данных. Состояние контроллера ТАР и текущей команды определяет регистр (инструкции или данных), который питает TDO. TDO изменяет состояние на убыва- ющем фронте ТСК и активен только во время смещения через устройство инструкций или данных
TMS Вход выбора режима тестирования. Этот контакт определяет последовательность состояний через контроллер ТАР на нарастающем фронте ТСК
ТСК Вход синхронизации тестирования. Этот контакт является синхросигналом JTAG. ТСК управ- ляет контроллером ТАР и регистрами JTAG
а также один выходной контакт TDO управляют контроллером ТАР граничного ска-
нирования JTAG-стандарта. Контроллер ТАР JTAG-стандарта является конечным
автоматом на 16 состояний.
Четыре обязательных контакта ТАР представлены в табл. 14.5. Эти контакты
расположены в банке конфигурирования 0. Для 2,5-вольтовой или 3,3-вольтовой ра-
боты установите на выводе VCCO.O напряжение 2,5 В или 3,3 В и подсоедините
CFGBVS к VCCCL0.
Все выводы TMS, TDI, TDO и ТСК имеют внутренние нагрузочные резисторы,
как определено в стандарте IEEE 1149.1. Эти внутренние нагрузочные резисторы ак-
тивны, независимо от выбранного режима. Чтобы разрешить подтягивающий или
понижающий резистор после конфигурирования для всех четырех обязательных кон-
тактов могут использоваться опции битового потока.
14.7.2. Временная диаграмма граничного сканирования
Функционирование порта JTAG для FPGA 7-й серии представлено на рис. 14.17.
Временные данные для параметров синхронизации, показанных на рис. 14.17, приво-
дятся в соответствующей документации (data sheet) для FPGA 7-й серии в таблицах
Configuration Switching Characteristics.
Рис. 14.17. Временная диаграмма порта граничного сканирования FPGA 7-й серии
14.7.3. Использование граничного сканирования в устройствах FPGA 7-й
серии
Если FPGA конфигурируется инструментами Xilinx, то для конфигурирования
единственного устройства команды контроллера ТАР выдаются автоматически. Ка-
бель загрузки должен быть присоединен к соответствующим четырем контактам JTAG
Конфигурирование FPGA 7-й серии
251
Device
Рис. 14.18. Соединения для программирования единственного устройства по JTAG интерфейсу
(TMS, ТСК, TDI и TDO). Инструменты автоматически проверяют надлежащие со-
единения и управляют командами, чтобы передавать и/или проверять, что биты кон-
фигурирования управляются должным образом.
На рис. 14.18 показана типичная установка JTAG с простым соединением единст-
венного устройства к кабелю JTAG, который может управляться от процессора или
находиться под управлением инструментов Xilinx. Для операций граничного сканиро-
вания используется синхросигнал ТСК.
14.7.4. Конфигурирование нескольких устройств
Возможно конфигурирование нескольких устройств FPGA 7-й серии (рис. 14.19).
Соединения TDO-TDI создают последовательный канал передачи данных для сме-
щения данных через цепочку JTAG. TMS управляет переходом между состояниями в
контроллере ТАР. Для функциональности порта JTAG важно надежное физические
соединение всех этих сигналов.
Если JTAG является единственным режимом конфигурирования, то выводы PRO-
GRAM_B, INIT_B и DONE могут подсоединяться к отдельным нагрузочным резисто-
рам. Устройства в цепочке JTAG конфигурируются последовательно одно за другим.
Многократные шаги конфигурирования устройства могут быть применены к цепочке
любого размера, пока сохраняется сигнальная целостность. Инструменты Xilinx ав-
томатически обнаруживают устройства в цепочке, начиная с самого близкого к TDI
главного устройства JTAG.
JTAG Header
TDO
TDI
TMS
TCK
Device 0
Device 1
Device 2
Рис. 14.19. Цепочка граничного сканирования нескольких устройств
252
Раздел 14
14.7.5. Трассировка сигналов JTAG
Сигналы ТСК и TMS переходят ко всем устройствам в цепочке, следовательно,
важно качество этих сигналов. Например, ТСК должен перейти последовательно
ко всем получателям, чтобы гарантировать надлежащую функциональность цепочки
JTAG и должен быть соответствующим образом закончен. Качество сигнала ТСК
может ограничить максимальную частоту для надежного конфигурирования JTAG.
Кроме того, если цепочка большая (три устройства или больше), TMS и ТСК должны
быть буферизованы, чтобы гарантировать, что у них была достаточная сила тока для
всех получателей и напряжение высокого уровня должно быть совместимым со всеми
устройствами в цепочке.
При взаимодействии через интерфейс к устройствам от других производителей
могут присутствовать дополнительные сигналы JTAG (такие как TRST и разрешения)
и, возможно, они должны управляться.
14.7.6. Конфигурирование через граничное сканирование
FPGA 7-й серии поддерживают конфигурацию через порт JTAG в любое время,
независимо от параметров настройки контактов режима конфигурирования. Однако
возможна явная установка режима конфигурирования JTAG, когда устройства долж-
ны быть сконфигурированы исключительно через порт JTAG.
У Xilinx есть собственные кабели программирования (параллельный и USB) и
инструменты программирования граничного сканирования для анализа прототипа це-
лей. Они не предназначены для производственных сред, но могут быть очень полезны
для проверки реализаций FPGA и цепочечной целостности сигналов JTAG.
При попытке получить доступ к другим устройствам в цепочке JTAG, важно знать,
что размер длины регистра команд гарантирует, что корректное устройство получает
надлежащие сигналы. Эта информация может быть найдена в файле BSDL для FPGA.
Одна из многих общих инструкций граничного сканирования, определяемых про-
изводителем, является инструкция конфигурирования. Если FPGA 7-й серии скон-
фигурированы через JTAG, инструкции конфигурирования выполняются независимо
от контактов режима М[2:0].
Конфигурирование JTAG для устройств на основе технологии Stacked Silicon
Interconnect (SSI) поддерживается только через программу iMPACT или программа-
тор устройств пакета Vivado используя либо кабельное соединение JTAG, либо файл
последовательного векторного формата (SVF).
14.8. Порт динамического реконфигурирования DRP
14.8.1. Динамическое реконфигурирование функциональных блоков
В FPGA 7-й серии конфигурационная память используется, прежде всего, чтобы
реализовать пользовательскую логику, связь и I/Os, но она также используется для
других целей. Например, она используется, чтобы определить множество статических
условий в функциональных блоках, таких как блоки управления синхронизацией СМТ.
Иногда приложение требует изменения в этих условиях во время функциониро-
вания блока. Это может быть выполнено частичным динамическим реконфигуриро-
ванием, используя JTAG, ICAPE2 или порты SelectMAP. Однако динамический порт
реконфигурирования (Dynamic Reconfiguration Port — DRP), который является неотъ-
емлемой частью многих функциональных блоков, значительно упрощает этот процесс.
Такие порты конфигурирования существуют в блоках СМТ, MMCM/PLL, XADC, по-
следовательных приемопередатчиках и в блоке PCL
Конфигурирование FPGA 7-й серии
253
14.8.2. Логика динамического реконфигурирования функциональных
блоков
В данном подразделе описывается параллельная память конфигурирования за-
писи-чтения, которая реализована в каждом функциональном блоке, и которая могла
бы потребовать реконфигурирования. У этой памяти есть следующие атрибуты:
• биты конфигурирования доступны непосредственно из логики FPGA; биты кон-
фигурирования могут быть записаны в и/или считаны из в зависимости от их
функции;
• каждый бит памяти инициализируется со значением соответствующего бита па-
мяти конфигурирования в потоке битов; биты памяти могут также быть изме-
нены позже через порт ICAPE2;
• выход каждого бита памяти управляет логикой функционального блока, так что
содержание этой памяти определяет конфигурацию функционального блока.
Адресное пространство может включать состояние (только для чтения) и функ-
циональные решения (только для записи). Операции только для записи и только для
чтения могут совместно использовать то же адресное пространство. На рис. 14.20
показано как логика реконфигурирования изменяет поток, чтобы считать или запи-
сать биты конфигурирования.
DCLK
DEN
DWE
DADDR[m:0]
Logic Plane
Reconfigurable Bits ’
Non-Reconfigurable Bits
Configuration Logic
AU Configuration Bits
for This Block
Standard
Dynamic
Reconfiguration
Port (to Logic)
♦>
Controller
Block Status
(Read-Only Ports)
Function Enables
(Write-Only Ports)
to Block Logic
to Block Logic
Functional Block
►
Рис. 14.20. Логика конфигурирования блока с динамическим интерфейсом
14.8.3. Определение порта DRP логики FPGA
В табл. 14.6 представлены сигналы порта динамической реконфигурации DRP для
логики FPGA. Отдельные функциональные блоки могут реализовать все или толь-
ко подмножество этих сигналов, и могут использовать различные имена. В целом
порт DRP является синхронным параллельным портом памяти с отдельными шинами
чтения и шинами записи, подобными интерфейсу блока RAM. Все сигналы имеют
активный высокий уровень.
Синхронные временные соотношения для порта обеспечивается входом DCLK,
а все другие входные сигналы запоминаются в регистрах функционального блока на
254
Раздел 14
Таблица 14.6
Определение сигналов порта динамической реконфигурирования
Имя Направление Описание
DCLK Вход Синхросигнал порта DRP. Нарастающий фронт этого сигнала являет- ся временной ссылкой для всех других сигналов порта. Обычно DCLK управляется глобальным буфером синхронизации
DEN Вход Разрешение порта DRP. Этот сигнал разрешает все операции порта. Ес- ли DWE = FALSE, то это операция чтения, иначе операция записи. DEN должен изменяться только в течение одного цикла DCLK
DWE Вход Разрешение чтения/записи. Когда активный, этот сигнал разрешает опе- рацию записи к порту (см. DEN)
DADDR[m:0] Вход Адрес ячейки памяти. Значение на этой шине определяет отдельную ячейку, которая будет записана или считана в следующем цикле DCLK. Адрес представляется в цикле, в котором DEN активен
DI[n:0] Вход Входные данные. Значение на этой шине являются данными, которые записываются в адресуемую ячейку. Данные представляются в цикле, в котором сигналы DEN и DWE активны, и запоминаются в регистре в конце этого цикла, но фактическая запись происходит в неопределенное время, прежде чем DRDY будет возвращен
DO[n 0] Выход Выходные данные. Если DWE был неактивен, когда DEN был активен, значение на этой шине, когда DRDY приходит активный, является данны- ми, считанными из адресуемой ячейки. Во все другие времена значение на DO[n:0] является неопределенным
DRDY Выход Готовность. Этот сигнал является ответом на DEN для указания, что цикл DRP завершен, и другой цикл DRP может инициироваться. В слу- чае чтения порта, шина DO должна быть прочитана на нарастающем фронте DCLK в цикле, в котором DRDY активен. Самый ранний момент, когда DEN может перейти в активное состояние, чтобы запустить следу- ющий цикл порта, является тот же цикл синхронизации, в котором DRDY активен
нарастающем фронте DCLK. Входные (записываемые) данные представлены однов-
ременно с адресом записи и сигналы DWE и DEN предшествуют до следующего по-
ложительного фронта DCLK. Порт устанавливает DRDY для одного цикла, когда он
готов принять больше данных. Выходные данные не запоминаются в регистрах в
функциональных блоках. Выходные (читаемые) данные доступны после некоторых
циклов следующих за циклом, в котором устанавливаются сигналы DEN и DADDR.
Доступность выходных данных указывается установкой сигнала DRDY.
Абсолютные временные параметры, такие как максимальная частота DCLK,
определяются из документации FPGA 7-й серии.
Для получения большей информации о динамической реконфигурирования функ-
циональных блоков с помощью порта DRP, обратитесь к следующим документам:
• ХАРР888 ММСМ and PLL Dynamic Reconfiguration;
• UG480 7 Series FPGAs and Zynq-7000 All Programmable SoC XADC Dual 12-Bit 1
MSPS Analog-to-Digital Converter User Guide;
• UG476 7 Series FPGAs GTX/GTH Transceiver User Guide;
• UG482 7 Series FPGAs GTP Transceiver User Guide;
• PG054 7 Series FPGAs Integrated Block for PCI Express v3.0 LogiCORE IP Product
Guide.
14.9. Выводы
FPGA 7-й серии конфигурируются путем загрузки конфигурационных данных, ко-
торые представляются в виде последовательного битового потока. FPGA могут за-
гружать себя от внешнего устройства энергонезависимой памяти типа ППЗУ или они
конфигурируются внешним микропроцессором.
Конфигурирование FPGA 7-й серии
255
Имеется два общих канала передачи данных конфигурирования: последователь-
ный, который используется для минимизации внешних контактов FPGA, и параллель-
ный (8-, 16- или 32-разрядный), используемый для более высокой производительности
или доступа к интерфейсам памяти промышленного стандарта.
FPGA фирмы Xilinx могут перепрограммироваться в системе неограниченное ко-
личество раз.
FPGA 7-й серии имеют следующие режимы конфигурирования:
• главный последовательный режим конфигурирования Master-Serial;
• подчиненный последовательный режим конфигурирования Slave-Serial;
• главный параллельный режим конфигурирования SelectMAP (х8 и х1б);
• подчиненный параллельный режим конфигурирования SelectMAP (х8, х16 и
х32);
• режим конфигурирования JTAG или режим граничного сканирования (boundary-
scan);
• главный режим конфигурирования последовательного периферийного интерфей-
са (Serial Peripheral Interface — SPI) флэш-памяти (xl, x2, x4);
• главный режим конфигурирования побайтного периферийного интерфейса (Byte
Peripheral Interface — BPI) флэш-памяти, использующий параллельную флэш-
память NOR (х8 и х16).
Определенный режим конфигурирования выбирается путем установки необходи-
мого уровня на специальных входах выбора режима конфигурирования М[2:0]. Выво-
ды режима не должны переключаться во время и после конфигурирования.
Термины главный (Master) и подчиненный (Slave) относятся к направлению син-
хросигнала конфигурирования CCLK. В основных режимах конфигурирования FPGA
управляют синхросигналом CCLK от внутреннего генератора. В подчиненных режи-
мах конфигурирования вывод CCLK является входом.
Интерфейс конфигурирования JTAG доступен всегда, независимо от установок
выводов режима.
Каждый режим конфигурирования использует выделенные контакты FPGA и мо-
жет временно использовать другие многофункциональные контакты только во время
конфигурирования. Когда конфигурирование заканчивается, эти многофункциональ-
ные контакты становятся доступными для общего использования.
Режим конфигурирования может устанавливать ограничения на значения напря-
жений для некоторых банков ввода-вывода FPGA.
Длина битового потока и, соответственно, объем конфигурационной памяти за-
висит от размеров FPGA.
В главном (master) режиме конфигурационная последовательность FPGA обычно
находится на той же плате во внешней к FPGA энергонезависимой памяти. В главном
режиме FPGA управляет процессом конфигурирования. Для этого FPGA генерирует
синхросигнал конфигурирования во внутреннем генераторе, который управляет логи-
кой конфигурирования и может наблюдаться на выходном контакте CCLK.
В подчиненном режиме (slave) внешнее «интеллектуальное» устройство, такое
как процессор, микроконтроллер, процессор DSP или тестер загружает образ кон-
фигурирования в FPGA. Преимущество подчиненных режимов конфигурирования со-
стоит в том, что конфигурационная последовательность FPGA может находиться,
практически, где угодно в системе: во флэш-памяти на плате, вместе с кодом глав-
ного процессора, на жестком диске, а также конфигурирование может произойти по
какому-либо сетевому или другому типу соединения.
256
Раздел 14
Независимо от режима конфигурирования для облегчения отладки в конечный
проект рекомендуется включать интерфейс конфигурирования JTAG.
В базовом конфигурационном решении FPGA при включении питания автома-
тически получает свою конфигурационную последовательность от устройства флэш-
памяти через последовательный периферийный интерфейс SPI.
Программа iMPACT пакета ISE может программировать флэш-память SPI. Для
этого программа iMPACT соединяется с FPGA через его стандартный интерфейс
JTAG и через FPGA может косвенно программировать флэш-память SPI. Подобная
возможность также имеется в пакете Vivado.
Время конфигурирования зависит от размера устройства и скорости логики кон-
фигурирования. При той же тактовой частоте параллельные режимы конфигуриро-
вания быстрее, чем последовательные режимы.
Конфигурирование одной FPGA всегда быстрее, чем конфигурирование несколь-
ких FPGA в конфигурационной цепи. В проекте с несколькими FPGA, где критична
скорость конфигурирования, каждая FPGA должна конфигурироваться отдельно и
параллельно.
В главных режимах FPGA внутренне генерирует синхросигнал конфигурирования
и выводит его на выход CCLK. По умолчанию частота CCLK начинается на низкой
частоте, но опции битового потока могут либо увеличить внутренне сгенерированную
частоту CCLK, либо переключить источник CCLK на источник внешнего синхросиг-
нала от вывода EMCCLK.
При конфигурировании FPGA во время включения питания появляется возмож-
ность сторонним лицам получить конфигурационную последовательность и создать
несанкционированную копию проекта. FPGA 7-й серии имеют несколько уровней за-
щиты проекта от несанкционированного доступа: AES с ключом SRAM с аварийным
батарейным питанием; AES с ключом eFUSE; идентификация устройства с помощью
универсального идентификатора устройства device DNA. Кроме того, устройства
FPGA 7-й серии имеют реализованный аппаратно стандарт шифрования AES.
Если в приложении все FPGA имеют тот же номер партии и используют ту же
конфигурационную последовательность, требуется только один образ битового пото-
ка. Для этого используется спаренное или поперечное конфигурирование, которое
поддерживается только в подчиненных последовательных режимах или подчиненных
режимах SelectMAP.
Инструменты пакета Vivado обеспечивают команду TCL calc_config_time, кото-
рая может использоваться для оценки времени конфигурирования. Можно также
использовать справку help calc_config_time для получения информации о времени кон-
фигурирования.
В случае возникновения проблем с конфигурированием, можно обратиться в
центр решений проблем конфигурирования фирмы Xilinx (Xilinx Configuration Solution
Center).
Устройства FPGA 7-й серии имеют пять интерфейсов конфигурирования: Serial,
SPI, BPI, SelectMAP и JTAG, которые поддерживают семь режимов конфигурирова-
ния: Master Serial, Master SPI, Master BPI, Master SelectMAP, JTAG, Slave SelectMAP,
Slave Serial (по умолчанию).
Выводы интерфейса JTAG и выделенные контакты конфигурирования располо-
жены в отдельном специализированном банке 0 со специальным напряжением пита-
ния (Vcco_o)- Многофункциональные контакты, которые используются в некоторых
режимах конфигурирования, расположены в банках 14 и 15.
Конфигурирование FPGA 7-й серии
257
Напряжение конфигурирования в различных банках определяется с помощью ло-
гического контакта CFGBVS, значение которого выбирается между VCCO.O и GND.
Когда CFGBVS = 1, ввод-вывод в банке 0 поддерживает функционирование на напря-
жениях 3,3 В или 2,5 В во время и после конфигурирования. Когда контакт CFGBVS
= 0, ввод-вывод в банке 0 поддерживает функционирование на напряжениях 1,8 В
или 1,5 В.
CFGBVS также управляет допуском по напряжению в банках 14 и 15, но только
во время конфигурирования.
Выбор напряжения конфигурирования может быть поручен пакету Vivado, пу-
тем установки свойства config.voltage или cfgbvs. Кроме того, свойство config_mode
может быть определено так, чтобы инструменты распознали, какие используются
контакты конфигурирования.
В последовательных режимах FPGA конфигурируется путем загрузки одного бита
за один цикл синхросигнала CCLK. Вывод CCLK является выходом в главном режиме
и входом в подчиненных режимах.
Подчиненный последовательный режим конфигурирования используется для
устройств FPGA в последовательной цепи или когда конфигурируется единственное
устройство FPGA от микропроцессора или CPLD.
Для FPGA 7-й серии режим Master SPI является доминирующим режимом конфи-
гурирования для конфигурирования с малым количеством выводов из флэш-памяти
последовательного типа.
Интерфейс конфигурирования SelectMAP предоставляет интерфейс двунаправ-
ленной шины данных шириной 8, 16 или 32 бита, который может использоваться как
для конфигурирования, так и для обратного чтения (readback). Обратное чтение и
прямое чтение шины данных применимы только в подчиненном режиме SelectMAP.
Ширина шины в режиме SelectMAP определяется автоматически.
Через шину SelectMAP может конфигурироваться одно или более устройств
FPGA.
Когда используется параллельная флэш-память, рекомендуется режим конфи-
гурирования BPI.
Для приложений, где микропроцессор или CPLD используются для конфигури-
рования единственного устройства FPGA, может использоваться главный или подчи-
ненный режим SelectMAP. Подчиненный режим является более предпочтительным.
Интерфейс SelectMAP обеспечивает непрерывную или прерывистую загрузку дан-
ных в FPGA. В подчиненном режиме SelectMAP конфигурирование может приоста-
навливаться путем остановки сигнала CCLK.
Режим конфигурирования Master SPI позволяет использовать для запоминания
образа конфигурирования устройства флэш-памяти индустриального стандарта SPI
с малым количеством выводов. Для чтения битового потока FPGA поддерживает
четырехконтактный интерфейс флэш-устройств SPI.
Режим конфигурирования Master SPI FPGA 7-й серии дополнительно может чи-
тать из устройств SPI, которые поддерживают операции быстрого чтения выходов х2
и х4. Кроме того, режим синхронизации на отрицательном фронте делает возмож-
ным лучшее использование каждого периода синхросигнала и допускает высокую ско-
рость синхронизации. Также поддерживается 32-битовая адресация устройств флэш-
памяти SPI с объемом свыше 128 Мбит.
Программное средство IMPACT пакета ISE обеспечивает возможность програм-
мировать последовательную флэш-память SPI, используя косвенные методы про-
258
Раздел 14
граммирования. Подобные свойства обеспечиваются также программатором паке-
та Vivado.
Режим конфигурирования Master BPI позволяет использовать для запоминания
конфигурационной последовательности стандартные параллельные устройства флэш-
памяти NOR (BPI). Для считывания запомненных данных FPGA 7-й серии поддержи-
вают прямое соединение адреса, данных и сигналов управления флэш-памяти BPI.
FPGA 7-й серии в режиме Master BPI предоставляют два режима чтения из флэш-
памяти BPI: синхронный и асинхронный. Самое быстрое время конфигурирования,
по сравнению с другими режимами конфигурирования, может быть достигнуто при
чтении из флэш-памяти в режиме Master BPI в синхронном режиме с использовани-
ем внешнего синхросигнала. Кроме того, для флэш-памяти большого объема шина
адреса может содержать до 29 линий.
По умолчанию FPGA 7-й серии используют асинхронный режим чтения из памяти
BPI. FPGA управляет адресной шиной от заданного начального адреса. По умолча-
нию начальным адресом является адрес 0. Начальный адрес может явно задаваться
в процедуре реконфигурирования MultiBoot. В асинхронном режиме ширина шины
данных х8 или х!6 определяется автоматически.
FPGA 7-й серии в режиме Master BPI могут дополнительно читать битовый поток
из выбранного устройства BPI, которое поддерживает пакетный синхронный режим
чтения. Такте устройства BPI защелкивают передаваемый от FPGA начальный адрес
во внутреннем адресном счетчике. Затем подается синхросигнал и флэш-память вы-
водит данные от ячейки следующего последовательного адреса на свою шину данных
в течение каждого периода синхросигнала. В синхронном режиме чтения устройство
BPI может поставлять данные во много раз быстрее, чем через асинхронный ин-
терфейс.
Программа iMPACT пакета ISE предоставляет возможность программировать па-
раллельную флэш-память NOR, используя косвенный метод программирования. По-
добные возможности предоставляет программатор пакета Vivado.
Многие устройства флэш-памяти NOR поддерживают асинхронное страничное
чтение. Размер страницы может быть 1 (по умолчанию), 4 или 8. Первый доступ
может занимать 1 (по умолчанию), 2, 3 или 4 цикла CCLK.
В синхронном режиме чтения поддерживается только ширина данных х16.
FPGA 7-й серии поддерживают стандарт IEEE 1149.1 (JTAG), определяя архи-
тектуру граничного сканирования и порт доступа для тестирования ТАР. Архитекту-
ра граничного сканирования предлагает гибкость для определяемых пользователем
инструкций конфигурирования и верификации, которые используются при загрузке
данных конфигурирования в FPGA.
Порт ТАР содержит четыре контакта: три входных контакта TDI, ТСК, TMS и
один выходной контакт TDO. Эти контакты расположены в банке конфигурирования 0.
Контроллер ТАР JTAG-стандарта является конечным автоматом на 16 состоя-
ний.
Все выводы TMS, TDI, TDO и ТСК имеют внутренние нагрузочные резисторы.
Эти внутренние нагрузочные резисторы активны, независимо от выбранного режима.
Для разрешения подтягивающих или понижающих резисторов после конфигурирова-
ния использоваться опции битового потока.
Если FPGA конфигурируется инструментами Xilinx, то для конфигурирования
единственного устройства команды контроллера ТАР выдаются автоматически. Ка-
бель загрузки должен быть присоединен к соответствующим четырем контактам JTAG
(TMS, ТСК, TDI и TDO). Инструменты Xilinx автоматически проверяют надлежащие
Конфигурирование FPGA 7-й серии
259
соединения и управляют командами, чтобы передавать и/или проверять, что биты
конфигурирования управляются должным образом.
С помощью JTAG-стандарта возможно конфигурирование нескольких устройств
FPGA 7-й серии. Для этого соединения TDO-TDI создают последовательный канал
для передачи данных через цепочку JTAG.
Качество сигнала ТСК может ограничить максимальную частоту для надежного
конфигурирования FPGA в цепочке JTAG. Кроме того, если цепочка большая (три
устройства или больше), TMS и ТСК должны быть буферизованы.
FPGA 7-й серии поддерживают конфигурацию через порт JTAG в любое время,
независимо от параметров настройки контактов режима конфигурирования. Однако
возможна явная установка режима конфигурирования JTAG, когда устройства долж-
ны быть сконфигурированы исключительно через порт JTAG.
У Xilinx есть собственные кабели программирования (параллельный и USB) и ин-
струменты программирования граничного сканирования для анализа прототипа целей.
Они не предназначены для производственных сред, но могут быть очень полезны для
проверки функционирования FPGA.
Динамический порт реконфигурирования DRP является частью таких функцио-
нальных блоков, как СМТ, ММСМ/PLL, XADC, последовательный приемопередат-
чик и блок PCI.
В каждом из этих блоков реализована параллельная память конфигурирования
записи-чтения, которая может быть реконфигурирована. Адресное пространство мо-
жет включать состояние (только для чтения) и функциональные решения (только
для записи).
В порт DRP является синхронным параллельным портом памяти с отдельными
шинами чтения и шинами записи, подобными интерфейсу блока RAM. Все сигналы
имеют активный высокий уровень.
Заключение
В данную книгу вошли основные компоненты архитектуры FPGA 7-й серии, без
использования которых практически не обходится ни один проект. Однако объем
одной книги не позволяет охватить всю информацию по архитектуре FPGA 7-й серии
фирмы Xilinx. В книгу не вошли такие важные темы, как:
• приемопередатчики GT;
• блоки поддержки стандарта PCI Express;
• аналого-цифровой преобразователь XADC;
• интерфейсы с микросхемами внешней памяти (DDR2, DDR3, АХИ, SRAM,
SDRAM, QDRII, PHY, RADRAM и др.).
Каждая из этих тем достаточно важная и объемная, а соответствующая архи-
тектура должна, по мнению автора, рассматриваться вместе со средствами проек-
тирования в отдельной книге.
Кроме знания архитектур при проектировании на основе ПЛИС, важно в совер-
шенствовании владеть средствами проектирования (программными и аппаратными),
а также знать методики проектирования, которые используются с помощью этих
средств. Данные вопросы также требуют отдельного рассмотрения.
Все свои замечания и пожелания читатель может направлять автору по адре-
су: valsol@mail.ru.
Приложение А. Примитивы FPGA 7-й серии
А.1. Примитивы внутренней логики
А.1.1. Примитивы запоминающих элементов
Возможные конфигурации запоминающих элементов, которые определяются с помощью примити-
вов, приведены в табл. А.1.
Запоминающие элементы внутренней логики FPGA 7-й серии могут быть сконфигурированы как триг-
геры или защелки, причем триггеры представлены только одним типом: D-триггеры. Все триггеры имеют
вход сигнала синхронизации С и разрешения синхронизации СЕ. При низком уровне сигнала на входе СЕ
триггер не реагирует на изменение синхросигнала.
Все триггеры имеют только один управляющий вход, который может быть ис-
пользован для установки или сброса триггера, но не может одновременно исполь-
зоваться и для сброса, и для установки. Примитивы триггеров также различаются
типом управления, сигнал управления может быть синхронным или асинхронным. На
рис. А.1 приведен пример примитива D-триггера с синхронным сбросом.
В случае конфигурации запоминающего элемента в качестве защелки (latch),
примитив имеет два управляющих входа: G — вентиля и GE — разрешение вентиля.
При высоком уровне на входах G и GE данные с входа D беспрепятственно проходят
на выход Q защелки. На отрицательном фронте сигнала на выходе G данные входа D
запоминаются в защелке (т. е. защелкиваются) и постоянно отображаются на выходе
Q. При низком уровне на входе GE данные не могут быть защелкнуты. Защелки
имеют только асинхронные сигналы управления. На рис. А.2 приведен примитив
LDCE защелки с асинхронным сбросом.
Порты запоминающих элементов приведены в табл. А.2.
Рис. А.1. При-
митив FDRE —
D-триггер с синх-
ронным сбросом
Таблица А.1
Примитивы запоминающих элементов
Примитив
Описание
FDCE
FDPE
FDRE
FDSE
LDCE
LDPE
D-триггер с сигналом разрешения синхронизации и асинхронным сбросом
D-триггер с сигналом разрешения синхронизации и асинхронной установкой
D-триггер с сигналом разрешения синхронизации и синхронным сбросом
D-триггер с сигналом разрешения синхронизации и синхронной установкой
Транспортная защелка с асинхронным сбросом и сигналом разрешения вентиля GE
Транспортная защелка с асинхронной установкой и сигналом разрешения вентиля GE
Таблица А.2
Порты примитивов запоминающих элементов
Порт Описание
D Вход данных
Q Выход данных
С Вход синхросигнала
СЕ Вход разрешения синхронизации
CLR Вход асинхронного сброса
PRE Вход асинхронной установки
R Вход синхронного сброса
S Вход синхронной установки
G Вход вентиля
GE Вход разрешения вентиля
Рис. 15.2. Примитив LDCE —
защелка с асинхронным сбросом
262
Приложение А. Примитивы FPGA 7-й серии
На вход синхронизации С всех примитивов может устанавливаться инвертор для срабатывания триг-
гера на отрицательном фронте Этот инвертор не требует использования дополнительных ресурсов секции.
С сигналом синхронизации С согласуются сигналы разрешения синхронизации СЕ, а также сигналы синх-
ронного сброса R и установки S, причем сигналы установки и сброса имеют приоритет над сигналом СЕ
В случае асинхронных сигналов управления все сигналы на входе запоминающих элементов отвергаются,
а триггер или защелка переходят в указанное состояние.
Всем примитивам запоминающих элементов может быть задано начальное значение (0 или 1) с
помощью атрибута INIT. Отметим, что одновременное использование двух управляющих сигналов — уста-
новки и сброса — требует использования дополнительных ресурсов и временных затрат
Отметим также, что все запоминающие элементы одной секции имеют общие управляющие сигна-
лы: SR, СЕ и CLK. Поэтому, запоминающие элементы с различными управляющими сигналами всегда
реализуются в разных секциях.
А. 1.2. Примитивы функциональных генераторов
Рис. А.З. Примитив LUT6
Имеется ряд примитивов, которые позволяют пользовате-
лю индивидуально определять конфигурацию функциональных
генераторов. Примитивы функциональных генераторов, приве-
дены в табл. А.З.
Примитив LUT6 (рис. А.З) представляет собой 6-входо-
вую таблицу поиска (look-up table) с одним выходом О и может
реализовать любую булеву функцию от 6 аргументов на входах
15-10 или может использоваться как 64-битовая память типа
ROM с ячейками памяти размером в 1 бит, при этом входы 15-
10 рассматриваются в качестве адресных входов памяти ROM.
Примитивы LUT6, LUT6-L и LUT6.D функционально эк-
вивалентны. Примитив LUT6-L определяет, что его выход LO
будет подсоединяться только к элементам внутри данной сек-
ции или блока CLB. Примитив LUT6JD имеет два выхода: об-
щий О и локальный LO, что позволяет подсоединять выход
таблицы поиска как к внутренним элементам секции, так и к
внешней логике.
Примитив LUT6 не устанавливает какие-либо определен-
ные соединения выхода и должен использоваться во всех случаях, за исключением ситуации, когда внут-
ренние соединения сигналов секции или CLB должны определяться явно.
Таблица А.З
Примитивы функциональных генераторов LUT
Прими- тив Число входов Число выходов Описание
LUT6 6 1 6-входовая таблица поиска с общим выходом О
LUT6.L 6 1 6-входовая таблица поиска с локальным выходом LO
LUT6-D 6 2 6-входовая таблица поиска с общим выходом О и локальным выходом LO
LUT6_2 6 2 6-входовая таблица поиска с одним общим выходом Об и одним выходом
05 от LUT5
LUT5 5 1 5-входовая таблица поиска с общим выходом О
LUT5.L 5 1 5-входовая таблица поиска с локальным выходом LO
LUT5JD 5 2 5-входовая таблица поиска с общим выходом О и локальным выходом LO
LUT4 4 1 4-входовая таблица поиска с общим выходом О
LUT4.L 4 1 4-входовая таблица поиска с локальным выходом LO
LUT4.D 4 2 4-входовая таблица поиска с общим выходом О и локальным выходом LO
LUT3 3 1 3-входовая таблица поиска с общим выходом 0
LUT3.L 3 1 3-входовая таблица поиска с локальным выходом LO
LUT3.D 3 2 3-входовая таблица поиска с общим выходом 0 и локальным выходом LO
LUT2 2 1 2-входовая таблица поиска с общим выходом 0
LUT2_L 2 1 2-входовая таблица поиска с локальным выходом LO
LUT2.D 2 2 2-входовая таблица поиска с общим выходом 0 и локальным выходом LO
LUT1 1 1 1-входовая таблица поиска с общим выходом 0
LUT1-L 1 1 1-входовая таблица поиска с локальным выходом LO
LUT1.D 1 2 1-входовая таблица поиска с общим выходом 0 и локальным выходом LO
Приложение А. Примитивы FPGA 7-й серии
263
Содержимое таблицы поиска примитива LUT6 определяет-
ся с помощью 16-цифрового 16-ричного значения атрибута INIT
языков HDL (VHDL или Verilog). Фактически INIT представляет
собой таблицу истинности реализуемой функции, где номер чи-
таемого бита определяется значением входов 15-10 Имеется два
способа определения значения атрибута INIT: в виде таблицы ис-
тинности и с помощью логических уравнений.
Примитивы LUTn, LUTn_L и LUTn_D, где п принимает зна-
чение от 1 до 5, аналогичны примитивам LUT6, LUT6-L и
LUT6-D, только имеют меньшее число входов.
Примитив LUT6-2 (рис. А.4) имеет два выхода: общий Об
и выход 05 от первого функционального генератора LUT5. На
выходе Об может быть реализована любая б-входовая функция
от аргументов на входах 15-10, а на выходе 05 отображается зна-
чение младшей части таблицы истинности функции выхода Об,
которое определяется входами 14-10. На выходах Об и 05 могут
быть также реализованы две независимые 5-входовые функции
от общих аргументов на входах 14-10.
Рис. А.4. Примитив LUT6-2
Отметим, что примитивы LUT1, LUT1_L и LUT1JD, по существу, представляют собой буферы или
инверторы, реализованные с помощью ресурсов LUT.
А. 1.3. Примитив CFGLUT5 динамически реконфигурируемого функционального
генератора LUT
FPGA 7-й серии позволяют динамически реконфигурировать свою внутреннюю логику во время функ-
ционирования системы. Для этого служит примитив CFGLUT5.
Примитив CFGLUT5 (рис. А.5) представляет собой 5-вхо-
довой динамически реконфигурируемый функциональный гене-
ратор LUT, который допускает изменение содержимого таблицы
поиска во время работы системы. Описание портов примитива
CFGLUT5 приведено в табл. А.4.
Примитив CFGLUT5 позволяет реализовать любую 5-вхо-
довую логическую функцию на выходе Об от аргументов на вхо-
дах 14-10, а также 4-входовую функцию на выходе 05 от аргу-
ментов на входах 13-10.
Начальное 32-битовое значение таблицы поиска определя-
ется атрибутом INIT. Новое значение таблицы поиска может
быть последовательно загружено с входа GDI, для этого требу-
ется 32 такта синхросигнала, поступающего на вход CLK. Наи-
более старший значащий бит (MSB) загружается первым, он со-
ответствует значению INIT[31], а наименее значащий бит (LSB)
загружается последним, он соответствует значению INIT[0].
Рис. А.5. Примитив CFGLUT5
Возможно также каскадирование примитивов CFGLUT5 в одну цепочку. Для этого служат выводы
CDO и GDI, которые позволяют создавать единую цепочку данных (по 32 бита на один LUT) для однов-
ременной реконфигурации нескольких LUT. При этом выход CDO некоторого примитива CFGLUT5 подсо-
Таблица А.4
Описание портов примитива CFGLUT5
Порт Направление Ширина Описание
Об Выход 1 Выход 5-входового LUT
05 Выход 1 Выход 4-входового LUT
10-14 Вход 1 Входы LUT
CDO Выход 1 Каскадный выход реконфигурации данных (может подсоединяться к CDI другого LUT)
GDI Вход 1 Последовательный вход реконфигурации данных
CLK Вход 1 Синхросигнал реконфигурации
СЕ Вход 1 Разрешение реконфигурации (активно высокий уровень разрешает реконфигурацию)
264
Приложение А. Примитивы FPGA 7-й серии
Рис. А.6.
Примитив CARRY4
Примитив MUXF7 (рис.
единяется к входу CDI следующего примитива. Во
время процесса реконфигурации выходы примити-
вов CFGLUT5 не должны использоваться.
Примитив CFGLUT5 позволяет также реали-
зовать на выходах Об и 05 две различные функции
от общих входов 13-10. Для этого необходимо вход
14 подсоединить к единице. В этом случае функ-
ция на выходе Об будет определяться значениями
инициализации INIT[31:16], а функция на выходе
05 - INIT[15:0].
А. 1.4. Примитив быстрого
арифметического переноса CARRY4
Примитив быстрого логического переноса
CARRY4 (рис. А.6) позволяет использовать в про-
екте схему логического переноса, которая содер-
жится в каждой секции блока CLB Этот примитив
всегда работает совместно с генераторами LUT со-
ответствующей секции. Соединение выводов схе-
мы переноса с элементами секции подробно были
рассмотрены в разделе 4.8.
Примитив CARRY4 является полезным при
создании сумматоров, счетчиков, вычитателей,
сумматоров/вычитателей, компараторов, декоде-
ров адреса и широких логических функций, осо-
бенно AND и OR.
Описание портов примитива CARRY4 приве-
дено в табл. А.5.
А. 1.5. Примитивы мультиплексоров
Секции FPGA 7-й серии представляют спе-
циальные средства для эффективной реализации
мультиплексоров. Пользователь может использо-
вать эти архитектурные средства с помощью при-
митивов MUXF7 и MUXF8.
А.7) представляет собой обычный мультиплексор
MUXF7
Рис. А.7. При-
митив MUXF7
«2:1», который в структуре секции реализуется с помощью мультиплексоров
F7AMUX или F7BMUX. При этом вход S может управляться любой внутренней
логикой.
Поскольку входы MUXF7 соединены с выходами LUT6, примитив MUXF7
совместно с двумя функциональными генераторами LUT позволяет реализовать:
• любую 7-входовую логическую функцию;
• мультиплексор «8:1»;
• другие логические функции с числом аргументов до 12.
Примитив MUXF8 также представляет собой обычный мультиплексор «2:1»,
который в структуре секции реализуется с помощью мультиплексора F8MUX. По-
Таблица А.5
Порты примитива CARRY4
Порт Направление Ширина Описание
0 Выход суммы 4 Общий выход данных, формируется на выходах вентилей XOR
СО Выход переноса 4 Значение переноса для каждого разряда
DI Вход данных 4 Значение сигналов генерации переноса, сформированных на выходах LUT
S Вход выбора 4 Значение сигналов распространения переносов, сформирован- ных на выходах LUT
CI Вход переноса 1 Вход переноса от предыдущей секции
CYINIT Вход инициали- зации переноса 1 Определяет начальное значение переноса во всей цепи
Приложение А. Примитивы FPGA 7-й серии
265
Таблица А.6
Примитивы мультиплексоров
Примитив Входы Используемые ресурсы Описание
MUXF7 Выходы LUT F7AMUX или F7BMUX Мультиплексор «2:1» функциональных генераторов LUT с общим выходом О
MUXF7.L Выходы LUT F7AMUX или F7BMUX Мультиплексор «2:1» функциональных генераторов LUT с локальным выходом LO
MUXF7.D Выходы LUT F7AMUX или F7BMUX Мультиплексор «2:1» функциональных генераторов LUT с локальным выходом LO и общим выходом О
MUXF8 Выходы F7AMUX и F7BMUX F8MUX Мультиплексор «2:1» выходов мультиплексоров F7AMUX и F7BMUX с общим выходом О
MUXF8-L Выходы F7AMUX и F7BMUX F8MUX Мультиплексор «2:1» выходов мультиплексоров F7AMUX и F7BMUX с локальным выходом LO
MUXF8-D Выходы F7AMUX и F7BMUX F8MUX Мультиплексор «2:1» выходов мультиплексоров F7AMUX и F7BMUX с локальным выходом LO и общим выходом О
скольку входы мультиплексора F8MUX соединены с
выходами мультиплексоров F7AMUX и F7BMUX, при-
митив MUXF8 объединяет ресурсы всех четырех LUT
одной секции и позволяет реализовать:
• любую 8-входовую функцию;
• мультиплексор «16:1»;
• другие логические функции с числом аргумен-
тов до 24.
Все доступные пользователю примитивы муль-
типлексоров приведены в табл. А.6.
А. 1.6. Примитивы сдвиговых регистров
Как было отмечено ранее, секции типа SLICEM
могут конфигурироваться для функционирования в ре-
жиме сдвиговых регистров. Для введения в проект
сдвиговых регистров служат два примитива: SRL16E
и SRLC32E (рис. А.8)
Описание портов примитива SRLC32E приведено
в табл. А.7.
При высоком значении на выходе СЕ каждый воз-
растающий фронт синхросигнала CLK инициирует
сдвиг данных и загрузку данных с выхода D в первый
бит сдвигового регистра. Выходные данные последо-
вательно появляются на выходе Q. Длина сдвигового
регистра постоянна и равна 32 битам, а значение вхо-
дов А[4:0] определяет номер бита сдвигового регист-
ра, значение которого выводится на выход Q. В случае
фиксированных значений на входах А сдвиговый ре-
гистр называют статическим, в противном случае —
динамическим. При А = 00000 длина сдвигового ре-
гистра равна 1 бит, при А - 11111 — 32 бита.
Выход Q31 служит для создания больших сдви-
говых регистров, при этом выход Q31 подсоединяется
к входу D следующего сдвигового регистра.
Примитив SRL16E позволяет создавать сдвиго-
вые регистры длиной до 16 битов. В этом примитиве
отсутствует выход, подобный Q31, что не позволяет
последовательно соединять примитивы SRL16E.
Рис. А.8. Примитив SRLC32E
266
Приложение А. Примитивы FPGA 7-й серии
Таблица А.7
Сигналы портов примитива SRLC32E
Примитив Название Описание
CLK D СЕ А[4:0] Q Q31 Сигнал синхронизации Вход данных Разрешение синхронизации Вход адреса Выход данных Выход данных Каждый возрастающий (или падающий) фронт синхросигнала использу- ется для операции синхронного сдвига; вывод CLK имеет опцию инди- видуального инвертирования для выбора активного положительного (по умолчанию) или отрицательного фронта Когда сигнал неактивен, данные в регистре не сдвигаются, а новые дан- ные не записываются Выбирает бит (в диапазоне от 0 до 31) для чтения; значение бита появ- ляется на выходе Q, не воздействует на выход каскадирования Q31 Принимает значение бита, выбираемого адресными входами Отображает значение последнего бита в 32-битовом сдвиговом регистре
А.1.7. Примитивы распределенной памяти RAM
Секции SLICEM также допускают конфигурацию для функционирования в режиме памяти RAM. Эле-
менты такой памяти называются распределенной памятью RAM и являются альтернативой блокам па-
мяти RAM. Доступные примитивы распределенной памяти приведены в табл. А.8, где суффикс в конфигу-
рации памяти означает следующее: S — однопортовая память; D — двухпортовая память: SDP — простая
двухпортовая память; Q — четырехпортовая память.
Примитивы RAM32X1S.1 и RAM64X1S.1 аналогичны примитивам RAM32X1S и RAM64X1S, только
запись в память осуществляется на отрицательном фронте синхросигнала.
Особо следует отметить примитивы RAM32M и RAM64M, которые позволяют реализовать сразу
несколько конфигураций распределенной памяти.
Условное обозначение примитивов распределенной памяти приведено на рис. А.9.
Для реализации блоков памяти большого размера могут использоваться несколько примитивов. Каж-
дый порт распределенной памяти RAM функционирует независимо от других портов, читая тот же самый
набор из ячеек памяти. Описание портов примитивов распределенной памяти приведено в табл. А.9.
Описание портов примитива SRLC32E приведено в табл. А.7.
Более подробно рассмотрим примитив RAM64M (рис. А.10), который представляет память типа RAM
глубиной 64 слова, каждое слово имеет ширину 4 бита.
Компонент RAM64M реализуется в одной секции блока CLB, содержит один порт записи шириной
4 бита или 1-битовый порт чтения и три отдельных 1-битовых порта чтения из одной и той же памяти,
Таблица А.8
Примитивы распределенной памяти RAM
Примитив Размер, бит Конфигурация реализуемой памяти Входы адреса Число выходов (названия выходов)
RAM32X1S 32 32xlS А[4:0] (read/wnte) 1(0)
RAM32X1S.1 32 32X1S А[4:0] (read/write) 1(0)
RAM32X2S 32 32x2S А[4:0] (read/write) 2 (ОО, О1)
RAM32X1D 32 32xlD А[4:0] (read/write) DPRA[4:0] (read) 2 (SPO, DPO)
RAM32M 32 32x6SDP 32x2Q 32x8S ADDRA[4:0] (read) ADDRB[4:0] (read) ADDRC[4:0] (read) ADDRD[4:0](read/write) 4 (DOA[1:0], DOB[1:0], DOC[1:0], DOD[l:Oj)
RAM64X1S 64 64xlS A[5:0] (read/write) 1 (O)
RAM64X1S.1 64 64X1S A[5:0] (read/write) 1(0)
RAM64X1D 64 64xlD A[5:0] (read/write) DPRA[5:0](read) 2 (SPO, DPO)
RAM64M 64 64xlQ 64x3SDP 64x4S ADDRA[5:0] (read) ADDRB[5:0] (read) ADDRC[5:0](read) ADDRD[5:0] (read/write) 4 (DOA, DOB, DOC, DOD)
RAM128X1D 128 128X1D 128X1S A[6:0] (read/write) DPRA[6:0] (read) 2 (SPO, DPO)
RAM256X1S 256 256xlS A[7:0] (read/write) 1(0)
Приложение А. Примитивы FPGA 7-й серии
267
RAWX1S RAM#X1D RAM#M
D— WE— WCLK— А[#:0]-Ч- > —о D yyg WCLK— А(#:0] -Ч- R/W Port DI[A:D][#:0j-V- — SPO WE WCLK ADDRD[#:0] > R/W Port
DPRA[#:0] h c Read Port DPO ADDRC[#:0bv мкЛ 1мм Read Port □ E — DOC[#:0]
ADDRB[#:0] - v ADDRA(#:0] -v- Read Port □ c Read Port — DOB[#:0] — DOA[#:0]
Рис. А.9. Примитивы одно-, двух- и четырехпортовой распределенной памяти RAM
Таблица А.9
Сигналы портов
Порт Название Описание
WCLK Clock Синхросигнал для синхронной записи; выводы входов данных и адреса имеют времена установки, привязанные к выводу WCLK; вывод WCLK имеет опцию индивидуального инвертирования, поэтому может использоваться положительный (по умолчанию) или отрицательный фронт синхросигнала
WE/WED Enable Сигнал разрешения записи; неактивное значение предотвращает какую-либо запись в ячейки памяти. Активное значение сиг- нала вызывает фронт синхросигнала для записи сигнала входа данных в ячейку памяти, указанную адресными входами
A[#:0] Address Входы адреса для одно и двухпортовой памяти
DPRA[#:0] Address Входы адреса для двухпортовой памяти
ADDRA[#:0] ADDRB[#:0] ADDRC[#:0] ADDRD[#:0] Address Входы адреса для четырехпортовой памяти, ширина портов определяет требуемые адресные входы; некоторые адресные вхо- ды не являются шинами в инстанциях языков VHDL и Verilog
D Data In Вход данных для одно и двухпортовой памяти
DID[#:0] Data In Вход данных для четырехпортовой памяти
0, SPO Data Out Выход данных для однопортовой памяти
DPO Data Out Выход данных для двухпортовой памяти
DOA[#:0]- DOD[#:0] Data Out Выход данных для четырехпортовой памяти; на следующем ак- тивном фронте синхросигнала записи, последние записанные данные отображаются на этих выводах
Таблица А.10
Описание портов примитива RAM64M
Порт Название Ширина Описание
DOA Выход 1 Выход данных порта чтения, адресуется ADDRА
DOB Выход 1 Выход данных порта чтения, адресуется ADDRB
DOC Выход 1 Выход данных порта чтения, адресуется ADDRC
DOD Выход 1 Выход данных порта чтения/записи, адресуется ADDRD
DIA Вход 1 Входы записываемых данных, адресуются ADDRD
DIB Вход 1 Входы записываемых данных, адресуются ADDRD
DIC Вход 1 Входы записываемых данных, адресуются ADDRD
DID Вход 1 Входы записываемых данных, адресуются ADDRD
ADDRA Вход 6 Шина А адреса чтения
ADDRB Вход 6 Шина В адреса чтения
ADDRC Вход 6 Шина С адреса чтения
ADDRD Вход 6 Шина D адреса 4-битового порта записи, 1-битового порта чтения
WE Вход 1 Разрешение записи
WCLK Вход 1 Синхросигнал записи
268
Приложение А. Примитивы FPGA 7-й серии
DIA
RAM64M
DOA
Attributes
‘МТ Ал-СЮООООООСООООООО
DIB
Attfbuies
imt в^ооомхтюоооооо
QIC
DID
WE
DOB
DOC
DOD
WCLK
64-Deep by 4-Wide
Multi-Port LUT RAM
Рис. A.10. Примитив RAM64M
позволяя записывать 4 бита и независимо читать
каждый бит. Примитив RAM64M допускает следу-
ющие конфигурации:
• если все входы DIA, DIB, DIC и DID подсоеди-
няются к одним и тем же входам данных, RAM
имеет 1 порт чтения/записи и 3 независимых
порта чтения, что соответствует конфигурации
RAM64X1Q;
• если DID подсоединяется к земле, то выход
DOD не используется;
• если адресные шины ADDRA, ADDRB и
ADDRC подсоединяются к одному и тому же
адресу, RAM становится простой двухпортовой
памятью с конфигурацией RAM64x3SDP;
• если шина ADDRD подсоединяется к ADDRA,
ADDRB и ADDRC, то RAM становится одно-
портовой памятью RAM64x4S.
Имеется также несколько других конфигураций
для этого примитива. Порты примитива RAM64M
представлены в табл. А. 10.
Если требуется синхронное чтение, выходы мо-
гут подсоединяться к примитивам триггеров FDRE
(FDCE) для улучшения временных характеристик вы-
ходной функции.
Дополнительные 64-битовые атрибуты INIT-A,
INIT-B, INIT_C и INITJD позволяют определить на-
чальное содержимое памяти для каждого порта с по-
мощью 16-ричного значения. Значение INIT соотно-
сится с адресацией RAM в соответствии со следу-
ющим выражением:
ADDRyfz] = INIT.y[z],
где у — одна из букв А, В, С или D.
Например, если port ADDRC адресуется 00001, то значение INIT_C[1] должно быть инициализиро-
вано значением, показанным на порте DOC до первой операции записи по этому адресу. По умолчанию
начальное содержимое памяти равно 0,
А. 1.8. Примитивы распределенной памяти ROM
Рис. А.11. При-
митив ROM256X1
Поскольку функциональные генераторы LUT, по существу, представляют
собой память типа ROM (Read Only Memory) с шириной слова в один бит, нет
ничего удивительного, что с помощью логических ресурсов блоков CLB может
быть реализована распределенная память ROM.
Имеется четыре примитива памяти типа ROM: ROM32X1, ROM64X1, ROM
128X1 и ROM256X1. Для реализации каждого примитива достаточно ресурсов
одной секции. В качестве примера рассмотрим примитив ROM256X1 (рис. А.11).
Примитив ROM256X1 представляет собой память типа ROM и содержит
256 однобитовых слов. Выход О примитива ROM256X1 отображает содержимое
ячейки памяти, адресуемое шиной А[7:0].
Обязательным для примитивов памяти ROM является инициализация со-
держимого памяти. Если инициализация памяти ROM не выполняется, это приво-
дит к ошибке компиляции. Начальное значение памяти ROM256xl определяется
на языках VHDL или Verilog с помощью атрибута IN IT, который представляет
собой 64-цифровое 16-ричное значение. Значение INIT загружается в память во
время конфигурирования устройства, начиная с наиболее значащей цифры.
А.1.9. Примитив STARTUPE2
Примитив STARTUPE2 (рис. А. 12) используется для реализации интерфей-
са (соединения) выводов устройства и логики с глобальным асинхронным сиг-
Приложение А. Примитивы FPGA 7-й серии
269
Таблица А. 11
Порты примитива STARTUPE2
Порт Тип Ширина Описание
CFGCLK Выход 1 Выход главного синхросигнала конфигурации
CFGMCLK Выход 1 Выход внутреннего генератора синхросигнала конфигурации
CLK Вход 1 Вход запуска пользовательской синхронизации
EOS Выход 1 Активный высокий уровень указывает на конец запуска (startup)
GSR Вход 1 Глобальный вход установки/сброса (не может использоваться для имени порта)
GTS Вход 1 Глобальный вход 3-го состояния (не может использоваться для имени порта)
KEYCLEARB Вход 1 Вход сброса ключа дескриптора AES для RAM с аварийным ба- тарейным питанием
Таблица А.12
Атрибуты примитива STARTUPE2
Атрибут Тип Допустимые значения Значения по умолчанию Описание
PROG-USR SIM_CCLK_FREQ STRING FLOAT (nS) «FALSE», «TRUE» 0.0 — 10.0 «FALSE» 0.0 Активизирует функцию безопасного про- граммирования, требует зашифрованного потока данных Устанавливает частоту синхросигнала кон- фигурации (в наносекундах) для модели- рования
налом установки/сброса GSR, глобальным сигналом
управления третьим состоянием GTS, внутренними сиг-
налами конфигурации или некоторыми специальными вы-
водами конфигурации.
Каждый глобальный сигнал GSR и GTS имеет от-
дельную сеть трассировки: GSR — ко всем триггерам в
устройстве, GTS — ко всем выходным буферам.
С помощью примитива STARTUPE2 определяются
и подсоединяются источники сигналов GSR и GTS. Этот
примитив позволяет пользователю определить источник
сигнала для этих специальных сетей. Во время конфигу-
рации сигналы GSR и GTS всегда являются активными,
а подсоединенные к ним сигналы с помощью примити-
ва STARTUPE2 определяют, как они управляются после
конфигурации. По умолчанию после конфигурации сиг-
налы GSR и GTS запрещаются (на выбранном цикле син-
хронизации фазы старта), разрешая в FPGA работу триг-
геров и элементов ввода-вывода. Примитив STARTUPE2
также включает другие сигналы, специально используе-
1 STARTUPE2 CLK CFGCLK GSR GTS CFGMCLK KEYCLEARB РАЖ USRCCLKO EOS USRCCLKTS USRDONEO PREQ USRDONETS
Рис. А.12. Примитив STARTUPE2
мые во время конфигурации. Описание портов примитива STARTUPE2 приведено в табл. А.11.
Примитив STARTUPE2 имеет также два атрибута, описание которых приведено в табл. А. 12.
А.2. Примитив секции DSP48E1
В данном разделе рассматривается примитив секции DSP48E1, который может быть инстанцирован
в любом языке HDL (VHDL или Verilog). Приводятся описания портов примитива, внутренних регистров,
а также атрибутов секции DSP48E1.
Примитив секции DSP48E1 приведен на рис. А. 13.
Описание портов примитива DSP48E1 приведено в табл. А.13.
Выполняемая в ALU функция определяется значением сигналов на шине ALUMODE. Возможные зна-
чения на управляющих входах ALUMODE и реализуемые при этом в ALU функции, приведены в табл. А. 14.
Напомним, в коде дополнения до двух —Z = not (Z) + 1.
270
Приложение А. Примитивы FPGA 7-й серии
30/ м А[29:0] ACOUT[29:0] В[17:0] BCOUT[17:0] С[47:0] PCOUT[47:0] D[24:0] OPMODE[6:0] ALUMODE[3:0] Р[47:0] CARRYIN CARRYINSEL[2:0] INMODE[4:0] CEA 1 CARRYOUT[3:0] CEA 2 CARRYCASCOUT CEB 1 MULTSIGNOUT CEB 2 CEC PATTERNDETECT CED PATTERNBDETECT CEM CEP CEAD OVERFLOW CEALUMODE UNDERFLOW CECTRL CECARRYIN CEINMODE RSTA RSTB RSTC RSTD RSTM RSTP RSTCTRL RSTALLCARRYIN RSTALUMODE RSTINMODE CLK ACIN[29:0] BCIN[17:0] PCIN[47:0] CARRYCASCIN MULTSIGNIN 30 /1
18/г 18/..
4^/г
25/ж 48/ .
7/^
с._
/ 4/_
3 / ~
5 / в
/
30 /г
18 Zz .
48 S
Рис. А.13. Примитив секции DSP48E1
Таблица А. 13
Описание портов примитива DSP48E1
Имя Направ- ление Ширина, бит Описание
A1 Вход 30 А[24:0] является входом А умножителя или пред сумматора. А[29:0] являются наиболее значащими битами (MSB) соеди- ненного входа А:В для ALU
ACIN2 Вход 30 Вход каскадирования данных с выхода ACOUT предыдущей секции DSP48E1 (мультиплексируется с А)
ACOUT2 Выход 30 Выход каскадирования данных к входу ACIN следующей секции DSP48E1
ALUMODE Вход 4 Управляющие сигналы выбора логической функции в секции DSP48E1 (см. табл. А. 14)
B1 Вход 18 Вход В умножителя. В[17:0] являются младшими значащими битами (LSB) соединенного входа А:В к ALU
Приложение А. Примитивы FPGA 7-й серии
271
Продол ж ние табл. А. 13
Имя Направ- ление Ширина, бит Описание
BCIN2 Вход 18 Вход каскадирования данных с выхода BCOUT предыдущей секции DSP48E1 (мультиплексируется с В)
BCOUT2 Выход 18 Выход каскадирования данных к входу BCIN следующей секции DSP48E1
С1 Вход 48 Вход данных к ALU или детектору шаблона
CARRYCASCIN2 Вход 1 Вход каскадирования переноса с выхода CARRYCASCOUT предыдущей секции DSP48E1
CARRYCASCOUT2 Выход 1 Выход каскадирования переноса к входу CARRYCASCIN сле- дующей секции DSP48E1. Этот сигнал внутренне поступает обратно на вход мультиплексора CARRYINSEL той же самой секции DSP48E1
CARRYIN Вход 1 Вход переноса от логики FPGA
CARRYINSEL Вход 3 Сигналы выбора источника переноса (см. табл. А. 15)
CARRYOUT Выход 4 4-битовый выход переноса от каждого 12-битового поля ALU. Обычно 48-битовая операция использует только CARRYOUT3. Операция SIMD может использовать четыре бита выхода пере- носа (CARRYOUT[3:0])
CEA1 Вход 1 Разрешение синхронизации для первого входного регистра А. Этот порт используется, только если AREG = 2 или INMODEO = 1
CEA2 Вход 1 Разрешение синхронизации для второго входного регистра А. Этот порт используется, только если AREG = 1 или 2 и INMODEO = 0
CEAD Вход 1 Разрешение синхронизации для конвейерного регистра AD вы- хода предсумматора
CEALUMODE Вход 1 Разрешение синхронизации для регистров ALUMODE (входы управления)
CEB1 Вход 1 Разрешение синхронизации для первого входного регистра В. Этот порт используется, только если BREG = 2 или INMODE4 = 1
CEB2 Вход 1 Разрешение синхронизации для второго входного регистра В. Этот порт используется, только если BREG = 1 или 2 и INMODE4 = 0
CEC Вход 1 Разрешение синхронизации для входного регистра С
CECARRYIN Вход 1 Разрешение синхронизации для регистра CARRYIN (вход от логики FPGA)
CECTRL Вход 1 Разрешение синхронизации для регистров OPMODE и CAR- RYINSEL (управляющие входы)
CED Вход 1 Разрешение синхронизации для входного регистра D
CEINMODE Вход 1 Разрешение синхронизации для регистров входов управления INMODE
CEM Вход 1 Разрешение синхронизации для (конвейерного) регистра М, выхода умножителя и регистра CARRYIN внутреннего округле- ния умножения
CEP Вход 1 Разрешение синхронизации для выходного регистра Р
CLK Вход 1 Общий порт синхронизации для всех внутренних регистров и триггеров секции DSP48E1
D1 Вход 25 25-битовый вход данных к предсумматору или альтернативный вход к умножителю
INMODE Вход 5 Пять битов управления, выбирают функцию предсуммато- ра, входы А, В и D, а также входные регистры; если оста- ются неподсоединенными, то по умолчанию имеют значение 5'Ь00000; дополнительно могут инвертироваться
MULTSIGNIN2 Вход 1 Знак результата умножения от предыдущей секции DSP48E1 для расширения МАСС
MULTSIGNOUT2 Выход 1 Знак результата умножения каскадируемого к следующей сек- ции DSP48E1 для расширения МАСС
OPMODE Вход 7 Управляющие входы мультиплексоров X, Y и Z (см. табл. А. 16, А.17 и А.18)
272
Приложение А. Примитивы FPGA 7-й серии
Продолжние табл. А.13
Имя Направ- ление Ширина, бит Описание
OVERFLOW Выход 1 Индикатор переполнения, когда используется с соответствую- щей установкой детектора шаблона
Р Выход 48 Выход данных ALU
PATTERNBDETECT Выход 1 Индикатор совпадения между Р[47:0] и шиной шаблона
PATTERNDETECT Выход 1 Индикатор совпадения между Р[47:0] и шаблоном
PCIN2 Вход 48 Вход каскадирования данных с выхода PCOUT предыдущей секции DSP48E1 к сумматору
PCOUT2 Выход 48 Выход каскадирования данных к входу PCIN следующей секции DSP48E1
RSTA Вход 1 Сброс для обоих входных регистров А
RSTALLCARRYIN Вход 1 Сброс для переноса (внутренний путь) и регистра CARRYIN
RSTALUMODE Вход 1 Сброс для регистров ALUMODE (управляющие входы)
RSTB Вход 1 Сброс для обоих входных регистров В
RSTC Вход 1 Сброс для входного регистра С
RSTCTRL Вход 1 Сброс для регистров OPMODE и CARRYINSEL (управляющие входы)
RSTD Вход 1 Сброс для регистра D (вход) и конвейерного регистра пред- сумматора AD (выход)
RSTINMODE Вход 1 Сброс для регистров INMODE (управляющий вход)
RSTM Вход 1 Сброс для регистра М (конвейерного)
RSTP Вход 1 Сброс для регистра Р (выход)
UNDERFLOW Выход 1 Индикатор потери значимости, когда используется с соответ- ствующей установкой детектора шаблона
1. Когда эти порты данных не используются, для уменьшения потребляемой мощности входные сиг-
налы порта данных должны подсоединяться к высокому уровню, должен выбираться входной регистр
порта, а управляющие сигналы СЕ и RST должны подсоединяться к низкому уровню. Например, для
неиспользуемого порта С рекомендуется установить С [47:0] = 1, CREG = 1, СЕС - Ои RSTC = 0.
2. Эти сигналы являются отдельными путями трассировки внутри столбца DSP-блоков. Они не исполь-
зуют общие ресурсы структуры трассировки FPGA.
3. Все сигналы являются активно высокими.
Таблица А.14
Функции 3-входового ALU
Значения ALUMODE [3:0] Реализуемая функция
0000 Z+ Х + Y + CIN
ООН Z — (X + Y + CIN)
0001 -Z + (X + Y + CIN) - 1 = not(Z) + X + Y + CIN
0010 not(Z + X + Y + CIN) = -Z - X - Y - CIN - 1
Таблица А. 15
Управление источником переноса
CARRYINSEL Выбор Замечания
2 1 0
0 0 0 CARRYIN Общее межсоединение
0 0 1 ~PCIN[47] Округление PCIN (округление к бесконечности)
0 1 0 CARRYCASCIN Наибольший сумматор/вычитатель/аккумулятор (параллельное функ- ционирование)
0 1 1 PCIN [47] Округление PCIN (округление к нулю)
1 0 0 CARRYCASCOUT Последовательное функционирование через внутреннюю обратную связь для наибольшего сумматора/ вычитателя/ аккумулятора. Дол- жен выбираться с PREG = 1
1 0 1 ~P[47] Округление Р (округление к бесконечности). Должен выбираться с PREG = 1
1 1 0 A[24] XNOR B[17] Округление Ах В
1 1 1 P[47] Для округления Р (округление к нулю). Должен выбираться с PREG = 1
Приложение А. Примитивы FPGA 7-й серии
273
Таблица А. 16
Биты управления OPMODE выбора выходов мультиплексора X
Z OPMODE[6:4] Y OPMODE[3:2] X OPMODE[1:0] Выход мульти- плексора X Замечания
XXX XX 00 0 По умолчанию
XXX 01 01 М Должен выбираться с
OPMODE[3:2] = 01
XXX XX 10 Р Должен выбираться с PREG = 1
XXX XX 11 А:В 48 битов ширины
Таблица А. 17
Биты управления OPMODE выбора выходов мультиплексора Y
Z OPMODE[6:4] Y OPMODE[3:2] X OPMODE[1:0] Выход мульти- плексора Y Замечания
XXX 00 XX X По умолчанию
XXX 01 01 М Должен выбираться с
XXX 10 XX 48'FFFFFFFFFFFF OPMODE[1:0] = 01 Используется в основном для
XXX 11 XX С логического устройства в по- битовых операциях на муль- типлексорах X и Z
Таблица А. 18
Биты управления OPMODE выбора выходов мультиплексора Z
Z OPMODE[6:4] Y OPMODE[3:2] X OPMODE[1:0] Выход мульти- плексора Z Замечания
000 XX XX 0 По умолчанию
001 XX XX PCIN
010 XX XX P Должен выбираться с PREG = 1
011 XX XX C
100 10 00 P Используется только для расши- рения МАСС. Должен выбираться с PREG = 1
101 XX XX 17-битовый сдвиг (PCIN)
по XX XX 17- битовый сдвиг (P) Должен выбираться с PREG = 1
111 XX XX XX Запрещенная комбинация
В ALU сигнал переноса CIN определяется с помощью управляющей шины CARRYINSEL. Возможные
значения управляющих сигналов и соответствующие им источники переноса приведены в табл. АЛБ.
Выход каждого из мультиплексоров X, Y и Z определяется с помощью значений битовых полей
управляющей шины OPMODE. В табл. А.16, табл. А.17 и табл. А.18 приведены значения сигналов шины
OPMODE и соответствующие им выходы мультиплексоров.
А.2.1. Внутренние регистры секции DSP48E1
Секция DSP48E1 имеет целый ряд внутренних регистров. Некоторые из этих регистров упоминались
при рассмотрении архитектуры секции DSP48E1. В табл. А. 19 приведены все внутренние регистры секции
DSP48E1, доступные пользователю.
А.2.2. Атрибуты примитива секции DSP48E1
Все атрибуты примитива секции DSP48E1 делятся на три категории: атрибуты управления регистра-
ми, атрибуты управления функциями и атрибуты управления детектором шаблона. Атрибуты управления
регистрами вызывают установку и определяют количество внутренних регистров секции DSP48E1, а атри-
буты управления функциями определяют функции, выполняемые секцией DSP48E1. Атрибуты управления
детектором шаблона определяют его функционирование, а также значение маски и шаблона. Атрибуты
примитива секции DSP48E1 приведены в табл. А.20.
274
Приложение А. Примитивы FPGA 7-й серии
Таблица А.19
Внутренние регистры секции DSP48E1
Регистр Сигналы выбора Сигналы разрешения Сигналы сброса Описание и соответствующий атрибут
Al. А2 AREG CEA1 и CEA2 RSTA Два дополнительных регистра для входа А
Bl, В2 BREG CEB1 и CEB2 RSTB Два дополнительных регистра для входа В
AD ADREG CEAD RSTD Регистр для дополнительного результата предсум матора
ALUMODE ALUMODE- REG CEALUMODE RSTALU- MODE Дополнительный конвейерный регистр для управляющего сигнала ALUMODE
С CREG CEC RSTC Дополнительный регистр для входа С
CARRYIN CARRYINREG CECARRYIN RSTALL- CARRYIN Дополнительный конвейерный регистр для управляющего сигнала CARRYIN
CARRYINSEL CARRY- INSELREG CECTRL RSTCTRL Дополнительный конвейерный регистр для управляющего сигнала CARRYINSEL
D DREG CED RSTD Регистр для дополнительного входа пред- сумматора D
INMODE Internal Mult Carry INMODEREG CEINMODE CEM RSTIN- MODE RSTM 5-битовый регистр выбирает пред сумма- тор и его режим, а также знак и источник регистра А Дополнительный конвейерный регистр для сигнала Internal Carry (используется толь- ко для кругового симметричного умноже- ния — Multiply Symmetric Rounding)
M MREG CEM RSTM Дополнительный конвейерный регистр вы- хода умножителя, содержит два 43-битовых частичных произведения. Эти два час- тичных произведения являются входами в мультиплексоры X и Y и окончательно в сумматор/вычитатель для создания выхода произведения
OPMODE OPMODE- REG CECTRL RSTCTRL Дополнительный конвейерный регистр для управляющего сигнала OPMODE
P. OVERFLOW, UNDERFLOW, PATTERN- DETECT, PAT- TERNDETECT. CARRYOUT Все регистры c PREG брасываются ci CEP /IHXpOHHO. RSTP Дополнительные регистры для выходов Р, OVERFLOW, UNDERFLOW. PATTERN- DETECT, PATTERNDETECT и CARRY- OUT
Таблица А.20
Описание атрибутов примитива секции DSP48E1
Имя атрибута Установки Описание атрибута
ACASCREG ADREG ALUMODEREG AREG BCASCREG BREG CARRYINREG CARRYINSEL- REG 0. 1, 2 (1) 0. 1 (1) 0. 1 (1) 0, 1. 2 (1) 0, 1. 2 (1) 0, 1. 2 (1) 0. 1 (1) 0. 1 (1) Атрибуты управления регистрами Совместно с AREG, выбирает число ACOUT входных регистров А на кас- кадном пути А. Этот атрибут должен быть равен или меньше чем величи- на AREG. AREG = 0: ACASCREG должно быть 0; AREG = 1: ACASCREG должно быть 1; AREG = 2: ACASCREG может быть 1 или 2 Выбирает число конвейерных регистров AD Выбирает число входных регистров ALUMODE Выбирает число входных регистров А Совместно с BREG, выбирает число BCOUT входных регистров В на кас- кадном пути В. Этот атрибут должен быть равен или меньше чем величи- на BREG: BREG = 0: BCASCREG должно быть 0; BREG = 1: BCASCREG должно быть 1; BREG = 2: BCASCREG может быть 1 или 2 Выбирает число входных регистров В Выбирает число входных регистров структуры CARRYIN Выбирает число входных регистров CARRYINSEL
Приложение А. Примитивы FPGA 7-й серии
275
Окончание табл. А.20
Имя атрибута Установки Описание атрибута
CREG DREG NMODEREG MREG OPMODEREG PREG AJNPUT BJNPUT USEJDPORT USE-MULT USE-SIMD AUTORESET- PATDET MASK PATTERN SEL-MASK SEL-PATTERN USE-PATTERN- DETECT 0, 1 (1) 0. 1 (1) 0. 1 (1) 0. 1 (1) 0. 1 (1) 0. 1 (1) DIRECT, CASCADE (DIRECT) DIRECT, CASCADE (DIRECT) TRUE, FALSE (FALSE) NONE, MULTIPLY, DYNAMIC (MULTIPLY) ONE48, TWO24, FOUR12 (ONE48) Z NO-RESET, RESET- MATCH, RESET_NOT_ MATCH (NO-RESET) 48-bit field (0011...11) 48-bit field (00...00) MASK, C, ROUNDING. MODE1, ROUNDING. MODE2 (MASK) PATTERN, C (PATTERN) NO.PATDET, PATDET (NO.PATDET) Выбирает число входных регистров С Выбирает число входных регистров D Выбирает число входных регистров INMODE Выбирает число конвейерных регистров М Выбирает число входных регистров OPMODE Выбирает число выходных регистров Р (также используемых CARRY- OUT/PATTERN-DETECT/CARRYCASCOUT/MULTSIGNOUT, etc.) Атрибуты управления функциями Выбирает вход к порту А между параллельным входом (DIRECT) или каскадным входом от предыдущей секции (CASCADE) Выбирает вход к порту В между параллельным входом (DIRECT) или каскадным входом от предыдущей секции (CASCADE) Определяет, будут использоваться предсумматор и порт D или нет Выбирает использование умножителя. Установка в NONE предна- значена для сохранения мощности, когда используется только ALU. Установка DYNAMIC указывает, что пользователь переключается между операциями А*В и А:В на лету и поэтому необходимо полу- чить синхронизацию наихудшего случая двух путей Выбирает режим функционирования для сумматора/вычитателя ALU. Установка атрибута может выбирать режим одного 48-битового сум- матора (ONE48), режим двух 24-битовых сумматоров (TWO24) или режим четырех 12-битовых сумматоров (FOUR12). Обычно функ- ции умножителя-сумматора поддерживаются, когда устанавливается режим ONE48. Когда выбираются режимы TWO24 или FOUR12 ум- ножитель не должен использоваться и атрибут USE.MULT должен быть установлен в NONE [трибуты детектора образа (шаблона) Автоматически сбрасывает регистр Р (значение аккумулятора или значение счетчика) на следующем цикле синхронизации, если на этом цикле синхронизации произошло событие обнаружения шаблона. Зна- чения RESET-MATCH и RESET_NOT_MATCH различают, либо сек- ция DSP48E1 должна вызвать автоматический сброс регистра Р на следующем цикле, если шаблон совпал или шаблон не совпал на теку- щем цикле, но совпал на предыдущем цикле синхронизации Это 48-битовое значение используется для маскирования опреде- ленных выходных битов во время обнаружения шаблона. Когда бит MASK установлен в 1, соответствующий бит шаблона игнорируется. Когда бит MASK установлен в 0, бит шаблона сравнивается Это 48-битовое значение используется в детекторе шаблона в качест- ве образца Выбирает маску, которая будет использоваться для детектора шаб- лона. Установки С и MASK являются стандартными использования- ми детектора шаблона (счетчика, обнаружение переполнения и др.). ROUNDING-MODE1 (левый сдвиг на 1) и ROUNDING-MODE2 (левый сдвиг на 2) выбирает специальные маски, основанные на дополни- тельном регистровом порте С. Эти модели трассировки могут исполь- зоваться для реализации сходящейся трассировки в секции DSP48E1, используя детектор шаблона Выбирает источник входа для области шаблона. Источником шаб- лона может быть либо 48-битовый динамический вход С либо 48- битовое поле атрибута Выбирает либо детектор шаблона и соответствующие функции ис- пользуются (PATDET), либо функции не используются (NO.PAT DET). Этот атрибут используется только с целью определения ско- рости и модели симуляции
276
Приложение А. Примитивы FPGA 7-й серии
А.З. Макросы секции DSP48E1
Примитив секции DSP48E1 содержит достаточно много портов и атрибутов, что может вызывать
определенные затруднения для практического использования Поэтому фирма Xilinx предлагает ряд мак-
росов для наиболее часто используемых режимов работы секции DSP48E1. Эти макросы находятся в
библиотеке UniMacro программных средств синтеза фирмы Xilinx и могут быть инстанцированы в язы-
ках VHDL и Verilog (детали см. в документе UG768 Libraries guide for HDL) Функциональное назначение
макросов секции DSP48E1 приведено в табл. А.21.
Таблица А.21
Макросы секции DSP48E1
Название Описание
MULT-MACRO MACC-MACRO ADDMACC-MACRO ADDSUB-MACRO COUNTER-LOAD_MACRO COUNTER-TC.MACRO EQ_COMPARE_MACRO Позволяет использовать секцию DSP48E1 в режиме умножителя целых чисел со знаком 25x18 битов; результат формируется на выходе Р Позволяет использовать секцию DSP48E1 в режиме умножителя с накоп- лением Позволяет использовать секцию DSP48E1 в режиме предварительного сумматора и умножителя с накоплением Позволяет использовать секцию DSP48E1 в режиме сумматора/вычи- тателя Позволяет использовать секцию DSP48E1 в режиме загружаемого счет- чика Позволяет использовать секцию DSP48E1 в режиме счетчика по модулю (счетчика до заданного значения) Позволяет использовать секцию DSP48E1 в режиме компаратора на равенство, т.е. компаратора, который реализует только одну функцию равенства
А.3.1. Макрос MULT-MACRO
Макрос MULT-MACRO (рис. А.14) позволяет в про-
екте создать простой умножитель двух целых чисел со зна-
ком размером 25x18 битов.
А.3.1. Макрос MACC-MACRO
Макрос MACC-MACRO (рис. А. 15) позволяет вво-
дить в проект умножитель с накоплением, дополнительно
позволяет устанавливать аккумулятор в режим сложения
или вычитания, а также загружать содержимое аккумуля-
тора.
А.3.3. Макрос ADDMACC-MACRO
Макрос ADDMACC-MACRO (рис. А. 16) в дополне-
ние к умножению с накоплением позволяет использовать
предварительный сумматор секции DSP48E1.
А.3.4. Макрос ADDSUB-MACRO
Макрос ADDSUB-MACRO (рис. А. 17) позволяет ис-
пользовать секцию DSP48E1 в качестве сумматора/вычи-
тателя.
А.3.6. Макросы COUNTER_LOAD_MACRO и
COUNTER_TC_MACRO
Макросы COUNTER_LOAD_MACRO (рис. А.18) и COUNTER_TC_MACRO (рис. А.19) используются
для построения счетчиков: загружаемого и по модулю.
А.3.7. Макрос EQ_COMPARE_MACRO
Макрос EQ-COM PARE-MACRO позволяет использовать детектор шаблона секции DSP48E1 для ре-
ализации функции равенства компаратора (рис. А.20).
Приложение А. Примитивы FPGA 7-й серии
277
MACCJVIACRO
A((WIDTH_A:1):0) B((WIDTHJ3:1:0)) LOAD„DATA((WIDTH„P:1 ):0) LOAD
Attributes
DEVICE-VIRTEX6 LATENCY-3 WlDTHA-18 WIDTH WIDTH „Р-48
ADDSUB CARRYIN P((WIDTH_P:1):0) RST CE >CLK MULTIPLY ACCUMULATE
Рис. А.15. Макрос MACC-MACRO
ADDMACC„MACRO
LOAD LOAD_DATA((WIDTH_PRODUCT-1 ):0) MULTIPLIER((WIDTH„MULTIPLIER-1):0) RST PRODUCTS (WIDTHPRODUCT-1 ):0)
Attributes
DEVICE-7 Series LATENCY-3 WIDTH_PREADD-18 WIDTH_MULTIPLIER-18 WIDTH PRODUCT-48
PREADD1 ((WIDTH „PREADD-1 ):0) PREADD2((WIDTH_PREADD-1 ):0) CE >CLK ADD MULTIPLY ACCUMULATOF
Рис. А.16. Макрос ADDMACC-MACRO
ADDSUBJVIACRO
A((WIDTH:1):0) B((WIDTH:1:0)) CARRYOUT
Attributes
DEVICE-VIRTEX6 LATENCY-3 WIDTH-48
ADDSUB CARRYIN RESULT((WIDTH:1):0) RST CE >CLK ADDER/SUBTRACTOR
Рис. А.17. Макрос ADDSUB.MACRO
COUNTER LOAD MACRO
RST
LOAD Q((WIDTH_DATA:1):0)
Attributes
DEVICE-SPARTAN6
COUNTBY-DOOOOOOO
STYLE-AUTO
WIDTH„DATA-48
LOAD_DATA(WIDTH_DATA:1 ):0)
CE
>CLK
Loadable Counter
Рис. A.18. Макрос COUNTER_LOAD_MACRO
A.3.8. Порты макросов секции DSP48E1
Все макросы секции DSP48E1 имеют три однобитовых входа: CLK — синхронизации; СЕ — раз-
решения синхронизации и RST — синхронного сброса. Описание остальных портов всех макросов при-
ведено в табл. А.22.
278
Приложение А. Примитивы FPGA 7-й серии
Таблица А.22
Порты макросов секции DSP48E1
Имя Макрос, в котором используется Направ- ление Ширина Функция
Р PRODUCT (для ADD- МАСС- MACRO) MULT_MACRO MACC-MACRO ADDMACC-MACRO Выход WIDTH-A + WIDTH-B Основной выход данных
А MULT_MACRO MACC-MACRO ADDSUB-MACRO Вход WIDTH-A WIDTH (для ADDSUB.MACRO) Вход А умножителя (сумматора/ вычитателя для ADDSUB.MACRO)
В MULT_MACRO MACC-MACRO ADDSUB-MACRO Вход WIDTH-B WIDTH (для ADDSUB.MACRO) Вход В умножителя (сумматора/ вычитателя для ADDSUB.MACRO)
CARRYIN MACC_MACRO ADDMACC-MACRO ADDSUB-MACRO Вход 1 Вход переноса
LOAD MACC-MACRO ADDMACC- MACRO COUNTER-LOAD- MACRO Вход 1 Загрузка
LOAD-DATA MACC_MACRO Вход WIDTH-A + WIDTH_B При активном LOAD регистр Р за- гружается значением А*В+ LOAD-DATA
LOAD-DATA ADDMACC-MACRO Вход WIDTH-PRODUCT При активном LOAD регистр Р за- гружается значением А*В+ LOAD-DATA
LOAD-DATA COUNTER-LOAD- MACRO Вход WIDTH-DATA При активном LOAD регистр Р загружается значением с входа LOAD-DATA
ADDSUB MACC-MACRO ADDSUB-MACRO Вход 1 Значение 1 устанавливает акку- мулятор в режим сложения, 0 — вычитания
PREADD1 ADDMACC-MACRO Вход WIDTH.PREADD Вход данных предсумматора
PREADD2 ADDMACC-MACRO Вход WIDTH.PREADD Вход данных предсумматора
MULTIPLIER ADDMACC-MACRO Вход WIDTH-MULTI- PLIER Вход данных умножителя
CARRYOUT ADDSUB-MACRO Выход 1 Выход переноса
RESALT ADDSUB-MACRO Выход WIDTH Выход данных
Q COUNTER-LOAD- MACRO COUNTER-TC. MACRO EQ-COMPARE- MACRO Выход WIDTH-DATA 1 (для EQ-COMPARE- MACRO) Выход счетчика; принимает зна- чение 1 при обнаружении шаблона (для EQ_COMPARE_MACRO)
DIRECTION COUNTER-LOAD- MACRO Вход 1 Направление счета: 1 — счет в сторону увеличения; 0 — умень- шения
TC COUNTER_TC_ MACRO Выход 1 Принимает значение 1 при дости- жении модуля TC.VALUE
DATA-IN COUNTER_TC_ MACRO Вход WIDTH Вход данных, которые будут срав- ниваться
DYNAMIC- PATTERN COUNTER.TC- MACRO Вход WIDTH Динамические данные для сравне- ния с DATA-IN
А.3.9. Атрибуты макросов секции DSP48E1
Возможные атрибуты всех макросов секции DSP48E1 приведены в табл. А.23.
Таблица А.23
Атрибуты макросов секции DSP48E1
Атрибут Макрос, в котором используется Тип данных Возможные значения Значение по умолчанию Описание
COUNT.BY COUNTER-LOAD -MACRO COUNTER-TC -MACRO 1б-ричное Любые 48-битовые 00.. .01 Константа, на которую увеличивается счетчик
DEVICE Все макросы Строка «7SERIES» «7SERIES» Целевое устройство
DIRECTION COUNTER_TC -MACRO Строка «UP», «DOWN» «UP» Направление счета
LATENCY MULT_MACRO MACC-MACRO ADDMACC-MACRO Целое 0, 1, 2, 3, 4 3 Число регистров конвейера: 1 — MREG = 1; 2 — AREG = BREG = 1 и MREG = 1 или MREG = PREG = 1; 3 - AREG = BREG = 1 и MREG = PREG = 1; 4 - AREG = BREG = 2 и MREG = PREG = 1
LATENCY ADDSUB-MACRO Целое 0,1,2 2 Число регистров конвейера: 1 — PREG = 1; 2 - AREG = BREG = CREG = PREG = 1
LATENCY EQ_COMPARE -MACRO Целое 0, 1, 2, 3 2 Число регистров конвейера: 1 — QREG = 1; 2 - AREG = BREG = CREG = QREG = 1; 3 - AREG = BREG = 2 и CREG = QREG = 1
MASK EQ_COMPARE -MACRO 1б-ричное Любые 48-битовые 00.. .00 Маска детектора шаблона
RESET-UPON.TC COUNTER_TC -MACRO Boolean True, False False Сброс счетчика при достижении модуля
SEL.MASK EQ_COMPARE -MACRO Строка «MASK», «DYNAMIC-PATTERN» «MASK» Выбирает статическую маску MASK или вход С в качестве маски детектора образа
SEL-PATTERN EQ_COMPARE -MACRO Целое 1-24 24 Ширина входов PREADD1 и PREADD2
STATIC-PATTERN EQ_COMPARE -MACRO 16-ричное Любые 48-битовые 00.. .00 Шаблон детектора образа
TC.VALUE COUNTER_TC -MACRO 16-ричное Любые 48-битовые 00.. .00 Значение модуля
WIDTH ADDSUB-MACRO Целое 1-48 48 Ширина портов А, В и REZULT; ширина портов В и REZULT может переопределяться
WIDTH EQ_COMPARE -MACRO Целое 1-48 48 Ширина входов DATAJN и DYNAMIC-PATTERN
WIDTH.A MULT-MACRO MACC-MACRO Целое 1-25 25 Ширина входа А
WIDTH-B MULT-MACRO MACC-MACRO Целое 1-25 25 Ширина входа В
WIDTH-DATA COUNTER-LOAD -MACRO COUNTER-TC -MACRO Целое 1-48 48 Ширина счетчика
WIDTH-MULTIPLIER ADDMACC -MACRO Целое 1-18 18 Ширина входа MULTIPLIER
WIDTH-PREADD ADDMACC -MACRO Целое 1-24 24 Ширина входов PREADD1 и PREADD2
WIDTH-PRODUCT ADDMACC -MACRO Целое 1-48 48 Ширина выхода MULTIPLIER
WIDTH.REZULT ADDSUB-MACRO Целое 1-48 48 Переопределенная ширина порта REZULT
Приложение А. Примитивы FPGA 7-й серии 279
280
Приложение А. Примитивы FPGA 7-й серии
EQ„COMPARE„MACRO
COU NTEFLTC-MACRO
ТС
RST
Q((DATA_WIDTH:1):0)
Attributes
DEVICE-VIRTEX6
DIRECTION-UP
COUNTRY-00000000
RESET ..UPON. ТС-FALSE
STYLE-AUTO
WIDTH DATA-48
TC VALUE-000000000
MH DATAJN((WIDTH_DATA:1):0)
RST
Q
Attributes
DEVICE-VIRTEX6
LATENCY-2
MASK-000000000
WIDTH -48
SEL. MASK-MASK
SEL_PATTERN-DYNAMIC_ PATTERN
STATIC „PATTERN-0000000000
DYNAMIC_PATTERN(WIDTH_DATA: 1 );0;
CE
>CLK
COUNTER W/ TERMINAL COUNT
CE
LOADABLE COUNTER
Рис. A.19. Макрос COUNTER_TC_MACRO
Рис. A.20. Макрос EQ_COMPARE_MACRO
CASCADEOUTA CASCADEOUTB
J f 1
32z DIADI DIPADIP ADDRARDADDR DOADO WEA DOPADOP ENARDEN REGCEAREGCE RSTREGARSTREG RSTRAMARSTRAM > CLKARDCLK
4 ,
16z 32z
—т
У /
DIBDI niDQDID
/ 4 z
/ UIKDUIr
Л ПППО1ЛЮЛПГ>П ПОДГУЗ 32z
AUUKoWHAUUK /
8г -V—
— ENBWREN
— REGCEB
— RSTREGB
— RSTRAMB
— >CLKBWRCLK
4 f
CASCADEINA CASCADEINB
Рис. A.21. Сигналы портов примитива
RAMB36E1
A.4. Примитивы блока памяти RAM
Для использования блока RAM в FPGA 7-й се-
рии имеются два основных примитива: RAMB18E1 и
RAMB36E1. Другие библиотечные примитивы и макро-
сы строятся на основе этих примитивов.
Шины входных и выходных данных представляют-
ся двумя шинами для конфигураций 9 (8+ 1), 18 (16+2)
и 36 (32+4) битов. Девятый бит, связанный с каж-
дым байтом, может запоминаться как бит четности, бит
коррекции ошибок или как дополнительный бит данных.
При обращении к памяти операции чтения или записи
одинаковы для битов данных и битов четности.
Примитив RAMB36E1 показан на рис. А.21.
В табл. А.24 приведены примитивы, которые стро-
ятся на основе примитива RAMB36E1.
А.4.1. Порты примитива RAMB36E1
Порты примитива RAMB36E1 представлены в
табл. А.25.
А.4.2. Сигналы портов примитива
RAMB36E1
Сигналы синхронизации CLKARDCLK и CLKB-
WRCLK. Все входные порты имеют время установки по
отношению к входу CLK. Шина выходных данных име-
ет время установки clock_to_out по отношению к выводу
CLK. Полярность синхросигнала CLK может изменять-
ся (по умолчанию активным фронтом является положи-
тельный фронт).
Сигналы разрешения ENARDEN и ENBWREN
Порты с неактивными выводами разрешения сохраняют
выходные выводы в предыдущем состоянии и не запи-
сывают данные в ячейки памяти.
Сигналы разрешения побайтной записи WEA и WEBWE. Для записи содержимого шины входных
данных в адресуемую ячейку памяти оба сигнала EN и WE должны быть действительны в пределах времени
Приложение А. Примитивы FPGA 7-й серии
281
Таблица А.24
Примитивы памяти типа RAM и FIFO
Примитив Описание
RAMB36E1 В режиме TDP поддерживает размеры портов xl, х2, х4, х9, х18, хЗб. В режиме SDP ширина портов чтения или записи равна хб4 или х72. Альтернативным портом является xl, х2, х4, х9. х18. хЗб, х72. В режиме ЕСС поддерживает 64-битовое ЕСС кодиро- вание и декодирование
RAMB18E1 В режиме TDP поддерживает размеры портов xl, х2, х4, х9, х18. В режиме SDP ши- рина портов чтения или записи равна х32 или хЗб. Альтернативным портом является xl, х2, х4, х9, х18, хЗб
FIFO36E1 В режиме FIFO36 поддерживает размеры портов х4, х9, х18, хЗб. В режиме FIFO36_72 ширина порта равна х72, дополнительно поддерживается ЕСС
FIFO18E1 В режиме FIFO18 поддерживает размеры портов х4, х9, х18. В режиме FIFO18.36 ши- рина порта равна хЗб
Таблица А.25
Описание портов примитива RAMB36E1
Имя Описание
DIADI[31:0] DIPADIP[3:0] DIBDI[31:0] DIPBDIP[3:0] ADDRARDADDR[15:0] ADDRBWRADDR[15:0] WEA[3:0] WEBWE[7:0] ENARDEN ENBWREN RSTREGARSTREG RSTREGB RSTRAMARSTRAM RSTRAMB CLKARDCLK CLKBWRCLK REGCEAREGCE REGCEB CASCADEINA CASCADEINB CASCADEOUTA CASCADEOUTB DOADO[31:0] DOPADOP[3:0] DOBDO[31:0] DOPBDOP[3:0] Входы данных порта А, адресуются шиной ADDRARDADDR Входы битов четности порта А, адресуются шиной ADDRARDADDR Входы данных порта В, адресуются шиной ADDRBWRADDR Входы битов четности порта В, адресуются шиной ADDRBWRADDR Шина адреса порта А. При RAM_MODE = SDP является шиной RDADDR Шина адреса порта В. При RAM_MODE = SDP является шиной WRADDR Разрешение побайтной записи порта А, не используется при RAM.MODE = = SDP Разрешение побайтной записи порта В, при RAM_MODE = SDP является раз- решением побайтной записи Разрешение порта А. При RAM_MODE - SDP является сигналом RDEN Разрешение порта В. При RAM.MODE = SDP является сигналом WREN Синхронная установка/сброс выходного регистра, как инициализирован SRVALJk (DOA.REG - 1). RSTREG.PRIORITYJk определяет приоритет над REGCE. При RAM.MODE = SDP является сигналом RSTREG Синхронная установка/сброс выходного регистра, как инициализирован SRVAL-B (DOA-REG = 1). RSTREG_PRIORITY_B определяет приоритет над REGCE Синхронная установка/сброс выходной защелки, как инициализирован SRVALJk (DOB.REG = 0). При RAM-MODE = SDP является сигналом RSTRAM Синхронная установка/сброс выходной защелки, как инициализирован SRVAL.B (DOB-REG = 0) Вход синхронизации порта А. При RAM.MODE = SDP это сигнал RDCLK Вход синхронизации порта В. При RAM-MODE = SDP это сигнал WRCLK Разрешение синхронизации выходного регистра порта A (DOA.REG = 1). При RAM.MODE = SDP это сигнал REGCE Разрешение синхронизации выходного регистра порта В (DOA.REG = 1) Вход каскадирования порта А. Используется только при RAM.MODE = TDP Вход каскадирования порта В. Используется только при RAM.MODE = TDP Выход каскадирования порта А. Используется только при RAM.MODE = TDP Выход каскадирования порта В. Используется только при RAM.MODE = TDP Шина выходных данных порта А, адресуемых шиной ADDRARDADDR Биты четности выходных данных порта А, адресуемых шиной ADDRARDADDR Шина выходных данных порта В, адресуемых шиной ADDRARDADDR Биты четности выходных данных порта В, адресуемых шиной ADDRARDADDR
установки (setup) до прихода активного фронта синхросигнала. Когда сигнал WE не является активным,
a EN — активный, осуществляется операция чтения, независимо от атрибута режима записи.
В режиме SDP порт WEBWE[7:0] является разрешением побайтной записи. В режиме TDP порты
WEA[3:0] и WEB[3:0] являются разрешением побайтной записи для портов А и В соответственно.
282
Приложение А. Примитивы FPGA 7-й серии
Сигналы разрешения регистров REGCE, REGCEA и REGCEB. Вывод REGCE управляет дополни-
тельным выходным регистром; при REGCE = 1 на выходе устанавливается дополнительный регистр.
Сигналы управления сбросом регистров RSTREGARSTREG, RSTREGB, RSTRAMARSTRAM и
RSTRAMB. В режиме защелки вывод RSTRAM синхронно вынуждает защелки выходных данных содер-
жать значение атрибута SRVAL. В случае доступности дополнительных выходных регистров (DCLREG =
1), сигнал RSTREG синхронно загружает выходные регистры значением SRVAL. Приоритет RSTREG над
REGCE определяется атрибутом RSTREG-PRIORITY.
Защелки или регистры выходных данных синхронно устанавливаются в 0 или 1, включая бит четности.
Каждый порт имеет независимый атрибут SRVAL[A/B] размером 36 битов, который определяет значение
выхода при активном значении сигнала RSTREG. Эта операция не воздействует на ячейки памяти RAM
и не нарушает функционирование другого порта. Полярность для обоих сигналов может изменяться (по
умолчанию активный уровень высокий).
В режиме SDP портом RSTREGA является порт RSTREG, а портом RSTRAMA — порт RSTRAM.
Шины адреса ADDRARDADDR и ADDRBWRADDR. Шины адреса выбирают ячейки памяти для
чтения или записи. В режиме SDP портом ADDRA является порт RDADDR, а портом ADDRB — порт
WRADDR.
Битовая ширина данных определяет требуемую ширину адресной шины для примитивов RAMB18E1
и RAMB36E1, как показано в табл. А.26-А.29.
Для каскадирования блока RAM используется примитив RAMB36E1, при этом ширина данных равна 1
биту, а ширина адресной шины — 16 битов [15:0]. Адресный бит 15 используется только при каскадировании
блока RAM, в остальных случаях подсоединен к высокому уровню.
В режиме SDP имена портов отображаются так, как приведено в табл. А.30.
Шины входных данных DIADI, DIPADIP, DIBDI и DIPBDIP. Основная шина входных данных DI
плюс шина битов четности выходных данных DIP (когда доступна) имеют суммарную ширину, равную
ширине порта. Например, ширина порта для 36 битов представляется шинами DI[31:0] и DIP[3:0].
Таблица А.26
Соотношения размеров шин данных и адреса для RAMB18E1 в режиме TDP
Ширина порта данных Ширина порта адреса Глубина Шина ADDR Шина DI. шина DO Шина DIP, шина DOP
1 14 16384 [13:0] [0] NA
2 13 8192 [13:1] [1:0] NA
4 12 4096 [13:2] [3:0] NA
9 11 2048 [13:3] [7:0] [0]
18 10 1024 [13:4] [15:0] [1:0]
Таблица А.27
Соотношения размеров шин данных и адреса для RAMB18E1 в режиме SDP
Ширина порта данных Альтернативная ширина порта Ширина порта адреса Глубина Шина ADDR Шина DI, шина DO Шина DIP, шина DOP
32 1 14 16384 [13:0] [0] NA
32 2 13 8192 [13:1] [1:0] NA
32 4 12 4096 [13:2] [3:0] NA
36 9 11 2048 [13:3] [7:0] [0]
36 18 10 1024 [13:4] [15:0] [1:0]
36 36 9 512 [13:5] [31:0] [3:0]
Таблица А.28
Соотношения размеров шин данных и адреса для RAMB36E1 в режиме TDP
Ширина порта данных Ширина порта адреса Глубина Шина ADDR Шина DI, шина DO Шина DIP, шина DOP
1 15 32768 [14:0] [0] NA
2 14 16384 [14:1] [1:0] NA
4 13 8192 [14:2] [3:0] NA
9 12 4096 [14:3] [7:0] [0]
18 И 2048 [14:4] [15:0] [1:0]
36 10 1024 [14:5] [31:0] [30]
1 (Cascade) 16 65536 [15:0] [0] NA
Приложение А. Примитивы FPGA 7-й серии
283
Таблица А.29
Соотношения размеров шин данных и адреса для RAMB36E1 в режиме SDP
Ширина порта данных Альтернативная ширина порта Ширина порта адреса Глубина Шина ADDR Шина DI, шина DO Шина DIP, шина DOP
64 1 15 32768 [14:0] [0] NA
64 2 14 16384 [14:1] [1:0] NA
64 4 13 8192 [14:2] [3:0] NA
72 9 12 4096 [14:3] [7:0] [0]
72 18 11 2048 [14:4] [15:0] [1:0]
72 36 10 1024 [14:5] [31:0] [3:0]
72 72 9 512 [14:6] [63:0] [7:0]
Таблица А.30
Отображение имен портов в режиме SDP
RAM18E1 в режиме SDP RAMB36E1 в режиме SDP
Режим Х36 (ширина = 36) Режим X18 (ширина 18) Режим X72 (ширина = 72) Режим X36 (ширина 36)
DI[15:0] = DIADI[15:0] DIP[1:O] = DIPADI[l:0] Dl[31:16] = DIBDI[15:0] DIP[3:2] = DIPBDIP[l:0] DO[15:0] = DOADO[15:0] DOP[1:0] = DOPADOP[1:0] DO[31:16] = DOBDO[15:0] DOP[3:2] = DOPBDOP[1:0] DI[15:0] = DIBDI[15:0] DIP[l:0] = = DIPBDIP[l:0] DO[15:0] = = DOADO[15:0] DOP[1:0] = = DOPADOP[1:0] DI[31:0] = DIADI[31:0] DIP[3:0] = DIPADI[3:0] Dl[63:32] = DIBDI[31:0] DIP[7:4] = DIPBDIP[3:0] DO[31:0] = DOADO[31:0] DOP[3:0] = DOPADOP[3:0] DO[63:32] = DOBDO[31:0] DOP[7:4] = DOPBDOP[3:0] DI[31:0] = DIBDI[31:0] DIP[3:0] = = DIPBDIP[3:0] DO[31:0] = = DOADO[31:0] DOP[3:0] = = DOPADOP[3:0]
Шины выходных данных DOADO, DOPADOP, DOBDO и DOPBDOP. Во время операции чтения
шины выходных данных отображают содержимое ячеек памяти, указанное адресной шиной для послед-
него активного синхросигнала.
Во время операции записи (конфигурации WRITE-FIRST или READ-FIRST) шины выходных дан-
ных отображают либо записываемые данные, либо запомненное значение предыдущей записи. Во время
операции записи в режиме NO-CHANGE шины выходных данных не изменяются.
Основная шина выходных данных DO плюс шина битов четности выходных данных DOP (когда до-
ступна), имеют суммарную ширину, равную ширине порта.
Сигналы каскадирования CASCADEINA, CASCADEINB, CASCADEOUTA и CASCADEOUTB.
Выводы CASCADEIN/CASCADEOUT используются для соединения двух блоков RAM, чтобы сформиро-
вать память размером 64Кх1. Если каскадирование не используется, эти выводы остаются неподсоеди-
ненными. Каскадирование возможно только в режиме TDP.
А.4.3. Атрибуты примитивов блока памяти RAM
Атрибуты блока памяти RAM FPGA 7-й серии рассмотрим на примере атрибутов примитива
RAMB36E1 (табл. А.31).
А.4.4. Описание атрибутов
Инициализация содержимого памяти (INIT_xx). Обычно для инициализации или обратного чтения
блока RAM в FPGA 7-й серии используется битовый поток конфигурации. Атрибуты INIT_xx определяют
начальное содержимое памяти. По умолчанию блок RAM инициализируется нулями. Для инициализа-
ции модуля RAMB18E1 требуется 64 атрибута от INIT-00 до INIT-3F, а для модуля RAMB36E1 — 128
атрибутов от INIT-00 до INIT-7F.
Каждый атрибут INIT_xx является 64-цифровым битовым вектором в 16-ричном коде. Содержимое
памяти может инициализироваться частично, при этом оставшиеся ячейки заполняются нулями. Для
определения битовых позиций каждого атрибута INIT_xx используется приводимая ниже формула, при
этом INIT-xx соответствует следующим ячейкам памяти:
от [(уу + 1) х256] — 1 до (уу) х256,
где уу — 10-ричное число, соответствующее 1б-ричному значению хх. Например, INIT-1F соответствует
ячейкам памяти (IFig = 31ю):
284
Приложение А. Примитивы FPGA 7-й серии
Таблица А.31
Атрибуты примитива RAMB36E1
Атрибут Тип Возможные значения Значение no умолчанию Описание
DOA.REG, DOB.REG Целое 0, 1 0 Разрешает введение конвейерных ре- гистров на выходе порта А или В
EN-ECC-READ Логи- ческий FALSE, TRUE FALSE Разрешает схему дешифратора в режи- ме ЕСС
EN-ECC-WRITE Логи- ческий FALSE. TRUE FALSE Разрешает схему шифратора в режиме ЕСС
INIT-A, INIT.B 16- ричное Любые 256-битовые Все нули Определяет начальное значение выход- ного порта после конфигурации
INIT-00-1 NIT_7 F 16- ричное Любые 256-битовые Все нули Определяет начальное содержимое матрицы памяти
INIT.FILE Строка Имя файла Нет Определяет имя файла для инициали- зации памяти
INITP-00- INITP-OF 16- ричное Любые 256-битовые Все нули Определяет начальное содержимое би- тов четности матрицы памяти
RAM.EXTEN- SION_A, RAM_ EXTENSION-B Строка «NONE», «LOWER», «UPPER» «NONE» Указывает расположение блоков RAMB36 для формирования памяти 64КХ1
RAM.MODE Строка «TDP», «SDP» «TDP» Выбирает простой двухпортовый (SDP) или действительно двухпорто- вый (TDP) режим
RDADDR.COLLI- SION-HWCONFIG Строка «DELAYED. WRITE», «PER- FORMANCE» «DELAYED -WRITE» Позволяет находить компромисс между производительностью и потенциальным перекрытием адреса (коллизией)
READ_WIDTH_A, READ-WIDTH-B, WRITE_WIDTH_A, WRITE_WIDTH_B Целое 0. 1, 2, 4, 9, 18, 36, 72 0 Определяет ширину данных для чте- ния/записи портов A/В, включая би- ты четности; 0 означает, что порт не используется
RSTREG-PRIORI- TY_A, RSTREG. PRIORITY-B Строка «RSTREG», «REGCE» «RSTREG» Выбирает приоритет регистров для «RSTREG» или «REGCE»
SIM-COLLISION- CHECK Строка «ALL», «GENE- RATE_X_ONLY», «NONE», «WAR- NING-ONLY» «ALL» Позволяет установить поведение про- граммы моделирования в случае колли- зии памяти
SIM-DEVICE Строка «7SERIES» «7SERIES» Определяет семейство целевого устройства
SRVALA SRVAL-B 16- ричное Любые 36-битовые Все нули Определяет значение выходных дан- ных блока RAM при установке сигнала синхронного сброса RSTREG
WRITE-MODE-A, WRITE_MODE_B Строка «WRITE.FIRST», «NO-CHANGE», «READ_FIRST» «WRITE- FIRST» Определяет поведение выхода порта во время операции записи
от [(31 + 1) х256] - 1 = 8191 до 31 х256 = 7936.
В табл. А.32 приведены некоторые примеры адресации ячеек памяти с помощью атрибута INIT_xx.
Инициализация содержимого битов четности (INITP_xx). Атрибуты INITP_xx определяют содер-
жимое ячеек памяти, соответствующих шинам DIP/DOP, т. е. битам четности. По умолчанию эти биты
инициализируются нулями. Для модуля RAMB18E1 имеются 8 атрибутов от INITP_00 до INITP_07, а для
модуля RAMB36E1 — 16 атрибутов от INITP.00 до INITP_0F. Все изложенное ранее в отношении атрибутов
INIT_xx, в том числе формулы, является справедливым и для атрибутов INITP_xx.
Инициализация выходных защелок (INIT, INIT_[A/B]). Атрибуты INIT (для одно портовой памяти)
или INIT-А и INIT.B (для двухпортовой памяти) определяют значение выходных защелок или регистров
после конфигурации. Ширина атрибутов INIT (INIT_A и INIT_B) равна ширине порта, как показано в
табл. А.33. Эти атрибуты являются битовыми векторами в 16-ричном коде; по умолчанию имеют зна-
чение 0. В каскадируемом режиме верхний и нижний блоки RAM должны инициализироваться одними
и теми же значениями.
Приложение А. Примитивы FPGA 7-й серии
285
Таблица А.32
Атрибуты инициализации блока RAM
Атрибут Расположение памяти
От До
INIT.00 255 0
INIT-01 511 256
INIT_02 767 512
INIT-OE 3839 3584
INIT-OF 4095 3840
INIT-10 4351 4096
Атрибут Расположение памяти
От До
INIT.1F 8191 7936
INIT.20 8447 8192
INIT.2F 12287 12032
INIT.30 12543 12288
INIT.3F 16383 16128
INIT.7F 32767 32512
Таблица А.33
Отображение атрибутов SRVAL и INIT на порты А и В для примитивов блока RAM
Ширина порта SRVAL/ INIT_[A/B] полная ширина SRVAL/INITJA/B] отображение в DO SRVAL/INIT.[A/B] отображение в DOP
DOADO/DOBDO SRVAL/INIT_[A/B] DOP[A/B]/DOP SRVAL/INIT_[A/B]
1 [0] Н [0] [0] N/A N/A
2 [1:0] [1:0] [1:0] N/A N/A
4 [3:0] [3:0] [3:0] N/A N/A
9 [8:0] [7:0] [7:0] [0] [8]
18 [17:0] [15:0] [15:0] [1:0] [17:16]
36 (для RAMB36E1) [35:0] [31:0] [31:0] [3:0] [35:32]
Синхронная установка/сброс выходных за щелок/регистров (SRVAL, SRVAL_[A/B]). Атрибуты
SRVAL (для однопортовой памяти) и SRVALA и SRVALB (для двухпортовой памяти) определяют значение
выходных защелок, когда устанавливается вход RSTRAM или RSTREG. Ширина этих атрибутов равна
ширине порта, как показано в табл. А.33. Данные атрибуты являются битовыми векторами в 16-ричном
коде и по умолчанию равны 0. Когда DO_REG = 1, атрибуты устанавливают значения выходного регистра,
в противном случае инсталлируется защелка.
В табл. А.34 представлено расположение битов атрибутов INIT при отображении на выходы шины
DO для примитивов блока RAM и макро SDP.
Приоритет сигналов Reset или СЕ (RSTREG_PRIORITY_[A/B]). Когда DO.REG = 1, атрибут
определяет приоритет сигналов RSTREG или REGCE во время активности сигнала синхронной установ-
ки/сброса выходных регистров RSTREG. Значениями атрибута являются RSTREG или REGCE.
Включение или исключение дополнительного выходного регистра (DO[A/B]_REG). Значение 1
разрешает дополнительные выходные регистры, обеспечивая наименьшую задержку чтения clock-to-out за
счет дополнительного цикла синхросигнала. Значение 0 позволяет читать в одном цикле синхросигнала,
но результат будет медленнее задержки clock-to-out. Применяется к портам А и В в режиме TDP и к
36 младшим битам в режиме SDP
Определение расширенного режима адресации (RAM_EXTENSION_[A/B]). Атрибут определяет
способ каскадирования блоков RAMB36 для формирования памяти 64Кх1. Если каскадирование не ис-
пользуется, то устанавливается в «NONE». Если блоки памяти каскадируются, то устанавливается либо
в «UPPER» либо в «LOWER» для указания отношения расположения блоков RAM. Не используется в
режиме SDP.
Макро SDP для примитивов блока RAM
Таблица А.34
Ширина порта SRVAL/ INIT полная ширина SRVAL/INIT отображение в DO SRVAL/INIT отображение в DOP
DO SRVAL/INIT DOP SRVAL/INIT
36 RAMB18E1 SDP MACRO [35:0] [31:0] [33:18]/[15:0] [3:0] [35:34]/[17:16]
72 RAMB36E1 SDP MACRO [71:0] [63:0] [67:36]/[31:0] [7:0] [71:68]/[35:32]
286
Приложение А. Примитивы FPGA 7-й серии
Ширина чтения (READ_WIDTH_[A/B]). Атрибут определяет ширину порта чтения А или В блока
RAM. Атрибут может принимать значения: 0 (по умолчанию), 1, 2, 4, 9, 18, 36 и 72 (при использовании
в режиме SDP модуля RAMB36E1 порта А). При значении 0 порт не используется.
Ширина записи (WRITE_WIDTH_[A/B]). Атрибут определяет ширину порта записи А или В блока
RAM. Атрибут может принимать значения: 0 (по умолчанию), 1, 2, 4, 9, 18, 36 и 72 (при использовании
в режиме SDP модуля RAMB36E1 порта А). При значении 0 порт не используется.
Выбор режима (RAM_MODE). Атрибут позволяет выбрать либо действительно двух портовый
«TDP» (по умолчанию), либо простой двухпортовый режим «SDP».
Режим записи (WRITE_MODE_[A/B]). Атрибут определяет поведение выхода порта во время опе-
рации записи:
• «WRITE-FIRST» — записываемое значение появляется на выходе порта;
• «READ-FIRST» — предыдущее содержимое ячейки памяти появляется на выходе порта;
• «NO-CHANGE» — предыдущее значение выхода порта остается тем же самым.
Когда RAM-MODE = «SDP», WRITE-MODE не может устанавливаться в «NO-CHANGE». Для ре-
жима SDT необходимо установить атрибут WRITE-MODE в значение «READ-FIRST», если используется
один и тот же синхросигнал для обоих портов, и в значение «WRITE-FIRST», если используются раз-
ные синхросигналы. Это приводит к улучшению коллизии или режима перекрытия адресов, когда в этой
конфигурации используется макрос BRAM.
Компромисс между производительностью и коллизией (RDADDR_COLLISION_HWCONFIG). Ат-
рибут позволяет находить компромисс между производительностью и потенциальным перекрытием адреса
(коллизией) в режимах SDP и TDP. Перекрытие адреса может случиться в синхронных или асинхронных
приложениях синхронизации, если блок RAM в режиме SDP устанавливается в READ-FIRST или в режиме
TDP имеет установку любого порта в режиме READ-FIRST.
Для модуля RAMB36E1 перекрытие адреса определяется в случае, когда адресные биты А14-А8
являются идентичными для обоих портов в одном и том же цикле синхросигнала и когда оба порта являются
доступными. То же для модуля RAMB18E1, только в отношении адресных битов А13-А7.
Если коллизия произойти не может, то полная производительность блока RAM может быть вос-
становлена установкой атрибута в значение PERFORMANCE. В противном случае пользователь должен
установить его в значение DELAYED.WRITE (по умолчанию). Если коллизия адреса происходит в режиме
PERFORMANCE, содержимое ячеек памяти может быть повреждено.
Моделирование в случае коллизии памяти (SIM_COLLISION_CHECK). Атрибут позволяет уста-
новить поведение программы моделирования в случае коллизии памяти:
• «ALL » = формируется предупреждение и затронутые выходы или ячейка памяти становятся неиз-
вестными (X);
• «WARNING-ONLY» = формируется предупреждение и затронутые выходы или ячейка памяти со-
храняют последнее значение;
• «GENERATE_X_ONLY» = не формируется предупреждение, однако затронутые выходы или ячейка
памяти становятся неизвестными (X);
• «NONE» = не формируется предупреждение, а затронутые выходы или ячейка памяти сохраняют
последнее значение.
Имя файла инициализации памяти (INIT-FILE). Атрибут указывает на дополнительный файл ини-
циализации памяти RAM. Значение может быть NONE (по умолчанию) или именем файла в виде строки
символов.
Семейство целевого устройства SIM-DEVICE. Атрибут устанавливает семейство целевого устрой-
ства для моделирования. Единственным возможным значением является «7-SERIES».
А.5. Макросы блока памяти RAM
Примитив блока памяти RAMB36E1 содержит достаточно много портов и атрибутов, что может вы-
зывать определенные затруднения для практического использования. Поэтому фирма Xilinx предлагает ряд
макросов для наиболее часто используемых режимов работы блока памяти RAM. Эти макросы находятся
в библиотеке UniMacro программных средств синтеза фирмы Xilinx и могут быть инстанцированы в языках
VHDL и Verilog (детали см. в документе UG768 Libraries guide for HDL).
Имеется три макроса, которые обеспечивают режимы работы блока памяти RAM: действительно
(истинно) двухпортовый TDP, простой двухпортовый SDP и одно портовый (single port) режим. Это сле-
дующие макросы: BRAM_TDP_MACRO. BRAM_ SDP.MACRO и BRAM_SINGLE_MACRO.
Приложение А. Примитивы FPGA 7-й серии
287
А.5.1. Макрос BRAM_TDP_MACRO
Макрос BRAM_TDP_MACRO предназначен для обеспечения работы блока RAM в действительно двух-
портовом режиме TDP. Изображение макроса BRAM_TDP_MACRO представлено на рис. А.22.
Описание портов макроса BRAM_TDP_MACRO приведено в табл. А.35.
DIA(WRITE„W1DTH„A-1:0)
BRAM_TDP_MACRO
ADDRA(WRITE_WIDTH_A-1:0)
WEA(WRITE„WIDTH_A-1:0)
DOA(READ_WIDTH_A-1:0)
ENA
RSTA
Attributes
REGCEA
OLKA
BRAN SlZ£-18Kfc
DOA^REG-O
INITO
READ_WDTH_A-1
WRITEJM0TM_A-1
WRITE_MOD£Ja-WRITE_RRSI
SfiVAL.AO
SIH_COUISiON_CHECK-ALL
INIT_FILE-NON£
ADDRB(ADDRBWIDTH-1:0)
WEB(WRITE„ WIDTH „8-1:0)
DIB(WRITE,WIDTH,.B*1:0)
DOB(READWIDTHB-1 iO)
RSTB
Attributes
ENB >
REGCEB
CLKB
REAQ_W0TH_B-1
VWHT_WDTH B-1
W?rrE_MO06_8-WRITE_FRST
SRVA,L_B-0
True Dual Port RAM
Рис. A.22. Макрос BRAM_TDP_MACRO
Таблица A.35
Порты макроса BRAM_TDP_MACRO
Имя Направление Ширина Функция
DOA Выход См. документ UG7681 Шина выходных данных, адресуемых ADDRA
DOB Выход См. документ UG7681 Шина выходных данных, адресуемых ADDRB
DIA Вход См. документ UG7681 Шина входных данных, адресуемых ADDRA
DIB Вход См. документ UG7681 Шина входных данных, адресуемых ADDRB
ADDRA. ADDRB Вход См. документ UG7681 Адресные шины портов А, В
WEA, WEB Вход См. документ UG7681 Разрешение побайтовой записи портов А, В
ENA, ENB Вход 1 Разрешение функционирования портов А, В
RSTA, RSTB Вход 1 Синхронный сброс выходных регистров портов
А, В
REGCEA, REGCEB Вход 1 Разрешение синхронизации выходных регист-
ров портов А, В (DO-REG = 1)
CLKA, CLKB Вход 1 Синхросигнал чтения/записи портов А, В
1. Размеры (ширина) портов входных данных DIA/DIB, выходных данных DOA/DOB, адресных шин
ADDRA/ADDRB и шин разрешения записи WEA/WEB строго взаимосвязаны и определяются таблицей
из документа UG768 (Libraries Guide for HDL Designs).
288
Приложение А. Примитивы FPGA 7-й серии
А.5.2. Макрос BRAM_SDP_MACRO
Макрос BRAM_SDP_MACRO предназначен для обеспечения работы блока RAM в простом двухпор-
товом режиме SDP. Изображение макроса BRAM_SDP_MACRO представлено на рис. А.23.
Описание портов макроса BRAM_SDP_MACRO приведено в табл. А.36.
DI(WRITE„ WIDTH: 1:0)
WRADDR(8:0)
WE(f(WRITE„WIDTH);O)
WREN
BRAM_SDP_MACRO
DO(READ, WIDTH-1:0)
RST
WRCLK
Attributes
ВАЛ» I
DO REG-0
IMT-0
WRITE WOTH-36
SlM C&LSiONCHECK ALL
5RVAL-C
ЙЧ1Т HlE-NOBWE
RDADDR(8:0)
RDEN
REGCE
RDCLK
Simple Dual Port RAM
Рис. A.23. Макрос BRAM_SDP_MACRO
Таблица A.36
Порты макроса BRAM_SDP_MACRO
Имя Направление Ширина Функция
DO DI WRADDR, RDADDR WE WREN, RDEN SSR REGCE WRCLK, RDCLK Выход Вход Вход Вход Вход Вход Вход Вход См. документ UG7681 См. документ UG7681 См. документ UG7681 См. документ UG7681 1 1 1 1 Шина выходных данных, адресуемых RDADDR Шина входных данных, адресуемых WRADDR Адресные шины записи и чтения Разрешение побайтовой записи Разрешение записи, чтения Синхронный сброс выходных регистров портов Разрешение синхронизации выходных регист- ров (DO-REG = 1) Синхросигнал записи, чтения
1. Размеры портов входных данных DI, выходных данных DO, адресных шин WRADDR и RDADDR, а
также шины разрешения побайтовой записи WEA/WEB строго взаимосвязаны и определяются табли-
цей из документа UG768 (Libraries Guide for HDL Designs).
Приложение А. Примитивы FPGA 7-й серии
289
A.5.3. Макрос BRAM_SINGLE_MACRO
Макрос BRAM_SINGLE_MACRO предназначен для обеспечения работы блока RAM в однопортовом
режиме. Изображение макроса BRAM_SINGLE_MACRO представлено на рис. А.24.
Описание портов макроса BRAM_SINGLE_MACRO приведено в табл. А.37.
DI(WRITE_WIDTH-1:0)
BRAM_SINGLE_MACRO
ADDR(f(BRAMj5IZE):0)
WE(f(WRITE_WIDTH):O)
DO(READ_WIDTH-1:0)
Attributes
DO.REG-O
IN IT-0
READ„WIDTH-1
WRITE WIDTH-1
WRITE „MOD&WRrrE. FIRST
SRVAL-0
{NIT.FKE-NONE
EN
REGCE
RST
CLK
Single Port RAM
Рис. A.24. Макрос BRAM_SINGLE_MACRO
Таблица A.37
Порты макроса BRAM_SINGLE_MACRO
Имя Направление Ширина Функция
DO Выход См. документ UG7681 Шина выходных данных, адресуемых ADDR
DI Вход См. документ UG7681 Шина входных данных, адресуемых ADDR
ADDR Вход См. документ UG7681 Адресная шина
WE Вход См. документ UG7681 Разрешение побайтовой записи
EN Вход 1 Разрешение записи, чтения
RST Вход 1 Синхронный сброс выходных регистров портов
REGCE Вход 1 Разрешение синхронизации выходных регист-
ров (DO.REG = 1)
CLK Вход 1 Синхросигнал
1. Размеры портов входных данных DI, выходных данных DO, адресной шины ADDR и разрешения
побайтовой записи WE строго взаимосвязаны и определяются таблицей из документа UG768 (Libraries
Guide for HDL Designs).
A.5.4. Атрибуты макросов блока памяти RAM
Атрибуты всех макросов блока памяти RAM приведены в табл. А.38.
290
Приложение А. Примитивы FPGA 7-й серии
Таблица А.38
Атрибуты макросов блока памяти RAM
Атрибут Макрос, в котором используется Тип Допустимые значения Значение по умолчанию Описание
BRAM_ SIZE BRAM_TDP_MACRO BRAM_SDP_MACRO BRAM.SINGLE-MACRO Строка «36КЬ», «18КЬ» «18КЬ» Конфигурирует память как «36КЬ» или «18КЬ»
DEVICE BRAM-TDP.MACRO BRAM_SDP_MACRO BRAM-SINGLE-MACRO Строка «7SERIES» «7SERIES» Целевое устройство
DO-REG BRAM-TDP.MACRO BRAM-SDP.MACRO BRAM-SINGLE-MACRO Целое 0, 1 0 Значение 1 разрешает дополнительный выход- ной регистр
INIT BRAM_TDP_MACRO BRAM_SDP_MACRO BRAM-SINGLE-MACRO 16- ричное Любое 72-битовое Все нули Определяет начальное значение выхода после конфигурации
INIT.FILE BRAM_TDP_MACRO BRAM_SDP_MACRO BRAM_SINGLE_MACRO Строка Имя файла NONE Имя файла, содержащего содержимое памяти
READ- WIDTH, WRITE- WIDTH BRAM-TDP.MACRO BRAM_SDP_MACRO BRAM-SINGLE_MACRO Целое 1-72 36 Определяет размер шин DI и DO. Допускают- ся следующие комби- нации: READ-WIDTH = WRITE-WIDTH; ес- ли ассиметричная па- мять, READ-WIDTH и WRITE-WIDTH долж- ны быть степенью 2 или должны иметь допусти- мые значения (1, 2, 4, 8, 9, 16, 18, 32. 36)
READ- WIDTH, WRITE- WIDTH BRAM_SDP_MACRO BRAM-SINGLE_MACRO Целое 1-72 36 То же, но допустимые значения (1, 2, 4, 8, 9, 16, 18, 32, 36, 64, 72)
SIM-COL- LISION- CHECK BRAM_TDP_MACRO BRAM_SDP_MACRO Строка «ALL», «WARN- ING-ONLY», «GENERATE_X_ ONLY», «NONE» «ALL» Определяет поведение программы моделирова- ния, в случае коллизии памяти
SRVAL A, SRVAL_B BRAM_TDP_MACRO 16- ричное Любое 72-битовое Все нули Определяет значение вы- хода порта DO при ак- тивном сигнале синхрон- ного сброса RST
SRVAL BRAM-SDP.MACRO BRAM_SINGLE_MACRO 16- ричное Любое 72-битовое Все нули То же
INIT-00- INIT.7F BRAM_TDP_MACRO BRAM-SDP.MACRO BRAM-SINGLE-MACRO 16- ричное Любое 256-битовое Все нули Определяет содержимое матрицы памяти данных 16 Кбит или 32 Кбит
INITP-00- INITP.OF BRAM_TDP_MACRO BRAM_SDP_MACRO BRAM-SINGLE-MACRO 16- ричное Любое 256-битовое Все нули Определяет содержимое матрицы памяти данных 2Кбит или 4Кбит для битов четности
WRITE- MODE BRAM_SINGLE_MACRO Строка «READ-FIRST», «WRITE-FIRST», «NO.CHANGE» «WRITE- FIRST» Определяет режим запи- си
А.6. Примитивы памяти FIFO
Для создания памяти FIFO служат два примитива: FIFO36E1 (рис. А.25) и FIFO18E1 (рис. А.26).
А.6.1. Порты примитивов памяти FIFO
Описание портов примитивов FIFO36E1 и FIFO18E1 дано в табл. А.39.
Приложение А. Примитивы FPGA 7-й серии
291
FIFO36 FIFO18
DI[63:0] DO[63:0] DIP(7:0] DOP[7:0] RDEN WRCOUNT[12:0] RDCLK RDCOUNT[12:0] WREN FULL WRCLK EMPTY ALMOSTFULL ALMOSTEMPTY RSTREG RDERR REGCE WRERR DI[31:0] DO[31:0] DIP[3:0] DOP[3:0] RDEN WRCOUNT[11:0] RDCLK RDCOUNTJ11:0] FULL WREN EMPTY WRCLK ALMOSTFULL RST ALMOSTEMPTY RSTREG RDERR REGCE WRERR
—
Рис. А.25. Примитив FIFO36E1 Рис. А.26. Примитив FIFO18E1
Таблица А.39
Порты примитивов памяти FIFO
Имя Описание
DI DIP WREN WRCLK RDEN RDCLK RST RSTREG REGCE DO DOP FULL ALMOST- FULL EMPTY ALMOST- EMPTY RDCOUNT WRCOUNT WRERR RDERR Вход данных Вход битов четности Вход разрешения записи. Когда WREN = 1, данные записываются в память. Когда WREN — 0, запись запрещена. Сигналы WREN и RDEN должны удерживаться на низ- ком уровне до установки сигнала сброса RST и в течение цикла сброса. Кроме того, для гарантирования временных соотношений WREN и RDEN должны удерживаться на низком уровне в течение двух циклов синхросигналов WRCLK и RDCLK после сигнала сброса RST Вход синхросигнала для операции записи Вход разрешения чтения. Когда RDEN = 1, данные читаются в выходной регистр. Когда RDEN = 0, чтение запрещено. Сигналы RDEN и WREN должны удерживаться на низком уровне до установки сигнала сброса RST и в течение цикла сброса Вход синхросигнала для операции чтения Вход сброса всех функций памяти FIFO, флагов и указателей. Сигнал RST должен уста- навливаться в течение пяти циклов синхронизации чтения и записи Вход синхронного сброса или установки выходного регистра. Используется, только ког- да EN.SYNC = TRUE и DO.REG = 1. Атрибут RSTREG-PRIORITY всегда установлен в RSTREG Вход разрешения синхронизации выходного регистра. Используется, только когда EN.SYNC = TRUE и DO-REG = 1. RSTREG имеет приоритет над REGCE Выход данных, синхронизирован с RDCLK Выход битов четности, синхронизирован с RDCLK Выход. Указывает, что все содержимое памяти FIFO заполнено. Дополнительные записи не допускаются. Синхронизирован с WRCLK Выход. Указывает, что все содержимое памяти FIFO почти заполнено. Число доступ- ных ячеек в FIFO меньше, чем величина ALMOST_FULL_OFFSET, синхронизирован с WRCLK. Смещение этого флага указывается пользователем (см. табл. А.43) Выход. Указывает, что память FIFO пустая. Дополнительные чтения не допускаются, синхронизирован с RDCLK Выход. Указывает, что почти все записи в памяти FIFO прочитаны. Число записей в па- мяти FIFO меньше, чем величина ALMOST_EMPTY_OFFSET, синхронизирован с RDCLK. Смещение для этого флага указывается пользователем (см. табл. А.43) Выход. Указатель чтения данных памяти FIFO, синхронизирован с RDCLK. Циклически повторяется, когда достигается максимальная величина указателя чтения Выход. Указатель записи данных памяти FIFO, синхронизирован с WRCLK. Циклически повторяется, когда достигается максимальная величина указателя записи Флаг ошибки записи. Устанавливается, когда память FIFO заполнена. Любая дополни- тельная операция записи генерирует флаг ошибки. Синхронизирован с WRCLK Флаг ошибки чтения. Устанавливается, когда память FIFO пустая. Любая дополнитель- ная операция чтения генерирует флаг ошибки. Синхронизирован с RDCLK
292
Приложение А. Примитивы FPGA 7-й серии
А.6.2. Атрибуты примитивов памяти FIFO
Список атрибутов для примитивов FIFO36E1 и FIFO18E1 приведен в табл. АЛО. Размер асинхронной
памяти FIFO определяется установкой значения атрибута DATA.WIDTH.
Отображение значений атрибутов SRVAL и INIT на выходную шину DO представлено в табл. А.41.
А.6.3. Диапазоны смещения флагов «почти полный» и «почти пустой»
Глубина памяти FIFO в различных конфигурациях представлена в табл. А.42, а диапазоны смещения
флагов «почти полный» и «почти пустой» — в табл. А.43.
Таблица АЛО
Список атрибутов для примитивов FIFO36E1 и FIFO18E1
Атрибут Описание
AI_MOST_FULL_OFFSET ALMOST_EMPTY_OFFSET FIRST_WORD-FALL_THROUGH DO_REG DATA.WIDTH FIFO-MODE EN_SYN SRVAL INIT Определяет разницу между условиями FULL и ALMOSTFULL; 13-би- товая 16-ричная величина, значения которой приведены в табл. А.43 Определяет разницу между условиями EMPTY и ALMOSTEMPTY; 13-битовая 16-ричная величина, значения которой приведены в табл. А.43 Определяет режим чтения первого слова, записанного в пустую па- мять FIFO; имеет значение FALSE (по умолчанию) и TRUE; если имеет значение TRUE, то первое слово, записанное в пустую память FIFO, появляется на выходе без установки сигнала RDEN При DO-REG = 1, к выходу синхронной памяти FIFO добавляется конвейерный регистр, при этом данные будут иметь один дополни- тельный цикл задержки синхронизации, однако улучшается время clock-to-out. Имеет значение 0 или 1 (по умолчанию), для асинхрон- ной памяти FIFO атрибут DO.REG должен иметь значение 1. Чтобы флаги и данные соответствовали стандартному функционированию памяти FIFO, для синхронной памяти FIFO атрибут DO.REG должен иметь значение 0 Определяет ширину данных памяти FIFO; может принимать значения 4 (по умолчанию), 9, 18, 36 и 72 Определяет режимы работы примитивов: для модуля FIFO36 может принимать значение FIFO36 (по умолчанию) и FIFO36.72; для мо- дуля FIFO18 может принимать значение FIFO18 (по умолчанию) и FIFO18.36 Определяет режим работы памяти FIFO: синхронный или асинхрон- ный. Имеет значение FALSE (по умолчанию) или TRUE. Когда уста- новлен в TRUE, соединяет синхросигналы WRCLK и RDCLK вместе, при этом FWFT должен быть FALSE. Когда установлен в FALSE, ат- рибут DO.REG должен быть равен 1 Определяет значения выходов после сброса, когда установлен сигнал RSTREG; 16-ричное значение, занимающее 36 битов для FIFO18E1 и 72 бита для FIFO36E1 (по умолчанию 00h); поддерживается, только когда DO.REG = 1 и EN-SYN = TRUE Определяет значения выходов после конфигурации; 16-ричное значе- ние (по умолчанию — 00h); поддерживается, только когда DO-REG = = 1 и EN.SYN = TRUE
Таблица АЛ1
Отображение значений атрибутов SRVAL и INIT на выходную шину DO
Ширина порта SRVAL/INIT полная ширина SRVAL/INIT отображение в DO SRVAL/INIT отображение в DOP
DO SRVAL/INIT DOP SRVAL/INIT
4 [3:0] [3:0] [3:0] NA NA
9 [8:0] [7:0] [7:0] [0] [8]
18 [17:0] [15:0] [15:0] [1:0] [17:16]
36 (для FIFO36E1) [35:0] [31:0] [31:0] [3:0] [35:32]
36 (для FIFO18.36) [35:0] [31:0] [33:18], [15:0] [3:0] [35:34], [17:16]
72 (для FIFO36-72) [71:0] [63:0] [67:36], [31:0] [7:0] [71:68], [35:32]
Приложение А. Примитивы FPGA 7-й серии
293
Таблица А.42
Глубина памяти FIFO
Ширина порта Глубина блока RAM Глубина памяти FIFO
Режим FIFO18 Режим FIFO36 Режим Standard Режим FWFT
х4 8192 8192 8193
х4 х9 4096 4096 4097
х9 Х18 2048 2048 2049
Х18 хЗб 1024 1024 1025
хЗб х72 512 512 513
1 Значения атрибутов ALMOST-EMPTY-OFFSET и ALMOST-FULL-OFFSET должны быть меньше, чем общая глубина памяти FIFO.
Таблица А.43
Диапазон смещение флагов «почти полный/почти пустой»
Ширина порта ALMOST_EMPTY_OFFSET ALMOST-FULL-OFFSET
Режим Standard Режим FWFT
Режим FIFO18 Режим FIFO36 Min Max Min Max Min Max
Режим с двойной синхронизацией (EN _SYN = FALSE)
х4 5 8186 6 8187 4 8185
х4 х9 5 4090 6 4091 4 4089
х9 Х18 5 2042 6 2043 4 2041
Х18 хЗб 5 1018 6 1019 4 1017
хЗб х72 5 506 6 507 4 505
Синхронный режим (EN.SYN = TRUE)
х4 1 8190 N/A N/A 1 8190
х4 х9 1 4094 N/A N/A 1 4094
х9 Х18 1 2046 N/A N/A 1 2046
Х18 хЗб 1 1022 N/A N/A 1 1022
хЗб х72 1 510 N/A N/A 1 510
1. Диапазоны з табл. А.43 применяются, когда синхросигналы RDCLK и WRCLK имеют одинако-
вую частоту.
А.7. Макросы памяти FIFO
Для упрощения использования примитивов памяти FIFO фирма Xilinx предлагает два макроса: FIFO-
SYNC-MACRO и FIFO_DUALCLOCK_MACRO для наиболее часто используемых режимов работы памяти
FIFO: синхронного и с двойной синхронизацией. Эти макросы находятся в библиотеке UniMacro програм-
мных средств синтеза фирмы Xilinx и могут быть инстанцированы в языках VHDL и Verilog (детали см.
в документе UG768 Libraries guide for HDL).
A.7.1. Макрос FIFO_DUALCLOCK_MACRO
Этот макрос конфигурирует примитив FIFO для использования с независимыми синхросигналами
чтения и записи. Данные читаются из памяти FIFO на положительном фронте синхросигнала чтения, а
записываются в память FIFO на положительном фронте синхросигнала записи.
В зависимости от смещения между фронтами синхросигналов чтения и записи флаги Empty, Almost
Empty и Almost Full могут устанавливаться на один цикл синхронизации позже. Из-за асинхронной природы
синхросигналов симуляционная модель отображает только аннулирование циклов задержки, перечисленных
в Руководстве пользователя.
Макрос FIFO_DUALCLOCK_MACRO показан на рис. А.27, а описание портов макроса FIFO.DUAL-
CLOCK.MACRO приведено в табл. А.44. Возможная конфигурация портов макроса FIFO-DUALCLOCK-
MACRO представлена в табл. А.45.
А.7.2. Макрос FIFO_SYNC_MACRO
Этот макрос конфигурирует память FIFO с одним сигналом для чтения и записи. Макрос FIFO-SYNC-
MACRO показан на рис. А.28, а описание портов приведено в табл. А.44. Возможная конфигурация портов
макроса FIFO-SYNC-MACRO приведена в табл. А.45.
294
Приложение А. Примитивы FPGA 7-й серии
DI(DATA_ WIDTH-1:0)
FIFO_DUALCLOCK_MACRO
WE(f(WRITE_WIDTH)'.O
WRERR
RST
WREN
ALMOSTFULL
FULL
WRCLK
V^COUNT(f(DATA_WIDTH):0)
RDEN
RDCLK
Attributes
DEVICE*? Senes
FIFO_SIZE=18Kb
A^MOST_FU„_CFFSET^C8C
cata~wioth=4
ALMOST EMPTY OFFSET-G80 ______
FlRST_WORD_FALL_THROUGH= FALSI
DO(CATA-WIDTH-1:0)
RDERR
ALMOSTEMPTY
EMPTY
RDCOUNT(f<DATAJWIDTH):0)
DUAL CLOCK
First-In, First-Out (FIFO) Buffer
Рис. A.27. Макрос FIFO_DUALCI_OCK_MACRO
DI(DATA__WIOTH:1:0)
FIFO„SYNCJV1ACRO
WE(f(WRITE„WIDTH):Oj^
RST
WREN
WRERR
ALMOSTFULL
FULL
WRCOUNT(f(DATA_WIDTH):0)
Attributes
CLK
RDEN
FIFO_SlZE^ 18Kb
ALMOST_FULL OFFSET-060 _
DATA WIDTHS ~
DO..HtU=l
ALMOSTEMPTYOfTSET-060
DO(DATA-WIDTH:1:0)
RDERR
ALMOSTEMPTY
EMPTY
RDCOUNTff (DATA ,.WI DTH) :0)
First-In. First-Out (FIFO) Buffer
Рис. A.28. Макрос FIFO-SYNC-MACRO
A.7.3. Порты макросов памяти FIFO
Описание портов макросов FIFO-DUALCLOCK-MACRO и FIFO.SYNC-MACRO представлено в
табл. А.44, а возможные конфигурации портов приведены в табл. А.45.
А.7.4. Атрибуты макросов памяти FIFO
Описание атрибутов макросов FIFO-DUALCLOCK-MACRO и FIFO-SYNC-MACRO представлено в
табл. А.46.
Приложение А. Примитивы FPGA 7-й серии
295
Таблица А.44
Порты макросов памяти FIFO
Имя Направление Ширина Функция
ALMOSTEMPTY Выход 1 Почти все введенные в FIFO значения были прочитаны
ALMOSTFULL Выход 1 Почти все содержимое памяти FIFO заполнено
DO Выход См. табл. А.45 Шина выходных данных, адресуется ADDR
EMPTY Выход 1 Память FIFO пустая
FULL Выход 1 Память FIFO полная
RDCOUNT Выход См. табл. А.45 Указатель чтения данных памяти FIFO
RDERR Выход 1 Когда память FIFO пустая, любая операция чтения генерирует этот флаг ошибки
WRCOUNT Выход См. табл. АЛБ Указатель записи данных памяти FIFO
WRERR Выход 1 Когда память FIFO полная, любая операция записи генерирует этот флаг ошибки
DI Вход См. табл. АЛБ Шина входных данных, адресуется ADDR
RDCLK Вход 1 Синхросигнал операции чтения в макросе FIFO_DUALCLOCK_MACRO
RDEN Вход 1 Разрешение чтения
RST Вход 1 Асинхронный сброс
WRCLK Вход 1 Синхросигнал записи в макросе FIFO_DUALCLOCK_MACRO
WREN Вход 1 Разрешение записи
CLK Вход 1 Вход синхросигнала для чтения и записи в макросе FIFO_SYNC_MACRO
Таблица АЛБ
Конфигурация портов макросов памяти FIFO
Ширина данных Размер FIFO, Кбит Размер WRCOUNT Размер RDCOUNT
72-37 36 9 9
36-19 36 10 10
18 9 9
18-10 36 11 11
18 10 10
Ширина данных Размер FIFO, Кбит Размер WRCOUNT Размер RDCOUNT
9-5 36 12 12
18 11 11
1-4 36 13 13
18 12 12
Таблица А.46
Атрибуты макросов памяти FIFO
Атрибут Тип данных Возможные значения Значение по умолчанию Описание
ALMOST_EMPTY_OFFSET 16- ричное 13-битовое значение 0 Устанавливает определенные раз- личия между условиями EMPTY и ALMOSTEMPTY
ALMOST-FULL-OFFSET 16- ричное 13-битовое значение 0 Устанавливает определенные раз- личия между условиями FULL и ALMOSTFULL
DATA.WIDTH Целое 1-72 4 Ширина шины DI/DO
DEVICE Строка «7SERIES» «7SERIES» Целевое устройство
FIFO-SIZE Строка «18КЬ», «36КЬ» «18КЬ» Конфигурирует FIFO как память раз- мером 18Кбит или ЗбКбит
FIRST-WORD-FALL- THROUGH (только для макроса FIFO.DUAL- CLOCK.MACRO) Логи- ческий FALSE, TRUE FALSE Если установлен в TRUE, то первое слово, записанное в пустую память FIFO появляется на выходе без уста- новки сигнала RDEN
DO.REG (только для мак- роса FIFO-SYNG-MACRO) Двоич- ный 0, 1 1 DO.REG должен быть установлен в 0 для стандартного синхронного, функционирования флагов и данных памяти FIFO. Когда DO.REG = 1, на выходах устанавливается дополни- тельный конвейерный регистр
296
Приложение А. Примитивы FPGA 7-й серии
А.8. Примитивы блока ЕСС
Примитив блока ЕСС для памяти RAM приведен на рис. А.29, а для памяти FIFO — на рис. А.30.
CASCADEOUTA CASCADEOUTB
(NC)
(NC)
1 RAMB36E1
D 1(31 0] 32' DIADI DIPADIP (Decode Only) ADDRARDADDR DOADO WEA DOPADOP ENARDEN — REGCEAREGCE ECCPARITY RSTREGARSTREG RSTRAMARSTRAM oniTrnn oBITtHH > CLKARDCLK DBITERR DIBDI (Standard or Encode Only) DIPBDIP ” ADDRBWRADDR DOBDO WEBWE DOPBDOP ENBWREN REGCEB RSTREGB RDADDRECC RSTRAMB INJECTSBITERR INJECTDBITERR >CLKBWRCLK 32.
ГИОГ'Э-П! "
q ОГкЛГЛГЛОГСП! ’
4 z
RDPN 8,
mUc.iN
d 3 2 Cc n Ь *
Dl[63:32]
32z
* *
9
WKAUUnp.ll] T- 8 / 4 /
9 ,
r
-X- INJECTSBITERR +
INJECTDBITERR
WHvLK
CASCADEINA
(NC)
CASCADEINB
(NC)
DO[31:0]
DOP[3:0]
ECCPARITY[7:0]
SBITERR
DBITERR
DO[71:36]
DOP[7:4]
RDADDRECC[8 0)
Рис. A.29. Блок RAMECC (в режиме SDP примитива RAMB36E1)
FIFO36E1
DI[63:0] DO[63:0] DIP[7:0] DOPt7:0] ECCPARITY[7:0] SBITERR DBITERR FULL WREN EMPTY RDEN _ ALMOSTFULL RST u/nr. w ALMOSTEMPTY WHCLK WRERR RDCLK RDERR INJECTSBITERR WRCOUNT[8:0] INJECTDBITERR RDCOUNT[8:0]
Рис. А.ЗО. Блок FIFOECC (в режиме FIFO36-72)
Модуль RAMB36E1 поддерживает блок
ЕСС только в режиме SDP. Модуль FIFO36E1
поддерживает стандартный режим блока ЕСС
только в режиме FIFO36-72, при этом не под-
держивается выход RDADDR ЕС С.
А.8.1. Порты примитивов блока ЕСС
Описание портов блока ЕСС для памяти
типа RAM приведено в табл. А.47, а для памяти
типа FIFO — в табл. А.48.
А.8.2. Атрибуты примитивов блока
ЕСС
Описание атрибутов блока ЕСС для памяти
типа RAM приведено в табл. А.49, а для памяти
типа FIFO — в табл. А.50.
Приложение А. Примитивы FPGA 7-й серии
297
Таблица А.47
Порты блока ЕСС для памяти RAM
Порт Описание
DIADI[31;0] DIPADIP[3:0] DIBDI[31:0] DIPBDIP[3:0] ADDRARDADDR[15:0] ADDRBWRADDR[15:0] WEA[3:0] WEBWE[7:0] ENARDEN ENBWREN RSTREGARSTREG RSTREGB RSTRAMARSTRAM RSTRAMB CLKARDCLK CLKBWRCLK REGCEAREGCE REGCEB CASCADEINA CASCADEINB CASCADEOUTA CASCADEOUTB DOADO[31:0] DOPADOP[3:0] DOBDO[31:0] DOPBDOP[3:0] INJECTSBERR INJECTDBERR ECCPARITY[7:0] SBERR DBERR RDADDRECC[8:0] Входы данных порта А, в режиме ЕСС адресуются ADDRBWRADDR Входы данных контроля четности порта А, в режиме ЕСС адресуются ADDRBWRADDR Входы данных порта В, в режиме ЕСС адресуются ADDRBWRADDR Входы данных контроля четности порта В, в режиме ЕСС адресуются ADDRBWRADDR Шина адреса порта А; в режиме RAM_MODE = SDP она является шиной RDADDR; в режиме ЕСС используются только биты [14:6] Шина адреса порта В; в режиме RAM-MODE = SDP она является шиной WRADDR; в режиме ЕСС используются только биты [14:6] Побайтное разрешение записи порта А, не используется в режиме RAM.MODE = SDP; в режиме ЕСС подсоединена к GND Побайтное разрешение записи порта В (WEBWE[3:0]); в режиме RAM.MODE = SDP это побайтное разрешение записи; в режиме ЕСС этот порт подсоеди- няется к высокому уровню Разрешение порта А, в режимах SDP или ЕСС это RDEN Разрешение порта В, в режимах SDP или ЕСС это WREN Синхронная установка или сброс выходного регистра порта А, в режиме SDP это RSTREG, в режиме ЕСС подсоединяется к GND Синхронная установка или сброс выходного регистра порта В, в режиме SDP это RSTREGB, в режиме ЕСС подсоединяется к GND Синхронная установка или сброс выходных защелок порта А, в режиме SDP это RSTRAM, в режиме ЕСС подсоединяется к GND Синхронная установка или сброс выходных защелок порта В, в режиме SDP это REGCEB, в режиме ЕСС подсоединяется к GND Вход синхронизации порта А; в режиме SDP это сигнал RDCLK Вход синхронизации порта В; в режиме SDP это сигнал WRCLK Разрешение синхронизации выходного регистра порта А, в режимах SDP и ЕСС это сигнал REGCE Разрешение синхронизации выходного регистра порта В, в режиме ЕСС подсо- единен к GND Вход каскадирования порта А, используется только в режиме TDP Вход каскадирования порта В, используется только в режиме TDP Выход каскадирования порта А, используется только в режиме TDP Выход каскадирования порта В, используется только в режиме TDP Шина выходных данных порта А, адресуется шиной ADDRARDADDR Шина выходных битов четности порта А, адресуется шиной ADDRARDADDR Шина выходных данных порта В, адресуется шиной ADDRARDADDR Шина выходных битов четности порта В, адресуется шиной ADDRARDADDR Если используется ЕСС, то вводит единичную ошибку; местонахождение бита указывается во время записи; блок ЕСС корректирует эту ошибку, когда эта ячейка читается обратно; ошибка создается в бите DI[30] Если используется ЕСС, то вводит двойную ошибку; местонахождение бита указывается во время записи; когда эта ячейка читается обратно, блок ЕСС указывает на ошибку установкой флагов; в случае активности одновременно двух сигналов NJECTSBERR и INJECTDBERR формируется двойная ошибка; ошибки создаются в битах DI[30] и Dl[62] Шина выхода шифратора ЕСС для использования в режиме только кодирова- ния (encode.only) Состояние выхода одиночной ошибки Состояние выхода двойной ошибки Адрес чтения ЕСС; указатель адреса на данные, считываемые в настоящее время; данные и соответствующий адрес являются доступными в одном и том же цикле
298
Приложение А. Примитивы FPGA 7-й серии
Таблица А.48
Порты блока ЕСС для памяти FIFO
Порт Описание
DI[63:0] DIP[7:0] WREN RDEN RSTREG RSTRAM RST WRCLK RDCLK INJECTSBITERR INJECTDBITERR DO[63;0] DOP[7:0] SBITERR DBITERR ECCPARITY[7:0] FULL ALMOSTFULL EMPTY ALMOSTEMPTY RDCOUNT WRCOUNT WRERR RDERR Шина входных данных Шина входных битов четности Вход разрешения записи Вход разрешения чтения Не используется, может подсоединяться к GND Не используется, может подсоединяться к GND Асинхронный сброс счетчиков и флагов памяти FIFO; сброс должен назначаться для трех циклов синхронизации; не воздействует на шину DO и сигналы блока ЕСС Синхросигнал для операций записи Синхросигнал для операций чтения Когда активен во время записи, создает однобитовую ошибку; блок ЕСС коррек- тирует эту ошибку, когда эта ячейка читается обратно; ошибка создается в бите DI[30] Создает двойную ошибку в битах DI[30] и DI[62] во время записи; логика блока ЕСС отличает двойную ошибку при считывании этой ячейки памяти Шина выходных данных Шина выходных битов четности Выход состояния одиночной ошибки Выход состояния двойной ошибки Не поддерживается Флаг «полный» Флаг «почти полный» Флаг «пустой» Флаг «почти пустой» Указатель читаемых данных Указатель записываемых данных Когда память FIFO полная, любая дополнительная операция записи генерирует этот флаг Когда память FIFO пустая, любая дополнительная операция чтения генерирует этот флаг
Таблица А.49
Атрибуты блока памяти RAM (примитив RAMB36E1)
Атрибут Значение
EN_ECC_WRITE EN_ECC_READ DO.REG Принимает значение TRUE или FALSE (по умолчанию); при установке TRUE включа- ет шифратор блока ЕСС Принимает значение TRUE или FALSE (по умолчанию); при установке TRUE включа- ет дешифратор блока ЕСС Принимает однобитовое значение 0 (по умолчанию) или 1; включает режим регистра или режим защелки
Таблица А.50
Атрибуты памяти FIFO (примитив FIFO36E1)
Атрибут Значение
EN_ECC_WRITE EN_ECC_READ DO.REG EN.SYN ALMOST_EMPTY_OFFSET Принимает значение TRUE или FALSE (по умолчанию); при установке TRUE включает шифратор блока ЕСС Принимает значение TRUE или FALSE (по умолчанию); при установке TRUE включает дешифратор блока ЕСС Принимает однобитовое значение 0 (по умолчанию) или 1; включает режим регистра или режим защелки Принимает значение TRUE или FALSE (по умолчанию); когда уста- новлен в TRUE, соединяет сигналы WRCLK и RDCLK вместе, при этом опция FWFT должна быть FALSE; когда установлен в FALSE, атрибут DO-REG должен быть 1 9-битовое шестнадцатеричное значение, которое определяет различие между условиями EMPTY и ALMOSTEMPTY
Приложение А. Примитивы FPGA 7-й серии
299
Окончание табл. А.50
Атрибут Значение
FIRST.WORD.FALL-THROUGH ALMOST_FULL_OFFSET Принимает значение TRUE или FALSE (по умолчанию); когда уста- новлен в TRUE, первое слово, записанное в пустую память FIFO, по- является на выходе в режиме FIFO36.72 без установки RDEN, имеет силу, только когда EN_SYN = FALSE 9-битовое шестнадцатеричное значение, которое определяет различие между условиями FULL и ALMOSTFULL
А.9. Примитивы элементов ввода-вывода
Библиотека фирмы Xilinx включает широкий набор примитивов ввода-вывода, поддерживающих раз-
личные стандарты ввода-вывода. Примитивы, поддерживающие большинство ассиметричных (single-ended)
стандартов ввода-вывода, представлены в табл. А.51, а дифференциальных — в табл. А.52.
Больше информации, включающей методы инстанцирования и возможные значения атрибутов для
этих и других примитивов ввода-вывода, можно найти в документе UG768.
А.9.1. Примитивы IBUF и IBUFG
Примитив IBUF (рис. А.31) средствами синтеза автоматически устанавливается для любого сиг-
нала, непосредственно подсоединяемому к входу верхнего уровня проекта или входному порту проекта
Однако при необходимости пользователь может самостоятельно вводить экземпляры данного примитива
Таблица А.51
Примитивы, поддерживающие большинство ассиметричных стандартов ввода-вывода
Примитив Описание
IBUF IBUFJBUFDISABLE IBUFJNTERMDISABLE IBUFG IOBUF OBUF OBUFT Входной буфер Входной буфер с управлением отключения буфера (для уменьшения энерго- потребления) Входной буфер с управлением отключения буфера и ограничения IN.TERM Входной буфер синхросигнала Двунаправленный буфер Выходной буфер Выходной буфер с 3-м состоянием
Таблица А.52
Примитивы, поддерживающие большинство дифференциальных стандартов ввода-вывода
Примитив Описание
IBUFDS IUFBDS.DIFF.OUT IBUFDS.DIFF.OUTJBUFDISABLE IBUFDS.DIFF-OUTJNTERMDISABLE IBUFDSJBUFDISABLE IBUFDSJNTERMDISABLE IBUFGDS IBUFGDS.DIFF.OUT IOBUFDS IOBUFDS-DCIEN IOBUFDS_DIFF_OUT OBUFDS OBUFTDS Дифференциальный входной буфер Дифференциальный входной буфер с комплементарными выходами Дифференциальный входной буфер и отключением буфера Дифференциальный входной буфер с отключением буфера и ограничения IN.TERM Дифференциальный входной буфер с управлением отключе- ния буфера Дифференциальный входной буфер с отключением буфера и ограничения IN.TERM Дифференциальный входной буфер синхросигнала Дифференциальный входной буфер синхросигнала с дополни- тельными выходами Дифференциальный двунаправленный буфер Дифференциальный двунаправленный буфер с отключением DCI и отключением входного буфера Дифференциальный двунаправленный буфер с дополнитель- ными выходами от входного буфера Дифференциальный выходной буфер Дифференциальный выходной буфер с 3-м состоянием
300
Приложение А. Примитивы FPGA 7-й серии
IBUFDISABLE
I (Input) [х|-
From device pad
О (Output)
into FPGA
Рис. A.31. Примитивы IBUF и IBUFG
Рис. A.32. Примитив IBUFJBUFDISABLE
(например, для изменения умалчиваемых значений атрибутов). Примитив IBUF управляется атрибутами
IBUF_LOW_PWR и IOSTANDARD.
Примитив IBUFG используется тогда, когда входной буфер используется как вход синхросигнала
Программное обеспечение Xilinx автоматически помещает IBUFG на входные выводы синхросигнала.
Примитив IBUFG предоставляет специализированные отдельные соединения от порта верхнего уровня
к блоку СМТ (который включает блоки ММСМ и PLL) или к буферу BUFG, при этом обеспечивается
минимальная величина задержки и флуктуаций синхросигнала. Вход примитива IBUFG может управляться
только соответствующими выводами синхросигнала (выводами MRCC или SRCC). Управляется примитив
IBUFG теми же атрибутами, что и IBUF.
А.9.2. Примитив IBUFJBUFDISABLE
Примитив IBUFJBUFDISABLE (рис. А.32) является входным буфером с запрещением порта, который
может использоваться как дополнительная возможность сохранения мощности, когда вход не используется.
Примитив IBUFJBUFDISABLE может запрещать входной буфер и переводить выход О в логически
высокое состояние, когда атрибут USEJBUFDISABLE устанавливается в TRUE и сигнал IBUFDISABLE
имеет высокое значение. Если атрибут USEJBUFDISABLE устанавливается в FALSE, вход IBUFDISABLE
игнорируется и должен быть подсоединен к земле. Это свойство может использоваться для уменьшения
потребляемой мощности в моменты времени, когда вывод является неактивным.
Примитив IBUFJBUFDISABLE управляется атрибутом USEJBUFDISABLE, а также атрибутами
IBUF_LOW_PWR и IOSTANDARD.
А.9.2. Примитив IBUFJNTERMDISABLE
Примитив IBUFJNTERMDISABLE показан на рис. А.33 и доступен в банках ввода-вывода типа HR.
Он похож на примитив IBUFJBUFDISABLE в том, что он имеет порт IBUFDISABLE, с помощью которо-
го входной буфер может запрещаться в моменты времени, когда буфер не используется. Дополнительно
примитив IBUFJNTERMDISABLE имеет порт INTERMDISABLE, который может использоваться для за-
прещения дополнительного свойства некалибрируемого расщепления нагрузки IN.TERM.
Управляющий вход IBUFDISABLE функционирует точно так же, как в примитиве IBUFJBUFDISABLE.
Если вывод использует дополнительное свойство некалибрируемого расщепления нагрузки (IN-
TERM), эти участки нагрузки запрещаются, когда драйвер является активным (Т является низким).
Примитив IBUFJNTERMDISABLE также позволяет отключать участки нагрузки при установке сигнала
INTERMDISABLE в высокое состояние для уменьшения потребляемой мощности, когда вход бездействует.
Этот примитив может использоваться для подсоединения внутренней логики к внешнему выводу.
Примитив IBUFJNTERMDISABLE управляется теми же атрибутами, что и IBUFJBUFDISABLE.
А.9.4. Примитивы IBUFDS и IBUFGDS
Примитив IBUFDS (рис. А.34) является входным буфером, который поддерживает дифференциаль-
ные сигналы. Примитив IBUFDS имеет два отдельных входных порта I и IB, которые соответствуют диф-
ференциальным каналам Р и N. Каналы Р (master) и N (slave) являются противоположными фазами одного
и того же логического сигнала. Дополнительно примитив IBUFDS позволяет программировать дифферен-
циальную нагрузку для улучшения целостности сигналов и сокращения внешних компонент.
Рис. А.33. Примитив IBUFJNTERMDISABLE Рис. А.34. Примитивы IBUFDS и IBUFGDS (канал
N имеет суффикс В)
Приложение А. Примитивы FPGA 7-й серии
301
Input from
Device Pad
Output
to FPGA
Рис. A.35. Примитивы IBUFDS_DIFF_OUT и
IBUFGDS.DIFF.OUT
Рис. A.36. Примитив
IBUFDS.DIFF.OUTJBUFDISABLE
Примитив IBUFDS управляется атрибутом DIFF.TERM, а также атрибутами IBUF_LOW_PWR и
IOSTANDARD.
Примитив IBUFGDS подобен примитиву IBUFDS, он применяется в случаях, когда дифференциальный
входной буфер используется как вход синхронизации
А.9.5. Примитивы IBUFDS_DIFF_OUT и IBUFGDS_DIFF_OUT
Эти примитивы, в отличие от IBUFDS и IBUFGDS, имеют комплементарные выходы О и ОВ, которые
представляют доступ к обоим фазам дифференциального сигнала (рис. А.35).
Примитивы IBUFDS_DIFF_OUT и IBUFGDS.DIFF.OUT являются подобными. Примитив IBUFGDS.
DIFF.OUT используется для входа синхросигнала. Эти примитивы рекомендуются для использования
только опытными разработчиками. Примитивы IBUFDS.DIFF.OUT и IBUFGDS.DIFF.OUT управляются
атрибутами DIFF.TERM. IBUF.LOW.PWR и IOSTANDARD.
А.9.6. Примитив IBUFDS_DIFF_OUTJBUFDISABLE
Примитив IBUFDS.DIFF.OUTJBUFDISABLE (рис. А.36) является дифференциальным входным бу-
фером с комплементарными дифференциальными выходами и запрещающим портом IBUFDISABLE, ко-
торый используется для уменьшения потребляемой мощности, когда вход не используется. Функции за-
прещения работают аналогично рассмотренным выше.
Этот примитив может использоваться для подсоединения внутренней логики к внешнему двуна-
правленному выводу. Примитив IBUFDS-DIFF.OUTJBUFDISABLE управляется атрибутами DIFF.TERM,
IBUF.LOW.PWR, IOSTANDARD и USEJBUFDISABLE.
А.9.7. Примитив IBUFDSJBUFDISABLE
Примитив IBUFDSJBUFDISABLE (рис. А.37) является дифференциальным входным буфером с за-
прещающим портом IBUFDISABLE для уменьшения потребляемой мощности. Запрещение функционирует
аналогично.
Примитив IBUFDSJBUFDISABLE управляется атрибутами DIFF.TERM, IBUF.LOW.PWR,
IOSTANDARD и USEJBUFDISABLE.
А.9.8. Примитив IBUFDS.INTERMDISABLE
Примитив IBUFDS.INTERMDISABLE (рис. А.38) разрешен в банках типа HR и подобен примитиву
IBUFDSJBUFDISABLE в том, что он имеет разрешающий порт IBUFDISABLE для запрещения входного
буфера, когда буфер не используется. Также имеется порт INTERMDISABLE, который может исполь-
зоваться для запрещения дополнительного свойства некалибрируемой расщепляемой нагрузки. Функции
запрещения работают аналогично рассмотренным выше.
Этот примитив является входным дифференциальным буфером, используемым для подсоединения
внутренней логики к внешнему двунаправленному выводу. Примитив IBUFDS.INTERMDISABLE управля-
ется атрибутами DIFF.TERM, IBUF.LOW.PWR, IOSTANDARD и USEJBUFDISABLE.
INTERMDISABLE
О
OB
Рис. А.37. Примитив IBUFDSJBUFDISABLE
Рис. А.38. Примитив IBUFDS.INTERMDISABLE
302
Приложение А. Примитивы FPGA 7-й серии
-□ Ю
io4rom
device pad
Рис. А.39. Примитив IOBUF
I/O
to/from
device pad
А.9.9. Примитив IOBUF
Примитив IOBUF (рис. А.39) реализует двунаправленный ассиметричный вывод с входным и выход-
ным буфером, причем в третье состояние выходной буфер переводится высоким уровнем сигнала Т.
Примитив IOBUF управляется атрибутами DRIVE, IOSTANDARD и SLEW. Данный примитив исполь-
зуется для соединения внутренней логики с двунаправленным выводом.
А.9.10. Примитив IOBUFDS
Примитив IOBUFDS (рис. АЛО) является примитивом дифференциального двунаправленного вывода.
Высокое значение на выводе Т запрещает выходной буфер.
Примитив IOBUFDS управляется атрибутами DIFF.TERM, IBUF_LOW_PWR, IOSTANDARD и SLEW.
А.9.11. Примитив IOBUFDS-DCIEN
Примитив IOBUFDS-DCIEN (рис. А.41) разрешен в банках типа HP. Он имеет порт IBUFDISABLE для
запрещения входного буфера, когда буфер не используется, а также порт DCITERMDISABLE, который мо-
жет использоваться для запрещения пользователем дополнительного свойства расщепления нагрузки DCL
Примитив IOBUFDS-DCIEN может запрещать входной буфер и переводить выход О в высокое состоя-
ние, когда атрибут USEJBUFDISABLE установлен в TRUE и сигнал IBUFDISABLE имеет высокое значение.
Если атрибут USEJBUFDISABLE установлен в FALSE, вход IBUFDISABLE игнорируется и должен быть
подсоединен к земле. Если вывод использует свойство расщепляемой нагрузки DCI, этот примитив по-
зволяет запрещать участки нагрузки DCI, когда сигнал DCITERMDISABLE принимает высокое значение.
Это свойство используется для уменьшения потребляемой мощности в моменты времени, когда вывод
неактивен, или во время длительного вывода данных.
Стандарты ввода-вывода DCI с тремя состояниями могут использоваться только на двунаправленных
выводах. В стандартах ввода-вывода DCI с тремя состояниями участки нагрузки DCI выключаются, когда
драйвер является активным.
Примитив IOBUFDS-DCIEN управляется атрибутами DIFF-TERM, IBUF_LOW_PWR, IOSTANDARD,
SLEW и USEJBUFDISABLE.
OB
Рис. А.41. Примитив IOBUFDS-DCIEN
Рис. А.42. Примитив IOBUFDS_DIFF_OUT
Приложение А. Примитивы FPGA 7-й серии
303
Рис. А.43. Примитив
IOBUFDS_DIFF_OUT_DCIEN
Рис. А.44. Примитив
IOBUFDS.DIFF.OUTJNTERMDISABLE
А.9.12. Примитив IOBUFDS_DIFF_OUT
Это дифференциальный двунаправленный буферный примитив с комплементарными выходами О и
ОВ (рис. А.42). Высокое значение на выходе Т запрещает выходной буфер. Этот примитив рекомендуется
для использования в интерфейсах памяти.
Примитив IOBUFDS_DIFF_OUT отличается от IOBUFDS тем, что он обеспечивает внутренний доступ
к обеим фазам дифференциального сигнала. Данный примитив управляется атрибутами DIFF_TERM,
IBUF.LOW.PWR и IOSTANDARD.
А.9.13. Примитив IOBUFDS_DIFF_OUT_DCIEN
Примитив IOBUFDS_DIFF_OUT_DCIEN (рис. А.43) доступен в банках типа HP. Он имеет компле-
ментарные дифференциальные выходы, порт IBUFDISABLE для запрещения входного буфера в течение
периодов, когда буфер не используется, а также порт DCITERMDISABLE, для запрещения пользователем
дополнительного свойства расщепления нагрузки DCL Использование этих портов аналогично рассмот-
ренным ранее.
Примитив IOBUFDS_DIFF_OUT_DCIEN отличается от примитива IOBUFDS.DCIEN тем, что он обес-
печивает внутренний доступ к обеим фазам дифференциального сигнала. Данный примитив управляется
атрибутами DIFF.TERM, IBUF_LOW_PWR, IOSTANDARD и USEJBUFDISABLE.
А.9.14. Примитив IOBUFDS.DIFF.OUTJNTERMDISABLE
Примитив IOBUFDS.DIFF-OUTJNTERMDISABLE показан на рис. А.44, доступен в банках типа HR.
Он имеет порт IBUFDISABLE для запрещения входного буфера, а также порт INTERMDISABLE для за-
прещения дополнительного свойства некалибрируемой расщепляемой нагрузки.
Функционирование входа IBUFDISABLE рассмотрено ранее. Если вывод использует дополнитель-
ное свойство некалибрируемой расщепляемой нагрузки (IN.TERM), то эти участки нагрузки запрещаются
всякий раз, когда драйвер является активным (вход TS является низким для выхода 10, вход ТМ являет-
ся низким для выхода ЮВ). Данный примитив также позволяет запрещать участки нагрузки всякий раз,
когда сигнал INTERMDISABLE устанавливается в высокое состояние.
Примитив lOBUFDS-DIFF.OUTJNTERMDISABLE управляется атрибутами DIFF.TERM, IBUF.
LOW.PWR, IOSTANDARD и USEJBUFDISABLE.
А.9.15. Примитив IOBUFDSJNTERMDISABLE
Примитив IOBUFDSJNTERMDISABLE показан на рис. А.45, он доступен в банках типа HR. Прими-
тив имеет вход IBUFDISABLE для запрещения входного буфера и выход INTERMDISABLE для запреще-
ния дополнительного свойства некалибрируемой расщепляемой нагрузки; функции этих входов рассмот-
рены выше.
Примитив IOBUFDSJNTERMDISABLE управляется атрибутами DIFF.TERM, IBUF.LOW.PWR,
IOSTANDARD, USEJBUFDISABLE и SLEW.
A.9.16. Примитив OBUF
Выходной буфер OBUF предназначен для управления выходными сигналами от внутренней логики
FPGA к внешним выходным контактам (рис. А.46).
Этот элемент изолирует схемы внутренней логики от внешнего вывода и обеспечивает требуемый ток
выходного сигнала. Умалчиваемым интерфейсным стандартом для элемента OBUF является LVCMOS18.
Примитив OBUF управляется атрибутами DRIVE, IOSTANDARD и SLEW.
304
Приложение А. Примитивы FPGA 7-й серии
INTERMDISABLE
IBUFDISABLE
Input from
FPGA
I (Input)
From FPGA
О (Output)
to device pad
Рис. A.46. Примитив OBUF
Output to
Device Pads
Рис. А.45. Примитив IOBUFDSJNTERMDISABLE
Рис. A.47. Примитив OBUFDS
Рис. A.49. Примитив OBUFTDS
A.9.17. Примитив OBUFDS
Это примитив дифференциального выходного буфера (рис. А.47).
Для примитива OBUFDS выходной сигнал представляется на двух отдельных портах О (master) и
OB (slave), которые являются противоположными фазами одного и того же сигнала. Примитив OBUFDS
управляется атрибутами IOSTANDARD и SLEW.
А.9.18. Примитив OBUFT
Это примитив обобщенного выходного буфера с управляемым третьим состоянием (рис. А.48), обыч-
но реализует выходы с тремя состояниями или двунаправленные выводы
При низком значении сигнала на входе Т входные данные передаются на выход, при высоком значе-
нии — выход переходит в третье высокоимпедансное состояние. Примитив OBUFT управляется атрибутами
DRIVE, IOSTANDARD и SLEW.
А.9.19. Примитив OBUFTDS
Этот примитив дифференциального выходного буфера с управляемым третьим состоянием
(рис. А.49).
Примитив OBUFTDS управляется атрибутами IOSTANDARD и SLEW.
А.9.20. Атрибуты примитивов ввода-вывода
Доступ к свойствам ресурсов ввода-вывода в FPGA 7-й серии осуществляется с помощью механиз-
ма атрибутов (детали см. в документах UG625). В табл. А.53 представлены все возможные атрибуты,
которыми управляются примитивы ввода-вывода.
Атрибут IBUF_LOW_PWR может применяться для следующих входов:
• всех стандартов с дифференциальными входами (LVDS, LVDS-25, PPDS.25, RSDS.25, MINI_LVDS_25,
DIFF-HSTL, DIFF-SSTL, DIFF_MOBILE_DDR, DIFF.HSUL);
• всех входов с опорным напряжением Vref (HSLVDCI, SSTL, HSTL, HSUL);
• всех входных двунаправленных примитивов.
Он позволяет находить компромисс между производительностью и потребляемой мощностью. Из-
менение производительности отображается в задержке сигналов, проходящих через входной буфер. Из-
менение мощности можно оценить с помощью программных средств XPower Estimator (XST) и XPower
Analyzer (ХРА). По умолчанию атрибут имеет значение TRUE, что соответствует режиму малой потребля-
емой мощности и низкой производительности. Синтаксис атрибута в файле UCF:
INST < l/O_BUFFERJNSTANTIATION_NAME> IBUF_LOW_PWR = [TRUE | FALSE];
Приложение А. Примитивы FPGA 7-й серии
305
Таблица А.53
Атрибуты примитивов ввода-вывода
Атрибут Возможные значения Значения по умолчанию Описание
IBUF.LOW.PWR Строки «TRUE», «FALSE» «TRUE» Значение «TRUE» позволяет уменьшить потребля- емую мощность для дифференциальных стандартов и стандартов, имеющих опорное напряжение Vref (подобных LVDS или HSTL). Значение «FALSE» уве- личивает быстродействие
IOSTANDARD Строка DEFAULT Определяет стандарт ввода-вывода согласно табл. 1- 56 документа UG471
USEJBUFDISABLE Строки «TRUE», «FALSE» «TRUE» Разрешает или запрещает свойство IBUFDISABLE
DIFF.TERM Строка «TRUE», «FALSE» «FALSE» Атрибут дифференциальной нагрузки, поддерживает дифференциальные стандарты ввода-вывода, исполь- зуется для установки встроенной дифференциальной нагрузки в ON («TRUE») или OFF («FALSE»)
DRIVE Целые числа 2, 4, 6, 8, 12, 16, 24 12 Определяет мощность (силу тока) выходных сигна- лов (в банках ввода-вывода типа HR от 4 до 24 мА, в банках HP — от 2 до 16 мА) для стандартов LVTTL, LVCMOS12, LVCMOS15, LVCMOS18, LVCMOS25 и LVCMOS33
SLEW Строки «SLOW», «FAST» «SLOW» Определяет скорость нарастания и падения фронта выходного сигнала
Значение по умолчанию атрибута IOSTANDARD являются LVCMOS18 для ассиметричных выводов
и DIFF_HSTL18_II для дифференциальных выводов. Атрибут IOSTANDARD в файле UCF имеет следу-
ющий синтаксис:
INST < l/O_BUFFERJNSTANTIATION_NAME> IOSTANDARD - «< IOSTANDARD VALUE> »;
Атрибут USEJBUFDISABLE разрешает или запрещает использовать свойство IBUFDISABLE динами-
ческого выключения входного буфера. Когда это свойство разрешено, атрибут USEJBUFDISABLE установ-
лен в значение TRUE, высокое значение управляющего сигнала IBUFDISABLE запрещает входной буфер
и переводит выход в высокое состояние. При установке атрибута USEJBUFDISABLE в значение FALSE
управляющий вход IBUFDISABLE игнорируется и должен быть подсоединен к земле (иметь низкое зна-
чение). Выключение входного буфера в момент времени, когда вывод не используется или работает как
выход, позволяет уменьшить потребляемую мощность.
Атрибут DIFF.TERM поддерживает дифференциальные стандарты ввода-вывода, когда они исполь-
зуются как входы. Он используется для включения или выключения встроенного дифференциального на-
грузочного резистора (концевика) на 100 Ом. Входной дифференциальный концевик на кристалле в FPGA
7-й серии обеспечивает главное преимущество над использованием дискретного резистора, полностью уда-
ляя заглушку в приемнике и, следовательно, значительно улучшает целостность сигналов. Кроме того,
уменьшается потребляемая мощность, по сравнению с использованием DCI, и не используются выводы
VRP/VRN.
Атрибут DIFF.TERM может применяться и входным выводом для следующих стандартов: LVDS,
LVDS.25, MINLLVDS-25, PPDS.25, RSDS.25. Вывод Vcco банка ввода-вывода должен подсоединяться к
1,8 В для LVDS и 2,5 В для других стандартов, чтобы обеспечить эффективный дифференциальный конце-
вик на 100 Ом. Значения атрибута: TRUE и FALSE (по умолчанию). Атрибут может определяться в язы-
ках HDL при инстанцировании примитивов IBUFDS, IBUFGDS, IBUFDS_DIFF_OUT и IOBUFDS_DIFF_OUT.
Синтаксис атрибута в файле UCF:
INST < l/O_BUFFER_INSTANTIATION_NAME> DIFF.TERM = «[TRUE| FALSE]»;
Атрибут DRIVE позволяет определить силу тока выходных сигналов для стандартов LVCMOS и
LVTTL. Возможные значения атрибута DRIVE приведены в табл. А.54. Значением по умолчанию яв-
ляется 12.
Синтаксис атрибута в файле UCF:
INST < l/O_BUFFER_INSTANTIATION_NAME> DRIVE = «< DRIVE_VALUE> »; .
306
Приложение А. Примитивы FPGA 7-й серии
Таблица А.54
Возможные значения атрибута DRIVE
Стандарт Ток передатчика банка HR, мА Ток передатчика банка HP, мА
LVCMOS12 4, 8 или 12 2, 4, 6 или 12
LVCMOS15 4, 8, 12 или 16 2, 4. 6, 8, 12 или 16
LVCMOS18 4, 8, 12, 16 или 24 2, 4, 6, 8, 12 или 16
LVCMOS25 4, 8, 12 или 16 N/A
LVCMOS33 4, 8, 12 или 16 N/A
LVTTL 4, 8, 12, 16 или 24 N/A
Атрибут SLEW позволяет определить требуемую (желаемую) скорость нарастания сигнала для вы-
ходных буферов в стандартах LVCMOS, LVTTL, SSTL, HSTL, MOBILEJDDR и HSUL, включая дифферен-
циальные версии. Синтаксис атрибута в файле UCF:
INST <I/O_BUFFERJNSTANTIATION_NAME> SLEW = «< SLEW_VALUE> »;
Значением по умолчанию является SLOW, он позволяет уменьшить потребляемую мощность. Зна-
чение FAST используется в высокоскоростных интерфейсах памяти.
А.9.21. Ограничения блоков ввода-вывода
Кроме атрибутов, блоки ввода-вывода могут также управляться с помощью ограничений (constraints),
которые определяются в файле ограничений UCF. Эти ограничения приведены в табл. А.55.
Ограничение DCLCASCADE. Ограничение DCLCASCADE в файле UCF использует следующий
формат:
CONFIG DCLCASCADE = «<master> <slavel> <slave2> ...»;
например,
CONFIG DCLCASCADE = «11 13 15 17»;
Ограничение LOC. Возможными значениями ограничения LOC являются все идентификаторы внеш-
них портов (т. е. А8, М8, АМ6 и т.д.). Это значение зависит от устройства и размера корпуса.
Ограничение LOC в файле UCF имеет следующий синтаксис:
INST < INSTANTIATION_NAME> LOC = «< EXTERNAL_PORT_IDENTIFIER> »;
например,
INST MYJO LOC = R7;
Ограничение PULLUP/PULLDOWN/KEEPER. Ограничение PULLUP/PULLDOWN/KEEPER мо-
жет применяться к примитивам IBUF, OBUFT и IOBUF. Входные буферы (IBUF), выходы с тремя со-
стояниями (OBUFT) и двунаправленные (IOBUF) буферы могут иметь резисторы для слабого подтяги-
вания вверх (PULLUP), слабого подтягивания вниз (PULLDOWN) или схему хранения значения сигнала
(KEEPER). Эта функция может вызываться путем добавления следующих возможных значений ограниче-
ния к соответствующим сетям буферов: PULLUP, PULLDOWN и KEEPER.
Более подробную информацию об индивидуальном и глобальном использовании ограничения PULL-
UP/PULLDOWN/KEEPER смотри в документе UG625 Constraints Guide.
Ограничение INTERNAL_VREF. Ограничение INTERNAL_VREF предназначено для определения
внутреннего опорного напряжения Vref- Опорное напряжение Vref для банков ввода-вывода может ге-
нерироваться внутри FPGA 7-й серии. Внутреннее сгенерированное напряжение устраняет необходимость
формировать напряжение Vref на печатной плате и позволяет многоцелевые выводы Vref (в данном банке
ввода-вывода) использовать как обычные выводы. Настоящее свойство является полезным, когда FPGA
7-й серии является единственным устройством на плате (в системе), требующим определенного уровня
напряжения Vref или имеется дефицит выводов в данном банке. Внутреннее сгенерированное напряжение
(INTERNAL.VREF) питается от напряжения Vccaux-
Таблица А.55
Ограничения блоков ввода-вывода
Ограничение Возможности
DCLCASCADE LOC (Location Constraints) PULLUP/PULLDOUN/ KEEPER DIFF.TERM INTERNAL.VREF VCCAUXJO Указывает главный и подчиненный банки при каскадном соединении DCI Определяет расположение (номер) контакта Определяет подтягивание вверх, вниз и слабое хранение значения сигнала Определяет дифференциальные свойства выводов Определяет внутреннее опорное напряжение Определяет значение напряжения Vccauxjo (1.8 или 2,0 В)
Приложение А. Примитивы FPGA 7-й серии
307
Каждый банк имеет единственный вывод Vref. поэтому каждый банк может иметь только одно огра-
ничение INTERNAL-VREF, установленное в один уровень напряжения для данного банка.
Пример 1. Банк 14 использует стандарт HSTLJI (1,5 В), который требует опорное напряжение
0,75 В; при этом используется следующее ограничение:
INTERNAL_VREF_BANK14 = 0.75;
Пример 2. Банк 15 использует стандарт HSTLJL18 (1,8 В), который требует опорное напряжение
0,9 В; при этом используется следующее ограничение:
INTERNAL_VREF_BANK15 = 0.90;
Правила использования ограничения INTERNAL-VREF:
• для банка может быть установлена одна величина Vref!
• ограничение INTERNAL-VREF может быть установлено только в номинальное значение опорного
напряжения данного стандарта ввода-вывода;
• допустимыми установками INTERNAL_VREF являются: 0.60, 0.675, 0.75 и 0.90;
• когда используется ограничение INTERNAL_VREF, вывод Vref может использоваться как обычный
вывод общего назначения.
Правила объединения стандартов в одном и том же банке применяются также и для ограничения
INTERNAL-VREF.
Ограничение VCCAUXJO. Ограничение VCCAUXJO доступно для цепей ввода- вывода и примити-
вов, которые должны определяться в проекте, если выводы Vccfuxjo Для любых банков HP являются
переходящими к установке в 2,0 В. По умолчанию Vccfuxjo установлено в значение DONTCARE, но мо-
жет быть установлено в NORMAL (1,8 В) или HIGH (2,0 В). Если выводы Vccfuxjo данного банка должны
быть подсоединены к напряжению 2,0 В, то по крайней мере одна цепь ввода-вывода или примитив в этом
банке должны иметь свое ограничение Vccfuxjo. установленное в HIGH, а все другие цепи и примитивы
должны быть установлены либо в HIGH, либо в DONTCARE.
Если выводы Vccfuxjo данного банка должны быть подсоединены к напряжению 1,8 В, то по крайней
мере одна цепь ввода-вывода или примитив в этом банке должны иметь это ограничение, установленное в
NORMAL, а все другие цепи и примитивы должны быть установлены либо в NORMAL, либо в DONTCARE.
Синтаксис атрибута в языке VHDL:
attribute VCCAUXJO of {component-name | labeLname}:
{component! labeljis «{NORMAL | HIGH | DONTCARE}»;
Синтаксис атрибута в языке Verilog:
(* VCCAUXJO = {NORMAL | HIGH| DONTCARE}*)
Синтаксис атрибута в файле UCF и NCF:
NET «net_name» VCCAUXJO = (0 | NORMAL | HIGH | DONTCARE);
INST «instance-name « VCCAUXJO = (NORMAL | HIGH | DONTCARE);
A. 10. Примитивы логических ресурсов ввода-вывода
А.10.1. Примитивы IDELAYE2 и ODELAYE2
Примитив IDELAYE2 показан на рис. А.50, а примитив ODELAYE2 — на рис. А.51.
IDELAYE2
С----- -----DATAOUT
REGRST------- ----CNTVALUEOUT(4:0]
LD------
СЕ------
INC-----
CINVCTRL------
CNTVALUEIN[4:0]-----
IDATAIN----
LDPIPEEN------
DATAIN-----
Рис. A.50. Примитив IDELAYE2
308
Приложение А. Примитивы FPGA 7-й серии
ODELAYE2
С
REGRST
LD
СЕ
INC
CINVCTRL
CNTVALUEIN[4:0]
CLKIN
ODATAIN
LDPIPEEN
Рис. A.51. Примитив ODELAYE2
DATAOUT
CNTVALUEOUT[4:0]
A. 10.2. Порты примитивов IDELAYE2 и ODELAYE2
Порты примитивов IDELAYE2 и ODELAYE2 представлены в табл. А.56.
Ниже более подробно рассматриваются особенности портов примитива IDELAYE2.
IDATAIN — вход данных от буфера ввода-вывода ЮВ, управляется своим буфером ЮВ IDELAY
может передавать данные через порт DATAOUT либо в блок ILOGIC, либо прямо во внутреннюю логику
FPGA, либо в оба пункта с задержкой, определяемой атрибутом IDELAY-VALUE.
DATAIN — вход данных от логики FPGA, управляется логикой FPGA. Данные передаются обратно
в логику FPGA через порт DATAOUT с задержкой, устанавливаемой атрибутом IDELAY-VALUE. Вход
DATAIN может локально инвертироваться. Данные не могут поступать в буфер ЮВ.
DATAOUT — выход данных, задержанные данные от двух входных портов данных. DATAOUT мо-
жет передавать данные каждому из блоков ILOGICE2/ISERDESE2 или ILOGICE3/ISERDESE2, а также
прямо в логику FPGA.
Таблица А.56
Порты примитива IDELAYE2
Порт Направление Ширина Функция
С Вход 1 Вход синхросигнала, используется в режимах VARIABLE, VAR.LOAD или VAR.LOAD-PIPE
REGRST Вход 1 Сброс для конвейерного регистра, используется только в ре- жиме VAR_LOAD_PIPE
LD Вход 1 В режиме VARIABLE в примитив загружается запрограмми- рованное значение; в режиме в примитив VAR.LOAD загру- жается значение CNTVALUEIN; в режиме VAR_LOAD_PIPE загружается актуальное значение в конвейерный регистр
СЕ Вход 1 Функция разрешения инкрементации/декрементации
INC Вход 1 Указатель операции инкрементации/декрементации величины задержки
CNVCTRL Вход 1 Динамически инвертирует синхросигнал
CNTVALUEIN Вход 5 Значение счетчика от логики FPGA для динамически загру- жаемого значения задержки
IDATAIN Вход 1 Вход данных для IDELAY от IBUF
DATAIN Вход 1 Вход данных для IDELAY от логики FPGA
CLKIN Вход 1 Вход синхросигнала для доступного ODELAY от CLKMUX в блоке ввода-вывода
ODATAIN Вход 1 Вход данных для ODELAYE от блока OLOGICE2/OSERDESE2
LDPIPEEN Вход 1 Разрешает конвейерный регистр для загружаемых данных
DATAOUT Выход 1 Задержанные данные от одного из двух портов входных дан- ных (IDATAIN или DATAIN)
CNTVALUEOUT Выход 5 Выход, значение актуальной задержки, приходящей в логику FPGA для мониторинга значения задержки
Приложение А. Примитивы FPGA 7-й серии
309
С — вход синхросигнала. Все управляющие входы примитива IDELAYE2 (REGRST, LD, СЕ и INC)
синхронизируются от входа С. Синхросигнал должен подсоединяться к этому порту, когда IDELAYE2 кон-
фигурируется в режимах VARIABLE, VAR.LOAD или VAR.LOAD.PIPE. Вход С может локально инверти-
роваться и должен питаться глобальным или региональным буфером синхронизации. Этот синхросигнал
должен подсоединяться к тому же самому синхросигналу, который использовался в блоке ILOGIC/ISERDES.
LD — загрузка модуля. Когда в режиме VARIABLE примитив IDELAY загружает порт, то LD загружает
значение, установленное атрибутом IDELAY.VALUE. Умалчиваемым значением атрибута IDELAY.VALUE
является ноль. Когда используется умалчиваемое значение, порт LD для ILDELAY действует как асинх-
ронный сброс. Сигнал LD является активно высоким сигналом и синхронизируется входом С. В режиме
VAR.LOAD сигнал LD загружает значение задержки, установленное на входе CNTVALUEIN. Значение, пред-
ставленное на выводах CNTVALUEIN[4:0], будет новым значением задержки. В режиме VAR_LOAD_PIPE
LD загружает актуальное значение задержки на выводах CNTVALUEIN в конвейерный регистр.
CINVCTRL — переключение полярности вывода С, используется для динамического переключения
полярности вывода С в приложениях, когда краткосрочные помехи (glitches) не являются проблемой. При
переключении полярности управляющие выводы примитива IDELAY не должны использоваться в течение
двух циклов синхронизации.
CNTVALUEIN — вход значения счетчика, выводы CNTVALUEIN используются для динамического
переключения загружаемого значения задержки.
CNTVALUEOUT — выход значения счетчика, выводы CNTVALUEOUT используются для контроля
(мониторинга) загружаемого значения задержки.
LDPIPEEN — загрузка конвейерного регистра, при высоком значении этот вход загружает конвей-
ерный регистр актуальным значением на выводах CNTVALUEIN
REGRST — сброс конвейерного регистра, при высоком значении сбрасывает конвейерный регистр
во все нули.
СЕ, INC — сигналы инкрементации/декрементации. Инкрементация/декрементация управляется сиг-
налом разрешения СЕ. Этот интерфейс доступен только в режимах VARIABLE, VAR.LOAD или VAR.LOAD.
PIPE. Пока СЕ остается в высоком значении, IDELAY будет инкрементироваться или декрементироваться
значением T|[>Elayresolution на каждом цикле синхросигнала С. При INC = 1 IDELAY инкрементирует,
при INC =0 — декрементирует. Если СЕ находится в низком состоянии, задержка через элемент IDELAY
не будет изменяться, несмотря на состояние сигнала INC.
Ниже более детально рассмотрены особенности некоторых портов примитива ODELAYE2.
ODATAIN — вход данных от блока OLOGICE2/OSERDESE2, управляется элементами OLOGICE2/
OSERDESE2. Вход ODATAIN управляет портом DATAOUT, который подсоединяется к блоку ЮВ с за-
держкой, устанавливаемой атрибутом ODELAY.VALUE.
CLKIN — вход синхросигнала от буферов синхронизации BUFIO, BUFG или BUFR. Синхросигнал по-
ступает обратно в логику FPGA через порт DATAOUT с задержкой, устанавливаемой атрибутом ODELAY.
VALUE.
DATAOUT — выход данных. Задержанные данные от одного или двух входных портов данных Выход
DATAOUT соединяется с блоком IOB или обратно с логикой межсоединений FPGA.
С — вход синхронизации. Все управляющие входы примитива ODELAYE2 (LD, СЕ и INC) синхронизи-
руются от входа С. Синхросигнал может подсоединяться к этим портам, когда ODELAYE2 конфигурируется
в режимах VARIABLE, VAR.LOAD или VAR_LOAD.PIРЕ. Вход С может локально инвертироваться и должен
поддерживаться глобальным или региональным буфером синхронизации. Этот синхросигнал должен под-
соединяться к тому же самому синхросигналу, который используется в ресурсах логики SelectIO. Например,
когда используется OSERDESE2, С подсоединяется к тому же самому синхросигналу, что и CLKDIV.
LD — загрузка модуля. В режиме VAR.LOAD LD загружает примитив задержки в значение, уста-
новленное шиной CNTVALUEIN. Значение, представленное на выводах CNTVALUEIN[4:0], будет новым
значением задержки. При этом значение атрибута ODELAY.VALUE игнорируется. В режиме VARIABLE
LD загружает примитив задержки в значение, установленное атрибутом ODELAY.VALUE. Если этот атри-
бут неопределен, назначается значение 0. Уровень активности сигнала LD высокий, он синхронизирован с
входом С. В режиме VAR_LOAD_PIРЕ LD загружает текущее значение в конвейерный регистр. Значение,
представленное в конвейерном регистре, будет новым значением задержки.
А. 10.3. Атрибуты примитивов IDELAYE2 и ODELAYE2
Все атрибуты примитива IDELAY приведены в табл. А.57.
Ниже рассматриваются особенности некоторых атрибутов.
Атрибут IDELAY .TYPE (ODELAY.TYPE). Атрибут I DELAY .TYPE устанавливает тип используемой
задержки. Когда атрибут IDELAY.TYPE равен FIXED, величина задержки в условных единицах (taps)
310
Приложение А. Примитивы FPGA 7-й серии
Таблица А.57
Атрибуты примитива IDELAY
Атрибут Значение Значение по умолчанию Описание
IDELAY-TYPE, ODELAY-TYPE Строка: FIXED, VARIABLE. VAR-LOAD, VAR_LOAD_PIPE FIXED Устанавливает тип задержки линии сигнала
DELAY.SRC (для IDELAY) Строка: IDATAIN, DATAIN IDATAIN Определяет вход данных для IDELAYE2: IDATAIN или DATAIN
DELAY.SRC (для ODELAY) Строка: ODATAIN, CLKIN ODATAIN Выбирает источник для входа данных к блоку ODELAYE2
IDELAY-VALUE, ODELAY_VALUE Целое от 0 до 31 0 Определяет величину задержки в режиме FIXED или начальное значение задержки в режиме VARIABLE. В режимах VAR-LOAD, VAR_LOAD_PIPE это значе- ние игнорируется и равно 0
HIGH-PERFOR- MANCE-MODE Строка: FALSE, TRUE TRUE Значение TRUE уменьшает флуктуацию (дрожа- ние) выхода, однако увеличивает потребляемую мощность
SIGNAL- PATTERN Строка: DATA, CLOCK DATA Дает указание временному анализатору составлять отчет для соответствующего количества флуктуаций цепи задержки в пути данных или синхросигнала
REFCLK-FRE- QUENCY Действительное число: от 190 до 210 или от 290 до 310 200 Устанавливает величину условной единицы задерж- ки (tap) в МГц, используя временной анализатор для статического временного анализа. Диапазон от 290.0 до 310.0 недоступен для всех градаций скорости
CINVCTRL-SEL Строка: FALSE, TRUE FALSE Разрешает выводу CINVCTRL-SEL динамически пе- реключать полярность вывода С
PIPE-SEL Строка: FALSE, TRUE FALSE Выбирает конвейерный режим работы примитива IDELAY/ ODELAY
фиксируется и определяется значением атрибута IDELAY_VALUE. После установки во время конфигурации
значение задержки не может быть изменено.
Когда равен VARIABLE, выбирается переменная задержка (в taps). Значение задержки может ин-
крементироваться при СЕ = 1 и INC = 1 или декрементироваться при СЕ = 1 и INC = 0. Операция
инкрементации/декрементации синхронна с С.
Когда равен VAR_LOAD и VAR_LOAD_PIPE. задержка (в taps) может изменяться, аналогично режиму
VARIABLE, или динамически загружаться. Вывод LD в этом режиме загружает значение, представленное
на входе CNTVALUEIN в режиме VAR.LOAD, или ранее записанное значение в конвейерном регистре в
режиме VAR_LOAD_PIPE. Это позволяет динамически устанавливать значение задержки.
Атрибут IDELAY-VALUE (ODELAY-VALUE). Этот атрибут определяет начальное значение задерж-
ки. Возможно целое число от 0 до 31. Умалчиваемым значением является 0. Значение задержки (в
порциях — tap) возвращается к величине атрибута IDELAY-VALUE, когда задержка сбрасывается с по-
мощью вывода LD. В режиме VARIABLE этот атрибут определяет начальную установку линии задержки.
В режиме VAR-LOAD и VAR_LOAD_PIPE этот атрибут не используется, следовательно, начальное значе-
ние линии задержки равно 0.
Атрибут HIGH_PERFORMANCE_MODE. Когда имеет значение TRUE, сокращает флуктуацию (дро-
жание) выхода. Это сокращение дрожания приводит к небольшому увеличению мощности, потребляемой
примитивом IDELAYE2
Атрибут SIGNAL-PATTERN Сигналы синхронизации и данных имеют различные электрические
профили и, следовательно, накапливают разное количество флуктуаций в цепи IDELAY. Путем установ-
ки атрибута SIGNAL-PATTERN пользователь разрешает временному анализатору составлять отчет для
соответствующих флуктуаций при временных вычислениях.
А. 10.4. Режимы функционирования примитивов IDELAYE2 и ODELAYE2
Режимы функционирования примитивов IDELAYE2 и ODELAYE2 идентичны. Поэтому режимы функ-
ционирования рассмотрим на примере примитива IDELAYE2. Имеется 4 режима функционирования при-
митива IDELAYE2.
Приложение А. Примитивы FPGA 7-й серии
311
Таблица А.58
Управляющие выводы режима VARIABLE
С LD СЕ INC Значение задержки
0 X X X Не изменяется
1 1 X X IDELAY-VALUE
1 0 0 X Не изменяется
1 0 1 1 Текущее значение +1
1 0 1 0 Текущее значение -1
Таблица А.59
Управляющие выводы режима VAR.LOAD
С LD СЕ INC CNTVALUEIN CNTVALUEOUT Значение задержки
0 X X X X He изменяется Не изменяется
1 1 X X CNTVALUEIN CNTVALUEIN CNTVALUEIN
1 0 0 X X He изменяется Не изменяется
1 0 1 1 X Текущее значение +1 Текущее значение +1
1 0 1 0 X Текущее значение -1 Текущее значение -1
1. Режим с фиксированной задержкой (IDELAY_TYPE = FIXED). В этом режиме величина задержки
устанавливается во время конфигурации в числе порций (taps), определяемых атрибутом IDELAY-VALUE.
Будучи однажды сконфигурированным, это значение не может быть изменено. Когда используется этот
режим, должен быть инстанцирован примитив IDELAYCTRL.
2. Режим с переменной задержкой (IDELAY-TYPE = VARIABLE). В этом режиме величина задержки
может изменяться после конфигурации манипулированием сигналов СЕ и INC. Когда используется этот ре-
жим, должен инстанцироваться примитив IDELAYCTRL. В табл. А.58 описываются управляющие выводы,
используемые в этом режиме.
3. Режим с загружаемой переменной задержкой (IDELAY-TYPE = VAR.LOAD). В дополнение к
функциям предыдущего режима, в этом режиме значение задержки IDELAY может загружаться через 5-
разрядную шину CNTVALUEIN< 4:0> от логики FPGA. Когда LD принимает высокий уровень, значение,
представленное на CNTVALUEIN< 4:0> будет новым значением задержки. При этом значение атрибу-
та IDELAY-VALUE игнорируется. Когда используется этот режим, должен инстанцироваться примитив
IDELAYCTRL. В табл. А.59 описываются выводы, используемые в режиме VAR.LOAD.
4. Режим с конвейерно загружаемой задержкой (IDELAY.TYPE = VAR_LOAD_PIPE). Этот режим по-
добен режиму VAR.LOAD. Он позволяет загружать значение CNTVALUEIN< 4:0> в конвейерном режиме.
А. 10.5. Примитив IDELAYCTRL
Примитив IDELAYCTRL показан на рис. А.52.
А.10.6. Примитивы IDDR и ODDR
Примитив IDDR показан на рис. А.53, а примитив ODDR — на рис. А.54.
Описание портов примитива IDELAYCTRL приведено в табл. А.60.
Порты примитивов IDDR и ODDR приведены в табл. А.61.
Атрибуты примитивов IDDR и ODDR представлены в табл. А.62.
IDELAYCTRL
— REFCLK RDY RST D СЕ С IDDR D1 Q1 Q2 D2 СЕ — с ODDR
SR----- SR
Рис. А.52. Примитив IDELAYCTRL Рис. А.53. Примитив IDDR Рис. А.54. Примитив ODDR
312
Приложение А. Примитивы FPGA 7-й серии
Таблица А.60
Порты примитива IDELAYCTRL
Порт Описание
RST Сигнал синхронного сброса; модуль IDELAYCTRL должен быть сброшен после конфигуриро- вания и стабилизации сигнала REFCLK
REFCLK Опорный синхросигнал, используется для калибровки модулей IDELAY и ODELAY в данном регионе; должен управляться буферами глобальной (BUFG) или горизонтальной (BUFH) син- хронизации; может питаться прямо от пользовательского источника или блока ММСМ и дол- жен направляться на глобальный буфер синхронизации
RDY Сигнал готовности, указывает, когда модули IDELAY и ODELAY калибруются; сигнал не ус- танавливается, если REFCLK задерживается на высоком или низком уровне один или бо- лее периодов синхросигнала. Если сигнал RDY задерживается на нулевом уровне, то модель IDELAYCTRL должен быть сброшен. Средства проектирования позволяют не подсоединять или игнорировать сигнал RDY
Таблица А.61
Порты примитивов IDDR и ODDR
Порт Функция Описание
Q1 и Q2 Q С СЕ D D1 и D2 SR Выходы данных DDR Выход данных Вход синхросигнала Разрешение синхрони- зации Вход данных примити- ва IDDR Входы данных DDR Установка/сброс Регистровые выходы DDR примитива IDDR Регистровый выход примитива ODDR Синхросигнал Низкое значение запрещает выходную синхронизацию на порте Q Регистровый вход примитива IDDR Регистровые входы DDR примитива ODDR Синхронная/асинхронная установка/сброс, указывается высоким уровнем
Таблица А.62
Атрибуты примитивов IDDR и ODDR
Атрибут Описание Возможные значения
DDR_CLK_EDGE INIT.Q1 INIT.Q2 INIT SRTYPE Устанавливает режим функционирования по от- ношению к фронту синхросигнала Устанавливает начальное значение для порта Q1 Устанавливает начальное значение для порта Q2 Устанавливает начальное значение порта Q Тип установки/сброса по отношения к синхро- сигналу С OPPOSITE_EDGE (по умолча- нию), SAME-EDGE, SAME-EDGE- PIPELINED (для IDDR) 0 (по умолчанию), 1 0 (по умолчанию), 1 0 (по умолчанию), 1 ASYNC (по умолчанию), SYNC
А.10.7. Примитив ISERDESE2
Примитив ISERDESE2 приведен на рис. А.55.
Порты примитива ISERDESE2 представлены в табл. А.63.
Регистровые выходы QI—Q8. Являются регистровыми выходами модуля ISERDESE2. Один блок
ISERDESE2 может поддерживать до 8 битов (т. е. реализуется преобразователь 1:8). Ширина слова больше
чем 8 (до 14) может поддерживаться только в режиме DDR. Первый принимаемый бит данных появляется
на наиболее старшем выходе Q.
Комбинационный выход О. Сигнал этого выхода может прямо приходить от входа данных D или
DDLY (через элемент задержки IDELAYE2).
Вход BITSLIP вызова функционирования подмодуля Bitslip. При установке входа BITSLIP вы-
полняется синхронизация подмодуля Bitslip синхросигналом CLKDIV. Когда вызывается Bitslip, данные на
выходах Q1-Q8 будут циклически сдвигаться (каждый раз на одну позицию). Функционирование подмо-
дуля Bitslip отличается в режимах DDR и SDR.
Входы разрешения синхронизации СЕ1 и СЕ2. Каждый блок ISERDESE2 содержит модуль раз-
решения синхронизации входа.
Приложение А. Примитивы FPGA 7-й серии
313
Таблица А.63
Порты примитива ISERDESE2
Порт Тип Ширина Описание
Q1-Q8 Выход 1 (каждый) Регистровые выходы
О Выход 1 Комбинационный выход
SHIFTOUT1 Выход 1 Выход переноса для расширения ширины данных, подсоединяется к входу SHIFTIN1 подчиненного (slave) блока ввода-вывода ЮВ
SHIFTOUT2 Выход 1 Выход переноса для расширения ширины данных, подсоединяется к входу SHIFTIN2 подчиненного (slave) блока ввода-вывода ЮВ
D Вход 1 Последовательные входные данные от блока ввода-вывода ЮВ
DDLY Вход 1 Последовательные входные данные от блока задержки IDELAYE2
CLK Вход 1 Вход высокоскоростного синхросигнала. Используется для синх- ронизации входного потока последовательных данных
CLKB Вход 1 Второй вход высокоскоростного синхросигнала, только для режи- ма MEMORY-QDR. В режиме MEMORY-QDR всегда соединяется с инверсией CLK
СЕ1, CE2 Вход 1 (каждый) Входы разрешения синхронизации
RST Вход 1 Сброс, активный уровень высокий
CLKDIV Вход 1 Вход разделенного синхросигнала. Синхросигналы элемента за- держки, преобразователя данных, подмодуля Bitslip и модуля СЕ
OCLK Вход 1 Вход высокоскоростного синхросигнала для приложений памяти, основанных на стробировании памяти
OCLKB Вход 1 Вход инвертированного высокоскоростного синхросигнала
BITSLIP Вход 1 Вызывает функционирование Bitslip
SHIFTIN1 Вход 1 Вход переноса для расширения ширины данных. Соединяется с SHIFTOUT1 главного (master) блока ввода-вывода ЮВ
SHIFTIN2 Вход 1 Вход переноса для расширения ширины данных. Соединяется с SHIFTOUT2 главного (master) блока ввода-вывода ЮВ
OFB Вход 1 Путь обратной связи от выходов блоков OLOGICE2, OLOGICE3 или OSERDESE2
DYNCLKDIVSEL Вход 1 Динамический выбор инверсии CLKDIV
DYNCLKSEL Вход 1 Динамический выбор инверсии CLK и CLKB
Когда NUM-СЕ = 1, вход СЕ2 не используется и вход СЕ1 является активно высоким разрешением
синхронизации, подсоединенным прямо к входным регистрам в блоке ISERDESE2.
Когда NUM.CE = 2, используются оба входа СЕ1 и СЕ2, с сигналом разрешения СЕ1 для 1/2 цикла
CLKDIV и с сигналом разрешения СЕ2 для другой 1/2 цикла CLKDIV. Внутренний сигнал разрешения
синхронизации ICE управляется от входов СЕ1 и СЕ2.
Вход высокоскоростного синхросигнала CLKB. Вход CLKB должен быть подсоединен к инверсии
сигнала CLK в любом режиме, отличном от MEMORY.QDR. В режиме MEMORY-QDR вход CLKB должен
быть подсоединен к уникальному, сдвинутому по фазе синхросигналу.
Вход разделенного синхросигнала CLKDIV. Типично является разделенной версией синхросигнала
CLK (в зависимости от ширины реализуемого преобразователя). Он управляет выходом последовательно-
параллельного преобразователя, подмодулем Bitslip и модулем разрешения синхронизации СЕ.
Порт OFB последовательных входных данных от OSERDESE2 Этот порт работает только со-
вместно с ресурсами блока OSERDESE2 FPGA 7-й серии.
Высокоскоростной синхросигнал OCLK для интерфейсов памяти, основанных на стробирова-
нии. Вход OCLK синхронизирует передачу данных в интерфейсах памяти, основанных на стробировании.
Вход сброса RST. При установке вход сброса асинхронно переводит выходы большинства триггеров
данных в доменах CLK и CLKDIV в низкое состояние. Исключением являются первые 4 триггера во
входной структуре, чьи значения после сигнала RESET устанавливаются в значение, указанное атрибутом
SRVAL.Qx инициализации компонента х. Когда RST аннулируется синхронно с CLKDIV, внутренняя логика
повторно синхронизирует это аннулирование к первому возрастающему фронту CLK.
Поэтому каждый блок ISERDESE2 в структуре многократного битового входа должен управляться од-
ним и тем же сигналом сброса, установленным асинхронно, а аннулироваться синхронно к сигналу CLKDIV,
чтобы гарантировать, что все элементы блока ISERDESE2 выходят из сброса синхронно. Сигнал сброса
должен аннулироваться только тогда, когда известно, что сигналы CLK и CLKDIV стабильны и существуют.
314
Приложение А. Примитивы FPGA 7-й серии
А. 10.8. Атрибуты примитива ISERDESE2
Описание атрибутов примитива ISERDESE2 представлено в табл. А.64.
Атрибут DATA_WIDTH. Допустимые значения этого атрибута зависят от значений атрибутов
INTERFACE_TYPE и DATA-RATE, как приведено в табл. А.65.
Когда DATA_WIDTH установлен на ширину больше 8, пара блоков ISERDESE2 должна каскадиро-
ваться в конфигурации главный-подчиненный (master-slave).
Атрибут INTERFACE-TYPE. Этот атрибут определяет, будет ли блок ISERDESE2 конфигуриро-
ваться в режиме памяти или в режиме сети. Допустимыми значениями для данного атрибута являются
MEMORY, MEMORY.DDR3, MEMORY.QDR, OVERSAMPLE или NETWORKING. Значением по умолча-
нию является MEMORY.
А.10.9. Примитив OSERDESE2
Примитив OSERDESE2 показан на рис. А.56.
Порты примитива OSERDESE2 представлены в табл. А.66.
Ниже приводится описание портов примитива OSERDESE2.
Выход пути данных OQ. Первыми на выходе OQ будут появляться данные входного порта D1. Этот
порт соединяет выход параллельно-последовательного преобразователя с входом данных блока 10В. Этот
порт не может управлять блоком задержки ODELAYE2, для этого следует использовать вывод OFB.
Обратная связь выхода от OSERDESE2 OFB. Этот порт является последовательным высокоско-
ростным портом блока OSERDESE2 для использования с примитивом ODELAYE2 или блоком ISERDESE2.
Выход управления третьим состоянием TQ. Этот порт соединяет выход параллельно-последова-
тельного преобразователя третьего состояния с управлением третьим состоянием или входом третьего
состояния блока ЮВ.
Выход управления третьим состоянием TFB. По требованию пользователя этот порт посылает
сигнал в структуру FPGA для указания, что OSERDESE2 находится в третьем состоянии.
Высокоскоростной вход синхросигнала CLK. Этот порт управляет последовательной стороной
параллельно-последовательного преобразователя.
Приложение А. Примитивы FPGA 7-й серии
315
Таблица А.64
Атрибуты примитива ISERDESE2
Атрибут Значение Значение по умолчанию Описание
DATA.RATE SDR, DDR DDR Разрешает приходящему потоку данных обраба- тываться как данные SDR или DDR
DATA.WIDTH Целое: 2, 3, 4, 5. 6, 7, 8, 10 или 14 4 Определяет ширину последовательно-парал- лельного преобразователя. При DATA.RATE = SDR допустимые значения: 2, 3, 4, 5, 6, 7 или 8. При DATA.RATE = DDR допустимые значения: 4, 6, 8, 10 или 14
DYN.CLKDIVJNV.EN TRUE, FALSE FALSE Когда установлен в TRUE, разрешает инвер- сию на выводе CLKDIV с помощью вывода DYN- CLKDIVSEL и запрещает инверсии в языке HDL
DYN.CLKJNV.EN TRUE, FALSE FALSE Когда установлен в TRUE, разрешает инвер- сию на выводах CLK и CLKB с помощью вывода DYNCLKDIVSEL и запрещает инверсии в языке HDL
INTERFACE-TYPE MEMORY, MEMORY-DDR3, MEMORY.QDR, OVERSAMPLE, NETWORKING MEMORY Выбирает модель использования блока ISERDESE2
NUM.CE 1 или 2 2 Определяет число разрешенных синхросигналов
OFB.USED TRUE, FALSE FALSE Разрешает путь от вывода OFB блоков OLOGICE2/3, OSERDESE2 к выводу OFB блока ISERDESE2. Запрещает использование входа D
SERDES-MODE MASTER, SLAVE MASTER При увеличении ширины слова определяет мо- дуль ISERDESE2 как главный или подчиненный
INIT.Ql/2/3/4 0 или 1 0 Устанавливает начальное значение для регистра выборки 1, 2, 3 или 4
SRVAL.Q1/2/3/4 0 или 1 1 Устанавливает значение после сброса регистра выборки 1, 2, 3 или 4
Таблица А.65
Поддерживаемая ширина слова данных
INTERFACE-TYPE DATA.RATE Допустимая ширина слова
NETWORKING SDR 2, 3, 4, 5, 6, 7, 8
MEMORY DDR 4, 6, 8, 10, 14
MEMORY.DDR3 SDR —
MEMORY.QDR DDR 4
Вход разделенного синхросигнала CLKDIV Этот порт управляет параллельной стороной парал-
лельно-последовательного преобразователя. Этот синхросигнал является разделенной версией синхро-
сигнала порта CLK.
Входы параллельных данных D1-D8. Все приходящие параллельные данные вводятся в модуль
OSERDESE2 через порты D1-D8. Эти порты подсоединяются к структуре FPGA и могут конфигуриро-
ваться в соотношении от двух до восьми битов (т.е. преобразовываться как 8:1). Разрядность шины
больше чем 8 (10 и 14) может образовываться с помощью использования второго модуля OSERDESE2
в подчиненном режиме SLAVE.
Вход сброса RST. Активно высокое значение данного порта асинхронно обнуляет все триггеры дан-
ных, находящихся в области управления синхросигналов CLK и CLKDIV. Когда аннулируется синхронно с
синхросигналом CLK, внутренняя логика повторно синхронизирует это аннулирование к первому возрастаю-
щему фронту CLK. Следовательно, каждый блок OSERDESE2 в многобитовой выходной структуре должен
управляться тем же самым сигналом сброса, устанавливаемым асинхронно и аннулируемым синхронно с
CLKDIV для уверенности, что все элементы OSERDESE2 выходят из сброса синхронно. Сигнал сброса дол-
жен аннулироваться только тогда, когда известно, что сигналы CLK и CLKDIV стабильны и сформированы.
Разрешение синхронизации выхода данных ОСЕ. Порт ОСЕ является активно высоким разреше-
нием синхронизации для пути данных.
316
Приложение А. Примитивы FPGA 7-й серии
Рис. А.56. Примитив 0SERDESE2
Таблица А.66
Порты примитива OSERDESE2
Имя Тип Ширина Описание
0Q Выход 1 Выход пути данных к блоку ЮВ
OFB Выход 1 Обратная связь выхода пути данных к ISERDESE2 или соедине- ние с ODELAYE2
TQ Выход 1 Выход управления третьим состоянием к блоку ЮВ
TFB Выход 1 Выход управления третьим состоянием к структуре FPGA
SHIFTOUT1 Выход 1 Выход переноса для увеличения ширины данных. Соединяется с SHIFTIN1 главного OSERDESE2
SHIFTOUT2 Выход 1 Выход переноса для увеличения ширины данных. Соединяется с SHIFTIN2 главного OSERDESE2
CLK Вход 1 Высокоскоростной вход синхросигнала
CLKDIV Вход 1 Разделенный вход синхросигнала. Синхронизирует элемент за- держки, преобразованные данные, подмодуль Bitslip и сигнал СЕ
D1-D8 Вход 1 (каждый) Входы параллельных данных
ТСЕ Вход 1 Разрешение синхронизации третьего состояния
ОСЕ Вход 1 Разрешение синхронизации выходных данных
TBYTEIN Вход 1 Группа байта входа третьего состояния
TBYTEOUT Выход 1 Группа байта выхода третьего состояния
RST Вход 1 Сигнал сброса, активный уровень — высокий
SHIFTIN1 Вход 1 Вход переноса для увеличения ширины данных. Соединяется с SHIFTOUT1 подчиненного OSERDESE2
SHIFTIN2 Вход 1 Вход переноса для увеличения ширины данных. Соединяется с SHIFTOUT2 подчиненного OSERDESE2
Т1-Т4 Вход 1 (каждый) Параллельные входы третьего состояния
Приложение А. Примитивы FPGA 7-й серии
317
Сигнал разрешения синхронизации третьего состояния ТСЕ. Порт ТСЕ является активно высоким
разрешением синхронизации для пути управления третьим состоянием.
Параллельные входы третьего состояния Т1-Т4. Все параллельные сигналы третьего состояния
вводятся в модуль OSERDESE2 через порты Т1-Т4. Эти порты подсоединяются к структуре FPGA и
могут конфигурироваться как один, два или четыре бита.
А. 10.10. Атрибуты примитива OSERDESE2
Атрибуты примитива OSERDESE2 представлены в табл. А.67.
В табл. А.68 приведены комбинации допустимых установок атрибутов для примитива OSERDESE2.
Таблица А.67
Атрибуты примитива OSERDESE2
Атрибут Значения Значение по умолчанию Описание
DATA_RATE_OQ SDR, DDR DDR Определяет, будут ли данные (OQ) изменяться на каждом фронте (DDR) или на каждом возрастающем фронте (SDR) синхросигнала CLK
DATA_RATE_TQ BUF, SDR, DDR DDR Определяет, будет ли управление третьим состоянием (TQ) изменяться на каждом фронте (DDR), на каж- дом возрастающем фронте (SDR) синхросигнала CLK или будет устанавливаться к конфигурации буфера (BUF)
DATA-WIDTH Целые: для SDR 2, 3, 4, 5, 6, 7 или 8; для DDR 2, 4, 6, 8, 10 или 14 4 Определяет ширину параллельно-последовательного преобразователя данных. Это значение зависит от значения атрибута DATA_RATE_OQ. При значениях 10 и 14 модули OSERDESE2 должны быть сконфигу- рированы в пару главный-подчиненный
SERDES-MODE MASTER, SLAVE MASTER Определяет, будет ли модуль OSERDESE2 главным (MASTER) или подчиненным (SLAVE), когда использу- ется увеличение ширины
TRISTATE-WIDTH Целые: 1 или 4 4 Определяет ширину параллельно- последовательного преобразователя третьего состояния. Это значение зависит от значения атрибута DATA_RATE_OQ. Ес- ли значение DATA-RATE.OQ установлено в SDR или BUF, то значение TRISTATE-WIDTH может быть уста- новлено только в 1; при установке DATA_RATE_OQ в DDR значением TRISTATE-WIDTH может быть 1 и 4
Таблица А.68
Комбинации допустимых установок атрибутов для примитива OSERDESE2
Тип интерфейса DATA-RATE.OQ DATA-RATE.TQ DATA-WIDTH TRISTATE-WIDTH
По умолчанию SDR SDR 1,2,3,4,5,6,7,8 1
DDR DDR 4 4
SDR 2,6,8,10,14 1
А.10.11. Примитив IN-FIFO
Примитив IN.FIFO показан на рис. А.57.
Порты примитива IN-FIFO представлены в табл. А.69.
А.10.12. Примитив OUT-FIFO
Примитив OUT-FIFO показан на рис. А.58.
Порты примитива OUT-FIFO представлены в табл. А.70.
Атрибуты элемента IO-FIFO представлены в табл. А.71.
318
Приложение А. Примитивы FPGA 7-й серии
D0[3:0] Q0[7:0] D1[3:0] О1[7:0] D2[3:0] 03(7:0] D3[3:0] Q3[7:0] D4[3:0] Q4[7:0] D5[7:0]l1) 0!Q5[7:0] D6[7:0]<1) <1,Q6[7:0] D7[3:0] Q7[7:0] D8[3:0] Q8[7:0] D9[3:0] Q9[7:0] RDEN EMPTY WREN FULL письгх ALMOSTEMPTY >WRCLK ALMOSTFULL RESET
—
Рис. A.57. Примитив IN_FIFO
Таблица А.69
Порты примитива 1N.FIFO
Имя Направление Описание
RDCLK Вход Синхросигнал чтения, подсоединяется к BUFR, BUFG или BUFH
WRCLK Вход Синхросигнал записи, подсоединяется к BUFR, BUFG или BUFH
RESET Вход Сброс, активный уровень высокий, очищает все счетчики, указатели и данные
D0[3:0]-D9[3:0] Вход 4-битовые данные в режиме 4x8, удвоенные 4-битовые данные пор- тов в режиме 4x4. Подсоединяется к ILOGIC, если используется для внешних интерфейсов
D5[7:4], D6[7:4] Вход Дополнительные данные в портах D10 и D11, используются только в режиме 4x4. Данные с этих портов появляются на выходных портах Q5[7:4] и Q6[7:4] соответственно
RDEN Вход Разрешение чтения
WREN Вход Разрешение записи
Q0[7:0]-Q9[7:0] Выход Десять 8-битных шин выходных данных в режиме 4x8. Подсоединя- ются к структуре FPGA, если используется для внешних интерфейсов
Q5[7:4], Q6[7:4] Выход Выходные порты дополнительных данных Q10 и Q11, используются только в режиме 4x4. Данные на этих портах приходят с входных портов D5[7:4] и D6[7:4] соответственно
EMPTY Выход Флаг «пустой», синхронизируется с RDCLK
FULL Выход Флаг «полный», синхронизируется с WRCLK
ALMOSTEMPTY Выход Программируемый уровень флага «пустой», синхронизируется с RDCLK
ALMOSTFULL Выход Программируемый уровень флага «полный», синхронизируется с WRCLK
Приложение А. Примитивы FPGA 7-й серии
319
.V] D1[7:0] D2[7:0] D3[7:0] D4[7:0] D5[7:0] (1) D6[7:0] (1) D7[7:0] D8[7:0] D9[7:0] WVlO.Vj Q1[3:0] Q2[3:0] Q3[3:0] Q4[3:0] co Q5[7:0] (D Q6[7:0] Q7[3:0] Q8[3:0] Q9[3:0]
RDEN WREN EMPTY FULL
>RDCLK > WRCLK RESET
ALMOSTEMPTY
ALMOSTFULL
Рис. А.58. Примитив OUT.FIFO
Таблица А.70
Порты примитива OUT.FIFO
Имя Направление Описание
RDCLK Вход Синхросигнал чтения, подсоединяется к BUFR, BUFG или BUFH
WRCLK Вход Синхросигнал записи, подсоединяется к BUFR, BUFG или BUFH
RESET Вход Сброс, активный уровень высокий, очищает счетчики, указатели и данные
D0[7:0]-D9[7:0] Вход 8-битовые порты данных в режиме 8x4, удвоенные 4-битовые данные портов в режиме 4x4. Подсоединяются к структуре FPGA, если ис- пользуются для внешних интерфейсов
D5[7:4], D6[7:4] Вход Дополнительные данные в портах D10 и D11, используются только в режиме 4x4. Данные на этих портах появляются на выходных портах Q5[7:4] и Q6[7:4] соответственно
RDEN Вход Разрешение чтения
WREN Вход Разрешение записи
Q0[3:0]-Q9[3:0] Выход Десять 4-битовых шин выходных данных. Подсоединяются к OLOGIC, если используются для внешних интерфейсов
Q5[7:4], Q6[7:4] Выход Дополнительные данные выходных портов Q10 и Q11, используются только в режиме 4x4. Данные на этих портах приходят с входных портов D5[7:4] и D6[7:4] соответственно
EMPTY Выход Флаг «пустой», синхронизируется с RDCLK
FULL Выход Флаг «полный», синхронизируется с WRCLK
ALMOSTEMPTY Выход Программируемый уровень флага «пустой», синхронизируется с RDCLK
ALMOSTFULL Выход Программируемый уровень флага «полный», синхронизируется с WRCLK
320
Приложение А. Примитивы FPGA 7-й серии
Таблица А.71
Атрибуты элемента IO.FIFO
Атрибут Значение Значение по умолчанию Описание
ARRAY.MODE (IN.FIFO) ARRAY-MODE (OUT_FIFO) ALMOST. EMPTY_VALUE ALMOST. FULL-VALUE OUTPUT- DISABLE ARRAY _MODE_4_X_8, ARRAY_MODE_4_X_4 ARRAY_MODE_8_X_4, ARRAY-M ODE_4 _X_4 1 или 2 1 или 2 TRUE или FALSE ARRAY_MODE_4_X_8 ARRAY-M ODE_8 _X_4 1 1 FALSE Определяет 4 входных бита и 4 или 8 выходных битов на порт Определяет 4 или 8 входных битов и 4 выходных бита на порт Определяет значение условной грани- цы для флага ALMOST EMPTY Определяет значение условной грани- цы для флага ALMOST FULL OUT_FIFO: когда RD_EN низкий, за- прещение выхода управляет высокими значениями выходов Qx
А.11. Примитивы ресурсов синхронизации
А. 11.1. Возможности соединений элементов ресурсов синхронизации
FPGA 7-й серии
Допустимые соединения элементов синхронизации FPGA 7-й серии представлены в табл. А.72.
Таблица А.72
Возможности соединений элементов ресурсов синхронизации FPGA 7-й серии
Элементы синхронизации Непосредственно управляется Используется для прямого управления
Выводы много ре- гиональной синх- ронизации MRCC (Multi-region Clock- Capable) Выводы синхрони- зации одного ре- гиона SRCC (Single- region Clock-Capable) Буфер BUFIO Буфер BUFR Внешним синхросигналом Внешним синхросигналом • выводами MRCC; • выводами SRCC; • выводами блока ММСМ. CLKOUT[0:3]; • CLKFBOUT; • Буферами BUFMR того же региона и регионов выше и ниже • Выводами MRCC; • выводами SRCC; • выводами блока ММСМ. CLKOUT[0:3]; • CLKFBOUT; • буферами BUFMR регионов выше и ниже; • общими (General) межсоединениями. • Четырьмя буферами BUFIO; • четырьмя буферами BUFR; • двумя буферами BUMR; • одним блоком СМТ (один ММСМ и один PLL); • блоками СМТ выше и ниже (исполь- зуя ограниченные ресурсы магистрали СМТ)1; • 16 буферами BUFG. MRCC в преде- лах того же смежного горизонтально региона синхронизации; • буферами BUFH • Четырьмя буферами BUFIO; • четырьмя буферами BUFR; • одним блоком СМТ (один ММСМ и один PLL); • блоками СМТ выше и ниже (исполь- зуя ограниченные ресурсы магистрали СМТ)1; • 16 буферами BUFG; • буферами BUFH • ILOGIC.dk • ILOGIC.clkb • OLOGIC.dk • OLOGIC.clkb • OLOGIC.oclk • OLOGIC.oclkb • блоком СМТ; • любой синхронизируемой точкой в том же регионе, которым BUFR может управлять; • 16 буферами BUFG (не рекомендует- ся)
Приложение А. Примитивы FPGA 7-й серии
321
Продолжение табл. А.72
Элементы синхронизации Непосредственно управляется Используется для прямого управления
Буфер BUFMR • Выводами MRCC; • выходами синхронизации блока GT, перечисленными в этой таблице (см. GT Transceiver Clocks); • межсоединениями (не рекомендуется) • Буферами BUFIO; • буферами BUFR
Буфер BUFG • Выводами SRCC; • выводами MRCC; • блоками СМТ; • выходами синхронизации блока GT, перечисленными в этой таблице (см. GT Transceiver Clocks); • буферами BUFR (не рекомендуется); • межсоединениями (не рекомендуется); • соседним буфером BUFG в той же по- ловине (верхней или нижней) устройства • Блоком СМТ; • выходами синхронизации блока GT, перечисленными в этой таблице (см GT Transceiver Clocks); • соседними буферами BUFG в той же половине (верхней или нижней) устрой- ства; • любой синхронизируемой точкой в структуре FPGA и вводе-вы воде; • управляющими сигналами блоков CLB; • буфером BUFH
Буфер BUFH • Выводом SRCC; • выводом MRCC; • блоком СМТ; • буфером BUFG; • выходами синхронизации блока GT, перечисленными в этой таблице (см. GT Transceiver Clocks); • межсоединениями (не рекомендуется) • Блоком СМТ; • выходами синхронизации блока GT, перечисленными в этой таблице (см GT Transceiver Clocks); • любой синхронизируемой точкой в том же регионе, которым BUFR может управлять
Синхросигналы приемопередатчи- ка GT: RXUSRCLK; RXUSRCLK2; TXUSRCLK; TXUSRCLK2 • Любым буфером BUFG; • буфером BUFH Не используется
Синхросигналы при- емопередатчика GT: RXOUTCLK TXOUTCLK Не используется • Буферами BUFG в пределах той же половины (верхней или нижней) устрой- ства; • блоком СМТ; • буфером BUFMR; • буфером BUFH и буфером BUFH го- ризонтально смежного региона
MGTREFCLK0/1P (MGTREFCLK0/1N) положительные (отрицательные) дифференциаль- ные выводы эталон- ных синхросигналов MGT Внешний эталонный синхросигнал блока GT Эталонным синхросигналом блока GT
Блок СМТ1 • Буфером BUFG; • выводом SRCC (того же и смежных регионов синхронизации); • выводом MRCC (того же и смежных регионов синхронизации); • блоками GT в том же регионе синхро- низации; • буфером BUFR в пределах того же региона синхронизации и региона выше или ниже, используя буфер BUFMR; • выводами CLKOUTO-3 блоков MMCM/PLL • Любым буфером BUFG в той же (верхней или нижней) половине устрой- ства; • буфером BUFIO (ММСМ); • буфером BUFR (ММСМ); • буфером BUFH и буфером BUFH в горизонтально смежном регионе синхро- низации; • блоками ММСМ/PLL (с фазовым сдвигом, если не смежные)
322
Приложение А. Примитивы FPGA 7-й серии
Продолжение табл. А.72
Элементы синхронизации Непосредственно управляется Используется для прямого управления
IDELAYCNTRL CLK Вывод CCLK Вывод EMCCLK Вывод ТСК 1. Применяются опр венный синхросигна; • Выводом MRCC/SRCC; • буфером BUFG; • буфером BUFH Логикой конфигурации Не используется Не используется. эеделенные ограничения (см. раздел Single 1, управляющий несколькими СМТ — в до» Не используется Логикой конфигурации Логикой конфигурации Логикой конфигурации JTAG и гранич- ным сканированием (Boundary Scan) Clock Driving Multiple CMTs — единст- <ументе UG472).
А. 11.2. Правила размещения СС-входов
Правила размещения входов синхронизации (СС-входов) приведены в табл. А.73.
• Когда управляющие синхросигналы в смежных регионах используют буфер BUFMR или блок СМТ,
уменьшенные ресурсы синхронизации могут повлиять на смежные регионы синхронизации Напри-
мер. используя буфер BUFMR для управления буфером BUFR в соседнем регионе синхронизации
запрещает одну из пар СС-входов в соседнем регионе от управления региональным деревом синх-
ронизации в ее собственном регионе синхронизации. В то же время буферы BUFH или BUFG мо-
гут все еще использоваться для управления глобальными линиями синхронизации в этом смежном
регионе синхронизации.
Таблица А.73
Правила размещения СС-входов
Входы синхронизации к Использование ресурсов и правила размещения
Элементам ввода-вывода и/или последова- тельным элементам всюду по устройству Элементу ввода-вывода и/или последова- тельным элементам в пределах данного региона синхронизации, используя буфер BUFH Элементам ввода-вывода и/или последо- вательным элементам, используя блоки СМТ1) Элементам ввода-вывода и/или после- довательным элементам в единственном регионе синхронизации, используя буфер BUFR Элементам ввода-вывода и/или последо- вательным элементам в до трех смежных регионах синхронизации^2) Высокопроизводителиные интерфейсы SelectIO в одном регионе синхронизации Высокопроизводительные интерфейсы SelectIO в до двух смежных регионах синхронизации^2) 1. Когда СС-входы управляют блоками СК/ в том же регионе, требуется установка атр СС-вход должен быть размещен в той же верхней или ниж- ней половине устройства, что и буфер BUFG СС-вход должен быть размещен в том же регионе или гори- зонтальном смежном регионе синхронизации, что и буфер BUFH СС-вход > СМТ > BUFG > глобальное дерево синхрониза- ции СС-вход > СМТ > BUFR/BUFH > региональное дерево синхронизации/горизонтальная линия синхронизации. СМТ должен размещаться в том же регионе, что и СС- вход; блоки СМТ могут размещаться в смежных регионах выше и ниже, когда необходимо много блоков СМТ СС-вход должен размещаться в том же регионе синхрониза- ции, что и буфер BUFR, элементы ввода-вывода и последо- вательные синхронизируемые элементы Элементы ввода-вывода и другие последовательные элемен- ты, которые управляются буферами BUFR, должны быть в том же регионе или в регионах выше и ниже, что и СС-вход СС-вход должен размещаться в том же регионе синхрони- зации, что и буфер BUFIO и синхронизируемые триггеры ввода-вы вода Последовательные элементы ввода-вывода и буферы BUFIO должны размещаться в том же регионе, что и СС-вход, или в смежных регионах синхронизации выше или ниже; буфер BUFMR должен использоваться для доступа к буфе- рам BUFIO и элементам ввода-вывода в том же регионе и смежных регионах синхронизации Т в других регионах синхронизации в том же столбце, но не ибута CLOCK_DEDICATED_ROUTE = BACKBONE.
Приложение А. Примитивы FPGA 7-й серии
323
• Если интерфейс памяти размещается в том же банке или регионе в котором находятся буферы BUFR
или BUFIO, соединение от BUFMR к этим буферам BUFR или BUFIO в этом банке или регионе
должно быть ограничено.
• Определенная пара СС-входов подсоединяется к определенным буферам BUFR и BUFIO. поэтому не
рекомендуется вручную размещать буферы BUFR и BUFIO.
А.11.3. Примитив BUFGCTRL
Все примитивы глобальной синхронизации основываются на примитиве
BUFGCTRL и образуются путем конфигурирования примитива BUFGCTRL.
Примитив BUFGCTRL показан на рис. А.59, где II, 10 — входы синхросигна-
лов; SI, S0 — выбор входов синхронизации; СЕ1, СЕО — разрешение синхро-
низации; IGNORE1, IGNOREO — управление входами синхросигналов.
Примитив BUFGCTRL может переключаться между двумя асинхронны-
ми синхросигналами, поступающими на входы II и 10. Примитив BUFGCTRL
имеет четыре линии выбора: SO, SI, СЕО и СЕ1, а также две линии управле-
ния: IGNOREO и IGNORE1.
Примитив BUFGCTRL спроектирован для переключения без помех
(glitch) между двумя входами синхронизации II и 10. Когда выбранный в
настоящее время синхросигнал переходит с высокого уровня на низкий после
изменения S0 и S1, выход сохраняет низкий уровень до тех пор, пока дру-
гой синхросигнал (который будет выбран в будущем) переходит от высокого
уровня к низкому. Затем новый синхросигнал начинает управлять выходом.
Конфигурацией по умолчанию для примитива BUFGCTRL является чувст-
вительность по убывающему (падающему - falling-edge) фронту и удержание
низкого уровня до входного переключения. Путем использования атрибута
Рис. А.59. При-
митив BUFGCTRL
INIT.OUT примитив BUFGCTRL может быть чувствительным к возрастающему фронту и удерживать вы-
сокий уровень до входного переключения.
В некоторых приложениях ранее описанные условия не желательны. Установка вывода IGNORE будет
обходить буфер BUFGCTRL от обнаружения условий для переключения между двумя входами синхрониза-
ции. Другими словами, активизация IGNORE заставляет мультиплексор MUX переключать входы в момент
изменений выбранного вывода. Сигнал IGNOREO заставляет выход немедленно переключаться от входа
10, когда изменяется выбранный вывод, a IGNORE1 заставляет выход немедленно переключаться от входа
II, когда изменяется выбранный вывод.
Выбор входного синхросигнала требует для «выбранной» пары (S0 и СЕО или S1 и СЕ1) установ-
ки высокого уровня. Если либо S, либо СЕ не установлены в высокий уровень, требуемые вход не будет
выбран. При нормальном функционировании обе пары S и СЕ (все 4 выбранных линии) не обязатель-
но должны устанавливаться в высокий уровень одновременно. Обычно только один вывод выбираемой
пары используется как линия выбора, в то время как другой вывод подсоединяется к высокому уровню.
В табл. А.74 приведена таблица истинности переключения входов синхронизации.
Хотя как S, так и СЕ используются для выбора
требуемого выхода, только S обеспечивает переклю-
чение свободное от помех. Однако когда использу-
ется СЕ для переключения синхросигналов, измене-
ние в выборе синхросигнала может быть быстрее, чем
когда используется S. Нарушение времени Setup/Hold
вывода СЕ вызывает помехи выхода синхросигнала.
С другой стороны, использование вывода S позволяет
позволяет пользователю переключаться между дву-
мя входами синхронизации без отношения к време-
ни Setup/Hold. Как результат, использование S для
переключения синхросигналов не приводит к помехам
(см. примитив BUFGMUX-CTRL). Вывод СЕ проекти-
ровался для совместимости с предыдущими архитек-
турами Virtex.
Таблица А.74
Таблица истинности переключения
входов синхронизации
СЕО S0 СЕ1 S1 о
1 1 0 X 10
1 1 X 0 10
0 X 1 1 11
X 0 1 1 и
1 1 1 1 Старый вход1
1. Старый вход относится к действительно-
му входному синхросигналу, прежде чем это со-
стояние будет достигнуто.
2. Для всех других состояний выход принимает
значение атрибута INIT.OUT и не переключает-
ся.
Временная диаграмма на рис. А.60 показывает различные условия переключения синхросигнала, ис-
пользуя примитив BUFGCTRL. Точные временные числовые значения лучше определяются, используя
спецификации скорости.
До момента времени 1 выход О использует вход 10.
324
Приложение А. Примитивы FPGA 7-й серии
Ю
И
СЕО
СЕ1
SO
S1
IGNOREO
I
твсско о
—
--------1—х
Xl
Begin Ю
IGNORE1! i,
ТВССКО..О твсско о
at Ю Begin 11
Рис. А.60. Временная диаграмма примитива BUFGCTRL
Таблица А.75
Атрибуты примитива BUFGCTRL
Атрибут Значения Описание
INIT.OUT PRESELECTJO PRESELECTJ1 1. Два атрибут 0 (по умолчанию), 1 False (по умолчанию), TRUE False (по умолчанию), TRUE a PRESELECT не могут Определяет значение выхода примитива BUFGCTRL после конфигурации В значении TRUE после конфигурации1 выход примитива BUFGCTRL будет использовать вход 10 В значении TRUE после конфигурации1 выход примитива BUFGCTRL будет использовать вход 11 одновременно иметь значение TRUE.
От времени Твссск_се Д° возрастающего фронта от момента 1, оба СЕО и SO сбрасываются в
низкий уровень.
От времени Твсссо.о после момента времени 3 выход О использует вход II. Это случилось после
перехода с высокого на низкий уровень входа 10 (событие 2), вызванное переходом с высокого на низ-
кий уровень входа II.
В момент времени 4 устанавливается IGORE1.
В момент времени 5 СЕО и S0 устанавливаются в высокий уровень, а СЕ1 и S1 — в низкий. От
времени Твсссо.о после события 6 выход О должен переключиться с II на 10 без требования перехода
с высокого на низкий уровень входа II
Другие свойства примитива BUFGCTRL:
• предварительный выбор входов 10 и II выполняется после конфигурации, но до начала функцио-
нирования устройства;
• начальное значение выхода после конфигурации может быть выбрано как высокий, тик и низкий
уровень;
• выбор синхронизации, использующий только СЕО и СЕ1 (S0 и S1 подсоединяются к высокому уров-
ню), может изменить выбор синхросигнала без ожидания для перехода с высокого на низкий уровень
на ранее выбранном синхросигнале.
Атрибуты примитива BUFGCTRL представлены в табл. А.75.
А.11.4. Примитив BUFG
Примитив BUFG является простым буфером синхронизации с одним входом и одним выходом. Этот
примитив основан на примитиве BUFGCTRL с некоторыми выводами, подсоединенными к высокому или
низкому уровням. На рис. А.61 показано отношение примитивов BUFG и BUFGCTRL. Ограничение LOC по-
зволяет ручное указание местоположения буфера BUFG (детали см. в документе UG625 Constraints Guide).
Временная диаграмма функционирования буфера BUFG показана на рис. А.62.
Приложение А. Примитивы FPGA 7-й серии
325
BUFG(I)
BUFG(O)
Рис. А.61. Примитив BUFG как BUFGCTRL
** н твсскоо
Рис. А.62. Временная диаграмма примитива BUFG
А.11.5. Примитивы BUFGCE и BUFGCE_1
Примитив BUFGCE подобен буферу BUFG с одним входом синхросигнала, одним выходом синхро-
сигнала и входом разрешения синхронизации. На рис. А.63 показано отношение примитивов BUFGCE
и BUFGCTRL.
Условие переключения для примитива BUFGCE аналогично примитиву BUFGCTRL. Если вход СЕ пе-
реходит на низкий уровень перед приходящим возрастающим фронтом синхросигнала, следующий импульс
синхросигнала не проходит через буфер и выход остается на низком уровне. Любое изменение уровня
СЕ во время приходящего высокого импульса синхросигнала не имеет никакого воздействия до прихода
низкого уровня синхросигнала. Выход становится низким, когда синхросигнал запрещается. Однако когда
синхросигнал запрещается, он завершает высокий импульс синхросигнала.
Поскольку линия разрешения синхронизации использует вывод СЕ примитива BUFGCTRL, выбира-
емый сигнал должен удовлетворять требуемому времени установки. Нарушение этому требованию может
вызвать помехи (glitch). Временная диаграмма примитива BUFGCE показана на рис. А.64.
Примитив BUFGCE.1 подобен примитиву BUFGCE, за исключением условия его переключения. Если
вход СЕ находится на низком уровне перед приходом падающего фронта синхросигнала, следующий импульс
BUFGCE
Рис. А.63. Примитив BUFGCE как BUFGCTRL
326
Приложение А. Примитивы FPGA 7-й серии
BUFGCE(I)
BUFGCE(CE)
BUFGCE(O)
ТВСССК СЕ
Рис. А.64. Временная диаграмма примитива BUFGCE
BUFGCE_1(I)
BUFGCE„1(CE)
BUFGCE„1(O)
Рис. А.65. Временная диаграмма примитива BUFGCE.1
синхросигнала не проходит через буфер синхронизации и выход остается на высоком уровне. Любое из-
менение уровня СЕ во время приходящего низкого импульса синхросигнала не имеет никакого воздействия
до прихода высокого уровня синхросигнала. Выход становится высоким, когда синхросигнал запрещается.
Однако, когда синхросигнал запрещается, он завершает низкий импульс синхросигнала.
Временная диаграмма примитива BUFGCE.1 показана на рис. А.65.
Различие между примитивами BUFGCE и BUFGCEJ. заключается в том, что при запрещении синхро-
низации в примитиве BUFGCE выход остается на низком уровне, а в примитиве BUFGCE-1 — на высоком
уровне.
А.11.6. Примитивы BUFGMUX и BUFGMUX.1
Примитив BUFGMUX является буфером синхронизации с двумя входами синхросигналов, одним вы-
ходом синхросигнала и линией выбора. На рис. А.66 показано отношение между примитивами BUFGMUX
и BUFGCTRL. Ограничение LOC позволяет ручное указание местоположения буфера BUFGMUX.
Поскольку примитив BUFGMUX использует выводы разрешения синхронизации СЕ как выводы вы-
бора, то использование выбора должно удовлетворять требуемому времени установки. Нарушение этого
требования может вызвать помехи (glitch).
Условия переключения для примитива BUFGMUX являются такими же, как выводы СЕ на примитиве
BUFGCTRL. Временная диаграмма примитива BUFGMUX показана на рис. А.67.
Пояснения к рис. А.67:
• текущим синхросигналом является 10;
• S активизируется высоким уровнем;
Рис. А.66. Примитив BUFGMUX как BUFGCTRL
Приложение А. Примитивы FPGA 7-й серии
327
switching using И
Рис. А.67. Временная диаграмма примитива BUFGMUX
Рис. А.68. Временная диаграмма примитива
BUFGMUX.1
Таблица А.76
Атрибуты примитива BUFGMUX
Атрибут Значения Описание
CLK_SEL_TYPE SYNC (по умолчанию), ASYNC Определяет синхронное или асинхронное переключение синхросигнала
• если 10 в настоящее время имеет высокий уровень, мультиплексор ожидает сброса 10 в низкий уровень;
• как только 10 является низким, выход мультиплексора остается низким до тех пор, пока II не перейдет
с высокого на низкий уровень;
• когда II переходит с высокого на низкий, выход переключается на II;
• если удовлетворено условие времени установки/удержания, помехи на выходе не появляются.
Примитив BUFGMUX.1 является чувствительным к возрастающему фронту и удерживает высокий
уровень перед переключением входа. Временная диаграмма примитива BUFGMUX.1 показана на рис. А.68.
Ограничение LOC позволяет ручное указание местоположения буферов BUFGMUX и BUFGMUX_1.
Пояснения к рис. А.68:
• текущим синхросигналом является 10;
• S активизируется высоким уровнем;
• если 10 в настоящее время имеет низкий уровень, мультиплексор ожидает установки 10 в высокий
уровень;
• как только 10 является высоким, выход мультиплексора остается высоким до тех пор, пока II не
перейдет с низкого на высокий уровень;
• когда II переходит с низкого на высокий уровень, выход переключается на II;
• если удовлетворено условие времени установки/удержания, помехи на выходе не появляются.
Атрибут примитива BUFGMUX приведен в табл. А.76.
А.11.7. Примитив BUFGMUX-CTRL
Примитив BUFGMUX-CTRL заменяет устаревший примитив BUFGMUX.VIRTEX4. Примитив BUFG
MUX.CTRL является буфером синхронизации с двумя входами синхросигналов, одним выходом синхросиг-
нала и линией выбора. Различие между примитивами BUFGMUX и BUFGMUX-CTRL заключается в том,
что в примитиве BUFGMUX для переключения между входами синхросигналов используются входы СЕ1 и
СЕО примитива BUFGCTRL, а в примитиве BUFGMUX-CTRL — входы S1 и S0 примитива BUFGCTRL. На
рис. А.69 показано отношение между примитивами BUFGMUX-CTRL и BUFGCTRL.
Вывод S используется как линия выбора, он может переключаться в любое время без создания помех.
Время установки/удержания на выводе S служит для определения передаст ли выход дополнительный
328
Приложение А. Примитивы FPGA 7-й серии
Рис. А.69. Примитив BUFGMUX-CTRL как BUFGCTRL
Рис. А.70. Временная диаграмма функционирования примитива BUFGMUX-CTRL
импульс ранее выбранного синхросигнала до переключения на новый синхросигнал. Если S изменяется,
как показано на рис. А.70, перед временем установки Tbccck_s и Д° переключения 10 с высокого на низкий
уровень, то выход не будет передавать дополнительный импульс входа 10. Если S изменяется после времени
удержания для S, то выход будет передавать дополнительный импульс Если S нарушает требуемое время
установки/удержания, выход может передать дополнительный импульс, но это не будет помехой (glitch).
В любом случае выход будет изменяться к новому синхросигналу в пределах трех циклов синхросигнала
самого медленного синхросигнала.
Требования времени установки/удержания для S0 и S1 относятся к падающему фронту синхросиг-
нала, а не возрастающему, как для СЕО и СЕ1. Условия переключения для примитива BUFGMUX-CTRL
являются такими же, как для вывода S примитива BUFGCTRL. Временная диаграмма для примитива
BUFGMUX.CTRL показана на рис. А.70.
Другие свойства примитива BUFGMUX-CTRL:
• предварительный выбор входа 10 и II после конфигурации;
• инициализация выхода высоким или низким значением после конфигурации.
А.11.8. Примитив BUFIO
Примитив буфера BUFIO является простым буфером с одним входом и одним выходом синхросигнала.
Однако здесь имеется фазовая задержка между входом и выходом. Для буфера BUFIO доступны локальные
ограничения. Примитив буфера BUFIO представлен на рис. А.71, а описание портов приведено в табл. А.77.
А.11.9 Примитив BUFR
На рис. А.72 и в табл. А.78 показан примитив буфера BUFR, который является буфером синхросиг-
нала с возможностью деления входной частоты синхросигнала.
Приложение А. Примитивы FPGA 7-й серии
329
Рис. А.71. Примитив буфера BUFIO
Таблица А.77
Порты примитива BUFR
Имя Тип Ширина Описание
О Выход 1 Выходной порт синхросигнала
1 Вход 1 Входной порт синхросигнала
Таблица А.78
Рис. А.72. Примитив буфера BUFR
Порты примитива BUFR
Имя Тип Ширина Описание
О Выход 1 Выходной порт синхросигнала
СЕ1 Вход 1 Асинхронное разрешение синхрони- зации; не может использоваться в режиме BYPASS
CLR Вход 1 Асинхронный сброс для логики де- ления и выхода; не может использо- ваться в режиме BYPASS
1 Вход 1 Входной порт синхросигнала
1. Вход СЕ не предназначен для использования как актив-
но переключающийся сигнал и не таймируется пакетами
ISE или Vivado.
Таблица А.79
Атрибут BUFR.DIVIDE
Имя Возможные значения Описание
BUFR.DMDE 1, 2, 3. 4, 5, 6, 7, 8, BYPASS (по умолчанию) Определяет коэффициент деления частоты входного синхросигнала
Когда сигнал СЕ устанавливается или сбрасывается, выходной сигнал синхронизации включается или
выключается. Когда глобальный сигнал установки/сброса GSR в высоком уровне, выход BUFR удержива-
ется в сбросе, даже если СЕ в высоком уровне. Выход буфера BUFR переключается после сброса сигнала
GSR, когда появляется синхросигнал на входном порту буфера BUFR.
Режимы и атрибуты примитива BUFR. Деление синхросигнала в буфере BUFR управляется про-
граммно с помощью атрибута BUFR. DIVIDE. В табл. А.79 приведены возможные значения атрибута
BUFR.DMDE.
Для буфера BUFR возможно применение локального ограничения. Задержка распространения через
буфер BUFR определяется при значениях BUFR.DIVIDE = 1 и BUFR.DIVIDE = BYPASS. При значении
1 задержка немного больше, чем при BYPASS. Все другие значения имеют такую же задержку, как при
значении 1. Фазовое соотношение между входным и выходным синхросигналами то же самое для всех
значений, за исключением BYPASS.
Временные соотношения между входом и выходом буфера BUFR, когда используется атрибут BUFR.
DIVIDE, показаны на рис. А.73 при значении BUFR.DIVIDE = 3. Ранее, до этой диаграммы был уста-
новлен сигнал CLR.
Пояснения к рис. А.73:
• до события 1 вход СЕ устанавливается в высокий уровень;
• после сброса входа СЕ и времени Tbrcko.o выход О начинает переключаться, деля на 3 скорость
синхросигнала на входе I (параметр Tbrcko.o и Другие временные параметры лучше находить для
определенной скорости);
• в момент времени 2 устанавливается CLR; после времени Tbrdo.clro от события 2 выход О пе-
рестает переключаться;
• в момент времени 3 CLR сбрасывается;
• в момент времени Tbrcko.o после события 4 выход О начинает снова переключаться, разделяя на
3 скорость синхросигнала на входе I.
Замечания.
• Скважность не является 50/50 для нечетного деления. Низкий импульс является одним циклом
длины (длиннее) I.
330
Приложение А. Примитивы FPGA 7-й серии
Рис. А.73. Временная диаграмма буфера BUFR с установленным значением атрибута BUFRJDIVIDE
• Для правильного функционирования, если подводимый к BUFR синхросигнал остановлен, то должен
быть применен сброс (CLR) после возобновления синхросигнала.
А.11.10. Примитив BUFMR
Примитивы BUFMR (рис. А.74, табл. А.80 и табл. А.81) являются буфером входа и выхода синхро-
сигнала с выводом разрешения синхронизации СЕ. Сброс входа СЕ останавливает выходной синхросигнал.
Буфер BUFMR должен управлять буферами BUFR и BUFIO для трассировки синхросигнала в данном ре-
гионе/банке или в соседних регионах/банках.
Для того чтобы использовать буфер BUFMR или BUFMRCE с буферами BUFIO, выводы интерфейса
должны располагаться в пределах трех банков. Аналогично, при использовании с буферами BUFR, ло-
гика должна располагаться не более чем в трех регионах (если используются три буфера BUFR). Если
интерфейс памяти располагается в том же самом банке ввода-вывода или регионе синхронизации, что и
буферы BUFIO/BUFR, связь от буфера BUFMR к этим буферам BUFH/BUFIO в этом банке или реги-
оне может быть ограничена.
На рис. А.75 показана топология буфера BUFMRCE.
Атрибут СЕ_ТУРЕ всегда должен быть установлен в значение SYNC для гарантии, что выход син-
хронизации свободен от помех. Если выход синхронизации буфера BUFMRCE останавливается (сбросом
вывода СЕ), то буфер BUFR должен сбрасываться сигналом CLR после того, как буфер BUFMRCE снова
разрешается. Главной целью вывода СЕ буфера BUFMRCE является обеспечение фазового выравни-
вания синхросигнала к буферам BUFMR и BUFIO. Детали использования буфера BUFMR в управлении
буферами BUFR и BUFIO приведены в приложении A «Multi-Region Clocking — многорегиональная син-
хронизация» документа UG472.
Рис. А.74. Примитивы буфера BUFMR
Таблица А.80
Порты примитивов BUFMR и BUFMRCE
Порт Тип Ширина Описание
О Выход 1 Выход синхросигнала
СЕ Вход 1 Разрешение выходного синхросигнала
1 Вход 1 Вход синхросигнала
Таблица А.81
Атрибуты примитивов BUFMR и BUFMRCE
Имя Возможные значения Описание
INIT.OUT 0 (по умолчанию), 1 Определяет значение выхода после конфигурации. Устанавливает положительный или отрицательный фронт поведения. Устанавли- вает значение выхода, когда изменяется выбор синхросигнала
CE-TYPE SYNC (по умолчанию), ASYNC Устанавливает синхронное или асинхронное поведение сигнала СЕ по отношению к выходу О
Приложение А. Примитивы FPGA 7-й серии
331
MRCC
Рис. А.75. Многорегиональная буферная топология
А.11.11. Примитивы BUFH и BUFHCE
Примитивы BUFH и BUFHCE показаны на рис. А.76, описание портов примитивов BUFH и BUFHCE
приведено в табл. А.82, а описание атрибутов — в табл. А.83.
Рис. А.76. Примитивы BUFH и BUFHCE
Таблица А.82
Порты примитивов BUFH и BUFHCE
Порт Тип Ширина Описание
О Выход 1 Выход синхросигнала
СЕ Вход 1 Разрешение выходного синхросигнала
1 Вход 1 Вход синхросигнала
Таблица А.83
Атрибуты примитивов BUFH и BUFHCE
Имя Возможные значения Описание
INIT-OUT CE-TYPE 0 (по умолчанию), 1 SYNC (по умолчанию), ASYNC Определяет значение выхода после конфигурации. Устанавливает положительный или отрицательный фронт поведения. Устанавли- вает значение выхода, когда изменяется выбор синхросигнала Устанавливает синхронное или асинхронное поведение сигнала СЕ по отношению к выходу О
А.12. Примитивы блоков ММСМ и PLL
А.12.1. Примитивы MMCME2J3ASE и MMCME2-ADV
Для использования блоков ММСМ в FPGA 7-й серии служат примитивы MMCME2J3ASE и ММСМЕ2_
ADV (рис. А.77).
Примитив MMCME2-BASE обеспечивает наиболее часто используемые функции отдельного блока
ММСМ, такие как устранение перекоса синхросигнала (clock deskew), синтез частоты, грубый (coarse)
фазовый сдвиг и программирование скважности (duty cycle). Порты примитива MMCME2-BASE пред-
ставлены в табл. А.84.
Примитив MMCME2-ADV обеспечивает доступ ко всем свойствам примитива MMCME2-BASE, плюс
к дополнительным портам для переключения синхросигналов, доступу к динамически реконфигурируемому
порту (Dynamic Reconfiguration Port - DRP), а также к динамическому тонкому (fine) фазовому сдвигу.
Порты примитива MMCME2ADV представлены в табл. А.85.
332
Приложение А. Примитивы FPGA 7-й серии
CLKIN1 CLKOUTO CLKOUTOB
CLKFBIN RST CLKOUT1 CLKOUT1B
PWRDWN CLKOUT2 CLKOUT2B CLKOUT3
CLKOUT3B
CLKOUT4 CLKOUT5 CLKOUT6 CLKFBOUT CLKFBOUTB
LOCKED
MMCME2_BASE
CLKIN 1 CLKOUTO CLKIN2 CLKOUTOB CLKFBIN CLKOUT1 RST CLKOUT 1В PWRDWN CLKOUT2 CLKINSEL CLKOUT2B DADDR[6:0] CLKOUT3 DI[15:0J CLKOUT3B DWE CLKOUT4 DEN CLKOUT5 DCLK CLKOUT6 PSINCDEC nor.kl CLKFBOUT PSEN nori i, CLKFBOUTB PSCLK LOCKED DO[15:0] DRDY PSDONE CLKINSTOPPED CLKFBSTOPPED
».
►
в»
MMCME2~ADV
Рис. А.77. Примитивы MMCME2.BASE и MMCME2JKDV
Таблица А.84
Порты примитива MMCME2JBASE
Порт Описание
CLKIN1, CLKFBIN RST CLKOUTO-CLKOUT6, CLKOUTOB-CLKOUT3B, CLKFBOUT и CLKFBOUTB LOCKED PWRDWN Входы синхронизации Вход управления Выходы синхронизации Выход состояния и данных Управление потребляемой мощностью
Таблица А.85
Порты примитива MMCME2JXDV
Порт Описание
CLKIN1, CLKIN2, CLKFBIN, DCLK. PSCLK RST, CLKINSEL, DWE, DEN, DADDR, DI, PSINCDEC, PSEN CLKOUTO-CLKOUT6, CLKOUTOB-CLKOUT3B, CLKFBOUT и CLKFBOUTB LOCKED, DO, DRDY, PSDONE, CLKINSTOPPED, CLKFBSTOPPED PWRDWN Входы синхронизации Входы управления и данных Выходы синхронизации Выходы состояния и данных Управление мощностью
А.12.2. Примитивы PLLE2.BASE и PLLE2-ADV
Для использования блока PLL служат примитивы PLLE2_BASE и PLLE2-ADV (рис. А.78).
Примитив PLLE2.BASE обеспечивает наиболее часто используемые функции отдельного блока PLL,
такие как устранение перекоса синхросигнала, синтез частоты, грубый фазовый сдвиг и программирование
скважности. Порты примитива PLLE2.BASE представлены в табл. А.86.
Примитив PLLE2JXDV обеспечивает доступ ко всем свойствам примитива PLLE2JBASE, плюс к до-
полнительным портам для переключения синхросигналов и доступу к динамически реконфигурируемому
порту DRP. Порты примитива PLLE2JXDV представлены в табл. А.87.
Приложение А. Примитивы FPGA 7-й серии
333
CLKIN1 CLKOUTO CLKIN1 CLKOUTO
CLKOUT1 CLKIN2 CLKOUT1 •-
в» CLKFBIN CLKOUT2 CLKFBIN CLKOUT2
*- RST CLKOUT3 — RST CLKOUT3
PWRDWN CLKOUT4 CLKINSEL CLKOUT4
CLKOUT5 «► DADDR[4:0] CLKOUT5 ►
CLKFBOUT DI(15:0] CLKFBOUT
DWE
DEN
DCLK
LOCKED p. LOCKED 0»..
PWRDWN
DO[15:0]
DRDY
PLLE2_ BASE PLLE2 ADV
Рис. А.78. Примитивы PLLE2-BASE и PLLE2JXDV
Таблица A.86 Порты примитива PLLE2_BASE Таблица А.87 Порты примитива PLLE2JXDV
Порт Описание Порт Описание
CLKIN1, CLKFBIN RST CLKOUTO-CLKOUT5, CLKFBOUT LOCKED Входы синхронизации Вход управления Выходы синхронизации Выход состояния и данных CLKIN1, CLKIN2, CLKFBIN, DCLK RST, CLKINSEL, DWE, DEN, DADDR, DI CLKOUTO-CLKOUT5, CLKFBOUT LOCKED, DO, DRDY PWRDWN Вход синхронизации Входы управления и данных Выходы синхронизации Выходы состояния и данных Управление мощностью
А.12.3. Порты блоков ММСМ и PLL
Порты блоков ММСМ и PLL представлены в табл. А.88.
Ниже приводится детальное описание портов блоков ММСМ и PLL.
CLKIN1 — основной (первичный) вход опорного синхросигнала. CLKIN1 может управляться непо-
средственно двунаправленными выводами SRCC или MRCC данного региона синхронизации, двунаправлен-
ными выводами SRCC или MRCC через магистраль СМТ в вертикальном соседнем регионе синхронизации,
буферами BUFG, BUFR, BUFH, межсоединениями (не рекомендуется) или прямо высокоскоростным по-
следовательным приемопередатчиком. Когда вход синхросигнала приходит от другого блока СМТ для
функций каскадирования СМТ, могут использоваться только CLKOUT[0:3].
CLKIN2 — вторичный вход опорного синхросигнала. CLKIN2 используется для динамического
переключения опорного синхросигнала блока MMCM/PLL. CLKIN2 может управляться непосредственно
двунаправленными выводами SRCC или MRCC данного региона синхронизации, двунаправленными выво-
дами SRCC или MRCC через магистраль СМТ в вертикальном соседнем регионе синхронизации, буферами
BUFG, BUFR, BUFH, межсоединениями (не рекомендуется) или прямо высокоскоростным последователь-
ным приемопередатчиком.
CLKFBIN — вход синхросигнала обратной связи. Должен подсоединяться либо прямо к CLKFB-
OUT для внутренней обратной связи, либо к буферам IBUFG (через СС-вход для устранения внешнего
перекоса), BUFG, BUFH, либо к межсоединениям (не рекомендуется). Для выравнивания внешнего синх-
росигнала тип буфера синхросигнала пути обратной связи должен согласовываться с типом буфера пред-
шествующего синхросигнала, за исключением BUFR. Буфер BUFR не может быть компенсироваться.
CLKFBOUT — специализированный выход обратной связи. Для допустимой конфигурации смотри
раздел «ММСМ and PLL Use Models» (модели использования блоков ММСМ и PLL). CLKFBOUT может
также управлять логикой подобно CLKO блока DCM семейства Virtex-5.
CLKFBOUTB — инвертированный CLKFBOUT. Этот сигнал не используется для обратной свя-
зи. Он обеспечивает дополнительный инвертированный выходной синхросигнал CLKFBOUT. CLKFBOUTB
может также управлять логикой подобно CLK180 блока DCM семейства Virtex-5.
334
Приложение А. Примитивы FPGA 7-й серии
Таблица А.88
Порты блоков ММСМ и PLL
Имя Тип Описание
CLKIN1 Вход Первичный (основной) вход синхронизации
CLKIN2 Вход Вторичный вход синхронизации для опорного синхросигнала блока MMCM/PLL
CLKFBIN Вход Вход синхросигнала обратной связи
CLKINSEL Вход Выбор входа синхросигнала, высокое значение — CLKIN1, низкое значе- ние — CLKIN2. Динамически переключает опорный синхросигнал MMCM/PLL
RST Вход Сигнал асинхронного сброса для MMCM/PLL. Блок MMCM/PLL будет себя повторно включать, когда этот сигнал освобождается. Сброс требу- ется тогда, когда изменяются условия входной синхронизации (например, частота)
PWRDWN Вход Выключает инстанцированный, но неиспользованный блок MMCM/PLL. Используется для сохранения мощности
DADDR[6:0] Вход Входная шина адреса динамической реконфигурации (dynamic reconfigura- tion address — DADDR). Когда не используется, всем битам должны быть назначены нули
DI[15:0] Вход Шина входных данных динамической реконфигурации. Когда не исполь- зуется, всем битам должны быть назначены нули
DWE Вход Вход разрешения записи динамической реконфигурации, обеспечивает управление записью данных DI по адресу DADDR. Когда не используется, должен быть подсоединен к низкому уровню
DEN Вход Разрешение динамической конфигурации, предоставляет управляющий сигнал разрешения для доступа возможности динамической реконфигура- ции. Когда динамическая реконфигурация не используется, должен быть подсоединен к низкому уровню
DCLK Вход Опорный синхросигнал для портов динамической реконфигурации
PSCLK Вход Синхросигнал фазового сдвига
PSEN Вход Разрешение фазового сдвига
PSINCDEC Вход Управление инкрементацией/декрементацией фазового сдвига
CLKOUT[0:6] (CLKOUT[0:5] для блока PLL) Выход Выходные синхросигналы, конфигурируемые пользователем, могут быть разделенными версиями фазовых выходов VCO (управляемые пользова- телем) от 1 (обход) до 128
CLKOUT[0:3]B Выход Инверсия CLKOUT[0:3]
CLKFBOUT Выход Специализированный выход обратной связи блока ММСМ
CLKFBOUTB Выход Инверсия CLKFBOUT
CLKINSTOPPED Выход Вывод состояния, указывающий, что входной синхросигнал остановлен
CLKFBSTOPPED Выход Вывод состояния, указывающий, что синхросигнал обратной связи оста- новлен
LOCKED Выход Вывод от MMCM/PLL, который указывает, когда MMCM/PLL достиг фа- зы выравнивания в предопределенном окне и частоты, соответствующей предопределенному диапазону PPM. ММСМ после включения автома- тически подстраивает частоту. Дополнительного сброса не требуется. LOCKED будет сбрасываться, если останавливается входной синхро- сигнал или нарушается выравнивание фазы (например, фазовый сдвиг входного синхросигнала). Блок MMCM/PLL должен быть сброшен после сброса LOCKED
DO[15:0] Выход Динамическая выходная шина реконфигурирования, обеспечивает вывод данных ММСМ при использовании динамической реконфигурации
DRDY Выход Выход готовности динамической реконфигурации, обеспечивает ответ на сигнал DEN для свойства динамической реконфигурации блоков ММСМ
PSDONE Выход Указывает на выполнение фазового сдвига
1. Для всех сигналов управления и состояний активный уровень высокий.
CLKINSEL — выбор входа синхросигнала. Управляет состоянием входных мультиплексоров синхро-
сигналов, высокий уровень — CLKIN1, низкий уровень — CLKIN2. Блок ММСМ/PLL должен удерживаться
в состоянии RESET во время переключения синхросигнала.
RST — сигнал асинхронного сброса. Сигнал RST является сигналом асинхронного сброса для бло-
Приложение А. Примитивы FPGA 7-й серии
335
ков MMCM/PLL. Когда этот сигнал аннулируется, блок MMCM/PLL должен синхронно повторно вклю-
читься.
PWRDWN — выключение. Выключает инстанцированные но не используемые блоки MMCM/PLL.
Этот режим может использоваться для сохранения мощности для временно неактивных частей проек-
та и/или блоков MMCM/PLL, которые не являются активными в определенных конфигурациях системы.
В этом режиме блоки MMCM/PLL не потребляют энергию.
DADDR[6:0] — адрес динамической реконфигурации. Входная шина DADDR обеспечивает адрес
реконфигурации для динамической реконфигурации. Значение адреса на этой шине определяет 16 битов
конфигурации, которые записываются или читаются в следующем цикле синхросигнала DCLK. Когда не
используется, всем битам должны назначаться нули.
01(1.5:0] — вход данных динамической реконфигурации. Шина DI обеспечивает данные рекон-
фигурации. Значение этой шины записывается в конфигурационные ячейки. Данные представляются в
цикле, когда DEN и DWE активны. Данные захватываются теневым регистром и записываются позже.
Сигнал DRDY указывает, когда порт DRP готов принять другую запись. Когда не используется, всем
битам должны назначаться нули.
DWE — разрешение записи динамической реконфигурации. Обеспечивает управляющий сигнал
разрешения записи/чтения для записи данных DI в или чтения данных DO из адреса DADDR. Когда не
используется, должен подсоединяться к низкому уровню.
DEN — строб разрешения динамической синхронизации. Обеспечивает сигнал управления для до-
ступа к функции динамической реконфигурации и разрешает все операции порта DRP. Когда динамической
реконфигурация не используется, должен подсоединяться к низкому уровню.
DCLK — опорный синхросигнал динамической реконфигурации. Возрастающий фронт этого сиг-
нала является временным эталоном для всех других сигналов портов. Время установки определяется из
документации (data sheet). Здесь нет требования времени удержания для других входных сигналов по отно-
шению к возрастающему фронту синхросигнала DCLK. Вывод может управляться буферами IBUF, IBUFG,
BUFG, BUFR или BUFH. Нет специализированных соединений с этим входом синхронизации.
PSCLK — синхросигнал фазового сдвига. Обеспечивает источник синхросигнала для интерфейса
динамического фазового сдвига. Все другие входы являются синхронными к положительному фронту
этого синхросигнала. Вывод может управляться буферами IBUF, IBUFG, BUFG, BUFR или BUFH. Нет
специализированных соединений с этим входом синхронизации.
PSEN — разрешение фазового сдвига. Динамическая (переменная) операция фазового сдвига
инициируется синхронной установкой этого сигнала. Он должен быть активным в течение одного цикла
синхросигнала PSCLK. После инициации фазового сдвига фаза шаг за шагом сдвигается до тех пор, пока
высокий импульс на выводе PSDONE не укажет, что операция закончилась. Здесь нет помех или случай-
ных изменений во время этой операции. От начала до конца операции фаза сдвигается в непрерывно
аналоговой манере.
PSINCDEC — управление инкрементацией/декрементацией фазового сдвига. Этот входной сиг-
нал синхронно указывает, если динамический фазовый сдвиг является операцией инкрементации или де-
крементации (положительный или отрицательный фазовый сдвиг). PSINCDEC устанавливается в высокий
уровень для инкрементации и в низкий уровень - для декрементации. Здесь нет переполнения фазового
сдвига, связанного с операцией динамического фазового сдвига. Если сдвиг больше, чем 360°, то фаза
будет просто повторяться, начиная от первоначальной фазы.
CLKOUT[0:6] — выходные синхросигналы. Это конфигурируемые пользователем выходные синхро-
сигналы (CLKOUT[0:6] для ММСМ и CLKOUT[0:5] для PLL) могут быть разделенными версиями фазовых
выходов VCO (управляемые пользователем) от 1 (обходится) до 128. Выходные синхросигналы фазово
выравниваются друг к другу (если только не смещена фаза) и выравниваются к входному синхросигналу
с надлежащей конфигурацией обратной связи. Прямые соединения НРС с BUFR/BUFIO поддерживают-
ся только на CLKOUT[0:3],
Когда используется буфер BUFR или BUFIO, блок ММСМ может прямо подсоединяться к HDC от
выходов синхронизации CLKOUT[0:3]. Дополнительно CLKOUT[0:3] могут подсоединяться к магистрали
СМТ для каскадирования блоков ММСМ и PLL. Подобно управлению блоков ММСМ и PLL от выводов
ССЮ к соседним регионам (см. «Clock-Capable Inputs»), каскадирование использует те же ограничен-
ные ресурсы, доступные в магистрали СМТ для подсоединения ресурсов синхронизации прямо в соседних
регионах. Результатом также будет фазовое смещение между элементами каскадирования в пределах
данного столбца.
Возможные конфигурации представлены в «ММСМ and PLL Use Models». Выводы CLKOUTO и
CLKFBOUT блока ММСМ могут использоваться в режиме дробного (fractional) деления. Все выводы
CLKOUT могут использоваться в не дробном режиме для обеспечения статического или динамического
336
Приложение А. Примитивы FPGA 7-й серии
фазового сдвига. В дробном режиме допускается только фиксированный фазовый сдвиг. Детали см. в
«Static Phase Shift Mode».
CLKOUT[0:3]B — инвертированные выходные синхросигналы. Инвертируются (сдвигаются на
180°) выводы CLKOUT[0:3],
CLKINSTOPPED — состояние входного синхросигнала. Вывод состояния указывает, что входной
синхросигнал остановлен. Этот сигнал устанавливается в пределах одного цикла синхронизации остановки
синхросигнала. Этот сигнал сбрасывается после рестарта синхросигнала и достигается LOCKED или син-
хросигнал переключается на альтернативный вход синхронизации и блок ММСМ повторно заблокирован.
CLKFBSTOPPED — состояние синхросигнала обратной связи. Вывод состояния указывает, что
синхросигнал обратной связи остановлен. Этот сигнал устанавливается в пределах одного цикла синхрони-
зации остановки синхросигнала. Этот сигнал сбрасывается после рестарта синхросигнала обратной связи
и повторной блокировки блока ММСМ.
LOCKED — выход от блока MMCM/PLL. Используется для указания, когда блок MMCM/PLL до-
стиг фазового и частотного выравнивания опорного синхросигнала и синхросигнала обратной связи при
входных выводах. Фазовое выравнивание в предопределенном окне и подходящая частота в предопределен-
ном диапазоне PPM. Блок ММСМ автоматически подстраивает частоту синхронизации после включения
питания, не требуя внешнего сброса. LOCKED будет аннулироваться в пределах одного цикла синхро-
сигнала детектора PFD, если остановится входной синхросигнал, нарушается фазовое выравнивание (т е.
фазовый сдвиг входного синхросигнала) или изменилась частота. Когда LOCKED аннулируется, блок
MMCM/PLL должен быть сброшен. Выходы синхросигналов не должны использоваться перед установ-
кой LOCKED.
DO[15:0] — выходная шина динамической реконфигурации. Обеспечивает выходные данные блока
ММСМ, когда используется динамическая реконфигурация. Если DWE является активным, в то время
как DEN активен на положительном фронте синхросигнала DCLK, то эта шина удерживает содержимое
конфигурационных ячеек, адресуемых DADDR. Шина DO должна захватываться на положительном фронте
DCLK, когда DRDY активен. Значение шины DO удерживается до следующей операции DRP.
DRDY — готовность динамической реконфигурации. Обеспечивает ответ к сигналу DEN для
свойства динамической реконфигурации блоков ММСМ. Этот сигнал указывает, что операция DEN/DCLK
завершена.
DSDONE — выполнение фазового сдвига. Этот выходной сигнал выполнения фазового сдвига
является синхронным по отношению к PSCLK. Когда текущая операция фазового сдвига завершается,
сигнал DSDONE устанавливается на один цикл синхронизации, указывая, что может инициироваться но-
вый фазовый сдвиг.
А. 12.4. Атрибуты примитивов блоков ММСМ и PLL
Атрибуты примитивов блоков ММСМ и PLL представлены в табл. А.89.
Таблица А.89
Атрибуты примитивов блоков ММСМ и PLL
Атрибут Значения Описание
BANDWIDTH CLKOUT[1:6]-DIVIDE (CLKOUT[0:5]_DIVIDE для PLL) CLKOUT[0] -DIVIDE.F (только для MMCM) CLKOUT[0:6]_PHASE (CLKOUT[0:5].PHASE для PLL) HIGH LOW OPTIMIZED (no умолчанию) От 1 (по умолчанию) до 128 От 1 (по умолчанию) до 128 или от 2.000 до 128.000 в приращениях 0.125 От -360.000 до 360.000 в приращениях 1/56 часто- ты Fvco и/или инкремен- тации в зависимости от CLKOUT-DIVIDE, 0.0 (по умолчанию) Определяет алгоритм программирования MMCM/PLL, поражающий флуктуацию, до- пустимое отклонение фазы и другие характе- ристики MMCM/PLL Определяет число для деления, связанное с выходным синхросигналом CLKOUT, если требуется другая частота. Это число в ком- бинации с значениями CLKFBOUT_MULT_F и DIVCLK_DIVIDE будут определять выход- ную частоту Позволяет определить отношение фазы вы- хода связанного выходного синхросигнала CLKOUT в числе градусов смещения (на- пример, 90 указывает фазовое смещение 90° или 1/4 цикла, 180 - 180° или 1/2 цикла)
Приложение А. Примитивы FPGA 7-й серии
337
Продолжение табл. А.89
Атрибут Значения Описание
CLKOUT[0;6]_DUTY-CYCLE (CLKOUT[0:5]_DUTY_CYCLE для PLL) CLKFBOUT_MULT_F (для ММСМ) CLKFBOUT-MULT (для PLL) DIVCLK-DIVIDE CLKFBOUT-PHASE REFJITTER1 REF-JITTER2 CLKINl-PERIOD CLKIN2.PERIOD CLKFBOUT_USE_FINE_PS (только для ММСМ) CLKOUTO_USE_FINE_PS (только для ММСМ) CLKOUTfl :6] JJSE_FINE_PS (только для ММСМ) STARTUP-WAIT CLKOUT4.CASCADE (только для ММСМ) COMPENSATION 0.01-0.99, 0.50 — по умолчанию 2-64 или 2.000- 64.000 (только для ММСМ) в прираще- ниях 0.125, 5 — по умолчанию 1 (по умолчанию) — 106 (56 для PLL) 0.0 (по умолчанию) — 360.000 0.000-0.999, 0.010 — по умолчанию 0.938-100.000 (52.631 для PLL), 0.0 — по умолчанию 0.938-100.000 (52.631 для PLL), 0.0 — по умолчанию FALSE (по умолча- нию), TRUE FALSE (по умолча- нию), TRUE FALSE (по умолча- нию), TRUE FALSE (по умолча- нию), TRUE FALSE (по умолча- нию), TRUE ZHOLD1 (по умол- чанию), EXTERNAL, INTERNAL, BUFJN Определяет скважность выхода синхросигнала CLKOUT в процентах (например, 0.50 будет ге- нерировать скважность 50 %) Определяет число для умножения всех выходов синхросигналов CLKOUT, если требуются раз- личные частоты. Это число в комбинации с со- ответствующими значениями CLKOUT#_DIVIDE и DIVCLK-DIVIDE будет определять выходную частоту Определяет коэффициент деления для всех вы- ходных синхросигналов по отношению к входному синхросигналу. Эффективно делит CLKIN, прихо- дящий в детектор PFD Определяет фазовое смещение в градусах выхода синхросигнала обратной связи. Сдвигающий син- хросигнал обратной связи получает результат в отрицательном сдвиге фаз всех выходных синхро- сигналов в MMCM/PLL Позволяет определить ожидаемую флуктуацию на опорном синхросигнале для того, чтобы лучше оп- тимизировать производительность MMCM/PLL. Установка полосы пропускания OPTIMIZED будет пытаться выбрать лучший параметр для входной синхронизации, когда неизвестно. Если известно, то представленное значение должно определять- ся в терминах единичного интервала (unit interval — UI), максимальный пик для пикового значения, ожидаемой флуктуации на входе синхросигнала Определяет входной период в нс для входа CLKIN1 блока MMCM/PLL. Разрешение дается в пс. Эта информация обязательна и должна быть предо- ставлена Определяет входной период в нс для входа CLKIN2 блока ММСМ. Разрешение дается в пс. Эта ин- формация обязательна и должна быть предостав- лена Разрешает тонкий сдвиг фазы переменной счетчи- ка CLKFBOUT Разрешает тонкий сдвиг фазы переменной счет- чика CLKOUTO. Атрибут CLKOUT0-DIVIDE дол- жен быть целым числом, поэтому дробное деление запрещено Разрешает тонкий сдвиг фазы переменной CLKOUT[1:6] Ожидание в течение цикла установки конфигура- ции для MMCM/PLL к автоматической подстройке частоты Каскадирует выходной делитель (счетчик) CLKOUT6 в вход делителя CLKOUT4 для дели- теля выходного синхросигнала, который является больше, чем 128, эффективно обеспечивая общее значение деления 16384 Компенсация входного синхросигнала. Должен быть установлен в ZHOLD. Определяет как конфи- гурируется обратная связь MMCM/PLL. ZHOLD’ указывает MMCM/PLL конфигурироваться для обеспечения отрицательного времени удержания на регистрах ввода-вывода. EXTERNAL: Указывает сети, внешней к FPGA, компенсироваться.
338
Приложение А. Примитивы FPGA 7-й серии
Продолжение табл. А.89
Атрибут Значения Описание
SS.EN (только для ММСМ) SS.MODE (только для ММСМ) SS_MOD_PERIOD (только для ММСМ) 1. Значения атрибута СОМР ISE автоматически выбирае управляйте вручную выборо FALSE (по умолча- нию), TRUE DOWN-LOW, DOWN-HIGH, CENTER-LOW, CENTER-HIGH (no умолчанию) 4000-40000, 10000 — по умолчанию ENSATION документик г подходящую компенс м значения компенсаци INTERNAL: указывает MMCM/PLL, использую- щему свой собственный внутренний путь обратной связи, так, что никакая задержка не компенсирует- ся. BUFJN: указывает, что конфигурация не согла- суется с другими компенсационными режимами и задержка не будет компенсироваться. Это являет- ся случаем, если вход синхросигнала управляется буферами BUFG, BUFH, BUFR или приемопередат- чиками GT Разрешает генерацию распространяемого спектра Управляет делением частоты распространяемого спектра и типом распространения Определяет период модуляции распространяемого спектра в нс >уются только с информационной целью. Программа ацию, основанную на определенной топологии. Не и, оставляйте значение атрибута по умолчанию.
А.13. Выводы конфигурирования FPGA 7-й серии
Выводы конфигурирования FPGA 7-й серии приведены в табл. А.90.
CFGBVS — выбор напряжения банков конфигурирования. CFGBVS определяет рабочий диапазон
напряжения ввода-вывода и допуск по напряжению для специального банка конфигурирования 0 и для
многофункциональных контактов конфигурирования в банках 14 и 15 в семействах Artix-7 и Kintex-7. Вывод
CFGBVS должен быть подсоединен к высокому уровню, если напряжение Vcco_o равно 2,5 В или 3,3 В, и к
GND, если меньше или равно 1.8 В. Контакт CFGBVS не доступен на Virtex-7 НТ устройства. Устройства
Virtex-7 НТ для банка 0 поддерживают работу только с напряжением 1,8 В/1,5 В.
Внимание. Неправильное подсоединение CFGBVS может привести к повреждению FPGA.
М[2:0] — режим конфигурирования. Выводы М[2:0] определяют режим конфигурирования согласно
табл. 2.3. В соответствии с выбранным режимом каждый вывод соединяется непосредственно или через
резистор < 1 кОм к Vcco.o или GND.
ТСК — синхросигнал стандарта IEEE Std 1149.1 (JTAG). Синхросигнал для всех устройств в
цепочке JTAG.
TMS — выбор режима JTAG. Выбор режима для всех устройств в цепочке JTAG.
TDI — Вход данных JTAG. Вход последовательных данных цепочки JTAG. Для изолированного
устройства или для первого устройства в цепочке JTAG, соедините с контактом TDI маркировки кабеля
Xilinx. Иначе, когда FPGA не первое устройство в цепочке JTAG, подключите к контакту TDO предыдущего
устройства в цепочке сканирования JTAG.
TDO — Выход данных JTAG. Выход последовательных данных цепочки JTAG. Для изолированного
устройства или для первого устройства в цепочке JTAG, соедините с контактом TDO маркировки кабеля
Xilinx. Иначе, когда FPGA не последнее устройство в цепочке JTAG, подключите к контакту TDI следующего
устройства в цепочке сканирования JTAG.
PROGRAM-B — программирование. Активно низкий сигнал сброса логики конфигурирования и
начала нового конфигурирования. Когда на PROGRAM.B приходит импульс низкого уровня, логика кон-
фигурирования FPGA очищается, и инициируется новая последовательность конфигурирования. Сброс
конфигурирования инициируется убывающим фронтом, а конфигурационная (т. е. программирующая) по-
следовательность начинается на следующем нарастающем фронте.
INIT-B — инициализация. Активно низкий вход инициализации FPGA или выходной сигнал ошибки
конфигурирования. FPGA устанавливает этот вывод в низкий уровень, когда FPGA находится в состоянии
сброса конфигурирования, когда FPGA инициализирует (очищает) свою конфигурационную память или
когда FPGA обнаруживает ошибку конфигурирования. После завершения процесса инициализации FPGA
вывод INIT.B переводится в высокоимпедансное состояние, в котором внешний резистор, как ожидается,
Приложение А. Примитивы FPGA 7-й серии
339
Таблица А.90
Выводы конфигурирования
Имя Банк1 Тип Направление Описание
CFGBVS 0 Выделенный Вход Выбор напряжения банков конфигури- рования
М[2:0] 0 Выделенный Вход Режим конфигурирования
ТСК 0 Выделенный Вход Синхросигнал стандарта IEEE Std 1149.1 (JTAG)
TMS 0 Выделенный Вход Выбор режима JTAG
TDI 0 Выделенный Вход Вход данных JTAG
TDO 0 Выделенный Выход Выход данных JTAG
PROGRAM.B 0 Выделенный Вход Программирование
INIT-B 0 Выделенный Д ву на п ра вл ен н ы й (открытый сток) Инициализация
DONE 0 Выделенный Д ву на п ра вл ен н ы й Выполнение
CCLK 0 Выделенный Вход или выход Синхросигнал конфигурирования
PUDC_B 14 Многофункциональный Вход Подтягивание вверх двунаправленных выводов во время конфигурирования
EMCCLK 14 Многофункциональный Вход Внешний главный синхросигнал кон- фигурирования
CSLB 14 Многофункциональный Вход Вход выбора кристалла в режиме SelectMAP
CSO_B 14 Многофункциональный Выход (открытый сток) Выход выбора кристалла
DOUT 14 М ногофункциональный Выход Выход данных
RDWR.B 14 Многофункциональный Вход Чтение/запись в режиме SelectMAP
DOO-MOSI 14 Многофункциональный Двунаправленный Выход для главного, вход для подчи- ненного
D01-DIN 14 Многофункциональный Двунаправленный Вход данных
D [00-31] 14 М ногофункциональный Двунаправленный Шина данных
A[00-28] 14 Многофункциональный Выход Шина адреса
FCS_B 14 М ногофункциона л ьный Выход Выбор кристалла флэш-памяти
FOE_B 15 Многофункциональный Выход Разрешение выхода флэш-памяти
FWE_B 15 Многофункциональный Выход Разрешение записи флэш-памяти
ADV.B 15 Многофункциональный Выход Действительный адрес
RS0, RSI VCCBATT 15 Многофункциональный Напряжение питания Выход Выбор версии Предоставление резервного аккумуля- тора
1. Каждый ввод-вывод ссылается к напряжению питания банка Vcco в котором расположен ввод-
вывод. Например, «0» указывает, что ввод-вывод ссылается к напряжению VCCO-0 банка 0.
подтянет IN 1Т_В к высокому уровню. Вывод INIT.B может внешне удерживаться на низком уровне во время
включения питания для того, чтобы останавливать последовательность конфигурирования по включению
питания в конце процесса инициализации.
DONE — выполнение. Высокий уровень на этом контакте указывает завершение последователь-
ности конфигурирования. Выход DONE является выходом с открытым стоком. DONE имеет внутренний
нагрузочный резистор приблизительно 10 кОм.
CCLK — синхросигнал конфигурирования. CCLK является синхросигналом конфигурирования
FPGA во всех режимах, за исключением режима JTAG. Для подчиненных режимов CCLK является входом
и требует подсоединения к внешнему источнику синхросигнала. Для главных режимов FPGA является ис-
точником синхросигнала синхронизации и управляет выводом CCLK как выходом. В режиме JTAG CCLK
находится в высокоимпедансном состоянии и может оставаться не подсоединенным.
PUDC-B — подтягивание двунаправленных выводов общего назначения вверх во время конфи-
гурирования. Активно низкий уровень входа PUDC-B разрешает внутренние подтягивающие резисторы на
общецелевых двунаправленных выводах после включения питания и во время конфигурирования. PUDC-B
должен прямо подсоединяться либо к Vcco_i4 через резистор 1 кОм, либо к GND.
Внимание. Не разрешайте этому выводу «плавать» до и во время конфигурирования.
EMCCLK — внешний главный синхросигнал конфигурирования. Дополнительный вход внешнего
таймера для функционирования логики конфигурирования в главном режиме (по сравнению с внутренним
340
Приложение А. Примитивы FPGA 7-й серии
генератором конфигурирования). Для получения дополнительной информации см. «Setting Configuration
Options in the Vivado Tools».
CSLB — вход выбора кристалла. Активно низкий вход, который разрешает FPGA интерфейс кон-
фигурирования SelectMAP.
CSO_B — выход выбора кристалла. Активно низкий выход с открытым стоком, который разреша-
ет подчиненный интерфейс конфигурирования SelectMAP для следующей в потоке FPGA в параллельной
цепочке конфигурирования.
DOUT — выход данных. Является выходом данных для последовательной цепочки конфигури-
рования.
RDWR-B — чтение/запись. Вывод RDWRJ3 определяет направление шины данных SelectMAP.
Когда RDWR.B имеет высокий уровень, выходы FPGA читают данные на шину данных SelectMAP. Когда
RDWRJ3 имеет низкий уровень, внешний контроллер может писать данные в FPGA через шину данных
SelectMAP.
DOO-MOSI — главный-выход, подчиненный-вход. Вывод главного FPGA в режиме SPI для отправки
команд к подчиненной флэш-памяти SPL
D01-DIN — вход данных. Является входом последовательных данных. По умолчанию, данные на
входе DIN захватываются на возрастающем фронте синхросигнала CCLK.
D[00-31] — шина данных. Подмножество или все выводы D[00-31] являются интерфейсом ши-
ны данных для режимов SPI х2, SPI х4, BPI или SelectMAP. По умолчанию, данные на шине данных
захватываются на возрастающем фронте синхросигнала CCLK.
Внимание. Подчиненный режим SelectMAP с конфигурацией шины данных Х16 и х32 не поддержи-
вает конфигурацию от битового потока с AES-шифрованием.
А[00-28] — шина адреса. Контакты А[00-28] выводят адреса к параллельной флэш-памяти NOR
(BPI) _
FCS_B — выбор чипа флэш-памяти. Активно низкий выход выбора чипа разрешает флэш-память
SPI или BPI для конфигурирования.
FOE_B — разрешение выхода флэш-памяти. Активно низкий сигнал управления разрешением
выхода для параллельной флэш-памяти NOR.
FWE_B — разрешение записи флэш-памяти. Активно низкий сигнал управления разрешением
записи для параллельной флэш-памяти NOR.
ADV_В — действительный адрес. Активно низкий выходной сигнал действительного адреса для
параллельной флэш-памяти NOR.
RSO, RS1 — выбор версии. RS0 и RS1 являются выходами выбора версии. Нормально RS0 и RS1
находятся в высокоимпедансном состоянии во время конфигурирования. Однако FPGA может управлять
выводами RS0 и RS1 в двух случаях. Когда разрешается опция ConfigFallback FPGA переводит RS0 и RS1 на
низкий уровень во время процесса конфигурирования при нейтрализации неисправности (fallback), которая
позволяет обнаружить ошибку конфигурирования. Когда инициируется вызванный пользователем процесс
конфигурирования MultiBoot. FPGA может управлять выводами RS0 и RS1 для определяемого пользо-
вателем состояния во время процесса конфигурирования MultiBoot. Если нейтрализация неисправности
запрещена (по умолчанию) и если не используется MultiBoot, то выводы находятся в высокоимпедансном
состоянии и могут оставаться неподсоединенными.
VCCBATT — предоставление резервного аккумулятора. Vccbatt является выводом напряжения
питания резервного аккумулятора для внутренней энергозависимой памяти FPGA, которая хранит ключ
дескриптора AES.
Приложение Б. Временные модели FPGA 7-й серии
Б.1. Временная модель CPLD семейства XC9500XL
Однородность архитектуры семейства XC9500XL позволяет рассматривать упрощенную временную
модель данных устройств Основная временная модель, показанная на рис. Б.1, допустима для функций
макроячеек, которые используют только прямые промежуточные шины со стандартной установкой питания
и стандартной установкой скорости возрастания выходных сигналов.
В табл. Б.1 представлено, как на значение временных параметров влияют распределитель проме-
жуточных шин, установка низкой мощности и установка ограничения скорости нарастания, где Труд —
задержка распределителя промежуточных шин, Tlp — дополнительная задержка в режиме малой потреб-
ляемой мощности.
Propagation Delay = Tpd
(а)
Setup Time ~ Tgg Clock to Out Time ~ Tqq
Setup Time - Tpsu Clock to Out Time = Tpco
(c)
Combinatorial
Internal System Cycle Time = TsySTEM
(Ф
Рис. Б.1. Основные временные модели
Таблица Б.1
Параметры временной модели
Параметр Описание Распределитель промежуточных шин Установка малой потребляемой мощности для макроячейки Установка ограничения ско- рости нарастания для выхода
Тро Задержка прохождения сигнала + Труд * S + Tlp + TsLEW
Tsu Тео Время установки глабального синхросигнала От глобального синхросигнала к выходу + Труд * S + Tlp + Tslew
Tpsu Трсо Время установки синхросигна- ла промежуточной шины От синхросигнала промежу- точной шины к выходу + Труд * S + Tlp + Tslew
Т SYSTEM Период внутреннего системно- го цикла + Труд * S + TLp —
342
Приложение Б. Временные модели FPGA 7-й серии
| Product "I erm
Allocator
I Product Term
I Allocator
Product Tens
Allocator
Рис. Б.2. Распределитель промежуточных шин с 15-ю
промежуточными шинами
Рис. Б.З. Распределитель промежуточных
шин с 18-ю промежуточными шинами
Время распределителя промежуточных шин зависит от логической длительности (span) функции мак-
роячейки, которая определяется как максимальное число распределителей, в пути промежуточной шины.
Если используются только прямые промежуточные шины, то логическая длительность равна 0. Например,
на рис. Б.2 показано до 15 промежуточных шин доступных с логической длительностью 1. На рис. Б.З
функция 18 промежуточных шин имеет логическую длительность 2.
Подробная информация о времени может быть получена из полной временной модели синхронизации,
показанной на рис. Б.4. Значения и объяснения каждого параметра даны в отдельных таблицах данных
(data sheets) для каждого устройства.
Б.2. Временная модель CPLD семейства CoolRunner-ll
На рис. Б.5 показана временная модель устройств семейства CoolRunner-ll.
В табл. Б.2 приведены отдельные временные параметры и определены их функции. Более детальное
рассмотрение некоторых примеров можно найти в документе ХАРР375.
Приложение Б. Временные модели FPGA 7-й серии
343
Рис. Б.4. Детализированная временная модель
Рис. Б.5. Временная модель устройств семейства CoolRunner-ll
Таблица Б.2
Временные параметры
Символ Параметр
Tin Tdin Tgck Tgsr Tout Ten Tslew Tlogii T|_CGI2 Буферные задержки Задержка входного буфера Входная задержка прямого регистра данных Задержка буфера глобального синхросигнала Задержка буфера глобальной установки/сброса Задержка буфера глобального разрешения выхода Задержка выходного буфера Задержка разрешения/запрещения выходного буфера Задержка управления скоростью нарастания выходного буфера Задержки промежуточных шин Задержка управляющего терма (сигнал РТ или FB-CT) Задержка логики единственной промежуточной шины Сумматор задержки логики многих промежу- точных шин
Символ Параметр
TpDI Tsui Thi Tecsu Тесно Tcoi Taoi Thys Tqem Задержки макроячеек От входа к достоверному выходу Установка регистра до синхросигнала Удержание регистра после синхросиг- нала Время установки разрешения синхро- низации регистра Время удержания разрешения синх- ронизации регистра От синхросигнала регистра к досто- верному выходу От сигнала установки/сброса регист- ра к достоверному выходу Гистерезисный сумматор задержки выбора Задержки обратной связи Задержка обратной связи Задержка от макроячейки к глобаль- ному ОЕ
344
Приложение В. Временные модели FPGA 7-й серии
Б.З. Временные модели внутренней логики FPGA 7-й серии
Отметим, что при использовании программного обеспечения Xilinx для реализации большинства про-
ектов нет необходимости понимать специфику различных Беременных параметров. Однако полная модель
синхронизации может помочь опытным пользователям в анализе критических путей или планировании
чувствительных к скорости проектов, особенно в больших и сложных FPGA 7-й серии. Пользователю ре-
комендуют использовать модели в этой главе в сочетании с программным временным анализатором Xilinx
Timing Analyzer и совместно с разделом по характеристикам переключения в соответствующей докумен-
тации FPGA 7-й серии Все имена выводов, названия параметров и путей являются непротиворечивыми
с отчетами временного анализатора.
Для каждой категории описываются три раздела временной модели:
• схема функционального элемента;
• временные параметры, определения временных параметров соответствующих таблиц данных FPGA
7-й серии;
• временная диаграмма, иллюстрации временных параметров функциональных элементов друг отно-
сительно друга.
Общая форма названия временного параметра синхронизации — Т, при этом в нижнем индексе опи-
сывается соединение начального и конечного контакта. Например, Тс^ск — время установки от СЕ к
синхросигналу, и Тсксе — время задержки от синхросигнала к СЕ. В некоторых случаях единственное
название параметра может применяться к разнообразным путям через секцию и может иметь различные
значения для каждого пути.
Б.3.1. Общие временные модели и параметры секции CLB
Упрощенная секция FPGA 7-й серии показана на рис. Б.6.
В табл. Б.З приведены общие временные параметры основных узлов секции, показанных на рис. Б.6.
Таблица Б.З
Общие временные параметры секции CLB
Параметр Функция Описание
1 ILO Тгго Тско TcKLO TshCKO Tas/Tah Tdick/Tckdi Тсеск/Тсксе Tsrck/Tcksr Trpw (Tsrmin) Trq Комби Входы A/B/C/D к выхо- дам A/B/C/D Входы A/B/C/D через прозрачную защелку к вы- ходам AQ/BQ/ CQ/DQ Последов Синхросигнал триггера (CLK) к выходам AQ/BQ/ CQ/DQ Синхросигнал защелки (CLK) к выходам AQ/BQ/ CQ/DQ Синхросигнал триггера (CLK) к выходам AMUX/ BMUX/CMUX/DMUX Времена установки и удерж Входы A/B/C/D Входы AX/BX/CX/DX Вход СЕ Вход SR У Вход SR Вход SR национные задержки Задержка распространения от входов через генераторы LUT к выходам A/B/C/D Задержка распространения от входов A/B/C/D через ге- нераторы LUT к выходам AQ/BQ/CQ/DQ последователь- ных элементов, сконфигурированных как защелки ательностные задержки Время стабилизации данных на выходах AQ/BQ/CQ/DQ последовательных элементов (сконфигурированных как триггеры) после прихода синхросигнала Время стабилизации данных на выходах AQ/BQ/CQ/DQ последовательных элементов (сконфигурированных как защелки) после прихода синхросигнала Время стабилизации данных на выходах AMUX/BMUX/ CMUX/DMUX (через триггеры) ания для последовательных элементов^ Время до/после CLK, когда данные от входов LUT А/В/ С/D должны быть стабильными Время до/после CLK, когда данные от входов LUT АХ/ BX/CX/DX должны быть стабильными Время до/после CLK, когда вход секции СЕ должен быть стабильным Время до/после CLK, когда вход секции SR (Set/Reset) должен быть стабильным становка/сброс Минимальная ширина импульса для SR Задержка распространения для асинхронной установ- ки/сброса последовательных элементов
Приложение Б. Временные модели FPGA 7-й серии
345
Окончание табл. Б.З
Параметр Функция Описание
Тсео Ftog 1. Этот пар 2- Тххск фронта сип Вход СЕ Вход CLK аметр включае = времени уст хросигнала). Другие Задержка распространения от входа разрешения СЕ к выходу защелки на выходах AQ/BQ/CQ/DQ Частота переключения — минимальная частота, на которой триггер мо- жет синхронизироваться. Для внешнего управления т LUT, сконфигурированный как две 5-входовые функции. ановки (до фронта синхросигнала) и Тскхх - времени удержания (после
D
Inputs
ШТ
Об
LUT
6
Об
05
/'•у
ШТ
6
Об
ШТ
D
СЕ
CLK
В
Inputs ’
С
Inputs
--------ODMUX
FF/LAT
05
F7BMUX
05
05
CLKO
SRO
— СЕ
— СК
Рис. Б.6. Упрощенная структура секции FPGA 7-й серии
F7AMUX
D
— СЕ
— СК
FF.1AT
D
СЕ
CLK
F8MUX
— СЕ
— СК
— СЕ
— СК
FF/LAT
D
СЕ
CLK
А
Inputs
Об
FF/LAT
D
СЕ
CLK
О AMUX
346
Приложение Б. Временные модели FPGA 7-й серии
Рис. Б.7. Общие временные диаграммы секции
CLK
CIN
(DATA)
AQ/BQ/CQ DQ
(OUT)
Рис. Б.8. Временные диаграммы
цепи переноса
На рис. Б.7 показаны общие временные диаграммы секции FPGA 7-й серии
В момент времени Тсеск до события 1 сигнал разрешения синхронизации принимает значение вы-
сокого уровня от входа СЕ регистра секции.
В момент времени Tdick до события 1 данные от каждого входа АХ. ВХ. СХ и DX принимают
высокий уровень от входа D регистра секции и отображаются на каждый выход AQ, BQ, CQ и DQ в
момент времени Тско после события 1.
В момент времени Tsrck Д° события 3 сигнал SR (сконфигурированный как синхронный сброс)
принимает высокий уровень, переустанавливая регистр секции. Это отображается на выводы AQ, BQ, CQ
и DQ в момент времени Тско после события 3.
Б.3.2. Временные параметры мультиплексоров секции CLB
В табл. Б.4 представлены временные параметры мультиплексоров секции CLB.
Таблица Б.4
Временные параметры мультиплексоров секции
Параметр Функция Описание
Задержм Тдхд/Тдхв/Твхв/ Тсхв/Тсхс Торав/ Торба/ Торвв/Торсв/ Торов/Торос T|LO_2 4 прохождения для секции Входы АХ/ВХ/СХ к вы- ходам AMUX/ BMUX/ CMUX Входы A/B/C/D к вы- ходам AMUX/ BMUX/ CMUX Входы А/С к выходам AMUX/ CMUX л, использующей широкие мультиплексоры Задержка прохождения от входов секции АХ/ВХ/СХ через входы выбора мультиплексоров к выходам сек- ции AMUX/ BMUX/ CMUX Задержка прохождения от входов A/B/C/D генера- тора LUT через мультиплексоры к выходам секции AMUX/ BMUX/CMUX Задержка прохождения от входа А генератора LUT через мультиплексор F7AMUX к выходу секции AMUX или от входа С генератора LUT через мультиплексор F7BMUX к выходу секции CMUX
Б.3.3. Временные параметры и характеристики цепи переноса
В табл. Б.5 приведены временные параметры цепей переноса блока CLB.
На рис. Б.8 показаны временные диаграммы цепи переноса.
В момент времени Tqnck Д° события 1 данные на входе CIN принимают действительно высокое
значение от входа Data регистра секции. Это отображается на любом из выходов AQ/BQ/CQ/DQ в
момент времени Тско после события 1.
Б.3.4. Временные модели и временные параметры распределенной памяти RAM
секции блока CLB
На рис. Б.9 показана упрощенная структура распределенной памяти FPGA 7-й серии, используемая
для понимания временной модели.
Временные параметры распределенной памяти RAM приведены в табл. Б.6.
На рис. Б. 10 показаны временные диаграммы распределенной памяти RAM.
Приложение В. Временные модели FPGA 7-й серии
347
Таблица Б.5
Временные параметры цепей переноса
Параметр Функция Описание
Задержк Т аха /Тдхв /Т АХС / Taxd/Tbxb/Tbxc/ т BXD /Т СХС /Т CXD / Tdxd Taxcy/Tbxcy/ Tcxcy/Tdxcy Tbyp T opcya/T opcyb/ TopCYC/TOPCYD Tcina/Tcinb/ TciNc/TciND Время устан Tcinck/Tckcin 1 Тххск — время и прохождения для секци Входы AX/BX/CX/DX к выходам AMUX/ BMUX/ CMUX/DMUX Входы AX/BX/CX/DX к выходу COUT Вход CIN к выходу соит Входы A/B/C/D к вы- ходу соит Вход CIN к выходам AMUX/BMUX/CMUX/ DMUX овки и удержания для се> Вход CIN установки; Тскхх — врем й, сконфигурированных как цепь переноса Задержка распространения от входов AX/BX/CX/DX через логику переноса к выходам AMUX/ BMUX/ CMUX/DMUX Задержка распространения от входов AX/BX/CX/DX к выходу COUT Задержка распространения от входа CIN к выходу соит Задержка распространения от входов LUT A/B/C/D к выходу COUT Задержка распространения от входа CIN к выходам AMUX/BMUX/CMUX/DMUX, используя XOR <ции, сконфигурированной как цепь переноса1 Время до/после CLK, когда вход секции CIN должен быть стабильным я удержания.
Таблица Б.6
Временные параметры распределенной памяти RAM
Параметр Функция Описание
Последова Tshcko Tshcko (TsHCKO-l) Время установки Тds/Тон (Tds_lram/Tdh_lram) Tas/Tah (Т AS-LRAM /Т AH-LRAM ) Tws/Twh (T WS-LRAM /ТWH-LRAM ) TmPW (TmPW-LRAm) Tmcp 1- Txs ~ время установг 2. Параметр включает Z тельные задержки как распр< CLK к выходам A/B/C/D CLK к выходам AMUX/BMUX/ CMUX/DMUX 1 сброса для LUT, AI/BI/CI/DI кон- фигурируются как входы данных (DI1)2 Входы адреса A/B/C/D Вход разрешения записи WE Си <и, Тхн — время уде <X/BX/CX/DX, коне цля генератора LUT, сконфигурированного оделенная память RAM Время после сигнала CLK операции записи, когда запи- санные в распределенную память RAM данные становят- ся стабильными на выходах секции A/B/C/D Время после сигнала CLK операции записи, когда запи- санные в распределенную память RAM данные стано- вятся стабильными на выходах секции AMUX/BMUX/ CMUX/DMUX сконфигурированного как распределенная память1 Время до/после синхросигнала, когда данные должны быть стабильными на входах секции AI/BI/CI/DI Время до/после синхросигнала, когда данные должны быть стабильными на входах LUT A/B/C/D Время до/после синхросигнала, когда сигнал разрешения записи должен быть стабильным на входе секции WE нхросигнал CLK Минимальная ширина импульса синхросигнала для рас- пределенной памяти RAM Минимальный период синхросигнала для удовлетворения времени цикла записи адреса зржания. }зигурируется как вход данных (DI2).
Событие 1: операция записи. Во время операции записи содержимое памяти от адреса на входах
ADDR изменяется. Данные записываются в ячейку этой памяти, отображаемую на выходах A/B/C/D,
синхронно.
В момент времени Tws до события синхросигнала 1 сигнал разрешения записи WE принимает дейст-
вительно высокое значение, разрешая память RAM для операции записи.
348
Приложение Б. Временные модели FPGA 7-й серии
Рис. Б.9. Упрощенная структура распределенной памяти FPGA 7-й серии
12 3 4 5 6 /
1 ‘MPW | | Г ^tmpwI | I I —*1 i CLK AV AX AX A X *1 Iх—4 — \ —I v —н—taS । i । ABC.0--xL>'"T t'V'fV'i 3 vH~~4— (ADDR) — (-/N-L-ZX4— <’4—“ —-j —Tds ’ \ 1 * ~~x 1 1! 1 p TWS I |TILO_] | Aq ь 1 1 \ 1 Xj 2 ZXj.._ xtzzz 1 ! itilo!
vvt A 1 XI i A 1 —। ^—। y-A j DATA-OUT ' *-TSHCKO j 1 ЛВ/С0 ; X 1 ; XMEM(F)X 0 Output . । 1 1 WRITE 1 READ 1 WRITE I X''—i i 1 I । L । X~ 1 !~ХГ 0 1 X MEM(E) i WRITE 1 WRITE I READ ।
Рис. Б.10. Временные диаграммы распределенной памяти RAM
Приложение Б. Временные модели FPGA 7-й серии
349
В момент времени Тдд до события синхросигнала 1 адрес (2) принимает действительное значение
на входах A/B/C/D памяти RAM.
В момент времени Тод Д° события синхросигнала 1 DATA принимает действительное значение на
входе DI памяти RAM и отображается на выходы A/B/C/D в момент времени Тднско после события
синхросигнала 1. Это также применимо к выходам AMUX, BMUX, CMUX, DMUX и COUT в момент
времени ТдНско после события синхросигнала 1.
Событие 2: операция чтения. В распределенной памяти RAM все операции чтения являются асин-
хронными. Так долго, как сигнал WE находится на низком уровне, значение на шине адреса может уста-
навливаться в любое время. Содержимое памяти RAM на шине адреса отображается на выходы A/B/C/D
после задержки Тц_о (задержка прохождения через LUT). Адрес (F) назначается после события синхросиг-
нала 2 и содержимое памяти RAM от адреса (F) отображается на выходе после задержки величиной Тц_о-
Б.3.5. Временная модель и временные характеристики сдвигового регистра SRL
На рис. Б. 11 показана упрощенная структура сдвигового регистра SRL секции блока CLB, исполь-
зуемая во временной модели.
Временные параметры сдвигового регистра SRL приведены в табл. Б.7.
На рис. Б. 12 показаны временные диаграммы сдвигового регистра SRL, реализуемого в FPGA 7-й се-
рии.
350
Приложение Б. Временные модели FPGA 7-й серии
Таблица Б.7
Временные параметры сдвигового регистра SRL
Параметр Функция Описание
После, Т1 1 REG Treg (Treg-MUx)1 Treg (Treg_M3i) Время Тсеск/Тсксе (Tceck_shfreg/ Tckceshfreg) Tws/Twh (Tws_shfreg/ Twh_shfreg) Tds/TdH (Tds_shfreg/ Tdh_shfreg) Tmpw 1. Этот параметр вк 2- Txs — время уст 3. Параметр включ щим сдвигом. цовательные задержка как Q CLK к выходам A/B/C/D CLK к выходам AMUX - DMUX CLK к выходу DMUX через выход МС31 установки и удержан Вход разрешения синхронизации СЕ Вход разрешения записи WE AI/BI/CI/DI кон- фигурируются как входы данных (DI) С слючает LUT, сконфигу ановки, Тхн — время у ает AX/BX/CX/DX, ск 1 для генератора LUT, сконфигурированного увиговый регистр SLR Время после CLK операции записи, когда данные, записы- ваемые в SRL, становятся стабильными на выходах секции A/B/C/D Время после CLK операции записи, когда данные, записы- ваемые в SRL, становятся стабильными на выходах секции AMUX - DMUX Время после CLK операции записи, когда данные, записы- ваемые в SRL, становятся стабильными на выходе секции DMUX через выход МС31 ия для LUT, сконфигурированного как SRL2 Время до/после синхросигнала, когда сигнал разрешения синхронизации должен быть стабильным на входе СЕ гене- ратора LUT Время до/после синхросигнала, когда сигнал разрешения записи должен быть стабильным на входе WE генератора LUT Время до/после синхросигнала, когда данные должны быть стабильными на входах секции AI/BI/CI/DI инхросигнал CLK Минимальная ширина импульса синхросигнала для распре- деленной памяти RAM 'рированный как двухбитовый сдвиговый регистр, держания. онфигурированные как вход данных DI2 или два бита с об-
Рис. Б.12. Временные диаграммы сдвигового регистра SRL
Событие синхронизации 1: «сдвиг в». Во время операции записи (сдвиг в — Shift In) содержимое
одного бита регистра по адресу на входах A/B/C/D изменяется, как данные сдвигаются через SRL. Данные,
записанные в этот регистр, отображаются на выходах A/B/C/D синхронно, если адрес не изменяется
во время события синхронизации Если входы A/B/C/D изменяются во время события синхронизации,
значение данных на адресуемых выходах (выходах A/B/C/D) является недействительным.
В момент времени Tws Д° события 1 сигнал разрешения записи WE принимает высокий уровень,
разрешая SRL операцию записи.
В момент времени Tqs до события 1 данные принимают действительное значение (0) на входе DI
сдвигового регистра SRL и отображаются на выходе A/B/C/D после задержки Treg после события 1.
Поскольку в событии 1 определен адрес 0, данные на входе DI записываются в регистр (триггер) 0
Приложение Б. Временные модели FPGA 7-й серии
351
Событие синхронизации 2: «сдвиг в». В момент времени Tqs до события 2 данные принимают
действительное значение (1) на входе DI сдвигового регистра SRL и отображаются на выходе A/B/C/D
после задержки Treg после события 2. Поскольку в событии 2 определен адрес 0, данные на входе DI
записываются в регистр (триггер) 0.
Событие синхронизации 3: «сдвиг в» адресуемое (асинхронное) чтение. Все операции чтения
являются асинхронными по отношению к синхросигналу CLK. Если адрес изменяется (между события-
ми синхронизации), содержимое регистра по этому адресу отображается на адресуемый выход (выходы
A/B/C/D) после задержки Тщэ (задержка распространения через генератор LUT).
В момент времени Tqs до события 3 данные принимают действительное значение (1) на входе DI
сдвигового регистра SRL и отображаются на выход A/B/C/D после задержки Treg после события 3.
Адрес изменяется (с 0 на 2). Значение запомненное в регистре 2 в это время есть 0 (в этом примере
это были первые данные, сдвинутые в) и отображается на выход A/B/C/D после задержки Tilo
Событие синхронизации 32: изменение наибольшего значащего бита. В момент времени Treg
после события 32 первый бит, сдвинутый в SRL, принимает действительное значение (в этом случае логи-
ческий 0) на выходе DMUX секции через выход МС31 генератора LUT А. Это также применяется к выходам
AMUX, BMUX, CMUX, DMUX и COUT в момент времени Treg после события 1.
Б.4. Временная модель блока RAM
Б.4.1. Временные параметры блока RAM
Временные параметры блока RAM представлены в табл. Б.8.
Б.4.2. Временные характеристики блока RAM
На рис. Б.13 приведены временные диаграммы однопортового блока RAM в режиме вначале запись
(write-first) без дополнительного выходного регистра. Режимы вначале чтение (read-first) и без изме-
нения (no-change) являются подобными. Для использования синхронизации дополнительного выходного
регистра на выводе DO применяется дополнительная задержка синхросигнала. Эти временные диаграммы
соответствуют режиму защелки, когда дополнительный выходной конвейерный регистр не используется.
В момент времени 0 блок RAM запрещен, сигнал EN на низком уровне.
Событие синхронизации 1. Операция чтения. Во время операции чтения содержимое памяти по
адресу, указываемому входами ADDR, остается без изменений.
В момент времени Trcck_addr до события 1, становится действительным адрес 00 на входах ADDR
блока RAM.
В момент времени Trcck_en До события 1, устанавливается высокий уровень на входе EN, разрешая
память для операции чтения, которая следует.
В момент времени Trcko-DO после события 1, содержимое памяти по адресу 00 становится ста-
бильным на выводах DO блока RAM.
Каждый раз, когда EN установлен, все изменения адреса должны удовлетворять определенному окну
установки и удержания. Асинхронные изменения адреса могут воздействовать на содержимое памяти и
функционирование блока RAM становится непредсказуемым.
CLK
ADDR
DI
DO
EN
RST
WE
Disabled
Wr te
Read
Reset
I Disabled
Рис. Б.13. Временная диаграмма блока RAM
352
Приложение Б. Временные модели FPGA 7-й серии
Таблица Б.8
Временные параметры блока RAM
Параметр Функция Управляю- щий сигнал Описание
RCCK-ADDR т RCKC-ADDR TrdCK_DI TrcKD_DI ТRCCK-RDEN ТRCKC-RDEN TrcCK-RSTREG! TrCCK-RSTRAM Trckc.rstreg: Тrckc-RSTram т RCCK-WEA т RCKC-WEA TrcCK-REGCE TrckC-REGCE T RCKO-DO (в режиме защелки) TRCKO-DO-REG (в режиме регистра) 1- Trxck_x — вРе синхросигнала). 2. Когда сигнал 1 установки/удерж; повреждению дан EN должен быть Установка и уде Входы адреса Входы данных Разрешение Синхронные установка/сброс Разрешение записи Разрешение до- полнительно- го выходного регистра Заде От синхросигна- ла к выходу мя установки (до с|: EN активен, входы / зния даже если сип ныхблока RAM. Ес неактивен (отклю ^ржание, отно ADDR DI EN RSTREG RSTRAM WE REGCE зржки ОТ СИНХ От CLK к DO )ронта синхрос XDDR должны нал WE неакти ли синхронизаг чен). сящиеся к синхросигналу CLK1 Время до синхросигнала, когда сигналы адреса должны быть стабильны на входах ADDR блока RAM2 Время после синхросигнала, когда сигналы адреса должны быть стабильны на входах ADDR блока RAM2 Время до синхросигнала, когда данные должны быть стабильны на входах DI блока RAM Время после синхросигнала, когда данные должны быть стабильны на входах DI блока RAM Время до синхросигнала, когда сигнал разрешения должен быть стабильным на входе EN блока RAM Время после синхросигнала, когда сигнал разре- шения должен быть стабильным на входе EN бло- ка RAM Время до синхросигнала, когда синхронный сигнал установки/сброса должен быть стабильным на входе RST блока RAM Время после синхросигнала, когда синхронный сигнал установки/сброса должен быть стабиль- ным на входе RST блока RAM Время до синхросигнала, когда сигнал разрешения должен быть стабильным на входе WE блока RAM Время после синхросигнала, когда сигнал разре- шения должен быть стабильным на входе WE бло- ка RAM Время до синхросигнала, когда сигнал разрешения выходного регистра должен быть стабильным на входе REGCE блока RAM Время после синхросигнала, когда сигнал разре- шения выходного регистра должен быть стабиль- ным на входе REGCE блока RAM росигнала к выходу Время после синхросигнала, когда выходные дан- ные стабилизируются на выходах DO блока RAM (без выходного регистра) Время после синхросигнала, когда выходные дан- ные стабилизируются на выходах DO блока RAM (с выходным регистром) игнала); Trckx_x — время удержания (после фронта быть стабильными в течение всего временного окна вен. Нарушение этого требования может привести к |ия ADDR могла бы нарушить указанные требования.
Событие синхронизации 2. Операция записи. Во время операции записи содержимое памяти по
адресу, указываемому входами ADDR заменяется значением на входах DI и немедленно отображается на
выходных защелках (в режиме WRITE-FIRST); когда WE в высоком уровне
В момент времени Trcck_addr до события 2, становится действительным адрес OF на входах ADDR
блока RAM.
В момент времени Trcck_di до события 2, данные СССС принимают действительное значение на
входах DI блока RAM.
Приложение Б. Временные модели FPGA 7-й серии
353
FPGA
Data р-~>— r Block RAM
TlOPI + NET] + TRDCK DI DI ADDR WE EN RSTREG RSTRAM >CLK DO 1 1 1 1 1 1 1 TRCKQ ..DO * [NET + ТЮОр]
Address р-> TiOPI + NET] + TRCCKADDR
Write Enable p-у (Tiopi + NET] + TRCCK WEN
Enable p-y Tiopi + NET] + TRCCKEN
Tiopi + NET] + tRCck ..rst
Synchronous О Set/Reset ।—y Tiopi + netj + trcckrst
[Твсско.о + NET]
Clock О—----------
I[T|OPI + NET)
Рис. Б.14. Временная модель блока RAM
В момент времени Trcck.we до события 2, разрешение записи становится допустимым на входе
WE после блока RAM.
В момент времени Trcko.do после события 2, данные СССС становятся действительными (доступ-
ными) на выходах DO блока RAM.
Событие синхронизации 4. Операция синхронной установки/сброса RST. Во время операции
RSTRAM значение SRVAL параметра инициализации загружается в выходные защелки блока RAM. Опе-
рация RSTRAM не изменяет содержимое памяти и является независимой от входов ADDR и DL
В момент времени Trcck.rst до события 4, сигнал синхронной установки/сброса становится дейст-
вительным (высокий уровень) на входе RSTRAM блока RAM.
В момент времени Trcko_do после события 4, значение SRVAL 0101 становится доступным на вы-
ходах DO блока RAM.
Событие синхронизации 5. Операция запрещения. Сброс сигнала разрешения EN запрещает
любые операции записи, чтения или RST. Операция запрещения не изменяет содержимое памяти или
значения выходных защелок.
В момент времени Trcck.en до события 5, сигнал разрешения становится недействительным (низкий
уровень) на входе EN блока RAM.
После события синхронизации 5 данные на выходах DO не изменяются
Б.4.3. Временная модель блока RAM
На рис. Б. 14 показаны пути задержек, связанные с реализацией блока RAM Эта временная модель
демонстрирует, как и где используются временные параметры блока RAM.
Здесь приняты следующие обозначения:
NET — различные задержки межсоединений;
TiOPi ~ задержка от контактной площадки к входу I блока ЮВ;
"Лоор — задержка от входа О блока ЮВ к контактной площадке;
Твсско.о ~ задержка BUFGCTRL.
Б.5. Временные параметры блока ЕСС
Б.5.1. Синхронизация стандартной записи
Временная диаграмма операции стандартной записи показана на рис. Б.15.
В момент времени Trcck_en Д° времени T1W становится действительным сигнал разрешения за-
писи WREN блока RAM.
В момент времени Trcck_addr до времени T1W становится действительным адрес записи а на входах
WRADDR[8:0] блока RAM. Вход WRADDR не нужен для памяти FIFO.
В момент времени Trdck_di_ecc (стандартный ЕСС) до времени T1W данные записи А становятся
действительными на входах DI[63:0] блока RAM.
В момент времени Trcko_ecc_parity (стандартный ЕСС) после времени T1W данные четности блока
ЕСС РА становятся действительными на выходах ECCPARITY[7:0] блока RAM.
354
Приложение Б. Временные модели FPGA 7-й серии
WRCLK
WREN
WRADDR[8:0]
DI(63:0]
DIP[7:0]
(Decode Only Mode)
ECCPARITY[7:0]
Рис. Б.15. Временная диаграмма операции стандартной записи
Синхронизация записи блока ЕСС в режиме только кодирование.
Время установки/удержания для WREN и WRADDR совпадает со стандартным ЕСС.
Во время TRDCKJDLECC (ЕСС в режиме только кодирования), перед временем T1W, записываемые
данные А становятся допустимыми на входах DI[63:0] блока RAM.
Во время TRCKO_ECC_PARITY (ЕСС в режиме только кодирования), после времени T1W, данные
четности РА блока ЕСС становятся допустимыми на выходах ECCPARITY[7:0] блока RAM.
Б.5.2. Синхронизация стандартного чтения
Временная диаграмма операции стандартного чтения показана на рис. Б. 16.
В момент времени Trcck_en Д° времени T1R становится действительным сигнал разрешения чтения
RDEN блока RAM.
В момент времени Trcck_addr до времени T1R становится действительным адрес записи а на входах
RDADDR[8:0] блока RAM. Вход RDADDR не нужен для памяти FIFO.
RDCLK
T2R
T3R
T4R
RDEN
RDADDR[8:0]
DO[63:01
(Latch Mode)
DOP(7:0]
(Latch Mode)
SBITERR
(Latch Mode)
DBITERR
(Latch Mode)
ECCRDADDR
(Latch Mode)
DO[63:0]
(Register Mode)
DOP[7:01
(Register Mode)
SBITERR
(Register Mode)
DBITERR
(Register Mode)
ECCRDADDR
(Register Mode)
1 1 1—. 1 1 2 Single Btt|Error \ | |
1 TRCKO Edc. SBITERR (Latcn Mode)l 1 j X Double Bit ^rror X j
1 1 X TRCKO.. ECp.DBITERR (Latch Mode) i
1 1 -►1 «*- TRCKO DO ^Register Mode) 1 I I. 1. , L ,
1 .... 'X?11 sXS X PA i X PB i X pc
1 1 1 Ц 1 | Single Bit Error | \
1 I -►* TRCKO_ECC. SbItERR (Register Mode 1
1 1 • । ylDouble Bit Error j”4 4
1 1 1 -*-l j-^-TRCKO.ECC.DBntRR (Register Mode) 1 1 1 1 1 ,
#1 w a I X e । X c
1 1 -*•! H*-TRCKO.„ RDADDR _ECC._REG
Рис. Б.16. Временная диаграмма операции стандартного чтения
Приложение Б. Временные модели FPGA 7-й серии
355
В режиме DO-REG = 0.
Во время TRCKO-DO (режим защелки), после времени T1R, данные А становятся допустимыми на
выходах DO[63:0] блока RAM.
Во время TRCKOJDOP (режим защелки), после времени T1R, данные РА становятся допустимыми
на выходах DOР[7:0] блока RAM.
Во время TRCKO_ECC_SBITERR (режим защелки), после времени T1R, устанавливается сигнал
SBITERR, если обнаружена однобитовая ошибка и исправлена на наборе данных А.
Во время TRCKO_ECC_DBITERR (режим защелки), после времени T2R, устанавливается сигнал
DBITERR, если обнаружена двухбитовая ошибка на наборе данных В.
В режиме DO.REG = 1.
Во время TRCKO.DO (режим регистра), после времени T2R, данные А становятся допустимыми
на выходах DO[63:0] блока RAM.
Во время TRCKO.DOP (режим регистра), после времени T2R, данных РА становятся допустимыми
на выходах DOР[7:0] блока RAM.
Во время TRCKO_ECCR_SBITERR (режим регистра), после времени T2R, устанавливается сигнал
SBITERR, если обнаружена однобитовая ошибка и исправлена на наборе данных А.
Во время TRCKO-ECCR-DBITERR (режим регистра), после времени T3R, устанавливается сигнал
DBITERR, если обнаружена двухбитовая ошибка на наборе данных В.
Синхронизация чтения ЕСС в режиме только кодирование. Синхронизация чтения ЕСС в режиме
только кодирование является таким же, как синхронизация чтения обычного блока RAM.
Синхронизация записи ЕСС в режиме только дешифрация. Синхронизация записи ЕСС в режиме
только дешифрация является таким же, как синхронизация записи обычного блока RAM.
Синхронизация чтения ЕСС в режиме только дешифрация Синхронизация чтения ЕСС в режиме
только дешифрация является таким же, как синхронизация чтения ЕСС в стандартном режиме.
Б.6. Временные модели памяти FIFO
Б.6.1. Временные параметры памяти FIFO
Временные параметры памяти FIFO приведены в табл. Б.9, где Trxck — общее обозначение для
времени установки setup до прихода фронта синхросигнала CLK, Trckd — общее обозначение для времени
удержания hold после прихода фронта синхросигнала.
Таблица Б.9
Временные параметры памяти FIFO
Параметр Функция Управляю- щий сигнал Описание
TRDCK.DI/ TRCKD.DI1 Входы данных DI Время до/после WRCLK для стабилизации DI
TRCCK.RDEN/ TRCKC.RDEN Разрешение чтения RDEN Время до/после RDCLK для стабилизации RDEN
TRCCK.WREN/ TRCKC-WREN Разрешение записи WREN Время до/после WRCLK для стабилизации WREN
TRREC-RST/ TRREM.RST Асинхронный сброс RST Время до/после сброса RDCLK/WRCLK; RST должен аннулироваться
TRCCK-REGCE/ TRCKC.REGCE Разрешение допол- нительного выход- ного регистра REGCE Время до/после RDCLK для стабилизации REGCE. Применяется только к синхронной памяти FIFO, когда DO_REG = 1
TRCCK-RSTREG/ TRCKC.RSTREG Синхронная уста- новка или сброс RSTREG Время до/после RDCLK для того, чтобы сиг- нал установки/сброса был стабильным на вы- воде RSTREG. Применяется только к синхрон- ной памяти FIFO, когда DO-REG = 1
TRCKO.DO2 Синхросигнал вы- ходных данных DO Время после RDCLK для стабилизации вы- ходных данных на выходе DO. Синхронная память FIFO с DO.REG = 0 отличается от режима с двойной синхронизацией
TRCKO.DO.REG2 Синхросигнал вы- ходных данных DO Время после RDCLK для стабилизации вы- ходных данных на выходе DO. Синхронная па- мять FIFO с DO.REG - 1 идентична режиму с двойной синхронизацией
356
Приложение Б. Временные модели FPGA 7-й серии
Окончание табл. Б.9
Параметр Функция Управляю- щий сигнал Описание
TRCKO.AEMPTY3 Синхросигнал выхо- да почти пустой AEMPTY Время после RDCLK для стабилизации сиг- нала Almost Empty (почти пустой) на выходах ALMOSTEMPTY
TRCKO-AFULL3 Синхросигнал выхо- да почти полный AFULL Время после WRCLK для стабилизации сиг- нала Almost Full (почти полный) на выходах ALMOSTFULL
TRCKO-EMPTY3 Синхросигнал выхо- да пустой EMPTY Время после RDCLK для стабилизации сигна- ла Пустой на выходах EMPTY
TRCKO-FULL3 Синхросигнал выхо- да полный FULL Время после WRCLK для стабилизации сигна- ла Full (полный) на выходах FULL
TRCKO-RDERR3 Синхросигнал выхо- да ошибки чтения RDERR Время после RDCLK для стабилизации сиг- нала Read Error (ошибка чтения) на выходах RDERR
TRCKO-WRERR3 Синхросигнал выхо- да ошибки записи WRERR Время после WRCLK для стабилизации сигна- ла Write Error (ошибка записи) WRERR
TRCKO-RDCOUNT4 Синхросигнал выхо- да указателя чтения RDCOUNT Время после RDCLK для стабилизации сигна- ла Read pointer (указатель чтения) RDCOUNT
TRCKO-WRCOUNT4 Синхросигнал выхо- да указателя записи WRCOUNT Время после WRCLK для стабилизации сигна- ла Write pointer (указатель записи) WRCOUNT
TRCO-AEMPTY Сброс выхода почти пустой AEMPTY Время после сброса для стабилизации сигнала Almost Empty на выходе ALMOSTEMPTY
TRCO-AFULL Сброс выхода почти полный AFULL Время после сброса для стабилизации сигнала Almost Full на выходе ALMOSTEMPT
TRCO-EMPTY Сброс выхода пус- той EMPTY Время после сброса для стабилизации сигнала Пустой на выходе EMPTY
TRCO-FULL Сброс выхода пол- ный FULL Время после сброса для стабилизации сигнала Full на выходе FULL
TRCO-RDERR Сброс выхода ошиб- ка чтения RDERR Время после сброса для стабилизации сигнала Read Error на выходе RDERR
TRCO.WRERR Сброс выхода ошиб- ка записи WRERR Время после сброса для стабилизации сигнала Write Error на выходе WRERR
TRCO-RDCOUNT Сброс выхода указа- тель чтения RDCOUNT Время после сброса для стабилизации сигнала Read pointer на выходе RDCOUNT
TRCO.WRCOUNT Сброс выхода указа- тель записи WRCOUNT Время после сброса для стабилизации сигнала Write pointer на выходе WRCOUNT
1. TRCDCKJDI включает входы четности.
2. TRCKO.DO включает выходы четности.
3. В FPGA 7-й серии параметры TRCKO-AEMPTY. TRCKO-AFULL, TRCKO-EMPTY, TRCKO.FULL,
TRCKO.RDERR, TRCKO-WRERR объединяются в TRCKO-FLAGS.
4. В FPGA 7-й серии параметры TRCKO-RDCOUNT и TRCKO-WRCOUNT объединяются в TRCKO-
POINTERS.
Б.6.2. Запись в пустую память FIFO
Временные диаграммы функционирования памяти FIFO при записи в пустую память приведены на
рис. Б.17.
События 1 и 3: операция записи и аннулирование сигнала EMPTY. В течение операции записи в
пустую память FIFO значение на выводах DI помещается по первому адресу памяти FIFO. Через три цик-
ла синхронизации (4 для режима FWFT) вывод EMPTY сбрасывается, поскольку память FIFO уже не
пустая. Также счетчик увеличивается на единицу в течение внутреннего чтения, перезагружая данные
в выходных регистрах.
На рис. Б.17 показано функционирование памяти FIFO в режиме FWFT. Момент времени (событие)
1 относится к синхросигналу записи, а момент времени 3 относится к синхросигналу чтения Событие 3
появляется на 4 цикла синхросигнала чтения позже, чем событие 1.
От времени TrDck_di перед событием 1 (WRCLK) данные 00 становятся доступными на входах DI
памяти FIFO. От времени Trcck_wren перед событием 1 (WRCLK) разрешение записи становится доступ-
ным на входе WREN. От времени Trcko_do после события 3 (RDCLK) данные 00 становятся доступными
на выходах DO памяти FIFO (в стандартном режиме данные 00 не появляются на выходах DO). От време-
Приложение Б. Временные модели FPGA 7-й серии
357
____________I__________________!__________Н------- TRCKO,DO
DO | i }~~Х00
| I*^1 H------------ TRCKO.„EMPTY
EMPTY | | | ________________
___________||| TRCKO AEMPTY------------------------------
AEMPTY '
Рис. Б.17. Запись в пустую память FIFO в режиме FWFT
ни Trcko-EMPTY после события 3 (RDCLK) сигнал EMPTY аннулируется (в стандартном режиме сигнал
EMPTY аннулируется раньше на один цикл синхросигнала чтения).
Если возрастающий фронт синхросигнала WRCLK близок к возрастающему фронту RDCLK, то ан-
нулирование сигнала EMPTY может произойти позже на один период синхросигнала RDCLK.
События 2 и 4: операция записи и аннулирование сигнала почти полный AEMPTY. После 4 циклов
синхронного чтения третьи данные записываются в память FIFO, аннулируется выход AEMPTY чтобы
показать, что память FIFO не находится в состоянии Almost Empty.
На рис. Б.17 приводится пример для режима FWFT. Событие 2 связано с синхросигналом записи,
а событие 4 — с синхросигналом чтения. Событие 4 появляется на 4 периода синхросигнала чтения
позже события 2.
От времени Trdck_di перед событием 2 (WRCLK) данные 02 становятся доступными на входах DI.
Разрешение записи остается установленным на входе WREN. В момент времени 4 на выходах DO остаются
значения данных 00, потому что не было выполнено ни одной операции чтения. В стандартном режиме
данные 00 никогда не появляются на выходах DO памяти FIFO. От времени Trcko_aempty после события
4 (RDCLK) аннулируется вывод почти пустой AEMPTY.
Если возрастающий фронт синхросигнала WRCLK близок к возрастающему фронту RDCLK, то ан-
нулирование сигнала AEMPTY может произойти позже на один период синхросигнала RDCLK.
Б.6.3. Запись в полную или почти полную память FIFO
Пусть перед выполнением операций на рис. Б.18 память FIFO почти полностью заполнена. В этом
примере временные диаграммы отображают оба режима функционирования: стандартный и FWFT.
Событие 1: операция записи и утверждение сигнала Almost Full. Во время операции записи в почти
полную память FIFO устанавливается сигнал AFULL (почти полный).
От времени операции Trdck_di перед событием 1 (WRCLK) данные 00 становятся доступными на
входах DI памяти FIFO. От времени Trdck.wren перед событием 1 (WRCLK) сигнал разрешения записи
становится действительным на входе WREN. От времени Trcko_afull после одного цикла синхронизации
от события 1 (WRCLK) устанавливается сигнал Almost Full на выходе AFULL.
Событие 2: операция записи и утверждения сигнала Full. Вывод сигнала FULL устанавливается, когда
память FIFO заполнена. От времени операции Trdck.di Д° события 2 (WRCLK) данные 04 становятся
доступными на входах DL Сигнал разрешения записи остается установленным на входе WREN. От времени
Trcko_full после события 2 (WRCLK) устанавливается сигнал Full на выходе FULL памяти FIFO.
Если память FIFO заполнена и выполняется чтение, сопровождаемое записью, то запись может не
быть успешной в зависимости от синхронизации между чтением и записью.
Событие 3: операция записи и установка сигнала ошибка записи WRERR. Сигнал на выходе WRERR
устанавливается в случае, когда данные, приходящие в FIFO, не записываются, поскольку память FIFO
находится в состоянии Full (FULL).
От времени Trdck_di Д° события 3 (WRCLK) данные 05 становятся доступными на входах DI. Сигнал
разрешения записи остается установленным на входе WREN. От времени Trcko.wrerr после события 3
(WRCLK) устанавливается выход WRERR ошибка записи. Данные 05 не записываются в память FIFO.
358
Приложение Б. Временные модели FPGA 7-й серии
WRERR
TRCKO_AFULL
TRCKO WERR
_______L.
Рис. Б.18. Запись в полную или почти полную память FIFO
Событие 4: операция записи и аннулирование сигнала ошибка записи Write Error. Вывод сигнала
Write Error аннулируется, когда пользователь прекращает попытки записи в полную память FIFO.
От времени Trcck_wren до события 4 (WRCLK) на входе WREN аннулируется сигнал разрешения за-
писи. От времени TRcco_wren До события 4 (WRCLK) аннулируется сигнал Write Error, на выходе WRERR.
Сигнал ошибки записи утверждается/аннулируется на каждом возрастающем фронте синхросигнала
записи. Пока оба сигнала разрешения записи WREN и полный FULL установлены, остается установленным
сигнал ошибка записи WRERR.
Б.6.4. Чтение из полной памяти FIFO
Временные диаграммы при чтении из полной памяти FIFO показаны на рис. Б. 19.
События 1 и 2: операция чтения и аннулирования сигнала Full. Во время операции чтения на
полной памяти FIFO содержимое памяти FIFO от первого адреса утверждается на выходах DO. Вывод FULL
аннулируется через три цикла синхросигнала WRCLK после первого чтения. Это поведение отличается от
функционирования FPGA семейства Virtex-б.
Пример на рис. Б. 19 показывает оба режима: стандартный и FWFT. Событие 1 связано с синхросиг-
налом чтения. Событие 2 появляется через три цикла синхросигнала записи после события 1.
От времени TRcck_rden до события 1 (RDCLK) сигнал разрешения чтения установится на входе
RDEN. От времени TRcko_do после события 1 (RDCLK) устанавливаются данные 00 на выходах DO. От
времени TRcko_full после события 2 (WRCLK) аннулируется сигнал FULL.
1 2 3 4
Рис. Б.19. Чтение из полной памяти FIFO
Приложение Б. Временные модели FPGA 7-й серии
359
Если возрастающий фронт синхросигнала WRCLK близок к возрастающему фронту RDCLK, то ан-
нулирование сигнала FILL может произойти позже на один период синхросигнала WRCLK.
События 3 и 4: операция чтения и аннулирование сигнала Almost Full. Через 4 цикла синхросигнал
записи четвертые данные читаются из памяти FIFO, вывод AFULL аннулируется, чтобы показать, что
память FIFO не находится в состоянии Almost Full.
На рис. Б.19 изображены два режима: стандартный и FWFT. Событие 3 связано с синхросигналом
чтения, а событие 4 — с синхросигналом записи. Атрибут ALMOST_FULL_OFFSET устанавливается ми-
нимум в значение 4. Событие 4 появляется через 4 цикла синхросигнала записи после события 3. Сигнал
разрешения чтения остается установленным на входе RDEN. От времени Trcko_afull после события 4
(RDCLK) сигнал Almost Full аннулируется на выводе AFULL.
Здесь имеется минимальное время между возрастающими фронтами синхросигналов чтения и записи
для гарантии, что сигнал AFULL будет аннулирован. Если этот минимум не удовлетворяется, аннулирован-
ный сигнал AFULL может потребовать дополнительный цикл синхросигнала записи.
Б.6.5. Чтение из пустой или почти пустой памяти FIFO
Этому случаю соответствуют временные диаграммы на рис. Б.20, которые соответствуют стандартно-
му режиму функционирования памяти FIFO. Для режима FWFT данные на выходе DO появляются раньше
на один цикл синхросигнала чтения.
События 1: операция чтения и утверждение сигнала Almost Empty. В течение операции чтения почти
пустой памяти FIFO удерживается сигнал Almost Empty. От времени Trcck.rden до события 1 (RDCLK) на
входе RDEN устанавливается сигнал разрешения чтения. От времени Trcko_do после события 1 (RDCLK)
значения данных 00 устанавливаются на выходах DO. От времени Trcko_aempty через один цикл, после
события 1 (RDCLK) от времени Trcko_aempty на выходе AEMPTY устанавливается сигнал Almost Empty
События 2: операция чтения и установка сигнала Empty. Вывод EMPTY сигнала Пустой уста-
навливается, когда память FIFO становится пустой. Сигнал разрешения чтения остается установленным
на входе RDEN. От времени Trcko.do после события 2 (RDCLK) значение последних данных 04 уста-
навливается на выходах DO. От времени Trcko.empty после события 2 (RDCLK) на выходе EMPTY
устанавливается сигнал Пустой.
Если память FIFO пустая и выполняется операция записи, сопровождаемая операцией чтения, то
чтение может не быть успешным в зависимости от таймирования между чтением и записью.
События 3: операция чтения и установки сигнала ошибка чтения Read Error. Вывод сигнала Read
Error устанавливается, когда нет данных для чтения, поскольку память FIFO пуста. Сигнал разрешения чте-
ния остается установленным на входе RDEN. От времени Trcko.rderr после события 3 (RDCLK) на выходе
RDERR устанавливается сигнал Read Error. На выходах DO значения данных 04 остаются неизменными.
События 4: операция чтения и аннулирование сигнала Read Error. Вывод сигнала Read Error анну-
лируется, когда пользователь прекращает пытаться читать из пустой памяти FIFO. От времени Trcck_rden
после события 4 (RDCLK) на выходе RDEN аннулируется сигнал разрешения чтения. От времени
Trcko.rderr после события 4 (RDCLK) на выходе RDERR аннулируется сигнал Read Error. Пока оба
сигнала разрешения чтения и полный установлены, остается утвержденным сигнал ошибки чтения.
1 2 3 4
Рис. Б.20. Чтение из пустой или почти пустой памяти FIFO в стандартном режиме
360
Приложение Б. Временные модели FPGA 7-й серии
RST
WRCLK
RDCLK
EMPTY
AEMPTY
FULL
AFULL
RCO EMPTY
Trco.aempty
Trco FULL
TrcO AFULL
Рис. Б.21. Переустановка всех флагов
Б.6.6. Переустановка всех флагов
На рис. Б.21 показаны временные диаграммы при сбросе всех флагов. Когда сигнал сброса RST
устанавливается, сбрасываются все флаги. От времени Trco.empty после установки сигнала RST на
выходе AEMPTY устанавливается сигнал Empty. От времени Trco_aempty после установки сигнала RST
на выходе EMPTY устанавливается сигнал Almost Empty. От времени Trco_full после установки сигнала
RST на выходе FULL аннулирует сигнал Full. От времени Trqo-Afull после установки сигнала RST на
выходе AFULL аннулирует сигнал Almost Full.
Сигнал сброса RST является асинхронным сигналом, используемым для сброса всех флагов. Сигнал
сброса должен удерживаться на высоком уровне в течение 5 циклов синхросигналов чтения и записи для
уверенности, что флаги всех внутренних состояний сбросились в корректные значения.
Б.6.7. Одновременное чтение и запись в режиме двойной синхронизации
Операции одновременного чтения и записи для асинхронной памяти FIFO являются недетерминиро-
ванными, когда память FIFO находится в условии установки флага состояния. Логика памяти FIFO решает
ситуацию (либо устанавливать, либо не устанавливать флаг), программа моделирования не может отобра-
зить это поведение и может случиться рассогласование. Когда используется единственный синхросигнал
для RDCLK и WRCLK, используйте памяти FIFO в синхронном режиме (EN-SYN = TRUE).
Б.7. Временные модели ресурсов ввода-вывода
Б.7.1. Временная модель примитива IDELAY
Переключательные характеристики примитива IDELAY представлены в табл. Б. 10.
На рис. Б.22 показана временная диаграмма примитива IDELAY (IDELAY_TYPE = VARIABLE, IDE-
LAY-VALUE = 0 и DELAY.SRC - IDATAIN).
Событие 1. На возрастающем фронте синхросигнала С обнаруживается сигнал сброса (высокое
значение LD), заставляя выход DATAOUT выбрать величину задержки ТарО.
Событие 2. На возрастающем фронте С обнаруживаются импульсы на входах СЕ и INC. Это указы-
вает на операцию инкрементации. Выход без искажений изменяется с ТарО на Tapi.
Событие 3. Выводы СЕ и INC больше не удерживаются, поэтому завершается операция инкремен-
тации. Выход остается в значении Тар! до тех пор, пока в будущем не активизируются выводы LD,
СЕ или INC.
На рис. Б.23 показана временная диаграмма примитива IDELAY в режиме VAR_LOAD.
Событие О. До импульса на выводе LD устанавливается значение задержки, выходы CNTVALUEOUT
имеют неопределенные значения.
Временные параметры примитива IDELAY
Таблица Б. 10
Обозначение Описание
ТIDELAYRESOLUTION T|INCCk/T|CKINC T|RSTCk/T|CKRST Разрешающая способность порции задержки примитива IDELAY Установка/сброс вывода СЕ по отношению к С Установка/сброс вывода INC по отношению к С Установка/сброс вывода LD по отношению к С
Приложение В. Временные модели FPGA 7-й серии
361
Рис. Б.22. Временная диаграмма примитива IDELAY в режиме VARIABLE
С
LD
INC
СЕ
CNTVALUEIN
CNTVALUEOUT
DATAOUT
Рис. Б.23. Временная диаграмма примитива IDELAY в режиме VAR_LOAD
Событие 1. На возрастающем фронте С обнаруживается высокий уровень на LD, заставляющий
выход DATAOUT сохранить задержку, определенную входами CNTINVALUEIN, и изменить установку на
Тар2 = 5’ЬОООЮ. Выход CNTVALUEOUT обновляется для представления нового значения задержки.
Событие 2. Импульсы на СЕ и INC обнаруживаются на возрастающем фронте С. Это указывает
на операцию инкрементации. Выход без искажений изменяется с Тар2 на ТарЗ = Тар2 + 1. Выход
CNTVALUEOUT обновляется для представления нового значения задержки.
Событие 3. На возрастающем фронте С обнаруживается высокое значение на LD, заставляя выход
DATAOUT задержаться на величину, установленную на выводах CNTINVALUEIN. Выход CNTVALUEOUT
показывает значение установки задержки. Выход будет сохранять значение TaplO бесконечно долго, пока
в будущем не активизируются выводы LD, СЕ или INC.
Б.7.2. Временная модель примитива IDELAYCTRL
В табл. Б. 11 приведены переключатель- ные характеристики примитива IDELAYCTRL. Таблица Б. 11 Временные параметры примитива IDELAYCTRL
На рис. Б.24 показаны временные соот- ношения между сигналами RDY и RST. Сиг- нал RST примитива IDELAYCTRL переключа- ется по фронту синхросигнала. Обозначение Описание
Fidelayctrl_ref IDELAYCTRL_REF_PRECISION ТIDELAYCTRLCO-RDY Частота REFCLK Точность REFCLK Сброс/запуск к Ready для IDELAYCTRL
Б.7.3. Временная модель примитива ODELAYE2
Временные параметры примитива ODELAYE2 приведены в табл. Б. 12.
На рис. Б.25 показана временная диаграмма функционирования примитива ODELAYE2 при следую-
щих установках: ODELAY-TYPE = VARIABLE, ODELAY.VALUE = 0 и DELAYER С = CLKIN/ODATAIN.
362
Приложение В. Временные модели FPGA 7-й серии
REFCLK
RDY
Рис. Б.24. Временная диаграмма взаимодействия сигналов RST и RDY
RST
Таблица Б. 12
Временные параметры примитива ODELAYE2
Обозначение Описание
ТIDELAYRESOLUTION Т|СЕСк/Т|СКСЕ Tiincck/Tickinc Tirstck/Tickrst Точность единицы задержки для ODELAYE2 Установка/удержание вывода СЕ по отношению к С Установка/удержание вывода INC по отношению к С Установка/удержание вывода LD по отношению к С
Событие 1. На возрастающем фронте синхросигнала С обнаруживается сигнал сброса (LD в высоком
состоянии), заставляя выход DATAOUT выбрать отвод ТарО как выход из 31-отводной цепи.
Событие 2. На возрастающем фронте синхросигнала С захвачены импульсы на входах СЕ и INC. Это
указывает на операцию инкрементации. Выход без искажений изменяется с ТарО на Tapi.
Событие 3. Сигналы СЕ и INC больше не удерживаются. Это указывает на завершение операции
инкрементации. Выход остается в Tapi до тех пор, пока не изменятся значение сигналов LD, СЕ или INC.
Функционирование примитива ODELAYE2 в режиме VAR.LOAD приведено на рис. Б.26.
Событие О. До импульса LD устанавливается величина задержки, на выходе CNTVALUEOUT —
неизвестное значения.
Событие 1. На возрастающем фронте С обнаруживается высокое значение LD, которое застав-
ляет выход DATAOUT быть равным CNTINVALUE и изменить установку величины задержки на Тар2.
CNTVALUEOUT обновляется для представления нового значения задержки.
Событие 2. Импульсы на СЕ и INC захватываются на возрастающем фронте С. Это указывает на
операцию инкрементации. Выход без искажений изменяется с Тар2 на ТарЗ.
Событие 3. На возрастающем фронте С обнаруживается высокое значение LD, которое заставляет
выход DATAOUT быть равным CNTINVALUE. CNTVALUEOUT показывает значение установки величины
задержки. Выход будет сохранять соединение с отводом TaplO.
1 2 3
DATAOUT Y Тар О Н I Тар 1
------------Г--------н--------1-----
Рис. Б.25. Временная диаграмма ODELAYE2 в режиме VARIABLE
Приложение Б. Временные модели FPGA 7-й серии
363
CNTVALUEIN 5Ъ00010 I I I 5Ъ01010 |
~Х —.........""".Г?...........г-----------
CNTVALUEOUT 5Ъ00010 \ 5Ъ00011 f б’ЬОЮЮ
DATAOUT "УТ;—j ТарЭ ; Тар ю ~
Рис. Б.26. Временная диаграмма ODELAYE2 в режиме VAR_LOAD
Б.7.4. Временные модели блока ILOGIC
В табл. Б.13 приведены временные параметры блока ILOGIC.
На рис. Б.27 показана временная диаграмма функционирования регистра ILOGIC в обычном регист-
ровом режиме (не DDR). Когда используется IDELAY параметр Тюоск заменяется на Тюоско-
Таблица Б. 13
Временные параметры ILOGIC
Обозначение Описание
Установки/удержания (setup/hold)
Ticeick/Tickcei Установка/удержание вывода СЕ1 по отношению к CLK
Tisrck/Ticksr Установка/удержание вывода SR по отношению к CLK
Tidock/Tiockd Установка/удержание вывода D по отношению к CLK
ТICOCKD /ТIOCKDD Установка/удержание вывода DDLY по отношению к CLK Комбинационные задержки
~T|DI Задержка распространения сигнала от D к О; на задержку Delay Последовательные задержки
T|DLO Задержка сигнала от D к Q1, используя триггер как защелку без задержки Delay
T|CKQ Задержка от CLK к выходам Q
Trq Задержка от SR к выходу OQ/TQ
Временные диаграммы и параметры вывода DDLY идентичны временным диаграммам и параметрам вывода D.
Рис. Б.27. Временные характеристики входного регистра ILOGIC
364
Приложение Б. Временные модели FPGA 7-й серии
Рис. Б.28. Временные диаграммы ILOGIC в режиме IDDR (режим OPPOSITE-EDGE)
Событие 1. В момент времени Ticeick Д° события 1 входной сигнал СЕ1 разрешения синхронизации
принимает высокое значение, разрешая входному регистру принять данные.
В момент времени Тцэоск до события 1 входной сигнал принимает высокое значение на входе D вход-
ного регистра и отображается на выходе Q1 входного регистра в момент времени Tickq после события 1.
Событие 4. В момент времени Tisrck до события 4 сигнал SR (в данном случае сконфигуриро-
ванный как синхронный сброс) принимает высокое значение, сбрасывая входной регистр, и этот сброс
отображается на выходе Q1 буфера ЮВ в момент времени Tickq после события 4.
Временные диаграммы ILOGIC в режиме DDR показаны на рис. Б.28. Когда используется IDELAY,
Tidock заменяется на Tidockd- Показанный пример использует IDDR в режиме OPPOSITE_EDGE. В
других режимах добавляются соответствующие задержки, как показано на рис. 10.4.
Событие 1. В момент времени Ticeick до события 1 входной сигнал разрешения синхронизации
принимает высокое значение на входе СЕ1 обоих входных регистров DDR, разрешая им принимать данные
(поскольку сигналы СЕ1 и D являются общими для обоих регистров DDR, особое внимание должно быть
уделено переключению этих сигналов между возрастающим и падающим фронтом CLK, а также удовлет-
ворению времени установки регистра по отношению к обоим фронтам).
В момент времени Тцэоск Д° события 1 (возрастающий фронт CLK) входной сигнал принимает
высокое значение на входе D обоих регистров и отображается на выходе Q1 входного регистра 1 в момент
времени Tickq после события 1.
Событие 4. В момент времени Тцэоск до события 4 (падающий фронт CLK) входной сигнал при-
нимает высокое значение на входе D обоих регистров и отображается на выходе Q2 входного регистра 2
в момент времени Tickq после события 4 (в данном случае не изменяется).
Событие 9. В момент времени T^rck Д° события 9 сигнал SR (в этом случае сконфигурированный
как синхронный сброс) принимает высокое значение, сбрасывая Q1 в момент времени Tickq после события
9 и Q2 в момент времени Tickq после события 10.
Б.7.5. Временные модели примитива OLOGIC
Временные параметры блока OLOGIC представлены в табл. Б. 14.
Таблица Б. 14
Временные параметры блока OLOGIC
Обозначение Описание
Tqdck/Tqckd Т ООСЕСК /Т ОСКОСЕ Tqsrck/Tqcksr Tqtck/Tqckt т ОТСЕСК /Т ОСКТСЕ TOCKQ Trq Установка/удержание выводов D1/D2 по отношению к CLK Установка/удержание вывода ОСЕ по отношению к CLK Установка/удержание вывода SR по отношению к CLK Установка/удержание выводов Т1/Т2 по отношению к CLK Установка/удержание вывода ТСЕ по отношению к CLK Задержка CLK к выводу OQ/TQ Задержка вывода SR к выводу OQ/TQ
Приложение Б. Временные модели FPGA 7-й серии
365
CLK
D1
ОСЕ
SR
OQ
Рис. Б.29. Временные диаграммы функционирования выходного регистра OLOGIC
Временные диаграммы функционирования блока OLOGIC показаны на рис. Б.29.
Событие 1. В момент времени Тоосеск перед событием 1 сигнал разрешения синхронизации выхо-
да принимает высокое значение на входе ОСЕ выходного регистра, разрешая выходному регистру при-
нимать данные.
В момент времени Tqdck перед событием 1 выходной сигнал принимает высокое значение на входе
D1 выходного регистра и отображается на выход OQ за время Tqckq после события 1.
Событие 4. В момент времени Tosrck перед событием 4 сигнал SR (в этом случае сконфигуриро-
ванный как синхронный сброс) принимает высокое значение, сбрасывая выходной регистр и отображаясь
на выход OQ за время Trq после события 4.
На рис. Б.30 показаны временные диаграммы функционирования регистра ODDR примитива OLOGIC.
Событие 1. В момент времени Tqqceck перед событием 1 сигнал разрешения синхронизации ODDR
принимает высокое значение на входе ОСЕ регистра ODDR, разрешая ODDR принимать данные. Необхо-
димо принять меры осторожности при переключении сигнала ОСЕ регистра ODDR между возрастающими
и падающими фронтами CLK, а также удовлетворять времени установки регистра по отношению к обо-
им фронтам синхросигнала.
Рис. Б.ЗО. Временные диаграммы функционирования регистра ODDR
366
Приложение В. Временные модели FPGA 7-й серии
В момент времени TODck до события 1 (возрастающий фронт CLK) сигнал данных D1 принимает вы-
сокое значение на входе D1 регистра ODDR и отображается на выход OQ за время Tqckq после события 1.
Событие 2. В момент времени TqDqk ДО события 2 (падающий фронт CLK) сигнал данных D2
принимает высокое значение на входе D2 регистра ODDR и отображается на выход OQ за время Tqckq
после события 2 (в данном случае выход OQ не изменяется).
Событие 9. В момент времени Tqsrck Д° события 9 (возрастающий фронт CLK) сигнал SR (в
этом случае сконфигурированный как синхронный сброс) принимает высокое значение, сбрасывая регистр
ODDR, отображается на выход OQ за время Trq после события 9, и сбрасывая регистр ODDR, отображая
на выход OQ за время Trq после события 10 (выход OQ в данном случае не изменяется).
На рис. Б.31 приведены временные диаграммы функционирования регистра управления 3-м состояни-
ем.
Событие 1. В момент времени Tqtceck до события 1 сигнал разрешения синхронизации 3-го со-
стояния принимает высокое значение на входе ТСЕ регистра 3-го состояния, разрешая регистру 3-го со-
стояния принимать данные.
В момент времени Tqtck до события 1 сигнал 3-го состояния принимает высокое значение на вхо-
де Т1 регистра 3-го состояния, переводя вывод в высокоимпедансное состояние за время Tqckq после
события 1.
Событие 2. В момент времени Tqsrck до события 2 сигнал SR (в этом случае сконфигурирован-
ный как синхронный сброс) принимает высокое значение, сбрасывая регистр 3-го состояния за время
Trq после события 2.
На рис. Б.32 показаны временные диаграммы регистра 3-го состояния DDR. Этот пример показывает
использование DDR в режиме противоположного фронта. Для других режимов добавляются соответст-
вующие задержки, как показано на рис. 10.4.
Событие 1. В момент времени Tqtceck Д° события 1 сигнал разрешения синхронизации 3-го состо-
яния принимает высокое значение на входе ТСЕ регистра ODDR 3-го состояния, разрешая ему принимать
данные. Необходимо принять меры осторожности при переключении сигнала ТСЕ регистра ODDR меж-
ду возрастающими и падающими фронтами CLK, а также удовлетворять времени установки регистра по
отношению к обоим фронтам синхросигнала.
В момент времени Tqtck до события 1 (возрастающий фронт CLK) сигнал 3- го состояния Т1 при-
нимает высокое значение на входе Т1 регистра 3-го состояния и отображается на выход TQ за время
Tqckq после события 1.
Событие 2. В момент времени Tqtck Д° события 2 (падающий фронт CLK) сигнал 3-го состояния
Т2 принимает высокое значение на входе Т2 регистра 3- го состояния и отображается на выход TQ за
время Tqckq после события 2 (в данном случае выход TQ не изменится) .
Событие 9. В момент времени Tqsrck до события 9 (возрастающий фронт CLK) сигнал SR (в этом
случае сконфигурированный как синхронный сброс) принимает высокое значение, сбрасывая регистр 3-го
состояния, отображается на выход TQ за время Trq после события 9 (в данном случае выход TQ не изме-
няется) и, сбрасывая регистр 3-го состояния, отображается на выход TQ за время Trq после события 10.
Приложение Б. Временные модели FPGA 7-й серии
367
Рис. Б.32. Временные диаграммы регистра 3-го состояния ODDR примитива OLOGIC
Б.8. Временные модели расширенных логических ресурсов ввода-вывода
Б.8.1. Временная модель блока ISERDESE2
В табл. Б.15 приведены временные параметры примитива ISERDESE2.
На рис. Б.33 показана временная диаграмма для входных данных в модуле ISERDESE2. Имена вре-
менных параметров изменяются в зависимости от режимов функционирования (SDR или DDR). Однако
имена не зависят от ширины слова. В режиме DDR вход данных D переключается на каждом фронте
синхросигнала CLK (возрастающем и падающем).
Событие 1. В момент времени Т|$сск_се Д° события 1 сигнал разрешения синхронизации устанав-
ливается в высокий уровень и модуль ISERDESE2 может производить выборку данных.
Событие 2. В момент времени T|sdck_d до события 2 вход данных D становится доступным и
производится выборка данных на следующем возрастающем фронте синхросигнала.
Таблица Б. 15
Временные параметры ISERDESE2
Обозначение Описание
т ISCCK_BITSLIp/T ISCKC-BITSLIP т ISCCK-CE /ТISCKC-CE т ISCCK-CE2/TISCKC-CE2 7ISDCK-D/T ISCKD.D т ISDCK_DDr/T ISCKD-DDR Т ISCKO.Q Установка/удержание вывода BITSLIP по отношению к CLKDIV Установка/удержание вывода СЕ по отношению к CLKDIV (для СЕ1) Установка/удержание вывода СЕ по отношению к CLKDIV (для СЕ2) Установка/удержание вывода D по отношению к CLK Установка/удержание вывода D по отношению к CLK в режиме DDR Задержка CLKDIV к выходам Q
2
CLK______ ______
Рис. Б.33. Временная диаграмма входных данных примитива ISERDESE2
368
Приложение Б. Временные модели FPGA 7-й серии
CLKDIV
Q4-Q1
Рис. Б.34. Диаграмма функционирования Bitslip в режиме DDR
Б.8.2. Временная модель подмодуля Bitslip
Рассмотрим временные модели контроллера Bitslip в конфигурации DDR 1:4. Данными (D) является
повторяющаяся 4-битовая преамбула ABCD. Преамбула ABCD может появиться на параллельных выходах
Q1-Q4 блока 1SERDESE2 в виде четырех возможных комбинаций: ABCD, BCDA, CDAB и DABC. Только
одна из этих четырех комбинаций (выравниваний) параллельного слова имеет смысл для пользовательской
логики, которая читает данные с выходов Q1-Q4 блока ISERDESE2. В данном случае ABCD является
выравниванием слова, которое имеет смысл. Установка Bitslip позволяет пользователю видеть все воз-
можные конфигурации входных данных и затем выбрать требуемое выравнивание (ABCD). На рис. Б.34
показана синхронизация функционирования Bitslip и соответствующие перестройки параллельных выходов
Q1-Q4 и блока ISERDESE2.
Событие 1. Все первое слово было выбрано во входные регистры ISERDESE2. Вывод BITSLIP не
установлен; слово проходит через ISERDESE2 без какого-либо выравнивания.
Событие 2. Устанавливается вывод BITSLIP, который заставляет контроллер Bitslip внутренне сдви-
нуть все биты на один бит вправо. Вывод BITSLIP удерживается на высоком уровне только для одного
цикла синхросигнала CLKDIV.
Событие 3. Через три цикла после установки вывода BITSLIP функционирование подмодуля Bitslip
заканчивается и новые сдвинутые данные (BCDA) становятся доступными на выходе.
После события 3. Вывод BITSLIP может полезно устанавливаться в высокое значение еще до двух
раз, поскольку блок ISERDESE2 был сконфигурирован как 1:4.
После второго сдвига (три позиции влево, поскольку это режим DDR) требуемый выход ABCD являет-
ся доступным на Q4-Q1. После третьего сдвига (одна позиция вправо) выход DABC становится доступным
на Q4-Q1. После четвертого сдвига (три позиции влево) оригинальный выход CDAB является доступным
на Q4-Q1 и Bitslip имеет законченную цикличность, проходящую через все четыре входные комбинации
Б.8.3. Временная модель блока OSERDESE2
Временные параметры примитива OSERDESE2 приведены в табл. Б. 16.
Временные диаграммы параллельно-последовательного преобразователя в режиме SDR 2:1 показаны
на рис. Б.35.
Событие 1. На возрастающем фронте CLKDIV слово АВ передается от логики FPGA к входам D1 и
D2 модуля OSERDESE2 (после некоторой задержки распространения)
Событие 2. На возрастающем фронте CLKDIV слово АВ выбирается в модуль OSERDESE2 с вхо-
дов D1 и D2.
Событие 3. Бит данных А появляется на выходе OQ на первом цикле CLK после выбора слова АВ.
На рис. Б.36 показаны временные диаграммы параллельно-последовательного преобразователя в ре-
жиме DDR 8:1. Все восемь битов соединяются с выводами D1-D6 главного модуля OSERDESE2, в отличие
от предыдущих поколений FPGA, где требовалось каскадирование.
Событие 1. На возрастающем фронте CLKDIV слово ABCDEFGH передается от логики FPGA к
входам D1-D8 модуля OSERDESE2.
Приложение Б. Временные модели FPGA 7-й серии
369
Таблица Б.16
Временные параметры примитива OSERDESE2
Обозначение Описание
Установка /удержание
Т OSDCK.D /Т OSCKD.D т OSDCK-Т /Т OSCKD-T Т OSDCK-OCE /Т OSCKD-OCE Т OSDCK.TCE /Т OSCKD.TCE Установка/удержание входа D по отношению к CLKDIV Установка/удержание входа Т по отношению к CLK Установка/удержание входа ОСЕ по отношению к CLK Установка/удержание входа ТСЕ по отношению к CLK
Последовательные задержки
ToSCKO_OQ ToSCKO_TQ Синхросигнал CLK к выходу OQ Синхросигнал CLK к выходу TQ
Комбинационные задержки
TqSCO-OQ TqSCO-TQ Асинхронный сброс к OQ Асинхронный сброс к TQ
Clock Clock Clock
Рис. Б.35. Временные диаграммы параллельно-последовательного преобразователя в режиме SDR 2:1
Clock
Event 1
Clock
Event 2
Clock
Event3
Clock
Event 4
1 1
Master. 01 Ц 1 ’ ?Y Д Л L_J )C" ।
Master.D2 < - / В _X i_ x : ж
Master.D3 С X К -
I I
MasterD4 Y D X
। ' 1
Master.D5 ¥ Е X
I i
Master.D6 F , X N Y /У-- i-i ' ! Г Tl П n rfl rrf 1 ГГ f Г1 f Г1 П 111 r 11 1111II. II111 f in II 1^1
11,1111 1111
Master. D7 G - - - -- г X °
i
Master.D8 Y H , X ₽ X ЭЗ
CLKDIV J
k 1 r
CLK * I 1 n_n_ FLTU 1 1 n_ru
Рис. Б.36. Временные диаграммы параллельно-последовательного преобразователя в режиме DDR 8:1
370
Приложение Б. Временные модели FPGA 7-й серии
Clock Clock
Event 1 Event 2
Рис. Б.37. Поток данных и задержки в режиме DDR 4:1
Событие 2. На возрастающем фронте CLKDIV слово ABCDEFGH выбирается в модуль OSERDESE2
с входов D1-D8.
Событие 3. Бит данных А появляется на выходе OQ через четыре цикла CLK после выбора слова
ABCDEFGH.
Второе слово IJKLMNOP выбирается в модуль OSERDESE2 с входов D1-D8.
Событие 4. Между событиями 3 и 4 введенное слово ABCDEFGH последовательно передается на
выход OQ, все восемь битов передаются в одном цикле CLKDIV.
Бит данных I появляется на выходе OQ через четыре цикла CLK после выбора слова ABCDEFGH.
На рис. Б.37 показано функционирование контроллера третьим состоянием. В примере показан слу-
чай для режима DDR 4:1 в двунаправленной системе, где буфер ЮВ часто должен быть в третьем со-
стоянии.
Событие 1. Выводы Т1, Т2 и Т4 управляются низким уровнем, чтобы освободить условие третьего
состояния. Пути параллельно-последовательного преобразователя Т1-Т4 и D1-D4 в модуле OSERDESE2
являются идентичными (включая задержки), поэтому биты EFGH являются всегда выровненными с зна-
чением 0010, представленном на выводах Т1-Т4, в течение события 1.
Событие 2. Бит данных Е появляется на выходе OQ на первом цикле синхросигнала CLK после
выбора слова EFGH в модуль OSERDESE2
Бит 0 третьего состояния с вывода Т1 в течение события 1 появляется на выходе TQ на первом
цикле синхросигнала CLK после выбора значения 0010 в блок третьего состояния модуля OSERDESE2.
Б.9. Временные характеристики непрерывной и прерывистой загрузки
данных в режиме SelectMAP
Непрерывная загрузка данных в режиме SelectMAP. Непрерывная загрузка данных используется
в приложениях, где контроллер конфигурирования может обеспечить непрерывный битовый поток После
Приложение В. Временные модели FPGA 7-й серии
371
PROGRAM.B \ /
2!_____________________________________________
)NIT„B \ /
cclk A/~\Z\Z\Z~\Z ••• XZ - XZ\Z~\Z~\
(1j_____________(5) (11)____
CSI_B \ /
(2)__________(4) (12)
RDWRJB \ /
(6) (7) (8) (9)
(10)
DONE /
Рис. Б.38. Непрерывная загрузка данных в режиме х8 SelectMAP
включения питания контроллер устанавливает значение RDWR.B в 0 для управления записью и делает
активным CSLB (т.е. CSLB - 0), причем RDWR.B должен переводиться на низкий уровень перед уста-
новкой CSLB, иначе будет вызвано аварийное состояние ABORT.
На следующем возрастающем фронте CCLK FPGA начинает захватывать данные. Вначале захваты-
ваются только выводы D[7:0], пока не будет определена ширина шины данных. После определения ширины
шины данных захватывается предложенная ширина шины данных для поиска синхронизирующего слова.
Конфигурирование начинается после тактированного ввода синхронизирующего слова в FPGA.
После загрузки конфигурационной последовательности FPGA вводит пусковую последовательность.
Для этого FPGA устанавливает свой вывод DONE в высокий уровень в фазе пусковой последовательности,
которая определяется битовым потоком. Контроллер должен посылать импульсы CCLK после окончания
пусковой последовательности (может потребоваться несколько импульсов CCLK после установки DONE
в высокий уровень).
Временная диаграмма непрерывной загрузки данных в режиме х8 SelectMAP показана на рис. Б.38.
Пояснения к рис. Б.38:
• Сигнал CSLB может подсоединяться к низкому уровню, если имеется только одно устройство на
шине SelectMAP. Если сигнал CSLB не подсоединен к низкому уровню, он может быть установлен
в любое время.
• Сигнал RDWR.B может подсоединяться к низкому уровню, если не требуется обратное чтение. Сиг-
нал RDWR-B не должен переключаться после установки CSLB, потому что это вызовент состояние
ABORT.
• Выводы режима М[2:0] захватываются, когда INIT.B переходит на высокий уровень. Регистр состо-
яния обновляется для указания режима х8
• Сигнал RDWR.B должен быть установлен перед CSLB для предотвращения аварийного состояния.
• Устанавливается CSLB, разрешая интерфейс SelectMAP.
• Загружается новый байт на первом, после установки CSLB, возрастающем фронте CCLK.
• Загружается конфигурационная последовательность по одному байту на каждый возрастающий
фронт CCLK.
• После загрузки команды пуск FPGA вводит пусковую последовательность.
• Пусковая последовательность вводится в течение минимум 8 циклов синхросигнала CCLK.
• Вывод DONE переходит на высокий уровень во время ввода стартовой последовательности. Для
завершения стартовой последовательности могут требоваться дополнительные циклы CCLK.
• После окончания конфигурирования CSLB может сбрасываться.
• После сброса CSLB может сбрасываться RDWRJ3.
• Для подчиненного режима SelectMAP шина данных может иметь ширину х8, Х16 или х32. Регистр
состояния обновляется после последовательности обнаружения ширины шины.
Прерывистая загрузка данных в режиме SelectMAP. Прерывистая загрузка данных используется в
приложениях, где контроллер не может обеспечить непрерывный конфигурационный поток данных напри-
мер контроллер вводит паузу в процессе конфигурирования, когда он принимает дополнительные данные.
372
Приложение Б. Временные модели FPGA 7-й серии
PROGRAM_B ~Д
Рис. Б.39. Временная диаграмма прерывистой загрузки данных в режиме SelectMAP со свободно
работающим CCLK
Рис. Б.40. Временная диаграмма прерывистой загрузки данных в режиме SelectMAP с управляемым
CCLK
Пауза в конфигурировании может создаваться двумя способами: путем сброса сигнала CSLB или путем
задержки синхросигнала CCLK.
Временная диаграмма прерывистой загрузки данных в режиме SelectMAP со свободно работающим
CCLK показана на рис. Б.39.
Прерывистая загрузка данных в режиме SelectMAP с управляемым CCLK показана на рис. Б.40.
Литература
Основная
1. DS054 XC9500XL High-Performance CPLD Family Data Sheet. Xilinx, 18 p.
2. DS090 Cool Runner-11 CPLD Family. Xilinx, 16 p.
3. DS180 7 Series FPGAs Overview. Xilinx, 16 p.
4. UG470 7 Series FPGAs Configuration. User Guide. Xilinx, 174 p.
5. UG471 7 Series FPGAs SelectIO Resources. User Guide. Xilinx, 184 p.
6. UG472 7 Series FPGAs Clocking Resources. User Guide. Xilinx, 114 p.
7. UG474 7 Series FPGAs Configurable Logic Block. User Guide. Xilinx, 72 p.
8. UG473 7 Series FPGAs Memory Resources. User Guide. Xilinx, 84 p.
9. UG479 7 Ser ies DSP48E1 Slice. User Guide. Xilinx, 56 p.
Дополнительная
10. DS181 Artix-7 FPGAs Data Sheet: DC and AC Switching Characteristics. Xilinx, 61 p.
11. DS182 Kintex-7 FPGAs Data Sheet: DC and AC Switching Characteristics. Xilinx, 68 p.
12. DS183 Virtex-7 T and XT FPGAs Data Sheet: DC and AC Switching Characteristics. Xilinx, 75 p.
13. PG054 7 Series FPGAs Integrated Block for PCI Express v3.0 LogiCORE IP Product Guide. Xilinx, 398 p.
14. UG429 7 Series FPGAs Migration. Methodology Guide. Xilinx, 26 p.
15. UG475 7 Series FPGAs Packaging and Pinout. Product Specification. Xilinx, 288 p.
16. UG476 7 Series FPGAs GTX/GTH Transceiver User Guide. Xilinx, 494 p.
17. UG480 7 Series FPGAs and Zynq-7000 All Programmable SoC XADC Dual 12-Bit 1 MSPS Analog-
to-Digital Converter User Guide. Xilinx, 92 p.
18. UG625 Constraints Guide. Xilinx, 319 p.
19. UG626 Synthesis and Simulation Design Guide. Xilinx, 171 p.
20. UG628 Command Line Tools. User Guide. Xilinx, 423 p.
21. UG687 XST User Guide for Virtex-6, Spartan-6, and 7 Series Devices. Xilinx, 485 p.
22. UG768 Xilinx 7 Series FPGA and Zynq-7000 All Programmable SoC Libraries Guide for HDL De-
signs. Xilinx, 446 p.
23. UG872 Large FPGA Methodology Guide. Including Stacked Silicon Interconnect (SSI). Xilinx, 64 p.
24. UG899 Vivado Design Suite User Guide I/O and Clock Planning. Xilinx, 76 p.
25. UG908 Vivado Design Suite User Guide Programming and Debugging. Xilinx, 170 p.
26. UG912 Vivado Design Suite Properties Reference Guide. Xilinx, 282 p.
27. WP170 CoolRunner-ll CPLDs in Secure Applications. Xilinx, 21 p.
28. WP380 Xilinx Stacked Silicon Interconnect Technology Delivers Breakthrough FPGA Capacity, Band-
width, and Power Efficiency. Xilinx, 10 p.
29. XAPP378 Using CoolRunner-ll Advanced Features. Xilinx, 12 p.
30. XAPP382 CoolRunner-ll I/O Characteristics. Xilinx, 12 p.
31. XAPP388 On the Fly Reconfiguration with CoolRunner-ll CPLDs. Xilinx, 10 p.
32. XAPP586 Using SPI Flash with 7 Series FPGAs. Xilinx, 17 p.
33. XAPP888 MMCM and PLL Dynamic Reconfiguration. Xilinx, 19 p.
Литература, относящаяся к данной теме
34. Кузелин М. ПЛИС CPLD компании Xilinx с малым потреблением. Серия CoolRunner // Компо-
ненты и технологии. 2001. № 5.
35. Кузелин М. О., Кнышев Д. А., Зотов В. Ю. Современные семейства ПЛИС фирмы Xilinx. — М.
: Горячая линия — Телеком, 2004.
36. Максфилд К. Проектирование на ПЛИС. Курс молодого бойца. — М.: Издательский дом «Додека-
XXI», 2007. - 408 с.
37. Зотов В. CoolRunner-ll — новое поколение высокопроизводительных ПЛИС CPLD фирмы Xilinx с
микромощным потреблением // Схемотехника. 2003. № 5-10.
374
Литература
38. Зотов В.Ю. Проектирование встраиваемых микропроцессорных систем на основе ПЛИС фирмы
Xilinx. — Горячая линия — Телеком, 2006.
39. Зотов В. Проектирование цифровых устройств, реализуемых на базе ПЛИС FPGA фирмы Xilinx,
с использованием средств CORE Generator // Компоненты и технологии. 2007. № 12.
40. Зотов В. Разработка базовых компонентов цифровых устройств, реализуемых на базе ПЛИС FPGA
фирмы Xilinx, с помощью генератора параметризированных модулей CORE Generator // Компоненты и
технологии. 2008. № 2-12. С. 1-8.
41. Зотов В. Особенности архитектуры нового поколения высокопроизводительных ПЛИС FPGA фир-
мы Xilinx серии Virtex-б // Компоненты и технологии. 2009. № 8.
42. Зотов В. Особенности архитектуры нового поколения ПЛИС FPGA фирмы Xilinx серии Spartan-6
// Компоненты и технологии. 2009. № 9.
43. Зотов В. Новое семейство высокопроизводительных ПЛИС с архитектурой FPGA фирмы Xilinx
Virtex-6 НХТ // Компоненты и технологии. 2010. № 1.
44. Зотов В. Особенности архитектуры нового поколения ПЛИС с архитектурой FPGA фирмы Xilinx
// Компоненты и технологии. 2010. Т. 12, № 113.
45. Зотов В. Инструментальные средства отладки устройств цифровой обработки сигналов, проекти-
руемых на основе ПЛИС FPGA фирмы Xilinx серий Virtex-б и Spartan-б // Компоненты и технологии.
2011. Т. 5, № 118.
46. Зотов В. Аппаратные средства разработки и отладки встраиваемых микропроцессорных систем,
проектируемых на основе расширяемых вычислительных платформ фирмы Xilinx семейства Zynq-7000 АР
SoC // Компоненты и технологии. — 2013. Т. 1, № 138. С. 80-88.
47. Зотов В. Разработка узлов синхронизации цифровых устройств и встраиваемых микропроцес-
сорных систем, реализуемых на базе ПЛИС фирмы Xilinx серии Spartan-б // Компоненты и технологии.
2013. Т. 4, N8 141. С. 89-100.
48. Зотов В. Разработка компонентов устройств ЦОС, реализуемых на базе аппаратных модулей
DSP48E в ПЛИС FPGA серии Virtex-5, с помощью «мастера» Architecture Wizard САПР серии Xilinx ISE
// Новости. 2014. Т. 2, № 8. С. 256.
49. Зотов В. Разработка VHDL-описаний цифровых устройств, проектируемых на основе ПЛИС фир-
мы Xilinx, с использованием шаблонов САПР ISE Design Suite // Новости. 2014. Т. 2, № 8. С. 256.
50. Соловьев В.В. Проектирование функциональных узлов цифровых систем на программируемых
логических устройствах. — Минск: Бестпринт, 1996. — 252 с.
51. Соловьев В.В., Васильев А.Г. Программируемые логические интегральные схемы и их применение.
— Минск: Беларуская навука, 1998. — 270 с.
52. Соловьев В.В. Проектирование цифровых систем на основе программируемых логических интег-
ральных схем. — Москва: Горячая линия — Телеком, 2001. — 636 с.
53. Соловьев В.В., Климович А. Логическое проектирование цифровых систем на основе программи-
руемых логических интегральных схем. — М.: Горячая линия — Телеком, 2008. — 376 с.
54. Соловьев В.В. Основы языка проектирования цифровой аппаратуры Verilog. — М.: Горячая ли-
ния — Телеком, 2014. — 208 с.
55. Тарасов И. Е. Разработка цифровых устройств на основе ПЛИС Xilinx с применением языка
VHDL. — М.: Горячая линия-Телеком, 2005. — 252 с.
56. Тарасов И. Анализ предварительных характеристик FPGA «серии 7» фирмы Xilinx // Компоненты
и технологии. 2010. Т. 8, № 109.
57. Тарасов И., Характеристики П. Семейство ПЛИС Virtex-5 FXT с встроенным процессорным ядром
PowerPC 440 // Новости. 2014. Т. 2, № 8. С. 256.
Список сокращений
AES — Advanced Encryption Standard
ALU — arithmetic logic unit
ASIC — Application Specific Integrated Circuit
ASMBL — Advanced Silicon Modular Block
ASSP — Application Specific Signal Processor
BPI — Byte Peripheral Interface
BST — Boundary Scan Test
CAM — content addressable memory
CC — clock-capable inputs
CCIO — clock-capable input-output
CCLK — configuration clock
CCLs — CMOS configuration latches
CDR — clock data recovery
CE — clock enable
CLB — Configurable Logic Block
CMT - clock management tiles
CP — charge pump
CPLD — Complex Programmable Logic Device
DCI — digitally controlled impedance
DCM — Digital Clock Manager
DDR — double data rate
DET — Dual Edge Triggered
DRAM — Distributed RAM
DRP — Dynamic Reconfiguration Port
DSP — Digital Signal Processing
ECC — Error Correction Code/ Coding
EMC — Electromagnetic Compatibility
EMI — electromagnetic interference
FB — Functional Block
FFT — fast Fourier trancform
FIFO — first-in, first-out
FIR — finite impulse response
FPGA — Field Programmable Gate Array
FWFT — first-word fall-through
GMACs — Giga Multiply-ACcumulate operations per
second
HDL — hardware description language
HKMG — high-k metal gate
HP — high-performance
HPC — High-Performance Clock
HR — high-range
HROW — horizontal clock row
IDDR — input double data rate
I FPS — Interpolated fine phase shift
IOB — Input-Output Block/input-output buffer
IOC — input-output cell
IP — Intellectual Property
ISP — In-System Programmable
JTAG — Joint Test Action Group
LF — loop filter
LUT - Look-Up Table
МАСС — Multiplier Accumulator
MMCM — mixed-mode clock manager
ODDR — output double data rate
OTF — On-The-Fly reconfiguration
PLL — phase-locked loop
P/N — positive/negative
PAL — Programmable Array Logic
PE — Parallel Expander
PFD — phase-frequency detector
PHY — Physical Interface
PLA — Programmable Logic Array
PLD — Programmable Logic Device
PROM — Programmable Read Only Memory
RAM — Random Access Memories
SDP — simple dual-port
SDR — single date rate
SE — Shared Expander
SEU — Single Event Upsets
SIMD — Single instruction, multiple data
SLR — Super Logic Region
SM — Switch Matrix
SoC — System On Chip
SPI — serial peripheral interface
SPS — static phase shift
SSCG — Spread-spectrum clock generation
SSI — stacked silicon interconnect
SSL — Super Long Line
TAP — Test Access Port
TDP — true dual-port
Ul — unit interval
UART — universal asynchronous receiver/traucmitter
VCO — Voltage Controlled Oscillator
XADC — configurable analog interface
ДНФ — дизъюнктивная нормальная форма
ПЛИС — программируемые логические интеграль-
ные схемы
ПЛМ — программируемая логическая матрица
ПЛУ — программируемое логическое устройство
ППЗУ — программируемое постоянное запоминаю-
щее устройство
СБФ — система булевых функций
СнК — система на кристалле
Предметный указатель
AES-шифрование - 27
СС-входы - 199, 214
DSP-процессор - 15
Firm-микропроцессор - 15
GMAC/s (гига операций умножения с накоплени-
ем в секунду) - 80
IP-ядро - 14
Soft-микропроцессор - 15
Асинхронное страничное чтение - 267
алгоритм Long-Term Evolution - 99
анализатор логический - 17
арифметическо-логическое устройство (arithmetic
logic unit - ALU) - 80, 84, 85
архитектура Advanced Silicon Modular Block
(ASMBL) - 24, 77
- с одним потоком команд и несколькими по-
токами данных (single instruction/multiple date -
SIMD) - 80
Базовое конфигурационное решение - 249
банки ввода-вывода высокопроизводительные
(high-performance - HP) - 141
— широкого диапазона (high-range - HR) - 141
библиотека UniMacro - 115
битовый поток (bitstream) - 246, 247
биты защиты блока ЕСС - 132, 133
---- записи - 41
---- чтения - 41
- четности (Parity Bits) - 107
блок ввода-вывода (Input-Output Block - ЮВ) -
10. 34
- встроенной памяти RAM - 104
- входной логики ILOGIC - 151, 170
- выходной логики OLOGIC - 153, 170
- интеллектуальной собственности (Intellectual
Property - IP), IP-ядро - 14
- конфигурируемый логический (Configurable
Logic Block - CLB) - 19, 53
- коррекции ошибок ЕСС (Error Correction
Coding) - 132
- последовательно-параллельного преобразовате-
ля ISERDESE2 - 170, 178, 179
- параллельно-последовательного преобразовате-
ля OSERDESE2 - 170, 178, 187
- распределенной памяти RAM - 55
- управления смешанными режимами синхрони-
зации (mixed-mode clock manager - ММСМ) -
27, 198, 224, 225, 227
- фазовой автоподстройки частоты (ФАПЧ -
phase-locked loop - PLL) - 27, 198, 224, 225,
227
- формирования синхросигналов (управления
синхронизацией) (clock management tiles -
СМТ) - 27, 198, 202, 224
- функциональный - 35, 44
быстрое преобразование Фурье (FFT) - 80
буфер BUFGMUX-CTRL с разрешением синхро-
низации - 213
- ввода-вывода (input-output buffer - ЮВ) - 149
- горизонтальной синхронизации BUFH и
BUFHCE - 216
- многорегиональной синхронизации BUFMR/
BUFMRCE - 216
- региональной синхронизации BUFR - 215
- с нулевой задержкой - 238
- синхронизации ввода-вывода BUFIO - 201,
214, 215
- глобальные BUFG (BUFGCTRL) - 201
- горизонтальные BUFH/BUFHCE - 201
- многорегиональные BUFMR - 201
- региональные BUFR - 201
Введение ошибки для проверки функционирова-
ния блока ЕСС - 132
восстановление синхронизации (clock data reco-
very - CDR) - 16
временное мультиплексирование - 99
вход парафазный - 5
- с удвоенной скоростью передачи данных (input
double data rate - IDDR) - 173
входы многорегиональной синхронизации
MRCC - 207
- синхронизации (clock-capable inputs - СС-
входы) - 204, 208, 214
вывод главный (P-side) - 209
- опорный - 155
- подчиненный (N-side) - 209
- специализированный (dedicated) - 5
Предметный указатель
377
выводы выбора режима конфигурирования - 246
- конфигурирования - 246
выход с удвоенной скоростью передачи данных
ODDR (output double data rate) - 175
Генератор, управляемый напряжением (Voltage
Controlled Osillator - VCO) - 225
генерация переноса - 72
- широкополосных синхросигналов (Spread-
spectrum clock generation - SSCG) - 240
главный (Master) - 246
горизонтальная центральная линия (Horizontal
Central Line) - 203
горячая вставка (hot-plugging) - 34
граничное сканирование (Boundary Scan Test -
BST) - 35, 43, 246, 270, 274
группа байта (byte group) - 191
Делители буфера BUFR - 216
делитель частоты синхросигнала (Clock Divi-
der) - 43
детектор шаблона (pattern detector) - 80, 84,
86, 88
дешифратор блока ЕСС (ЕСС Decoder) - 132
дизъюнктивная нормальная форма (ДНФ) - 5
динамическая реконфигурация - 18, 274
дифференциальная пара (differential pair) - 16
дребезг сигналов (bounce) - 164
дробное (фракционное - fractional) деление -
225
дробный (fractional) счетчик - 202, 226, 229
Единичный интервал (unit interval - Ul) - 233
Загрузка данных в FPGA (data loading) непре-
рывная (continuous) - 258
- прерывистая (non-continuous) - 258
задержка входная IDELAY - 170
- выходная ODELAY - 173
заказная специализированная микросхема (App-
lication Specific Integrated Circuit - ASIC) - 4
запас помехоустойчивости (noise margin) - 164
запоминающие элементы - 60
защелки конфигурирования типа CMOS (CMOS
configuration latches - CCLs) - 246
звон (ringing) сигналов - 154
Интерфейс памяти промышленного стандарта -
246
- пользовательский конфигурируемый анало-
говый (configurable analog interface - XADC) -
27
интерфейс конфигурирования FPGA - 233
- граничного сканирования JTAG - 249
- параллельный шинный интерфейс SelectMAP -
256
- побайтный периферийный интерфейс (Byte
Peripheral Interface - BPI) флэш-памяти - 249
- последовательный (Serial) - 249
- последовательный периферийный интерфейс
(serial peripheral interface - SPI) флэш-памяти -
249
Канал глобальной синхронизации (Global Clock
Column) - 198
- горизонтальной синхронизации (horizontal clock
row - HROW) - 199
конфигурирование ПЛИС - 4
комплект разработчика (development kit) - 13,
14
кабель для программирования - 13
коммутационный шум - 17
комбинационная функция - 37
каналы межсоединений (interconnect resources) -
54
карты генерации (generic maps) для языка
VHDL - 116
каскадирование (каскадное соединение) блоков
СМТ - 224, 239
- блоков DSP - 80, 83, 86, 91, 93, 94, 96, 97,
98, 99, 100, 101
- блоков MMCM/PLL - 228, 232, 240
- блоков RAM - 104, 107, 112, 117, 120
- логического переноса - 77
- памяти FIFO для увеличения глубины - 128
- цифрового управления импедансом DCI - 155,
156, 165, 166
квадрант приемопередатчиков GT (GT Quad) -
206
код с исправлением ошибок (error-correcting
code - ЕСС) - 104
канал передачи данных параллельный - 246
-----последовательный - 246
конвейерная обработка - 91
контурный фильтр (loop filter - LF) - 226
контакты многофункциональные - 247
конфигурирование FPGA - 288
- динамическое - 274
- нескольких устройств - 250, 257, 273
- последовательное - 253
- с помощью интерфейса JTAG - 270
--параллельного шинного интерфейса Select-
MAP - 256
--побайтного периферийного интерфейса
BPI - 263
--последовательного периферийного интер-
фейса SPI - 258
- спаренное (ganged) или поперечное (broad-
side) - 250
- через граничное сканирование - 274
378
Предметный указатель
Логика переноса (Carry Logic) - 71
логическая ячейка (Logic Cell) - 10, 19
логический элемент (Logic Element) - 10, 19
Магистраль блока СМТ (СМТ Backbone) - 203,
206, 224
- глобальной синхронизации (Global Clocking
Backbone) - 200
- синхронизации (Clock Backbone) - 203
макроячейка выходная - 5
- скрытая (buried) - 36
макетная плата - 14
матрица переключений (Switch Matrix - SM) -
8, 55
межсоединения (interconnect) - 54, 76
метод граничного сканирования (boundary
scan) - 17
методы защиты битового потока
- AES с ключом eFUSE - 250
- AES с ключом SRAM с аварийным батарей-
ным питанием - 250
- идентификация устройства с помощью уни-
версального идентификатора устройства (device
DNA) - 250
- усовершенствованный стандарт шифрования
(Advanced Encryption Standard - AES) - 250
многоканальная фильтрация - 100
мультиплексор - 70
- синхросигналов асинхронный 212
- каналов передачи данных - 84
мультипроцессорная система - 16
Накопитель заряда (charge pump - СР) - 226
некалибрируемая расщепляющая нагрузка - 162
Обратное чтение (readback) - 50, 256
обучающий шаблон (training pattern) - 178
общий расширитель (Shared Expander - SE)
промежуточных шин - 9
одновременно переключающиеся выходы (simul-
taneous switching outputs - SSOs) - 163
операции с плавающей точкой - 80
операция bitslip - 186
- вычитания - 91
определение параметров (defparams) в языке
Verilog - 116
открытый сток (open-drain) - 43
отображение (mapping) - 72
отображаемые на память регистры ввода-
вывода - 100
отражения сигналов (reflections) - 154
ошибка двойная - 132
- единичная - 132
Память ассоциативная (content addressable
memory - САМ) - 67, 110
- распределенная RAM (Distributed RAM -
DRAM) - 26. 61
- распределенная типа ROM - 67
- типа FIFO (first-in, first-out) - 67, 123
- асинхронная (с двойной синхронизацией) -
123, 125
- ввода-вывода - 191
- синхронная - 123, 126
пара P/N (positive/negative - положитель-
ный/отрицательный) - 145
передача данных с удвоенной скоростью (double-
date-rate - DDR) - 141
перекос (фазовый сдвиг - deskew) - 198, 202
- сети синхронизации - 236
перекрестные помехи - 17
переполнение - 90
петля гистерезиса на входе (input hysteresis) -
34
план кристалла (floorplanning) - 72, 76, 217
ПЛИС энергонезависимая - 4
- энергозависимая- 4
плитка (tile) DSP48E1 - 80
- ввода-вы вода - 189
побайтовая запись данных (byte-wide write) -
113, 117
подмодуль Bitslip - 178, 186
подтягивание слабое (weak pull-up) - 43
поле межсоединений (interconnect routing) - 10
помеха (glitch), кратковременный импульс - 198
поразрядные логические функции - 86, 88
порт динамического реконфигурирования (Dyna-
mic Reconfiguration Port - DRP) - 274
- доступа для тестирования (Test Access Port -
TAP) - 270
потеря значимости - 90
преамбула - 186
предварительный сумматор (pre-adder) - 80, 84,
85
преобразователь из последовательной формы в
какую-либо другую форму (deserializers) - 178
- параллельно-последовательный OSERDES -
141
- параллельно-последовательный данных (Data
Parallel-to-Serial Convert) - 188
- параллельно-последовательный / последова-
тельно-параллельный (serializer/deserializer -
SERDES) - 201
- параллельно-последовательный третьего состо-
яния (3-State Parallel-to-Serial Convert) - 188
- последовательно-параллельный ISERDES - 141
- последовательно-параллельный (Serial-to-
Parallel Converter) - 179
примитив IDELAYCTRL - 172
- IDELAYE2 - 171
- ODELAYE2- 173
- STARTUPE2 - 76
Предметный указатель
379
примитивы буферов глобальной синхронизации -
211
присоединенное свойство (параметр) LOC - 115
проводной сдвиг вправо - 84, 86, 91
программа Clocking Wizard - 229, 230, 234, 236
- CORE Generator - 74
- iMPACT - 249, 258, 264, 274
- LogiCORE IP - 202
- Plan Ahead - 162, 163, 164
- SSN - 163
- Unisim - 94
- Xilinx Power Estimator (XPE) - 219
- Xilinx Power Analyzer (XPower) - 219
программатор - 4, 13
программирование ПЛИС - 4
программирование в системе (In-System Pro-
grammable - ISP) - 4, 35
программируемая логика - 11
программируемые логические интегральные схе-
мы (ПЛИС) - 1, 4
- программируемая логическая матрица (ПЛМ -
Programmable Logic Array - PLA) - 5, 44
- программируемая матрица логики (Programm-
able Array Logic - PAL) - 5
- программируемая пользователем вентиль-
ная матрица (Field Programmable Gate Array -
FPGA) - 10, 19
— программируемое логическое устройство
(ПЛУ - Programmable Logic Device - PLD) -
6
- программируемое постоянное запоминающее
устройство (ППЗУ - Programmable Read Only
Memory - PROM) - 4, 5, 246
- система на кристалле (СнК - System On
Chip - SoC) - 1, 10, 15
- сложное программируемое логическое уст-
ройство (Complex Programmable Logic Device -
CPLD)- 8
программируемое подсоединение к земле (User-
Programmable Ground) - 40
промежуточные шины (product terms) - 5, 36
протокол PCI Express - 16
прототип (макет) - 12
процессор MicroBlaze - 249
Распределитель промежуточных шин (Product
Term Allocator) - 9, 36
распространение (propagate) переноса - 71
расширение спектра (spread spectrum) - 225
расширитель промежуточных шин параллельный
(Parallel Expander - РЕ)- 9
расщепляющая нагрузка на микросхеме (on-chip
split-termination) - 162
регионы синхронизации - 198
региональные сети синхронизации - 214
регистры передачи данных с удвоенной ско-
ростью (double data rate - DDR) - 170
режим функционирования CPLD семейства
CoolRunnerll - 48
- делителя частоты синхросигнала ClockDivi-
der - 48
- реконфигурирования «в полете» (On-The-Fly
reconfiguration - OTF) - 44, 50
- с удвоенной частотой синхросигнала Dual Edge
Triggered (DET) - 49
- снижения энергопотребления DataGATE - 47
- совмещения схемы делителя синхросигнала с
удвоенной частотой синхросигнала CoolCLOCK -
50
режим функционирования CPLD семейства
XC9500XL - 50
- пониженного энергопотребления - 41
режим записи в блок памяти RAM - 125
- NO.CHANGE - 104, 109
- READ-FIRST - 104, 109
- WRITE-FIRST - 104, 109
- кодирования с исправлением ошибок (Error
Correction Code - ЕСС) - 114
- обнаружения одиночной ошибки (Single Event
Upsets - SEU) - 247
- передачи данных блоками ISERDESE2 и
OSERDESE2
-----с базовой скоростью (single date rate -
SDR) - 178
-----с удвоенной скоростью (double date rate -
DDR) - 178
- фазового сдвига блока ММСМ
- интерполированного тонкого фазового сдвига
(Interpolated fine phase shift - IFPS) - 231
- статического - 230
- функционирования блока (тип интерфейса)
ISERDESE2
- MEMORY - 183
- MEMORY-DDR3 - 184
- MEMORY-QDR - 183
- NETWORKING - 183
- OVERSAMPLE - 184
режим функционирования блока коррекции оши-
бок ЕСС
- стандартный - 134, 135
- «только шифратор» - 134, 138
- «только дешифратор» - 134, 138
режим функционирования блока памяти RAM
- действительно двух-портовый (true dual-port -
TDP) - 104, 108, 113
- одно-портовый (single port) - 104, 108
- простой двух-портовый (simple dual-port -
SDP) - 104, 108, 111, 113
режим функционирования входного элемента
IDDR
- OPPOSITE-EDGE - 153, 173
- SAME-EDGE - 153, 174
- SAME_EDGE_PIPELINED - 153, 174
380
Предметный указатель
режим функционирования выходного элемента
ODDR
- OPPOSITE-EDGE - 154. 175
- SAME-EDGE - 154. 175
режим функционирования памяти FIFO
- с двойной синхронизацией (асинхронный) -
124, 125
- синхронный - 124, 126
режим функционирования примитива IDELAYE2
- FIXED - 172
- VAR-LOAD - 172
- VAR.LOAD-PIPE - 172
- VARIABLE - 172
режим функционирования элемента IO-FIFO
4x4 - 192
------ 4x8 - 193
----элемента OUT.FIFO 4x4 - 193
------ 8x4 - 194
- чтения первого слова, записанного в пустую
память FIFO
- FWFT (first-word fall-through - первое слово
выпадает) - 123, 125
- стандартный - 123, 125
- конфигурирования FPGA
— последовательный - 253
— главный - 248
--подчиненный - 248
--главный последовательный Master-Serial —
246, 255
--подчиненный последовательный Slave-Serial -
246, 249, 254
— главный параллельный Master SelectMAP -
246
— подчиненный параллельный Slave Select-
MAP - 246, 249
- JTAG - 246, 249, 270
- главный последовательного периферийного
интерфейса флэш-памяти Master SPI - 246, 249,
255, 258
- главный побайтного периферийного интерфей-
са флэш-памяти Master BPI - 246, 249, 263
- функционирования ALU
--2-входовое логическое устройство - 84, 87
--3-входовой сумматор/вычитатель/аккумуля-
тор - 85, 86
- один поток команд, несколько потоков данных
(SIMD) - 87
- функционирования предварительного суммато-
ра - 85
-- распределенной памяти двухпортовой - 67
----- однопортовой - 67
----- простой двухпортовой - 67
-----четырехпортовой - 67
--сумматора/вычитателя с одним потоком
команд и несколькими потоками данных SIMD
--двойной 24-битовый сумматор/вычитатель/
аккумулятор SIMD с двумя отдельными сигнала-
ми CARRYOUT - 83
- учетверенный 12-6итовый сумматор/вычита-
тель/аккумулятор SIMD с четырьмя отдельными
сигналами CARRYOUT - 83
резистор подтягивающий - 246
- понижающий - 246
Свойство пакета Vivado
- cfgbvs - 253
- config_mode - 253
- config_voltage - 253
сдвиговый регистр - 67, 68
- - SRL - 55
секция DSP48E1 - 80
- SLICEL - 55, 58
- SLICEM - 55, 57
сигнал разрешения синхронизации (clock en-
able - СЕ) - 206
синхронное тактирование (synchronous clock-
ing) - 109
синхросигнал асимметричный (single-ehded) -
209
- высокой производительности (High-Performance
Clock - НРС) - 202, 208, 219
- дифференциальный (differential) - 209
- конфигурирования (configuration clock -
CCLK) - 246
- конфигурирования внешний EMCCLK - 253
Предметный указатель
381
система булевых функций (СБФ) - 5
- ввода-вывода SelectIO - 141
скважность синхросигнала - 198
скорость нарастания сигнала (slew rate) - 34
сопротивление Thevenin - 162
состояние стирания (erased) - 41
специализированный процессор (Application
Specific Signal Processor - ASSP) - 24
специальные выводы синхронизации (clock-
capable input-output - ССЮ) - 199
стандарты ввода-вывода ассиметричные (single-
ended) - 141, 145
--дифференциальные (differential) - 141, 145
- комплементарные ассиметричные (DIFF-HSTL
и DIFF-SSTL) - 189
- с управляемой параллельной оконечной на-
грузкой - 155
- с управляющими импедансом драйверами -
155
супер логический регион (Super Logic Region -
SLR) - 25. 77
супер длинная линия (Super Long Line - SSL) -
25, 77
схема Lock Detect - 226
- Thevenin - 159, 162
- удержания шины (bus-hold circuit) - 34
Таблица поиска, таблица перекодировки, функ-
циональный генератор (Look-Up Table - LUT) -
19
тактирование
- асинхронное (asynchronous clocking) - 109
технологии проектирования на основе ПЛИС -
12
- архитектуры ПЛИС - 12
- аппаратные средства проектирования - 13
- блоки интеллектуальной собственности (IP-
ядра) - 14
- динамическое и частичное реконфигурирова-
ние ПЛИС - 18
- защита проекта - 19
- конфигурирование ПЛИС - 18
- методологии проектирования на основе
ПЛИС - 14
- обеспечение целостности сигналов - 17
- отладка проектов - 16
- проектирование интерфейсов - 16
- проектирование печатных плат для проектов
на ПЛИС - 17
- проектирование со встроенными микропроцес-
сорами - 15
- средства автоматизированного проектирова-
ния - 13
- цифровая обработка сигналов - 15
- энергосбережение - 18
- языки проектирования - 13
технология FastFLASH CMOS - 34
- high-k metal gate (HKMG) - 24
- стековых кремниевых межсоединений (stacked
silicon interconnect - SSI) - 24, 25, 77, 274
типы интерфейса блока ISERDESE2 - 165
- MEMORY - 183
- MEMORY.DDR3 - 184
- MEMORY_QDR - 183
- NETWORKING - 183
- OVERSAMPLE - 184
тупиковое отражение (stub reflection) - 155
Удержание (захват) шины (Bus-Hold) - 40
умножитель с накоплением (МАСС - Multiplier
Accumulator) - 80, 84
универсальная PAL - 7
универсальные макросы (unimacros) - 74
универсальный асинхронный приемопередат-
чик (universal asynchronous receiver/transmitter -
UART) - 17
управление скоростью назрастания сигнала (Slew
Rate Control) - 40
учебная плата - 14
Фазово-частотный детектор (phase-frequency
detector - PFD) - 226
фазовый сдвиг - 227, 228, 230
--тонкий (fine) - 227
--динамический - 227, 231
--статический (static phase shift - SPS) - 230
--интерполированный тонкий (Interpolated fine
phase shift - IFPS) - 231
файл последовательного векторного формата
(SVF) - 274
физический интерфейс (Physical Interface -
PHY) - 191
физическое расположение ячеек памяти RAM -
114
фильтр с импульсной характеристикой конечной
длины (FIR-фильтр) - 91, 95, 98
- симметричный (symmetrical filter) - 85
- систолический симметричный FIR-фильтр - 99
- флуктуаций - 229
- цифровой - 80
фильтрация с симметричными коэффициентами
(symmetric coefficient filtering) - 27
флаги состояний памяти FIFO - 127
флуктуация (jitter - дрожание фронтов сигна-
ла) - 198, 202, 229
флэш-память - 246
функциональный блок (Functional Block - FB) -
34
функциональный генератор типа LUT (Look Up
Table) - 10, 55, 59
функция регистровая - 37
Целостность сигналов (signal integrity) - 17, 154
центр решений проблем конфигурирования
(Xilinx Configuration Solution Center) - 251
цифровая обработка сигналов (ЦОС - Digital
Signal Processing - DSP) - 1, 15, 80
цифровое управление импедансом (digitally
controlled impedance - DCI) - 17, 141, 154, 155
цифровой контроллер синхросигнала DCM
(Digital Clock Manager) - 224
382 Предметный указатель
Частичная реконфигурация - 19 частичные произведения (partial products) - 86 электромагнитные помехи (electromagnetic interference - EMI) - 240
Ширина порта чтения - 104 - порта записи - 104 шифратор блока ЕСС (ЕСС Encoder) - 132 шум общего провода - 17 элемент задержки входной (IDELAY) - 170 - выходной (ODELAY) - 170 Ядро интеллектуальной собственности (IP- ядро) - 250 язык HDL (hardware description language) - 101
Электромагнитная совместимость (Electromagne- tic Compatibility - EMC) - 241 ячейка ввода-вывода (input-output cell - ЮС) - 9
Оглавление
Предисловие ............................................................ 3
1. Программируемые логические интегральные схемы............................ 7
1.1. Введение в программируемые логические интегральные схемы .............. 7
1.1.1. Что такое ПЛИС? ................................................ 7
1.1.2. Чем ПЛИС отличаются от микроконтроллеров?....................... 7
1.1.3. Программируемые логические матрицы ............................. 8
1.1.4. Программируемые логические устройства (PLD) .................... 9
1.1.5. Сложные программируемые логические устройства (CPLD) .......... 11
1 1.6. Программируемые пользователем вентильные матрицы (FPGA) .... 12
117 Системы на одном кристалле (SoC).................................. 13
1.1.8. Применение CPLD, FPGA и SoC ................................... 13
1.1.9. Технологии проектирования на основе ПЛИС....................... 14
1.2. ПЛИС фирмы Xilinx .................................................... 22
1.2.1. Историческая справка .......................................... 22
1 2.2. CPLD фирмы Xilinx........................................... 23
1.2.3. FPGA фирмы Xilinx.............................................. 24
1.2.4. Микросхемы UltraScale ......................................... 24
1.2.5. Микросхемы SoC ................................................ 25
1.2.6. Переход от ПЛИС к ASIC ........................................ 26
1.3. Основные свойства FPGA 7-й серии фирмы Xilinx ........................ 26
1 3.1. Семейства микросхем FPGA 7-й серии ............................ 26
1.3.2. Архитектура ASMBL.............................................. 27
1.3.3 Технология SSI ................................................. 27
1.3.4. Свойства FPGA 7-й серии ....................................... 28
1.3.5. Семейство Artix-7.............................................. 29
1.3.6. Семейство Kintex-7 ............................................ 30
1.3.7. Семейство Virtex-7 ............................................ 31
1.4. Выводы ............................................................... 32
2. CPLD семейства XC9500XL ................................................ 36
2.1. Описание архитектуры ................................................. 37
2.1.1. Общая структура ............................................... 37
2.1.2. Структура функционального блока ............................... 37
2.1.3. Архитектура макроячеек......................................... 38
2 1.4. Архитектура блока ввода-вывода.............................. 40
2.2. Архитектурные особенности CPLD семейства XC9500XL .................... 41
2.2.1. Архитектурные свойства буферов ввода-вывода ................... 41
2.2.2. Безопасность проекта .......................................... 42
2.3.3. Режим пониженного энергопотребления............................ 42
2.4. Выводы ............................................................... 42
3. CPLD семейства CoolRunnerll ..................................... 43
384
Оглавление
3.1. Описание архитектуры ................................................ 45
3.1 1 Общая структура ............................................... 45
3.1.2. Структура функционального блока .............................. 45
3.1.3. Архитектура макроячеек........................................ 46
3.1.4. Архитектура блока ввода-вывода................................ 47
3.2. Архитектурные особенности CPLD семейства CoolRunnerll ............... 48
3.2.1. Режим снижения энергопотребления DataGATE..................... 48
3 2 2 Режим делителя частоты синхросигнала ClockDivider........... 48
3.2 3 Режим функционирования с удвоенной частотой синхросигнала DualEDGE 49
3.2.4. Режим совмещения схемы делителя синхросигнала с удвоенной частотой
синхросигнала CoolCLOCK.............................................. 49
3.2.5. Защита проекта ............................................... 49
3.2.6. Режим реконфигурации «на лету» On-The-Fly reconfiguration .... 50
3.3. Программирование CPLD................................................ 50
3.4. Выводы .............................................................. 51
4. Внутренняя логика FPGA: конфигурируемые логические блоки CLB, секции,
функциональные генераторы LUT ............................................ 53
4.1. Конфигурируемые логические блоки CLB................................. 53
4.2. Секции блоков CLB ................................................... 55
4.3. Функциональный генератор LUT ........................................ 57
4 3 1. Запоминающие элементы......................................... 58
4.3.2. Сигналы управления запоминающих элементов .................... 59
4.4. Распределенная память RAM ........................................... 60
4.4.1. Однопортовая распределенная память RAM ....................... 60
4.4.2. Двух-портовая распределенная память RAM ...................... 61
4 4.3 Простая двухпортовая распределенная память RAM ............. 61
4 4 4 Четырехпортовая распределенная память RAM .................. 62
4.4.5. Другие конфигурации распределенной памяти, реализуемые в одной секции 64
4.4.6. Функционирование распределенной памяти RAM ................... 64
4.5. Распределенная память ROM ........................................... 65
4.6. Сдвиговые регистры, реализуемые в секциях SLICEM .................... 65
4.7. Мультиплексоры ...................................................... 67
4.8. Логика переноса ..................................................... 68
4.9. Особенности применения внутренней логики ........................... 69
4.9.1. Общие рекомендации для эффективного использования блоков CLB . 69
4.9.2. Использование защелок в качестве логических вентилей ......... 71
4.9.3. Использование схемы логического переноса...................... 71
4 9 4. Реализация синхронных сдвиговых регистров ................. 72
4.9 5. Реализация больших сдвиговых регистров ...................... 72
4.9.6 Использование распределенной памяти ........................... 73
4.9.7. Использование глобальных управляющих сигналов GSR и GTS ...... 73
4.9.8. Оптимизация ресурсов межсоединений ........................... 73
4.9.9. Особенности применения устройств, использующих технологию SSI. 74
4.10. Выводы............................................................... 75
5. Секции цифровой обработки сигналов DSP48E1............................. 78
5.1. Архитектура секции DSP48E1........................................... 79
5.2. Функционирование секции DSP48E1 ..................................... 82
5.2.1. Функционирование ALU в режиме сумматора/вычитателя............ 84
Оглавление
385
5.2.2. Режим один поток команд, несколько потоков данных (SIMD) ..... 84
5.2.3. Функционирование ALU в режиме логического устройства ......... 85
5.2.4. Детектор шаблона.............................................. 86
5.2.5. Логика переполнения и потери значимости....................... 87
5.2.6 Другие функциональные возможности ............................. 88
5.3. Особенности применения ...................................... 88
5.3.1. Реализация операции вычитания................................. 88
5.3.2. Сигналы MULTSIGNOUT и CARRYCASCOUT ........................... 90
5.3.3. Реализация FIR-фильтров в виде дерева сумматоров.............. 91
5.3.4. Реализация FIR-фильтров в виде каскада сумматоров............. 94
5.3.5. Применение предварительного сумматора ........................ 94
5.3.6. Временное мультиплексирование секции DSP48E1 ................. 94
5.3.7. Применение отображаемых на память регистров ввода-вывода ..... 96
5.3.8. Рекомендации по повышению производительности и уменьшению потреб-
ляемой мощности ..................................................... 96
5.3.9. Рекомендации по применению секций DSP48E1 .................... 97
5.4. Выводы............................................................... 98
6. Блоки памяти RAM...................................................... 101
6.1. Архитектура блока памяти RAM....................................... 102
6.1.1 Логическая схема функционирования памяти RAM.................. 102
6.1.2. Потоки данных в блоке памяти RAM ............................ 103
6.2. Функционирование блока памяти RAM .................................. 104
6.2.1. Режимы функционирования блока памяти RAM .................... 104
6.2.2. Операции чтения и записи..................................... 104
6.2.3 Синхронное и асинхронное тактирование......................... 105
6.2.4. Дополнительные выходные регистры для конвейерных приложений . 106
6.2.5. Независимая ширина данных портов чтения и записи ............ 106
6.2.6 Простой двухпортовый режим SDP ............................... 107
6.2.7. Каскадирование блока RAM .................................... 107
6.2.8. Побайтовая запись данных .................................... 107
6.2.9. Режим кодирования с исправлением ошибок ЕСС ................. 109
6.2.10. Минимизация потребляемой мощности .......................... 109
6.2.11. Некоторые архитектурные особенности ........................ 109
6.3. Особенности применения блоков памяти RAM ........................... 110
6.3.1. Ограничения на расположение блоков RAM ...................... 110
6.3.2. Инициализация блока RAM в языках VHDL и Verilog ............. 110
6.3.3. Дополнительные выходные регистры............................. 110
6.3.4. Независимые размеры порта чтения и записи.................... 111
6.3.5. Правила проектирования отображения портов для примитивов RAMB18E1
и RAMB36E1 ......................................................... 111
6.3.6 Каскадирование блоков RAM .................................... Ill
6.3.7 Возможность побайтной записи ................................. 112
6.3.8. Создание больших структур RAM ............................... 112
6.3.9. Блок RAM в регистровом режиме RSTREG ........................ 112
6.4. Выводы ............................................................. 113
7. Память типа FIFO ..................................................... 117
7.1. Архитектура памяти FIFO ............................. 117
7.2. Функционирование памяти FIFO ....................................... 118
386
Оглавление
7.2.1. Режимы функционирования: стандартный и FWFT................. 118
7.2 2. Начало функционирования памяти FIFO (сигнал сброса RST) ... 119
7.2 3. Режим двойной синхронизации памяти FIFO ................... 119
7.2.4. Синхронный режим функционирования памяти FIFO .............. 120
7.2.5. Флаги состояний ............................................ 120
7.2.6. Диапазоны смещения флагов «почти полный» и «почти пустой» .. 121
7.3. Применение памяти FIFO ............................................ 121
7.3 1 Каскадирование памяти FIFO для увеличения глубины ........... 121
7 3.2. Параллельное соединение модулей FIFO для увеличения ширины слова дан-
ных ............................................................... 122
7.3.3. Допустимые комбинации блоков памяти RAM и FIFO ............. 123
7.4. Выводы ............................................................ 123
8. Встроенная коррекция ошибок блоков памяти ........................... 125
8.1. Архитектура блока ЕСС.............................................. 125
8.2. Функционирование блока ЕСС ...................................... 127
8.3. Применение блока ЕСС .............................................. 128
8.3.1. Стандартный режим ЕСС ...................................... 130
8.3.2. Режим ЕСС «только шифратор» ................................ 130
8.3.3. Режим ЕСС «только дешифратор» .............................. 131
8.3.4. Использование режима «только дешифратор» для введения одиночной
ошибки ............................................................ 131
8.3.5. Использование режима «только дешифратор» для введения двойной
ошибки ............................................................ 131
8.4. Выводы............................................................. 132
9. Система ввода-вывода SelectIO....................................... 134
9.1. Банки ввода-вывода ............................................... 134
9.2. Ресурсы системы ввода-вывода в семействах FPGA 7-й серии .......... 135
9.3. Основные свойства ресурсов ввода-вывода общего назначения ......... 136
9.4. Напряжения питания элементов ввода-вывода ........................ 137
9.5. Стандарты ввода-вывода, поддерживаемые FPGA 7-серии 14............. 138
9.6. Архитектура блоков ввода-вывода ................................... 139
9.6.1. Обобщенная структура ввода-вывода .......................... 139
9.6.2. Архитектура буферов ввода-вывода ........................... 140
9.6.3. Архитектура блока ILOGIC.................................... 141
9.6.4. Архитектура блока OLOGIC.................................... 143
9.7. Цифровое управление импедансом (DCI) .............................. 144
9 7 1. Реализация DCI в FPGA 7-й серии 15.......................... 145
9.7.2. Каскадирование DCI ......................................... 146
9 7.3 Драйвер управляемого импеданса 15............................ 147
9.7.4. Драйвер управляемого импеданса с половинным импедансом...... 148
9.7.5. Расщепление нагрузки DCI ................................... 148
9.7.6. DCI и третье состояние (T_DCI) ............................. 149
9.7.7. DCI в стандартах ввода-вывода, поддерживаемых FPGA 7-й серии. 150
9.7.8. Некалибрируемая расщепляющая нагрузка в банках ввода-вывода HR (огра-
ничение IN.TERM) .................................................. 150
9.8. Применение ресурсов системы ввода-вывода .......................... 151
9.8.1. Правила совмещения стандартов в одном банке ввода-вывода ... 151
9.8.2. Одновременно переключающиеся выходы (SSO) .................. 151
Оглавление 387
9.8.3. Планирование выводов для уменьшения влияния SSO ............ 152
9.8.4. Рекомендации для корректного использования DCI в FPGA 7-й серии .... 152
9.8.5. Руководство для выводов VRN и VRP при перемещении проектов с FPGA
предыдущих семейств на FPGA 7-й серии ............................. 153
9.8.6. Рекомендации по использованию каскадирования DCI ........... 154
9.9. Выводы............................................................. 154
10. Логические ресурсы ввода-вывода...................................... 158
10.1. Входная задержка IDELAY............................................ 158
10.1.1. Примитив IDELAYE2 ......................................... 159
10.1.2. Элемент IDELAYCTRL ........................................ 160
10.2. Выходная задержка ODELAY .......................................... 160
10.3. Вход IDDR блока ILOGIC ............................................ 160
10.4. Выход ODDR блока OLOGIC ........................................... 162
10.5. Выводы............................................................. 163
11. Расширенные логические ресурсы ввода-вывода.......................... 165
11.1. Последовательно-параллельный преобразователь ISERDRSE2 ............ 165
11.1.1. Основные свойства.......................................... 165
11.1.2. Архитектура блока ISERDESE2 ............................... 166
11.1.3. Методы синхронизации блока ISERDESE2 ...................... 169
11.1.4. Расширение ширины слова блока ISERDESE2.................... 171
11.2. Подмодуль BITSLIP.................................................. 172
11.3. Параллельно-последовательный преобразователь OSERDESE2 ............ 174
11.3.1. Архитектура блока OSERDESE2 ............................... 174
11.3.2. Методы синхронизации блока OSERDESE2 ...................... 175
11.3.3. Расширение ширины слова блока OSERDESE2.................... 175
11.3.4. Задержки блока OSERDESE2................................... 176
11.4. Память FIFO ввода-вывода .......................................... 177
11.4.1. Элемент IN.FIFO ........................................... 178
11.4.2. Элемент OUT.FIFO .......................................... 179
11.4.3. Перезагрузка элемента IN.FIFO.............................. 180
11.4.4. Флаги элемента IO.FIFO .................................... 180
11.5. Выводы............................................................. 180
12. Ресурсы синхронизации FPGA 7-й серии................................. 183
12.1. Введение в ресурсы синхронизации FPGA 7-й серии ................... 183
12.1.1. Ресурсы трассировки синхронизации.......................... 185
12.1.2. Буферы синхронизации....................................... 185
12.1.3. Блоки формирования синхросигналов СМТ...................... 186
12.2. Архитектура ресурсов синхронизации FPGA 7-й серии ................. 187
12.2.1. Обобщенная архитектура системы синхронизации............... 187
12.2.2. Архитектура региона синхронизации ......................... 188
12.2.3. Взаимодействие буферов BUFG, BUFH и блока СМТ.............. 189
12.2.4. Взаимодействие буферов BUFR, BUFIO, BUFMR и приемопередатчиков
GT ................................................................ 190
12.2.5. Архитектурные особенности отдельных семейств и устройств FPGA 7-й
серии 191
12.2.6. Возможности соединения элементов синхронизации FPGA 7-й серии .... 192
12.3. Входы синхронизации (СС-входы) .................................... 192
12.3.1. Подсоединение СС-входов к блокам СМТ ...................... 193
388
Оглавление
12 3 2 Правила размещения СС-входов ................................. 193
12.4. Ресурсы глобальной синхронизации..................................... 194
12.4.1. Буферы глобальной синхронизации ............................. 194
12.4.2. Примитивы буферов глобальной синхронизации................... 195
12.4.3. Дополнительные модели использования буфера BUFGCTRL ......... 197
12.5. Ресурсы региональной синхронизации .................................. 198
12 5.1 Буферы синхронизации ввода-вывода BUFIO ...................... 198
12.5.2. Буфер региональной синхронизации BUFR........................ 199
12 5.3. Модели использования буферов BUFIO и BUFR ................ 199
12.5.4. Многорегиональный буфер синхронизации BUFMR/BUFMRCE.......... 199
12.5.5. Буферы горизонтальной синхронизации BUFH и BUFHCE............ 200
12.5.6. Выбор буфера синхросигнала................................... 200
12 5.7. Синхросигналы высокой производительности (НРС) ........... 202
12 5.8. Стробирование синхросигналов для сохранения мощности ..... 202
12.6. Выводы............................................................... 202
13. Блоки формирования синхросигналов СМТ ................................. 207
13.1. Общее описание блока СМТ............................................. 207
13.2. Архитектура блоков ММСМ и PLL........................................ 208
13.3. Функционирование блоков ММСМ и PLL .................................. 210
13 3.1. Определение частоты генератора VCO и частоты выходных синхросигна-
лов ................................................................. 210
13.3.2. Устранение перекоса сети синхросигнала ...................... 210
13.3.3. Синтез частоты путем использования только целочисленного делителя . 211
13.3.4. Синтез частоты путем использования дробных делителей в блоке ММСМ 211
13 3.5. Фильтр флуктуаций ........................................... 212
13 3.6. Ограничения для блоков MMCM/PLL ............................. 212
13.4. Фазовый сдвиг ....................................................... 212
13.4.1. Режим статического фазового сдвига........................... 213
13.4.2. Интерполяция тонкого фазового сдвига в блоке ММСМ для фиксирован-
ного или динамического режима ....................................... 213
13.4.3. Интерфейс динамического фазового сдвига в блоке ММСМ ........ 214
13 4 4. Каскадирование счетчика ММСМ ............................. 215
13.5. Программирование MMCM/PLL ........................................... 215
13.5.1. Определение входной частоты ................................. 215
13.5.2. Определение значений М и D .................................. 216
13.6. Использование блоков ММСМ и PLL ..................................... 217
13.6.1. Входные сигналы синхронизации блока ММСМ .................... 217
13.6.2. Управление счетчиком ........................................ 217
13 6.3. Фазовое соотношение выходных счетчиков ................... 218
13.6.4. Переключение опорного синхросигнала ......................... 218
13.6.5. Потеря входного синхросигнала или синхросигнала обратной связи. 219
13.6.6. Устранение перекоса сети синхронизации ...................... 219
13.6.7. Блок ММСМ с внутренней обратной связью ...................... 220
13.6.8. Буфер с нулевой задержкой ................................... 220
13.6.9. Каскадирование блоков СМТ ................................... 221
13.6.10. Генерация широкополосных синхросигналов .................... 223
13.6.11. Пример использования блока ММСМ ............................ 224
13.7. Выводы .............................................................. 224
Оглавление
389
14. Конфигурирование FPGA 7-й серии ....................................... 228
14.1. Основы конфигурирования ............................................. 228
14.1.1. Режимы конфигурирования...................................... 228
14.1.2. Длина конфигурационного битового потока 24................... 229
14.1.3. Главные и подчиненные режимы ................................ 229
14.1.4. Соединение JTAG ............................................. 231
14.1.5. Базовое конфигурационное решение............................. 231
14.1.6. Конфигурационные решения низкой стоимости ................... 231
14.1.7. Конфигурационные решения высокой скорости ................... 231
14.1.8. Защита битового потока от несанкционированного копирования... 232
14.1.9. Загрузка нескольких FPGA с помощью одной конфигурационной последо-
вательности ......................................................... 232
14.1.10. Оценка факторов конфигурирования ........................... 232
14.1.11. Отладка конфигурирования.................................... 233
14.2. Интерфейсы конфигурирования ......................................... 233
14.2.1. Интерфейсы и режимы конфигурирования ........................ 233
14.2.2. Выводы конфигурирования ..................................... 233
14.2.3. Выбор напряжения банков конфигурирования..................... 234
14.2.4. Установка опций конфигурирования в пакете Vivado ............ 234
14.2.5. Опция внешнего главного синхросигнала конфигурирования EMCCLK ... 235
14.3. Последовательный режим конфигурирования ............................. 235
14.3.1. Подчиненный последовательный режим конфигурирования.......... 236
14.3.2. Главный последовательный режим конфигурирования.............. 236
14.3.3. Синхронизация данных последовательного конфигурирования...... 237
14.4. Режим конфигурирования SelectMAP..................................... 237
14.4.1. Конфигурирование в режиме SelectMAP одного устройства ....... 238
14.4.2. Загрузка данных в режиме SelectMAP .......................... 238
14.5. Режим конфигурирования Master SPI ................................... 239
14.5.1. Команды чтения в режимах Master SPI Dual (х2) и Quad (х4) ... 241
14.5.2. Память SPI свыше 128 Мбит ................................... 241
14.5.3. Временная диаграмма конфигурирования SPI .................... 241
14.5.4. Определение максимальной частоты синхросигнала конфигурирования .. 242
14.5.5. Особенности при включении питания ........................... 243
14.6. Интерфейс конфигурирования в режиме Master BPI ...................... 243
14.6.1. Поддержка режима асинхронного чтения......................... 244
14.6.2. Поддержка страничного режима ................................ 245
14.6.3. Поддержка режима синхронного чтения.......................... 246
14.6.4. Определение максимальной частоты синхросигнала конфигурирования .. 248
14.6.5. Особенности последовательности включения питания............. 248
14.7. Граничное сканирование и JTAG конфигурирование ...................... 249
14.7.1. Контроллер ТАР и архитектура JTAG ........................... 249
14.7.2. Временная диаграмма граничного сканирования ................. 250
14.7.3. Использование граничного сканирования в устройствах FPGA 7-й серии . 250
14.7.4. Конфигурирование нескольких устройств ....................... 251
14.7.5. Трассировка сигналов JTAG ................................... 252
14.7.6. Конфигурирование через граничное сканирование................ 252
14.8. Порт динамического реконфигурирования DRP............................ 252
14.8.1. Динамическое реконфигурирование функциональных блоков ....... 252
14.8.2. Логика динамического реконфигурирования функциональных блоков .... 253
390
Оглавление
14.8.3. Определение порта DRP логики FPGA....................... 253
4.9. Выводы.......................................................... 254
Заключение...................................................... 260
Приложение А. Примитивы FPGA 7-й серии ......................... 261
А.1. Примитивы внутренней логики..................................... 261
А.1.1. Примитивы запоминающих элементов ........................ 261
А. 1.2. Примитивы функциональных генераторов.................... 262
А. 1.3. Примитив CFGLUT5 динамически реконфигурируемого функционального
генератора LUT ................................................... 263
АЛД. Примитив быстрого арифметического переноса CARRY4 ........... 264
А. 1.5. Примитивы мультиплексоров ................................ 264
А. 1.6. Примитивы сдвиговых регистров ............................ 265
А. 1.7. Примитивы распределенной памяти RAM ...................... 266
А.1.8. Примитивы распределенной памяти ROM........................ 268
А.1.9. Примитив STARTUPE2 ........................................ 268
А.2. Примитив секции DSP48E1 .......................................... 269
А.2.1. Внутренние регистры секции DSP48E1......................... 273
А.2.2. Атрибуты примитива секции DSP48E1 ......................... 273
А.З. Макросы секции DSP48E1 ........................................... 276
А.3.1. Макрос MULT-MACRO.......................................... 276
А.3.2. Макрос MACC-MACRO ......................................... 276
А.3.3. Макрос ADDMACC-MACRO ...................................... 276
А.3.4. Макрос ADDSUB-MACRO........................................ 276
А.З.5. Макросы COUNTER_LOAD_MACRO и COUNTER_TC_MACRO.............. 276
А.3.6. Макрос EQ_COMPARE_MACRO ................................... 277
А.З.7. Порты макросов секции DSP48E1 ............................. 278
А.З.8. Атрибуты макросов секции DSP48E1 .......................... 280
А.4. Примитивы блока памяти RAM ....................................... 280
А.4.1. Порты примитива RAMB36E1 .................................. 280
А.4.2. Сигналы портов примитива RAMB36E1 ......................... 283
А.4.3. Атрибуты примитивов блока памяти RAM ...................... 283
А.4.4. Описание атрибутов......................................... 283
А.5. Макросы блока памяти RAM ......................................... 286
А.5.1. Макрос BRAM_TDP_MACRO ..................................... 287
А.5.2. Макрос BRAM_SDP_MACRO ..................................... 288
А.5.3. Макрос BRAM_SINGLE_MACRO .................................. 289
А.5.4. Атрибуты макросов блока памяти RAM ........................ 289
А.6. Примитивы памяти FIFO ............................................ 290
А.6.1. Порты примитивов памяти FIFO............................... 290
А.6.2. Атрибуты примитивов памяти FIFO ........................... 292
А.6.3. Диапазоны смещения флагов «почти полный» и «почти пустой» . 292
А.7. Макросы памяти FIFO .............................................. 293
АЛЛ. Макрос FIFO_DUALCLOCK_MACRO ................................. 293
А.7.2. Макрос FIFO-SYNC .MACRO ................................... 293
А.7.3. Порты макросов памяти FIFO ................................ 294
А.7.4. Атрибуты макросов памяти FIFO ............................. 294
А.8. Примитивы блока ЕСС ............................................. 296
А.8.1. Порты примитивов блока ЕСС................................. 296
А.8.2. Атрибуты примитивов блока ЕСС ............................. 296
Оглавление
391
А.9. Примитивы элементов ввода-вывода................................. 299
А.9.1. Примитивы IBUF и IBUFG.................................... 299
А.9.2. Примитив IBUFJBUFDISABLE ................................. 300
А.9.3. Примитив IBUFJNTERMDISABLE................................ 300
А.9.4. Примитивы IBUFDS и IBUFGDS ............................... 300
А.9.5. Примитивы IBUFDS_DIFF_OUT и IBUFGDS_DIFF_OUT ............. 301
А.9.6. Примитив IBUFDS_DIFF_OUTJBUFDISABLE ..................... 301
А.9.7. Примитив IBUFDSJBUFDISABLE .............................. 301
А.9.8. Примитив IBUFDSJNTERMDISABLE ............................ 301
А.9.9. Примитив IOBUF .......................................... 302
А.9.10. Примитив IOBUFDS ........................................ 302
А.9.11. Примитив IOBUFDS-DCIEN .................................. 302
А.9.12. Примитив IOBUFDS_DIFF_OUT ............................... 303
А.9.13. Примитив IOBUFDS_DIFF_OUT_DCIEN ......................... 303
А.9.14. Примитив IOBUFDS_DIFF_OUTJNTERMDISABLE................... 302
А.9.15. Примитив IOBUFDSJNTERMDISABLE ........................... 303
А.9.16. Примитив OBUF ........................................... 303
А.9.17. Примитив OBUFDS ......................................... 304
А.9.18. Примитив OBUFT .......................................... 304
А.9.19. Примитив OBUFTDS ........................................ 304
А.9.20. Атрибуты примитивов ввода-вывода......................... 304
А.9.21. Ограничения блоков ввода-вывода ......................... 306
А. 10. Примитивы логических ресурсов ввода-вывода ..................... 307
А.10.1. Примитивы IDELAYE2 и ODELAYE2 ........................... 307
А. 10.2. Порты примитивов IDELAYE2 и ODELAYE2 ................... 308
А. 10.3. Атрибуты примитивов IDELAYE2 и ODELAYE2 ................ 309
А. 10.4. Режимы функционирования примитивов IDELAYE2 и ODELAYE2 . 311
А.10.5. Примитив IDELAYCTRL...................................... 311
А.10.6. Примитивы IDDR и ODDR ................................. 311
А.10.7. Примитив ISERDESE2 ...................................... 312
А.10.8. Атрибуты примитива ISERDESE2............................. 314
А.10.9. Примитив OSERDESE2 ...................................... 314
А. 10.10. Атрибуты примитива OSERDESE2 .......................... 317
А.10.11. Примитив IN-FIFO ....................................... 317
А.10.12. Примитив OUT-FIFO ...................................... 317
А. 11. Примитивы ресурсов синхронизации ............................... 320
А. 11.1. Возможности соединений элементов ресурсов синхронизации FPGA 7-й
серии............................................................. 320
А.11.2. Правила размещения СС-входов.............................. 322
А.11.3. Примитив BUFGCTRL ........................................ 323
А.11.4. Примитив BUFG ............................................ 324
А.11.5. Примитивы BUFGCE и BUFGCE.1............................... 325
А.11.6. Примитивы BUFGMUX и BUFGMUX.1 ............................ 326
А.11.7. Примитив BUFGMUX-CTRL..................................... 327
А.11.8. Примитив BUFIO ........................................... 328
А.11.9. Примитив BUFR ............................................ 328
А.11.10. Примитив BUFMR .......................................... 330
А.11.11. Примитивы BUFH и BUFHCE ............................ 331
А.12. Примитивы блоков ММСМ и PLL ................................. 331
392
Оглавление
А.12 1. Примитивы ММСМЕ2.BASE и MMCME2_ADV ......................... 331
А 12.2. Примитивы PLLE2.BASE и PLLE2_ADV ........................... 332
А.12.3. Порты блоков ММСМ и PLL .................................... 333
А.12.4. Атрибуты примитивов блоков ММСМ и PLL....................... 336
А. 13. Выводы конфигурирования FPGA 7-й серии ............................ 338
Приложение Б. Временные модели FPGA 7-й серии ....................... 341
Б.1. Временная модель CPLD семейства XC9500XL ........................... 341
Б.2. Временная модель CPLD семейства CoolRunner-ll ...................... 342
Б.З. Временные модели внутренней логики FPGA 7-й серии .................. 344
Б.З 1. Общие временные модели и параметры секции CLB ............... 344
Б.З 2. Временные параметры мультиплексоров секции CLB .............. 346
Б.3.3. Временные параметры и характеристики цепи переноса .......... 346
Б.З.4. Временные модели и временные параметры распределенной памяти RAM
секции блока CLB ................................................... 346
Б.3.5. Временная модель и временные характеристики сдвигового регистра SRL 349
Б.4. Временная модель блока RAM ......................................... 351
Б.4.1. Временные параметры блока RAM ............................... 351
Б.4 2. Временные характеристики блока RAM .......................... 351
Б.4.3. Временная модель блока RAM .................................. 353
Б.5. Временные параметры блока ЕСС ...................................... 353
Б 5 1. Синхронизация стандартной записи ............................ 353
Б.5.2. Синхронизация стандартного чтения ........................... 354
Б.6. Временные модели памяти FIFO ....................................... 355
Б.6.1. Временные параметры памяти FIFO ............................. 355
Б.6.2. Запись в пустую память FIFO ................................. 356
Б.6 3. Запись в полную или почти полную память FIFO ................ 357
Б 6.4. Чтение из полной памяти FIFO................................. 358
Б.6.5. Чтение из пустой или почти пустой памяти FIFO ............... 359
Б.6.6. Переустановка всех флагов.................................... 360
Б.6.7. Одновременное чтение и запись в режиме двойной синхронизации. 360
Б.7. Временные модели ресурсов ввода-вывода.............................. 360
Б 7.1. Временная модель примитива IDELAY............................ 360
Б.7.2. Временная модель примитива IDELAYCTRL ....................... 361
Б.7.3. Временная модель примитива ODELAYE2 ......................... 361
Б.7.4. Временные модели блока ILOGIC ............................... 363
Б 7.5. Временные модели примитива OLOGIC ........................... 364
Б.8. Временные модели расширенных логических ресурсов ввода-вывода....... 367
Б 8.1. Временная модель блока 1SERDESE2............................. 367
Б.8.2. Временная модель подмодуля Bitslip........................... 368
Б.8.3. Временная модель блока OSERDESE2............................. 368
Б.9. Временные характеристики непрерывной и прерывистой загрузки данных
в режиме SelectMAP................................................... 370
Литература ................................................... 374
Список сокращений ............................................ 375
Предметный указатель.......................................... 376
Соловьев В. В.
Архитектуры ПЛИС
фирмы XILINX:
CPLD и FPGA 7-й серии
Рассмотрены архитектуры программируемых логических инте-
гральных схем (ПЛИС) фирмы Xilinx. Приведена краткая классифика-
ция ПЛИС, дано введение в технологии проектирования на основе
ПЛИС, описаны архитектуры CPLD и подробно рассмотрены архи-
тектуры FPGA 7-й серии. В частности, внутренняя логика FPGA: конфи-
гурируемые логические блоки, распределенная память, сдвиговые
регистры, мультиплексоры и логика переноса; блоки цифровой
обработки сигналов; блоки памяти RAM; режим памяти FIFO; блок
встроенной коррекции ошибок при записи и чтения памяти. Кроме
того, подробно рассмотрена система ввода-вывода, ресурсы синхро-
низации и вопросы конфигурирования FPGA. В приложениях дано
описание примитивов и макросов, а также временных моделей
элементов архитектуры FPGA. Большинство глав заканчивается
особенностями применения соответствующих функциональных
блоков, что значительно упрощает практическое использование
компонентов архитектуры FPGA.
Для инженеров-практиков, разработчиков электронных систем на
основе ПЛИС, студентов и преподавателей, может быть полезна
аспирантам и научным работникам, а также менеджерам, специ-
алистам по продаже ПЛИС.
САЙТ ИЗДАТЕЛЬСТВА:
ISBN 978-5-9912-0500-9
9 785991 205009